
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,877,424 | Error of servlet | A post by deenanath pandey | 0 | 2024-06-05T02:17:42 | https://dev.to/deenanath1991/error-of-servlet-1jfd | help |
| deenanath1991 |
1,877,423 | What is cloud computing ? | In simple words, cloud computing is delivery of resource, IT environments that enable on-demand... | 0 | 2024-06-05T02:08:18 | https://dev.to/leonardosantosbr/what-is-cloud-computing--13f1 | learning, cloudcomputing, aws, azure | In simple words, cloud computing is delivery of resource, IT environments that enable on-demand services like computing, storage, networking, which can be accessed over the Internet using a cloud provider.
**Advantages of Cloud Computing**
- _Agility_
Being able to implement technology services in a short time, bein... | leonardosantosbr |
1,877,422 | How to Build AI-Driven Retrieval by Integrating Langchain and Elasticsearch | Discover how the synergistic power of Langchain and Alibaba Cloud Elasticsearch can revolutionize the... | 0 | 2024-06-05T02:06:52 | https://dev.to/a_lucas/how-to-build-ai-driven-retrieval-by-integrating-langchain-and-elasticsearch-35j0 | tutorial, ai, productivity, learning | Discover how the synergistic power of Langchain and Alibaba Cloud Elasticsearch can revolutionize the way you search and analyze data. This article provides an expert insight into blending these technologies for smarter, AI-driven data retrieval.
## The Power of Langchain
Langchain is a library designed to streamline... | a_lucas |
1,877,421 | Shanghai Rumi Electromechanical Technology's Impact on the Industry | 2d7cce047a34a7d66425e4880c976d2438d4b051ac669e9e8e35cad6f7f82f10.png Shanghai Rumi Electromechanical... | 0 | 2024-06-05T02:04:44 | https://dev.to/sylvia_joyceke_6f128206ac/shanghai-rumi-electromechanical-technologys-impact-on-the-industry-oal | 2d7cce047a34a7d66425e4880c976d2438d4b051ac669e9e8e35cad6f7f82f10.png
Shanghai Rumi Electromechanical Technology's Impact on the Industry
Shanghai Rumi Electromechanical Technology's impact on the Industry Technology can be a group which try ongoing creates products that will do factors for example {creating cars as... | sylvia_joyceke_6f128206ac | |
1,877,396 | The Backbone of Collaboration: Understanding Merge Request Reviews | Introduction Merge request reviews form an integral part of successful collaborative... | 0 | 2024-06-05T02:00:02 | https://dev.to/iswanjumat/the-backbone-of-collaboration-understanding-merge-request-reviews-3c8g | ### Introduction
Merge request reviews form an integral part of successful collaborative projects, especially in the field of software development. They ensure high-quality code, facilitate knowledge sharing, and foster a more collaborative team environment. In this blog post, we will delve into the importance of merg... | iswanjumat | |
1,877,395 | JavaScript Language Quick Start | Background This section gives a little background on JavaScript to help you understand why... | 0 | 2024-06-05T01:51:51 | https://dev.to/fmzquant/javascript-language-quick-start-obl | javascript, cryptocurrency, trading, fmzquant | ## Background
This section gives a little background on JavaScript to help you understand why it is the way it is.
## JavaScript Versus ECMAScript
ECMAScript is the official name for JavaScript. A new name became necessary because there is a trademark on JavaScript (held originally by Sun, now by Oracle). At the momen... | fmzquant |
1,877,394 | Innovations at Shanghai Rumi Electromechanical Technology | 1216ade8501ce3c06cb6ee9f82decf63dd8e4eadde06e8ba78254e1d37c398d9.png "Discover the Innovations at... | 0 | 2024-06-05T01:49:05 | https://dev.to/sylvia_joyceke_6f128206ac/innovations-at-shanghai-rumi-electromechanical-technology-37pn | 1216ade8501ce3c06cb6ee9f82decf63dd8e4eadde06e8ba78254e1d37c398d9.png
"Discover the Innovations at Shanghai Rumi Electromechanical Technology "
Introduction:
Shanghai Rumi Electromechanical Technology is a {|ongoing} company that are ongoing concentrates which can be ongoing the production of top-quality goods... | sylvia_joyceke_6f128206ac | |
1,877,393 | Overview of Shanghai Rumi Electromechanical Technology Co., L | 74c6cebcd045f665789222bb7e6488bc7e75fcf91216525d541f0d998ef07dea.png Overview of Shanghai Rumi... | 0 | 2024-06-05T01:30:35 | https://dev.to/sylvia_joyceke_6f128206ac/overview-of-shanghai-rumi-electromechanical-technology-co-l-1736 | 74c6cebcd045f665789222bb7e6488bc7e75fcf91216525d541f0d998ef07dea.png
Overview of Shanghai Rumi Electromechanical Technology Co., Ltd
Looking for a {|continuing} business which provides top-quality, revolutionary, plus merchandise that is safer? Look no further than Shanghai Rumi Electromechanical Technology Co. Ltd... | sylvia_joyceke_6f128206ac | |
1,877,621 | Pipeline Validación de Código | Siguiendo con la construcción de nuestro pipeline para aplicaciones en react, vamos a agregar... | 0 | 2024-06-05T13:26:37 | https://www.ahioros.info/2024/06/pipeline-validacion-de-codigo.html | azure, cloud, devops, spanish | ---
title: Pipeline Validación de Código
published: true
date: 2024-06-05 01:30:00 UTC
tags: Azure,cloud,DevOps,spanish
canonical_url: https://www.ahioros.info/2024/06/pipeline-validacion-de-codigo.html
---
Siguiendo con la construcción de nuestro pipeline para aplicaciones en react, vamos a agregar herramientas para ... | ahioros |
1,877,350 | How to make basic express api | ExpressJS is a JavaScript framework that allows you to make advanced api for your web app first you... | 0 | 2024-06-05T01:12:41 | https://dev.to/cache/how-to-make-basic-express-api-2o7g | express, javascript, api, webdev | ExpressJS is a JavaScript framework that allows you to make advanced api for your web app
first you need to make a `my-project`folder
Then open terminal and type this code
```
npm init -y
```
Then you need to install express, you can install express by this code
```
npm i express
```
After this code you need to r... | cache |
1,877,349 | Understanding Spring Annotations: A Comprehensive Overview | Introduction Working with Spring implies using lots of annotations to configure your... | 27,602 | 2024-06-05T01:02:28 | https://springmasteryhub.com/2024/06/04/understanding-spring-annotations-a-comprehensive-overview/ | java, spring, springboot, programming | # Introduction
Working with Spring implies using lots of annotations to configure your application, link components, and manage behaviors. These annotations can be separated into some categories: Initialization annotations, Configuration Specifics annotations, Stereotypes, Behavioral, and Testing.
This overview aims ... | tiuwill |
1,875,734 | it's all about the least worst combination of trade-offs | i remember that early in my computer science career in the industry hearing a lot of silver bullet... | 0 | 2024-06-05T01:02:03 | https://dev.to/marcostx/its-all-about-the-least-worst-combination-of-trade-offs-17fc | books, softwareengineering, architecture | i remember that early in my computer science career in the industry hearing a lot of silver bullet frameworks/packages that fit all the cases you want and (apparently) didn't have any disadvantages or drawbacks. "using this MVP framework X will solve your PHP development problems", "the best API interface for Java is Y... | marcostx |
1,877,347 | How to Merge Two Arrays in Java: A Simple Guide | Merging two arrays is a common operation in Java, often encountered in various programming tasks.... | 0 | 2024-06-05T00:50:09 | https://dev.to/raajaryan/how-to-merge-two-arrays-in-java-a-simple-guide-13hc | java, programming, tutorial, beginners |
Merging two arrays is a common operation in Java, often encountered in various programming tasks. This article explores multiple methods to merge two arrays in Java, catering to different preferences and scenarios.
## Method 1: Using Predefined Function
```java
import java.util.Arrays;
public class MergeTwoArrays1... | raajaryan |
1,877,291 | Building Connections: Exploring Bing Search Engine APIs | In the vast landscape of digital information, search engines play a pivotal role in helping users... | 0 | 2024-06-04T23:08:47 | https://dev.to/ericksmith14/building-connections-exploring-bing-search-engine-apis-2a3b | api, bing | In the vast landscape of digital information, search engines play a pivotal role in helping users navigate through the abundance of data available on the internet. Among the myriad of search engines available, Bing stands out as a robust platform offering powerful APIs (Application Programming Interfaces) that develope... | ericksmith14 |
1,877,342 | Developing Interactive E-Learning Content with HTML5 and JavaScript | Introduction With the rapid growth of technology, e-learning has become a popular medium... | 0 | 2024-06-05T00:31:51 | https://dev.to/kartikmehta8/developing-interactive-e-learning-content-with-html5-and-javascript-2hio | webdev, javascript, beginners, programming | ## Introduction
With the rapid growth of technology, e-learning has become a popular medium for education and training. In order to keep up with this changing trend, developers are now turning to HTML5 and JavaScript to create interactive and engaging e-learning content. In this article, we will discuss the advantages... | kartikmehta8 |
1,877,340 | GraphQL vs. REST: Qual é a Melhor Escolha para sua API? | No mundo do desenvolvimento de APIs, REST tem sido o padrão de fato por muitos anos. No entanto, com... | 0 | 2024-06-05T00:21:32 | https://dev.to/thiagohnrt/graphql-vs-rest-qual-e-a-melhor-escolha-para-sua-api-59cj | graphql, restapi, webdev, braziliandevs | No mundo do desenvolvimento de APIs, REST tem sido o padrão de fato por muitos anos. No entanto, com o surgimento do GraphQL, os desenvolvedores agora têm uma alternativa poderosa e flexível. Este artigo compara GraphQL e REST, destacando as vantagens e desvantagens de cada abordagem, e fornece orientações sobre quando... | thiagohnrt |
1,878,150 | What is the best web scraping API service? | Web scraping API services are becoming very popular as the demand for web data is sky-rocketing.... | 0 | 2024-06-05T15:18:01 | https://scrapeway.com/blog/what-is-the-best-web-scraping-api-service | benchmark, webscraping, data, datascience | ---
title: What is the best web scraping API service?
published: true
date: 2024-06-05 00:00:55 UTC
tags: benchmark,webscraping,data,datascience
canonical_url: https://scrapeway.com/blog/what-is-the-best-web-scraping-api-service
---

Web scrapi... | scrapeway |
1,851,897 | OCR with tesseract, python and pytesseract | Python is super versatile, it has a giant community that has libraries that allow to achieve great... | 0 | 2024-06-05T03:12:02 | https://coffeebytes.dev/en/ocr-with-tesseract-python-and-pytesseract/ | python, ai, ocr, machinelearning | ---
title: OCR with tesseract, python and pytesseract
published: true
date: 2024-06-05 00:00:00 UTC
tags: python,ai,ocr,machinelearning
canonical_url: https://coffeebytes.dev/en/ocr-with-tesseract-python-and-pytesseract/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/sx0no0vh23re7lra4w6b.jpg
---
... | zeedu_dev |
1,877,290 | React: Design Patterns | Understanding Layout Components | Layout components in React are specialized components designed to arrange other components on a page.... | 0 | 2024-06-04T23:04:03 | https://dev.to/andresz74/react-design-patterns-understanding-layout-components-4jcm | Layout components in React are specialized components designed to arrange other components on a page. Their primary role is to manage the layout, allowing the main content components to remain agnostic about their placement. This separation of concerns enhances flexibility and reusability. Examples include split screen... | andresz74 | |
1,812,683 | Welcome Thread - v279 | Leave a comment below to introduce yourself! You can talk about what brought you here, what... | 0 | 2024-06-05T00:00:00 | https://dev.to/devteam/welcome-thread-v279-2mg1 | welcome | ---
published_at : 2024-06-05 00:00 +0000
---

---
1. Leave a comment below to introduce yourself! You can talk about what brought you here, what you're learning, or just a fun fact about yourself.
2. Reply to so... | sloan |
1,877,296 | Implementing Native Code in React Native | Hey devs! React Native is an excellent tool for building mobile applications with a single codebase... | 0 | 2024-06-04T23:57:18 | https://dev.to/paulocappa/implementing-native-code-in-react-native-2282 | kotlin, swift, reactnative, javascript | Hey devs!
React Native is an excellent tool for building mobile applications with a single codebase that can run on both iOS and Android. However, sometimes we need to access platform-specific functionalities that are not available in the standard React Native library. In these situations, we can turn to native code i... | paulocappa |
1,877,295 | How to Create a Responsive Card Using Plain HTML & CSS | When you go online, and visit different websites, you will always come across websites that have an... | 0 | 2024-06-04T23:26:33 | https://dev.to/george_kingi/how-to-create-a-responsive-card-using-plain-html-css-1j3b | webdev, css, html, animation | When you go online, and visit different websites, you will always come across websites that have an image with text at either the top or bottom of the image. A profile picture on a platform with bio text at the bottom is a perfect example of this context.
The image with the text is called a CARD in HTML and CSS. A ca... | george_kingi |
1,875,908 | Elanat CMS One Year Birthday | Today, June 5, 2024, is the one year anniversary of Elanat CMS. The first version of Elanat CMS... | 0 | 2024-06-04T23:23:01 | https://dev.to/elanatframework/elanat-cms-one-year-birthday-bif | news, opensource, dotnet, github | Today, June 5, 2024, is the one year anniversary of [Elanat CMS](https://github.com/elanatframework/Elanat). The first version of Elanat CMS (1.0.0.0) was released on June 5, 2023. Before the release of version 1, Elanat CMS was developed by Mohammad Rabie in more than 10 years. Elanat CMS is a large CMS-Framework that... | elanatframework |
1,877,293 | React: Design Patterns | Container Components | In the world of React, there's a design pattern called Container Components. If you're a beginner or... | 0 | 2024-06-04T23:13:04 | https://dev.to/andresz74/react-design-patterns-container-components-5g70 | react, javascript, designpatterns | In the world of React, there's a design pattern called Container Components. If you're a beginner or intermediate React developer, you might be used to having each child component load its own data. Typically, you'd use hooks like `useState` and `useEffect` along with libraries like Axios or Fetch to get data from a se... | andresz74 |
1,873,946 | Deploying static webs apps with the Azure cli and bicep | Deploying static webs apps via the cli and bicep | 0 | 2024-06-04T22:49:08 | https://dev.to/danwright/deploying-static-webs-apps-1dib | azure, devops, bicep, react | ---
title: Deploying static webs apps with the Azure cli and bicep
published: true
description: Deploying static webs apps via the cli and bicep
tags: #Azure #devops #Bicep #react
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-02 20:49 +0000
---
## Deplo... | danwright |
1,877,285 | Best Practices for Working with Next.js | Next.js has rapidly become one of the most popular frameworks for building React applications,... | 0 | 2024-06-04T22:45:37 | https://dev.to/enitanogun1/best-practices-for-working-with-nextjs-49np |
Next.js has rapidly become one of the most popular frameworks for building React applications, offering a range of features that simplify development and enhance performance. Here are some best practices to follow when working with Next.js:
1. Leverage Static Generation and Server-Side Rendering
Next.js provides po... | enitanogun1 | |
1,877,284 | How to create a Storage Account For a Public Website in Microsoft Azure | Skilling tasks • Create a storage account. • Configure basic settings for security and... | 0 | 2024-06-04T22:33:29 | https://dev.to/atony07/how-to-create-a-storage-account-in-microsoft-azure-44e7 | Skilling tasks
• Create a storage account.
• Configure basic settings for security and networking.
Follow these steps below;
Step:1: Create a Resource group or make use of an existing Resource group.
An existing Resource group was used here.
Step:2: In the Azure portal, search for and select Storage accounts
 !!
[Daftar KLIK DI SINI BOSKU](https://bigprofitbuzz.com/) !!

[QDAL88](https://bigprofitbuzz.com/) menawarkan berbagai macam jenis permainan sl... | qdal88login | |
1,877,282 | Mastering Python Comprehensions: Crafting Efficient and Readable Code | There are a lot of things that Python can do, and one of the things Python is good at is making code... | 0 | 2024-06-04T22:31:17 | https://medium.com/gitconnected/mastering-python-comprehensions-d7cef457165a | python, beginners | There are a lot of things that Python can do, and one of the things Python is good at is making code more readable and easy to follow. Python comprehension is one of those patterns that will make your code more efficient and readable, unless you go overboard.
**So what is comprehension?** In technical terms, comprehen... | sahilfruitwala |
1,877,281 | Seeing the world: Think of at least five places you'd like to visit | `let listName:string[]=['hello world','Today is weather is very beatuiful','I going to cenima ','I... | 0 | 2024-06-04T22:30:45 | https://dev.to/osaid4624/seeing-the-world-think-of-at-least-five-places-youd-like-to-visit-bfl | `let listName:string[]=['hello world','Today is weather is very beatuiful','I going to cenima ','I start a learn typscript',]
// console.log("Orignal Order", listName);
// console.log("Alpebatic Order", [...listName].sort());
// console.log("Orginal Order", listName);
// console.log("Revers Alphabet",[...listName].s... | osaid4624 | |
1,877,280 | Day 963 : My Computer | liner notes: Professional : Had a day of no meetings so I tried to take full advantage. I finally... | 0 | 2024-06-04T22:29:09 | https://dev.to/dwane/day-963-my-computer-4eog | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Had a day of no meetings so I tried to take full advantage. I finally got a library that I've been working on published. Going to test it out in an application tomorrow. Spent some time responding to community questions.
- Personal : Last night, I worked on a side project. Went through ... | dwane |
1,877,279 | AI-Powered Tools to Unleash Your Creativity: From Fiction to Fact | In the realm of creative expression, Artificial Intelligence (AI) is rapidly transforming... | 0 | 2024-06-04T22:28:59 | https://dev.to/malconm/ai-powered-tools-to-unleash-your-creativity-from-fiction-to-fact-312l | ai, productivity, design | In the realm of creative expression, Artificial Intelligence (AI) is rapidly transforming possibilities. From crafting captivating narratives to generating awe-inspiring visuals, AI tools are empowering artists and content creators to push boundaries and streamline their workflows.
Here are 4 compelling AI tools you c... | malconm |
1,877,278 | 🚀What is BXDev Technology? | Hey Dev.to community! I'm thrilled to introduce you to BXDev Technology, a dynamic and... | 0 | 2024-06-04T22:25:12 | https://dev.to/bxdevtech/what-is-bxdev-technology-111d | webdev, programming, opensource, career | ## Hey Dev.to community!
I'm thrilled to introduce you to BXDev Technology, a dynamic and forward-thinking tech company dedicated to pushing the boundaries of innovation and creating impactful digital solutions. As our inaugural post on Dev.to, we're excited to share our story and vision with you.
## Who We Are?
BXDe... | cptbuuya |
1,877,351 | The Game-Changing Strategy: How Playables on YouTube, Netflix, LinkedIn, and NYT Are Driving Disruption! | Have you played a Playable yet? If you've played games like Wordle, Connections, Tiles, or Sudoku... | 0 | 2024-06-06T12:12:28 | https://brianchristner.io/the-game-changing-strategy-how-playables-on-youtube-netflix-linkedin-and-nyt-are-driving-disruption/ | business, marketing, gaming | ---
title: The Game-Changing Strategy: How Playables on YouTube, Netflix, LinkedIn, and NYT Are Driving Disruption!
published: true
date: 2024-06-04 22:21:26 UTC
tags: business,marketing,gaming
canonical_url: https://brianchristner.io/the-game-changing-strategy-how-playables-on-youtube-netflix-linkedin-and-nyt-are-driv... | vegasbrianc |
1,877,274 | some of the great beaches around the world | A post by Prithiwis Das | 0 | 2024-06-04T22:20:01 | https://dev.to/prithiwis_das_39b4df24b0b/some-of-the-great-beaches-around-the-world-188i | prithiwis_das_39b4df24b0b | ||
1,877,273 | Trying to give some new tag lines | A post by Prithiwis Das | 0 | 2024-06-04T22:18:45 | https://dev.to/prithiwis_das_39b4df24b0b/trying-to-give-some-new-tag-lines-46i7 | prithiwis_das_39b4df24b0b | ||
1,877,272 | Introducing PixShuffle | Hey Dev.to community! We're thrilled to introduce PixShuffle, a revolutionary new way to experience... | 0 | 2024-06-04T22:18:01 | https://dev.to/cptbuuya/introducing-pixshuffle-23gj | Hey Dev.to community!
We're thrilled to introduce PixShuffle, a revolutionary new way to experience visual content like never before.
What is PixShuffle?
PixShuffle is an innovative picture slideshow platform that brings your images to life with dynamic shuffling and customizable features. Whether you're a photograph... | cptbuuya | |
1,877,271 | Add "Login with Passkeys" to your Django app | Passkeys, passkeys, passkeys! Everyone's talking about them. With Amazon rolling out passkeys last... | 0 | 2024-06-04T22:15:40 | https://pangea.cloud/blog/add-login-with-passkeys-to-your-django-app/ | Passkeys, passkeys, passkeys! Everyone's talking about them. With [Amazon](https://www.theverge.com/2023/10/23/23928589/amazon-passkey-support-web-ios-shopping-mobile-app) rolling out passkeys last year and [Google](https://blog.google/technology/safety-security/passkeys-default-google-accounts/) encouraging users to m... | vmvilla | |
1,877,269 | exciting beaches all over the world | This is a submission for [Frontend Challenge... | 0 | 2024-06-04T22:13:16 | https://dev.to/prithiwis_das_39b4df24b0b/exciting-beaches-all-over-the-world-493n | devchallenge, frontendchallenge, css | _This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
## What I Built
<!-- Tell us what you built and what you were looking to achieve. -->
## Demo
<!-- Show us your project! You can directly embed an editor into this post (see the FAQ s... | prithiwis_das_39b4df24b0b |
1,877,268 | Ruby function design and other stuff I like ranting about | Why? If the posts title looks weird: it is. This is a small rant about code-functionality... | 0 | 2024-06-04T22:09:31 | https://dev.to/aneshodza/ruby-function-design-and-other-stuff-i-like-ranting-about-32oe | ruby, watercooler | ## Why?
If the posts title looks weird: it is. This is a small rant about code-functionality that makes little to no sense (in my eyes).
This whole article can be summed up like this:

## How?
I was talking to a cowo... | aneshodza |
1,877,267 | I Babaji labaran Adamu sole proprietor/product manager ABU ABDULRAHMAN Communication, | T**his is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration ... | 0 | 2024-06-04T22:08:28 | https://dev.to/1b2a3b4j5i/i-babaji-labaran-adamu-sole-proprietorproduct-manager-abu-abdulrahman-communication-197d | frontendchallenge, devchallenge, css | _T**his is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
<!-- What are you highlighting today? -->
## Demo
<!-- Show us your CSS Art! You can directly embed an editor into this post (see the FAQ section of the challenge page) or you can... | 1b2a3b4j5i |
1,877,263 | Babylon.js Browser MMO - DevLog - Update #4 - Entering / Leaving game synchronization | Hello, This time, a short presentation on the synchronization of entering and leaving zones. As you... | 0 | 2024-06-04T22:03:58 | https://dev.to/maiu/babylonjs-browser-mmo-devlog-update-4-entering-leaving-game-synchronization-3no6 | babylonjs, gamedev, indie, mmo | Hello,
This time, a short presentation on the synchronization of entering and leaving zones. As you may have noticed, when a player joins a zone, a message is displayed on the UI and player is rendered. The synchronization of position and rotation is currently functioning smoothly without any apparent issues, aside fr... | maiu |
1,854,413 | Dev: Blockchain | A Blockchain Developer is a specialized professional responsible for designing, developing, and... | 27,373 | 2024-06-04T22:00:00 | https://dev.to/r4nd3l/dev-blockchain-akg | blockchain, developer | A **Blockchain Developer** is a specialized professional responsible for designing, developing, and implementing blockchain-based solutions and decentralized applications (DApps). Here's a detailed description of the role:
1. **Understanding Blockchain Technology:**
- Blockchain Developers possess a deep understand... | r4nd3l |
1,865,859 | SAST Scanning with SonarQube and Docker | Learn how to set up and use SonarQube for Static Application Security Testing (SAST) with Docker. | 27,513 | 2024-06-04T21:59:45 | https://damienjburks.hashnode.dev/sast-scanning-with-sonarqube-and-docker | docker, cybersecurity, owasp, tutorial | ## Table of Contents
- [Introduction](#introduction)
- [Prerequisites](#prerequisites)
- [Understanding SonarQube](#understanding-sonarqube)
- [What is SonarQube?](#what-is-sonarqube)
- [Understanding Docker Compose](#understanding-docker-compose)
- [Key Features and Benefits](#key-features-and-benefits)
- [Scannin... | damienjburks |
1,877,266 | Daily Notes | Durable Skills - Networking Quality and Quantity in opportunities, numbers game Reuben... | 0 | 2024-06-04T21:58:59 | https://dev.to/dylansarikas/daily-notes-1m8f | ## Durable Skills - Networking
1. Quality and Quantity in opportunities, numbers game
2. Reuben has a list of updated networking events, email for list
3. Do your research before events, Name, Title, Company
4. Find connection, ask questions, get the person to talk
5. Singular Focus, make the person feel like the only ... | dylansarikas | |
1,877,265 | Babylon.js Browser MMO - DevLog - Update #5 - Area of interest with spatial hash grid | Hello, Next short presentation with the current progress. Today I'm presenting effect of working... | 0 | 2024-06-04T21:51:52 | https://dev.to/maiu/babylonjs-browser-mmo-devlog-update-5-area-of-interest-with-spatial-hash-grid-ifd | babylonjs, gamedev, indie, mmo | Hello,
Next short presentation with the current progress. Today I'm presenting effect of working spatial hash grid on the game server side. Server is sending two types of packages. First that someone is in range and should be visible and second to tell that entity is out of range should not be visible. Underneath whol... | maiu |
1,877,264 | [Game of Purpose] Day 17 | Today I created a new project called Sky Patrol. I added it to a Perforce repository, configured my... | 27,434 | 2024-06-04T21:49:31 | https://dev.to/humberd/game-of-purpose-day-17-ajm | gamedev | Today I created a new project called Sky Patrol. I added it to a Perforce repository, configured my user, set up stream depot, added Main stream and submitted initial commit.
I want to create a game, where you are a drone operator and drop granades on the enemy troops or vehicles. You could have different kind of dron... | humberd |
1,877,262 | My Journey of Programming Life | MY PROGRAMMING JOURNEY SO FAR. Every programmer's journey is unique, filled with challenges, moments... | 0 | 2024-06-04T21:48:11 | https://dev.to/collins_bright_d813903974/my-journey-of-programming-life-hbj |
**MY PROGRAMMING JOURNEY SO FAR.**
Every programmer's journey is unique, filled with challenges, moments of clarity and continuous Learning. My journiy to web development started three weeks ago and despite this short time, it had been an exciting journey. This article is a reflection of some initial steps, hurdles c... | collins_bright_d813903974 | |
1,875,347 | Let's Build HTTP Parser From Scratch In Rust | A week ago, I stumbled upon this fantastic article about learning Rust's iterators and pattern... | 0 | 2024-06-04T21:47:08 | https://dev.to/hiro_111/lets-build-http-parser-from-scratch-in-rust-5gih | rust, http | A week ago, I stumbled upon [this fantastic article](https://www.freecodecamp.org/news/rust-tutorial-build-a-json-parser/) about learning Rust's iterators and pattern matching by building a JSON parser. What really resonated with me was how it explained using Rust's built-in traits. If you're also learning Rust, I high... | hiro_111 |
1,877,261 | Architecting an AI App for Appointment Confirmation: Node.js, AWS & AI Calling Agent API | In this video, I'll walk you through the system design of a project that I have built that integrates... | 0 | 2024-06-04T21:40:36 | https://dev.to/gkhan205/architecting-an-ai-app-for-appointment-confirmation-nodejs-aws-ai-calling-agent-api-5820 | aws, node, javascript, ai | In this video, I'll walk you through the system design of a project that I have built that integrates Node.js, AWS, third-party APIs, and an AI Calling Agent (Talks like a real person). You'll learn how to efficiently fetch data from an external API using cron jobs, process and store it in a database, and then use anot... | gkhan205 |
1,877,260 | NextJS Project: How to create QR code from any URL | In this video, I’m excited to share my latest project – a QR code generator app with built-in... | 0 | 2024-06-04T21:36:40 | https://dev.to/gkhan205/build-advanced-qr-code-generator-app-with-nextjs-1kol | nextjs, webdev, javascript, beginners | In this video, I’m excited to share my latest project – a QR code generator app with built-in analytics. After finding existing solutions costly, I decided to create my own. This app will help you generate QR codes easily, and track their usage effectively.
Let's build this app together! I'll be developing it right he... | gkhan205 |
1,877,259 | Why Servicenow is better IT Career | ServiceNow is widely regarded as a strong choice for an IT career due to several compelling... | 0 | 2024-06-04T21:35:14 | https://dev.to/priya_rao_123/why-servicenow-is-better-it-career-450a | servicenow, technology, it, javascript | ServiceNow is widely regarded as a strong choice for an IT career due to several compelling reasons:

**1. High Demand for ServiceNow Professionals**
Growing Market: ServiceNow is a leading platform in IT service ma... | priya_rao_123 |
1,876,968 | 2024 Complete Full-Stack Developers Roadmap | Getting into tech may be nutcracking especially if you don't know your way about it. Things may be a... | 0 | 2024-06-04T21:33:16 | https://dev.to/code_duchess/2024-complete-full-stack-developers-roadmap-1co9 | webdev, javascript, beginners, programming | Getting into tech may be nutcracking especially if you don't know your way about it. Things may be a bit confusing and most Developers would wish they could go back in time and start their tech journey from afresh. I have saved you from your future what-ifs by writing this complete Full-Stack Developer road map, which ... | code_duchess |
1,877,256 | Welcome Me | Hi everyone, I'm excited to have discovered this space, I'm hoping to learn from everyone here and... | 0 | 2024-06-04T21:25:09 | https://dev.to/hacksoul/welcome-me-2oa3 | Hi everyone, I'm excited to have discovered this space, I'm hoping to learn from everyone here and also contribute to on going discussion in areas such as Infomation Security, Machine Learning, Compliance, and many more.
Thanks for having me Guys!☺️ | hacksoul | |
1,877,252 | Revolutionizing Business Intelligence: Unicloud’s Pioneering Approach to Cloud-Enabled Data Analytics and AI | The fusion of cloud computing with data analytics and AI is a significant milestone in the... | 0 | 2024-06-04T21:16:55 | https://dev.to/unicloud/revolutionizing-business-intelligence-uniclouds-pioneering-approach-to-cloud-enabled-data-analytics-and-ai-5hge | ai | The fusion of cloud computing with data analytics and AI is a significant milestone in the technological evolution, marking a new era in business data handling. This integration is pivotal in transforming the way organizations process, analyze, and utilize data for strategic decisions. Unicloud is a key player in this ... | unicloud |
1,877,251 | rest-api-with-express-typescript | https://rsbh.dev/blogs/rest-api-with-express-typescript | 0 | 2024-06-04T21:15:43 | https://dev.to/dingzhanjun/rest-api-with-express-typescript-563d | node, rest, express, swagger | https://rsbh.dev/blogs/rest-api-with-express-typescript | dingzhanjun |
1,877,250 | Upstream preview: Government carrot, government stick: Exploring two contrasting approaches to improving open source security | Upstream is tomorrow on June 5, and wow, our schedule is brillant. We’re giving you a sneak preview... | 0 | 2024-06-04T21:15:03 | https://dev.to/tidelift/upstream-preview-government-carrot-government-stick-exploring-two-contrasting-approaches-to-improving-open-source-security-3g16 | upstream, opensource, government, security | <p style="font-size: 18px;"><em>Upstream is </em><strong><em>tomorrow</em></strong><em> on June 5, and wow, our schedule is brillant. We’re giving you a sneak preview into some of the talks and the speakers giving them via posts like these. RSVP </em><a href="https://upstream.live/register?__hstc=23643813.d1ddc767e9f49... | kristinatidelift |
1,877,697 | You need to know about these amazing ai websites | In the digital age, high-quality images are essential for everything from professional photography to... | 0 | 2024-06-04T21:00:00 | https://dev.to/valterseu/you-need-to-know-about-these-amazing-ai-websites-1f84 | ai, development, devops, design |
In the digital age, high-quality images are essential for everything from professional photography to social media posts. However, enhancing image resolution can often be a challenging and costly endeavor. Enter Upscayl, a free AI-powered image upscaler that promises to make high-quality image enhancement accessible t... | valterseu |
1,877,247 | Entendendo o Uso de Offset em Tópicos do Kafka | O Apache Kafka é uma plataforma de streaming distribuída que permite a publicação, armazenamento e... | 0 | 2024-06-04T20:59:22 | https://dev.to/romerodias/entendendo-o-uso-de-offset-em-topicos-do-kafka-82 | O Apache Kafka é uma plataforma de streaming distribuída que permite a publicação, armazenamento e processamento de fluxos de registros em tempo real. Um dos conceitos fundamentais no Kafka é o "offset", que desempenha um papel crucial na forma como os dados são consumidos e gerenciados dentro dos tópicos. Neste post, ... | romerodias | |
1,877,246 | SHBJSKSBJBDAKDABJKABADA | SHBJSKSBJBDAKDABJKABADASHBJSKSBJBDAKDABJKABADASHBJSKSBJBDAKDABJKABADASHBJSKSBJBDAKDABJKABADASHBJSKSBJ... | 0 | 2024-06-04T20:59:16 | https://dev.to/brucezelda/shbjsksbjbdakdabjkabada-1e4n | SHBJSKSBJBDAKDABJKABADASHBJSKSBJBDAKDABJKABADASHBJSKSBJBDAKDABJKABADASHBJSKSBJBDAKDABJKABADASHBJSKSBJBDAKDABJKABADA
SHBJSKSBJBDAKDABJKABADA
[https://github.com/h4ikyu-du3p5t3r-b4ttl3-index](https://github.com/h4ikyu-du3p5t3r-b4ttl3-index)
[https://github.com/m4mel-kannnja-crawel-index](https://github.com/m4mel-kannnja... | brucezelda | |
1,877,245 | Golang REST API boilerplate | Upon meticulous investigation into the top Golang RESTful API project architectures, I have... | 0 | 2024-06-04T20:58:49 | https://dev.to/haithambh/golang-rest-api-boilerplate-165k | go, restapi, webdev |
Upon meticulous investigation into the top Golang RESTful API project architectures, I have discovered that the Goffers community shares a number of common structures. I'll share my decision with you along with a boilerplate that makes use of **MongoDB** and the **Golang Echo framework**.
## 1. Project initialization
... | haithambh |
1,877,244 | How to use Notion as a backend in a project using Next.js | How to use Notion as backend In the world of web development, the choice of backend is... | 27,625 | 2024-06-04T20:56:24 | https://www.johnatanortiz.tech/blog/how-to-use-notion-as-a-backend-in-a-project-using-next.js | # How to use Notion as backend
In the world of web development, the choice of backend is crucial for the functioning and scalability of an application. However, what if we could harness the capabilities of a versatile tool like Notion as the backend for our applications? In this article, we will explore how we can int... | johnatan_stevenortizsal | |
1,877,243 | Shadcn-ui codebase analysis: How is the hero section built on ui.shadcn.com website? | I wanted to find out how the hero section is developed on ui.shadcn.com, so I looked at its source... | 0 | 2024-06-04T20:50:16 | https://dev.to/ramunarasinga/shadcn-ui-codebase-analysis-how-is-the-hero-section-built-on-uishadcncom-website-1hom | javascript, opensource, nextjs, shadcnui | I wanted to find out how the hero section is developed on [ui.shadcn.com](http://ui.shadcn.com), so I looked at its [source code](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/(app)/layout.tsx). Because shadcn-ui is built using app router, the files I was interested in were [Layout.tsx](https://github.com/shad... | ramunarasinga |
1,874,782 | Quick Guide | MERN Stack Application Development | Developing a full-stack application offers a comprehensive understanding of application architecture.... | 0 | 2024-06-04T20:29:17 | https://dev.to/ishi_hisashi/quick-guide-mern-stack-application-development-4noe | webdev, react, mongodb, node | Developing a full-stack application offers a comprehensive understanding of application architecture. In this article, we will explore the development process of a full-stack application using the MERN stack, one of the most popular tech stacks today. This article will provide a hands-on guide for the steps to build a ... | ishi_hisashi |
1,877,165 | Market Weekly Recap: Notcoin Doubles In Price, Bitcoin Struggles, Base Enters Memecoin Race | NOT achieving milestone and memecoins updating the capitalisation mark community-driven... | 0 | 2024-06-04T20:46:32 | https://dev.to/endeo/market-weekly-recap-notcoin-doubles-in-price-bitcoin-struggles-base-enters-memecoin-race-3ohi | webdev, javascript, web3, blockchain | #### NOT achieving milestone and memecoins updating the capitalisation mark community-driven tokens as the ruling tendency in the market
As Bitcoin struggles to overcome the $70,000 barrier, community-driven altcoins enter the market spotlight with a continuous surge in trend momentum.
How The Open Network’s token ra... | endeo |
1,872,081 | 💣Not Learning New Things at Work is Destroying Your Career | Goals with this article In this article, I want to focus on these points: Explain the... | 0 | 2024-06-04T20:44:56 | https://dev.to/lucaschitolina/not-learning-new-things-at-work-is-destroying-your-career-34g9 | programming, productivity, career | ## Goals with this article
In this article, I want to focus on these points:
- Explain the rule of hooks and how this motivated me to write this article.
- Sometimes, we don't have time to learn at work, this is a problem
- Identifying and noting new concepts for future study is a key skill.
- Share my approach of c... | lucaschitolina |
1,875,928 | Design para programadores - Cores | Design é uma área que muitos programadores acabam por ter bastante dificuldade em lidar, em alguns... | 0 | 2024-06-04T20:41:53 | https://dev.to/terminalcoffee/design-para-programadores-1m28 | braziliandevs, beginners, tutorial, design | Design é uma área que muitos programadores acabam por ter bastante dificuldade em lidar, em alguns casos, a pessoa pode achar que não leva jeito para isso, que ela não tem criatividade, que ela não sabe desenhar (mesmo que essas áreas não tenham tanto assim em comum), que ela funciona melhor com lógica e números, enfim... | terminalcoffee |
1,877,155 | The Ultimate Guide to Hibernate: Importance, Usage, and Best Practices in Java Development | Exploring Hibernate: In the realm of Java development, managing databases efficiently is... | 0 | 2024-06-04T20:38:38 | https://dev.to/fullstackjava/importance-and-usage-in-java-development-56bm | webdev, beginners, programming, tutorial | # Exploring Hibernate:
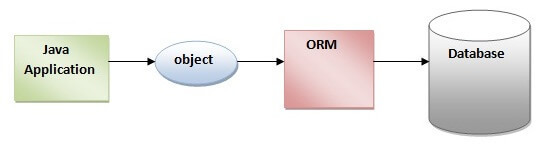
In the realm of Java development, managing databases efficiently is crucial for building robust and scalable applications. Hibernate, a popular Object-Relational Mapping (ORM) framework, a... | fullstackjava |
1,877,153 | Why "Chat over Your Data" Is Harder Than You Think | Overview While Large Language Models (LLMs) are increasingly capable of performing... | 0 | 2024-06-04T20:34:28 | https://dev.to/sahinera/why-chat-over-your-data-is-harder-than-you-think-1e69 | ai, llm, programming |
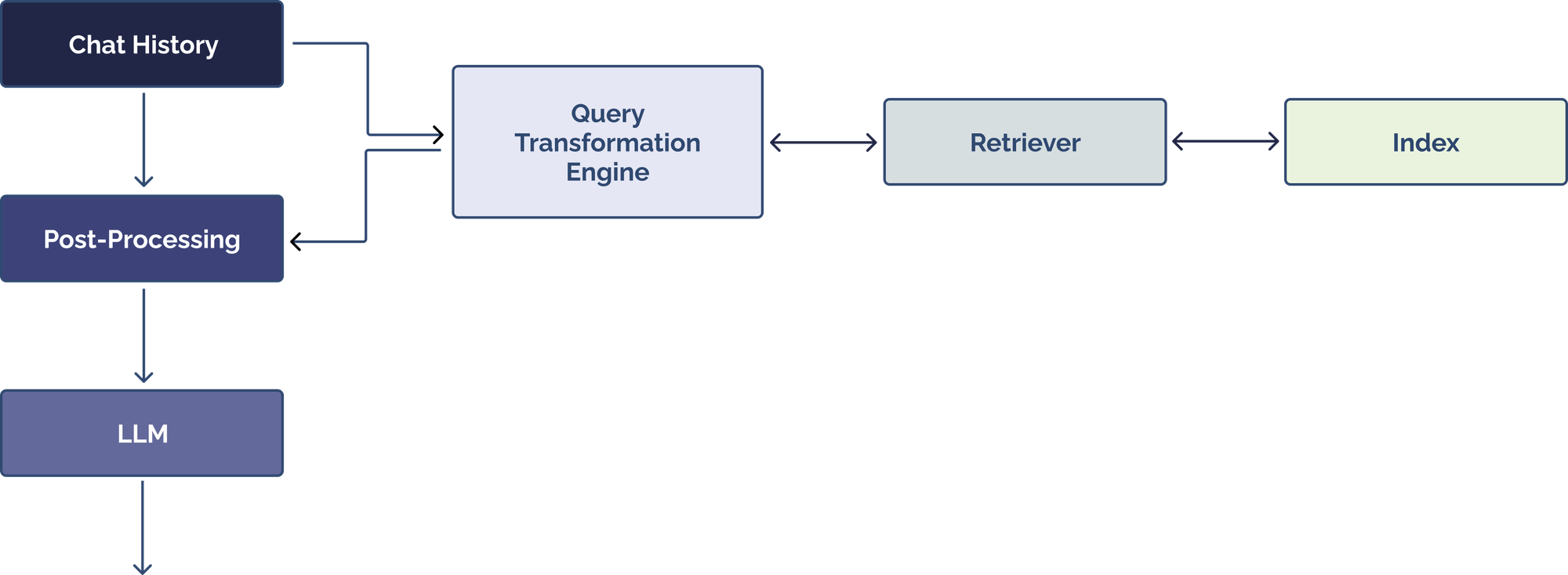
## Overview
While Large Language Models (LLMs) are increasingly capable of performing general reasoning and solving everyday tasks, they typically lack the context to address specialized use cases, like a... | sahinera |
1,877,152 | Understanding the Difference between Google Ads and PPC Advertising | Our digital IT world is growing rapidly day by day and it has given us many benefits. When we talk... | 0 | 2024-06-04T20:28:57 | https://dev.to/liong/understanding-the-difference-between-google-ads-and-ppc-advertising-34mh | googleads, clicks, malays, kualalumpur | Our digital IT world is growing rapidly day by day and it has given us many benefits. When we talk about this digital world, this shows us the digital marketing pattern, here many businesses are truly successful and striving so much due to the presence of more audience. This audience who sees our brand and enjoys it is... | liong |
1,877,150 | Title | Test Title Test Content | 0 | 2024-06-04T20:26:34 | https://dev.to/tyler_kendrick_b8e3240e37/title-55np | test | # Test Title
## Test Content | tyler_kendrick_b8e3240e37 |
1,877,148 | comment on i need a hacker to recover money from binary trading | It is worthy of the world to hear this testimony. I'm here to spread the word about Captain... | 0 | 2024-06-04T20:25:55 | https://dev.to/martin_luther_8cb8da3c599/comment-on-i-need-a-hacker-to-recover-money-from-binary-trading-4klb | It is worthy of the world to hear this testimony. I'm here to spread the word about Captain WebGenesis's wonderful deeds. My name is Martin Luther. I lost USD 232,000.00 in a binary investment trading scam and didn't realize it until a few weeks later. The site and services I utilized appeared authentic, and everything... | martin_luther_8cb8da3c599 | |
1,877,147 | Nginx Alias Path Traversal | Path Traversal Overview of the Vulnerability Path traversal uses a server misconfiguration to access... | 0 | 2024-06-04T20:22:50 | https://dev.to/c4ng4c31r0/nginx-alias-path-traversal-1498 | **Path Traversal**
Overview of the Vulnerability
Path traversal uses a server misconfiguration to access hidden files and directories that are stored on the served web application. This can include sensitive operating files, code and data that runs the application, or in some cases, user credentials.
An attacker can l... | c4ng4c31r0 | |
1,877,146 | FlowerShop | The Flower Shop NYC offers an incredible selection of tops that combine style and comfort perfectly.... | 0 | 2024-06-04T20:21:56 | https://dev.to/valikoole24/flowershop-4iaj | The Flower Shop NYC offers an incredible selection of tops that combine style and comfort perfectly. Whether you're dressing up for a special occasion or looking for something casual, their collection has something for everyone. For the latest in fashionable tops, make sure to [visit](https://www.theflowershopnyc.com/t... | valikoole24 | |
1,877,145 | Understanding Java Variables: A Comprehensive Guide | Java, as a statically typed language, requires the declaration of variables before they can be used.... | 0 | 2024-06-04T20:21:38 | https://dev.to/fullstackjava/understanding-java-variables-a-comprehensive-guide-3dme | webdev, beginners, programming, tutorial | Java, as a statically typed language, requires the declaration of variables before they can be used. This aspect of Java programming ensures type safety and improves code readability and maintainability. In this blog, we will delve into the different types of variables in Java, their scopes, and provide examples to ill... | fullstackjava |
1,877,099 | Event Driven services using Kafka, SurrealDB, Rust, and Go. | Kafka? To understand the purpose of Kafka you need to experiment with it in various... | 0 | 2024-06-04T20:18:36 | https://dev.to/sourabpramanik/event-driven-services-using-kafka-surrealdb-rust-and-go-43k1 | eventdriven, kafka, rust, go | ## Kafka?
To understand the purpose of Kafka you need to experiment with it in various contexts and reason with it. This small project is a very slight overview of one of the use cases of Kafka: streaming messages to drive multiple service-agnostic applications. Streaming messages using Kafka is not required to specif... | sourabpramanik |
1,877,098 | MediaPipe HandGestureRecognizer Task for web | Check out this Pen I made! | 0 | 2024-06-04T20:16:40 | https://dev.to/ankkerbintang/mediapipe-handgesturerecognizer-task-for-web-2bni | codepen | Check out this Pen I made!
{% codepen https://codepen.io/mediapipe-preview/pen/zYamdVd %} | ankkerbintang |
1,877,097 | E-commerce: The History and Future of online shopping | The e-commerce setup has been revolutionized so that it can amaze millions of people with its... | 0 | 2024-06-04T20:15:39 | https://dev.to/liong/e-commerce-the-history-and-future-of-online-shopping-1lgm | socialmedia, onlineshopping, malaysia, kualalumpur | The e-commerce setup has been revolutionized so that it can amaze millions of people with its services. It can ease people's lives by giving shopping options in their comfort zone. This is what e-commerce online shopping feels like. When we try to remember the old times, there were mostly thick catalogs, our excitement... | liong |
1,877,096 | My New Full-Stack Developer Portfolio | I've always admired the stunning portfolios created by designers, so I decided to try my hand at... | 0 | 2024-06-04T20:14:32 | https://dev.to/kiraaziz/my-new-portfolio-1h9k | webdev, javascript, beginners, programming | I've always admired the stunning portfolios created by designers, so I decided to try my hand at creating my own fancy portfolio as a full-stack developer. I'd love to get your feedback and suggestions on how I can improve it!
You can check out my portfolio here: [My Portfolio](http://coolkira.vercel.app/)
If you're ... | kiraaziz |
1,877,095 | Frontend axios middleware | import axios from 'axios' import jwt_decode from "jwt-decode"; import dayjs from 'dayjs' import {... | 0 | 2024-06-04T20:10:00 | https://dev.to/vimal_adithan/frontend-axios-middleware-3nd4 | interceptor, webdev, beginners, programming | import axios from 'axios'
import jwt_decode from "jwt-decode";
import dayjs from 'dayjs'
import { useContext } from 'react'
import AuthContext from '../context/AuthContext'
const baseURL = 'http://127.0.0.1:8000'
const useAxios = () => {
const {authTokens, setUser, setAuthTokens} = useContext(AuthContext)
... | vimal_adithan |
1,877,093 | E-commerce: Shopping From Your Comfort Zone | You need to remember those days when you used to just randomly do planned shopping trips, moving... | 0 | 2024-06-04T20:07:23 | https://dev.to/liong/e-commerce-shopping-from-your-comfort-zone-1nkm | shopping, online, malaysia, kualalumpur | You need to remember those days when you used to just randomly do planned shopping trips, moving through the crowds and even holding those heavy bags back home. See, here at this point I got you, because now thankfully those stressful times are over. E-commerce is particularly the art of buying or selling goods or prod... | liong |
1,854,416 | Utilização e Benefícios do Rerender em Testes de Componentes React com Jest e React Testing Library | Introdução No desenvolvimento de aplicações React, garantir que os componentes se... | 27,693 | 2024-06-04T20:06:35 | https://dev.to/vitorrios1001/utilizacao-e-beneficios-do-rerender-em-testes-de-componentes-react-com-jest-e-react-testing-library-5glp | testing, react, webdev, jest | ## Introdução
No desenvolvimento de aplicações React, garantir que os componentes se comportam conforme esperado após atualizações de estado ou props é crucial. O uso de bibliotecas de teste, como Jest e React Testing Library, é fundamental para validar a lógica de renderização e a resposta a interações do usuário. Es... | vitorrios1001 |
1,877,090 | Linux Date Commands | Explaining different date formats according to your needs 1.Date date -u :Displays the time in... | 0 | 2024-06-04T20:01:48 | https://dev.to/abdallah_kordy_94db275ef5/linux-commands-22mk | linux, gnu, commands | Explaining different date formats according to your needs
1.Date
- date -u :Displays the time in Coordinated Universal Time (UTC).
```
04 يون, 2024 UTC 07:32:39 م
```
- date -d "next Friday"
```
07 يون, 2024 EEST 12:00:00 ص
```
- date -R Outputs the date and time in RFC 2822 format.
output
```
Tue, 04 Jun 202... | abdallah_kordy_94db275ef5 |
1,877,089 | Top Video Processing APIs for 2024 | What are your top Video Processing APIs? Video processing APIs allow developers to automate tasks... | 0 | 2024-06-04T20:01:20 | https://dev.to/nikoldimit/top-video-processing-apis-for-2024-93e | What are your top Video Processing APIs?
Video processing APIs allow developers to automate tasks like video encoding, video decoding, video editing, video resizing, video watermarking, and extracting video metadata from video files.
There are 5 types of video processing APIs:
1. Video Preview APIs
2. Video Encod... | nikoldimit | |
1,877,088 | Benefits of E-commerce for Customers and Businesses | E-commerce is the miracle that happened to us in this world. This miracle has blessed us with nonstop... | 0 | 2024-06-04T19:57:29 | https://dev.to/liong/benefits-of-e-commerce-for-customers-and-businesses-26b | ecommerce, customers, malaysia, kualalumpur | E-commerce is the miracle that happened to us in this world. This miracle has blessed us with nonstop tremendous and awesome benefits because it is seriously not limited in giving us the blessing of itself. The benefits are in both ways, for example, it can give many benefits to their loyal e-commerce store customers a... | liong |
1,877,086 | Understanding the SQL ORDER BY Clause | Introduction The ORDER BY clause in SQL is a powerful tool used to sort the result set of... | 0 | 2024-06-04T19:49:43 | https://dev.to/kellyblaire/understanding-the-sql-order-by-clause-llg | sql, sqlserver, database, sorting | ## Introduction
The `ORDER BY` clause in SQL is a powerful tool used to sort the result set of a query. Sorting data is a common requirement when retrieving records from a database, whether you want to order products by price, employees by name, or records by date. In this article, we will explore the `ORDER BY` claus... | kellyblaire |
1,877,082 | Top 7 Featured DEV Posts of the Week | Welcome to this week's Top 7, where the DEV Team handpicks our favorite posts from the previous... | 0 | 2024-06-04T19:47:12 | https://dev.to/devteam/top-7-featured-dev-posts-of-the-week-pg0 | top7 | _Welcome to this week's Top 7, where the DEV Team handpicks our favorite posts from the previous week._
Congrats to all the authors that made it onto the list 👏
{% embed https://dev.to/fsh02/the-long-path-of-javascript-from-es6-until-today-3gc3 %}
Farid walks us through how JavaScript has transformed since the laun... | thepracticaldev |
1,877,081 | NULL Handling in SQL | Introduction Dealing with NULL values in SQL is a fundamental aspect that every database... | 0 | 2024-06-04T19:44:22 | https://dev.to/kellyblaire/null-handling-in-sql-1mp2 | sql, sqlserver, database, mysql | ## Introduction
Dealing with `NULL` values in SQL is a fundamental aspect that every database professional must grasp. `NULL` represents missing or undefined values in a database table, and it is crucial to handle these values correctly to ensure the integrity and accuracy of your data operations. This article will de... | kellyblaire |
1,877,078 | Resum tècnic de l'"Artificial Intelligence Risk Management Framework (AI RMF 1.0) | L'"Artificial Intelligence Risk Management Framework (AI RMF 1.0)", desenvolupat pel National... | 0 | 2024-06-04T19:34:59 | https://dev.to/gcjordi/resum-tecnic-de-lartificial-intelligence-risk-management-framework-ai-rmf-10-4aia | ai, ia, ciberseguretat, nist | L'"[Artificial Intelligence Risk Management Framework (AI RMF 1.0)](https://www.nist.gov/itl/ai-risk-management-framework)", desenvolupat pel National Institute of Standards and Technology (NIST), és un document fonamental per a la gestió de riscos associats als sistemes d'intel·ligència artificial (IA). Aquest marc té... | gcjordi |
1,877,077 | What are Shopify theme app extensions? (and how to build with them) | When you think of a Shopify app, there’s a good chance you’re thinking of one of two things: an app... | 0 | 2024-06-04T19:33:10 | https://gadget.dev/blog/understanding-shopify-theme-app-extensions-what-they-are-and-how-to-build-with-them | shopify, liquid, javascript, themes | When you think of a Shopify app, there’s a good chance you’re thinking of one of two things: an app that helps a merchant optimize things behind the scenes, like an analytics tool, or an app that adds buyer-facing functionality to the storefront. If you think of the latter, then you’re probably thinking of a theme app ... | gadget |
1,877,075 | FastAPI Beyond CRUD Part 6 - CRUD With Async SQLModel (An Introduction to Dependency Injection) | In this video, we build our CRUD functionality replacing the in-memory database (Python-list) with... | 0 | 2024-06-04T19:32:34 | https://dev.to/jod35/fastapi-beyond-crud-part-6-crud-with-async-sqlmodel-an-introduction-to-dependency-injection-5d1e | fastapi, api, python, programming | In this video, we build our CRUD functionality replacing the in-memory database (Python-list) with persistence from a real database (PostgreSQL). We also look at organizing our CRUD code to separate database logic from the route code.
{%youtube AtHEX76Wysw%} | jod35 |
1,877,074 | localforage vs localstorage | Localforage vs Localstorage So, whats the difference between localforage and localstorage?... | 0 | 2024-06-04T19:31:13 | https://dev.to/dumorando/localforage-vs-localstorage-43ap | javascript, webdev | # Localforage vs Localstorage
So, whats the difference between localforage and localstorage? And why do people recommend localforage rather then localstorage?
Its quite simple actually.
## Localforage
Localforage is an asynchronous based local database simular to localstorage but internally it uses IndexedDB.
Indexe... | dumorando |
1,877,073 | How to Debug Using the Developer Console | The developer console in modern web browsers provides a powerful suite of tools for debugging web... | 0 | 2024-06-04T19:29:12 | https://dev.to/vidyarathna/how-to-debug-using-the-developer-console-1o0d | devtools, debugging, webdebugging, techcommunity |
The developer console in modern web browsers provides a powerful suite of tools for debugging web applications. Whether you're inspecting elements, monitoring network activity, or adjusting device settings, the developer console has you covered. Here’s how you can make the most of these tools:
### 1. **Opening the D... | vidyarathna |
1,877,072 | Registrations for Eastern India's largest Hackathon are officially OPEN! 🔥 | Hack4Bengal 3.0: Registrations Now Open! Hack4Bengal 3.0, Eastern India's largest... | 0 | 2024-06-04T19:28:51 | https://dev.to/arup_matabber/registrations-for-eastern-indias-largest-hackathon-are-officially-open-2l4m | ## Hack4Bengal 3.0: Registrations Now Open!
Hack4Bengal 3.0, Eastern India's largest hackathon, is now open for registrations! This premier event, set to take place in Kalyani, West Bengal on June 28, 2024, is a golden opportunity for coders of all levels to showcase their skills, collaborate on innovative solutions, a... | arup_matabber | |
1,877,071 | Sell Backstage like a salesperson | I've chatted with many platform/infra teams who are struggling to get buy-in for internal tools... | 0 | 2024-06-04T19:28:40 | https://dev.to/timnichols/sell-backstage-like-a-salesperson-83a | platform, idp, devex | I've chatted with many platform/infra teams who are struggling to get buy-in for internal tools (ex:[backstage](https://backstage.io/)) in the current market.
The problem is that they're using the wrong sales process!
Typically, someone sets up backstage during a hackweek, wins 1-2 HC and then after a year of mixed ... | timnichols |
1,877,069 | Install Notion on Ubuntu | Install Notion on Ubuntu effortlessly! This guide provides clear steps to set up Notion on your... | 0 | 2024-06-04T19:25:09 | https://dev.to/abdul_sattar/install-notion-on-ubuntu-533j | notion, linux, ubuntu | **Install Notion on Ubuntu effortlessly**! This guide provides clear steps to set up Notion on your Ubuntu system and boost your productivity
[Notion](https://www.notion.so/) can be your hero! This powerful workspace goes beyond just a database, tackling your note-taking, tasks, projects, and keeping everything organi... | abdul_sattar |
1,877,015 | 13 Best OS for Old Laptops - Revive Your Hardware! | If there's one thing people dread more than work, it's change. Especially when it comes from planned... | 0 | 2024-06-04T19:19:22 | https://dev.to/denis_valcu_b31f71d81032a/13-best-os-for-old-laptops-revive-your-hardware-54mn | webdev | If there's one thing people dread more than work, it's change. Especially when it comes from planned obsolescence. Picture this: you've got a perfectly functioning laptop, but suddenly it's too old to keep up with the latest OS. Sound familiar?
\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | vevet15033 |
1,875,440 | Building a customizable dashboard with Dashy | Written by Shalitha Suranga✏️ With the Web 3.0 era, the availability of the internet and evolution... | 0 | 2024-06-04T19:07:37 | https://blog.logrocket.com/customizable-dashboard-dashy | dashy, webdev | **Written by [Shalitha Suranga](https://blog.logrocket.com/author/shalithasuranga/)✏️**
With the Web 3.0 era, the availability of the internet and evolution of web technologies helped web developers implement platform-independent, web-based software. Before this, software folks could only develop platform-dependent, s... | leemeganj |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.