
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,873,475 | 🕒 Task vs Promise: Encadenación | El primer lenguaje en el que aprendí a trabajar de forma asíncrona fue JavaScript. Al principio, me... | 0 | 2024-06-04T15:00:00 | https://oscarlp6.dev/blogs/task-vs-promises/ | csharp, javascript, async | El primer lenguaje en el que aprendí a trabajar de forma *asíncrona* fue *JavaScript*. Al principio, me costó mucho trabajo porque era una forma de pensar completamente distinta a la que aprendí en la universidad. Una vez que logré interiorizar los principios de la programación *asíncrona*, me fue mucho más sencillo. E... | oscareduardolp6 |
1,864,508 | How to unit test a private method in Kotlin without making it public | Table of contents The problem I am facing Why not make it public? My app on... | 0 | 2024-06-04T14:57:56 | https://dev.to/theplebdev/how-to-unit-test-a-private-method-in-kotlin-without-making-it-public-glc | android, kotlin, mobile, tristan | ### Table of contents
1. [The problem I am facing](#problem)
2. [Why not make it public?](#make)
### My app on the Google play store
- [The app](https://play.google.com/store/apps/details?id=elliott.software.clicker)
### My app's GitHub code
- [The GitHub ](https://github.com/thePlebDev/Clicker)
### The problem I am... | theplebdev |
1,876,800 | AI indoor navigation service | Infrastructure development for indoor tracking application, the project from A to Z. Abto Software... | 0 | 2024-06-04T14:57:54 | https://dev.to/abtosoftware/ai-indoor-navigation-service-2a1p | webdev, ai, devops, machinelearning | _[Infrastructure development for indoor tracking application](https://www.abtosoftware.com/portfolio/ai-indoor-navigation-service), the project from A to Z._
Abto Software was contracted by a mapping and accessibility organization providing indoor navigation services. Our company has covered application refactoring, s... | abtosoftware |
1,876,799 | Frontend challenge June edition | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. ... | 0 | 2024-06-04T14:56:14 | https://dev.to/sharmi2020/frontend-challenge-june-edition-51ma | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
<!-- What are you highlighting today? -->
Sizzling Summer
## Demo
<!-- Show us your CSS Art! You can directly embed an editor into this post (see the FAQ section of the challenge pa... | sharmi2020 |
1,876,795 | ToonCrafter: Amazing AI Cartoon Generator | In the world of animation, a revolutionary new tool is changing the game - ToonCrafter. This... | 0 | 2024-06-04T14:46:19 | https://dev.to/christianhappygo/tooncrafter-amazing-ai-cartoon-generator-1b4e | animation, ai, aigc |

In the world of animation, a revolutionary new tool is changing the game - [ToonCrafter](https://www.tooncrafter.app). This innovative technology uses a generative interpolation method to create smooth transitions betwe... | christianhappygo |
1,876,021 | Recapping the AI, Machine Learning and Data Science Meetup - May 30, 2024 | We just wrapped up the May '24 AI, Machine Learning and Data Science Meetup, and if you missed it or... | 0 | 2024-06-04T14:44:22 | https://voxel51.com/blog/recapping-the-ai-machine-learning-and-data-science-meetup-may-30-2024/ | computervision, machinelearning, datascience, ai | We just wrapped up the May '24 AI, Machine Learning and Data Science Meetup, and if you missed it or want to revisit it, here's a recap!
In this blog post you'll find the playback recordings, highlights from the presentations and Q&A, as well as the upcoming Meetup schedule so that you can join us at a future event.
... | jguerrero-voxel51 |
1,876,789 | Lifting State 🏋🏻♀️ | WHY ? Think of an online grocery store containing 100,000+ products. Each product has a... | 26,254 | 2024-06-04T14:41:41 | https://dev.to/jorjishasan/lifting-state-31g3 | webdev, beginners, react, programming | ## WHY ?
Think of an online grocery store containing 100,000+ products. Each product has a common feature, which is the toggle feature. They will show certain things on click. To function that feature in React, each product must have a state variable. Now, the popup question is, if 100,000 products have 100,000 state v... | jorjishasan |
1,876,787 | How we migrated our codebase from fp-ts to Effect | Summary At Inato, we migrated from fp-ts to Effect in early 2024. Given our substantial... | 0 | 2024-06-04T14:30:41 | https://medium.com/inato/how-we-migrated-our-codebase-from-fp-ts-to-effect-b71acd0c5640 | fpts, effect, migration, typescript | ## Summary
At Inato, we migrated from fp-ts to Effect in early 2024. Given our substantial codebase (around 500k lines of typescript code), we needed a way of ensuring any new code could be written using Effect while allowing existing fp-ts code to coexist. We achieved this goal in just two months, dedicating around 1... | laurerc |
1,876,783 | Top External Email Providers for Your Strapi Application | Email is one of the most critical communication channels between businesses and their users. It can... | 0 | 2024-06-04T14:23:55 | https://strapi.io/blog/top-external-email-providers-for-your-strapi-application | strapi, webdev, email, nextjs | Email is one of the most critical communication channels between businesses and their users. It can be used to send notifications, updates, newsletters, offers, or other communications. [A global study](https://sendgrid.com/en-us/why-sendgrid) showed that 83% of people prefer to receive communications from businesses o... | gitchimp88 |
1,873,237 | Heroku for ChatOps: Start and Monitor Deployments from Slack | In our last two articles, we explored how to configure CI/CD for Heroku using Heroku pipelines. When... | 0 | 2024-06-04T14:22:23 | https://dev.to/thawkin3/heroku-for-chatops-start-and-monitor-deployments-from-slack-3kle | webdev, programming, devops, heroku | In our last two articles, we explored how to [configure CI/CD for Heroku using Heroku pipelines](https://dev.to/thawkin3/how-i-finally-got-all-my-cicd-in-one-place-getting-my-cicd-act-together-with-heroku-flow-4fo2). When viewing a pipeline within the Heroku dashboard, you can easily [start a deployment or promote your... | thawkin3 |
1,876,725 | Do you know how the code you write in JavaScript gets executed? How JavaScript supports asynchronous execution? | JavaScript is quite unique in that it’s single-threaded, meaning it processes code in a specific... | 0 | 2024-06-04T14:20:13 | https://dev.to/afnan_ahmed/do-you-know-how-the-code-you-write-in-javascript-gets-executed-how-javascript-supports-asynchronous-execution-315d | webdev, javascript, programming, tutorial | JavaScript is quite unique in that it’s single-threaded, meaning it processes code in a specific order. But despite this, it manages to handle time-consuming tasks without freezing up. So, how does it do that? Well, let me break it down for you.
First off, there’s the call stack. Think of it like a stack of plates in ... | afnan_ahmed |
1,876,724 | Scripting vs. Programming Languages: Uncover the Key Differences Every Developer Should Know! | Discover key insights into scripting vs. programming languages that every developer should know!... | 0 | 2024-06-04T14:18:19 | https://dev.to/afnan_ahmed/scripting-vs-programming-languages-uncover-the-key-differences-every-developer-should-know-3haa | webdev, programming, learning, development | Discover key insights into scripting vs. programming languages that every developer should know! Understanding the difference between scripting and programming languages is key in software development.
Scripting languages are interpreter-based, while programming languages are compiler-based, defining their distinct use... | afnan_ahmed |
1,876,262 | What is Automation Testing? | In the fast-paced world of software development, maintaining high quality and reliability of... | 0 | 2024-06-04T06:45:12 | https://dev.to/perfectqa/what-is-automation-testing-422e | testing | In the fast-paced world of software development, maintaining high quality and reliability of applications is crucial. As applications become more complex, manual testing can become time-consuming, error-prone, and inefficient. This is where automation testing comes into play. But [what is automation testing?](https://w... | perfectqa |
1,876,723 | Fundamentals Of Set Theory | Definitions and Examples Sets Definition: A set is a collection of distinct objects,... | 0 | 2024-06-04T14:18:15 | https://dev.to/niladridas/fundamentals-of-set-theory-44ie | database, computerscience, programming, machinelearning | ## Definitions and Examples
- **Sets**
**Definition**: A set is a collection of distinct objects, known as elements of the set. Sets are typically denoted using curly braces.
**Example**: Consider "A = {2, 4, 6, 8, 10}". This represents a set of the first five even numbers. Another example might be "C = {apple, bana... | niladridas |
1,876,722 | Post de desarrollo web | A post by BYRON LOARTE | 0 | 2024-06-04T14:16:22 | https://dev.to/byrontosh/post-de-desarrollo-web-55lb | webdev | byrontosh | |
1,860,249 | Hosting Your Company's landing page (static website) on Google Cloud Using HTTPS & HTTP With Azure DNS Zone record | Introduction Imagine getting a job or being assigned a task in your organization, probably... | 0 | 2024-06-04T14:16:21 | https://dev.to/clouddiadem/hosting-your-companys-landing-page-static-website-on-google-cloud-using-https-http-with-azure-dns-zone-record-3n58 | googlecloud, dnsserver, dnsnamerecord, azure | ## Introduction
Imagine getting a job or being assigned a task in your organization, probably as a new intern to host the company's website on Google Cloud but you must use a load balancer to share network traffic appropriately and also secure it using an SSL certificate. Do you know how to do that? If not, let's walk... | clouddiadem |
1,876,721 | Fetch API React | import "./styles.css"; import React, { useEffect } from "react"; import { useState } from... | 0 | 2024-06-04T14:13:05 | https://dev.to/alamfatima1999/fetch-api-react-3787 | ```JS
import "./styles.css";
import React, { useEffect } from "react";
import { useState } from "react";
import axios from "axios";
export default function App() {
const URL = `https://jsonplaceholder.typicode.com/todos`;
const [todoList, setTodoList] = useState([]);
useEffect(() => {
// let todos;
// a... | alamfatima1999 | |
1,876,720 | Combing Kubeflow With A Dedicated Stack: Enter deployKF | In a world where there are thousands of tools in the cloud-native realm, we need methods to make our... | 0 | 2024-06-04T14:11:56 | https://dev.to/thenjdevopsguy/combing-kubeflow-with-a-dedicated-stack-enter-deploykf-3mak | kubernetes, devops, programming, git | In a world where there are thousands of tools in the cloud-native realm, we need methods to make our jobs more efficient. Software stacks have helped us out with this a ton. For example, LAMP (Linux, Apache, MySQL, Python) made deploying Linux web stacks far more efficient. Not because you **had** to use the specific s... | thenjdevopsguy |
1,876,719 | The Common Struggle of Automation Testing: Programming Knowledge | You’ve probably been thinking about exploring the field of automation testing for a long time. You... | 0 | 2024-06-04T14:10:28 | https://dev.to/sadia/the-common-struggle-of-automation-testing-programming-knowledge-3h50 | testing, automation, tester, programming | You’ve probably been thinking about exploring the field of automation testing for a long time. You even started working on it according to your thoughts. But when you started working, you got into trouble. This problem has been faced by more or less everyone, including me, you, and us. So let’s share some of my limited... | sadia |
1,876,716 | RTSP: Real Time Streaming Protocol Explained | In this article we are going to learn about RTSP RTSP (Real Time Streaming Protocol) is a network... | 0 | 2024-06-04T14:08:12 | https://www.metered.ca/blog/rtsp-real-time-streaming-protocol-explained-3/#meteredca-the-global-turn-server-solution | webdev, javascript, devops, webrtc | In this article we are going to learn about RTSP
RTSP (Real Time Streaming Protocol) is a network control protocol designed to use in communication systems.
RTSP protocol provides a framework for real time streaming of audio and video
RTSP provides efficient management of audio and video streams with extreamly low l... | alakkadshaw |
1,876,715 | TanStack Form Tutorial: Arrays & Dynamic Fields | Your form might not have a fixed number of fields, that's where arrays come in! Let's see today how... | 27,295 | 2024-06-04T14:07:50 | https://leonardomontini.dev/tanstack-form-arrays-dynamic-fields/ | react, angular, tutorial, codenewbie | Your form might not have a fixed number of fields, that's where arrays come in! Let's see today how TanStack Form behaves in this scenario.
This is Chapter 3 of the TanStack Form series, talking about this new Form library which supports React, Angular, Vue, Solid, and Lit.
We'll learn how to setup an array field and... | balastrong |
1,876,717 | What Really Determines Your Starups Success in the Long Run. | This ONE thing determines your business’s success in the long run And no it’s not cutting-edge... | 0 | 2024-06-04T14:07:00 | https://dev.to/martinbaun/what-really-determines-your-starups-success-in-the-long-run-19l | productivity, career, performance | This **ONE** thing determines your business’s success in the long run
And no it’s not cutting-edge technology
Not even **flashy marketing strategies**.
But it’s **clear communication** in the organization, by ensuring everyone is on the same page, you’re not just saving time, money, and energy—you’re laying the found... | martinbaun |
1,867,062 | ¿POR QUÉ no estás usando estos providers de Angular? | En este blog post, vamos a explorar 4 características que no se utilizan comúnmente en Angular, pero... | 0 | 2024-06-04T14:05:11 | https://dev.to/marianocodes/por-que-no-estas-usando-estos-providers-de-angular-406g | angular, providers, patterns, javascript | En este blog post, vamos a explorar 4 características que no se utilizan comúnmente en Angular, pero que ofrecen un gran poder y flexibilidad para escribir código escalable.
Ponte en al situación que necesitas implementar una lógica para manejar los logs en tu aplicación. Inicialmente, quieres configurar el tipo de lo... | marianocodes |
1,875,192 | Advanced Error Handling in Node.js | Error handling is an important aspect of software development that ensures your application behaves... | 0 | 2024-06-04T14:02:28 | https://dev.to/amritak27/advanced-error-handling-in-nodejs-1ep8 | node, javascript, webdev, express | Error handling is an important aspect of software development that ensures your application behaves predictably and provides meaningful feedback when something goes wrong. In Node.js, effective error handling can be particularly challenging due to its asynchronous nature. This article delves into advanced techniques an... | amritak27 |
1,876,680 | Code With Heroines : Availability && Redundancy && Fall of the Han Dynasty | Explanation This illustration demonstrates Availability by showing the abundance of... | 0 | 2024-06-04T14:01:14 | https://dev.to/fubumingyu/availability-redundancy-fall-of-the-han-dynasty-58h7 |

## Explanation
This illustration demonstrates Availability by showing the abundance of goods and military presence.
## Fall of the Han Dynasty
The Western Han Dynasty faced financial deterioration due to extens... | fubumingyu | |
1,876,229 | VScode: How to Chain Multiple Devcontainer for Development | Introduction Hello, I am Ise, an engineer at WESEEK who is in charge of the development... | 27,131 | 2024-06-04T14:00:00 | https://dev.to/weseek-inc/vscode-how-to-chain-multiple-devcontainer-for-development-2aep | docker, vscode, devops, programming | ## Introduction
Hello, I am Ise, an engineer at WESEEK who is in charge of the development and operation of [GROWI.cloud](https://growi.cloud/?utm_source=dev+community&utm_medium=referral&utm_campaign=VScode_How_to_Chain_Multiple_Devcontainer_for_Development).
In this issue, I would like to share a story about a time... | weseek-inc |
1,872,676 | What are Your Best Tips for Building a Coding Portfolio? | I am building my web page and my portfolio from scratch. Did you make yours from scratch as well or... | 0 | 2024-06-04T14:00:00 | https://dev.to/anitaolsen/what-are-your-best-tips-for-building-a-coding-portfolio-415f | discuss, coding, portfolio |
I am building my web page and my portfolio from scratch. Did you make yours from scratch as well or do you use a free portfolio template?
I am looking for inspiration and tips on how to make a great coding portfolio. I sort of have a real small one coded with basic HTML displaying two of my Python games (from some Co... | anitaolsen |
1,867,768 | Bucles de JavaScript | Últimamente he estado trabajando en una aplicación que solo cuenta con front-end, ya que el cliente... | 0 | 2024-06-04T13:55:43 | https://dev.to/terminator_true/for-vs-while-vs-map-4956 | javascript, webdev, programming, beginners | Últimamente he estado trabajando en una aplicación que solo cuenta con **front-end**, ya que el cliente nos proporciona en **back-end**.
Debido a que muchos de los datos no se nos dan de la manera exacta que necesita el front, he tenido que procesar los datos para poder mostrarlos como se requería.
Mientras pensaba... | terminator_true |
1,876,714 | GitOps for CI/CD: Managing Infrastructure and Applications as Code | GitOps is a set of practices that combines the principles of DevOps and Git to manage infrastructure... | 0 | 2024-06-04T13:55:41 | https://dev.to/platform_engineers/gitops-for-cicd-managing-infrastructure-and-applications-as-code-3hop | GitOps is a set of practices that combines the principles of DevOps and Git to manage infrastructure and applications as code. This approach enables platform engineering teams to manage and deploy infrastructure and applications in a consistent and reproducible manner. In this blog, we will explore the technical aspect... | shahangita | |
1,876,713 | Buy PVA Google Voice Accounts | Hello friends. In this blog post I want to share some piece of information and this informations are... | 0 | 2024-06-04T13:54:51 | https://dev.to/buypva_89f9eea18aef5a853e/buy-pva-google-voice-accounts-2ej3 | gmail, communication, email, googlevoice | Hello friends. In this blog post I want to share some piece of information and this informations are going to help you in [buying Google Voice accounts](https://pvamails.com/pva-google-voice-accounts-pva-mails-copy/) and [Gmail accounts.](https://pvamails.com/old-accounts/)
If you have any type of question related to ... | buypva_89f9eea18aef5a853e |
1,876,711 | Desarrollo de Software: Mantén la Motivación y Estudia de Manera Inteligente | En el emocionante camino del desarrollo de software, la motivación y la eficiencia en el estudio son... | 0 | 2024-06-04T13:52:50 | https://dev.to/farley_piedrahita_orozco/desarrollo-de-software-manten-la-motivacion-y-estudia-de-manera-inteligente-845 |
En el emocionante camino del desarrollo de software, la motivación y la eficiencia en el estudio son clave para el éxito. Descubre estrategias efectivas para mantener el impulso y optimizar tu aprendizaje en este viaje digital.
1. **Establece Metas Claras:** Define metas específicas y alcanzables. Establecer hitos c... | farley_piedrahita_orozco | |
1,876,710 | Tips and Tricks for Visual Studio Code | Terminal info: -Our standard bash prompt environment for entering commands like rake grade or... | 0 | 2024-06-04T13:52:33 | https://dev.to/mayas1111/tips-and-tricks-for-visual-studio-code-2ln1 | vscode, softwaredevelopment, beginners |
Terminal info:
-Our standard bash prompt environment for entering commands like rake grade or bin/server
-Pry for interacting with a database (we could also run rails console for that)
-Irb for typing in pure Ruby code
Commands:
-Reopen a pane
-Left
Mac OS: ⌘ + B
Windows: Ctrl + B
... | mayas1111 |
1,876,867 | How do I start to incorporate AI into my business? | 1. Spend at least 10 minutes playing with ChatGPT Start chatting without needing to... | 0 | 2024-06-04T20:03:07 | https://blog.jonathanflower.com/artificial-intelligence/how-do-i-start-to-incorporate-ai-into-my-business/ | ai, softwaredevelopment, aiempowerment | ---
title: How do I start to incorporate AI into my business?
published: true
date: 2024-06-04 13:51:58 UTC
tags: ArtificialIntelligence,SoftwareDevelopment,AI,AIEmpowerment
canonical_url: https://blog.jonathanflower.com/artificial-intelligence/how-do-i-start-to-incorporate-ai-into-my-business/
---
## 1. Spend at leas... | jfbloom22 |
1,876,709 | Extending Kubernetes Functionality: A Practical Guide to Custom Resource Definitions | Kubernetes provides a robust API for managing your cluster. API uses a RESTful design, allowing to... | 0 | 2024-06-04T13:51:56 | https://dev.to/gianlucam76/extending-kubernetes-functionality-a-practical-guide-to-custom-resource-definitions-5ag8 | showdev, kubernetes, opensource, tutorial | Kubernetes provides a robust API for managing your cluster. API uses a RESTful design, allowing to perform common actions like creating, retrieving, updating, deleting, listing, patching, and watching various resources within your cluster,
Kubernetes APIs are divided into groups:
- **core** group: this includes _Node... | gianlucam76 |
1,876,681 | k8s Executor 적용기(1) | 1. 발단 airflow에 대해 잘 모르던 시기에 사정상 내가 구축하지 않은 시스템을 유지보수할 일이 생겼다. airflow를 좀 아는 팀원이랑 같이 가서... | 27,593 | 2024-06-04T13:49:55 | https://dev.to/hj_lee/k8s-executor-jeogyonggi1-1n9e | airflow, datapipeline, k8s | ## 1. 발단
airflow에 대해 잘 모르던 시기에 사정상 내가 구축하지 않은 시스템을 유지보수할 일이 생겼다.
airflow를 좀 아는 팀원이랑 같이 가서 살펴보니 celery executor를 사용하는 전통적인(?) airflow 구조였음.
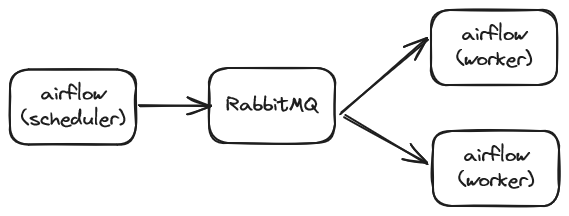
scheduler가 job을 배치하고, worker가 가져가서 수행한다는 전형적인 구조인데,
시스템에 문제가 생긴 이유는 R... | hj_lee |
1,876,706 | How to Deploy Flutter Apps to the Google Play Store and App Store | Today, we embark on an adventure – a journey to launch your captivating Flutter app onto the vast... | 0 | 2024-06-04T13:48:50 | https://dev.to/devitpl/how-to-deploy-flutter-apps-to-the-google-play-store-and-app-store-mko | webdev, flutterapps, deploy, development | Today, we embark on an adventure – a journey to launch your captivating [Flutter app onto the vast landscapes of the Google Play Store and App Store](https://www.devitpl.com/application-development/how-to-deploy-flutter-apps-to-the-google-play-store-and-app-store/).
This comprehensive guide will be your trusty compass... | devitpl |
1,876,705 | Azure Service Bus and Azure Functions Integration | Create and reading messages on service bus | 27,592 | 2024-06-04T13:48:46 | https://dev.to/campelo/azure-service-bus-and-azure-functions-integration-4p3h | servicebus, queue, funcions, message | ---
title: Azure Service Bus and Azure Functions Integration
series: Azure Service Bus and Azure Functions Integration
published: true
description: Create and reading messages on service bus
tags: 'servicebus, queue, funcions, message'
cover_image: 'https://raw.githubusercontent.com/campelo/documentation/master/posts/a... | campelo |
1,876,704 | Power BI Dashboard: Ultimate Tool for Dynamic Data Visualization and Storytelling | Are you ready to unleash the power of data storytelling with Power BI? Take the first step today and... | 0 | 2024-06-04T13:45:11 | https://dev.to/devitpl/power-bi-dashboard-ultimate-tool-for-dynamic-data-visualization-and-storytelling-246 | powerbi, dashboard, bi, microsoft | Are you ready to unleash the [power of data storytelling with Power BI](https://www.devitpl.com/microsoft-power-platform/power-bi-dashboard-ultimate-tool-for-dynamic-data-visualization-and-storytelling/)? Take the first step today and embark on a journey of data discovery. Explore the vast potential of Power BI and wat... | devitpl |
1,876,699 | Exploring the Power of Adobe Photoshop: A Comprehensive Guide | Adobe Photoshop stands as the cornerstone of [digital image]editing and manipulation, revolutionizing... | 0 | 2024-06-04T13:38:45 | https://dev.to/rai_touqeer_af431ddbdfbd2/exploring-the-power-of-adobe-photoshop-a-comprehensive-guide-1on4 |
Adobe Photoshop stands as the cornerstone of [digital image]editing and manipulation, revolutionizing the way we perceive and interact with visual content. From amateur photographers to seasoned graphic designers, Photoshop has become an indispensable tool for unleashing creativity and turning concepts into captivati... | rai_touqeer_af431ddbdfbd2 | |
1,876,698 | Play.HT : Le pouvoir de la voix IA au service de votre communication | Dans un monde numérique en constante évolution, où l'information est omniprésente et l'attention des... | 0 | 2024-06-04T13:36:19 | https://dev.to/vulgar_ia/playht-le-pouvoir-de-la-voix-ia-au-service-de-votre-communication-17dm | Dans un monde numérique en constante évolution, où l'information est omniprésente et l'attention des consommateurs est précieuse, se démarquer et captiver son audience devient un défi crucial. C'est là que [Play.ht](https://www.vulgaria.fr/outils-ia/mon-avis-play-ht-meilleur-generateur-de-voix-ia/) entre en jeu, révolu... | vulgar_ia | |
1,876,697 | Building Dynamic Forms in Angular | In Angular applications, forms are a fundamental aspect of collecting and managing user input. While... | 0 | 2024-06-04T13:33:11 | https://dev.to/bytebantz/building-dynamic-forms-in-angular-476m | angular, javascript, webdev, typescript | In Angular applications, forms are a fundamental aspect of collecting and managing user input. While static forms are common, there are scenarios where you need to create dynamic forms that adapt to user interactions, such as adding or removing form fields dynamically. In this article, we’ll explore how to build dynami... | bytebantz |
1,876,696 | Another Framework What's So Special About It ? | I've been dreaming of a ui library that lets me use declarative javascript. Okay, but what do i mean... | 0 | 2024-06-04T13:32:04 | https://dev.to/oarabiledev/another-framework-whats-so-special-about-it--3ejk | webdev, javascript, ui, library | I've been dreaming of a ui library that lets me use declarative javascript.
Okay, but what do i mean cause every framework/library calls itself declarative.
I mean by this !
`ui.addButton(parent, text, width, height, options)`
And not jsx or a compiled framework. The mission is to keep the core library code under a ... | oarabiledev |
1,876,695 | User Authorization with Postgres Row Level Security Policy | Supabase has a storage gateway that uses RLS for authorization. It requires a JWT that provides the... | 0 | 2024-06-04T13:31:02 | https://dev.to/keming/user-authorization-with-postgres-row-level-security-policy-4g91 | postgres, sql, database, security | Supabase has a [storage gateway](https://github.com/supabase/storage) that uses [RLS](https://www.postgresql.org/docs/current/ddl-rowsecurity.html) for authorization.
It requires a JWT that provides the role information to perform the SQL, here is an example of the JWT payload:
```json
{
"sub": "authenticated",
"... | keming |
1,876,694 | What is an Attack Surface Management? | Imagine every application, system, device, and online service you utilize as potential gateways for... | 0 | 2024-06-04T13:30:55 | https://www.clouddefense.ai/what-is-an-attack-surface-management/ |

Imagine every application, system, device, and online service you utilize as potential gateways for cybercriminals to infiltrate your digital domain. Alarming, isn't it? This is the current real... | clouddefenseai | |
1,876,693 | Here are 14 essential design principles for microservices: | Interface Segregation: Different types of clients (e.g., mobile apps, web apps, CLI programs) should... | 0 | 2024-06-04T13:30:15 | https://dev.to/akshansh_shrivastava_b0d2/here-are-14-essential-design-principles-for-microservices-21c7 | webdev, beginners, programming, tutorial | 1. Interface Segregation: Different types of clients (e.g., mobile apps, web apps, CLI programs) should be able to interact with services through the contract that best suits their needs.
2. Deployability: In the microservice era, developers need to make critical design decisions and technology choices regarding packa... | akshansh_shrivastava_b0d2 |
1,876,692 | Kubernetes installation | These instructions are for Kubernetes v1.30 (debian-based) controlplane & worker node Update... | 0 | 2024-06-04T13:28:19 | https://dev.to/abdallah_kordy_94db275ef5/kubernetes-installation-54e1 | kubernetes, containers, docker | **These instructions are for Kubernetes v1.30 (debian-based)** controlplane & worker node
1. Update the apt package index install packages needed to use the Kubernetes apt repository:
```
sudo apt-get update
# apt-transport-https may be a dummy package; if so, you can skip that package
sudo apt-get install -y apt-tr... | abdallah_kordy_94db275ef5 |
1,876,691 | Evolving Big Data Strategies with Data Lakehouses | In the rapidly evolving world of data technology, the need for sophisticated data management... | 0 | 2024-06-04T13:27:25 | https://dev.to/linda0609/evolving-big-data-strategies-with-data-lakehouses-ej | In the rapidly evolving world of data technology, the need for sophisticated data management solutions is more pressing than ever. The rise of [data lakehouses and data mesh](https://us.sganalytics.com/blog/evolving-big-data-strategies-with-data-lakehouses-and-data-mesh/) represents significant advancements in the way ... | linda0609 | |
1,875,548 | JS Builders Meetup - Dive Deep Into Kafka with JavaScript | Are you a JavaScript enthusiast eager to expand your understanding of modern web technologies? Join... | 0 | 2024-06-04T13:27:07 | https://dev.to/buildwebcrumbs/js-builders-meetup-tomorrow-dive-deep-into-kafka-with-javascript-47bi | community, javascript, kafka, coding | Are you a JavaScript enthusiast eager to expand your understanding of modern web technologies?
**Join us at our upcoming JS Builders Meetup**, where we'll explore the powerful world of Kafka and how it integrates with JavaScript.
This session is perfect for developers of all levels interested in enhancing their skill... | pachicodes |
1,864,880 | JavaScript arrays | JavaScript arrays are a versatile and powerful data structure used to store and manipulate... | 0 | 2024-05-25T14:06:54 | https://dev.to/raju-sarkar/new-title-45i7 | JavaScript arrays are a versatile and powerful data structure used to store and manipulate collections of data. An array in JavaScript is a special variable that can hold more than one value at a time, making it ideal for managing lists of items. Each item in an array is called an element, and elements are ordered by t... | raju-sarkar | |
1,875,354 | What is Supabase? How to Integrate It with Your React Application | As a developer, you're always looking for efficient, powerful tools to streamline your workflow and... | 0 | 2024-06-04T13:25:00 | https://dev.to/jehnz/what-is-supabase-how-to-integrate-it-with-your-react-application-5hea | react, supabase | As a developer, you're always looking for efficient, powerful tools to streamline your workflow and enhance your applications. Enter Supabase, an open-source alternative to Firebase that leverages the power of PostgreSQL databases. In this blog post, we'll explore what Supabase is, its standout features, and how you ca... | jehnz |
1,876,689 | Auth0 integration - Node.js + ExpressJS | This is a simple guide to demonstrate backend Auth0 integration. There will be no frontend involved.... | 0 | 2024-06-04T13:24:18 | https://dev.to/franklinthaker/auth0-integration-nodejs-expressjs-54l0 | auth0, express, node, beginners | This is a simple guide to demonstrate backend Auth0 integration. There will be no frontend involved. User sign-up, log-in, log-out, all operations will be done through backend only.
```
// index.js
require('dotenv').config();
const { auth, requiresAuth } = require("express-openid-connect");
const app = require("expres... | franklinthaker |
1,876,688 | Cent's Two Cents - HTML | Hi all! Cent here with my third day of updates! Continuing with the Odin Project, we've starting... | 27,574 | 2024-06-04T13:24:13 | https://dev.to/centanomics/cents-two-cents-html-26ak | Hi all!
Cent here with my third day of updates!
Continuing with the Odin Project, we've starting diving into HTML. It's been nice going over this stuff again. It makes me think about how we know stuff, but might not actively think about if that makes sense. It's hard to describe that feeling I think.
Today was mainl... | centanomics | |
1,876,687 | Python unit testing is even more convenient than you might realize | Introduction As software developers, we all write lots and lots of lines of code while building an... | 0 | 2024-06-04T13:23:28 | https://keploy.io/blog/community/unit-testing-in-python | unittesting, development, keploy, codepen |

Introduction
As software developers, we all write lots and lots of lines of code while building an application. But to ensure that each and every components work perfectly in the software, we really need to do some... | keploy |
1,876,667 | Build an AI Content Generator Using Gemini API and ToolJet in 10 Minutes 🛠️ | In this quick tutorial, we'll build an AI-powered content generator using the Gemini API and ToolJet,... | 0 | 2024-06-04T13:18:51 | https://blog.tooljet.com/build-an-ai-content-generator-using-gemini-api-and-tooljet-in-10-minutes/ | webdev, javascript, beginners, geminiapi | In this quick tutorial, we'll build an AI-powered content generator using the Gemini API and ToolJet, all within just 10 minutes. This app will generate content based on the uploaded images, selected content type, and additional info entered by the user. Whether you need titles, short descriptions, long descriptions, c... | karanrathod316 |
1,873,347 | O que realmente significa ser um Engenheiro de Software? | Introdução Iniciei minha carreira na área de TI por volta de 2018, enquanto ainda era... | 0 | 2024-06-04T13:10:55 | https://dev.to/j0suetm/o-que-realmente-significa-ser-um-engenheiro-de-software-o16 | softwareengineering, history | ## Introdução
Iniciei minha carreira na área de TI por volta de 2018, enquanto ainda era estudante. Após alguns anos, já no meu primeiro emprego, comecei a me autodenominar "Engenheiro de Software" nas redes sociais. Não, esse não era meu título profissional, nem eu compreendia completamente seu significado; simplesme... | j0suetm |
1,876,676 | A step-by-step guide to building an MLOps pipeline | The failure of DevOps pipelines to control Machine Learning(ML) development workflows gave rise to... | 0 | 2024-06-04T13:09:34 | https://jozu.com/blog/a-step-by-step-guide-to-building-an-mlops-pipeline/ | machinelearning, beginners, devops, learning | The failure of DevOps pipelines to control Machine Learning(ML) development workflows gave rise to [MLOps pipelines](https://jozu.com/blog/the-transitory-nature-of-mlops-advocating-for-devops-mlops-coalescence). These workflows require iterative interactions and management of numerous components and processes in develo... | jwilliamsr |
1,876,678 | Top Commercial Video Advertisement Production Services | Commercial Video Advertisement Production is a valuable asset for businesses seeking to expand their... | 0 | 2024-06-04T13:06:48 | https://dev.to/fbefilms/top-commercial-video-advertisement-production-services-24cl | Commercial Video Advertisement Production is a valuable asset for businesses seeking to expand their reach and establish a distinctive brand presence. Through broadcast videos, companies can connect with a broader audience, conveying their message effectively and fostering brand recognition. The dynamic nature of video... | fbefilms | |
1,873,942 | Help test Python 3.13! | Calling all Python library maintainers! 🐍 The Python 3.13 beta is out! 🎉 PEP 719 defines the... | 0 | 2024-06-04T13:04:03 | https://dev.to/hugovk/help-test-python-313-14j1 | python, testing, ci, githubactions | Calling all Python library maintainers! 🐍
The Python 3.13 beta is out! 🎉
[PEP 719](https://peps.python.org/pep-0719/#release-schedule) defines the release schedule for Python 3.13.0:
* The first beta candidate came out on 8th May 2024
* The first release candidate is set for 30th July 2024
* And the full release i... | hugovk |
1,876,671 | Exploring the Exciting New Features in React 18 | React 18 is a significant update for one of the most popular JavaScript libraries used for building... | 0 | 2024-06-04T12:54:18 | https://dev.to/shantih_palani/exploring-the-exciting-new-features-in-react-18-54m4 | react, react18, reactjsdevelopment | React 18 is a significant update for one of the most popular JavaScript libraries used for building user interfaces. This version introduces several exciting new features and improvements that aim to enhance performance, improve the developer experience, and enable new use cases. In this post, we’ll explore some of the... | shantih_palani |
1,876,677 | How to Use Firebase Authentication for Secure User Login | Project:- 5/500 Firebase Authentication Project Description Firebase... | 27,575 | 2024-06-04T13:03:41 | https://dev.to/raajaryan/how-to-use-firebase-authentication-for-secure-user-login-3df9 | react, javascript, opensource, beginners |
### Project:- 5/500 Firebase Authentication Project
## Description
Firebase Authentication provides a comprehensive and secure solution for authenticating users in web applications. It supports various authentication methods, including email and password, Google Sign-In, Facebook Login, and more. This project demon... | raajaryan |
1,876,442 | TW Elements - TailwindCSS IntelliSense. Free UI/UX design course | Colors Colours in Tailwind CSS are defined as classes that you can apply directly to your... | 25,935 | 2024-06-04T12:59:00 | https://dev.to/keepcoding/tw-elements-tailwindcss-intellisense-free-uiux-design-course-296f | tailwindcss, html, beginners, tutorial | ## Colors
Colours in Tailwind CSS are defined as classes that you can apply directly to your HTML elements. In this lesson, we'll learn how they work.
## Colour utility classes
Tailwind CSS comes with a wide variety of predefined colours. Each colour has different shades, ranging from 100 (lightest) to 900 (darkest)... | keepcoding |
1,876,675 | Styling in React: CSS-in-JS vs. Traditional CSS | Styling in React can be approached in various ways, including using traditional CSS and modern... | 0 | 2024-06-04T12:56:04 | https://dev.to/elightwalk/styling-in-react-css-in-js-vs-traditional-css-cnk | styling, react, css, reactjsdevelopment | Styling in React can be approached in various ways, including using traditional CSS and modern CSS-in-JS libraries. Each method has advantages and disadvantages, and choosing the right one depends on your project's needs.
Overview of CSS-in-JS Libraries
CSS-in-JS libraries allow you to write CSS directly within your J... | elightwalk |
1,876,673 | Top 8 Mặt Dây Chuyền Phong Thủy Hot Nhất | https://styleyoushop.com/top-nhung-mat-day-chuyen-phong-thuy-duoc-ua-chuong-nhat-hien-nay/ | 0 | 2024-06-04T12:54:38 | https://dev.to/styleyoushop12/top-8-mat-day-chuyen-phong-thuy-hot-nhat-166e | https://styleyoushop.com/top-nhung-mat-day-chuyen-phong-thuy-duoc-ua-chuong-nhat-hien-nay/ | styleyoushop12 | |
1,876,672 | StyleYouShop | https://styleyoushop.com/ | 0 | 2024-06-04T12:54:25 | https://dev.to/styleyoushop12/styleyoushop-24l2 | https://styleyoushop.com/ | styleyoushop12 | |
1,876,668 | E-commerce for Beginners: A Detailed Guide to Understanding and Getting Started | E-commerce, short for virtual exchange, has basically transformed the manner corporations operate and... | 0 | 2024-06-04T12:50:57 | https://dev.to/liong/e-commerce-for-beginners-a-detailed-guide-to-understanding-and-getting-started-3583 | benefits, shopify, wordpress, malaysia | E-commerce, short for virtual exchange, has basically transformed the manner corporations operate and consumers keep. As technology maintains to increase and internet get proper of entry to becomes extra big, e-commerce is turning into an an increasing number of important part of the worldwide economy. This particular ... | liong |
1,876,669 | Everything to Know about Selenium and its Role in Test Automation | Selenium is a testing environment and framework that, simply put, lets you automate browsers. This is... | 0 | 2024-06-04T12:50:57 | https://dev.to/morrismoses149/everything-to-know-about-selenium-and-its-role-in-test-automation-5go0 | selenium, testautomation, testgrid | Selenium is a testing environment and framework that, simply put, lets you automate browsers. This is great for creating test environments where your application and its resource utilization can be tested across real world user stories.
## What is Selenium
From their website,
“Selenium automates browsers”
It’s an auto... | morrismoses149 |
1,876,666 | Towards Lightweight Super-Resolution with Dual Regression Learning | Towards Lightweight Super-Resolution with Dual Regression Learning | 0 | 2024-06-04T12:50:04 | https://aimodels.fyi/papers/arxiv/towards-lightweight-super-resolution-dual-regression-learning | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Towards Lightweight Super-Resolution with Dual Regression Learning](https://aimodels.fyi/papers/arxiv/towards-lightweight-super-resolution-dual-regression-learning). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslet... | mikeyoung44 |
1,875,553 | Getting started with Drata.com APIs | Intro Integrating Drata's compliance automation tool can significantly streamline your... | 0 | 2024-06-04T12:50:00 | https://dev.to/jam3sperkins/getting-started-with-dratacom-apis-2j7l | compliance, drata, iso27001, postman | ## Intro
Integrating Drata's compliance automation tool can significantly streamline your compliance processes. This tutorial will guide you through utilising Drata's APIs with Postman. We'll cover importing the Drata Postman collection, setting an environment and making an API call.
We won't cover first time installa... | jam3sperkins |
1,876,664 | Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities | Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities | 0 | 2024-06-04T12:49:29 | https://aimodels.fyi/papers/arxiv/audio-flamingo-novel-audio-language-model-few | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities](https://aimodels.fyi/papers/arxiv/audio-flamingo-novel-audio-language-model-few). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi... | mikeyoung44 |
1,876,663 | Relightable Gaussian Codec Avatars | Relightable Gaussian Codec Avatars | 0 | 2024-06-04T12:48:55 | https://aimodels.fyi/papers/arxiv/relightable-gaussian-codec-avatars | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Relightable Gaussian Codec Avatars](https://aimodels.fyi/papers/arxiv/relightable-gaussian-codec-avatars). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitte... | mikeyoung44 |
1,876,661 | Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities | Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities | 0 | 2024-06-04T12:48:20 | https://aimodels.fyi/papers/arxiv/zipper-multi-tower-decoder-architecture-fusing-modalities | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities](https://aimodels.fyi/papers/arxiv/zipper-multi-tower-decoder-architecture-fusing-modalities). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](h... | mikeyoung44 |
1,876,659 | Uncertainty of Thoughts: Uncertainty-Aware Planning Enhances Information Seeking in Large Language Models | Uncertainty of Thoughts: Uncertainty-Aware Planning Enhances Information Seeking in Large Language Models | 0 | 2024-06-04T12:47:46 | https://aimodels.fyi/papers/arxiv/uncertainty-thoughts-uncertainty-aware-planning-enhances-information | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Uncertainty of Thoughts: Uncertainty-Aware Planning Enhances Information Seeking in Large Language Models](https://aimodels.fyi/papers/arxiv/uncertainty-thoughts-uncertainty-aware-planning-enhances-information). If you like these kinds of analysis, you... | mikeyoung44 |
1,876,658 | Diffusion On Syntax Trees For Program Synthesis | Diffusion On Syntax Trees For Program Synthesis | 0 | 2024-06-04T12:47:10 | https://aimodels.fyi/papers/arxiv/diffusion-syntax-trees-program-synthesis | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Diffusion On Syntax Trees For Program Synthesis](https://aimodels.fyi/papers/arxiv/diffusion-syntax-trees-program-synthesis). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or f... | mikeyoung44 |
1,876,657 | PlaceFormer: Transformer-based Visual Place Recognition using Multi-Scale Patch Selection and Fusion | PlaceFormer: Transformer-based Visual Place Recognition using Multi-Scale Patch Selection and Fusion | 0 | 2024-06-04T12:46:36 | https://aimodels.fyi/papers/arxiv/placeformer-transformer-based-visual-place-recognition-using | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [PlaceFormer: Transformer-based Visual Place Recognition using Multi-Scale Patch Selection and Fusion](https://aimodels.fyi/papers/arxiv/placeformer-transformer-based-visual-place-recognition-using). If you like these kinds of analysis, you should subsc... | mikeyoung44 |
1,872,432 | [WIP] JavaScript Vs Golang: Complexity | A lot of beginners start with JavaScript. The main reason for this is its simplicity: It's so simple... | 27,240 | 2024-06-04T12:46:11 | https://dev.to/henriqueleite42/wip-javascript-vs-golang-complexity-47f3 | go, javascript, typescript | A lot of beginners start with JavaScript. The main reason for this is its simplicity: It's so simple that you can literally press F12 right now and start coding.
In this article I'll compare Golang and JavaScript in production environments, to see how their complexity scales over time.
## The basics
Let's see what t... | henriqueleite42 |
1,876,656 | Track a Cruise Ship: Essential Information and Methods In an age of advanced technology and real-time data | Track a cruise ship has never been more accessible or useful - whether for family members, travel... | 0 | 2024-06-04T12:46:11 | https://dev.to/cruise_tracker_/track-a-cruise-ship-essential-information-and-methods-in-an-age-of-advanced-technology-and-real-time-data-1ecd | trackacruiseship | 
[Track a cruise ship](https://cruisetracker.com/) has never been more accessible or useful - whether for family members, travel enthusiasts, maritime professionals, or maritime professional safety officers alike. Kn... | cruise_tracker_ |
1,876,655 | Laboratory-Scale AI: Open-Weight Models are Competitive with ChatGPT Even in Low-Resource Settings | Laboratory-Scale AI: Open-Weight Models are Competitive with ChatGPT Even in Low-Resource Settings | 0 | 2024-06-04T12:46:02 | https://aimodels.fyi/papers/arxiv/laboratory-scale-ai-open-weight-models-are | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Laboratory-Scale AI: Open-Weight Models are Competitive with ChatGPT Even in Low-Resource Settings](https://aimodels.fyi/papers/arxiv/laboratory-scale-ai-open-weight-models-are). If you like these kinds of analysis, you should subscribe to the [AImodel... | mikeyoung44 |
1,876,654 | Context Injection Attacks on Large Language Models | Context Injection Attacks on Large Language Models | 0 | 2024-06-04T12:45:27 | https://aimodels.fyi/papers/arxiv/context-injection-attacks-large-language-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Context Injection Attacks on Large Language Models](https://aimodels.fyi/papers/arxiv/context-injection-attacks-large-language-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack... | mikeyoung44 |
1,876,653 | Formalizing and Benchmarking Prompt Injection Attacks and Defenses | Formalizing and Benchmarking Prompt Injection Attacks and Defenses | 0 | 2024-06-04T12:44:53 | https://aimodels.fyi/papers/arxiv/formalizing-benchmarking-prompt-injection-attacks-defenses | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Formalizing and Benchmarking Prompt Injection Attacks and Defenses](https://aimodels.fyi/papers/arxiv/formalizing-benchmarking-prompt-injection-attacks-defenses). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter... | mikeyoung44 |
1,876,652 | I made a VS Code extension to delete files content on right click | I was working on my new product where I needed to use the same name for about 100s of files across... | 0 | 2024-06-04T12:44:41 | https://dev.to/mike_andreuzza/i-made-an-vs-code-extension-to-delete-files-content-2e01 | vscode, extensions | 
I was working on my new product where I needed to use the same name for about 100s of files across different folders.
Removing the content manually after copying the folders was tedious.
So, I created a VS Code ex... | mike_andreuzza |
1,876,461 | MICROSOFT AZURE ARCHITECTURAL COMPONENTS | Azure architectural components refer to the building blocks of Microsoft Azure that can be combined... | 27,595 | 2024-06-04T12:44:34 | https://dev.to/aizeon/microsoft-azure-architectural-components-gbg | beginners, azure, cloud, cloudcomputing | Azure architectural components refer to the building blocks of Microsoft Azure that can be combined to create robust, scalable, and secure architectures for developers, architects, and organizations to design, deploy, and manage scalable, secure, and efficient cloud-based systems.
## **AVAILABILITY ZONES, REGIONS AND ... | aizeon |
1,868,450 | Mastering eksctl Commands: A Comprehensive Guide | eksctl is an incredibly powerful tool for managing Amazon EKS clusters, and it quickly became our... | 0 | 2024-06-04T12:44:19 | https://dev.to/vmgomez/mastering-eksctl-commands-a-comprehensive-guide-1h75 | kubernetes, aws, devops, cloud |

eksctl is an incredibly powerful tool for managing Amazon EKS clusters, and it quickly became our goto solution for automating Kubernetes deployments. With its extensive set of commands, we were able to streamlin... | vmgomez |
1,876,651 | Contextual Position Encoding: Learning to Count What's Important | Contextual Position Encoding: Learning to Count What's Important | 0 | 2024-06-04T12:44:18 | https://aimodels.fyi/papers/arxiv/contextual-position-encoding-learning-to-count-whats | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Contextual Position Encoding: Learning to Count What's Important](https://aimodels.fyi/papers/arxiv/contextual-position-encoding-learning-to-count-whats). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https:... | mikeyoung44 |
1,876,649 | Neural Network Parameter Diffusion | Neural Network Parameter Diffusion | 0 | 2024-06-04T12:43:44 | https://aimodels.fyi/papers/arxiv/neural-network-parameter-diffusion | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Neural Network Parameter Diffusion](https://aimodels.fyi/papers/arxiv/neural-network-parameter-diffusion). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitte... | mikeyoung44 |
1,876,648 | Is In-Context Learning Sufficient for Instruction Following in LLMs? | Is In-Context Learning Sufficient for Instruction Following in LLMs? | 0 | 2024-06-04T12:43:10 | https://aimodels.fyi/papers/arxiv/is-context-learning-sufficient-instruction-following-llms | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Is In-Context Learning Sufficient for Instruction Following in LLMs?](https://aimodels.fyi/papers/arxiv/is-context-learning-sufficient-instruction-following-llms). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslette... | mikeyoung44 |
1,876,647 | Oil & Water? Diffusion of AI Within and Across Scientific Fields | Oil & Water? Diffusion of AI Within and Across Scientific Fields | 0 | 2024-06-04T12:42:35 | https://aimodels.fyi/papers/arxiv/oil-water-diffusion-ai-within-across-scientific | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Oil & Water? Diffusion of AI Within and Across Scientific Fields](https://aimodels.fyi/papers/arxiv/oil-water-diffusion-ai-within-across-scientific). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aim... | mikeyoung44 |
1,876,646 | Learning to Model the World with Language | Learning to Model the World with Language | 0 | 2024-06-04T12:42:01 | https://aimodels.fyi/papers/arxiv/learning-to-model-world-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Learning to Model the World with Language](https://aimodels.fyi/papers/arxiv/learning-to-model-world-language). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [T... | mikeyoung44 |
1,876,645 | The Impacts of Data, Ordering, and Intrinsic Dimensionality on Recall in Hierarchical Navigable Small Worlds | The Impacts of Data, Ordering, and Intrinsic Dimensionality on Recall in Hierarchical Navigable Small Worlds | 0 | 2024-06-04T12:41:27 | https://aimodels.fyi/papers/arxiv/impacts-data-ordering-intrinsic-dimensionality-recall-hierarchical | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [The Impacts of Data, Ordering, and Intrinsic Dimensionality on Recall in Hierarchical Navigable Small Worlds](https://aimodels.fyi/papers/arxiv/impacts-data-ordering-intrinsic-dimensionality-recall-hierarchical). If you like these kinds of analysis, yo... | mikeyoung44 |
1,876,644 | Text clustering with LLM embeddings | Text clustering with LLM embeddings | 0 | 2024-06-04T12:40:52 | https://aimodels.fyi/papers/arxiv/text-clustering-llm-embeddings | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Text clustering with LLM embeddings](https://aimodels.fyi/papers/arxiv/text-clustering-llm-embeddings). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](... | mikeyoung44 |
1,876,643 | Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks | Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks | 0 | 2024-06-04T12:40:17 | https://aimodels.fyi/papers/arxiv/rotational-equilibrium-how-weight-decay-balances-learning | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks](https://aimodels.fyi/papers/arxiv/rotational-equilibrium-how-weight-decay-balances-learning). If you like these kinds of analysis, you should subscribe to the [AImodels.... | mikeyoung44 |
1,876,642 | How Artificial Intelligence Is Redefining Human Interaction | Artificial Intelligence (AI) is revolutionizing various sectors, enhancing efficiencies and... | 27,548 | 2024-06-04T12:39:55 | https://dev.to/aishikl/how-artificial-intelligence-is-redefining-human-interaction-4902 | # Artificial Intelligence (AI) is revolutionizing various sectors, enhancing efficiencies and capabilities while posing ethical challenges such as privacy concerns and job displacement. This blog post explores AI's dual impact on society, emphasizing the need for robust ethical frameworks like the "Blueprint for an AI ... | aishikl | |
1,876,641 | Training-Free Long-Context Scaling of Large Language Models | Training-Free Long-Context Scaling of Large Language Models | 0 | 2024-06-04T12:39:43 | https://aimodels.fyi/papers/arxiv/training-free-long-context-scaling-large-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Training-Free Long-Context Scaling of Large Language Models](https://aimodels.fyi/papers/arxiv/training-free-long-context-scaling-large-language). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimode... | mikeyoung44 |
1,876,640 | Certifiably Robust RAG against Retrieval Corruption | Certifiably Robust RAG against Retrieval Corruption | 0 | 2024-06-04T12:39:09 | https://aimodels.fyi/papers/arxiv/certifiably-robust-rag-against-retrieval-corruption | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Certifiably Robust RAG against Retrieval Corruption](https://aimodels.fyi/papers/arxiv/certifiably-robust-rag-against-retrieval-corruption). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.sub... | mikeyoung44 |
1,876,638 | Sparse maximal update parameterization: A holistic approach to sparse training dynamics | Sparse maximal update parameterization: A holistic approach to sparse training dynamics | 0 | 2024-06-04T12:38:34 | https://aimodels.fyi/papers/arxiv/sparse-maximal-update-parameterization-holistic-approach-to | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Sparse maximal update parameterization: A holistic approach to sparse training dynamics](https://aimodels.fyi/papers/arxiv/sparse-maximal-update-parameterization-holistic-approach-to). If you like these kinds of analysis, you should subscribe to the [A... | mikeyoung44 |
1,876,637 | Grokfast: Accelerated Grokking by Amplifying Slow Gradients | Grokfast: Accelerated Grokking by Amplifying Slow Gradients | 0 | 2024-06-04T12:38:00 | https://aimodels.fyi/papers/arxiv/grokfast-accelerated-grokking-by-amplifying-slow-gradients | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Grokfast: Accelerated Grokking by Amplifying Slow Gradients](https://aimodels.fyi/papers/arxiv/grokfast-accelerated-grokking-by-amplifying-slow-gradients). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https... | mikeyoung44 |
1,876,636 | Understanding Mixins in Dart and Flutter. | Hello friends, Today we'll explore an interesting and powerful concept in Dart and Flutter... | 0 | 2024-06-04T12:37:26 | https://dev.to/jitesh_yadav_de0e26fd6439/understanding-mixins-in-dart-and-flutter-61 | flutter, dart | Hello friends,
Today we'll explore an interesting and powerful concept in Dart and Flutter programming called mixins. Mixins are a fundamental feature that can greatly enhance the way we write and manage our code, especially in large-scale applications.
**Introduction to Mixins**
A mixin in Dart is a way to reuse co... | jitesh_yadav_de0e26fd6439 |
1,876,635 | An Introduction to Vision-Language Modeling | An Introduction to Vision-Language Modeling | 0 | 2024-06-04T12:37:25 | https://aimodels.fyi/papers/arxiv/introduction-to-vision-language-modeling | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [An Introduction to Vision-Language Modeling](https://aimodels.fyi/papers/arxiv/introduction-to-vision-language-modeling). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follo... | mikeyoung44 |
1,876,617 | Migrating from Class Components to Functional Components in React | Read originally blog post on my website https://antondevtips.com. React has evolved significantly... | 0 | 2024-06-04T12:37:13 | https://antondevtips.com/blog/migrating-from-class-components-to-functional-components-in-react | webdev, react, javascript, programming | ---
canonical_url: https://antondevtips.com/blog/migrating-from-class-components-to-functional-components-in-react
---
_Read originally blog post on my website_ [_https://antondevtips.com_](https://antondevtips.com/blog/migrating-from-class-components-to-functional-components-in-react?utm_source=devto&utm_medium=refer... | antonmartyniuk |
1,876,634 | Easy Problems That LLMs Get Wrong | Easy Problems That LLMs Get Wrong | 0 | 2024-06-04T12:36:50 | https://aimodels.fyi/papers/arxiv/easy-problems-that-llms-get-wrong | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Easy Problems That LLMs Get Wrong](https://aimodels.fyi/papers/arxiv/easy-problems-that-llms-get-wrong). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter]... | mikeyoung44 |
1,876,633 | Kotlin ML Pack: Technical Report | Kotlin ML Pack: Technical Report | 0 | 2024-06-04T12:36:16 | https://aimodels.fyi/papers/arxiv/kotlin-ml-pack-technical-report | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Kotlin ML Pack: Technical Report](https://aimodels.fyi/papers/arxiv/kotlin-ml-pack-technical-report). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](ht... | mikeyoung44 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.