
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,877,012 | T-Shirt Tuesday | Welcome back to T-Shirt Tuesday, our weekly post inspired by the creative ideas in our Discord... | 0 | 2024-06-04T19:04:58 | https://dev.to/buildwebcrumbs/t-shirt-tuesday-44g1 | Welcome back to T-Shirt Tuesday, our weekly post inspired by the creative ideas in [our Discord Community](https://discord.gg/4PWXpPd8HQ).
Each week, we bring fun and unique phrases that you'd love to see on a t-shirt.
This week's cover image features piece of code that many developers live by!
``` js
if (brain!emp... | opensourcee | |
1,877,011 | How to Capitalize String Python Dataframe Pandas | There are two main ways to capitalize strings in a pandas DataFrame: 1.... | 0 | 2024-06-04T19:02:38 | https://pleypot.com/blog/how-to-capitalize-string-python-dataframe-pandas/ | python, datascience, webdev | There are two main ways to capitalize strings in a pandas DataFrame:
### 1. str.capitalize():
This method capitalizes the first letter of each word in a string element.
```python
import pandas as pd
# Create a DataFrame
df = pd.DataFrame({'text': ['hello world', 'python programming', 'pandas']})
# Capitalize the fi... | saim_ansari |
1,876,662 | BST (Binary Search Tree) and AVL Tree, Data Structures: (Trees, Part II) | Binary Search Tree (BST) A Binary Search Tree (BST) is a binary tree data structure where... | 0 | 2024-06-04T19:01:10 | https://dev.to/harshm03/bst-binary-search-tree-and-avl-tree-data-structures-trees-part-ii-2lp8 | dsa, datastructures | ## Binary Search Tree (BST)
A Binary Search Tree (BST) is a binary tree data structure where each node has at most two children, referred to as the left child and the right child. The key property of a BST is that for every node, all elements in its left subtree are less than or equal to the node's value, and all elem... | harshm03 |
1,877,009 | How to Select the Right Data Discovery Tool for Your Requirements | Sensitive data, like customer information and internal processes, often lurks hidden in employee... | 0 | 2024-06-04T19:00:40 | https://spectralops.io/blog/how-to-select-the-right-data-discovery-tool-for-your-requirements/ | cybersecurity, devops, database | Sensitive data, like customer information and internal processes, often lurks hidden in employee devices or in unmanaged spreadsheets. This "shadow data" poses a security risk because it's difficult for IT teams to monitor and protect. Without visibility into this hidden data, organizations can't effectively enforce se... | yayabobi |
1,877,008 | Upstream preview: Welcome to Upstream 2024 | Upstream is this week on Wednesday (June 5!), and wow, our schedule is shaping up brilliantly. For... | 0 | 2024-06-04T19:00:13 | https://dev.to/tidelift/upstream-preview-welcome-to-upstream-2024-2p06 | upstream, opensource, cybersecurity, maintenance | <p><em>Upstream is this week on Wednesday (June 5!), and wow, our schedule is shaping up brilliantly. For the rest of this week, we’ll be giving you a sneak preview into some of the talks and the speakers giving them via posts like these. </em><a href="https://upstream.live/" style="font-style: normal;">RSVP now</a>!</... | caitbixby |
1,876,359 | Introduction to Trees and Binary Tree, Data Structures: (Trees, Part I) | Tree A tree is a hierarchical data structure used in computer science to represent data in... | 0 | 2024-06-04T18:59:22 | https://dev.to/harshm03/introduction-to-trees-and-binary-tree-data-structures-trees-part-i-4cmf | datastructures, dsa | ## Tree
A tree is a hierarchical data structure used in computer science to represent data in a parent-child relationship. Starting from a root node, each node can branch out to multiple child nodes, forming a structure that resembles a tree. This makes trees ideal for representing hierarchical data like organizationa... | harshm03 |
1,877,002 | Introduction to "Accel Record": A TypeScript ORM Using the Active Record Pattern | In this article, we'll briefly introduce Accel Record, an ORM for TypeScript that we're... | 27,598 | 2024-06-04T18:57:50 | https://dev.to/koyopro/introduction-to-accel-record-a-typescript-orm-using-the-active-record-pattern-2oeh | typescript, activerecord, orm, database | In this article, we'll briefly introduce [Accel Record](https://www.npmjs.com/package/accel-record), an ORM for TypeScript that we're developing.
## Overview of Accel Record
[accel-record - npm](https://www.npmjs.com/package/accel-record)
Accel Record is a type-safe, synchronous ORM for TypeScript.
It adopts the Ac... | koyopro |
1,877,007 | How to Implement Dropdown on Hover in React with Ant Design 5 | In this tutorial, we'll create a dropdown-on-hover feature in React using Ant Design 5. First, you'll... | 0 | 2024-06-04T18:57:02 | https://frontendshape.com/post/how-to-use-dropdown-on-hover-in-react-ant-design-5 | react, antdesign, webdev | In this tutorial, we'll create a dropdown-on-hover feature in React using Ant Design 5. First, you'll need to set up a React project with Ant Design 5.
<br>
[install & setup vite + react + typescript + ant design 5](https://frontendshape.com/post/install-setup-vite-react-typescript-ant-design-5)
1.Create a simple dropd... | aaronnfs |
1,868,053 | Using Pieces: A Technical Writer's Perspective | Hello! I’m super excited to share a new tool I've been using recently that has significantly boosted... | 0 | 2024-06-04T18:56:23 | https://dev.to/elliezub/using-pieces-a-technical-writers-perspective-39ip | productivity, beginners, webdev, ai | Hello! I’m super excited to share a new tool I've been using recently that has significantly boosted my productivity and made my writing process a lot smoother.
As you might have guessed from the title, I’ll be talking about [Pieces](https://pieces.app/?utm_source=youtube&utm_medium=cpc&utm_campaign=ellie-partner-twit... | elliezub |
1,876,993 | Effortless Django & React: Introducing Reactivated | Django, a powerful Python web framework, excels in backend development. But for interactive user... | 0 | 2024-06-04T18:53:00 | https://dev.to/topunix/effortless-django-react-introducing-reactivated-218f | react, django, webdev, python |
Django, a powerful Python web framework, excels in backend development. But for interactive user interfaces, you might find yourself reaching for a separate frontend framework like React. Here's where Reactivated comes in - a game-changer for building Django applications with React.
**Reactivated: Zero-Configuration... | topunix |
1,877,005 | Building An E-Commerce Store With NextJS | In this tutorial, you'll learn how to build an e-commerce store where customers can purchase products... | 0 | 2024-06-04T18:52:25 | https://novu.co/blog/building-an-e-commerce-store-with-nextjs/ | webdev, javascript, tutorial, programming | In this tutorial, you'll learn how to build an e-commerce store where customers can purchase products and make payments via Stripe. After a successful payment, an email notification is sent to the customer, and an in-app notification to the Admin user. The Admin user can also create and delete products within the appli... | empe |
1,877,003 | Professional Ants Pest Removal Services in Sydney | Do you have ants intruding on your personal space within your house or business premises? If you are... | 0 | 2024-06-04T18:48:47 | https://dev.to/most_mimakther_e98efd0a3/professional-ants-pest-removal-services-in-sydney-54mo |
Do you have ants intruding on your personal space within your house or business premises? If you are in search of the excellent ants-removal/ then [Elegance Pest Control](https://elegancepestcontrol.au/) will meet your expectations. We have developed our pest control for ants to be efficient with a focus on ensuring t... | most_mimakther_e98efd0a3 | |
1,875,909 | How to use fetch in JavaScript | Hello, everyone. In this article, I would explain fetch in JavaScript. It is recommended to read the... | 0 | 2024-06-04T18:40:06 | https://dev.to/makoto0825/how-to-use-fetch-in-javascript-9on | javascript, webdev | Hello, everyone. In this article, I would explain fetch in JavaScript. It is recommended to read the following article and understand the concept of asynchronous, synchronous processing and Promise before reading this article. This is because these concepts are connected with fetch.
[➡async/sync in Javascript ](https:... | makoto0825 |
1,877,001 | Exception In java and hierarchy | While trying to understand the concept of exception in java , it becomes necessary to understand the... | 0 | 2024-06-04T18:37:57 | https://dev.to/rajubora/exception-in-java-and-hierarchy-53f5 | While trying to understand the concept of exception in java , it becomes necessary to understand the hierarchy of exceptions becauce
we can see a famous interview question from exception hierarchy in java developer interview.
suppose we have a parent class with a method that throws **IO exception** , also there is a ... | rajubora | |
1,877,000 | Realtime Pub/Sub meets Amazon SQS Elasticity | In this blog post, we will explore one standout feature: real-time message forwarding to Amazon SQS... | 0 | 2024-06-04T18:37:49 | https://dev.to/kyberneees/realtime-pubsub-meets-amazon-sqs-elasticity-480k | aws, sqs, messaging, javascript | In this blog post, we will explore one standout feature: real-time message forwarding to Amazon SQS queues.
We’ll delve into the details and provide a hands-on example of how to process and respond to your WebSocket clients requests using an Amazon SQS queue as a proxy layer between your application clients and the bac... | kyberneees |
1,876,999 | Authenticate Realtime Pub/Sub WebSocket clients with Supabase | In this blog post, we describe how to authenticate your Realtime Pub/Sub Application WebSocket... | 0 | 2024-06-04T18:34:41 | https://dev.to/kyberneees/authenticate-realtime-pubsub-websocket-clients-with-supabase-59ko | supabase, realtime, messaging, authentication |
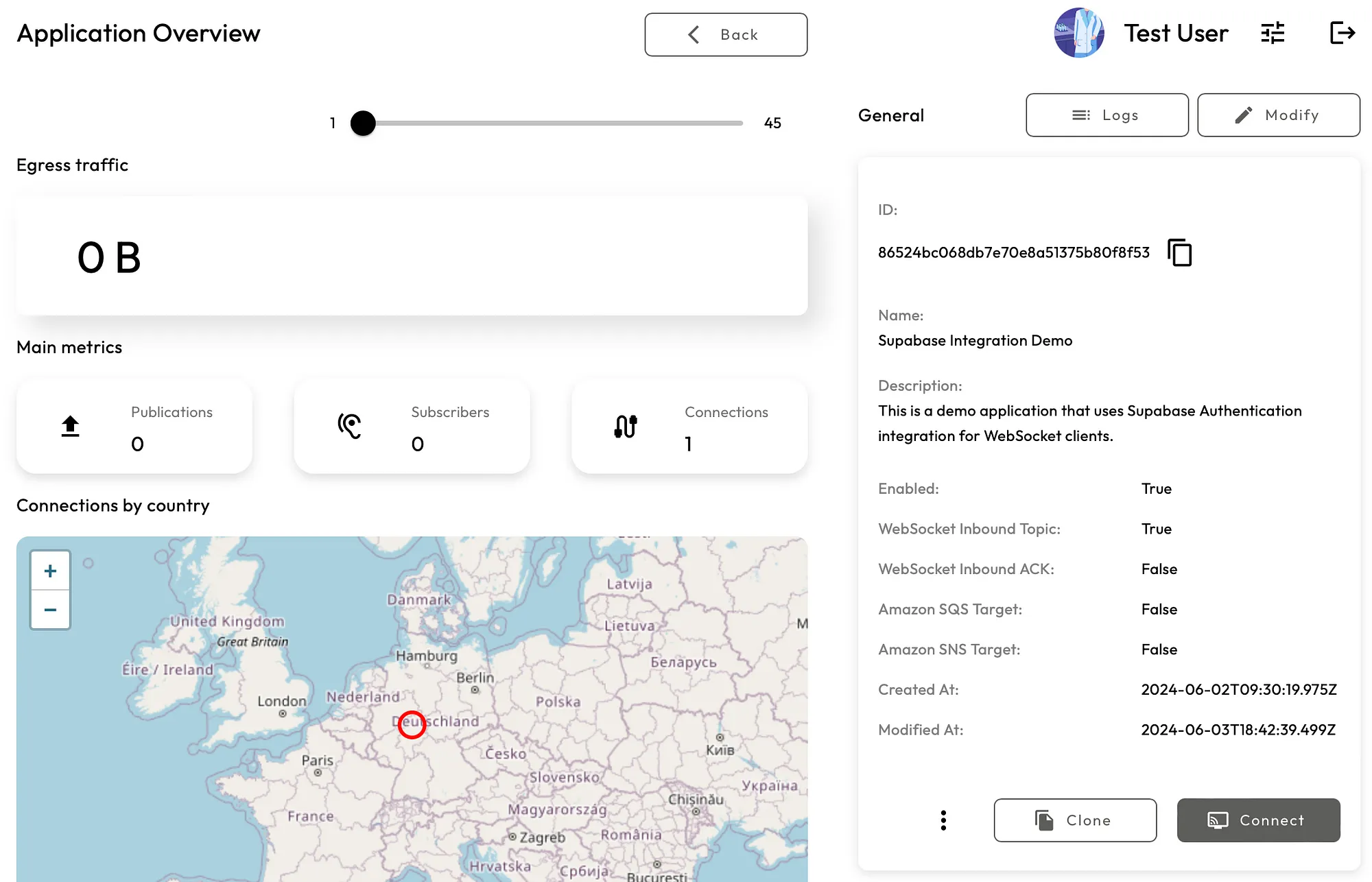
In this blog post, we describe how to authenticate your Realtime Pub/Sub Application WebSocket clients using Supabase users.
https://medium.com/@kyberneees/authenticate-realtime-pub-sub-websocket-clients-with-supa... | kyberneees |
1,876,998 | calculator program | In gpt chat I asked how to program a calculator in htmo, css and java script and it looks beautiful... | 0 | 2024-06-04T18:34:10 | https://dev.to/mokko/calculator-program-41jh | In gpt chat I asked how to program a calculator in htmo, css and java script and it looks beautiful in codepen, but in the android studio emulator it looks a disaster.
I'm new, what am I doing wrong? | mokko | |
1,871,874 | Ensuring Scalable Application Design and Development: A Comprehensive Guide | In today's digital age, applications are vital in driving business success. However, as the user base... | 0 | 2024-06-04T18:30:08 | https://dev.to/norbybaru/ensuring-scalable-application-design-and-development-a-comprehensive-guide-4mn6 | scaling, webapp, devops, development | In today's digital age, applications are vital in driving business success. However, as the user base and data volume increase, many applications struggle to meet the demand, leading to performance and scalability problems. Ensuring scalable application design and development is crucial to handle growing traffic, data,... | norbybaru |
1,876,996 | From Blind Spots to Brilliance: Achieve API Excellence with Observability | In the intricate world of modern applications, APIs (Application Programming Interfaces) act as the... | 0 | 2024-06-04T18:23:27 | https://dev.to/syncloop_dev/from-blind-spots-to-brilliance-achieve-api-excellence-with-observability-m99 | webdev, javascript, programming, api | In the intricate world of modern applications, APIs (Application Programming Interfaces) act as the invisible workhorses, facilitating seamless communication between various components. But ensuring their smooth operation and identifying potential issues can be a challenge. This is where API observability and monitorin... | syncloop_dev |
1,876,992 | HOW I RECOVER MY LOST CRYPTO'S FROM FAKE BROKER ONLINE | I was the subject of a cryptocurrency heist. My wallet was broken into, and some bitcoin was taken... | 0 | 2024-06-04T18:16:39 | https://dev.to/abigail_697d5af1af245afed/how-i-recover-my-lost-cryptos-from-fake-broker-online-4kig | I was the subject of a cryptocurrency heist. My wallet was broken into, and some bitcoin was taken and transferred to an unauthorized account. They notified my wallet management, but they had me wait a week to get back to me by email. Instead of helping, they suggested that my phone might have been compromised and advi... | abigail_697d5af1af245afed | |
1,876,991 | Populating Select Input with data from an API using Nextjs and typescript | After a series of nerve racking attempts and failures including combing through the entire internet I... | 0 | 2024-06-04T18:16:28 | https://dev.to/romkev/populating-select-input-with-data-from-an-api-using-nextjs-and-typescript-4jcn | nextjs, nestjs, node, api | After a series of nerve racking attempts and failures including combing through the entire internet I was finally able to achieve this feat. I shall share with you the function I currently use to populate select input using Nextjs from a Nest js api backend.
Working with asynchronous functions can be a real paid and s... | romkev |
1,876,990 | How Odoo ERP Revolutionizes Retail Business Management? | Odoo ERP (Enterprise Resource Planning) has been gaining popularity in the retail sector due to its... | 0 | 2024-06-04T18:13:10 | https://dev.to/serpent2024/how-odoo-erp-revolutionizes-retail-business-management-9ei | odooerp, erpdevelopment, softwaredevelopment, software | Odoo ERP (Enterprise Resource Planning) has been gaining popularity in the retail sector due to its comprehensive suite of integrated applications that streamline and optimize various business processes.
## **Best way to Odoo ERP revolutionizes retail business management**
### 1. **Integrated Point of Sale (POS) Sy... | serpent2024 |
1,875,434 | WinterJS vs. Bun: Comparing JavaScript runtimes | Written by Emmanuel Odioko✏️ Speed, as we know, is always a plus in a programming environment, and... | 0 | 2024-06-04T18:10:56 | https://blog.logrocket.com/winterjs-vs-bun-comparing-javascript-runtimes | javascript, webdev | **Written by [Emmanuel Odioko](https://blog.logrocket.com/author/emmanuelodioko/)✏️**
Speed, as we know, is always a plus in a programming environment, and runtimes are expected to support this need. A faster runtime typically translates to more quickly executed code, which in turn directly impacts UX, as users don’t ... | leemeganj |
1,876,987 | Entenda a diferença entre modelo conceitual e modelo lógico em Banco de Dados | Modelagem de dados é o processo de criar um #modelo de dado específico para um determinado... | 0 | 2024-06-04T18:07:06 | https://dev.to/edsonaraujobr/entenda-a-diferenca-entre-modelo-conceitual-e-modelo-logico-em-banco-de-dados-4bg4 | webdev, beginners, programming, learning | Modelagem de dados é o processo de criar um #modelo de
#dado específico para um determinado problema de domínio. Domínio é uma área claramente definida no mundo real, com escopo bem definido.
Usamos modelos para o gerenciamento da complexidade, comunicação entre pessoas envolvidas e redução de custos no desenvolvimen... | edsonaraujobr |
1,876,986 | Elementary Logic And Proof Techniques | 1. Statements and Truth Values Definitions and Detailed... | 0 | 2024-06-04T18:04:55 | https://dev.to/niladridas/elementary-logic-and-proof-techniques-4541 | startup, coding, datascience, machinelearning | ## 1. Statements and Truth Values
## Definitions and Detailed Explanations
**Statement**:
A statement in logic is a declarative sentence that can definitively be classified as true or false. This is distinct from questions, commands, or expressions of uncertainty. Statements are the fundamental building blocks in lo... | niladridas |
1,876,985 | HeyRuu | 🌺 | 0 | 2024-06-04T18:04:43 | https://dev.to/heyruu/heyruu-1bne | laravel, csharp | `🌺` | heyruu |
1,876,984 | Choosing an online pharmacy you can trust | Choosing a trustworthy online pharmacy is crucial for your health and safety. DiRx outlines five key... | 0 | 2024-06-04T18:04:07 | https://dev.to/skyline_entertainment_843/choosing-an-online-pharmacy-you-can-trust-4fi | mentalhealth, webdev, beginners, react | Choosing a trustworthy online pharmacy is crucial for your health and safety. DiRx outlines five key factors: ensuring the pharmacy sells only FDA-approved medicines, is licensed and accredited, offers pharmacist support, monitors prescription interactions, and complies with privacy laws. By focusing on these aspects,... | skyline_entertainment_843 |
1,876,280 | How to Check if an Array is Sorted | There are many times we need to check if an array is sorted or not. Checking if an array is sorted... | 27,580 | 2024-06-04T18:01:00 | https://blog.masum.dev/how-to-check-if-an-array-is-sorted | algorithms, computerscience, cpp, tutorial | There are many times we need to check if an array is sorted or not. Checking if an array is sorted can be approached in multiple ways. Here, we we'll discuss two solutions: a **brute force approach** and an **optimal approach**.
### Solution 1: Brute Force Approach
This method involves comparing each element with eve... | masum-dev |
1,876,982 | The Future of Remote Work: Tech Innovations Shaping the Workplace | Advanced Collaboration Tools: Platforms like Slack, Microsoft Teams, and Zoom are constantly... | 0 | 2024-06-04T18:00:45 | https://dev.to/bingecoder89/the-future-of-remote-work-tech-innovations-shaping-the-workplace-1l12 | remote, web3, javascript, beginners | * Advanced Collaboration Tools: Platforms like Slack, Microsoft Teams, and Zoom are constantly evolving to offer more than just video conferencing. They now feature integrated project management, file sharing, and real-time collaboration tools, creating a more seamless virtual workspace.
* Virtual and Augmented Reali... | bingecoder89 |
1,876,981 | A Comprehensive Guide to Building Recommendation Systems | Recommendation systems are an integral part of our digital experience, influencing our choices on... | 0 | 2024-06-04T18:00:34 | https://dev.to/abhaysinghr1/a-comprehensive-guide-to-building-recommendation-systems-4me7 | python, machinelearning, datascience | Recommendation systems are an integral part of our digital experience, influencing our choices on platforms like Netflix, Amazon, and Spotify. These systems analyze vast amounts of data to suggest products, movies, music, and even friends or jobs. In this guide, we will delve deep into the world of recommendation syste... | abhaysinghr1 |
1,876,980 | Discover Top-Notch Anomaly Pool Services in the USA! 🌊🏊♂️ | Looking for reliable and professional anomaly pool services in the USA? Look no further! Our expert... | 0 | 2024-06-04T18:00:29 | https://dev.to/nikolaprem/discover-top-notch-anomaly-pool-services-in-the-usa-1n75 | Looking for reliable and professional anomaly pool services in the USA? Look no further! Our expert team specializes in identifying and resolving any unusual issues with your pool, ensuring it stays in pristine condition all year round.
🔍 What We Offer:
Comprehensive anomaly detection and analysis
Expert **[repair a... | nikolaprem | |
1,876,979 | RECOVERING LOST, HACKED, OR STOLEN BITCOIN THROUGH HACK SAVVY TECHNOLOGY | HACK SAVVY TECHNOLOGY CONTACT INFO: Mail them via: contactus@hacksavvytechnology. com Mail them via:... | 0 | 2024-06-04T17:59:47 | https://dev.to/jennifer_andrew_54643684f/recovering-lost-hacked-or-stolen-bitcoin-through-hack-savvy-technology-5aad | HACK SAVVY TECHNOLOGY CONTACT INFO:
Mail them via: contactus@hacksavvytechnology. com
Mail them via: Support@hacksavvytechrecovery. com
WhatsApp No: +7 999 829‑50‑38,
website: https://hacksavvytechrecovery.com
After successfully running and then selling my t-shirt printing business, I netted $800,000 in revenue aft... | jennifer_andrew_54643684f | |
1,876,978 | How safe is your prescription information online? How safe is your prescription information online? | https://bit.ly/3yMW1Ru Ensuring the safety of your prescription information online is crucial. DiRx... | 0 | 2024-06-04T17:58:18 | https://dev.to/emily_alba_889fc8556d3dd8/how-safe-is-your-prescription-information-onlinehow-safe-is-your-prescription-information-online-4b36 | https://bit.ly/3yMW1Ru
Ensuring the safety of your prescription information online is crucial. DiRx emphasises the importance of understanding who has access to your health data, how it is used, and the security measures to protect it. With HIPAA compliance and secure database protocols, DiRx guarantees that your priva... | emily_alba_889fc8556d3dd8 | |
1,876,973 | Bringing up BPI-F3 - Part 3 | Initramfs Initially I was hoping that it would not be needed, but since the SoC has a... | 27,455 | 2024-06-04T17:45:32 | https://dev.to/luzero/bringing-up-bpi-f3-part-3-101h | riscv, bpif3, gentoo | ## Initramfs
Initially I was hoping that it would not be needed, but since the SoC has a [remote processor](https://www.kernel.org/doc/html/latest/staging/remoteproc.html) and the defconfig for it enables it, I guess it is simpler to use an initramfs.
### Remoteproc firmware
As seen [here](https://github.com/BPI-SIN... | luzero |
1,876,977 | What is Front End Development? | Hello! So you may have heard of the phrase "front-end" development before, but you don't quite know... | 0 | 2024-06-04T17:44:42 | https://dev.to/jockko/what-is-front-end-development-17ak | Hello! So you may have heard of the phrase "front-end" development before, but you don't quite know what it means. Let's dive into it. Front-End Development is what I like to call the "umbrella" of our code that contains the visual side of things for our client. Essentially, everything you see on the webpage. Our role ... | jockko | |
1,876,975 | How Technology and Programming Help My Hikes | I love hiking, especially in the mountains. There's something magical about being in the middle of... | 0 | 2024-06-04T17:29:30 | https://dev.to/outofyourcomfortzone/how-technology-and-programming-help-my-hikes-28ap | I love hiking, especially in the mountains. There's something magical about being in the middle of nature, tackling challenging trails, and admiring breathtaking views. But let's be real, hiking in the mountains isn't just about throwing a backpack on and heading out. Luckily, technology and programming are here to giv... | outofyourcomfortzone | |
1,876,971 | FUNCTIONAL & NON-FUNCTIONAL TESTING | FUNCTIONALITY TESTING: It is a type of testing to test the feature of the product .Whether it covers... | 0 | 2024-06-04T17:21:13 | https://dev.to/samu_deva/functional-non-functional-testing-1724 | FUNCTIONALITY TESTING:
It is a type of testing to test the feature of the product .Whether it covers all its purpose and list of all functionalities and also to check whether it is created as per the requirements from the SRS or BRS document.
Functional testing is also a type of black box testing that holds the test ca... | samu_deva | |
1,876,970 | Day 10 of my progress as a vue dev | About today Today was a little better than yesterday, I made progress with my DSA visualizer project... | 0 | 2024-06-04T17:18:55 | https://dev.to/zain725342/day-10-of-my-progress-as-a-vue-dev-177b | webdev, vue, typescript, tailwindcss | **About today**
Today was a little better than yesterday, I made progress with my DSA visualizer project and spent quite a few time learning new concepts practicing and trying to come up with new ideas by brainstorming. My thought process is simple at the point, implement whatever is easy to understand and good to visu... | zain725342 |
1,876,969 | 409. Longest Palindrome | 409. Longest Palindrome Easy Given a string s which consists of lowercase or uppercase letters,... | 27,523 | 2024-06-04T17:18:40 | https://dev.to/mdarifulhaque/409-longest-palindrome-127o | php, leetcode, algorithms, programming | 409\. Longest Palindrome
Easy
Given a string `s` which consists of lowercase or uppercase letters, return the length of the **longest** palindrome[^1]
that can be built with those letters.
Letters are **case sensitive**, for example, `"Aa"` is not considered a palindrome.
**Example 1:**
- **Input:** s = "abccccdd"... | mdarifulhaque |
1,876,348 | App runner with CloudFormation AWS (json, nodejs, java ) | Refer to the previous article to understand the architectural... | 0 | 2024-06-04T17:16:19 | https://dev.to/huydanggdg/app-runner-with-cloudformation-aws-json-nodejs-java--433i | apprunner, aws, cloudformation, iac | Refer to the previous article to understand the architectural model:
https://dev.to/huydanggdg/migrate-heroku-to-aws-1d73
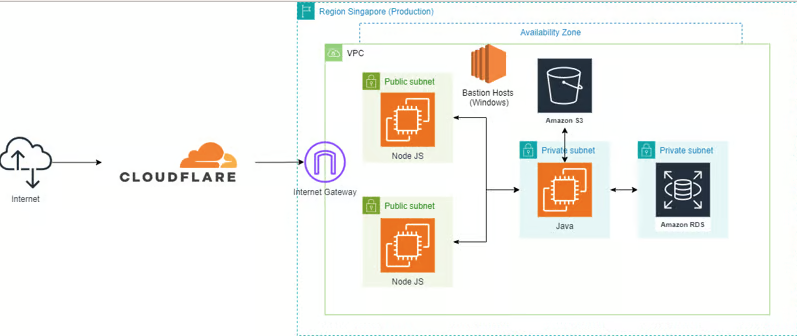
**1.Setup connect github**

The "CEO Math" lesson with the "The more you buy, the more you save" conclusion has reminded me of another b... | maximsaplin |
1,876,967 | Learning AWS Day by Day — Day 80 — Amazon Cloud Directory | Exploring AWS !! Day 80 AWS Cloud Directory A directory-based store in AWS, where directories... | 0 | 2024-06-04T17:11:44 | https://dev.to/rksalo88/learning-aws-day-by-day-day-80-amazon-cloud-directory-5b5f | aws, beginners, cloud, cloudcomputing | Exploring AWS !!
Day 80
AWS Cloud Directory
A directory-based store in AWS, where directories can scale to millions of objects. No need of managing the directory infrastructure, just focus on your development and... | rksalo88 |
1,876,966 | So I tried Rust for the first time. | My first attempt at writing a program in rust. | 0 | 2024-06-04T17:11:42 | https://dev.to/martinhaeusler/so-i-tried-rust-for-the-first-time-4jdb | rust | ---
title: So I tried Rust for the first time.
published: true
description: My first attempt at writing a program in rust.
tags: rust, rustlang
cover_image: https://www.rust-lang.org/static/images/rust-social-wide.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-04 16:01 +0000
---
In my profession... | martinhaeusler |
1,876,965 | Lost your README? | When this happens, this is kind of a loss of a mojo as well and this has happened to me a lot. I am... | 0 | 2024-06-04T17:10:44 | https://dev.to/fion21/lost-your-readme--129f | git, push, github, origin | When this happens, this is kind of a loss of a mojo as well and this has happened to me a lot.
I am had to do a `git push -u origin master` and then the commit was rejected. Has this happened to you too[](url)? Fret not.
Image courtesy of [http://Studytonight.com](url).
I stumbled upon a post on Stackoverflow on how ... | fion21 |
1,876,954 | ** Los Mejores Entornos de Desarrollo Integrado (IDE) Explicados con la Magia de Escandalosos **🐻❄️🐼🐻 | ¡Hola Chiquis! 👋🏻 Acompáñenme en este viaje donde los Escandalosos se convierten en desarrolladores y... | 0 | 2024-06-04T16:59:42 | https://dev.to/orlidev/-los-mejores-entornos-de-desarrollo-integrado-ide-explicados-con-la-magia-de-escandalosos--m07 | webdev, tutorial, programming, beginners | ¡Hola Chiquis! 👋🏻 Acompáñenme en este viaje donde los Escandalosos se convierten en desarrolladores y nos enseñan todo sobre los IDEs, esos increíbles entornos de desarrollo integrado.

¿Qué son los IDEs? 🌳
Imagí... | orlidev |
1,876,952 | Upstream preview: The value of open source software | Upstream is next week on June 5, and wow, our schedule is shaping up brilliantly. For the rest of... | 0 | 2024-06-04T16:41:29 | https://dev.to/tidelift/upstream-preview-the-value-of-open-source-software-2pfm | opensource, upstream, cybersecurity, security | <p><em>Upstream is next week on June 5, and wow, our schedule is shaping up brilliantly. For the rest of this week, we’ll be giving you a sneak preview into some of the talks and the speakers giving them via posts like these. RSVP </em><a href="https://upstream.live/register?__hstc=23643813.d1ddc767e9f4955f3bdd2f1c64c7... | caitbixby |
1,876,951 | Top 10 Youtube channels to follow if you're a Programmer 🚀 | PS: nothing fancy in the blog; Just listing here, some of the best youtube channels that will make... | 0 | 2024-06-04T16:40:49 | https://dev.to/prathamjagga/top-10-youtube-channels-to-follow-if-youre-a-programmer-28c8 | PS: nothing fancy in the blog; Just listing here, some of the best youtube channels that will make you fall in love with software development.
(i) ThePrimeTime -- This guy reacts to programming blogs, videos, etc, sharing his opinion and insights.
(ii) ByteByteGo -- Videos on System Design concepts and case studies.
(... | prathamjagga | |
1,876,939 | ♾️All about Infinite Scrolling | Introdution Social media platforms like TikTok, Instagram, and Twitter use infinite... | 0 | 2024-06-04T16:35:04 | https://dev.to/algoorgoal/why-intersection-observer-is-better-than-scroll-event-for-infinite-scrolling-list-a99 | webdev, react, ux | ## Introdution
Social media platforms like TikTok, Instagram, and Twitter use infinite scrolling instead of pagination. However, I wasn't sure when to use the classic pagination or infinite scrolling. Sometimes I implemented infinite scrolling using `IntersectionObserver`, but later I realized there are more ways to i... | algoorgoal |
1,876,938 | เริ่มต้น Quarkus 3 part 2.3 Renarde | Renarde เป็นอีกตัวช่วยในการทำ SSR ในรูปแบบ MVC เช่นเดียวกับ Spring MVC... | 0 | 2024-06-04T16:34:08 | https://dev.to/pramoth/erimtn-quarkus-3-part-23-renarde-2bgd | quarkus | Renarde เป็นอีกตัวช่วยในการทำ SSR ในรูปแบบ MVC เช่นเดียวกับ Spring MVC ที่มีเครื่องมือให้พร้อมหยิบมาใช้งานเลย เช่น form validator,csrf,routing,email,htmx support,barcode,gen pdf,security....
เริ่มต้นใช้งานก็เพิ่ม dependency ใน pom.xml จากบทความก่อนๆได้เลย โดยคง web-bundler ไว้เหมือนเดิม แต่สามารถเอา qute-web ,rest-qu... | pramoth |
1,873,798 | Jenkins up and running on Kubernetes 🚀 | Introduction 👋 In this hands-on, we'll cover: Deploy Jenkins controller on k8s... | 0 | 2024-06-04T16:32:02 | https://dev.to/tungbq/jenkins-on-kubernetes-a-comprehensive-guide-5d6a | devops, jenkins, kubernetes, cicd | ## Introduction 👋
In this hands-on, we'll cover:
- Deploy Jenkins controller on k8s cluster
- Configure k8s cluster as Jenkins agents
- Create and run a sample pipeline on a k8s Pod Jenkins agent
- Watch the Pod life cycle for a pipeline run
## Environment ☁️
This hands-on is for a PoC or Pilot environment, to expl... | tungbq |
1,876,896 | Writing an Obsidian Plugin Driven By Tests | I recently developed the initial version of Obsidian DEV Publish Plugin, a plugin that enables... | 0 | 2024-06-04T16:31:36 | https://dev.to/stroiman/writing-an-obsidian-plugin-driven-by-tests-1b35 | typescript, obsidian, tdd, javascript | I recently developed the initial version of [Obsidian DEV Publish Plugin](https://github.com/stroiman/obsidian-dev-publish), a plugin that enables publishing Obsidian notes as articles on [DEV](https://dev.to). The first prototype was developed during a ~4 hour live stream.
When I was ready to try the plugin for real... | stroiman |
1,876,936 | #117 Introduction to Natural Language Processing with Python | 93 ReALM: Apple's AI Revolution for Seamless Siri Conversations Figure 2: AI Visual... | 0 | 2024-06-04T16:30:05 | https://dev.to/genedarocha/117-introduction-to-natural-language-processing-with-python-5847 |
#93 ReALM: Apple's AI Revolution for Seamless Siri Conversations
<svg xmlns="http://www.w3.org/2000/... | genedarocha | |
1,876,935 | Recursion 遞迴 | 接下來想要緩慢的把自己的 CS 相關基礎補上,多多接觸寬廣的技術知識,就先從遞迴開始吧! 🐳 遞迴的種類 如果一個 function 裡面有 self-calling... | 0 | 2024-06-04T16:27:31 | https://simonecheng.github.io/recursion/ | dsa | 接下來想要緩慢的把自己的 CS 相關基礎補上,多多接觸寬廣的技術知識,就先從遞迴開始吧!
## 🐳 遞迴的種類
如果一個 function 裡面有 self-calling 的敘述,便稱為遞迴,遞迴概略可以分為三個種類,分別是:
- Direct Recursion
- Indirect Recursion
- Tail Recursion
下面舉一些簡單的例子來說明這三個遞迴。
### 🦀 Direct Recursion
Direct Recursion,直接遞迴,應該蠻好理解的。如果某個 function 在 function 內部呼叫自己,就可以稱為直接遞迴。可以參考下面的 psuedo code:
```c... | simonecheng |
1,876,924 | LLM Evaluations: Why They Matter | When building applications powered by large language models, it's easy to get excited about the rapid... | 0 | 2024-06-04T16:25:58 | https://dev.to/petrbrzek/you-need-llm-evaluations-to-make-your-app-stable-1j94 | When building applications powered by large language models, it's easy to get excited about the rapid prototyping capabilities. However, as you move beyond the initial prototype phase, you'll encounter various challenges that can impact the stability and reliability of your app. To address these issues and ensure a rob... | petrbrzek | |
1,876,923 | Day 5 of 30 | This is one of those days I was very overwhelmed and decided I needed to set one thing straight and... | 0 | 2024-06-04T16:24:05 | https://dev.to/francis_ngugi/day-5-of-30-3bh3 | This is one of those days I was very overwhelmed and decided I needed to set one thing straight and come up with a friendly schedule I actually got a nice schedule from Monica AI:
## **Phase 1 (Weeks 1-3):**
- Focus on learning React.js fundamentals, building various React projects, and becoming proficient in React.
... | francis_ngugi | |
1,876,922 | Recreating Stripe’s Roles in PropelAuth | Stripe is a platform that allows companies of all sizes to accept payments, issue invoices and... | 0 | 2024-06-04T16:22:24 | https://www.propelauth.com/post/recreating-stripes-roles-propelauth | webdev, product, tutorial, security | [Stripe](https://stripe.com/?ref=propelauth.com) is a platform that allows companies of all sizes to accept payments, issue invoices and generally manage their billing. Their offering is necessarily a bit complex, and they have a roles structure to match.
Every user can have a combination of roles that allows them acc... | victoria_propel |
1,876,921 | Learn Rust by building a real web application. | I heard about Rust few years back but was hesitant to learn it mainly due to its unique syntax. But i... | 0 | 2024-06-04T16:22:09 | https://dev.to/phunsukh_wangdu_2c0990752/learn-rust-by-building-a-real-web-application-4m99 | rust, learning, webapplication | I heard about Rust few years back but was hesitant to learn it mainly due to its unique syntax. But i kept stumbling on it ever since either on podcasts or YouTube channels or talks on how major companies are embracing it for C++.
I finally decided, I want to learn the language. I started reading the book but in no t... | phunsukh_wangdu_2c0990752 |
1,876,919 | Supercharge Your React App's SEO: Tips and Tricks | Introduction: In today's digital landscape, having a website or web application with excellent search... | 0 | 2024-06-04T16:19:21 | https://dev.to/vyan/supercharge-your-react-apps-seo-tips-and-tricks-34pm | webdev, javascript, beginners, react | **Introduction:**
In today's digital landscape, having a website or web application with excellent search engine optimization (SEO) is crucial for success. However, when it comes to Single Page Applications (SPAs) built with React, SEO can be a bit tricky. React's client-side rendering approach can pose challenges for ... | vyan |
1,876,918 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-04T16:17:02 | https://dev.to/tarrantteafo/buy-verified-cash-app-account-4dma | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\n\n\n\n\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | tarrantteafo |
1,876,917 | Buy verified cash app account | Buy verified cash app account Cash app has emerged as a dominant force in the realm of mobile banking... | 0 | 2024-06-04T16:16:48 | https://dev.to/whitemartin9875/buy-verified-cash-app-account-381a | Buy verified cash app account
Cash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with ... | whitemartin9875 | |
1,825,792 | AND / OR operators, Short-Circuiting and Nullish Coalescing in Javascript | Introduction Short Circuiting and Nullish Coalescing are mechanisms available in... | 0 | 2024-06-04T16:16:26 | https://dev.to/hatemtemimi/and-or-operators-short-circuiting-and-nullish-coalescing-in-javascript-1292 | webdev, javascript, logicalgates, operators | ## Introduction
Short Circuiting and Nullish Coalescing are mechanisms available in javascript to enhance code efficiency and readability, by providing special way of evaluating values.
It relies on the logical operators `&&` and `||`, while nullish Coalescing relies on the operator `??`, Both tools are powerful, ... | hatemtemimi |
1,876,916 | OpenSSF Case Study: Enhancing Open Source Security with Sigstore at Stacklok | Stacklok was founded in 2023 by Craig McLuckie (co-creator of Kubernetes) and Luke Hinds (creator of... | 0 | 2024-06-04T16:15:57 | https://dev.to/ninfriendos1/openssf-case-study-enhancing-open-source-security-with-sigstore-at-stacklok-50h0 | siggstore, openssf, opensource, security | Stacklok was founded in 2023 by Craig McLuckie (co-creator of [Kubernetes](https://kubernetes.io/)) and Luke Hinds (creator of the OpenSSF project [Sigstore](https://www.sigstore.dev/)), with the goal of helping developers produce and consume open source software more safely.
As malicious attacks on open source softwa... | ninfriendos1 |
1,876,911 | Google Play developer | Hello, I do not want a used Google Play developer account (verified) for sale, bypassed application... | 0 | 2024-06-04T16:14:51 | https://dev.to/taha_iraq_37650aded2ca6b5/google-play-developer-3dc |
Hello, I do not want a used Google Play developer account (verified) for sale, bypassed application verification | taha_iraq_37650aded2ca6b5 | |
1,876,906 | Discover the Power of Node.js: Highlights from Zibtek's Blog | Node.js has revolutionized the way developers approach web development, offering a versatile and... | 0 | 2024-06-04T16:09:31 | https://dev.to/cachemerrill/discover-the-power-of-nodejs-highlights-from-zibteks-blog-160d | node, mean, javascript |
Node.js has revolutionized the way developers approach web development, offering a versatile and efficient platform for building server-side applications. At Zibtek, we have extensively covered various aspects of Node.js, highlighting its benefits, use cases, and comparisons with other technologies. Here are some of t... | cachemerrill |
1,872,115 | Taming FluxCD HelmReleases: The Kustomize Way approach | HelmRelease looks like a good idea… but it has many problems. Let's see how to do better without HelmRelease for a better GitOps | 0 | 2024-06-04T16:00:00 | https://dev.to/davinkevin/taming-fluxcd-helmreleases-the-kustomize-way-approach-48l8 | kubernetes, fluxcd, yaml, helm | ---
title: Taming FluxCD HelmReleases: The Kustomize Way approach
published: true
description: HelmRelease looks like a good idea… but it has many problems. Let's see how to do better without HelmRelease for a better GitOps
tags: kubernetes, fluxcd, yaml, helm
cover_image: https://dev-to-uploads.s3.amazonaws.com/uplo... | davinkevin |
1,876,903 | From Monolith to Microservices or Enhanced SOA: A Comprehensive Guide to Modernizing Your Application Architecture | The software world is changing fast. Monolithic applications, once the go-to choice, are struggling... | 0 | 2024-06-04T15:59:35 | https://dev.to/marufhossain/from-monolith-to-microservices-or-enhanced-soa-a-comprehensive-guide-to-modernizing-your-application-architecture-26fa | The software world is changing fast. Monolithic applications, once the go-to choice, are struggling to keep up with the demands of today's dynamic business landscape. Imagine a giant, single server holding all your application code – that's a monolith. It works well at first, but as features pile on, it becomes sluggis... | marufhossain | |
1,876,901 | I Got Tired of the Way I Type Parentheses on a QWERTY Keyboard | I was used to AZERTY layout I was forced to use AZERTY keyboards because, they are the... | 0 | 2024-06-04T15:57:50 | https://dev.to/zinnwan/i-got-tired-of-the-way-i-type-parentheses-on-a-qwerty-keyboard-55ff | linux, keymap, qwerty | <h2 id="i-was-used-to-azerty-layout">I was used to AZERTY layout</h2>
<p>I was forced to use AZERTY keyboards because, they are the default
layout in my region. Recently I acquired a QWERTY keyboard. I’m getting
used to it but, there are some keys that shouldn’t be placed the way
they are. My first and major issue was ... | zinnwan |
1,876,900 | How to find FunCaptcha | By using CapSolver Extension | Understanding FunCaptcha FunCaptcha is a security solution that uses a variety of advanced... | 0 | 2024-06-04T15:57:43 | https://dev.to/trebolese/how-to-identify-funcaptcha-by-using-capsolver-extension-28 | ## Understanding FunCaptcha
FunCaptcha is a security solution that uses a variety of advanced technologies to enhance security and user experience, including:
- **Behavioral Analysis**: This feature tracks user behavior during the challenge, such as mouse movements and click patterns, to differentiate between humans a... | trebolese | |
1,876,899 | I need help in node ,anyone up? | sequelize //.sync({ force: true })it's task to overide the table. .sync() .then((result) =>... | 0 | 2024-06-04T15:57:10 | https://dev.to/nishant_ba92a27bea59a6002/i-need-help-in-node-anyone-up-1434 | help | sequelize
//.sync({ force: true })it's task to overide the table.
.sync()
.then((result) => {
return User.findByPk(1);
// app.listen(3000);
})
.then((user) => {
if (!user) {
console.log("ankuuser", user);
return User.create({ name: "Max", email: "test@test.com" });
}
return us... | nishant_ba92a27bea59a6002 |
1,876,898 | How to identify the extra parameters required for solve Google ReCaptcha | Deciphering Additional Parameters reCaptcha v2: reCaptcha versions: These come in... | 0 | 2024-06-04T15:55:17 | https://dev.to/trebolese/how-to-identify-the-extra-parameters-required-for-solve-google-recaptcha-4enp | # Deciphering Additional Parameters
**reCaptcha v2:**
- **reCaptcha versions**: These come in different forms:
- **reCaptcha v2 Normal**: The basic version where users solve a puzzle to confirm they're not a bot.
- **reCaptcha v2 Enterprise**: A premium, paid version with enhanced features and customization options... | trebolese | |
1,876,897 | What is zoom in Web Design? A funny story. | Almost every software engineer comes across a time where they start designing. And when you are... | 0 | 2024-06-04T15:54:44 | https://dev.to/alishgiri/what-is-zoom-in-web-design-3ddb | webdev, design, css | Almost every software engineer comes across a time where they start designing. And when you are designing your own product you want to make sure that it is close to perfection!
But something terrible happened which made me realize the importance of setting browser's zoom to 100% when designing on web lol.
Since I hav... | alishgiri |
1,876,895 | How to build a chrome extension in 2024 | Happy to be here! This is a walkthrough on creating the 'Scrolling Zombie' chrome extension which... | 0 | 2024-06-04T15:52:05 | https://dev.to/kalisen/how-to-build-a-chrome-extension-in-2024-1ba3 | extensions, chrome, howto | Happy to be here!
This is a walkthrough on creating the 'Scrolling Zombie' chrome extension which tracks the amount of scrolling a user does to make them aware of their browsing behavior and help them fight dark UI patterns.
In this guide I walk you through my typical approach to bringing an idea to life. I cover:
* ... | kalisen |
1,876,894 | Unlocking the Power of Expired Domains: A Comprehensive Guide to Buying Them | In the vast landscape of the internet, domain names play a crucial role in establishing a brand's... | 0 | 2024-06-04T15:50:16 | https://dev.to/seowhiz/unlocking-the-power-of-expired-domains-a-comprehensive-guide-to-buying-them-2g2b | In the vast landscape of the internet, domain names play a crucial role in establishing a brand's online identity. However, not all domains are created equal. One often-overlooked treasure trove in the world of domains is expired domains. These domains, once active websites that have lapsed, can hold significant value ... | seowhiz | |
1,876,882 | Raising a Web Studio Without Selling Your Soul 👹 | Building a business is hard. That’s a pretty obvious statement, but there’s so much nuance to it that... | 0 | 2024-06-04T15:47:31 | https://houseofgiants.com/blog/raising-a-web-studio-without-selling-your-soul | webdev, learning, career, community | Building a business is hard. That’s a pretty obvious statement, but there’s so much nuance to it that it bears repeating. How am I going to get more work? How am I going to finish the work that I have? What about taxes? Did I send out that status update on time? Are my clients properly informed about the status of thei... | magnificode |
1,876,881 | Jotai atomWithStorage | What is atomWithStorage? Basically to put it simply atomWithStorage is a cool way for you... | 0 | 2024-06-04T15:47:17 | https://dayvster.com/blog/jotai-atomwithstorage/ | react, webdev, typescript, javascript |
## What is atomWithStorage?
Basically to put it simply `atomWithStorage` is a cool way for you the developer to persist data in your application, it's a function that will automatically store the data of the atom in `localStorage`, `sessionStorage` for React or `AsyncStorage` for React Native.
That means you can pers... | dayvster |
1,876,879 | Buzz Off Expert Bee, Wasp, and Hornet Exterminator in Greenwich | A post by Green pest management | 0 | 2024-06-04T15:40:27 | https://dev.to/greenpest/buzz-off-expert-bee-wasp-and-hornet-exterminator-in-greenwich-8b6 | pest, home, control | [](urlhttps://greenpestmanagementct.com/pest-control-greenwich/)

| greenpest |
1,876,878 | How to create a cloud server for many projects in AWS | There are many tools or services on the internet for making this kind of server. They are almost all... | 0 | 2024-06-04T15:40:16 | https://dev.to/cocodelacueva/how-to-create-a-cloud-server-for-many-projects-in-aws-26l6 | webdev, aws, tutorial | There are many tools or services on the internet for making this kind of server. They are almost all easy to work with front-end frameworks such as React, Angular and Astro. There are others for back-end frameworks as well. However, this tutorial will be useful to learn about how a server works or to practice becoming ... | cocodelacueva |
1,876,877 | How to create a cloud server for many projects in AWS | There are many tools or services on the internet for making this kind of server. They are almost all... | 0 | 2024-06-04T15:40:16 | https://dev.to/cocodelacueva/how-to-create-a-cloud-server-for-many-projects-in-aws-11dg | webdev, aws, tutorial | There are many tools or services on the internet for making this kind of server. They are almost all easy to work with front-end frameworks such as React, Angular and Astro. There are others for back-end frameworks as well. However, this tutorial will be useful to learn about how a server works or to practice becoming ... | cocodelacueva |
1,876,876 | respinix | Discover the limitless possibilities of Respinix. At respinix.com, you'll have access to an... | 0 | 2024-06-04T15:39:21 | https://dev.to/respinix3/respinix-1a1b | Discover the limitless possibilities of Respinix. At [respinix.com](https://respinix.com/), you'll have access to an impressive collection of over 20,300 demo slot machines from 457 leading software providers. This unique platform allows you to try a wide variety of slot themes and styles for free and without any oblig... | respinix3 | |
1,876,874 | MICROSOFT AZURE CORE SERVICES | Azure Core Services are the primary offerings of Microsoft Azure. Services refer to individual... | 27,595 | 2024-06-04T15:38:27 | https://dev.to/aizeon/microsoft-azure-core-services-24g1 | beginners, azure, cloud, cloudcomputing | Azure Core Services are the primary offerings of Microsoft Azure.
_Services refer to individual offerings or capabilities provided by CSPs.
Solutions are integrated packages that bring together multiple services to solve a specific need._
## **COMPUTE**
Azure Compute is a cloud computing service that offers a range o... | aizeon |
1,876,875 | Transitioning into an AI Career: A Step-by-Step Guide | Advancements in technology, specifically in the field of artificial intelligence (AI), have created a... | 0 | 2024-06-04T15:36:55 | https://dev.to/ganesh_p_96bc2f769a6049e1/transitioning-into-an-ai-career-a-step-by-step-guide-50b2 | java, python, ai, programming | Advancements in technology, specifically in the field of artificial intelligence (AI), have created a high demand for professionals with expertise in this area. If you are looking to enter the world of AI, there are several steps you can take to successfully transition into an AI career. Here is a guide to help you get... | ganesh_p_96bc2f769a6049e1 |
1,875,769 | JavaScript30 - 4 Array Cardio Day 1 | Let me just start by saying my initial thoughts about this challenge were completely wrong. I... | 0 | 2024-06-04T15:36:31 | https://dev.to/virtualsobriety/javascript30-4-array-cardio-day-1-3a0b | javascript, beginners, javascript30, learning | Let me just start by saying my initial thoughts about this challenge were completely wrong. I figured this would be the easiest challenge BY FAR and was expecting to complete it and write this post in the same day. Here I am, almost two weeks later having just finished watching Wes Bos's video with his solutions.
He... | virtualsobriety |
1,876,873 | Sklep z Obrazami i Dekoracjami Ściennymi - Feeby | Witamy w Feeby - Twoim ulubionym sklepie z obrazami, dekoracjami ściennymi i tapetami! Nasz sklep z... | 0 | 2024-06-04T15:34:49 | https://dev.to/opm-med/sklep-z-obrazami-i-dekoracjami-sciennymi-feeby-1343 | design | Witamy w Feeby - Twoim ulubionym sklepie z obrazami, dekoracjami ściennymi i tapetami! Nasz sklep z dekoracjami ściennymi oferuje szeroki wybór produktów, które odmienią każde wnętrze. Odkryj naszą kolekcję i znajdź idealne obrazy online, które podkreślą charakter Twojego domu.
Sklep z Obrazami - Sztuka na Wyciągnięci... | opm-med |
1,876,798 | Creando un Tetris con JavaScript | Insertrix: un tetris ligeramente distinto. | 27,594 | 2024-06-04T15:30:07 | https://dev.to/baltasarq/creando-un-tetris-con-javascript-15ba | spanish, gamedev, javascript, tutorial | ---
title: Creando un Tetris con JavaScript
published: true
series: JavaScript Tetris
description: Insertrix: un tetris ligeramente distinto.
tags: #spanish #gamedev #javascript #tutorial
cover_image: https://upload.wikimedia.org/wikipedia/commons/4/46/Tetris_logo.png
# Use a ratio of 100:42 for best results.
# publish... | baltasarq |
1,876,871 | Understanding the Different EDI Standards: ANSI X12, EDIFACT, and More | In the ever-evolving landscape of supply chain management, Electronic Data Interchange (EDI) is the... | 0 | 2024-06-04T15:29:42 | https://dev.to/actionedi/understanding-the-different-edi-standards-ansi-x12-edifact-and-more-17of | In the ever-evolving landscape of supply chain management, Electronic Data Interchange (EDI) is the backbone of efficient and error-free communication between trading partners. But with a variety of EDI standards in use globally, it can be challenging to navigate which one suits your business needs best. Today, we'll d... | actionedi | |
1,876,869 | เริ่มต้น Quarkus 3 part 2.2 web bundler | หลังจากที่เราได้ serverside rendering Qute แล้วจากบทความก่อนหน้านี้... | 0 | 2024-06-04T15:21:06 | https://dev.to/pramoth/erimtn-quarkus-3-part-2-web-bundler-1fdk | quarkus | หลังจากที่เราได้ serverside rendering Qute แล้วจากบทความก่อนหน้านี้ https://dev.to/pramoth/erimtn-quarkus-3-part-2-web-4bkm ในบทความนี้เราจะเอา javascript dependencies (npm) เข้ามาใช้ใน Qute template โดยใช้ตัวช่วยที่ชื่อว่า Web Bundler ซึ่งเจ้าตัวนี้จะใช้ mvnpm(ก็เหมือน webjar แต่ว่ามันสร้าง jar auto ฉนั้นมันจึงมี vers... | pramoth |
1,876,812 | 10 Luxury Corporate Gifts to Give Your VIPs | You must distinguish yourself from the competition in this crowded world if you want to impress your... | 0 | 2024-06-04T15:17:18 | https://dev.to/blog-business/how-to-sell-soap-online-step-by-step-guide-541g |
You must distinguish yourself from the competition in this crowded world if you want to impress your clients. One way to do that is by impressing them with your luxury corporate gifts. This approach is always effective since it allows companies to appeal to customers and capture their attention without asking for any... | blog-business | |
1,876,344 | Why is Kubernetes Debugging so Problematic? | The Immutable Nature of Containers The Limitations of kubectl exec Avoiding Direct... | 0 | 2024-06-04T15:15:04 | https://debugagent.com/why-is-kubernetes-debugging-so-problematic | kubernetes, devops, tutorial, java | - [The Immutable Nature of Containers](#the-immutable-nature-of-containers)
- [The Limitations of `kubectl exec`](#the-limitations-of-raw-kubectl-exec-endraw-)
- [Avoiding Direct Modifications](#avoiding-direct-modifications)
- [Enter Ephemeral Containers](#enter-ephemeral-containers)
* [Using `kubectl debug`](#usin... | codenameone |
1,876,811 | The Future of Conferences: Navigating the Shift to Virtual | As we move further into 2024, conferences are changing because of technology advancements. The global... | 0 | 2024-06-04T15:14:19 | https://dev.to/priyanka_aich/the-future-of-conferences-navigating-the-shift-to-virtual-34ad | devops, ai | As we move further into 2024, conferences are changing because of technology advancements. The global shift towards virtual gatherings, accelerated by necessity, has evolved into a preference for many, driven by convenience, accessibility, and new technological possibilities. 89% of event planners see virtual conferenc... | priyanka_aich |
1,876,809 | BEST CRYPTOCURRENCY RECOVERY COMPANY - CONTACT DIGITAL WEB RECOVERY | The promise of easy money, of turning a small investment into a fortune, can be difficult to resist.... | 0 | 2024-06-04T15:12:00 | https://dev.to/genci_zane_bd4a22e84fad39/best-cryptocurrency-recovery-company-contact-digital-web-recovery-f6l | The promise of easy money, of turning a small investment into a fortune, can be difficult to resist. I, like many others, was captivated by the allure of binary options, drawn in by the promise of quick profits and financial freedom. The initial investment, a substantial $152,000 poured into the platform over a mere tw... | genci_zane_bd4a22e84fad39 | |
1,876,808 | Search Component React | import "./styles.css"; import React, { useEffect } from "react"; import { useState } from... | 0 | 2024-06-04T15:11:38 | https://dev.to/alamfatima1999/search-component-react-11b8 | ```JS
import "./styles.css";
import React, { useEffect } from "react";
import { useState } from "react";
import axios from "axios";
export default function App() {
const URL = `https://jsonplaceholder.typicode.com/todos`;
const [todoList, setTodoList] = useState([]);
const [text, setText] = useState("");
const... | alamfatima1999 | |
1,876,806 | Deep Dive into SideEffects Configuration | In Webpack2, support for ES Modules was added, allowing Webpack to analyze unused export content and... | 0 | 2024-06-04T15:11:03 | https://dev.to/markliu2013/deep-dive-into-sideeffects-configuration-14me | javascript | In Webpack2, support for ES Modules was added, allowing Webpack to analyze unused export content and then tree-shake it away. However, code in the module that has side effects will be retained by Webpack.
For example, there are modules utils/a.js and utils/b.js in the project, and a unified entry is provided through u... | markliu2013 |
1,876,804 | Explore GRASS: The Web sharing revolution, the benefits of 24-hour automated, unmanned online mining. | A post by whldasd | 0 | 2024-06-04T15:08:39 | https://dev.to/whldasd/explore-grass-the-web-sharing-revolution-the-benefits-of-24-hour-automated-unmanned-online-mining-j15 | whldasd | ||
1,876,805 | Explore GRASS: The Web sharing revolution, the benefits of 24-hour automated, unmanned online mining. | A post by whldasd | 0 | 2024-06-04T15:08:39 | https://dev.to/whldasd/explore-grass-the-web-sharing-revolution-the-benefits-of-24-hour-automated-unmanned-online-mining-51dd | whldasd | ||
1,876,803 | Optimizing Node.js Performance: Best Practices for High-Traffic Apps | Node.js is a powerful platform for building scalable and high-performance applications. However, as... | 0 | 2024-06-04T15:08:15 | https://dev.to/codesensei/optimizing-nodejs-performance-best-practices-for-high-traffic-apps-4do9 | webdev, javascript, tutorial, performance | Node.js is a powerful platform for building scalable and high-performance applications. However, as traffic increases, so does the need for optimization to ensure efficiency and speed. In this article, I'll share techniques for optimizing Node.js applications to handle high traffic, drawing from my experience in develo... | codesensei |
1,876,288 | PACX ⁓ Connect to Dataverse environment | We introduced PACX here, as a toolbelt containing commands to streamline the application development... | 0 | 2024-06-04T15:05:44 | https://dev.to/_neronotte/pacx-connect-to-dataverse-environment-55c | powerplatform, pacx, dataverse, opensource | We [introduced PACX here](https://dev.to/_neronotte/pacx-command-line-utility-belt-for-power-platform-dataverse-e4e), as a toolbelt containing commands to streamline the application development on Dataverse environments.
In order to run a command, **PACX** must be aware of the Dataverse environment where you want to r... | _neronotte |
1,876,802 | Introduction to Docker and Kubernetes with Node.js | Hey devs! With the growing adoption of microservices and the need for scalability, Docker and... | 0 | 2024-06-04T15:00:41 | https://dev.to/paulocappa/introduction-to-docker-and-kubernetes-with-nodejs-112f | docker, kubernetes, node, javascript | Hey devs!
With the growing adoption of microservices and the need for scalability, Docker and Kubernetes have become indispensable technologies. While Docker facilitates the creation and management of containers, Kubernetes orchestrates these containers in a cluster, providing high availability and scalability. Let's ... | paulocappa |
1,876,801 | cryptogram-assistant | I wrote this in React at the start of my new learning journey back in 2021. The goal was to be able... | 0 | 2024-06-04T15:00:01 | https://dev.to/cmcrawford2/cryptogram-assistant-2d2k | I wrote this in React at the start of my new learning journey back in 2021. The goal was to be able to format the very difficult cryptograms that I was trying to solve in my puzzle magazines. All I needed was a way to enter the cryptogram, with slots for the guessed letters. Then I would try out letters to break the co... | cmcrawford2 | |
1,873,476 | 🕒 Task vs Promise: Chaining | The first language in which I learned to work asynchronously was JavaScript. Initially, it was very... | 0 | 2024-06-04T15:00:00 | https://oscarlp6.dev/en/blogs/task-vs-promises/ | csharp, javascript, async | The first language in which I learned to work asynchronously was *JavaScript*. Initially, it was very challenging because it was a completely different way of thinking from what I had learned in university. Once I internalized the principles of *asynchronous* programming, it became much easier. So, when I started worki... | oscareduardolp6 |
1,865,084 | Database Observability: An Introductory Guide | Ever wondered what happens behind the scenes when you use an app or website? A crucial part of the... | 0 | 2024-06-04T15:00:00 | https://www.neurelo.com/post/database-observability-introduction | postgres, mongodb, mysql, database | Ever wondered what happens behind the scenes when you use an app or website? A crucial part of the magic lies in the database—a vast digital system storing all the information that keeps things running smoothly. But just like any complex system, databases require constant care and attention to ensure optimal performanc... | shohams |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.