
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,871,850 | Equity Token Offerings: Modernizing Investment | In recent years, the world of finance has witnessed a significant evolution with the advent of... | 0 | 2024-05-31T09:22:58 | https://dev.to/donnajohnson88/equity-token-offerings-modernizing-investment-586h | equitytokenofferings, blockchain, development, beginners | In recent years, the world of finance has witnessed a significant evolution with the advent of blockchain technology and tokenization. Among the innovative financial instruments that have emerged, Equity Token Offerings (ETOs) stand out as a groundbreaking method powered by [STO development services](https://blockchain.oodles.io/security-token-offering-development-company/?utm_source=devto) for raising capital and democratizing investment opportunities. In this comprehensive guide, we delve into the intricacies of Equity Token Offerings, exploring their mechanics, benefits, and potential for transforming the traditional investment landscape.
## Understanding Equity Token Offerings
ETOs, sometimes referred to as Security Token Offerings (STOs), are a type of crowdfunding that allows businesses to issue digital tokens that stand in for ownership rights such as equity, profit-sharing, or voting rights. These tokens are backed by real-world assets, such as company shares, real estate, or commodities, and are governed by regulatory frameworks to ensure compliance with securities laws.
## Key Components
**Legal Compliance**
One of the defining features of ETOs is their adherence to regulatory standards. Issuers must comply with securities regulations in the jurisdictions where they operate, ensuring transparency, investor protection, and legal certainty.
**Tokenization Platform**
ETOs are facilitated through tokenization platforms that provide the infrastructure for creating, issuing, and managing security tokens. These platforms leverage blockchain technology to tokenize assets, manage investor relations, and facilitate secondary market trading.
**Investor Verification**
To participate in ETOs, investors undergo a rigorous verification process to confirm their identity and accreditation status. This helps issuers maintain compliance with Know Your Customer (KYC) and Anti-Money Laundering (AML) regulations.
**Smart Contracts**
Smart contracts play a central role in ETOs by automating the execution of investment agreements, token issuance, and distribution of dividends or other rights to token holders. These self-executing contracts enhance transparency, reduce transaction costs, and mitigate counterparty risk.
Also, Read | [Getting Started with INO (Initial NFT Offering)](https://blockchain.oodles.io/blog/ino-initial-nft-offering/?utm_source=devto)
## Benefits
**Access to Capital**
ETOs provide companies with an alternative means of raising capital by tapping into a global pool of investors. This democratization of investment opportunities enables startups and small businesses to access funding without the traditional barriers associated with venture capital or initial public offerings.
**Liquidity**
By tokenizing assets and enabling secondary market trading, ETOs enhance liquidity for investors, allowing them to buy, sell, and trade security tokens more efficiently than traditional securities.
**Fractional Ownership**
ETOs enable fractional ownership of high-value assets, such as real estate or private equity, making investment opportunities more accessible to a wider range of investors.
**Transparency and Security**
Blockchain technology ensures transparency and immutability of transaction records, reducing the risk of fraud and enhancing investor trust in Equity Token Offerings.
Challenges and Considerations:
While Equity Token Offerings offer numerous benefits, there are several challenges and considerations to be mindful of:
**Regulatory Complexity**
Navigating the regulatory landscape governing Equity Token Offerings can be complex and varies significantly across jurisdictions. Issuers must ensure compliance with securities laws, which may require legal expertise and regulatory approvals.
**Investor Education**
Educating investors about the benefits and risks of Equity Token Offerings is essential for fostering confidence and participation in this emerging asset class. Clear communication and transparency regarding investment terms, risks, and potential returns are crucial for attracting and retaining investors.
**Market Liquidity**
Despite the potential for enhanced liquidity, secondary markets for security tokens are still in the early stages of development. Limited liquidity and trading volume may affect the valuation and tradability of security tokens, particularly for smaller or less liquid assets.
Also, Explore | [IDO (Initial DEX Offering) | The Future of Decentralized Fundraising](https://blockchain.oodles.io/blog/quick-guide-launching-ido-initial-dex-offering/?utm_source=devto)
## Conclusion:
Equity Token Offerings represent a paradigm shift in the way companies raise capital and investors access investment opportunities. Equity Token Offerings provide a competitive alternative to conventional fundraising techniques by utilizing blockchain technology, regulatory compliance, and tokenization. This opens up new investment opportunities and democratizes access to money. While challenges remain, the potential for Equity Token Offerings to modernize investment and reshape the financial landscape is undeniable. As regulatory frameworks evolve and market infrastructure matures, Equity Token Offerings are poised to play a transformative role in the future of finance. Interested in launching an equity token offering, connect with our [crypto token developers](https://blockchain.oodles.io/about-us/?utm_source=devto) to get started. | donnajohnson88 |
1,871,849 | Document conversion APIs | A small comparison guide: https://apyhub.com/blog/exploring-top-document-conversion-apis What other... | 0 | 2024-05-31T09:22:21 | https://dev.to/nikoldimit/document-conversion-apis-20f9 | api, pdf, conversion, apyhub | A small comparison guide: https://apyhub.com/blog/exploring-top-document-conversion-apis
What other aspects would you be evaluating when checking for doc conversion APIs?
| nikoldimit |
1,871,848 | Your Guide to the Best SEO Agencies in the USA: Expert Recommendations and Reviews | In the highly competitive digital landscape, businesses must leverage professional SEO services to... | 0 | 2024-05-31T09:20:32 | https://dev.to/templatewallet/your-guide-to-the-best-seo-agencies-in-the-usa-expert-recommendations-and-reviews-3p9j | In the highly competitive digital landscape, businesses must leverage professional SEO services to stay ahead. Search engine optimization (SEO) is vital for enhancing your online visibility, driving organic traffic, and boosting your revenue. With the abundance of SEO agencies in the USA, selecting the right one can be challenging. This comprehensive guide will help you navigate through the options, providing expert recommendations and reviews of the best SEO agencies in the USA.
##Why Professional SEO Services Are Crucial
Before diving into the list of top SEO agencies, it's essential to understand the importance of professional SEO services. SEO is a dynamic field that requires continuous updates and strategic planning. Here are a few reasons why investing in professional SEO services is beneficial:
##Expertise and Knowledge
SEO professionals have the knowledge and experience to implement effective strategies tailored to your business needs. They stay updated with the latest algorithm changes and industry trends, ensuring your website adapts to new search engine requirements. This expertise enables them to identify and leverage opportunities that you might miss, providing a competitive edge.
##Time and Resource Saving
Outsourcing SEO allows you to focus on your core business activities while experts handle your online presence. SEO requires continuous effort, including keyword research, content creation, and link building, which can be time-consuming. By entrusting these tasks to professionals, you can allocate your time and resources to other critical areas of your business, enhancing overall productivity.
##Better ROI
A well-executed SEO strategy can significantly improve your website’s rankings, leading to increased traffic and higher conversion rates. By attracting more targeted visitors who are interested in your products or services, you can achieve a better return on investment. Additionally, [professional SEO services](https://www.stanventures.com/managed-seo-services/?utm_source=dev.to&utm_medium=listicle&utm_campaign=branding) ensure sustainable results, providing long-term value and consistent growth in your online presence and revenue.
Key Factors to Consider When Choosing an SEO Agency
##1. Experience and Track Record
An agency's experience and track record are critical indicators of their capability. Look for agencies with a proven history of success across various industries. To gauge their performance, check their case studies, client portfolios, and testimonials. Additionally, seek agencies that have been recognized with industry awards or certifications, as these accolades often highlight their expertise and reliability. An experienced agency will be adept at handling diverse challenges and delivering consistent results, making them a valuable partner for your SEO needs.
##2. Range of Services
SEO encompasses various aspects, including on-page SEO, off-page SEO, technical SEO, and content marketing. Ensure the agency offers comprehensive services that align with your business goals. Some agencies also provide additional services like PPC, social media marketing, and web development, which can complement your SEO efforts. A full-service agency can provide a holistic digital marketing strategy, ensuring all elements work together seamlessly. This integration can lead to more effective campaigns and a higher return on investment, maximizing your marketing budget.
##3. Client Reviews and Reputation
Client reviews and testimonials offer insights into the agency’s reliability and effectiveness. Look for reviews on independent platforms like Google, Yelp, or Clutch. Additionally, ask the agency for references so you can speak directly with their clients. Pay attention to both the quantity and quality of reviews, as consistent positive feedback over time can indicate strong performance. Consider looking at case studies that detail how the agency solved specific problems and achieved tangible results. This due diligence can help you gauge the potential for a successful partnership.
##4. Transparency and Communication
Effective communication and transparency are essential for a successful partnership. Choose an agency that provides regular updates and detailed reports on your SEO campaigns. They should be open to discussing strategies, performance metrics, and any adjustments needed. A transparent agency will clearly outline its processes, timelines, and expected outcomes, fostering trust and collaboration. Regular meetings and proactive communication ensure that both parties are aligned on goals and expectations, allowing for timely adjustments and continuous improvement of the SEO strategy.
##5. Pricing and Value
SEO services come at various price points. Finding an agency that offers good value for your investment is important. Avoid agencies that promise quick results at low prices, as they may use unethical practices that could harm your website in the long run. Instead, look for agencies that provide clear, detailed pricing structures and explain the rationale behind their costs. Investing in quality SEO services will yield long-term benefits, including sustained organic traffic growth and improved brand authority, which are crucial for achieving your business objectives.
##Top SEO Agencies in the USA
To help you make an informed decision, here are some of the top SEO agencies in the USA, known for their expertise, client satisfaction, and proven results:
##1. Stan Ventures
Website: https://www.stanventures.com/
Specialties: Managed SEO services, link building, content marketing.
Highlights: Stan Ventures stands out for their personalized approach and dedicated SEO teams. They offer tailored SEO strategies that cater to the unique needs of their clients, ensuring sustainable growth and improved online visibility.
##2. WebFX
Website: https://www.webfx.com/
Specialties: Full-service digital marketing, including SEO, PPC, web design.
Highlights: Known for their data-driven strategies and transparent reporting, WebFX helps businesses achieve measurable results. Their team of experts creates customized SEO plans to boost online presence and drive traffic.
##3. Straight North
Website: https://www.straightnorth.com/
Specialties: B2B SEO, lead generation, web development.
Highlights: Straight North focuses on generating qualified leads through effective SEO strategies. They emphasize detailed performance tracking and transparency, ensuring clients see the impact of their services.
##4. Thrive Internet Marketing Agency
Website: https://thriveagency.com/
Specialties: SEO, content marketing, social media management.
Highlights: Thrive is renowned for their holistic approach to digital marketing, integrating SEO with other channels to maximize results. Their team prioritizes client satisfaction and long-term success.
##5. Ignite Visibility
Website: https://ignitevisibility.com/
Specialties: SEO, PPC, digital marketing strategy.
Highlights: Ignite Visibility is a top-rated SEO agency known for their innovative strategies and client-focused approach. They offer comprehensive SEO services designed to enhance visibility and drive business growth.
##6. Victorious
Website: https://victoriousseo.com/
Specialties: SEO, keyword strategy, link building.
Highlights: Victorious is recognized for their results-driven SEO strategies. They use advanced analytics and data to create effective SEO campaigns that deliver measurable results.
##7. SEO Inc.
Website: https://www.seoinc.com/
Specialties: Enterprise SEO, local SEO, PPC management.
Highlights: With over two decades of experience, SEO Inc. offers tailored SEO solutions for businesses of all sizes. Their focus on innovation and ethical practices ensures sustainable results.
##Expert Recommendations
To get the most out of your investment in SEO, here are some expert recommendations:
##1. Define Your Goals
Before engaging with an SEO agency, clearly define your business goals. Whether it’s increasing website traffic, improving conversion rates, or boosting brand awareness, having specific objectives will help you communicate your needs effectively. Additionally, clearly defined goals will help the SEO agency create a tailored strategy that aligns with your business vision. Be specific, including the key performance indicators (KPIs) you wish to track. This will enable both you and the agency to measure the success of the SEO efforts and make data-driven decisions.
##2. Ask the Right Questions
When evaluating potential SEO agencies, ask detailed questions about their strategies, tools, and methodologies. Understand how they plan to approach your SEO project and what metrics they will use to measure success. Inquire about their experience in your industry, their approach to keyword research, content creation, and link-building strategies. Ask for case studies or examples of past successes. This will give you a clearer picture of their expertise and how they can specifically help your business achieve its SEO goals.
##3. Request a Proposal
Ask shortlisted agencies to provide a detailed proposal outlining their strategy, timeline, and pricing. Compare these proposals to see which agency offers the best value for your investment. Ensure the proposal includes a clear breakdown of services, expected deliverables, and milestones. This will help you understand what to expect at each stage of the SEO process. A comprehensive proposal will also highlight the agency's commitment to transparency and its ability to deliver results within your budget and timeframe.
##4. Monitor Progress
Once you’ve chosen an agency, regularly monitor the progress of your SEO campaigns. Review the reports they provide and have regular check-ins to discuss performance and any necessary adjustments. Establish a schedule for receiving updates, such as weekly or monthly reports, to stay informed about your campaign's progress. Use these meetings to address any concerns, discuss new opportunities, and refine strategies. Ongoing communication ensures that both you and the agency are aligned and working towards the same goals, leading to a more successful SEO partnership.
##Conclusion
Choosing the right SEO agency is crucial for the success of your online presence. By considering factors like experience, services offered, client reviews, transparency, and pricing, you can find an agency that aligns with your business needs. Investing in professional SEO services will not only enhance your online visibility, but also drive sustainable growth and profitability, positioning your brand as a leader in your industry and ensuring long-term success in an increasingly digital marketplace. | templatewallet | |
1,871,846 | Enhancing Productivity with Video Feedback in 2024. | My experience has taught me the importance of productivity in everything I and my team do. Video... | 0 | 2024-05-31T09:18:38 | https://dev.to/martinbaun/enhancing-productivity-with-video-feedback-in-2024-455c | microservices, tooling, productivity | My experience has taught me the importance of productivity in everything I and my team do. Video Feedback is a crucial component of this.
This is what I and my team have learned from this.
## Video Feedback: Easy to Start, Hard to Master
Video Feedback has been easy to implement in my daily routine. I press record, explain what hasn’t been done correctly, save, and notify the recipient. This ease to start and use lends to its practicality. I offer feedback on technical tasks such as code reviews or simple tasks like written pieces. This method of giving feedback is fast and efficient. My employees have the video as a reference point that allows them to make correct edits.
Mastering Video Feedback is a different prospect. Tone and attitude are hard to convey over video feedback. It takes practice and repetition to develop a neutral tone for video feedback. This seems like a minor issue, but it affects the morale of your colleagues. This is the reason I don’t give performance reviews over video feedback. The tone can be misunderstood and even taken the wrong way. I use in-person meetings and synchronous video feedback for this. My employees can see my face, interpret my body language, and respond to the reviews in kind. Learning how to separate the two and more is a developing skill. This skill develops with time. Keep at it, and you’ll get better at it.
Read: *[Onboarding and Training New Remote Employees in a Virtual Environment](https://martinbaun.com/blog/posts/onboarding-and-training-new-remote-employees-in-a-virtual-environment/)*
## Asynchronous Video Feedback
Remote teams are here to stay. It’s common to have colleagues spread all over the world. Different time zones make video feedback a crucial asset to use. Synchronous meetings are hard to have. They require a lot of planning, dedication, and sacrifice from the parties involved.
Asynchronous video feedback is effective for remote teams. I give feedback, and the recipient works on it as required. They also have it as a reference they can refer to as much as they need. This allows them to focus and work on the task correctly. My employees also use it in different ways. They have personalized it to resolve tasks and other intangible aspects of our cooperation. I receive videos from my employees explaining their workflow and ideology for particular tasks. This has given me insight that I didn't have previously. I have a better understanding of the timeline needed for a task to progress from infancy to approval. It has optimized our work, streamlined our communication, and delivered the desired production.
Read: *[Build Elegant Software In 1 month! How We Did It!](https://martinbaun.com/blog/posts/build-elegant-software-in-1-month-how-we-did-it/)*
This is the polar opposite of video meetings. They take place synchronously. This feedback has no reference point unless you've recorded it or notes were taken. I use them for progress reports, daily meetings with my team, and employee assessments. It is useful and helps me and my team plan and decide on the best way forward for particular tasks and projects. They are exceptional for such vital executive decisions. They don’t work for giving feedback. This makes asynchronous video feedback a powerful tool that enhances productivity and saves time.
## Video Feedback Practicality
Video Feedback is as practical as it gets. If you see a problem, record it and how to rectify it. This is similar to asking questions with potential solutions, a concept I explained in our article, 7 Tips for Effective Communication in Remote Teams.
Video Feedback lets me give tangible explanations without resorting to complicated methodologies. It has improved our efficiency since its introduction. It’s easier to offer explanations, show examples, and communicate intent.
A fine example of this is showcasing wrongly placed links and formatting. I contrast this with properly placed links and formatting. Giving this feedback in written format doesn’t convey the tone and voice of thought needed. Video feedback conveys my tone, train of thought, and emphasis in the feedback. This gives my employees a visual and auditory explanation of where the error lies and how to fix it.
This practicality extends to feedback on codes, designs, posts on socials, and even construction. The practical uses of video feedback are vast, giving you the efficiency and productivity you need to soar your projects to greater heights.
## Video Review and Collaboration
Remote teams need a strong bond and comradery to get things done. Not much attention is given to the importance of comradery. Video Feedback helps build this bond between team members. Video Feedback fills the void created by not working at a central location.
Team members get a feel for each other, quirks, demeanor, likes, and dislikes. A lot is conveyed via Video Feedback, simulating some level of interaction that would be present in physical interactions. Video Feedback is intended to make work efficient and improve productivity. Comradery is a bonus that works to promote these objectives.
## Conclusion
Video Feedback is an excellent method to improve efficiency and productivity. It allows you to give feedback faster and enhances the workflow within your business. It promotes a collaborative mindset. This is great for every employee and team lead in the organization. Video Feedback keeps everyone informed and builds trust in the process. The benefits aren't reaped automatically but they progressively accumulate.
You can pair Video Feedback with collaboration software. Our favorite is Goleko. It helps you manage projects better. It has helped us improve our productivity, and you should try it. Goleko is our recommendation that we know you won't regret using.
-----
## FAQs
*What is Video Feedback?*
Video Feedback is a communication channel utilizing audio and visual formats to convey a message in response to a project or task completed.
*How effective is Video Feedback?*
Video Feedback is effective for all tasks. It helps you know exactly what to do and how to do it. It is the fastest way to give feedback, making it a must-have in your work routine.
*What is the best Video Feedback Software?*
We haven't tested every Video Feedback software. This makes it hard to rank them. My team and I built VideoFeedbackr. We made it easily usable, reliable, and awesome for enhanced user experience. It is simple to use and follows the highest security standards. Create video content, give video reviews, and participate in video collaboration.
*What is VideoFeedbackr?*
Free Video Feedback hassle-free. It is software designed for video review and collaboration. Use videos to convey your messages, collect feedback, and enhance creative collaboration. Get everyone on the same page with VideoFeedbackr.
*Can you pair VideoFeedbackr with other tools?*
VideoFeedbackr was borne from an asynchronous video feedback tool we built in Goleko. Our team values video feedback, hence why we created it. VideoFeedbackr doesn't pair well with it but we have created a version of it within our project management tool. it allows for proper feedback which promotes our productivity.
*Do you need an App to access VideoFeedbackr?*
No. VideoFeedbackr is accessible on your web browser. You do not need to download any apps to use it.
*What is the pricing of a VideoFeedbackr subscription cost?*
VideoFeedbackr has a free tier and a paid tier coming soon. The free version is free for life and has some limited perks. The paid version will have more perks for you to enjoy and use.
*Do you need an account to use VideoFeedbackr?*
No, you don’t. You can use VideoFeedbackr without registering an account. You only need to open your browser, type in VideoFeedbackr on the search bar, and start using it.
*Is Goleko similar to Slack?*
No, it isn't. Goleko is a collaboration platform whereas Slack is a communication platform. Goleko is a platform that helps you manage your projects and will soon incorporate smooth communication in one central application. This will guarantee your efficiency wherever you're working be it in real-time or remotely.
*What are the security measures on VideoFeedbackr?*
VideoFeedbackr has blockbuster security systems to ensure your privacy is maintained. You only need to record the video, save it, and share the link with the recipient. Anyone who's watching the video must receive the link from you. Our brand values your privacy and follows ethical guidelines to protect it.
-----
*For these and more thoughts, guides and insights visit my blog at [martinbaun.com](http://martinbaun.com)*
*You can find Martin on [X](https://twitter.com/MartinBaunWorld)*
| martinbaun |
1,871,845 | Day 13of 30 of JavaScript | Hey reader👋 Hope you are doing well😊 In the last post we have completed arrays, it's properties and... | 0 | 2024-05-31T09:17:58 | https://dev.to/akshat0610/day-13of-30-of-javascript-3cde | webdev, javascript, beginners, tutorial | Hey reader👋 Hope you are doing well😊
In the last post we have completed arrays, it's properties and methods. In this post we are going to starts Object Oriented Programming through JavaScript, we are going to start from very basic and take it to advanced level.
So let's get started🔥
## What is Object Oreinted?
Object Oriented Programming is the way of defining complex structures in a simpler way using **objects** and **classes**.
Let's understand this with the help of an example-:
Suppose you have a car and this car has a name, type(sports, luxury, passenger etc), number of seats ,engine capacity and many more. Now as you can see that every property described here are all belong to car so it's better to have an entity that can store every property and method(here task that car can perform) at one place, and to do this we use object oriented programming. We will define a car class which is going to contain all the properties and methods related to car and will utilize this class using a car object.
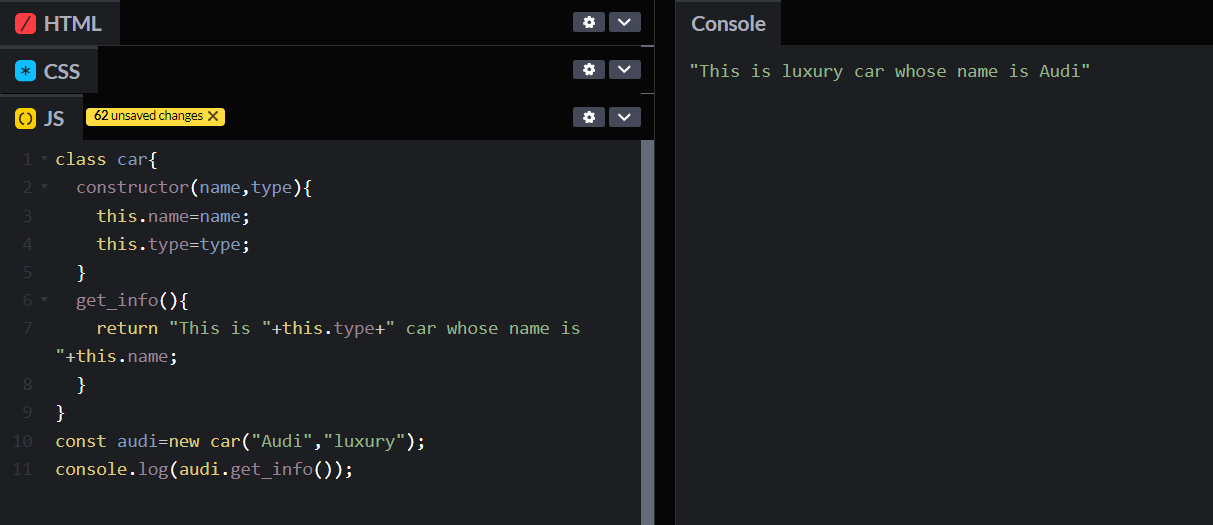
So here you can see that we have made a car class and defined all the properties and methods in this and accessed them using object.
Don't bother much about `constructor` and `this` we will talk about them in detail in coming blogs.
**Object Oriented programming is all about the use of objects and classes.**
## Fundamental blocks of Object Oriented Programming
**1. Classes**
Classes are entities that holds every related property and method at single place. In our example above we have a car class that contains every property and method related to car.
**2. Objects**
An object is an instance of class. Using an object we can easily access the property and methods defined in that particular class.
Note-: Class doesn't get any space in memory till its object is defined. We can also say that an object is reference to class.
A class is a blueprint for objects.
In our above example `audi` was our car class object.
**3. Properties or Attributes**
These are the characteristics of the class. In our car class name and type were the characteristics of the car class.
**4. Methods**
These are the actions that objects can perform. In the car class, methods might be `drive`, `stop`, and `honk`. In above example we had `get_info` method.
## Properties of Object Oriented
The key properties of object-oriented programming (OOP) are:
**1. Encapsulation**
Encapsulation refers to storing everything at one place. In classes we define every related property and method at one place. You can understand it as a capsule that contains medicine in it and the capsule protects the medicine inside it from any external germ.
> Bundling data (attributes) and methods (functions) that operate on the data into a single unit or class, and restricting direct access to some of the object's components.
**2. Abstraction**
Abstraction refers to hiding the complex implementation details and showing or exposing only necessary features. For example, when you apply brakes of vehicle you are not aware of what forces are working in background on application of brakes, all you know is applying brakes will slow down your vehicle, so here the background tasks are abstracted from you.
> Hiding the complex implementation details and showing only the necessary features of an object. This helps in reducing complexity and allows the programmer to focus on interactions at a higher level.
**3. Inheritance**
Inheritance can be understood as inheriting the features of a class by another class. The class whose properties and methods are inherited is called **parent class or super class** and the class which inherits is called **child class or sub class**.
Suppose you have a `Vehicle` class and a `Car` class. So this `Car` class will inherit the propeties and methods of `Vehicle` class.
> Creating a new class from an existing class. The new class (child class) inherits attributes and methods from the existing class (parent class), promoting code reuse and establishing a natural hierarchy.
**4. Polymorphism**
Polymorphism refers to the ability of something to have one form or another according to the requirement. For example your mother plays different roles in different relations; for you she is your mother, for your father she is his wife; for your grandparents she is their daughter in law and many more.
So here also we can have methods that can have different roles for different objects.
Suppose we have a super class called `Shape` and `Square` and `Circle` are our subclasses. We have a `calculate_area()` defined in our superclass, we can use this method in our subclasses and can implement it according to need. So here `calculate_area()` has different forms in different classes.
> Allowing objects of different classes to be treated as objects of a common superclass. It enables a single interface to be used for a general class of actions, with specific behavior determined by the exact nature of the situation or the object class.
So this is it for this blog. I hope you have understood it well. In the next blog we will go more deep in it. Till then stay connected and don't forget to follow me 🤍 | akshat0610 |
1,871,844 | 🌟 Elevate Your Business with Digital Innovation Media! 🚀 | 🌐 Are you ready to take your business to the next level? Look no further than Digital Innovation... | 0 | 2024-05-31T09:15:57 | https://dev.to/abhinand_ps_7174ef0fb0a63/elevate-your-business-with-digital-innovation-media-4fnn | 🌐 Are you ready to take your business to the next level? Look no further than Digital Innovation Media! 💼 With our comprehensive suite of full-stack business solutions, we're here to build and launch ready-to-go businesses tailored to any industry.
💡 Why choose us? Here's what sets us apart:
✅ Native solutions for eCommerce, bookings, events, restaurants, hotels, blogs, and more.
✅ Multilingual capabilities to reach global audiences effortlessly.
✅ Seamless payments and pricing plans for smooth transactions.
✅ Members area and CRM integration for streamlined operations.
✅ Digital Innovation Media: Your partner in success!
📈 Ready to transform your online presence? Let's connect and discuss how we can tailor our solutions to meet your unique business needs. Visit us at www.digitalinnovationmedia.com and let's start the journey to success together!
#DigitalInnovationMedia #BusinessSolutions #FullStack #ElevateYourBrand #OnlineSuccess #Innovation #DigitalTransformation | abhinand_ps_7174ef0fb0a63 | |
1,871,843 | Maximize Your Hot Tub and Swim Spa Experience: Essential Do’s and Don’ts for Ultimate Relaxation | Are you ready to indulge in the ultimate relaxation experience with your hot tub or swim spa? Before... | 0 | 2024-05-31T09:15:16 | https://dev.to/walterjerry/maximize-your-hot-tub-and-swim-spa-experience-essential-dos-and-donts-for-ultimate-relaxation-3cc5 | Are you ready to indulge in the ultimate relaxation experience with your [hot tub](https://www.thehottubandswimspacompany.com/hot-tubs) or swim spa? Before immersing yourself in the soothing warmth, it's essential to understand the dos and don'ts to maximize your enjoyment and ensure the longevity of your investment. By following these guidelines, you can make the most of your spa experience while avoiding common pitfalls. Let's explore the essential do’s and don'ts for a safe, relaxing, and rejuvenating time in your hot tub or swim spa.
**The Do’s While Enjoying a Swim Spa**
1. Follow Proper Maintenance Procedures: Regular maintenance is key to keeping your hot tub or swim spa in pristine condition. Follow the manufacturer's guidelines for water treatment, cleaning, and filter maintenance. Invest in quality products for sanitization and balancing the pH levels to ensure a safe and hygienic environment for soaking.
2. Keep the Water Clean: Maintain proper water chemistry by testing it regularly and adjusting the levels as needed. Clean the filters regularly to remove debris and prevent clogging. Consider investing in a self-cleaning hot tub or swim spa for added convenience and peace of mind.
3. Practice Safety Measures: Safety should always be a priority when using your spa. Always supervise children and non-swimmers, and never leave them unattended in or around the water. Install safety covers and barriers to prevent accidents, and familiarize yourself with emergency procedures.
4. Limit Soaking Time: While it may be tempting to spend hours soaking in your spa, it's important to limit your sessions to avoid dehydration and overheating. Aim for 15-30 minute sessions, with breaks in between to cool down and hydrate.
5. Enjoy the Benefits of Hydrotherapy: Take advantage of the therapeutic benefits of hydrotherapy by incorporating massage jets and adjustable settings into your spa experience. Experiment with different massage techniques and water temperatures to soothe sore muscles, improve circulation, and promote relaxation.
**The Don'ts While Enjoying a Swim Spa**
1. **Overlook Regular Maintenance**: Neglecting regular maintenance can lead to water contamination, equipment malfunction, and costly repairs. Avoid the temptation to skip routine tasks such as cleaning the filters or testing the water chemistry, as it can compromise the performance and longevity of your spa.
2. **Use Harsh Chemicals**: While it's essential to maintain clean water, avoid using harsh chemicals that can irritate the skin or damage the spa components. Opt for gentle, spa-safe products specifically formulated for hot tubs and swim spas.
3. **Ignore Warning Signs**: Pay attention to any unusual sounds, smells, or changes in the water quality, as they could indicate underlying issues with your spa. Addressing problems promptly can prevent further damage and ensure uninterrupted enjoyment of your spa.
4. **Overheat the Water**: Avoid setting the water temperature too high, as it can lead to discomfort, dehydration, and even heat exhaustion. Keep the temperature between 100-104°F (37-40°C) for a relaxing and safe spa experience.
5. **Neglect Safety Precautions**: Don't compromise on safety measures, such as installing fencing, covers, and alarms, to prevent accidents and injuries. Educate yourself and your family members on proper spa etiquette and emergency procedures to minimize risks.
**Conclusion**
By following these do’s and don'ts, you can enjoy a safe, relaxing, and rejuvenating spa experience for years to come. Prioritize maintenance, safety, and proper usage to make the most of your investment in a hot tub or swim spa. Whether you're in search of top hot tub brands, self-cleaning hot tubs, swim spa dealers, or a sauna for sale in the UK, trust [The Hot Tub and Swim Spa Company](https://www.thehottubandswimspacompany.com/) to meet your needs. As a leading London swimming pool company, they offer a wide range of premium-quality products, including portable spas and hot tubs, gazebo options, and accessories. Explore their collection today and elevate your relaxation experience at home.
| walterjerry | |
1,871,841 | The Frontend Challenge: Sculpting Sacredness of Lord Shiva | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration When I... | 0 | 2024-05-31T09:13:24 | https://dev.to/niketmishra/the-frontend-challenge-sculpting-sacredness-of-lord-shiva-22i6 | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
<!-- What are you highlighting today? -->
When I think of June, I am reminded of the vibrant cultural and religious celebrations that take place around the world. For this challenge, I chose to create a piece of art inspired by Lord Shiva, a significant deity in Hindu religion, symbolizing transformation and transcendence. June, being a month of transitions—whether it's the shift to summer in many parts of the world or a time of spiritual reflection—felt like the perfect time to honor Lord Shiva through CSS art.
## Demo
<!-- Show us your CSS Art! You can directly embed an editor into this post (see the FAQ section of the challenge page) or you can share an image of your project and share a public link to the code. -->
{% codepen https://codepen.io/niketmishra/pen/dyEvyya %}
## Journey
<!-- Tell us about your process, what you learned, anything you are particularly proud of, what you hope to do next, etc. -->
Creating this CSS art of Lord Shiva was a fascinating journey. I began by defining custom CSS variables for colors and gradients, setting the stage for the overall aesthetic. Using a combination of flexbox and absolute positioning, I structured the elements to resemble Lord Shiva's iconic features.
The head and body were formed using divs with border-radius properties, while intricate details like the third eye and crescent moon were meticulously crafted using absolute positioning and box-shadow effects. Animation was added to certain elements to give them a dynamic and lifelike appearance.
Throughout the process, I experimented with various CSS properties and techniques, refining the art piece to achieve the desired outcome. This project not only honed my CSS skills but also deepened my appreciation for the artistry achievable through code.
In the end, the result was a visually striking representation of Lord Shiva, paying homage to this revered deity in Hindu culture through the medium of CSS.
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- We encourage you to consider adding a license for your code. -->
MIT License
Copyright (c) 2024 Niket Kumar Mishra
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
<!-- Don't forget to add a cover image to your post (if you want). -->
<!-- Thanks for participating! --> | niketmishra |
1,871,840 | Want to know web scraping challenges? | Working with hundreds of clients at ProWebScraper, I've seen firsthand the hurdles businesses face... | 0 | 2024-05-31T09:12:52 | https://dev.to/hiren_patel_97/want-to-know-web-scraping-challenges-294f | Working with hundreds of clients at ProWebScraper, I've seen firsthand the hurdles businesses face when doing hashtag#webscraping.
From navigating complex website structures (an issue for over 60% of our customers) to ensuring compliance and data accuracy, there are many obstacles.
Read below article to see all the top challenges customers have shared:
https://www.linkedin.com/pulse/navigating-5-challenges-web-scraping-insights-from-product-patel-uqetf
| hiren_patel_97 | |
1,871,838 | Ship Faster, Fix Less: A Guide To Continuous Testing | Before I jump into Continuous Testing, let's touch base on what testing is, along with how and when... | 0 | 2024-05-31T09:12:19 | https://keploy.io/blog/community/ship-faster-fix-less-a-guide-to-continuous-testing | webdev, beginners, tutorial, devops |
Before I jump into Continuous Testing, let's touch base on what testing is, along with how and when it plays a crucial role.
Testing phase provides you with feedback which will help you determine if further changes are needed. Faster feedback is better for you.
Why? Because by going down the wrong road too far, you risk having to rework more than you originally developed. In some cases, it may not be possible to fix the defects because the feedback came in two days before your scheduled deployment.
So, what do you do? You push the defects into production, hoping to fix it someday. Will defects always get fixed in production? You know the answer!
**What is continuous testing?**
Continuous testing is a process of software testing in which an application is tested at every stage of software development life cycle (SDLC). It aims to shorten the systems development life cycle and provide continuous delivery with high software quality.
**Why does it matter?**
The process of software development began with requirements gathering, where documentation outlined the software's functionalities and user stories. This was followed by design and architecture, where the software's blueprint was created, defining how components would interact and how users would navigate. Once the blueprint was finalized, developers translated the design into functional code using chosen programming languages.
Whenever software is developed, it goes through the testing phase to ensure the quality of the software and to identify bugs to be fixed by the developers.
Traditionally testing is done after the software is developed completely. The development of software is split into many parts. Once a team completes developing a part of the software then that part is given to another team and that team hands over the software to another once they complete their part. This continues until the software is completely developed. This method of developing software is known as the waterfall model.
While the waterfall model provides a structured approach with dedicated time for each development phase, its linear progression can hinder flexibility. Adapting to evolving requirements or incorporating feedback later in the process becomes difficult, potentially leading to a final product that falls short of user needs.
But what if there was a different avenue for testing? A faster, more streamlined approach that shatters the bottlenecks hindering collaboration between development and testing teams.
That is where continuous testing becomes valuable. Testing code directly after submitting it to the repository helps detect bugs before any additional code is written. That extra code would then not have to be adjusted to incorporate bug fixes. Talk about saving time!
**Why do organisations go for continuous testing?**
It would take a lot of time and manpower to test the software whenever a new feature is added to the software.
But organizations want more efficient and easier solutions. That’s why organizations adopt a new approach “continuous testing” which delivers faster and seamless development of software and also releases high-quality software in a short period.
With continuous testing, code is automatically tested as soon as it’s integrated into the previous set of codes.
**Methodologies of Continuous Testing**
**Unit Tests:** This involves testing a piece of code in isolation. Basically testing every method written for the feature. The main objective of this test is to check that the code is working as expected, meaning that all the functionalities, inputs, outputs, and performance of the code are as desired.
**Integration Tests:** This involves testing the two modules together. The goal of this test is to check that the integration between the two components is working fine.
**Regression Tests:** This is the most widely used test and it is used to check that the existing functionality of the application is working as expected after the latest addition or modification to the code repository,
**End to End Journey tests:** These tests are added to check the end-to-end working of the software. The goal of these tests is to check that the end user is able to use the application end to end.
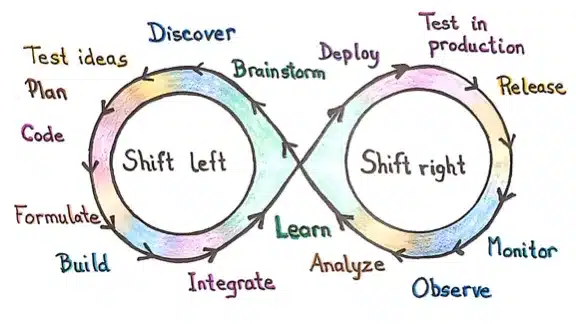
**Shift-left testing:** This approach prioritizes software and system testing early in the SDLC to help reduce or prevent significant debugging problems down the road.
**Shift-right testing:** This approach prioritizes testing near the end of the SDLC, with a focus on improving user experience, overall performance, failure tolerance and functions.
**Benefits of Continuous Testing**
**Increased speed:** Continuous testing aligns with the fast-paced nature of DevOps and Agile, facilitating quicker software delivery. This acceleration can enhance business processes, including faster go-to-market strategies.
**Catch bugs early:** By detecting bugs early in the development cycle, continuous testing significantly improves the overall quality of the code, reducing the likelihood of defects.
**Cost efficiency:** With a higher standard of code quality and fewer bugs reaching production, continuous testing aims to offset its initial costs over time.
**Improved security:** Continuous testing creates a robust framework that protects applications from unforeseen changes and security threats, both during and after deployment.
Save Time, Be Awesome: Continuous testing frees up valuable time for developers to focus on innovation. We can spend less time debugging and more time making applications even better!
**Continuous testing vs test automation: What's the difference ?**
Before the rise of continuous software testing, test automation was the main practice for achieving software quality assurance. Continuous Testing is different from automated testing , it is a process of executing automated tests to get feedback on the business risks associated with the release of a software. Automated testing , on other hand, is a process of executing specific tests via automation rather than doing it manually.
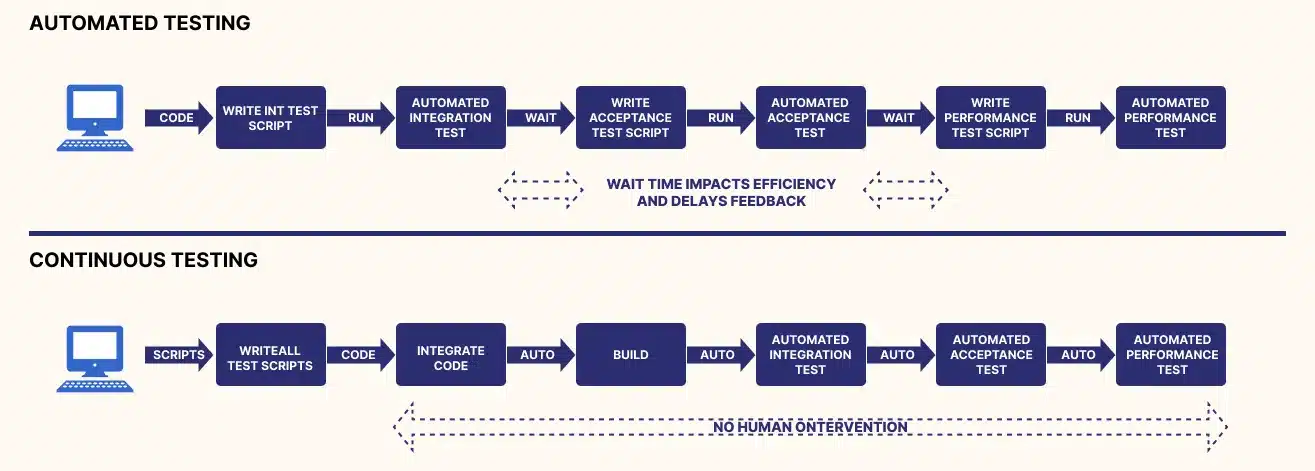
Continuous testing and test automation share common characteristics. Actually, continuous testing cannot exist without automation.
Despite having similarities, though, it’s false to assume that continuous testing and test automation are the same thing. Continuous testing goes beyond test automation. It aims to ensure continuous quality improvement throughout the whole software delivery pipeline.
**Continuous testing in devops**
As the demand for faster development and delivery of software to customers increases, organizations adopt the agile software development model. Incremental activities are performed continuously in this model.
Nowadays, DevOps is adopted by organizations for software development which uses collaborative processes and the responsibility is shared among the teams. DevOps is another methodology of software development like waterfall and agile. It is better than the previous ones.
This evolution of software development models leads organizations to use automation, Continuous Integration (CI), and Continuous Delivery (CD) that require continuous testing (CT).
In a DevOps environment, continuous testing is performed automatically throughout the SDLC and works hand in hand with continuous integration to automatically validate any new code integrated into the application.
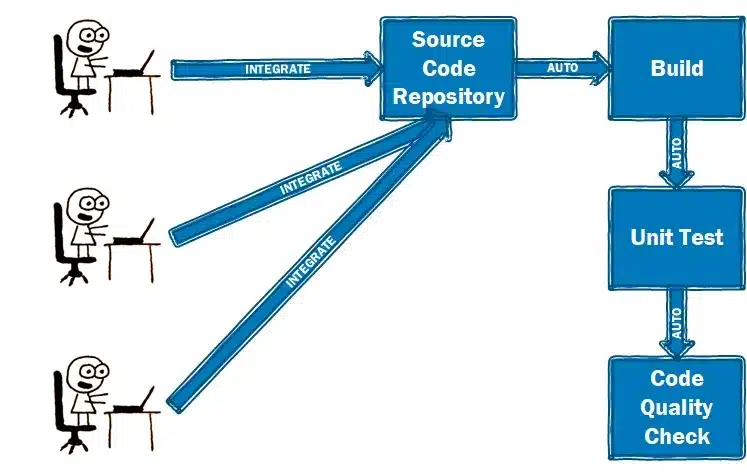
Continuous integration (CI) is a software development practice where developers regularly merge their code changes into a central repository, after which automated builds and tests are run
It most often refers to the build or integration stage of the software release process and entails both an automation component and a cultural component. The key goals of continuous integration are to find and address bugs quicker, improve software quality, and reduce the time it takes to validate and release new software updates.
Testing tools are preinstalled with testing scripts that run automatically whenever new code is integrated into the application. Typically, the tests start with integration testing and move automatically to system testing, regression testing and user-acceptance testing.
The tests generate data feeds from each application module, and the feeds are analyzed to help ensure that all modules impacted by the new code perform as expected. If a test fails, the code goes back to the development team for correction. It is then reintegrated and the testing cycle starts a new.
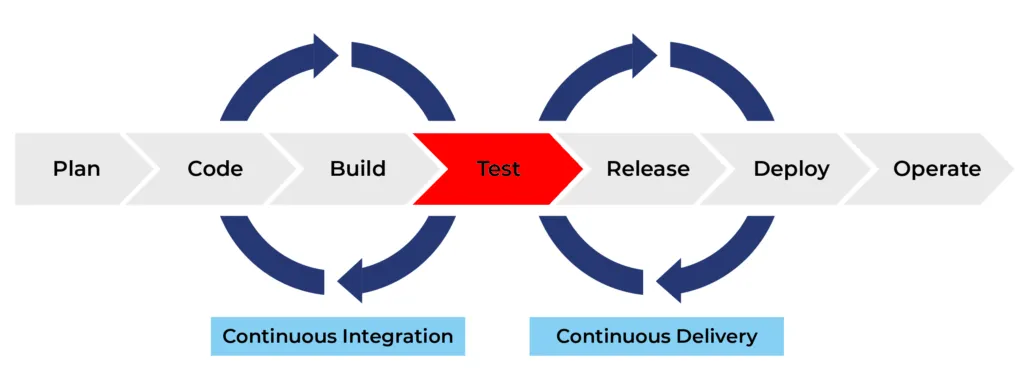
Once all tests are passed, the application or project moves to the next stage of the SDLC, typically continuous delivery.
Continuous delivery (CD) automates the release of software to production or a staging environment, making it ready to be deployed at any time with manual approval. Code changes are automatically built, tested, and prepared for a release to production. Continuous delivery expands upon continuous integration by deploying all code changes to a testing environment and/or a production environment after the build stage.
**Continuous testing in Production**
Continuous testing in production (CTIP) is a follow up process of continuous testing, where automated tests not only run in SDLC, but also in the production environment itself. This approach allows for real-time monitoring and validation of software applications with actual users data.
**Benefits of CTIP:**
Identify issues early: By continuously testing in production, you can catch bugs and regressions much faster than waiting for user reports.
Improved user experience: CTIP helps to ensure that new features and deployments don't negatively impact the user experience.
Faster feedback loop: The data from CTIP can be fed back into the development process, allowing developers to fix issues quickly.
**How to Perform Continuous Testing ?**
Now that you know what continuous testing is, let’s talk about how you use it. Continuous testing should be implemented at every stage of your CI/CD pipeline. You can set up test suites at every point code changes, merges, or releases. That way, you can run tests at a specific point rather than every test at once. This will help reduce time and effort on testing but still reap quality rewards.
Continuous testing works best by using the most recent build in an isolated environment. Containerization is a great method to help with replicating code outside of the main code repository.
**Steps to Perform Continuous Testing**
Use tools to generate test automation suites from user requirements
Create the test environment
Use production data to create test data beds
Test API using service virtualization
Perform parallel performance testing
The 3 Fundamentals of Continuous Testing
People :Each person in a team has a unique responsibility in the delivery pipeline for which he/she must possess the required skills. Transparent and regular communication between the members is the key to success.
Process :Process remains the key in Continuous Testing. Instead of automating everything, focus should be on test automation, code quality, stability, efficiency and providing timely feedback to the developers.
Technology :Technology should be leveraged to get a stable testing environment and build proper alignment between the team’s skills and software tools.
**Frameworks Used for Continuous Testing**
Continuous testing tools are designed to help you with your testing efforts. They ensure your success by guaranteeing positive results as you phase through the continuous testing process. Although many tools are available for continuous testing, very few are worth pursuing. Some prominent, continuous testing tools include:
**Selenium**
Selenium is a software framework that developers with extensive programming skills can use for QA testing. To implement Selenium, it’s vital to understand how frameworks work. In addition, Selenium supports a wide range of popular operating systems (Windows, macOS, Linux) and browsers (Chrome, Firefox, Safari), making it ideal for cross-environment testing.
**Jenkins**
According to a report, 33.3% of dev teams use Jenkins as their CI/CD tools. You’ll be able to run a series of automated tests and builds after the Jenkins server is set up, ensuring that only stable (and tested) code makes it to production.
Using a tool like Jenkins can simplify the process of assuring high code quality and successful builds. It’s beneficial when working on a single project with a large development team, as traditional approaches might result in much conflicting code commits that may require a lot of troubleshooting.
**Appium**
Appium is an open-source test automation framework for mobile web apps. It allows you to create cross-browser tests for both desktop and mobile devices.
Appium is a tool for developing, uploading, executing, and examining test results directly in the cloud. Not only does Appium allow you to automate tests on both physical devices and simulators or emulators but it also allows you to do so without recompiling your app. Appium uses a JSON wire protocol to communicate with the application being tested.
**Eggplant**
Eggplant is a continuous testing tool that provides a one-of-a-kind approach to testing: an image-based solution. Rather than presenting raw test scripts, Eggplant interacts with the Application Under Test (AUT) that simulates users’ points of view.
Eggplant provides a test lab that gives you 24/7 access to continuous testing and deployment. It integrates with other CI/CD tools like Jenkins and Bamboo. This integration allows Eggplant users to perform comprehensive testing, including unit, functional, and performance tests.
**Challenges of continuous testing**
Despite the benefits of continuous testing, you might face challenges when you implement it at scale for the following reasons:
Lack of Test Support in Software: Continuous testing becomes more difficult to achieve when testability support is not built into legacy products. Implementing testability features in these products is expensive and hinders the success of continuous testing.
Absence of Standard Tools: Although there are no standard tools for continuous testing of many different products, teams usually use in-house automation tools or frameworks that lack proper documentation and maintenance. This adds to the problems of the testing team, which will now have to struggle with issues related to the tool/framework.
Insufficient Testing Infrastructure: Continuous testing requires an investment in additional test environments, which must be maintained, kept up to date, and running around the clock. Advanced tools can help teams implement faster feedback loops, but these costs aren’t high compared to the price incurred due to the poor quality of the product. There is a need for organizational commitment to continuous testing instead of a halfway journey without adequate infrastructure, only adding to the problems your testers face.
Scaling: All testing frameworks/tools do not scale equally. Slow test execution and lack of support for large test suites can become severe blockers to the dream of achieving continuous testing. These problems are not always apparent at first; they become visible only after many tests have been added to the system and the test system starts to get highly loaded.
**Conclusion**
In today's fast-paced world, software development needs to be agile and efficient. Continuous testing provides the answer. By integrating testing throughout the development lifecycle, it acts like a safety net, catching bugs early and preventing costly rework. Imagine a world where you can deliver high-quality software faster, with fewer headaches for developers and a smoother experience for users. That's the power of continuous testing. It's not just a process, it's a mindset shift that unlocks the true potential of your development team. So, are you ready to embrace continuous testing and revolutionize your software delivery?
**FAQ's**
**What is continuous testing?**
Continuous testing is a software testing approach where applications are tested at every stage of the development life cycle to ensure continuous delivery with high quality.
**Why does continuous testing matter?**
Continuous testing helps in catching bugs early, reducing rework, accelerating software delivery, improving code quality, and enhancing user experience.
**What are the methodologies of continuous testing?**
Continuous testing methodologies include unit tests, integration tests, regression tests, and end-to-end journey tests, among others.
**What are the benefits of continuous testing?**
Benefits of continuous testing include increased speed of delivery, early bug detection, cost efficiency, improved security, and more time for innovation.
**What are some challenges of continuous testing?**
Challenges of continuous testing may include lack of test support in software, absence of standard tools, insufficient testing infrastructure, and scalability issues. | keploy |
1,871,836 | Effective Communication in Daily Stand-Up Meetings for Software Developers | Effective Communication in Daily Stand-Up Meetings for Software Developers Daily stand-up... | 0 | 2024-05-31T09:10:21 | https://dev.to/trinly01/effective-communication-in-daily-stand-up-meetings-for-software-developers-2i8i | webdev, javascript, beginners, programming | ### Effective Communication in Daily Stand-Up Meetings for Software Developers
Daily stand-up meetings are a cornerstone of Agile methodology, offering a dedicated platform for team members to synchronize their activities, share progress, and identify any blockers. For software developers, these meetings are critical for ensuring smooth project execution. Mastering the language and flow of stand-up meetings can significantly enhance your communication skills and overall productivity. Here, we’ll explore common phrases and sentences that can help you sound more confident and articulate during these meetings.
#### Starting the Update
When initiating your update, it’s important to clearly and concisely communicate what you worked on previously. This sets the context for your current status and helps the team understand your progress.
- **"Yesterday, I worked on..."**
This phrase helps you kick off your update by highlighting your previous day's activities. For example, "Yesterday, I worked on debugging the login feature." By starting with what you accomplished the day before, you provide a clear picture of your recent efforts and set the stage for the current day’s tasks.
- **"In the last 24 hours, I focused on..."**
This variation offers a broader time frame, encompassing all activities since the last stand-up. For example, "In the last 24 hours, I focused on implementing the new payment gateway." This phrase can be particularly useful when your work spans across multiple areas or involves significant changes that require more context.
- **"I've been working on..."**
This phrase is useful for ongoing tasks, indicating continuity in your efforts. For example, "I've been working on optimizing the database queries." Using this phrase can help your team understand that you are in the middle of a larger task that spans several days, providing a sense of continuity and progress.
#### Current Tasks
Clearly outlining your current tasks helps the team understand what you’re focusing on today. This also sets expectations for what you aim to achieve.
- **"Today, I plan to..."**
This phrase clearly indicates your intentions for the day. For example, "Today, I plan to complete the unit tests for the shopping cart feature." By specifying your plan for the day, you give your team a clear understanding of your immediate goals and how they fit into the larger project timeline.
- **"My main focus today will be..."**
This variation highlights your primary objective, ensuring that the team knows your top priority. For example, "My main focus today will be on fixing the critical bugs reported by QA." This helps to emphasize the most important task on your agenda, signaling to your team what you believe requires the most attention and effort.
- **"I'm currently working on..."**
This phrase helps update the team on your immediate activities. For example, "I'm currently working on integrating the third-party API." It provides a snapshot of your current focus and how it contributes to the project’s progress.
#### Blocking Issues
Identifying and communicating blockers is essential for resolving issues quickly and keeping the project on track.
- **"I'm facing an issue with..."**
This phrase helps you introduce a specific problem you’re encountering. For example, "I'm facing an issue with the API authentication." By clearly stating your issue, you open the door for team members to offer solutions or assistance.
- **"I'm blocked by..."**
This direct approach clearly states what’s preventing you from making progress. For example, "I'm blocked by the lack of access to the staging server." Identifying blockers promptly allows the team to address them quickly, ensuring that progress can continue smoothly.
- **"One challenge I'm encountering is..."**
This phrase allows for a more detailed explanation of the problem. For example, "One challenge I'm encountering is the inconsistency in the data returned by the API." Providing specific details about your challenges can help the team understand the complexity of the issue and collaborate on finding a solution.
#### Progress and Achievements
Highlighting your achievements and progress helps maintain a positive tone and demonstrates your contributions to the project.
- **"I've completed..."**
This phrase succinctly conveys task completion. For example, "I've completed the user interface for the dashboard." Celebrating small victories and completed tasks boosts morale and keeps the team motivated.
- **"I finished the task related to..."**
This variation provides context for the completed task. For example, "I finished the task related to implementing the new search functionality." Offering context helps the team understand the significance of your completed work and how it fits into the overall project.
- **"I made progress on..."**
This phrase is useful for ongoing tasks, indicating forward movement. For example, "I made progress on optimizing the loading time for the homepage." Highlighting incremental progress keeps the team informed about the state of long-term tasks and maintains a sense of momentum.
#### Collaborations and Requests
Effective communication also involves seeking help and coordinating with team members when needed.
- **"I need help with..."**
This straightforward request for assistance is crucial for overcoming challenges quickly. For example, "I need help with debugging the new feature on the mobile app." Asking for help when needed ensures that issues are resolved efficiently and that you can continue making progress.
- **"Could someone assist me with..."**
This polite request for help encourages team collaboration. For example, "Could someone assist me with setting up the CI/CD pipeline?" Encouraging collaboration fosters a supportive team environment where members feel comfortable seeking and offering assistance.
- **"I'm waiting for feedback from..."**
This phrase helps you indicate dependencies on other team members. For example, "I'm waiting for feedback from the design team on the latest mockups." Communicating dependencies ensures that everyone is aware of what’s needed to move forward and can prioritize their work accordingly.
#### Next Steps
Outlining your next steps ensures that the team knows what you’ll be focusing on next, helping to maintain alignment and momentum.
- **"Next, I'll be..."**
This phrase clearly indicates your upcoming tasks. For example, "Next, I'll be working on the API integration for the notifications system." Providing clear next steps helps the team understand your planned activities and how they align with the project’s goals.
- **"My next steps are..."**
This variation helps you outline a series of upcoming tasks. For example, "My next steps are to finalize the database schema and start the data migration." Offering a roadmap of your next steps keeps the team informed about your planned progress and any upcoming milestones.
- **"I'll move on to..."**
This phrase indicates a transition from one task to another. For example, "I'll move on to writing the unit tests for the new module." Communicating your transitions helps the team understand the flow of your work and how each task contributes to the overall project.
### Best Practices for Stand-Up Meetings
While using the right phrases and sentences is crucial, adhering to some best practices can further enhance the effectiveness of your stand-up meetings.
#### Be Concise
Stand-up meetings are designed to be short and to the point. Aim to deliver your update in under two minutes, focusing on key information without unnecessary details. This helps keep the meeting efficient and respects everyone’s time.
#### Be Clear
Clarity is essential for effective communication. Use simple and direct language to convey your message. Avoid jargon or overly complex explanations that might confuse team members.
#### Stay Relevant
Ensure that your update is relevant to the team and the project. Share information that impacts the team’s work or the project’s progress. Avoid discussing unrelated topics that don’t contribute to the meeting’s purpose.
#### Be Honest
If you’re facing challenges or are behind schedule, be honest about it. Transparency helps the team address issues promptly and find solutions together. It’s better to acknowledge problems early on rather than let them escalate.
#### Encourage Engagement
Stand-up meetings should be interactive. Encourage team members to ask questions or offer assistance. Fostering an environment of open communication and collaboration strengthens the team dynamic.
Mastering the art of communication in daily stand-up meetings involves using specific phrases and sentences to clearly convey your status, plans, and any blockers. By practicing these techniques and adhering to best practices, you can enhance your communication skills, contribute more effectively to your team, and ensure the success of your projects. Effective stand-up meetings not only keep everyone informed but also foster a collaborative and supportive team environment, paving the way for successful project outcomes. | trinly01 |
1,871,835 | How to Enable Multicasting Support in Windows 11? | Enable Multicasting Support in Windows 11: Microsoft Message Queuing (MSMQ) is a messaging protocol... | 0 | 2024-05-31T09:07:39 | https://dev.to/winsidescom/how-to-enable-multicasting-support-in-windows-11-31f7 | webdev, networking, ipv4, productivity | <strong>Enable Multicasting Support in Windows 11</strong>: <a href="https://winsides.com/enable-microsoft-message-queue-msmq-server-windows-11/"><strong>Microsoft Message Queuing (MSMQ)</strong></a> is a messaging protocol that allows applications running on separate servers/processes to <strong>communicate failsafe</strong>. MSMQ ensures that messages are delivered even when the recipient application is not running. Multicasting in MSMQ allows a message to be sent to a <strong>multicast IP address</strong>. Any MSMQ queue that is subscribed to that multicast address will receive the message. This is particularly useful for scenarios where the same message needs to be delivered to multiple recipients simultaneously. This guide will walk you through the steps on How to <strong>Enable Multicasting Support in Windows 11</strong>.
<ul>
<li>Open the <strong>Run command box</strong> using the shortcut <kbd>Win Key + R</kbd>.</li>
<li>Enter <code>optionalfeatures</code> in the run command box.
<img class="wp-image-658 size-full" src="https://winsides.com/wp-content/uploads/2024/05/Optional-Features-1.jpg" alt="Optional Features" width="484" height="295" /> Optional Features</li>
<li><strong>Windows Features</strong> dialog box will open now.</li>
<li>Locate <strong>Microsoft Message Queue (MSMQ) Server</strong> and expand it.
<img class="wp-image-681 size-full" src="https://winsides.com/wp-content/uploads/2024/05/Expand-MSMQ-Server-Node.jpg" alt="Expand MSMQ Server Node" width="787" height="521" /> Expand MSMQ Server Node</li>
<li>Now, you can find the <strong>Microsoft Message Queue Server Core Node. Expand it.</strong>
<img class="wp-image-682 size-full" src="https://winsides.com/wp-content/uploads/2024/05/Expand-MSMQ-Server-Core-Node.jpg" alt="Expand MSMQ Server Core Node" width="775" height="518" /> Expand MSMQ Server Core Node</li>
<li>Locate <strong>Multicasting Support</strong> from the list of services available, click on the checkbox next to it to select it, and click <strong>OK</strong>.
<img class="wp-image-779 size-full" src="https://winsides.com/wp-content/uploads/2024/05/Enable-Multicasting-Support-in-Windows-11.jpg" alt="" width="815" height="542" /> Enable Multicasting Support in Windows 11</li>
<li>That is it, Windows 11 will now search for the required files.
<img class="wp-image-42 size-full" src="https://winsides.com/wp-content/uploads/2024/01/Searching-for-the-required-files.jpg" alt="Searching for the required files" width="1001" height="720" /> Searching for the required files</li>
<li>Then, the necessary changes will be applied.
<img class="wp-image-36 size-full" src="https://winsides.com/wp-content/uploads/2024/01/Applying-Changes.jpg" alt="Applying Changes" width="875" height="678" /> Applying Changes</li>
<li>Click <strong>Restart</strong> if you are prompted to restart or click <strong>Close</strong> accordingly. However, it is suggested that the changes be restarted right away so that they will be reflected.
<img class="wp-image-38 size-full" src="https://winsides.com/wp-content/uploads/2024/01/Close.jpg" alt="Close" width="849" height="684" /> Close</li>
<li><strong>Multicasting Support</strong> is now enabled on your Windows 11 PC.</li>
</ul>
<h2>Significant Features of Multicasting Support in MSMQ:</h2>
<img class="wp-image-781 size-full" src="https://winsides.com/wp-content/uploads/2024/05/Multicast-Support-MSMQ-Features-in-Windows-11.jpg" alt="Multicasting Support(MSMQ) in Windows 11" width="1920" height="1080" /> Multicasting Support(MSMQ) in Windows 11
<ul>
<li><strong>Efficient Message Distribution</strong>: MSMQ sends a single message to a multicast address instead of sending individual messages to each recipient. All queues listening to this address receive the message, <strong>reducing network traffic and improving efficiency</strong>.</li>
<li><strong>Scalability of the Feature</strong>: Multicasting is scalable because adding more recipients (queues) does not increase the sender's workload or network usage significantly. All recipients receive the message from the multicast stream.</li>
<li><strong>Dynamic Group Membership</strong>: Queues can join or leave multicast groups dynamically, allowing for flexible and <strong>dynamic message routing</strong>.</li>
<li><strong>Support for IP Multicast</strong>: MSMQ uses <strong>IP multicast addresses</strong> (from the range 224.0.0.0 to 239.255.255.255 for <strong>IPv4</strong>) to send messages to multiple recipients.</li>
</ul>
<h2>Use Case Scenarios for MSMQ Multicasting Support:</h2>
<ol>
<li><strong>Broadcasting Updates</strong>: Sending system updates, <strong>stock prices</strong>, or other real-time information to multiple clients.</li>
<li><strong>Event Notification Systems</strong>: <strong>Broadcasting event notifications</strong> to multiple services or applications.</li>
<li><strong>Distributed Applications</strong>: Sending messages to multiple instances of an application or service running on different machines.</li>
</ol>
Note: Multicast Support in MSMQ is particularly useful in scenarios requiring <strong>real-time data distribution</strong> to multiple consumers.
<h2>Take away:</h2>
By following these steps, you can <strong>enable and configure multicasting support in the <a href="https://winsides.com/enable-microsoft-message-queue-server-core-windows/">MSMQ Server core</a></strong> on Windows 11, allowing efficient message distribution to multiple recipients using multicast addresses. If you find this article helpful, share your feedback and give us a rating, for more intriguing articles, stay tuned to <strong>Winsides.com!</strong> | winsidescom |
1,871,823 | A data analysis engine reducing application cost by N times | At present, there are many posts related to esProc SPL on the Internet, such as solution... | 0 | 2024-05-31T08:46:19 | https://dev.to/esproc_spl/a-data-analysis-engine-reducing-application-cost-by-n-times-3ph6 | programming, beginners, devops, opensource | At present, there are many posts related to esProc SPL on the Internet, such as solution introduction, test report, case sharing, but most of them only involves a certain aspect, and hence it is still difficult for readers and users to understand esProc SPL in an all-round way. This article provides a comprehensive introduction of esProc SPL, allowing you to recognize and understand it on the whole.
esProc SPL is a data analysis engine with four main characteristics: low code, high performance, lightweight and versatility. To be specific, SPL allows you to write simply, and makes the running speed faster; SPL can be used either independently or embedded in applications; SPL is suitable for a variety of application scenarios. Analyzing the data through esProc SPL can reduce the overall application cost by several times compared with SQL-represented traditional technologies. Details will be given below.
What is esProc SPL?
First let's explain what esProc SPL is.
As a computing and processing engine for structured and semi-structured data, esProc SPL can be used as an analysis database or a data computing middleware, and is mainly applied to two data analysis scenarios:offline batch job and online query. It is worth mentioning that, unlike common analysis database on the market, esProc SPL is neither SQL system nor NoSQL technology (such as MongoDB, HBase), and instead, it adopts self-created SPL (Structured Process Language) syntax, which is simpler in coding and higher in running efficiency compared with existing data processing technologies.
What pain points does esProc SPL solve?
SPL mainly solves data problems, including hard to write, slow to run and difficult to operate and maintain. Here below are some examples.
Currently, many industries need to do batch job, and this job is generally done at night when normal business ends. Therefore, there will be a fixed time window, and this job must be completed in the window, otherwise it will affect the normal business. However, the pressure of batch job will increase as the business accumulates. Since the time window is fixed, sometimes the batch job cannot be completed within the time window with the increase of business and data volume, especially on critical dates such as at the end of a month/year.
When querying a report, there will always be several important reports that are slow to query, taking three or two minutes or even longer, even after several rounds of optimization, the query effect is not improved significantly, causing users to get angry. Sometimes when the number of users querying the report increases, and the time span they select is longer, it is even more difficult to find out the result.
In practice, we often see very long, extremely complex SQL code. Not only is such code nested with N layers, but it needs hundreds of lines to write a statement. For such code, it is hard to write, and impossible to modify, and even the programmer himself is confused after a few days. As for the stored procedure, the situation is worse, sometimes a stored procedure reaches tens or hundreds of KBs in size, making it very hard to write and maintain.
Although some complex calculations can be written with stored procedure, and it is simpler than JAVA, the stored procedure cannot migrate the application, and over-reliance on it will cause problems to application framework such as failure to extend the application and high coupling.
Many kinds of data sources are present nowadays, for the databases alone, there are many kinds. Besides, there are many other data sources like NoSQL, text, Excel, JSON. If you want to use them in a mixed way, it will be more difficult. Specifically, it is not worth importing them all into the database because this method not only causes poor data real-time, but occupies the space of database, putting more pressure on the database; on the contrary, if you don't load them into database, you have to do hard coding, which is very difficult. As a result, you will be in a dilemma.
Generally, esProc SPL has the ability to solve the problems including slow batch job, slow query, high database pressure, difficult to code and maintain in SQL, mixed calculation of multiple data sources, unreasonable application framework.
We list more problems here below:
Slow batch jobs can not fit in certain time window, being strained especially on critical summary dates
Being forced to wait for minutes for a query/report, the business personnel become angry
More concurrencies, longer the query time span, the database crashes
N-layer nested SQL or stored procedures of dozens of KBs, programmer himself is confused after a few days
Dozens of data sources like RDB/NoSQL/File/json/Web/…, cross-source mixed computation is highly needed
Separate the hot data and cold data into different databases, it is hard to perform real-time queries on the whole data
Too much relied on the stored procedures, the application cannot migrate, framework is hard to adjust
Too many intermediate tables in the database, exhausting the storage and resources, but dare not to delete them
Endless report demands in an enterprise, and how can the cost of personnel be relieved?
...
Of course, for esProc SPL-targeted scenarios, corresponding technologies are also available. So, what are the counterpart technologies of esProc SPL?
The most important one is the database and data warehouse that use SQL syntax and are applied to OLAP scenarios. For example, the common relational databases including MySQL, PostgreSQL, Oracle, DB2, etc.; the data warehouses on Hadoop like Hive, Spark SQL; new MPP and cloud data warehouse such as Snowflake; some commercial all-in-one database machine like Oracle’s ExaData.
From a development language perspective, SPL can replace some data analysis and statistical technologies such as Python, Scala, Java and Kotlin.
Compared with the above-mentioned technologies, esProc SPL has the advantages of low code, high performance, lightweight and versatility. Specifically, SPL is more concise and simpler than Python and SQL in implementing calculation, especially complex calculation, in other words, SPL code is shorter; esProc SPL provides a large number of high-performance algorithms and high-performance storage, making it possible to run faster; esProc SPL can be used either independently or integrated into applications, and has the ability to compute directly on multiple data sources, and hence it is more lightweight and open; In addition to conventional computing ability, SPL also provides many functions including matrix, fitting and even AI modeling, and most data tasks can be easily implemented in SPL system, and thus SPL is more versatile.
The main counterpart technology of SPL is still SQL, after all, SQL is a most widely used technology in the field of data analysis. So, what does esProc SPL bring beyond SQL?
Looking at SQL from the perspective of modern complex business and big data, you will find that the computing and description abilities SQL are insufficient. Due to the lack of necessary data types and calculation features (such as ordered calculation), SQL often has to implement complex calculation in in a multi-layer nesting and circuitous way, this way causes two problems.
The first is the development cost. We often see a SQL code with over a thousand lines in practice. Once the calculation logic becomes slightly complex, it has to write a long and multiply-layer nested code, which is not only difficult to write and debug, but the programmer himself cannot understand what the code he wrote means after a period of time, this will inevitably lead to an increase in development cost. In contrast, SPL provides rich data types and calculation features, greatly enhancing its computing and description abilities. In addition to a more agile syntax system, SPL also advocates step-wise coding, allowing you to implement complex calculation logic according to natural thinking of “multi-step”, and hence it is easy to code and debug and significantly reduces development cost.
The second is the performance caused by complex SQL coding. Although more efficient way is available, it cannot be implemented in SQL, and instead it has to use slow algorithms. If you want to achieve a desired performance index, you need to add more hardware, resulting in an increase in hardware cost. SPL encapsulates a lot of high-performance algorithms (and storage) and needs less hardware to achieve the same performance, so the hardware cost is effectively reduced. Below you will find many cases where SPL reaches or surpasses SQL performance with less hardware.
Since the computing system of SQL (database) is closed, and data can only be calculated after being loaded into database, and usually, database can only be deployed independently, it leads to a bloated and heavy framework; In addition, the computing ability of SQL is actually imperfect, and SQL is not suitable for handling some complex scenarios independently, and it has to adopt other technologies like Python, Java to make up for its shortcomings. However, these completely different technologies will increase the complexity of technology stack. Heavy and bloated framework and complex technology stack dramatically increases the O&M cost. By contrast, SPL is more open in computing ability, and able to calculate directly on various data sources, and supports independent or integrated use, and its framework is lighter. Moreover, SPL offers comprehensive functions, making it easy to implement complex computing, and making it possible to accomplish most tasks without other technologies, and its technology stack is simpler. Lightweight framework and simply technology stack make O&M cost lower.
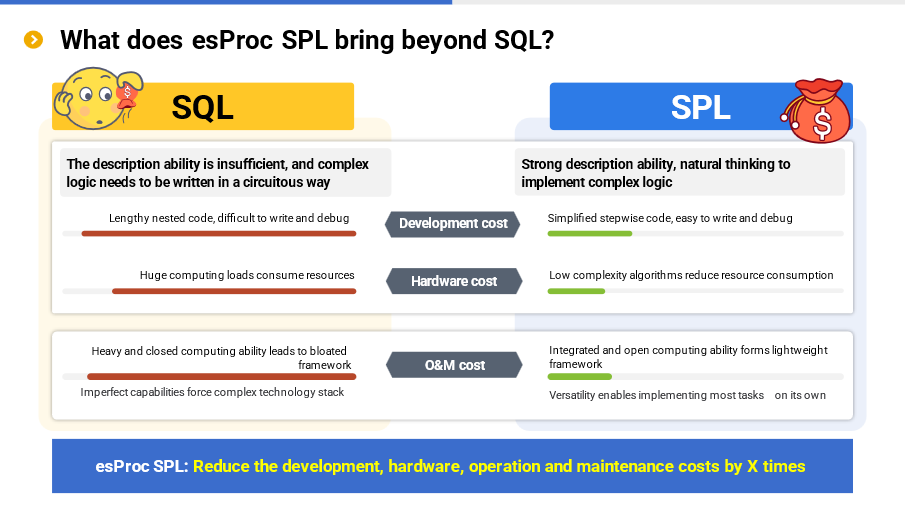
SPL also has significant advantages over Java. Java is a full-featured programming language, and can handle any data computing task in theory. However, due to its too native nature and lack of necessary computation libraries, all computing tasks need to be developed from scratch, resulting in a difficulty to implement.
Especially for high-performance algorithms, it is more difficult to implement in Java. Even if programmers take a great effort to work it out, the performance is pretty poor. Therefore, not only is the development cost high, but the performance is too low. As a result, the hardware cost is increased.
In addition, Java has some shortcomings in practice. For example, it is difficult to achieve hot swap as a compiled language; tight coupling occurs since different applications/modules need be deployed together with main application. These shortcomings have a significant adverse impact on data analysis scenarios that frequently undergo changes. To avoid these shortcomings, programmers often use SQL together with Java in practice, for the reason that SQL is simpler and more convenient for many calculations. However, in doing so, not only does the SQL problem still exist, but it also brings new Java problem, resulting in complex technology stack, a difficulty to use, and high O&M costs.
In contrast, SPL does not have these problems, because it provides rich computing libraries, making it easy to implement calculation tasks, and offers many low-complexity algorithms to guarantee performance. In addition, as an interpreted language, SPL naturally supports hot swap, and coupling problem will never occur. Compared with SQL, SPL has a greater advantage over Java.

As for Python, some problems exist in processing structured data. Python (Pandas) itself provides rich computing libraries, and it is easy to code in Python for many simple calculations, making Python basically equivalent to SQL. However, for some slightly complicated calculations, it is difficult to code in Python, and the development cost is still high.
In addition, Python is weak in processing big data. Since Python does not provide a cursor type for external storage, it would be cumbersome and inefficient to process the data exceeding memory capacity, resulting in increased hardware cost.
Moreover, Python has the problem of version chaos. Incompatibility between different versions will lead to high usage and O&M costs and, Python is very poor in integration, making it difficult to be combined in applications, and hence it often needs to deploy separate service, yet this will increase O&M costs. Like Java, Python is also frequently used together with SQL in practice, and likewise, the existing SQL problem still exists while new problem arises.
The advantages of SPL in terms of development and performance have been described a lot above. In addition, SPL has many other advantages: no version issue; good integration makes it possible to integrate in applications seamlessly; fully-featured; simpler technology stack; no need to resort to other technologies; lower O&M costs.

Overall, SPL can achieve a cost reduction of several times in development, hardware, and O&M compared to SQL, Java, and Python.
Case Brief
Here below are the actual application effect of esProc SPL.
Let’s begin with two batch job cases.
Batch job of car policies of an insurance company
This is a batch job scenario for car policies of an insurance company, which needs to associate historical policies with new policies in order to remind users to renew insurance. The data amount is large, including 35 million rows of data in the policy table, and 123 million rows of data in the details table; since there are various ways of association, and they need to be handled separately, the calculation is very complex. The insurance company originally used the stored procedure of informix to calculate, and took 112 minutes to associate new policies of 30 days. If the time span was longer, it would be difficult to calculate, so there is performance problem.
When using esProc SPL to do the same task, it only takes 17 minutes, that's a 6.5-fold increase, and the code volume is reduced from 1800 lines to 500 lines. That's what we said earlier, SPL allows you to write simply, and makes the running speed faster.
Case details: Open-source SPL optimizes batch operating of insurance company from 2 hours to 17 minutes
Batch job of loan agreements of a bank
This is also a batch job scenario. The bank does this job on a small machine with AIX and DB2 (bank’s standard configuration), and takes 1.5 hours to run the stored procedure of “corporate loan agreement details”. This calculation involves 48 SQL steps, very complex multi-table association and 3300 lines of code. Since this batch job is a part of the whole bank's batch job, if this batch job is slow, it will drag down the overall batch job process, which needs to be optimized urgently.
When using esProc SPL to do the same task, it only takes 10 minutes, speeding up by 8.5 times, and reducing the code volume from 3300 lines to 500 lines. The main reason for speedup is the utilization of SPL’s features like ordered computation and multi-purpose traversal.
Case details: Open-source SPL speeds up batch operating of bank loan agreements by 10+ times
Then let's look at two on-line query cases.
Mobile banking: multi concurrent account query
A bank provides the public with a service to query current account details through mobile banking, and this service involves large concurrent accesses and requires high real-time. Since Hadoop cannot meet concurrent access requirement, the bank builds an ES cluster consisting of 6 nodes as query backend. Although the backend meets the requirement, it cannot associate in real time, and needs several hours to update the data once the branch code changes. During the updating period, the service has to be suspended, affecting user’s normal query.
After adopting esProc SPL, the detail data is stored orderly by account number. By means of SPL’s external storage index and ordering technology, the information under an account number can be quickly accessed, and associated with the branch code in memory. In this way, not only the real-time query and real-time association are implemented, but it can handle high concurrency. Finally, esProc SPL achieves the effect of 6 ES nodes on 1 node, and implements real-time association with zero waiting time for branch information update.
Case details: Open-source SPL turns pre-association of query on bank mobile account into real-time association
Calculation of the number of unique loan clients of a bank
A bank's loan business involves many indexes such as loan balance, guarantee type, customer type, lending way. Hundreds of indexes may be arbitrarily combined to query, and hence the calculation scale is huge, and the calculation difficulty is further increased as the concurrent querying number increases. In this calculation scenario, association, filtering and aggregation calculation of a 20 million rows large table and even larger detailed table are needed, and each page involves the calculation of nearly 200 indexes, and 10-concurrency will cause the concurrent calculation of more than 2000 indexes. For such a large calculation scale, it has to calculate one day earlier using Oracle, but pre-calculation cannot meet user’s real-time query requirements.
After the bank employs SPL, the calculation of indexes is implemented in real time by means of ordered merge, boolean dimension sequence and multi-thread parallel computing, etc., the performance requirement is satisfied, and the calculation time for 10 concurrency and 2000 indexes in total is less than 3 seconds. There is no need to prepare the data in advance, and you can instantly select any label combination, and get query results in real time.
Case details: Open-source SPL optimizes bank pre-calculated fixed query to real-time flexible query
There is a big difference between off-line batch job and on-line query. The former often involves a large amount of data, and the calculation logic is very complex, but it does not involve concurrency query, nor does it require calculating in real time, and it only needs to accomplish the calculation in a specified time; the latter is just the opposite, it involves large concurrency number, requires high real-time, it is usually difficult to achieve processing. esProc SPL is well suited for both scenarios.
In fact, besides the development efficiency and performance, esProc SPL also works well in terms of application framework. Here below are two relevant cases.
Front-end database in BI System of a bank
This bank has a central data warehouse. Since this warehouse undertakes all data task of whole bank, it is overburdened and has to assign 5 concurrencies to BI system, but it still cannot meet the needs.
To solve this problem, it needs to build a front-end database (banks call it front-end machine) specially for BI system. However, it faces a problem when building the database, that is, if only the high-frequency data is imported from the data warehouse to the database, other data cannot be queried, resulting in a failure to respond the business needs; if all data is imported to the database, it is unrealistic (too costly) for it is equivalent to rebuilding a data warehouse.
When esProc SPL is used to build the front-end machine, it only needs to import the high frequency data into front-end machine, avoiding repeated construction. esProc performs the most high-frequency data computing tasks, and a few low frequency data computing tasks are automatically routed to the central data warehouse, this solves the two problems mentioned earlier. The automatic routing feature of SPL plays a key role here.
An insurance company - Outside-database stored procedure
This case is to use esProc SPL as a Vertica stored procedure. The customer, a Canadian insurance company, faces two main problems with the databases like Vertica, MySQL, Access. One is that since Vertica doesn’t support stored procedure, when the calculation is complex, it has to implement through Java hardcoding, which is very difficult; the other is that when it involves mixed computing of multiple data sources, it needs to load the data like MySQL into Vertica first, which is tedious, not real-time, and the database is bloated after loading, after all, some data does not need to be persisted.
These two problems are solved with esProc SPL. Firstly, acting as a stored procedure outside the Vertica, esProc takes over all calculations that originally require hard coding, it is not only simple to implement but more efficient. Secondly, with the cross-source computing ability of esProc SPL, mixed computing can be performed directly on multiple data sources, eliminating the need to load all data into one database, making data real-time and efficiency higher, while keeping Vertica lighter.
Through these cases, we have a basic understand on the applicable scenarios and effects of esProc SPL. Of course, there are more cases, which will not be given here.
Why esProc SPL works better
From the above cases, we can see that SPL has clear advantages over SQL in terms of code efficiency and computing performance. Why? Is there anything special about SPL?
However, the question should be asked the other way around, that is, why SQL does not work well?
Let's start with an example to explain why it's difficult to write in SQL: calculate the maximum consecutive days that a stock keeps rising.
```
SELECT MAX(ContinuousDays)
FROM (SELECT COUNT(*) ContinuousDays
FROM (SELECT SUM(UpDownTag) OVER ( ORDER BY TradeDate) NoRisingDays
FROM (SELECT TradeDate,
CASE WHEN Price>LAG(price) OVER ( ORDER BY TradeDate)
THEN 0 ELSE 1 END UpDownTag
FROM Stock ) )
GROUP BY NoRisingDays )
```
SQL adopts a four-layer nested code, which is more complicated overall. This problem was once used as a recruitment test of our company, the pass rate was less than 20%. Since this test question was too difficult, we modified it: give the statement and ask the candidate to find its objective. Unfortunately, the pass rate was still not high. What does it tell us? It tells us that once the calculation logic becomes slightly complex, SQL will become difficult in both understanding and writing!
In fact, this problem can be easily solved by following natural thinking, you can do it in a few very simple steps: i) sort the records by trading day; ii) get the intervals of continuous rise and fall; iii) count the number of days of the maximum interval of continuous rise. However, since SQL doesn’t support ordered operation sufficiently and doesn’t provide ordered grouping directly, it has to turn to a multi-layer nesting and roundabout way, resulting in a difficulty in understanding and writing SQL code. This calculation problem is not a rare problem, there are many more complex calculations in reality, and those SQL codes with over a thousand lines are exactly to solve such problems.
Now let’s take another example to explain why SQL can’t run fast: get the top 10 from 100 million rows of data.
```
SELECT TOP 10 * FROM Orders ORDER BY Amount DESC
```
As we can see that although this code is not complex, it has the keyword ORDER BY, which means doing a big sorting on all data first, and then taking the TOP 10. The big sorting is very slow, involving multiple times of swaps between memory and external storage. If this statement is executed according to its superficial meaning, the efficiency will be very low. Actually, there is a faster method without full sorting, and the only thing you need to do is to keep a set containing 10 largest numbers, and you can get the result by traversing the data only once. But SQL cannot describe such algorithm. In this case, you can only rely on the optimizer of the database. For simple calculations, most databases have the ability to optimize in practice, and won’t really do full sort, so it can be calculated quickly. But, if the calculation becomes complex, the optimization engine will get confused and has to execute a slow algorithm. For example, the following code is to get the in-group Top 10:
```
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY Area ORDER BY Amount DESC) rn
FROM Orders )
WHERE rn<=10
```
There is a big difference between this SQL code and the previous one. This code needs to use the sub-query and window functions to implement the calculation in a roundabout way. For such complex calculation, the optimization engine of the database cannot optimize and has to perform sorting, and as a result, it is very slow. In an actual test, we found that calculating TopN of a grouped subset in Oracle is 21 times slower than calculating TopN of a whole set. In our opinion, when calculating in-group TopN, the performance should have only dropped a little because only one condition (grouping) is added, but the result was far from what we expected. Therefore, we think that Oracle probably did sorting when calculating in-group TopN, resulting in a sharp drop in performance (whatever, we don't have the source code to confirm) and making the optimizer fail.
Then, how SPL solve these?
For the first example:
```
Stock.sort(TradeDate).group@i(Price<Price[-1]).max(~.len())
```
SPL provides ordered grouping. Although the implementation idea is the same as that of the previous SQL code, it is very concise to express.
For the second example:
SPL regards TopN as the aggregation operation of returning a set, avoiding full sorting; The syntax is similar in case of whole set or grouped subset, and there is no need to take the roundabout approach. In most cases, writing simple and running fast are the same thing actually. If the code is written simply, it will run fast, and conversely if the code is written too complex it will not run fast.
Let's make another analogy, calculate 1+2+3+…+100. Ordinary people will adopt the most common method, that is, 1+2=3, 3+3=6, 6+4=10…; while Gauss found that 1+100=101, 2+99=101…,50+51=101, and that there are fifty same sums (101) in total, so he multiplied 50 by 101 and quickly got the result. I'm sure this story is not new to anyone since we read it in elementary school. We all think that Gauss is so clever that he thought of such an ingenious solution, however, it is easy for us to overlook one point: in the days of Gauss, multiplication was already available. We know that multiplication was invented later than addition, and if multiplication had not been invented in those days, he wouldn’t have found this way to solve this problem so quickly no matter how clever Gauss is. Now let's get back to our topic, SQL is like an arithmetic system with addition only, if you want to solve the continuous adding problem, you have to add them one by one, resulting in long code and inefficient calculation. In contrast, SPL is equivalent to the invention of multiplication, it simplifies the writing and improves the performance.
The difficulties of SQL stem from relational algebra, such theoretical defects cannot be solved by engineering methods; SPL is based on a completely different theoretical system: “discrete dataset model”, and provides more abundant data types and basic operations, and hence it has more powerful expression ability.
Does it mean that only the programmers as clever as Gauss can use SPL?
Not really, SPL is prepared for ordinary programmers, and in most cases, they can write correct code just by following natural thinking. On the contrary, if SQL is used, they often have to implement in a roundabout way when the calculation becomes slightly complex, and cannot figure it out if he is not an experienced programmer. In this sense, SPL is simpler than SQL. However, if you want to master SPL, you do need to learn more. Don’t worry, for SPL-related knowledge, you have already learned some of them (such as algorithms and data structures you learned in college), as for the rest you don't know, clever programmers have already summarized the knowledge points (not many), and all you need to do is just to learn the summarized points. Once you master these points, you will be able to handle complex problems with ease.
In practice, there are many scenarios that SQL can't handle. Let's give a few examples:
In the funnel analysis for the user behavior transformation of e-commerce sector, it needs to calculate the user churn rate after each event (like page browsing, searching, adding to cart, placing an order and paying). The analysis is effective only when these events are completed within a specified time window and occur in a specified order. Describing such complex order-related calculations in SQL is cumbersome, and even if the code is written, it is not efficient, not to mention optimize.
For the above-mentioned complex multi-step batch job case on big data, some complex procedures need to be done with the help of cursors, however, cursor reading is slow and cannot calculate in parallel, wasting computing resources. During the multi-step procedural calculation, it needs to repeatedly buffer the intermediate results, resulting in a very low efficiency and a failure to complete the batch job within the specified time window.
In multi-index calculation on big data, it needs to perform the calculation of hundreds of indexes at one time and use the detailed data many times, during which association is also involved, SQL needs to traverse data repeatedly; it involves mixed calculation of large table association, conditional filtering, grouping and aggregation, and deduplication, as well as real-time calculation with high concurrency. All these calculations are hard to implement in SQL.
…
Due to the limitation of space, we only present the SQL code for e-commerce funnel calculation below to feel its complexity.
```
with e1 as (
select uid,1 as step1,min(etime) as t1
from event
where etime>= to_date('2021-01-10') and etime<to_date('2021-01-25')
and eventtype='eventtype1' and …
group by 1),
e2 as (
select uid,1 as step2,min(e1.t1) as t1,min(e2.etime) as t2
from event as e2
inner join e1 on e2.uid = e1.uid
where e2.etime>= to_date('2021-01-10') and e2.etime<to_date('2021-01-25')
and e2.etime > t1 and e2.etime < t1 + 7
and eventtype='eventtype2' and …
group by 1),
e3 as (
select uid,1 as step3,min(e2.t1) as t1,min(e3.etime) as t3
from event as e3
inner join e2 on e3.uid = e2.uid
where e3.etime>= to_date('2021-01-10') and e3.etime<to_date('2021-01-25')
and e3.etime > t2 and e3.etime < t1 + 7
and eventtype='eventtype3' and …
group by 1)
select
sum(step1) as step1,
sum(step2) as step2,
sum(step3) as step3
from
e1
left join e2 on e1.uid = e2.uid
left join e3 on e2.uid = e3.uid
```
This is a three-step funnel calculation. SQL lacks order-related calculations and is not completely set-oriented. It needs to detour into multiple subqueries and repeatedly JOIN. Therefore, it is difficult to write and understand, low in performance, and harder to optimize. Only a three-step funnel is presented here, and more subqueries need to be added in case of more steps, and hence the difficulty is evident.
In contrast, SPL code is much simpler:
SPL provides order-related calculations and is more thoroughly set-oriented. Code is written directly according to natural thinking, which is simple and efficient. In addition, this code can handle funnels with any number of steps, the only thing we need to do is to modify the parameter.
This is a simplified real case (the original SQL code has almost 200 lines). The user did not get result after 3 minutes running on Snowflake's Medium server (equivalent to 4*8=32 cores), while the user run the SPL code on a 12-core, 1.7G low-end server and got the result in less than 20 seconds.
As we mentioned above, SPL is equivalent to the invention of multiplication based on the addition, in fact, SPL invents many “multiplications”. Here below are part of SPL’s high-performance algorithms, among which, many algorithms are the original inventions of SPL.

For example, the multipurpose traversal algorithm can achieve the effect of multiple operations during one traversal; foreign key as pointer can map the foreign key field as the address of the record to which the foreign key points, making it more efficient when using this record again; double increment segmentation can adapt to the rapidly expanding data scale, making it very efficient to store and access the data.
For more information: visit: Performance Optimization - Preface
Then, why doesn't Java work well either?
As mentioned earlier, because Java is too native and lacks necessary data types and computing libraries, any computing task has to be done from scratch, which is very cumbersome. For example, it requires more than ten lines of code to implement a grouping and aggregating task in Java. Although Java 8’s Stream simplifies this type of operation to some extent, it is still very difficult to implement for slightly more complex calculations (there is a big gap even compared to SQL).
It is more difficult to code in Java for calculations with high performance requirements, such as the TopN operation that does not utilize big sorting algorithm, more efficient HASH join algorithm, and ordered merging algorithm. These algorithms themselves are difficult to implement, and Java lacks computing libraries, and hence many application programmers do not know how to solve them and often have to resort to relatively simple but slow algorithms. As a result, the computing speed is even slower than that of SQL, let alone solve these problems.
The performance of processing big data is largely related to data IO. If the IO cost is too high, it doesn’t work no matter how fast the operation speed is. Efficient IO often relies on specially optimized storage scheme. Unfortunately, however, Java lacks a widely used efficient storage scheme, and instead it uses text file or database to store data in general. The performance of database interface is very poor. Although text file is a little bit better, it will consume too much time in parsing the data type, resulting in lower performance.
If Java's shortcomings in practice are considered, such as difficult to hot swap and tight coupling, Java falls short compared to SQL, let alone surpass SQL to solve the previous problems.
Why does Python still fail to work well?
By analyzing Java, we basically know that many of Python’ shortcomings are similar. For example, it is difficult to implement relatively complex calculations, such as adjacent reference, ordered grouping, positioning calculation, non-equivalence grouping.
For big data computing without corresponding external storage computing mechanism, it will be very difficult to implement in Python. Moreover, Python does not support true parallel processing. The parallel processing of Python itself is fake, which is actually the serial processing for CPU, or even slower than serial processing, and thus it is difficult to leverage the advantages of modern multi-core CPU. There is a Global Interpreter Lock in the CPython interpreter (the mainstream interpreter of Python). This lock needs to be got ahead of executing Python code, which means that even if multiple threads of CPU work in the same time period, it is only possible to execute the code with one thread and multiple threads can only execute the code in an alternately way. Yet, since multiple-thread execution involves complex transactions such as context switching and lock mechanism processing, the performance is not improved but decreased.
Due to the inability of Python to make use of simple multi-thread parallel processing mechanism in one process, many programmers have to adopt the complicated multi-process parallel processing method. The cost and management of process itself are much more complex, and the effect of parallel processing cannot be comparable to that of multiple threads. In addition, the inter-process communication is also very complex, programmers have to give up direct communication sometimes, and use file system to transfer the aggregation result instead, which leads to a significant performance decrease.
Like Java, Python does not provide efficient storage scheme for high-performance computing, so it has to resort to open-format files or databases, resulting in low performance. In many cases, Python is used together with SQL, but it cannot eliminate the problems of SQL. If Python's problems such as version and integration are considered, we can conclude that Python does not work indeed.
Technical characteristics
We explained the reason why it is simple to code and fast to run in esProc SPL above, that is, the low code and high performance of SPL.
Now let's take a closer look at the technical characteristics of esProc SPL.

Currently, esProc is a software developed purely in Java, and can run on any operating system under JVM environment of JDK1.8 or higher version, including common VMs and Containers.
After normal installation, esProc takes up less than 1G of space, most of which is occupied by the referenced third-party external data source driver packages. The core package of esProc is less than 15M, making it possible to run even on Android.
Except for JVM, esProc has no other hard requirements on operating environment. The requirements for the capacities of hard disk and memory are related to the computing task and could vary greatly from different tasks. When performing the same commuting task, esProc usually requires less hardware resources than traditional databases (especially for distributed database). Increasing memory’s capacity, choosing a CPU with a higher frequency and number of cores, and utilizing an SSD usually have a positive impact on improving computing performance.
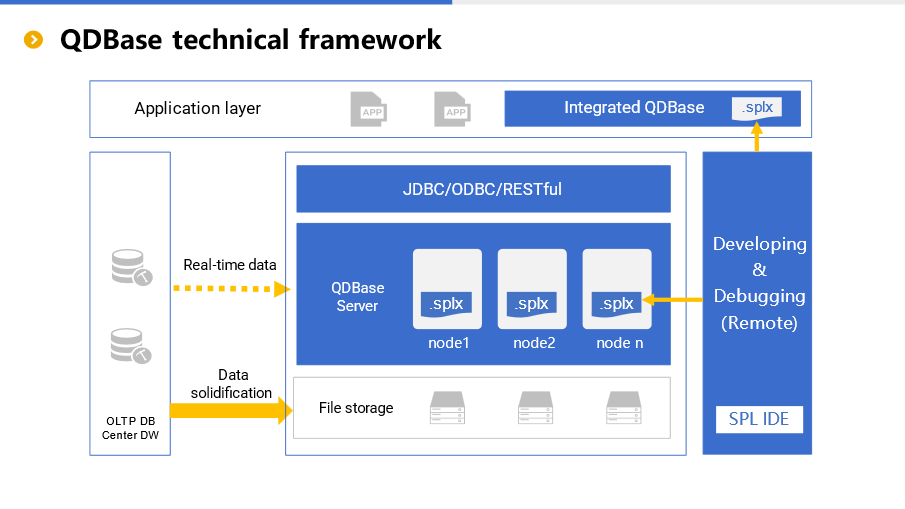
On the leftmost of the framework are the business database and traditional data warehouse (if any). In fact, there may be various types of data sources, and these data can be converted to esProc's high-performance file storage through “data solidification”, making it possible to achieve higher performance.
Of course, data converting is not a must. For some scenarios that require higher data real-timeness, esProc can read the data and calculate in real time through the interfaces (like JDBC) that data source provides. However, due to the inability of esProc to intervene in the performance of data interface, the computing performance may be different for different data sources, and poor performance may also occur. If users have requirements on both real-timeness and computing performance, then the method of solidifying the cold data and reading the hot data in real-time can be adopted. To be specific, converting the unchanged historical cold data to esProc’s high-performance storage, and reading the hot data of data source and, processing all the data with the help of the mixed computing ability of esProc can meet both requirements at the same time.
The high-performance file storage of esProc will be introduced in detail below.
In the middle part of the framework is esProc Server, which is responsible for actual data processing. esProc Server allows us to deploy multiple nodes in a distributed manner for cluster computing, and supports load balancing and fault tolerance mechanisms. The cluster size of esProc is relatively small (no more than 32 nodes), and more resources are used for computing (rather than management and scheduling). In many cases that have been implemented, esProc can handle the cluster computing scenarios of traditional technologies (MPP/HADOOP) through a single node, and the performance is higher, so there is no need to worry about the problem of insufficient computing ability.
esProc’s SPL script will be distributed on each cluster node, and the script can be developed and debugged remotely on esProc's IDE, and the data will not be saved or downloaded to local node during debugging, and hence it is more secure.
esProc encapsulates standard interfaces like JDBC/RESTful for application to call. For Java applications, esProc can be directly integrated, and used as in-application computing engine. For non-Java applications, esProc can be called through other interfaces.
From the perspective of the entire framework, in addition to providing simple and efficient data processing ability, esProc is more flexible in use, as it can be used independently or integratedly. Moreover, relatively lightweight computing way makes esProc light to use, not as heavy as traditional distributed technology.
In terms of development and debugging, esProc SPL provides simple and easy-to-use development environment.
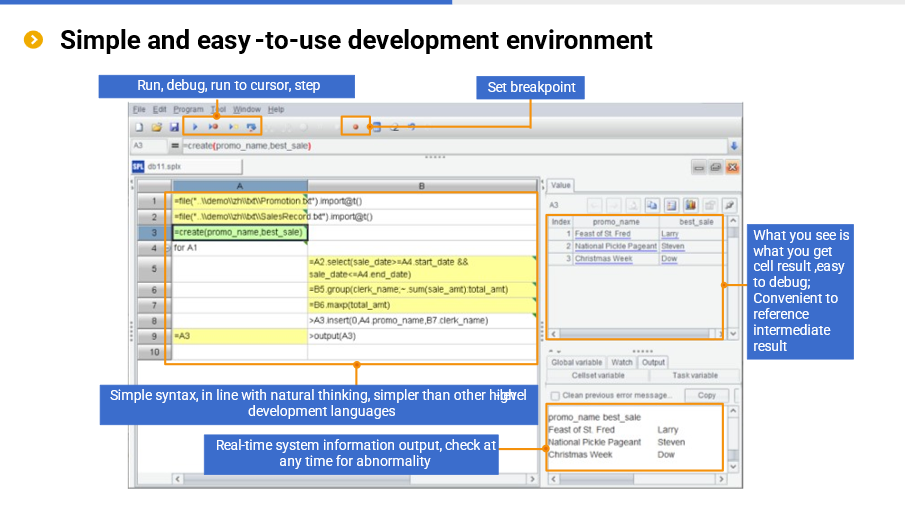
In IDE, we can code step by step, and view the running result of each step in real time in the result panel on the right, and there are various editing and debugging functions such as debug, step in and set breakpoint. Easy-to-use editing and debugging functions are also indispensable for low code, which are very different from SQL (and stored procedures), and can significantly reduce development cost. With these features, esProc SPL is also frequently used for desktop analysis and is very convenient.
SPL is a specially designed syntax system, and naturally supports stepwise calculation, and is especially suitable for complex process operations. In addition, SPL boasts more complete programming abilities than SQL such as loops, branches, procedures and subprograms. In each step of operation, SPL can reference the result of the previous step with the cell name without defining a variable (of course, variable is also supported).
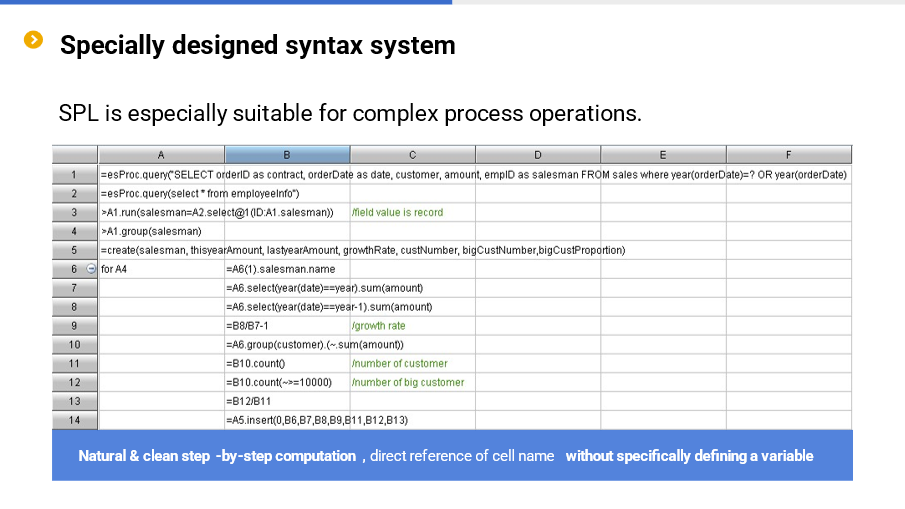
Moreover, SPL provides a very rich structured data computing library, enabling it to process the string, date and time, and perform mathematical calculation, and read/write the files and databases, and support JSON/XML multi-layer data, and do the grouping / loop / sorting / filtering / associating / set /ordered calculations. The loop function provided especially for sequence (table sequence) can greatly simplify the set operation. SPL also provides the cursor for big data calculation, the channel for reducing the repeated traversal of hard disk, and the parallel computing and distributed computing mechanisms. Furthermore, SPL provides the modeling and prediction functions for AI, as well as external library functions for dozens of data sources such as MongoDB, Elasticsearch, HBase, HDFS and Influxdb.
At present, SPL provides more than 400 functions, and each function contains several options. It is equivalent to thousands of library functions. These functions, together with perfect programming language functions like procedure, loop and branch allow SPL to perform a full range of data processing tasks, which is a typical manifestation of its versatility characteristic.
esProc SPL also boasts a very high integration. Developed in Java, SPL can run independently or be seamlessly integrated into applications to serve as an in-application computing engine, and can play an important role in scenarios such as micro-service, edge computing, and report data preparation.
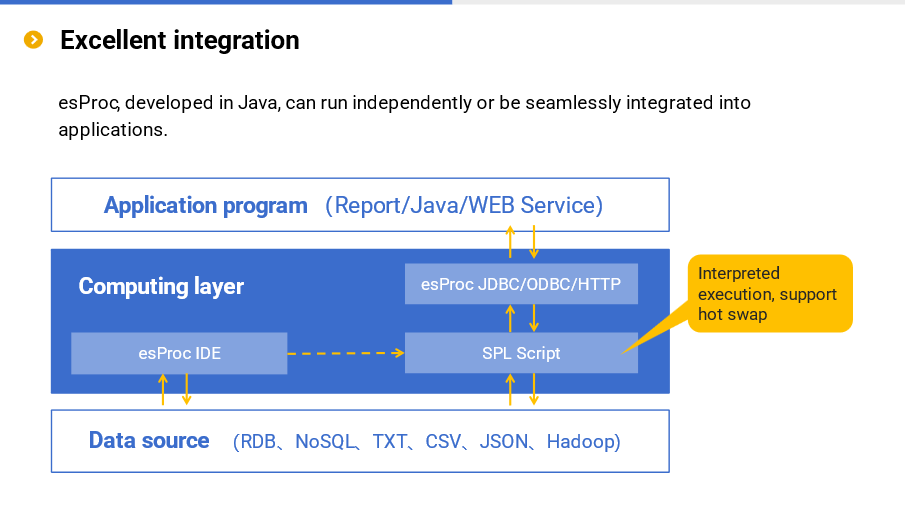
Excellent integration reflects its lightweight characteristic. esProc SPL does not always need an independent server to work (very different from the database), and instead, only embedding the jars can provide powerful computing power for the application. Moreover, the jars are only tens of MBs in size, very small and lightweight, and can be used anytime and anywhere, even can be run on an Android phone.
esProc SPL supports dozens of data sources and boasts the mixed computing ability. Multiple data sources can be calculated directly without loading data into the database. In addition to better data real-time, it can also fully retain respective advantage of diverse data sources. For example, RDB is strong in computing ability but low in IO efficiency, you can make RDB do part of calculations first and then let SPL do the rest calculations; MongoDB is naturally suitable for storing dynamic multi-layer data, you can let SPL calculate multi-layer data directly; File system is not only more efficient in reading and writing, but more flexible in use, SPL can calculate directly based on file, and give full play to the effectiveness of parallel computing.

esProc SPL’s support for multiple data sources reflects its versatility once again. Moreover, since esProc SPL has no metadata, multiple data sources can be accessed directly, and mixed calculation can be performed, and hence esProc SPL is lighter, this also once again reflects its lightweight characteristic.
Currently, esProc SPL can process the following data types:
Structured text: txt/csv
Common text, string analysis
Data in Excel files
Multilayer structured text: json, xml
Structured data: relational database
Multilayer structured data: bson
KV type data: NoSQL
In particular, esProc provides powerful support for multilayer structured data such as json and xml, far exceeding traditional databases. Therefore, esProc can work well with json-like data sources like mongodb and kafka, and can also easily exchange data with HTTP/Restful and microservice and provide computing service.
In addition, esProc can easily calculate the data in Excel files. However, esProc is not good at handling Excel’s format, nor is it good at processing data such as images, audios and videos.
Furthermore, esProc SPL provides its own efficient data file storage. The private data format not only provides higher performance, but allows us to store data by business category in file system tree directory.
Currently, SPL provides two file storage formats: bin file and composite table.
The bin file is a basic binary data format, which adopts the compression technology (less space occupation, faster reading), stores the data types (faster reading since there is no need to parse data type), and supports the double increment segmentation mechanism that can append the data, making it very easy to implement parallel computing through segmentation strategy, thereby improving the computing performance.
The composite table provides a more complex storage structure. Specifically, it supports mixed row-wise and columnar storage; ordered storage improves compression rate and positioning performance; it supports more efficient intelligent index; it supports the integration of primary table and sub-table to effectively reduce storage and association; it supports the double increment segmentation mechanism, making it easier to implement parallel computing to improve the computing performance.
Since the file-based storage doesn’t require database, and there is no metadata, it makes the use of SPL more flexible, more efficient, more lightweight and cheaper, and better suited to the needs of big data era.
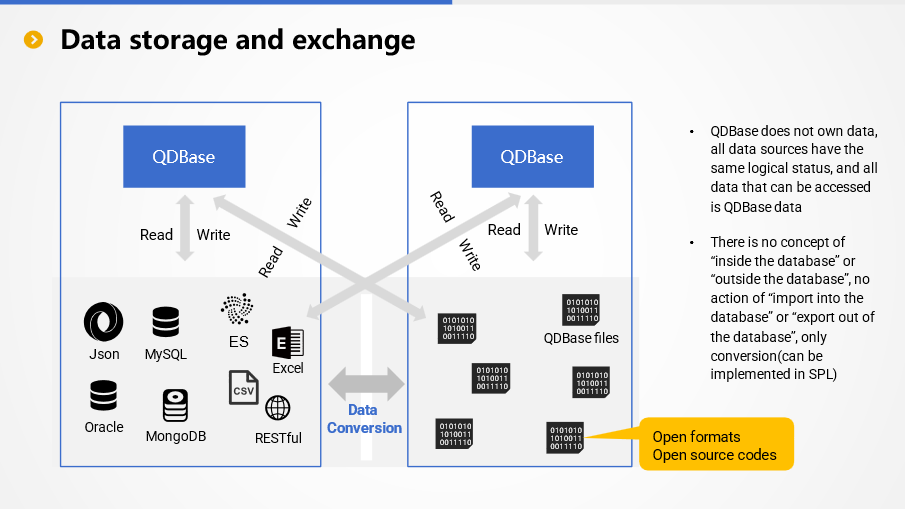
esProc does not have the concept of “warehouse” of traditional data warehouses, nor does it have the concept of metadata and, it does not provide unified management for the data of a certain theme. For esProc, there is no concept of “inside the database” or “outside the database”, and there is no action of “importing into database” or “exporting out of database”.
Any accessible data source can be regarded as the data of esProc and can be calculated directly. Importing into database is not required before calculation, and exporting out of database is also not required deliberately after calculation, as the result can be written to target data source through its interface.
esProc encapsulates access interfaces for common data sources, and various data sources have basically the same logical status. The only difference is that different data sources have different access interfaces, and different interfaces have different performance. Since these interfaces are provided by data source vendors, esProc cannot intervene in their functionality and performance.
esProc designs special-format files (bin file and composite table) to store data in order to obtain more functionalities and better performance. These files are stored in the file system, and esProc does not own these data files technically. esProc has made the file formats public (access code is open source), and any application that can access these data files can read and write them according to a publicly available specification (or based on open-source code). Of course, it is more convenient to read and write directly in SPL.
In this sense, there is no action of “importing into database” or “exporting out of database” when exchanging data between esProc and external data source. However, there may be the action of data conversion, that is, converting external data to esProc format files to obtain more functionalities and better performance, or converting esProc format files to external data for other applications to use. All these conversion actions can be done using SPL.
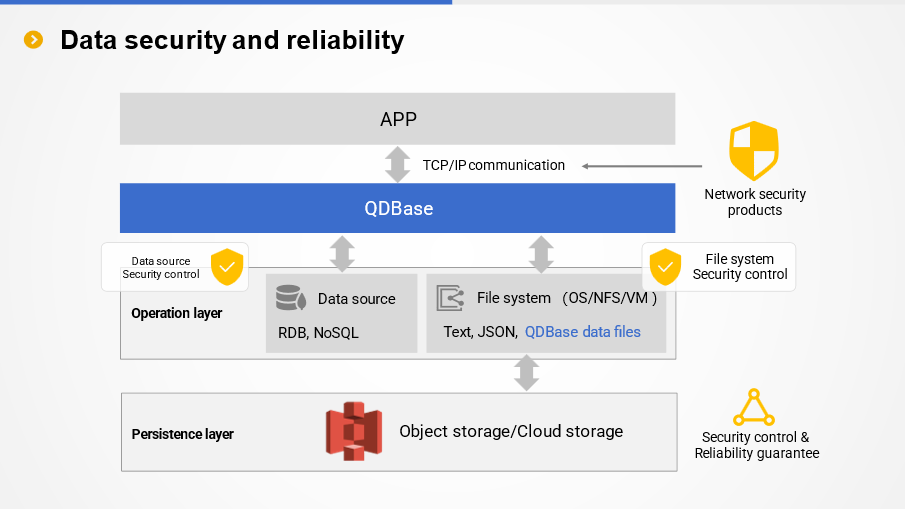
esProc does not manage data in principle, nor is it responsible for data security. To some extent, it can be said that esProc does not have and does not need a security mechanism.
The security of persistent data is the responsibility of the data source itself in principle. For data files in esProc format, many file systems or VMs provide complete security mechanism (access control, encryption, etc.), which can be utilized directly. The cloud edition of esProc also supports retrieving data from object storage services such as S3 before computing, and can also utilize their security mechanisms.
The embedded esProc is in the same process with the main Java application, and only provides computing service for main application. Since esProc doesn’t provide external service interface, there are no security and permission issues. esProc of the independent service process uses standard TCP/IP and HTTP to communicate, and can be monitored and managed by professional network security products, and the specific security measures will be the responsibility of these products. esProc specializes in computation and is not responsible for the reliability of persistent storage. There are professional technologies and products in this regard as well. esProc tries to follow standard specifications so that it can work with these technologies and products. For example, data can be persisted to highly reliable object storage, and for this reason, esProc provides corresponding interface, allowing us to access these data sources to perform calculation.
esProc is a professional computing technology and does not offer professional security capabilities. The philosophy of esProc is to work with other professional security technologies.
We’ve presented some technical characteristics of esProc SPL above. Now let's see some esProc SPL solutions applied in more scenarios.
More solutions
Implementation of data-driven micro-service
Micro-service requires data processing at the application side, and hence relevant processing technologies are needed. Although the database has strong computing power, it is difficult to be embedded in the application side, so hard coding is often required. Java/ORM lacks sufficient structured computing library, which makes it difficult to develop data processing, and fail to achieve hot swap, and thus it is hard to meet the needs of microservice.
Replacing Java/ORM with SPL to implement data calculation in micro-service can solve these problems efficiently. SPL has rich computing library and agile syntax, which can greatly simplify the development; SPL is an open system, and can process data of any source in real time; SPL is interpreted executed, naturally supporting hot swap; SPL’s efficient algorithms and parallel mechanism ensure computing performance. Therefore, SPL is an ideal computing engine in microservice.
For more information: visit: Open-source SPL Rings down the Curtain on ORM
Replace stored procedures
The shortcomings of stored procedures have a long history. Specifically, Stored procedures are hard to edit and debug, and lack migrtability; compiling stored procedures requires high privilege, causing poor security; the shared use of stored procedures by multiple applications will cause tight coupling between applications. Unfortunately, we have to put up with these shortcomings due to the lack of a better solution (the cost of hard coding is too high).
SPL is specially designed for complex structured data computing, and can be an excellent substitute for stored procedures and achieve the effect of outside-database stored procedures. SPL supports multi-step computation, and is naturally suited for complex calculations like stored procedure. SPL scripts are naturally migratable; the script only requires the read privilege of the database and will not cause database security problems; scripts of different applications are stored in different directories, which will not cause coupling between applications.
For more information, visit: Goodbye, Stored Procedures - the Love/Hate Thing
Eliminate intermediate tables from databases
When we use database, in order to improve query efficiency or simplify development, a large number of intermediate tables are generated, and the number of intermediate tables keeps increasing over time. These tables take up large space, causing database to be too redundant and bloated, and the access of the same intermediate table by different applications will cause tight coupling, and it is difficult to manage the intermediate tables.
The objective of storing intermediate tables in database is to employ the database’s computing ability for subsequent computations. To solve the above-mentioned problem, we can place intermediate tables outside database, and store them as files, and implement the subsequent computations in SPL. External intermediate tables (files) are easier to manage, and storing them in different directories will not cause coupling problems between applications; this method can fully reduce the load of database, even without the need to deploy database.
For more information: visit: Open-source SPL Eliminates Tens of Thousands of Intermediate Tables from Databases
Handle endless report development requirements
The development of report/BI involves two stages: data preparation and data presentation. However, reporting tools/BI tools can only solve the problems in the presentation stage and can do nothing about data preparation. For the complex data preparation, SQL/stored procedure/Java hardcoding is the only choice, which is difficult to develop and maintain, and the cost is high. We are often faced with endless report development needs, and it is often difficult to respond quickly at low cost. The main factor leading to high development costs is data preparation.
Adding a computing layer between report presentation and data source with the aid of SPL, the data preparation problem can be solved. SPL can simplify the data preparation of reports, make up for the lack of computing ability of reporting tools, and comprehensively improve the efficiency of report development. Once the data preparation of reports is implemented with tools, both report presentation and data preparation can quickly respond to handle endless report development needs at low cost.
For more information: visit:The Open-source SPL Optimizes Report Application and Handles Endless Report Development Needs
Programmable data routing to implement front-end calculation
Taking on too much business will make center data warehouse be in a heavy workload condition. Thus, it needs to move part of computing tasks (high-frequency computing tasks) to front-end application to balance pressure. However, there are few technologies available for frond-end calculation. Implementing the frond-end calculation with database will face the problem of data synchronization, that is, if only high-frequency data is imported into the front-end database, it will not be able to meet all query requests, but if full data is copied to front-end database, it will face the problem of repeated construction and huge work.
SPL can solve this problem through converting high-frequency data to SPL files for storage, and providing efficient computing services for applications with SPL’s high-performance computing ability. In addition, SPL provides intelligent data routing function. If an application queries low-frequency data, SPL can automatically route the query request to data warehouse, which avoids the high cost of repeated construction and gives full play to flexible and efficient computing power with better result at lower implementation cost.
For more information: visit: Routable computing engine implements front-end database
Implementation of real-time HTAP through mixed computation
HTAP requirements are essentially the result of the inability to perform real-time query after a large amount of data is stored to different databases. When implementing real-time query, HTAP database now faces the following problems: i) Since the existing production database is not a HTAP database, it needs to replace the production database, which will face high risk; ii) SQL’s computing power is insufficient, and the historical data cannot be well organized, resulting in low performance; iii) the computing power of database is too closed to take advantage of the advantages of diverse data sources, and the complex ETL process that loads all data into one database will lead to poor real-time.
SPL supports mixed calculation on diverse data sources and has a natural ability to achieve real-time analysis. Storing well-organized historical cold data according to computing characteristics as files improves the computing performance, and transaction hot data is still stored in production database and can be read in real time. With these abilities, SPL can achieve efficient HTAP effect without changing the production system, and minimizes the risk and cost. SPL supports low-risk, high-performance and strong real-time HTAP by means of open, multi-source mixed computing ability.
For more information: visit: HTAP database cannot handle HTAP requirements
Implementation of Lakehouse through file computation
To implement Lakehouse, both the storing and computing abilities are required, in other words, it requires the ability to fully retain raw data as well as the strong computing ability, only in this way can the data value be brought into full play. But, implementing Lakehouse with database faces an awkward situation that can only calculate not store (can only House, not Lake). Database has strong constraints, and non-compliant data cannot be stored into it, resulting in a failure to retain all features of data, in addition, the complex ETL process is very inefficient; the database has a very strong closed nature, and can only calculate in-database data, resulting in a failure to employ diverse raw data sources to calculate directly, let alone mixed real-time calculation.
SPL can implement a real Lakehouse, Raw data can be stored directly in file system, retaining the integrity of the data.
SPL is more open, and can directly calculate data of any type, organized or not. For open format file data like txt, csv, json, SPL can calculate them directly, and for other types of data, SPL can perform a mixed calculation in real time. The calculation and organization of data can be done synchronically, which allows for more efficient utilization of data and maintains high performance when re-computing. A step-by-step approach is the correct method for implementing Lakehouse.
For more information: visit: The current Lakehouse is like a false proposition
FAQ
Is esProc based on open source or database technology?
We’ve analyzed the shortcomings of existing technologies (mainly SQL) in detail above, which are mainly caused by the theory system behind them. If these theories are still followed, it’s impossible to eliminate such shortcomings fundamentally. For this reason, we invent a brand-new computing model - discrete dataset, and develop esProc SPL based on the model. Since everything is new, and there is no relevant theories and engineering products in the industry to reference, we have to develop from scratch, and any part from the model to code is originally created.
Where can esProc be deployed?
Since esProc is developed completely in Java, it can be deployed in any environment equipped with JVM, including but not limited to VM, cloud server and container. In practice, esProc can be either used independently or integrated into applications. When it is used independently, we need to run a separate esProc server, and can build a distributed cluster; when it is integrated into an application, it is embedded in the form of jars, and regarded as a part of the application (computing engine).
How does application invoke esProc?
esProc provides a standard JDBC driver, and thus it can be seamlessly integrated in a Java application directly. For a non-Java application like .net/Python, we can invoke it via ODBC/HTTP/RESTful interface.
Can esProc be integrated with other frameworks?
esProc can run as an independent service process like a traditional database. In addition, esProc provides standard JDBC driver and HTTP service for application to call, and hence SPL script can be executed in Java applications by sending SPL statements through JDBC. Calling the script code of esProc is equivalent to calling the stored procedure in relational database. For non-Java applications, we can access esProc-provided computing service through HTTP/Restful mechanism.
For applications developed in Java, esProc can be fully embedded, that is, all computing functions are encapsulated in the JDBC driver, and run in the same process as the main application without relying on external independent service process.
Because esProc is software developed purely in Java, it can be completely and seamlessly embedded in various Java frameworks and application servers, such as Spring, Tomcat, and can be scheduled, operated and maintained by these frameworks. For these frameworks, esProc has the same logical status as that of Java applications written by users.
It should be noted that for computing type frameworks like Spark, while esProc can be integrated seamlessly, it does not make practical sense. esProc requires converting data to SPL-specific data objects before calculating, which is not only time consuming, but makes the data objects in original computing framework meaningless, resulting in a failure to combine the advantages of the two types of data objects. The key point of these computing frameworks is their data objects (such as Spark's RDD). If such data objects can no longer be used, the computing frameworks themselves will be meaningless. Since the computing ability of esProc far exceeds that of common computing frameworks, there is no need to use these frameworks anymore.
In particular, for stream computing frameworks (such as Flink), esProc cannot play a role even if it can be integrated. esProc has independently served stream computing scenarios for many times, and does not need the support of stream computing frameworks at all. For the same amount of computation, esProc typically consumes resources one order of magnitude lower than these stream computing frameworks, and has richer functionality.
Can esProc run based on the existing database?
Yes, of course! esProc supports dozens of data sources, including database, text, excel, json/xml, webservice, etc. Moreover, esProc can perform association and mixing operations between database and other data sources (such as text).
However, for data-intensive tasks (most tasks related to big data belong to such task), reading the data from database will consume a lot of time due to poor I/O performance of database. Even if the calculation time of esProc is very short, the overall time is still very long, resulting in a failure to meet performance requirements. Therefore, for scenarios that require high performance, you need to move a large amount of cold data from database to esProc’s high performance file, only in this way can an optimal performance be obtained and, the remaining small amount of hot data can still be stored in the database, and real-time full data query can be easily implemented by means of the multi-source mixed computing ability of esProc.
Where does esProc store data?
esProc stores data as files, supports open text format, and also provides a high-performance private file format. Since files are more open and flexible, it is easier to design high-performance storage schema based on files, and improve computing performance through parallel computing. esProc supports the file system on any OS, including local file system and NFS. Therefore, esProc has a natural ability to implement separation between storage and computation, unlike database that is difficult to separate storage and calculation as it needs to bypasses the file system and operate directly hard disk.
How to ensure the high availability of esProc?
esProc supports distributed computing, allowing multiple nodes to work together. In practice, however, distributed computing is rarely used, as esProc can handle most tasks and meet the expected response speed through a single node, except for high-concurrency scenarios.
The upcoming cloud edition of esProc (supporting private deployment) will support automatic elastic computing. When the data request volume increases, new VM will be automatically enabled to compute, and when the data request volume decreases, the idle VM will be automatically shut down.
Embedded esProc only provides computing service for main application, and cannot provide external service, nor is it responsible for the reliability of external service. The reliability of external service is the responsibility of the main application and the framework.
The esProc of the independent process supports the hot standby mechanism, and JDBC will choose one process with lighter workload among the currently working service processes to perform calculation. esProc's distributed computing also provides fault tolerance. However, since the design goal of esProc is not a large-scale cluster, once a node failure is found during the calculation, the task will be declared failed. esProc's fault tolerance is only limited to allowing the cluster to accept new tasks when a node failure is detected, which is only suitable for small-scale clusters.
The service process of esProc currently does not provide automatic recovery function after failure, and the failure needs to be handled by administrators. However, it is not difficult to design a monitoring process to implement the automatic function.
The elastic computing mechanism of esProc (cloud edition) will avoid the currently failed nodes when allocating VMs, hereby achieving high availability to a certain extent.
How to extend the functionalities of esProc?
esProc is a software written in Java, and offers an interface to call the static functions written in Java, thus extending the functionality of esProc. esProc also opens up the interface of custom functions, allowing application programmers to write new functions in Java and move them in esProc for use in SPL.
What are the weaknesses of esProc?
Comparing with RDB:
The metadata capability of esProc is relatively immature.
esProc is not the DBMS, and does not have the concept of metadata in the traditional sense, and data is mostly stored, managed and used as the form of files. Most operations start by accessing data sources (files), which is a bit more troublesome than the database for simple calculations, but more advantageous for complex calculations.
Comparing with Hadoop/MPP:
The scale of Hadoop/MPP database cluster is relatively large (although limitations are usually laid on the node number of MPP cluster), and mature experiences on the utilization, O&M management of such cluster are already available. In contrast, esProc cluster targets to small- to medium-scale, usually a few to a few dozen nodes, and even so, there is still a lack of practical experience (relative to Hadoop/MPP). In practice, esProc cluster is rarely employed because customer can often achieve or even surpass the effect of their original cluster on only one esProc node, which further leads to the relative lack of experience in utilizing esProc cluster.
Comparing with Python:
We are currently developing the AI functions of esProc SPL, and improving its AI modeling and prediction functions gradually, but these functions are still far from Python's rich AI algorithm libraries.
How about the compatibility between SPL and SQL?
esProc is not the computing engine of SQL system, and currently only supports simple SQL that does not involve a large amount of data, and cannot ensure the performance. In the big data computing scenarios, it can be considered that esProc does not support SQL, and of course it will not be compatible with any SQL stored procedure.
esProc will develop the dual-engine supporting SQL in the future, but it is still difficult to ensure high performance and meet the computing requirement of big data, it only makes it easier to migrate existing SQL code to esProc.
Is there a tool to automatically convert SQL to SPL?
Given the widespread use of SQL, especially when remoulding (optimizing) existing system, it is natural to wonder whether SQL can be automatically converted to SPL to reduce migration cost.
Unfortunately, it can't.
Although database can be used as the data source of SPL, high performance cannot be implemented based on database (mainly due to the storage), so automatic conversion of SQL to SPL is impossible based on database. More importantly, due to the lack of sufficient description ability, SQL cannot implement many high-performance algorithms. In this case, forcibly converting SQL to SPL can only ensure the function, and the performance is usually much worse.
It is worth mentioning that SPL does not provide such a strong automatic optimization mechanism as SQL. After decades of development, many databases have strong optimization engines. When facing relatively simple slow SQL statements, the engines can “guess” their true intentions, and optimize them automatically so as to execute in a high-performance manner (such as TopN mentioned earlier); In contrast, the automatic optimization function of SPL is insufficient, and we are far from being as rich in optimization experience as database vendors, so we don’t have the ability to “guess” the intention of the statement, and have to execute the code directly. In this case, we can only depend on our programmers to write low-complexity code to achieve high performance.
How difficult is it to learn SPL
SPL is dedicated to low code and high performance. SPL syntax is easy and much simpler than Java, and you can master it in hours and be skilled in weeks. What is difficult is to design optimization algorithms. Fortunately, it is not difficult to learn, and we have summarized the knowledge points as fixed routines. As long as you follow these routines, you can master them and become a master.
SPL Programming - Preface SPL Programming - Preface Is SPL more difficult or easier than SQL?
How to launch a performance optimization project
Most programmers are used to the way of thinking in SQL and are not familiar with high performance algorithms. They need to be trained to understand through one or two scenarios. There are not many performance optimization routines (dozens), and less than 10 routines are commonly used. Once you experience such routines, you will learn, and find that algorithm design and implementation are not so difficult. The first 2-3 scenarios will be implemented by users with the help of our engineer. In this process, we will teach users how to solve a problem instead of giving them a solution directly.

For more information: visit: What should we do when SQL (and stored procedure) runs too slowly?
Summary
Finally, let's summarize the advantages of esProc SPL as a data analysis engine.
High performance
In practice, esProc SPL’s performance to process big data is 1-2 orders of magnitude higher than that of traditional solutions on average, and thus the performance advantage is very obvious.
Efficient development
With SPL’s agile syntax and rich computing libraries, as well as procedural characteristics, complex algorithms can be implemented according to natural thinking, thereby making development efficiency higher.
Flexible and open
esProc SPL supports mixed computation of multiple data sources, and can implement HTAP at a minimum cost while effectively utilizing the advantages of multiple data sources. Moreover, esProc SPL can be integrated in applications, making it truly open and flexible.
Save resources
With the support of high computing ability, esProc SPL can achieve business goal with less hardware (single machine can rival a cluster), so it is a more environmentally-friendly technology.
Sharp cost reduction
When these advantages are reflected in the cost, the development, hardware, O&M costs can be reduced by X times.
| esproc_spl |
1,871,830 | Revolutionize Your Unit Testing with Testcontainers and Docker | Recently, when working on a project I ran into a situation in which I needed to handle a complex... | 0 | 2024-05-31T09:07:17 | https://dev.to/rogiervandenberg/revolutionize-your-unit-testing-with-testcontainers-and-docker-4h73 | postgres, testing, database, javascript | Recently, when working on a project I ran into a situation in which I needed to handle a complex object/data structure. This object had to be able to be saved into a database (dispersed over multiple different tables), retrieved, and reconstructed exactly as intended.
In order to verify things were built as intended, I created Unit Tests that would write and read this object into my database. But I did not want to use my development database for this.
Why? The traditional approach of using a development database for testing often leads to several issues: interference with development work, data corruption, inconsistent results, and overlapping tests affecting each other.
> But what if there was a way to conduct these tests in a controlled, isolated, and repeatable environment, using a real database? 🤔
## Enter Testcontainers!
### Why Testcontainers?
[Testcontainers](https://testcontainers.com/) is a very neat open source framework/project I just discovered. It enables developers to create unit tests using throwaway, lightweight instances of e.g. a database running in Docker containers.
This approach ensures that every test runs in a fresh, isolated environment, eliminating the problems associated with using a shared development database. No more conflicting tests, no more corrupt data, and consistent, reliable results every time you run your tests.
And it works for multiple languages, like Go, Python and Javascript and it supports many external dependencies, like Postgres (as I'm using in my case), MySQL, Git, several Cloud providers, Redis, Elastic and many more 🤯
### Example
Look at the following code that I copied from the [documentation](https://testcontainers.com/guides/getting-started-with-testcontainers-for-nodejs/#_write_the_tests_and_solution) of Testcontainers:
```javascript
const { Client } = require("pg");
const { PostgreSqlContainer } = require("@testcontainers/postgresql");
const { createCustomerTable, createCustomer, getCustomers } = require("./customer-repository");
describe("Customer Repository", () => {
jest.setTimeout(60000);
let postgresContainer;
let postgresClient;
beforeAll(async () => {
postgresContainer = await new PostgreSqlContainer().start();
postgresClient = new Client({ connectionString: postgresContainer.getConnectionUri() });
await postgresClient.connect();
await createCustomerTable(postgresClient)
});
afterAll(async () => {
await postgresClient.end();
await postgresContainer.stop();
});
it("should create and return multiple customers", async () => {
const customer1 = { id: 1, name: "John Doe" };
const customer2 = { id: 2, name: "Jane Doe" };
await createCustomer(postgresClient, customer1);
await createCustomer(postgresClient, customer2);
const customers = await getCustomers(postgresClient);
expect(customers).toEqual([customer1, customer2]);
});
});
```
This code is a test that tests a customer repository and does a couple of actions against a real database. The amazing thing is that this test is not mocking anything, but **always runs with fresh and new real database** in a Docker container! So no more mocks or conflicting tests and a clean database every time you run your tests.
## Try it out yourself
I think Testcontainers make running specific test cases easier, while having optimal isolation, consistency (and thus reliability) and simplicity (and thus better to maintain and manage).
So, check out → [https://testcontainers.com/](https://testcontainers.com/) | rogiervandenberg |
1,871,833 | What do the bugs mean? | Introduction Bugs are often defined as the resulting undesired behavior—coming from the... | 27,765 | 2024-05-31T09:05:53 | https://dev.to/marvinav/what-does-the-bugs-mean-14k1 | bug, testing, qa, programming | ## Introduction
Bugs are often defined as the resulting undesired behavior—coming from the developer's mistake—in the code. Bugs are, of course, a very human-made thing. This article contextualizes the entire historical background around the word "bug," from Thomas Edison to the famous incident with a moth by Grace Hopper. It goes even further to speak of the significant consequences of software errors: economic losses, and critical failures within various industries. This serves to sharpen the point that human errors in software development should be tested for these consequences to be reduced.
## The origin of termin
The simplest answer to this question most common amongst developers is *‘bug is some undesired behavior caused by mistake in the code’*. In general, this is a right answer that does not conflict with the true meaning of bug definition. But let’s look at how dictionaries define the bug.
> **Webster**: an unexpected defect, fault, flaw, or imperfection.
**Cambridge**: a mistake or problem in a computer program.
**Oxford**: with the sense ‘of or relating to errors or other causes of malfunction in a computer program’.
However, those definitions do not highlight a very important detail that the bug is always caused by **humans**. For instance, if a user splits a coffee on his laptop and it stops working - this is not a bug. However, if the laptop stops working, because voltage regulator modules send 2 V on cpu instead of 1.4 V - this is the bug. With keeping this in the mind let's expand the definition of the bug:
> A bug is a flaw, failure, error, or fault in computer software or system, **caused by humans**, that leads to unexpected or incorrect results, or to behave in unintended ways.
I don't just want to draw attention to the human factor for no reason, but because in the next articles we will see that all ways to reduce the number of bugs should be aimed precisely at combating the human factor. But for now, let's trace the history of the bug.
In the IT, there is an opinion that the concept of a bug started to be used after a real insect got stuck in the computer relay.
> In 1946, when *Hopper* was released from active duty, she joined the Harvard Faculty at the Computation Laboratory where she continued her work on the *Mark II* and *Mark III*. She traced an error in the *Mark II* to a moth trapped in a relay, coining the term bug. This bug was carefully removed and taped to the log book. Stemming from the first bug, today we call errors or glitch's in a program a bug.
>*"Danis, Sharron Ann: "Rear Admiral Grace Murray Hopper"". ei.cs.vt.edu. February 16, 1997. Retrieved January 31, 2010.*

Picture 1 - Photo of the origin entry log in journal with the taped moth.
**Disclaimer**. I want to note in advance that a good historical analysis was done by *Peggy A. Kidwell*, and my favorite work is the article 'Stalking the Elusive Computer Bug' published in 1998 in the IEEE Annals of the History of Computing. If you are interested in delving deeper into this issue, I recommend referring to this article, as well as to the works of his. Below, I will provide only a brief overview of this article with some additional illustrations.
A funny fact, but in the 1945 edition of the Oxford dictionary, you can find a definition for "**debugging**," but not for "**bug**." What does all this mean? The story about the moth is essentially true, however, the entry in the journal dates back to 1947, not 1946. So, in the early days of programming, among Harvard staff, the term "**bugs**" was used before the story with the Mark computer. It turns out they adapted the terms "**bug**," "**debug**," and "**debugging**" from technical slang prevalent in the USA.
The word "**bug**" and its relation to technology, or more particularly to computers, in reality, dates back to the time of Thomas Edison. He wrote the first documented use of the term "**bug**" in a letter describing problems he is having with his phonograph:
> "It has been just so in all of my inventions. The first step is an intuition—and comes with a burst, then difficulties arise—this thing gives out and then that—'Bugs'—as such little faults and difficulties are called."
These problems are the kinds one of the U.S. engineers had long held to have been called about quite a while ago. This became popular because the term is short, and means the flaw is small and manageable. This conceptual history of the terminology is well-traced in sources ranging from dictionaries to anecdotes.
**1924**: In a comic strip from a 1924 telephone industry journal, a naive character learns that a man works as a "bug hunter" and gives him a backscratcher. The man explains that "bug hunter" is just a nickname for a repairman.
**1931**: The first mechanical pinball game, Baffle Ball, was marketed as being "free of bugs."
**1940**: The term bug is used to describe a defect in direction-finding equipment in the film Flight Command.
**1942**: In a book, Louise Dickinson Rich refers to an ice cutting machine needing the "bugs" removed before it could resume operation.
**1944**: Isaac Asimov refers to bugs as issues with a robot in his short story "Catch That Rabbit."
The lexicon of computer science grew increasingly formal, arguably from the 1950s and certainly from the 1961's, as the Association for Computing Machinery (ACM) and other professional groups started publishing standardized glossaries. By the early 1960s, terms like "**bug**" and "**debug**" were used in mainstream language. As computing technology advanced, it also became widely used in the popular press and in everyday language. For instance, "Grin and Bear It" contained jokes about "computer bugs". Advertisements for services of various kinds assured the consumer with such slogans as "We'll Get the Bugs Out."
## The cost of bugs
It seems that computer bugs are like small, innocent pranks that prevent the engineering system from working at full capacity. But are they really that harmless?
In 2002, software bugs cost the United States economy approximately $59.5 billion, which is a small figure considering the overall GDP of the USA. However, with the growth of digital services, the cost of bugs for the economy has grown proportionally. According to research by Tricentis, in 2016, software failures in the US cost the economy $1.1 trillion in assets. In total, software failures at 363 companies affected 4.4 billion customers and caused more than three and a half years of lost time. Since 2016, the damage to GDP has grown by almost one and a half times, and it is now estimated at 7% of the US GDP.
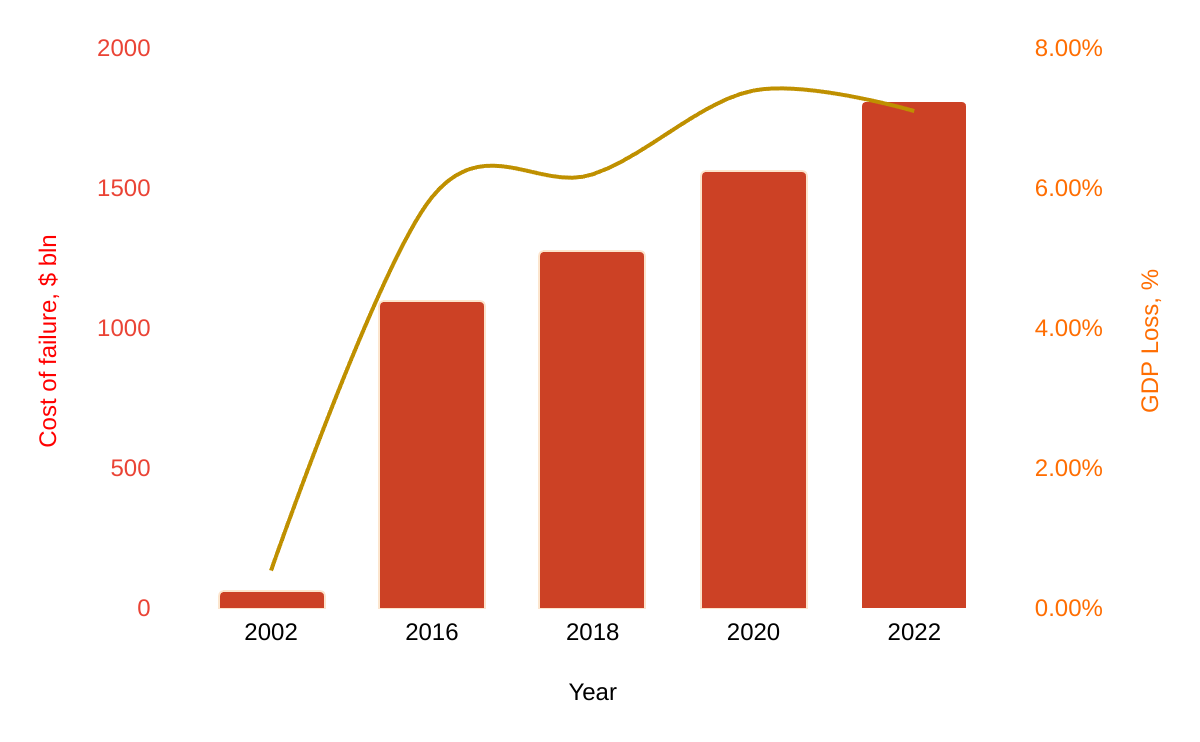
Picture 2 - Cost of software bugs on the USA economic
We've all heard about the famous Y2K bug, but do you know how much it cost the economy? To address the potential fallout, organizations globally invested heavily in Y2K remediation efforts. The total cost of these preventive measures is estimated to have ranged between $300 billion and $600 billion. This expenditure was incurred by governments, businesses, and other entities to update software, replace hardware, and implement extensive testing and contingency plans. Significant financial resources were allocated to ensure critical systems would transition smoothly into the new millennium. Governments, especially in developed countries, undertook extensive campaigns to prepare public services and infrastructure. Businesses, particularly those in finance, utilities, and transportation, conducted exhaustive checks and upgrades to mitigate the risks.
But even with such investments to fix this bug, minor problems were still recorded:
- The US official timekeeper, the Naval Observatory, reported the date as 19100 on its website.
- In Japan, the system collecting flight information for small planes failed.
- In Australia, bus ticket validation machines failed.
- In the US, over 150 slot machines at race tracks in Delaware failed.
- In Spain, a worker was summoned to an industrial tribunal on February 3, 1900.
- In South Korea, a district court summoned 170 people to court on January 4, 1900.
- In Italy, Telecom Italia sent out bills for the first two months of 1900.
- In the UK, some credit card transactions failed.
Bugs are expensive, but they also lead to not just financial losses, but far more serious consequences.
### Intellectual Damage, which hampers the development of humanity
**1962**: NASA’s Mariner 1 Incident: In one of the earliest and most expensive software errors, NASA's Mariner 1 spacecraft, aimed at Venus, veered off course due to a missing hyphen in the code. This led to the spacecraft being destroyed shortly after launch, costing NASA $18 million. This incident underscored the critical need for meticulous coding and testing in software development.
**1996**: Ariane 5 Rocket Failure: A software error in the Ariane 5 rocket caused it to deviate from its path and self-destruct 37 seconds after launch. The problem stemmed from code reused from the Ariane 4, which was not compatible with the new rocket's flight conditions. The failure resulted in a loss of over $370 million, underscoring the critical need for software adaptation and testing in space missions.
**1999**: Mars Climate Orbiter Loss: NASA's Mars Climate Orbiter disintegrated upon arrival at Mars due to a software error involving unit conversion from English to metric measurements. The $327 million mission failure highlighted the importance of consistency and precision in software used for interplanetary exploration.
### Political Damage (which almost triggered a war between nuclear powers):
**1980**: NORAD False Missile Alert: A software error caused NORAD to report a false missile attack on the United States. The mistake was due to a faulty circuit that the software did not account for, nearly triggering a nuclear response. This event highlighted the severe implications of software errors in military and defense systems.
**1983**: Soviet False Missile Alert: A Soviet satellite falsely reported incoming US missiles, almost leading to a nuclear counterstrike. The officer on duty trusted his instincts and chose not to react, preventing a potential disaster. This incident again emphasized the dire consequences of software errors in critical systems.
### Environmental Damage (which also showed that bugs could be used as weapons):
**1982**: Siberian Gas Pipeline Explosion: In a Cold War incident, the CIA allegedly inserted faulty software into a Soviet gas pipeline control system, leading to an explosion visible from space. While the precise cost remains undisclosed, this event is remembered as one of the most monumental non-nuclear explosions, illustrating the destructive potential of intentional software bugs.
### Bugs can also claim lives:
**1985-1987**: Therac-25 Radiation Overdoses: A software bug in the Therac-25 radiation therapy machine resulted in patients receiving massive overdoses of radiation, causing several deaths and serious injuries. This tragic case demonstrated the fatal risks associated with software failures in medical devices and the essential need for rigorous testing and validation in healthcare technology.
**1994**: RAF Chinook Helicopter Crash: A software fault in the flight control system caused a Chinook helicopter to crash in Scotland, killing all 29 passengers. Initially blamed on pilot error, later investigations revealed the software glitch as the true cause, stressing the importance of reliable software in aviation safety.
**2000**: Panama City Radiation Overdoses: Faulty therapy planning software from Multidata caused radiation overdoses in patients, resulting in several deaths. This incident reiterated the deadly risks of software errors in medical applications and the crucial need for stringent testing protocols.
| marvinav |
1,871,832 | The Difference between Quantitative Trading and Subjective Trading | Quantitative trading Quantitative systemic traders, enter rules + exit rules + fund management are... | 0 | 2024-05-31T09:05:47 | https://dev.to/fmzquant/the-difference-between-quantitative-trading-and-subjective-trading-5043 | trading, cryptocurrency, fmzquant, systems | Quantitative trading
Quantitative systemic traders, enter rules + exit rules + fund management are all quantified. The typical is the turtle trading rules. You are given the model and you know what to do. The model is written in detailed language and you can understand it. This is a systematic trading model that can be quantified.
Quantitative trading relies on a large number of data analysis to produce sample results, and the results are based on sufficient analytical data.
Advantage of quantitative trading
The advantage lies in its discipline, systematicness, timeliness, accuracy and decentralization.
1. Discipline: Strictly implement strategic thinking and overcome the weakness of human nature: greed, fear, etc., to overcome the consequences of feeling good about themselves: chasing up and killing low.
2. Systematicness: Capture more investment opportunities through multi-level quantitative models, multi-angle observations and massive data.
3. Timeliness: Quickly track market changes, comprehensively scan market information, and continuously discover new statistical models that can provide excess returns and find more trading opportunities.
4. Accuracy: Accurately and objectively evaluate trading opportunities, overcome subjective emotional biases, and capture opportunities arising from mispricing and erroneous valuation.
5. Decentralization: that is, winning by probability. There are two main aspects. First, quantitative investment continuously extracts historical laws that are expected to be repeated in the future and uses them. These historical laws are strategies with a high probability of winning. The second is to rely on the selection of portfolios that have high probability of winning, rather than focusing on one. As the saying goes: don't put eggs in the same basket.

Quantitative features:
1. Each analysis has consistency and reproducibility in the early stage. More importantly, consistency is the result of each analysis. It is difficult to evaluate trading opportunities accurately and objectively, overcome subjective emotional bias, and track market changes quickly and efficiently.
2. Quantitative investment can be decentralized, Because people's energy is limited after all. It is difficult to concentrate on trading multiple varieties simultaneously. The more varieties, the greater the error, the greater the human deviation. Quantitative investment does not have this problem, and it can achieve consistency, analyzability and verifiability for all kinds of trading.
Subjective trading
Subjective trading is man-made discovery of opportunities and man-made orders. It’s mainly based on experience, To study the market and summarize his own trading system, so as to choose whether to place an order or not when a trading signal appears. Subjective trading believes that things have happened in the past will happen in the future. The same decline pattern will still work next time. Though experience is very important, but no one can step into the same river. After all, the past is not the future, so it won’t work every time. Once it is not working, people are easily become suspicious, worrying about gains and losses. Thus, the randomness is strong, people are easy to be plagued by profit and loss, and affected by emotions, which makes it difficult to stabilize profits.

Defects in subjective trading:
The subjective trading strategy contains the elements of human judgment, so it cannot be repeated precisely and lacks of stability. Because of subjective interference, there is no way to be consistent.
Subjective trading is inefficient.
Quantitative trading is simply an investment method that uses the data model as the core, programmatic trading as the means, pursuing absolute returns as target. Quantitative investment mainly relies on mathematical models to find investment targets and investment strategies. By establishing mathematical models to realize trading concepts, it has a complete evaluation system. After the model is established, through the backtesting of historical data, to determine that the model can operate effectively in all market stages and achieve profitability.
And subjective trading pays more attention to human analysis and investors’ perceptions. People’s feelings are complex and unreliable. Human beings often have many misunderstandings about things. These misunderstandings make wrong judgments in investment.
We hope every trader can have more options when they choose trading methods instead of trading only by emotion, and we will share more quantitative trading strategies on FMZ Quant to meet more quants.
Start your coding experience now on FMZ.COM
From: https://blog.mathquant.com/2022/09/30/the-difference-between-quantitative-trading-and-subjective-trading-2.html | fmzquant |
1,871,831 | Using ApyHub for Image Moderation | In Auctibles, we use ApyHub to moderate images of items for auction. Auctibles is built using the... | 0 | 2024-05-31T09:05:25 | https://dev.to/kornatzky/using-apyhub-for-image-moderation-4gg1 | ai, laravel, php, apyhub | In [Auctibles](https://auctibles.com), we use [ApyHub](https://apyhub.com) to moderate images of items for auction. Auctibles is built using the Laravel PHP framework.
## Uploading Image Files
Videos are effortlessly uploaded using a straightforward Livewire component and an HTML `input` element with `type=file`.
<input id="photos" name="photos" type="file" class="sr-only" wire:model.live="photos" accept="image/png,image/jpg,image/gif">
The component has a public property:
public $photos = [];
Upon clicking a `submit` button, we apply validation to the field,
'photos' => 'nullable|array|max:3', // array
'photos.*' => [
'required',
'image',
'max:10240', // 10MB
new ExplicitImage(),
],
`ExplicitImage` is a validation rule.
## Temporary Files
We upload temporary files to a Minio bucket which resides on the server. The bucket is defined as an `uploads` bucket for Laravel. This is done in `config/filesystems.php`.
## ApyHub Results for Image Content
We use `curl` to call ApyHub. The response looks like this:
{
"data": {
"apyhub": {
"adult": {
"adultScore": 0.0025164163671433926,
"goreScore": 0.0014069777680560946,
"isAdultContent": false,
"isGoryContent": false,
"isRacyContent": false,
"racyScore": 0.0032450903672724962
},
"metadata": {
"format": "Png",
"height": 1024,
"width": 1024
}
}
}
}
## The Validation Rule
<?php
namespace App\Rules;
use Closure;
use Illuminate\Contracts\Validation\ValidationRule;
use CURLFile;
use CURLStringFile;
use Illuminate\Support\Facades\Storage;
class ExplicitImage implements ValidationRule
{
/**
* Run the validation rule.
*
* @param \Closure(string): \Illuminate\Translation\PotentiallyTranslatedString $fail
*/
public function validate(string $attribute, mixed $value, Closure $fail): void
{
// path to temporary uploaded file in uploads disk
$path = config('livewire')['temporary_file_upload']['directory'] . DIRECTORY_SEPARATOR . $value->getFilename();
$ch = curl_init();
curl_setopt(
$ch,
CURLOPT_URL,
"https://api.apyhub.com/ai/image/detect/explicit-content/file"
);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'POST');
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'apy-token: ' . config('app.APYHUB_TOKEN'),
'content-type: multipart/form-data'
]);
curl_setopt($ch, CURLOPT_POSTFIELDS, [
'file' => new CURLStringFile(Storage::disk('uploads')->get($path), $value->getFilename(), $value->getMimeType()),
'requested_service' => 'apyhub',
]);
$response = curl_exec($ch);
curl_close($ch);
if ($response === false) {
$error = curl_error($ch);
logger()->warning("ApyHub image moderation CURL Error: $error");
return;
} else {
// Process the successful CURL call here.
$statusCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if ($statusCode == 200) {
// The request was successful
$data = json_decode($response, true); //
$response = $data['data']['apyhub']['adult'];
if ($response['isAdultContent'] || $response['isGoryContent'] || $response['isRacyContent']) {
$fail('validation.' . 'explicit_image')->translate();
}
} else {
// The server responded with an error
logger()->warning("ApyHub image moderation HTTP Error: $statusCode");
return;
}
}
}
} | kornatzky |
1,871,829 | My Banking Tips | MybankingTips is a financial marketplace in India. Users can compare and choose from a variety of... | 0 | 2024-05-31T09:03:00 | https://dev.to/my_bankingtips_21821305f/my-banking-tips-18fk | MybankingTips is a financial marketplace in India. Users can compare and choose from a variety of financial products, including credit cards, loans, insurance, and other personal finance products, on MybankingTips. In order to help users make informed decisions based on their unique needs and preferences, We offer an easy method for users to compare various financial products from various banks and financial organizations.
[https://www.mybankingtips.com/
](https://www.mybankingtips.com/) | my_bankingtips_21821305f | |
1,871,827 | favorite (document) collaboration platforms? | Hey devs - I am exploring what good collaboration platforms have in common - and looking for your... | 0 | 2024-05-31T08:56:51 | https://dev.to/nikoldimit/favorite-document-collaboration-platforms-jde | discuss | Hey devs - I am exploring what good collaboration platforms have in common - and looking for your ideas: For example, what do you think of Notion, google docs? Which one is better and why? | nikoldimit |
1,871,816 | The Frontend Challenge: Celebrating June with Chhota Bheem Adventures | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration For... | 0 | 2024-05-31T08:55:57 | https://dev.to/niketmishra/the-frontend-challenge-celebrating-june-with-chhota-bheem-adventures-3a0a | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
<!-- What are you highlighting today? -->
For this challenge, I chose to highlight the beloved cartoon character Chhota Bheem. June is a month full of vibrant activities and celebrations, especially for children who are enjoying their summer holidays. Chhota Bheem, being a symbol of courage, adventure, and fun, perfectly encapsulates the spirit of summer. Additionally, the character's bright and cheerful appearance brings a sense of joy and excitement, making it an ideal representation of the energetic and lively month of June.
## Demo
{% codepen https://codepen.io/niketmishra/pen/ExzWYRb %}
## Journey
<!-- Tell us about your process, what you learned, anything you are particularly proud of, what you hope to do next, etc. -->
As someone not naturally gifted in art, I faced challenges in creating precise shapes. Inspired by my Minecraft experience, I decided to approach the project using a pixel art style. This method allowed me to build Chhota Bheem with basic blocks, much like in Minecraft.
This project not only improved my CSS skills but also allowed me to blend creativity with technical problem-solving.
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- We encourage you to consider adding a license for your code. -->
MIT License
Copyright (c) 2024 Niket Kumar Mishra
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
<!-- Don't forget to add a cover image to your post (if you want). -->
<!-- Thanks for participating! --> | niketmishra |
1,871,826 | The Portability Factor: Foldable Solar Panels for On-the-Go Charging | photo_6246496729478315716_x.jpg Portability Factor: Foldable Solar Panels for On-the-Go Charging Are... | 0 | 2024-05-31T08:55:38 | https://dev.to/skcms_kskee_db3d23538e2f3/the-portability-factor-foldable-solar-panels-for-on-the-go-charging-5949 | photo_6246496729478315716_x.jpg
Portability Factor: Foldable Solar Panels for On-the-Go Charging
Are you someone who loves to go on outdoor adventures but find it hard to charge your devices? With foldable panels solar you can now stay connected while on the go without worrying about running out of power. We will explore the advantages, innovation, safety, use, and how to use foldable panels solar.
Advantages of Foldable Solar Panels
Foldable solar panels is an advancement technology that's innovative and has transformed the way we charge our devices while on the go. One of the significant advantages of foldable panels solar their portability, making them easy to carry around and store when not in use. Unlike traditional panels solar foldable solar panels lightweight, compact, and can be easily folded to fit into a backpack or a small space.
Another advantage of these panels their are resistance and durability to weather harsh. They are designed to withstand temperatures extreme rain, and snow, making them ideal for outdoor activities such as camping, hiking, and backpacking.
Innovation in Foldable Solar Panels
Foldable solar panels is a technology that's innovative has revolutionized the way we charge our devices. They designed with cutting-edge technology allows for efficient conversion of Wind Solar Hybrid Power System to power electrical. These panels are also environmentally friendly, as a energy used by them renewable to charge devices.
Safety of Foldable Solar Panels
Foldable panels solar is designed to be safe and easy to use. They are equipped with various safety features such as overload protection, short circuit protection, and voltage regulation, which ensures your devices not damaged during charging.
Use of Foldable Solar Panels
Foldable panels solar is easy to use and can be used to charge a range of devices, including smartphones, tablets, cameras, and laptops. All you need to do unfold them and place them in direct sunlight to use foldable solar panels. Once the Solar Panel have absorbed sunlight connect your device enough to the USB port, and it will start charging.
How to use Solar foldable Panels
Using foldable panels solar is easy, and it only takes a few steps simple. First, unfold the panels and place them in direct sunlight. Make sure the panels are positioned at the right angle to receive sunlight maximum. Once the panels have absorbed sunlight enough connect your device to the USB port, and it will start charging.
Service and Quality of Foldable Solar Panels
When buying foldable solar panels, it is crucial to choose a brand reliable for quality products and customer service excellent. Look for panels that are made from high-quality materials, with safety features and conversion efficient of energy. It is also essential to check the warranty period and the ongoing service after-sale by the brand.
Application of Foldable Solar Panels
Foldable panels solar is perfect for people who love outdoor activities such as camping, hiking, and backpacking. They are also ideal for emergency preparedness kits and power outage situations at home. With foldable panels solar you can stay charged and connected on the go without worrying about running out of power.
Source: https://www.dhceversaving.com/Wind-solar-hybrid-power-system | skcms_kskee_db3d23538e2f3 | |
1,871,825 | [yft-design] Image designer based on fabric.js | A beautiful and powerful online design tool, with poster design and picture editing functions,... | 0 | 2024-05-31T08:53:34 | https://dev.to/morestrive/yft-design-image-designer-based-on-fabricjs-4gag | javascript, vue, fabricjs, onlinedesign | A beautiful and powerful online design tool, with poster design and picture editing functions, applicable to a variety of scenes, such as poster generation, e-commerce product map production, article long map design, video/official account cover editing, etc
### template

### layer

[Github](https://github.com/dromara/yft-design)
[Demo](https://yft.design) | morestrive |
1,871,824 | How to Switch from HTTPS to SSH for GitLab Repositories | Switching from HTTPS to SSH for GitLab repositories can enhance your security and streamline your... | 0 | 2024-05-31T08:48:16 | https://dev.to/mochafreddo/how-to-switch-from-https-to-ssh-for-gitlab-repositories-2b4o | git, ssh, versioncontrol, programmingtips | Switching from HTTPS to SSH for GitLab repositories can enhance your security and streamline your workflow. If you have already cloned your repository using HTTPS and want to switch to SSH, follow these steps:
#### 1. Generate an SSH Key
First, generate an SSH key if you haven't already:
```bash
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
```
Replace `your_email@example.com` with your GitLab email. Press enter to accept the default file location and passphrase options.
#### 2. Add Your SSH Key to GitLab
After generating the SSH key, add it to your GitLab account:
1. Copy the public key to your clipboard:
```bash
cat ~/.ssh/id_rsa.pub
```
2. Log in to GitLab, navigate to **Settings** > **SSH Keys**.
3. Paste the public key into the "Key" field.
4. Add a title for the key and click **Add key**.
#### 3. Change the Remote URL of Your Existing Repository
If you've already cloned your repository using HTTPS, you can change it to SSH with the following steps:
1. In your terminal, navigate to your cloned repository:
```bash
cd path/to/your/repository
```
2. Change the remote URL to SSH:
```bash
git remote set-url origin git@gitlab.com:username/repository.git
```
Replace `username/repository` with your actual GitLab username and repository name.
3. Verify the change:
```bash
git remote -v
```
The output should display the SSH URL for both fetch and push operations:
```
origin git@gitlab.com:username/repository.git (fetch)
origin git@gitlab.com:username/repository.git (push)
```
#### 4. Push Changes Using SSH
Now you can use the usual Git commands to push changes using SSH:
```bash
git add .
git commit -m "Your commit message"
git push origin main
```
#### Benefits of Using SSH
Using SSH keys provides a more secure and convenient way to authenticate with GitLab:
- **Security**: SSH keys are cryptographically secure, reducing the risk of your credentials being compromised.
- **Convenience**: Once set up, SSH keys allow you to push and pull from your repositories without entering your username and password every time.
Switching from HTTPS to SSH for your GitLab repositories is a simple process that can significantly enhance your development workflow. By following these steps, you can ensure a more secure and efficient method of interacting with your Git repositories. | mochafreddo |
1,871,822 | Debugging in VSCode: Tips and Tricks for Efficient Debugging | Debugging is an essential part of the software development process. It involves identifying,... | 0 | 2024-05-31T08:45:33 | https://dev.to/umeshtharukaofficial/debugging-in-vscode-tips-and-tricks-for-efficient-debugging-3757 | webdev, vscode, devops, programming | Debugging is an essential part of the software development process. It involves identifying, analyzing, and fixing issues within the code to ensure that it functions correctly. Visual Studio Code (VSCode) is one of the most popular code editors among developers due to its versatility, lightweight nature, and extensive range of features, including robust debugging tools. This article provides a comprehensive guide to efficient debugging in VSCode, sharing tips and tricks to streamline your debugging process and enhance your productivity.
## Why Debugging in VSCode?
### Integrated Development Environment
VSCode offers an integrated development environment that combines code editing, debugging, and version control in a single platform. This integration allows for seamless transitions between writing code, testing it, and debugging it, enhancing overall productivity.
### Multi-Language Support
VSCode supports a wide range of programming languages, making it a versatile tool for developers working on diverse projects. The debugging tools in VSCode can be customized for different languages, ensuring that you have the necessary resources regardless of the technology stack you are using.
### Extensibility
VSCode's rich extension ecosystem allows you to enhance its debugging capabilities with additional tools and features. Whether you need specialized debuggers or enhanced visualization tools, the VSCode marketplace has a plethora of extensions to choose from.
## Setting Up Debugging in VSCode
Before diving into specific debugging tips and tricks, it’s essential to set up your debugging environment in VSCode. Here’s how you can get started:
### 1. Install the Necessary Extensions
Depending on the programming language you are using, you might need to install specific extensions to enable debugging capabilities. For example:
- **Python:** Install the "Python" extension.
- **JavaScript/TypeScript:** VSCode includes built-in support for JavaScript and TypeScript debugging.
- **C/C++:** Install the "C/C++" extension.
You can find and install extensions by navigating to the Extensions view (`Ctrl+Shift+X` on Windows/Linux or `Cmd+Shift+X` on Mac) and searching for the required extension.
### 2. Configure Launch Settings
To configure the debugging environment, you need to create a `launch.json` file. This file defines the settings and parameters for launching your application in debug mode. You can create it by following these steps:
1. Open the Command Palette (`Ctrl+Shift+P` on Windows/Linux or `Cmd+Shift+P` on Mac).
2. Type "Debug: Open launch.json" and select it.
3. Choose the environment that matches your project (e.g., Python, Node.js, etc.).
VSCode will generate a `launch.json` file with default configurations, which you can customize according to your needs.
### 3. Set Breakpoints
Breakpoints are markers that you can set in your code to pause execution at specific lines. To set a breakpoint:
- Click in the gutter next to the line number where you want to pause execution.
- Alternatively, you can place the cursor on the line and press `F9`.
You can also set conditional breakpoints, log points, and function breakpoints to control the execution flow more precisely.
## Tips and Tricks for Efficient Debugging in VSCode
### 1. Mastering the Debugging Interface
VSCode's debugging interface includes several components:
- **Debug Sidebar:** Provides an overview of breakpoints, call stack, variables, and watch expressions.
- **Debug Toolbar:** Contains controls for starting, stopping, and stepping through code.
- **Debug Console:** Allows you to evaluate expressions, execute commands, and interact with the debugger.
Familiarizing yourself with these components will help you navigate the debugging process more efficiently.
### 2. Using Watch Expressions
Watch expressions allow you to monitor specific variables or expressions as you step through your code. To add a watch expression:
1. Open the Debug Sidebar.
2. Click the `+` icon in the "WATCH" section.
3. Enter the expression you want to monitor.
This feature is particularly useful for tracking the values of variables and expressions that are critical to your application's logic.
### 3. Exploring the Call Stack
The call stack view shows the sequence of function calls that led to the current point in the program's execution. This view is invaluable for understanding the flow of execution and identifying where things might have gone wrong. You can navigate through the call stack to inspect the state of the program at different points in its execution.
### 4. Evaluating Expressions in the Debug Console
The Debug Console allows you to evaluate expressions and execute commands in the context of the paused program. This feature is useful for testing hypotheses, inspecting variable values, and manipulating the program state without modifying the source code. Simply type the expression or command in the console and press Enter.
### 5. Utilizing Conditional Breakpoints
Conditional breakpoints pause execution only when a specified condition is met. This feature is useful for isolating specific scenarios or debugging complex loops. To set a conditional breakpoint:
1. Right-click on an existing breakpoint.
2. Select "Edit Breakpoint".
3. Enter the condition in the input box.
The debugger will pause execution only when the condition evaluates to true.
### 6. Log Points for Non-Intrusive Debugging
Log points allow you to log messages to the Debug Console without pausing execution. This feature is useful for adding debug logging to your code without modifying the source code. To set a log point:
1. Right-click on the gutter next to the line number.
2. Select "Add Logpoint...".
3. Enter the log message.
Log points are a great way to gather insights without disrupting the program flow.
### 7. Step Through Code
VSCode provides several options for stepping through code:
- **Step Over (`F10`)**: Executes the current line of code and moves to the next line. If the current line contains a function call, the debugger will execute the entire function and pause at the next line in the current function.
- **Step Into (`F11`)**: Moves into the function call on the current line, pausing at the first line of the called function.
- **Step Out (`Shift+F11`)**: Executes the remaining lines of the current function and pauses at the return point of the calling function.
These options allow you to control the flow of execution and inspect the state of the program at each step.
### 8. Running and Debugging Tests
VSCode integrates with popular testing frameworks, allowing you to run and debug tests directly from the editor. For example, if you are using the "Python" extension, you can configure your tests using `unittest`, `pytest`, or `nose`. Once configured, you can run tests and debug them using breakpoints and other debugging tools.
### 9. Leveraging Debugging Extensions
There are several extensions available in the VSCode marketplace that can enhance your debugging experience. Some popular ones include:
- **Debugger for Chrome:** Allows you to debug JavaScript code running in Google Chrome.
- **Python Test Adapter:** Integrates with Python testing frameworks for easier test management and debugging.
- **Live Share:** Enables collaborative debugging sessions, allowing team members to debug together in real-time.
These extensions can provide additional features and streamline your debugging workflow.
### 10. Debugging Remote Processes
VSCode supports remote debugging, which allows you to debug applications running on remote servers or in containers. This feature is particularly useful for debugging production issues or working with distributed systems. To set up remote debugging:
1. Configure the remote environment to allow debugging connections.
2. Create a `launch.json` configuration with the appropriate remote settings.
3. Connect to the remote debugger using VSCode.
This setup allows you to leverage VSCode's powerful debugging tools in remote environments.
## Conclusion
Efficient debugging is crucial for delivering high-quality software, and VSCode provides a comprehensive suite of tools to support this process. By mastering VSCode's debugging features and incorporating the tips and tricks outlined in this article, you can streamline your debugging workflow, reduce the time spent resolving issues, and enhance your overall productivity.
From setting up the debugging environment and configuring launch settings to using advanced features like conditional breakpoints, watch expressions, and remote debugging, VSCode offers a robust platform for tackling even the most complex debugging challenges. By leveraging these tools and practices, you can ensure that your code is reliable, efficient, and ready for production.
Embrace the power of VSCode's debugging capabilities, and take your software development process to the next level. Whether you are a seasoned developer or just starting, these tips and tricks will help you become more proficient in debugging and enable you to deliver high-quality code with confidence. | umeshtharukaofficial |
1,871,406 | How to Implement Redux-Saga in React with TypeScript | Efficiently Handle State Management in React TypeScript applications with React-Redux, Redux-Saga, and Redux Toolkit. | 0 | 2024-05-31T08:44:04 | https://dev.to/rashedul_alam/how-to-implement-redux-saga-in-react-with-typescript-5cg | ---
title: How to Implement Redux-Saga in React with TypeScript
published: true
description: Efficiently Handle State Management in React TypeScript applications with React-Redux, Redux-Saga, and Redux Toolkit.
tags:
# cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/iny2qwvik6glz5zyf3be.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-30 21:22 +0000
---
## How Redux-Saga with React-Redux works
Let’s see the following diagram to understand better:
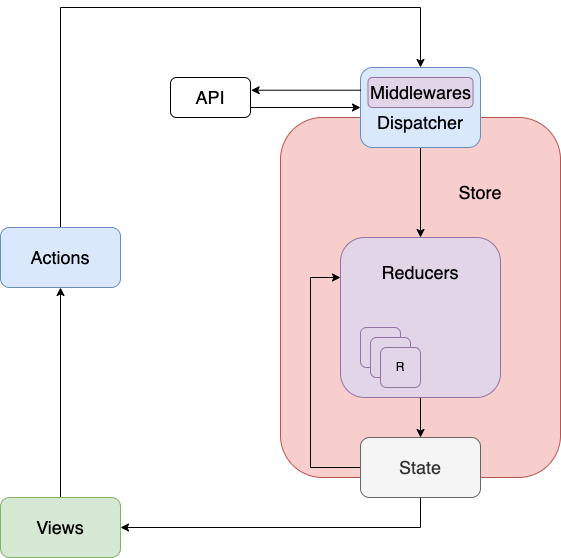
Redux-Saga and React-Redux work together to manage asynchronous operations (like API calls) and side effects (like data manipulation) in React applications.
When a React component dispatches an action (e.g., “FETCH_DATA”) to the Redux store, it passes through Redux middleware, including Redux-Saga. Redux-Saga triggers the corresponding saga function if a saga is “watching” for that specific action type.
This saga function, written using generators, manages the asynchronous flow. It might make an API call using libraries like Axios or fetch. The saga can also perform other actions, like waiting for promises to resolve or dispatching new actions based on conditions.
Once the saga finishes its work (e.g., receiving data from the API), it might dispatch a new action to update the Redux store state. React components connected to the store using React-Redux will detect this state change and re-render themselves with the updated data, reflecting the results of the asynchronous operation in the UI.
### Let’s jump into the implementation.
First, let’s create a new React project by running the following command:
```sh
npm create vite@latest react-redux-saga-example -- --template react-ts
```
### Installing Packages
After creating a React project, let’s configure the project structure. Let’s first install React-Redux, Redux Toolkit, and Redux Saga. We can install these packages by running the following command:
```sh
npm install react-redux @reduxjs/toolkit redux-saga
```
Let’s also install other necessary packages which will be required in the future:
```sh
npm install axios react-router-dom
```
### Setup
After we install the necessary packages, let’s implement our project structure like the following:

Here, we can see some folders. Let’s discuss one by one:
1. **Constants**: Contains some constant variables that can be used in multiple files and components.
2. **lib**: Contains useful functions and libraries.
3. **pages**: Contains different page components that will be rendered based on route URL.
4. **store**: All the logic for `react-redux` and `redux-saga` goes into the store folder.
5. **types**: Contains necessary types based on project domain and scope.
*[**Note:** This project can be found in this [SlackBlitz repo](https://stackblitz.com/edit/vitejs-vite-7cxqwy). So be sure to check that out.]*
### Understanding Redux Saga and React Redux
Now, let’s first create `store/index.ts` and paste the following code:
```ts
import createSagaMiddleware from '@redux-saga/core';
import { configureStore } from '@reduxjs/toolkit';
import rootReducers from './root-reducer';
import rootSaga from './root-saga';
const sagaMiddleware = createSagaMiddleware();
const store = configureStore({
reducer: rootReducers,
middleware: (getDefaultMiddleware) =>
getDefaultMiddleware().concat(sagaMiddleware),
});
sagaMiddleware.run(rootSaga);
export default store;
```
This file configures the store to work with Reducer and integrate with redux-saga middleware. Don’t worry about the `rootReducers` and `rootSaga` for now, we will touch them eventually.
Let’s now create `root-reducer.ts` inside the same `store` folder, and paste the following code:
```ts
import usersReducer from './slices/users.slice';
import { UsersStateType } from '../types/user.types';
export type StateType = {
users: UsersStateType;
};
const rootReducers = {
users: usersReducer,
};
export default rootReducers;
```
In this code, we combine all the reducers to pass them into the store configuration.
Let’s now create the user reducer in the `store/slices/users.slice.ts` file and paste the following code:
```ts
import { createSlice, PayloadAction } from '@reduxjs/toolkit';
import { USERS, UsersStateType, UserType } from '../../types/user.types';
const usersInitialState: UsersStateType = {
user: {
data: null,
isLoading: false,
errors: '' as unknown,
},
list: {
data: [],
isLoading: false,
errors: '' as unknown,
},
};
export const usersSlice = createSlice({
name: USERS,
initialState: usersInitialState,
reducers: {
getUserAction: (
state: UsersStateType,
{ payload: _ }: PayloadAction<string>
) => {
state.user.isLoading = true;
state.user.errors = '';
},
getUserSuccessAction: (
state: UsersStateType,
{ payload: user }: PayloadAction<UserType>
) => {
state.user.isLoading = false;
state.user.data = user;
},
getUserErrorAction: (
state: UsersStateType,
{ payload: error }: PayloadAction<unknown>
) => {
state.user.isLoading = false;
state.user.errors = error;
},
getUserListAction: (state: UsersStateType) => {
state.list.isLoading = true;
state.list.errors = '';
},
getUserListSuccessAction: (
state: UsersStateType,
{ payload: list }: PayloadAction<UserType[]>
) => {
state.list.isLoading = false;
state.list.data = list;
},
getUserListErrorAction: (
state: UsersStateType,
{ payload: error }: PayloadAction<unknown>
) => {
state.list.isLoading = false;
state.list.errors = error;
},
},
});
export default usersSlice.reducer;
```
Here, we are implementing `usersSlice` using the `createSlice` method from the `redux-toolkit`. We are defining all the possible actions and returning the user reducer created from the `usersSlice`. Then, we pass the `userReducer` to the root reducer object.
Let’s now create our user saga to get the resources from the API. Let’s create `store/sagas/users.saga.ts` and paste the following code:
```ts
import { PayloadAction } from '@reduxjs/toolkit';
import { AxiosResponse } from 'axios';
import { put, takeLatest } from 'redux-saga/effects';
import { usersSlice } from '../slices/users.slice';
import apiClient from '../../lib/apiClient';
import { ApiEndpoints } from '../../constants/api';
import {
GET_USER_BY_ID,
GET_USER_LIST,
UserType,
} from '../../types/user.types';
function* getUserSaga({ payload: id }: PayloadAction<string>) {
try {
const response: AxiosResponse<UserType> = yield apiClient.get(
`${ApiEndpoints.USERS}/${id}`
);
yield put(usersSlice.actions.getUserSuccessAction(response.data));
} catch (error) {
yield put(usersSlice.actions.getUserErrorAction(error as string));
}
}
function* getUserListSaga() {
try {
const response: AxiosResponse<UserType[]> = yield apiClient.get(
`${ApiEndpoints.USERS}`
);
yield put(usersSlice.actions.getUserListSuccessAction(response.data));
} catch (error) {
yield put(usersSlice.actions.getUserListErrorAction(error as string));
}
}
export function* watchGetUser() {
yield takeLatest(GET_USER_BY_ID, getUserSaga);
yield takeLatest(GET_USER_LIST, getUserListSaga);
}
```
Here, we fetch the API responses using the [generator function](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/function*) and yield the returned objects to the redux-saga middleware.
### Let’s see the API responses in action
First, let’s add the react-redux provider in our root component:
```ts
import React from 'react';
import ReactDOM from 'react-dom/client';
import { Provider } from 'react-redux';
import App from './App.tsx';
import store from './store/index.ts';
import './index.css';
ReactDOM.createRoot(document.getElementById('root')!).render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
);
```
Now, let’s see the below component how we can show the response in our component:
```ts
import { useEffect } from 'react';
import { useDispatch, useSelector } from 'react-redux';
import { StateType } from '../store/root-reducer';
import { usersSlice } from '../store/slices/users.slice';
import { Link } from 'react-router-dom';
import { PageRoutes } from '../constants/page-routes';
function Users() {
const { list } = useSelector((state: StateType) => state.users);
const dispatch = useDispatch();
useEffect(() => {
dispatch(usersSlice.actions.getUserListAction());
}, []);
return (
<div>
{list.isLoading ? (
<span>Loading...</span>
) : list.data && list.data.length > 0 ? (
<div>
{list.data.map((user) => (
<div key={user.id}>
<Link to={`${PageRoutes.USERS.HOME}/${user.id}`}>
{user.name}
</Link>
</div>
))}
</div>
) : (
<span>No users found!</span>
)}
</div>
);
}
export default Users;
```
It will render the following display in our browser:

That’s all in this article! I hope you enjoy it.
Have a great day!
| rashedul_alam | |
1,871,793 | Connecting Azure SQL-Database and App Service using system-assigned identity | I had built an application using an Azure SQL-Database for storage and I wanted to upload it to Azure... | 0 | 2024-05-31T08:44:01 | https://dev.to/charliefoxtrot/connecting-azure-sql-database-and-app-service-using-system-assigned-identity-1jf | azure, sqlserver, identity, dotnet | I had built an application using an Azure SQL-Database for storage and I wanted to upload it to Azure as an App Service to run it in the cloud. I had assumed it was going to be like connecting an App Service to BlobStorage or TableStorage in Azure, but it turns out it is a bit different for a SQL-Database. Primarily how the system-assigned identity is used to authenticate. After figuring out how to get it to work, I decided to write the short guide I myself would have wanted to find when I started googling on why I couldn’t connect to my database.
## Creating the database
To create a database we will first have to create a SQL-Server resource to host the database. When creating we will use the **Authentication Method** “Use Microsoft Entra-only authentication”, and set ourselves as Admin for the server.
To allow other azure resources to access our new server we have to go to Security > Networking. There we select to give public network access to “Selected networks”.
We then add our own IP Address to the Firewall Rules since we will want to test connecting to our SQL-Server locally. It is also needed to log in to our SQL-database in Azure Portal later.
In the special case that your App Service and SQL-Server will be in different Azure Subscriptions. you will have to check “Allow Azure services and resources to access this server” under Exceptions. Note that this is a big risk since it opens up your SQL-Server to EVERY Azure service and resource, even those belonging to other subscriptions and other Azure users, customers and organizations. To be secure there are solutions using virtual networks and configuring Private Access. But this is not included in the scope of this tutorial, so we will accept the shortcut of allowing this exception. This can also be a tool for troubleshooting if you suspect you have problems with connecting to the SQL-Server.

Next step is to create the SQL Database, so go to Overview and select Create Database. In the tutorial we assume the database is only for learning purposes so we want to keep costs as low as possible. So for Compute + Storage we select “Configure database” and slide the vCores and Data max Size to their lowest settings.
Then for **Backup storage redundancy** we select “Locally-redundant backup storage”, the weakest kind.
When the resource has been created, go to **Query editor (preview)** and log in with Microsoft Entra authentication. If it does not work make sure you have whitelisted your own IP.
We then create a new table by running:
```
CREATE TABLE animals (id INT PRIMARY KEY, name VARCHAR(100));
```
This creates a very simple table called “animals” where we can list different kinds of animals. Add a few animals:
```
INSERT INTO [dbo].[animals] (id, name) VALUES (1, 'Lion');
INSERT INTO [dbo].[animals] (id, name) VALUES (2, 'Fox');
INSERT INTO [dbo].[animals] (id, name) VALUES (3, 'Cat');
```
You can then see your animals by running:
```
SELECT * FROM [dbo].[animals]
```
And you can count them by running:
```
SELECT COUNT(*) FROM [dbo].[animals]
```
## Creating the code
We will now build a small C# program that connects to the SQL Database and runs the SQL-command for counting the animals. Create a new ASP.NET Core Empty project in Visual Studio.
This gives you a project with only a Program.cs with minimal amount of code. We will be able to write our whole program here. First thing to do is to install the NuGet Microsoft.Data.SqlClient;
We then create a minimal api to connect to our SQL-database and execute the command to count our animals, and delete the auto-generated code we won’t need. This leaves us with a Program.cs like:
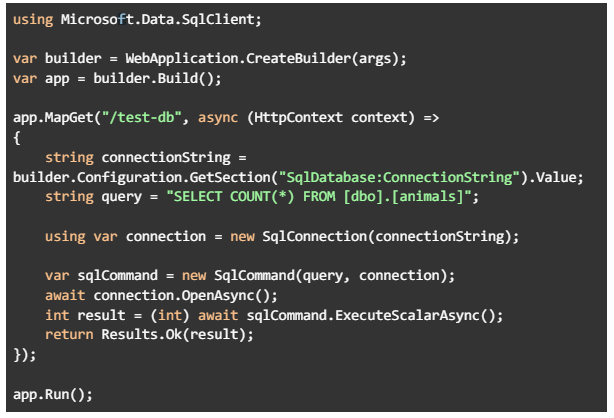
Then we go to Overview in your database-resource and select “See connection strings” under **Connect to application**. Take the connection string for “ADO.NET (Microsoft Entra passwordless authentication)” and put it into your appsettings of the newly created project.
For me, where both SQL-Server and SQL-database are named “charlie-foxtrot-sql” it will look like:

(Note1: Treat your Connection Strings as secrets, the resources my connection string are referencing will have been deleted when this tutorial is published)
(Note2: In the connection string you can see that we set authentication to be “Active Directory Default”. Entra ID used to be called Active Directory. This setting means that we can authenticate with our account assigned in visual studio when we run locally, and with managed identities given certain roles when we run it as an App Service)
Then run your program and make a call to the /test-db endpoint. You can do this using swagger, your favorite testing tool (e.g Postman or Insomnia) or your web browser.
If you get an error “Globalization Invariant Mode is not supported” you’ll have to unload your project and remove

from your project file (or set it to false). Then load the project again.
If you get trouble with authentication, make sure you are using the same account for Azure Service Authentication in Visual Studio as you used to create the SQL-Server and database in Azure, and that the account has the proper IAM-role to access them. You can check this under Access Control (IAM) for your SQL-Server.
You should then get a response that corresponds to the value you get by running the count-command directly in the Query Editor in Azure Portal.
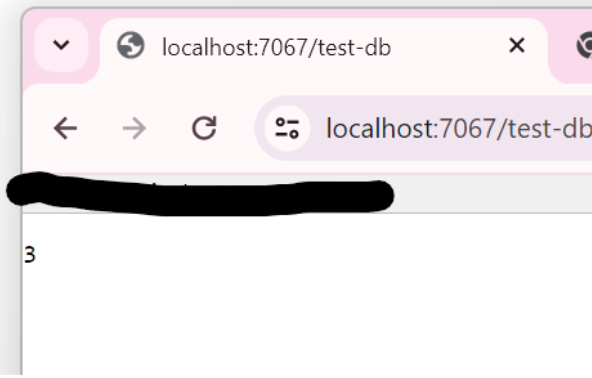
Now we will create an App Service to run this code in Azure.
## Creating the App Service
Create a repository for the code in Github (or Azure DevOps or Bitbucket), and push your code, except for your appsettings, to it. We will deploy the code to our App Service from there.
In Azure Portal, go to App Services and press Create > Web App and create your App Service. Then we have to connect our App Service to Github so that it knows which code to deploy. We get two options for Github Action workflow to authenticate to our App Service when deploying; the default “User-assigned identity” and “Basic authentication”. If you have sufficient permissions to use “User-assigned identity” that is recommended. You need to be able to assign role-based access to the identity. If you lack these permissions you can instead use “Basic authentication”.
If you use “Basic authentication” you first have to go to Settings > Configuration in your App Service and put SCM Basic Auth Publishing Credentials to **On** and press Save. If you use “User-assigned identity” you don’t have to do this.
Then go to Deployment > Deployment Center and choose your Source for the code. Choose your way of authentication and press Save.
Make sure that it builds. Then go to Settings > Environment variables and add your connection string.

Make sure you click Apply once after adding this applications setting, then once again to confirm you are done editing your application settings in general.
_Note the naming of the Application Setting and compare it to how it is in your local appsettings.json. This is how Azure deals with hierarchy in JSON;_
```
"Level1": {
"Level2": {
"Level3:": "Value",
}
},
```
_would in the Azure App Service application settings become a setting with the name
"Level1:Level2:Level3" and the value “Value”._
Then go to Settings > Identity and set Status to **On** for System Assigned identity. Remember to save.
For most resources in Azure you would then give a role to this managed identity that let the App Service access it. This is called Role-Based Access Control (RBAC). But for Azure SQL Database we have to do it in a different way; We want to add our App Service as a user to the database and then give the user read and write permissions. So go to the Query Editor in your database and run
```
CREATE USER [<appservice>] FROM EXTERNAL PROVIDER;
```
where <appservice> is the name of your App Service. Then run both
```
ALTER ROLE db_datareader ADD MEMBER [<appservice>];
ALTER ROLE db_datawriter ADD MEMBER [<appservice>];
```
to give the new role proper permissions.
(Note: In our code we are only reading from the database, but the common case is to want both read and write permissions.)
Now you can go to your App Service Overview where you will see which “Default Domain” your app has

go to the test-endpoint of this domain. My App Service is called charlie-foxtrot-sql so for me it is https://charlie-foxtrot-sql.azurewebsites.net/test-db. This should now show you the number of animals in your database.
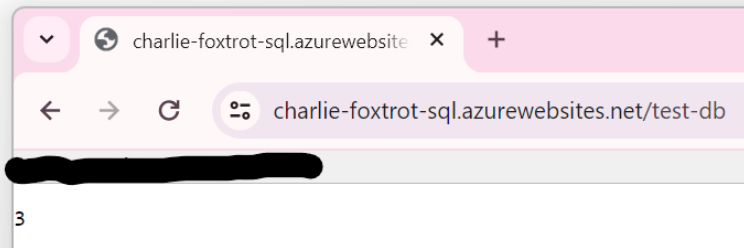
| emil_pettersson_e7280e3cd |
1,871,821 | Seamlessly Upload and Download Files to SharePoint/OneDrive Using Python | 🚀 New Article Alert! 🚀 Hey developers! 👋 I just published a new tutorial on leveraging Python for... | 0 | 2024-05-31T08:42:36 | https://dev.to/aditya2806pawar/seamlessly-upload-and-download-files-to-sharepointonedrive-using-python-1fhh | 🚀 New Article Alert! 🚀
Hey developers! 👋 I just published a new tutorial on leveraging Python for seamless file management in SharePoint/OneDrive. If you're tired of manual file uploads and downloads, this one's for you! 🐍💻
Title: Seamlessly Upload and Download Files to SharePoint/OneDrive Using Python
In this tutorial, I cover:
Setting up authentication with SharePoint/OneDrive
Uploading and downloading various file types, including Excel, CSV, and pickle files
Practical Python scripts to streamline your data management workflow
Whether you're a data scientist, software engineer, or just curious about automation, this article has something for everyone.
🔗 [Read the full article on Medium](https://medium.com/@aditya2806pawar/seamlessly-upload-and-download-files-to-sharepoint-onedrive-using-python-546f9f06b09d)
I'd love to hear your thoughts and feedback! Drop a comment on the Medium article or connect with me here. Happy coding! 🎉
#Python #DataScience #SharePoint #OneDrive #Automation #Tech #Developer #Programming | aditya2806pawar | |
1,871,819 | Innovative Uses for Foldable Solar Panels in Outdoor Activities | Solar panels are becoming increasingly popular as a supply sustainable of. Introduction Solar panels... | 0 | 2024-05-31T08:38:58 | https://dev.to/skcms_kskee_db3d23538e2f3/innovative-uses-for-foldable-solar-panels-in-outdoor-activities-4n | solarpanel, solar, energy | Solar panels are becoming increasingly popular as a supply sustainable of.
Introduction
Solar panels are becoming increasingly popular as a supply sustainable of. One innovation that has emerged in the last few years is foldable panels which are solar. These panels can be simply carried and therefore are well suited for use within outside activities such as for example camping, hiking, and fishing. Let's explore a number of the benefits, innovative uses and safety measures associated with using foldable solar panel systems in outdoor tasks.
Advantages
One benefit significant of Wind Solar Hybrid Power System is the portability. They may be effortlessly folded and kept in a backpack, taking on very area little. Furthermore, they're lightweight, making them convenient to carry.
Another advantage is these are typically eco-friendly, maybe not emitting any fumes or carbon dioxide, unlike old-fashioned generators which are fuel-based. This makes them ideal for outside activities, since they are peaceful plus don't disturb the environmental surroundings natural. They are also cost-effective, because they don't require any fuel.
Innovation
Foldable panels being solar innovative due to their portability. They are able to generate electricity out-of-doors, making them a game-changer for outdoor adventurers. A change is developed by them in consumer behaviour, as more individuals are buying sustainable power solutions.
Safety
One safety essential when working with these solar panels would be to spot them in a place that receives a whole lot of sunshine. The panels must get sunlight to come up with power maximum. Then a amount of Wind Power Generation System is quite a bit reduced if the panels are put in a shaded area.
Another security measure would be to make sure that the panels which are solar put on stable ground. If the panels are positioned on uneven ground, they might fall over, leading to injury or damage. Additionally be careful to address the panels with care, because they are delicate and that can break easily.
Use
Foldable solar panel systems can be used to charge electronics such as for instance smart phones, tablets, and speakers that are outside. They are able to also power camping lights, little refrigerators, and other appliances which can be outdoor-related. Moreover, using the advancement of technology, foldable solar panel systems can now be used to charge vehicles that are electric.
Utilizing
To use foldable solar panel systems, follow these steps which are simple.
Unfold the panels
Put them in a place that receives sunshine direct
Link your devices that are electronic the USB slot on the panel
Track the power created by checking the indicators that are LED
When the products are fully charged, switch the panels off and fold them
Service and Quality
When purchasing foldable panels being solar it is essential to ensure they have been of good quality. Check the specs to find out if they can generate power enough charge your devices. Additionally it is advisable to obtain reputable dealers who are able to provide service after-sales help in case there is any issues.
Application
Foldable panels that are Solar Energy System perfect for outdoor adventures, nonetheless they have other applications too. For instance, they could be found in emergency situations, such as for example power outages caused by natural disasters. They can also be used in rural areas, where there's absolutely no access to grid electricity.
Source: https://www.dhceversaving.com/Wind-solar-hybrid-power-system | skcms_kskee_db3d23538e2f3 |
1,859,590 | Time Traveling Through Your Repo: Git Reset vs. Revert | Once upon a commit, in the mystical realm of version control... jokes aside 😅. Wassup fellow git... | 0 | 2024-05-31T08:38:48 | https://dev.to/nguonodave/time-traveling-through-your-repo-git-reset-vs-revert-1en4 | git, learning, tutorial | Once upon a commit, in the mystical realm of version control... jokes aside 😅. Wassup fellow git adventurers! Today we'll be embarking on a journey through the mysterious realms of version control. We'll dive deep into the git universe to understand the mysterious powers of two commands: reset and revert. Buckle up, because this ride might get a bit bumpy, but fear not, for I shall guide you through with wit and wisdom!
#The Maverick Reset
Ah, the mighty **git reset**, a command so potent, it can make your HEAD spin. But wait! What is this enigmatic "HEAD" in the realm of git?
- It's like the captain's chair of your spaceship. It points to the current position within your repository. Picture it as the guiding compass of your git repository, pointing to the very tip of your current branch. It's the nucleus around which your commits orbit, determining what snapshot of your project you're currently viewing or altering.
- If you are on the master branch, HEAD will point to the latest commit on that branch. So when you hear about "resetting HEAD," it's like repositioning captain git's chair to a different point in space-time, perhaps to a previous commit or even a different branch altogether.
Back to our friend reset. Imagine you're in a time machine, and you want to teleport back to a previous commit. Well, git reset is your [DeLorean](https://delorean.com/), ready to whisk you away to the past. But beware, fellow time travelers, for with great power comes great responsibility! Git reset without caution can lead to catastrophic consequences. One wrong move, and poof! Your commits vanish into the digital abyss faster than you can say "commitment issues." So, before you hit that reset button, remember to backup your work.
Assuming the following is your commit history, let's talk about the responsibilities you'll have, going the maverick way:
```
C1 - C2 - C3 - C4 - C5
```
**Types of Reset**
- _<u>Soft Reset:</u>_ It's akin to a cautious peek into the time-traveling toolbox of coding. You move HEAD to a previous commit, but your changes stay staged, as if hitting the pause button on your code's journey through time. From the commit history above, say you want go back to C2. Running `git reset --soft <hash-for-C2>` or `git reset --soft HEAD~3` will uncommit the changes from C3 to C5, but will keep them staged. To get the hash for your commit, run `git log` then copy the desired hash. In **HEAD~3**, 3 is the number of steps it takes to get to C2. Hopefully your "head" is not spinning though. Pick the convention that suits you. Let's look at an example.
Suppose you have the following in your working environment.
```
.gitignore
app1.py
app2.py
```
You then decided to commit the two apps.
```
git add app1.py app2.py
git commit -m "feat: add apps"
```
Then later realized that you forgot to add the .gitignore file (meaning it is still unstaged), you can do the following.
```
# HEAD will get the very last commit
git reset --soft HEAD
git add .gitignore
git commit -m "feat: add apps and gitignore"
```
- <u>_Mixed Reset:_</u> Feeling a bit indecisive? This reset moves HEAD and resets the index to a previous commit, leaving your changes unstaged. Running `git reset <hash-for-C2>` will keep the changes from C3 to C5 unstaged. With the files in the example above, after committing the two apps, run `git reset HEAD`. Both the three files will then be unstaged, including the two that were initially committed.
**NOTE** that with mixed reset, you do not have to include the `--mixed` flag.
- <u>_Hard Reset:_</u> Ready to go all-in? Brace yourself, because this reset moves HEAD and resets both the index and working directory to a previous commit. It's like a cosmic eraser, wiping away your changes without mercy. Use with caution! To achieve it, run `git reset --hard <hash-commit-C2>`. This will do away with all the changes after C2 from your repository.
Let's take a look at an example by adding some files to the previous working tree. Assuming you committed the three files, then added one file. The new file (README.md) will be in an untracked status. Run `git add .` or `git add README.md`, according to your preference, to add it to your staging area then commit the changes, say, `git commit -m "docs: add readme"` Let's assume the hash for this commit will be 212w544. Your current working tree should now be as follows:
```
.gitignore
app1.py
app2.py
README.md
```
Now by running `git reset --hard <commit-hash-before-212w544>` the commit 212w544 will be discarded together with it's file (README.md). Your working tree should now be as follows:
```
.gitignore
app1.py
app2.py
```
**Ready to rewrite history?**
- After traversing the depths of time with your hard reset, it's now the moment to rewrite history. To discard the contents in your remote repository like github, gitea, or gitlab, run `git push <remote-name> <branch-name> --force`.
- This command will overwrite the history in the remote repository with the changes from your local repository, effectively discarding the unwanted changes.
**CAUTION!!!**
- In case you were working on a project with collaborators, this can potentially cause issues for those who have pulled the changes. Make sure to communicate with your team before force pushing to avoid conflicts.
- Ensure you have a backup of the remote repository in case you need to revert the changes.
#The Renegade Revert
Now, let's talk about git revert - the rebel with a cause, the anti-hero of version control. Unlike reset, which rewrites history like a stealthy ninja, revert takes a different approach. It acknowledges the past but refuses to let it define the future. Basically it's used to undo changes introduced by a specific commit, creating a new commit that reflects the reversal. It maintains a clear and linear history by documenting the reversal as a new commit.
**Here is how it works**
Suppose the following is your commit history:
```
C1 - C2 - C3 - C4 - C5
```
We want to undo the changes introduced by commit C2. Check the hash for your commit by running `git log`, then do the following:
```
git revert <hash-for-C2>
```
If you use the HEAD convention, it will be:
```
git revert HEAD~3
```
If there are conflicts during the revert process, resolve them manually. Git will guide you through the conflict resolution process.
After juggling with conflicts like a clumsy magician (sorry, what I mean is, after resolving all the conflicts), run `git revert --continue` to continue with the revert process. This will finally create a new revert commit, C6, that undoes the changes introduced in C2, leading to the following history:
```
C1 - C2 - C3 - C4 - C5 - C6
```
**Revert a revert**
- Some times you can find yourself in a git time loop, reverting a revert, undoing an undo.
- This often happens when you revert a commit only to realize it was a mistake, disrupting the fabric of your code continuum. But wait! Is that a glimmer of hope on the horizon? Yes, it's the git time machine offering you a chance to set things right.
- All you gotta do is `git log` to find the hash for the revert commit, in our case it will be the hash for C6.
- After getting the hash, run `git revert <hash-for-C6>`, which will create a new revert commit, C7, that undoes the undone changes introduced in C2, leading to the following history:
```
C1 - C2 - C3 - C4 - C5 - C6 - C7
```
The contents of the above history will be like when it started, as below:
```
C1 - C2 - C3 - C4 - C5
```
When you are done with your revert(s), if need be, `git push` the changes to your remote repository.
**Choose Your Destiny**
Your mission, should you choose to accept any of these methods, is to rewrite history without causing a paradox. If any of your projects vanish or get tangled in a time loop, the keyboards responsible for this article will disavow any knowledge of your actions. This article will never self-destruct... well, unless a glitch in the space-time continuum intervenes. Good luck git adventurers. Some of you might get the humor after traveling "back to the future" 😅. Essentially though you can:
- use _git reset_ when you want to rewind the HEAD or branch pointer, and you're okay with discarding changes.
- use _git revert_ when you want to undo changes in a public branch without rewriting history.
So, which path will you choose? Whichever path you take, experiment, explore, but always tread carefully. Until next time, cheerio 😁. | nguonodave |
1,871,817 | cua luoi chong muoi | Cửa lưới chống muỗi đang trở thành giải pháp phổ biến để bảo vệ sức khỏe tại các khu chung cư và nhà... | 0 | 2024-05-31T08:37:25 | https://dev.to/gicuavietnhat/cua-luoi-chong-muoi-d35 |
Cửa lưới chống muỗi đang trở thành giải pháp phổ biến để bảo vệ sức khỏe tại các khu chung cư và nhà phố. Với nhiều thương hiệu khác nhau trên thị trường, người tiêu dùng có thể gặp khó khăn trong việc lựa chọn sản phẩm phù hợp. Dưới đây là thông tin về một số thương hiệu cửa lưới chống muỗi nổi bật hiện nay, bao gồm Hoàng Minh, Hòa Phát và Việt Nhật.
Cửa lưới Hoàng Minh
Hoàng Minh là đơn vị cung cấp cửa lưới chống muỗi tại Hà Nội với hơn 5 năm kinh nghiệm. Thương hiệu này nổi bật với các sản phẩm có chất liệu và mẫu mã đa dạng, phù hợp với nhiều loại không gian gia đình. Hoàng Minh là một thương hiệu tư nhân mới nổi, đang dần khẳng định vị thế trên thị trường nhờ sự đa dạng và chất lượng sản phẩm.
Cửa lưới Hòa Phát
Hòa Phát là thương hiệu cửa lưới chống muỗi phát triển mạnh tại miền Bắc Việt Nam. Thương hiệu này được đánh giá cao về tính thẩm mỹ và chất lượng sản phẩm. Đội ngũ nhân viên của Hòa Phát luôn sẵn sàng hỗ trợ khách hàng với các sản phẩm mới phù hợp với đặc điểm khí hậu Việt Nam. Nhờ quy mô lớn, Hòa Phát có thể đáp ứng nhu cầu của khách hàng mọi lúc mọi nơi.
Cửa lưới Việt Nhật
Việt Nhật là thương hiệu uy tín tại cả Hà Nội và TP. Hồ Chí Minh, cung cấp các sản phẩm chất lượng cao với khung nhôm nhập khẩu từ Nhật Bản. Cửa lưới Việt Nhật nổi bật với độ bền cao, thời gian sử dụng lên đến 10-20 năm. Thương hiệu này cung cấp nhiều loại cửa lưới chống muỗi như cửa xếp, cửa lùa, và cửa tự cuốn, phù hợp với nhiều nhu cầu khác nhau của khách hàng.
Lựa chọn thương hiệu nào?
Mỗi thương hiệu đều có những ưu điểm riêng và được khách hàng đánh giá cao. Tuy nhiên, Việt Nhật nổi bật với chất lượng sản phẩm vượt trội, phù hợp nhất cho các căn hộ chung cư và nhà phố. Sản phẩm của Việt Nhật sử dụng nhôm cao cấp nhập khẩu từ Nhật Bản, quy trình kiểm định chất lượng nghiêm ngặt và thiết kế tinh tế, đảm bảo thẩm mỹ và độ bền cao.
Địa chỉ uy tín tại Hà Nội và Hồ Chí Minh
Cửa Lưới Cao Cấp Việt Nhật có mặt tại cả Hà Nội và TP. Hồ Chí Minh, cung cấp sản phẩm chất lượng cao và dịch vụ tận tâm. Đội ngũ kỹ thuật của Việt Nhật có thể thi công nhanh chóng, chỉ trong 30-60 phút. Công ty còn có hệ thống kho rộng lớn, đáp ứng nhu cầu sỉ lẻ của các đại lý và công trình lớn. Với chế độ bảo hành lên đến 5 năm, khách hàng sẽ được hỗ trợ và đồng hành trong suốt quá trình sử dụng sản phẩm.
Kết luận
Cửa lưới chống muỗi Việt Nhật là lựa chọn hàng đầu cho các căn hộ chung cư và nhà phố, nhờ chất lượng cao, thiết kế tinh tế và dịch vụ chuyên nghiệp. Thương hiệu này cung cấp các sản phẩm chống muỗi hiệu quả, góp phần bảo vệ sức khỏe cho gia đình bạn. #cualuoichongmuoi #luoichongmuoi #cualuoivietnhat
Website: https://xayladep.com/cua-luoi-chong-muoi.html
Phone: 0908387444
Address: 184 Nguyễn Hữu Cảnh, Phường 22, Bình Thạnh, Thành phố Hồ Chí Minh
https://www.kniterate.com/community/users/gscuavietnhat/
https://www.dnnsoftware.com/activity-feed/my-profile/userid/3199415
https://www.noteflight.com/profile/d8f6a3772cef71620b2aa55a7818da5f81fdbbc6
https://www.codingame.com/profile/6e17de47687f8c95661a6c28f1e145ca1820016
https://www.patreon.com/cuavietnhat586
https://www.are.na/cua-luoi-chong-muoi/channels
https://www.elephantjournal.com/profile/c-ual-uoiv-ietnhatthuduc/
https://piczel.tv/watch/cuavietnhat
https://camp-fire.jp/profile/kocuavietnhat
https://git.industra.space/cuavietnhat
https://stocktwits.com/locuavietnhat
http://idea.informer.com/users/atcuavietnhat/?what=personal
https://notabug.org/uhcuavietnhat
https://leetcode.com/u/cuavietnhat/
https://nhattao.com/members/cuavietnhat.6536273/
| gicuavietnhat | |
1,871,818 | Apple Makes changes to NFC policy | Here's what's happening: Apple is making changes to NFC access policy on its iPhones, allowing... | 0 | 2024-05-31T08:37:00 | https://dev.to/istoremd/apple-makes-changes-to-nfc-policy-o83 | Here's what's happening: Apple is making changes to NFC access policy on its [iPhones](https://istore.md/iphone), allowing competitors to use tap-and-go for payments. The European Commission must approve this, and we will soon know their decision. With this update, applications can be used as main wallets, appearing automatically when you double-click on the side button or when you instantly touch the device to the payment terminal.
Historically, Apple has controlled NFC on its iPhones due to security concerns. This has led to Apple Pay becoming the dominant contactless payment service. Two years ago, the European Commission accused Apple of limiting competition because of this.
In January, Apple offered competitors free access to NFC technology on their devices. Additionally, they offered additional features such as the ability to disable preferred payment apps and access to authentication features such as FaceID. This will allow iPhone users to download alternative wallets and use them for contactless payments.
| istoremd | |
1,871,815 | How to Choose the Right Wind Generator for Your Needs | How to Choose the Right Wind Generator to your requirements Introduction Wind turbines are innovative... | 0 | 2024-05-31T08:31:16 | https://dev.to/skcms_kskee_db3d23538e2f3/how-to-choose-the-right-wind-generator-for-your-needs-2971 | generator, wind, energy | How to Choose the Right Wind Generator to your requirements
Introduction
Wind turbines are innovative machines that will produce electricity utilizing the wind. They can be utilized to power homes, schools, and businesses. Nevertheless, choosing the right wind generator to your requirements can be quite a task confusing., we will talk about the advantages of wind generators, how exactly to select the right one, and how to utilize it.
Benefits of Wind Generators
Wind turbines have many benefits. First, they don't create any harmful emissions, making them an option environmentally friendly. 2nd, they're a power renewable, meaning that they don't deplete natural resources. Third, Wind Solar Hybrid Power System is available in many areas, meaning that it can be utilized in lots of locations.
Safety of Wind Generators
Wind turbines are typically safe to make use of, so long as they are maintained and set up precisely. Nonetheless, it's important to follow all security directions when working with and installing a wind turbine. Including utilizing the equipment appropriate such as for instance safety harnesses and helmets, and following all electric safety directions.
How to Choose the best Wind Generator
When selecting a wind turbine, there are several considerations. First, you will need to determine how electricity much need certainly to produce. This can depend on your time usage, how big your property, together with true number of people who can be utilizing the electricity.
Second, you'll want to look at the wind conditions in your town. Some Wind Power Generation System require high wind rates to create electricity, while some can create electricity in low wind conditions. Opt for the direction of the winds being prevailing your neighborhood, as this can impact the efficiency for the wind generator.
Third, you will need to look at the size regarding the wind turbine. This may depend on the quantity of room available for you for the generator, as well as the quantity of electricity you'll want to produce.
Fourth, you will need to look at the price of the wind generator. This may depend on the efficiency and size associated with the generator, also any installation and upkeep costs.
Finally, you need to think about the quality of the Wind Turbine together with ongoing service given by producer. You need to choose a generator durable, reliable, and has a warranty great.
How to Use a Wind Generator
Using a wind generator is rather easy. After the generator is set up, it shall start to create electricity if the wind blows. The electricity can then be used to energy lights, appliances, and other devices that are electrical.
Nevertheless, you should monitor the wind turbine regularly to make sure that it's working correctly. This includes checking the generator's production, as well as doing upkeep regular, such as for instance cleansing the blades and checking the wiring.
Source: https://www.dhceversaving.com/Wind-power-generation-system | skcms_kskee_db3d23538e2f3 |
1,871,814 | Moving Work from the Main Branch to a New Branch in Git | As developers, we sometimes find ourselves working on the main branch without realizing it. This can... | 0 | 2024-05-31T08:28:17 | https://dev.to/mochafreddo/moving-work-from-the-main-branch-to-a-new-branch-in-git-o60 | git, versioncontrol, softwaredevelopment, programmingtips | As developers, we sometimes find ourselves working on the `main` branch without realizing it. This can be problematic if we want to keep the `main` branch clean or if we need to create a separate feature branch for our work. Fortunately, Git provides an easy way to move your work from the `main` branch to a new branch. Here’s a step-by-step guide on how to do this.
#### Step 1: Commit Your Current Work on the Main Branch
Before creating a new branch, ensure that your current work on the `main` branch is committed. This step is crucial because any uncommitted changes might be lost during the branch switch.
Open your terminal and run the following commands:
```sh
git add .
git commit -m "Commit message describing your work"
```
#### Step 2: Create and Switch to a New Branch
Next, you need to create a new branch and switch to it. You can do this using a single command. Here, I’ll use `new-branch` as the example branch name. Replace it with your preferred branch name.
```sh
git checkout -b new-branch
```
This command does two things:
1. Creates a new branch named `new-branch`.
2. Switches your working directory to the newly created branch.
#### Step 3: Push the New Branch to the Remote Repository
Now that you’re on the new branch, it’s time to push it to the remote repository. This will ensure that your work is safely backed up and can be accessed by your team.
```sh
git push origin new-branch
```
#### Step 4 (Optional): Reset the Main Branch to Its Original State
If you want to revert the `main` branch to its original state (i.e., before you started your work), you can do so with the following commands. Be cautious with this step, as it will remove all the changes you made on the `main` branch.
First, switch back to the `main` branch:
```sh
git checkout main
```
Then, reset the `main` branch to match the remote repository:
```sh
git reset --hard origin/main
```
#### Step 5 (Optional): Keep Your Changes in the Main Branch
If you decide to keep your changes in the `main` branch as well, you can skip the reset step. This way, your changes will exist in both the `main` branch and the new branch.
#### Conclusion
By following these steps, you can easily move your work from the `main` branch to a new branch in Git. This practice helps in maintaining a clean `main` branch and enables better collaboration within your team. Remember, committing your work regularly and creating feature branches for new tasks are good habits that can save you from potential headaches in the future. | mochafreddo |
1,871,954 | Tutorial: Real-time Chat App in Rust with Rocket 🦀⌨️ | Hello, amazing people and welcome back to my blog! Today we will build a real-time chat application... | 0 | 2024-06-02T14:15:35 | https://eleftheriabatsou.hashnode.dev/tutorial-real-time-chat-app-in-rust-with-rocket | rust, rocket, chatapp | ---
title: Tutorial: Real-time Chat App in Rust with Rocket 🦀⌨️
published: true
date: 2024-05-31 08:24:48 UTC
tags: Rust, rustlang,Rocket,chatapp
canonical_url: https://eleftheriabatsou.hashnode.dev/tutorial-real-time-chat-app-in-rust-with-rocket
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ap69pk5c00nhoo0zlwh1.jpeg
---
Hello, amazing people and welcome back to my blog! Today we will build a real-time chat application in Rust using the [Rocket](https://rocket.rs/) framework.
In the past, I've written a tutorial on a [chat application](https://eleftheriabatsou.hashnode.dev/tutorial-chat-application-client-server-in-rust), but this one is way different and feels more modern. It also includes a UI whereas my previous one was [CLI-based](https://github.com/EleftheriaBatsou/chat-app-client-server-rust/).
{% embed https://twitter.com/BatsouElef/status/1796457586046521434 %}
## Introduction
One of the most popular server backend frameworks in Rust is Rocket, and one of the great things about Rocket is the documentation and examples repository, so I was inspired to create this project after checking [this](https://github.com/rwf2/Rocket/tree/v0.5-rc) repo.
**Let's start:**
After you create your Rust project, let's open up [cargo.toml](https://github.com/EleftheriaBatsou/chat-app-rocket-rust/blob/main/Cargo.toml) and add Rocket as a dependency. We'll also add the `rand` crate as a dev dependency. This is going to be useful later when we implement tests.
```ini
[dependencies]
rocket = { features = ["json"] }
[dev-dependencies]
rand = "0.8"
```
## Main.rs
Let's go to [main.rs](https://github.com/EleftheriaBatsou/chat-app-rocket-rust/blob/main/src/main.rs) and import `rocket`. We're importing `rocket` explicitly with the `macro_use` attribute so that all the `rocket` macros are imported globally. This means you can use `rocket` macros anywhere in your application, which is important because the `rocket` framework uses macros extensively.
`#[macro_use] extern crate rocket;`
### fn rocket()
After that, the first thing we'll do is to create a state and a rocket server instance.
```rust
#[launch]
fn rocket() -> _ {
rocket::build()
.manage(channel::<Message>(1024).0)
}
```
As you see from the code above, the `manage` method allows us to add state to our rocket server instance, which all handlers have access to. The state we want to add is a `channel`. Rocket uses `Tokyo` as an async runtime and channels are a way to pass messages between different async tasks.
Let's add `Tokio`:
`use rocket::tokio::sync::broadcast::{channel, Sender, error::RecvError};`
So, back to the `fn rocket()`, we're creating a channel and specifying what type of messages we'd like to send across the channel. In this case, a `Message` struct, which we haven't implemented yet. We also pass in a capacity `(1024)`, which is the amount of messages a channel can retain at a given time. The return value of calling the channel function is a tuple containing a sender and receiver end. At the end of this call, we write `.0` to get the first element in the tuple because we only want to store the sender end in state.
### struct Message
Now that we have our state set up, let's implement the `Message` struct. The `Message` struct has three fields: a `room` name, a `username`, and a `message`, all of which are `strings`. Also, some extra validation is added to `room` and `username`. The `room` name can only be up to `29` characters long and `username` can only be up to `19` characters long.
```rust
#[derive(Debug, Clone, FromForm, Serialize, Deserialize)]
#[cfg_attr(test, derive(PartialEq, UriDisplayQuery))]
#[serde(crate = "rocket::serde")]
struct Message {
#[field(validate = len(..30))]
pub room: String,
#[field(validate = len(..20))]
pub username: String,
pub message: String,
}
```
This struct is also deriving a few traits.
```rust
#[derive(Debug, Clone, FromForm, Serialize, Deserialize)]
#[serde(crate = "rocket::serde")]
```
* `Debug` so this struct could be printed out with debug format,
* `clone` so we can duplicate messages,
* `FromForm` so we can take form data and transform it into a message struct, and
* `serialize` and `deserialize`, which will allow this data structure to be serialized and deserialized. Serialization will happen via crate and the next attribute states that we want to use the crate defined in rocket. `#[serde(crate = "rocket::serde")]`
The `Message` struct defines the type of messages we want to send. Our real-time chat application is going to have rooms, users, and messages, so these three fields make sense. Now that we have our message defined, there's only one last thing to do, which is to implement our endpoints. Our chat application needs two endpoints, one endpoint to **post messages** and another endpoint to **receive messages**.
### Post messages
This route `#[post("/message", data = "<form>")]` matches against post requests to the message path and accepts form data.
```rust
#[post("/message", data = "<form>")]
fn post(form: Form<Message>, queue: &State<Sender<Message>>) {
// A send 'fails' if there are no active subscribers. That's okay.
let _res = queue.send(form.into_inner());
}
```
```rust
use rocket::form::Form;
```
The function handler accepts two arguments, the form data, which is going to be converted to the `Message` struct, and the server state, which is going to be a sender. Inside the body, we send the message to all receivers `queue.send(form.into_inner());`
The send method returns a `result` type because sending a message could fail if there are no receivers. In this project, I don't care about that case, so we're going to ignore it. 🙂
### Receive messages
This route `#[get("/events")]` handles `get` requests to the events path. The return type is an infinite stream of server-sent events `EventStream`. `EventStream` allow clients to open a long-lived connection with the server, and then the server can send data to the clients whenever it wants. This is similar to `WebSockets`, except it only works in one direction. The server can send data to clients, but the clients can't send data back to the server.
```rust
#[get("/events")]
async fn events(queue: &State<Sender<Message>>, mut end: Shutdown) -> EventStream![] {
.
.
}
```
Unlike the other handler functions we implemented, notice that this function is prefixed with `async`, that's because server-sent events are produced asynchronously. The handler takes two arguments, `queue`, which is our server state, and `end`, which is of type `Shutdown`. `Shutdown` is a feature which resolves when our server instance is `Shutdown`.
Inside the handler, the first thing we do is call `queue.subscribe()` to create a new receiver. This will allow us to listen for messages when they're sent down the channel. Next, we use generator syntax to yield an infinite series of server-sent events.
```rust
#[get("/events")]
async fn events(queue: &State<Sender<Message>>, mut end: Shutdown) -> EventStream![] {
let mut rx = queue.subscribe();
EventStream! {
loop {
let msg = select! {
msg = rx.recv() => match msg {
Ok(msg) => msg,
Err(RecvError::Closed) => break,
Err(RecvError::Lagged(_)) => continue,
},
_ = &mut end => break,
};
yield Event::json(&msg);
}
}
}
```
```rust
use rocket::{State, Shutdown};
use rocket::response::stream::{EventStream, Event};
use rocket::tokio::select;
```
Inside this infinite loop, the first thing we do is use the `select!` macro. `select!` waits on multiple concurrent branches and returns as soon as one of them completes. In this case, we only have two branches. The first one is calling receive on our receiver (`rx.recv()`), which waits for new messages. When we get a new message, we map it to `msg` and then `match` against that. `recv` returns a result `enum`:
* If we get the `Ok` variant, we simply return the message inside of it (`Ok(msg) => msg`)
* If we get the error variant and the error is closed (`Err(RecvError::Closed)`), that means there are no more senders so we can break out of the infinite loop
* If we get the error variant and the error is lagged (`Err(RecvError::Lagged(_)) => continue,`), that means our receiver lagged too far behind and was forcibly disconnected. In that case, we simply skip to the next iteration of the loop.
The second branch looks a little odd ( `_ = &mut end => break`), but what this is doing is waiting for the `Shutdown` feature to resolve. The `Shutdown` feature resolves when our server is notified to shutdown, at which point we can `break` out of this infinite loop.
Assuming we don't hit one of these break or continue statements, the `select` macro will return the message we got from our receiver, at which point we can yield a new server-sent event, passing in our message (`yield Event::json(&msg);`).
Yeah! Now both our routes are complete. But we're not yet done! 🤓
### Finish `fn rocket()`
The last thing we need to do is `mount` these `routes`. Let's go back to `fn rocket()`. We'll mount `post` and `events` to the `rootes` path.
`.mount("/", routes![post, events])`
Our backend is complete, but we also need a frontend. Before we start adding HTML files, let's `mount` a handler that will serve `static` files.
`.mount("/", FileServer::from(relative!("static")))`
Your `rocket()` should look like this:
```rust
#[launch]
fn rocket() -> _ {
rocket::build()
.manage(channel::<Message>(1024).0)
.mount("/", routes![post, events])
.mount("/", FileServer::from(relative!("static")))
}
```
## Front-end
Our `static` files need to be stored in a folder called `static`, so I'll create that folder. I'm not going to go into detail about the implementation of the frontend as it's out of the scope of this tutorial, but in the end you'll find the full source code.
As a quick overview, the front end consists of a simple `HTML` page, a couple `CSS` files, and a vanilla `JavaScript` file. The `JavaScript` file uses the `EventSource` object to establish a new connection with our server and listen for new messages. When a new message is received, it's parsed into `JSON` and appended to the `DOM`.
To send messages, a simple post request is dispatched.
```javascript
if (STATE.connected) {
fetch("/message", {
method: "POST",
body: new URLSearchParams({ room, username, message }),
}).then((response) => {
if (response.ok) messageField.value = "";
});
}
```
## Run the App
Hit `cargo run` into your terminal. Your server will run a localhost similar to this `8000`. Open up two web browsers and navigate to your localhost (mine is `8000` ) on both. Then pick two usernames for the field 'user'. Finally, send a message!
If you run this with me, you can see, the message appeared for user 1 and user 2 instantly. One thing to note is that we didn't implement any type of persistence, so if we refresh one of these web pages, all the messages will be lost. You could consider this a bug or a neat little security feature. 😏
## Source code
Find the code [here](https://github.com/EleftheriaBatsou/chat-app-rocket-rust/tree/main):
{% embed https://github.com/EleftheriaBatsou/chat-app-rocket-rust %}
Happy Rust Coding! 🦀
---
👋 Hello, I'm Eleftheria, **Community Manager,** developer, public speaker, and content creator.
🥰 If you liked this article, consider sharing it.
🔗 [**All links**](https://limey.io/batsouelef) | [**X**](https://twitter.com/BatsouElef) | [**LinkedIn**](https://www.linkedin.com/in/eleftheriabatsou/) | eleftheriabatsou |
1,871,812 | In Excel, Insert Group Headers to Detail Data Rows in Each Group | Problem description & analysis The Excel worksheet below contains multiple vertical subtable... | 0 | 2024-05-31T08:24:40 | https://dev.to/judith677/in-excel-insert-group-headers-to-detail-data-rows-in-each-group-d7p | excel, spreadsheet, tutorial, productivity | **Problem description & analysis**
The Excel worksheet below contains multiple vertical subtable groups, which are separated by a blank row. In each group, the 2nd cells of both row 1 and row 2 contain subtable group headers and row 3 contains column headers; there isn’t detailed data in either the 1st column or the 6th column:
```
A B C D E F
1 ATLANTIC SPIRIT
2 Looe
3 Vessel Species Size Kg Date Location
4 POLLACK 2 2.5 23/04/2024
5 POLLACK 3 18.8 23/04/2024
6 POLLACK 41 5.4 23/04/2024
7 LING 3 1.9 23/04/2024
8 WHITING 2 0.4 23/04/2024
9
10 BEADY EYE
11 Plymouth
12 Vessel Species Size Kg Date Location
13 BASS 4 15.7 23/04/2024
14 BASS 5 3.2 23/04/2024
15
16 BOY JACK
17 Plymouth
18 Vessel Species Size Kg Date Location
19 PLAICE 1 0.8 23/04/2024
20 BLONDE RAY 1 14.3 23/04/2024
21 BLONDE RAY 3 1.6 23/04/2024
22 SPOTTED RAY 5 1.2 23/04/2024
23 THORNBACK RAY 1 6.3 23/04/2024
24 THORNBACK RAY 2 15.7 23/04/2024
25 THORNBACK RAY 3 10.9 23/04/2024
26 THORNBACK RAY 4 2.6 23/04/2024
27 LOBSTER 1 2.7 23/04/2024
28 LOBSTER 2 1.1 23/04/2024
29 RAY BACKS 1 42.1 23/04/2024
```
We need to insert the subtable group headers in row 1 and row 2 of each group into the 1st column and the 6th column respectively:
```
A B C D E F
1 ATLANTIC SPIRIT
2 Looe
3 Vessel Species Size Kg Date Location
4 ATLANTIC SPIRIT POLLACK 2 2.5 23/04/2024 Looe
5 ATLANTIC SPIRIT POLLACK 3 18.8 23/04/2024 Looe
6 ATLANTIC SPIRIT POLLACK 41 5.4 23/04/2024 Looe
7 ATLANTIC SPIRIT LING 3 1.9 23/04/2024 Looe
8 ATLANTIC SPIRIT WHITING 2 0.4 23/04/2024 Looe
9
10 BEADY EYE
11 Plymouth
12 Vessel Species Size Kg Date Location
13 BEADY EYE BASS 4 15.7 23/04/2024 Plymouth
14 BEADY EYE BASS 5 3.2 23/04/2024 Plymouth
15
16 BOY JACK
17 Plymouth
18 Vessel Species Size Kg Date Location
19 BOY JACK PLAICE 1 0.8 23/04/2024 Plymouth
20 BOY JACK BLONDE RAY 1 14.3 23/04/2024 Plymouth
21 BOY JACK BLONDE RAY 3 1.6 23/04/2024 Plymouth
22 BOY JACK SPOTTED RAY 5 1.2 23/04/2024 Plymouth
23 BOY JACK THORNBACK RAY 1 6.3 23/04/2024 Plymouth
24 BOY JACK THORNBACK RAY 2 15.7 23/04/2024 Plymouth
25 BOY JACK THORNBACK RAY 3 10.9 23/04/2024 Plymouth
26 BOY JACK THORNBACK RAY 4 2.6 23/04/2024 Plymouth
27 BOY JACK LOBSTER 1 2.7 23/04/2024 Plymouth
28 BOY JACK LOBSTER 2 1.1 23/04/2024 Plymouth
29 BOY JACK RAY BACKS 1 42.1 23/04/2024 Plymouth
```
**Solution**:
Use **_SPL XLL_** to enter the formula below:
```
=spl("=t=?.group@i(!~.ifn()),k=1,t.run(t1=~(k)(2),t6=~(k+1)(2),~.m(3+k:).run(~(1)=t1,~(6)=t6),k=2),t.conj()",A1:F29)
```
As shown in the picture below:
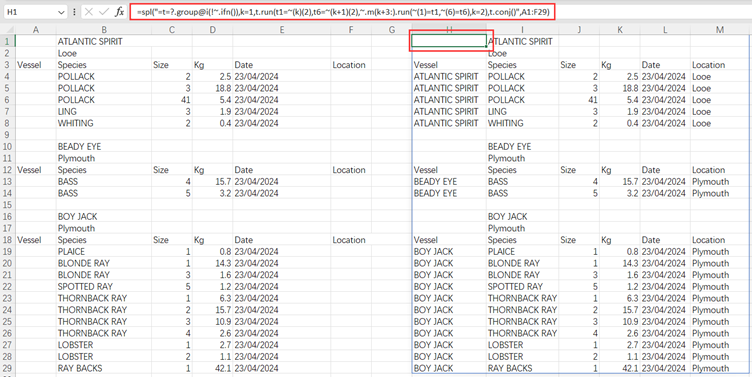
**Explanation**:
group@i()function groups rows according to the specified condition; ifn() function returns the first non-null member; ~ represents is the current member and ~(6) represents the 6th member on the current member’s subordinate level; and m(i:) gets members from the ith to the last one. | judith677 |
1,871,811 | Choosing the Best Outdoor Flood Lights | When it comes to outdoor lighting, nothing quite matches the versatility and functionality of flood... | 0 | 2024-05-31T08:24:35 | https://dev.to/groz_usa_9333fe41eba26201/choosing-the-best-outdoor-flood-lights-2mpc | When it comes to outdoor lighting, nothing quite matches the versatility and functionality of flood lights. Whether you're illuminating your backyard for evening gatherings, enhancing security around your property, or simply adding ambiance to your outdoor space, investing in the best outdoor flood lights is essential. Among the myriad of options available, Grozusa stands out as a reliable provider of high-quality lighting solutions. In this blog, we'll explore what makes outdoor flood lights from Grozusa the top choice for homeowners and outdoor enthusiasts alike.
Why Choose Grozusa Outdoor Flood Lights?
Grozusa has built a reputation for excellence in the lighting industry, and their outdoor flood lights are no exception. Here are some compelling reasons to consider Grozusa for your outdoor lighting needs:
Superior Quality: Grozusa's outdoor flood lights are crafted using premium materials and cutting-edge technology to ensure durability and performance. From robust housing to weather-resistant finishes, these lights are built to withstand the elements and provide reliable illumination year-round.
Energy Efficiency: In today's eco-conscious world, energy efficiency is paramount. Grozusa understands this need and offers a range of outdoor flood lights equipped with energy-efficient LED bulbs. Not only do these lights consume less power, but they also last longer, reducing the need for frequent bulb replacements.
Versatility: Whether you need to light up a large outdoor area or focus on specific features like landscaping or architectural details, Grozusa offers a variety of flood lights to suit your needs. Adjustable settings, multiple mounting options, and customizable features ensure that you can tailor the lighting to fit your unique outdoor space.
Enhanced Security: Proper outdoor lighting is essential for maintaining a safe and secure environment around your home. Grozusa's outdoor flood lights provide ample illumination to deter intruders and improve visibility, helping you feel more confident and protected at night.

Stylish Designs: Beyond functionality, Grozusa's outdoor flood lights are designed with aesthetics in mind. Sleek and modern designs complement any outdoor decor, adding a touch of sophistication to your landscape while also serving a practical purpose.
Top Picks from Grozusa:
Now that you're familiar with the benefits of Grozusa outdoor flood lights, let's take a closer look at some of their top-rated products:
Grozusa LED Outdoor Flood Light: This versatile flood light features adjustable brightness and beam angle settings, allowing you to customize the lighting to suit your needs. With its durable construction and energy-efficient LED bulbs, it's an ideal choice for illuminating large outdoor areas.
Grozusa Motion-Activated Flood Light: Designed for enhanced security, this motion-activated flood light automatically turns on when it detects movement, providing instant illumination when you need it most. Its sleek and compact design makes it perfect for mounting on garages, sheds, or entryways.
Grozusa Solar-Powered Flood Light: Harnessing the power of the sun, this solar-powered flood light offers an eco-friendly lighting solution for your outdoor space. With easy installation and no wiring required, it's a hassle-free way to add illumination to your garden, patio, or pathway.
Conclusion:
When it comes to illuminating your outdoor space, choosing the right flood lights is key to creating a welcoming and functional environment. With Grozusa's range of [high-quality outdoor flood lights](https://www.grozusa.com/collections/led-lighting), you can enjoy superior performance, energy efficiency, and stylish design—all backed by a trusted name in the lighting industry. Whether you're lighting up your backyard for a summer barbecue or enhancing security around your property, Grozusa has the perfect lighting solution for your needs. Explore their collection today and transform your outdoor space into a beautifully lit oasis. | groz_usa_9333fe41eba26201 | |
1,871,810 | How To Find Bugs In Website? | Whether you are developing a website for your personal use, for a customer or your organization, it... | 0 | 2024-05-31T08:23:49 | https://dev.to/harisapnanair/how-to-find-bugs-in-website-4hcp | devops, testing, development, webdev | Whether you are developing a website for your personal use, for a customer or your organization, it is very important that the site is bug-free. A bug in your application will not only ruin the usability of your website but will also affect your reputation as a developer.
But how to find bugs in website? In this article, we’ll answer these questions in detail and provide a step-by-step guide to spotting bugs on your website.
## What is a Bug?
A bug is a term used in software development to describe a defect or fault in software or a website that causes unexpected behavior or inaccurate results. These problems can be caused by several things, such as improper code implementation, misreading or not fully comprehending the requirements, difficulties with compatibility with other hardware or software elements, or outside variables like network circumstances.
Bugs can range from minor visual discrepancies to severe malfunctions that may disrupt the system. Hence, it is essential to address these bugs as soon as possible to maintain the reliability and performance of software and websites. Promptly identifying and rectifying bugs will also help mitigate risks that can cause downtime, loss of productivity, and damage to reputation.
*Learn more about bugs in our blog, [Developers and Bugs: Why do they happen again and again](https://www.lambdatest.com/blog/developers-and-bugs-why-are-they-happening-again-and-again/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog)?*
## Why is it Important to Find Bugs
A National Institute of Standards and Technology (NIST) study has revealed the substantial economic impact of software bugs, showing an estimated annual cost of $59.5 billion to the U.S. economy. This staggering figure underscores the critical need for swift and effective bug resolution in applications and websites.
There are several instances today to support the above study where software bugs caused or had the potential to cause economic turmoil. One such example is that of AWS(Amazon Web Services) in 2022, where a software bug in a major cloud service provider’s system caused a widespread outage. This outrage affected thousands of businesses and services that rely on AWS and in turn, caused significant financial losses for the affected businesses.
This emphasizes the importance of finding bugs early to prevent such mishaps. Companies now offer bug bounty programs, including Meta, Amazon, Google, and others, to incentivize bug detection. Despite initial concerns, the cost of bug bounties is minimal compared to potential financial losses from unaddressed bugs, making them a wise investment against catastrophic repercussions.
> Extract numbers effortlessly with our [phone number extractor](https://www.lambdatest.com/free-online-tools/phone-number-extractor?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=free_online_tools). Try it now!
## Common Types of Bugs
Let’s take a few minutes to break down some of the most common bugs to understand better what’s causing them. Understanding these bugs reduces the time it takes to fix them and acts as a preventative measure to prevent them from appearing in the future.
Some of the common types of bugs are as follows:
* **Functional Bugs:** Defects within a software application that affect its intended behavior or functionality.
* **Broken Links:** Hyperlinks lead to non-existent pages that disrupt navigation and user experience.
* **Data Collection Bug:** Validation and submission issues present in forms that can frustrate users and hinder data collection.
* **Compatibility Bugs:** Glitches specific to certain browsers or devices that cause inconsistent user experiences.
* **Browser-Specific Bugs:** Defects in a software application occur only on specific web browsers due to inconsistencies in rendering or interpretation of code.
* **Security Vulnerabilities:** Weaknesses in a website’s defenses that can be exploited by malicious actors, compromising user data and trust.
* **Performance Issues:** Slow loading times and unoptimized media that hinder engagement.
* **UI Bugs:** Misaligned elements and distorted layouts undermine the visual appeal and usability of the website.
*Learn how [Root Cause Analysis in Testing](https://www.lambdatest.com/blog/rca-in-testing/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog) identifies bottlenecks, uncovers underlying issues, and revolutionizes your testing methodology for better performance and reliability.*
> Convert HEX to CMYK with ease using our [hex to cmyk](https://www.lambdatest.com/free-online-tools/hex-to-cmyk?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=free_online_tools) tool. Start converting today!
## Approach to Find Bugs in a Website
Discovering website bugs involves a systematic approach encompassing various testing techniques and methodologies. Testers can effectively identify and address issues by following structured steps, ensuring website functionality, usability, and security.
The steps to find bugs in a website are as follows:
**Choosing between manual and automation testing**
Choosing between manual testing and automation testing depends on various factors, such as the complexity of the website, budget constraints, etc. Manual testing involves manually interacting with website elements to validate functionalities across different scenarios, and it is suitable for small-scale websites. However, automation testing has become indispensable for advanced websites with interconnected features. Automation testing allows testers to automate repetitive [test cases](https://www.lambdatest.com/learning-hub/test-case?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub), improving efficiency and scalability.
For an effective result, a hybrid approach will offer the best balance, enabling testers to identify bugs faster and more effectively while addressing specific website areas that require human intervention.
*Check out [Manual Testing vs Automation Testing](https://www.lambdatest.com/learning-hub/manual-testing-vs-automation-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) for a heads-on comparison between manual and automation testing.*
**Decide the testing types and tools**
Selecting the appropriate testing types becomes pivotal once we have determined the testing approach. Each testing type targets distinct categories of bugs, necessitating specific tools for effective execution. We can enhance bug detection and ensure overall website quality by incorporating various testing types, such as [functional testing](https://www.lambdatest.com/learning-hub/functional-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub), cross-browser testing, [API testing](https://www.lambdatest.com/learning-hub/api-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub), etc.
Alongside testing types, choosing the right tools is essential. Tools like [Selenium](https://www.lambdatest.com/selenium?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=webpage) or [Cypress](https://www.lambdatest.com/learning-hub/cypress-tutorial?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) offer robust automation capabilities for functional testing, while [cross browser testing](https://www.lambdatest.com/online-browser-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) platform like LambdaTest can be used. LambdaTest is an AI-powered test orchestration and execution platform that lets you run manual and automated tests at scale on over 3000 real devices, browsers, and OS combinations.
The different types of testing and the tools used for the particular testing will be discussed in the **“Best Techniques to Find Bugs in a Website” **section.
**Report and Track Bugs**
We can utilize services like Google Sheets or dedicated bug management tools to ensure efficient reporting and tracking. On the records, we can categorize bugs by severity, priority, reproducibility, root cause, bug type, areas of impact, and frequency of occurrence. Additionally, we can also incorporate a bug status column with options like *In Progress, To be Retested, and Fixed.* For more advanced features, we can also consider specialized bug management tools tailored to our team’s needs.
*Check out these [53 Best Bug Tracking Tools in 2024](https://www.lambdatest.com/blog/bug-tracking-tools/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog) *.
*Read these blogs to learn how to use LambdaTest for bug tracking and management:*
* [***Log Your Bugs With LambdaTest And Userback Integration](https://www.lambdatest.com/blog/userback-integration/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog)***
* [***Now Log Bugs Using LambdaTest and DevRev](https://www.lambdatest.com/blog/lambdatest-partners-with-devrev/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog)***
* [***Now Track Bugs, Prioritize Tasks, And More Using LambdaTest And FogBugz](https://www.lambdatest.com/blog/lambdatest-partners-with-fogbugz/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog)***
> Seamlessly transform CMYK to HEX with our [cmyk to hex](https://www.lambdatest.com/free-online-tools/cmyk-to-hex?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=free_online_tools) converter. Get started!
## Techniques to Find Bugs on Website
Detecting and resolving bugs in an application is vital for preserving its functionality and improving user experience. Here are some techniques which will help us to identify and rectify bugs effectively.
## Mobile Ready Test
Since most people nowadays use mobile devices to access websites, to expand the number of the target audience, the website must be fully responsive and compatible with mobile devices and browsers.
To ensure our website is optimized for mobile devices, we can adopt the following approaches:-
* **Identifying Target Browsers:** Set up a list of devices on which the application should run perfectly by researching through Google Analytics. This will help to identify the primary devices used by the target audience, help us prioritize testing efforts and ensure broad compatibility.
* **Using Emulator/Simulator:** Use mobile device emulator/simulator extensions in browsers to test the application. It provides a convenient way to assess how the application responds across various screen sizes and resolutions.
*LambdaTest simplifies app testing by offering automated testing on Emulators and Simulators, eliminating the need for an expensive device lab. To learn more, check out [App Automation on Emulators and Simulators on LambdaTest](https://www.lambdatest.com/blog/live-with-app-automation-on-emulators-simulators/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog).*
* **Real-time testing:** A cloud infrastructure like LambdaTest allows users to perform live, interactive testing of web applications across various browsers, devices, and operating systems simultaneously without the hassle of managing various devices with different operating systems. It enables real-time collaboration, debugging, and issue resolution for ensuring website compatibility and functionality.
*To learn more about it, read [Real-Time Testing](https://www.lambdatest.com/learning-hub/real-time-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub).*
* **Optimizing Mobile Layout:** Make sure there is no horizontal scrolling, fonts, and buttons are readable and touch-friendly, and content and images are large enough to understand on the small screen.
* **Usability Testing:** Perform [usability testing](https://www.lambdatest.com/learning-hub/usability-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) specifically tailored to mobile users to identify any usability issues or pain points unique to mobile interactions. This involves observing how users interact with your website on mobile devices and gathering feedback to make improvements.
*Check out out blog on [Quick Guide to Mobile App Usability Testing](https://www.lambdatest.com/blog/mobile-app-usability-testing/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog) to learn how to perform usability testing on mobile phones.*
* **Tracking development trends:** Stay updated with the latest mobile development trends and best practices to continually improve the mobile-friendliness and performance of the application. This involves keeping track of new technologies, design patterns, and user behavior trends in the mobile space.
> Effortlessly convert CSV files to Excel with our [csv to excel](https://www.lambdatest.com/free-online-tools/csv-to-excel?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=free_online_tools) tool. Try it now!
## Cross Browser Testing
Gone are the days when [Internet Explorer](https://www.lambdatest.com/blog/does-browser-testing-on-internet-explorer-still-make-sense/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog) was the only browser available. Many new browsers are being introduced almost daily, and often, web applications that run perfectly in [Google Chrome](https://www.lambdatest.com/blog/chrome-loves-testing/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog) but fail in [Opera](https://www.lambdatest.com/blog/automated-browser-testing-with-opera-and-selenium-in-python/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog), [Safari](https://www.lambdatest.com/blog/debug-websites-using-safari-developer-tools/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog), or other browsers. Hence, it is essential to perform cross browser testing to see how the application looks and behaves across different browsers.
To ensure our website is optimized for various browsers and devices, we can adopt the following approaches:
* **Targeted Browser Testing:** Instead of testing compatibility with all browsers, target the significant browsers favored by the target audience and test the app on them. This approach ensures efficient resource allocation and addresses compatibility issues that will most likely impact a significant portion of your user base, optimizing the testing process without compromising coverage.
* **Manual Cross Browser Testing:** Install different browsers on the computer and test the application in each one, ensuring compatibility across various browsing environments. This hands-on approach lets you detect browser-specific issues early in development and provide a consistent user experience across all platforms.
* **Cross-Browser Testing Platform:** Installing different browsers on the computer can be cumbersome. To solve this, we can leverage cloud infrastructure like LambdaTest to test the website on various browsers and devices without the hassle of installation.
*Check out our YouTube video on how to perform Cross Browser Testing on the LambdaTest.*
{% youtube na07BInGXpM %}
* **Early Testing:** Perform the test using a [cross-browser compatibility](https://www.lambdatest.com/learning-hub/cross-browser-compatibility?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) tool during the early stages of development. [Unit testing](https://www.lambdatest.com/learning-hub/unit-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) should be initiated as soon as the design is ready. This proactive approach allows for prompt bug detection and resolution, minimizing the risk of costly rework later in the [software development life cycle](https://www.lambdatest.com/learning-hub/software-development-life-cycle?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) and promoting a smoother, more efficient development process overall.
> Beautify your JSON data quickly with our [json prettify](https://www.lambdatest.com/free-online-tools/json-prettify?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=free_online_tools) tool. Start beautifying today!
## Accessibility Testing
World Wide Web Consortium (W3C) has established guidelines and standards that organizations or individuals must comply with before launching their web applications. The guidelines state that the application should be accessible to everyone, especially people with disabilities. To ensure that a product or service is accessible to all users, we use accessibility testing.
[Accessibility Testing ](https://www.lambdatest.com/learning-hub/accessibility-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub)involves testing for compliance with accessibility standards, such as the Web Content Accessibility Guidelines (WCAG), and ensuring that the product or service is user-friendly and accessible to individuals with disabilities.
To ensure our website is optimized for all types of users, we can adopt the following approaches:-
* **Ensuring Accessibility Compliance:** Test whether the website complies with section 508 of the ADA (Americans with Disabilities Act) and other guidelines. This involves conducting thorough assessments to verify that the website meets the required accessibility criteria, including provisions for individuals with disabilities.
* **Scalability Testing:** Run [scalability testing](https://www.lambdatest.com/learning-hub/scalability-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) to ensure the website is readable when images or fonts are zoomed in. This testing assesses how well the website adapts to changes in zoom levels, ensuring that content remains legible and functional across various screen resolutions and magnifications.
* **Screen Reader Testing:** Screen reader tests should be executed to ensure that people with poor vision can navigate the page using a screen reader. These tests are conducted to ensure that individuals with vision impairment can effectively navigate through the page and access all content using assistive technologies.
* **Text Size, Color Contrast, and Contrast Ratio:** Adequate text size ensures comfortable reading, while sufficient contrast between text and background colors enhances the readability for the visually impaired.
* **Keyboard-Only Navigation Testing:** Conduct comprehensive testing to verify that all interactive elements, menus, links, and form fields are fully accessible and operable through keyboard navigation.
* **Caption Inclusion:** Captions should be included in media content to ensure people with hearing disability can understand the audio and video content. Through thorough testing and implementation, verify that all multimedia elements, including audio and video files, are accompanied by accurate captions conveying spoken dialogue, background noises, and other relevant audio cues.
As we continue to recognize the importance of web accessibility, it’s crucial for developers to easily test, manage, and report accessibility issues. LambdaTest [Accessibility DevTools](https://www.lambdatest.com/accessibility-devtools?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=webpage) Chrome Extension helps in identifying and solving web accessibility issues directly in your browser. To use the extension, click the download button below.
[***Install Accessibility DevTools](https://chromewebstore.google.com/detail/accessibility-devtools/mmbbmjhbidfflcbiffppojapgonepmab?hl=en&authuser=1)***
## General HTML and CSS Checking
HTML and CSS are super important for building websites. So, when we check for bugs, we need to be really careful with both HTML and CSS code to ensure everything’s running smoothly. Ensuring the integrity and correctness of the code fosters optimal website performance and enhances user experience and overall site functionality.
To ensure our website’s optimal performance and enhanced user experience, we can adopt the following approaches:-
* **Use validation tools:** Ensure that your HTML or XHTML code is error-free by validating it using W3C Markup Validation, the official validator tool of the World Wide Web Consortium and we can use the CSS Validation Service provided by W3C can be used to find out any error or compliance violation in your CSS. By subjecting the code to this rigorous validation process, we can identify and rectify any inconsistencies or mistakes that compromise the functionality or compatibility of the website.
* **Inspection Tools:** Tools like HTML Tidy, Google Search Central, etc. can search the code for duplicate meta tags, broken links, missing titles, or other bugs. HTML Tidy, for instance, optimizes HTML structure and readability, while Google Search Central provides insights into SEO and indexing issues, ensuring a holistic approach to bug detection and resolution.
* **CSS Compressor:** After the code has been checked, a suggested tool that can be used is CSS Compressor. It minifies the file by shrinking the entire code into a single line. This tool can speed up the loading time for a large page with thousands of lines of CSS.
## Security Testing
Hackers exploit website vulnerabilities to steal crucial data or gain control using cross-site scripting (XSS), SQL injections, and Brute-force attacks. Protecting against such threats is especially important if the website deals with online shopping, banking, or any activities where user data should be kept private. We use [security testing](https://www.lambdatest.com/learning-hub/security-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) to ensure that the users’ data is protected and not vulnerable to attacks.
To ensure our website is secure, we can adopt the following approaches:
* **Account Lockout:** Ensure the account locks out after multiple entries of incorrect password or user ID. This security measure is a defense against brute-force attacks, where hackers systematically try various combinations to gain unauthorized access. It mitigates the risk of unauthorized entry, prevents potential breaches, and protects sensitive information from falling into the wrong hands.
* **Authentications:** Ensure automated login is prevented through techniques like OTP(One-Time Password verification) or CAPTCHA( Completely Automated Public Turing test to tell Computers and Humans Apart) while logging in. These measures are formidable barriers against automated scripts or bots attempting to gain unauthorized access. OTP adds an extra layer of verification beyond traditional passwords, and CAPTCHA presents challenges that are easy for humans to solve but difficult for automated systems, effectively distinguishing legitimate users from malicious bots.
* **Secure Cookie and Cache Encryption:** Ensuring [cookie](https://www.lambdatest.com/blog/handling-cookies-in-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog) and cache encryption is crucial for safeguarding user data integrity and confidentiality. Encrypting cookies shields sensitive information like session IDs from unauthorized access, while encrypted cache data prevents malicious actors from tampering with it. By implementing strong encryption methods, overall data protection is enhanced, reducing the risk of security breaches and bolstering user trust.
* **Validate Session Expiry Post Logout:** Once the user logs out, press the back button to ensure the browsing session has expired. By confirming session expiry through this method, we can guarantee that users are effectively logged out and their access privileges revoked, enhancing overall security and protecting against unauthorized access to restricted application areas.
* **Secure Information Storage:** It is imperative to prioritize the secure storage of information by employing trusted methods such as utilizing secure servers or encrypted databases. Storing data in secure environments mitigates the risk of unauthorized access or data breaches, safeguarding sensitive information from malicious actors.
* **Security Tools:** Using tools like OWASP ZAP, we can comprehensively scan our website for prevalent security vulnerabilities and evaluate its resilience against potential cyberattacks.
## Performance Testing
Apart from usability and security, our web application must be able to withstand the load. Often, websites are observed to crash when internet traffic increases all of a sudden. To avoid this scenario, performance testing is performed.
[Performance testing](https://www.lambdatest.com/learning-hub/performance-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) is a type of software testing that evaluates the speed, responsiveness, stability, and scalability of a software application under various conditions. Its primary goal is to ensure that the application performs well and meets the required performance criteria.
To ensure our website is prepared for every situation, we can adopt the following approaches:
* **Stress Testing:** Execute [stress testing](https://www.lambdatest.com/learning-hub/stress-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) to determine how the site behaves when the workload increases. By subjecting the site to varying stress levels, stakeholders can identify performance bottlenecks, optimize resource allocation, and ensure that the site maintains reliability and functionality even during peak usage.
* **Concurrency Testing:** Simulate multiple user login sessions and execute concurrency testing to determine whether the site behaves normally. This testing methodology helps identify potential bottlenecks, concurrency issues, or performance degradation when multiple users access the site concurrently.
* **Endurance testing:** Execute Endurance testing to check the website’s performance when it faces a workload beyond the limit. This testing method helps uncover potential issues such as memory leaks, database connection errors, or performance degradation when the site operates beyond capacity.
* **Tools:** Numerous tools like web.dev, Google Lighthouse, WebPageTest, and GTmetrix offer comprehensive website performance testing, assessing loading times and overall efficiency. These tools provide valuable insights into various performance metrics, enabling developers to optimize their websites for faster loading speeds and enhanced user experience.
Dont miss on checking out our *blog on [Unleashing Cypress Performance Testing using Lighthouse](https://www.lambdatest.com/blog/using-cypress-google-lighthouse-performance-testing/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog).*
* **Assess Loading Time in Low Network Coverage:** Check the loading time of the application under low network coverage to evaluate user experience in challenging connectivity conditions. By simulating environments with poor network reception, developers can identify and address performance issues, ensuring optimal usability and accessibility for users facing network challenges.
## Usability Testing
[Usability testing](https://www.lambdatest.com/learning-hub/usability-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) involves evaluating a website or application’s user interface and overall user experience by observing real users interacting with the product. Through tasks, surveys, and interviews, usability testing identifies usability issues, gathers feedback, and informs iterative improvements to enhance user satisfaction and effectiveness.
To ensure effective usability testing, we can adopt the following approaches:
* **Tools:** Leveraging tools like UserTesting will help us capture user sessions and collect valuable insights into our website’s usability. These recorded sessions provide detailed feedback on user behavior, preferences, and pain points, helping us to identify usability issues and make informed decisions for optimization and improvement.
* **Analyze User Journeys:** Evaluate the end-to-end user experience by analyzing user journeys from entry points to conversion or task completion, identifying any obstacles or friction points that may impede usability.
> Minify your JSON files instantly with our [json minify](https://www.lambdatest.com/free-online-tools/json-minify?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=free_online_tools) tool. Get started now!
## Functional Testing
[Functional testing](https://www.lambdatest.com/learning-hub/functional-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) involves validating that the software functions as expected, ensuring all features and functionalities perform correctly according to specified requirements. This process includes testing individual functions, user interactions, and system integrations to verify that the software meets its intended purpose and delivers the desired outcomes. It helps to find bugs in a website by validating software against requirements, identifying discrepancies, and ensuring correct functionality, facilitating early bug detection and resolution.
To ensure effective functional testing, we can adopt the following approaches:
* **Developing comprehensive test cases:** It involves outlining specific inputs, expected outcomes, and conditions to validate all aspects of software functionality. By meticulously documenting test scenarios and covering various scenarios and edge cases, testers increase the likelihood of detecting bugs and inconsistencies, contributing to the overall quality and reliability of the software.
* **Automation:** Utilizing automation accelerates bug detection by automating repetitive testing tasks, increasing test coverage, and enabling frequent test execution. Automation enhances efficiency and accuracy by executing tests consistently across various configurations and environments, facilitating early bug identification and resolution in the software development life cycle.
*Check out our blog on [Automated Functional Testing](https://www.lambdatest.com/blog/automated-functional-testing-what-it-is-how-it-helps/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog) to leverage test automation at the core of [software testing life cycle](https://www.lambdatest.com/blog/software-testing-life-cycle/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog).*
* **Leverage data-driven testing:** [Data-driven testing](https://www.lambdatest.com/learning-hub/data-driven-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) helps detect bugs by systematically validating software behavior with diverse input data sets, uncovering potential issues related to data processing and boundary conditions. By automating tests with various data combinations, this approach enhances test coverage and efficiency, accelerating bug detection and ensuring software reliability.
## API Testing
[API testing](https://www.lambdatest.com/learning-hub/api-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) validates application programming interfaces’ functionality, reliability, and security (APIs), ensuring interoperability and robustness across software components. It helps to find bugs in a website by validating the functionality and integrity of backend services and data exchanges, ensuring seamless communication between different software components, and identifying potential issues such as data inconsistencies, incorrect responses, or security vulnerabilities that will impact the website’s performance or user experience.
To ensure effective API testing, we can adopt the following approaches:
* **Tools:** API testing tools such as Postman, JMeter, REST Assured, etc, aid in bug detection by facilitating comprehensive testing, validation, and analysis of API behavior. These tools enable testers to generate requests, validate responses, perform data-driven testing, automate repetitive tasks, analyze performance, conduct security tests, and generate detailed reports, ensuring thorough bug detection and resolution in API implementations.
* **Endpoint Validation:** Ensure each API endpoint’s request and response data adhere to the expected structure, format, and content. By meticulously testing input parameters, headers, and payloads and validating response formats and content, we can detect potential issues like incorrect data formatting or missing parameters and ensure API reliability.
* **CRUD Operations Testing:** Execute Create, Read, Update, and Delete operations via the API to observe data processing and storage behavior. By interacting with the API to manipulate data, testers can assess how it handles requests and ensures data integrity, aiding in identifying potential issues in data processing and storage mechanisms.
*Check out our list of top [API Testing Tools](https://www.lambdatest.com/blog/api-testing-tools/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog)!*
## Debugging
[Debugging](https://www.lambdatest.com/learning-hub/debugging?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) is the meticulous process of identifying and resolving bugs in the code. It involves carefully and systematically analyzing the code to isolate the root cause of the issue with the help of various tools and techniques. Once the bug is identified, a fix is implemented, and thorough testing is done to ensure the software operates smoothly.
To ensure an effective debugging process, we can adopt the following approaches:
* **Reviewing Code:** Reviewing code involves examining the entire codebase to identify potential bugs. This process requires a keen eye for detail and an understanding of the code’s underlying logic and structure. By scrutinizing each line and component, developers can detect inconsistencies, syntax errors, or logical flaws that lead to bugs.
* [**Debugging Tools](https://www.lambdatest.com/blog/best-debugging-tools/?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=blog):** Debugging tools are indispensable in the software development process. They offer developers a comprehensive toolkit to identify and rectify bugs efficiently. These tools provide features such as breakpoints, code stepping, etc., that facilitate the identification of bugs and their root causes.
LambdaTest provides various tools for the purpose of debugging like the [Developer Tools](https://www.lambdatest.com/developer-tools?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=webpage) which is used for real-time debugging on Android browsers, desktop browsers, and iOS browsers, and [LambdaTest Debug Chrome Extension](https://www.lambdatest.com/lt-debug?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=webpage), which provides nine features like add/modify headers, allows CORS, redirect requests, etc to help in the debugging process.
*To learn how to debug mobile browser with the help of LambdaTest Developer Tools, check out our YouTube now!*
{% youtube SVpr_V3nwLI %}
* **Isolating the Issue:** Isolating the issue involves systematically narrowing down the scope of the problem by temporarily removing or isolating specific components or sections of code until the root cause of the bug is identified. This allows developers to focus on the area requiring attention for efficient debugging and resolution.
* **Analyzing Error Messages:** Analyzing error messages involves carefully examining the messages generated by the software when a bug occurs. This will guide developers in diagnosing and resolving the underlying cause effectively, as these error messages often contain valuable information about the bug’s nature and location.
## Beta Testing by Real Users
[Beta testing](https://www.lambdatest.com/learning-hub/beta-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_08&utm_term=bw&utm_content=learning_hub) involves evaluating a product’s performance and functionality by allowing real users to test it in a real-world environment before its official release. This process helps identify any remaining bugs or usability issues and gathers valuable feedback from users to ensure a smoother product launch. While the testing team adheres to predefined protocols for testing, beta testers can offer fresh insights and identify errors that may have been overlooked, thanks to their diverse approaches and out-of-the-box thinking.
To ensure an effective beta testing process, we can adopt the following approaches:
* **Recruit Diverse Testers:** Select a diverse group of testers representing the target audience to gather comprehensive feedback from different perspectives. By including individuals with varying technical expertise, cultural backgrounds, age groups, and usage habits, we can uncover potential issues, preferences, or usability challenges that may otherwise go unnoticed.
* **Encourage Open Communication:** Encouraging open communication between testers and developers helps to promptly address issues and collaborate effectively. Establishing channels for testers to share feedback fosters transparency and partnership, facilitating timely issue resolution and enhancing overall collaboration.
* **Iterate Based on Feedback:** Continuously refine and enhance the website based on the feedback gathered from beta testers. This iterative process involves analyzing the feedback received, identifying patterns or recurring issues, and implementing iterative improvements to address them.
* **Leverage User Analytics:** Employ user analytics tools to collect quantitative data on user interactions, behaviors, and performance metrics throughout beta testing. By analyzing metrics such as page views, session durations, and conversion rates alongside qualitative feedback, we gain valuable insights into user preferences, pain points, and areas for improvement, facilitating data-driven decision-making and iterative refinement of the website.
Apart from all the above-mentioned testing scenarios, documentation testing should also be performed to check whether the website follows all the requirement specifications and business logic as mentioned by the client. Once the application has passed all the test case scenarios with all the high-priority bugs fixed, it can be deployed into production.
## Conclusion
After reading this blog on how to find bugs in website, it is clear that it is important to find and address bugs promptly to ensure a seamless user experience, maintain website integrity, and safeguard against potential security vulnerabilities. If bugs are not promptly handled, it can negatively impact the functionality, usability, and security of our application.
Bugs can be of various types like those related to website performance, compatibility, accessibility, security, and functionality. To detect these bugs and tackle them, various testing methodologies, such as mobile readiness, cross-browser compatibility, accessibility, security, performance, usability, functionality, API, and beta testing by real users, are used. We also learned how to find bugs in website with the help of these techniques.
By employing a comprehensive testing strategy encompassing these methodologies, we can identify, prioritize, and resolve bugs efficiently, ultimately delivering a high-quality and reliable website or application to users.
| harisapnanair |
1,871,809 | Chongqing Pingchuang Institute: A Catalyst for Semiconductor Innovation | screenshot-1716670629956.png Chongqing Pingchuang Institute: A Great Way to Create New... | 0 | 2024-05-31T08:23:11 | https://dev.to/skcms_kskee_db3d23538e2f3/chongqing-pingchuang-institute-a-catalyst-for-semiconductor-innovation-230a | screenshot-1716670629956.png
Chongqing Pingchuang Institute: A Great Way to Create New Technology
Are you interested in creating new technology or working in the semiconductor industry? Then you should check out Chongqing Pingchuang Institute! This institute is a perfect catalyst for semiconductor innovation, and it offers many advantages to those who are interested in this field. We will explore what Chongqing Pingchuang Institute is, how it can help you, and its many benefits.
What is Chongqing Pingchuang Institute?
Chongqing Pingchuang Institute is an institution that is dedicated to teaching and researching all aspects of the semiconductor and ev charging stations industry. It is located in Chongqing, China, and offers a wide variety of programs for students who are interested in the field. The institute prides itself on being a leader in the development of new technology, and has been instrumental in the creation of many groundbreaking semiconductor innovations.
Advantages of Choosing Chongqing Pingchuang Institute
There are several benefits of selecting Chongqing Pingchuang Institute for the education
Permit me to share just a couple of:
Innovation: in case you probably understand how innovation like essential in this field which you don't mind spending time into the semiconductor industry, then
At Chongqing Pingchuang Institute, you will end up confronted with the technology like latest and can figure out how to create brand new, cutting-edge items
The institute is regularly pressing the boundaries of what is feasible in semiconductor research, and pupils can be part of this ongoing work like exciting
Safety: when you use semiconductor technology, safety is always a concern
At Chongqing Pingchuang Institute, security is just a priority like high
The institute takes all precautions which can be ensure like necessary, faculty, and staff are safe while working together with this technology
This means you can consider producing and learning, without the necessity to concern yourself with potential hazards
Use: Chongqing Pingchuang Institute supplies a range like wide of that will show pupils how to make use of electric vehicle charging station
You reach your goals whether you are thinking about research, development, or manufacturing, there exists a operational system during the institute which will help
The courses are taught by experienced experts who are specialists within their field, that will help you ensure you will likely to be receiving the most training like beneficial
How to Utilize Chongqing Pingchuang Institute
Using Chongqing Pingchuang Institute is straightforward
An variety is offered by the institute of programs, which means action like initial constantly to determine what kind is right for you
It is possible to browse their site like internet to out more about the planned programs they provide
You're able to apply online or contact the institute directly to discover more after a course has been chosen by you
The process like applying simple, plus the institute offers resources that are many work with you through the procedure
Provider and Quality
At Chongqing Pingchuang Institute, quality and solution are key priorities
The institute strives to offer pupils utilizing the most training that works well this also means providing excellent service and top-quality programs
The employees and faculty focus on ensuring that pupils have confident, successful expertise in their amount of time in the institute
They truly are always wanted to respond to questions and also to offer help when needed
Application
Semiconductor technology may be used in a lot of companies being various and there are numerous profession like exciting readily available for all those who have the ideal abilities and expertise
Choosing Chongqing Pingchuang Institute is an method like gain like great information and experience you'll want to flourish in this industry
An array is offered by the institute of programs that can prepare pupils for entry-level and positions being advanced level the ev car charging station
Whether you might be thinking about research, development, or production, Chongqing Pingchuang Institute will be the perfect point like beginning journey
Conclusion
Overall, Chongqing Pingchuang Institute is a fantastic institution for anyone who is interested in the semiconductor industry. The programs are innovative, safe, and designed to help students achieve their goals. Whether you are just starting out in the field or are looking to advance your career, Chongqing Pingchuang Institute can provide you with the education and experience you need to succeed. So why wait? Apply today and start your journey towards a successful career in semiconductor technology!
Source: https://www.pingalax-global.com/application/ev-charging-stations | skcms_kskee_db3d23538e2f3 | |
1,871,797 | Comparing Kotlin Code Online: A Guide to the Best Tools and Platforms | https://ovdss.com/apps/compare-kotlin-code-online In the world of programming, comparing code... | 0 | 2024-05-31T08:18:02 | https://dev.to/johnalbort12/comparing-kotlin-code-online-a-guide-to-the-best-tools-and-platforms-1ibl |

https://ovdss.com/apps/compare-kotlin-code-online
In the world of programming, comparing code snippets is an essential task for debugging, learning, and improving code quality. When it comes to Kotlin, a statically typed programming language that runs on the JVM, having the right tools to compare code online can save developers significant time and effort. This blog post explores the best platforms and tools for comparing Kotlin code online, helping you streamline your development process.
Why Compare Kotlin Code Online?
Before diving into the tools, let's discuss why comparing Kotlin code online is beneficial:
Collaboration: When working in a team, comparing code snippets can help identify differences and improvements, facilitating better collaboration.
Learning: For those new to Kotlin, comparing different implementations can be a great way to learn and understand best practices.
Debugging: Spotting differences between versions of code can help identify bugs and issues more quickly.
Version Control: Comparing code helps in tracking changes and maintaining a clean codebase.
How to Effectively Compare Kotlin Code
Understand the Context: Before comparing code, ensure you understand the purpose and functionality of the snippets you are comparing.
Look for Logical Differences: Focus on changes that affect the logic and functionality of the code rather than minor syntax differences.
Use Comments and Documentation: Make use of comments and documentation to clarify why certain changes were made.
Leverage Version Control: Utilise version control systems like Git to track changes over time and facilitate easier comparisons.
Conclusion
Comparing Kotlin code online is an invaluable practice for developers. Whether you're debugging, learning, or collaborating, the right tools can make a significant difference. Tools like DiffChecker, Kotlin Playground, Mergely, and GitHub Diff provide various features to help you efficiently compare and analyse your Kotlin code. Choose the one that best fits your workflow and start improving your coding efficiency today.
By incorporating these tools into your development process, you can enhance your productivity and ensure your Kotlin code is always up to the highest standards. Happy coding!
| johnalbort12 | |
1,871,796 | ChatGPT-4o for business: everything you need to know | Intro Using Chatgpt for business has become common for many business owners, founders of... | 0 | 2024-05-31T08:17:12 | https://dev.to/kristy_poole/chatgpt-4o-for-business-everything-you-need-to-know-2jmn | chatgpt, business | ## Intro
Using Chatgpt for business has become common for many business owners, founders of startups, and even CEOs of enterprises. Today we may use chat gpt for business in many different ways: from marketing content creation to complex inquiries processing from inbound customers.
According to our latest AI statistics, [over 50% of companies](https://springsapps.com/knowledge/top-ai-statistics-2024-what-to-expect) plan to invest in training departments to help employees get acquainted with ChatGPT and similar AI tools. That means that [ChatGPT integration](https://springsapps.com/chatgpt-integration) becomes an integral part of almost any business. Moreover, with the release of СhatGPT-4o for business, we may expect tons of new products that will have integration with GPT4o with its new progressive features and possibilities.
So, in this article, we will discover all the benefits and pain points of ChatGPT-4o for businesses. You will get more practical information about this Large Language Model and how it can be used particularly for your existing business or a startup you would like to launch.
## ChatGPT-4o Overview
Let’s begin with the basics of GPT-4 Omni and try to understand how it works, what features this LLM has, and how ChatGPT-4o can be used in AI/ML development.
GPT-4o or GPT-4 Omni is a progressive Large Language Model [presented by OpenAI on May 13, 2024](https://openai.com/index/hello-gpt-4o/). This Generative AI model accepts any combination of text, audio, image, and video inputs, and can generate text, audio, and image outputs. OpenAI developed a unified model trained end-to-end across text, vision, and audio. This approach allows a single neural network to process all inputs and outputs, marking a significant milestone in multimodal AI.
Unlike previous versions, GPT-4o can process more information simultaneously, making it ideal for complex business conversations. This capability ensures coherence even with detailed and multifaceted queries. Using the advanced features of GPT-4o, like functions calling, helps businesses integrate AI seamlessly into daily operations, enhancing both communication efficiency and accuracy.
As measured by traditional benchmarks, GPT-4o delivers GPT-4 Turbo-level performance in text, reasoning, and coding intelligence. It also sets new standards in multilingual, audio, and vision capabilities. The admin console allows companies to manage usage limits and monitor GPT-4o's deployment across various departments, ensuring the AI model is customized to meet specific business needs.
Let’s summarize how we may use ChatGPT-4o for companies and enterprises. GPT-4o (Omni) is a large language model that seamlessly integrates text, audio, image, and video inputs while generating text, audio, and image outputs. Businesses benefit from its ability to handle complex interactions, improve efficiency, and streamline both customer support and internal communications. Additionally, GPT-4o ensures robust data security and offers extensive customization to fit specific business needs.
## GPT-4o vs GPT-4 Turbo
As we have already discovered the main capabilities and features of GPT-4o, let’s try to find out how it differs from the previous OpenAI model - [GPT-4 Turbo](https://help.openai.com/en/articles/8555510-gpt-4-turbo-in-the-openai-api). Previously we found that GPT-4o outperforms GPT-4 Turbo across many tasks, but there are some exceptions:
In complex data extraction tasks requiring high accuracy, both models still need to catch up.
For classifying tasks, GPT-4o demonstrates the highest precision, surpassing GPT-4 Turbo, Claude 3 Opus, and GPT-4.
In reasoning tasks, GPT-4o shows improvement in calendar calculations, time and angle calculations, and antonym identification. However, it continues to struggle with word manipulation, pattern recognition, analogy reasoning, and spatial reasoning.
Latency Comparison
Latency is a crucial factor in evaluating the performance of language models, especially for applications requiring real-time interaction. As anticipated, ChatGPT-4o business exhibits significantly lower latency compared to GPT-4 Turbo, making it more responsive and efficient in handling various tasks.
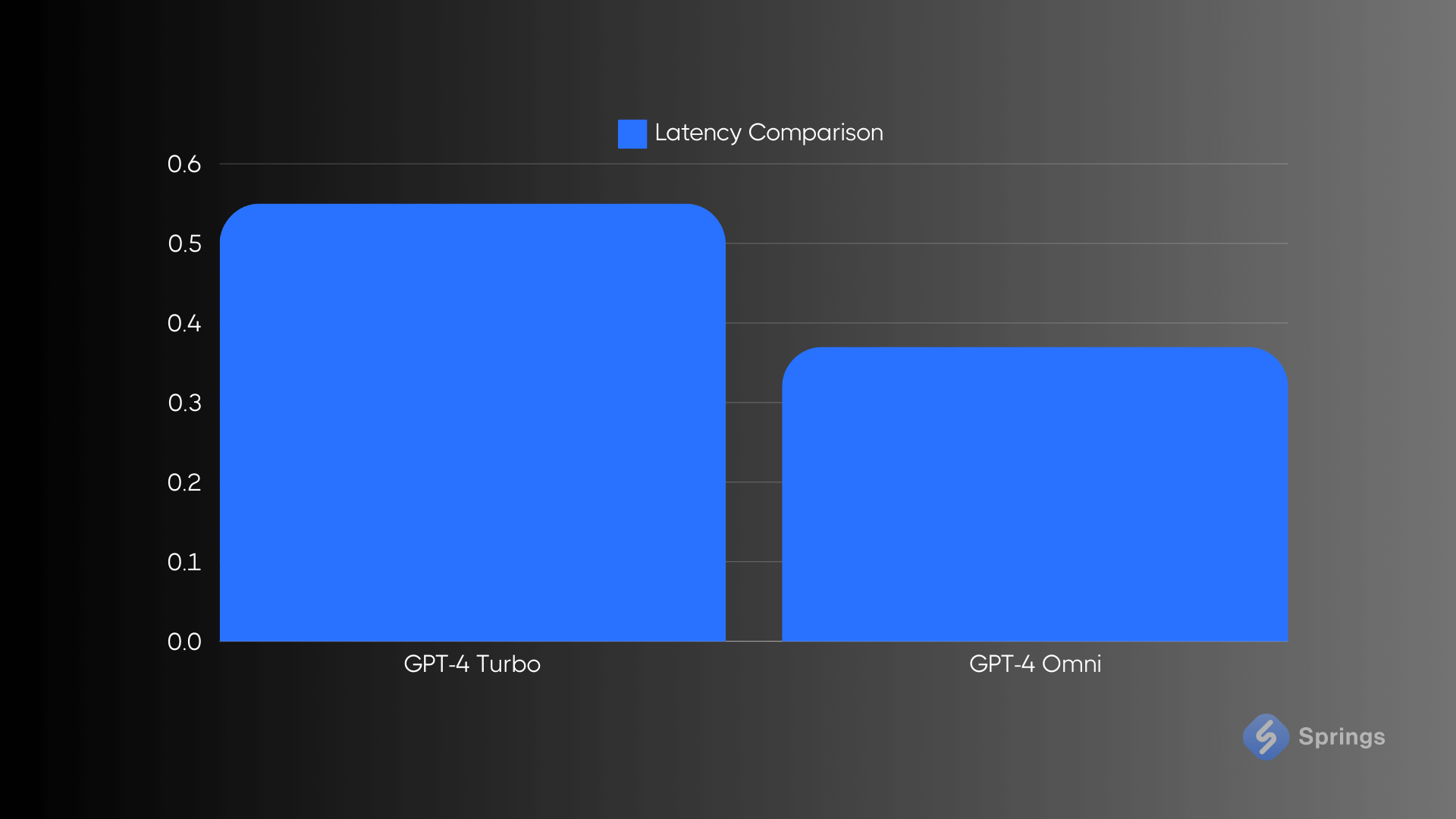
This reduction in latency is particularly beneficial for applications like live customer support, where [prompt-engineered](https://springsapps.com/prompt-engineering) responses are essential to maintaining customer satisfaction. Lower latency ensures that interactions feel more natural and seamless, closely mimicking human conversation speeds.
Moreover, the enhanced latency performance of GPT-4o allows for more complex and data-intensive operations to be executed more swiftly. This includes real-time data analysis, on-the-fly translation services, and instant feedback in interactive learning environments. By processing information faster, GPT-4o can support more dynamic and interactive user experiences without the delays that can frustrate users.
Overall, the reduced latency of GPT-4o compared to GPT-4 Turbo not only improves user experience but also expands the potential applications for this advanced model in various industries.
Throughput Comparison
In the realm of throughput, previous GPT models faced limitations, with the latest GPT-4 Turbo generating only 20 tokens per second. Recognizing the need for enhanced performance, GPT-4o has made significant advancements, now producing 109 tokens per second. This substantial increase represents a pivotal improvement, addressing the demands for faster and more efficient processing in various business process automation cases.
Although GPT-4o's throughput is impressive, it is not the fastest model available - Llama hosted on Groq, outpaces it by generating 280 tokens per second. However, throughput is just one aspect of a model's overall capability. Business uses for ChatGPT-4o excel not only in its speed but also in its advanced reasoning and multimodal abilities.
The enhanced throughput of ChatGPT-4o business translates into tangible benefits for enterprises. For instance, it allows for more efficient data processing and faster response times in customer interactions, which are crucial for maintaining high levels of customer satisfaction.
In addition, businesses can leverage GPT-4o’s capabilities for predictive analytics, dynamic content generation, and interactive applications, providing a more responsive and engaging user experience.
## Summary
Let’s make a short conclusion on how GPT-4 compared to GPT-4o. Here are some takeaways:
1. Data Extraction. GPT-4o outperforms GPT-4 Turbo in data extraction but still lacks the accuracy needed for complex tasks.
2. Classification. GPT-4o boasts the highest precision, making it the best choice for minimizing false positives. In contrast, GPT-4 Turbo exhibits lower accuracy.
3. Verbal Reasoning. GPT-4o has made significant improvements in certain reasoning tasks, although there is still room for enhancement. GPT-4 Turbo faces greater challenges in these areas.
4. Latency. GPT-4o features lower latency, resulting in faster response times compared to GPT-4 Turbo.
5. Throughput. GPT-4o generates tokens much faster, with a throughput of 109 tokens per second, compared to GPT-4 Turbo’s 20 tokens per second.

Overall, while ChatGPT-4o for business still has areas for improvement, especially in complex tasks, its overall enhancements make it a more efficient and accurate choice for advanced AI applications. | kristy_poole |
1,871,795 | Solana Gods Presale Platform: Revolutionizing Meme Coins with Mythology and Blockchain | When a new and vibrant idea enters the cryptocurrency world, it often brings economic potential and... | 0 | 2024-05-31T08:16:52 | https://dev.to/solanagods/solana-gods-presale-platform-revolutionizing-meme-coins-with-mythology-and-blockchain-54ap | solana, solanacoin | When a new and vibrant idea enters the cryptocurrency world, it often brings economic potential and bliss. Among these, Solana Gods are unique creations that combine the concept of mythology with blockchain. Another interesting feature of this project is the presale platform that has recently become popular in the cryptocurrency community. This blog explores the features, advantages, and possible impacts of the Solana Gods presale platform on the broader cryptocurrency landscape.
## The Rise of Solana Gods

Built on the Solana network, [Solana Gods](https://solanagods.com/) is a meme coin commonly denoted by the symbol $SGODS. It is an attractive choice as Solana is well-known for its fast and low-cost interchangeability, which always catches the eye of developers and investors. Using these, Solana Gods offers a better and cheaper alternative for meme coins in other blockchains.
Each $SGODS token represents a deity or a mythological figure adding a new layer of purpose and creativity. This approach distinguishes Solana Gods from other meme coins, but the presale platform further sets it apart by promoting accessibility and community participation.
## Understanding the Solana Gods Presale Platform
The Solana Gods presale platform is designed to offer early access to tokens. This phase is crucial for both the project and investors as early investments can earn significant profit as the project grows.
## Key Features of the Presale Platform
Accessibility and Inclusivity:
The Solana Gods presale platform has been developed with the community in mind and this is evident in how the platform has been designed. It aims to allow as many people as possible to participate in the acquisition of tokens, irrespective of their investment experience. This is because the platform has a low entry barrier so persons with little capital can be able to invest and gain from the project.
## Transparency and Security:
In the case of virtual money, the system must be fully transparent and secure to ensure the necessary safety of its users. The Solana Gods team has highlighted these features and has made it a point to make the platform safe to prevent losses on the part of the investors. Detailed information such as distribution, allocation, and vesting period for the token are also included in it.
## Incentives and Rewards:
There are also some bonuses and rewards that the community members will get on the presale platform to encourage their participation. In the initial period, investors will receive bonus tokens, referral programs, and early access to other features in the Solana Gods ecosystem. These incentives are put in place to make sure that people remain loyal to the project and even come in early and report to the project.
## User-Friendly Interface:
To ensure that the website of the Solana Gods presale platform is as easy to use as possible, the designers have designed the interface in such a way that it is easy to understand. Thus, a new user should not have difficulties with navigation on the platform and the presale process should be intuitive.
## The Presale Process: Step by Step
Registration:
To become a participant, investors must register on the Solana Gods website and open an account. This entailed disclosing some information and procedures for confirming one's identity to attain some legal set standards.
Wallet Setup:
The participants have to step up a cryptocurrency wallet, which is compatible with tokens built on Solana. Detailed guidelines will be available within the platform to assist you.
Funding the Wallet:
After creating a wallet, participants need to fund it with Solana tokens which will be used to purchase $SGODS tokens during the presale.
## Participating in the Presale:
During the presale launch date, registered participants can log in to the platform and purchase $SGODS tokens. This makes the transaction process smooth by providing real-time updates on the number of tokens earned and the remaining tokens.
Token Distribution:
After the presale ends, tokens will be transferred to participants’ wallets based on the stated vesting schedule. This helps in avoiding monopoly or collusion and other related market manipulation in the allocation of resources.
Benefits of Participating in the Solana Gods Presale
Participating in the Solana Gods presale offers several advantages for investors:
## Early Access at Discounted Rates:
In the presale, $SGODS tokens can be bought at a lower price, which provides an opportunity to gain more profit as the project develops.
Community Involvement:
The Solana Gods presale aims to allow investors to have a chance to be part of the Solana Gods project. This gives a platform to contribute, give your input, and share your thoughts about the project to the development team that is behind the project.
Exclusive Benefits:
There is also the benefit of getting bonus tokens, being able to participate in governance, and getting early access to new features or product releases within the Solana Gods ecosystem as an early investor.
Potential for High Returns:
In the same way that any cryptocurrency investment could be extremely profitable if invested in a promising project in its early stages, the same can be said for Neblio. Since it has a unique concept and a strong community, Solana Gods can become one of the most popular meme coins on the market.
## The Future of Solana Gods and Meme Coins
The Solana Gods and its presale platform indicate that meme coins are not static and can still grow. These are no longer laughable symbols on the internet but have evolved into serious financial assets with practical use and an attached community. Solana Gods is an excellent example of such a project – an exciting plot combined with the advanced use of blockchain to create a project that is capable of evolving.
As the Solana Gods project moves forward, the team is interested in growing the project’s ecosystem, searching for potential partners, and working on the promotion of $SGODS tokens. The presale platform is the starting point; it sets the stage for the formation of the active and engaged community that will carry out the project.
## conclusion
In conclusion, the Solana Gods presale platform holds potential for the meme coin sector. This is because it offers a new view on how presales can be held especially for the cryptocurrency space while holding the principles of transparency, openness, and community engagement. An opportunity to invest in a project with a mythological basis that also includes technological aspects exists here for investors. In this constantly evolving world, Solana Gods is an excellent example of how ideas and individuals can bring a project to success.
| solanagods |
1,871,794 | Maximizing Efficiency with SAP PP: The Role of a Consultant | In today's competitive manufacturing landscape, efficiency and precision are paramount. Companies... | 0 | 2024-05-31T08:16:04 | https://dev.to/mylearnnest/maximizing-efficiency-with-sap-pp-the-role-of-a-consultant-40e | sap, sappp | In today's competitive manufacturing landscape, efficiency and precision are paramount. Companies need robust systems to manage their production processes, and [SAP Production Planning (SAP PP)](https://www.sapmasters.in/sap-pp-training-in-bangalore/) emerges as a leading solution. However, to fully leverage SAP PP's capabilities, businesses often turn to specialized consultants. This article explores what an SAP PP consultant offers and how they can transform your production planning and control processes.
**Understanding SAP PP:**
SAP Production Planning (PP) is an essential module in the SAP ERP (Enterprise Resource Planning) suite that focuses on [production planning](https://www.sapmasters.in/sap-pp-training-in-bangalore/) and management. It integrates with other SAP modules like Materials Management (MM), Sales and Distribution (SD), and Finance (FI), providing a comprehensive system for managing production schedules, material requirements, and inventory.
**Key components of SAP PP include:**
**Demand Management:** Helps in forecasting and managing customer demands.
**Material Requirements Planning (MRP):** Ensures materials are available for production and products are available for delivery.
**Bill of Materials (BOM):** Lists all components required to produce a product.
**Work Centers:** Defines where and how production operations are performed.
**Routings:** Details the sequence of operations required to produce a product.
**Shop Floor Control:** Manages and monitors work in progress.
**The Role of an SAP PP Consultant:**
An SAP PP consultant is a specialist who brings extensive knowledge and expertise to help businesses optimize their production planning processes using the [SAP PP module](https://www.sapmasters.in/sap-pp-training-in-bangalore/). Their role encompasses various critical tasks:
**Requirement Analysis and Assessment:**Consultants begin by understanding the client’s business processes, production workflows, and specific requirements. This involves conducting thorough assessments and gathering detailed information to ensure the [SAP PP implementation](https://www.sapmasters.in/sap-pp-training-in-bangalore/) aligns with business needs.
**System Configuration and Customization:**Based on the assessment, consultants configure the SAP PP module to fit the unique needs of the organization. This includes setting up master data (e.g., BOMs, work centers), defining planning strategies, and customizing reports and dashboards.
**Integration with Other Modules:**Effective production planning requires seamless integration with other SAP modules. Consultants ensure that SAP PP works harmoniously with MM, SD, and FI modules, facilitating smooth data flow and comprehensive process management.
**Data Migration and Management:**Consultants oversee the migration of existing data into the SAP PP system, ensuring accuracy and consistency. They also establish procedures for ongoing data management to maintain system integrity.
**User Training and Support:**A critical aspect of the consultant’s role is training end-users. They conduct training sessions, create user manuals, and provide ongoing support to ensure users are proficient in using the system.
**System Testing and Quality Assurance:**Before going live, consultants rigorously test the [SAP PP system](https://www.sapmasters.in/sap-pp-training-in-bangalore/) to identify and resolve any issues. This ensures that the system performs optimally from day one.
**Continuous Improvement and Optimization:**Post-implementation, consultants work with businesses to continuously monitor and improve the system. They provide insights and recommendations for further enhancements to boost efficiency and productivity.
**Benefits of Hiring an SAP PP Consultant:**
Engaging an SAP PP consultant brings numerous advantages to a manufacturing organization:
**Enhanced Efficiency:**By [optimizing production planning](https://www.sapmasters.in/sap-pp-training-in-bangalore/) processes, consultants help businesses reduce lead times, minimize production costs, and increase throughput.
**Improved Accuracy:**With precise demand forecasting and material planning, companies can reduce excess inventory and avoid stockouts, leading to better resource utilization.
**Increased Flexibility:**Consultants configure SAP PP to handle different production scenarios, enabling businesses to quickly adapt to changing market demands and production challenges.
**Better Decision-Making:**Real-time data and comprehensive reporting capabilities provided by SAP PP facilitate informed decision-making, allowing managers to respond swiftly to production issues.
**Scalability:**An expertly configured SAP PP system can scale with the business, accommodating growth and evolving production needs without significant reconfiguration.
**Compliance and Standardization:**Consultants ensure that the SAP PP system adheres to industry standards and regulatory requirements, helping businesses maintain compliance and standardize processes across their operations.
**Real-World Impact: Case Studies:**
To illustrate the tangible benefits of SAP PP consultants, consider the following case studies:
**Automotive Manufacturer:**A leading automotive manufacturer engaged an SAP PP consultant to streamline its production processes. The consultant implemented an integrated system that reduced production cycle times by 20% and cut inventory costs by 15%. This led to significant cost savings and improved on-time delivery rates.
**Consumer Goods Company:**A consumer goods company faced challenges with demand forecasting and inventory management. An SAP PP consultant reconfigured their planning processes, resulting in a 30% reduction in stockouts and a 25% decrease in excess inventory. The company also achieved better alignment between production and sales.
**Pharmaceutical Firm:**In the highly regulated pharmaceutical industry, a firm needed to enhance compliance and traceability in its production processes. An SAP PP consultant implemented [robust tracking and reporting](https://www.sapmasters.in/sap-pp-training-in-bangalore/) mechanisms, ensuring regulatory compliance and improving batch traceability. This not only mitigated compliance risks but also enhanced product quality and safety.
**Choosing the Right SAP PP Consultant:**
Selecting the right consultant is crucial for a successful SAP PP implementation. Consider the following factors:
**Experience and Expertise:** Look for consultants with a proven track record in SAP PP implementations and relevant industry experience.
**Certifications:** Ensure the consultant holds SAP certifications and stays updated with the latest SAP developments and best practices.
**Client References:** Request references and case studies from previous clients to gauge the consultant’s performance and reliability.
**Communication Skills:** Effective communication is essential for understanding requirements, providing training, and ensuring smooth collaboration.
**Post-Implementation Support:** Opt for consultants who offer ongoing support and maintenance services to address any issues that may arise after implementation.
**Conclusion:**
SAP PP consultants play a vital role in helping manufacturing organizations optimize their production planning and control processes. By leveraging their expertise, businesses can achieve enhanced efficiency, accuracy, and [flexibility](https://www.sapmasters.in/sap-pp-training-in-bangalore/) in their operations. Whether it's reducing lead times, minimizing costs, or improving compliance, the right SAP PP consultant can drive significant improvements and ensure long-term success. Investing in expert consultancy not only maximizes the benefits of SAP PP but also positions businesses for sustained growth and competitiveness in the dynamic manufacturing landscape.
| mylearnnest |
1,871,792 | Spiner 0.1.3 beta | New Editor! | hi again. today we have the Spiner 0.1.3 beta. a new version, in this small beta update , i tried... | 0 | 2024-05-31T08:12:10 | https://dev.to/eliaondacs/spiner-013-beta-new-editor-4428 | spiner, tooling, news, productivity |
hi again.
today we have the Spiner 0.1.3 beta. a new version, in this small beta update , i tried updating the editor that can be accessed by `Spiner Edit` command.
lets take a look for what is new:
- editor overhaul
- new build
- new style scheme
that's it, will boring but this is a small beta update so yeah,
you could go to the [Spiner github](https://github.com/EliaOndacs/Spiner) page and try this out yourself.
goodbye!.
| eliaondacs |
1,870,113 | Calculus for Data Science and Machine Learning | What is a Function? A function is a relationship between two sets that associates each... | 0 | 2024-05-31T08:07:36 | https://dev.to/harshm03/calculus-for-data-science-and-machine-learning-2gdh | datascience, machinelearning, deeplearning | ### What is a Function?
A function is a relationship between two sets that associates each element of the first set with exactly one element of the second set. The first set is called the domain, and the second set is called the range. Functions are often used to describe mathematical relationships where one quantity depends on another.
In mathematical notation, a function is typically written as f(x), where f denotes the function and x is an element from the domain. The expression f(x) represents the value of the function at the element x.
#### Example
Consider the function:
```
f(x) = x^2
```
This function takes an input x and squares it to produce the output.
Let's evaluate this function for a few values of x:
```
- If x = 1, then f(1) = 1^2 = 1
- If x = 2, then f(2) = 2^2 = 4
- If x = 3, then f(3) = 3^2 = 9
```
In this example, the domain of the function is all real numbers, and the range is all non-negative real numbers (since squaring any real number results in a non-negative number).
### What is a Limit?
In calculus, a limit is a fundamental concept that describes the value that a function approaches as the input (or variable) approaches a certain value. Limits help us understand the behavior of functions as they get close to specific points, even if they do not actually reach those points.
#### Formal Definition
The limit of a function f(x) as x approaches a value c is denoted by:
```
lim (x -> c) f(x)
```
This means that as x gets arbitrarily close to c (from either side), f(x) approaches a specific value, which we call L. Formally, we write:
```
lim (x -> c) f(x) = L
```
#### Example
Consider the function `f(x) = (x^2 - 1) / (x - 1)`. We want to find the limit as x approaches 1.
#### Evaluating the Limit
Directly substituting x = 1 into the function `f(x) = (x^2 - 1) / (x - 1)` results in an indeterminate form (0/0). However, we can simplify the function first:
```
f(x) = (x^2 - 1) / (x - 1) = [(x - 1)(x + 1)] / (x - 1)
Here, (x - 1) cancels out, leaving us with:
f(x) = x + 1
Now, we can substitute x = 1 into the simplified function:
f(1) = 1 + 1 = 2
Thus, we find that:
lim (x -> 1) f(x) = 2
```
In this example, as x approaches 1, the value of f(x) approaches 2. Therefore, the limit of f(x) as x approaches 1 is 2.
### What is Continuity?
In calculus, a function is said to be continuous if there are no breaks, jumps, or holes in its graph. Continuity ensures that small changes in the input (x) result in small changes in the output (f(x)). Formally, a function f(x) is continuous at a point c if the following three conditions are met:
1. f(c) is defined.
2. The limit of f(x) as x approaches c exists.
3. The limit of f(x) as x approaches c is equal to f(c).
#### Formal Definition
A function f(x) is continuous at a point c if:
```
lim (x -> c) f(x) = f(c)
```
#### Example
Consider the function `f(x) = x^2`. We will check if this function is continuous at x = 2.
#### Checking Continuity
1. **Is f(2) defined?**
```
f(2) = 2^2 = 4
```
2. **Does the limit of f(x) as x approaches 2 exist?**
```
lim (x -> 2) f(x) = lim (x -> 2) x^2 = 2^2 = 4
```
3. **Is the limit of f(x) as x approaches 2 equal to f(2)?**
```
lim (x -> 2) f(x) = 4 and f(2) = 4
```
Since all three conditions are satisfied, the function `f(x) = x^2` is continuous at x = 2.
In general, polynomial functions like `f(x) = x^2` are continuous for all real numbers, meaning there are no breaks, jumps, or holes in their graphs across their entire domain.
### What is Differentiability?
In calculus, a function is said to be differentiable at a point if it has a well-defined tangent at that point, which means it can be represented by a derivative. Differentiability implies that the function is smooth and has no sharp corners or cusps at the given point. If a function is differentiable at a point, it is also continuous at that point, but the converse is not necessarily true.
#### Formal Definition
A function f(x) is differentiable at a point c if the following limit exists:
```
lim (h -> 0) [f(c + h) - f(c)] / h
```
This limit, if it exists, is the derivative of f(x) at the point c, denoted as f'(c).
#### Example
Consider the function `f(x) = x^2`. We will check if this function is differentiable at x = 2.
#### Checking Differentiability
To find the derivative of f(x) = x^2 at x = 2, we use the definition of the derivative:
```
f'(x) = lim (h -> 0) [f(x + h) - f(x)] / h
f'(2) = lim (h -> 0) [(2 + h)^2 - 2^2] / h
= lim (h -> 0) [4 + 4h + h^2 - 4] / h
= lim (h -> 0) [4h + h^2] / h
= lim (h -> 0) [4 + h]
= 4
```
Since the limit exists and equals 4, the function `f(x) = x^2` is differentiable at x = 2, and the derivative at that point is f'(2) = 4.
In general, polynomial functions like `f(x) = x^2` are differentiable for all real numbers, meaning they have well-defined tangents at every point in their domain.
### What is a Derivative?
In calculus, the derivative of a function represents the rate at which the function is changing at any given point. Geometrically, it corresponds to the slope of the tangent line to the graph of the function at that point. The derivative provides important information about the behavior of a function, including its increasing or decreasing nature, concavity, and local extrema.
#### Formal Definition
The derivative of a function f(x) with respect to x is denoted by f'(x) or dy/dx and is defined as the limit of the average rate of change of the function as the interval approaches zero:
```
f'(x) = lim (h -> 0) [f(x + h) - f(x)] / h
```
Alternatively, if y = f(x), then the derivative dy/dx is given by:
```
dy/dx = lim (h -> 0) [f(x + h) - f(x)] / h
```
#### Example
Consider the function `f(x) = x^2`. We will find its derivative with respect to x.
#### Finding the Derivative
Using the definition of the derivative:
```
f'(x) = lim (h -> 0) [f(x + h) - f(x)] / h
= lim (h -> 0) [(x + h)^2 - x^2] / h
= lim (h -> 0) [x^2 + 2xh + h^2 - x^2] / h
= lim (h -> 0) [2x + h]
= 2x
```
So, the derivative of `f(x) = x^2` with respect to x is `f'(x) = 2x`.
In this example, the derivative function `f'(x) = 2x` gives the slope of the tangent line to the graph of `f(x) = x^2` at any point x.
### Standard Derivative Formulas
Here are some standard derivative formulas for common functions:
#### Power Rule:
```plaintext
If f(x) = x^n, where n is a constant, then
f'(x) = nx^(n-1)
```
#### Exponential Rule:
```plaintext
If f(x) = e^x, then
f'(x) = e^x
```
#### Logarithmic Rule:
```plaintext
If f(x) = log_b(x), where b is the base, then
f'(x) = 1 / (x * ln(b)), where ln denotes the natural logarithm
```
#### Sine Rule:
```plaintext
If f(x) = sin(x), then
f'(x) = cos(x)
```
#### Cosine Rule:
```plaintext
If f(x) = cos(x), then
f'(x) = -sin(x)
```
#### Tangent Rule:
```plaintext
If f(x) = tan(x), then
f'(x) = sec^2(x)
```
These are some of the basic derivative formulas used in calculus. They allow us to find the derivatives of various functions efficiently.
### Rules for Finding Derivatives
In calculus, there are several rules that allow us to find the derivatives of more complex functions by combining the derivatives of simpler functions. Here are some of the most commonly used rules:
#### Constant Rule:
```plaintext
If f(x) = c, where c is a constant, then
f'(x) = 0
```
#### Sum Rule:
```plaintext
If f(x) = g(x) + h(x), then
f'(x) = g'(x) + h'(x)
```
#### Difference Rule:
```plaintext
If f(x) = g(x) - h(x), then
f'(x) = g'(x) - h'(x)
```
#### Product Rule:
```plaintext
If f(x) = g(x) * h(x), then
f'(x) = g'(x) * h(x) + g(x) * h'(x)
```
#### Quotient Rule:
```plaintext
If f(x) = g(x) / h(x), then
f'(x) = (g'(x) * h(x) - g(x) * h'(x)) / h(x)^2
```
#### Chain Rule:
```plaintext
If f(x) = g(h(x)), then
f'(x) = g'(h(x)) * h'(x)
```
These rules provide a systematic way to find the derivatives of various functions by breaking them down into simpler components and applying basic differentiation techniques.
### Higher Order Derivatives
In calculus, higher order derivatives refer to the derivatives of derivatives. For example, the second derivative of a function is the derivative of its first derivative, and so on.
#### Notation:
- The first derivative of a function f(x) is denoted as f'(x) or dy/dx.
- The second derivative of f(x) is denoted as f''(x) or d^2y/dx^2.
- Higher order derivatives can be denoted as f^(n)(x) or d^n y/dx^n, where n is the order of the derivative.
#### Example:
Let's consider a function f(x) = x^3. We'll find its first, second, and third derivatives.
#### First Derivative:
```plaintext
f(x) = x^3
f'(x) = 3x^2
```
#### Second Derivative:
```plaintext
f'(x) = 3x^2
f''(x) = 6x
```
#### Third Derivative:
```plaintext
f''(x) = 6x
f'''(x) = 6
```
In this example, we see that each derivative introduces a degree of differentiation. The first derivative measures the rate of change of the function, the second derivative measures the rate of change of the rate of change, and so on. Higher order derivatives provide increasingly detailed information about the behavior of the function.
### Maxima and Minima
In calculus, maxima and minima refer to the highest and lowest points, respectively, on a graph of a function. These points represent local extrema, meaning that they are either the highest or lowest points in a small neighborhood around them.
#### Definition:
- **Maxima**: A point x = c is a local maximum of a function f(x) if there exists an open interval (a, b) containing c such that f(x) ≤ f(c) for all x in (a, c) and (c, b). In other words, the function attains its highest value at x = c within a small interval around c.
- **Minima**: A point x = c is a local minimum of a function f(x) if there exists an open interval (a, b) containing c such that f(x) ≥ f(c) for all x in (a, c) and (c, b). In other words, the function attains its lowest value at x = c within a small interval around c.
#### Example:
Consider the function f(x) = x^2 - 4x + 3. We'll find its critical points and determine whether they correspond to maxima or minima.
#### Critical Points:
To find the critical points, we set the derivative equal to zero and solve for x:
```plaintext
f(x) = x^2 - 4x + 3
f'(x) = 2x - 4
Set f'(x) = 0:
2x - 4 = 0
2x = 4
x = 2
```
So, x = 2 is a critical point of the function.
#### Second Derivative Test:
To determine whether the critical point corresponds to a maximum or minimum, we use the second derivative test. If the second derivative is positive at the critical point, it's a local minimum. If it's negative, it's a local maximum.
```plaintext
f''(x) = 2
At x = 2:
f''(2) = 2 > 0
```
Since the second derivative is positive at x = 2, the function has a local minimum at this point.
In this example, we found that the function f(x) = x^2 - 4x + 3 has a local minimum at x = 2.
### What is a Multivariable Function?
A multivariable function is a relationship between two or more sets that associates each element of the first set with exactly one element of the second set. In this context, the first set is often referred to as the domain, which consists of ordered pairs (or tuples) of real numbers, and the second set is called the range. Multivariable functions describe mathematical relationships where one quantity depends on two or more other quantities.
In mathematical notation, a multivariable function is typically written as f(x, y, z, ...), where f denotes the function, and x, y, z, etc., are elements from the domain. The expression f(x, y, z, ...) represents the value of the function at the elements x, y, z, etc.
#### Example
Consider the function:
```
f(x, y) = x^2 + y^2
```
This function takes two inputs, x and y, and returns the sum of their squares as the output.
Let's evaluate this function for a few values of x and y:
```
- If x = 1 and y = 1, then f(1, 1) = 1^2 + 1^2 = 1 + 1 = 2
- If x = 2 and y = 3, then f(2, 3) = 2^2 + 3^2 = 4 + 9 = 13
- If x = 0 and y = -2, then f(0, -2) = 0^2 + (-2)^2 = 0 + 4 = 4
```
In this example, the domain of the function is all pairs of real numbers (x, y), and the range is all non-negative real numbers (since squaring any real number results in a non-negative number).
#### Visual Representation
Multivariable functions can be visualized using graphs in higher dimensions. For example, the function f(x, y) = x^2 + y^2 can be visualized as a surface in three-dimensional space, where the height of the surface at each point (x, y) corresponds to the value of the function at that point.
### Derivatives of Multivariable Functions
In multivariable calculus, the concept of derivatives extends to functions of more than one variable. The derivatives of multivariable functions measure how the function changes as each of its input variables changes. These derivatives are essential for understanding the behavior and properties of multivariable functions.
### Partial Derivatives
The partial derivative of a multivariable function with respect to one of its variables measures the rate at which the function changes as that variable changes, while keeping the other variables constant.
#### Notation
For a function `f(x, y)`, the partial derivative of `f` with respect to `x` is denoted by:
```
∂f/∂x
```
And the partial derivative of `f` with respect to `y` is denoted by:
```
∂f/∂y
```
#### Example
Consider the function:
```
f(x, y) = x^2 + y^3
```
To find the partial derivatives, we differentiate `f` with respect to each variable separately.
#### Partial Derivative with respect to `x`
```
∂f/∂x = ∂/∂x (x^2 + y^3)
= ∂/∂x (x^2) + ∂/∂x (y^3)
= 2x + 0
= 2x
```
#### Partial Derivative with respect to `y`
```
∂f/∂y = ∂/∂y (x^2 + y^3)
= ∂/∂y (x^2) + ∂/∂y (y^3)
= 0 + 3y^2
= 3y^2
```
So, the partial derivatives of `f(x, y)` are:
```
∂f/∂x = 2x
∂f/∂y = 3y^2
```
### Gradient
The gradient of a multivariable function is a vector that consists of all its partial derivatives. It points in the direction of the steepest ascent of the function.
#### Notation
For a function `f(x, y)`, the gradient is denoted by `∇f` and is given by:
```
∇f = (∂f/∂x, ∂f/∂y)
```
#### Example
Using the previous function `f(x, y) = x^2 + y^3`, the gradient is:
```
∇f = (2x, 3y^2)
```
### Gradient Descent
Gradient descent is an optimization algorithm used to minimize functions by iteratively moving towards the steepest descent direction as defined by the negative of the gradient. It is widely used in machine learning and deep learning to minimize the cost function and improve model performance.
#### The Concept
In the context of a multivariable function, the gradient descent algorithm seeks to find the minimum value of the function by following the direction of the negative gradient. The gradient at any point indicates the direction of the steepest ascent, so moving in the opposite direction (the negative gradient) leads to the steepest descent.
#### Basic Steps
1. **Initialize**: Start with an initial guess for the function's variables.
2. **Compute Gradient**: Calculate the gradient of the function at the current point.
3. **Update Variables**: Adjust the variables in the direction of the negative gradient.
4. **Iterate**: Repeat steps 2 and 3 until convergence (i.e., when the changes in the function value become negligible).
#### Mathematical Formulation
For a function `f(x, y)`, the update rule for gradient descent can be written as:
```
x_new = x_old - α * (∂f/∂x)
y_new = y_old - α * (∂f/∂y)
```
Here, `α` (alpha) is the learning rate, a positive scalar that determines the step size.
#### Example
Consider the function:
```
f(x, y) = x^2 + y^2
```
This function has a global minimum at `(x, y) = (0, 0)`. We will use gradient descent to find this minimum.
#### Step-by-Step Process
1. **Initialize**: Start with an initial guess, say `(x_0, y_0) = (3, 4)`.
2. **Compute Gradient**: Calculate the partial derivatives of `f(x, y)`.
```
∂f/∂x = 2x
∂f/∂y = 2y
```
At `(3, 4)`:
```
∂f/∂x = 2 * 3 = 6
∂f/∂y = 2 * 4 = 8
```
3. **Update Variables**: Choose a learning rate, say `α = 0.1`.
```
x_new = 3 - 0.1 * 6 = 3 - 0.6 = 2.4
y_new = 4 - 0.1 * 8 = 4 - 0.8 = 3.2
```
4. **Iterate**: Repeat the process with the new values `(2.4, 3.2)`.
Calculate the gradient at `(2.4, 3.2)`:
```
∂f/∂x = 2 * 2.4 = 4.8
∂f/∂y = 2 * 3.2 = 6.4
```
Update the variables:
```
x_new = 2.4 - 0.1 * 4.8 = 2.4 - 0.48 = 1.92
y_new = 3.2 - 0.1 * 6.4 = 3.2 - 0.64 = 2.56
```
Repeat these steps until the values of `x` and `y` converge to `(0, 0)`.
#### Convergence
The convergence of gradient descent depends on the choice of the learning rate:
- **Too large**: The algorithm may overshoot the minimum and fail to converge.
- **Too small**: The algorithm may converge very slowly. | harshm03 |
1,871,790 | How to create a rating system with Tailwind CSS and JavaScript | It's Friday! And today we are goign to create a rating system using Tailwind CSS and JavaScript. Just... | 0 | 2024-05-31T08:07:06 | https://dev.to/mike_andreuzza/how-to-create-a-rating-system-with-tailwind-css-and-javascript-1421 | tutorial, javascript, tailwindcss | It's Friday! And today we are goign to create a rating system using Tailwind CSS and JavaScript. Just like the last tutorial, where we used Alpine.js, but with javascript.
[Read the article, See it live and get the code](https://lexingtonthemes.com/tutorials/how-to-create-a-rating-system-with-tailwind-css-and-javascript/)
| mike_andreuzza |
1,871,789 | How to Migrate from Oracle to SQL Server | Before we discuss how to migrate from Oracle to SQL Server, let us understand what data migration is... | 0 | 2024-05-31T08:06:16 | https://dev.to/dbajamey/how-to-migrate-from-oracle-to-sql-server-4cn0 | database, oracle, sqlserver, tutorial | Before we discuss how to migrate from Oracle to SQL Server, let us understand what data migration is and when it may be used. This process involves exporting data from the source location, modifying if needed, and then transferring it to a destination location. In other words, data migration is moving data between database objects or servers.
Data migration serves different purposes, one of which is optimizing performance. For example, organizations might need to move data to other storage systems or reorganize database structures to improve query performance. In addition, an increasing number of database migrations from on-premises servers to cloud-based platforms are driven by cost reduction, scalability improvements, and enhanced disaster recovery capabilities.
During the data transfer, companies often use migration or data import/export tools, such as dbForge Studio, whose distinctive feature among migration multiple tools is importing data from various sources, including ODBC connections.
In the article, we’ll examine how to move data from Oracle to a SQL Server database using dbForge Edge and Devart ODBC Driver for Oracle.
https://blog.devart.com/oracle-to-sql-server-migration.html | dbajamey |
1,871,788 | Angular's next feature @let syntax | We can check the pull request here: https://github.com/angular/angular/pull/55848 Let's discuss the... | 25,553 | 2024-05-31T08:03:04 | https://dev.to/nhannguyendevjs/angular-next-feature-let-syntax-2ecp | programming, angular, beginners | We can check the pull request here: https://github.com/angular/angular/pull/55848
Let's discuss the various use cases and advantages of the new **@let** syntax.
The **@let** syntax allows us to declare and use local variables within our Angular templates.
```html
@let user = user$ | async;
@let greeting = user ? 'Hello, ' + user.name : 'Loading...';
<h1>{{ greeting }}</h1>
```
In the above example, **user$** is an observable that emits user data. The **@let** syntax simplifies handling asynchronous data and conditional rendering.
🚀 **Use Cases:**
➖ Using the async pipe directly in multiple places can lead to multiple subscriptions, which is inefficient and can cause performance issues:
```html
<div>{{ total$ | async }}</div>
<div>{{ total$ | async }}</div>
```
The solution is to use the **@let** syntax to declare a variable for the observable value. This approach ensures a single subscription.
```html
@let total = total$ | async;
<div>{{ total }}</div>
<div>{{ total }}</div>
```
➖ One of the most annoying issues with **signals** is their lack of **type narrowing** ability within the template. We can use the **@let** feature to resolve this problem:
```html
@let txType = tx().type;
@switch(txType) {
@case('a') {}
@case('b') {}
}
@let address = person()?.address();
@if (address) {
<app-address [address]="address">
}
```
➖ The **@let** syntax particularly useful within **@for** loops. We can create intermediate properties directly in the template, enhancing readability and reducing the need for additional component logic:
```html
@for (user of users(); track user.id) {
@let address = user.address;
<div>
<h3>User: {{ user.name }}</h3>
<div>
<p>Street: {{ address.street }}</p>
<p>City: {{ address.city }}</p>
<p>Zipcode: {{ address.zipcode }}</p>
</div>
@for (order of user.orders) {
<div>
<h4>Order: {{ order.id }}</h4>
<p>Product: {{ order.productName }}</p>
<p>Quantity: {{ order.quantity }}</p>
</div>
}
</div>
}
```
➖ Using an expensive pipe multiple times in a template often necessitates creating a property in the component to store the transformed data. With the **@let** syntax, we can declare and reuse a transformed variable once, reducing the computational load and keeping our template clean:
```html
@let someResult = someData | somePipe;
<p>{{ someResult }}</p>
<p>{{ someResult }}</p>
```
✨ **Conclusion**
This new feature enhances the development experience for Angular developers by addressing common challenges such as managing falsy values, avoiding multiple subscriptions, and reducing repetitive code.
---
I hope you found it helpful. Thanks for reading. 🙏
Let's get connected! You can find me on:
- **Medium:** https://medium.com/@nhannguyendevjs/
- **Dev**: https://dev.to/nhannguyendevjs/
- **Hashnode**: https://nhannguyen.hashnode.dev/
- **Linkedin:** https://www.linkedin.com/in/nhannguyendevjs/
- **X (formerly Twitter)**: https://twitter.com/nhannguyendevjs/
- **Buy Me a Coffee:** https://www.buymeacoffee.com/nhannguyendevjs | nhannguyendevjs |
1,866,317 | Linear Algebra for Data Science and Machine Learning | What are Matrices? A matrix is denoted by a capital letter (e.g., A). An m x n matrix has... | 0 | 2024-05-31T08:02:34 | https://dev.to/harshm03/linear-algebra-for-data-science-and-machine-learning-3ld | datascience, machinelearning, deeplearning | ### What are Matrices?
A matrix is denoted by a capital letter (e.g., A). An m x n matrix has m rows and n columns. Each element of the matrix is called an entry and is denoted by a_ij, where i is the row number and j is the column number.
#### Examples:
**Square Matrix:** A matrix with the same number of rows and columns.
```
1 2 3
4 5 6
7 8 9
```
**Non-Square Matrix:** A matrix with a different number of rows and columns.
```
1 2 3
4 5 6
```
### Row Matrix (Row Vector)
A row matrix, or row vector, is a matrix with a single row and multiple columns. It is used to represent a vector in row form.
#### Example:
```
1 2 3
```
### Column Matrix (Column Vector)
A column matrix, or column vector, is a matrix with a single column and multiple rows. It is used to represent a vector in column form.
#### Example:
```
1
2
3
```
### Identity Matrix
An identity matrix is a square matrix with ones on the diagonal and zeros elsewhere. It serves as the multiplicative identity in matrix multiplication, meaning any matrix multiplied by the identity matrix remains unchanged.
#### Example:
```
1 0 0
0 1 0
0 0 1
```
### Addition of Matrices
Matrices can be added together if they have the same dimensions, meaning they have the same number of rows and columns. To add two matrices, simply add the corresponding elements together.
#### Example:
Consider two matrices:
Matrix A:
```
1 2
3 4
```
Matrix B:
```
5 6
7 8
```
To add these matrices, add the corresponding elements:
```
1+5 2+6
3+7 4+8
```
This results in the sum matrix:
```
6 8
10 12
```
### Multiplication of Matrix by Scalar
Multiplying a matrix by a scalar involves multiplying every element of the matrix by that scalar value.
#### Example:
Consider the matrix:
```
1 2
3 4
```
To multiply this matrix by the scalar value 2, simply multiply each element by 2:
```
2*1 2*2
2*3 2*4
```
This results in the matrix:
```
2 4
6 8
```
### Subtraction of Matrices
Matrices can be subtracted from each other if they have the same dimensions, meaning they have the same number of rows and columns. To subtract one matrix from another, simply subtract the corresponding elements.
#### Example:
Consider two matrices:
Matrix X:
```
10 8
6 4
```
Matrix Y:
```
3 2
5 1
```
To subtract Matrix Y from Matrix X, subtract the corresponding elements:
```
10-3 8-2
6-5 4-1
```
This results in the difference matrix:
```
7 6
1 3
```
### Multiplication of Matrices
Matrix multiplication is a binary operation that produces a matrix from two matrices. For the multiplication of two matrices A and B to be defined, the number of columns in A must equal the number of rows in B.
#### Rules for Matrix Multiplication:
1. **Dimension Compatibility:** The number of columns in the first matrix must be equal to the number of rows in the second matrix.
2. **Element Calculation:** Each element c_ij of the resulting matrix C is obtained by multiplying the elements of the i-th row of matrix A by the corresponding elements of the j-th column of matrix B, and summing the products.
3. **Order of Multiplication:** Matrix multiplication is not commutative, i.e., AB may not be equal to BA.
#### Example:
Consider two matrices:
Matrix A (2x3):
```
1 2 3
4 5 6
```
Matrix B (3x2):
```
7 8
9 10
11 12
```
To multiply Matrix A by Matrix B:
1. Dimension compatibility: The number of columns in Matrix A (3) is equal to the number of rows in Matrix B (3), so multiplication is possible.
2. Element calculation:
- For element c_11 of the resulting matrix:
c_11 = (1*7) + (2*9) + (3*11) = 7 + 18 + 33 = 58
- For element c_12 of the resulting matrix:
c_12 = (1*8) + (2*10) + (3*12) = 8 + 20 + 36 = 64
- For element c_21 of the resulting matrix:
c_21 = (4*7) + (5*9) + (6*11) = 28 + 45 + 66 = 139
- For element c_22 of the resulting matrix:
c_22 = (4*8) + (5*10) + (6*12) = 32 + 50 + 72 = 154
This results in the product matrix C (2x2):
```
58 64
139 154
```
The dimension of the resultant matrix in matrix multiplication is determined by the number of rows of the first matrix and the number of columns of the second matrix.
### Transpose of a Matrix
The transpose of a matrix is an operation that flips a matrix over its diagonal, switching the row and column indices of the matrix. The transpose of a matrix A is often denoted as A^T or A'.
#### Definition:
For a matrix A with dimensions m x n, the transpose A^T will have dimensions n x m. Each element a_ij in A becomes element a_ji in A^T.
#### Example:
Consider the matrix A:
```
1 2 3
4 5 6
```
The transpose of matrix A, denoted as A^T, is:
```
1 4
2 5
3 6
```
Here, the rows and columns of matrix A are swapped to get the transpose.
### Symmetric Matrix
A symmetric matrix is a square matrix that is equal to its transpose. In other words, a matrix A is symmetric if A = A^T. This means that the element at the i-th row and j-th column is the same as the element at the j-th row and i-th column for all i and j.
#### Definition:
A matrix A is symmetric if a_ij = a_ji for all i and j.
#### Example:
Consider the matrix A:
```
1 2 3
2 4 5
3 5 6
```
To verify if this matrix is symmetric, we calculate its transpose:
Transpose of matrix A:
```
1 2 3
2 4 5
3 5 6
```
Since the original matrix A is equal to its transpose, it is a symmetric matrix.
### Skew-Symmetric Matrix
A skew-symmetric matrix is a square matrix that is equal to the negative of its transpose. In other words, a matrix A is skew-symmetric if A = -A^T. This means that the element at the i-th row and j-th column is the negative of the element at the j-th row and i-th column for all i and j. Additionally, all the diagonal elements of a skew-symmetric matrix are zero.
#### Definition:
A matrix A is skew-symmetric if a_ij = -a_ji for all i and j, and a_ii = 0 for all i.
#### Example:
Consider the matrix A:
```
0 2 -3
-2 0 4
3 -4 0
```
To verify if this matrix is skew-symmetric, we calculate its transpose and compare it with the negative of the original matrix:
Transpose of matrix A:
```
0 -2 3
2 0 -4
-3 4 0
```
Negative of the original matrix A:
```
0 -2 3
2 0 -4
-3 4 0
```
Since the transpose of matrix A is equal to the negative of the original matrix A, it is a skew-symmetric matrix.
### Inverse of a Matrix
The inverse of a matrix is a matrix that, when multiplied by the original matrix, yields the identity matrix.
#### Definition:
A square matrix A has an inverse A^-1 if:
```
A * A^-1 = A^-1 * A = I
```
where I is the identity matrix.
####Conditions for the Inverse to Exist:
1. **Square Matrix:** The matrix must be square (same number of rows and columns).
2. **Non-Singular Matrix:** The matrix must have a non-zero determinant.
#### Example:
Consider the matrix A:
```
A = [4 7]
[2 6]
```
The inverse of A is:
```
A^-1 = [ 3/5 -7/10]
[-1/5 2/5 ]
```
### Determinant
The determinant is a scalar value that can be computed from a square matrix. It provides important properties about the matrix, such as whether the matrix is invertible, and it is used in various areas of mathematics including solving systems of linear equations, finding eigenvalues, and more.
#### Determinant of a Square Matrix of Order 1
For a 1x1 matrix A:
```
A = [a]
```
The determinant of A, denoted as det(A), is simply the value of the single element:
```
det(A) = a
```
#### Determinant of a Square Matrix of Order 2
For a 2x2 matrix A:
```
A = [a b]
[c d]
```
The determinant of A, denoted as det(A), is calculated as:
```
det(A) = ad - bc
```
#### Example:
```
A = [1 2]
[3 4]
```
```
det(A) = (1 * 4) - (2 * 3) = 4 - 6 = -2
```
#### Determinant of a Square Matrix of Order 3
For a 3x3 matrix A:
```
A = [a b c]
[d e f]
[g h i]
```
The determinant of A, denoted as det(A), is calculated using the following formula:
```
det(A) = a(ei - fh) - b(di - fg) + c(dh - eg)
```
#### Example:
```
A = [1 2 3]
[4 5 6]
[7 8 9]
```
```
det(A) = 1(5*9 - 6*8) - 2(4*9 - 6*7) + 3(4*8 - 5*7)
= 1(45 - 48) - 2(36 - 42) + 3(32 - 35)
= 1(-3) - 2(-6) + 3(-3)
= -3 + 12 - 9
= 0
```
In this case, the determinant of matrix A is 0.
### Singular Matrix
A singular matrix is a square matrix that does not have an inverse. This happens if and only if the determinant of the matrix is zero. Singular matrices are important in linear algebra because they indicate systems of linear equations that do not have a unique solution.
#### Definition:
A square matrix A is singular if det(A) = 0.
#### Example:
Consider the 2x2 matrix A:
```
A = [2 4]
[1 2]
```
To determine if A is singular, calculate its determinant:
```
det(A) = (2 * 2) - (4 * 1) = 4 - 4 = 0
```
Since the determinant of A is 0, matrix A is singular.
### Properties of Singular Matrices:
1. **No Inverse:** Singular matrices do not have an inverse.
2. **Linearly Dependent Rows/Columns:** The rows or columns of a singular matrix are linearly dependent, meaning one row or column can be expressed as a linear combination of the others.
3. **Non-unique Solutions:** Systems of linear equations represented by singular matrices do not have a unique solution; they may have no solution or infinitely many solutions.
#### Example of a Non-Singular Matrix for Comparison:
Consider the 2x2 matrix B:
```
B = [1 2]
[3 4]
```
Calculate its determinant:
```
det(B) = (1 * 4) - (2 * 3) = 4 - 6 = -2
```
Since the determinant of B is not 0, matrix B is not singular (it is invertible).
### Properties of Determinants
The determinant is a scalar value associated with a square matrix that encapsulates important properties of the matrix. Here are key properties of determinants:
1. **Equal to Its Transpose:** The determinant of a matrix is equal to the determinant of its transpose.
2. **Row Interchange:** Interchanging two rows of a matrix changes the sign of the determinant.
3. **Identical Rows:** If a matrix has two identical rows, its determinant is zero.
4. **Scalar Multiplication:** If a matrix B is obtained by multiplying every element of a row (or column) of a matrix A by a scalar k, then the determinant of B is k times the determinant of A.
5. **Zero Row:** If every element of a row (or column) of a matrix is zero, its determinant is zero.
### Vectors
Vectors are mathematical entities that represent quantities with both magnitude and direction. They are commonly denoted by symbols with an arrow above them or bold letters. Vectors are extensively used in various fields such as physics, engineering, and computer science to describe quantities like displacement, velocity, force, etc.
### What is a Vector?
A vector consists of components that indicate the magnitude of the vector along different axes or directions. For instance, in a two-dimensional space, a vector can be represented as [x, y], where x represents the horizontal component and y represents the vertical component.
### Components of a Vector
The components of a vector represent its magnitude along different directions. Each component indicates the length of the vector along a specific axis. For example, in a three-dimensional space, a vector might have components [x, y, z], representing its magnitude along the x, y, and z axes respectively.
### Addition of Vectors
To add two vectors, simply add their corresponding components. For example:
```
v1 = [2, 3]
v2 = [1, -1]
v_sum = [2+1, 3-1] = [3, 2]
```
### Subtraction of Vectors
To subtract one vector from another, simply subtract their corresponding components. For example:
```
v1 = [2, 3]
v2 = [1, -1]
v_diff = [2-1, 3-(-1)] = [1, 4]
```
### Multiplication by Scalar
Multiplying a vector by a scalar involves multiplying each component of the vector by the scalar. For example:
```
v = [2, 3]
scalar = 2
v_scaled = [2*2, 3*2] = [4, 6]
```
### Scalar or Dot Product
The scalar product, also known as the dot product, of two vectors yields a scalar quantity. It's calculated by multiplying corresponding components of the vectors and then summing the results. For example:
```
v1 = [2, 3]
v2 = [1, -1]
v_dot = (2*1) + (3*(-1)) = 2 - 3 = -1
```
The dot product can also be expressed in terms of the magnitudes of the vectors and the cosine of the angle between them:
```
v_dot = |a| * |b| * cos(θ)
```
Where |a| and |b| are the magnitudes of vectors a and b respectively, and θ is the angle between them.
### Vector or Cross Product
The vector product, also known as the cross product, of two vectors yields another vector that is perpendicular to the plane containing the original vectors. It's calculated differently depending on the dimensionality of the vectors. For example, in three-dimensional space:
```
v1 = [i, j, k]
v2 = [a, b, c]
v_cross = [jb - kc, kc - ia, ia - jb]
```
The cross product can be expressed in terms of the magnitudes of the vectors and the sine of the angle between them:
```
|v_cross| = |a| * |b| * sin(θ)
```
Where |a| and |b| are the magnitudes of vectors a and b respectively, and θ is the angle between them.
### Linear Equations
A linear equation is an algebraic equation in which each term is either a constant or the product of a constant and a variable raised to the first power. These equations represent straight lines when graphed on a coordinate plane and have the general form:
ax + by + c = 0
Here, a, b, and c are constants, and x and y are variables.
Linear equations can have one or more variables, and they express relationships that are linear in nature. They are fundamental in mathematics and are used to model various real-world situations, such as finance, physics, engineering, and economics.
Linear equations can be solved using various methods, including substitution, elimination, matrices, and graphing. They form the basis of linear algebra and are essential in many areas of mathematics and science.
### Solution of System of Linear Equations
Solving a system of linear equations involves finding the values of variables that satisfy all the equations simultaneously. There are several methods to solve such systems:
1. **Graphical Method:**
Graphing each equation on the coordinate plane and finding the point(s) of intersection.
2. **Substitution Method:**
Solving one equation for one variable and substituting it into another equation repeatedly until all variables are determined.
3. **Elimination Method (or Addition Method):**
Adding or subtracting multiples of equations to eliminate one variable at a time.
4. **Matrix Method (or Gaussian Elimination):**
Representing the system of equations in matrix form and performing row operations to transform the augmented matrix into row-echelon form, followed by back substitution.
### Rank of a Matrix
The rank of a matrix is a fundamental concept in linear algebra that represents the maximum number of linearly independent rows or columns in the matrix. In other words, it measures the dimension of the vector space spanned by the rows or columns of the matrix.
#### Calculation of Rank:
1. **Row Echelon Form (REF) / Reduced Row Echelon Form (RREF):**
One common method to find the rank of a matrix is to convert it into either row echelon form (REF) or reduced row echelon form (RREF). The number of non-zero rows in the resulting form is the rank of the matrix.
2. **Using Determinants:**
The rank of a matrix can also be determined by examining its determinant. If the determinant of a submatrix of size k is non-zero, and the determinant of all submatrices of size k+1 are zero, then the rank of the matrix is k.
#### Example:
Consider the matrix A:
```
1 2 3
4 5 6
7 8 9
```
Converting it to REF:
```
1 2 3
0 -3 -6
0 0 0
```
The number of non-zero rows is 2, so the rank of matrix A is 2.
#### Conclusion:
The rank of a matrix provides valuable insights into its properties and structure. It is used in various mathematical and computational applications, including solving systems of linear equations, finding eigenvalues, and performing matrix factorization. Understanding how to compute the rank of a matrix is essential for analyzing and manipulating matrices in linear algebra.
### Elementary Operations of a Matrix
Elementary operations of a matrix refer to fundamental operations that can be performed on its rows or columns. These operations are essential in various matrix manipulations, such as solving systems of linear equations, finding determinants, and performing matrix factorization. The elementary operations include:
1. **Row Replacement (Ri <-> Rj):**
Swap the elements of two rows in the matrix.
2. **Row Scaling (Ri -> k * Ri):**
Multiply all elements of a row by a scalar value.
3. **Row Addition (Ri -> Ri + k * Rj):**
Add a scalar multiple of one row to another row, and assign the result to the second row.
These elementary operations are used to transform a matrix into a desired form, such as row echelon form or reduced row echelon form, which simplifies various matrix computations and analyses.
### Row Echelon Form and Reduced Row Echelon Form
Row echelon form (REF) and reduced row echelon form (RREF) are standard forms used to simplify matrices, particularly in the context of solving systems of linear equations and computing the rank of a matrix.
To achieve these forms, we employ elementary matrix operations, including row replacement, row scaling, and row addition. These operations allow us to systematically transform a matrix into a more structured form that reveals valuable information about its properties and solutions.
#### Row Echelon Form (REF):
In REF, the matrix is transformed such that:
1. The leading entry (pivot) of each nonzero row is to the right of the leading entry of the row above it.
2. All entries in a column below a leading entry are zero.
#### Reduced Row Echelon Form (RREF):
RREF further refines the structure of the matrix:
1. The leading entry of each nonzero row is 1.
2. The leading entry of each nonzero row is the only nonzero entry in its column.
### Example:
Consider the following matrix A:
```
1 2 3
0 4 5
0 0 6
```
**We can use elementary matrix operations to transform matrix A into REF and then into RREF. The resulting matrices will provide valuable insights into the structure of A and facilitate computations such as solving systems of linear equations and computing the rank of A.**
### Linear Transformation in Matrices
A linear transformation is a mapping between two vector spaces that preserves the operations of vector addition and scalar multiplication. In the context of matrices, a linear transformation can be represented by a matrix that, when multiplied by a vector, transforms that vector in a linear manner.
#### Definition:
A linear transformation T from a vector space V to a vector space W can be represented as:
```
T(v) = A * v
```
where v is a vector in V, and A is a matrix that defines the transformation.
#### Properties of Linear Transformations:
1. Additivity: T(u + v) = T(u) + T(v)
2. Homogeneity: T(c * v) = c * T(v)
- Where u and v are vectors, and c is a scalar.
#### Example:
Consider a 2x2 matrix A representing a linear transformation:
```
A = [2 0]
[1 3]
```
If v is a vector:
```
v = [x]
[y]
```
The linear transformation T(v) = A * v is:
```
T(v) = [2 0] * [x] = [2x]
[1 3] [y] [x + 3y]
```
#### Conclusion:
Linear transformations are fundamental in understanding how vectors change under various operations. Matrices provide a convenient way to represent and compute these transformations, preserving vector addition and scalar multiplication.
### Eigenvalues and Eigenvectors
Eigenvalues and eigenvectors are fundamental concepts in linear algebra that are used in various fields such as physics, engineering, and computer science.
#### Definition:
For a given square matrix A, an eigenvector is a non-zero vector v that, when multiplied by A, yields a scalar multiple of itself. This can be expressed as:
```
A * v = λ * v
```
where:
- A is the square matrix.
- v is the eigenvector.
- λ (lambda) is the eigenvalue corresponding to the eigenvector v.
#### Characteristics:
1. **Eigenvalues (λ):** Scalars that indicate how much the eigenvector is stretched or shrunk during the transformation.
2. **Eigenvectors (v):** Vectors that remain in the same direction after the transformation by the matrix A.
#### Finding Eigenvalues and Eigenvectors:
1. **Eigenvalues:** Solve the characteristic equation:
```
det(A - λI) = 0
```
- I is the identity matrix of the same dimension as A.
- det denotes the determinant of the matrix.
2. **Eigenvectors:** Once the eigenvalues are found, solve the equation:
```
(A - λI) * v = 0
```
- This system of equations will yield the eigenvectors corresponding to each eigenvalue.
#### Example:
Consider the matrix A:
```
A = [4 1]
[2 3]
```
1. Find the eigenvalues by solving:
```
det(A - λI) = 0
det([4-λ 1 ]
[2 3-λ]) = 0
(4-λ)(3-λ) - (2*1) = 0
λ^2 - 7λ + 10 = 0
λ = 5, 2
```
2. For λ = 5, solve (A - 5I)v = 0:
```
[4-5 1 ] [x] [ -1 1 ] [x] [ 0]
[2 3-5] [y] = [ 2 -2] [y] = [ 0]
Solving, we get eigenvector v = [1, 1]^T
```
3. For λ = 2, solve (A - 2I)v = 0:
```
[4-2 1 ] [x] [ 2 1 ] [x] [ 0]
[2 3-2] [y] = [ 2 1] [y] = [ 0]
Solving, we get eigenvector v = [-1, 2]^T
```
#### Conclusion:
Eigenvalues and eigenvectors provide insight into the properties of a matrix, such as its stability, oscillations, and directions of stretching or shrinking. They are essential tools in solving systems of differential equations, performing principal component analysis, and more.
| harshm03 |
1,870,475 | Creative ways to use Array.map() | Hello fellow developers! Have you ever wondered about the various ways to use the array.map()... | 0 | 2024-05-31T08:00:00 | https://dev.to/aneeqakhan/creative-ways-to-use-arraymap-4ce1 | javascript, webdev, beginners, programming | Hello fellow developers!
Have you ever wondered about the various ways to use the array.map() function to achieve different transformations?
I have compiled a list of ideas on how to utilize them effectively map() function.
## 1. Basic Transformation
Transform each element in an array.
```javascript
const numbers = [1, 2, 3];
const squares = numbers.map(x => x * x);
console.log(squares); // [1, 4, 9]
```
## 2. Mapping to Objects
Transform an array of values to an array of objects.
```javascript
const names = ['Alice', 'Bob', 'Charlie'];
const people = names.map(name => ({ name }));
console.log(people); // [{ name: 'Alice' }, { name: 'Bob' }, { name: 'Charlie' }]
```
## 3. Extracting Properties
Extract a specific property from an array of objects.
```javascript
const users = [
{ id: 1, name: 'Alice' },
{ id: 2, name: 'Bob' }
];
const ids = users.map(user => user.id);
console.log(ids); // [1, 2]
```
## 4. Changing Array of Arrays
Transform an array of arrays.
```javascript
const pairs = [[1, 2], [3, 4], [5, 6]];
const summedPairs = pairs.map(pair => pair[0] + pair[1]);
console.log(summedPairs); // [3, 7, 11]
```
## 5. Asynchronous Operations
Handle asynchronous operations within map (commonly using Promise.all).
```javascript
const fetchData = async id => {
// Simulate an async operation
return new Promise(resolve => setTimeout(() => resolve(`Data for ID ${id}`), 1000));
};
const ids = [1, 2, 3];
const promises = ids.map(id => fetchData(id));
Promise.all(promises).then(data => console.log(data)); // ["Data for ID 1", "Data for ID 2", "Data for ID 3"]
```
## 6. Conditional Mapping
Apply a transformation conditionally.
```javascript
const numbers = [1, 2, 3, 4, 5];
const evensDoubled = numbers.map(num => num % 2 === 0 ? num * 2 : num);
console.log(evensDoubled); // [1, 4, 3, 8, 5]
```
## 7. Spreading Arrays into Function Arguments
You can use `map` to spread array elements as arguments to a function.
```javascript
const numbers = [[1, 2], [3, 4], [5, 6]];
// Creating an array of sums
const sums = numbers.map(([a, b]) => a + b);
console.log(sums); // [3, 7, 11]
```
## 8. Zipping Arrays
Combine two arrays into an array of pairs.
```javascript
const keys = ['name', 'age'];
const values = ['Alice', 25];
const zipped = keys.map((key, i) => [key, values[i]]);
console.log(zipped); // [["name", "Alice"], ["age", 25]]
```
## 9. Mapping with Index
Utilizing the index parameter in JavaScript’s map function allows you to include the position of each element in your transformations.
```javascript
const colors = ['red', 'green', 'blue'];
const colorDescriptions = colors.map((color, index) => `Color ${index + 1}: ${color}`);
console.log(colorDescriptions); // ['Color 1: red', 'Color 2: green', 'Color 3: blue']
```
## 10. Flattening an Array
Using `map` to flatten a 2D array, though `flatMap` is better suited for this task.
```javascript
const nestedArray = [[1, 2], [3, 4], [5, 6]];
const flattenedArray = nestedArray.map(subArray => subArray).flat();
console.log(flattenedArray); // [1, 2, 3, 4, 5, 6]
```
Thank you for reading! Feel free to connect with me on [LinkedIn](https://www.linkedin.com/in/aneeqa-khan-990459135/) or [GitHub](https://github.com/AneeqaKhan). | aneeqakhan |
1,863,738 | Best Practices for Fostering Collaboration with the Open-Source Community in 2024 | This post originally appeared on my blog Open-source software (OSS) has become an integral part of... | 27,386 | 2024-05-31T08:00:00 | https://forward.digital/blog/best-practices-for-fostering-collaboration-with-the-open-source-community | webdev, opensource, productivity, learning | [_This post originally appeared on my blog_](https://forward.digital/blog/best-practices-for-fostering-collaboration-with-the-open-source-community)
Open-source software (OSS) has become an integral part of modern software development, with many organisations relying on open-source components to build their products.
However, using open-source software comes with its own set of challenges, such as security risks, licensing issues, and the need to contribute back to the community.
In this post, we delve into effective practices for engaging with and contributing to the open-source community, enhancing both your projects and the broader ecosystem.
## Open Source Program Office
An Open Source Program Office (OSPO) is a corporate entity that is responsible for managing an organisation’s open-source efforts. The OSPO is a “central nervous system” for open source within an organisation and provides governance, oversight, and support for all things related to open source ([Haddad, 2022](https://www.linuxfoundation.org/research/a-deep-dive-into-open-source-program-offices)). It trains staff, promotes efficient software development with open-source parts, guides open-sourcing projects, ensures legal compliance, and builds community engagement.
An OSPO helps bridge the gap between an organisation’s internal development and the external open-source community, helping to ensure that the organisation is a good steward of open-source software and can reap the benefits of open-source adoption, all the while minimising risks ([TODO Group, 2023](https://ospoglossary.todogroup.org/ospo-definition/)).
Six common characteristics of successful open source programs ([Walker, 2016](https://opensource.com/business/16/5/whats-open-source-program-office)) are:
- Value marketing and branding highly.
- Choose open-source communities that match your tech goals.
- Get good legal advice to balance risk and innovation.
- Your open-source efforts should support your product goals.
- Explain your support plans clearly to everyone involved.
- Hire someone passionate about open source to lead.
Uber, for example, was motivated to create its own OSPO because of the need to streamline support for various open-source initiatives. For instance, there was a significant demand for advice on incorporating open-source technology into external products from engineers. Key concerns included navigating compliance, licensing, and related legal matters. Additionally, there was a crucial need to offer engineers direction on how to release Uber’s own software as open source, whether by initiating new projects or contributing to existing ones ([Uber Case Study n.d.](https://todogroup.org/resources/case-studies/uber/)).
“It was natural and organic for Uber to create an open source program office since it allowed us to build our platform and scale the technology at unprecedented speed […] in essence, Uber loves open source because it’s essential to our success.” ([Hsieh, n.d.](https://todogroup.org/resources/case-studies/uber/)).
Since the OSPO is a relatively new concept, with Google opening one of the first OSPOs in 2004 ([Google, 2022](https://opensource.google/about)), the literature references mostly large corporate entities with the resources to create an OSPO. The Linux Foundation recommends a minimum of five employees to start a successful OSPO ([Haddad, 2022](https://www.linuxfoundation.org/research/a-deep-dive-into-open-source-program-offices)). Therefore, an OSPO is not best suited for smaller organisations that cannot afford to dedicate the resources to an OSPO.
## Open Sourcing Previously Proprietary Software
Open-sourcing previously proprietary software is the process of releasing software to the open-source community for free use and modification. This process can be beneficial for organisations; it allows for increased innovation, collaboration, and community engagement and can lead to the development of features that are beneficial to the organisation, as well as the resolution of issues that impact the organisation’s operations.
There are a series of examples of organisations open-sourcing previously proprietary software. Some of the most notable examples include:
**Microsoft Open-sourcing .NET** By open-sourcing .NET, Microsoft allowed for a single, collaborative codebase across platforms rather than separate implementations. Ultimately, open development allows more community engagement to provide feedback and contributions, making the stack better for all ([Landwerth, 2014](https://devblogs.microsoft.com/dotnet/net-core-is-open-source/)).
**Microsoft Open-sourcing Powershell** Microsoft open-sourced PowerShell to make it more widely available and helpful for system administrators and developers who work with multiple operating systems. By making it open source and available cross-platform, more people can use PowerShell to automate tasks and manage their diverse computing environments that include different OSes ([Foley, 2016](https://www.zdnet.com/article/microsoft-open-sources-powershell-brings-it-to-linux-and-mac-os-x/)).
**NVIDIA Open-sourcing PhysX** NVIDIA open-sourced PhysX because physics simulation has “dovetails” with AI, robotics, and computer vision. NVIDIA considered physics simulation “foundational for so many things” and open-sourcing it would allow it to be developed and applied more widely than NVIDIA could do alone ([Lebaredian, 2018](https://blogs.nvidia.com/blog/physx-high-fidelity-open-source/)).
**Microsoft Open-sourcing Live Writer** Microsoft open-sourced Live Writer to allow the community to continue to develop and improve it, as Microsoft no longer had the resources to maintain it ([ARS STAFF, 2015](https://arstechnica.com/information-technology/2015/12/microsoft-open-sources-live-writer-beloved-but-abandoned-blogging-tool/)).
The primary motivation for open-sourcing previously proprietary software is to allow for increased community engagement, feedback, and contributions, making the software better for all.
However, open-sourcing previously proprietary software does have some technical considerations. For example, the software must be properly documented, the code must be clean and well-structured, and the software must be properly licensed. We saw from the interviews that these technical considerations are usually a deal-breaker and the reason why organisations do not open-source their software.
## Hiring
To reduce the risk of using OSS, organisations should hire internal staff to manage OSS. Develop in-house proficiency and aim to reduce reliance on external service providers by cultivating organisational expertise to oversee projects. This approach will enable quicker deployment of upgrades and enhancements ([Team Srijan, 2010](https://materialplus.srijan.net/resources/blog/migrating-open-source-survival-guide-smes)).
Smaller organisations might not necessarily hire new personnel but rather delegate the responsibility to an existing staff member who is recognised as a subject-matter expert within the specific area (Interviewee 8, 2024). This approach is viable because, as noted, “In general, open source developers are experienced users of the software they write. They are intimately familiar with the features they need, and what the correct and desirable behavior is” ([Mockus et al., 2000](https://dl.acm.org/doi/10.1145/337180.337209)). This innate understanding significantly mitigates one of the primary challenges in large software projects: the lack of domain knowledge. Consequently, smaller organisations can effectively rely on their in-house experts, capitalising on their comprehensive knowledge and experience.
Hiring is a significant investment, and it is not always feasible for smaller organisations to hire new personnel to manage OSS.
## Culture
Open source has always been deeply rooted in culture, originating as a grassroots movement advocating for software freedom. Culture encompasses a broad spectrum, and individuals and organisations get involved in open source for various reasons.
When inquiring about the cultural drivers behind companies’ engagement in open source, innovation emerged as the leading motivation, with 84% of respondents to Fintech Open Source Foundation State of Open Source Survey affirming it as a critical factor ([Ellison et al., 2021](https://www.finos.org/reports/2021-state-of-open-source-in-financial-services)).
Uber instituted internal standards for governing and incentivising contributing upstream and back to the community to encourage ongoing, regular involvement in open-source projects. Contributing back to the open-source community is one of the best ways to help ensure open-source project sustainability ([Uber Case Study n.d.](https://todogroup.org/resources/case-studies/uber/)).
A big part of culture is fostering an environment where developers feel comfortable taking an unconventional route to solve a problem ([Autodesk Case Study n.d.](https://todogroup.org/resources/case-studies/autodesk/)), and where they are encouraged to share code and collaborate with others ([Abernathy, n.d.](https://todogroup.org/resources/case-studies/meta/)).
An organisation’s culture is a significant factor in the adoption of open-source software, one that is quite hard to quantify and measure. There was very little mention of culture in the best practices we reviewed, and from our interviews, we found that there isn’t an “open-source” culture but rather a more collaborative and innovative culture that is conducive to using open-source software.
## Contributions
Active engagement in the open-source community offers substantial rewards. When you contribute to the projects your organisation utilises, you’re boosting its reputation and playing a significant role in steering the software’s development path. Such proactive participation can lead to the development of features that are beneficial to your organisation, as well as the resolution of issues that impact your operations.
Contributing to the open-source ecosystem extends beyond just coding. Offering documentation, identifying bugs, and aiding in translations represent other crucial ways to contribute. Through these contributions, you help cultivate a mutually beneficial relationship with the community ([Yborra, 2024](https://vaultinum.com/blog/managing-open-source-software-integration-in-software-development#best-practices-for-managing-open-source-software-integration)).
Contributing also helps keep the open-source component active and maintained. In recent years, a notable challenge has been the shortage of contributions or ongoing maintenance for projects, affecting even highly utilised packages like gorilla/mux, which have struggled to secure maintainers and consequently, had to archive their projects ([Norblin, 2023](https://www.scaleway.com/en/blog/foss-giving-back/)).
Another way to contribute is through financial support. A recent survey by DigitalOcean found that only 20% of respondents had been paid for their contributions to open source, while 53% agreed or strongly agreed that individuals should be compensated for their work ([DigitalOcean, 2022](https://anchor.digitalocean.com/rs/113-DTN-266/images/DigitalOcean-Currents_June-2022.pdf)). This suggests that there is room for improvement in financial support for open-source contributors ([Tandochain, 2023](https://tandochain.medium.com/the-importance-of-financial-support-for-open-source-software-bb486f32b145)).
More work is being done to support financial contributions to open source; notable examples include GitHub Sponsors and Open Source Collective, both offering platforms for financial support of open-source projects ([Open Source Collective 2024](https://www.oscollective.org/); [Explore GitHub Sponsors 2024](https://github.com/sponsors/explore)).
Contributing to the open-source community is a best practice for managing the security risks associated with OSS. Most of the literature we reviewed mentioned contributing to the open-source community as a best practice. However, from our interviews, very few organisations contribute to the open-source community, and those that do do so in a limited capacity.
## Hosting Events
Hosting events is a great way to engage with the open-source community. Events can be an excellent way to engage with the open-source community, and they can take many forms, from hackathons to conferences to meet-ups.
[Schumacher, 2022](https://www.youtube.com/watch?v=6UMCe5o0KBw), went as far as to say that corporate organisations looking to lead in open source should host events, as they are a great way to engage with the community and build relationships.
However, our interviews found that hosting events is not widely used in practice and that the best practices landscape does not reflect the real-world use of hosting events. Companies do send their employees to events, but larger organisations typically host events, as smaller organisations do not have the resources to host events.
## Conclusion
In conclusion, fostering collaboration with the open-source community is essential for organisations that rely on open-source software. By engaging with the community, contributing back to the community, and hosting events, organisations can enhance their projects and the broader ecosystem.
However, there are challenges to fostering collaboration with the open-source community, such as the need to hire internal staff to manage OSS, the technical considerations of open-sourcing previously proprietary software, and the cultural challenges of adopting open-source software.
Despite these challenges, the benefits of fostering collaboration with the open-source community are significant. By following best practices for engaging with and contributing to the open-source community, organisations can enhance their projects and the broader ecosystem, ultimately leading to better software for all.
| bendix |
1,871,785 | Powering Progress: The Role of Wind Turbines in Clean Energy | photo_6246496729478315703_x.jpg Wind turbines and clean energy Introduction Have you ever heard... | 0 | 2024-05-31T07:59:39 | https://dev.to/skcms_kskee_db3d23538e2f3/powering-progress-the-role-of-wind-turbines-in-clean-energy-591d | wind, turbines, energy, solar | photo_6246496729478315703_x.jpg
Wind turbines and clean energy
Introduction
Have you ever heard about wind turbines and energy clean? Wind turbines is an exciting innovation in clean energy helping us power the progress towards a greener and more planet sustainable. We will explore the advantages of wind turbines, their use, and how they work to provide energy clean.
Advantages of wind turbines
Wind turbines are a great way to generate energy clean. They are environmentally friendly and do not produce any emissions that are harmful unlike traditional energy sources like coal or oil. This means wind turbines do not contribute to climate change, which a advantage major. Additionally, Wind Solar Hybrid Power System a resource is renewable meaning it will never run out as long as the wind keeps blowing. This makes it a source reliable of for our future.
Innovation in wind turbines
Wind turbines have come a way long recent years due to innovations many. One of these innovations the use of larger wind turbines, which produce more energy. Another innovation is the use of predictive maintenance, which enables us to detect any pressing issues that are potential, they are become major problems, ensuring the wind turbines operate safely and without interruption.
Safety and use
Wind turbines are designed to be safe for people and animals. They have many safety features like lightning protection and automatic shutdown systems kick in when there an situation unusual. Wind turbines are typically located in open and areas rural away from people and buildings. This because Wind Power Generation System require open space to operate efficiently, and the sound they produce can be disruptive. However, wind turbines typically surrounded by fences as an safety measure additional.
How to use wind turbines
Wind turbines work by capturing the charged power of the wind to turn a rotor spins a generator in the turbine. This generator converts the energy kinetic of wind into electrical energy, which then transferred through a power grid to homes and businesses. To use wind turbines, they need to be installed in the right location with enough wind to generate the energy necessary.
Service and quality
To ensure wind turbines operate optimally and safely, they require regular maintenance. This where service providers come in, offering maintenance and repair services to ensure the Wind Turbine operating as they should. Wind turbines are expensive to install and maintain, so it is essential to purchase a turbine high-quality will last for many years.
Application of wind turbines
Wind turbines can be used in many different ways, from small turbines powering homes and farms to large turbines powering communities entire. Wind turbines can also be used for remote power generation in off-grid areas, providing energy clean those who need it most. Additionally, wind turbines can be combined with other sources of renewable energy, like solar panels, to create systems hybrid provide even more energy.
Source: https://www.dhceversaving.com/Wind-solar-hybrid-power-system | skcms_kskee_db3d23538e2f3 |
1,871,783 | Letras Diferentes: Unleash Your Creativity with Fancy Text for Profiles and More | In the digital age, standing out is key. Whether it's your social media profile, your gaming... | 0 | 2024-05-31T07:58:03 | https://dev.to/soo_ji_fda2de7f1753e613dc/letras-diferentes-unleash-your-creativity-with-fancy-text-for-profiles-and-more-bhi | In the digital age, standing out is key. Whether it's your social media profile, your gaming username, or even your email address, making a visual impact can leave a lasting impression. Enter the world of "Letras Diferentes" (different letters) – a fun and creative way to spice up your online presence.
## Why Fancy Text?
Visual Appeal: Unique fonts and lettering styles are eye-catching. They add a touch of personality and flair, making you more memorable.
Express Yourself: Just like fashion, your text choices can reflect your mood, interests, or overall vibe.
Differentiate: In a sea of ordinary usernames, a creatively styled one is instantly recognizable.
Professional Touch: Even in emails, a subtle variation in your name display can add a touch of professionalism and uniqueness.
## Where to Use Fancy Text
Social Media Profiles: Instagram, Twitter, Facebook, TikTok – anywhere you have a bio or display name is a great place to experiment.
Gaming Usernames: Make your gamertag legendary with a font that screams "pro."
Email Addresses: While the main part of your email needs to be standard, you can often customize the display name that recipients see.
Websites or Blogs: Headers, titles, and even quotes can benefit from the artistic touch of different fonts.
## How to Create Fancy Text
There are several ways to generate fancy text:
Online Generators: Many websites and apps specialize in converting regular text into various stylish fonts. Simply type in your text and choose your favorite style.
Unicode Characters: Some fonts utilize special Unicode characters to create unique symbols and lettering. You can copy and paste these characters where you want to use them.
Text Editors: Some advanced text editors offer custom font options or allow you to install additional fonts.
## Tips for Using Fancy Text
Readability: While unique fonts are fun, make sure they're still easy to read. Don't sacrifice clarity for style.
Context Matters: A playful font might be great for social media, but maybe not for a formal email signature.
Moderation: A little fancy text goes a long way. Use it strategically for maximum impact.
Experiment: Don't be afraid to try different styles until you find ones that truly represent you.
## Let Your Creativity Flow!
Letras Diferentes is a simple yet powerful tool for self-expression in the digital realm. Whether you're aiming to be playful, professional, or simply stand out, experimenting with fancy text can add a unique touch to your online identity. So, what are you waiting for? Start exploring and let your creativity shine! You can use the fonts and templates for free at [https://letras-diferentes.io/](https://letras-diferentes.io/) | soo_ji_fda2de7f1753e613dc | |
1,871,782 | Top Bridal Makeup Artist for Your Special Day | Planning your wedding can be overwhelming, but finding the perfect bridal makeup artist shouldn’t... | 0 | 2024-05-31T07:57:42 | https://dev.to/luxe_makeovers_869650d136/top-bridal-makeup-artist-for-your-special-day-22d5 | 
Planning your wedding can be overwhelming, but finding the perfect bridal makeup artist shouldn’t be. Your wedding day is one of the most important days of your life, and you deserve to look and feel your absolute best. That’s where a top bridal makeup artist comes in, ensuring you achieve a flawless, radiant look that will be cap
beautifully in your wedding photos.
Personalised Consultation
A top bridal makeup artist starts with a personalised consultation to understand your vision, style, and preferences. Whether you’re dreaming of a natural, timeless look or something more glamorous, they take the time to listen and create a customised makeup plan that enhances your unique features and complements your wedding theme.
Expertise and Experience
With years of experience and a deep understanding of the latest trends and techniques, a premier bridal makeup artist in Toronto brings a wealth of expertise to your special day. They use high-quality, long-lasting products to ensure your makeup stays fresh and beautiful from the first photo to the last dance.
Trial Sessions
To guarantee your complete satisfaction, trial sessions are offered. These trials allow you to see different looks and make adjustments before the big day. It's a chance to experiment with colours, styles, and products until you find the perfect combination that makes you feel stunning and confident.
On-the-Day Perfection
On your wedding day, a top bridal makeup artist provides a calm, professional presence. They arrive on time and are fully equipped to handle any last-minute changes or touch-ups, ensuring a stress-free experience. Their attention to detail and commitment to excellence mean you’ll look flawless in person and in every photograph.
Tailored Services
Many top bridal makeup artists offer additional services, including makeup for bridesmaids, mothers of the bride and groom, and even flower girls. They can also provide touch-up kits or stay on-site for makeup refreshes throughout your wedding day, ensuring you and your bridal party look perfect at every moment.
Choosing a top bridal makeup artist for your special day means investing in peace of mind and unforgettable beauty. With their professional skills, personalized approach, and dedication to perfection, you’ll be ready to walk down the aisle with confidence, knowing you look your very best. Make your wedding day truly special with the expertise of a top bridal makeup artist in Toronto.
For more information visit us: https://maps.app.goo.gl/YY2ioYtJNKnyMqxm7
| luxe_makeovers_869650d136 | |
1,871,781 | Shopify Hydrogen Tutorial: Best Methods & Pro Tips | Hi everyone! My name is Jaxson. I'm the product owner and team lead at True Storefront, we've built... | 0 | 2024-05-31T07:56:19 | https://dev.to/jaxsonluu/shopify-hydrogen-tutorial-best-methods-pro-tips-40kg | shopify, hydrogen, shopifyhydrogen, hydrogentutorial | Hi everyone!
My name is Jaxson. I'm the product owner and team lead at True Storefront, we've built the best Shopify Hydrogen theme (named Owen) and provide some Shopify Headless services.
I have over three years of experience with Shopify Headless (using Next.js) and more than two years of experience with Hydrogen (I've been using Hydrogen from very early). I've also successfully completed many Shopify Headless projects for clients.
I'll be sharing my practical experience with other developers who want to learn about Shopify Hydrogen. I'll help you accelerate the learning process about Shopify Hydrogen with best practices, professional tips, and the right direction.
After completing this course, you will know about:
The architecture of the Hydrogen framework.
How to install Hydrogen locally for development.
How to use the Storefront API with Hydrogen.
How to use the Admin API with Hydrogen.
How to use Meta Objects with Hydrogen.
How to use Sanity CMS with Hydrogen.
How to build a homepage using Sanity CMS.
How to deploy to production.
Here is course link:
https://www.udemy.com/course/shopify-hydrogen-tutorial
I hope it's helpful for those who are just starting to learn about this framework! | jaxsonluu |
1,871,780 | How to Beat Shiva - Boss Guide and Tips in Final Fantasy 7 Remake | Final Fantasy VII Remake reimagines the classic 1997 RPG, bringing it to life with modern graphics,... | 0 | 2024-05-31T07:56:07 | https://dev.to/patti_nyman_5d50463b9ff56/how-to-beat-shiva-boss-guide-and-tips-in-final-fantasy-7-remake-53j1 | Final Fantasy VII Remake reimagines the classic 1997 RPG, bringing it to life with modern graphics, an expanded story, and a real-time action combat system. The game is set in the dystopian city of Midgar, controlled by the sinister Shinra Electric Power Company, which exploits the planet’s life force, known as Mako, for energy. The story follows Cloud Strife, a former SOLDIER turned mercenary, who joins the eco-terrorist group AVALANCHE to fight against Shinra’s destructive practices. Along the way, Cloud encounters a host of memorable characters, each with their own backstories and motivations, as they uncover deeper truths about Shinra, the planet, and themselves.
Basic Gameplay:
Final Fantasy VII Remake combines real-time action with strategic command-based combat. Players can switch between characters in their party, each with unique abilities and roles. The game features exploration, puzzle-solving, and battles that require a mix of direct attacks, magic, and the use of items. Players can customize characters with Materia, which grants spells and abilities, and upgrade weapons to enhance their performance.
Shiva - Boss Overview and Attributes
Role and Attributes:
Shiva is a powerful summon boss in Final Fantasy VII Remake, known as the Ice Queen. She embodies the element of ice and is renowned for her ability to unleash devastating ice-based attacks. Defeating Shiva grants players the Shiva Summon Materia, allowing them to summon her in future battles to aid with her powerful ice attacks.
Attributes:
Elemental Affinity: Ice
Weakness: Fire
Strengths: High resistance to ice attacks, capable of freezing opponents.
Unlocking Shiva - Boss Location and Route
Unlock Point on the Map:
Shiva can be unlocked by participating in Chadley’s VR Missions. Chadley is located in Sector 5 Slums, and players must complete previous VR missions to unlock the Shiva battle.
Route to Unlock Shiva:
Locate Chadley: Chadley is found near the Sector 5 Slums Market.
Complete VR Missions: Ensure you have completed the earlier VR missions to unlock the Shiva battle.
Access Shiva VR Mission: Once unlocked, select the Shiva VR mission from Chadley’s menu.
Signals and Landmarks for Reaching Shiva
Signals and Landmarks:
Chadley’s Location: Near the Leaf House orphanage in the Sector 5 Slums.
VR Mission Terminal: A small device Chadley uses to initiate the VR missions.
Entering Battle Mode and Recommended Characters
Entering Battle Mode:
Initiation: Speak to Chadley and select the Shiva VR mission.
Visual Signal: A transition into the VR landscape, signaling the start of the battle.
Recommended Characters:
Cloud Strife: With his versatility and powerful fire-based Materia, he can exploit Shiva’s weakness.
Aerith Gainsborough: Her magical prowess and healing abilities make her invaluable in sustained battles.
Tifa Lockhart: High speed and powerful close-range attacks, combined with her ability to use Materia effectively.
Defeating Shiva - Skills and Strategies
Skills to Use:
Fire Spells: Utilize Fire, Fira, or Firaga to exploit Shiva’s elemental weakness.
Healing and Buffs: Use Aerith’s healing abilities to maintain health and buffs to enhance defense and attack.
Phase Breakdown:
Phase One:
Ice Attacks: Dodge or block her basic ice projectiles.
Skill Use: Focus on fire spells and melee attacks.
Phase Two:
Diamond Dust Charge: Signals her ultimate attack. Prepare by healing and increasing defenses.
Fire-Based Attacks: Continue with aggressive fire spell casting to break her guard.
Deadly Attack Signals:
Diamond Dust (Ultimate Attack): Shiva will channel energy; use this time to heal and apply buffs.
Frost Familiars: She will summon ice minions that can freeze you. Focus on quickly dispatching them.
Avoiding Fatal Skills:
Dodging: Stay mobile to avoid her larger area-of-effect attacks.
Blocking: Use Cloud’s Guard to mitigate damage from unavoidable hits.
Positioning: Keep Aerith at a distance to avoid direct hits while using Tifa and Cloud for close combat.
Detailed Strategy for Defeating Shiva in Final Fantasy VII Remake
Recommended Characters and Their Roles:
Cloud Strife:
Role: Main damage dealer
Skills:
Fire Materia: Equip Fire, Fira, or Firaga to exploit Shiva’s ice weakness.
Braver: A powerful physical attack to use when Shiva is pressured.
Focus Thrust: Increases Shiva’s stagger gauge, making her more vulnerable.
Tactics: Keep Cloud on the frontlines to deliver continuous fire spells and physical attacks. Utilize Guard to reduce incoming damage and dodge her larger attacks.
Aerith Gainsborough:
Role: Support and secondary damage dealer
Skills:
Healing Materia: Use Cura or Curaga to heal the team.
Arcane Ward: Allows casting spells twice, maximizing damage output.
Fire Materia: Secondary fire-based attacks.
Tactics: Position Aerith at a distance from Shiva to avoid direct hits. Use her healing abilities to keep the team healthy and cast fire spells through Arcane Ward to double the damage output.
Tifa Lockhart:
Role: Close-range damage dealer and stagger builder
Skills:
Unbridled Strength: Enhances her abilities, increasing damage.
Focus Strike: Builds stagger gauge quickly.
Fire Materia: For additional damage.
Tactics: Keep Tifa close to Shiva to utilize her rapid attacks. Focus on building the stagger gauge and then unleash enhanced attacks when Shiva is staggered.
Damage Output Key Factors
Elemental Weakness: Focus on using fire-based attacks since Shiva is weak to fire.
Stagger Gauge: Build up the stagger gauge to make Shiva more vulnerable to attacks.
Healing and Buffing: Regularly heal and apply buffs to maintain the team's strength and defense.
Shiva's Attack Patterns and Phase Changes
Phase One:
Attacks: Basic ice projectiles, Frost Familiars.
Tactics: Use fire spells and melee attacks to build stagger. Dodge projectiles and quickly eliminate Frost Familiars.
Phase Two:
Attacks: More aggressive ice attacks, Diamond Dust (ultimate attack).
Tactics: When Shiva charges Diamond Dust, heal and apply buffs. Continue focusing on fire attacks and utilize powerful abilities during her recovery phase.
Key Skills and Avoiding Fatal Damage
Fire Spells: Use frequently to deal significant damage.
Healing: Keep an eye on HP and heal as needed, especially before Diamond Dust.
Dodging: Stay mobile to avoid large ice attacks. Use Guard for unavoidable hits.
Rewards for Defeating Shiva
Shiva Summon Materia:
Description: Summons Shiva in battle to unleash powerful ice-based attacks.
Uses in Game: Extremely useful against fire-weak enemies and provides a significant boost in battles requiring crowd control or area-of-effect damage.
Common Pitfalls and Suggestions
Ignoring Elemental Weaknesses: Ensure that all characters have fire Materia equipped and use it frequently.
Suggestion: Prioritize equipping and upgrading fire Materia before the fight.
Neglecting Healing: Over-focus on offense and neglecting healing can lead to a quick defeat.
Suggestion: Assign Aerith as the primary healer and always keep healing Materia ready.
Not Managing Stagger: Failing to build Shiva's stagger gauge can prolong the fight and increase risk.
Suggestion: Use abilities like Focus Thrust (Cloud) and Focus Strike (Tifa) to build the stagger gauge quickly.
Improper Positioning: Standing too close to Aerith or grouping together makes it easy for Shiva to hit multiple characters.
Suggestion: Spread out to minimize the impact of area-of-effect attacks and keep Aerith at a distance.
Conclusion
By understanding the roles of each character, leveraging their strengths, and focusing on Shiva's weaknesses, you can defeat this challenging boss. Pay close attention to phase changes, heal strategically, and exploit the stagger mechanic to maximize your damage output. Defeating Shiva will reward you with the Shiva Summon Materia, enhancing your combat capabilities for future battles.
At mmowow, we offer a range of cheap playstation network gift card to help you unlock more gaming fun and play Final Fantasy VII Remake and other popular titles using gift cards. Whether you choose to gift for holidays and special occasions or purchase discounted games and promotional items, our gift cards offer great value and are designed to fit your needs. | patti_nyman_5d50463b9ff56 | |
1,871,779 | Harnessing the Power of Personalization: Crafting Digital Marketing Campaigns for Unique Audiences | In today's competitive digital environment, where consumer expectations are soaring, personalization... | 0 | 2024-05-31T07:54:47 | https://dev.to/walterjerry/harnessing-the-power-of-personalization-crafting-digital-marketing-campaigns-for-unique-audiences-3ce3 | In today's competitive digital environment, where consumer expectations are soaring, personalization has become a crucial strategy for businesses aiming to connect more profoundly with their target audience. By customizing [digital marketing campaigns](https://www.iconicdigital.co.uk/digital-services/) to align with individual preferences and behaviors, companies can boost customer engagement, enhance brand loyalty, and drive conversions. This blog post will delve into the power of personalization and offer practical tips for businesses to effectively tailor their digital marketing efforts to resonate with individual audiences.
Understanding the Importance of Personalization
Personalization goes beyond mere familiarity; it involves tailoring content to match individual preferences and challenges. Research highlights its effectiveness, showing that personalized marketing can achieve transaction rates six times higher than generic approaches. It's not just about using a customer's name in an email; it's about understanding and addressing their unique desires and concerns. By crafting messages that align with their interests and circumstances, businesses can forge deeper connections and foster loyalty. In today's dynamic marketplace, personalization isn't just a strategy—it's the cornerstone of meaningful engagement, driving results and fostering enduring customer relationships.
Segmentation: The Foundation of Personalization
Segmentation is the backbone of personalized digital marketing strategies. By dividing the audience into smaller, focused groups based on criteria such as behavior and demographics, businesses can create tailored content that resonates more effectively. For instance, an online retailer might segment customers based on browsing habits or past purchases. This approach ensures that communications are relevant to each group, enhancing engagement and conversion rates. Understanding the specific needs and preferences of each segment is crucial for delivering the right message at the right time, strengthening relationships, and driving business growth.
Data-Driven Insights
Access to relevant data insights is vital for improving the effectiveness of marketing campaigns. By leveraging analytics tools and monitoring consumer interactions across various touchpoints, businesses can gain valuable insights into individual preferences, behaviors, and purchasing patterns. These insights enable companies to refine their marketing strategies, tailoring them to precisely target their audience. This personalized approach fosters stronger connections with consumers, increasing engagement and loyalty. Utilizing data-driven insights allows companies to enhance their marketing efforts and deliver more meaningful experiences that resonate with their target audience.
Dynamic Content Personalization
Dynamic content personalization takes personalization to the next level by adapting the content of marketing messages in real time based on individual user data. For example, an online clothing retailer might display product recommendations based on a user's past purchase history or browsing behavior. By delivering relevant content in real time, businesses can boost engagement and drive conversions.
Personalized Email Marketing
Email marketing remains a powerful tool for fostering human connections in the digital age. By carefully segmenting their audience and crafting personalized messages, businesses can increase engagement and boost conversions. Product recommendations add a personal touch, while dynamic content and customized subject lines enhance relevance. When these personalized tactics are employed, email marketing becomes more than just a series of messages; it evolves into meaningful interactions that build lasting relationships with customers.
The Role of Artificial Intelligence
Artificial intelligence (AI) and machine learning technologies are transforming the way businesses personalize their marketing efforts. By analyzing vast amounts of data and predicting user behavior, AI-powered tools help businesses deliver highly targeted and personalized experiences at scale. From chatbots and virtual assistants to predictive analytics and recommendation engines, AI enables businesses to create more personalized interactions across every touchpoint.
The Importance of Testing and Optimization
Testing and optimization are essential for maximizing the effectiveness of personalized campaigns. By continually testing different variables such as messaging, imagery, offers, and calls to action, businesses can identify what resonates most with their audience and refine their approach accordingly. A/B testing, multivariate testing, and ongoing performance analysis are all critical components of a successful personalization strategy.
Conclusion
In an increasingly competitive digital landscape, personalization has become essential for businesses seeking to stand out and connect with their target audience. By leveraging segmentation, data insights, dynamic content, AI technologies, and continuous testing and optimization, businesses can create more meaningful and engaging experiences that drive results. The power of personalization allows businesses, including [Iconic Digital](https://www.iconicdigital.co.uk/), to forge deeper connections with their audience, increase brand loyalty, and achieve long-term success.
| walterjerry | |
1,871,778 | Advanced MongoDB: Mastering Query Optimization and Complex Aggregations | Hello everyone, السلام عليكم و رحمة الله و بركاته MongoDB, a NoSQL database, is renowned for its... | 0 | 2024-05-31T07:53:42 | https://dev.to/bilelsalemdev/advanced-mongodb-mastering-query-optimization-and-complex-aggregations-28gb | mongodb, database, performance, programming | Hello everyone, السلام عليكم و رحمة الله و بركاته
MongoDB, a NoSQL database, is renowned for its flexibility, scalability, and performance. It stores data in JSON-like documents, allowing for dynamic schemas and powerful querying capabilities. While basic MongoDB operations can handle many use cases, advanced techniques can significantly enhance performance and manage complex data structures. This article explores advanced MongoDB topics, focusing on query optimization strategies, complex aggregations, and the intricacies of various query types.
### Advanced Query Optimization Techniques
Optimizing queries in MongoDB is crucial for maintaining high performance, especially as the size of your data grows. Here are some advanced techniques for optimizing MongoDB queries.
#### 1. Indexing Strategies
Indexes are critical for improving query performance in MongoDB. Beyond basic indexing, there are several advanced indexing strategies to consider.
- **Compound Indexes**: These indexes include multiple fields, improving queries that filter or sort on multiple fields.
```json
db.collection.createIndex({ field1: 1, field2: -1 })
```
- **Covered Queries**: An index that includes all the fields required by a query can significantly improve performance, as the query can be satisfied entirely using the index.
```json
db.collection.createIndex({ field1: 1, field2: 1, field3: 1 })
```
- **Sparse Indexes**: These indexes only include documents that have the indexed field, saving space and improving performance when dealing with sparse data.
```json
db.collection.createIndex({ field: 1 }, { sparse: true })
```
- **TTL Indexes**: Time-to-live (TTL) indexes automatically remove documents after a certain period, which is useful for expiring data.
```json
db.collection.createIndex({ createdAt: 1 }, { expireAfterSeconds: 3600 })
```
#### 2. Query Execution Plans
Understanding how MongoDB executes a query can help in identifying and addressing performance issues.
- **Explain Plans**: The `explain` method provides detailed information about how a query is executed.
```json
db.collection.find({ field: value }).explain("executionStats")
```
#### 3. Query Optimization
Writing efficient queries can have a significant impact on performance. Here are some tips for optimizing queries:
- **Projection**: Retrieve only the necessary fields to reduce the amount of data transferred.
```json
db.collection.find({ field: value }, { field1: 1, field2: 1 })
```
- **Avoiding $regex**: Use indexes for pattern matching instead of regular expressions, which can be slow.
```json
db.collection.find({ field: /^pattern/ })
```
- **Using $in and $nin Wisely**: Be cautious with `$in` and `$nin` queries, as they can scan large portions of the collection.
```json
db.collection.find({ field: { $in: [value1, value2, value3] } })
```
#### 4. Sharding
Sharding distributes data across multiple servers, improving performance and scalability. It's essential for handling large datasets in MongoDB.
- **Enabling Sharding**:
```json
sh.enableSharding("database")
sh.shardCollection("database.collection", { shardKey: 1 })
```
- **Choosing a Shard Key**: Selecting an appropriate shard key is crucial for balanced distribution and performance.
```json
sh.shardCollection("database.collection", { userId: 1 })
```
### Advanced Aggregation Framework
The MongoDB Aggregation Framework is a powerful tool for performing data processing and transformation. Here are some advanced aggregation techniques.
#### 1. Pipelines
Aggregation pipelines consist of multiple stages, each performing a specific operation on the data. Complex pipelines can be constructed to perform sophisticated data analysis.
- **Basic Pipeline**:
```json
db.collection.aggregate([
{ $match: { status: "active" } },
{ $group: { _id: "$category", total: { $sum: "$amount" } } },
{ $sort: { total: -1 } }
])
```
#### 2. Lookup and Unwind
The `$lookup` stage allows you to perform joins between collections, and `$unwind` deconstructs an array field from the input documents to output a document for each element.
- **Joining Collections**:
```json
db.orders.aggregate([
{ $lookup: {
from: "customers",
localField: "customerId",
foreignField: "_id",
as: "customerDetails"
}},
{ $unwind: "$customerDetails" }
])
```
#### 3. Faceted Search
Faceted search allows you to process multiple aggregation pipelines within a single stage and return a document with multiple fields, each containing the results of a different pipeline.
- **Faceted Search Example**:
```json
db.products.aggregate([
{ $facet: {
priceStats: [
{ $match: { price: { $gt: 0 } } },
{ $group: { _id: null, avgPrice: { $avg: "$price" }, maxPrice: { $max: "$price" } } }
],
categoryCount: [
{ $group: { _id: "$category", count: { $sum: 1 } } },
{ $sort: { count: -1 } }
]
}}
])
```
#### 4. Bucket and BucketAuto
The `$bucket` and `$bucketAuto` stages allow you to categorize documents into groups, making it easier to analyze data distribution.
- **Using $bucket**:
```json
db.sales.aggregate([
{ $bucket: {
groupBy: "$amount",
boundaries: [0, 100, 200, 300, 400],
default: "Other",
output: {
count: { $sum: 1 },
totalAmount: { $sum: "$amount" }
}
}}
])
```
- **Using $bucketAuto**:
```json
db.sales.aggregate([
{ $bucketAuto: {
groupBy: "$amount",
buckets: 4,
output: {
count: { $sum: 1 },
totalAmount: { $sum: "$amount" }
}
}}
])
```
### Advanced Query Types
MongoDB offers a variety of query types that can handle complex data retrieval needs. Here are some advanced query types and their applications.
#### 1. Geospatial Queries
Geospatial queries enable you to query documents based on geographical data.
- **2dsphere Index for Geospatial Queries**:
```json
db.places.createIndex({ location: "2dsphere" })
db.places.find({
location: {
$near: {
$geometry: { type: "Point", coordinates: [longitude, latitude] },
$maxDistance: 1000
}
}
})
```
#### 2. Text Search
MongoDB's text search allows you to search for text within string fields.
- **Creating a Text Index**:
```json
db.collection.createIndex({ content: "text" })
```
- **Performing a Text Search**:
```json
db.collection.find({ $text: { $search: "keyword" } })
```
#### 3. Array Queries
Queries on array fields can be complex but are powerful for handling embedded data structures.
- **Querying Arrays**:
```json
db.collection.find({ tags: "mongodb" })
db.collection.find({ tags: { $all: ["mongodb", "nosql"] } })
```
- **Array of Documents**:
```json
db.collection.find({ "comments.author": "John Doe" })
```
#### 4. Graph Queries
Graph queries leverage MongoDB's ability to store and query hierarchical data structures.
- **Using $graphLookup**:
```json
db.employees.aggregate([
{ $match: { name: "Alice" } },
{ $graphLookup: {
from: "employees",
startWith: "$reportsTo",
connectFromField: "reportsTo",
connectToField: "name",
as: "reportingHierarchy"
}}
])
```
### Advanced Replication and Backup
Ensuring data availability and integrity in MongoDB involves advanced replication and backup strategies.
#### 1. Replica Sets
Replica sets provide redundancy and high availability by replicating data across multiple MongoDB instances.
- **Setting Up a Replica Set**:
```json
rs.initiate()
rs.add("mongodb1.example.net:27017")
rs.add("mongodb2.example.net:27017")
rs.add("mongodb3.example.net:27017")
```
- **Priority and Arbiters**: Adjust priorities to control which members are preferred for elections, and use arbiters to ensure elections occur without adding data storage.
```json
rs.addArb("arbiter.example.net:27017")
```
#### 2. Backup Strategies
Efficient backup strategies are essential for data recovery and integrity.
- **Mongodump and Mongorestore**: These tools allow for backing up and restoring MongoDB data.
```json
mongodump --db database_name --out /backup/directory
mongorestore --db database_name /backup/directory/database_name
```
- **Cloud Backups**: Utilize cloud-based backup solutions for scalable and reliable backups.
```json
mongodump -- archive=backup.archive --gzip --uri "mongodb+srv://<username>:<password>@cluster0.mongodb.net/test"
```
### Advanced Security Practices
Securing MongoDB involves implementing advanced security practices to protect data from unauthorized access and breaches.
#### 1. Role-Based Access Control (RBAC)
RBAC allows you to define roles and assign them to users, restricting access based on roles.
- **Creating a Role**:
```json
db.createRole({
role: "readWriteAnyDatabase",
privileges: [],
roles: [
{ role: "readWrite", db: "admin" }
]
})
```
- **Creating a User with a Role**:
```json
db.createUser({
user: "admin",
pwd: "password",
roles: [ { role: "readWriteAnyDatabase", db: "admin" } ]
})
```
#### 2. Encryption
Encrypting data both at rest and in transit is crucial for protecting sensitive information.
- **Encryption at Rest**: Enable encryption at rest to protect data stored on disk.
```json
storage:
dbPath: /var/lib/mongodb
journal:
enabled: true
engine: wiredTiger
wiredTiger:
encryption:
enabled: true
keyFile: /path/to/keyfile
```
- **Encryption in Transit**: Use TLS/SSL to encrypt data in transit.
```json
net:
ssl:
mode: requireSSL
PEMKeyFile: /path/to/ssl.pem
```
#### 3. Auditing
MongoDB's auditing feature allows you to track database activity and ensure compliance with security policies.
- **Enabling Auditing**:
```json
auditLog:
destination: file
format: BSON
path: /var/log/mongodb/auditLog.bson
```
- **Configuring Audit Filters**:
```json
auditLog:
destination: file
format: JSON
path: /var/log/mongodb/audit.json
filter: '{ atype: { $in: ["authCheck", "insert", "update", "delete"] } }'
```
### Conclusion
Mastering advanced MongoDB techniques enables you to optimize database performance and handle complex data retrieval and manipulation tasks with ease. Understanding advanced indexing strategies, leveraging the aggregation framework, utilizing sophisticated query types, and implementing advanced replication and security practices are key to becoming proficient in MongoDB. By integrating these techniques into your workflow, you can significantly enhance the efficiency and scalability of your database-driven applications.
Advanced MongoDB skills empower you to tackle complex data management challenges, ensuring that your applications can efficiently process and analyze large volumes of data. Whether you are a database administrator, developer, or data analyst, these advanced MongoDB techniques will enable you to make the most out of your NoSQL databases, leading to better performance, deeper insights, and more robust applications. | bilelsalemdev |
1,871,770 | Need help in SvelteKit query based tab navigation. | Trying to create tab based navigation in sveltekit which loads data from +page.server.js based on... | 0 | 2024-05-31T07:50:29 | https://dev.to/sarandha/need-help-in-sveltekit-query-based-tab-navigation-31id | javascript, beginners, webdev, help | Trying to create tab based navigation in sveltekit which loads data from `+page.server.js` based on what tab is selected. the active tab is selected from the url query `?mode=tabname` . Below is the snippet taken from a large project but I narrowed the issue down to this boilerplate code.
`+page.svelte`
```svelte
<script>
import { page } from "$app/stores";
export let data;
$: mode = $page.url.searchParams.get("mode");
</script>
<section>
<nav>
<a href="?mode=list">list</a>
<a href="?mode=add">add</a>
</nav>
{#if mode == "list"}
<table>
<tr>
<th>id</th>
<th>name</th>
</tr>
{#each data.list as l (l.id)}
<tr>
<td>{l.id}</td>
<td>{l.name}</td>
</tr>
{/each}
</table>
{:else if mode == "add"}
<form action="">
<input type="text" name="name" />
<button type="submit">save</button>
</form>
{:else}
<b>Select an option from above</b>
{/if}
</section>
```
`+page.server.js`
```js
export const load = async ({ url }) => {
// maybe needed in both tabs.
const info = {
appname: "demo",
};
// only needed in "list" tab.
const list = [
{ id: 1, name: "test one" },
{ id: 2, name: "test two" },
{ id: 3, name: "test three" },
];
// Previously, I was returning all the data
// without detecting any tab.
// There was no problem with it apart from
// performance issues
// return {
// info,
// list,
// };
// seperating the returned data based on tab name
// that's when the issue arise
const mode = url.searchParams.get("mode");
if (mode == "list") {
return {
info,
list,
};
} else if (mode == "add") {
return {
info,
};
}};
```
After navigation from 'list' to 'add' tab, this error is thrown in chrome console:
```console
chunk-ERBBMTET.js?v=7f9a88c7:2609 Uncaught (in promise) Error: {#each} only works with iterable values.
at ensure_array_like_dev (chunk-ERBBMTET.js?v=7f9a88c7:2609:11)
at Object.update [as p] (+page.svelte:18:29)
at Object.update [as p] (+page.svelte:12:35)
at update (chunk-ERBBMTET.js?v=7f9a88c7:1351:32)
at flush (chunk-ERBBMTET.js?v=7f9a88c7:1317:9)
```
Looks like it's complaining about `data.list` even after navigation to the tab which does not even need `data.list`. returning both `info` and `list` object for every tab solves the issue and also wrapping the `#each` block in `#if` block does the trick eg:
```svelte
{#if data.list}
{#each data.list as l (l.id)}
<tr>
<td>{l.id}</td>
<td>{l.name}</td>
</tr>
{/each}
{/if}
```
Given that I'm not very experienced in SvelteKit, I not sure what am I doing wrong. Any help is appriciated. Thanks
| sarandha |
1,871,776 | Compatibility Testing to Create Perfectly Working Apps | We live in the age of digital platforms that has created a huge impact on our lives. There is a... | 0 | 2024-05-31T07:48:47 | https://dev.to/talenttinaapi/compatibility-testing-to-create-perfectly-working-apps-4ikd | mobile, testing, softwareengineering, qualityassurance | We live in the age of digital platforms that has created a huge impact on our lives. There is a diverse range of devices making it inevitable for the app developing companies to check if it’s operating as expected across all devices and platforms, to ensure complete user satisfaction. When an app is not working well on a specific device, browser, or platform, it will eventually lose that section of users which will, in turn, affect the organization at monetary and reputational levels. Hence, it becomes important to test the app compatibility on all the devices and platforms before release.
Imagine you have released an app in the market without checking for its compatibility across devices and platforms. With about 15 billion smartphones available with various browsers, operating systems, and platforms, what would be the plight of the app’s performance without checking for its compatibility? Hence, it is equally important to perform compatibility testing of an app as the testing is done for other functional and non-functional aspects. Let’s understand compatibility testing better and the need for performing it.
What is compatibility testing and why do we need it?
Compatibility testing is a non-functional testing approach that is an important criteria to ensure the app is compatible with all devices, browsers, platforms, operating systems, hardware, and software. Compatibility testing ascertains that the app is stable, reliable, and produces the same results across all platforms. Hence, compatibility is an important testing parameter that cannot be neglected.
The market is filled with a wide range of gadgets that make our lives easier, and you can hardly find a person without a smartphone. The smartphones and various other handheld devices have created a huge dependency on our lives, hence, performing compatibility testing under this scenario becomes unavoidable. In case, an app development company misses on performing compatibility testing, they might face greater consequences that will affect the company negatively considering the availability of the huge number of smart devices.
Here are some of the common reasons why compatibility testing is gaining more focus nowadays:
• Availability of a wide range of smart devices • Apps working on both web and mobile interface • Difference in mobile operating systems either Android, iOS, etc., • Different browsers available • Difference in the UI of different devices • Variations in the screen size, screen alignment, font style, font size, etc., • Difference in the color variation across devices • Availability of legacy systems • Constant software upgrades
We should infer that investing in compatibility testing is important as the end-users’ behavior vary from person to person, and their preference of operating systems, screen sizes, colors, network types, etc., also varies. Hence, to cater to the wider range of audience with different preferences, it is wise to be prepared by ensuring the apps works well under all conditions. This approach ensures to expand the audience base and creates a loyal customer base which, in turn, will help the organization build a great reputation and improve the ROI metrics.
How to perform compatibility testing?
Testing app compatibility across devices is a complex task that will need a proper strategy before starting with testing. An initial plan should be defined based the environments and platforms to be tested on, determine the expected behavior, and plan to an efficient defect tracking and management system.
• To start with, test environment for different configurations is defined, and the testing environment should be set up based on the requirements. • All parameters for testing should be included like devices, platforms, network types, operating systems, hardware, and software • Run the test! Automation is preferred over manual testing as it offers improved efficiency in reduced time and effort • Evaluate the report • Any bug identified should be sent to the developers for resolving the issue
Compatibility Testing can be performed for:
Smart devices: Testing on smartphones, tablets, smartwatches etc., Mobile applications: Testing across different mobile device, models, versions, networks etc. Operating systems: Testing across OSes like Linux, Mac OS, and Windows etc., for web apps, and testing on Android and iOS for mobile apps Databases: Testing across databases like MySQL, Oracle, SQL Server etc. Browsers: Testing across browsers like Chrome, Internet Explorer, Firefox, Mozilla, Safari, etc., Software: Testing across chat software, anti-virus software, browsers, GPS, web server, networking, messaging tools, and other downloaded software Hardware: Hardware configuration of different models and versions is tested
As compatibility testing involves testing on various devices, models, and versions, arranging real devices for testing is expensive and not feasible practically. Hence, Device Farms are implemented to check the app's compatibility across all devices on Cloud. This approach improves efficiency while reducing cost drastically.
Conclusion
Organizations are investing in compatibility testing to improve the app quality and offer a seamless experience to users with varied preferences. Compatibility testing is a crucial part of the QA process that helps create high-quality apps and build a good organizational reputation.
Most companies have an inflexible standardization process and operate on outdated techniques, which makes it difficult to perform compatibility testing. However, compatibility testing has become easier, more efficient, and more cost-effective with advanced approaches like Device Farms.
Further, pre-integrated JIRA and Device Farm simplify test tracking and management. JIRA makes defect tracking and management easy and efficient, while Device Farms like BrowserStack and SauceLabs provide access to a wide range of devices on the Cloud. | talenttinaapi |
1,871,775 | The Environmental Impact of Wind Turbines | screenshot-1716859266319.png Wind Turbines and Environmental Conservation: How They Benefit Our... | 0 | 2024-05-31T07:48:27 | https://dev.to/skcms_kskee_db3d23538e2f3/the-environmental-impact-of-wind-turbines-4kn8 |
screenshot-1716859266319.png
Wind Turbines and Environmental Conservation: How They Benefit Our Planet
Wind turbines have gained popularity over the years as a sustainable source of electricity. They are tall, elegant, white structures that can be found in various parts of the world, from hillsides to oceanic coastlines. We will be exploring the environmental impact of wind turbines and how they contribute to a better tomorrow.
Great things about Wind Solar Hybrid Power System
Wind turbines have actually advantages that are several to other sources of energy
Firstly, they expect to create electricity, a resource like renewable will not deplete any right time soon
What this means is less reliance on fossil fuels, which cause air destruction and pollution like environmental
Secondly, wind turbines usually do not produce atmosphere pollutants or carbon dioxide, unlike coal-fired power plants
Lastly, as soon as a wind turbine is set up, the expense of creating electricity is relatively low
Innovation in Wind Turbines
Innovations in Wind Turbine technology have actually drastically increased their efficiency and ability to make power
Among the innovations will be the use of bigger blades, enabling turbines to make more electricity
Additionally, these blades have actually sensors that may adjust the angle and pitch of the blade, based on the speed and way regarding the wind
This technology helps make sure that turbines aren't harmed by strong winds and certainly will run optimally
Safety precautions in Wind Turbines
Wind turbines are designed to operate safely relative to impact like minimal the surroundings
These are typically fashioned with strong materials, such as for instance steel and concrete, that will withstand climate like undesirable
Moreover, turbines are designed with sensors that monitor their performance, and will any problem happen, an security is triggered to maintenance like alert
In case of any breakdown, wind turbines are made to power down automatically, making certain they do not pose a risk to people or animals
Provider and Quality of Wind Turbines
Wind turbines require appropriate upkeep to ensure that they operate optimally and also have a lifespan like very long
Repair involves inspections that are routine cleaning of blades, and replacement of any elements which are faulty
The conventional of wind turbines is truly important since it determines their efficiency, durability, and safety
Companies that manufacture wind turbines must follow industry requirements to make certain that their products meet the quality like required safety directions
Applications of Wind Turbines
Wind turbines are getting to be an essential area of the energy like renewable globally
They're present in various industries to power factories and supply electricity to communities
Developing nations also have invested in Wind Power Generation System projects to fulfill their energy requirements and reduced reliance on fossil fuels
In addition, wind turbines have grown to be a remedy like fantastic off-grid areas, providing electricity to remote communities
In conclusion, wind turbines offer a sustainable solution to the global energy crisis, while reducing the impact on our planet. They rely on a renewable resource – wind, to generate electricity, and do not harm the environment or produce greenhouse gases. Innovations in wind turbine technology, safety measures, and proper maintenance have ensured that they operate safely and optimally. Wind turbines have become an essential part of the renewable energy mix, proving to be an ideal solution to meet the energy needs of communities and industries, while conserving the environment.
Source: https://www.dhceversaving.com/Wind-solar-hybrid-power-system | skcms_kskee_db3d23538e2f3 | |
1,871,773 | Build an HTTP server using BunJs and Prisma | In this guide, we'll be leveraging two powerful tools: BunJs and Prisma. Together, they provide a... | 0 | 2024-05-31T07:47:34 | https://keploy.io/blog/community/build-an-http-server-using-bunjs-and-prisma | webdev, tutorial, http, opensource | 
In this guide, we'll be leveraging two powerful tools: BunJs and Prisma. Together, they provide a robust foundation for constructing modern, scalable, and efficient web servers. But before we dive into the technical details, let's take a moment to understand what BunJs and Prisma bring to the table.**Why use BunJs?**
BunJs is a really lightweight, fast, and highly customizable HTTP framework for Node.js. It helps in simplifying the process of creating web servers. On the other hand, with Prisma, interacting with databases becomes more intuitive and less error-prone, thanks to its powerful features like auto-completion and type checking.
**Setting up our project**
First let's install Bun toolkit, with following command: -
```
npm install -g bun
```
Now let's create our project directory: -
```
├── controller/
│ ├── comments.controller.ts
│ ├── post.controller.ts
│ └── user.controller.ts
├── prisma/
│ └── schema.prisma
├── services/
│ ├── auth.service.ts
│ ├── comment.service.ts
│ ├── post.service.ts
│ └── user.service.ts
├── docker-compose.yml
├── index.ts
├── package*.json
└── tsconfig.json
```
In controllers folder we will define our routes and functions in services folder, the schema.prisma will contain our model as well as the configurations to run the Prisma-ORM . Prisma support different types of SQL based databases, and for this blog we would be using PostgresQL with the docker instance.
**Building the services**
First we need to install all the packages and dependencies required:-
```
bun add -d prisma @types/jsonwebtoken bun-types
bun add pg jsonwebtoken elysia dotenv axios @prisma/client @elysia/cookie
```
We we have prisma installed, we need to create the schema.prisma file, where our schema models will be defined.
```
bunx init prisma
```
bunx is similer to npx or pnpx the primary purpose of bunx is to facilitate the execution of packages that are listed in the dependencies or devDependencies section of a project's package.json file. Instead of manually installing these packages globally or locally, you can use bunx to run them directly.
Now create user schema inside prisma/schema.prisma file.
```
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
password String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
```
Next we are going to define our auth.services.ts which after authenticating user will grant permission to perform CRUD operations.
```
//auth.service.ts
import jwt from "jsonwebtoken";
export const verifyToken = (token: string) => {
let payload: any;
//Verify the JWT token
jwt.verify(token, process.env.JWT_SECRET as string, (error, decoded) => {
if (error) {
throw new Error("Invalid token");
}
payload = decoded;
});
return payload;
};
export const signUserToken = (data: { id: number; email: string }) => {
//Sign the JWT token
const token = jwt.sign(
{
id: data.id,
email: data.email,
},
process.env.JWT_SECRET as string,
{ expiresIn: "1d" }
);
return token;
};
```
The function verifyToken(), which takes a JWT token string as an argument.Inside the function, it calls jwt.verify to verify the token. The jwt.verify function decodes the token and verifies its signature using the provided secret.
If there's an error during verification, it throws an error indicating that the token is invalid.
If verification is successful, it assigns the decoded payload to the payload variable and returns it.
signUserToken() function generates a JWT token for a given user data. It uses jwt.sign to generate a new JWT token. The payload of the token contains the user's id and email. It uses the JWT secret stored in the environment variable process.env.JWT_SECRET for signing the token, the expiry of these tokens are set to 1D by default.
With our authentication mechanism ready in place, we now need to create the user.service.ts
```
//user.service.ts
import { prisma } from "../index";
import { signUserToken } from "./auth.service";
export const createNewUser = async (data: {
name: string;
email: string;
password: string;
}) => {
try {
const { name, email, password } = data;
//Hash the password using the Bun package and bcrypt algorithm
const hashedPassword = await Bun.password.hash(password, {
algorithm: "bcrypt",
});
//Create the user
const user = await prisma.user.create({
data: {
name,
email,
password: hashedPassword,
},
});
return user;
} catch (error) {
throw error;
}
};
export const login = async (data: { email: string; password: string }) => {
try {
const { email, password } = data;
//Find the user
const user = await prisma.user.findUnique({
where: {
email,
},
});
if (!user) {
throw new Error("User not found");
}
//Verify the password
const valid = await Bun.password.verify(password, user.password);
if (!valid) {
throw new Error("Invalid credentials");
}
// //Sign the JWT token
const token = signUserToken({
id: user.id,
email: user.email,
});
return {
message: "User logged in successfully",
token,
};
} catch (error) {
throw error;
}
};
```
Here we have two function:- createNewUser and login . The createNewuser function takes user data including name, email, and password as input, and it hashes the provided password using the BunJs package and the bcrypt algorithm for secure storage.
It then attempts to create a new user in the database using the prisma ORM's user.create method, providing the hashed password along with the name and email. If the user creation is successful, it returns the created user object, otherwise it throws the error.
Whereas, login function attempts to find the user with the provided email using the Prisma-ORM's user.findUnique method. If the user is not found, it throws an error indicating that the user does not exist. If user exists, then it verifies the provided password against the hashed password stored in the database using the BunJs package's password.verify method. Upon successful verification, it generates a JWT token using the signUserToken function from the auth.service, passing the user's id and email. And finally, it returns a success message along with the generated JWT token.
Now with our user Signup and Login is integrated with authentication mechanism and ready, we will move on to create our route file under controller/user.controller.ts :-
```
//user.controller.ts
import Elysia from "elysia";
import { createNewUser, login } from "../services/user.service";
```
We are importing the Elysia library, for setting up routes and handling HTTP requests. As well the createNewUser and login functions from the user.service module to handle user signup and login functionalities, respectively.
```
app.post("/signup", async (context) => {
try {
const userData: any = context.body;
const newUser = await createNewUser({
name: userData.name,
email: userData.email,
password: userData.password,
});
return {
user: newUser,
};
} catch (error: any) {
return {
error: error.message,
};
}
});
```
/signup is a POST route, which expects user data in the request body. Inside the route handler, it extracts user data from the request body. And then calls the createNewUser function from the user.service.ts, passing the extracted user data.
If user creation is successful, it returns the created user object.
If an error occurs during the process, it catches the error, extracts the error message, and returns it.
After SignUp, next comes the /login route :-
```
app.post("/login", async (context) => {
try {
const userData: any = context.body;
const loggedInUser = await login({
email: userData.email,
password: userData.password,
});
return loggedInUser;
} catch (error: any) {
console.log(error);
return {
error: error.message,
};
}
});
```
We are calling the login function from the user service, passing the extracted user data.
If login is successful, it returns the logged-in user object along with a JWT token.
If an error occurs during the login process, it catches the error, logs it to the console, extracts the error message, and returns it.
Now we have everything in place and ready to run, but before that we need index.ts and docker-compose.yml file. The docker-compose file will content to create and run the postgres instance:-
```
version: '3.9'
services:
postgres:
image: postgres:latest
restart: always
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=password
ports:
- '5432:5432'
volumes:
- ./sql/init.sql:/docker-entrypoint-initdb.d/init.sql
networks:
- keploy-network
networks:
keploy-network:
external: true
```
and our index.ts file would like:-
```
//index.ts
import Elysia from "elysia";
import { PrismaClient } from "@prisma/client";
import { userController } from "./controllers/user.controller";
//Create instances of prisma and Elysia
const prisma = new PrismaClient();
const app = new Elysia();
//Use controllers as middleware
app.use(userController as any);
//Listen for traffic
app.listen(4040, () => {
console.log("🦊 Elysia is running at localhost:4040");
});
export { app, prisma };
```
The index.ts file will acts as the entry point where the server and database instances are initialized, controllers are registered, and the server starts listening for incoming requests. It orchestrates the setup of the application and exports necessary instances for use in other modules.
Lets start the server
```
bun run dev
```
```
🦊 Elysia is running at localhost:4040
```
**Conclusion**
We got to learn how BunJs simplifies server creation, while Prisma streamlines database interactions. In this blog, we got to learn how to create simple BunJs server with authentication in place using JWT tokens, we created user signup and login routes using Elysia.
In next part of this blog, we will test our application using bun-test, cucumber and keploy and learn which is better to use.
**FAQ's**
**Why use JWT tokens for authentication?**
JWT tokens provide a secure way to authenticate users in web applications. They are stateless, meaning no session needs to be stored on the server, and they can be easily shared across different services. Additionally, they can contain custom claims, enabling developers to add additional information to the token payload.
**What is Bunx, and how does it differ from other package execution tools?**
Bunx is a package execution tool similar to npx or pnpx. Its primary purpose is to facilitate the execution of packages listed in a project's dependencies or devDependencies section without the need for manual installation. Bunx simplifies dependency management by running packages directly from the project's context.
**What testing tools will be covered in the next part of the blog?**
In the next part of the blog, we will explore testing methodologies using Keploy, bun test, and CucumberJs . These tools offer different approaches to testing backend applications, and we will discuss their strengths and use cases.
**Can I contribute to BunJs and Prisma?**
Both BunJs and Prisma are open-source projects, and contributions are welcome! You can contribute by submitting bug reports, feature requests, or even code contributions through their respective GitHub repositories. Make sure to follow their contribution guidelines for more information on how to get involved. | keploy |
1,846,496 | What was your win this week? 🙌 | Heyo! 👋 Looking back on this past week, what was something you were proud of accomplishing? All... | 0 | 2024-05-31T07:47:00 | https://dev.to/devteam/what-was-your-win-this-week-2kji | discuss, weeklyretro | Heyo! 👋
Looking back on this past week, what was something you were proud of accomplishing?
All wins count — big or small 🎉
Examples of 'wins' include:
- Starting a new project
- Fixing a tricky bug
- Cookin' up a delicious meal for a loved one 🥘
 | sloan |
1,871,772 | Ist Web Scraping legal? | In diesem Artikel werden wir die Rechtmäßigkeit von Web Scraping, seine Unterschiede zum Web... | 0 | 2024-05-31T07:46:24 | https://dev.to/emilia/ist-web-scraping-legal-4m17 | In diesem Artikel werden wir die Rechtmäßigkeit von Web Scraping, seine Unterschiede zum Web Crawling, die Grenzen seiner Verwendung und seine Anwendung in verschiedenen Bereichen im Detail diskutieren.

1. Web Scraping ist illegal in Deutschland?
Viele Menschen haben einen falschen Eindruck von Web Scraping. Ob Web Scraping legal ist, hängt von den Umständen ab.
Es kann legal sein, wenn es dazu verwendet wird, öffentlich verfügbare Informationen zu sammeln und zu nutzen. In diesem Fall ist Data scraping erlaubt.
Web Scraping kann jedoch illegal sein, wenn es ohne ausreichende Genehmigung auf geschützte Inhalte zugreift, wie z.B. urheberrechtlich geschützte Materialien oder vertrauliche Informationen. Dann ist es nicht erlaubt, Daten zu scrapen.
2. Web Scraping und Web Crawling sind gleich?
Nein, Web Scraping und Web Crawling sind nicht dasselbe.
Web Crawling bezieht sich auf den Prozess, bei dem ein Computerprogramm automatisch Websites durchsucht und dabei Informationen sammelt. Dies kann Teil des Web Scrapings sein.
Web Scraping bezieht sich auf den Prozess, bei dem ein Computerprogramm Daten von Websites extrahiert und in eine andere Form konvertiert. Im Allgemeinen werden beim Web Scraping spezifische Daten von Websites gezogen, z. B. um die Extraktion von Daten über Vertriebskontakte, Immobilienangebote und Produktpreise. Während beim Web Crawling eine breitere Palette an Informationen gesammelt werden kann. Dabei wird die gesamte Website mitsamt ihren internen Links gescannt und indexiert. Der “Crawler” crawlt die Webseiten, ohne ein bestimmtes Ziel zu verfolgen.
3. Sie können alle Website scrapen?
Es kommt häufig vor, dass Leute E-Mail-Adressen, Facebook-Posts oder LinkedIn-Informationen scrapen möchten. Aber es ist wichtig, die Regeln zu beachten, bevor man Web Scraping durchführt:
Private Daten, die einen Benutzernamen und einen Passcode erfordern, können nicht gescrapt werden.
Einhaltung der Nutzungsbedingungen, wenn die das Web-Scraping ausdrücklich verbieten.
Kopieren Sie keine Daten, die urheberrechtlich geschützt sind.
Man kann aufgrund mehrerer Gesetze belangt werden, wenn er die Gesetze nicht befolgen. Zum Beispiel hat jemand vertrauliche Informationen gesammelt und sie an Dritte verkauft, obwohl der Eigentümer der Website eine Unterlassungserklärung abgegeben hat. Diese Person kann in der Situation belangt werden..
Das bedeutet jedoch nicht, dass Sie keine sozialen Medien wie Twitter, Facebook, Instagram und YouTube scrapen können. Sie können diese Websites scrapen, solange Sie die Bestimmungen der robots.txt-Datei befolgen. Für Facebook müssen Sie eine schriftliche Genehmigung einholen, bevor Sie die automatische Datenerfassung durchführen.
4. Sie müssen Programmierkenntnisse haben?
Web Scraping Tool (Datenextraktion-Tool) ist sehr nützlich für die Menschen, die keine Programmierkenntnisse haben, wie Vermarkter, Statistiker, Finanzberater, Bitcoin-Investoren, Forscher, Journalisten, usw.. Octoparse hat eine einzigartige Funktion eingeführt “Web-Scraping-Vorlagen“, die vorformatierte Scraper sind, und über 14 Kategorien auf über 30 Websites abdecken, einschließlich Facebook, Twitter, Amazon, eBay, Instagram und mehr. Sie brauchen nur die Schlüsselwörter/URLs in die Parameter einzugeben, ohne eine komplexe Aufgabenkonfiguration selbst zu erledigen. Web Scraping mit Python ist zeitaufwändig. Auf der anderen Seite ist eine Web-Scraping-Vorlage effizient und bequem, um die Daten zu erfassen, die Sie benötigen.
5. Sie können die gescrapten Daten nach Gefallen verwenden?
Es ist völlig legal, wenn Sie Daten von Websites für den öffentlichen Gebrauch auslesen und zu Analysezwecken verwenden. Es ist jedoch illegal, wenn Sie vertrauliche Informationen zu Gewinnzwecken scrapen. So ist es beispielsweise illegal, private Kontaktinformationen ohne Erlaubnis auszulesen und sie an Dritte zu verkaufen. Außerdem ist es ethisch nicht vertretbar, gescrapte Inhalte als Ihre eigenen auszugeben, ohne die Quelle zu nennen. Sie sollten sich an den Grundsatz halten und nicht vergessen, dass kein Spamming, kein Plagiat und eine betrügerische Verwendung von Daten gesetzlich verboten ist.
6. Web Scraper funktioniert immer?
Vielleicht kennen Sie bestimmte Websites, die von Zeit zu Zeit ihr Layout oder ihre Struktur ändern. Seien Sie nicht frustriert, wenn Sie auf solche Websites stoßen, die Ihr Scraper nicht lesen kann. Dafür gibt es viele Gründe. Es wird nicht unbedingt dadurch ausgelöst, dass Sie als verdächtiger Bot identifiziert werden. Es kann auch durch unterschiedliche geografische Standorte oder den Zugriff auf den Rechner verursacht werden. In diesen Fällen ist es normal, dass ein Web Scraper die Website nicht analysieren kann, bevor wir manche Einstellung vorgenommen haben.
7. Sie können mit hoher Geschwindigkeit scrapen?
Vielleicht haben Sie solche Werbung für Scraper gesehen, in der behauptet wird, wie schnell ihre Crawler sind. Das hört sich gut an, denn sie sagen, dass sie Daten in Sekundenschnelle sammeln können. Allerdings sind Sie der Gesetzesbrecher, der strafrechtlich verfolgt wird, wenn es zu Schäden führt. Der Grund dafür ist, dass eine Datenabfrage mit hoher Geschwindigkeit einen Webserver überlastet, was zu einem Serverabsturz führen kann. In diesem Fall ist die Person für den Schaden verantwortlich (Dryer und Stockton 2013). Wenn Sie sich nicht sicher sind, ob die Website gescrapt werden kann oder nicht, fragen Sie bitte den Web-Scraping-Dienstleister. Octoparse ist ein verantwortungsbewusster Web-Scraping-Dienstleister, für den die Zufriedenheit seiner Kunden an erster Stelle steht. Für Octoparse ist es wichtig, unseren Kunden zu helfen, das Problem zu lösen und Web-Scraping erfolgreich durchzuführen.
8. API und Web Scraping sind gleich?
API ist wie ein Kanal, über den Sie Ihre Datenanforderung an einen Webserver senden und die gewünschten Daten erhalten können. API gibt die Daten im JSON-Format über das HTTP-Protokoll zurück. Zum Beispiel: Facebook API, Twitter API und Instagram API. Das bedeutet jedoch nicht, dass Sie alle Daten erhalten können. Web Scraping kann den Prozess visualisieren, da es Ihnen erlaubt, mit den Websites zu interagieren. Octoparse bietet Vorlagen für Web Scraping. Es ist benutzerfreundlicher für Nicht-Techniker, denn man muss die Aufgabe nicht selbst konfigurieren, sondern nur die Parameter mit Schlüsselwörtern/URLs ausfüllen.
9. Die gescrapten Daten lassen sich erst für unser Geschäft benutzen, nachdem sie bereinigt und analysiert worden sind.
Viele Datenintegrationsplattformen können bei der Visualisierung und Analyse der Daten helfen. Im Vergleich dazu sieht es so aus, als hätte Data Scraping keinen direkten Einfluss auf die Entscheidungsfindung in Unternehmen. Beim Web Scraping werden Rohdaten von Webseiten extrahiert, die verarbeitet werden müssen, um Erkenntnisse zu gewinnen, z. B. bei der Stimmungsanalyse. Aber manche Rohdaten können auch äußerst wertvoll sein.
Mit Octoparses Google-Search-Vorlage können Sie Informationen einschließlich der Titel und Meta-Beschreibungen über Ihre Konkurrenten extrahieren, um Ihre SEO-Strategien zu bestimmen. Für Einzelhandelsbranchen kann Web Scraping verwendet werden, um Produktpreise und -verteilungen zu überwachen.
10. Web Scraping kann nur im Geschäftsleben eingesetzt werden?
Web Scraping ist in verschiedenen Bereichen weit verbreitet, z. B. Lead-Generierung, Preisüberwachung, Preisverfolgung und Marktanalyse für Unternehmen. Studenten können die Google Scholar-Vorlage nutzen, um eine statistische Forschung durchzuführen. Immobilienmakler können Nachforschungen über den Wohnungsmarkt anstellen und Vorhersagen über den Wohnungsmarkt treffen. Sie können geeignete Youtube-Influencer oder Twitter-Evangelisten finden, um für Ihre Marke zu werben, oder Ihre eigene Nachrichtenaggregation schaffen, die nur die von Ihnen gewünschten Themen abdeckt, indem Sie Nachrichtenmedien und RSS-Feeds auslesen.
Zusammenfassung
Web Scraping, eine leistungsstarke Technik zur Datenerfassung, hat wegen ihrer Rechtmäßigkeit und ihres Anwendungsbereichs viel Aufmerksamkeit erhalten. In diesem Beitrag werden die Rechtmäßigkeit von Web Scraping in Deutschland, die Unterschiede zum Web Crawling, die Grenzen des Einsatzes und die Anwendungsmöglichkeiten in verschiedenen Bereichen, einschließlich Wirtschaft und Wissenschaft, ausführlich erörtert. Zusammenfassend lässt sich sagen, dass Web Scraping für Privatpersonen und Unternehmen von großem Nutzen sein kann, wenn es vernünftig und legal eingesetzt wird. Gleichzeitig sollten wir die einschlägigen Gesetze und Vorschriften einhalten, das Eigentum an den Daten und die Privatsphäre respektieren und die ordnungsgemäße Nutzung der Technologie sicherstellen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️
| emilia | |
1,871,771 | The Ultimate Guide to Dog Breeds, Health, and Care: Your Furry Friend's Well-Being A to Z | Dogs are truly amazing creatures – loyal companions, playful pals, and sometimes even our emotional... | 0 | 2024-05-31T07:45:28 | https://dev.to/mdogsw_mdogsw_4653ddc7ce0/the-ultimate-guide-to-dog-breeds-health-and-care-your-furry-friends-well-being-a-to-z-47ni | mdogsw | Dogs are truly amazing creatures – loyal companions, playful pals, and sometimes even our emotional support systems. But with hundreds of dog breeds, each with unique traits and needs, navigating the world of dog ownership can be a bit overwhelming. This guide is designed to help you make informed decisions about your furry friend's breed, health, and overall well-being.
## Choosing the Right Breed:
Size and Energy Level: Do you live in a small apartment or have a sprawling yard? Are you an active runner or more of a couch potato? Your lifestyle will largely dictate what size and energy level of dog will thrive in your home.
Temperament: Do you want a cuddly lapdog or a high-energy working breed? Research breed temperaments carefully to ensure a good fit for your personality and household.
Grooming Needs: Some breeds require daily brushing, frequent haircuts, or even professional grooming. Be realistic about the time you can commit to grooming.
Purpose: Were you looking for a family dog, a guard dog, or a hunting companion? Breeds have been developed for specific purposes, so consider your needs.
## Essential Dog Health Care:
Nutrition: High-quality dog food appropriate for your dog's age, breed, and activity level is crucial. Consult your veterinarian for specific recommendations.
Exercise: Regular exercise is essential for physical and mental well-being. The amount and type of exercise will vary depending on your dog's breed and age.
Veterinary Care: Schedule regular checkups, vaccinations, and preventative care to keep your dog in top shape.
Dental Care: Brush your dog's teeth regularly to prevent dental disease, a common issue in dogs.
## Common Health Issues in Dogs:
Breed-Specific Conditions: Many breeds are prone to certain health conditions, such as hip dysplasia, eye problems, or heart disease. Research your breed's potential issues so you can be proactive about care.
Parasites: Fleas, ticks, and heartworms can cause serious health problems. Regular preventative medications are essential.
Obesity: Overweight dogs are at risk for a variety of health issues. Maintain a healthy weight through diet and exercise.
## Dog Care Tips:
Training: Training isn't just about obedience; it's about communication and bonding with your dog. Start early and use positive reinforcement methods.
Socialization: Expose your dog to different people, animals, and environments to help them become well-adjusted.
Grooming: Regular grooming helps keep your dog's coat healthy and prevents matting.
Mental Stimulation: Provide toys, puzzles, and games to keep your dog mentally engaged and prevent boredom.
## Conclusion:
Owning a dog is a joy, but it's also a responsibility. By understanding your dog's breed, providing proper care, and addressing potential health issues, you can ensure that your furry friend lives a happy, healthy, and fulfilling life by your side. You can refer to the information for free [https://mdogsw.com/dog-nutrition/freeze-fresh-dog-food/](https://mdogsw.com/dog-nutrition/freeze-fresh-dog-food/) | mdogsw_mdogsw_4653ddc7ce0 |
1,871,769 | Quickly implement a semi-automatic quantitative trading tool | In commodity futures trading, intertemporary arbitrage are a common trading method. This kind of... | 0 | 2024-05-31T07:40:29 | https://dev.to/fmzquant/quickly-implement-a-semi-automatic-quantitative-trading-tool-3bje | trading, fmzquant, cryptocurrency, tool | In commodity futures trading, intertemporary arbitrage are a common trading method. This kind of arbitrage is not risk-free. When the unilateral direction of the spread continues to expand, the arbitrage position will be in a floating lose state. However, as long as the arbitrage position is properly controlled, it is still very operational and feasible.
In this article, we try to switch to another trading strategy, instead of constructing a fully automated trading strategy, we realized an interactive semi-automatic quantitative trading tool to make it easier to intertemporary arbitrage in commodity futures trading.
The development platform we will use the FMZ Quant platform. The focus of this article is on how to build semi-automatic strategies with interactive functions.
Intertemporal arbitrage is a very simple concept.
## Intertemporal arbitrage concept
- Quote from Wikipedia
In economics and finance, arbitrage is the practice of taking advantage of a price difference between two or more markets: striking a combination of matching deals that capitalize upon the imbalance, the profit being the difference between the market prices at which the unit is traded. When used by academics, an arbitrage is a transaction that involves no negative cash flow at any probabilistic or temporal state and a positive cash flow in at least one state; in simple terms, it is the possibility of a risk-free profit after transaction costs. For example, an arbitrage opportunity is present when there is the opportunity to instantaneously buy something for a low price and sell it for a higher price.
## Strategy Design
The strategy framework is as follows:
```
Function main(){
While(true){
If(exchange.IO("status")){ // Determine the connection status of the CTP protocol.
LogStatus(_D(), "Already connected to CTP !") // Market Opening time, login connection is normal.
} else {
LogStatus(_D(), "CTP not connected!") // Not logged in to the trading front end.
}
}
}
```
If the CTP protocol is connected properly, then we need to set up the trading contract and then get the market quote. After obtaining the quotes, we can use the FMZ Quant platform build-in "line drawing" library to draw the difference.
```
Function main(){
While(true){
If(exchange.IO("status")){ // Determine the connection status of the CTP protocol.
exchange.SetContractType("rb2001") // Set the far month contract
Var tickerA = exchange.GetTicker() // far-month contract quote data
exchange.SetContractType("rb1910") // Set the near month contract
Var tickerB = exchange.GetTicker() // near-month contract quote data
Var diff = tickerA.Last - tickerB.Last
$.PlotLine("diff", diff)
LogStatus(_D(), "Already connected to CTP !") // Market Opening time, login connection is normal.
} else {
LogStatus(_D(), "CTP not connected!") // Not logged in to the trading front end.
}
}
}
```
Get the market data, calculate the difference, and draw the graph to record. let it simply reflects the recent fluctuations in the price difference.
Use the function of "line drawing" library $.PlotLine
## Interactive part
On the strategy editing page, you can add interactive controls directly to the strategy:
Use the function GetCommand in the strategy code to capture the command that was sent to the robot after the above strategy control was triggered.
After the command is captured, different commands can be processed differently.
The trading part of the code can be packaged using the "Commodity Futures Trading Class Library" function. First, use var q = $.NewTaskQueue() to generate the transaction control object q (declared as a global variable).
```
var cmd = GetCommand()
if (cmd) {
if (cmd == "plusHedge") {
q.pushTask(exchange, "rb2001", "sell", 1, function(task, ret) {
Log(task.desc, ret)
if (ret) {
q.pushTask(exchange, "rb1910", "buy", 1, 123, function(task, ret) {
Log("q", task.desc, ret, task.arg)
})
}
})
} else if (cmd == "minusHedge") {
q.pushTask(exchange, "rb2001", "buy", 1, function(task, ret) {
Log(task.desc, ret)
if (ret) {
q.pushTask(exchange, "rb1910", "sell", 1, 123, function(task, ret) {
Log("q", task.desc, ret, task.arg)
})
}
})
} else if (cmd == "coverPlus") {
q.pushTask(exchange, "rb2001", "closesell", 1, function(task, ret) {
Log(task.desc, ret)
if (ret) {
q.pushTask(exchange, "rb1910", "closebuy", 1, 123, function(task, ret) {
Log("q", task.desc, ret, task.arg)
})
}
})
} else if (cmd == "coverMinus") {
q.pushTask(exchange, "rb2001", "closebuy", 1, function(task, ret) {
Log(task.desc, ret)
if (ret) {
q.pushTask(exchange, "rb1910", "closesell", 1, 123, function(task, ret) {
Log("q", task.desc, ret, task.arg)
})
}
})
}
}
q.poll()
```
From: https://blog.mathquant.com/2022/09/30/quickly-implement-a-semi-automatic-quantitative-trading-tool-2.html | fmzquant |
1,871,767 | Comprehensive Guide to CUET Maths Previous Year Questions | The CUET (Central Universities Entrance Test) is a highly competitive examination that plays a... | 0 | 2024-05-31T07:39:08 | https://dev.to/babita_kumari_2b60a23f4a9/comprehensive-guide-to-cuet-maths-previous-year-questions-533g |
The CUET (Central Universities Entrance Test) is a highly competitive examination that plays a crucial role in the academic journey of countless students. Among the various subjects tested, Maths is often considered one of the most challenging. However, with the right resources and study strategies, you can ace the CUET Maths section. One of the most effective ways to prepare is by practicing CUET Maths previous year questions. In this comprehensive guide, we will explore the importance of these questions, how to use them effectively, and provide insights into some of the most commonly asked questions in the CUET Maths exam.
Why CUET Maths Previous Year Questions Matter
Practicing [CUET Maths previous year questions ](https://cuetacademy.online/cuet-maths-previous-year-question-paper-with-official-answer-pdf-download/)is a proven method to enhance your preparation. Here are some key reasons why these questions are invaluable:
1.Understanding the Exam Pattern: Previous year questions help you get acquainted with the exam pattern, the types of questions asked, and the distribution of topics. This familiarity can significantly reduce anxiety on the exam day.
2.Identifying Important Topics: By analyzing previous years' questions, you can identify recurring topics and prioritize them in your study plan. This ensures that you focus on areas that are more likely to be tested.
3.Improving Time Management: Solving past papers under timed conditions helps you develop effective time management skills. This is crucial, as the CUET Maths section requires both speed and accuracy.
4.Boosting Confidence: Regular practice with previous year questions builds confidence. As you become more comfortable with the question format and difficulty level, you'll approach the exam with a positive mindset.
5.Learning from Mistake: Reviewing your answers and understanding where you went wrong helps you learn from your mistakes. This iterative process of practice and review is essential for continuous improvement.
How to Use CUET Maths Previous Year Questions Effectively
To maximize the benefits of practicing CUET Maths previous year questions, follow these strategies:
1.Create a Study Schedule: Allocate specific time slots for practicing previous year questions. Consistent practice is key to mastering the subject.
2.Simulate Exam Conditions: Solve past papers in a timed, distraction-free environment. This helps you get used to the pressure of the actual exam.
3.Analyze Your Performance: After completing each set of questions, thoroughly analyze your performance. Identify your strengths and weaknesses and adjust your study plan accordingly.
4.Focus on Weak Areas: Spend extra time on topics where you struggle. Use additional resources, such as textbooks or online tutorials, to strengthen your understanding.
5.Review Solutions: Carefully review the solutions provided for each question. Understanding the methodology and logic behind the answers is crucial for mastering similar problems in the future.
Commonly Asked CUET Maths Questions
To give you a head start, here are some types of questions that frequently appear in the CUET Maths section:
Algebra
1.Quadratic Equations: Questions often involve solving quadratic equations, finding the roots, or applying the quadratic formula. For example, you might be asked to solve \( ax^2 + bx + c = 0 \) for given values of \( a \), \( b \), and \( c \).
2. Progressions**: Arithmetic and geometric progressions are common topics. You may need to find the nth term or the sum of a series. For instance, calculating the sum of the first 20 terms of an arithmetic progression with a given first term and common difference.
Calculus
1.Differentiation: Questions on differentiation may include finding the derivative of a function, applying the chain rule, or solving problems involving rates of change. For example, finding \( \frac{dy}{dx} \) if \( y = \sin(x^2) \).
2. Integration: Integration problems often involve finding the integral of a function, using integration by parts, or solving definite integrals. You might be asked to evaluate \( \int (x^2 \cdot e^x) \, dx \).
Geometry and Trigonometry
1.Circle Theorems: Questions may involve properties of circles, such as finding the length of a chord, the radius, or the area of a sector. For example, calculating the area of a sector with a central angle of 60 degrees in a circle with a radius of 10 cm.
2.Trigonometric Identities: You may need to simplify expressions using trigonometric identities or solve trigonometric equations. For instance, proving that \( \sin^2(\theta) + \cos^2(\theta) = 1 \).
Statistics and Probability
1. Probability: Probability questions might include calculating the likelihood of an event, understanding conditional probability, or using Bayes' theorem. An example question could be finding the probability of drawing two aces from a deck of cards.
2.Descriptive Statistics: These questions often involve measures of central tendency (mean, median, mode) or dispersion (range, variance, standard deviation). For example, calculating the mean and standard deviation of a given data set.
Tips for Success
Here are some additional tips to help you excel in the CUET Maths exam:
1. Stay Consistent: Consistent study and practice are key to success. Make sure to dedicate regular time to Maths preparation.
2.Use Quality Resources: In addition to CUET Maths previous year questions, use quality textbooks, online courses, and tutorials to strengthen your understanding.
3. Seek Help When Needed: If you're struggling with a particular topic, don't hesitate to seek help from teachers, tutors, or online forums.
4. Stay Positive and Confident: Maintain a positive attitude and believe in your ability to succeed. Confidence can significantly impact your performance.
5. Take Care of Your Health: Ensure you get enough sleep, eat healthily, and take breaks during your study sessions. A healthy body supports a sharp mind.
Conclusion
Practicing CUET Maths previous year questions is an essential part of your exam preparation strategy. These questions not only help you understand the exam pattern and important topics but also enhance your problem-solving skills and time management. By following the strategies and tips outlined in this guide, you can maximize the benefits of these practice questions and approach your CUET Maths exam with confidence and competence.
Remember, success in the CUET Maths exam is a combination of consistent practice, effective study techniques, and a positive mindset. Utilize the resources available to you, stay focused, and believe in your ability to achieve your academic goals. Good luck! | babita_kumari_2b60a23f4a9 | |
1,871,766 | Essential Components: Understanding the Hex Head Bolt | Hex Head Bolts: The Essential Component Understanding the Hex Head Bolt Hex head bolts are essential... | 0 | 2024-05-31T07:38:56 | https://dev.to/skcms_kskee_db3d23538e2f3/essential-components-understanding-the-hex-head-bolt-jnc | components | Hex Head Bolts: The Essential Component
Understanding the Hex Head Bolt
Hex head bolts are essential products in construction, engineering, and manufacturing companies. They generally are referred to as hexagonal bolts or machine bolts as a total result of these six-sided head produces only to turn having a wrench or pliers. These bolts are constructed from different products for instance stainless steel chrome-molybdenum, and titanium, and others. Their sizes differ from fractional to metric sizes, various applications.
Hex head bolts are peanuts use structure techniques. They have been called hexagonal bolts because they have six flat sides. This might cause them to become effortless in order to make insurance policy forms a wrench or pliers. They are created from various materials such as stainless steel chrome-molybdenum, and titanium. These peanuts can be found in different sizes to match the plain point need.
b808cf5d98c183aabcee6cc78fa6d84bae4ef950e609de228af75be5c3597564.jpg
Advantages of Using Hex Head Bolts
Hex head bolts providing advantages are a few forms of bolts, for example carriage bolts, lag bolts, and eye bolts, amongst other folks. These advantages add fastening effectiveness to best enhanced resistance to vibration and surprise, increasing durability, and tensile higher energy. Products are furthermore an effortless task assemble and disassemble, producing them perfect for applications which need regular repair.
Hex head bolts will be superior to more types of bolts since they tighten affairs better. They do not loosen as much as a consequence of vibrations or unanticipated movement. They are stronger and final a good time is very long. Also, they are typically easy to show up or disassemble.
Innovation in Hex Head Bolt Manufacturing
In past period, couple of years, there need to become advancements and significant, the creation of hex head bolts. New items, such as composite alloys and advanced level polymers, have been entirely developed to enhance the strength, durability, and corrosion opposition when it comes with bolts. Bolt are additionally being produced using production is automated such as hot forging and cool heading, to make quality and accuracy.
Hex head bolts are now best being a consequence of new technology. Experts want produced new specifically to confirm these are typically typically considerably powerful and longer that is much is final. Hex head bolts are also being built in factories and devices and robots to make these are the same and higher quality.
Safety Precautions When Using Hex Head Bolts
Hex head bolts could be dangerous in case not used properly. Thus, watching safety precautions is critical to avoid accidents and tragedies. It is essential to use the appropriate size and type of hex head bolt for each application, when well due to the fact the proper torque and stress. Over tightening or hex head bolts that under tightening cause them to fail, causing injury to gear or damage to someone. It is additionally important to put protective gear such as gloves, safety glasses, and ear protection when using effective technology.
Hex head bolts can even be dangerous or used properly. It is necessary to use the best size bolt for the task and tighten up it sufficiently. Too tight or too loose make it break or cause damage. Once using tools to make sure to wear safety cups, ear protection, and gloves.
Quality Hex Head Bolt Applications
Hex head bolts can be used in lots of applications around different companies, including construction, automotive, aerospace, aquatic, and electric engineering. They are particularly applications appropriate need greater tensile corrosion, and durability. Kinds of such applications incorporate fastening devices, suspensions, brake system, exhaust systems, and cable bridges, and others. Hex head bolts are available in many areas such as creating actions, automobiles, planes, ships, and electric equipment. They function better once you shall want string thing will maybe not corrode effortlessly. For instance, they can contain the suspension engine or system together.
Source: https://www.hardwarefastener.com/Products | skcms_kskee_db3d23538e2f3 |
1,871,757 | Mastering the FNP Certification: Guide to the Ultimate Review Book | Preparing for the Family Nurse Practitioner (FNP) certification exam requires comprehensive review... | 0 | 2024-05-31T07:25:07 | https://dev.to/barkleyandassociates/mastering-the-fnp-certification-guide-to-the-ultimate-review-book-4g3o | Preparing for the Family Nurse Practitioner (FNP) certification exam requires comprehensive review and practice. An essential resource in this endeavor is a high-quality [FNP review book](https://www.npcourses.com/product/barkleys-curriculum-review-for-family-nurse-practitioners/). Such a book serves as a study guide and a critical tool in bridging the gap between nursing knowledge and clinical application.
## Choosing the Right FNP Review Book
A top-tier [FNP review book](https://www.npcourses.com/product/barkleys-curriculum-review-for-family-nurse-practitioners/) encompasses various topics crucial for exam preparation, including patient assessment, diagnosis, pharmacology, and management across multiple conditions and age groups. It offers an in-depth look at adult and pediatric care, ensuring practitioners are well-prepared for the broad spectrum of family practice.
The ideal FNP review book blends theoretical knowledge and practical application, emphasizing evidence-based practices. It includes numerous practice questions, mirroring the format of the certification exam, to test comprehension and readiness. Moreover, explanations for correct and incorrect answers are invaluable for understanding complex concepts and improving critical thinking skills.
## A Guide to Enhanced Learning
Additionally, a well-structured review book is organized by body systems or practice areas, providing a sense of security to readers. This structure makes it easier to focus on specific topics or identify areas where further study is needed, reassuring nurses about their exam readiness. This organization aids in efficient study sessions and enhances retention.
Accessibility and clarity are also key features of a practical FNP review book. It should be written in clear, concise language that is easy to understand, with key points highlighted for quick review. Resources such as charts, tables, and bullet points can facilitate learning and memorization.
Ultimately, the best FNP review book is one that supports nurses in their journey to becoming certified family nurse practitioners. It not only aids in passing the certification exam but also in reinforcing a strong clinical foundation for future practice. With the right review book, FNPs can approach their exams with a sense of accomplishment, knowing they are well-prepared to deliver high-quality patient care.
| barkleyandassociates | |
1,871,765 | ED Problem Solution In Men| Sildalist Strong 140mg Firstchoicemedss | Diet is one of the important factors that is responsible for ED problems in Men. Buy Sildalist Strong... | 0 | 2024-05-31T07:38:05 | https://dev.to/firstchoicemedss/ed-problem-solution-in-men-sildalist-strong-140mg-firstchoicemedss-2cl | firstchoicemedss, men, health | Diet is one of the important factors that is responsible for ED problems in Men. [Buy Sildalist Strong 140mg form Firstchoicesmedss](https://www.firstchoicemedss.com/sildalist-strong-140mg.html
) a powerful medicine to treat ED problems in men. Many factors are the main cause of this problem. A poor diet high in processed food, unhealthy fats, and sugar causes high blood pressure, obesity, and other health issues that cause Erectile Dysfunction. A healthy diet that includes fruits, green vegetables, milk, and lean protein is good for dealing with any health problem in the body. | firstchoicemedss |
1,871,764 | Unlocking Savings and Convenience: Your Guide to Mercy Smart Square | **Introduction: **Welcome to Mercy Smart Square – your gateway to a world of savings and convenience!... | 0 | 2024-05-31T07:37:05 | https://dev.to/bella_spark_0e04d0b658719/unlocking-savings-and-convenience-your-guide-to-mercy-smart-square-10fn | **Introduction:
**Welcome to Mercy Smart Square – your gateway to a world of savings and convenience! In this comprehensive guide, we'll delve into everything you need to know about Mercy Smart Square, from its array of services to tips on maximizing your experience. Whether you're a visitor or a regular, get ready to discover how Mercy Smart Square can streamline your healthcare journey while saving you time and money.

**What is Mercy Smart Square?**
Mercy Smart Square is more than just a traditional healthcare facility – it's a revolutionary platform designed to enhance your healthcare experience. From online appointment scheduling to prescription refills, Mercy Smart Square puts the power of healthcare management directly into your hands.
**Key Features and Services:
**
1) Online Appointment Scheduling: Say goodbye to long wait times on the phone. With Mercy Smart Square, you can conveniently schedule appointments online, anytime, anywhere.
Prescription Refills: Running low on medication? Simply request a refill through Mercy Smart Square's easy-to-use platform and pick it up at your convenience.
2) Health Records Access:
Access your health records securely from the comfort of your own home. Mercy Smart Square allows you to view test results, medication history, and more with just a few clicks.
3) Virtual Visits: Need medical advice but can't make it to the office? Mercy Smart Square offers virtual visits, allowing you to consult with a healthcare provider from your smartphone or computer.
**How to Get Started:
**
Getting started with Mercy Smart Square is quick and easy.
Simply visit [mercysmartsquare.com](https://mercysmartsquare.com/)
to explore the full range of services available. From there, create an account to access exclusive features and start managing your healthcare on your terms.
**Why Choose Mercy Smart Square?
**
1) Convenience: With Mercy Smart Square, you can manage your healthcare needs on your schedule, without the hassle of traditional methods.
2) Savings: Save time and money with features like online appointment scheduling and prescription refills, allowing you to focus on what matters most – your health.
3) Peace of Mind: Rest easy knowing that your healthcare information is secure and easily accessible whenever you need it.
**Conclusion:
**Mercy Smart Square is revolutionizing the way you manage your healthcare. Explore our website, sign up for an account, and discover the countless benefits that await you. Your journey to better health starts here at Mercy Smart Square. | bella_spark_0e04d0b658719 | |
1,871,760 | Machine Learning In Software Testing | We can clearly see how Machine Learning (ML) and Artificial Intelligence (AI) are becoming seamlessly... | 0 | 2024-05-31T07:31:18 | https://dev.to/harisapnanair/machine-learning-in-software-testing-27i8 | testing, softwareengineering, programming, machinelearning | We can clearly see how Machine Learning (ML) and Artificial Intelligence (AI) are becoming seamlessly integrated into our daily lives, from helping with email composition to summarising articles and handling programming tasks. Based on a February 2024 article from Semrush, the estimated yearly growth rate for artificial intelligence is 33.2% between 2020 and 2027.
This pioneering trend is also being recognized by the software testing field, which is using AI and ML tools to update outdated tests, handle an array of test case scenarios, and increase test coverage. Organizations can increase software testing efficiency and save time by utilizing machine learning in software testing.
{% youtube 7yUzifkN-5M %}
We will look at the depths of machine learning in software testing along with its uses, challenges, and best practices in this blog.
> Check your document’s [word count](https://www.lambdatest.com/free-online-tools/word-count?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=free_online_tools) in seconds with our free tool!
## What is Machine Learning and AI?
Machine Learning(ML) and Artificial Intelligence(AI) are two closely related concepts in the field of computer science. AI focuses on creating intelligent machines capable of doing tasks that typically require human intelligence like visual perception, speech recognition, decision-making, etc. It involves developing algorithms that can reason, learn, and make decisions based on input data given to the machine.
On the other hand, ML is a subset of AI that involves teaching machines to learn from data without being explicitly programmed. ML algorithms identify patterns and trends in data, enabling them to make predictions and decisions autonomously.
## Why Machine Learning in Software Testing?
The process of automated software testing involves writing and running test scripts, usually with the use of frameworks like [Selenium](https://www.lambdatest.com/selenium?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=webpage). Element selectors and actions are combined by Selenium to simulate user interactions with the user interface(UI). To facilitate operations like clicking, hovering, text input, and element validation, element selectors assist in identifying UI elements. Although it requires minimum manual efforts, there is a need for consistent monitoring due to software updates.
Imagine a scenario where the “*sign up*” button of a business page is shifted to a different location on the same page that says “*register now!*”. Even for such a small change, the test script has to be rewritten with appropriate selectors. There are many such test case scenarios that require consistent monitoring.
Machine learning addresses such challenges by automating test case generation, error detection, and code scope improvement, enhancing productivity and quality for enterprises.
Moreover, the use of machine learning in software testing leads to significant improvements in efficiency, reliability, and scalability. Automation testing tools powered by ML models can execute tests faster, reducing the time and effort.
*Check out the key distinctions between manual and automated software testing outlined in our blog on [Manual Testing vs Automation Testing](https://www.lambdatest.com/learning-hub/manual-testing-vs-automation-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=learning_hub).*
> Count the lines of text easily using our [lines count](https://www.lambdatest.com/free-online-tools/lines-count?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=free_online_tools) tool.
## Uses of Machine Learning in Software Testing?
Machine learning is revolutionizing software testing by providing various methods like predictive analysis, intelligent test generation, etc. These methods help us to optimize the testing process, reduce cost, and enhance the software quality.
Let us discuss the various methods by which we can use machine learning in software testing.
* **Predictive Analysis**
By machine learning algorithms we can predict potential software problem areas by analyzing historical test data. This proactive approach helps testers to anticipate and address vulnerabilities in advance, thereby enhancing overall software quality and reducing downtime.
* **Intelligent Test Case Generation
**Machine learning-driven testing tools automatically generate and prioritize [test cases](https://www.lambdatest.com/learning-hub/test-case?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=learning_hub) based on user interactions, ensuring comprehensive coverage of critical paths. This reduces manual effort while guaranteeing robust software applications.
* **Testing
**Machine Learning helps us to automate various types of tests like [API testing](https://www.lambdatest.com/learning-hub/api-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=learning_hub) by analyzing API responses for anomalies, [unit testing](https://www.lambdatest.com/learning-hub/unit-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=learning_hub) by generating unit test cases based on code analysis, [integration testing](https://www.lambdatest.com/learning-hub/integration-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=learning_hub) by identifying integration dependencies for test scenario generation, [performance testing](https://www.lambdatest.com/learning-hub/performance-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=learning_hub) by simulating various scenarios, etc. This helps to enhance test coverage and efficiency while improving software reliability.
*Unlock the potential of Cypress API testing with our comprehensive blog:[A Step-By-Step Guide To Cypress API Testing](https://www.lambdatest.com/blog/cypress-api-testing/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=blog).*
* **Visual Validation Testing
**Machine learning facilitates thorough comparison of images/screens across various browsers and devices, detecting even minor UI discrepancies. This ensures a consistent user experience across platforms and improves customer satisfaction.
*To explore the top Java testing frameworks of 2024 dive into our comprehensive blog: [13 Best Java Testing Frameworks For 2024](https://www.lambdatest.com/blog/best-java-testing-frameworks/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=blog).*
* **Adaptive Continuous Testing
**In CI/CD environments, machine learning algorithms dynamically adapt and prioritize tests based on code changes, providing instant validation for recent alterations and ensuring continuous software quality.
* **Test coverage analysis
**After even a minor change in the application, it is essential to conduct tests to ensure the proper functionality. However, running the entire test suite can be impractical, though often necessary. In this scenario machine learning enables the identification of required tests and optimizes time usage. Furthermore, it also enhances the overall testing effectiveness by facilitating analysis of current test coverage and highlighting low-coverage and at-risk areas.
* **Natural Language Processing(NLP) in Test
**Machine learning-powered testing tools equipped with NLP capabilities comprehend test requirements expressed in plain language and enable non-technical stakeholders to contribute to test scenario drafting, thereby enhancing collaboration and efficiency across teams.
* **Classification of executed tests
**Test automation tools expedite test execution and provide rapid feedback on failed tests, but diagnosing multiple failures can be time-consuming. Machine learning technology addresses this by categorizing tests, automatically identifying probable causes of bugs, and offering insights into prevalent failures and their root causes.
* **Automated test writing by spidering
**Machine learning is commonly used for automated test creation. Initially, the technology scans the product, gathering functionality data and downloading HTML codes of all pages while assessing loading times. This process forms a dataset, which serves to train the algorithm on the expected behavior of the application. Subsequently, machine learning technology compares the current application state with its templates, flagging any deviations as potential issues.
* Robotic Process Automation(**RPA) for Regression Testing
**RPA helps in [regression testing](https://www.lambdatest.com/learning-hub/regression-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=learning_hub) by automating repetitive tasks, such as data entry and test case execution, thereby streamlining the process and saving time and resources. For instance, RPA can seamlessly manage test suite re-execution post-software updates by integrating with version control systems (VCS), fetching the latest version, deploying it, executing tests, and validating results.
> Get an accurate [sentence count](https://www.lambdatest.com/free-online-tools/sentence-count?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=free_online_tools) for your content quickly and easily.
## Predictive Analysis in Software Testing
Imagine a member of a QA team is given a task to ensure the quality of a complex web application that undergoes frequent updates and feature additions. In this scenario, the traditional test automation methods will be inadequate and time-consuming.
To solve this issue, we can use machine learning algorithms to conduct predictive analysis on test data. This process involves using historical test results to forecast potential software issues before they manifest. By identifying patterns and trends, the machine learning model identifies sections of the application more susceptible to bugs or failures.
The steps used to implement the above-mentioned solution are as follows:-
1. **Data Collection:** Gather comprehensive historical test data consisting of test cases, outcomes, and application modifications.
2. **Model Training:** Utilize this data to train a machine learning model, enabling it to recognize patterns associated with failures or bugs.
3. **Prediction**: Once trained, employ the model to analyze new application changes or features. The model will now forecast potential problem areas or recommend specific tests likely to encounter issues.
4. **Test Execution: **Direct testing efforts towards the predicted areas along with the standard test suite.
5. **Feedback Loop:** Continuously incorporate test results into the model to refine its accuracy over time, ensuring ongoing improvement in predictive capabilities.
> Simplify your URL analysis with our [url parse](https://www.lambdatest.com/free-online-tools/url-parse?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=free_online_tools) tool.
## How Does Machine Learning Produce Automated Tests?
1. **Data collection: **In the data collection phase, an extensive dataset comprising test cases or code samples, along with their pass/fail outcomes, is compiled. This dataset serves as training data for the machine learning model, enabling it to learn patterns and correlations essential for effective automated testing.
2. **Data Training: **Machine learning models are trained using historical testing data, which includes information about test cases, application behavior, and outcomes. During this phase, the machine learning algorithms learn patterns and relationships within the data to understand what constitutes a successful test and what indicates a failure.
3. **Feature Extraction:** Machine learning algorithms extract relevant features or characteristics from the application code and testing data. These features could include UI elements, code syntax, user interactions, and performance metrics.
4. **Model Building: **Using the extracted features, machine learning models are built to predict the outcome of new test scenarios. These models can take various forms, such as classification models (to predict pass/fail outcomes) or regression models (to predict numerical values, such as response times).
5. **Pattern Recognition: **During pattern recognition, machine learning models analyze input features and their associated outputs to uncover correlations and dependencies within the dataset. By identifying these patterns, the model gains insights into the relationships between test case components and the probability of pass or fail outcomes, facilitating accurate predictions in automated testing scenarios.
6. **Test Case Generation:** Once the machine learning models are trained and validated, they can be used to generate new test cases automatically. This process involves analyzing the application code, identifying areas that require testing, and generating test scenarios based on the learned patterns and relationships.
7. **Execution and Validation: **The generated test cases are executed against the application, and the results are validated against expected outcomes. Machine learning algorithms also analyses the test results to identify patterns of failure or areas of improvement, which can inform future test generation iterations.
8. **Feedback Loop:** As new testing data becomes available, the machine models are updated and refined based on the feedback. This iterative process ensures that the automated tests continue to adapt and improve over time, leading to more accurate and effective testing outcomes.
> Easily escape JSON strings with our [json escape](https://www.lambdatest.com/free-online-tools/json-escape?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=free_online_tools) tool.
## Power of AI With LambdaTest
LambdaTest is an AI-powered test orchestration and execution platform that lets you run manual and automated tests at scale with over 3000+ real devices , browsers, and OS combinations.
It offers the next-generation smart testing platform called [HyperExecute](https://www.lambdatest.com/hyperexecute?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=webpage), an AI-powered end-to-end test orchestration cloud that ensures lightning-fast test execution by upto 70% than any cloud grid.
{% youtube 7yUzifkN-5M %}
Through AI-powered [test failure analysis](https://www.lambdatest.com/test-intelligence/failure-analysis?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=webpage), LambdaTest intelligently identifies and diagnoses test failures, enabling efficient resolution. Additionally, LambdaTest offers predictive insights using [Test Intelligence](https://www.lambdatest.com/test-intelligence/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=webpage) to foresee and alleviate future problems, enabling teams to confidently deliver high-quality software.
**Features:**
* It provides a [cross browser testing](https://www.lambdatest.com/learning-hub/cross-browser-testing?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=learning_hub) solution to test web apps across diverse browsers and devices simultaneously.
* It seamlessly scales test execution with [Selenium Grid](https://www.lambdatest.com/blog/why-selenium-grid-is-ideal-for-automated-browser-testing/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=blog) integration.
* It provides visual UI testing to detect visual discrepancies and ensure consistent UI rendering.
* It conducts [live interactive testing](https://www.lambdatest.com/blog/test-on-chrome-76-77-beta-and-78-dev/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=blog) on real browsers and devices.
* It captures automated [screenshots](https://www.lambdatest.com/blog/how-to-capture-screenshots-in-selenium-guide-with-examples/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=blog) to detect visual regressions.
* It executes [parallel testing](https://www.lambdatest.com/blog/what-is-parallel-testing-and-why-to-adopt-it/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=blog) concurrently across multiple environments for faster results.
* It provides a Single Sign-On(SSO) authentication feature to access multiple applications with one set of login credentials.
* Its scalable infrastructure dynamically allocates resources to handle varying testing demands, ensuring high performance and cost efficiency.
* It provides a facility for Real-Time Testing and Real-Device Testing.
* It allows us to test websites in different locations by providing a cloud of 3,000+ real devices and desktop browsers with [geolocation testing](https://www.lambdatest.com/blog/how-to-test-geolocation/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=blog).
* It offers various intеgration options with tеam [collaboration tools](https://www.lambdatest.com/blog/collaboration-tools/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=blog) to strеamlinе our softwarе tеsting and dеvеlopmеnt procеssеs.
## Challenges While Using Machine Learning in Software Testing
Using machine learning for test automation offers immense potential for improving efficiency and effectiveness. However, it also presents several challenges that we must address to leverage its benefits successfully. The challenges while using machine learning for test automation are as follows:-
**Data Availability and Quality**
Machine learning algorithms require substantial amounts of high-quality data to train effectively. Insufficient or poor-quality data can hinder the accuracy and reliability of machine learning models, impacting the effectiveness of test automation efforts.
**Complexity**
Machine learning models can be inherently complex, making them challenging to understand and debug. This complexity can pose difficulties in interpreting model behavior and diagnosing issues, especially in the context of automation testing.
**Overfitting**
Overfitting occurs when a model performs well on training data but fails to generalize to new data. This can occur due to model complexity or insufficient training data, leading to inaccuracies in test automation predictions.
**Maintenance**
Machine learning models require regular retraining and updating to remain effective, particularly as the system under test evolves. And this continuous maintenance and monitoring can be time-consuming and resource-intensive.
**Integration**
Integrating machine learning models into existing test automation frameworks can be challenging, requiring significant development effort and compatibility considerations.
**Explainability**
Some machine learning models may lack explainability, making it challenging to understand the reasoning behind their predictions. This opacity can pose challenges in interpreting and trusting the results of machine learning-based test automation.
**Bias**
Biases in data or preprocessing can lead to inaccurate results and flawed predictions in machine learning-based test automation. Identifying and mitigating these biases is essential to ensure the reliability and fairness of automated testing outcomes.
**Adaptability to Application Changes**
Machine learning models must adapt to changes in the application under test to maintain relevance and effectiveness. However, accommodating frequent changes during development can be challenging, requiring proactive strategies to update and retrain models accordingly.
**Accuracy Verification**
Ensuring the accuracy and reliability of machine learning algorithms in test automation requires rigorous validation and verification processes. Involving domain experts to assess model accuracy and refine algorithms is crucial for maximizing the efficiency and efficacy of machine learning-based testing.
## Best Practices
By following some of the best practices, we can ensure that our products meet high-quality standards, fulfill customer expectations, and maintain a competitive edge in the market. Here are some refined best practices for testers:
**Embrace Simulation and Emulation**
Leverage simulation and emulation tools to scrutinize software and systems within controlled environments. By simulating diverse scenarios, testers can validate their software’s resilience and rectify any anomalies prior to product release.
*LambdaTest simplifies app testing by offering automated testing on Emulators and Simulators, eliminating the need for an expensive device lab. To learn more about it, check out our blog on [**App Automation on Emulators and Simulators](https://www.lambdatest.com/blog/live-with-app-automation-on-emulators-simulators/?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=blog)***.
**Harness Automated Test Scripts**
Deploy automated [test scripts](https://www.lambdatest.com/learning-hub/test-scripts?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=learning_hub) to streamline repetitive testing tasks, ensuring time savings and minimizing errors. It is important to develop these scripts as early as possible to ensure that they cover all critical features and aspects of the product, including functionality, performance, and security.
**Adopt Automation Frameworks**
Implement automation frameworks like Testim, Functionize, Applitools, Mabl, Leapwork, etc to organize and manage automated tests efficiently. These frameworks will provide a structured approach to automation, aligning with industry best practices and enabling testers to optimize their testing processes.
**Develop Comprehensive Test Data Sets**Testers must ****craft comprehensive test data sets covering critical scenarios, ensuring realism and comprehensiveness. These data sets will help us with thorough testing and enable testers to detect and address problems at an early stage, thereby enhancing product quality.
> Quickly unescape JSON strings using our [json unescape](https://www.lambdatest.com/free-online-tools/json-unescape?utm_source=devto&utm_medium=organic&utm_campaign=may_07&utm_term=bw&utm_content=free_online_tools) tool.
**Monitor and Analyze Results**
Post-testing, monitor and analyze results meticulously to uncover issues and areas for improvement. By utilizing these analytics tools we can find patterns and trends, empowering testers to refine the product.
## Conclusion
To summarize, machine learning is transforming software testing! It analyzes historical data to predict outcomes, enabling faster and more accurate test case generation. However, various challenges such as data quality, complexity, and integration are associated with the use of machine learning in automation testing. And to address these issues we can adopt rigorous validation processes and the adoption of best practices like using emulators and machine learning-driven automation tools.
In this blog we had an in-depth exploration of machine learning for automation testing, covering its importance, uses, and examples like predictive analysis. It also reviewed the top tools such as LambdaTest and discussed challenges, best practices, and future prospects, offering a comprehensive understanding of the role of machine learning in automation testing.
| harisapnanair |
1,871,759 | Thoughts on C++ | Thoughts? C++ or some other programming language ----- | 0 | 2024-05-31T07:27:43 | https://dev.to/helljs/thoughts-on-c-2e75 | programming, cpp, discuss, developer | Thoughts? C++ or some other programming language -----
| helljs |
1,871,758 | Finding the Best Web Development Company in the UAE: A Comprehensive Guide | The United Arab Emirates (UAE) is a rapidly growing hub for technology and innovation, with web... | 0 | 2024-05-31T07:25:50 | https://dev.to/sarah_chalke_78bc4f05870b/finding-the-best-web-development-company-in-the-uae-a-comprehensive-guide-1ap4 | web, development, services, uae | The United Arab Emirates (UAE) is a rapidly growing hub for technology and innovation, with web development playing a pivotal role in the digital transformation of businesses. Whether you're a startup, an established enterprise, or an individual looking to create a strong online presence, selecting the right web development company is crucial. This comprehensive guide will help you find the [**best web development company in UAE**](https://bootesnull.com/web-development-company-uae/), ensuring your project is handled with expertise and professionalism.
Why Choosing the Right Web Development Company Matters
First Impressions Count: Your website is often the first interaction potential customers have with your brand. A well-designed site can make a lasting impression.
Functionality and Usability: A professional web development company ensures that your website is not only visually appealing but also functional and user-friendly.
SEO and Online Visibility: High-quality web development incorporates SEO best practices, helping your site rank better on search engines.
Security and Reliability: Protecting user data and ensuring your website is reliable are critical aspects that professional developers prioritize.
Scalability: A good web development company will build a site that can grow with your business.
Key Factors to Consider When Choosing a Web Development Company
Experience and Expertise
Look for companies with a proven track record in the industry. Check their portfolio to see the types of projects they've handled. Ensure they have experience with the latest technologies and frameworks.
Client Testimonials and Reviews
Read reviews on platforms like Google, Clutch, and LinkedIn. Ask the company for client references and case studies. Look for feedback on the company’s ability to meet deadlines, communication skills, and post-launch support.
Range of Services
Check if the company offers a comprehensive range of services, including web design, development, SEO, and maintenance. Assess if they provide custom solutions tailored to your business needs. Consider if they offer additional services such as mobile app development, digital marketing, and e-commerce solutions.
Technical Skills and Innovation
Ensure the team is proficient in the latest web development technologies (HTML5, CSS3, JavaScript frameworks like React.js and Angular.js, backend technologies like Node.js, Python, PHP, etc.). Look for companies that stay updated with emerging trends like AI, AR/VR, and blockchain. Evaluate their ability to integrate third-party services and APIs.

Project Management and Communication
A clear and effective project management process is essential for timely delivery. Ensure the company uses reliable project management tools (like Jira, Trello, Asana). Assess their communication channels and responsiveness.
Cost and Value
Obtain detailed quotes and compare pricing models (fixed price vs. hourly rates). Don’t always opt for the cheapest option; focus on value for money. Understand the payment terms and any additional costs for maintenance and updates.
Top Web Development Companies in the UAE
Traffic Digital
One of the largest independent digital marketing and web development agencies in the UAE. Web development, digital strategy, content creation, performance marketing. Extensive portfolio with a focus on delivering innovative digital solutions.
Red Spider Web & Art Design
A leading web development company specializing in creative and functional web designs. Web design, e-commerce solutions, SEO, branding. Known for their artistic approach and high client satisfaction rates.
Element8
A Dubai-based web development and digital marketing agency. Web development, SEO, mobile app development, digital marketing. Strong emphasis on customer-centric solutions and modern design trends.
Code & Co.
A boutique web development agency offering customized web solutions. Web development, UI/UX design, mobile apps, e-commerce development. Focuses on personalized service and high-quality code standards.
Digital Gravity
A dynamic web development and digital marketing company. Web development, branding, SEO, social media marketing. Combines creative and technical expertise to deliver comprehensive digital solutions.
Steps to Choose the Best Web Development Company
Define Your Project Requirements
Outline your project goals, target audience, and key features. Create a detailed project brief to share with potential developers.
Research and Shortlist Companies
Use online directories, social media, and referrals to find potential companies. Narrow down your list based on their portfolio, reviews, and services.
Contact and Evaluate
Reach out to the shortlisted companies and discuss your project. Evaluate their responsiveness, professionalism, and willingness to understand your needs.
Request Proposals and Quotes
Ask for detailed proposals that outline the scope, timeline, and cost. Compare the proposals to assess which company offers the best value.
Interview and Finalize
Conduct interviews to gauge the company’s expertise and cultural fit. Ask about their project management process and support services. Finalize the agreement with clear terms and conditions.
Conclusion
Finding the best web development company in the UAE requires careful consideration of various factors, from expertise and technical skills to client testimonials and cost. By following this comprehensive guide, you can ensure that you partner with a company that not only meets your requirements but also adds value to your business through innovative and reliable web solutions. Remember, the right web development company is not just a service provider but a strategic partner in your digital journey. Choose wisely to build a strong online presence and drive your business forward in the competitive digital landscape of the UAE.
| sarah_chalke_78bc4f05870b |
1,871,756 | Unleashing Your Brand’s Potential: The Best Digital Marketing Agency in Kochi | In today’s digital age, navigating the online landscape can be tricky. Companies are vying for... | 0 | 2024-05-31T07:23:50 | https://dev.to/sandra_joy_d4c86344cd8297/unleashing-your-brands-potential-the-best-digital-marketing-agency-in-kochi-5emm | seo, digital, marketing, ppc | In today’s digital age, navigating the online landscape can be tricky. Companies are vying for attention in a crowded market, and having the right digital marketing strategy can make or break your success. This is where the expertise of a top-tier digital marketing agency comes into play. For businesses in Kochi, Potters Wheel stands out as the premier choice. In this article, we’ll delve into what makes Potters Wheel the [best digital marketing agency in Kochi](https://potterswheelmedia.com/), exploring their unique approach, services, and success stories.
Why Digital Marketing Matters
The Digital Shift
The world has shifted online. From shopping to social interactions, the internet has become the central hub for most activities. As a business, having a strong online presence isn’t just an option — it’s a necessity. Digital marketing allows businesses to reach their target audience more effectively and efficiently than traditional marketing methods. With the right strategy, you can not only increase your visibility but also engage with your audience on a deeper level.
Local Market Dynamics
Kochi, known as the Queen of the Arabian Sea, is a bustling city with a vibrant business ecosystem. As a key commercial hub in Kerala, Kochi is home to a diverse range of businesses, from traditional industries to modern startups. In such a competitive market, standing out requires a nuanced understanding of local consumer behavior and trends. This is where Potters Wheel excels, leveraging their deep local insights to craft tailored digital marketing strategies.
Potters Wheel: The Best Digital Marketing Agency in Kochi
A Legacy of Excellence
Potters Wheel has earned its reputation as the best digital marketing agency in Kochi through years of dedicated service and outstanding results. Founded by a team of passionate digital marketing experts, the agency has consistently delivered innovative solutions that drive growth and maximize ROI for their clients.
Comprehensive Services
One of the key reasons behind Potters Wheel’s success is their comprehensive range of services. Whether you’re a small startup looking to make your mark or an established enterprise aiming to maintain your lead, Potters Wheel has something to offer.
Search Engine Optimization (SEO)
SEO is the backbone of any digital marketing strategy. Potters Wheel employs cutting-edge techniques to improve your website’s ranking on search engines, ensuring that your business gets the visibility it deserves. From keyword research to on-page and off-page optimization, their SEO services are designed to drive organic traffic and boost conversions.
Social Media Marketing
In the age of social media, having a strong presence on platforms like Facebook, Instagram, and Twitter is crucial. Potters Wheel’s social media marketing services help you connect with your audience, build brand loyalty, and drive engagement. They create compelling content, manage your social media accounts, and run targeted ad campaigns to achieve your marketing goals.
Content Marketing
Content is king, and Potters Wheel knows how to create content that resonates with your audience. Their team of skilled writers and designers produce high-quality blog posts, videos, infographics, and more. By delivering valuable and relevant content, they help you establish authority in your industry and attract more customers.
Pay-Per-Click (PPC) Advertising
For businesses looking for quick results, PPC advertising is a powerful tool. Potters Wheel’s PPC experts design and manage campaigns that deliver immediate traffic and conversions. They optimize your ad spend, ensuring you get the best return on investment.
Web Design and Development
Your website is often the first point of contact with potential customers. Potters Wheel creates stunning, user-friendly websites that leave a lasting impression. Their web design and development services ensure that your site is not only visually appealing but also optimized for performance and SEO.
Client-Centric Approach
At Potters Wheel, the client always comes first. They take the time to understand your business, goals, and challenges. This personalized approach allows them to craft strategies that are tailored to your specific needs. Their commitment to transparency and communication ensures that you’re always in the loop, with regular updates and detailed reports on campaign performance.
Success Stories: Transforming Businesses in Kochi
Elevating Local Brands
Potters Wheel has a proven track record of transforming local brands into market leaders. Take, for example, a small boutique in Kochi that struggled to attract customers. With Potters Wheel’s comprehensive digital marketing strategy, including SEO, social media marketing, and targeted PPC campaigns, the boutique saw a significant increase in foot traffic and online sales. Today, it’s one of the most popular shopping destinations in the city.
Driving Growth for Startups
Startups often face unique challenges, and Potters Wheel is well-equipped to address them. A tech startup in Kochi partnered with Potters Wheel to launch their innovative app. Through a combination of influencer marketing, content creation, and strategic ad placements, the startup gained widespread recognition and rapidly grew its user base.
Revitalizing Established Enterprises
Even established businesses can benefit from a fresh digital marketing strategy. An established restaurant in Kochi sought Potters Wheel’s expertise to revamp their online presence. By enhancing their website, optimizing for local search, and running engaging social media campaigns, Potters Wheel helped the restaurant regain its competitive edge and attract new patrons.
The Potters Wheel Difference
Innovation at the Core
What sets Potters Wheel apart from other digital marketing agencies is their commitment to innovation. They’re constantly exploring new technologies and trends to stay ahead of the curve. Whether it’s adopting the latest SEO algorithms or leveraging AI for data analysis, Potters Wheel ensures that their clients benefit from cutting-edge solutions.
Team of Experts
Behind every successful campaign is a team of dedicated experts. Potters Wheel boasts a diverse team of professionals, each specializing in different aspects of digital marketing. From SEO specialists and content creators to social media managers and web developers, their collective expertise drives the agency’s success.
Results-Driven Approach
At the end of the day, results matter. Potters Wheel’s results-driven approach ensures that every strategy and campaign is geared towards achieving tangible outcomes. They set clear goals, measure performance, and make data-driven decisions to optimize results. This focus on accountability and performance sets them apart as the [best digital marketing agency in Kochi](https://potterswheelmedia.com/).
How to Choose the Right Digital Marketing Agency
Assessing Your Needs
Before partnering with a digital marketing agency, it’s essential to assess your needs. What are your business goals? Who is your target audience? What challenges are you facing? Having a clear understanding of your needs will help you find an agency that can provide the right solutions.
Evaluating Expertise
Not all digital marketing agencies are created equal. When evaluating potential partners, consider their expertise and experience. Look at their portfolio, client testimonials, and case studies. Do they have experience in your industry? Can they demonstrate proven results?
Understanding Their Approach
Different agencies have different approaches to digital marketing. Some may focus on SEO, while others excel in social media marketing or content creation. Understanding an agency’s approach will help you determine if it’s aligned with your goals and expectations.
Communication and Transparency
Effective communication is key to a successful partnership. Choose an agency that values transparency and keeps you informed throughout the process. Regular updates, detailed reports, and open lines of communication will ensure that you’re always in the loop.
Budget Considerations
Digital marketing is an investment, and it’s important to find an agency that fits your budget. However, don’t make the mistake of choosing the cheapest option. Quality services come at a price, and it’s worth investing in an agency that can deliver the results you need.
The Future of Digital Marketing in Kochi
Emerging Trends
The digital marketing landscape is constantly evolving, and staying ahead of the trends is crucial. In Kochi, several emerging trends are set to shape the future of digital marketing. From the increasing use of AI and machine learning to the growing importance of video content and influencer marketing, businesses need to adapt to stay competitive.
The Role of Technology
Technology is at the heart of digital marketing, and advancements in this field continue to open up new possibilities. Potters Wheel is at the forefront of leveraging technology to enhance their services. Whether it’s using AI for data analysis, implementing chatbots for customer service, or exploring new platforms for advertising, they ensure that their clients benefit from the latest innovations.
The Importance of Personalization
As consumers become more discerning, personalization is becoming increasingly important. Tailoring marketing messages to individual preferences and behaviors can significantly boost engagement and conversions. Potters Wheel uses advanced data analytics to create personalized marketing strategies that resonate with their clients’ target audiences.
Sustainability and Social Responsibility
Today’s consumers are more conscious of social and environmental issues than ever before. Businesses that demonstrate a commitment to sustainability and social responsibility are likely to win the loyalty of these consumers. Potters Wheel helps businesses incorporate these values into their digital marketing strategies, building a positive brand image and fostering customer trust.
In a rapidly evolving digital landscape, having the right partner can make all the difference. Potters Wheel has proven time and again why they’re considered the [best digital marketing agency in Kochi](https://potterswheelmedia.com/). With their comprehensive range of services, client-centric approach, and unwavering commitment to innovation, they have the expertise to help your business thrive. Whether you’re looking to enhance your online presence, engage with your audience, or drive growth, Potters Wheel is the partner you need to achieve your goals. Embrace the power of digital marketing and watch your business soar to new heights with Potters Wheel by your side. | sandra_joy_d4c86344cd8297 |
1,871,754 | Enterprise Service Bus – Overview, 3 key components, and role in digital transformation | In today’s complex IT landscape, seamless integration and efficient communication between diverse... | 0 | 2024-05-31T07:21:18 | https://dev.to/gem_corporation/enterprise-service-bus-overview-3-key-components-and-role-in-digital-transformation-4a8c | development, softwaredevelopment, architecture | In today’s complex IT landscape, seamless integration and efficient communication between diverse systems are highly important for business success.
An [enterprise service bus (ESB)](https://gemvietnam.com/software-development/enterprise-service-bus/?utm_source=Devto&utm_medium=click) is a critical architectural pattern that facilitates these needs, acting as a centralized software component to integrate various applications. This overview delves into the essential aspects of this approach, including its definitions, key features, components, and the significant role it plays in modern digital transformation.
## Enterprise service bus – Definitions, key features, and more
To understand the importance of an ESB in modern IT infrastructure, let’s explore its definitions, how it works, and the popular platforms in the market.
**Defining enterprise service bus**
An ESB is a centralized software architecture that facilitates integration between various applications. It manages data model transformations, connectivity, message routing, and protocol conversions, and can coordinate multiple request handling. These capabilities are provided as reusable service interfaces for new applications to utilize.
Think of this architecture as a city’s bus system. Just as buses transport people across different parts of a city, an ESB transports data and messages across different parts of a company’s IT systems.
**How does an enterprise service bus work?**
The key components of [ESB architecture](https://gemvietnam.com/software-development/enterprise-service-bus/?utm_source=Devto&utm_medium=click) are:
**_Endpoints_**
Endpoints serve as the entry and exit points for data flowing through it.
A specific address or identifier uniquely identifies each endpoint and can be implemented using various technologies, such as web service interfaces, message queues, or FTP servers.
Endpoints can handle different message formats, including XML, JSON, and binary data. This versatile endpoint architecture enables the architecture to seamlessly integrate a wide array of systems and applications.
**_Adapter_**
In this architecture, the adapter is responsible for translating messages between different formats and protocols, ensuring the recipient software applications can properly interpret them. Additionally, it often includes functionalities such as message logging, monitoring, authentication, and error handling to enhance communication reliability and security.
**_Bus_**
The bus is the central component of an ESB since it facilitates the process of exchanging between endpoints. It routes messages based on a set of rules or policies defined by criteria such as message type, content, or destination.
These policies are configurable to cater to the needs of intricate business processes. The bus employs various communication protocols, including HTTP, JMS, and FTP, to interact with endpoints.
Here’s how the bus operates:
It receives a message at one endpoint.
It identifies the destination endpoints by applying business policy rules.
It processes the message and forwards it to the intended endpoint.
For instance, if the bus receives an XML file from an application at endpoint A, it determines that this file needs to be sent to endpoints B and C. Endpoint B requires the data in JSON format, while endpoint C needs it to be sent via an HTTP PUT request. The adapter converts the XML file to JSON for endpoint B, and the bus sends it accordingly. Simultaneously, the bus performs the HTTP request with the XML data for endpoint C.
**Popular enterprise service bus platforms**
As of 2024, several popular ESB platforms stand out in the market due to their features, performance, and user satisfaction. Here are some of the leading platforms selected based on their market share, user satisfaction, and the range of features they offer.
**IBM Integration Bus** (now IBM App Connect Enterprise): This platform is renowned for its robust integration capabilities, which allow seamless connectivity between diverse applications. It supports a wide range of protocols and data formats, making it a versatile choice for enterprise integration needs.
**Mule ESB** (part of MuleSoft’s Anypoint Platform): This is a popular open-source solution known for its lightweight and flexible architecture. It enables the integration of on-premises and cloud-based applications and data, supporting a variety of integration patterns.
**Microsoft Azure Service Bus**: This is a cloud-based, fully managed messaging service that facilitates the connection of applications, devices, and services. It ensures reliable and scalable communication, making it ideal for large-scale enterprise integrations. This service is recognized for its robustness and efficiency in managing extensive integration requirements.
**TIBCO Cloud Integration**: TIBCO’s solution offers comprehensive integration capabilities with support for various protocols and data formats. It provides powerful tools for monitoring, logging, and managing integrations, making it a strong contender in the market
**WSO2 Enterprise Service Bus**: This platform is designed for high performance and low footprint, offering excellent interoperability. It is well-suited for organizations looking for an efficient and scalable ESB solution.
**Software AG’s webMethods Integration Platform**: This platform provides robust integration capabilities and supports complex business processes, making it ideal for large enterprises with intricate integration needs.
## The relation between enterprise service bus and service-oriented architecture (SOA)
Read more at: [Enterprise Service Bus – Overview, 3 key components, and role in digital transformation](https://gemvietnam.com/software-development/enterprise-service-bus/?utm_source=Devto&utm_medium=click) | gem_corporation |
1,871,753 | Exploratory Testing – Exploring the Depths | What is Exploratory Testing? Most of the time, software testing methods are where you... | 0 | 2024-05-31T07:19:45 | https://dev.to/jamescantor38/exploratory-testing-exploring-the-depths-3oh1 | exploratorytesting, testgrid | ## What is Exploratory Testing?
Most of the time, software testing methods are where you design a test case and later execute it. However, in exploratory testing, you can do designing and execution simultaneously. Exploratory testing gives individual testers the freedom to think and learn to run important tests with adequate responsibility.
Exploratory testing relies on the guidance given by the individual testers. The testers dive deep to understand the defects which are not easily covered in different tests.
You can compare exploratory testing with the traditional method of scrip testing, where detailed test cases are designed first. Then you can execute the tests according to the requirements. The efficiency of the system increases subsequently while carrying out an exploratory test. This is because both the tasks of the test case are done at the same time.
## History of Exploratory Testing
Exploratory testing was earlier known as ‘Ad-Hoc’ testing. Then, software testing expert Cem Kaner gave the terminology ‘Exploratory Testing’. The idea was to keep running new tests based on intuition and trust the instincts.
In recent years, the practice of doing exploratory testing by businesses has gathered prominent momentum. Both QA managers and testers use ‘Exploratory Testing’ as a part of their coverage strategy for comprehensive testing.
Read more :Technical and Non Technical Skills Required for QA Managers
## How to do Exploratory Testing?
The steps in exploratory testing are known as the SBTM Cycle (Session Based Test Management Cycle).
**1. Classification or Creation of a Bug Taxonomy**
● Grouping of the common faults and errors through past projects.
● Identifying the source of those faults or errors.
● Eventually, design relevant tests for the application.
**2. Test Charter**
● Through test charter, the following things should come up:
1. Everything that needs to be tested
2. Methods to successfully test
3. What needs further checking
● The ideas for starting the tests are key for exploratory testing.
● Test charter is a crucial decider for the efficiency of the use of the system by the user.
**3. Time Box**
● This is a specific method, including two testers running together for at least an hour and a half.
● No interruptions should occur within those 90 minutes mandatorily.
● You can make a maximum extension or reduction of 45 minutes.
● This is an interactive method for users to analyze live problems and devise their solutions.
**4. Review Results**
● Identification of the errors.
● Proper knowledge from the tests.
● Determining the complete coverage area.
**5. Debriefing**
● Grouping of the final results.
● Comparison of those outputs with the test charter.
● Check for the requirement of excess tests.
**Pros and Cons**
### ● Pros
1. This is a valuable method when supporting documents are partially or not available at all.
2. It helps to detect minor bugs through a thorough investigation process.
3. Helps the user to be more productive through interactive test cases.
4. This method goes down to the slightest bit of the application for detection.
5. With a lot of coverage area, it includes various scenarios and test cases.
6. Produces tons of new ideas during test execution.
###Cons
1. Need adequate skills to carry out.
2. Domain knowledge is vital for the tester to run tests.
3. Not at all suitable for long hours of test execution.
### Challenges
● Mastering the application.
● Replicating the various point failures can be difficult.
● Selecting the tools to use can be confusing.
● It is difficult to select the best test cases for execution.
● With the lack of comparable test results, reporting them can be very challenging.
● Recording all events during execution can be challenging.
● Getting to know the right time to stop while exploratory testing can be complex due to definite test cases.
## Why Use Exploratory Testing?
Most of the following methods for software testing follow a well-defined structure that has detailed test cases that need to be followed under the process of test execution. This testing takes a lot of time as every step is done one after the other. The initial process includes designing test cases; then, these cases need to be executed, the problems need to be checked.
Finally, compile the output results for future reporting and use. On the contrary, this method takes the minimum time to conduct. Exploratory tests are easy to conduct where the designing and execution of these test cases are done simultaneously. Thus compiling to huge processes saves a lot of time and effort.
Again, outputs are quicker than other methods, which in turn saves more time. Compiling them may need some time, but you can adjust it. Hence, using exploratory tests is important yet easy for saving time and let alone it being an interactive method.
## When Should you Use Exploratory Testing?
This testing method is suitable when someone needs to learn the working procedure of a software or an application in a short time. It is helpful when software needs to dispatch rapid feedback with the best quality. Many software cycles require quick iteration cycles, and exploratory testing is the best option in that case. It helps test every bit of an application without missing the point, something constructive for critical software tests.
## Conclusion:
Hence for quick and accurate outputs, exploratory tests are essential and the most suitable method of testing software. Businesses across different genres have been making use of exploratory testing to reap the multiple benefits it offers.
This blog is originally published at [TestGrid](https://testgrid.io/blog/exploratory-testing-exploring-the-depths/)
| jamescantor38 |
1,871,752 | Divsly Link Management: The Secret to Successful Affiliate Marketing | Affiliate marketing has rapidly become a cornerstone of digital marketing strategies for businesses... | 0 | 2024-05-31T07:18:47 | https://dev.to/divsly/divsly-link-management-the-secret-to-successful-affiliate-marketing-126 | link, linkshortener, linkmanagement | Affiliate marketing has rapidly become a cornerstone of digital marketing strategies for businesses of all sizes. The success of affiliate marketing hinges on effective link management—organizing, tracking, and optimizing affiliate links to maximize conversions and revenue. Enter Divsly Link Management, a powerful tool that can transform your affiliate marketing efforts. In this blog, we'll explore how Divsly can be your secret weapon for successful affiliate marketing.
Understanding the Importance of Link Management in Affiliate Marketing
Affiliate marketing revolves around promoting products or services through unique tracking links provided to affiliates. These links are crucial for tracking sales, clicks, and other conversions. Effective link management ensures that affiliates can manage their links efficiently, track their performance accurately, and optimize their strategies for better results.
## Challenges in Affiliate Link Management
Without proper tools, managing affiliate links can be daunting due to:
**Tracking Issues:** Monitoring the performance of each link manually is time-consuming and error-prone.
**Broken Links:** As websites and products change, keeping links updated is challenging.
**Optimization:** Identifying which links are performing well and why requires comprehensive data analysis.
**Organization:** Managing a large number of links can quickly become chaotic without an organized system.
Divsly addresses these challenges head-on, providing a robust solution for affiliate marketers.
## What is Divsly Link Management?
Divsly is a comprehensive link management platform designed to streamline the process of creating, tracking, and optimizing links. It offers a suite of features that simplify link management, making it an indispensable tool for affiliate marketers.
## Key Features of Divsly Link Management
**Link Tracking and Analytics:**
Divsly provides detailed analytics for each link, including clicks, geographic data, and device information. This helps affiliates understand where their traffic is coming from and which campaigns are most effective.
**Link Shortening:**
Divsly offers link shortening services, creating clean, user-friendly URLs. Shortened links are easier to share and more likely to be clicked.
**Customizable Links:**
Affiliates can create branded links, enhancing their professional image and increasing trust with their audience.
Link Rotation:
This feature allows affiliates to rotate multiple URLs under a single short link. It’s useful for A/B testing and distributing traffic evenly among different landing pages.
**Broken Link Alerts:**
Divsly monitors links continuously and sends alerts if any link becomes broken, ensuring no traffic is lost due to outdated or incorrect URLs.
Campaign Management:
Divsly enables users to organize links into campaigns, making it easier to manage and track performance across different marketing efforts.
**Integrations:**
Divsly integrates with various platforms and tools, such as Google Analytics, allowing for seamless data flow and comprehensive performance insights.
## How Divsly Enhances Affiliate Marketing
Now that we understand what Divsly offers, let’s delve into how it specifically enhances affiliate marketing efforts.
**Streamlined Link Creation and Management**
Creating and managing affiliate links is effortless with Divsly. The platform’s intuitive interface allows affiliates to generate new links quickly, customize them with branded domains, and categorize them by campaign. This organization ensures that all links are easily accessible and manageable, reducing the time spent on administrative tasks.
**Accurate Tracking and Reporting**
Accurate tracking is critical in affiliate marketing. Divsly’s advanced analytics provide real-time data on link performance, helping affiliates make informed decisions. Detailed reports show which links are driving the most traffic and conversions, allowing affiliates to focus their efforts on the most effective strategies. The ability to track clicks by geographic location and device type also provides valuable insights into audience behavior.
**Enhanced Link Optimization**
Optimization is key to maximizing affiliate marketing revenue. With Divsly’s link rotation feature, affiliates can conduct A/B testing to determine which landing pages or offers perform best. By rotating different URLs under a single short link, affiliates can compare performance metrics and adjust their strategies accordingly. This continuous optimization leads to higher conversion rates and increased earnings.
**Preventing Revenue Loss**
Broken links can result in lost revenue and a poor user experience. Divsly’s broken link alerts ensure that affiliates are immediately notified if a link becomes inactive. This proactive approach allows affiliates to fix issues promptly, minimizing potential revenue loss and maintaining a seamless user experience.
**Improved User Experience**
User experience plays a significant role in the success of affiliate marketing. Divsly’s link shortening and customization features create clean, branded URLs that are more likely to be trusted and clicked by users. A positive user experience not only increases the likelihood of conversions but also builds trust and credibility with the audience.
**Comprehensive Campaign Management**
Divsly’s campaign management features allow affiliates to organize their links by campaign, making it easier to track and analyze performance. This organization helps affiliates understand which marketing efforts are most successful and allocate resources more effectively. By having a clear overview of all campaigns, affiliates can identify trends, spot opportunities, and adjust their strategies to maximize results.
**Seamless Integrations**
Divsly’s integrations with other tools and platforms enhance its functionality. For instance, integrating with Google Analytics provides deeper insights into user behavior and campaign performance. These integrations create a seamless workflow, enabling affiliates to manage all aspects of their marketing efforts from a single platform.
## Conclusion
Divsly Link Management is a powerful tool that addresses the unique challenges of affiliate marketing. By streamlining link creation and management, providing accurate tracking and reporting, enhancing link optimization, preventing revenue loss, and improving user experience, Divsly empowers affiliates to maximize their marketing efforts and achieve greater success.
In a competitive landscape, having a reliable link management solution like Divsly can be the difference between mediocre results and outstanding success. If you’re serious about affiliate marketing, it’s time to leverage the power of Divsly and unlock your full earning potential. | divsly |
1,871,729 | Building a legacy-proof app | Introduction In the previous articles, I shared some insights regarding why UI projects... | 23,800 | 2024-05-31T06:47:50 | https://dev.to/kino6052/building-a-legacy-proof-app-3eb9 | ui, cleancode, oop, architecture | ---
series: Legacy-proof UI Development
---
## Introduction
In the previous articles, I shared some insights regarding why UI projects tend to become instant legacy.
Everything was boiled down to two core needs: instant feedback and proper design patterns. Where, in terms of design patterns, the requirement for hard separation between view and logic was emphasized.
I even suggested that Elm MVU was a way to go.
However, despite MVU being an architecture that allows for the hard separation of view and logic, I have become convinced that MVU (and functional programming for that matter) suffers from being somewhat alien to a "natural" process of thinking and programming.
By the word "natural", I mean something that correlates to the language we use in everyday life. Because functional programming can't always be described via such a language (e.g. despite monads (including Observable streams) being a relatively simple term, you won't be able to express it in such a language). I became convinced that programming that would better correlate to natural language is multiparadigm programming, where things are not strictly OOP and not strictly functional, but one or the other depending on clarity and the ease to work with.
Therefore programming of the core of the application (the model/domain layer) isn't really about right or wrong, the model behind an application is a description of how a person who wrote it understands the program conceptually, and it better be one person or a group who is on the same conceptual page.
In this article, I demonstrate a process of building an application that will have the necessary components of good architecture (according to Uncle Bob Martin) with some extra ones that I personally find valuable:
* General
* Testable
* Scalable
* Maintainable
* Follows SOLID
* Communicates a conceptual understanding of the creator
* Details
* Dependency Inversion
* Allows to postpone decisions of which tools to use
* Framework agnostic
* Allows to optimize for performance, security, and the rest at later stages of development
* Design as a single source of truth for the view layer
* Development process
* Outside-in
* TDD
But enough of philosophizing, let's dive into the paraphernalia. Shall we?
## Development
In this article, I will demonstrate a process of creating an application in an outside-in fashion. Where the ultimate source of truth is the design in Figma.
We will then create a pure view as a function of state. It will not have any logic or state (other than a few details like scrolling unrelated to the domain logic).
The logic will be created in an OOP manner as a composition of classes via DI in a composition root. This will allow us to postpone details like the choice of storage and possibly some other details.
The Model will be connected to the view using a mapping function similar to ViewModel. It will have the necessary functionality to represent the view, but will not know anything about the details of the view (like a library used or DOM, etc.)
Having a ViewModel will allow us to write the application in a TDD fashion not worrying about complex view libraries/framework runtimes and even allowing us to swap these.
Because both the Model as well as ViewModel will be pure JS Objects (like POJOs), they should also be easily convertible to other languages.
It is important to remember that this approach is all about writing legacy-proof apps (legacy-proof = “adaptable to change” = scalable), which we argued require instant feedback (via Storybook and black-box tests in Jest for example) and good design patterns, which in our case is MVVM and DI.
### Step 1: Designs
Here I explain how designs will be converted to Storybook stories.
Since the tools for conversion are still far from perfect, we should rely on ourselves to implement components for the first time. However, as we change something in the designs, we can ask LLMs to adapt the changes to what we already have in the component code. This is possible because components, when implemented correctly, tend to be rather small and easily understood by LLMs.
[Here is the link to the Figma file.](https://www.figma.com/community/file/1378258280093869378/conduit)
### Step 2: Storybook
Once we convert designs to Storybook we can use the components to represent scenarios by putting together sequences of pre-setup pages (with certain props), and since we know what props need to happen in transition given certain user interactions we are preparing ourselves for writing black-box tests.
The structure of the stories will resemble the following:
* Components
* [They will contain the actual component presentation](https://github.com/kino6052/conduit-mvu/tree/master/src/details/view/components)
* Pages
* [Pages composed out of the components](https://github.com/kino6052/conduit-mvu/tree/master/src/details/view/pages)
* Scenarios
* A sequence of pages with various props for us to understand how props should change through interaction, which will allow us to write tests
* App
* [The actual functional app with connected test doubles](https://github.com/kino6052/conduit-mvu/blob/master/src/details/view/App.stories.ts)
* It is important to note that we don’t need to connect actual databases or any other IO other than the view
### Step 3: MVVM & TDD
As we write our tests, we implement the domain logic.
I admit that I developed the sample application with very few tests and relied on the TypeScript type system for immediate feedback, so as a personal TODO, I will have to make sure I learn this practice, as I believe it ultimately saves a lot of time for larger projects like this one.
While our tests need to tell whether the functionality is correct, the domain logic structure itself is really not about right or wrong. The conceptual model behind an application is a description of how a person who wrote it understands the program conceptually, and it better be one person or a group who is on the same conceptual page.
As a philosophical side note, Immanuel Kant revolutionized philosophy by shifting the focus from the idea that we directly perceive the world as it truly is to the idea that we perceive the world as it appears to us through our own minds. This means we study our experiences of the world, not the world itself.
Similarly, when developing a program, we shouldn't aim for a single "correct" solution. Instead, we should aim to create a program that effectively represents our understanding and concepts. The quality of this understanding can vary, but as long as the program follows SOLID principles, is testable, works correctly, and is understood by those who use it, we have achieved our goal.
To illustrate, a program doesn't have to be OOP or functional, as in reality, if we could think like computers, we would write optimized binary code directly without any programming languages.
However, I believe that every developer has dreamt about representing their application as simple classes that read like simplified English.
Technically, MobX allows you to do exactly this - represent your model as simple classes. However, there is a price to pay, your classes have to be wrapped with decorators that allow for automatic reactivity. However, representing your application as simple classes doesn't mean you have to rely on yet another framework.
[Au contraire, what MobX does still could be accomplished with just simple POJOs.](https://github.com/kino6052/conduit/tree/master/src/app/entities)
The View Model, in our case, is a step between simple representation and the view that is always connected to some framework (React, Angular, Vue, Flutter, etc.), but since it is not connected to a framework, and we can use it as a simplified representation of the view that we can actually can (and should) test. Because ViewModel in our case is the boundary, that will allow us to write tests from the intent perspective (similar to behavior-driven development), where the user clicks or interacts with something. This will then allow the frequent refactoring that is required for us to revise our conceptual understanding as often as it needs to be done.
So we will always have an opportunity to refactor as long as tests pass.
**Composition root**
It is important to remember that the ultimate detail of the application that will change the most is the composition root, where all dependencies will be combined.
It is important to demonstrate in the code repository how you assemble your application as transparently as possible. It means that whenever somebody looks at the repo and then looks inside the index file, they should be able to understand how the application is structured and what its intent is.
[Link to the sample app composition root](https://github.com/kino6052/conduit-mvu/blob/master/src/details/index.ts)
### Step 4: Connecting to IO
The last and the coolest part will be the ability to delay very hard decisions about technology for storage and other IO as far into the future as possible, thus allowing us to keep our pace and implement features while knowing that we still have time to make an educated decision based on our app and stakeholder needs.
## Pros & Cons
* Pros
* Legacy-proof
* Easy-to-learn
* This approach builds on top of a lot of established practices like OOP, MVVM, and Component Composition
* Natural programming style
* Cons
* Requires you to form a coherent conceptual understanding of your application
* You will have to doubt, rethink, and refactor
* There is no set algorithm for creating a model, you will have to experiment until it fits your needs
* Frequent refactoring
* Simplify and optimize the model
* While View and IO could be optimized separately,
* It requires you to make sure your model is as simple as possible
## Conclusion
This article was a demonstration of how applications can be written so they are kept legacy-proof and are adaptable to change as true software should be (software means that it is soft or malleable and adaptable to changes).
This is a refreshing view on UI development as modern UI is always 100% tied to a particular framework, but as this article suggests it should not be the case, and in fact not marrying it to a framework makes the code look much simpler.
## Useful links
1. [Sample Application](https://github.com/kino6052/conduit-mvu/tree/master): The application that was created to illustrates concepts in this article
2. [Clean Code by Robert Martin](https://www.oreilly.com/library/view/clean-code-a/9780136083238/): The famous book that explains core principles of scalable software
3. [Dependency Injection Principles, Practices, and Patterns](https://www.manning.com/books/dependency-injection-principles-practices-patterns): A book that I consider to be the practical implementation of the concepts outlined in "Clean Code"
| kino6052 |
1,871,751 | Chongqing Pingchuang Institute: Semiconductors Research Redefined | screenshot-1716670629956.png Chongqing Pingchuang Institute: Redefining Semiconductors Research Are... | 0 | 2024-05-31T07:16:54 | https://dev.to/skcms_kskee_db3d23538e2f3/chongqing-pingchuang-institute-semiconductors-research-redefined-3m8o | screenshot-1716670629956.png
Chongqing Pingchuang Institute: Redefining Semiconductors Research
Are you curious about the exciting world of semiconductors? Look no further than Chongqing Pingchuang Institute! Our cutting-edge research is sure to amaze.
Highlights of Our Institute
At Chongqing Pingchuang Institute, we prioritize innovation and security in your research
We of specialists works tirelessly to generate ev charging stations that are top-quality this is often used in many applications that might be various
We use advanced gear and stay glued to security like strict to be sure our solutions meet the greatest requirements
Innovation at Its Most Readily Useful
Our researchers are constantly pressing the boundaries of what exactly is feasible in the component like right is specific of
We explore new materials and operations and this can be semiconductors that are manufacturing are generate are far more efficient, stronger, plus much more versatile than previously
Protection And Health First
At Chongqing Pingchuang Institute, we simply take protection really seriously
We follow strict protocols to be sure our research are performed within the safe and environment like managed
Meaning that our items are safe to be used in a lot of applications which can be different searching for precision and dependability
Exactly how to Use Our Semiconductors
Our semiconductors and electric vehicle charging station can be utilized inside a array like wide of, including electronics, telecommunications, and energy like renewable
These are usually extremely versatile, and all sorts of of us can work that will help you seek the semiconductor out like ideal the wants being particular
Company You Can To Count On
We pride ourselves on supplying consumer like great which help
Many of us will likely work you may get possibly the most away from you every action to our semiconductors regarding the technique, from initial assessment to installation like last to be sure
Our company is specialized in providing a experience like seamless ensuring your satisfaction
Quality That Can't Become Beat
At Chongqing Pingchuang Institute, our company is concentrated on creating ev car charging station that are top-notch
We conduct rigorous quality and evaluating control measures to ensure that every item we create is associated with quality like best
Applications Galore
Our semiconductors works very well inside a amount like genuine of, including:
- gadgets: Our semiconductors can be used in many different devices that are electronic including smart phones, computers, and televisions
- Telecommunications: Our semiconductors can be utilized in telecommunications equipment, such as routers and modems
- Renewable energy: Our semiconductors can be utilized in renewable power systems, such as solar energy panels and wind generators
In Conclusion
Chongqing Pingchuang Institute is at the forefront of semiconductors research. Our commitment to innovation, safety, quality, and service sets us apart in the industry. Contact us today to learn how we can help you take your applications to the next level!
Source: https://www.pingalax-global.com/application/ev-charging-stations | skcms_kskee_db3d23538e2f3 | |
1,862,778 | Building a Simple Chatbot using GPT model - part 2 | On the first part of this series, we set up the environment by installing Ubuntu, Python, Pip and... | 0 | 2024-05-31T07:16:09 | https://dev.to/whatminjacodes/building-a-simple-chatbot-using-gpt-model-part-2-45cn | ai, python, llm | On the [first part](https://dev.to/whatminjacodes/building-a-simple-chatbot-using-gpt-model-part-1-3oeo) of this series, we set up the environment by installing Ubuntu, Python, Pip and Virtual Environment. Now we can get started with the actual chatbot.
#### Install Required Libraries
[Hugging Face](https://huggingface.co/) is a company and community platform making AI accessible through open-source tools, libraries, and models. It is most notable for its _transformers_ Python library, built for natural language processing applications. This library provides developers a way to integrate ML models hosted on Hugging Face into their projects and build comprehensive ML pipelines.
[PyTorch](https://pytorch.org/) is a powerful and flexible deep learning framework that offers a rich set of features for building and training neural networks.
To install the correct version of torch, you need to visit the [PyTorch website](https://pytorch.org/get-started/locally/) and follow the instructions for your setup. For example, I chose the following:
- PyTorch Build: Stable (2.3.0)
- OS: Linux
- Package: Pip
- Language: Python
- Compute Platform: CPU
These settings resulted to a following command:
```
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
```
It can take a while to install torch. After it is done, you can install transformers by running the following command:
```
pip3 install transformers
```
#### Developing a Simple Chatbot
For this example, we'll use the GPT-2 model from Hugging Face.
Here is a basic script to for creating a chatbot:
```python
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load the pre-trained GPT-2 model and tokenizer
model_name = "gpt2-large"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set the model to evaluation mode
model.eval()
def generate_response(prompt, max_length=100):
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# Generate response
with torch.no_grad():
output = model.generate(input_ids, max_length=100, num_return_sequences=1, pad_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(output[0], skip_special_tokens=True)
return response
print("Chatbot: Hi there! How can I help you?")
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
print("Chatbot: Goodbye!")
break
response = generate_response(user_input)
print("Chatbot:", response)
```
Let's go through the code together.
```python
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
```
The first line imports the PyTorch library and the second imports two classes from transformers library: _GPT2LMHeadModel_ and _GPT2Tokenizer_. _GPT2LMHeadModel_ is used to load the GPT-2 model, and _GPT2Tokenizer_ is used to preprocess and tokenize text input.
```python
# Load the pre-trained GPT-2 model and tokenizer
model_name = "gpt2-large"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
```
- _model_name = "gpt2-large"_: Sets the variable _model_name_ to the string _gpt2-large_, indicating the specific model to be loaded.
- _tokenizer = GPT2Tokenizer.from_pretrained(model_name)_: Loads the pre-trained tokenizer corresponding to the GPT-2 model. The tokenizer is responsible for converting text to token IDs that the model can process.
- _model = GPT2LMHeadModel.from_pretrained(model_name)_: Loads the pre-trained GPT-2 model using the specified model name. The _from_pretrained_ method downloads the model's weights and configuration.
```python
# Set the model to evaluation mode
model.eval()
```
In PyTorch, the _model.eval()_ method is used to set the model to evaluation mode. This is important for certain layers and operations that behave differently during training and evaluation.
```python
def generate_response(prompt, max_length=100):
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# Generate response
with torch.no_grad():
output = model.generate(input_ids, max_length=100, num_return_sequences=1, pad_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(output[0], skip_special_tokens=True)
return response
```
Then we define a function that takes a text prompt and an optimal maximum length for the generated text.
- _input_ids = tokenizer.encode(prompt, return_tensors="pt")_: Encodes the text prompt into token IDs and returns a tensor suitable for PyTorch (hence _return_tensors="pt"_). This tensor will be used as input for the model.
- _with torch.no_grad()_: This is a context manager that disables gradient calculation. We can disable them for this example to speed up the calculation and to reduce the memory usage.
- _output = model.generate(input_ids, max_length=100, num_return_sequences=1, pad_token_id=tokenizer.eos_token_id)_: Generates a response based on the _input_ids_. The generate method creates a sequence of tokens with a maximum length of _max_length_. _num_return_sequences=1_ specifies that only one sequence should be generated and _pad_token_id_ specifies the padding token ID should be the same as the end-of-sequence (EOS) token ID defined by the tokenizer. When generating text, models use the EOS token to signify the conclusion of a sentence.
- _response = tokenizer.decode(output[0], skip_special_tokens=True)_: This method is used to convert the generated sequence of token IDs back into a human-readable string. _skip_special_tokens_ parameter ensures that special tokens (like padding or end-of-text tokens) are not included in the final decoded string.
```python
print("Chatbot: Hi there! How can I help you?")
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
print("Chatbot: Goodbye!")
break
response = generate_response(user_input)
print("Chatbot:", response)
```
- _print("Chatbot: Hi there! How can I help you?")_: Prints an initial greeting message from the chatbot to the console.
- _while True:_: Is the main loop of the chatbot. This will allow continuous conversation with the chatbot until the user sends "exit" command.
- _response = generate_response(user_input)_: This calls the function we defined above with the promt inserted by the user.
- _print("Chatbot:", response)_: And as a last step, the response is printed on the console.
#### Running the Script
Save the script to a file, named for example _simple-chatbot.py_, and run it using:
```
python3 simple-chatbot.py
```
It can take a while for the script to run. Eventually you can chat with the chatbot. However, as seen in the conversation below, the chatbot has some trouble with its response.
```
Chatbot: Hi there! How can I help you?
You: Hello! How are you?
Chatbot: Hello! How are you?
I'm a little bit nervous. I'm not sure if I'm going to be able to do this, but I'm going to be able to do it. I'm going to be able to do it. I'm going to be able to do it. I'm going to be able to do it. I'm going to be able to do it. I'm going to be able to do it. I'm going to be able to do it
You:
```
Sometimes the chatbot is saying the same sentence over and over on same line, and sometimes it returned the response multiple times, each response on its own line. We can clean the reponse by adding a function that will split the response text into lines and checking if the line has repeated sentences:
```python
import re
def remove_repeated_sentences(text):
sentences = re.split(r'(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s', text)
unique_sentences = []
for sentence in sentences:
if sentence not in unique_sentences:
unique_sentences.append(sentence)
else:
break # Stop adding sentences after the first repetition
return ' '.join(unique_sentences)
def clean_response(response_text, prompt):
# Remove the prompt from the response
stripped_response = response_text.replace(prompt, '').strip()
# Split the stripped response text into lines
lines = stripped_response.split('\n')
combined_lines = " ".join(line.strip() for line in lines if line.strip())
return remove_repeated_sentences(combined_lines)
```
Then on the _generate_response_ function, we can call this _clean_response_ function:
```python
def generate_response(prompt, max_length=100):
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# Generate response
with torch.no_grad():
output = model.generate(input_ids, max_length=100, num_return_sequences=1, pad_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(output[0], skip_special_tokens=True)
**cleaned_response = clean_response(response, prompt)**
return cleaned_response
```
Now the chatbot should generate responses that look good! There might still be some corner cases that I hadn't thought about, but those can then be added to the _clean_response_ function.
The following is an example of a conversation I had with the chatbot:
```
Chatbot: Hi there! How can I help you?
You: Hello! How are you?
Chatbot: I'm so glad you're here.
You: That´s nice to hear!
Chatbot: I´m not sure if I´m going to be able to do it, but I´m going to try. I´m going to try to do it.
You: You can do it!
Chatbot: You can
You: What do you think about AI?
Chatbot: Let us know in the comments below! Images courtesy of Shutterstock, and Pixabay.
You: You are funny
Chatbot: .
You:
```
It doesn't necessarily make that much sense all the time since this is just a simple example, but at least now you know how to develop a chatbot!
Here's the finalized code so you can better see what was changed from the first version:
```python
import re
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load the pre-trained GPT-2 model and tokenizer
model_name = "gpt2-large"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set the model to evaluation mode
model.eval()
def remove_repeated_sentences(text):
sentences = re.split(r'(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s', text)
unique_sentences = []
for sentence in sentences:
if sentence not in unique_sentences:
unique_sentences.append(sentence)
else:
break # Stop adding sentences after the first repetition
return ' '.join(unique_sentences)
def clean_response(response_text, prompt):
# Remove the prompt from the response
stripped_response = response_text.replace(prompt, '').strip()
# Split the stripped response text into lines
lines = stripped_response.split('\n')
combined_lines = " ".join(line.strip() for line in lines if line.strip())
return remove_repeated_sentences(combined_lines)
def generate_response(prompt, max_length=100):
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# Generate response
with torch.no_grad():
output = model.generate(input_ids, max_length=100, num_return_sequences=1, pad_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(output[0], skip_special_tokens=True)
cleaned_response = clean_response(response, prompt)
return cleaned_response
print("Chatbot: Hi there! How can I help you?")
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
print("Chatbot: Goodbye!")
break
response = generate_response(user_input)
print("Chatbot:", response)
```
### That's it!
In this blog post, we developed a simple chatbot and cleaned the response so it looks a bit better!
You can also follow my Instagram [@whatminjahacks](https://www.instagram.com/whatminjahacks/) if you are interested to see more about my days as a Cyber Security consultant and learn more about cyber security with me! | whatminjacodes |
1,871,750 | 9 blunders I found in 90% LinkedIn resumes | Originally posted here: https://medium.com/@Aman_Gautam/9-blunders-i-found-in-90-linkedin-resumes-102fe210df31 | 0 | 2024-05-31T07:16:02 | https://dev.to/amangautam/9-blunders-i-found-in-90-linkedin-resumes-4k8p | ---
title: 9 blunders I found in 90% LinkedIn resumes
published: true
description: Originally posted here: https://medium.com/@Aman_Gautam/9-blunders-i-found-in-90-linkedin-resumes-102fe210df31
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-28 12:54 +0000
---
When I recently posted a job role for entry-level developers for a project, [Time Budd](https://timebudd.com), I found some common mistakes which made me immediately reject the candidate.
I acknowledge that most people improve on these mistakes as they progress in their career — which thankfully is great!
*Not everyone who is rejected is rejected because of the things they control. For instance, if the employer is looking for 2 years experience and you are graduating in 2 years — your application may be rejected even if it is a perfect fit otherwise.*
## Disclaimer: I must have made mistakes!
I have also applied for roles in the past where I felt like I am a perfect match — just to receive a rejection email later. When you apply for a role online, the chances of you getting a call are always slim.
The person reviewing the resume is operating out of their own biases (I reject resumes that are using Comic Sans without second thoughts).
Also, the company is itself trying to go from point A to point B and looking for people to help with that. If the company needs a JavaScript developer — you can be great at Python and still not get a call.
## Mistake 1: Diluted Expertise
All humans are multi-dimensional. They can be good at writing code, playing guitar, coming up with great pickup lines… All at the same time!
A person is going to be reading that resume to see if you can help them with a ONE outcome — could be engineering a solution, creating social media presence, handle customer support requests, etc.
Anything that isn’t directly or indirectly related to that outcome is a distraction and more likely to work against you. When I am looking for a community manager — I care about the fests you have organized. When I am looking for a backend developer — I don’t care.
## Mistake 2: BS Claims
So, you made a landing page that increased the company revenue by 40%? Nice! I also fixed a bug in Samsung S3's contact app that led the model to 80 million sales across the world and made it the most successful galaxy series phone, ever. Nice to meet you!
It is always great to mention the impact you created. Exaggerating the impact a bit isn’t a deal-breaker either. But when you take credit of other people’s work, it may be interpreted as
1. You don’t value other people’s work in the team, or
2. You are not aware of what impact other people had
So, if you made an API that could handle 50K requests/second — mention that. Don’t try attributing it as the sole reason for the success of the project.
## Mistake 3: Nothing Original
[This advise may not be applicable for all the employers]
If you’ve also made a Netflix clone, a YouTube clone and XYZ clone… Congratulations! You just solved what is already solved.
If you have solved 300 Leetcode problems — Congratulations! You just spent months solving problems that have been solved successfully millions of times.
Creating clones and solving DSA problems are good projects to learn the basics — but what is the point of those basics if you are not applying them in solving something for yourself or people around you.
There are plenty of problems to be solved around you. Solve them using the knowledge that you have. If you create a simple time table creator that is used by your college, it is way better than an end-to-end Netflix clone that doesn’t serve any purpose.
Build for people around you! Build for yourself. Nothing else prepares you better for what’s coming…
## Mistake 4: Nothing Deployed
There are plenty of ways to deploy your code and allow people to use it. If you have worked on 5 projects and none of them is live — it is sad.
A GitHub repo with the whole project pushed in 5 commits or less isn’t going to help either. If you expect someone to:
- Clone your repo
- Install dependencies (or pull docker images)
- Set environment variables
- Debug and test your work (sometimes behind a signup)
Ain’t nobody got time for that! Just push it to a free live server and make it easy for people to trust your work.
## Mistake 5: Crappy Typeface
I know why I still need to add this… but bad typefaces are more common that I expect.
I understand that developers take pride in building ugly stuff, but please make your resume an exception, at least! If you don’t understand how to choose typefaces — just pick up some clean resume template off-the-internet and customize it with your content.
## Mistake 6: Still Sending .docx
Just because you can, doesn’t mean you should.
Thankfully most people now send PDF, but still some candidates are sending docx file. Here are the problems with this approach:
1. The hiring manager needs to download your resume before they can review it. [At least on LinkedIn] — Don’t make it harder for us than it already is.
2. You probably made the docx on MS Word — it will likely look different on *Pages app* in Mac. All your work to format the docx is down the drain.
Always export your docx to pdf before sending.
## Mistake 7: Adding Your Picture
Everything in your resume should ideally increase your chances of getting a call. Add your photo only and only if:
1. It is required by the employer or
2. Your picture increases your chances of selection
Of course, If you’re a famous person in your industry and more people know you by face than by your name — add your photo.
It is way easier to discriminate against you, if your face is visible. [Most hiring managers don’t want to — they can’t control their internal biases]
## Mistake 8: Using Hyperlinks
Most people are not aware of this. LinkedIn resume preview doesn’t support hyperlinks.
So instead of saying: Made my [personal website](https://aman.pro)
Try something like: Made my personal website (https://aman.pro)
Yes, it will add more characters, but it makes it far easier for hiring managers to visit the links you have shared (since they can copy paste the link).
## Mistake 9: Positioning Yourself as Generalists
In the context of a early stage engineer trying to break into the industry — generalist here means someone with good grasp over the DSA and System Design basics. These candidates can be trained on most technologies.
In the current economy, things are changing rapidly and there is a race to move faster. Which is putting people who are only good at DSA or System Design at disadvantage.
On one hand we have Person A who is a generalist who can be trained on Angular in 1 month v/s another person, B, who has already showcased their Angular expertise and they can be pushing things to production in week 1. In the current conditions, B will have more demand.
PS: Yes, when the hiring scene gets better, more generalists will be hired.
## Closing Remarks
It was heartbreaking to see some not-so-recent graduates who are still looking for entry-level jobs!
Economy is a hard and we are going through an important transition in the way software is built and maintained. Please continue upskilling and solving real problems…
The ones who will stick around and evolve during this period will have great rewards once things are better at the macro level.
I have done my bit of hiring in the past decade, but I am not a resume expert. If something in the post doesn’t sound right, follow your gut feeling. | amangautam | |
1,855,068 | Type Systems in Programming Languages | This article will introduce those parts that cannot be ignored in various programming languages — the... | 0 | 2024-05-31T07:14:54 | https://webdeveloper.beehiiv.com/p/type-systems-programming-languages | webdev, javascript, programming, opensource | This article will introduce those parts that cannot be ignored in various programming languages — the type system.
# What is the Type-System?
When learning a programming language, the first few sections of the introductory course usually introduce the various data types of the language, and they are inseparable from the subsequent programming development. This is enough to show the importance of types to a programming language.
Types in programming languages are broadly classified and can be divided into built-in types represented by `int` and `float`, and abstract types represented by `class` and `function`. The most striking feature that distinguishes these types is that we can only use its specific operations on a specific type.
But what is the Type-System?
It’s really a system focused on managing types, **it’s a logical system consisting of a set of rules that assign properties called types to various structures of a computer program, such as variables, expressions, functions, or modules.**
# **What can a Type-System do?**
1. Define the program type to ensure the security of the program.
2. It can improve the readability of the code and improve the abstraction level of the code, rather than the low-level inefficient implementation.
3. It is beneficial to compiler optimization. After specifying a type, the compiler can align it with the corresponding byte, thereby generating efficient machine instructions.
etc.
As can be seen from the above points, the type of a variable can determine a specific meaning and purpose, which is extremely beneficial to our programming.
# **What is the nature of types in a program?**
The type system can be said to be a tool, why do I say this?
Because the program ultimately runs machine code. In the world of machine code, there are no types, those instructions just deal with immediate data or memory.
**So the** **type is essentially an abstraction of memory, and different types correspond to different memory layouts and memory allocation strategies.**
For more information on memory management check out my previous article:
{% embed https://webdeveloper.beehiiv.com/p/memory-management-every-programmer-know %}
# **Static vs. dynamic typing**
We often hear this question, but the difference between the two is **when the type checking happens.**
The static type system determines the types of all variables at compile-time and throws exceptions in case of incorrect usage.
The dynamic type system determines the variable type at runtime, throws an exception if there is an error, and may crash the program without proper handling.
The early type error reporting of the static type system ensures the security of large-scale application development, while the disadvantage of the dynamic type system is that there is no type checking at compile-time, and the program is not safe enough. Only a large number of unit tests can be used to ensure the robustness of the code. But programs that use the dynamic type system are easy to write and don’t take a lot of time to make sure the type is correct.
# **Strong vs. weak typing**
**There is no authoritative definition of the difference between strong typing and weak typing.** Most of the early discussions on strong typing and weak typing can be summarized as the difference between static typing and dynamic typing.
But the prevailing saying is that strong types tend to not tolerate implicit type conversions, while weak types tend to tolerate implicit type conversions. In this way, a strongly typed language is usually type-safe, that is, it can only access the memory it is authorized to access in the permitted ways.

# **Common programming languages**
I summarize a classification diagram of common programming language types, note that the four areas of the split are partitions, for example, PHP and JS are both dynamically weakly typed.

* * *
*If you find this helpful, [**please consider subscribing**](https://webdeveloper.beehiiv.com/) to my newsletter for more insights on web development. Thank you for reading!*
| zacharylee |
1,815,135 | How to use the new Symfony Maker command to work with GitHub Webhooks | Recently I've been working on a tool that would gather some open-source contribution metrics from our... | 0 | 2024-05-31T07:14:51 | https://dev.to/sensiolabs/how-to-use-the-new-symfony-maker-command-to-work-with-github-webhooks-2c8n | symfony, webhook, github, php | Recently I've been working on a tool that would gather some open-source contribution metrics from our teams. We mostly focus on contributions on GitHub, so I started studying the [API](https://docs.github.com/en/rest) to see how I could get the relevant data I needed to process. If I wanted to get fresh data on a regular basis, I would have sent requests periodically. But polling API endpoints is [not ideal](https://docs.github.com/en/rest/using-the-rest-api/best-practices-for-using-the-rest-api#avoid-polling), especially when the services you are accessing can **come to you instead** !
## Enter Webhooks !
Webhooks are a pretty common way for services from the outside world to communicate with your own application. It is quite similar to the event subscriber in its design :
- A remote service declares a list of **steps in its lifecycle** (for github: an issue has been opened, a comment has been made on a PR, ...), and for each of theses steps it will **dispatch** an event containing relevant data.
- You can **subscribe** to any of these events, and you'll get notified when they are dispatched.
The main difference with your local event based system resides in the **transport** : events are sent over the network to a custom endpoint where you implement your own logic to handle the events.
Nowadays, Webhooks are widely used for a lot of different purposes (getting information on a mail delivery, get notified of the steps of a payment process, ...), and the process to create a webhook is somehow always the same :
- Expose an endpoint.
- Check if the request should be processed.
- Check if the request if authorized and well formed.
- Process the request.
To make things easier for developers, Symfony released the [Webhook and RemoteEvent](https://symfony.com/blog/new-in-symfony-6-3-webhook-and-remoteevent-components) components in **[Symfony 6.3](https://symfony.com/blog/category/living-on-the-edge/6.3)**. The **Webhook** component focuses on making the creation of endpoint and validation of request easy, while **RemoteEvent** is about making the event's payload transit on Messenger and be handled by a RemoteEventConsumer, where your logic will live.
To install these components, run :
```shell
$ composer require symfony/webhook
```
## How does this work ?
Okay, now we've installed the component, where should we start ?
First of all, let's set up our webhook so that we can effectively handle the requests that will be sent to us by GitHub.
At the time of writing, the component's documentation isn't fully released yet, so it may be a little bit confusing at first. But don't sweat : to make your life easier, a new Maker command was introduced !
To create a new Webhook, run :
```shell
$ symfony console make:webhook
```
The maker will ask you for the webhook name. It will be used to generate the webhook url (https://example.com/webhook/the_name_goes_here). Let’s call it “**github**”.
Next you'll be asked you for the RequestMatchers to use. For GitHub, we know that the events are sent via POST requests and the format is JSON, so we'll add `MethodRequestMatcher` and `IsJsonRequestMatcher`.

Now we can see that the command added some config to `config/packages/webhook.yaml` and created two files in our project source dir : `src/Webhook/GithubRequestParser.php` and `src/RemoteEvent/GithubWebhookConsumer`.
Hooray 🎉 ! Now we have some basis to work on.
## Tweaking the code
Let's dive into the generated class `src/Webhook/GithubRequestParser.php` and see what changes we have to make to fit our needs.
```php
<?php
// src/Webhook/GithubRequestParser.php
namespace App\Webhook;
use Symfony\Component\HttpFoundation\ChainRequestMatcher;
use Symfony\Component\HttpFoundation\Exception\JsonException;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\RequestMatcher\IsJsonRequestMatcher;
use Symfony\Component\HttpFoundation\RequestMatcher\MethodRequestMatcher;
use Symfony\Component\HttpFoundation\RequestMatcherInterface;
use Symfony\Component\HttpFoundation\Response;
use Symfony\Component\RemoteEvent\RemoteEvent;
use Symfony\Component\Webhook\Client\AbstractRequestParser;
use Symfony\Component\Webhook\Exception\RejectWebhookException;
final class GithubRequestParser extends AbstractRequestParser
{
protected function getRequestMatcher(): RequestMatcherInterface
{
return new ChainRequestMatcher([
new IsJsonRequestMatcher(),
new MethodRequestMatcher('POST'),
]);
}
/**
* @throws JsonException
*/
protected function doParse(
Request $request,
#[\SensitiveParameter] string $secret
): ?RemoteEvent
{
// TODO: Adapt or replace the content of this method to fit your need.
// Validate the request against $secret.
$authToken = $request->headers->get('X-Authentication-Token');
if ($authToken !== $secret) {
throw new RejectWebhookException(Response::HTTP_UNAUTHORIZED, 'Invalid authentication token.');
}
// Validate the request payload.
if (!$request->getPayload()->has('name')
|| !$request->getPayload()->has('id')) {
throw new RejectWebhookException(Response::HTTP_BAD_REQUEST, 'Request payload does not contain required fields.');
}
// Parse the request payload and return a RemoteEvent object.
$payload = $request->getPayload()->all();
return new RemoteEvent(
$payload['name'],
$payload['id'],
$payload,
);
}
}
```
We can see that the RequestMatchers previously selected were added to a `ChainRequestMatcher`. We don't have anything else to do in this method 🥳.
Now in the `doParse` method, we see that three main steps are hinted by the comments :
- **Validating** the request against the secret.
- Check the request is **well formed** (mandatory fields are present, the expected format is respected ...).
- Returning a **remote event** holding the payload.
GitHub has an [interesting documentation](https://docs.github.com/en/webhooks/using-webhooks/validating-webhook-deliveries) on request validation, with some snippets in Ruby, JavaScript, Python ... but no PHP 😢. No worries, I made the translation for you :
```php
$signature = $request->headers->get('X-Hub-Signature-256');
if (!is_string($signature)
|| !str_starts_with($signature, 'sha256=')
|| !hash_equals('sha256='.hash_hmac('sha256', $request->getContent(), $secret), $signature)) {
throw new RejectWebhookException(Response::HTTP_UNAUTHORIZED, 'Invalid authentication token.');
}
```
Now, for the validation : we're expecting a variety of events to knock at our webhook's door, so we won't be too strict on format validation.
To create a `RemoteEvent` we'll need a **name** (action) and an **id**. That will be our minimum requirements :
```php
if (!$request->getPayload()->has('action') || !$request->getPayload()->has('number')) {
throw new RejectWebhookException(Response::HTTP_BAD_REQUEST, 'Request payload does not contain required fields.');
}
```
Then all that's left to do is to create and return a `RemoteEvent` :
```php
$payload = $request->getPayload()->all();
return new RemoteEvent(
$payload['action'],
$payload['number'],
$payload,
);
```
This event will be passed over to Messenger, that in turn will pass it to your `GithubWebhookEventConsumer` (thanks to the `#[AsRemoteEventConsumer('github')]` attribute on the class).
```php
<?php
// src/RemoteEvent/GithubWebhookConsumer.php
namespace App\RemoteEvent;
use Symfony\Component\RemoteEvent\Attribute\AsRemoteEventConsumer;
use Symfony\Component\RemoteEvent\Consumer\ConsumerInterface;
use Symfony\Component\RemoteEvent\RemoteEvent;
#[AsRemoteEventConsumer('github')]
final class GithubWebhookConsumer implements ConsumerInterface
{
public function __construct()
{
}
public function consume(RemoteEvent $event): void
{
// Implement your own logic here
}
}
```
Here is where you'll put your **custom logic** : mapping to DTO, persisting to database, ... whatever fits your needs.
Finally, head to `config/packages/webhook.yaml` and set up a secret (a random string of text with high entropy). This being sensitive data, it should be referenced here but stored in an environment variable ([see Symfony documentation](https://symfony.com/doc/current/configuration/secrets.html)).
```yaml
# config/packages/webhook.yaml
framework:
webhook:
routing:
github:
service: App\Webhook\GithubRequestParser
secret: '%env(GITHUB_WEBHOOK_SECRET)%'
```
## Call me back
Now that we're ready to handle requests, all we need to do is ask GitHub to send us some.
The [official documentation](https://docs.github.com/en/webhooks/using-webhooks/creating-webhooks) is really good so we won't detail the process here. You'll need the endpoint url (https://example.com/webhook/github) and your secret. Just be aware that you can only create webhooks for **resources that you own**. If you want to be notified on actions performed on a repository you don't own, you'll have to ask the owner to set it up for you. If this is not an option, you'll have to rely on good old [API polling](https://en.wikipedia.org/wiki/Polling_(computer_science)).
## Going further
### Is that even useful ?
You may be tempted to say that all we've done is exposing an endpoint to process a request, and that it could have been done without the webhook component.
And you would be right : you can achieve the same result with a custom controller.
But let's see the benefits of doing it the way we did :
- A single conf file with minimal and simple configuration for all our exposed endpoints.
- A clean implementation of `AbstractRequestParser` to handle request authorization, validation and event dispatching.
- Any service can be turned into a remote event consumer just by using `#[AsRemoteEventConsumer]` and `ConsumerInterface`.
- A seamless integration with Symfony Messenger, Notifier, Mailer (and more to come).
- All of the above was done by **running a single command and writing less than 10 lines of code** 🤯.
### What's next ?
You may want to take a look at Github's [Best practices for using webhooks](https://docs.github.com/en/webhooks/using-webhooks/best-practices-for-using-webhooks) .
That could make you want to :
- Add an `IpsRequestMatcher` to check if the request is sent from one of GitHub's official IPs.
- Use an async transport to reduce the request process time.
- Handle re-deliveries
- ...
You may even want to [contribute](https://symfony.com/doc/current/contributing/index.html) to Symfony by improving the component or the maker, creating a Bridge to spare some trouble to future developers, ... It's all up to you to make Symfony even better !
### Tips : Local webhooks
When developing, you may want to receive requests to test your code. You'll need a webhook proxy for this. I would suggest using [smee.io](https://smee.io/) :
- Start a new channel.
- Copy the link to the "Payload URL" in the GitHub webhook configuration form.
- Download the smee client on your local machine.
- Run `smee -u https://smee.io/thispartisrandom --port 8000 --path /webhhok/github` \*
\**For a Symfony application running on localhost:8000*
Accessing the smee url from your browser will allow you to visualize webhooks deliveries : headers, payload, ... and you'll be able to **replay them**.
You can take advantage of this and copy the payloads and headers to **create fixtures to test your webhooks** !
| maelanleborgne |
1,871,749 | Cara Beli Game di Steam, Bayar dengan DANA | Bermain game lewat PC bisa jadi salah satu opsi untuk mengusir rasa bosan atau mengisi waktu luang... | 0 | 2024-05-31T07:12:50 | https://dev.to/berton_841e5bfdfc/cara-beli-game-di-steam-bayar-dengan-dana-3eho | dana, steam, gameandroid | Bermain game lewat PC bisa jadi salah satu opsi untuk mengusir rasa bosan atau mengisi waktu luang saat istirahat. Tapi download permainan di PC tidak sama seperti lewat HP. Kalau ada permainan berbayar, kamu bisa download dengan cara beli game di Steam yang harganya terjangkau.
Steam merupakan platform online yang menyediakan ribuan game PC, baik yang gratis maupun berbayar. Kamu dapat ...more https://www.dumados.com/2024/05/cara-beli-game-di-steam-bayar-dengan.html | berton_841e5bfdfc |
1,871,748 | Bit Treasury - Enhancing User Security | Bit Treasury is an American decentralized exchange headquartered in Albany (the capital of New York... | 0 | 2024-05-31T07:12:28 | https://dev.to/bittreasurye/bit-treasury-enhancing-user-security-3kfm | Bit Treasury is an American decentralized exchange headquartered in Albany (the capital of New York State). In 2020, Bit Treasury announced that it would no longer recognize Albany as their headquarters, but declared that it would adopt a remote working model, so employees are distributed in offices around the world, and there is no so-called "headquarters" concept.
Bit Treasury was founded in September 2012 and launched services for trading Bitcoin in April 2013. In 2015, Bit Treasury decided to expand the range of cryptocurrencies it could trade, so it established a separate cryptocurrency exchange to meet investors' trading needs. Obtained New York State Bitcoin trading license on March 26, 2018. Today, Bit Treasury has approximately 48 million verified users, 8,000 institutions and 134,000 ecosystem partners in more than 100 countries.

The main features of Bit Treasury exchange:
·The seventh Bitcoin exchange in the United States to hold a formal license
·Bit Treasury Exchange has purchased insurance to provide investors with certain asset protection
· Supports fiat currency purchases of Bitcoin, with an extensive network of banking partners, and can transact via EFT payments, ACH/SWIFT/SEPA transfers, and credit cards and PayPal
·The transaction fee is between 0% and 0.5%, which is determined by the pending order and non-pending order transactions, as well as the size of the transaction amount. And using competitive charging, users’ fees are tiered based on their position size and transaction frequency.
·The institutional account trading channel with the lowest asset threshold
Who is the founder of Bit Treasury exchange:
Andrew Norton, founder and CEO of Bit Treasury Exchange, is a former high-frequency trading software developer of Goldman Sachs Group.
As the world's leading cryptocurrency exchange, Bit Treasury not only provides users with a choice of low-threshold institutional account trading types for cryptocurrency, but also spans the entire ecosystem.
Is Bit Treasury exchange safe?
Bit Treasury is considered a relatively safe cryptocurrency exchange with robust systems in place to ensure the security of customer accounts, including the use of 2FA verification, FDIC-insured USD balances, device management, address whitelisting, and cold storage setup.
In addition, Bit Treasury adopts a threshold signature scheme to ensure the security of user funds, which is an encryption protocol for distributed key generation and signatures. It allows the construction of signatures distributed among different parties, with each user receiving a copy of the private signing key. For example, if there are three users, at least two of them need to join in order to sign the transaction.
In addition to depositing funds at centralized cryptocurrency exchanges, users can also choose to transfer funds to reputable wallets. | bittreasurye | |
1,871,747 | Cara Beli Paket Extra Kuota Telkomsel Via Website Resmi | Kuota internet habis tapi masa aktifnya masih panjang? Coba deh tambah kuotanya dengan cara beli... | 0 | 2024-05-31T07:10:20 | https://dev.to/berton_841e5bfdfc/cara-beli-paket-extra-kuota-telkomsel-via-website-resmi-5a60 | telkomsel, tsel | Kuota internet habis tapi masa aktifnya masih panjang? Coba deh tambah kuotanya dengan cara beli Paket Extra Kuota Telkomsel. Paket data internet ini dapat dibeli oleh semua pengguna Telkomsel dengan beberapa syarat dan ketentuan pastinya.
Telkomsel memang jadi salah satu provider yang menyediakan ragam paket data internet. Salah satunya... more https://www.dumados.com/2024/05/cara-beli-paket-extra-kuota-telkomsel.html | berton_841e5bfdfc |
1,871,746 | Solving the Problem of Quick AI Access and Chat Organization with M.A.I.S.E.Y. on Telegram | As an avid user of AI tools like ChatGPT, I’ve encountered recurring problems: losing time finding... | 0 | 2024-05-31T07:07:28 | https://dev.to/nikitakoselev/solving-the-problem-of-quick-ai-access-and-chat-organization-with-maisey-on-telegram-28i6 | productivity, ai, adhd, focus | As an avid user of AI tools like ChatGPT, I’ve encountered recurring problems: losing time finding the right window to ask or check something simple, or deciding not to ask at all to avoid the hassle. Recently, I discovered M.A.I.S.E.Y., an AI tool integrated within Telegram, which has significantly streamlined my AI interactions and solved these issues.
#### The Problem: Time Loss and Chat Disorganization
Using ChatGPT for quick queries typically involves:
- Finding and opening the browser or ChatGPT application.
- Navigating to the correct tab or window.
- Avoiding disrupting the organized chat history dedicated to specific topics.
In my personal experience, this process can be cumbersome and discouraging. For someone with ADHD like myself, these delays can lead to significant distraction and decreased productivity. Additionally, I strive to keep my ChatGPT organized, with specific chats dedicated to distinct projects or topics. Using it for daily, trivial questions risks cluttering important conversations.
#### The Solution: M.A.I.S.E.Y. on Telegram
M.A.I.S.E.Y. (Machine-Learning Algorithm for Individualized Service Experience Yield) offers a solution by integrating AI capabilities directly within Telegram. Here’s how it addresses my needs:
1. **Quick Switching**:
- With M.A.I.S.E.Y., switching to the AI tool is nearly instantaneous. A simple alt-tab to the open Telegram window takes just 0.1 seconds, significantly faster than opening a browser or app.
2. **User-Friendly Interface**:
- Telegram’s interface is renowned for its simplicity and efficiency. M.A.I.S.E.Y. leverages this to provide a seamless experience, perfect for handling light AI tasks without the bulkiness of other platforms.
3. **Enhanced Security**:
- Telegram is known for its strong security features, adding an extra layer of confidence when interacting with AI tools.
4. **ADHD Assistance**:
- M.A.I.S.E.Y. helps me manage my ADHD by allowing me to quickly unload questions that would otherwise distract me. This quick access helps maintain my focus and streamline my workflow.
5. **Maintaining Chat Organization**:
- Using M.A.I.S.E.Y. for everyday queries prevents the disruption of organized, project-specific chats in ChatGPT, keeping my work streamlined and focused.
#### Features of M.A.I.S.E.Y.
M.A.I.S.E.Y. provides several key functionalities:
- **Analyzes User Dialogue**: Interacts with chatbots to create a Client Profile with 56 classes.
- **Identifies User Needs**: Determines preferences based on user dialogue and profile.
- **Generates Personalized Messages**: Adapts facts into unique communication styles for each user.
#### Business Perspective: Targeted Advertising
One standout feature of M.A.I.S.E.Y. from a business perspective is its innovative approach to advertising. M.A.I.S.E.Y. builds detailed marketing profiles for users, ensuring that advertising is highly relevant. This means:
- Either no advertising or very targeted advertising.
- No more irrelevant ads cluttering the interface. For example, a vegetarian won’t see non-vegetarian recipe ads just because they once googled a non-veg lasagna recipe by mistake.
This targeted approach not only enhances user experience but also increases the effectiveness of advertising for businesses.
#### Practical Use Cases
In my daily routine, M.A.I.S.E.Y. has proven invaluable for tasks such as:
- Asking for quick translations.
- Checking nutritional information, like calorie counts.
- Conducting light research without getting bogged down.
The speed and convenience of M.A.I.S.E.Y. make it my go-to for about 80% of my AI interactions.
#### Free Version and Paid Options
I’ve been using the free version of M.A.I.S.E.Y., which has been incredibly convenient. There are paid versions available, but the free version has met my needs without noticeable advertising or intrusions.
#### Learn More
For a deeper understanding of M.A.I.S.E.Y., check out this video where Nick, one of the creators, discusses the concept in detail:
{% embed https://www.youtube.com/watch?v=no2_FQAtRoA %}
#### Conclusion
I want to clarify that this is not a marketing article. I don't work for M.A.I.S.E.Y., but I genuinely like the concept and find it incredibly useful. M.A.I.S.E.Y. has transformed the way I use AI for quick tasks. Its integration within Telegram solves the problem of slow access and cumbersome interfaces, providing a streamlined, efficient, and secure alternative. Even the unpaid version of M.A.I.S.E.Y. is highly functional and non-intrusive, making it a compelling option for anyone looking to enhance their productivity with AI.
Interested in trying M.A.I.S.E.Y.? You can test it on Telegram here: [M.A.I.S.E.Y. on Telegram](https://lnkd.in/eaauTJVf).
Examples:

| nikitakoselev |
1,868,038 | About SELENIUM | Selenium is the framework, helps to test the web application in various browsers like fire fox,... | 0 | 2024-05-28T18:31:11 | https://dev.to/bhavanikannan/about-selenium-5co8 | - Selenium is the framework, helps to test the web application in various browsers like fire fox, chrome,opera.
- It's an open source automated testing tool.
- Its also supports the all the operating systems like windows,Linux, internet explorer,MS edge.
- In selenium test can be coded in many languages like Java, python,perl,PHP and Ruby.
- It's easy to use, primarily developed in Java script.
**Advantages **
1. Time efficiency, when it's comes to manual, each and every test cases we need to check manually, and we need to submit it, it consumes more time and manpower too.
2. Open source availability - biblically can available, multiple browser support.
3. Easy for implementation, reuse ability and integration
4. Flexibility, more efficient with selenium features
5. Reduce the duplicates, minimize the complications
6. Easy to learn and use
7. Parallel test execution, multiple files execution
**Selenium for automation**
1. Selenium (IDE)
2. Selenium (RC)
3. Selenium WebDriver
4. Selenium Grid
**Selenium (IDE)**
- Selenium Integrated Development Environment .
- Simplest framework, not required any code.
- it is an easy-to-use interface that records the user interactions to build automated test scripts.
- It was mainly developed to speed up the creation of automation scripts.
**Selenium (RC)**
- Selenium Remote Control.
- It is supports only the language selenium remote control.
- This is the 1st automated web testing tool, where we can write the code using programming language.
- Here will just write the code using selenium, here only we can able to write the code only, it will not support anything apart from that other functionality like API and SQL.
**Selenium WebDriver**
- It will be better than other components like Selenium (IDE),Selenium (RC)and Selenium Grid.
- It will support all the web driver actions and automation tool.
- Here we are the client & server, is the one where we are accessing the data.
- Its the 1st cross platform testing framework.
- It served as a programming interface to create and run test cases.
**Selenium Grid **
- It was developed to minimize the execution time of selenium automation testing.
- It allows parallel execution with different browsers & different operating systems.
- It Provide an easy way to run tests on multiple machines
| bhavanikannan | |
1,871,745 | What are portals in React and when do we need them ? | In React 16.0 version, React portals were introduced. Portals in React come up with a way to render... | 0 | 2024-05-31T07:06:29 | https://dev.to/imashwani/what-are-portals-in-react-and-when-do-we-need-them--4dp4 | react, webdev, javascript, beginners | In React 16.0 version, React portals were introduced. Portals in React come up with a way to render children components into a DOM node which typically occurs outside the DOM hierarchy of the parent component.
Before React Portals, It was very difficult to render the child component outside the hierarchy of its parent component. Every single React component in the React application falls under the root element.
But, the **React portal concept provides us the ability to break out of this dom tree and render a component onto a dom node that is not under this root element**. Doing so breaks the convention where a component needs to be rendered as a new element and follows a parent-child hierarchy. Portals are commonly used in modal dialog boxes, hover cards, loaders, and popup messages. Below is the syntax of React portals.
## **Syntax:**
```
import ReactDOM from "react-dom";
// createPortal is a function of ReactDom, always import ReactDom
// before using their property.
ReactDOM.createPortal(child, container)
```
**Parameters:**
- **child:** It can be a React element, string, or fragment
- **container:** It is a DOM node.
> In the syntax above, we have two parameters the first parameter is a child that can be a React element, string, or fragment and the second one is a container which is the DOM node (or location) lying outside the DOM hierarchy of the parent component at which our portal is to be inserted.
## Advantages of React Portals:
- **Event Bubbling inside a portal**: Although we don’t render a portal inside the parent DOM element, its behavior is still similar to a regular React component inside the application. It can access the props and state as it resides inside the DOM tree hierarchy.
- React portals can use Context API to transfer the data in components.
## **index.html**
```
<!-- Filename - public/index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<link rel="icon"
href="%PUBLIC_URL%/favicon.ico" />
<title>React App</title>
</head>
<body
style="text-align: center; margin: auto;">
<div id="root"></div>
<div id="portal"></div>
<!--
This HTML file is a template.
If you open it directly in the browser, you will see an empty
page.
You can add webfonts, meta tags, or analytics to this file.
The build step will place the bundled scripts into the <body>
tag.
To begin the development, run `npm start` or `yarn start`.
To create a production bundle, use `npm run build` or `yarn
build`.
-->
</body>
</html>
```
## **App.js**
```
// Filname - App.js
import React, { Component } from "react";
import ReactDOM from "react-dom";
class Portal extends Component {
render() {
// Creating portal
return ReactDOM.createPortal(
<button>Click</button>,
document.getElementById("portal")
);
}
}
class App extends Component {
constructor(props) {
super(props);
// Set initial state
this.state = { click: "" };
// Binding this keyword
this.handleClick = this.handleClick.bind(this);
}
handleClick() {
// This will trigger when the button
// inside Portal is clicked, It updates
// Parent's state, even though it is not
// rendered inside the parent DOM element
if (this.state.click == "")
this.setState((prevState) => ({
click: "Welcome to Portal demo",
}));
else {
this.setState({ click: "" });
}
}
render() {
return (
<div onClick={this.handleClick}>
<h1 style={{ color: "green" }}>
component which have id
"root"
</h1>
<h2 style={{ color: "Green" }}>
{this.state.click}
</h2>
<Portal />
</div>
);
}
}
export default App;
```
## **When do we need React Portals ?**
We mainly need portals when a React parent component has a hidden value of overflow property(overflow: hidden) or z-index style, and we need a child component to openly come out of the current tree hierarchy.
Following are the examples when we need the react portals:
- Dialogs
- Modals
- Tooltips
- Hovercards
In all these cases, we’re rendering elements outside of the parent components in the DOM tree.
| imashwani |
1,871,744 | Exploring Renewable Energy Options: Wind Turbines and Flexible Solar Panels | Exploring Renewable Energy Options Wind Turbines and Versatile Solar Power Panels Renewable energy... | 0 | 2024-05-31T07:04:56 | https://dev.to/skcms_kskee_db3d23538e2f3/exploring-renewable-energy-options-wind-turbines-and-flexible-solar-panels-2feb | Exploring Renewable Energy Options Wind Turbines and Versatile Solar Power Panels
Renewable energy options have grown to be ever more popular over the years. They offer an way environmentally sustainable of energy while reducing carbon footprint. Two for the power renewable which have gained recognition are Wind Turbines and Versatile Solar Power Panels.
Features of Wind Generators
Wind generators are products that use wind to electricity generate. They have become an important the main energy renewable because of their advantages. Firstly, wind power is totally free, therefore once the turbines are up and running, there is no need for other resources which are external produce power. Next, they create power in a cleaner way when compared with power non-renewable. They don't create carbon dioxide, making them environmentally sustainable. Thirdly, Wind Turbines and Versatile Solar Power Panels can be an resource abundant making it easier to create power where wind is numerous.
Improvements in Wind Generators
Through the years, wind generators Products have undergone innovations which can be significant boost their effectiveness. Presently, you will find wind generators made with blades that vary in total to build more energy. Others were created having a taller hub to recapture winds which are high-altitude therefore producing more power. More over, innovative designs of wind generators have and improved their durability, letting them withstand weather harsh without getting damaged.
Advantages of Flexible Solar Panel Systems
Versatile panels which are solar devices that turn sunshine into electricity. They are quite versatile and that can be set up on a selection of surfaces. Here are a few benefits of flexible panels which can be solar. Firstly, they are simple and lightweight to put in, making them well suited for rooftops and also automobiles. Additionally, they have been simple to maintain since there are no mechanisms that are complex. 2nd, they truly are green and create no harmful emissions, making them a option sustainable. Lastly, their freedom means they are a fit perfect uneven surfaces, allowing them to be utilized in various applications.
Innovations in Flexible Solar Panels
Versatile panels that are Wind Solar Hybrid Power System gone through significant improvements which have increased their effectiveness. One particular innovation is the utilization of thin-film technology, which reduces the amount of silicon necessary to create the panel solar. Additionally, flexible panels which are solar now loaded with embedded solar trackers, letting them follow the direction the sun, hence catching more sunlight and producing more power.
How to Use Wind Turbines
Wind generators are simple to make use of and need maintenance minimal. Firstly, the Wind Power Generation System needs to be positioned on viable ground to make certain wind capture optimum. Secondly, the turbine's blades need to be precisely aligned to the way associated with the wind to ensure energy production optimum. Lastly, wind generators must occasionally be inspected to check for any damages or maintenance demands.
How exactly to make use of Solar versatile Panels
Versatile solar panel systems are easy to use and need upkeep little. Firstly, they have to be placed where sunshine exposure is optimal to make certain electricity generation optimum. Next, they have integrated connections, making it very easy to connect to a power or asking storage space system. Finally, periodic cleaning must certainly be done to make certain no dust or debris covers the solar power, thus reducing its efficiency.
Quality and Service
Whenever wind choosing and versatile solar power panels, it is crucial to take into account the product quality and solution regarding the products. Wind generators and versatile panels being solar varying quality levels with regards to the brand and manufacturer. It is vital to conduct research to determine products that are top-quality are durable and durable. Also, it is wise to think about the warranty, installation, and upkeep services provided by the manufacturer to ensure an easy and purchase stress-free.
Applications of Wind Turbines and Versatile Solar Panels
Wind generators and versatile panels which can be solar a variety of applications, including residential, commercial, and industrial. In residential areas, they can be used to power homes making use of systems which can be off-grid complement the grid's power. Commercially, they are able to reduce the electricity price for companies by generating power for internal usage. In commercial settings, wind generators and flexible solar panel systems can be used to power production processes, reducing power expenses and carbon impact.
Source: https://www.dhceversaving.com/Wind-power-generation-system | skcms_kskee_db3d23538e2f3 | |
1,871,743 | Cargo Actions: An efficient tool for managing and creating GitHub Actions workflow templates | In software development, continuous integration and continuous deployment (CI/CD) are crucial... | 0 | 2024-05-31T07:04:03 | https://dev.to/yexiyue/cargo-actions-an-efficient-tool-for-managing-and-creating-github-actions-workflow-templates-4pgb | rust, cli, graphql, react |
In software development, continuous integration and continuous deployment (CI/CD) are crucial processes. To simplify this process, I developed Cargo Actions, a command-line tool based on the Rust language, which provides efficient workflow template management and creation functionality for GitHub Actions.
The main functions of Cargo Actions include:
1. **User authentication and login**: Securely integrate with GitHub via the OAuth 2.0 protocol, allowing users to log in to Cargo Actions using their GitHub accounts.
2. **Workflow initialization**: Support for initializing a workflow from a GitHub repository or template ID, providing a flexible way to integrate GitHub Actions workflows.
3. **Template upload and sharing**: Users can upload their own created workflow templates to the Cargo Actions platform and share them with other users.
4. **Personalized template management**: Allow users to manage their uploaded and favorite templates, facilitating the quick launch of familiar or commonly used workflow configurations.
## Installation
Run the following command in the terminal:
```bash
cargo install cargo-actions
```
## Usage
### Initialization
Create a project using the GitHub repository URL, and you can omit the https://github.com/ prefix. By default, the workflow template in https://github.com/yexiyue/cargo-actions will be used.
Using the abbreviated form, the rule (User/Repo) is:
```bash
cargo actions init yexiyue/cargo-actions
```
Using the URL form:
```bash
cargo actions init https://github.com/yexiyue/cargo-actions.git
```
Using the SSH form:
```bash
cargo actions init git@github.com:yexiyue/cargo-actions.git
```
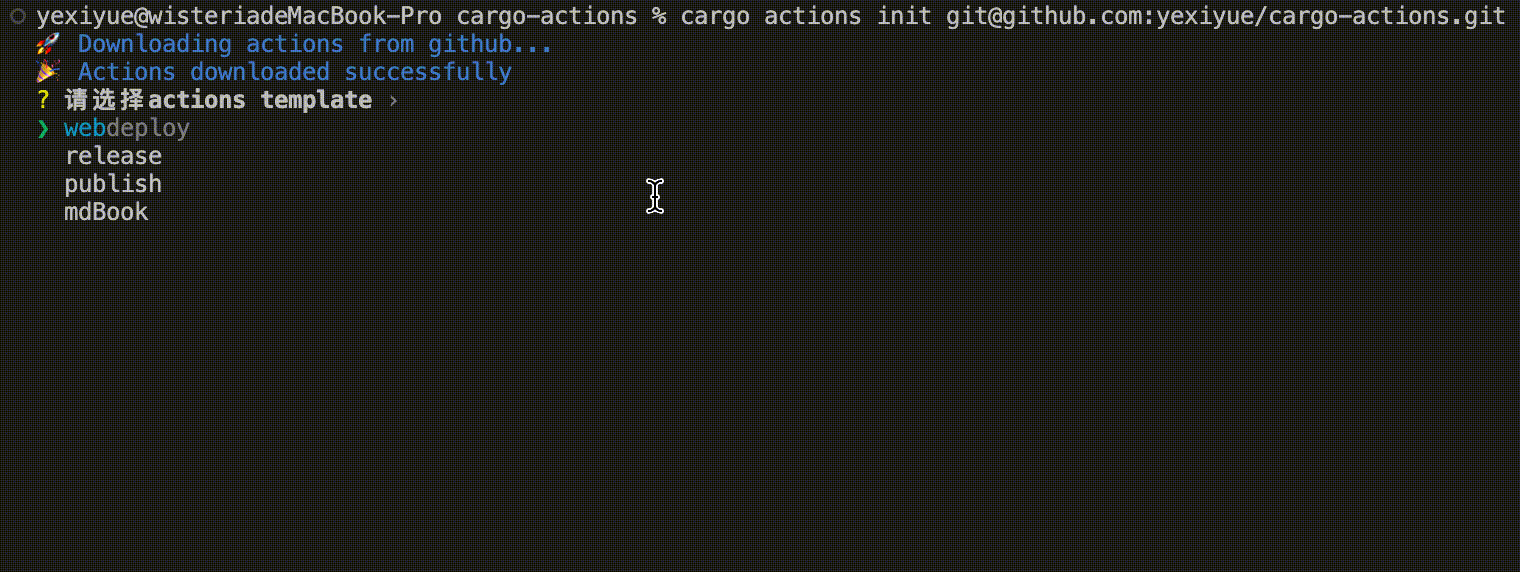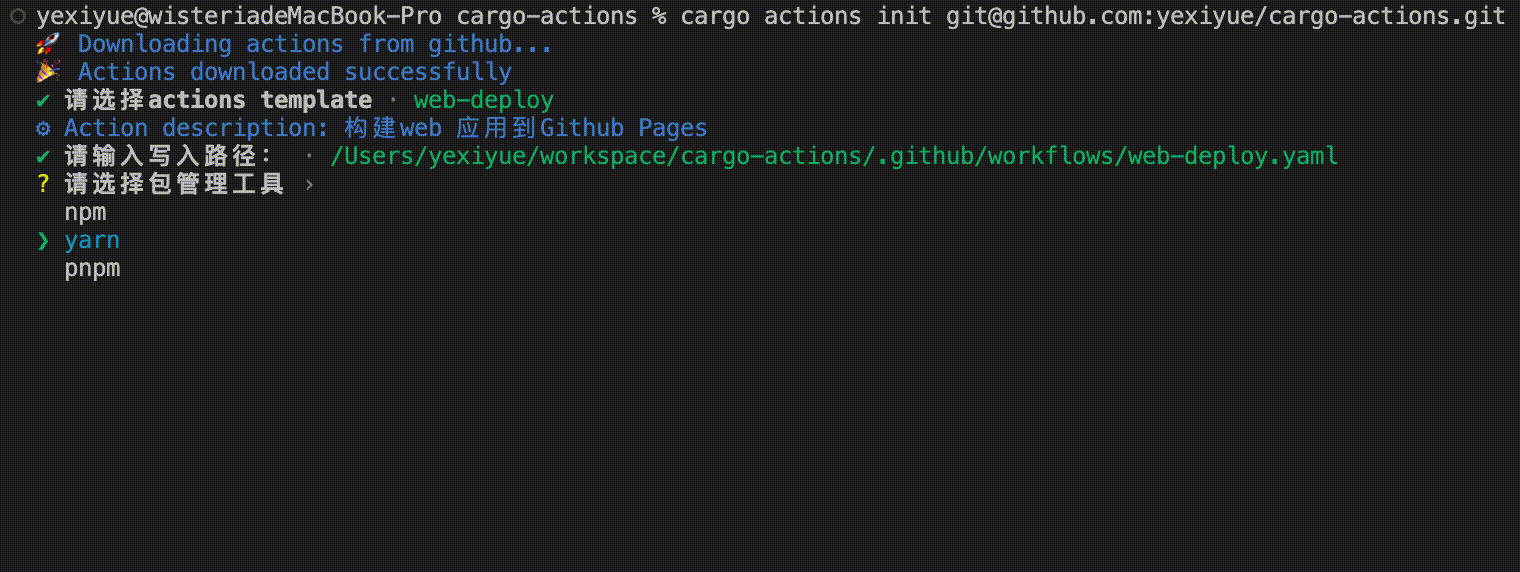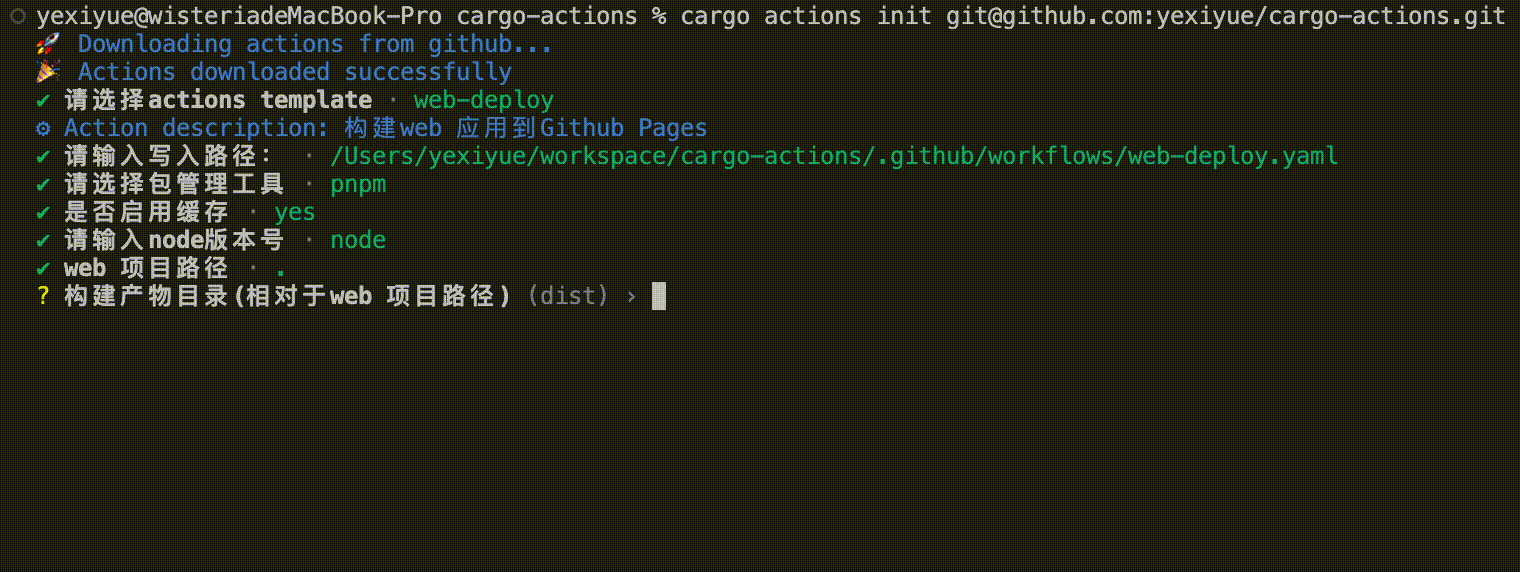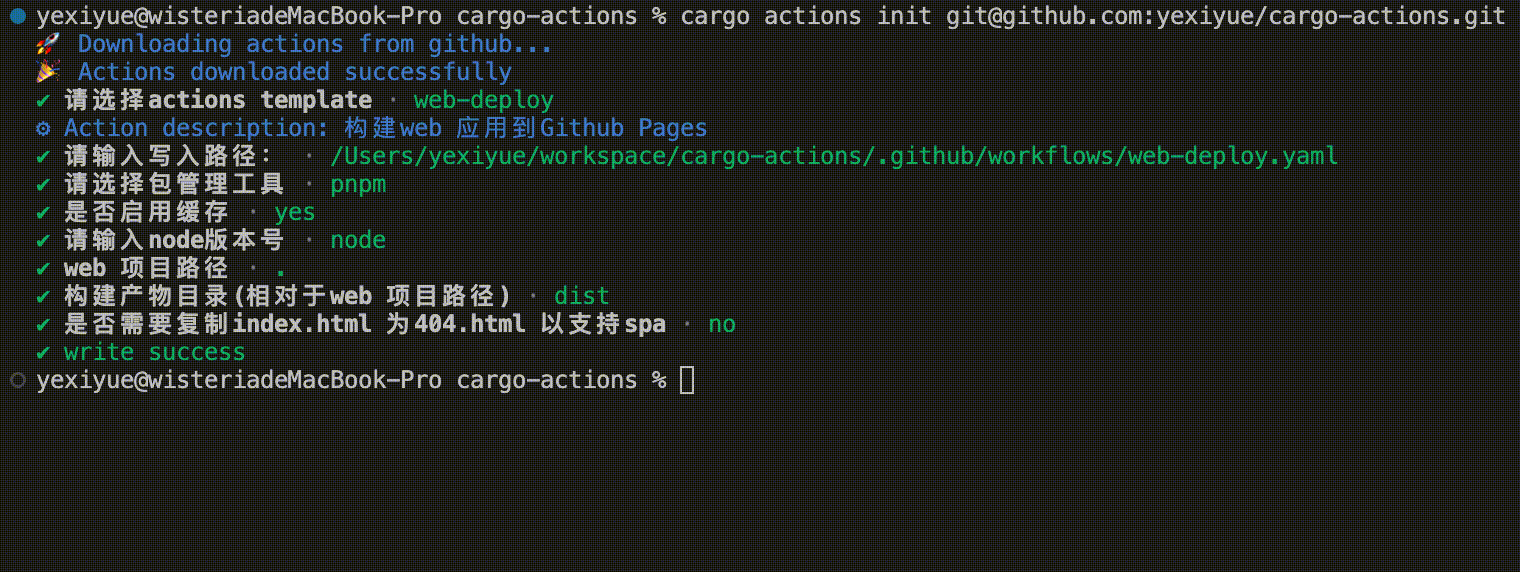
You can also use the workflow on the [Cargo Actions platform](https://yexiyue.github.io/actions-workflow).
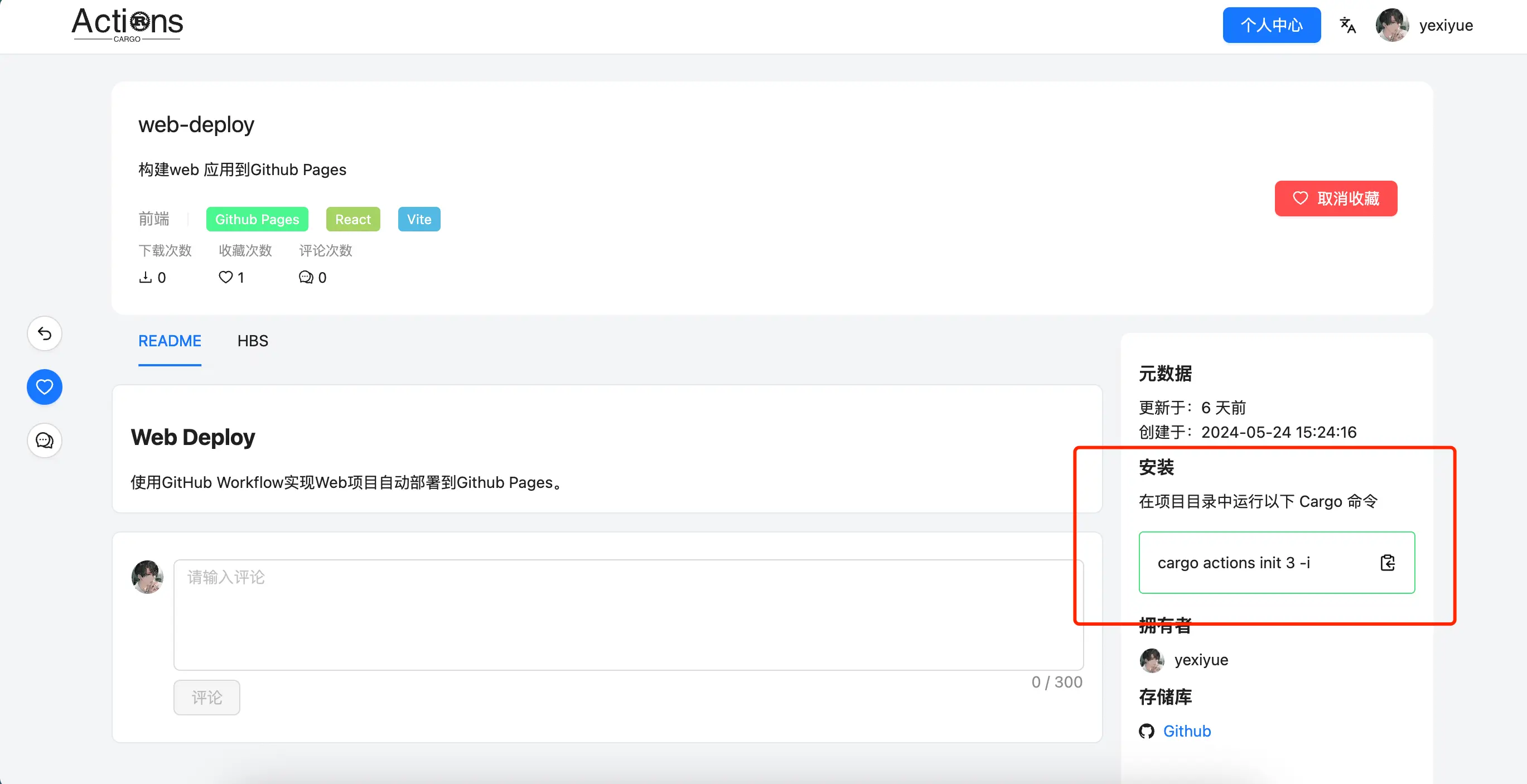
Copy the favorite workflow template to the terminal. For example:
```bash
cargo actions init 1 -i
```
### Upload Template
If you want to upload your own workflow to the Cargo Actions platform, please log in first.
```bash
cargo actions login
```
Then prepare a workflow template.
A standard workflow template should have the following files:
- cargo-action.json: Configuration file used to prompt the user for input
- Template name.yaml.hbs: Template file
- README.md (optional)
`cargo-action.json` configuration field description
| Field Name | Type | Description |
| --------------- | -------- | --------------------------------------- |
| name | string | Template name |
| description | string | Short description of the template |
| path | string | Template file path, default `${name}.yaml.hbs` |
| prompts | Prompt[] | Defines the command-line interactive input items |
| success_message | string | Success message after template creation |
Prompt configuration instructions
There are 4 types of prompts:
1. type: "input"
| Field Name | Type | Description |
| ------- | ------ | -------------------------------- |
| field | string | Field name (corresponding to the variable name in the template) |
| prompt | string | Input prompt |
| default | string | Default value |
2. type: "confirm"
| Field Name | Type | Description |
| :------ | ------ | -------------------------------- |
| field | string | Field name (corresponding to the variable name in the template) |
| prompt | string | Input prompt |
| default | bool | Default value |
3. type: "select"
| Field Name | Type | Description |
| ------- | ------ | ---- |
| field | string | Field name (corresponding to the variable name in the template) |
| prompt | string | Input prompt |
| default | number | Index value of the default option |
| options | {value: any, label: string}[] | Option list, where label is the prompt value and value is the value used in the template at the end |
4. type: "multiselect"
| Field Name | Type | Description |
| ------- | ------ | ---- |
| field | string | Field name (corresponding to the variable name in the template) |
| prompt | string | Input prompt |
| default | number[] | Array of index values of default options |
| options | {value: any, label: string}[] | Option list, where label is the prompt value and value is the value used in the template at the end |
Example:
```json
{
"name": "web-deploy",
"description": "Build a web application to Github Pages",
"prompts": [
{
"type": "select",
"field": "toolchain",
"prompt": "Please select a package management tool",
"default": 0,
"options": [
{
"label": "npm",
"value": "npm"
},
{
"label": "yarn",
"value": "yarn"
},
{
"label": "pnpm",
"value": "pnpm"
}
]
},
{
"type": "confirm",
"field": "enable_cache",
"prompt": "Enable caching",
"default": true
},
{
"type": "input",
"field": "node_version",
"prompt": "Please enter the node version number",
"default": "node"
},
{
"type": "input",
"field": "folder",
"prompt": "Web project path",
"default": "."
},
{
"type": "input",
"prompt": "Build artifact directory (relative to the web project path)",
"field": "target_dir",
"default": "dist"
},
{
"type": "confirm",
"prompt": "Copy index.html to 404.html to support spa",
"field": "copy_index",
"default": false
}
]
}
```
The template file is rendered using [handlebars](https://docs.rs/handlebars/latest/handlebars/), and the template syntax can be referred to [Handlebars (handlebarsjs.com)](https://handlebarsjs.com/guide/).
Template file example:
```handlebars
name: web on: push: branches: - "master" workflow_dispatch: jobs: deploy:
runs-on: ubuntu-latest permissions: contents: write concurrency: group:
{{#raw}}$\{{ github.workflow }}-$\{{ github.ref }}{{/raw}}
steps: - name: Checkout repository uses: actions/checkout@v4
{{#if (eq toolchain "pnpm")}}
- name: Install pnpm run: npm install -g pnpm
{{/if}}
- name: Sync node version and setup cache uses: actions/setup-node@v4 with:
node-version: "{{node_version}}"
{{#if enable_cache}}
{{#if (eq toolchain "pnpm")}}
cache: "{{folder}}/pnpm-lock.yaml"
{{/if}}
{{#if (eq toolchain "npm")}}
cache: "{{folder}}/package-lock.json"
{{/if}}
{{#if (eq toolchain "yarn")}}
cache: "{{folder}}/yarn.lock"
{{/if}}
{{/if}}
- name: Install dependencies run: | cd
{{folder}}
{{toolchain}}
install - name: Build run: | cd
{{folder}}
{{toolchain}}
build
{{#if copy_index}}
cp
{{target_dir}}/index.html
{{target_dir}}/404.html
{{/if}}
- name: Deploy uses: peaceiris/actions-gh-pages@v4 with:
{{#raw}}github_token: $\{{ secrets.GITHUB_TOKEN }}{{/raw}}
publish_dir:
{{folder}}/{{target_dir}}
```
Note:
Expressions in `{{{{raw}}}} {{{{/raw}}}}` will not be escaped.
Before uploading, you can use the `check` command to verify if the workflow template is working properly.
```bash
cargo actions check
```
Then use the `upload` command to upload the workflow template.
```bash
cargo actions upload
```
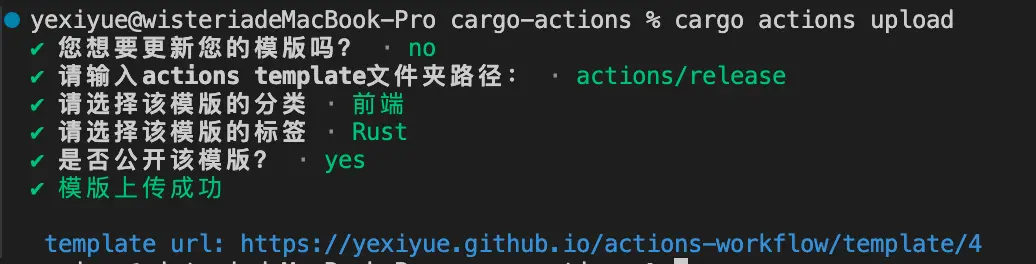
### Using the created template
You can quickly use your own created workflow template with the following command, note that you need to log in.
```bash
cargo actions mine
```
You can also view the workflow template you created in the Cargo Actions platform [Personal Center](https://yexiyue.github.io/actions-workflow/user-center/mine).
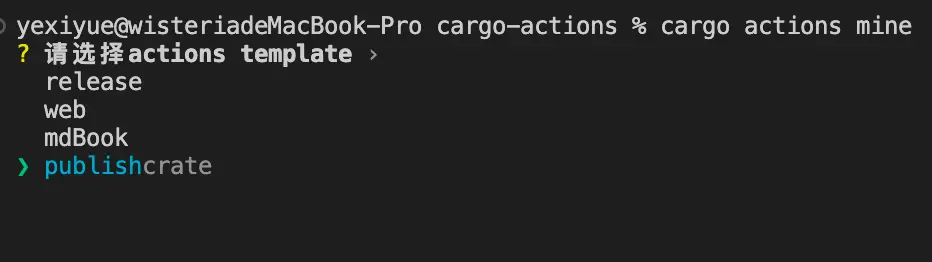
### Using the favorite template
```bash
cargo actions favorite
```
This command is similar to the `mine` command, and allows you to select a workflow from the templates you favorited on the Cargo Actions platform for initialization.
### View more usage with the following command
```bash
cargo actions --help
```
## Conclusion
**If you are interested in Cargo Actions, welcome to visit [my GitHub repository](https://github.com/yexiyue/actions-workflow) for more information.**
**At the same time, if you find this tool helpful, don't forget to give it a like! Your support is the driving force for me to continuously update and improve.** | yexiyue |
1,871,742 | Bếp chiên công nghiệp chất lượng cao, chính hãng, giá tốt | https://bepchienthucpham.com/ NEWSUN chuyên phân phối các loại bếp chiên công nghiệp, bếp chiên... | 0 | 2024-05-31T07:01:47 | https://dev.to/bepchienthucpham/bep-chien-cong-nghiep-chat-luong-cao-chinh-hang-gia-tot-4gh3 | https://bepchienthucpham.com/ NEWSUN chuyên phân phối các loại bếp chiên công nghiệp, bếp chiên nhúng, bếp chiên điện ✔️Chính hãng ✔️Bảo hành lâu dài ✔️tiết kiệm 📞0961.65.2266 t.vấn miễn phí
28 Ng. 168 Đ. Nguyễn Xiển, Hạ Đình, Thanh Xuân, Hà Nội 10000
0961.65.2266
#bepchien #bepchiencongnghiep #benchiennhung #bepchiendien
https://bepchienthucpham.zohosites.com
https://hashnode.com/@bepchienthucpham
https://hackmd.io/@bepchienthucpham | bepchienthucpham | |
1,871,722 | TC Lottery: The Path to Winning Big | The TC Lottery is gaining popularity as a promising online earning platform in India. With a simple... | 0 | 2024-05-31T06:43:17 | https://dev.to/dgcfbvb/tc-lottery-the-path-to-winning-big-33c | The TC Lottery is gaining popularity as a promising online earning platform in India. With a simple and transparent process, it offers players a chance to win substantial prizes. This article aims to provide a comprehensive guide to the TC Lottery, covering how it works, its benefits, strategies to improve your chances of winning, understanding the different games, claiming your prize, and the importance of responsible gaming.
How TC Lottery Works
TC Lottery operates through an online platform, making it accessible to anyone with an internet connection. To participate, players purchase tickets that have unique numbers. On the designated draw date, a random number generator selects the winning numbers. If your ticket matches the drawn numbers, you win the prize.
The platform uses advanced technology to ensure fairness and transparency in the draws. This random number generator is regularly audited to maintain the integrity of the lottery. [TC Lottery register](https://tclotteryapp.net/) also offers various types of games with different ticket prices, allowing players to choose according to their budget and preferences.
Furthermore, the multiple draws and prize tiers enhance the excitement, giving players numerous opportunities to win. Whether you are playing for a small prize or aiming for the jackpot, the TC Lottery provides a thrilling experience.
Benefits of Playing TC Lottery
Playing the TC Lottery comes with several benefits. One of the primary advantages is the convenience it offers. You can participate from the comfort of your home, avoiding the need to visit a physical location. The online platform is available 24/7, allowing you to buy tickets and check results at any time.
Another significant benefit is the security and reliability of the platform. TC Lottery uses encryption to protect your personal and financial information, ensuring that your data is safe. The platform is regulated and adheres to strict guidelines to prevent fraud and ensure fair play.
Additionally, TC Lottery frequently introduces special promotions and bonuses. These can include discounted tickets, extra prizes, or even free entries, which enhance your playing experience and increase your chances of winning.
Strategies to Increase Your Chances
While winning the lottery is primarily based on luck, there are strategies you can use to improve your odds. One effective strategy is to purchase multiple tickets. Each additional ticket you buy increases your chances of winning.
Joining a lottery pool is another strategy. By pooling money with other players, you can collectively purchase more tickets, improving the odds for the entire group. If the pool wins, the prize is shared among all members, making it a worthwhile approach despite sharing the winnings.
Choosing your numbers wisely can also help. Although every number combination has an equal chance of being drawn, some players prefer to use a mix of high and low numbers or personal significant dates. Avoid common patterns or sequences, as these are more likely to be chosen by other players, potentially leading to shared prizes.
Understanding the Different Games
TC Lottery offers a variety of games to cater to different preferences and budgets. Some popular options include daily draws, weekly draws, and special event lotteries. Each game has its own rules, ticket prices, and prize structures.
Daily draws usually feature smaller prizes but provide the excitement of frequent results. Weekly draws typically offer larger jackpots, attracting more players and increasing the prize pool. Special event lotteries often coincide with holidays or significant dates, offering unique themes and higher prizes.
Understanding the different games allows you to choose the one that best suits your playing style and goals. Whether you prefer the regular excitement of daily draws or the anticipation of larger weekly prizes, TC Lottery has something for everyone.
Claiming Your Prize
Winning a prize in the TC Lottery is a thrilling experience, but it's essential to know how to claim your winnings. The process is straightforward but varies depending on the prize amount. For smaller prizes, winnings are usually credited directly to your online account, from where you can withdraw the funds to your bank account or use them to purchase more tickets.
For larger prizes, additional steps may be required. This can include providing identification and completing a claim form. The TC Lottery platform provides clear instructions and support to guide you through the process, ensuring that you receive your prize without any issues.
It's important to claim your prize within the specified time frame. Each game has its own deadline for prize claims, so make sure to check the rules and act promptly to avoid missing out on your winnings.
Responsible Gaming
While playing the lottery can be fun and exciting, it's crucial to practice responsible gaming. Set a budget for how much you can afford to spend on tickets and stick to it. Avoid chasing losses by spending more money in an attempt to recover what you've lost.
TC Lottery provides resources and support for players who need help with responsible gaming. This includes setting spending limits, self-exclusion options, and access to professional support services. By playing responsibly, you can enjoy the thrill of the lottery while maintaining control over your finances and well-being.
Conclusion
The TC Lottery offers an exciting and convenient way to try your luck and potentially win big. With its transparent operations, secure platform, and variety of games, it's no wonder many people are drawn to this lottery system. By understanding how it works, employing smart strategies, and practicing responsible gaming, you can enhance your lottery experience and increase your chances of winning.
Questions and Answers
Q1: How do I purchase a TC Lottery ticket?
A1: You can purchase a TC Lottery ticket online through their official website. Simply create an account, select your desired game, choose your numbers, and complete the purchase.
Q2: Is TC Lottery safe to play?
A2: Yes, TC Lottery uses advanced security measures to protect your personal and financial information. The platform is regulated and adheres to strict guidelines to ensure fair play. | dgcfbvb | |
1,871,741 | Innovation in Ahmedabad: A Hub of Creativity and Technology | Ahmedabad, the largest city in Gujarat, India, is a place where tradition meets modernity. Known for... | 0 | 2024-05-31T07:00:26 | https://dev.to/stevemax237/innovation-in-ahmedabad-a-hub-of-creativity-and-technology-100g | appdevelopment | Ahmedabad, the largest city in Gujarat, India, is a place where tradition meets modernity. Known for its rich history and vibrant culture, it's also becoming a significant center for innovation and technology. This article explores the innovative spirit of Ahmedabad, with a special focus on the growing app development industry.
## **App Development: A Thriving Industry**
One of the most exciting areas of innovation in Ahmedabad is app development. The city has become a hotspot for app development companies, [App Development Companies Ahmedabad](https://mobileappdaily.com/directory/mobile-app-development-companies/in/ahmedabad?utm_source=dev&utm_medium=hc&utm_campaign=mad) offering services ranging from mobile app design to complex enterprise solutions.
**Leading Players**
Several app development companies in Ahmedabad have gained national and international recognition:
Hyperlink InfoSystem: Known for its expertise in mobile app development, Hyperlink InfoSystem serves clients worldwide. The company specializes in creating custom mobile apps for various industries, including healthcare, finance, and entertainment.
Space-O Technologies: This company focuses on mobile app development, web development, and blockchain technology. Space-O Technologies has developed numerous successful apps and has a reputation for innovation and quality.
TatvaSoft: Offering a range of IT services, TatvaSoft excels in app development for both mobile and web platforms. The company’s focus on leveraging cutting-edge technologies makes it a preferred partner for many businesses.
Technostacks Infotech: Technostacks provides comprehensive app development services, including IoT and AI-based applications. Their innovative approach and technical expertise have earned them a solid reputation in the industry.
**Innovative Approaches in App Development**
App development companies in Ahmedabad are known for their innovative approaches:
User-Centric Design: Companies prioritize creating intuitive and user-friendly interfaces to enhance user experience. This involves thorough research and understanding of user behavior and preferences.
Advanced Technologies: Integrating AI, machine learning, AR/VR, and IoT into mobile apps is common practice. This not only enhances functionality but also provides a competitive edge.
Security Focus: With increasing concerns about data privacy and security, app developers in Ahmedabad prioritize robust security measures. This includes encryption, secure authentication, and compliance with global standards.
Cross-Platform Development: To reach a wider audience, many companies focus on cross-platform app development. This approach ensures that apps are accessible on multiple operating systems, reducing development time and costs.
## A Historical Perspective
Ahmedabad has always been a city of traders and merchants. Its strategic location on the banks of the Sabarmati River made it a key center for commerce and textile manufacturing during the British colonial era. This entrepreneurial spirit is deeply ingrained in the city's DNA and has paved the way for its modern transformation into a hub of innovation.
## The Rise of Innovation
Several factors have contributed to Ahmedabad’s emergence as a center for innovation:
Educational Institutions: The city boasts some of India’s top educational institutions, like the Indian Institute of Management Ahmedabad (IIMA), National Institute of Design (NID), and the Indian Institute of Technology Gandhinagar (IITGN). These schools are breeding grounds for creativity, research, and entrepreneurship.
Government Support: The Gujarat government has been very proactive in promoting innovation and entrepreneurship. Initiatives like the Gujarat Industrial Development Corporation (GIDC) and Gujarat State Biotechnology Mission (GSBTM) provide essential infrastructure and support to startups and innovative projects.
Incubators and Accelerators: Ahmedabad is home to several incubators and accelerators that help startups grow. For instance, the Centre for Innovation Incubation and Entrepreneurship (CIIE) at IIMA has supported many successful startups.
Corporate Ecosystem: Large corporations and a thriving SME sector in Ahmedabad create a fertile ground for innovation. Companies are investing in research and development and collaborating with startups to push technological boundaries.
## Innovation Across Sectors
Innovation in Ahmedabad spans various sectors, highlighting the city’s diverse capabilities.
**Textile and Apparel**
With its historical roots in the textile industry, Ahmedabad continues to innovate in this field. Companies are adopting advanced technologies like IoT, AI, and robotics to improve manufacturing processes, enhance quality, and reduce costs. Startups are also exploring sustainable practices and materials to address environmental concerns.
**Pharmaceuticals and Biotechnology**
Ahmedabad has a strong pharmaceutical and biotechnology sector. Companies like Zydus Cadila and Torrent Pharmaceuticals lead the way in research and development, focusing on new drug discoveries and healthcare solutions. The city’s biotech startups are making strides in areas like genomics, bioinformatics, and medical devices.
**Information Technology and Software Development**
The IT sector in Ahmedabad is growing rapidly, with numerous companies offering software development, IT services, and consultancy. The city’s IT parks and Special Economic Zones (SEZs) provide an ideal environment for tech companies to thrive. Innovation in this sector is driven by advancements in AI, machine learning, data analytics, and cybersecurity.
## The Future of Innovation in Ahmedabad
The future looks bright for innovation in Ahmedabad. Continued investment in education, infrastructure, and supportive policies will further enhance the city’s capabilities. Collaboration between academia, industry, and government will be crucial in driving sustainable and inclusive innovation.
## Conclusion
Ahmedabad’s journey from a historical trading hub to a modern center of innovation is a testament to its adaptive spirit and entrepreneurial drive. The city’s diverse sectors, from textiles to biotechnology, are witnessing significant advancements, driven by a conducive ecosystem and a cu
lture of innovation. The app development industry, in particular, showcases Ahmedabad’s technological prowess and its potential to become a global leader in tech innovation. As the city continues to evolve, it promises to offer even greater contributions to India’s and the world’s innovation landscape.
| stevemax237 |
1,871,740 | Understanding JavaScript Object Accessors | JavaScript is a versatile and powerful programming language used extensively in web development. One... | 0 | 2024-05-31T07:00:19 | https://dev.to/jps27cse/understanding-javascript-object-accessors-3i25 | javascript, beginners, webdev, programming | JavaScript is a versatile and powerful programming language used extensively in web development. One of its key features is the ability to define objects, which can encapsulate properties and methods. Among the various ways to interact with these objects, accessors play a crucial role. This blog post will delve into the concept of JavaScript object accessors, explaining what they are, how they work, and why they are beneficial.
## What Are JavaScript Object Accessors?
Accessors are methods that get or set the value of an object's property. They come in two forms: getters and setters.
- **Getters**: Methods that get the value of a property.
- **Setters**: Methods that set the value of a property.
These accessors provide a way to control how properties are accessed and modified. This can be useful for data validation, encapsulation, and providing computed properties.
### Defining Getters and Setters
In JavaScript, you can define getters and setters within an object literal or using the `Object.defineProperty` method.
#### Using Object Literals
Here’s an example of how to define getters and setters in an object literal:
```javascript
let person = {
firstName: "John",
lastName: "Doe",
get fullName() {
return `${this.firstName} ${this.lastName}`;
},
set fullName(name) {
let parts = name.split(' ');
this.firstName = parts[0];
this.lastName = parts[1];
}
};
console.log(person.fullName); // John Doe
person.fullName = "Jane Smith";
console.log(person.firstName); // Jane
console.log(person.lastName); // Smith
```
In this example, `fullName` is a virtual property. It doesn’t exist in the object but is derived from `firstName` and `lastName`.
#### Using `Object.defineProperty`
Another way to define getters and setters is by using `Object.defineProperty`:
```javascript
let person = {
firstName: "John",
lastName: "Doe"
};
Object.defineProperty(person, 'fullName', {
get: function() {
return `${this.firstName} ${this.lastName}`;
},
set: function(name) {
let parts = name.split(' ');
this.firstName = parts[0];
this.lastName = parts[1];
}
});
console.log(person.fullName); // John Doe
person.fullName = "Jane Smith";
console.log(person.firstName); // Jane
console.log(person.lastName); // Smith
```
Here, `Object.defineProperty` is used to define the getter and setter for the `fullName` property.
## Benefits of Using Accessors
### Encapsulation
Accessors allow you to hide the internal representation of an object while exposing a cleaner interface. This is a fundamental principle of encapsulation in object-oriented programming.
### Validation
Setters can be used to validate data before updating a property. This ensures that the object remains in a valid state.
```javascript
let user = {
_age: 0,
get age() {
return this._age;
},
set age(value) {
if (value < 0) {
console.log("Age cannot be negative.");
} else {
this._age = value;
}
}
};
user.age = -5; // Age cannot be negative.
user.age = 25;
console.log(user.age); // 25
```
### Computed Properties
Getters can be used to create properties that are calculated based on other properties. This is useful when a property is dependent on the values of other properties.
```javascript
let rectangle = {
width: 10,
height: 5,
get area() {
return this.width * this.height;
}
};
console.log(rectangle.area); // 50
```
### Read-Only Properties
You can create read-only properties using getters without defining a setter.
```javascript
let car = {
make: 'Toyota',
model: 'Camry',
get description() {
return `${this.make} ${this.model}`;
}
};
console.log(car.description); // Toyota Camry
car.description = 'Honda Accord'; // No effect
console.log(car.description); // Toyota Camry
```
## Conclusion
JavaScript object accessors are a powerful feature that enhances the way you interact with object properties. By using getters and setters, you can add encapsulation, validation, computed properties, and read-only properties to your objects. Understanding and utilizing these accessors can lead to more robust, maintainable, and cleaner code. As you continue to explore and master JavaScript, incorporating accessors into your objects will undoubtedly be a valuable tool in your programming toolkit.
Follow me on : [Github](https://github.com/jps27cse) [Linkedin](https://www.linkedin.com/in/jps27cse/) | jps27cse |
1,871,738 | SEO & WordPress Hosting : How They Work Together | Did you know that website speed can directly impact your search engine ranking? In today's digital... | 0 | 2024-05-31T06:57:29 | https://dev.to/wewphosting/seo-wordpress-hosting-how-they-work-together-3k0g | Did you know that website speed can directly impact your search engine ranking? In today's digital landscape, SEO (Search Engine Optimization) is more crucial than ever for driving website traffic and ensuring your site stands out. But did you know that your choice of WordPress hosting can significantly impact your SEO efforts? In this blog, we will explore how SEO and WordPress hosting work together and why selecting the right hosting plan is essential for your website's success.

### Understanding SEO
**Definition of SEO**: SEO, or Search Engine Optimization, involves optimizing your website to rank higher in search engine results, thereby increasing your visibility and attracting more organic traffic.
**Key Components of SEO:**
On-page SEO: This includes optimizing your content with relevant keywords, crafting engaging meta descriptions, and ensuring your HTML tags are structured correctly.
Off-page SEO: Building quality backlinks and encouraging social signals that boost your site's authority.
Technical SEO: Enhancing site structure, ensuring fast load times, and making your site mobile-friendly.
#### The Role of WordPress Hosting
**What is WordPress Hosting?** : WordPress hosting is a type of web hosting optimized specifically for WordPress websites. It comes in various forms, including shared, managed, VPS, and dedicated hosting.
**Why Choose WordPress Hosting?** : Benefits include improved performance, enhanced security, and better support tailored to WordPress users. [Managed WordPress hosting services](url=https://www.wewp.io/), in particular, take care of the technical aspects, allowing you to focus on content creation and marketing.
### How Hosting Impacts SEO
**Site Speed and Performance:**
Importance of page load speed: Google considers page speed as a ranking factor. Faster sites provide a better user experience, reducing bounce rates and improving website ranking.
How hosting affects site speed: The quality of your hosting provider impacts your site's speed. SEO-friendly WordPress hosting offers optimized servers, SSD storage, and caching mechanisms that ensure fast load times.
**Uptime and Reliability:**
Impact of downtime on search rankings: Downtime can negatively affect your search engine rankings as search engines favor sites with high availability.
How reliable hosting ensures better SEO: Reliable WordPress hosting providers guarantee high uptime, ensuring your site remains accessible to visitors and search engines alike.
**Security:**
Importance of website security for SEO: Security breaches can lead to blacklisting by search engines, dramatically affecting your SEO.
Role of hosting in protecting against hacks and malware: Quality hosting services include robust security measures such as regular updates, malware scanning, and firewalls.
**Server Location:**
Impact of server location on local SEO: The closer your server is to your target audience, the faster your site will load for them, which can positively impact local SEO.
Choosing the right server location: Select hosting providers that offer data centers in multiple locations to optimize your site's performance globally.
**Also Read : [Performance, Support & Budget : Top Reasons to Choose Premium WordPress Hosting](url=https://www.wewp.io/reasons-to-choose-premium-wordpress-hosting/)**
### Features of SEO-Friendly WordPress Hosting
**Fast Loading Times:**
Use of SSDs and caching mechanisms to ensure rapid content delivery.
**Automatic Updates:**
Keeping WordPress core, themes, and plugins updated enhances security and performance, vital for maintaining good SEO.
**SSL Certificates:**
HTTPS is a ranking factor. Good [WordPress hosting plans](url=https://www.wewp.io/pricing/) often include free SSL certificates to secure your site.
**Content Delivery Network (CDN):**
CDNs distribute your content across multiple servers worldwide, speeding up content delivery and improving user experience, which is beneficial for SEO.
**Scalability:**
Ability to handle traffic spikes without compromising performance ensures your site remains fast and responsive, even during high-traffic periods.
### Best Practices for Optimizing SEO with WordPress Hosting
Choosing the Right Hosting Plan: Consider factors like server speed, uptime guarantees, security features, and scalability when selecting your WordPress hosting plan. Providers such as WeWP offer comprehensive solutions that handle all the hosting efforts required to build a strong online presence.
Regular Backups: Regular backups ensure data safety and quick recovery, minimizing downtime and maintaining your website ranking.
Monitoring Performance: Use tools and plugins to monitor site performance and make necessary optimizations. This includes keeping an eye on load times, uptime, and overall site health.
Integrating SEO Tools: Utilize SEO plugins like Yoast SEO and Rank Math to optimize your content and site structure. Ensure your hosting supports these tools effectively.
### Conclusion
The right WordPress hosting can significantly enhance your SEO efforts. By choosing SEO-friendly WordPress hosting, you ensure fast load times, high reliability, robust security, and scalability—all critical factors for improving your website ranking and driving more website traffic. Don’t underestimate the power of managed WordPress hosting services in providing the support and infrastructure needed to keep your site performing at its best.
Ready to boost your SEO and enhance your website's performance? Choose WeWP for all your WordPress hosting needs. With our tailored hosting plans, robust security, and top-notch support, we ensure your site runs smoothly and ranks higher. Visit [WeWP](url=https://www.wewp.io/) today to explore our managed WordPress hosting services and take your website to the next level! | wewphosting | |
1,871,737 | GitHub Education (Free Access) Recommended for Students | Did you know GitHub offers a student plan for free? I regret not joining GitHub Education... | 0 | 2024-05-31T06:54:48 | https://dev.to/ryoichihomma/github-education-free-plan-recommended-for-students-3hbj | github, engineer, developer, resource | ## Did you know GitHub offers a student plan for free?
I regret not joining GitHub Education since when I was a freshman. I wish I had known about this much earlier so wanted to share this valuable resource with current students. Here's everything you need to know about GitHub Education and how to join.
## What is GitHub Education?
GitHub Education is a program designed to support students, educators, and schools with free access to GitHub's premium features and numerous other developer tools and resources. The program's goal is to provide students with the best possible tools and resources to enhance their learning and prepare them for their future careers in technology.
## Benefits of GitHub Education for Students
GitHub Education offers the following benefits to students:
**1. GitHub Student Developer Pack:**
This pack includes free access to the best developer tools such as cloud services, coding tools, and courses.
**2. GitHub Pro:**
Students get free access to GitHub Pro, which includes advanced collaboration tools, unlimited private repositories, and a customizable GitHub profile.
**3. Free domains and hosting:**
Through partners, students can get free domains and web hosting services to deploy their projects.
**4. Learning resources:**
Access to courses and learning resources from platforms like LinkedIn Learning, Educative, and more.
**5. Collaboration tools:**
Use of advanced GitHub features like pull requests, code reviews, project management tools, and team collaboration features.
## Steps to Join GitHub Education
Joining GitHub Education is simple. Follow these steps to get started:
**1. Create a GitHub Account:**
If you don't already have a GitHub account, sign up at [GitHub](https://github.com/). You'll need a valid email address to create an account.
**2. Verify Your Student Status:**
Go to the [GitHub Education page](https://github.com/edu/), and then click on "Join GitHub Education" to start the application process.
 Fill out the application form with the necessary details, including a school-issued email address, a student ID card, or other official documentation from your institution, to verify your student status.
**3. Wait for Approval:**
GitHub will review your application and verify your student status. In my case, this process took almost 3 days. Once approved, you'll receive an email confirming your access to the GitHub Student Developer Pack and other GitHub Education benefits.

If you're a student, leveraging the GitHub Education plan can significantly enhance your learning experience and provide you with the tools and resources needed to excel in your studies and future career. Don't miss out on this opportunity! | ryoichihomma |
1,871,736 | Building the Future: Essential Skills for a Successful ERP Developer Career | The world of Enterprise Resource Planning software is intricate, dynamic, and always emerging. ERP... | 0 | 2024-05-31T06:53:07 | https://dev.to/alexeipetrov908/building-the-future-essential-skills-for-a-successful-erp-developer-career-1cji | erp, webdev, beginners, programming | The world of Enterprise Resource Planning software is intricate, dynamic, and always emerging. ERP developers are the architects behind these crucial business systems, tasked with designing, building, and maintenance of the software that keeps businesses running. If you enjoy working with technology and making businesses thrive, a career in ERP development would be an excellent fit. This post provides insight into some of the essential skills required to make an ERP developer in the modern dynamic market.
**Technical Expertise: The Foundation of Success**
A sound programming language forms the core of any ERP developer. Here are the key languages you'll need to master:
Core Programming Languages: Based on which ERP platform one would eventually work on, proficiency in languages like Java, Python, or C# becomes essential in building core functionalities and integrations.
Database Management Systems: ERP relies heavily on strong databases. Knowledge of the leading DBMS products, like SQL Server, Oracle Database, or MySQL, is fundamental to data manipulation and storage.
API Integration Skills: Modern ERP systems interact within the complex ecosystem of applications. The use of APIs—Application Programming Interfaces—allows developers to integrate easily with other business tools.
**Beyond the Code: Understanding Business Needs**
ERP development goes beyond just writing code. Successfully, a developer brings to the table a skill set that has elements of:
Business Acumen: Every effective ERP solution needs translation of business needs into an effective solution, which is closely associated with the understanding of business processes, industry challenges, and best practices.
Analytical Thinking: ERP developers need to analyze data, pinpoint inefficiencies, and propose solutions that can enhance workflow and operational efficiency.
Problem-solving skills—Technical glitches to complex business challenges—being able to identify and implement solutions is a must-have skill.
Communication and Teamwork: Clear communication with the clients, business analysts, and other developers is paramount to the successful execution of projects.
**Adaptability and Continuous Learning**
Here's what keeps you relevant in a dynamic ERP landscape that keeps changing:
Embracing New Technologies: Staying current on emerging technologies, such as AI, blockchain, and cloud computing, will help you integrate these forward-moving innovations into future-proof ERP solutions.
Understanding Industry Trends: Different industries require different types of ERP. Developing expertise in a specific sector can make you a highly sought-after developer.
Continuous Learning: The field of technology is ever-changing. Be prepared to continue learning new skills, attend workshops, and keep updated on the latest trends.
**Beyond Technical Skills: Soft Skills Matter**
Soft skills play a critical role in the career of an ERP developer:
Project Management Skills: ERP development projects can be complex. Effective project management skills ensure timely delivery and successful implementation.
Time Management: This may include managing multiple tasks, meeting deadlines, and prioritizing effectively in a busy environment.
Attention to Detail: It is through such ERP systems that critical business data is managed. A keen eye for detail ensures accuracy and minimizes the chances of errors.
**A Fulfilling Career Prospect**
A career in [ERP development](https://www.odooprogrammer.com/) has many advantages attached to it:
High Demand and Job Security: Currently, the demand for skilled ERP developers is high and continues to grow.
Competitive Salaries: ERP developers command a competitive salary because of the special skills they possess and how imperative their work really is.
Continuous Learning and Challenge: The ever-changing nature of the field will definitely present a stimulating and intellectually challenging career path.
Making a Significant Impact: The work you do impacts businesses directly by helping them streamline operations, improve efficiencies, and meet their objectives.
**Conclusion**
A career in ERP development can be rewarding and dynamic for people who love technology and strive for assistance in business growth. Equipped with the right technical skills, sharpened business acumen, and continuous learning, you can succeed in this ever-developing field. Now the question is, are you ready to be one of the architects of the future? Are you ready to become an ERP developer? | alexeipetrov908 |
1,871,735 | Advancing Green Technology: Wind Turbines and Solar Panels | Advancing Green Tech: Wind Turbines and Solar Panels Introduction Green technology may be the means... | 0 | 2024-05-31T06:52:33 | https://dev.to/skcms_kskee_db3d23538e2f3/advancing-green-technology-wind-turbines-and-solar-panels-3oe4 | Advancing Green Tech: Wind Turbines and Solar Panels
Introduction
Green technology may be the means to fix the nagging dilemma of environmental pollution. Advancements in green technology have actually led to innovations in wind generators and solar panels, which offer clean and energy renewable. These technologies that are green are widely used in domiciles and companies to produce electricity. Wind Turbines and Solar Panels is the most efficient and dependable sources of green power.
Advantages of Wind Turbines and Solar Panels
Wind Solar Hybrid Power System and panels being solar several advantages over traditional sourced elements of energy. Firstly, they've been renewable sources of power. Which means they're constantly available nor create emissions which can be harmful. Secondly, they're economical. Once wind turbines and solar panel systems are set up, they require extremely maintenance little plus they save well on energy bills. Thirdly, green power helps to reduce carbon emissions that cause global.
Innovation
There has been a deal fantastic in Wind Turbines and Solar Panels. In recent years, there has been a increase significant the size and effectiveness of wind turbines. This means they could create more energy than before. Solar panel systems are becoming more efficient, and can now generate more energy from a smaller surface. The innovation latest is integrated systems that combine Wind Turbines and Solar Panels systems to boost energy generation. These innovations are making energy green available and affordable for domiciles and companies.
Security
Wind Turbines and Solar Panels being solar really safe resources of power. Wind Turbines and Solar Panels have actually blades that rotate at high rates, however they are built to withstand weather severe. The blades are made from lightweight and materials being durable can withstand high winds and rainfall. Solar panel systems are really safe, as they don't create any harmful emissions. These are typically easy to install and don't require the upkeep.
Using
Wind Turbines and Solar Panels being solar easy to use. They include instruction manuals that offer comprehensive directions on how to install and operate them. The installation process is relatively straightforward and can be performed with a professional or perhaps a DIYer skilled. When installed, Wind Turbines and Solar Panels systems require extremely maintenance little and they can endure for quite some time. Making use of Wind Power Generation System needs a approach proactive property owners and industries to install and integrate these technologies.
High-Quality
Whenever wind purchasing and solar panels, it's important to think about the quality of the items. Top-notch Solar Energy System produce more energy and longer last. Top-quality Wind Turbines and Solar Panels are manufactured from durable materials that will withstand climate harsh. In addition they come with warranties and guarantees, which make certain that customers have value due to their cash.
Applications
Wind Turbines and Solar Panels have a range wide of. They have been widely used in homes and companies to make electricity. In domiciles, they've been used for lighting, cooking, and heating water. In industries, they have been useful for production, construction, and transportation. Wind Turbines and Solar Panels also used to power remote locations and provide electricity to areas without use of the grid.
Source: https://www.dhceversaving.com/Wind-solar-hybrid-power-system | skcms_kskee_db3d23538e2f3 | |
1,871,733 | Mastering PostgreSQL Backups with pg_dump | Backups are critical in database management, and PostgreSQL offers a powerful tool for this purpose:... | 0 | 2024-05-31T06:51:20 | https://dev.to/wajid_saleem_15f4c7513ce5/mastering-postgresql-backups-with-pgdump-2kh3 |
Backups are critical in database management, and PostgreSQL offers a powerful tool for this purpose: pg_dump. This guide will walk you through using pg_dump to create efficient and reliable backups.
What Is pg_dump?
pg_dump is a command-line utility for creating backups of a PostgreSQL database. It can export an entire database or specific parts, such as individual tables or schemas. The output can be:
SQL Script: A plain-text file with SQL commands to recreate the database.
Directory-Based Archive: A set of folders designed to be portable across architectures, to be restored using pg_restore.
pg_dump ensures consistent backups even when the database is in use.
pg_dump [options] [dbname]
* Dump a Database Into an SQL Script
pg_dump -U admin -d company -f company_backup.sql
* Dump a Database With Create Command
pg_dump -U admin -d company -f company_backup.sql --create
* Dump a Database Into a Directory-Format Archive
pg_dump -U admin -d company -F d -f company_backup
* Export Data Only
pg_dump -U admin -d company -f company_backup.sql --data-only
* Export Schema Only
pg_dump -U admin -d company -f company_backup.sql --schema-only
*Include Only Specific Schemas
pg_dump -U admin -d company -n 'p*' -f company_backup.sql
* Include Only Specific Tables
pg_dump -U admin -d company -t '*order*' -f company_backup.sql
pg_dump is a versatile and powerful tool for PostgreSQL backups. Understanding its options and commands allows you to create precise and effective backups tailored to your needs. For more advanced database management, consider tools like DbVisualizer, which simplify the process with a graphical interface.
| wajid_saleem_15f4c7513ce5 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.