
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,882,368 | My idea and submission for problem 1 on Leetcode(very detailed) | 1. the analysis of the problem Now we get some information from the question: A array... | 0 | 2024-06-09T22:06:35 | https://dev.to/hallowaw/my-idea-and-submission-for-problem-1-on-leetcodevery-detailed-4p57 | beginners, cpp, tutorial | ## **1. the analysis of the problem**
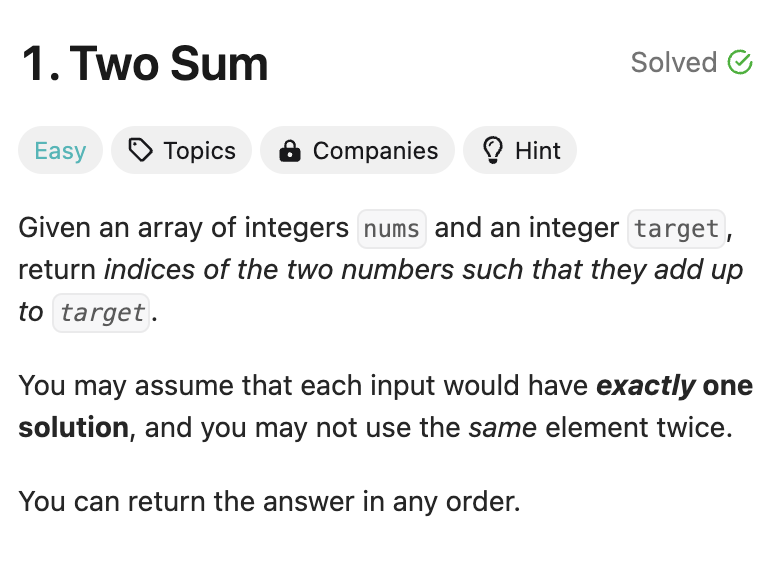
**Now we get some information from the question:**
A array named nums,it includeds some intergers;
An integer named target;
What should we do:we need add two numbers from the n... | hallowaw |
1,882,391 | Building Android Automotive OS: A Beginner-Friendly Guide | Introduction Android Automotive OS is a version of Android tailored for in-vehicle use. It... | 0 | 2024-06-09T22:01:27 | https://dev.to/hpnightowl/building-android-automotive-os-a-beginner-friendly-guide-4f67 | aaos, android, androiddev, aosp |
## Introduction
Android Automotive OS is a version of Android tailored for in-vehicle use. It provides a seamless experience for drivers and passengers by integrating various automotive functions with Android applications. This guide will walk you through the process of building Android Automotive OS from scratch, co... | hpnightowl |
1,854,417 | Dev: Data Engineer | A Data Engineer Developer is a professional who specializes in designing, building, and maintaining... | 27,373 | 2024-06-09T22:00:00 | https://dev.to/r4nd3l/dev-data-engineer-on1 | datascience, developer | A **Data Engineer Developer** is a professional who specializes in designing, building, and maintaining data pipelines and infrastructure to support the storage, processing, and analysis of large volumes of data. Here's a detailed description of the role:
1. **Data Infrastructure Design:**
- Data Engineer Developer... | r4nd3l |
1,882,388 | I'm not a designer, but ... | I am a developer, not a designer, but I have strong opinions on UI. I helped thousands of new... | 0 | 2024-06-09T21:46:55 | https://dev.to/lisacee/im-not-a-designer-but--lke | ui, modal | I am a developer, not a designer, but I have strong opinions on UI. I helped thousands of new computer users while working at a public library. I got a very informal introduction to the world of UI and UX, accessibility and expected behaviors. It was these interactions that led me to becoming a software engineer. I wo... | lisacee |
1,851,500 | 🌐Extensões para produtividade de um dev no Navegador (Arc Browser) | Introdução Navegador 🌐 (Arc Browser) Extenções uBlock Origin WhatRuns AI... | 0 | 2024-06-09T21:40:07 | https://dev.to/neiesc/extensoes-para-produtividade-de-um-dev-no-navegador-arc-browser-3of | ## Introdução
Navegador 🌐 (Arc Browser)

## Extenções
1. [uBlock Origin](https://chromewebstore.google.com/de... | neiesc | |
1,882,384 | Babylon.js Browser MMORPG - DevLog- Update #7 - Player combat abilities | Hello, Last few day i spent on refactoring server code and redesigning architecture on client side... | 0 | 2024-06-09T21:34:24 | https://dev.to/maiu/babylonjs-browser-mmorpg-devlog-update-7-player-combat-abilities-2g7i | babylonjs, indie, mmorpg, indiegamedev | Hello,
Last few day i spent on refactoring server code and redesigning architecture on client side for ECS like, but to be honest most of it is event based approach.
Anyway it feels much more better than before when i reached code complexity critical point and further development wasn't possible. Right now adding new... | maiu |
1,882,367 | Transactional Outbox: from idea to open-source | Hey there! Misha Merkushin here, Team Lead of the Ruby Platform team at Kuper Tech. We’re the crew... | 0 | 2024-06-09T21:27:45 | https://dev.to/bibendi/transactional-outbox-from-idea-to-open-source-34ia | ruby, kafka, sidekiq, opensource | Hey there! Misha Merkushin here, Team Lead of the Ruby Platform team at Kuper Tech. We’re the crew behind the internal libraries and microservice architecture improvements for everything Ruby. This article dives into the Transactional Outbox pattern and a tool we built and iteratively developed in-house that we've just... | bibendi |
1,882,382 | What is Selenium? Why do we use Selenium for automation? | Selenium is a automation tool used for web application testing. It is a popular open source testing... | 0 | 2024-06-09T21:25:09 | https://dev.to/jayachandran/what-is-selenium-why-do-we-use-selenium-for-automation-3phh | Selenium is a automation tool used for web application testing. It is a popular open source testing tool. Selenium enables testers to write automated tests in various programming languages to test the functionality of web applications. It can be run in many different browsers and operating systems. It can be used ... | jayachandran | |
1,866,262 | HDMI 2.0 TV Backlight Kit | Welcome to the enchanting world of deerdance, where smart lighting takes center stage in... | 0 | 2024-05-27T07:52:55 | https://dev.to/deerdance_43156f231259b9d/hdmi-20-tv-backlight-kit-1j25 | Welcome to the enchanting world of deerdance, where smart lighting takes center stage in revolutionizing the way we illuminate our spaces. As a leading brand in intelligent lighting solutions, deerdance seamlessly combines state-of-the-art technology, breathtaking design, and unparalleled functionality to create an ext... | deerdance_43156f231259b9d | |
1,882,372 | Strategies for Debugging Immutable Code | As any seasoned developer can attest, debugging code can often feel like a never-ending battle... | 0 | 2024-06-09T21:10:54 | https://dev.to/cherrypick14/strategies-for-debugging-immutable-code-1a8b | go, immutablecode, debuggingtechniques, codequality | As any seasoned developer can attest, debugging code can often feel like a never-ending battle against an ever-multiplying army of bugs – a relentless game of whack-a-mole where squashing one issue only seems to spawn two more in its place. In the world of Go programming, immutability is a powerful ally that can make y... | cherrypick14 |
1,882,371 | [Game of Purpose] Day 21 | Today I was travelling, so no progress. I even forgot to make an update that day, so I'm writing this... | 27,434 | 2024-06-09T21:06:52 | https://dev.to/humberd/game-of-purpose-day-21-3828 | gamedev | Today I was travelling, so no progress. I even forgot to make an update that day, so I'm writing this 1 day later. | humberd |
1,882,370 | A Voyage through Algorithms using Javascript - Recursion | What is Recursion? Recursion is a powerful and elegant technique that forms the backbone... | 0 | 2024-06-09T21:02:21 | https://www.sahinarslan.tech/posts/a-voyage-through-algorithms-using-javascript-recursion | webdev, javascript, computerscience, algorithms | ## What is Recursion?
Recursion is a powerful and elegant technique that forms the backbone of many algorithms. It allows a function to call itself repeatedly until a specific condition is met, enabling the solution of complex problems by breaking them down into simpler subproblems.
## Anatomy of a Recursive function... | humblecoder00 |
1,882,318 | World Bicycle Day CSS Art : Frontend Challenge (June Edition) | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration Today,... | 0 | 2024-06-09T20:51:05 | https://dev.to/israebenboujema/world-bicycle-day-css-art-frontend-challenge-june-edition-31oc | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
Today, we are highlighting World Bicycle Day. Cycling has been a favorite hobby for both of us since we were kids, and it holds a special place in our hearts. When we saw the challeng... | israebenboujema |
1,882,366 | Discover Jaipur's Best Cafes! | Top Cafes in Jaipur -Cafe Romeo Juliet | Jaipur, the vibrant capital of Rajasthan, is renowned for its rich history, stunning architecture,... | 0 | 2024-06-09T20:50:51 | https://dev.to/caferomeojuliet/discover-jaipurs-best-cafes-top-cafes-in-jaipur-cafe-romeo-juliet-b1b | food, cafe |

Jaipur, the vibrant capital of Rajasthan, is renowned for its rich history, stunning architecture, and bustling bazaars. Amidst its regal charm, Jaipur also boasts a thriving café culture, offering a blend of tradit... | caferomeojuliet |
1,882,362 | How to get html from the server using javascript using fetch (hmpl-js module)? | You can use the hmpl-js package to load HTML from the server. It works on fetch, so it can help you... | 0 | 2024-06-09T20:41:02 | https://dev.to/antonmak1/how-to-get-html-from-the-server-using-javascript-using-fetch-1kih | webdev, javascript, programming, tutorial | You can use the hmpl-js package to load HTML from the server. It works on `fetch`, so it can help you avoid writing a bunch of code:
```html
<div id="wrapper"></div>
<script src="https://unpkg.com/hmpl-js"></script>
<script>
const templateFn = hmpl.compile(
`<div>
<button class="getHTML">Get HTML!</button>
<... | antonmak1 |
1,882,361 | Revolutionizing Technology Solutions in Pakistan | Welcome to CodeHuntSPK, a leading software solutions company based in Islamabad, Pakistan. Our... | 0 | 2024-06-09T20:35:14 | https://dev.to/hmzi67/revolutionizing-technology-solutions-in-pakistan-pc7 | webdev, cloudcomputing, android, web3 | Welcome to CodeHuntSPK, a leading software solutions company based in Islamabad, Pakistan. Our mission is to transform your digital ideas into reality through cutting-edge technology and innovative strategies. With over two years of experience and a portfolio of 12 completed projects, we specialize in:
- **Web Develop... | hmzi67 |
1,882,360 | Solving Tailwind's "Unknown at rule @apply" | Chances are you are using VSCode, and chances are you're also using Tailwind in one of your projects.... | 0 | 2024-06-09T20:33:11 | https://www.oh-no.ooo/snippets/unknown-at-rule-apply-k-thx-bye | tailwindcss, webdev, vscode, css | Chances are you are using VSCode, and chances are you're also using Tailwind in one of your projects. Chances are that at my first *chances are...* you went immediately *nuh-uh* and moved on (and if you're a NeoVim user I can't help you anyway, you're already doomed and lost in the recommended plugins someone chose for... | mahdava |
1,882,332 | Using interactive rebase in Git | About An interactive rebase in Git is a process that allows you to edit a sequence of... | 0 | 2024-06-09T20:20:38 | https://dev.to/lyumotech/using-interactive-rebase-in-git-361d | repository, github, versioncontrol, git | ## About
An interactive rebase in Git is a process that allows you to edit a sequence of commits. This is typically used to clean up commit history before sharing changes with other members of the team.
## Case study
Let's study an example of making a clear 3-commit history out of the initial 5 commits.
1. **Start ... | lyumotech |
1,882,323 | Why Python is a Great Language for Coding Games | Introduction Python is a great coding language for beginners. The syntax is easy to read and it makes... | 0 | 2024-06-09T20:18:11 | https://dev.to/walkera1/why-python-is-a-great-language-for-coding-games-3088 | Introduction
Python is a great coding language for beginners. The syntax is easy to read and it makes sense. Python is good for building beginner friendly games. The language is also useful in many more ways than just making games. Python is very popular so there are lots of resources out there to help you code and lea... | walkera1 | |
1,882,322 | TypeError: Object of type AgentChatResponse is not JSON serializable | Getting this error while using chat_history for agent chat in Llama Index. Need a quick resolution.... | 0 | 2024-06-09T20:12:52 | https://dev.to/sourav_mukherjee_te/typeerror-object-of-type-agentchatresponse-is-not-json-serializable-aj9 | openai, llm, llamaindex | Getting this error while using chat_history for agent chat in Llama Index. Need a quick resolution. Any help on this? You can get the code below-
'''chat_history.append(ChatMessage(role= MessageRole.USER, content=user_message))
response = agent.chat(message=user_message, chat_history= chat_history)
chat_history.appe... | sourav_mukherjee_te |
1,882,321 | How to work with .hmpl file extension in javascript? | In order to work with files with the .hmpl extension, you can install a webpack and loader for it... | 0 | 2024-06-09T20:12:21 | https://dev.to/antonmak1/how-to-work-with-hmpl-file-extension-in-javascript-28hf | webdev, javascript, programming, tutorial | In order to work with files with the `.hmpl` extension, you can install a [webpack](https://www.npmjs.com/package/webpack) and loader for it [hmpl-loader](https://www.npmjs.com/package/hmpl-loader). Since version `0.0.2`, the loader connection looks like this:
### webpack.config.js
```javascript
module.exports = {
... | antonmak1 |
1,878,727 | Prisma ORM | Introduction Prisma ORM is an open-source ORM made up of 3 parts: Prisma Client, Prisma... | 0 | 2024-06-09T20:08:19 | https://dev.to/allyn/prisma-orm-kjh | ## Introduction
Prisma ORM is an open-source ORM made up of 3 parts: Prisma Client, Prisma Migrate, and Prisma Studio. Prisma Client is an auto-generated, type-safe database client for Node.js and TypeScript. Prisma Migrate is a migration system, and Prisma Studio is an interface to view and manipulate data in the data... | allyn | |
1,882,056 | Exploring GitHub Copilot with Microsoft Visual Studio | Introduction Learn how to use GitHub Copilot in Microsoft Visual Studio 2022 with real... | 27,651 | 2024-06-09T20:07:55 | https://dev.to/karenpayneoregon/exploring-github-copilot-with-microsoft-visual-studio-4jfo | ai, productivity | ## Introduction
Learn how to use GitHub Copilot in Microsoft Visual Studio 2022 with real world usage from documenting code, improving code, explain code and more. Also, will talk about some features of Copilot in Microsoft Visual Studio Code.
:heavy_check_mark: Do not have a Copilot subscription, [go here](https://g... | karenpayneoregon |
1,881,903 | Python Basics 3: Operators | Operators are one of the most utilized elements of any programming language. We have to use operators... | 0 | 2024-06-09T20:06:14 | https://dev.to/coderanger08/python-basics-3-operators-2ee1 | python, programming, beginners, tutorial | Operators are one of the most utilized elements of any programming language. We have to use operators in Python for numerous cases. From mathematical calculations to building any project, operators are inevitable. As usual, operators have classifications.
**_Arithmetic Operators:_**
**1.Addition(+):** Add values on e... | coderanger08 |
1,882,320 | Pixel perfect squarespace website | Pixel perfect Squarespace website. Links:... | 0 | 2024-06-09T20:03:03 | https://dev.to/deknows/pixel-perfect-squarespace-website-25hj | website, webdev, company, softwaredevelopment |

Pixel perfect Squarespace website.
Links: https://dribbble.com/shots/24322764-Pixel-Perfect-Squarespace-Website-Design
https://dribbble.com/shots/24322764-Pixel-Perfect-Squarespace-Website-Design
https://www.d... | deknows |
1,882,319 | They Say Frontend is Easy | They say becoming a front-end dev is easy... Then, I have to show them the reality: ... | 0 | 2024-06-09T20:00:02 | https://dev.to/syedmuhammadaliraza/they-say-frontend-is-easy-agk | frontend, webdev, development, developers | ### They say becoming a front-end dev is easy...
Then, I have to show them the reality:
### Beginner Level
1. div
2. button
3. i
4. b
5. font-size: 16px
6. index.html
### Intermediate Level
7. script
8. img
9. form
10. iframe
11. $(function(){...});
### Advanced Level
12. useEffect
13. center a <div>
14. unit te... | syedmuhammadaliraza |
1,882,316 | Fixing the Draggable Element Background Issue in Chromium Browsers | When developing a chess game today, I stumbled upon a peculiar behavior in Chromium browsers while... | 0 | 2024-06-09T19:48:27 | https://www.jayganatra.com/blog/draggable-element-in-chromium-browsers | css, html, webdev, tutorial | When developing a chess game today, I stumbled upon a peculiar behavior in Chromium browsers while implementing draggable elements. If you've ever noticed that dragging an element causes it to inherit its parent’s background, you're not alone. This odd effect can be quite a nuisance, but fortunately, there are ways to ... | ganatrajay2000 |
1,882,315 | Documenting my pin collection with Segment Anything: Part 1 | As a hobby that spans across various cultures and ages, pin collecting allows enthusiasts like me to... | 27,656 | 2024-06-09T19:46:04 | https://blog.feregri.no/blog/documenting-my-pin-collection-with-segment-anything-part-1/ | imagesegmentation, python, objectdetection |
As a hobby that spans across various cultures and ages, [pin collecting](https://en.wikipedia.org/wiki/Pin_trading) allows enthusiasts like me to hold onto pieces of art, history, and personal milestones. Whether the... | feregri_no |
1,882,314 | Wie man django in Entwicklung Containerisiert - via docker compose | Kontext Des öfteren gibt es in der Entwicklung das Problem, dass es einen Fehler gibt, der... | 0 | 2024-06-09T19:45:51 | https://dev.to/rubenvoss/wie-man-django-in-entwicklung-containerisiert-via-docker-compose-3n0b | ## Kontext
Des öfteren gibt es in der Entwicklung das Problem, dass es einen Fehler gibt, der nur auf einem Gerät auftaucht.

Häufig liegt das daran, dass in den verschiedenen Entwicklungsumgebungen versch... | rubenvoss | |
1,882,313 | Hi, I'm Justin Goncalves | Hello All I'm Justin I am a 16yo Self Learning Developer from the United States I mostly... | 0 | 2024-06-09T19:40:42 | https://dev.to/justingonca/hi-im-justin-goncalves-3bc8 | ## Hello All
I'm Justin
I am a 16yo Self Learning Developer from the United States
I mostly post every week on Mondays, Wednesdays and Fridays as well as Saturday and Sunday.
Well that's everything about me,
See you later,
Bye | justingonca | |
1,880,939 | Two Flags, One Country, Same Message | *Note: _This is my submission for this month's CSS Art challenge on Dev.to * Table of... | 27,663 | 2024-06-09T19:39:40 | https://dev.to/cbid2/two-flags-one-country-same-message-6d7 | frontendchallenge, css, devchallenge | **Note: _This is my submission for [this month's CSS Art challenge on Dev.to](https://dev.to/challenges/frontend-2024-05-29) **
**Table of content:**
- [What I built](#what-i-built)
- [Demo](#demo)
- [Struggles](#struggles)
- [My overall feelings about this challenge](#my-overall-feelings-about-this-challenge)
- ... | cbid2 |
1,882,312 | Buy verified cash app account | .https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-09T19:39:26 | https://dev.to/futhalsope322/buy-verified-cash-app-account-4lcp | webdev, javascript, beginners, python | .https://dmhelpshop.com/product/buy-verified-cash-app-account/

Buy verified cash app account
Cash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience... | futhalsope322 |
1,882,123 | Frontend Challenge: CSS is a Beach | This is a submission for [Frontend Challenge... | 0 | 2024-06-09T19:37:00 | https://dev.to/kelseyrh/frontend-challenge-css-is-a-beach-5911 | devchallenge, frontendchallenge, css, javascript |

_This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
## What I Built
This... | kelseyrh |
1,882,310 | HIRE THE MOST POPULAR BITCOIN RECOVERY EXPERT ADWARE RECOVERY SPECIALIST | Website info: www.adwarerecoveryspecialist.expert The wild west of cryptocurrency investing, where... | 0 | 2024-06-09T19:35:45 | https://dev.to/cynthia_creech_efb48d686d/hire-the-most-popular-bitcoin-recovery-expert-adware-recovery-specialist-1jpl | Website info: www.adwarerecoveryspecialist.expert
The wild west of cryptocurrency investing, where promises of quick riches often collide with the harsh reality of scams and swindlers,finding a reliable partner is akin to discovering a rare gem amidst a sea of rubble. My foray into this world began with bright hopes ... | cynthia_creech_efb48d686d | |
1,882,280 | Building a command line photo tagger using Docker, .Net and ExifTool | In this post, I will cover what photo Geotagging is, my use of the concept over time and a brief... | 0 | 2024-06-09T19:33:38 | https://dev.to/syamaner/building-a-command-line-photo-tagger-using-docker-net-and-exiftool-1gc4 | geotagging, docker, dotnet, gps | In this post, I will cover what photo Geotagging is, my use of the concept over time and a brief discussion of a basic tool I put together for the travels over the past few weeks.
## Part 1 - Geotagging
Geotagging (adding location information as a metadata) images is quite fun allowing us not only revisit the memori... | syamaner |
1,882,301 | Adding Interactivity to JavaScript Importance of interactivity in web development | Importance of Interactivity in Web Development Interactivity in web development is just... | 0 | 2024-06-09T19:20:36 | https://dev.to/ellaokah/adding-interactivity-to-javascriptimportance-of-interactivity-in-web-development-4cho | webdev, javascript, tutorial | ## Importance of Interactivity in Web Development
Interactivity in web development is just like adding the fun stuff to a website that makes you want to stay and explore.
Interactivity is necessary in web development for several reasons:
#### Enhanced User Engagement:
It keeps one interested. When you are clicking arou... | ellaokah |
1,882,268 | THE PYTHON BLUEPRINT: A Beginners Guide to getting started | What is Python Language Python is a backend tool that is used by programmers and tech developers.... | 0 | 2024-06-09T19:18:22 | https://dev.to/davidbosah/the-python-blueprint-a-beginners-guide-to-getting-started-2chm | python, beginners, programming, developer | **What is Python Language**
Python is a backend tool that is used by programmers and tech developers. It's objective/Use cuts across different sectors of programming including:
1. Web development.
2. Data service.
3. Artificial Intelligence.
4. Gaming.
**Merits of Python Language**
Firstly the Python is generally ... | davidbosah |
1,882,063 | Helix Editor: a matter of questionable existence | As a learning junior dev, I went from the depiction of soyest dev imaginable(python my beloved,... | 0 | 2024-06-09T19:11:24 | https://dev.to/yappaholic/helix-editor-a-matter-of-questionable-existence-5cho | vim, editors, helix, codenewbie | As a learning junior dev, I went from the depiction of soyest dev imaginable(python my beloved, windows and VS Code) to the true struggle and learning enjoyer(Neovim btw, Arch btw and Typescript(bearable)). So recently I landed my vim-motions on the helix editor to try and figure out: was it really necessary for helix ... | yappaholic |
1,882,298 | Tool to create quick mockup | I am a developer, not a designer, but I want to write about UI and I want to include example UI... | 0 | 2024-06-09T19:07:42 | https://dev.to/lisacee/tool-to-create-quick-mockup-1eb6 | discuss | I am a developer, not a designer, but I want to write about UI and I want to include example UI images. What is a tool that y'all use to quickly create a sharable or embeddable image to accompany your writing here on dev.to?
I don't want a tool so in-depth that I have to spend a lot of time to figure it out. It would ... | lisacee |
1,882,285 | Set up an automated incident management response using AWS | Incident management Excited to share my latest AWS project focusing on automating an... | 0 | 2024-06-09T19:05:27 | https://dev.to/monica_escobar/set-up-an-automated-incident-management-response-using-aws-mp6 | aws, security, incident, automation | ## Incident management
Excited to share my latest AWS project focusing on automating an incident response following what I found to be a really engaging AWS made workshop.
The project involves setting up a core configuration of 3 EC2 instances with its corresponding security groups and a VPC in us-east-1 through a ... | monica_escobar |
1,882,296 | about kelvin, a terminal password manager i'm building | overview kelvin is a password manager for the linux terminal, it generates passwords, and... | 0 | 2024-06-09T19:03:16 | https://dev.to/dompehbright/about-kelvin-a-terminal-password-manager-im-building-a1c | rust, security, linux | ### overview
kelvin is a password manager for the linux terminal, it generates passwords, and it could be used as a vault to save and secure passwords. kelvin creates your vault locally. vault is encrypted and made a hidden directory.
in building kelvin, i depended on a skeleton of three structs, admin, deck and deck_... | dompehbright |
1,882,295 | New Developer | hello friends i am a new person here i wish see a new world special technology world | 0 | 2024-06-09T18:59:43 | https://dev.to/hakim_alabbasi_574021419d/hello-friends-i-am-a-new-person-here-i-wish-see-a-new-world-special-technology-world-49b9 | hello friends i am a new person here i wish see a new world special technology world | hakim_alabbasi_574021419d | |
1,882,294 | React hooks nobody told you before | TLDR 🔥 React.js is one of the most popular JavaScript libraries for building beautiful... | 0 | 2024-06-09T18:59:10 | https://dev.to/kumarkalyan/react-hooks-nobody-told-you-before-14 | webdev, reactnative, react, programming | ## TLDR :fire:
React.js is one of the most popular JavaScript libraries for building beautiful user interfaces and single-page applications. And the average salary of a react developer goes up to 100K usd a year . React is used by some of the most popular tech companies around the world. The React ecosystem is vast and... | kumarkalyan |
1,882,292 | Understanding React.memo: Optimizing Your React Applications | Introduction Have you ever noticed your React app slowing down as it grows? If yes, you... | 0 | 2024-06-09T18:58:55 | https://dev.to/ak_23/understanding-reactmemo-optimizing-your-react-applications-436a | react, programming, learning, webdev |
#### Introduction
Have you ever noticed your React app slowing down as it grows? If yes, you are not alone. React.memo is one of those handy tools that can help you optimize your React application, making it more efficient and faster. Let's dive into what React.memo is, how it works, and how you can use it to boost yo... | ak_23 |
1,882,293 | Benefits of Using AJAX | AJAX, which stands for Asynchronous JavaScript and XML, is a technique used in web development to... | 0 | 2024-06-09T18:57:42 | https://dev.to/infobijoy/explanation-of-the-example-and-benefits-of-using-ajax-3gjf | webdev, javascript, jquery, programming | AJAX, which stands for Asynchronous JavaScript and XML, is a technique used in web development to create dynamic and interactive web applications. It allows web pages to be updated asynchronously by exchanging small amounts of data with the server behind the scenes. This means that parts of a web page can be updated wi... | infobijoy |
1,882,291 | Benefits of Using jQuery And Downsides | jQuery is a fast, small, and feature-rich JavaScript library. It simplifies many tasks commonly... | 0 | 2024-06-09T18:54:38 | https://dev.to/infobijoy/benefits-of-using-jquery-and-downsides-2pln | webdev, javascript, jquery, programming | jQuery is a fast, small, and feature-rich JavaScript library. It simplifies many tasks commonly associated with JavaScript, such as HTML document traversal and manipulation, event handling, animation, and AJAX. jQuery is designed to make things like DOM manipulation and AJAX interactions simpler and more concise.
### ... | infobijoy |
1,882,290 | 2024 Guide to Succeeding in Technical Interviews | Whether you are an aspiring software engineer or a professional seeking a career change, finding your... | 0 | 2024-06-09T18:54:13 | https://dev.to/abdullah-dev0/2024-guide-to-succeeding-in-technical-interviews-ek2 | webdev, interview, beginners, tutorial | Whether you are an aspiring software engineer or a professional seeking a career change, finding your dream job in the modern tech industry can be challenging. Receiving an interview call is a significant achievement. However, the real challenge begins after you pass the rigorous application phase and secure an intervi... | abdullah-dev0 |
1,882,257 | Modular Monolith: A disruptive guide to architecting your React app | Intro This writing was inspired by the article: “How to Structure Vue Projects”. It... | 0 | 2024-06-09T18:52:19 | https://dev.to/artiumws/modular-monolith-a-disruptive-guide-to-architecting-your-react-app-2gji | webdev, javascript, programming, react | ## Intro
This writing was inspired by the article: “[How to Structure Vue Projects](https://dev.to/alexanderop/how-to-structure-vue-projects-20i4)”.
It explains various front-end application structures. It’s really insightful and can be applied to other front-end frameworks.
A year ago, my team and I started a new ... | artiumws |
1,882,288 | Optimizing Web Performance: Tips and Techniques | Why Web Performance Matters: Web development is crucial because it shapes the way we... | 0 | 2024-06-09T18:47:39 | https://dev.to/ellaokah/optimizing-web-performance-tips-and-techniques-1h60 | webdev, javascript, performance, css |
## Why Web Performance Matters:
[Web development](https://en.wikipedia.org/wiki/Web_development#:~:text=Web%20development%20is%20the%20work,businesses%2C%20and%20social%20network%20services.) is crucial because it shapes the way we experience the internet.
Websites and web applications are essential for businesses, or... | ellaokah |
1,882,287 | Searching Castles Using Go, MongoDB, Github Actions And Web Scraping | It’s Been A While! It’s been a while since last one! TL;DR: work, life, study… you know... | 0 | 2024-06-09T18:42:28 | https://www.buarki.com/blog/find-castles | go, mongodb, webscraping, opendata |
## It’s Been A While!
It’s been a while since last one! TL;DR: work, life, study… you know :)
## A Project Of Open Data Using Go
In March 2024, I created a small project to experiment with using **Server-Sent Events (SSE)** in a Go web server to continuously send data to a frontend client. It wasn’t anything partic... | buarki |
1,882,284 | Cypress Testing Framework | Cypress is a testing framework for Javascript that allows you to easily create tests for your web... | 0 | 2024-06-09T18:40:35 | https://dev.to/uhrinuh/cypress-testing-framework-32jh | Cypress is a testing framework for Javascript that allows you to easily create tests for your web application. You're able to test the app directly in the browser, debug issues directly in the browser, and eliminates flaky tests by interacting with your application the same way users do so you can discover bugs before ... | uhrinuh | |
1,882,282 | JavaScript Latest Version: What's New? | JavaScript's latest update, ECMAScript 2023 (ES14), released in June 2023, brings several exciting... | 0 | 2024-06-09T18:37:27 | https://dev.to/azeem_shafeeq/javascript-latest-version-whats-new-532m | javascript, webdev, programming, tutorial | JavaScript's latest update, ECMAScript 2023 (ES14), released in June 2023, brings several exciting features to enhance coding efficiency and capabilities. Here's a quick overview of what's new:
- Well-Formed Unicode Strings: Ensures better handling of global text standards.
- Atomic waitSync: Improves communication in... | azeem_shafeeq |
1,882,281 | Download Output – FX Bundle for (Windows) | Looking to enhance your music production experience on your Windows platform? Look no further than... | 0 | 2024-06-09T18:36:14 | https://dev.to/plugins_forest05_90df5565/download-output-fx-bundle-for-windows-387j | musicproduction, windows, fxbundle, downloadoutput | Looking to enhance your music production experience on your Windows platform? Look no further than the Download [Output – FX Bundle (Windows)](https://pluginsforest.com/product/output-fx-bundle-windows/), a comprehensive suite designed to elevate your sound game to unprecedented heights. Packed with cutting-edge featur... | plugins_forest05_90df5565 |
1,882,277 | HackerRank SQL Preparation: Weather Observation Station 1(MySQL) | Problem Statement: Query a list of CITY and STATE from the STATION table. Link: HackerRank - Weather... | 0 | 2024-06-09T18:31:33 | https://dev.to/christianpaez/hackerrank-sql-preparation-weather-observation-station-1mysql-1gke | sql, writeups, hackerrank, mysql |
**Problem Statement:**
Query a list of CITY and STATE from the **STATION** table.
**Link:** [HackerRank - Weather Observation Station 1](https://www.hackerrank.com/challenges/weather-observation-station-1/problem)
**Solution:**
```sql
SELECT CITY, STATE FROM STATION;
```
**Explanation:**
- `SELECT CITY, STATE`: ... | christianpaez |
1,882,276 | Handling AWS WAF Capacity Limits with Terraform | When managing AWS WAF resources using Terraform, one common issue is exceeding the Web ACL Capacity... | 0 | 2024-06-09T18:28:02 | https://dev.to/mukulsharma/handling-aws-waf-capacity-limits-with-terraform-1741 | terraform, aws, webacl, waf | When managing AWS WAF resources using Terraform, one common issue is exceeding the Web ACL Capacity Units (WCUs) limit, which can lead to deployment failures. This blog post will guide you through understanding WCUs, checking capacity using AWS CLI, and integrating this process into your Terraform workflow to ensure sm... | mukulsharma |
1,882,275 | Gold Bangles Design | The Timeless Elegance of Gold Bangles Design Gold bangles have long been a symbol of elegance,... | 0 | 2024-06-09T18:27:26 | https://dev.to/parakkatjewels/gold-bangles-design-45fa | The Timeless Elegance of Gold Bangles Design
Gold bangles have long been a symbol of elegance, tradition, and timeless beauty. Their captivating designs not only adorn the wrists but also tell a story of cultural heritage, personal style, and exquisite craftsmanship. Whether you’re a jewelry enthusiast or someone looki... | parakkatjewels | |
1,882,274 | HackerRank SQL Preparation: Japanese Cities' Names(MySQL) | Problem Statement: Query the names of all Japanese cities in the CITY table. The COUNTRYCODE for... | 0 | 2024-06-09T18:24:42 | https://dev.to/christianpaez/hackerrank-sql-preparation-japanese-cities-namesmysql-5ap1 | sql, mysql, writeups, hackerrank |
**Problem Statement:**
Query the names of all Japanese cities in the **CITY** table. The `COUNTRYCODE` for Japan is `JPN`.
**Link:** [HackerRank - Japanese Cities Name](https://www.hackerrank.com/challenges/japanese-cities-name/problem)
**Solution:**
```sql
SELECT NAME FROM CITY WHERE COUNTRYCODE = 'JPN';
```
**Ex... | christianpaez |
1,882,273 | Learn the Linked List Data Structure by Building a Blockchain in JavaScript | Overview Building a blockchain from scratch is an excellent way to understand both the... | 0 | 2024-06-09T18:24:05 | https://dev.to/hasan_py/learn-the-linked-list-data-structure-by-building-a-blockchain-in-javascript-1gcb | javascript, dsa, beginners, programming | ### Overview
Building a blockchain from scratch is an excellent way to understand both the intricacies of blockchain technology and fundamental data structures like linked lists. In this article, we’ll explore how to create a simple blockchain using JavaScript, highlighting how the blockchain resembles a singly linked... | hasan_py |
1,882,270 | Building a Plant Diagnosis Assistant using Lyzr SDK | In the age of technology, even plant care is getting an upgrade. Imagine having a personal plant... | 0 | 2024-06-09T18:19:01 | https://dev.to/akshay007/building-a-plant-diagnosis-assistant-using-lyzr-sdk-2i21 | ai, plants, programming, python | In the age of technology, even plant care is getting an upgrade. Imagine having a **personal plant expert** at your fingertips, ready to diagnose and remedy any issues your green friends may be facing. In this post, we’ll explore how this AI-powered app is transforming the way we care for our plants, powered by Lyzr SD... | akshay007 |
1,882,269 | Beaches frontend | This is a submission for [Frontend Challenge... | 0 | 2024-06-09T18:16:32 | https://dev.to/abelotegbola/beaches-frontend-2o51 | devchallenge, frontendchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
## What I Built
Using the html provided, custom features were added to provide better user experience. Some of these features are:
1. Custom font using google fonts - inter
2. Theme tog... | abelotegbola |
1,882,267 | Como resolver o erro "Execução de scripts desabilitada neste sistema" (Execution scripts is disabled on this system error) | Nós, como desenvolvedores, não podemos nos restringir apenas aos conhecimentos das nossas respectivas... | 0 | 2024-06-09T18:14:42 | https://dev.to/devaugusto/como-solucionar-o-erro-execucao-de-scripts-desabilitada-neste-sistema-execution-scripts-is-disabled-on-this-system-error-25ch | webdev, tutorial, productivity | Nós, como desenvolvedores, não podemos nos restringir apenas aos conhecimentos das nossas respectivas áreas na programação, precisamos também entender como o sistema operacional que você está utilizando funciona e como resolver erros com eficácia, sem tomar muito tempo.
O erro “Execution scripts is disabled on this sy... | devaugusto |
1,882,266 | vue mess detector | I started to put together a static code analysis tool for detecting code smells and best practice... | 0 | 2024-06-09T18:12:34 | https://dev.to/rrd/vue-mess-detector-34cp | vue, nuxt | I started to put together a static code analysis tool for detecting code smells and best practice violations in Vue.js and Nuxt.js projects.
Vscode extension is coming soon.
[https://github.com/rrd108/vue-mess-detector](https://github.com/rrd108/vue-mess-detector)
| rrd |
1,882,265 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-09T18:11:34 | https://dev.to/pippapaperkle/buy-verified-cash-app-account-48n0 | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | pippapaperkle |
1,882,253 | Day 13 of my progress as a vue dev | About today Today was one of the good day, I learned a few new programming approaches and a lot more... | 0 | 2024-06-09T17:34:53 | https://dev.to/zain725342/day-13-of-my-progress-as-a-vue-dev-2d37 | webdev, vue, typescript, tailwindcss | **About today**
Today was one of the good day, I learned a few new programming approaches and a lot more things on how I wanna give direction to this journey I'm on. Basically, this journey is all about being disciplined, learning more about things, and polishing my craft, and also to achieve something along the way t... | zain725342 |
1,882,264 | My First Postmortem: Outage Incident on Web Application | Postmortem: Outage Incident on Web Application Issue Summary: Duration: 4th June 2024, 08:00 AM —... | 0 | 2024-06-09T18:11:23 | https://dev.to/jacques00077/my-first-postmortem-outage-incident-on-web-application-3aj9 | Postmortem: Outage Incident on Web Application
Issue Summary: Duration: 4th June 2024, 08:00 AM — 5th June 2024, 1:00 PM (GMT) Impact: The web application experienced intermittent downtime, resulting in slow response times and partial service disruption. Approximately 35% of users were affected during this period.
Ti... | jacques00077 | |
1,882,185 | Integrating Google Translate API with Yii2 | In this post, I'll be sharing how to integrate the Google Translate API with Yii2. As developers, we... | 27,655 | 2024-06-09T17:57:40 | https://dev.to/toru/integrating-google-translate-api-with-yii2-c7o | yii2, php, googlecloud, programming | In this post, I'll be sharing how to integrate the Google Translate API with Yii2. As developers, we often encounter challenges when building multilingual sites with translation capabilities. Whether we're manually adding them or relying on a CMS, the process can be incredibly time-consuming and tedious.
<img width="1... | ifrah |
1,882,234 | Take me to the beach: Frontend | This is a submission for [Frontend Challenge... | 0 | 2024-06-09T17:54:37 | https://dev.to/gloria_gyemfa/take-me-to-the-beach-frontend-1oij | devchallenge, frontendchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
## What I Built
Welcome to our curated list of the best beaches in the world. Hover over the gallery of beaches for detailed information about each beach and where they are located
<!-... | gloria_gyemfa |
1,882,262 | Can you beat the 'Maze Of Monsters'? | Hello Dev.To community. This is my first post and it's the final step to my Codecademy training class... | 0 | 2024-06-09T17:48:06 | https://dev.to/bryson_noblesbemomusi/can-you-beat-the-maze-of-monsters-23ce | terminal, python, codene, discuss | Hello Dev.To community. This is my first post and it's the final step to my Codecademy training class in Python. My final project was to create a game/tool using Python code that could be run in the Terminal of your computer. The idea that I ended up going with was the "Maze Of Monsters" where you have to complete 5 st... | bryson_noblesbemomusi |
1,882,261 | why ReLU activation is preffered over sigmoid activation in hidden layers? | A post by 3129 Abhinav Kumar | 0 | 2024-06-09T17:46:32 | https://dev.to/abhinavkumar/why-relu-activation-is-preffered-over-sigmoid-activation-in-hidden-layers-3038 | machinelearning, deeplearning | abhinavkumar | |
1,882,260 | Deploying a Web Socket Application on Kubernetes | What is a WebSocket WebSocket is a computer communications protocol, providing a... | 0 | 2024-06-09T17:44:53 | https://dev.to/adilansari/deploying-a-web-socket-application-on-kubernetes-2h33 | websocket, kubernetes, devops, tutorial | ## What is a WebSocket
WebSocket is a computer communications protocol, providing a simultaneous two-way communication channel over a single Transmission Control Protocol (TCP) connection. [[Wikipedia]](https://en.wikipedia.org/wiki/WebSocket)
Deploying a WebSocket application on Kubernetes can seem daunting, but this... | adilansari |
1,882,259 | How to Get Udemy Premium Account Cookies Unlocking Udemy Premium Courses for Free | Learn how to get Udemy Premium account cookies and unlock premium courses for free. Follow our... | 0 | 2024-06-09T17:44:36 | https://dev.to/muhammadsuheer/how-to-get-udemy-premium-account-cookies-unlocking-udemy-premium-courses-for-free-28l | webdev, javascript, programming, tutorial | Learn how to get Udemy Premium account cookies and unlock premium courses for free. Follow our step-by-step guide to using Udemy Premium cookies effectively.
## Introduction
In the digital age, access to quality education has become easier and more affordable. Online learning platforms like Udemy offer a plethora of ... | muhammadsuheer |
1,882,258 | Best Beaches in the World! | This is a submission for [Frontend Challenge... | 0 | 2024-06-09T17:44:15 | https://dev.to/monik2002/best-beaches-in-the-world-12k9 | devchallenge, frontendchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
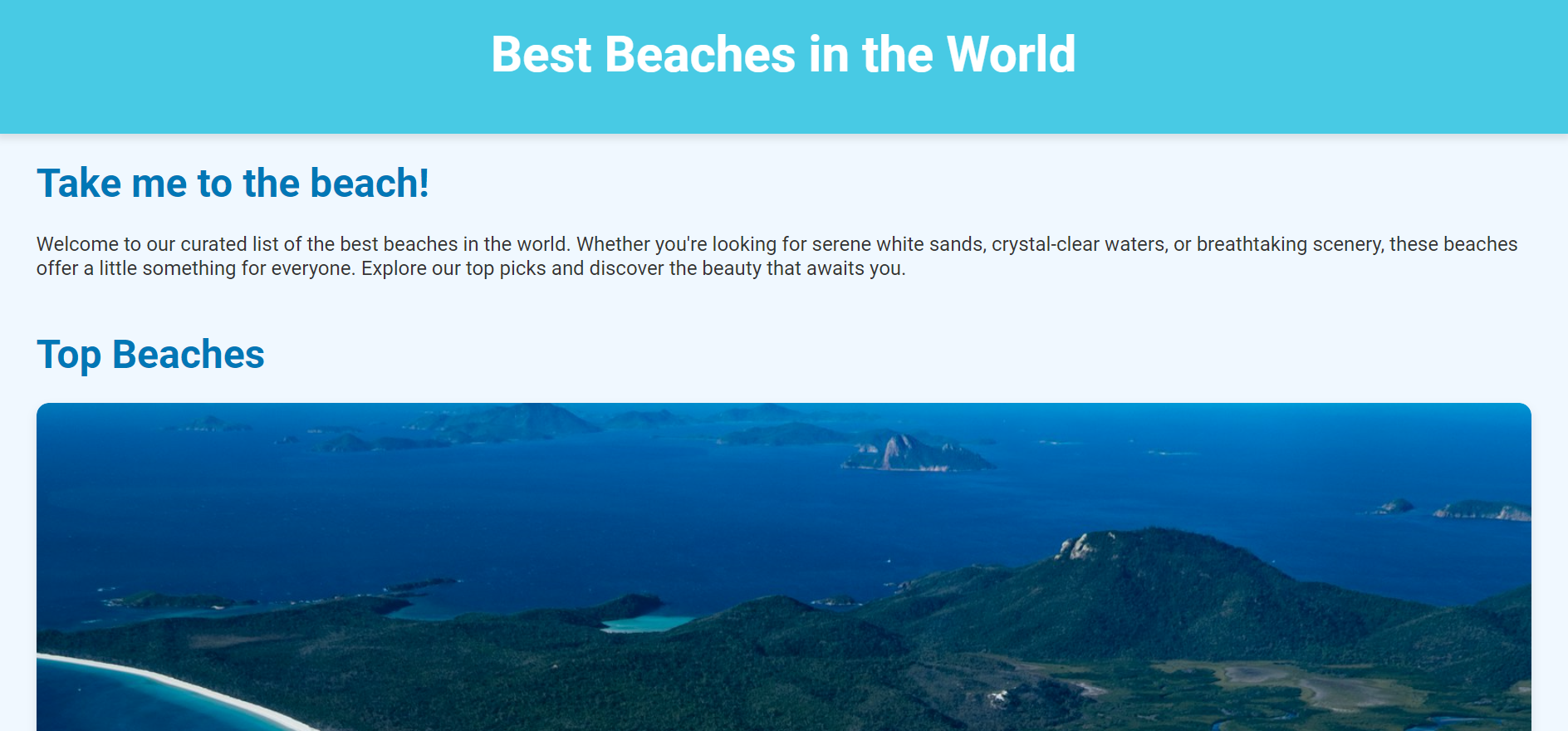
## What I Built
<!-- Tell us what you built and what you were looking to achie... | monik2002 |
1,882,256 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-06-09T17:39:59 | https://dev.to/unapapere865/buy-verified-paxful-account-ppg | tutorial, react, python, ai | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\n \n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | unapapere865 |
1,882,254 | CSS CANVAS | https://github.com/Shivaya007/css-canva.git Inspiration My growing enthusiasm for web... | 0 | 2024-06-09T17:38:55 | https://dev.to/176_shivaya_gupta_516b185/css-canvas-30fi | frontendchallenge, devchallenge, css | ERROR: type should be string, got "\nhttps://github.com/Shivaya007/css-canva.git\n\n## Inspiration\nMy growing enthusiasm for web designing fuels my desire to dive deeper into this field. This passion motivates me to embrace new challenges, continually expand my knowledge, and refine my skills. I am excited to explore innovative design techniques, learn cutting-edge technologies, and create engaging, user-friendly websites. This challenge represents an opportunity for personal and professional growth, driving me to push my limits and achieve excellence in web design\n\n## Demo \n\n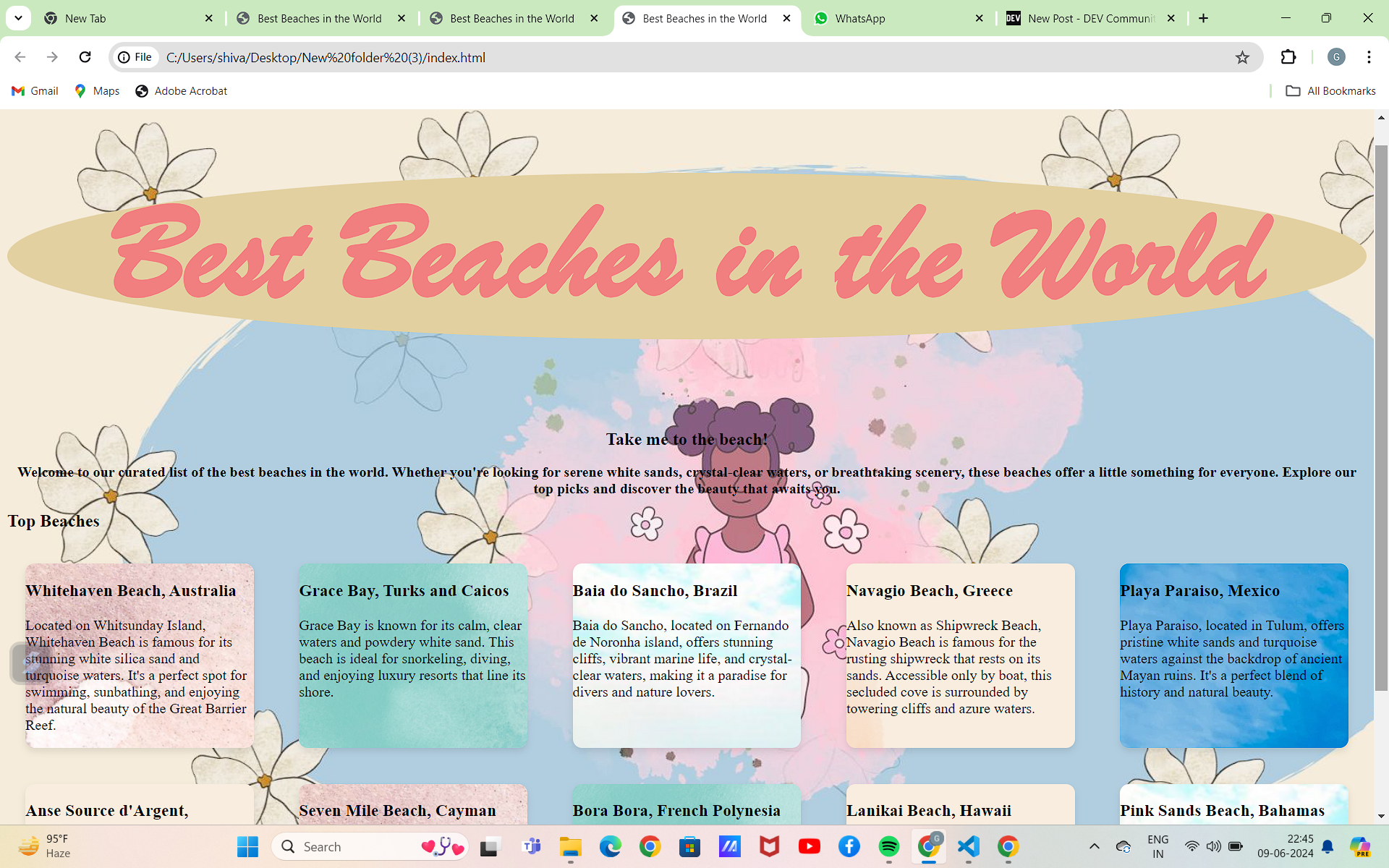\n\n" | 176_shivaya_gupta_516b185 |
1,882,252 | Exploring The Pieces for Developers AI App - My Initial Thoughts | These days we are so fortunate to live in a time where we have access to dozens of applications which... | 0 | 2024-06-09T17:34:17 | https://dev.to/andrewbaisden/exploring-the-pieces-for-developers-ai-app-my-initial-thoughts-cc5 | productivity, writing, ai, webdev | These days we are so fortunate to live in a time where we have access to dozens of applications which can dramatically boost our productivity. I use quite a few popular productivity tools because I follow the Getting Things Done (GTD) workflow which is essentially a personal productivity philosophy that reinvents how y... | andrewbaisden |
1,882,251 | Improving Developer Productivity With Pieces | Introduction Hello everyone! Recently, I got introduced to a developer tool from a Twitter... | 0 | 2024-06-09T17:32:56 | https://dev.to/olibhiaghosh/improving-developer-productivity-with-pieces-if3 | tutorial, ai, productivity, development | ## Introduction
Hello everyone! Recently, I got introduced to a developer tool from a Twitter space where I got to know about its superb features and thus decided to use it. Today I'll be sharing that and yeah, you guessed it right it's **Pieces for Developers.**
I was working on a project named Makaut Buddy and that... | olibhiaghosh |
1,882,250 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ __ Buy verified cash app account Cash... | 0 | 2024-06-09T17:28:21 | https://dev.to/unapapere865/buy-verified-cash-app-account-5egi | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n__\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | unapapere865 |
1,882,249 | Cách làm bánh dẻo trung thu bằng bột nếp tại nhà | Nguyên Liệu làm bánh dẻo trung thu bằng bột nếp Nguyên liệu làm bánh dẻo trung thu bằng bột... | 0 | 2024-06-09T17:26:56 | https://dev.to/blinkbakery/cach-lam-banh-deo-trung-thu-bang-bot-nep-tai-nha-26nn | 1. Nguyên Liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm nước đường bánh dẻo
300g đường trắng (đường tinh luyện)
5ml nước cốt chanh
300ml nước
Nguyên liệu làm vỏ bánh
392ml nước đường bánh dẻo
12ml dầu ăn
6ml nướ... | blinkbakery | |
1,882,248 | Cách làm bánh dẻo trung thu bằng bột nếp tại nhà | Nguyên Liệu làm bánh dẻo trung thu bằng bột nếp Nguyên liệu làm bánh dẻo trung thu bằng bột... | 0 | 2024-06-09T17:26:55 | https://dev.to/blinkbakery/cach-lam-banh-deo-trung-thu-bang-bot-nep-tai-nha-4f50 | 1. Nguyên Liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm nước đường bánh dẻo
300g đường trắng (đường tinh luyện)
5ml nước cốt chanh
300ml nước
Nguyên liệu làm vỏ bánh
392ml nước đường bánh dẻo
12ml dầu ăn
6ml nướ... | blinkbakery | |
1,882,247 | Cách làm bánh dẻo trung thu bằng bột nếp tại nhà | Nguyên Liệu làm bánh dẻo trung thu bằng bột nếp Nguyên liệu làm bánh dẻo trung thu bằng bột... | 0 | 2024-06-09T17:26:55 | https://dev.to/blinkbakery/cach-lam-banh-deo-trung-thu-bang-bot-nep-tai-nha-5dc9 | 1. Nguyên Liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm nước đường bánh dẻo
300g đường trắng (đường tinh luyện)
5ml nước cốt chanh
300ml nước
Nguyên liệu làm vỏ bánh
392ml nước đường bánh dẻo
12ml dầu ăn
6ml nướ... | blinkbakery | |
1,882,246 | Cách làm bánh dẻo trung thu bằng bột nếp tại nhà | Nguyên Liệu làm bánh dẻo trung thu bằng bột nếp Nguyên liệu làm bánh dẻo trung thu bằng bột... | 0 | 2024-06-09T17:26:55 | https://dev.to/blinkbakery/cach-lam-banh-deo-trung-thu-bang-bot-nep-tai-nha-1m6i | 1. Nguyên Liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm bánh dẻo trung thu bằng bột nếp
Nguyên liệu làm nước đường bánh dẻo
300g đường trắng (đường tinh luyện)
5ml nước cốt chanh
300ml nước
Nguyên liệu làm vỏ bánh
392ml nước đường bánh dẻo
12ml dầu ăn
6ml nướ... | blinkbakery | |
1,882,245 | Emulate User Activity with Bots | In our sales events platform, Auctibles, sellers have the exciting opportunity to create various... | 0 | 2024-06-09T17:26:03 | https://dev.to/kornatzky/emulate-user-activity-with-bots-5hdd | laravel, ecommerce, bots, php | In our sales events platform, [Auctibles](https://auctibles.com), sellers have the exciting opportunity to create various events. These range from a sale event at a fixed price to live auctions, where buyers bid the price up, providing a dynamic and engaging experience.
# The Technology
We use the Laravel framework ... | kornatzky |
1,882,244 | Cách làm bánh dẻo trung thu bằng bột nếp tại nhà | Làm bánh dẻo trung thu bằng bột nếp chắc hẳn đang được rất nhiều chị em quan tâm. Vào những dịp tết... | 0 | 2024-06-09T17:21:50 | https://dev.to/blinkbakery/cach-lam-banh-deo-trung-thu-bang-bot-nep-tai-nha-38hh | Làm bánh dẻo trung thu bằng bột nếp chắc hẳn đang được rất nhiều chị em quan tâm. Vào những dịp tết trung thu bên cạnh món bánh nướng quen thuộc, thì không thể không nhắc đến món bánh dẻo với đa dạng các loại nhân bánh và cách làm khác nhau như: Bánh dẻo truyền thống, bánh dẻo lạnh – món bánh dẻo trung thu với nhân bên... | blinkbakery | |
1,882,243 | Cách làm bánh dẻo trung thu bằng bột nếp tại nhà | Làm bánh dẻo trung thu bằng bột nếp chắc hẳn đang được rất nhiều chị em quan tâm. Vào những dịp tết... | 0 | 2024-06-09T17:21:49 | https://dev.to/blinkbakery/cach-lam-banh-deo-trung-thu-bang-bot-nep-tai-nha-3p3o | Làm bánh dẻo trung thu bằng bột nếp chắc hẳn đang được rất nhiều chị em quan tâm. Vào những dịp tết trung thu bên cạnh món bánh nướng quen thuộc, thì không thể không nhắc đến món bánh dẻo với đa dạng các loại nhân bánh và cách làm khác nhau như: Bánh dẻo truyền thống, bánh dẻo lạnh – món bánh dẻo trung thu với nhân bên... | blinkbakery | |
1,882,242 | Cách làm bánh dẻo trung thu bằng bột nếp tại nhà | Làm bánh dẻo trung thu bằng bột nếp chắc hẳn đang được rất nhiều chị em quan tâm. Vào những dịp tết... | 0 | 2024-06-09T17:21:48 | https://dev.to/blinkbakery/cach-lam-banh-deo-trung-thu-bang-bot-nep-tai-nha-11lk | Làm bánh dẻo trung thu bằng bột nếp chắc hẳn đang được rất nhiều chị em quan tâm. Vào những dịp tết trung thu bên cạnh món bánh nướng quen thuộc, thì không thể không nhắc đến món bánh dẻo với đa dạng các loại nhân bánh và cách làm khác nhau như: Bánh dẻo truyền thống, bánh dẻo lạnh – món bánh dẻo trung thu với nhân bên... | blinkbakery | |
1,882,241 | Time for A Change | So here I am at the beginning of a new journey. I am making this post today to make my introduction... | 0 | 2024-06-09T17:21:04 | https://dev.to/reina_simms/time-for-a-change-2mnb | So here I am at the beginning of a new journey. I am making this post today to make my introduction and to talk about something I learned.
I was a teacher until about two months. I have taught for more than 15 years in total and done much work in special education. I wont go on too much about it at this point however... | reina_simms | |
1,882,233 | etcd: The Vital Key-Value Store Powering Kubernetes | etcd is an open-source, distributed key-value store that serves as the backbone for storing and... | 0 | 2024-06-09T17:16:53 | https://dev.to/nuwan_weerasinhge_d93fd5b/etcd-the-vital-key-value-store-powering-kubernetes-10n9 |

etcd is an open-source, distributed key-value store that serves as the backbone for storing and managing critical data in Kubernetes clusters. It acts as a highly available and consistent repository for all the co... | nuwan_weerasinhge_d93fd5b | |
1,882,232 | Secure Shell (SSH): Accessing Remote Machines Securely | SSH, or Secure Shell, is a fundamental tool for securely connecting to and managing remote computer... | 0 | 2024-06-09T17:15:31 | https://dev.to/nuwan_weerasinhge_d93fd5b/secure-shell-ssh-accessing-remote-machines-securely-518i |
SSH, or Secure Shell, is a fundamental tool for securely connecting to and managing remote computer systems. It enables you to log in to a remote machine, execute commands, transfer files, and manage resources as if you were sitting directly in front of it. This article delves into the world of SSH, explaining its fu... | nuwan_weerasinhge_d93fd5b | |
1,882,176 | Create Floating Label Input Using Tailwind CSS | Hi guys, I wanna show you about floating label input of course using tailwind css😎 Here's the... | 0 | 2024-06-09T17:15:20 | https://dev.to/driannaird/create-floating-label-input-using-tailwind-css-3409 | webdev, tailwindcss, frontend, css | **Hi guys, I wanna show you about floating label input of course using tailwind css😎**
Here's the result

You wanna try?, lets go.
_1. We assume that you already have a tailwind project._
_2. Create a structure HT... | driannaird |
1,882,231 | Tourney Cap | Our surgical caps are made from soft, breathable fabric that ensures comfort during long surgeries.... | 0 | 2024-06-09T17:14:48 | https://dev.to/nelson_murdock_92092a944a/tourney-cap-1n5f | surgical, medical | Our [surgical caps](https://tourneycap.com/product-category/surgical-caps/) are made from soft, breathable fabric that ensures comfort during long surgeries. They come in various colors and patterns, allowing medical professionals to express their personalities while maintaining a professional appearance. The caps are ... | nelson_murdock_92092a944a |
1,882,230 | Frontend Challenge | Best Beaches in the World! | This is a submission for Frontend Challenge v24.04.17, Glam Up My Markup : Beaches 🌴🏖️ Welcome to My... | 0 | 2024-06-09T17:13:22 | https://dev.to/hikolakita/frontend-challenge-best-beaches-in-the-world-ddg | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup : Beaches_
**🌴🏖️ Welcome to My June CSS Frontend Challenge Submission! 🌊🌅
Inspiration ✨**
## Inspiration 🤔
**Today**, I am highlighting a serene and visually appealing web page dedicated to... | hikolakita |
1,882,229 | DOM Guardians: Exploring JavaScript’s MutationObserver API | Welcome to the world of JavaScript Observers! If you've ever needed a way to keep an eye on changes... | 0 | 2024-06-09T17:11:14 | https://dev.to/mini2809/dom-guardians-exploring-javascripts-mutationobserver-api-29hd | javascript, mutationobserverapi, webdev | Welcome to the world of JavaScript Observers! If you've ever needed a way to keep an eye on changes in your DOM and react dynamically, then observers are your best friends. Let's break it down.
**What Exactly Are Observers?**
As the name suggests, an observer watches for changes or events to occur and then springs int... | mini2809 |
1,882,228 | Performance optimization with useMemo | One of those things that you don't know enough, and then when you know somewhat you tend to use a bit... | 0 | 2024-06-09T17:08:15 | https://www.oh-no.ooo/articles/performance-optimization-with-usememo | react, webdev, performance, javascript | One of those things that you don't know enough, and then when you know somewhat you tend to use a bit too much is React beloved and behated <a href="https://react.dev/reference/react/useMemo" target="_blank">useMemo hook</a>. In my quest of trying to understand more the features of React that I use on a regular basis, ... | mahdava |
1,819,859 | HOW TO DEAL WITH EXCEPTIONS IN LARAVEL | Laravel is a free and open-source PHP web framework, created by Taylor Otwell and intended for the... | 0 | 2024-06-09T17:06:03 | https://dev.to/yzpeedro/how-to-deal-with-exceptions-in-laravel-mnl | laravel, php, backend | Laravel is a free and open-source PHP web framework, created by Taylor Otwell and intended for the development of web applications, Laravel is based on Symfony ([wiki](https://en.wikipedia.org/wiki/Laravel)).
The Framework provides a lot of features to help developers improve the error handling avoinding your applicat... | yzpeedro |
1,882,227 | From Idea to Reality: Building Supaclip in 2 Weeks | It started with an ambitious idea - transforming videos into searchable assets with transcripts,... | 0 | 2024-06-09T17:05:28 | https://dev.to/bobde_yagyesh/from-idea-to-reality-building-supaclip-in-2-weeks-4n1g | productivity, webdev, tooling, nextjs | It started with an ambitious idea - transforming videos into searchable assets with transcripts, summaries, and an AI assistant to make video learning efficient. Could we build this in just 2 weeks?
We leveraged existing libraries for accurate youtube transcripts, and Gemini's free API for concise summaries and an int... | bobde_yagyesh |
1,882,226 | Ethical AI: Balancing Innovation with Responsibility | Defining Ethical AI: Ethical AI refers to the development and deployment of artificial intelligence... | 0 | 2024-06-09T16:56:34 | https://dev.to/bingecoder89/ethical-ai-balancing-innovation-with-responsibility-2lgk | ai, productivity, machinelearning, datascience | 1. **Defining Ethical AI**: Ethical AI refers to the development and deployment of artificial intelligence systems that prioritize fairness, transparency, accountability, and the minimization of harm to individuals and society.
2. **Fairness in AI**: Ensuring AI systems are designed to avoid biases and discrimination,... | bingecoder89 |
1,882,225 | Building a Multi step form with XState and React Hook Form | What will we be building Recently I needed a multi step form for one of my personal... | 0 | 2024-06-09T16:55:58 | https://dev.to/ato_deshi/building-a-funnel-with-xstate-and-react-hook-form-4an3 | typescript, webdev, tutorial, react |
## What will we be building
Recently I needed a multi step form for one of my personal projects https://www.cvforge.app/, in this app users can create resumes. Starting from scratch with a new resume can be quite overwhelming, to help with this I offer users the option to start from an example.
This is what that lo... | ato_deshi |
1,882,223 | Como se destacar em qualquer processo seletivo que você participe | Postado originalmente no Dev na Gringa Substack. Se você manda bem nas entrevistas técnicas mas... | 0 | 2024-06-09T16:52:48 | https://dev.to/lucasheriques/como-se-destacar-em-qualquer-processo-seletivo-que-voce-participe-294l | braziliandevs, career | Postado originalmente no [Dev na Gringa Substack](https://open.substack.com/pub/devnagringa/p/como-se-destacar-em-qualquer-processo?r=gb7rl&utm_campaign=post&utm_medium=web).
---
Se você manda bem nas entrevistas técnicas mas no final rejeitado, esse artigo é pra você. Eu nunca fui a pessoa que sabe todas as resposta... | lucasheriques |
1,882,221 | 📱🎉 iPhone 15 Pro Max Giveaway 🎉📱 | 📱🎉 iPhone 15 Pro Max Giveaway 🎉📱 🌟 Get ready for the ultimate tech upgrade! 🌟 We're thrilled to... | 0 | 2024-06-09T16:48:26 | https://dev.to/apple99/iphone-15-pro-max-giveaway-3l64 | javascript, webdev, beginners, tutorial | 📱🎉 iPhone 15 Pro Max Giveaway 🎉📱
🌟 Get ready for the ultimate tech upgrade! 🌟
We're thrilled to announce our iPhone 15 Pro Max Giveaway! 🎁✨
[Follow Link](https://sites.google.com/view/21222324/home) | apple99 |
1,882,220 | 974. Subarray Sums Divisible by K | 974. Subarray Sums Divisible by K Medium Given an integer array nums and an integer k, return the... | 27,523 | 2024-06-09T16:45:04 | https://dev.to/mdarifulhaque/974-subarray-sums-divisible-by-k-dd | php, leetcode, algorithms, programming | 974\. Subarray Sums Divisible by K
Medium
Given an integer array `nums` and an integer `k`, return _the number of non-empty **subarrays** that have a sum divisible by `k`_.
A **subarray** is a **contiguous** part of an array.
**Example 1:**
- **Input:** nums = [4,5,0,-2,-3,1], k = 5
- **Output:** 7
- **Explanation... | mdarifulhaque |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.