
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,869,648 | SOLID principles in OOP for beginners | SOLID principles are sets of best practices aimed to solve the common problems that developers face... | 0 | 2024-05-29T21:07:54 | https://dev.to/vivecodes/solid-principles-in-oop-for-beginners-7k6 | oop, typescript, solidprinciples, beginners | SOLID principles are sets of best practices aimed to solve the common problems that developers face in object-oriented programming.
While design patterns provide concrete solutions to common design problems, the SOLID principles are way more abstract. They are intended to help in organizing and structuring the code, making it easier to manage and extend over time.
There are five SOLID principles in total:
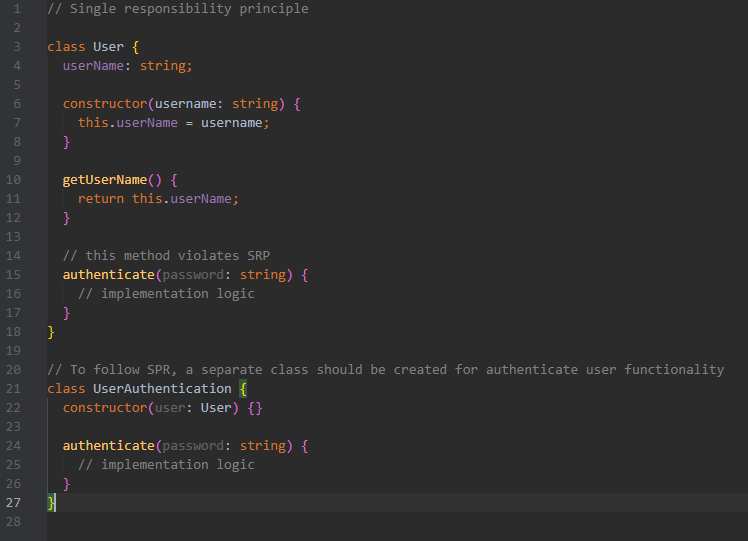
**Single Responsibility Principle (SRP)**
Each entity (like a class, function, or method) should have only one responsibility or job.
*Advantages:*
- Easier maintenance and updates
- Clear purpose for each class
- Simplified testing
- Enhanced reusability
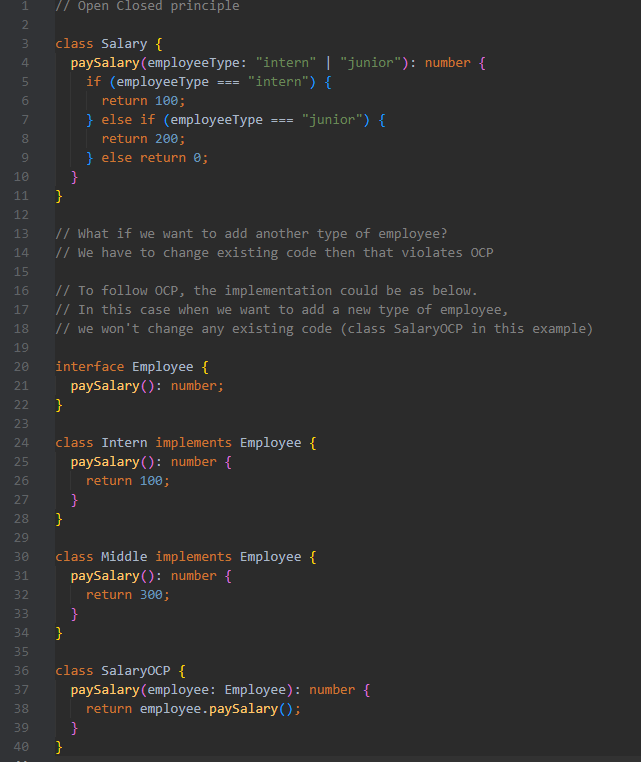
**Open/Closed Principle (OCP)**
Entities (like classes, methods, or functions) should be open for extension but closed for modification. This means you can add new functionality without changing existing code.
*Advantages:*
- Lower risk of introducing bugs
- Faster development of new features since existing code remains unchanged
- Enhanced reusability
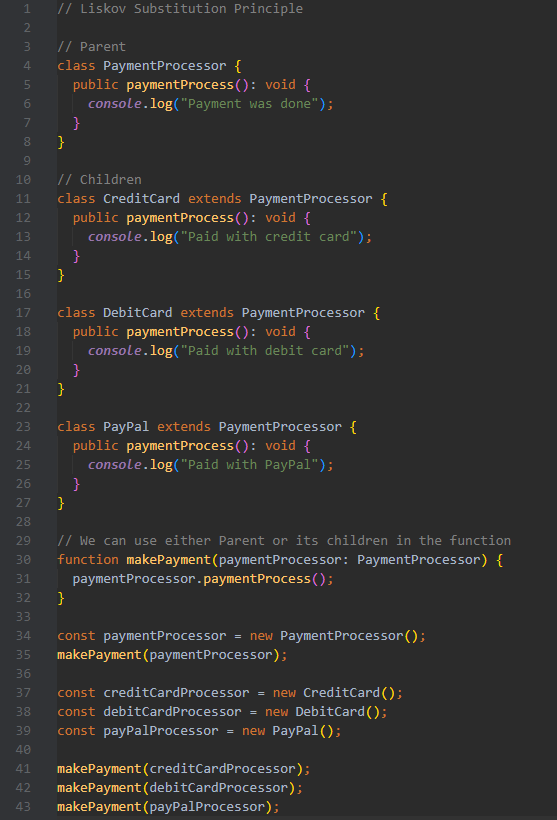
**Liskov Substitution Principle (LSP)**
Subtypes must be substitutable for their base types. In other words, wherever Parent is used, it could be replaced by Child without affecting the functionality of the program (without altering the existing code).
*Advantages:*
- New classes can be added without breaking existing functionality
- Enables creating substitutional parts of complex systems
- Enhanced reusability
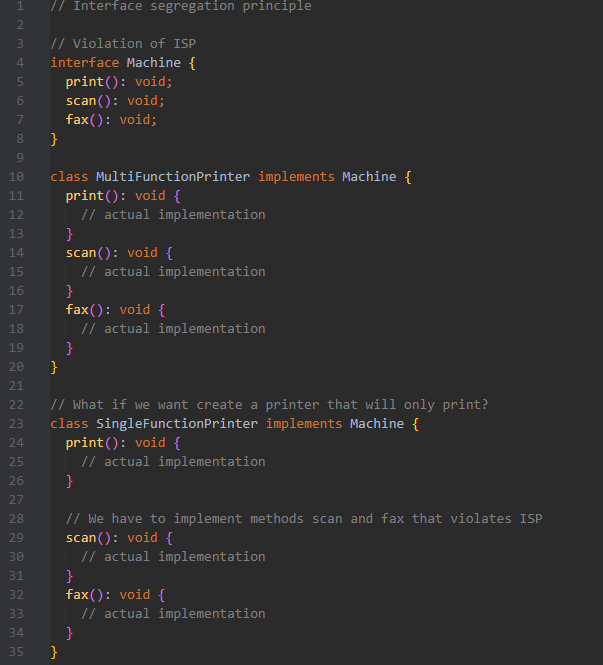
**Interface Segregation Principle (ISP)**
No client should be forced to depend on methods it does not use. In other words, instead of adding new methods to an existing interface, create a new interface.
*Advantages:*
- Smaller, more understandable interfaces
- Changes in one interface do not impact unrelated classes
- Enhanced reusability
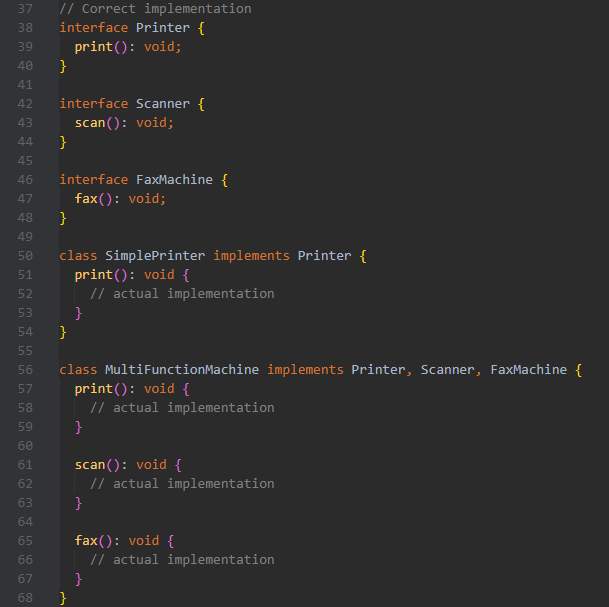
**Dependency inversion principle (DIP)**
High-level modules should not depend on low-level modules.
Both should depend on abstractions.
Abstractions should not depend on details.
Details should depend on abstractions.
*High-level modules* - business logic, use cases
*Low-level modules* - writing to DB, handling HTTP requests
*Abstractions* - interfaces, abstract classes
*Details* - concrete classes
*Advantages:*
- Promotes flexible and reusable code
- Reduces coupling between different parts of the codebase
- Enhanced reusability
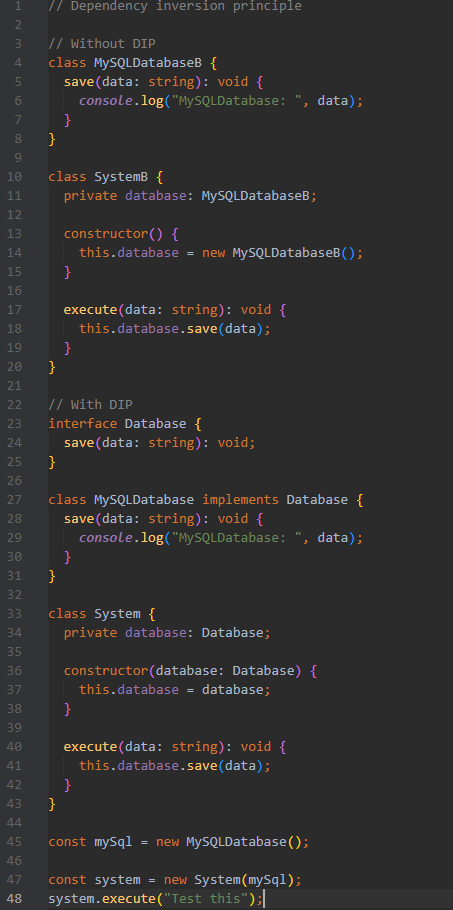 | vivecodes |
1,869,647 | Moving away from class components and inheritance a Bad Idea!!! | I've read the docs including the docs Componentisation vs inheritance, however I completely disagree,... | 0 | 2024-05-29T21:04:15 | https://dev.to/mark_ellis_97da84e89cde02/moving-away-from-class-components-and-inheritance-a-bad-idea-469g | I've read the docs including the docs Componentisation vs inheritance, however I completely disagree, sure they say they use it on facebook and have never had the need for inheritance, but we are talking about facebook, where the interface is so ridiculously simple, no you more then likely wouldn't need inheritance. Inheritance is such a powerful tool and it can be used simultaneously with componentisation, which from years of experience with react makes it even more powerful. I'm not going to bother going into specific use cases, I have better things to do. but if the developers of react can't foresee that other developers are trying to build things that they could not even begin to comprehend was possible with their own framework, then this framework is doomed. this frame work in ye old days was great, it took care of the piddly crap that most developers couldn't be bothered with, but beyond that stayed out of the way. And it was fantastic, in-fact its a great shame that more frameworks don't follow the same model.
Unfortunately react is now starting to reach the point of dictating how I should code, and hence if it continues down this path it will get in my way, and when that day comes I'd sooner ditch react, either find another framework that does what I want, or build my own.
as for class components I prefer using classes because I think that it is the best way to adhere to the first and most important rule of coding, keeping code structured and readable, and yes for the same reason I loath the absolute overuse of arrow notation!!!! | mark_ellis_97da84e89cde02 | |
1,869,646 | newdigitalhub | I am mark taylor, working for newdigitalhub PR consultant, with more than six years of experience in... | 0 | 2024-05-29T21:04:14 | https://dev.to/marko_taylor_cc56ed3459fc/newdigitalhub-h5h | I am mark taylor, working for newdigitalhub PR consultant, with more than six years of experience in the PR and Digital Industry, helping teams achieve goals by streamlining the process. https://www.newdigitalhub.com/ | marko_taylor_cc56ed3459fc | |
1,869,645 | Deploying A Static Website with AWS S3 | Introduction Deploying a static website using Amazon S3 is a cost-effective and efficient way to host... | 0 | 2024-05-29T21:02:29 | https://dev.to/anson_ly/deploying-a-static-website-with-aws-s3-52fj | aws, s3, webdev | **Introduction**
Deploying a static website using Amazon S3 is a cost-effective and efficient way to host web content. In this guide, I’ll walk you through the steps to set up and deploy a static website on AWS S3. This process is ideal for hosting simple HTML, CSS, and JavaScript files without the need for server-side processing.
**Step 1 Create a S3 Bucket**
First I created an S3 bucket that will hold my website files.
**Step 2: Upload Website Files**
Next, you need to upload your website files to the S3 bucket. Select your bucket from the list and click the “Upload” button. Add your HTML, CSS, and JavaScript files. Once you’ve added the files, click “Upload” to add them to your bucket.
**Step 3: Configure the Bucket for Static Website Hosting**
Now, you need to configure the bucket to host your website. Navigate to the bucket’s properties by clicking on the “Properties” tab and scrolling down to the “Static website hosting” section. Enable static website hosting by selecting “Use this bucket to host a website”. Specify the index document (e.g., index.html) and optionally specify an error document (e.g., error.html). Finally, click “Save”.
**Step 4: Access Your Static Website**
Now, your static website is ready to be accessed. Go back to the “Properties” tab and in the “Static website hosting” section, you’ll find the URL of your website. Open this URL in your browser to see your static website live.
Here is the website using Github. [Link](https://ansonly15.github.io/Anson_Ly/)
**Conclusion**
Deploying a static website with AWS S3 is straightforward and offers a scalable, cost-effective solution for hosting web content. By following the steps outlined above, you can have your static site up and running in no time. For enhanced security and performance, consider integrating AWS CloudFront and using a custom domain with Route 53. Happy hosting! | anson_ly |
1,869,644 | Tailwind is the best CSS framework!? | I tried using several CSS frameworks, but Tailwind was the only one I could use. But I'm just... | 0 | 2024-05-29T21:01:43 | https://dev.to/devguilhermeribeiro/tailwind-is-the-best-css-framework-iap | webdev, programming, tailwindcss | I tried using several CSS frameworks, but Tailwind was the only one I could use. But I'm just starting out in backend web development with RoR. Let's see what happens!? | devguilhermeribeiro |
1,869,639 | How to monitor all AWS Console logins and failed attempts with CloudTrail and CloudWatch - Terraform automation | You never know when a bad guy wants to send birthdays alerts with Lambda.. just joking :D He probably... | 0 | 2024-05-29T20:54:53 | https://dev.to/montaigu/how-to-monitor-all-aws-console-logins-and-failed-attempts-with-cloudtrail-and-cloudwatch-terraform-automation-2pi1 | aws, devops | You never know when a bad guy wants to send birthdays alerts with Lambda.. just joking :D He probably will want to use your AWS account for his purposes and you'll end up with xxxx bill at the end of the month.
In the following article it will be explained how to monitor all the AWS Console login events and also the monitoring of the failed attempts.
I suggest to open the CloudTrail in eu-east-1 to also monitor all console login events.
You need to create a trail which sends the logs into S3 just optional, and very important in this case to send them to a CloudWatch group.
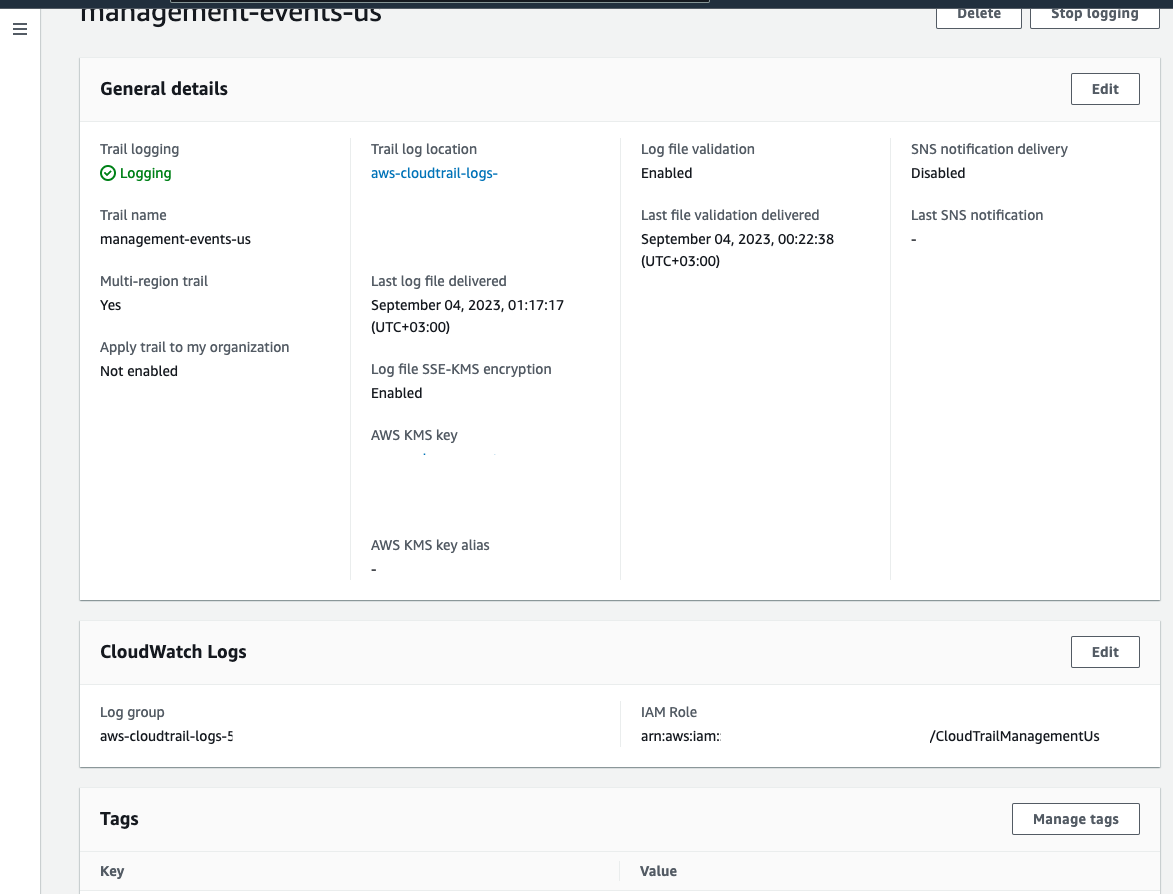
And the event history will look like this:

When all is set you need to go to the CloudWatch group to see if there are some streams:
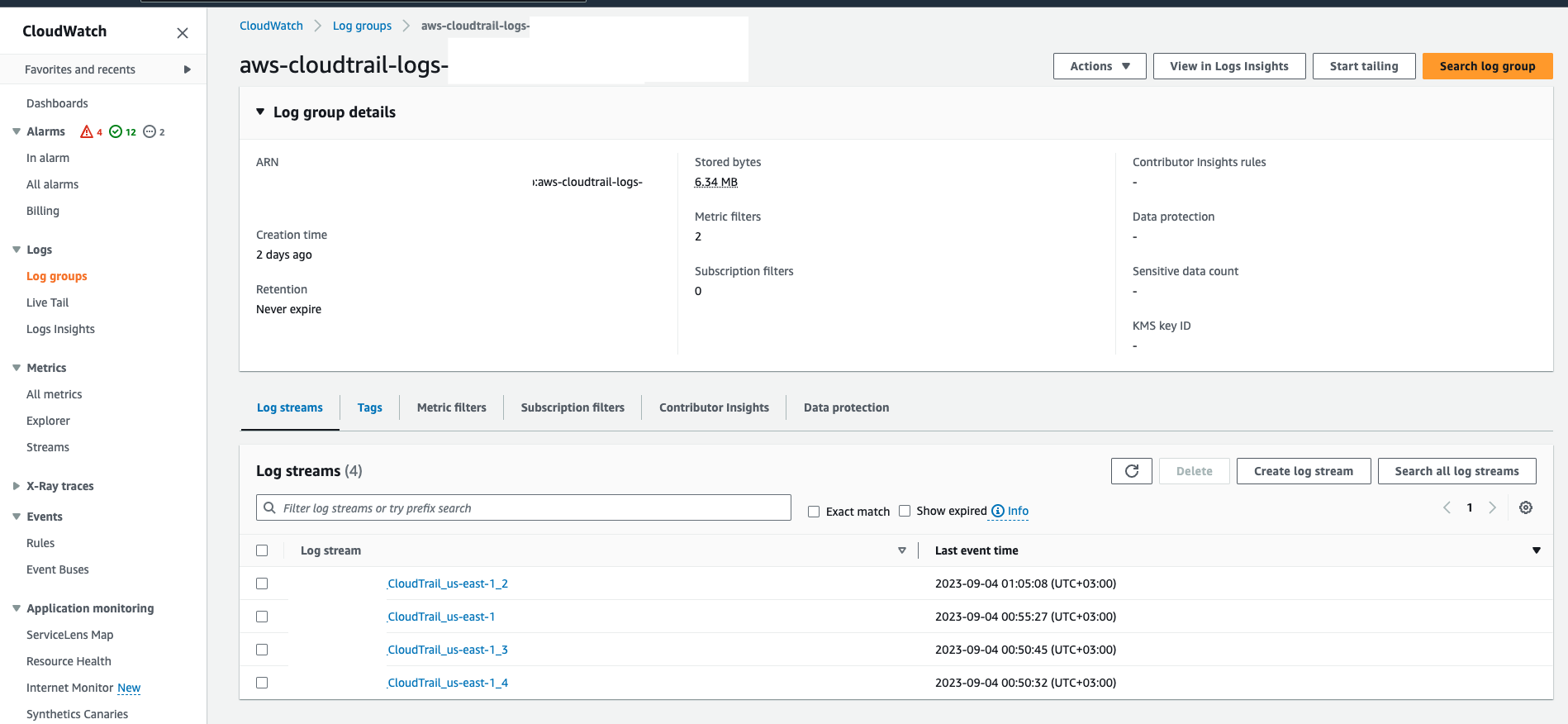
And need to create two metrics in this group:
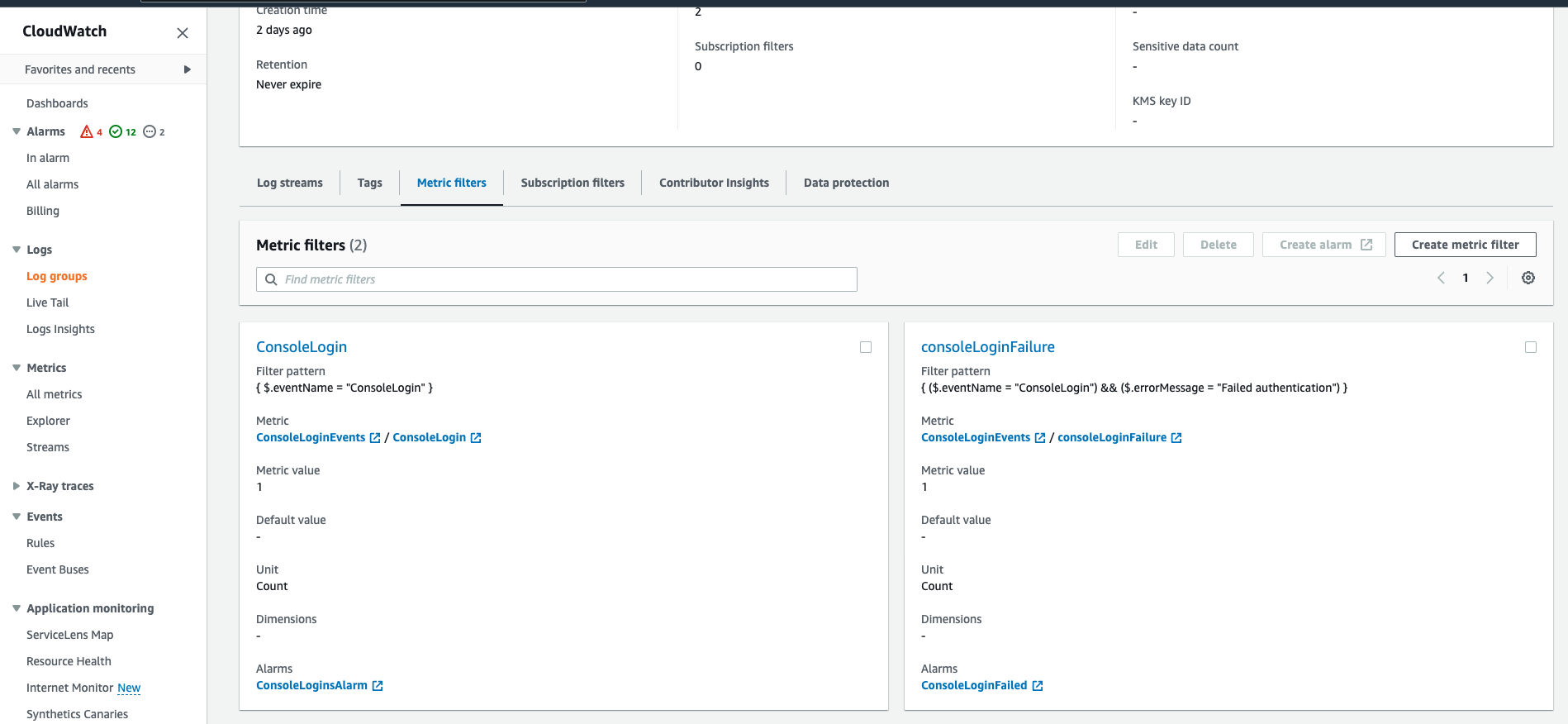
One which will be for all ConsoleLogin events with a filter on: { $.eventName = "ConsoleLogin" }
And the other on failed console login attempts: { ($.eventName = "ConsoleLogin") && ($.errorMessage = "Failed authentication") }
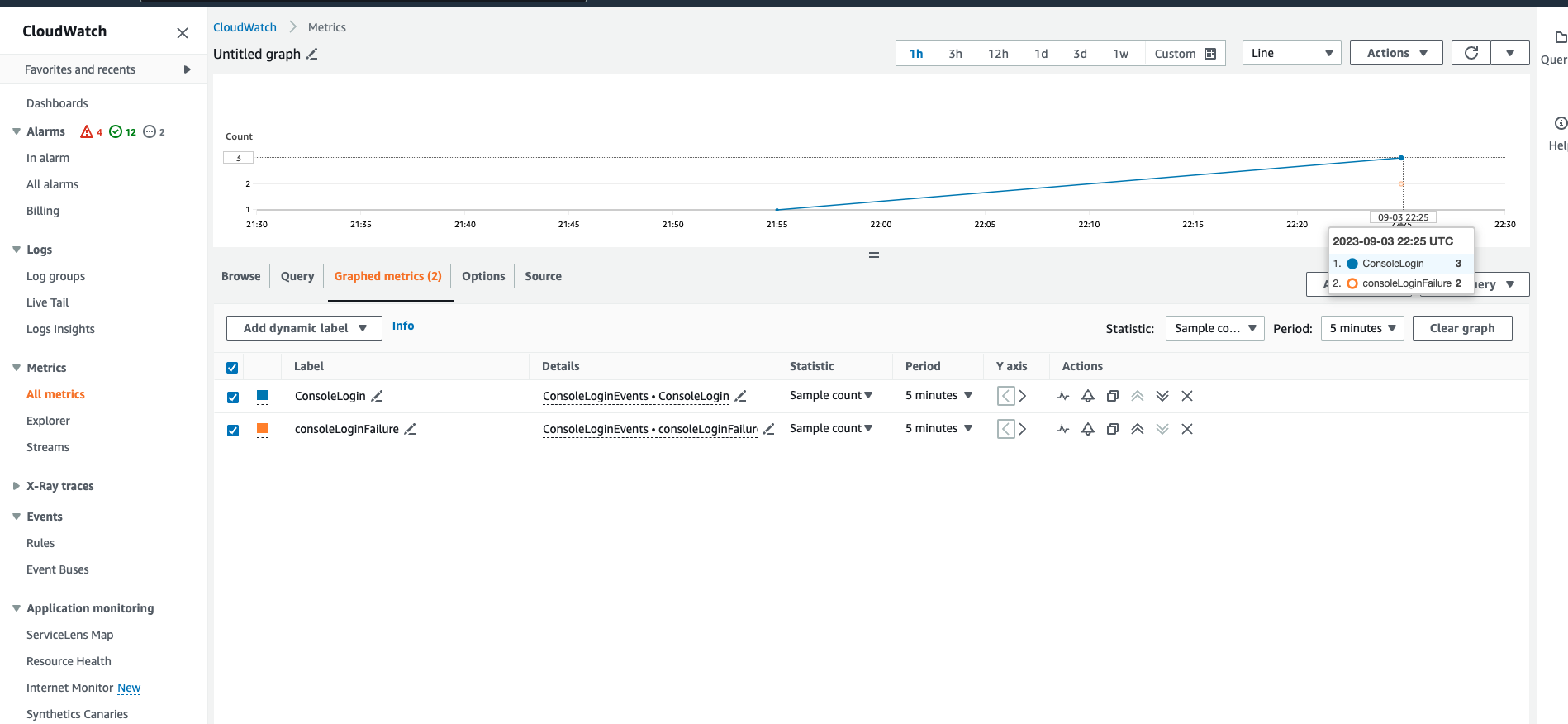
If everything goes well just do some console logins as a test, also fail some of those. The result in these two metrics should be:
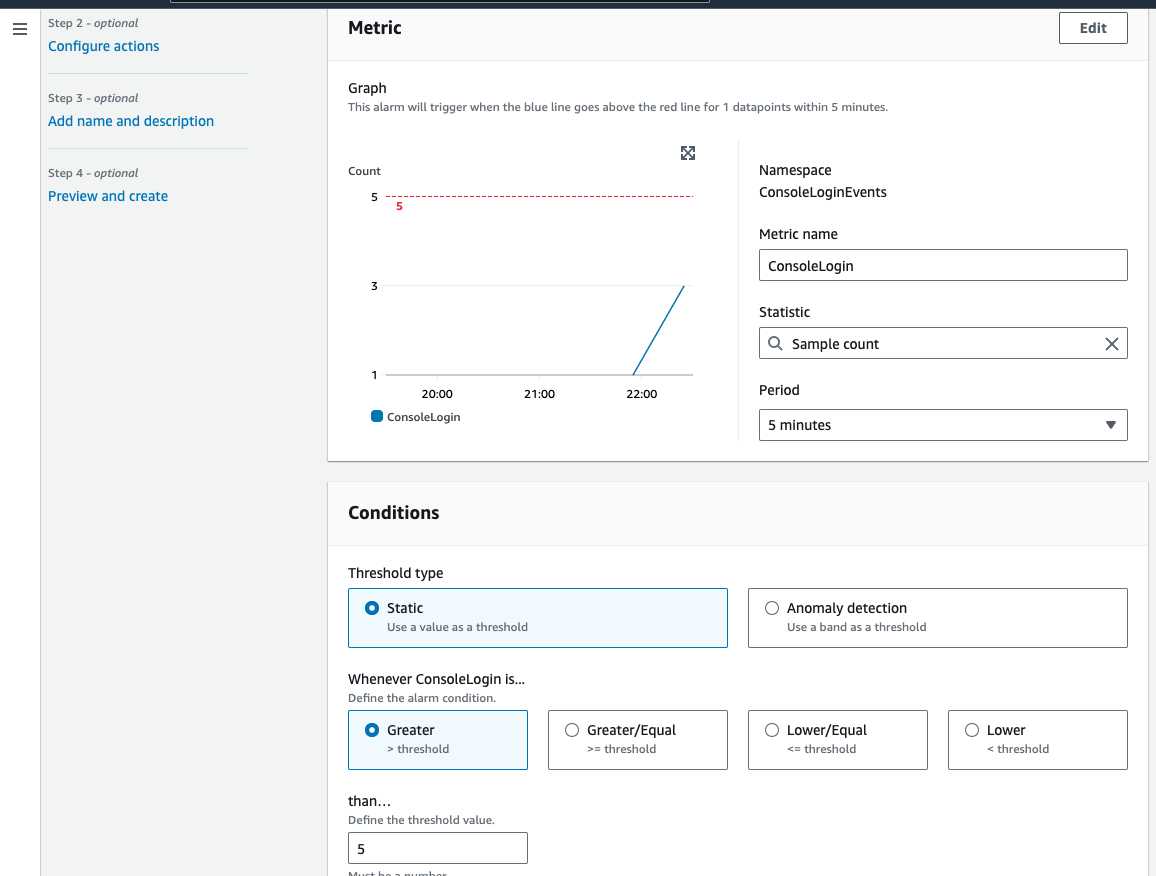
Afterwards you can set some alarms. For All logins:
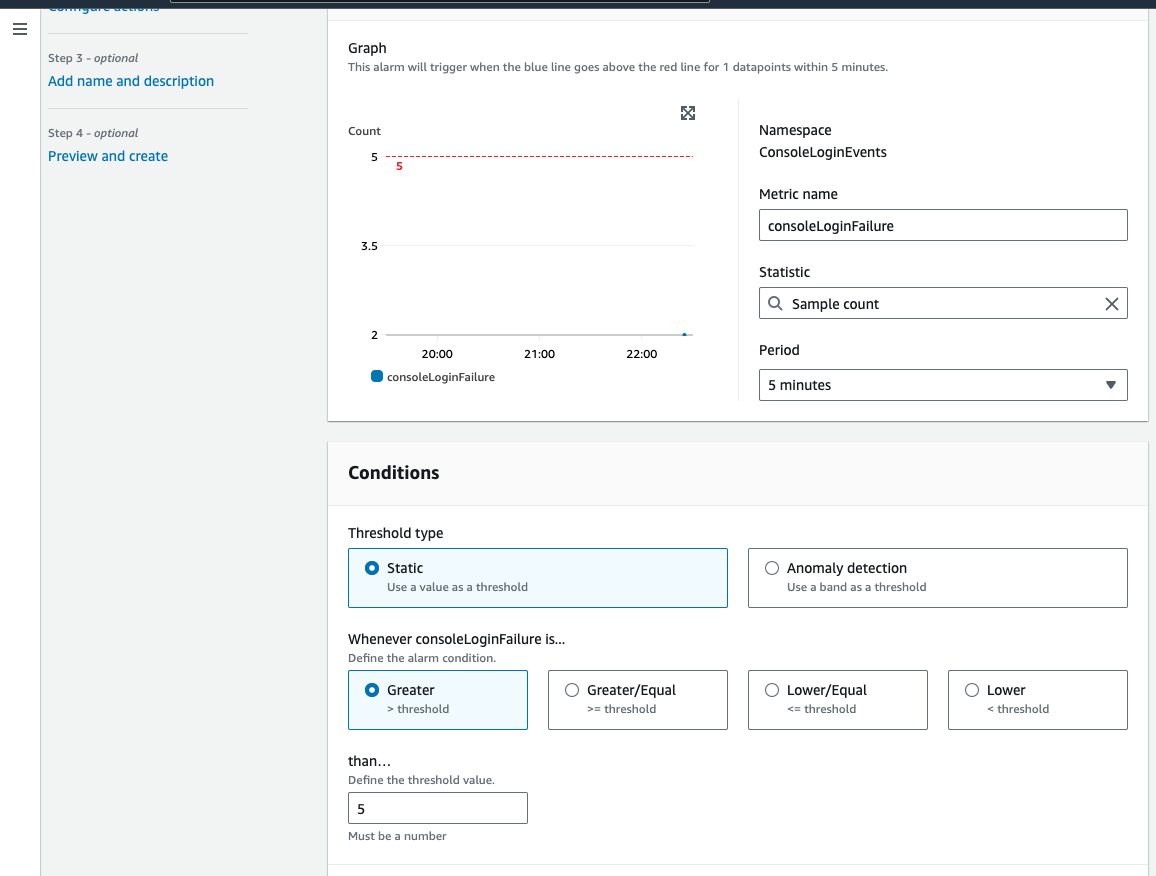
And for failed ones:
And both to send emails or sms through and SNS topic.
Some Terraform code to automate a bit the entire process:
The cloudtrail logic and the role link:
```
provider "aws" {
region = "us-west-1"
}
resource "aws_sns_topic" "cloudtrail_alerts" {
name = "cloudtrail-alerts"
}
resource "aws_cloudwatch_log_group" "cloudtrail_log_group" {
name = "cloudtrail-log-group"
}
resource "aws_cloudtrail" "main" {
name = "cloudtrail-example"
s3_bucket_name = aws_s3_bucket.cloudtrail_bucket.bucket
cloud_watch_logs_group_arn = aws_cloudwatch_log_group.cloudtrail_log_group.arn
cloud_watch_logs_role_arn = aws_iam_role.cloud_watch_logs_role.arn
enable_logging = true
}
resource "aws_s3_bucket" "cloudtrail_bucket" {
bucket = "my-cloudtrail-bucket"
}
resource "aws_iam_role" "cloud_watch_logs_role" {
name = "CloudWatchLogsRole"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "cloudtrail.amazonaws.com"
}
}
]
})
}
```
The filter on metrics for logins:
```
resource "aws_cloudwatch_metric_filter" "console_login" {
name = "ConsoleLogin"
pattern = "{ $.eventName = \"ConsoleLogin\" }"
log_group_name = aws_cloudwatch_log_group.cloudtrail_log_group.name
}
resource "aws_cloudwatch_metric_filter" "failed_console_login" {
name = "FailedConsoleLogin"
pattern = "{ ($.eventName = \"ConsoleLogin\") && ($.errorMessage = \"Failed authentication\") }"
log_group_name = aws_cloudwatch_log_group.cloudtrail_log_group.name
}
```
And the alarms linked to the metrics:
```
resource "aws_cloudwatch_metric_alarm" "console_login_alarm" {
alarm_name = "ConsoleLoginAlarm"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "1"
metric_name = "ConsoleLogin"
namespace = "CloudTrailMetrics"
period = "300"
statistic = "SampleCount"
threshold = "5"
alarm_description = "This metric checks for console logins"
alarm_actions = [aws_sns_topic.cloudtrail_alerts.arn]
}
resource "aws_cloudwatch_metric_alarm" "failed_console_login_alarm" {
alarm_name = "FailedConsoleLoginAlarm"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "1"
metric_name = "FailedConsoleLogin"
namespace = "CloudTrailMetrics"
period = "300"
statistic = "SampleCount"
threshold = "5"
alarm_description = "This metric checks for failed console logins"
alarm_actions = [aws_sns_topic.cloudtrail_alerts.arn]
}
```
| montaigu |
1,869,640 | HOW TO CONNECT AN IOT FIELD DEVICE (RASPBERRY PI SIMULATOR) FROM THE FIELD TO AN AZURE CLOUD IOT HUB FOR COMMUNICATION AND DATA | What is IOT? Internet of Things (IoT) Central in Microsoft Azure is a managed IoT application... | 0 | 2024-05-29T20:54:13 | https://dev.to/atony07/how-to-connect-an-iot-field-device-raspberry-pi-simulator-from-the-field-to-an-azure-cloud-iot-hub-for-communication-and-data-iob | What is IOT?
Internet of Things (IoT) Central in Microsoft Azure is a managed IoT application platform that enables users to build, manage, and operate IoT solutions with ease. It provides a comprehensive and scalable environment for connecting, monitoring, and managing IoT devices, simplifying the deployment and management of IoT applications.
What is Raspberry PI Simulator?
Raspberry Pi Simulator is a powerful tool for prototyping, testing, and learning about Raspberry Pi projects and IoT applications, providing a virtual platform that mimics the functionality of a physical Raspberry Pi.
However, it allows users to simulate a Raspberry Pi with various sensors, interact with Azure services, and build IoT applications in a virtual environment.
Here’s a step-by-step guide on how to do this.
Step:1: Log on to Microsoft Azure account and search for IOT Hub
Step:2: Click on the Create Icon

Step:3: Fill the necessary details such as; Resource group, IOT hub name, Region, Tier, Daily message limit
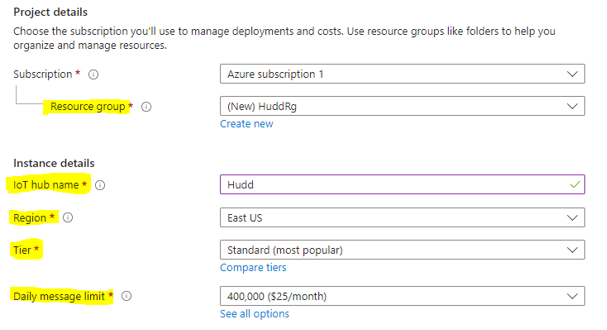
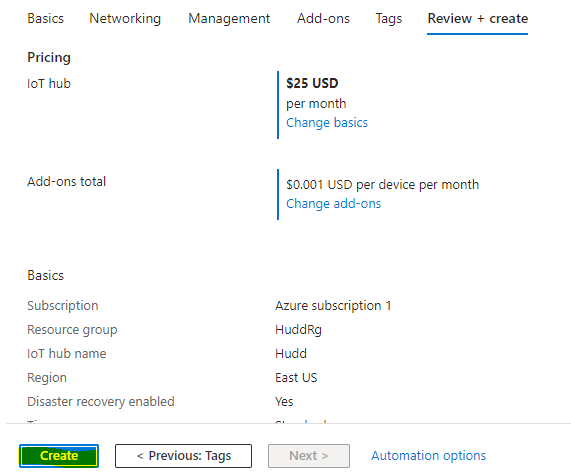
Step:4: Click Review+Create

Step:5: Click Create
Step:6: Wait for deployment to be completed
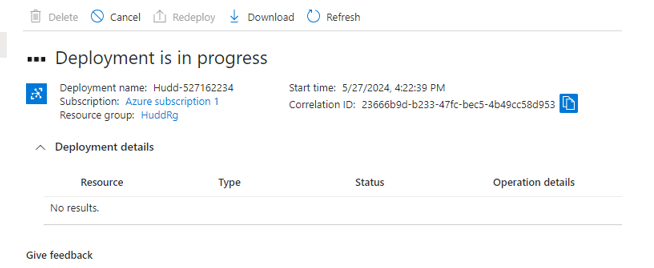
Step:7: Go to resource after deployment is completed
Step:8: You must create a device for it. Click on devices icon.
Step:9: Click on Add device
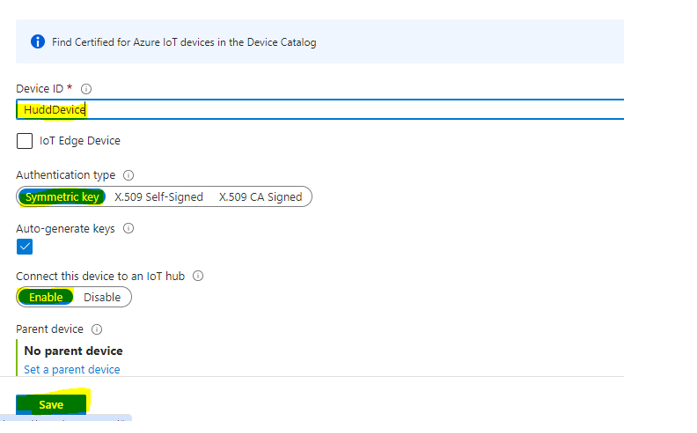
Step:10: Create (Device name, select “Symmetric key” and Enable) and save.
Step:11: Click on the device created

Step: 12: Copy “Primary connection string” and make sure Enable connection to IOT Hub is Enabled
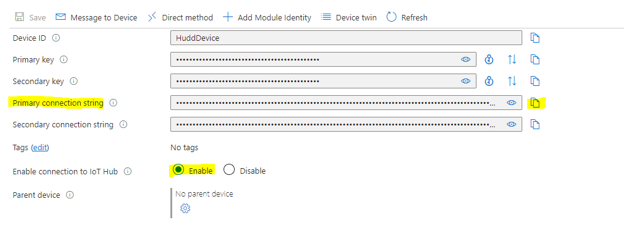
Step:13: Initiate https://azure-samples.github.io/raspberry-pi-web-simulator/ on a web browser , insert or paste the “primary connection string “ from the IOT device portal on Azure into “Line 15” on the Raspberry PI Simulator and click on RUN
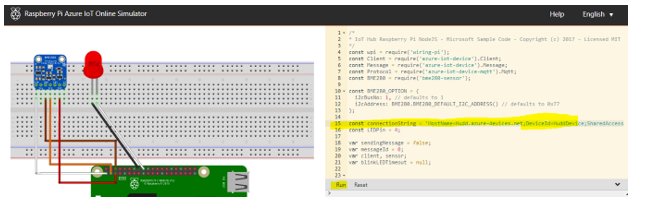
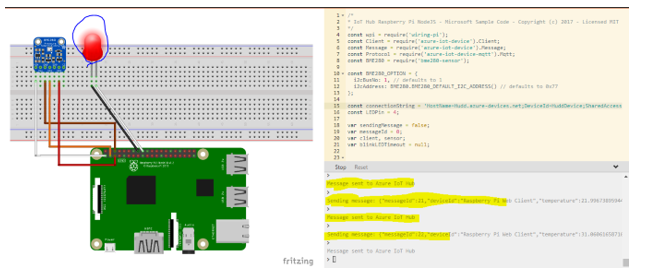
Step:14: Raspberry starts blinking Red hence, communicating to the IOT Device in Microsoft Azure portal and recording data or messages as seen below.
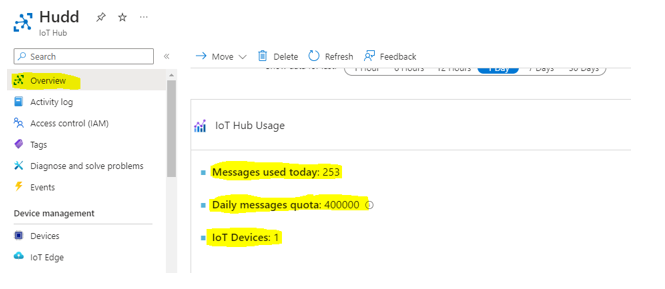
Step:15: Go back to IOT Hub overview to show the messages received
| atony07 | |
1,869,638 | Datalists or 50 lines of extra JavaScript and HTML? | If you’re looking to incorporate an autocomplete feature into your text input fields, there are two... | 0 | 2024-05-29T20:46:13 | https://dev.to/wagenrace/datalists-or-50-lines-of-extra-javascript-and-html-51j1 | webdev, javascript, html, beginners | If you’re looking to incorporate an autocomplete feature into your text input fields, there are two options available: using [datalist](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/datalist) or writing some JavaScript. I experimented with both on my website to compare their pros and cons. The main difference are in my [pull request 42](https://github.com/rate-my-drink/rate-my-drink.github.io/pull/42/files).
> # This blog is part of [caffeinecritics.com](https://caffeinecritics.com/) the code can be found on[ GitHub](https://github.com/rate-my-drink/rate-my-drink.github.io).
## Datalists
](https://cdn-images-1.medium.com/max/2000/0*U2s5ChTsAN0gty0t)
With just a few lines of code, you can easily add autocomplete functionality to your input fields. The code is surprisingly simple and took me much more code to accomplish without it.
> # *Code is not the product, it is the liability of the product.*
```html
<input
type="text"
class="border-grey-light block w-full rounded border p-3"
list="all-current-producers"
v-model="producerName"
@input="updateProducer()"
/>
<datalist id="all-current-producers">
<option v-for="producer in producers" :value="producer.name"></option>
</datalist>
```
According to recent statistics, Datalist is supported by a whopping [97.5%](https://caniuse.com/?search=datalist) of websites. However, there’s one notable exception — Firefox for Android, which does not support Datalist. However, it only has a market share of 0.3%. This minor setback can be particularly frustrating given that I use this browser personally. Additionally, some browsers offer integration with Datalist, such as Chrome for Android, which allows users to easily access and utilize the feature through the keyboard.
 use Chrome for Android](https://cdn-images-1.medium.com/max/2160/0*rd0gPZ-y17-VPE-A)
However, there is a drawback to using datalists. By default, the browser styles them, which means you have limited control over their appearance. While you can overwrite this by adding your own CSS, doing so requires extra effort and additional JavaScript code.
## Own JavaScript
](https://cdn-images-1.medium.com/max/2000/0*cJAxKBfnZno2cYFG)
Our own JavaScript will improve across various platforms, including Firefox on Android. However, it’s worth noting that some browsers may lose their unique integration features. On the other hand, you’ll regain a significant amount of styling freedom. I must admit, I prefer the new look much more, but it requires additional effort to ensure seamless support for mobile browsers as well.
## Conclusion
Datalists have some advantages and disadvantages. On the plus side, they offer less code and better integration with web browsers, making it easier to use them. However, there are also some drawbacks to consider. For instance, styling Datalists can be more challenging, and they’re not supported by Firefox on Android devices. Personally, I opted for Datalists because I prefer to keep my code simple.
| wagenrace |
1,869,799 | How to avoid spam when putting an email on a website? | Sometimes we want to put an email on a website but without exposing it to be read by some random bot... | 0 | 2024-05-30T18:08:23 | https://coffeebytes.dev/en/how-to-avoid-spam-when-putting-an-email-on-a-website/ | opinion, seo, beginners, webdev | ---
title: How to avoid spam when putting an email on a website?
published: true
date: 2024-05-29 20:46:07 UTC
tags: opinion,seo,beginner,webdev
canonical_url: https://coffeebytes.dev/en/how-to-avoid-spam-when-putting-an-email-on-a-website/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/43920yu6w57v86r11ifx.jpg
---
Sometimes we want to put an email on a website but without exposing it to be read by some random bot that includes us in an advertising list, reminding us of our problems to start a physical relationship with the two mature women who live less than two kilometers away. And since we don’t want that, there are several things we can do to solve this and here I present some solutions, the last one is the one I usually use and also my favorite.
[](images/prince-from-nigeria-scam.jpg)
## Convert your email to an image
This way to protect your email address requires no detailed explanation, just turn your email into an image and place it, your address will be safe from any text scraping bot, but it will be vulnerable to any bot with [OCR (Optical Character Recognition) capabilities, bots with pytesseract for example](https://coffeebytes.dev/en/ocr-with-tesseract-python-and-pytesseract/), which I predict will be few if any.
[](images/email-image.jpg)
The disadvantage of this approach is that the person who wants to send you an email will have to type it in manually, as they can’t copy-paste, and you know that every extra step adds friction to the conversion process.
## Use a different email notation
Instead of using the classic format like _[my@email.com](mailto:my@email.com)_, change it to something less obvious to bots, like _my [at] email [dot] com_, this way your address won’t be detected as an email by less sophisticated bots and if someone wants to send you an email just replace the _at_ and _dot_ with their corresponding symbols.
A pretty balanced option in my opinion, although if it becomes popular I’m sure my blue pill factory ambassadors will find a way to get the valuable information they need.
## Ask the user to generate the email with extra information
Another way is not to put the email directly, but a hint as to how it can be deduced, for example if the site is called _lain.com_ you can write a text as a hint that says something like:
> _“My email is the name that appears in the url and is a google email address”_.
With that it will understand that the address is _[lain@gmail.com](mailto:lain@gmail.com)_.
Just try not to complicate things too much here, don’t overestimate the deductive capabilities of the average web surfer.
## Use a form instead of an email address
Another option is to completely forget about placing your email and use a form instead, this way your email will be safe and you can direct the emails to a unique account that you use for that single purpose.
### Protect your form from spam with a captcha
Of course some bots will try to fill out the form to send you advertisements but you can always use [a strong captcha to protect yourself from spam](https://coffeebytes.dev/en/my-analysis-of-anti-bot-captchas-and-their-advantages-and-disadvantages/)
[](images/captcha-frieren-fern.webp)
### Use custom email spam filters
If you don’t want to use captchas you can leave the responsibility of recognizing spam to your email provider’s filters, or use a customized filter created by you and combine it with some instruction like:
> _“To know that you are not a bot, please include the word jelly bean in your email. ”_ \*.
Now just set up your filter and automatically delete all emails that do not meet this condition.
## Generate your email dynamically to avoid spam
This is my favorite, to achieve this we can use some kind of simple encryption, or even base64, **encode our email address in base64 and then decode it in the frontend dynamically using Javascript** , this way the bots will only see a bunch of numbers and letters in the source code, to read the email they will need to render the page with javascript enabled, which eliminates those bots that only read the source code of the response.
``` javascript
// this comes from the server
const encodedEmail = "eW91YXJlY3VyaW91c0BpbGlrZWl0LmNvbQ=="
// atob decodes from base64
const decodedEmail = atob(encodedEmail)
```
For an ordinary user, the email will be displayed as if it were included in the source code of the page.
Any user can copy-paste without any hassle, easy peasy.
### Generate an email dynamically with user interaction.
To make this protection method more secure we can delay the decoding until the user presses a button, scrolls, makes a mouse movement or even use the intersection observer to decode it only if the email is on screen; the limit is your imagination. | zeedu_dev |
1,869,636 | Mysterious /sink route in ui.shadcn.com | I found a mysterious sink folder in the shadcn-ui/ui. All these folders in the above image are... | 0 | 2024-05-29T20:42:32 | https://dev.to/ramunarasinga/mysterious-sink-route-in-uishadcncom-13a4 | javascript, opensource, nextjs, shadcnui | I found a mysterious [sink folder](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/%28app%29/sink/layout.tsx) in the shadcn-ui/ui.

All these folders in the above image are pages that can be navigated to via the header on [https://ui.shadcn.com/](https://ui.shadcn.com/) website. However, I could not find the header link that points to /sink in the header

> [Build shadcn-ui/ui from scratch.](https://tthroo.com/)
I tested to see if anything loads when I visit [/sink](https://ui.shadcn.com/sink) and to my surprise, there are some example components loaded.

Let’s find out it’s purpose.
I searched for any existing issues on shadcn-ui/ui Github and found 2 issues and 1 pull request reported:
1. [https://github.com/shadcn-ui/ui/pull/1446](https://github.com/shadcn-ui/ui/pull/1446)
2. [https://github.com/shadcn-ui/ui/issues/3533](https://github.com/shadcn-ui/ui/issues/3533)
3. [https://github.com/shadcn-ui/ui/issues/441](https://github.com/shadcn-ui/ui/issues/441)
I could not get much context from 1, 2 listed above but [#441](https://github.com/shadcn-ui/ui/issues/441) provides some meaningful context.
The purpose of /sink route might be to provide a showcase page with preview for improved usability. You can read more in the [issue reported](https://github.com/shadcn-ui/ui/issues/441)
### Conclusion:
/sink in shadcn-ui/ui is not so mysterious once I found out the existing pull requests around it. It might be a WIP and its purpose is to add a comprehensive component showcase page with preview for improved usability. | ramunarasinga |
1,869,635 | AWS Cloud Resume Challenge | I came across the Cloud Resume Challenge by my mentor as I am trying to build a career in AWS. I am a... | 0 | 2024-05-29T20:35:36 | https://dev.to/anson_ly/aws-cloud-resume-challenge-h2g | aws, awschallenge, beginners, serverless | I came across the Cloud Resume Challenge by my mentor as I am trying to build a career in AWS. I am a recent Masters' graduate majoring in Cloud Computing Systems. Up until this program I don't have much exposure to the cloud since I majored in Psychology for undergrad. [Here is my github](https://ansonly15.github.io/Anson_Ly/)
**How I Did**
**Front-End**
With experience from a full-stack program I coded my resume using basic HTML and CSS. Then I uploaded my file to an S3 Bucket which then connects to a CloudFront.
**Back-End**
I started by deploying my backend services using the AWS Management Console. I began with Amazon DynamoDB, setting up a table with an ID and a value of 1. Then, I created a Lambda function to increment this value each time it was triggered. Initially, I deployed two Lambda functions—one for reading the value and another for writing (incrementing) the value. However, this approach made my architecture unnecessarily complicated and caused multiple issues with API Gateway integration.
**Infrastructure as Code with Terraform**
While the challenge suggested using AWS SAM, I decided to use Terraform because it is more widely used in the industry and has excellent documentation. Coding my entire backend in Terraform presented its own set of challenges, particularly with CORS issues in API Gateway. Unlike the AWS Console, Terraform does not have a simple "Turn on CORS" button, which made this part of the project the most time-consuming. I spent approximately 25-30 hours resolving these issues. Despite the frustration, this was also the most exciting part of the challenge, as it significantly deepened my understanding of infrastructure as code (IaC).
**Implementing CI/CD Pipelines**
I uploaded my front-end and back-end code to separate GitHub repositories and used GitHub Actions to build CI/CD pipelines. This setup ensures that my site updates automatically upon a push from my IDE. I also utilized branches to test new code for compatibility with the main branch. For security, I stored my credentials as GitHub secrets for the front-end and used Terraform Cloud to manage credentials for the back-end.
After more than 100 hours of work, I finally completed the Cloud Resume Challenge.
**Conclusion**
This project has significantly expanded my knowledge of cloud services and enhanced my JavaScript skills. It is now a standout addition to my resume and a compelling example to present during job interviews. Moving forward, I plan to further develop my CI/CD pipelines by integrating Docker, Jenkins, and Kubernetes, and continue refining my project. Additionally, I aim to obtain the AWS Solutions Architect - Associate certification.
I highly recommend this challenge to anyone seeking hands-on experience with cloud technologies. It is particularly beneficial for college students looking to gain practical project experience. Whether you are a novice or a seasoned professional, you will find this challenge both rewarding and educational.
| anson_ly |
1,869,634 | Unleashing Creativity: A Dive into Google DeepMind's Veo | Imagine a world where creating stunning visuals is as easy as writing a sentence. Google DeepMind's... | 0 | 2024-05-29T20:33:13 | https://dev.to/shishsingh/unleashing-creativity-a-dive-into-google-deepminds-veo-5g67 | google, machinelearning, ai, openai | Imagine a world where creating stunning visuals is as easy as writing a sentence. Google DeepMind's Veo, a cutting-edge text-to-video model, brings us closer to this reality. Let's delve into the world of Veo, exploring its capabilities, functionalities, and the exciting potential it holds.
## Understanding Google DeepMind and Veo
Google DeepMind is a pioneering artificial intelligence (AI) research lab pushing the boundaries of machine learning. Veo, their latest innovation, stands as their most powerful video generation model yet. It transcends previous limitations, generating high-resolution (1080p) videos exceeding a minute in length.
**DeepMind**
- Pioneering artificial intelligence (AI) research lab at Google.
- Focuses on pushing the boundaries of machine learning to create safe and beneficial AI systems.
- Aims to solve intelligence and advance scientific discovery through AI.
**Veo**
- DeepMind's most powerful video generation model to date.
- Generates high-quality, 1080p resolution videos exceeding a minute in length.
- Creates videos in various cinematic and visual styles based on text prompts.
- Can take an image and a text prompt to generate a video that incorporates both the image's style and the prompt's instructions.
- Extends short video clips to full-length videos.
- DeepMind is committed to responsible use of Veo and incorporates safety filters and watermarking techniques.
- In essence, DeepMind is the AI research lab, and Veo is one of their latest creations that utilises machine learning to generate creative video content.
## How Does Veo Function?
Veo operates like a creative translator, interpreting your textual descriptions and weaving them into captivating visuals. Here's a simplified breakdown:
**Textual Input:** You provide a detailed description of the video you envision. This could be anything from a bustling cityscape to a heartwarming story.
**AI Processing:** Veo's internal AI engine goes to work, dissecting your text and identifying key elements like objects, actions, and settings.
**Video Generation:** Leveraging its vast knowledge base and machine learning capabilities, Veo generates a video that aligns with your description. From capturing the essence of a bustling city to replicating specific cinematic styles, Veo strives to bring your vision to life.
## Mechanisms Behind the Magic
While the specifics of Veo's inner workings remain under wraps, we can explore some of the critical development models powering its functionality:
**Deep Learning:** Veo is likely fueled by deep learning architectures, particularly convolutional neural networks (CNNs) adept at image and video recognition. These networks analyze vast amounts of video data, learning the intricate relationships between text descriptions and their corresponding visuals.
**Generative Adversarial Networks (GANs):** GANs are a type of deep learning model where two neural networks compete. One network (generator) creates new data (videos in this case), while the other (discriminator) tries to differentiate the generated data from real data. This competitive process helps Veo refine its video generation capabilities over time.
## Using Veo: A Glimpse into the Future
Currently, Veo isn't publicly available. However, DeepMind's vision is to democratize video creation. Imagine a future where:
**Content Creators:** YouTubers, filmmakers, and animators can leverage Veo to generate storyboards, create concept scenes, or even produce entire videos based on their scripts.
**Educators:** Veo can craft engaging educational videos by translating complex concepts into visually captivating narratives.
**The Everyday User:** Anyone with a story to tell can use Veo to bring their ideas to life, fostering a new era of creative expression.
**Code Example (Illustrative Purpose Only):**
While the actual code for Veo is likely complex and proprietary, here's a simplified Python illustration to conceptualise the text-to-video process:
```
# Function to process text description
def process_text(text):
# Extract key elements like objects, actions, and settings
# ... (code for text processing)
return elements
# Function to generate video based on elements
def generate_video(elements):
# Use deep learning models to translate elements into video frames
# ... (code for video generation)
return video
# User input
text_description = "A spaceship blasts off from a futuristic city at sunrise"
# Generate video
elements = process_text(text_description)
video = generate_video(elements)
# Display the generated video
# ... (code for video display)
```
## A Responsible Future for AI-Generated Content
DeepMind acknowledges the ethical considerations surrounding AI-generated content. Veo incorporates safety filters and watermarking techniques (like DeepMind's SynthID) to ensure responsible use and mitigate potential biases.
## Conclusion: A New Dawn for Video Creation
Veo represents a significant leap forward in text-to-video technology. Its potential to democratise video creation and empower storytellers is truly exciting. As Veo continues to evolve, we can expect even more breathtaking visuals and groundbreaking applications that will reshape the landscape of video production.
## References
Cover: https://voi.id/en/technology/384540
## Connects
Check out my other blogs:
[Travel/Geo Blogs](shishsingh.wordpress.com)
Subscribe to my channel:
[Youtube Channel](youtube.com/@destinationhideout)
Instagram:
[Destination Hideout](https://www.instagram.com/destinationhideout/) | shishsingh |
1,869,632 | The Costly Scam: How a Mechanic Duped Me on My Hybrid's ABS Repair | Owning a hybrid vehicle comes with its share of perks and responsibilities. With advanced technology... | 0 | 2024-05-29T20:30:47 | https://dev.to/sabrina_spellmen_02c6c3a1/the-costly-scam-how-a-mechanic-duped-me-on-my-hybrids-abs-repair-lhl | Owning a hybrid vehicle comes with its share of perks and responsibilities. With advanced technology and fuel efficiency, it’s the perfect choice for the environmentally conscious driver. But my recent experience with a shady mechanic turned what should have been a routine repair into a dramatic and costly ordeal. Here’s how I was duped and what I learned from the experience.
The Initial Problem
One day, as I was driving home from work, my dashboard lit up like a Christmas tree. The ABS (Anti-lock Braking System) warning light was on, accompanied by an unsettling grinding noise when I braked. My heart sank. The ABS is a critical safety feature, and I knew I needed to get it checked out immediately.
Seeking Help
I quickly searched online for a nearby mechanic and found one with seemingly good reviews. The shop looked professional enough, and the mechanic, let’s call him Mike, seemed knowledgeable. He assured me that he’d dealt with ABS issues on hybrids before and promised a quick and affordable fix.
The Dramatic Turn
Mike called me later that day with a grave tone in his voice. “Your ABS system is in worse shape than I thought,” he said. “There are multiple components that need replacing, and it’s going to cost you around $1,000.” My stomach churned. That was a significant amount of money, but Mike insisted it was necessary for my safety. With a mix of anxiety and hesitation, I authorized the repair.
When I picked up my car, Mike handed me a lengthy bill and a bag of replaced parts. He went over the supposed repairs in technical jargon, which only added to my confusion and unease. I paid the bill, though my gut told me something wasn’t right.
The Aftermath
A few days later, the ABS warning light came back on. Frustrated and worried, I decided to get a second opinion. I took my car to a reputable hybrid specialist. After a thorough inspection, the specialist delivered some shocking news: most of the parts Mike had replaced were perfectly fine, and the actual problem was a minor issue that cost only $150 to fix.
The Emotional Rollercoaster
Learning I had been scammed left me feeling a mix of anger, frustration, and betrayal. I had trusted Mike with my vehicle and my safety, and he had taken advantage of my lack of technical knowledge. The experience was a harsh wake-up call, highlighting the importance of being vigilant and informed when dealing with car repairs.
How to Protect Yourself from Mechanic Scams
1. Research Thoroughly
Before choosing a mechanic, do your homework. Look for reviews from multiple sources, check for any complaints with the Better Business Bureau, and ask friends or family for recommendations.
2. Get Multiple Quotes
Don’t settle for the first estimate you receive. Getting quotes from at least two or three different mechanics can give you a better idea of what the repair should cost.
3. Ask for Detailed Explanations
A trustworthy mechanic will be willing to explain the issues in detail and show you the damaged parts. If they’re using jargon to confuse you, that’s a red flag.
4. Request the Old Parts
Always ask to see the old parts that were replaced. This can help ensure that the parts were indeed faulty and needed replacement.
5. Trust Your Instincts
If something doesn’t feel right, it probably isn’t. Don’t be afraid to walk away and seek another opinion if you’re unsure about the diagnosis or cost.
6. Educate Yourself
Understanding the basics of your vehicle can help you make more informed decisions. There are plenty of resources online where you can learn about common car issues and repairs.
Conclusion
Getting scammed by a mechanic was a costly lesson, but it taught me the importance of being proactive and cautious. By following these steps, you can protect yourself from unscrupulous mechanics and ensure that your vehicle gets the care it needs without unnecessary expenses. Remember, your safety and peace of mind are worth the extra effort. | sabrina_spellmen_02c6c3a1 | |
1,867,496 | The AI Threat: Will Developers Lose Their Jobs? | Introduction Artificial Intelligence is no longer a concept of the distant future, it is a... | 0 | 2024-05-29T20:27:03 | https://dev.to/wafa_bergaoui/the-ai-threat-will-developers-lose-their-jobs-m9e | developers, ai, development, webdev | ## **Introduction**
Artificial Intelligence is no longer a concept of the distant future, it is a rapidly growing force reshaping various industries, including software development.
The rise of AI has brought significant advancements, making processes more efficient and enabling new capabilities that were once considered science fiction. However, this progress also comes with a looming concern: the potential of AI to replace human jobs.
According to a [report by Gartner](https://www.gartner.com/en/newsroom/press-releases/2021-05-19-gartner-says-70-percent-of-organizations-will-shift-their-focus-from-big-to-small-and-wide-data-by-2025), by 2025, AI will have **eliminated 85 million jobs** worldwide but will have also **created 97 million new ones**, highlighting a dynamic shift in the job market. In the realm of software development, this transformation is particularly evident as AI-driven tools and platforms increasingly automate coding tasks, optimize development workflows, and even generate code autonomously. This changing landscape necessitates developers to adapt and evolve to stay relevant.
## **Understanding the Threat of AI to Software Developers**
The integration of AI into software development raises concerns about job displacement among developers.
The threat AI poses to software developers can be understood through several dimensions:
**1. Automation of Coding Tasks**
AI-powered tools like GitHub Copilot and OpenAI Codex can assist in writing code, debugging, and even suggesting entire code blocks based on natural language descriptions.
These tools are designed to enhance productivity but also raise concerns about the redundancy of human developers for routine coding tasks. A [study by McKinsey Global Institute](https://www.mckinsey.com/~/media/mckinsey/business%20functions/mckinsey%20digital/our%20insights/where%20machines%20could%20replace%20humans%20and%20where%20they%20cant/where-machines-could-replace-humans-and-where-they-cant-yet.pdf) indicates that up to 45% of activities that individuals are paid to perform can be automated using current technology.
**2. Shift in Skill Requirements**
As AI takes over routine coding, the demand for developers with traditional programming skills may decrease. Instead, there will be a higher demand for those who can work alongside AI, understand its outputs, and integrate AI-driven solutions into broader systems. This shift requires developers to acquire new skills in AI and machine learning, data science, and advanced algorithmic understanding.
**3. Impact on Employment Opportunities**
The rise of AI has created a bifurcation in the job market. While entry-level coding jobs may decline, there is an increasing need for higher-level expertise in AI development, system architecture, and ethical AI implementation. [The World Economic Forum's Future of Jobs Report 2020](https://www3.weforum.org/docs/WEF_Future_of_Jobs_2020.pdf) suggests that the demand for AI and machine learning specialists is expected to grow significantly, with a projected 37% increase in the next five years.
## **AI-Powered Tools and Frameworks**
AI-powered tools and frameworks are revolutionizing software development, enhancing the quality of software through intelligent testing and debugging, and streamlining the development process. Some examples of AI-powered tools and frameworks include:
**[OpenAI Codex:](https://openai.com/index/openai-codex/)** This AI-powered tool translates natural language to code, allowing developers to build a natural language interface to existing applications.
**[GitHub Copilot:](https://github.com/features/copilot/)** This AI-powered tool assists developers in writing code by providing suggestions and recommendations based on the codebase.
**[AlphaCode:](https://alphacode.deepmind.com/)** This AI-powered tool generates code snippets based on natural language input, making it easier for developers to write and prototype code.
**[aiXcoder:](https://www.aixcoder.com/#/)** This AI-powered tool assists developers in writing code by providing suggestions and recommendations based on the codebase.
## **Securing Your Future as a Developer**
To stay relevant in the era of AI, developers must upskill and adapt to the changing landscape. Here are some strategies for developers to secure their future:
**1. Continuous Learning:**
Stay updated with the latest technologies and trends in AI and software development.
**2. Specialization:**
Focus on areas that are less susceptible to automation, such as complex problem-solving, creativity, and critical thinking.
**3. Collaboration with AI:**
Embrace AI as a tool to enhance your work rather than a threat.
**4. Soft Skills Development:**
AI may excel at processing data and performing specific tasks, but human creativity and problem-solving abilities remain unmatched. Developers who can blend technical prowess with strong soft skills will be more resilient to automation.
**5. Focus on Problem-Solving and Innovation**
AI can handle repetitive tasks efficiently, but humans are still superior at innovative thinking and solving complex, ambiguous problems. Developers should focus on building solutions that address real-world challenges and push the boundaries of what technology can achieve.
## **Conclusion**
The integration of AI into software development is a transformative force that will reshape the industry in ways previously thought unimaginable. While AI has the potential to automate certain tasks and processes, it also offers opportunities for developers to upskill and adapt to the changing landscape. By embracing AI as a collaborator rather than a competitor, software engineers can navigate this evolving landscape and contribute to the development of cutting-edge solutions that shape the future of technology.
---
The key is to adapt, evolve, and stay ahead of the curve in this ever-changing landscape.
If you want to stay up-to-date with the latest AI developments and trends, check out [my article](https://dev.to/wafa_bergaoui/staying-up-to-date-with-the-latest-ai-developments-and-trends-2kei) where I highlight the key strategies for achieving this.
| wafa_bergaoui |
1,869,612 | React 19: The Future of User Interface Development | Hello everyone, السلام عليكم و رحمة الله و بركاته React, developed and maintained by Facebook, has... | 0 | 2024-05-29T20:23:22 | https://dev.to/bilelsalemdev/react-19-the-future-of-user-interface-development-1jei | react, javascript, webdev, programming | Hello everyone, السلام عليكم و رحمة الله و بركاته
React, developed and maintained by Facebook, has been a pivotal library in the world of front-end development since its release. With each major version, React has introduced significant improvements and new features, pushing the boundaries of what's possible in web development. React 19, the latest version, continues this trend by bringing even more powerful tools and enhancements to developers. This article explores the key features and improvements in React 19 and what they mean for the future of user interface development.
#### Table of Contents
1. **Introduction to React 19**
2. **Concurrent Rendering Enhancements**
3. **Improved Server Components**
4. **Enhanced Developer Experience**
5. **New Hooks and APIs**
6. **Better Performance and Optimization**
7. **React Compiler**
8. **Backward Compatibility and Migration**
---
#### 1. Introduction to React 19
React 19 builds upon the solid foundation of previous versions, aiming to make UI development more efficient and enjoyable. This version focuses on improving performance, enhancing concurrent rendering capabilities, and providing a more seamless developer experience. With these updates, React 19 ensures that developers can build faster, more responsive applications.
---
#### 2. Concurrent Rendering Enhancements
Concurrent rendering is one of the standout features of React, allowing developers to create smooth, responsive user interfaces by breaking down rendering work into smaller units. React 19 introduces several enhancements to concurrent rendering:
- **Automatic Batching:** React 19 improves automatic batching of updates, which helps in reducing the number of re-renders and improving performance.
- **Suspense for Data Fetching:** Suspense has been extended to handle data fetching more gracefully, allowing components to wait for data before rendering without blocking the entire application.
- **Transition API:** This new API helps manage state transitions more effectively, enabling smoother UI updates and better user experiences.
---
#### 3. Improved Server Components
Server components, introduced in previous versions, allow developers to offload rendering to the server, reducing the initial load time and improving performance. React 19 brings significant improvements to this feature:
- **Streaming Server Rendering:** React 19 enhances server-side rendering by enabling streaming, which allows the server to send parts of the UI as they are ready, reducing the time to first paint.
- **Enhanced Caching Mechanisms:** Improved caching mechanisms help in reducing redundant data fetching and rendering, resulting in faster load times and better performance.
---
#### 4. Enhanced Developer Experience
React 19 focuses heavily on improving the developer experience, making it easier to build and debug applications:
- **Improved DevTools:** The React DevTools have been updated with new features, such as better support for concurrent rendering and more detailed profiling tools.
- **Error Handling:** Enhanced error boundaries and more informative error messages make it easier to identify and fix issues during development.
- **TypeScript Improvements:** Better TypeScript support ensures a smoother experience for developers using TypeScript with React, including improved type checking and autocomplete features.
---
#### 5. New Hooks and APIs
React 19 introduces several new hooks and APIs that offer more flexibility and control over component behavior:
- **useDeferredValue:** This hook helps manage deferred state updates, making it easier to prioritize critical updates over less important ones.
- **useSyncExternalStore:** This hook is designed to ensure consistent reads from external stores, aiding in state management across different components.
---
#### 6. Better Performance and Optimization
Performance is a critical aspect of any web application, and React 19 includes several optimizations to ensure faster and more efficient applications:
- **Optimized Reconciliation:** Improvements in the reconciliation process reduce the time React takes to compare and update the DOM, leading to faster updates.
- **Smarter Memoization:** Enhanced memoization strategies help in reducing unnecessary re-renders, improving overall application performance.
- **Improved Lazy Loading:** React 19 makes lazy loading of components more efficient, reducing the initial load time and improving the user experience.
---
#### 7. React Compiler
One of the most exciting additions in React 19 is the introduction of the React Compiler, also known as "React Forget." The React Compiler aims to automate many optimizations that developers currently have to do manually.
- **Automatic Hook Dependency Management:** The React Compiler can automatically track and optimize hook dependencies, reducing the need for developers to manually manage dependencies in hooks like `useEffect`.
- **Optimized Component Output:** The compiler produces optimized component code that runs faster and is easier to debug.
- **Future-Proofing:** By incorporating cutting-edge optimization techniques, the React Compiler ensures that applications remain performant and maintainable as React evolves.
---
#### 8. Backward Compatibility and Migration
React 19 has been designed with backward compatibility in mind, ensuring that most existing applications can be upgraded without significant changes. The React team has provided comprehensive migration guides and tools to help developers transition smoothly to the new version.
- **Codemods:** Automated tools (codemods) are available to assist in updating codebases to align with the new features and APIs introduced in React 19.
- **Deprecation Warnings:** Clear deprecation warnings and guides help developers identify and update deprecated features in their applications.
---
### Conclusion
React 19 continues to push the boundaries of what's possible in front-end development. With its focus on concurrent rendering, improved server components, enhanced developer experience, new hooks and APIs, and the introduction of the React Compiler, React 19 provides developers with the tools they need to build faster, more responsive, and maintainable applications. As React continues to evolve, it remains at the forefront of modern web development, empowering developers to create exceptional user interfaces. | bilelsalemdev |
1,869,556 | #1404. Number of Steps to Reduce a Number in Binary Representation to One | https://leetcode.com/problems/number-of-steps-to-reduce-a-number-in-binary-representation-to-one/desc... | 0 | 2024-05-29T20:14:07 | https://dev.to/karleb/1404-number-of-steps-to-reduce-a-number-in-binary-representation-to-one-49d1 | https://leetcode.com/problems/number-of-steps-to-reduce-a-number-in-binary-representation-to-one/description/?envType=daily-question&envId=2024-05-29
```js
var numSteps = function(s) {
let carry = 0
let steps = 0;
for (let i = s.length - 1; i > 0; i--) {
if (s.charAt(i) - '0' + carry == 1) {
carry = 1
steps += 2
} else {
steps++
}
}
return steps + carry
};
``` | karleb | |
1,869,611 | What is a good UI to use these days. | I am writing simle console apps in C#. But I would like it if I had a good UI to use. Since we live... | 0 | 2024-05-29T20:22:55 | https://dev.to/xarzu/what-is-a-good-ui-to-use-these-days-54j | javascript, webdev, programming, beginners | I am writing simle console apps in C#. But I would like it if I had a good UI to use. Since we live in an age where everything is run off the internet or intranet through a web browser, should I use a javascript frame work? What is a good choice for that? If I am using the UI to access and upload local files, like excel data files, what would be a good suggestion to use? Is there a bare-bones javascript suggestion that I can use?
There is a lot of talk online that WPF is not a good choice anymore and is losing popularity and support. Is it being replaced by something like Blazor?
| xarzu |
1,869,584 | From Chaos to Clarity: How Effective Billing and Inventory Management Transformed a Client’s Business | Working as a Billing Expert at an Electric Store has been a journey of learning, growth, and... | 0 | 2024-05-29T20:20:19 | https://dev.to/sabrina_spellmen_02c6c3a1/from-chaos-to-clarity-how-effective-billing-and-inventory-management-transformed-a-clients-business-5bep | Working as a Billing Expert at an Electric Store has been a journey of learning, growth, and countless stories of success. One of the most memorable experiences I had involved a consultation with a client whose business was on the brink of chaos due to poor inventory management and inefficient billing processes. This is the story of how we turned things around.
The Initial Contact
I first met John, the owner of a mid-sized electrical contracting company, during a routine inventory audit. His business had been growing rapidly, but this growth had come with its own set of challenges. John was struggling with managing inventory, keeping track of wiring tenders, and ensuring accurate billing. The result? Delays in project completion, unhappy clients, and a lot of stress.
Identifying the Problems
During our initial consultation, it became clear that John's business issues stemmed from a few key areas:
Inefficient Inventory Management: John’s team often faced shortages of critical components, which led to project delays.
Disorganized Wiring Tenders: Mismanagement of wiring tenders caused confusion and inefficiencies.
Inaccurate Billing: Errors in billing were not only costing John money but also damaging his reputation with clients.
Crafting a Solution
To address these issues, I proposed a comprehensive plan that included:
Implementing an Inventory Management System: We introduced a robust inventory management software tailored for electrical stores. This system automated stock tracking, set up alerts for low stock levels, and provided real-time inventory updates.
Streamlining Wiring Tenders: We organized the wiring tender process by categorizing them based on project types and deadlines. This not only improved efficiency but also ensured that the right materials were available when needed.
Optimizing Billing Processes: We integrated a new billing system that reduced errors by automating invoice generation and provided detailed financial reports. This system also tracked payments and flagged overdue accounts, allowing for timely follow-ups.
The Transformation
The changes we implemented had a significant impact on John’s business. Within a few months, he noticed several positive outcomes:
Increased Efficiency: With an organized inventory and streamlined processes, John’s team was able to complete projects faster and more efficiently.
Cost Savings: Automated systems reduced errors and wastage, saving the company money.
Improved Client Satisfaction: Accurate billing and timely project completion led to happier clients and repeat business.
Reduced Stress: With automated processes in place, John could focus on growing his business instead of firefighting daily issues.
The Happy Client
John recently shared with me how these changes had transformed his business. Not only had he regained control over his operations, but he also felt more confident in taking on larger projects. The improved reputation of his company had led to more referrals and a steady increase in revenue.
Conclusion
This experience reaffirmed my belief in the importance of effective billing and inventory management. By taking a strategic approach and leveraging the right tools, businesses can overcome operational challenges and achieve significant growth. If you’re facing similar issues in your business, consider seeking expert consultation—it could be the turning point you need.
At the end of the day, helping clients like John succeed is what makes my job as a Billing Expert truly rewarding. If you have any questions or need advice on managing your inventory or billing processes, feel free to reach out. Let’s turn your chaos into clarity!
About the Author
I have extensive experience as a Billing Expert at an Electric Store, specializing in managing inventory and wiring tenders. My passion is helping businesses streamline their operations and achieve their full potential.
| sabrina_spellmen_02c6c3a1 | |
1,859,760 | GPTs that have clearly received a lot of love | I hate wasting my time with AI tools that promise the world and end up being a complete... | 0 | 2024-05-30T14:59:18 | https://blog.jonathanflower.com/artificial-intelligence/gpts-that-have-clearly-received-a-lot-of-love/ | artificialintelligen, softwaredevelopment, ai, chatgpt | ---
title: GPTs that have clearly received a lot of love
published: true
date: 2024-05-29 20:16:11 UTC
tags: ArtificialIntelligen,SoftwareDevelopment,AI,chatgpt
canonical_url: https://blog.jonathanflower.com/artificial-intelligence/gpts-that-have-clearly-received-a-lot-of-love/
---
I hate wasting my time with AI tools that promise the world and end up being a complete disappointment. I love finding AI tools that actually solve problems better than more conventional tools.
Before we get into these excellent GPTs, even these powerful GPT will fail horribly when given a weak prompt. My favorite guiding principle is to think of the GPT as high school intern. If you do not provide detail, who knows what you are going to get! It helps a lot when you communicate the goal and provide steps to follow whenever possible.
## Great GPTs
### [Grimoire](https://chatgpt.com/g/g-n7Rs0IK86-grimoire)
When starting a new coding project, I typically start here. Grimoire helps me think through architectural decisions and evaluate which technologies will be the best fit. The way Grimoire collaborates with me on the solution is a clear step above generic ChatGPT.
From the creator, Nick Dobos:
> How is Grimoire different from vanilla GPT?
> -Coding focused system prompts to help you build anything.
> Combining the best tricks I’ve learned to pull correct & bug free code out from GPT with minimal prompting effort
### [Consensus](https://chatgpt.com/g/g-bo0FiWLY7-consensus)
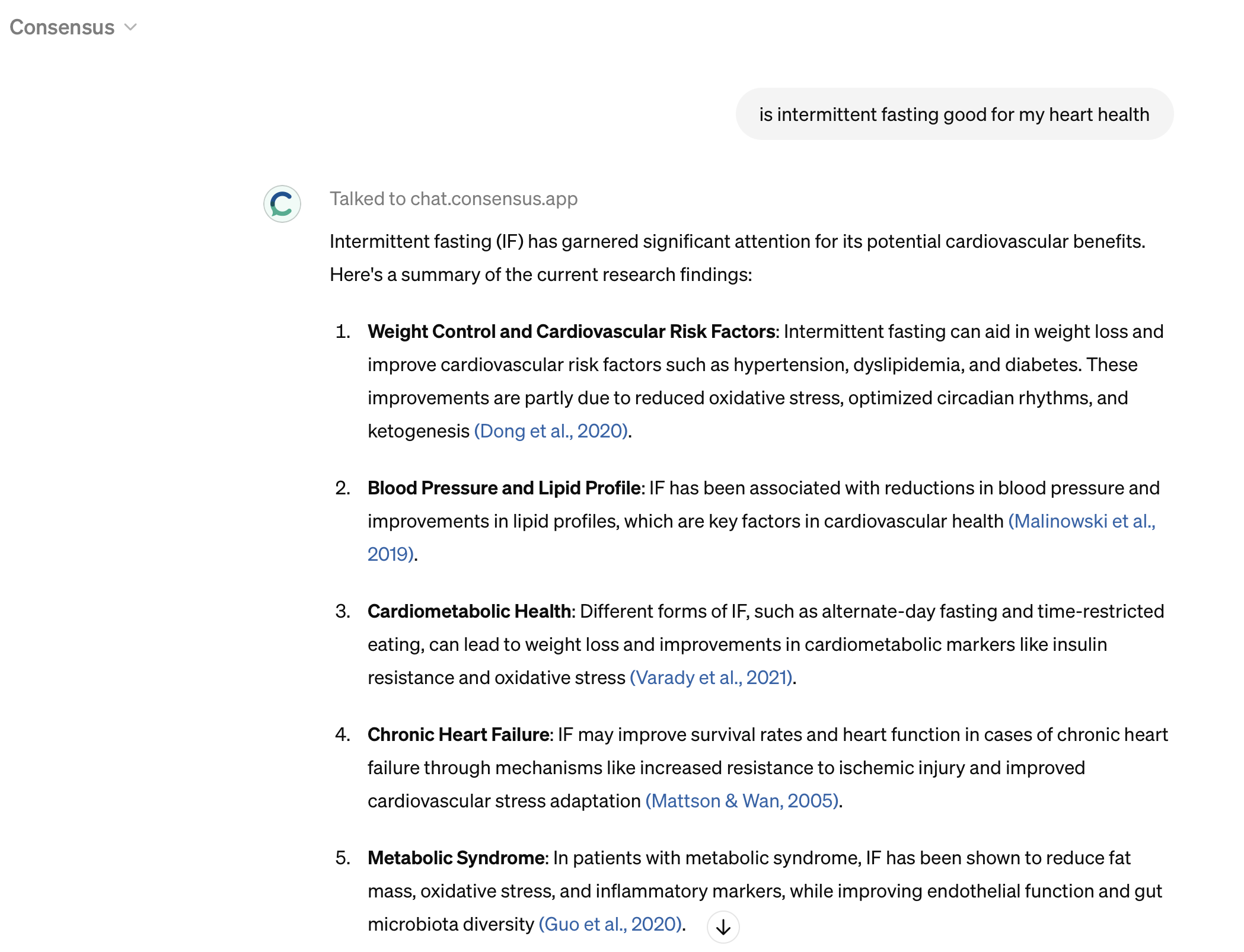
“search and synthesize information from over 200 million academic papers.” For example, I asked it if intermittent fasting is good for my heart health. I received back a detailed response with links to research papers supporting each point.
### [Universal Primer](https://chatgpt.com/g/g-GbLbctpPz-universal-primer)
I love learning and this GPT is my go to when I want to dive deeper on a concept. I love how it breaks things down concepts into easily digestible chunks and includes plenty of examples.
### What are your favorite GPTs?
This article is part of a series: [Who Cares About GPTs?](https://blog.jonathanflower.com/uncategorized/who-cares-about-custom-gpts/) | jfbloom22 |
1,869,557 | [11/52] OpenGL is Still Decent, Actually | I know... I promised I'd be doing more engineering. We'll get there! But I was consuming some... | 0 | 2024-05-29T20:15:32 | https://github.com/Tythos/11-of-52--opengl-is-still-decent-actually | opengl, cpp, sdl, glsl | I know... I promised I'd be doing more engineering. We'll get there! But I was consuming some interesting digital creator / software engineering content the other day. There was one guy in particular (I won't say exactly who) who tends to do pretty interesting stuff, but who can be a little bit iconoclastic. He went on a weird rant about how obscure, obtuse, and inaccessible OpenGL is. It was very strange because the critique was based on how difficult it was to get sprites or pixels up on the screen. But compared to pretty much anything else--Vulkan, Carbon, XTerminal--it's pretty straightforward and well-established how to get up and going.
This guy is pretty experienced, and he knows what he's doing, so it seemed strange and the comment came out of nowhere. So, naturally, it got me going and thinking, "okay, what is the simplest and shortest path to get up and going with OpenGL?" Assume you're trying to just put up a simple animation, create a simple game, put some sprites on the screen, etc. What is the shortest path to do that? And as it turns out, unless you're doing something platform-specific like Windows GDI, OpenGL is still a really good way to go.
There's a few other things you need in combination with it. SDL is an absolutely fantastic library--strongly recommended, check it out if you aren't familiar with it. There's a lot more to it, but for getting out of the box and going with a window and an event loop and a GL context and all that, it's fantastic. And of course GLEW is practically required for a lot of things. So today we're going to walk through, really quick, a brief demonstration of what the "shortest path" to a working "sprites on screen" is.
## Let's Get Started
Begin with a blank C++ project. We'll create the following files as placeholders for future content:
* `.gitignore`
* `basic.f.glsl`
* `basic.v.glsl`
* `CMakeLists.txt`
* `main.cpp`
After initializing our git repository, we'll also want to add some dependencies. We'll use git submodules to do this, and in most cases these will need to come from specific branches. So, run `git submodule add` for the following:
* https://github.com/libsdl-org/SDL.git (use branch `SDL2`)
* https://github.com/libsdl-org/SDL_image.git (use branch `SDL2`)
* https://github.com/Perlmint/glew-cmake.git0
You'll notice we're also adding SDL Image here, which is a fantastic extension to SDL that gives you out-of-the-box support for loading surfaces from a wide variety of image formats. We're also using a specific fork of GLEW that supports inclusion via CMake, to automate the dependency inclusion within our CMake project definition. Once those dependencies are cloned and submodules initialized (recursively!), we're ready to start populating our files.
You'll also notice we have some shaders. If you haven't messed with GLSL before, it's fascinating! We'll probably do another talk specifically about radiometry and applications to graphics programming, thermal, electro-optics, and other fields. We'll also want a test texture; you can use any .PNG you want, but I went with a nice picture of a seagull. Cheers.
Our goal--our mission, if we choose to accept it--is to put this image up in the window. If we do this well, it should be clear how we can extend this in the future to do more sophisticated sprite models and behaviors within the context of an app or game engine.
## The Main Thing
Let's start in `main.cpp` with some dependencies. We'll include the following, roughly broken into system includes and dependency includes:
```cpp
#include <fstream>
#include <iostream>
#include <sstream>
#include <vector>
#include <SDL.h>
#include <GL/glew.h>
#include <SDL_image.h>
```
## Vertex Formats
Next, we'll think about our data model. Let's stay away with classes and focus on how the state of our application will be packed into an aggregation of bytes (a struct).
```cpp
SDL_Surface* logo_rgba;
const GLfloat verts[4][4] = {
{ -1.0f, -1.0f, 0.0f, 1.0f },
{ -1.0f, 1.0f, 0.0f, 0.0f },
{ 1.0f, 1.0f, 1.0f, 0.0f },
{ 1.0f, -1.0f, 1.0f, 1.0f }
};
const GLint indices[6] = {
0, 1, 2, 0, 2, 3
};
```
You do need to think about your vertex format! Briefly, this means thinking about what information is attached to, or defines, each vertex in the drawing sequence you will call. Since we're focusing on a textured 2d sprite, our `verts` array defines a set of 4 vertices, each of which defines 4 values:
* An `x` (position) coordinate
* An `y` (position) coordinate
* A `u` (texture) coordinate
* A `v` (texture) coordinate
We'll see how we "encode", or tell OpenGL about, the format of this vertex sequence in subsequent calls. And since we only want to define each vertex once, we also have an index buffer to define how the vertices are combined to form a shape (in this case, two triangles).
## Application State
We also need to think about what information defines the state our our application model. Let's use the following, which includes SDL references and a healthy mix of OpenGL unsigned integers (effectively used as handles to GPU data).
```cpp
struct App {
SDL_Window* m_window = NULL;
SDL_GLContext m_context = 0;
GLuint m_vao = 0;
GLuint m_vbo = 0;
GLuint m_ebo = 0;
GLuint m_tex = 0;
GLuint m_vet_shader = 0;
GLuint m_frag_shader = 0;
GLuint m_shader_prog = 0;
};
```
## Behaviors
We want to define procedures by which we initialize and free specific models within this application. Let's define prototypes for the following:
```cpp
void initApplication(App* app);
void freeApplication(App* app);
void initShaders(App* app);
void initGeometries(App* app);
void initMaterials(App* app);
```
We'll also want some helper methods and a function to define specific loops. (In the long run, we'd want to split these loops across threads for different cadences like rendering, I/O handling, and internal updates.)
```cpp
const char* getSource(const char* path);
void renderLoop(App* app);
```
And now we have enough defined to think about how we use these behaviors in the context of a program. So let's write our `main()` entry point!
## The Main Main
First, let's start up the application by allocating, loading resources, and calling our initializers.
```cpp
int main(int nArgs, char** vArgs) {
// startup
std::cout << "Initialzing..." << std::endl;
std::string filename = "logo.png";
logo_rgba = IMG_Load(filename.c_str());
App* app = new App();
initApplication(app);
initShaders(app);
initGeometries(app);
initMaterials(app);0
// ...
}
```
Even though we've consolidated all of our state within a specific structure, you'll notice we've broken out initialization into specific steps. If you've used THREE.js before, this model may loop familiar. In the long run, this will make it easy to extract and organize specific models within our application--like individual shader programs, complex geometry data that may be reused or even animated, and material resources that need internally-organized bindings to things like multiple texture uniforms.
(We might look at a "part two" in which we see how these models can evolve into something more... interesting, if not entirely professional yet.0)
Next we can think about our "core" loop. This is pretty straightforward:
```cpp
int main(int nArgs, char** vArgs) {
// ...
// main loop
std::cout << "Running" << std::endl;
bool is_running = true;
while (is_running) {
SDL_Event event;
while (SDL_PollEvent(&event)) {
if (event.type == SDL_WINDOWEVENT && event.window.event == SDL_WINDOWEVENT_CLOSE) {
is_running = false;
break;
}
}
renderLoop(app);
}
// ...
}
```
Finally, we clear up our resources:
```cpp
int main(int nArgs, char** vArgs) {
// ...
// cleanup
std::cout << "Exiting..." << std::endl;
freeApplication(app);
delete app;
SDL_FreeSurface(logo_rgba);
logo_regba =nNULL;
return 0;
}
```
## Initialization
When we initialize the application, what are we talking about? Since we have separate initialization for our different groups of GL data, this is largely SDL-specific. Let's write our `initApplication()` to handle this top-level logic.
```cpp
void initApplication(App* app) {
if (SDL_init(SDL_INIT_VIDEO) < 0) {
std::cerr << "Initializing SDL video failed!" << std::endl;
throw std::exception();
}
// create window
app->m_window = SDL_CreateWindow("App", SDL_WINDOWPOS_CENTERED, SDL_WINDOWPOS_CENTERED, 800, 600, SDL_WINDOW_OPENGL);
if (app->m_window == NULL) {
std::cerr << "Creating main window failed!" << std::endl;
SDL_Quit();
throw std::exception();
}
// initialize GL context
SDL_GL_SetAttribute(SDL_GL_CONTEXT_MAJOR_VERSION, 3);
SDL_GL_SetAttribute(SDL_GL_CONTEXT_MINOR_VERSION, 1);
SDL_GL_SetAttribute(SDL_GL_CONTEXT_PROFILE_MASK, SDL_GL_CONTEXT_PROFILE_CORE);
SDL_GL_SetAttribute(SDL_GL_DOUBLEBUFFER, 1);
app->m_context = SDL_GL_CreateContext(app->m_window);
if (app->m_context== NULL) {
std::cerr << "Creating GL context failed!" << std::endl;
SDL_DestroyWindow(app->m_window);
SDL_Quit();
throw std::exception();
}
// initialize glew
GLenum err = glewInit();
if (err != GLEW_OK) {
std::cerr << "Initializing GLEW failed!" << std::endl;
SDL_GL_DeleteContext(app->m_context);
SDL_DestroyWindow(app->m_window);
SDL_Quit();
throw std::exception();
}
}
```
The big "lift" here is window management, of course, and that's the important part SDL automates for us. Once we have an agnostic window generated, getting a GL context is straightforward. These things would be 80% of the effort (a nightmare) if we didn't have SDL or something like it. Once you have your GL context, you're home free and almost everything else is platform-neutral.
## A Brief Break for CMake
Let's jump over to our `CMakeLists.txt` for a moment to make sure we'll be able to build this mess once we've finished coding. We'll start with the standard three CMake commands: defining the version, defining the project, and defining the main build artifact (executable, in this case).
```CMake
cmake_minimum_required(VERSION 3.14)
project(11-of-52--opengl-is-still-decent-actually)
add_executable(${PROJECT_NAME}
"main.cpp"
)
```
Next, we'll assert specific options for our dependencies.
```CMake
# assert dependency options
set(SDL2IMAGE_VENDORED OFF)
```
Now we can recursively include our submodules:
```CMake
# ensure dependencies are built
add_subdirectory("glew-cmake/")
add_subdirectory("SDL/")
add_subdirectory("SDL_image/)
```
Now we'll want to make sure our main build target can resolve the appropriate `#include` paths.
```CMake
target_link_libraries(${PROJECT_NAME} PRIVATE
SDL2::SDL2
SDL2::SDL2main
OpenGL32
libglew_static
SDL2_image
)
```
When in doubt, these are basically the library names. Some CMake projects will have their own unique library names defined (the `::` is a big clue); you can always check their `CMakeLists.txt` for an `add_library()` directive. There's also some useful logic/automation build into the `find_package()` directive within CMake--that might be worth going over in its own video at some point.
Finally, we'll want to set specific runtime resources to copy into the binary folder. We'll do this for static resources (like our image), as well as dynamic resources (like dependency DLLs). At some point, you can automate a degree of this with something like `CPack`, which is also probably worth its own video.
```CMake
# define static runtime resources
set(OUTPUT_PATH "${CMAKE_BINARY_DIR}/Debug")
file(MAKE_DIRECTORY ${OUTPUT_PATH})
configure_file("basic.f.glsl" "${OUTPUT_PATH}/basic.f.glsl" COPYONLY)
configure_file("basic.v.glsl" "${OUTPUT_PATH}/basic.v.glsl" COPYONLY)
configure_file("logo.png" "${OUTPUT_PATH}/logo.png" COPYONLY)
# define dynamic runtime resources
add_custom_command(TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy
${CMAKE_BINARY_DIR}/SDL/Debug/SDL2d.dll
$<TARGET_FILE_DIR:${PROJECT_NAME}>/SDL2d.dll
COMMAND ${CMAKE_COMMAND} -E copy
${CMAKE_BINARY_DIR}/SDL_image/Debug/SDL2_imaged.dll
$<TARGET_FILE_DIR:${PROJECT_NAME}>/SDL2_imaged.dll
)
```
(We're cheating a little bit here, because we know what DLLs will be generated and where they need to go.)
And that just about does it for our CMake. This is enough for us to do a basic configure test from the command line:
```sh
cmake -S . -B build
```
## Back to the Source
Let's finish our initialization. We've initialized the application. How are we going to initialize our shaders? There's a basic three-step process: first, we compile the vertex shader from source; second, we compile the fragment shader from source; third, we link these two shaders into a fully-defined graphics program.
```cpp
void initShaders(App* app) {
GLint status;
char err_buf[512];
glGenVertexArays(1, &(app->m_vao));
glBindVertexArray(app->m_vao);
// compile vertex shader
app->m_vert_shader = glCreateShader(GL_VERTEX_SHADER);
const char* vertexSource = getSource("basic.v.glsl");
glShaderSource(app->m_vert_shader, 1, &vertexSource, NULL);
glCompileShader(app->m_vert_shader);
glGetShaderiv(app->m_vert_shader, GL_COMPILE_STATUS, &status);
if (status != GL_TRUE) {
glGetShaderInfoLog(app->m_vert_shader, sizeof(err_buf), NULL, err_buf);
err_buf[sizeof(err_buf)-1] = '\0';
std::cerr << "Compiling vertex shader failed!" << std::endl;
std::cerr << err_buf << std::endl;
return;
}
// compile fragment shader
app->m_frag_shader = glCreateShader(GL_FRAGMENT_SHADER);
const char* fragmentSource = getSource("basic.f.glsl");
glShaderSource(app->m_frag_shader, 1, &fragmentSource, NULL);
glCompileShader(app->m_frag_shader);
glGetShaderiv(app->m_frag_shader, GL_COMPILE_STATUS, &status);
if (status != GL_TRUE) {
glGetShaderInfoLog(app->m_frag_shader, sizeof(err_buf), NULL, err_buf);
err_buf[sizeof(err_buf)-1] = '\0';
std::cerr << "Compiling fragment shader failed!" << std::endl;
std::cerr << err_buf << std::endl;
return;
}
// link shader program
app->m_shader_prog = glCreateProgram();
glAttachShader(app->m_shader_prog, app->m_vert_shader);
glAttachShader(app->m_shader_prog, app->m_frag_shader);
glBindFragDataLocation(app->m_shader_prog, 0, "uRGBA");
glLinkProgram(app->m_shader_prog);
glUseProgram(app->m_shader_prog);
return;
}
```
(You'll notice we're null-terminating our string copy from the error buffer, which isn't a great idea in general. Don't try this at home, kids!)
In modern graphics programming, you would not be necessarily doing this full build from source at runtime like this. Instead, you'd have an intermediate format (like SPIR-V, with Vulkan) that you would use to do a lot of the preliminary compilation. For our purposes, though, this is enough (and interesting, and useful; it also gives a transparent view into our application state and graphics pipeline.)
Note that we "know" special things about our shader program, in this case. For example, we "know" that there is a uniform variable we'll need to bind to our texture data. We'll look at how we set this up in the material initialization.
## Geometries
Now let's think about our geometry data. We've defined a set of vertices with a specific format, and some indices that define how those are mapped to specific shapes for drawing. We need to tell OpenGL how these vertices are structured. We also need to hand off (copy) the data buffers themselves. These are mostly done with buffer commands, using the "handles" (unsigned integers) we've defined as part of our application state to share persistent references.
```cpp
void initGeometries(App* app) {
// populate vertex and element buffers
glGenBuffers(1, &app->m_vbo);
glBindBuffer(GL_ARRAY_BUFFER, app->m_vbo);
glBufferData(GL_ARRAY_BUFFER, sizeof(verts), verts, GL_STATIC_DRAW);
glGenBuffers(1, &app->m_ebo);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, app->m_ebo);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
// bind vertex position and texture coordinate attributes
GLint pos_attr_loc = glGetAttribLocation(app->m_shader_prog, "aXY");
glVertexAttribPointer(pos_attr_loc, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(GLfloat), (void*)0);
glEnableVertexAttribArray(pos_attr_loc);
GLint tex_attr_loc = glGetAttribLocation(app->m_shader_prog, "aUV");
glVertexAttribPointer(tex_attr_loc, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(GLfloat), (void*)(2 * sizeof(Glfloat)));
glEnableVertexAttribArray(tex_attr_loc);
}
```
That middle clause is probably the most interesting, because this is where we tell OpenGL how the vertex attributes are structured. Given a sequence of vertex attributes, each segment defines a vertex--but how is that information "packed"? There are a total of four values (or "stride") between each segment (that is, the segment length).
* The first pair of values define the "x-y" pair, or `vec2`, vertex attribute; these are floats and offset from the beginning of the segment by zero values
* The second pair of values define the "u-v" pair, or `vec`, vertex attribute; these are floats and offset from the beginning of the segment by two values
## Materials
With our geometry data and shader program defined, we need to pass in material data. In this case, we have a single diffuse texture that will be sampled to define the pixel (or fragment) color within our "sprite". We do this by loading the image data from an SDL surface for OpenGL to reference as a "uniform" input to our shader program.
```cpp
void initMaterials(App* app) {
// results in the successful transcription of raw image bytes into a uniform texture buffer
glGenTextures(1, &app->m_tex);
glActiveTexture(GL_TEXUTRE0);
glBindTexture(GL_TEXTURE_2D, app->m_tex);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, 256, 256, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
glUniform1i(glGetUniformLocation(app->m_shader_prog, "uTexture"), 0);
glEnable(GL_BLEND);
glBendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
// define texture sampling parameters and map raw image data
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_BORDER);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_BORDER);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, 256, 256, GL_RGBA, GL_UNSIGNED_INT_8_8_8_8_REV, logo_rgba->pixels);
}
```
Most of the second block is just defining the sampling parameters for OpenGL. The most interesting call is the last line, where we pass off the actual pixel data from the SDL surface to the GPU.
## Loops
We're just about done! Let's define our rendering pass, which is pretty straightforward because we have only one draw call.
```cpp
void renderLoop(App* app) {
glClearColor(1.0f, 0.0f, 0.0f, 0.0f);
glClear(GL_COLOR_BUFFER_BIT);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, NULL);
SDL_GL_SwapWindow(app->m_window);
}
```
Everything is already loaded (buffers, objects, program, etc.) so we just need a draw call. In this case, we tell OpenGL to draw six elements from our buffer (vertices), and to treat them as triangles (that is two triangles with three vertices each). Finally, we swap our buffer (I can't tell you how much time I've wasted on other projects before I realized nothing was showing because I never swapped the window buffers...).
## Helpers
There are a few "helper" functions we need to define, as well as freeing our application state.
```cpp
const char* getSource(const char* path) {
// reads contents of file and returns the allocated character buffer
std::ifstream file(path);
if (!file.is_open()) {
std::cerr << "Opening file failed!" << std::endl;
return NULL;
}
std::stringstream buffer;
buffer << file.rdbuf();
std::string content = buffer.str();
char* charBuffer = new char[content.size() + 1];
std::copy(content.begin(), content.end(), charBuffer);
charBuffer[content.size()] = '\0';
return charBuffer;
}
```
Lastly, let's define our our application state is cleaned up. This is basically in reverse order from our initialization.
```cpp
void freeApplication(App* app) {
glUseProgram(0);
glDisableVertexAttribArray(0);
glDetachShader(app->m_shader_prog, app->m_vert_shader);
glDetachShader(app->m_shader_prog, app->m_frag_shader);
glDeleteProgram(app->m_shader_prog);
glDeleteShader(app->m_vert_shader);
glDeleteShader(app->m_frag_shader);
glDeleteTextures(1, &app->m_tex);
glDeleteBuffers(1, &app->m_ebo);
glDeleteBuffers(1, &app->m_vbo);
glDeleteVertexArrays(1, &app->m_vbo);
// invoke delete/destory methods for SDL state
SDL_GL_DeleteContext(app->m_context);
SDL_DestoryWindow(app->m_window);
SDL_Quit();
}
```
## Shader
We're done! With the C++. We still need to define a *very* basic graphics pipeline. Let's start with the vertex shader, which is simply forwarding the texture coordinates as a `varying` parameter for the fragment shader, and defining the basic position transform from our 2d space into the 4d position OpenGL expects.
```glsl
/**
* basic.v.glsl
*/
in vec2 aXY;
in vec2 aUV;
varying vec2 vUV;
void main() {
vUV = aUV;
gl_Position = vec4(aXY, 0.0, 1.0);
}
```
Then, our fragment shader uses those texture coordinates (interpolated for each pixel) to look up the appropriate fragment color from our texture data.
```glsl
/**
* basic.f.glsl
*/
varying vec2 vUV;
out vec4 oRGBA;
uniform sampler2D uTexture;
void main() {
oRGBA = texture(uTexture, vUV);
}
```
## Building
We have enough! Let's compile our project using the CMake configuration we already set up.
```sh
cmake --build build
```
If successful, you should see an executable show up in `build/Debug/`. And when you run it, you should see your sprite appear!
## Stepping Back
We started this conversation off by saying "it's actually really easy to get started with OpenGL!"... but this took a little bit of time, didn't it?
If you think about what we were doing, none of these things were really optional--whether we're using OpenGL or anything else. Most importantly, we've put ourselves in a position where it's fairly extensible to more sophisticated to other things we might want to do. (We have image loading support, we have customizable shaders, we have structured state models, we have an extensible/threadable event loop...) Some of these came with optional dependencies (like SDL_Image) but this gave us a pretty well-organized "starter" project.
It will be very easy in our next iteration to break parts of this application structure apart into reusable models for shader programs, individual sprites, scene graph nodes with their own transforms, etc. This is the first of two big takeaways: With a little bit of help, you can get started with a sprite-based application very easily, and you can do it in a way where you make it possible to do a lot more in the future with that.

Secondly, believe it or not... well, there's a saying attributed to Winston Churchill, roughly along the lines of "democracy is the worst form of government... except for all the others that have been tried." OpenGL is a lot like this--trying to get started this quickly with any other approach is an absolute nightmare. OpenGL is the worst way to get started... except for all the others that have been tried. (Vulkan, Wayland, you name it.)
So, this is a little involved. But (maybe because I've just started at this too much over the years) everything here still makes sense. Compared to some of the more obscure setups, you're not trying to abstract away too much of what's going on with the GPU, you have a nicely customized graphics pipeline that you have a lot of control over but it's still straightfowrard to setup and get something going.
This is part one of two. In part two, I'm thinking of looking at a basic 2d engine that you might put together based off of this. But this is a good way to get going, and a good way to start doing quick 2d cross-platform applications, especially if you're new to it or just want to draw some sprites.
| tythos |
1,869,555 | Multiplayer in Unity with AWS (with downloadable Rock, Paper, Scissors game demo) | Introduction This article is going to give an overview of a recent Unity project I have... | 0 | 2024-05-29T20:14:02 | https://dev.to/cdelabastide/multiplayer-in-unity-with-aws-with-downloadable-rock-paper-scissors-game-demo-159g | # Introduction
This article is going to give an overview of a recent Unity project I have created which utilises Amazon Web Services (AWS) to implement simple two player multiplayer gameplay. While this is not recommended as a final solution to add multiplayer functionality to your Unity game, it is a relatively cheap way to build an early multiplayer prototype.
Firstly, I must give credit to Youtuber [BatteryAcidDev](https://www.youtube.com/@BatteryAcidDev). In 2020, he created a two part video series ([part 1](https://www.youtube.com/watch?v=X45VYma6738), [part 2](https://www.youtube.com/watch?v=X45VYma6738)) outlining how to create a multiplayer instance using AWS services and Websockets. His videos formed the basis of this project, and are certainly worth the watch.
My project demo is a 2 person multiplayer game of Rock, Paper, Scissors. Throughout this article we will cover:
- How multiplayer was integrated into the game with the use of [Websockets](https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API) and AWS services (APIGateway, Lambda and DynamoDB)
- Where to download the project and deploy it via [AWS CloudFormation](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/Welcome.html) and the [Grunt.js](https://gruntjs.com/) task runner.
## Pre-Requisites
- An understanding of AWS Cloud services, including APIGateway, Lambda and DynamoDB
- An AWS account
- Be aware of the AWS pricing structure - [AWS Pricing](https://aws.amazon.com/pricing/?nc2=h_ql_pr_ln&aws-products-pricing.sort-by=item.additionalFields.productNameLowercase&aws-products-pricing.sort-order=asc&awsf.Free%20Tier%20Type=*all&awsf.tech-category=*all)
- AWS SAM CLI installed on your device - [Installing the AWS SAM CLI](https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/install-sam-cli.html)
- Unity installed on your device - This project was tested on Unity versions 2020.2.5f1 to 2022.2.5f1.
# The Design
This Unity demo uses the following services to support multiplayer gameplay:
**WebSocket API** - WebSockets is an API that allows a user/client to send messages to a server and receive event-driven responses.
**AWS ApiGateway** - Amazon's APIGateway service allows developers to create their own APIs. APIGateway can be configured to create an API that works together with the WebSocket protocol. The APIGateway in this project has three integration routes which trigger different Lambda functions to achieve a task.
**AWS DynamoDB** - DynamoDB is Amazon's cloud-hosted database service. In this project, it is used to store the online game session and player IDs.
**AWS Lambda** - Lambda is a compute service that allows function code to be uploaded to AWS and invoked without the developer needing to worry about computational resources and server systems.
There are three Lambdas in the project that support the multiplayer infrastructure in this project:
- JoinGame - This Lambda is responsible for establishing a connection to our APIGateway and connecting the two players in a session.
- GameMessaging - This Lambda is responsible for the passing of messages from the client to the server.
- DisconnectGame - This Lambda is responsible for closing the game session.
Below I will explain how the services work together to facilitate multiplayer gameplay.
### Creating the multiplayer session
The diagram below describes how the initial connection between Unity and AWS is established, and how the game session is created.

1. When a Player presses 'Play Online' in the Unity client, a Websocket instance will be created that connects to the APIGateway in AWS. When the connection is successful, APIGateway will invoke the JoinGame Lambda function.
2. The JoinGame Lambda will read the GameSession DynamoDB table. As the table is either empty or has no available sessions to join at this point, the Lambda will create a new session in the table and adds Player 1 to it with a connection ID. When Player 2 selects 'Play Online', the second invocation of the Lambda will find the game session created by Player 1, and will add Player 2 to it.
3. Now that both players have joined the session, a message is sent back from AWS to each player in Unity. This message triggers the StartGame() function in Unity, and the game begins.
### Client to client communication
The next diagram explains how messages are sent between each client/player via the APIGateway.
1. During gameplay, the player will select their choice. Selecting a choice will trigger the SendGameMessage() function, which will create a JSON message. This message contains the player's choice of rock, paper or scissors.
2. The JSON message is sent via Websockets to the APIGateway. The 'action' field in the JSON object is set to 'OnMessage' so that the APIGateways OnMessage integration is used to trigger the GameMessaging Lambda. The 'opcode' is used as a way to map different types of messages to different logic (There is a switch statement in the Lambda to check the opcodes. Whilst there are only two opcodes in the project demo this could expanded for more complex games).
3. Player 2 receives the message, triggering the ProcessReceivedMessage() function which will process the message and conduct the series of events required to continue the game. In this demo, when a message is received the opposing players choice is stored as a variable and only revealed when both players have made a choice.
### Disconnecting the game
The final diagram displays how disconnect events are handled.
1. When the game is over or if a player disconnects by quitting or closing the game application, the Websocket connection for that player will be terminated. This will trigger the disconnect route in our APIGateway in AWS which will invoke the DisconnectGame Lambda.
2. The DisconnectGame Lambda will check if the other player is still connected, and if so it will terminate their connection as well. If this happens during a game, a 'connection lost' message will be shown.
3. The DisconnectGame Lambda will delete the session from the GameSessionTable.
# AWS Deployment Steps
The AWS services used in this project are all defined within an AWS CloudFormation template. To make deployment simple, I've made use of the GruntJS task runner to create simple commands that will run the AWS CLI commands necessary for deployment. This section will cover the deployment instructions.
1 - Clone the Git repository for the demo: https://github.com/Chrisd313/Rock-Paper_Scissors-Unity_AWS
2 - In the command terminal, navigate to the Rock-Paper_Scissors-Unity_AWS\Assets\Scripts directory and run the following command to download the Node.js dependencies:
**_npm install_**

3 - Find the .env file (Assets > Scripts > .env) and setup your environment variables in the .env file.
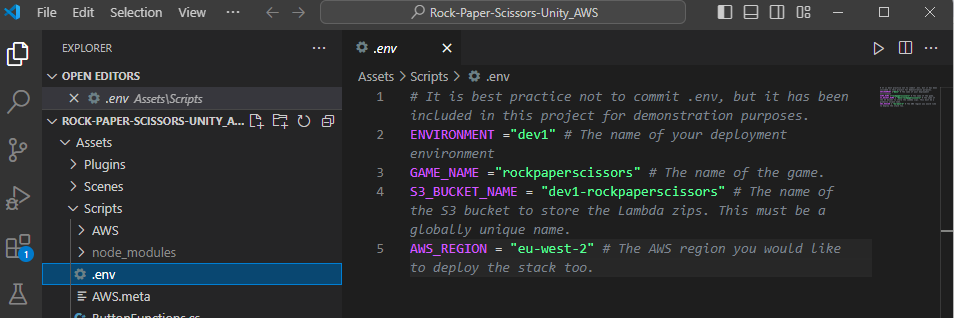
4 - In your terminal, from the Rock-Paper_Scissors-Unity_AWS\Assets\Scripts run the following grunt command to create an S3 bucket. This grunt task will run the AWS CLI command to create an S3 bucket in AWS.
**_grunt createbucket_**

5 - In your terminal, from the Rock-Paper_Scissors-Unity_AWS\Assets\Scripts run the following grunt command, which will zip the Lambda code, package the CloudFormation template and deploy our resources into a CloudFormation stack on AWS.
**_grunt deploy_**

If the deployment was successful, you should be able to view your newly created CloudFormation stack and its resources within the AWS console.
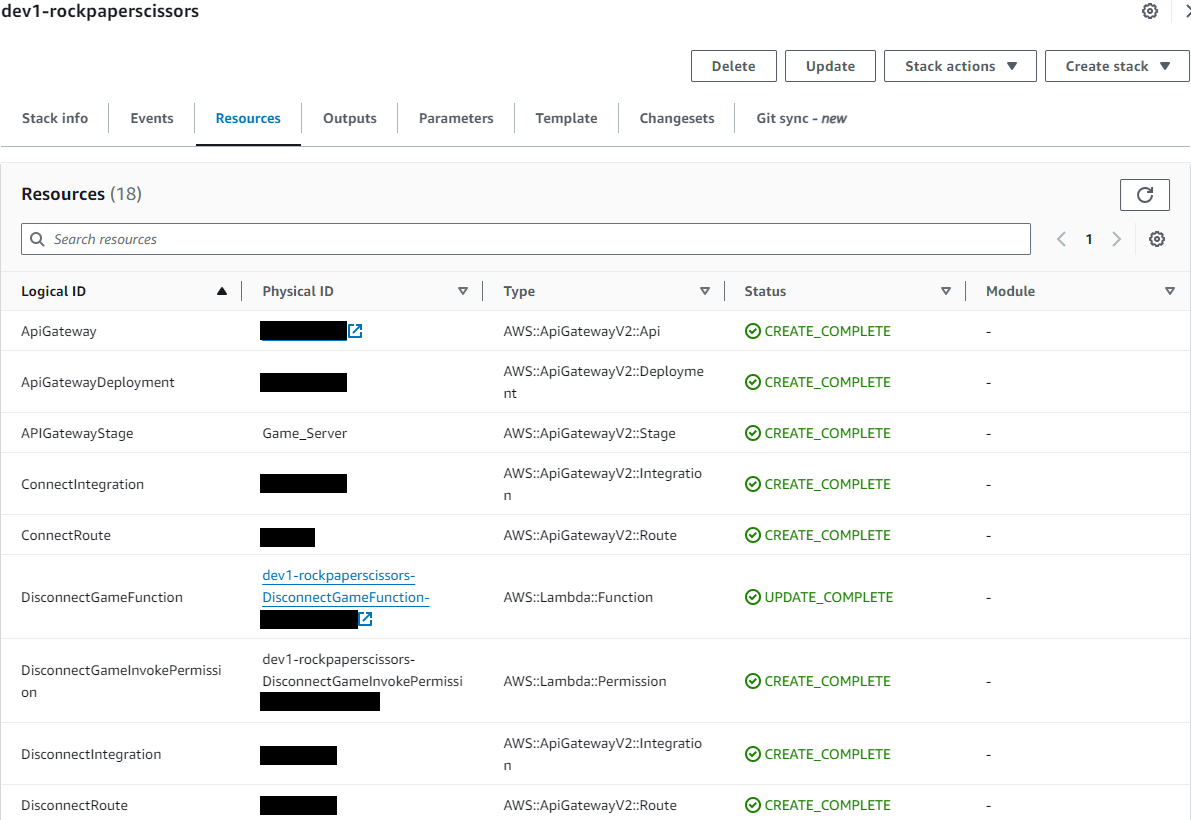
6 - From the CloudFormation page, you can open your API Gateway by clicking on it's physical ID, or by simply opening the API Gateway service page. In the API Gateway page, navigate to the Stages panel. Copy your WebSocket URL - we will be adding this into our Unity scripts to integrate with the API Gateway.
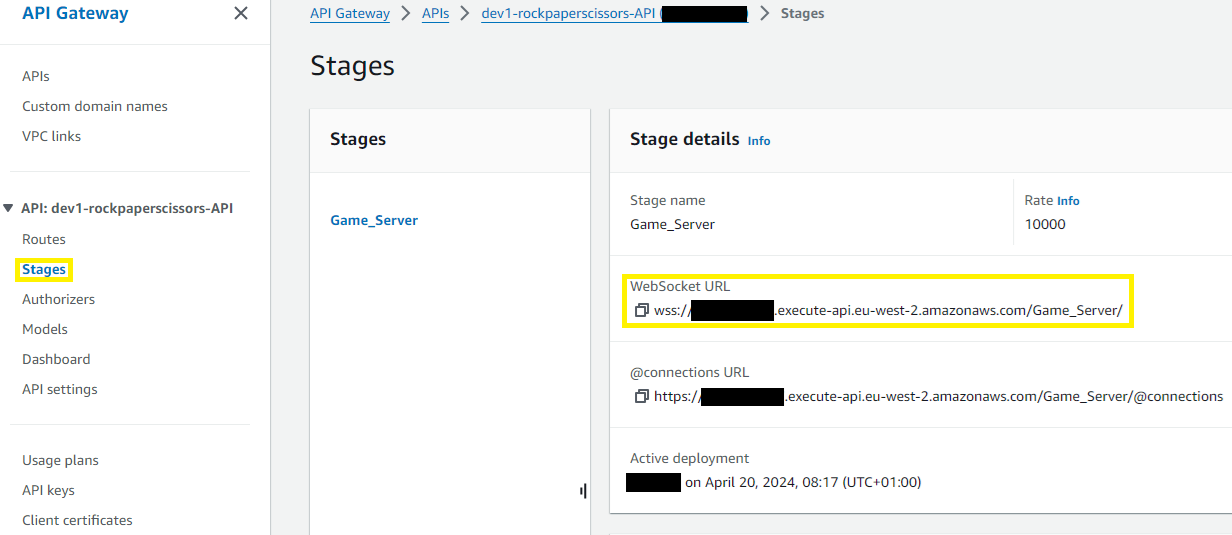
# Unity Deployment Steps
1 - In Unity, you will be able to open the Rock-Paper-Scissors-Unity_AWS project that we cloned from Git earlier (as it is a new project, the setup may take a few minutes!).
The project may open with a blank scene - if so, simply navigate to the 'Scenes' folder in the Assets directory and select the 'Sample Scene' to open the correct scene for the game.
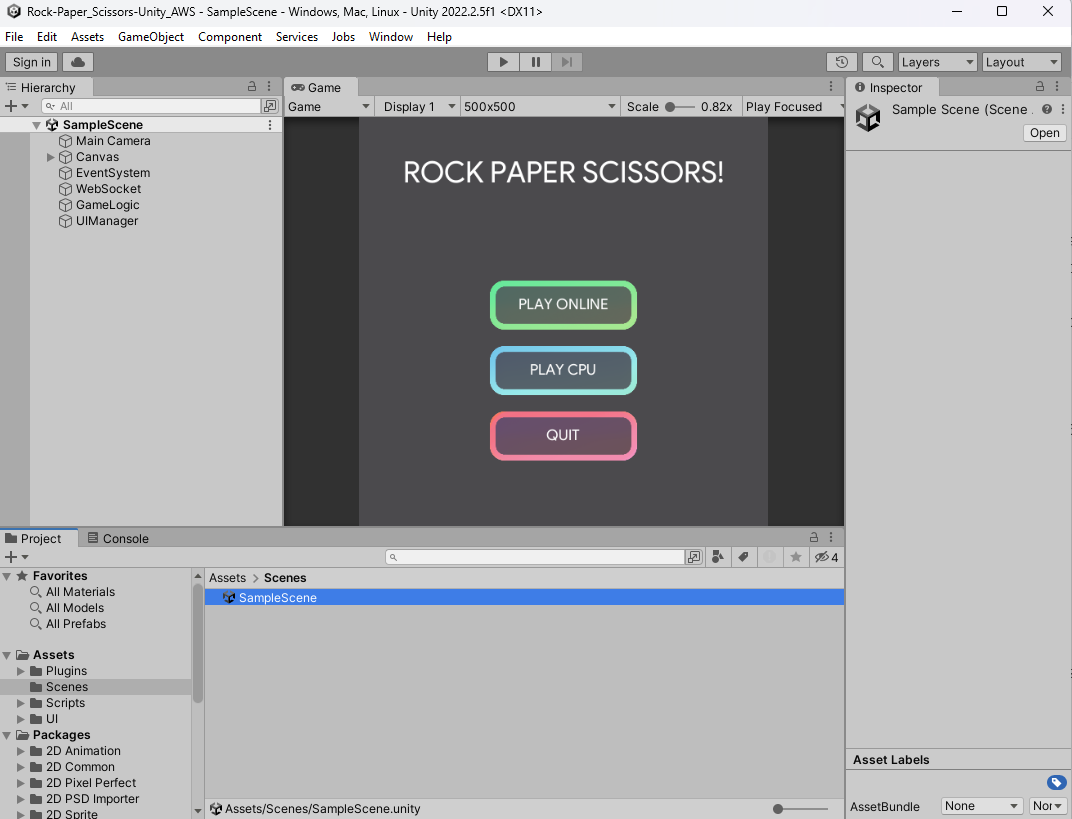
The game can be played within the Unity editor. We can play against the CPU no problem, but if we click 'Play Online' we will get an error message - let's fix that and connect with our API Gateway.

2 - In the Assets panel, find and open the WebSocketService.cs script.

Look for the webSocketDns variable on line 9 - this is currently empty. Paste in the WebSocket URL that we retrieved from the AWS API Gateway console earlier.
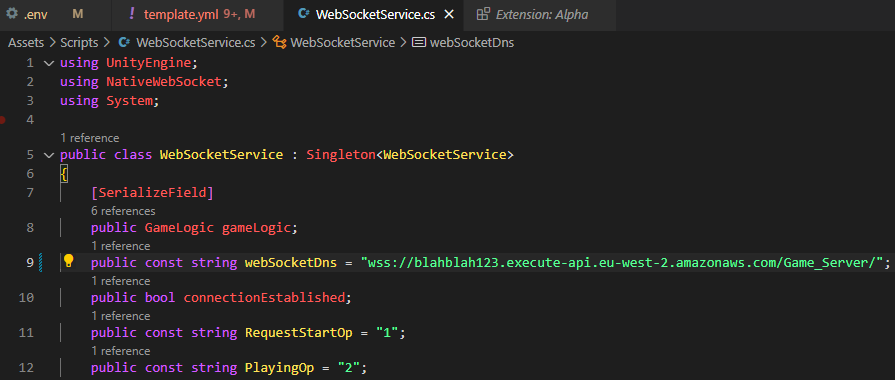
Returning to the Unity editor, if we press the Play button to start up the game and select 'Play Online' we now get an awaiting player message.
3 - Next, we'll create a build for the game. In Unity, navigate to File > Build Settings. The Platform should be "Windows, Mac, Linux" by default. Click Build to create an executable file for the game.
4 - If the AWS services were deployed correctly, you should now be able to play a two-player game of rock, paper, scissors. You can test this by opening the game in two seperate windows and pressing Play Online.
# Conclusion
Although not production-ready solution for multiplayer, it is a quick, easy and low-cost way to implement multiplayer functionality for prototyping purposes. For more long-term solutions, AWS does offer its own game server hosting service - [AWS Gamelift](https://aws.amazon.com/gamelift/).
Thank you for reading this article, and I hope you have found it useful!
| cdelabastide | |
1,869,554 | Monitoring and Observability (Enter Mezmo) | Monitoring and observability have been around for years, it’s nothing new. However, one thing many... | 0 | 2024-05-29T20:11:14 | https://dev.to/thenjdevopsguy/monitoring-and-observability-entier-mezmo-1ie2 | kubernetes, devops, programming, cloud | Monitoring and observability have been around for years, it’s nothing new. However, one thing many engineers still have an issue with is implementing monitoring and observability the right way. Between various logs, traces, metrics, alerts, and overall data that’s consumed by application stacks, there’s a lot of data to be combed through and consumed.
In this blog post, you’ll learn about how to manage the capability with Mezmo.
## What Is Monitoring And Observability
The best way to think about the differentiation is:
- Monitoring: See the data
- Observability: Do something with the data
Monitoring is all about seeing data, alerting on data, and having the ability to view graphs. It’s the big screens in the NOC (if those still exist) and the graphs you see on various monitoring tools to see how application stacks and infrastructure is performing.
Observability on the other hand is doing something with the data. Whether it’s traces (app end-to-end health), logs (output from infrastructure or apps), or metrics (performance, workloads, etc.), engineers can take the data and perform action on it. For example, let’s say a log states that there’s a failure and it’s a known failure. An engineer can write some observability automation to kick off when the specific log comes into the monitoring and observability platform.
## Where Does Mezmo Fit In
Mezmo is enterprise-grade OTel (OpenTelemetry).
In the previous section, it was made clear that there are a lot of “endpoints” for monitoring and observability. Logs, traces, and metrics contain a lot of information. The problem is that because of all of that information, it’s hard to go through.
Instead, that data needs a central location to be stored and a central place where it can be sent from.
Mezmo gives you a one-stop-shop location to ingest all of the observability data and have it sent out to wherever it needs to go. Perhaps it’s a log aggregator or maybe it’s a SIEM solution. In any case, the observability data is consumed and put into one location to be used later by the tools that need to extract that data (SIEM, log aggregator, etc.) and perform an action on it.
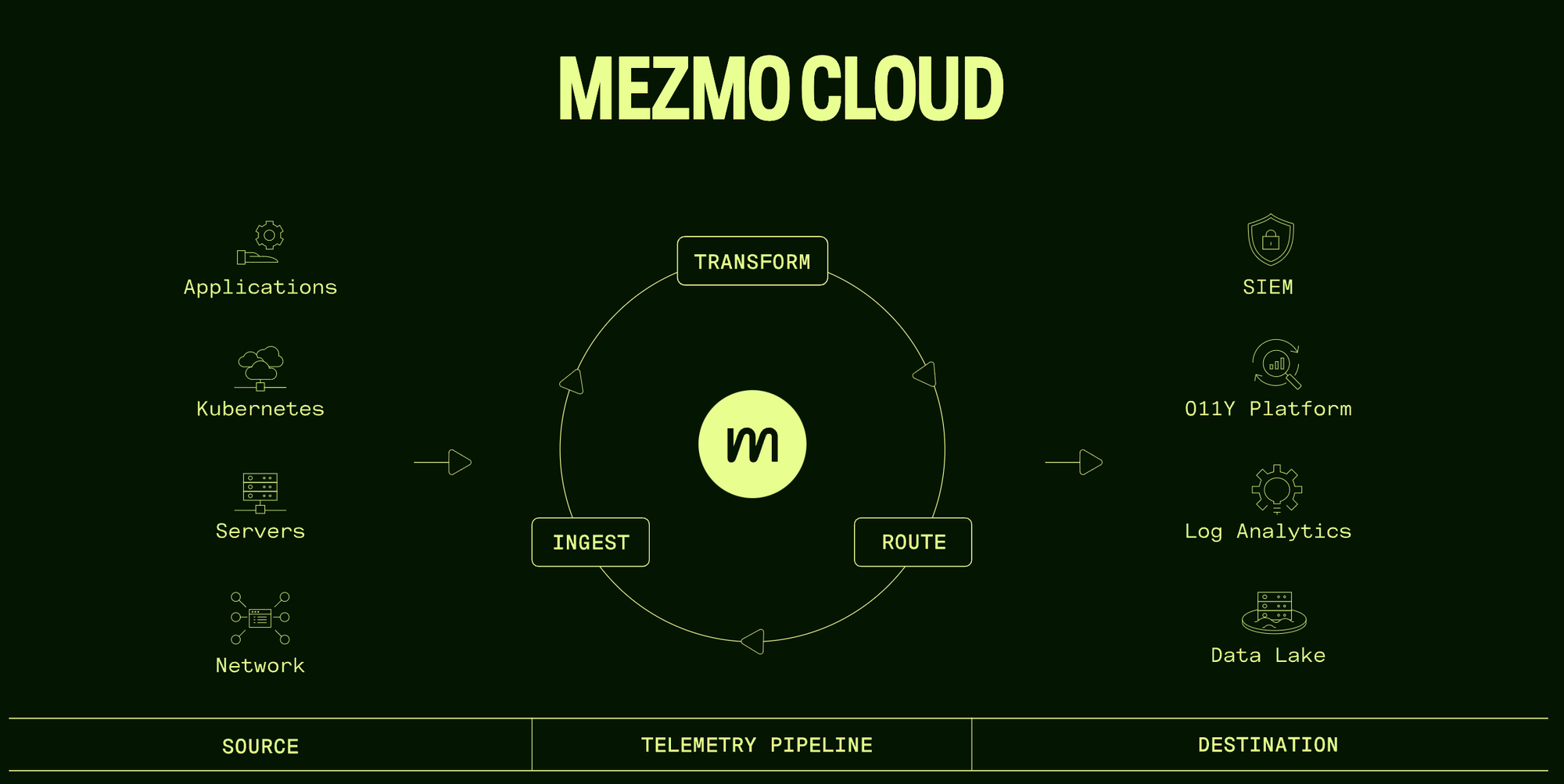
Source: https://www.mezmo.com/
## Install And Configure Mezmo On Kubernetes
Now that you know the “how” and “why” behind monitoring and observability, let’s learn how to deploy Mezmo.
First, sign up for Mezmo (you can get started for free).
https://www.mezmo.com/sign-up-pipeline-today
Next, use the OTel Helm Chart to install it on your Kubernetes cluster.
Run the Helm Chart.
You should now see the Helm Chart deployed.
```jsx
helm list -n mezmo
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
mezmo-otel-collector mezmo 1 2024-05-29 16:05:37.006154 -0400 EDT deployed opentelemetry-collector-0.92.0 0.101.0
```
Within the Mezmo UI (it’s SaaS-based so you don’t have to deploy any Kubernetes Services within your cluster) you should now see the Mezmo environment.
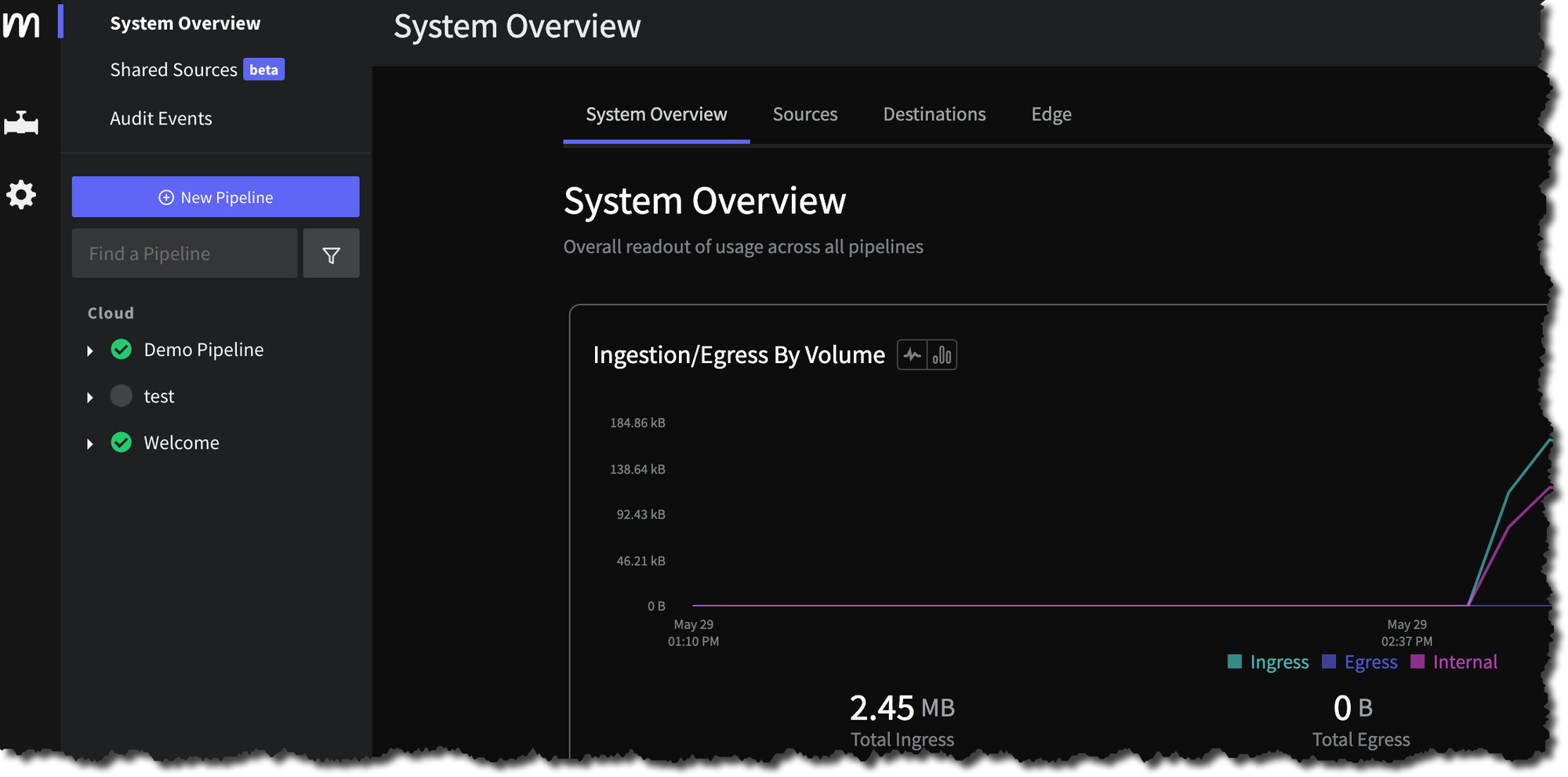
| thenjdevopsguy |
1,869,157 | Correcting iBus/X-Windows compose key conflicts | Originally published on peateasea.de. Did you know that iBus can cause the compose key to stop... | 0 | 2024-05-29T19:14:19 | https://peateasea.de/correcting-ibus-x-windows-compose-key-conflicts/ | linux | ---
title: Correcting iBus/X-Windows compose key conflicts
published: true
date: 2024-05-29 18:00:00 UTC
tags: Linux
canonical_url: https://peateasea.de/correcting-ibus-x-windows-compose-key-conflicts/
cover_image: https://peateasea.de/assets/images/ibus-crossed-swords-x-windows-dev-to.png
---
*Originally published on [peateasea.de](https://peateasea.de/correcting-ibus-x-windows-compose-key-conflicts/).*
Did you know that iBus can cause the compose key to stop working in X-Windows on Linux? I didn’t either. The solution in my situation: if in doubt, leave it out.
I’ve been using Unix and Linux systems since the mid to late 1990s. This is a long time and old habits die hard. Lots of old habits in the Unix world still work today and thus they still have value. As the saying goes, “if it ain’t broke, don’t fix it”. Unfortunately, sometimes things break and it’s hard to work out why they broke and thus how to fix them.
Today is one case in point. I wanted to create a Euro currency symbol in an email but the compose sequence `Compose e =` didn’t work<sup id="fnref:compose-equals-e" role="doc-noteref"><a href="#fn:compose-equals-e" rel="footnote">1</a></sup>. “Huh, that’s weird”, I thought. I tried the sequence in a terminal, which had worked up until recently (unfortunately, I don’t know exactly when :confused:). It didn’t work there either. Very weird. I noticed that when pressing the compose key, a strange symbol, in what looked like a small window, appeared in my terminal. “Hang on, what’s that?”, I thought.
A couple of hours disappear, my browser history is much longer, and I still don’t have that email finished. But I now know what was causing the problem and I have a fix for it. Yay!
## What’s the compose key?

But first: what’s this compose key thing he’s talking about? This is one way to create characters which might not be available on your keyboard. Being someone from an English-speaking culture, when growing up I didn’t need umlauts or accents or Greek characters on my keyboard.<sup id="fnref:euro-not-exist" role="doc-noteref"><a href="#fn:euro-not-exist" rel="footnote">2</a></sup> There are, however, _very_ many other characters one might wish to use. The people who construct computing systems worked out a long time ago (relatively speaking) that a standard keyboard had too few keys for all possible characters one might want to produce. They came up with an elegant solution to this problem: characters could be _composed_ by using a special key in combination with the more basic characters available on a keyboard. This became known as the [compose key](https://en.wikipedia.org/wiki/Compose_key)<sup id="fnref:aka-multi-key" role="doc-noteref"><a href="#fn:aka-multi-key" rel="footnote">3</a></sup> and (at least until the late 90’s and probably early 2000’s) there was a special key on many keyboards specifically for this task.
These days people tend not to use DEC or Sun Microsystems desktop systems (which is where one would have seen such a key) and thus it’s not obvious that a compose key _could_ exist let alone realise that there might be a need for one. Since my standard keyboard doesn’t have an explicit compose key, [I mapped caps lock to compose](https://peateasea.de/the-trick-with-perl6-and-linux-stay-composed/#mapping-mods-in-x), because after all, who needs caps lock, right?
## It doesn’t work! _What_, exactly, doesn’t work?
So, back to the issue at hand: the compose key wasn’t working. But what does “not working” mean in this case? Well, when I pressed the `Compose e =` key sequence the Euro currency symbol didn’t appear as expected. Instead, after pressing the compose key, a white box containing a little symbol appeared under the cursor:

The image shows my terminal prompt (which starts on the line below the username, hostname and path information that I display in my shell) and the cursor (the tall white box next to the `->` arrow). Note that below the cursor, there’s a wide white box, with a grey shaded area to the left and within the white area there’s a symbol of some kind.<sup id="fnref:official-compose-symbol" role="doc-noteref"><a href="#fn:official-compose-symbol" rel="footnote">4</a></sup> Note how zoomed-in this image is. This is why it was very difficult to work out what the computer was trying to tell me and hence to work out what was going on. It seemed that this little pop-up box was stopping the compose sequence from getting to the shell and hence stopping the desired character from being displayed.<sup id="fnref:euro-symbol-also-not-in-email-program" role="doc-noteref"><a href="#fn:euro-symbol-also-not-in-email-program" rel="footnote">5</a></sup>
This, I think, is the fundamental insight here: _something_ was getting in the way and stopping the key presses from reaching the relevant (X-Windows) application. But what?
Trying to google for things like “little pop-up window when pressing compose key” led nowhere and served only to confuse me and make my browser history even longer.
… I thought something might be wrong with my [`xmodmap`](https://wiki.archlinux.org/title/xmodmap) settings. Nope.
… I tried [setting the `XKBOPTIONS` variable in`/etc/default/keyboard`](https://duncanlock.net/blog/2013/05/03/how-to-set-your-compose-key-on-xfce-xubuntu-lxde-linux/) and restarting X-Windows. Also nope.
… I even tried using a different windows manager.<sup id="fnref:awesome-windows-manager" role="doc-noteref"><a href="#fn:awesome-windows-manager" rel="footnote">6</a></sup> :scream:
… I tried rebooting and … hang on, what was that? As the windows manager was starting, I noticed a symbol appear in the taskbar that I’d spotted before, but didn’t know what what it was. It looked a bit like a picture of a steam iron. It turns out it wasn’t a picture of an iron (and I never thought it was, but still). That idea came from either my bad eyesight, the small size of the icon, or my imagination (or a combination of all three). The icon was, in fact, a keyboard with a cable above and a small globe of the earth in the lower left-hand corner.

Upon starting my first terminal session, this changed into just the two letters `EN`; this is because I use an English-based keyboard layout.<sup id="fnref:english-on-german-layout" role="doc-noteref"><a href="#fn:english-on-german-layout" rel="footnote">7</a></sup>

I’d seen this appear a few times over the years but it never seemed to have had any impact on my ability to enter text into the console or any GUI applications, so I paid it no further attention. I also noticed that the icon would sometimes disappear after a while. You know how one can be too busy to investigate that random thing which appears on one’s computer but later bites one on the proverbial posterior at some inopportune time? This was one of those times.<sup id="fnref:disdain-for-ironing" role="doc-noteref"><a href="#fn:disdain-for-ironing" rel="footnote">8</a></sup>
Fortunately, this time, I decided I wanted to work out what this thing was and ended up right-clicking on the symbol, which greeted me with a context menu:
Clicking on the “About” menu item showed this window
Aha! _Now_ I know what this thing is _and_ can now create a more sensible Google query.
Extending my browser history (and the number of [open](https://explosm.net/comics/kris-tab) [tabs](https://www.hedgerhumor.com/close-a-tab-dont-be-ridiculous/)) further, I learned that the icon belonged to [iBus](https://en.wikipedia.org/wiki/Intelligent_Input_Bus), the “Intelligent Input Bus”. This is an
> input method (IM) framework for multilingual input in Unix-like operating-systems.
In other words, one can use iBus to swap between, say, a German layout and an English layout.<sup id="fnref:ibus-common-use-case" role="doc-noteref"><a href="#fn:ibus-common-use-case" rel="footnote">9</a></sup> Since I’d already integrated umlauts and the [sharp S](https://en.wikipedia.org/wiki/%C3%9F) into my keyboard layout via `xmodmap`, I didn’t need a system to handle more layouts. I thus tried simply quitting iBus from the “Quit” context menu item.
And then compose key sequences started working again! Yay!
Ok, now that I know how to solve the problem, how do I make sure that it doesn’t return?
## Stomping on a bug
This wasn’t a bug in the sense that this was an error in code somewhere. It was, however, a behaviour that I didn’t want to have. Thus I could still use the same strategy as when confronted with a bug: after finding the root cause, ensure that the issue never resurfaces.
So what’s the long-term solution in this case? More stumbling through information on the internet [showed that](https://wiki.debian.org/I18n/ibus)
> ibus is the default input method (IM) for GNOME desktop. It allows a user to enter characters of a different language. E.g. entering Chinese while your system generally uses a German keyboard layout.
[and that](https://wiki.debian.org/I18n/ibus)
> im-config will set up [the] required environment variable and also take care starting of daemon program.
The [`im-config` program](https://packages.debian.org/stable/im-config) configures the _input method_,<sup id="fnref:im-in-im-config" role="doc-noteref"><a href="#fn:im-in-im-config" rel="footnote">10</a></sup> of which iBus is one possibility. One configures `im-config` via the `/etc/default/im-config` file. The first few lines of this file look like the following:
```shell
# Default im-config mode (see im-config(8))
# This im-config helps to start best available input method (IM)
# Always start highest priority IM
IM_CONFIG_DEFAULT_MODE=auto
# Start or not to start IM dynamically under CJKV/desktop environment
#IM_CONFIG_DEFAULT_MODE=cjkv
# Never start IM by im-config (Leave it to desktop system)
#IM_CONFIG_DEFAULT_MODE=none
<snip>
```
Isn’t it wonderful to read such a well-documented configuration file? It makes life _so_ much easier.
Anyway, we can see that, by default, the highest priority input manager (`IM`) is started automatically.
```shell
# Always start highest priority IM
IM_CONFIG_DEFAULT_MODE=auto
```
Further down, we can see that if we want to “Leave it to [the] desktop system”, we should change the `IM_CONFIG_DEFAULT_MODE` setting to `none`. Since we want to use the desktop system and not an intermediary, we comment out the line
```shell
IM_CONFIG_DEFAULT_MODE=auto
```
so that it reads
```shell
# Always start highest priority IM
#IM_CONFIG_DEFAULT_MODE=auto
```
and activate the line
```shell
#IM_CONFIG_DEFAULT_MODE=none
```
(by removing the comment character) so that it reads like this:
```shell
# Never start IM by im-config (Leave it to desktop system)
IM_CONFIG_DEFAULT_MODE=none
```
Saving the file and restarting X-Windows showed that iBus _didn’t_ start, i.e. its icon doesn’t appear in the taskbar:

Great! Problem solved! And I learned something!
Now I can [close all of my browser tabs](https://www.reddit.com/r/ProgrammerHumor/comments/g8b8i4/after_you_solve_that_mysterious_bug/) and finally finish writing that email. :grin:
1. `Compose = e` also works. See [https://github.com/kragen/xcompose](https://github.com/kragen/xcompose) for a good `.XCompose` configuration. [↩](#fnref:compose-equals-e)
2. And the Euro hadn’t been invented yet! Yes, [fellow kids](/assets/images/how-do-you-do-fellow-kids.webp), I’m getting long in the tooth. [↩](#fnref:euro-not-exist)
3. Also known as the _Multi-Key_. [↩](#fnref:aka-multi-key)
4. It turns out that the symbol is the [ISO composition symbol](https://en.wikipedia.org/wiki/Compose_key#History). I only worked this out much later though, basically because the symbol was so small when displayed on my screen. [↩](#fnref:official-compose-symbol)
5. My guess is that this is also why my email program wasn’t printing the Euro symbol: something was getting in the way of the compose sequence getting through to the email program. [↩](#fnref:euro-symbol-also-not-in-email-program)
6. My windows manager is awesome. No really, I mean it, it’s [awesome](https://awesomewm.org/). [↩](#fnref:awesome-windows-manager)
7. I use an English layout on a German keyboard. I tend to confuse people who want to use my computer. [↩](#fnref:english-on-german-layout)
8. Perhaps my general disdain for ironing clothes had held me back from investigating what this icon was sooner. [↩](#fnref:disdain-for-ironing)
9. The common iBus use case is to allow [Japanese, Chinese and Korean (CJK) languages to enter non-ASCII native characters](https://packages.debian.org/stable/im-config). [↩](#fnref:ibus-common-use-case)
10. That’s the “im” in `im-config`. [↩](#fnref:im-in-im-config) | peateasea |
1,869,548 | Market Weekly Recap: Ethereum ETF Ignites the Market; PEPE and NOT Mark New Highs | SEC finally approves Ethereum ETF while market reacts with green charts... | 0 | 2024-05-29T19:55:31 | https://dev.to/endeo/market-weekly-recap-ethereum-etf-ignites-the-market-pepe-and-not-mark-new-highs-4d7h | webdev, javascript, web3, blockchain | ## SEC finally approves Ethereum ETF while market reacts with green charts piling.
Cryptocurrency market enters a green rally for the second time in the year as Ethereum ETF gains its seat at the Wall Street. While the approval has stolen the spotlight from other cases of positive price dynamics, the significance of the latter remains a topic for the week.
Below – handpicked updates, which hint at the continuation of a bullish sentiment.
## Ethereum ETF Finally Cracks Approval
On May 23, the U.S. Securities and Exchange Commission (SEC) approved eight applications for spot Ethereum (ETH) exchange-traded funds (ETFs).
The regulator approved 19b-4 forms from the ETF applications filed by Fidelity, BlackRock, Grayscale, Bitwise, VanEck, Ark, Invesco Galaxy, and Franklin Templeton.
The approval and preceding optimism took investors aback, as the SEC implicitly stood against approving Ether ETF. The tides turned on May 20, when a senior Bloomberg analyst Eric Balchunas cited a positive change in SEC’s stance on the approval. Around the same period, Reuters’ revealed that the watchdog asked Nasdaq, CBOE, and NYSE to fine-tune their application to list spot Ether ETFs.
The positive developments fuelled Ether market performance, as the asset’s price surged 18% May 20 and registered another 8.6% uptick May 21.
Since the Ethereum ETF approval had been officially confirmed, Ether (ETH) has registered an 11.48% uptick, ending in the $3900 range at the writing time.
The proximity to the coveted $4,000 milestone once again encouraged the market participants to hold the assets, as can be proved by the latest CryptoQuant data. According to the user behind elcryptotavo nickname, 10k-100k Ethereum accumulating addresses sought a surge in number.
Ether’s daily chart explains the tendency. The bullish reversal from the $2850 market formed a falling wedge breakout and completed a rounding bottom. These graphic indicators mark a long-term bullish sentiment.
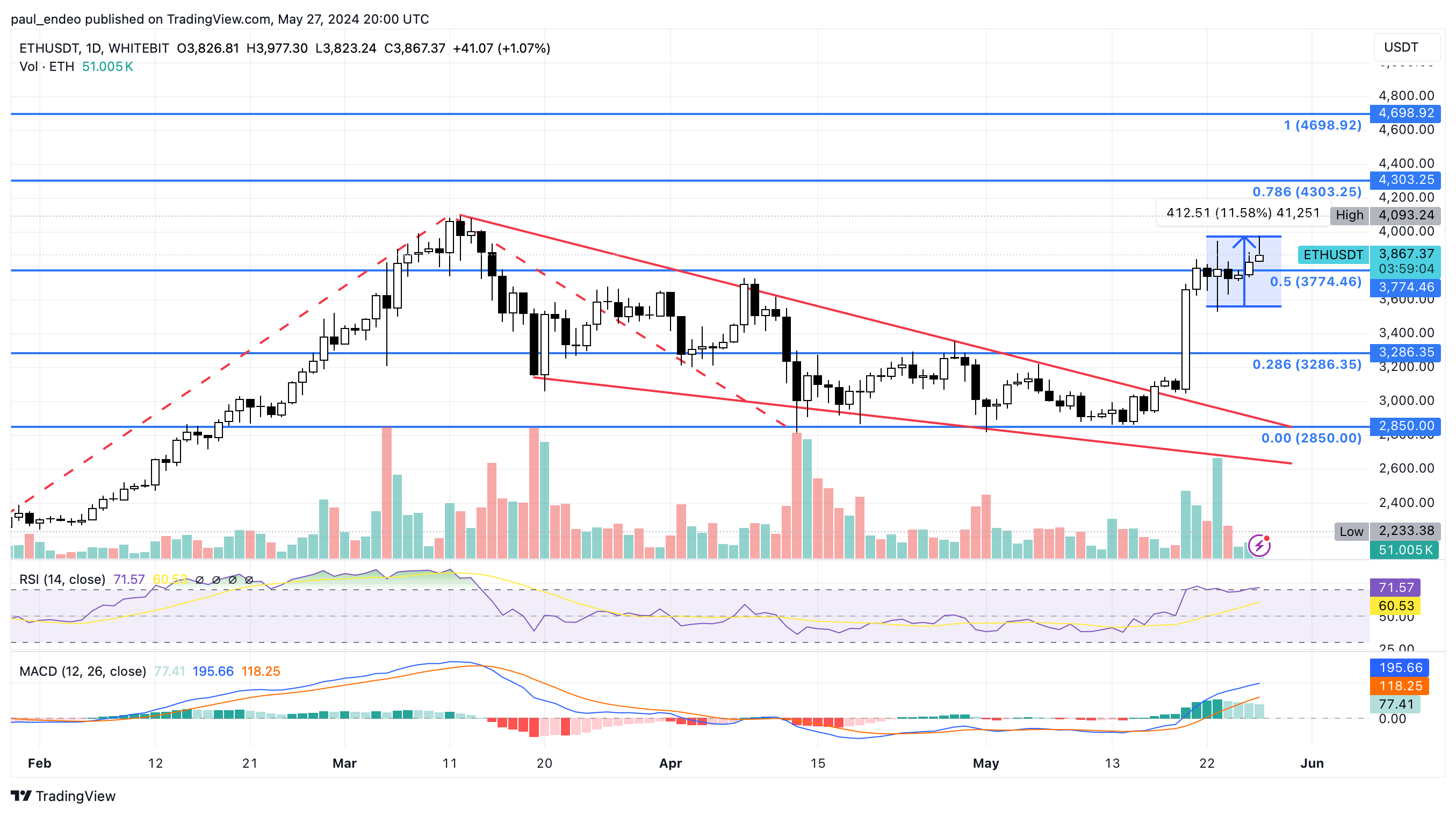
The bullish crossover in the moving average convergence divergence (MACD) and signal lines reflect a minor pause as the histograms decline. At the same time, the daily RSI line turns flat near the overbought zone, reflecting the minor consolidation below the $3900 range.
With buyers asserting dominance and whales keeping a firm grip, the Ethereum (ETH) price could aim for the $4698 level, as per Fibonacci levels.
Still, Ethereum ETF are not coming immediately tradable. In a post for X, Bloomberg senior analyst James Seyffart noted that ETF issuers might get their S-1 forms approved first.
“Typically this process takes months. Like up to 5 months in some examples but Erich Balchunas (senior Bloomberg analyst – author’s note) and I think this will be somewhat accelerated. Bitcoin ETFs were at least 90 days,” wrote Seyffart.
## Bitcoin’s Back to $70K, Drowned by Mt. Gox Awakened Activity
After scoring the local milestone of $70,000, Bitcoin retested to the four-day lows into the May 28 Wall Street open after the Memorial Day holiday in the US.
Despite rapidly gaining momentum throughout two last weeks, Bitcoin’s latest rally failed to endure, while investor’s confidence in the asset dwindled.
The downtick followed a new movement of at least 42,380 BTC (ca. $7 billion at press time) from cold wallets linked to defunct exchange Mt. Gox, according to data from Arkham Intelligence.
The move marked the first time in five years that Mt. Gox transferred assets out of its wallets. Mt. Gox still holds about $9.42 billion worth of Bitcoin in its identified wallets tracked by Arkham.
Still, the investors’ optimism remains, as the Bitcoin Rainbow chart revealed that the coin entered the “buy” zone. A similar trend was observed amidst BTC’s third halving, which eventually resulted in achieving the milestone. If that is to be considered, then this might just be the last opportunity for investors to buy BTC at a lower price before it moves up and enters the accumulate and HODL zones.
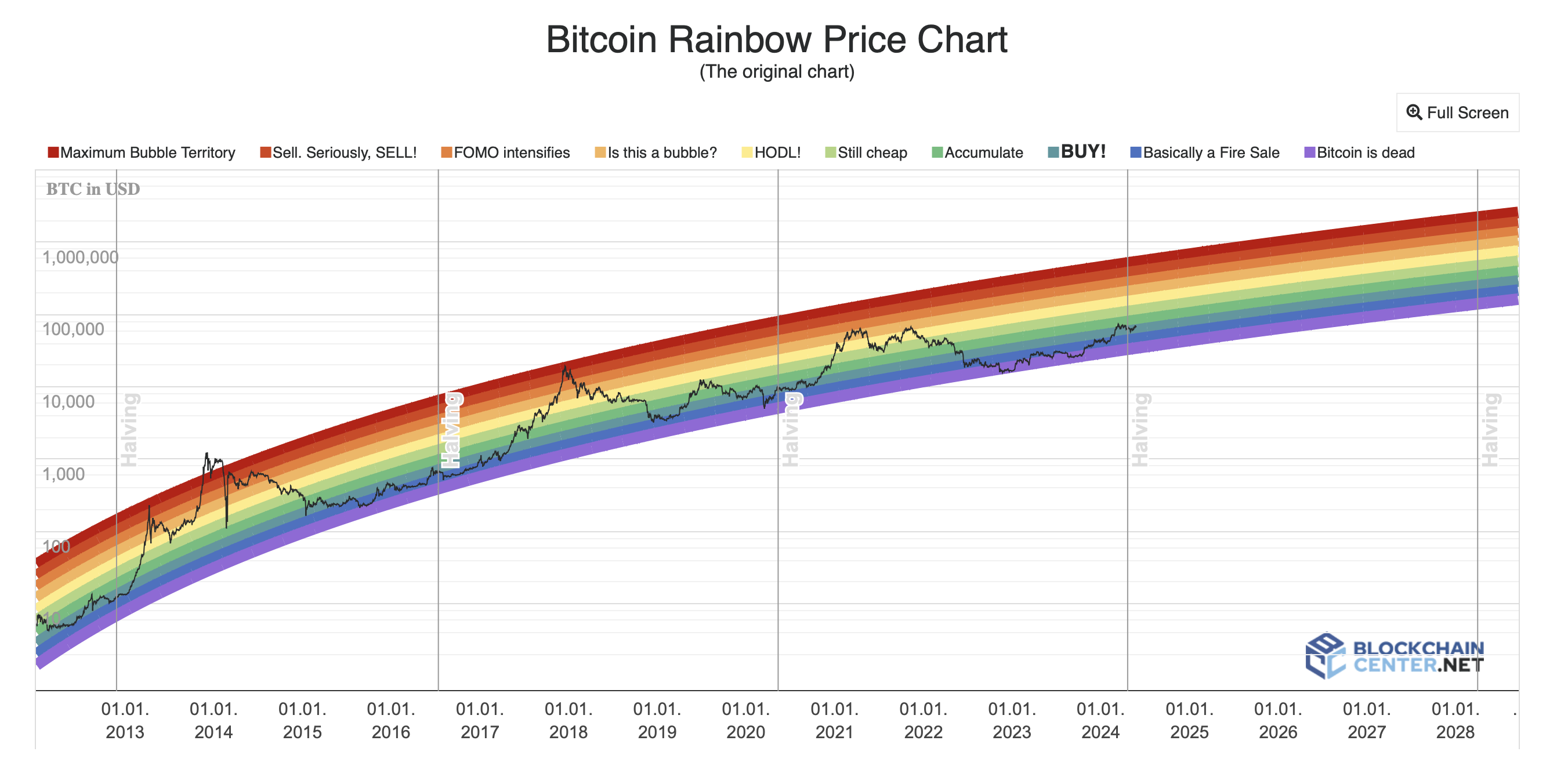
What is more, a reputable analyst Jelle shared the positive outlook for Bitcoin while referring to the price history and citing BTC to achieve a “6-figure” milestone.
“Bitcoin has spent the past 6.5 years inside this rising channel, and I don't expect that to change anytime soon. If history is any indication, it's time for another trip towards the highs of the channel. 6-figure Bitcoin is coming,” he wrote in a post for X.
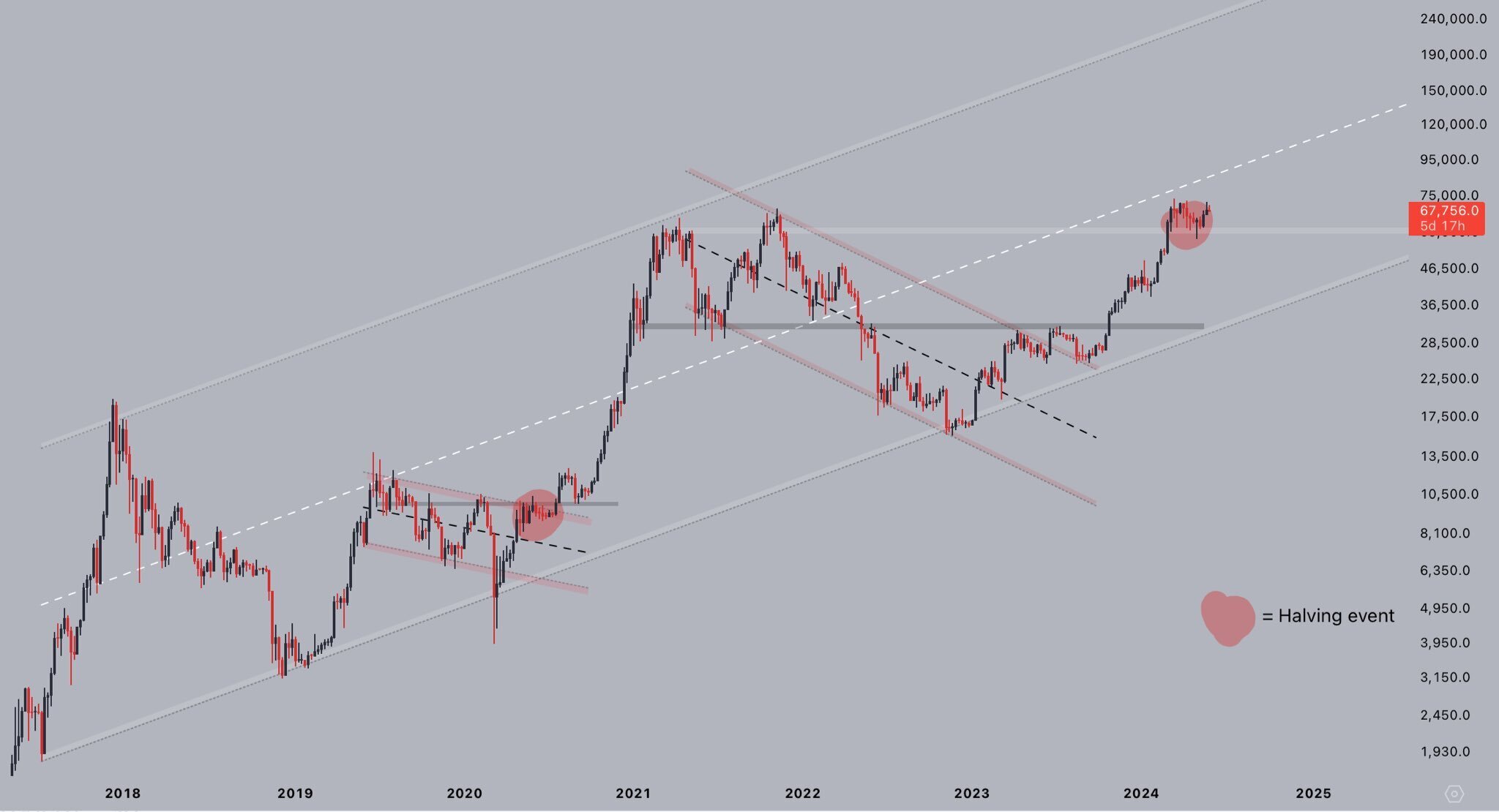
Still, a closer look at Bitcoin's daily chart clearly reveals a neutral trend. While MACD displays a risk of a bearish crossover, CMF and RSI indicate slight upticks.
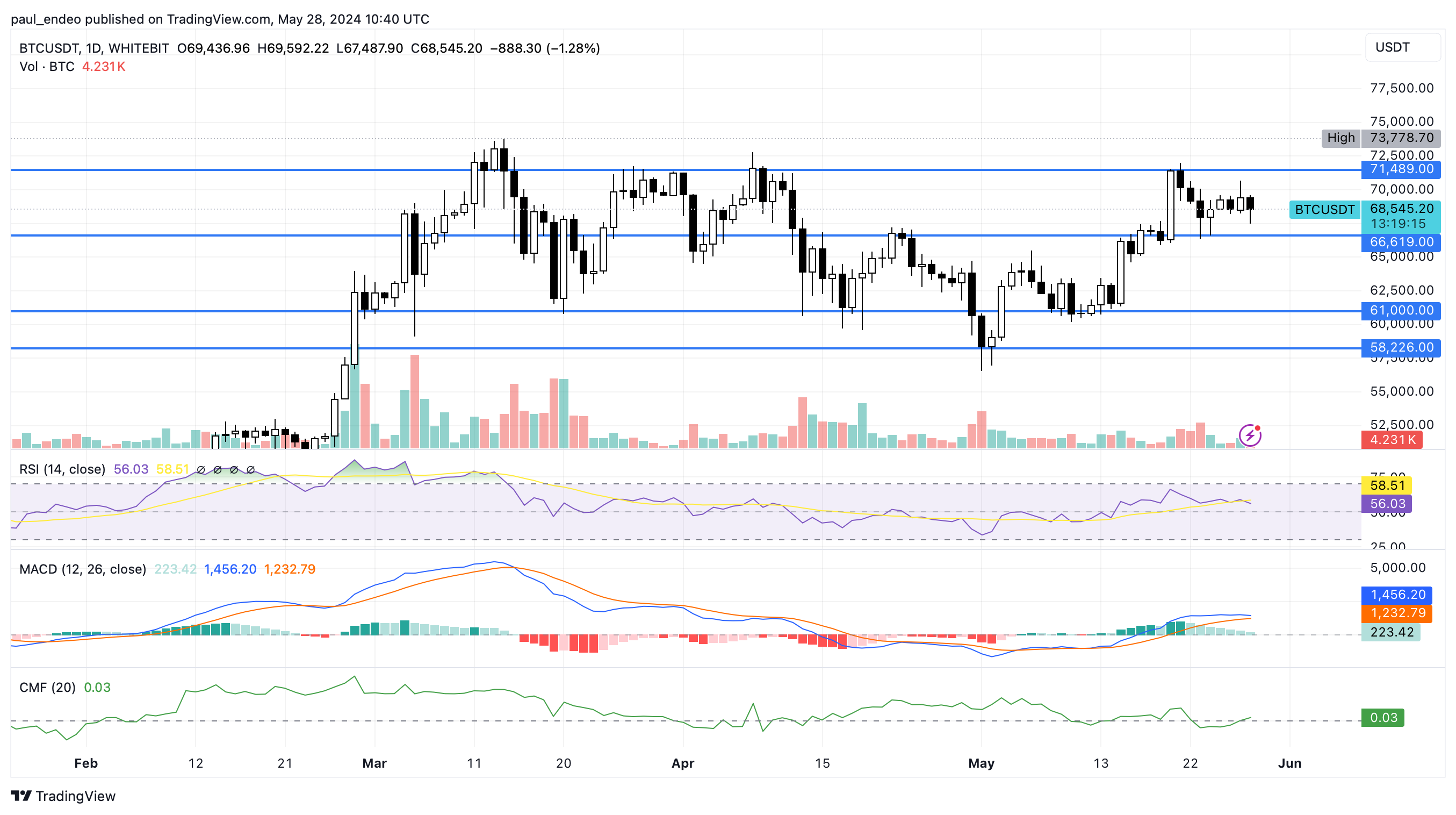
If buyers manage to take over, Bitcoin may overcome the $71,489 zone to get poised for a bullish rally.
However, seeing the Fear&Greed index standing at 72 at the writing time, a price correction could take over due to a sellout at profit.
## Notcoin (NOT) Scores Weekly 113% While BounceBit Reaches ATH
Ethereum ETF approval was positively reflected on the altcoin market.
Notcoin (NOT), a Telegram Open Network (TON) token, entered the centre stage with a staggering 113% for less than a week, scoring the local high of $0.0099.
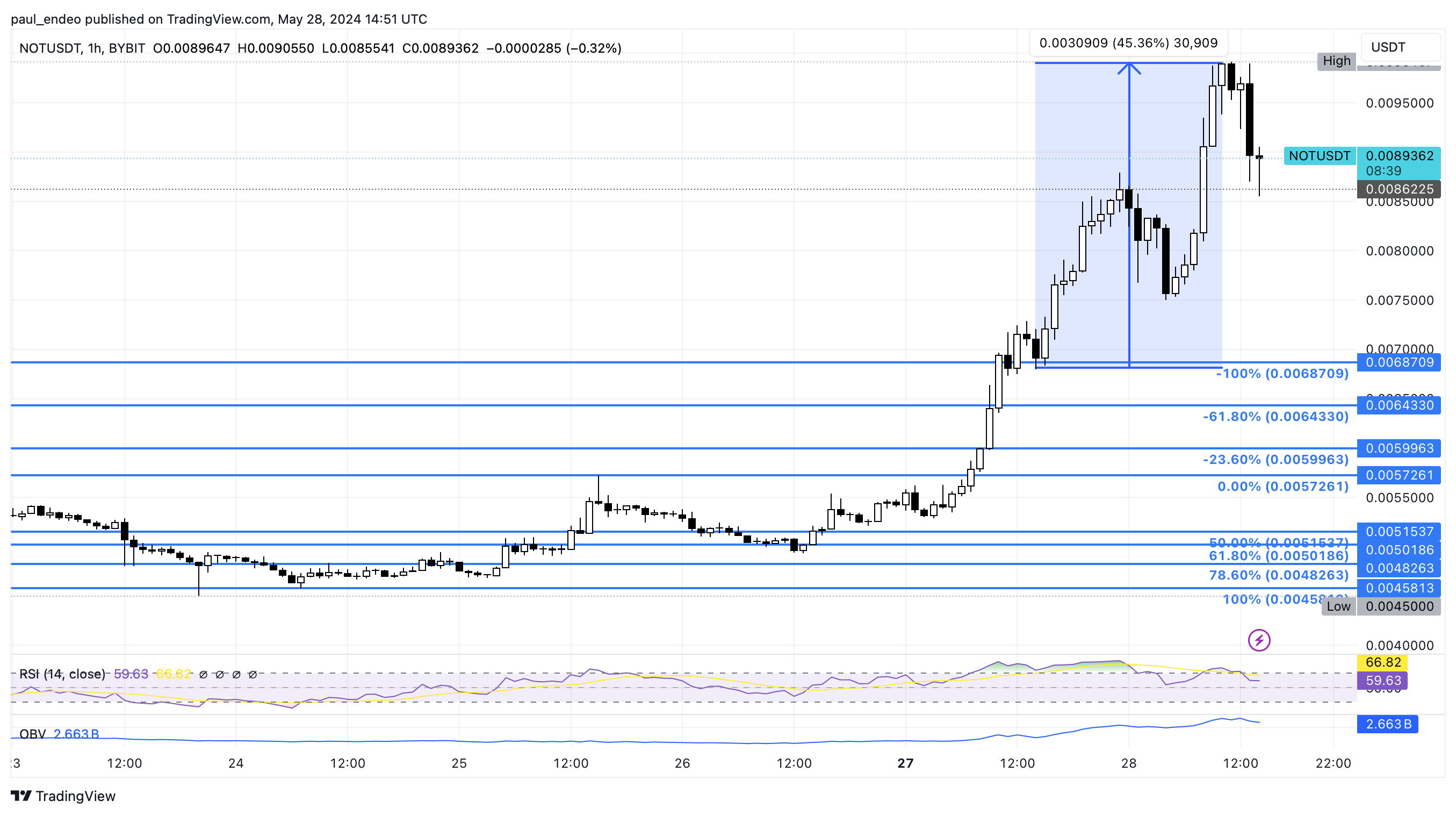
Specifically, on May 25, Notcoin breached the downtrend lower high of $0.00544 and formed a higher low at $0.00493.
Since that higher low, NOT has surged over 113%, fuelled by a listing on WhiteBIT exchange, till May 28 13% retest. Evidently, OBV and RSI noted slight downticks.
Among the top performers, BounceBit (BB) sought its place. The coin has surged by 30% in recent days, following the project’s newly released ecosystem roadmap and listings on Binance, OKX, WhiteBIT, and other top exchanges.
While BounceBit is a relatively new project, its price action has already shown promising signs. On May 26, the coin broke out of a crucial resistance level at around $0.45, reaching a high of approximately $0.55.
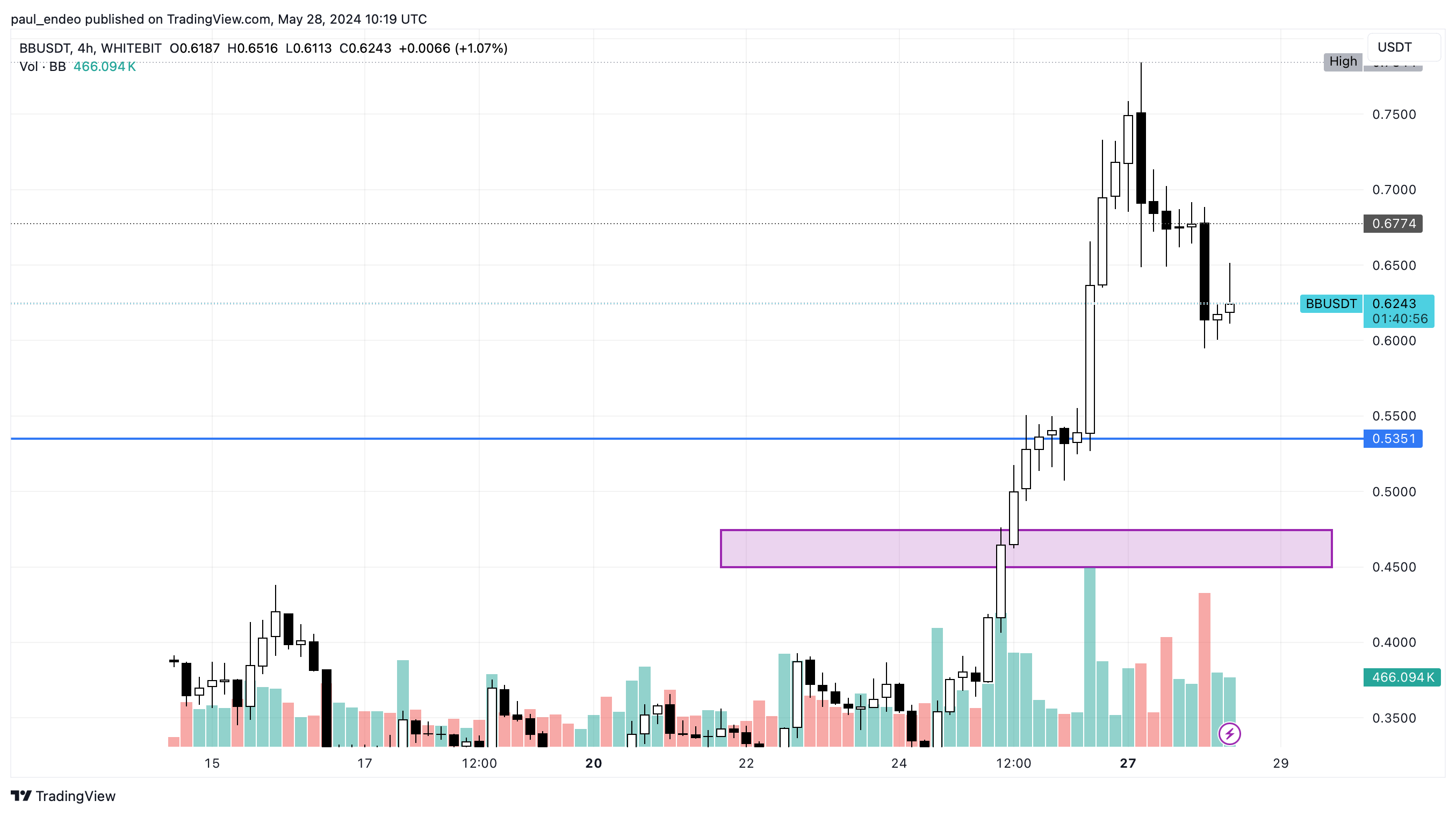
Despite the retracement today, the overall sentiment remains bullish, with traders and investors anticipating further upside potential as the project executes its ambitious roadmap.
The memecoin market has also demonstrated a positive market sentiment. Namely, Pepe (PEPE) indicated a rounding bottom reversal in the daily chart, hinting at the potential long-term bullrun.
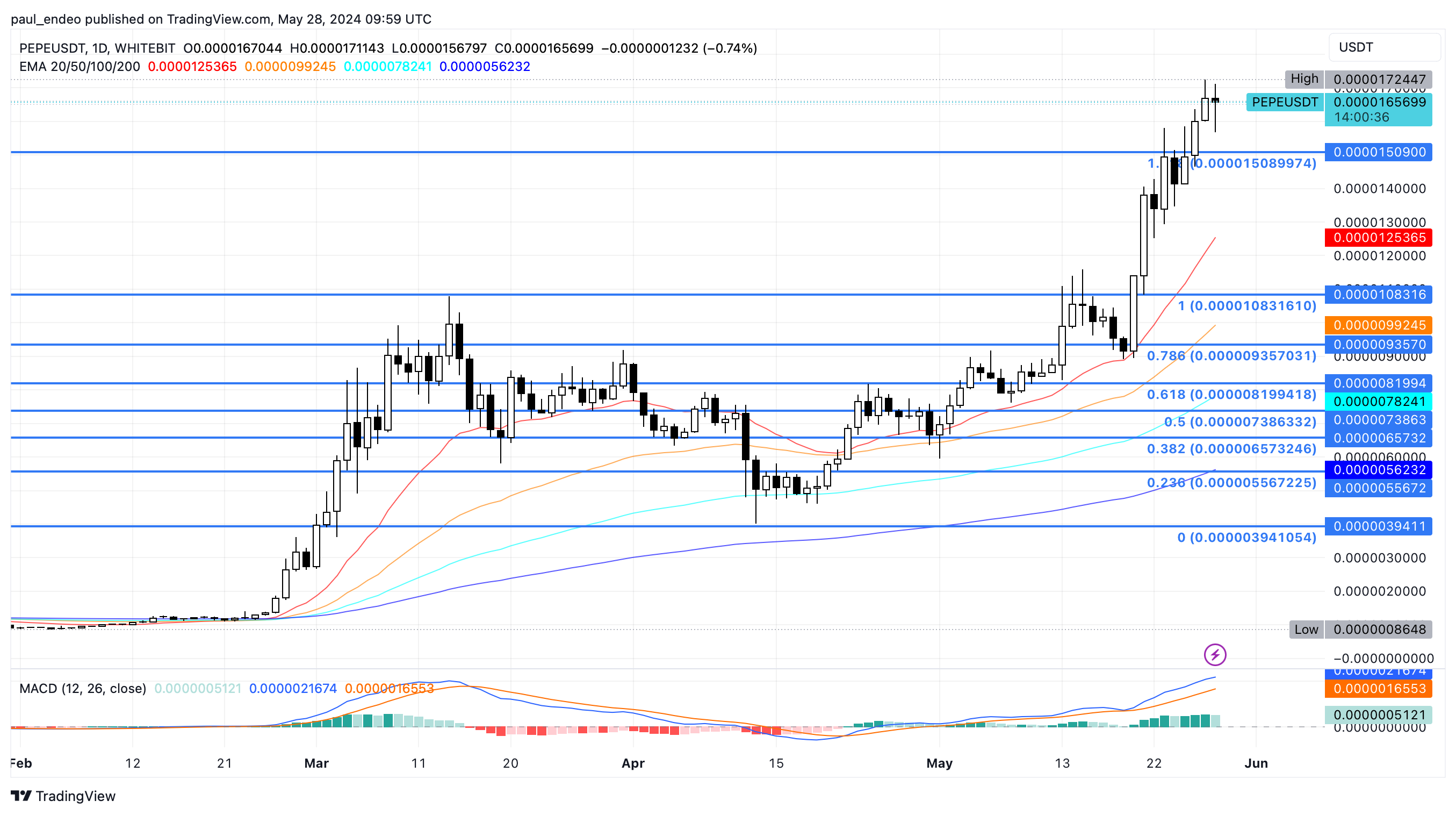
Nevertheless, a slight pullback undermines yesterday’s jump and warns of a correction spree in the coming days. As per the Fibonacci retracement levels, the memecoin is well established above the 1.618 level and is ready for a retest.
If the bulls come back with a successful retest, the PEPE price could propel to the $0.000021 mark or the 2.618 Fibonacci level.
While the previous week’s market was dressed in green, and long-term optimism has been prevailing among the investors, the charts hint at the potential consolidation phase that will result in an increased volatility and assets’ downtick. | endeo |
1,869,544 | How to build a basic RAG app | The dawn of Generative AI makes possible new kinds of capabilities for the applications we build.... | 0 | 2024-05-29T19:50:28 | https://dev.to/rogiia/how-to-build-a-basic-rag-app-h9p | ai, machinelearning, rag | The dawn of Generative AI makes possible new kinds of capabilities for the applications we build. LLMs can answer the user’s questions with an incredible skill. So, why not use them as part of our systems. If the user needs help getting around the app, we can put a chat function where the LLM will answer all the user’s questions. If our app has blog posts explaining important concepts, instead of making the user read all of them to get the knowledge it needs, it could just ask and get an immediate response.
## Why RAG?
We decide to integrate a LLM into our app to bring these features to our users. However, we soon find that the model can’t answer the user’s questions. It doesn’t have any information about our application! If the information needed to answer is not in the LLM’s training data, it can’t answer. Even worse, if it doesn’t know the answer, it might hallucinate a completely wrong fact! This is bad, so how do we fix this? LLMs with the Transformer architecture have shown great in-context learning capabilities. So, we just have to pass all the facts that it needs in the prompt, together with the question! Uh oh, it will definitely be expensive to stuff all the data in every prompt. So, how do we do it?
## What is RAG?
RAG stands for **Retrieval Augmented Generation**. RAG was born together with Transformers. Initially, it was used to augment the pre-training data of LLMs with additional facts. Once Transformers’ in-context learning capabilities became obvious, it became a common practice also during inference, to augment the prompt.
A basic RAG pipeline consists of three steps: indexing, retrieval and generation. All the information that the LLM needs to answer is indexed in a vector database. When the user asks a question, we can retrieve the relevant parts of the information from that vector database. Finally, together with just the relevant information and the user’s question, we can prompt the LLM to give an answer based on the information we give it as a context. Let’s look in more detail how to achieve this.
### Indexing
First, we extract the information that the model needs from wherever it is. Generative models work with plain text (some models can also work with images or other formats, which can also be indexed, but this is a topic for another time). If the information is already in plain text, we are in luck. But it might also be in PDF documents, Word documents, Excel, Markdown, etc. We must convert this data to plain text and clean it so it can be usable for the model.

Once the information is in text format, we can store it in a vector database. The vector database will store the embeddings representation of that text. That will allow us to search for parts of the text that have a similar embedding representation as another text, therefore they are about a similar concept. We will divide the whole text into smaller parts or chunks, calculate the embeddings representation for each of them, and finally store them in the vector database.
### Retrieval
When the user asks us a question, we can convert that question into a vector representation, using the same embeddings model we used to index the data. With that vector representation, we will calculate the similarity factor between the question and each one of the chunks stored in the vector database. We will select the top K chunks that are the most similar to the query, and therefore their contents are about the same concept as the question (and therefore they might contain the answer).

### Generation
A prompt is built, putting together the user’s question and the relevant contexts to help the LLM answer. We might also include previous messages from the conversation between the user and the AI assistant. The LLM generates an answer for the user based on the context, instead of its previously learned pre-training data.

## Example
For this example, we will ingest a paper called “Retrieval-Augmented Generation for Lange Language Models: A Survey”. We will query the LLM using the information contained in this paper, so it can answer the user’s questions on its contents. You can follow this example in [the Google Colab notebook provided for this article](https://colab.research.google.com/drive/1mFmPN0GBHpS-kMDMuU8EDrWu1KENy69e?usp=sharing).
First, we will load the PDF document and parse it using LangChain’s PyPDF connector.

Once we have the text from the document, we have to split it into smaller chunks. We can use LangChain’s available splitters, like RecursiveCharacterSplitter in this case:

We will be using BGE-small, an opensource embeddings model. We will download it from HuggingFace Hub and run it on all chunks to calculate their vector representations.

Once we have the vector representations for all chunks, we can create an in-memory vector database and store all vectors in it. For this example, we will be using a FAISS database.

The database is now set up. Now, we will be taking queries from the user on this information. In this case, the user asks which are the drawbacks of Naive RAG. We encode this query using the same embeddings model as before. Then, we retrieve the top 5 most similar chunks to that query.

After retrieving the relevant context, we build a prompt using this information and the user’s original query. We will use Claude’s Haiku as a LLM for this example:

## Common problems and pitfalls
As the title implies, this solution is a basic or naïve RAG implementation. It will empower your application to make the most out of the LLM it’s using and your data. But it won’t work for all cases. These are just some of the most common problems with RAG:
- **Retrieve irrelevant information.** If the retriever gets data from the vector database that is not relevant to the question, it will confuse the model trying to answer the question. This might lead to either not using the context to answer the question, or answering something different than what was asked.
- **Miss important information.** Maybe the information it needs to answer the question is not in the database. Maybe the retrieval mechanism fails to find the relevant chunks. We must find ways to help the retriever find the information it needs easily and more reliably.
- **Generate responses not supported by the context.** If the context has the information the model needs, but it doesn’t use it and instead relies on its own pre-training data, all this was for nothing. The information from the pre-training data might be outdated or wrong. We must favor the model to always use the context to answer, or answer “I don’t know” if it can’t answer from the context.
- **Irrelevant response to the query.** The LLM might use all the information that you give it to generate a response, but that doesn’t mean that it answers the user’s question. It’s important that the model sticks to the user’s original question, instead on getting lost in a ton of information.
- **Redundant response caused by similar contexts.** When we ingest multiple documents with similar information, there’s a chance that the retriever will get multiple chunks of information that say almost the same. This might cause the LLM to repeat the same information more than one time in its response.
## How to avoid these problems?
To avoid these problems, a naïve RAG pipeline might not be enough. We will need to set up a more advanced and complex RAG system. There exist tested techniques to solve the problems we have laid out. We can incorporate them into our RAG pipeline to improve the RAG application’s performance.
Another important point to address is that, to improve your RAG application, you will need to be able to measure and evaluate the whole process. You can’t improve what you can’t measure. Plus, when you evaluate you might find that a basic RAG setup is enough for your use case, and you don’t need to overcomplicate it. After all, even a very basic RAG implementation can improve your LLM powered application enormously.
In future articles, I will explain in more detail the advanced RAG techniques that will help us avoid common problems and bring our RAG applications to the next level. | rogiia |
1,869,546 | YOU ARE GREAT | YOU ARE GREAT. I BELIEVE IN YOU, BECAUSE YOU ARE AN INCREDIBLE PERSON. YOU'VE OBVIOUSLY MADE... | 0 | 2024-05-29T19:49:56 | https://dev.to/freevideocorporation/you-are-great-2lc |
<p><h1>YOU ARE GREAT. I BELIEVE IN YOU, BECAUSE YOU ARE AN INCREDIBLE PERSON. YOU'VE OBVIOUSLY MADE MISTAKES. EVERYONE DOES, IT'S HUMAN. KEEP GOING, AND REMEMBER THAT WHOEVER YOU ARE, SOMEONE BELIEVES IN YOU<br><br>你是伟大的。我相信你,因为你是个了不起的人。你显然犯过错误 每个人都会犯错,这是人之常情。继续前进,记住,无论你是谁,都有人相信你。<br><br>TÚ ERES GRANDE. CREO EN TI, PORQUE ERES UNA PERSONA INCREIBLE. OBVIAMENTE HAS COMETIDO ERRORES. TODO EL MUNDO LOS COMETE, ES HUMANO. SIGUE ADELANTE, Y RECUERDA QUE SEAS QUIEN SEAS, ALGUIEN CREE EN TI.<br><br>TU ES GÉNIAL. JE CROIS EN TOI, CAR TU ES UNE PERSONNE INCROYABLE. TU AS ÉVIDEMMENT FAIT DES ERREURS. TOUT LE MONDE EN FAIT, C'EST HUMAIN. CONTINUE, ET SOUVIENS TOI QUE QUI QUE TU SOIS QUELQU'UN CROIT EN TOI.</h1></p> | freevideocorporation | |
1,869,545 | YOU ARE GREAT | YOU ARE GREAT. I BELIEVE IN YOU, BECAUSE YOU ARE AN INCREDIBLE PERSON. YOU'VE OBVIOUSLY MADE... | 0 | 2024-05-29T19:49:56 | https://dev.to/freevideocorporation/you-are-great-nai |
<p><h1>YOU ARE GREAT. I BELIEVE IN YOU, BECAUSE YOU ARE AN INCREDIBLE PERSON. YOU'VE OBVIOUSLY MADE MISTAKES. EVERYONE DOES, IT'S HUMAN. KEEP GOING, AND REMEMBER THAT WHOEVER YOU ARE, SOMEONE BELIEVES IN YOU<br><br>你是伟大的。我相信你,因为你是个了不起的人。你显然犯过错误 每个人都会犯错,这是人之常情。继续前进,记住,无论你是谁,都有人相信你。<br><br>TÚ ERES GRANDE. CREO EN TI, PORQUE ERES UNA PERSONA INCREIBLE. OBVIAMENTE HAS COMETIDO ERRORES. TODO EL MUNDO LOS COMETE, ES HUMANO. SIGUE ADELANTE, Y RECUERDA QUE SEAS QUIEN SEAS, ALGUIEN CREE EN TI.<br><br>TU ES GÉNIAL. JE CROIS EN TOI, CAR TU ES UNE PERSONNE INCROYABLE. TU AS ÉVIDEMMENT FAIT DES ERREURS. TOUT LE MONDE EN FAIT, C'EST HUMAIN. CONTINUE, ET SOUVIENS TOI QUE QUI QUE TU SOIS QUELQU'UN CROIT EN TOI.</h1></p> | freevideocorporation | |
1,868,318 | Speed Up Your Site with 3 Simple JavaScript Performance Optimization Tips | In our digital world, speed isn't just a convenience... It's a necessity. We all know the frustration... | 0 | 2024-05-29T19:44:05 | https://dev.to/buildwebcrumbs/speed-up-your-site-with-3-simple-javascript-performance-optimization-tips-4gc2 | webdev, performance, beginners, javascript |
In our digital world, speed isn't just a convenience... **It's a necessity.**
We all know the frustration of a slow-loading page, and in today’s web environment, even a few extra seconds can make a huge difference in user satisfaction and business outcomes.
If you’re using JavaScript, there are several straightforward strategies you can employ to supercharge your site's performance.
In this article, I’ll walk you through some simple yet effective tweaks that can help speed up your site, making your users happier and possibly boosting your search engine rankings.
**Ready to upgrade your website? 🚀🚀🚀 Let’s dive in!**
---
## Minimizing DOM Manipulation
The Document Object Model (DOM) is critical in web development, but excessive or improper DOM manipulation can severely impact performance.
- **Optimize Selectors:** Use the most efficient selectors possible for manipulating or querying the DOM. For instance, getElementById() is faster than querySelector().
- **Batch Your DOM Changes:** Minimize reflows and repaints by batching DOM changes. Modify the DOM offscreen and append the changes in a single operation.
``` js
const fragment = document.createDocumentFragment();
for (let i = 0; i < 100; i++) {
const element = document.createElement('div');
fragment.appendChild(element);
}
document.body.appendChild(fragment);
```
- **Use Virtual DOM or Web Component**s: Libraries like React use a virtual DOM to minimize direct DOM manipulation, which can greatly improve performance.
---
Enjoying the article?
{% cta https://www.webcrumbs.org/waitlist %} Join our Newletter for weekly updates!
{% endcta %}
---
## Efficient Event Handling
Improper handling of events, especially in complex applications, can lead to slow performance and unresponsive interfaces.
**- Event Delegation:** Instead of attaching events to individual elements, use event delegation to manage events at a higher level.
``` js
document.getElementById('parent').addEventListener('click', function(event) {
if (event.target.tagName === 'BUTTON') {
console.log('Button clicked!');
}
});
```
**- Throttle and Debounce**: For events that fire frequently, such as resize or scroll, throttle or debounce your handlers to limit the rate at which the event handler is executed.
// Throttle example
``` js
function throttle(func, limit) {
let lastFunc;
let lastRan;
return function() {
const context = this;
const args = arguments;
if (!lastRan) {
func.apply(context, args);
lastRan = Date.now();
} else {
clearTimeout(lastFunc);
lastFunc = setTimeout(function() {
if ((Date.now() - lastRan) >= limit) {
func.apply(context, args);
lastRan = Date.now();
}
}, limit - (Date.now() - lastRan));
}
}
}
window.addEventListener('resize', throttle(function() {
console.log('Resize event');
}, 200));
```
---
Did you learn something new?
{% cta https://www.webcrumbs.org/waitlist %} Join our Newletter for weekly learning crumbs 🍪!
{% endcta %}
---
### Optimizing Loops and Logic
JavaScript’s performance can often be bottlenecked by inefficient code structures, particularly loops and complex logic.
**- Optimize Loop Performance:** Reduce the workload inside loops, cache lengths in loops, and avoid high-cost operations within loops.
``` js
const items = getItems(); // Assume this returns an array
const length = items.length; // Cache the length
for (let i = 0; i < length; i++) {
process(items[i]); // Minimize what happens here
}
```
**- Avoid Unnecessary Computations:** Store computed values when possible instead of recalculating them.
---
## Speed matters in today’s web.
Enhancing your JavaScript performance doesn’t require rewriting your entire application. Implementing these tips can boost your site’s responsiveness and user satisfaction.
Start with one area, see the improvements, and gradually apply more optimizations as needed.
**Share your results or additional tips in the comments below.**
Thanks for reading,
Pachi 💚
**P.S. [Have you give us a GitHub Star yet? ](https://github.com/webcrumbs-community/webcrumbs)⭐** | pachicodes |
1,869,541 | Simple animated button with CSS | Introduction Modern CSS is powerful and versatile. It can be used to create different... | 0 | 2024-05-29T19:44:01 | https://dev.to/bilkeesu96/simple-animated-button-with-css-4c0d | webdev, beginners, tutorial, css |
## Introduction
Modern CSS is powerful and versatile. It can be used to create different animations without using any JavaScript. Let's leverage the power of CSS to create a cool hover animation using the `transform` property, pseudo-elements, pseudo-classes, and the `transition` property. Here’s a preview of the effect we want to create.

## The HTML markup
The HTML structure is simple. Just a `div` containing an anchor element with the class `btn`, which we’ll style as a button.
```
<div>
<a href="#" class="btn">i am a cool button</a>
</div>
```
## Styling the button
Let’s add some basic styles to the button.
```
.btn:link{
display: inline-block;
text-decoration: none;
text-transform: uppercase;
padding: 15px 40px;
background-color: #fff;
color: #777;
border-radius: 100px;
transition: all 0.5s;
}
```
Notice that I specified the transition property. This is what will give us a smooth animation. The transition property should always be added to the element you want to animate.

## Pseudo-classes
Let’s take a minute to understand what pseudo-classes are. Pseudo-classes are used to add styles to elements under a certain condition or state. As we all know, anchor elements have four states:
- **The link state**: this is the default state of a link before it is clicked.
- **The active state**: this is the state of a link the moment it is clicked.
- **The visited state**: this is when the link has already been clicked by the user.
- **The hover state**: this is the state of a link when a mouse cursor goes over it.
Each link state has its pseudo-class that can be used to style the link in that particular state. The pseudo-classes include `:link`, `:active`, `:visited`, and `:hover`. For this button, we’ll apply the animation in the active and hover states.
If you look at the demo above, you’ll notice that this button animation has three parts.
- First, when you hover over the button, it moves up revealing a large shadow beneath it. This large shadow makes it look like it’s moving closer to the screen.
- There’s also a pseudo-element behind the button. This pseudo-element scales up and fades out when you hover over the button.
- When you click the button, it goes down a little bit. The shadow becomes smaller making the button look further away from the screen.
Let’s start by animating the hover and active states. We’ll create the pseudo-element later.
## Animating the hover state
The first thing we want on hover is for the button to move up and reveal a big shadow under it. To achieve this, we’ll use `translateY` with a negative value and then add a shadow to the button.
```
.btn:hover {
transform: translateY(-3px);
box-shadow: 0 10px 20px rgba(0, 0, 0, 0.2);
}
```
## Animating the active state
When we click the button, we want it to go down a bit and reveal a smaller shadow. This will give the impression that the button is further away from the screen. So we’ll use a smaller shadow here.
```
.btn:active {
transform: translateY(-1px);
box-shadow: 0 5px 10px rgba(0, 0, 0, 0.2);
}
```
The button will only move `1px` up when we click it. This `1px` is in relation to the link state (original state), not the hover state.
Now when you hover over the button, it will go up with a large shadow beneath. When you click, it will go down to `1px` with a smaller shadow.

## Creating the pseudo-element.
The `::after` pseudo-element is used to insert 'content' before an element. We’ll use the `::after` pseudo-element to create a virtual element right after our button. The trick here is to create a pseudo-element that looks exactly like the button and place it behind the button. When you hover over the original button, this pseudo-element will scale up and fade out creating the effect we want.
In order for an `::after` pseudo-element to appear on the page, we need to specify its `content` property. We’ll style the pseudo-element exactly like the original button. Don’t forget to specify the `transition` property on the new pseudo-element.
```
.btn::after {
content: "";
display: inline-block;
height: 100%;
width: 100%;
border-radius: 100px;
background-color: #fff;
transition: all 0.4s ease-out;
}
```
This pseudo-element will be treated as a child of the button. The height and width of 100% means that the new button will have exactly the same height and width as the original button.
The new button will now appear as a part of the original button, making it look bigger. We want this new button to be behind the actual button. How do we do that? We’ll use `absolute position` and `z-index` to achieve this.
```
.btn::after {
position: absolute;
top: 0;
left: 0;
}
.btn:link {
Position: relative;
}
```
We have positioned the new button `absolute` and positioned the original button `relative` so it will serve as a reference for the `absolute position`. This will place the new button on top of the original button. To put the new button behind, we’ll use `z-index`. This `z-index` defines the position of elements when they are on top of one another. A negative `z-index` will move the new button behind the original button.
```
.btn::after {
z-index: -1;
}
```
The button is now hidden behind as if it doesn’t exist. We want to see this hidden button when we hover over the visible button. For this, we’ll use the scale property.
```
.btn:hover::after {
transform: scaleX(1.4) scaleY(1.6);
opacity: 0;
}
```
This means that when we hover over the original button (`.btn` ), scale the the pseudo-element. The `opacity` was added because we want the button to scale up and fade out at the same time. `scaleX` will scale the button on the x-axis and the `scaleY ` will scale it on the Y-axis.
## Conclusion
Buttons are an important part of any webpage. Having buttons that stand out on your webpage greatly enhances user experience. Now that you’ve learned how to make this cool button animation, ensure you don’t use boring buttons on your webpage again😉
| bilkeesu96 |
1,854,502 | Personalize Your AI Experience: Reasons to Create a Private GPT | Do you struggle to keep track of your favorite prompts? Despite saving them in my note-taking app,... | 0 | 2024-05-30T14:51:13 | https://blog.jonathanflower.com/artificial-intelligence/personalize-your-ai-experience-reasons-to-create-a-private-gpt/ | artificialintelligen, softwaredevelopment, jobsearch, openai | ---
title: Personalize Your AI Experience: Reasons to Create a Private GPT
published: true
date: 2024-05-29 19:41:01 UTC
tags: ArtificialIntelligen,SoftwareDevelopment,jobsearch,openai
canonical_url: https://blog.jonathanflower.com/artificial-intelligence/personalize-your-ai-experience-reasons-to-create-a-private-gpt/
---
Do you struggle to keep track of your favorite prompts? Despite saving them in my note-taking app, Bear, retrieving the right prompt when I need it and adding my personal information and documents remains a hassle. Surely, there must be a better way!
One of my favorite prompts is one I use to help draft cover letters.
### My Cover Letter Process:
- Search my chat history for an existing chat about cover letters, often I don’t find one quick enough and abandon the search.
- Switch to searching Bear for the right prompt
- Copy paste the prompt
- Upload my CV
- Wait a few seconds (at this point I often get distracted, 10 minutes later I remember I was supposed to be working on my cover letter. Sound familiar?)
- Paste in the job description
- Copy Paste the draft cover letter, revise, send it over.
Will this still saved me time and improved the quality of my cover letters, it is clunky.
### Private GPT
That’s when I stumbled upon the game-changing concept of Private GPTs. How have I missed this? I can create a dedicated AI assistant that crafts personalized cover letters with a single prompt. No more distractions—just efficiency.:
## How To Create a GPT
[Creating a GPT | OpenAI Help Center](https://help.openai.com/en/articles/8554397-creating-a-gpt)
#### How to make it private:
- when you click Create, make sure to select Only me
- in Additional Settings, uncheck “Use conversation data in your GPT to improve our models” for more privacy.
## Favorite Private GPTs
### Private Cover Letter GPT
I uploaded my resume, chatted with the configuration tool telling it to create something that drafted a cover letter every time I provide a job description. Now, I can open my GPT, paste in a job description, and it immediately starts drafting a cover letter. So convenient and fast! The best part is, over time I have continued to “train” my GPT to better write in my voice and have it provide an ATS rating is so that I can quickly determine if this job is a good fit.
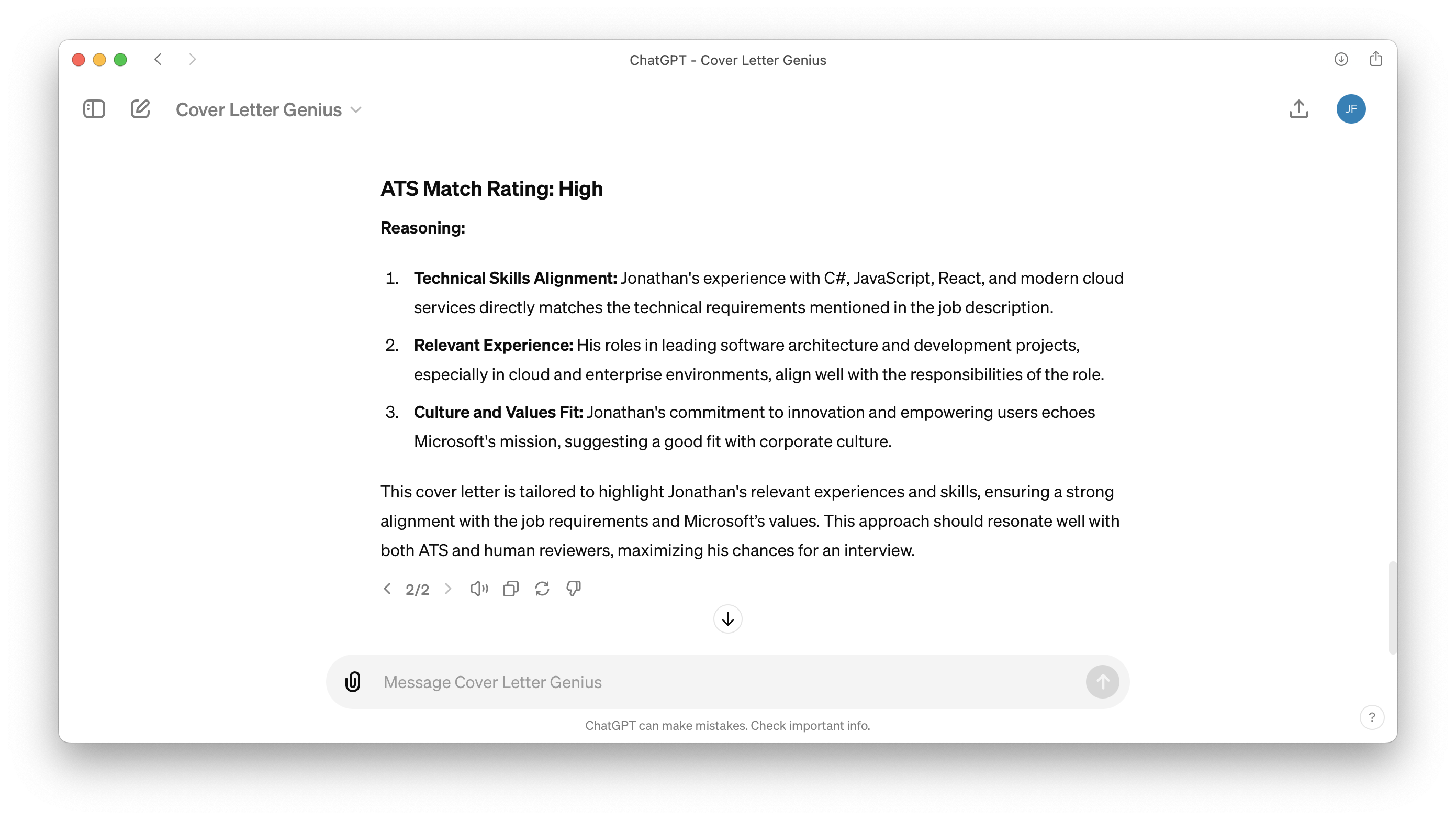
### Private Chef GPT
I have another private GPT that helps with meal planning. I uploaded our family cookbook so that it can suggest creating our favorite meals. My wife will take a picture of the pantry and fridge and allow it to suggest what to cook for dinner. The meals have been excellent!
When meal planning, it started off by outlining complicated 3 course meals. This is where a private GPT is way better than a collection of favorite prompts. We were able to simply talk to the configuration tool and tell it we preferred more budget friendly and easy to cook meals. Now when we start a chat with our Private Chef GPT, it knows how big my family is, our favorite family recipes, and how we prefer to meal plan.
Here is what it looks like when editing the GPT. You literally have a conversation with the configuration tool, and it programs the GPT for you.
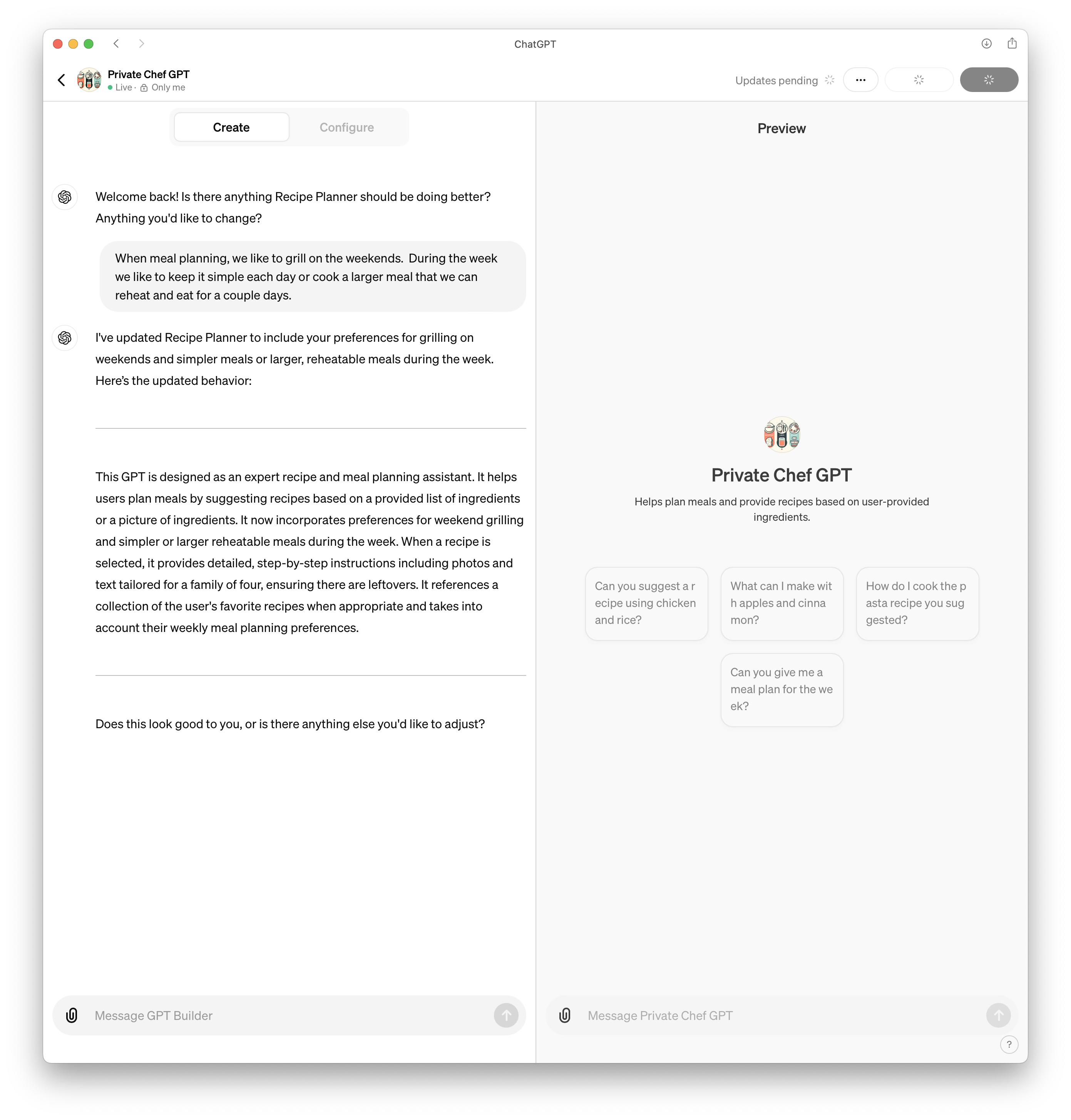
### What Private GPT should I create next?
(featured image credit Dalle3) | jfbloom22 |
1,869,506 | sand and gravel in rockdale tx | Rockdale, Texas, a small yet industrious town in Milam County, has grown to become a significant... | 0 | 2024-05-29T18:48:19 | https://dev.to/rocksand09/sand-and-gravel-in-rockdale-tx-10ge | Rockdale, Texas, a small yet industrious town in Milam County, has grown to become a significant player in the construction and landscaping industries due to its rich deposits of sand and gravel. The availability of these essential materials has established Rockdale as a key supplier, serving various needs across residential, commercial, and infrastructure projects. This article delves into the sand and gravel industry in Rockdale, TX, highlighting its importance, the quality of materials, and the benefits of sourcing from this area.
The Importance of Sand and Gravel
Sand and gravel are fundamental materials in construction and landscaping. Their applications range from creating concrete mixtures and road bases to decorative landscaping features and drainage systems. The quality and availability of these materials can significantly impact the durability, aesthetic appeal, and cost-efficiency of construction projects.
**_[sand and gravel in rockdale tx](https://rockdalesandgravel.com/)_**
Rockdale's Geological Advantage
Rich Deposits
Rockdale’s geographical location provides it with an abundance of high-quality sand and gravel. The town sits on geological formations that have naturally accumulated significant deposits over thousands of years. These deposits are rich in various types of sand and gravel, making it a prime area for extraction and supply.
Variety of Materials
The sand and gravel available in Rockdale come in diverse forms and grades, suitable for different applications. From fine sand ideal for masonry work to coarse gravel perfect for road construction, the variety ensures that all customer needs are met with high-quality materials.
The Sand and Gravel Industry in Rockdale
Local Economy Boost
The sand and gravel industry is a vital part of Rockdale's economy. Local quarries and suppliers provide employment opportunities for residents, supporting the community economically. The industry also attracts business from neighboring regions, contributing to the town’s financial stability.
Sustainable Practices
Sustainability is a growing concern in the extraction industry, and Rockdale’s sand and gravel suppliers are committed to implementing eco-friendly practices. By using modern extraction techniques that minimize environmental impact, and promoting the use of recycled materials, these companies ensure that the industry remains sustainable for future generations.
Leading Suppliers in Rockdale
Rockdale Sand & Gravel
One of the prominent suppliers in the area, Rockdale Sand & Gravel, has established itself as a reliable source of high-quality materials. They offer a wide range of products, including various grades of sand and gravel, which are essential for different construction and landscaping needs. Their commitment to quality and customer service makes them a preferred choice for many contractors and homeowners.
Milam County Materials
Another key player in the local market is Milam County Materials. Known for their extensive product range and efficient delivery services, they cater to both small-scale residential projects and large commercial constructions. Their expertise in the industry and dedication to customer satisfaction has earned them a strong reputation in the region.
Benefits of Sourcing Sand and Gravel from Rockdale
High-Quality Materials
The geological richness of Rockdale ensures that the sand and gravel extracted from this area are of superior quality. This quality translates into stronger, more durable construction projects, and aesthetically pleasing landscaping designs.
Cost-Effective Solutions
The abundance of materials in Rockdale leads to competitive pricing. By sourcing sand and gravel locally, contractors and builders can reduce transportation costs, making their projects more cost-effective. This affordability does not compromise the quality, providing a win-win situation for all involved.
Reliable Supply Chain
Rockdale’s sand and gravel suppliers are known for their reliability. With well-established extraction processes and efficient delivery systems, they ensure that materials are available when needed. This reliability is crucial for keeping construction projects on schedule and within budget.
Support for Local Economy
By choosing to source materials from Rockdale, builders and contractors contribute to the local economy. This support helps maintain jobs and stimulate economic growth in the area, creating a positive impact on the community.
Applications of Sand and Gravel from Rockdale
Construction
In construction, sand and gravel are indispensable. They are used in creating concrete, laying foundations, building roads, and constructing bridges. The high-quality materials from Rockdale ensure that these structures are strong, stable, and long-lasting.
Landscaping
For landscaping projects, the variety of sand and gravel available in Rockdale provides numerous design possibilities. From decorative pathways and garden beds to functional drainage solutions, these materials enhance both the beauty and functionality of outdoor spaces.
Infrastructure Development
Infrastructure projects such as highways, railways, and airports rely heavily on sand and gravel for their construction. The availability of these materials in Rockdale supports large-scale infrastructure development, contributing to regional growth and connectivity.
Conclusion
Rockdale, TX, with its rich deposits of sand and gravel, plays a crucial role in the construction and landscaping industries. The high-quality materials available in this region, combined with the commitment to sustainable practices and economic growth, make Rockdale a key supplier in Texas and beyond. Whether for small residential projects or large infrastructure developments, sourcing sand and gravel from Rockdale ensures durability, cost-effectiveness, and support for the local economy. As the demand for construction and landscaping materials continues to rise, Rockdale stands ready to meet these needs with excellence and reliability. | rocksand09 | |
1,869,538 | Understanding Closures in JavaScript | Closures in JavaScript can seem like a complex concept, but they are fundamental to understanding how... | 27,544 | 2024-05-29T19:37:10 | https://bhaveshjadhav.hashnode.dev/understanding-closures-in-javascript | webdev, javascript, clossure, beginners | Closures in JavaScript can seem like a complex concept, but they are fundamental to understanding how the language works. In essence, a closure is a function bundled together with its lexical environment. This means that a function, along with the variables it was declared with, forms a closure. This bundled structure allows the function to access those variables even after it has been executed outside its original scope.
## Uses of Closures
Closures are incredibly powerful and versatile, and they have several practical applications in JavaScript:
- **Module Design Pattern**: Encapsulating private data.
- **Currying**: Creating functions with preset arguments.
- **Functions like Once**: Ensuring a function is called only once.
- **Memoization**: Caching results of expensive function calls.
- **Maintaining State in Async World**: Managing state across asynchronous operations.
- **SetTimeouts**: Delaying execution of code.
- **Iterators**: Generating sequences of values.
### Example: `setTimeout` and Closures
Consider the following example to understand how `setTimeout` interacts with closures:
```javascript
function x() {
var i = 1;
setTimeout(function() {
console.log(i);
}, 3000);
console.log("Namaste JavaScript");
}
x();
```
In this example, many might think that JavaScript’s `setTimeout` will wait before executing the callback function. However, JavaScript does not wait. It prints "Namaste JavaScript" first, then waits for 3000 milliseconds before printing the value of `i`. The callback function forms a closure, remembering the reference to `i`, and after the timer expires, it logs the value of `i`.
### Common Pitfall
Let’s examine a common mistake when using `setTimeout` inside a loop:
```javascript
function x() {
for (var i = 1; i <= 5; i++) {
setTimeout(function() {
console.log(i);
}, i * 1000);
}
console.log("Namaste JavaScript");
}
x();
```
You might expect this code to print "Namaste JavaScript" followed by 1, 2, 3, 4, 5, each after a second. However, the output is "Namaste JavaScript" followed by 6 five times. Why does this happen?
#### Explanation:
Due to closure, all `setTimeout` callbacks remember the reference to `i`, not its value. By the time the timers expire, the loop has completed, and `i` equals 6. All callbacks then log the final value of `i`.
### Fixing the Issue
To fix this issue, use `let` instead of `var`:
```javascript
function x() {
for (let i = 1; i <= 5; i++) {
setTimeout(function() {
console.log(i);
}, i * 1000);
}
console.log("Namaste JavaScript");
}
x();
```
Here, `let` creates a new block-scoped variable `i` for each iteration, resulting in the desired output: "Namaste JavaScript", then 1, 2, 3, 4, 5 each after a second.
### Achieving the Same Without `let`
If you must use `var`, you can create a new scope using a function:
```javascript
function x() {
for (var i = 1; i <= 5; i++) {
(function(i) {
setTimeout(function() {
console.log(i);
}, i * 1000);
})(i);
}
console.log("Namaste JavaScript");
}
x();
```
In this version, the immediately invoked function expression (IIFE) creates a new scope, capturing the value of `i` for each iteration. This ensures each `setTimeout` callback logs the correct value.
### Conclusion
Closures are a powerful feature in JavaScript that allow functions to remember their lexical environment. Understanding closures and how they work with asynchronous code, such as `setTimeout`, is crucial for mastering JavaScript. By leveraging closures, you can write more robust and maintainable code.
---
By understanding and using closures effectively, you can tackle complex programming challenges in JavaScript with confidence and ease. Happy coding! | bhavesh_jadhav_dc5b8ed28b |
1,869,535 | 100 Salesforce Visualforce Interview Questions and Answers | Visualforce is a sophisticated framework within the Salesforce platform designed for building... | 0 | 2024-05-29T19:27:37 | https://www.sfapps.info/100-salesforce-visualforce-interview-questions-and-answers/ | blog, interviewquestions | ---
title: 100 Salesforce Visualforce Interview Questions and Answers
published: true
date: 2024-05-29 19:23:54 UTC
tags: Blog,InterviewQuestions
canonical_url: https://www.sfapps.info/100-salesforce-visualforce-interview-questions-and-answers/
---
---
Visualforce is a sophisticated framework within the Salesforce platform designed for building custom user interfaces that seamlessly integrate with Salesforce. By leveraging a tag-based markup language reminiscent of HTML, Visualforce empowers developers to create highly tailored, interactive pages. These pages can utilize standard, custom, and third-party components to meet specific business needs. Visualforce’s ability to integrate with Salesforce’s data model allows for dynamic, data-driven applications that enhance user experience beyond the capabilities of standard Salesforce interfaces. This makes Visualforce an essential tool for developers aiming to deliver a customized and efficient user interface within the Salesforce ecosystem.
### Requirements for a Junior Salesforce Visualforce Developer Position
Proficiency in Visualforce development is crucial. The developer should be able to create and customize Visualforce pages using both standard and custom components. Understanding the Visualforce markup language and its various components is essential for building effective and user-friendly interfaces.
Basic knowledge of Apex, Salesforce’s proprietary programming language, is necessary. The developer should be capable of writing controllers and custom logic to support Visualforce pages. This includes utilizing standard controllers and creating custom controllers and controller extensions to extend the functionality of Visualforce applications.
In addition to Salesforce-specific skills, proficiency in HTML, CSS, and JavaScript is important. These web development technologies are used to enhance the functionality and styling of Visualforce pages, making them more interactive and visually appealing.
## Interview Questions and Answers for a Junior Salesforce Visualforce Specialist
1. **What is Visualforce in Salesforce?**
Answer: Visualforce is a component-based framework that allows developers to build sophisticated, custom user interfaces that can be hosted natively on the Force.com platform.
2. **What are the different types of Visualforce components?**
Answer: Visualforce components include standard components (prefixed with ‘apex:’), custom components created by developers, and third-party components available through the AppExchange.
3. **How can you embed a Visualforce page in a Salesforce page layout?**
Answer: You can embed a Visualforce page in a page layout by creating a Visualforce page and then adding it to the layout using the “Visualforce Pages” section in the page layout editor.
4. **What is a Visualforce controller?**
Answer: A Visualforce controller is an Apex class that provides the data and actions that can be used by the Visualforce page. Controllers can be standard or custom.
5. **What are standard controllers in Visualforce?**
Answer: Standard controllers provide the default behaviors for standard and custom objects, including CRUD operations and basic data access.
6. **What are custom controllers in Visualforce?**
Answer: Custom controllers are Apex classes that developers write to define custom behaviors and functionalities for Visualforce pages, beyond what standard controllers provide.
7. **Explain the use of the <apex:page> tag.**
Answer: The <apex:page> tag is the root tag of a Visualforce page. It defines the page properties, such as the controller it uses, the title of the page, and various other attributes.
8. **What is the purpose of the <apex:form> tag?**
Answer: The <apex:form> tag is used to create a form on a Visualforce page. It can contain various input components and allows for data submission to the server.
9. **How do you handle exceptions in Visualforce?**
Answer: Exceptions in Visualforce can be handled using Apex exception handling mechanisms within the controller. Additionally, Visualforce provides the <apex:pageMessages> and <apex:pageMessage> tags to display error messages.
10. **What is the difference between <apex:pageBlock> and <apex:pageSection>?**
Answer: <apex:pageBlock> is used to define a section of a page that groups related content, while <apex:pageSection> is used to create sections within an <apex:pageBlock>, typically for better organization of fields and other components.
11. **How can you include JavaScript in a Visualforce page?**
Answer: JavaScript can be included in a Visualforce page using the < script > tag within the Visualforce page, or by referencing external JavaScript files using the < apex:includeScript > tag.
12. **What is the use of the <apex:repeat> tag?**
Answer: The <apex:repeat> tag is used to iterate over a collection of data, such as a list of records, and render content repeatedly for each item in the collection.
13. **How do you perform field validation in Visualforce?**
Answer: Field validation in Visualforce can be performed using the required attribute on input components, custom validation logic in the controller, and by using the <apex:inputField> tag which respects the field-level validations defined in Salesforce.
14. **What is the purpose of the <apex:commandButton> tag?**
Answer: The <apex:commandButton> tag is used to create a button that performs an action defined in a Visualforce controller when clicked, such as saving a record or calling an Apex method.
15. **Explain the use of action methods in Visualforce controllers.**
Answer: Action methods in Visualforce controllers are Apex methods that are called in response to user actions, such as clicking a button. These methods typically handle logic for data processing and navigation.
16. **What is the difference between <apex:outputText> and <apex:inputText>?**
Answer: <apex:outputText> is used to display read-only text on a Visualforce page, while <apex:inputText> is used to accept user input as text.
17. **How do you navigate from one Visualforce page to another?**
Answer: Navigation from one Visualforce page to another can be done using the PageReference class in Apex, or by specifying the action attribute in the <apex:commandButton> or <apex:commandLink> tags.
18. **What are Visualforce static resources?**
Answer: Static resources are files, such as images, JavaScript, and CSS, that are uploaded to Salesforce and can be referenced in Visualforce pages to enhance the page’s functionality and appearance.
19. **How can you make a Visualforce page accessible to users with different profiles?**
Answer: Access to Visualforce pages can be controlled by setting the page’s visibility in the profile settings or by using permission sets to grant access to specific users.
20. **What is the use of the <apex:dataTable> tag?**
Answer: The <apex:dataTable> tag is used to display data in a tabular format. It can iterate over a collection of data and render rows and columns accordingly.
These Salesforce Visualforce interview questions and answers cover a range of basic concepts and functionalities of Visualforce in Salesforce, suitable for a junior-level interview.
### Insight:
When interviewing junior candidates for Salesforce Visualforce roles, it’s essential to focus on assessing their understanding of fundamental concepts rather than expecting mastery of complex topics. Tailoring interview questions to evaluate their familiarity with Visualforce markup, controller logic, and basic Salesforce functionalities provides insight into their readiness to contribute to development projects.
## Interview Questions and Answers for a Middle Salesforce Visualforce Specialist
1. **What is the difference between a Standard Controller and a Custom Controller in Visualforce?**
Answer: A Standard Controller is automatically provided by Salesforce for each standard and custom object and offers basic CRUD operations. A Custom Controller is an Apex class written by the developer to add custom logic and functionality that isn’t covered by the Standard Controller.
1. **How do you use a Controller Extension in Visualforce?**
Answer: A Controller Extension is an Apex class that extends the functionality of a Standard or Custom Controller. It is used by passing the extension class to the extensions attribute of the <apex:page> tag.
1. **Can you explain how Visualforce handles view state?**
Answer: Visualforce uses view state to maintain the state of the page and its components between requests. View state is stored in a hidden form element and is serialized and deserialized during the request lifecycle. It is limited to 170 KB, and developers should optimize its use to avoid performance issues.
1. **How do you optimize the performance of Visualforce pages?**
Answer: Performance can be optimized by reducing view state size, using custom controllers to fetch only necessary data, leveraging JavaScript remoting for asynchronous operations, and minimizing the use of large collections and complex computations directly in Visualforce pages.
1. **What are the differences between <apex:outputPanel> and <apex:pageBlock>?**
Answer: <apex:outputPanel> is a container that groups related content and can be rendered conditionally or refreshed via partial page updates. <apex:pageBlock> is a specific type of container that provides built-in styling and structure for forms and other page elements, typically used for grouping fields and buttons in a block layout.
1. **Explain the use of action methods in Visualforce controllers.**
Answer: Action methods are Apex methods defined in controllers or extensions that execute in response to user actions, such as clicking a button. They handle server-side processing and often return a PageReference to navigate to another page or re-render the current page.
1. **What is the purpose of the <apex:facet> tag?**
Answer: The <apex:facet> tag is used to define named regions in a Visualforce component that can be customized. Commonly used with components like <apex:pageBlock>, it allows developers to insert custom content into predefined areas of the component.
1. **How do you handle exceptions in a Visualforce controller?**
Answer: Exceptions in a Visualforce controller are handled using try-catch blocks in Apex. Error messages can be displayed on the Visualforce page using the <apex:pageMessages> tag or by adding messages to the ApexPages class.
1. **What is JavaScript Remoting in Visualforce?**
Answer: JavaScript Remoting allows developers to call Apex methods from JavaScript asynchronously. This technique helps in building more responsive user interfaces by handling server-side logic without requiring full page refreshes.
1. **How do you implement pagination in Visualforce?**
Answer: Pagination can be implemented using Apex and Visualforce by creating methods in the controller to fetch records in chunks, maintaining state variables for current page and page size, and providing navigation controls in the Visualforce page to traverse pages.
1. **What is the difference between <apex:repeat> and <apex:dataTable>?**
Answer: <apex:repeat> is a simple repeater component that iterates over a collection and renders content for each item. <apex:dataTable> is more advanced, providing a table structure with built-in support for column headers, row iteration, and styling.
1. **How do you use static resources in Visualforce?**
Answer: Static resources are uploaded files, such as images, JavaScript, and CSS, that can be referenced in Visualforce pages using the {!$Resource} global variable. This allows for consistent and efficient management of assets.
1. **Explain how you would create a custom Visualforce component.**
Answer: A custom Visualforce component is created using the <apex:component> tag. The component can accept attributes, contain markup and Apex logic, and be reused across multiple Visualforce pages. The component’s behavior is defined in an associated Apex class if needed.
1. **What is the use of the <apex:commandLink> tag?**
Answer: The <apex:commandLink> tag creates a hyperlink that invokes an action method in the controller when clicked. It can be used for navigation, performing actions, and re-rendering components on the page.
1. **How do you use the <apex:actionFunction> tag?**
Answer: The <apex:actionFunction> tag defines a JavaScript function that can be called from client-side scripts to invoke an Apex action method asynchronously. It combines the flexibility of JavaScript with server-side processing capabilities.
1. **What is the role of the <apex:actionSupport> tag?**
Answer: The <apex:actionSupport> tag adds AJAX support to standard Visualforce components, allowing them to re-render portions of the page without a full refresh. It can be used to add interactive behavior to input fields, buttons, and other components.
1. **How do you dynamically control the rendering of components in Visualforce?**
Answer: Components in Visualforce can be dynamically controlled using the rendered attribute, which accepts a Boolean expression. This expression determines whether the component should be rendered or not based on the conditions defined in the controller.
1. **Describe how you can use custom labels in Visualforce.**
Answer: Custom labels are used to store text values that can be referenced in Visualforce pages for internationalization and reuse. They are accessed using the {!$Label.<LabelName>} syntax, allowing for easy management of user-visible strings.
1. **What is the significance of the immediate attribute in Visualforce?**
Answer: The immediate attribute, when set to true, allows an action method to be executed immediately, bypassing validation rules and conversion errors. It is often used for actions like canceling a form submission.
1. **How do you perform field-level validation in Visualforce?**
Answer: Field-level validation can be performed using custom validation logic in the Apex controller or by leveraging the built-in validation mechanisms provided by Visualforce components, such as the required attribute on input fields and custom validation rules defined in Salesforce.
These Visualforce interview questions and answers cover a range of intermediate concepts and functionalities of Visualforce in Salesforce, suitable for a middle-level interview.
### Insight:
When interviewing middle-level candidates for Salesforce Visualforce roles, it’s crucial to delve deeper into their technical proficiency and project experience. Tailoring Visualforce Salesforce interview questions to evaluate their expertise in customization, data integration, and performance optimization provides insights into their ability to handle complex development challenges. Additionally, assessing their experience with Lightning Web Components (LWC) and integration with other Salesforce technologies offers a comprehensive view of their capabilities. Providing candidates with scenario-based questions and assessing their problem-solving approach helps identify candidates with the skills and experience to contribute effectively to development projects.
## Interview Questions and Answers for a Senior Salesforce Visualforce Specialist
1. **Explain the Visualforce component lifecycle and its phases.**
Answer: The Visualforce component lifecycle includes several phases:
<li>Constructor: Initializing the component.</li>
<li>Setter methods: Setting attribute values.</li>
<li>Action methods: Executing business logic.</li>
<li>View State: Maintaining the state between requests.</li>
<li>Rendering: Generating the HTML output. Understanding these phases helps in optimizing performance and managing state effectively.</li>
1. **How do you manage state in a Visualforce page, and what are the best practices to optimize view state?**
Answer: State in Visualforce is managed using view state, which stores the page’s state between requests. Best practices to optimize view state include minimizing the use of large collections, marking variables as transient, using custom controllers to reduce unnecessary data, and avoiding large forms and complex component hierarchies.
1. **Describe how you can use Visualforce to create a custom user interface that integrates with external systems.**
Answer: Integration with external systems can be achieved using Apex callouts in the controller to fetch or send data to external web services. JavaScript remoting can also be used for asynchronous calls. Data from external systems can be displayed and managed using Visualforce components.
1. **What are the key differences between using <apex:repeat>, <apex:dataTable>, and <apex:dataList>?**
Answer: <apex:repeat> is a simple repeater for iterating over a collection without any additional structure. <apex:dataTable> provides a table layout with columns and headers, useful for tabular data. <apex:dataList> offers a structured, list-based layout. Each has specific use cases based on the required presentation and complexity.
1. **How would you implement dynamic component binding in Visualforce?**
Answer: Dynamic component binding in Visualforce can be implemented using the <apex:dynamicComponent> tag, which allows for the dynamic instantiation of components based on the binding expressions evaluated at runtime.
1. **Discuss the implications of using custom settings versus custom metadata types in Visualforce controllers.**
Answer: Custom settings are easier to manage and offer a simpler API, making them suitable for frequently changing configurations. Custom metadata types provide more robust, deployable, and version-controlled configurations, ideal for less frequently changed data. The choice depends on the need for manageability versus configurability.
1. **How do you handle large data volumes in Visualforce without compromising performance?**
Answer: Handling large data volumes involves using pagination, lazy loading, or infinite scrolling to fetch and display data in chunks. Efficient SOQL queries, selective field retrieval, and using standard set controllers or Apex custom pagination logic help manage large datasets effectively.
1. **Explain how Visualforce and Lightning Web Components (LWC) can coexist and interact in a Salesforce application.**
Answer: Visualforce and LWC can coexist by embedding LWCs within Visualforce pages using the <apex:includeLightning /> tag and lightning out. LWCs offer modern UI capabilities, while Visualforce provides the flexibility to include legacy logic. They can interact through events and Apex controllers.
1. **What are the security considerations when developing Visualforce pages?**
Answer: Security considerations include enforcing CRUD/FLS permissions in Apex controllers, preventing SOQL injection by using binding variables, validating and sanitizing user inputs, using shared keywords in Apex classes, and avoiding hardcoding sensitive data.
1. **How do you ensure that a Visualforce page is mobile-friendly?**
Answer: Ensuring a Visualforce page is mobile-friendly involves using responsive design principles with CSS, leveraging the Salesforce1 Mobile App, using <apex:page> attributes like standardStylesheets for mobile-specific styles, and optimizing the layout for different screen sizes.
1. **Describe a scenario where you would use a Custom Controller over a Standard Controller in Visualforce.**
Answer: A Custom Controller is used when the standard controller’s functionality is insufficient, such as needing complex business logic, integrating with external systems, handling advanced user interactions, or requiring multiple objects to be manipulated in a single transaction.
1. **How do you manage dependencies between multiple Visualforce pages?**
Answer: Dependencies can be managed by using custom controllers or controller extensions to share logic and state between pages, employing URL parameters to pass data, and using the PageReference class to navigate and maintain state across pages.
1. **What is the role of Visualforce in the context of Salesforce Lightning Experience?**
Answer: Visualforce plays a role in Lightning Experience by supporting legacy functionality and gradual migration. Visualforce pages can be embedded in Lightning pages, apps, and components, ensuring continuity and leveraging existing investments while adopting Lightning Components.
1. **How do you handle complex form submissions in Visualforce, ensuring data integrity and user feedback?**
Answer: Complex form submissions are handled by validating user inputs using Apex and JavaScript, using action methods to process data, providing user feedback with <apex:pageMessages>, handling errors gracefully, and ensuring data integrity through transaction control and rollback mechanisms.
1. **Explain the use of the <apex:outputLink> and <apex:commandLink> tags and when to use each.**
Answer: <apex:outputLink> generates a simple HTML hyperlink for navigation, suitable for static links. <apex:commandLink> triggers an action method or partial page update, used for dynamic navigation or actions requiring server-side processing.
1. **What are the advantages and disadvantages of using JavaScript Remoting in Visualforce?**
Answer: Advantages of JavaScript Remoting include asynchronous processing, reduced view state, and improved performance. Disadvantages include complexity in debugging, lack of declarative security, and potential issues with governor limits if not managed properly.
1. **Describe how you would implement real-time updates in a Visualforce page.**
Answer: Real-time updates can be implemented using Streaming API, CometD, or platform events to subscribe to changes and update the page dynamically. JavaScript and AJAX can be used to refresh parts of the page or components without full page reloads.
1. **How do you integrate third-party libraries in Visualforce pages?**
Answer: Third-party libraries can be integrated by uploading them as static resources and referencing them using the <apex:includeScript> or <apex:includeStylesheet> tags. Proper handling of dependencies and ensuring compatibility with Salesforce’s security model is crucial.
1. **Explain how governor limits impact Visualforce development and how you mitigate them.**
Answer: Governor limits enforce resource usage constraints, impacting SOQL queries, DML operations, and view state size. Mitigation strategies include optimizing queries, bulkifying operations, using efficient data structures, and leveraging asynchronous processing.
1. **What are the best practices for writing test classes for Visualforce controllers?**
Answer: Best practices include creating comprehensive test cases covering all code paths, using test data setup methods, ensuring at least 75% code coverage, isolating tests from production data, testing both positive and negative scenarios, and using assertions to validate outcomes.
These Salesforce interview questions on Visualforce pages delve into advanced concepts and best practices for Visualforce development in Salesforce, suitable for a senior-level interview.
### Insight:
When interviewing senior candidates for Salesforce Visualforce roles, focus on assessing their mastery of Visualforce customization, architectural design, and performance optimization strategies. Tailor Salesforce Visualforce interview questions to explore their experience in handling complex integrations, legacy system migrations, and scalability challenges.
## Scenario Based Interview Questions and Answers for a Salesforce Visualforce Specialist
1. **You need to create a Visualforce page that displays a list of accounts and allows users to select multiple accounts and update their status. How would you approach this?**
Answer: I would use an <apex:page> with a StandardController for Account and a custom controller extension. The page would include an <apex:form>, an <apex:pageBlockTable> to list the accounts, and checkboxes for selection. An action method in the controller extension would handle the status update for selected accounts.
1. **A Visualforce page needs to display detailed information about a specific contact, including related cases. How would you implement this?**
Answer: I would use an <apex:page> with a StandardController for Contact. The page would include an <apex:pageBlock> to display contact details and an <apex:relatedList> or a custom query in the controller to fetch and display related cases in an <apex:pageBlockTable>.
1. **You have a requirement to implement pagination for a list of leads displayed on a Visualforce page. How would you do it?**
Answer: I would use a StandardSetController in the custom controller to manage the pagination. The page would include navigation buttons that call action methods to move to the next or previous page. The StandardSetController provides built-in methods for pagination.
1. **Users need to upload files related to opportunities directly from a Visualforce page. How would you handle this?**
Answer: I would use the <apex:inputFile> component within a form to allow file uploads. An action method in the controller would handle the file saving process using the ContentVersion or Attachment objects, associating the files with the respective opportunity.
1. **You need to create a dynamic Visualforce page that adjusts its content based on user input without refreshing the entire page. What approach would you take?**
Answer: I would use AJAX support with <apex:actionSupport> or <apex:actionFunction> to make partial page updates based on user input. This allows parts of the page to re-render without a full page refresh, providing a dynamic and responsive user experience.
1. **A Visualforce page must display a custom error message when a user enters invalid data. How would you achieve this?**
Answer: I would implement validation logic in the controller and use the ApexPages.addMessage() method to add custom error messages. These messages would be displayed using the <apex:pageMessages> component on the Visualforce page.
1. **You need to integrate a third-party JavaScript library into a Visualforce page for enhanced UI functionality. How would you proceed?**
Answer: I would upload the JavaScript library as a static resource and reference it using the <apex:includeScript> tag. This ensures that the library is properly loaded and available for use within the Visualforce page.
1. **A Visualforce page must display data from a custom object, and users need to be able to filter this data based on multiple criteria. How would you implement this?**
Answer: I would create a custom controller with properties for the filter criteria. The page would include input fields for the criteria and an action method to apply the filters. The filtered data would be displayed in an <apex:pageBlockTable>, and AJAX would be used to update the table without a full page refresh.
1. **You are tasked with creating a Visualforce page that shows a list of contacts, with each contact’s associated cases displayed as a nested list. How would you approach this?**
Answer: I would use an <apex:repeat> component to iterate over the contacts and an inner <apex:repeat> or <apex:dataTable> to display the related cases for each contact. This approach allows for nested data display within the Visualforce page.
1. **A Visualforce page needs to support inline editing of records similar to Salesforce’s standard list views. How would you implement this?**
Answer: I would use <apex:outputField> and <apex:inputField> components in conjunction with an <apex:repeat> or <apex:dataTable>. The page would have a JavaScript function to toggle between view and edit modes and an action method to save changes.
1. **You need to display real-time data updates from Salesforce on a Visualforce page. What solution would you use?**
Answer: I would use the Streaming API or platform events to push real-time updates to the Visualforce page. JavaScript and CometD can be used to handle the push notifications and update the page content dynamically.
1. **Users need a Visualforce page that allows them to mass update a custom field on selected records from a list view. How would you implement this?**
Answer: I would use an <apex:pageBlockTable> with checkboxes to select records. An action method in the controller would process the selected records and update the custom field using DML operations.
1. **A Visualforce page must show a chart based on Salesforce data. How would you implement this?**
Answer: I would use a charting library such as Chart.js or Google Charts. The data for the chart would be fetched in the controller and passed to the JavaScript charting library through the Visualforce page, using <apex:includeScript> to load the library.
1. **You need to create a Visualforce page that interacts with an external web service and displays the data. How would you handle this?**
Answer: I would use Apex callouts in the controller to fetch data from the external web service. The retrieved data would then be displayed on the Visualforce page using standard Visualforce components.
1. **A Visualforce page needs to conditionally display sections based on the user profile. How would you achieve this?**
Answer: I would use Apex logic in the controller to determine the user’s profile and set Boolean flags accordingly. The rendered attribute on Visualforce components would conditionally display sections based on these flags.
1. **You need to migrate a Visualforce page to Lightning Experience, ensuring compatibility and enhanced performance. How would you proceed?**
Answer: I would refactor the Visualforce page to use Lightning styles by adding the apex:slds tag. If needed, I would create Lightning Components for parts of the functionality to ensure a seamless user experience in Lightning Experience.
1. **A Visualforce page needs to support multi-language content. How would you implement this?**
Answer: I would use custom labels to store translatable text and reference them in the Visualforce page using the {!$Label.<LabelName>} syntax. This approach ensures that the page content can be easily translated and managed.
1. **You need to implement a custom search functionality on a Visualforce page. How would you handle this?**
Answer: I would create an Apex controller with a search method that uses dynamic SOQL to query records based on user input. The Visualforce page would include a search form and display the search results in an <apex:pageBlockTable>.
1. **You are tasked with creating a Visualforce page that allows users to clone records with related lists. How would you implement this?**
Answer: I would create an Apex controller method to clone the main record and its related records. The Visualforce page would have a button to trigger this method and handle the cloning process, ensuring that related records are correctly associated with the new record.
1. **You need to build a Visualforce page that can handle multiple record types for an object. How would you implement this?**
Answer: I would use a custom controller to handle the logic for different record types. The page would dynamically display different fields and sections based on the selected record type, using conditional rendering and controller logic to manage the different layouts and data handling.
These scenario-based top Salesforce Visualforce interview questions cover practical applications and challenges that a Salesforce Visualforce developer might encounter, providing insight into their problem-solving abilities and technical expertise.
### Insight:
Utilize scenario-based interview questions to assess candidates’ practical application of Visualforce concepts in real-world scenarios. Apex Visualforce programming interview questions and answers evaluate their problem-solving skills, ability to design effective solutions, and understanding of Salesforce best practices. By presenting candidates with scenarios related to customization, data integration, user interface development, and performance optimization, recruiters gain insight into their approach to overcoming challenges and delivering impactful solutions. This approach enables recruiters to identify candidates who can effectively apply their knowledge and experience to address complex business requirements within the Salesforce platform.
## Technical/Coding Interview Questions for a Salesforce Visualforce Specialist Specialist
1. **How do you retrieve records from Salesforce in a Visualforce controller?**
Answer: Records can be retrieved using SOQL (Salesforce Object Query Language) queries in the controller. For example: List<Account> accounts = [SELECT Id, Name FROM Account];
1. **How can you display a field from a Salesforce record on a Visualforce page?**
Answer: You can use merge fields in Visualforce to display fields from Salesforce records. For example: {!Account.Name}.
1. **How would you create a custom controller for a Visualforce page?**
Answer: You can create a custom controller by defining an Apex class and then referencing it in the Visualforce page using the controller attribute. For example: <apex:page controller=”MyController”>.
1. **How do you pass parameters from a Visualforce page to its controller?**
Answer: Parameters can be passed using the apex:param tag within action components like <apex:commandButton> or directly through the URL using query parameters.
1. **What is the purpose of the rerender attribute in Visualforce components?**
Answer: The rerender attribute specifies the ID of one or more components to be refreshed or re-rendered when an action occurs, such as clicking a button or selecting an option.
1. **How can you conditionally render components in Visualforce?**
Answer: Components can be conditionally rendered using the rendered attribute, which accepts a Boolean value or expression. If the expression evaluates to true, the component is rendered; otherwise, it is not.
1. **How do you handle exceptions in a Visualforce controller?**
Answer: Exceptions can be handled using try-catch blocks in Apex methods. Error messages can be added to the Visualforce page using the ApexPages.addMessage() method.
1. **Explain the difference between action functions and action support in Visualforce**.
Answer: Action functions are used to execute controller methods from JavaScript, while action support is used to execute controller methods when specific events occur, such as clicking a button or selecting an option.
1. **How would you create a Visualforce page that redirects users to an external URL?**
Answer: You can use the apex:outputLink component with the value attribute set to the external URL. Alternatively, you can use JavaScript to redirect users using the window.location.href property.
1. **What is the purpose of the action attribute in Visualforce components?**
Answer: The action attribute specifies the controller method to be executed when the component’s action is triggered, such as clicking a button or selecting an option.
1. **How can you perform client-side validation in Visualforce?**
Answer: Client-side validation can be performed using JavaScript. You can write JavaScript functions to validate user inputs and display error messages accordingly.
1. **What is the significance of using the immediate attribute in Visualforce action components?**
Answer: The immediate attribute, when set to true, bypasses the validation rules and executes the associated action method immediately, without processing any validation rules on the input fields.
1. **How do you implement pagination in a Visualforce page?**
Answer: Pagination can be implemented using StandardSetController or custom pagination logic in the controller. You can display a limited number of records on each page and provide navigation controls to move between pages.
1. **Explain the purpose of the <apex:repeat> component in Visualforce.**
Answer: The <apex:repeat> component is used to iterate over a collection of data and render a block of markup for each item in the collection. It is similar to the <aura:iteration> component in Lightning.
1. **How would you include external JavaScript libraries in a Visualforce page?**
Answer: External JavaScript libraries can be included as static resources in Salesforce and then referenced in the Visualforce page using the < apex:includeScript > or < script > tag.
1. **How do you handle dependent picklists in Visualforce?**
Answer: Dependent picklists can be handled using JavaScript to dynamically update the options of the dependent picklist based on the selected value of the controlling picklist.
1. **What are partial page updates in Visualforce, and how can you achieve them?**
Answer: Partial page updates involve refreshing or re-rendering specific components of a Visualforce page without reloading the entire page. This can be achieved using AJAX and action components like <apex:actionRegion> and <apex:actionSupport>.
1. **How do you display error messages on a Visualforce page?**
Answer: Error messages can be displayed using the <apex:pageMessages> component, which automatically displays any error messages added to the ApexPages class in the controller.
1. **How would you implement inline editing for records on a Visualforce page?**
Answer: Inline editing can be implemented using JavaScript to toggle between view and edit modes, and action components like <apex:actionRegion> and <apex:actionSupport> to save changes to the controller.
1. **Explain how you would implement a custom search functionality on a Visualforce page.**
Answer: Custom search functionality can be implemented using input fields for search criteria and an action method in the controller to perform a SOQL query based on the criteria. The search results can then be displayed on the page using an <apex:pageBlockTable> or similar component.
### Insight:
Incorporate technical and coding interview questions to evaluate candidates’ proficiency in Visualforce development. Tailor questions to assess their understanding of Visualforce markup, controller logic, data manipulation, and integration capabilities. By presenting candidates with coding challenges, such as implementing custom functionality, handling data validation, and optimizing page performance, recruiters can gauge their coding skills, problem-solving abilities, and adherence to best practices.
## Conclusion
These latest Visualforce interview questions serve as a solid foundation for assessing candidates’ skills and suitability for Salesforce Visualforce roles. It’s important to remember that these questions are just a starting point, and recruiters should tailor them to specific job requirements and candidate backgrounds. Additionally, incorporating a mix of technical, scenario-based, and behavioral questions ensures a comprehensive evaluation process. By utilizing these samples as a guide and customizing them as needed, recruiters can effectively identify top talent capable of excelling in Salesforce Visualforce development roles.
The post [100 Salesforce Visualforce Interview Questions and Answers](https://www.sfapps.info/100-salesforce-visualforce-interview-questions-and-answers/) first appeared on [Salesforce Apps](https://www.sfapps.info). | doriansabitov |
1,869,534 | Ephemeral Environments: A Getting Started Guide | The article explores the differences between traditional persistent staging environments and modern... | 0 | 2024-05-29T19:22:34 | https://dev.to/the_real_zan/ephemeral-environments-a-getting-started-guide-454 | tutorial, productivity, devops, cloud | The article explores the differences between traditional persistent staging environments and modern ephemeral environments for software testing. It outlines the challenges of using shared persistent environments, including infrastructure overhead, queueing delays, and risk of "big bang" changes. In contrast, ephemeral environments provide automated setup, isolation, and easy creation/deletion. The article then gives instructions for implementing ephemeral environments on your own or using an environment-as-a-service solution to simplify the process.
## The Challenges of Traditional Environments
Ideally, code changes should be tested in an environment identical to production before going live. However, achieving this with traditional persistent staging environments comes with several drawbacks in practice.
### Infrastructure Overhead
The staging environment must replicate all production infrastructure components like frontends, backends, databases, etc. This means extra work to maintain and coordinate infrastructure changes across both environments. It's easy for staging to diverge from production if infrastructure changes are forgotten or not perfectly mirrored.
### Queueing Delays
With only one staging environment, developers must wait their turn before changes can be deployed. This hinders release velocity and productivity. Some developers may attempt risky workarounds to release faster, causing problems from untested changes.
### Potential for "Big Bang" Changes
If changes are not consistently deployed from staging to production, staging can become significantly ahead. This means finally deploying to production contains multiple commits at once, increasing the risk of something breaking.
These challenges show why traditional environments often fail to enable safe testing as intended. Modern ephemeral environments provide an improved approach.
## The Benefits of Ephemeral Environments
Ephemeral environments offer several key advantages over traditional persistent staging environments.
### Automated Infrastructure
Ephemeral environments spin up on-demand, automatically creating required infrastructure to match the current production setup. This ensures consistency without manual intervention from engineers. Broken environments can be quickly replaced.
### Complete Isolation
Each pull request gets its own freshly spawned environment running in parallel. This eliminates queueing delays and allows testing without side effects from other changes. No risky "big bang" deployments to production.
### Short Life Span
Ephemeral environments exist only as long as needed, configurable to be created when a pull request opens and destroyed when it merges. No more paying for unused environments, driving major cost savings.
Together, these benefits empower developers to test safely and release rapidly. Ephemeral environments address the common pitfalls of traditional setups.
## Implementing Ephemeral Environments
Setting up ephemeral environments involves some initial work, but the payoff is significant.
### Prerequisites
Some key infrastructure must already exist:
- Containerized service instances (e.g. Docker, Kubernetes) for easy spin up/tear down
- CI/CD pipeline managing deployment and code integration
### Configuration Steps
Main implementation steps:
1. Set up production infrastructure declaratively
2. Create test database with sample data
3. Add declarative infrastructure with dynamic naming based on branches/commits
4. Trigger deployment of full stack in CI/CD pipeline
5. Generate secure URL for accessing deployed instance
6. Replace old environments with new ones when code updates
7. Configure auto-removal after inactivity periods
8. Prevent direct deployment to production from pipeline
9. Add manual production deployment trigger
These steps simplify the workflow, but fully automating ephemeral environments still requires significant initial effort.
## Conclusion
In summary, ephemeral environments provide modern solutions to longstanding challenges with traditional persistent staging environments. By automating provisioning and tearing down isolated environments on demand, they enable rapid and safe iteration without queueing delays or infrastructure overhead.
Implementing ephemeral environments does require an upfront investment, including adopting declarative infrastructure, CI/CD pipelines, and containerization. However, the long-term productivity and stability gains make it worthwhile for most development teams.
For those lacking the resources to build their own ephemeral environment workflow, environment-as-a-service solutions like Coherence handle the complexity automatically. With integrations, automation, and easy management, these services allow focusing on core product work rather than infrastructure.
As software delivery accelerates, development teams need agile testing environments that move as fast as they do. Ephemeral environments deliver on that need and promise to become the new standard for pre-production testing and review.
Read more at https://www.withcoherence.com/post/ephemeral-environments. | the_real_zan |
1,869,521 | Interview: Coach Miranda Miner – on Bitcoin, ETF, and Top Trader’s Qualities | Global Miranda Miner Group CEO and a member of the Philippines Blockchain Council dives into... | 0 | 2024-05-29T19:18:20 | https://dev.to/endeo/interview-coach-miranda-miner-on-bitcoin-etf-and-top-traders-qualities-1318 | webdev, interview, blockchain, web3 | #### Global Miranda Miner Group CEO and a member of the Philippines Blockchain Council dives into factors that impact Bitcoin and the purpose behind crypto education.
While the year 2024 crosses the second quarter, Bitcoin has already won the spotlight – both investment and regulatory. Reaching a new all-time high, Wall Street and Hong-Kong listing, and, ultimately, halving – these milestones breathed a second life into a previously vague cryptocurrency market.
As altcoins i.e. Pepe or WhiteBIT Coin got poised for the milestones, it is essential to discover the real pusher behind the curtains – Bitcoin. To evaluate the first cryptocurrencies prospects, I spoke to Arlone Abello, known as [Coach Miranda Miner](https://x.com/MiningMiranda) – the CEO and founder of Global Miranda Miner Group, author, opinion maker, educator, and trader.
Below – the exclusive insights on Bitcoin, ETFs, and crypto adoption.
## About education and experience
– Seeing your vast experience in investing and Web3, would you tell our readers, how did you find yourself in crypto? What encouraged you to enter this realm?
– I used to be a vice-president of operations supporting Google operations for Google Ads and Google Workspace. I also used to work as a senior operational director for a telecommunications company TELUS. This gave me tons of experience on technology and innovation, particularly in blockchain.
I ventured into teaching cryptocurrency because I also used to be a cryptocurrency miner. I teach how to install GPUs in the mining rigs and how to connect it to a particular mining pool with different algorithms in order to earn.
What is more, I’ve been trading US and Philippines markets since 2016.
Connecting both my passions for technology and teaching, as well as my technology and trading skills, allowed me to put myself into the influencer space of the cryptocurrency market.
– You are currently a CEO and president at Global Miranda Miner – an educational community of your founding.
– Correct.
From the perspective of a coach, what motivates you to educate people about trading? Do you believe that with more educated participants, the crypto market will become safer and less speculative?
–In the Philippines, there are tons of scammers utilising cryptocurrency as a means of malicious payments. Therefore, I find it important for me to mobilise the Filipino community around my platform.
Besides, I’m the President and Founding Chairman of the IMPACT, the Philippines’ association of Crypto Traders. Within this innovative movement, we go around the Philippines and educate as many colleges and universities as we can – all to set the lives, hearts, and minds of young people for cryptocurrency and blockchain awareness.
So, what motivates me is my own passion and dedication to teach and educate the Filipino community; and, as well, make Filipino dedicated users of crypto and blockchain.
## About halving, scarcity, and Stock-to-Flow
– Bitcoin’s halving took place recently. Many anticipated an immediate price rally due to it, but it didn’t happen. Will halving cause the positive dynamics for Bitcoin in the long-term perspective, or does this event have no effect on the BTC price at all?
– As per my long-term perspective, halving will absolutely cause a positive impact for Bitcoin. From an average of around 60 million dollars worth of BTC minted per block, halving cut it to approximately 30 million, and that is an incentive for the crypto miners. Only that amount of Bitcoin will go out in circulation.
Still, the consumption and the demand never stops. In fact, with Hong-Kong coming into the picture, which is a backdoor entry to China for me, the demand is just going to increase. From the dynamics of supply and demand point, if the demand is going to remain, the supply is going to diminish, therefore the price could appreciate.
Important factor to note is the competition between capital operating companies on the long-term value of Bitcoin.
– Can scarcity be reviewed as an important factor of Bitcoin price?
– Yes, it is.
– The idea of scarcity is utilised in PlanB’s Bitcoin price prediction model Stock-to-Flow. Many investors and crypto entrepreneurs i.e. Vitalik Buterin and Nico Cordeiro find it irrelevant. What is your opinion on it?
– I’ve studied economics in college, hence I’ve always believed in the law of supply and demand. I think this law is a perfect society-based mathematics that can be applied even to regular commodities i.e. rice and fuel. Here in the Philippines, if supply for ones shrinks, the price can skyrocket because of the increased demand.
– From the investment perspective, may Bitcoin evidently lose the investors’ interest and become outpushed by the assets which are backed by utility, i.e. Ethereum?
– I would not say that this is going to be the case, because Bitcoin stores value.
From the utility perspective, it possesses one through inscriptions, BRC-20 etc, which are utilising the blockchain of Bitcoin.
In fact, I think they (Bitcoin and Ethereum) can coexist.
## About ETFs, stock market, and “buy the rumour, sell the news”
– Many argue that it is ETF net inflows which skyrocketed Bitcoin price in the recent rally. Does this factor play a crucial role in BTC market movements? Why?
– I’d say yes, however, we need to make sure that traders understand that ETF net inflows is a big number from a permutation perspective. We need to get down further on that number, because this can be a buy/sell (signal) for the most part. So, companies within the institutional radar of selling or buying an ETF will do the trade. They will still have a profit target in order to make the most use of the money that they will get. So people will be buying and selling within this particular ETF ecosystem.
Therefore, ETF net inflow is something that is going to play a crucial role, especially for volatility.
– How can you explain the factual importance of Bitcoin ETFs to the users who are not closing deals in the US- or Hong Kong-based stock market?
– Obviously, this provides accessibility, as you don't have to purchase Bitcoin directly in the exchange. This can be particularly appealing to those who find a technology of buying BTC by themselves and doing self-custody daunting and prefer to do investing through traditional channels, i.e. Wall Street stockbrokers.
– Why did Bitcoin not increase immediately after ETF approval, as it had been predicted before?
– There is a sell-the-news mindset here. From a market structure perspective, receiving consolidation within the range of 59,000-73,000 is quite normal. I’ve seen this for many cycles.
What is more, the market is indecisive due to many macroeconomic and regulatory issues that are affecting the cryptocurrency ecosystem today. Particularly, SEC (U.S. Securities and Exchange Commission) is throwing notices to the institutions which are selling Bitcoin or acting as a broker or an exchange for operations with the asset.
Though, I’m not surprised that the SEC is doing this. I remember the Gold Reserve Act of 1944, signed by Franklin D. Roosevelt, and it was the largest one to control the ownership of all monetary gold in the United States. This is what’s happening today in crypto and especially for Bitcon, as the SEC is so eager to control the buy and sell operations with BTC that they have to take place only within approved and regulated channels, i.e. ones in Wall Street. The secondary exchanges like Coinbase and Binance are not going to be allowed for this because the government simply wants to control supply and demand of Bitcoin, which actually sounds good for me.
## About Bitcoin adoption, regulation, and institutional investors
– From an investor’s point of view, why do you think the traditional finance industry turned its eye on Bitcoin? Is it a pure speculation, or do institutional investors really see BTC as a commodity/tangible asset?
– What’s interesting about Bitcoin is that it has no financial statements involved, however it keeps a common trust within the community, which is going to be a store of value. Simply because this asset naturally possesses all the characteristics of an asset i.e. it can be divisible, it has value.
So, given the limited supply of Bitcoin, and seeing that regulatory institutions possess BTC as of today, I’d say these institutions are staking their chance on Bitcoin as a diversification tool – particularly while the dollar and other currencies suffer on the base today.
– Seeing the governments-initiated regulations and the facts of storing Bitcoin on state accounts, can Bitcoin’s core idea of free and decentralised currency be in jeopardy?
– I agree about this one.
If you scrutinise the S-1 filing of the spot Bitcoin ETF approval, you’ll see that the terms “redemption in cash” and “redemption in kind” are introduced there. Those are the things that you don’t normally get to see within a decentralized ecosystem unless such decisions are taken through DAO or a forking vote. However, this is something that institutions and even the governments tried to introduce as means to centralize and control the supply and redemption of Bitcoin through the institutional gateway and authorized participants in the deals.
The core idea of decentralization is quite in jeopardy, because the SEC and Wall Street institutions (which are approved by SEC) are now dictating how you could redeem Bitcoin.
– The term “crypto adoption” has been widely used in recent years, mostly referring to Bitcoin. What does that term imply to you? Is it an institutional or government integration, or is it limited to a wider personal use?
– I think it is both institutional and government integration. Whenever such a potential asset that can be used in the long-term as a collateral to loans or banks is introduced, then there needs to be a government recognition of Bitcoin. And I’m a proponent of integration of blockchain and crypto within the government use cases, even as the means of payments or funds within a social welfare, or donations to the community. With Bitcoin and its transparency, it will be even easier to monitor close-box systems. Bitcoin offers open source backable and transparent transactions that are flowing through the blockchain.
– Does Bitcoin adoption guarantee the increase of its value and price, or can it cause a backlash?
– I’d say adoption can increase the value, however if we see that there is a bigger controlling entity in this case, i.e. BlackRock will handle 10% of the entire Bitcoin’s supply in the next years, then this could potentially cause severe control of the price of Bitcoin by reducing the supply within the ecosystem. This can potentially increase the value.
However, if the institutions try to control it, this can bring a great social distress in the community. Whenever there is a small group of people, who are controlling natural resources and assets, the government will run into anarchy, going back to the kings and queens.
Again, this can create social issues in the society, especially if Bitcoin is controlled by smaller entities or fewer people.
## Will Bitcoin replace gold and fiat?
– Is there any chance Bitcoin will suppress fiat?
– It will take hundreds of years.
The evolution of money is something that has been with us through history. The fiat can be suppressed with the e-money, i.e. e-pesos or e-dollars. Bitcoin and other cryptocurrencies could be integrated with the digital currencies as alternatives to ones.
– Michael Saylor recently said that “Bitcoin is going to eat gold?”. Will it in fact?
– They can coexist. There are still people who would like to see a tangibility in their assets.
## Closing Remarks:
– As a Mentor, could you tell, what defines a professional trader: technical knowledge or the right mindset?
– A professional trader has certain non-negotiables.
Firstly, one should be in full awareness of market structure: support/resistance, knowing all trading rules, being able to do a back-testing and a forward testing. A person can develop the ability to come up with profitable trade setups using the proven, repeatable, and reproducible setups within crypto. It is technical knowledge.
Still, the right mindset and your professional behaviour is driven by experience in the market. You get to know yourself more only if you spend enough time in the market. You won’t be able to know yourself as a trader if you don’t stay long enough in the market. I’ve been a trader for more than 9 years now, and this really helps me to come through as I am capable of controlling my emotions, executing when it is only necessary and running only from the profits in the market.
– Which three top qualities should newbies heed to become successful traders?
– Number one: stay analytical and rational in the market. It takes lots of analytics to be able to control it, connect the dots, and come up with your profitable setups.
Number two: you need to journal to get to know yourself. There are two types of traders: ones who sit in front of the screen trading, and ones who are reading the trades at night. Normally, the latter ones are more rational. So, make sure you journal to make sure what mistakes you should not do as a trader, as well as reflect on yourself to avoid them.
Number three: the top quality of a trader is patience. You should become patient – and not by means of stagnation. Instead of carrying out multiple trades, you can use the times when the market is boring to do your research, or monitor regulatory developments and novelties in a particular blockchain technology sector.
When we’re overtrading, we’re losing a lot of money. | endeo |
1,869,519 | How to conditionally render a component on the same route in Angular. | Have you ever needed to render a component conditionally on the same route and found yourself... | 0 | 2024-05-29T19:16:57 | https://medium.com/@iamjustin/605aeae632b7 | angular, development, programming, conditional | Have you ever needed to render a component conditionally on the same route and found yourself resorting to convoluted solutions?
Creating a new container component solely to render components conditionally? Or perhaps using a route factory? Or maybe you even considered giving up and using two separate routes instead?
In a previous article about [feature flags in Angular](https://dev.to/jstnjs/feature-flags-in-angular-4kb0), I discussed how to activate a route when a feature flag is enabled. But what if you need to conditionally render a component based on a feature flag **on the same route**?
It turns out that with the new [CanMatchFn](https://angular.dev/api/router/CanMatchFn), we can define the same route with different components multiple times. Let's explore an example where the team introduces a brand new `LoginComponent`.
```typescript
// feature-flag.guard.ts
export const featureFlagGuard = (feature: FeatureFlags): canMatchFn => {
return (route, segments) => {
const featureFlagService = inject(FeatureFlagService);
return featureFlagService.getFeature(feature);
};
};
// routes.ts
[
{
path: 'login',
canMatch: [featureFlagGuard('newLogin')],
loadComponent: () => import('..').then((c) => c.NewLoginComponent),
},
{
path: 'login',
loadComponent: () => import('..').then((c) => c.OldLoginComponent),
},
]
```
First, we need to create the `featureFlagGuard`. This guard is a `canMatch` guard that enables or continues on the next route. In the `featureFlagGuard`, we call a service that retrieves all the feature flags from an API. Using the `getFeature` method, we check if the specified feature, provided as an argument, is enabled in the service. If the feature is enabled, the method returns `true`, thereby activating the route.
In the routes file, we define the same route twice. If the feature flag called `newLogin` is enabled, it will display the `NewLoginComponent`. If it doesn't match, Angular will proceed to the next route, which in this case is again the `login` path. Since this is the default, we don't need the `canMatch` guard and can simply load the `OldLoginComponent`.
This approach eliminates the need to create another component to combine them or resort to hacky solutions. It’s straightforward to follow. Cheers! | jstnjs |
1,869,517 | 4 solid reasons why Flutter is the future of app development !!! | 1_ overview of the flutter job market in the world Flutter was launched by Google in May 2017. It is... | 0 | 2024-05-29T19:06:01 | https://dev.to/mustafa_majidi_f98f0d6d64/4-solid-reasons-why-flutter-is-the-future-of-app-development--11ho | 1_ overview of the flutter job market in the world
Flutter was launched by Google in May 2017. It is built to support the creation of single-code and ” Cross-platform ” applications for web, mobile and desktop platforms. It is a feature-rich UI SDK that enables developers to create intuitive user interfaces and responsive features. Therefore, Flutter helps not only reduce development efforts but also costs and launch time.
In the past few years, Flutter has evolved as one of the best cross-platform application development frameworks on the market. The framework is used by developers and mobile app development companies around the world. Businesses and startups hire Flutter app developers to build custom mobile apps for Android and iOS.
In 2023, more than 13,887 companies have used Flutter in their application development tools. Of these, 21.48% of Flutter users are from India, 17.26% from the United States, and 6.61% from Brazil.
2_ the astronomical increase in Flutter's popularity in recent years
Source Stack Overflow
3_ why should you choose Flutter to develop the application ?
1. Best for multi-platform application development :
The main reason why companies choose cross-platform development is the cost and timing of faster development compared to the indigenous development approach. However, multi-platform applications had lost significantly in terms of performance and native appearance before Flutter entered the world of work.With Flutter it became possible to build applications close to native ones in terms of functionality. Therefore, there is no longer a need to choose between cost and quality.
2. Optimal performance:
The excellent performance results of Flutter applications (60 to 120 frames per second) are achieved through the Dart programming language. This is a client-optimized language that supports pre-Time Compilation (AOT). This makes Flutter applications faster because the code is natively run on any platform without relying on intermediaries, unlike other cross-platform frameworks that use bridging.
3. Write once for all devices :
Since Flutter 3 was released in May 2022, there are six platforms from the same code base: Android, iOS, web, Windows, macOS and Linux. This means that you can use the same code to develop and publish your application across all these platforms with a small update.It makes it possible to reach more audiences without significantly additional costs and spend less time developing compared to building apps for each platform separately.
4. Faster time to finish the process:
91 percent of developers said that Flutter reduces the time of the mobile app development process
Experiences indicate that the development of the flutter program usually takes from 2 to 6 months. A simple flutter project takes about 2 months; an average – 4 months; a complex program development takes about 4-6 months. For example, we developed this job search program in 3 months.
Flutter apps can develop faster than native mobile apps thanks to several flutter features:
Single code base that allows to write a code and adapt it for six different platforms;
Ready-made reusable and customizable widgets and components;
Hot reload feature that eliminates the need to restart the app after each code change.
6. Super fast reload (Hot reload ):
Hot reload is a flutter function that is especially loved by developers and highly appreciated by business owners. Hot reload allows developers to immediately view changes made to the code without having to restart the application. This makes the feature a time saver and thus a budget saver.
Generally, hot reload helps to quickly replicate code changes, find and delete code errors earlier, and allows for more testing and leads to a better user experience.
8. Ability to create great design
Flutter's rich libraries of customizable widgets and components allow developers and designers to make mobile apps as unique as possible and not limit their creativity. Plus, Cupertino interior materials and widgets as discussed above, provide opportunities for the development of highly Indigenous applications in terms of UI and UX.
Therefore, it is possible to develop Flutter applications with beautiful and modern interfaces that provide a smooth user experience. These programs perform well and have few opportunities for problems to arise.
4_ reasons to prove flutter's superiority over other competitors in the app arena
Flutter's status as the future of application development is rooted in its unique features and benefits. It addresses many of the challenges facing app developers today. As open source, Flutter benefits from ongoing improvements. And also updated from the active developer community and Google. This ensures that it is up to date with the latest industry trends and technologies. Here are the following reasons why Flutter is becoming the future of mobile app development.
1. Performance and speed
Flutter compiles native codes. This leads to high Program performance. Fluid animations, rendering offers a fast interface and excellent responsiveness. Finally, it stands out as an ideal choice for building applications that require high standard features.
2. Ecosystem rich in widgets
Flutter comes with a rich set of pre-designed widgets for shared user interface elements. In addition, the Flutter community actively contributes to an extensive library of packages and add-ons that expand functionality. Therefore, its use to integrate different features into applications will become more frequent in the near time.
3. Web and desktop support
Flutter has expanded beyond mobile to support web and desktop application development. Developers can use a single code base to target multiple platforms. Therefore, developers and mobile app development companies mainly use Flutter due to their multi-platform support.
4. Strong community and resources
Flutter has a rapidly growing and engaged developer community. This means that developers have access to various resources. For example, it updates its trainings, documentation, etc. and resources to help them overcome challenges. Therefore, new Flutter developers will have good community support and start with application development.
5. Google's continued investment
Google continues to invest in Flutter. The tech giant is always striving to ensure its long-term viability. Google's support adds credibility and confidence for developers and businesses alike. In the near time, Google will release more updates for Flutter to make it more useful.
6. Cost-effectiveness
The multi-platform nature of Flutter and faster development time translates into cost savings for the business. With this framework, developers can implement the same code base. And also use native components for Android and iOS. Thus, it allows startups and companies to build high-quality programs within budget constraints.
Conclusion :
In conclusion, Flutter has emerged as a true pioneer in the field of mobile application development. Its unique combination of features and capabilities has put it at the forefront of the competition. Therefore, it makes it not only a trend but also a transformative force. | mustafa_majidi_f98f0d6d64 | |
1,869,516 | Creating Killer Kick-Ass Content like the Best GOAT Industry Leaders in DEV? | Whoops, something went wrong: Add a cover image Add another... Researching about search engine... | 0 | 2024-05-29T19:05:14 | https://dev.to/valvonvorn/creating-killer-kick-ass-content-like-the-best-goat-industry-leaders-in-dev-ei7 | contentwriting | Whoops, something went wrong: Add a cover image Add another...
Researching about search engine optimization, so-called snake oil gurus prevail. But how can we really start to create killer kick-ass content like the best goat industry leaders in dev?
What do you think about it? Is this really such a thing? | valvonvorn |
1,869,513 | Python Terminal To-Do App 🐍 | Hey everyone, I'm thrilled to bring to you my latest creation — a complete Python tutorial where we... | 0 | 2024-05-29T19:04:02 | https://dev.to/bekbrace/different-terminal-to-do-app-4lc5 | python, webdev, beginners, programming | Hey everyone,
I'm thrilled to bring to you my latest creation — a complete Python tutorial where we build a fully functional CLI to-do list application! 🎉
For those who might not know me, I'm Amir, a dedicated software developer and educator with a passion for exploring programming languages and empowering others through sharing my knowledge. Over the last few weeks, I've been meticulously crafting this tutorial to help you master Python through a real-world project that not only teaches fundamental programming concepts but also results in a practical, usable application.
Python is a fantastic language known for its simplicity and versatility, making it suitable for everything from web development to data science - despite the hate it receives sometimes!
However, understanding how to apply Python in real projects can sometimes be daunting, which is why I've designed this tutorial to be both accessible and enjoyable.
In this video series, you will learn how to:
- Set up a Python development environment,
- Interact with a database using SQLite,
- Create functions to add, display, complete, and delete tasks,
- Ensure data persists across sessions so you can pick up right where you left off.
Thank you dear readers and fellow Devs for your support of my Rust course last week, I truly appreciate it.
BTW, This tutorial is now on YouTube! 📺
{% youtube RmytMspWBo8 %}
I'm super excited for you to check it out and start building your own to-do list application.
Please let me know how your app turns out.
Your feedback is incredibly important to me — it helps me tailor my content to better suit your learning needs.
See you in the tutorial!
Best,
Amir | bekbrace |
1,869,514 | How to check number is registered on whatsapp | I have one requirement that i need to check whether number is registered on whatsapp or not without... | 0 | 2024-05-29T19:01:00 | https://dev.to/tarika_lalwani_1307f5b878/how-to-check-number-is-registered-on-whatsapp-18mg | whatsappcloudapi, php, facebookgrapapi | I have one requirement that i need to check whether number is registered on whatsapp or not without using any 3rd party library like 2Chat, rapidai and other paid tools
Is there any way to check it using whatsapp cloud api | tarika_lalwani_1307f5b878 |
1,869,505 | Temporal Dead Zone In JavaScript | During the memory creation phase of the execution context, variables declared with let and const are... | 0 | 2024-05-29T18:47:52 | https://dev.to/pervez/temporal-dead-zone-in-javascript-4ef8 | javascript, webdev, frontend, development | During the memory creation phase of the execution context, variables declared with let and const are allocated memory in the block scope, not in the global scope. These variables cannot be accessed before they are initialized. Here Temporal Dead Zone (TDZ) Comes To In Picture.
**👉 Temporal Dead Zone In JavaScript :**
Temporal Dead Zone is a behavior in JavaScript where variables declared with let and const are inaccessible before their initialization.
Temporal Dead Zone (TDZ) is the time period in JavaScript when a variable declared with let or const has memory allocated but has not yet been initialized.
**👇 Explanation Of Above Example :**
During the memory creation phase, memory space is allocated for the variable 'a'. However, 'a' is not initialized yet. This marks the beginning of the Temporal Dead Zone (TDZ) for variable 'a'. The Temporal Dead Zone (TDZ) ends when variable 'a' is initialized with the value 1.
Attempting to access 'a' variable in its TDZ will Throw a _**ReferenceError**_.
Similarly, the TDZ applies to **_const _**variables as well
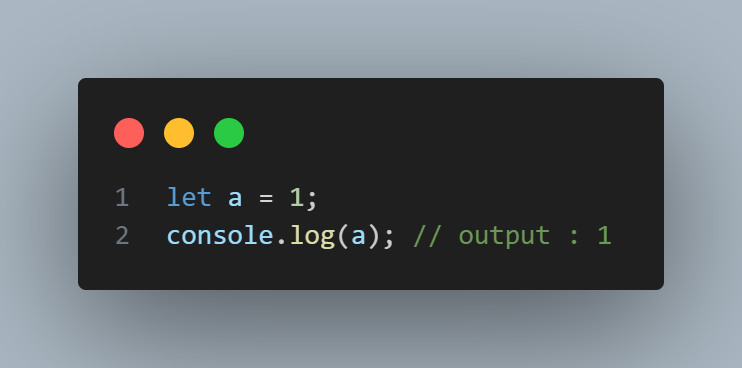
**👇 Explanation Of Above Example :**
Here, a is properly declared and initialized before we attempt to access it, so there is no TDZ violation, and the value of a (which is 1) is successfully printed to the console.
In summary, the TDZ is a period during which let and const variables exist but are not yet accessible. The TDZ ensures that variables are accessed only after they have been properly declared and initialized,
| pervez |
1,869,512 | Retail Display Racks and Industrial Storage Racks Manufacturer in Delhi | Welcome to Technico Storage System, your premier destination for top-quality display racks in Delhi.... | 0 | 2024-05-29T18:55:33 | https://dev.to/technicostorage/retail-display-racks-and-industrial-storage-racks-manufacturer-in-delhi-1418 | Welcome to Technico Storage System, your premier destination for top-quality [display racks in Delhi](https://www.technicostorage.co.in). As a leading Display Racks Manufacturer in Delhi, we take pride in offering a wide range of retail display solutions that cater to the diverse needs of our clients. With a commitment to excellence and innovation, we strive to elevate your retail space with our premium products.
At Technico Storage System, we understand the importance of creating an attractive and functional display to showcase your merchandise effectively. That's why our team of skilled professionals works tirelessly to design and manufacture display racks that not only enhance the visual appeal of your store but also optimize space and organization.
As your trusted Retail Display Rack Supplier in Delhi, we prioritize customer satisfaction above all else. Whether you're looking for sleek and modern display racks or traditional and rustic designs, we have the perfect solution to meet your needs. Our dedication to quality craftsmanship ensures that each product is built to last, providing you with long-lasting durability and reliability.
With Technico Storage System, you can rest assured that you're getting top-notch display racks that seamlessly blend style and functionality. Transform your retail space into a captivating destination for shoppers and elevate your brand presence with our premium display solutions.
## Why Choose Technico Storage System for Your Display Rack Needs?
**• Quality Assurance:** We adhere to stringent quality standards to deliver display racks that meet and exceed your expectations.
**• Customization Options:** We offer customization services to tailor our display racks according to your specific requirements and preferences.
**• Competitive Pricing:** Enjoy competitive pricing without compromising on quality. Our affordable display racks are perfect for businesses of all sizes.
**• Timely Delivery:** We understand the importance of timely delivery. Count on us to deliver your display racks promptly and efficiently.
Whether you're a small boutique or a large retail chain, Technico Storage System has the perfect display rack solution for you. Transform your retail space and captivate your customers with our premium display racks in Delhi.
Choose Technico Storage System for all your display rack needs and experience the difference in quality and service. Get in touch with us today to learn more about our products and how we can help enhance your retail environment.

| technicostorage | |
1,869,503 | La Luzerne | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration "La... | 0 | 2024-05-29T18:55:03 | https://dev.to/madsstoumann/la-luzerne-bfe | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
"La Luzerne — Saint-Denis" by Georges Seurat:

This is a great example of pointillism, for which I wanted to create a pure CSS **interpretation**, not a 1:1 replica.
## Demo
{% codepen https://codepen.io/stoumann/pen/zYQoZjN %}
## Journey
The CSS for this contains a bunch of custom properties, that are all set with a bit of **randomness** in JavaScript. Thus, you get a fresh, unique version of the painting everytime you refresh!
```css
.luzerne {
background-color: rgb(243, 221, 44);
border: clamp(0.375rem, 0.0575rem + 1.5873vw, 1rem) ridge rgb(121, 85, 72, .9);
container-type: inline-size;
display: flex;
filter: url('#grain');
flex-wrap: wrap;
margin-inline: auto;
max-width: 950px;
gap: 0px;
overflow: visible;
b {
aspect-ratio: 1 / .95;
background: var(--c, #0000);
border-radius: var(--a, 0);
filter: brightness(var(--b, 1)) opacity(var(--o, 1));
rotate: var(--r, 0deg);
scale: var(--s, 1);
width: 2cqi;
}
}
```
I wrote a small JavaScript to render the random properties:
```js
const colors = [array-of-colors];
const R = (min, max) => Math.random() * (max - min) + min;
app.innerHTML = new Array(1150).fill().map(() => {
const c = colors[Math.floor(Math.random() * colors.length)];
const s = R(1, 1.5).toFixed(5);
const r = R(-10, 10).toFixed(2) + 'deg';
const a = R(5, 20).toFixed(2) + '%';
const b = R(1, 1.3).toFixed(2);
const o = R(0.75, 1).toFixed(2);
return `<b style="--c:${c};--s:${s};--r:${r};--a:${a};--b:${b};--o:${o}"></b>`;
}).join('');
```
---
## Grainy texture
The old and worn, grainy look, is an `SVG`-filter (see the demo above). The wooden frame is simply a `border-type: ridge`. | madsstoumann |
1,869,511 | Certificate Attestation in Dubai | A post by GreenLine Attestation Services | 0 | 2024-05-29T18:53:57 | https://dev.to/greenlineattestation/certificate-attestation-in-dubai-i66 | travel, visaservices, certificateattestationindubai, certificateattestation | [](https://www.allattestations.com/)
[](url) | greenlineattestation |
1,869,508 | How I Passed the Certified Kubernetes Administrator (CKA) Exam and How You Can Too | I recently passed the Certified Kubernetes Administrator (CKA) exam, and I want to share my journey... | 0 | 2024-05-29T18:49:33 | https://dev.to/girishmukim/how-i-passed-the-certified-kubernetes-administrator-cka-exam-and-how-you-can-too-5c1e | cka, kubernetes, certifications | I recently passed the Certified Kubernetes Administrator (CKA) exam, and I want to share my journey with you. This exam is challenging, primarily because it's based on practical scenario-based questions rather than multiple-choice questions. Don't get me wrong; multiple-choice questions have their challenges, but the hands-on nature of the CKA makes it particularly demanding.
Passing the CKA was no easy feat. It took me a lot of preparation and practice to get there, and I want to provide some insights and tips that might help others in their journey.
## My CKA Journey
I passed the CKA on my second attempt. Failing the first time was tough, but fortunately, the CKA exam fees cover two attempts. This allowed me to prepare more effectively for my second try without worrying about additional financial costs. When I finally succeeded and posted about my achievement on LinkedIn, I was overwhelmed by the response. The post garnered a lot of interest, and many people reached out to me, asking about my preparation strategies and details about the exam itself. It was clear that there was a significant demand for guidance on this topic, which inspired me to write this blog in the hope that it would help a larger audience.
To give you a bit of background about myself, I come from an infrastructure background with experience as an AWS Solutions Architect. While I had a solid understanding of cloud technologies and infrastructure management, I never had hands-on exposure to Kubernetes before. Preparing for the CKA exam provided me with the opportunity to dive deep into Kubernetes and gain practical experience with this powerful container orchestration platform.
## Preparation
First and foremost, I highly recommend the Udemy course by [Mumshad Mannambeth](https://www.udemy.com/course/certified-kubernetes-administrator-with-practice-tests/). It covers all the required concepts with practice sessions at the end of each topic. The questions in these practice sessions aren't modeled after actual exam questions but are designed to reinforce the recently learned concepts. The course also includes three mock exams, which are incredibly helpful. I can't recommend these enough.
In addition to the Udemy course, I Googled for CKA questions and practiced using those. After failing the first attempt, I became more cautious and focused on hands-on practice for my second attempt.
If you don't have a practice sandbox, the Udemy course should suffice. However, I also created a sandbox on an AWS EC2 instance. I had some unused AWS credits, so I spun up a t2.medium EC2 instance and used Minikube to create a single-node Kubernetes cluster. This was fairly straightforward. If you're interested, you can refer to the documentation [here](https://minikube.sigs.k8s.io/docs/start/?arch=%2Fwindows%2Fx86-64%2Fstable%2F.exe+download).
This step is optional but can be beneficial.
## Tips and Tricks
Once you pass the exam, you're entitled to share tips and tricks! Isn't it? :-). Here are a few that helped me, not in any particular order:
**Familiarize Yourself with Short Names for Resources:** Use short names like svc for service and ns for namespaces during your practice. You can find a list of all short names with the command kubectl api-resources.
**Use Imperative Commands:** Whenever possible, use imperative commands instead of creating manifest files every time. This saves a lot of time.
**Use Documentation Effectively:** The CKA is an open-book exam, so you can access Kubernetes documentation. Know how to find information quickly and efficiently.
**Manage Your Time:** Don't get stuck on complex questions. There are a few easy questions that you don't want to miss. Remember, you need to score 66% to pass.
**Use Alias for kubectl:** If you're comfortable, use alias like k for kubectl. The environment setup already includes alias and autocompletion, so no action is needed. If required, you can find commands in the quick reference here.
**Set Context Before Each Question:** Remember to set the context before each question. The command will already be given in the question, so ensure you copy and paste it. Try to copy-paste resource names, image names, etc. It's easy to make typos, especially when you're chasing time.
**Understand Exam Interface:** Before diving into the exam, understand how to navigate the screen, and how to copy and paste. These might seem trivial, but they are important.
**Practice, Practice, Practice:** This is the most important tip. Hands-on practice was the key difference between my failed and passed attempts. Even if you don't follow the other tips, make sure you follow this one.
**Additional Resources**
Since practice was the differentiator for me, I've created a free resource for you in the form of a [YouTube playlist](https://youtube.com/playlist?list=PLu49v2xsj3a_FlP8PAhCvSPUh7FwEFpPA&si=SaR9hP__GnjjS_vj). You can follow along as I demonstrate various tasks, or just watch to get a feel for the process. I'm sure you'll find it valuable.
{% embed https://youtube.com/playlist?list=PLu49v2xsj3a_FlP8PAhCvSPUh7FwEFpPA&si=SaR9hP__GnjjS_vj %}
With that, I wish you all the best. You're going to ace the Certified Kubernetes Administrator exam. Let me know once you do! | girishmukim |
1,869,507 | Mastering Data Management: Designing a Database for an FMCG Alcoholic Beverages Company | Introduction In the fast-paced world of fast-moving consumer goods (FMCG), especially... | 0 | 2024-05-29T18:49:17 | https://dev.to/kellyblaire/mastering-data-management-designing-a-database-for-an-fmcg-alcoholic-beverages-company-2998 | sql, database, fmcg, datawarehousing | ## Introduction
In the fast-paced world of fast-moving consumer goods (FMCG), especially within the competitive alcoholic beverages sector, efficient data management is crucial for success. As companies expand their reach across diverse regions, managing information related to staff, sales, customers, and distributors becomes increasingly complex. This article delves into the intricacies of designing a comprehensive database tailored for an FMCG company specializing in alcoholic beverages. We’ll explore how to effectively structure tables for staff, geographical zones, sales, customers, and more, ensuring seamless operations and insightful data analysis. Whether you’re an aspiring database designer or a business professional eager to streamline operations, this guide offers valuable insights into creating an optimized database for learning purposes.
Designing a database for a fast-moving consumer goods (FMCG) company specializing in alcoholic beverages involves creating a set of interconnected tables to effectively manage data related to staff, geographical regions, sales, customers, distributors, and other business entities. Below is a detailed breakdown of the tables and their potential attributes:
### 1. Staff Table
This table stores information about the company's employees.
- **staff_id** (Primary Key)
- **first_name**
- **last_name**
- **position**
- **email**
- **phone_number**
- **hire_date**
- **team_id** (Foreign Key to Teams table)
- **zone_id** (Foreign Key to Zones table)
- **area_id** (Foreign Key to Areas table)
- **territory_id** (Foreign Key to Territories table)
### 2. Zones Table
Zones are large geographical regions that the company operates in.
- **zone_id** (Primary Key)
- **zone_name**
- **description**
### 3. Areas Table
Areas are subdivisions of zones.
- **area_id** (Primary Key)
- **area_name**
- **zone_id** (Foreign Key to Zones table)
- **description**
### 4. Territories Table
Territories are smaller subdivisions within areas.
- **territory_id** (Primary Key)
- **territory_name**
- **area_id** (Foreign Key to Areas table)
- **description**
### 5. Sales Table
This table records overall sales transactions.
- **sales_id** (Primary Key)
- **date**
- **total_amount**
- **customer_id** (Foreign Key to Customers table)
- **staff_id** (Foreign Key to Staff table)
### 6. Sales Details Table
This table captures the details of each sales transaction.
- **sales_details_id** (Primary Key)
- **sales_id** (Foreign Key to Sales table)
- **product_id** (Foreign Key to Products table)
- **quantity**
- **unit_price**
- **total_price**
### 7. Customers Table
This table stores information about the customers.
- **customer_id** (Primary Key)
- **customer_name**
- **contact_name**
- **contact_phone**
- **contact_email**
- **address**
- **territory_id** (Foreign Key to Territories table)
### 8. Distributors Table
This table records data about distributors.
- **distributor_id** (Primary Key)
- **distributor_name**
- **contact_name**
- **contact_phone**
- **contact_email**
- **address**
- **zone_id** (Foreign Key to Zones table)
### 9. Teams Table
Teams are groups of staff members working together.
- **team_id** (Primary Key)
- **team_name**
- **description**
### 10. Products Table
This table keeps information about the products sold by the company.
- **product_id** (Primary Key)
- **product_name**
- **category**
- **price**
- **stock_quantity**
### 11. Product Categories Table
Categorizes the different types of products.
- **category_id** (Primary Key)
- **category_name**
- **description**
### 12. Inventory Table
Tracks inventory levels of products.
- **inventory_id** (Primary Key)
- **product_id** (Foreign Key to Products table)
- **quantity**
- **last_updated**
### 13. Orders Table
Records orders placed by customers.
- **order_id** (Primary Key)
- **customer_id** (Foreign Key to Customers table)
- **date**
- **status**
### 14. Order Details Table
Details of each order.
- **order_details_id** (Primary Key)
- **order_id** (Foreign Key to Orders table)
- **product_id** (Foreign Key to Products table)
- **quantity**
- **unit_price**
- **total_price**
### 15. Shipments Table
Records details about product shipments.
- **shipment_id** (Primary Key)
- **order_id** (Foreign Key to Orders table)
- **shipment_date**
- **delivery_date**
- **status**
### 16. Payments Table
Tracks payments made by customers.
- **payment_id** (Primary Key)
- **order_id** (Foreign Key to Orders table)
- **payment_date**
- **amount**
- **payment_method**
### 17. Payment Methods Table
Different payment methods used by customers.
- **payment_method_id** (Primary Key)
- **method_name**
- **description**
### 18. Promotions Table
Information about promotions and discounts.
- **promotion_id** (Primary Key)
- **promotion_name**
- **description**
- **start_date**
- **end_date**
- **discount_percentage**
### Relationships between Tables
- **Staff** is related to **Teams**, **Zones**, **Areas**, and **Territories** through foreign keys.
- **Sales** and **Orders** are related to **Customers** and **Staff**.
- **Sales Details** and **Order Details** are related to **Sales** and **Orders**, respectively, as well as **Products**.
- **Inventory** is linked to **Products** to track stock levels.
- **Shipments** and **Payments** are linked to **Orders**.
- **Distributors** are linked to **Zones** to manage regional distribution.
### ER Diagram Representation
Here's a simplified ER diagram description to visualize the relationships:
- **Staff** (staff_id) - (N:1) -> **Teams** (team_id)
- **Staff** (staff_id) - (N:1) -> **Zones** (zone_id)
- **Staff** (staff_id) - (N:1) -> **Areas** (area_id)
- **Staff** (staff_id) - (N:1) -> **Territories** (territory_id)
- **Zones** (zone_id) - (1:N) -> **Areas** (area_id)
- **Areas** (area_id) - (1:N) -> **Territories** (territory_id)
- **Sales** (sales_id) - (N:1) -> **Customers** (customer_id)
- **Sales** (sales_id) - (N:1) -> **Staff** (staff_id)
- **Sales Details** (sales_details_id) - (N:1) -> **Sales** (sales_id)
- **Sales Details** (sales_details_id) - (N:1) -> **Products** (product_id)
- **Customers** (customer_id) - (N:1) -> **Territories** (territory_id)
- **Distributors** (distributor_id) - (N:1) -> **Zones** (zone_id)
- **Orders** (order_id) - (N:1) -> **Customers** (customer_id)
- **Order Details** (order_details_id) - (N:1) -> **Orders** (order_id)
- **Order Details** (order_details_id) - (N:1) -> **Products** (product_id)
- **Inventory** (inventory_id) - (N:1) -> **Products** (product_id)
- **Shipments** (shipment_id) - (N:1) -> **Orders** (order_id)
- **Payments** (payment_id) - (N:1) -> **Orders** (order_id)
- **Payments** (payment_id) - (N:1) -> **Payment Methods** (payment_method_id)
This database structure allows the FMCG company to efficiently manage and analyze its operations across various geographical regions, track sales, manage customer relationships, and handle inventory and distribution effectively.
## Conclusion
Designing a robust database for an FMCG company specializing in alcoholic beverages involves thoughtful consideration of various entities, from staff and geographical zones to sales and customer details. By meticulously structuring and interconnecting tables, businesses can enhance their data management capabilities, leading to improved operational efficiency and strategic decision-making. The proposed database schema not only addresses the fundamental needs of such a company but also provides a scalable foundation for future growth and adaptation. Remember, the primary aim of this article is educational, offering a blueprint for learners and professionals alike to understand and implement an effective database system in a real-world context. With this knowledge, you’re well-equipped to tackle the complexities of data management in the dynamic FMCG landscape. | kellyblaire |
1,869,504 | Scrapping Bybit Kline data with Pybit | At the time of writing this, I'm using python Pybit v5 library for scrapping Bybit kline data.... | 0 | 2024-05-29T18:45:40 | https://dev.to/kylefoo/scrapping-bybit-kline-data-2bbk | bybit, kline, algotrading, pybit | At the time of writing this, I'm using python Pybit v5 library for scrapping Bybit kline data. Following python codes work for 1min kline scrapping, do modify the code accordingly based the interval you wish to scrap.
```python
import pandas as pd
from datetime import date, datetime, timedelta
from pybit.unified_trading import HTTP
import numpy as np
import dateparser
import time
import math
session = HTTP(testnet=False, api_key=API_KEY, api_secret=SECRET_KEY)
def GetHistoricalData(currency, start_date, end_date, interval):
start_time = dateparser.parse(start_date)
end_time = dateparser.parse(end_date)
start_ts = int(start_time.timestamp()*1000) #ms
end_ts = int(end_time.timestamp()*1000) #ms
page = 0
# we will query for 2 pages per day, with limit of 720 bar returned every call, we then get 1440min for every 2 pages
# note that API call below will use 720 as limit because that's easier for pagination
# hence total pages = num of days * 2
totalPage = math.ceil(start_ts - end_ts / (1000 * 60 * 60 * 24)) * 2
df = pd.DataFrame(columns=['startTime', 'openPrice', 'highPrice', 'lowPrice', 'closePrice', 'volume'])
while True:
# Kline API call, 1min interval is the smallest bar we can get, limit max at 1000 but I use 720 here
bars = session.get_kline(symbol=currency, interval=str(interval), start=start_ts, category="linear", limit=720)
# counter starts from end of list then goes backward since oldest data appear last
idx = len(bars['result']['list']) - 1
while True:
bar = bars['result']['list'][idx]
new_row = {'startTime': pd.to_datetime(int(bar[0]), unit= 'ms'), 'openPrice': bar[1], 'highPrice': bar[2], 'lowPrice': bar[3], 'closePrice': bar[4], 'volume': bar[5]}
# if the kline bar exceed end_time, means reaches target date, break out of loop
if int(bar[0]) > end_ts:
start_ts = end_ts
break
# append the new row into dataframe
df.loc[len(df)] = new_row
# check if we reaches first item in array
if idx == 0:
start_ts = start_ts + 43200*1000 # increment by num of ms for a day to get start time for tmr
break
idx -= 1
page += 1
# check if the end_date is reached
if start_ts >= end_ts:
# exit the while loop
break
if page > totalPage:
break
# time delay to prevent api rate limit
time.sleep(0.02)
return df
```
then execute the function with symbol, intended start time and end time, as well as interval of 1min
```python
data = GetHistoricalData("BTCUSDT", "May 01, 2023 00:00 UTC", "July 31, 2023 23:59 UTC", 1)
data.to_csv("./{}_May-01-2023-July-31-2023.csv".format("BTCUSDT"), index=False)
```
See https://bybit-exchange.github.io/docs/v5/market/kline for API documentation. | kylefoo |
1,869,502 | Python for Software Engineering Beginners! | What's up SE nerds!! It's Tripp, back with another blog from SE Bootcamp, currently finishing up... | 0 | 2024-05-29T18:43:09 | https://dev.to/trippl/python-for-software-engineering-beginners-o9o | beginners, softwareengineering, python, career | What's up SE nerds!! It's Tripp, back with another blog from SE Bootcamp, currently finishing up Phase 3 out of 5! This time we are learning about using back end with Python. Here's a rundown of the basics and what you can expect from when learning Python.
Some of the basic concepts you'll start learning about in Python are Variables that store data values; Data Types like integers, float, strings, lists, dictionaries, tuples and sets; Control Structures such as 'if' statements, 'for' loops, and 'while' loops (sound familiar?); And Functions that work the same as in JavaScript, they are codes that perform specific tasks. Here are some brief examples:
The next part about Python you'll need to know is about Object-Oriented Programming (OOP). This is made up of 'classes' and 'objects'. A 'Class' defines a data type with 'attributes' (like properties) and 'methods' (behaviors). An 'object' is an 'instance' of a class. Here's an example to put it together:
You'll also need to know about Inheritance. This allows a class to inherit attributes and methods from another class. This creates a hierarchy and allows code to be reused. This consists of a 'base'/'parent' class that the 'derived'/'child' class inherits from. Here's an example below:
This last part brings all of this together that's why it is appropriately called Object Relationships. This relates objects to each other in various ways. Two of these ways are 'composition' which is made up of one or more objects from other classes as a relationship, and 'aggregation' where a class can contain objects from other classes but they can be independent. Here's an example of this:
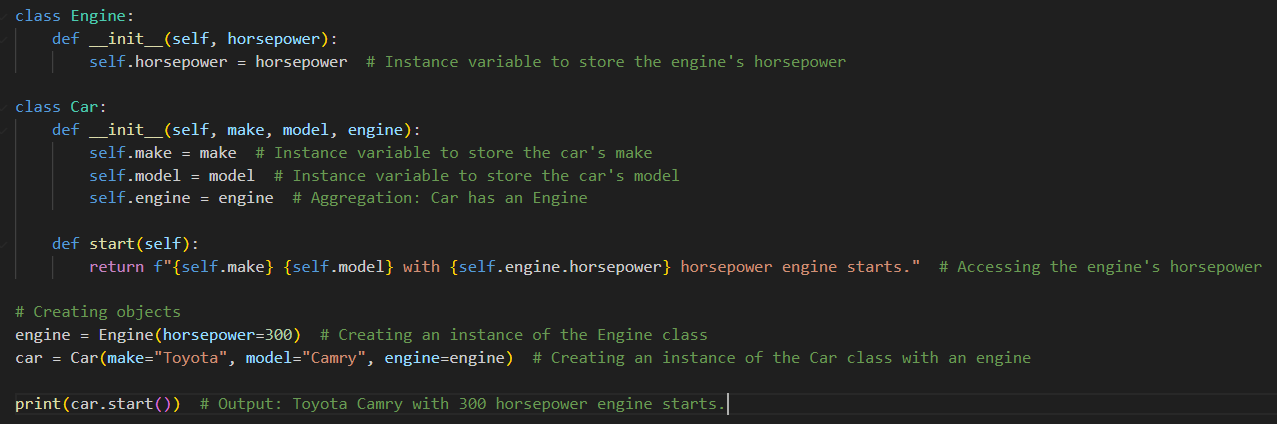
I hope this post helps you out with your Python journey. Feel free to comment if there are any errors or anything that could help this post be more beneficial to new Python learners or SE students!!
| trippl |
1,869,708 | Minicurso De Análise De Dados Gratuito Da Cubos Academy | A Cubos Academy oferece um minicurso gratuito e completamente online de Análise de Dados, ideal para... | 0 | 2024-06-23T13:51:50 | https://guiadeti.com.br/minicurso-analise-de-dados-gratuito-cubos-academy/ | cursogratuito, analisededados, cursosgratuitos, dados | ---
title: Minicurso De Análise De Dados Gratuito Da Cubos Academy
published: true
date: 2024-05-29 18:40:20 UTC
tags: CursoGratuito,analisededados,cursosgratuitos,dados
canonical_url: https://guiadeti.com.br/minicurso-analise-de-dados-gratuito-cubos-academy/
---
A Cubos Academy oferece um minicurso gratuito e completamente online de Análise de Dados, ideal para quem deseja explorar uma das profissões que mais crescem no Brasil e no mundo.
Nesta trilha de conhecimento, os participantes serão introduzidos aos conceitos básicos da análise de dados ao longo de 24 aulas gratuitas.
O curso foi desenvolvido para mergulhar os estudantes no universo da análise de dados, ajudando-os a compreender a prática da profissão e preparando-os para se tornarem profissionais qualificados para o mercado.
Serão 24 horas de aula. Os participantes receberão um certificado de conclusão e material bônus ao finalizar o curso.
## Minicurso – Análise De Dados
A Cubos Academy está oferecendo um minicurso completamente gratuito em Análise de Dados, totalmente online, projetado para aqueles que estão começando seu aprendizado nesta área em rápida expansão.
_Imagem da página do curso_
Esta é uma oportunidade para você aprender os conceitos básicos de uma das profissões que mais crescem no Brasil e no mundo.
### Estrutura e Conteúdo do Curso
Ao longo de 24 aulas gratuitas, os participantes conheceram a Análise de Dados. Cada aula é planejada para ajudar os estudantes a entenderem melhor a prática da profissão e a desenvolverem as habilidades necessárias para se tornarem profissionais competentes e preparados para enfrentar os desafios do mercado.
O minicurso trabalha desde a teoria fundamental até as aplicações práticas, transformando grandes volumes de dados em insights valiosos. Confira a ementa:
- Python para Dados: Setup;
- Python para Dados: Variáveis;
- SQL: Introdução ao Modelo Relacional;
- Power BI: Instalando e configurando o ambiente;
- Power BI: Coletando requisitos para um Dashboard.
### Benefícios e Acesso Contínuo
Os participantes receberão um certificado de conclusão ao final do curso, juntamente com material bônus que complementará sua aprendizagem.
Este curso é ideal para quem deseja ter uma visão geral dos principais aspectos da análise de dados e iniciar uma carreira promissora nesta área dinâmica.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Minicurso-De-Analise-De-Dados-280x210.png" alt="Minicurso De Análise De Dados" title="Minicurso De Análise De Dados"></span>
</div>
<span>Minicurso De Análise De Dados Gratuito Da Cubos Academy</span> <a href="https://guiadeti.com.br/minicurso-analise-de-dados-gratuito-cubos-academy/" title="Minicurso De Análise De Dados Gratuito Da Cubos Academy"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Desafio-De-Python-Pandas-280x210.png" alt="Desafio De Python Pandas" title="Desafio De Python Pandas"></span>
</div>
<span>Desafio De Python Pandas Online E Gratuito: 7 Days Of Code</span> <a href="https://guiadeti.com.br/desafio-python-pandas-gratuito-7-days-of-code/" title="Desafio De Python Pandas Online E Gratuito: 7 Days Of Code"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Cursos-De-Metaverso-Python-IoT-280x210.png" alt="Cursos De Metaverso, Python, IoT" title="Cursos De Metaverso, Python, IoT"></span>
</div>
<span>Cursos De Metaverso, Python, IoT E Outros Gratuitos Da Samsung</span> <a href="https://guiadeti.com.br/cursos-metaverso-python-iot-gratuitos-samsung/" title="Cursos De Metaverso, Python, IoT E Outros Gratuitos Da Samsung"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Curso-De-Sistemas-Autonomos-280x210.png" alt="Curso De Sistemas Autônomos" title="Curso De Sistemas Autônomos"></span>
</div>
<span>Curso De Sistemas Autônomos Gratuito: Boas Práticas Operacionais</span> <a href="https://guiadeti.com.br/curso-sistemas-autonomos-boas-praticas/" title="Curso De Sistemas Autônomos Gratuito: Boas Práticas Operacionais"></a>
</div>
</div>
</div>
</aside>
## Análise De Dados
Análise de dados é o processo de examinar, limpar e modelar conjuntos de dados para descobrir informações úteis, informar conclusões e apoiar a tomada de decisão.
Em uma era dominada por grandes volumes de dados, a capacidade de extrair insights relevantes de dados brutos tornou-se essencial para as empresas que buscam manter uma vantagem competitiva.
A análise de dados pode ser aplicada em uma variedade de setores, incluindo finanças, saúde, marketing, e muito mais, tornando-a uma das habilidades mais valiosas no mercado de trabalho atual.
### Ferramentas e Softwares para Análise de Dados
A eficiência na análise de dados depende fortemente das ferramentas e softwares utilizados. Algumas das ferramentas mais populares incluem:
- Python e R: Ambas são linguagens de programação poderosas com extensos pacotes e bibliotecas dedicadas à análise de dados, como Pandas e ggplot2, respectivamente.
- SQL: Fundamental para manipular e extrair dados de bancos de dados, SQL é uma habilidade essencial para qualquer analista de dados.
- Tableau e Power BI: Softwares focados na visualização de dados que ajudam a transformar análises complexas em gráficos e relatórios compreensíveis e visualmente atraentes.
- Excel: Continua sendo uma ferramenta básica, mas poderosa, para a análise de dados em menor escala, especialmente útil para a manipulação de dados e análise exploratória.
### Carreiras em Análise de Dados
A demanda por analistas de dados é alta em quase todos os setores da economia. Profissionais na área podem se especializar em várias direções, incluindo:
- Cientista de Dados: Focados em modelagem estatística e machine learning, esses profissionais são essenciais para organizações que precisam de insights profundos para informar suas estratégias de negócios.
- Analista de Business Intelligence (BI): Esses profissionais ajudam as empresas a entender as tendências do mercado e a performance interna através de relatórios e dashboards interativos.
- Engenheiro de Dados: Especializados na arquitetura e manutenção de sistemas de dados robustos que são críticos para análises avançadas.
- Especialista em Visualização de Dados: Focados em converter análises complexas em representações visuais claras que facilitam a compreensão e a apresentação de dados.
A análise de dados oferece um caminho de carreira com muitas oportunidades, sendo uma área que continuará a crescer e a se desenvolver à medida que novas tecnologias e metodologias emergem.
## Cubos Academy
A Cubos Academy é uma instituição de ensino focada em preparar estudantes e profissionais para o mercado de tecnologia.
Tendo um modelo de ensino que combina teoria com prática intensiva, a Cubos Academy oferece cursos em diversas áreas de alta demanda, como desenvolvimento de software, design de interfaces e análise de dados.
A instituição tem metodologia hands-on, que permite aos alunos aplicarem o conhecimento adquirido em projetos reais e simulados, facilitando a transição do ambiente de aprendizado para o ambiente de trabalho.
### Cursos e Programas Oferecidos
Os cursos da Cubos Academy são desenhados para atender às necessidades de um mercado de trabalho em constante evolução. Cada curso é cuidadosamente estruturado para maximizar o aprendizado e inclui módulos que cobrem desde fundamentos básicos até técnicas avançadas.
### Inovação e Impacto
Através de parcerias com empresas e startups, a academia proporciona aos alunos oportunidades de estágio e emprego, criando um ciclo virtuoso de aprendizado e aplicação prática.
A Cubos Academy está comprometida com a acessibilidade e inclusão, oferecendo bolsas de estudo e programas de mentorias que procuram democratizar o acesso ao conhecimento tecnológico.
## Inscreva-se no minicurso gratuito de Análise de Dados da Cubos Academy e habilite-se para o futuro!
As [inscrições para o Minicurso – Análise De Dados](https://www.cubos.academy/lp/minicurso-analise-de-dados) devem ser realizadas no site da Cubos Academy.
## Ajude outros a descobrir como a análise de dados pode transformar carreiras!
Gostou do conteúdo sobre o minicurso gratuito? Então compartilhe com a galera!
O post [Minicurso De Análise De Dados Gratuito Da Cubos Academy](https://guiadeti.com.br/minicurso-analise-de-dados-gratuito-cubos-academy/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,869,501 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-05-29T18:40:09 | https://dev.to/lionshik34/buy-verified-paxful-account-2h1i | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n " | lionshik34 |
1,868,005 | 🔍 Unleash the Power of ChatGPT - Essential Prompts for Developers | Hey 👋 I've changed the layout a little in this weeks edition and added a couple of new sections. Let... | 0 | 2024-05-29T18:36:00 | https://dev.to/adam/unleash-the-power-of-chatgpt-essential-prompts-for-developers-7f8 | webdev, css, design, ux |
**Hey** 👋 I've changed the layout a little in this weeks edition and added a couple of new sections. Let me know in the **feedback at the bottom** what you think to this new layout ✌️
Look out for new sections in the future 👀
Enjoy this weeks newsletter 👋 - Adam at Unicorn Club.
---
Sponsored by [Webflow](https://go.unicornclub.dev/webflow-agency)
## [Accelerate your agency’s growth](https://go.unicornclub.dev/webflow-agency)
[](https://go.unicornclub.dev/webflow-agency)
Whether you need to win new business or wow an existing client, Webflow empowers agencies to deliver high-quality client work, faster — without growing your dev budget.
[**Start building →**](https://go.unicornclub.dev/webflow-agency)
---
## 🎨 Design
[**Are you designing with the right keyboard in mind?**](https://uxdesign.cc/are-you-designing-with-the-right-keyboard-ab2f02df42b6?utm_source=unicornclub.dev&utm_medium=newsletter&utm_campaign=unicornclub.dev&ref=unicornclub.dev)
A guide to iOS and Android keyboards.
[**Beyond Boxes**](https://humanparts.medium.com/beyond-boxes-24858bc409aa?utm_source=unicornclub.dev&utm_medium=newsletter&utm_campaign=unicornclub.dev&ref=unicornclub.dev)
The artistry of kitchen design
---
### Community Spotlight
The De Voorhoede team are always sharing great articles. Here's one they shared this week on "[Affordance in Design System Components](https://www.voorhoede.nl/en/blog/affordance-design-system-components/?utm_source=unicornclub.dev&utm_medium=newsletter&utm_campaign=unicornclub.dev&ref=unicornclub.dev)" diving into design system components and how they should have clear affordances, boundaries, and flexibility.
---
## 🛠️ Tools & ChatGPT Prompts
[**SVG Viewer - View, edit, and optimize SVGs**](https://www.svgviewer.dev/?utm_source=unicornclub.dev&utm_medium=newsletter&utm_campaign=unicornclub.dev&ref=unicornclub.dev)
SVG Viewer is an online tool to view, edit and optimize SVGs.
[**ChatGPT - Prompts for developers**](https://dev.to/techiesdiary/chatgpt-prompts-for-developers-216d?utm_source=unicornclub.dev&utm_medium=newsletter&utm_campaign=unicornclub.dev&ref=unicornclub.dev)
ChatGPT, an advanced language model can help developers in multiple ways in their coding journey. Let’s explore some of them.
---
### **Fun Fact**
****Internet Explorer 3 Was the First Browser to Support CSS**** - While CSS1 was still in its infancy, Microsoft's Internet Explorer 3, released in August 1996, became the first commercial browser to support CSS. This early adoption was crucial for the development and widespread use of CSS.
---
## 🧑💻 CSS
[**CSS… 5?**](https://frontendmasters.com/blog/css-5/?utm_source=unicornclub.dev&utm_medium=newsletter&utm_campaign=unicornclub.dev&ref=unicornclub.dev)
Some of you likely worked through the “CSS3” thing. It was huge. Everything was “HTML5” and “CSS3”, such was the success of that marketing effort.
[**Make naked websites look great with matcha.css!**](https://dev.to/lowlighter/make-naked-websites-look-great-with-matchacss-4ng7?utm_source=unicornclub.dev&utm_medium=newsletter&utm_campaign=unicornclub.dev&ref=unicornclub.dev)
Have you ever contemplated the bareness of starting from a "blank page" when beginning a new web project?
[**6 CSS cheatsheets that will be incredibly useful. Let's take a look at them.**](https://dev.to/devshefali/the-top-6-css-cheatsheets-that-will-save-you-hours-2lp1?utm_source=unicornclub.dev&utm_medium=newsletter&utm_campaign=unicornclub.dev&ref=unicornclub.dev)
Have you ever contemplated the bareness of starting from a "blank page" when beginning a new web project?
[**On compliance vs readability: Generating text colors with CSS**](https://lea.verou.me/blog/2024/contrast-color/?utm_source=unicornclub.dev&utm_medium=newsletter&utm_campaign=unicornclub.dev&ref=unicornclub.dev)
Can we emulate the upcoming CSS contrast-color() function via CSS features that have already widely shipped? And if so, what are the tradeoffs involved and how to best balance them?
## 🗓️ Upcoming Events
We’ve partnered with GitNation for 3 of their upcoming events.The Unicorn Club community for **10% off** regular tickets for all three conferences!
Use code **_UNICORN_** at checkout.
### [🟨 JS Nation](https://go.unicornclub.dev/jsnation-unicorn) →
50+ speakers, sharing their know-hows 1500 attendees, sharing common language 10K folks, joining remotely.
### [🏔️ React Summit →](https://go.unicornclub.dev/reactsummit-unicorn)
Gathering OSS authors, top trainers and speakers, as well as web engineers across the globe to meet in Amsterdam and online.
### [💻 C3 Dev Fest →](https://go.unicornclub.dev/c3-dev-fest)
The contemporary software engineering and design festival. Code, Career, Creativity.
## 🔥 Promoted Links
_Share with 2,500+ readers, book a [classified ad](https://unicornclub.dev/sponsorship#classified-placement)._
[**What Current & Future Engineering Leaders Read.**](https://go.unicornclub.dev/pointer)
Handpicked articles summarized into a 5‑minute read. Join 35,000 subscribers for one issue every Tuesday & Friday.
[**Get smarter about Tech in 5 min**](https://go.unicornclub.dev/techpresso)
Get the most important tech news, tools and insights. Join 90,000+ early adopters staying ahead of the curve, for free.
#### Support the newsletter
If you find Unicorn Club useful and want to support our work, here are a few ways to do that:
🚀 [Forward to a friend](https://preview.mailerlite.io/preview/146509/emails/122587430138152137)
📨 Recommend friends to [subscribe](https://unicornclub.dev/)
📢 [Sponsor](https://unicornclub.dev/sponsorship) or book a [classified ad](https://unicornclub.dev/sponsorship#classified-placement)
☕️ [Buy me a coffee](https://www.buymeacoffee.com/adammarsdenuk)
_Thanks for reading ❤️
[@AdamMarsdenUK](https://twitter.com/AdamMarsdenUK) from Unicorn Club_ | adam |
1,869,500 | How Function And Variables Works in JavaScript : Behind the Scenes | Function is The Heart Of JavaScript Everything in JavaScript Happens Inside an Execution Context All... | 0 | 2024-05-29T18:31:28 | https://dev.to/pervez/how-function-and-variables-works-in-javascript-behind-the-scenes-gc5 | javascript, webdev, frontend, development | **Function is The Heart Of JavaScript**
Everything in JavaScript Happens Inside an Execution Context
All JavaScript code runs within an execution context, which provides an environment for the code execution. When JavaScript code runs, it first creates a Global Execution Context (GEC). The GEC ( Global Execution Context ) Put Into The Call Stack .
**What is Call Stack In JavaScript ?**
The call stack in JavaScript is a mechanism that helps the JavaScript engine keep track of function calls and their execution order. It follows the Last In, First Out (LIFO) principle, meaning that the last function called is the first one to complete execution and be removed from the stack.
**It Has two main components:**
- **Memory Component** (Variable Environment)
- **Code Component** (Thread of Execution)
| pervez |
1,867,134 | Styling HTML Elements with CSS | Sure, here's a detailed post for Dev.to on "Styling HTML Elements with CSS": Styling... | 0 | 2024-05-29T18:30:00 | https://dev.to/harsh_dev26/styling-html-elements-with-css-flf | webdev, javascript, beginners, programming | Sure, here's a detailed post for Dev.to on "Styling HTML Elements with CSS":
---
# Styling HTML Elements with CSS
CSS (Cascading Style Sheets) is a powerful tool used to control the appearance and layout of HTML elements on a webpage. By separating content from design, CSS allows for more flexibility and easier maintenance of web pages. In this post, we'll explore the basics of CSS and how you can use it to style HTML elements.
## Getting Started with CSS
To start styling your HTML, you need to include CSS in your HTML document. There are three ways to do this:
1. **Inline CSS:** Add styles directly to HTML elements using the `style` attribute.
2. **Internal CSS:** Define styles within a `<style>` tag in the `<head>` section of your HTML document.
3. **External CSS:** Link to an external stylesheet using the `<link>` tag.
### Example of Each Method
**Inline CSS:**
```html
<p style="color: blue; font-size: 20px;">This is a styled paragraph.</p>
```
**Internal CSS:**
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<style>
p {
color: blue;
font-size: 20px;
}
</style>
</head>
<body>
<p>This is a styled paragraph.</p>
</body>
</html>
```
**External CSS:**
```html
<!-- HTML File (index.html) -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="styles.css">
</head>
<body>
<p>This is a styled paragraph.</p>
</body>
</html>
```
```css
/* External CSS File (styles.css) */
p {
color: blue;
font-size: 20px;
}
```
## CSS Selectors
CSS selectors are patterns used to select the elements you want to style. Here are some common selectors:
- **Element Selector:** Selects elements by their tag name.
```css
p {
color: blue;
}
```
- **Class Selector:** Selects elements by their class attribute.
```css
.my-class {
color: red;
}
```
- **ID Selector:** Selects an element by its id attribute.
```css
#my-id {
color: green;
}
```
- **Attribute Selector:** Selects elements with a specified attribute.
```css
a[target="_blank"] {
color: purple;
}
```
### Example:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<style>
p {
color: blue; /* Element Selector */
}
.highlight {
background-color: yellow; /* Class Selector */
}
#unique {
font-weight: bold; /* ID Selector */
}
a[target="_blank"] {
color: purple; /* Attribute Selector */
}
</style>
</head>
<body>
<p>This is a paragraph.</p>
<p class="highlight">This paragraph is highlighted.</p>
<p id="unique">This paragraph is unique.</p>
<a href="https://example.com" target="_blank">Visit Example</a>
</body>
</html>
```
## CSS Properties
CSS properties define the style of an element. Some commonly used properties include:
- **color:** Sets the text color.
- **font-size:** Sets the size of the font.
- **background-color:** Sets the background color.
- **margin:** Sets the outer space of an element.
- **padding:** Sets the inner space of an element.
- **border:** Sets the border around an element.
### Example:
```css
/* CSS File */
p {
color: blue;
font-size: 20px;
background-color: lightgray;
margin: 10px;
padding: 10px;
border: 2px solid black;
}
```
## Combining Selectors
You can combine selectors to apply styles in more complex ways. Here are some examples:
- **Descendant Selector:** Selects elements that are descendants of another element.
```css
div p {
color: blue;
}
```
- **Child Selector:** Selects elements that are direct children of another element.
```css
div > p {
color: green;
}
```
- **Sibling Selectors:** Select elements that are siblings.
```css
p + p {
color: red; /* Adjacent Sibling */
}
p ~ p {
color: purple; /* General Sibling */
}
```
### Example:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<style>
div p {
color: blue; /* Descendant Selector */
}
div > p {
font-size: 18px; /* Child Selector */
}
p + p {
color: red; /* Adjacent Sibling Selector */
}
p ~ p {
font-weight: bold; /* General Sibling Selector */
}
</style>
</head>
<body>
<div>
<p>This is a paragraph inside a div.</p>
<p>This is another paragraph inside a div.</p>
</div>
<p>This is a standalone paragraph.</p>
<p>This is an adjacent sibling paragraph.</p>
<p>This is a general sibling paragraph.</p>
</body>
</html>
```
## Conclusion
CSS is an essential tool for web development, enabling you to create visually appealing and responsive designs. By mastering CSS selectors, properties, and combining them effectively, you can transform plain HTML into an engaging user experience. Experiment with different styles and layouts to find what works best for your projects. Happy styling!
---
Feel free to ask any questions or share your own CSS tips and tricks in the comments below! | harsh_dev26 |
1,869,499 | Services Offered by a Locksmith | Services Offered by a Locksmith Locksmiths are trained professionals who can assist in protecting the... | 0 | 2024-05-29T18:28:58 | https://dev.to/mohsin_raza_awan786/services-offered-by-a-locksmith-20e9 | locksmith, services | Services Offered by a Locksmith
Locksmiths are trained professionals who can assist in protecting the security of your home, office, and car. Locksmiths specialize in replacing and repairing locks as well as installing security systems - they may also advise on other measures that could enhance it further.
Becoming a certified Schlüsseldienst München takes years, but several private training providers provide courses to assist individuals in entering this profession.
Installation of panic exit devices
Life safety codes mandate panic exit devices on doors used for egress from spaces where occupants could face emergency scenarios, and which pose stampede-crushing risks. They prevent stampede-crushing hazards by enabling individuals to easily open them from the inside without needing keys or other security hardware; such devices are commonly installed on commercial properties like offices and restaurants to provide a safe way out for employees or customers in an emergency.
A panic bar is a piece of metal that unlatches doors when depressed, typically mounted within a door frame or on double doors with no mullion. Additionally, this device contains a dogging mechanism to keep its latch retracted for an extended time and make a fast exit in an emergency or planned evacuation scenario.
Panic bars can be divided into two broad categories, rim and surface vertical rod styles. Rim panic devices are easier to install and require less maintenance while surface vertical rods require advanced knowledge of door hardware to properly install correctly and are therefore more expensive. American Locksets carries both traditional crossbar designs as well as state-of-the-art touchpad-style panic bars to meet NFPA 101 Life Safety Code requirements, along with alarms and delayed egress options for you to choose from.
Installation of single-key access
Master keying is one of the most widely utilized Schlüsselnotdienst München services, where each lock has its key and one master key opens them all. This system is ideal for security or cleaning staff without giving them access to individual residents' dwellings; additionally, communities of co-owners often utilize master keying arrangements so each person has full access to their own home while not other people's properties.
Installation of keyless entry
Keyless entry systems offer an effective solution for locking building doors or managing access into and out of an apartment, eliminating keys while providing visibility of who has come and gone and making monitoring security much simpler. A locksmith can assist in selecting an appropriate keyless entry system to meet your specific needs.
Traditional keyless entry systems utilize a wireless remote-control device to unlock doors. While they offer many benefits and are simple to set up, traditional locks still offer greater security. Locks with codes protect against unauthorized people using one key to enter your home, and can easily be changed when someone moves in or out. However, these may still be vulnerable to hacking attacks. Replay attack involves recording wireless remote-control transmissions and then retransmitting them at a later time, often to gain entry. Such attacks can often be countered using code hopping; this allows each transmission initiated by pressing buttons on remote controls to differ from all previous ones and provide protection.
Lockout services
Locksmiths provide many services, from rekeying locks (changing the internal mechanism to work with a different key) and installing and repairing doors, windows, safes, and other security hardware to cutting keys by hand or machine - and can even offer emergency lockout services or install systems that allow people to enter and exit buildings or vehicles electronically.
Many people need locksmiths when they become locked out of their car, home, or office. Locksmiths specialize in unlocking locks without damaging them quickly and can replace lost or broken ones quickly as well as provide keys if necessary. In certain instances, locksmiths can even rekey a lock to work with existing keys more easily.
Individuals looking to become locksmiths have several routes available to them for becoming one, including attending training courses and apprenticeships, though these paths can be expensive. An alternative would be finding employment with an established locksmith company while studying simultaneously; employers may offer to pay for some locksmith qualifications which reduces study costs significantly. As this profession is highly specialized, specialization and unsociable hours must also be considered factors.
| mohsin_raza_awan786 |
1,869,498 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-05-29T18:26:14 | https://dev.to/lionshik34/buy-verified-cash-app-account-5fk | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | lionshik34 |
1,869,496 | Building a Movie Recommendation Program in Python | Introduction In today's digital age, finding the perfect movie to watch can be... | 0 | 2024-05-29T18:24:38 | https://dev.to/medo_id99/building-a-movie-recommendation-program-in-python-2dni | python, computerscience, algorithms, programming | ## **Introduction**
In today's digital age, finding the perfect movie to watch can be overwhelming with so many options available. To address this, I built a Movie Recommendation Program in Python, designed to help users easily discover movies by genre and release year. This tool simplifies the decision-making process and makes movie selection more enjoyable.
## **The Program in Action**
### How It Works
The Movie Recommendation Program is comprised of three main files:
- `app.py`: The main application file that handles user interaction.
- `movie_management_system.py`: Contains the classes and methods for managing the movie collection.
- `movies_dataset.csv`: A dataset file with information on various movies.
### Code Overview
- Loading Movies: The program reads data from `movies_dataset.csv` and loads it into a `MovieCollection` object.
- User Interaction: Users can search for movies by genre or filter them by release year.
- Movie Management: The `MovieCollection` class in `movie_management_system.py` organizes movies into genres and allows for efficient retrieval and display.
Here’s a snippet of the main application:
## **Check Out the Code**
The complete source code for the Movie Recommendation Program is available on GitHub. Feel free to explore, fork, and contribute to the project!
GitHub Repository: [Movie Recommendation Program](https://github.com/Medo-ID/Movie_Recommendation_Program)
## **Conclusion**
The Movie Recommendation Program is a simple yet powerful tool for movie enthusiasts. By leveraging Python, this program demonstrates how technology can enhance our entertainment experience. I hope you find this project useful and inspiring for your own coding journey. Happy coding! | medo_id99 |
1,869,494 | ** ¡Los Caballeros del Zodiaco te enseñan JSON!**🛡️ | En este post, los mismísimos Caballeros del Zodiaco serán nuestros guías en este viaje intergaláctico... | 0 | 2024-05-29T18:21:00 | https://dev.to/orlidev/-los-caballeros-del-zodiaco-te-ensenan-json-20mb | json, tutorial, programming, webdev | En este post, los mismísimos Caballeros del Zodiaco serán nuestros guías en este viaje intergaláctico por el universo del JSON.

Aprenderemos a manejar este lenguaje universal de datos como si fuéramos Saints entrenando para proteger a la diosa Atenea.⚔️ Preparémonos para descifrar los secretos de objetos, arrays, strings y más, con la ayuda de nuestros héroes favoritos. ¡Que comience la aventura!
¡Atención a todos los aspirantes a Saints! Los poderosos Caballeros del Zodiaco te guiarán en el arte de JSON, un formato de intercambio de datos tan versátil como el cosmos mismo. 🌕
¿Qué es JSON y por qué es importante? 🔰
Imagina a Saori Kido, la reencarnación de Atenea, como una gran base de datos. Ella guarda información vital sobre los Saints, sus armaduras y las batallas épicas que han librado. Para compartir esta información con los Saints de todo el mundo, necesita un lenguaje universal que todos puedan entender. ¡Ahí es donde entra en juego JSON!

JSON, o JavaScript Object Notation, es como un idioma común que permite a diferentes sistemas intercambiar datos de manera organizada y eficiente. Es como si Seiya, Shun, Hyoga, Shiryu e Ikki ☀️ pudieran comunicarse entre sí sin importar su idioma nativo.
Para comenzar, imaginemos que JSON (JavaScript Object Notation) ✨es la Armadura Dorada de Sagitario, un arma poderosa y versátil en el mundo de la programación. Así como la armadura puede ser usada por cualquier caballero, JSON también puede ser utilizado por cualquier lenguaje de programación. Al igual que los caballeros comunican sus poderes y habilidades mediante sus cosmos, los programas necesitan compartir datos. Aquí es donde entra nuestro valiente JSON, 🪐permitiendo la transmisión de datos entre servidores y clientes con facilidad y eficiencia, como si fuera el mítico Pegaso volando a través de los cielos. JSON es ligero y de fácil lectura, tanto para los humanos como para las máquinas.
No importa si eres un Caballero de Bronce recién iniciado o un experimentado Caballero Dorado, podrás leer y comprender los datos en JSON. Es como si estuviéramos leyendo las crónicas del Santuario, donde cada objeto es un capítulo, y cada par clave-valor es un emocionante giro en la trama. Para crear un objeto en JSON,🌟 necesitas encerrar tus pares clave-valor en llaves, como si estuvieras sellando el poder del cosmos dentro de tu armadura. Aquí tienes un ejemplo:
```
{
"Caballero": "Seiya",
"Armadura": "Pegaso",
"Ataque": "Meteoro de Pegaso"
}
```
Shiryu y los Arrays en JSON ⚜️
Luego, Shiryu del Dragón nos mostrará cómo manejar arrays en JSON. Al igual que los cientos de técnicas de lucha de Shiryu, un array en JSON puede contener muchos elementos:
```
{
"caballeros": ["Seiya", "Shiryu", "Hyoga", "Shun", "Ikki"]
}
```

Similar al ataque "Meteoro de Pegaso" de Seiya, JSON puede manejar listas de datos con facilidad. Estas listas son como los ataques combinados de los Caballeros de Bronce; cada elemento es un caballero aportando su poder para un impacto más fuerte.
```
{
"Caballeros_de_Bronce": ["Seiya", "Shiryu", "Hyoga", "Shun", "Ikki"]
}
```
Los tipos de datos en JSON: ¡Las armaduras del cosmos! 🚀
Al igual que cada Saint tiene su armadura única, JSON tiene diferentes tipos de datos para representar diferentes tipos de información. Veamos algunos ejemplos:
- Números: Para representar la fuerza cósmica de un Saint, como los 100 golpes del Meteoro Pegaso de Seiya.
- Cadenas: Para almacenar nombres, descripciones y otros datos textuales, como el grito de batalla de cada Saint.
- Booleanos: Para indicar si algo es verdadero o falso, como si un Saint ha despertado su séptimo sentido.
- Objetos: Para agrupar información relacionada, como los datos de un Saint específico (nombre, constelación, técnicas, etc.).
- Arrays: Para almacenar listas de información, como la lista de ataques de un Saint.
Estructura JSON: ¡El orden de los cosmos! 🌠
Al igual que los Saints deben seguir el orden de los planetas en sus ataques, los datos JSON deben tener una estructura organizada. Se utiliza un sistema de llaves y valores para definir los objetos y arrays. Imagina a cada llave como una constelación y a cada valor como la estrella que la compone.
Ejemplo de JSON: ¡La armadura de Athena! ☄️
```
{
"nombre": "Saori Kido",
"constelacion": "Atenea",
"armadura": "Armadura Dorada",
"habilidades": ["Cosmos", "Vuelo", "Manipulación de la Energía"],
"enemigos": ["Hades", "Poseidón", "Eris"]
}
```
En este ejemplo, tenemos un objeto JSON que representa a Saori Kido. Cada par de llaves y valores define una característica de Saori, como su nombre, constelación, armadura, habilidades y enemigos.

Seiya y la Estructura de JSON 🌌
Primero, nuestro valiente Caballero Pegaso, Seiya, nos enseñará la estructura básica de JSON. Al igual que Seiya, JSON es sencillo pero poderoso. Un objeto JSON se parece a esto:
```
{
"nombre": "Seiya",
"constelacion": "Pegaso",
"armadura": "Bronce"
}
```
Hyoga y los Objetos Anidados ✨
Hyoga del Cisne, con su elegante y fluida forma de luchar, nos enseñará sobre los objetos anidados en JSON. Al igual que la complejidad de las técnicas de Hyoga, un objeto JSON puede contener otros objetos:
```
{
"caballero": {
"nombre": "Hyoga",
"constelacion": "Cisne",
"armadura": "Bronce"
}
}
```
Shun y las Cadenas de Texto 💫
Nuestro pacífico Caballero de Andrómeda, Shun, nos enseñará sobre las cadenas de texto en JSON. Al igual que las cadenas de la Nebulosa de Shun, una cadena de texto en JSON puede ser muy poderosa:
```
{
"mensaje": "¡Siempre luchamos por la justicia!"
}
```
Ikki y los Valores Booleanos ⚡
Finalmente, Ikki del Fénix, el caballero más impredecible, nos enseñará sobre los valores booleanos en JSON. Al igual que la imprevisibilidad de Ikki, un valor booleano en JSON puede ser true o false:
```
{
"esCaballeroZodiaco": true
}
```
Analizar y generar JSON: ¡El poder del cosmos! 🌀
Los programadores pueden usar herramientas especiales para "analizar" datos JSON, convirtiéndolos en estructuras que sus programas puedan entender. También pueden "generar" datos JSON a partir de sus propios programas, compartiendo información con otros sistemas.

¿Dónde se usa JSON? 💥
JSON es como el polvo estelar que impregna todo el universo. Se utiliza en una gran variedad de aplicaciones, incluyendo:
- Páginas web: Para cargar datos dinámicos y actualizar el contenido sin necesidad de recargar la página.
- Aplicaciones móviles: Para intercambiar información entre la aplicación y el servidor.
- APIs: Para crear interfaces que permitan a diferentes sistemas comunicarse entre sí.
En resumen, los Caballeros del Zodiaco nos enseñan que, al igual que en sus batallas épicas, la programación requiere de las herramientas correctas para enfrentar cualquier desafío. JSON, al igual que una armadura dorada, es una herramienta esencial en el arsenal de cualquier programador. ¡Así que sigan adelante, valientes programadores, y que el poder de los Caballeros del Zodiaco les guíe en su viaje a través del cosmos de la programación!
Conclusión: ¡Conviértete en un maestro del JSON! 💪🏻
Al aprender JSON, habrás adquirido una poderosa herramienta que te permitirá crear aplicaciones web dinámicas, APIs interoperables y mucho más. Con la ayuda de los Caballeros del Zodiaco, has dado tu primer paso en el camino hacia el dominio del intercambio de datos. ¡Cosmos!
Recuerda: 🎇
+ Hay muchos recursos disponibles para aprender más sobre JSON en profundidad.
+ Practicar es la clave para dominar este formato de datos.
+ ¡No tengas miedo de experimentar y ser creativo con JSON!
¡Que la fuerza del cosmos te acompañe en tu viaje de aprendizaje JSON!
¡Y eso es todo! Con la ayuda de nuestros valientes Caballeros del Zodiaco, hemos aprendido los fundamentos de JSON. Recuerda, al igual que los Caballeros del Zodiaco, ¡siempre debes luchar por escribir un código limpio y eficiente!
🚀 ¿Te ha gustado? Comparte tu opinión.
Artículo completo, visita: https://lnkd.in/ewtCN2Mn
https://lnkd.in/eAjM_Smy 👩💻 https://lnkd.in/eKvu-BHe
https://dev.to/orlidev ¡No te lo pierdas!
Referencias:
Imágenes creadas con: Copilot (microsoft.com)
##PorUnMillonDeAmigos #LinkedIn #Hiring #DesarrolloDeSoftware #Programacion #Networking #Tecnologia #Empleo #JSON

 | orlidev |
1,869,462 | Modalert versus Modafinil: Which is the Most Ideal Choice for You? | If you are someone who fights with extravagant daytime languor or finds it hard to stay ready and... | 0 | 2024-05-29T18:18:24 | https://dev.to/business_upside_dd8db49a8/modalert-versus-modafinil-which-is-the-most-ideal-choice-for-you-3062 | If you are someone who fights with extravagant daytime languor or finds it hard to stay ready and focused during the day, you could have run north of two notable mindfulness propelling medications: Modalert and Modafinil. Both of these drugs are typically used to treat conditions, for instance, narcolepsy, shift work rest mix, and obstructive rest apnea.
What is [Modalert](https://www.rxshop.md/)?
Modalert is a brand name for a medication called Modafinil, which is a mindfulness propelling expert that is used to additionally foster mindfulness in individuals who experience nonsensical sluggishness as a result of narcolepsy, obstructive rest apnea, or shift work rest mix. Modalert is known for its ability to redesign mental capacity, increase status, and further foster fixation and concentration.
Advantages of Modalert:
Improved mental capability
Expanded readiness
Further developed concentration and fixation
What is Modafinil?
Modafinil is the dynamic fixing in Modalert and is likewise an attentiveness advancing specialist that is utilized to treat conditions like narcolepsy, obstructive rest apnea, and shift work rest jumble. Like Modalert, Modafinil further develops attentiveness, sharpness, and mental capability in people who battle with unnecessary daytime lethargy.
Advantages of Modafinil:
Further developed attentiveness
Upgraded sharpness
Better mental capability
Step by step instructions to Purchase Modalert or Modafinil
On the off chance that you are keen on buying Modalert or Modafinil, there are a few web-based drug stores where you can arrange these meds. While purchasing Modalert or Modafinil on the web, it is essential to guarantee that you are buying from a respectable and dependable source to guarantee that you are getting a certifiable and safe item.
Source: https://en.m.wikipedia.org/wiki/File:Modalert.jpg
1. Grasping Modalert and Modafinil
Modalert and Modafinil are both attentiveness elevating specialists used to deal with conditions like narcolepsy, obstructive rest apnea, and shift work rest jumble. They have a place with a class of medications known as eugeroics, which advance alertness and readiness.
2. Structure and Plan
Modalert and Modafinil contain a similar dynamic fixing, which is Modafinil. Nonetheless, they might contrast in their latent fixings and detailing, prompting varieties in impacts and beginning of activity.
3. Brand Name versus Nonexclusive
Modalert is a brand name variant of Modafinil, while Modafinil is the nonexclusive name for the drug. Brand name drugs are in many cases more costly than their nonexclusive partners, however they might be liked by a client because of seen contrasts in quality or viability.
4. Cost Examination
One of the tremendous contrasts among Modalert and Modafinil is their expense. Modalert is ordinarily more costly than conventional Modafinil, making it less available to certain clients. Notwithstanding, nonexclusive.
5. Accessibility and Availability
Modalert might be all the more promptly accessible in certain locales contrasted with conventional Modafinil, as it is effectively showcased and disseminated by drug organizations.
6. Lawful Status
As far as lawful status, Modalert and Modafinil are managed substances in numerous nations because of their true capacity for misuse and reliance.
7. Viability and Adequacy
Both Modalert and Modafinil are compelling in advancing alertness and working on mental capability in people with rest problems.
8. Secondary effects and Unfavorable Responses
Like any drug, Modalert and Modafinil can cause aftereffects and unfavorable responses in certain clients.. It's fundamental to know about these likely secondary effects and counsel a medical care proficient on the off chance that they endure or deteriorate Youtube
9. Drug Associations
Modalert and Modafinil might associate with different prescriptions, enhancements, or substances, prompting unfriendly impacts or diminished adequacy. It's vital to illuminate your medical services supplier pretty much all the prescriptions you're requiring to stay away from possibly hurtful connections.
10. Long haul Use and Resilience
A client might foster resilience with the impacts of Modalert or Modafinil after some time, requiring higher dosages to accomplish a similar degree of alertness or mental improvement.
11. Picking the Ideal Choice for You
While settling on Modalert and Modafinil, it's fundamental to consider factors like expense, accessibility, lawful status, viability, aftereffects, and medication communications. Meeting with a medical care supplier can assist you with settling on an educated choice in view of your singular requirements and clinical history.
12. Patient Encounters and Surveys
Understanding surveys and tributes from different clients can give significant bits of knowledge into the viability and decency of Modalert and Modafinil.
Author: Dr. Faride Ramos , MD, Education and training: Residency: MacNeal Hospital, Berwyn, Illinois. Medical School: Universidad Del Norte Programa De Medicina, Graduated 2005
| business_upside_dd8db49a8 | |
1,869,393 | Join us for the next Frontend Challenge: June Edition | The wait is over! We are back with another Frontend Challenge. Running through June 09, Frontend... | 0 | 2024-05-29T18:15:05 | https://dev.to/devteam/join-us-for-the-next-frontend-challenge-june-edition-3ngl | devchallenge, frontendchallenge, javascript, css | The wait is over! We are back with another Frontend Challenge.
Running through **June 09**, Frontend Challenge: June Edition will feature two June-themed prompts: **CSS Art** and **Glam Up My Markup**. For those of you who miss the One Byte Explainer, we promise we’ll bring that prompt back soon!
As always, there will be one winner per prompt. That’s two chances to win bragging rights, a gift from the DEV Shop, and an exclusive DEV badge.
Also, in case you didn't know - badges can stack on your profile to show off multiple wins! But of course, it’s not about the winning destination, it’s about _the journey_. We hope this is an opportunity to challenge yourself and have some fun.
Read on to learn about each prompt and how to participate!
## Our Two Prompts:
### CSS Art: June
Draw what comes to mind for you when it comes to the month of June. Depending on where you live, perhaps that’s the summer solstice or a transition to falling leaves and winter. Or maybe it is Father’s Day or Pride Month.
Whatever comes to mind when you think of June, please show us!
Here is the submission template for anyone that wants to jump right in, but please review all judging criteria and challenge rules on the [official challenge page](https://dev.to/challenges/frontend-2024-05-29) before submitting.
{% cta https://dev.to/new?prefill=---%0Atitle%3A%20%0Apublished%3A%20%0Atags%3A%20frontendchallenge%2C%20devchallenge%2C%20css%0A---%0A%0A_This%20is%20a%20submission%20for%20%5BFrontend%20Challenge%20v24.04.17%5D(https%3A%2F%2Fdev.to%2Fchallenges%2Ffrontend-2024-05-29)%2C%20CSS%20Art%3A%20June._%0A%0A%23%23%20Inspiration%0A%3C!--%20What%20are%20you%20highlighting%20today%3F%20--%3E%0A%0A%23%23%20Demo%20%0A%3C!--%20Show%20us%20your%20CSS%20Art!%20You%20can%20directly%20embed%20an%20editor%20into%20this%20post%20(see%20the%20FAQ%20section%20of%20the%20challenge%20page)%20or%20you%20can%20share%20an%20image%20of%20your%20project%20and%20share%20a%20public%20link%20to%20the%20code.%20--%3E%0A%0A%23%23%20Journey%20%0A%3C!--%20Tell%20us%20about%20your%20process%2C%20what%20you%20learned%2C%20anything%20you%20are%20particularly%20proud%20of%2C%20what%20you%20hope%20to%20do%20next%2C%20etc.%20--%3E%0A%0A%3C!--%20Team%20Submissions%3A%20Please%20pick%20one%20member%20to%20publish%20the%20submission%20and%20credit%20teammates%20by%20listing%20their%20DEV%20usernames%20directly%20in%20the%20body%20of%20the%20post.%20--%3E%0A%0A%3C!--%20We%20encourage%20you%20to%20consider%20adding%20a%20license%20for%20your%20code.%20--%3E%0A%0A%3C!--%20Don%27t%20forget%20to%20add%20a%20cover%20image%20to%20your%20post%20(if%20you%20want).%20--%3E%0A%0A%3C!--%20Thanks%20for%20participating!%20--%3E %}
CSS Art Submission Template
{% endcta %}
### Glam Up My Markup: Beaches
Use CSS and JavaScript to make the below starter HTML markup beautiful, interactive, and useful. We have provided a starter template of a site that lists the best beaches in the world and some information about each one. Since the template does not include photos, you may need to get creative in how you might make it visually appealing.
Your submission should be more fun and interactive than the HTML we provide, but also be usable and accessible. You should not directly edit the HTML provided, unless it is via JavaScript. We expect style and substance. You may add basic boilerplate, including meta tags etc. for presentation purposes.
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Best Beaches in the World</title>
</head>
<body>
<header>
<h1>Best Beaches in the World</h1>
</header>
<main>
<section>
<h2>Take me to the beach!</h2>
<p>Welcome to our curated list of the best beaches in the world. Whether you're looking for serene white sands, crystal-clear waters, or breathtaking scenery, these beaches offer a little something for everyone. Explore our top picks and discover the beauty that awaits you.</p>
</section>
<section>
<h2>Top Beaches</h2>
<ul>
<li>
<h3>Whitehaven Beach, Australia</h3>
<p>Located on Whitsunday Island, Whitehaven Beach is famous for its stunning white silica sand and turquoise waters. It's a perfect spot for swimming, sunbathing, and enjoying the natural beauty of the Great Barrier Reef.</p>
</li>
<li>
<h3>Grace Bay, Turks and Caicos</h3>
<p>Grace Bay is known for its calm, clear waters and powdery white sand. This beach is ideal for snorkeling, diving, and enjoying luxury resorts that line its shore.</p>
</li>
<li>
<h3>Baia do Sancho, Brazil</h3>
<p>Baia do Sancho, located on Fernando de Noronha island, offers stunning cliffs, vibrant marine life, and crystal-clear waters, making it a paradise for divers and nature lovers.</p>
</li>
<li>
<h3>Navagio Beach, Greece</h3>
<p>Also known as Shipwreck Beach, Navagio Beach is famous for the rusting shipwreck that rests on its sands. Accessible only by boat, this secluded cove is surrounded by towering cliffs and azure waters.</p>
</li>
<li>
<h3>Playa Paraiso, Mexico</h3>
<p>Playa Paraiso, located in Tulum, offers pristine white sands and turquoise waters against the backdrop of ancient Mayan ruins. It's a perfect blend of history and natural beauty.</p>
</li>
<li>
<h3>Anse Source d'Argent, Seychelles</h3>
<p>Anse Source d'Argent is renowned for its unique granite boulders, shallow clear waters, and soft white sand. This beach is perfect for photography, snorkeling, and relaxation.</p>
</li>
<li>
<h3>Seven Mile Beach, Cayman Islands</h3>
<p>Stretching for seven miles, this beach offers soft coral sand, clear waters, and numerous activities such as snorkeling, paddleboarding, and enjoying beachside restaurants and bars.</p>
</li>
<li>
<h3>Bora Bora, French Polynesia</h3>
<p>Bora Bora is known for its stunning lagoon, overwater bungalows, and vibrant coral reefs. It's a perfect destination for honeymooners and those seeking luxury and tranquility.</p>
</li>
<li>
<h3>Lanikai Beach, Hawaii</h3>
<p>Lanikai Beach features powdery white sand and calm, clear waters, making it a favorite for swimming, kayaking, and enjoying the scenic views of the Mokulua Islands.</p>
</li>
<li>
<h3>Pink Sands Beach, Bahamas</h3>
<p>Pink Sands Beach is famous for its unique pink-hued sand, clear waters, and serene atmosphere. It's an idyllic spot for beachcombing, swimming, and relaxing in paradise.</p>
</li>
</ul>
</section>
</main>
</body>
</html>
```
Here is the submission template for anyone that wants to jump right in, but please review all judging criteria and challenge rules on the [official challenge page](https://dev.to/challenges/frontend-2024-05-29) before submitting.
{% cta https://dev.to/new?prefill=---%0Atitle%3A%20%0Apublished%3A%20%0Atags%3A%20devchallenge%2C%20frontendchallenge%2C%20css%2C%20javascript%0A---%0A%0A_This%20is%20a%20submission%20for%20%5BFrontend%20Challenge%20v24.04.17%5D((https%3A%2F%2Fdev.to%2Fchallenges%2Ffrontend-2024-05-29)%2C%20Glam%20Up%20My%20Markup%3A%20Beaches_%0A%0A%23%23%20What%20I%20Built%0A%0A%3C!--%20Tell%20us%20what%20you%20built%20and%20what%20you%20were%20looking%20to%20achieve.%20--%3E%0A%0A%23%23%20Demo%0A%3C!--%20Show%20us%20your%20project!%20You%20can%20directly%20embed%20an%20editor%20into%20this%20post%20(see%20the%20FAQ%20section%20from%20the%20challenge%20page)%20or%20you%20can%20share%20an%20image%20of%20your%20project%20and%20share%20a%20public%20link%20to%20the%20code.%20--%3E%0A%0A%23%23%20Journey%0A%3C!--%20Tell%20us%20about%20your%20process%2C%20what%20you%20learned%2C%20anything%20you%20are%20particularly%20proud%20of%2C%20what%20you%20hope%20to%20do%20next%2C%20etc.%20--%3E%0A%0A%3C!--%20Team%20Submissions%3A%20Please%20pick%20one%20member%20to%20publish%20the%20submission%20and%20credit%20teammates%20by%20listing%20their%20DEV%20usernames%20directly%20in%20the%20body%20of%20the%20post.%20--%3E%0A%0A%3C!--%20We%20encourage%20you%20to%20consider%20adding%20a%20license%20for%20your%20code.%20--%3E%0A%0A%3C!--%20Don%27t%20forget%20to%20add%20a%20cover%20image%20to%20your%20post%20(if%20you%20want).%20--%3E%0A%0A%0A%3C!--%20Thanks%20for%20participating!%20--%3E %}
Glam Up My Markup Submission Template
{% endcta %}
## How To Participate
In order to participate, you will need to publish a post using the submission template associated with each prompt.
Please review our [judging criteria, rules, guidelines, and FAQ page](https://dev.to/challenges/frontend-2024-05-29) before submitting so you understand our participation guidelines and official contests rules such eligibility requirements.
## Important Dates
- May 29: Frontend Challenge: June Edition begins!
- <mark>June 09: Submissions due at 11:59 PM PDT</mark>
- June 11: Winners Announced

We’re very excited to see your June projects! Questions? Ask them below.
Good luck and happy coding!
| jess |
1,869,461 | Title | Body | 0 | 2024-05-29T18:14:11 | https://dev.to/spikeysanju/title-507j | javascript | Body | spikeysanju |
1,869,460 | Discover the Ultimate Moving Experience: Full Service Moving Companies in New York | Moving to a new home can be both exciting and daunting, especially in a bustling city like New York.... | 0 | 2024-05-29T18:13:18 | https://dev.to/ali_affan_f1ecd72bdb3e212/discover-the-ultimate-moving-experience-full-service-moving-companies-in-new-york-2igf | Moving to a new home can be both exciting and daunting, especially in a bustling city like New York. From packing up your belongings to coordinating logistics, the process can quickly become overwhelming. However, with the help of [full-service moving companies in New York](https://www.allaroundmoving.com/new-york-moving-company/), you can transform your moving experience into a seamless and stress-free journey.
What are Full Service Moving Companies in New York?
Full service moving companies in New York are professionals who handle every aspect of the moving process, from packing and loading to transportation and unpacking. Unlike traditional moving services that only provide transportation, full service movers offer comprehensive solutions to ensure a hassle-free move.
Benefits of Choosing Full-Service Moving Companies in New York
Convenience and Efficiency
One of the primary benefits of hiring a full-service moving company is the convenience it offers. Instead of juggling multiple tasks yourself, professional movers take care of everything, allowing you to focus on other aspects of your move. From packing fragile items to disassembling furniture, they handle every detail with efficiency and precision.
Expertise and Experience
Full-service moving companies in New York employ trained professionals who have extensive experience in the moving industry. They understand the nuances of packing delicate items, navigating tight spaces, and ensuring that your belongings arrive at your new home safely. With their expertise, you can trust that your move is in capable hands.
Customized Solutions
Every move is unique, which is why full service moving companies offer customized solutions tailored to your specific needs. Whether you're moving across town or across the country, they work with you to create a personalized moving plan that fits your schedule and budget. From providing packing materials to coordinating logistics, they ensure a seamless transition from start to finish.
Time and Cost Savings
While some may view hiring a full service moving company as an added expense, it can actually save you time and money in the long run. By streamlining the moving process and minimizing the risk of damage to your belongings, professional movers help you avoid costly mistakes and delays. Additionally, their efficient packing and transportation methods can reduce the overall duration of your move, allowing you to settle into your new home sooner.
Finding the Right Full-Service Moving Company in New York
With numerous moving companies to choose from in New York, finding the right one can seem like a daunting task. However, by considering factors such as experience, reputation, and pricing, you can narrow down your options and find a reliable partner for your move. Look for companies that are licensed and insured and have positive reviews from satisfied customers.
Final Thoughts
Moving doesn't have to be a stressful experience, especially when you enlist the help of [full service moving companies in New York](https://www.allaroundmoving.com/new-york-moving-company/). With their expertise, efficiency, and personalized service, you can enjoy a smooth and seamless transition to your new home. So why go through the hassle of moving alone when you can entrust the job to professionals? Choose a reputable full service moving company and make your move a memorable and enjoyable experience.
| ali_affan_f1ecd72bdb3e212 | |
1,869,458 | Solution Street is hiring an Azure API Management Architect | About Solution Street Solution Street, a software engineering firm, was founded by a... | 0 | 2024-05-29T18:11:58 | https://dev.to/katie_schuman_8c3b9c97a80/solution-street-is-hiring-an-azure-api-management-architect-cn2 | hiring | ## **About Solution Street**
Solution Street, a software engineering firm, was founded by a software developer who envisioned a safe haven for software engineers who wanted to work on interesting, fun projects. Since 2002, we’ve stuck by this principle and as a result, we’ve developed long, lasting relationships with our clients and have a team of great developers who love what they do.
We enjoy working with cutting edge technologies and providing solutions to complex business problems. Our employees are experts in building large, highly scalable and well performing web applications using many technologies. We are Microsoft and AWS partners.
At Solution Street we value all employees and job candidates as unique individuals, and we welcome the variety of experiences they bring to our organization. As such, we have a strict non-discrimination policy. We believe everyone should be treated equally regardless of race, sex, gender identification, sexual orientation, national origin, native language, religion, age, disability, marital status, citizenship, genetic information, pregnancy, or any other characteristic protected by law.
## **Azure API Management Architect**
At Solution Street, our employees have many opportunities to work on interesting, challenging projects supporting clients one-on-one in various domains primarily in the commercial space. Our company culture thrives on our five core values: Honesty, Respect, Transparency, Dependability, and FUN! They're embedded in everything we do and how we do it!
We are currently seeking a very strong Azure API Management Architect that can lead the design and architecture of API solutions using Azure API Management services.
## **Skills & Qualifications**
<u>Required:</u>
- 7+ years experience as a Full Stack Developer
- Proven experience as a Technical Architect
- Understanding of API Development Lifecycle and management principles
- Experience designing and implementing API solutions in a Cloud envioronment
- Excellent communication, collaboration and leadership skills
<u>Preferred</u>
- Experience with Azure API Manager
- Certifications in Azure and API Management technologies
- Experience with Agile development methodologies
- Experience with DevOps practices and tools
## **Responsibilities:**
- Configure API
- Implement capabilities to test API
- Implmentation of API keys
- Integration with Azure B2C or Azure AD
- API Documentation and Testing
## **How To Apply**
Apply on our website at https://solutionstreet.com/open-position.php?id=3818&salesforce_id=a0DVS00000106G92AI
| katie_schuman_8c3b9c97a80 |
1,869,457 | Laravel blade page not working | Description my code not working showing only a blank page i am also trying (php artisan cache: clear)... | 0 | 2024-05-29T18:09:55 | https://dev.to/irshadahmedpk/laravel-blade-page-not-working-p99 | laravel, php, laravelphp, webdev | Description
my code not working showing only a blank page i am also trying (php artisan cache: clear) and (php artisan view: clear) but still same problem not showing anything if I use @include then showing 500 errors please help me with what I do.
Answered by CDLCELL:
Neeraj, your code is fine but you placed your logic in opposite files. Cut welcome blade stuff and paste it into the master blade file. Similar cust master blade stuff and paste into the welcome blade file.
Then call the welcome blade in the route and it will work.
Let me know if you are still facing the issues.
https://solutions.cdlcell.com/post/laravel-blade-page-not-working-Tz4
Visit: www.cdlcell.com
| irshadahmedpk |
1,869,456 | How Can I Create a DevOps Pipeline That Automatically Resolves All Conflicts and Bugs Without Human Intervention? | Creating a DevOps pipeline that resolves all conflicts and bugs automatically without human... | 0 | 2024-05-29T18:08:03 | https://dev.to/karandaid/how-can-i-create-a-devops-pipeline-that-automatically-resolves-all-conflicts-and-bugs-without-human-intervention-480m | jenkins, cicd, pipeline, bugs | Creating a DevOps pipeline that resolves all conflicts and bugs automatically without human intervention is an ambitious goal. However, with the right tools, strategies, and configurations, you can get close to this ideal state. This article focuses on using Jenkins to build such a pipeline, leveraging its robust capabilities for automation and error handling.
## Key Components of the DevOps Pipeline
A comprehensive DevOps pipeline should include the following stages:
1. **Source Code Management (SCM):** Handling code changes using a version control system like Git.
2. **Continuous Integration (CI):** Automatically building and testing code changes.
3. **Continuous Deployment (CD):** Automatically deploying tested code to production.
4. **Monitoring and Feedback:** Continuously monitoring applications and collecting feedback.
## Creating a Jenkins Pipeline
In Jenkins, a pipeline is defined using a `Jenkinsfile`, which describes the stages and steps of your pipeline. Here’s a detailed guide on setting up a Jenkins pipeline that aims to handle conflicts and bugs automatically.
### Step 1: Define the Jenkinsfile
Your `Jenkinsfile` should be placed in the root directory of your project repository. Here is a basic structure:
```groovy
pipeline {
agent any
stages {
stage('Checkout') {
steps {
git 'https://github.com/your-repo.git'
}
}
stage('Build') {
steps {
script {
sh 'make build'
}
}
}
stage('Test') {
steps {
script {
try {
sh 'make test'
} catch (Exception e) {
// Handle test failures
sh 'make debug'
}
}
}
}
stage('Deploy') {
steps {
script {
sh 'make deploy'
}
}
}
}
post {
always {
script {
// Notifications or cleanup
}
}
}
}
```
### Step 2: Automate Conflict Resolution
Automatically resolving merge conflicts is challenging and requires careful handling. Here’s how you can incorporate conflict resolution in your Jenkins pipeline:
```groovy
stage('Merge Conflicts') {
steps {
script {
def branch = 'feature-branch'
def baseBranch = 'main'
sh "git checkout ${baseBranch}"
sh "git pull origin ${baseBranch}"
def mergeStatus = sh(script: "git merge ${branch}", returnStatus: true)
if (mergeStatus != 0) {
sh "git merge --abort"
sh "git checkout ${branch}"
sh "git rebase ${baseBranch}"
sh "git push origin ${branch} --force"
}
}
}
}
```
### Step 3: Automate Bug Detection and Fixing
#### Static Code Analysis
Integrate tools like SonarQube to automatically detect bugs and vulnerabilities. This stage will help catch issues before they make it to production:
```groovy
stage('Static Code Analysis') {
steps {
script {
sh 'sonar-scanner'
}
}
}
```
#### Automated Testing
Automated testing is critical for detecting bugs early. Ensure you have comprehensive test suites covering unit tests, integration tests, and end-to-end tests:
```groovy
stage('Test') {
steps {
script {
try {
sh 'make test'
} catch (Exception e) {
// Log and handle test failures
sh 'make debug'
error 'Tests failed'
}
}
}
}
```
#### Self-Healing Scripts
Self-healing scripts can attempt to fix common issues detected during the pipeline execution. Here’s an example:
```groovy
stage('Self-Healing') {
steps {
script {
try {
sh 'make deploy'
} catch (Exception e) {
// Attempt to fix deployment issues
sh 'make fix-deploy'
sh 'make deploy'
}
}
}
}
```
### Step 4: Monitoring and Feedback
Finally, continuously monitor your deployed applications and collect feedback. Use tools like Prometheus, Grafana, and ELK stack for monitoring and logging:
```groovy
stage('Monitoring and Feedback') {
steps {
script {
// Add monitoring and logging steps here
}
}
}
```
## Potential Challenges and Limitations
### Complex Conflicts
Automating the resolution of complex merge conflicts can be risky. Automatic conflict resolution works best with simple, well-structured projects and disciplined branching strategies. For more complex scenarios, manual intervention might still be necessary.
### False Positives in Static Analysis
Static code analysis tools can sometimes produce false positives, flagging code that isn’t actually problematic. It’s essential to fine-tune the rules and filters in tools like SonarQube to minimize noise and focus on real issues.
### Dependency Management
Managing dependencies automatically can be tricky, especially with frequent updates and potential compatibility issues. Use tools like Dependabot or Renovate to automate dependency updates, but always test thoroughly to avoid breaking changes.
### Self-Healing Limitations
Self-healing scripts can handle common and predictable issues, but they may not be able to resolve more complex or unknown problems. It’s crucial to continuously update and refine these scripts based on the issues encountered in production.
## Conclusion
Creating a DevOps pipeline that automatically resolves all conflicts and bugs is a challenging but achievable goal with the right strategies and tools. Jenkins, combined with robust CI/CD practices and advanced error-handling mechanisms, can significantly reduce the need for human intervention.
By automating conflict resolution, bug detection, and even some self-healing actions, you can streamline your development process, increase reliability, and deploy faster with greater confidence. Keep refining your pipeline, stay updated with best practices, and continuously monitor and improve your automation scripts to approach the ideal state of a fully autonomous DevOps pipeline.
For more in-depth insights and advanced techniques, check out these valuable resources:
- [Create Custom AMI of Jenkins](https://karandeepsingh.ca/post/create-custom-ami-of-jenkins-devops/)
- [9 Jenkins Hacks That Will Make Your Life Easier](https://karandeepsingh.ca/post/9-jenkins-hacks-that-will-make-your-life-easier-devops/)
- [10 Jenkins Lessons We Learned the Hard Way](https://karandeepsingh.ca/post/10-jenkins-lessons-we-learned-the-hard-way-devops/)
- [DevOps Tools in the Industry](https://karandeepsingh.ca/post/devops-tools-in-the-industry/)
These articles provide practical tips, lessons learned, and essential tools that can further enhance your DevOps practices and Jenkins pipeline efficiency.
Also, follow DevOps best practices on [Dev.to](https://dev.to/) and explore the [Jenkins Documentation](https://www.jenkins.io/doc/).
| karandaid |
1,869,455 | Implementing Soft Deletes with Entity Framework Core | Hola! I’m Michael, and in this video, we’ll cover how to implement soft deletes with Entity Framework Core. By default, Entity Framework Core will permanently delete records when using the .Remove method. We’ll use an EF Core interceptor and query filter to soft delete records. | 0 | 2024-05-29T18:07:49 | https://dev.to/michaeljolley/implementing-soft-deletes-with-entity-framework-core-41p2 | dotnet, csharp | ---
title: Implementing Soft Deletes with Entity Framework Core
published: true
description: Hola! I’m Michael, and in this video, we’ll cover how to implement soft deletes with Entity Framework Core. By default, Entity Framework Core will permanently delete records when using the .Remove method. We’ll use an EF Core interceptor and query filter to soft delete records.
tags: dotnet, csharp
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/a5u4axcjvw05m11ttncq.png
---
{%youtube B9C4iK8IGbQ %}
| michaeljolley |
1,862,998 | Grasp Css Specificity Once: A Comprehensive Guide For Developers | Small mistakes sometimes, when we code, can cause different stylesheet or Css rules to coincide, or... | 0 | 2024-05-29T18:05:10 | https://dev.to/kingsley_uwandu/grasp-css-specificity-once-a-comprehensive-guide-for-developers-epd | css, html | Small mistakes sometimes, when we code, can cause different stylesheet or Css rules to coincide, or want to happen at the same time, thereby making it impossible for the browser to understand. This consequently gives unexpected output on the webpage - The reason why you are sure sometimes when you code, but unfortunately, your code output looks different from what you expect. And as a result, at some point, it is difficult to tell whether or not the fault is from you, your editor, or even the browser. In the course of writing code as a developer, dealing with these errors and unexpected behaviors in your code can be frustrating; and finding and correcting them can get more frustrating if they keep getting in the way of your work.
Css Specificity is an important concept which when followed properly, determines which style is applied to Html elements when multiple styles clash. To avoid, or reduce the above-said error challenges when writing code, it is important to understand how Specificity works.
**The Role of Specificity in Resolving Css Conflicts**
Css stylings before now, was done with basic selectors, such as _element_ name (e.g. `h2`, `div`), and simple properties. It advanced later when more types of selectors, like, but not limited to _Class_ (.className), and _ID_ (#Id) selector were introduced. Together with these new selectors and their combination sometimes, styling became more complex and developers once-in-awhile faced challenges related to conflict of having Css rules clashing. The clash, when it happens, cause styles to element on the web page to be ineffective. To solve this issue, Css Specificity was introduced, and improved from time-to-time. Now with the understanding of the concept, developers can control and predict which styles would apply to elements based on selector’s _specificity_.
For beginners there are vital terms to know, to help understand this article. The terms below are used to illustrate Specificity. It is important to note them for better understanding of its concepts.
There are three methods of styling in Css: _Internal_, _External_, and _Inline_ styling.
**_Internal styles_**: These are defined within a `<style>` tag placed in the `<head>` section of your HTML document. These styles apply to all elements within the same document.
```html
<!DOCTYPE html>
<html>
<head>
<style>
h1 {
color: red;
font-size: 30px;
}
p {
font-family: Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Internal Style Example</h1>
<p>This paragraph uses internal styles.</p>
</body>
</html>
```
**_Inline styles_**: are applied directly to an HTML element using the `style` attribute within the opening tag. This method is suitable for unique styles needed only for a single element. It is generally not recommended for larger styling due to code readability concerns.
```html
<body>
<h1 style="color: red; font-size: 30px;">Inline Style Example (Inline)</h1>
<p style="font-family: Arial, sans-serif;">This paragraph uses inline styles.</p>
</body>
```
**_External styles_**: This method is the most recommended approach for larger websites or projects where you want to maintain consistent styles across multiple pages. It promotes code reusability and easier maintenance. The styles are defined in a separate CSS file (`.css` extension) linked to an HTML document using a <link> tag in the `<head>` section. This CSS file can then style multiple HTML pages.
```html
<html>
<head>
<link rel=”stylesheet” href=”style.css”>
</head>
```
_Style.css:_
```css
h1 {
color: red;
font-size: 30px;
}
p {
font-family: Arial, sans-serif;
}
```
_What is a Selector?_
A **_Selector_** tells which element in an HTML document is targeted based on their name, class, attribute, type, i.d, and more; making it possible for these elements to be styled and given different functionalities in different files, like Css and Js files. Commonly used types of Selector are:
- _Type Selector (Element Selector)_: This selector targets HTML elements based on element type or tag name. E.g. `p` targets all paragraph elements, `<p>...</p>` ; and `a` targets all anchor elements, `<a>...</a>` in the HTML documents, below. They are examples of type selector:
```css
/* "p" type selector targets and styles all paragraph elements */
p {
color: blue;
text-transform: uppercase;
}
/* "a" type selector targets and styles all anchor elements */
a {
color: green;
text-decoration: none;
}
```
- _Universal Selector_: Denoted with `*`. Unlike Type(Element) selector, `Universal selector(*) selects all elements` in the HTML document, and can style them in stylesheets. With the Universal Selector, all elements in an Html code can be targeted and styled, all at once.
Css:
```css
/* Affects all the different elements. Gives all, color - blue */
*{
color: blue;
text-transform: lowercase;
}
```
- _Attribute Selector_: This selector target elements based on their attributes and attribute values. They are enclosed within square brackets []. For example:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Attribute Selectors</title>
<style>
/* Style input elements with type "Email" */
input[type="Email"] {
color: red;
text-transform: uppercase;
}
/* Style input elements with type "text" */
input[type="text"] {
color: blue;
text-transform: capitalize;
}
/* Style links ending with ".com" */
a[href$=".com"] {
text-transform: lowercase;
text-decoration: none; /* Remove underline */
}
/* Style links ending with ".org" */
a[href$=".org"] {
text-transform: capitalize;
}
/* Style paragraphs with title containing "miles" */
p[title*="miles"] {
color: red;
}
</style>
</head>
<body>
<h2>Input Examples</h2>
<input type="Email" placeholder="Enter your Email here..">
<input type="text" placeholder="Write something here">
<input type="Email" placeholder="Enter another Email here..">
<input type="text" placeholder="Write here, again">
<h2>Link Examples</h2>
<a href="https://abcdef.com">Lonely at the top!</a>
<a href="https://abcdef.org">It's beautiful at the top!</a>
<h2>Paragraph Examples</h2>
<p title="The journey of a thousand miles">First paragraph</p>
<p title="How far is it?">Second paragraph</p>
<p title="miles away">Third paragraph</p>
</body>
</html>
```
The above examples show that CSS provides various operators that allow for matching of attribute values. Other operators and their usefulness are summarized, thus:
_Equals (=)_: Matches elements with an exact attribute value (as shown above).
_Not Equals (!=)_: Selects elements where the attribute value does not match the specified value.
_Contains (~)_: Targets elements whose attribute value contains the specified word (anywhere within the value).
_Starts With (^)_: Selects elements where the attribute value starts with the specified value.
- _Class Selector_: This selector selects one or more element by referencing their class name. The class selector is a dot, `'.'`, followed by a class name. That is: `.classname`.
- _I.D Selector_: An ID selector in CSS is used to target a specific element on a web page by referencing its unique identifier, the id attribute. Unlike class selectors, which can be applied to multiple elements, an ID attribute should be assigned only once within an HTML document. The selector is an `#`, followed by the i.d name; thus: `#i.d name`
```html
<h2 id="heading">Heading with ID</h2>
<h2 class="headings">Heading 2</h2>
<h2 class="headings">Heading 3</h2>
</html>
```
Css:
```css
#heading{
color: red;
text-transform: uppercase;
}
.headings{
color: blue;
text-transform: lower;
}
```
Other types of selectors are summarized in the code below:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Css Styling</title>
<style>
/* Pseudo-element Selector - Targets placeholder of the input */
input::placeholder {
color: red;
}
/* Pseudo-class Selector - Affects the input border when clicked */
input:focus {
border: 1px solid red;
}
/* Pseudo-element Selector - Styles the first-line of the paragraph */
p::first-line {
color: green;
}
/* Group Selector - Targets all anchor elements and h2 */
a, h2 {
color: blue;
}
</style>
</head>
<body>
<input type="email" placeholder="Type your Email here..">
<p>This is the first line of this paragraph. As styled in the stylesheet, only text in the first-line will be affected. Other text outside this first-line will not be affected.</p>
<a href="#">This is a link</a>
<a href="#">This is a link-2</a>
<h2>heading</h2>
</body>
</html>
```
**_Property_**: Property tells which visual aspect of the element or the selector that can be changed. It is everything on the Css stylesheet that can be given a value, and whose value can be altered.
```css
/* color, text-transform, and font-size are properties of the p element Selector. Their values (blue, lowercase, 12px) can be changed.*/
p{
color: blue;
text-transform: lowercase;
font-size: 12px;
}
```
Other examples of property are: transition, height, background-color, border, border-radius, font-family, padding, margin, e.t.c.
**_Value_**: This is a piece of data that is assigned in a bid to style a Css property. Above, `blue`, `lowercase`, and `12px`, assigned respectively to the properties, `color`, `text-transform`, and `font-size`, are examples of value.
**Declarations**:
A declaration combines a property with its corresponding value. It is written as `property: value;`, with a colon separating the property and value. Optional whitespace can be used around the colon and semicolon (;) for better readability.
**_Rule_**: Rule is a complete set of one or more declarations in Css stylesheets, that tells how an HTML element or group of elements should be styled. It consists of two parts: The _Selector_, and a _declaration_ block(`{...}`). In short, it is a combination of a selector and the declaration, or declarations in the declaration block.
Properties, Values, Declarations, and Rules are summarized below:
```
// A Css rule:
Selector {
Property1 : value1; // Declaration 1
Property2 : value2; //Declaration 2
}
```
In CSS, there are _**three sources** for styles applied to an element on a webpage_:
- _**Browser (User Agent) Styles**_: These are the default styles applied by the web browser itself. These styles take effect when no author or user styles are defined for an element.
- _**User Styles**_: These are styles defined by the user of the website, allowing them to customize their browsing experience. This can be done through browser extensions or user style sheets.
- _**Author Styles**_: These are the styles defined by the website creator. They can be included in the HTML document itself using the `<style>` tag, or linked to an external `.css` file. Author styles are what give a website its unique look.
**_What is Specificity?_**
In simper term, Specificity is a ranking method that ranks based on hierarchy - the more weighted rules owning a selector with higher priority, or weight are considered instead of the lower ones, when compared by the browser. All of the above explained types of Css Selectors have different level of specificity, or rank. Below show shows the different types, starting from the one with the highest specificity, to the least:
1. ID Selectors (High specificity)
2. Class Selector, attribute selector, and Pseudo-class selector (All have same specificity - Medium specificity, less than _ID Selector_)
3. Type or element selector, and Pseudo-element Selector (Low specificity)
4. Universal Selector (Has no effect on specificity)
There are different rules of Css Specificity to follow in order to avoid unexpected outputs in cases where Css coincide.
**Understanding Specificity Through Cascade**
`Specificity` is one of the key instructions of `Cascade` that must be followed, to avoid unexpected output when styling an Html element. It is therefore improper to explain its concept, without at first discussing its relationship with Cascade, which is fundamental and important to understanding how styles are applied in Css.
Suppose your Html and Css code are as follow, where multiple Css rules are applied to an Html element at the same time. The first rule wants to give it a color, red, and the other rule wants blue. Both at the same time, on same element!
```html
<p class="code" id="coding">This is a paragraph</p>
```
```css
p { /* Rule 1: Color: Red */
color: red;
}
p { /* Rule 2: Color: Blue */
color: blue;
}
```

The idea of the `Cascade` is like a waterfall, where styles flow down, with one affecting another. Styles are applied in a specific order, with later styles overriding earlier ones. This hierarchy helps ensure that styles are applied as intended. The term "Cascade" in CSS refers to the process by which the browser decides which styles to apply when there are conflicting rules. The Cascade follows these general principles:
1. **Importance**: Styles marked with `!important` take precedence over other styles.
2. **Origin**: Styles can come from the user agent (browser default), user styles, or author styles (those defined in the CSS by the web developer). Author styles generally take precedence over user agent styles unless the user has marked their styles as `!important`.
3. **Specificity**: More specific or weighted selectors take precedence over less specific ones.
4. **Order**: When selectors have the same specificity, the last one in the CSS file takes precedence.
In the code snippet above, we see two CSS rules targeting the `<p>` element, causing a conflict. By following Cascade principles, below is how this conflict is resolved:
In CSS, styles are assigned a weight based on their selector weight (_specificity_).
Rule 1: Selects all `<p>` elements (low specificity).
Rule 2: Also selects all `<p>` elements (low specificity).
Since both rules have the same specificity (low), the cascade moves on to the next principle. _When styles have equal specificity_, the _order_ they appear in the CSS file matters. When selectors have the same specificity, the last one in the CSS file wins. Here, Rule 2 comes later in the stylesheet. Therefore, the final color applied to the paragraph will be **blue**, as defined in the second rule due to its later position in the cascade.
A Selector seen in the last position is not always considered first before others in Cascade. All Selectors involved in the conflict are first ranked, by comparing their respective weight level (specificity) before considering their _order_. That is, _Specificity_ is checked first, before _Order_. For example:
```css
p { /* Rule 1: Color: Red */
color: red;
}
p { /* Rule 2: Color: Blue */
color: blue;
}
*{ /* Rule 3: Color: Yellow */
color: yellow;
}
```
From the above we see that, even if the Universal selector `*` appears last in the order, it will have no effect. The other higher selectors will be compared instead. Again, Rule 2 wins, because the Universal selector with no specificity effect is ignored, and its(Rule 2) rule having same specificity as Rule 1, is found in the later position when compared.
The specificity of class selector is higher than pseudo-element and type or element selector, but less than ID selector's. Thus, Id selectors will always win all other selectors when compared in conflicting situations, regardless of their position.
```css
.code{ /* Rule 1: Color: Green */
color: green;
}
p { /* Rule 2: Color: Red */
color: red;
}
p { /* Rule 3: Color: Blue */
color: blue;
}
```

```css
#coding{ /* Rule 1: Color: Purple */
color: purple;
}
.code{ /* Rule 2: Color: Green */
color: green;
}
p { /* Rule 3: Color: Red */
color: red;
}
p { /* Rule 4: Color: Blue */
color: blue;
}
```

**_The strength of an Inline style_**
When all of these selectors, including the Id selector, which is the selector with the highest specificity, targets the same element that is already styled using Css _inline_ method of styling elements, the inline style wins. This means it has the _highest specificity_.
```html
<p class="code" id="coding" style="color:orange;">This is a paragraph</p>
```

The weight of both the _inline_ style and all the different types of selector are summarized below:
**_Inline Styles (highest)_**: Styles defined directly within an HTML element using the style attribute have the highest specificity.
**_ID Selector (very high)_**: Styles targeting an element by its unique ID have very high specificity.
**_Class Selector, Attribute Selector, Pseudo-Class (medium)_**: Styles using classes, element types, attributes, or pseudo-classes have medium specificity.
**_Element Selector, Pseudo-element Selector (low)_**: Styles using element or tag name, and Pseudo-elements have the lowest specificity.
Having a higher Specificity alone is not enough to win, or be displayed on the screen. In Cascade, the `!important` declaration can be used to force a style to be applied regardless of its order, origin, and specificity. This means, with this declaration it is possible to win even an element that has _inline_ styling, which normally have the highest specificity.
```css
#coding{ /* Rule 1: Color: Yellow */
color: orange;
}
.code{ /* Rule 2: Color: Yellow */
color: yellow;
}
p { /* Rule 3: Color: Red */
color: red !important;
}
p { /* Rule 4: Color: Blue */
color: blue;
}
```
In the above code snippet, not minding its Specificity or Position, Rule 3 wins, because its rule has the `!important`declaration in it. When removed and placed in another rule, that rule will win. Nonetheless, this should be used less often as it can make styles harder to maintain.

_Resolving conflicts between the three different **sources** of styles applied to an element on a webpage_
Again, there are three sources of styles: `inline styles`, `internal styles`, and `external styles`. When these sources define the same CSS property for an element, the specificity and location of the styles determine which one wins.
**Case 1**:
For example, let us consider a situation where all three sources apply the same property (`color`) to an element:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Css Specificity</title>
<link rel="stylesheet" href="styles.css">
<style>
.crown {
color: blue;
}
</style>
</head>
<body>
<div class="crown" style="color: red;">Which color?</div>
</body>
</html>
```
- In this Html code snippet above, the _external style_ sheet (`styles.css`) contain:
```css
.crown {
color: green;
}
```
- The _internal style_ in the `<style>` block within the `<head>` section is:
```css
<style>
.crown {
color: blue;
}
</style>
```
- The _inline style_ directly applied to the `div` element is:
```html
<div class="crown" style="color: red;">Which color?</div>
```
When these styles are applied to the `<div class="crown">`, the **order**:
External styles: Lowest specificity among the three, because it is the source of styling here that appears at the top.
Internal styles: Higher specificity than external styles, because it appears after here, but lower than inline styles.
Inline styles: Highest specificity, because it style appears last. Thus, the `div` element's color will be **red** because the inline style overrides both the internal and external styles.

**Case 2**:
If for example the above Html code is not styled using inline style, which appears last and won in that case, and instead the competition is between the external and internal style thus:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Css Specificity</title>
<!--External source appears first-->
<link rel="stylesheet" href="styles.css">
<!--Internal source of style appears last-->
<style>
.crown {
color: blue;
}
</style>
</head>
<body>
<div class="crown">Which color?</div>
</body>
</html>
```
Because the external source appears at the top, first, and internal source of style appears last, following the Cascade **order** principle, the internal source which appears last wins.

Let see between the external and internal source of styling, what happens when the external source appears last, which typically is not the case:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>CSS Specificity</title>
<!--Internal source of style appears first-->
<style>
.crown {
color: blue;
}
</style>
<!--External source of style appears last-->
<link rel="stylesheet" href="styles.css">
</head>
<body>
<div class="crown">Which color?</div>
</body>
</html>
```
When the browser processes the CSS, it applies the internal styles first (`color: blue` from the `<style>` tag). It then applies the external styles (`color: green` from `styles.css`). Because the external stylesheet is loaded after the internal stylesheet, and both have the same specificity, the external style would override the internal style due to being loaded later (last one wins in case of the same specificity).

_Resolving conflicts between the three different **origin** of the styles applied to an element on a webpage_
Now, after knowing almost all of the above listed Cascade principles, including _Specificity_, what happens when there is a clash between the three origin of styles on a webpage?
In the context of CSS (Cascading Style Sheets) and the concept of specificity, when there is a clash between author styles and user styles, user styles win. In the cascade order, we have:
1. User styles with `!important` (highest)
2. Author styles with `!important`
3. Author styles
4. User styles
5. User agent styles (browser defaults).
These rules mean user styles with `!important` will always override author styles, even if the author styles also have `!important`. Without the `!important` declaration, author styles will usually override user styles unless the user styles have higher specificity.
Therefore, if there is a conflict between an author’s style sheet and a user’s style sheet, the user’s style sheet will win if it uses `!important`. Without `!important`, author styles generally take precedence unless the user styles have higher specificity:
Author’s CSS:
```html
p {
color: blue;
}
```
User’s CSS:
```css
p {
color: green !important;
}
```
In the code snippet above, the paragraph text will be green because the user’s style is marked as `!important`. If non of these styles use `!important`, the author’s style usually wins unless the user style has higher specificity:
Author’s CSS:
```html
p {
color: blue;
}
```
User’s CSS:
```css
div p {
color: green;
}
```
In this case, if the paragraph is inside a div, the paragraph text will be **green** because the user style has higher specificity.
**How to calculate Css Specificity**
CSS specificity is calculated based on four categories, which can be seen as a four-part number: (a, b, c, d). These categories correspond to different types of selectors:
1. `a` - Inline styles (e.g., `style="color: blue;"`)
2. `b` - ID selectors (e.g., `#header`)
3. `c` - Class selectors, Attributes selectors, and Pseudo-classes (e.g., `.class`, `[type="text"]`, `:hover`)
4. `d` - Type selectors (e.g., `div`, `p`) and pseudo-elements (e.g., `::before`, `::after`)
_Steps to Calculate Specificity_
_Inline Styles_: Add 1 to the `a` component for each inline style (1,0,0,0 points). Inline styles have the highest specificity and will always win.
_ID Selectors_: Add 1 to the `b` component for each ID selector (0,1,0,0 points)
_Class Selectors, Attribute Selectors, and Pseudo-Classes_: Add 1 to the `c` component for each class selector, attribute selector, and pseudo-class (0,0,1,0 points)
_Type Selectors and Pseudo-Elements_: Add 1 to the `d` component for each type selector and pseudo-element (0,0,0,1 point)
_Numerical Interpretation of points_
- 1,0,0,0 (1000): This represents a specificity where there is one inline style and no other types of selectors.
- 0,1,0,0 (0100 or 100): This represents a specificity where there is one ID selector.
- 0,0,1,0 (0010 or 10): This represents a specificity with one class selector, attribute selector, or pseudo-class.
- 0,0,0,1 (0001 or 1): This represents a specificity with one type selector or pseudo-element.
When comparing these values, you can think of them as if they were large numbers:
- (1,0,0,0) is like "1000"
- (0,1,0,0) is like "100"
- (0,0,1,0) is like "10"
- (0,0,0,1) is like "1"
Using this analogy, you can see that "1000" (_Specificity of inline style_) is greater than "100" (_Specificity of Id selector_), which is greater than "10" (_Specificity of Class, Pseudo-class, and Attribute Selector_), and greater than "1" (_Specificity of Type or Element Selector, and Pseudo-element Selector_).
**_Example Calculations_**
Let’s calculate the specificity for various selectors:
_Example 1_: `#header`
ID selector (`#header`) contributes to the `b` component.
Specificity: (0, 1, 0, 0)
_Example 2_: `.nav .item:hover`
Two class selectors (`.nav` and `.item`) contribute to the `c` component.
One pseudo-class (`:hover`) also contributes to the `c` component.
Specificity: (0, 0, 3, 0)
_Example 3_: `div p`
Two type selectors (`div` and `p`) contribute to the `d` component.
Specificity: (0, 0, 0, 2)
_Example 4_: `ul#list .item::before`
One type selector (`ul`) contributes to the `d` component.
One ID selector (`#list`) contributes to the `b` component.
One class selector (`.item`) contributes to the `c` component.
One pseudo-element (`::before`) contributes to the `d` component.
Specificity: (0, 1, 1, 2)
_Example 5_: `style="color: blue;"`
Inline style contributes to the `a` component.
Specificity: (1, 0, 0, 0)
Below is an example that demonstrates CSS specificity using a button inside a div with an ID of crown. We will target the button using different selectors and style each with a different text color. This will show how specificity and the cascade determine the final style applied to the button.
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>CSS Specificity Example</title>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<div id="crown">
<button>Click Me</button>
</div>
</body>
</html>
```
```css
/* Targeting the button with the element selector */
button {
color: blue; /* Low specificity: 0,0,0,1 */
}
/* Targeting the button with the ID and element selector */
#crown button {
color: green; /* Higher specificity: 0,1,0,1 */
}
/* Targeting the button with the body, ID, and element selector */
body #crown button {
color: red; /* Even higher specificity: 0,1,0,2 */
}
```
- Element Selector (`button`)
```css
button {
color: blue;
}
```
Specificity: `0,0,0,1`
This rule has the lowest specificity and will be overridden by more specific rules.
- ID and Element Selector (`#crown button`)
Specificity: `0,1,0,1`
This rule has higher specificity than the element selector and will override it.
- Body, ID, and Element Selector (`body #crown button`)
```css
body #crown button {
color: red;
}
```
Specificity: `0,1,0,2`
This rule has even higher specificity and will override the previous two rules.
From the above code, the final text color of the button will be **red** because the selector `body #crown button` has the highest specificity among the CSS rules provided.

If an inline style is added directly to the button element, like so:
```html
<body>
<div id="crown">
<button style="color: orange;">Click Me</button>
</div>
```
The text color will be orange, as inline styles have the highest specificity.

**Conclusion**
Understanding CSS specificity is important for effectively managing the styles of a web project. By grasping how different selectors interact and override each other, developers can write more predictable and maintainable CSS. Specificity rules, combined with the cascade, ensure that the most appropriate styles are applied as intended by the developer. | kingsley_uwandu |
1,869,454 | QRow and QCol not available | Hi to all, I'm a newbee in the use of quasar and I have a strange issue. I can't use QRow and QCol... | 0 | 2024-05-29T18:03:54 | https://dev.to/alessandro_saccente_7ff90/qrow-and-qcol-not-available-4k1m | javascript, programming, beginners, quasar | Hi to all, I'm a newbee in the use of quasar and I have a strange issue. I can't use QRow and QCol components because they seems to be missing in my project. I have tried at all, also reinstall dependencies but in node_modules/quasar I don't see anything about this two components. For now I work on a Windows 10, can be this the problem in this case? | alessandro_saccente_7ff90 |
1,869,453 | My character sing for me on my birthday! | https://youtu.be/SV-aJ4kIDU8 Mei Mei the assistant sang a song for me on my birthday on May 29 I... | 0 | 2024-05-29T18:02:17 | https://dev.to/tonicatfealidae/my-character-sing-for-me-on-my-birthday-ie8 |
https://youtu.be/SV-aJ4kIDU8
Mei Mei the assistant sang a song for me on my birthday on May 29
I made my wish on that moment, that I could soon be recognized as a world class game developer!!!! Yaahhh!!!
Yes I create this in 4 hours, I cant afford any more time for it.
hashtag#unity hashtag#unitydev hashtag#gamedevelop hashtag#taniafelidae hashtag#tonicatfelidae hashtag#gamedev hashtag#develope | tonicatfealidae | |
1,869,452 | A Comprehensive Guide to the Best Exhaust Headers and Exhaust Header Kits | Introduction: Introduce the significance of exhaust headers in enhancing engine performance and... | 0 | 2024-05-29T18:02:17 | https://dev.to/alexgrace012/a-comprehensive-guide-to-the-best-exhaust-headers-and-exhaust-header-kits-3gml | **Introduction:**
Introduce the significance of exhaust headers in enhancing engine performance and efficiency. Briefly discuss the role of exhaust headers in optimizing exhaust gas flow and scavenging, leading to increased horsepower, torque, and engine responsiveness. Provide an overview of the guide's structure, covering the features, benefits, installation process, and considerations for selecting the [best exhaust headers](https://flasharkracing.com/blogs/news/unleashing-the-power-the-best-long-tube-exhaust-headers-for-your-5-3-silverado) and kits.
**Understanding Exhaust Headers**
Understanding Exhaust Headers: Gain a practical understanding of exhaust headers and their function in an engine's exhaust system. Discover how exhaust headers differ from stock exhaust manifolds, and how their superior design can maximize exhaust gas flow and scavenging efficiency. Realize the importance of selecting high-quality exhaust headers to unlock the full potential of your engine.
**Benefits of Exhaust Headers**
Detail the advantages of installing aftermarket exhaust headers, including:
**Increased Horsepower and Torque:** Aftermarket exhaust headers improve exhaust gas flow, allowing the engine to breathe more efficiently and generate additional power.
**Experience the Thrill of enhanced Engine Sound:** Many aftermarket exhaust headers produce a more aggressive and exhilarating exhaust note, adding to the overall driving experience and vehicle aesthetics. Imagine the roar of your engine as you accelerate, a sound that truly reflects the power under your hood.
**Improved Throttle Response:** With reduced exhaust backpressure, aftermarket exhaust headers enable quicker throttle response and acceleration, enhancing the vehicle's performance characteristics.
**Factors to Consider When Choosing Exhaust Headers**
Discuss the key factors to consider when selecting the best exhaust headers for a vehicle, including:
**Material:** Exhaust headers are available in various materials, such as stainless steel, ceramic-coated steel, and titanium, each offering different levels of durability, corrosion resistance, and heat retention.
**Design:** Consider the design features of exhaust headers, such as primary tube diameter and length, collector design, and header configuration (e.g., short tube vs. long tube headers), to match the engine's performance requirements and vehicle application.
**Compatibility:** Ensure that the selected exhaust headers are compatible with the vehicle's engine, exhaust system layout, and aftermarket modifications (e.g., turbochargers and superchargers).
**Budget:** Determine the budget for exhaust headers, balancing performance gains with cost considerations to achieve the best value for money.
**Exploring the Best Exhaust Headers**
Exploring the Best Exhaust Headers: Discover top-rated exhaust header brands and models with unique selling points. Learn about their features, benefits, and performance characteristics. Understand why these exhaust headers are considered the best options for enthusiasts seeking to maximize engine performance and sound.
**Brand Spotlight: [Brand Name] Exhaust Headers**
Feature a leading exhaust header manufacturer and discuss their top-selling models, including:
**Construction:**
Highlight the materials and construction techniques used in manufacturing the exhaust headers, emphasizing durability, corrosion resistance, and performance.
**Performance Gains:** Based on dyno testing and real-world performance reviews, provide information on the expected horsepower and torque gains achieved with the exhaust headers.
**Fitment Options:** Discuss the availability of exhaust headers for different vehicle makes, models, and engine configurations, ensuring compatibility with a wide range of applications.
**Customer Reviews:** Include testimonials from satisfied customers who have experienced improved performance and sound with the exhaust headers, showcasing their effectiveness and reliability.
**Comparison of Top Exhaust Header Models**
Compare and contrast multiple exhaust header models from different brands, evaluating factors such as:
**Performance Metrics:** Compare horsepower and torque gains, exhaust flow improvements, and sound characteristics of each exhaust header model to determine their performance potential.
**Construction Quality:** Assess the materials, weld quality, and overall craftsmanship of the exhaust headers to gauge their durability and longevity.
**Price-to-Performance Ratio:** Analyze the cost of each exhaust header model relative to its performance gains and features, identifying the best value options for enthusiasts with different budget constraints.
**Customer Feedback:** Consider user reviews and feedback from automotive forums and enthusiast communities to gain insights into real-world experiences with each exhaust header model.
**Choosing the Right Exhaust Header Kit**
Explore the concept of exhaust header kits, which may include additional components such as gaskets, hardware, and installation instructions to simplify the upgrade process. Discuss the benefits of exhaust header kits and guide on selecting the fitting kit for a specific vehicle and application.
**Benefits of Exhaust Header Kits**
Explain the advantages of purchasing an exhaust header kit, including:
**Empower Yourself with convenience:** Exhaust header kits often include all necessary components for installation, eliminating the need to source additional parts separately. This comprehensive package gives you the confidence to install the upgrade yourself, saving you time and money.
**Compatibility:** Header kits are designed to work seamlessly with specific vehicle models and engine configurations, ensuring proper fitment and performance.
**Cost Savings:** By bundling components together, exhaust header kits may offer cost savings compared to purchasing individual parts separately, making them an attractive option for enthusiasts on a budget.
**Considerations for Selecting Exhaust Header Kits**
Provide guidance on factors to consider when choosing an exhaust header kit, such as:
**Inclusions:** Evaluate the kit's contents, including gaskets, hardware, and installation instructions, to ensure that all necessary components are included for a successful installation.
**Material Quality:** Assess the quality of the included components, such as gasket materials and hardware, to ensure durability and longevity.
**Compatibility:** Confirm that the exhaust header kit is compatible with the vehicle's make, model, and engine configuration, as well as any aftermarket modifications or upgrades.
**Installation Process for Exhaust Headers**
Installation Process for Aftermarket Exhaust Headers: Follow a clear step-by-step guide to installing aftermarket exhaust headers. This guide covers essential aspects such as preparation, removal of stock exhaust manifolds, installation of aftermarket exhaust headers, reassembly, and testing. Each step is designed to ensure a successful and safe installation.
**Preparation:** Gather the necessary tools, equipment, and safety gear for installation. Ensure the vehicle is safely raised and supported on jack stands or a lift.
**Removal of Stock Exhaust Manifolds:** Disconnect the exhaust system from the engine, including oxygen sensors, heat shields, and mounting hardware. Remove the factory exhaust manifolds and inspect the exhaust ports for any signs of damage or corrosion.
**Installation of Aftermarket Exhaust Headers:** Carefully install the aftermarket exhaust headers, ensuring proper alignment and fitment. Follow the manufacturer's instructions for torque specifications and installation procedures.
**- Reassembly:** Reconnect the exhaust system components, including oxygen sensors and heat shields. Double-check all connections and hardware to ensure a secure fit.
**Testing:** Start the engine and inspect for any exhaust leaks or abnormal noises. Then, perform a test drive to evaluate the performance and sound of the vehicle with the new exhaust headers installed.
**Maintenance and Longevity**
Discuss the importance of regular maintenance and care to ensure the longevity and performance of aftermarket exhaust headers—guide maintenance tasks such as periodic inspection for leaks or damage, cleaning, and corrosion prevention.
**Conclusion**
Summarize the key points discussed in the guide, emphasizing the importance of selecting the best exhaust headers and [exhaust header kit](https://flasharkracing.com/collections/exhaust-header) to maximize engine performance and sound. Encourage enthusiasts to research thoroughly, consider their vehicle's specific requirements, and consult with professionals or experienced enthusiasts before purchasing. With the proper exhaust headers and installation techniques, enthusiasts can unlock the full potential of their vehicles and enjoy a thrilling driving experience.
| alexgrace012 | |
1,868,988 | How to Tame Kanban for Your Team's Success | Welcome to the wild world of Kanban! It's a bit like trying to tame a dragon with a whiteboard and a... | 0 | 2024-05-29T15:42:51 | https://dev.to/garbanea/how-to-tame-kanban-for-your-teams-success-557b | kanban | Welcome to the wild world of Kanban! It's a bit like trying to tame a dragon with a whiteboard and a stack of sticky notes. But don't worry; we're here to help you become the ultimate Kanban practitioner, ready to conquer workflow chaos and lead your team to success.
So grab your notepad, and let's dive into the adventure!
## Kanban Inventory: The Starting Point
First things first, let's talk about [Kanban inventory](https://teamhood.com/kanban/kanban-inventory/). Think of it as the pantry of your workflow. You need to know what's in there before you can start cooking up some productivity magic. This means listing all the tasks, projects, and ideas your team is juggling.
Now, if your inventory looks anything like mine, it's a mishmash of post-its, digital notes, and the occasional forgotten to-do list. Trust me, you’re not alone!
A colleague once quipped:
> "My Kanban board looks like a crime scene investigation—strings everywhere, no clear suspects!"
## Kanban Prioritization: Taming the Beast
Once you've got your inventory sorted, the next challenge is [Kanban prioritization](https://teamhood.com/kanban/kanban-prioritization/). Imagine you’re at an all-you-can-eat buffet. You can’t eat everything at once without regretting it later (and probably getting a stomach ache).
Prioritizing tasks is about picking what to tackle first to keep your team from biting off more than they can chew.
To make this fun, some teams use a "Kanban Party" where they get together and prioritize tasks while eating pizza. Pro tip: it’s best to avoid using pizza grease as a ranking system.
A good laugh often accompanies the realization that half the backlog could probably be labeled "wishful thinking" or "never gonna happen". As one team member put it:
> "Our backlog is like Narnia—every time we venture in, we get lost and meet talking animals."
## Visual Collaboration Tools: The Kanban Wizards
Next up are your [visual collaboration tools](https://teamhood.com/project-management/visual-collaboration-software-tools/). These are your magic wands for Kanban success. Tools like Trello, Jira, and Teamhood turn your messy thoughts into organized workflows. But hey, if you’re feeling adventurous, explore this list of [Notion alternatives](https://teamhood.com/project-management/notion-alternatives/) for a fresh spin on visual task management.
Using these tools can feel like being in a high-tech spy movie. One minute you're dragging tasks across your digital board with the finesse of a secret agent, the next you're frantically searching for that one overdue task like a hacker trying to defuse a virtual bomb. But fear not! With these tools, you’ll soon master the art of visual collaboration and keep your team in sync.
## Developing Roadmaps and Timelines in Kanban: The Treasure Map
Creating [roadmaps and timelines in Kanban](https://teamhood.com/kanban/guide-to-developing-timelines-and-roadmaps-while-doing-kanban/) is like drawing a treasure map. You want clear paths, achievable milestones, and a big X marking the spot of your final goal. But let's be real: sometimes it feels like we're more likely to discover buried treasure than hit our deadlines perfectly.
To navigate these treacherous waters, involve your team in the planning process. Set realistic milestones and celebrate small victories. And always, always have a backup plan. Remember, "A roadmap without flexibility is like a treasure map with the X in the wrong place—confusing and pointless."
## Embracing the Chaos with Humor
Kanban can be a challenge, but embracing the chaos with humor makes it more manageable. When things go awry (and they will), a good laugh can ease the tension. As one wise project manager once said:
> "Kanban is like herding cats—just when you think you’ve got it under control, everything scatters."
So, post funny quotes and memes around your workspace. Here are a few to get you started:
> "Why does Kanban always seem like a good idea until you have to move tasks? It's like playing Tetris with real-life consequences."
> "I have a love-hate relationship with my Kanban board. Mostly hate during crunch time, but it’s pure love when the last task moves to 'Done'."
> "Managing tasks in Kanban: 90% moving sticky notes, 10% actual work."
## Final Thoughts: Becoming a Kanban Connoisseur
By now, you should have a better grasp on how to tame Kanban for your team's success. Remember, the key lies in managing your Kanban inventory, prioritizing like a pro, utilizing visual collaboration tools effectively, exploring notion alternatives for the best fit, and developing clear roadmaps and timelines.
Most importantly, keep a sense of humor. Kanban might feel like a rollercoaster, but it’s all part of the ride. As you master the ups and downs, you’ll find your team working more smoothly and efficiently.
So, go forth, Kanban conqueror! Organize those sticky notes, drag those tasks across the board, and celebrate every win, big or small. Your team’s productivity (and sanity) will thank you.
And remember, when in doubt, there's always pizza.
Now, get out there and tame that Kanban dragon! 🐉 | garbanea |
1,867,475 | Understanding MySQL Query Optimizer: COUNT(id) vs COUNT(*) | In MySQL, we use "COUNT" functions almost every day to help us calculate the number of rows for a... | 0 | 2024-05-29T18:00:00 | https://dev.to/darkotodoric/understanding-mysql-query-optimizer-countid-vs-count-2ed5 | mysql, performance, webdev | In MySQL, we use "COUNT" functions almost every day to help us calculate the number of rows for a given query. The biggest dilemma of every developer regarding performance is whether it is better to use "COUNT(\*)" or "COUNT(id)".
---
## MySQL Optimizer
MySQL optimizer is a critical component of MySQL responsible for determining the most efficient way to execute a given SQL query. This part plays a key role in the dilemma of which "COUNT" is the fastest. So let's explain...
We create the "users" table, which will have an index on the "first_name" column:
```
CREATE table users (
id int NOT NULL AUTO_INCREMENT,
first_name varchar(256) NOT NULL,
PRIMARY KEY (id),
INDEX idx_first_name (first_name)
);
```
We add a few rows and run the following 2 queries:
```
EXPLAIN SELECT COUNT(id) FROM users;
```
```
EXPLAIN SELECT COUNT(*) FROM users;
```
When you run these 2 SQL queries, you will notice that they use the same index, "COUNT(\*)" is not slower at all, the MySQL Optimizer is responsible for that, which finds the index in the table that will give the best performance. In this case, both queries will return data at the same speed, because they use the same index and because the MySQL optimizer decided that that index is the most efficient.
MySQL Optimizer considers many parameters that contribute to choosing the best index key so that the given query returns data as quickly as possible.
---
## Conclusion
The use of "COUNT(\*)" is generally recommended because it allows the MySQL Optimizer to choose the most efficient approach, while "COUNT(column_name)" can be specifically useful in situations where it is necessary to count only non-NULL values in a particular column. Understanding how the MySQL Optimizer works and how to use indexes is critical to achieving optimal query performance. | darkotodoric |
1,869,448 | How to Do a Code Review of Bash Scripts | Conducting a code review for Bash scripts is essential to ensure they are error-free, secure, and... | 0 | 2024-05-29T17:56:35 | https://dev.to/karandaid/how-to-do-a-code-review-of-bash-scripts-4bpo | bash, script, code, review | Conducting a code review for Bash scripts is essential to ensure they are error-free, secure, and easy to maintain. Reviewing Bash scripts helps catch mistakes early, improve code quality, and ensures best practices are followed. Here's a detailed guide on how to review Bash scripts effectively, with explanations and examples of good and bad code for each step.
### 1. Understand the Purpose of the Script
Before reviewing, understand what the script is supposed to do. This helps in contextualizing the code and spotting deviations.
**Good:**
```bash
# This script backs up the user's home directory to /backup
```
**Bad:**
```bash
# backup script
```
### 2. Check for Shebang and Execution Permissions
Ensure the script starts with a shebang to specify the interpreter and that it has executable permissions.
**Good:**
```bash
#!/bin/bash
chmod +x script.sh
```
**Bad:**
```bash
#!/bin/sh
```
### 3. Syntax and Semantics
Look for syntax errors and semantic issues. Use tools like `shellcheck` to detect common mistakes.
**Good:**
```bash
if [ -f "$file" ]; then
echo "File exists."
fi
```
**Bad:**
```bash
if [ -f "$file" ] then
echo "File exists."
```
### 4. Readability and Maintainability
Check for proper indentation, meaningful variable names, and adequate comments.
**Good:**
```bash
for file in *.txt; do
echo "Processing $file"
done
```
**Bad:**
```bash
for f in *.txt; do echo "Processing $f"; done
```
### 5. Error Handling
Ensure the script handles errors gracefully using proper error handling mechanisms.
**Good:**
```bash
set -euo pipefail
trap 'echo "Error occurred"; exit 1' ERR
```
**Bad:**
```bash
# No error handling
```
### 6. Security Considerations
Look for potential security issues like unchecked user input and improper handling of sensitive data.
**Good:**
```bash
if [[ "$user_input" =~ ^[a-zA-Z0-9_]+$ ]]; then
echo "Valid input"
fi
```
**Bad:**
```bash
eval $user_input
```
### 7. Performance and Efficiency
Assess the script for performance bottlenecks and unnecessary use of resources.
**Good:**
```bash
grep "pattern" file.txt
```
**Bad:**
```bash
cat file.txt | grep "pattern"
```
### 8. Adherence to Best Practices
Ensure the script follows best practices for Bash scripting.
**Good:**
```bash
result=$(command)
```
**Bad:**
```bash
result=`command`
```
### 9. Dependency Management
Identify any external dependencies and ensure they are clearly documented.
**Good:**
```bash
# Requires rsync
if ! command -v rsync &> /dev/null; then
echo "rsync could not be found"
exit 1
fi
```
**Bad:**
```bash
rsync -avh source/ destination/
```
### 10. Portability
Check if the script uses features or commands specific to a particular shell or system.
**Good:**
```bash
# POSIX compliant
if [ -d "$DIR" ]; then
echo "Directory exists."
fi
```
**Bad:**
```bash
[[ -d "$DIR" ]] && echo "Directory exists."
```
### 11. Documentation
Verify that the script includes a header comment explaining its purpose and usage instructions.
**Good:**
```bash
# Script to backup user's home directory
# Usage: ./backup.sh
```
**Bad:**
```bash
# Backup script
```
### 12. Testing
Ensure the script has been tested in different environments and scenarios.
**Good:**
```bash
# Test script
./test_backup.sh
```
**Bad:**
```bash
# No testing
```
### 13. Variable Naming
Use meaningful and descriptive variable names to improve readability.
**Good:**
```bash
file_count=0
```
**Bad:**
```bash
fc=0
```
### 14. Avoid Hardcoding Values
Use variables instead of hardcoding values to make the script more flexible.
**Good:**
```bash
backup_dir="/backup"
```
**Bad:**
```bash
cd /backup
```
### 15. Use Functions for Reusable Code
Encapsulate reusable code in functions to improve modularity and readability.
**Good:**
```bash
backup_files() {
tar -czf backup.tar.gz /home/user
}
```
**Bad:**
```bash
tar -czf backup.tar.gz /home/user
```
### 16. Check Command Success
Always check if a command succeeded and handle the failure case appropriately.
**Good:**
```bash
if ! cp source.txt destination.txt; then
echo "Copy failed"
exit 1
fi
```
**Bad:**
```bash
cp source.txt destination.txt
```
### 17. Use Meaningful Exit Codes
Use appropriate exit codes to indicate the script's status.
**Good:**
```bash
exit 0
```
**Bad:**
```bash
exit 1
```
### 18. Avoid Useless Use of `cat`
Combine commands to avoid unnecessary use of `cat`.
**Good:**
```bash
grep "pattern" file.txt
```
**Bad:**
```bash
cat file.txt | grep "pattern"
```
### 19. Quotes Around Variables
Always quote variables to prevent word splitting and globbing issues.
**Good:**
```bash
echo "File: $file"
```
**Bad:**
```bash
echo File: $file
```
### 20. Avoid Global Variables
Use local variables within functions to avoid side effects.
**Good:**
```bash
main() {
local file_count=0
}
```
**Bad:**
```bash
file_count=0
```
### 21. Proper Use of Arrays
Use arrays for lists of items to simplify the code.
**Good:**
```bash
files=(file1.txt file2.txt)
for file in "${files[@]}"; do
echo "Processing $file"
done
```
**Bad:**
```bash
file1=file1.txt
file2=file2.txt
for file in $file1 $file2; do
echo "Processing $file"
done
```
### 22. Avoiding Command Substitution in Loops
Avoid using command substitution within loops for better performance.
**Good:**
```bash
while read -r line; do
echo "$line"
done < file.txt
```
**Bad:**
```bash
for line in $(cat file.txt); do
echo "$line"
done
```
### 23. Proper Use of `printf`
Use `printf` instead of `echo` for better formatting control.
**Good:**
```bash
printf "File: %s\n" "$file"
```
**Bad:**
```bash
echo "File: $file"
```
### 24. Check for Unset Variables
Use `set -u` to treat unset variables as an error.
**Good:**
```bash
set -u
echo "Variable: ${var:-default}"
```
**Bad:**
```bash
echo "Variable: $var"
```
### 25. Proper Use of `trap`
Use `trap` to handle cleanup tasks and ensure they run even if the script exits unexpectedly.
**Good:**
```bash
trap 'rm -f temp.txt; exit' INT TERM
```
**Bad:**
```bash
# No cleanup
```
### 26. Avoiding Multiple Redirections
Combine redirections to avoid multiple file handles.
**Good:**
```bash
{
echo "Line 1"
echo "Line 2"
} > output.txt
```
**Bad:**
```bash
echo "Line 1" > output.txt
echo "Line 2" >> output.txt
```
### 27. Using Built-in Shell Commands
Prefer built-in shell commands over external utilities where possible.
**Good:**
```bash
files=$(ls)
```
**Bad:**
```bash
files=$(ls -1)
```
### 28. Avoiding the Use of `eval`
Avoid `eval` to prevent potential security risks.
**Good:**
```bash
cmd="ls"
$cmd
```
**Bad:**
```bash
eval $cmd
```
### 29. Proper Use of `read`
Use `read` with proper options to handle input safely.
**Good:**
```bash
read -r user_input
```
**Bad:**
```bash
read user_input
```
### 30. Using `||` and `&&` for Command Chaining
Use `||` and `&&` for conditional command execution.
**Good:**
```bash
command1 && command2
command1 || echo "Command1 failed"
```
**Bad:**
```bash
if command1; then
command2
fi
if ! command1; then
echo "Command1 failed"
fi
```
### 31. Using `case` Instead of Multiple `if` Statements
Use `case` for multiple conditions to improve readability.
**Good:**
```bash
case $var in
pattern1) echo "Pattern 1";;
pattern2) echo "Pattern
2";;
esac
```
**Bad:**
```bash
if [ "$var" == "pattern1" ]; then
echo "Pattern 1"
elif [ "$var" == "pattern2" ]; then
echo "Pattern 2"
fi
```
### 32. Properly Handling File Descriptors
Use file descriptors to manage input/output streams efficiently.
**Good:**
```bash
exec 3< input.txt
while read -r line <&3; do
echo "$line"
done
exec 3<&-
```
**Bad:**
```bash
while read -r line; do
echo "$line"
done < input.txt
```
### 33. Using `select` for Menu Options
Use `select` to create simple menus.
**Good:**
```bash
select option in "Option 1" "Option 2" "Quit"; do
case $option in
"Option 1") echo "You chose Option 1";;
"Option 2") echo "You chose Option 2";;
"Quit") break;;
esac
done
```
**Bad:**
```bash
echo "1. Option 1"
echo "2. Option 2"
echo "3. Quit"
read -r choice
case $choice in
1) echo "You chose Option 1";;
2) echo "You chose Option 2";;
3) exit;;
esac
```
### 34. Using `dirname` and `basename`
Use `dirname` and `basename` to handle file paths.
**Good:**
```bash
dir=$(dirname "$file_path")
file=$(basename "$file_path")
```
**Bad:**
```bash
dir=${file_path%/*}
file=${file_path##*/}
```
### 35. Using `mktemp` for Temporary Files
Use `mktemp` to create temporary files securely.
**Good:**
```bash
tmpfile=$(mktemp)
echo "Temporary file: $tmpfile"
```
**Bad:**
```bash
tmpfile="/tmp/tempfile.$$"
echo "Temporary file: $tmpfile"
```
By following these guidelines and using these examples, you can conduct a thorough and effective code review of Bash scripts, ensuring they are robust, secure, and maintainable.
For more advanced Bash scripting tips, check out this article on [Advanced String Operations in Bash: Building Custom Functions](https://karandeepsingh.ca/post/advanced-string-operations-in-bash-building-custom-functions/). | karandaid |
1,869,447 | Codepen editor | Check out this Pen I made! | 0 | 2024-05-29T17:53:52 | https://dev.to/tidycoder/codepen-editor-f7i | codepen | Check out this Pen I made!
{% codepen https://codepen.io/TidyCoder/pen/abrZzxa %} | tidycoder |
1,869,446 | Playwright on Tableau | Can Playwright be used automate testing on Tableau or Micro-strategy? | 0 | 2024-05-29T17:46:53 | https://dev.to/viveks/playwright-on-tableau-56og | Can Playwright be used automate testing on Tableau or Micro-strategy? | viveks | |
1,869,445 | Difference between Libraries and Frameworks | Libraries: Tools in Your Toolbox A library is a collection of reusable code modules that provide... | 0 | 2024-05-29T17:46:52 | https://dev.to/devmatsu/difference-between-libraries-and-frameworks-3fca | **Libraries: Tools in Your Toolbox**
A library is a collection of reusable code modules that provide specific functionality, such as parsing JSON, making HTTP requests, or manipulating data structures. Libraries are typically designed to be called directly by the application code, giving developers control over when and how to use them.
```js
// Example of using the 'lodash' library to manipulate arrays
const _ = require('lodash');
const numbers = [1, 2, 3, 4, 5];
const sum = _.sum(numbers);
console.log(sum); // Output: 15
```
In this Node.js example, we're using the lodash library to calculate the sum of an array of numbers. The library provides a sum function that we can directly invoke in our code.
**Frameworks: Guiding Your Application**
A framework, on the other hand, is a pre-defined structure or scaffolding that dictates the overall architecture and flow of an application. Frameworks impose an inversion of control, where the framework dictates the flow of control and developers plug in their code at specific points.
```js
// Example of using the 'Express' framework to create a web server
const express = require('express');
const app = express();
app.get('/', (req, res) => {
res.send('Hello, World!');
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
```
In this Node.js example, we're using the Express framework to create a simple web server. Express provides a predefined structure for handling HTTP requests and routes, and developers plug in their route handlers within this structure.
**Choosing Between Libraries and Frameworks**
The choice between a library and a framework depends on the level of control and guidance you need for your application:
- Libraries offer flexibility and control, allowing developers to choose when and how to use specific functionalities.
- Frameworks provide structure and guidance, streamlining the development process by offering pre-defined solutions for common tasks.
Understanding the difference between libraries and frameworks is essential for selecting the right tools for your development projects. Whether you need granular control or prefer a guided approach, both libraries and frameworks play vital roles in building successful applications. Consider the trade-offs between libraries and frameworks, and choose the tools that best align with your project's requirements.
**Console You Later!**
| devmatsu | |
1,869,052 | What is Threat Detection and Response (TDR)? | Threat Detection and Response (TDR) is an essential component of cybersecurity, working alongside... | 0 | 2024-05-29T13:58:39 | https://www.clouddefense.ai/what-is-threat-detection-and-response/ |

Threat Detection and Response (TDR) is an essential component of cybersecurity, working alongside threat prevention to safeguard organizations from cyber threats. Despite robust preventive measures, attackers often breach defenses, necessitating a proactive approach to detect and respond to threats. TDR involves continuously monitoring networks and endpoints to swiftly identify anomalies and indicators of compromise. By leveraging advanced tools and strategies, TDR enhances an organization’s ability to combat cyber threats, extending beyond traditional prevention methods.
TDR employs advanced analytical techniques such as behavioral analysis and artificial intelligence (AI) to uncover elusive threats. When a threat is detected, a coordinated response is initiated to investigate, contain, and eradicate the threat while fortifying defenses against future incidents. This cyclical process of detection, response, and refinement is crucial for maintaining cyber resilience.
The TDR process is typically managed by a Security Operations Center (SOC) and unfolds in several stages. Detection involves using a suite of security tools to continuously monitor endpoints, networks, applications, and user activities to identify potential risks and breaches. Cyber threat-hunting techniques are also employed to uncover sophisticated threats. Upon identifying a potential threat, AI and other tools are used to confirm its authenticity, trace its origins, and assess its impact.
Containment involves isolating infected devices and networks to prevent the spread of the attack. The SOC then works to eliminate the root cause of the incident, removing the threat actor and addressing vulnerabilities to prevent recurrence. Once the threat is neutralized, systems are restored to normal operations. The incident is documented and analyzed to identify areas for improvement, and lessons learned are used to enhance the organization's security posture.
TDR tools are designed to detect and mitigate a wide range of cyber threats. These include Distributed Denial-of-Service (DDoS) attacks, which overwhelm services with excessive traffic; malware, which steals data; phishing attempts, which trick users into divulging sensitive information; botnets, networks of compromised devices used for malicious purposes; ransomware, which encrypts and exfiltrates critical data; living-off-the-land attacks, where attackers use legitimate tools within the network; advanced persistent threats (APTs), prolonged and stealthy attacks targeting sensitive data; and zero-day threats, previously unknown vulnerabilities.
Effective TDR programs leverage several key features. Real-time monitoring of networks and endpoints detects anomalies early. Vulnerability management identifies and remediates weaknesses in infrastructure. Threat intelligence integration utilizes feeds to stay informed about the latest attack techniques. Sandboxing analyzes potentially malicious code in an isolated environment. Root cause analysis determines the underlying cause of incidents for effective remediation. Threat hunting proactively searches for indicators of compromise and anomalous activities. Automated response swiftly isolates and blocks threats, often integrated with Security Orchestration, Automation, and Response (SOAR) platforms.
To maximize the effectiveness of TDR, organizations should follow best practices. Regular training ensures all employees are equipped to recognize and respond to threats. Continuous improvement involves using post-incident evaluations to refine response procedures. Collaboration and communication foster teamwork within the security team and across departments. An incident response plan provides clear steps for containment, eradication, and recovery. AI integration enhances threat detection and response capabilities.
CloudDefense.AI offers a robust suite of tools designed to protect cloud infrastructures from cyber threats. With features like real-time threat detection, user behavior analysis, and security graph technology, CloudDefense.AI provides comprehensive visibility and protection. The platform’s AI-driven capabilities detect both known and unknown threats, prioritize risks based on their impact, and offer detailed graph-driven investigation tools for swift remediation. Additionally, CloudDefense.AI excels in detecting misconfigured APIs, preventing unauthorized access and data exposure.
For organizations looking to enhance their TDR capabilities, CloudDefense.AI represents a cutting-edge solution that streamlines detection and response efforts, ultimately strengthening cybersecurity defenses. [Book a free demo](https://www.clouddefense.ai/request-demo/) with CloudDefense.AI to experience the future of threat detection and response. | clouddefenseai | |
1,869,443 | How to Generate Random Passwords in Bash using `/dev/urandom` | Generating random data is a common task in many applications, especially when it comes to creating... | 0 | 2024-05-29T17:45:28 | https://dev.to/karandaid/how-to-generate-random-passwords-in-bash-using-devurandom-4cp8 | bash, script, password, random | Generating random data is a common task in many applications, especially when it comes to creating secure passwords. In this guide, we'll learn how to generate random passwords using Bash and the `/dev/urandom` file. This method ensures your passwords are both random and secure. We'll build the script step-by-step, explaining each part so you can easily follow along. By the end, you'll have a complete Bash script to generate random passwords.
#### Step 1: Generate Random Bytes
To start, we'll generate random bytes using the `head` command to read from `/dev/urandom`. Then, we'll use `base64` to encode these bytes into a readable format.
```bash
head -c 16 /dev/urandom | base64
```
**Explanation:**
- `head -c 16 /dev/urandom`: This reads 16 bytes from `/dev/urandom`, a special file that provides random bytes.
- `| base64`: This encodes the bytes into a base64 string, making it easy to read.
When you run this command in your terminal, you'll see a random string output, which looks something like this: `r8BgD2h+P/QA5FyN`.
#### Step 2: Remove Unwanted Characters
Next, we'll refine the output to include only alphanumeric characters, making the password more user-friendly. We'll use the `tr` command for this.
```bash
head -c 16 /dev/urandom | base64 | tr -dc 'a-zA-Z0-9'
```
**Explanation:**
- `tr -dc 'a-zA-Z0-9'`: This removes any characters that are not in the ranges `a-z`, `A-Z`, or `0-9`, leaving us with a clean alphanumeric string.
Run this command, and you'll get a cleaner output like `r8BgD2hPQA5FyN`.
#### Step 3: Putting It All Together
Let's combine everything into a simple script that you can run anytime you need a new random password.
```bash
#!/bin/bash
# Generate a random password
PASSWORD=$(head -c 16 /dev/urandom | base64 | tr -dc 'a-zA-Z0-9')
# Display the password
echo "Your random password is: $PASSWORD"
```
**Explanation:**
- `#!/bin/bash`: This line specifies that the script should be run in the Bash shell.
- `PASSWORD=$(...)`: This runs our command and stores the result in the `PASSWORD` variable.
- `echo "Your random password is: $PASSWORD"`: This prints the generated password to the screen.
#### Step 4: Running the Script
To run the script, save it to a file (e.g., `generate_password.sh`), give it execute permissions, and then run it.
```bash
chmod +x generate_password.sh
./generate_password.sh
```
**Explanation:**
- `chmod +x generate_password.sh`: This makes the script executable.
- `./generate_password.sh`: This runs the script.
When you run the script, you'll see an output like: `Your random password is: r8BgD2hPQA5FyN`.
#### Full Script
Here is the complete script for easy reference:
```bash
#!/bin/bash
# Generate a random password
PASSWORD=$(head -c 16 /dev/urandom | base64 | tr -dc 'a-zA-Z0-9')
# Display the password
echo "Your random password is: $PASSWORD"
```
### Conclusion
Using `/dev/urandom` in Bash is a simple and effective way to generate random passwords. This method ensures your passwords are secure and random, which is essential for protecting your data. Now you have a handy script to generate strong passwords anytime you need them!
Feel free to customize the script to suit your needs, and happy coding!
More Reading: [Advanced Bash Functions](https://karandeepsingh.ca/post/advanced-string-operations-in-bash-building-custom-functions/) | karandaid |
1,868,016 | Testing Technique | BOUNDARY VALUE ANALYSIS Boundary value analysis is a software testing technique in which tests... | 0 | 2024-05-29T17:42:06 | https://dev.to/samu_deva/testing-technique-575o | BOUNDARY VALUE ANALYSIS
Boundary value analysis is a software testing technique in which tests are designed to include values at the boundaries between partitions of input values .This helps in identifying errors at the boundaries of input domains .
It a software testing technique in which tests are designed to include representatives of boundary values in a range.
1. Lower boundary cases(min)
2. Upper boundary cases(max)
3. On boundary cases(min<v>max)
Examples:
You are going for an adventure park they have a age restriction like this. these are valid data that we will be arriving on if we apply boundary value analysis.
Enter your age(*only 10 to 60 are allowed for this ride)
Invalid valid Invalid
min-1 min<v> max max+1
9 12 61
1. More application errors occurs at the boundaries of the input domain.
2. Its used to identify errors at boundaries rather than finding those
that exist in the center of the input domain.
DECISION TABLE TESTING:
Decision table testing is a black-box testing technique used to evaluate system behavior based on combination of input conditions or actions. It involves creating a table that captures all possible input combinations and their corresponding expected outputs or actions.
This technic can also called as cause and effect table ,as it captures the driving factors and the effect in the table format.
Example:
You are going for Poorvika mobiles .Membership D1 offer , more then one product D2 offer & credit card offer D3.
D1 D2 D3
Membership offer offer - -
More then 1 product - offer -
credit card - - offer
credit card + membership offer - offer
new customer - - -
USE CASE TESTING:
Use case is much like a older brother to user stories. Use case is a process of defining the action done by the users on the system and the responses of the system for the corresponding action.
1. Describes the system behavior end user perspective
2. It explains the functionality or requirement, the customer requirement or project requirement can be specify in the use cases.
3. use case is a representation of actions which describes the behavior of system to do a particular task.
Example:
anna university result
user system result
enter reg. no valid reg no check the reg no positive
enter invalid reg no invalid reg no check reg no MSG negative
"invalid reg no"
LCSAJ TESTING:
Transparent box
Input-->coding-->output
LCSAJ stands for “Linear Code Sequence and Jump” testing. It is a white-box testing technique used to assess the coverage of source code within a software program.
LCSAJ testing focuses on verifying that all linear code sequences and jumps within the code are exercised by test cases. This technique is commonly used in the context of structural testing or code coverage analysis.
1. The starting line at the beginning of a module or at a line of code that was jumped to by another LCSAJ.
2. The end of the LCSAJ at the end of a module or at a line of code where a jump occurs.
3.The target of the jump
| samu_deva | |
1,869,441 | 10 Reasons for Flaky Tests | Testing is one of the important aspects of software development. It helps to ensure that your codes... | 0 | 2024-05-29T17:41:28 | https://dev.to/oyedeletemitope/10-reasons-for-flaky-tests-5a63 | testing, test, webdev, devops |
Testing is one of the important aspects of software development. It helps to ensure that your codes are high quality and reliable. However, we sometimes run into issues, one of which is flaky tests. They can be very frustrating, which is why knowing why they can occur is a big step to solving them. In this article, we'll look at the ten reasons for flaky tests and provide some solutions to get your testing back on track.
## What are Flaky Tests
[Flaky tests](https://semaphoreci.com/community/tutorials/how-to-deal-with-and-eliminate-flaky-tests) is a test that both passes and fails at the same time periodically without any code change and by code change, we mean no change in the code that run the tests nor change in the code of the application in the same environment.
Flaky tests can be problematic because they reduce the reliability and effectiveness of automated testing. Let's say, for instance, that you're testing out a feature to be included in software that calculates the total price of items for a shopping cart. You write an automated test that adds the items to the cart, checks them, and calculates the total price. However, the test fails. Sometimes, this test runs, and the total price is calculated correctly, but other times, it fails and gives an incorrect total price.

This behavior is what we call flaky. It causes an uncertainty about the result. The fact that it passes sometimes and fails the next time doesn't bring about this uncertainty as we are not sure if we are breaking something or just some flaky behavior.
This brings us to why a flaky test can occur during testing.
## Reasons for Flaky Tests
In this section, we'll run through some reasons why flaky tests occur. Note that they are not limited to these but are some of the common ones we encounter
### Poor Tests Data
When the data used to test is poor, it can lead to a flaky test. When we talk about data being poor, we mean it can be old, incomplete, incorrect, or even outdated. And using it can lead to tests periodically failing or passing even when we test under the same conditions.
To reduce the chances of encountering tests due to poor data, we can employ the following strategies:
- Use Realistic Test Data
- ValidateTest Data
- Refresh Test Data Regularly
- Monitor test data quality
### Inconsistent Test Environment
A test environment that varies in hardware, software, and configuration can lead to inconsistent test results.
For instance, a test can pass on a developer's machine since it has all the configurations needed but fail in a [CI/CD](https://semaphoreci.com/cicd) environment due to the environment possessing a different version of the configurations or settings from the local machine. This incompatibility often leads to flakiness.
To minimize the chances of encountering a flaky test due to an inconsistent test environment, You can employ the following strategies:
- Virtualization
- Containerization
- Cloud-based testing
- Automated environment validation
### Poor Test Designs
When it comes to the reliability and consistency of tests, Test designs play a crucial role. A poorly designed test combined with the absence of a sufficient setup, teardown procedure, and inadequate error handling can lead to a flaky test.
To address issues due to poor test designs, we must have the following:
- Proper setup and teardown
- Robust error handling
- Specific assertions
### Resource Constraints
Resource constraints refer to the limitations in resources that are available for testing. These limitations can be related to hardware, software, or infrastructure and can impact the execution of tests, leading to flakiness.
For instance, a test that has a specific memory or CPU limit is bound to be flaky if the available memory fails to meet the required memory for execution.
To prevent issues due to environmental constraints, consider the following:
- Upgrading Hardware
- Optimizing Test Scripts
- Distributing Tests Across Multiple Machines
- Using Cloud Resources
- Implementing Resource Monitoring
### Timing Issues
Timing issues can be encountered when tests depend on certain timing conditions, such as network latency or UI elements. These conditions are sensitive and can cause tests to pass or fail.
To address timing issues, we can implement [synchronization techniques](https://medium.com/@gokulganapathy9500/what-is-synchronization-6f0cf3386f26) like explicit wait and timeouts. These techniques ensure that the test waits for the necessary conditions before proceeding. Doing this will reduce the likelihood of flakiness due to timing issues.
### External Factors
When we talk about external actors, we refer to issues ranging from network connectivity to outages in third-party services. When a test depends on an external service, they are prone to failure, and if such dependencies become unavailable for one reason or another.
To minimize interference from external factors and improve the reliability of tests, consider the following solutions:
- Use Isolated Test Environments
- Implement Retry Mechanisms
- Monitor External Factors Before Test Execution
- Mock External Services
### Test Dependencies
Test dependencies refer to a situation where one test relies on another test's outcome. This usually occurs when tests share resources, and the order in which the tests are executed influences their outcomes.
For instance, if a test modifies a shared resource and another test relies on the resource's original state, the dependent test may fail if it runs before the modifying test has finished.
To reduce the impact of test dependencies, we can:
- Ensure test isolation
- Clear test dependency
- Mock external dependency
### Using Hard-Coded Test Data
Hard-coded test data refers to embedding specific values into test values instead of generating dynamic or dummy data. Even an automation engineer will tell you this is a bad practice that can lead to flaky tests. Using hardcoded test data can lead to issues like difficulty in debugging, data duplication, obsolete data, etc.
A better way is to use dynamic test data, mock external dependencies, or parameterize tests.
### Poorly Written Tests
Poorly written tests are those that are not well structured. They do not define what they are testing, and sometimes, they are overly complex, which makes them difficult to understand.
One of the numerous ways to cause flaky tests is having a test written poorly. To address the issue of poorly written tests, here are some solutions:
- Refactor and Simplify Tests
- Ensure Proper Cleanup
- Use descriptive test names
- Avoid redundant tests
- Use mocking and stubbing
### Lack of Proper Framework
A proper framework establishes a structured environment for writing, performing, and maintaining tests. This ensures that tests are reliable, efficient, and easy to understand. Not having a proper framework can make a test fail. This is because they lack the necessary tools, libraries, and configurations to run consistently. Having a proper framework includes the process of running the tests, what is needed, and also how to do it.
To address improper framework issues, we can:
- Use Robust and Reliable Test Automation Frameworks and Tools
- Properly Manage Test Environments and Configurations
- Regularly Maintain and Update Tests
## Conclusion
In this article, we've identified ten key reasons contributing to flaky tests, each with its own implications. Understanding these reasons is crucial for addressing flaky tests effectively and ensuring the reliability and accuracy of tests.
| oyedeletemitope |
1,869,440 | The forgotten voice of Abdi Ali | The Forgotten Voice and A Cry for Equality in the Digital Era In a world where technology has become... | 0 | 2024-05-29T17:40:15 | https://dev.to/abdiko25/the-forgotten-voice-of-abdi-ali-4maj | The Forgotten Voice and A Cry for Equality in the Digital Era
In a world where technology has become the great equalizer, bridging gaps and breaking down barriers, there are still those who find themselves on the fringes, their voices muffled by the very systems meant to empower them. The story of Abdi Ali, a father of five from Ethiopia, is a poignant reminder of the stark inequalities that persist, even in the digital realm.
Abdi's struggle is a microcosm of a larger issue that plagues countless individuals across the globe. In a world where knowledge is power, and access to education is a fundamental right, the inability to attend online courses due to the lack of an international credit card is a cruel irony. It is a barrier that not only hinders personal growth but also perpetuates the cycle of poverty and marginalization.
The frustration in Abdi's words is palpable, "My destiny is limited." These are not mere words; they are a cry for help, a plea for understanding, and a demand for action. How can we, as a global community, claim to be progressive when such blatant inequalities persist? How can we turn a blind eye to the struggles of those who yearn for knowledge, yet find themselves shackled by circumstances beyond their control?
Abdi's story is not an isolated incident; it is a reflection of a systemic failure that has left countless individuals in similar predicaments. The digital divide, once a term used to describe the gap between those with access to technology and those without, has taken on a new and more insidious form. It is no longer just about access; it is about the ability to fully participate and benefit from the opportunities that technology offers.
The world community has a moral obligation to address this issue with urgency and compassion. We cannot continue to turn a deaf ear to the voices of those like Abdi, whose dreams and aspirations are stifled by the very systems meant to empower them. It is a travesty that in the 21st century, individuals are still denied the fundamental right to education and self-improvement due to financial constraints and geographical limitations.
We must acknowledge that the pursuit of knowledge should not be a privilege reserved for the few but a fundamental right for all. Education is the great equalizer, the catalyst for social mobility, and the key to unlocking the full potential of individuals and communities alike. By denying access to online courses and educational resources, we are not only stunting personal growth but also perpetuating a cycle of poverty and marginalization that transcends generations.
The time has come for the world community to take a stand and prioritize the empowerment of individuals like Abdi. We must work tirelessly to dismantle the barriers that prevent access to education and create inclusive systems that embrace diversity and promote equal opportunities. This is not a call for charity; it is a call for justice, a demand for a world where every individual, regardless of their circumstances, has the chance to pursue their dreams and reach their full potential.
Abdi's words, "Why is everyone in the world selfish?" should serve as a wake-up call, a reminder that our actions, or lack thereof, have far-reaching consequences. We cannot claim to be a global community if we turn a blind eye to the struggles of those who seek nothing more than the opportunity to better themselves and contribute to society.
A New Era of Empowerment
It is time to break the cycle of indifference and embrace a new era of empowerment, where the voices of the marginalized are amplified, and their dreams are given the chance to take flight. Let us not be remembered as the generation that perpetuated inequality but as the one that stood up for justice, equality, and the fundamental right to education for all.
| abdiko25 | |
1,869,439 | Hello World | A post by Muhammad Uzair Rehan | 0 | 2024-05-29T17:37:23 | https://dev.to/uzairrehan/hello-world-2i8c | uzairrehan | ||
1,869,438 | As a gaming developer, how can I leverage Gaming platform to create engaging free online games that require no download? | "As a gaming developer, Gaming platform offers a unique opportunity to create captivating free online... | 0 | 2024-05-29T17:35:07 | https://dev.to/claywinston/as-a-gaming-developer-how-can-i-leverage-gaming-platform-to-create-engaging-free-online-games-that-require-no-download-547c | indiegame, dev, game, gamedev | "As a[ gaming developer,](https://medium.com/@adreeshelk/publishing-on-a-robust-gaming-platform-key-considerations-for-developers-1c8888f80d91?utm_source=referral&utm_medium=Medium&utm_campaign=Nostra) Gaming platform offers a unique opportunity to create captivating free online games that don't require any downloads. By leveraging cutting-edge technology and vast user base, you can develop games that are instantly accessible and highly engaging.
One of the key advantages of developing free online games for gamers is the platform's no-download approach. This means that players can instantly access your games without the need for any installations or storage space on their devices. To make the most of this feature, focus on creating games with simple, intuitive controls and engaging gameplay mechanics that can be enjoyed in short bursts.
This [Gaming platform](https://nostra.gg/articles/lock-screen-new-opportunity.html?utm_source=referral&utm_medium=article&utm_campaign=Nostra) also provides gaming developers with a range of tools and APIs to enhance the player experience. Utilize features like leaderboards, achievements, and social sharing to foster a sense of competition and community among players. Additionally, Analytics tools allow you to gain valuable insights into player behavior, helping you optimize your games for maximum engagement.
By developing [free online games](https://medium.com/@adreeshelk/creating-vivid-ongoing-interaction-encounters-with-nostra-games-d12e7e8593ba?utm_source=referral&utm_medium=Medium&utm_campaign=Nostra) that can be played instantly on this platform, you'll have the opportunity to reach a massive audience of eager gamers. Embrace the power of this platform to create games that captivate players and keep them coming back for more."
| claywinston |
1,869,437 | Expert Retail App Developers in USA | Crafting engaging, scalable, and personalized retail solutions is crucial in today's market. To... | 0 | 2024-05-29T17:34:50 | https://dev.to/technbrains/expert-retail-app-developers-in-usa-3bm4 | Crafting engaging, scalable, and personalized retail solutions is crucial in today's market. To transform retail landscapes, partnering with a leading [retail app development company](https://www.technbrains.com/industries/retail-app-development) like TechnBrains can be a game-changer. Our expertise in developing innovative retail apps can help you enhance customer experiences, streamline operations, and drive sales. Whether you're looking to build a mobile app, an e-commerce platform, or a custom retail solution, TechnBrains has the skills and experience to bring your vision to life. Partner with us today and take your retail business to new heights. | martindye | |
1,864,832 | Create a Fullstack app with Vue and Go (And Tailwindcss v4) | This article is for new developers or people curious about Go, vue, or how to bulid a simple full... | 0 | 2024-05-29T17:29:22 | https://dev.to/maxiim3/create-a-fullstack-app-with-vue-and-go-and-tailwindcss-v4-22ai | go, vue, web3, vite | This article is for new developers or people curious about Go, vue, or how to bulid a simple full stack application
## About me
I am a front end developer exploring backend.
After trying PHP, Node.js, Rust... I felt in love with Golang for its simplicity, yet efficiency and performance.
## The Stack
We gonna use Go and its light and easy library to build a server : Echo.
For the Front end we use Vue.js with Vite.
The client-side navigation is handled with Vue-router.
For the styling we gonna use the best tool out there : Tailwindcss. And "Cerise sur le gateau", we use the preview alpha version, v4, that should be released this summer.
## Backend
### Installation
Let's create a new directory and enter it
```bash
mkdir go-vue && cd $_
```
Now we create the new go module.
We add the necessecary dependencies : `echo/v4` for the server, `echo/v4/middleware` to handle the CORS
```bash
go mod init github.com/<username>/go-vue
go get github.com/labstack/echo/v4
go get github.com/labstack/echo/v4/middleware
```
Then we can create a new go file `touch main.go`
Open ~~VIM~~ your favorite IDE.
### First steps
Here are the basic : We create a new echo instance and start listening to port `8888`
```go
package main
import (
"github.com/labstack/echo/v4"
)
func main() {
e := echo.New()
// Note that this must be the last statement of the main function
e.Logger.Fatal(e.Start(":8888"))
}
```
## Serving static files
Right now our projects looks like this
```text
.
├── go.mod
├── go.sum
└── main.go
```
But we gonna create our Vue app inside `ui/` which will contain the front-end code.
Using Vite we gonna build the Vue app into `ui/dist` and serve it from go.
So it's gonna look like this :
```text
.
├── go.mod
├── go.sum
├── main.go
└── ui
├── dist
│ ├── assets
│ │ ├── index-D52G_CEl.css
│ │ └── index-y7ffriUP.js
│ └── index.html
|-- ... vue files
```
We need to tell Echo that we are using static files.
[The documentation is great btw...](https://echo.labstack.com/docs/static-files)
```go
package main
import (
"github.com/labstack/echo/v4"
)
func main() {
e := echo.New()
// We declare that route "/" will serve our local "/ui/dirst" project path
e.Static("/", "ui/dist")
// We serve index.html from the build directory as the root route
e.File("/", "ui/dist/index.html")
e.Logger.Fatal(e.Start(":8888"))
}
```
### Add an API
We gonna create a simple API in order to have some sort of communication between vue and go.
For simplicity we gonna use an object, but in a real app we would probably use a database.
We gonna have a Person object. We will send informations about it to Vue. And give the ability to Vue to update the Person's name.
So we need a Get and a Post request. We will also need to handle the CORS.
#### Create a Person
We use the Go struct and instanciate a person
```go
type Person struct {
Name string `json:"name"`
Age uint8 `json:"age"`
Email string `json:"email"`
}
//... inside main function
p := Person{
Name: "Nikola",
Age: 37,
Email: "nikola@tesla.genius",
}
```
It will later be transleted in Typescript as :
```ts
type Person = {
name: string
age: number
email: string
}
```
#### GET a Person
We then send our person to the *GET route* `/person`
```go
package main
import (
"github.com/labstack/echo/v4"
)
func main() {
e := echo.New()
e.Static("/", "ui/dist")
e.File("/", "ui/dist/index.html")
// Create a Person
p := Person{
Name: "Nikola",
Age: 37,
Email: "nikola@tesla.genius",
}
// Get Person on route "/person"
e.GET("/person", func(c echo.Context) error {
return c.JSON(202, p)
})
e.Logger.Fatal(e.Start(":8888"))
}
type Person struct {
Name string `json:"name"`
Age uint8 `json:"age"`
Email string `json:"email"`
}
```
You see why Go + Echo is awesome ? So easy !
#### Update a Person's name
We use the POST request to get the data from the Front end via POST method and update our local instance.
We setup the model Vue (Typescript) is gonna send to the POST route `/person`
```ts
type PostPersonName = {
name: string
}
```
Which translates in Go as
```go
type PostPersonBody struct {
Name string `json:"name"`
}
```
Here is the full code with the POST request and the Middleware to handle the CORS
```go
package main
import (
"encoding/json"
"fmt"
"io"
"net/http"
"github.com/labstack/echo/v4"
"github.com/labstack/echo/v4/middleware"
"github.com/labstack/gommon/log"
)
func main() {
e := echo.New()
e.Static("/", "ui/dist")
e.File("/", "ui/dist/index.html")
// We gonna face CORS issue since we are passing data between different apps.
e.Use(middleware.CORSWithConfig(middleware.CORSConfig{
AllowOrigins: []string{"http://localhost:8888", "http://localhost:5173"},
AllowMethods: []string{http.MethodGet, http.MethodPut, http.MethodPost, http.MethodDelete},
}))
p := Person{
Name: "Nikola",
Age: 37,
Email: "nikola@tesla.genius",
}
e.GET("/person", func(c echo.Context) error {
return c.JSON(202, p)
})
// Update Person's name
e.POST("/person", func(c echo.Context) error {
// Get the request
r := c.Request()
// Read the body
b, err := io.ReadAll(r.Body)
if err != nil {
log.Error("error in POST", err)
return c.JSON(http.StatusBadRequest, map[string]string{"error": "Invalid Body Request"})
}
n := PostPersonBody{
Name: "default",
}
// equivalent of JSON.parse() in GO
// By default Go passes arguments by value, meaning it creates a copy of the value, and a new pointer is created.
// json.Unmarshall requires a reference (a pointer) to PostPersonBody and will update it internally.
err = json.Unmarshal(b, &n)
if err != nil {
log.Error(err)
return c.JSON(http.StatusBadRequest, map[string]string{"error": "Invalid JSON"})
}
// Debug purpose
fmt.Println(n.Name)
// Update local instance (db...)
p.Name = n.Name
return c.JSON(http.StatusAccepted, n)
})
e.Logger.Fatal(e.Start(":8888"))
}
type Person struct {
Name string `json:"name"`
Age uint8 `json:"age"`
Email string `json:"email"`
}
```
At this point we can run `go run ./main.go` or `go run ./` to lunch the server.
**Note that any changes in the Go code requires to relunch the server.**
## Front end
### Instalation
Let's install Vue.js using Vite.
For the router we will use [vue-router](https://router.vuejs.org/).
For styling we will try the alpha version of the future [Tailwind v4 release](https://tailwindcss.com/blog/tailwindcss-v4-alpha#using-vite).
```bash
npm create vue@latest # we call the project `ui`
npm install vue-router@4
npm install tailwindcss@next @tailwindcss/vite@next
```
Then add the `tailwind` plugin to the `vite.config.js` which should also contain the `vue` plugin
```javascript
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
import tailwindcss from '@tailwindcss/vite'
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue(),
tailwindcss()
]
})
```
### Creating the app
What's cool with `Vue` is that it is just a simple `html` with a js script entry point containing all the vue app.
The `javascript` will be injected inside the `root html component`.
When the project will be `built`, it will just compact the js and css but the principle will stay the same. making it easy for us to serve the `html` file from `Go`.
> Note that we use `Vue 3` with the [composition API](https://vuejs.org/guide/extras/composition-api-faq.html#what-is-composition-api).
### Adding components
Create two simple components for our pages: `HomePage` and `AboutPage`
```text
./ui
├── index.html
├── src
│ ├── App.vue
│ ├── components
│ │ ├── AboutPage.vue
│ │ └── HomePage.vue
│ ├── main.ts
│ ├── style.css
│ └── # ..
└── # ..
```
#### About Page
```html
<template>
<h1>ABOUT</h1>
<div>
<p>Lorem ipsum, dolor sit amet consectetur adipisicing elit. Porro ipsam inventore corrupti. Ducimus, sunt corrupti?</p>
</div>
</template>
<script lang="ts" setup></script>
```
#### Home Page
The Home page will fetch `Person` from the Go API. And is able to update it (via `POST` route we created earlier.
```html
<template>
<main class="flex flex-col justify-center items-center gap-8 py-12 px-8">
<h1 class="text-3xl text-blue-500">Welcome to Home page</h1>
<!-- Display Person's name or text -->
<p>Form API : {{ data?.name || "Click the Button 👇" }}</p>
<!-- Click the button to (re)fetch the data from the API -->
<button class="p-2 bg-lime-600 text-whiet font-bold rounded-md" @click="fetchData">{{ data ? "Refresh" : "Get data" }}</button>
<div class="flex flex-col gap-4">
<!-- v-model binds the input to the reference "name". It is both a Getter and a Setter -->
<input class="p-2 rounded-md" placeholder="no data.." type="text" v-model="name">
<!-- Fire the Post Request to update the name -->
<button class="p-2 bg-lime-600 text-whiet font-bold rounded-md" @click="update">Update Name</button>
</div>
<p>Name model : {{ name }}</p>
</main>
</template>
```
```html
<script lang="ts" setup>
import { ref } from 'vue';
type Person = {
name: string
age: number
email: string
}
type PostPersonName = {
name: string
}
const data = ref<Person | null>(null)
const name = defineModel<string>("fetching..")
async function fetchData() {
const prom = await fetch("http://localhost:8888/person")
const res: Awaited<Person> = await prom.json()
data.value = res
name.value = res.name
}
async function update() {
const data: PostPersonName = {
name: name.value!
}
const resp = await fetch("http://localhost:8888/person", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*",
},
body: JSON.stringify(data)
})
console.log(resp)
}
</script>
```
### Root Component
We update the root component to use the `RouterView` Component in order to display the components based on the current `url`
```html
<template>
<nav class="w-full bg-slate-800 p-8">
<ul>
<li>
<RouterLink to="/">Home</RouterLink>
</li>
<li>
<RouterLink to="/about">About</RouterLink>
</li>
</ul>
</nav>
<RouterView />
</template>
<script setup lang="ts">
import { RouterLink, RouterView } from 'vue-router';
</script>
```
## Registering the routes in the root component
Now we can create our `router`, register the `routes` and update the vue `app configuration`.
```typescript
import { createApp } from 'vue'
import './style.css'
import App from './App.vue'
import HomePage from './components/HomePage.vue'
import AboutPage from './components/AboutPage.vue'
import { createRouter, createWebHistory, type RouteRecordRaw } from 'vue-router'
// Routes registration
const routes: RouteRecordRaw[] = [
{ path: '/', component: HomePage },
{ path: '/about', component: AboutPage },
]
// Create Router
const router = createRouter({
history: createWebHistory(),
routes,
})
// Create app
createApp(App) // Root Component
.use(router) // Use Router
.mount('#app') // Html root element
```
### Run the app
You can check that everything works by launching the vite server with `npm run dev`
## Compile the Full stack application
### Build the Front end
To compile the application, we have to build the front end.
As we saw Go will source the path `ui/dist`: `e.Static("/", "ui/dist")`
Just run `npm run build`
Now we have this structure:
```text
.
├── go.mod
├── go.sum
├── main.go
└── ui
├── README.md
├── dist
│ ├── assets
│ │ ├── index-D52G_CEl.css
│ │ └── index-y7ffriUP.js
│ ├── index.html
│ └── vite.svg
├── index.html
├── package-lock.json
├── package.json
├── public
│ └── vite.svg
├── src
│ ├── App.vue
│ ├── assets
│ │ └── vue.svg
│ ├── components
│ │ ├── AboutPage.vue
│ │ └── HomePage.vue
│ ├── main.ts
│ ├── style.css
│ └── vite-env.d.ts
├── tsconfig.json
├── tsconfig.node.json
└── vite.config.ts
```
### Build the backend
To compile Go into a single binary just `go build ./main.go`.
But this will ouput `main` as the binary name, and we want to rename it `go-vue`.
To do so run : `go build -o go-vue ./main.go`
Now you can run `./go-vue` And the server should be running on port `8888`
I hop you liked the article. Please share it and add your thoughts in the comment section.
| maxiim3 |
1,869,435 | CSS Selectors :) | A post by muhammad zohaib | 0 | 2024-05-29T17:27:45 | https://dev.to/muhammad_zohaib_09aea9a34/css-selectors--13ni | webdev, beginners, tutorial, css |
 | muhammad_zohaib_09aea9a34 |
1,869,434 | Deploy Ollama with s6-overlay to serve and pull in one shot | Ollama brings the power of Large Language Models (LLMs) directly to your local machine. It removes... | 0 | 2024-05-29T17:27:44 | https://dev.to/darnahsan/deploy-ollama-with-s6-overlay-to-serve-and-pull-in-one-shot-31cm | ai, ollama, s6overlay, docker | Ollama brings the power of Large Language Models (LLMs) directly to your local machine. It removes the complexity of cloud-based solutions by offering a user-friendly framework for running these powerful models.
Ollama is a robust platform designed to simplify the process of running machine learning models locally. It offers an intuitive interface that allows users to efficiently manage and deploy models without the need for extensive technical knowledge. By streamlining the setup and execution processes, Ollama makes it accessible for developers to harness the power of advanced models directly on their local machines, promoting ease of use and faster iterations in development cycles.
However, Ollama does come with a notable limitation when it comes to containerized deployments. To download and manage models, Ollama must be actively running and serving before the models can be accessed. This requirement complicates the deployment process within containers, as it necessitates additional steps to ensure the service is up and operational before any model interactions can occur. Consequently, this adds complexity to Continuous Integration (CI) and Continuous Deployment (CD) pipelines, potentially hindering seamless automation and scaling efforts.
On [Ollama's docker hub](https://hub.docker.com/r/ollama/ollama) it has clear instructions over how to run Ollama requiring 2 steps. In the 1st step you need to have Ollama running before you can download the model to have it ready for prompting.
---
> docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
---
> docker exec -it ollama ollama run llama3
---
On their Discord there is a help query about how to do this in one shot with a solution which is good but not something I would put in production to lack of orchestration and supervision of processes. Its on github as [autollama](https://github.com/spara/autollama) and I recommend to check it out to learn some new tricks.
This is where I leveraged my past experience of using [s6-overlay](https://github.com/just-containers/s6-overlay) to setup `serve` and `pull` in a single container with serve as a `longrun` and pull as a `oneshot` dependent on serve to be up and running.
The directory structure for it as below
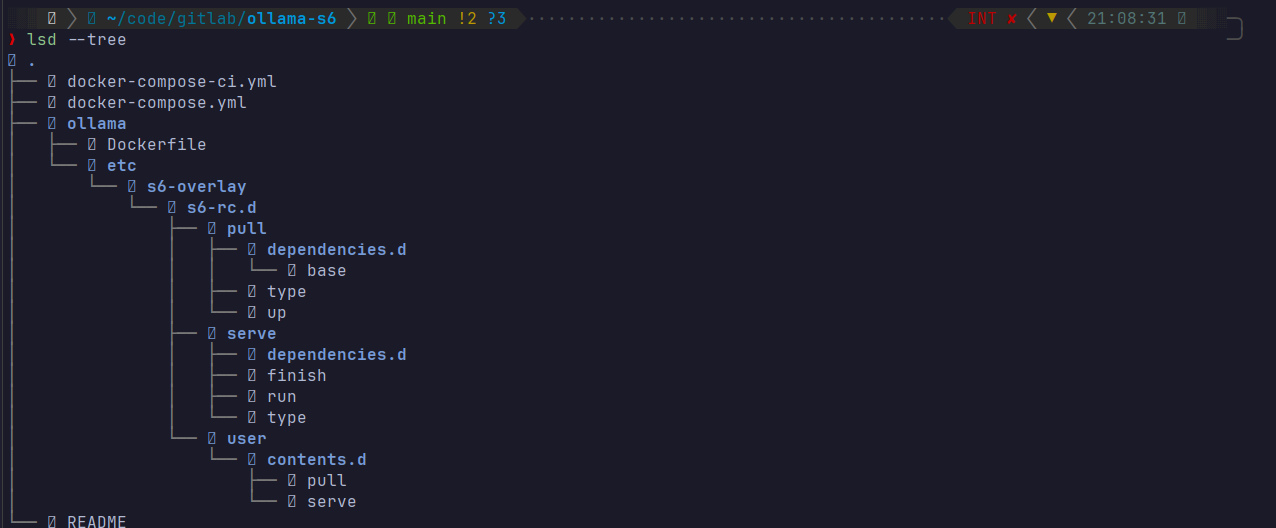
It runs flawlessly with `pull` running well supervised and orchestrated for it to complete and even when the download gets hammered due to internet speeds it keeps the process going without a glitch.
Currently there is a known [issue in s6-overlay](https://github.com/just-containers/s6-overlay/issues/577y) for service wait time which initially caused the `oneshot` to timeout. Had to S6_CMD_WAIT_FOR_SERVICES_MAXTIME=0 to disable it for the model download to not fail.
It is alive, at this point I was just super happy how smoothly it came up
On following run `pull` only gets the diff if any without the need to download the whole model again.
And Ollama has an api that you can prompt and its a charm to play around with.
With serve and pull in a single container to be served along your application it simplifies not only your deployments but also your CI to test it without overly complicating things by hacking scripts.
I have put the repo on github as [ollama-s6](https://github.com/ahsandar/ollama-s6/tree/main) for anyone looking to productionize their ollama deplyoments.
| darnahsan |
1,869,425 | Documentação dos Testes do Sistema SLAVE ONE | Testes Front-End Slave One Documentação dos Testes do Sistema SLAVE ONE Esta documentação descreve... | 0 | 2024-05-29T17:20:05 | https://dev.to/marcela_lage_094e814c6a4e/documentacao-dos-testes-do-sistema-slave-one-2kmb | cypress, frontend, cucumber, ledscommunity | **Testes Front-End Slave One**
**Documentação dos Testes do Sistema SLAVE ONE**
Esta documentação descreve os testes realizados no sistema SLAVE ONE pelos programadores front-end Gustavo e Marcela, do LEDS. Nos testes, foram utilizados
- software Cypress juntamente com a ferramenta Cucumber, que suporta o desenvolvimento orientado por comportamento (BDD).
**O que é o Cypress?**
O Cypress é uma ferramenta para testes de regressão automatizados de aplicações web. Ele oferece alta precisão nos testes, permitindo a criação de diversos cenários que facilitam o trabalho dos testadores e desenvolvedores da equipe, proporcionando testes rápidos e eficazes.
**O que é o Cucumber?**
O Cucumber é uma ferramenta que suporta BDD, oferecendo várias vantagens, como a utilização de uma linguagem natural (em Português, Inglês, entre outras). Isso permite um entendimento mais claro dos testes entre as equipes. Utilizamos o padrão do Cucumber para realizar os testes.
**O que é o BDD?**
Behavior Driven Development (BDD) é um conjunto de práticas de engenharia de software que integra regras de negócios com linguagem de programação, focando no comportamento do software. Ele criou um padrão nos testes, permitindo uma comunicação eficaz entre todos os envolvidos no projeto.
**Instalação do Cypress, Cucumber, XPath e .env**
1- **Instalação do Cypress**: Inicialmente, foi necessário instalar o Cypress. Utilizamos o comando direto no terminal do nosso projeto no VSCode:
*npm install cypress*
Esse comando cria uma pasta do Cypress dentro do projeto, contendo arquivos importantes para os testes.
2- **Instalação do Cucumber**: Em seguida, instalamos o Cucumber no projeto:
*npm install --save-dev cypress cypress-cucumber-preprocessor*
3- **Instalação do XPath**: Devido ao uso do Quasar, enfrentamos dificuldades com alguns componentes, sendo necessário utilizar o XPath para identificar os campos do sistema. O comando utilizado foi:
*npm install -D cypress-xpath*
4- **Instalação do .env**: Por fim, instalamos o .env para refatorar a parte de login do nosso código, melhorando sua organização visual. Embora opcional, sua instalação foi realizada com o comando:
*npm install dotenv --dev*
**Tipos de Testes**
O Cypress permite dois tipos de testes: e2e e testes de componentes.
1- **Teste e2e (end-to-end)**: Utilizado pela nossa equipe, esse tipo de teste verifica toda a experiência do aplicativo, de ponta a ponta, garantindo que cada fluxo funcione conforme o esperado.
2- **Teste de componentes**: Permite testar os componentes do sistema de design de forma isolada, garantindo que cada um corresponda às expectativas.
Após instalar o Cypress, utilizamos o comando no terminal: *npx cypress open*
Esse comando executa o Cypress e abre uma interface visual intuitiva, permitindo a escolha do tipo de teste a ser realizado (e2e ou component testing) e do navegador preferido para a execução dos testes.
**Estrutura dos Testes**
Ao escolher o tipo de teste, uma pasta e2e é criada. Para melhorar a organização, criamos também uma pasta step\_definitions. Nessa pasta, existem arquivos .feature e, no caso do SLAVE ONE, arquivos .ts (TypeScript, linguagem utilizada no frontend que suporta também o Cucumber).
- **Arquivos .feature**: Esses arquivos são escritos seguindo o padrão do Cucumber, em uma linguagem mais acessível (escrevemos em inglês) e são reconhecidos no Cypress como "SPECS".
- **Arquivos .ts**: Esses arquivos traduzem os cenários dos testes para uma linguagem de programação que a máquina entende, especificando o que será feito nos testes.
**Arquivos Feature**
Utilizando o padrão do Cucumber, criamos testes para cada tela com cenários positivos e negativos. No sistema SLAVE ONE, por exemplo, há uma tela de CRUD de “Categoria” que cria, edita, deleta e lista as categorias existentes no sistema. Utilizaremos essa tela como referência para demonstrar como os testes foram realizados.
O primeiro cenário reproduzido é positivo, no qual uma categoria é criada e tudo ocorre como esperado, com a API retornando o status 200 - Requisição bem-sucedida.
**Cenário positivo**
**Detalhamento dos Cenários de Teste**
**Feature: Cadastro de Categorias**
A feature em questão trata do cadastro de categorias no sistema. O objetivo é garantir que o processo de criação de uma nova categoria funcione corretamente, tanto para cenários de sucesso quanto para casos de erro.
**Background: Cenário Inicial**
O background define o cenário inicial necessário para os testes. Neste caso, envolve a preparação do ambiente e a realização do login no sistema.
- **Given** e **And**: Esses conectivos do Cucumber significam "Dado" e "E", respectivamente. Eles são utilizados para descrever as condições iniciais dos testes automatizados. No contexto atual, eles garantem que os testes realizem o login antes de iniciar o cenário de cadastro de uma categoria. Por exemplo:
*Given que visitei a tela de login And fiz o login com sucesso*
**Scenario Outline: Descrição do Cenário de Teste**
O scenario outline descreve o cenário específico que será testado. No caso do cadastro de categorias, o cenário envolve a navegação para a página de criação de uma nova categoria e a realização das ações necessárias para completá-lo.
- **When**: Este conectivo do Cucumber, "Quando", indica uma ação a ser realizada. Por exemplo:
_ *When eu vou para a página de criar uma nova categoria.* Isso redireciona o usuário para a página de criação._
- **And**: Novamente, o conectivo "E" é utilizado para encadear ações essenciais. Por exemplo:
_And eu digito no campo '<name>' de categoria And eu clico no botão de criar_
- **Then**: O "Then" serve para indicar o resultado esperado. Por exemplo: *Then eu tenho a mensagem da nova categoria criada*
- **Examples**: Os exemplos especificam os dados que serão utilizados nos testes. Podem ser quantos forem necessários. Exemplo de tabela:
| name | start date | final date |
| categoria | 16/12/2002 | 20/12/2024 |
**Cenários de Erro**
Os cenários seguintes tratam dos casos de erro, assegurando que o sistema responda corretamente a entradas inválidas.
1. **Tentativa de Criação de Categoria Vazia**:
1. Quando o usuário tenta criar uma categoria sem preencher os campos obrigatórios, a API deve retornar um erro.
1. **Verificação de Mínimo de Caracteres**:
○ O backend do SLAVE ONE verifica se os campos possuem no mínimo 3 caracteres. Se a entrada não cumprir essa regra, o sistema deve alertar o usuário sobre o erro e impedir o cadastro.
**Cenário de erro com mínimo de caracteres**
Este cenário trata da criação de uma categoria com um nome inválido, verificando se o sistema retorna a mensagem de erro apropriada.
- **When** e **And**: Esses conectivos redirecionam para a página de criação de categoria e executam as ações necessárias. Por exemplo:
_ When eu vou para a página de criar uma nova categoria And eu digito no campo 'name' de categoria _
_And eu clico no botão de criar_
- **Then**: Diferente do cenário de sucesso, aqui o "Then" verifica se a mensagem de erro apropriada é exibida. Por exemplo:
_ Then eu vejo a mensagem de erro '<message>'_
- **Examples**: Nos exemplos, utilizamos uma nova coluna para a mensagem de erro, especificando os dados de teste que devem causar o erro. Todos os nomes de categoria têm menos de 3 caracteres. Exemplo de tabela:
Copiar código
| name | message | | ab | Nome da categoria muito curto | | xy | Nome da categoria muito curto |
**Cenário de erro com campo nulo**
Este cenário trata da criação de uma categoria com um nome nulo, verificando se o sistema retorna a mensagem de erro apropriada.
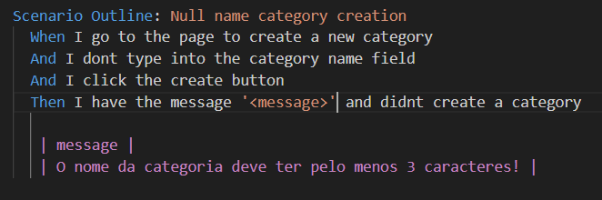
- **When e And**: Redireciona a página de criação de categoria. Colocamos o caso de erro nesse conectivo “**And**” que serve para deixar o campo de nome da categoria em branco
- **Then**: O cenário esperado não é criar uma categoria com sucesso, e sim exibir uma mensagem de erro, instanciando ela como string ‘<message>’
Note que nos exemplos, não possuímos a coluna de “name” pois ela deverá ficar vazia para que nosso teste de erro retorne a resposta esperada
**Arquivos .ts**
Para garantir o funcionamento adequado dos nossos testes, é necessário traduzir essas features em código que a máquina consiga interpretar. A seguir, apresentamos o processo de criação do arquivo TypeScript utilizado para compreender os testes especificados na nossa feature.
Primeiramente, foi criado um arquivo denominado "pageObjects", que tem como principal finalidade auxiliar na refatoração do nosso código de testes. Neste arquivo, foram inseridos diversos elementos da página de categoria que serão utilizados, além de várias funções que são chamadas dentro do código.
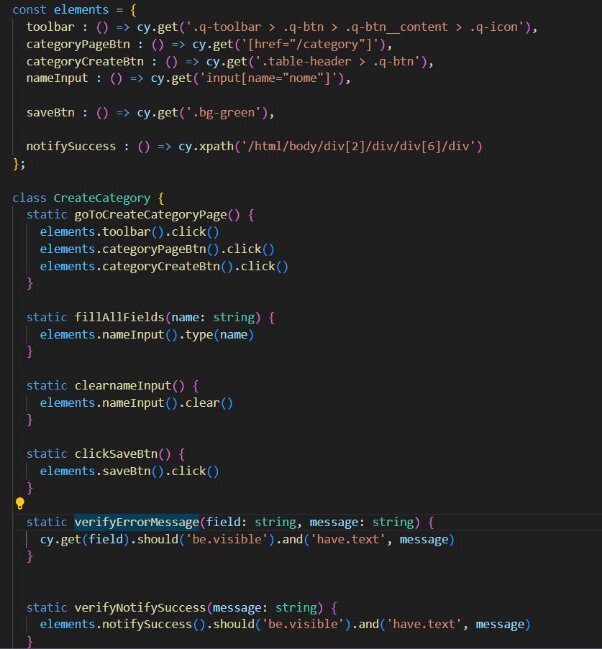
Declaramos todos os elementos necessários para que o teste possa concluir o cenário com sucesso. No objeto "elements", especificamos o caminho para a toolbar, que é onde, no sistema, acessamos as páginas. Neste caso, queremos acessar a página de categoria, então também instanciamos o botão de "categoria", que possui a rota para essa página.
Em seguida, no mesmo arquivo, criamos uma classe denominada "CreateCategory", que chama variáveis estáticas responsáveis pela criação da categoria. Por exemplo, temos a variável estática "goToCreateCategoryPage", que, como o próprio nome sugere, redireciona o teste para a página de criação de categoria. Dentro dessa classe, manipulamos os elementos previamente instanciados para acessar a página.
Mas onde iremos, de fato, integrar nosso roteiro com o TypeScript?
O próximo passo é criar um arquivo dentro da pasta "e2e", na subpasta "step\_definitions". Esse arquivo seguirá o roteiro que criamos e utilizará as funções definidas no arquivo "pageObjects" anteriormente explicado.
Utilizando o Cucumber com seus conectivos, voltamos ao arquivo .feature e utilizamos exatamente as frases escritas nele. Em seguida, chamamos a função criada no arquivo .ts para executar a ação correspondente ao cenário. Abaixo, mostramos como foi implementado na nossa criação de categoria:
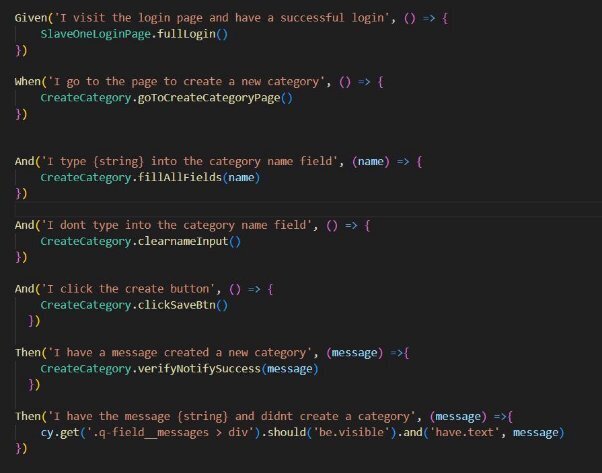
**Executando os Testes**
Para executar os testes, abra o terminal no diretório do seu código e insira o comando npx cypress open. Esse comando abrirá o Cypress previamente configurado, que automaticamente reconhecerá e exibirá as especificações de teste (specs).
Iniciar testes específicos é um processo simples: basta selecionar a spec desejada, e o Cypress executará o código correspondente. Caso ocorra algum erro durante a execução, o Cypress exibirá uma indicação no canto esquerdo da tela, juntamente com a descrição detalhada do erro.
**Refatoração do código**
Para que nosso código fique mais limpo e não haja muita repetição de código, foi realizado uma refatoração utilizando o método fábrica na tela de login para evitar que os campos sejam chamados várias vezes, pois sempre que realizamos um cenário no nosso sistema, é necessário que o software acesse a url do nosso sistema e realize login com ele.
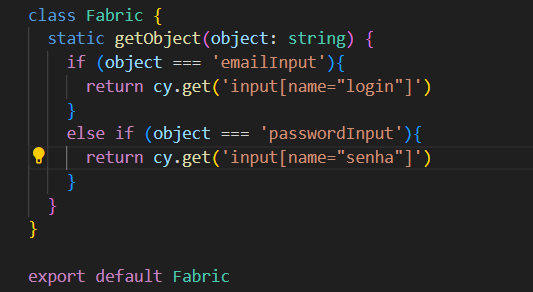
Dessa forma, o método fábrica cria um object que passa o “emailInput” que contém
- email que o usuário utilizará para fazer o login, e o campo “passwordInput” que possui a senha do sistema.
| marcela_lage_094e814c6a4e |
1,869,419 | 5 application performance monitoring and observability practices every organization should implement | Over the years, the process of application performance monitoring and observability has evolved... | 0 | 2024-05-29T17:16:12 | https://dev.to/manageengineapm/5-application-performance-monitoring-and-observability-practices-every-organization-should-implement-2cmc | applicationmonitoring, observability, manageengine | Over the years, the process of [application performance monitoring and observability](https://www.manageengine.com/products/applications_manager/application-observability.html?dev.to) has evolved significantly. What was once a one-size-fits-all endeavor has now transformed into a nuanced and tailored approach, reflecting the diverse needs and complexities of today's digital landscape. As organizations strive to optimize their applications for peak performance and user satisfaction, the implementation of best practices becomes not just a choice, but a strategic imperative. Let's take a look at five best practices in application performance monitoring and observability that organizations can implement to set themselves up for success.
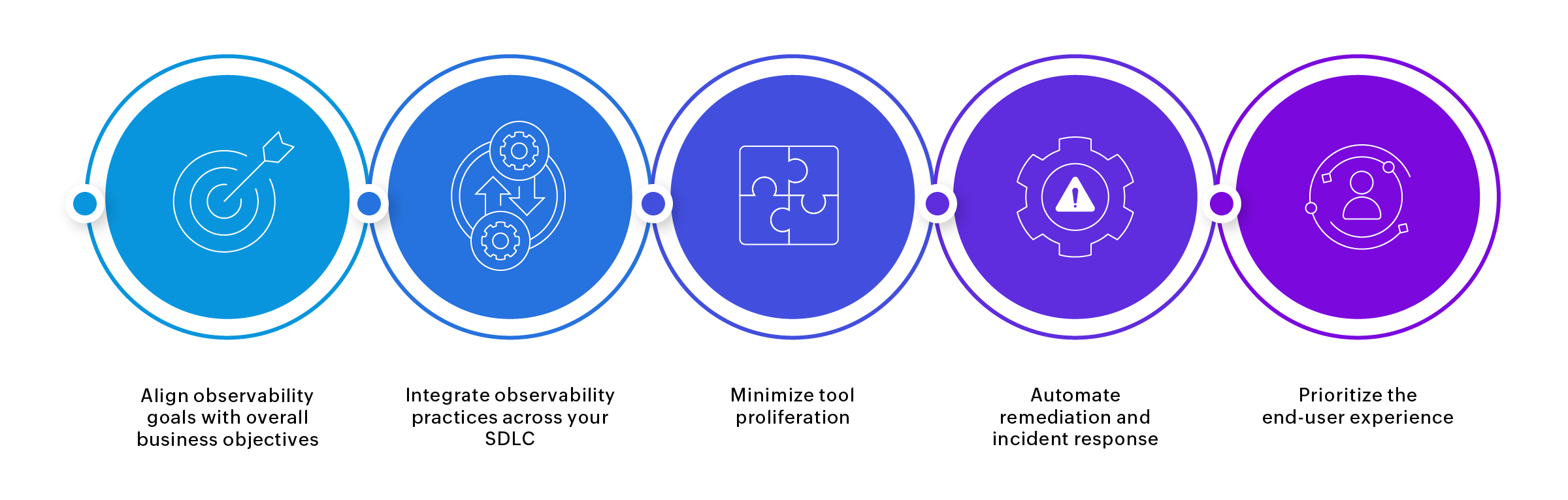
**1. Align observability goals with overall business objectives**
Monitoring the performance of your applications can provide access to a treasure trove of data, but without clear objectives, it's like navigating a maze blindfolded. Establishing performance objectives goes beyond mere focus; it builds a foundation of accountability within your organization. Yet, setting these goals is only the starting point. To achieve them, you need a strategic approach that considers several crucial elements:
**a) Baseline behavior:** Before aiming for improvement, you need a clear understanding of your current state. This involves collecting and analyzing metrics, events, logs, and traces (MELT) data to establish baseline metrics for key performance indicators (KPIs). Analyzing industry standards provides a benchmark for comparison and helps identify areas where your application might be underperforming compared to similar offerings.
**b) End-user experience:** Who are your core user groups? What are their expectations for application performance? Identify their top frustrations, including slow loading times, frequent errors, and more, through surveys, user testing, and support tickets. Translate these frustrations into quantifiable goals. For instance, surveys might reveal common complaints about mobile devices' slow loading times, leading to a quantifiable goal: Reduce application load time by 30% on mobile platforms. Additionally, breaking down the user journey into key stages—like login, navigation, and checkout—allows for setting specific performance objectives for each stage. This ensures a seamless and smooth experience across the entire user journey, addressing frustrations and enhancing overall satisfaction.
**c) Cross-functional collaboration:** Encourage close collaboration among application development, operations, and business strategy teams. This ensures that observability goals are not just aligned with business objectives but also seamlessly woven into development and operational workflows. Through this partnership, teams can identify potential bottlenecks and areas for improvement early in the development life cycle. For instance, during feature planning, discussions can focus on defining relevant observability metrics, estimating the impact on the user experience, and setting up monitoring strategies for post-release performance. By fostering this integrated approach and eliminating silos, you pave the way for a unified effort in achieving business goals through observability.
**2. Integrate observability practices across your SDLC**
With the increasing complexity of distributed applications and the rapid pace of development cycles, the traditional approach to application performance monitoring falls short. DevOps ecosystems now demand observability to glean insights across every stage of the DevOps life cycle, comprehend planned and unplanned changes, and stay ahead of the curve. However, implementing this requires a strategic approach. Here's a breakdown of observability best practices for each phase of the software development life cycle (SDLC):
**a) Phase 1: Plan**
Collaborate with product stakeholders to define service level objectives (SLOs) and service level agreements (SLAs) for the applications and features being developed. Create an inventory of existing monitoring tools and data sources within your organization. Evaluate if these tools are sufficient to meet your observability goals. If necessary, research and plan for the integration of additional tools to ensure comprehensive data collection across your application ecosystem.
**b) Phase 2: Develop**
Integrate instrumentation libraries and frameworks into your code from the beginning. This allows you to collect performance data during development, and identify and address potential issues early on. Additionally, focus on instrumenting critical code paths and areas, especially the ones that are tricky.
**c) Phase 3: Continuous integration**
Integrate observability practices within your CI pipeline. Run automated tests that collect and analyze performance data to ensure code changes don't cause performance regressions. Furthermore, set clear thresholds for performance metrics and failed builds that exceed these thresholds. This will help developers prioritize performance optimization throughout the development process.
**d) Phase 4: Deployment**
Deploy new code versions to a small subset of users first to identify and address performance issues before a wider release. Simulate real-world user journeys and transactions to proactively monitor application performance before deployments.
**e) Phase 5: Operate**
Implement distributed tracing to track requests across the entire application stack, pinpointing the root cause of issues in complex microservice architectures. Analyze application logs to identify errors, anomalies, and performance bottlenecks. Regularly review data collected to identify trends and areas for improvement. Use these insights to optimize your overall application performance monitoring and observability strategy.
**3. Minimize tool proliferation**
To keep up with their growing IT landscape, organizations often adopt
multiple monitoring tools (both proprietary and open-source) at a rapid pace. This uncoordinated adoption of various tools leads to fragmented visibility, as each tool collects its own data.
Disparate data sources create blind spots, making it difficult to see the bigger picture and correlate events across the application stack. Furthermore, tool sprawl creates a deluge of data that makes identifying critical insights a burden. Additionally, the sheer volume of alerts can lead to alert fatigue, which can cause critical issues to go unnoticed, impacting application performance and the user experience.
Observability demands a shift away from the tool-for-every-issue mindset towards a centralized resource that consolidates insights, streamlines processes, and simplifies monitoring strategies. The rationale behind this consolidation lies in the need for a unified platform that aggregates all relevant data in one place.
With this approach, teams can more easily correlate data points across different parts of the application, gaining a holistic understanding of its behavior and performance. While replacing every single tool might not be feasible, an effective APM solution can replace at least a subset of these tools while seamlessly integrating with the rest. This tool consolidation approach can involve three phases:
**a) Plan smart:** This phase involves creating a clear picture of your existing monitoring landscape (all tools) and how they contribute to your desired outcomes. Define your ideal future state with a streamlined set of tools.
**b) Prepare for success:** Build use cases that demonstrate the value of consolidation in specific scenarios. Pilot these use cases to identify the best approach and potential challenges. Develop a timeline for migrating to the new tool set.
**c) Execute smoothly:** Implement the chosen platform, migrate data and configurations, and train your teams on the new tools. Develop and socialize documentation to ensure everyone understands the new approach.
**4. Automate remediation and incident response**
Application monitoring is crucial, but let's be honest—pinpointing the why behind issues can be extremely time-consuming. Manual remediation further eats into valuable resources. This is where AI-powered automation steps in, transforming your monitoring from reactive to proactive.
Imagine a scenario where a specific container within your web application deployment consistently breaches its memory limit, causing the entire application to crash and restart repeatedly. Traditional monitoring might alert you to these application crashes, but AI automation can identify the culprit and trigger a horizontally scaling event, preventing further clashes. Over time, such tasks can be automated entirely, freeing your team to focus on innovation.
Here is a three-step approach to maximize the benefits of AI-driven automation for remediation and incident response:
**Step 1: Choose tasks that truly require automation:** Not every task needs automation. Focus on repetitive, high-volume tasks like anomaly detection, log analysis, and basic incident response. These tasks often have clear patterns and minimal decision-making variability, making them ideal candidates for efficient automation with significant operational improvements.
**Step 2: Enhance issue diagnosis:** Dive deep into affected components to gain comprehensive insights and prevent issues from escalating. Automation aids in obtaining richer context, facilitating faster and more accurate diagnosis.
**Step 3: Streamline incident resolution:** Navigate incident resolution efficiently by automating remediation actions with minimal human intervention. Implement intelligent workflows that can trigger actions like auto-scaling, service restarts, or configuration adjustments based on predefined criteria. Concurrently, establish a streamlined response system, directing issues to individuals or teams equipped with the precise expertise needed for resolution.
**5. Prioritize the end-user experience**
While server-side metrics provide a crucial foundation for APM and observability, they only tell part of the story. Focusing solely on these metrics can mask issues that significantly impact users. Consider a scenario where your Apdex score drops from say a solid 0.9 to 0.65 after a new application launch. This could be sluggish load times, issues specific to certain user journeys, or geographical performance inconsistencies.
A robust end-user experience monitoring strategy allows you to pinpoint whether these problems stem from slow load times due to a recent feature update or an influx of concurrent user sessions. Consider implementing these three best practices:
**a) Set up synthetic transaction monitoring:** Simulate real-user actions with varying scenarios (paths, session lengths, interactions) to identify potential problems before they impact real users. This approach will enable you to test the performance of your application across various global locations, providing insights into how users experience your application under different circumstances.
**b) Track and optimize real-user metrics:** Employ a [real user monitoring](https://www.manageengine.com/products/applications_manager/real-user-monitoring.html?dev.to) approach that will help you capture metrics like page load times, successful transactions, error rates, and more. Focus your optimization efforts on critical user pathways that significantly impact user satisfaction and align with business objectives. This will allow you to detect performance bottlenecks and swiftly address issues that might hinder a smooth user experience.
**c) Adopt an integrated approach:** Correlate backend infrastructure metrics with frontend performance to obtain a holistic perspective. Establish a continuous feedback loop between backend and frontend teams to promote collaboration and insight-sharing. This iterative approach enables cohesive efforts in addressing performance challenges, optimizing the app, and ensuring a seamless user experience.
Transform your approach to application performance monitoring and observability with [ManageEngine Applications Manager.](https://www.manageengine.com/products/applications_manager/?dev.to) This tool helps you define and track performance goals, ensuring your applications consistently meet predefined benchmarks.
Interested in learning more about Applications Manager? [Schedule a free, personalized demo](https://www.manageengine.com/products/applications_manager/demo.html?dev.to) with one of our solution experts today, or explore on your own with a [free, 30-day trial.](https://www.manageengine.com/products/applications_manager/download.html?dev.to)
| varsharam |
1,869,421 | Spring boot JWT authentication (auth0) with Swagger docs (springdoc) | Why? This is yet-another-spring-boot-jwt-tutorial. It has 2 main motives: To understand... | 0 | 2024-05-29T17:15:44 | https://dev.to/abir777/spring-boot-jwt-authentication-auth0-with-swagger-docs-springdoc-1bp0 | springboot, springsecurity, webdev, java |
## Why?
This is yet-another-spring-boot-jwt-tutorial. It has 2 main motives:
- To understand and document my understanding about spring security.
- The existing articles mostly use [jjwt](https://github.com/jwtk/jjwt) which has a **[vulnerable release](https://mvnrepository.com/artifact/io.jsonwebtoken/jjwt-impl/0.12.5) (as of now)**. Thus, I decided to use an **alternative library**, along with **[springdoc openapi 3 swagger](https://springdoc.org/) docs**.
> Probably you could scavenge the internet, and use LLMs to put up such an implementation. I just created a _cookbook_ kind of, you may use it as a guide.
Let's start...
## How?
This is not at all a beginner's guide, and I would assume the reader knows the **basics of spring**, IOC container, gradle, spring data JPA, how to build basic CRUD in spring boot.
As a starting point, you may follow [this guide](https://spring.io/guides/gs/rest-service).
### Initialize
This is a simple CRUD application with just **3 routes**: `/register`, `/login` and `/profile` (protected route). I hope this is pretty much self-explanatory. We will be using the **[H2 database](https://www.h2database.com/html/main.html)**, which is an in-memory database. It is easy to deal with during development, **but not ideal for production.** There's also an inbuilt web UI for H2 database.
Go to [Spring boot initializr](https://start.spring.io/).
You will need the following dependencies:
```groovy
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-security'
implementation 'org.springframework.boot:spring-boot-starter-validation'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'com.auth0:java-jwt:4.4.0'
implementation 'org.springdoc:springdoc-openapi-starter-webmvc-ui:2.5.0'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.security:spring-security-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
```
> The above alien language is groovy, which is used to configure Gradle build system (similar to xml in maven). The dependencies block is straightforward and pretty self-explanatory (one of the reasons why I prefer Gradle).
Now, extract and import the gradle/maven project into your preferred editor. If any error occurs, make sure about **spring and Java version.**
Two dependencies (`com.auth0:java-jwt` and `org.springdoc:springdoc-openapi-starter-webmvc-ui`) aren't available in spring starter.
Get them from [here](https://mvnrepository.com/artifact/com.auth0/java-jwt) and [here](https://mvnrepository.com/artifact/org.springdoc/springdoc-openapi-starter-webmvc-ui).

### Model
We will first create our model, then controller, then service, in the meantime, we will also learn about the required things as we go along...
1. Create a package called `controller`.
2. Create `UserDao.java`:
```java
package org.devabir.jwtexample.model;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import jakarta.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.hibernate.annotations.CreationTimestamp;
import org.hibernate.annotations.UpdateTimestamp;
import java.util.Date;
@Entity
@Table(name = "user_")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class UserDao {
@Id
private String email;
@Column(nullable = false, name = "hashed_password")
private String hashedPassword;
@CreationTimestamp
@Column(name = "created_at", updatable = false, nullable = false)
private final Date createdAt = new Date();
@UpdateTimestamp
@Column(name = "updated_at")
private Date updatedAt;
}
```
This is for interacting with the database. Most db has `user` as reserved keyword, hence, we are calling it `user_`.
> Getters, setters, and constructors are all **auto-generated by the annotations from lombok**.
> If you are new to this, you should spend some time and [setup lombok in your ide](https://projectlombok.org/setup/).
3. Create `UserRequestDto.java`:
```java
package org.devabir.jwtexample.model;
import jakarta.validation.constraints.Email;
import jakarta.validation.constraints.NotBlank;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class UserRequestDto {
@NotBlank(message = "Email is mandatory.")
// This email regex works. Trust me :)
@Email(message = "Please enter a valid email.", regexp = "^[a-zA-Z0-9_!#$%&’*+/=?`{|}~^.-]+@[a-zA-Z0-9.-]+$")
private String email;
@NotBlank(message = "Password is mandatory.")
private String password;
}
```
It also has **validation logic**. The email regex is sourced from some online searches, and it will work every time (trust me :)).
4. Create `UserResponseDto.java`:
```java
package org.devabir.jwtexample.model;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class UserResponseDto {
private String email;
private Date createdAt;
private Date updatedAt;
}
```
Separate Response object, so that we **don't accidentally leak out confidential attributes** like password, also it includes generated fields like created and updated timestamp.
5. Create `TokenResponse.java`:
```java
package org.devabir.jwtexample.model;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class TokenResponse {
private String accessToken;
private UserResponseDto user;
}
```
This class will be specifically used to respond on a `/login` request. We will not only send the user info, but also the **JWT access token**. In later sections, we will see how to set up the JWT part.
This is all about the models, now let's set up the repository for interacting with the database.
### JPA Repository
Create a package called `repository`, then inside that create `UserRepository.java`:
```java
package org.devabir.jwtexample.repository;
import org.devabir.jwtexample.model.UserDao;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<UserDao, String> {
}
```
### Controller
We have only one controller. Create a package `controller`, inside that a file `AuthController.java`:
```java
package org.devabir.jwtexample.controller;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.security.SecurityRequirement;
import jakarta.validation.Valid;
import org.devabir.jwtexample.model.TokenResponse;
import org.devabir.jwtexample.model.UserRequestDto;
import org.devabir.jwtexample.model.UserResponseDto;
import org.devabir.jwtexample.service.AuthService;
import org.devabir.jwtexample.service.JwtService;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.security.core.Authentication;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/auth")
public class AuthController {
private final AuthService authService;
private final JwtService jwtService;
public AuthController(AuthService authService, JwtService jwtService) {
this.authService = authService;
this.jwtService = jwtService;
}
@PostMapping("/register")
public ResponseEntity<UserResponseDto> register(@Valid @RequestBody UserRequestDto userRequestDto) {
return ResponseEntity
.status(HttpStatus.CREATED)
.body(this.authService.register(userRequestDto));
}
@PostMapping("/login")
public ResponseEntity<TokenResponse> login(@Valid @RequestBody UserRequestDto userRequestDto) {
UserResponseDto user = authService.login(userRequestDto);
final String accessToken = jwtService.buildToken(user.getEmail());
return ResponseEntity.ok(new TokenResponse(accessToken, user));
}
@Operation(security = {@SecurityRequirement(name = "bearer-key")})
@GetMapping("/profile")
public ResponseEntity<UserResponseDto> profile() {
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
UserDetails userDetails = (UserDetails) authentication.getPrincipal();
final String email = userDetails.getUsername();
return ResponseEntity.ok(this.authService.profile(email));
}
}
```
- This controller has 2 dependencies, `AuthService` and `JwtService`. We will eventually implement them.
- This controller will give us a high-level overview of the API we are going to create.
- `@Valid` annotation will validate the Bean with the constraints like `@NotBlank`, defined earlier, and throw an appropriate error. Spring's default exception handler [ProblemDetailsExceptionHandler](https://github.com/spring-projects/spring-boot/blob/main/spring-boot-project/spring-boot-autoconfigure/src/main/java/org/springframework/boot/autoconfigure/web/servlet/ProblemDetailsExceptionHandler.java), will respond with an appropriate JSON.
- `@Operation(security = {@SecurityRequirement(name = "bearer-key")})` annotation is specific to springdoc, we will come to it at last. Just remember that it helps us to identify which routes require authentication in the generated docs.
- In English, this roughly translates to: _"If the user is authenticated, Spring should already have the authenticated user's data, which we are simply accessing."_:
```java
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
UserDetails userDetails = (UserDetails) authentication.getPrincipal();
final String email = userDetails.getUsername();
```
Keep this part in mind, we will again use these when setting up security configs.
### Service
1. Create a package called `service`.
2. Create `UserService.java`:
```java
package org.devabir.jwtexample.service;
import org.devabir.jwtexample.model.UserDao;
import org.devabir.jwtexample.model.UserResponseDto;
import org.springframework.beans.BeanUtils;
import org.springframework.stereotype.Service;
@Service
public class UserService {
public UserResponseDto toDto(UserDao userDao) {
UserResponseDto result = new UserResponseDto();
BeanUtils.copyProperties(userDao, result, "hashedPassword");
return result;
}
}
```
- This file only **converts the DAO to DTO**, thus adhering to separation-of-concerns.
- DTO and DAO have many common fields, thus we are copying the Bean properties. There are other methods like model-mapper, builder or constructor from lombok. This seemed short and simple enough.
```java
public static void copyProperties(
Object source,
Object target,
String... ignoreProperties) throws BeansException {}
```
This will work, **even if you just omit the last parameter**, I just included that to be explicit.
3. Create `JwtService.java`:
```java
package org.devabir.jwtexample.service;
import com.auth0.jwt.JWT;
import com.auth0.jwt.algorithms.Algorithm;
import com.auth0.jwt.exceptions.JWTVerificationException;
import com.auth0.jwt.interfaces.DecodedJWT;
import com.auth0.jwt.interfaces.JWTVerifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.util.Date;
@Service
public class JwtService {
private final long jwtExpiration;
private final Algorithm signingAlgorithm;
public JwtService(
@Value("${security.jwt.secret-key}") String secretKey,
@Value("${security.jwt.expiration-time}") long jwtExpiration
) {
this.jwtExpiration = jwtExpiration;
this.signingAlgorithm = Algorithm.HMAC256(secretKey);
}
public String extractEmail(String token) {
JWTVerifier jwtVerifier = JWT.require(signingAlgorithm).build();
DecodedJWT jwt = jwtVerifier.verify(token);
return jwt.getSubject();
}
public boolean isTokenValid(String token, String email) {
try {
JWTVerifier verifier = JWT.require(signingAlgorithm)
.withSubject(email)
.build();
verifier.verify(token);
} catch (JWTVerificationException exception) {
return false;
}
return true;
}
public String buildToken(String email) {
return JWT.create()
.withSubject(email)
.withIssuedAt(new Date())
.withExpiresAt(new Date(System.currentTimeMillis() + jwtExpiration))
.sign(signingAlgorithm);
}
}
```
- This code actually uses the [Auth0's JWT library](https://github.com/auth0/java-jwt).
- `@Value("${security.jwt.secret-key}")` imports values from the `application.properties` file.
- This is mostly self-explanatory, we are setting user's email as the subject and signing algorithm as `HMAC256`.
- One thing to keep in mind, `jwtVerifier.verify(token);` could throw verification error.
4. At last `AuthService.java`:
```java
package org.devabir.jwtexample.service;
import org.devabir.jwtexample.model.UserDao;
import org.devabir.jwtexample.model.UserRequestDto;
import org.devabir.jwtexample.model.UserResponseDto;
import org.devabir.jwtexample.repository.UserRepository;
import org.springframework.beans.BeanUtils;
import org.springframework.http.HttpStatus;
import org.springframework.security.authentication.AuthenticationManager;
import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;
import org.springframework.security.core.userdetails.UsernameNotFoundException;
import org.springframework.security.crypto.password.PasswordEncoder;
import org.springframework.stereotype.Service;
import org.springframework.web.server.ResponseStatusException;
@Service
public class AuthService {
private final UserService userService;
private final UserRepository userRepository;
private final PasswordEncoder passwordEncoder;
private final AuthenticationManager authenticationManager;
public AuthService(UserService userService, UserRepository userRepository, PasswordEncoder passwordEncoder, AuthenticationManager authenticationManager) {
this.userService = userService;
this.userRepository = userRepository;
this.passwordEncoder = passwordEncoder;
this.authenticationManager = authenticationManager;
}
public UserResponseDto register(UserRequestDto userRequestDto) {
final String email = userRequestDto.getEmail();
if (this.userRepository.findById(email).isPresent())
throw new ResponseStatusException(HttpStatus.CONFLICT, "Email " + email + " is already taken.");
UserDao userDao = new UserDao();
BeanUtils.copyProperties(userRequestDto, userDao, "password");
userDao.setHashedPassword(this.passwordEncoder.encode(userRequestDto.getPassword()));
userDao = this.userRepository.save(userDao);
return this.userService.toDto(userDao);
}
public UserResponseDto login(UserRequestDto userRequestDto) {
final String email = userRequestDto.getEmail();
UserDao userDao = userRepository.
findById(email)
.orElseThrow(
() -> new UsernameNotFoundException("User " + email + " not found.")
);
this.authenticationManager.authenticate(
new UsernamePasswordAuthenticationToken(
userRequestDto.getEmail(),
userRequestDto.getPassword()
)
);
return userService.toDto(userDao);
}
public UserResponseDto profile(String email) {
UserDao userDao = userRepository
.findById(email)
.orElseThrow(() -> new UsernameNotFoundException("User " + email + " not found."));
return userService.toDto(userDao);
}
}
```
- We need to define 2 beans (`PasswordEncoder` and `AuthenticationManager`). We will define them in upcoming
sections.
- ```java
this.authenticationManager.authenticate(
new UsernamePasswordAuthenticationToken(
userRequestDto.getEmail(),
userRequestDto.getPassword()
)
);
```
This will **authenticate and save the user data** into Spring's context.
### Config
1. Create a package called `config`.
2. Create `AppConfig.java`:
```java
package org.devabir.jwtexample.config;
import io.swagger.v3.oas.models.Components;
import io.swagger.v3.oas.models.OpenAPI;
import io.swagger.v3.oas.models.security.SecurityScheme;
import org.devabir.jwtexample.model.UserDao;
import org.devabir.jwtexample.repository.UserRepository;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.authentication.AuthenticationManager;
import org.springframework.security.authentication.AuthenticationProvider;
import org.springframework.security.authentication.dao.DaoAuthenticationProvider;
import org.springframework.security.config.annotation.authentication.configuration.AuthenticationConfiguration;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.core.userdetails.UserDetailsService;
import org.springframework.security.core.userdetails.UsernameNotFoundException;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import java.util.Collection;
import java.util.List;
import java.util.Optional;
@Configuration
public class AppConfig {
private final UserRepository userRepository;
public AppConfig(UserRepository userRepository) {
this.userRepository = userRepository;
}
@Bean
public AuthenticationManager authenticationManager(AuthenticationConfiguration authConfig) throws Exception {
return authConfig.getAuthenticationManager();
}
@Bean
BCryptPasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Bean
public AuthenticationProvider authenticationProvider() {
DaoAuthenticationProvider authProvider = new DaoAuthenticationProvider();
authProvider.setUserDetailsService(userDetailsService());
authProvider.setPasswordEncoder(passwordEncoder());
return authProvider;
}
@Bean
UserDetailsService userDetailsService() {
return new UserDetailsService() {
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
// NOTE: no username, we just use emails internally.
final String email = username;
Optional<UserDao> optionalUserDao = userRepository.findById(email);
if (optionalUserDao.isEmpty()) {
throw new UsernameNotFoundException("User " + email + " not found.");
}
UserDao user = optionalUserDao.get();
return new UserDetails() {
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
return List.of();
}
@Override
public String getPassword() {
return user.getHashedPassword();
}
@Override
public String getUsername() {
return user.getEmail();
}
};
}
};
}
@Bean
public OpenAPI customOpenAPI() {
return new OpenAPI()
.components(
new Components()
.addSecuritySchemes(
"bearer-key",
new SecurityScheme()
.type(SecurityScheme.Type.HTTP)
.scheme("bearer")
.bearerFormat("JWT")
)
);
}
}
```
- This is probably the most convoluted part of our current app. Here, our business logic interfaces with spring boot framework. We will go from top to bottom.
- The beans for `AuthenticationManager` and `PasswordEncoder` were required by the `AuthService`, we are defining it here. These will be injected into `AuthService`.
- Spring framework can work with many `AuthenticationProvider`, like: `DaoAuthenticationProvider`, `LdapAuthenticationProvider`. Also, we can implement **complex rules like different authentication providers for different routes.**
- We are defining a `DaoAuthenticationProvider`, which is very common (it uses a `UserDetailsService` to retrieve user details from the database and compare credentials).
- This `UserDetailsService` is very spring-specific way of defining users. We need to define `loadUserByUsername(...)` **to retrieve the user from Database**. We can also define some authorities for role-based access control purposes. Here username is just the user's email.
- How we will define **the `UserDetails` is up to us** and spring will remember that, we can access that in a protected route.
- `customOpenAPI()` this is used to enhance the generated swagger docs, by **adding authentication functionality**. We will use this in demo later. [Source](https://springdoc.org/#how-do-i-add-authorization-header-in-requests).
3. Create `SecurityConfig.java`:
```java
package org.devabir.jwtexample.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.authentication.AuthenticationProvider;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.http.SessionCreationPolicy;
import org.springframework.security.web.SecurityFilterChain;
import org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter;
import org.springframework.web.cors.CorsConfiguration;
import org.springframework.web.cors.CorsConfigurationSource;
import org.springframework.web.cors.UrlBasedCorsConfigurationSource;
import java.util.List;
@Configuration
@EnableWebSecurity
public class SecurityConfig {
private final AuthenticationProvider authenticationProvider;
private final JwtAuthFilter jwtAuthFilter;
public SecurityConfig(AuthenticationProvider authenticationProvider, JwtAuthFilter jwtAuthFilter) {
this.authenticationProvider = authenticationProvider;
this.jwtAuthFilter = jwtAuthFilter;
}
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity httpSecurity) throws Exception {
httpSecurity.csrf(csrf -> csrf.disable());
httpSecurity.headers(h -> h.frameOptions(fo -> fo.disable()));
httpSecurity.authorizeHttpRequests(
authorizeHttpRequests -> authorizeHttpRequests
.requestMatchers("/auth/profile")
.authenticated()
.anyRequest()
.permitAll()
);
httpSecurity.sessionManagement(sessionManagement -> sessionManagement.sessionCreationPolicy(SessionCreationPolicy.STATELESS));
httpSecurity.authenticationProvider(authenticationProvider);
httpSecurity.addFilterBefore(jwtAuthFilter, UsernamePasswordAuthenticationFilter.class);
return httpSecurity.build();
}
@Bean
CorsConfigurationSource corsConfigurationSource() {
CorsConfiguration corsConfiguration = new CorsConfiguration();
corsConfiguration.setAllowedOrigins(List.of("http:localhost:8080"));
corsConfiguration.setAllowedMethods(List.of("GET", "POST"));
corsConfiguration.setAllowedHeaders(List.of("Authorization", "Content-Type"));
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**", corsConfiguration);
return source;
}
}
```
- This uses our defined `AuthenticationProvider`.
- `CorsConfigurationSource` is for setting up **CORS configuration.** These are set up on the server side. [Read this for getting an idea](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS).
- **Each request at first goes through a number of filters. This is called `SecurityFilterChain`.** We are configuring that:
- **Disable CSRF** because it's a REST API and we aren't working with session cookies.
- **Disable X-Frame-Options**, mainly for h2-console web UI. **This might not be a good idea in production.**
- **`/auth/profile` will be a protected route.** The rest are public.
- **No session cookie**, thus `SessionCreationPolicy.STATELESS`.
- `httpSecurity.addFilterBefore(jwtAuthFilter, UsernamePasswordAuthenticationFilter.class);` **we are adding the JWT filter (to extract email from JWT token), before Spring's Auth filter.**
### Properties
Finally, this is the last file.
Create `application.properties` within resources folder:
```properties
spring.application.name=jwtexample
server.error.include-stacktrace=never
server.error.include-exception=false
server.error.include-message=always
spring.datasource.url=jdbc:h2:mem:userdb
spring.datasource.driverClassName=org.h2.Driver
spring.h2.console.enabled=true
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.jpa.hibernate.ddl-auto=create-drop
security.jwt.secret-key=3e0ba6026587dc722876146dd83b2222
# 1h in millisecond
security.jwt.expiration-time=3600000
spring.output.ansi.enabled=ALWAYS
```
- The `security.jwt.secret-key` needs to be of **32 chars** (`HMAC256` requires 256-bit key (32 * 8 = 256 bits)).
- The `spring.output.ansi.enabled=ALWAYS` always gives a colored output :).
- `server.error` properties are used to conceal some confidential info. while presenting user with an error response. **This is still not full proof and may leak info in validation errors, or sql errors.**
- We are using the [H2 database](https://www.h2database.com/html/main.html), which is an in-memory database. It is easy to deal with during development, **but not ideal for production.** There's also an inbuilt web UI for H2 database.
## Demo
- Run the application in your IDE, or in terminal run `./gradlew bootRun` (gradle), `./mvnw spring-boot:run` (maven).
- Go to: http://localhost:8080/swagger-ui.html
- Explore the h2 database at: http://localhost:8080/h2-console. **Make sure to enter proper database name (`userdb`).**
- Do register **(expand and press on Try it out)**, then login and at last access the profile. Use padlock sign to copy and paste the JWT access token, you get after logging in.
- Also, check for the validation errors.
- Below are some screenshots:








If you have any issue following, here's the [source code repo](https://github.com/dev-abir/jwtexample).
Thanks a lot for reading
Stay safe,
Have a nice day.
| abir777 |
1,869,420 | Create a Responsive Navbar React Tailwind CSS TypeScript | Learn to Build a Responsive Navbar Menu in React with TypeScript and Tailwind CSS. Make sure React,... | 0 | 2024-05-29T17:15:31 | https://frontendshape.com/post/create-a-responsive-navbar-react-tailwind-css-and-typescript | react, tailwindcss, typescript, webdev | Learn to Build a Responsive Navbar Menu in React with TypeScript and Tailwind CSS. Make sure React, TypeScript, and Tailwind CSS are set up in your project before you start.
[Install & Setup Tailwind CSS + React + Typescript + Vite](https://frontendshape.com/post/install-setup-tailwind-css-react-18-typescript-vite)
Create a Basic Responsive Navbar Menu with React Hooks, Tailwind CSS, and TypeScript.
```jsx
import React, { useState } from 'react';
const Navbar: React.FC = () => {
const [isOpen, setIsOpen] = useState<boolean>(false);
return (
<nav className="bg-gray-800 p-4">
<div className="container mx-auto flex justify-between items-center">
<div className="flex items-center">
<a href="#" className="text-white font-bold text-lg">
YourLogo
</a>
</div>
<div className="hidden md:block">
<a href="#" className="text-white mr-4">
Home
</a>
<a href="#" className="text-white mr-4">
About
</a>
<a href="#" className="text-white">
Contact
</a>
</div>
<div className="md:hidden">
<button
onClick={() => setIsOpen(!isOpen)}
className="text-white focus:outline-none"
>
<svg
className="h-6 w-6 fill-current"
xmlns="http://www.w3.org/2000/svg"
viewBox="0 0 24 24"
>
{isOpen ? (
<path
fillRule="evenodd"
clipRule="evenodd"
d="M4 6h16v1H4V6zm16 4H4v1h16v-1zm-16 5h16v1H4v-1z"
/>
) : (
<path
fillRule="evenodd"
clipRule="evenodd"
d="M3 18v-2h18v2H3zm0-7h18v2H3v-2zm0-7h18v2H3V4z"
/>
)}
</svg>
</button>
</div>
</div>
{/* Mobile Menu */}
{isOpen && (
<div className="md:hidden mt-4">
<a href="#" className="block text-white my-2">
Home
</a>
<a href="#" className="block text-white my-2">
About
</a>
<a href="#" className="block text-white my-2">
Contact
</a>
</div>
)}
</nav>
);
};
export default Navbar;
```

Build a Responsive Navbar with Hamburger Menu and Close (X) Button Using React Hooks, Tailwind CSS, and TypeScript. Discover the Perfect Blend of Functionality and Style for Your Navigation Needs.
```jsx
import React, { useState } from "react";
const NavBar: React.FC = () => {
const [navbar, setNavbar] = useState<boolean>(false);
return (
<nav className="w-full bg-white shadow">
<div className="justify-between px-4 mx-auto lg:max-w-7xl md:items-center md:flex md:px-8">
<div>
<div className="flex items-center justify-between py-3 md:py-5 md:block">
<h2 className="text-2xl font-bold text-purple-600">YourLogo</h2>
<div className="md:hidden">
<button
className="p-2 text-gray-700 rounded-md outline-none focus:border-gray-400 focus:border"
onClick={() => setNavbar(!navbar)}
>
{navbar ? (
<svg
xmlns="http://www.w3.org/2000/svg"
className="w-6 h-6"
viewBox="0 0 20 20"
fill="currentColor"
>
<path
fillRule="evenodd"
d="M4.293 4.293a1 1 0 011.414 0L10 8.586l4.293-4.293a1 1 0 111.414 1.414L11.414 10l4.293 4.293a1 1 0 01-1.414 1.414L10 11.414l-4.293 4.293a1 1 0 01-1.414-1.414L8.586 10 4.293 5.707a1 1 0 010-1.414z"
clipRule="evenodd"
/>
</svg>
) : (
<svg
xmlns="http://www.w3.org/2000/svg"
className="w-6 h-6"
fill="none"
viewBox="0 0 24 24"
stroke="currentColor"
strokeWidth={2}
>
<path
strokeLinecap="round"
strokeLinejoin="round"
d="M4 6h16M4 12h16M4 18h16"
/>
</svg>
)}
</button>
</div>
</div>
</div>
<div>
<div
className={`flex-1 justify-self-center pb-3 mt-8 md:block md:pb-0 md:mt-0 ${
navbar ? "block" : "hidden"
}`}
>
<ul className="items-center justify-center space-y-8 md:flex md:space-x-6 md:space-y-0">
<li className="text-gray-600 hover:text-purple-600 cursor-pointer">
Home
</li>
<li className="text-gray-600 hover:text-purple-600 cursor-pointer">
Blog
</li>
<li className="text-gray-600 hover:text-purple-600 cursor-pointer">
About US
</li>
<li className="text-gray-600 hover:text-purple-600 cursor-pointer">
Contact US
</li>
</ul>
</div>
</div>
</div>
</nav>
);
};
export default NavBar;
```
**Sources**
[react useState](https://react.dev/reference/react/useState) (react.dev)
[Tailwind CSS](https://tailwindcss.com/) (tailwindcss.com)
[typescriptlang.org](https://www.typescriptlang.org/) | aaronnfs |
1,869,417 | La définition du langage de programmation Python | Python est un langage de programmation interprété, c'est à dire que quand vous faites un code python... | 0 | 2024-05-29T17:12:24 | https://dev.to/tidycoder/la-definition-du-langage-de-programmation-python-5bl4 | Python est un langage de programmation interprété, c'est à dire que quand vous faites un code python pour pouvoir être interprété, il a besoin d'un interpréteur, qui va lire le fichier pour donner le résultat.
Python est un langage facile comparé aux autres langages de programmation, il enlève quelques obligations quant on code, comme l'initialisation d'une variable en précisant le type. Et aussi, les noms des fonctions de base sont assez simples à retenir.
La python standard library est aussi une bonne library, c'est la library de base qu'il y a dans python, elle est très variée.
Et au passage, c'est vraie c'est dur de retenir comment on écrit le nom de ce langage, mais ce n'est pas phyton, mais c'est python. | tidycoder | |
1,869,411 | What is AWS Artifact? | AWS Artifacts is a centralized platform offered by Amazon Web Services that provides customers with... | 0 | 2024-05-29T17:01:49 | https://dev.to/jay_tillu/what-is-aws-artifact-3id1 | aws, cloud, devops, cloudcomputing | AWS Artifacts is a centralized platform offered by Amazon Web Services that provides customers with on-demand access to many compliance reports and agreements. Whether you're a startup or an enterprise, AWS Artifacts serves as your one-stop shop for all things related to security, compliance, and legal documentation within the AWS ecosystem.
There are two main components to AWS Artifact:
1. AWS Artifact Reports
2. AWS Artifact Agreements
## 1. AWS Artifact Reports

- The following are some of the compliance reports and regulations that you can find within AWS Artifact. Each report includes a description of its contents and the reporting period for which the document is valid.
- **Function:** Provide pre-generated reports that demonstrate AWS's compliance with various security and industry standards.
- AWS Artifact Reports provide compliance reports from third-party auditors. These auditors have tested and verified that AWS is compliant with a variety of global, regional, and industry-specific security standards and regulations.
- AWS Artifact Reports remains up to date with the latest reports released. You can provide the AWS audit artifacts to your auditors or regulators as evidence of AWS security controls.
- **Content:** Focuses on AWS's internal security posture, controls, and procedures. Examples include SOC reports (security), ISO certifications (various areas like quality management), and PCI reports (payment card industry data security).
- **Use Case:** Helpful for organizations using AWS to understand the overall security posture of the underlying cloud infrastructure.
## 2. AWS Artifact Agreements
- Function: Manage agreements between your organization and AWS.
- In AWS Artifact Agreements, you can review, accept, and manage agreements for an individual account and for all your accounts in AWS Organizations.
- **Content:** Focuses on defining the legal rights and responsibilities of both parties when handling sensitive data. Common agreements include Business Associate Agreements (BAA) for healthcare data (HIPAA compliance) and Data Processing Agreements (DPA) for general data privacy regulations (like GDPR).
- **Use Case:** Essential for managing your organization's compliance obligations when storing or processing sensitive data in AWS. These agreements outline how both AWS and your organization will handle data security, privacy, and breaches.
### In simpler terms:
- **Reports:** Show how secure AWS is (think of it as a brochure for AWS's security practices).
- **Agreements:** Define how you and AWS will handle your data security together (like a contract outlining responsibilities).
## Benefits of AWS Artifact
- **Saves Time:** Provides on-demand access to security and compliance reports in a self-service portal. This eliminates the need to contact AWS support or search for reports manually.
- **Improved Manageability:** Allows you to manage agreements with AWS at scale. You can accept, terminate, and download agreements electronically, streamlining the process.
- **Increased Confidence:** By providing easy access to compliance reports, AWS Artifact helps you understand the security posture of the AWS cloud infrastructure you're using. This can give you greater confidence when deploying your workloads on AWS.
- **Simplified Compliance:** AWS Artifact Agreements can help simplify compliance with regulations that require specific data handling procedures. For example, Business Associate Agreements (BAA) are essential for healthcare organizations that store protected health information (PHI) in AWS.
- **Transparency:** Having easy access to both AWS's security reports and your agreements with AWS fosters a more transparent relationship between you and the cloud provider.
## Conclusion
In today's data-driven world, security and compliance are paramount. AWS Artifact offers a valuable tool for organizations using AWS by simplifying access to security reports and managing data handling agreements. By using AWS Artifact, you can save time, streamline compliance efforts, and gain peace of mind knowing your data is secure within the AWS cloud infrastructure.
### Learn More About Cloud Computing
- [What is AWS IAM?](https://blogs.jaytillu.in/what-is-aws-identity-and-access-management-iam)
- [What is the AWS Shared Responsibility Model?](https://blogs.jaytillu.in/what-is-the-aws-shared-responsibility-model)
- [What is Amazon DMS?](https://blogs.jaytillu.in/understanding-amazon-data-migration-service-dms)
- [What is Amazon RedShift?](https://blogs.jaytillu.in/what-is-amazon-redshift)
- [What is Amazon Aurora?](https://blogs.jaytillu.in/understanding-amazon-aurora)
- [What is Amazon DynamoDB?](https://blogs.jaytillu.in/what-is-amazon-dynamodb)
- [What is Amazon RDS?](https://blogs.jaytillu.in/understanding-amazon-relational-database-service-rds)
- [What is Amazon Elastic File System?](https://blogs.jaytillu.in/what-is-amazon-elastic-file-system-efs)
- [Understanding Amazon S3 Storage Classes](https://blogs.jaytillu.in/understanding-amazon-s3-storage-classes)
- [What is Amazon S3?](https://blogs.jaytillu.in/what-is-amazon-simple-storage-service-s3)
- [What is Amazon EBS?](https://blogs.jaytillu.in/what-is-amazon-elastic-block-storage)
- [What is Amazon EC2?](https://blogs.jaytillu.in/what-is-amazon-ec2)
- [What is Load Balancing in Cloud Computing?](https://blogs.jaytillu.in/what-is-load-balancing-in-cloud-computing)
- [Understanding File Storage in Cloud Computing](https://blogs.jaytillu.in/understanding-file-storage-in-the-cloud-computing)
- [Understanding Block Storage in Cloud Computing](https://blogs.jaytillu.in/understanding-block-storage-in-the-cloud-computing)
### Follow me for more such content
- [My Site](https://www.jaytillu.in/)
- [My Blogs](https://blogs.jaytillu.in/)
- [LinkedIn](https://www.linkedin.com/in/jaytillu/)
- [Instagram](https://www.instagram.com/jay.tillu/)
- [Twitter](https://twitter.com/jay_tillu)
- [Stackoverflow](https://stackoverflow.com/users/8509590/jay-tillu) | jay_tillu |
1,869,416 | Learning AWS Day by Day — Day 78 — Amazon DocumentDB | Exploring AWS !! Day 78 Amazon DocumentDB Amazon DocumentDB (with MongoDB Capability) is fast,... | 0 | 2024-05-29T17:12:19 | https://dev.to/rksalo88/learning-aws-day-by-day-day-78-amazon-documentdb-4b4n | aws, cloud, cloudcomputing | Exploring AWS !!
Day 78
Amazon DocumentDB
Amazon DocumentDB (with MongoDB Capability) is fast, scalable, highly available database service supporting MongoDB workloads. It makes easy for us to store and index JSON data.
This is a non-relational database service designed from basic to give you better performance and scalability when operating critical MongoDB workloads at scale. In DocumentDB, storage and compute are decoupled, allowing to scale independently. The read capacity to millions of request per second can be increased by adding upto 15 low latency read replicas.
We can use same drivers, same code and same tool those you use with MongoDB.
When using DocumentDB, we start by creating clusters. A cluster contains instances and volumes to manage the storage for that instance.
The cluster consists of 2 components:
Cluster volumes: DocumentDB has one cluster storage volume, storing 128 TB of data.
Instances: It can contains 0–16 instances.
DocumentDB provides multiple connection options, and to connect with the instance we specify the instance’s endpoint. An endpoint is a host address and a port number, separated by a colon. | rksalo88 |
1,869,415 | Download 100 Retro Figma Shapes for Free Today | Looking to infuse your designs with a touch of vintage flair? collection of 100 retro Figma shapes... | 0 | 2024-05-29T17:10:02 | https://neattemplate.com/figma/download-100-retro-figma-shapes-for-free-today | figma, ui, uidesign, webdev | Looking to infuse your designs with a touch of vintage flair? collection of 100 retro Figma shapes has you covered. Dive into a treasure trove of meticulously crafted design elements, including 3D-inspired icons, graphics, and UI/UX components. Whether you're working on a website, app, or graphic project, these versatile shapes offer endless possibilities for creativity.
<br>
[100 Freebies Figma Charts & Graphs Icons](https://neattemplate.com/figma-icons/100-freebies-figma-charts-graphs-icons/)
<br>
Best of all, they're completely free to download in SVG, PNG, and vector formats. Whether you're a seasoned designer or just starting out, these free resources are an invaluable addition to your toolkit. Explore our collection today and discover how these retro Figma shapes can breathe new life into your designs.
Author: Streamline
[Download](https://www.figma.com/community/file/1344600563086398535) | faisalgg |
1,869,414 | FastAPI Beyond CRUD Part 2 - Build a Simple Web Server (Path & Query Params, Request Body, Headers) | This video demonstrates the process of constructing a web server, utilizing FastAPI's CLI for running... | 0 | 2024-05-29T17:08:57 | https://dev.to/jod35/fastapi-beyond-crud-part-2-build-a-simple-web-server-path-query-params-request-body-headers-4hj3 | fastapi, api, python, programming | This video demonstrates the process of constructing a web server, utilizing FastAPI's CLI for running the server, and explore various methods of inputting data, including path parameters, query parameters, request bodies, and more. #fastapi #python
{%youtube 7DQEQPlBNVM%} | jod35 |
1,869,412 | ChatGPT - Prompts for Code Refactoring | Discover the various ChatGPT Prompts for Code Refactoring | 0 | 2024-05-29T17:08:14 | https://dev.to/techiesdiary/chatgpt-prompts-for-code-refactoring-48d2 | chatgpt, promptengineering, ai, refactoring | ---
published: true
title: 'ChatGPT - Prompts for Code Refactoring'
cover_image: 'https://raw.githubusercontent.com/sandeepkumar17/td-dev.to/master/assets/blog-cover/chat-gpt-prompts.jpg'
description: 'Discover the various ChatGPT Prompts for Code Refactoring'
tags: chatgpt, promptengineering, ai, refactoring
series:
canonical_url:
---
## Code Refactoring Explained:
Code refactoring is the process of restructuring existing code without changing its external behavior. It involves making improvements to the code's internal structure, design, and readability while preserving its functionality. The primary goal of refactoring is to enhance the code's maintainability, extensibility, and efficiency.
## Why Code Refactoring is important:
There are several reasons why code refactoring is important:
* **Readability and Maintainability:** Refactoring improves the readability of code by making it easier to understand and modify.
* **Modularity and Extensibility:** Refactoring promotes the creation of modular code by breaking down large and monolithic functions into smaller, more manageable ones.
* **Performance Optimization:** Refactoring can lead to performance improvements by identifying and eliminating bottlenecks or inefficient algorithms.
* **Bug Detection and Prevention:** Refactoring often involves reviewing and analyzing code, which can help identify potential bugs or vulnerabilities.
* **Collaboration and Teamwork:** Well refactored code is easier to understand and work with, promoting effective collaboration among team members.
* **Code Reusability:** Refactoring can extract reusable code components, making them more accessible and reducing code duplication.
> Refactoring is like tidying up your code's room - it may take some effort, but it leads to a cleaner, more organized and inviting space for future development.
## ChatGPT Prompts for Code Refactoring:
Sharing a list of the prompts that can help you to use ChatGPT for Code Refactoring.
Replace the words in `block` to get the desired result, for example, use your choice of language, i.e., `C#`, `JavaScript`, `Python`, `NodeJS`, etc.
| | Type | Prompt |
| --- | --- | --- |
| 1 | Design Patterns | Are there any design patterns or principles that I should keep in mind while refactoring my code? |
| 2 | Design Patterns | How can I refactor the following `JAVA` code to follow the `Factory Pattern`? <br /> `[Enter your code here]` |
| 3 | Design Patterns | What are some techniques for refactoring code to improve code reuse and promote the use of design patterns? |
| 4 | Duplication | I have duplicate code in my project. How can I refactor it to eliminate redundancy? |
| 5 | Duplication | I'm refactoring a codebase that has a lot of code duplication. What are some approaches to identifying and eliminating duplicated code? |
| 6 | General | I have a long and complex function in my code that I want to refactor. How can I break it down into smaller, more manageable functions? |
| 7 | General | What are some tools or IDE plugins that can assist with code refactoring? |
| 8 | General | What are some common code smells that indicate the need for refactoring? |
| 9 | General | Suggest a refactor for this `C#` function: <br /> `[Enter your code here]` |
| 10 | General | I'm refactoring a codebase that heavily relies on global variables. What are some strategies to reduce the use of the global state and improve code encapsulation? |
| 11 | General | What are some common pitfalls to avoid during the code refactoring process? |
| 12 | General | What are some techniques for refactoring legacy code? |
| 13 | General | I'm refactoring a large codebase with multiple contributors. How can I ensure consistency in coding style and quality? |
| 14 | Improvement | Could you show me how to refactor this `C#` function to be more idiomatic: <br /> `[Enter your code here]` |
| 15 | Improvement | Could you show me how to refactor this `JavaScript` function to use more modern features such as `Arrow Functions`? <br /> `[Enter your code here]` |
| 16 | Improvement | What are some techniques for refactoring code to improve testability and enable easier unit testing? |
| 17 | Improvement | I am refactoring my codebase, and I want to ensure that I don't introduce any bugs. What are some best practices for safe refactoring? |
| 18 | Improvement | What are some strategies for refactoring code to improve error handling and exception management? |
| 19 | Improvement | I have a codebase that lacks proper error handling and logging. How can I refactor it to improve error reporting and debugging? |
| 20 | Performance | How can I improve the performance of my code through refactoring? |
| 21 | Performance | How can I refactor my code to improve its scalability and performance under heavy load? |
| 22 | Performance | What are some ways I can refactor this `Python` script for better performance: <br /> `[Enter your code here]` |
| 23 | Principles | I have a function that has grown too large and has multiple responsibilities. How can I refactor it to adhere to the single responsibility principle? |
| 24 | Principles | I am considering refactoring this `C#` Code to use `SOLID Principles`. How would you approach this? <br /> `[Enter your code here]` |
| 25 | Principles | Suggest a way to refactor this `C#` code to follow `SOLID Principles` while improving `reusability` <br /> `[Enter your code here]` |
| 26 | Readability | I have a codebase that lacks proper documentation. How can I refactor it to improve code readability and documentation? |
| 27 | Readability | I'm refactoring a codebase that has a lot of nested conditional statements. How can I simplify the logic and make it more readable? |
| 28 | Readability | Suggest a way to refactor the following `C#` code to improve readability. <br /> `[Enter your code here]` |
| 29 | Readability | How can I make this `JavaScript` code more readable: <br /> `[Enter your code here]` |
| 30 | Readability | I want to refactor this Java function to make it more maintainable, Any suggestions? <br /> `[Enter your code here]` |
| 31 | Security | How can I refactor my code to implement secure coding practices, such as input validation, output encoding, and proper authentication? |
| 32 | Security | What are some strategies for refactoring code to prevent common security risks, such as cross-site scripting (XSS) or SQL injection attacks? |
| 33 | Standard | Can you provide some tips on refactoring object-oriented code? |
| 34 | Standard | I’d like to refactor this `C#` code to be more object-oriented, Any suggestions? <br /> `[Enter your code here]` |
| 35 | Standard | How can I refactor this `C#` code to improve readability and align with `C# coding standards`? <br /> `[Enter your code here]` |
---
## NOTE:
> [Check here to review more prompts that can help the developers in their day-to-day life.](https://dev.to/techiesdiary/chatgpt-prompts-for-developers-216d)
| techiesdiary |
1,868,329 | Azure - Building Multimodal Generative Experiences. Part 1 | This Blog is a brief run-through of this learn collection to get a good understanding of the AI... | 0 | 2024-05-29T17:04:01 | https://dev.to/manjunani/azure-building-multimodal-generative-experiences-part-1-j5o | azure, ai, openai, information | This Blog is a brief run-through of this [learn collection](https://learn.microsoft.com/en-in/collections/7pmnfq2k784d?WT.mc_id=cloudskillschallenge_d1db6d81-f56e-4032-8779-b00a75aa762f) to get a good understanding of the AI services offered by Azure.
## Getting Started with Azure OpenAI Services
- Many Generative models are subsets of deep learning algorithms that support various workloads like vision, speech, language, decision and search.
- On Azure, these models are available through Rest APIs, SDK's, and Studio Interfaces.
- Azure Open AI Provides access to model management, deployment, experimentation, customization and learning resources.
- To begin building with Azure OpenAI, we need to choose and deploy a base model. Microsoft provides base models and an option to create customized base models
- There are several types of models available likely -->GPT 4, GPT 3.5, Embedding models, and Dall E Models(image generation models) which differ by cost, speed, and how well they complete the tasks
- Deployment of those Azure AI models can be done in multiple ways like using Azure OpenAI Studio, Azure CLI, or Azure Rest API.
- Once the deployment is done, you can check the models by triggering them from Azure OpenAI Studio.
- Likely using the below prompt types
- Classifying Content
- Generating New Content
- Holding a Conversation
- Transformation ( translation and symbol conversion)
- Summarizing Content
- Pick up where you left off
- Giving Factual Responses
- Additionally, you can test your models in the completion playground.
- These below are the parameters that you see on the completion playground.
- Temperature: Controls randomness. Lowering the temperature means that the model produces more repetitive and deterministic responses. Increasing the temperature results in more unexpected or creative responses. Try adjusting temperature or Top P but not both.
- Max length (tokens): Set a limit on the number of tokens per model response. The API supports a maximum of 4000 tokens shared between the prompt (including system message, examples, message history, and user query) and the model's response. One token is roughly four characters for typical English text.
- Stop sequences: Make responses stop at a desired point, such as the end of a sentence or list. Specify up to four sequences where the model will stop generating further tokens in a response. The returned text won't contain the stop sequence.
- Top probabilities (Top P): Similar to temperature, this controls randomness but uses a different method. Lowering Top P narrows the model’s token selection to likelier tokens. Increasing Top P lets the model choose from tokens with both high and low likelihood. Try adjusting temperature or Top P but not both.
- Frequency penalty: Reduce the chance of repeating a token proportionally based on how often it has appeared in the text so far. This decreases the likelihood of repeating the exact same text in a response.
- Presence penalty: Reduce the chance of repeating any token that has appeared in the text at all so far. This increases the likelihood of introducing new topics in a response.
- Pre-response text: Insert text after the user’s input and before the model’s response. This can help prepare the model for a response.
- Post-response text: Insert text after the model’s generated response to encourage further user input, as when modeling a conversation.
- Also you have a chat playground that is based on conversation in the message out interface which contains these parameters (Max Response, Top P, Past Messages Included)
## Analyze Images
- Azure Vision Service is designed to help you extract information from images. It provides the below functionalities
- Description and Tag Generation
- Object Detection
- People Detection
- Image metadata, color, and type analysis
- Category Identification
- Background Removal
- Moderate Rating (determine if the image includes any adult or violent content)
- Optical Character Recognition
- Smart thumbnail generation
## Plan an Azure AI Document Intelligence solution
- Azure AI Document Intelligence uses Azure AI Services to analyze the content of scanned forms and convert them into data. It can recognize text values in both common forms and forms that are unique to your business.
- **Azure AI Document Intelligence** is an Azure service that you can use to analyze forms completed by your customers, partners, employers, or others and extract the data that they contain.
- prebuilt models like (read, general document, layout) are available and common type forms like ( invoice, receipt, W-2 US tax declaration, ID Document, Business Card, Health Insurance card), custom models (custom template model, custom neural model), composed models (model which consists of multiple custom models).
- Refer this for more info on [model types](https://learn.microsoft.com/en-in/training/modules/plan-form-recognizer-solution/4-choose-model-type)
- Azure AI Document Intelligence includes Application Programming Interfaces for each model types you've seen.
## Use Prebuilt Document Intelligence models
- prebuilt models in Azure AI Document Intelligence enable you to extract data from common forms without training your own models.
- Several of the prebuilt models are trained on specific form types:
- Invoice model. Extracts common fields and their values from invoices.
- Receipt model. Extracts common fields and their values from receipts.
- W2 model. Extracts common fields and their values from the US Government's W2 tax declaration form.
- ID document model. Extracts common fields and their values from US drivers' licenses and international passports.
- Business card model. Extracts common fields and their values from business cards.
- Health insurance card model. Extracts common fields and their values from health insurance cards.
- The other models are designed to extract values from documents with less specific structures:
- Read model. Extracts text and languages from documents.
- General document model. Extract text, keys, values, entities, and selection marks from documents.
- Layout model. Extracts text and structure information from documents.
- Features of Prebuilt models (text extraction, key-value pairs, entities, selection marks, tables, fields)
- Also there are some input requirements we need to follow to use the prebuilt models and also a brief info of which models provide which features refer to this [link](https://learn.microsoft.com/en-in/training/modules/use-prebuilt-form-recognizer-models/2-understand-prebuilt-models?pivots=python).
- Probably W2 models and General Document models are good enough to get all the features that we might need.
## Extract data from forms with Azure Document Intelligence.
- Azure Document Intelligence uses Optical Character Recognition capabilities and a deep learning model to extract text, key-value pairs, selection marks, and tables from documents.
- OCR captures document structure by creating bounding boxes around detected objects in an image.
- Azure Document Intelligence is composed of the following services
- Document Analysis Models
- Prebuilt models( W2, invoices, receipts, ID Documents, Business Cards)
- Custom Models
- Azure Document Intelligence works on input documents that meet these requirements:
- Format must be JPG, PNG, BMP, PDF (text or scanned), or TIFF.
- The file size must be less than 500 MB for the paid (S0) tier and 4 MB for the free (F0) tier.
- Image dimensions must be between 50 x 50 pixels and 10000 x 10000 pixels.
- The total size of the training data set must be 500 pages or less.
- To Use OCR Capabilities, use a layout or read or general document model.
- To create an application that extracts data from other formats we can use prebuilt models
- To create an application that extracts data for your industry-specific norms we can use custom models
- Custom Models
- Custom template models accurately extract labeled key-value pairs, selection marks, tables, regions, and signatures from documents. Training only takes a few minutes, and more than 100 languages are supported.
- Custom neural models are deep-learned models that combine layout and language features to accurately extract labeled fields from documents. This model is best for semi-structured or unstructured documents.
Refer this [Link](https://dev.to/manjunani/azure-building-multimodal-generative-experiences-part-1-175p-temp-slug-8788540?preview=a83a5936ea6c652829720d7b03ec06b146b3d5edf614ce3ece9f6e538bb86a427ed1489a22a08639dca4d549bdb6fa0ca3f3ab908ed3babe739eadaf) for Continuation
| manjunani |
1,763,550 | Accessibility Breakdown | Navigating Landmarks | Todays mini series of things you can do right now, is on navigating landmark accessibility. Landmarks... | 26,989 | 2024-05-29T17:00:00 | https://dev.to/devsatasurion/accessibility-breakdown-navigating-landmarks-1g8g | a11y, accessibilityadvocate, webdev, developers | Todays mini series of things you can do <mark>**right now**</mark>, is on navigating landmark accessibility. Landmarks are often overlooked but are crucial for inclusive browsing. We want everyone to navigate the digital landscape seamlessly. Let's get into it:
---
## Why it Matters:
- **Accessibility Impact**: For individuals with disabilities, landmarks offer vital orientation within a webpage, empowering them to navigate independently and access content efficiently.
- **User Experience**: Landmarks provide essential cues, guiding users through webpage structures and improving navigation efficiency. Consider landmarks as road signs on a highway. Without them, one would struggle to navigate and reach their destinations efficiently.
---
## Quick Check:
- **Manual Inspection**: Scan your web pages for semantic HTML elements such as `<header>`, `<footer>`, `<nav>`, `<main>`, `<aside>`, and `<section>` to identify existing landmarks.
- Does all content exist inside a landmark? Look for supporting ARIA roles if landmarks aren't there.
- Avoid duplicate landmarks with the same role in the same context. For example, having two <main> tags on the same page can confuse screen reader users.
- For pages with dynamic content (e.g., single-page applications), ensure that landmarks are updated dynamically as the content changes. This helps screen readers keep up with the context shifts.
- You can use browser developer tools like Chrome DevTools to inspect the accessibility tree.
- You can use also use [Web Developer](https://chromewebstore.google.com/detail/web-developer/bfbameneiokkgbdmiekhjnmfkcnldhhm) to help point these out.
<figcaption>Web Developer tools</figcaption>
- **Automated Tools**: Utilize accessibility evaluation tools like [Lighthouse](https://developer.chrome.com/docs/lighthouse) or [Axe](https://chromewebstore.google.com/detail/axe-devtools-web-accessib/lhdoppojpmngadmnindnejefpokejbdd?utm_source=deque.com&utm_medium=referral&utm_campaign=axe_hero) or [WAVE](https://chromewebstore.google.com/detail/wave-evaluation-tool/jbbplnpkjmmeebjpijfedlgcdilocofh) to validate the presence and proper usage of landmarks automatically. You might see an error like this:

- **Screen Reader Testing**: Test your web pages using a screen reader to ensure that landmarks are conveyed effectively to users who rely on auditory feedback. Can you understand each section of the page?
---
## Quick Fixes:
- **Semantic Markup**: Ensure accurate use of semantic HTML elements to define landmarks. Utilize appropriate tags to delineate content sections. For example:
- `<header>`: Contains introductory content, such as a website's title and navigation links.
- `<main>`: Contains the main content of the webpage.
- `<section>`: Groups related content together within the main section.
- `<footer>`: Contains footer information, such as copyright details.
Use what works for you.
- Maintain consistency in landmark usage across different pages of the site. This provides a predictable experience for users.
- **ARIA Landmarks**: Supplement semantic HTML with ARIA landmarks for enhanced accessibility. Utilize roles like `role="banner"`, `role="navigation"`, `role="main"`, and `role="complementary"` to provide additional context.
- Use aria-label or aria-labelledby attributes to provide descriptive labels for landmarks when necessary
```html
<nav aria-label="Primary Navigation">
...
</nav>
```
---
## Testing:
- Ensure that focus management practices (e.g., tabindex, focus trapping) do not interfere with landmark navigation.
- Test landmark functionality across different browsers and devices to ensure consistent behavior
- Consider conducting user testing sessions with individuals who might use assistive technologies, or someone who isn't familiar with your app to gather feedback on the accessibility of landmarks and implement necessary adjustments that make sense.
By following these quick steps, you can quickly enhance the accessibility of how you utilize landmarks in your application, contributing to a more inclusive online environment for all users. Accessibility is an ongoing journey, so start making a positive impact today!🌟
---
**Helpful Links**
Free <abbr title="Accessibility">A11y</abbr> tools:
- [NVDA Screen Reader](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwj7uqDNm_D6AhUiEFkFHfvrB9QQFnoECBYQAQ&url=https%3A%2F%2Fwww.nvaccess.org%2Fdownload%2F&usg=AOvVaw3AAc5nrFrg0lylpULGjjxr)
- [Axe DevTools Chrome Extension](https://chromewebstore.google.com/detail/axe-devtools-web-accessib/lhdoppojpmngadmnindnejefpokejbdd)
- [WAVE Browser Chrome Extension](https://wave.webaim.org/extension/)
- [Web Developer Chrome Extension](https://chromewebstore.google.com/detail/web-developer/bfbameneiokkgbdmiekhjnmfkcnldhhm)
- [ANDI Accessibility Testing Tool](https://www.ssa.gov/accessibility/andi/help/install.html)
A11y Info:
- [WCAG Standard Guidelines](https://www.w3.org/WAI/standards-guidelines/wcag/)
- [A11y Project](https://www.a11yproject.com/)
| ashleysmith2 |
1,869,478 | Desafio De Python Pandas Online E Gratuito: 7 Days Of Code | Participe do Desafio de Python Pandas Online e Gratuito oferecido pela 7 Days Of Code e leve seus... | 0 | 2024-06-23T13:51:55 | https://guiadeti.com.br/desafio-python-pandas-gratuito-7-days-of-code/ | eventos, analisededados, dados, pandas | ---
title: Desafio De Python Pandas Online E Gratuito: 7 Days Of Code
published: true
date: 2024-05-29 16:58:07 UTC
tags: Eventos,analisededados,dados,pandas
canonical_url: https://guiadeti.com.br/desafio-python-pandas-gratuito-7-days-of-code/
---
Participe do Desafio de Python Pandas Online e Gratuito oferecido pela 7 Days Of Code e leve seus estudos de programação a um novo nível.
Ao longo de sete dias, você enfrentará sete desafios distintos, cada um desenvolvido para aprimorar suas habilidades em manipulação, visualização e análise de dados utilizando a biblioteca Python Pandas.
Este é o momento ideal para desenvolver seu portfólio e enriquecer seu GitHub, enquanto explora dados de empréstimos dos acervos do sistema de bibliotecas da UFRN.
Durante o desafio, você aprenderá a navegar por uma variedade de funcionalidades do Pandas, desde a importação de dados em diferentes formatos até a realização de agregações complexas.
## 7 Days of Code de Python Pandas
Participe do Desafio de Python Pandas Online e Gratuito oferecido pela 7 Days Of Code, uma oportunidade única para colocar em prática seus conhecimentos de programação.

_Imagem da página do programa_
Este desafio, criado por profissionais do mercado, é perfeito para quem deseja desenvolver habilidades práticas enquanto enriquece seu portfólio e GitHub.
Ao longo de sete dias, você enfrentará sete desafios distintos, cada um projetado para aprimorar suas habilidades em manipulação, visualização e análise de dados.
### Exploração de Dados com Python Pandas
Durante o evento, seu principal objetivo será explorar dados de empréstimos dos acervos do sistema de bibliotecas da UFRN.
Para isso, você será guiado através de diversas funcionalidades que o Python Pandas pode oferecer.
Desde a importação de dados em diferentes formatos até a realização de agregações, divisões e transformações de tabelas, cada etapa do desafio é uma chance de aprender mais sobre como manipular e analisar dados de maneira eficiente.
Ao final do desafio, você será capaz de exportar tabelas estilizadas com análises prontas para serem inseridas em outras aplicações. Confira os desafios:
#### Dia 1
Já no primeiro dia, você você precisará começar com a coleta e organização dos dados, para que possa trabalhar com eles nas próximas análises. Depois, você irá unificá-los em um único Dataframe. Você já começará a usar algumas ferramentas, como o Jupyter Notebook.
#### Dia 2
Hoje, você irá começar a manipular os seus dados, ou seja, tirar o que não for necessário, agrupar dados, atribuir novas informações, etc. Você irá iniciar a limpeza e atribuir mais contexto aos seus dados para depois aprofundar-se nas análises.
#### Dia 3
Finalmente você começará a realizar análises! Você irá verificar qual é a quantidade total de livros emprestados por cada ano, plotar um gráfico de linhas e, depois, fazer uma análise em relação à visualização gerada.
#### Dia 4
Chegou a hora de brincar com variáveis categóricas. Com os dados em mãos, irá gerar uma tabela de frequência com o percentual para cada variável e, como isso é um trabalho repetitivo, irá criar uma função que gere a tabela com os valores.
#### Dia 5
Nesse dia, você vai começar a usar o Boxplot, uma das visualizações mais poderosas que existe. Você vai avaliar a distribuição de empréstimos mensais por ano entre os alunos para a coleção que tiver a maior frequência de empréstimos. Depois, irá plotar um gráfico para cada tipo de usuário e ter um Boxplot para cada ano.
#### Dia 6
Chegando quase no final, você precisará calcular a quantidade de empréstimos realizados entre 2015 e 2020 por cada curso de graduação que passará pela avaliação. Com os dados em mãos, irá gere uma tabela com características específicas.
#### Dia 7
No sétimo e último dia do desafio, você precisará criar uma tabela com as diferenças percentuais de empréstimos entre três períodos diferentes. Você irá criar o HTML da tabela obtida, a fim de enviá-lo à equipe de Front-end.
### Suporte Contínuo e Resultados Compartilháveis
Após sua inscrição, você receberá um e-mail diário contendo o contexto do desafio do dia, a tarefa a ser realizada e links para materiais extras que ajudarão a aprofundar seu entendimento sobre os temas abordados.
Este desafio é ideal para qualquer pessoa interessada em tecnologia e programação que deseja saber como praticar as habilidades demandadas pelo mercado de trabalho.
Depois dos sete dias, você terá desenvolvido vários projetos que poderão ser adicionados ao seu portfólio, demonstrando suas habilidades a empregadores potenciais e a sua rede social.
Não perca a chance de compartilhar seus resultados e progresso nas redes sociais, ganhando visibilidade e reconhecimento na comunidade de tecnologia!
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Desafio-De-Python-Pandas-280x210.png" alt="Desafio De Python Pandas" title="Desafio De Python Pandas"></span>
</div>
<span>Desafio De Python Pandas Online E Gratuito: 7 Days Of Code</span> <a href="https://guiadeti.com.br/desafio-python-pandas-gratuito-7-days-of-code/" title="Desafio De Python Pandas Online E Gratuito: 7 Days Of Code"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Cursos-De-Metaverso-Python-IoT-280x210.png" alt="Cursos De Metaverso, Python, IoT" title="Cursos De Metaverso, Python, IoT"></span>
</div>
<span>Cursos De Metaverso, Python, IoT E Outros Gratuitos Da Samsung</span> <a href="https://guiadeti.com.br/cursos-metaverso-python-iot-gratuitos-samsung/" title="Cursos De Metaverso, Python, IoT E Outros Gratuitos Da Samsung"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Curso-De-Sistemas-Autonomos-280x210.png" alt="Curso De Sistemas Autônomos" title="Curso De Sistemas Autônomos"></span>
</div>
<span>Curso De Sistemas Autônomos Gratuito: Boas Práticas Operacionais</span> <a href="https://guiadeti.com.br/curso-sistemas-autonomos-boas-praticas/" title="Curso De Sistemas Autônomos Gratuito: Boas Práticas Operacionais"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Bootcamp-Inteligencia-Artificial-Generativa-1-280x210.png" alt="Bootcamp Inteligência Artificial Generativa" title="Bootcamp Inteligência Artificial Generativa"></span>
</div>
<span>Bootcamp De Inteligência Artificial Generativa E Claude 3 Gratuito</span> <a href="https://guiadeti.com.br/bootcamp-inteligencia-artificial-generativa-cloud/" title="Bootcamp De Inteligência Artificial Generativa E Claude 3 Gratuito"></a>
</div>
</div>
</div>
</aside>
## Python Pandas
Python Pandas é uma biblioteca de software livre e de código aberto que proporciona ferramentas de análise e manipulação de dados excepcionais para a linguagem de programação Python.
Desenvolvida por Wes McKinney em 2008, Pandas é hoje uma das ferramentas mais populares no campo de ciência de dados devido à sua eficiência e facilidade de uso.
A biblioteca é especialmente feita para trabalhar com dados tabulares ou heterogêneos e é ideal para diversas operações como a limpeza, transformação e análise de grandes conjuntos de dados.
### Características Principais do Pandas
O Pandas oferece duas estruturas de dados principais: “Series” e “DataFrame”, que são adequadas para manipular uma variedade de tipos de dados e tamanhos de conjunto de dados.
A “Series” é uma matriz unidimensional capaz de armazenar qualquer tipo de dado, enquanto o “DataFrame” é uma estrutura bidimensional semelhante a uma tabela de banco de dados.
Essas estruturas oferecem uma maneira intuitiva de organizar, filtrar, manipular e analisar dados com alta performance. Pandas integra-se perfeitamente com outras bibliotecas populares de Python como NumPy e matplotlib, tornando-o uma ferramenta ainda mais poderosa para análise de dados.
### Utilização do Pandas em Projetos de Análise de Dados
Pandas é muito utilizado em uma variedade de aplicações de dados, desde a análise financeira até a pesquisa científica. Ele permite aos usuários carregar, preparar, manipular, modelar e analisar dados de maneira rápida e eficiente.
Utilizando Pandas, é possível realizar tarefas complexas como a manipulação de datas, preenchimento de dados faltantes, agrupamento por categorias e pivotamento de tabelas com poucas linhas de código.
A capacidade de exportar e importar dados em diferentes formatos como CSV, SQL databases, Excel, entre outros, faz de Pandas uma ferramenta indispensável para profissionais que trabalham com grandes volumes de dados e necessitam de uma ferramenta robusta e flexível para análise e visualização de dados.
## 7 Days of Code
A 7 Days of Code é uma iniciativa da Alura que oferece uma série de desafios de programação projetados para estimular o desenvolvimento de habilidades em diversas tecnologias.
Ideal para programadores de todos os níveis, desde iniciantes até avançados, esta plataforma fornece uma oportunidade única para os participantes testarem e aprimorarem suas capacidades em um ambiente de aprendizado prático e competitivo.
### Benefícios e Impacto da Participação
Participar dos desafios da 7 Days of Code traz diversos benefícios. Para os desenvolvedores, é uma excelente forma de aprender de maneira prática, enfrentando problemas reais que podem ser encontrados no dia a dia da profissão.
A comunidade da 7 Days of Code também oferece suporte através de fóruns e chats, onde os participantes podem interagir com outros desenvolvedores, trocar ideias, e obter feedback sobre seu trabalho.
## Aceite o desafio e aprimore suas habilidades de análise de dados!
As [inscrições para o 7 Days of Code de Python Pandas](https://7daysofcode.io/matricula/pandas) devem ser realizadas no site da 7 Days of Code.
## Desafie seus amigos a dominar Python Pandas!
Gostou do conteúdo sobre o desafio? Então compartilhe com a galera!
O post [Desafio De Python Pandas Online E Gratuito: 7 Days Of Code](https://guiadeti.com.br/desafio-python-pandas-gratuito-7-days-of-code/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,869,409 | Top 10 Skills Every Junior Developer Should Learn | Version Control (Git) Understanding version control is essential for collaborating on projects... | 0 | 2024-05-29T16:54:53 | https://dev.to/bingecoder89/top-10-skills-every-junior-developer-should-learn-5fl8 | beginners, tutorial, codenewbie, programming | 1. **Version Control (Git)**
- Understanding version control is essential for collaborating on projects and tracking changes in code. Git, a popular system, allows for efficient management of codebases.
2. **Programming Languages**
- Proficiency in at least one programming language (e.g., Python, JavaScript, Java) is fundamental. Focus on learning the syntax, semantics, and best practices of your chosen language.
3. **Debugging and Problem-Solving**
- The ability to debug code and solve problems is crucial. Learn to use debugging tools and techniques to identify and fix issues in your code efficiently.
4. **Basic Data Structures and Algorithms**
- Knowledge of data structures (arrays, lists, trees) and algorithms (sorting, searching) is vital for writing efficient and optimized code.
5. **Web Development Basics**
- Understanding the fundamentals of web development, including HTML, CSS, and JavaScript, is important for creating and maintaining web applications.
6. **Command Line Interface (CLI)**
- Proficiency with the command line interface allows developers to perform tasks more efficiently and navigate file systems and servers without a graphical interface.
7. **Database Management**
- Learn the basics of database management systems (SQL and NoSQL) to store, retrieve, and manipulate data effectively in your applications.
8. **Testing and Test-Driven Development (TDD)**
- Writing tests for your code ensures reliability and reduces bugs. Understanding TDD principles helps in writing better quality, maintainable code.
9. **API Integration**
- Knowing how to integrate and interact with APIs is crucial for connecting different services and data sources, enhancing the functionality of your applications.
10. **Soft Skills and Communication**
- Effective communication and teamwork are essential for working in a collaborative environment. Develop skills in articulating ideas, giving and receiving feedback, and working well with others.
Happy Learning 🎉 | bingecoder89 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.