
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,871,542 | Demystifying Version Control: Your Guide to Git | Imagine working on a complex project, constantly editing and revising files. Wouldn't it be helpful... | 0 | 2024-05-31T03:09:53 | https://dev.to/epakconsultant/demystifying-version-control-your-guide-to-git-3jn | git | Imagine working on a complex project, constantly editing and revising files. Wouldn't it be helpful to rewind time and see previous versions? Or collaborate with others without version conflicts? This is where version control systems (VCS) come in, and Git, the most popular VCS, is your key to mastering this essential skill.
## What is Version Control?
Think of version control as a time machine for your files. It tracks changes made over time, allowing you to revert to previous versions, see who made what edits, and collaborate seamlessly. This is particularly crucial for software development, where a single wrong line can break everything. But VCS benefits extend far beyond code. Writers, designers, and even students can leverage its power.
[Trading Cryptocurrencies: Understanding the Basics and Mastering the Fundamentals](https://www.amazon.com/dp/B0CR9DV5HT)
## Why Use Git?
Git, a free and open-source VCS, stands out for its distributed nature. Unlike some systems that store everything on a central server, Git creates a local copy of the entire project history on each user's machine. This makes collaboration efficient, as everyone has a complete picture and can work offline. Additionally, Git excels at:
• Tracking Changes: It meticulously records every edit, allowing you to see the evolution of your project.
• Reverting to Previous States: Accidentally deleted a crucial section? No worries! Revert to a previous version with ease.
• Collaboration: Multiple users can work on the same project simultaneously without conflicts. Git helps merge changes smoothly.
• Branching: Create isolated branches to experiment with new features without affecting the main project.
• Security: Git ensures data integrity and allows access control for secure collaboration.
## Getting Started with Git
While Git might seem intimidating at first, understanding its core concepts is crucial. Here's a simplified breakdown:
• Repository (Repo): This is where all your project files and their version history are stored. Imagine it as a central archive.
• Working Directory: This is your local copy of the repo where you make changes to files.
• Staging Area: This is a temporary holding zone for changes you plan to commit to the main repository.
• Commit: This is the act of capturing a snapshot of your project at a specific point in time, along with a descriptive message.
## The basic Git workflow involves:
1.Making changes: Edit files in your working directory.
2.Staging changes: Use the git add command to mark specific changes for inclusion in the next commit.
3.Committing changes: Use the git commit command to create a permanent snapshot with a message describing the changes.
4.Pushing changes: (For collaboration) Upload your local commits to a remote repository, often hosted on platforms like GitHub.
## Beyond the Basics
As you become comfortable with Git, explore its more advanced features:
• Branching and Merging: Create isolated branches to experiment with features and seamlessly merge them back into the main project.
• Version Control for Different File Types: While Git excels with code, it can also manage documents, images, and other file types.
• Remote Collaboration with Platforms like GitHub: GitHub provides a user-friendly interface to manage your Git repositories, collaborate with others, and share code.
## Embrace the Power of Version Control
Git empowers you to work smarter, not harder. It streamlines collaboration, safeguards your work, and provides valuable insights into your project's history. Whether you're a developer, designer, or simply someone who values keeping track of revisions, Git is an invaluable tool. Take the first step today and unlock the power of version control!
## Additional Resources:
There are plenty of resources available to delve deeper into Git. Consider exploring the official Git documentation https://www.git-scm.com/ or online tutorials for a more hands-on learning experience. With dedication and practice, Git will become an indispensable part of your workflow.
| epakconsultant |
1,871,540 | Fortuna Tiger: slot online, mergulhe no mundo da sorte e da emoção | No mundo dos jogos de azar online, existem muitos jogos emocionantes que fazem seu coração bater mais... | 0 | 2024-05-31T03:07:24 | https://dev.to/tommydorton/fortuna-tiger-slot-online-mergulhe-no-mundo-da-sorte-e-da-emocao-433o | No mundo dos jogos de azar online, existem muitos jogos emocionantes que fazem seu coração bater mais rápido e sua respiração ficar mais lenta de excitação. Porém, entre todos esses jogos, há um que se destaca pelo seu charme único e atmosfera emocionante - Fortuna Tiger. Você deve [clicar na ligação](https://fortunatiger.org/). Neste artigo veremos o que torna este slot online tão único e emocionante.
**O fascinante mundo da Fortuna**
Fortuna Tiger não é apenas uma máquina caça-níqueis, é todo um mundo de aventuras e oportunidades emocionantes. Assim que você inicia este jogo, você fica imerso na emocionante atmosfera da China antiga, onde cada símbolo e som o transporta para o mundo da sorte e da riqueza.
**Ótimo design e gráficos**
Um dos aspectos mais impressionantes do Fortuna Tiger é seu design impressionante e gráficos de qualidade. Cada elemento do jogo é trabalhado nos mínimos detalhes, desde símbolos coloridos até animações emocionantes. Isso cria uma atmosfera única e torna a jogabilidade ainda mais emocionante.
**Recursos de bônus exclusivos**
Fortuna Tiger não oferece apenas um jogo de azar, mas também oferece muitos bônus interessantes que tornam a experiência de jogo ainda mais emocionante. Desde rodadas grátis até multiplicadores de ganhos, há algo para todos.
**Jogue em dispositivos móveis**
O mundo moderno exige acessibilidade e comodidade, por isso o Fortuna Tiger está disponível não só em computadores, mas também em dispositivos móveis. Isso significa que você pode aproveitar o jogo a qualquer hora e em qualquer lugar, sem estar limitado por tempo e lugar.
**Conclusão**
Fortuna Tiger não é apenas um jogo, é uma imersão em um mundo de sorte e emoção, onde cada rolo giratório pode trazer ganhos incríveis. Do design cativante aos emocionantes recursos de bônus, este jogo promete ser seu parceiro em suas aventuras no caminho para a riqueza. Faça uma viagem com Fortuna Tiger hoje e sinta a magia da sorte! | tommydorton | |
1,812,820 | 1. Concorrência Java: Threads! Processando em Paralelo e Ganhando Throughput | Seja bem vindo, esse daqui é o primeiro de 6 posts sobre concorrência em ... | 26,999 | 2024-05-31T03:00:00 | https://kaue.cat/posts/concorrencia-java/threads-java/ | programming, java, braziliandevs | Seja bem vindo, esse daqui é o primeiro de 6 posts sobre concorrência em
# Contexto
<mark style="background: #D2B3FFA6;">Threads são unidades de execução dentro de um processo</mark>. <mark style="background: #D2B3FFA6;">Um processo é um programa em execução que contém pelo menos uma thread.</mark> As threads permitem que um programa execute várias tarefas ao mesmo tempo (ou pelo menos aparentemente).
# **Vantagens de programar com múltiplas threads:**
Uma das principais razões para usar múltiplas threads é melhorar o desempenho de um programa. Tarefas pesadas e demoradas podem ser divididas em threads separadas, permitindo que diferentes partes do programa sejam executadas em paralelo. Isso pode levar a uma utilização mais eficiente dos recursos da CPU e, consequentemente, a um tempo de resposta mais rápido.
![[Untitled 109.png|Untitled 109.png]]
No entanto, programar com threads também traz desafios, como a necessidade de lidar com concorrência (quando várias threads tentam acessar ou modificar os mesmos recursos ao mesmo tempo) e a possibilidade de erros difíceis de depurar (como as condições de corrida), pois os resultados de um mesmo código não serão necessariamente os mesmos (não determinísticos).
# O multithreading ajuda ou não?
**1. Operações de I/O:**
Quando um programa precisa realizar operações de entrada/saída -- I/O (e elas são o gargalo), como leitura/gravação de arquivos, comunicação com bancos de dados ou solicitações de rede, <mark style="background: #D2B3FFA6;">há frequentemente momentos em que a CPU fica ociosa</mark>, esperando que os dados sejam lidos ou escritos.
Nessa situação, se uma nova thread tomasse conta da situação, ela não seria mais executada pelo processador enquanto estivesse ociosa, pois aconteceria o que chamamos de troca de contexto, que é basicamente fazer com que outra thread seja processada. Isso permite que outras threads que necessitem de processamento real tenham suas operações executadas pelos núcleos da CPU, ou até mesmo lançar (ou usar) mais threads para já lançar outras chamadas que também exigem esse tempo de espera, conhecidas como <mark style="background: #D2B3FFA6;">bloqueantes</mark>. Isso ajuda a aproveitar melhor o tempo da CPU, **melhorando a eficiência geral do programa.**
Imagine um contexto onde você precisa ler dois arquivos .txt, essa operação poderia ser realizada paralelamente se lançássemos duas threads, uma para ler cada arquivo, sendo cada uma processada em um núcleo, diminuindo o tempo de execução essencialmente pela metade
**2. Código CPU-bound:**
Quando o programa está executando tarefas intensivas em CPU, como cálculos matemáticos complexos, simulações ou processamento de imagem, uma única thread pode não ser capaz de aproveitar totalmente a capacidade de processamento da CPU. Dividir essas tarefas em threads separadas permite que múltiplos núcleos da CPU trabalhem em paralelo, acelerando o processamento.
Nesse caso, devemos tomar cuidado, pois a quantidade de tarefas que pode ser paralelizada realmente é igual a quantidade de núcleos do seu processador (lógicos + físicos).
![[Pasted image 20240404211738.png]]
A imagem acima representa a troca de contexto, note que esse processo não é necessariamente instantâneo e resulta em possível perda de cache, o que pode ser agressor à performance - [Fonte](https://wiki.inf.ufpr.br/maziero/lib/exe/fetch.php?media=socm:socm-05.pdf).
> A frequência de trocas de contexto tem impacto na eficiência do sistema operacional: quanto menor o número de trocas de contexto e menor a duração de cada troca, mais tempo sobrará para a execução das tarefas em si. Assim, é possível definir uma medida de eficiência E do uso do processador, em função das durações médias do quantum de tempo *t* e da troca de contexto *c*.
# Java: Threads!
## O Objeto Thread
O objeto `java.lang.Thread` é um *wrapper* em cima das threads do sistema operacional
> [!important]
> Note que as Threads são objetos wrappers em torno das threads do SO, portanto, se essas threads do S.O são pesadas (e são), as Threads em Java também são.
Em Java, podemos trabalhar com threads de algumas maneiras, a primeira que veremos é com a classe Thread, essas classes precisam dar o override do método `run`:
```Java
class ThreadExample extends Thread{
char c;
public ThreadExample(char c) {
this.c = c;
}
@Override
public void run() {
System.out.printf("\nComeçouuu!: %s\n", c);
for (int i = 0; i < 100 ; i++) {
System.out.print(c);
}
}
}
```
```Java
public static void main(String[] args) {
/* Todo programa em execução é "feito" de threads, esse não é uma exceção*/
Thread.currentThread().getName();
ThreadExample t1 = new ThreadExample('A');
ThreadExample t2 = new ThreadExample('B');
ThreadExample t3 = new ThreadExample('C');
t1.run();
t2.run();
t3.run();
}
```
![[Untitled 110.png|Untitled 110.png]]
Pronto! (Só que não) → Note que os objetos thread ainda estão rodando na mesma thread, nesse caso, usar `Thread.run()` executa o método run, nao inicia a thread, nesse caso, devemos rodar `start()`!
```Java
public class Thread01 {
public static void main(String[] args) {
/* Todo programa em execução é "feito" de threads, esse não é uma exceção*/
Thread.currentThread().getName();
ThreadExample t1 = new ThreadExample('A');
ThreadExample t2 = new ThreadExample('B');
ThreadExample t3 = new ThreadExample('C');
t1.start();
t2.start();
t3.start();
}
}
```
![[Untitled 1 70.png|Untitled 1 70.png]]
> [!question] Reflexão
> Criar um objeto do tipo thread faz sentido? Você está especializando uma thread realmente? A herança faz sentido nesse caso? [[2. SOLID]]
## 1. Interface Runnable
Nesse caso, acho válido começar diferente, vamos ler uma parte da javadoc da classe runnable
## 0. Javadoc
> The Runnable interface should be implemented by any class whose instances are intended to be executed by a thread. The class must define a method of no arguments called run.
>
> In addition, Runnable provides the means for a class to be active while not subclassing Thread. A class that implements `Runnable` can run without subclassing Thread by instantiating a Thread instance and passing itself in as the target.
> **<mark style="background: #D2B3FFA6;">In most cases, the Runnable interface should be used if you are only planning to override the run() method and no other Thread methods. This is important because classes should not be subclassed unless the programmer intends on modifying or enhancing the fundamental behavior of the class.</mark>**
A documentação do JAVA responde perfeitamente a reflexão anterior, se você discorda, pode seguir em frente, mas *particularmente* acho que é um argumento difícil de rebater.
Exemplo:
```Java
class ThreadRunnable implements Runnable {
char c;
public ThreadRunnable(char c) {
this.c = c;
}
@Override
public void run() {
System.out.printf("\nComeçouuu!: %s\n", c);
for (int i = 0; i < 100; i++) {
System.out.print(c);
}
}
}
public class Thread01 {
public static void main(String[] args) {
/* Todo programa em execução é "feito" de threads, esse não é uma exceção*/
Thread.currentThread().getName();
var t1Runnable = new ThreadRunnable('a');
var t2Runnable = new ThreadRunnable('b');
var t3Runnable = new ThreadRunnable('c');
Thread t1 = new Thread(t1Runnable);
Thread t2 = new Thread(t2Runnable);
Thread t3 = new Thread(t3Runnable);
t1.start();
t2.start();
t3.start();
}
}
```
![[Untitled 2 56.png|Untitled 2 56.png]]
# Estados de uma thread
![[Untitled 3 42.png|Untitled 3 42.png]]
É interessante sabermos disso, pois podemos dar dicas para o S.O como dizer para que uma thread running pare, ou notificando que uma thread se tornou *Runnable*.
# Melhorando o Código
Se não precisarmos de construtor! podemos usar uma lambda, pois Runnable é uma `@FunctionalInterface`:
```Java
Thread t1 = new Thread( () -> {/*codigo*/});
```
Ou, um pouco mais verboso:
```java
Runnable simplerRunnable = () -> {
System.out.printf("\nComeçouuu!: %s\n", c);
for (int i = 0; i < 100; i++) {
System.out.print(c);
}
};
```
## Prioridade
Prioridades podem ser atribuídas à threads, conforme mostra o código:
```Java
Thread t3 = new Thread(t3Runnable,"nomeC");
t3.setPriority(Thread.MAX_PRIORITY);
```
![[Untitled 111.png|Untitled 111.png]]
> [!important]
> Note que prioridades são indicações do que você deseja para o scheduler, uma thread de prioridade 1 pode rodar andar da prioridade 10, você não deve desenvolver um código baseado em prioridade
## Sleep
Imagine que você deseja que uma thread ocorra sem fim, mas rode a cada 2 minutos, como pode fazer isso? 🤔
Uma das maneiras é usar um `Thread.sleep(milis)` e pedir para que a thread pare por algum tempo, note que é importante esse código estar dentro de um try-catch, por sua possibilidade de gerar uma exceção (caso a thread seja interrompida, por exemplo)
```Java
@Override
public void run() {
System.out.printf("\nComeçouuu!: %s\n", c);
for (int i = 0; i < 100; i++) {
System.out.print(c);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
```
![[Untitled 1 71.png|Untitled 1 71.png]]
## Yield
Yield serve para indicarmos / darmos uma **<mark style="background: #D2B3FFA6;">dica</mark>** para o scheduler do JVM faça a thread voltar para Runnable (pare) por um tempo. [[2. Começando com o Código]]
![[Untitled 2 57.png|Untitled 2 57.png]]
O *yield* é um dos principais elementos que permitem a existência de *Virtual Threads*.
## Join
![[Untitled 3 43.png|Untitled 3 43.png]]
Join serve para avisarmos a thread main que ela deve **esperar** para continuar seu fluxo q uando as operações terminarem
Quando você chama o método `join` em uma determinada (thread), você está essencialmente dizendo: "Pera ai, só continua quando essa tarefa terminar". Isso é útil quando você tem partes do programa que precisam estar totalmente prontas antes que outras partes possam prosseguir.
Um exemplo seria um cenário onde você precisa comparar 3 pesquisas de viagem de avião para conseguir ver o preço mais barato, você pode dar o `join` nas 3 threads que rodaram essa operação de I/O (a ordem não irá importar, pois estaremos limitados pela última de qualquer jeito) e então depois comparamos os resultados
Resumidamnete, o `join` é especialmente útil quando você precisa garantir a ordem correta das operações ou quando precisa coletar resultados de várias threads antes de prosseguir.
```Java
// t1 roda antes de t1 e t2
Thread t1 = new Thread(new ThreadRunnableYieldJoin('A'));
Thread t2 = new Thread(new ThreadRunnableYieldJoin('B'));
Thread t3 = new Thread(new ThreadRunnableYieldJoin('C'));
t1.start();
try {
t1.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
var threads = List.of(t2,t3);
threads.forEach(Thread::start);
```
```Java
public static void main(String[] args) {
// t1 e t2 em paralelo
Thread t1 = new Thread(new ThreadRunnableYieldJoin('A'));
Thread t2 = new Thread(new ThreadRunnableYieldJoin('B'));
Thread t3 = new Thread(new ThreadRunnableYieldJoin('C'));
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
t3.start();
}
}
```
# Referências
> [!info] Qual a finalidade do Transient e Volatile no Java?
> As vezes quando vou declarar meus atributos noto o transient e o volatile.
> [https://pt.stackoverflow.com/a/116080](https://pt.stackoverflow.com/a/116080)
> [!info] Maratona Java Virado no Jiraya
> Melhor, maior, e o mais completo curso de Java em português grátis de toda Internet está de volta.
> [https://www.youtube.com/playlist?list=PL62G310vn6nFIsOCC0H-C2infYgwm8SWW](https://www.youtube.com/playlist?list=PL62G310vn6nFIsOCC0H-C2infYgwm8SWW)>)
| kauegatto |
1,871,537 | Glam Up My Markup: Beaches | This is a submission for [Frontend Challenge... | 0 | 2024-05-31T02:54:12 | https://dev.to/altafsyah/glam-up-my-markup-beaches-4hfg | devchallenge, frontendchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
## What I Built
This is my first time doing challenge, so in this challenge i built a list of card for the beaches in the template that provided. I try not editing the HTML and make it pure CSS and JavaScript. I would challenge myself to do it with basic, without frameworks and libraries. I want to learn the basic and re-memorized the fundamental of CSS and also JavaScript DOM.
## Demo

You guys can see the code in here : [Repo](https://github.com/altafsyah/dev.to-beach)
Visit the live preview in [here](https://dev-to-beach.vercel.app/)
## Journey
In this challenge, I'm editing the HTML using JavaScript DOM to insert element and adding styles into it. Since the template doesn't included with phots. I challenge myself to make the visual design using SVG path. It's really challenging, but I learn a lot from this.
I re-learn about the fundamental of Javascript, CSS Flexbox, and using path in SVG to draw. It's worth the time, maybe I would make this website as my experiment for SVG path and animation, since I found out it's really fun to do.
I'm looking forward for the next challenges. | altafsyah |
1,871,535 | Next.js: Simple Example using revalidateTag | In Next.js, revalidating data is the process of clearing the Data Cache and retrieving the latest... | 0 | 2024-05-31T02:52:02 | https://dev.to/jonathan-dev/nextjs-simple-example-using-revalidatetag-41f5 | nextjs, beginners, typescript, tutorial | In Next.js, [revalidating data](https://nextjs.org/docs/app/building-your-application/data-fetching/fetching-caching-and-revalidating#revalidating-data) is the process of clearing the Data Cache and retrieving the latest data. This allows you to display the latest information to your users as your data changes.
There are two types of revalidation:
- Time-Base
- On-demand - `revalidatePath` and `revalidateTag`
In this post, we'll focus on On-demand revalidation `revalidateTag`, which manually revalidates data based on an event such as a form submission. This can only called in a Server Action or Router Handler.
Next.js has a cache tagging system for invalidating `fetch` requests across routes. In order to use `revalidateTag`, you'll need to add a tag in the `fetch` request:
```TS
const res = await fetch('https://baseurl.com', { next: { tags: ['mytag'] } });
```
This adds the cache tag `mytag` to the `fetch` request.
Then you can revalidate the `fetch` call by calling `revalidateTag` in a Server Action:
```TS
'use server'
import { revalidateTag } from 'next/cache'
export default async function action() {
revalidateTag('mytag')
}
```
Basic Next.js 14 example with Typescript can be found here: https://github.com/juhlmann75/Next.js-Examples/tree/main/src/app/examples/revalidateTag
More on how [On-demand revalidation works](https://nextjs.org/docs/app/building-your-application/caching#on-demand-revalidation).
| jonathan-dev |
1,871,534 | Estudo do KTO Casino: Novo Horizonte de Jogos Virtuais | Desde o advento dos casinos online no mundo do entretenimento online, os jogadores têm procurado... | 0 | 2024-05-31T02:47:15 | https://dev.to/tommydorton/estudo-do-kto-casino-novo-horizonte-de-jogos-virtuais-5ace | Desde o advento dos casinos online no mundo do entretenimento online, os jogadores têm procurado sites confiáveis que ofereçam jogos emocionantes, bónus generosos e um ambiente de jogo seguro. Neste contexto, o KTO Casino representa um fenômeno interessante. Vejamos [aqui](https://mixjogos.com.br/cassino/kto/) o que torna esta plataforma única e se vale a pena investir seu dinheiro e tempo nos jogos oferecidos por esta operadora.
**Plataforma de jogos**
O KTO Casino oferece uma ampla variedade de jogos, incluindo slots, jogos de mesa, jogos com crupiê ao vivo e muito mais. A colaboração com os principais desenvolvedores de software, como NetEnt, Microgaming e Evolution Gaming, garante conteúdo de jogos de alta qualidade. Os usuários podem desfrutar de slots emocionantes com uma variedade de temas, bem como jogos de mesa clássicos como blackjack, roleta e pôquer.
**Bônus e Promoções**
Um dos principais aspectos para atrair jogadores para cassinos online são os bônus e promoções. O KTO Casino oferece uma variedade de ofertas de bônus, incluindo bônus de boas-vindas para novos jogadores, rodadas grátis em slots, cashback e muito mais. Os bônus podem aumentar significativamente o saldo do jogo e melhorar suas chances de ganhar.
**Segurança e Confiabilidade**
Um dos aspectos mais importantes na escolha de um casino online é a segurança. O KTO Casino oferece um alto nível de proteção para os dados pessoais e transações financeiras dos jogadores usando modernas tecnologias de criptografia. Uma licença emitida pelas autoridades competentes garante a conformidade com os padrões da indústria de jogos e a justiça do processo de jogo.
**Suporte ao usuário**
Um bom suporte ao cliente desempenha um papel importante na experiência do jogador no cassino online. O KTO Casino oferece suporte 24 horas por dia, 7 dias por semana, via chat ao vivo, e-mail e telefone. A equipe profissional está pronta para ajudar os jogadores com quaisquer dúvidas ou problemas que surjam durante o jogo.
**Cassino Móvel**
Com a crescente popularidade dos dispositivos móveis, muitos jogadores preferem jogar jogos de casino nos seus smartphones ou tablets. O KTO Casino oferece uma plataforma móvel compatível com vários sistemas operacionais, permitindo aos jogadores desfrutar de jogos a qualquer hora e em qualquer lugar.
**Conclusão**
KTO Casino é uma plataforma que combina uma ampla seleção de jogos, bônus generosos, alto nível de segurança e atendimento de qualidade. Para quem procura uma experiência emocionante de jogo de cassino em um ambiente seguro, o KTO Casino pode ser uma ótima escolha. No entanto, os jogadores devem sempre lembrar-se de jogar com responsabilidade e gerir as suas finanças. | tommydorton | |
1,869,413 | Azure - Building Multimodal Generative Experiences. Part 2 | Previous Post Link Create a composed Document Intelligence Model Composed models in... | 0 | 2024-05-31T02:14:17 | https://dev.to/manjunani/azure-building-multimodal-generative-experiences-part-2-i3 | azure, ai, openai, information | Previous Post [Link](https://dev.to/manjunani/azure-building-multimodal-generative-experiences-part-1-j5o)
## Create a composed Document Intelligence Model
- Composed models in Azure AI document intelligence enable users to submit a form when they don't know which is the best model to use.
- Composed Models
- when you have forms with unusual or unique formats, you can create and train your own custom models in Azure AI Document Intelligence.
- You can create custom model of 2 types (custom template model and custom neural models) refer to previous post to know more about them.
- Once you have created a set of custom models, you must assemble them into a composed model. you can do this on the Azure AI Studio.
- Custom model Compatibility
- Custom template models are responsible with other custom template models across 3.0 and 2.1 API versions
- Custom neural models are composable with other custom neural models.
- Custom neural models can't be composed with custom template models.
- [Custom models](https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/concept-composed-models)
## Build a document intelligence custom skill for azure search.
- If you integrate AI Search with an Azure AI Document intelligence solution, you can enrich your index with fields that your Azure AI Document Intelligence models are trained to extract.
- Azure AI Search is a search service hosted in Azure that can index content on your permises or in a cloud location.
- There are 5 stages in Indexing process
- Document Cracking. In document cracking, the indexer opens the content files and extracts their content.
- Field Mappings. Fields such as titles, names, dates, and more are extracted from the content. You can use field mappings to control how they're stored in the index.
- Skillset Execution. In the optional skillset execution stage, custom AI processing is done on the content to enrich the final index.
- Output field mappings. If you're using a custom skillset, its output is mapped to index fields in this stage.
- Push to index. The results of the indexing process are stored in the index in Azure AI Search.
- AI Search Skillset
- Key Phrase extraction
- Language Detection
- Merge
- Sentiment
- Translation
- Image Analysis
- Optical character recognition
- we can use custom skills too and they can be used for 2 reasons
- The list of built-in skills doesn't include the type of AI Enrichment you need.
- you want to train your own model to analyze the data
- 2 types of custom skills that you can create
- Azure Machine Learning Custom Skills
- Custom Web API Skills
Refer to this [link](https://learn.microsoft.com/en-in/training/modules/build-form-recognizer-custom-skill-for-azure-cognitive-search/3-build-custom-skill) for building an Azure AI Document Intelligence Custom Skill
| manjunani |
1,871,533 | Water-Cooled Generators: Maintenance Tips and Tricks | Keep Your Water-Cooled Generator Running Smoothly with These Maintenance Tips and Tricks Are you... | 0 | 2024-05-31T02:45:45 | https://dev.to/hanna_prestonle_101c638d5/water-cooled-generators-maintenance-tips-and-tricks-578c | generators | Keep Your Water-Cooled Generator Running Smoothly with These Maintenance Tips and Tricks
Are you tired of dealing with power outages during storms or other emergencies? A water-cooled generator is a great solution that can provide reliable backup power when you need it most. But to keep your generator running smoothly, you need to perform regular maintenance. We'll explore the advantages, innovation, safety, use, service, quality, and application of water-cooled generators and provide tips and tricks for keeping them in tip-top shape.
Advantages of Water-Cooled Generators
A generator like water-cooled a type of that makes use of water to cool the motor and avoid overheating
These generators tend to be more efficient and sturdy than air-cooled generators, making them a option like popular commercial and commercial applications
They are able to also run for longer periods without the need for maintenance, which can be well suited for crisis situations
Innovation in Water-Cooled Generators
In recent times, water-cooled generator are becoming more energy-efficient and eco-friendly
They now use less fuel and produce fewer emissions, making them a option like fantastic those who are environmentally aware
Many generators which can be water-cooled have features such as for example automated shutdown and monitoring systems, which can make them more user-friendly and dependable
Safety and Use of Water-Cooled Generators
When using a generator like water-cooled it's important to follow all security directions to stop harm or injury
First of all, it's required to understand owner's manual completely before running the generator
Always make certain that the generator has air flow like proper counter carbon monoxide poisoning
Additionally it is important to shut the generator down before refueling in addition to only utilize authorized fuels
Maintaining a distance like secure the generator during procedure can be recommended also
Simple suggestions to make use of Water-Cooled Generator
Working with a generator like water-cooled fairly simple
After reading the master's manual, make certain you have the desired fuel and lubricants to use the generator
Check out the generator's oil coolant and degree, and ensure that every filters are clean
Connect the generator to an transfer like electric or extension cable, and begin the engine in line with the maker's directions
Monitor the generator's performance, and shut it well if it is not any longer needed
Provider and Maintenance of Water-Cooled Generators
Proper upkeep is crucial to keep your generator like water-cooled running
Regularly check out the oil level, coolant level, and air filters
Replace the oil after each and every 100 hours of operation or according to the maker's guidelines
The coolant ought to be changed and flushed every 500 hours of operation or every couple of years, whichever comes first
Clean the new air filters every 50 hours of procedure or more often in dusty surroundings
Regular upkeep and service will prolong the lifespan of your generator and ensure you'll need it that it's ready to operate whenever
Quality and Application of Water-Cooled Diesel engine Generators
When purchasing a generator like water-cooled it is necessary to decide on a professional brand recognized for quality and reliability
Choose for your energy needs as the application related to generator
As an example, a little generator could possibly be ideal for residential usage or a small company, while a more substantial generator could be required for a commercial or facility like commercial
Always pick a generator out that meets your needs that are specific
Conclusion
A water-cooled Diesel generator sets is a reliable backup power option for emergencies and other situations where power is unavailable. By following the maintenance tips and tricks discussed, you can ensure that your generator is always ready to operate when you need it. Remember to always follow safety guidelines and choose a generator that meets your specific needs for quality and application. With these tips, you'll be well on your way to being prepared for any power outage that may occur!
Source: https://www.kangwogroup.com/Diesel-generator-sets | hanna_prestonle_101c638d5 |
1,871,532 | Why You Should Choose TypeScript Over JavaScript | As the web development landscape continues to evolve, developers are constantly seeking tools and... | 0 | 2024-05-31T02:44:28 | https://dev.to/vyan/why-you-should-choose-typescript-over-javascript-d5m | webdev, javascript, typescript, beginners | As the web development landscape continues to evolve, developers are constantly seeking tools and technologies that enhance productivity, maintainability, and scalability. One of the most significant debates in this realm is whether to use TypeScript (TS) or JavaScript (JS). While JavaScript has been the backbone of web development for decades, TypeScript has rapidly gained popularity. In this blog post, we will explore why you should consider choosing TypeScript over JavaScript for your next project.
**1. Type Safety**
**JavaScript:**
JavaScript is a dynamically typed language, meaning that variable types are determined at runtime. This can lead to unexpected errors that are only caught during execution, making debugging a challenge.
**TypeScript:**
TypeScript introduces static typing, allowing developers to define types for variables, function parameters, and return values. This type safety helps catch errors at compile time, reducing the likelihood of runtime errors and making the code more predictable and easier to debug.
```
// JavaScript
function add(a, b) {
return a + b;
}
console.log(add(5, "10")); // Output: "510"
// TypeScript
function add(a: number, b: number): number {
return a + b;
}
console.log(add(5, 10)); // Output: 15
```
**2. Enhanced IDE Support**
**JavaScript:**
While modern IDEs offer some level of code completion and error checking for JavaScript, the dynamic nature of the language can limit the accuracy and usefulness of these features.
**TypeScript:**
TypeScript provides superior IDE support, with features like intelligent code completion, real-time type checking, and refactoring tools. This improved tooling leads to a more efficient and enjoyable development experience.
**3. Improved Code Readability and Maintainability
JavaScript:**
JavaScript's flexibility can sometimes lead to inconsistent coding practices, making it harder to maintain large codebases. Lack of type information can make the code less readable, especially for new team members.
**TypeScript:**
TypeScript enforces a more structured and consistent codebase. The explicit types and interfaces make the code self-documenting, improving readability and making it easier to maintain and refactor, especially in larger projects.
**4. Scalability
JavaScript:**
As JavaScript projects grow in size and complexity, managing the codebase can become increasingly difficult due to the lack of a robust type system.
**TypeScript:**
TypeScript's strong type system and modular approach make it easier to scale applications. The ability to define interfaces, generics, and custom types allows for better code organization and modularity, making large-scale applications more manageable.
**5. Backward Compatibility
JavaScript:**
JavaScript is a highly compatible language, but using newer features often requires polyfills or transpilers like Babel to ensure compatibility with older browsers.
**TypeScript:**
TypeScript is a superset of JavaScript, meaning any valid JavaScript code is also valid TypeScript code. Additionally, TypeScript can be transpiled to different versions of JavaScript (ES3, ES5, ES6, etc.), ensuring compatibility across different environments without the need for additional tools.
**6. Community and Ecosystem**
**JavaScript:**
JavaScript boasts a vast ecosystem and community with countless libraries and frameworks. However, managing dependencies and ensuring compatibility can sometimes be challenging.
**TypeScript:**
TypeScript has seen widespread adoption and support from major frameworks like Angular, React, and Vue. Many popular libraries are now written in or have type definitions for TypeScript, making it easier to integrate and use them in TypeScript projects.
**7. Error Reduction**
**JavaScript:**
Due to its dynamic nature, JavaScript code can be prone to type-related errors, which can be difficult to trace and debug.
**TypeScript:**
TypeScript's compile-time type checking helps catch errors early in the development process, reducing the number of bugs and issues that make it to production. This leads to more robust and reliable code.
**Conclusion**
While JavaScript remains a powerful and versatile language, TypeScript offers several compelling advantages that make it a superior choice for many projects. From type safety and enhanced IDE support to improved maintainability and scalability, TypeScript provides a robust framework for modern web development. By choosing TypeScript over JavaScript, you can create more reliable, readable, and maintainable code, ultimately leading to more successful and scalable applications.
| vyan |
1,871,531 | Industrial Generators: Cost-Effective Power Solutions | Are you looking for a reliable source of power for your daily needs? Industrial generators are here... | 0 | 2024-05-31T02:35:08 | https://dev.to/hanna_prestonle_101c638d5/industrial-generators-cost-effective-power-solutions-1of9 | industrial, generators | Are you looking for a reliable source of power for your daily needs? Industrial generators are here to provide you with cost-effective solutions. Generators are an innovative and advanced system designed to cater to people’s needs. Here are some advantages and innovative features of industrial generators, how to use them in a safe way, and maintain the quality and integrity of service.
Top features of Industrial Generators:
Industrial generator really are a reliable supply like alternate of that may be used anywhere once you want
A generator can offer ability to factories which can be tiny offices, also whole cities
The bonus like biggest of industrial generators will be the power to deliver stable and uninterrupted power for an excessive period
They've been considerably economical them a investment like worthy both residential and commercial purposes while they reduce electricity invoices, making
Innovations in Industrial Generators:
Below are a few innovative attributes of commercial which help them to stand call during the market:
Digital Controller: Digital controllers provide remote accessibility, monitoring, and diagnostics associated with generator system
This feature enables users to manage the generator from anywhere, rendering it simpler and much more convenient to use
Soundproofing: Industrial generators are really noisy, but with advanced soundproofing technology, they can now operate inside a environment like noise-free
Eco-Friendly: Most generators operate using fuel like non-renewable however with new technological advancements, generators are now able to run utilizing biogas like eco-friendly biodiesel, decreasing their carbon footprint
Safety:
Commercial Diesel generator sets is actually a bit intimidating for some individuals, however with all the safety that's right, you can properly run the generator
Check out fundamental ideas to just take really whenever running a generator:
Never ever run the generator inside
Generators produce fuel, that can be toxic in closed areas
Make certain the generator is correctly earthed before activating it to be able to prevent accidents
Keep carefully the generator not even close to any fluids that are flammable materials that could ignite and result in a fire
Usage:
Below are a actions that are few stick to whenever using an generator like commercial
Before you start the generator, examine the equipment visually to confirm its in good condition
Stick to an manual like individual know tips which are easy operate the generator properly
Link the generator to the load like required is electric ensure all connected products are deterred
Service:
To help keep the product quality up and integrity associated with solution, generators need regular maintenance
Consider recommendations that are easy maximize the lifespan concerning the generator:
Modify the oil and oil filter usually
Frequently inspect the atmosphere filters and clean or replace them if needed
Routinely check the battery away
Obtain the generator serviced by the technician that has experience as this helps identify dilemmas early
Application:
Industrial Diesel engine generators can supply ability to industries which are different factories, mining sites, construction websites, hospitals, and even schools
These structures often require uninterrupted power, and generators can provide just that
They could will also be obtainable in handy in the event of an outage like electric an all-natural tragedy and acquire used to restore energy
In conclusion, industrial generators provide cost-effective and reliable sources of energy. With innovative features, safety precautions, proper usage, and maintenance, they are an excellent investment for both commercial and residential use. Their applications are endless, and they are a must-have for those who need power solutions.
Source: https://www.kangwogroup.com/Diesel-generator-sets | hanna_prestonle_101c638d5 |
1,871,530 | Silent Generators: Solutions for Noise-Sensitive Environments | Silent Generators: Solutions for Noise-Sensitive Environments Are you tired of the loud noise that... | 0 | 2024-05-31T02:27:01 | https://dev.to/hanna_prestonle_101c638d5/silent-generators-solutions-for-noise-sensitive-environments-115b | silent, generators | Silent Generators: Solutions for Noise-Sensitive Environments
Are you tired of the loud noise that generators make? Do you live or work in a noise-sensitive environment where conventional generators are not an option? Then, you might want to consider getting a silent generator. We will discuss the advantages of silent generators, their innovation, safety, use, how to use them, their service, quality, and application.
Options that come with Silent Generators
Silent generators provide lots of benefits that traditional generatorare not able to
First, they create extremely noise that's low, making them well suitable for domestic areas, hospitals, schools, along side other places where levels which can be sound to be held towards the very least
Next, silent are safer when it comes to environment since they create less emissions than main-stream generators
Finally, they've been more fuel-efficient and possess a lengthier lifespan when compared with generators that can be conventional
What this means is you might save money on upkeep and gas costs as time passes
Innovation of Silent Generators
Quiet generators have really advanced notably since they certainly were first introduced in the marketplace
By means of technical development, manufacturers were created to make generators that are calm are lighter, scaled-down, more fuel-efficient, and safer to utilize
Some generators being peaceful operating on solar energy systems, consequently you don't have to stress about fuel prices or emissions
Other people have movement sensors that turn them on and off automatically, with regards to the conventional of power use
These are revolutionary features that make quiet generators more dependable and user-friendly
Security of Silent Generators
Quiet Diesel generator sets are produced with safety in your head
They truly are high in a safety like few that ensure they operate in the safe and manner like dependable
For example, they have automatic shutdown systems that activate when the generator overheats or you have a autumn like oil force like quick
This prevents the generator from causing harm or damage
Provider and Quality of Silent Generators
Peaceful generators are top-quality and reliable
They are developed to final so are made to withstand conditions being harsh are environmental
Moreover, they are supported by manufacturers' warranties, and so you'll be guaranteed associated with durability and quality
You should have to choose a more supplier like developed maker who offers client like exemplary and help like technical
Due to this, you'll be particular you encounter any problems or dilemmas with your generator you'll get aid that positively is prompt the reality
Application of Silent Generators
Peaceful generators can be used in several applications
Included in these are ideal for domestic areas, hospitals, schools, and locations where are various noise levels needs become held to your lowest
They are furthermore well suited for camping, outside activities, as well as other occasions where you may possibly require usage of reliable and energy like noise-free
Additionally, they could be correctly utilized as backup power sources for domiciles, businesses, as well as other facilities that be determined by electricity
In conclusion, silent Diesel engine generators are an excellent solution for noise-sensitive environments. They offer many advantages, are innovative, safe, and easy to use. Silent generators provide high-quality service and are suitable for various applications. So, if you are looking for a reliable, quiet, and efficient source of power, then a silent generator is definitely worth considering.
Source: https://www.kangwogroup.com/Diesel-generator-sets | hanna_prestonle_101c638d5 |
1,871,529 | Add an alarm clock to the trading strategy | Traders who design trading strategies often ask me how to design timing functions for strategies so... | 0 | 2024-05-31T02:17:40 | https://dev.to/fmzquant/add-an-alarm-clock-to-the-trading-strategy-4bo4 | trading, strategy, fmzquant, cryptocurrency | Traders who design trading strategies often ask me how to design timing functions for strategies so that strategies can handle certain tasks at specified times. For example, some intraday strategies need to close positions before the first section end in a trading day. How to design such requirements in the trading strategy? A strategy may use a lot of time control. In this way, we can encapsulate the time control function to minimize the coupling between the time control code and the strategy, so that the time control module can be reused and is concise in use.
## Design an "alarm clock"
```
// triggerTime: 14:58:00
function CreateAlarmClock(triggerHour, triggerMinute) {
var self = {} // constructed object
// Set members and functions to the constructed object below
self.isTrigger = false // Has it been triggered that day
self.triggerHour = triggerHour // The planned trigger hour
self.triggerMinute = triggerMinute // The planned trigger minute
self.nowDay = new Date().getDay() // what day is the current time
self.Check = function() { // Check function, check trigger, return true when triggered, return false if not triggered
var t = new Date() // Get the current time object
var hour = t.getHours() // Get the current decimal: 0~23
var minute = t.getMinutes() // Get the current minute: 0~59
var day = t.getDay() // Get the current number of days
if (day != self.nowDay) { // Judge, if the current day is not equal to the day of the record, reset the trigger flag as not triggered and update the number of days for the record
self.isTrigger = false
self.nowDay = day
}
if (self.isTrigger == false && hour == self.triggerHour && minute >= self.triggerMinute) {
// Determine whether the time is triggered, if it meets the conditions, set the flag isTrigger to true to indicate that it has been triggered
self.isTrigger = true
return true
}
return false // does not meet the trigger condition, that is, it is not triggered
}
return self // return the constructed object
}
```
We have designed and implemented a function to create an alarm clock object (can be understood as a constructor), and other languages can directly design an alarm clock class (for example, using Python, we will implement one in Python later).
Design the function to construct the "alarm clock" object, and only need one line of code to create an "alarm clock" object in use.
```
var t = CreateAlarmClock(14, 58)
```
For example, create an object t and trigger it at 14:58 every day.
You can create another object t1, which is triggered every day at 9:00.
```
var t1 = CreateAlarmClock(9, 0)
```
## Test strategy
We write a test strategy. The strategy uses the simplest moving average system. The strategy is just for testing and does not care about the profit.
The strategy plan is to open a position (long, short, no trade) based on the daily moving average golden cross and dead cross when the market opens at 9:00 every day, and close the position at 14:58 in the afternoon (close at 15:00).
```
function CreateAlarmClock(triggerHour, triggerMinute) {
var self = {} // constructed object
// Set members and functions to the constructed object below
self.isTrigger = false // Has it been triggered that day
self.triggerHour = triggerHour // The planned trigger hour
self.triggerMinute = triggerMinute // The planned trigger minute
self.nowDay = new Date().getDay() // what day is the current time
self.Check = function() {// Check function, check trigger, return true when triggered, return false if not triggered
var t = new Date() // Get the current time object
var hour = t.getHours() // Get the current decimal: 0~23
var minute = t.getMinutes() // Get the current minute: 0~59
var day = t.getDay() // Get the current number of days
if (day != self.nowDay) {// Judge, if the current day is not equal to the day of the record, reset the trigger flag as not triggered and update the number of days for the record
self.isTrigger = false
self.nowDay = day
}
if (self.isTrigger == false && hour == self.triggerHour && minute >= self.triggerMinute) {
// Determine whether the time is triggered, if it meets the conditions, set the flag isTrigger to true to indicate that it has been triggered
self.isTrigger = true
return true
}
return false // does not meet the trigger condition, that is, it is not triggered
}
return self // return the constructed object
}
function main() {
var q = $.NewTaskQueue()
var p = $.NewPositionManager()
// You can write: var t = CreateAlarmClock(14, 58)
// You can write: var t1 = CreateAlarmClock(9, 0)
var symbol = "i2009"
while (true) {
if (exchange.IO("status")) {
exchange.SetContractType(symbol)
var r = exchange.GetRecords()
if(!r || r.length <20) {
Sleep(500)
continue
}
if (/*Judging the conditions for opening a position at 9:00*/) {// You can write: t1.Check()
var fast = TA.MA(r, 2)
var slow = TA.MA(r, 5)
var direction = ""
if (_Cross(fast, slow) == 1) {
direction = "buy"
} else if(_Cross(fast, slow) == -1) {
direction = "sell"
}
if(direction != "") {
q.pushTask(exchange, symbol, direction, 1, function(task, ret) {
Log(task.desc, ret)
})
}
}
if (/*Judging 14:58 conditions for closing the position near the market close*/) {// You can write: t.Check()
p.CoverAll()
}
q.poll()
LogStatus(_D())
} else {
LogStatus(_D())
}
Sleep(500)
}
}
```
Put the CreateAlarmClock function we have implemented in the strategy, and construct two "alarm clock" objects at the beginning of the main function. In the strategy to determine the position of opening and closing, add the code that the "alarm clock" object calls the Check function, such as the commented out part of the code.
## Backtest

You can see the backtest, opening positions after 9 am and closing positions at 14:58 pm.
It can also be used for multi-variety strategies. Multiple such "alarm clock" objects can be created in multi-variety strategies for time control of multiple varieties without affecting each other.
## Python language implements alarm clock class
Implementation and test code:
```
import time
class AlarmClock:
def __init__(self, triggerHour, triggerMinute):
self.isTrigger = False
self.triggerHour = triggerHour
self.triggerMinute = triggerMinute
self.nowDay = time.localtime(time.time()).tm_wday
def Check(self):
t = time.localtime(time.time())
hour = t.tm_hour
minute = t.tm_min
day = t.tm_wday
if day != self.nowDay:
self.isTrigger = False
self.nowDay = day
if self.isTrigger == False and hour == self.triggerHour and minute >= self.triggerMinute:
self.isTrigger = True
return True
return False
def main():
t1 = AlarmClock(14,58)
t2 = AlarmClock(9, 0)
while True:
if exchange.IO("status"):
LogStatus(_D(), "Already connected!")
exchange.SetContractType("rb2010")
ticker = exchange.GetTicker()
if t1.Check():
Log("Market Close", "#FF0000")
if t2.Check():
Log("Market Open", "#CD32CD")
else :
LogStatus(_D(), "not connected!")
Sleep(500)
```
Backtest test run:

It should be noted that for backtest, the K-line cycle of the bottom layer cannot be set too large, otherwise the time detection point may be skipped directly and there will be no trigger.
From: https://blog.mathquant.com/2020/08/07/add-an-alarm-clock-to-the-trading-strategy-2.html | fmzquant |
1,867,140 | How To Tell An Amateur Programmer From a Professional | You are always learning new programming languages or frameworks. I think all of us have fallen... | 0 | 2024-05-31T02:10:00 | https://dev.to/thekarlesi/how-to-tell-an-amateur-programmer-from-a-professional-1dnn | webdev, beginners, html, programming | You are always learning new programming languages or frameworks.
I think all of us have fallen victims to this. Whether it is the hype of a certain technology, or you just decide one day that you want to master something completely new just for the challenge of it.
It is really a vain pursuit. Why? Well I'm all for you being a constant learner. That is a good thing you actually have to do in this industry. You have to always be learning.
But the question is, "What are you learning?"
It is much more beneficial to be learning and mastering the concepts of programming and how things are really working than learning many different languages.
Which to be honest, each one is just a new syntax. It is just the new language. Why do that.
Before we continue, If you are interested in more web related content, [subscribe to my newsletter](karlgusta.substack.com), especially if you are in a job search so that you don't miss future posts.
If you really understand the concepts that underline programming, a loop can be looked up in any language. A switch statement can be looked up in any language.
It is all just syntax!
So, if you are asked to build a feature in a new language or frameworks, something that you haven't used before, you should be able to:
1. Read a quick overview of that technology and how it works.
2. Be able to build that feature based on programming concepts or pseudo code even and then transforming it into whatever syntax that language speaks.
Also, and I did an article on this one recently. I will share a link. But if you are going to learn a new language for the sake of doing so, pick a lower level language like C or Rust or even Go or C#, if you are coming from Python or something high level like that.
And once you have put in the work of learning the deeper concepts that those languages force you to understand, you can really jump in anywhere.
## Too Many Things At Once
You are working on too many different things at once.
As a new developer, you want to look competent. And you want people to think that you are very efficient.
That you just happen to be this coding prodigy that came out of nowhere.
But take a look at senior to mid level devs.
They reject the extra work because they are in the middle of something. They are in the middle of, one thing.
They have a really good grasp of that one thing, and the requirements for that one thing.
And they get it done well.
You, on the other hand, have 3 things going on. Of which you don't fully understand. And your brain has to jump back and forth between them.
As a new dev, don't be embarrassed to say, "I'm currently in the middle of something. Let me get this done first, then I will jump on that."
Stop volunteering for everything.
Get your one assignment, understand the requirements well, and then knock out the park.
Be a dev that always delivers over one that is always in the middle of 10 different things. And always has to give updates and excuses for all the things that you are doing.
Take one task assignment at a time, and complete it.
And commit to a new task only when the previous task is delivered as requested.
In fact, building software is a slower process than you think. Especially if you want to do it right.
Happy Coding!
Karl
P.S. My new course [The 2 Hour Web Developer](https://karlgusta.gumroad.com/l/eofdr) will help you build ANY website you want. | thekarlesi |
1,742,432 | Dev Archetypes: How to Recognize Yours and Leverage It | Sorry to say this, but you can't be good at everything. Everyone, by design, has strengths and... | 0 | 2024-05-31T02:07:02 | https://dev.to/jeriel/dev-archetypes-how-to-recognize-yours-and-leverage-it-3o4o | programming, productivity, devjournal | Sorry to say this, but you can't be good at everything. Everyone, by design, has strengths and weaknesses, even in software development. We're all built differently and have our own contributions to bring to the table.
In many ways, recognizing that everyone is different will help you to collaborate better as a team. It also humbles you to know that you will have limitations but also that that's okay. While you may lack refinement in certain areas, you will still shine elsewhere.
The aim, then, is to figure out what those skills are and focus on expanding them.
## Archetypes
While the following archetypes are fun to think about, remember that they're not discrete buckets. There is lots of room for overlap, and you may find yourself excelling in one or more areas. The important thing to remember is that you'd rarely find anyone who's maxed out in all areas, if that's even possible. Ultimately, the idea isn’t to pigeonhole yourself but to recognize and embrace your strengths.
The following is a breakdown of what I believe are common developer archetypes on a given team. It may not be an exhaustive list, so if you have ideas of your own, feel free to share some in the comments!
#### The Artisan
When it comes to quality, syntax, and semantics, the Artisan crafts clean code that is maintainable and readable. This goes a long way in keeping tech debt out of the codebase. Additionally, you also excel at doing careful refactors, sometimes on a large scale, with minimal errors. This naturally comes along with thoughtful unit tests that protect the integrity of the code. In short, you pay attention to detail and have the sharpest eye for software quality, what it looks like and what it doesn’t look like.
You can almost liken the Artisan to a gardener, caring for and tending to the needs of the code, making sure to prune any weeds before they become too unwieldy to manage.
#### The Encyclopedia
The Encyclopedia is a fountain of knowledge, having a natural ability to recall nitty-gritty APIs and tools. You're able to maintain this knowledge through an appetite for blogs and podcasts since the software landscape changes almost weekly. Thus, people with an eagerness to learn and an excitement for new tech will usually excel at this. This comes in especially useful when the approach to implementing a new feature or bug fix isn't readily apparent.
One great way to continue sharpening this trait is to experiment with various side projects as your sandbox environment. By knowing broadly what tools are available, you're usually the first to ask, "What if we tried using XYZ?"
#### The Debugger
The Debugger is really good at pinpointing issues and finding a fix for them. For some reason, you have a sort of "sixth sense" in feeling out the root cause of a bug, which will oftentimes point to its solution.
Debuggers are typically methodical in their approach. Instead of banging your head against the wall when something isn't working, you tend to step back and look at the bigger picture. In this way, you're more efficient at diagnosing the issue because you're quick to synthesize the common denominator between what's working and what isn't. As a Debugger, you're not afraid to roll up your sleeves and use all the tools at your disposal to go deep into a particular problem.
#### The Architect
The Architect has a broad vision for software design and can identify the pros and cons of a given solution. This skill doesn't typically show itself until you've had years of experience, particularly after working on longer-term projects where you've been able to witness firsthand the consequences of bad design.
Still, the Architect has a natural ability of seeing how all the pieces of a larger system connect together and laying out the plan to put those pieces together, one step at a time. People trust your judgment because you're able to articulate and address the flaws in a software solution before spending time and resources to build it.
#### The Communicator
Bridging the gap between technical jargon and product value is a difficult balance. Especially when you're deep in the weeds of the code and all its edge cases, trying to explain any of that to someone outside your team will simply fall on deaf ears if you don't speak their language.
The Communicator excels at understanding what's relevant to non-developers and articulating that information in a way that will get buy-in from stakeholders and drive the product to completion. This is an important role that runs in tandem with your product owner because, as someone who also has your hands deep in the code, you deeply understand the “why” in what you’re building.
#### The Mentor
Similar to the Communicator, the Mentor understands the perspective of a new developer and how overwhelming onboarding can be. Not everyone can easily explain a codebase or advanced topics in a way that will stick with a developer who doesn’t have the same amount of context. Here, that context is the key piece, and empathy is the strongest trait of the Mentor. While everyone else on the team has had time to build up a shared understanding of historical decisions and past mistakes, a junior developer or new joiner has not. The Mentor acts as their representative and exercises patience and generosity with their time.
As the Mentor, you understand the multiplicative effects of raising up everyone else on the team, even if it takes time away from your own tasks.
## Caveats
Knowing your archetype isn't meant to be a way for you to flex. At least, it shouldn't be. Rather, it's a way to discover where your strengths lie so that you can bring the most value to your team. It also helps you remember that no one is perfect, allowing you to give yourself and others more grace.
Taking a step back, finding your niche skill(s) should not be an excuse to ignore all the other areas. Knowing your limits also has an upside by allowing you to understand where else you can improve. While it's important to work as a team, there's a fine line between collaboration and over-dependence. Harness your strengths but also find ways to understand and work around your weaknesses. | jeriel |
1,871,528 | First Glance at Ansible | What is ansible Ansible is an open-source IT automation tool that automates provisioning,... | 0 | 2024-05-31T02:03:37 | https://dev.to/feng_wei/first-glance-at-ansible-3522 | ansible | What is ansible
Ansible is an open-source IT automation tool that automates provisioning, configuration management, application deployment, orchestration, and many other IT processes. Ansible is written in Python and uses OpenSSH for transport.
Hands-on Ansible
1. Install ansible on a Linux machine, which is called control node. Use "ssh-keygen" and "ssh-copy-id"commands to generate ssh key and copy it to managed nodes for authentication
2. Playbooks are the simplest way in Ansible to automate repeating tasks in the form of reusable and consistent configuration files. Playbooks are scripts defined in YAML files and contain any ordered set of steps to be executed on managed nodes.
[My first playbook]
- hosts: webserver
remote_user: whocare
tasks:
- name: make ~/whocare directory
ansible.builtin.file:
path: ~/whocare
state: directory
- name: Copy file
copy:
src: /home/whocare.deb
dest: /home/whocare.deb
owner: whocare
group: whocare
mode: '0700'
- name: install whocare
become: true
become_method: sudo
ansible.builtin.apt:
deb: /home/whocare.deb
- name: copy dat file to /opt/Tanium/TaniumClient
become: true
become_method: sudo # need "-K" parameter, which is short form "--ask-become-pass". $ ansible-playbook <1.yaml> -K.
copy:
src: /home/whocare.dat
dest: /opt/whocare.dat
- name: restart service
become: true
become_method: sudo
service:
name: whocare
state: restarted
| feng_wei |
1,871,527 | How to host your Next14 app on Netlify in 2 minutes | To follow this tutorial, you need to create a Netlify account and sign in to it, also the code for... | 0 | 2024-05-31T02:03:09 | https://dev.to/joeskills/how-to-host-your-next14-app-on-netlify-in-2-minutes-566f | netlify, nextjs, webdev, howto | To follow this tutorial, you need to create a Netlify account and sign in to it, also the code for your Next app should be hosted on an online repository. I’m using GitHub to host the code.
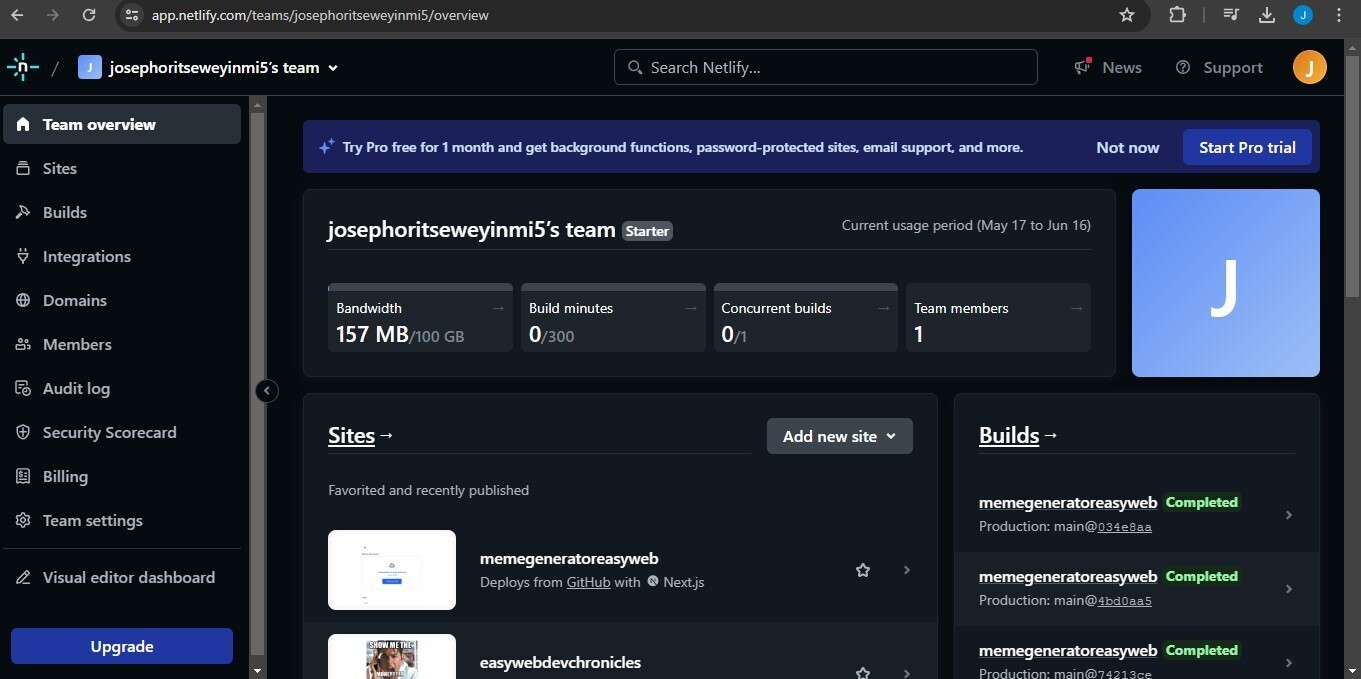
---
## **Add a new site🔗:**
You will be taken to your Netlify dashboard after you log in. After you click on the add new site button. It will bring up a popup menu, choose the 'import an existing project' option.
---
## **Choose your code repository platform👨💻:**
Click on the platform of your choice and grant Netlify access to it. I'll choose GitHub because I'm using it to host my code.
---
## **Pick the repository of your Next.js app👩🏻💻:**
After choosing a platform, Netlify will show you a list of repositories hosted on your platform. Pick the repository that contains the Next14 app.
---
## **Choose the correct branch & build settings⚙️:**
Netlify automatically infers if you're using Next.js, the build settings will allow your app to run normally, but you'll also be able to customize your site name, build command, the base directory, and your publish directory here. This is where you can also add your environment variables. If you're using a different branch other than the default main branch, you can switch to it with the select menu. Once you're done, click on deploy 'site name' at the bottom.
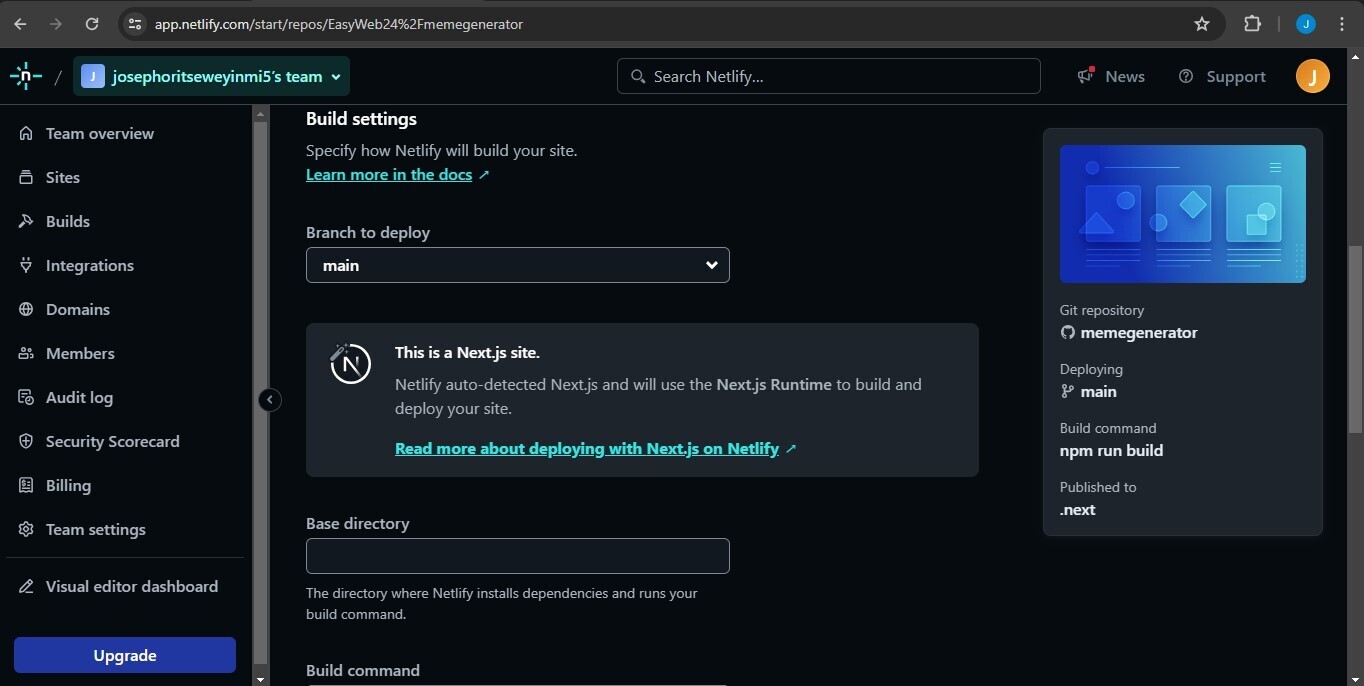
---
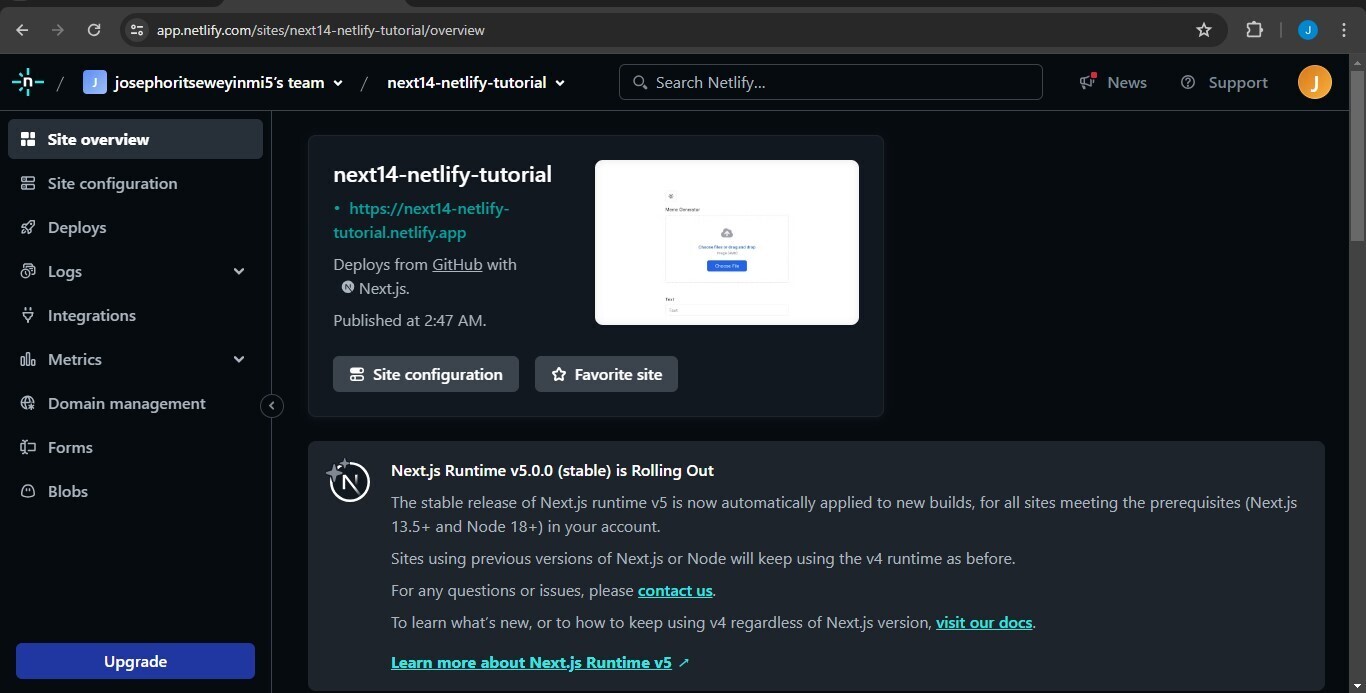
## **You Next14 app is now live⚡**
Your site is live! If there were no build errors, all you have to do is wait for Netlify to deploy your site. Once it's done deploying, it'll provide a domain name for you that you can use to visit your site. You might need to reload the page if you're being shown 'site in progress' for a long time.
---
Happy Coding!
You can hear more from me on:
𝕏 - https://x.com/code_withjoseph
| joeskills |
1,871,526 | Ensino superior na área de tecnologia | Ensino superior na área de tecnologia: benefícios e impacto na carreira | 0 | 2024-05-31T02:02:56 | https://dev.to/lexipedia/ensino-superior-na-area-de-tecnologia-39a2 | tecnologia, ensinosuperior, graduacao, educacao | ---
title: Ensino superior na área de tecnologia
published: true
description: Ensino superior na área de tecnologia: benefícios e impacto na carreira
tags: #tecnologia #ensinosuperior #graduacao #educacao
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-31 01:55 +0000
---
## A polêmica
Com certeza, o tema "faculdade na área de tecnologia" é um assunto que dá o que falar. Há quem seja fortemente contra a ideia de entrar na universidade se o objetivo é mergulhar no mercado de trabalho tecnológico. E há aqueles que são fervorosamente a favor da educação superior, independentemente do resto. Hoje, estou aqui para compartilhar minha visão sobre isso, então sem mais enrolações, vamos lá!
## Impacto da Educação Superior na Carreira em Tecnologia: Uma Perspectiva de Curto e Longo Prazo
### Início de carreira
Sem dúvidas cursar ou terminar uma graduação não é estritamente necessário para profissionais do mercado de tecnologia. Mas muitos conhecimentos que se ganha durante uma graduação podem ser relevantes no mercado, direta ou indiretamente. Análise de requisitos, estruturas de dados, algoritmos, programação orientada à objetos e engenharia de software são exemplos de matérias de faculdade que podem ser aplicadas facilmente no mercado de trabalho. Entendo que algumas pessoas que são contra a ideia do ensino superior talvez não vejam uma aplicação direta desses conteúdos, que às vezes são aplicados de forma mais abstrata ou indireta. Mas, se olharmos mais de perto, eles ainda estão lá.
### Carreira à longo prazo
Para profissionais que já têm uma carreira consolidada, acredito que ainda faz sentido investir em uma educação superior. Isso se deve às mesmas razões que mencionei ao falar sobre o início de carreira. Além disso, principalmente porque cargos de maior senioridade têm mais chances de exigir uma educação superior e até mesmo pós-graduação, dependendo da empresa. Sinto que isso é ainda mais evidente quando olhamos para duas coisas: vagas no exterior e o tamanho da empresa. As empresas maiores tendem a ter mais poder para definir os pré-requisitos de seus funcionários. Junto com isso, vejo que as vagas para o exterior geralmente exigem uma educação superior com mais frequência. Se você está sonhando em trabalhar para grandes empresas, como por exemplo as FAANG ou outras empresas de grande influência no mercado, acredito que o ensino superior se torna ainda mais essencial.
## Ensino superior público vs. privado
Escolher entre uma faculdade pública ou particular é uma decisão significativa que pode influenciar significativamente sua jornada profissional. As faculdades públicas, comumente, investem mais tempo em aprofundar a teoria, o que pode fortalecer sua base de conhecimento. Esta abordagem intensiva pode ajudá-lo a ter uma melhor compreensão das disciplinas estudadas, preparando-o para enfrentar desafios complexos que podem surgir em sua carreira.
Por outro lado, as faculdades particulares tendem a enfatizar mais as habilidades práticas e atualizadas. Elas se concentram em fornecer uma educação que está alinhada com as demandas do mercado de trabalho atual, o que pode ser extremamente benéfico para se destacar em um ambiente de trabalho competitivo.
Ambos os tipos de instituições têm seus pontos fortes. Portanto, a melhor escolha depende dos seus objetivos individuais de carreira e da sua situação pessoal. É importante ponderar cuidadosamente suas metas, seu estilo de aprendizado preferido e suas aspirações de carreira ao tomar essa decisão.
## Competências desenvolvidas durante o processo de graduação
### Habilidades Sociais e de Comunicação
O ensino superior não só fornece conhecimento técnico, mas também contribui para o desenvolvimento de habilidades sociais e de comunicação. Trabalhar em equipe, resolver problemas complexos e comunicar ideias de forma eficaz são habilidades valiosas no mercado de tecnologia. Durante a graduação, os alunos têm a oportunidade de aprimorar essas habilidades por meio de projetos de grupo, apresentações e interações com colegas e professores.
### Estágios e Experiências Práticas
Muitas instituições de ensino superior têm parcerias com empresas e indústrias locais, permitindo aos estudantes participarem de programas de cooperação e estágios. Essas experiências práticas dão aos alunos a oportunidade de aplicar o conhecimento teórico no mundo real, obtendo uma visão valiosa do ambiente de trabalho e das demandas do mercado.
### Certificações e Educação Continuada
Além do diploma de graduação, certificações em TI de empresas reconhecidas internacionalmente, como AWS(Amazon Web Services), GCP(Google Cloud Plataform), Microsoft e Cisco, são altamente valorizadas no mercado. Muitas instituições oferecem cursos preparatórios para estar certificações e até oportunidades de tirar elas por preços mais acessíveis
### Recursos gratuitos
Estar vinculado à uma instituição de ensino traz a oportunidade de ter acesso à uma série de ferramentas e recursos que originalmente seriam pagos, de forma gratuita ou com um significativo desconto. A maioria destes estão são oferecidos no [GitHub Student Developer Pack](https://education.github.com/pack). Esses benefícios não só economizam dinheiro, mas também proporcionam aos estudantes uma vantagem significativa no aprendizado e na prática do desenvolvimento de software com ferramentas usadas por profissionais ao redor do mundo.
### Networking e Eventos
A participação em eventos, conferências e hackathons oferece a chance de fazer networking e aprender com outros profissionais da área. Essas atividades podem abrir portas no mercado de trabalho e fornecer insights valiosos sobre as mais recentes inovações e tendências na indústria de tecnologia.
### Inclusão e Diversidade
A diversidade e a inclusão são aspectos cada vez mais importantes no ensino superior e no mercado de tecnologia. A promoção da inclusão e da diversidade não apenas enriquece o ambiente de aprendizado e de trabalho, mas também contribui para a inovação e a criatividade na indústria de tecnologia. Iniciativas e programas que incentivam a participação de grupos sub-representados na área de TI são passos importantes para criar um setor mais inclusivo e diversificado.
## Conclusão
Em conclusão, o ensino superior na área de tecnologia pode desempenhar um papel significativo na preparação de indivíduos para uma carreira no setor. Apesar de não ser estritamente necessário para entrar no mercado de trabalho tecnológico, a educação superior proporciona uma série de benefícios que podem ser úteis em todo o percurso profissional. Desde o desenvolvimento de habilidades sociais e de comunicação, à oportunidade de realizar estágios práticos e obter certificações reconhecidas. Além disso, a escolha entre uma instituição de ensino superior público ou privado deve ser pensada com base em suas metas de carreira e situação pessoal. Portanto, enquanto se reflete sobre essa decisão, é importante considerar cuidadosamente todos os aspectos e benefícios de uma educação superior na área de tecnologia. | lexipedia |
1,837,568 | Task18 | Describe the Python Selenium architecture in detail? What is the significance of the Python Virtual... | 0 | 2024-04-29T16:44:11 | https://dev.to/vignesh_89/task18-141c | **Describe the Python Selenium architecture in detail?**
**What is the significance of the Python Virtual Environment? Give Some Example to support your answer?**
**Python Selenium Architecture:**
Selenium WebDriver stands as a widely utilized open-source library and integral element within the Selenium automation framework. Its primary function involves automating the testing procedures for web applications. This technology comprises a set of APIs that provide a programming interface, empowering developers, and testers to craft scripts in diverse programming languages like Java, JavaScript, C#, Python, etc. These scripts are designed to automate actions within web browsers and extract information from web pages. WebDriver operates by replicating user actions, navigating across web pages, engaging with various elements (ranging from buttons, text fields, dropdown menus, forms, links, etc.), submitting forms, executing validations, performing assertions, and executing numerous other functions through test scripts.
The architecture of Selenium WebDriver (Selenium 3) comprises four primary components:
**Selenium Client library:** The Selenium Client Library encompasses languages such as Java, Ruby, Python, C#, and more. Once the test cases are initiated, the complete Selenium code will be transformed into JSON format.
**JSON wire protocol over HTTP:** JSON stands for JavaScript Object Notation, handling the transmission of information from the server to the client. The JSON Wire Protocol predominantly manages the transfer of data between HTTP servers. The produced JSON is accessible to browser drivers via the HTTP protocol.
**Browser Drivers:** Selenium’s browser drivers are inherently specific to each browser, establishing secure connections and enabling interaction with the browser. Selenium extends support for various browser drivers such as ChromeDriver, GeckoDriver, Microsoft Edge WebDriver, SafariDriver, and InternetExplorerDriver.
**Browsers:** One of the greatest advantages of Selenium WebDriver is its compatibility with all major browsers including Firefox, Google Chrome, Apple Safari, IE, Edge, and Opera. Each browser has its dedicated WebDriver for running automation scripts.
**<u>Selenium WebDriver Architecture</u>**
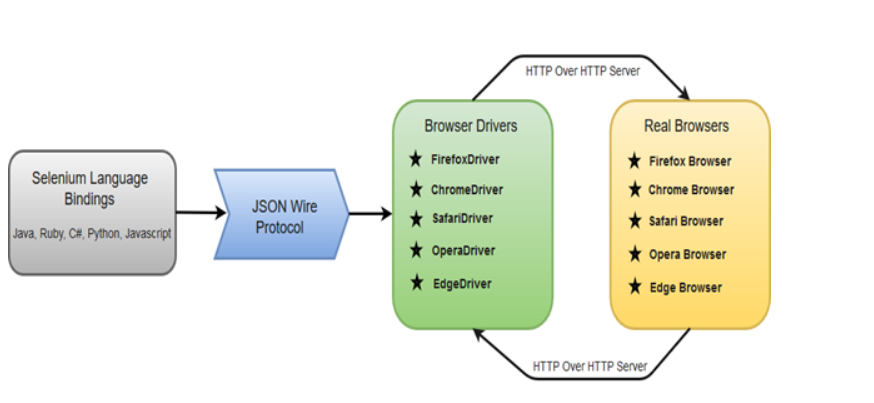
**Python Virtual Environment:**
A Python virtual environment refers to an independent Python environment enabling the management of distinct dependencies for individual Python projects. Creating a Python virtual environment for each project guarantees that it will possess its necessary requirements without any interference from other projects.
What is the reason behind using a Python Virtual Environment?
While working with Python, we might find the need to install packages and modules that aren’t included in the standard library. Employing ‘pip install –user some_package’ enables the installation of Python packages in your home directory. However, potential issues may arise later regarding package dependencies.
**Eg:**
If developers are simultaneously handling two different projects — Project A requiring version 1.0 of a library and Project B necessitating version 2.0 of the same library — installing the dependency for Project B could potentially disrupt Project A. To circumvent this issue, creating separate virtual environments for each project is a simple solution. These virtual environments remain isolated from one another, allowing you to install dependencies for one project without concerns about affecting the other.
**Functioning principle of a virtual environment**
**Installing virtualenv:**
$ pip install virtualenv
**Test the installation:**
$ virtualenv — version
**Creating a virtualenv using the following command:**
$ virtualenv dir_name
*dir_name- Directory name
**To create a Python 3 virtual environment, use the following command:**
$ virtualenv -p /usr/bin/python3.X virtualenv_name
**Deactivate a Python virtualenv:**
(virtualenv_name)$ deactivate
| vignesh_89 | |
1,871,525 | Desenvolvimento Full-Stack: Integrando Front-end e Back-end com Eficiência | Introdução O desenvolvimento full-stack tem ganhado popularidade nos últimos anos,... | 0 | 2024-05-31T01:59:52 | https://dev.to/thiagohnrt/desenvolvimento-full-stack-integrando-front-end-e-back-end-com-eficiencia-4djk | fullstack, frontend, backend, braziliandevs | ## Introdução
O desenvolvimento full-stack tem ganhado popularidade nos últimos anos, permitindo que desenvolvedores dominem tanto a criação de interfaces de usuário quanto a lógica de servidor. A integração eficiente entre front-end e back-end é essencial para o sucesso de qualquer aplicação web. Este artigo explorará as melhores práticas e ferramentas que facilitam essa integração.
### 1. Escolha das Tecnologias Certas
A primeira etapa para uma integração eficiente é a escolha das tecnologias adequadas para o projeto. Algumas combinações populares incluem:
- **MERN Stack** (MongoDB, Express, React, Node.js): Oferece uma abordagem JavaScript completa, do servidor ao cliente.
- **MEAN Stack** (MongoDB, Express, Angular, Node.js): Similar ao MERN, mas com Angular para o front-end.
- **MEVN Stack** (MongoDB, Express, Vue, Node.js): Similar ao MEAN, mas com Vue.js para o front-end.
- **LAMP Stack** (Linux, Apache, MySQL, PHP): Uma stack tradicional, ainda amplamente usada para aplicações web robustas.
### 2. Comunicação Entre Front-end e Back-end
A comunicação eficiente entre o front-end e o back-end é fundamental. As APIs RESTful são uma escolha comum, permitindo que o front-end faça requisições HTTP para o back-end. Alternativamente, o GraphQL oferece uma abordagem mais flexível e eficiente, permitindo que o front-end solicite exatamente os dados necessários.
#### RESTful APIs
- **Simplicidade**: Usam os métodos HTTP (GET, POST, PUT, DELETE) para operações CRUD.
- **Padronização**: Seguem um padrão bem definido, facilitando a manutenção.
#### GraphQL
- **Flexibilidade**: Permite ao cliente especificar exatamente quais dados são necessários.
- **Eficiência**: Reduz a quantidade de dados transferidos e evita múltiplas chamadas de API.
### 3. Ferramentas e Frameworks
Existem várias ferramentas e frameworks que facilitam a integração e aumentam a produtividade:
- **Express.js**: Um framework web minimalista para Node.js que facilita a criação de APIs.
- **Next.js**: Um framework React que oferece renderização do lado do servidor e geração estática de páginas.
- **Nuxt.js**: Um framework Vue.js que simplifica o desenvolvimento de aplicações universais e de página única.
- **NestJS**: Um framework para construir aplicações Node.js escaláveis e eficientes, inspirado no Angular.
- **Apollo Client**: Uma biblioteca de gerenciamento de estado para GraphQL que facilita a comunicação com o back-end.
- **Prisma**: Um ORM moderno que facilita o acesso a bancos de dados em aplicações Node.js e TypeScript.
- **TypeORM**: Um ORM para Node.js que suporta TypeScript e JavaScript (ES7, ES6).
- **Webpack**: Um empacotador de módulos para JavaScript que ajuda a compilar grandes conjuntos de arquivos em um ou mais pacotes.
- **Babel**: Um transpilador JavaScript que permite usar a próxima geração do JavaScript, hoje.
- **Docker**: Uma plataforma para desenvolver, enviar e executar aplicações dentro de contêineres, facilitando a criação de ambientes consistentes.
- **Jest**: Um framework de testes em JavaScript que oferece uma experiência de teste agradável, com suporte a mock e cobertura de código.
- **Cypress**: Uma ferramenta de teste end-to-end que facilita a escrita de testes para aplicações web.
Cada uma dessas ferramentas e frameworks oferece funcionalidades específicas que podem melhorar a integração entre o front-end e o back-end, dependendo das necessidades do seu projeto.
### 4. Boas Práticas de Desenvolvimento
Para garantir uma integração eficiente e um código de alta qualidade, é importante seguir algumas boas práticas:
#### 4.1. Modularidade
- **Componentização**: Divida o código em componentes reutilizáveis.
- **Separation of Concerns**: Mantenha a lógica de negócio separada da lógica de apresentação.
#### 4.2. Automação de Tarefas
- **CI/CD**: Utilize pipelines de integração contínua e entrega contínua para automatizar testes e deploys.
- **Linters e Formatadores**: Ferramentas como ESLint e Prettier ajudam a manter a consistência do código.
#### 4.3. Testes
- **Testes Unitários**: Testam funções individuais para garantir que cada uma funcione corretamente.
- **Testes de Integração**: Verificam se diferentes partes do sistema funcionam bem juntas.
- **Testes End-to-End**: Simulam a experiência do usuário final para garantir que a aplicação funcione como um todo.
### 5. Desafios e Soluções
#### 5.1. Gerenciamento de Estado
Gerenciar o estado da aplicação pode ser complexo, especialmente em aplicações grandes. Bibliotecas como Redux (para React), Vuex (para Vue.js) e NgRx (para Angular) podem ajudar.
#### 5.2. Autenticação e Autorização
Garantir que apenas usuários autenticados e autorizados possam acessar certos recursos é crucial. Ferramentas como JWT (JSON Web Tokens) e OAuth podem simplificar esse processo.
#### 5.3. Manutenção e Escalabilidade
Manter o código limpo e bem documentado é essencial para a manutenção a longo prazo. Além disso, arquiteturas baseadas em microservices podem facilitar a escalabilidade.
### Conclusão
Integrar front-end e back-end de maneira eficiente é uma habilidade essencial para desenvolvedores full-stack. Com a escolha das tecnologias certas, boas práticas de desenvolvimento e ferramentas adequadas, é possível criar aplicações web robustas e escaláveis. O foco na modularidade, automação de tarefas e testes contínuos garantirá um fluxo de trabalho mais eficiente e um produto final de alta qualidade. | thiagohnrt |
1,871,524 | AI's Unleashing Chaos in the Media World (And It's Kinda Epic) | Artificial intelligence ain't messing around when it comes to flipping the script on how we create,... | 0 | 2024-05-31T01:58:28 | https://dev.to/kevintse756/ais-unleashing-chaos-in-the-media-world-and-its-kinda-epic-3ahg | Artificial intelligence ain't messing around when it comes to flipping the script on how we create, share, and consume media these days. As we dive headfirst into 2024, AI applications are becoming deeply woven into the media landscape's fabric, causing major disruptions (in the most thrilling way imaginable!). Let's dive into the biggest trends fueling this AI-driven revolution:
AI That Actually "Gets" Creativity
Ever felt like your design tools just can't seem to vibe with your creative vision? Adobe's got your back with their Sensei AI platform, using AI wizardry to supercharge creative workflows. It can conjure up killer visuals, automate those soul-sucking mundane tasks, and offer smart editing suggestions – freeing creatives to focus on bringing their wildest, most out-there ideas to life.
In the live video space, TVU Networks' [MediaMind](https://mediamind.tvunetworks.com/) is an AI-powered game-changer for streamlining production. With smart tagging, metadata sorcery, and multi-platform distribution, it's like having a digital genius dedicated to making your live broadcasts pop off the screen.
AI's Cranking Up Workplace Productivity
From live broadcasts to next-gen customer service, AI is proving to be a productivity beast across the media industry. Take [TVU Networks](https://www.tvunetworks.com/)' AI transcription service Transcriber - it does real-time captioning and translation, ensuring global audiences can tune in without missing a single beat.
As AI infiltrates workplaces, new job roles are sprouting up like mushrooms after rain. Companies like Synthesia are pioneering groundbreaking AI video generation tools, creating demand for AI engineers, ethicists, and data masterminds to develop and govern these cutting-edge systems.

Personalization at Mind-Boggling Scale
Remember when Netflix used to recommend titles that made you go "huh, why though?". Thanks to AI algorithms studying our viewing habits like a pro stalker, those days are ancient history. Now, the streaming giants serve up personalized suggestions tailored to your unique tastes, keeping you glued to the screen for ages.
Social behemoths like TikTok are also using similar AI sorcery to personalize your feed with scary accuracy, ensuring you're never far from content that just gets you. In 2024, this hyper-personalized, AI-driven experience is the new standard for maximizing user engagement and retention.
When AI Generates Content (and Cash Rolls In)
From crafting marketing magic to automating customer support, AI is being commercialized to generate all kinds of content at scale. Adobe's Creative Cloud is tapping into the power of generative AI, empowering even design rookies to unleash their creative genius and produce slick visuals fit for the pros.
Synthesia's brilliant AI video generation platform lets companies craft hyper-personalized videos for marketing campaigns, training programs and more – a triple threat that boosts engagement, streamlines production, and helps businesses stand out in today's oversaturated digital landscape.
Open Source and Localized AI Models on the Rise
For cost-savvy companies, open-source AI models are gaining major traction, allowing them to customize these bad boys to suit their unique needs. TVU Networks is using these open source gems to power innovative broadcasting tools like [TVU Producer](https://www.tvunetworks.com/products/tvu-producer-cloud-production/), keeping them at the cutting edge without breaking the bank.
In sectors handling sensitive data, the move towards localized AI models is accelerating rapidly. These allow companies to process confidential info securely in-house, without relying on third-party providers – and as data privacy regulations get stricter, this trend is only going to intensify.
AI Meets Quantum Computing: A Tech Power Duo
The fusion of AI and quantum computing is a tech power couple made in heaven, with the ability to solve complex problems that would make classical computers cry uncle. From insanely accurate weather forecasting to accelerating new drug discoveries, this dynamic duo is already making massive waves across industries.
Ethical AI Development: Not Optional, But Essential
As AI's influence explodes, ensuring its ethical and responsible use is absolutely paramount. The big tech players like Adobe are joining forces to develop robust guidelines promoting transparency, accountability and fairness in AI applications.
Companies pioneering AI breakthroughs, like Synthesia with its deepfake video generation, are proactively building in safeguards against misuse – striking a fine balance between disruptive innovation and ethical duty. It's a crucial step in maintaining public trust as AI's capabilities continue to evolve at a blistering pace.
AI Assistants Are Leveling Up, For Real
AI-powered virtual assistants are leaving their basic customer service roots far behind, tackling complex operations like a boss. TVU Networks' AI assistants help streamline entire live broadcast workflows – handling tasks like scheduling, distribution, and more – freeing up the human team to focus on creating killer content.
As these AI assistants get smarter at retrieving info and coordinating tasks seamlessly (peep Adobe's AI tools for managing digital assets), their applications will only keep expanding, driving efficiency across all sectors. Imagine having an AI assistant that can practically run your entire business – that future may be just around the corner, fam!
There's no denying it, the AI revolution is in full swing in the media realm. Powerhouses like [Adobe](https://www.adobe.com/), [TVU Networks](https://www.tvunetworks.com/), [Netflix](https://www.netflix.com/) and [Synthesia](https://www.synthesia.io/) are leading the charge – reimagining how we create, share and experience content through the limitless possibilities of AI. From hyper-personalized experiences to rock-solid ethical development frameworks, these trends are setting the stage for an AI-driven media future that's going to blow our collective minds. Better buckle up tight, it's gonna be one wild, chaotic ride we're all here for! | kevintse756 | |
1,871,523 | Python 熱門套件的前 10 名 | 本篇我將會介紹 Python 熱門套件的前 10 名,下面表格是收集到的數據: 頭兩個 boto3 和 botocore 都是與亞馬遜的雲端服務平台 AWS... | 0 | 2024-05-31T01:50:40 | https://dev.to/neilskilltree/python-re-men-tao-jian-de-qian-10-ming-1lc9 | beginners, programming, tutorial, python | 本篇我將會介紹 Python 熱門套件的前 10 名,下面表格是收集到的數據:
頭兩個 boto3 和 botocore 都是與亞馬遜的雲端服務平台 AWS 相關的套件,允許用戶與其上的服務進行互動。
然而,我並不建議新手們在初期就學習這類套件,其中一個原因是雲端技術相對複雜。Python 新手們常犯的錯誤就是一次接觸兩種(或以上)的技術,最終只會得到邯鄲學步的結果。
接下來的 urllib3 和 requests 是進行網頁抓取或透過 HTTP API(一種呼叫另一台機器上的程式/函式的方法)與其他機器互動的理想選擇。
不過別被 urllib3 的說明誤導了,雖然號稱 user-friendly,但在 requests 誕生之前我也被它苦毒許久⋯⋯艱澀難懂,有點像是以前大學時寫網路 socket 程式般的難受。因此我建議直接從 requests 下手即可。
其他包括 wheel,一個打包 Python 套件的工具;certifi,用於驗證 SSL 憑證和 TLS 主機;typing-extensions,處理 Python 型別;idna,用於處理 IDNA 網路通訊協定;setuptools 也是與套件打包有關;以及 charset-normalizer,用於偵測和轉換字元編碼。
這些套件涉及較專業的技術細節,對初學者來說可能較難直接應用,因此可以先將心思放在更重要的套件上面,比如說 requests。
從這樣的介紹中,你可能已經注意到,雖然 Python 有超過 50 萬個套件,我們日常實際會用到的只是其中的一小部分。而且如果根據領域再進行細分,實際需要學習的套件數量就更少了。這樣一想,學習 Python 套件是不是似乎沒有想象中那麼困難了呢?
| neilskilltree |
1,871,522 | 把 ChatGPT 當成程式助手可能反倒讓你陷入困境 | 我能理解為何你會相信它是一個助手,因為連我自己一開始也是這麼被「教育」的。現今的媒體和 YouTuber 們都是這樣在誇讚這些新興的 AI... | 0 | 2024-05-31T01:49:40 | https://dev.to/neilskilltree/ba-chatgpt-dang-cheng-cheng-shi-zhu-shou-ke-neng-fan-dao-rang-ni-xian-ru-kun-jing-46f0 | beginners, programming, tutorial, python | 我能理解為何你會相信它是一個助手,因為連我自己一開始也是這麼被「教育」的。現今的媒體和 YouTuber 們都是這樣在誇讚這些新興的 AI 工具,宣稱它們無所不能,甚至預言許多工作(尤其是我們程式設計師的職位)將被取代。
但我想先請你回想一下與它互動時的情形。你是否每次都必須費盡心思拼湊出那些 AI 專家們反覆強調的「詠唱咒語」,希望能像施展魔法一般,神奇地憑空變出完美的成品?
如果它真如主流所言無所不能,且已推出超過一年,那理應能直接理解你的需求,無需所謂的「咒語」。當 Google、YouTube 和 Facebook 能如讀心術般預測你的需求,精準投放廣告時,為何ChatGPT卻做不到?
此外,在 ChatGPT 初期,不少網紅專家曾浮誇的說它能迅速讓任何零基礎的人學會任何技能。那為何你現在還是個一直卡關的 Python 新手?
那麼,要如何看待 ChatGPT 所扮演的角色?又要怎樣正確地與之互動?讓我用上週的一個例子來說明它的真正角色。
當我在研究如何獲得熱門 Python 套件的下載量時,我利用 ChatGPT 來理解 BigQuery 的文件,並幫我生成一條可以在 PyPI 資料庫查詢相關資訊的 SQL 指令。
執行它的第一條指令時,我無腦的複製貼上,然後就直接遇到了錯誤,原因是它沒有正確理解 PyPI 資料庫表格的格式,導致欄位名稱錯誤。儘管它辨識出了表格中的兩個關鍵欄位,但不知為何在日期欄位上出了錯。
我指出了它的錯誤,經過幾次修正後,最終得到了正確的查詢結果。這讓我意識到,我的角色更像是「主管」,而它則像是「員工」。我負責指揮它的動作,並在它犯錯或未達預期時進行糾正。透過彼此長處的互補,本來需要數天完成的工作,在不到兩小時內便完美完成。這就是我們應該與這類 AI 工具應有的互動與合作方式。
現在你知道了新的思維方式來看待這些 AI 工具,你還會像以前一樣把它當成「助手」,卻過度依賴它,反倒失去了自我思考的能力嗎?還是你會調整自己的角色,以「領導者」的身份來引導和合作?
歡迎在下方分享你的感想和體悟!
| neilskilltree |
1,871,521 | 如何取得 PyPI 上所有註冊的套件 | 根據 PEP 503 (Simple Repository API) 文件裡的說明,我們可以透過 https://pypi.org/simple/ 這支 API 來取得所有登記在 PyPI 之下的... | 0 | 2024-05-31T01:48:34 | https://dev.to/neilskilltree/ru-he-qu-de-pypi-shang-suo-you-zhu-ce-de-tao-jian-38cg | beginners, programming, tutorial, python | 根據 PEP 503 (Simple Repository API) 文件裡的說明,我們可以透過 https://pypi.org/simple/ 這支 API 來取得所有登記在 PyPI 之下的 Python 套件。當我們向這個 API 發出請求後, 便可得到類似下面的回應:
```
<!DOCTYPE html>
<html>
<body>
<a href="/frob/">frob</a>
<a href="/spamspamspam/">spamspamspam</a>
</body>
</html>
```
這是一個 HTML 網頁的寫法,其中 href 之後的文字,例如 /frob/ 或 /spamspamspam/,顯示了該套件的詳細資訊所在的位置,中間的字串是該套件的標準化名稱;而在角括弧中間的文字,例如 frob 或 spamspamspam,則是套件的原始名稱。
因此我們就可以寫一支簡單的 shell script 來取得這份 HTML 的內容:
```
$ curl -s https://pypi.org/simple/
<!DOCTYPE html>
<html>
<head>
<meta name="pypi:repository-version" content="1.1">
<title>Simple index</title>
</head>
<body>
<a href="/simple/0/">0</a>
<a href="/simple/0-0/">0-._.-._.-._.-._.-._.-._.-0</a>
<a href="/simple/000/">000</a>
…
```
為了更有效地篩選資訊,我們增加過濾條件,只保留含有 href 的項目:
```
$ curl -s https://pypi.org/simple/ | grep -Eo 'href="[^"]+"'
href="/simple/0/"
href="/simple/0-0/"
href="/simple/000/"
href="/simple/00000/"
href="/simple/0000000/"
href="/simple/00000000/"
href="/simple/000000000000000000000000000000000000000000000000000000000/"
href="/simple/00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000/"
href="/simple/0-0-1/"
href="/simple/00101s/"
…
```
接著,我們移除 href、simple 以及其他符號,只留下標準化名稱:
```
$ curl -s https://pypi.org/simple/ | grep -Eo 'href="[^"]+"' | awk -F '/' '{print $3}'
0
0-0
000
00000
0000000
00000000
000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
0-0-1
00101s
```
這樣我們便能取得所有在 PyPI 上登記的套件。
為了確認我們拿到的列表準確無誤,再進行一道處理程序:
```
$ curl -s https://pypi.org/simple/ | grep -Eo 'href="[^"]+"' | awk -F '/' '{print $3}' | wc -l
534413
```
這數字與 PyPI 官網上的非常接近,大工告成!
| neilskilltree |
1,871,520 | Silent Generators for Offices and Commercial Buildings | Generators for Offices and Commercial Buildings :Ensuring Uninterrupted Power Supply Innovative and... | 0 | 2024-05-31T01:47:22 | https://dev.to/hanna_prestonle_101c638d5/silent-generators-for-offices-and-commercial-buildings-3kmk | generators | Generators for Offices and Commercial Buildings :Ensuring Uninterrupted Power Supply
Innovative and solutions being safe Uninterrupted Power Supply
Silent generators are innovative and safe solutions for uninterrupted power in workplaces and structures that are commercial. These generators are made to offer electricity during power outages, making sure businesses can carry on their operations with no interruptions. They are safe to use them perfect for interior or outside usage while they produce less noise and emissions, making.
Features of Using Generators for Offices and Commercial Buildings
Silent Diesel generator sets have several benefits whenever utilized in workplaces and buildings that are commercial. Firstly, they supply uninterrupted power supply which can be critical for organizations that depend on electricity. The generators are capable of powering lights, computer systems, air-con, and other gear essential. Next, they're designed to be quiet, producing less noise than conventional generators. This makes them ideal for interior use without causing interruptions to workers. Also, quiet generators tend to be more environmentally friendly, producing less emissions and helping reduce steadily the carbon impact of businesses.
How to Use Silent Generators Generators for Offices and Commercial Buildings
Utilizing Generators for Offices and Commercial Buildings is not hard and simple. The generators are generally fuelled by gasoline or diesel and need refuelling periodic have them running. You should make certain that the generators are put in a area well-ventilated prevent carbon monoxide poisoning. It is also important to have a install professional generator and offer regular upkeep to make certain it operates at peak performance.
Quality and Service of Generators for Offices and Commercial Buildings
When selecting a Generators for Offices and Commercial Buildings, it is vital to decide on a Diesel engine generator high-quality. Look for a reputable manufacturer that provides warranties and service after-sales. This will guarantee your generator is of good and can offer performance reliable energy outages. Furthermore, regular servicing and maintenance will make sure that your generator stays in good condition and operates at peak performance.
Application of Silent Generators for Offices and Commercial Buildings
Diesel water pump generator for Offices and Commercial Buildings can be utilized in a number of applications in workplaces and structures that are commercial. They are commonly used to produce power backup energy outages or even to supply energy in areas where electric connections aren't available. Silent generators can be utilized for also outdoor activities or construction jobs where energy is required. They truly are a vital piece of equipment for businesses that depend on electricity to work and need to ensure power uninterrupted.
Source: https://www.kangwogroup.com/Diesel-generator-sets | hanna_prestonle_101c638d5 |
1,871,519 | 探索 Python 套件的啟程 | Python 初學者們最大的困難點之一是「套件不熟」,因此好奇想知道哪些 Python 套件是目前最受歡迎、最主流的。 不過找來找去,似乎找不到一個直接且可信的網頁可供參考。主要原因是無論... | 0 | 2024-05-31T01:46:52 | https://dev.to/neilskilltree/tan-suo-python-tao-jian-de-qi-cheng-301 | beginners, programming, tutorial, python | Python 初學者們最大的困難點之一是「套件不熟」,因此好奇想知道哪些 Python 套件是目前最受歡迎、最主流的。
不過找來找去,似乎找不到一個直接且可信的網頁可供參考。主要原因是無論 Python 官方或是套件主站 PyPI 都無法提供具體的下載數據,了解這些套件的實際使用程度。
問了問 ChatGPT,它說有一支 API 可以提供相關資訊,是以 HTML 網頁形式呈現。那麼這就屬於寫程式可以解決的範疇,也是學會寫程式的好處之一,畢竟在 PyPI 上登記的共有超過 533,000 個套件!這絕不是單靠人工就有辦法處理的任務。
利用這種「非 project」形式來學習,不但能增進自己寫程式的能力,也能擴展自己的技能樹。讓自己不只是會寫程式而已,更能培養解決問題的思考能力。
所以接下來會寫支小程式來取得 Python 套件的熱門程度,讓各位有個初步的認識,知道哪些是最多工程師在使用的套件。有了這樣的印象之後,往後在遇到新專案時就能節省一些尋找適合工具的時間。 | neilskilltree |
1,871,518 | 程式不會通靈 | 程式其實是重覆我們人類的行為,以節省我們的腦力和勞力。如果連自己都搞不懂要怎麼操作,程式(或機器)就更不可能知道。 程式不會通靈!👻 | 0 | 2024-05-31T01:45:37 | https://dev.to/neilskilltree/cheng-shi-bu-hui-tong-ling-n07 | python, beginners, programming, tutorial | 程式其實是重覆我們人類的行為,以節省我們的腦力和勞力。如果連自己都搞不懂要怎麼操作,程式(或機器)就更不可能知道。
程式不會通靈!👻
| neilskilltree |
1,860,992 | AWS Security Groups for Network Engineers | Hello and welcome, Network Engineers! In this blog post, I hope to explain the basic... | 0 | 2024-05-31T01:41:24 | https://dev.to/friday963/aws-security-groups-for-network-engineers-ja7 | aws, networking, cloud | ## Hello and welcome, Network Engineers!
In this blog post, I hope to explain the basic functionality of AWS's security groups, how they are applied in production, and draw some comparisons to networking features that we, as network engineers, already understand.
## What are Security Groups (SGs) in AWS?
SGs are like a firewall or an ACL, if you may, that is applied directly to a networking interface. In AWS, these network interfaces are called "ENIs," therefore I'll refer to them by their proper naming convention going forward. SGs, like most network filtering constructs, allow you to define traffic allowed ingress or egress (there is an implicit deny for anything not explicitly granted an allow). They are also stateful, which means we are free from having to explicitly allow ephemeral (outbound) ports when a client initiates a conversation on a port we've allowed on the ingress. In simpler terms, this means that if we've allowed a client to initiate a conversation on port 443, the server can respond on an ephemeral port; we do not need to configure that functionality.
## Where can we use SGs?
In AWS, there are many services that directly place an ENI in our VPC (Virtual Private Cloud). To name just a few services that you'll likely understand based on their naming convention:
- Amazon EC2 (Elastic Compute Cloud) Instances
- Amazon RDS (Relational Database Service) Instances
- Amazon Elastic Load Balancers (ELB)
- Amazon Elastic File System (EFS)
- Amazon EKS (Elastic Kubernetes Service)
There are many more, but these are just a few services that ultimately end up creating a network interface in a VPC that you, as a consumer, will directly interact with.
## How do SGs work?
SGs are evaluated in a top-down manner, looking at the source, destination, and port to determine if an allow or a deny should occur. SGs operate like most rules-based traffic filtering mechanisms; there is little left to explain beyond this.
The only caveat to mention related to how SGs work because it's unique to them is that SGs can act as a source or destination for other SGs to reference. This cool feature means that you can do more "intent"-based traffic filtering and stop filtering solely based on IP. Take, for example, a fleet of EC2 (compute) instances acting as web servers, all using the same SG with a rule that allows ingress on port 443 (let's call the security group "webServerSecurityGroup-123"). Let's also say there is a group of database servers that should only ever allow the web servers to make SQL queries against them (let's call the database security group "databaseSecurityGroup-456"). Instead of creating unique SGs that have explicit IPs defined, we can simply refer to both in our source and destination declarations.
In the ASCII table below, notice the webserver security group allows inbound traffic on port 443. On the outbound, the only conversation that the web server can INITIATE is to the host with the database security group applied to it and only on port 3306. On the database security group, we only allow traffic from one source on port 3306, and that is from any host with the web server security group applied to it.
```
+--------------------------------------------------------------------------------------------+
| webServerSecurityGroup-123 |
|--------------------------------------------------------------------------------------------|
| Inbound Rules |
|--------------------------------------------------------------------------------------------|
| Rule # | Type | Protocol | Port Range | Source |
|--------------------------------------------------------------------------------------------|
| 100 | HTTPS (443) | TCP | 443 | 0.0.0.0/0 |
|--------------------------------------------------------------------------------------------|
| Outbound Rules |
|--------------------------------------------------------------------------------------------|
| Rule # | Type | Protocol | Port Range | Destination |
|--------------------------------------------------------------------------------------------|
| 100 | MySQL/Aurora | TCP | 3306 | databaseSecurityGroup-456 |
+--------------------------------------------------------------------------------------------+
+--------------------------------------------------------------------------------------------+
| databaseSecurityGroup-456 |
|--------------------------------------------------------------------------------------------|
| Inbound Rules |
|--------------------------------------------------------------------------------------------|
| Rule # | Type | Protocol | Port Range | Source |
|--------------------------------------------------------------------------------------------|
| 100 | MySQL/Aurora | TCP | 3306 | webServerSecurityGroup-123 |
+--------------------------------------------------------------------------------------------+
```
## Drawing comparisons between networking ACL's and SGs
As Network Engineers, more likely than not, you've dealt with ACL's. I'm going to draw some comparisons and point out where they differ because they do differ, however, I hope that if you still aren't clear how SGs work this will drive home the point.
As I stated earlier, SGs are applied to network interfaces; similarly, traditional ACL's can be applied to a physical or virtual interface to protect/filter traffic. In both instances, they are evaluated in a top-down approach, looking at each entry in the list looking for a matching source/destination/port and the action to take. One major difference is the stateful behavior of a traditional ACL vs. an SG, which is stateful by design.
If you're curious about how to further explore their functionality, please check out my GitHub repo for a few examples. You can pull the code down and deploy these examples in your environment to get hands-on with them.
https://github.com/friday963/networklabs/tree/main/security_groups | friday963 |
1,871,516 | The Durability of DG Diesel Generators in Tough Environments | Introduction: Kangwo Diesel Generators are an incredible innovation in the field of power... | 0 | 2024-05-31T01:32:33 | https://dev.to/hanna_prestonle_101c638d5/the-durability-of-dg-diesel-generators-in-tough-environments-2690 | diesel, engine | Introduction:
Kangwo Diesel Generators are an incredible innovation in the field of power generation. They are used in various industries, including manufacturing, oil and gas plants, and mining. The Kangwo Diesel Generators have become popular because of their durability and ability to operate in harsh conditions. Their popularity has led to an increase in demand for them, and for good reason.
Advantages:
The Kangwo Diesel generator have actually numerous advantages over other generator kinds
The benefit like first the ability to supply power like continuous making them well suited for crisis back-up power
Also, they have been developed to be extremely efficient, which translates to reduce fuel usage and costs which can be functional
Also, they generally have actually an lifespan like extended and their upkeep requirements are minimal, making them cost-effective
Finally, the Kangwo Diesel are versatile that can be utilized for most applications being different
Innovation:
The Kangwo Diesel Generators’ innovation is based on their design
They are typically built to run in tough environments, this also happens to be achieved through the use of top-quality materials such as stainless steel
The generators can be equipped with also higher level technologies such as for example governors that are electronic which can make sure the capability production is stable and constant
Using these technologies has resulted in a decrease in emissions, like ideal for the surroundings
Security:
Safety can be an consideration like very important terms of use of Kangwo Diesel Generators
The generators are manufactured to lower the threat of accidents, this also continues to be accomplished through various measures including the installing of security switches that automatically down turn the generator in the eventuality of a crisis
Additionally, the generators are equipped with noise decrease systems, which can make them safe to work with in domestic areas or areas with noise limitations
Usage:
The Kangwo Diesel generator sets are easy to utilize, and you can now run all of them with minimal training
The generators have a individual manual giving you directions that are clear how to use them
An manual like individual contains essential safety information that users need to remember when running the generators
Before aided by the generator, users must ensure that it's installed correctly and therefore all security features are offered in destination
Service and Quality:
The standard of Kangwo Diesel Generators is unrivaled, and they're developed to keep for quite a while
But, like most machine, they could require maintenance from time to time to make sure that they run efficiently
It really is highly suggested that users have their generators serviced by qualified specialists regularly
The service will include tasks such as for example oil modifications, air conditioner filter replacement, and cleaning like general
Regular servicing helps to make sure that the generator runs optimally and prevents breakdowns
Application:
The Kangwo Diesel Generators are versatile and that may be applied in a variety of applications
These include trusted in industries such as production, mining, and coal and oil plants, when the need for reliable and energy like high like continuous
Furthermore, they may be used in residential areas as backup power during power outages
The generators is likely to be popular in also remote places where power is restricted
Conclusion:
In conclusion, Kangwo Diesel engine Generators are an excellent investment for individuals and businesses looking for reliable and durable backup power. They come with many advantages, including efficiency, durability, versatility, and ease of use. Safety is also a top consideration when it comes to Kangwo Diesel Generators, and they are designed to operate safely in various environments. Finally, with regular maintenance and servicing, the generators can last for many years, making them a cost-effective investment in the long run.
Source: https://www.kangwogroup.com/Diesel-generator-sets | hanna_prestonle_101c638d5 |
1,871,474 | TradingViewWebHook alarm directly connected to FMZ robot | Recently, more and more TradingView users have connected the TradingView chart signal to FMZ platform... | 0 | 2024-05-31T01:16:24 | https://dev.to/fmzquant/tradingviewwebhook-alarm-directly-connected-to-fmz-robot-58f7 | robot, tradingview, fmzquant, alarm | Recently, more and more TradingView users have connected the TradingView chart signal to FMZ platform (FMZ.COM) and let the robot strategy on FMZ execute the transaction according to the chart signal, which saves a lot of code writing and design work. Directly, indicators can be used for programmatic and automated trading, which reduces the barriers for many programmatic and quantitative trading development. There are several design schemes for realizing automatic trading on TradingViewWebHook.
The previous solution: https://www.fmz.com/digest-topic/5533.
The previous plan was to extend the API interface of FMZ Platform to send instructions to the robot. Today, let’s take a look at another solution. Let TradingView’s alarm WebHook request be sent directly to the FMZ platform robot, so that it can directly send instructions and order robot transactions.
## Robot strategy source code
The strategy is written in Python. After the robot is created and started using this strategy, the robot will create a thread, which will start a service to monitor the set port. Waiting for external requests and processing. When I tested it, it was tested by the host on the server, and the device where the host is located must be accessible from the outside. When the robot executes the transaction, it uses the market order interface. in addition, this strategy can also be modified to implement the limit order order logic. In order to be easy to understand and streamlined, the market order is used here, so the exchange must support the market order.
```
'''
Request format: http://x.x.x.x:xxxx/data?access_key=xxx&secret_key=yyy&type=buy&amount=0.001
Strategy robot parameters:
- Type: Encrypted string, AccessKey, SecretKey, you can use the low-privileged API KEY of the FMZ platform, or you can generate the KEY yourself.
- Type: string, contract ID, ContractType
- Type: numeric value, port number, Port
'''
import _thread
import json
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Executor(BaseHTTPRequestHandler):
def do_POST(self):
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
# check
if len(dictParam) == 4 and dictParam["access_key"] == AccessKey and dictParam["secret_key"] == SecretKey:
del dictParam["access_key"]
del dictParam["secret_key"]
Log("Request received", "parameter:", dictParam, "#FF0000")
'''
map[access_key:xxx amount:0.001 secret_key:yyy type:buy]
'''
isSpot = True
if exchange.GetName().find("Futures") != -1:
if ContractType != "":
exchange.SetContractType(ContractType)
isSpot = False
else :
raise "No futures contract set"
if isSpot and dictParam["type"] == "buy":
exchange.Buy(-1, float(dictParam["amount"]))
Log(exchange.GetAccount())
elif isSpot and dictParam["type"] == "sell":
exchange.Sell(-1, float(dictParam["amount"]))
Log(exchange.GetAccount())
elif not isSpot and dictParam["type"] == "long":
exchange.SetDirection("buy")
exchange.Buy(-1, float(dictParam["amount"]))
Log("Holding Position:", exchange.GetPosition())
elif not isSpot and dictParam["type"] == "short":
exchange.SetDirection("sell")
exchange.Sell(-1, float(dictParam["amount"]))
Log("Holding Position:", exchange.GetPosition())
elif not isSpot and dictParam["type"] == "cover_long":
exchange.SetDirection("closebuy")
exchange.Sell(-1, float(dictParam["amount"]))
Log("Holding Position:", exchange.GetPosition())
elif not isSpot and dictParam["type"] == "cover_short":
exchange.SetDirection("closesell")
exchange.Buy(-1, float(dictParam["amount"]))
Log("Holding Position:", exchange.GetPosition())
# Write data response
self.wfile.write(json.dumps({"state": "ok"}).encode())
except Exception as e:
Log("Provider do_POST error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Executor)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except Exception as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
# Start a thread
try:
_thread.start_new_thread(createServer, (("0.0.0.0", Port), )) # Test on VPS server
except Exception as e:
Log("Error message:", e)
raise Exception("stop")
Log("Account asset information:", _C(exchange.GetAccount))
while True:
LogStatus(_D())
Sleep(2000)
```
## Strategy parameters:
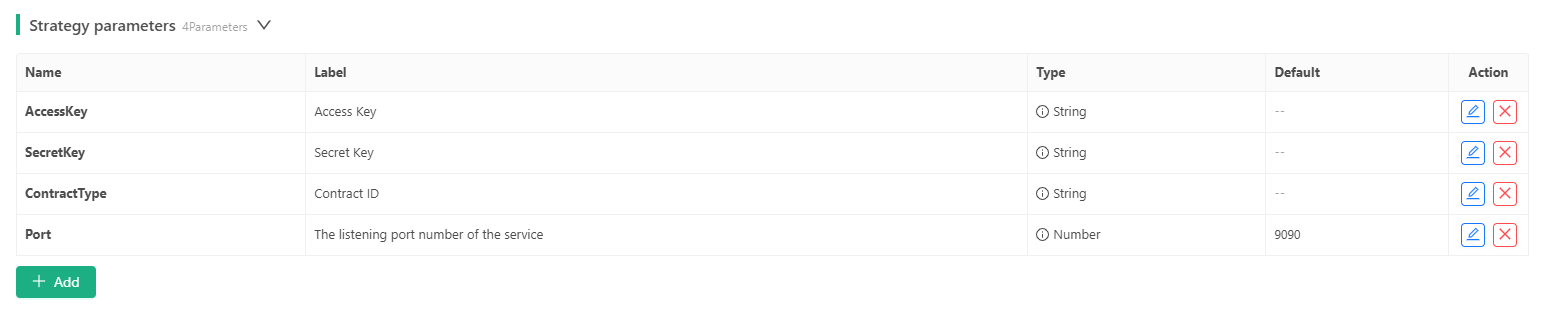
**TradingView's WebHook alarm request**
The alarm request setting is:
```
http://xxx.xxx.xxx.xxx:80/data?access_key=e3809e173e23004821a9bfb6a468e308&secret_key=45a811e0009d91ad21154e79d4074bc6&type=sell&amount=0.1
```
Since TradingView sends POST requests, the monitoring service must monitor POST requests, and TradingView only allows port 80 for the http protocol.
- xxx.xxx.xxx.xxx is the device IP address of the host where the robot is located. Fill in the specific IP address of your own device, you need to be aware that it must be accessible from the external network.
- The access_key and secret_key can be generated by themselves, as long as the access_key and secret_key in the WebHook alarm request are the same as those configured on the robot parameters.
- Type, trading direction, buying or selling, opening or closing, note that spots and futures are distinguished. If it is a futures, note that the futures contract code must be set on the robot parameters, and the configured exchange object needs to be a futures exchange.
- amount, the number of transactions.
## Running Test
Use wexApp to simulate the real market test.

## END
Full strategy address: https://www.fmz.com/strategy/221850
The access_key and secret_key in the scheme are only for identification, and there is no security for using http. This solution is just an idea and an introduction. In practical applications, security considerations should be added and https communication should be used.
From: https://blog.mathquant.com/2023/03/10/tradingviewwebhook-alarm-directly-connected-to-fmz-robot.html | fmzquant |
1,871,473 | Sealing the Deal: The Role of China's Door Seal Suppliers in Fire Protection | Sealing the Deal: China's Door Seal Suppliers Keep You Safe from Fire! You can never feel too... | 0 | 2024-05-31T01:11:50 | https://dev.to/hanna_prestonle_101c638d5/sealing-the-deal-the-role-of-chinas-door-seal-suppliers-in-fire-protection-23pp | fire, protection | Sealing the Deal: China's Door Seal Suppliers Keep You Safe from Fire!
You can never feel too careful when it seems to fire protection. That is why getting the hinged ideal door seal for their house or company is so essential. In China, there are numerous door seal vendors who offer revolutionary, safer, and top-notch items can assist shield you and your liked people in case for the fire. We will have a closer look throughout the advantages of using door seals from China, along with explore a number associated with the several kinds of goods open to help you create the top option to your account.
Advantages of Using China's Door Seals:
One of the many biggest advantages of using Door Frame Seal from China is the incorporated high-quality with their products. Chinese door seal suppliers just take pride in creating durable seals could withstand extreme temperatures and lots of different circumstances. Which means that you might trust which their services and products will go longer and create better safeguards than more, economical choices. Furthermore, because many Chinese providers work closely and international safety regulations, you can feel confident realizing that their door seals are up to date and meet up with the safety greatest guidelines.
bf3eff216904641b88ce3093facfda8218ffd76dc0f9dea663ab3aaabaaa7d08.jpg
Innovations in Door Seals:
An additional advantage of using door seals from China is the present innovation in their products. Chinese providers are known with regards to their ability to appear and new and creative solutions to old conditions. This implies you'll find more door seals effective, simpler to use, and more affordable than previously before. A number of the latest innovations in door seals from China include fire-retardant materials, newer securing mechanisms and even designs that help alleviate difficulties with drafts and atmosphere leaks.
Safety and Use of Door Seals:
In relation to door seals, safety is key. In China, Door Frame Seal suppliers take safety and work hard to ensure their goods are because safer as possible. This means that they don't pose any more safety issues that you can trust that your door seals will maybe not just succeed in protecting your property or business from fires, but. Additionally, using door seals is extremely simple – simply install them across the sides of these doors and windows, ensuring that we've got no gaps or holes for air to flee. And simple several easy steps you could help protect their household, belongings, and business through the devastating aftereffects of fire.
How to Use Door Seals:
Using door seals from China is extremely effortless, even for people who may possibly not have any experience and DIY projects. First, gauge the width and length of your doors and windows to determine how much'll seal require. Then you're able to slice the seal to size using a couple of scissors or the razor blade. Next, apply the seal round the edges of one's doors and windows, making sure to press securely therefore that it adheres properly. Finally, test the seal by shutting your doors and windows to make sure you will find not any gaps or holes for air to escape. Till you have got a taut fit, you will find any leakages, simply add more seal.
Service and Quality:
Among the most essential factors to search for once shops for door seals from China is both quality and service. You need to make you're getting high-quality merchandise that will succeed in protecting their residence or business from fire, nonetheless you would also prefer to make you are certain to get exemplary consumer through the supplier. Chinese door seal suppliers are understood his or her dedication to quality and service, and many offer and guarantees in the ongoing services and products to promise your satisfaction. Furthermore, a lot of companies provide free delivery and also installation able to ensure their door seals are correctly installed and functioning because they ought to feel.
Applications of Door Seals:
Finally, it is imperative to understand the various applications of door seals with regards to fire protection. front door seal let you protect homes, companies, and facilities being even commercial the devastating impact of fires. By making a barrier that prevents air, smoke, and fire from distributing from a single area to a different, door seals will help have fires and limitation harm. Additionally, door seals enable you to adhere to building codes and laws, making sure their property is legal and safer.
Source: https://www.firestopchina.com/Door-frame-seal | hanna_prestonle_101c638d5 |
1,866,809 | Meet MajorDom: a smart home of the future that is really smart | MajorDom - a brand new open-source smart home ecosystem, built for privacy, autonomy, and wide device... | 23,137 | 2024-05-31T01:05:00 | https://dev.to/markparker5/meet-majordom-a-smart-home-of-the-future-that-is-really-smart-22gk | smarthome, voiceassistant, opensource, ai | MajorDom - a brand new open-source smart home ecosystem, built for privacy, autonomy, and wide device support. The platform combines intelligent automations with easy plug-n-play design and a really smart voice assistant.
---
In the world of smart homes, you often have to choose between usability and functionality. Thinking about what an ideal smart home could be, we came up with the idea of MajorDom — a system that seeks to change this balance and simplify life without sacrifice. In this post, we'll share our vision and some core principles of the new ecosystem, including privacy, autonomy, and broad device support.

## Gadgets
Today there are many different gadgets for the home: lamps, curtains, heaters, vacuum cleaners, security, and microclimate sensors. They are designed to make life easier, but not everything is so simple.
Previously, each device had its own control protocol, its own standards, its own security methods, and each of them needed a separate application. The more devices there are in the house, the more time you need to devote to managing them, which turns into a new routine. It's like juggling too many balls.

## Current solutions
Smart home (or home automation) systems were supposed to solve this problem, but they are still far from ideal. There are two types of such systems: proprietary from digital corporations and popular open source. Unfortunately, both of them have disadvantages. I propose to draw up a graph in which the ease of use of complex to simple ones will be on the `x` axis, and the smartness and functionality of the system will be on the `y` axis.
It turns out that all proprietary systems are located somewhere in the center-bottom. They provide some functionality that the average person can handle after spending some time learning. Most often, these systems are closed and support only their limited list of devices in their special application. Their functionality boils down to replacing the physical switch with a button on the phone or simple voice commands. Sometimes there are elementary automations, or rather scripts that need to be written manually.
At the same time, they are too dependent on cloud solutions. A server failure, changes in geopolitics, new regulations, or a simple lack of Internet means a smart home shutdown.
But what’s worse is that the most popular systems belong to advertising or marketplace giants who make money by selling users’ personal data. This is the basis of their business model, which is why they cannot change, so trust and privacy are out of the question.

Those who want more features or don't want surveillance have to switch to open solutions and pay for it with the complexity of configuration and installation. This is the area above and to the left of center, but often it's worth it. Open systems offer more freedom, integration with almost any device and protocol (thanks to plugins), unlimited customization and full control. This is a task for techies who want to spend their evenings studying forums and developing their own configurations. Likewise, some people like to spend hours in the garage going through all the parts of the car. I'm not saying it's bad, everybody deserves a hobby, but most people want a car just to drive it. Of course, you can hire a professional to handle all the devices for a fortune. But what if you don't want to hire a professional or become one yourself?
We want to make a system that will occupy the upper right corner: it will work right out of the box, support a wide range of devices, securely store user data, and at the same time be smarter and more functional than the rest.
## Smart home ecosystem
Let's talk about how smart home ecosystems work and how they differ from home automation systems. It all starts with devices that directly control the house: lamps, relays, modules with a motor. This is the first "physical" layer. The second layer is for interface, mobile apps, voice assistants, etc.; let's call it "application" layer. Now, let's connect them via wifi or bluetooth.
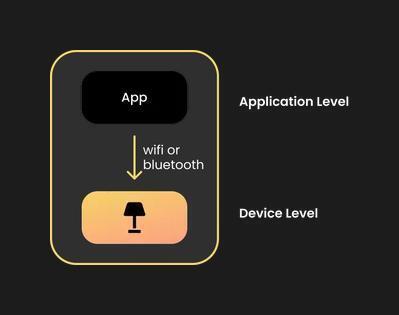
But let's imagine that we have several devices, and each one has an app. Doesn't look very comfortable, does it?
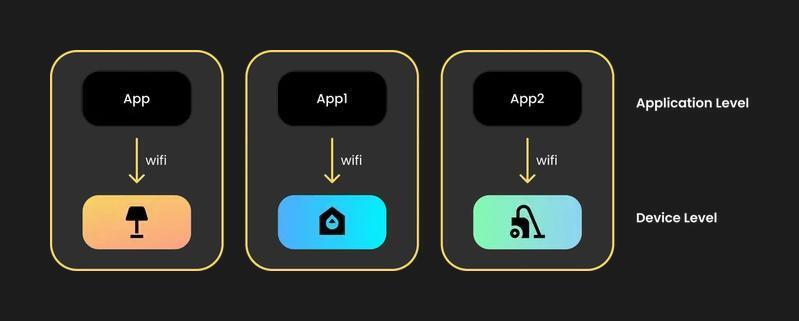
Now we will transfer the devices to more energy-efficient radio protocols. But how now to connect them to your smartphone? Let's add an intermediary in the form of a hub, which has a radio module on one side and the same wifi on the other. As a bonus, we will connect all devices from the same manufacturer to it. Now each app can control a few devices, but only produced by the same brand. This is what closed “ecosystems” look like. Each uses its own protocols and standards, so they are not compatible with each other.
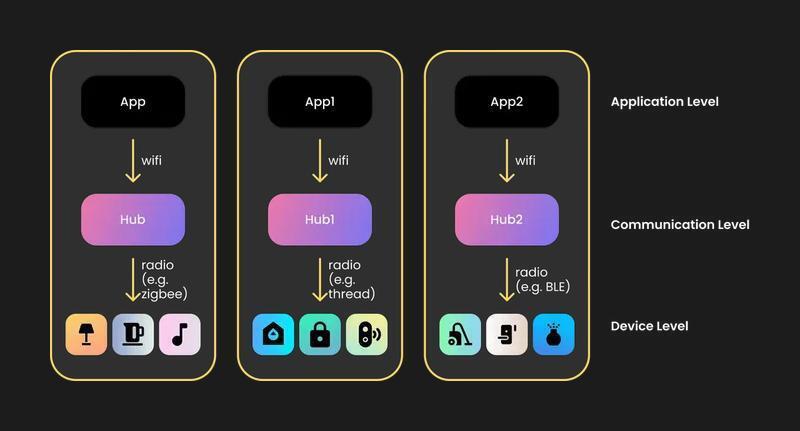
But what’s worse is that not all applications can communicate with the hub directly within a local network (LAN) and use the server even when you are at home. This is the case when turning off the Internet means a complete blackout, while turning on means remote control of the home from the cloud (do you trust the cloud of a company that makes money from selling your personal data but doesn't care about keeping it safe?)
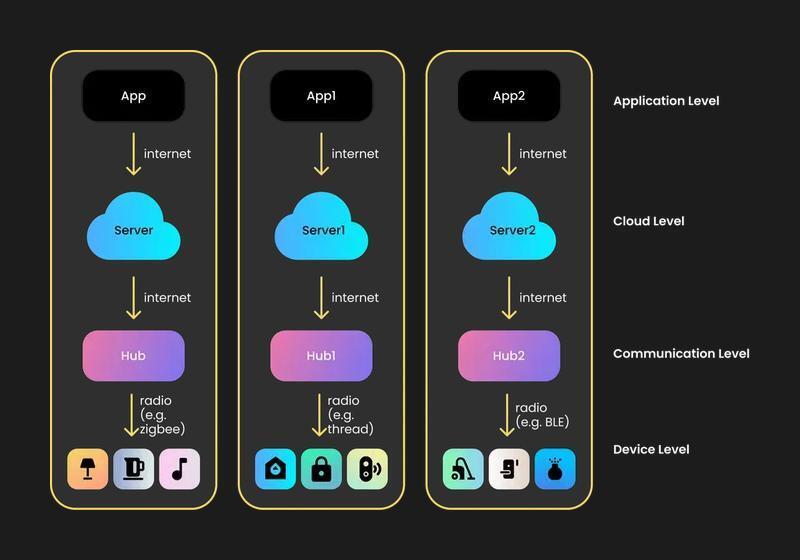
To fix this, we’ll replace the proprietary hub with a raspberry pi with some open source home automation system, and also add plugins for device integration. This makes it possible to combine all devices into one system, for example to program global automations or advanced scenarios. It's better, but one little thing called the interface is missing.
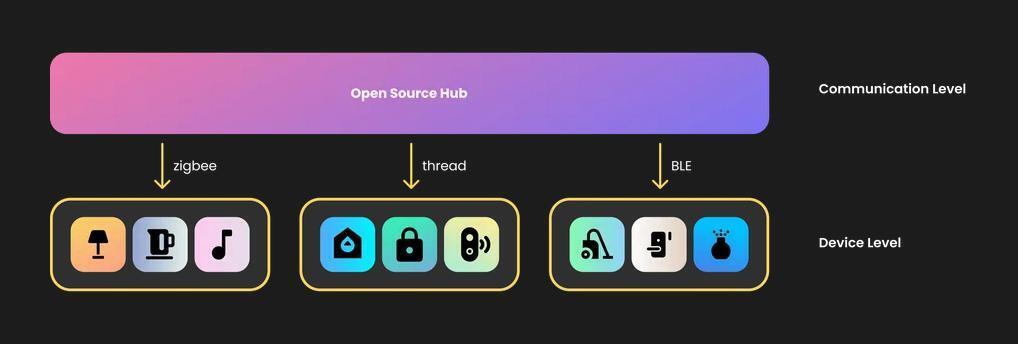
Fortunately, some open source solutions come with a web frontend or even a mobile application (not always user-friendly). By adding a couple more plugins, we can forward some devices (or all, if we are very lucky) of the devices to an application of one of the ecosystems. In this case, the hub acts as an intermediary or adapter for third-party devices. But now we are dependent on this ecosystem and receive all its disadvantages, which were discussed at the beginning of the article. Alternatively, we can connect another plugin with for a custom or 3rd-party cloud solution, but this becomes either too complicated or still not secure enough.
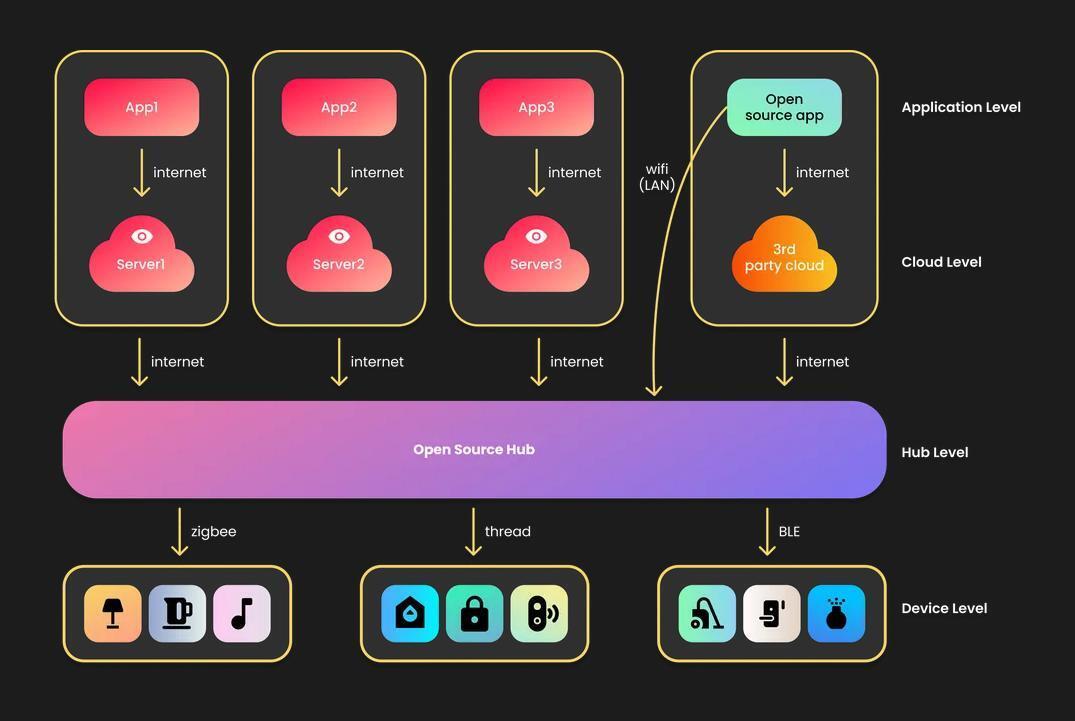
> I would like to note that it is not always possible to completely replace a proprietary hub with a custom one. Often you will need to have both hubs (proprietary and custom) for the system to work and support required devices and applications. This could end up becoming a tangle of technology. In short, it's too complicated, and it's not worth it.
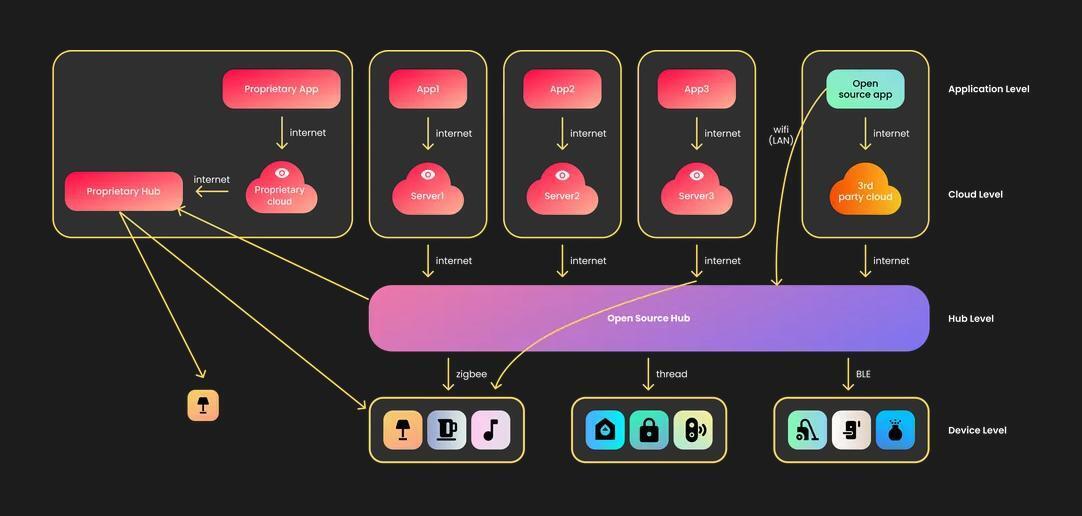
By the way, this example reminds me of something:

So we have 4 layers: devices, hub (automation, software control), servers, interface (apps, voice assistants, etc.). The ecosystem is all 4 layers and their connection, not just one. To make everything work perfectly, we don't just do one of the layers, for example an automation system at the hub level. We do all three top levels: app, voice assistant, cloud, and hub with maximum support for third-party devices, thus maximizing compatibility and integration of the whole system out of the box: autonomous, private, independent and secure. This is MajorDom.
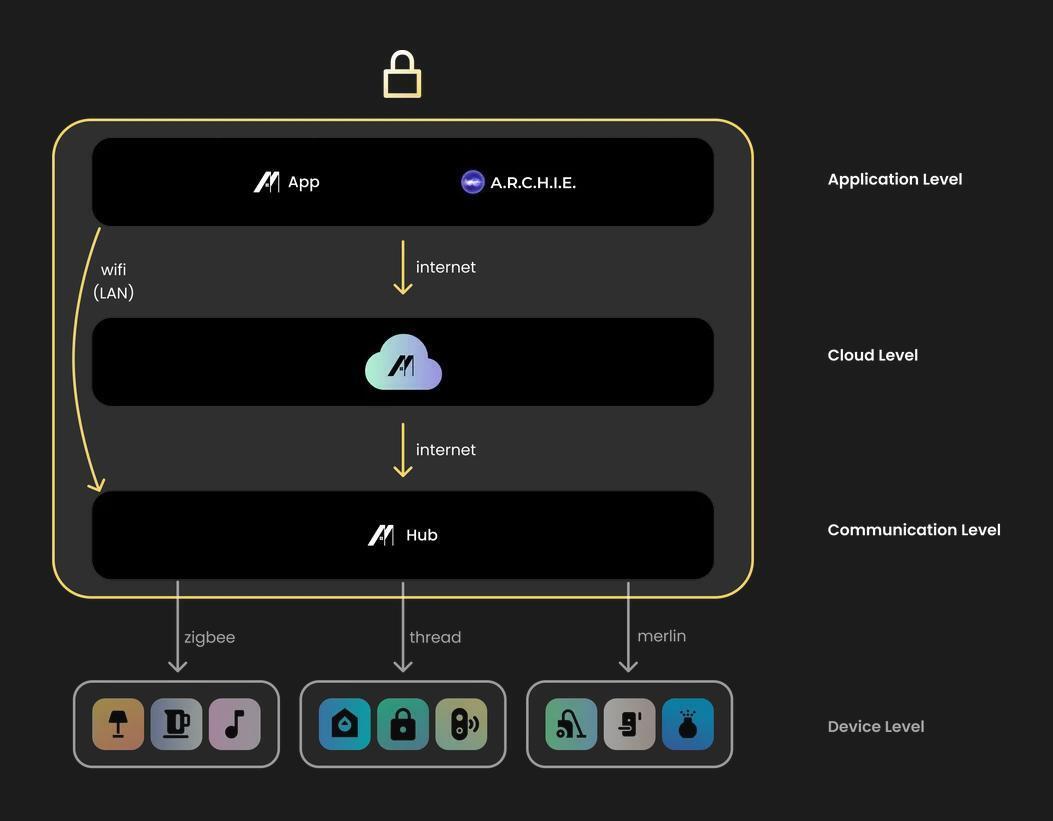
## Why our ecosystem is smarter: our philosophy
We lay the following principles as the foundation of our work:
- Complete privacy of personal data — home is not a place for prying eyes. Privacy is a basic right of every user.
- Autonomy — maximum independence from the outside world, disconnected Internet should not be a problem
- Ease of setup and use — technology should serve people, and not vice versa. It's fine to dive deep into hobbies, but many just need something that works right out of the box.
- Maximum support for different devices, protocols, and integrations — in addition to the previous point
- No artificial restrictions — avoid being Apple and give the opportunity for deep configuration and customization to those who require it.
We make a completely private, fully autonomous, truly SMART home that is different to the options promoted by big tech. We are convinced that privacy is not just something abstract, not even a promise. Privacy — is your core right. And we believe that technology must work for you, not the other way around.
No sacrifices, no exceptions.
So, we are going to reinvent the smart home. In our vision, a true smart home has an invisible army of devices, that are working autonomously in the background, improving your everyday life and covering your back. It's like having a digital majordomo.
A true smart home must be independent from the outside world. No failures because the internet or a random server is down. It's a fully autonomous ecosystem that doesn't require anything else, either: not internet, not cloud services, and not even a human.
At the same time, a system must be simple to use. No long installations or configurations. No periodical change of settings. No code writing. Just plug and play. **Technology must work for you, remember?**
## How: Architecture design
But, how do we do it? First things first, the system needs a name. We called the system MajorDom. And it perfectly fits the description.
### Privacy Implementation
But how we deal with the most important thing — your data?
While all other systems are black boxes, we believe that MajorDom must be open source, so there is no behind-the-scenes manipulation and anyone can open and read it, highlight issues, suggest changes, or even contribute to it.
While the source code is publicly available, your data is protected like never before. Let’s talk about some technical solutions MajorDom utilizes.
To make the system private and autonomous, most of the data is stored locally on the devices and generally on the Hub. This guarantees privacy, and since all data is stored locally, automations and all the other features work perfectly even in the absence of the Internet. This is unlike other systems, which always rely on the internet connection because all data is sent and stored somewhere on the server. We have no 3rd-party services, no extra transfers, no data collectors.
But in some cases data must be transferred though the internet, for example with remote control when you're on the go. In this case, data is securely end-to-end encrypted and keys are stored only on user’s physical devices. That means you can actually access all of your accessories remotely, only you, and absolutely no one else, including admins and developers.
### Supported Devices: Matter, Merlin.
Of course, before setting up automation, you need devices in the house. The Zigbee Alliance, renamed the Connectivity Standards Alliance or CSA, is a coalition of various smart home companies that have decided to create a universal communication protocol for all home automation devices. They called this protocol Matter. And MajorDom is compatible with it. This means you can add any Matter compatible device to your MajorDom system. And that is not all.
Matter natively only supports the most common underlying devices, which is why we created the Merlin communication protocol. Thanks to a more flexible architecture, it not only significantly expands the list of supported devices, but also makes it endless.

At the same time, we understand that today only a small portion of devices already released support one of these protocols, so we are also going to add integrations of devices using zigbee, z-wave, wifi and BLE, thus becoming the most universal ecosystem.

### Interface
Now, how are we going to communicate with this? For this task, we designed a beautiful application, with customizable themes. It's a real pleasure to use. And it's available for all major platforms: android, including smartphones, tablets, and watches, and iOS family with iPhones, iPads, Macs, Watches, tvOS, and even future visionOS. The app also includes widgets that you can add to your desktop, home, or lock screen with any supported device, so you can access your home even without launching the app. We have ensured that full control of your home is always at your fingertips.
But a truly smart home must work autonomously most of the time, in the background, so you don't even notice it. Now, how are we going to automate this? Write scripts, like every other system, right? We’re going to use scripts? No. Nobody wants to write scripts. And we know this. Instead of this:
For automations, we added the second amazing tab to the app, which helps you set up any scenario with ease.
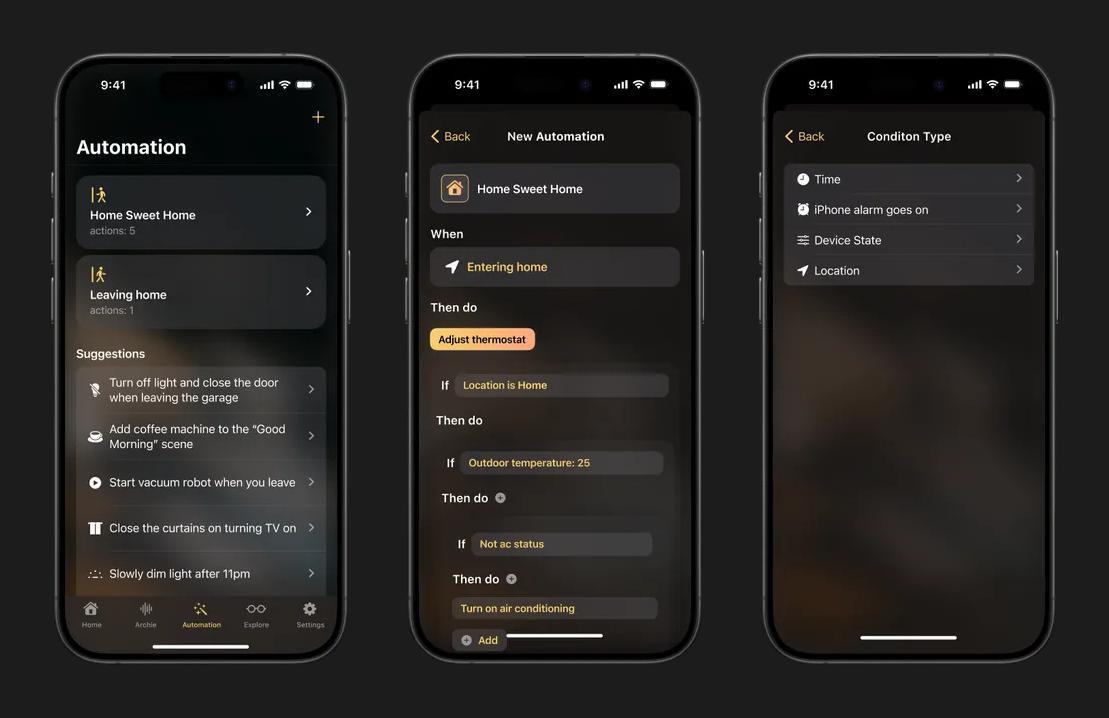
To simplify the process even more, we invented a smart suggestions technology that predicts what you want to automate. And sometimes it's so smart, so it even doesn't require the user’s help. For instance, you can just add all accessories and start using them without adding any automation or scenario. After a short time, this technology will suggest scenes and automations based on your habits. You can even allow it to add scenes and automations without confirmation in the background. It's that easy. And it's phenomenal. It works like magic. We called this technology Smart Automation.
### Archie — a Smart Voice Assistant
Automations are good for everyday routine. But sometimes you need a more personal touch that's more than just commands and controls.
Archie, the Autonomous Responsive Cognitive Home Interaction Engine. The voice assistant that outsmarts all others and really understands you. Archie is able to understand what you need to an extremely high level of precision and makes communication effortless by offering a live language experience that feels spontaneous and conversational. Top of the line.

Like a truly professional majordomo, Archie speaks many languages. He can simultaneously listen to up to three preselected languages.
But Archie isn't just for controlling your home; it's for every facet of your daily life, from managing tasks to providing general information.
Archie inherits all the core values of MajorDom: private, autonomous, easy to use, and truly smart. Archie can work completely offline, but the Internet expands its possibilities to an unlimited range. Powered by the largest language models, Archie's skills are closer to real artificial intelligence than ever before in human history.

### Work out of the box: we make our own devices
“People who are serious about software should make their own hardware” — this quote is especially relevant for a smart home. This is the only way to ensure seamless integration of multiple protocols out of the box. The same goes for the assistant: not every platform can handle offline speech recognition, processing, and synthesis. In addition, you can completely trust it only when you know that there are no third-party software on the device with access to the microphone. That's why we're developing two of our own: MajorDom Hub for device management, automation; a portal to the ecosystem — like the hands of the home. And MajorDom Audio — a smart speaker for Archie; the ears and voice of the home.

## One last thing… for Contributors.
We want to make it as easy as possible for people to integrate their ideas — whether hardware or software. To this end, we have created two major tools to allow everybody to become a contributor.
First, in the development of MajorDom, we've established the 'Idea Forge'. This platform transforms user proposals into practical features. Anyone can submit ideas through the idea suggestion form. You don't need to be a coder; you just need a spark of innovation. These suggestions then appear on a community voting board, allowing everyone to influence the development process. Democracy in action. The most popular ideas are considered for implementation by the MajorDom Team. This isn't just about users; it's about turning users into makers.
But it's not just a waiting game. If you're feeling adventurous, or you just can't wait, you can roll up your sleeves and code any feature yourself. You contribute, you create, and who knows, you might just end up part of the MajorDom team.
Secondly, we are simplifying the job for all developers. We build modular hub firmware with plugin support and convenient libraries with detailed documentation.
## Conclusion
At the moment, the project is still under active development, but most of what is mentioned has already been implemented, including the core of the system, integration of some protocols, remote control, automations, the offline part of Archie and the mobile app. We will publish further news here, but I also recommend subscribing to the relevant project pages on social networks. Sign up for early access at [majordom.io](https://majordom.io)
## Join the project
The project is quite complex and large-scale, and a high-quality result requires many hours of work by professional engineers, programmers and designers. In the modern capitalist world, only commercial development can guarantee a stable result.
### Pre-orders, Kickstarter, Donations
In the future, the project will be published on Kickstarter — a crowdfunding platform on which it will be possible to place the earliest pre-orders of devices, but you already can financially support the project on [patreon](https://patreon.com/MarkParker5) or [buymeacoffee](https://buymeacoffee.com/markparker5).
### Become part of the team
Our team already has designers, software engineers for the frontend, backend, mobile apps, the Hub, and the voice assistant. At the same time, we are looking for industrial designers, embedded hardware engineers, as well as programmers who understand the low-level details of popular protocols in the smart home field. If you are doing something else, but want to join the project, write your suggestions, everyone is welcome.
### Investors
We are also considering receiving investment from a $50k pre-seed round for a share of the company. Speaking of numbers, the current smart home market is valued at US$100 billion, with a projected growth of up to US$600 billion in 2033. Looks like a great investment opportunity.
### Contacts
Telegram: [t.me/MarkParker5](https://t.me/MarkParker5)
Email: [mark@parker-programs.com](mailto:mark@parker-programs.com) | markparker5 |
1,871,472 | Why AI Can Never Replace a Developer? or Can it? | Artificial Intelligence (AI) has made significant strides in recent years, revolutionizing various... | 0 | 2024-05-31T01:04:42 | https://dev.to/simplyrave/why-ai-can-never-replace-a-developer-or-can-it-4afc | ai, doomsday, aigeddon |
Artificial Intelligence (AI) has made significant strides in recent years, revolutionizing various industries with its ability to automate tasks, analyze vast datasets, and even create content. However, despite these advancements, AI can never fully replace a developer. While AI tools can assist and augment the capabilities of developers, the intricate and creative nature of software development ensures that human developers remain indispensable. Here’s why:
**Creativity and Innovation**
Software development is inherently a creative process. Developers don't just write code; they solve problems, design systems, and innovate new solutions. AI, while powerful, operates within the confines of its programming and training data. It lacks the ability to think outside the box or create something truly novel. Human developers, on the other hand, can conceptualize and build unique applications, invent new algorithms, and approach problems from diverse perspectives that AI simply cannot emulate.
**Understanding Context**
Developers bring a deep understanding of context to their work, an aspect that AI struggles with. Whether it's grasping the nuances of a business problem, understanding user needs, or considering the broader implications of a software solution, human developers excel in these areas. They can make informed decisions based on a wide array of contextual information, from market trends to user feedback. AI, in contrast, often misses the subtleties and complexities of real-world applications, leading to solutions that may be technically correct but practically inadequate.
**Ethical Considerations**
Ethics play a crucial role in software development, particularly as technology increasingly impacts society. Developers must navigate complex ethical landscapes, considering issues such as privacy, security, and fairness. While AI can be programmed to follow ethical guidelines, it lacks the intrinsic moral reasoning that humans possess. Developers must often make judgment calls that balance technical feasibility with ethical responsibility, a domain where human intuition and empathy are irreplaceable.
**Adaptability and Learning**
The technology landscape is ever-changing, requiring developers to continually learn and adapt. While AI can be updated and retrained, it relies on human developers to do so. Moreover, developers possess the ability to quickly pivot and learn new technologies or methodologies as needed. This flexibility is crucial in an industry where change is the only constant. Human developers can integrate new knowledge with their existing expertise in ways that AI, which operates on pre-existing data and models, cannot match.
**Collaboration and Communication**
Software development is rarely a solitary endeavor. It often involves collaboration among team members, stakeholders, and end-users. Effective communication, empathy, and teamwork are essential skills that human developers bring to the table. They can understand and articulate requirements, negotiate trade-offs, and collaborate on solutions in a way that fosters innovation and ensures project success. AI lacks the interpersonal skills necessary for such collaboration, making it an inadequate replacement in team-based environments.
**Debugging and Problem-Solving**
When it comes to debugging and problem-solving, human intuition and experience are invaluable. Developers can diagnose and fix issues that fall outside the scope of what an AI might recognize as a problem. They can draw on their experience to identify patterns, hypothesize solutions, and iterate quickly. While AI can assist by suggesting potential fixes or identifying anomalies, it cannot replace the critical thinking and diagnostic skills that experienced developers bring to the table.
**Conclusion**
AI is a powerful tool that can enhance the capabilities of developers, making them more efficient and productive. However, the unique combination of creativity, context understanding, ethical reasoning, adaptability, collaboration, and problem-solving skills that human developers possess ensures that they remain irreplaceable. As AI continues to evolve, it will undoubtedly change the landscape of software development, but it will do so as an assistant to, rather than a replacement for, human developers. | simplyrave |
1,871,471 | Build Serverless Application In AWS | Introduction The LinkedIn Learning course "Building a Serverless Application in AWS" by Lucy Wang is... | 0 | 2024-05-31T00:47:21 | https://dev.to/anson_ly/build-serverless-application-in-aws-4b2i | aws, beginners, serverless, linkedin | **Introduction**
The LinkedIn Learning course "Building a Serverless Application in AWS" by Lucy Wang is an in-depth, hands-on guide designed to equip learners with the skills and knowledge needed to develop and deploy serverless applications using AWS services. The course covers the fundamental concepts of serverless architecture, the benefits of using serverless computing, and detailed instructions on how to utilize various AWS services to create a fully functional serverless application.
**Objectives**
One of the primary objectives of the course is to provide a thorough understanding of serverless architecture principles. It explains the significant differences between serverless and traditional server-based applications, highlighting the advantages of serverless computing such as reduced operational overhead, automatic scaling, and cost efficiency. Real-world use cases are presented to illustrate scenarios where serverless architecture can be particularly beneficial.
**Overview**
The project also covers API Gateway, which is used to create RESTful APIs that interface with Lambda functions. Learners are shown how to set up API Gateway, define resources and methods, and secure APIs using authentication and authorization mechanisms. This section is crucial for understanding how to expose serverless applications to the web and handle client requests securely.
Integration with AWS DynamoDB is another essential part of the course. DynamoDB is a key-value and document database that is fully managed and serverless. The course teaches how to design and set up DynamoDB tables, perform CRUD operations, and integrate these operations with Lambda functions. It ensures that learners understand the importance of data modeling and query optimization in DynamoDB to achieve efficient data retrieval and storage.
AWS S3, a service for object storage, is also covered extensively. The course details how to set up S3 buckets, manage data uploads and downloads, and configure event triggers to initiate Lambda functions. Security best practices for S3 buckets are discussed to ensure data protection and compliance with industry standards.
The practical project component of the course involves building a serverless application using the aforementioned AWS services. The application architecture includes API Gateway for API management, AWS Lambda for business logic, DynamoDB for data persistence, and S3 for storage of static assets. This hands-on project enables learners to apply theoretical knowledge in a real-world scenario, enhancing their understanding and skills.
**Challenges**
Throughout the project, several challenges were encountered and addressed. For instance, initial latency issues with Lambda functions were resolved by optimizing the code and adjusting memory allocation. Ensuring API security was achieved through implementing IAM roles and API Gateway authorization mechanisms. Data consistency in DynamoDB was managed by properly configuring read/write capacity units and handling errors gracefully within Lambda functions.
**Conclusion**
This project offered by Lucy Wang provided a comprehensive and practical guide to building serverless applications using AWS. It emphasized the importance of hands-on learning, allowing participants to understand and implement key AWS services effectively. By the end of the course, learners were able to deploy robust, scalable, and cost-efficient serverless applications, adhering to best practices in security and performance optimization. | anson_ly |
1,871,470 | Belair's Best: Tow Truck Near Me Solutions | In moments of vehicular distress, a reliable tow truck service becomes an indispensable ally. Whether... | 0 | 2024-05-31T00:47:14 | https://dev.to/universaltowingbaltimore/belairs-best-tow-truck-near-me-solutions-3lgp | business, towing, towingservices | In moments of vehicular distress, a reliable tow truck service becomes an indispensable ally. Whether stranded on a deserted highway or caught in a bustling urban sprawl, the urgency of finding a "tow truck near me" resonates deeply with motorists. Belair's Best emerges as a beacon of reassurance, offering swift and efficient solutions to drivers in need.
With a fleet of well-equipped vehicles and a team of skilled professionals, they embody reliability at every turn. Beyond mere transportation, they provide peace of mind, swiftly responding to calls for assistance regardless of the hour or the circumstance.
In this blog series, we delve into the myriad facets of Belair's Best, exploring their unparalleled commitment to customer satisfaction, advanced technology integration, and the stories of gratitude from those they've rescued from roadside predicaments. Join us as we uncover what makes Belair's Best the epitome of tow truck excellence.
**Rapid Response Team**
At Belair's Best, swift assistance to motorists in distress is a promise and a core commitment embedded in their operational ethos. With a meticulously trained rapid response team, they ensure that every call for help is answered. Every team member is adept at assessing situations quickly, strategizing the best course of action, and deploying resources with unparalleled efficiency.
Whether it's a stranded vehicle on a deserted highway or a fender-bender in the city's heart, Belair's Best prides itself on its ability to reach the scene promptly, offering reassurance and relief to drivers in need. Their rapid response isn't just about speed; it's about delivering peace of mind in moments of uncertainty, demonstrating their unwavering dedication to customer satisfaction.
**Advanced Fleet Technology**
Advanced Fleet Technology is pivotal in revolutionizing the towing industry, enhancing efficiency, and ensuring reliable service. At its core, it empowers towing companies like Belair's Best to meet the diverse needs of motorists with precision and speed.
GPS Optimization: State-of-the-art GPS systems optimize route planning, enabling tow trucks to navigate efficiently to the scene of an incident.
Specialized Towing Mechanisms: Tailored towing mechanisms for different vehicle types ensure safe and secure transportation, regardless of size or condition.
Vehicle Maintenance Technology: Advanced technology prioritizes vehicle maintenance and diagnostics, keeping each truck in optimal condition, minimizing downtime, and ensuring reliability.
Remote Monitoring: Remote monitoring systems provide real-time updates on fleet performance, allowing for proactive maintenance and swift response to any issues that may arise.
Enhanced Communication Tools: Advanced communication tools facilitate seamless coordination between dispatchers and tow truck operators, ensuring smooth operations and timely assistance.
Integrating advanced fleet technology elevates towing services to new heights, enabling companies like Belair's Best to deliver efficient, effective, and dependable solutions to needy motorists.
**24/7 Availability**
Belair's Best understands that vehicular emergencies don't adhere to a strict schedule. That's why they stand ready to assist 24 hours a day, seven days a week, regardless of the weather conditions or time of day. Whether it's the dead of night or the peak of rush hour, drivers can rely on Belair's Best to answer their call for help promptly and professionally.
This unwavering commitment to round-the-clock availability ensures that no driver is left stranded for long, fostering a sense of trust and reliability within the community they serve.
**Customer-Centric Approach**
At Universal Towing Baltimore, our customer-centric approach lies at the heart of everything we do. Here's how we prioritize your needs:
Personalized Service: We understand that every driver's situation is unique. That's why we tailor our assistance to address your specific needs and preferences, ensuring a personalized experience from start to finish.
Clear Communication: From the moment you contact us, we provide clear and concise communication, keeping you informed every step of the way. Whether it's updates on arrival times or alternative solutions, we keep you in the loop throughout the towing process.
Compassionate Support: We know that facing a roadside emergency can be stressful. That's why our team is here not just to tow your vehicle but to lend a compassionate ear and offer support during this challenging time.
Flexible Solutions: Whether you require towing, roadside assistance, or other services, we offer flexible solutions to accommodate your needs. Our goal is to make the towing experience as seamless and stress-free as possible.
Customer Satisfaction Guarantee: Your satisfaction is our top priority. We go above and beyond to ensure you are delighted with our services, striving to exceed your expectations with every interaction.
When you choose Universal Towing Baltimore, you're not just getting a towing company – you're getting a dedicated partner committed to providing the highest customer care. Contact us today for reliable towing services with a personalized touch.
**Local Expertise**
One key to Belair's Best's success is its intimate knowledge of the areas it serves. With years of experience navigating the local roads and highways, its team possesses a deep understanding of traffic patterns, alternate routes, and potential obstacles that may arise during towing operations.
This local expertise allows them to respond swiftly to calls for assistance, minimizing delays and maximizing efficiency. Whether it's a shortcut through a residential neighborhood or a detour around a construction site, Belair's Best knows the ins and outs of the local terrain like no other, ensuring that stranded motorists are never left waiting for long.
**Safety Protocols**
Safety is paramount at Belair's Best for their customers and staff. They've implemented stringent safety measures to protect everyone involved during towing operations. From regular safety training sessions for their team members to the use of high-visibility gear and traffic cones at the scene of an incident, they leave no stone unturned when it comes to ensuring a safe working environment.
Additionally, Belair's Best's fleet of tow trucks is equipped with the latest safety features and technology, further minimizing the risk of accidents or injuries. With Belair's Best, customers can rest assured that their safety is always the top priority.
**Transparent Pricing**
Belair's Best believes in honesty and transparency when it comes to pricing. They understand that unexpected towing expenses can add stress to an already challenging situation, so they strive to make their pricing structures clear and upfront. Before any towing operation begins, they provide customers with a detailed breakdown of costs, ensuring no surprises when the final bill arrives.
Additionally, their rates are competitive and fair, reflecting the quality of service they provide without breaking the bank. With Belair's Best, customers can trust that they're getting the best value for their money, with no hidden fees or gimmicks.
**Community Engagement**
Beyond their towing services, Belair's Best is deeply committed to giving back to the community they serve. Whether sponsoring local events, supporting charitable organizations, or participating in community clean-up initiatives, they actively make their neighborhood a better place for all.
By fostering strong ties with residents and businesses alike, they've built a reputation as more than just a towing company; they're a trusted ally and neighbor, dedicated to making a positive impact wherever they can.
**Emergency Roadside Assistance**
When faced with a roadside emergency, having access to reliable assistance can make all the difference. Emergency roadside assistance services are designed to provide immediate support and solutions when you encounter unexpected car troubles.
Immediate Response: Emergency roadside assistance providers offer rapid response times, ensuring that help arrives promptly when you need it most.
Versatile Solutions: From jump-starts and tire changes to fuel delivery and towing, these services offer various solutions to address roadside issues.
Peace of Mind: Knowing that help is just a phone call away can provide invaluable peace of mind, especially during stressful situations.
Professional Expertise: Trained technicians with the necessary skills and equipment to handle your roadside assistance needs, minimizing the risk of further damage or complications.
24/7 Availability: Whether it's the middle of the night or during a holiday weekend, emergency roadside assistance services are available round-the-clock, ensuring assistance whenever and wherever you need it.
Emergency roadside assistance offers a reliable lifeline for drivers facing unexpected car troubles, providing quick, versatile, and professional support to get you back on the road with minimal hassle.
**Testimonials and Success Stories**
The most compelling testament to Belair's Best's excellence is the countless testimonials and success stories from satisfied customers. From heartfelt thank-you notes to glowing online reviews, their reputation for professionalism, reliability, and exceptional service precedes them.
Whether it's a driver stranded on the side of the road or a business owner needing a towing partner they can trust, Belair's Best has consistently delivered, earning the loyalty and admiration of the communities they serve. Through these firsthand accounts, it's clear that Belair's Best is truly in a league of its own regarding tow truck solutions.
When you need towing services, whether due to a roadside emergency or vehicle malfunction, you can trust Belair's Best to provide prompt, reliable assistance. With their rapid response team, advanced fleet technology, and unwavering commitment to customer satisfaction, they excel at delivering peace of mind in moments of uncertainty.
Their customer-centric approach ensures that each driver receives personalized support tailored to their unique situation, while their local expertise and safety protocols guarantee efficient and secure towing operations. Moreover, their transparent pricing and community engagement efforts further demonstrate their dedication to excellence and integrity.
For dependable towing solutions backed by two decades of family-owned and -operated experience, contact Belair's Best at 410-984-7768. Don't let a roadside mishap derail your plans – trust Belair's Best to get you back on track safely and efficiently.
[Universal Towing Baltimore](https://universaltowingbaltimore.com/
) | universaltowingbaltimore |
1,871,468 | Book Synopsis & Review - Docs Like Code | A synopsis and brief review of the book Docs Like Code by Anne Gentle, a resource for technical writing teams using or wanting to use the docs-as-code approach. | 0 | 2024-05-31T00:36:00 | https://dev.to/dreamlogic/book-synopsis-review-docs-like-code-5g7c | ---
title: Book Synopsis & Review - Docs Like Code
published: true
description: A synopsis and brief review of the book Docs Like Code by Anne Gentle, a resource for technical writing teams using or wanting to use the docs-as-code approach.
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
published_at: 2024-05-31 00:36 +0000
---
## ABOUT THIS BOOK
This book is meant as a resource for technical writing teams who are using, or are moving toward, a docs-as-code approach. The first edition was published in 2017, and I read the third edition, published in 2022. Anne Gentle (Cisco) and Diane Skwish are co-authors, and Kelly Holcomb (Oracle) is listed as a contributor. Eric Holscher (founder of the ReadTheDocs platform and the WriteTheDocs community & conference) wrote the foreword for this edition.
## BOOK CONTENTS
At only 127 numbered pages, this book is slim but densely packed with useful information. There is a lot of technical detail, so I don't consider it suitable for anyone brand new to software documentation. Mainly, if you have never used git (a software version control and collaboration system), the many discussions on git pull requests and git branches and such won't make much sense to you. This book is not intended to teach you these concepts. It does, however, provide a list of resources for learning git, and a glossary of git-related terms and definitions.
_Docs Like Code_ contains four chapters:
- Introducing docs as code
- Plan for docs as code
- Optimize workflows with docs as code systems
- Lessons learned with docs as code
The first chapter defines a docs-as-code framework as one where you:
- Store the doc source files in a version control system
- Build the doc artifacts automatically
- Ideally, run automated tests on the docs
- Ensure that a trusted set of reviewers meticulously review the docs
- Publish the artifacts without much human intervention
The second chapter (_Plan for docs as code_) includes sections on:
- Requirements gathering
- Planning for automating, testing, and site hosting
- Organizing source files and repositories
- API reference documentation
- and more
Many topics are covered in these sections, from choosing a markup language (Markdown, AsciiDoc, RST, etc...), to using mermaid diagrams, to determining API complexity, to choosing a static site generator. This book doesn't provide a deep dive into single topic; it provides seasoned advice and enough to get you started.
The requirements gathering section presents a wide variety of useful questions, such as:
- Does the source repository need to be private or can it be publicly available?
- How do users access the docs, and how often from each platform?
- How much [of the budget] should you allocate per author, per deliverable, and for hosting?
- Are you relying on an internal team or a third party to have "pager duty" if the docs site goes down?
If you are a team planning to adopt docs-as-code, this section alone is worth the book as a useful checklist for everything you need to consider.
The third chapter (_Optimize workflows with docs as code systems_) is the thickest of the four. It's also where prior knowledge of how to use git is most necessary, as much of it is concerned with git-based workflows.
Questions considered in this chapter include:
- Are the docs in their own repo?
- How will you publish?
- Will contributors preview docs locally or on a server?
- How will you collaborate with others?
- How many pull requests and reviews do you expect?
This chapter also includes advice on using a CODEOWNERS file, creating a docs contributors guide, writing a style guide, building locally, automation, review processes, versioning, and more. Many useful docs-as-code tools are recommended, such as the prose linter Vale, broken link checkers, Docker, GitHub Actions, Jekyll, and others.
The final chapter (_Lessons learned with docs as code_) is the thinnest - only 9 pages, with a few paragraphs devoted to each of these lessons:
- Find your community and learn from others
- Create a great web experience
- Equip your contributors with a style guide
- How will you collaborate with others?
- Empower your contributors
- Write a contributor's guide
- Write a reviewer's guide
- Build in continuous integration for docs
- Teach everyone to respect the docs
- Test and measure outcomes
- Set up a Git support chat room
## What's not in this book
This book does not contain any information about the use of AI in docs-as-code, aside from mentioning the rise of AI/ML in documentation.
There is no index, which I found disappointing. Considering the breadth of topics covered, an index would be quite useful.
## Overall
This book is not a tutorial. It will not teach you how to use docs-as-code. However, it's an extremely useful book that covers countless facets about docs-as-code. Pick it up if you're thinking about switching to docs-as-code or if you want to figure out holes in your existing approach that need to be considered.
## Learn more about docs-as-code
- [Docs Like Code](https://docslikecode.com) (a companion website to the book, with supplementary articles and tutorials)
- [Write The Docs - Docs As Code](https://www.writethedocs.org/guide/docs-as-code/)
- [I'd Rather Be Writing - Docs as code](https://idratherbewriting.com/trends/trends-to-follow-or-forget-docs-as-code.html)
- [I'd Rather Be Writing - Docs-as-code tools](https://idratherbewriting.com/learnapidoc/pubapis_docs_as_code.html) | dreamlogic | |
1,871,467 | Developing Custom Plugins for WordPress | Introduction One of the most appealing aspects of using WordPress as a website platform is... | 0 | 2024-05-31T00:31:16 | https://dev.to/kartikmehta8/developing-custom-plugins-for-wordpress-36pi | webdev, javascript, beginners, programming | ## Introduction
One of the most appealing aspects of using WordPress as a website platform is its ability to be customized with plugins. These plugins allow users to add extra features and functionality to their website without the need for coding. However, what if a specific feature or design element is not available as a pre-made plugin? In such cases, developing custom plugins for WordPress can be the solution. In this article, we will discuss the advantages, disadvantages, and features of developing custom plugins for WordPress.
## Advantages of Developing Custom Plugins
1. **Uniqueness and Tailored Experience:** The most significant advantage of developing custom plugins is the ability to create a unique and tailored experience for users.
2. **Efficiency and Performance:** Custom plugins also tend to be more efficient and streamlined, leading to improved website speed and performance.
3. **Cost-Effectiveness in the Long Run:** Developing custom plugins can save costs in the long run as it eliminates the need for purchasing multiple pre-made plugins.
## Disadvantages of Developing Custom Plugins
1. **Increased Time and Cost:** The main disadvantage of developing custom plugins is the added time and cost it requires.
2. **Technical Expertise Required:** It also requires a certain level of technical expertise and knowledge of WordPress development.
3. **Compatibility and Maintenance Issues:** Custom plugins may not always be compatible with future updates, requiring regular maintenance.
## Features of Custom Plugins
Custom plugins can have a wide range of features, from simple design elements to complex and advanced functionalities. Some popular features include:
1. **Custom Post Types:** Enhance the way content is managed and presented, tailored to specific needs.
2. **Dynamic Forms:** Create forms that react to user input, offering a more interactive experience.
3. **Advanced Search Options:** Improve search functionality with filters and custom queries that are optimized for the specific data on the site.
4. **Social Media Integrations:** Seamlessly integrate social media platforms to enhance user engagement and content sharing.
### Example of a Custom Plugin for Social Media Integration
```php
<?php
/*
Plugin Name: My Custom Social Media Plugin
Description: This plugin adds customized social media share buttons to your WordPress site.
Version: 1.0
Author: Your Name
*/
function my_custom_social_media_buttons() {
$content = '<div class="social-buttons">';
$content .= '<a href="https://facebook.com" target="_blank">Share on Facebook</a>';
$content .= '<a href="https://twitter.com" target="_blank">Tweet</a>';
$content .= '</div>';
return $content;
}
add_shortcode('social_buttons', 'my_custom_social_media_buttons');
?>
```
This PHP snippet demonstrates a simple custom plugin that adds social media sharing buttons to a WordPress site using a shortcode.
## Conclusion
While there are certain disadvantages to developing custom plugins for WordPress, the benefits often outweigh them. Custom plugins allow for a unique and personalized website experience, and with the right developer, the process can be smooth and hassle-free. With the increasing demand for custom and unique websites, developing custom plugins has become a vital aspect of WordPress development. As such, it is a valuable skill for developers to have and a valuable investment for businesses to make. | kartikmehta8 |
1,870,385 | Open AI with Vercel: Solution to Gateway Timeouts | Vercel and OpenAI: Not a Perfect Match. Vercel is great for starting small projects quickly and for... | 0 | 2024-05-31T00:24:28 | https://dev.to/buildwebcrumbs/open-ai-with-vercel-a-way-around-gateway-timeouts-1ec9 | vercel, ai, programming, webdev | **Vercel and OpenAI: Not a Perfect Match.**
Vercel is great for starting small projects quickly and for free. However, using AI, like OpenAI, with Vercel can cause issues that only show up when you deploy.

Fixing these errors can take up a lot of our precioussss time. Here’s a quick checklist before we start:
* Are enviromental variables set?
* Is database access allowed?
* Does CORS allow origin?
## The Solution
To avoid Vercel's Gateway Timeout problems, split the OpenAI API call into two endpoints and one async function:
* Endpoint `/request/initiate`
* Function `processRequestInBackground`
* Endpoint `/request/status/:hash`
## Starting a Request
The endpoint `/request/initiate` begins a new request. It takes a user's message, creates a unique hash, and checks the database for an existing request. If found, it informs the user of the status. If new, it saves it as 'pending' and starts processing in the background.
```javascript
app.post('/request/initiate', async (req, res) => {
const { message } = req.body;
const hash = crypto.createHash('sha256').update(message).digest('hex');
try {
const client = await getDbClient();
const db = client.db('my_db_name');
const requestsCollection = db.collection('requests');
const resourcesCollection = db.collection('resources');
const existingRequest = await requestsCollection.findOne({ hash });
if (existingRequest) {
return res.json({ hash, status: existingRequest.status });
}
await requestsCollection.insertOne({ hash, message, status: 'pending' });
res.status(202).json({ hash, status: 'pending' });
processRequestInBackground(message, hash, requestsCollection, resourcesCollection);
} catch (error) {
console.error('DB error on request initiation:', error);
res.status(500).json({ message: 'Database error during request initiation.' });
}
});
```
## Background Processing
The `processRequestInBackground` function handles request processing. It sends the message to the OpenAI API, then updates the database with the result. If successful, it records the content and tokens used. On error, it updates the status and logs the error.
``` javascript
async function processRequestInBackground(message, hash, requestsCollection, resourcesCollection) {
try {
const headers = {
"Content-Type": "application/json",
"Authorization": `Bearer YOUR_OPEN_AI_API_KEY`
};
const payload = {
model: 'gpt-4o',
messages: [
{ role: 'system', content: YOUR_GPT_INSTRUCTIONS },
{ role: 'user', content: message }
],
max_tokens: 1000
};
const response = await fetch('https://api.openai.com/v1/chat/completions', {
method: 'POST',
headers,
body: JSON.stringify(payload)
});
const jsonResponse = await response.json();
if (!response.ok) {
throw new Error('API request failed: ' + jsonResponse.error.message);
}
const tokens = jsonResponse.usage.total_tokens;
const content = jsonResponse.choices[0].message.content;
await resourcesCollection.updateOne({ resource: 'openai' }, { $inc: { tokens } });
await requestsCollection.updateOne({ hash }, { $set: { status: 'completed', content, tokens } });
} catch (error) {
console.error('Error during request processing:', error);
await requestsCollection.updateOne({ hash }, { $set: { status: 'error', errorDetails: error.message } });
}
}
```
## Checking Request Status
The endpoint `/request/status/:hash` checks the status of a specific request. It returns the current status, content, and tokens used. If no record is found, it informs the user.
``` javascript
app.get('/request/status/:hash', async (req, res) => {
const hash = req.params.hash;
try {
const client = await getDbClient();
const db = client.db('my_db_name');
const requestsCollection = db.collection('requests');
const requestRecord = await requestsCollection.findOne({ hash });
if (!requestRecord) {
return res.status(404).json({ message: 'Request record not found.' });
}
res.json({ status: requestRecord.status, content: requestRecord.content || null, tokens: requestRecord.tokens || 0 });
} catch (error) {
console.error('Error retrieving request status:', error);
res.status(500).json({ message: 'Error processing your request', details: error.message });
}
});
```
## And That's It!
If you enjoy JavaScript and want to join our open-source community at Webcrumbs, check out our [Discord](https://discord.com/invite/ZCj5hFv8xV), [GitHub](https://github.com/webcrumbs-community/webcrumbs), and [Waitlist](https://www.webcrumbs.org/). Follow us for more posts like this one.
See you all soon! | opensourcee |
1,871,466 | What programming language would be dealing more with AI? | The programming languages most commonly used for dealing with AI are: Python: Python is the most... | 0 | 2024-05-31T00:22:44 | https://dev.to/gaebh/what-programming-language-would-be-dealing-more-with-ai-kgh | The programming languages most commonly used for dealing with AI are:
Python: Python is the most popular language for AI and machine learning due to its simplicity and readability. It has a vast ecosystem of libraries and frameworks such as TensorFlow, Keras, PyTorch, Scikit-learn, and many more that facilitate AI development.
R: R is highly regarded in the data science community for statistical analysis and data visualization, making it useful in certain AI and machine learning applications, particularly in research and academic settings.
Java: Java is used in large-scale enterprise-level applications and has libraries like Deeplearning4j and Weka. It’s also used in big data technologies which are often integrated with AI.
C++: C++ is known for its performance and is used in AI projects where execution speed is critical. It’s often used in the development of game engines, real-time systems, and for implementing certain parts of AI algorithms.
Julia: Julia is gaining traction for its high performance in numerical and scientific computing, which is essential in some AI applications, especially in research.
MATLAB: MATLAB is widely used for numerical computing and has powerful tools for AI, particularly in academia and industries that require heavy mathematical computations.
Lisp: Lisp is one of the oldest languages used in AI. It’s known for its excellent support for symbolic reasoning and rapid prototyping.
Prolog: Prolog is used in AI for applications involving rule-based logical queries, natural language processing, and expert systems.
These languages have their own strengths and are chosen based on the specific requirements of the AI project, such as the need for rapid development, performance, integration with other systems, or specific libraries and tools. | gaebh | |
1,871,427 | HELP ME | i want space in center of both boxes without disturbing the alignment of boxes my code... | 0 | 2024-05-31T00:19:58 | https://dev.to/msalman12345/help-me-2o9c | help | i want space in center of both boxes without disturbing the alignment of boxes
my code
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Bootstrap demo</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.3/dist/css/bootstrap.min.css" rel="stylesheet"
integrity="sha384-QWTKZyjpPEjISv5WaRU9OFeRpok6YctnYmDr5pNlyT2bRjXh0JMhjY6hW+ALEwIH" crossorigin="anonymous">
<link rel="stylesheet" href="./statics/style.css">
</head>
<body>
<div class=" container-fluid">
<div class="col-3">
<div class="one">
<div class="">
<div class="form-group">
<input type="text" class="form-control my-3" id="inputField" placeholder="John etc.....">
</div>
<div class="form-group">
<select class="form-control" id="dropdown">
<option value="">Class</option>
<option value="option1">1-5</option>
<option value="option2">5-7</option>
<option value="option3">9-10</option>
</select>
</div>
</div>
</div>
<div class="two">
<div class="row">
<div class="col-6 ok">
<h3>salman</h3>
<h3>salman</h3>
</div>
<div class="col-6 ok">
<h3>salman</h3>
<h3>salman</h3>
</div>
</div>
</div>
</div>
<div class="col-9"></div>
</div>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.3/dist/js/bootstrap.bundle.min.js"
integrity="sha384-YvpcrYf0tY3lHB60NNkmXc5s9fDVZLESaAA55NDzOxhy9GkcIdslK1eN7N6jIeHz"
crossorigin="anonymous"></script>
</body>
</html> | msalman12345 |
1,871,426 | Purchasing Tech Woes: Combining Remote and Onsite IT Support | When you talk about business and on the other hand technology, both are connected like they both have... | 0 | 2024-05-31T00:14:51 | https://dev.to/liong/purchasing-tech-woes-combining-remote-and-onsite-it-support-48fj | remote, techtalks, malaysia, kualalumpur | When you talk about business and on the other hand technology, both are connected like they both have the same kind of meaning. Technology and business have the same meanings according to this digital modernized world. Every daily procedure, including data management and awesome connection, is forced by it. When that technological foundation fails, what should we do? This is where IT support can offer to take the burden of maintaining your IT solutions with their experience and toolset.
However, your [it support onsite and remote](https://ithubtechnologies.com/top-developer-in-malaysia/?utm_source=dev.to&utm_campaign=itsupportonsiteandremote&utm_id=Offpageseo+2024) are both important as routes. These are two major methods of delivering testing — onsite and remote, deciding which route to take might not be easy. Fear not, tech warriors! In this blog, you are going to be aware of how and what is onsite and remote support.
## On-Site IT Support - The Trustable Maintenance team at your service
This is where having an IT expert come to your door directly can help with onsite IT support.
Picture a benevolent technician; a professional who has a complex array of solutions in their toolbox, ensuring they pull you out from the throes of IT woes, easily.
## What Makes Onsite Support Bright:
- **Hands-on issues-solving:** Device on the fritz, network not connecting . Many of these require a body in the area to solve. Field technicians will issue and find it much smoother to locate quick solutions as a result, which will cut down on system downtime.
- **Handled:** Social communication can be important at times. Having a more type of relationship with your IT provider is made possible by local support. The technicians can see how the field is working and can offer solutions designed for you.
- **Building trust:** Businesses with sensitive data or a security focus will find offline technicians to allow for a greater level of control and transparency in the troubleshooting process.
## Onsite support does have some shortcomings, however:
- **Expensive:** Onsite Visits are much more expensive than remote support as they involve travel and are cost-prohibitive.
- **Scheduling Limitations:** Technicians need to coordinate with their next on-site job and are limited to their location, and if it is too far it could lead to reschedules.
- **Limited Coverage:** Onsite support is limited by geography. Less appropriate for multi-location companies or workforces that are dispersed.
## The Remote Saviors: How Remote IT Support is Moving the Needle
By contrast, Remote IT support uses the technology available at the time to connect technicians to your devices. It's as if you had an IT genie inside your computer who was there to grant your IT wishes (well, at least solve your problems) from hundreds or even thousands of miles away. This is why remote support is indeed a great prospect:
1. **Swift service:** Remote connections facilitate faster turn-around time, specifically concerning software matters and basic tools. That way, your systems can be accessed by technicians remotely, so you experience less downtime.
2. **Affordable:** Once more, removing travel makes online support less costly than an onsite visit. This is a fantastic option for businesses with small budgets.
3. **Accessibility:** As this is a remote support it's overcoming geographical limits. Whether you are in a bustling city or a lonely village, help is just a virtual connection away. This works great for businesses that have teams all over the globe.
## Of course, remote support is not a solution for all your problems. It only goes so far…
1. **No physical control:** While remote support is convenient, it is not ideal for hardware-related issues or if you need to physically inspect equipment. Techs are dependent on your descriptions to diagnose problems, which could mean misunderstandings.
2. **Security Concerns:** When you allow access to your systems remotely, you have to ensure the right security for the data you have.
3. **Technical limitations:** Remote support needs the internet and if you have a slow or unstable internet connection, your remote session will not be as effective.
## To get That Balance: A Hybrid Method
For IT following an assessment, hybrid is commonly the best choice. To get the best of all worlds, the most widely known combinations mix remote and on-site services. This is how it works:
- **First Party Spread:** Most IT issues all seem to be security policy issues, which means they can be resolved remotely. Professionals use secure wireless access methods to identify software problems, customize settings, and assist clients in real-time.
- **Onsite when required:** When remote assessment is not possible or for powerful hardware failure investigations, onsite technicians can be scheduled to find out what's wrong face-to-face.
This half-and-half technique gives the advantages of expense investment funds and quick goals from remote help joined with the hands-on mastery during an actual on-location meeting when required.
## Picking the Winner: What to Look For
Well, That is why we want to help you choose — What is the greatest methodology for your business? When you are trying your best to choose the right thing then it's better if you take a look at the following factors.
**(i)Hardware Requirements**:
A hybrid approach is best suited if you need special software that isn't available on a software platform, or if you have a lot of hardware.
**(ii)Money limitations:**
On-site visits raise the price of support; remote support is generally less expensive.
**(iii)Culture of your company:**
If your organization is dependent upon personal interaction and relies on your IT provider to have a keen understanding of your business, you might be better suited for onsite support.
With issues that usually require the highest level of technical expertise, Out of State might also be sufficient when the troubleshooting abilities of such problems lie within your in-house IT staff.
## Conclusion: Creating a Comprehensive IT Support Strategy
According to the above highlighted points in the blog, it can be concluded that IT support is a blessing for us as we should be aware that it is very beneficial. IT support is not just limited to one area but to both places, whether it can be in the onsite area or the remote base. When you can get an idea of its pros and cons, then you can choose the right thing for yourself.
| liong |
1,871,422 | HOW I SPIED ON MY BABY DADDY'S PHONE | I met my baby daddy on tinder. We talked for a month i was living in newyork and he was living in... | 0 | 2024-05-31T00:00:43 | https://dev.to/kristencora72/how-i-spied-on-my-baby-daddys-phone-1jif | catchcheatingpartners, spyonphone, recoverdeletedmessages | I met my baby daddy on tinder. We talked for a month i was living in newyork and he was living in Georgia. I had plans on moving to Georgia within a month so i did the global settings on tinder. He told me everything i wanted to hear for that month, he even invited me to stay with him for a week while i get my apartment together. This was in May btw , late May into June. So yea, we did the deed and we spoke after i moved to my place but his busy work schedule just wasn’t working for me so i decided to end whatever we had going on. My period was due and it didn’t come, i found out i was 5 weeks pregnant. I told the guy how i need him to take a dna test. Anyways. I had to wait until September to take the dna test and the guy quickly came around. At first he was very distant since he didn’t know, it was the lonely months of my life since i have no family here and i didn’t tell nobody about the father situation because i was ashamed. So fast forward, we are living together and doing okay. However, i am in this specific group for a reason lol. I suspected him of cheating, so I had to get proof. I saw an ad about a phone spying app and so I clicked it and it directed me to this website; CYBERPUNKERSORG. I filled out his details and after 8 hours I had access to his phone from my iPad. I found out he has other women in his life and has a serious romantic affair with his co worker. So here I am. | kristencora72 |
1,871,808 | DevX Status Update | June coming in already and we are closing May with a couple of announcements. New triage... | 0 | 2024-06-14T17:33:29 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-05-31-devx-status-update/ | puppet, community, devrel | ---
title: DevX Status Update
published: true
date: 2024-05-31 00:00:00 UTC
tags: puppet,community,devx
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-05-31-devx-status-update/
---
June coming in already and we are closing May with a couple of announcements.
## New triage visibility
We are working on moving our current triage process from internal boards to GitHub Projects. We are hoping this will bring a bit more transparency into how we approach community raised PRs and issues. Make sure to check the [board](https://github.com/orgs/puppetlabs/projects/73) out if you are interested.
## puppetlabs-dsc\_lite adoption
We have officially adopted puppetlabs-dsc\_lite into our toolset! This module suffered a bit of neglect over the last few years, as we worked on other projects. However, we have given it a fresh coat of paint and it is now up to speed with the rest of tools/modules, ready to be used with Puppet 7 and 8.
## New PDK download pointers
Another event worth mentioning is that we have moved our PDK download links to the Forge. That means that we no longer offer PDK package downloads from our puppet website. Instead, those links will be redirected to the Forge.
## Holiday time
As we have mentioned previously, June is already here. This means that, over the next few weeks, we might be a bit lighter on resources, as some of us are heading to holidays. I’m sure many of you might also have plans soon enough. We just wanted to let you know that some common events, like our community PR/issue triage or Office hours will probably move a bit slower than usual.
May you have a nice summer start! | puppetdevx |
1,871,807 | Modules Status Update | Friday Again! As we come to the end of yet another week, there isn’t much news from the... | 0 | 2024-06-14T17:32:40 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-05-31-modules-status-update/ | puppet, community | ---
title: Modules Status Update
published: true
date: 2024-05-31 00:00:00 UTC
tags: puppet,community
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-05-31-modules-status-update/
---
## Friday Again!
As we come to the end of yet another week, there isn’t much news from the Pune office about Modules. Instead, we’ve been busy working on our commitments for Forge. Forge is becoming an exciting place with all new features. We hope you will love this change once it is out in Production for all to use.
Have a great weekend ahead and keep your contributions coming..
## Community Contributions
We’d like to thank the following people in the Puppet Community for their contributions over this past week:
## New Module Releases
- [`puppetlabs-firewall`](http://github.com/puppetlabs/puppetlabs-firewall) (`8.0.2`) | puppetdevx |
1,871,994 | Git Diff Explained: Understanding Code Differences with Ease | Ever struggled to remember what changes you made in your code? Or maybe you've accidentally deleted a... | 26,070 | 2024-05-31T11:27:32 | https://ionixjunior.dev/en/git-diff-explained-understanding-code-differences-with-ease/ | git | ---
title: Git Diff Explained: Understanding Code Differences with Ease
published: true
date: 2024-05-31 00:00:00 UTC
tags: git
canonical_url: https://ionixjunior.dev/en/git-diff-explained-understanding-code-differences-with-ease/
cover_image: https://ionixjuniordevthumbnail.azurewebsites.net/api/Generate?title=Git+Diff+Explained%3A+Understanding+Code+Differences+with+Ease
series: mastering-git
---
Ever struggled to remember what changes you made in your code? Or maybe you've accidentally deleted a vital line and spent hours trying to figure out how to recover it? Or just you make some changes and want to review it before to commit? We've all been there. But fear not, dear coder! There's a powerful tool in Git's arsenal that can make your life significantly easier: Git Diff. In this post we'll learn about it.
## Understanding Git Diff’s Basics
**Git Diff** is like having a magnifying glass for your code changes. It lets you compare two versions of your code and see exactly what has been added, removed, or modified.
Imagine you’re working on a document with “track changes” enabled. **Git Diff** works similarly, but for your code. It highlights the differences between two versions of a file, making it easy to understand what’s changed and how.
### How to Use It:
The basic **Git Diff** command is: `git diff`. This command will compare the current state of your working directory to the last commit you made. Here’s a simple example using a file called `Foo.swift`:
```
class Foo {
func bar() {
print("Hello, world!")
}
}
```
Let’s say you make a change to `Foo.swift`:
```
class Foo {
func bar() {
print("Hello, world! I've been updated.")
}
}
```
Now, if you run `git diff` in your terminal, you’ll see the following output:
```
git diff
diff --git a/Foo.swift b/Foo.swift
index 495198a..6543e6d 100644
--- a/Foo.swift
+++ b/Foo.swift
@@ -3,4 +3,4 @@
class Foo {
func bar() {
- print("Hello, world!")
+ print("Hello, world! I've been updated.")
}
}
```
This output shows:
- **- - - a/Foo.swift** : This line represents the original version of the file.
- **+++ b/Foo.swift** : This line represents the modified version of the file.
- **@@ -3,4 +3,4 @@** : This line indicates the line numbers where the changes occurred.
- **- print(“Hello, world!”)**: This line shows the original code that was deleted.
- **+ print(“Hello, world! I’ve been updated.”)**: This line shows the new code that was added.
By visualizing the changes, **Git Diff** helps you grasp the impact of your code modifications and track the evolution of your project.
In the next section, we’ll delve into some handy **Git Diff** arguments that can take your code comparison skills to the next level!
## Essential Git Diff Arguments (Tips and Tricks)
**Git Diff** offers a variety of arguments that can fine-tune its output and make your code comparison experience even more insightful. Here are some essential arguments to boost your **Git Diff** skills:
### “staged” or “cached” argument
`git diff --staged`
`git diff --cached`
These commands compare the changes you’ve staged for your next commit (using git add) to the current state of your working directory. It’s incredibly useful for reviewing your staged changes before committing, ensuring you’re only committing the intended modifications.
### “w” argument
`git diff -w`
Only shows changes to the actual content, ignoring whitespace changes. This is useful when you’re focused on the logic of the code and don’t care about formatting.
### “word-diff” argument
`git diff --word-diff`
This is an amazing option to see text differences. This argument displays word-level diffs, highlighting the specific words that have been changed within a line. This makes it easier to identify subtle changes and understand the context of the modifications.
Consider the last change in `Foo.swift`. If we use the `git diff --word-diff`, we’ll see the following result:
```
git diff --word-diff
diff --git a/Foo.swift b/Foo.swift
index 495198a..6543e6d 100644
--- a/Foo.swift
+++ b/Foo.swift
@@ -3,4 +3,4 @@
class Foo {
func bar() {
print("Hello, [-world!")-]{+world! I've been updated.")+}
}
}
```
Using this argument would clearly show you that phrase “I’ve been updated.” has been added, while the rest of the line remains unchanged. Maybe this was not so clearly here on the blog post, but if you’re using **Git** on the command line, probably you’ll see a colored **Git Diff** result and it turns easier to understand changes.
### “color-words” argument
`git diff --color-words`
This argument highlights changed words with different colors, making it easier to visually distinguish the modified parts of the code. Is very similar than “word-diff”, but can be easier to understand.
### “HEAD” argument
`git diff HEAD`
This command shows the differences between your current working directory and the last commit (HEAD). It’s useful for reviewing your unstaged changes before committing or checking what changes you’ve made since the last commit. This is the default option when you don’t specify anything after the `diff`.
### branch argument
`git diff branch_name`
This argument compares your current branch with another branch, like “feature-branch.” This is invaluable for understanding the differences between branches, especially before merging or when trying to identify conflicts.
### Using an external diff tool
Sometimes, the default **Git diff** output might not be visually appealing or provide enough context. In these cases, you can use external **diff tools** to enhance your code comparison experience.
One popular external **diff tool** is [**Difftastic**](https://github.com/Wilfred/difftastic), a structural **diff tool** that compares files based on their syntax.
To use **Difftastic** , you need to install it. You can check out instructions in the link above. After install it, you can configure **Git** to use it as the default external **diff tool** :
```
git config --global diff.external difft
```
After setting up **difft** , simply run **git diff** as usual. **Git** will automatically use **difft** to display the differences, providing a more visually appealing and informative output. The same diff of `Foo.swift` will appears this way:
```
Foo.swift --- Swift
File permissions changed from 100600 to 100644.
1 class Foo { 1 class Foo {
2 func bar() { 2 func bar() {
3 print("Hello, world!") 3 print("Hello, world! I've been updated.")
4 } 4 }
5 } 5 }
```
This is similar a side-by-side option that we can see on GitHub or GitLab. I like so much this tool.
These are just a few of the many helpful arguments offered by **Git Diff**. Exploring the **Git** documentation will reveal even more advanced options for fine-tuning your code comparison experience.
By mastering these arguments and exploring external **diff tools** , you’ll be equipped to efficiently understand and manage code changes, leading to cleaner code, better debugging, and smoother collaboration.
## Conclusion: The Power of Git Diff
In this post, we’ve explored its basic functionality, and learned essential arguments to enhance its capabilities. From tracking code changes to pinpointing bugs and streamlining code reviews, **Git Diff** proves to be an indispensable tool in any developer’s arsenal.
Now that you’ve gained a better understanding of **Git Diff** , it’s time to put your knowledge into practice. Experiment with different arguments, explore advanced options, and discover how **Git Diff** can transform your development workflow.
Don’t let code changes be a mystery! Embrace the power of **Git Diff** and unlock a new level of efficiency and understanding in your development journey.
Happy coding! | ionixjunior |
1,872,087 | Installing Playwright on Heroku for Programmatic Node.js Browser Automation | Installing Playwright on Heroku is a bit more involved than just running npm install playwright and... | 0 | 2024-06-07T18:58:46 | https://lirantal.com/blog/installing-playwright-on-heroku-for-programmatic-nodejs-browser-automation/ | node, playwright, heroku, testing | ---
title: Installing Playwright on Heroku for Programmatic Node.js Browser Automation
published: true
date: 2024-05-31 00:00:00 UTC
tags: nodejs, playwright, heroku, testing
canonical_url: https://lirantal.com/blog/installing-playwright-on-heroku-for-programmatic-nodejs-browser-automation/
---
Installing Playwright on Heroku is a bit more involved than just running `npm install playwright` and `npm install @playwright/test` and setting it as a dependency that gets installed when you deploy your app to Heroku. Installing the browser dependencies didn’t work out of the box for me and I had to do some additional steps to get it working.
I added Playwright web automation capabilities to my Heroku hosted Node.js backend but it wasn’t as seamless as I thought it would be. Here’s how I did it and what I learned along the way.
## Adding Playwright as a Dependency
First off, when it comes to the Playwright dependencies, you need both `playwright` and `@playwright/test` installed. The former is the core Playwright library and the latter is the test runner that you can use to run your Playwright tests.
If your Playwright use-case isn’t end-to-end testing but rather browser automation and scraping (only from approved websites, of course), you probably need just one browser installed. In my case, I only needed Chromium. So, I switched `playwright` for `playwright-chromium`.
```
npm install playwright-chromium @playwright/test
```
## Playwright Browser Automation via Code
Since I want to run Playwright browser automation tool programmatically via code and not via the classic test runner (although, I do want to run Playwright tests as well), I structured the code so that I separate between the web interaction and the tests being run:
- A `PageScraper.js` file defines the code used to interact with the browser and scrape the data I need.
- An `e2e/` directory contains the Playwright tests that use the `PageScraper.js` file to interact with the browser.
This way, I can actually use the `PageScraper.js` code in my backend API to drive the needed logic, as well as use it as the basis of sanity end-to-end tests.
The `PageScraper.js` file looks like this:
```
import { chromium } from "playwright-chromium";
export default class PageScraper {
constructor({ Logger }) {
this.Logger = Logger;
}
async scrapePage({ url }) {
const browser = await chromium.launch({ chromiumSandbox: false });
const page = await browser.newPage();
await page.goto(url);
// the title of the blog post in this web page is found via the `txt-headline-large` class on the h1 element:
const title = await page.$eval(
".txt-headline-large",
(el) => el.textContent
);
// the contents of the blog post in this web page is found via the `txt-rich-long` class on the div element:
const content = await page.$eval(".txt-rich-long", (el) => el.textContent);
await browser.close();
return {
title,
content,
};
}
}
```
Then the E2E (end-to-end) test file can be as the follows `scrapers/page-scraper.spec.js`:
```
import { container, initDI } from "../infra/di";
import { test, expect } from "@playwright/test";
await initDI({ config: {}, database: {} });
test("url provided to scraper gets title and content", async ({ page }) => {
const scraper = container.resolve("PageScraper");
const { title, content } = await scraper.scrapePage({
url: "https://www.example.com",
});
// Expect a title "to contain" a substring
await expect(title).toContain(
"Title goes here..."
);
// Expect the page content to be at least 1000 characters long
await expect(content.length).toBeGreaterThan(1000);
});
```
Now we can also further update the `package.json` section for `scripts` to allow easily running these tests:
```
{
"scripts": {
"test:scrapers": "npx playwright test scrapers/*.spec.js",
}
}
```
## Installing Playwright on Heroku
Getting Playwright to work on Heroku wasn’t smooth sailing. It looked for browser dependencies that weren’t installed by default and not in the location it expected them.
So the Heroku Node.js application build failed with errors like this:
```
remote: > app-api@1.0.0 postinstall
remote: > npx playwright install chromium --with-deps
remote:
remote: Installing dependencies...
remote: Switching to root user to install dependencies...
remote: Password: su: Authentication failure
remote: Failed to install browsers
remote: Error: Installation process exited with code: 1
remote: npm error code 1
remote: npm error path /tmp/build_e814256b
remote: npm error command failed
remote: npm error command sh -c npx playwright install chromium --with-deps
remote:
remote: npm error A complete log of this run can be found in: /tmp/npmcache.KPL0X/_logs/2024-05-08T06_12_14_978Z-debug-0.log
```
That command `npx playwright install chromium --with-deps` was failing because it was trying to install the browser dependencies as the root user and Heroku doesn’t allow that, and I added this as a `postinstall` script in my `package.json` file to make sure that browser dependencies are installed when the app is deployed to Heroku. However, that didn’t work out.
The solution was to install the browser dependencies via buildpacks, which is something like container images that can be layered. That meant that I also needed to use the `heroku/nodejs` buildpack as well, and couldn’t just leave it to only having a `Procfile` and default to Heroku knowing how to build the app.
And so, add to your `app.json` (or create one, I guess), the following buildpacks directives:
```
{
"buildpacks": [
{
"url": "https://github.com/mxschmitt/heroku-playwright-buildpack.git"
},
{
"url": "https://github.com/heroku/heroku-buildpack-nodejs"
}
]
}
```
And then, you can deploy your app to Heroku and it should work. The Playwright browser dependencies should be installed and you should be able to run your Playwright tests on Heroku.
## Follow-up Playwright Heroku Deployment Resources
See the official Heroku documentation for a [Playwright community buildpack](https://elements.heroku.com/buildpacks/playwright-community/heroku-playwright-buildpack) and an [example Express Playwright repository](https://github.com/playwright-community/heroku-playwright-buildpack) for practical examples. | lirantal |
1,868,790 | AWS DevOps Projects List 2024 | Here are some mini projects and exercises related to various areas in DevOps, SRE, Platform... | 27,495 | 2024-05-31T00:00:00 | https://dev.to/aws-builders/aws-devops-projects-list-2024-41fn | devops, docker, kubernetes, aws |
Here are some mini projects and exercises related to various areas in DevOps, SRE, Platform Engineering, Cloud Infrastructure, and Security.
1. **Linux Projects**:
- **Linux System Administration**:
- **Story Problem**: You work for a web hosting company. A client's website is experiencing slow performance. Investigate the server logs, identify bottlenecks, optimize configurations, and improve overall system performance.
2. **AWS Solution Architect Projects**:
- **Story Problem**: A startup wants to deploy a scalable web application on AWS. Design an architecture that ensures high availability, fault tolerance, and efficient resource utilization. Consider EC2, S3, RDS, VPC, Route 53, and CloudWatch.
3. **Jenkins OR Circle CI CI/CD Projects**:
- **Story Problem**: A software development team wants to automate their deployment process. Set up a CI/CD pipeline using Jenkins or CircleCI. Include stages for building, testing, and deploying code to production.
4. **IT Resource Monitoring and Alerting: Incident Management**:
- **Story Problem**: Your company's critical application experiences downtime. Implement monitoring using New Relic APM or AppDynamics. Set up alerts for performance degradation and incident response workflows.
5. **APM Tools: New Relic APM, AppDynamics, AWS CloudWatch, Sensu, Nagios, Zabbix, Icinga, Pingdom, Pagerduty (call and SMS), AWS SNS/SES**:
- **Story Problem**: A large e-commerce platform faces intermittent outages. Choose an APM tool and configure it to monitor critical services. Set up alerting and incident management.
6. **Logging Security: Wazuh, Elasticsearch, Logstash, Kibana Stack, Grafana, and Prometheus Tools**:
- **Story Problem**: A security breach occurs. Implement Wazuh for intrusion detection, centralize logs using the ELK stack (Elasticsearch, Logstash, Kibana), and visualize security metrics with Grafana and Prometheus.
7. **Docker Projects**:
- **Story Problem**: A development team wants to containerize their application. Create Docker images for a web app and a database. Set up a Docker Compose file to orchestrate the containers.
8. **AWS ECS Service Projects (How to build the Docker image, push to Docker repo, configure Task definition, Service, CloudWatch log, Scaling of Docker service, Request route from Route53 to Load balance (Path-based routing) to EC2 server to Docker container)**:
- **Story Problem**: A company plans to migrate its microservices to AWS ECS (Elastic Container Service). Build Docker images, set up ECS services, configure auto-scaling, and ensure proper routing using Route 53.
9. **Kubernetes Projects**:
- **Story Problem**: A startup wants to deploy applications on Kubernetes. Set up a local Minikube cluster for development. Explore Kubernetes concepts like pods, services, and deployments. Prepare for the Certified Kubernetes Administrator (CKA) or Certified Kubernetes Application Developer (CKAD) exam.
Feel free to share github repos and make projects opensource and contribute for hands-on experience! 😊 | yashvikothari |
1,871,421 | AWS Cost Optimization To-Do List | Managing AWS cost optimization can be more complicated than anticipated. While it might be more... | 0 | 2024-05-30T23:55:32 | https://dev.to/nmend/aws-cost-optimization-to-do-list-21a1 | devops, aws, cost, job |
Managing AWS cost optimization can be more complicated than anticipated. While it might be more straightforward for companies "born" in the cloud, those that have "migrated" might face increased costs due to the complexity of managing, governing, and automating their on-premises infrastructures.
Many organizations are shifting to models such as platform as a service (PaaS), infrastructure as a service (IaaS), and software as a service (SaaS) for their applications and services. Consequently, understanding your cloud bill and budget with providers like AWS is becoming critical as a significant portion of IT budgets is now allocated to these services. In this article, we explore the key principles and practical methods for reducing cloud expenses.
**1. Identify Waste and Excessive Costs**
**Unused Instances:** Regularly check for and terminate underutilized Amazon EC2 instances.
**Idle Resources:** Identify and remove unused EBS volumes, snapshots, and load balancers.
**Optimize Instances:** Utilize Spot and Reserved Instances for cost savings of 50% to 90%.
**Savings Plans:** Implement Savings Plans to reduce compute costs by committing to a minimum AWS spend.
**Auto-scaling:** Ensure auto-scaling is implemented optimally to avoid over-provisioning resources.
**2. Follow AWS Design Guidelines for Cost Management**
**Assess and Assign Expenses:** Use AWS tools to attribute costs transparently to specific tasks or departments.
**Evaluate Overall Efficiency:** Measure business output relative to costs to find opportunities for cost reduction.
**Adopt Cloud Financial Management:** Invest in processes, resources, and tools to manage cloud finances effectively.
**Avoid Heavy Lifting:** Leverage AWS-managed services to reduce the operational burden.
**Implement a Consumption Model:** Pay only for the resources you need and turn off unused resources to save costs.
**3. Optimize Storage**
**Choose Appropriate Storage Tiers:** Select the right AWS storage options based on performance needs and costs.
**Automate Cost Allocation:** Use cost allocation tags and enforce their use to track expenses accurately.
**Regular Reviews:** Regularly review storage usage and performance to ensure optimal configuration.
**4. Properly Size Resources**
**Right-Size Instances:** Ensure compute resources match your workload requirements to avoid underutilization.
**Monitor Metrics:** Set up monitoring for key metrics to maintain visibility into resource utilization and costs.
**Set Goals and Review Data:** Define clear cost optimization goals and review data regularly to adjust as needed.
**5. Use the Appropriate Pricing Model**
**Select Suitable Pricing Plans:** Choose from spot instances, reserved instances, and on-demand pricing based on your workload demands.
**Match Resources to Needs:** Ensure reserved instances and savings plans are properly utilized for predictable workloads.
**6. Enhance Elasticity**
**Leverage Elasticity Features:** Use AWS’s elasticity to match resource usage with demand, turning off resources when not needed.
**Utilize AWS Cost Optimization Tools**
**1. Cost Explorer**
Visualize and analyze AWS cost and usage data to identify trends and spikes.
**2. AWS Instance Scheduler**
Automate the scheduling of EC2 and RDS instances to match usage patterns.
**3. Amazon CloudWatch**
Set alarms for resource utilization to detect underutilization or unexpected spikes, enabling proactive cost management.
**4. AWS Budgets**
Set up budgets for specific services or accounts and receive notifications when usage exceeds thresholds.
**5. Amazon Trusted Advisor**
Get recommendations on optimizing costs, improving security, and enhancing performance based on best practices.
**6. Cost and Usage Report Tool**
Generate detailed reports on AWS costs and usage to monitor and manage expenditures effectively.
**7. AWS CloudTrail**
Track and log API calls and account activities to identify unusual patterns that may indicate excessive costs.
Effective AWS cost optimization requires a multifaceted approach, involving regular monitoring, strategic use of AWS tools, and continual education and process improvement. By following these principles and best practices, businesses can significantly reduce their cloud expenses while maintaining performance and scalability. | nmend |
1,871,420 | Building Your Dream Team: In-House vs. Outsourced Software Development | The software development world is a battleground of opportunities. You have a vision; a disruptive... | 0 | 2024-05-30T23:54:16 | https://dev.to/liong/building-your-dream-team-in-house-vs-outsourced-software-development-52j9 | softwaredevelopment, outsource, malaysia, kualalumpur | The software development world is a battleground of opportunities. You have a vision; a disruptive app, the next big platform, a digital product ready to change the game. The question is who is going to develop this vision? The [in-house vs outsourced software development](https://ithubtechnologies.com/top-developer-in-malaysia/?utm_source=dev.to&utm_campaign=inhousevsoutsoucedevelopment&utm_id=Offpageseo+2024). The million-dollar question — Do you go in for building your in-house development team or outsource the project? Each has its pros and cons and comes down to what your unique needs are and what resources you have.
Now you will understand that you are going to get a lot more information on these two different software development options, whether it's outsourcing or in-house software development. This will also help you to identify the things that are needed when you are doing outsourced software development or in-house software development.
## Building Your Fortress: The Appeal of In-house Development
Here you are going to get an idea of what makes an in-house development different. The vision in your mind is now a well-oiled team of developers, designers, and project managers all working together seamlessly in-house. In-house development offers a feeling of control and communication clarity:
1. **Direct communication:** You are needed To clarify any feature with anyone at any time, close cooperation allows in-house teams to make decisions quickly and offer feedback in real-time.
2. **Organization with company culture:** When you talk about an in-house development it has an in-house team which is an extension of your company and gains a greater understanding of your vision and values. The result is software that combines effortlessly with the way you work and how your organization works.
3. **Intellectual Property (IP) Security:** This includes maintaining your codebase in-house giving even more control over your delicate documents and licensed innovation.
## But, it is not always a doozy — creating your dream team includes its complications:
When you are trying your best to make a great team, getting sweaty and in pain, but still your hard work pays off, then you forget about the difficulties you faced at that time. Am I right? Now you must be aware of the complications and be aware of them in the future.
- **Cost:** You need to know that money is everything at this point. It takes great financial help to recruit, hire, and maintain top-tier talent. Salaries, benefits, and office space are not cheap, and the costs rapidly accumulate.
- **Scalability:** It can be hard to scale your development team based on the demands of the project. Or you will have trouble scaling to larger projects, or you will have a lot of underutilized resources during slow periods.
- **Finding the right talent:** In the tech talent pool, it is fierce. Recruiting top-notch developers is also equally time-consuming, particularly for a niche like theirs.
## Going Beyond: Outsource Development Pros
Let me explain to you in simple words that you team up with another company that will manage your project or some of the elements of software development including the development process (backend or frontend development), testing, and quality assurance.
## What Makes It Attractive:
- **Cost-Effectiveness:** The outsourced companies usually have a competitive hourly rate, and that too when compared to the cost to build an in-house team. The groundwork is all laid out for you, so the overhead cost is reduced.
- **Global Talent Pool:** Utilize an extended range of skilled developers with diverse backgrounds. This makes sense; outsourcing sources in areas with some of the top technical talent.
- **Scalability:** Add or remove developers from your teams quickly and easily depending on project requirements. You need only to scale resources as per your requirements with Outsourcing partners.
## Outsourcing: Set of Hazards
When you are choosing to outsource development, then you must know that it can have some problems. The problems can be :
1. **Lack of control:** Letting go of the reins in the development process can be scary. They need clear communication which means that the project scope must be well-defined.
2. **Concerns Regarding Intellectual Property:**
Finally, if you want to protect your code base and your proprietary information, then you need a sturdy legal background and security handling.
3. **Connection issue:** Here, sometimes working in different time zones can be a bit of a trouble to tackle everything at one time but it then clashes with another person's time.
## The Hybrid Hero: Dual-path Builds Harnessing The Best of Both
A hybrid approach might be the most likely option. But the good news is that it has the best part which is, that it is the combination of both the on-site and off-site development.
- **Core team in-house:** Have a core team of developers who understand the product and processes of your company.
- **Outsource select tasks:** These outsource select tasks include special tasks. Specialized tasks—such as backend development, testing, or UI/UX design—can be outsourced to a dedicated team for cost efficiency and expert access.
It allows you the advantages of working closely — and closely you must work — while sidestepping many of the problems linked with climbing an in-house team.
## Choosing Your Champion: Factors to Consider
In the end, the choice between in-house development or outsourcing depends on your needs. Some important things to think about include:
- **Difficulty level of the project:** Organizations undertaking complex projects with niche requirements might find the varied skill set of the partner may bring the necessary niche talent to the table.
- **Financial needs:**
In some cases, it may be cheaper to outsource (private equity firms/small companies).
- **Timeline:**
You may not have the necessary time to work and deliver a project by yourself, outsourcing will bring more minds and potentially a faster project.
- **In-House Know-How:**
Can your company handle this entire project internally from a technical standpoint? This is what it matters the most.
## Essentially Building a Software Development Dream Team
There is no silver bullet for software development. In-house outsourced, or a hybrid model, it is important to evaluate your needs and resources with depth. To maximize the benefits of both of these approaches, you need to know the characteristics of each one of them and create a software development team that will execute your vision in a way only your company can.
## Conclusion:
According to the above-highlighted points, it can be concluded that software development of both types like in-house vs outsourced software development, has its very own advantages but disadvantages on the side too. You will thank me later for getting you aware of such things.
| liong |
1,871,396 | Live Coding React Interview Questions | React is one of the most popular libraries for building user interfaces. It's no surprise that React... | 0 | 2024-05-30T23:46:52 | https://dev.to/allenarduino/live-coding-react-interview-questions-2ndh | React is one of the most popular libraries for building user interfaces. It's no surprise that React developers are in high demand. If you're preparing for a React interview, live coding challenges are an essential part of the process. These challenges test your understanding of React concepts, your problem-solving skills, and your ability to write clean, efficient code.
In this blog post, we'll cover 20 advanced React coding challenges that can help you ace your next interview. Each challenge includes a problem description and an example solution to help you understand the concept better. Let's dive in!
**Table of Contents**
1. Create a Counter Component
2. Implement a Toggle Switch
3. Build a To-Do List
4. Fetch Data from an API
5. Create a Search Bar
6. Build a Dropdown Menu
7. Implement a Tabs Component
8. Create a Modal Component
9. Build a Carousel Component
10. Implement a Star Rating Component
11. Create a Real-Time Search Filter
12. Build a Multi-Step Form
13. Implement a Virtualized List
14. Create a Reusable Form Component with Validation
15. Implement a Dynamic Form with Field Arrays
16. Implement a Context API for Global State
17. Create a Custom Hook
18. Build a Todo List with Drag-and-Drop
19. Create a Countdown Timer
20. Implement Formik with Yup Validation
Conclusion
**1. Create a Counter Component.**
***Problem:***
Create a simple counter component that increases or decreases the count when clicking buttons.
***Solution:***
```js
import React, { useState } from 'react';
const Counter = () => {
const [count, setCount] = useState(0);
return (
<div>
<p>Count: {count}</p>
<button onClick={() => setCount(count + 1)}>Increase</button>
<button onClick={() => setCount(count - 1)}>Decrease</button>
</div>
);
};
export default Counter;
```
**2. Implement a Toggle Switch**
***Problem:***
Create a toggle switch component between "On" and "Off" states.
***Solution:***
```js
import React, { useState } from 'react';
const ToggleSwitch = () => {
const [isOn, setIsOn] = useState(false);
return (
<div>
<button onClick={() => setIsOn(!isOn)}>
{isOn ? 'Off' : 'On'}
</button>
</div>
);
};
export default ToggleSwitch;
```
**3. Build a To-Do List**
***Problem:***
Create a to-do list component where users can add, remove, and mark items as complete.
***Solution:***
```js
import React, { useState } from 'react';
const TodoList = () => {
const [todos, setTodos] = useState([]);
const [text, setText] = useState('');
const addTodo = () => {
if (text) {
setTodos([...todos, { text, completed: false }]);
setText('');
}
};
const toggleTodo = index => {
const newTodos = [...todos];
newTodos[index].completed = !newTodos[index].completed;
setTodos(newTodos);
};
const removeTodo = index => {
const newTodos = [...todos];
newTodos.splice(index, 1);
setTodos(newTodos);
};
return (
<div>
<input value={text} onChange={(e) => setText(e.target.value)} placeholder="Add a to-do" />
<button onClick={addTodo}>Add</button>
<ul>
{todos.map((todo, index) => (
<li key={index} style={{ textDecoration: todo.completed ? 'line-through' : 'none' }}>
{todo.text}
<button onClick={() => toggleTodo(index)}>Toggle</button>
<button onClick={() => removeTodo(index)}>Remove</button>
</li>
))}
</ul>
</div>
);
};
export default TodoList;
```
**4. Fetch Data from an API**
***Problem:***
Create a component fetching data from an API and displaying it in a list.
***Solution:***
```js
import React, { useState, useEffect } from 'react';
const DataFetcher = () => {
const [data, setData] = useState([]);
const [loading, setLoading] = useState(true);
useEffect(() => {
fetch('https://api.example.com/data')
.then(response => response.json())
.then(data => {
setData(data);
setLoading(false);
});
}, []);
if (loading) return <p>Loading...</p>;
return (
<ul>
{data.map(item => (
<li key={item.id}>{item.name}</li>
))}
</ul>
);
};
export default DataFetcher;
```
**5. Create a Search Bar**
***Problem:***
Create a search bar component that filters a list of items as the user types.
***Solution:***
```js
import React, { useState } from 'react';
const SearchBar = ({ items }) => {
const [query, setQuery] = useState('');
const filteredItems = items.filter(item =>
item.toLowerCase().includes(query.toLowerCase())
);
return (
<div>
<input
type="text"
value={query}
onChange={e => setQuery(e.target.value)}
placeholder="Search..."
/>
<ul>
{filteredItems.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
</div>
);
};
const App = () => {
const items = ['Apple', 'Banana', 'Cherry', 'Date', 'Elderberry'];
return <SearchBar items={items} />;
};
export default App;
```
**6. Build a Dropdown Menu**
***Problem:***
Create a dropdown menu component that displays a list of items when clicked.
***Solution:***
```js
import React, { useState } from 'react';
const DropdownMenu = ({ items }) => {
const [isOpen, setIsOpen] = useState(false);
return (
<div>
<button onClick={() => setIsOpen(!isOpen)}>Menu</button>
{isOpen && (
<ul>
{items.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
)}
</div>
);
};
const App = () => {
const items = ['Profile', 'Settings', 'Logout'];
return <DropdownMenu items={items} />;
};
export default App;
```
**7. Implement a Tabs Component**
***Problem:***
Create a tabs component where each tab displays different content when selected.
***Solution:***
```js
import React, { useState } from 'react';
const Tabs = ({ tabs }) => {
const [activeTab, setActiveTab] = useState(0);
return (
<div>
<div className="tab-buttons">
{tabs.map((tab, index) => (
<button
key={index}
className={index === activeTab ? 'active' : ''}
onClick={() => setActiveTab(index)}
>
{tab.label}
</button>
))}
</div>
<div className="tab-content">
{tabs[activeTab].content}
</div>
</div>
);
};
const App = () => {
const tabs = [
{ label: 'Tab 1', content: <div>Content of Tab 1</div> },
{ label: 'Tab 2', content: <div>Content of Tab 2</div> },
{ label: 'Tab 3', content: <div>Content of Tab 3</div> },
];
return <Tabs tabs={tabs} />;
};
export default App;
```
**8. Create a Modal Component**
***Problem:***
Create a reusable modal component that can be opened and closed and display any content passed to it.
***Solution:***
```js
import React, { useState, useEffect } from 'react';
import ReactDOM from 'react-dom';
const Modal = ({ isOpen, onClose, children }) => {
useEffect(() => {
if (isOpen) {
document.body.style.overflow = 'hidden';
} else {
document.body.style.overflow = 'auto';
}
}, [isOpen]);
if (!isOpen) return null;
return ReactDOM.createPortal(
<div className="modal-overlay" onClick={onClose}>
<div className="modal-content" onClick={e => e.stopPropagation()}>
<button className="modal-close" onClick={onClose}>Close</button>
{children}
</div>
</div>,
document.body
);
};
const App = () => {
const [isModalOpen, setIsModalOpen] = useState(false);
return (
<div>
<button onClick={() => setIsModalOpen(true)}>Open Modal</button>
<Modal isOpen={isModalOpen} onClose={() => setIsModalOpen(false)}>
<h1>Modal Content</h1>
<p>This is the content inside the modal</p>
</Modal>
</div>
);
};
export default App;
```
**9. Build a Carousel Component**
***Problem:***
Create a carousel component that cycles through a set of images.
***Solution:***
```js
import React, { useState } from 'react';
const Carousel = ({ images }) => {
const [currentIndex, setCurrentIndex] = useState(0);
const goToNext = () => {
setCurrentIndex((currentIndex + 1) % images.length);
};
const goToPrevious = () => {
setCurrentIndex((currentIndex - 1 + images.length) % images.length);
};
return (
<div className="carousel">
<button onClick={goToPrevious}>Previous</button>
<img src={images[currentIndex]} alt="carousel" />
<button onClick={goToNext}>Next</button>
</div>
);
};
const App = () => {
const images = [
'https://via.placeholder.com/600x400?text=Image+1',
'https://via.placeholder.com/600x400?text=Image+2',
'https://via.placeholder.com/600x400?text=Image+3',
];
return <Carousel images={images} />;
};
export default App;
```
**10. Implement a Star Rating Component**
***Problem:***
Create a star rating component where users can rate something from 1 to 5 stars.
***Solution:***
```js
import React, { useState } from 'react';
const StarRating = ({ totalStars = 5 }) => {
const [rating, setRating] = useState(0);
return (
<div>
{[...Array(totalStars)].map((star, index) => {
const starValue = index + 1;
return (
<span
key={index}
onClick={() => setRating(starValue)}
style={{ cursor: 'pointer', color: starValue <= rating ? 'gold' : 'gray' }}
>
★
</span>
);
})}
</div>
);
};
const App = () => {
return (
<div>
<h1>Star Rating</h1>
<StarRating />
</div>
);
};
export default App;
```
**11. Create a Real-Time Search Filter**
***Problem:***
Create a search filter component that filters a list of items in real-time as the user types.
***Solution:***
```js
import React, { useState } from 'react';
const RealTimeSearch = ({ items }) => {
const [query, setQuery] = useState('');
const filteredItems = items.filter(item =>
item.toLowerCase().includes(query.toLowerCase())
);
return (
<div>
<input
type="text"
value={query}
onChange={e => setQuery(e.target.value)}
placeholder="Search..."
/>
<ul>
{filteredItems.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
</div>
);
};
const App = () => {
const items = ['Apple', 'Banana', 'Cherry', 'Date', 'Elderberry'];
return <RealTimeSearch items={items} />;
};
export default App;
```
**12. Build a Multi-Step Form**
***Problem:***
Create a multi-step form where users can navigate between different steps of the form.
***Solution:***
```js
import React, { useState } from 'react';
const Step1 = ({ next }) => (
<div>
<h2>Step 1</h2>
<button onClick={next}>Next</button>
</div>
);
const Step2 = ({ next, previous }) => (
<div>
<h2>Step 2</h2>
<button onClick={previous}>Previous</button>
<button onClick={next}>Next</button>
</div>
);
const Step3 = ({ previous }) => (
<div>
<h2>Step 3</h2>
<button onClick={previous}>Previous</button>
<button type="submit">Submit</button>
</div>
);
const MultiStepForm = () => {
const [step, setStep] = useState(1);
const nextStep = () => setStep(step + 1);
const previousStep = () => setStep(step - 1);
const handleSubmit = (e) => {
e.preventDefault();
console.log('Form submitted');
};
return (
<form onSubmit={handleSubmit}>
{step === 1 && <Step1 next={nextStep} />}
{step === 2 && <Step2 next={nextStep} previous={previousStep} />}
{step === 3 && <Step3 previous={previousStep} />}
</form>
);
};
const App = () => {
return (
<div>
<h1>Multi-Step Form</h1>
<MultiStepForm />
</div>
);
};
export default App;
```
**13. Implement a Virtualized List**
***Problem:***
Create a virtualized list component that efficiently renders a large list of items, only rendering items that are visible within the viewport.
***Solution:***
```js
import React, { useState, useRef, useCallback } from 'react';
const VirtualizedList = ({ items, itemHeight, height }) => {
const [scrollTop, setScrollTop] = useState(0);
const totalHeight = items.length * itemHeight;
const viewportRef = useRef(null);
const handleScroll = () => {
setScrollTop(viewportRef.current.scrollTop);
};
const startIndex = Math.floor(scrollTop / itemHeight);
const endIndex = Math.min(items.length - 1, startIndex + Math.ceil(height / itemHeight));
const visibleItems = items.slice(startIndex, endIndex + 1).map((item, index) => (
<div key={index} style={{ height: itemHeight }}>
{item}
</div>
));
return (
<div ref={viewportRef} onScroll={handleScroll} style={{ height, overflowY: 'auto', position: 'relative' }}>
<div style={{ height: totalHeight, position: 'relative' }}>
<div style={{ position: 'absolute', top: startIndex * itemHeight, width: '100%' }}>
{visibleItems}
</div>
</div>
</div>
);
};
const App = () => {
const items = Array.from({ length: 1000 }, (_, i) => `Item ${i + 1}`);
return (
<div>
<VirtualizedList items={items} itemHeight={50} height={400} />
</div>
);
};
export default App;
```
**14. Create a Reusable Form Component with Validation**
***Problem:***
Build a reusable form component that handles form state and validation for various form fields.
***Solution:***
```js
import React, { useState } from 'react';
const useForm = (initialValues, validate) => {
const [values, setValues] = useState(initialValues);
const [errors, setErrors] = useState({});
const handleChange = (e) => {
const { name, value } = e.target;
setValues({ ...values, [name]: value });
const error = validate({ [name]: value });
setErrors({ ...errors, [name]: error[name] });
};
const handleSubmit = (callback) => (e) => {
e.preventDefault();
const validationErrors = validate(values);
setErrors(validationErrors);
if (Object.keys(validationErrors).length === 0) {
callback();
}
};
return { values, errors, handleChange, handleSubmit };
};
const Form = ({ onSubmit }) => {
const initialValues = { username: '', email: '' };
const validate = (values) => {
const errors = {};
if (!values.username) {
errors.username = 'Username is required';
}
if (!values.email) {
errors.email = 'Email is required';
} else if (!/\S+@\S+\.\S+/.test(values.email)) {
errors.email = 'Email is invalid';
}
return errors;
};
const { values, errors, handleChange, handleSubmit } = useForm(initialValues, validate);
return (
<form onSubmit={handleSubmit(() => onSubmit(values))}>
<div>
<label>Username</label>
<input name="username" value={values.username} onChange={handleChange} />
{errors.username && <p>{errors.username}</p>}
</div>
<div>
<label>Email</label>
<input name="email" value={values.email} onChange={handleChange} />
{errors.email && <p>{errors.email}</p>}
</div>
<button type="submit">Submit</button>
</form>
);
};
const App = () => {
const handleSubmit = (values) => {
console.log('Form Submitted:', values);
};
return (
<div>
<h1>Reusable Form</h1>
<Form onSubmit={handleSubmit} />
</div>
);
};
export default App;
```
**15. Implement a Dynamic Form with Field Arrays**
***Problem:***
Create a dynamic form that allows users to add or remove fields dynamically.
***Solution:***
```js
import React, { useState } from 'react';
const DynamicForm = () => {
const [fields, setFields] = useState([{ value: '' }]);
const handleChange = (index, event) => {
const newFields = fields.slice();
newFields[index].value = event.target.value;
setFields(newFields);
};
const handleAdd = () => {
setFields([...fields, { value: '' }]);
};
const handleRemove = (index) => {
const newFields = fields.slice();
newFields.splice(index, 1);
setFields(newFields);
};
const handleSubmit = (e) => {
e.preventDefault();
console.log('Form submitted:', fields);
};
return (
<form onSubmit={handleSubmit}>
{fields.map((field, index) => (
<div key={index}>
<input
type="text"
value={field.value}
onChange={(e) => handleChange(index, e)}
/>
<button type="button" onClick={() => handleRemove(index)}>Remove</button>
</div>
))}
<button type="button" onClick={handleAdd}>Add Field</button>
<button type="submit">Submit</button>
</form>
);
};
const App = () => {
return (
<div>
<h1>Dynamic Form</h1>
<DynamicForm />
</div>
);
};
export default App;
```
**16. Implement a Context API for Global State**
***Problem:***
Create a global state using React's Context API to manage the state of posts across the application.
***Solution:***
```js
import React, { createContext, useContext, useReducer } from 'react';
// Create a Context for the posts
const PostsContext = createContext();
// Define a reducer to manage the state of posts
const postsReducer = (state, action) => {
switch (action.type) {
case 'ADD_POST':
return [...state, action.payload];
case 'REMOVE_POST':
return state.filter((post, index) => index !== action.payload);
default:
return state;
}
};
// Create a provider component
const PostsProvider = ({ children }) => {
const [posts, dispatch] = useReducer(postsReducer, []);
return (
<PostsContext.Provider value={{ posts, dispatch }}>
{children}
</PostsContext.Provider>
);
};
// Create a custom hook to use the PostsContext
const usePosts = () => {
return useContext(PostsContext);
};
const App = () => {
const { posts, dispatch } = usePosts();
const addPost = () => {
dispatch({ type: 'ADD_POST', payload: 'New Post' });
};
const removePost = (index) => {
dispatch({ type: 'REMOVE_POST', payload: index });
};
return (
<div>
<button onClick={addPost}>Add Post</button>
<ul>
{posts.map((post, index) => (
<li key={index}>
{post} <button onClick={() => removePost(index)}>Remove</button>
</li>
))}
</ul>
</div>
);
};
const Root = () => (
<PostsProvider>
<App />
</PostsProvider>
);
export default Root;
```
**17. Create a Custom Hook**
***Problem:***
Create a custom hook that fetches and caches data from an API.
***Solution:***
```js
import { useState, useEffect } from 'react';
const useFetch = (url) => {
const [data, setData] = useState(null);
const [loading, setLoading] = useState(true);
const [error, setError] = useState(null);
useEffect(() => {
let isMounted = true;
fetch(url)
.then((response) => response.json())
.then((data) => {
if (isMounted) {
setData(data);
setLoading(false);
}
})
.catch((error) => {
if (isMounted) {
setError(error);
setLoading(false);
}
});
return () => {
isMounted = false;
};
}, [url]);
return { data, loading, error };
};
const App = () => {
const { data, loading, error } = useFetch('https://api.example.com/data');
if (loading) return <p>Loading...</p>;
if (error) return <p>Error: {error.message}</p>;
return (
<ul>
{data.map((item) => (
<li key={item.id}>{item.name}</li>
))}
</ul>
);
};
export default App;
```
**18. Build a Todo List with Drag-and-Drop**
***Problem:***
Create a todo list application with drag-and-drop functionality to reorder items.
***Solution:***
```js
import React, { useState } from 'react';
import { DragDropContext, Droppable, Draggable } from 'react-beautiful-dnd';
const TodoList = () => {
const [todos, setTodos] = useState([
'Learn React',
'Learn Redux',
'Build a React App',
]);
const handleOnDragEnd = (result) => {
if (!result.destination) return;
const reorderedTodos = Array.from(todos);
const [removed] = reorderedTodos.splice(result.source.index, 1);
reorderedTodos.splice(result.destination.index, 0, removed);
setTodos(reorderedTodos);
};
return (
<DragDropContext onDragEnd={handleOnDragEnd}>
<Droppable droppableId="todos">
{(provided) => (
<ul {...provided.droppableProps} ref={provided.innerRef}>
{todos.map((todo, index) => (
<Draggable key={todo} draggableId={todo} index={index}>
{(provided) => (
<li ref={provided.innerRef} {...provided.draggableProps} {...provided.dragHandleProps}>
{todo}
</li>
)}
</Draggable>
))}
{provided.placeholder}
</ul>
)}
</Droppable>
</DragDropContext>
);
};
const App = () => {
return (
<div>
<h1>Todo List with Drag-and-Drop</h1>
<TodoList />
</div>
);
};
export default App;
```
**19. Create a Countdown Timer**
***Problem:***
Create a countdown timer component that counts down from a given time.
***Solution:***
```js
import React, { useState, useEffect } from 'react';
const CountdownTimer = ({ initialSeconds }) => {
const [seconds, setSeconds] = useState(initialSeconds);
useEffect(() => {
const timer = setInterval(() => {
setSeconds((prevSeconds) => prevSeconds - 1);
}, 1000);
return () => clearInterval(timer);
}, []);
return (
<div>
<h1>Countdown Timer</h1>
<p>{seconds} seconds remaining</p>
</div>
);
};
const App = () => {
return (
<div>
<CountdownTimer initialSeconds={60} />
</div>
);
};
export default App;
```
**20. Implement Formik with Yup Validation**
***Problem:***
Create a form with validation using Formik and Yup.
***Solution:***
```js
import React from 'react';
import { Formik, Form, Field, ErrorMessage } from 'formik';
import * as Yup from 'yup';
const validationSchema = Yup.object().shape({
username: Yup.string().required('Username is required'),
email: Yup.string().email('Invalid email').required('Email is required'),
});
const App = () => {
return (
<div>
<h1>Formik Form with Yup Validation</h1>
<Formik
initialValues={{ username: '', email: '' }}
validationSchema={validationSchema}
onSubmit={(values) => {
console.log('Form Submitted', values);
}}
>
{() => (
<Form>
<div>
<label>Username</label>
<Field name="username" />
<ErrorMessage name="username" component="div" />
</div>
<div>
<label>Email</label>
<Field name="email" type="email" />
<ErrorMessage name="email" component="div" />
</div>
<button type="submit">Submit</button>
</Form>
)}
</Formik>
</div>
);
};
export default App;
```
**Conclusion**
These coding challenges cover various React concepts and techniques, from state management and hooks to custom components and libraries. Each challenge provides a problem and a solution, helping you build practical skills that can be applied in real-world projects. Whether preparing for an interview or just looking to improve your React knowledge, these challenges are a great way to practice and learn. Happy coding!
| allenarduino | |
1,871,416 | Local Reverse Proxy | Laziness drove me to install NGINX as a reverse proxy and to set up a local domain name with a... | 0 | 2024-05-30T23:44:02 | https://dev.to/tboreux/local-reverse-proxy-26ig | nginx, macos, docker, certificates |
*Laziness drove me to install NGINX as a reverse proxy and to set up a local domain name with a self-signed certificate.*
## Context
On my Mac, I have installed [Docker](https://www.docker.com) and deployed several applications within their containers. I don't need to access these applications over the Internet, so I keep them local, accessing them with my browser using `localhost` and their exposed ports.
However, I'm tired of remembering the ports. To simplify access, I decided to install NGINX on my Mac to set up a local reverse proxy.
## Installation
I'm using [Homebrew](https://brew.sh), so the installation is straightforward:
```bash
brew install nginx
```
Now, NGINX is installed on my Mac, nothing complicated.
## NGINX Configuration
By default, NGINX serves content on port 8080. I want to change it to port 80:
```bash
vim /usr/local/etc/nginx/nginx.conf
```
Search for the `http` block. Inside it, there is a `server` block. In this `server` block, change `listen 8080;` to `listen 80;`.
## SSL Configuration
If you're going to use a custom local domain name, you might as well use a self-signed SSL certificate. I'll use [OpenSSL](https://www.openssl.org) for this:
```bash
openssl req -x509 -newkey rsa:4096 -sha256 -days 3650 \
-nodes -keyout home.arpa.key -out home.arpa.crt -subj "/CN=home.arpa" \
-addext "subjectAltName=DNS:home.arpa,DNS:*.home.arpa,IP:127.0.0.1"
```
You can replace `home.arpa` with your custom domain name.
Once you have your `.key` and `.crt` files, store them carefully. I chose to copy them to a folder next to `nginx.conf`:
```bash
mkdir -p /usr/local/etc/nginx/ssl
mv home.arpa.key home.arpa.crt /usr/local/etc/nginx/ssl/
```
## Server Block Creation
Instead of having one large `nginx.conf` file with all my server declarations, I decided to use the `servers/` directory in `/usr/local/etc/nginx/servers`:
```bash
vim /usr/local/etc/nginx/servers/portainer.home.arpa.conf
```
### Configuration Example
```nginx
server {
listen 443 ssl;
server_name portainer.home.arpa;
ssl_certificate /usr/local/etc/nginx/ssl/home.arpa.crt;
ssl_certificate_key /usr/local/etc/nginx/ssl/home.arpa.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_prefer_server_ciphers on;
ssl_ciphers HIGH:!aNULL:!MD5;
location / {
proxy_pass https://127.0.0.1:9443;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
server {
listen 80;
server_name portainer.home.arpa;
return 301 https://$host$request_uri;
}
```
## NGINX Restart
To apply the changes, restart NGINX with:
```bash
sudo brew services restart nginx
```
## Local DNS
Don't forget to update your local DNS. Add this line to your `/etc/hosts` file:
```bash
127.0.0.1 portainer.home.arpa
```
## Conclusion
That's it! Now, you can browse your application using `https://portainer.home.arpa` instead of `https://127.0.0.1:9443`.
Happy me! 🌱 | tboreux |
1,871,415 | [Winforms] Rate my UI (UNFINISHED) | THIS IS ONLY A UI DESIGN Rate my UI (UNFINISHED) -> https://streamable.com/lo04d9 🎨 This is my... | 0 | 2024-05-30T23:37:58 | https://dev.to/cdx_/winforms-rate-my-ui-unfinished-25hn | csharp, design, winform, dotnetframework | **THIS IS ONLY A UI DESIGN**
Rate my UI (UNFINISHED) -> **https://streamable.com/lo04d9**
🎨 This is my third Exploit UI which ive made in WinForms.
💻 Things i can do using C# .NET:
- Custom high Quality Loader Design's.
- Remake Loader's which are made in C# .NET.
- High Quality Console Design's.
- Basic Protected C# .NET Loaders
🛒 If your intrested buying any of my uis, or if you would like a custom UI make sure to contact me on discord!
My Discord User is **physmeme**
My Discord Nickname is: **Cdx_**
🏬 My Market for C# .NET Winform UI's [](https://discord.gg/WsSnAY4czC)
https://discord.gg/w6BJCNtBdT
❓ What does my Market have?
- We provide High Quality C# .NET Designs (Console and Winform)
- Secure Obfuscation Service for C# .NET, and unity.
Some other **Designs** by me:
**
| cdx_ |
1,871,414 | GUARANTEED BITCOIN RECOVERY HACKER HIRE DANIEL MEULI WEB RECOVERY | I dropped out of college four years ago to fully concentrate on day trading. I saw Bitcoin as a gold... | 0 | 2024-05-30T23:36:56 | https://dev.to/francine_pascal_a78c72d3e/guaranteed-bitcoin-recovery-hacker-hire-daniel-meuli-web-recovery-1234 | I dropped out of college four years ago to fully concentrate on day trading. I saw Bitcoin as a gold mine after my close friend, who was successful in the field, mentored me for over a year. I started off with a $15,000 investment just to test the waters. To my delight, I made over $60,000 in a span of six months. Encouraged by this success, I invested an even more substantial amount—up to $390,000.For the first two years, things went well. I decided to switch brokers due to constant changes in rates. The new broker’s rates were attractive to any trader, and I thought it would be a good move. Little did I know, it was the worst decision of my life. The new broker turned out to be a scam. When I tried to withdraw my profits, I was met with delays and poor communication. My emails were ignored, and my calls went unanswered. Panic set in as I realized that my substantial investment was at risk. The trading site eventually went offline, and I was left in the dark. Feeling desperate, I shared my experience with a fellow trader who had faced a similar situation. He recommended Daniel Meuli Web Recovery, a team that had helped him recover his account. I reached out to them, hoping for a miracle. Daniel Meuli Web Recovery proved to be a beacon of hope. Their team was relentless in tracking down the scammers and recovering my account. They provided me with the support and guidance I desperately needed during this crisis. Without their help, I might have never recovered my losses. Switching brokers turned out to be the worst decision I ever made, but reaching out to Daniel Meuli Web Recovery was the best. They acted quickly and professionally, helping me through a very dark time. My experience is a cautionary tale. Be vigilant and skeptical with online investments. Trust must be earned, and it’s crucial to safeguard your financial well-being. If you ever find yourself in a similar situation, remember that there are experts like Daniel Meuli Web Recovery who can help you find a way out. Email hireus (@) danielmeulirecoverywizard (.) online Telegram (@) Danielmeuli | francine_pascal_a78c72d3e | |
1,871,413 | ONLINE EXAM HELP AND EDUCATION SERVICES | Online exam help and education services offer valuable resources and support for students navigating... | 0 | 2024-05-30T23:28:54 | https://dev.to/maxx1/online-exam-help-and-education-services-39h5 | onlinneexam, help | Online exam help and education services offer valuable resources and support for students navigating their academic journey. These services provide assistance in various forms, including tutoring, exam preparation, study guides, and access to educational materials. Whether you need help understanding complex concepts, preparing for exams, or improving your study skills, online exam help and education services can offer personalized guidance to meet your needs. While some may be tempted to <a href='https://getexamdone.com/'>hire someone to do my exam</a> or <a href='https://getexamdone.com/'>take my exam online</a> , it's essential to engage with these services ethically and responsibly. Additionally, they often leverage technology to provide convenient and flexible learning options, such as virtual classrooms, interactive quizzes, and on-demand tutoring sessions. By utilizing these services, students can enhance their academic performance, build confidence in their abilities, and achieve their educational goals more effectively. | maxx1 |
1,871,411 | Creating a Table Component in React with Tailwind CSS | Introduction Building a reusable and customizable table component in React can... | 0 | 2024-05-30T23:28:49 | https://dev.to/timmy471/creating-a-table-component-in-react-with-tailwind-css-2he3 | ## Introduction
Building a reusable and customizable table component in React can significantly streamline your development process, especially when working on data-driven applications. Leveraging Tailwind CSS for styling ensures that your table is both stylish and responsive. In this article, we'll walk through the steps to create a fully functional table component in React using Tailwind CSS.
## Prerequisites
Before we begin, ensure you have the following set up:
1. Node.js and npm installed.
2. A React project set up. You can create one using Create React App:
```
npx create-react-app react-tailwind-table
cd react-tailwind-table
```
3. Tailwind CSS installed and configured. Follow the official Tailwind CSS installation guide for React.
###Step 1: Setting Up Tailwind CSS
First, set up Tailwind CSS in your React project. If you haven't already, follow these steps:
1. Install Tailwind CSS and its dependencies:
```
npm install -D tailwindcss postcss autoprefixer
```
2. Initialize Tailwind CSS:
```
npx tailwindcss init -p
```
3. Configure tailwind.config.js:
```
/** @type {import('tailwindcss').Config} */
module.exports = {
content: [
"./src/**/*.{js,jsx,ts,tsx}",
],
theme: {
extend: {},
},
plugins: [],
}
```
4. Add Tailwind CSS directives to src/index.css:
```
@tailwind base;
@tailwind components;
@tailwind utilities;
```
#### Step 2: Creating the Table Component
Create a new file Table.js in the src/components directory. This component will be responsible for rendering the table.
```
import React from 'react';
const Table = ({ columns, data }) => {
return (
<div className="overflow-x-auto">
<table className="min-w-full bg-white border border-gray-200">
<thead className="bg-gray-200">
<tr>
{columns.map((column) => (
<th
key={column.accessor}
className="py-2 px-4 border-b border-gray-200 text-left text-gray-600"
>
{column.Header}
</th>
))}
</tr>
</thead>
<tbody>
{data.map((row, rowIndex) => (
<tr key={rowIndex} className="even:bg-gray-50">
{columns.map((column) => (
<td
key={column.accessor}
className="py-2 px-4 border-b border-gray-200 text-gray-800"
>
{row[column.accessor]}
</td>
))}
</tr>
))}
</tbody>
</table>
</div>
);
};
export default Table;
```
#### Explanation
**Props:**
- `columns`: An array of objects defining the headers and accessors for the table columns.
- `data`: An array of objects representing the rows of data to display.
**Table Structure**
- The table is wrapped in a div with overflow-x-auto to ensure it is scrollable on smaller screens.
- The table element uses Tailwind CSS classes for styling.
- The thead contains the table headers, which are dynamically generated from the columns prop.
- The tbody contains the table rows, dynamically generated from the data prop. Each row alternates background colors using the even:bg-gray-50 class.
## Step 3: Using the Table Component
Now, let's use the `Table` component in our application. Update src/App.js to include the table component with sample data.
```
import React from 'react';
import Table from './components/Table';
const App = () => {
const columns = [
{ Header: 'Name', accessor: 'name' },
{ Header: 'Age', accessor: 'age' },
{ Header: 'Email', accessor: 'email' },
];
const data = [
{ name: 'John Doe', age: 28, email: 'john@example.com' },
{ name: 'Jane Smith', age: 34, email: 'jane@example.com' },
{ name: 'Mike Johnson', age: 45, email: 'mike@example.com' },
];
return (
<div className="container mx-auto p-4">
<h1 className="text-2xl font-bold mb-4">User Table</h1>
<Table columns={columns} data={data} />
</div>
);
};
export default App;
```
#### Explanation
- The columns array defines the table headers and the keys to access each column's data in the data array.
- The data array contains the sample data to be displayed in the table.
- The Table component is rendered inside a div with Tailwind CSS classes for padding and styling.
## Conclusion
You've now created a reusable and customizable table component in React using Tailwind CSS. This component can easily be extended with additional features such as sorting, filtering, and pagination. By leveraging the power of Tailwind CSS, you ensure that your table is responsive and visually appealing across different screen sizes.
| timmy471 | |
1,871,410 | Beginners Coding Troubles | I think the coolest function that I’ve learned and not struggle too much with is the fetch request... | 0 | 2024-05-30T23:24:08 | https://dev.to/daphneynep/beginners-coding-troubles-4481 | I think the coolest function that I’ve learned and not struggle too much with is the fetch request function. I felt like with everything I had to learn and digest this was it for me. Below is what I was able to use to get some data that we need to work with.
Fetch(“string representing a URL to a data source”)
.then(response => response.json()
.then(data => console.log(‘data’)
You can also do:
Fetch(“string representing a URL to a data source”)
.then(response => {
Console.log(response)
Return response.json()
.then(data => {
Console.log(data)
There’s a lot I had to learned these past four weeks about coding and there’s more to come. Although I had a lot of challenging moments where I was confused on what code to use or what certain verbiages mean, I was still able to understand a lot of information that wasn’t familiar with. Maybe I am over thinking it but I’m understanding it little by little, because this is all new to me. I’ve also realized that I need to practice and do more of coding samples, to increase the level of my understanding and get more familiar with coding. Going into this course I wasn’t sure what to expect but I do have an appreciation for those who are learning or who have already mastered this field.
| daphneynep | |
1,871,408 | Azure Storage - On-Behalf-Of token and audit log | Azure Storage - On-Behalf-Of token and audit log | 0 | 2024-05-30T22:59:02 | https://dev.to/campelo/azure-storage-on-behalf-of-token-and-audit-log-502l | onbehalfof, blob, storage, token | ---
title: Azure Storage - On-Behalf-Of token and audit log
published: true
description: Azure Storage - On-Behalf-Of token and audit log
tags: 'onbehalfof, blob, storage, token'
cover_image: 'https://raw.githubusercontent.com/campelo/documentation/master/posts/azure/assets/cover.png'
canonical_url: null
id: 1871408
---
###### :postbox: Contact :brazil: :us: :fr:
[Twitter](https://twitter.com/campelo87)
[LinkedIn](https://www.linkedin.com/in/flavio-campelo/?locale=en_US)
# Setting Up Front-End and Back-End Applications with Azure Blob Storage Access
This document provides a step-by-step guide to configure Front-End (FE) and Back-End (BE) applications to access Azure Blob Storage using the On-Behalf-Of (OBO) flow.
## Prerequisites
- Azure Subscription
- Azure CLI
- Visual Studio or any C# development environment
## Steps
### 1. Register Back-End (BE) Application in Azure AD
1. **Register the BE Application:**
- Navigate to "Microsoft Entra ID" > "App registrations".
- Click on "New registration".
- Note the `Application (client) ID` and `Directory (tenant) ID`.
2. **Add Client Secret:**
- Go to "Certificates & secrets".
- Add a new client secret and note it down.
3. **Expose API:**
- Go to "Expose an API".
- Add a new scope, e.g., `api://{client_id_be}/user_impersonation`.
4. **Add API Permissions:**
- Go to "API Permissions".
- Add delegated and application permissions for `https://storage.azure.com/.default`.
### 2. Register Front-End (FE) Application in Azure AD
1. **Register the FE Application:**
- Navigate to "Microsoft Entra ID" > "App registrations".
- Click on "New registration".
- For this sample we are using mobile and desktop applications.
- Note the `Application (client) ID` and `Directory (tenant) ID`.
2. **Configure Redirect URI:**
- Go to "Authentication" under the FE application.
- Add a Redirect URI (e.g., `http://localhost`).
3. **Add API Permissions:**
- Go to "API Permissions".
- Click on "Add a permission".
- Select "Microsoft Graph" and add delegated permissions such as `user.read`.
- Click on "Add a permission" again.
- Select "APIs My organization uses" and find the BE application.
- Add the delegated permission `api://{client_id_be}/user_impersonation`.
4. **Grant Admin Consent:**
- Ensure admin consent is granted for the added permissions.
### 3. Configure Azure Blob Storage
1. **Create a Storage Account:**
- Navigate to "Storage accounts" and create a new storage account.
- Note the storage account name.
2. **Create a Container:**
- Inside the storage account, create a new container.
- Note the container name.
3. **Assign Roles:**
- Go to the storage account.
- Navigate to "Access Control (IAM)".
- Click on "Add role assignment".
- Assign roles like `Storage Blob Data Reader` or `Storage Blob Data Contributor` to the appropriate users or service principals.
4. **Enable logging in Azure Storage Container:**
- Go to the storage account.
- Navigate to "Diagnostics settings".
- Click on the resource to view diagnostic settings.
- Click on "Add diagnostic setting".
- Select "StorageAccountLog" and "Blob".
- Click on "Review + create" and then "Create".
- This will enable logging for the Azure Storage Container.
### 4. Implement the Code
This sample uses a console application for demo purposes only. After creating a new application, you have to install these nuget packages.
```
Azure.Storage.Blobs
Microsoft.Identity.Client
```
You can get the sample code [here](https://github.com/campelo/obo-blob-storage).
```csharp
using Azure.Core;
using Azure.Storage.Blobs;
using Microsoft.Identity.Client;
using System;
using System.Threading;
using System.Threading.Tasks;
string tenantId = "tenant_id";
// FE
string clientIdFE = "fe_id";
string[] scopesFE = { "user.read", "api://be_id/user_impersonation" };
// BE
string clientIdBE = "be_id";
string clientSecretBE = "be_secret";
string[] scopesBE = new[] { "https://storage.azure.com/.default" };
// BLOB
string storageAccountName = "storage_name";
string containerName = "container_name";
string blobName = "blob_name";
string userAccessToken = await GetUserAccessTokenAsync();
Console.WriteLine($"User Access Token: {userAccessToken}");
string oboToken = await GetOboTokenAsync(userAccessToken);
Console.WriteLine($"OBO Token: {oboToken}");
await AccessBlobStorageAsync(oboToken);
async Task<string> GetUserAccessTokenAsync()
{
var app = PublicClientApplicationBuilder.Create(clientIdFE)
.WithAuthority(new Uri($"https://login.microsoftonline.com/{tenantId}"))
.WithRedirectUri("http://localhost")
.Build();
var accounts = await app.GetAccountsAsync();
AuthenticationResult result;
try
{
result = await app.AcquireTokenSilent(scopesFE, accounts.FirstOrDefault())
.ExecuteAsync();
}
catch (MsalUiRequiredException)
{
result = await app.AcquireTokenInteractive(scopesFE)
.ExecuteAsync();
}
return result.AccessToken;
}
async Task<string> GetOboTokenAsync(string userAccessToken)
{
var confidentialClient = ConfidentialClientApplicationBuilder.Create(clientIdBE)
.WithClientSecret(clientSecretBE)
.WithAuthority(new Uri($"https://login.microsoftonline.com/{tenantId}"))
.Build();
var oboResult = await confidentialClient.AcquireTokenOnBehalfOf(scopesBE, new UserAssertion(userAccessToken))
.ExecuteAsync();
return oboResult.AccessToken;
}
async Task AccessBlobStorageAsync(string oboToken)
{
TokenCredential tokenCredential = new ObTokenCredential(oboToken);
BlobServiceClient blobServiceClient = new BlobServiceClient(new Uri($"https://{storageAccountName}.blob.core.windows.net"), tokenCredential);
BlobContainerClient containerClient = blobServiceClient.GetBlobContainerClient(containerName);
BlobClient blobClient = containerClient.GetBlobClient(blobName);
var response = await blobClient.DownloadAsync();
using (var stream = response.Value.Content)
{
Console.WriteLine("Blob content read successfully.");
}
}
class ObTokenCredential : TokenCredential
{
private readonly string _token;
public ObTokenCredential(string token)
{
_token = token;
}
public override AccessToken GetToken(TokenRequestContext requestContext, CancellationToken cancellationToken)
{
return new AccessToken(_token, DateTimeOffset.MaxValue);
}
public override ValueTask<AccessToken> GetTokenAsync(TokenRequestContext requestContext, CancellationToken cancellationToken)
{
return new ValueTask<AccessToken>(new AccessToken(_token, DateTimeOffset.MaxValue));
}
}
```
### 5. Check OBO and logs
Run the code and check the logs to see all information about who accessed the file.
## Conclusion
By following these steps, you can configure FE and BE applications to access Azure Blob Storage using the On-Behalf-Of (OBO) flow. Ensure all permissions and configurations are correctly set in Azure AD and the Blob Storage account.
---
## Typos or suggestions?
If you've found a typo, a sentence that could be improved or anything else that should be updated on this blog post, you can access it through a git repository and make a pull request. If you feel comfortable with github, instead of posting a comment, please go directly to https://github.com/campelo/documentation and open a new pull request with your changes.
| campelo |
1,850,723 | Thoughts about SOLID - The Letter "I" | In this fifth part of my reflections, we continue with the letter "I," following the order proposed... | 27,430 | 2024-05-30T22:48:24 | https://dev.to/mdeamp/thoughts-about-solid-the-letter-i-3gp7 | solidprinciples, programming, designpatterns, typescript | In this fifth part of my reflections, we continue with the letter "I," following the order proposed by the SOLID acronym. I will use TypeScript in the examples.
---
## In this article
[Interface Segregation Principle](#interface-segregation-principle)
[Abstract example](#abstract-example)
[Technical example (Front-End)](#technical-example-frontend)
[Technical example (Back-End)](#technical-example-backend)
[Personal example](#personal-example)
[Functional example](#functional-example)
[Applicabilities](#applicabilities)
[Final thoughts](#final-thoughts)
---
## Interface Segregation Principle
A very important starting point is the fact that this principle is the **only principle focused on interfaces, not classes**. It is expected that the reader understands this difference, but a very practical summary is: interfaces define what a class should implement.
The Interface Segregation Principle proposes that **a class should not depend on methods it does not need**, and that one should prefer **multiple interfaces over a single interface with multiple responsibilities**.
The most interesting aspect is how this principle fits with the theme of the first principle, **Single Responsibility**. Both promote the idea of segregation of responsibilities and guide the development of the system towards ensuring class scalability. A class or interface with many responsibilities is naturally more complicated to manage, as an improper change can cause many undesirable side effects.
Let's understand, with examples, how we can identify and apply this principle.
---
## Abstract example
Let's continue with our **library** example. This time, imagine that the library has not only books but also DVDs and Blu-Rays of movies and series. Well, in this scenario:
- Each **library item** should be mapped;
- We would like to know the name of each item through a method;
- For books, we would like to know the number of pages;
- For movies and series, we would like to know the duration;
**🔴 Incorrect Implementation**
```typescript
// Let's imagine an interface that requires the implementation of three methods.
interface LibraryItem {
getName(): string; // For both books and series/movies, we want to know the item's name.
getPages(): number; // Only for books, how many pages it has.
getDuration(): number; // Only for series and movies, what the duration is in minutes.
}
// Now, let's create our Book class, implementing the LibraryItem interface.
// This will force us to comply with what the LibraryItem contains. Let's follow along.
class Book implements LibraryItem {
constructor(private title: string, private pages: number) {}
// No problems with this method.
getName() {
return this.title;
}
// No problems with this method.
getPages(): number {
return this.pages;
}
getDuration(): number {
// PRINCIPLE VIOLATION: The getDuration method, although it belongs to library items,
// doesn't make sense in the context of books and will not be implemented.
// Therefore, books are forced to depend on and implement a method they don't use.
throw new Error("Books do not have a duration in minutes");
}
}
class DVD implements LibraryItem {
constructor(private title: string, private duration: number) {}
// No problems with this method.
getName(): string {
return this.title;
}
// PRINCIPLE VIOLATION: Same observation as the above item, but now from the perspective
// of movies and series, which don't have a number of pages but are forced to implement.
getPages(): number {
throw new Error("DVDs do not have a number of pages");
}
// No problems with this method.
getDuration(): number {
return this.duration;
}
}
```
**🟢 Correct Implementation**
```typescript
// It is preferable to segregate the interfaces. It is better to have multiple interfaces, each with its own responsibility,
// than a single one that forces classes to implement methods they don't need.
interface LibraryItem {
getName(): string; // Common method for all.
}
interface BookItem {
getPages(): number; // Specific method for books.
}
interface DVDItem {
getDuration(): number; // Specific method for DVDs.
}
// Now, each class implements only what it uses.
class Book implements LibraryItem, BookItem {
constructor(private title: string, private pages: number) {}
getName() {
return this.title;
}
getPages(): number {
return this.pages;
}
}
class DVD implements LibraryItem, DVDItem {
constructor(private title: string, private duration: number) {}
getName(): string {
return this.title;
}
getDuration(): number {
return this.duration;
}
}
```
---
## Technical example (Front-End)
Let's suppose we have 3 types of butons in our application: **PrimaryButton**, **IconButton** and **ToggleButton**. If all of them depend on a single master interface, we can start seeing problems.
**🔴 Incorrect Implementation**
```typescript
// Interface too generic for the various types of buttons that exist.
interface Button {
render(): void; // Method to render the button.
setLabel(label: string): void; // Method to set the button's label.
setIcon(icon: string): void; // Method to associate an icon with the button.
toggle(): void; // Method for toggle buttons, to switch on/off.
}
class PrimaryButton implements Button {
constructor(private label: string) {}
render(): void {
console.log("Rendering button...", this.label);
}
setLabel(label: string): void {
this.label = label;
}
// PRINCIPLE VIOLATION: PrimaryButton doesn't support icons but is forced to implement the method.
setIcon(icon: string): void {
throw new Error("This button does not support icons");
}
// PRINCIPLE VIOLATION: Same observation as above.
toggle(): void {
throw new Error("This button does not support toggle");
}
}
// PRINCIPLE VIOLATION: Below, we have two more classes, IconButton and ToggleButton, which exemplify the opposite of PrimaryButton.
// Each implements its respective method, setIcon and toggle, but is also forced to implement methods they
// don't use.
class IconButton implements Button {
constructor(private label: string, private icon: string) {}
render(): void {
console.log("Rendering button...", this.label, this.icon);
}
setLabel(label: string): void {
this.label = label;
}
setIcon(icon: string): void {
this.icon = icon;
}
toggle(): void {
throw new Error("This button does not support toggle");
}
}
class ToggleButton implements Button {
constructor(private label: string, private state: boolean) {}
render(): void {
console.log("Rendering button...", this.label, this.state);
}
setLabel(label: string): void {
this.label = label;
}
setIcon(icon: string): void {
throw new Error("This button does not support icons");
}
toggle(): void {
this.state = !this.state;
}
}
```
**🟢 Correct Implementation**
```typescript
// The simplicity and elegance of the solution lie in segregating into multiple interfaces, unifying in the
// Button interface what is truly generic.
interface Button {
render(): void;
setLabel(label: string): void;
}
interface WithIcon {
setIcon(icon: string): void;
}
interface WithToggle {
toggle(): void;
}
// Classes now only implement the interfaces they need.
class PrimaryButton implements Button {
constructor(private label: string) {}
render(): void {
console.log("Rendering button...", this.label);
}
setLabel(label: string): void {
this.label = label;
}
}
class IconButton implements Button, WithIcon {
constructor(private label: string, private icon: string) {}
render(): void {
console.log("Rendering button...", this.label, this.icon);
}
setLabel(label: string): void {
this.label = label;
}
setIcon(icon: string): void {
this.icon = icon;
}
}
class ToggleButton implements Button, WithToggle {
constructor(private label: string, private state: boolean) {}
render(): void {
console.log("Rendering button...", this.label, this.state);
}
setLabel(label: string): void {
this.label = label;
}
toggle(): void {
this.state = !this.state;
}
}
```
---
## Technical example (Back-End)
Let's start with the assumption that transactions can be performed on relational databases but not on non-relational databases. We acknowledge that this isn't an absolute truth (it highly depends on the vendor and storage model), but for educational purposes, we'll assume this to be the case.
**🔴 Incorrect Implementation**
```typescript
// Generic interface for databases, implementing connections, queries, and transactions.
interface Database {
connect(): void;
disconnect(): void;
runQuery(query: string): unknown;
startTransaction(): void;
commitTransaction(): void;
rollbackTransaction(): void;
}
// For relational databases, all implementations work.
class RelationalDatabase implements Database {
connect(): void {
console.log("Successfully connected");
}
disconnect(): void {
console.log("Successfully disconnected");
}
runQuery(query: string): unknown {
console.log(`Executing query: ${query}`);
return { ... };
}
startTransaction(): void {
console.log("Transaction - Started");
}
commitTransaction(): void {
console.log("Transaction - Committed");
}
rollbackTransaction(): void {
console.log("Transaction - Rolled back");
}
}
class NonRelationalDatabase implements Database {
connect(): void {
console.log("Successfully connected");
}
disconnect(): void {
console.log("Successfully disconnected");
}
runQuery(query: string): unknown {
console.log(`Executing query: ${query}`);
return { ... };
}
// PRINCIPLE VIOLATION: If transactions don't work for all database types, why is it part of the generic interface, forcing classes to implement it?
startTransaction(): void {
throw new Error("Non-relational databases do not support transactions");
}
commitTransaction(): void {
throw new Error("Non-relational databases do not support transactions");
}
rollbackTransaction(): void {
throw new Error("Non-relational databases do not support transactions");
}
}
```
**🟢 Correct Implementation**
```typescript
// We an still have a generic interface, but we segregate what is considered specific.
interface Database {
connect(): void;
disconnect(): void;
}
interface DatabaseQueries {
runQuery(query: string): unknown;
}
interface DatabaseTransactions {
startTransaction(): void;
commitTransaction(): void;
rollbackTransaction(): void;
}
class RelationalDatabase implements Database, DatabaseQueries, DatabaseTransactions {
connect(): void {
console.log("Successfully connected");
}
disconnect(): void {
console.log("Successfully disconnected");
}
runQuery(query: string): unknown {
console.log(`Executing query: ${query}`);
return { ... };
}
startTransaction(): void {
console.log("Transaction - Started");
}
commitTransaction(): void {
console.log("Transaction - Committed");
}
rollbackTransaction(): void {
console.log("Transaction - Rolled back");
}
}
// Now, our non-relational database only implements what makes sense.
class NonRelationalDatabase implements Database, DatabaseQueries {
connect(): void {
console.log("Successfully connected");
}
disconnect(): void {
console.log("Successfully disconnected");
}
runQuery(query: string): unknown {
console.log(`Executing query: ${query}`);
return { ... };
}
}
```
---
## Personal example
In **Super Mario Kart**, there are some items that are specific to certain characters - a behavior that may be questionable, but that's not the focus of this article. In this scenario, how can we implement the interfaces for these items and adhere to the principle?
**🔴 Incorrect Implementation**
```typescript
interface Items {
throwShell(): void; // Item that any character can have.
throwFire(): void; // Exclusive item of Bowser, being a fireball.
throwMushroom(): void; // Exclusive item of Peach (at the time Princess Toadstool) and Toad.
}
// PRINCIPLE VIOLATION: We will encounter several errors in each of the specific scenarios.
class Mario implements Items {
throwShell(): void {
console.log('Throwing "Shell" item');
}
throwFire(): void {
throw new Error("Mario does not have access to this item.");
}
throwMushroom(): void {
throw new Error("Mario does not have access to this item.");
}
}
class Bowser implements Items {
throwShell(): void {
console.log('Throwing "Shell" item');
}
throwFire(): void {
console.log('Throwing "Fire" item');
}
throwMushroom(): void {
throw new Error("Bowser does not have access to this item.");
}
}
class Princess implements Items {
throwShell(): void {
console.log('Throwing "Shell" item');
}
throwFire(): void {
throw new Error("Princess does not have access to this item.");
}
throwMushroom(): void {
console.log('Throwing "Mushroom" item');
}
}
```
**🟢 Correct Implementation**
```typescript
// We can split our single interface into multiple interfaces, separating what's generic from what's specific.
interface CommonItems {
throwShell(): void;
}
interface FireSpecialItems {
throwFire(): void;
}
interface MushroomSpecialItems {
throwMushroom(): void;
}
```
---
## Functional example
Let's imagine **a data processor interface**. We would like to parse both JSON and CSV files, but each with its own specificity. If we implement the options for each of them in a unified way, we may violate the principle.
**🔴 Incorrect Implementation**
```typescript
// In this interface, we define a function that processes data.
type DataProcessor = (
data: string, // The data to be processed.
jsonToObject: boolean, // Only for JSON, indicating whether to convert to object.
csvSeparator: string // Only for CSV, indicating the column separator.
) => string[];
// PRINCIPLE VIOLATION: Every function defined based on this interface will be dependent on
// parameters that it may not need. A JSON processor, or a CSV processor, will need to
// implement those parameters regardless.
const jsonProcessor: DataProcessor = (data, jsonToObject, csvSeparator) => {
let result = validateJSON(data);
if (jsonToObject) {
result = transformJSON(result);
}
return result;
};
const csvProcessor: DataProcessor = (data, jsonToObject, csvSeparator) => {
let result = validateJSON(data);
result = transformCSV(result, csvSeparator);
return result;
};
// Note that function calls are forced to pass unnecessary parameters.
const json = jsonProcessor(jsonData, true, false);
const csv = csvProcessor(csvData, false, ",");
```
**🟢 Correct Implementation**
```typescript
// With functional programming, there are several ways to approach this solution.
// Here, I chose to segregate the interfaces into option objects.
type DataProcessorJSONOptions = {
toObject: boolean;
};
type DataProcessorCSVOptions = {
separator: string;
};
type DataProcessor = (
data: string,
// Now, the second parameter has options for each type, being optional.
options: {
json?: DataProcessorJSONOptions;
csv?: DataProcessorCSVOptions;
}
) => string[];
const jsonProcessor: DataProcessor = (data, { json }) => {
let result = validateJSON(data);
if (json?.toObject) {
result = transformJSON(result);
}
return result;
};
const csvProcessor: DataProcessor = (data, { csv }) => {
let result = validateJSON(data);
result = transformCSV(result, csv?.separator);
return result;
};
// As I mentioned, there are other ways to solve this problem.
// This would be a basic approach, using optional parameters.
// Another way would be to use Union Types or something similar.
const json = jsonProcessor(jsonData, { json: { toObject: true } });
const csv = csvProcessor(csvData, { csv: { separator: "," } });
```
---
## Applicabilities
Being the only principle applied to interfaces, personally, I see a very interesting potential. Adverse situations to this principle can be found in very complex classes, or even as a result of the lack of application of the other SOLID principles - as I have referred to, mainly the first one.
The exercise of defining class interfaces before their effective implementations can help identify these problems. It is important to question how generic the implementation would be and how reusable the methods can be across different scenarios. Nowadays, we can also work a lot with **optional methods**, which can be a safeguard for such scenarios, but may end up generating the need for "type gymnastics" to check if the method has been implemented or not.
---
## Final thoughts
There is a great discussion about **generalization** in various aspects of Software Engineering, and this is definitely essential - the problem lies in excess, and also when it is not clear where to draw the boundary line. If we treat everything as generic, then what is specific will end up affecting all other scenarios; otherwise, if everything is specific, we will have a huge pile of classes to maintain, and we lose sight of their correct existence.
The ideal is to use this principle as a starting point for building new classes with various purposes: What methods will I have? In which scenarios will they be applied? Am I forcing classes to implement something that will not be useful to them? Starting from these assumptions, it becomes a little easier to identify the need for the principle, which simply proposes that we should **take care not to create code just out of obligation**, but for a purpose implemented.
| mdeamp |
1,850,724 | Reflexões sobre SOLID - A Letra "I" | Nesta quinta parte de minhas reflexões, seguimos com a letra "I", obedecendo a ordem proposta pelo... | 27,238 | 2024-05-30T22:48:20 | https://dev.to/mdeamp/reflexoes-sobre-solid-a-letra-i-1684 | solidprinciples, programming, designpatterns, typescript | Nesta quinta parte de minhas reflexões, seguimos com a letra "I", obedecendo a ordem proposta pelo acrônimo SOLID. Trabalharei com TypeScript nos exemplos.
---
## Neste artigo
[Interface Segregation Principle](#interface-segregation-principle)
[Exemplo abstrato](#exemplo-abstrato)
[Exemplo técnico (Front-End)](#exemplo-técnico-frontend)
[Exemplo técnico (Back-End)](#exemplo-técnico-backend)
[Exemplo pessoal](#exemplo-pessoal)
[Exemplo funcional](#exemplo-funcional)
[As aplicabilidades](#as-aplicabilidades)
[Reflexões finais](#reflexões-finais)
---
## Interface Segregation Principle
Um ponto de partida muito importante é o fato de que este princípio é o **único princípio focado em interfaces, e não classes**. Espera-se que o leitor entenda essa diferença, mas um resumo muito prático é: interfaces compõe aquilo que a classe deve se encarregar em implementar.
O Interface Segregation Principle (ou _Princípio da Segregação de Interface_) propõe que **uma classe não deve depender de métodos dos quais não precisa**, e que deve-se optar por **múltiplas interfaces ao invés de uma única interface com múltiplas responsabilidades**.
O mais interessante é o quanto este princípio se encaixa no tema do primeiro princípio, o de **Single Responsibility**. Ambos trazem essa visão de segregação de responsabilidades, e direcionam o desenvolvimento do sistema aos propósitos de garantir a escalabilidade das classes. Uma classe ou interface com muitas responsabilidades é, naturalmente, mais complicada de lidar, pois uma alteração indevida pode gerar muitos efeitos colaterais indesejados.
Vamos entender, com exemplos, como podemos identificar esse princípio e aplicá-lo.
---
## Exemplo abstrato
Continuemos com nosso exemplo de **biblioteca**. Dessa vez, imagine que a biblioteca possui não somente livros, mas DVDs e Blu-Rays de filmes e séries também. Bom, nesse cenário:
- Cada **item da biblioteca** deve ser mapeado;
- Gostaríamos de saber o nome de cada item através de um método;
- Para livros, gostaríamos de saber a quantidade de páginas;
- Para filmes e séries, gostaríamos de saber a duração;
**🔴 Implementação Incorreta**
```typescript
// Imaginemos uma interface que solicita a implementação de três métodos.
interface LibraryItem {
getName(): string; // Tanto para livros quanto para séries e filmes, queremos saber o nome do item.
getPages(): number; // Somente para livros, quantas páginas possuem.
getDuration(): number; // Somente para séries e filmes, qual a duração em minutos.
}
// Agora, vamos criar nossa classe Book, implementando a interface LibraryItem.
// Isso irá nos obrigar a obedecer o que a LibraryItem contém. Vamos acompanhando.
class Book implements LibraryItem {
constructor(private title: string, private pages: number) {}
// Sem problemas nesse método.
getName() {
return this.title;
}
// Sem problemas nesse método.
getPages(): number {
return this.pages;
}
getDuration(): number {
// VIOLAÇÃO DO PRINCÍPIO: O método getDuration, apesar de pertencer a itens de biblioteca, não faz sentido
// no contexto de livros, e não será implementado. Portanto, os livros estão sendo obrigados a depender e
// implementar um método do qual não se utilizam.
throw new Error("Livros não possuem duração em minutos");
}
}
class DVD implements LibraryItem {
constructor(private title: string, private duration: number) {}
// Sem problemas nesse método.
getName(): string {
return this.title;
}
// VIOLAÇÃO DO PRINCÍPIO: Mesma obsevação do item acima, só que agora da visão de filmes e séries, que não
// possuem quantidade de páginas, mas são obrigados a implementar.
getPages(): number {
throw new Error("DVDs não possuem quantidade de páginas");
}
// Sem problemas nese método.
getDuration(): number {
return this.duration;
}
}
```
**🟢 Implementação Correta**
```typescript
// É preferível que segreguemos as interfaces. É melhor ter múltiplas, cada qual com sua responsabilidade,
// do que uma única que força as classes a implementarem métodos dos quais não precisam.
interface LibraryItem {
getName(): string; // Método em comum para todos.
}
interface BookItem {
getPages(): number; // Método específico para livro.
}
interface DVDItem {
getDuration(): number; // Método específico para DVDs.
}
// Agora, cada classe implementa somente o que utiliza.
class Book implements LibraryItem, BookItem {
constructor(private title: string, private pages: number) {}
getName() {
return this.title;
}
getPages(): number {
return this.pages;
}
}
class DVD implements LibraryItem, DVDItem {
constructor(private title: string, private duration: number) {}
getName(): string {
return this.title;
}
getDuration(): number {
return this.duration;
}
}
```
---
## Exemplo técnico (Front-End)
Suponhamos que temos 3 tipos de botões na nossa aplicação: **PrimaryButton**, **IconButton** e **ToggleButton**. Se todas dependerem de uma única interface mestra, começamos a encontrar problemas.
**🔴 Implementação Incorreta**
```typescript
// Interface genérica demais para os diversos tipos de botões existentes.
interface Button {
render(): void; // Método para renderizar o botão.
setLabel(label: string): void; // Método para definir a label do botão.
setIcon(icon: string): void; // Método para associar o ícone ao botão.
toggle(): void; // Método para botões toggle, de ligar/desligar.
}
class PrimaryButton implements Button {
constructor(private label: string) {}
render(): void {
console.log("Renderizando o botão...", this.label);
}
setLabel(label: string): void {
this.label = label;
}
// VIOLAÇÃO DO PRINCÍPIO: PrimaryButton não tem suporte para ícones, mas é obrigado a implementar o método.
setIcon(icon: string): void {
throw new Error("Este botão não possui suporte para ícones");
}
// VIOLAÇÃO DO PRINCÍPIO: Mesma observação do exemplo acima.
toggle(): void {
throw new Error("Este botão não possui suporte para toggle");
}
}
// VIOLAÇÃO DO PRINCÍPIO: Abaixo, temos mais duas classes, IconButton e ToggleButton, que exemplificam o contrário do PrimaryButton.
// Cada uma implementa seu método respectivo, setIcon e toggle, mas também são obrigadas a implementar métodos que
// não utilizam.
class IconButton implements Button {
constructor(private label: string, private icon: string) {}
render(): void {
console.log("Renderizando o botão...", this.label, this.icon);
}
setLabel(label: string): void {
this.label = label;
}
setIcon(icon: string): void {
this.icon = icon;
}
toggle(): void {
throw new Error("Este botão não possui suporte para toggle");
}
}
class ToggleButton implements Button {
constructor(private label: string, private state: boolean) {}
render(): void {
console.log("Renderizando o botão...", this.label, this.state);
}
setLabel(label: string): void {
this.label = label;
}
setIcon(icon: string): void {
throw new Error("Este botão não possui suporte para ícones");
}
toggle(): void {
this.state = !this.state;
}
}
```
**🟢 Implementação Correta**
```typescript
// A simplicidade e elegância da solução é segregar em múltiplas interfaces, unificando na inteface
// Button aquilo que for realmente genérico.
interface Button {
render(): void;
setLabel(label: string): void;
}
interface WithIcon {
setIcon(icon: string): void;
}
interface WithToggle {
toggle(): void;
}
// Classes agora implementam somente o que precisam.
class PrimaryButton implements Button {
constructor(private label: string) {}
render(): void {
console.log("Renderizando o botão...", this.label);
}
setLabel(label: string): void {
this.label = label;
}
}
class IconButton implements Button, WithIcon {
constructor(private label: string, private icon: string) {}
render(): void {
console.log("Renderizando o botão...", this.label, this.icon);
}
setLabel(label: string): void {
this.label = label;
}
setIcon(icon: string): void {
this.icon = icon;
}
}
class ToggleButton implements Button, WithToggle {
constructor(private label: string, private state: boolean) {}
render(): void {
console.log("Renderizando o botão...", this.label, this.state);
}
setLabel(label: string): void {
this.label = label;
}
toggle(): void {
this.state = !this.state;
}
}
```
---
## Exemplo técnico (Back-End)
Vamos partir de um princípio de que é possível executar _transactions_ em bancos de dados relacionais, mas não em bancos de dados não-relacionais. Sabemos que isso não é uma verdade absoluta (depende muito do _vendor_ e do modelo de armazenamento), mas para sermos didáticos, vamos partir deste princípio.
**🔴 Implementação Incorreta**
```typescript
// Interface genérica para bancos de dados, implementando conexões, queries e transactions.
interface Database {
connect(): void;
disconnect(): void;
runQuery(query: string): unknown;
startTransaction(): void;
commitTransaction(): void;
rollbackTransaction(): void;
}
// Para bancos de dados relacionais, todas as implementações funcionam.
class RelationalDatabase implements Database {
connect(): void {
console.log("Conectado com sucesso");
}
disconnect(): void {
console.log("Desconectado com sucesso");
}
runQuery(query: string): unknown {
console.log(`Executando query: ${query}`);
return { ... };
}
startTransaction(): void {
console.log("Transaction - Iniciada");
}
commitTransaction(): void {
console.log("Transaction - Encerrada com Commit");
}
rollbackTransaction(): void {
console.log("Transaction - Encerrada com Rollback");
}
}
class NonRelationalDatabase implements Database {
connect(): void {
console.log("Conectado com sucesso");
}
disconnect(): void {
console.log("Desconectado com sucesso");
}
runQuery(query: string): unknown {
console.log(`Executando query: ${query}`);
return { ... };
}
// VIOLAÇÃO DO PRINCÍPIO: Se transações não funcionam para todo tipo de banco de dados, por que
// faz parte da interface genérica, forçando as classes a implementá-las?
startTransaction(): void {
throw new Error("Bancos de dados não-relacionais não suportam Transactions")
}
commitTransaction(): void {
throw new Error("Bancos de dados não-relacionais não suportam Transactions")
}
rollbackTransaction(): void {
throw new Error("Bancos de dados não-relacionais não suportam Transactions")
}
}
```
**🟢 Implementação Correta**
```typescript
// Ainda podemos ter nossa interface genérica, mas segregamos o que é específico.
interface Database {
connect(): void;
disconnect(): void;
}
interface DatabaseQueries {
runQuery(query: string): unknown;
}
interface DatabaseTransactions {
startTransaction(): void;
commitTransaction(): void;
rollbackTransaction(): void;
}
class RelationalDatabase implements Database, DatabaseQueries, DatabaseTransactions {
connect(): void {
console.log("Conectado com sucesso");
}
disconnect(): void {
console.log("Desconectado com sucesso");
}
runQuery(query: string): unknown {
console.log(`Executando query: ${query}`);
return { ... };
}
startTransaction(): void {
console.log("Transaction - Iniciada");
}
commitTransaction(): void {
console.log("Transaction - Encerrada com Commit");
}
rollbackTransaction(): void {
console.log("Transaction - Encerrada com Rollback");
}
}
// Agora, nosso banco de dados não-relacional implementa somente o que faz sentido.
class NonRelationalDatabase implements Database, DatabaseQueries {
connect(): void {
console.log("Conectado com sucesso");
}
disconnect(): void {
console.log("Desconectado com sucesso");
}
runQuery(query: string): unknown {
console.log(`Executando query: ${query}`);
return { ... };
}
}
```
---
## Exemplo pessoal
Em **Super Mario Kart**, existem alguns itens que são específicos de alguns personagens - comportamento que pode ser questionável, mas este não é o foco do artigo. Neste cenário, como podemos implementar as interfaces desses itens e aderir ao princípio?
**🔴 Implementação Incorreta**
```typescript
interface Items {
throwShell(): void; // Item que qualquer personagem pode ter.
throwFire(): void; // Item exclusivo do Bowser, sendo uma bola de fogo.
throwMushroom(): void; // Item exclusivo da Peach (na época Princess Toadstool) e do Toad.
}
// VIOLAÇÃO DO PRINCÍPIO: Encontraremos diversos erros em cada um dos cenários específicos.
class Mario implements Items {
throwShell(): void {
console.log('Lançando o item "Casco"');
}
throwFire(): void {
throw new Error("Mario não possui acesso a esse item.");
}
throwMushroom(): void {
throw new Error("Mario não possui acesso a esse item.");
}
}
class Bowser implements Items {
throwShell(): void {
console.log('Lançando o item "Casco"');
}
throwFire(): void {
console.log('Lançando o item "Fogo"');
}
throwMushroom(): void {
throw new Error("Bowser não possui acesso a esse item.");
}
}
class Princess implements Items {
throwShell(): void {
console.log('Lançando o item "Casco"');
}
throwFire(): void {
throw new Error("Princess não possui acesso a esse item.");
}
throwMushroom(): void {
console.log('Lançando o item "Cogumelo"');
}
}
```
**🟢 Implementação Correta**
```typescript
// Podemos quebrar nossa interface em várias, separando o genérico do específico.
interface CommonItems {
throwShell(): void;
}
interface FireSpecialItems {
throwFire(): void;
}
interface MushroomSpecialItems {
throwMushroom(): void;
}
```
---
## Exemplo funcional
Imaginemos **a interface de um processador de dados**. Gostaríamos de interpretar tanto arquivos JSON quanto arquivos CSV, mas cada um com sua especificidade. Se implementarmos as opções de cada um deles de forma unificada, podemos ferir o princípio.
**🔴 Implementação Incorreta**
```typescript
// Nessa interface, definimos uma função que processa dados.
type DataProcessor = (
data: string, // Os dados que serão processados.
jsonToObject: boolean, // Somente para JSON, indicando se deseja converter para objeto.
csvSeparator: string // Somente para CSV, indicando qual o separador de colunas.
) => string[];
// VIOLAÇÃO DO PRINCÍPIO: Toda função definida com base nessa interface ficará dependente de
// parâmetros dos quais, talvez, não precise. Um processador só de JSON, ou só de CSV, precisará
// obrigatoriamente implementar aqueles parâmetros.
const jsonProcessor: DataProcessor = (data, jsonToObject, csvSeparator) => {
let result = validateJSON(data);
if (jsonToObject) {
result = transformJSON(result);
}
return result;
};
const csvProcessor: DataProcessor = (data, jsonToObject, csvSeparator) => {
let result = validateJSON(data);
result = transformCSV(result, csvSeparator);
return result;
};
// Veja que as chamadas de função são obrigadas a chamar parâmetros desnecessários.
const json = jsonProcessor(jsonData, true, false);
const csv = csvProcessor(csvData, false, ",");
```
**🟢 Implementação Correta**
```typescript
// Com programação funcional, existem diversas formas de se abordar essa solução.
// Aqui, optei por segregar as interfaces em objetos de opção.
type DataProcessorJSONOptions = {
toObject: boolean;
};
type DataProcessorCSVOptions = {
separator: string;
};
type DataProcessor = (
data: string,
// Agora, o segundo parâmetro possui opções para cada tipo, sendo opcional.
options: {
json?: DataProcessorJSONOptions;
csv?: DataProcessorCSVOptions;
}
) => string[];
const jsonProcessor: DataProcessor = (data, { json }) => {
let result = validateJSON(data);
if (json?.toObject) {
result = transformJSON(result);
}
return result;
};
const csvProcessor: DataProcessor = (data, { csv }) => {
let result = validateJSON(data);
result = transformCSV(result, csv?.separator);
return result;
};
// Como comentei, existem outras formas de solucionar este problema.
// Esta seria uma visão básica, utilizando parâmetros opcionais.
// Outra forma seria usar Union Types ou algo do gênero.
const json = jsonProcessor(jsonData, { json: { toObject: true } });
const csv = csvProcessor(csvData, { csv: { separator: "," } });
```
---
## As aplicabilidades
Por ser o único princípio aplicado em interfaces, pessoalmente, vejo um potencial muito interessante. É possível encontrarmos situações adversas a esse princípio em classes muito complexas, ou até mesmo como resultado da falta de aplicação dos demais princípios do SOLID - como tenho me referido, principalmente o primeiro.
O exercício de se definir as interfaces das classes antes de suas efetivas implementações pode ajudar na identificação desses problemas. É importante se questionar sobre o quão genérica a implementação seria, e o quão reaproveitável os métodos podem ser entre diferentes cenários. Hoje em dia, também podemos trabalhar muito com **métodos opcionais**, o que pode ser uma salvaguarda para cenários assim, mas pode acabar gerando a necessidade de "ginástica de tipagem" para checar se o método foi implementado ou não.
---
## Reflexões finais
Existe uma grande discussão sobre a **generalização** em diversos aspectos da Engenharia de Software, e isso é definitivamente essencial - o problema é o excesso, e também quando não fica claro onde demarcar a linha de limite. Se tratarmos tudo como genérico, então o que é específico acabará afetando todos os outros cenários; do contrário, se tudo for específico, teremos um amontoado gigantesco de classes para dar manutenção, e perdemos a noção de sua correta existência.
O ideal é utilizarmos este princípio como ponto de base para construção de novas classes com diversos propósitos: Quais métodos terei? Em quais cenários eles serão aplicados? Será que estou forçando classes a implementarem algo que não lhes será útil? Partindo de tais pressupostos, fica um pouco mais fácil de identificar a necessidade do princípio, que simplesmente propõe que devemos **cuidar para não criarmos código apenas por obrigação**, mas sim para um propósito implementado. | mdeamp |
1,871,397 | [Game of Purpose] Day 12 - VCS thoughts | Today I am still travelling and has only access to a weak laptop, so I cannot do any Unreal work. I... | 27,434 | 2024-05-30T22:02:53 | https://dev.to/humberd/game-of-purpose-day-12-vcs-thoughts-bdb | gamedev | Today I am still travelling and has only access to a weak laptop, so I cannot do any Unreal work. I even installed Unreal, but even running a started project is a pain in 2 FPS.
On the other hand I've been thinking about a VCS (Version Control System). My whole programming life I've been using Git, but it turns out the most popular is Perforce. Well, Git was created mainly to handle text files and it does that wonderfully, but it is not optimal for binary file, which I think Unreal uses the most.
To use Git I just create a project on GitHub and select it in IntelliJ IDEA and that's basically all. I can commit, push, pull, merge, etc.
However it looks like it's not that simple with Perforce. There is no free hosting service, so I'd need to spend some money to even host my files. Well, that is understandable, because even one of the biggest git projects with thousands of commits take a couple of GBs of space. Not the project, all the history! Regular small projects don't exceed dozen of MBs.
I deployed Helix Core to Digital Ocean as a Droplet. It will cost me 28 USD/month. That's quite a money. I wanted to have some monthly budget, but that would eat a great deal of it. Anyway, I'll talk about the budget another day.
I then created a sample Unreal project and tried to commit and push it to my Perforce server but I was stuck. Knowing git I couldn't figure out anything. There were some depots, stream depots and workspaces. I created 3 workspaces, but for some reason Unreal saw only 1 of them. I don't know why. I tried to make an init commit through Unreal, but there were some errors about wrong mapping. Don't know what it is. I read somewhere we first need to init it via a GUI program called P4V. I created pushed the files, but could only do it to a workspace that was not seen by Unreal. Then I wanted to remove them, but there were some errors... and so one and so one. I would probably need to watch some tutorial on YouTube. | humberd |
1,871,388 | MuleSoft Associate Certification: Essential Tips and Key Concepts | I was a little stressed, do you know why? Because I forgot the date of the exam. Fortunately, I had a... | 0 | 2024-05-30T22:45:27 | https://dev.to/this-is-learning/mulesoft-associate-certification-essential-tips-and-key-concepts-505m | architecture, api, tooling, productivity | I was a little stressed, do you know why? Because I forgot the date of the exam. Fortunately, I had a small reminder from my agenda 30 minutes before the exam. I tried my best to quickly review the documentation I wrote when I was preparing for the exam.
Make sure to have a good internet connection, and it might be helpful to restart your laptop. This will close all running programs that could potentially interrupt the browser required for taking the exam, which you will need to download before starting.
The first thing you should know is that the associate certification tests your knowledge of Enterprise Integration concepts. You need to understand why we use MuleSoft, not just how to implement a listener and an object store. These technical details are important but not sufficient for the associate exam.
It's also about your knowledge of cloud solutions. Having a good understanding of the differences between SaaS, PaaS, and IaaS, and knowing when to use them, will be beneficial. I can say that I had two or three questions about cloud solutions, including CloudHub and PCE. You should understand the differences, as well as the why and when of using these solutions.
Before starting the exam, make sure you are familiar with the structure of a YAML file. You might have a question about that, as well as about JSON and XML. Additionally, review communication protocols such as gRPC, REST, and SOAP. There will be questions on these topics as well.
Understanding systems such as Supply Chain Management (SCM), Customer Relationship Management (CRM), Enterprise Resource Planning (ERP), and Content Management Systems (CMS) is crucial. You should know the purpose of each system and read some scenarios of their use to have a solid understanding of the differences between them.
Knowledge of project management methodologies is essential. You should understand what Kanban, Waterfall, Agile, and Scrum are. These concepts might seem irrelevant for a MuleSoft certification, but they are not. You will get at least one question about these concepts, so don't forget to review them.
A thorough understanding of Integration Patterns, such as Consolidation, Orchestration, Aggregation, and Choreography, are unavoidable. A good understanding of these concepts is required because the exam focuses heavily on them. My advice is to thoroughly read about each one and try to implement them, which will give you a solid understanding of these patterns.
Finally, ensure you know the components of the Anypoint Platform including Anypoint Exchange, Anypoint Runtime Plane, Anypoint Control Plane, Anypoint Runtime Manager, Anypoint API Manager, Anypoint Design Center, and Anypoint API Designer...Knowing the use of each component will help you answer at least three or four questions in the exam. | ayoub_alouane |
1,871,407 | Null... | Deleted... | 0 | 2024-05-30T22:37:52 | https://dev.to/softwaredeveloping/new-versatile-developers-community-37b1 | Deleted... | softwaredeveloping | |
1,871,405 | Fast and Consistent Deployments with Terraform | Most types of internet-first businesses have become incredibly competitive. You're not just competing... | 0 | 2024-05-30T22:33:44 | https://dev.to/scottwrobinson/fast-and-consistent-deployments-with-terraform-43k | terraform, saas, devops | Most types of internet-first businesses have become incredibly competitive. You're not just competing with people in your town, but everyone around the world. Because of this, the speed at which you can launch new products and features can be the difference between success and failure. This is why it is important to have a good infrastructure in place that allows you to not only launch fast, but update fast too.
In this article, I'll be giving a brief overview of Terraform and show you how I used it to launch my new monitoring tool, [Ping Bot](https://pingbot.dev).
## What is Terraform?
Terraform is an open-source **infrastructure as code** software tool created by HashiCorp. It lets you define and provision data center infrastructure using a declarative configuration language. Terraform manages external resources like public cloud infrastructure, private cloud infrastructure, network appliances, software as a service, platform as a service, DNS, and a whole lot more with a code.
Let's see a simple example:
```hcl
provider "aws" {
region = "us-west-2"
}
resource "aws_instance" "example" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
}
```
This code will create an EC2 instance in the `us-west-2` region with the `t2.micro` instance type. You could do the same thing for most other cloud providers, like Azure, Google Cloud, and Digital Ocean.
For a single instance, Terraform doesn't give you much of an advantage. But when you add in all of the other resources and configurations, it becomes a powerful tool. Not just for the time-saving, but consistency and repeatability as well. If your service only uses a small number of resources, you might not see the benefits of Terraform.
There are 3 main reasons I decided to use Terraform:
1. **Speed**: I wanted to be able to launch my products as fast as possible. Terraform allowed me to quickly create all of the resources I needed in AWS. From servers to databases to S3 buckets, I could do it all with a single command.
2. **Consistency**: I wanted to make sure that my infrastructure was consistent across all of my environments. When you have dozens of resources, manually creating and configuring them can lead to mistakes. Terraform ensures that everything is created the same way every time.
3. **Repeatability**: I wanted to be able to easily recreate my infrastructure in case of a disaster. If something were to happen to my AWS account or I needed to transfer accounts, I could easily recreate everything.
## Terraform Setup
Before we get ahead of ourselves, let's talk about setup. There are a ton of resources on [installing](https://developer.hashicorp.com/terraform/tutorials/aws-get-started/install-cli) and using Terraform, so in this article I'll mostly be talking about how I used it. This kind of setup is probably best for single-person projects or small teams. For larger teams, you might want to look into more advanced configurations and tooling.
If you're like me, you have a few different AWS accounts for different projects. Because of this, I've set up my different profiles in the `~/.aws/credentials` file. This allows me to easily switch between accounts.
```ini
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEY
[pingbot]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEY
```
I can then use this in my Terraform config to switch between AWS accounts, depending on which environtment I want to deploy to:
```hcl
provider "aws" {
region = "us-west-2"
profile = "pingbot"
}
```
I also took advantage of Terraform's workspace feature. This allows you to have multiple environments, like `dev`, `staging`, and `production`, all in the same codebase. This is great because you can easily test changes in a safe environment before deploying to production.
Once I've created my workspaces with `terraform workspace new [NAME]`, I can switch between them with `terraform workspace select [NAME]`. Then in my configuration code, I use the workspace throughout to create different resources based on the environment. This can be done using `locals`.
```hcl
locals {
ns = {
dev = "-dev"
stage = "-stage"
prod = ""
}
instance_type = {
dev = "t2.micro"
stage = "t2.medium"
prod = "t2.large"
}
}
resource "aws_instance" "example" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = local.instance_type[terraform.workspace]
}
resource "aws_s3_bucket" "pingbot" {
bucket = "pingbot${local.ns[terraform.workspace]}"
}
resource "aws_route53_record" "pingbot" {
zone_id = aws_route53_zone.pingbot.zone_id
name = terraform.workspace == "prod" ? "pingbot.dev" : "${terraform.workspace}.pingbot.dev"
type = "A"
ttl = "300"
records = [aws_instance.pingbot.public_ip]
}
```
Here I'm changing the instance size, S3 bucket name, and Route53 record based on the workspace.
## Modules
One of the most powerful features of Terraform is modules. Modules are reusable Terraform configurations that can be called multiple times. This is great for creating reusable components that can be used multiple times in a project or shared across different projects.
For exampale, with Ping Bot I wanted to be able to [monitor infrastructure](https://pingbot.dev) for our customers from multiple locations around the world. Manually creating these resources in different AWS regions would've been tedious and error-prone. Instead, I created a module that would create the SQS queues and Lambdas in each location and installs the necessary software to run the pings.
```hcl
module "ping_infra" {
source = "./modules/ping_infra"
locations = ["us-west-2", "us-east-1", "eu-west-1", "ap-southeast-1"]
}
```
Instead of taking an hour or two to set up ping infra in the Asia Pacific region, for example, I can do it in a few minutes with a single line change and `terraform apply` command.
A lot of teams are also pretty opinionated about how they want their infrastructure set up. By creating modules, you can create a standard way of doing things that everyone can use. This can help with onboarding new team members and make it easier to move between projects.
## Cons of Terraform
While Terraform is a great tool, it's not without its downsides. Here are a few things to consider before using it:
1. **Complexity**: Terraform can be complex, especially when you start using modules and more advanced features. This can make it hard for new team members to get up to speed if your setup isn't well thought-out or you don't have someone who specifically owns the process.
2. **State Management**: Terraform uses a state file to keep track of the resources it creates. This file can get out of sync with your actual infrastructure if you're not careful. This can lead to some pretty bad situations if you're not careful. You'll often find yourself needing to migrate state as files change, which can be a huge pain.
3. **Learning Curve**: Terraform has a bit of a learning curve. While the basics are pretty easy to pick up, the more advanced features and edge cases can be confusing, especially for more junior developers. This can make it hard to get started if you're not already familiar with infrastructure as code tools.
4. **Cost**: Terraform can be expensive, especially if you're using it to manage a lot of resources. This isn't exactly Terraform's fault, but when your resources just become code, it's easy to lose track of what you're actually spending. This can lead to some pretty big bills if you're not careful. Self-funded startups, in particular, should be careful!
## Conclusion
Terraform is a powerful tool that can help you launch faster and more consistently. By defining your infrastructure as code, you can easily create and manage resources across multiple environments. This can help you move faster and reduce the risk of mistakes. While it's definitely not perfect, it's a great tool to have in your toolbox if you're looking to launch fast and stay competitive.
Thoughts? Feedback? I'd love to hear from you - there are plenty of places to [reach me](https://linktr.ee/scottwrobinson). | scottwrobinson |
1,871,404 | Building My First iOS Application | Welcome to the wild, wild, wonderful world of iOS app development, where dreams are coded into... | 0 | 2024-05-30T22:29:59 | https://dev.to/emmanuellebe24/building-my-first-ios-application-4oba | ios, gamedev, tutorial, programming | Welcome to the wild, wild, wonderful world of iOS app development, where dreams are coded into reality, and caffeine fuels our relentless pursuit of innovation. Imagine yourself in a tech startup's open office, buzzing with the low hum of creativity, the rhythmic click-clack of mechanical keyboards, and the occasional expletive-laden outburst as someone battles with building the next Tim Cook-level application.
In this article, we're diving headfirst into the adventure of creating a basic two-player card game. Get ready to turn lines of code into an engaging, interactive experience that will bring your vision to life on the screen.
### THE SETUP
Before we can start coding, we need to get our development environment up and running. This involves a few key steps to ensure we have everything in place to build and test our iOS application. Here’s what you need to do:
- **Install Xcode**:
Xcode is Apple’s integrated development environment (IDE) for macOS. It includes everything you need to create apps for all Apple devices. Head over to the Mac App Store and download the latest version of Xcode. Once it's installed, open it up and take a moment to familiarize yourself with the interface.
- **Create a New Project**:
Launch Xcode and create a new project by selecting "Create a new Xcode project" from the welcome screen. Choose the "App" template under the iOS tab, and click "Next." Fill in the project details:
- **Product Name**: Give your game a name (e.g., "CardGame").
- **Team**: Select your Apple ID or team if you’re part of one.
- **Organization Name**: Your company or personal name.
- **Organization Identifier**: A unique identifier, typically a reverse domain name (e.g., com.yourname).
- **Language**: Swift.
- **User Interface**: SwiftUI.
- **Set Up Version Control**:
Version control is essential for any development project. Xcode integrates seamlessly with Git, allowing you to track changes and collaborate with others. Initialize a Git repository by selecting the "Create Git repository on my Mac" option when setting up your project.
- **Familiarize Yourself with SwiftUI**:
SwiftUI is Apple’s framework for building user interfaces across all Apple platforms. Spend some time exploring the basics of SwiftUI if you're not already familiar with it. Apple’s official documentation and tutorials are great resources.
- **Set Up Your Simulator**:
Xcode comes with a built-in simulator that allows you to test your app on various virtual devices. Select the iPhone model you want to use from the device toolbar and launch the simulator to ensure everything is working correctly.
- **Prepare Your Assets**:
Gather all the necessary assets for your card game. This includes images for the cards, backgrounds, and any other graphical elements you'll need. Make sure your assets are appropriately sized and formatted for iOS.
With everything set up, we’re now ready to dive into the coding phase. In the next section, we'll start by laying out the basic structure of our card game and implementing the core functionality. So, roll up your sleeves, fire up Xcode, and let’s bring this game to life!
### THE BUILD
Now that we have our development environment ready, it's time to jump into the fun part: building our game. We're going to create a simple yet engaging card game with a deck of 13 cards, where each card ranks from 2 to 14. Here's the plan:
- Two sets of cards are placed on the board.
- A random function generates a card for each player.
- The player with the higher card wins the round and earns a point.
- The game continues until all cards are played, and the player with the most points wins.
Let's get started!
### Step 1: Define the Player variable
Create a rewrite Swift file named `ContentView.swift` and define a variable for our card player:
```swift
// player card
@State var player_card:String = "back"
@State var player_card2:String = "back"
// player score value
@State var player_scorevalue:Int = 0
@State var player_scorevalue2:Int = 0
// player rounds
@State var player_rounds:Int = 0
```
### Step 2: Create the Random deck function
In the same file, add a function to generate and shuffle a deck of cards:
```swift
func Deal(){
// Player Random number generator
var PlayerScoreValue:Int = Int.random(in: 2...14)
var PlayerScoreValue2:Int = Int.random(in: 2...14)
// Card generator
player_card = "card" + String(PlayerScoreValue)
player_card2 = "card" + String(PlayerScoreValue2)
if PlayerScoreValue > PlayerScoreValue2 {
player_scorevalue += 1
}else{
player_scorevalue2 += 1
}
player_rounds += 1;
}
```
### Step 3: Set Up the Game Board
Create a Game UI. This view will display the cards and the scores for each player:
```swift
var body: some View {
ZStack {
Image("background-plain")
VStack{
Image("logo")
HStack{
Image(player_card)
Image(player_card2)
}
Button{
Deal()
}label: {
Image("button")
}
.padding(.all)
HStack{
VStack{
Text("Player 1")
.font(.title)
.fontWeight(.bold)
.foregroundColor(Color.white)
Text(String(player_scorevalue))
.font(.title2)
.fontWeight(.bold)
.foregroundColor(Color.white)
.padding(.all, 3.0)
}
.padding(.all)
VStack{
Text("Player 2")
.font(.title)
.fontWeight(.bold)
.foregroundColor(Color.white)
Text(String(player_scorevalue2))
.font(.title2)
.fontWeight(.bold)
.foregroundColor(Color.white)
.padding(.all, 3.0)
}
.padding(.all)
}
.padding(.all, 18.0)
Text(String(player_rounds))
.font(.title)
.fontWeight(.heavy)
.foregroundColor(Color.red)
.padding(.all)
.frame(width: nil)
.border(Color.white, width: 3)
.cornerRadius(10.0)
}
}
.padding()
```
### Step 4: Final Code
Finally, the code :
```swift
import SwiftUI
struct ContentView: View {
// player card
@State var player_card:String = "back"
@State var player_card2:String = "back"
// player score value
@State var player_scorevalue:Int = 0
@State var player_scorevalue2:Int = 0
// player rounds
@State var player_rounds:Int = 0
var body: some View {
ZStack {
Image("background-plain")
VStack{
Image("logo")
HStack{
Image(player_card)
Image(player_card2)
}
Button{
Deal()
}label: {
Image("button")
}
.padding(.all)
HStack{
VStack{
Text("Player 1")
.font(.title)
.fontWeight(.bold)
.foregroundColor(Color.white)
Text(String(player_scorevalue))
.font(.title2)
.fontWeight(.bold)
.foregroundColor(Color.white)
.padding(.all, 3.0)
}
.padding(.all)
VStack{
Text("Player 2")
.font(.title)
.fontWeight(.bold)
.foregroundColor(Color.white)
Text(String(player_scorevalue2))
.font(.title2)
.fontWeight(.bold)
.foregroundColor(Color.white)
.padding(.all, 3.0)
}
.padding(.all)
}
.padding(.all, 18.0)
Text(String(player_rounds))
.font(.title)
.fontWeight(.heavy)
.foregroundColor(Color.red)
.padding(.all)
.frame(width: nil)
.border(Color.white, width: 3)
.cornerRadius(10.0)
}
}
.padding()
}
func Deal(){
// Player Random number generator
var PlayerScoreValue:Int = Int.random(in: 2...14)
var PlayerScoreValue2:Int = Int.random(in: 2...14)
// Card generator
player_card = "card" + String(PlayerScoreValue)
player_card2 = "card" + String(PlayerScoreValue2)
if PlayerScoreValue > PlayerScoreValue2 {
player_scorevalue += 1
}else{
player_scorevalue2 += 1
}
player_rounds += 1;
}
}
struct ContentView_Previews: PreviewProvider {
static var previews: some View {
ContentView()
}
}
```
Thank you for taking the time to read this article! I hope you found it informative and useful.
👍 If you appreciated this post, please give it a like!
🔄 Feel free to share this with anyone who might benefit from it.
💬 I’d love to hear your thoughts and any tips you might have — drop a comment below!
👤 Follow me for more insightful blogs in the future!
Support my work with a [coffee](https://buymeacoffee.com/lebemanuel) ☕ — thank you for your generosity!
[](https://buymeacoffee.com/lebemanuel)
| emmanuellebe24 |
1,871,398 | Exploring Amsterdam's Vibrant Cannabis Culture: Your Ultimate Guide to Online Coffeeshop Experience | Welcome to Amsterdam, the cannabis capital of Europe! Renowned for its liberal attitude towards... | 0 | 2024-05-30T22:15:41 | https://dev.to/mowersking/exploring-amsterdams-vibrant-cannabis-culture-your-ultimate-guide-to-online-coffeeshop-experience-579e | Welcome to Amsterdam, the cannabis capital of Europe! Renowned for its liberal attitude towards marijuana, Amsterdam boasts a vibrant coffeeshop culture that attracts cannabis enthusiasts from around the globe. Whether you're a seasoned smoker or a curious traveler, exploring Amsterdam's coffeeshops is an essential part of the experience. In this guide, we'll delve into the world of online coffeeshop shopping, offering insights into the best places to buy your favorite strains and products.
As you embark on your journey through Amsterdam's cannabis scene, convenience and accessibility are key. That's why we're excited to introduce you to Smartbuds Coffeeshop, your premier destination for online coffeeshop shopping in Amsterdam.
## Online Coffeeshop Amsterdam: A Gateway to Cannabis Paradise
Smartbuds Coffeeshop takes pride in providing customers with a diverse range of high-quality cannabis products sourced from reputable suppliers. From classic strains like Orange Crush and Blue Dream to exotic varieties like Gelato and Agent Orange, Smartbuds Coffeeshop caters to every taste and preference. With detailed product descriptions, customer reviews, and expert recommendations, you can make informed decisions and discover new favorites with ease.
## Exploring Smartbuds Coffeeshop: Your Virtual Cannabis Dispensary
With the rise of online coffeeshop platforms, such as Smartbuds Coffeeshop, you can now enjoy a seamless shopping experience from the comfort of your home or hotel room. Smartbuds Coffeeshop's user-friendly website allows you to explore their extensive catalog, place orders securely, and track your delivery in real-time. Whether you're stocking up for a weekend getaway or indulging in a solo smoke session, online coffeeshop shopping offers unparalleled convenience and flexibility.
## Amsterdam Coffee Shop Online Shopping: A Convenient Alternative
Gone are the days of wandering the streets in search of the perfect coffeeshop. With Amsterdam coffee shop online shopping, you can browse, order, and enjoy your favorite cannabis products with just a few clicks. Smartbuds Coffeeshop's user-friendly website allows you to explore their extensive catalog, place orders securely, and track your delivery in real-time. Whether you're stocking up for a weekend getaway or indulging in a solo smoke session, online coffeeshop shopping offers unparalleled convenience and flexibility.
## Experience Amsterdam's Cannabis Culture with Smartbuds Coffeeshop
At Smartbuds Coffeeshop, we're more than just a cannabis dispensary—we're your gateway to Amsterdam's vibrant cannabis culture. Whether you're a local enthusiast or a curious traveler, we invite you to explore our virtual coffeeshop and discover the best that Amsterdam has to offer. With our commitment to quality, transparency, and customer satisfaction, we strive to provide an unforgettable shopping experience that celebrates the spirit of Amsterdam's cannabis community.
## Conclusion:
As you navigate the bustling streets of [online coffeeshop in Amsterdam](https://smartbudscoffeeshop.com/), don't forget to immerse yourself in the city's rich cannabis culture. With online coffeeshop shopping at Smartbuds Coffeeshop, you can enjoy the ultimate convenience and accessibility while exploring a diverse range of premium-quality products. Whether you're seeking relaxation, inspiration, or simply a taste of Amsterdam's legendary cannabis scene, Smartbuds Coffeeshop has you covered. So sit back, relax, and let the journey begin! | mowersking | |
1,871,438 | Migrating my blog from Jekyll to Hugo | A few weeks ago, I migrated my blog for the third time…after WordPress, Blogofile and Jekyll it’s now... | 0 | 2024-06-03T19:34:50 | https://christianspecht.de/2024/05/30/migrating-my-blog-from-jekyll-to-hugo/ | jekyll, hugo, webdev | ---
title: Migrating my blog from Jekyll to Hugo
published: true
date: 2024-05-30 22:00:00 UTC
tags: jekyll,hugo,webdev
canonical_url: https://christianspecht.de/2024/05/30/migrating-my-blog-from-jekyll-to-hugo/
---
A few weeks ago, I migrated my blog for the third time…after WordPress, [Blogofile](https://christianspecht.de/2013/01/29/switched-from-wordpress-to-blogofile/) and [Jekyll](https://christianspecht.de/2013/12/31/hello-jekyll/) it’s now powered by [Hugo](https://gohugo.io/).
There’s nothing wrong with Jekyll. I just became more proficient with Hugo in the meantime _(I hope I’m behind the steepest part of Hugo’s learning curve now…)_ and besides its insane build speed, I like the simplicity of installing/updating Hugo (compared to Ruby/Jekyll) on Windows machines.
And not to forget [all the things I learned about processing images with Hugo](https://christianspecht.de/2020/08/10/creating-an-image-gallery-with-hugo-and-lightbox2/).
My blog has a few old posts which directly load multiple larger images (e.g. [this one](https://christianspecht.de/2013/06/17/tinkerforge-weather-station-part-1-intro-and-construction/)). The images are not _that_ large…but still, it would make more sense to auto-generate thumbnails and load just the thumbnails directly with the post. Not sure if it’s worth the effort, I don’t have that many posts with large images yet, but who knows…
Even though this is not the first Hugo site I built, I still learned a few new things about Hugo…and noticed some differences between Hugo and Jekyll:
* * *
## Some things are easier in Hugo
…like getting the number of posts per year, for example.
Compare [the Jekyll and Hugo versions of the “Archives” box in the sidebar](https://github.com/christianspecht/blog/commit/9816be021377604ef83555c2b0e1012338698316). In Jekyll, I had to create logic for this myself, whereas Hugo supports it out of the box.
* * *
## Hugo template code works ONLY in templates
In Jekyll, I could just create a page (the [archive](https://christianspecht.de/archive/), for example) and write code like this directly in the page:
```
{% for post in site.posts %}
<a href="{{ post.url }}">{{ post.title }}</a>
{% endfor %}
```
Hugo just ignores all template code inside regular pages. To build something like the archive page, you need [the actual (empty) page](https://github.com/christianspecht/blog/blob/6f2767c191c92bab234fb771b1cb393d2891a42a/src/content/archive.html), and a [special template](https://github.com/christianspecht/blog/blob/6f2767c191c92bab234fb771b1cb393d2891a42a/src/layouts/page/archive.html) which contains all the logic and is used only by that single page.
* * *
## Render hooks
Hugo has so-called render hooks, which allow things like auto-prefixing ALL image URLs with the complete site URL.
In my old Jekyll site, I created all hyperlinks (in all templates and in all Markdown pages) without domain, e.g. `/page.html`.
When I switched to Hugo, I decided to use “proper” hyperlinks with full URLs (`https://christianspecht.de/page.html`). Pasting `{{ "/page.html" | absURL }}` all over the main template (for the menus etc.) was one thing, but all images in all posts are also linked without domain ([example](https://github.com/christianspecht/blog/blob/c81ed4255e043ec371fefc01fc452e5a8641725c/src/content/posts/2021-10-06-deleting-ssh-key-from-git-gui-the-easy-windows-solution/index.md?plain=1#L23)).
But - as noted in the last paragraph - in Hugo it’s not even possible to put template code into regular pages, so I couldn’t just do something like `{{ "/image.png" | absURL }}`.
Hugo’s solution for this is called [Render Hooks](https://gohugo.io/render-hooks/images/) _(there are more types of them, but I needed the ones for images)_.
You just need to create [one file with what looks similar to a shortcode](https://github.com/christianspecht/blog/commit/716f5341d30ae3bafcef13aaaf8375c6ee080b28), and this causes Hugo to render **all** images with full URLs.
For example, the example Markdown image code linked above looks like this when rendered with this hook:
```
<img src="https://christianspecht.de/img/git-ssh-2.png" alt="Git Gui screen" />
```
* * *
## No HTML comments
Hugo also removes all HTML comments when generating the output, including the ASCII art I have at the top of my blog’s HTML code.
Apparently the only way to get a `<!-- -->` comment block into a Hugo site is [converting it to Unicode, storing it in Hugo’s config file and loading it in the template with `safeHTML`](https://github.com/christianspecht/blog/commit/b6762142d4ca24406ceb581cd63a1809af33a350).
* * *
## Creating PHP pages is more complicated
My blog contains some PHP pages (for [the project pages](https://christianspecht.de/2014/11/09/how-to-display-markdown-files-from-other-sites-now-with-caching/)), and apparently it’s not that easy to generate PHP pages in Hugo.
Jekyll treats all files (as long as they contain YAML front-matter) equally and doesn’t really care about the file extension.
Hugo treats files with different extensions **completely** different. To create PHP pages with Hugo, I would have to [create a copy of all layout files](https://discourse.gohugo.io/t/how-can-i-include-php-code-in-hugo/28589), just with .php instead of .html.
In the end, I decided to “cheat”, [generate the project pages as `.html` files](https://github.com/christianspecht/blog/commit/2ccac56d91984782b4ed18809c03ecd979784f0d) _(so they use the same layout files as all other pages)_, and [rename them to `.php` in the build script](https://github.com/christianspecht/blog/commit/d8f638ae9ef9c4e3c999d8d7f24af6387a25d3fb). | christianspecht |
1,854,409 | Dev: Embedded Systems | An Embedded Systems Developer is a specialized professional responsible for designing, developing,... | 27,373 | 2024-05-30T22:00:00 | https://dev.to/r4nd3l/dev-embedded-systems-3l6h | embedded, systems, developer | An **Embedded Systems Developer** is a specialized professional responsible for designing, developing, and testing software and firmware for embedded systems. Here's a detailed description of the role:
1. **Hardware Interaction:**
- Embedded Systems Developers work closely with hardware engineers to understand the specifications and requirements of the embedded system.
- They write code to interface with hardware components such as microcontrollers, sensors, actuators, and communication interfaces (e.g., UART, SPI, I2C).
2. **Firmware Development:**
- Embedded Systems Developers write firmware code, which is low-level software that runs directly on the embedded hardware.
- They use programming languages like C, C++, or assembly language to develop efficient and reliable firmware that controls the behavior of the embedded system.
3. **Real-Time Operating Systems (RTOS):**
- Embedded Systems Developers may work with real-time operating systems (RTOS) or develop their own real-time kernels for embedded applications.
- They handle tasks such as task scheduling, interrupt handling, and resource management to ensure timely and predictable execution of critical functions.
4. **Device Drivers and BSPs:**
- Embedded Systems Developers develop device drivers and board support packages (BSPs) to enable communication between the firmware and hardware peripherals.
- They write drivers for components like display screens, input devices, storage devices, and networking interfaces to ensure proper functionality and compatibility.
5. **Low-Level Programming:**
- Embedded Systems Developers have a deep understanding of low-level programming concepts such as memory management, register manipulation, and bitwise operations.
- They optimize code for performance, memory usage, and power consumption, taking into account the limited resources available in embedded systems.
6. **Protocols and Communication Interfaces:**
- Embedded Systems Developers implement communication protocols such as UART, SPI, I2C, CAN, Ethernet, and USB to enable data exchange between embedded devices and external systems.
- They ensure robustness, reliability, and compatibility when transmitting and receiving data over various communication interfaces.
7. **Embedded Networking and IoT:**
- Embedded Systems Developers may specialize in embedded networking and Internet of Things (IoT) applications, where they connect embedded devices to local networks or the internet.
- They develop protocols, middleware, and security mechanisms to facilitate communication, data transfer, and remote management of IoT devices.
8. **Testing and Debugging:**
- Embedded Systems Developers conduct thorough testing and debugging of firmware code using tools such as emulators, simulators, and hardware debuggers.
- They identify and resolve issues related to functionality, performance, reliability, and compatibility to ensure the quality and stability of embedded systems.
9. **Power Management and Optimization:**
- Embedded Systems Developers optimize power consumption in embedded systems by implementing techniques such as sleep modes, clock gating, and dynamic voltage scaling.
- They design power-efficient algorithms and strategies to prolong battery life and reduce energy consumption in portable and battery-powered devices.
10. **Regulatory Compliance and Safety:**
- Embedded Systems Developers ensure compliance with industry standards, regulations, and safety requirements applicable to embedded systems, especially in safety-critical applications like automotive, aerospace, and medical devices.
- They follow best practices for design, development, and documentation to meet quality, reliability, and safety standards mandated by regulatory bodies.
In summary, an Embedded Systems Developer plays a crucial role in the design, development, and deployment of firmware for embedded systems across various industries and applications. By leveraging their expertise in hardware-software interaction, real-time programming, and low-level optimization, they contribute to the creation of innovative and reliable embedded solutions that power modern technologies and devices. | r4nd3l |
1,871,395 | Database Design | Today we focused on database design, specifically exploring the concepts that drive relational... | 0 | 2024-05-30T21:59:57 | https://dev.to/brvarner/database-design-5g4j | Today we focused on database design, specifically exploring the concepts that drive relational databases.
## What's a relational database?
It's a collection of tables storing different data pieces that refer to one another to form a complete picture of something. By referencing other tables, we can stick to one value per field design principles while adding organized complexity to our entries.
### What?
Today, we used a film database as an example. This database had tables for films, actors, and directors.
You can't just include a list of every actor in a movie in the films table, so you need a way to keep track of each film's cast. This is where a one-to-many join table comes into play.
You can create a table where each record is a film ID, an actor's ID, and the name of the role they played. A query to this table can then return each actor ID matched with a single film's ID and provide a comprehensive list of every actor in that film.
This way, you can keep track of the dozens of actors that make up a film's cast without bogging down every table.
## Conclusion
This form of database design applies to SQL, it's been a while since I've studied SQL, so it was nice to get a refresher. | brvarner | |
1,871,394 | Exploring Orthodontics Braces | Hey everyone, Let's dive into the fascinating world of orthodontics braces types! As someone who's... | 0 | 2024-05-30T21:59:36 | https://dev.to/dianawilson/exploring-orthodontics-braces-21e8 | Hey everyone,
Let's dive into the fascinating world of [orthodontics braces types](https://www.celebratedental.com/)! As someone who's recently been exploring options for straightening teeth, I thought I'd share some insights and gather opinions on the various types of braces out there.
First off, it's essential to understand that not all braces are created equal. From traditional metal braces to newer, more discreet options, there's a wide range to choose from depending on your preferences and needs.
Traditional Metal Braces: These are the ones most of us are familiar with. They consist of metal brackets attached to each tooth, connected by wires that are periodically tightened by your orthodontist. While they may be the most noticeable option, they're also typically the most affordable.
Ceramic Braces: For those concerned about the aesthetics of metal braces, ceramic braces are a popular alternative. They work similarly to traditional braces but use tooth-colored or clear brackets that blend in more seamlessly with your teeth.
Lingual Braces: If you're looking for ultimate discretion, lingual braces might be the way to go. These braces are placed on the backside of your teeth, making them virtually invisible from the front. They're custom-made to fit the contours of your teeth, offering a comfortable and discreet straightening solution.
Clear Aligners (e.g., Invisalign): Perhaps the most modern option available, clear aligners have gained popularity for their convenience and aesthetics. These custom-made trays gradually shift your teeth into place, and they're removable, making eating and oral hygiene a breeze.
Self-Ligating Braces: These braces use a specialized clip system to hold the wire in place, eliminating the need for elastic bands. They're said to move teeth more efficiently and require fewer adjustments compared to traditional braces.
Each type of braces comes with its pros and cons, and the best option for you will depend on factors such as your budget, treatment goals, and personal preferences. It's crucial to consult with an orthodontist to determine the most suitable option for your specific case.
For those of you who have undergone orthodontic treatment or are currently considering it, I'd love to hear about your experiences and insights. Which type of braces did you choose, and what factors influenced your decision? Feel free to share your thoughts on the different types of braces and any tips you have for those embarking on their orthodontic journey.
Let's celebrate the diversity of orthodontic braces types and empower each other with knowledge and experiences!
Looking forward to the discussion.
[Diana Wilson]
 | dianawilson | |
1,871,393 | app/(app) route group in shadcn-ui/ui | You can tell shadcn-ui/ui is built using app router by looking at its folder structure inside... | 0 | 2024-05-30T21:57:38 | https://dev.to/ramunarasinga/appapp-route-group-in-shadcn-uiui-j3 | javascript, opensource, shadcnui, nextjs | You can tell shadcn-ui/ui is built using app router by looking at its folder structure inside [apps/www](https://github.com/shadcn-ui/ui/tree/main/apps/www/app).

since the folder name inside [app](https://github.com/shadcn-ui/ui/tree/main/apps/www/app) is (app) , in Next.js, this means that this folder is a [route group](https://nextjs.org/docs/app/building-your-application/routing/route-groups).
### Route Groups
In the app directory, nested folders are normally mapped to URL paths. However, you can mark a folder as a Route Group to prevent the folder from being included in the route's URL path.
> [_Build shadcn-ui/ui from scratch._](https://tthroo.com/)
This allows you to organize your route segments and project files into logical groups without affecting the URL path structure.
Route groups are useful for:
* [Organizing routes into groups](https://nextjs.org/docs/app/building-your-application/routing/route-groups#organize-routes-without-affecting-the-url-path) e.g. by site section, intent, or team.
* Enabling [nested layouts](https://nextjs.org/docs/app/building-your-application/routing/pages-and-layouts) in the same route segment level:
* [Creating multiple nested layouts in the same segment, including multiple root layouts](https://nextjs.org/docs/app/building-your-application/routing/route-groups#creating-multiple-root-layouts)
* [Adding a layout to a subset of routes in a common segment](https://nextjs.org/docs/app/building-your-application/routing/route-groups#opting-specific-segments-into-a-layout)
Next.js docs provide the following examples, be sure to check them out:
1. [Organize routes without affecting the URL path](https://nextjs.org/docs/app/building-your-application/routing/route-groups#organize-routes-without-affecting-the-url-path)
2. [Opting specific segments into a layou](https://nextjs.org/docs/app/building-your-application/routing/route-groups#opting-specific-segments-into-a-layout)t
3. [Creating multiple root layouts](https://nextjs.org/docs/app/building-your-application/routing/route-groups#creating-multiple-root-layouts)
Shadcn-ui/ui leverages route group to share the common layout among docs, components, themes, examples, blocks pages.

Common layout in this case is the header and footer that can be found in [components folder](https://github.com/shadcn-ui/ui/tree/main/apps/www/components).
### site-footer.tsx

### site-header.tsx

### About me:
Website: https://ramunarasinga.com/
Linkedin: https://www.linkedin.com/in/ramu-narasinga-189361128/
Github: https://github.com/Ramu-Narasinga
Email: ramu.narasinga@gmail.com
### References:
1. [https://github.com/shadcn-ui/ui/blob/main/apps/www/app/(app)/layout.tsx](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/(app)/layout.tsx)
2. [https://github.com/shadcn-ui/ui/tree/main/apps/www/components](https://github.com/shadcn-ui/ui/tree/main/apps/www/components)
3. [https://github.com/shadcn-ui/ui/blob/main/apps/www/components/site-footer.tsx](https://github.com/shadcn-ui/ui/blob/main/apps/www/components/site-footer.tsx)
4. [https://github.com/shadcn-ui/ui/blob/main/apps/www/components/site-header.tsx](https://github.com/shadcn-ui/ui/blob/main/apps/www/components/site-header.tsx)
5. [https://nextjs.org/docs/app/building-your-application/routing/route-groups](https://nextjs.org/docs/app/building-your-application/routing/route-groups) | ramunarasinga |
1,870,809 | Defer Statements in Go: A Short Crash Course | What is the defer statement? In Go, a defer statement gives you the ability to execute a... | 0 | 2024-05-30T20:31:34 | https://dev.to/blazingbits/defer-statements-in-go-a-short-crash-course-1e61 | go | ## What is the defer statement?
In Go, a `defer` statement gives you the ability to execute a function **AFTER** its containing function has finished execution.
The easiest way to think about it is a callback, or a finally block for developers more familiar with Java.
You will commonly see defer statements being used to clean up resources, such as files and database connections.
## defer Statement Syntax
```
func main() {
myFile, err := os.Open("my-file.txt")
defer myFile.close()
if err != nil {
panic(err)
}
}
```
The above is an example of using `defer` to clean up resources, in this case, closing a file after we are done with it. The `defer` statement will not execute until after our `main` method has finished its execution.
Using defer directly after opening a resource that needs to be manually closed or handled (like files!) is a best practice. This way you know for sure there be no left over resources and you won't forget to manually close it later on in the code.
I like to keep such defer statements as close as possible, ideally right under, the line that opens the resources.
## Using Multiple Defer statements
`defer` statements are placed on a stack. Meaning the last defined statement will be the first to be executed. This is something I had to learn the hard way after facing a particularly confusing bug!
Consider the following code:
```
import "fmt"
func main() {
defer deferredPrint("0")
defer deferredPrint("1")
defer deferredPrint("2")
}
func deferredPrint(s string) {
fmt.Printf("%s\n", s)
}
```
What might its output be?
Since `defer` statements are placed in a call stack (LIFO) the output is the following:
```
2
1
0
```
Notice that the last defined `defer` statement is executed first!
| blazingbits |
1,870,886 | Library of Tooltips. | Welcome aboard to explore my tooltips library! If you're ready to infuse your web pages with dynamic... | 0 | 2024-05-30T21:52:48 | https://popply-library.vercel.app/ | webdev, nextjs, ui, animations | Welcome aboard to explore my tooltips library! If you're ready to infuse your web pages with dynamic interactivity, you're in the right place. Dive into a world of captivating animations and effects curated just for your tooltips.
---
Curious to witness these effects in action? Embark on your journey now by clicking right here:
[PopplyLibrary](https://popply-library-bgnevqx5q-rousdevprojects.vercel.app/)

But that's not all! Popply Library isn't just a destination; it's a treasure trove of CSS animations ready to be seamlessly integrated into your projects. With its user-friendly copy-and-paste feature, you can effortlessly incorporate these animations into your codebase. Plus, unlock the secrets of crafting captivating tooltips using React and Tailwind, all at your fingertips.
Ready to make your mark? Join on GitHub and become a part of the Popply Library community. Let's code, collaborate, and create together.
[GithubProject](https://github.com/JhojanGgarcia/PopplyLibrary)
| jhojanggarcia |
1,871,389 | Ruby Sinatra Bootstrap view accordion | Below is my code where I had used bootstrap syntax to display info in a accordion using an api call... | 0 | 2024-05-30T21:51:17 | https://dev.to/adolfonava/ruby-sinatra-bootstrap-view-accordion-2pag | ruby, bootstrap, webdev, css | Below is my code where I had used bootstrap syntax to display info in a accordion using an api call the structure of depending on if there was the data available. Sometimes when I called the data the definitions didn't have an example ready to use so I had to account that in my work. When working in a loop the accordion doesn't work properly if the accordion div id wasn't unique. if you don't have unique identifiers available, consider making a counter whenever you move on to the next value so that it lets the accordion act independently from each other.
```ruby
<% count = 0 %>
<% @data['collection'].each do |col| %>
<h3><%=col['title']%></h3>
<% col['definitions'].each do |deF| %>
<%count = count + 1%>
<%if deF.has_key?('example')%>
<div class="accordion" id="accordion<%=count%>">
<div class="accordion-item">
<h2 class="accordion-header" id="headingOne">
<button class="accordion-button" type="button" data-bs-toggle="collapse" data-bs-target="#collapse<%=count%>" aria-expanded="true" aria-controls="collapseOne">
<%= "#{count}. #{deF['definition']}" %>
</button>
</h2>
<div id="collapse<%=count%>" class="accordion-collapse collapse" aria-labelledby="headingOne" data-bs-parent="#accordion<%=count%>">
<div class="accordion-body">
<p><strong>Example:</strong> <%=deF['example']%></p>
</div>
</div>
</div>
</div>
<%else%>
<h5><%= "#{count}. #{deF['definition']}" %></h5>
<%end%>
<%end%>
<%end%>
``` | adolfonava |
1,871,387 | Next.js MongoDB Prisma Auth Template 🚀 | Simple Starter Template with proper protected routes setup via middleware! 🚀 I always use... | 0 | 2024-05-30T21:49:40 | https://dev.to/mmvergara/nextjs-mongodb-prisma-auth-template-aa8 | nextjs, mongodb, prisma, webdev | ### Simple Starter Template with proper protected routes setup via middleware! 🚀
I always use this stack because you can literally **host it for free**. But, I noticed that I kept repeating the same boilerplate code for my projects. So, I decided to streamline the process by making a template for it and here I am sharing it with you.
**[Repository Link](https://github.com/mmvergara/nextjs-mongodb-prisma-auth-template/)**
### Includes
- Next.js
- MongoDB
- Prisma
- NextAuth
- zod
- bcryptjs
Contributions are welcome 🙌🙌🙌 | mmvergara |
1,871,244 | Quick overview of reactivity in Vue3 | In my opinion, one of Vue’s most powerful features is its reactivity system. Reactivity allows the... | 0 | 2024-05-30T21:48:16 | https://dev.to/pentektimi/quick-overview-of-reactivity-in-vue3-3cbh |
In my opinion, one of Vue’s most powerful features is its reactivity system. Reactivity allows the framework to automatically update the UI when the information behind it changes. By default, Javascript is not naturally reactive, if nobody tells it, it won’t know that the state changed.
In Vue3 with the Composition API it is common to use ref() and reactive() to add reactivity to a variable/object. Under the hood, Vue converts the data into a proxy object, which enables Vue to perform dependency tracking and change-notification when properties are accessed or modified. In-depth blog about reactivity here: https://blog.logrocket.com/your-guide-to-reactivity-in-vue-js/
The most common ways in Vue Composition API to achieve reactive states are by using reactive() or ref().
**reactive()**
This function only works with objects, and it does not work with primitives. The returned value from reactive() is a Proxy of the original object. When implementing reactive() we can avoid using the ‘.value’ to retrieve the properties of the object, in contrast with the ref() function where we have to use ‘.value’. To access a property we can do so by using ‘object.key’ notation.
The question is, however, if losing ‘.value’ is a benefit or not. I have seen many opinions that losing ‘.value’ can make it harder to track which line of code is triggering a reactive effect. This issue is not so noticeable with small projects, but it can become much more difficult to track reactive objects in a large project. In fact, Vue dropped the reactivity transform feature which got rid of the ‘.value’ when using ref() mainly for this reason.
In addition to this, reactive has a few limitations such as limited value types (only works with objects), can’t replace entire reactive objects because the reactivity connection to the first reference would get lost, and is not destructure-friendly because, again, reactivity connection would get lost.
Because of these limitations, Vue currently recommends using ref as the primary API to declare a reactive state.
**ref()**
Ref works with any data type, including objects. To create a reactive value for primitives (boolean, string, number, etc) we can only use ref(). Whenever we want to access the current value of the reactive property we have to use ‘(name of the value/object).value’. You do not need to append the ‘.value’ when using the ref in the HTML template. With ref, if you are passing it an object you can completely replace it with another one, this is not possible with reactive.
Hopefully, with this quick overview you've gained a bit more clarity about the differences of the two. | pentektimi | |
1,870,737 | End of Phase 2: My Journey with React | After three intense weeks, "Phase 2" has come to an end. This phase was all about diving into the... | 0 | 2024-05-30T21:47:02 | https://dev.to/johnjohnpenafiel/end-of-phase-2-my-journey-with-react-1n0i | react, css, webdev, beginners |
After three intense weeks, "Phase 2" has come to an end. This phase was all about diving into the basics of React and using its enhanced functionality to create web applications more efficiently.
Week 1: Overwhelmed but Determined
As you might know, our bootcamp splits each phase into three weeks. Coming into "Phase 2" felt different from "Phase 1" because I knew the drill—yet, I still found myself overwhelmed in the first week.
Week 1 was a whirlwind of information. I tried to keep up with Canvas lectures and videos while soaking in a ton of knowledge during in-person lectures. By the end of the week, I felt like I had more gaps in my understanding than a slice of Swiss cheese. I knew I had to catch up and fill in those holes.
Week 2: Finding My Groove
Heading into Week 2, I realized I needed a solid plan to digest all the info from Week 1. Unfortunately, I'm the type who needs to understand every core concept before moving on to more complex ideas. So, I decided to slow down, focus on my strengths, and learn at my own pace.
Every day, I isolated myself, diving deep into Canvas lectures, videos, and extensive note-taking. Yes, I was a week behind, but I was determined to catch up. It was time for some hardcore studying—bootcamp style.
Week 3: Gaining Clarity and Confidence
By Week 3, my method was finally paying off. Concepts started to click, and I felt more confident each day. Even though I wasn’t done with all the Canvas lectures, I knew I had a good grasp of the material.
We had an oral assessment coming up to test our understanding. Thanks to my tireless study sessions, I felt prepared and aced the assessment. With just one day left to work on my project (yes, we were supposed to have a whole week), I pulled an all-nighter to get everything done and make my webpage look sleek and functional enough to get the MVP deliverables done.
Looking Ahead
For the next phase, I know I need to start studying at my own pace from day one. It's unrealistic to master every complex subject in just three weeks, but consistent effort and practice will get me there. Coding, to me, is like a game—a mix of puzzles and creativity. Just like chess and Jiu-Jitsu, it's all about practice and continual learning once you get the basics down. | johnjohnpenafiel |
1,858,805 | 🌟 Welcome to BitNest Loop! 🌟 | BitNest Loop is an innovative blockchain and decentralized finance (DeFi) platform dedicated to... | 0 | 2024-05-20T04:49:14 | https://dev.to/appwo/welcome-to-bitnest-loop-5mb | BitNest Loop is an innovative blockchain and decentralized finance (DeFi) platform dedicated to providing users with a fair, efficient and secure financial services environment. Whether you are new to blockchain or a seasoned investor, BitNest Loop has you covered!
Our core goals:
Financial inclusion: enabling everyone, regardless of background or location, to participate in the global financial system.
Transparency and security: Utilize the transparency and non-tamperability of blockchain technology to ensure that every transaction and operation is public and secure.
Diversified investment opportunities: Provide users with a variety of cryptocurrencies and DeFi projects to help you achieve wealth appreciation.
Strong community: Through community activities, education and promotion, build a vibrant user group to jointly promote the sustainable development of BitNest Loop.
Future plan:
We plan to establish our own ecological chain, corresponding to the ecological chains of BNB and Ethereum networks, to further enhance the interoperability and user experience of the platform.
Join us now!
Participate in BitNest Loop and explore the infinite possibilities of blockchain and DeFi. Whether you want to learn, invest or engage with the community, there's an opportunity for you.
If you want to know about BitNest Loop, you can contact me via Telegram: https://t.me/Serena16890 | appwo | |
1,870,887 | Building Resilience: Key Questions for Disaster Recovery Preparedness | *What if your organization suddenly experiences significant downtime due to an unforeseen event? Do... | 0 | 2024-05-30T21:45:39 | https://dev.to/nmend/building-resilience-key-questions-for-disaster-recovery-preparedness-4634 | disaster, recovery, job, devops | **What if your organization suddenly experiences significant downtime due to an unforeseen event? Do you have a comprehensive disaster recovery plan in place to swiftly navigate such challenges? **
In this article, we'll delve into the essential components of a robust disaster recovery plan to ensure business continuity in times of crisis. This article is the first installment of a series of four, each exploring key questions to assess our preparedness for such events.
**First, let's examine our Critical Systems and Data.** Start by creating a comprehensive inventory of all systems, applications, and data repositories within your organization. Identify which systems and data are essential for core business functions, customer service, financial transactions, and regulatory compliance. Prioritize critical systems based on their impact on business operations and potential consequences of downtime. Develop a detailed plan outlining backup frequencies, data retention policies, and recovery procedures for each critical system and dataset. Regularly review and update the inventory and recovery plan to reflect changes in the organization's technology landscape and business priorities.
**Next, let's assess How Strong are our Backup and Recovery Procedures.** Evaluate the current backup strategy, including the frequency of backups, backup retention policies, and backup storage locations. Implement automated backup solutions to ensure regular backups are performed according to predefined schedules. Store backup data securely in offsite locations, such as cloud storage or remote data centers, to protect against on-premises failures and disasters. Test the restoration process regularly to verify the integrity of backup data and validate recovery time objectives (RTOs) and recovery point objectives (RPOs). Document backup and recovery procedures in detail, including step-by-step instructions and contact information for key personnel responsible for executing the plan.
**Moving forward, let's consider if we Are Embracing Redundancy and Failover Mechanisms.** Assess the current infrastructure architecture to identify potential single points of failure and areas where redundancy and failover mechanisms can be implemented. Deploy redundant hardware, such as servers, storage devices, and networking equipment, to minimize the risk of service disruptions due to hardware failures. Implement clustering and load balancing technologies to distribute workloads across multiple servers and ensure high availability. Leverage cloud-based services, such as AWS Elastic Load Balancing and Azure Traffic Manager, to achieve geographic redundancy and automatic failover capabilities. Develop failover plans and conduct regular failover tests to validate the effectiveness of redundancy and failover mechanisms and minimize downtime during a disaster.
**Moreover, let's ensure that we Have an Effective Emergency Response Plan in place.** Collaborate with key stakeholders to develop a comprehensive emergency response plan that outlines roles, responsibilities, and communication protocols during a crisis. Define clear escalation paths and establish procedures for incident detection, notification, and response. Conduct tabletop exercises and simulated drills to test the effectiveness of the emergency response plan and identify areas for improvement. Document incident response procedures in a centralized playbook and distribute copies to all relevant personnel. Review and update the emergency response plan regularly to incorporate lessons learned from past incidents and changes in the organization's infrastructure and operations.
**Finally, let's address if we Are Fostering Collaboration Across Teams and Partners.** Facilitate cross-functional collaboration by establishing regular meetings and communication channels for cybersecurity, SRE, DevOps, and development teams. Clearly define roles and responsibilities for each team member and establish channels for sharing information and coordinating activities during a crisis. Engage with external partners, vendors, and suppliers to align disaster recovery plans and establish protocols for collaboration and information sharing. Conduct joint training exercises and workshops with external partners to ensure alignment and readiness for coordinated response efforts. Regularly review and update collaboration protocols to accommodate changes in team dynamics, organizational structure, and external partnerships. | nmend |
1,870,885 | WHERE AND HOW CAN I HIRE A HACKER ONLINE? GRAYHATHACKS CONTRACTOR | I found myself in a difficult situation when I reached out to Grayhathacks. My ex-boyfriend had... | 0 | 2024-05-30T21:40:39 | https://dev.to/amelia_brown_45d6471bb9e5/where-and-how-can-i-hire-a-hacker-online-grayhathacks-contractor-5d25 | hackathon, webdev, hirehacker | I found myself in a difficult situation when I reached out to Grayhathacks. My ex-boyfriend had posted incredibly embarrassing pictures of me on his social media accounts, and I was desperate to have them removed. Despite my attempts to reason with him, he was uncooperative and refused to comply. That's when I made the decision to give Grayhathacks a chance.
The process of hiring their services was remarkably smooth and efficient. I was amazed at how simple it was to hire a hacker online. The only challenge I faced was ensuring I selected the right hacker for the job and how I could verify their legitimacy. Fortunately, my older brother had previously utilized Grayhathacks' services and had a positive experience. I reached out to them via email, detailing my issue, and received a prompt response from one of their team members. From that moment on, I felt confident that I was on the path to resolving my problem. The team at Grayhathacks was professional, empathetic, and guided me through each step of the process.
Their first course of action was to conduct a thorough investigation of my ex-boyfriend's social media accounts and the origin of the pictures. They then informed me that they required some time to gather the necessary information and devise a plan of action. Throughout this period, they kept me informed of their progress through both email and WhatsApp.
Once they had gathered all the necessary information, they presented their proposed method to me. It involved a strategic blend of social engineering, phishing, and, as a last resort, a potential DoS attack. Initially, I was hesitant, but Grayhathacks reassured me of their expertise and resources to handle the situation delicately, ensuring no harm would come to my ex-boyfriend's accounts. My sole desire was to erase all traces of my photos from his accounts and backups, freeing myself from any potential blackmail.
The plan was executed flawlessly. Grayhathacks maintained constant communication, updating me at every turn. Within a matter of days, my ex-boyfriend's social media accounts were rid of the incriminating photos. They even provided me with screenshots as evidence of their success. To ensure thoroughness, they continued to monitor his accounts to prevent any unexpected surprises. Their efficiency and professionalism left me in awe, and I am immensely grateful for their assistance.
For all your hacking needs, Grayhathacks is the ultimate solution. Contact them via email at grayhathacks@contractor.net or reach out on WhatsApp at +1 (843) 368-3015. Trust in their expertise to handle your situation with precision and discretion.
 | amelia_brown_45d6471bb9e5 |
1,870,884 | GitHub Skills Challenge | 🚀 📚Join our GitHub Challenge! This is part of the Microsoft Learn Challenge | Build Edition... | 0 | 2024-05-30T21:38:08 | https://dev.to/mukuastephen/github-skills-challenge-238m | githubcopilot, github, githubactions, git |

🚀 📚Join our GitHub Challenge! This is part of the Microsoft Learn Challenge | Build Edition 2024!
✨This challenge can help you prepare for the GitHub Foundations certification exam by covering a few topics that may appear on the exam. By completing this challenge before June 21st, 2024, you will receive a special and distinctive digital badge on your Microsoft Learn profile for finishing this learning experience. You can share your badge on your LinkedIn!
🤩 This badge is only available during Microsoft Build, our largest developer event of the year. Register now at: https://aka.ms/GitHubChallengeBuild?wt.mc_id=studentamb_360864 More information here:
https://aka.ms/InfoGitHubChallenge?wt.mc_id=studentamb_360864 After the challenge, one will learn on numerous benefits of GitHub🚀🌟 e.g.
1)Collaboration and real-time development. Where teams can work together on code, content, research, and web pages. Also, team members can access recent versions of files and make edits that others can see instantly. 😇🤓
2) Version Control And Tracking changes 🤖🌟 3) Documentation and showcase. GitHub makes it easier to create and maintain excellent documentation.✅ | mukuastephen |
1,870,883 | Comparing Compiled and Interpreted Languages: A Focus on JavaScript and C++ | INTRODUCTION Computers and humans are deeply connected, almost like extensions of... | 0 | 2024-05-30T21:37:23 | https://dev.to/alabi_ololade_675051f2396/comparing-compiled-and-interpreted-languages-a-focus-on-javascript-and-c-31m9 | webdev, javascript, programming, productivity | ## **INTRODUCTION**
Computers and humans are deeply connected, almost like extensions of ourselves. While we are far more intelligent, computers still play a crucial role in our daily lives. However, when we tell a computer what to do, it doesn't understand us directly. Instead, it translates our brilliant human ideas into machine language that the computer can understand. This translation process defines whether a language is compiled or interpreted.
I started learning JavaScript a year ago, and I have to say, it's a bit like instant coffee compared to the slow brew of C++. Some might argue that C++ is the premium option because it’s compiled and therefore faster. But JavaScript? It's that quick fix that gets you through the day, especially when you're building dynamic web pages.
This article will explore the differences between compiled and interpreted languages, Additionally, we will compare JavaScript with C++, a well-known compiled language, to understand their unique strengths and applications. Buckle up, it's going to be an enlightening ride!
**UNDERSTANDING COMPILED AND INTERPRETED LANGUAGES**
**Compiled Languages**
Compiled languages, such as C, C++, and Java, Fortran, COBOL, Objective-C require the source code to be translated into machine language by a compiler before it can be executed. This process creates an executable file that can run on a computer's hardware, making the execution fast and efficient. However, any changes to the code require recompilation, which can slow down the development process.
Like I said, we humans are far more intelligent than computers because we are the ones that tell the computers what to do. But as you know, the computer does not understand us directly, so what does it do? It translates our ideas into machine language. If it decides to translate at the end of us writing our code, it is called a compiled programming language.
So, how does this work? As a programmer, I write a set of instructions using a compiled language, and at the end of it, I run it through a special compiler that interprets and converts it into machine language. But guess what... What if I want to make changes to my code? Tears That means I have to make the changes and again run it through the special compiler, which causes a lot of delay. Even though this process can be time-consuming, we can still say that compiling provides a higher level of performance and efficiency in programming.
**Interpreted Languages**
Interpreted languages, including JavaScript, Python, Ruby, PHP, Perl, and Haskell, are executed by an interpreter that translates code in real-time while the program runs. My lovely JavaScript is here 😊, thriving in this category. This real-time compilation by the user's web browser allows for easy changes and rapid development, but it can slow down performance since the browser does extra work during execution.
This is why JavaScript is sometimes seen as less serious than compiled languages like C++ 😞. However, advancements in just-in-time compilers and faster processors are changing this perception, with JavaScript making a significant impact in improving performance and efficiency.
**COMPARING JAVASCRIPT AND C++**
1) **Used Cases**
JavaScript excels in web development, both on the client and server sides, thanks to its ability to manipulate web pages and handle asynchronous operations. Need a web page to update without refreshing? JavaScript's got it covered, like a magician pulling rabbits out of a hat! 🎩🐇. C++, on the other hand, is preferred for system/software development, game development, and applications requiring high performance and direct hardware manipulation.
2) **Performance**
C++ generally offers superior performance due to its compiled nature, making it suitable for resource-intensive applications. JavaScript, being an interpreted language, may have slower execution but offers greater flexibility and faster iteration during development.
3) **Development Speed**
JavaScript allows for rapid development and quick testing, making it ideal for projects that require frequent updates and real-time feedback. C++ development can be slower due to the need for recompilation after code changes, but it provides robust performance optimizations.
4) **Versatility**
JavaScript's versatility shines in web and server applications, while C++ is unmatched in environments where performance and resource management are critical, such as game engines, operating systems, and real-time simulations.
**CONCLUSION**
We have come to the end of my JavaScript vs. C++ showdown. I'm sure you all know which one I prefer, but at the end of the day, it depends on what you want to build. JavaScript and C++ each have their unique strengths and are suited for different types of projects. JavaScript's flexibility and ease of use make it a go-to language for web development and rapid prototyping. On the other hand, C++'s performance and efficiency are essential for system-level programming and high-performance applications.
Understanding the differences between compiled and interpreted languages helps developers choose the right language for their specific needs, leveraging the strengths of each to build efficient and effective software. But like I said, JavaScript is my love. I can have a change of mind, though! Let me know your thoughts in the comment section. 😊🚀
**ATTRIBUTES**
Minnick, C., & Holland, E. Coding with Dummies. Publisher.
| alabi_ololade_675051f2396 |
1,870,882 | Advanced SQL: Mastering Query Optimization and Complex Joins | Hello everyone, السلام عليكم و رحمة الله و بركاته SQL (Structured Query Language) is an essential... | 0 | 2024-05-30T21:34:05 | https://dev.to/bilelsalemdev/advanced-sql-mastering-query-optimization-and-complex-joins-4gph | sql, performance, programming, database | Hello everyone, السلام عليكم و رحمة الله و بركاته
SQL (Structured Query Language) is an essential tool for managing and manipulating relational databases. While basic SQL skills can get you started, advanced SQL techniques can greatly enhance your ability to handle complex queries and optimize database performance. This article delves into advanced SQL topics, focusing on sophisticated query optimization strategies, advanced join types, and the intricacies of `SELECT` statements.
### Advanced Query Optimization Techniques
Optimizing SQL queries is a critical skill for database administrators and developers. Advanced query optimization goes beyond basic indexing and query refactoring to include a range of sophisticated techniques.
#### 1. Query Execution Plans
Understanding the execution plan of a query is crucial for optimization. The execution plan shows how the SQL engine executes a query, revealing potential bottlenecks.
- **EXPLAIN**: The `EXPLAIN` statement provides insights into how a query will be executed, allowing you to identify inefficiencies.
```sql
EXPLAIN SELECT column1, column2 FROM table_name WHERE condition;
```
- **ANALYZE**: The `ANALYZE` statement, used in conjunction with `EXPLAIN`, executes the query and provides runtime statistics, offering a deeper understanding of the query performance.
```sql
EXPLAIN ANALYZE SELECT column1, column2 FROM table_name WHERE condition;
```
#### 2. Subquery Optimization
Subqueries can sometimes be replaced with more efficient joins or with the `WITH` clause (Common Table Expressions).
- **Replacing Subqueries with Joins**:
```sql
-- Subquery
SELECT * FROM table1 WHERE column1 IN (SELECT column1 FROM table2);
-- Equivalent Join
SELECT table1.* FROM table1 INNER JOIN table2 ON table1.column1 = table2.column1;
```
- **Using Common Table Expressions (CTEs)**:
```sql
WITH CTE AS (
SELECT column1, column2 FROM table_name WHERE condition
)
SELECT * FROM CTE WHERE another_condition;
```
#### 3. Indexing Strategies
Advanced indexing strategies include using composite indexes and covering indexes.
- **Composite Index**: Indexes that include multiple columns can speed up queries that filter on those columns.
```sql
CREATE INDEX idx_composite ON table_name (column1, column2);
```
- **Covering Index**: An index that includes all the columns retrieved by the query can significantly improve performance.
```sql
CREATE INDEX idx_covering ON table_name (column1, column2, column3);
```
#### 4. Partitioning
Partitioning a large table into smaller, more manageable pieces can improve query performance by limiting the amount of data scanned.
- **Range Partitioning**:
```sql
CREATE TABLE orders (
order_id INT,
order_date DATE,
...
) PARTITION BY RANGE (order_date) (
PARTITION p0 VALUES LESS THAN ('2024-01-01'),
PARTITION p1 VALUES LESS THAN ('2025-01-01'),
...
);
```
- **Hash Partitioning**: Distributes data across a specified number of partitions based on a hash function, providing uniform distribution.
```sql
CREATE TABLE users (
user_id INT,
username VARCHAR(255),
...
) PARTITION BY HASH(user_id) PARTITIONS 4;
```
- **List Partitioning**: Divides data into partitions based on a list of values.
```sql
CREATE TABLE sales (
sale_id INT,
region VARCHAR(255),
...
) PARTITION BY LIST (region) (
PARTITION p0 VALUES IN ('North', 'South'),
PARTITION p1 VALUES IN ('East', 'West')
);
```
#### 5. Materialized Views
Materialized views store the result of a query physically and can be refreshed periodically, improving performance for complex queries that are executed frequently.
- **Creating a Materialized View**:
```sql
CREATE MATERIALIZED VIEW sales_summary AS
SELECT region, SUM(sales_amount) AS total_sales
FROM sales
GROUP BY region;
```
- **Refreshing a Materialized View**:
```sql
REFRESH MATERIALIZED VIEW sales_summary;
```
## Note:
In MySQL, views exist, but materialized views do not exist natively. MySQL supports standard views, which are virtual tables that store the query definition and generate the result set dynamically when queried. However, it does not have built-in support for materialized views, which store the result set physically.
### Views in MySQL
#### Creating a View
You can create a view in MySQL using the `CREATE VIEW` statement. Here's an example:
```sql
CREATE VIEW ActiveCustomers AS
SELECT CustomerID, CustomerName, ContactName, Country
FROM Customers
WHERE Status = 'Active';
```
This creates a view named `ActiveCustomers` that includes only active customers from the `Customers` table. Querying this view looks like:
```sql
SELECT * FROM ActiveCustomers;
```
#### Updating a View
Views can be updated with the `CREATE OR REPLACE VIEW` statement:
```sql
CREATE OR REPLACE VIEW ActiveCustomers AS
SELECT CustomerID, CustomerName, ContactName, Country
FROM Customers
WHERE Status = 'Active' AND Country = 'USA';
```
This modifies the `ActiveCustomers` view to include only active customers from the USA.
#### Dropping a View
You can remove a view with the `DROP VIEW` statement:
```sql
DROP VIEW ActiveCustomers;
```
#### Materialized Views in MySQL
MySQL does not support materialized views natively, but there are workarounds to achieve similar functionality. Here are a couple of methods:
##### 1. Using a Table and Scheduled Updates
One common approach is to create a table that stores the results of the query and update it periodically using scheduled events (cron jobs) or triggers.
##### Creating the Table
First, create a table to store the results:
```sql
CREATE TABLE MaterializedActiveCustomers AS
SELECT CustomerID, CustomerName, ContactName, Country
FROM Customers
WHERE Status = 'Active';
```
##### Updating the Table
Use a scheduled event to update the table periodically. This example uses a MySQL event to update the table every hour:
```sql
CREATE EVENT UpdateMaterializedActiveCustomers
ON SCHEDULE EVERY 1 HOUR
DO
BEGIN
DELETE FROM MaterializedActiveCustomers;
INSERT INTO MaterializedActiveCustomers
SELECT CustomerID, CustomerName, ContactName, Country
FROM Customers
WHERE Status = 'Active';
END;
```
This event clears and repopulates the `MaterializedActiveCustomers` table every hour with the latest active customers.
##### 2. Using Triggers
Another approach is to use triggers to keep the table in sync with the base tables. However, this can become complex and may not be as efficient for large datasets.
#### Example of Using Triggers
##### Creating the Table
First, create the table:
```sql
CREATE TABLE MaterializedActiveCustomers AS
SELECT CustomerID, CustomerName, ContactName, Country
FROM Customers
WHERE Status = 'Active';
```
##### Creating Triggers
Create triggers to keep the materialized table updated:
```sql
DELIMITER //
CREATE TRIGGER after_customer_insert
AFTER INSERT ON Customers
FOR EACH ROW
BEGIN
IF NEW.Status = 'Active' THEN
INSERT INTO MaterializedActiveCustomers (CustomerID, CustomerName, ContactName, Country)
VALUES (NEW.CustomerID, NEW.CustomerName, NEW.ContactName, NEW.Country);
END IF;
END //
CREATE TRIGGER after_customer_update
AFTER UPDATE ON Customers
FOR EACH ROW
BEGIN
IF OLD.Status = 'Active' AND NEW.Status != 'Active' THEN
DELETE FROM MaterializedActiveCustomers WHERE CustomerID = OLD.CustomerID;
ELSEIF NEW.Status = 'Active' THEN
REPLACE INTO MaterializedActiveCustomers (CustomerID, CustomerName, ContactName, Country)
VALUES (NEW.CustomerID, NEW.CustomerName, NEW.ContactName, NEW.Country);
END IF;
END //
CREATE TRIGGER after_customer_delete
AFTER DELETE ON Customers
FOR EACH ROW
BEGIN
DELETE FROM MaterializedActiveCustomers WHERE CustomerID = OLD.CustomerID;
END //
DELIMITER ;
```
These triggers will ensure that the `MaterializedActiveCustomers` table stays updated with changes to the `Customers` table.
#### Conclusion
While MySQL supports views, it does not have native support for materialized views. However, you can achieve similar functionality using tables with scheduled updates or triggers. By using these workarounds, you can maintain precomputed results that can be queried quickly, similar to materialized views in other database systems.
### Advanced Join Types and Techniques
Joins are fundamental to SQL, allowing you to combine data from multiple tables. Beyond basic joins, advanced join techniques can handle more complex requirements.
#### 1. Self Joins
A self join is a regular join but the table is joined with itself. It is useful for comparing rows within the same table.
```sql
SELECT a.employee_id, a.name, b.name AS manager_name
FROM employees a
INNER JOIN employees b ON a.manager_id = b.employee_id;
```
#### 2. Lateral Joins
The `LATERAL` join allows subqueries to reference columns from preceding tables in the `FROM` clause. This is useful for more complex queries.
```sql
SELECT a.*, b.*
FROM table1 a
LEFT JOIN LATERAL (
SELECT *
FROM table2 b
WHERE b.column1 = a.column1
ORDER BY b.column2 DESC
LIMIT 1
) b ON TRUE;
```
#### 3. Full Outer Joins with COALESCE
Handling cases where you need a full outer join but want to avoid `NULL` values in the result.
```sql
SELECT COALESCE(a.column1, b.column1) AS column1, a.column2, b.column2
FROM table1 a
FULL OUTER JOIN table2 b ON a.column1 = b.column1;
```
#### 4. Advanced Join Filters
Applying complex conditions in joins to filter results more precisely.
```sql
SELECT a.column1, b.column2
FROM table1 a
INNER JOIN table2 b ON a.column1 = b.column1 AND a.date_column BETWEEN '2023-01-01' AND '2023-12-31';
```
#### 5. Anti Joins and Semi Joins
These joins are useful for exclusion and inclusion queries respectively.
- **Anti Join**: Retrieves rows from the left table that do not have a matching row in the right table.
```sql
SELECT a.*
FROM table1 a
LEFT JOIN table2 b ON a.column1 = b.column1
WHERE b.column1 IS NULL;
```
- **Semi Join**: Retrieves rows from the left table where one or more matches exist in the right table.
```sql
SELECT a.*
FROM table1 a
WHERE EXISTS (SELECT 1 FROM table2 b WHERE a.column1 = b.column1);
```
### Advanced `SELECT` Statements
The `SELECT` statement can be extended with advanced features to meet complex data retrieval requirements.
#### 1. Window Functions
Window functions perform calculations across a set of table rows related to the current row, providing powerful analytics capabilities.
- **Row Number**:
```sql
SELECT column1, column2, ROW_NUMBER() OVER (PARTITION BY column1 ORDER BY column2) AS row_num
FROM table_name;
```
- **Running Total**:
```sql
SELECT column1, column2, SUM(column2) OVER (ORDER BY column1) AS running_total
FROM table_name;
```
- **Ranking**:
```sql
SELECT column1, column2, RANK() OVER (PARTITION BY column1 ORDER BY column2) AS rank
FROM table_name;
```
- **Moving Average**:
```sql
SELECT column1, column2, AVG(column2) OVER (PARTITION BY column1 ORDER BY column2 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS moving_avg
FROM table_name;
```
#### 2. Recursive CTEs
Recursive CTEs allow you to perform recursive queries, useful for hierarchical data.
```sql
WITH RECURSIVE cte AS (
SELECT column1, column2
FROM table_name
WHERE condition
UNION ALL
SELECT t.column1, t.column2
FROM table_name t
INNER JOIN cte ON t.column1 = cte.column1
)
SELECT * FROM cte;
```
#### 3. JSON Functions
Modern SQL databases often include functions to handle JSON data, enabling you to store and query JSON documents.
- **Extracting JSON Values**:
```sql
SELECT json_column->>'key' AS value
FROM table_name;
```
- **Aggregating into JSON**:
```sql
SELECT json_agg(row_to_json(t))
FROM (SELECT column1, column2 FROM table_name) t;
```
- **Updating JSON Data**:
```sql
UPDATE table_name
SET json_column = jsonb_set(json_column, '{key}', '"new_value"', true)
WHERE condition;
```
#### 4. Pivoting Data
Pivoting transforms rows into columns, providing a way to reorganize and summarize data for reporting purposes.
- **Using CASE Statements for Pivoting**:
```sql
SELECT
category,
SUM(CASE WHEN year = 2021 THEN sales ELSE 0 END) AS sales_2021,
SUM(CASE WHEN year = 2022 THEN sales ELSE 0 END) AS sales_2022
FROM sales_data
GROUP BY category;
```
#### 5. Dynamic SQL
Dynamic SQL allows for the construction and execution of SQL statements at runtime, providing flexibility for complex queries that need to be generated dynamically.
- **Executing Dynamic SQL**:
```sql
EXECUTE 'SELECT * FROM ' || table_name || ' WHERE ' || condition;
```
- **Using Prepared Statements**:
```sql
PREPARE stmt AS SELECT * FROM table_name WHERE column1 = $1;
EXECUTE stmt('value');
```
### Conclusion
Mastering advanced SQL techniques allows you to optimize database performance and handle complex queries with ease. Understanding execution plans, leveraging advanced joins, utilizing sophisticated `SELECT` statements, and implementing advanced indexing strategies are key to becoming proficient in SQL. By integrating these techniques into your workflow, you can significantly enhance the efficiency and scalability of your database-driven applications.
Advanced SQL skills enable you to tackle complex data manipulation and retrieval tasks, ensuring that your applications can handle large volumes of data efficiently and effectively. Whether you are a database administrator, developer, or data analyst, these advanced SQL techniques will empower you to make the most out of your relational databases, leading to better performance, deeper insights, and more robust applications. | bilelsalemdev |
1,870,881 | 9 Quick Hacks to Skyrocket Your App Downloads | I have a confession to make. I’m not a big fan of reading on mobile devices. I’ve tried to force... | 0 | 2024-05-30T21:29:02 | https://dev.to/kaiakalwert/9-quick-hacks-to-skyrocket-your-app-downloads-4lab | <p>I have a confession to make.</p>
<p>I’m not a big fan of reading on mobile devices. I’ve tried to force myself to do it, but I’d just rather read a book or read on my laptop. I’d rather watch a video or listen to a podcast, too.</p>
<p>I’m not alone, either. According to a survey by comScore, 70% of people don’t like reading on their mobile devices, and they do so for shorter periods of time than they do on their desktops.</p>
<p>But there’s one thing I’d much rather do on my mobile device than on my laptop: Use apps.</p>
<p>I’m not alone there, either. According to that same survey, 87% of people’s time spent on mobile is in apps.</p>
<p>That’s why I was excited to dive into
<a target="_blank" href="https://news.simplybook.me/6-powerful-video-marketing-tips-to-boost-your-app-downloads/">
<span style="color:rgb(17, 85, 204);">app marketing</span>
</a>. I knew that if I could create a
<a target="_blank" href="https://ling-app.com">
<span style="color:rgb(17, 85, 204);">popular app</span>
</a>, it would be used more than my blog.</p>
<p>I was wrong.
<a target="_blank" href="https://appsgeyser.com/">
<span style="color:rgb(17, 85, 204);">Creating an app</span>
</a>
was just as hard as creating a popular blog. I had to market it. I had to get people to download it.</p>
<p>I quickly learned
<a target="_blank" href="https://www.osiaffiliate.com/marketing/best-wix-affiliate-apps/">
<span style="color:rgb(17, 85, 204);">that app marketing</span>
</a>
is just like content marketing. It’s a grind. It takes time. It takes patience.</p>
<p>But there are some quick hacks that can help you get some downloads while you grind away.</p>
<h2>1. Optimize Your App Store Listing</h2>
<p>Your app store listing is your first impression. It should be designed to convert.</p>
<p>There are a lot of elements that go into an app store listing, but the most important ones to focus on are your app name, app icon, screenshots, description and keywords.</p>
<p>Your app name and keywords should be focused on what your app does. Use the most relevant keywords in your app name and the rest in your keyword field.</p>
<p>Your app icon should be simple and convey what your app does. You want to be able to tell what your app does by looking at the icon.</p>
<p>Your screenshots should be high quality and show off the best features of your app. You can add text to your screenshots to call out specific features.</p>
<p>Your app description should be focused on the benefits of your app and why people should download it. Use bullet points to break up the text and make it easy to read.</p>
<h2>2. Create a Demo Video</h2>
<p>Creating a demo video is one of the most effective ways to show your audience how your app works.</p>
<p>A demo video is a short video that shows your app in action. You can use it to demonstrate the features and benefits of your app, as well as how to use it.</p>
<p>The key to creating a successful demo video is to keep it short and to the point. You want to show your audience what your app does and how it can help them, but you don’t want to overwhelm them with too much information.</p>
<p>You can use a demo video on your website, in your app store listing, and in your app marketing campaigns.</p>
<h2>3. Get Your App Reviewed</h2>
<p>Reviews are a great way to build trust with potential customers. In fact,
<a target="_blank" href="https://birdeye.com/blog/positive-review-examples/">
<span style="color:rgb(17, 85, 204);">84% of people trust online reviews</span>
</a>
as much as a personal recommendation.</p>
<p>There are a couple of different ways you can get your app reviewed. You can reach out to bloggers and journalists who write about apps in your industry and ask them to review your app. You can also submit your app to review websites.</p>
<p>Another great way to
<a target="_blank" href="https://appfollow.io/blog/how-app-reviews-can-grow-your-apps-ltv-and-lower-cpi">
<span style="color:rgb(17, 85, 204);">get your app reviewed</span>
</a>
is to ask your existing customers to review your app. You can do this by adding a review section to your app and asking your customers to leave a review. You can also offer incentives, such as discounts or free products, to customers who leave a review.</p>
<h2>4. Create a Microsite</h2>
<p>A microsite is a small, individual web page that is designed to promote your app. It’s a great way to provide potential users with all the information they need in one place.</p>
<p>On your microsite, you can include things like app features, screenshots, customer testimonials, and download links. You can also include an FAQ section to answer any potential questions your audience may have.</p>
<p>
<span style="color:rgb(13, 13, 13);">Additionally, integrating a
</span>
<a target="_blank" href="https://website.maintenanceconnection.com/resources/knowledge-hub/what-is-maintenance-management-software">
<span style="color:rgb(17, 85, 204);">maintenance planning software</span>
</a>
<span style="color:rgb(13, 13, 13);">
can streamline your app's update schedules and improve overall user experience.</span>
</p>
<p>Microsites are a great way to drive traffic to your app and increase downloads. You can promote your microsite on social media, in
<a target="_blank" href="https://outgrow.co/blog/email-marketing-trends">
<span style="color:rgb(17, 85, 204);">email marketing</span>
</a>
campaigns, through
<a target="_blank" href="https://clevenio.com/how-to-write-follow-up-emails/">
<span style="color:rgb(17, 85, 204);">automated emails</span>
</a>, and in paid ads.</p>
<h2>5. Create a Press Kit</h2>
<p>If you want your app to be taken seriously, you need to treat it like a real business. And that means creating a press kit for your
<a target="_blank" href="https://solveit.dev/blog/how-to-launch-an-app">
<span style="color:rgb(17, 85, 204);">app launch</span>
</a>.</p>
<p>A press kit is a collection of promotional materials that journalists and bloggers can use to write about your app. It should include high-quality images, a press release, a fact sheet, and any other relevant information about your app.</p>
<p>Your press kit should be available on your website, and you should also include a link to it in your app store listing. This will make it easy for journalists and bloggers to find the information they need to write about your app, and it will also help to improve your app’s credibility.</p>
<h2>6. Use Social Media</h2>
<p>
<a target="_blank" href="https://blog.powr.io/the-social-media-blueprint-for-business-success">
<span style="color:rgb(17, 85, 204);">Social media</span>
</a>
is a great way to reach potential users and get them to download your app. You can post links to your app in your social media profiles and in your posts.</p>
<p>You can also use social media to run app download ads. These are ads that appear in the news feeds of potential users. When they click on the ad, they are taken to your app’s page in the app store.</p>
<p>You can also use social media to run app install campaigns. These are ads that appear in the news feeds of potential users. When they click on the ad, they are taken to your app’s page in the app store.</p>
<p>In addition to these methods, consider incorporating a
<a target="_blank" href="https://socialwalls.com/blog/live-hashtag-feed/">
<span style="color:rgb(17, 85, 204);">live hashtag feed</span>
</a>
to further boost engagement. This feed would display tweets or posts from users who are mentioning your app-related hashtag. </p>
<h2>7. Leverage App Store Optimization</h2>
<p>
<a target="_blank" href="https://get.appfollow.io/the-importance-of-aso-in-mobile-marketing-strategy-and-where-to-start-if-you-havent-done-it-before">
<span style="color:rgb(17, 85, 204);">App Store Optimization (ASO</span>
</a>) is the process of improving your app’s visibility in the app store’s search results.</p>
<p>The idea is to use targeted keywords and phrases in your app’s title, description, and other metadata to help it rank higher in the app store search results.</p>
<p>
<a target="_blank" href="https://www.ranktracker.com/blog/beyond-keywords-a-comprehensive-guide-to-seo-in-mobile-app-development/">
<span style="color:rgb(17, 85, 204);">ASO is a lot like SEO</span>
</a>, but it’s specific to mobile apps. If you want to increase your app downloads, ASO is a must.</p>
<p>The higher your app ranks in the app store search results, the more visible it will be to potential users, and the more likely they are to download it.</p>
<h2>8. In-App Referral Programs</h2>
<p>In-app referral programs are a great way to get your existing users to help you find new users.</p>
<p>With an in-app referral program, you can reward your users for referring their friends and family to your app. This can be a great way to get more people talking about your app and to get more people to download it.</p>
<p>Make sure you offer a good incentive for people to refer their friends. This could be a discount on your app, a free trial, or even a cash reward.</p>
<p>The more people who are talking about your app, the more people will be interested in downloading it. So, make sure you use an in-app referral program to help increase your app downloads.</p>
<h2>9. Use App Install Ads</h2>
<p>App install ads are a great way to promote your app on social media. These ads as well as
<a target="_blank" href="https://blog.adplayer.pro/2024/05/15/in-app-video-advertising-2024-best-practices-pro-tips/">
<span style="color:rgb(17, 85, 204);">in-app video advertisements</span>
</a>
are designed to encourage people to download your app directly from the ad.</p>
<p>App install ads can be targeted to specific audiences based on their interests, demographics and more. This allows you to reach the people who are most likely to be interested in your app.</p>
<p>You can create app install ads on Facebook, Instagram, Twitter and other social media platforms. Be sure to research which platforms your target audience is most likely to be on, and focus your efforts there.</p>
<h2>Conclusion</h2>
<p>So, these are some of the quick hacks you can use to skyrocket your app downloads. Which of these strategies are you planning to use for your app? Let us know in the comments below.</p> | kaiakalwert | |
1,870,880 | I just started learning Blazor and I hit a speed bump right out of the gate. | I just started learning Blazor and I hit a speed bump right out of the gate. I am trying to come up... | 0 | 2024-05-30T21:23:19 | https://dev.to/xarzu/i-just-started-learning-blazor-and-i-hit-a-speed-bump-right-out-of-the-gate-5dn7 | blazor, webdev, javascript, programming | I just started learning Blazor and I hit a speed bump right out of the gate.
I am trying to come up to speed on Blazor. I am following a tutorial on youtube. The tutorial has this image.
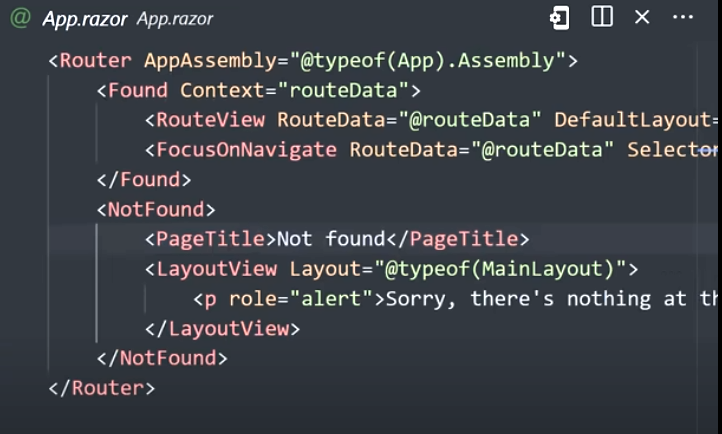
But when I am working with Visual Studio 2024 Community Version, I have this:
It is because things are completely different with Visual Studio Code?
Please advise. | xarzu |
1,870,819 | Problem Solved!! | Hey everyone! I'm back with an exciting update on my internship journey into the realm of game... | 0 | 2024-05-30T21:14:41 | https://dev.to/angeljrp/problem-solved-4opi | Hey everyone!
I'm back with an exciting update on my internship journey into the realm of game development! Thanks to the incredible support from my peers and some invaluable feedback, I've managed to overcome the pesky error that had been hindering my progress. It's amazing what a fresh perspective and a collaborative spirit can achieve!
During one of our team meetings, I received some fantastic suggestions for refining the mechanics of my space-themed math game. One of the most significant pieces of feedback was to allow the players more freedom of movement within the game. Instead of restricting them to simple up-and-down motions, I revamped the gameplay to enable players to navigate their spacecraft freely across the screen. This not only enhances the gameplay experience but also adds an extra layer of excitement and challenge.
Another insightful suggestion was to modify the interaction with the floating numbers in the game. Rather than having the numbers collected from a distance, the feedback emphasized making the collection mechanic more intuitive and engaging. As a result, I adjusted the game mechanics so that players now have to directly touch the numbers with their spacecraft to collect them. This subtle tweak adds a tactile element to the gameplay, making it more immersive and enjoyable.
Now, let's talk about the changes I made to the code. Here's an overview of the modifications:
this was the code used for the free-movement mechanic
```
public void OnDrag(PointerEventData eventData)
{
Vector3 mousePosition = eventData.position;
transform.position = mousePosition;
}
private Vector3 offset;
void OnMouseDown()
{
offset = transform.position - GetMousePosition();
}
void OnMouseDrag()
{
transform.position = GetMousePosition() + offset;
}
Vector3 GetMousePosition()
{
return Camera.main.ScreenToWorldPoint(Input.mousePosition);
}
private void OnCollisionEnter2D(Collision2D collision)
{
if (collision.gameObject.tag == "Number")
{
objectCollidedWith = collision.gameObject;
PickUp();
}
}
```
and this is the one for picking up the numbers
```
public void PickUp()
{
Destroy(objectCollidedWith);
eqM.AddNumber(gm.number);
}
```
With these adjustments, the gameplay feels more dynamic and interactive, offering players a truly immersive experience. I'm thrilled with the progress we've made, and I can't wait to see how players respond to the updated version of the game.
Thank you to everyone who has been following along on this adventure and providing invaluable support and feedback. Together, we're crafting something truly special, and I'm incredibly grateful for the opportunity to learn and grow with such an amazing community.
Stay tuned for more updates as I continue to dive deeper into the world of game development! | angeljrp | |
1,870,818 | Net Aspire - O Futuro é Lindo | Net Aspire - Cloud o que? Faaala Galeraaa. Na minha rotina de estudos decidi dedicar um... | 0 | 2024-05-30T21:08:25 | https://dev.to/cristian_lopes/net-aspire-o-futuro-e-lindo-4hm5 | dotnet, docker, blazor, cloudnative |
## Net Aspire - Cloud o que?
Faaala Galeraaa.
Na minha rotina de estudos decidi dedicar um tempo ao .Net Aspire para entender porque tá todo mundo ouriçado com a mais nova "Cloud Ready Stack"
E... Yes, Yes, Aspire é simplesmente sensacional.
**Orchestration (Pelo pouco que entendi até aqui)**
Em poucas palavras...
Sabe o cursinho de docker que tu comprou? Cancela que tu não vai mais usar.
> "Já matamos o Javascript com o Blazor"
> "Flutter com o MAUI"
> "Agora chegou a hora de matar o Docker com o Aspire"
Brincadeiras a parte, mas ficou extremamente mais ágil desde a adição até a configuração das aplicações, mano, é tudo C# tá dominado.
Segue os passos para adicionar um banco de dados Postgres como exemplo
**Adicionar Nuget Package "Aspire.Hosting.PostgreSQL"**
**Configurar tudo com C# + Intellisense + Copilot**
``` C#
var dbPassword = builder.AddParameter("DatabasePassword", secret: true);
var dbServer = builder.AddPostgres("dbServer", password: dbPassword);
var db = dbServer.AddDatabase("TodoApp");
dbServer.WithDataVolume()
.WithPgAdmin();
builder.AddProject<Projects.TodoApp_Api>("todoapp-api")
.WithReference(db)
.WithExternalHttpEndpoints();
```
Aaaah voltando ao Docker, calmem, ele ainda está lá e ele precisa estar rodando né para não tomar estes erros como eu hahahaha.
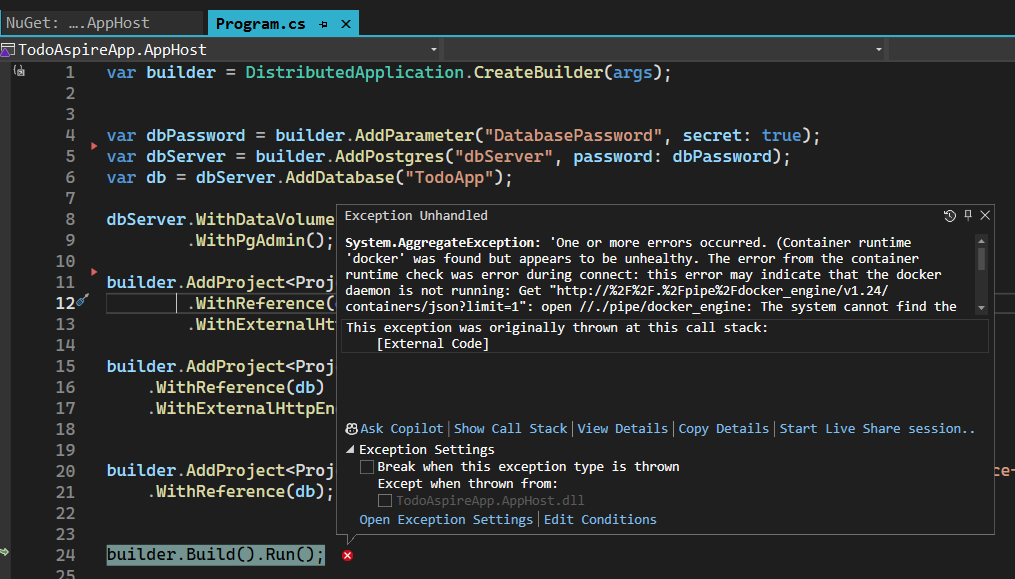
**Observabilidade**
Para mim a melhor parte, como Dev algumas vezes já tive que ficar acessando diferentes máquinas para analisar os logs da aplicação para entender um determinado comportamento da aplicação.
E ter uma ferramenta como o Net Aspire onde tu consegue acompanhar desempenho, registrar logs e rastrear execuções tudo em tempo real é incrível, isso vira o jogo ao nosso favor.
**Logs estruturados**
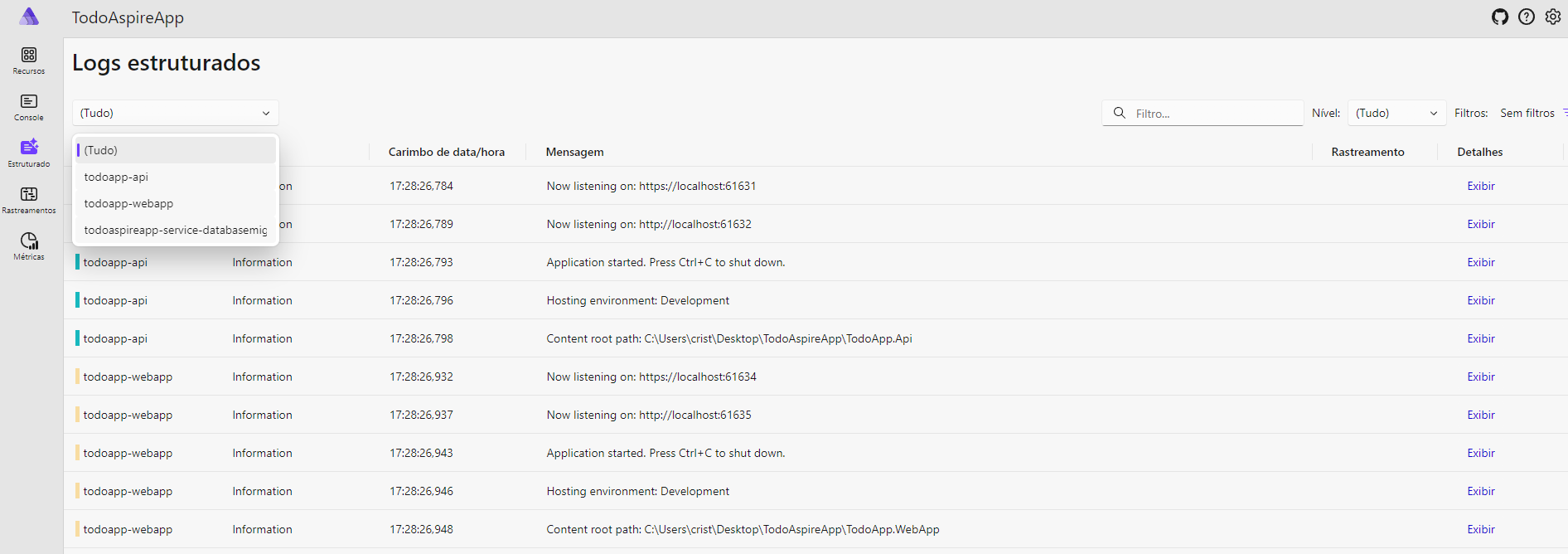
**Rastreamento da API**
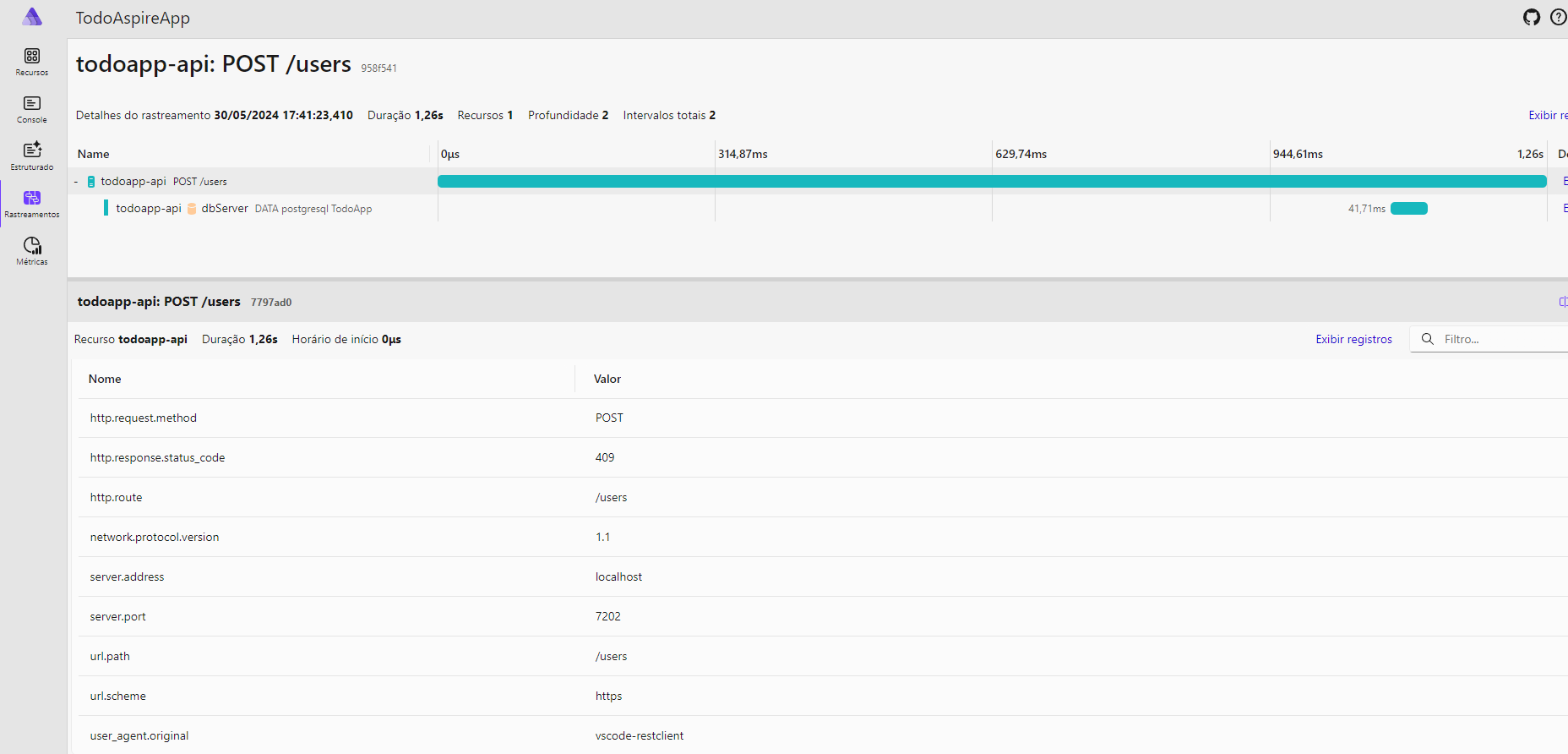
**Logs do console**
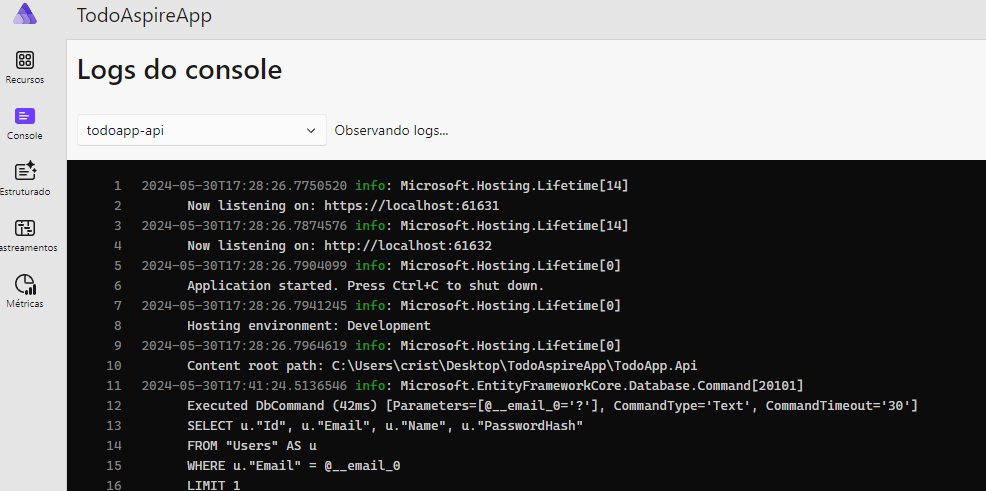
**Tooling**
Bom, acho que se você chegou até aqui já tem uma noção da quantidade de ferramentas que nós Dev's teremos para utilizar ao nosso favor.
Bom e sem falar que estamos apenas no começo do Aspire muito ainda esta por vir, não vejo a hora de brincar de verdade.
**Tá querendo bater um papo sobre Tech e não sabe como me achar?**
[Github >> Cristian Lopes](https://github.com/CristianLopes/TodoAspireApp)
[LinkedIn >> Cristian Lopes](https://www.linkedin.com/in/cristian-lopes-3110029a/)
Ou da um pulo no Sul do nosso Brasilzão e bora assar uma carne.
**Refêrencias**:
https://learn.microsoft.com/en-us/dotnet/aspire/get-started/aspire-overview
https://www.youtube.com/watch?v=jwDC_UQ8H70
| cristian_lopes |
1,870,817 | The 5 Most Used AWS Lambda Functions | AWS Lambda has transformed the way we think about deploying and managing serverless applications. By... | 0 | 2024-05-30T21:02:55 | https://dev.to/nmend/the-5-most-used-aws-lambda-functions-24hh | aws, lambda, devops, python |
AWS Lambda has transformed the way we think about deploying and managing serverless applications. By allowing developers to run code without provisioning or managing servers, Lambda enables scalable and cost-effective computing. Among the myriad ways Lambda can be used, there are some functions that stand out due to their frequent application in various projects. Here are the five most used AWS Lambda functions:
**1. Data Processing**
Data processing is one of the most common uses for AWS Lambda. It allows for the transformation, filtering, and aggregation of data in real-time or batch mode.
Example Use Case:
Log Processing: Lambda can be triggered by logs stored in AWS S3 or Amazon Kinesis to process and transform data before sending it to a destination like Amazon Elasticsearch for analysis.
ETL Pipelines: Extract, Transform, Load (ETL) processes can be streamlined using Lambda to handle each step, from extracting data from one source to transforming it and loading it into another database.
```
import json
def lambda_handler(event, context):
# Process the event data
for record in event['Records']:
payload = json.loads(record['body'])
# Transform the data
transformed_payload = transform_data(payload)
# Load the transformed data to a destination
load_to_destination(transformed_payload)
return {'statusCode': 200, 'body': json.dumps('Data processed successfully')}
def transform_data(data):
# Example transformation logic
data['processed'] = True
return data
def load_to_destination(data):
# Logic to load data to a destination
pass
```
**2. Web Applications and APIs**
Lambda functions are frequently used to build web applications and APIs due to their ability to handle HTTP requests seamlessly when integrated with API Gateway.
Example Use Case:
RESTful APIs: Create RESTful endpoints that trigger Lambda functions to handle requests and return responses.
Webhooks: Respond to events from third-party services by processing incoming webhooks.
```
def lambda_handler(event, context):
# Parse the HTTP request
request = json.loads(event['body'])
# Example logic to handle the request
response = handle_request(request)
return {
'statusCode': 200,
'body': json.dumps(response)
}
def handle_request(request):
# Logic to process the request and generate a response
return {'message': 'Hello, World!'}
```
**3. File Processing**
Lambda is perfect for automating the processing of files as they are uploaded to S3. This can include tasks like image resizing, format conversion, and data extraction.
Example Use Case:
Image Resizing: Automatically resize images uploaded to S3 and save the resized versions to another S3 bucket.
File Format Conversion: Convert files from one format to another upon upload.
```
import boto3
from PIL import Image
import io
s3 = boto3.client('s3')
def lambda_handler(event, context):
# Get the uploaded file details
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# Download the file from S3
file = s3.get_object(Bucket=bucket, Key=key)
# Resize the image
image = Image.open(file['Body'])
resized_image = image.resize((100, 100))
# Save the resized image back to S3
buffer = io.BytesIO()
resized_image.save(buffer, 'JPEG')
buffer.seek(0)
s3.put_object(Bucket=bucket, Key=f'resized/{key}', Body=buffer)
return {'statusCode': 200, 'body': 'Image resized successfully'}
```
**4. Event-Driven Automation**
Lambda is excellent for creating event-driven automation workflows and responding to changes in data or state within your AWS environment.
Example Use Case:
Database Triggers: Automatically trigger functions to perform actions when data in a DynamoDB table changes.
Notifications: Send notifications or alerts when specific events occur in your AWS infrastructure.
Sample Code:
```
import boto3
sns = boto3.client('sns')
def lambda_handler(event, context):
# Process the DynamoDB stream event
for record in event['Records']:
if record['eventName'] == 'INSERT':
new_image = record['dynamodb']['NewImage']
# Send an alert
send_alert(new_image)
return {'statusCode': 200, 'body': 'Event processed successfully'}
def send_alert(data):
message = f"New record inserted: {data}"
sns.publish(
TopicArn='arn:aws:sns:region:account-id:topic-name',
Message=message,
Subject='New DynamoDB Record'
)
```
**5. Scheduled Tasks**
Lambda can be used to run scheduled tasks using Amazon CloudWatch Events. This is ideal for running periodic jobs like backups, maintenance tasks, or data cleanups.
Example Use Case:
Database Backups: Perform automated backups of your database at regular intervals.
Cleanup Tasks: Clean up old files or records from your storage and databases on a schedule.
Sample Code:
```
import boto3
s3 = boto3.client('s3')
def lambda_handler(event, context):
# Perform the scheduled task
perform_backup()
return {'statusCode': 200, 'body': 'Backup completed successfully'}
def perform_backup():
# Logic to perform backup
backup_data = "Backup data"
s3.put_object(Bucket='backup-bucket', Key='backup-file', Body=backup_data)
```
AWS Lambda functions are incredibly versatile, enabling developers to build scalable and efficient applications. The five functions highlighted—data processing, web applications and APIs, file processing, event-driven automation, and scheduled tasks—represent some of the most common and powerful ways Lambda simplifies and enhances serverless computing. You can leverage Lambda to its fullest potential by mastering these functions and optimizing your workflows and infrastructure. | nmend |
1,852,990 | vlone hoodie | https://officialvlone.net/ | 0 | 2024-05-14T18:03:19 | https://dev.to/vlonehoodie3/vlone-hoodie-35a8 | https://officialvlone.net/ | vlonehoodie3 | |
1,870,815 | #1442. Count Triplets That Can Form Two Arrays of Equal XOR | https://leetcode.com/problems/count-triplets-that-can-form-two-arrays-of-equal-xor/solutions/5228488/... | 0 | 2024-05-30T20:51:59 | https://dev.to/karleb/1442-count-triplets-that-can-form-two-arrays-of-equal-xor-2lp1 | https://leetcode.com/problems/count-triplets-that-can-form-two-arrays-of-equal-xor/solutions/5228488/98-33-easy-solution-with-explanation/?envType=daily-question&envId=2024-05-30
```js
/**
* @param {number[]} arr
* @return {number}
*/
var countTriplets = function (arr) {
let n = arr.length
let prefix = new Array(n + 1).fill(0)
for (i = 0; i < n; i++) {
prefix[i + 1] = prefix[i] ^ arr[i]
}
let count = 0
for (let i = 0; i < n; i++) {
for (let k = i + 1; k < n; k++) {
if (prefix[i] === prefix[k + 1]) {
count += (k - i)
}
}
}
return count
};
``` | karleb | |
1,870,812 | Frontend Challenge June Edition - Take me to the beach | This is a submission for [Frontend Challenge... | 0 | 2024-05-30T20:43:44 | https://dev.to/shantih_palani/frontend-challenge-june-edition-take-me-to-the-beach-2h6h | devchallenge, frontendchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
## What I Built
Take me to the beach!
Welcome to our collection of the world's top beaches. Experience it all with two breathtaking views: the tranquil night scene and the vibrant morning ambiance. Plus, immerse yourself further with a gallery of stunning beach snapshots.
The application isbuilt in a responsive way.
<!-- Tell us what you built and what you were looking to achieve. -->
## Demo
<!-- Show us your project! You can directly embed an editor into this post (see the FAQ section from the challenge page) or you can share an image of your project and share a public link to the code. -->
{% codepen https://codepen.io/shanthipalani/pen/JjqExVB %}
## Journey
**Process:**
**Envisioning Enhancement:** Upon reviewing the HTML markup and objectives, I visualized ways to amplify its appeal and interactivity, ensuring seamless user experience.
**Strategic Blueprinting:** I sketched a roadmap, delineating stages for each improvement, ranging from style infusion with CSS to functionality infusion via JavaScript.
**Artful Execution:** With a blend of precision and creativity, I executed enhancements incrementally, prioritizing user engagement and accessibility.
**Meticulous Refinement:** At each juncture, I meticulously refined the design and functionality, leveraging feedback loops and rigorous testing for refinement.
**Comprehensive Documentation:** Finally, I encapsulated the journey in comprehensive documentation, elucidating the rationale behind each tweak and the cumulative impact on user delight.
**Learning:**
**Advanced Layout Techniques:** I honed skills in CSS Grids and Flexbox to sculpt responsive layouts, ensuring harmonious display across diverse screen dimensions.
**Eloquent Event Handling:** Through JavaScript, I mastered the orchestration of DOM events, seamlessly choreographing interactive elements like toggling night mode and modal unveilings.
**Artistry of Animation:** Experimenting with the parallax effect unveiled a realm where CSS and JavaScript seamlessly converge to imbue interfaces with dynamism and allure.
**Proud Moments:**
**Innovative Solutions:** Crafting inventive avenues for features such as night mode, modal pop-ups, and the parallax effect fostered a sense of accomplishment.
**User-Centric Design:** Fusing aesthetics with accessibility, I endeavored to fashion an interface that beckons users with visual charm and navigational ease.
**Next Steps:**
**Unceasing Growth:** Fuelled by an insatiable appetite for learning, I aspire to delve deeper into advanced CSS techniques, explore emerging JavaScript frameworks, and delve into UX/UI design principles.
**Feedback Integration:** I eagerly anticipate assimilating feedback, thereby fortifying future endeavors with insights garnered from real-world usage.
**Exquisite Craftsmanship:** With each project, I aim to refine my craft, infusing it with finesse and flair, to craft digital experiences that captivate and inspire.
Embracing the dynamism of web development, I relish the journey of continuous improvement and innovation, as I strive to craft interfaces that dazzle and delight users.
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- We encourage you to consider adding a license for your code. -->
<!-- Don't forget to add a cover image to your post (if you want). -->
<!-- Thanks for participating! --> | shantih_palani |
1,870,813 | Learn React composition in 15 minutes | Motivation I used to use React UI libraries such as MUI or Chakra or something else. Some... | 0 | 2024-05-30T20:43:05 | https://dev.to/lgtome/react-components-composition-2djl | react, javascript, typescript, webdev | ## Motivation
I used to use `React` UI libraries such as `MUI` or `Chakra` or something else. Some of these libraries create components in a composition way, so today I want to describe the way how you can do it in your project with your own realization.
Let's grab some coffee and let's go.
<img width="100%" style="width:100%" src="https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExM2ZwbnR3YW8zZ2ppNzlyMnVjdXk4aWw1a3ZzZGxldzlvbGo3cW15OCZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/3o6ozw0cY70PJXQGBO/giphy.gif">
_Sorry for the gif, though :D_
## Prerequisites
- `React`
- _coffee **||** tea_
- _good attitude_
## Composition
A couple of words about composition, simple explanation: _combining smaller, independent components to create complex UIs_.
## Why?
From the explanation, combining some components to create a complex UI, or, in some cases, creating an independent group of components to handle its ecosystem.
## Simple composition example
So firstly we need to run a new react project. The way I done with it:
- `yarn init -y`
- `yarn add react react-dom vite`
- `yarn add -D typescript @types/react-dom @types/react`
Then I created a typescript config file:
**tsconfig.json**
```json
{
"compilerOptions": {
"outDir": "build/dist",
"module": "NodeNext",
"target": "es6",
"lib": ["es6", "dom"],
"jsx": "react-jsx",
"moduleResolution": "NodeNext",
"rootDir": "src",
"noImplicitReturns": true,
"noImplicitThis": true,
"noImplicitAny": true,
"strictNullChecks": true
},
"exclude": ["node_modules", "build"],
"include": ["src/**/*"]
}
```
and `index.html` in the root of repository, following `vite` doc
**index.html**
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>React Composition Example</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="/src/index.tsx"></script>
</body>
</html>
```
and also the `index.tsx` file to run our `React`
**index.tsx**
```ts
import { createRoot } from 'react-dom/client'
import { App } from './App'
const root = createRoot(document.getElementById('root') as HTMLDivElement)
root.render(<App />)
```
and the `App.tsx` as an entry point for our app.
**App.tsx**
```ts
import React from 'react'
export const App = () => {
return (
<>
Hi there!
</>
)
}
```
So now we can add a script to the `package.json` and run the app:
**package.json**
```json
//...
"scripts": {
"dev": "vite"
}
//...
```
So where are we? We created a simple react app with vite and we can run it.
Now we need to create a folder, I named `Composition`, where we will store all our composition files.
I created a simple `types.ts` file for shared types between composition files.
**types.ts**
```ts
import { FC, PropsWithChildren } from 'react'
export type FCWithChildren<T> = FC<PropsWithChildren<T>>
```
just for having children with `FC` type.
Then I created 3 components, `Head`, `Footer`, `Body` and `Wrapper`.
I will share it further, but for now, we need to create a main logic with `Provider` and `Context` itself.
So, I created a file called `Context.tsx`
**Context.tsx**
```ts
import { createContext, Dispatch, SetStateAction, useContext, useState } from 'react'
import { FCWithChildren } from './types'
interface ContextState {
initialContext: boolean
data: unknown[]
setData: Dispatch<SetStateAction<ContextState['data']>>
}
const CompositionContext = createContext<ContextState>({ initialContext: true } as ContextState)
export const useCompositionContext = () => {
const context = useContext(CompositionContext)
if (context.initialContext) {
throw new Error('Use context inside provider.')
}
return context
}
export const CompositionContextProvider: FCWithChildren<unknown> = ({ children }) => {
const [data, setData] = useState<unknown[]>([])
return (
<CompositionContext.Provider value={{ initialContext: false, data, setData }}>
{children}
</CompositionContext.Provider>
)
}
```
The key points of this file are:
- this file has an interface for context
- this file has `CompositionContextProvider` to provide the context to nested components
- this file has `useCompositionContext` function, which we will invoke in our nested under `CompositionContextProvider` components
- simple condition statement, but I will describe it more little bit later
<img width="100%" style="width:100%" src="https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExM2tidGdpdTdhcnJoeml5Mzh0cHFteGtpZWViazQ1M3VjNWQ2MGJzZSZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/5Jnzd5fuvipfZa4797/giphy.gif">
So now time to create nested components to use the context.
**Head.tsx**
```ts
import React, { FC } from 'react'
import { useCompositionContext } from './Context'
export const Head: FC<{ order?: number }> = ({ order }) => {
const context = useCompositionContext()
return <div>Head</div>
}
```
**Footer.tsx**
```ts
import React from 'react'
import { useCompositionContext } from './Context'
export const Footer = () => {
const context = useCompositionContext()
return <div>Footer</div>
}
```
**Body.tsx**
```ts
import React from 'react'
import { useCompositionContext } from './Context'
export const Body = () => {
const context = useCompositionContext()
return <div>Body</div>
}
```
Also, I created an `index.tsx` for re-exporting our composition and assigning it to the constant.
**Composition/index.tsx**
```ts
import { Body } from './Body'
import { Footer } from './Footer'
import { Head } from './Head'
import { Wrapper } from './Wrapper'
export const Composition = { Body, Footer, Head, Wrapper }
```
Also, I created a `Wrapper.tsx` file to compose our components with context.
**Wrapper.tsx**
```ts
import React from 'react'
import { FCWithChildren } from './types'
import { CompositionContextProvider } from './Context'
export const Wrapper: FCWithChildren<unknown> = ({ children }) => {
return <CompositionContextProvider>{children}</CompositionContextProvider>
}
```
and also the last one `Layout.tsx` to render our components:
**Layout.tsx**
```ts
import React from 'react'
import { Composition } from '.'
export const CompositionLayout = () => {
return (
<Composition.Wrapper>
<Composition.Head />
<Composition.Body />
<Composition.Footer />
</Composition.Wrapper>
)
}
```
Now it is time to modify `App.tsx` file to apply our changes from the composition.
**App.tsx**
```ts
import React from 'react'
import { CompositionLayout } from './Composition/CompositionLayout'
export const App = () => {
return (
<>
<CompositionLayout />
</>
)
}
```
As I said above we have the condition and now this is an explanation why.
This condition:
```ts
if (context.initialContext) {
throw new Error('Use context inside provider.')
}
```
was about to prevent using components outside the provider,
so if we try to use it outside.
<img width="100%" style="width:100%" src="https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExMWZuODdscmNvcHJmYmZpZXN3bW5sb3p2NnE5Mjg3MmI0dmtiNmtzaiZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/daOkKrzlWaKXtZxxwW/giphy-downsized-large.gif">
**App.tsx**
```ts
import React from 'react'
import { CompositionLayout } from './Composition/CompositionLayout'
import { Composition } from './Composition'
export const App = () => {
return (
<>
<CompositionLayout />
<Composition.Head />
</>
)
}
```
we get an error from our `throw new Error(...)`, cuz we trying to use it outside.
## GitHub
Repository from article: https://github.com/lgtome/react-composition
## Outro
I will be glad to see your comments, some enhancements, questions, and concerns.
<img width="100%" style="width:100%" src="https://i.giphy.com/media/v1.Y2lkPTc5MGI3NjExanFpOWZ3ZjUyMXppNXBxbzlvbGcxMnhudHNmZGE2NDkzem9wa3hjdiZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/osjgQPWRx3cac/giphy.gif"> | lgtome |
1,870,811 | Creating a Smaller Docker Image: A Practical Guide | To illustrate the process of creating a smaller Docker image, let's consider a simple Python... | 0 | 2024-05-30T20:32:48 | https://dev.to/nmend/creating-a-smaller-docker-image-a-practical-guide-17b | docker, optimization, devops, kubernetes | To illustrate the process of creating a smaller Docker image, let's consider a simple Python application. We'll leverage several strategies to minimize the image size.
**Step 1: Choose a Minimal Base Image**
Start with a minimal base image like Alpine or scratch instead of larger ones like Ubuntu. Alpine Linux is a security-oriented, lightweight Linux distribution.
```
# Use a minimal base image
FROM python:3.9-alpine
```
**Step 2: Install Only Necessary Dependencies**
Install only the dependencies required by your application.
```
# Install dependencies
RUN apk add --no-cache gcc musl-dev
```
**Step 3: Use Multi-Stage Builds**
Multi-stage builds allow you to separate the build environment from the runtime environment, ensuring only necessary artifacts are included in the final image.
```
# First stage: Build environment
FROM python:3.9-alpine AS builder
WORKDIR /app
COPY requirements.txt .
RUN apk add --no-cache gcc musl-dev && \
pip install --user -r requirements.txt
# Second stage: Runtime environment
FROM python:3.9-alpine
WORKDIR /app
COPY --from=builder /root/.local /root/.local
COPY . .
ENV PATH=/root/.local/bin:$PATH
CMD ["python", "app.py"]
```
**Step 4: Optimize Layers and Remove Unnecessary Files**
Combine commands to reduce the number of layers and remove unnecessary files and directories.
```
# Combining commands to reduce layers
RUN apk add --no-cache gcc musl-dev && \
pip install --user -r requirements.txt && \
apk del gcc musl-dev && \
rm -rf /var/cache/apk/*
```
**Complete Dockerfile Example**
Here’s the complete Dockerfile incorporating all the strategies mentioned:
```
# First stage: Build environment
FROM python:3.9-alpine AS builder
WORKDIR /app
COPY requirements.txt .
RUN apk add --no-cache gcc musl-dev && \
pip install --user -r requirements.txt && \
apk del gcc musl-dev && \
rm -rf /var/cache/apk/*
# Second stage: Runtime environment
FROM python:3.9-alpine
WORKDIR /app
COPY --from=builder /root/.local /root/.local
COPY . .
ENV PATH=/root/.local/bin:$PATH
CMD ["python", "app.py"]
```
Smaller Docker images bring significant advantages, including faster deployment times, enhanced security, and optimized resource usage. By using minimal base images, installing only necessary dependencies, leveraging multi-stage builds, and optimizing layers, you can create efficient and compact Docker images. This not only streamlines your development and deployment processes but also enhances the overall security and maintainability of your applications. Embracing these best practices will help you make the most out of Docker's capabilities. | nmend |
1,870,808 | Defer Statements in Go: A Short Crash Course | What is the defer statement? In Go, a defer statement gives you the ability to execute a... | 0 | 2024-05-30T20:31:34 | https://dev.to/blazingbits/defer-statements-in-go-a-short-crash-course-3khl | go | ## What is the defer statement?
In Go, a `defer` statement gives you the ability to execute a function **AFTER** its containing function has finished execution.
The easiest way to think about it is a callback, or a finally block for developers more familiar with Java.
You will commonly see defer statements being used to clean up resources, such as files and database connections.
## defer Statement Syntax
```
func main() {
myFile, err := os.Open("my-file.txt")
defer myFile.close()
if err != nil {
panic(err)
}
}
```
The above is an example of using `defer` to clean up resources, in this case, closing a file after we are done with it. The `defer` statement will not execute until after our `main` method has finished its execution.
Using defer directly after opening a resource that needs to be manually closed or handled (like files!) is a best practice. This way you know for sure there be no left over resources and you won't forget to manually close it later on in the code.
I like to keep such defer statements as close as possible, ideally right under, the line that opens the resources.
## Using Multiple Defer statements
`defer` statements are placed on a stack. Meaning the last defined statement will be the first to be executed. This is something I had to learn the hard way after facing a particularly confusing bug!
Consider the following code:
```
import "fmt"
func main() {
defer deferredPrint("0")
defer deferredPrint("1")
defer deferredPrint("2")
}
func deferredPrint(s string) {
fmt.Printf("%s\n", s)
}
```
What might its output be?
Since `defer` statements are placed in a call stack (LIFO) the output is the following:
```
2
1
0
```
Notice that the last defined `defer` statement is executed first!
| blazingbits |
1,870,810 | Defer Statements in Go: A Short Crash Course | What is the defer statement? In Go, a defer statement gives you the ability to execute a... | 0 | 2024-05-30T20:31:34 | https://dev.to/blazingbits/defer-statements-in-go-a-short-crash-course-31ab | go, beginners, tutorial, learning | ## What is the defer statement?
In Go, a `defer` statement gives you the ability to execute a function **AFTER** its containing function has finished execution.
The easiest way to think about it is a callback, or a finally block for developers more familiar with Java.
You will commonly see defer statements being used to clean up resources, such as files and database connections.
## defer Statement Syntax
```
func main() {
myFile, err := os.Open("my-file.txt")
defer myFile.close()
if err != nil {
panic(err)
}
}
```
The above is an example of using `defer` to clean up resources, in this case, closing a file after we are done with it. The `defer` statement will not execute until after our `main` method has finished its execution.
Using defer directly after opening a resource that needs to be manually closed or handled (like files!) is a best practice. This way you know for sure there will be no left over resources and you won't forget to manually close it later on in the code.
I like to keep such defer statements as close as possible, ideally right under, the line that opens the resources.
## Using Multiple defer Statements
`defer` statements are placed on a stack. Meaning the last defined statement will be the first to be executed. This is something I had to learn the hard way after facing a particularly confusing bug!
Consider the following code:
```
import "fmt"
func main() {
defer deferredPrint("0")
defer deferredPrint("1")
defer deferredPrint("2")
}
func deferredPrint(s string) {
fmt.Printf("%s\n", s)
}
```
What might its output be?
Since `defer` statements are placed in a call stack (LIFO) the output is the following:
```
2
1
0
```
Notice that the last defined `defer` statement is executed first!
| blazingbits |
1,870,741 | Criando monorepo com biblioteca reutilizavel, usando PNPM (React + TypeScript) | Introdução: Neste artigo aborda a criação de um monorepo para desenvolvimento de projetos,... | 0 | 2024-05-30T20:25:33 | https://dev.to/romulospl/criando-monorepo-com-biblioteca-reutilizavel-usando-pnpm-react-typescript-57p7 | # Introdução:
Neste artigo aborda a criação de um monorepo para desenvolvimento de projetos, com destaque para a configuração de um workspace e a publicação de um pacote no GitHub Package Registry. Demonstramos também como utilizar esse pacote em um novo projeto externo ao monorepo, fornecendo uma visão abrangente do desenvolvimento modular e colaborativo.
## Passo 1: Configurando o Ambiente Inicial
Vamos começar criando o diretório do projeto e inicializando nosso workspace monorepo usando _pnpm_. Primeiro, crie uma nova pasta para o projeto no local de sua preferência. No exemplo abaixo, criaremos a pasta no diretório home:
```
mkdir ~/monorepo-project
```
Essa pasta servirá como o workspace do nosso monorepo. Em seguida, navegue até essa pasta e inicialize um novo projeto Node.js com _pnpm_:
```
cd ~/monorepo-project
pnpm init
```
Após inicializar o projeto, vamos configurar o controle de versão com Git e criar um arquivo .gitignore para ignorar a pasta node_modules:
```
git init
echo -e "node_modules" > .gitignore
```
O comando git init inicializa um novo repositório Git no diretório atual, e o comando echo -e "node_modules" > .gitignore cria um arquivo .gitignore com a entrada node_modules, que informa ao Git para ignorar essa pasta, evitando que ela seja incluída nos commits.
Finalmente, vamos configurar o projeto para usar módulos ES6 alterando o tipo de módulo no arquivo package.json:
```
npm pkg set type="module"
```
Isso adiciona a seguinte linha ao seu package.json:
```
{
....
"type": "module"
}
```
A configuração "type": "module" permite que você use a sintaxe de módulos ES6 (import/export) no seu projeto Node.js.
## Passo 2: Estruturando o Projeto
Agora que temos o ambiente inicial configurado, vamos estruturar nosso monorepo criando as pastas necessárias e inicializando um projeto de biblioteca de componentes.
Primeiro, crie duas pastas chamadas **`packages`** e **`apps`**:
```
mkdir packages apps
```
A pasta packages será usada para armazenar pacotes reutilizáveis, como nossa biblioteca de componentes, e a pasta apps conterá nossos aplicativos.
### Criando o Projeto de Biblioteca de Componentes (UI Kit)
Dentro da pasta packages, vamos criar um projeto de biblioteca de componentes chamado uikit usando o Vite. Para isso, execute os seguintes comandos:
```
cd packages
pnpm create vite
```
Durante a criação do projeto com o Vite, você será solicitado a fornecer algumas informações, como o nome do projeto e o template a ser usado. Siga as instruções e escolha as opções apropriadas para o seu projeto de biblioteca de componentes.
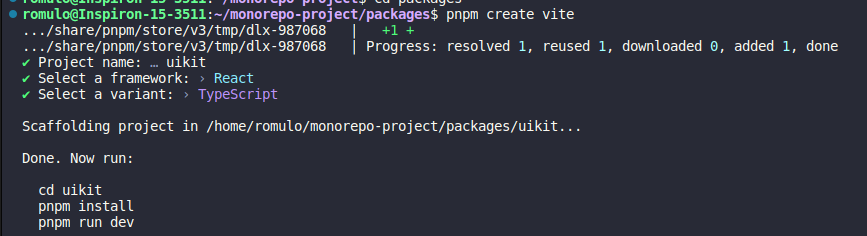
Depois de concluir a criação do projeto, sua estrutura de diretórios deverá se parecer com isto:
```
monorepo-project/
├── packages/
│ └── uikit/
├── apps/
├── package.json
├── .gitignore
├── pnpm-lock.yaml
```
## Passo 3: Criando o Componente de UI
Agora que temos nosso projeto de biblioteca de componentes configurado, vamos criar um simples componente de botão dentro do **`uikit`**.
Primeiro, navegue até a pasta **`uikit`**:
```
cd uikit
pnpm install
```
Em seguida, dentro da pasta src do projeto uikit, crie a estrutura de diretórios components/Button:
```
mkdir -p src/components/Button
```
Dentro dessa pasta Button, crie um arquivo chamado index.tsx e adicione o seguinte código:
```
// src/components/Button/index.tsx
export default function ButtonTeste() {
return <div style={{ backgroundColor: 'green', borderRadius: '25px', padding: '10px' }}>Button</div>
}
```
Este código define um componente React simples chamado **`ButtonTeste`** que renderiza um botão estilizado com uma cor de fundo verde, bordas arredondadas e padding.
Após criar o componente, sua estrutura de diretórios deve se parecer com isto:
```
cssCopiar código
monorepo-project/
├── packages/
│ └── uikit/
│ └── src/
│ └── components/
│ └── Button/
│ └── index.tsx
├── apps/
├── package.json
├── .gitignore
├── pnpm-lock.yaml
```
## Passo 4: Configurando o Vite para Modo Biblioteca
Para que nosso projeto uikit funcione como uma biblioteca, precisamos ajustar a configuração do Vite. Por padrão, o Vite busca um arquivo index.html como ponto de entrada no modo de aplicação. No entanto, queremos que ele procure main.ts para exportar nossos componentes.
### Instalando o Plugin DTS
Primeiro, vamos instalar o plugin DTS, que gera arquivos de declaração (*.d.ts) a partir de arquivos .ts(x) quando o Vite está configurado no modo biblioteca. Execute o seguinte comando dentro da pasta uikit:
```
pnpm add -D vite-plugin-dts
```
### Configurando o Vite
Se o arquivo vite.config.ts não existir, crie-o na raiz do projeto uikit e adicione o seguinte código:
```
// vite.config.ts
import { defineConfig } from 'vite';
import { resolve } from 'path';
import dts from 'vite-plugin-dts';
export default defineConfig({
build: {
lib: {
entry: resolve(__dirname, 'src/main.ts'),
formats: ['es', 'cjs'],
fileName: (format) => `main.${format}.js`,
},
rollupOptions: {
external: ['react', 'react-dom'],
output: {
globals: {
react: 'React',
'react-dom': 'ReactDOM',
},
},
},
},
resolve: {
alias: {
src: resolve(__dirname, 'src/'),
},
},
plugins: [
dts({
tsconfigPath: './tsconfig.json', // Caminho para o arquivo tsconfig.json
outDir: 'dist', // Diretório de saída dos arquivos de definição de tipos
}),
],
});
```
- _Se der erro na importação do resolve do pacote ‘path’ basta dar o seguinte comando dentro da pasta uikit: pnpm install --save-dev @types/node_
### Criando o Arquivo main.ts
Agora, crie o arquivo main.ts dentro da pasta src que será o responsável exportar nossos componentes:
```
touch src/main.ts
```
Adicione o seguinte conteúdo ao arquivo main.ts para exportar o componente ButtonTeste:
```
// src/main.ts
import ButtonTeste from './components/Button';
export { ButtonTeste }
```
Após essas configurações, sua estrutura de diretórios deve se parecer com isto:
```
monorepo-project/
├── packages/
│ └── uikit/
│ ├── src/
│ │ ├── components/
│ │ │ └── Button/
│ │ │ └── index.tsx
│ │ └── main.ts
│ └── vite.config.ts
├── apps/
├── package.json
├── .gitignore
├── pnpm-lock.yaml
```
## Passo 5: Configurando o package.json para Suporte a CommonJS e ES Modules
Para garantir que nossa biblioteca uikit suporte tanto CommonJS quanto ES Modules, precisamos atualizar o package.json com as entradas apropriadas para os pontos de entrada do módulo e as declarações de tipos.
### Atualizando o package.json
Abra o arquivo package.json do projeto uikit e adicione as seguintes configurações:
```
{
...
"main": "./dist/main.es.js",
"module": "./dist/main.es.js",
"types": "./dist/main.d.ts",
"exports": {
".": {
"import": "./dist/main.es.js",
"require": "./dist/main.es.js",
"types": "./dist/main.d.ts"
}
},
"files": [
"dist"
],
...
}
```
Detalhes do arquivo package.json:
- **`"main": "./dist/main.cjs.js"`**: Especifica o ponto de entrada para consumidores CommonJS.
- **`"module": "./dist/main.js"`**: Especifica o ponto de entrada para consumidores ES Modules.
- **`"types": "./dist/main.d.ts"`**: Especifica o arquivo de declarações de tipos TypeScript.
- **`"exports"`**: Define como os diferentes módulos podem ser importados.
- **`"import"`**: Usado por ES Modules.
- **`"require"`**: Usado por CommonJS.
- **`"types"`**: Define o caminho para os arquivos de declarações de tipos.
- **`"files"`**: Especifica quais arquivos devem ser incluídos no pacote publicado. Neste caso, apenas a pasta **`dist`** será incluída.
- **`"scripts"`**: Adiciona um script de build para compilar a biblioteca usando Vite.
## Passo 6: Criando o Projeto Web App e Configurando o Workspace
Agora vamos criar o projeto web-app, que fará uso da nossa biblioteca de componentes uikit, dentro do mesmo repositório.
### Criando o Projeto Web App
Navegue até a pasta apps dentro da raiz do projeto monorepo-project e crie o projeto web-app usando o Vite:
```
# dentro de monorepo-project/apps execute:
pnpm create vite
```
entre dentro da pasta web-app execute `pnpm install` para instalar as dependências.
### Configurando o Workspace
Após criar o projeto web-app, precisamos configurar um workspace para gerenciar todos os projetos dentro do mesmo repositório.
Volte para a pasta raiz do monorepo-project e crie um arquivo chamado pnpm-workspace.yaml:
```
cd ..
touch pnpm-workspace.yaml
```
Dentro desse arquivo, insira o seguinte conteúdo:
```
packages:
- 'apps/*'
- 'packages/*'
```
Essa configuração informa ao pnpm para reconhecer os diretórios apps e packages como parte do workspace, permitindo que eles sejam gerenciados em conjunto.
Após realizar essas etapas, sua estrutura de diretórios deve se parecer com isto:
```
monorepo-project/
├── packages/
│ └── uikit/
│ ├── src/
│ │ ├── components/
│ │ │ └── Button/
│ │ │ └── index.tsx
│ │ └── main.ts
│ ├── tsup.config.ts
│ └── package.json
├── apps/
│ └── web-app/
│ ├── src/
│ ├── package.json
├── package.json
├── pnpm-lock.yaml
├── pnpm-workspace.yaml
├── .gitignore
```
Com isso, temos o projeto web-app criado e o workspace configurado para gerenciar todos os projetos dentro do mesmo repositório.
## Passo 7: Instalando e Configurando o tsup
O tsup é uma ferramenta rápida para transpilar arquivos TypeScript em JavaScript. Ele simplifica o processo de configuração e execução, facilitando a compilação de código TypeScript para uso em projetos JavaScript.
### Instalando o tsup
Para instalar o tsup, execute o seguinte comando dentro da pasta uikit:
```
pnpm add tsup -D
```
### Criando o Arquivo de Configuração tsup.config.ts
Agora, crie o arquivo tsup.config.ts na raiz do projeto uikit e adicione o seguinte código:
```
// tsup.config.ts
import { defineConfig } from 'tsup';
export default defineConfig({
entry: ['src/main.ts'],
format: ['cjs', 'esm'],
dts: true,
sourcemap: true,
clean: true,
outDir: 'dist',
external: ['react', 'react-dom'],
});
```
detalhes o tsup.config.ts
- **`entry`**: Especifica o arquivo de entrada ou uma lista de arquivos de entrada para transpilação.
- **`format`**: Define os formatos de saída desejados, neste caso, CommonJS (**`cjs`**) e ES Module (**`esm`**).
- **`dts`**: Habilita a geração de arquivos de definição de tipos TypeScript.
- **`sourcemap`**: Habilita a geração de sourcemaps para depuração.
- **`clean`**: Limpa o diretório de saída antes de compilar.
- **`outDir`**: Especifica o diretório de saída dos arquivos transpilados.
- **`external`**: Lista de módulos que serão considerados externos e não incluídos no pacote.
Após essas configurações, sua estrutura de diretórios deve se parecer com isto:
```
cssCopiar código
monorepo-project/
├── packages/
│ └── uikit/
│ ├── src/
│ │ ├── components/
│ │ │ └── Button/
│ │ │ └── index.tsx
│ │ └── main.ts
│ ├── tsup.config.ts
│ └── package.json
├── apps/
├── package.json
├── .gitignore
├── pnpm-lock.yaml
```
## Passo 8: Configurando o Web App para Usar o UI Kit
Agora vamos configurar o projeto web-app para utilizar o uikit que criamos anteriormente.
### Adicionando o UI Kit como Dependência
Abra o arquivo package.json do projeto web-app e adicione o uikit como uma dependência:
```
{
"name": "web-app",
"version": "1.0.0",
"dependencies": {
"uikit": "workspace:*"
}
}
```
Execute o comando pnpm install na pasta web-app para que as dependências sejam instaladas e o uikit seja reconhecido pelo projeto.
### Atualizando o App.tsx
Atualize o arquivo App.tsx do projeto web-app para importar e utilizar o componente ButtonTeste do uikit:
```
// web-app/src/App.tsx
import { ButtonTeste } from "uikit";
function App() {
return (
<>
<ButtonTeste />
</>
);
}
export default App;
```
### Compilando o UI Kit
Antes de iniciar o servidor de desenvolvimento, certifique-se de compilar o uikit. Navegue até a pasta uikit e execute o comando pnpm build.
### Iniciando o Servidor de Desenvolvimento
Por fim, execute o comando pnpm run dev dentro da pasta web-app para iniciar o servidor de desenvolvimento e visualizar o botão na tela.
```
cd monorepo-project/apps/web-app
pnpm run dev
```
Isso iniciará o servidor de desenvolvimento e você poderá acessar o projeto web-app em seu navegador para visualizar o botão do UI Kit.
## Passo 9: Publicando o UI Kit no GitHub Package Registry
Agora vamos publicar nosso pacote uikit no GitHub Package Registry.
### Configurando o Arquivo .npmrc
Crie um arquivo chamado .npmrc na raiz do projeto uikit e adicione o seguinte conteúdo, substituindo seuNomeDeUsuario pelo seu nome de usuário do GitHub e SeuToken pelo seu token de acesso (certifique-se de que seu token tenha permissões para criar pacotes no GitHub):
```
@seuNomeDeUsuario:registry=https://npm.pkg.github.com/
//npm.pkg.github.com/:_authToken=SeuToken
```
### Criando o Arquivo .npmignore
Também na raiz do projeto uikit, crie um arquivo chamado .npmignore com o seguinte conteúdo:
```
# Ignore everything
*
# Mas não ignore a pasta dist
!dist
# Você também pode querer incluir o package.json e outros arquivos importantes
!package.json
!README.md
```
### Modificando o package.json
Abra o arquivo package.json do projeto uikit e modifique o nome do pacote e o atributo private. Seu package.json deve ficar semelhante a isso:
```
{
"name": "@seuNomeDeUsuario/nomeDoPacote",
"private": false,
...
}
```
Substitua seuNomeDeUsuario pelo seu nome de usuário do GitHub e nomeDoPacote pelor exemplo o meu projeto fica da seguinte forma:
```
{
"name": "@romulospl/uikit",
"private": false,
...
}
```
### Publicando o Pacote
Agora estamos prontos para publicar nosso pacote. Execute o seguinte comando na raiz do projeto uikit:
npm publish --registry=https://npm.pkg.github.com
Isso irá publicar o pacote uikit no GitHub Package Registry.
Após publicar o pacote uikit no GitHub Package Registry, é importante verificar se a publicação foi realizada com sucesso.
### Acessando o GitHub Package Registry
Acesse o seguinte link em seu navegador, substituindo **`seuNomeDeUsuario`** pelo seu nome de usuário do GitHub:
https://github.com/seuNomeDeUsuario?tab=packages
### Verificando o Pacote Publicado
Na página dos pacotes do seu perfil do GitHub, você deve ser capaz de ver o pacote uikit listado. Isso confirma que o pacote foi publicado com sucesso no GitHub Package Registry.
Verifique se todas as informações estão corretas e se o pacote está disponível para uso.
## Passo 10: Criando o Projeto use-component e Utilizando o UI Kit
Agora vamos criar um novo projeto chamado use-component fora do monorepo-project e utilizá-lo para demonstrar o uso do nosso pacote uikit do GitHub Package Registry.
### Criando o Projeto `use-component`
Na pasta de sua preferência (por exemplo, na sua pasta pessoal), execute o seguinte comando para criar o projeto `use-component` usando Vite:
```
pnpm create vite use-component
```
Em seguida, entre na pasta do projeto e execute pnpm install para instalar as dependências:
```
cd use-component
pnpm install
```
### Instalando o Pacote `uikit` do GitHub Package Registry
Acesse o GitHub e vá para a página dos seus pacotes, substituindo _seuNomeDeUsuario_ pelo seu nome de usuário do GitHub:
https://github.com/seuNomeDeUsuario?tab=packages
Clique no pacote **`uikit`** para acessar sua página. Lá você encontrará o comando para instalar o pacote.
Copie o comando, substituindo @romulospl/uikit pelo nome do seu pacote e 0.0.0 pela versão desejada.
Em seguida, crie um arquivo chamado `.npmrc` na raiz do projeto `use-component` e adicione a seguinte linha, substituindo _seuNomeDeUsuario_ pelo seu nome de usuário do GitHub:
```
@seuNomeDeUsuario:registry = https://npm.pkg.github.com
```
Depois disso, cole o comando que você copiou anteriormente para instalar o pacote uikit, substituindo as informações necessárias.
```
pnpm install @seuNomeDeUsuario/uikit@0.0.0
```
### Utilizando o Componente do UI Kit
Agora que o pacote `uikit` está instalado, vamos utilizá-lo no arquivo `App.tsx` dentro da pasta src do projeto _use-component_.
Modifique o arquivo App.tsx para importar e utilizar o componente ButtonTeste do pacote uikit:
```
// use-component/src/App.tsx
import './App.css';
import { ButtonTeste } from '@seuNomeDeUsuario/uikit';
function App() {
return (
<>
<ButtonTeste />
</>
);
}
export default App;
```
### Executando a Aplicação
Agora execute a aplicação com o comando pnpm run dev e você verá o botão do UI Kit em funcionamento na tela.
Se você verificar a pasta _node_modules_ dentro do projeto use-component, verá uma pasta `@seuNomeDeUsuario` (por exemplo, [@romulospl](https://github.com/romulospl)). Dentro dessa pasta, há uma pasta uikit, contendo apenas a pasta dist do projeto e o arquivo package.json com as configurações de entrada e exportação.
[Link para o repositório monorepo-project](https://github.com/romulospl/monorepo-project)
| romulospl | |
1,870,807 | Keydown Event Listener and Focus | Hello readers! Welcome to my first blog where I will be discussing the issues and resolution I had... | 0 | 2024-05-30T20:24:17 | https://dev.to/gianni_cast/keydown-event-listener-and-focus-bg3 | Hello readers! Welcome to my first blog where I will be discussing the issues and resolution I had with the "Keydown" event listener in JavaScript. When trying to implement my last event listener I struggled for an hour trying to understand why it was not working although the logic was all there. Here is the original HTML, JavaScript, and CSS for my code:
**HTML**
```
<img src="https://pbs.twimg.com/profile_images/1364220282790109188/uT0fQV56_400x400.jpg" alt="blue party hat" id="easterEgg" tabindex="0">
<div>
```
**JavaScript**
```
const easterEggImage = document.getElementById('easterEgg')
easterEggImage.addEventListener("keydown", handleKeyDown);
function handleKeyDown(event) {
if (event.key.toLowerCase() === "h") {
easterEggImage.style.display = "block";
}
}
```
**CSS**
```
#easterEgg {
display: none;
position: fixed;
left: 0;
bottom: 0px;
margin-left: 5%;
max-width: 90%;
}
```
The idea of this was to make an image appear whenever the user pressed the "h" key. Unfortunately it was not working and I could not understand why. After doing research I became more familiar with the concepts of "Event Delegation" and "direct event attachment". When I was using the descendant element `easterEggImage` I was only giving instruction for to apply the event to that element only. This is not what I intended so in order to fix this I attached the `addEventListener` to the document instead. Here is the working code below:
```
document.addEventListener("keydown", handleKeyDown);
```
Now my keydown event will trigger anywhere in the document! So after my hour long struggle I was able to get my image to appear with this function. | gianni_cast | |
1,870,749 | 300+ FREE APIs Every Developer Needs to Know | Table of Contents Weather APIs ⛅️🌦️🌩️ Exchange Rates APIs 💱💲💹 Cryptocurrency APIs... | 0 | 2024-05-30T20:20:00 | https://dev.to/falselight/300-free-apis-every-developer-needs-to-know-3j76 | api, webdev, programming, tutorial | # Table of Contents
1. [Weather APIs ⛅️🌦️🌩️](#weather-apis)
2. [Exchange Rates APIs 💱💲💹](#exchange-rates-apis)
3. [Cryptocurrency APIs ₿💰🔗](#cryptocurrency-apis)
4. [Placeholder Image APIs 📸🖼️🎨](#placeholder-image-apis)
5. [Random Generators APIs 🎲🔀🎰](#random-generators-apis)
6. [News APIs 📰📢🗞️](#news-apis)
7. [Maps and Geolocation APIs 🗺️📍🌍](#maps-and-geolocation-apis)
8. [Search APIs 🔍📑🕵️](#search-apis)
9. [Machine Learning APIs 🤖🧠🔮](#machine-learning-apis)
10. [Screenshot and Picture APIs 📷🌐🖼️](#screenshot-and-picture-apis)
11. [SEO APIs 🔍📈💡](#seo-apis)
12. [Shopping APIs 🛍️🛒📦](#shopping-apis)
13. [Developer APIs 💻🔧🛠️](#developer-apis)
14. [Travel and Transportation APIs 🛫🚗🚉](#travel-and-transportation-apis)
15. [Communication APIs 📞💬📧](#communication-apis)
16. [Payment and Financial APIs 💳💸🏦](#payment-and-financial-apis)
17. [Analytics and Monitoring APIs 📊📈📉](#analytics-and-monitoring-apis)
18. [Natural Language Processing (NLP) APIs 🗣️🔍💬](#natural-language-processing-nlp-apis)
19. [Utilities and Tools APIs 🛠️🔧⚙️](#utilities-and-tools-apis)
20. [Government and Open Data APIs 🏛️📜📊](#government-and-open-data-apis)
[Qit.tools](https://qit.tools/) - ⚡ Interactive Online Web 🛠️ Tools
---
## Weather APIs ⛅️🌦️🌩️
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| OpenWeatherMap | Global weather data including forecasts and current weather | 60 calls/min | API key | [Link](https://openweathermap.org/api) |
| Weatherstack | Real-time and historical weather data | 1000 calls/month | API key | [Link](https://weatherstack.com/documentation) |
| Weatherbit | Weather data including forecasts and current weather | 500 calls/day | API key | [Link](https://www.weatherbit.io/api) |
| Climacell | Hyper-local weather data and insights | 100 calls/day | API key | [Link](https://docs.climacell.co/) |
| AccuWeather | Weather data and forecasts | 50 calls/day | API key | [Link](https://developer.accuweather.com/apis) |
| Visual Crossing | Historical and current weather data | 1000 calls/day | API key | [Link](https://www.visualcrossing.com/weather-api) |
| Weather2020 | Weather forecasts | 100 calls/day | API key | [Link](https://www.weather2020.com/weather-api/) |
| Storm Glass | Marine weather data | 50 calls/day | API key | [Link](https://stormglass.io/docs/) |
| WeatherAPI | Weather data including forecasts and current weather | 1000 calls/month | API key | [Link](https://www.weatherapi.com/docs/) |
| AerisWeather | Weather data and imagery | 1000 calls/month | API key | [Link](https://www.aerisweather.com/support/docs/api/) |
| HERE Weather | Weather data including forecasts and current weather | 250,000 calls/month | API key | [Link](https://developer.here.com/documentation/weather/dev_guide/index.html) |
| World Weather Online | Global weather data including forecasts and historical weather | 500 calls/day | API key | [Link](https://www.worldweatheronline.com/developer/) |
| Tomorrow.io | Hyper-local weather data and insights | 100 calls/day | API key | [Link](https://docs.tomorrow.io/) |
| Dark Sky | Weather data including forecasts and current weather | 1000 calls/day | API key | [Link](https://darksky.net/dev) |
| National Weather Service | US government weather data | Unlimited | None | [Link](https://www.weather.gov/documentation/services-web-api) |
---
## Exchange Rates APIs 💱💲💹
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| ExchangeRate-API | Accurate exchange rates for 160 currencies | 1500 calls/month | API key | [Link](https://www.exchangerate-api.com/docs) |
| Open Exchange Rates| Real-time and historical exchange rates | 1000 calls/month | API key | [Link](https://docs.openexchangerates.org/) |
| Currencylayer | Real-time exchange rates for 168 world currencies | 1000 calls/month | API key | [Link](https://currencylayer.com/documentation) |
| Fixer | Real-time exchange rates and currency conversion | 1000 calls/month | API key | [Link](https://fixer.io/documentation) |
| XE Currency Data | Real-time and historical exchange rates | 1000 calls/month | API key | [Link](https://xecdapi.xe.com/) |
| Forex Rate API | Real-time and historical foreign exchange rates | 1000 calls/month | API key | [Link](https://www.forexrateapi.com/documentation) |
| RatesAPI | Free foreign exchange rates and currency conversion | Unlimited | None | [Link](https://ratesapi.io/documentation/) |
| Exchange Rates API | Accurate exchange rates for 160 currencies | 1500 calls/month | API key | [Link](https://www.exchangerate-api.com/docs) |
| OANDA Exchange Rates | Real-time and historical exchange rates | 1000 calls/month | API key | [Link](https://www.oanda.com/fx-for-business/fx-data-services) |
| CurrencyConverter API | Real-time exchange rates and currency conversion | 1000 calls/month | API key | [Link](https://www.currencyconverterapi.com/docs) |
| ExchangeRatesAPI | Exchange rates and currency conversion | 1000 calls/month | API key | [Link](https://www.exchangeratesapi.io/documentation) |
| Alphavantage | Real-time and historical exchange rates | 500 calls/day | API key | [Link](https://www.alphavantage.co/documentation/) |
| Xignite | Foreign exchange rates API | 1000 calls/month | API key | [Link](https://www.xignite.com/xforex-rates) |
| Everbase Currency | Exchange rates and currency conversion | 1000 calls/month | API key | [Link](https://currency-api.everbase.com/documentation) |
| ExchangeRateHost | Foreign exchange rates API | Unlimited | None | [Link](https://exchangerate.host/#/#docs) |
---
## Cryptocurrency APIs ₿💰🔗
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| CoinGecko | Cryptocurrency data for over 6000 coins | Unlimited | None | [Link](https://www.coingecko.com/en/api/documentation) |
| CoinMarketCap | Cryptocurrency market cap rankings, charts, and more | 333 calls/day | API key | [Link](https://coinmarketcap.com/api/documentation/) |
| CryptoCompare | Cryptocurrency data and price comparison | 250,000 calls/month | API key | [Link](https://min-api.cryptocompare.com/documentation) |
| Coinpaprika | Cryptocurrency market data | 25,000 calls/month | API key | [Link](https://api.coinpaprika.com) |
| Nomics | Cryptocurrency market cap and pricing data | 125,000 calls/month | API key | [Link](https://nomics.com/docs/) |
| CoinAPI | Real-time and historical cryptocurrency data | 100,000 calls/month | API key | [Link](https://docs.coinapi.io/) |
| Messari | Cryptocurrency data and research | 1000 calls/day | API key | [Link](https://messari.io/api) |
| Coinlore | Cryptocurrency market data | Unlimited | None | [Link](https://www.coinlore.com/cryptocurrency-data-api) |
| Coinlib | Cryptocurrency data including prices and market cap | 100 requests/day | API key | [Link](https://coinlib.io/apidocs) |
| Bitfinex | Cryptocurrency trading platform API | Unlimited | None | [Link](https://docs.bitfinex.com/docs) |
| Bittrex | Cryptocurrency trading platform API | Unlimited | None | [Link](https://bittrex.github.io/api/v3) |
| Binance | Cryptocurrency trading platform API | Unlimited | None | [Link](https://binance-docs.github.io/apidocs/spot/en/) |
| KuCoin | Cryptocurrency trading platform API | Unlimited | None | [Link](https://docs.kucoin.com/) |
| Kraken | Cryptocurrency trading platform API | Unlimited | None | [Link](https://www.kraken.com/features/api) |
| Poloniex | Cryptocurrency trading platform API | Unlimited | None | [Link](https://docs.poloniex.com/) |
---
## Placeholder Image APIs 📸🖼️🎨
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Lorem Picsum | Random placeholder images | Unlimited | None | [Link](https://picsum.photos/) |
| Placeholder.com | Custom placeholder images | Unlimited | None | [Link](https://placeholder.com/) |
| Unsplash Source | High-quality placeholder images | Unlimited | None | [Link](https://source.unsplash.com/) |
| Placekitten | Placeholder images of kittens | Unlimited | None | [Link](https://placekitten.com/) |
| PlaceDog | Placeholder images of dogs | Unlimited | None | [Link](https://place.dog/) |
| Placebear | Placeholder images of bears | Unlimited | None | [Link](https://placebear.com/) |
| Fill Murray | Placeholder images of Bill Murray | Unlimited | None | [Link](http://www.fillmurray.com/) |
| FakerAPI | Fake data and placeholder images | Unlimited | None | [Link](https://fakerapi.it/en) |
| DummyImage.com | Custom placeholder images | Unlimited | None | [Link](https://dummyimage.com/) |
| ImagePlaceholder.com | Custom placeholder images | Unlimited | None | [Link](https://imageplaceholder.com/) |
| PlaceholderImage | Placeholder images with custom text | Unlimited | None | [Link](https://placeholderimage.dev/) |
| Picsum.photos | Random images from Unsplash | Unlimited | None | [Link](https://picsum.photos/) |
| RandomImageApi | Random placeholder images | Unlimited | None | [Link](https://random.imagecdn.app/) |
| Plachold.it | Custom placeholder images | Unlimited | None | [Link](https://placehold.it/) |
| LoremFlickr | Random placeholder images | Unlimited | None | [Link](https://loremflickr.com/) |
---
## Random Generators APIs 🎲🔀🎰
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Random.org | True random number generation | 1,000,000 bits/day | API key | [Link](https://www.random.org/) |
| RandomUser | Generate random user data | Unlimited | None | [Link](https://randomuser.me/) |
| FakerAPI | Fake data generation | Unlimited | None | [Link](https://fakerapi.it/en) |
| UUID Generator | Generate random UUIDs | Unlimited | None | [Link](https://www.uuidgenerator.net/) |
| DiceBear Avatars | Generate random avatars | Unlimited | None | [Link](https://avatars.dicebear.com/) |
| PasswordGenerator | Generate random passwords | Unlimited | None | [Link](https://passwordwolf.com/api/) |
| Cat Facts | Random cat facts | Unlimited | None | [Link](https://catfact.ninja/) |
| Fun Translations | Generate fun translations | 5 requests/day | None | [Link](https://funtranslations.com/api) |
| Quotes.rest | Generate random quotes | 10 requests/hour | None | [Link](https://quotes.rest/) |
| Advice Slip | Random advice generator | Unlimited | None | [Link](https://api.adviceslip.com/) |
| BoredAPI | Suggestions for activities to do | Unlimited | None | [Link](https://www.boredapi.com/) |
| Lorem Ipsum | Generate random placeholder text | Unlimited | None | [Link](https://loripsum.net/) |
| Uinames | Generate random names | Unlimited | None | [Link](https://uinames.com/) |
| Pipl | Generate random people profiles | Unlimited | None | [Link](https://pipl.ir/) |
| Random Data API | Generate random data for testing | Unlimited | None | [Link](https://random-data-api.com/) |
---
## News APIs 📰📢🗞️
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| NewsAPI | Aggregates news articles from various sources | 500 calls/day | API key | [Link](https://newsapi.org/docs) |
| CurrentsAPI | Real-time news data | 1000 calls/month | API key | [Link](https://currentsapi.services/en/docs/) |
| ContextualWebNews | Real-time news search and discovery | 10,000 calls/month | API key | [Link](https://rapidapi.com/contextualwebsearch/api/web-search) |
| Bing News Search | Microsoft Bing's news search results | 3000 calls/month | API key | [Link](https://docs.microsoft.com/en-us/azure/cognitive-services/bing-news-search/) |
| Mediastack | Real-time news data | 500 calls/month | API key | [Link](https://mediastack.com/documentation) |
| New York Times API | Access to The New York Times articles and archives | Unlimited | API key | [Link](https://developer.nytimes.com/apis) |
| Guardian API | Access to The Guardian articles and archives | Unlimited | API key | [Link](https://open-platform.theguardian.com/documentation/) |
| Event Registry | Real-time news and event data | 500 calls/month | API key | [Link](https://eventregistry.org/documentation) |
| GDELT Project | Real-time event data and news | 10,000 calls/month | API key | [Link](https://blog.gdeltproject.org/gdelt-2-0-our-global-world-in-realtime/) |
| NewsData.io | Real-time news articles from various sources | 200 calls/day | API key | [Link](https://newsdata.io/docs) |
| ContextualWeb | Search for news articles based on context | 1000 calls/month | API key | [Link](https://contextualwebsearch.com/news-api) |
| MyNewsAPI | Access to various news sources | 500 calls/month | API key | [Link](https://mynewsapi.com/documentation) |
| Webz.io | Real-time news and blog data | 1000 calls/month | API key | [Link](https://webz.io/documentation) |
| AYLIEN News API | News articles from various sources with analysis | 200 calls/day | API key | [Link](https://newsapi.aylien.com/docs) |
| HackerNews | Access to Hacker News articles | Unlimited | None | [Link](https://github.com/HackerNews/API) |
---
## Maps and Geolocation APIs 🗺️📍🌍
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Google Maps API | Comprehensive mapping and geolocation data | $200 free usage/month| API key | [Link](https://developers.google.com/maps/documentation) |
| Mapbox | Custom maps and geolocation services | 50,000 views/month | API key | [Link](https://docs.mapbox.com/) |
| OpenCage Geocoding | Forward and reverse geocoding | 2,500 calls/day | API key | [Link](https://opencagedata.com/api) |
| HERE Maps | Mapping and location data services | 250,000 calls/month | API key | [Link](https://developer.here.com/documentation) |
| OpenStreetMap | Free editable map of the world | Unlimited | None | [Link](https://operations.osmfoundation.org/policies/nominatim/) |
| Positionstack | Geocoding API for forward and reverse geocoding | 25,000 calls/month | API key | [Link](https://positionstack.com/documentation) |
| TomTom | Mapping and geolocation data services | 2,500 calls/day | API key | [Link](https://developer.tomtom.com/) |
| MapQuest | Mapping and geolocation data services | 15,000 calls/month | API key | [Link](https://developer.mapquest.com/documentation/) |
| Ipstack | IP geolocation API | 10,000 calls/month | API key | [Link](https://ipstack.com/documentation) |
| Geocodio | Geocoding and reverse geocoding | 2,500 calls/day | API key | [Link](https://www.geocod.io/) |
| LocationIQ | Geocoding and reverse geocoding | 5,000 calls/day | API key | [Link](https://locationiq.com/docs) |
| Maptiler | Maps, geocoding, and geolocation services | 100,000 tile requests/month | API key | [Link](https://www.maptiler.com/cloud/) |
| What3words | Location services using 3-word addresses | 1000 calls/month | API key | [Link](https://what3words.com/products) |
| SmartyStreets | Address validation and geocoding | 250 requests/month | API key | [Link](https://smartystreets.com/docs) |
| Geoapify | Geocoding, routing, and other location services | 30,000 requests/month| API key | [Link](https://apidocs.geoapify.com/) |
---
## Search APIs 🔍📑🕵️
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Google Custom Search| Search the web or specific sites | 100 queries/day | API key | [Link](https://developers.google.com/custom-search/v1/overview) |
| Algolia | Fast, reliable search as a service | 10,000 records | API key | [Link](https://www.algolia.com/doc/) |
| Bing Search API | Microsoft Bing's search results | 3,000 calls/month | API key | [Link](https://docs.microsoft.com/en-us/azure/cognitive-services/bing-web-search/) |
| Elastic Search | Search engine based on Lucene | Free tier available | API key | [Link](https://www.elastic.co/guide/en/elasticsearch/reference/current/search.html) |
| Swiftype | Custom search engine for your site | 1000 requests/month | API key | [Link](https://swiftype.com/documentation) |
| MeiliSearch | Fast, open-source search engine | Unlimited | None | [Link](https://docs.meilisearch.com/) |
| AddSearch | Custom search for your website | 50 searches/day | API key | [Link](https://www.addsearch.com/docs/) |
| Yandex Search API | Search the web using Yandex | 10,000 requests/day | API key | [Link](https://yandex.com/dev/search/) |
| Yahoo Search | Search the web using Yahoo | 5,000 queries/day | API key | [Link](https://developer.yahoo.com/boss/search/) |
| Wolfram Alpha | Computational knowledge engine | 2,000 queries/month | API key | [Link](https://products.wolframalpha.com/api/documentation/) |
| ContextualWebSearch| Web search with context filtering | 10,000 calls/month | API key | [Link](https://rapidapi.com/contextualwebsearch/api/web-search) |
| Site Search 360 | Search your website or app | 1,500 requests/month | API key | [Link](https://www.sitesearch360.com/docs/) |
| DuckDuckGo API | Search the web anonymously | Unlimited | None | [Link](https://duckduckgo.com/api) |
| Search.io | Search as a service | 1000 operations/month| API key | [Link](https://search.io/docs) |
| Apache Solr | Highly reliable, scalable search platform | Open-source | None | [Link](https://solr.apache.org/guide/) |
---
## Machine Learning APIs 🤖🧠🔮
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Google Cloud ML | Machine learning services and APIs | $300 free credit | API key | [Link](https://cloud.google.com/products/ai) |
| Amazon SageMaker | Build, train, and deploy machine learning models | Free tier available | API key | [Link](https://aws.amazon.com/sagemaker/) |
| IBM Watson | AI and machine learning services | Free tier available | API key | [Link](https://www.ibm.com/watson/products-services/) |
| Microsoft Azure ML | Machine learning services and APIs | $200 free credit | API key | [Link](https://azure.microsoft.com/en-us/services/machine-learning/) |
| Hugging Face | State-of-the-art NLP models and APIs | Free tier available | API key | [Link](https://huggingface.co/docs) |
| OpenAI | AI models including GPT-3 | Free tier available | API key | [Link](https://beta.openai.com/docs/) |
| BigML | Machine learning platform and APIs | Free tier available | API key | [Link](https://bigml.com/) |
| Clarifai | Image and video recognition services | Free tier available | API key | [Link](https://docs.clarifai.com/) |
| DataRobot | Machine learning model deployment and management | Free tier available | API key | [Link](https://www.datarobot.com/) |
| MonkeyLearn | Text analysis and machine learning | 300 queries/month | API key | [Link](https://monkeylearn.com/api/) |
| Aylien | Natural language processing and machine learning | Free tier available | API key | [Link](https://aylien.com/text-api/) |
| Algorithmia | Algorithm marketplace and machine learning APIs | 10,000 queries/month | API key | [Link](https://algorithmia.com/developers) |
| Spell | Machine learning infrastructure and tools | Free tier available | API key | [Link](https://spell.run/docs) |
| Neptune.ai | Machine learning model management and monitoring | Free tier available | API key | [Link](https://neptune.ai/) |
| Vize.ai | Custom machine learning model creation | Free tier available | API key | [Link](https://vize.ai/) |
---
## Screenshot and Picture APIs 📷🌐🖼️
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| ScreenshotAPI | Capture screenshots of websites | 100 screenshots/month| API key | [Link](https://screenshotapi.net/documentation) |
| URLBox | Capture screenshots and convert web pages to PDFs | 100 captures/month | API key | [Link](https://urlbox.io/docs) |
| Page2Images | Capture screenshots of web pages | 1000 screenshots/month| API key | [Link](https://www.page2images.com/) |
| ShrinkTheWeb | Capture screenshots and thumbnails of web pages | 1000 captures/month | API key | [Link](https://www.shrinktheweb.com/) |
| Browshot | Capture screenshots of websites | 1000 credits/month | API key | [Link](https://browshot.com/api/documentation) |
| Thumbnail.ws | Capture screenshots of websites | 500 screenshots/month| API key | [Link](https://thumbnail.ws/) |
| Urlbox | Capture screenshots of websites | 1000 captures/month | API key | [Link](https://www.urlbox.io/) |
| ScreenshotLayer | Capture screenshots of websites | 100 captures/month | API key | [Link](https://screenshotlayer.com/documentation) |
| ApiFlash | Capture screenshots of websites | 100 screenshots/month| API key | [Link](https://apiflash.com/documentation) |
| AbstractAPI Screenshot | Capture screenshots of websites | 100 screenshots/month| API key | [Link](https://www.abstractapi.com/website-screenshot-api) |
| Snapito | Capture screenshots of websites | 100 captures/month | API key | [Link](https://snapito.com/) |
| Website2PDF | Convert web pages to PDFs | 100 captures/month | API key | [Link](https://website2pdf.io/) |
| ScreenshotMachine | Capture screenshots of websites | 1000 screenshots/month| API key | [Link](https://www.screenshotmachine.com/) |
| Stillio | Automatic website screenshot capture | 1000 captures/month | API key | [Link](https://stillio.com/) |
| GemPixel | Capture screenshots of websites | 100 captures/month | API key | [Link](https://www.gempixel.com/) |
---
## SEO APIs 🔍📈💡
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Moz | SEO metrics and data | 100 requests/month | API key | [Link](https://moz.com/products/api) |
| SEMrush | SEO metrics and data | 100 requests/month | API key | [Link](https://www.semrush.com/api/) |
| Serpstat | SEO metrics and data | 1000 queries/day | API key | [Link](https://serpstat.com/api/) |
| SpyFu | SEO metrics and competitor analysis | 500 requests/month | API key | [Link](https://www.spyfu.com/api) |
| DataForSEO | SEO data for keywords, SERPs, and more | 100 requests/month | API key | [Link](https://docs.dataforseo.com/) |
| CognitiveSEO | SEO metrics and data | 1000 requests/month | API key | [Link](https://cognitiveseo.com/api/) |
| Majestic | SEO metrics and data | 100 requests/month | API key | [Link](https://developer.majestic.com/) |
| SERP API | Real-time search engine results | 1000 requests/month | API key | [Link](https://serpapi.com/) |
| RankRanger | SEO metrics and rank tracking | 1000 requests/month | API key | [Link](https://www.rankranger.com/api) |
| Seobility | SEO metrics and data | 1000 requests/month | API key | [Link](https://seobility.net/en/api/) |
| BrightLocal | Local SEO data and metrics | 1000 requests/month | API key | [Link](https://www.brightlocal.com/api/) |
| SearchMetrics | SEO metrics and data | 1000 requests/month | API key | [Link](https://www.searchmetrics.com/api/) |
| STAT | Real-time search engine results | 1000 requests/month | API key | [Link](https://getstat.com/api/) |
| Linkody | Backlink checker and SEO metrics | 1000 requests/month | API key | [Link](https://www.linkody.com/api) |
---
## Shopping APIs 🛍️🛒📦
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Amazon Product Advertising API | Access to Amazon product data | 1,000 requests/month | API key | [Link](https://webservices.amazon.com/paapi5/documentation) |
| eBay API | Access to eBay product data and marketplace | 5,000 requests/day | API key | [Link](https://developer.ebay.com/api-docs/static/apis.html) |
| Walmart API | Access to Walmart product data and marketplace | 5,000 requests/day | API key | [Link](https://developer.walmart.com/) |
| Best Buy API | Access to Best Buy product data | 5,000 requests/day | API key | [Link](https://developer.bestbuy.com/) |
| Etsy API | Access to Etsy product data and marketplace | 5,000 requests/day | API key | [Link](https://www.etsy.com/developers/documentation) |
| Rakuten API | Access to Rakuten product data and marketplace | 5,000 requests/day | API key | [Link](https://webservice.rakuten.co.jp/documentation/) |
| Shopify API | Access to Shopify store data and marketplace | Unlimited | API key | [Link](https://shopify.dev/api) |
| WooCommerce API | Access to WooCommerce store data and marketplace | Unlimited | API key | [Link](https://woocommerce.github.io/woocommerce-rest-api-docs/) |
| BigCommerce API | Access to BigCommerce store data and marketplace | Unlimited | API key | [Link](https://developer.bigcommerce.com/api-reference) |
| AliExpress API | Access to AliExpress product data and marketplace | 1,000 requests/day | API key | [Link](https://developers.aliexpress.com/en/doc.htm) |
| Zalando API | Access to Zalando product data and marketplace | 5,000 requests/day | API key | [Link](https://developers.zalando.com/) |
| Target API | Access to Target product data and marketplace | 1,000 requests/day | API key | [Link](https://developer.target.com/) |
| Flipkart API | Access to Flipkart product data and marketplace | 5,000 requests/day | API key | [Link](https://affiliate.flipkart.com/api-docs) |
| Costco API | Access to Costco product data and marketplace | 5,000 requests/day | API key | [Link](https://costco.com/) |
| Home Depot API | Access to Home Depot product data and marketplace | 5,000 requests/day | API key | [Link](https://developer.homedepot.com/) |
---
## Developer APIs 💻🔧🛠️
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| GitHub API | Access to GitHub data | Unlimited | OAuth | [Link](https://docs.github.com/en/rest) |
| GitLab API | Access to GitLab data | Unlimited | OAuth | [Link](https://docs.gitlab.com/ee/api/) |
| Bitbucket API | Access to Bitbucket data | Unlimited | OAuth | [Link](https://developer.atlassian.com/bitbucket/api/2/reference/) |
| Travis CI API | Access to Travis CI data | Unlimited | API key | [Link](https://developer.travis-ci.com/) |
| Jenkins API | Access to Jenkins data | Unlimited | API key | [Link](https://www.jenkins.io/doc/book/using/remote-access-api/) |
| CircleCI API | Access to CircleCI data | Unlimited | API key | [Link](https://circleci.com/docs/api/v2/) |
| GitKraken API | Access to GitKraken data | Unlimited | API key | [Link](https://support.gitkraken.com/developers/) |
| Heroku API | Access to Heroku data and services | Unlimited | OAuth | [Link](https://devcenter.heroku.com/articles/platform-api-reference) |
| Vercel API | Access to Vercel data and services | Unlimited | API key | [Link](https://vercel.com/docs/api) |
| Netlify API | Access to Netlify data and services | Unlimited | OAuth | [Link](https://docs.netlify.com/api/get-started/) |
| Firebase API | Access to Firebase data and services | Unlimited | API key | [Link](https://firebase.google.com/docs/reference/rest) |
| DigitalOcean API | Access to DigitalOcean data and services | Unlimited | OAuth | [Link](https://developers.digitalocean.com/documentation/v2/) |
| AWS API | Access to AWS data and services | Free tier available | API key | [Link](https://docs.aws.amazon.com/) |
| Azure API | Access to Azure data and services | Free tier available | API key | [Link](https://docs.microsoft.com/en-us/azure/azure-api-management/) |
| Google Cloud API | Access to Google Cloud data and services | $300 free credit | API key | [Link](https://cloud.google.com/apis) |
---
## Travel and Transportation APIs 🛫🚗🚉
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Skyscanner API | Access to flight search and booking data | 500 requests/day | API key | [Link](https://developers.skyscanner.net/docs) |
| Amadeus API | Access to travel booking and search data | 500 calls/day | API key | [Link](https://developers.amadeus.com/) |
| Google Flights API | Access to flight search and booking data | 1000 requests/day | API key | [Link](https://developers.google.com/flights) |
| Rome2Rio API | Access to multimodal travel search data | 1000 requests/day | API key | [Link](https://www.rome2rio.com/documentation/search) |
| Sabre API | Access to travel booking and search data | 500 requests/day | API key | [Link](https://developer.sabre.com/docs/read/rest_apis) |
| Kayak API | Access to flight and hotel search data | 500 requests/day | API key | [Link](https://developer.kayak.com/) |
| Expedia API | Access to travel booking and search data | 500 requests/day | API key | [Link](https://developers.expediagroup.com/docs/apis) |
| Priceline API | Access to travel booking and search data | 500 requests/day | API key | [Link](https://developer.priceline.com/docs/apis) |
| TripAdvisor API | Access to travel reviews and search data | 500 requests/day | API key | [Link](https://developer-tripadvisor.com/home/docs) |
| Airbnb API | Access to short-term rental data | 500 requests/day | API key | [Link](https://developer.airbnb.com/docs) |
| Lyft API | Access to ride-sharing data | 1000 requests/day | API key | [Link](https://developer.lyft.com/docs) |
| Uber API | Access to ride-sharing data | 1000 requests/day | API key | [Link](https://developer.uber.com/docs) |
| BlaBlaCar API | Access to carpooling data | 500 requests/day | API key | [Link](https://dev.blablacar.com/docs) |
| Yelp API | Access to business and review data | 5000 requests/day | API key | [Link](https://www.yelp.com/developers/documentation/v3) |
| TransportAPI | Access to public transport data | 1000 requests/day | API key | [Link](https://developer.transportapi.com/docs) |
---
## Communication APIs 📞💬📧
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Twilio API | Access to SMS, voice, and messaging services | Free tier available | API key | [Link](https://www.twilio.com/docs/usage/api) |
| SendGrid API | Access to email sending services | 100 emails/day | API key | [Link](https://docs.sendgrid.com/) |
| Mailgun API | Access to email sending services | 5,000 emails/month | API key | [Link](https://documentation.mailgun.com/en/latest/) |
| Nexmo API | Access to SMS, voice, and messaging services | Free tier available | API key | [Link](https://developer.nexmo.com/api) |
| Plivo API | Access to SMS, voice, and messaging services | Free tier available | API key | [Link](https://www.plivo.com/docs/) |
| Pusher API | Real-time communication services | Free tier available | API key | [Link](https://pusher.com/docs) |
| Postmark API | Access to email sending services | 100 emails/month | API key | [Link](https://postmarkapp.com/developer) |
| SignalWire API | Access to SMS, voice, and messaging services | Free tier available | API key | [Link](https://signalwire.com/resources/docs) |
| Mandrill API | Access to email sending services | 2,000 emails/month | API key | [Link](https://mandrillapp.com/api/docs/) |
| ClickSend API | Access to SMS, voice, and messaging services | Free tier available | API key | [Link](https://developers.clicksend.com/docs/rest/v3/) |
| Tropo API | Access to SMS, voice, and messaging services | Free tier available | API key | [Link](https://www.tropo.com/docs) |
| Slack API | Access to Slack messaging services | Free tier available | API key | [Link](https://api.slack.com/) |
| Discord API | Access to Discord messaging services | Free tier available | API key | [Link](https://discord.com/developers/docs/intro) |
| Zoom API | Access to Zoom video conferencing services | Free tier available | API key | [Link](https://marketplace.zoom.us/docs/api-reference/zoom-api) |
| Intercom API | Access to Intercom messaging services | Free tier available | API key | [Link](https://developers.intercom.com/intercom-api-reference) |
---
## Payment and Financial APIs 💳💸🏦
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Stripe API | Access to payment processing services | Free tier available | API key | [Link](https://stripe.com/docs/api) |
| PayPal API | Access to payment processing services | Free tier available | API key | [Link](https://developer.paypal.com/docs/api/overview/) |
| Square API | Access to payment processing services | Free tier available | API key | [Link](https://developer.squareup.com/reference/square) |
| Braintree API | Access to payment processing services | Free tier available | API key | [Link](https://developer.paypal.com/braintree/docs/guides/overview) |
| Authorize.net API | Access to payment processing services | Free tier available | API key | [Link](https://developer.authorize.net/api/reference/index.html) |
| Plaid API | Access to financial data and services | Free tier available | API key | [Link](https://plaid.com/docs/) |
| Dwolla API | Access to payment processing services | Free tier available | API key | [Link](https://developers.dwolla.com/guides/) |
| Wise API | Access to international money transfer services | Free tier available | API key | [Link](https://developer.transferwise.com/) |
| Worldpay API | Access to payment processing services | Free tier available | API key | [Link](https://developer.worldpay.com/docs) |
| WePay API | Access to payment processing services | Free tier available | API key | [Link](https://developer.wepay.com/) |
| Revolut API | Access to financial data and services | Free tier available | API key | [Link](https://developer.revolut.com/docs) |
| Xero API | Access to accounting and financial data | Free tier available | API key | [Link](https://developer.xero.com/documentation/api) |
| QuickBooks API | Access to accounting and financial data | Free tier available | API key | [Link](https://developer.intuit.com/app/developer/qbo/docs/get-started) |
| Yodlee API | Access to financial data and services | Free tier available | API key | [Link](https://developer.yodlee.com/apidocs) |
| Intuit API | Access to accounting and financial data | Free tier available | API key | [Link](https://developer.intuit.com/) |
---
## Analytics and Monitoring APIs 📊📈📉
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Google Analytics API | Access to Google Analytics data | Free tier available | API key | [Link](https://developers.google.com/analytics/devguides/reporting/core/v4) |
| Mixpanel API | Access to Mixpanel analytics data | Free tier available | API key | [Link](https://developer.mixpanel.com/docs) |
| Amplitude API | Access to Amplitude analytics data | Free tier available | API key | [Link](https://www.amplitude.com/developers/apis) |
| Hotjar API | Access to Hotjar analytics data | Free tier available | API key | [Link](https://developer.hotjar.com/docs) |
| Heap API | Access to Heap analytics data | Free tier available | API key | [Link](https://docs.heap.io/docs) |
| Piwik PRO API | Access to Piwik PRO analytics data | Free tier available | API key | [Link](https://piwikpro.dev/documentation) |
| Segment API | Access to Segment analytics data | Free tier available | API key | [Link](https://segment.com/docs/) |
| Crazy Egg API | Access to Crazy Egg analytics data | Free tier available | API key | [Link](https://www.crazyegg.com/api) |
| Woopra API | Access to Woopra analytics data | Free tier available | API key | [Link](https://www.woopra.com/docs/api) |
| Kissmetrics API | Access to Kissmetrics analytics data | Free tier available | API key | [Link](https://www.kissmetrics.io/api) |
| Clicky API | Access to Clicky analytics data | Free tier available | API key | [Link](https://clicky.com/help/api) |
| Open Web Analytics API | Access to Open Web Analytics data | Free tier available | API key | [Link](https://www.openwebanalytics.com/api/) |
| Yandex Metrica API | Access to Yandex Metrica analytics data | Free tier available | API key | [Link](https://yandex.com/support/metrica/quick-start.html) |
| StatCounter API | Access to StatCounter analytics data | Free tier available | API key | [Link](https://statcounter.com/docs/) |
| Chartbeat API | Access to Chartbeat analytics data | Free tier available | API key | [Link](https://chartbeat.com/docs/api/) |
---
## Natural Language Processing (NLP) APIs 🗣️🔍💬
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Google Cloud NLP | Natural language processing services | $300 free credit | API key | [Link](https://cloud.google.com/natural-language/docs) |
| IBM Watson NLP | Natural language processing services | Free tier available | API key | [Link](https://www.ibm.com/watson/services/natural-language-understanding/) |
| Microsoft Azure NLP| Natural language processing services | $200 free credit | API key | [Link](https://azure.microsoft.com/en-us/services/cognitive-services/text-analytics/) |
| Amazon Comprehend | Natural language processing services | Free tier available | API key | [Link](https://aws.amazon.com/comprehend/) |
| TextRazor | Natural language processing services | 5000 requests/month | API key | [Link](https://www.textrazor.com/docs) |
| Aylien NLP | Natural language processing services | Free tier available | API key | [Link](https://aylien.com/text-api/) |
| MonkeyLearn | Text analysis and natural language processing | 300 queries/month | API key | [Link](https://monkeylearn.com/api/) |
| MeaningCloud | Text analysis and natural language processing | 20,000 requests/month| API key | [Link](https://www.meaningcloud.com/developer/apis) |
| Algorithmia NLP | Natural language processing algorithms | 10,000 queries/month | API key | [Link](https://algorithmia.com/developers) |
| Wit.ai | Natural language processing and chatbot integration | Free tier available | API key | [Link](https://wit.ai/docs) |
| Lexalytics | Text analysis and natural language processing | Free tier available | API key | [Link](https://www.lexalytics.com/developers) |
| SapienAPI | Natural language processing services | Free tier available | API key | [Link](https://www.sapien.com/api) |
| ChatterBot | Natural language processing and chatbot integration | Free tier available | None | [Link](https://chatterbot.readthedocs.io/en/stable/) |
| TisaneAPI | Text analysis and natural language processing | 30,000 requests/month| API key | [Link](https://tisane.ai/documentation) |
| DeepAI Text API | Natural language processing services | Free tier available | API key | [Link](https://deepai.org/machine-learning-model/text-tagging) |
---
## Utilities and Tools APIs 🛠️🔧⚙️
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| IPinfo | IP address information and geolocation | 50,000 requests/month| API key | [Link](https://ipinfo.io/developers) |
| OpenWeatherMap | Weather data including forecasts and current weather | 60 calls/min | API key | [Link](https://openweathermap.org/api) |
| Twilio API | Access to SMS, voice, and messaging services | Free tier available | API key | [Link](https://www.twilio.com/docs/usage/api) |
| SendGrid API | Access to email sending services | 100 emails/day | API key | [Link](https://docs.sendgrid.com/) |
| Clearbit API | Business intelligence data | 50,000 requests/month| API key | [Link](https://clearbit.com/docs) |
| IPStack | IP geolocation and information | 10,000 requests/month| API key | [Link](https://ipstack.com/documentation) |
| AbstractAPI | Various utility APIs like IP geolocation, email validation | 500 requests/month | API key | [Link](https://www.abstractapi.com/) |
| Apify API | Web scraping and automation | 10,000 requests/month| API key | [Link](https://docs.apify.com/api/v2) |
| ScraperAPI | Web scraping tool | 5000 requests/month | API key | [Link](https://www.scraperapi.com/documentation/) |
| Postman API | API development and testing tools | Unlimited | API key | [Link](https://www.postman.com/api-documentation/) |
| Sentry API | Application monitoring and error tracking | 5000 events/month | API key | [Link](https://docs.sentry.io/api/) |
| Stripe API | Access to payment processing services | Free tier available | API key | [Link](https://stripe.com/docs/api) |
| PDF.co API | PDF generation and data extraction | 1000 requests/month | API key | [Link](https://apidocs.pdf.co/) |
| Bitly API | URL shortening and link management | 1000 requests/month | API key | [Link](https://dev.bitly.com/docs/) |
| OpenCage Geocoding | Forward and reverse geocoding | 2,500 calls/day | API key | [Link](https://opencagedata.com/api) |
---
## Government and Open Data APIs 🏛️📜📊
| Name | Description | Free Tier Limit | Authentication | Documentation |
|--------------------|---------------------------------------------------------|----------------------|--------------------|----------------------------------|
| Data.gov API | US government open data | Unlimited | None | [Link](https://www.data.gov/developers/apis) |
| UK Government API | UK government open data | Unlimited | None | [Link](https://www.gov.uk/guidance/using-the-api) |
| EU Open Data Portal API | European Union open data | Unlimited | None | [Link](https://data.europa.eu/euodp/en/developers-corner) |
| World Bank API | Global development data | Unlimited | None | [Link](https://datahelpdesk.worldbank.org/knowledgebase/topics/125589) |
| UN Data API | United Nations open data | Unlimited | None | [Link](https://data.un.org/Host.aspx?Content=API) |
| OECD Data API | Economic and social data from OECD | Unlimited | None | [Link](https://data.oecd.org/api/) |
| Census.gov API | US Census Bureau data | Unlimited | API key | [Link](https://www.census.gov/data/developers/data-sets.html) |
| Open Data Soft | Various open data from different sources | Unlimited | API key | [Link](https://www.opendatasoft.com/) |
| City of New York API | New York City open data | Unlimited | None | [Link](https://opendata.cityofnewyork.us/) |
| USGS API | US Geological Survey data | Unlimited | API key | [Link](https://www.usgs.gov/products/data-and-tools/apis) |
| NASA API | Access to NASA data and imagery | Unlimited | API key | [Link](https://api.nasa.gov/) |
| Open States API | US state legislative data | Unlimited | API key | [Link](https://openstates.org/data/) |
| USA.gov API | US government information and services | Unlimited | None | [Link](https://www.usa.gov/developer) |
| Data.gov.au API | Australian government open data | Unlimited | None | [Link](https://data.gov.au/) |
| HealthData.gov API | US health-related open data | Unlimited | None | [Link](https://healthdata.gov/) |
| Gov.br API | Brazil | Unlimited | None | [Link](https://gov.br/conecta/catalogo/) |
---
**If you found this content helpful,
Please, [Buy Me A Coffee](https://buymeacoffee.com/deyurii) 🌟✨** | falselight |
1,870,746 | Stand with Ukraine | My blog has gone beyond just providing IT guides and advice. Today, we stand as a voice against the... | 0 | 2024-05-30T20:12:27 | https://www.heyvaldemar.com/stand-with-ukraine/ | standwithukraine, ukraine, discuss, help | My blog has gone beyond just providing IT guides and advice. Today, we stand as a voice against the lies and injustices that have engulfed our world due to the merciless actions of the bloody Russian regime.
Freedom of speech in Russia exists mostly in theory, not in practice. The reality is that finding reliable information in Russian-language open sources is quite difficult. Most media in Russia provide information that often passes through the filter of state propaganda and reflects the interests of the political leadership.
Nevertheless, everyone has access to important information from [verified sources](https://linktr.ee/ukraine_ua).

> The State Emergency Service continues to deal with the aftermath of Russia’s massive missile attack on Ukraine on January 2, 2024. Photo from State Emergency Service of Ukraine
As the founder and chief editor, I not only condemn but also express deep contempt for the Russian military invasion of Ukraine. This act is a blatant war crime that has already claimed hundreds of thousands of lives, including children. Responsibility lies not only with the Russian government and President Vladimir Putin personally but also with the citizens of Russia, whose political indifference and inaction ultimately led to another war.
Examples from the past, when Russians could more freely express their opinions, highlight the contrast with the current situation. For example, in 2006, human rights activist Lev Ponomarev was arrested and detained for three days after organizing a picket in Moscow, but such actions were then considered relatively mild.
In subsequent years, the situation has changed drastically. Legislation has tightened the requirements for conducting protests, significantly increased fines, and introduced criminal liability for repeated violations of the law on rallies. Since 2014, nine of the thirteen significant amendments to the law have been introduced, aimed at limiting the right to peaceful assemblies. These legislative changes have led to the fact that peaceful street protests in the eyes of the authorities have come to be seen as a crime, and an act of heroism for those Russians who still believe it is their right to exercise it.
Cases such as mass arrests of participants in peaceful protests, often accompanied by brutal treatment by the police, have become commonplace. The lack of response from the authorities to cases of excessive use of force by the police, such as in January 2021, only reinforces the atmosphere of impunity.
These examples emphasize how in the past, when the conditions for protests were less strict, Russian society had greater opportunities to express their disagreement with the actions of the authorities without fear of serious consequences. This highlights the importance of political activism and the ability to change public and political situations through peaceful demonstrations and protests.
These links provide more detailed information on the development and change in the legal regulation of protest activities in Russia:
- [Wikipedia: Freedom of assembly in Russia](https://en.wikipedia.org/wiki/Freedom_of_assembly_in_Russia)
- [Amnesty International: Russia: End of the road for those seeking to exercise their right to protest](https://www.amnesty.org/en/latest/news/2021/08/russia-end-of-the-road-for-those-seeking-to-exercise-their-right-to-protest/)
- [Human Rights Watch: Russia Criminalizes Independent War Reporting, Anti-War Protests](https://www.hrw.org/news/2022/03/07/russia-criminalizes-independent-war-reporting-anti-war-protests)
Since 1991, modern Russia has participated in several military conflicts. Some of the key wars include:
- First Chechen War (1994–1996)
- Second Chechen War (1999–2009)
- Russo-Georgian War (2008)
- Annexation of Crimea and intervention in Ukraine (since 2014)
- Military intervention in Syria (since 2015)
- Invasion of Ukraine (since 2022)
More detailed information about these and other military conflicts can be found [here](https://en.wikipedia.org/wiki/List_of_wars_involving_Russia).

> Two Ukrainian soldiers walk along the frontline city of Avdiivka in the Donetsk region. It is one of the hotspots nowadays after Russia launched a major offensive in mid-October 2023. Photo by Kostiantyn Liberov & Vlada Liberova / Getty Images
We stand at a historic moment, and I urge you, our readers, to join the ranks of those who oppose this violence. Your actions in support of Ukraine are of immense importance. Whether it’s financial assistance, supporting refugees, providing asylum, or resources, every step you take contributes to thefight for peace and humanity in these tragic times. I believe that our solidarity and determination can overcome cruelty and lawlessness.

> A man with a bicycle goes through the city during a break between Russian shellings in the frontline Avdiivka, the Donetsk region. October 17, 2023. Photo by Ozge Elif Kizil / Anadolu Agency / Getty Images
To assist the people of Ukraine, you can use the following official and verified resources:
1. **[UNITED24](https://u24.gov.ua/)**: This is the official platform for collecting charitable donations to support Ukraine, launched by the President of Ukraine, Volodymyr Zelenskyy. Here you can direct funds to defense, humanitarian demining, medical assistance, reconstruction of Ukraine, as well as education and science.
2. **[EU Solidarity with Ukraine](https://eu-solidarity-ukraine.ec.europa.eu/index_ru)**: This European Union initiative provides information on how to help Ukrainians who have fled the war or stayed in Ukraine. The website lists various organizations, including major international agencies and charitable organizations, providing assistance on the ground.
3. **[UNICEF assistance to Ukraine](https://help.unicef.org/ukraine-emergency-mv)**: This international organization urgently needs funds to assist children and their families in Ukraine. UNICEF provides assistance in safe water supply, healthcare, education, and protection.
These resources will help you direct aid where it is most needed, and ensure that your contribution is used effectively and transparently.

> Artem, a serviceman of the infantry battalion of the 61st Mechanised Brigade, pets a dog in a trench at a position near the frontline in the Kharkiv region. Photo by Sofia Gatilova / Reuters
View more [photos of the war in Ukraine](https://war.ukraine.ua/photos/).
{% embed https://www.youtube.com/embed/9RtSN8hCz70?start=18 %}
> Fight and you shall overcome!
God helps you!
With you are truth, glory
And holy freedom!
*Taras Shevchenko, “Caucasus”, 1859*
**In Ukrainian**:
> Борітеся — поборете!
Вам Бог помагає!
За вас правда, за вас слава
І воля святая!
*Тарас Шевченко, "Кавказ", 1859*
| heyvaldemar |
1,870,747 | LinkedIn Hacks to Get Hired Now | Two in-person Nashville meetups in one week?? Yep. My social battery is going to be dead by tomorrow.... | 0 | 2024-05-30T20:12:08 | https://dev.to/tdesseyn/linkedin-hacks-to-get-hired-now-4con | job, hiring | Two in-person Nashville meetups in one week?? Yep. My social battery is going to be dead by tomorrow. I had the chance to hang out with the JavaScript User Group for a quick second last night giving away two RenderATL tickets, and I am speaking on a panel this evening aka Thursday night on how to keep yourself sane through the job search. Pretty pumped about this meetup…it’s a joint meetup between RenderATL and The Black Codes.
But wanted to talk about in-person meetups for a second. Listen, I get it, it’s annoying to get out of your house and go to one. Especially when you live like 45 minutes away HOWEVER it was so nice to be around people last night even though I was at the meetup for 15 minutes. I’m thoroughly looking forward to hanging out with folks this evening, and I was even talking to a Director of Eng last night about the fact he literally has his job now because of a meetup.
As someone who lives his life down to the minute by my schedule (my wife hates it) I’m encouraging you to start showing up once a month to a local meetup. Who knows, maybe your next job is at the next meetup you attend!
Wanted to summarize [my live recently](https://www.youtube.com/live/HhDTMwWt5k0) talking about how to use LinkedIn to find a job. Lotta folks have been asking me so I figured I would share!
Is your LinkedIn just a couple coworkers and some people you took a class with in college? Then you’re not using it to it’s fullest potential. And, tbh, LinkedIn is a little clunky. But, as of right now, there’s no better platform to connect people with other professionals, companies, and job openings all in the same space.
Now if one of y’all wants to help me build a new/better platform, hit me up.
So here’s how you’re going to use LinkedIn to find your next job:
**Use search filters**
Always search job posting from the last 24 hrs. You’re going to be served some stale old postings otherwise. And I would check the postings this way at least once a day.
**Don’t go too narrow too quickly**
Some of the senior postings you see in title are actually a mid-senior position. So read the details.
**Look for connections**
Instead of quick applying, see if there’s a connection you could reach out to instead. And if you don’t have a connection…
**Connect with people from the company & send a note**
Make every note intentionally and tactfully crafted. Copy and paste is not appropriate here.
**Work on your DM skills**
You only have your opening line to humanize yourself from all the other spam bots in their DMs. Work within the formula of flattery/acknowledgment + specific question + specific amount of time.
**Your title should match the role you’re looking for**
Titles are the tl;dr of profiles for recruiters and hiring managers. Make sure you’re easily searchable and visible.
**Invest in Premium**
*not sponsored. You can literally do your whole job search on LinkedIn so pay the $30 or whatever and give yourself the freedom to connect and talk to all the people you need to.
**You don’t have to post to make yourself visible**
Liking and commenting could honestly be just as effective as posting your own content every day. It’s all about making sure people are familiar with you and your name. If you are posting, take into account your content will be pushed to the people you most recently connected or interacted with.
I’ve given you my recruiter insight before, but I think it’s really important to add in more of a personal narrative and branding strategy. I mean looking for a job is just trying to find someone to invest in you and your skills. It never hurts to already have who and what that is established. Alright, happy searching. | tdesseyn |
1,870,565 | Open Source Isn't Itself Insecure - but Your Supply Chain Could Be | Since the dawn of the proprietary and open source software divergence there has been the on-going... | 0 | 2024-05-30T20:07:32 | https://dev.to/drgoeschel/open-source-isnt-itself-insecure-but-your-supply-chain-could-be-26f | supplychainsecurity, security, supplychain, opensourcesecurity | Since the dawn of the proprietary and open source software divergence there has been the on-going debate on the security implications of these two distinct approaches to software development.
Proponents for proprietary software have championed that since their code is not publicly shared that it is harder for bad actors to exploit these systems and applications. However, open source advocates have argued that since their code is open and editable by all that it promotes more scrutiny on the code itself and thereby increases its overall security posture.
In the early 2000’s there was much research and several publications on this topic. Much of the research supported the argument that open source was more secure and the debates subsided. As a result, some historically strict proprietary organizations shifted their software development practices to a more open source model.
In recent years the debate has begun to arise once again. However, nothing has changed to the software development models for either of these approaches. The conversation should not simply reignite the _same question_ but rather focus on what has _actually changed_ - the method of attacks.
Therefore, it is important to distinguish that open source software _itself_ is not less secure than proprietary software but rather that supply chain attacks have exploited open source practices. The focus should be on securing the software supply chain, not that open source software is insecure.
### Security of Open Source Software
In the 1990's and early 2000's there was a debate and open question on the security posture of open source software. Proprietary software organizations went on the attack against open source applications stating that they were less secure. Why would these organizations make these claims? I personally can not speak to their motives but I can wager that it was most likely because open source was a threat to their bottom line.
Open source shares its source code to all. It makes the code free, accessible, sellable, and editable by anyone. Who would want to pay for software if they could access something of a similar quality for free? The claim that open source was less secure than proprietary software was a highly targeted argument directed right to the audience of corporate America.
Corporations and Governments could not afford to have insecure software. If open source software was less secure than proprietary software - this would give corporations and Governments the reason to buy proprietary software - even if a free and comparable alternative existed.
Open source advocates worked to prove that open source was not less secure. Data was collected, papers were written, presentations at conferences were presented [1][2][3]. Eventually, the debate subsided as more and more empirical evidence that open source was not less secure than proprietary software amassed. Many proprietary software companies ended up embracing the open source model [4][5][6]. The open question appeared to be answered and the debate settled.
### Increases in Supply Chain Attacks
In December of 2020, supply chain attacks were brought to the forefront with the SolarWinds attack [7] when malware was used to insert a backdoor into software during the build process by replacing one of the source code files via a highly utilized network performance monitoring tool. This action was executed at a key point in the build process and impacted organizations of all sizes across the globe. Since then, several other notable supply chain attacks have taken place such as JFrog, Okta, and Log4J to name a few. Attacks such as these are costing organizations millions, and sometimes billions [8], of dollars.
Of particular concern is that these attacks have only provided evidence of their ability to greatly and vastly impact organizations across the globe quite efficiently. As a result, the increase of these attacks is astonishing. According to Statista [9] the number of supply chain attacks increased 58.8% from 2022 to 2023; and have increased a staggering 1,090% from 2019 to 2023.
Even as the industry overall is diligently trying to mitigate these attacks with educational campaigns, publishing security frameworks, implementing regulatory changes, and promoting the practice of sound security principles - these attacks continue.
Of course it is much easier for some to reignite the argument that open source software is to blame; however, this is a red herring. The use of open source software _itself_ is not insecure. An insecure software build process is the real culprit. If supply chain attacks are used as a premise that proprietary software is more secure than open source then it would be negligent to not clarify that proprietary software is often composed of hundreds, if not thousands, of open source packages itself. Similarly, propriety software also utilizes a supply chain to build and release it's products - at which point _all_ software is vulnerable.
### Securing The Supply Chain
Now that we have clarified that _all_ software is vulnerable and that the everyone's software supply chain must be secured, there are some simple actionable steps that you can take that will increase the security of your software supply chain. In order for this article to be beneficial and relevant for years to come I will point the reader (that's you) to some helpful references, frameworks, and standards that will evolve as the software ecosystem changes. Following these standards and frameworks will allow you to take actionable steps to secure your supply chain over time.
A great first step is to delve into SLSA (pronounced salsa), an open source community for Supply chain Levels for Software Artifacts [10]. It outlines levels of supply chain security with actionable steps to take at each level. Start at Level 1 and grow as your organization grows! The documentation is extremely helpful - and hey - who doesn't like salsa? And if you like salsa, how about trying out some Guac [11]? This project is extremely exciting and gives you actionable information and insight into your supply chain by helping you interpret whats in your software.
Some other very helpful references would be to head over to The National Institute of Standards and Technology and read [12][13][14]; The Cloud Native Computing Foundation (CNCF) also has a great read entitled “Software Supply Chain Best Practices” [15].
At the core of these frameworks is to know, document, and ask for the who, what, when, where, and how of your software build process. Know which libraries and packages are in your software, what systems are being used to build your software, who is doing what to your software during the build process, who has access to modify code during your build process, are they authorized to make those changes, what vulnerabilities currently exist in your software and what is their severity, and be able to verify or validate all actions taken on the source code from the developers workstation (or git repo) to the product release end-point and/or customer. Only by knowing this information will you be able to adequately and quickly respond to the inevitable supply chain attack your organization will experience.
Most importantly, I would urge the reader (_that's you again_) that implementing _any_ of the suggested activities is better than doing nothing at all. Please don't view security as an _all-or-nothing_ activity. Address security like you would a healthy lifestyle, yes it's ideal to do _all-the-things_ - but in reality _any_ healthy behavior will indeed benefit your body in one way or another.
### Conclusion
Open source software is not inherently insecure but is rather being exploited in a different way. Additionally, no software (proprietary or open source) is immune from supply chain attacks. It is crucial that we continue to focus our efforts on securing the software supply chain and not reigniting a debate to a previously answered question.
<u>References:</u>
1. Payne, C. (2002). On the security of open source software. Information systems journal, 12(1), 61-78.
2. Erturk, E. (2012, June). A case study in open source software security and privacy: Android adware. In World Congress on Internet Security (WorldCIS-2012) (pp. 189-191). IEEE.
3. Boulanger, A. (2005). Open-source versus proprietary software: Is one more reliable and secure than the other?. IBM Systems Journal, 44(2), 239-248.
4. Open source. Microsoft Legal. (n.d.). https://www.microsoft.com/en-us/legal/intellectualproperty/open-source
5. Google open source. Google Open Source. (n.d.). https://opensource.google/
6. Open source at IBM. IBM Developer. (n.d.). https://www.ibm.com/opensource/
7. Team, C. I. (2021, July 13). Sunspot malware: A technical analysis: CrowdStrike. crowdstrike.com. https://www.crowdstrike.com/blog/sunspot-malware-technical-analysis/
8. Page, C. (2023, August 25). Moveit, the biggest hack of the year, by the numbers. TechCrunch. https://techcrunch.com/2023/08/25/moveit-mass-hack-by-the-numbers/?guccounter=1&guce_referrer=aHR0cHM6Ly93d3cuZ29vZ2xlLmNvbS8&guce_referrer_sig=AQAAALAzT_UDiJfBBeJAxwQmnL44EINEbtSE2JPOaZKyGmbAG9UDx3cWekJsImFydQkUFh9xUgeXGV-knuFWKcPiYePf9jT8Z1QRrN38lcEWTfE1-HUMokDREbVtE8fYX8l6M6O-atP9Pm4fq5RSRRNlcps7zyCW5GUdNdo2QVMvehSN
9. Ani Petrosyan, & 26, M. (2024, March 26). Annual number of Supply Chain Cyber attacks U.S. 2023. Statista. https://www.statista.com/statistics/1367208/us-annual-number-of-entities-impacted-supply-chain-attacks/#:~:text=U.S.%20number%20of%20entities%20impacted%20in%20supply%20chain%20cyber%20attacks%202017%2D2023&text=In%202023%2C%20supply%20chain%20cyber,percent%20year%2Dover%2Dyear.
10. Supply-chain levels for software artifacts. SLSA. (n.d.). https://slsa.dev/
11. Guac. guac. (n.d.). https://guac.sh/
12. Computer Security Division, I. T. L. (n.d.). Cybersecurity Supply Chain Risk Management: CSRC. CSRC. https://csrc.nist.gov/projects/cyber-supply-chain-risk-management
13. Cloud Native Computing Foundation (CNCF) at Main · CNCF/tag-security. (n.d.-a). https://github.com/cncf/tag-security/blob/main/supply-chain-security/supply-chain-security-paper/CNCF_SSCP_v1.pdf
14. Souppaya, M., Scarfone, K., & Dodson, D. (2022). Secure software development framework (ssdf) version 1.1 NIST Special Publication, 800, 218. https://csrc.nist.gov/pubs/sp/800/218/final
15. Order, E. (2021). 14028, Improving the Nation’s Cybersecurity. https://www.nist.gov/itl/executive-order-improving-nations-cybersecurity/software-supply-chain-security ; https://www.whitehouse.gov/briefing-room/presidential-actions/2021/05/12/executive-order-on-improving-the-nations-cybersecurity/
16. Software bill of materials. SOFTWARE BILL OF MATERIALS | National Telecommunications and Information Administration. (n.d.). https://www.ntia.gov/page/software-bill-materials
17. Owasp Mobile top 10. OWASP Mobile Top 10 | OWASP Foundation. (n.d.). https://owasp.org/www-project-mobile-top-10/ | drgoeschel |
1,872,271 | Frictionless Authentication for Devoted Fans: How MojoAuth Empowers Customer-Centric Brands | In today’s competitive landscape, customer experience reigns supreme. Brands that prioritize seamless... | 0 | 2024-06-22T07:24:40 | https://mojoauth.com/blog/how-mojoauth-empowers-customer-centric-brands/ | ---
title: Frictionless Authentication for Devoted Fans: How MojoAuth Empowers Customer-Centric Brands
published: true
date: 2024-05-30 20:03:58 UTC
tags:
canonical_url: https://mojoauth.com/blog/how-mojoauth-empowers-customer-centric-brands/
---
In today’s competitive landscape, customer experience reigns supreme. Brands that prioritize seamless interactions and foster genuine connections with their audience are the ones winning hearts and market share. Enter passwordless authentication – a revolution transforming how customers interact with the brands they love. MojoAuth emerges as a powerful ally, empowering customer-centric brands to deliver frictionless experiences that strengthen customer loyalty and drive business growth.
This in-depth exploration delves into the challenges brands face when relying solely on passwords and how MojoAuth’s innovative passwordless solutions pave the way for a more engaging and secure customer journey.
## The Password Problem: Friction and Frustration in the Customer Experience
Passwords present a significant hurdle in the customer journey, hindering interactions and potentially driving customers away:
- **Signup and Login Hassle:** Complex passwords, remembering credentials across multiple platforms, and the constant struggle with password resets create frustration for customers eager to engage with a brand.
- **Abandoned Carts and Lost Sales:** Password-related friction at checkout stages can lead to abandoned carts and lost sales opportunities, impacting a brand’s bottom line.
- **Reduced Mobile Engagement:** Cumbersome password entry on mobile devices discourages frequent app usage and interaction with brand loyalty programs.
- **Security Vulnerabilities:** Reliance on passwords exposes customer data to breaches and compromises user trust in the brand’s ability to safeguard information.
## Why Customer-Centric Brands Need to Rethink Authentication
Brands focused on customer experience understand the need to move beyond passwords. Here’s why a customer-centric approach necessitates a shift:
- **Prioritizing Convenience:** Empowering customers with easy access demonstrates respect for their time and builds a positive association with the brand.
- **Building Loyalty Through Trust:** Eliminating password-related frustrations fosters trust and loyalty, encouraging repeat business and positive word-of-mouth recommendations.
- **Optimizing Mobile Experiences:** Frictionless authentication streamlines mobile app usage, a crucial touchpoint for modern customer engagement.
- **Enhancing Data Security:** Passwordless solutions significantly reduce the risk of data breaches, protecting customer information and safeguarding the brand’s reputation.
## MojoAuth: The Passwordless Solution for Customer-Centric Brands
MojoAuth offers a suite of passwordless options designed to elevate the customer experience while bolstering security:
1. **A Range of Frictionless Options:**
- **Biometric Authentication:** Facial recognition or fingerprint logins on mobile devices provide a secure and convenient way for customers to access accounts.
- **Magic Links:** Seamless one-click logins via email or SMS eliminate the need for remembering passwords and expedite account access.
- **Social Logins:** Customers can leverage existing social media credentials to sign up and log in, minimizing signup friction.
- **FIDO Security Keys:** For high-security transactions, FIDO keys offer unparalleled protection for brand accounts holding sensitive customer information.
1. **Tailored for Customer Journeys:**
- **Adaptive Authentication:** MojoAuth evaluates risk factors like location, device, and behavior patterns to determine the most appropriate authentication method for each login attempt, balancing security with convenience.
- **Frictionless Account Creation:** Streamline onboarding with rapid sign-ups via magic links or social logins, especially valuable for mobile app acquisition.
- **Seamless Multi-Factor Authentication (MFA):** Where necessary, enhance security with easy-to-use MFA steps that don’t disrupt the user flow.
1. **Integration with Existing Systems:**
- **API-Driven Approach:** MojoAuth seamlessly integrates with existing brand platforms and loyalty programs, minimizing disruption during implementation.
- **Customizable Workflows:** Brand teams can tailor authentication flows based on customer segments, account types, or specific user actions within the customer journey.
## MojoAuth in Action: Empowering Customer-Centric Brands
Let’s delve into scenarios showcasing how MojoAuth transforms customer experiences across different industries:
### Scenario 1: Premium Retail Loyalty Program
A high-end retail brand with a mobile app uses MojoAuth. Customers create accounts effortlessly with social logins. In-store purchases are a breeze with fingerprint authentication on the app at checkout, eliminating the need for physical loyalty cards. Secure passwordless access to exclusive member content and personalized offers within the app fosters deeper brand engagement.
### Scenario 2: On-Demand Streaming Service
A popular streaming service leverages MojoAuth to streamline access across devices. Users enjoy one-tap logins using biometrics on their smart TVs or mobile devices. Sharing accounts within households becomes secure and convenient with family member management features within the platform. Frictionless logins encourage frequent app use and content exploration.
### Scenario 3: Subscription-Based Wellness App
A wellness app offering personalized workout plans and nutrition advice prioritizes eliminating signup friction. MojoAuth’s magic links encourage fast sign-ups. Customers enjoy quick logins with biometrics on their mobile devices, ensuring easy access to their fitness and nutrition programs on the go. Strong authentication protects sensitive health data and fosters user trust.
## Elevating the Customer-Centric Approach with MojoAuth
Beyond the scenarios, MojoAuth’s positive impact is far-reaching for customer-driven brands:
- **Boosting Customer Acquisition:** Frictionless onboarding minimizes new customer signup drop-off, contributing to growth metrics.
- **Encouraging Repeat Engagements:** Effortless logins fuel customer retention and encourage regular interactions with the brand.
- **Enhancing Data Collection:** More frequent logins and interactions generate valuable data to personalize experiences, tailor communication, and improve product or service offerings.
- **Reducing Support Costs:** Fewer password-related support inquiries free up resources for more valuable customer service interactions that build relationships.
- **Strengthening Brand Perception:** Customer-centric brands offering effortless authentication solidify their commitment to a smooth customer journey, enhancing the brand’s reputation and fostering a competitive edge.
## Advanced MojoAuth Features for Customer Journeys
MojoAuth offers additional features that empower customer-centric brands to deliver exceptional experiences:
- **Granular Access Control and Permissions:** Securely manage access to special offers, loyalty rewards, or premium content based on customer tiers or specific customer segments.
- **Personalization Capabilities:** Securely integrate authentication data with personalization tools to tailor offers and communication based on login history or app preferences.
- **Customer Insights and Analytics:** Leverage MojoAuth’s authentication data and analytics to understand customer behavior patterns, optimizing onboarding, and identifying pain points for refinement.
- **Fraud Detection and Prevention:** Protect customer accounts by integrating with specialized fraud detection tools that identify anomalies and prevent unauthorized access.
## The Evolving Future: Adapting to Customer Expectations
The field of authentication is constantly evolving alongside changing demands in customer experience. MojoAuth is actively involved in shaping this future:
- **Continuous Authentication:** Leveraging behavioral biometrics for ongoing verification without disrupting customer interactions. This offers protection that adapts to the user’s unique patterns.
- **Cross-Device Journeys:** Seamless authentication as customers effortlessly switch between devices (smartphone, tablet, laptop) with minimal or even zero prompts.
- **Collaboration for Industry Standards:** MojoAuth’s participation in developing new industry authentication standards ensures its solutions remain adaptable as expectations for frictionless experiences solidify.
## Strategic Considerations: Successful Implementation in a Customer-Focused Brand
Customer-centric brands embracing passwordless authentication should prioritize the following:
- **Customer Communication and Education:** Clear communication about the benefits and processes of passwordless authentication ensures a smooth transition and user acceptance.
- **Phased Implementation:** Gradually introduce passwordless options alongside traditional login methods to give users time to adapt.
- **Robust Support Channels:** Initially anticipate an uptick in support requests as users acclimate and offer resources to guide them through any potential issues.
- **Ongoing Analysis and Optimization:** Evaluate metrics (signup conversion, cart abandonment, authentication success rates) to tailor authentication workflows for maximum user experience gains as you gain insights through usage patterns.
## Conclusion
In an era where exceptional customer experiences drive loyalty, frictionless authentication has evolved from a luxury into a necessity. MojoAuth partners with customer-centric brands to ditch cumbersome passwords and embrace a secure, seamless login experience that aligns with their values.
By prioritizing convenience and security, customer-centric businesses pave the way for increased engagement, lasting relationships, and overall brand success. The question is, are you ready to say goodbye to password friction and create experiences that your customers will love? | auth-mojoauth |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.