
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,876,632 | Generate for Free the UI of your App with AI - Magic AI Blocks | With AI becoming more common, companies are using it to make their products better and offer improved... | 0 | 2024-06-04T12:35:45 | https://dev.to/creativetim_official/generate-for-free-the-ui-of-your-app-with-ai-magic-ai-blocks-5da7 | ai, webdev, ui, tailwindcss |
With AI becoming more common, companies are using it to make their products better and offer improved experiences to their customers. At [Creative Tim](https://creative-tim.com/?ref=devto), we are also using AI to help developers finish their projects faster.
Recently, we combined our popular Tailwind CSS framework,... | creativetim_official |
1,876,631 | LLMs achieve adult human performance on higher-order theory of mind tasks | LLMs achieve adult human performance on higher-order theory of mind tasks | 0 | 2024-06-04T12:35:41 | https://aimodels.fyi/papers/arxiv/llms-achieve-adult-human-performance-higher-order | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [LLMs achieve adult human performance on higher-order theory of mind tasks](https://aimodels.fyi/papers/arxiv/llms-achieve-adult-human-performance-higher-order). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](... | mikeyoung44 |
1,876,630 | There and Back Again: The AI Alignment Paradox | There and Back Again: The AI Alignment Paradox | 0 | 2024-06-04T12:35:07 | https://aimodels.fyi/papers/arxiv/there-back-again-ai-alignment-paradox | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [There and Back Again: The AI Alignment Paradox](https://aimodels.fyi/papers/arxiv/there-back-again-ai-alignment-paradox). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follo... | mikeyoung44 |
1,876,629 | Flutter Bloc | BLoC (Business Logic Component) separates business logic from UI in a Flutter application, ensuring a... | 0 | 2024-06-04T12:35:02 | https://dev.to/rampsad27/flutter-bloc-1e2p | BLoC (Business Logic Component) separates business logic from UI in a Flutter application, ensuring a clean and testable codebase. It utilizes streams to handle events and states, allowing for a reactive approach to state management. By adopting BLoC, you can create scalable and maintainable applications that are easie... | rampsad27 | |
1,876,627 | Using Disposable Emails for a Demo | We have a demo environment in Auctibles, the dynamic prices and sales events platform. ... | 0 | 2024-06-04T12:34:40 | https://dev.to/kornatzky/using-disposable-emails-for-a-demo-130m | ecommerce, demo, email, disposable | We have a demo environment in [Auctibles](https://auctibles.com), the dynamic prices and sales events platform.
# Demo Compared to Production
The demo environment has:
1. Emulated shipping that takes 10 minutes in each direction.
2. Emulated payment - you click the `Pay Now` button to pay, and the payment is immed... | kornatzky |
1,876,628 | BadLlama: cheaply removing safety fine-tuning from Llama 2-Chat 13B | BadLlama: cheaply removing safety fine-tuning from Llama 2-Chat 13B | 0 | 2024-06-04T12:34:33 | https://aimodels.fyi/papers/arxiv/badllama-cheaply-removing-safety-fine-tuning-from | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [BadLlama: cheaply removing safety fine-tuning from Llama 2-Chat 13B](https://aimodels.fyi/papers/arxiv/badllama-cheaply-removing-safety-fine-tuning-from). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https:... | mikeyoung44 |
1,876,626 | Large Language Models Can Self-Improve At Web Agent Tasks | Large Language Models Can Self-Improve At Web Agent Tasks | 0 | 2024-06-04T12:33:58 | https://aimodels.fyi/papers/arxiv/large-language-models-can-self-improve-at | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Large Language Models Can Self-Improve At Web Agent Tasks](https://aimodels.fyi/papers/arxiv/large-language-models-can-self-improve-at). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substac... | mikeyoung44 |
1,876,625 | Top Small Service Business Ideas to Start Today | Starting a small service business can be an incredibly rewarding endeavor, offering the chance to... | 0 | 2024-06-04T12:33:52 | https://dev.to/anuj_mishra_c52b14f34f667/top-small-service-business-ideas-to-start-today-4b5h |
Starting a [small service business](https://www.mobileappdaily.com/knowledge-hub/service-business-ideas?utm_source=dev&utm_medium=anuj&utm_campaign=mad) can be an incredibly rewarding endeavor, offering the chance to make a positive impact in your community while generating a steady income. Whether you have a specific... | anuj_mishra_c52b14f34f667 | |
1,876,624 | SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering | SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering | 0 | 2024-06-04T12:33:24 | https://aimodels.fyi/papers/arxiv/swe-agent-agent-computer-interfaces-enable-automated | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering](https://aimodels.fyi/papers/arxiv/swe-agent-agent-computer-interfaces-enable-automated). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslett... | mikeyoung44 |
1,876,623 | ToonCrafter: Generative Cartoon Interpolation | ToonCrafter: Generative Cartoon Interpolation | 0 | 2024-06-04T12:32:50 | https://aimodels.fyi/papers/arxiv/tooncrafter-generative-cartoon-interpolation | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [ToonCrafter: Generative Cartoon Interpolation](https://aimodels.fyi/papers/arxiv/tooncrafter-generative-cartoon-interpolation). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or... | mikeyoung44 |
1,876,622 | Mammography Market: Global Outlook, Trends, Key Players, Growth Statistics, and Market Dynamics (2024-2033) | The global Mammography market, valued at US$ 2.3 Billion in 2023, is expected to exhibit a robust... | 0 | 2024-06-04T12:32:28 | https://dev.to/swara_353df25d291824ff9ee/mammography-market-global-outlook-trends-key-players-growth-statistics-and-market-dynamics-2024-2033-348d | The global [Mammography market](https://www.persistencemarketresearch.com/market-research/mammography-market.asp), valued at US$ 2.3 Billion in 2023, is expected to exhibit a robust growth trajectory, expanding at a CAGR of 11.6% from 2024 to 2033, reaching US$ 6.9 Billion by the end of the forecast period. Digital Sys... | swara_353df25d291824ff9ee | |
1,876,621 | Compressed-Language Models for Understanding Compressed File Formats: a JPEG Exploration | Compressed-Language Models for Understanding Compressed File Formats: a JPEG Exploration | 0 | 2024-06-04T12:32:15 | https://aimodels.fyi/papers/arxiv/compressed-language-models-understanding-compressed-file-formats | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Compressed-Language Models for Understanding Compressed File Formats: a JPEG Exploration](https://aimodels.fyi/papers/arxiv/compressed-language-models-understanding-compressed-file-formats). If you like these kinds of analysis, you should subscribe to ... | mikeyoung44 |
1,876,620 | PayPal is now accepted on Rails Designer | This is just a quick service announcement (but a highly requested one—from multiple dozen dev.to... | 0 | 2024-06-04T12:31:56 | https://railsdesigner.com/paypal-enabled/ | rails, ruby, webdev, tailwindcss | _This is just a quick service announcement (but a highly requested one—from multiple dozen dev.to readers, so posting here for reach)_
---
Starting today you can get a copy of Rails Designer using PayPal! 😊 Head over to [Get Access](https://railsdesigner.com/pricing/), choose your preferred option and on the next sc... | railsdesigner |
1,876,603 | The Road Less Scheduled | The Road Less Scheduled | 0 | 2024-06-04T12:23:38 | https://aimodels.fyi/papers/arxiv/road-less-scheduled | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [The Road Less Scheduled](https://aimodels.fyi/papers/arxiv/road-less-scheduled). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mik... | mikeyoung44 |
1,876,619 | Assessing Large Language Models on Climate Information | Assessing Large Language Models on Climate Information | 0 | 2024-06-04T12:31:41 | https://aimodels.fyi/papers/arxiv/assessing-large-language-models-climate-information | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Assessing Large Language Models on Climate Information](https://aimodels.fyi/papers/arxiv/assessing-large-language-models-climate-information). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.... | mikeyoung44 |
1,876,618 | Metaheuristics and Large Language Models Join Forces: Towards an Integrated Optimization Approach | Metaheuristics and Large Language Models Join Forces: Towards an Integrated Optimization Approach | 0 | 2024-06-04T12:31:06 | https://aimodels.fyi/papers/arxiv/metaheuristics-large-language-models-join-forces-towards | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Metaheuristics and Large Language Models Join Forces: Towards an Integrated Optimization Approach](https://aimodels.fyi/papers/arxiv/metaheuristics-large-language-models-join-forces-towards). If you like these kinds of analysis, you should subscribe to... | mikeyoung44 |
1,876,616 | LLaMA Pro: Progressive LLaMA with Block Expansion | LLaMA Pro: Progressive LLaMA with Block Expansion | 0 | 2024-06-04T12:30:31 | https://aimodels.fyi/papers/arxiv/llama-pro-progressive-llama-block-expansion | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [LLaMA Pro: Progressive LLaMA with Block Expansion](https://aimodels.fyi/papers/arxiv/llama-pro-progressive-llama-block-expansion). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com)... | mikeyoung44 |
1,876,615 | Privacy-Aware Visual Language Models | Privacy-Aware Visual Language Models | 0 | 2024-06-04T12:29:56 | https://aimodels.fyi/papers/arxiv/privacy-aware-visual-language-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Privacy-Aware Visual Language Models](https://aimodels.fyi/papers/arxiv/privacy-aware-visual-language-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Tw... | mikeyoung44 |
1,876,614 | 5 Web Design Trends You Can Implement Today | The digital landscape is constantly evolving, and staying updated with the latest web design trends... | 0 | 2024-06-04T12:29:34 | https://dev.to/robertadler/5-web-design-trends-you-can-implement-today-41ol | The digital landscape is constantly evolving, and staying updated with the latest web design trends is crucial for any business or individual looking to maintain a competitive edge. In 2024, we see a mix of new innovations and refined techniques that can enhance user experience, engagement, and overall aesthetic appeal... | robertadler | |
1,876,613 | Faithful Logical Reasoning via Symbolic Chain-of-Thought | Faithful Logical Reasoning via Symbolic Chain-of-Thought | 0 | 2024-06-04T12:29:22 | https://aimodels.fyi/papers/arxiv/faithful-logical-reasoning-via-symbolic-chain-thought | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Faithful Logical Reasoning via Symbolic Chain-of-Thought](https://aimodels.fyi/papers/arxiv/faithful-logical-reasoning-via-symbolic-chain-thought). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimod... | mikeyoung44 |
1,876,612 | Is Complexity an Illusion? | Is Complexity an Illusion? | 0 | 2024-06-04T12:28:47 | https://aimodels.fyi/papers/arxiv/is-complexity-illusion | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Is Complexity an Illusion?](https://aimodels.fyi/papers/arxiv/is-complexity-illusion). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.c... | mikeyoung44 |
1,876,611 | Executable Code Actions Elicit Better LLM Agents | Executable Code Actions Elicit Better LLM Agents | 0 | 2024-06-04T12:28:13 | https://aimodels.fyi/papers/arxiv/executable-code-actions-elicit-better-llm-agents | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Executable Code Actions Elicit Better LLM Agents](https://aimodels.fyi/papers/arxiv/executable-code-actions-elicit-better-llm-agents). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.... | mikeyoung44 |
1,876,610 | LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning | LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning | 0 | 2024-06-04T12:27:38 | https://aimodels.fyi/papers/arxiv/lisa-layerwise-importance-sampling-memory-efficient-large | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning](https://aimodels.fyi/papers/arxiv/lisa-layerwise-importance-sampling-memory-efficient-large). If you like these kinds of analysis, you should subscribe to the [A... | mikeyoung44 |
1,876,609 | The rising costs of training frontier AI models | The rising costs of training frontier AI models | 0 | 2024-06-04T12:26:30 | https://aimodels.fyi/papers/arxiv/rising-costs-training-frontier-ai-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [The rising costs of training frontier AI models](https://aimodels.fyi/papers/arxiv/rising-costs-training-frontier-ai-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or f... | mikeyoung44 |
1,876,608 | Building Your E-Commerce Store with Nuxt.js: A Step-by-Step Guide to Project Setup | Check this post in my web notes! In our previous post, we laid the groundwork for our e-commerce... | 27,540 | 2024-06-04T12:25:57 | https://webcraft-notes.com/blog/building-your-ecommerce-store-with-nuxtjs-a | vue, nuxt, javascript, tutorial |

> Check [this post](https://webcraft-notes.com/blog/building-your-ecommerce-store-with-nuxtjs-a) in my [web notes](https://webcraft-notes.com/blog/)!... | webcraft-notes |
1,876,607 | Human vs. Machine: Behavioral Differences Between Expert Humans and Language Models in Wargame Simulations | Human vs. Machine: Behavioral Differences Between Expert Humans and Language Models in Wargame Simulations | 0 | 2024-06-04T12:25:55 | https://aimodels.fyi/papers/arxiv/human-vs-machine-behavioral-differences-between-expert | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Human vs. Machine: Behavioral Differences Between Expert Humans and Language Models in Wargame Simulations](https://aimodels.fyi/papers/arxiv/human-vs-machine-behavioral-differences-between-expert). If you like these kinds of analysis, you should subsc... | mikeyoung44 |
1,876,606 | AnyLoss: Transforming Classification Metrics into Loss Functions | AnyLoss: Transforming Classification Metrics into Loss Functions | 0 | 2024-06-04T12:25:21 | https://aimodels.fyi/papers/arxiv/anyloss-transforming-classification-metrics-into-loss-functions | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [AnyLoss: Transforming Classification Metrics into Loss Functions](https://aimodels.fyi/papers/arxiv/anyloss-transforming-classification-metrics-into-loss-functions). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslet... | mikeyoung44 |
1,876,605 | Evaluating AI-generated code for C++, Fortran, Go, Java, Julia, Matlab, Python, R, and Rust | Evaluating AI-generated code for C++, Fortran, Go, Java, Julia, Matlab, Python, R, and Rust | 0 | 2024-06-04T12:24:46 | https://aimodels.fyi/papers/arxiv/evaluating-ai-generated-code-c-fortran-go | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Evaluating AI-generated code for C++, Fortran, Go, Java, Julia, Matlab, Python, R, and Rust](https://aimodels.fyi/papers/arxiv/evaluating-ai-generated-code-c-fortran-go). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi ne... | mikeyoung44 |
1,876,604 | You Need to Pay Better Attention: Rethinking the Mathematics of Attention Mechanism | You Need to Pay Better Attention: Rethinking the Mathematics of Attention Mechanism | 0 | 2024-06-04T12:24:12 | https://aimodels.fyi/papers/arxiv/you-need-to-pay-better-attention-rethinking | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [You Need to Pay Better Attention: Rethinking the Mathematics of Attention Mechanism](https://aimodels.fyi/papers/arxiv/you-need-to-pay-better-attention-rethinking). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslett... | mikeyoung44 |
1,876,602 | Green Cement Market: Comprehensive Trends and Growth Forecast for 2024-2030 | Projected to grow from US$ 31.5 billion in 2024 to US$ 56.5 billion by 2030, the global green cement... | 0 | 2024-06-04T12:23:04 | https://dev.to/swara_353df25d291824ff9ee/green-cement-market-comprehensive-trends-and-growth-forecast-for-2024-2030-p87 | cement | Projected to grow from US$ 31.5 billion in 2024 to US$ 56.5 billion by 2030, the global [green cement market](https://www.persistencemarketresearch.com/market-research/green-cement-market.asp) is expected to expand at a CAGR of 10.2%. This market, which previously grew at 7.4% from 2018 to 2023, is transforming constru... | swara_353df25d291824ff9ee |
1,876,601 | Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models | Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models | 0 | 2024-06-04T12:23:03 | https://aimodels.fyi/papers/arxiv/algorithm-thoughts-enhancing-exploration-ideas-large-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models](https://aimodels.fyi/papers/arxiv/algorithm-thoughts-enhancing-exploration-ideas-large-language). If you like these kinds of analysis, you should subscribe to the [AImodels... | mikeyoung44 |
1,876,599 | Bovine Pregnancy Test Kit by BBC Dairy Solutions | Introducing the “AniEasy Bovine Pregnancy Rapid Test Kit” – Revolutionizing Pregnancy Detection in... | 0 | 2024-06-04T12:21:58 | https://dev.to/bbcdairy/bovine-pregnancy-test-kit-by-bbc-dairy-solutions-1em | Introducing the “AniEasy Bovine Pregnancy Rapid Test Kit” – Revolutionizing Pregnancy Detection in Cows & Buffaloes! Experience a modern and superior approach to pregnancy detection with the AniEasy Bovine Pregnancy Rapid Test Kit.
In the heart of India, a community of passionate and pioneering women dairy entrepreneu... | bbcdairy | |
1,876,598 | NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models | NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models | 0 | 2024-06-04T12:21:54 | https://aimodels.fyi/papers/arxiv/nv-embed-improved-techniques-training-llms-as | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models](https://aimodels.fyi/papers/arxiv/nv-embed-improved-techniques-training-llms-as). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter]... | mikeyoung44 |
1,876,597 | On the Brittle Foundations of ReAct Prompting for Agentic Large Language Models | On the Brittle Foundations of ReAct Prompting for Agentic Large Language Models | 0 | 2024-06-04T12:21:20 | https://aimodels.fyi/papers/arxiv/brittle-foundations-react-prompting-agentic-large-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [On the Brittle Foundations of ReAct Prompting for Agentic Large Language Models](https://aimodels.fyi/papers/arxiv/brittle-foundations-react-prompting-agentic-large-language). If you like these kinds of analysis, you should subscribe to the [AImodels.f... | mikeyoung44 |
1,876,596 | gzip Predicts Data-dependent Scaling Laws | gzip Predicts Data-dependent Scaling Laws | 0 | 2024-06-04T12:20:11 | https://aimodels.fyi/papers/arxiv/gzip-predicts-data-dependent-scaling-laws | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [gzip Predicts Data-dependent Scaling Laws](https://aimodels.fyi/papers/arxiv/gzip-predicts-data-dependent-scaling-laws). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow... | mikeyoung44 |
1,876,595 | Look Once to Hear: Target Speech Hearing with Noisy Examples | Look Once to Hear: Target Speech Hearing with Noisy Examples | 0 | 2024-06-04T12:19:37 | https://aimodels.fyi/papers/arxiv/look-once-to-hear-target-speech-hearing | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Look Once to Hear: Target Speech Hearing with Noisy Examples](https://aimodels.fyi/papers/arxiv/look-once-to-hear-target-speech-hearing). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substa... | mikeyoung44 |
1,876,594 | Generate and Pray: Using SALLMS to Evaluate the Security of LLM Generated Code | Generate and Pray: Using SALLMS to Evaluate the Security of LLM Generated Code | 0 | 2024-06-04T12:19:03 | https://aimodels.fyi/papers/arxiv/generate-pray-using-sallms-to-evaluate-security | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Generate and Pray: Using SALLMS to Evaluate the Security of LLM Generated Code](https://aimodels.fyi/papers/arxiv/generate-pray-using-sallms-to-evaluate-security). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslette... | mikeyoung44 |
1,876,592 | Arrows of Time for Large Language Models | Arrows of Time for Large Language Models | 0 | 2024-06-04T12:18:28 | https://aimodels.fyi/papers/arxiv/arrows-time-large-language-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Arrows of Time for Large Language Models](https://aimodels.fyi/papers/arxiv/arrows-time-large-language-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [T... | mikeyoung44 |
1,876,589 | Using Dependency Injection in Elixir | While controversial in functional programming, dependency injection can be a useful pattern in Elixir... | 27,591 | 2024-06-04T12:18:21 | https://blog.appsignal.com/2024/05/21/using-dependency-injection-in-elixir.html | elixir | While controversial in functional programming, dependency injection can be a useful pattern in Elixir for managing dependencies and improving testability.
In this, the first part of a two-part series, we will cover the basic concepts, core principles, and types of dependency injection. We'll explore its benefits in te... | allanmacgregor |
1,876,590 | NPGA: Neural Parametric Gaussian Avatars | NPGA: Neural Parametric Gaussian Avatars | 0 | 2024-06-04T12:17:20 | https://aimodels.fyi/papers/arxiv/npga-neural-parametric-gaussian-avatars | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [NPGA: Neural Parametric Gaussian Avatars](https://aimodels.fyi/papers/arxiv/npga-neural-parametric-gaussian-avatars). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me... | mikeyoung44 |
1,876,587 | Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality | Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality | 0 | 2024-06-04T12:16:11 | https://aimodels.fyi/papers/arxiv/transformers-are-ssms-generalized-models-efficient-algorithms | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality](https://aimodels.fyi/papers/arxiv/transformers-are-ssms-generalized-models-efficient-algorithms). If you like these kinds of analysis, you should... | mikeyoung44 |
1,876,586 | The Importance of Duct Repair: Enhancing Comfort and Efficiency | Regular maintenance and timely repairs can extend the lifespan of an HVAC system, including its... | 0 | 2024-06-04T12:15:57 | https://dev.to/remodelmagic34/the-importance-of-duct-repair-enhancing-comfort-and-efficiency-mcb | Regular maintenance and timely repairs can extend the lifespan of an HVAC system, including its ductwork. Neglected duct issues can strain the entire system, causing components such as the furnace or air conditioner to work harder than necessary. Over time, this additional strain can lead to premature wear and tear, re... | remodelmagic34 | |
1,876,585 | MoEUT: Mixture-of-Experts Universal Transformers | MoEUT: Mixture-of-Experts Universal Transformers | 0 | 2024-06-04T12:15:03 | https://aimodels.fyi/papers/arxiv/moeut-mixture-experts-universal-transformers | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [MoEUT: Mixture-of-Experts Universal Transformers](https://aimodels.fyi/papers/arxiv/moeut-mixture-experts-universal-transformers). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com)... | mikeyoung44 |
1,876,584 | Explorando o Método concat() em JavaScript | JavaScript é uma linguagem rica em funcionalidades, especialmente quando se trata de manipulação de... | 0 | 2024-06-04T12:08:12 | https://dev.to/iamthiago/explorando-o-metodo-concat-em-javascript-10b |
JavaScript é uma linguagem rica em funcionalidades, especialmente quando se trata de manipulação de arrays. Um dos métodos mais úteis e frequentemente utilizados é o `concat()`. Este método permite combinar dois ou mais arrays em um novo array, preservando os arrays originais. Vamos explorar em detalhes como o método ... | iamthiago | |
1,875,542 | Design It Practical and Simple (DIPS) | Design It Practical and Simple (DIPS): A Philosophy for Modern Living In an increasingly... | 0 | 2024-06-04T12:06:44 | https://dev.to/alialp/design-it-practical-and-simple-dips-fh8 | architecture, productivity, dips, efficiency | ---
title: Design It Practical and Simple (DIPS)
published: true
description:
tags: #architecture #productivity #DIPS #efficiency
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/c97roweudbi2rn43dx94.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-03 14:26 +0000
---
### Desig... | alialp |
1,876,582 | Understanding Shared Preferences in Flutter with Practical Examples | What are Shared Preferences? Shared Preferences in Flutter allow you to store key-value... | 0 | 2024-06-04T12:05:29 | https://dev.to/sk00l/understanding-shared-preferences-in-flutter-with-practical-examples-1a9k | #What are Shared Preferences?
Shared Preferences in Flutter allow you to store key-value pairs of primitive data types. This storage method is perfect for saving small amounts of data, such as user settings or application preferences, that need to persist across sessions but do not require the overhead of a database.
... | sk00l | |
1,876,581 | Taking my first step with technical blogging! | About me.. I am software engineer with avid interest in software quality testing. I have... | 0 | 2024-06-04T12:02:58 | https://debasmita-a.hashnode.dev/taking-my-first-step-with-blogging | writing | ## About me..
I am software engineer with avid interest in software quality testing. I have extensive experience is manual testing, though few years ago, I decided to move on to learning automation testing. Well, who doesn't like to see stuff happening on their screen on clicking Run button!
I would always start, beca... | debasmita-a |
1,875,427 | Migrating a project from Visual studio to Rider | I have been dabbling with Rider and JetBrains throughout my career and finally made the full plunge... | 0 | 2024-06-04T11:57:33 | https://dev.to/doki_kapoki/migrating-a-project-from-visual-studio-to-rider-4o7k | csharp, ide, visualstudio, rider | I have been dabbling with Rider and JetBrains throughout my career and finally made the full plunge for my personal projects. So far these are the things that I wish I knew about or quickly ran into an issue with due to a feature being in a slightly different location.
## Learning about the ide
I immediately appreciat... | doki_kapoki |
1,876,579 | What is PAM Software and Its Five Essential Elements | In this highly competitive world of online betting, the Player Account Management (PAM) system stands... | 0 | 2024-06-04T11:55:52 | https://dev.to/simonbrown01/what-is-pam-software-and-its-five-essential-elements-50na | igamingsoftwareprovider, playeraccountmanagement, igaming | In this highly competitive world of online betting, the Player Account Management (PAM) system stands out as an innovative tool. It is designed to smoothly manage player accounts on digital betting platforms. PAM software is a powerful system at the center of online gaming operations. It streamlines processes and i... | simonbrown01 |
1,876,866 | Automatically Close Apps That Drain your Battery | Ever feel the need to close certain apps that drain your battery and then later on forget to relaunch... | 0 | 2024-06-04T20:02:27 | https://blog.jonathanflower.com/software-development/automatically-close-apps-that-drain-your-battery/ | softwaredevelopment, codingtools | ---
title: Automatically Close Apps That Drain your Battery
published: true
date: 2024-06-04 11:51:48 UTC
tags: SoftwareDevelopment,CodingTools
canonical_url: https://blog.jonathanflower.com/software-development/automatically-close-apps-that-drain-your-battery/
---
Ever feel the need to close certain apps that drain y... | jfbloom22 |
1,876,576 | Top Digital Marketing Institute in Noida: Boost Your Career Fast | Safalta Digital Marketing Institute in Noida also provides advanced classes for individuals seeking... | 0 | 2024-06-04T11:47:58 | https://dev.to/gaurav_joshi_9326ed3b2ec2/top-digital-marketing-institute-in-noida-boost-your-career-fast-1omk | Safalta Digital Marketing Institute in Noida also provides advanced classes for individuals seeking to develop their expertise and skills in this field.
Read more: https://www.safalta.com/online-digital-marketing/best-digital-marketing-institute-in-noida
| gaurav_joshi_9326ed3b2ec2 | |
1,876,575 | i | A post by Xi Li | 0 | 2024-06-04T11:47:11 | https://dev.to/xi_li_705159194a6c3006c5c/i-2dlh | xi_li_705159194a6c3006c5c | ||
1,876,574 | Frontdesk/Visitor Management System project | Introduction A front desk / visitor management system is an essential aspect of any... | 0 | 2024-06-04T11:45:29 | https://dev.to/md-sazzadul-islam/frontdeskvisitor-management-system-project-2m8o |
## Introduction
A front desk / visitor management system is an essential aspect of any business. It serves as the first point of contact for customers, potentially making or breaking their experience. Our Welcome - Frontdesk/Visitor Management System is designed to handle all customer inquiries and requests, track t... | md-sazzadul-islam | |
1,876,573 | Internet security through lava lamps | Discover how Cloudflare uses lava lamps to secure the Internet. A fascinating insight into innovative... | 0 | 2024-06-04T11:42:42 | https://blog.disane.dev/en/internet-security-through-lava-lamps/ | internet, security, curiosities, cloudflare | Discover how Cloudflare uses lava lamps to secure the Internet. A fascinating insight into innovative cybersecurity! 🔒
---
In the age of digital transformation, cyber security is more important than ever. Companies an... | disane |
1,859,920 | TASK14 | 1.Difference Between MANUAL TESTING: Manual testing involves humans testing and interacting with a... | 0 | 2024-05-21T02:34:23 | https://dev.to/dineshrajavel/task14-2g2k | 1.Difference Between
MANUAL TESTING: Manual testing involves humans testing and interacting with a software application or product to identify issues. Does not programming knowledge. Consume lot of time and human effort. More reliable for performing exploratory testing and for identifying subtle issues or inconsistenci... | dineshrajavel | |
1,876,571 | Internetsicherheit durch Lavalampen | Entdecke, wie Cloudflare Lavalampen nutzt, um das Internet zu schützen. Ein faszinierender Einblick... | 0 | 2024-06-04T11:36:27 | https://blog.disane.dev/internetsicherheit-durch-lavalampen/ | internet, sicherheit, kurioses, cloudflare | Entdecke, wie Cloudflare Lavalampen nutzt, um das Internet zu schützen. Ein faszinierender Einblick in innovative Cybersicherheit! 🔒
---
Im Zeitalter der digitalen Transformation ist Cybersicherheit wichtiger denn je. ... | disane |
1,876,570 | The Ultimate Guide to IT Asset Disposition (ITAD) | In modern rapidly evolving technological landscape, organizations continuously improve their IT... | 0 | 2024-06-04T11:33:41 | https://dev.to/liong/the-ultimate-guide-to-it-asset-disposition-itad-14a0 | data, recovery, malaysia, kualalumpur | In modern rapidly evolving technological landscape, organizations continuously improve their IT gadget to preserve tempo with improvements. This frequent turnover increases a crucial query: What ought to be finished with the vintage gadget? Enter [IT Asset Disposition (ITAD)](https://ithubtechnologies.com/it-hardware-... | liong |
1,876,569 | Medical Waste Incinerator Manufacturer In India | Medical Waste Incinerator Manufacturer Company In India best Incinerator Company is Name Microteknik.... | 0 | 2024-06-04T11:32:36 | https://dev.to/medicalwastemanufacturer/medical-waste-incinerator-manufacturer-in-india-2o3g | [Medical Waste Incinerator](https://www.microteknik.com/product/medical-waste-incinerator/) Manufacturer Company In India best Incinerator Company is Name Microteknik. This Company is All Incinerator Machine manufacturer Company. | medicalwastemanufacturer | |
1,876,568 | Unified Framework: Boosting Effortless Collaboration | In a bustling design studio, teams often comprise individuals with diverse skill sets and approaches.... | 0 | 2024-06-04T11:32:23 | https://dev.to/yujofficial/unified-framework-boosting-effortless-collaboration-1e46 | uxdesign, designthinking, impactbydesign, yuj | In a bustling design studio, teams often comprise individuals with diverse skill sets and approaches. Picture a scenario where one team member conceptualises user flows, another crafts interface designs, and yet another conducts usability tests. With each member possessing their unique style and method, standardising p... | yujofficial |
1,867,378 | Azure API Management: Harnessing Bicep for Effortless User and Subscription Creation | Introduction In the realm of cloud computing, the management of users and subscriptions is... | 0 | 2024-06-04T11:26:27 | https://dev.to/axeldlv/azure-api-management-harnessing-bicep-for-effortless-user-and-subscription-creation-30c7 | azure, cloud, apim, bicep | ## Introduction
In the realm of cloud computing, the management of users and subscriptions is a fundamental task that can quickly become a bottleneck in operational efficiency. Clicking through interfaces to create each user and subscription individually is not only tedious but also prone to errors.
Fortunately, there... | axeldlv |
1,876,567 | Remote Development: Using VSCode for Remote Coding and Collaboration | The rise of remote work has transformed the landscape of software development, making remote coding... | 0 | 2024-06-04T11:25:59 | https://dev.to/umeshtharukaofficial/remote-development-using-vscode-for-remote-coding-and-collaboration-36ep | webdev, vscode, devops, programming | The rise of remote work has transformed the landscape of software development, making remote coding and collaboration more important than ever. Visual Studio Code (VSCode), a versatile and powerful code editor, provides robust tools and extensions that facilitate remote development and team collaboration. This article ... | umeshtharukaofficial |
1,876,565 | Can Project IDX Overtake VS Code as the Preferred Code Editor? | In this article, we'll explore Project IDX, a new code editor developed by Google. It has the... | 0 | 2024-06-04T11:22:16 | https://dev.to/proflead/can-project-idx-overtake-vs-code-as-the-preferred-code-editor-3c41 | projectidx, vscode, webdev, google | In this article, we'll explore Project IDX, a new code editor developed by Google. It has the potential to change the way we write and manage code.
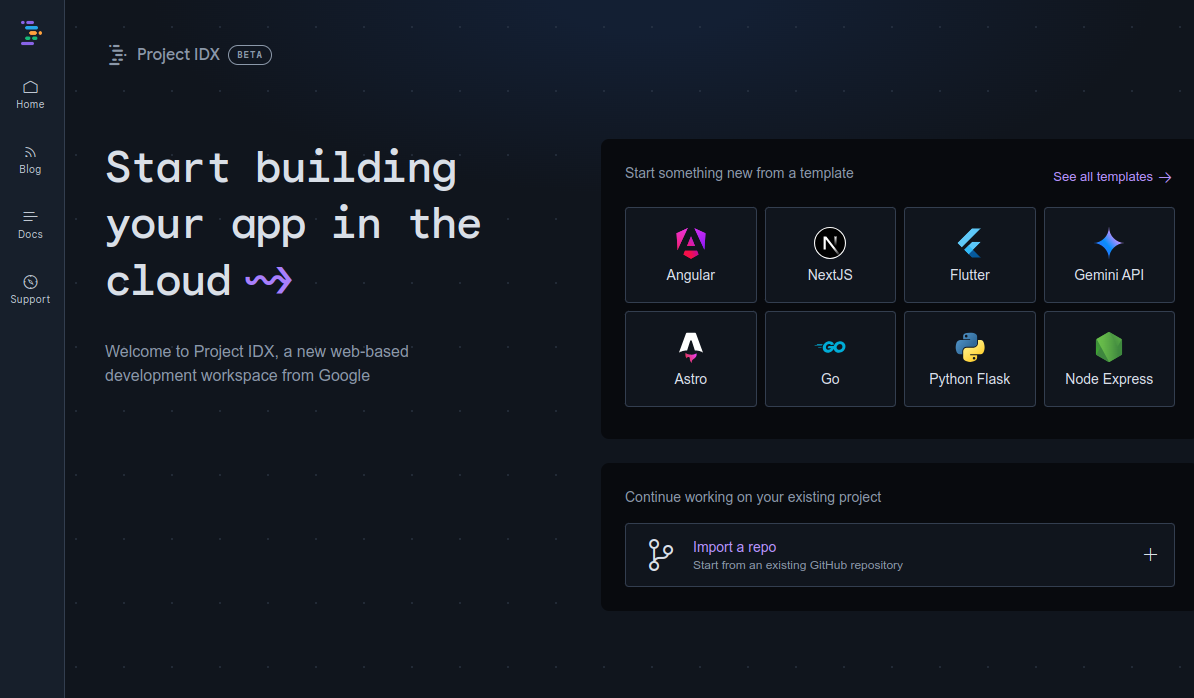
## What is Project... | proflead |
1,876,557 | How to Scrape Dynamic Content with Selenium and Beautiful Soup | Discover how to scrape dynamic content with Selenium and BeautifulSoup as well as how you can leverage Crawlbase Crawling API to achieve your web scraping goals. | 0 | 2024-06-04T11:19:35 | https://crawlbase.com/blog/scrape-dynamic-content-with-selenium-and-beautifulsoup/ | scrapedynamiccontent, scrapejavascriptrenderedpages, seleniumfordynamiccontent | ---
title: How to Scrape Dynamic Content with Selenium and Beautiful Soup
published: true
description: Discover how to scrape dynamic content with Selenium and BeautifulSoup as well as how you can leverage Crawlbase Crawling API to achieve your web scraping goals.
tags: scrapedynamiccontent, scrapejavascriptrenderedpag... | crawlbase |
1,876,556 | 在K8s内自建Git远程仓库 | 1、先解决持久化的问题 在Kind容器内创建持久化目录,宿主机(服务器),执行下面命令: docker exec -it dbe0bb145add mkdir -p... | 0 | 2024-06-04T11:18:16 | https://dev.to/dragon72463399/zai-k8snei-zi-jian-gityuan-cheng-cang-ku-285k | - **1、先解决持久化的问题**
> 在Kind容器内创建持久化目录,宿主机(服务器),执行下面命令:
```
docker exec -it dbe0bb145add mkdir -p /data/gitea
```
> **校验是否成功**
```
(base) [root@ip-10-242-18-237 ec2-user]# docker exec -it dbe0bb145add ls /data/
docker gitea jenkins
```
> **创建持久化卷**
```
apiVersion: v1
kind: PersistentVolume
metadata:
name: gitea-pv-v... | dragon72463399 | |
1,876,526 | The Importance of Quality Roofing Replacement in Mesa | When it comes to maintaining the structural integrity and aesthetic appeal of your home, few elements... | 0 | 2024-06-04T10:37:50 | https://dev.to/kylelansing/the-importance-of-quality-roofing-replacement-in-mesa-4eik | When it comes to maintaining the structural integrity and aesthetic appeal of your home, few elements are as critical as the roof. In places like Mesa, where weather conditions can be unpredictable and sometimes harsh, having a durable and well-maintained roof is essential. Whether you’re dealing with an aging roof or ... | kylelansing | |
1,876,553 | My top 7 tips for engineers who want to write their first blog post | I kicked off my career journey as an IT project manager, but my curiosity led me down exciting paths... | 0 | 2024-06-04T11:17:45 | https://dev.to/annelaure13/my-top-5-tips-for-engineers-who-want-to-write-their-first-blog-post-3pd7 | writing, beginners, learning | I kicked off my career journey as an IT project manager, but my curiosity led me down exciting paths into coding (especially front-end and iOS) before moving into journalism.
Over the past 6 years, I've had the pleasure of supporting numerous developers and engineers in French tech companies with their blog writing in... | annelaure13 |
1,876,555 | #Day 4 - Basic Linux Shell Scripting for DevOps Engineers | Tasks 1. What is Kernel? A kernel is a crucial part of a computer's operating system (OS) that acts... | 0 | 2024-06-04T11:17:44 | https://dev.to/oncloud7/day-4-basic-linux-shell-scripting-for-devops-engineers-fjm | linux, devops, scripting, 90daysofdevops |
**Tasks**
**1. What is Kernel?**
A kernel is a crucial part of a computer's operating system (OS) that acts as an intermediator between the hardware and the user-level applications. It plays a central role in managing key functions such as system calls, disk operations, and memory utilization.
The kernel is the first... | oncloud7 |
1,876,554 | Can someone suggest me some nodejs packages or workarounds that can convert natural language queries into mongodb queries. | I'm building a simple full stack application that takes user input and convert it into MongoDB query... | 0 | 2024-06-04T11:16:48 | https://dev.to/animesh_dwivedi_dd53dfbfd/can-someone-suggest-me-some-nodejs-packages-or-workarounds-that-can-convert-natural-language-queries-into-mongodb-queries-6lo | nlp, node, help | I'm building a simple full stack application that takes user input and convert it into MongoDB query and then give the query output to user.
What I have tried:
I have found nlp.js package that can be used with Nodejs but I want some more options to be available so that I can experiment with them as well. | animesh_dwivedi_dd53dfbfd |
1,876,549 | Introductions | Hello to all! This is my first official post on the platform. I wanted to introduce myself and share... | 0 | 2024-06-04T11:11:43 | https://dev.to/taylorcastle27/introductions-5fkb | webdev, learning, beginners | Hello to all! This is my first official post on the platform. I wanted to introduce myself and share my journey with devs around the world. | taylorcastle27 |
1,845,546 | Ibuprofeno.py💊| #118: Explica este código Python | Explica este código Python Dificultad: Fácil my_tuple = (1, 2, True * 2,... | 25,824 | 2024-06-04T11:00:00 | https://dev.to/duxtech/ibuprofenopy-118-explica-este-codigo-python-el5 | python, spanish, learning, beginners | ## **<center>Explica este código Python</center>**
#### <center>**Dificultad:** <mark>Fácil</mark></center>
```py
my_tuple = (1, 2, True * 2, 3)
print(sum(my_tuple))
```
👉 **A.** `8`
👉 **B.** `6`
👉 **C.** `7`
👉 **D.** `SyntaxError`
---
{% details **Respuesta:** %}
👉 **A.** `8`
Siempre y cuando todos los val... | duxtech |
1,876,548 | How Much Does it Cost to Develop a Blockchain App? | The recent trend toward decentralized data processing and administration has resulted in considerable... | 0 | 2024-06-04T11:08:35 | https://dev.to/tarunnagar/how-much-does-it-cost-to-develop-a-blockchain-app-epm | blockchainappdevelopment, blockchain, hireblockchainappdeveloper, blockchaindevelopmentcompany | The recent trend toward decentralized data processing and administration has resulted in considerable growth in the demand for the development of blockchain applications, particularly in business.
There has been a significant increase in the demand for blockchain technology in the market over the course of the past se... | tarunnagar |
1,876,547 | CodeHuntspk: From Pixel Perfect to Powerhouse Performance - Unleashing Your Software Dreams | Ever dreamt of a software solution so perfect it feels magical? Forget the fairy... | 0 | 2024-06-04T11:07:51 | https://dev.to/hmzi67/codehuntspk-from-pixel-perfect-to-powerhouse-performance-unleashing-your-software-dreams-26mi | webdev, javascript, beginners, programming | Ever dreamt of a software solution so perfect it feels magical? Forget the fairy godmother—[CodeHuntspk](https://codehuntspk.com/) turns groundbreaking software ideas into reality.
## We Don't Just Code, We Craft Experiences
At CodeHuntspk, a premier software development company in Pakistan, we excel at crafting exce... | hmzi67 |
1,876,545 | Difference Between Online MBA And Offline MBA | Online MBA vs Regular MBA: Which One is Best For You In the fast-paced world of business, the... | 0 | 2024-06-04T11:06:54 | https://dev.to/profcyma_career/difference-between-online-mba-and-offline-mba-ahk | Online MBA vs Regular MBA: Which One is Best For You
In the fast-paced world of business, the decision to pursue a Master of Business Administration (MBA) is a significant step toward career advancement. However, the choice between a Regular MBA and an Online MBA can be a challenging decision. In this comprehensive gui... | profcyma_career | |
1,876,544 | Common Myths About CSS | CSS (Cascading Style Sheets) is an important tool for making websites seem good, but there are a lot... | 0 | 2024-06-04T11:05:07 | https://www.swhabitation.com/blogs/common-myths-about-css | CSS (Cascading Style Sheets) is an important tool for making websites seem good, but there are a lot of misconceptions about it. Whether you're just starting out or have some experience, you've probably heard some of these. Let's clear up some of the most common misconceptions concerning CSS.
**1. CSS Is Super Easy**
... | swhabitation | |
1,876,543 | What Are the Benefits of Working with Real Estate Developers? | Introduction Building and developing properties require the services of real estate developers.... | 0 | 2024-06-04T11:00:31 | https://dev.to/tvasteconstructions/what-are-the-benefits-of-working-with-real-estate-developers-kho |
Introduction
Building and developing properties require the services of real estate developers. Whether you are a homeowner, investor, or business owner, understanding the benefits of working with real estate developers is essential. Explore the advantages of collaborating with real estate developers and how it... | tvasteconstructions | |
1,876,533 | How AI is Transforming Salesforce Document Generation Tool? | Logic becomes, if you aren’t gaining knowledge when you are learning, you are losing money in time.... | 0 | 2024-06-04T10:59:22 | https://dev.to/zoyazenniefer/how-ai-is-transforming-salesforce-document-generation-tool-300b | salesforce, webdev, beginners, ai | Logic becomes, if you aren’t gaining knowledge when you are learning, you are losing money in time. The best example is Salesforce, the primary CRM platform. As the business needs continually evolve, Salesforce has realized that the integration of artificial intelligence (AI) is the key to innovating document generatio... | zoyazenniefer |
1,876,542 | Best Penis Enlargement Capsule | How effective are BullRun Ero capsules? Advice; Price; Location of purchase? A small penis is a... | 0 | 2024-06-04T10:59:11 | https://dev.to/svo958d376efdc5/best-penis-enlargement-capsule-374k |

**How effective are BullRun Ero capsules? Advice; Price; Location of purchase?**
A small penis is a common problem among men. Research indicates that 45 percent of males desire a larger penis. It makes sense that ... | svo958d376efdc5 | |
1,876,517 | How to find a software architecture course suited for your stack | Things to Consider When Choosing a Software Architecture Course In the software... | 0 | 2024-06-04T10:56:34 | https://dev.to/tectrain_academy/how-to-find-a-software-architecture-course-suited-for-your-stack-36p8 | learning, career, softwaredevelopment, ai | #Things to Consider When Choosing a Software Architecture Course
In the software development world, finding the right course can sometimes be challenging. For the past year, I’ve been helping people find suitable courses. During this process, I’ve created content in various fields to support software professionals in ... | tectrain_academy |
1,876,540 | Apartment renovation NYC | Another option is half walls, which visually create another “room” for privacy. This is the best of... | 0 | 2024-06-04T10:54:47 | https://dev.to/remodelmagic34/apartment-renovation-nyc-4op9 | Another option is half walls, which visually create another “room” for privacy. This is the best of both worlds without feeling walled in or blocking natural light.
Skim coating for smooth walls
Skim coating is a technique that can make the walls of your home look perfect. Nicks and scratches are filled in and bumps a... | remodelmagic34 | |
1,876,452 | Kubernetes Cluster Architecture | etcd Cluster State Storage: etcd stores the state of all Kubernetes objects, such as... | 0 | 2024-06-04T10:53:08 | https://dev.to/abdallah_kordy_94db275ef5/kubernetes-cluster-architecture-2cpl | kubernetes, devops, containers, container |
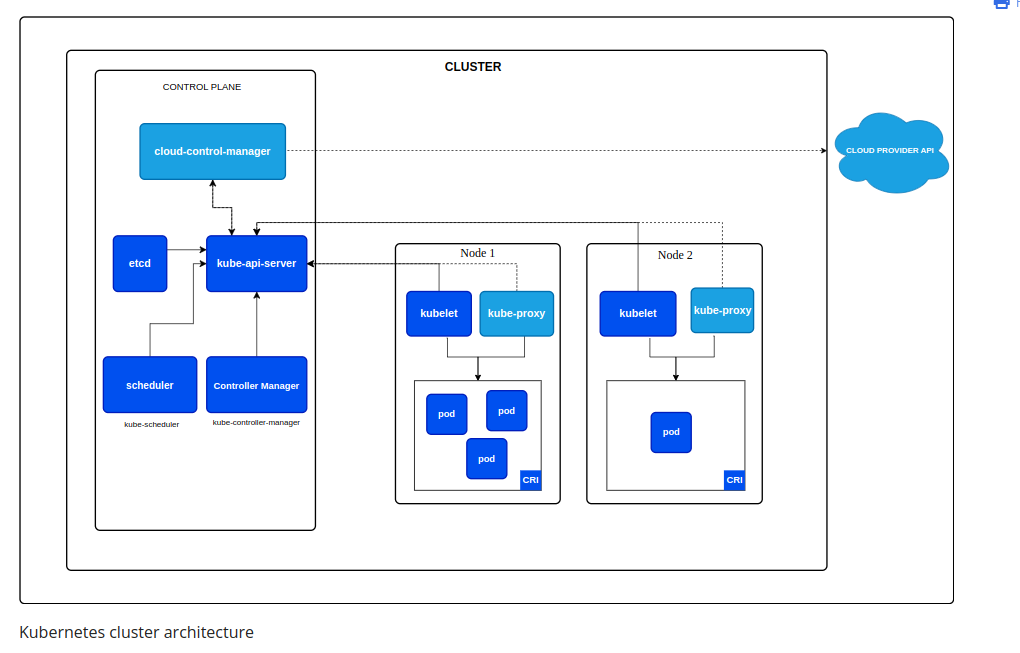
## etcd
**Cluster State Storage**: etcd stores the state of all Kubernetes objects, such as deployments, pods, services, config maps, and secrets.
**Configuration Management**: Changes to the cluster... | abdallah_kordy_94db275ef5 |
1,876,539 | TryParse in C# 🚀- Level up your Code with this Incredible Feature | TryParse in C#: Full Guide Have you ever wanted to master the TryParse method in C#?... | 0 | 2024-06-04T10:52:30 | https://dev.to/bytehide/tryparse-in-c-level-up-your-code-with-this-incredible-feature-5fif | tryparse, csharp, coding, programming | ## TryParse in C#: Full Guide
Have you ever wanted to master the TryParse method in C#? You’re in the right place; let’s dive deep into the world of C# parsing.
### Understanding TryParse
It turns potential disasters into harmless little mistakes. But what does `TryParse` do in C# exactly? Let’s see!
`TryParse` tri... | bytehide |
1,876,538 | Unraveling the Mystery; Genetics and Parkinson's Disease | Picture yourself waking up feeling rigid and shaky, sounds overwhelming, correct? Well, these are... | 0 | 2024-06-04T10:51:47 | https://dev.to/advancells/unraveling-the-mystery-genetics-and-parkinsons-disease-4e4h | stem, cells, parkinsons, advancells |

Picture yourself waking up feeling rigid and shaky, sounds overwhelming, correct? Well, these are the first symptoms that might indicate Parkinson's. Have you ever considered that the solution may not solely lie in ... | advancells |
1,876,536 | Cea mai bună capsulă pentru mărirea penisului | Cât de eficiente sunt capsulele BullRun Ero? Sfat; Preț; Locația achiziției? Un penis mic este o... | 0 | 2024-06-04T10:50:39 | https://dev.to/svo958d376efdc5/cea-mai-buna-capsula-pentru-marirea-penisului-2nik |

**Cât de eficiente sunt capsulele BullRun Ero? Sfat; Preț; Locația achiziției?**
Un penis mic este o problemă comună în rândul bărbaților. Cercetările arată că 45% dintre bărbați își doresc un penis mai mare. Este ... | svo958d376efdc5 | |
1,876,535 | NAVIGATING MEDICAL EMERGENCIES WITH PRIVATE AIR AMBULANCE SERVICES | Private air ambulance, also known as air medical transport, refers to the specialized service of... | 0 | 2024-06-04T10:48:07 | https://dev.to/anaviation/navigating-medical-emergencies-with-private-air-ambulance-services-3k5b | [Private air ambulance](https://an.aero/navigating-medical-emergencies-with-private-air-ambulance-services/), also known as air medical transport, refers to the specialized service of transporting patients in need of urgent medical care via aircraft. Unlike commercial flights or traditional ground ambulances, private a... | anaviation | |
1,876,534 | THE ROLE OF WEATHER RADAR SYSTEMS IN AIRCRAFT | Aircraft weather radar is a specialized instrument installed on aircraft to detect and track weather... | 0 | 2024-06-04T10:47:30 | https://dev.to/anaviation/the-role-of-weather-radar-systems-in-aircraft-25p2 | [Aircraft weather radar](https://an.aero/the-role-of-weather-radar-systems-in-aircraft/) is a specialized instrument installed on aircraft to detect and track weather phenomena in the surrounding airspace. It operates by emitting radio waves and analyzing the reflections (echoes) received from precipitation particles i... | anaviation | |
1,876,531 | Exploring Cypress and Keploy: Enhancing Test Automation Efficiency | As an Automation Enthusiats exploring in the realm of software testing, I've traversed a various... | 0 | 2024-06-04T10:45:19 | https://keploy.io/blog/community/exploring-cypress-and-keploy-streamlining-test-automation | test, automation, programming, devops |

As an Automation Enthusiats exploring in the realm of software testing, I've traversed a various tools and frameworks aimed at enhancing test automation processes. Because as the landscape of software testing contin... | keploy |
1,876,530 | THE ULTIMATE GUIDE TO CHARTER FLIGHTS TO EGYPT | Charter flights to Egypt involve several key processes to ensure a smooth and hassle-free journey.... | 0 | 2024-06-04T10:42:47 | https://dev.to/anaviation/the-ultimate-guide-to-charter-flights-to-egypt-dpb | [Charter flights to Egypt](https://an.aero/the-ultimate-guide-to-charter-flights-to-egypt/) involve several key processes to ensure a smooth and hassle-free journey. Here’s a breakdown of what you can expect:
PLANNING YOUR ITINERARY:
Determine your travel dates and desired destination in Egypt, whether it’s Cairo, Lux... | anaviation | |
1,876,529 | How to Build a Classic Snake Game Using React.js | Hello folks! Welcome to this tutorial on developing the classic Snake game using ReactJS. I've been... | 0 | 2024-06-04T10:41:45 | https://blog.bibekkakati.me/how-to-build-a-classic-snake-game-using-reactjs | webdev, gamedev, javascript, react | Hello folks! Welcome to this tutorial on developing the classic Snake game using ReactJS.
I've been working with technology for over six years now, but I've never tried building a game that many of us loved during our childhood. So, this weekend, I decided to create this classic Snake game using web technologies, spec... | bibekkakati |
1,876,528 | How Do Captcha Solvers Work Overall? | Introduction to Captcha Solvers Captcha solvers are tools designed to automatically decipher... | 0 | 2024-06-04T10:40:03 | https://dev.to/media_tech/how-do-captcha-solvers-work-overall-4l7a | **Introduction to Captcha Solvers**
Captcha solvers are tools designed to automatically decipher CAPTCHAs, which are tests intended to distinguish between human users and automated programs. CAPTCHAs are essential in preventing spam and automated data scraping. However, the rise of sophisticated algorithms has led to ... | media_tech | |
1,876,527 | The Benefits of SMILE Eye Surgery for Vision Correction | SMILE (Small Incision Lenticule Extraction) eye surgery has emerged as a revolutionary technique for... | 0 | 2024-06-04T10:39:38 | https://dev.to/shrawan_gohil/the-benefits-of-smile-eye-surgery-for-vision-correction-n1a | webdev | SMILE (Small Incision Lenticule Extraction) eye surgery has emerged as a revolutionary technique for vision correction, offering numerous benefits over traditional LASIK procedures. In this comprehensive guide, we'll explore the advantages of SMILE eye surgery and its potential to transform the field of refractive surg... | shrawan_gohil |
1,876,525 | Meet the Major Updates of dotConnect products | Devart, a recognized vendor of world-class data connectivity solutions for various data connection... | 0 | 2024-06-04T10:35:05 | https://dev.to/devartteam/meet-the-major-updates-of-dotconnect-products-22i3 | adonet, dotconnect, devart | Devart, a recognized vendor of world-class data connectivity solutions for various data connection technologies and frameworks, rolled out updated [ADO.NET Data providers](https://www.devart.com/dotconnect/) with many improvements.
**The list of the updates:**
- A new level of efficiency and flexibility is availabl... | devartteam |
1,876,523 | Rasakan Panasnya Alam Liar: Ulasan Slot Fire Stampede | Memasuki Petualangan Seru dengan Fire Stampede Slot Fire Stampede Slot adalah game slot... | 0 | 2024-06-04T10:32:52 | https://dev.to/erikarutter/rasakan-panasnya-alam-liar-ulasan-slot-fire-stampede-397m |
# Memasuki Petualangan Seru dengan Fire Stampede Slot
Fire Stampede Slot adalah game slot online yang memukau dengan tema alam liar Afrika. Dikembangkan oleh salah satu penyedia perangkat lunak terkemuka, game ini menawarkan pengalaman bermain yang mendebarkan dan penuh kegembiraan. Dengan grafis yang memuka... | erikarutter | |
1,876,516 | Is Google's search algorithm hurting smaller websites? | I discovered recently that my website saw an abrupt, large drop in traffic from Google Search at the... | 0 | 2024-06-04T10:27:23 | https://www.roboleary.net/2024/06/02/google-hurt.html | webdev |
I discovered recently that my website saw an abrupt, large drop in traffic from Google Search at the beginning of October of last year. When I looked in [Google Search Console](https://search.google.com/search-console/about), I was surprised to see that the **total clicks from Google Search for my website dropped 46% ... | robole |
1,876,522 | Building A Restful API With Amazon S3: Efficient Data Management In The Cloud | REST API S3 refers to the use of RESTful APIs to interact with Amazon Web Services (AWS) Simple... | 0 | 2024-06-04T10:24:56 | https://dev.to/saumya27/building-a-restful-api-with-amazon-s3-efficient-data-management-in-the-cloud-50k0 | REST API S3 refers to the use of RESTful APIs to interact with Amazon Web Services (AWS) Simple Storage Service (S3), enabling developers to efficiently manage and manipulate data stored in the cloud. This approach leverages the principles of Representational State Transfer (REST) to provide a simple and flexible metho... | saumya27 | |
1,876,521 | Aditya City Grace | Aditya City Grace NH 24 Ghaziabad | Aditya City Grace in Ghaziabad offers luxurious 2 & 3 BHK apartments starting at 54 Lakhs. Here,... | 0 | 2024-06-04T10:24:32 | https://dev.to/narendra_kumar_5138507a03/aditya-city-grace-aditya-city-grace-nh-24-ghaziabad-46pj | realestate, realestateinvestment, realestateagent, adityacitygrace | Aditya City Grace in Ghaziabad [**offers luxurious 2 & 3 BHK apartments**](https://adityacitygrace.site/)
starting at 54 Lakhs. Here, modern living blends effortlessly with elegance and comfort. Whether you're a young professional, a growing family, or an investor, these spacious apartments are designed to meet your n... | narendra_kumar_5138507a03 |
1,876,520 | Generate featured images for your posts | Hey developers, Have you ever spent a lot of time writing an article, only to struggle with finding... | 0 | 2024-06-04T10:24:30 | https://dev.to/jiajunyan/generate-featured-images-for-your-posts-1llb | showdev | Hey developers,
Have you ever spent a lot of time writing an article, only to struggle with finding the perfect [featured image](https://link.zhihu.com/?target=https://picgenieai.com/)?
As a content creator and developer, I understand this frustration all too well. A well-matched featured image can significantly incr... | jiajunyan |
1,876,519 | Cloudflare's ZeroTrust Part 1: How can I access to my web/app in private network without NAT | Quá đơn giản, có rất nhiều tool để làm việc này rồi, có người thì sử dụng ngrok hoặc các tool tương... | 0 | 2024-06-04T10:24:05 | https://dev.to/bachhuynh/cloudflares-zerotrust-part-1-how-can-i-access-to-my-webapp-in-private-network-without-nat-50g3 | codeserver, cloudflare, zerotrust, tunnel | Quá đơn giản, có rất nhiều tool để làm việc này rồi, có người thì sử dụng `ngrok` hoặc các tool tương tự.
Nhưng hãy thử nghỉ xem nếu bạn public ra theo kiểu đó thì ai cũng access được nếu web/app của bạn không có basic authen hoặc không code phần login.
Vậy để có thể vừa cho bên ngoài mạng private truy cập vào được, ... | bachhuynh |
1,876,518 | What is Dialzy ? | Dialzy is a website that offers a free and exciting way to connect with new people through random... | 0 | 2024-06-04T10:23:24 | https://dev.to/dialzy/what-is-dialzy--3cop | Dialzy is a website that offers a free and exciting way to connect with new people through random video calls. It allows you to create unique and amazing experiences by chatting with complete strangers.
check it out at https://www.dialzy.fun
Connect with Confidence: Dialzy utilizes moderation tools and anonymous prof... | dialzy | |
1,876,468 | A Comprehensive Guide to Media Queries in CSS | Today, people use differently-sized devices, including smartphones, tablets, and laptops to access... | 0 | 2024-06-04T10:22:11 | https://dev.to/odhiambo_ouko/a-comprehensive-guide-to-media-queries-in-css-1kc6 | webdev, css, learning, beginners | Today, people use differently-sized devices, including smartphones, tablets, and laptops to access the internet. Since screen sizes differ from user to user, creating websites that respond to varying screen sizes, no matter the device, is essential. That’s where CSS media queries come in. But what are media queries, an... | odhiambo_ouko |
1,876,470 | Latest Trends in Women’s Nightwear | Nightwear has come a long way from just being pajamas! Today, it’s all about embracing comfort and... | 0 | 2024-06-04T10:07:44 | https://dev.to/zilon_innerwear_8ae947027/latest-trends-in-womens-nightwear-18ap | nigtwear, womenwear, clothing | Nightwear has come a long way from just being pajamas! Today, it’s all about embracing comfort and style, allowing you to feel confident and chic even as you drift off to dreamland. Gone are the days of sacrificing looks for function. Zilon, a leading name in nightwear, understands this shift and offers a range of tren... | zilon_innerwear_8ae947027 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.