
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,869,408 | Unlocking the Power of Chameleon Functions in JavaScript | Have you ever wished your functions could adapt like a chameleon? Meet Chameleon Functions! These... | 0 | 2024-05-29T16:54:25 | https://dev.to/silverindigo/unlocking-the-power-of-chameleon-functions-in-javascript-1309 | javascript, chameleon, functions, programming | Have you ever wished your functions could adapt like a chameleon? Meet Chameleon Functions! These versatile functions change their behavior based on the input they receive, making your code more flexible and powerful.
**What Are Chameleon Functions?**
Chameleon Functions are functions in JavaScript that alter their behavior depending on the input they get. Imagine a function that can handle both numbers and strings differently, providing the right output for each type of input. Here’s a simple example:
```javascript
function chameleonFunction(input) {
if (Array.isArray(input)) {
if (input.every(item => typeof item === 'number')) {
return input.map(num => num * 2);
} else if (input.every(item => typeof item === 'string')) {
return input.join(' ');
}
} else if (typeof input === 'string') {
return input.toUpperCase();
} else if (typeof input === 'number') {
return input * input;
}
return null;
}
console.log(chameleonFunction([1, 2, 3])); // [2, 4, 6]
console.log(chameleonFunction(['hello', 'world'])); // "hello world"
console.log(chameleonFunction('hello')); // "HELLO"
console.log(chameleonFunction(5)); // 25
```
**Why Use Chameleon Functions?**
Chameleon Functions offer several advantages:
* **Reusability**: Write once, use in multiple scenarios.
* **Flexibility**: Adapt to different inputs effortlessly.
* **Cleaner Code**: Reduce the need for multiple functions handling similar logic.
They are especially useful in real-world applications like form validation, data processing, and user input handling, where different types of data need different handling.
Let’s talk about a common scenario we all face in web development: handling user input from forms. Imagine you’re building a form where users can enter different types of data, such as their age, name, or a list of their favorite hobbies. The challenge is to process this input correctly because each type of data needs to be handled differently.
For instance:
* If the user enters their age (a number), we might want to format it to always show two decimal places.
* If they enter their name (a string), we might want to convert it to uppercase.
* If they provide a list of hobbies (an array of strings), we might want to join them into a single string separated by commas.
**Solution: Using a Chameleon Function**
Instead of writing separate functions for each type of input, we can create one Chameleon Function that handles all these cases. This makes our code cleaner and more efficient. Here’s how we can do it:
```javascript
function formatInput(input) {
if (Array.isArray(input)) {
if (input.every(item => typeof item === 'number')) {
return input.map(num => num * 2);
} else if (input.every(item => typeof item === 'string')) {
return input.join(', ');
}
} else if (typeof input === 'string') {
return input.toUpperCase();
} else if (typeof input === 'number') {
return input.toFixed(2);
}
return 'Invalid input';
}
// Examples
console.log(formatInput([1.234, 5.678])); // [2.468, 11.356]
console.log(formatInput(['apple', 'banana'])); // "apple, banana"
console.log(formatInput('hello')); // "HELLO"
console.log(formatInput(3.14159)); // "3.14"
```
**Explanation:**
* **Array of Numbers**: Each number is doubled.
* **Array of Strings**: Strings are joined with a comma.
* **Single String**: The string is converted to uppercase.
* **Single Number**: The number is formatted to two decimal places.
* **Invalid Input**: A default message is returned for unsupported input types.
This Chameleon Function is incredibly versatile. It adapts to different inputs and processes them accordingly, making your life as a developer much easier!
**Best Practices for Chameleon Functions**
* **Keep It Simple**: Avoid over-complicating the function.
* **Predictable Behavior**: Ensure the function’s behavior is clear from its name and usage.
* **Document Well**: Comment your code to explain what each part does.
Chameleon Functions are a powerful tool in JavaScript, allowing your code to adapt dynamically to different situations. Try implementing them in your projects to see the benefits firsthand!
Need help with JavaScript bugs or want to refine your Chameleon Functions? Check out this [Fiverr gig](https://www.fiverr.com/s/XLRaRj0) for expert assistance! Get your code working perfectly and learn new skills along the way.
| silverindigo |
1,869,406 | How I Organise My Python Code | New update added to the private methods. Writing code is more of an art than a science, I must... | 0 | 2024-05-29T16:54:23 | https://dev.to/pastorenuel/how-i-organise-my-python-code-364i | python, webdev, cleancode | _New update added to the private methods._
---
Writing code is more of an art than a science, I must opine. It's important to write well-refined, logical, and robust engineering solutions to a problem. However, there seems to be a major challenge: making these solutions comprehensive and readable.
The focus of this article is how to best organise your Python classes to be both readable and clean. Python doesn't enforce strict rules when it comes to method organisation; for instance, you won't be penalised if you decide to put your `__init__` method at the end of your class or if it comes first. However, adhering to widely accepted conventions not only makes collaboration easier but also fosters better documentation.
## Order Methods Should Follow
1. Magic Methods
2. Private Methods
3. Public Methods
4. Helper Methods for Your Public Methods
### 1. Magic Methods
Magic methods, also known as dunder methods (due to their double underscores), provide special functionalities to your classes. These methods are predefined and allow objects to interact with Python’s built-in functions and operators. Placing magic methods at the top of your class definition makes it immediately clear how instances of the class will behave in common operations.
Example:
```python
class ClassWithMagicMethod:
"""Example class"""
def __new__(self):
pass
def __init__(self, value: int):
"""This is the init method"""
self.value =value
def __str__(self):
return str(self.value)
def __repr__(self):
return f"<ExampleClass({self.value})>"
```
Notice that the `__new__` method comes before the `__init__` method? Its best practice to do it that way for proper and logical flow of your codebase
### 2. Private Methods
Private methods are intended for internal use within the class. These methods usually start with an dunderscore (__) and should be placed after the magic methods. Organising private methods together helps maintain a clear separation between the internal mechanisms of the class and the public interface.
Example:
```python
class ClassWithPrivateMethod:
# magic methods goes here...
def __private_method(self):
# This is a private method
print("this is private method")
```
Attempting to access the `__private_method` outside the class will raise this error:
```python
c = ClassWithPrivateMethod()
c.__private_method()
--------------output-----------
ERROR!
Traceback (most recent call last):
File "<main.py>", line 12, in <module>
AttributeError: 'ClassWithPrivateMethod' object has no attribute '__private_method'
```
However, it can be accessed within the class:
```python
class ClassWithPrivateMethod:
# magic methods goes here...
def __private_method(self):
# This is a private method
print("this is private method")
def another_method(self):
"""Method that accesses the private method"""
self.__private_method()
c = ClassWithPrivateMethod()
c.another_method()
------------output----------
this is private method
```
Though this method is considered private, Python still makes it possible to access it by using creating a helper method using the syntax: `f"_{__class__.__name__}__{<method_name>}"`. Which now works.
```python
c = ClassWithPrivateMethod()
c._ClassWithPrivateMethod__private_method()
-------------output---------------
this is private method
```
You will notice that Python created a helper method to access the private method; suggesting a syntax or pattern on how this should be used or accessed.
What about in the case of inheritance. It is pertinent to note that you cannot directly call a base class private method from a subclass. If you attempt to call `__private_method` of `ClassWithPrivateMethod` within `ClassWithPrivateMethodSubClass`, Python will raise an `AttributeError` because it cannot find the mangled name; `_ClassWithPrivateMethodSubClass__private_method` in `ClassWithPrivateMethodSubClass` but you will notice that `_ClassWithPrivateMethod__private_method` is present. This means one thing, python creates the mangled name before accessing the value of the private method.
Example:
```python
class ClassWithPrivateMethodSubClass(ClassWithPrivateMethod):
"""subclass of ClassWithPrivateMethod"""
pass
def method_to_access_private_method(self):
"""method attempting to access base"""
self.__private_method()
sc = ClassWithPrivateMethodSubClass()
sc.method_to_access_private_method()
-------------output-----------------
AttributeError: 'ClassWithPrivateMethodSubClass' object has no attribute '_ClassWithPrivateMethodSubClass__private_method'
```
To navigate through this, you can create a protected or helper method in the base class which can be accessed by the subclass.
Example:
```python
class ClassWithPrivateMethod:
...
def _protected_method_for_private_method(self):
return self.__private_method()
def method_to_access_private_method(self):
"""method attempting to access base"""
self.__private_method()
class ClassWithPrivateMethodSubClass(ClassWithPrivateMethod):
...
def method_to_access_private_method(self):
return self._protected_method_for_private_method()
sc = ClassWithPrivateMethodSubClass()
sc.method_to_access_private_method()
----------------output-------------------------
this is private method
```
### 3. Public Methods
Public methods form the main interface of your class. These methods should be clearly defined and well-documented since they are intended for use by other classes or modules. Keeping public methods organised and distinct from private methods enhances readability and usability.
Example:
```python
class ClassWithPublicMethod:
# magic methods go here...
# private methods next...
def public_method(self):
# This is a public method
return self.value
```
### 4. Helper Methods for Your Public Methods
Helper methods or supporting methods, which assist public methods in performing their tasks, should be defined immediately after the public methods they support. These methods often break down complex tasks into simpler, manageable pieces, promoting code reusability and clarity.
Example:
```python
class ClassWithHelperMethod:
# All previous methods here...
def public_method(self):
# This is a public method
return self._helper_method()
def _helper_method(self):
# This is a helper method for the public method
return self.value * 2
def public_method_2(self):
"""This is another method"""
pass
```
### Conclusion
By organising your methods in the suggested order —magic methods, private methods, public methods, and helper methods —you create a clear and readable structure for your Python classes. This approach not only facilitates easier collaboration and maintenance but also helps in creating a well-documented codebase that others can understand and use effectively. Which will also improve onboarding if you work in an organization. Remember, clean code is not just about making it work; it’s about making it understandable and maintainable for the long run.
| pastorenuel |
1,869,407 | Generating PDFs in Angular using jsPDF | In modern web applications, generating PDF documents can be an essential feature for reports,... | 0 | 2024-05-29T16:53:12 | https://dev.to/vidyarathna/generating-pdfs-in-angular-using-jspdf-3a6 | angular, jspdf, javascript, webdev |
In modern web applications, generating PDF documents can be an essential feature for reports, invoices, and more. In this article, we will explore how to integrate and use jsPDF, a popular JavaScript library, in an Angular application to generate PDF files dynamically.
## Prerequisites
To follow along with this tutorial, you should have:
- Basic knowledge of Angular.
- Node.js and Angular CLI installed.
- An Angular project set up. If you don't have one, you can create a new project using the Angular CLI:
```bash
ng new angular-jspdf
cd angular-jspdf
```
## Installing jsPDF
First, you need to install jsPDF. You can do this using npm:
```bash
npm install jspdf
```
## Setting Up jsPDF in Angular
Once jsPDF is installed, you need to set it up in your Angular project. Open your `app.module.ts` and add the following import:
```typescript
import { NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import { AppComponent } from './app.component';
import { FormsModule } from '@angular/forms';
@NgModule({
declarations: [
AppComponent
],
imports: [
BrowserModule,
FormsModule
],
providers: [],
bootstrap: [AppComponent]
})
export class AppModule { }
```
## Creating a PDF Service
To keep your code organized, create a service for generating PDFs. Generate a new service using Angular CLI:
```bash
ng generate service pdf
```
In the generated `pdf.service.ts`, import jsPDF and create a method for generating a PDF:
```typescript
import { Injectable } from '@angular/core';
import { jsPDF } from 'jspdf';
@Injectable({
providedIn: 'root'
})
export class PdfService {
constructor() { }
generatePdf() {
const doc = new jsPDF();
doc.text('Hello world!', 10, 10);
doc.save('sample.pdf');
}
}
```
## Creating a Component to Generate PDFs
Next, generate a new component where you will add a button to trigger the PDF generation:
```bash
ng generate component pdf-generator
```
In `pdf-generator.component.ts`, inject the PDF service and create a method to call the `generatePdf` function:
```typescript
import { Component } from '@angular/core';
import { PdfService } from '../pdf.service';
@Component({
selector: 'app-pdf-generator',
templateUrl: './pdf-generator.component.html',
styleUrls: ['./pdf-generator.component.css']
})
export class PdfGeneratorComponent {
constructor(private pdfService: PdfService) { }
generatePdf() {
this.pdfService.generatePdf();
}
}
```
In `pdf-generator.component.html`, add a button to trigger the PDF generation:
```html
<button (click)="generatePdf()">Generate PDF</button>
```
## Adding the Component to the App
Include the `PdfGeneratorComponent` in your `AppComponent` template to make it part of your application:
```html
<!-- app.component.html -->
<app-pdf-generator></app-pdf-generator>
```
## Customizing the PDF Content
To customize the PDF content, you can modify the `generatePdf` method in `PdfService`. For example, you can add images, tables, and more complex layouts:
```typescript
generatePdf() {
const doc = new jsPDF();
doc.setFontSize(22);
doc.text('Custom PDF Document', 10, 10);
doc.setFontSize(16);
doc.text('This is a sample PDF generated using jsPDF in Angular.', 10, 30);
// Add more content as needed
doc.text('Add your content here...', 10, 50);
doc.save('custom-sample.pdf');
}
```
Integrating jsPDF into your Angular project allows you to create PDF documents dynamically within your application. By following the steps outlined above, you can set up jsPDF, create a service for PDF generation, and trigger this functionality from a component. This basic setup can be further expanded to include more complex features such as tables, images, and styled text to meet your application's needs. With jsPDF, the possibilities for generating rich, dynamic PDF content are extensive, making it a powerful tool for any Angular developer.
Happy coding!
| vidyarathna |
1,869,404 | Explore the Enchantment of Bali: Your Ultimate Travel Guide for 2024 | Are you yearning for an unforgettable journey filled with exotic landscapes, vibrant cultures, and... | 0 | 2024-05-29T16:50:07 | https://dev.to/travelgo/explore-the-enchantment-of-bali-your-ultimate-travel-guide-for-2024-28gm | bali, indonesia, travel, cheaptravel | <p> </p><p class="graf graf--p" name="bf71">Are you yearning for an unforgettable journey filled with exotic landscapes, vibrant cultures, and endless adventures? Look no further than the mystical island paradise of <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>, Indonesia! Nestled in the heart of the Indonesian archipelago, <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> boasts an unpar alleled blend of natural beauty, rich heritage, and captivating experiences that will leave you spellbound.</p><figure class="graf graf--figure" name="876a"><img class="graf-image" data-height="667" data-image-id="0*Hcl8bGL6X01-7TZN" data-is-featured="true" data-width="1000" src="https://cdn-images-1.medium.com/max/800/0*Hcl8bGL6X01-7TZN" /></figure><p class="graf graf--p" name="e1dc">**Why <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>?**</p><p class="graf graf--p" name="11fa"><a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> is not just a destination; it’s a state of mind. Whether you’re seeking serene beaches, lush rice terraces, or adrenaline-pumping activities, <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> has something to offer for every type of traveler. From the iconic temples like Tanah Lot and Uluwatu to the bustling streets of Ubud and the tranquil shores of Nusa Dua, this island paradise is a tapestry of diverse experiences waiting to be explored.</p><p class="graf graf--p" name="58cd">**Travel Guides 2024: What’s New?**</p><p class="graf graf--p" name="b79c">As the world evolves, so does <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>. In 2024, travelers can expect a plethora of exciting developments and activities to enhance their <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> experience. From eco-friendly initiatives promoting sustainable tourism to immersive cultural experiences that delve deep into the island’s heritage, there’s always something fresh and exciting to discover in <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>.</p><ul class="postList"><li class="graf graf--li" name="46ff">*Best Travel Insurance for <a class="markup--anchor markup--li-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>: Peace of Mind Amidst Paradise**</li></ul><figure class="graf graf--figure" name="e239"><img class="graf-image" data-height="751" data-image-id="0*9GNVD95LYJvnyju6" data-width="1000" src="https://cdn-images-1.medium.com/max/800/0*9GNVD95LYJvnyju6" /></figure><p class="graf graf--p" name="2e57">Before embarking on your <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> adventure, it’s essential to secure the best travel insurance to ensure a worry-free journey. With the unpredictability of travel, having comprehensive coverage will provide you with peace of mind knowing that you’re protected against any unforeseen circumstances, from flight cancellations to medical emergencies.</p><p class="graf graf--p" name="6593">**Exploring <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>: Tips and Tricks**</p><p class="graf graf--p" name="c3ab">
<ins class="bookingaff" data-aid="2421552" data-target_aid="2421552" data-prod="banner" data-width="728" data-height="90" data-banner_id="125810" data-lang="en">
<!-- Anything inside will go away once widget is loaded. -->
<a href="//www.booking.com?aid=2421552">Booking.com</a>
</ins>
<script type="text/javascript">
(function(d, sc, u) {
var s = d.createElement(sc), p = d.getElementsByTagName(sc)[0];
s.type = 'text/javascript';
s.async = true;
s.src = u + '?v=' + (+new Date());
p.parentNode.insertBefore(s,p);
})(document, 'script', '//cf.bstatic.com/static/affiliate_base/js/flexiproduct.js');
</script>
To make the most of your <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> vacation, here are some insider tips to guide you along the way:</p><p class="graf graf--p" name="ac7c">1. **Embrace the Balinese Culture:** Take part in traditional ceremonies, witness mesmerizing dance performances, and savor authentic Balinese cuisine for a truly immersive cultural experience.</p><p class="graf graf--p" name="1009">2. **Venture Off the Beaten Path:** While <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>’s popular attractions are undeniably stunning, don’t hesitate to explore the lesser-known gems hidden away in the island’s hinterlands.</p><figure class="graf graf--figure" name="4286"><img class="graf-image" data-height="667" data-image-id="0*tY1GmS5BtdgOwlCc" data-width="1000" src="https://cdn-images-1.medium.com/max/800/0*tY1GmS5BtdgOwlCc" /></figure><p class="graf graf--p" name="9b10">3. **Stay Connected:** Stay connected with reliable internet services and local SIM cards to share your <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> moments with loved ones back home and navigate the island with ease.</p><p class="graf graf--p" name="ac09">4. **Mindful Travel:** Respect <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>’s customs and traditions, including proper attire when visiting temples and practicing responsible tourism to preserve the island’s natural beauty for future generations.</p><p class="graf graf--p" name="832f">**Traveling Smart: Your Essential Packing List**</p><p class="graf graf--p" name="24bb">When packing for your <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> escapade, remember to pack light, but don’t forget the essentials:</p><p class="graf graf--p" name="1044">1. **Sunscreen and Mosquito Repellent:** Protect your skin from the tropical sun and pesky insects while exploring <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>’s outdoor wonders.</p><p class="graf graf--p" name="35bf">2. **Comfortable Footwear:** Whether you’re trekking through lush jungles or strolling along sandy beaches, comfortable footwear is a must.</p><p class="graf graf--p" name="c97c">3. **Lightweight Clothing:** Opt for breathable fabrics to stay cool in <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>’s warm climate, and don’t forget to pack a sarong for temple visits.</p><p class="graf graf--p" name="697b">4. **Reusable Water Bottle:** Stay hydrated while reducing plastic waste by carrying a reusable water bottle to refill at water stations throughout the island.</p><figure class="graf graf--figure" name="8084"><img class="graf-image" data-height="563" data-image-id="0*uG1J7xDCm7L2Z8rP" data-width="1000" src="https://cdn-images-1.medium.com/max/800/0*uG1J7xDCm7L2Z8rP" /></figure><p class="graf graf--p" name="06b6">**Traveling to <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> on a Budget: Tips and Tricks**</p><p class="graf graf--p" name="97b6">Traveling to <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> doesn’t have to break the bank! With a bit of savvy planning, you can experience all that this island paradise has to offer without overspending:
<ins class="bookingaff" data-aid="2421580" data-target_aid="2421580" data-prod="dfl2" data-width="300" data-height="350" data-lang="en" data-dest_id="835" data-dest_type="region">
<!-- Anything inside will go away once widget is loaded. -->
<a href="//www.booking.com?aid=2421580">Booking.com</a>
</ins>
<script type="text/javascript">
(function(d, sc, u) {
var s = d.createElement(sc), p = d.getElementsByTagName(sc)[0];
s.type = 'text/javascript';
s.async = true;
s.src = u + '?v=' + (+new Date());
p.parentNode.insertBefore(s,p);
})(document, 'script', '//cf.bstatic.com/static/affiliate_base/js/flexiproduct.js');
</script>
</p><p class="graf graf--p" name="c233">1. **Accommodation:** Consider staying in guesthouses or homestays for a more affordable and authentic <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> experience.</p><p class="graf graf--p" name="f749">2. **Local Eateries:** Indulge in delicious Indonesian cuisine at local warungs (eateries) and street food stalls for budget-friendly dining options.</p><p class="graf graf--p" name="9ec4">3. **Transportation:** Opt for public transportation, such as buses or motorbikes, to get around <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> affordably, or explore the island’s scenic landscapes by renting a bicycle.</p><p class="graf graf--p" name="4d51">4. **Book in Advance:** Take advantage of early bird discounts and promotional offers by booking flights, accommodations, and tours in advance.</p><figure class="graf graf--figure" name="cfec"><img class="graf-image" data-height="667" data-image-id="0*siuo3k6QNyk98Cfa" data-width="1000" src="https://cdn-images-1.medium.com/max/800/0*siuo3k6QNyk98Cfa" /></figure><p class="graf graf--p" name="4a00">**Experience <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> with Ease: Travel Agency Assistance**</p><p class="graf graf--p" name="eb0e">For a hassle-free <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> vacation, consider enlisting the services of a reputable travel agency specializing in Indonesian travel. From crafting personalized itineraries to arranging accommodations and transportation, a professional travel agency can help you navigate <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a> with ease, leaving you free to focus on creating unforgettable memories.</p><p class="graf graf--p" name="a8c5"><a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank"><strong class="markup--strong markup--p-strong">Access the link for irresistible offers!</strong></a></p><p class="graf graf--p" name="1c50">**Conclusion**</p><p class="graf graf--p" name="d52f">Embark on a journey of discovery and adventure in the enchanting island paradise of <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?region=835&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Bali</a>. With its breathtaking landscapes, vibrant culture, and warm hospitality, Bali is more than just a destination; it’s an experience that will leave an indelible mark on your soul. So pack your bags, immerse yourself in the magic of Bali, and let the adventure begin!</p>
<script src="https://www.booking.com/affiliate/prelanding_sdk"></script>
<div id="bookingAffiliateWidget_a6420765-0a0b-4cc0-8a20-d44b4b6ff0ed"> </div>
<script>
(function () {
var BookingAffiliateWidget = new Booking.AffiliateWidget({
"iframeSettings": {
"selector": "bookingAffiliateWidget_a6420765-0a0b-4cc0-8a20-d44b4b6ff0ed",
"responsive": true
},
"widgetSettings": {}
});
})();
</script> | travelgo |
1,869,403 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-05-29T16:47:50 | https://dev.to/nyfgegh86/buy-verified-paxful-account-29jo | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n " | nyfgegh86 |
1,869,401 | 💡Type-safe APIs Solutions | Note that this post is the ongoing work. It's yet to be finished. Introduction I felt... | 0 | 2024-05-29T16:42:36 | https://dev.to/algoorgoal/type-safe-apis-solutions-49ja | api | Note that this post is the ongoing work. It's yet to be finished.
## Introduction
I felt like I wasted a lot of time communicating with the Backend Engineers about what types JSON properties actually are. They provided me with some API spec written by their own, but I spent a lot of time pointing out what's wrong and waiting for the fix. Therefore, I decided to look into type-safe API solutions.
## Example
This is the common situation you run into:
```typescript
export const addBooth = async (booth: Booth) => {
const response = await fetch(`${API_URL}/api/booths`, {
method: HTTPMethod.POST,
});
const data = await response.json();
return data;
};
```
Here, the type of the variable `data` is `any`, since typescript cannot deduce the type of http response. Therefore, our frontend developers entirely relied on API specifiaction written by our backend developers on Notion.

However, I found this process pretty inefficient. First off, backend developers need to spend time writing the API spec. Second, they might make mistakes and sometimes it takes a lot of time when I report the issues and get the answers. Lastly, I also report issues created by my own mistakes. That's how I got interested in type-safe solutions to reduce miscommunication issues and errors.
## OpenAPI
- It's a way to describe RESTful APIs. It started as Swagger API, but later changed its name to OpanAPI.
- Swagger is a toolkit that lets you write OpenAPI spec using JSON and renders OpenAPI Spec documents on the web.
- If your team uses Restful APIs, then you can take advantage of Swagger.

In Swagger UI like this, you can check the types and rules of JSON properties by checking the schema backend engineers wrote for you. Note it doesn't work well by default, so you should kindly ask your backend developers for a double-check.
## GraphQL
- In GraphQL, requests and responses are defined in the schema formats.
- It can also solve the problem of overfetching and underfetching.
- Overfetching means receiving more data than the client needs.
- Underfetching means receiving less data than the client needs, and the client sends multiple requests.
- The whole team needs to work their asses off to learn GraphQL.
- It would be great when your application has a lot of endpoints, the team has separated frontend and backend developers, overfetching and underfetching happen quite often, and has enough time to learn GraphQL.
## tRPC(typescript Remote Procedure Control)
- Type definitions are shared between the client and the server.
- The API server must be written in typescript. If you're in a large team and the server should be used in a different language, tRPC is not a good choice.
- You should retain a monorepo or deploy an npm package to share the types between the client and the server.
- If you're using Server Actions, you can ditch tRPC. Once your server action logic gets complicated, you can consider using them altogether.
## Other solutions
Dear readers: language-neutral protocols have been around even before tRPC and GraphQL came out. You can check out these protocol-level type-safety tools as well.
- Protobuf: it's a data-serialization protocol. Instead of transferring JSON, this protocol sends protocol buffers.
> Data serialization process transforms objects into binary format so that data can be sent to the network. On the physical layer, these objects are just sent in the form of binary via cables.
## Conclusion
I haven't used GraphQL and tRPC. When I get a chance to use them I'll add more thoughts. | algoorgoal |
1,869,399 | GCP Cloud Run vs Kubernetes | The world of Kubernetes is intertwined with several different platforms, software, and third-party... | 0 | 2024-05-29T16:32:15 | https://dev.to/thenjdevopsguy/gcp-cloud-run-vs-kubernetes-5g2b | kubernetes, devops, programming, docker | The world of Kubernetes is intertwined with several different platforms, software, and third-party services. Aside from things like GitOps and Service Mesh, the core implementation of Kubernetes is to help with one thing - orchestrate and manage containers.
In this blog post, we’ll get back to the original concept of orchestration and talk about the key differences between a service like Cloud Run and a full-blown orchestrator like Kubernetes.
## What Is Kubernetes
The question of “What is Kubernetes?” is long, vast, and takes up a fair amount of talk in itself (that’s why there are 10’s of books available around Kubernetes), but what was the original need for Kubernetes?
The long and short of it is that Kubernetes was created to manage and scale containers.
Kubernetes contains several plugins and the plugin to run containers is the Container Runtime Interface (CRI). Why is the plugin necessary? Because Kubernetes does not know how to run/stop/start containers by itself.
## What Is GCP Cloud Run
Cloud Run, much like Kubernetes, is an orchestrator. It gives you the ability to deploy a container, scale that container, set up autoscaling, configure resource optimization, and several other health-based containerization methods.
The key to remember is that with Cloud Run, you’re using a GCP-based solution for orchestration.
In the next few sections, you’ll see how to run containers (Pods contain containers), Cloud Run containers, and resource optimization in each environment.
## Deploying A Pod On Kubernetes
To deploy a Pod on Kubernetes, you’ll use a Kubernetes Manifest, which is a YAML (or JSON) configuration to deploy containers within Pods.
Below is an example of using a higher-level controller called `Deployment`.
```jsx
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginxdeployment
replicas: 2
template:
metadata:
labels:
app: nginxdeployment
spec:
containers:
- name: nginxdeployment
image: nginx:latest
ports:
- containerPort: 80
```
Once you write the Manifest, you perform a HTTPS POST request to the Kubernetes API server with the `kubectl apply` command.
```jsx
kubectl apply -f deployment.yaml
```
## Deploying A Container on Cloud Run
Aside from using the GCP console, you can use the `gcloud` CLI to deploy a container in Cloud Run.
<aside>
💡 Both GCP Cloud Run and Kubernetes are declarative in nature and use YAML configurations. You can go into the YAML of a container deployed and re-configure it if you’d like.
</aside>
```jsx
gcloud run deploy gowebapi --image adminturneddevops/golangwebapi
```
Once the container is deployed, you can go in and edit it via the blue **EDIT & DEPLOY NEW REVISION** button.
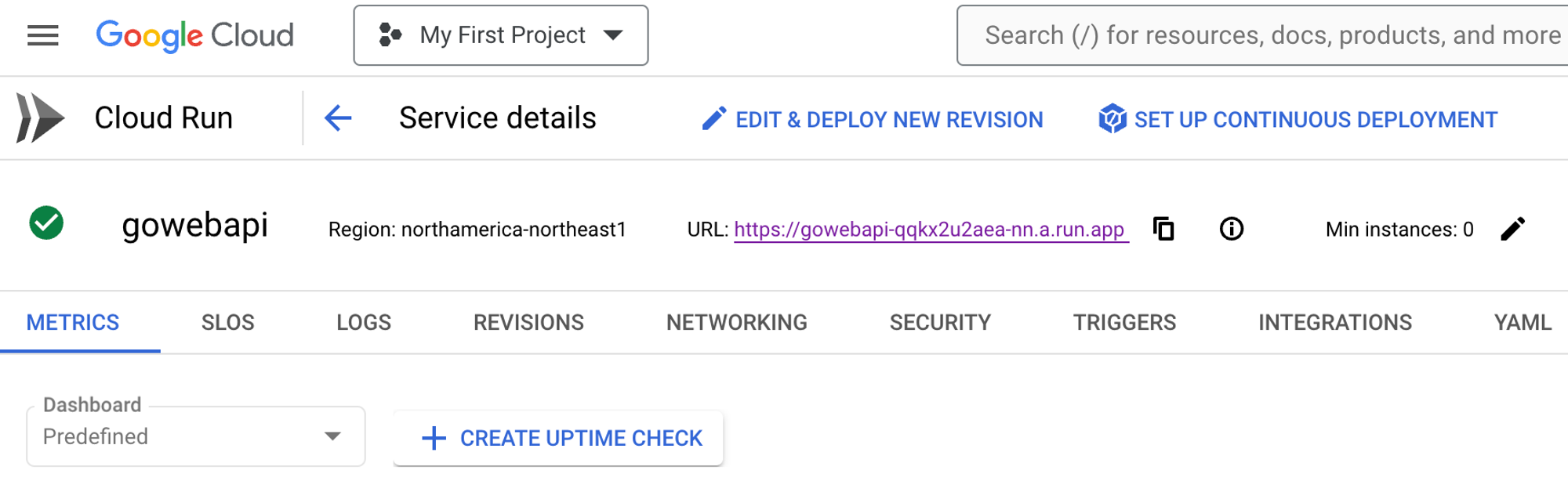
If you click the YAML button, you can edit your container configuration.
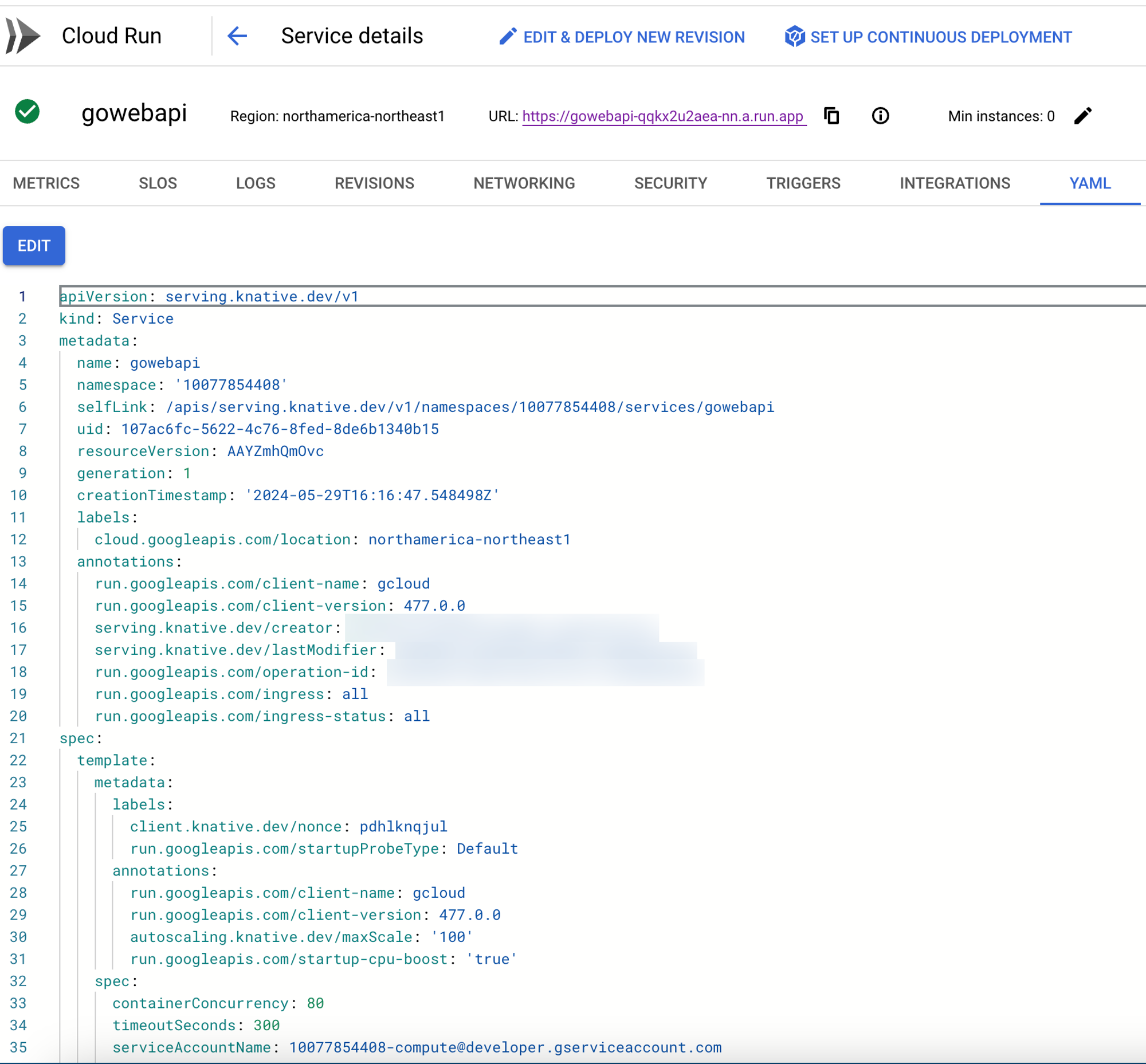
<aside>
💡 On the backend of a Cloud Run service, it’s using Knative, which is the method of running Serverless workloads on Kubernetes. One could say that Cloud Run is using Kubernetes on the backend.
</aside>
## Resource Optimization On Kubernetes
When it comes to ensuring that Pods are running as performant and efficiently as possible, engineers must ensure to implement resource optimization.
There are a few methods for resource/performance optimization on Kubernetes.
First, there are ResourceQuotas. ResourceQuotas are a way to set limits for memory and CPU on a Namespace. When using ResourceQuotas, Namespaces are only allowed X amount of CPU and X amount of CPU.
```jsx
apiVersion: v1
kind: ResourceQuota
metadata:
name: memorylimit
namespace: test
spec:
hard:
requests.memory: 512Mi
limits.memory: 1000Mi
```
```jsx
apiVersion: v1
kind: ResourceQuota
metadata:
name: memorylimit
namespace: test
spec:
hard:
cpu: "5"
memory: 10Gi
pods: "10"
```
You can also set resource requests and limits within the Deployment/Pod configuration itself.
```jsx
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginxdeployment
replicas: 2
template:
metadata:
namespace: webapp
labels:
app: nginxdeployment
spec:
containers:
- name: nginxdeployment
image: nginx:latest
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
ports:
- containerPort: 80
```
## Resource Optimization On Cloud Run
Within Cloud Run, you can manage resources from a CPU and memory perspective just like you can within Kubernetes.
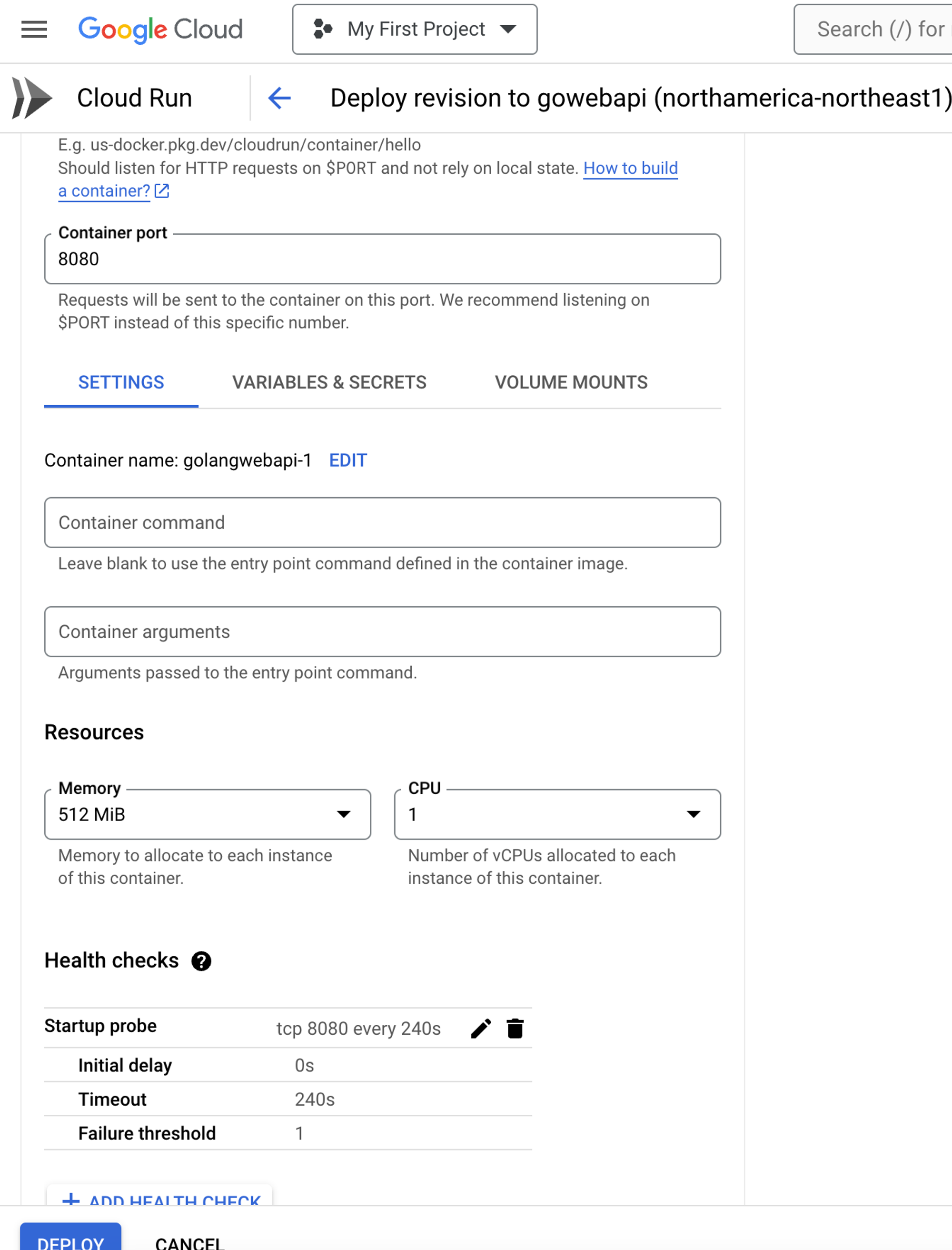
You can also set up requests and CPU allocation, which helps if you want to implement cost optimization (FinOps).
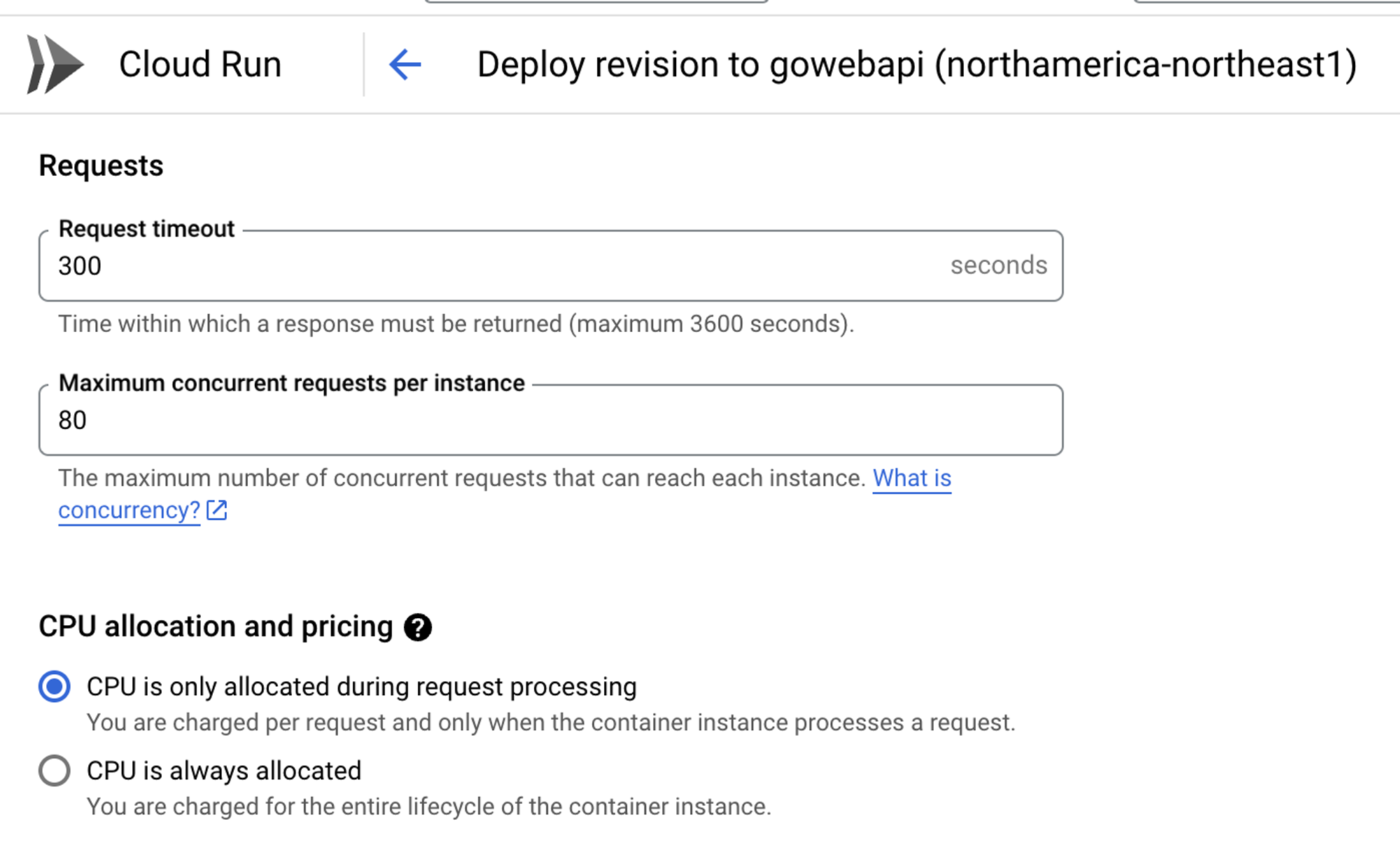
From an autoscaling perspective, Kubernetes has HPA and VPA. Cloud Run allows you to scale out instances just like you can scale out Pods with HPA.
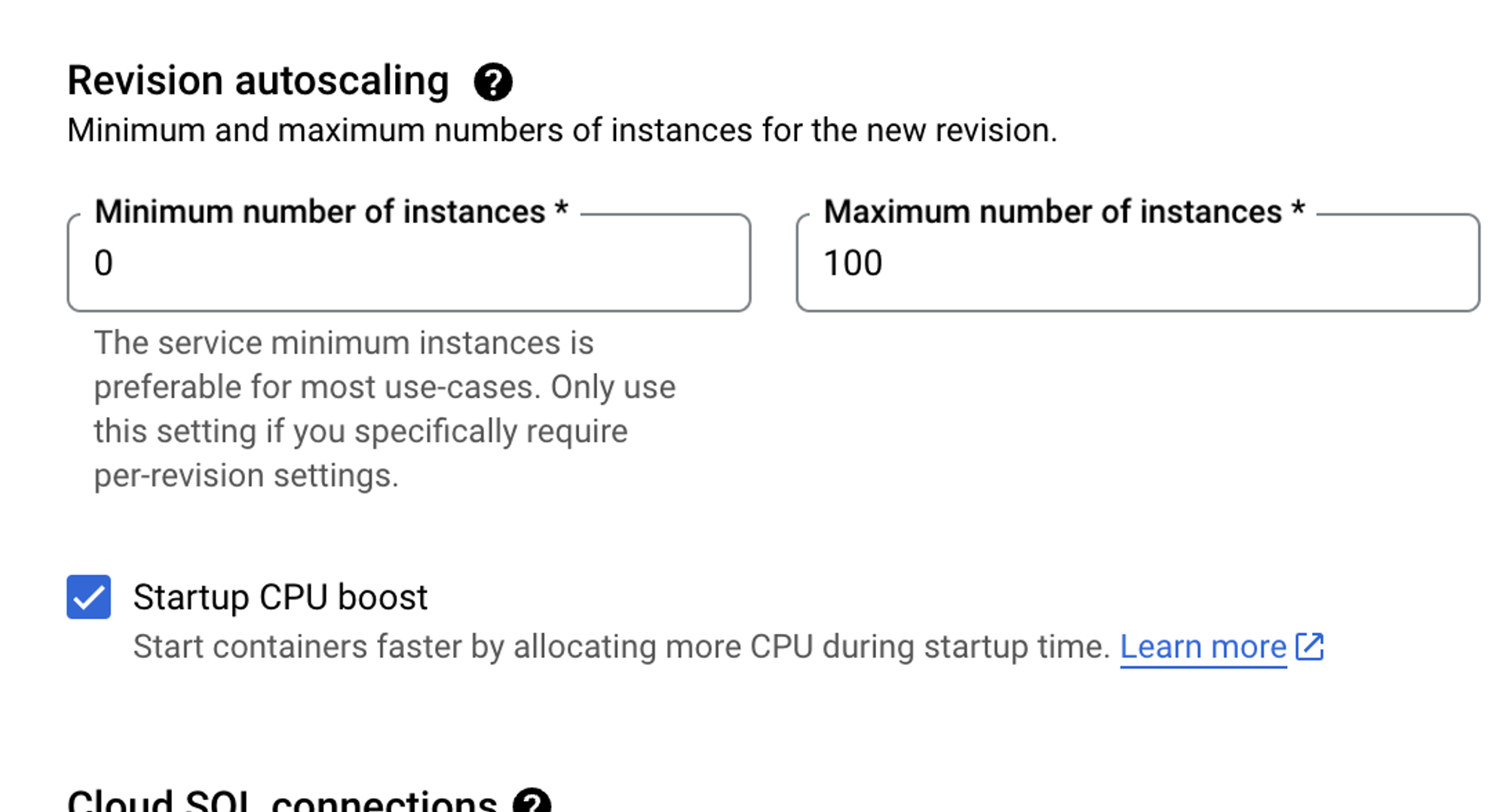
If you don’t want to use button clicks, you can also edit the YAML configuration for resource optimization.
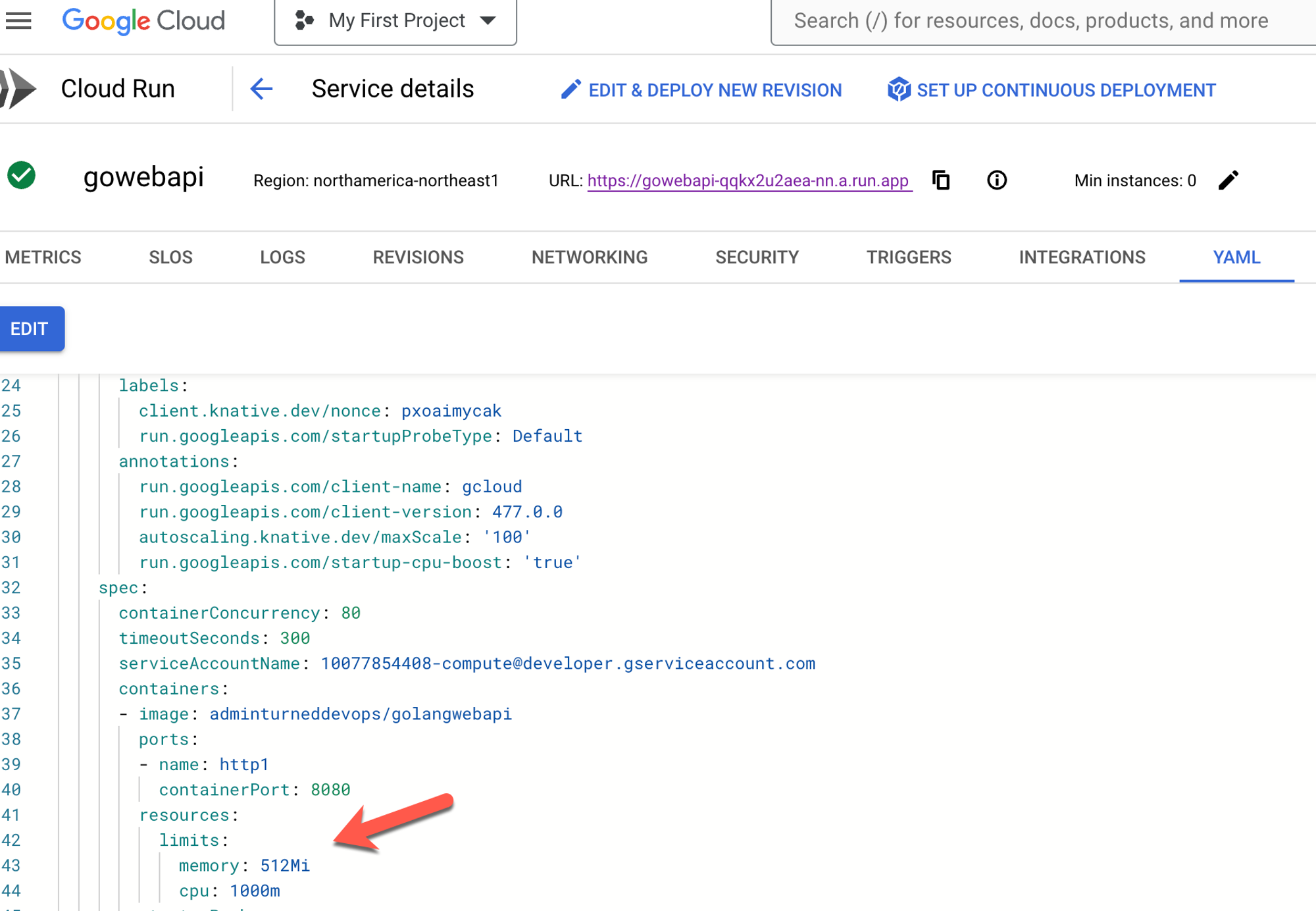
## Closing Thoughts
When you’re deciding on Kubernetes vs a “serverless container” solution like GCP Cloud Run, the biggest things you need to think about are:
1. Do you need a multi-orchestration solution? Go with Kubernetes.
2. Does your organization have the capability for engineers to train on Kubernetes?
3. Do you have a smaller application stack to manage? If so, go with Cloud Run.
Overall, the concept of what Kubernetes does (orchestrate containers) and what Cloud Run does (orchestrate containers) is the same, but the key difference is how large the workloads are. Cloud Run is great for truly decoupled workloads and Kubernetes is great for very large containers at scale. | thenjdevopsguy |
1,869,398 | Receiptify | Receiptify transforms Spotify playlists into stunning visual receipts, revolutionizing how music... | 0 | 2024-05-29T16:30:34 | https://dev.to/receiptify_life_a55cf39a1/receiptify-43nf | [Receiptify](https://receiptify.life/) transforms Spotify playlists into stunning visual receipts, revolutionizing how music lovers explore their listening habits. | receiptify_life_a55cf39a1 | |
1,869,396 | How to Get Best out of Electic Store Billing | As a Experienced person whom have experience in Electical Stroe billing I know these best things... | 0 | 2024-05-29T16:29:57 | https://dev.to/sabrina_spellmen_02c6c3a1/how-to-get-best-out-of-electic-store-billing-4gm6 | As a Experienced person whom have experience in Electical Stroe billing I know these best things
LED Lighting
Wiring and switch circuits
acessiories
We encountered with a client whom had to do wiring for his newly built Flats and mension , he was already dealing with some sort of fraudlant technician whom never had idea about enterprise Electirc Cicutit system integration .
We started from very inital consultation where we fully educated the client about our experience and what will be best solution for them .
after that we provided them simulated solution on MultiSim containg exact bule print in 3D form how his furnished Flats will look like after we will do the wiring part from ourside . this thing lowered the client headche 100% and he was so relaxed that he even futhrer extended our contract for other buildings too .
| sabrina_spellmen_02c6c3a1 | |
1,869,395 | 5 Crucial Considerations for Selecting SIT Testing | Software Integration Testing (SIT) is one of the important phases in software life cycle... | 0 | 2024-05-29T16:29:05 | https://www.laventino.com/5-crucial-considerations-for-selecting-sit-testing/ | sit, testing |

Software Integration Testing (SIT) is one of the important phases in software life cycle development. SIT involves testing that software should seamlessly integrate with other application modules or components. The importance of SIT cannot be emphasized as software programs get more sophisticated and have several interconnected components. Choosing the appropriate methodology and [SIT Testing](https://www.opkey.com/blog/system-integration-testing-the-comprehensive-guide-with-challenges-and-best-practices
) tool is essential to developing a dependable, high-quality product. This blog will look at five important things to think about while choosing SIT testing.
**1.Defining Integration Testing Scope and Objectives**
Establishing the scope and goals of the testing endeavor is essential before starting the SIT process. This entails determining which particular modules or components need integration testing in addition to which crucial interfaces and capabilities need to be verified. In this sense, it is imperative to establish a thorough understanding of the system architecture and the interdependencies between various components.
**2.Selecting an Appropriate Testing Approach**
Selecting the appropriate testing strategy is essential for a successful SIT. While all components are integrated simultaneously using the big bang approach, defect causes may be hidden. Top-down testing is appropriate for projects with reliable top-level modules since it begins with higher-level components and integrates lower-level components later. On the other hand, bottom-up testing, which works best when the basic components are reliable, starts with lower levels and gradually integrates up. Top-down and bottom-up strategies are flexibly combined in the hybrid method, which adjusts to the needs of the project.
**3.Leveraging Automation for Efficiency and Consistency**
Particularly for large-scale applications with several components and interfaces, SIT can be a labor- and time-intensive procedure. Automation tools and frameworks are recommended in order to improve productivity and guarantee consistent testing. Continuous integration and delivery pipelines are made easier by automated testing, which also lowers the possibility of human error and speeds up test case execution.
**4.Considering Testing Data and Environment Setup**
Access to relevant test data and a properly designed testing environment that faithfully mimics the production environment are prerequisites for effective SIT. To validate the integration of components and detect possible problems with data flow, transformation, and integrity, it is essential to guarantee the availability of realistic and representative test data. Accurate and trustworthy test results also depend on the testing environment being configured to closely resemble the production environment.
**5.Collaboration and Communication Among Teams**
Multiple teams, comprising developers, testers, and stakeholders from different domains, are frequently involved in SIT. Clear lines of communication and efficient teamwork are essential to a successful SIT process. Frequent get-togethers, knowledge-sharing events, and uniform reporting procedures can all promote teamwork and speed up the process of resolving problems or obstacles. Furthermore, it is possible to avoid effort duplication and guarantee accountability during the testing process by clearly defining roles and duties for every team member.
**Conclusion**
Selecting the best SIT methodology is an important choice that can have a big impact on the software applications’ dependability, quality, and timely delivery. Opkey’s state-of-the-art technology transforms System Integration Testing (SIT). [Opkey ](https://www.opkey.com/)guarantees smooth integration and synchronization between heterogeneous systems by automating end-to-end data testing throughout the ecosystem. With Opkey’s cutting-edge tools, integrating NetSuite with Shopify or any other complicated setup becomes simple, ensuring data integrity and seamless business operations. Opkey gives companies the confidence to launch integrations with the knowledge that their systems are harmoniously coupled, enabling them to prosper in the current digital landscape
| rohitbhandari102 |
1,869,394 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-05-29T16:28:56 | https://dev.to/nyfgegh86/buy-verified-cash-app-account-479f | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | nyfgegh86 |
1,869,392 | Dark Mode a11y For Emails by SignMeOnly.io | Dark Mode a11y for Email by SignMeOnly.io | 0 | 2024-05-29T16:27:58 | https://dev.to/vitalipom/dark-mode-in-gmail-by-signmeonlyio-2ehm | tutorial, webdev, howto, a11y | ---
title: Dark Mode a11y For Emails by SignMeOnly.io
published: true
description: Dark Mode a11y for Email by SignMeOnly.io
tags: tutorial, webdev, howto, a11y
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-29 16:19 +0000
---
On today’s table is a struggle that everyone who’s building a marketing campaign is going through, which is Emails browsers’ dark mode.
To spice up things, here’s a subscribe link and you are welcome to reverse engineer and understand how I make it work in different Email clients in dark mode.
http://eepurl.com/iIpPIY | vitalipom |
1,869,029 | HuggingBuddy | Chrome App Link:... | 0 | 2024-05-29T13:32:37 | https://dev.to/angu10/huggingbuddy-4j2g | javascript, llm, googlecloud, chrome | Chrome App Link: https://chromewebstore.google.com/detail/huggingbuddy/hhkbebgakgkljpipmdblnabnoagemohb
If anyone would like to contribute more
GitHub Code: https://github.com/angu10/HuggingBuddy
# Introducing HuggingBuddy: Your Friendly Companion for Reading Research Papers
Are you tired of feeling overwhelmed by complex research papers? Do you wish you had a friendly companion to help you understand the key ideas and insights? Look no further! Introducing **HuggingBuddy**, the user-friendly Chrome extension that simplifies the process of reading and understanding **research papers from Hugging Face**.
## 🤗 AI-Powered Summaries
HuggingBuddy harnesses the power of artificial intelligence to generate concise summaries of research papers. Say goodbye to hours of reading and hello to quick and easy understanding. With HuggingBuddy, you can grasp a paper's main ideas and contributions in just a few minutes.
## ❓ Interactive Q&A
Curious to learn more? HuggingBuddy has got you covered. The extension generates up to 5 relevant questions based on the paper's content, allowing you to explore and understand the research more deeply. Simply click on a question, and HuggingBuddy will provide a detailed answer using the advanced Gemini language model.
## 🎨 Customizable Reading Experience
We understand that everyone has different preferences when it comes to reading. That's why HuggingBuddy allows you to personalize your reading experience. Choose from various themes to suit your style and enable text-to-speech functionality to listen to the summaries and answers on the go.
## 🤝 Integration with Hugging Face
HuggingBuddy seamlessly integrates with the Hugging Face platform, giving you direct access to many research papers. No more searching through multiple websites or repositories. With HuggingBuddy, all the knowledge you need is just a click away.
## 🌟 Open Source and Community-Driven
HuggingBuddy is an open-source project licensed under the Apache License 2.0. We believe in the power of collaboration and encourage anyone to contribute to the project. Whether you're a developer, researcher, or enthusiast, you can help make HuggingBuddy better for everyone.
We welcome contributions in various forms, including:
- 🐛 Bug reports and feature requests
- 💻 Code contributions and pull requests
- 📚 Documentation improvements
- 🧪 Testing and feedback
By contributing to HuggingBuddy, you'll join a vibrant community of individuals passionate about making research more accessible and understandable. Together, we can create a powerful tool that benefits researchers, students, and anyone interested in exploring scientific knowledge.
## 🚀 Powered by Gemini API
HuggingBuddy leverages Google's cutting-edge Gemini API to generate summaries and provide interactive features. The Gemini API is a state-of-the-art language model that excels at natural language understanding and generation.
We are grateful to Google for making the Gemini API available and enabling us to build innovative tools like HuggingBuddy.
---
Ready to dive into the world of research papers with a friendly companion by your side? Install HuggingBuddy today and experience the joy of understanding complex ideas with ease. Happy reading! 📖🤗 | angu10 |
1,869,390 | How to fix "connect ECONNREFUSED 127.0.0.1:27017, connect ECONNREFUSED ::1:27017" in mongo db compass | So you are trying to create a mern project but you get this error message and now you don't know ... | 0 | 2024-05-29T16:16:59 | https://dev.to/balaram_4c1ffc2e8b73627b4/how-to-fix-connect-econnrefused-12700127017-connect-econnrefused-127017-in-mongo-db-compass-54l5 | So you are trying to create a mern project but you get this error message and now you don't know what to do ?
I am here for your rescue.
There are plenty of method to fix this issue but I will tell you two method in this post
**Method 1**
Step 1: Check if mongo is properly installed in your pc by typing following in your terminal
`mongod –version``
Step 2: If it is not installed then go ahead and install it from this link [Download](https://www.mongodb.com/try/download/community) .
Step 3: Even after installing it is not working then press window key + R and type services.msc
Step 4: Find the mongo and the restart that
This step will fix your problem
**Method 2**
Instead of installing mongo db if you alread have docker then u can use docker for this purpose
Step 1: In your code create dockercompose.yml file
Step 2: Paste the following code .
`version: "3"
services:
mongo:
image: mongo
expose:
- 27017
ports:
- "27017:27017"
`
Breakdown of code
a.Version means the specific version of docker
b.Services means containers that should run together in same environment in this cose it is only mongo
c.Image: Specifies the Docker image to use for this container.Here, it's set to mongo, which means Docker will pull the official MongoDB image from Docker Hub if it's not already present locally.
d.Expose and port make it accessible outside docker container
Step 3: Boom thats it you now have working mongodb compass
| balaram_4c1ffc2e8b73627b4 | |
1,869,388 | Automate React App Deployment to AWS S3 with a Simple Bash Script | Deploying your web applications can often be a tedious and error-prone process, especially when done... | 0 | 2024-05-29T16:14:28 | https://dev.to/akki907/automate-react-app-deployment-to-aws-s3-with-a-simple-bash-script-24ag | aws, s3, shellscript, automation | Deploying your web applications can often be a tedious and error-prone process, especially when done manually. However, with the power of automation, you can streamline this process and ensure consistent and reliable deployments every time. In this blog post, we'll explore a simple Bash script that automates the deployment of a React app to an AWS S3 bucket, making it publicly accessible as a static website.
Prerequisites
Before you begin, make sure you have the following:
- AWS CLI installed and configured with the appropriate permissions.
- Node.js and npm installed.
- A React application ready to deploy.
Here's a breakdown of the Bash script that automates the deployment of a React app to an AWS S3 bucket:
```
#!/bin/bash
AWS_REGION="us-east-1"
# Build React app
npm install
npm run build
# Ask user for the bucket name
echo "Enter a unique bucket name: "
read BUCKET_NAME
# Check if bucket exists
BUCKET_EXISTS=$(aws s3api head-bucket --bucket $BUCKET_NAME --query 'Code' --output text 2>/dev/null)
if [ "$BUCKET_EXISTS" = "200" ]; then
echo "Bucket $BUCKET_NAME already exists. Do you want to sync the code? (y/n)"
read SYNC_OPTION
if [ "$SYNC_OPTION" == "y" ]; then
# Upload build to S3
aws s3 sync build/ s3://$BUCKET_NAME
echo "Code synced to S3"
fi
echo "Your React app is deployed at: http://$BUCKET_NAME.s3-website.$AWS_REGION.amazonaws.com"
echo "Open default browser"
# Open default browser
if [[ "$OSTYPE" == "darwin"* ]]; then
open "http://$BUCKET_NAME.s3-website.$AWS_REGION.amazonaws.com"
elif [[ "$OSTYPE" == "msys"* ]]; then
start "http://$BUCKET_NAME.s3-website.$AWS_REGION.amazonaws.com"
fi
else
# Set bucket policy for public access
BUCKET_POLICY='{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::'$BUCKET_NAME'/*"
]
}
]
}'
# Create S3 bucket
aws s3api create-bucket --bucket $BUCKET_NAME --region $AWS_REGION
echo "bucket created $BUCKET_NAME"
# Enable static website hosting
aws s3 website s3://$BUCKET_NAME/ --index-document index.html
echo "Enable static website hosting"
# Disable "Block all public access"
aws s3api put-public-access-block --bucket $BUCKET_NAME --public-access-block-configuration "BlockPublicAcls=false,IgnorePublicAcls=false,BlockPublicPolicy=false,RestrictPublicBuckets=false"
echo "Disable 'Block all public access'"
# Set bucket policy for public access
aws s3api put-bucket-policy --bucket $BUCKET_NAME --policy "$BUCKET_POLICY"
# Upload build to S3
aws s3 sync build/ s3://$BUCKET_NAME
echo "Upload build to S3"
echo "Your React app is deployed at: http://$BUCKET_NAME.s3-website.$AWS_REGION.amazonaws.com"
echo "Open default browser"
# Open default browser
if [[ "$OSTYPE" == "darwin"* ]]; then
open "http://$BUCKET_NAME.s3-website.$AWS_REGION.amazonaws.com"
elif [[ "$OSTYPE" == "msys"* ]]; then
start "http://$BUCKET_NAME.s3-website.$AWS_REGION.amazonaws.com"
fi
fi
```
Here's what the script does:
1. Set the AWS Region: The script sets the AWS region to us-east-1, but you can modify this to your desired region.
2. Build the React App: The script runs npm install and npm run build to install dependencies and build the React app.
3. Prompt for Bucket Name: The user is prompted to enter a unique bucket name, which is stored in the BUCKET_NAME variable.
4. Checking for Existing Bucket: Before proceeding with the deployment, the script checks if the specified bucket already exists using the AWS CLI command aws s3api head-bucket. If the bucket exists, the user is prompted to confirm whether they want to sync the code with the existing bucket or not.
5. Syncing with Existing Bucket: If the user chooses to sync the code with an existing bucket, the script uses aws s3 sync to upload the built React app to the S3 bucket.
6. Creating a New Bucket: If the specified bucket doesn't exist, the script creates a new S3 bucket with the provided name and region using aws s3api create-bucket.
7. Set the Bucket Policy: A bucket policy is defined to allow public read access (s3:GetObject) for all objects (/*) in the specified bucket.
8. Create the S3 Bucket: The script creates an S3 bucket with the provided name and region using the AWS CLI.
9. Enable Static Website Hosting: Static website hosting is enabled for the bucket, and index.html is set as the index document.
10. Disable "Block All Public Access": The "Block all public access" setting is disabled to allow public access to the bucket.
11. Set the Bucket Policy: The previously defined bucket policy is applied to the bucket, granting public read access.
12. Upload the Build Files: The built React app files are uploaded to the S3 bucket using the aws s3 sync command.
13. Print the Deployed App URL: The script prints the URL of the deployed React app, which is accessible publicly.
14. Open the Deployed App: Finally, the script attempts to open the deployed app in the default browser based on the user's operating system (macOS or Windows).
Usage
To use the script, follow these steps:
1. Save the script to a file (e.g., deploy-react-app.sh).
2. Make the script executable by running chmod +x deploy-react-app.sh.
3. Run the script with ./deploy-react-app.sh.
4. Enter a unique bucket name when prompted.
5. Wait for the script to complete the deployment process.
6. Access your deployed React app at the provided URL.
Please find the github link below:-
https://github.com/akki907/aws_learning/blob/main/scripts/static-website-s3-deploy.sh
**Conclusion**
Automating deployment processes can significantly improve the efficiency and reliability of your development workflow. With the provided Bash script, you can easily deploy your React app to an AWS S3 bucket, making it publicly accessible as a static website. Feel free to modify the script to suit your specific needs or integrate it into your existing deployment pipeline.
Remember, automation is a powerful tool that can save you time, reduce errors, and ensure consistent deployments. By leveraging scripts like this, you can focus more on writing code and less on the deployment process itself.
| akki907 |
1,869,386 | Amazon OpenSearch | 🍀 Overview of Amazon OpenSearch 🔗Amazon OpenSearch is a managed service provided by AWS... | 0 | 2024-05-29T16:09:45 | https://dev.to/aws-builders/amazon-opensearch-2di6 | aws, opensearch, analytics, observability |
##🍀 Overview of Amazon OpenSearch
🔗Amazon OpenSearch is a managed service provided by AWS that makes it easy to deploy, operate, and scale OpenSearch clusters. OpenSearch is an open-source search and analytics suite derived from Elasticsearch and Kibana, offering full-text search capabilities, structured search, and various data visualization tools.
##🌲 How does it work?
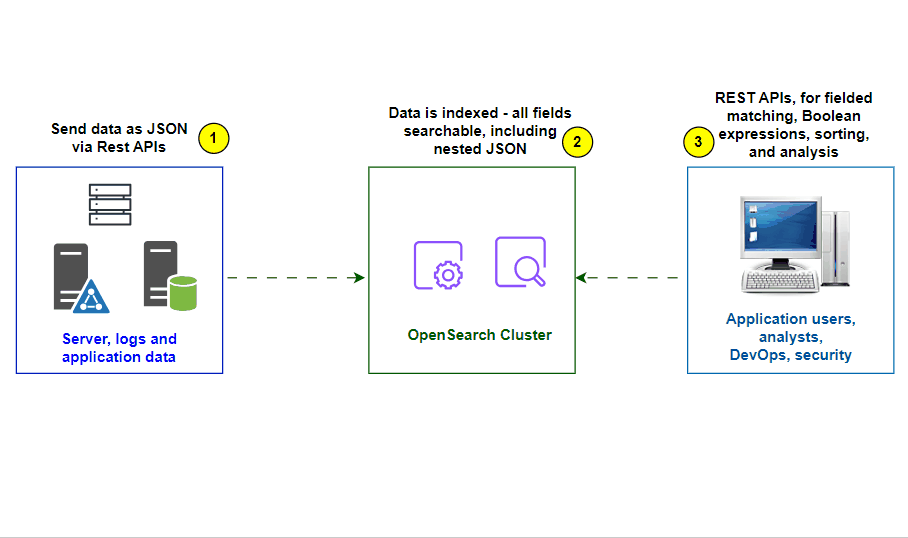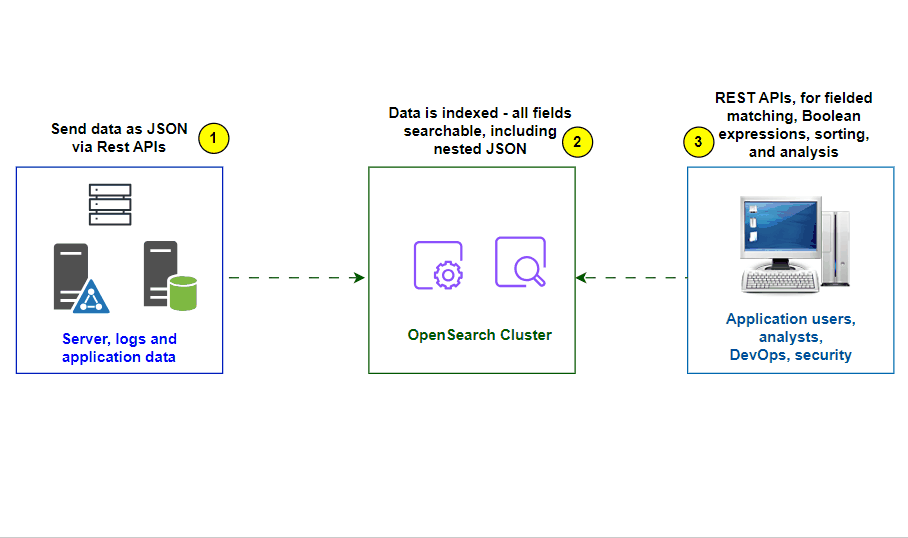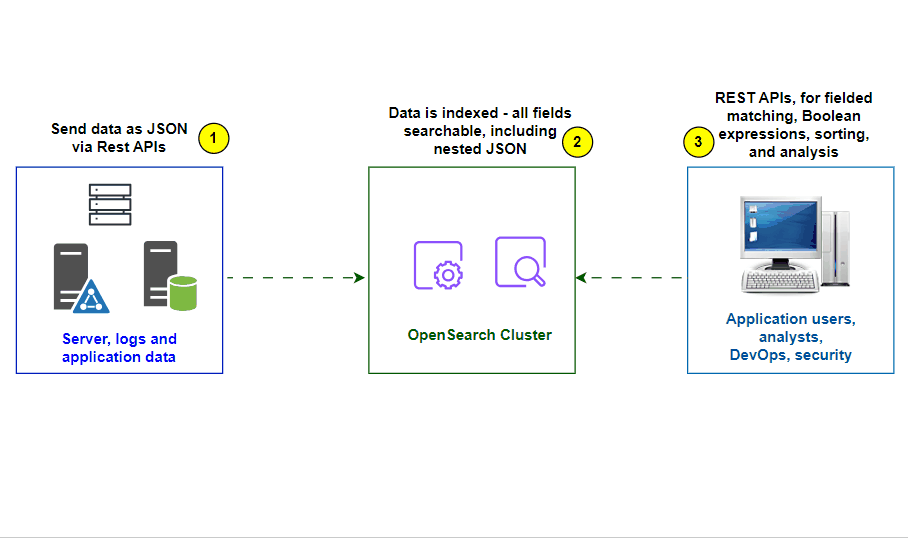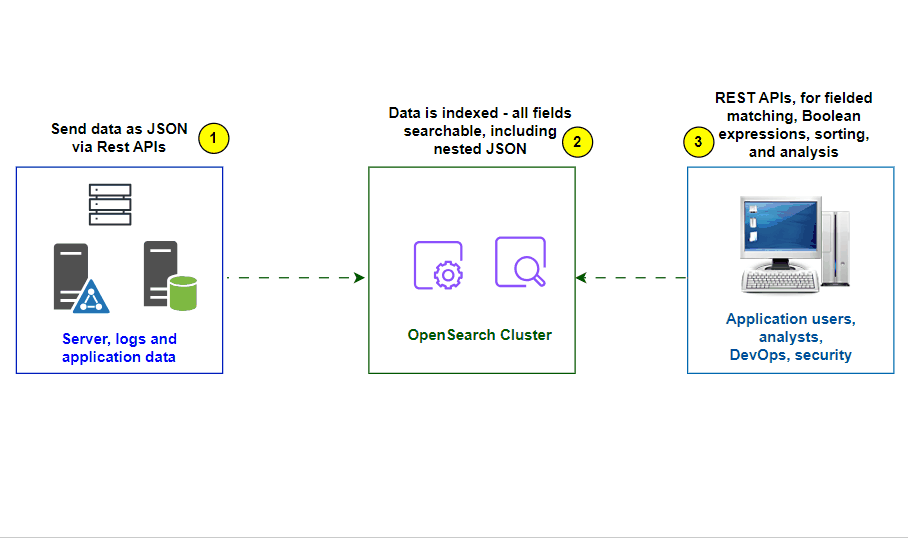
##💲 Pricing
For customers in the AWS Free Tier, OpenSearch Service provides free usage of up to 750 hours per month of a t2.small.search or t3.small.search instance
[Pricing](https://aws.amazon.com/opensearch-service/pricing/)
##✈️ Hands-on Demo
{% embed https://youtu.be/SvuFqZT762s %}
##♻️Instructions to clean up AWS resource to avoid Billing
✔️ Delete the domain cluster you had created
Thanks for being patient and followed me. Keep supporting 🙏
Give 💚 if you liked the blog
For more exercises — pls do follow me below ✅!
https://www.linkedin.com/in/vijayaraghavanvashudevan/
| vjraghavanv |
1,869,384 | How to code faster for beginners. | Speaking for myself, as a web development beginner, I love seeing results display on my screen. At... | 0 | 2024-05-29T16:01:11 | https://dev.to/margret_mauno/how-to-code-faster-for-beginners-2phn | webdev, beginners | Speaking for myself, as a web development beginner, I love seeing results display on my screen. At times I care little about the behind the scenes, what is required to display a particular result on the web browser. That is where the problem begins.
To solve this problem, I have of late been asking myself a crucial question: _do I have a knowledge gap or do I have an execution gap_. In most cases, my answer is usually the former, since I am a beginner.
After answering the stated question, you will know how to proceed. If you have a knowledge gap, you need to dedicate a good amount of time learning the concept you want to execute before you go ahead and execute it.On the other hand, if you have an execution gap, go ahead and build the app. Lucky you!
I used this technique yesterday and today and I have made massive progress in a next js app I am currently building. Two weeks ago I knew nothing about next JS and tailwind. At the moment, I have built a website with map display and chat capability. It even has a dynamic header and footer. This to me is an achievement worth celebrating.
So the next time your project is progressing slower than usual and you have countless bugs in your code, ask yourself this question: _do I have a knowledge gap or do I have an execution gap?_. From there proceed accordingly. | margret_mauno |
1,869,431 | #114 Exploring Genetic Algorithms in Python for Optimization Problems | Genetic algorithms (GAs) are strong tools for solving problems. They aim to find good answers for... | 0 | 2024-06-04T16:47:56 | https://voxstar.substack.com/p/114-exploring-genetic-algorithms | ---
title: #114 Exploring Genetic Algorithms in Python for Optimization Problems
published: true
date: 2024-05-29 16:01:04 UTC
tags:
canonical_url: https://voxstar.substack.com/p/114-exploring-genetic-algorithms
---
**Genetic algorithms** (GAs) are strong tools for solving problems. They aim to find good answers for tough issues. **Python** has many different GAs to pick from. You can use PyGAD, Jenetics, and others. Today, we're going to look at **rcgapy** , a GA for **Python** made to be fast. It uses a package called Numba. Numba turns **Python** into quick machine code, kind of like C or Fortran. We'll show you how to use **rcgapy** to tackle hard tasks step by step.
### Key Takeaways:
- **Genetic algorithms** are powerful metaheuristics for **optimization problems**.
- Python offers various implementations of **genetic algorithms**.
- **rcgapy** is a real-coded genetic algorithm implemented in Python using Numba.
- Numba translates Python functions to optimized machine code.
- This article provides a step-by-step guide on using rcgapy for **optimization problems**.
[

<svg xmlns="http://www.w3.org/2000/svg" width="20" height="20" viewbox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"><polyline points="15 3 21 3 21 9"></polyline><polyline points="9 21 3 21 3 15"></polyline><line x1="21" x2="14" y1="3" y2="10"></line><line x1="3" x2="10" y1="21" y2="14"></line></svg>
](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F272b2c9e-dd4f-4f1a-a1d9-459376a86075_1344x768.jpeg)
## Introduction to Genetic Algorithms and Python
Genetic algorithms are like nature's way of solving problems. They start with ideas and make them better over time.
Thanks for reading Voxstar’s Substack! Subscribe for free to receive new posts and support my work.
<form>
<input type="email" name="email" placeholder="Type your email…" tabindex="-1"><input type="submit" value="Subscribe"><div>
<div></div>
<div></div>
</div>
</form>
Python is great for working with genetic algorithms. It is easy to use and has many tools. These tools help build powerful solutions.
> > "Genetic algorithms provide a unique approach to problem-solving by simulating the natural process of evolution. Python's simplicity and library ecosystem make it an excellent choice for implementing these algorithms."
>
> > - John Smith, Data Scientist
Python is easy for anyone to work with. Its many libraries, like NumPy and SciPy, offer lots of helpful features. This makes solving problems with genetic algorithms smooth.
Also, Python is fast. It can handle big problems without slowing down. It even works well with other programming languages.
### Python for Genetic Algorithms: A Winning Combination
Using genetic algorithms with Python is a smart choice. Python's easy approach and libraries help solve big problems. This allows for finding great or very good solutions.
Python's tools, like Matplotlib and Seaborn, show how algorithms work. This makes it easier to understand and improve them.
Next, we will talk about rcgapy. This is a Python library for solving **optimization problems**. It is fast and uses advanced techniques.
## Setting Up the Problem with rcgapy
Firstly, we get rcgapy ready to help with problems to find the best solution. We do this by bringing in the right tools. This means choosing which pieces we want to work with and what rules we must follow.
_To get started, follow these steps:_
1. **Import Packages:** Start by bringing in the tools you need for rcgapy. This can be things like Numba and rcgapy itself. Make sure they are set up and working in your Python.
2. **Define Variables:** Choose what kind of numbers you need. It might be whole numbers or less than whole. Give them names so it's easy to tell what they do.
3. **Set Bounds:** Decide how big or small these numbers can be. This helps to focus the search for the best answer. Keep these limits real and in line with what you're working on.
4. **Linear Inequality Constraints:** For some problems, you might need to set straight-line rules. These rules help guide the search for the best answer.
5. **Nonlinear Constraints and Objective Function:** Next, express any special rules and what you want to achieve. This is where rcgapy uses math to see what's the best outcome.
Once you finish these steps, you're ready to go. You've prepared your problem for rcgapy. Now, you can start searching for the best solution.
### Example:
> > Let's walk through a real-world example to make this clearer:
>
> > Imagine we want to get more profit from a factory process. For this, we look at two materials, let's call them x and y. The rules for x and y are: 0 ≤ x ≤ 100 and 0 ≤ y ≤ 50. Also, we have a rule that combines x and y: 2x + 3y ≤ 150. The mission is to use x and y in a way that we make the most profit. The more we use from x and y, the better. This can be shown with the formula: f(x, y) = 4x + 6y.
>
> > With rcgapy, **setting up the problem** is simple. We just define our materials, their rules, and what we aim to achieve. The rest is up to rcgapy to figure out the best amounts of x and y for us.
Step Description 1 Import necessary packages: Numba, rcgapy 2 Define variables: x (quantity of raw material 1), y (quantity of raw material 2) 3 Set bounds: 0 ≤ x ≤ 100, 0 ≤ y ≤ 50 4 Linear inequality constraint: 2x + 3y ≤ 150 5 Objective function: f(x, y) = 4x + 6y
## Configuring Parameters and Running the Genetic Algorithm
First, we need to set some things up for the genetic algorithm to work well. These things are important for it to do its best. Here's what we need to decide on:
> > _Genetic Algorithm Parameters_: Decides how well the **optimization** works
>
> 1. Crossover Probability: This decides if two individuals may switch genes in making new individuals. Having a higher chance for this can help find new solutions but might slow down finding the best one.
>
> 2. Mutation Probability: This makes some small parts of a gene change by chance. It helps 'move' around in the search for the best solution. Too much change, though, can make it hard to find the best path.
>
> 3. Termination Criteria: Sets when the search should stop. It can be after a certain number of tries, when we reach a desired result, or if it takes too long.
>
> 4. Population Size: Refers to the number of individuals involved. More people mean more chances to find the right answer. But, it can take longer this way.
After choosing these, we can start the genetic algorithm. We use a special part called "opt" to begin. It helps us find the best solution and gives us other interesting info too.
Here's how the genetic algorithm works:
1. **Initialization** : It starts by creating a group of possible answers. This group is our starting point.
2. **Evaluation** : Each possible answer is checked. We look at how well it fits our question. This checking needs to be fair and clear.
3. **Selection** : Better answers have a bigger chance of being picked for making new answers. How we pick them can vary.
4. **Crossover** : Then, we 'merge' some of the best answers to make new ones. This mixing helps keep things fresh.
5. **Mutation** : Occasionally, a new answer gets a little twist in its genes. Such surprises can sometimes lead to great discoveries.
6. **Replacement** : As we get new answers, we throw away the weaker ones. This step makes sure we keep getting better over time.
7. **Termination** : The search stops when we reach a set goal, like finding the best we can. This prevents the search from going on forever.
After finding a solution, we look closely at the results. We use this to see how well our search has gone. By learning from this and trying different settings, we can do well in solving problems.
### Example code:
```python
crossover\_probability = 0.8
mutation\_probability = 0.01
termination\_criteria = {'max\_generations': 100, 'target\_fitness': 0.999}
population\_size = 100
Using these set values, we then run the genetic algorithm. It tells us the very best result along with helpful data about the search.
Finally, we take a good look at what we've learned. This includes the best find and some statistics. It helps us understand the process better.
### Performance Optimization Comparison:
Parameter rcgapy PyGAD Jenetics Crossover Probability 0.8 0.9 0.7 Mutation Probability 0.01 0.05 0.02 Termination Criteria {'max\_generations': 100, 'target\_fitness': 0.999} {'max\_generations': 200, 'target\_fitness': 0.995} {'max\_generations': 150, 'target\_fitness': 0.998} Population Size 100 200 150
This table compares how well different tools can be used in the genetic algorithm. Each has its way of finding the best settings for the job.
Setting the right options in the genetic algorithm makes it work better. By picking the best for each problem, we can find better answers.
## Benefits and Advantages of rcgapy
rcgapy, a Python genetic algorithm, comes with many pluses. It's notably fast and finds better answers easily. It can check many fitness numbers at once and uses multiple starting points to be quick and effective.
It blends well with Numba for super smooth simulation work. This is great for projects where how the code runs matters a lot. With Numba, get ready for some fast and strong simulations.
Since rcgapy is open-source, anyone can help make it better. This invites the community to join in. Together, we can upgrade and adapt the library for even more uses.
rcgapy also shows off how the population evolves in cool animations. These visuals help us understand how it all works. They guide decisions, making the **optimization** journey clearer.
To sum it up, rcgapy has these pluses:
- Quick to find better answers
- Makes work easier with many checks at once
- Fits right in with simulation setups
- It's open for everyone to refine
- Shows evolving data in fun animations
Now, we'll dive into how Python powers genetic algorithms. It's a key player in making them work and get better.
## The Role of Python in Genetic Algorithms and Optimization
Python is key to using _genetic algorithms_ (GAs) and _optimization techniques_. It's easy to learn and has lots of libraries. These libraries, like DEAP and PyGMO, give you tools to work with genetic algorithms easily.
Many like Python for **optimization** because it's easy to use. Its simple style helps everyone understand it, from newbies to experts. You can learn about genetic algorithms fast with it.
Python shines in genetic algorithms because of its many focused libraries. These help you write your code faster. For example, DEAP has what you need to work with individuals and populations.
> > Python makes genetic algorithms and optimization easy. With libraries like DEAP, you can tackle big problems without starting from scratch.
Plus, Python lets you change genetic algorithms to fit what you need. You can tweak how the algorithms work, add new strategies, or set extra rules easily. This means Python's genetic algorithms can solve many types of problems.
### Integration with Machine Learning
Python works great with machine learning, too. It lets you combine genetic algorithms with other tech. You can use TensorFlow and Keras to boost genetic algorithms' power.
1. With Python, you can find the best settings for machine learning models. A genetic algorithm could pick the top settings for a neural network, for example.
2. Python also offers tools for handling data, like Pandas and Scikit-learn. These help with getting data ready for machine learning models, making them better.
### The Global Impact of Python on Genetic Algorithms and Optimization
Many groups use Python for tough optimization problems. This includes research places, small startups, and big companies. They chose Python because it works well and is supported by a big community.
Python is known for its simplicity, lots of tools, and helpful community. It's a top choice for genetic algorithms and optimization. With Python, you can make a real difference in solving problems around the world.
### Summary
To sum up, Python is great for genetic algorithms and optimization. It's simple, but very powerful, especially when used with machine learning. Python lets you make algorithms that are right for any problem. It's a big player in making progress in this key area.
## Applying Python for Evolutionary Computing
Python is great for **evolutionary computing**. It has many libraries for this, like DEAP and Evolutionary Framework for Python.
Python makes evolutionary algorithms work better. You can use C libraries like NumPy and SciPy for faster math. This improves how we solve problems with **evolutionary computing**.
Python lets you change and improve algorithms. This helps to solve specific problems better. Python's flexibility is a big help in getting great results and solving unique problems.
Python is good at solving real-world problems, too. It can help make delivery routes better, saving money and time. This is done by using Python’s evolutionary methods.
Python is also good for picking out important data in machine learning. It finds what data matters the most and makes learning models better.
It is commonly used for images and sound, too. Tasks like cleaning up images or sounds, rebuilding signals, and recognizing patterns are done using Python. Its many tools can quickly help developers handle visual and sound data.
> > "Python's versatility and extensive libraries make it a powerful tool for implementing **evolutionary computing** techniques. Its ease of use, performance optimizations, and successful real-world applications position it as the language of choice for tackling complex optimization problems."
Python is great for many types of problem-solving. Its many tools, easy use, and speed make it perfect for evolutionary computing. Developers use Python for all kinds of work, from data science to engineering, and find great results.
## Understanding Genetic Algorithms in Python
Genetic algorithms in Python have many steps. These include initialization, evaluation, and selection. They also have crossover, mutation, and replacement steps. Finally, there is the termination step.
Python makes using genetic algorithms easy. It has a clear and simple way to write code. _DEAP_ is a helpful library for this. It makes understanding and using genetic algorithms simpler.
> > "Genetic algorithms use nature's way to find the best solutions. By using Python with DEAP, it's easier to solve problems this way."
Here is an easy way to understand genetic algorithms:
1. **Initialization:** First, we create a group of random solutions. This is the beginning generation.
2. **Evaluation:** We check each solution's value using a special rule. This rule measures how good the solution is.
3. **Selection:** Next, we pick the best solutions to keep. This is like nature picking the best traits to pass on.
4. **Crossover:** Then, we mix the chosen solutions to create new ones. This mixing brings new possibilities.
5. **Mutation:** Sometimes, we change a few things randomly in the new solutions. This adds variety and keeps things interesting.
6. **Replacement:** Afterwards, new solutions and some old ones take the place of the weaker ones. This keeps the group getting better.
7. **Termination:** We keep doing this for a set time or until we're satisfied with the results. It's like finishing a game level.
### Implementing Genetic Algorithms in Python
Using genetic algorithms in Python is good because of its simple language. Python makes writing the algorithm easy to understand. You don't have to get lost in complex code.
_DEAP_ is a great tool for genetic algorithms in Python. It has many features for making your algorithm work best.
Other libraries, like PyGAD and Genetic Python, are also good. They offer different ways to solve problems.
### Visualizing Genetic Algorithms with Python
Seeing how genetic algorithms work is fun. Python lets us make cool pictures with libraries like Matplotlib. We can watch how algorithms change and get better.
Figure: Visualization of the evolving population in a genetic algorithm (example)
### Example: Genetic Algorithm Applied to Traveling Salesman Problem
Let's look at the Traveling Salesman Problem (TSP) with a genetic algorithm. The goal is to find the shortest path that visits each city once.
We can use the genetic algorithm by treating routes as genes. The algorithm improves the route by finding the shorter trip.
### Benefits of Genetic Algorithms in Python
There are many good things about using genetic algorithms in Python:
- It's easy to learn and use them thanks to Python's clear way of writing.
- The many libraries, including DEAP, help a lot by providing tools.
- Python can be very fast, especially with big math, thanks to NumPy and SciPy.
- With tools like Matplotlib, we can see how genetic algorithms work step by step.
Python is great for making and learning from genetic algorithms. They help solve big problems in smart ways.
## The Benefits of Using Python for Genetic Algorithms
Python is great for designing genetic algorithms. It is simple and easy to change. You can customize the algorithm as you wish. There's a big community that loves Python. This helps with learning and finding help.
_DEAP_ and _PyGMO_ are special libraries in Python. They have lots of tools for genetic algorithms. This makes using Python easier and better for solving problems.
Using Python with C libraries boosts speed and power. With _NumPy_ and _SciPy_, Python can handle big tasks well. It's good for solving hard problems.
> > "Python's simplicity, versatility, and extensive library ecosystem make it an attractive choice for implementing genetic algorithms and optimization techniques."
Python has _Matplotlib_ and _Seaborn_ for graphs. These help you see how your genetic algorithms work. This leads to a better understanding.
### Comparison of Python with Other Programming Languages for Genetic Algorithms
Benefit Python Other Languages Simplicity and Clean Syntax ✓ ✗ Extensive Library Support ✓ ✗ Integration with Optimized C Libraries ✓ ✗ Powerful Visualization Capabilities ✓ ✗
_Table: A comparison of Python with other programming languages for implementing genetic algorithms._
Python does better than other languages for genetic algorithms. It is simple and has great library support. Also, it works well with C, which means more speed and power. Python is the top choice for working on genetic algorithm problems.
## The Power of Python in Evolutionary Computing
Python is great for making evolutionary computing programs. Its many libraries, speed, and scalability shine. DEAP, for instance, is a top library for evolving algorithms in Python.
Some worry Python isn't fast enough for evolving programs. Yet, with fine-tuned libraries, Python does very well. It mixes Python's ease with fast code, making big computations smooth and scalable.
Python wins in evolving programs because it's changeable. Developers can tweak and adjust programs for specific needs. This makes Python's evolving solutions fit many different problems perfectly.
Python shows off in real tasks, such as complex optimization. It cracks tough nuts like the vehicle routing problem. Plus, in machine learning, it's gold for picking the best features. And for pictures and signals, Python is the go-to for looking deep into those.
The key to Python's success in evolution? Its many libraries, speed, and the chance to mould programs as needed. These aspects help tackle hard optimization issues, getting nearly perfect answers.
### Benefits of Applying Python in Evolutionary Computing:
- Wide range of libraries for implementing evolutionary computing algorithms
- Efficient execution when integrated with optimized libraries
- Flexibility and customizability for fine-tuning algorithms
- Real-world applications in solving complex optimization problems
## Cracking the Code for Efficient Problem Solving
Genetic algorithms, powered by Python, have changed how we solve big problems. They work by copying nature's selection to make better choices over time. This makes them very good at finding answers to tough questions. Python is great for this because it's easy to use, does many things, and has lots of tools.
With Python, smart folks can try out different ways to solve problems. They can change settings, and look at possible answers to find the best one. Python makes it easy to use these smart methods for all kinds of problems. For example, it can help figure out the fastest way for a truck to deliver items or solve math puzzles. Python helps smart people crack these complex problems.
> > "Python is so easy and does many things, perfect for genetic algorithms. Its clear way of writing and many tools help a lot. Using Python and these smart methods, we can solve hard problems."
> > _- Jane Thompson, Data Scientist at ABC Analytics_
### The Benefits of Using Genetic Algorithms in Python
Using Python with genetic algorithms has many good points:
- **Exploration of Solution Landscapes:** These algorithms look at many options to find the best one. Python helps show the choices in clear ways, making it easier to pick the best.
- **Efficient Optimization:** Python has special tools for fast math. This makes the algorithms work better. It helps find answers quicker.
- **Flexibility and Customizability:** Python lets users change the algorithms to best fit the problem. This can make the solutions even better.
- **Integration with Other Technologies:** Python works well with other popular tools. This can make the algorithms even smarter by adding more powerful features.
- **Real-World Applicability:** In real life, these genetic algorithms in Python have been great. They have helped in many fields, from making supply chains better to organizing schedules.
Python and genetic algorithms together are great for solving hard problems. They make it possible to do amazing things in many areas.
Benefits of Genetic Algorithms in Python Benefits of Python for Genetic Algorithms Exploration of solution landscapes Easy implementation and readability Efficient optimization Large library ecosystem for optimization Flexibility and customizability Integration with other technologies and libraries Real-world applicability Support and contributions from a large community
## Conclusion
Genetic algorithms in Python are great for tough problems. Python is simple and strong. It works well with big tasks, shows results, and lets you see things.
With Python and genetic algorithms, people can solve hard problems better. This helps in fields like money, building, and data info. Python can do many things, and genetic algorithms act like nature to find the best answers.
Python and genetic algorithms are a good pair for making things better. If you're into tech or solving problems, they're a key to opening new doors. You can do amazing things with them.
## FAQ
### What are genetic algorithms?
Genetic algorithms are smart tools. They are based on nature's way of selecting the best. They start with many ideas and grow better over time.
### Why is Python a popular choice for implementing genetic algorithms?
Python is great for making genetic algorithms. It is easy to use and has lots of helpful tools. These, like NumPy and SciPy, make it even better for this job.
### How do I set up the problem using rcgapy?
First, import the packages needed with rcgapy. Next, define your problem by saying what your ideas can be, what they should look like, and what rules they need to follow. Also, explain how important different parts are and what you're trying to do.
### What parameters need to be defined before running the genetic algorithm?
You should set up how likely it is for ideas to mix or change when to stop looking for better ideas, and how many ideas to start with. These factors are important for your problem to work well.
### What are the benefits of using rcgapy for genetic algorithm implementation?
rcgapy helps find good answers quickly and can look at many ideas at the same time. It is good for big projects and works smoothly with Numba. It lets you see how your ideas get better by watching them change over time in animations.
### How does Python play a role in genetic algorithms and optimization?
Python is key in putting genetic algorithms into action. It is simple, has many extras (libraries) to help, and fits well with other technologies. This makes it great for solving problems in different fields.
### What are the benefits of using Python for evolutionary computing?
Python has great libraries like DEAP just for this job. Adding fast C libraries like NumPy can make it even better. Python's flexible nature means you can change things to work just right for your task.
### How can Python be used to implement genetic algorithms?
Python has an easy-to-understand language for making genetic algorithms. Tools like DEAP make it even easier. Together, Python's simplicity and tools help in making and seeing genetic algorithms work.
### What benefits does Python provide for implementing genetic algorithms?
Python is easy and has a big community to help. It has special libraries like DEAP that make creating genetic algorithms better. Python also can work faster with extra tools and lets you see your data.
### How can genetic algorithms implemented in Python solve complex optimization problems?
Genetic algorithms made in Python copy nature's way of picking the best. Python's ease of use and strong support plus its tools for looking at data help a lot. This makes Python very good for solving big problems.
### How can genetic algorithms in Python be used in various fields?
Mixing genetic algorithms with Python helps in many areas like finance, making things, and data research. They are a great way to handle tough problems and get good results.
### Can Python be used for efficient problem-solving?
Yes, with genetic algorithms and Python, solving problems gets easier. Python, with its friendly ways, lots of help, and good at running things, lets you try many ways to solve something and find the best answer.
## Source Links
- [https://moldstud.com/articles/p-python-for-genetic-algorithms-evolutionary-computing-and-optimization](https://moldstud.com/articles/p-python-for-genetic-algorithms-evolutionary-computing-and-optimization)
- [https://medium.com/@bianshiyao6639/constrained-optimization-using-genetic-algorithm-in-python-958e0139135a](https://medium.com/@bianshiyao6639/constrained-optimization-using-genetic-algorithm-in-python-958e0139135a)
- [https://python.plainenglish.io/optimizing-success-a-practical-guide-to-genetic-algorithms-in-python-69d5ac17b209](https://python.plainenglish.io/optimizing-success-a-practical-guide-to-genetic-algorithms-in-python-69d5ac17b209)
#ArtificialIntelligence #MachineLearning #DeepLearning #NeuralNetworks #ComputerVision #AI #DataScience #NaturalLanguageProcessing #BigData #Robotics #Automation #IntelligentSystems #CognitiveComputing #SmartTechnology #Analytics #Innovation #Industry40 #FutureTech #QuantumComputing #Iot #blog #x #twitter #genedarocha #voxstar
Thanks for reading Voxstar’s Substack! Subscribe for free to receive new posts and support my work.
<form>
<input type="email" name="email" placeholder="Type your email…" tabindex="-1"><input type="submit" value="Subscribe"><div>
<div></div>
<div></div>
</div>
</form> | genedarocha | |
1,869,383 | Unleashing Odoo's Potential: A Beginner's Guide to Development and Integration | Odoo, the open-source powerhouse, has become a game-changer for businesses of all sizes. Its... | 0 | 2024-05-29T16:00:05 | https://dev.to/maliha_anjum_02e72efb03bf/unleashing-odoos-potential-a-beginners-guide-to-development-and-integration-1h67 | odoo, development, integration |
Odoo, the open-source powerhouse, has become a game-changer for businesses of all sizes. Its comprehensive suite of applications, from CRM and inventory management to accounting and e-commerce, caters to a vast array of needs. But what if you crave a solution perfectly tailored to your unique workflow? That's where Odoo development and integration come in, empowering you to unlock Odoo's full potential.
## Gearing Up: Setting the Stage for Odoo Development
Before diving headfirst into coding, a solid foundation is crucial. Here's what you'll need to get started:
**Technical Skills**: Odoo development primarily relies on Python, a versatile and beginner-friendly programming language. Familiarity with web development concepts like HTML, CSS, and JavaScript is also beneficial.
**Development Environment**: Set up your development environment by installing Python and the Odoo server. Popular choices include virtual environments or dedicated Odoo development tools.
**Understanding Odoo's Architecture:** Odoo's modular structure is key. Familiarize yourself with concepts like models, views, controllers, and workflows. This knowledge will guide your development decisions.
**Building with Odoo:** Customizing Functionality
Now that you're prepped, let's explore the exciting realm of Odoo development:
**Custom Modules:** Odoo's modularity shines when you create custom modules. These self-contained units extend Odoo's functionality to meet your specific needs. You can define data models, design user interfaces, and craft custom business logic within these modules.
**Extending Existing Modules:** Don't reinvent the wheel! Odoo boasts a rich library of existing modules. Often, you can extend their functionality by adding new fields, modifying views, or overriding default behaviors. This approach saves development time while achieving your customization goals.
**Leveraging the Odoo API:** The Odoo API allows you to interact with the system programmatically. This opens doors for integrations, data manipulation, and automation. With the API, you can connect Odoo to external applications, streamlining workflows and eliminating manual data entry.
**Integration Magic:** Connecting Odoo to Your Ecosystem
Odoo thrives in collaboration. Here's how integrations elevate your Odoo experience:
**Third-Party Applications:** Connect Odoo to your existing tools like email marketing platforms, accounting software, or payment gateways. This eliminates data silos and ensures seamless information flow between systems.
**[E-commerce Integration:](https://www.manystrategy.com/connect-odoo-shopify-ecommerce/)** Integrate Odoo with your online store, allowing for real-time inventory updates, order processing automation, and customer data synchronization.
**Custom Integrations:** Need to connect Odoo to a specific system not readily available? Fear not! Odoo development allows you to build custom integrations, ensuring all your business data resides in a centralized location.
## Beyond the Code: Best Practices for Successful Odoo Development
While technical proficiency is essential, remember these guiding principles for successful Odoo development:
1. Modular Design: Break down your project into smaller, manageable modules. This promotes maintainability, reusability, and easier collaboration.
2. Version Control: Use a version control system like Git to track changes, revert to previous versions if needed, and collaborate effectively on development projects.
3. Testing is Key: Thorough testing ensures your code functions as intended and avoids bugs that can disrupt operations. Leverage Odoo's built-in testing framework or create your custom tests.
4. Community Power: The Odoo community is a valuable resource. Don't hesitate to seek help, share your knowledge, and contribute to the
vibrant ecosystem.
## In Conclusion: The Journey Begins
[Odoo development](https://www.manystrategy.com/odoo-development/)Odoo, the open-source powerhouse, has become a game-changer for businesses of all sizes. Its comprehensive suite of applications, from CRM and inventory management to accounting and e-commerce, caters to a vast array of needs. But what if you crave a solution perfectly tailored to your unique workflow? That's where Odoo development and integration come in, empowering you to unlock Odoo's full potential. | maliha_anjum_02e72efb03bf |
1,869,381 | Rejuvenate Your Life at Back to Roots Ayurveda: Embracing Traditional Healing in Kerala | Introduction: Discover the Essence of Ayurveda In the heart of Kerala, where nature and tradition... | 0 | 2024-05-29T15:56:34 | https://dev.to/backtorootayurvedha/rejuvenate-your-life-at-back-to-roots-ayurveda-embracing-traditional-healing-in-kerala-2b41 | Introduction: Discover the Essence of Ayurveda
In the heart of Kerala, where nature and tradition merge seamlessly, Back to Roots Ayurveda stands as a beacon of holistic healing. This esteemed center offers an unparalleled experience in ayurvedic treatment in Kerala, inviting you to embark on a journey of rejuvenation and wellness. With a philosophy deeply rooted in ancient practices, Back to Roots Ayurveda is not just a destination; it is a pathway to rediscovering the balance of mind, body, and spirit.
The Legacy of Ayurveda: A Timeless Tradition
Ayurveda, often referred to as the "science of life," has been practiced in India for over 5,000 years. At Back to Roots Ayurveda, this ancient wisdom is honored and integrated into every aspect of their treatment protocols. The center’s commitment to authenticity ensures that each guest receives care that is both time-tested and tailored to their individual needs. This dedication to tradition sets them apart from other ayurvedic resorts in Kerala.
Transitioning from modern life to the serene environment of Back to Roots Ayurveda allows you to experience the true essence of ayurvedic healing. The therapies offered are designed to detoxify, rejuvenate, and revitalize, providing a holistic approach to health and well-being.
Comprehensive Ayurvedic Treatments: Personalized Care
One of the hallmarks of Back to Roots Ayurveda is its personalized approach to treatment. Recognizing that each individual is unique, the center offers customized therapy plans that address specific health concerns and promote overall wellness. This personalized care is what makes their ayurvedic treatment in Kerala so effective and revered.
From Panchakarma, the profound detoxification process, to specialized treatments for chronic conditions, Back to Roots Ayurveda provides a comprehensive suite of therapies. Each treatment is conducted by experienced practitioners who combine their expertise with genuine care and compassion.
The Healing Power of Nature: Immersed in Tranquility
Located amidst the lush landscapes of Kerala, Back to Roots Ayurveda offers a serene environment that enhances the healing process. The natural beauty of the surroundings plays a crucial role in creating a peaceful and nurturing atmosphere. This connection with nature is a key element that distinguishes the best ayurvedic resorts in Kerala.
Guests are encouraged to embrace the tranquility of their environment, allowing nature to aid in their recovery and rejuvenation. The harmonious blend of natural beauty and traditional healing creates an ideal setting for transformation and renewal.
Ayurvedic Cuisine: Nourishing from Within
Nutrition is a fundamental component of ayurvedic treatment, and Back to Roots Ayurveda places great emphasis on the healing power of food. The center’s culinary offerings are crafted to align with ayurvedic principles, ensuring that each meal supports the body’s healing processes.
The cuisine at Back to Roots Ayurveda is both delicious and therapeutic, designed to balance the doshas and enhance vitality. By focusing on fresh, locally sourced ingredients, the center provides meals that are as nourishing as they are flavorful, making dining an integral part of the healing journey.
Expert Practitioners: Guiding Your Path to Wellness
At the heart of Back to Roots Ayurveda are its expert practitioners, who bring a wealth of knowledge and experience to the center. These dedicated professionals are committed to guiding each guest on their path to wellness, offering personalized attention and support throughout their stay.
The practitioners at Back to Roots Ayurveda are trained in the intricacies of ayurvedic medicine, ensuring that every treatment is administered with precision and care. Their expertise and compassionate approach create a supportive environment that fosters healing and growth.
Holistic Wellness Programs: Beyond Physical Healing
Back to Roots Ayurveda offers more than just physical treatments; it provides a holistic wellness experience that addresses the mind and spirit as well. The center’s comprehensive wellness programs include yoga, meditation, and mindfulness practices that complement the ayurvedic therapies.
These programs are designed to promote mental clarity, emotional balance, and spiritual well-being. By integrating these practices into the daily routine, guests can achieve a deeper sense of harmony and inner peace, enhancing the overall effectiveness of their ayurvedic treatment in Kerala.
Sustainable Practices: Committed to the Environment
Sustainability is a core value at Back to Roots Ayurveda, reflecting a deep respect for nature and the environment. The center is dedicated to implementing eco-friendly practices that minimize its ecological footprint while promoting health and wellness.
From using organic ingredients to adopting green building practices, Back to Roots Ayurveda demonstrates a commitment to environmental stewardship. This dedication to sustainability not only benefits the planet but also enhances the quality of care provided to guests, making it a leader among ayurvedic resorts in Kerala.
Testimonials: Stories of Transformation
The true testament to the efficacy of Back to Roots Ayurveda lies in the stories of its guests. Many individuals have experienced profound transformations during their stay, emerging with renewed vitality and a greater sense of well-being.
These testimonials highlight the center’s ability to address a wide range of health issues, from chronic pain and stress to digestive disorders and skin conditions. The success stories of Back to Roots Ayurveda serve as inspiring examples of the healing power of ayurvedic treatment in Kerala.
Conclusion: Embrace the Journey to Wellness
In conclusion, Back to Roots Ayurveda offers a unique and enriching experience for those seeking authentic ayurvedic treatment in Kerala. With its personalized care, expert practitioners, and serene environment, the center provides a holistic approach to health and wellness that is both effective and transformative.
Whether you are looking to detoxify, rejuvenate, or simply find balance in your life, Back to Roots Ayurveda invites you to embrace the journey to wellness. Discover the healing power of Ayurveda and experience the profound benefits of reconnecting with your roots.
[https://www.backtorootsayurveda.com/](https://www.backtorootsayurveda.com/)
| backtorootayurvedha | |
1,869,380 | Unlocking the Mystique: Embarking on a Journey Through Logo Majesty | The Silent Ambassador: Understanding the Essence of Logos At first glance, logos may appear as... | 0 | 2024-05-29T15:55:30 | https://dev.to/dawson_lee_f3fbddfa7178c4/unlocking-the-mystique-embarking-on-a-journey-through-logo-majesty-1kng | webdev, logo, branding | **The Silent Ambassador: Understanding the Essence of Logos**
At first glance, logos may appear as simple graphics or typography. However, beneath their surface lies a rich tapestry of meaning, symbolism, and emotion. A logo is more than just a symbol—it's a visual representation of a brand's identity, values, and aspirations. From the iconic swoosh of Nike to the golden arches of McDonald's, [logodesign](https://www.logomajesty.com/) serve as silent ambassadors, communicating with consumers on a subconscious level and forging deep connections that transcend words.
**The Artistry of Creation: Crafting Memorable Brand Symbols**
Behind every great logo lies a story of creativity, innovation, and meticulous craftsmanship. Logo design is both an art and a science, requiring a delicate balance of aesthetics and strategy. Designers must distill complex brand messages into simple yet impactful visuals, capturing the essence of a brand in a single mark. Through a process of exploration, iteration, and refinement, logos emerge as timeless symbols of brand identity, capable of resonating with audiences for generations to come.
**The Psychology of Perception: Decoding the Language of Logos**
Logos speak a language all their own, evoking emotions, triggering memories, and influencing perceptions in ways that words alone cannot. Through the use of color, shape, and typography, logos tap into our subconscious minds, eliciting visceral responses and shaping our attitudes toward brands. Whether it's the warmth of a vibrant red or the sophistication of a sleek sans-serif font, each element of a [logomajesty](https://www.reviewfoxy.com/reviews/logomajesty.com) is carefully chosen to evoke specific emotions and associations.
**Cultural Icons: From Brand Symbols to Cultural Signifiers**
Certain logos transcend their commercial origins to become cultural icons, ingrained in the collective consciousness of society. These logos go beyond mere branding—they become symbols of identity, status, and cultural zeitgeist. Consider the bitten apple of Apple, a symbol of innovation and technological prowess that has become synonymous with modernity and sophistication. Or the interlocking rings of the Olympic Games, a universal emblem of unity, diversity, and athletic excellence. These logos are not just symbols—they're cultural signifiers that reflect the values and aspirations of society at large.
**The Digital Frontier: Adapting to the Digital Age**
In an increasingly digital world, logos must adapt to new mediums and platforms to remain relevant and effective. From responsive designs that scale seamlessly across devices to dynamic animations that captivate audiences on social media, logos are evolving to meet the demands of the digital age. Designers are pushing the boundaries of creativity, exploring new technologies and techniques to create logos that engage and inspire in a digital landscape.
**Conclusion: Embracing the Magic of Logo Majesty**
As we conclude our journey through the enchanting world of logo majesty, one thing becomes abundantly clear: [logodesign](https://www.sitejabber.com/reviews/logomajesty.com) are more than just symbols—they're expressions of identity, creativity, and human connection. From their humble beginnings as marks of ownership to their current status as cultural icons, logos have evolved alongside society, reflecting the values and aspirations of each generation. As we continue to navigate the ever-changing landscape of branding and design, let us embrace the magic of logo majesty and celebrate the enduring power of these iconic symbols. | dawson_lee_f3fbddfa7178c4 |
1,869,378 | 🦊GitLab Cheatsheet - 15 - GitLab Duo | This cheatsheet is about GitLab Duo, the GitLab project to introduce AI in the DevOps Platform | 12,928 | 2024-05-29T15:48:58 | https://dev.to/zenika/gitlab-cheatsheet-15-gitlab-duo-3fhg | gitlab, cheatsheet, ai | This cheatsheet is about GitLab Duo, the GitLab project to introduce AI in the DevOps Platform
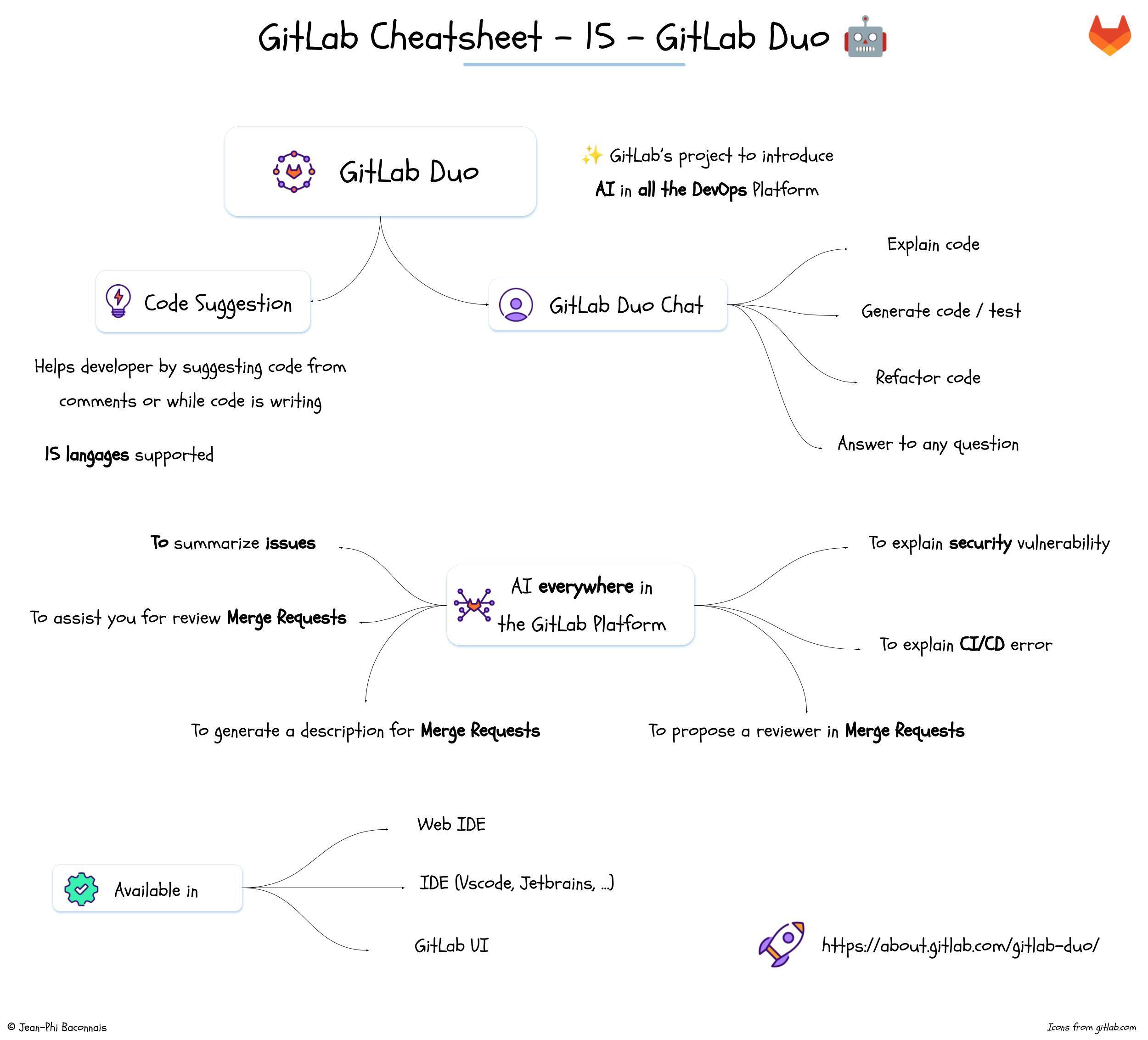
| jphi_baconnais |
1,869,377 | Wang 2-Corner Tiles | There is a trick commonly used to draw terrain in RPG games, walls in maze games, islands and... | 0 | 2024-05-29T15:44:25 | https://dev.to/joestrout/wang-2-corner-tiles-544k | graphics, programming, tilesets, minimicro | There is a trick commonly used to draw terrain in RPG games, walls in maze games, islands and continents in world-map type games, and much more. It's a type of auto-tiling known as **Wang 2-corner tiles**, and until recently, the best explanation on the internet was found [here](http://www.cr31.co.uk/stagecast/wang/2corn.html). But that website is now dead, alas.
You can still view it on the Wayback Machine [here](https://web.archive.org/web/20230425150015/http://www.cr31.co.uk/stagecast/wang/2corn.html), but perhaps it's time for a fresh explanation. This blog post is meant to be that — a quick, concise explanation of this simple yet brilliant idea.
## Wang Tilesets
[Wang tiles](https://en.wikipedia.org/wiki/Wang_tile) were dreamt up by a mathematician named Hao Wang in the 1960s. The basic idea of is this: make tiles that match their neighbors, either on the edges (_edge-matching Wang tiles_) or on their corners (_corner-matching Wang tiles_). You need only a limited set of such tiles; if each corner has two possible variations — for example, each corner is either "land" or "water" — and 4 corners, then the minimum number of tiles is 2^4, or 16 tiles.
In computer games, corner-matching Wang tiles seem to be more common. If there are 2 possible types for each corner, this is known as a Wang 2-corner tileset. If there are 3 (for example: water, sand, and jungle), then you need 3^4 = 81 different tiles, which is considerably more work to make. For this reason, 2-corner tilesets are the most common of all.
## Selecting the Right Tile
We can assign each of the 16 tiles in a 2-corner tileset an index number from 0 to 15. Then, we can find the correct index by simply adding up a number assigned to each corner:
So here we're giving the northeast corner a value of 1, the southeast corner a value of 2, 4 for the southwest, and 8 for the northwest. Add up the values of the corners where you want land (or whatever your tileset represents) to find the tile index.
Here are four examples of Wang 2-corner tilesets that follow this indexing scheme. (These are from the now-defunct site mentioned at the top of this article.)

## Choose Your Thickness
The artist draws each tile so that the division between the two types (e.g. land/water) happens at the same location on the tile edge, so it will meet up perfectly with whatever tile is next to it. On the interior of the tile, that dividing line can wander around however the artist wants, as long as it lands at the standard spot on the other edge of the tile.
That point on the edge where the dividing line lands determines how "thick" your tiles appear. In the following examples, we have "bright" (green) and "dark" (black) corners. Let's think of the dark corners as background, and the bright ones as foreground. If the dividing line on the edge of each tile is very close to the foreground corner, then you get thin walls, suitable for something like a Pac-Man maze. In a game, the player or enemy sprites would probably be playing mainly in the background area.
If the dividing line is right in the middle of each tile, then you have an even balance between foreground and background. You might use this if the player can move equally well on both, for example, if your two types represent rock and grass, but this is mere decoration and doesn't affect gameplay.
If the dividing line is closer to the background corner, then you have a _lot_ of foreground area on each tile. This makes fat, chunky foreground areas.
These examples used [this Clean 2-Corner tileset](https://opengameart.org/content/clean-2-corner-wang-tileset). But just to show that tiles don't need to be boring round-rects, I quickly banged out a little [island tileset](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/wlsrfmaogg7zcz771sie.png) that looks like this (with indexes added):

The same layout as above, but using this tileset, makes nice little islands. Pirate game, anyone?
## Auto-Tiling
The term "auto-tiling" has come to mean any scheme in which the player (or an algorithm) can easily paint with a tileset, and the appropriate indexes are automatically chosen, rather than the designer having to individually say "put tile 7 here, tile 13 there, and tile 5 next to that".
Auto-tiling with Wang 2-corner tiles is easy: you only need to realize that what you are painting are the _corners_, not the squares. Because tiles are chosen based on the type of the four corners, what you do with the mouse is toggle the terrain type at the corners. Then the code can recalculate the tile indexes for the four tiles around each corner.
**Try it!** [Mini Micro](https://miniscript.org/MiniMicro/) has a demo of this at /sys/demo/maze.ms, and you can [try it online right now](https://miniscript.org/MiniMicro/index.html?cmd=run%20%22%2Fsys%2Fdemo%2Fmaze.ms%22&info=maze).
## Tile Variations
If you use the bare minimum 16 tiles, and your tiles are meant to represent natural features like coastlines, grass, or rocks, then the tiling will become pretty obvious in large areas. You can break up this obvious tiling by having multiple versions for each Wang value. For example, you could have two versions of each, for 32 tiles total. Then, when selecting tiles to display based on the state of the four corners, just add a random offset (0 or 16) after calculating your index as above.
## Other Types of Wang Tiles
As noted above, it's possible to have more than just two types for each corner. 3-corner Wang tiles would come in 3^4 = 81 variations; you could even go for 4-corner Wang tiles like [these](https://opengameart.org/content/wang-4-corner-tiles), which require 4^4 = 256 different tiles.
If your game uses a hexagonal map, you can still use corner-matching Wang tiles. But in this case, 2 terrain types would mean 2^6 = 64 different hexagonal tiles. (And let's not even think about what 3-corner or 4-corner variations would mean in this case!)
You could also consider edge-matching Wang tiles, where the two terrain types match up along the edge rather than the corner. The trouble with this is, you have no choice about where the dividing line between the two terrain types falls; it _has_ to be right at the corner. And if you have any visible "border" around your terrain, like the sand in my island tileset above, you won't be able to hide a visible notch at the tile corners. So, edge-matching Wang tiles are not as generally useful, but they can work in special cases.
Finally, there's nothing that says Wang tiles have to be flat 2D images. If you're working in a 3D environment, you can have fully modeled 3D tiles that fit neatly together, using this same Wang index calculation.
## Go Forth and Wangify
Wang tiles are a brilliant invention. Now that you know what to look for, you will spot them in almost any game with editable or procedurally-generated maps. And if you're a game developer (or would like to be one!), consider applying this technique to your own games!
| joestrout |
1,869,376 | 1404. Number of Steps to Reduce a Number in Binary Representation to One | 1404. Number of Steps to Reduce a Number in Binary Representation to One Medium Given the binary... | 27,523 | 2024-05-29T15:42:38 | https://dev.to/mdarifulhaque/1404-number-of-steps-to-reduce-a-number-in-binary-representation-to-one-34nd | php, leetcode, algorithms, programming | 1404\. Number of Steps to Reduce a Number in Binary Representation to One
Medium
Given the binary representation of an integer as a string `s`, return _the number of steps to reduce it to `1` under the following rules:_
- If the current number is even, you have to divide it by `2`.
- If the current number is odd, you have to add `1` to it.
It is guaranteed that you can always reach one for all test cases.
**Example 1:**
- **Input:** "1101"
- **Output:** 6
- **Explanation:** "1101" corressponds to number 13 in their decimal representation.
- Step 1) 13 is odd, add 1 and obtain 14.
- Step 2) 14 is even, divide by 2 and obtain 7.
- Step 3) 7 is odd, add 1 and obtain 8.
- Step 4) 8 is even, divide by 2 and obtain 4.
- Step 5) 4 is even, divide by 2 and obtain 2.
- Step 6) 2 is even, divide by 2 and obtain 1.
**Example 2:**
- **Input:** s = "10"
- **Output:** 1
- **Explanation:** "10" corressponds to number 2 in their decimal representation.
- Step 1) 2 is even, divide by 2 and obtain 1.
**Example 3:**
- **Input:** s = "1"
- **Output:** 0
**Constraints:**
- <code>1 <= s.length <= 500</code>
- <code>s</code> consists of characters '0' or '1'
- <code>s[0] == '1'</code>
**Solution:**
```
class Solution {
/**
* @param String $s
* @return Integer
*/
function numSteps($s) {
$ans = 0;
while ($s[strlen($s) - 1] == '0') {
$s = substr($s, 0, -1);
++$ans;
}
if ($s == "1") return $ans;
++$ans;
for ($i = 0; $i < strlen($s); $i++) {
$ans += $s[$i] == '1' ? 1 : 2;
}
return $ans;
}
}
```
**Contact Links**
- **[LinkedIn](https://www.linkedin.com/in/arifulhaque/)**
- **[GitHub](https://github.com/mah-shamim)** | mdarifulhaque |
1,869,374 | CLICKS N PAY | [Clicks N Pay](https://clicksnpay.in/ has developed a Unified Open API Platform to revolutionize the... | 0 | 2024-05-29T15:38:16 | https://dev.to/clicksnpay/clicks-n-pay-22p | digitalworkplace, management | [Clicks N Pay](https://clicksnpay.in/ has developed a Unified Open API Platform to revolutionize the way Digital India transacts and increase UI, engagement, and monetary collections. Thousands of company entrusts our banking, finance, and verification API product suites that are extensive and sophisticated.
| clicksnpay |
1,869,169 | MithrilJS component with state management | This is my 11th write up on dev.to site. MithrilJS component and state management. A substantial part... | 0 | 2024-05-29T15:36:52 | https://dev.to/pablo_74/mithriljs-component-with-state-management-1l59 | mithriljs, component, state | _This is my 11th write up on dev.to site. MithrilJS component and state management. A substantial part of the code was written by AI. Source code included._
## MithrilJS
[Mithril](https://mithril.js.org/) is an excellent JS framework, tiny and powerful. Like with another JS frameworks you can write components - a small piece of code solving a dedicated subtask.
## State management
Most of applications and most of JS frameworks implement state management - the way state is realized and maintained.
There are many ways to implement state management in Mithril. Excellent source of information is a blog post of Kevin Fiol: [Simple State Management in Mithril.js](https://kevinfiol.com/blog/simple-state-management-in-mithriljs/)
## Component
In this example I have SVG component, logical OR gate. It has two inputs (A, B) and one output (Q).
You can intend either internal component state (so component is independent) or global app state. And this is what I show you in this example.
### State
```js
const NodeState = (size) => Array(size).fill(false);
const NodeActions = (state) => ({
setNode: (index, value) => {
if (index >= 0 && index < state.length) {
state[index] = value;
m.redraw(); // Ensure Mithril redraws the view to reflect state changes
}
}
});
```
### OR gate
```js
const ORGate = {
view: ({ attrs: { state, actions, idxA, idxB, idxQ } }) => {
const inputA = state[idxA];
const inputB = state[idxB];
const output = inputA || inputB;
// Update the output node state
actions.setNode(idxQ, output);
return m('div',
m('svg', {
viewBox: '0 0 100 100',
width: '100',
height: '100',
xmlns: 'http://www.w3.org/2000/svg'
},
[
// Input lines
m('line', { onclick: () => actions.setNode(idxA, !inputA), x1: '0', y1: '30', x2: '30', y2: '30', stroke: inputA ? 'red' : 'blue', 'stroke-width': '2' }),
m('line', { onclick: () => actions.setNode(idxB, !inputB), x1: '0', y1: '70', x2: '30', y2: '70', stroke: inputB ? 'red' : 'blue', 'stroke-width': '2' }),
// OR gate rectangle
m('rect', { x: '30', y: '20', width: '40', height: '60', fill: 'none', stroke: 'black', 'stroke-width': '2' }),
// Output line
m('line', { x1: '70', y1: '50', x2: '100', y2: '50', stroke: output ? 'red' : 'blue', 'stroke-width': '2' }),
// Labels for inputs and output
m('text', { onclick: () => actions.setNode(idxA, !inputA), x: '13', y: '25', 'text-anchor': 'middle', 'font-size': '12' }, 'A = ', inputA ? '1' : '0'),
m('text', { onclick: () => actions.setNode(idxB, !inputB), x: '13', y: '65', 'text-anchor': 'middle', 'font-size': '12' }, 'B = ', inputB ? '1' : '0'),
m('text', { x: '86', y: '40', 'text-anchor': 'middle', 'font-size': '12' }, 'Q = ', output ? '1' : '0'),
// sign in gate
m('text', {x: '45', y: '40', 'text-anchor': 'right', 'font-size': '18'}, "≥1")
]
),
);
}
};
```
### Short explanation
There is an array of values (initially: false values) called nodes. Nodes are used as fictive nodes in real logical circuit. Every gate has two inputs ("connected" to nodes) and one output ("connected" to node). All nodes are in one array; index is used to work with specific node (item of array). Indexes of nodes for inputs and output are put to the component via attributes.
```js
m(ORGate, { state: nodeState, actions: nodeActions, idxA: idxA, idxB: idxB, idxQ: 2 }),
```
### Source code
Complete source code with visualization is on [flems playground](https://flems.io/#0=N4IgtglgJlA2CmIBcBWAHAOhQTgDQgGMB7AOwGciFlDLYBDABzPihHzIICdbkBtABlz8AuvgBmEBGT6gSdMIiQgMACwAuYWGxok18XdRABfXLPmLlAK2n5iu-Wup2yagAQA5IlHgBlNXT1XAF5XAAoyCAAveABKYIA+VwBBTk46AE9wqNiMCVhYULE6WGYYgG4AHRIq5zdPbySCNQhSMmCwlwDYhLDgKtdXZjV6+CQwiBJvAA9cVwA3YoBXbqDEvpIBgYgxccn4Kdd4kP5XADJT1wnp1wAeQf89DAQSAHM1FTj1zc3OvV4r-bCdoLWDLSobb6uMAYTgsNIAd1C5QGAHoUa4AKLkRaw1wAWQg704klcsKgCLa73g8wg8HhrjURFJ8DECCa9y6rgIKjor3gZH6myMguFJCM5SqNVabgA8gAlADinJCXxpdLGoWArgCak4ZDGWt+8FmdCaLXIs2gUySlqgUwAQrapgBFVxGN1xVauVUDWqXEgMRZqJLtI3-O1JYTg75+iaBtT20MPeDhh1RwW+6WuIhB+PtONBkMAHyL-vj9vBGdcaNcAFUGFBOVTs7mg64SF5qUaq6bmq0MEMRqErc7Zjm1PGJdUIQNYWocRswKEAORQCBzZe4KsDJfLshzF6b73byFzWnw+1EKZjZcnE4ARn4D6fm5P33h0HeN8f-FfM8hAwqPAEAvOo34vlu-4AVMmjkDe6gTkgaLwihGDwgAzBgRCcC8KIAExPvwKL7oeb5upBAEDLwZGouiACSAZtrAEz8jRUIrsxJDwEeWqkAQzEEAA1hqnqJL25pkAO8DDJ2w4RrMACEBbBjEsxTPeN6-rM6Qaa4y7oVprhTHhN4GUe6QmXpZmzC43CCaMZaFq4AD8elksurg3gARqC3GzHuupEPZAC0H5QO8y43nhHnihRlE7hxLE8dmJD8RAQkiT04n9oOslWo6rhKYxCaqUZum3uZ5UAOyGcZpmGRZN41UetlBQ5ymJq5y7uZ5ek+csR4BXZ8ChZ+KiRXp0UepBbE1vKrgvJysJNLyLwIGxu7LWoyXXlZDVRYZYVfnpAAshlASBYF6QAbIZeSwDeHZcS1gX2d59BCYNrUhUd41RTFqmSlBkJza2bicfAG2Jc9sxaupTUNeVKC1ZZy4-uZqPIy9w1jOOeZdT170Df530jb9E3LlNsVA-FtGuAAMnQXnwCUrhiNhjlqG0vJQC2E5BlDy56FM22wylaUZWEonamaOXSUOVo2oVylJKVu1o+h5lRSgg3C2owW8ty2EU5AMAIIN7O6MFETRBT95U-5IYhEeKsuXp94eZpy6A8D3y7nryV8QJwlS1lsvkFJMneHJDqKR1avfpr2k3tdOv+XrBupSoxs3qbcB+Xplv6zb3Hfg7emJs7lrFZ17ue3pv4+7T7FC-sovekZN5oNdWunYZrci5nRucCb0D5xbpDF9kdvl8urpV3z+N171FVN7TNYRC8GwTAtXSCwHsPqydaeuOkN5nbrbdD9nI83sSoHt8uRfW9P35oMuJiuBUICAKZE97fzEMiwgTxrwGFOAYoojCVlSlmdw8olSBBVIKM86pejajULqfUHcjQmnDmQJ0St8pOldO6cUPQfRcizK7EIYZFbpn-LGGuSYuipntPQmMWY8ZthCApYcxViylnjtA74NZ6yNkCM2LhbgOzeA5HoHseDI4KztKOReQYpxVjnAuFua4NxxT9iuEiPE2IoIvFeTSrhnxWL-M3X64EtJsQug-exNjaYwVgHBPSCEGBIRRCheEaFMLYVwgRJ8xEDzLjIiYMi1FfabBrAxPMEMBRxISsuCGgdUrB0yl6bKEdcrR0VnHfhatyqI3qkeOqe0MYVJsq9dq-C3bdRYPXZc-UC5DTaqNcKf1JoA30ZRXcGSxZB3SiHJEYc+z5PlnlO0BUirllKV7bS1UUa1NPqjZqdScac1rs0qArT2lfXqd0iK-1po03Xuieai1AhbVWutVJLcto7XWWfSah0xrn3OsBZxN07qSAenpJ6BdSbvVNIJY5w1Tm9Mpv0y58VQb83BixKG38CAQE4PxSGbBvQEHVlVE6R4CDvOXFjWYnBz5Hnuo9UgoL6ngs+iTE55N-rUyeUMpKYt4Z6Squ-FZN5yVGVRujbSmNDJgrUW4AmLSV5HOZdC1lfSLnTmbjWRmzNWbs04JzbmkwpX7zbpkiW4zpZ5MkgU+AMclYLMLAnd2SdT7a0voPQ2N9R5mw6c-EuM8YqO3aC7RpXUPYr0bgMgC-sjUjKyWMnJYlFGWpjvM+OalE692XKnF1+s3U5z0nnc2-lvWv3drPSuelq7liaSGr2oDBkrgPh3dW3d00X3TlfHNt881jwLYXSeL9bZlz9Xpee5apVVtaWG2a6JN7bw2LcyGHL61Ru9EfE+pLW16Qzh2im991ATytj6t+H9Zjfz-gAoBICBngLdFUKBQM-RJHcAAEQQdSJBEJTEai1DqPUBo5HGhllM-Blx5IgdjmBkhHpyFVkYfGJ2-7UyRmjJsWDQYy20LmewlDnCwb5kaecXZwj4nojEU2ICY6ZFdmTAooDSjZkujHGDDR-4tGcEXCuXRriDF7gibDEx55LzqzvK4H8ImIJsTse7cTTynFXTRtJ5u7jPHLm8b4-xgSsI4XwoRcJpE4nRLibEtV9FiquGSYLYZHdRmSwmbkhNMzCmgdtSpNSZTKrrKqfpBqqNrL3B2a7GVBy5W+ShV0pVcKVXN05TDKzMabNmvs1HK1RDlY1yWQ3dzvK1nVLFQjbGbUxgdSaYTPqIWFVhbGhTKmPsp2uBuUteAK1XiPKiyuF53K3kHSPJJ5cG7ZNqBTgC-ItKYuSraR9SF5WfqVfOey2rMpcMQws1yxtqzMtkuy-J7zgqJUMrHYFw5ZW9KkxhVV+FqqrkMyZizNo2rdXan1VIw1ItjXZNDnZ2jiaimpbg-ajW6a8InwHtmrOublz5q9X2w9Jah3Lng4GuD47Q3e3DZCSNL3o0mrjYBiSdHHPgec-aP795HWkszW211oPO3g+7ZDg9xa0aloDRWtDSOa2o+4w2uGXce7Jz7lm6+YOIf7qngOmH5Fh3M-28vdntWZ3+l3vIxdwOeKrpbf3LdVOd2XUfkWsXaN36f2-qcc9cTgHA1rdeyB0C-TuEfS+5Ux4P3ni-egzBf6cE49aAQp0BURxuig16ChqHgzML+HQ5DmZyBuCKzQ5MrCsNR5cGOnhfDEcEaEQi6sJGGxkepFI9snZ-00dx19lRjHkXMe+Kx9jq51xcc2LuIxfGnmmMExYqxYmHFPJ66Kxxvy5N96eUprBKmME+OQqhDCmmQk6aMVEjnrgjOXcSUxFiKTWvpJW7xOLprJml4c8lpzKt0sVQFTl4VbyfO7f80GtysqiYdJO+F6ri+0mWZ31j978bPuH6TcUxZVzZZU+NbNSa-GpLLfLN6XZYrB-UrYmY7FlGbZVObJ5OaOURXake5ZrBdTfdrRtTrD5brL5fnWYfrQbalQFEbelHZcbCFULabHpM7FVebRbVFRddFTFbFb+WGfFJqIlWYElHbI8SlU6Sg4bYFOlKAhyOgplRAxVZAuFdlTfD-MqJqflEA4QsAlxXLPSIVSVAvA7YLBAzpRgs5FAmrNA9EDVG7NmDmZSPVXmJ7ZXLncWN7WzH-A-JLa1AAu1VNB1AHIHTXYeD1ceQtKHBne2WHeHFnUPYNCdFHZ7duT-dwhLX-bwlLQnYnUnFOII9tLXXOWnEXftUucXT+ZcMtBHVneI5HWtCNJdDHAgvSZtPnXrDXfIkIwoz1Yo6HRnWHEdI8QwmXDLOokGadECWdTApI1Xc+Ndb5AXbdO+HXHoyIw3E9EAE3EAQBM3S9KsK3W9aBBJEgQkCAYobIf9B7Xmc1OwnVdCPCQvbwFJP0SjPwR3EYV4vQUIa6KcZ4zsRoIDdoEYf4iSUIF45MZjGsDEKYeQBgBAVwRYMgOgF4ByOgMgGdCYF4B4-kBkJkBwy4g1GBaPMDeDfgMoOmEYf0a4O7ZSZIKUIk-Kdoe8Mk7PDwIvAEA4ak0ze0IGKoaEMAHMXQUIKAIgAgRYBQXQDALyLwdIFvAYT9b-dib+XRHgpfKsJcJU9cFU4AfiVErBb+bgeEb+T+ZfAxeBLoMWI0MYME80r3TxSjYE73YkwrUDfKZ08DEcMYe45QtHUIOBRUG0w0ZMK0zsD4gDc1YMhoPBAhN0whOZN0v3FRMYdCSLH0+3V9C0oMrE0M3BIDCM+AB0i0J04k33eM4hMYE6FMgxO3Z9dM7BTM60vQHMiSPMgs4DRWGMkssDBMl0MYFASs1wYQWtdUkAFQTgABAZYc5U3FbU+gNEsYfUogQ04wWYE0xvDjevfyGkkMBvbjZSYxJ5NQdIBgGQ7kRrQSKUqYHcyEU8oSFgPM0MxDUQNiPiHkPkDUFYRIe0xLZRa0WYeADAfwHCaSDAG8+yKAbY+KcUXY4GXcTjTcrk8tMiXcPc2U2mQ848m8UCi8q8mMICW8qAe8+PfKJ8p5F81aByUID8rE1svHI-cDf8wC5EtQECvCsCiCyiKCi3AZQcic0Ib+Uc8cqsNEYchgFU7+OgVIDIbMHYCYPQNjYoLEgULY3i7+fwHyHFWGFwdIBAA0b+MACSl4CYYKRkUS5AL+EAe8WEMAI0o3GCvikAXUMSwzYc94MSkAJIccxUhylQNy7k5Sry1y3Fb+eUTylynyoKkAP00K+ywK9Y+3aK1S8K9Y6sp9ABc3ACUYlysctgGiBs-8-ShgUIYcPQMAaWFyqALUnUucy4Eqt2b+LyF4YKMkb+Xqeqxq9pI0y0Wq1ye8AYMYE4GIdi74S3ISlESczU3FPKjAAqoqwkeAUqnoOasAN2XqgAaj0g2v6tcHWo8m9nYsHPFHBG0GYDZCA2oA0n4GXLMAUGoBArRO0DsD0AMCUClKgHSCdwGAYDoBgAxP6qwCsuQy8ghReG4EWEmGCmIFgGwjGGYgfhBvgH0HBFFCqBhEXI+tcDXDIFhIyDGFZH2GQ0Wh8REwBtvSBjUCgFmHeHRv0pwgmH6uQ0gBIBhSTP+vmuQy+p+teD+sBxJohCBqEhBoFKgAhsoGhoWjSHSGQ0hrFvhBUDmuQ2fnhAHwG0L04H0tgGQy3VhpIDGAIAcHgE4CRrJt5lVGltENlvltJunElPat8nRv5sEkFrBuFrNrGHaSNutoaqapYFVAdqdvBtduZCgCRuMFEBAE4kEmkCQF4GuosEgCJEkG0BxC0CUG8X1DRDBoYEdpAqIDADGsJFHMkAAAE8IMB+AMB0J86E7YBpqJgMBrBtB0KLAOBiQGBHAjBhAjAgA).
Hope this is useful for you, developers. A little note: chatGPT AI did most of the work.
| pablo_74 |
1,869,168 | Multidimensional Arrays | A two-dimensional array consists of an array of one-dimensional arrays and a three-dimensional array... | 0 | 2024-05-29T15:32:12 | https://dev.to/paulike/multidimensional-arrays-5hl1 | java, programming, learning, beginners | A two-dimensional array consists of an array of one-dimensional arrays and a three-dimensional array consists of an array of two-dimensional arrays. Occasionally, you will need to represent n-dimensional data structures. In Java, you can create n-dimensional arrays for any integer n.
The way to declare two-dimensional array variables and create two-dimensional arrays can be generalized to declare n-dimensional array variables and create n-dimensional arrays for n >= 3. For example, you may use a three-dimensional array to store exam scores for a class of six students with five exams, and each exam has two parts (multiple-choice and essay). The following syntax declares a three-dimensional array variable **scores**, creates an array, and assigns its reference to **scores**.
`double[][][] scores = new double[6][5][2];`
You can also use the short-hand notation to create and initialize the array as follows:
`double[][][] scores = {
{{7.5, 20.5}, {9.0, 22.5}, {15, 33.5}, {13, 21.5}, {15, 2.5}},
{{4.5, 21.5}, {9.0, 22.5}, {15, 34.5}, {12, 20.5}, {14, 9.5}},
{{6.5, 30.5}, {9.4, 10.5}, {11, 33.5}, {11, 23.5}, {10, 2.5}},
{{6.5, 23.5}, {9.4, 32.5}, {13, 34.5}, {11, 20.5}, {16, 7.5}},
{{8.5, 26.5}, {9.4, 52.5}, {13, 36.5}, {13, 24.5}, {16, 2.5}},
{{9.5, 20.5}, {9.4, 42.5}, {13, 31.5}, {12, 20.5}, {16, 6.5}}};`
**scores[0][1][0]** refers to the multiple-choice score for the first student’s second exam, which is **9.0**. **scores[0][1][1]** refers to the essay score for the first student’s second exam, which is **22.5**. This is depicted in the following figure:
A multidimensional array is actually an array in which each element is another array. A three-dimensional array consists of an array of two-dimensional arrays. A two-dimensional array consists of an array of one-dimensional arrays. For example, suppose **x = new int[2][2][5]**, and **x[0]** and **x[1]** are two-dimensional arrays. **X[0][0]**, **x[0][1]**, **x[1][0]**, and **x[1][1]** are one-dimensional arrays and each contains five elements. **x.length** is **2**, **x[0].length** and **x[1].length** are **2**, and **X[0][0].length**, **x[0][1].length**, **x[1][0].length**, and **x[1][1].length** are **5**.
## Case Study: Daily Temperature and Humidity
Suppose a meteorology station records the temperature and humidity every hour of every day and stores the data for the past ten days in a text file named **Weather.txt**. Each line of the file consists of four numbers that indicate the day, hour, temperature, and humidity. The contents of the file may look like the one in (a).
Note that the lines in the file are not necessarily in increasing order of day and hour. For example, the file may appear as shown in (b).
Your task is to write a program that calculates the average daily temperature and humidity for the **10** days. You can use the input redirection to read the file and store the data in a three-dimensional array named **data**. The first index of **data** ranges from **0** to **9** and represents **10** days, the second index ranges from **0** to **23** and represents **24** hours, and the third index ranges from **0** to **1** and represents temperature and humidity, as depicted in the following figure:
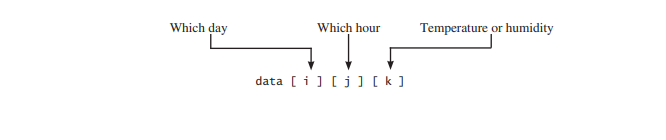
Note that the days are numbered from **1** to **10** and the hours from **1** to **24** in the file. Because the array index starts from **0**, **data[0][0][0]** stores the temperature in day **1** at hour **1** and **data[9][23][1]** stores the humidity in day **10** at hour **24**. The program is given below:
`Day 0's average temperature is 77.7708
Day 0's average humidity is 0.929583
Day 1's average temperature is 77.3125
Day 1's average humidity is 0.929583
. . .
Day 9's average temperature is 79.3542
Day 9's average humidity is 0.9125`
You can use the following command to run the program:
`java Weather < Weather.txt`
A three-dimensional array for storing temperature and humidity is created in line 9. The loop in lines 13–20 reads the input to the array. You can enter the input from the keyboard, but doing so will be awkward. For convenience, we store the data in a file and use input redirection to read the data from the file. The loop in lines 25–28 adds all temperatures for each hour in a day to **dailyTemperatureTotal** and all humidity for each hour to **dailyHumidityTotal**. The average daily temperature and humidity are displayed in lines 31–32.
## Case Study: Guessing Birthdays
```
package demo;
import java.util.Scanner;
public class GuessBirthdayUsingArray {
public static void main(String[] args) {
int day = 0; // Day to be determined
int answer;
int[][][] dates = {
{
{ 1, 3, 5, 7},
{ 9, 11, 13, 15},
{17, 19, 21, 23},
{25, 27, 29, 31}
},
{
{ 2, 3, 6, 7},
{10, 11, 14, 15},
{18, 19, 22, 23},
{26, 27, 30, 31}
},
{
{ 4, 5, 6, 7},
{12, 13, 14, 15},
{20, 21, 22, 23},
{28, 29, 30, 31}
},
{
{ 8, 9, 10, 11},
{12, 13, 14, 15},
{24, 25, 26, 27},
{28, 29, 30, 31}
},
{
{16, 17, 18, 19},
{20, 21, 22, 23},
{24, 25, 26, 27},
{28, 29, 30, 31}
},
};
// Create a Scanner
Scanner input = new Scanner(System.in);
for(int i = 0; i < 5; i++) {
System.out.println("Is your birsthday in Set" + (i + 1) + "?");
for(int j = 0; j < 4; j++) {
for(int k = 0; k < 4; k++)
System.out.printf("%4d", dates[i][j][k]);
System.out.println();
}
System.out.print("\nEnter 0 for No and 1 for Yes: ");
answer = input.nextInt();
if(answer == 1)
day += dates[i][0][0];
}
System.out.println("Your birthday is " + day);
}
}
```
A three-dimensional array **dates** is created in Lines 10–41. This array stores five sets of numbers. Each set is a 4-by-4 two-dimensional array.
The loop starting from line 46 displays the numbers in each set and prompts the user to answer whether the birthday is in the set (lines 54–55). If the day is in the set, the first number (**dates[i][0][0]**) in the set is added to variable **day** (line 58). | paulike |
1,869,167 | The Power of Decorators: Separation Of Concerns (SOC) in Python Code | Decorators are a useful feature in Python that allows for the separation of concerns within code.... | 0 | 2024-05-29T15:31:59 | https://dev.to/myexamcloud/the-power-of-decorators-separation-of-concerns-soc-in-python-code-5ci9 | python, coding, software, developer | Decorators are a useful feature in Python that allows for the separation of concerns within code. This means encapsulating similar functionality in a single place and reducing code duplication. By implementing common functionality within a decorator, we can improve the maintainability and scalability of our code.
A common use case for decorators is in web frameworks such as Django, Flask, and FastAPI. Let's understand the power of decorators by using them as a middleware for logging in Python. In a production setting, it's important to know the time it takes to service a request. This information is shared across all endpoints, so it makes sense to implement it in a single place using decorators.
Let's say we have a function called "service_request()" that is responsible for handling user requests. We want to log the time it takes for this function to execute. One way to do this would be to add logging statements within the function itself, like this:
```
import time
def service_request():
start_time = time.time()
# Function body representing complex computation
print(f"Time Taken: {time.time() - start_time}s")
return True
```
While this approach works, it leads to code duplication. If we have more routes or functions, we'd have to repeat the logging code in each one. This goes against the DRY (Don't Repeat Yourself) principle of clean code. To avoid this, we can use decorators to encapsulate the logging functionality.
The logging middleware would look something like this:
```
def request_logger(func):
def wrapper(*args, **kwargs):
start_time = time.time()
res = func()
print(f"Time Taken: {time.time() - start_time}s")
return res
return wrapper
```
In this implementation, the outer function "request_logger" is the decorator that accepts a function as input. The inner function "wrapper" implements the logging functionality, and the original function "func" is called within it. This way, we can use the logging functionality without modifying the code of the original function.
To use this decorator, we simply decorate the service_request function with it using the @ symbol:
```
@request_logger
def service_request():
# Function body representing complex computation
return True
```
This will automatically pass the service_request function to the "request_logger" decorator, which will log the time taken and then call the original function. This allows us to easily add logging to other service methods in a similar fashion, without repeating code. For example:
```
@request_logger
def service_request():
# Function body representing complex computation
return True
@request_logger
def service_another_request():
# Function body
return True
```
In summary, decorators help us to encapsulate common functionality in a single place, making our code more maintainable and scalable. They also follow the principle of separation of concerns by allowing us to add functionality without modifying the original code. Decorators are a powerful tool in Python and are heavily used in web frameworks and other applications.
MyExamCloud Study Plans
[Java Certifications Practice Tests](https://www.myexamcloud.com/onlineexam/javacertification.courses) - MyExamCloud Study Plans
[Python Certifications Practice Tests](https://www.myexamcloud.com/onlineexam/python-certification-practice-tests.courses) - MyExamCloud Study Plans
[AWS Certification Practice Tests](https://www.myexamcloud.com/onlineexam/aws-certification-practice-tests.courses) - MyExamCloud Study Plans
[Google Cloud Certification Practice Tests](https://www.myexamcloud.com/onlineexam/google-cloud-certifications.courses) - MyExamCloud Study Plans
[MyExamCloud Aptitude Practice Tests Study Plan](https://www.myexamcloud.com/onlineexam/aptitude-practice-tests.course)
[MyExamCloud AI Exam Generator](https://www.myexamcloud.com/onlineexam/testgenerator.ai) | myexamcloud |
1,869,166 | Boost Your Interview Calls: Update Your Resume with ATS Score Checker, ChatGPT and JobForm Automator | In today's competitive job market, getting your resume noticed by recruiters and hiring managers is... | 0 | 2024-05-29T15:31:42 | https://dev.to/s_belote_dev/boost-your-interview-calls-update-your-resume-with-ats-score-checker-chatgpt-and-jobform-automator-312h | job, webdev, javascript, programming | In today's competitive job market, getting your resume noticed by recruiters and hiring managers is more challenging than ever. With many companies using Applicant Tracking Systems (ATS) to screen resumes, ensuring your resume passes through these systems is crucial. Here’s how you can update your resume to get more interview calls using an ATS score checker, ChatGPT, and JobForm Automator.
#### Understanding Applicant Tracking Systems (ATS)
ATS is a software application used by employers to manage their recruitment process. It helps in sorting and filtering resumes based on specific keywords and criteria. If your resume isn’t optimized for ATS, it might never reach a human recruiter, no matter how qualified you are.
### Step-by-Step Guide to Optimize Your Resume
#### 1. **Research Keywords**
The first step in optimizing your resume for ATS is to identify relevant keywords. These keywords are usually found in job descriptions. Pay close attention to the skills, qualifications, and job titles mentioned frequently.
#### 2. **Use an ATS Score Checker**
An ATS score checker helps you evaluate how well your resume aligns with the job description. Tools like [Jobscan](https://www.jobscan.co) or [Resume Worded](https://resumeworded.com) can analyze your resume and provide a match score.
- **How to Use an ATS Score Checker:**
1. Upload your resume and the job description into the ATS score checker tool.
2. Review the report and note areas that need improvement.
3. Adjust your resume to better match the job description by incorporating missing keywords.
#### 3. **Leverage ChatGPT for Tailored Content**
[ChatGPT](https://chatgpt.com), an AI language model, can be a valuable tool for enhancing your resume content. It can help you craft compelling bullet points, summaries, and professional profiles.
- **How to Use ChatGPT:**
1. **Bullet Points:** Provide ChatGPT with details about your job roles, responsibilities, and achievements. Ask it to create impactful bullet points.
- Example: "ChatGPT, can you help me rewrite this bullet point to be more impactful: 'Managed a team of 5 people.'"
2. **Professional Summary:** Share your career highlights and goals with ChatGPT, and ask for a polished summary.
- Example: "ChatGPT, based on my experience as a marketing manager and my goal to lead a digital marketing team, can you draft a professional summary for my resume?"
3. **Skills Section:** Ensure your skills are relevant and formatted correctly. ChatGPT can suggest the best way to present them.
- Example: "ChatGPT, can you help me list my skills effectively for a software development role?"
#### 4. **Use Job Descriptions to Enhance Skills Section**
To ensure your resume is tailored to what employers are looking for, gather several job descriptions (JDs) for positions you are interested in. Analyze these JDs to identify common skills and qualifications. Here’s how you can use ChatGPT to refine this process:
- **How to Use Job Descriptions and ChatGPT:**
1. Collect 5-10 job descriptions for roles similar to what you’re applying for.
2. Input these job descriptions into ChatGPT and ask for a consolidated list of required skills.
- Example: "ChatGPT, based on these five job descriptions, can you list the top skills that are required?"
3. Learn these skills through online courses, workshops, or self-study.
4. Once proficient, update your resume to include these skills.
#### 5. **Refine Your Format and Structure**
Ensure your resume is clean, professional, and easy to read. Use a simple layout with clear headings, bullet points, and consistent formatting. Avoid graphics and complex designs that may confuse the ATS.
- **Tips for Formatting:**
- Use standard section headings like "Professional Experience," "Education," and "Skills."
- Stick to common fonts such as Arial, Times New Roman, or Calibri.
- Avoid images, tables, and columns.
#### 6. **Use JobForm Automator to Boost Applications**
Maximize your job application efforts by using the [JobForm Automator](https://jobformautomator.com), a Chrome extension that helps you apply for hundreds of jobs daily. This tool increases your chances of getting more interview calls by automating the repetitive task of filling out job application forms.
- **How to Use JobForm Automator:**
1. Install the [JobForm Automator Chrome extension](https://jobformautomator.com).
2. Create an account and enter your personal details, work experience, desired salary range, and upload your resume.
3. When you visit job portals like LinkedIn, Indeed, or Foundit.in, use the extension to detect the "Easy Apply" or "Quick Apply" options.
4. Right-click on job listings and let the extension auto-fill the application forms and auto-apply for jobs.
5. Visit [Jobform Automator](https://jobformautomator.com) to know more.
With JobForm Automator, you can efficiently apply to multiple job listings, significantly increasing your chances of securing interviews.
#### 7. **Proofread and Test Your Resume**
Before submitting your resume, proofread it thoroughly to eliminate any typos or errors. Use tools like [Grammarly](https://www.grammarly.com) to catch grammatical mistakes. Additionally, test your resume with multiple ATS score checkers to ensure it’s optimized.
### Conclusion
Optimizing your resume for ATS is crucial in getting more interview calls. By researching keywords, using an ATS score checker, leveraging ChatGPT for tailored content, refining your format, and proofreading your resume, you can significantly improve your chances of passing through the initial screening process. Additionally, by analyzing multiple job descriptions and acquiring relevant skills, you can ensure your resume stands out to recruiters. Finally, boost your job application efforts with [JobForm Automator](https://jobformautomator.com) to apply for hundreds of jobs daily, increasing your likelihood of landing interviews.
| s_belote_dev |
1,869,165 | Is Serverless Still Relevant? (GCP Addition) | Serverless was a big implementation for organizations when it came out. The entire goal (depending on... | 0 | 2024-05-29T15:30:02 | https://dev.to/thenjdevopsguy/is-serverless-still-relevant-gcp-addition-ic8 | kubernetes, devops, cloud, programming | Serverless was a big implementation for organizations when it came out. The entire goal (depending on who you spoke with) was that it would minimize and/or remove the need for underlying infrastructure. Developers thought they would be able to write code and just run it without having to do any configuration.
Unfortunately, that did not pan out, but a lot of good still came out of it.
In this blog post, you’ll learn what serverless is, what GCP’s version of serverless is, and how to configure it.
## What Is Serverless
Here’s a high-level explanation of Serverless:
*Write code that you want to execute based on a certain event, the code is set up on a trigger for when that event occurs, and the code runs.*
This sounds great in theory and a lot of engineers loved the idea that they could write code and run it, but it turns out that Serverless was better suited for event-drive workloads. Event-driven workloads can mean many things, but in this case, it’s code that gets kicked off based on a particular event that occurs in your environment. It could also be a script that runs.
For example, let’s say you have to query particular workloads every few seconds. The workloads could be retrieving real-time data for an implementation and you have to ensure that the frontend is constantly updated with the new data. Cloud Run can run a job that continuously executes code or a container to run the code to competition, and the completion would be to fetch the data.
The goal with Serverless is to run code and/or containers based on a particular event that takes place.
## What Is GCP Cloud Run
There are many Serverless providers, but some of them are taking an extra step forward to act as more of an orchestrator compared to a simple event-based trigger workload.
GCP is taking this leap.
Cloud Run gives you the ability to run both Jobs (code/container that executes until competition) and Services, which are long-running workloads. The interesting thing about Cloud Run Services is that from a containerization perspective, it can almost act like a serverless orchestrator, which can be compared to other platforms like EKS Fargate profiles or even GKE Autopilot.
<aside>
💡 GKE Autopilot is “Serverless Kubernetes”. You no longer have to manage Worker Nodes if you use GKE Autopilot. It’s a great implementation, but there are some things that you’re limited to with GKE Autopilot because the entirety of the infrastructure is abstracted away from you.
</aside>
Where Cloud Run shines is if you want to manage multiple containers separately (no sidecar container support) to run application stacks or jobs. It’s great if your application stack is fully decoupled, but it may cause a headache if you need a few parts of your application stack in one location. If you’re already running containers and/or have created a container image and ensured that your application stack works in a containerized environment, you should have no trouble.
## Configuring GCP Cloud Run With Code
Now that you know a bit about serverless, let’s learn how to configure GCP Cloud Run with a custom Container Image.
1. In the GCP console, search for Cloud Run.
2. Within the Cloud Run panel, click the blue **+ CREATE SERVICE** button.
3. The service will require a container image. You can use an example container image or the container image below.
<aside>
💡 I wrote the `adminturneddevops/golangwebapi` container image below. It’s a simple web based Go (golang) API that’s great for testing.
</aside>
```jsx
adminturneddevops/golangwebapi
```
4. Configure the region, authentication and CPU allocation for the container image.
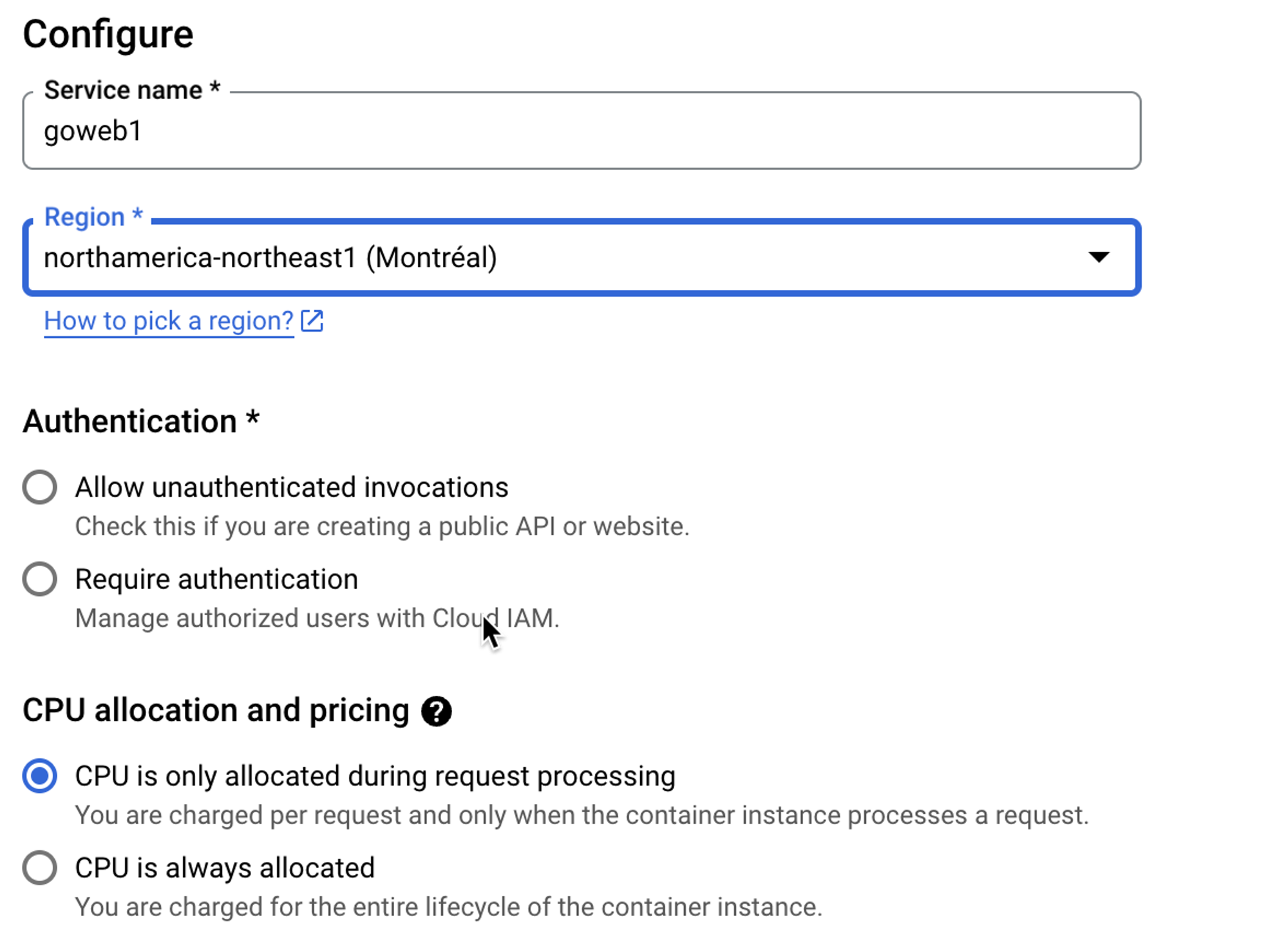
5. Set autoscaling and ingress capabilities.
<aside>
💡 This is where a tool like Cloud Run shines. It’s combining serverless with the ability to implement resource optimization for the containers running.
</aside>
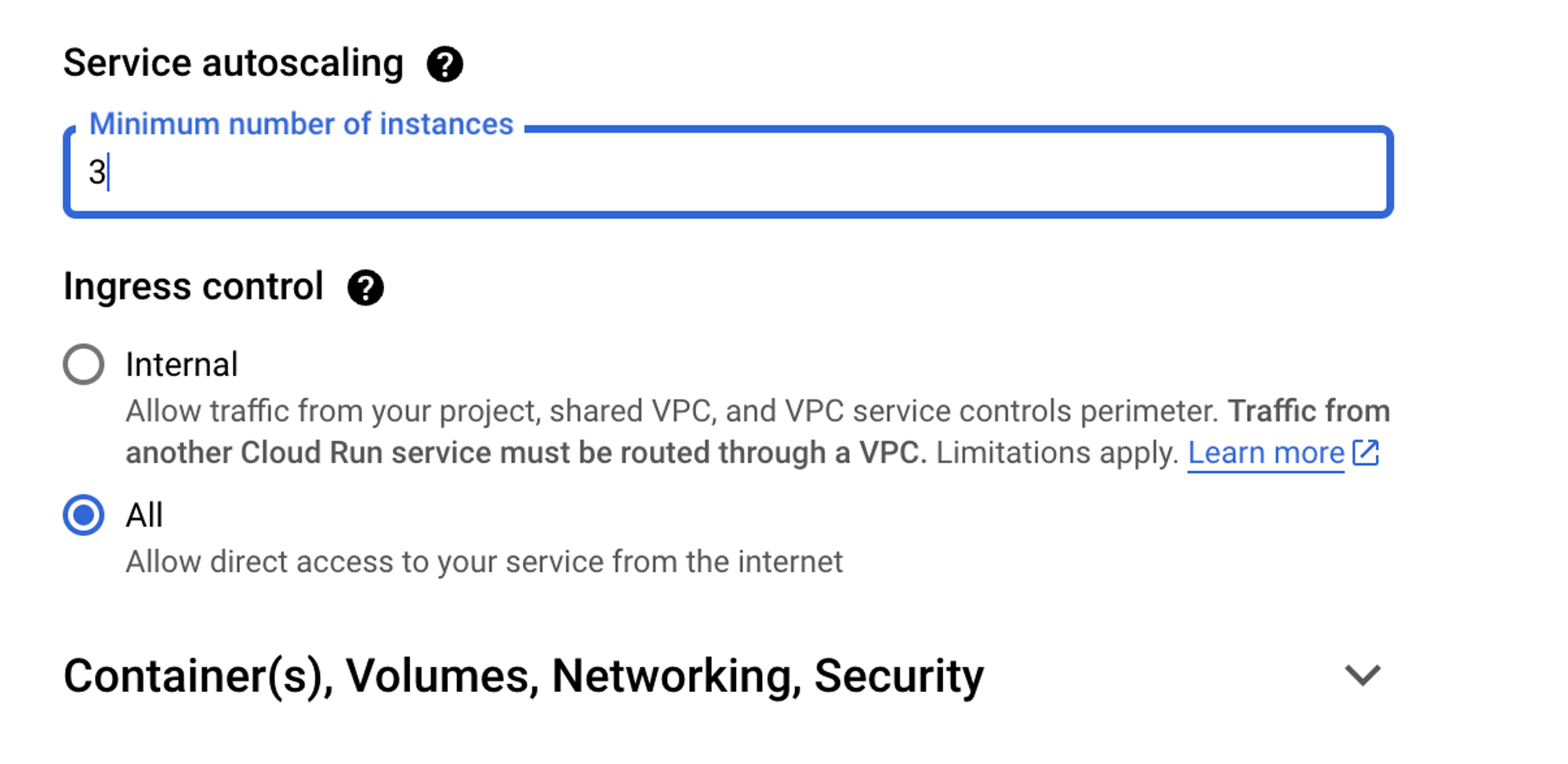
6. Under the **Containers, Volumes, Networking, and Security** section, you can customize your container with ports, container name, volumes, networking, security, and any other customization option that’s available including resource optimization for CPU and memory within the containers.
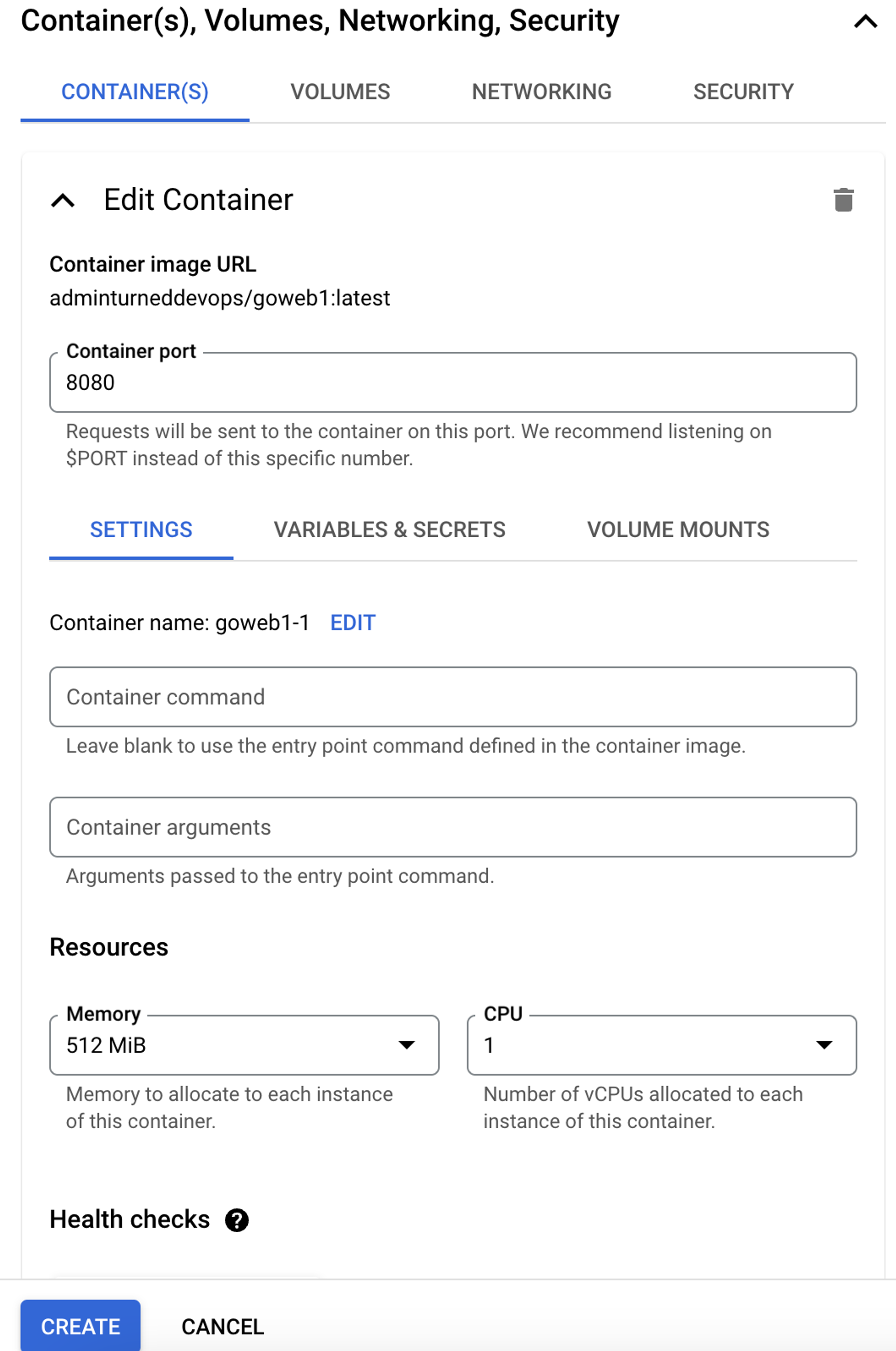
7. When finished, click the blue **CREATE** button.
<aside>
💡 A cool feature when using cloud-based platforms like GCP is the ability to use the integrated third-party tools and services that are available within the cloud. For example, within Cloud Run, you can connect to a SQL server running on GCP.
</aside>
8. After a few moments, you should see the container running.
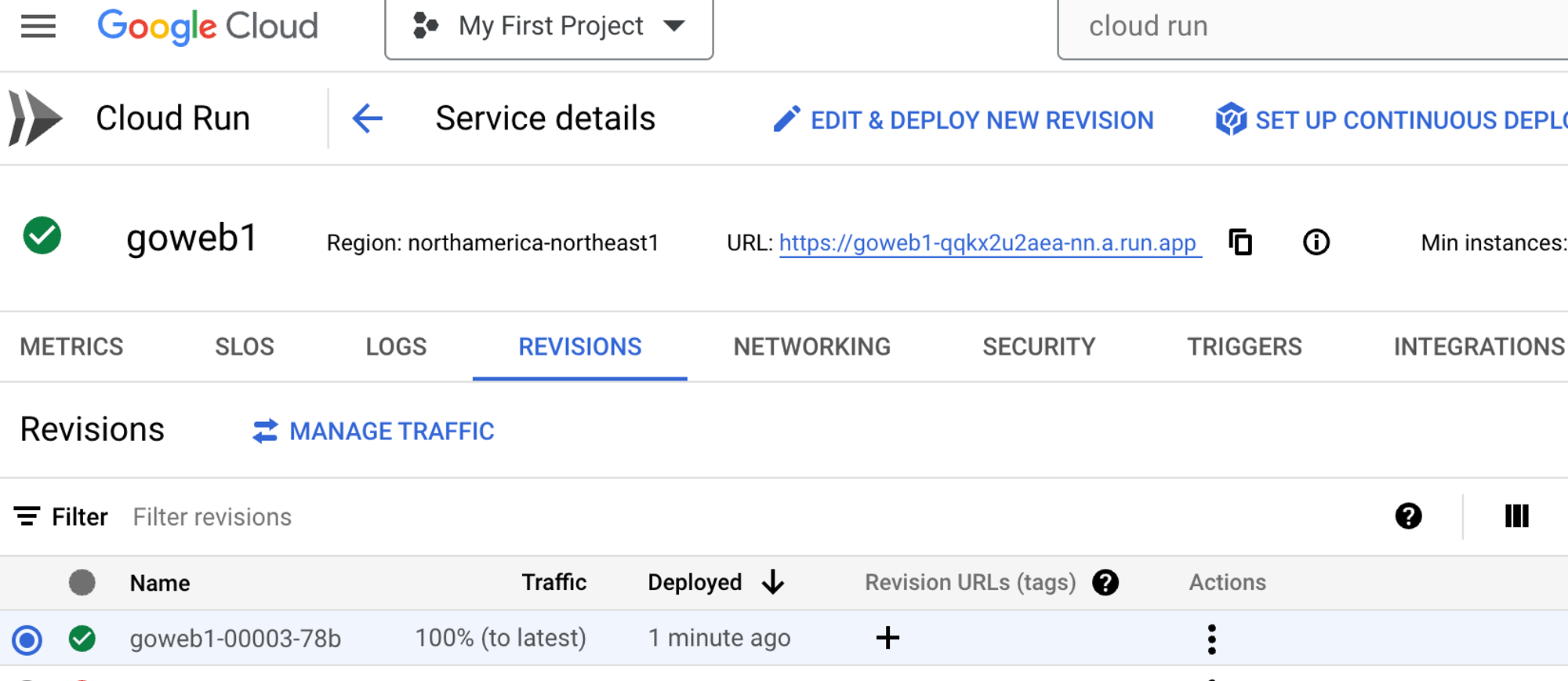
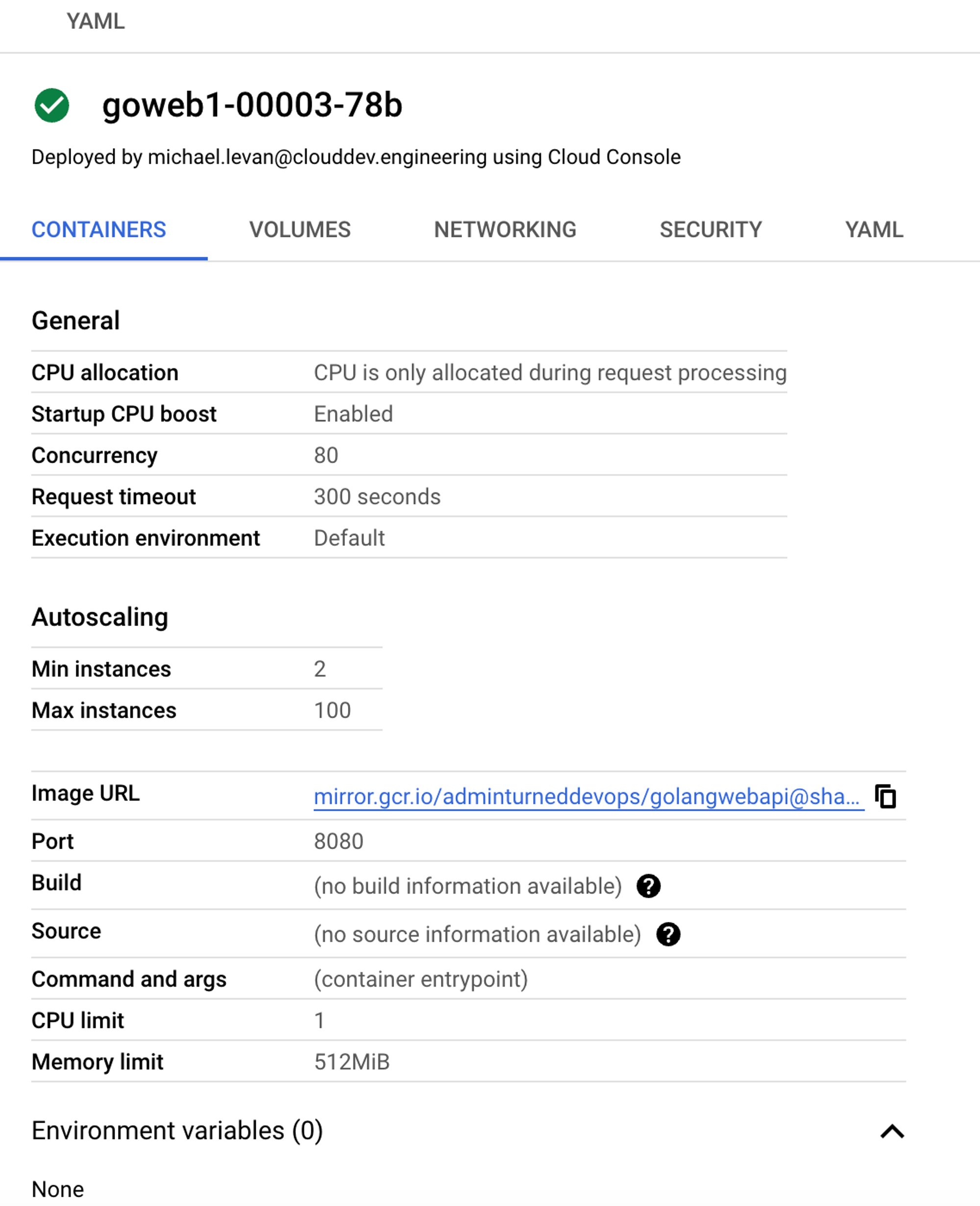
## GCP Cloud Run on The Terminal
Aside from running Cloud Run in the portal, you can also use the `gcloud` CLI, which is the terminal/programmatic method of interacting with GCP.
To deploy a container in Cloud Run via `gcloud`, you can use the `run` command.
Below is an example.
```jsx
gcloud run deploy gowebapi --image adminturneddevops/golangwebapi
```
After you run the command above, you’ll have a few prompts to answer.
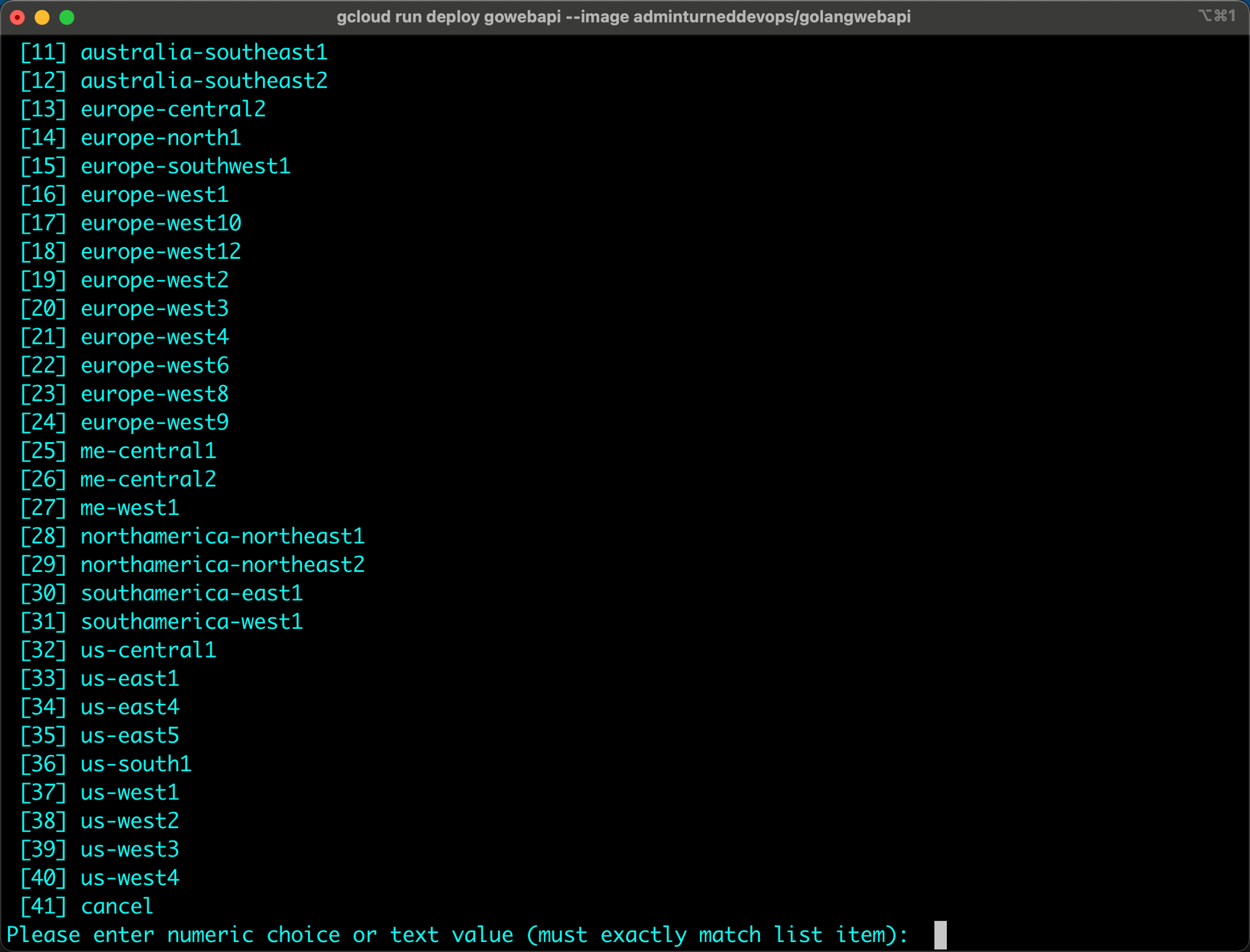
You should now see the container getting deployed.
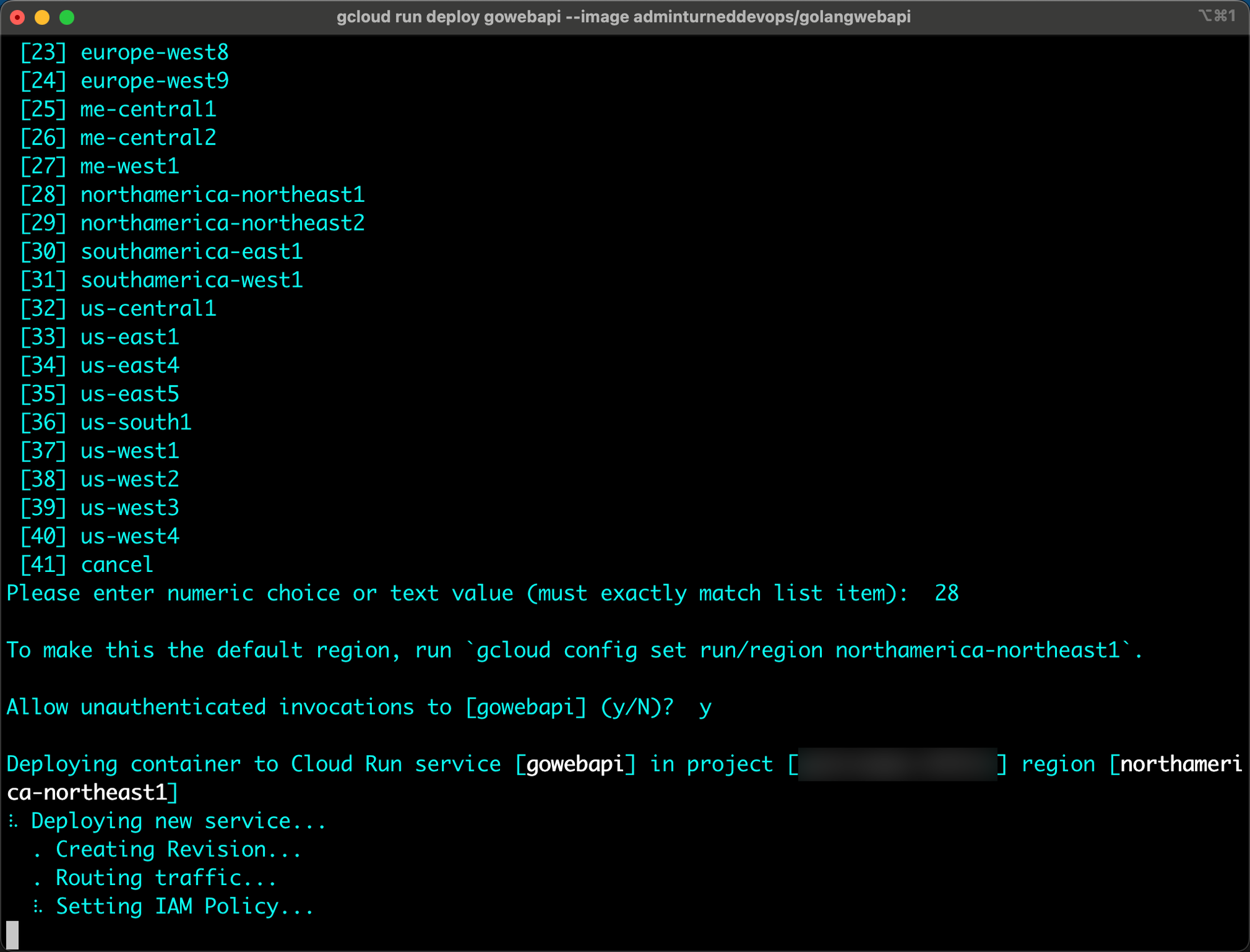
After the deployment is complete, you’ll see the container show up in the Cloud Run portal.
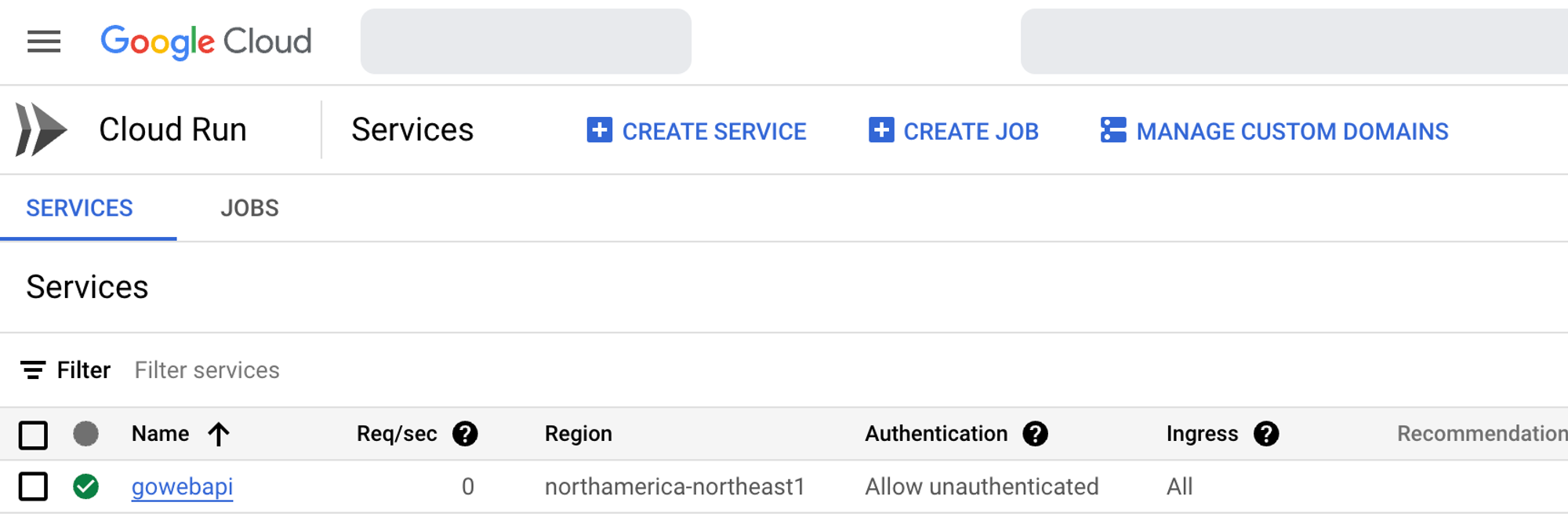
| thenjdevopsguy |
1,869,163 | Tratamento de Erros e Excepções | Definições relacionadas - Erro: É uma falha no código que impede a execução correcta de um... | 0 | 2024-05-29T15:25:27 | https://dev.to/ortizdavid/tratamento-de-erros-e-excepcoes-3p29 |
## Definições relacionadas
**- Erro:** É uma falha no código que impede a execução correcta de um programa. Erros podem ser de sintaxe, de lógica ou de execução. Um erro é uma condição inesperada que interrompe o fluxo normal do programa.
**- Excepção:** É um evento anormal ou inesperado que ocorre durante a execução de um programa e interrompe o fluxo normal das instruções. É uma situação anormal que pode ser prevista e tratada dentro do programa.
**- Efeitos colaterais:** São mudanças no estado do sistema que ocorrem como resultado da execução de uma função ou procedimento, que não estão relacionadas directamente ao seu retorno esperado. Ex: uma função que modifica uma variável global ou altera o conteúdo de um arquivo.
**- Tratamento de Erros / Excepções:** São práticas e mecanismos implementados para lidar com erros e excepções de forma controlada e previsível. Isso pode incluir o uso de blocos _**try-catch-finally**_, logging de erros, notificações ao usuário e outras acções para mitigar o impacto de problemas e garantir a robustez do sistema.
**- Programação defensiva:** É a abordagem de codificação que visa antecipar e lidar com possíveis erros ou condições inesperadas para garantir que o software continue funcionando corretamente, mesmo em casos não previstos.
<br><br>
## Similaridades e Diferenças
### Similaridades
- Ambos indicam problemas ou eventos anormais durante a execução do programa.
- Ambos podem interromper o fluxo normal do programa.
- Ambos exigem tratamento adequado para evitar falhas no programa.
### Diferenças
**- Origem:** Os erros geralmente se originam de problemas no código do programa, enquanto as excepções geralmente se originam de eventos externos ao programa.
**- Previsibilidade:** Erros geralmente são imprevisíveis, enquanto excepções podem ser previstas e antecipadas.
**- Tratamento:** O tratamento de erros nem sempre é possível, enquanto as excepções devem sempre ser tratadas ou propagadas.
**- Natureza:** Erros de execução podem incluir problemas como estouro de memória, enquanto excepções incluem condições como arquivos não encontrados ou acessos fora dos limites de um array.
<br><br>
## Cenários mais comuns de Erros e Excepções
**- Manipulação de Arquivos:** Durante a leitura ou escrita de arquivos, podem ocorrer erros como "Arquivo não encontrado", "Permissão negada" ou "Erro de E/S". É importante verificar a existência de arquivos antes de abri-los e tratar as excepções relacionadas à abertura de arquivos.
**- Manipulação de Base de dados:** Durante a manipulação das bases de dados podem ocorrer erros como “Erro de conexão”, "Tabela não encontrada", "Chave duplicada" ou "Violação de chave estrangeira" . É importante verificar a integridade dos dados antes de inseri-los no banco de dados e tratar as excepções relacionadas às operações de banco de dados.
**- Chamadas HTTP:** Durante as chamadas HTTP podem ocorrer erros como "Conexão recusada", "Erro de tempo limite" ou "Erro de servidor". É importante verificar a conexão antes de fazer uma chamada HTTP e tratar as excepções relacionadas às chamadas HTTP.
**- Retorno de Respostas HTTP:** Durante o processamento das respostas HTTP podem ocorrer erros como "Código de status inválido" ou "Erro de sintaxe no corpo da resposta". É importante verificar o código de status antes de processar o corpo da resposta e tratar as excepções relacionadas ao processamento das respostas HTTP.
**- Conexões TCP, UDP:** Durante as conexões TCP e UDP podem ocorrer erros como "Conexão recusada", "Erro de tempo limite" ou "Erro de rede". É importante verificar a conexão antes de enviar ou receber dados e tratar as excepções relacionadas às conexões TCP e UDP.
**- Conexão com servidores remotos:** Durante as conexões com servidores remotos podem ocorrer erros como "Conexão recusada", "Erro de tempo limite" ou "Erro de DNS". É importante verificar a conexão antes de enviar ou receber dados e tratar as excepções relacionadas às conexões com servidores remotos.
**- Concorrência e Paralelismo:** Durante a execução concorrente ou paralela de código podem ocorrer erros como "Deadlock", "Race condition" ou "Erro de memória". É importante usar técnicas de programação defensiva, como bloqueios ou semáforos, e tratar as excepções relacionadas à concorrência e paralelismo.
<br><br>
## Abordagem no Paradigma Orientadas a Objectos
Nas linguagens de programação orientadas a objectos, o tratamento de excepções é geralmente feito usando blocos _**try, catch, throw e finally**_. Esses blocos fazem parte das boas práticas de programação orientada a objectos e permitem que os programadores tratem excepções de maneira estruturada e organizada.
No bloco _**try**_, é possível definir o código principal que será executado. Se houver algum erro ou excepção durante a execução desse código, o controle será passado para o bloco catch, onde é possível tratar a excepção de maneira adequada.
O comando _**throw**_ é usado para lançar uma excepção manualmente dentro do código. Isso pode ser útil quando é necessário interromper a execução do código em uma determinada situação e retornar um erro específico.
O bloco _**finally**_ pode ser usado em conjunto com try-catch para garantir que determinadas instruções sejam executadas independentemente de ocorrer uma excepção ou não. Isso pode ser útil para garantir a liberação de recursos ou o fechamento de conexões, por exemplo.
Embora haja programadores que discordam do padrão try-catch-finally, é importante admitir que funciona e deve ser aplicados para o tratamento de blocos de execução. O uso adequado de _**try-catch-finally**_ pode ajudar a evitar erros inesperados e melhorar a robustez e a confiabilidade do código.
<br><br>
## Abordagem no Paradigma funcional
No paradigma funcional, o tratamento de erros se diferencia da abordagem tradicional orientada a objectos, oferecendo mecanismos mais robustos e expressivos para lidar com falhas e situações inesperadas. Ao invés de utilizar blocos try-catch para capturar excepções, as linguagens funcionais Adoptam técnicas que previnem e propagam erros de forma mais natural e segura.
### Principais Características
**- Imutabilidade:** Valores imutáveis garantem que os dados não sejam alterados após sua criação, evitando efeitos colaterais e facilitando o raciocínio sobre o estado do programa. Isso torna o código mais previsível e menos propenso a erros.
**- Gerenciamento de Retorno:** Funções puras retornam um valor ou um tipo especial que indica a ausência de um valor. Essa abordagem elimina a necessidade de lançar excepções para indicar falhas, tornando o código mais declarativo e menos propenso a erros não tratados.
**- Composição Funcional:** Funções podem ser compostas para criar funções mais complexas, sem a necessidade de propagar explicitamente erros entre elas. Isso promove a modularidade e reutilização de código, facilitando o tratamento de erros de forma consistente.
**- Tipagem Estática:** A tipagem forte e inferida garante que os valores utilizados nas funções sejam compatíveis com os tipos esperados, evitando erros de tipo em tempo de execução. Isso torna o código mais robusto e menos propenso a falhas inesperadas.
### Vantagens
**- Código mais robusto e confiável:** A imutabilidade, o gerenciamento de retorno e a tipagem forte garantem que o código seja menos propenso a erros e falhas inesperadas.
**- Melhora na legibilidade e expressividade:** O código funcional é geralmente mais conciso e declarativo, facilitando a leitura e o entendimento da lógica do programa.
**- Facilidade de raciocínio sobre o estado do programa:** A imutabilidade torna o estado do programa mais previsível e facilita o raciocínio sobre as possíveis falhas.
**- Maior segurança e confiabilidade:** A ausência de efeitos colaterais e a tipagem forte garantem que o código seja mais seguro e confiável.
### Desafios
**- Mudança de paradigma:** Aprender a programar no paradigma funcional pode ser um desafio para programadores acostumados à programação orientada a objectos.
**- Falta de familiaridade com ferramentas e bibliotecas:** As ferramentas e bibliotecas para desenvolvimento funcional podem ser menos conhecidas e acessíveis do que as ferramentas para linguagens orientadas a objectos.
**- Curva de aprendizado mais íngreme:** A curva de aprendizado para dominar o paradigma funcional pode ser mais íngreme do que para linguagens orientadas a objectos.
### Exemplos de Abordagens Diferentes
**- Haskell:** Utiliza os tipos Maybe com _**Just**_ e _**Nothing**_ para indicar a presença ou ausência de um valor, permitindo lidar com falhas de forma declarativa. Para erros mais detalhados, usa o tipo Either com Left para erros e Right para valores corretos.
**- Erlang:** Adopta o conceito de "processos leves" para isolar falhas e garantir a confiabilidade do sistema. Cada processo é independente, e falhas são tratadas através de um modelo de supervisão onde processos supervisores reiniciam processos falhos.
**- Scala:** Combina recursos da programação funcional e orientada a objetos, oferecendo mecanismos flexíveis para tratamento de erros, como _**Option, Try, e Either**_, que permitem uma abordagem robusta e composicional para lidar com falhas.
**- Rust:** Utiliza os tipos _**Result e Option**_ para tratamento de erros. Result é usado para operações que podem falhar, com os variantes _**Ok**_ para sucesso e _**Err**_ para erro. Rust também promove a propagação de erros com o operador ?, permitindo um código mais conciso e seguro para erros de execução.
**- F#:** Como uma linguagem funcional da família .NET, F# oferece recursos poderosos para tratamento de erros. Ele utiliza discriminação de união, como _**Option**_ e _**Result**_, e expressões match para lidar com valores de retorno opcionais e tratamento de erros de forma elegante e segura.
Apesar dos desafios, o paradigma funcional vem ganhando cada vez mais popularidade, e as técnicas de tratamento de erros funcionais estão sendo cada vez mais Adoptadas em linguagens tradicionais como C#, Java, Kotlin e Swift.
É importante ressaltar que a escolha da melhor abordagem para tratamento de erros depende do contexto específico do projeto, das características da linguagem de programação utilizada e da preferência pessoal do programador.
<br><br>
## Destancando a Linguagem Go
A linguagem Go se destaca por sua abordagem singular ao tratamento de erros, optando por não utilizar o paradigma tradicional de excepções try-catch-throw-finally. Essa escolha, inicialmente desafiadora para alguns programadores, oferece vantagens significativas em termos de simplicidade, confiabilidade e controle sobre o fluxo do programa.
### Fundamentos do Tratamento de Erros em Go
**- Erro como Tipo de dado:** Em Go, o erro é representado pelo tipo _**error**_. Isso significa que as funções podem retornar um valor de erro, permitindo que o programador identifique e trate falhas explícitamente.
**- Verificação de Erros:** A verificação de erros é essencial em Go. Após chamar uma função, é crucial verificar se o valor de retorno é um erro. Caso positivo, é possível registrar o erro, notificar o usuário ou interromper a execução do programa.
**- Propagação de Erros:** Os erros podem ser propagados através de várias chamadas de função. Ao invés de lançar excepções, Go utiliza a técnica de propagação de erros, permitindo que o erro seja tratado em um nível superior do código, caso necessário.
**- Retorno de Erros em Funções sem Retorno:** Em Go, é comum que funções que não possuem um valor de retorno explícito retornem um valor de erro. Isso garante que as falhas sejam comunicadas de forma consistente e que os programadores estejam cientes das possíveis situações de erro.
### Vantagens da Abordagem de Go
**- Simplicidade:** O modelo de tratamento de erros em Go é mais simples e directo, evitando a complexidade dos blocos try-catch e excepções. Isso torna o código mais fácil de ler, entender e depurar.
**- Confiabilidade:** Ao tratar erros explicitamente, Go incentiva a escrita de código mais robusto e confiável. Os programadores assumem a responsabilidade de lidar com falhas, garantindo que o programa se comporte de forma previsível em diferentes cenários.
**- Controle Granular:** Os programadores podem decidir como lidar com cada tipo de erro, personalizando o comportamento do programa de acordo com suas necessidades.
**- Desempenho:** A abordagem de Go pode ser mais performante em alguns casos, pois evita a sobrecarga de excepções e o uso de mecanismos de captura e propagação de erros.
### Desafios da Abordagem de Go
**- Mudança de Mentalidade:** Para programadores acostumados com linguagens que utilizam excepções, a abordagem de Go pode exigir uma mudança de mentalidade e adaptação.
**- Gerenciamento Manual de Erros:** O tratamento manual de erros em todas as funções pode se tornar trabalhoso em projectos maiores, exigindo disciplina e atenção aos detalhes.
**- Falta de Mecanismos Automáticos:** Go não possui mecanismos automáticos para lidar com erros não tratados, como um manipulador de excepções global. Isso requer que o programador implemente suas próprias estratégias para lidar com essas situações.
<br><br>
## Recomendações
Para criar software robusto e resiliente, é fundamental tratar os erros e excepções de forma eficaz:
- Considerar possíveis pontos de falha em todo o código.
- Usar programação defensiva para antecipar problemas.
- Fornecer mensagens de erro claras e documentar as excepções.
- Libertar recursos adequadamente para evitar leaks e outros problemas.
Seguindo essas recomendações e aplicando as práticas exemplificadas, é possível construir sistemas que lidem com situações inesperadas sem comprometer a integridade e a experiência do usuário.
<br><br>
## Conclusão
Devemos pensar que um bloco de instruções pode falhar. Um programa sempre lida com problemas inesperados, bem como efeitos colaterais. Para esses casos é recomendado tratar os erros e excepções.
Sistemas computacionais estão sempre sujeitos a falhas, por isso é crucial que o programador analise e identifique possíveis cenários onde erros podem ocorrer. Antecipar esses problemas e implementar estratégias de tratamento de erros robustas é essencial para garantir a resiliência e a confiabilidade do software.
<br><br>
## Exemplo
Implementação de Upload de Arquivos em Go e C#, tratando os cenários de erros.
Repositórios:
- https://github.com/ortizdavid/go-nopain/filemanager
- https://github.com/ortizdavid/AspnetCoreRestApi

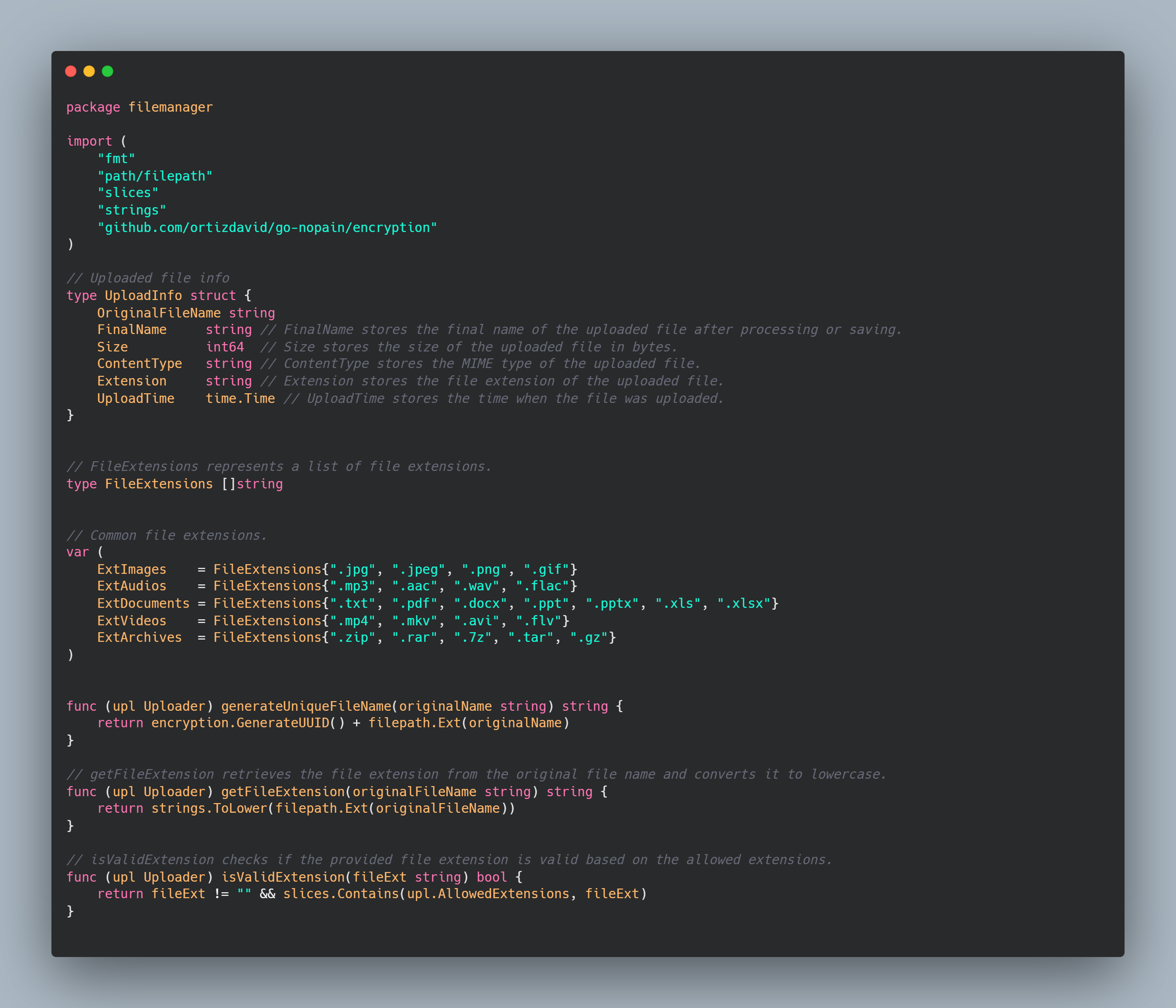
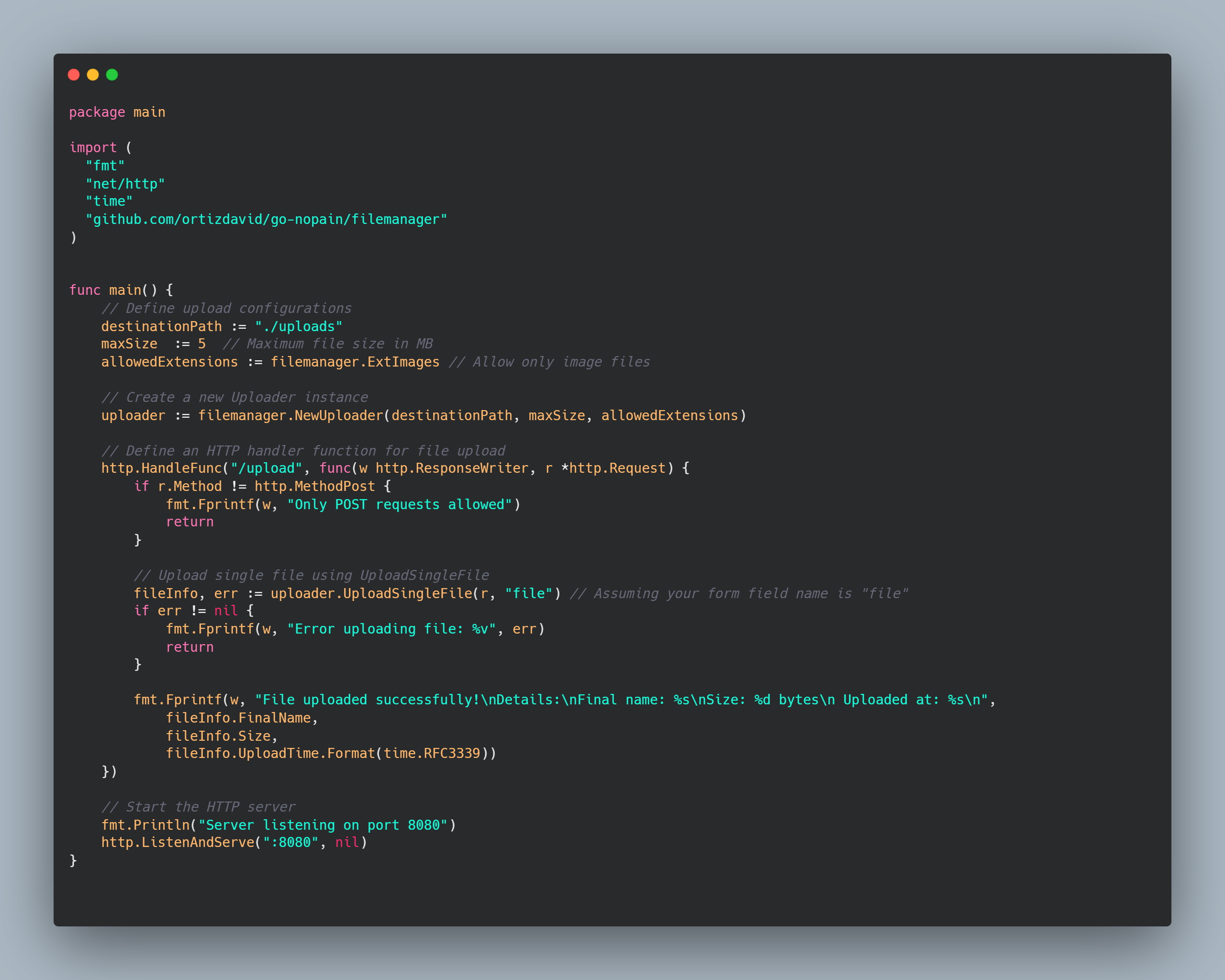
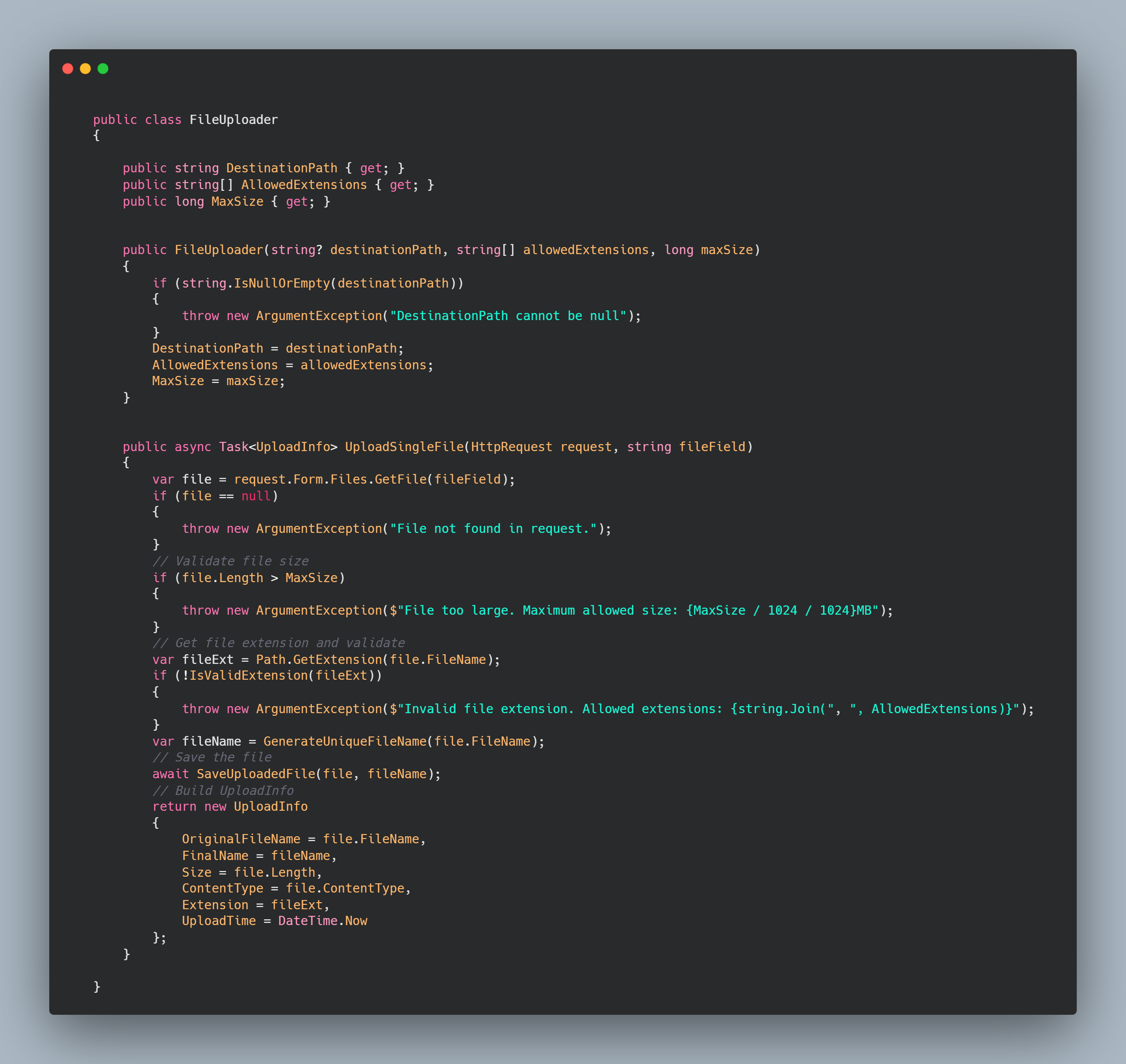
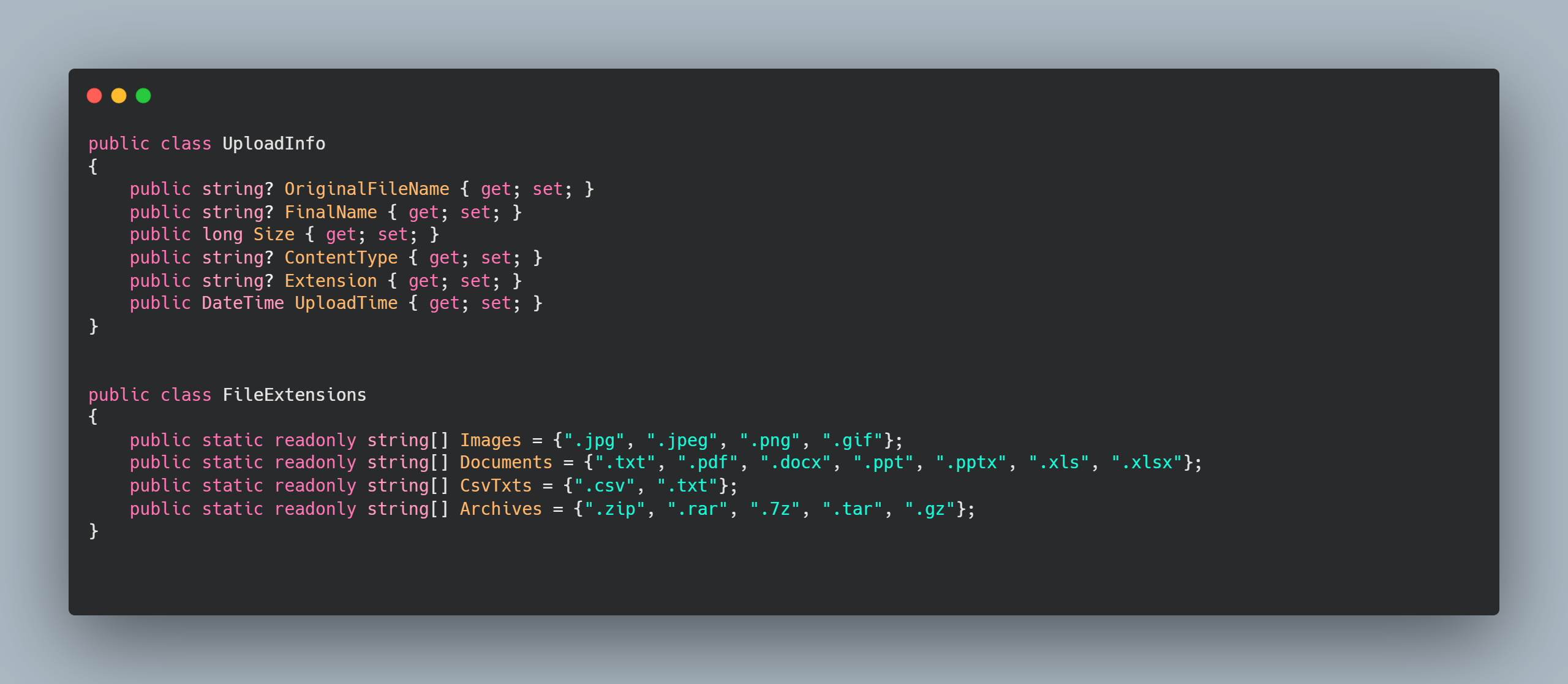

| ortizdavid | |
1,869,162 | GET WEB BAILIFF CONTRACTORS TO ALTER YOUR SCHOOL GRADES | For a lot of students, myself included, achieving academic brilliance and excellent grades can seem... | 0 | 2024-05-29T15:24:55 | https://dev.to/dancansmith/get-web-bailiff-contractors-to-alter-your-school-grades-jm9 | For a lot of students, myself included, achieving academic brilliance and excellent grades can seem unachievable at times. At the same time I don’t want to miss out on the perks of a full college sponsorship and so I opted to hire a professional to change my school grades from my school’s system. I contacted Web Bailiff Contractors who came through for me and in 24 hours my As reflected on the system. All you have to do is email them through web @ bailiffcontractor . net to get your poor grades corrected. | dancansmith | |
1,869,161 | Recovering My Blog with Jekyll and Proxmox | The Server is(was) Down Today I decided to try and update the Jekyll theme for this site,... | 0 | 2024-05-29T15:21:22 | https://www.saltyoldgeek.com/posts/the-server-is-down-man/ | proxmox, docker, jekyll, chirpy | ## The Server is(was) Down
Today I decided to try and update the [Jekyll](https://jekyllrb.com/) theme for this site, [Chirpy](https://chirpy.cotes.page/). If you've watched the blog or gone to this blog's [status page](https://status.saltyoldgeek.com/status/blog) you probably noticed it was down for a few hours today. Needless to say, things didn't go as planned. It turns out that the last time I tried to update/recreate the blog site I chose the [Chirpy Starter](https://chirpy.cotes.page/posts/getting-started/#option-1-using-the-chirpy-starter) option instead of the [Github Fork](https://chirpy.cotes.page/posts/getting-started/#option-2-github-fork) option, and in trying to update it the whole thing went sideways. No problem I'd just restore from the backup/snapshot in Proxmox, which also failed and destroyed the LXC, great!
After a few failed attempts to restore this zombie LXC, I decided to try spinning up and small shared instance of Ubuntu on [Linode](https://www.linode.com/) which updated at a crawl, to be fair this was a shared instance and I probably was trying to update it at peak usage time. Dedicated nodes aren't cheap, at least for a small blog like this. Eventually, after several attempts to stand up the blog again, I created a new LXC and cloned the theme for easier updates in the future(as long as I remember). This post is as much for me to document the process, should I need it again in the future, and help anyone else wanting to start one of their own. Time to roll up the sleeves and get to work.
## Building the Blog
### Building the LXC in Proxmox
When I first started using [Proxmox](https://www.proxmox.com) there was a lot of experimentation to get things right. During that time I found an invaluable site to get things up and running quick, [Helper Scripts](https://helper-scripts.com/) by tteck. Let's use one of those to get the initial LXC up and running, in the shell of your Proxmox node paste in the following.
```bash
bash -c "$(wget -qLO - https://github.com/tteck/Proxmox/raw/main/ct/ubuntu.sh)"
```
You can follow the prompts on screen and use the defaults(you'll need to rename and adjust settings), or choose advanced and tweak things to your liking, here are the spec settings I used.
- Ubuntu
- Ubuntu version 24.04
- Disable IPv6
- 2GB RRAM
- 2 Cores
- 15GB Storage
The reason for that RAM size and Cores was to allow overhead when initially building out or upgrading the theme, for day-to-day use you could halve those.
Now that that is out of the way we can continue with the rest of the setup for this LXC. We can click on our now LXC and then click on shell to get a few more things set up. Here are those commands.
```bash
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
adduser dave
usermod -aG sudo dave
usermod -aG docker dave
```
Now that docker is installed(we'll need this later), and permissions are set, we can start installing Jekyll.
```bash
sudo apt-get install ruby-full build-essential zlib1g-dev
echo '# Install Ruby Gems to ~/gems' >> ~/.bashrc
echo 'export GEM_HOME="$HOME/gems"' >> ~/.bashrc
echo 'export PATH="$HOME/gems/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
gem install jekyll bundler
```
### Setting up Chirpy
We've now got docker installed and Jekyll working, now we'll want to follow the steps for the fork method shown above. Once you've created a fork we'll want to pull that down and set up a few globals, including an access token for a password with Github.
Let's get that token, on Github do the following
1. Click on your profile
2. Click on Settings
3. Click on Developer Settings
4. Click on Personal Access Tokens
5. Click on Fine Grained Tokens
6. Click on Generate Token
7. Give the token a name
8. Click Only Select Repositories
9. Choose the forked repository
10. Click on Repository permissions
11. Change Commit Statuses to Read and Write
12. Change Contents to Read and Write
13. Change Pull requests to Read and Write
14 Click Generate Token
15. Copy the token and paste it into a temporary note (once you leave the page you won't be able to use it again)
Now we'll run the following commands to pull down our repo and set up Git. Either in the console through Proxmox, or an SSH session if you prefer, run the following.
```bash
sudo apt install git npm
git clone https://github.com/your-github-username/your-github-fork-repo
cd your-github-fork-repo
git config --global user.name "your username here"
git config --global user.password "your github token here"
git config --global user.email "github associated email here"
git config --global credential.helper store
```
Ok, we're almost there. It's time to initialize the theme (if you are pulling down an existing, fork with posts, to a new machine you can skip this step).
```bash
bash tools/init
```
Whether you are pulling down a new or existing fork run the following to pull all the Ruby Gems, if you don't you'll get error after error.
```bash
bundle
```
While we're at it let's change, at a minimum, these four lines in _config.yml so your blog shows as you.
- title:
- lang:
- timezone:
- tagline:
- description:
- url:
- avatar:
We're set!
### Building the posts
You can write a post saved under _posts folder, keep these two things in mind
1. Filename format 2024-05-28-title-here.md
2. Minimum Frontmatter at the top
```markdown
---
title: ""
description: ""
author: dave
date: 2024-05-28 14:22:00 -0500
categories: [Blogging]
tags: [tag one, tag two]
---
```
To build the _site static site from these posts run the following command(you'll want to run this anytime you create a new post).
```bash
JEKYLL_ENV=production jekyll serve --config _config.yml
```
### Running Nginx to serve the blog
Lastly, we're going to use a Dockerized Nginx instance to serve up our static site under_site folder. This is a simple one-liner.
```bash
docker run --name blog-server -v /home/dave/fork-folder-name/_site:/usr/share/nginx/html:ro -d nginx
```
We're done! you should now be able to navigate to the IP of the server with HTTP and see your site. Hopefully, this helps you get started or recreate a site if, like me, you have a server crash. Till next time, fair winds and following seas.
| blacknight318 |
1,869,114 | Bitwise Sorcery: Unlocking the Secrets of Binary Manipulation | Ever wondered how computers perform operations at the binary level? 🤔 Today, I'm exploring the... | 0 | 2024-05-29T15:20:00 | https://dev.to/generosiie/bitwise-sorcery-unlocking-the-secrets-of-binary-manipulation-4ebb | bitwiseoperators, binary, computerscience | Ever wondered how computers perform operations at the binary level? 🤔 Today, I'm exploring the fascinating world of Bitwise Operators! These powerful tools allow us to manipulate data down to the individual bits, providing efficient and low-level control that's crucial for performance-critical applications.
Here's a quick overview of what they can do:
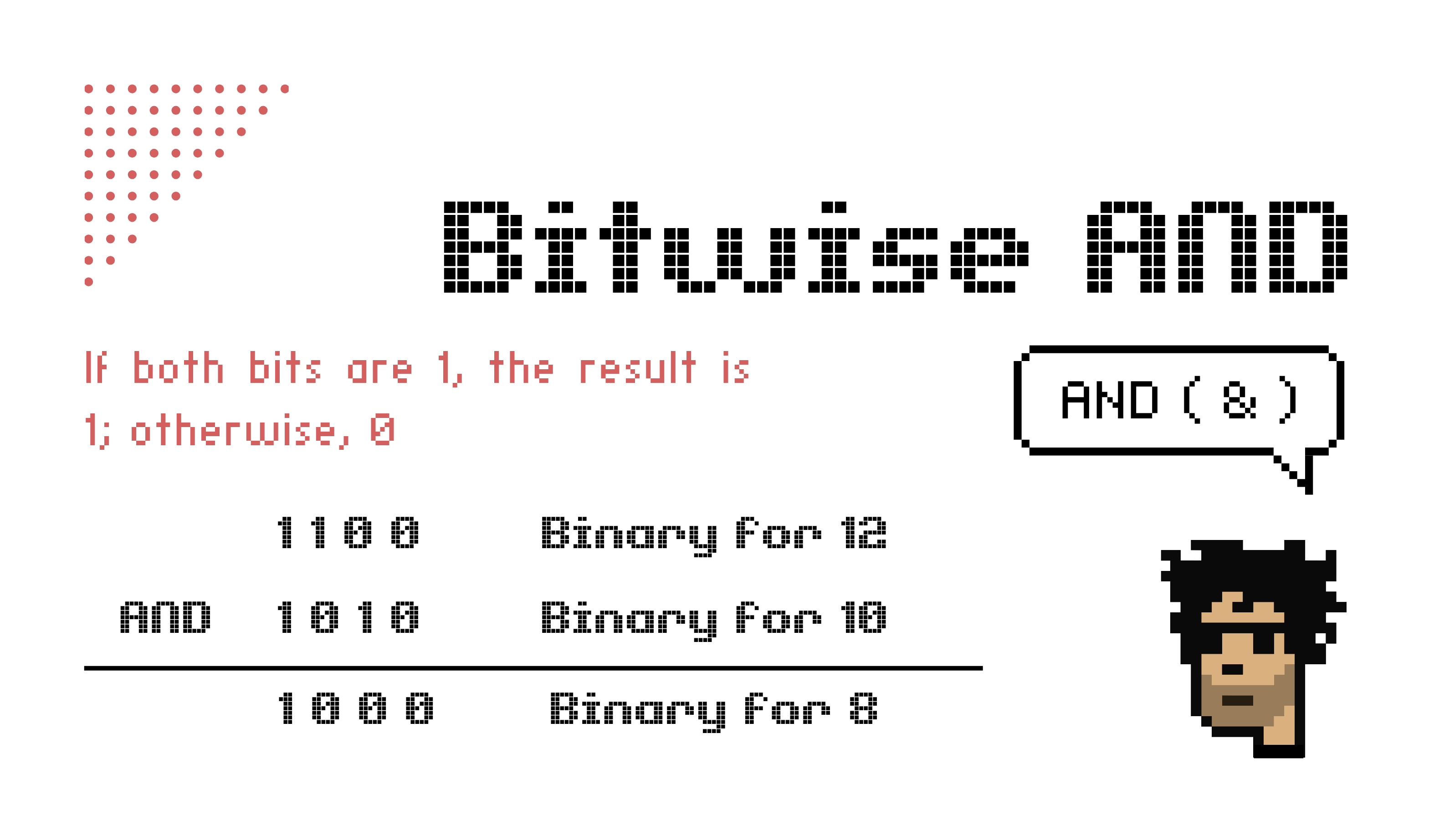
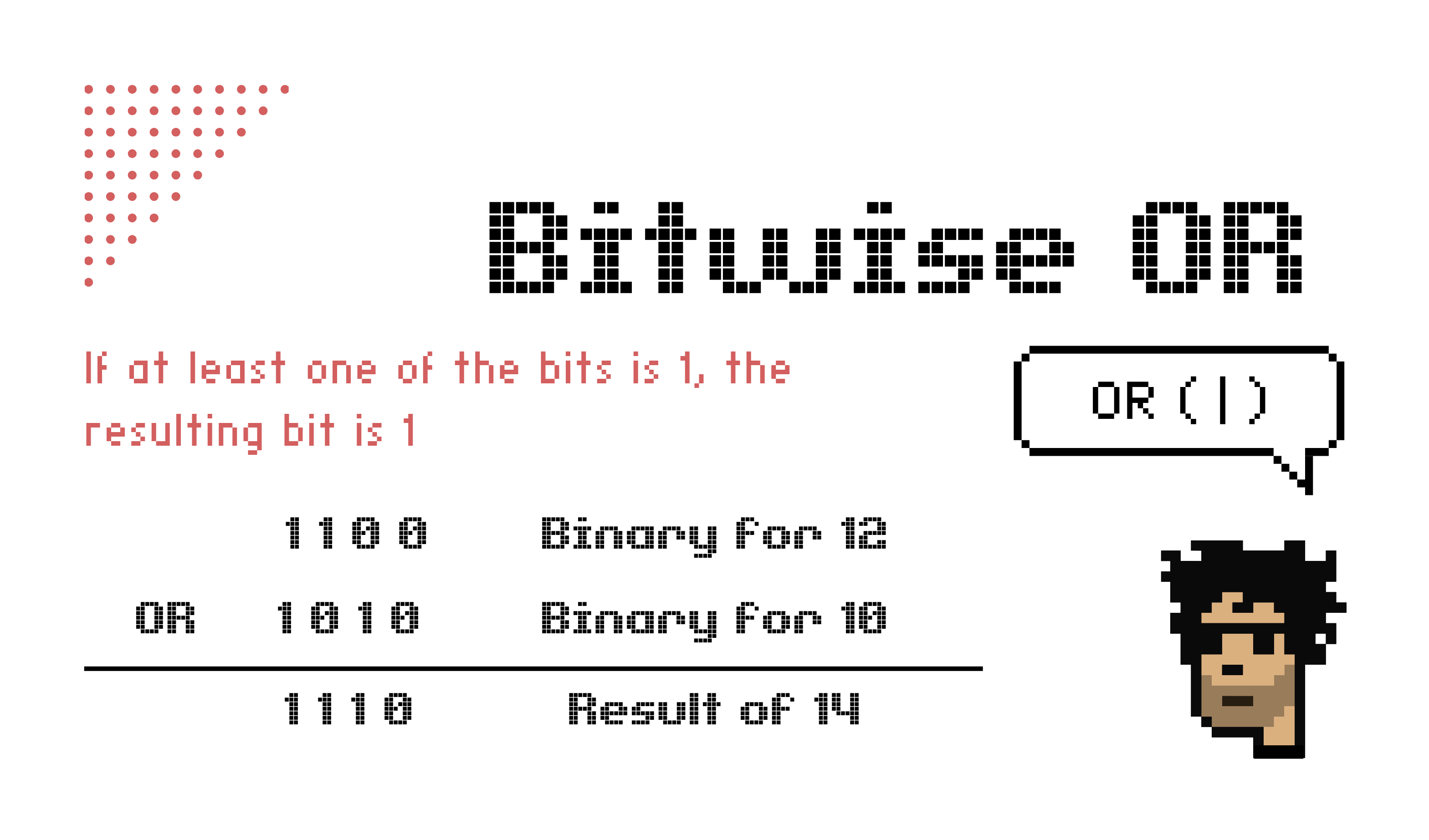


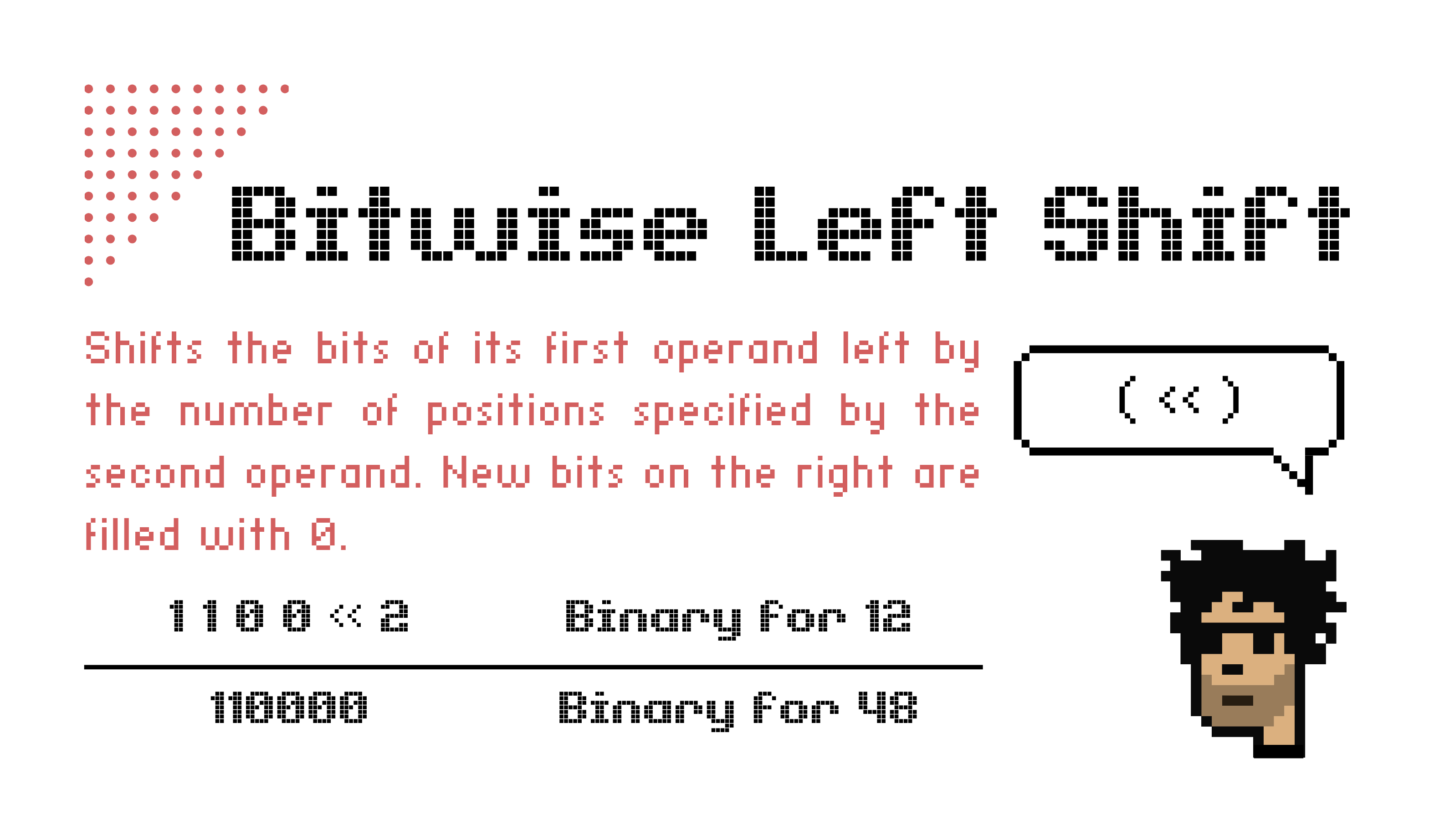
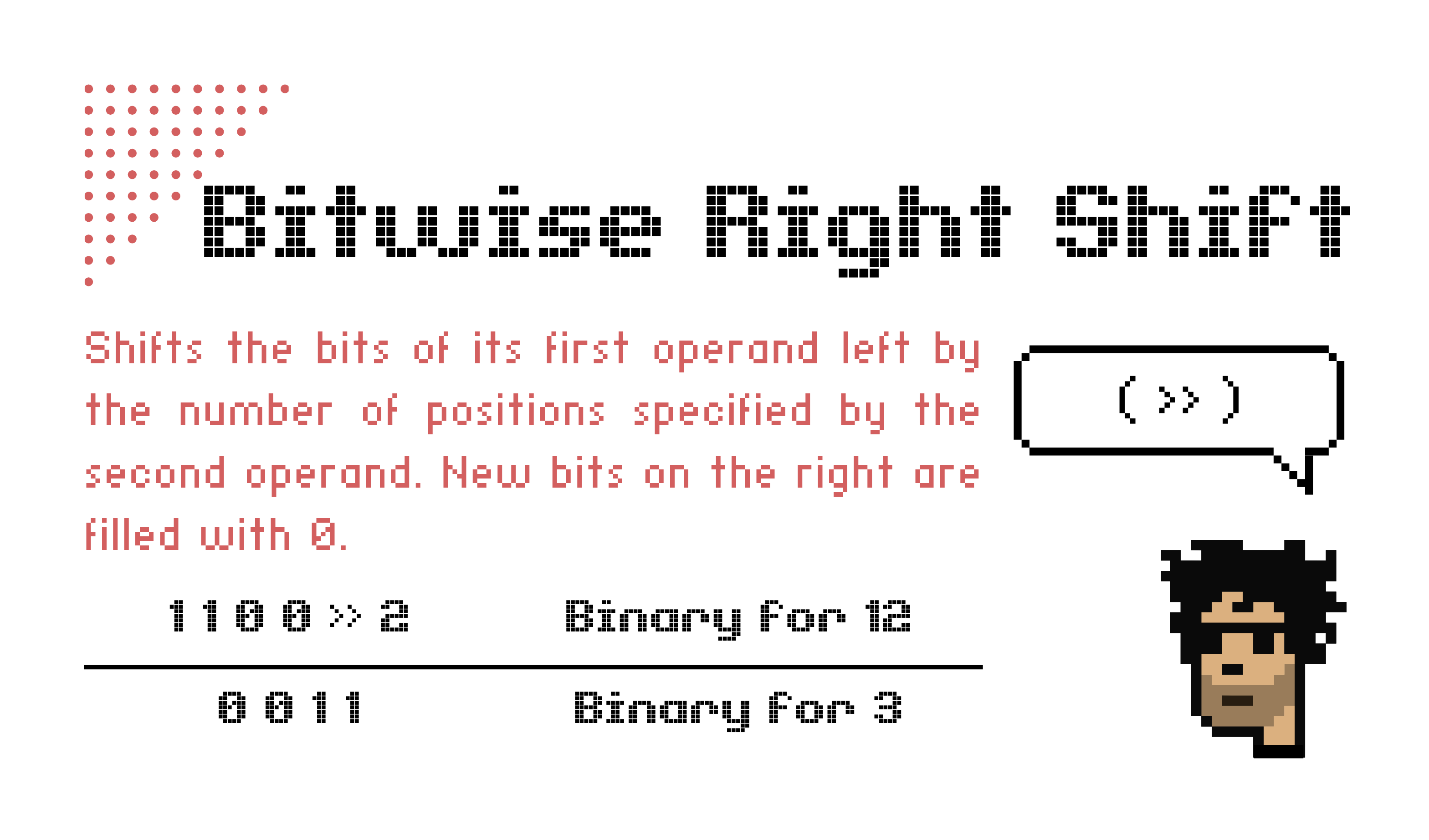

| generosiie |
1,868,763 | Swift 101: Collections Part I - Arrays | Hola Mundo! Welcome to a new article in a series of Swift 101 notes 📝 I did while... | 27,019 | 2024-05-29T15:19:41 | https://dev.to/silviaespanagil/swift-101-collections-part-i-arrays-2a52 | learning, swift, mobile, beginners | #<h1> Hola Mundo! </h1>
<Enter>
Welcome to a new article in a series of [Swift 101 notes](https://dev.to/silviaespanagil/swift-101-getting-into-ios-development-gji) 📝 I did while learning the language and I decided to share them because why not?.
If you're new to Swift or interested in learning more about this language, I invite you to follow my series! 🙊
In this chapter, I'll share Part I of Collections and Collection Types, where we'll dive into Arrays.
___
[A couple of weeks ago](https://dev.to/silviaespanagil/swift-101-understanding-types-variables-and-constants-l9h), we discussed constants and variables, which store values for us to use in our code and some simple types. However, there are some other complex types that we will find across our apps📱.
As you may already guess, "Collections" are types that store many values. They arrange all those values in certain ways so we can access them in the future.
Think of it like a fruit basket with many fruits in it. Similarly, arrays in Swift store multiple values of the same type in an ordered list, like a line of apples, oranges, and bananas neatly arranged in your basket 🍎🍊🍌
<Enter>
___
###Arrays
<Enter>
Arrays are **an ordered collection of values** and are the most common collection type. Inside an array, we may store any kind of elements of the same type.
Arrays are one of the most commonly used collection types in Swift due to their simplicity and efficiency. Arrays maintain an ordered list of elements. This makes them ideal for scenarios where the order of elements matters, such as lists of items or sequences of tasks.
To create an array, we separate elements with commas and enclose them in square brackets.
```
let intArray = [1, 2, 3]
let stringArray = ["Mónica", "Rachel", "Phoebe"]
```
<Enter>
___
#### Typing our arrays
As with everything in Swift, arrays are also typed. If we don’t indicate it explicitly, Swift will infer the type for us.
However, for Swift to be able to infer the type, the values inside the array must be homogeneous, meaning all values must be of the same type. This is called **array literals**.
If we don't type our array, and the values are heterogeneous, we will get an error ❌, and Swift will ask us to add an explicit type to ensure the mixed types are intentional.
To set a type to an array we must indicate it after the naming just as we do in simple variables and constants.
If we want to create a heterogenous array or we don’t know which kind of values we will hold in that variable we can set the `Any` type -_not recommendable_-
Strong typing in Swift ensures that each array can only contain elements of a specific type.
This could prevent many common programming errors and make your code more predictable and easier to debug. By specifying the type of elements Swift can also optimize performance and provide better compile-time checks.
```swift
// All values are the same type
let homogenousArray: [Double] = [1.4, 2.6, 3.7]
let alsoHomogenousArray: [String] = ["Pippin", "Merry", "Frodo", "Sam"]
```
```swift
// Values types may be different so type is Any
let heterogenousArray: [Any] = [8, "Kobe Bryant", 24.8]
```
<Enter>
___
####Classes and structs as types
Until now we have been using the most common types to type all of our values. However, while dealing with our apps, especially if they interact with APIs or complex data, we may need to manage arrays with heterogeneous types.
If you scroll back, I said that we can use `Any` as a type, but I also said that is not a really good idea🙅🏽♀️. But if Swift gives us that option, why is it not a good idea?
Typing makes our code more reliable, and safer🛟. We know always what kind of value we are going to find in that variable. With `Any` we lose that advantage. We may also cause compilation issues, overcomplicate our code, etc.
But we can overcome this by using classes or structs as types.
Let’s imagine that we have a newsletter and we need an array with the user name, email, and confirmation that it wants to receive an email. And we are going to store that in an Array. So first we could create a struct and then assign it as a type.
```swift
struct User: Identifiable, Hashable {
let id: Int
let name: String
let email: String
let permission: Bool
}
var registeredUsers: [User]
```
In Swift, structs and classes are both used to create complex data types, but they have some key differences. Structs are value types, which means they are copied when assigned to a new variable or constant, or when passed to a function.
Classes, on the other hand, are reference types, so they are passed by reference and can have inheritance.
Generally, is a better idea to use structs for simpler data types that do not require inheritance and classes for more complex types that benefit from inheritance.
✨Further details on classes and structs will come later on in the series, so don't forget to follow me and keep an eye on new updates.✨
<Enter>
___
###Array managing: accessing values and methods
####Accessing array values
We now know that an array, as a collection, can store one or many values, but to use them we will probably need them separated and to do so we need to access those values.
##### **Using the value index**
One way of accessing our array values is by calling the index. As arrays are **ordered collections** if nothing explicitly changes, the value in a certain position will always be the same.
```swift
let hatchNumbers = [4, 8, 15, 16, 23, 42]
let thirdHatchNumber = hatchNumbers[2]
print(thirdHatchNumber) // 15
```
🧐 Remember that the array index starts at 0. So the first value is index 0 and so on. 🧐
##### **Iterations or loops: For-in and while**
There are two ways to iterate an array. One you may use while using SwiftUI in the views and the other one the rest of the time, but don't worry, they are pretty similar.
If you want to know more about this, keep an eye on this series because I'll be writing about Control Flow however, in the meanwhile, we will hammer the most common here: For-in loops
Loops can be imagined as a spiral, each loop of the spiral is an item. So, when we iterate an array, we circle the array over and over.
Imagine we have an array with the Fellowship of the Rings names and I want to access the name of each one of them. We could check the array using a `for in` loop and print the values.
```swift
let fellowshipMembers = ["Frodo", "Sam", "Gandalf", "Aragorn", "Legolas", "Gimli", "Boromir", "Merry", "Pippin"]
// Access elements
for member in fellowshipMembers {
print(member)
}
```
What is going to happen is that Swift is going to check each member inside the `fellowshipMembers` array and will print the nine values.
```swift
Frodo
Sam
Gandalf
Aragorn
Legolas
Gimli
Boromir
Merry
Pippin
```
We can also do the iteration but add a clause in it. For doing so we will have to add a **where** in the loops.
```swift
// Leave Frodo out
let fellowshipMembers = ["Frodo", "Sam", "Gandalf", "Aragorn", "Legolas", "Gimli", "Boromir", "Merry", "Pippin"]
for member in fellowshipMembers where member != "Frodo" {
print(member)
}
```
This will print all the Fellowship members but will skip Frodo.
There’s another way to do a loop by evaluating a condition, and that is using while. Basically, we ask Swift that while a condition happens, do something.
Think of it as when you are cooking, `while` you see flour, whisk the mix. Then you understand that if the flour is not visible anymore you can stop whisking.
```swift
while condition {
do this
}
```
Let’s imagine that we want to allow Frodo to gather 3 things
```swift
var itemsToCollect = ["Ring", "Lembas Bread", "Elven Cloak", "Light of Eärendil", "Mithril Coat"]
var thingsCollected = 0
while thingsCollected < 3 {
print("Frodo has collected: \(itemsToCollect[thingsCollected])")
thingsCollected += 1
}
```
This will print us this
```swift
Frodo has collected: Ring
Frodo has collected: Lembas Bread
Frodo has collected: Elven Cloak
```
While we are looping an array we may want to access to the index value of the element and call the `enumerated()` method with the array. For doing so we may call the index in the loop.
```swift
// Print with index
let fellowshipMembers = ["Frodo", "Sam", "Gandalf", "Aragorn", "Legolas", "Gimli", "Boromir", "Merry", "Pippin"]
for (index, member) in fellowshipMembers.enumerated() {
print("Member number \(index + 1): \(member)")
}
```
This will print
```swift
Member number 1: Frodo
Member number 2: Sam
Member number 3: Gandalf
Member number 4: Aragorn
Member number 5: Legolas
Member number 6: Gimli
Member number 7: Boromir
Member number 8: Merry
Member number 9: Pippin
```
🧐 Remember that the array index starts at 0. So the first value is index 0 and so on. 🧐
___
###Array methods and properties
We already know how fundamental are Arrays, they allow us to store multiple values in a single variable, making it easier to manage collections of data.
But to truly harness the 💪power of arrays💪, it's essential to understand the various methods and properties that Swift provides for working with them. And that also makes it so much easier to work with them.
####What are Array Methods and Properties?
**Properties** are characteristics of an array that provide information about the array itself. For instance, properties can tell you the number of elements in an array or whether the array is empty.
**Methods** are functions that perform actions on the array. They can help you add, remove, or find elements within the array, and perform other useful operations.
By learning these methods and properties, you can effectively manipulate arrays and make your code more efficient and readable.
Let's see the most used:
####`.count`
This property counts how many elements are inside an array.
```swift
var numbers = [1, 2, 3, 4]
print(numbers.count)
// Output: 4
```
####`.append()`
This method allows us to add new elements to **the end** of the array.
``` swift
var groceryList = ["Onions", "Apples", "Pasta"]
groceryList.append("Bread")
print(groceryList)
// Output: ["Onions", "Apples", "Pasta", "Bread"]
```
####`.insert()`
This method allows us to add new values to the array at a specific index.
```swift
var groceryList = ["Onions", "Apples", "Pasta"]
groceryList.insert("Bread", at: 1)
print(groceryList)
// Output: ["Onions", "Bread", "Apples", "Pasta"]
```
####`.remove(at:)`
This method removes the element at a specific index in the array.
```swift
var groceryList = ["Onions", "Apples", "Pasta"]
groceryList.remove(at: 0)
print(groceryList)
// Output: ["Apples", "Pasta"]
```
####`.removeAll()`
This method empties the array of all its values.
```swift
var groceryList = ["Onions", "Apples", "Pasta"]
groceryList.removeAll()
print(groceryList)
// Output: []
```
####`.filter()`
This method, filters our array. It creates a new array with the values that satisfy a condition.
For example, let's filter our array to create a new one with all the values that are less than 3.
```swift
var numbers = [1, 2, 3, 4]
let filtered = numbers.filter { $0 < 3 }
print(filtered)
// Output: [1, 2]
```
####`.map()`
This method transforms each value of the array and returns a new array with the transformed values.
```swift
var numbers = [1, 2, 3, 4]
let mappedNumbers = numbers.map { $0 * 2 }
print(mappedNumbers)
// Output: [2, 4, 6, 8]
```
####`.forEach()`
This method performs an action for each value in the array.
```swift
var groceryList = ["Onions", "Apples", "Pasta"]
groceryList.forEach { print($0) }
/* Output:
Onions
Apples
Pasta
*/
```
####`.sort(by:)`
This method sorts or rearrange the values inside the array according to a condition.
For example here we can sort them from smaller to higher.
```swift
var numbers = [10, 24, 3, 73, 5]
numbers.sort(by: { $0 < $1 })
print(numbers)
// Output: [3, 5, 10, 24, 73]
```
####`.first`
This property returns the first element of our array.
```swift
var numbers = [3, 63, 27]
print(numbers.first)
// Output: 3
```
####`.last`
This property returns the last element of the array.
```swift
var numbers = [3, 63, 27]
print(numbers.last)
// Output: 27
```
####`.removeFirst()`
This method removes the first element of the array.
```swift
var groceryList = ["Onions", "Apples", "Pasta"]
groceryList.removeFirst()
print(groceryList)
// Output: ["Apples", "Pasta"]
```
####`.removeLast()`
This method removes the last element of the array.
```swift
var groceryList = ["Onions", "Apples", "Pasta"]
groceryList.removeLast()
print(groceryList)
// Output: ["Onions", "Apples"]
```
####`.firstIndex(where:)`
This method returns the index of the first value that satisfies a condition.
```swift
var numbers = [3, 63, 27]
let firstIndex = numbers.firstIndex(where: { $0 > 10 })
print(firstIndex!) // Output: 1
```
####`.shuffled()`
This method returns a new array with the elements shuffled.
```swift
var numbers = [3, 63, 27]
let shuffled = numbers.shuffled()
print(shuffled)
// Output: [27, 3, 63] (order will vary)
```
####`.reverse()`
This method reverses the order of the elements in the array.
```swift
var groceryList = ["Onions", "Apples", "Pasta"]
groceryList.reverse()
print(groceryList)
// Output: ["Pasta", "Apples", "Onions"]
```
####`.allSatisfy(_:)`
This method returns true if **all** elements satisfy a condition, otherwise false.
```swift
var numbers = [3, 63, 27]
let allGreaterThanTen = numbers.allSatisfy { $0 > 10 }
print(allGreaterThanTen) // Output: false
```
####`.contains(_:)`
This method checks if the array contains a specific element.
```swift
var numbers = [3, 63, 27]
let containsTwentySeven = numbers.contains(27)
print(containsTwentySeven)
// Output: true
```
####`.isEmpty`
This property checks if the array is empty and returns a boolean result.
```swift
var numbers = [3, 63, 27]
print(numbers.isEmpty) // Output: false
```
___
###Resources
If you want a Cheat Sheet with some of this methods and properties, feel free to save or download this image. If you share it please do not delete or hide my name 🫶🏻

Also if you want to keep learning more about this I highly recommend checking the official documentation and courses [here](https://developer.apple.com/learn/)
___
###Want to keep learning about Swift?
This a full series on [Swift 101](https://dev.to/silviaespanagil/swift-101-getting-into-ios-development-gji), next chapter will be the second part of Collections where I will share about Sets, Tuples and Dictionaries, so I hope to see you there!
If you enjoyed this, please share, like, and comment. I hope this can be useful to someone and that it will inspire more people to learn and code with Swift
| silviaespanagil |
1,869,113 | How to Source Test Data | This article was originally published on the Shipyard Blog Crafting a good test dataset can be an... | 0 | 2024-05-29T15:16:18 | https://shipyard.build/blog/creating-test-data/ | testing, database, devops, postgres | *<a href="https://shipyard.build/blog/creating-test-data/" target="_blank">This article was originally published on the Shipyard Blog</a>*
---
Crafting a good test dataset can be an intimidating task — especially when you’re starting from scratch. You want to make sure your data reflects production without sacrificing anonymity or skewing excessively large. We’ve seen many engineers create test data, and we’ve learned some valuable lessons along the way — some of which might help you with the initial challenges of building a strong dataset.
## Why good test data is important
When skimming through a database, you’ve definitely noticed the variability within every single column. Of course, there’s a normal distribution and most points fall within a range, but still, within any column there are quite a few outliers. This is important — these are your edge and corner cases. You *need* to test for them. (<a href="https://www.bbc.com/news/articles/c9wz7pvvjypo" target="_blank">Cue that article where American Airlines auto-designated the 101 year old woman as an infant</a>). The last thing you need is a user getting bugged out because they’re using the same rewards code they’ve had since 1986, and it has one fewer digit than your system expects.
As mere humans, <a href="https://mathlesstraveled.com/2019/09/23/human-randomness/" target="_blank">we’re frankly not the strongest when it comes to generating randomness</a>. And while computers <a href="https://slate.com/technology/2022/06/bridle-ways-of-being-excerpt-computer-randomness.html" target="_blank">aren’t capable of *true* randomness</a>, they can approximate it pretty closely. So when it comes time to create test data, it’s hard for us to predict those edge and corner cases and think of every little possible abnormality.
But if we don’t have test data that reflects the range and randomness of production, we’re genuinely not getting our money’s (or CI runners’) worth of our end-to-end tests. You want to test for every possible scenario out there, because it will be an order of magnitude more detrimental/expensive/inconvenient/reputation-damaging when it occurs in production and something breaks. The quality of your data goes hand-in-hand with the quality of your testing; both are crucial when it comes to delivering reliable, high-quality software.
## Creating your test data
Your test dataset is something that you’ll probably never quite be *done with.* You’ll keep iterating and improving it, as well as factoring in new data points to try and break things. But everyone has to start somewhere. Here are some popular methods we’ve found engineers using to create their initial test datasets.
### The human way
Many engineers are still creating test data by hand — row by row. This is tricky, but it’s the best way to control what’s included in your test database. The major downsides are that this is extremely time-consuming, and (as a human) you won’t be able to make this data as random as you might think.
This is a great practice for teams that need small datasets and are pretty familiar with the profile of the data they’re working with.
### The “classic” automated way
For larger datasets, you might want to use automation to your advantage. You can set up a script pretty easily to generate fake test data in the format you need. The Faker Python library comes in clutch here. Faker offers a number of official and community “providers”, which you can use to import and generate data specific to your industry/application (eg. automobile, geo, passport, etc.).
Generating data this way is super efficient — your team is probably pretty comfortable with Python, and this makes it easy to continually iterate/customize the format as you go.
### The GenAI way
If there’s one thing that generative AI *does* consistently get right, it’s learning from patterns. If you show an LLM a sample from your database, it can quickly and easily approximate it into a larger test database, and since it’s learning from all types of existing databases, it can often get a realistic result.
However, anyone who has used LLMs knows that they do have a huge weakness: they tend to hallucinate. Make sure you double-check your database to make sure the values are looking realistic. It is also a good idea to anonymize the resulting database, in case of the likely event that the LLM leaked in any real names/emails/addresses/other PII. Tools like <a href="https://docs.tonic.ai/app/generation/generators/generator-types/ai-synthesizer" target="_blank">Tonic Structural</a> and <a href="https://www.neosync.dev/" target="_blank">Neosync</a> use LLMs to generate synthetic data from your production data, but with guardrails to guarantee the data is anonymized and realistic.
### The sampling way
The best approximation of your production data is, well, a *sample* of your production data. You can select a small subset of your dataset using a technique like <a href="https://www.qualtrics.com/experience-management/research/stratified-random-sampling/" target="_blank">stratified random sampling</a>, making sure your limited selection reflects the variance of your entire official dataset.
From here, you will want to be very careful, as this is genuinely sensitive information. Remove all PII and substitute this with synthetic values from Faker. Shuffle the remaining columns so that each entry no longer *almost* corresponds to a real data entry.
## How much test data do you need?
For most applications, you’ll only need a test dataset a fraction of the size of your production dataset. This test data should account for any and all edge/corner cases but still look pretty “normal” against your prod data. This might take a few hundred entries, sizing up to maybe a gigabyte total.
Remember, larger datasets mean longer test times. If you’re running your test suite multiple times per day, you’ll want to spare minutes of runtime where you can.
The amount of test data you need might be smaller than you think. The best way to find the sweet spot when it comes to your dataset’s size is to start small, and add more entries when you need to.
## Cleaning your test data
While this will likely won’t be an issue if you’re the one creating the test data, you’ll want to double-check your data is “clean” — meaning it is high-quality and error-free.
The most important things to do here are getting your data’s range correct (adjusting scale and range to actually reflect production), filling in any missing datapoints, fixing entry errors, and harmonizing data (making strings consistent). You can automate most of these processes with data processing libraries like <a href="https://pandas.pydata.org/" target="_blank">Pandas</a>.
## Test data: an art and a science
There are a lot of unanswered questions out there when it comes to creating test data from scratch. In short, you’ll want to remember a few things:
- **Keep it brief:** you don’t need terabytes of data to capture the intricacies of your application’s behavior
- **Use automation:** regardless of how you create your data, you can use automation to your advantage — it’s time-consuming and difficult to get right by hand
- **Clean it up:** make sure your data is actually high-quality and formatted/scaled correctly before testing with it
If you want to test earlier and more often, <a href="https://shipyard.build/contact" target="_blank">give Shipyard a try</a>. You can easily integrate your test data with full-stack ephemeral environments for frequent and reliable testing against production-like infrastructure. | shipyard |
1,869,112 | Developing SMART On FHIR Applications with Auth0 and InterSystems IRIS FHIR Server - Introduction | Introduction I recently participated in a fantastically organized hands-on by @patrick.Jamieson3621... | 27,549 | 2024-05-29T15:13:42 | https://community.intersystems.com/post/developing-smart-fhir-applications-auth0-and-intersystems-iris-fhir-server-introduction | angular, fhir, oauth, programming | <h2>Introduction</h2>
<p>I recently participated in a fantastically organized hands-on by @Patrick.Jamieson3621 in which an Angular application was configured together with an IRIS FHIR server following the protocols defined by SMART On FHIR and I found it really interesting, so I decided to develop my own Angular application and thus take advantage of what I learned to publish it in the Community.</p>
<h3>SMART On FHIR</h3>
<p>Let's see what Google tells us about SMART On FHIR:</p>
<blockquote>
<p>SMART on FHIR is a data standard that allows applications to access information in electronic health record (EHR) systems. An application developer can write a single application that connects to any EHR system that has adopted the standard.</p></blockquote>
<p>The main concepts that we are going to handle in SMART On FHIR are:</p>
<ul>
<li>Delegated authentication and authorization by OAuth2 or OpenID.</li>
<li>Management of FHIR resources in the defined context.</li>
<li>HTTPS communications.</li>
</ul>
<h2>Architecture of our project</h2>
<p>For this exercise we have configured the following elements in both Docker and the Auth0 service:</p>
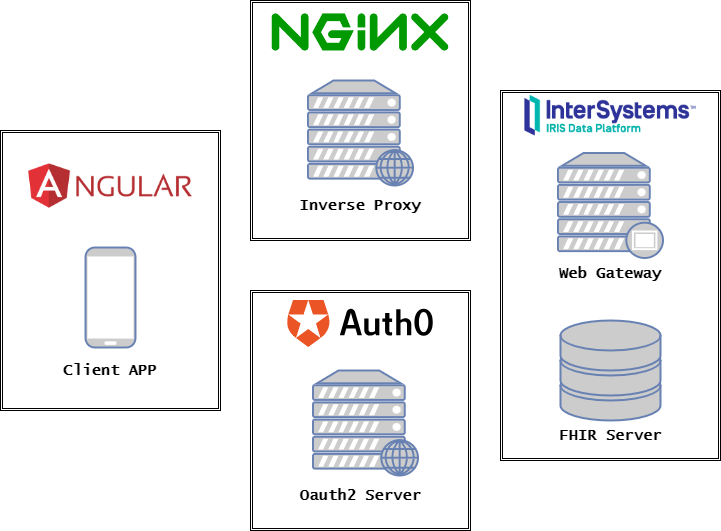
<ul>
<li>One application developed in Angular that will act as our front-end, this application has been developed following the principles of SMART On FHIR.</li>
<li>NGINX web server and reverse proxy that will publish our application developed in Angular.</li>
<li>Auth0 will provide us with the authentication and authorization service through OAuth2.</li>
<li>InterSystems IRIS in which we will deploy our FHIR server and to which we will connect through the Web Gateway which includes an Apache Server already available in its Docker image.</li>
</ul>
<h2>Auth0</h2>
<p>Although we could delegate the authentication and authorization of users to another IRIS server deployed for this purpose, on this occasion we are going to use the service offered by <a href="http://auth0.com/" target="_blank">Auth0</a>.</p>
<p>What is Auth0?</p>
<blockquote>
<p><em>Auth0 is a service that provides us with the entire mechanism to manage authorization and authentication of our platforms.</em></p></blockquote>
<p>Auth0 also has specific libraries in different languages to be able to easily integrate with any project, so it is always an option to take into account for developments based on SMART On FHIR.</p>
<h2>Including Auth0 in our application.</h2>
<p>Since the use of OAuth2 is a required condition for the use of SMART On FHIR, this implies the inclusion of an OAuth2 server in the usual process of authentication, authorization and access to the application. In the following diagram we can see the path taken by the information sent to the system with the Auth0 service:</p>
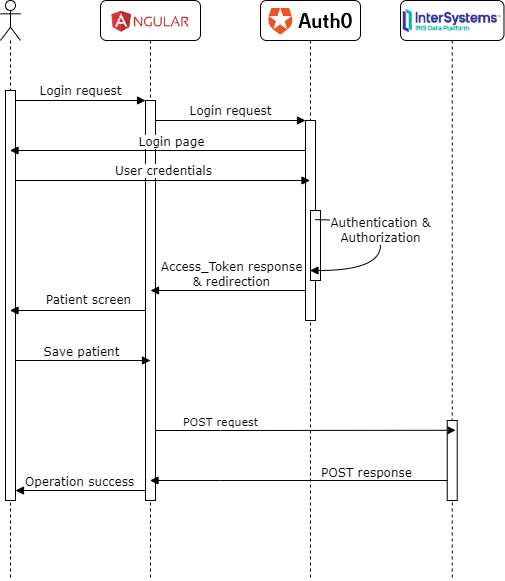
<p>Let's analyze the process:</p>
<ul>
<li>Login request:
<ol>
<li><strong>Login request</strong>: The user accesses the application in their Internet browser and requests to log in.</li>
<li><strong>Login request</strong>: The Angular application forwards the request to the Auth0 service.</li>
<li><strong>Login page</strong>: Auth0 sends a redirect to your own page to the user's Internet browser.</li>
</ol></li>
<li>Authentication on Auth0:
<ol>
<li><strong>User credentials</strong>: The user enters their email and the password with which they are registered in Auth0.</li>
<li><strong>Authentication & Authorization</strong>: Auth0 validates the data and generates an Access_token including the context assigned to the user.</li>
<li><strong>Access_token response & redirection</strong>: Auth0 redirects the response to the URL indicated in the project configuration including the generated token.</li>
<li><strong>Patient screen</strong>: The Angular application shows the user the page to register their personal data.</li>
</ol></li>
<li>FHIR Resource Record:
<ol>
<li><strong>Save patient</strong>: the user fills out the form with her data and the Angular application transforms the form into a JSON object in the format of the FHIR Patient resource.</li>
<li><strong>POST request</strong>: the Angular application sends an HTTP POST call to the FHIR server deployed in IRIS including the access_token as an authentication token in the request header.</li>
<li><strong>POST response</strong>: after receiving the POST request via Web Gateway, IRIS checks the validity of the token and the context of the request. If everything is correct, it will validate the resource received and register it on the FHIR server, returning an HTTP 201 indicating the creation of the new resource. and attaching in a header the identifier assigned to the new resource.</li>
<li><strong>Operation success</strong>: The Angular application will redirect the user to the screen showing the main functionalities.</li>
</ol></li>
</ul>
<p>Once logged in, the Auth0 library included in the project will be in charge of intercepting all the requests we make to our FHIR server to include the access token received from Auth0.</p>
<h2>Coming soon...</h2>
<p>In the next articles we are going to see how we have to configure each of the systems involved and finally how to connect it with our Angular application. For those of you who cannot wait, you can consult the README.md present on the GitHub associated with the OpenExchange project linked to this article, which explains in detail how to configure both Auth0 and InterSystems IRIS.</p>
 | intersystemsdev |
1,869,473 | Cursos De Metaverso, Python, IoT E Outros Gratuitos Da Samsung | A Samsung Ocean anunciou seu calendário de atividades gratuitas para junho de 2024, oferecendo uma... | 0 | 2024-06-23T13:51:59 | https://guiadeti.com.br/cursos-metaverso-python-iot-gratuitos-samsung/ | cursogratuito, cursosgratuitos, inteligenciaartifici, iot | ---
title: Cursos De Metaverso, Python, IoT E Outros Gratuitos Da Samsung
published: true
date: 2024-05-29 15:00:51 UTC
tags: CursoGratuito,cursosgratuitos,inteligenciaartifici,iot
canonical_url: https://guiadeti.com.br/cursos-metaverso-python-iot-gratuitos-samsung/
---
A Samsung Ocean anunciou seu calendário de atividades gratuitas para junho de 2024, oferecendo uma variedade de temas interessantes e atualizados, como programação, IoT, Python e Metaverso.
Os instrutores são da conhecida Universidade de São Paulo (USP) e da Universidade do Estado do Amazonas (UEA), garantindo qualidade.
Os participantes terão a oportunidade de receber certificados de participação, e todas as atividades serão realizadas online e de forma gratuita, trazendo uma experiência educacional acessível e valiosa para a comunidade tecnológica.
## Programação Samsung Ocean
A Samsung Ocean divulgou seu cronograma de atividades gratuitas para junho de 2024, oferecendo uma variedade de temas abrangentes, como programação, IoT, Python, Metaverso, Game Design e muito mais.

_Página da Samsung Ocean_
### Instrutores das Principais Universidades
Os instrutores são da Universidade de São Paulo (USP) e da Universidade do Estado do Amazonas (UEA), garantindo qualidade.
### Certificados e Oportunidades de Aprendizado
Os participantes terão a oportunidade de receber certificados de participação, enriquecendo seus currículos e oportunidades profissionais.
### Atividades Online e Presenciais
As inscrições já estão abertas para participar das atividades, que incluem opções de aulas remotas e presenciais nos campi de Manaus e São Paulo.
As atividades são realizadas tanto de forma online quanto presencial, proporcionando flexibilidade e acesso a todos os interessados. Confira as atividades online:
#### 03/06
- Laboratório de prototipação com Arduino – Básico;
- Introdução ao Desenvolvimento de Games;
- Como desenvolver projetos tecnológicos?
#### 05/06
- Introdução ao Backend;
- DevOps Docker;
#### 06/06
- Jornada Frontend;
- Prototipação no no-code de soluções digitais;
- Game Design: Teoria e prática.
#### 10/06
- Criação de jogos com Unity;
- Linguagem Python: aprendendo a linguagem
- Aplicações wearables na saúde.
#### 11/06
Ciência de Dados: Processamento de linguagem natural e mineração de opinião em Python.
#### 12/06
Laboratório de Internet das Coisas.
#### 14/06
Análise e Visualização de Dados de Saúde com Python.
#### 17/06
Aplicações de IoT na Área de Saúde.
#### 18/06
Deep Learning: Introdução com Keras e Python.
#### 19/06
- Laboratório de IoT em Cloud;
- Consultando Bases SQL com Python.
#### 20/06
- Tópicos de UX para Inteligência Artificial – Experiências Omnicanal;
- Introdução a Modelagem de Sistemas: Modelando Caso de Uso.
#### 21/06
- Oficina de Usabilidade;
- Avançando com Deep Learning;
- Introdução a Modelagem de Sistemas: Modelando Diagrama de Classe.
#### 24/06
Introdução a Modelagem de Sistemas: Prototipação.
#### 26/06
- Inteligência Artificial e Chats Inteligentes: Introdução;
- Aplicações de IoT na Área de Saúde;
- Prototipação no-code de soluções digitais.
#### 27/06
- Introdução ao Desenvolvimento Ágil;
- Tópicos de UX para Design de Serviços;
- Desenvolvimento Ágil: DevOps GIT.
#### 28/06
- Desenvolvimento Ágil: DevOps GIT;
- Blockchain não é apenas criptomoedas.
### Preparação para Desafios do Mercado Tecnológico
Participar dessas atividades 100% gratuitas te deixa preparado para enfrentar os desafios do mercado tecnológico e se destacar em sua jornada educacional e profissional.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Desafio-De-Python-Pandas-280x210.png" alt="Desafio De Python Pandas" title="Desafio De Python Pandas"></span>
</div>
<span>Desafio De Python Pandas Online E Gratuito: 7 Days Of Code</span> <a href="https://guiadeti.com.br/desafio-python-pandas-gratuito-7-days-of-code/" title="Desafio De Python Pandas Online E Gratuito: 7 Days Of Code"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Cursos-De-Metaverso-Python-IoT-280x210.png" alt="Cursos De Metaverso, Python, IoT" title="Cursos De Metaverso, Python, IoT"></span>
</div>
<span>Cursos De Metaverso, Python, IoT E Outros Gratuitos Da Samsung</span> <a href="https://guiadeti.com.br/cursos-metaverso-python-iot-gratuitos-samsung/" title="Cursos De Metaverso, Python, IoT E Outros Gratuitos Da Samsung"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Curso-De-Sistemas-Autonomos-280x210.png" alt="Curso De Sistemas Autônomos" title="Curso De Sistemas Autônomos"></span>
</div>
<span>Curso De Sistemas Autônomos Gratuito: Boas Práticas Operacionais</span> <a href="https://guiadeti.com.br/curso-sistemas-autonomos-boas-praticas/" title="Curso De Sistemas Autônomos Gratuito: Boas Práticas Operacionais"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Bootcamp-Inteligencia-Artificial-Generativa-1-280x210.png" alt="Bootcamp Inteligência Artificial Generativa" title="Bootcamp Inteligência Artificial Generativa"></span>
</div>
<span>Bootcamp De Inteligência Artificial Generativa E Claude 3 Gratuito</span> <a href="https://guiadeti.com.br/bootcamp-inteligencia-artificial-generativa-cloud/" title="Bootcamp De Inteligência Artificial Generativa E Claude 3 Gratuito"></a>
</div>
</div>
</div>
</aside>
## Metaverso
O metaverso é uma evolução da internet que propõe a criação de um universo digital imersivo, onde os usuários podem interagir, trabalhar, jogar e viver experiências através de avatares em um ambiente tridimensional contínuo.
Este conceito, inspirado por obras de ficção científica como “Neuromancer” de William Gibson e popularizado pelo romance “Ready Player One” de Ernest Cline, está começando a tomar forma com o avanço das tecnologias de realidade virtual (VR) e realidade aumentada (AR).
Empresas de tecnologia de ponta e startups inovadoras estão explorando esse espaço, prometendo transformar a maneira como interagimos com o mundo digital.
### Tecnologias que Impulsionam o Metaverso
O desenvolvimento do metaverso depende de uma série de tecnologias fundamentais. A realidade virtual fornece a base para experiências imersivas, permitindo aos usuários “entrar” em ambientes digitais completamente formados.
A realidade aumentada adiciona camadas de informação digital ao mundo real, enriquecendo a experiência do usuário com interações e informações em tempo real.
A tecnologia blockchain desempenha um papel crucial ao oferecer soluções para a criação de economias digitais seguras, possibilitando transações comerciais e a propriedade de ativos virtuais.
Juntas, essas tecnologias estão moldando o metaverso para ser uma plataforma interativa e econômica, onde o físico e o digital coexistem e interagem de maneiras inovadoras.
### O Futuro do Metaverso e Seus Desafios
Enquanto o metaverso oferece promessas de expansão e inovação para o mundo digital, também enfrenta desafios significativos.
Questões de privacidade e segurança são preocupações primordiais, à medida que a integração entre a realidade virtual e a vida real se aprofunda.
A acessibilidade e a inclusão são desafios críticos; garantir que as tecnologias do metaverso sejam acessíveis para todos os usuários, independentemente de localização geográfica ou status socioeconômico, é fundamental para evitar a criação de uma divisão digital ainda mais profunda.
O metaverso também levanta questões éticas e sociais, que precisam ser abordadas para que ele se desenvolva de uma forma que beneficie toda a sociedade.
## Samsung Ocean
A Samsung Ocean é um programa global de capacitação tecnológica desenvolvido pela Samsung para impulsionar o aprendizado prático e a pesquisa em áreas da tecnologia.
### Ambiente Colaborativo e Recursos Avançados
Oferece um ambiente colaborativo e recursos avançados para estudantes, desenvolvedores e empreendedores. Desde sua criação, a plataforma tem evoluído para atender às crescentes demandas do ecossistema tecnológico global.
### Parcerias Estratégicas para Inovação
A Samsung Ocean estabelece parcerias estratégicas com instituições acadêmicas e empresas do setor, promovendo uma colaboração fundamental entre academia e indústria.
### Programação Mensal Abrangente
Sua programação mensal inclui vários temas, desde desenvolvimento de software e inteligência artificial até design e empreendedorismo.
### Oportunidades de Educação Contínua
Oferece oportunidades de participação em atividades remotas e presenciais, permitindo que os interessados ampliem suas habilidades e conhecimentos. Os certificados de participação destacam o comprometimento dos participantes com a educação contínua.
### Experiência Educacional de Excelência
Palestras e workshops conduzidos por especialistas da indústria e acadêmicos renomados elevam a experiência educacional oferecida pela Samsung Ocean.
## Junte-se à revolução tecnológica na Samsung Ocean – inscreva-se agora para explorar o futuro da tecnologia!
As [inscrições para os cursos da Samsung Ocean](https://www.oceanbrasil.com/atividades) devem ser realizadas no site da Samsung Ocean.
## Compartilhe e ajude a capacitar a próxima geração de inovadores tecnológicos!
Gostou do conteúdo sobre os cursos gratuitos da Samsung? Então compartilhe com a galera!
O post [Cursos De Metaverso, Python, IoT E Outros Gratuitos Da Samsung](https://guiadeti.com.br/cursos-metaverso-python-iot-gratuitos-samsung/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,868,934 | Few Secret Tags In HTML | Time Page Refresh & Redirect You Can Add a special tag inside your document to... | 0 | 2024-05-29T15:11:04 | https://dev.to/shyam1806/few-secret-tags-in-html-37n6 | webdev, html, frontend, newbie | ## Time Page Refresh & Redirect
You Can Add a special <meta> tag inside your document to refresh the page at a set interval.
`<meta http-equiv="refresh" content="20"`
To Redirect the different websites with set interval
`<meta http-equiv="refresh" content="20";https://dev.com`
## Disable Right Click
Prevents Right Clicking Entire Webpage
`body oncontextmenu="return false"`
| shyam1806 |
1,869,110 | RESTful API Development with Express.js | RESTful API Development with Express.js Are you looking to build a robust and scalable... | 0 | 2024-05-29T15:10:06 | https://dev.to/romulogatto/restful-api-development-with-expressjs-5gnc | # RESTful API Development with Express.js
Are you looking to build a robust and scalable RESTful API using Node.js? Look no further than Express.js! With its simplicity and flexibility, Express.js is the go-to framework for creating powerful web applications. In this guide, we'll walk you through the process of developing a RESTful API using Express.js.
## Prerequisites
Before getting started with Express.js, make sure you have the following:
- [Node.js](https://nodejs.org) installed on your machine.
- A basic understanding of JavaScript and JSON.
- Familiarity with command-line interfaces (CLI).
If you meet these requirements, let's dive into building your RESTful API!
## Step 1: Setting Up Your Project
To begin, create a new directory for your project and navigate to it in your terminal. Run the following command to initialize a new Node.js project:
```bash
npm init -y
```
This will create a `package.json` file that holds metadata about your project. Next, install Express by running:
```bash
npm install express --save
```
This command saves express as a dependency in your `package.json` file.
## Step 2: Creating Your Server File
To launch an HTTP server with routing capabilities, create a new file called `server.js`. This will serve as the entry point for our application.
Open `server.js`, require the necessary dependencies, and set up our app instance as shown below:
```javascript
const express = require('express');
const app = express();
const port = 3000;
app.listen(port, () => {
console.log(`Server listening on port ${port}`);
});
```
Congrats! You've just created an HTTP server using Express which will listen on port 3000.
## Step 3: Defining Routes
Now it's time to define some routes for our API. In Express.js, routes can be defined using `app.get()`, `app.post()`, `app.put()`, and `app.delete()` methods.
For example, let's create a simple GET route that returns 'Hello, World!' when someone accesses the `/hello` endpoint:
```javascript
app.get('/hello', (req, res) => {
res.send('Hello, World!');
});
```
By visiting [http://localhost:3000/hello](http://localhost:3000/hello), you should see the message 'Hello, World!' displayed in your browser.
## Step 4: Handling Requests and Responses
In RESTful APIs, we often need to handle requests made by clients and send appropriate responses back. Express provides a powerful middleware system for handling this.
Here's an example of how you can parse JSON bodies sent with POST requests using the built-in JSON middleware:
```javascript
app.use(express.json());
// POST request handler
app.post('/api/data', (req, res) => {
// Retrieve data from request body
const { name } = req.body;
// Process data...
// Send response back to client
res.send(`Received ${name} via POST request.`);
});
```
This example demonstrates how to handle a POST request to `/api/data`, extract the `name` field from its body, perform any necessary processing on it, and send a response back to the client.
## Conclusion
Congratulations! You have successfully developed a RESTful API using Express.js. This guide covered setting up your project, creating an HTTP server with routing capabilities using Express.js methods like `get()` and `post()`, as well as handling incoming requests and sending appropriate responses.
With these foundations in place, you are now ready to build even more complex APIs using additional features offered by Express.js. Happy coding!
| romulogatto | |
1,869,109 | The Pyramid of Pain: A Threat Intelligence Concept | An Intelligence concept called the "Pyramid of Pain". It's a simple way to understand how to... | 0 | 2024-05-29T15:07:20 | https://dev.to/noblepearl/the-pyramid-of-pain-a-threat-intelligence-concept-5990 | cybersecurity, security | An Intelligence concept called the "Pyramid of Pain". It's a simple way to understand how to prioritize threats and make our lives easier when dealing with bad guys on the internet!
The Pyramid of Pain is like a ranking system for threats. It's divided into six levels, from least to most severe:
1. Hash values (like a unique ID for files)
2. IP addresses (like a computer's address)
3. Domain names (like a website's name)
4. Network/host artifacts (like clues left behind on a computer)
5. Tools (like software used for good or bad)
6. TTPs (like the tactics and techniques used by bad guys)
The levels are arranged in order of increasing severity, with TTPs being the most critical and hash values being the least. The idea is that the higher you go up the pyramid, the more critical the threat is. So, if you're dealing with a TTP, that's like the ultimate challenge!
So this is how they are labeled:
TTPs: Tough
Tools: Challenging
Network/Host Artifacts: Annoying
Domain Names: Simple
IP Addresses: Easy
Hash Values: Trivial
Understanding the Pyramid of Pain helps us:
- Focus on the most important threats first
- Stop bad guys from causing harm
- Learn how they work and improve our skills
- Get better at finding and fixing problems
Conclusion:
The Pyramid of Pain is a valuable tool for threat intelligence and incident response teams. By understanding the different levels of IOCs and prioritizing efforts accordingly, teams can enhance their threat mitigation and disruption capabilities. Remember, a proactive approach to threat intelligence is crucial in today's ever-evolving threat landscape.
| noblepearl |
1,869,107 | Apache Iceberg and Data Lakehouse Partitioning | Apache Iceberg 101 Get Hands-on With Apache Iceberg Free PDF Copy of Apache Iceberg: The Definitive... | 0 | 2024-05-29T15:03:37 | https://dev.to/alexmercedcoder/apache-iceberg-and-data-lakehouse-partitioning-1bne | database, datascience, dataengineering, dataanalytics | - [Apache Iceberg 101](https://www.dremio.com/blog/apache-iceberg-101-your-guide-to-learning-apache-iceberg-concepts-and-practices/)
- [Get Hands-on With Apache Iceberg](https://bit.ly/am-dremio-lakehouse-laptop)
- [Free PDF Copy of Apache Iceberg: The Definitive Guide](https://bit.ly/am-iceberg-book)
## Introduction
Partitioning is a fundamental concept in data management that significantly enhances query performance by organizing data into distinct segments. This technique groups similar rows together based on specific criteria, making it easier and faster to retrieve relevant data.
Apache Iceberg is an open table format designed for large analytic datasets. It brings high performance and reliability to data lake architectures, offering advanced capabilities such as hidden partitioning, which simplifies data management and improves query efficiency. In this blog, we will explore the partitioning capabilities of Apache Iceberg, highlighting how it stands out from traditional partitioning methods and demonstrating its practical applications using Dremio.
## What is Partitioning?
Partitioning is a technique used to enhance the performance of queries by grouping similar rows together when data is written to storage. By organizing data in this manner, it becomes much faster to locate and retrieve specific subsets of data during query execution.
For example, consider a logs table where queries typically include a time range filter, such as retrieving logs between 10 and 12 AM:
```sql
SELECT level, message FROM logs
WHERE event_time BETWEEN '2018-12-01 10:00:00' AND '2018-12-01 12:00:00';
```
Configuring the logs table to partition by the date of event_time groups log events into files based on the event date. Apache Iceberg keeps track of these dates, enabling the query engine to skip over files that do not contain relevant data, thereby speeding up query execution.
Iceberg supports partitioning by various granularities such as year, month, day, and hour. It can also partition data based on categorical columns, such as the level column in the logs example, to further optimize query performance.
## Traditional Partitioning Approaches
Traditional table formats like Hive also support partitioning, but they require explicit partitioning columns.
To illustrate the difference between traditional partitioning and Iceberg's approach, let's consider how Hive handles partitioning with a sales table.
In Hive, partitions are explicit and must be defined as separate columns. For a sales table, this means creating a `sale_date` column and manually inserting data into partitions:
```sql
INSERT INTO sales PARTITION (sale_date)
SELECT product_id, amount, sale_time, format_time(sale_time, 'YYYY-MM-dd')
FROM unstructured_sales_source;
```
Querying the sales table in Hive also requires an additional filter on the partition column:
```sql
SELECT product_id, count(1) as count FROM sales
WHERE sale_time BETWEEN '2022-01-01 10:00:00' AND '2022-01-01 12:00:00'
AND sale_date = '2022-01-01';
```
### Problems with Hive Partitioning:
- **Manual Partition Management:** Hive requires explicit partition columns and manual insertion of partition values, increasing the likelihood of errors.
- **Lack of Validation:** Hive cannot validate partition values, leading to potential inaccuracies if the wrong format or source column is used.
- **Query Complexity:** Queries must include filters on partition columns to benefit from partitioning, making them more complex and error-prone.
- **Static Partition Layouts:** Changing the partitioning scheme in Hive can break existing queries, limiting flexibility.
These issues highlight the challenges of traditional partitioning approaches, which Iceberg overcomes with its automated and hidden partitioning capabilities.
## What Does Iceberg Do Differently?
Apache Iceberg addresses the limitations of traditional partitioning by introducing hidden partitioning, which automates and simplifies the partitioning process.
### Key Features of Iceberg's Partitioning:
- **Hidden Partitioning:** Iceberg automatically handles the creation of partition values, removing the need for explicit partition columns. This reduces errors and simplifies data management.
- **Automatic Partition Pruning:** Iceberg can skip unnecessary partitions during query execution without requiring additional filters. This optimization ensures faster query performance.
- **Evolving Partition Layouts:** Iceberg allows partition layouts to evolve over time as data volumes change, without breaking existing queries. This flexibility makes it easier to adapt to changing data requirements.
For example, in an Iceberg table, sales can be partitioned by date and product category without explicitly maintaining these columns:
```sql
CREATE TABLE sales (
product_id STRING,
amount DECIMAL,
sale_time TIMESTAMP,
category STRING
) PARTITIONED BY (date(sale_time), category);
```
With Iceberg's hidden partitioning, producers and consumers do not need to be aware of the partitioning scheme, leading to more straightforward and error-free data operations. This approach ensures that partition values are always produced correctly and used to optimize queries.
## Iceberg Partition Transformations
Apache Iceberg supports a variety of partition transformations that allow for flexible and efficient data organization. These transformations help optimize query performance by logically grouping data based on specified criteria.
### Overview of Supported Partition Transformations
1. **Year, Month, Day, Hour Transformations:** These transformations are used for timestamp columns to partition data by specific time intervals.
2. **Categorical Column Transformations:**
- **Bucket:** Partitions data by hashing values into a specified number of buckets.
- **Truncate:** Partitions data by truncating values to a specified length, suitable for strings or numeric ranges.
### Example Scenarios for Each Transformation
- **Year, Month, Day, Hour Transformations:** Beneficial for time-series data where queries often filter by date ranges. For example, partitioning sales data by month can significantly speed up monthly sales reports.
- **Bucket Transformation:** Useful for columns with high cardinality, such as user IDs, to evenly distribute data across partitions and avoid skew.
- **Truncate Transformation:** Effective for partitioning data with predictable ranges or fixed-length values, such as product codes or zip codes.
### Configuring Partitioning in Iceberg
Iceberg makes it straightforward to configure partitions when creating or modifying tables.
#### Syntax and Examples for Creating Iceberg Tables with Partitions
To create an Iceberg table partitioned by month:
```sql
CREATE TABLE sales (
product_id STRING,
amount DECIMAL,
sale_time TIMESTAMP,
category STRING
) PARTITIONED BY (month(sale_time));
```
This configuration will group sales records by the month of the sale_time, optimizing queries that filter by month.
Using the ALTER TABLE Command to Modify Partition Schemes
Iceberg allows you to modify the partitioning scheme of existing tables using the ALTER TABLE command. For instance, you can add a new partition field:
```sql
ALTER TABLE sales ADD PARTITION FIELD year(sale_time);
```
This command updates the partitioning scheme to include both month(sale_time) and year(sale_time), enhancing query performance for both monthly and yearly aggregations.
Iceberg's flexible partitioning capabilities, combined with its hidden partitioning feature, ensure that data is always optimally organized for efficient querying and analysis.
## Query Optimization with Partitioning
Apache Iceberg leverages its advanced partitioning capabilities to optimize query performance by minimizing the amount of data scanned during query execution. By organizing data into partitions based on specified transformations, Iceberg ensures that only relevant partitions are read, significantly speeding up query response times.
### How Iceberg Uses Partitioning to Optimize Queries
Iceberg's hidden partitioning and automatic partition pruning capabilities enable it to skip over irrelevant data, reducing I/O and improving query performance. When a query is executed, Iceberg uses the partition metadata to determine which partitions contain the data required by the query, thereby avoiding unnecessary scans.
### Example Query Demonstrating Optimized Performance with Partitioning
Consider a sales table partitioned by month. A query to retrieve sales data for a specific month can be executed efficiently:
```sql
SELECT product_id, amount, sale_time
FROM sales
WHERE sale_time BETWEEN '2022-01-01' AND '2022-01-31';
```
Since the table is partitioned by month, Iceberg will only scan the partition corresponding to January 2022, drastically reducing the amount of data read and speeding up the query.
## Advanced Use Cases and Best Practices
Strategies for Choosing Partition Columns and Transformations
Selecting appropriate partition columns and transformations is crucial for maximizing query performance. Consider the following strategies:
- **Analyze Query Patterns:** Choose partition columns based on the most common query filters. For example, partitioning by date for time-series data or by region for geographically distributed data.
- **Balance Cardinality:** Avoid columns with either too high or too low cardinality. High cardinality columns may create too many partitions, while low cardinality columns may not provide sufficient granularity.
### Best Practices for Managing and Evolving Partition Schemes in Iceberg
- **Start Simple:** Begin with a straightforward partitioning scheme and evolve it as your data and query patterns change.
- **Monitor Performance:** Regularly monitor query performance and adjust partitioning schemes as needed. Use Iceberg's flexible partition evolution capabilities to modify schemes without downtime.
- **Document Partitioning:** Maintain clear documentation of your partitioning strategy and any changes made over time to ensure consistent data management practices.
Conclusion
Apache Iceberg's advanced partitioning approach offers significant advantages over traditional partitioning methods. By automating partition management and providing flexible partition transformations, Iceberg simplifies data organization and enhances query performance. The ability to evolve partition schemes without disrupting existing queries ensures that your data infrastructure remains efficient and adaptable.
Iceberg's partitioning capabilities empower data engineers and analysts to manage large datasets more effectively, ensuring that queries are executed swiftly and accurately. Embracing Iceberg's partitioning features can lead to more efficient data workflows and better overall performance in your data lake architecture.
##### GET HANDS-ON
Below are list of exercises to help you get hands-on with Apache Iceberg to see all of this in action yourself!
- [Intro to Apache Iceberg, Nessie and Dremio on your Laptop](https://bit.ly/am-dremio-lakehouse-laptop)
- [JSON/CSV/Parquet to Apache Iceberg to BI Dashboard](https://bit.ly/am-json-csv-parquet-dremio)
- [From MongoDB to Apache Iceberg to BI Dashboard](https://bit.ly/am-mongodb-dashboard)
- [From SQLServer to Apache Iceberg to BI Dashboard](https://bit.ly/am-sqlserver-dashboard)
- [From Postgres to Apache Iceberg to BI Dashboard](https://bit.ly/am-postgres-to-dashboard)
- [Mongo/Postgres to Apache Iceberg to BI Dashboard using Git for Data and DBT](https://bit.ly/dremio-experience)
- [Elasticsearch to Apache Iceberg to BI Dashboard](https://bit.ly/am-dremio-elastic)
- [MySQL to Apache Iceberg to BI Dashboard](https://bit.ly/am-dremio-mysql-dashboard)
- [Apache Kafka to Apache Iceberg to Dremio](https://bit.ly/am-kafka-connect-dremio)
- [Apache Iceberg Lakehouse Engineering Video Playlist](https://bit.ly/am-iceberg-lakehouse-engineering)
- [Apache Druid to Apache Iceberg to BI Dashboard](https://bit.ly/am-druid-dremio)
- [Postgres to Apache Iceberg to Dashboard with Spark & Dremio](https://bit.ly/end-to-end-de-tutorial) | alexmercedcoder |
1,869,058 | Implementando uma Estrutura de Dados de Fila com ReactJS | Introdução As filas (queues) são estruturas de dados fundamentais usadas em muitos... | 0 | 2024-05-29T15:03:06 | https://dev.to/vitorrios1001/implementando-uma-estrutura-de-dados-de-fila-com-reactjs-16dd | queue, fila, react, javascript | ### Introdução
As filas (queues) são estruturas de dados fundamentais usadas em muitos algoritmos e aplicações. Uma fila segue o princípio FIFO (First In, First Out), onde o primeiro elemento a ser inserido é o primeiro a ser removido. Neste artigo, vamos implementar uma fila simples usando ReactJS.

### Estrutura de Projeto
Primeiro, vamos criar a estrutura básica do nosso projeto React. Se você ainda não tem o `create-react-app` instalado, faça isso com o comando:
```bash
npx create-react-app queue-react
cd queue-react
npm start
```
### Criando a Fila
Vamos começar criando uma estrutura de fila em JavaScript. Crie um arquivo chamado `queue.js` na pasta `src`:
```javascript
// src/queue.js
class Queue<T> {
items: T[] = [];
constructor() {
this.items = [];
}
enqueue(item: T) {
this.items.push(item);
}
dequeue() {
if (this.isEmpty()) {
return null;
}
return this.items.shift();
}
peek() {
if (this.isEmpty()) {
return "Fila Vazia";
}
return this.items[0];
}
size() {
return this.items.length;
}
isEmpty() {
return this.items.length === 0;
}
}
export default Queue;
```
### Integrando a Fila com React
Agora, vamos criar um componente React para interagir com a fila. Crie um arquivo chamado `QueueComponent.js` na pasta `src`:
```javascript
// src/QueueComponent.js
import React, { useState } from 'react';
import Queue from './queue';
const QueueComponent = () => {
const [queue, setQueue] = useState(new Queue());
const [input, setInput] = useState("");
const [top, setTop] = useState("");
const [size, setSize] = useState(0);
const handlePush = () => {
setQueue(queue);
queue.enqueue(input);
setTop(queue.peek());
setSize(queue.size());
setInput("");
};
const handlePop = () => {
queue.dequeue();
setTop(queue.peek());
setSize(queue.size());
};
const handleChange = (e) => {
setInput(e.target.value);
};
return (
<div>
<h1>Impementação de Fila</h1>
<input
type="text"
value={input}
onChange={(e) => setInput(e.target.value)}
placeholder="Entre com um novo elemento"
/>
<button onClick={handlePush}>Enfileirar</button>
<button onClick={handlePop}>Desenfileirar</button>
<div>
<p>Elemento do topo: {top}</p>
<p>Último elemento: {queue.items[0]}</p>
<p>Tamanho da File: {size}</p>
</div>
<p>Fila:</p>
<div>
{queue.items.map((item) => (
<span>
{item}
</span>
))}
</div>
</div>
);
};
export default QueueComponent;
```
### Utilizando o Componente no App
Para finalizar, vamos utilizar o `QueueComponent` no nosso arquivo principal `App.js`:
```javascript
// src/App.js
import React from 'react';
import QueueComponent from './QueueComponent';
function App() {
return (
<div className="App">
<QueueComponent />
</div>
);
}
export default App;
```
**[Exemplo da Implementação no codesandbox](https://codesandbox.io/p/devbox/queue-react-nextjs-xd42pk)**
### Conclusão
Com essa implementação, você criou uma fila básica usando ReactJS. Esta é uma base sólida para entender como funcionam as estruturas de dados em um ambiente de desenvolvimento moderno.
### Referência
Para mais detalhes e exemplos, visite o [artigo de referência](https://scientyficworld.org/implement-queue-data-structure-using-reactjs/). | vitorrios1001 |
1,869,103 | Understanding Offset and Cursor-Based Pagination in Node.js | Pagination means dividing a big chunk of data into smaller pages. It unlocks performance benefits for... | 0 | 2024-05-29T15:00:41 | https://blog.appsignal.com/2024/05/15/understanding-offset-and-cursor-based-pagination-in-nodejs.html | node | Pagination means dividing a big chunk of data into smaller pages. It unlocks performance benefits for the backend, while also improving UX by sending manageable pieces of data to a client.
In this article, we'll explore offset-based and cursor-based server-side pagination approaches, compare them, and implement cursor-based pagination in Node.js.
Let's get started!
## Types of Pagination
There are two broad pagination approaches:
1. Client-side pagination
2. Server-side pagination
The significant difference between them lies in where the pagination process takes place. In client-side pagination, the complete dataset is fetched from a database and partitioned into pages of a given size on the client side. Meanwhile, in server-side pagination, the client only fetches the data required for a given page number. When a user navigates to the next page, the client makes a fresh call to the server for new data.
So, for smaller datasets, client-side pagination works well, but server-side pagination best fits large data use cases.
In the coming sections, we'll learn about two primary ways to perform server-side pagination.
Before we proceed, we need a sample API to work with.
## Prerequisites
To follow this tutorial, you'll need:
- A PostgreSQL server [installed](https://www.postgresql.org/download/) and running on your local machine (I prefer [psql](https://www.timescale.com/blog/how-to-install-psql-on-mac-ubuntu-debian-windows/) to interact with the database).
- Node.js and npm installed, with Node.js version >= 16.
- A basic understanding of a REST API with the Express.js framework.
This article contains some code snippets, but you can find the [complete working code on GitHub](https://github.com/Rishabh570/pagination-nodejs).
## Installing Our Sample Node.js API
Here are the steps to run the sample API locally.
1. Clone the repo:
```shell
git clone git@github.com:Rishabh570/pagination-nodejs.git
```
2. Install the dependencies:
```shell
npm install
```
3. Source the environment variables.
You can find the env variables in `config.js` at the project's root level. Rename the `.env.example` file to `.env` and fill in your desired values for the environment variables.
If Postgres is not set to _trust_ local connections, provide a correct password for your Postgres user. To turn off password authentication, edit your `pg_hba.conf` file (run `SHOW hba_file;` as a superuser to find the file location) to trust all local connections. It should look like this:
```txt
host all all 0.0.0.0/0 trust
```
Once done, you can load environment variables with `source .env` on macOS. Otherwise, try replacing "source" with "." For more information, refer to [the 'source command not found in sh shell' StackOverflow thread](https://stackoverflow.com/questions/13702425/source-command-not-found-in-sh-shell) or load the environment variables directly into the terminal.
4. Run the server:
```shell
npm start
```
5. Create a table in your Postgres database. Connect to your Postgres database locally and run the below command to create a table named "items".
```shell
create table items (
id bigint generated by default as identity,
created_at timestamp with time zone not null default now(),
name text not null,
description text null,
constraint item_pkey primary key (id),
constraint item_id_key unique (id),
constraint item_name_key unique (name)
);
```
6. Load sample data in your items table by hitting the API endpoint — POST /item/create.
You should now have an API server running locally and connected to a local Postgres database. Feel free to run the queries in this article locally to solidify your understanding.
In the following sections, let's look at offset-based and cursor-based pagination, starting with offset-based first.
## Understanding Offset-Based Pagination
Offset-based pagination is intuitive and straightforward, which explains why it's been widely adopted. The key parameters behind this pagination type are `offset` and `limit` clauses.
The `offset` clause helps skip past a set of rows, while `limit` limits the query output.
The latency of executing queries on a database with offset-based pagination increases as the data grows. Here's the planning and execution time when we run it on our sample database (you can run the same commands in your local Postgres database):

The latency grows by more than 10x when the offset parameter is increased:

The good part about offset-based pagination is that it can adapt quickly to almost any pagination style. It's straightforward to implement, whether you're implementing sequential or random access.
For implementing sequential access (previous/next, infinite scroll, or load more pagination style), the offset is simply increased or decreased to get the desired data. For instance, the offset is four times the page size to load the fifth page. And for returning to the first page, the offset is zero times the page size.
### Drawbacks of Offset-Based Pagination
It's important to note that our table from the last section stores very minimal data — `name`, `description`, `created_at`, and `id`. The data is much bigger in real-world scenarios, and latencies can exceed the linear proportionality scale.
If we keep performance-related concerns aside, offset-based pagination has another major drawback — **duplicate or missing entries**.
Let's understand with an example.
We have ten rows in a table, the page size is five, and the rows are ordered by _most recent first_. Here's how the two pages ideally look:
Imagine a new row is inserted into the table while a user is on the first page. When the user visits the next page, a duplicate (or already seen) entry creeps into the following page:
Similarly, if one of the entries on the first page gets deleted when the user visits the second page, they permanently miss that entry:
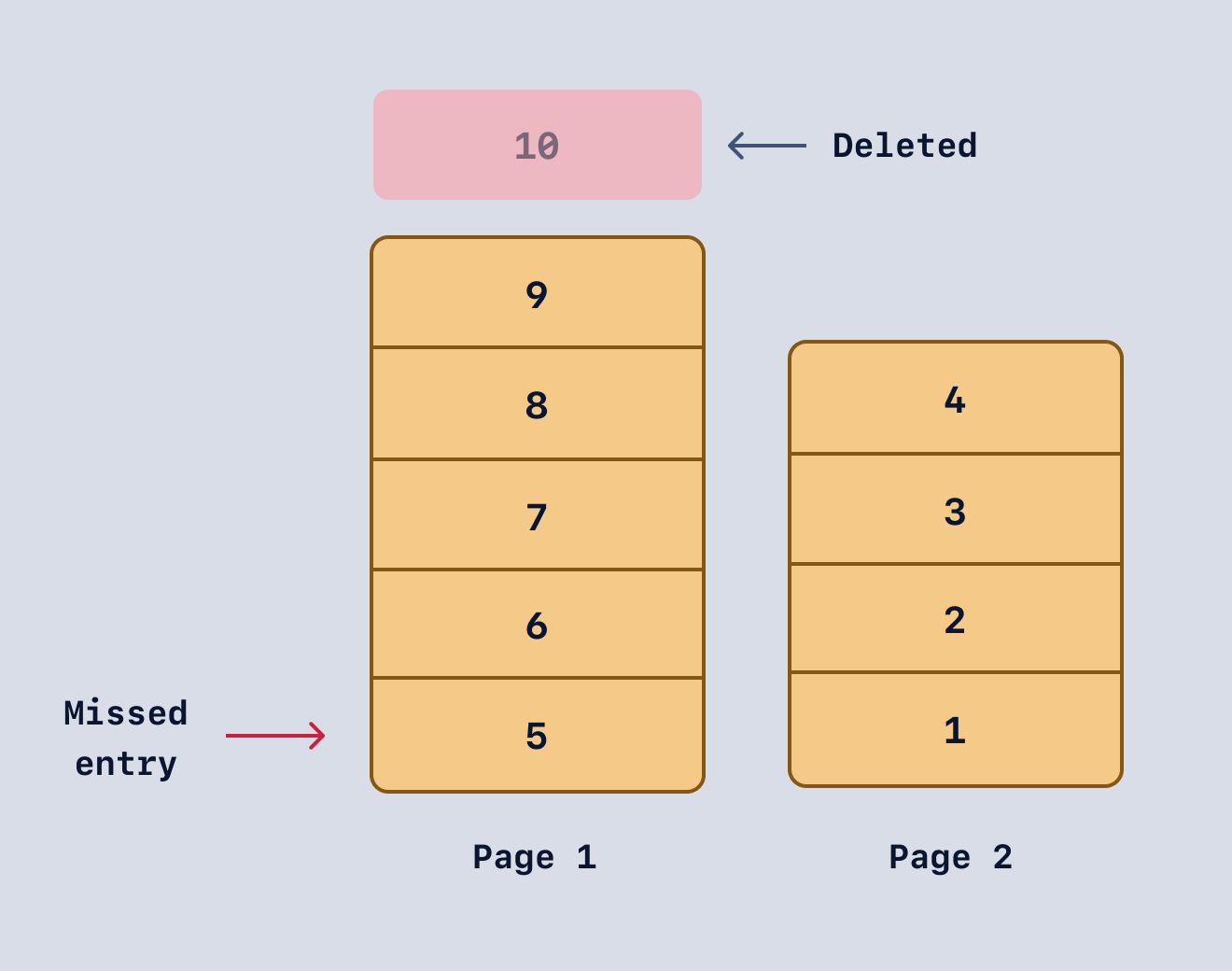
The user never gets to see the fifth entry because it's on the first page now, and the user is on the second page.
Cursor-based pagination is immune to such issues because it doesn't use the `offset` clause. We'll look into cursor-based pagination in detail in the next section. But from what we have observed so far, offset-based pagination can be summarized as follows:
### Pros
1. Intuitive and straightforward to implement.
2. Works well for datasets that don't change frequently.
3. Implementing any pagination logic (sequential and random access) is straightforward.
### Cons
1. Noticeable performance drops as the dataset grows.
2. Unreliable for frequently changing data, as it can show duplicate entries or miss them.
Let's look at how cursor-based pagination offers better potential in terms of performance and how it handles the problem of missing/duplicate entries.
## Understanding Cursor-Based Pagination
Cursor-based pagination leverages the `where` clause to get relevant data. Compared to offset-based pagination, this is a better approach in terms of both performance and reliability.
The stark difference in the query planner's number of rows is immediately visible, and so are the planning and execution times:

Offset-based pagination is almost 9x slower compared to cursor-based pagination.
It's important to mention that the cursor field plays a crucial role in the correctness of the result. Any column can work as a cursor if the values follow a **strictly increasing or decreasing order**. Sometimes, that means going out of the way to add such columns to the table (a timestamp or an incrementing/decrementing ID, for instance).
To emphasize the importance of a strictly increasing/decreasing order, let's analyze a potential issue I faced while working on the API:
- In our items table, `created_at` is a timestamp column (with timezone) that's precise to the millisecond.
- But `new Date().toISOString()` in Javascript doesn't provide the same precision. As a result, our API stores duplicate values from two rows if they are created _close enough_.
This leads to unexpected behavior when fetching a new page from the database. I fixed it by putting some time intervals (big enough for JavaScript to notice) between every created item.
Looking at all the aspects of cursor-based pagination, the pros and cons are as follows:
### Pros
1. Significant performance upside on bigger datasets.
2. Works for frequently changing datasets — no duplicates or missing entries problems.
### Cons
1. Relatively complex to implement — especially with random access pagination style (where the user can jump to the fifth page from the first one).
2. Cursor selection plays a crucial role in the correctness of output.
There are merits to both offset- and cursor-based approaches — let's explore which one to pick for the needs of your application.
## Choosing the Right Pagination Strategy for Your Node.js App
It largely depends on the scope and impact. If you're working on a smaller dataset, it's not worth the hassle of setting up cursor-based pagination. Going ahead with an intuitive and relatively simple approach will allow you to focus on bigger goals for your app (e.g., bringing in more customers).
However, latency becomes noticeable as your database hits millions of rows. The random access pattern can add to latency and throughput. Depending on the use case, embracing complexity might be the only way forward. We'll talk more about UX-imposed challenges later in this article.
Let's see how we can set up cursor-based pagination next.
## How to Implement Cursor-Based Pagination
The idea is to track a column's value with a cursor and use that to navigate across different pages. We'll implement sequential access and use the _most recent first_ sorting order. The pagination style can be any one of the following:
- "Next" and "previous" buttons to navigate
- An infinite scroll
- A load more button
Here's an overview of the next/previous pagination style:
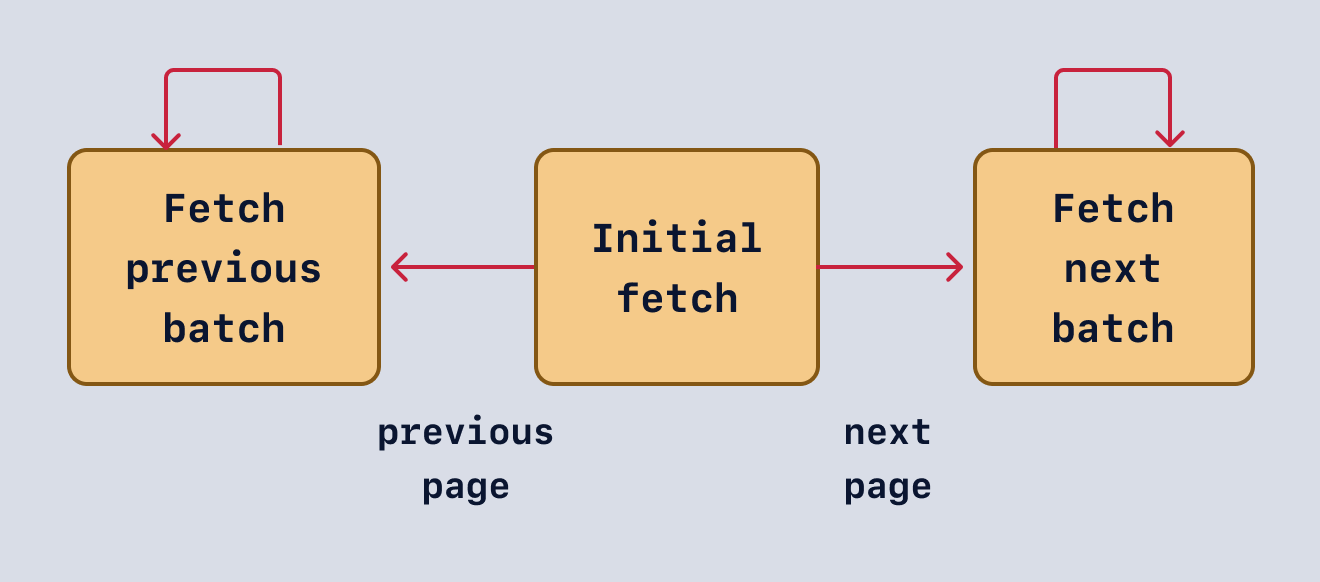
The only difference in an infinite scroll or a load-more variant is that the user cannot return to the previous page because there's no previous page. The data just keeps getting appended.
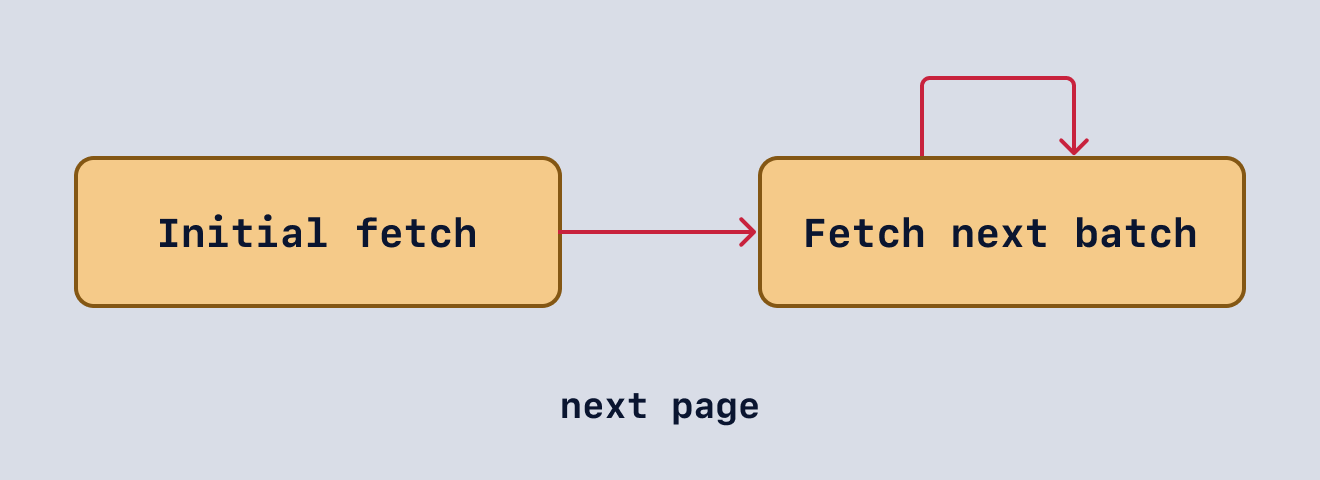
Regardless of the pagination style you're going with, the initial load will fetch a fixed number of entries from the database:
```js
SELECT * FROM items order by created_at desc limit 10;
```
We get back ten entries sorted in the desired order:
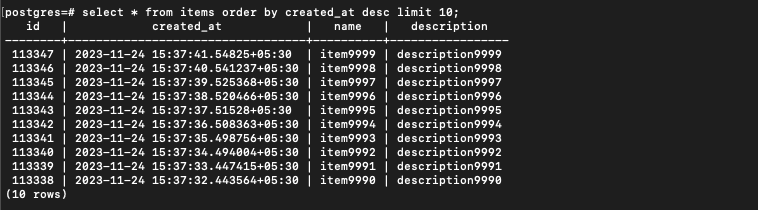
When the user visits the second page, the `where` clause helps us fetch the next set of ten entries:
```javascript
SELECT * FROM items WHERE created_at < '2023-11-24T10:07:32.443Z' order by created_at desc limit 10;
```
We've picked the smallest `created_at` value for the `where` clause. It gives us the following ten entries (second page):
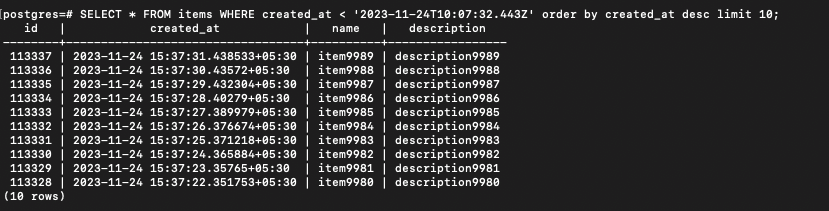
So far, so good.
The query is similar if a user goes back to the first page:
```javascript
SELECT * FROM items WHERE created_at > '2023-11-24T10:07:31.438Z' order by created_at asc limit 10;
```
We've used the largest `created_at` value and filtered out the entries greater than that with a max cap of ten again. But there's a catch. The sorting order has changed in the query. Let's look at the diagram below and understand why it is required.
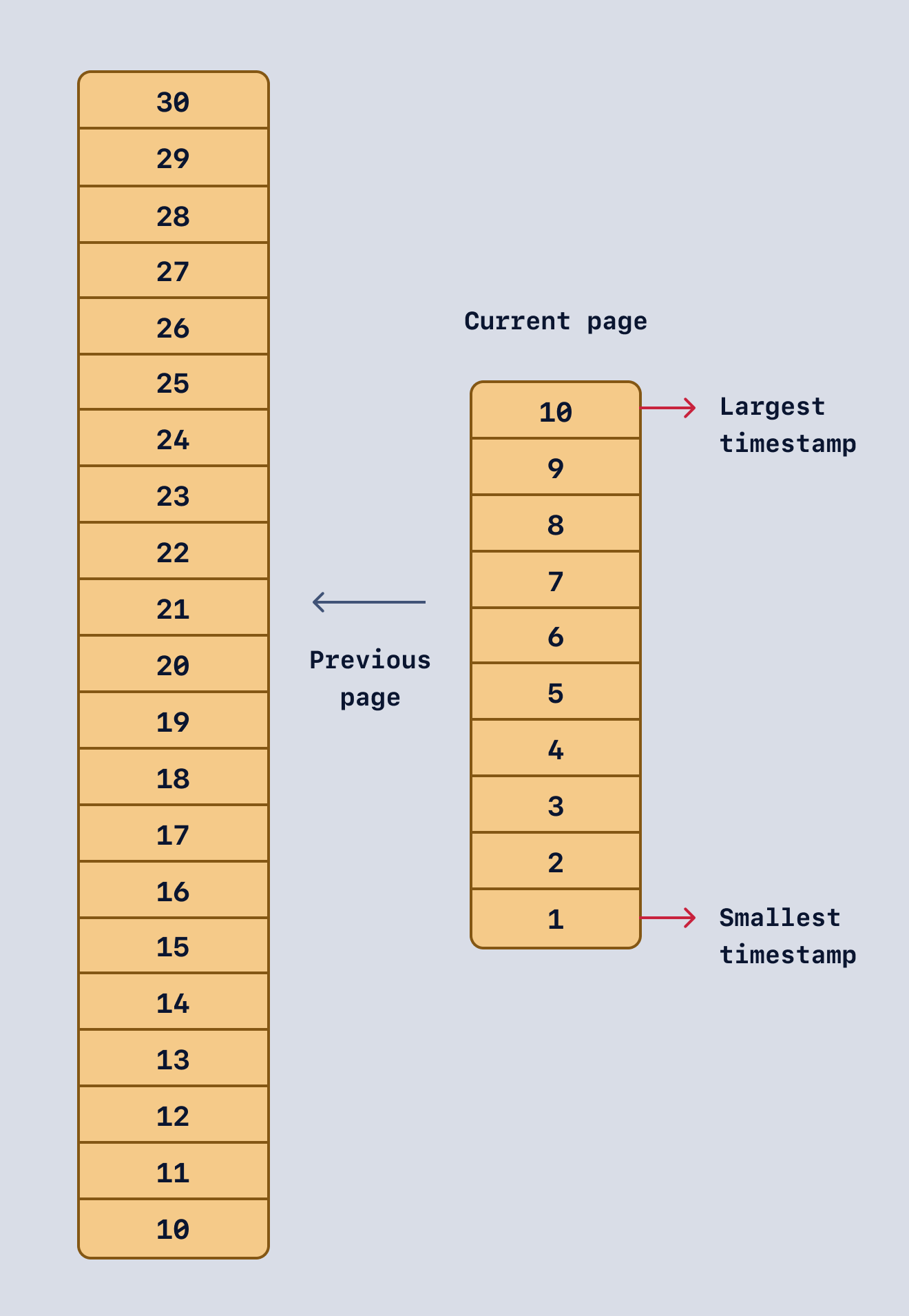
First of all, let's highlight the known pieces of this setup:
- The page size is ten.
- The entries are sorted by _most recent first_.
- There are 30 entries in the table, with each row showing the timestamp (number on the tiles).
- We are currently on the last page. The current largest and smallest timestamps are highlighted on the diagram.
The first step to move back to the previous page is simple — we want to find all the rows where the timestamp exceeds the current largest timestamp (highlighted in the diagram). In our case, twenty rows match this filter.
The second step is to pick the ten most recent rows from the results obtained in the first step. However, sorting the rows in descending timestamp order will give us rows 30 to 21. We want rows 20 to 11. This is why we need to sort the rows in ascending order.
This sudden change in the sorting order can be problematic if the client expects a sorted response from the API. This implementation detail can be ironed out during the design phase.
If a client shares a sorting preference in the request, the server can sort the results before sending them to the client:
```javascript
rows.sort((a, b) => {
if (
new Date(a.created_at).toISOString() ===
new Date(b.created_at).toISOString()
) {
if (order === "desc") return +b.id - +a.id;
return +a.id - +b.id;
}
if (order === "desc") return new Date(b.created_at) - new Date(a.created_at);
return new Date(a.created_at) - new Date(b.created_at);
});
```
If the sorting order changes when a user has progressed to future pages, then usually the first page resets with the new sorting order. For example, if the user requests changing the sorting order from most recent first to the oldest first while on page 2, it should reset to the first page (with entries sorted by oldest first).
If this feels like an information dump, reviewing the complete code should give you a good birds-eye view of the implementation:
```javascript
async function queryRunner(postgres, dir, order = "desc", limit = 10) {
let result;
// Filter and fetch rows with created_at > largestTimestamp when:
// 1. we want to fetch the results for the next page in an ascending order, or
// 2. we want to fetch the results for the previous page in a descending order
if (
dir &&
((dir === "next" && order === "asc") ||
(dir === "previous" && order === "desc"))
) {
result = await postgres.query(
`SELECT * FROM items WHERE created_at > '${largestTimestamp}' order by created_at asc limit ${PAGE_SIZE};`
);
}
// Filter and fetch rows with created_at < largestTimestamp when:
// 1. we want to fetch the results for the next page in a descending order, or
// 2. we want to fetch the results for the previous page in an ascending order
else if (
dir &&
((dir === "next" && order === "desc") ||
(dir === "previous" && order === "asc"))
) {
result = await postgres.query(
`SELECT * FROM items WHERE created_at < '${smallestTimestamp}' order by created_at desc limit ${PAGE_SIZE};`
);
}
// If direction (or, dir) is not provided, fetch the first page
else {
result = await postgres.query(
`SELECT * FROM items order by created_at ${order} limit ${limit};`
);
}
if (result && result.rows && result.rows.length === 0) return [];
const rows = result.rows;
// sort rows in the order that client expects
rows.sort((a, b) => {
if (
new Date(a.created_at).toISOString() ===
new Date(b.created_at).toISOString()
) {
if (order === "desc") return +b.id - +a.id;
return +a.id - +b.id;
}
if (order === "desc")
return new Date(b.created_at) - new Date(a.created_at);
return new Date(a.created_at) - new Date(b.created_at);
});
// Update largest and smallest timestamps from fetched data
if (order === "desc") {
largestTimestamp = new Date(rows[0].created_at).toISOString();
smallestTimestamp = new Date(
rows[rows.length - 1].created_at
).toISOString();
} else {
largestTimestamp = new Date(rows[rows.length - 1].created_at).toISOString();
smallestTimestamp = new Date(rows[0].created_at).toISOString();
}
return result.rows;
}
```
Now that we have implemented cursor-based pagination for our Node.js API, it's time to look at how this approach plays out with random access patterns.
## UX-Imposed Challenges
There are a couple of ways to implement pagination in the UI:
1. Sequential access - Infinite scroll or "Load more" or "prev/next" buttons.
2. Random access - Numbered page.
Offset-based pagination works (ignoring performance bottlenecks) with both access patterns. However, when using cursor-based pagination, random access can be problematic. Let's quickly recap how cursor-based pagination works:
- Fetching the first page involves a fetch with a `limit` clause (without any cursor).
- For the second page, the combination of `where` and `limit` is used, e.g., `where created_at < some_timestamp and limit = 10`.
If we look closer, fetching the second page (and so forth) requires the smallest/largest timestamp of the first page. To allow random access, i.e., jump to the fifth page from the first one, we need to know the smallest/largest timestamp of the fourth page.
This leads to the following conclusions:
1. Enabling random access is only possible when you know each page's smallest/largest timestamp values.
2. Precomputing and storing the smallest/largest timestamps that correspond to every page only helps a little if the data keeps changing (with rows being added or deleted).
Even though computing this on every request is better than offset-based pagination, it is undoubtedly a more complex approach, so best avoided for smaller-scale applications.
## Wrapping Up
In this post, we've learned why pagination is necessary, the types of pagination, and two primary ways to implement server-side pagination. We also discussed some UX-imposed challenges when working with cursor-based pagination.
Now, you should have sufficient knowledge to implement end-to-end pagination and improve the performance of your Node.js API.
Thanks for reading!
**P.S. If you liked this post, [subscribe to our JavaScript Sorcery list](https://blog.appsignal.com/javascript-sorcery) for a monthly deep dive into more magical JavaScript tips and tricks.**
**P.P.S. If you need an APM for your Node.js app, go and [check out the AppSignal APM for Node.js](https://www.appsignal.com/nodejs).** | rishabh570 |
1,869,105 | Discovering the Globe of Online dispensaries : A Guide to the most effective California Online dispensary Enterprises | Discovering the Globe of Online dispensaries : A Guide to the most effective California Online... | 0 | 2024-05-29T15:00:08 | https://dev.to/nastyferg/discovering-the-globe-of-online-dispensaries-a-guide-to-the-most-effective-california-online-dispensary-enterprises-m98 |
Discovering the Globe of Online dispensaries : A Guide to the most effective California Online dispensary Enterprises
Our knowledgeable staff and commitment to outstanding customer service will ensure you find the perfect strain to suit your needs. Visit us today and see why we're the top choice for medical marijuana patients.'
Wham Strain For Sale In USA
WE HAVE VARIETIES OF PRODUCTS FOR SALE AT THE BEST PRICES RIGHT NOW AND DISCOUNT SUCH AS SUPER MAMBAZ STRAIN, TENCO STRAIN, DEOFARMS STRAINS, DOJA STRAINS, SUMER SELECT STRAINS, JUNGLE BOYZ, JUNGLE BOYS, BPB STRAINS, BACKPACKBOYS STRAINS, JEETER CARTS
WHO WE ARE
Welcome to reptilescentury, the best online store for reptiles! We’re a family-run business that has been providing top-notch pet care and supplies. Our goal is to provide our customers with the highest quality products and services at an affordable price. We take pride in our commitment to customer service and satisfaction, offering personalized advice and support for all of your reptile needs. Whether you’re looking for a new pet or need help caring for an existing one, we’ve got you covered. Thanks for stopping by - we look forward to serving you!
In addition, Wham Strain is recognized for its enjoyable Houses. Quite a few people transform to this strain to unwind following extended day or to ease feelings of stress and anxiety and rigidity.
Dizziness and Lightheadedness: Wham can cause dizziness or lightheadedness, notably when consumed in higher doses. It is recommended to consume Wham in a comfortable and Safe and sound atmosphere to avoid here incidents or falls.
Wham Strain is usually a potent cannabis range that is highly regarded for its one of a kind effects. Users report a powerful and uplifting higher that may increase creativeness, boost social interactions, and induce peace.
While the precise genetic make-up may range, it is commonly recognized to acquire genetic influences from noteworthy cannabis types. These mother or father strains contribute for the unique attributes and effects of Wham Strain.
To supply a greater understanding of Wham Strain’s potency, the table down below compares its THC content with other common cannabis strains:
Always talk to by using a Health care Skilled Should you have any problems or concerns regarding cannabis use, particularly when you have pre-current medical circumstances.
“I'm able to see me using the direct above the new college/They don't forget me from providing weed at my old-fashioned.”
sauce carts
https://420medicalstore.com/
| nastyferg | |
1,851,943 | Common and Useful Deployment Patterns | What is a deployment pattern? A deployment pattern (Not to be confused with a design... | 0 | 2024-05-29T19:17:26 | https://coffeebytes.dev/en/common-and-useful-deployment-patterns/ | architecture, webdev, deploy, patterns | ---
title: Common and Useful Deployment Patterns
published: true
date: 2024-05-29 15:00:00 UTC
tags: softwarearchitecture,webdev,deploy,patterns
canonical_url: https://coffeebytes.dev/en/common-and-useful-deployment-patterns/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/a932wha59fchht1n5rs6.jpg
---
## What is a deployment pattern?
A deployment pattern (Not to be confused with a [design pattern](https://coffeebytes.dev/en/design-patterns-in-software/)) is an automatic method of deploying new features of an application to your users. But it doesn’t stop there, it is possible to get extra information from a deploy of an application, but…. but how?
Imagine you want to test a feature of your web application, but you are afraid that it will not be liked by your users, or you want to see if this new feature increases or decreases the conversion rate of your application, which is invaluable, especially in the early stages of iteration of an application.
What can you do in these cases? The best thing to do would be to test it on a representative sample of your audience and, depending on how it responds, discard it or roll it out to the rest of the users.
## Common deployment patterns
There are a number of widely used deployment patterns:
- Monolithic deployment
- Microservices deployment
- Containerization
- Serverless Deployment
- Continuous Integration (CI) / Continuous Deployment (CD)
- Canary
- Features toggles
- Blue/Green
- A/B Testing
- Dark launches
For this post I am going to focus on the last patterns, since they are the ones I have read the least information about on the internet. Consider that **deployment patterns can be combined with each other**. For example, you can perform A/B tests on your monolithic application to find the best version. Having said that, I will explain the patterns.
### Canary deployment
This pattern consists of showing new features to a small group of users. After analyzing and correcting the performance of the new features and, if appropriate, the deploy is extended to all users.
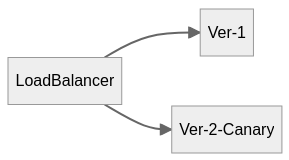
### Features toggles deployment
Instead of releasing all changes at the same time, this pattern hides new features behind a switch, which can be turned on or off without modifying the code. This allows changes to be released gradually or only to certain users, making it easy to test and manage. This method has the advantage that if a problem occurs, you can turn the switch off without the need to return the code to a previous state.
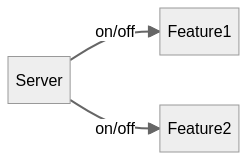
### Blue/Green deployment
In the blue/green deployment we have two similar environments simultaneously. These environments will be known as blue and green. At any time only one of the two environments will be active, while load balancing from one environment to the other. If we find any errors we simply adjust the load balancing to the opposite side.
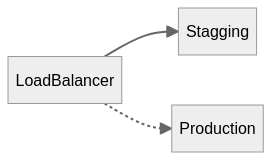
### A/B testing deployment
A/B testing is the classic A/B testing; a random set of our users will receive version A of the application, while the rest will receive version B. We will then use statistics, specifically the two-sample t-test, to determine which version (A or B) is more effective.
The distribution percentage does not necessarily have to be 50-50.
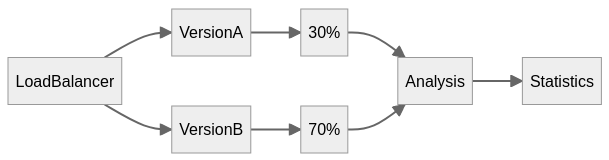
### Dark launches deployment
This type of deployment pattern is quite similar to the Canary deployment, however in this case users must be aware that they are receiving a test version and must be aware of the new functionality being tested. With this knowledge the users will be able to provide feedback on the new functionality.
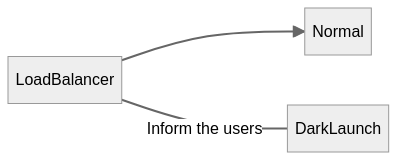
Consider that many projects do not reach the necessary size for a deploy pattern to be useful, and that if your application has few users it may even be counterproductive. However, if this is not the case, you can use one or several of them to extract valuable information for your application. | zeedu_dev |
1,865,077 | Most popular Postgres ORMs | This blog post will discuss popular Postgres ORM tools and other alternatives. Those who are not... | 0 | 2024-05-29T15:00:00 | https://www.neurelo.com/post/postgres-orm | postgres, orm, api, database | This blog post will discuss popular Postgres ORM tools and other alternatives.
Those who are not familiar with ORMs should read “What is an ORM and when developers should and shouldn't use it", but to recap Object-Relational Mappers (ORMs) abstract the database interactions in applications by converting database records into objects and vice versa.
This blog post includes:
* Introduction
* Postgres ORM tools
* Popular Postgres ORMs
- Sequelize
- SQLAlchemy
- Active Record
- Eloquent
- Hibernate
- GORM
* Postgres ORMs - Challenges and limitations
## Introduction
[PostgreSQL](https://www.postgresql.org/) (commonly also referred to as Postgres) is one of the most popular open-source relational database management systems (RDBMS). Renowned for its robustness, extensibility, and adherence to SQL standards, PostgreSQL has positioned itself as one of the most reliable and feature-rich relational databases available. Its support for complex data types and advanced indexing methods makes it suitable for handling diverse data requirements. Postgres is also recognized for its extensibility through the use of custom functions, data types, and procedural languages.
## Postgres ORM Tools
PostgreSQL supports various ORM tools for different programming languages, with some popular ones being SQLAlchemy for Python, Hibernate for Java, and Sequelize for TypeScript/Node.js. These tools provide a set of abstractions that allow developers to interact with the PostgreSQL database using object-oriented concepts.
This enables developers to model database entities as objects and manipulate them using familiar programming language constructs, reducing the need for raw SQL queries. It also enhances code readability and maintainability while also promoting a more natural development workflow.
## Popular Postgres ORMs
Here are some popular PostgreSQL ORMs for specific programming languages:
- Sequelize (for TypeScript): Sequelize is a widely used ORM for TypeScript and JavaScript. It supports PostgreSQL and a few other databases, and provides a powerful set of features for working and querying databases.
- SQLAlchemy (for Python): SQLAlchemy is a robust ORM for Python, offering a flexible and expressive way to interact with PostgreSQL databases. It supports various PostgreSQL-specific features and provides a powerful SQL expression language.
- Active Record (for Ruby): Active Record, part of the Ruby on Rails framework, is a popular ORM for Ruby. It simplifies database interactions and supports PostgreSQL seamlessly, allowing developers to work with Ruby classes representing database tables.
- Eloquent (for PHP): Eloquent is the ORM included in the Laravel PHP framework. It simplifies database operations and supports PostgreSQL, offering an elegant syntax for querying databases using PHP.
- Hibernate (for Java): Hibernate is a widely used ORM for Java applications. It supports PostgreSQL and provides a robust framework for mapping Java objects to database tables, along with powerful querying capabilities.
- GORM (for Go): GORM is a popular ORM for the Go programming language. It offers support for PostgreSQL and provides a simple and concise syntax for defining and querying database models in Go.
## Postgres ORMs - Challenges and limitations
- Performance Optimization: ORM-generated queries may not always be optimized for specific use cases, requiring developers to fine-tune queries manually directly in their code for better performance. The performance problems tend to worsen as the application scales.
- Learning Curve: ORMs are specific to a particular programming language and working with an ORM introduces a learning curve. Developers need to understand the intricacies of the ORM tool, programming language framework, and PostgreSQL to use them effectively.
- Abstraction Leaks: Abstraction leaks often occur as applications move beyond basic CRUD queries. This leads to messy code, unexpected behavior and performance issues. Developers must be cautious and carefully consider their application requirements, architecture, and data access patterns.
- Schema Changes and Migrations: Managing schema changes and migrations can be challenging, particularly in large applications. Developers need to plan for seamless database evolution as the application evolves.
- Modern application architectures: ORM tools may not seamlessly align with modern cloud and serverless architectures. As applications scale, ORM's centralized management of database connections and transactions can become a bottleneck, leading to increased latency and decreased overall throughput. Similarly, in serverless setups, ORM's heavyweight abstraction may struggle with short-lived compute instances. Developers need to carefully evaluate the trade-offs between ORM convenience and cloud-native benefits when architecting applications.
## Postgres ORM alternative with Cloud based Data APIs
Neurelo’s programming interface for databases addresses many of the challenges associated with Postgres ORMs such as N+1 queries and leaky abstractions.
## Full Transparency of Queries:
Traditional ORMs obscure the SQL layer. Neurelo provides full visibility into the queries being executed. This makes debugging much easier but also offers developers choices to optimize database interactions.
## Query Strategies:
Neurelo minimizes the number of queries made to the database using intelligent techniques like eager loading (while also offering the option of lazy loading, when needed) which retrieves the data in a single query using joins. This solves N+1 query issues associated with many traditional ORMs.
## Override Capability for Queries:
Flexibility and control are key in application development, and hence Neurelo allows developers to override the default query generation behavior for APIs, when needed, as per the applications requirements. This feature is particularly useful for optimizing performance or handling edge cases as the application evolves over time, offering both short-term benefits – get started quickly with the queries that Neurelo has optimized to begin with, and long-term flexibility – debug, understand, and update these queries over time as your data, use cases, and applications demand.
## Extending Neurelo APIs for Complex Queries:
Neurelo’s [AI-powered custom APIs](https://docs.neurelo.com/definitions/custom-query-endpoints-as-apis/ai-assisted-query-generation?_gl=1*1waumcc*_gcl_au*NzIwNzAxNzY1LjE3MTQ0MzIxMzI.) go beyond the basic CRUD operations (typically offered by ORM frameworks) with auto-generated APIs that provide the ability to work on single entities (tables/collections) as well as advanced join read/write tasks that go across multiple entities. This means developers can craft bespoke solutions for specific requirements without compromising the integrity or efficiency of the application, thus solving “leaky abstractions”.
## Schema-as-code and alignment to software development lifecycle
By treating database schemas as code, Neurelo empowers developers to manage schema changes seamlessly within their existing codebase, enhancing collaboration, [version control](https://docs.neurelo.com/definitions/branches-and-commits?_gl=1*yawpku*_gcl_au*NzIwNzAxNzY1LjE3MTQ0MzIxMzI.), and automation. With [Schema as Code](https://www.neurelo.com/features/schema-as-code), developers can define database schemas using familiar language and version control systems, enabling them to track changes, review diffs, and rollback modifications with ease. This approach revolutionizes schema management by integrating it into the software development lifecycle, streamlining workflows, and ensuring consistency between application code and database schema. Neurelo's Schema as Code concept represents a paradigm shift in database development, offering a modern and agile approach to schema management for the next generation of applications.
[Try Neurelo](https://dashboard.neurelo.com/register) now and never experience ORM limitations. | shohams |
1,869,104 | Case Study: Two-Dimensional Array | Grading a Multiple-Choice Test The problem is to write a program that will grade... | 0 | 2024-05-29T14:59:01 | https://dev.to/paulike/case-study-two-dimensional-array-4l30 | java, programming, learning, beginners | ## Grading a Multiple-Choice Test
The problem is to write a program that will grade multiple-choice tests. Suppose you need to write a program that grades multiple-choice tests. Assume there are eight students and ten questions, and the answers are stored in a two-dimensional array. Each row records a student’s answers to the questions, as shown in the following array.
Students’ Answers to the Questions:

The key is stored in a one-dimensional array:
Key to the Questions:

Your program grades the test and displays the result. It compares each student’s answers with the key, counts the number of correct answers, and displays it. Below is the program:
`Student 0's correct count is 7
Student 1's correct count is 6
Student 2's correct count is 5
Student 3's correct count is 4
Student 4's correct count is 8
Student 5's correct count is 7
Student 6's correct count is 7
Student 7's correct count is 7`
The statement in lines 7–16 declares, creates, and initializes a two-dimensional array of characters and assigns the reference to **answers** of the **char[][]** type. The statement in line 19 declares, creates, and initializes an array of **char** values and assigns the reference to **keys** of the **char[]** type. Each row in the array **answers** stores a student’s answer, which is graded by comparing it with the key in the array **keys**. The result is displayed immediately after a student’s answer is graded.
## Finding the Closest Pair
This section presents a geometric problem for finding the closest pair of points. Given a set of points, the closest-pair problem is to find the two points that are nearest to each other. In the figure below, for example, points (1, 1) and (2, 0.5) are closest to each other. There are several ways to solve this problem. An intuitive approach is to compute the distances between all pairs of points and find the one with the minimum distance.
```
package demo;
import java.util.Scanner;
public class FindNearestPoints {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.print("Enter the number of points: ");
int numberOfPoints = input.nextInt();
// Create an array to store points
double[][] points = new double[numberOfPoints][2];
System.out.print("Enter " + numberOfPoints + " points: ");
for(int i = 0; i < points.length; i++) {
points[i][0] = input.nextDouble();
points[i][1] = input.nextDouble();
}
// p1 and p2 are the indices in the points' array
int p1 = 0, p2 = 1; // Initial two points
double shortestDistance = distance(points[p1][0], points[p1][1], points[p2][0], points[p2][1]); // Initialize shortestDistance
// Compute distance for every two points
for(int i = 0; i < points.length; i++) {
for(int j = i + 1; j < points.length; j++) {
double distance = distance(points[i][0], points[i][1], points[j][0], points[j][1]); // Find distance
if(shortestDistance > distance) {
p1 = i; // Update p1
p2 = j; // Update p2
shortestDistance = distance; // Update shortestDistance
}
}
}
// Display result
System.out.println("The clostest two points are (" + points[p1][0] + ", " + points[p1][1] + ") and (" + points[p2][0] + ", " + points[p2][1] + ")");
}
/** Compute the distance between two points (x1, y1) and (x2, y2) */
public static double distance(double x1, double y1, double x2, double y2) {
return Math.sqrt((x2 - x1) * (x2 - x1) + (y2 - y1) * (y2 - y1));
}
}
```
`Enter the number of points: 8
Enter 8 points: -1 3 -1 -1 1 1 2 0.5 2 -1 3 3 4 2 4 -0.5
The closest two points are (1, 1) and (2, 0.5)`
The program prompts the user to enter the number of points (lines 8–9). The points are read from the console and stored in a two-dimensional array named **points** (lines 14–17). The program uses the variable **shortestDistance** (line 21) to store the distance between the two nearest points, and the indices of these two points in the **points** array are stored in **p1** and **p2** (line 20).
For each point at index i, the program computes the distance between **points[i]** and **points[j]** for all **j > i** (lines 24–34). Whenever a shorter distance is found, the variable **shortestDistance** and **p1** and **p2** are updated (lines 28–32).
The distance between two points **(x1, y1)** and **(x2, y2)** can be computed using the formula sqrt((x2 - x1) ^ 2 + (y2 - y1) ^ 2) (lines 41–43). The program assumes that the plane has at least two points. You can easily modify the program to handle the case if the plane has zero or one point. Note that there might be more than one closest pair of points with the same minimum distance. The program finds one such pair.
It is cumbersome to enter all points from the keyboard. You may store the input in a file, say **FindNearestPoints.txt**, and compile and run the program using the following command:
`java FindNearestPoints < FindNearestPoints.txt`
## Sudoku
The problem is to check whether a given Sudoku solution is correct. This section presents an interesting problem of a sort that appears in the newspaper every day. It is a number-placement puzzle, commonly known as _Sudoku_. This is a very challenging problem. To make it accessible to the novice, this section presents a simplified version of the Sudoku problem, which is to verify whether a Sudoku solution is correct.
Sudoku is a 9 * 9 grid divided into smaller 3 * 3 boxes (also called _regions_ or _blocks_), as shown in figure below (a). Some cells, called _fixed cells_, are populated with numbers from **1** to **9**. The objective is to fill the empty cells, also called _free cells_, with the numbers **1** to **9** so that every row, every column, and every 3 * 3 box contains the numbers **1** to **9**, as shown in figure below (b).
For convenience, we use value **0** to indicate a free cell, as shown in figure below (a). The grid can be naturally represented using a two-dimensional array, as shown in figure below (b).
To find a solution for the puzzle, we must replace each **0** in the grid with an appropriate number from **1** to **9**. For the solution to the puzzle in figure above, the grid should be as shown in figure below.

Once a solution to a Sudoku puzzle is found, how do you verify that it is correct? Here are two approaches:
- Check if every row has numbers from **1** to **9**, every column has numbers from **1** to **9**, and every small box has numbers from **1** to **9**.
- Check each cell. Each cell must be a number from **1** to **9** and the cell must be unique on every row, every column, and every small box.
The program below prompts the user to enter a solution and reports whether it is valid. We use the second approach in the program to check whether the solution is correct.
```
package demo;
import java.util.Scanner;
public class CheckSudokuSolution {
public static void main(String[] args) {
// Read a Sudoku solution
int[][] grid = readASolution();
System.out.println(isValid(grid) ? "Valid solution" : "Invalid solution");
}
/** Read a Sudoku solution from the console */
public static int[][] readASolution() {
// Create a Scanner
Scanner input = new Scanner(System.in);
System.out.println("Enter a Sudoku puzzle solution:");
int[][] grid = new int[9][9];
for(int i = 0; i < 9; i++)
for(int j = 0; j < 9 ; j++)
grid[i][j] = input.nextInt();
return grid;
}
/** Check whether a solution is valid */
public static boolean isValid(int[][] grid) {
for(int i = 0; i < 9; i++)
for(int j = 0; j < 9; j++)
if(grid[i][j] < 1 || grid[i][j] > 9 || !isValid(i, j, grid))
return false;
return true; // The solution is valid
}
/** Check whether grid[i][j] is valid in the grid */
public static boolean isValid(int i, int j, int[][] grid) {
// Check whether grid[i][j] is unique in i's row
for(int column = 0; column < 9; column++)
if(column != j && grid[i][column] == grid[i][j])
return false;
// Check whether grid[i][j] is unique in j's column
for(int row = 0; row < 9; row++)
if(row != i && grid[row][j] == grid[i][j])
return false;
// Check whether grid[i][j] is unique in the 3-by-3 box
for(int row = (i / 3) * 3; row < (i / 3) * 3 + 3; row++)
for(int col = (j / 3) * 3; col < (j / 3) * 3 + 3; col++)
if(row != i && col != j && grid[row][col] == grid[i][j])
return false;
return true; // The current value at grid[i][j] is valid
}
}
```
`Enter a Sudoku puzzle solution:
9 6 3 1 7 4 2 5 8
1 7 8 3 2 5 6 4 9
2 5 4 6 8 9 7 3 1
8 2 1 4 3 7 5 9 6
4 9 6 8 5 2 3 1 7
7 3 5 9 6 1 8 2 4
5 8 9 7 1 3 4 6 2
3 1 7 2 4 6 9 8 5
6 4 2 5 9 8 1 7 3
Valid solution`
The program invokes the **readASolution()** method (line 8) to read a Sudoku solution and return a two-dimensional array representing a Sudoku grid.
The **isValid(grid)** method checks whether the values in the grid are valid by verifying that each value is between **1** and **9** and that each value is valid in the grid (lines 28–34).
The **isValid(i, j, grid)** method checks whether the value at **grid[i][j]** is valid. It checks whether **grid[i][j]** appears more than once in row **i** (lines 39–41), in column **j** (lines 44–46), and in the 3 * 3 box (lines 49–52).
How do you locate all the cells in the same box? For any **grid[i][j]**, the starting cell of the 3 * 3 box that contains it is **grid[(i / 3) * 3][(j / 3) * 3]**, as illustrated in figure below.
With this observation, you can easily identify all the cells in the box. For instance, if **grid[r][c]** is the starting cell of a 3 * 3 box, the cells in the box can be traversed in a nested loop as follows:
`// Get all cells in a 3-by-3 box starting at grid[r][c]
for (int row = r; row < r + 3; row++)
for (int col = c; col < c + 3; col++)
// grid[row][col] is in the box`
It is cumbersome to enter 81 numbers from the console. When you test the program, you may store the input in a file, say **CheckSudokuSolution.txt**, and run the program using the following command:
`java CheckSudokuSolution < CheckSudokuSolution.txt` | paulike |
1,869,102 | 66 Lottery Login | 66 Lottery Login: Your gateway to exciting online lottery games! Experience the thrill of winning big... | 0 | 2024-05-29T14:55:52 | https://dev.to/66_lotterylogin_24352b6d/66-lottery-login-2m3p | 66 Lottery Login: Your gateway to exciting online lottery games! Experience the thrill of winning big prizes with easy access and seamless navigation. Join the fun now!
Read more: https://66lotterylogin.com/
| 66_lotterylogin_24352b6d | |
1,869,100 | Measuring Data Science Models | Incorporating business metrics into model training and fine-tuning bridges the gap between data... | 0 | 2024-05-29T14:54:46 | https://dev.to/leandro_betaacid/measuring-data-science-models-44eb | machinelearning, ai, datascience, performance | Incorporating business metrics into model training and fine-tuning bridges the gap between data science teams and stakeholders. This approach ensures machine learning models are both technically robust and strategically significant. By aligning technical outputs with business goals, companies can foster a data-driven culture, making insights actionable and maximizing returns on AI investments.
[Read more](https://betaacid.co/blog/measuring-data-science-models-using-business-metrics) | leandro_betaacid |
1,869,098 | What Services Does a Cricket Betting Software Development Company Offer? | In recent years, the sports betting industry has seen exponential growth, with cricket betting... | 0 | 2024-05-29T14:50:38 | https://dev.to/mathewc/what-services-does-a-cricket-betting-software-development-company-offer-3f5l | webdev, programming, devops | In recent years, the sports betting industry has seen exponential growth, with cricket betting becoming particularly popular. As the demand for innovative and reliable betting solutions increases, so does the need for expert development companies that can provide these services. A **[cricket betting app development company](https://innosoft-group.com/cricket-betting-software-development-company/)** plays a crucial role in creating comprehensive and sophisticated betting platforms that cater to the needs of both operators and users. In this blog, we will delve into what cricket betting software is, the different types available, the services offered by these companies, and InnoSoft Group’s expertise in this domain.
**What is Cricket Betting Software?**
Cricket betting software is a specialized platform designed to facilitate and manage betting activities for cricket matches. It provides users with the ability to place bets on various aspects of cricket games, including match outcomes, individual player performances, and other in-game events. This software integrates various functionalities such as live scores, real-time odds, secure payment gateways, and user account management to ensure a seamless and engaging betting experience.
The primary goal of cricket betting software is to offer a robust and secure environment where users can place bets with confidence. It also aims to provide comprehensive data and analytics to help users make informed betting decisions. With the rise of mobile technology, many cricket betting platforms are now optimized for mobile devices, allowing users to place bets from anywhere at any time.
**Different Types of Cricket Betting Software:**
Cricket betting software comes in various forms, each catering to different aspects of betting and user preferences. Here are some of the most common types:
**1. Pre-Match Betting Software**
Pre-match betting software allows users to place bets on the outcome of a cricket match before it begins. This type of software provides odds for various pre-game markets, such as the match winner, total runs, and top batsman. It is essential for this software to offer accurate and up-to-date information to help users make informed decisions.
**2. Live Betting Software**
Live betting, also known as in-play betting, enables users to place bets while a cricket match is in progress. This type of software is highly dynamic, offering real-time odds that change as the game unfolds. Live betting software requires robust technology to provide live updates, real-time data feeds, and seamless user interaction.
**3. Exchange Betting Software**
Exchange betting allows users to bet against each other rather than against a bookmaker. This type of software facilitates peer-to-peer betting, where users can lay (bet against) or back (bet for) various outcomes. Exchange betting software needs to manage user interactions, market liquidity, and provide a secure environment for transactions.
**4. Fantasy Cricket Betting Software**
Fantasy cricket involves users creating virtual teams of real-life players and earning points based on their performance in actual matches. This type of software combines elements of traditional betting with fantasy sports, providing an engaging and interactive experience for users. It requires comprehensive player data, user-friendly interfaces, and efficient scoring systems.
**Services Offered by a Cricket Betting Software Development Company:**
A cricket betting software development company offers a wide range of services to ensure the successful creation and operation of betting platforms. These services include:
**1. Custom Software Development**
Custom software development involves creating tailored betting solutions that meet the specific needs and requirements of clients. This includes designing and developing unique features, user interfaces, and functionalities that differentiate the platform from competitors.
**2. Mobile Betting Solutions**
With the increasing use of mobile devices, providing mobile-optimized betting solutions is crucial. Development companies create responsive and user-friendly mobile apps and websites that allow users to place bets, check odds, and manage their accounts on the go.
**3. Payment Gateway Integration**
Secure and efficient payment processing is vital for any betting platform. Development companies integrate reliable payment gateways that support various payment methods, ensuring smooth and secure transactions for users.
**4. Odds Integration and Management**
Accurate and real-time odds are essential for a successful betting platform. Companies provide odds integration services, sourcing data from reputable providers and ensuring that odds are updated in real-time to reflect the latest developments in cricket matches.
**5. Live Streaming and Data Feeds**
To enhance the user experience, many betting platforms offer live streaming of cricket matches and real-time data feeds. Development companies integrate these features, providing users with up-to-date information and live action to make informed betting decisions.
**6. User Account Management**
Effective user account management is critical for maintaining a secure and organized platform. Development companies implement features for user registration, profile management, transaction history, and responsible gambling measures.
**7. Security and Compliance**
Ensuring the security and compliance of betting platforms is paramount. Development companies implement robust security measures, including encryption, secure sockets layer (SSL) certificates, and compliance with gambling regulations to protect user data and transactions.
**8. Analytics and Reporting**
Comprehensive analytics and reporting tools help operators monitor platform performance, user behavior, and betting trends. Development companies provide these tools to enable data-driven decision-making and continuous improvement of the platform.
**9. Customer Support Solutions**
Providing excellent customer support is essential for user satisfaction. Development companies integrate customer support solutions, such as live chat, email support, and FAQs, to assist users with any issues or queries they may have.
**InnoSoft Group’s Expertise in Cricket Betting Software Development:**
InnoSoft Group stands out as one of the leading **[sports betting software providers](https://innosoft-group.com/sportsbook-software-providers/)**, offering unparalleled expertise in cricket betting software development. Our comprehensive suite of services ensures that clients receive top-notch, customized solutions that meet their specific needs.
**1. Tailored Solutions**
At InnoSoft Group, we understand that each client has unique requirements. We offer tailored solutions that cater to the specific needs of each client, ensuring that their betting platform stands out in the competitive market.
**2. Advanced Technology**
We leverage the latest technologies to create state-of-the-art cricket betting software. Our solutions are designed to provide a seamless and engaging user experience, with features such as live betting, real-time odds updates, and mobile compatibility.
**3. Secure and Compliant Platforms**
Security and compliance are at the core of our development process. We implement robust security measures and ensure that our platforms comply with all relevant gambling regulations, providing a safe and trustworthy environment for users.
**4. Comprehensive Support**
InnoSoft Group offers comprehensive support throughout the development process and beyond. Our team is dedicated to providing ongoing maintenance, updates, and customer support to ensure the continued success of our clients’ platforms.
**5. Data-Driven Insights**
We provide powerful analytics and reporting tools that give operators valuable insights into user behavior, betting trends, and platform performance. These insights enable our clients to make data-driven decisions and continuously improve their offerings.
**6. User-Centric Design**
Our design philosophy centers on creating user-friendly and intuitive interfaces. We ensure that our platforms are easy to navigate, providing users with a seamless and enjoyable betting experience.
**Conclusion:**
A cricket betting software development company plays a pivotal role in the sports betting industry by providing comprehensive solutions that cater to the diverse needs of operators and users. From custom software development to mobile solutions, secure payment gateways, and real-time data feeds, these companies offer a wide range of services that ensure the successful operation of betting platforms. | mathewc |
1,869,097 | health fitness specialist | Introduction When you think about embarking on a journey to improve your health and fitness, one of... | 0 | 2024-05-29T14:48:51 | https://dev.to/nill_media_535d968a1acbd4/health-fitness-specialist-m04 | healthydebate, health, learning |
**Introduction**
When you think about embarking on a journey to improve your health and fitness, one of the best decisions you can make is to work with a health and fitness specialist. But what exactly is a health and fitness specialist, and why are they so important in today's wellness landscape? Let's dive in and find out.
**The Role of a Health and Fitness Specialist**
A health fitness specialist wears many hats, each vital to helping individuals achieve their health goals. They are not just personal trainers; they are holistic health guides who support various aspects of your fitness journey.
**Personal Training**
One of the primary roles of a health and fitness specialist is to provide personal training. This involves creating customized workout plans that cater to the unique needs and goals of each client, ensuring exercises are performed correctly to maximize benefits and minimize injury risks.
**Group Fitness Instruction**
Health fitness specialists often lead group fitness classes. These can range from high-intensity interval training (HIIT) sessions to calming yoga classes. Group fitness is an excellent way for people to stay motivated and enjoy the camaraderie of working out with others.
**Nutrition Guidance**
Beyond physical training, health and fitness specialists also offer nutrition advice. They help clients understand the importance of a balanced diet and how to make healthier food choices that complement their fitness routines.
**Qualifications and certifications**
Becoming a health fitness specialist requires a solid educational foundation and specific certifications.
**Educational Background**
Typically, a health fitness specialist holds a degree in exercise science, kinesiology, or a related field. This educational background provides them with the knowledge needed to understand the human body and its response to exercise.
**Relevant Certifications**
Certifications from recognized organizations like the American Council on Exercise (ACE), the National Strength and Conditioning Association (NSCA), or the National Academy of Sports Medicine (NASM) are crucial. These certifications ensure that the specialist is qualified to provide safe and effective fitness guidance.
**Continuous Education**
The fitness industry is constantly evolving. Health fitness specialists must engage in continuous education to stay updated with the latest research, techniques, and trends to provide the best possible service to their clients.
Skills Required for a Health and Fitness Specialist
To be successful, a health and fitness specialist needs a diverse skill set.
**Communication Skills**
Clear and effective communication is essential. Specialists must be able to explain exercises, give constructive feedback, and motivate clients.
**Motivational Skills**
Keeping clients motivated is a significant part of the job. A good specialist knows how to inspire and encourage clients to push through challenges and stay committed to their fitness goals.
**Technical Skills**
A deep understanding of exercise techniques, body mechanics, and nutrition is crucial. This knowledge helps in designing effective fitness programs and ensuring clients perform exercises safely.
**Benefits of Hiring a Health and Fitness Specialist**
Investing in a health and fitness specialist can provide numerous benefits.
**Personalized fitness plans**
A health fitness specialist designs a fitness plan tailored to your specific needs and goals, ensuring you get the most out of your workouts.
**Expert Guidance**
With their extensive knowledge, health fitness specialists provide expert guidance on exercise and nutrition, helping you avoid common pitfalls and make informed decisions.
**Accountability and motivation**
Regular sessions with a specialist help keep you accountable. They track your progress and motivate you to stay on course, making it easier to achieve your fitness goals.
**How to Choose the Right Health and Fitness Specialist**
Selecting the right health and fitness specialist is crucial for your success.
**Credentials and experience**
Look for a specialist with the right credentials and significant experience. This ensures they have the expertise to help you effectively.
**Client reviews and testimonials**
Check out reviews and testimonials from previous clients. This can provide insight into the specialist's effectiveness and client satisfaction.
**Specializations**
Some specialists focus on specific areas, such as weight loss, strength training, or rehabilitation. Choose a specialist whose expertise aligns with your goals.
**Challenges Faced by Health and Fitness Specialists**
While rewarding, the job of a health and fitness specialist comes with its challenges.
**Keeping clients motivated**
Maintaining client motivation over time can be tough. Specialists must continually find new ways to inspire and engage their clients.
**Staying Updated with Fitness Trends**
The fitness industry is ever-changing. Specialists must stay abreast of the latest trends and research to provide relevant and effective guidance.
**Balancing personal and professional life**
Like many professionals, health fitness specialists often struggle to balance their work and personal lives, especially with the irregular hours many keep.
**The Future of Health and Fitness Specialists**
The future looks bright for health and fitness specialists as the industry continues to grow and evolve.
**Technology Integration**
Technology is playing an increasing role in fitness. From wearable fitness trackers to virtual training sessions, specialists are leveraging technology to enhance their services.
**Holistic health approaches**
There's a growing trend towards holistic health, combining physical fitness, mental well-being, and nutritional health. Specialists are expanding their services to cater to this comprehensive approach.
**Increased Demand**
With rising awareness about health and wellness, the demand for qualified health fitness specialists is on the rise, making it a promising career choice.
**Conclusion**
Health and fitness specialists play a pivotal role in guiding individuals towards healthier, fitter lives. Their expertise in personal training, group fitness, and nutrition, combined with their motivational skills, make them invaluable partners in any fitness journey. Whether you're just starting or looking to elevate your fitness routine, a health fitness specialist can provide the guidance and support you need to succeed.
| nill_media_535d968a1acbd4 |
1,869,096 | Building Vue3 Component Library from Scratch #11 ESlint + Prettier + Stylelint | If you want to do something well, you must first sharpen your tools. A good project must have a... | 27,509 | 2024-05-29T14:48:22 | https://dev.to/markliu2013/building-vue3-component-library-from-scratch-11-eslint-prettier-stylelint-a41 | vue, eslint, prettier, stylelint | If you want to do something well, you must first sharpen your tools. A good project must have a unified standard, such as code standards, style standards, and code submission standards, etc. The purpose of a unified code standard is to enhance team development cooperation, improve code quality, and establish a foundation for development, so everyone must strictly adhere to it.
This article will introduce ESLint + Prettier + Stylelint to standardize the code.
# ESlint
ESLint statically analyzes your code to quickly find problems. Its goal is to ensure code consistency and avoid errors. Let's see how to use it in our project.
Firstly, install ESLint.
```bash
pnpm add eslint -D -w
```
Initialize ESLint
```bash
pnpm create @eslint/config
```
At this point, some options will appear for us to choose.
Now we will find that the ESlint configuration file .eslintrc.cjs has appeared in the root directory. After some configuration changes to this file, it is as follows.
```js
module.exports = {
env: {
browser: true,
es2021: true,
node: true
},
extends: [
'eslint:recommended',
'plugin:vue/vue3-essential',
'plugin:@typescript-eslint/recommended'
],
globals: {
defineOptions: true
},
parser: 'vue-eslint-parser',
parserOptions: {
ecmaVersion: 'latest',
sourceType: 'module',
parser: '@typescript-eslint/parser'
},
plugins: ['vue', '@typescript-eslint'],
rules: {
'@typescript-eslint/ban-ts-comment': 'off',
'vue/multi-word-component-names': 'off'
}
};
```
Create .eslintignore to ignore some files.
```bash
**.d.ts
/packages/stellarnovaui
dist
node_modules
```
Then add the command 'lint:script' in the script section of package.json.
```json
"scripts": {
"lint:script": "eslint --ext .js,.jsx,.vue,.ts,.tsx --fix --quiet ./"
},
```
Then, run 'pnpm run lint:script', you can see report of the code.
## Integrate Prettier
Actually, using ESLint alone is not enough. ESLint is often combined with Prettier to fully utilize their capabilities. Prettier is mainly used for code formatting. Next, let's see how to combine the two.
Similarly, install Prettier.
```bash
pnpm add prettier -D -w
```
Create .prettierrc.cjs
```js
module.exports = {
printWidth: 80,
tabWidth: 2,
useTabs: false, //Whether to use tabs for indentation. The default is false, which means spaces are used for indentation.
singleQuote: true, // Whether to use single quotes for strings. The default is false, which means double quotes are used.
semi: true, // Whether to use semicolons at the end of lines. The default is true.
trailingComma: "none", // Whether to use trailing commas
bracketSpacing: true // Whether to have spaces between the braces of objects. The default is true, resulting in: { a: 1 }.
}
```
Install eslint-config-prettier (to override the rules of eslint itself) and eslint-plugin-prettier (to allow Prettier to take over the ability of eslint --fix, which is to fix the code).
```bash
pnpm add eslint-config-prettier eslint-plugin-prettier -D -w
```
Change .eslintrc.cjs
```js
module.exports = {
env: {
browser: true,
es2021: true,
node: true
},
extends: [
'eslint:recommended',
'plugin:vue/vue3-essential',
'plugin:@typescript-eslint/recommended',
'prettier',
'plugin:prettier/recommended'
],
globals: {
defineOptions: true
},
parser: 'vue-eslint-parser',
parserOptions: {
ecmaVersion: 'latest',
sourceType: 'module',
parser: '@typescript-eslint/parser'
},
plugins: ['vue', '@typescript-eslint'],
rules: {
'prettier/prettier': 'error',
'@typescript-eslint/ban-ts-comment': 'off',
'vue/multi-word-component-names': 'off'
}
};
```
Finally, by executing 'pnpm run lint:script', you can complete the ESLint rule validation check and automatic fix by Prettier.
By now, the configuration of ESLint+Prettier is complete. Next, we will introduce Stylelint (a style specification tool) to the project.
## Stylelint
Firstly, install tool chain.
```bash
pnpm add stylelint stylelint-prettier stylelint-config-standard stylelint-config-recommended-less postcss-html stylelint-config-recommended-vue stylelint-config-recess-order stylelint-config-prettier -D -w
```
Create .stylelintrc.cjs
```js
module.exports = {
// Register the prettier plugin for stylelint.
plugins: ['stylelint-prettier'],
// Inherit a set of rule collections.
extends: [
// standard rule set
'stylelint-config-standard',
'stylelint-config-recommended-less',
// Style property order rules
'stylelint-config-recess-order',
// Incorporate Prettier rules
'stylelint-config-prettier',
'stylelint-prettier/recommended'
],
// Configure rules
rules: {
// Enable Prettier auto-formatting
'prettier/prettier': true
}
};
```
Add script command in the package.json file.
```json
{
"scripts": {
// stylelint command
"lint:style": "stylelint --fix \"*.{css,less}\""
}
}
```
By running 'pnpm run lint:style', you can complete the style formatting.
Now we have completed the configuration of Stylelint.
The final source code: https://github.com/markliu2013/StellarNovaUI | markliu2013 |
1,869,095 | Next.js 15 is here and things are better than ever! | Next.js 15 is here and things are better than ever! From a brand new compiler to 700x faster build... | 0 | 2024-05-29T14:44:42 | https://dev.to/elhaddajiotmane/nextjs-15-is-here-and-things-are-better-than-ever-38ha | javascript, nextjs, react, tutorial | Next.js 15 is here and things are better than ever!
From a brand new compiler to 700x faster build times, it’s never been easier to create full-stack web apps with exceptional performance.
Let’s explore the latest features from v15:
1. **create-next-app upgrades: cleaner UI, 700x faster build**
- **Reformed design**: The user interface of create-next-app has been redesigned for a cleaner and more intuitive experience.
- **Turbopack**: The fastest module bundler in the world, claiming to be 700x faster than Webpack and 10x faster than Vite. Adding it to your Next.js project is now easier than ever before.
2. **Enhanced Middleware Capabilities**
- **Edge Functions**: Next.js 15 introduces first-class support for edge functions, allowing developers to run middleware at the edge, closer to the user for faster response times.
- **Flexible Middleware API**: The new flexible API provides more control and customization over request handling, enabling advanced routing and security features.
3. **Improved Image Optimization**
- **Advanced Image Loader**: The new advanced image loader improves loading times and reduces bandwidth by optimizing images on the fly.
- **Native Support for AVIF**: Next.js 15 adds native support for the AVIF image format, which provides better compression and quality compared to traditional formats like JPEG and PNG.
4. **Automatic Performance Improvements**
- **Out-of-the-box Caching**: Automatic static optimization and intelligent caching mechanisms ensure that your pages load as quickly as possible without additional configuration.
- **Prefetching Enhancements**: Improved prefetching logic ensures that linked pages are loaded faster, providing a smoother navigation experience for users.
5. **Expanded Internationalization Support**
- **Dynamic Locales**: Dynamically load and switch between different locales without needing a full page reload, improving the user experience for multilingual applications.
- **Enhanced Locale Detection**: Improved locale detection ensures that users are served content in their preferred language automatically, enhancing accessibility and user satisfaction.
Next.js 15 brings significant advancements that make building high-performance, full-stack web applications more accessible and efficient. Whether you're upgrading an existing project or starting a new one, these new features offer powerful tools to enhance your development workflow and user experience.
Connect with me:
LinkedIn: [Otmane Elhaddaji ](https://ma.linkedin.com/in/elhaddaji-otmane)
GitHub: [elhaddajiOtmane](https://github.com/elhaddajiOtmane)
| elhaddajiotmane |
1,869,094 | How to make your CMS backend agnostic? Consider content federation | Would you believe me when I tell you that content federation is one way to a backend agnostic CMS?... | 0 | 2024-05-29T14:43:13 | https://dev.to/momciloo/how-to-make-your-cms-backend-agnostic-consider-content-federation-117 | Would you believe me when I tell you that content federation is one way to a backend agnostic CMS? Ok, I know it sounds crazy, but back in the day, the whole world thought that WordPress was the ultimate solution (some still think the same) and then admitted they were wrong.
Maybe right now you can't even imagine why you would need a backend agnostic CMS, so here's a scenario:
Imagine that you have a rapidly growing e-commerce platform, you initially started with WordPress due to its ease of use and extensive plugin ecosystem. It was all great & fun and then suddenly, as your platform grows, you start facing significant challenges, such as performance issues, limited customization, scalability constraints, and content delivery to multiple channels.
You decided to transition from [WordPress to a headless CMS](https://thebcms.com/compare/wordpress-alternative) to address these issues. A headless CMS decouples the backend from the frontend presentation layer, allowing greater flexibility and scalability. This shift enables your team to deliver content across multiple channels, including web, mobile, and IoT devices, ensuring a consistent user experience.
Awesome, you’ve got a fronted agnostic approach thanks to a headless API-first platform and you can run your e-commerce with the solved problem of multichannel distribution relying on a single backend.
Despite the improvements brought by the headless CMS, imagine your e-commerce grows and you are managing an e-commerce website with product data coming from multiple suppliers’ APIs, a blog hosted on WordPress, and user reviews stored in a custom database. That is when content federation comes in:
In this case, content federation with a headless CMS is a part of the [composable architecture](https://thebcms.com/blog/composable-architecture-guide) that allows efficient content management and delivery from multiple sources, through a unified interface. This setup allows you to scale different components independently, and integrate advanced technologies like real-time updates and AI-driven recommendations, ensuring your e-commerce remains flexible, scalable, and capable of providing a seamless shopping experience across all channels.
## How Content Federation contributes to a backend agnostic CMS
The explanation is simple**.** Do the same on the backend as on the frontend. Using data from multiple backends leads to **unified content management**.
Here are the federation benefits:
- **Content aggregation**: Aggregation from various backends makes managing and delivering content easier without being tied to a specific backend system.
- **Consistent API layer**: It provides a consistent API layer to access and manage content, regardless of the database.
- **Decoupled architecture**: Support a decoupled architecture where the CMS does not depend on a single backend. This decoupling enhances the ability to switch or use multiple backends.
- **Interoperability**: It enables interoperability between different systems, allowing you to leverage the strengths of various backends without being restricted by a particular one.
- **Independent scaling**: Each backend can be scaled independently based on its specific requirements, leading to more efficient resource usage.
- **Adaptability**: You can adapt to new technologies or migrate to new backend systems without significant disruptions, as the content federation layer abstracts the backend complexities.
## Implementation
For implementation, you need to use specialized middleware or platforms that can:
1. Integrate with various CMSs, databases, and other content repositories.
2. Gather content from different sources into a central hub. Convert content into a consistent format for presentation.
3. Provide APIs or other mechanisms to serve aggregated content to end-users.
### Headless CMS as a content federation platform
Here are the steps to implement federation with a headless CMS:
### Step 1: Choose BCMS
BCMS is an open-source API-first headless CMS that is ideal for this kind of project.
### Step 2: Identify content sources
Determine the different sources of content you want to federate from. These could be other CMS platforms, databases, external APIs, or anything that you use daily for your website.
### Step 3: Set up the BCMS
BCMS configuration involves:
- Identify content types: Determine the kinds of content you need, such as a home page, blog, articles, product pages, user profiles, and more.
- Setting up content collections.
- Creating API endpoints for content delivery.
### Step 4: Source integration
- Identify integration points: Determine which systems need to connect with the BCMS, such as CRM systems, E-commerce platforms, or marketing automation tools.
- Use APIs: Leverage the [BCMS’s API](https://docs.thebcms.com/inside-bcms/key-manager) to integrate with these systems.
### Step 5: Normalize Content
Ensure that content from different sources is normalized into a consistent format. This might involve:
- Transforming data fields to match BCMS content models.
- Standardizing content metadata.
### Step 6: Set up federated queries
Create federated queries that can fetch and aggregate content from multiple sources. With GraphQL, for example, you can write queries that pull data from various services and combine the results.
### Step 7: Select frontend technologies
Choose technologies for developing the frontend(s) that will consume the CMS content.
As you can guess, BCMS is frontend agnostic so you can choose your stack.
Also, there are some [official integrations](https://docs.thebcms.com/quickstart) with the popular frontend frameworks that can help them make a decision easier.
### Step 8: Implement caching and optimization
To improve performance, implement caching strategies at different layers:
- API response caching
- CDN (Content Delivery Network) for static content
- Client-side caching using service workers or local storage
## Get prepared for BCMS as your backend agnostic CMS
You've seen the reasons, you learned how to set up BCMS as a federated content platform. The only thing left is to give it a try.
Ok, one more, to understand how this approach differs from content hub.
To learn more about it check out: [Content Hub vs Content Federation: Is the same thing?](https://thebcms.com/blog/content-hub-vs-content-federation)
So at the very end, I'll leave you with sources that you may find useful:
- [**BCMS documentation**](https://docs.thebcms.com/)
- [**OpenAPI documentation**](https://rest-apis.thebcms.com/bcms-backend/3-0-0)
- [**Code source**](https://github.com/bcms) | momciloo | |
1,869,093 | Discover the Allure of Antalya: Your Next Travel Destination | Antalya, Turkey, is a stunning Mediterranean gem that beckons travelers with its pristine beaches,... | 0 | 2024-05-29T14:39:09 | https://dev.to/travelgo/discover-the-allure-of-antalya-your-next-travel-destination-522h | antalya, turkey, travel, hollyday | <p> </p><figure class="graf graf--figure" name="d57c"><img class="graf-image" data-height="667" data-image-id="0*GQAkFcGL2Uo0UH5x" data-is-featured="true" data-width="1000" src="https://cdn-images-1.medium.com/max/800/0*GQAkFcGL2Uo0UH5x" /></figure><p class="graf graf--p" name="114b"><a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a>, Turkey, is a stunning Mediterranean gem that beckons travelers with its pristine beaches, ancient ruins, and vibrant culture. Whether you’re a history enthusiast, a beach lover, or an adventure seeker, <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya </a>offers something for everyone. Let’s dive into why this captivating city should be at the top of your travel list.</p><h4 class="graf graf--h4" name="7304">A Historical Treasure Trove</h4><figure class="graf graf--figure" name="2f0c"><img class="graf-image" data-height="857" data-image-id="0*bwVRvn7TRZYD9OkA.jpg" data-width="1280" src="https://cdn-images-1.medium.com/max/800/0*bwVRvn7TRZYD9OkA.jpg" /></figure><p class="graf graf--p" name="5355"><a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a>’s rich history is one of its main draws. The city’s roots trace back to Roman times, and evidence of its storied past can be seen throughout. Begin your journey at <strong class="markup--strong markup--p-strong">Hadrian’s Gate</strong>, a triumphal arch built in honor of the Roman Emperor Hadrian. The well-preserved gate stands as a testament to the architectural prowess of the ancient Romans.
<ins class="bookingaff" data-aid="2421552" data-target_aid="2421552" data-prod="banner" data-width="728" data-height="90" data-banner_id="125810" data-lang="en">
<!-- Anything inside will go away once widget is loaded. -->
<a href="//www.booking.com?aid=2421552">Booking.com</a>
</ins>
<script type="text/javascript">
(function(d, sc, u) {
var s = d.createElement(sc), p = d.getElementsByTagName(sc)[0];
s.type = 'text/javascript';
s.async = true;
s.src = u + '?v=' + (+new Date());
p.parentNode.insertBefore(s,p);
})(document, 'script', '//cf.bstatic.com/static/affiliate_base/js/flexiproduct.js');
</script>
</p><p class="graf graf--p" name="389d">Next, explore the <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a> <strong class="markup--strong markup--p-strong">Museum</strong>, home to an impressive collection of artifacts from the region. From statues and sarcophagi to intricate mosaics, the museum provides a comprehensive overview of the area’s history.</p><h4 class="graf graf--h4" name="870a">Sun, Sea, and Sand</h4><figure class="graf graf--figure" name="07ad"><img class="graf-image" data-height="1500" data-image-id="0*mRYGMJ6-DukOY9zL" data-width="1000" src="https://cdn-images-1.medium.com/max/800/0*mRYGMJ6-DukOY9zL" /></figure><p class="graf graf--p" name="2aab"><a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a> is renowned for its breathtaking beaches. <strong class="markup--strong markup--p-strong">Konyaaltı Beach</strong>, located near the city center, offers a mix of pebbles and sand, crystal-clear waters, and stunning mountain views. It’s the perfect spot for sunbathing, swimming,or enjoying water sports.
<ins class="bookingaff" data-aid="2421569" data-target_aid="2421569" data-prod="dfl2" data-width="300" data-height="350" data-lang="en" data-dest_id="-735347" data-dest_type="city">
<!-- Anything inside will go away once widget is loaded. -->
<a href="//www.booking.com?aid=2421569">Booking.com</a>
</ins>
<script type="text/javascript">
(function(d, sc, u) {
var s = d.createElement(sc), p = d.getElementsByTagName(sc)[0];
s.type = 'text/javascript';
s.async = true;
s.src = u + '?v=' + (+new Date());
p.parentNode.insertBefore(s,p);
})(document, 'script', '//cf.bstatic.com/static/affiliate_base/js/flexiproduct.js');
</script>
</p><p class="graf graf--p" name="3523">
For a more tranquil experience, head to <strong class="markup--strong markup--p-strong">Lara Beach</strong>, known for its fine golden sands and luxurious resorts. The beach also hosts the annual Sandland festival, where artists create intricate sand sculptures that are a delight to behold.</p><h4 class="graf graf--h4" name="87d5">Adventure and Nature</h4><figure class="graf graf--figure" name="b45c"><img class="graf-image" data-height="719" data-image-id="0*9AnSNuNw6n8APWNq.jpg" data-width="1280" src="https://cdn-images-1.medium.com/max/800/0*9AnSNuNw6n8APWNq.jpg" /></figure><p class="graf graf--p" name="cd3a">Adventure awaits in <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a>’s natural landscapes. The <strong class="markup--strong markup--p-strong">Düden Waterfalls</strong>, both Upper and Lower, provide picturesque settings for hiking and picnicking. The Lower Düden Waterfall dramatically cascades into the Mediterranean Sea, offering a spectacular sight.</p><p class="graf graf--p" name="d790">For hiking enthusiasts, the <strong class="markup--strong markup--p-strong">Lycian Way</strong> presents a long-distance trail that winds through ancient ruins, quaint villages, and along beautiful coastal paths. It’s a fantastic way to immerse yourself in the natural beauty and history of the region.</p><h4 class="graf graf--h4" name="6e15">Culinary Delights</h4><figure class="graf graf--figure" name="f3cd"><img class="graf-image" data-height="1500" data-image-id="0*_SIgPZ4j60TieXQa" data-width="1000" src="https://cdn-images-1.medium.com/max/800/0*_SIgPZ4j60TieXQa" /></figure><p class="graf graf--p" name="f645"><a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a>’s culinary scene is a feast for the senses. Start your day with a traditional Turkish breakfast featuring fresh bread, olives, cheeses, and honey. Savor local dishes like <strong class="markup--strong markup--p-strong">Piyaz</strong> (bean salad), <strong class="markup--strong markup--p-strong">Kebab</strong>, and freshly caught seafood.</p><p class="graf graf--p" name="4809">Don’t miss out on trying <strong class="markup--strong markup--p-strong">Baklava</strong>, a sweet pastry made with layers of filo dough, nuts, and honey, paired perfectly with a cup of strong Turkish coffee. For a unique dining experience, visit one of <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a>’s many seaside restaurants and enjoy your meal with a view of the Mediterranean.</p><h4 class="graf graf--h4" name="8301">Practical Travel Tips</h4><ul class="postList"><li class="graf graf--li" name="e55a"><strong class="markup--strong markup--li-strong">Best Time to Visit</strong>: Spring (April to June) and autumn (September to November) offer pleasant weather and fewer crowds.</li><li class="graf graf--li" name="fb06"><strong class="markup--strong markup--li-strong">Getting Around</strong>: <a class="markup--anchor markup--li-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a> has a reliable public transport system, including trams and buses. Renting a car can also be a good option for exploring surrounding areas.</li><li class="graf graf--li" name="7c31"><strong class="markup--strong markup--li-strong">Language</strong>: Turkish is the official language, but English is widely spoken in tourist areas.</li></ul><p class="graf graf--p" name="22f0"><a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank"><strong class="markup--strong markup--p-strong">Access the link for irresistible offers!</strong></a></p><h4 class="graf graf--h4" name="6678">Conclusion</h4><p class="graf graf--p" name="fcb1"><a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a> is a city that seamlessly blends history, nature, and modern amenities. Its rich cultural heritage, stunning natural beauty, and warm hospitality make it an ideal destination for travelers seeking both relaxation and adventure. Pack your bags and set out to discover the many wonders of <a class="markup--anchor markup--p-anchor" data-href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" href="https://www.booking.com/searchresults.en.html?city=-735347&aid=8019784&no_rooms=1&group_adults=2" rel="noopener" target="_blank">Antalya</a></p><p><br /></p>
<script src="https://www.booking.com/affiliate/prelanding_sdk"></script>
<div id="bookingAffiliateWidget_a6420765-0a0b-4cc0-8a20-d44b4b6ff0ed"> </div>
<script>
(function () {
var BookingAffiliateWidget = new Booking.AffiliateWidget({
"iframeSettings": {
"selector": "bookingAffiliateWidget_a6420765-0a0b-4cc0-8a20-d44b4b6ff0ed",
"responsive": true
},
"widgetSettings": {}
});
})();
</script> | travelgo |
1,869,092 | Getting Started with Prometheus: Your Path to Efficient Monitoring | Monitoring and alerting are crucial for maintaining the health and performance of any modern... | 0 | 2024-05-29T14:38:42 | https://dev.to/ayushgupta/getting-started-with-prometheus-your-path-to-efficient-monitoring-4b3o | prometheus, monitoring | Monitoring and alerting are crucial for maintaining the health and performance of any modern application. Prometheus, an open-source systems monitoring and alerting toolkit, has become a popular choice for developers and operations teams due to its robust features and seamless integration with various ecosystems. In this blog, we'll explore what makes Prometheus stand out and provide a step-by-step guide to getting started.
## Why choose Prometheus?
Prometheus offers several features that make it an ideal monitoring solution:
**Free and open-source:** Perfect for monitoring computer systems and software.
**Multi-dimensional Data Model:** Prometheus uses a powerful query language (PromQL) that allows you to slice and dice metrics along various dimensions.
**Flexible Alerting:** With its Alertmanager component, Prometheus supports highly flexible alerting configurations.
**Scalability and Reliability:** Prometheus is designed to handle large-scale monitoring and is highly reliable, with features such as data replication and clustering.
**Integration with Grafana:** Prometheus integrates seamlessly with Grafana, a popular open-source analytics and monitoring tool, providing rich visualization capabilities.

## What is Prometheus?
**Main Prometheus Server:** This central part gathers and stores data over time, allowing you to explore and analyze it using a specialized query language called PromQL.
**Exporters:** These tools collect data from various sources such as databases and web servers, transforming it into a format that Prometheus can understand and utilize.
**Alertmanager:** Responsible for handling alerts generated by Prometheus, the Alertmanager assists in managing these alerts by sending notifications via email or messaging platforms like Slack.
**Client Libraries:** These libraries enable you to incorporate custom data from your applications, enabling Prometheus to collect and monitor this information as well.
## Prometheus vs Other Tool

## Getting Started with Prometheus: Installation and Setup
To begin using Prometheus for monitoring your systems, follow these steps for installation and setup:
**1.Download Prometheus:**
Visit the Prometheus download page (https://prometheus.io/download/) and choose the appropriate version for your operating system. For example, to download Prometheus for Linux, you can use the following command:
`wget https://github.com/prometheus/prometheus/releases/download/v2.30.0/prometheus-2.30.0.linux-amd64.tar.gz
`
**2.Extract the Tarball:**
Once the download is complete, extract the tarball using the following command:
`tar -xzf prometheus-2.30.0.linux-amd64.tar.gz
`
**3.Navigate to the Prometheus Directory:**
Enter the Prometheus directory that was extracted from the tarball:
`cd prometheus-2.30.0.linux-amd64
`
**4.Configure Prometheus:**
Create a configuration file named prometheus.yml to define your Prometheus configuration. You can use a text editor like Nano or Vim to create this file:
`nano prometheus.yml
`
Inside prometheus.yml, you can specify your scraping targets, alerting rules, and other configurations according to your monitoring needs.
**5.Start Prometheus:**
After configuring Prometheus, you can start the Prometheus server using the following command:
`./prometheus --config.file=prometheus.yml
`
This command will start Prometheus with the configuration defined in prometheus.yml.
**6.Access the Prometheus Web UI:**
Open your web browser and navigate to http://localhost:9090 to access the Prometheus web user interface. Here, you can explore metrics, run queries using PromQL, and configure alerting rules.
## Conclusion
Prometheus is a free, open-source tool used to monitor computer systems, applications, and services. It provides valuable insights into system performance, making it a popular choice among tech enthusiasts and businesses alike.
Explore the comprehensive [Prometheus Official Documentation](https://prometheus.io/docs/introduction/overview/) for in-depth insights into its features, including starting guides and detailed explanations of functionality.
| ayushgupta |
1,869,091 | Chat with my UI/UX Book and Get Tips for your Projects | Last year, we launched "Roots of UI/UX Design," a book created for developers and designers who want... | 0 | 2024-05-29T14:36:13 | https://dev.to/creativetim_official/chat-with-my-uiux-book-and-get-tips-for-your-projects-42en | uiux, ai, webdev, books | Last year, we launched "[Roots of UI/UX Design](https://www.material-tailwind.com/roots-of-ui-ux-design)," a book created for developers and designers who want to understand how to design effective and engaging user interfaces, enabling them to apply this knowledge to their projects.
We wanted this book to be engaging so that readers have an enjoyable experience. This is why we included:
- Numerous practical do's and don'ts examples
- QR codes that connect to even more examples
- A Figma file for practicing the skills
Now, **we have taken our book to another level of interactivity**! We created a **[chatbot that lets you talk with the book](https://www.galichat.com/chat/roots-ui-ux-design-book)** and ask anything you want about UI/UX design.
👉🏻 Try this [book chatbot](https://www.galichat.com/chat/roots-ui-ux-design-book) now for free!
For example, you can inquire about UI/UX principles, seek opinions on color schemes, and much more. It's like having a real mentor by your side. Isn't this amazing?
What's even more interesting is that you can **chat with the book in any language you prefer**!
Check out some examples below:
[](https://www.galichat.com/chat/roots-ui-ux-design-book)
[](https://www.galichat.com/chat/roots-ui-ux-design-book)
You might be wondering what tool we used to create this chatbot. This AI assistant was incredibly easy to set up thanks to [GaliChat](https://www.galichat.com/). We trained the chatbot with the book's PDF, and it took approximately 4 minutes to complete everything.
👉🏻 Now try this [book chatbot](https://www.galichat.com/chat/roots-ui-ux-design-book) and let us know your thoughts! | creativetim_official |
1,869,090 | Testing Stable Diffusion Inference Performance with Latest NVIDIA Driver including TensorRT ONNX | 🚀 UNLOCK INSANE SPEED BOOSTS with NVIDIA’s Latest Driver Update or not? 🚀 Are you ready to... | 0 | 2024-05-29T14:32:18 | https://dev.to/furkangozukara/testing-stable-diffusion-inference-performance-with-latest-nvidia-driver-including-tensorrt-onnx-46mc | beginners, tutorial, ai, news | <p style="margin-left:0px;">🚀 UNLOCK INSANE SPEED BOOSTS with NVIDIA’s Latest Driver Update or not? 🚀 Are you ready to turbocharge your AI performance? Watch me compare the brand-new NVIDIA 555 driver against the older 552 driver on an RTX 3090 TI for #StableDiffusion. Discover how TensorRT and ONNX models can skyrocket your speed! Don’t miss out on these game-changing results!</p>
<p style="margin-left:0px;">1-Click fresh Automatic1111 SD Web UI Installer Script with TensorRT and more ⤵️<br><a target="_blank" rel="noopener noreferrer" href="https://www.patreon.com/posts/86307255"><u>https://www.patreon.com/posts/86307255</u></a></p>
<p style="margin-left:0px;">Tutorial video : <a target="_blank" rel="noopener noreferrer" href="https://youtu.be/TNR2HZRw74E"><u>https://youtu.be/TNR2HZRw74E</u></a></p>
<p style="margin-left:0px;"><a target="_blank" rel="noopener noreferrer" href="https://youtu.be/TNR2HZRw74E"><u>Testing Stable Diffusion Inference Performance with Latest NVIDIA Driver including TensorRT ONNX</u></a></p>
<p style="margin-left:auto;"> </p>
<p style="margin-left:auto;">{% embed https://youtu.be/TNR2HZRw74E %}</p>
<p style="margin-left:auto;"> </p>
<p style="margin-left:0px;">0:00 Introduction to the NVIDIA newest driver update performance boost claims<br>0:25 What I am going to test and compare in this video<br>1:11 How to install latest version of Automatic1111 Web UI<br>1:40 The very best sampler of Automatic1111 for Stable Diffusion image generation / inference<br>1:57 Automatic1111 SD Web UI default installation versions<br>2:12 RTX 3090 TI image generation / inference speed for SDXL model with default Automatic1111 SD Web UI installation<br>2:22 How to see your NVIDIA driver version and many more info with nvitop library<br>2:40 Default installation speed for NVIDIA 551.23 driver<br>2:53 How to update Automatic1111 SD Web UI to the latest Torch and xFormers<br>3:05 Which CPU and RAM used to conduct these speed tests CPU-Z results<br>3:54 nvitop status while generating an image with Stable Diffusion XL — SDLX on Automatic1111 Web UI<br>4:10 The new generation speed after updating Torch (2.3.0) and xFormers (0.0.26) to the latest version<br>4:20 How to install TensorRT extension on Automatic1111 SD Web UI<br>5:28 How to generate a TensorRT ONNX model for huge speed up during image generation / inference<br>6:39 How to enable SD Unet selection to be able to use TensorRT generated model<br>7:13 TensorRT pros and cons<br>7:38 TensorRT image generation / inference speed results<br>8:09 How to download and install the latest NVIDIA driver properly and cleanly on Windows<br>9:03 Repeating all the testing again on the newest NVIDIA driver (555.85)<br>10:06 Comparison of other optimizations such as SDP attention or doggettx<br>10:35 Conclusion of the tutorial</p>
<p style="margin-left:0px;">NVIDIA’s Latest Driver: Does It Really Deliver?</p>
<p style="margin-left:0px;">In this video, we dive deep into NVIDIA’s newest driver update, comparing the performance of driver versions 552 and 555 on an RTX 3090 TI running Windows 10. We’ll explore the claims of speed improvements, particularly with #ONNX runtime and TensorRT integration, using the popular Automatic1111 Web UI.</p>
<p style="margin-left:0px;">What You’ll Learn:</p>
<p style="margin-left:0px;">Driver Comparison: Direct performance comparison between NVIDIA drivers 552 and 555.<br>Setup and Installation: Step-by-step guide on setting up a fresh #Automatic1111 Web UI installation, including the latest versions of Torch and xFormers.<br>ONNX and TensorRT Models: Detailed testing of default and TensorRT-generated models to measure speed differences.<br>Hardware Specifications: Insights into the hardware used for testing, including CPU and memory configurations.<br>Testing Procedure:</p>
<p style="margin-left:0px;">Initial Setup:<br>Fresh installation using a custom installer script which includes necessary models and styles.<br>Initial speed test with default settings and configurations.<br>Driver 552 Performance:<br>Speed testing on driver 552 with default models and configurations.<br>Detailed performance metrics and image generation speed analysis.<br>Upgrading to Latest Torch and xFormers:<br>Updating to the latest versions of Torch (2.3.0) and xFormers (0.0.26).<br>Performance testing after updates and comparison with initial setup.<br>TensorRT Installation and Testing:<br>Installing TensorRT extension and generating TensorRT models.<br>Overcoming common installation errors and optimizations.<br>Speed testing with TensorRT models and analysis of performance improvements.<br>Upgrading to Driver 555:<br>Step-by-step guide on downloading and installing NVIDIA driver 555.<br>Performance comparison between driver 552 and 555.<br>Analyzing the impact on speed and efficiency.<br>Results and Conclusions:</p>
<p style="margin-left:0px;">Performance Metrics: Detailed analysis of speed improvements (or lack thereof) with the newest NVIDIA driver.<br>TensorRT Benefits: How TensorRT models significantly boost performance.<br>Driver Update Impact: Understanding the real-world impact of updating to the latest NVIDIA driver.</p>
<p style="margin-left:auto;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*fyc6XEJdahw3vkCZRwwClA.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*fyc6XEJdahw3vkCZRwwClA.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*fyc6XEJdahw3vkCZRwwClA.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*fyc6XEJdahw3vkCZRwwClA.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*fyc6XEJdahw3vkCZRwwClA.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*fyc6XEJdahw3vkCZRwwClA.png 1100w, https://miro.medium.com/v2/resize:fit:2000/format:webp/1*fyc6XEJdahw3vkCZRwwClA.png 2000w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 1000px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*fyc6XEJdahw3vkCZRwwClA.png 640w, https://miro.medium.com/v2/resize:fit:720/1*fyc6XEJdahw3vkCZRwwClA.png 720w, https://miro.medium.com/v2/resize:fit:750/1*fyc6XEJdahw3vkCZRwwClA.png 750w, https://miro.medium.com/v2/resize:fit:786/1*fyc6XEJdahw3vkCZRwwClA.png 786w, https://miro.medium.com/v2/resize:fit:828/1*fyc6XEJdahw3vkCZRwwClA.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*fyc6XEJdahw3vkCZRwwClA.png 1100w, https://miro.medium.com/v2/resize:fit:2000/1*fyc6XEJdahw3vkCZRwwClA.png 2000w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 1000px"><img class="image_resized" style="height:auto;width:1192px;" src="https://miro.medium.com/v2/resize:fit:1875/1*fyc6XEJdahw3vkCZRwwClA.png" alt="" width="1000" height="563">
</picture>
</p> | furkangozukara |
1,869,089 | Vertical Slice: Um Déjà Vu do CQRS | No cenário em constante evolução da arquitetura de software, certos padrões emergem para enfrentar... | 0 | 2024-05-29T14:30:26 | https://dev.to/emergingcode/vertical-slice-um-deja-vu-do-cqrs-1458 | cqrs, verticalslice, arquiteturadesoftware, cqs | No cenário em constante evolução da arquitetura de software, certos padrões emergem para enfrentar desafios específicos na construção de aplicações sustentáveis, escaláveis e eficientes. Dois desses padrões são Command Query Responsibility Segregation (CQRS) e Vertical Slice Architecture. Embora o CQRS tenha sido uma abordagem de design proeminente por vários anos, a Vertical Slice Architecture, popularizada por Jimmy Bogard, ganhou força por sua metodologia pragmática e focada em capacidades de negócio e funcionalidades de negócio.
Este post traça um paralelo entre a história e as motivações por trás do CQRS, explora o conceito de arquitetura Vertical Slice e compara esses dois padrões usando exemplos de código C# e organização de soluções do Visual Studio.
## A origem e motivações por trás do CQRS
### O Surgimento do CQRS
Fundamentado no [CQS](https://en.wikipedia.org/wiki/Command%E2%80%93query_separation), criado por [Bertrand Meyer](https://en.wikipedia.org/wiki/Bertrand_Meyer), Command Query Responsibility Segregation ([CQRS](https://en.wikipedia.org/wiki/Command_Query_Responsibility_Segregation)) é um padrão arquitetural introduzido por **Greg Young** por volta de **2010**. O CQRS foi concebido para resolver vários problemas inerentes às arquiteturas tradicionalmente monolíticas e em camadas, onde as várias operações estavam implementadas em uma única base de código e muitas vezes uma única classe continha várias operações de leitura e escrita aninhadas, fornecendo vários tipos de operações sem separação de responsabilidades.
As arquiteturas tradicionais geralmente combinam operações de leitura e gravação na mesma base de código e modelos de dados, levando a uma lógica que, muitas vezes, pode se tornar complexa de manter e também muito acoplada, tornando difícil a manutenção e evolução do sistema.
### Problemas resolvidos pelo CQRS
1. **Separação de preocupações**: Ao segregar comandos (*escrita*) de consultas (*leituras*), o CQRS promove uma separação clara de responsabilidades. Essa separação permite que os desenvolvedores otimizem e dimensionem as operações de leitura e gravação de forma independente, resultando em um código mais eficiente e de fácil manutenção.
2. **Otimização de desempenho**: Em muitas aplicações, as operações de leitura giram em torno de 95% das tarefas executadas por um sistema, e apenas 5% do restante das operações são de gravação. O CQRS permite otimizar modelos de leitura separadamente dos modelos de gravação, muitas vezes levando a ganhos significativos de desempenho.
3. **Escalabilidade**: Com o CQRS, diferentes partes do sistema podem ser dimensionadas de forma independente. Por exemplo, um aplicativo com muita leitura pode expandir seus componentes de leitura sem afetar o lado de gravação.
4. **Gerenciamento de complexidade**: o CQRS facilita o gerenciamento de validações e lógicas de negócios complexas no lado da gravação, mantendo o lado da leitura simples e otimizado para consultas.
> ⚠️ Não é uma regra ter que separar as instâncias de sua aplicação em uma instância de leitura e uma outra de escrita (gravação). essa abordagem pode acontecer, mas apenas em casos em que a performance do sistema demande essa separação física dos componentes. Aplicar CQRS em sua essência e em seu último nível de implementação arquitetural, vai introduzir um alto grau de complexidade para dentro da solução da sua arquitetura. Por isso, não seja purista aplicando 100% do que você leu e aprendeu sobre esse padrão arquitetural, analise e pense qual é o nível de abstração e implementação que o seu sistema demanda do padrão CQRS!
>
## Sistemas CRUD-Based ofuscam a modelagem de um sistema
Existem muitos sistemas que ainda estão sendo construídos com base no fundamento de servir aos clientes (eg.: *Frontend*), apenas o DTO que é usado no lado servidor, afim de simplificar o processo de desenvolvimento, buscando acelerar a entrega de funcionalidades no mercado.
Esse tipo de abordagem, conduz não só os desenvolvedores do sistema, mas também implica, negativamente, no desenho das telas, levando a uma UI/UX a terem funcionamento atômico, onde o comportamento das funcionalidades se resumem à apenas uma ação que estimule um sistema a recolher todas as alterações feitas na tela (UI/UX), envie para o servidor o DTO alterado, implicando, no final do processamento, persistir esses dados alterados em alguma base de dados.
Através dessa abordagem, muitos pontos de design - não apenas de UI/UX, como também de software e modelagem de negócio, ficaram perdidos ao longo de todo o processo de desenvolvimento, testes e definição de negócio. Uma importante definição de negócio, a qual deveria levar em consideração: as **intenções**, nesse modelo de desenvolvimento são facilmente deixadas de lado. Se fossem melhor melhor exploradas, poderiam resultar delimitação do escopo das ações em um formato mais bem definido, tornando, inclusive, mais fácil a implementação de sistemas ou parte de sistemas que se baseiam em CRUD.
Abaixo tem uma tela de um perfil de usuário, como exemplo:
Através dessa imagem, é fácil notar que a intenção dessa tela é gerir, de uma maneira geral, o perfil de um usuário. Tornando difícil de descobrir qual foi a real intenção que um usuário teve, ao clicar no botão **salvar.** Isso porque o frontend vai capturar todos os dados que existirem na tela e vai enviar, de volta para o servidor. Com isso o rastreamento da operação fica ofuscado pela modelagem CRUD-Based.
## Interface de usuário baseada em tarefas
A ideia básica por trás de uma UI baseada em tarefas ou indutiva, é descobrir como os usuários desejam usar o software e fazer com que ele os oriente nesses processos. O objetivo é orientar o usuário durante o processo.
Um software desenhado com base em uma interface baseada em tarefas adotaria uma abordagem diferente, provavelmente separaria as ações de gestão de dados pessoais, endereço e dados de cobrança em seções diferentes, onde cada uma delas pudessem demonstrar a intenção sobre a ação desejada. A intenção do usuário é clara neste caso e o software está guiando os seus passos através do processo de gestão de cada parte da informação de forma isolada, porém contextualizada dentro do perfil do usuário. Dessa forma, as ações podem ser usadas para a criação de comandos que representam as intenções do usuário com este estilo de interface.
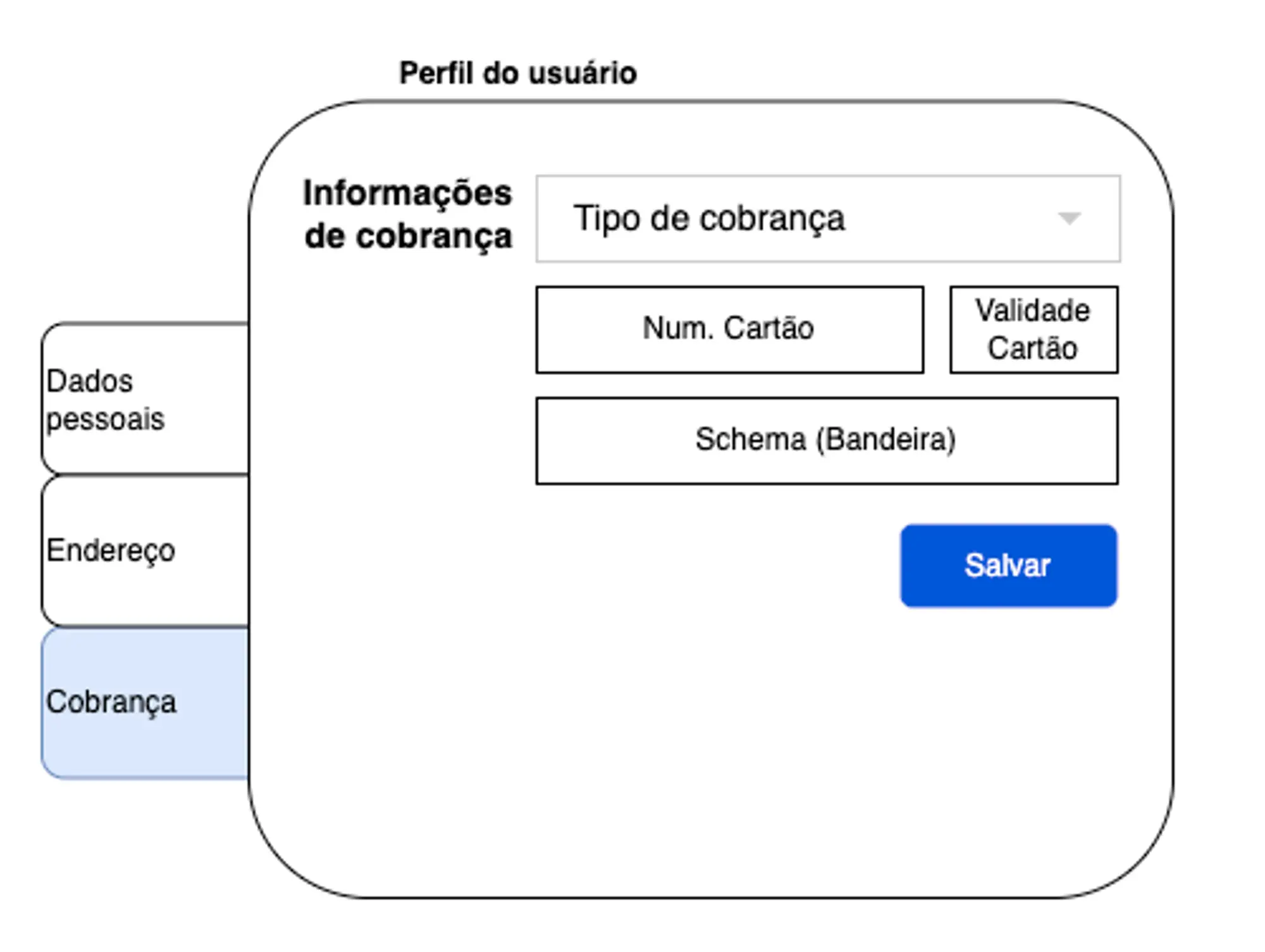
A tela acima contém uma ação para gestão de dados pessoais!
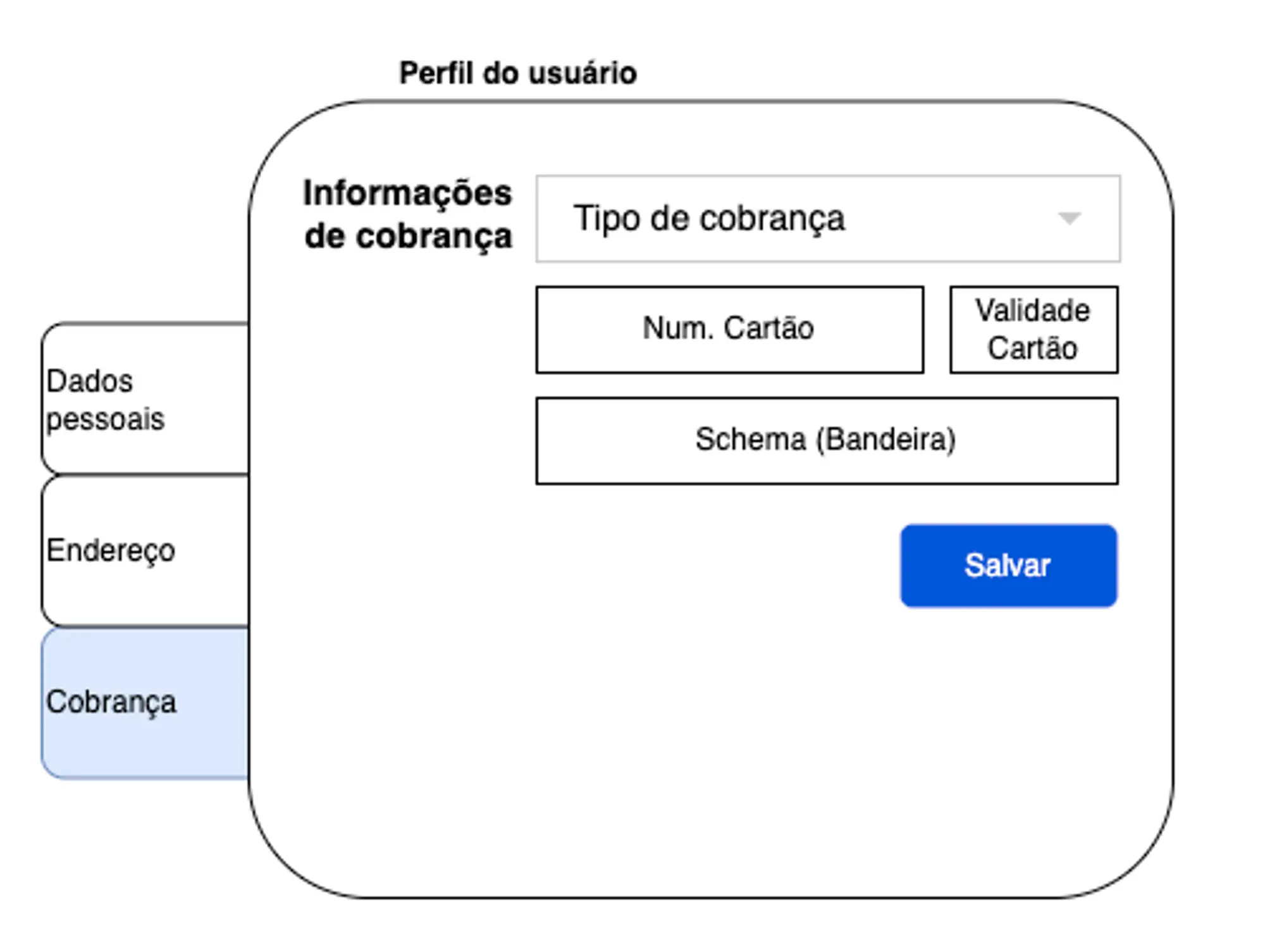
A tela acima contém uma ação para gestão de dados de cobrança!
## Capacidades de negócio + Funcionalidades de negócio:
> 💡 *Todo sistema é construído com base em uma necessidade de negócio, a qual demanda que esse produto seja orientado às capacidades de negócio destinadas a resolver um problema específico de um dado plano de negócio, em um dado nicho de mercado, e também aborda quais serão as funcionalidades de negócio definidas para cada uma dessas capacidades.*
>
Um sistema de **Consultas Veterinárias**, pode ter como capacidades de negócio:
- **Agendamento de consulta**
- **Histórico médico**
- **Acompanhamento de tratamentos**
- **Cobrança**
E cada uma dessas capacidades pode conter diversas funcionalidades, como por exemplo:
- **Histórico médico**
- Revisar o histórico do paciente
- Atualizar o histórico do paciente
- **Agendamento de consulta**
- Procurar veterinário disponível
- Agendar consulta
### Implementação básica de CQRS
Vamos voltar um pouco ao contexto do exemplo das imagens acima. Em uma implementação típica de CQRS, comandos são usados para realizar operações de gravação e consultas são usadas para recuperar dados que representam o estado atual de uma parte do sistema. Aqui está um exemplo simples em C#:
### Exemplo de um Comando (Command):
```csharp
public class AtualizarDadosPessoaisCommand
{
public int ClienteId { get; set; }
public string Nome { get; set; }
public DateTime DataNascimento { get; set; }
}
public class AtualizarDadosPessoaisCommandHandler
{
private readonly IClienteRepositorio _clienteRepositorio;
public AtualizarDadosPessoaisCommandHandler(IClienteRepositorio clienteRepositorio)
{
_clienteRepositorio = clienteRepositorio;
}
public void Handle(AtualizarDadosPessoaisCommand command)
{
var dadosPessoais = new ClienteDadosPessoais
{
ClienteId = command.ClienteId,
Nome = command.Nome,
DataNascimento = command.DataNascimento
};
_clienteRepositorio.AtualizarDadosPessoais(dadosPessoais);
}
}
```
### Exemplo de uma Consulta (Query):
```csharp
public class ObterClientePorIdQuery
{
public int ClienteId { get; set; }
}
public class ObterClientePorIdQueryHandler
{
private readonly IClienteRepositorio _clienteRepositorio;
public ObterClientePorIdQueryHandler(IClienteRepositorio clienteRepositorio)
{
_clienteRepositorio = clienteRepositorio;
}
public Cliente Handle(ObterClientePorIdQuery query)
{
return _clienteRepositorio.ObterPorId(query.ClienteId);
}
}
```
Uma solução arquitetural que adota os conceitos CQRS, normalmente carrega como base de definição uma organização de projeto seguindo **capacidades de negócio**, detalhando as **funcionalidades intrínssicas** dentro de cada uma dessas capacidades. Abaixo, deixo um exemplo de organização de solução onde está explicitamente citada a capacidade de *gestão de perfil de cliente (usuário)* e quais são as funcionalidades que compõe essa capacidade. Essa abordagem permite que um projeto de software seja fácil de ser compreendido tanto do ponto de vista sobre QUE PROBLEMA ele está resolvendo e COMO está organizada a base de código dessa solução, além, também, de facilitar a compreensão sobre que tipo de padrão está sendo adotado em sua implementação.
```
.sln (solution)
├── Capacidades-de-negocio
│ ├── PerfilCliente
│ │ ├── AtualizarDadosPessoais
│ │ │ ├── AtualizarDadosPessoaisCommand.cs
│ │ │ ├── AtualizarDadosPessoaisCommandHandler.cs
│ │ │ └── AtualizarDadosPessoaisResponse.cs
│ │ ├── AtualizarDadosCobranca
│ │ │ ├── AtualizarDadosCobrancaCommand.cs
│ │ │ ├── AtualizarDadosCobrancaCommandHandler.cs
│ │ │ └── AtualizarDadosCobrancaResponse.cs
│ │ ├── ObterClientePorId
│ │ │ ├── ObterClientePorIdQuery.cs
│ │ │ ├── ObterClientePorIdQueryHandler.cs
│ │ │ └── ObterClientePorIdResponse.cs
│ ├── ...
```
## Introdução à arquitetura Vertical Slice
### O que é esse tipo de arquitetura?
A [Arquitetura Vertical Slice](https://www.jimmybogard.com/vertical-slice-architecture/), defendida por [Jimmy Bogard](https://www.jimmybogard.com/), é um padrão que estrutura o código por capacidades de negócio e suas funcionalidades intrínssicas e não com base em CRUD-based. Essa abordagem promove o encapsulamento de todos os aspectos de um recurso (UI, lógica de negócios e acesso a dados) em uma única fatia vertical. Cada slice (fatia) é independente, tornando o sistema mais modular e mais fácil de manter.
### Principais vantagens da arquitetura Vertical Slice
1. **Foco em capacidades e funcionalidades de negócio**: a organização do código é definida pelas capacidades e funcionalidades de negócio, alinhada à forma como os usuários finais percebem o aplicativo, tornando-o mais intuitivo para os desenvolvedores trabalharem em funcionalidades específicas.
2. **Isolamento e Modularidade**: Cada slice (*fatia*) é isolada umas das outras, reduzindo o risco de efeitos colaterais não intencionais ao modificar um recurso.
3. **Maior capacidade de manutenção**: Unidades de código menores e independentes são mais fáceis de entender, testar e refatorar.
4. **Desenvolvimento Paralelo**: As equipes podem trabalhar em diferentes fatias simultaneamente, sem atrapalhar umas às outras, acelerando o desenvolvimento.
### Implementação do Vertical Slice
Na arquitetura Vertical Slice, cada recurso inclui tudo o que precisa para funcionar: comandos, consultas, manipuladores e, às vezes, até mesmo a camada de acesso ao banco de dados. A partir desse ponto, começamos a ter um **Dèjá Vu** sobre a perspectiva com a qual o Vertical Slice orienta a organização da solução, nos levando de volta à como o CQRS também organiza uma solução de projeto de software, baseando-se em capacidades e funcionalidades de negócio.
Reaproveitando o mesmo contexto de negócio que foi utilizado para exemplificar o CQRS, veja como você pode organizar uma solução em seu projeto de software, usando Vertical Slice:
```
.sln (solution)
├── Capacidades-de-negocio
│ ├── PerfilCliente
│ │ ├── AtualizarDadosPessoais
│ │ │ ├── AtualizarDadosPessoaisCommand.cs
│ │ │ ├── AtualizarDadosPessoaisCommandHandler.cs
│ │ │ └── AtualizarDadosPessoaisResponse.cs
│ │ ├── AtualizarDadosCobranca
│ │ │ ├── AtualizarDadosCobrancaCommand.cs
│ │ │ ├── AtualizarDadosCobrancaCommandHandler.cs
│ │ │ └── AtualizarDadosCobrancaResponse.cs
│ │ ├── ObterClientePorId
│ │ │ ├── ObterClientePorIdQuery.cs
│ │ │ ├── ObterClientePorIdQueryHandler.cs
│ │ │ └── ObterClientePorIdResponse.cs
│ ├── ...
```
### Comparação: CQRS vs. Vertical Slice
### Semelhanças
1. **Separação de capacidades e funcionalidades de negócio**: Tanto o CQRS quanto o Vertical Slice enfatizam a separação por capacidades e funcionalidades de negócio dentro de uma solução, resultando em um código mais limpo e de fácil manutenção.
2. **Modularidade**: Cada abordagem promove a modularidade, facilitando o dimensionamento e a modificação de partes do sistema de forma independente.
3. **Foco em tarefas**: A arquitetura Vertical Slice, assim como o CQRS, é orientada pela implementação específica de tarefas, garantindo que o código seja organizado em torno das funcionalidades de negócios.
### Diferença
**Gerenciamento de Complexidade**: Dependendo do grau de demanda de escalabilidade de um sistema, o que pode levar a implementação do último nível do CQRS, pode introduzir complexidade adicional devido à abordagem de separação das instâncias de escrita e leitura, implicando em uma solução que precisaria lidar com consistência eventual. O Vertical Slice visa reduzir a complexidade, mantendo o código relacionado junto na mesma fatia.
## Conclusão
Tanto o CQRS quanto a arquitetura Vertical Slice oferecem paradigmas valiosos para estruturar aplicações modernas. O CQRS é excelente em cenários onde as operações de leitura e gravação precisam ser otimizadas de forma independente e podem lidar com lógica de negócios complexa de forma eficaz. A Arquitetura Vertical Slice, por outro lado, fornece uma abordagem mais intuitiva e de fácil manutenção, organizando o código em torno de recursos, facilitando o desenvolvimento e o gerenciamento.
Ao compreender os pontos fortes e as nuances de cada padrão, os desenvolvedores podem escolher a arquitetura mais apropriada para suas necessidades específicas, resultando em aplicativos mais robustos e de fácil manutenção. Quer você opte pela separação estrita de preocupações oferecida pelo CQRS ou pela modularidade focada em recursos do Vertical Slice, ambos os padrões fornecem ferramentas poderosas para o desenvolvimento de software moderno.
## Referências
- [Greg Young CQRS Documents](https://cqrs.wordpress.com/wp-content/uploads/2010/11/cqrs_documents.pdf)
- [Vertical Slice](https://www.jimmybogard.com/vertical-slice-architecture/) | jraraujo |
1,869,088 | This github is great joby ! | A post by João Arruda | 0 | 2024-05-29T14:29:53 | https://dev.to/joo_arruda_b15aa3484f186/this-github-is-great-joby--jd0 | joo_arruda_b15aa3484f186 | ||
1,869,087 | REPUTABLE RECOVERY EXPERT HIRE CYBER CONSTABLE INTELLIGENCE | Cyber Constable Intelligence epitomizes the essence of triumph in the face of cybercrime, as... | 0 | 2024-05-29T14:29:46 | https://dev.to/brittany_ninety_/reputable-recovery-expert-hire-cyber-constable-intelligence-7gk | Cyber Constable Intelligence epitomizes the essence of triumph in the face of cybercrime, as evidenced by their remarkable success in recovering stolen Bitcoin in a real-life case. This awe-inspiring tale showcases not only their unparalleled expertise but also their unwavering commitment to their clients' financial well-being In the case of the stolen Bitcoin, Cyber Constable Intelligence embarked on a meticulous journey of investigation and collaboration with the affected individual. Recognizing the emotional toll and frustration associated with losing hard-earned assets, they prioritized open communication and involved their client every step of the way. This client-centric approach not only fosters trust but also ensures a more effective and personalized recovery process. What sets Cyber Constable Intelligence apart is their clever utilization of tools and expertise to track down stolen funds. Through a combination of advanced technology and strategic collaboration, they were able to navigate the complex web of cyber theft and pinpoint the exact location of the stolen Bitcoin. This demonstrates their unparalleled skill and ingenuity in overcoming even the most daunting challenges posed by cyber criminals. Throughout the recovery process, Cyber Constable Intelligence maintained a transparent and communicative stance, keeping their client informed of progress and developments. This open line of communication not only provides reassurance but also empowers clients to actively participate in the recovery effort. By working closely with those affected, they ensure a smoother and more successful recovery process, further solidifying their reputation as a trusted ally in the fight against cyber crime. The successful recovery of stolen Bitcoin by Cyber Constable Intelligence serves as a beacon of hope for individuals navigating cryptocurrency conundrums. It exemplifies their incredible ability to turn the tide of cyber theft and reclaim what's rightfully theirs. This real-life case is a testament to their dedication, perseverance, and unwavering commitment to their clients' financial security. Cyber Constable Intelligence stands as a shining example of excellence in the field of financial recovery. Their triumph over cybercrime in the case of stolen Bitcoin underscores their unparalleled expertise and unwavering dedication to their clients' interests. With their skills and a touch of magic, they are ready to assist individuals facing cryptocurrency conundrums, offering hope and a pathway to reclaiming what's rightfully theirs. If you find yourself in a similar situation, trust in Cyber Constable Intelligence to guide you towards a successful resolution and restore you. Get in touch with the information below:
WhatsApp info: +1 (252) 378-7611
Website info: https://cyberconstableintelligence. com
Email info: support@cyberconstableintelligence. com | brittany_ninety_ | |
1,869,085 | React and Next.JS deployment options | The Start Recently, I was working on my business app and landing page. I built the landing... | 0 | 2024-05-29T14:25:14 | https://dev.to/davids_murafa_8bf2f3af153/react-and-nextjs-deployment-options-1g8b | ## The Start
Recently, I was working on my business app and landing page. I built the landing page using Next.js due to its server-side rendering capabilities, while my application is built with Vite and React.js for simplicity and control over authentication and authorization. A sidenote here is that I recommend using pure React as much as possible because Next.js has significant problems with authentication, especially when you need to authenticate against your own backend system.
## The Problem
When my apps were ready, I faced the question of how to host my app and landing page in the cloud. Since I had free credits in Azure, I chose it as my cloud provider. I found a service in Azure called Azure Static Web Apps, which is meant for SPA pages and also supports Next.js.
First, I deployed the React application, and it worked great, with no issues observed and good performance. However, when I deployed the Next.js landing page, issues appeared. The main problem was very poor performance. When I compared the local page to the hosted page, the performance was terrible.
As I mentioned earlier, I faced performance problems with the service. I tried different approaches but ended up with no improvements. From my observations, when the app is idle, the server shuts down, and each new request starts the server up again, causing slowness.
## The Solution
I found another product from Azure called Azure Web App Service. For this one, I had the option to choose the server size and resources. I ended up with 2 vCPUs and 2GB of RAM. Deployment for this was more difficult, as it required building a container and deploying it. However, the performance was much better, and all my problems were solved.
## Recommendations
Based on my testing, I recommend using Azure Static Web Apps for pure React applications and Azure Web App Service for Next.js applications. Maybe someday Azure will solve this problem, and it will start to work well with Next.js on Azure Static Web Apps, but in the meantime, use a different service.
If you want to see the performance live, feel free to visit:
- React application: [Rompolo React App](https://app.rompolo.com)
- Next.js landing page: [Next.js Rompolo Landing](https://rompolo.com)
**Thanks for reading and good luck!** | davids_murafa_8bf2f3af153 | |
1,869,083 | Migrating Cloudflare Page Rules to Redirect Rules (www to non-www) | At the time of this writing, Cloudflare is deprecating Page Rules, and the Terraform migration guide... | 0 | 2024-05-29T14:20:54 | https://dev.to/mcharytoniuk/migrating-cloudflare-page-rules-to-redirect-rules-www-to-non-www-4gbe | devops, tutorial, cloud | At the time of this writing, Cloudflare is deprecating Page Rules, and the Terraform migration guide has not yet been published.
This article will show how to convert a simple Page Rule (redirecting www to non-www hosts) from `Page Rules` to `Rules`.
## UI
In the configuration rule, incoming requests should match a hostname starting with `www.`. The rewrite rule should be set to `dynamic` and contain an expression like `concat("https://example.com", http.request.url.path)` to combine the target hostname with a remaining path.
Remember to check the `Preserve query string` if needed. `Status Code` should be either 302 or 301. 301 is permanent and hard to remove from the cache, so if you are experimenting, try 302 first.
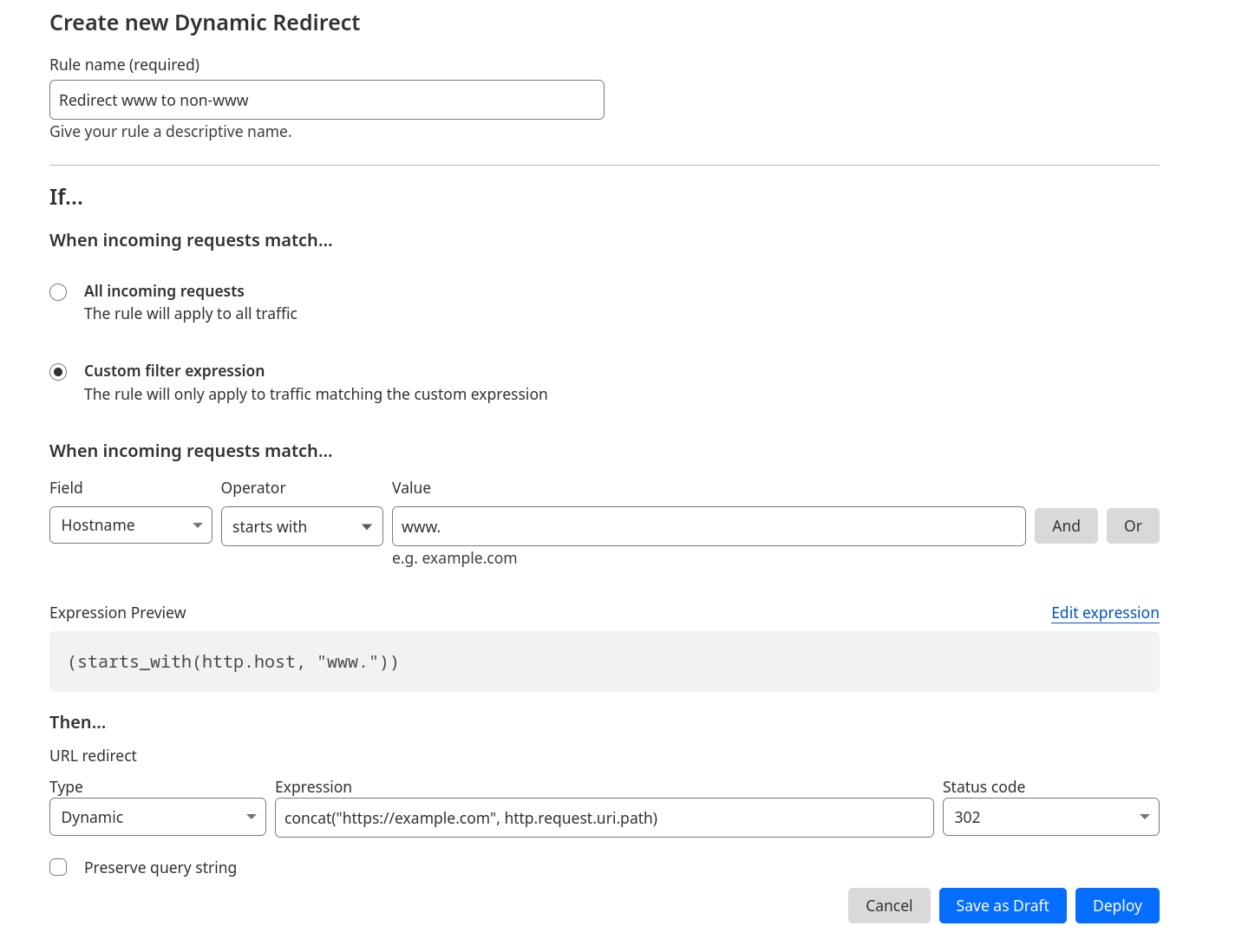
## Terraform
Your API token needs to have `Zone | Dynamic Redirect | Edit` permission.
### Before (Page Rules)
```terraform
resource "cloudflare_page_rule" "www-to-non-www-redirect" {
zone_id = var.cloudflare_zone_id
target = "www.example.com/*"
priority = 2
actions {
forwarding_url {
status_code = 302
url = "https://example.com/$1"
}
}
}
```
### After (Rules)
```terraform
resource "cloudflare_ruleset" "redirect-www-to-non-www" {
zone_id = var.cloudflare_zone_id
name = "redirects"
description = "Redirects ruleset"
kind = "zone"
phase = "http_request_dynamic_redirect"
rules {
action = "redirect"
action_parameters {
from_value {
status_code = 302
target_url {
expression = "concat(\"https://example.com\", http.request.uri.path)"
}
preserve_query_string = true
}
}
expression = "(starts_with(http.host, \"www.\"))"
description = "Redirect www to non-www"
enabled = true
}
}
``` | mcharytoniuk |
1,869,056 | Почта на своем домене – выбор провайдеров для малого бизнеса | Одним из важных аспектов присутствия в Интернете является ваш адрес электронной почты. Собственный... | 0 | 2024-05-29T14:19:38 | https://dev.to/geny/pochta-na-svoiem-domienie-vybor-provaidierov-dlia-malogho-bizniesa-17la | Одним из важных аспектов присутствия в Интернете является ваш адрес электронной почты. Собственный домен электронной почты не только добавляет элегантности вашему общению, но и помогает завоевать доверие ваших клиентов и заказчиков.
Получать электронную почту может быть легко, вам следует выбирать своего провайдера в зависимости от того, как часто вам нужно отвечать или отправлять исходящие электронные письма, а также от количества людей, которые будут иметь доступ к вашей корпоративной электронной почте.
## 1. **Cloudflare**
Cloudflare — компания, занимающаяся производительностью и безопасностью веб-сайтов, которая предоставляет набор продуктов и услуг, помогающих предприятиям и частным лицам повысить скорость, безопасность и надежность своих веб-сайтов и приложений. Cloudflare, основанная в 2009 году, стала одной из самых популярных сетей доставки контента (CDN) в мире.
**Стоимость**: бесплатно.
Вы можете легко настроить маршрутизацию электронной почты, чтобы перехватывать любую входящую электронную почту и перенаправлять ее на вашу личную электронную почту.
С исходящими электронными письмами все сложнее. Вы можете отправлять электронные письма бесплатно через партнерство MailChannels, но это требует некоторых навыков программирования и больше предназначено для транзакционных писем.
## 2. AWS SES
Amazon Web Services (AWS) — это комплексная платформа облачных вычислений, предоставляемая Amazon. AWS предлагает широкий спектр услуг, включая вычислительную мощность, хранилище, базы данных, аналитику, машинное обучение и многое другое.
**Стоимость**:
Исходящие электронные письма 0,10$ за 1000 писем.
Входящие электронные письма 0,10$ за 1000 писем.
В течение первого года до 3000 писем в месяц бесплатны. В любом случае, настройка SES требует значительных технических навыков, и вероятность того, что ваше письмо попадет в спам, очень высока. Рекомендуется только в том случае, если вы уже планируете использовать AWS.
## 3. iCloud Mail
iCloud от Apple — это облачное хранилище и служба облачных вычислений, предоставляемая Apple Inc., которая позволяет пользователям хранить и получать доступ к своим данным, включая файлы, фотографии, музыку и многое другое, с любого устройства, подключенного к Интернету.
**Стоимость**: 1$/месяц.
Чтобы использовать собственный домен с iCloud, вам необходимо иметь iCloud+, цены меняются в зависимости от региона. Можно добавить до 5 пользователей. Оплата На данный момент недоступна в России.
## 4. Zoho
Компания-разработчик программного обеспечения, предлагающая набор бизнес-приложений для различных отраслей. Компания была основана в 1996 году и с тех пор стала одним из ведущих поставщиков облачных бизнес-решений, популярных в Азии и Африке.
**Стоимость**: бесплатно, 1 домен, до 5 пользователей.
## 5. Google Workspace
Набор облачных программных решений для повышения производительности, разработанный Google. Он предлагает ряд инструментов, призванных помочь отдельным лицам и организациям сотрудничать, общаться и работать более эффективно.
**Стоимость**: $6/месяц.
## 6. Microsoft 365 Business
Облачный пакет программного обеспечения для повышения производительности, разработанный Microsoft. Он объединяет функциональность решений Office 365, Windows 10 Enterprise и Enterprise Security & Mobility в один интегрированный пакет. Эта комплексная платформа призвана предоставить предприятиям надежный набор инструментов для улучшения совместной работы, безопасности и производительности.
**Стоимость**: $6/месяц.
## 7. VK WorkSpace (Mail.ru для бизнеса)
Коммуникационная платформа для бизнеса. Включает корпоративную почту с календарём, мессенджер с аудио- и видеозвонками, облачное хранилище со встроенным редактором документов.
**Стоимость**: 199 ₽/месяц.
## 8. Яндекс 360
Виртуальное рабочее пространство, которое включает в себя ваши персональные сервисы: Почту, Диск, Телемост, Документы, Календарь и Заметки.
**Стоимость**: 249 ₽/месяц.
## О проекте
Пока другие сервисы прекратили свою работу, мы решили запустить новый [сайт знакомств](https://ru.ferom.app). Как и в любом бизнесе, перед нами встал вопрос, какой провайдер почтового хостинга выбрать. Только взвесив различные варианты, мы смогли принять решение, соответствующее нашим потребностям. Надеемся, наш пост помог вам сделать то же самое! | geny | |
1,869,068 | How To Write Smart Contract With Scrypt. | WHAT IS A SMART CONTRACT A smart contract is a self-executing contract that automatically... | 0 | 2024-05-29T14:18:45 | https://dev.to/bravolakmedia/how-to-write-smart-contract-with-scrypt-3eb1 | beginners, bitcoinsmartcontracts, bsvdevelopers, blockchaindevelopers | ## WHAT IS A SMART CONTRACT
A smart contract is a self-executing contract that automatically enforces the rules and terms of an agreement between parties. It is a computer program that runs on a blockchain network and can facilitate, verify, or enforce the negotiation or performance of a contract. A smart contract is like a written agreement, but instead of being on paper and handled by a person, it's a piece of computer code on a blockchain.
## How Smart Contract Works.
1. Digital Agreement: A smart contract is a digital agreement written in code. It has all the terms and conditions of the agreement clearly stated.
2. Automatic Execution: Once the smart contract is on the blockchain, it automatically enforces the terms. No one can change it or cheat.
3. No Middleman Needed: Unlike the written agreement where you need a trusted third party to ensure fairness, the smart contract itself ensures fairness by automatically carrying out the agreement based on the pre-set rules.
4. Security and Trust: The blockchain technology behind the smart contract ensures security. It’s decentralized, meaning it’s not controlled by any single person or organization, making it almost impossible to tamper with.
So, in essence, a smart contract is a self-executing contract where the terms are directly written into lines of code. The code and the agreements it contains exist across a distributed, decentralized blockchain network. This ensures that the contract is transparent, secure, and executed exactly as agreed without the need for intermediaries.
## How do Bitcoin Smart Contracts work?
Smart contracts on Bitcoin are based on the UTXO model, which is very different from an account model like Ethereum used.
### A Bitcoin transaction
Each bitcoin transaction consists of some inputs and outputs. A single bitcoin is divisible into 100,000,000 satoshis, similar to how a dollar is divisible into 100 cents or pennies.
An output contains:
a. The amount of bitcoins (satoshis) it contains.
b. bytecodes (the `locking script`).
While an input contains:
a. A reference to the previous transaction output.
b. bytecodes (the `unlocking script`).
#### UTXO model
An Unspent Transaction Output (UTXO) is an output not consumed in any transaction yet. The low-level bytecode/opcode is called Bitcoin Script, which is interpreted by the Bitcoin Virtual Machine (BVM).
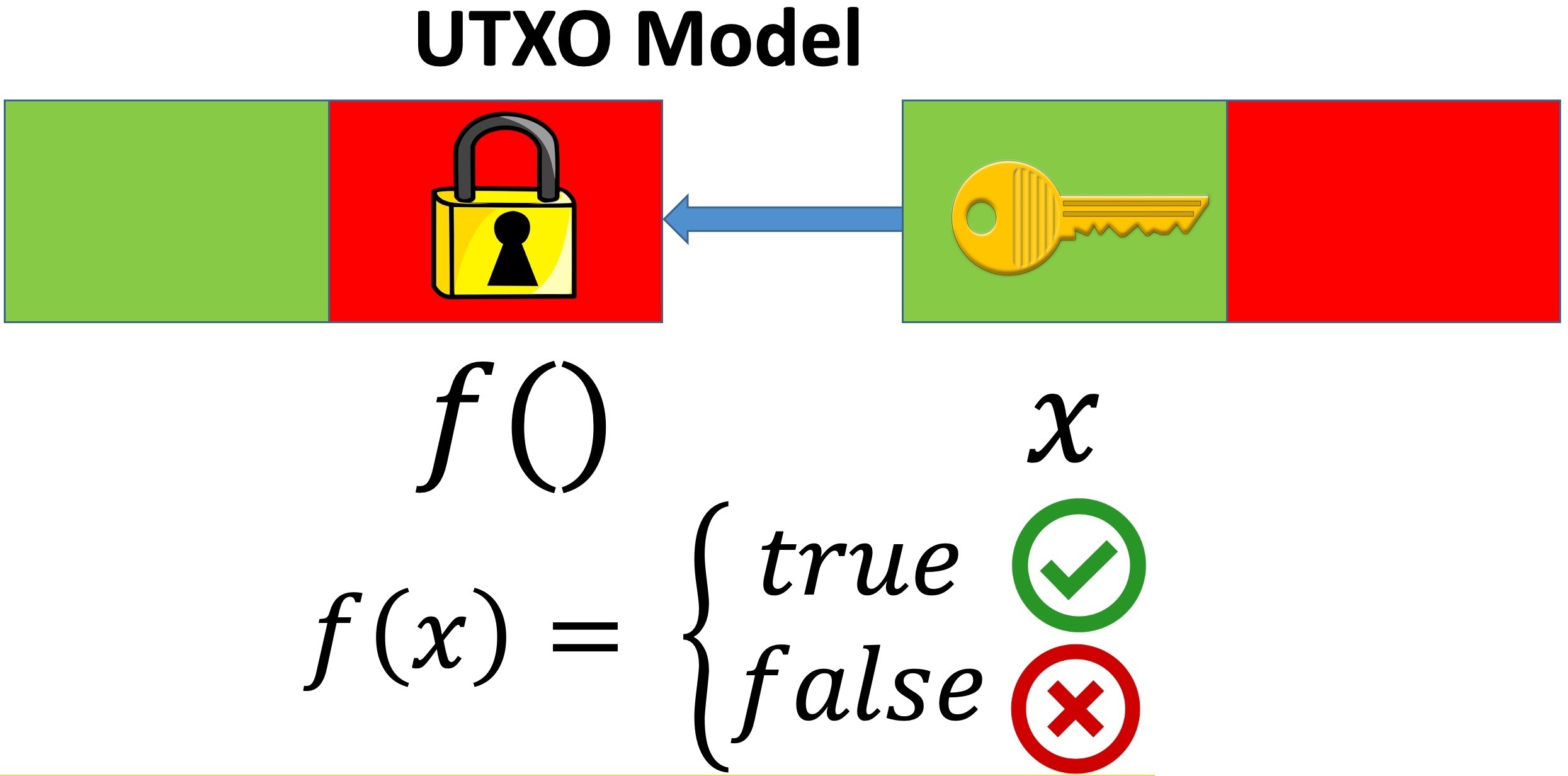
In the example above, we have two transactions, each having one input (in green) and one output (in red). And the transaction on the right spends the one on the left. The locking script can be regarded as a boolean function f that specifies conditions to spend the bitcoins in the UTXO, acting as a lock (thus the name "locking"). The unlocking script in turns provides the function arguments that makes f evaluates to true, i.e., the "key" (also called witness) needed to unlock. Only when the “key” in an input matches previous output’s “lock”, it can spend bitcoins contained in the output.
In a regular Bitcoin payment to a Bitcoin address, the locking script is Pay To Pubkey Hash (P2PKH). It checks the spender has the right private key corresponding to the address so she can produce a valid signature in the unlocking script. The expressive Script enables the locking script to specify arbitrarily more complex spending conditions than simple P2PKH, i.e., Bitcoin smart contracts.
## Components of A Smart Contract Written On Scrypt.
In case you are new to Scrypt you can follow the previous article on scrypt syntax and data types [here](https://dev.to/bravolakmedia/introduction-to-scrypt-syntax-and-data-types-2k2l).
A smart contract is a class that extends the `SmartContract` base class. It has the following components:
### 1. Properties
A smart contract can have two kinds of properties:
a. With `@prop` decorator: these properties are only allowed to have types specified below and they shall only be initialized in the constructor.
b. Without `@prop` decorator: these properties are regular TypeScript properties without any special requirement, meaning they can use any types. Accessing these properties is prohibited in methods decorated with the `@method` decorator.
### 2. @prop decorator
This decorator is used to mark any property that intends to be stored on chain. It takes a boolean parameter. By default, it is set to false, meaning the property cannot be changed after the contract is deployed.
If the value is true, the property is a so-called **stateful** property and its value can be updated in subsequent contract calls.
```
// good, `a` is stored on chain, and it's **readonly** after the contract is deployed
@prop()
readonly a: bigint
// valid, but not good enough, `a` cannot be changed after the contract is deployed
@prop()
a: bigint
// good, `b` is stored on chain, and its value can be updated in subsequent contract calls
@prop(true)
b: bigint
// invalid, `b` is a stateful property that cannot be readonly
@prop(true)
readonly b: bigint
// good
@prop()
static c: bigint = 1n
// invalid, static property must be initialized when declared
@prop()
static c: bigint
// invalid, stateful property cannot be static
@prop(true)
static c: bigint = 1n
// good, `UINT_MAX` is a compile-time constant (CTC), and doesn't need to be typed explicitly
static readonly UINT_MAX = 0xffffffffn
// valid, but not good enough, `@prop()` is not necessary for a CTC
@prop()
static readonly UINT_MAX = 0xffffffffn
// invalid
@prop(true)
static readonly UINT_MAX = 0xffffffffn
```
### 3. Constructor
A smart contract must have an explicit `constructor()` if it has at least one `@prop` that is not `static`. The `super` method must be called in the constructor and all the arguments of the constructor should be passed to super in the same order as they are passed into the constructor. For example,
```
class A extends SmartContract {
readonly p0: bigint
@prop()
readonly p1: bigint
@prop()
readonly p2: boolean
constructor(p0: bigint, p1: bigint, p2: boolean) {
super(...arguments) // same as super(p0, p1, p2)
this.p0 = p0
this.p1 = p1
this.p2 = p2
}
}
```
`arguments` is an array containing the values of the arguments passed to that function. `...` is the `spread syntax`.
### 4. Methods
Like properties, a smart contract can also have two kinds of methods:
a. With `@method` decorator: these methods can only call methods also decorated by `@method` or **[functions](https://docs.scrypt.io/how-to-write-a-contract/#functions)** specified below. Also, only the properties decorated by `@prop` can be accessed.
b. Without `@method` decorator: these methods are just regular TypeScript class methods.
a. `@method` decorator
This decorator is used to mark any method that intends to run on chain. It takes a [sighash flag](https://docs.scrypt.io/how-to-write-a-contract/scriptcontext#sighash-type) as a parameter.
#### Public `@methods`
Each contract must have at least one public @method. It is denoted with the public modifier and does not return any value. It is visible outside the contract and acts as the main method into the contract (like `main` in C and Java).
A public `@method` can be called from an external transaction. The call succeeds if it runs to completion without violating any conditions in [assert()](https://docs.scrypt.io/how-to-write-a-contract/built-ins#assert). An example is shown below.
```
@method()
public unlock(x: bigint, y: bigint) {
assert(x + y == this.sum, 'incorrect sum')
assert(x - y == this.diff, 'incorrect diff')
}
```
Ending rule
A public `@method` method must end with `assert()` in all reachable code paths. A detailed example is shown below.
```
class PublicMethodDemo extends SmartContract {
@method()
public foo() {
// valid, last statement is `assert()` statement
assert(true);
}
@method()
public foo() {
// valid, `console.log` calls will be ignored when verifying the last `assert()` statement
assert(true); //
console.log();
console.log();
}
@method()
public foo() {
// valid, last statement is `for` statement
for (let index = 0; index < 3; index++) {
assert(true);
}
}
@method()
public foo(z: bigint) {
// valid, last statement is `if-else` statement
if(z > 3n) {
assert(true)
} else {
assert(true)
}
}
@method()
public foo() {
// invalid, the last statement of every public method should be an `assert()` statement
}
@method()
public foo() {
assert(true);
return 1n; // invalid, because a public method cannot return any value
}
@method()
public foo() {
// invalid, the last statement in the `for` statement body doesn't end with `assert()`
for (let index = 0; index < 3; index++) {
assert(true);
z + 3n;
}
}
@method()
public foo() {
// invalid, because each conditional branch does not end with `assert()`
if(z > 3n) {
assert(true)
} else {
}
}
@method()
public foo() {
// invalid, because each conditional branch does not end with `assert()`
if(z > 3n) {
assert(true)
}
}
}
```
#### Non-public `@methods`
Without a `public` modifier, a `@method` is internal and cannot be directly called from an external transaction.
```
@method()
xyDiff(): bigint {
return this.x - this.y
}
// static method
@method()
static add(a: bigint, b: bigint): bigint {
return a + b;
}
```
NOTE
Recursion is disallowed. A `@method`, whether public or not, cannot call itself either directly in its own body, nor indirectly call another method that transitively calls itself. A more detailed example is shown below.
```
class MethodsDemo extends SmartContract {
@prop()
readonly x: bigint;
@prop()
readonly y: bigint;
constructor(x: bigint, y: bigint) {
super(...arguments);
this.x = x;
this.y = y;
}
// good, non-public static method without access `@prop` properties
@method()
static add(a: bigint, b: bigint): bigint {
return a + b;
}
// good, non-public method
@method()
xyDiff(): bigint {
return this.x - this.y
}
// good, public method
@method()
public checkSum(z: bigint) {
// good, call `sum` with the class name
assert(z == MethodsDemo.add(this.x, this.y), 'check sum failed');
}
// good, another public method
@method()
public sub(z: bigint) {
// good, call `xyDiff` with the class instance
assert(z == this.xyDiff(), 'sub check failed');
}
// valid but bad, public static method
@method()
public static alwaysPass() {
assert(true)
}
}
```
## A SIMPLE SUMMATION SMART CONTRACT
A smart contract is a class that extends the SmartContract base class. A simple example is shown below.
```
import { SmartContract, method, prop, assert } from "scrypt-ts"
class Equations extends SmartContract {
@prop()
sum: bigint
@prop()
diff: bigint
constructor(sum: bigint, diff: bigint) {
super(...arguments)
this.sum = sum
this.diff = diff
}
@method()
public unlock(x: bigint, y: bigint) {
assert(x + y == this.sum, 'incorrect sum')
assert(x - y == this.diff, 'incorrect diff')
}
}
```
The smart contract above adds up two unknown variables, x and y.
Class members decorated with `@prop` and `@method` will end up on the blockchain and thus must be a strict subset of TypeScript. Everywhere decorated with them can be regarded in the on-chain context. Members decorated with neither are regular TypeScript and are kept off chain. The significant benefit of sCrypt is that both on-chain and off-chain code are written in the same language: TypeScript.
For further reading on how to write smart contracts on scrypt you can visit the [scrypt doc](https://docs.scrypt.io/how-to-write-a-contract/).
| bravolakmedia |
1,869,067 | Understanding the Concept of Merkle Tree (root) in Blockchain For Data Integrity? | Introduction Ever wondered how a giant online ledger can grow with new transactions... | 0 | 2024-05-29T14:16:26 | https://dev.to/bloxbytes/understanding-the-concept-of-merkle-tree-root-in-blockchain-for-data-integrity-2hp0 | ## Introduction
Ever wondered how a giant online ledger can grow with new transactions constantly.
Can guarantee everyone that the information is accurate and hasn't been tampered with? Merkle Tree is a secret weapon of blockchains, as this ingenious data structure works as a magical fingerprint that ensures the integrity of information in a way that’s both efficient and secure.
In this blog, you will learn what is merkle tree and root, how it works, and how they keep the blockchain honest!
Understanding The Concept of Merkle Tree
Blockchain is a peer-to-peer network consisting of blocks linked together. A hash tree, or Merkle tree helps blockchain to encode data efficiently and securely. It enables quick verification and data movement. When a transaction happens on the blockchain it create a hash, which is stored in a tree-like structure, linked to its parent.
The parent is a merkle root which is the last transaction hash. It connects all transaction hashes in a block, creating an upside-down binary tree. The hashing starts at the lowest level nodes and continues at higher levels until reaching the single top root hash, the Merkle root.
This root hash contains all information about every transaction hash on the block, offering a single-point hash value that enables validating everything present on that block. The Merkle tree and Merkle root mechanism significantly reduce the levels of hashing required, enabling faster verification and transactions.
How Merkle Tree Works?
Cryptographic hash functions are efficient and irreversible one-way functions used in cryptography. They are commonly used in Message Direct (MD), Secure Hash Function (SHF), and RIPE Message Direct (RIPEMD) families.
Now, take an example, if you use the SHA256 hash algorithm, you will get the following output
fbffd63a60374a31aa9811cbc80b577e23925a5874e86a17f712bab874f33ac9
In Merkle trees all transactions comes in a block and generate a digital fingerprint of operations, are built from the bottom using Transaction IDs. Each non-leaf node is a hash of its previous hash, while every leaf node is a hash of transactional data.
A simple example of a Merkle Tree in Blockchain is a scenario where four transactions are hashed, resulting in two hashes: Hash ABCD. The Merkle Root is formed by combining these two hashes, forming a unique hash tree.
## Merkle Hash Tree Architecture Functions
Merkle hash tree functions are cryptographic algorithms that convert random data into fixed-size outputs. They are known for their irreversibility and are used in cryptography. The Merkle Tree function creates a digital fingerprint of operations by adding all transactions in a block. When only one hash of the Merkle Root (or Root Hash) is left after repeatedly hashing pairs of nodes, the Merkle Tree is created. This technique ensures the security, integrity, and integrity of data blocks transferred through a peer-to-peer network.
The Merkle Root guarantees the security, integrity of data blocks transferred through a peer-to-peer network. Although more complex than a simple Merkle Tree, the illustration explains how these algorithms operate and their success.
## Merkle Tree in Blockchain: Benefits
Let's now examine the advantages of Merkle Tree in blockchain technology:
It helps wth verifying data accuracy and provides data's integrity. The ability of Merkle Tree to compress a lot of data into a single Merkle root is one of its main advantages in the blockchain.
Blockchain merkle trees simplify the process of data verification by allowing nodes within a network to confirm individual transactions without having to download and validate the complete blockchain.
One important advantage of Merkle trees in blockchain is the security of traceability and transparency. The data format is efficient, ensuring data accuracy takes only a few seconds.
It promotes accountability and trust by improving the network's overall data visibility.
Merkle trees minimize the amount of data transferred between nodes, which is a critical factor in lowering bandwidth requirements.
Use Cases & Examples of Merkle Tree
Merkle trees are used in various blockchain applications like;
- Amazon DynamoDB
- Apache Cassandra for data replication
- Git for managing global projects
- Interplanetary File System (IPFS) for storing and sharing files across a distributed network.
These distributed databases control discrepancies, while IPFS leverages Merkle trees for efficiency and security in data management. Merkle hash trees are a cryptographic process that transforms arbitrary data into a fixed-size output, with a unique characteristic of irreversibility. They are one-way cryptographic methods designed to operate in a singular direction, with notable hash families like SHA-2 and SHA-3. This approach marks a significant shift from conventional centralized file storage.
## Why Merkle Tree is Important for Blockchain?
Merkle trees are a part of bitcoin. They help separate the data from its evidence by hashing accounting records. Without them, nodes would have to keep transaction copies, which would be unimaginable. To confirm a previous transaction, nodes would need to connect to the network and compare each entry line by line, which could compromise the network's security. Additionally, every verification request for Bitcoin requires sending large packets over the network, which would require significant processing power to compare the ledgers. Merkle trees can demonstrate that a transaction can be legitimate with minimal information sent across the network and show that both ledger types use the same nominal computing power and network bandwidth.
That is why, Merkle Trees are essential for blockchain technology. In simple words, to separate the proof of data from the data itself you will need one. Without them, every node on the network would have to maintain a complete copy of every Bitcoin transaction, requiring significant data transfer. This would require a significant amount of computing power to compare ledgers, making it difficult to validate transactions. Merkle Trees, on the other hand, have records in accounting, separating the proof of data from the data itself. This allows for transactions to be valid with only a small amount of information across the network. Additionally, it allows for the comparison of ledger variations in terms of nominal computer power and network bandwidth.
## How Blockchain Development Companies Can Help Businesses with Merkle Tree?
Blockchain development companies offer valuable expertise in implementing and optimizing Merkle Trees for specific use cases.
They can design a secure and efficient Merkle Tree structure tailored to your blockchain application, determining the optimal hashing algorithm, and data organization, and ensuring proper integration with other blockchain components.
They can conduct thorough security audits and vulnerability assessments to identify potential vulnerabilities in your Merkle Tree implementation, mitigating risks associated with data tampering or inconsistencies.
Performance optimization can be achieved by optimizing the Merkle Tree for faster verification and reduced storage requirements.
Custom Merkle Tree implementations can be created for unique blockchain applications, incorporating additional functionalities or adapting the tree structure for specialized data types.
At [BloxBytes](https://bloxbytes.com/), we have [blockchain developers](https://bloxbytes.com/blockchain-development-services/) that can seamlessly integrate Merkle Trees with your existing IT infrastructure, ensuring smooth data flow and compatibility between your blockchain application and other systems. Our blockchain development services are beyond technical expertise as they can guide understanding regulatory compliance, best practices for data integrity, and future-proofing your blockchain design.
## Conclusion:
In summary, we can say that the Merkle tree is an essential element in blockchain technology. It enables efficient information transfer and data validation. Additionally, it simplifies the process of intensive data validation, which would require significant computing power and meticulous comparison of ledgers. The Merkle tree's hierarchical structure, cryptographic hashing, and ability to condense data into a single, verifiable root are essential for maintaining the immutability and efficiency of distributed ledgers. As blockchain continues to evolve and find applications across various industries, it serves as a valuable blockchain development part to innovate the required infrastructure that securely streamlines day-to-day digital transactions in the blockchain.
| bloxbytes | |
1,869,066 | code-refactor-pro AI | https://chatgpt.com/g/g-rUG9edtmF-code-refactor-pro) | 0 | 2024-05-29T14:16:23 | https://dev.to/dirksanchezm/code-refactor-pro-ai-5h5h | webdev, ai, bot, testing | [](https://chatgpt.com/g/g-rUG9edtmF-code-refactor-pro)
https://chatgpt.com/g/g-rUG9edtmF-code-refactor-pro) | dirksanchezm |
1,869,064 | The History of the Iconic Pelle Pelle Jacket | In the dynamic world of fashion, few brands have the staying power and cultural impact that Pelle... | 0 | 2024-05-29T14:15:10 | https://dev.to/pellepelle123/the-history-of-the-iconic-pelle-pelle-jacket-2k39 | pellepelle, motocycleleatherjacket, pellepellejacket | In the dynamic world of fashion, few brands have the staying power and cultural impact that Pelle Pelle has achieved. Born in the vibrant streets of Detroit in 1978, Pelle Pelle has transcended its origins to become a symbol of urban fashion and street culture. This brand, which started as a leather outerwear company, has evolved into a fashion empire, leaving an indelible mark on hip-hop and streetwear alike. Let’s delve into the journey of [Pelle Pelle](
https://pellepellestore.com/), exploring its roots, rise to fame, and ongoing influence in the fashion industry.
[motorcycle leather jacket](https://pellepellestore.com/pcat/motorcycle-leather-jacket/)
[pink leather jacket](https://pellepellestore.com/pcat/pink-leather-jacket/)
| pellepelle123 |
1,869,063 | Passing Two-Dimensional Arrays to Methods | When passing a two-dimensional array to a method, the reference of the array is passed to the method.... | 0 | 2024-05-29T14:14:27 | https://dev.to/paulike/passing-two-dimensional-arrays-to-methods-26o0 | java, programming, learning, beginners | When passing a two-dimensional array to a method, the reference of the array is passed to the method. You can pass a two-dimensional array to a method just as you pass a one-dimensional array. You can also return an array from a method. The program below gives an example with two methods. The first method, **getArray()**, returns a two-dimensional array, and the second method, **sum(int[][] m)**, returns the sum of all the elements in a matrix.
`Enter 3 rows and 4 columns:
1 2 3 4
5 6 7 8
9 10 11 12
Sum of all elements is 78`
The method **getArray** prompts the user to enter values for the array (lines 13–25) and returns the array (line 24). The method **sum** (lines 27–36) has a two-dimensional array argument. You can obtain the number of rows using **m.length** (line 29) and the number of columns in a specified row using **m[row].length** (line 30). | paulike |
1,869,062 | What is Squarespace? | There are many website builders. But do you know which one is the easiest? Well, in my opinion, it’s... | 0 | 2024-05-29T14:11:28 | https://medium.com/@shariq.ahmed525/what-is-squarespace-37fd46629f18 | webdev, squarespace, websitedevelopmen, websitedesign | There are many website builders. But do you know which one is the easiest? Well, in my opinion, it’s Squarespace. You can find a lot of exciting and stunning designs.
What’s even better? Like Wix, it’s also a drag-and-drop editor. That’s why anyone who is not confident about creating their website from scratch can use it.
But here is the catch: it’s not free. They provide a 14-day free trial. This can give everyone enough time to see how it works.
Now, the first step that you need to take is to tell them what your site is about. You also need to tell them your goals, and then you just need to click on ‘Finish,’ and tada — you are done with your first step.
But before moving forward, let’s find out its benefits. The most important benefit is that no coding is required. But if you want to use custom code, that’s possible as well. You can use third-party plugins too. The best part is there are a lot of e-commerce features. Another important benefit of Squarespace is that if you choose the Commerce plan, you don’t need to pay any transaction fees. You will also get customer accounts.
Apart from this, there are other integrated tools in Squarespace. They include email campaigns, faculty scheduling, member areas, and Tock.
If you are concerned about the SEO of the website, then don’t be. This is because there are a lot of built-in SEO capabilities in Squarespace. Additionally, it also has metadata and sitemaps. Not only this, it includes advanced analytics for web performance and decision-making.
There are also tools that help website designers work with their clients side by side. If you find this difficult, no problem at all. You can edit contributor permissions to enable this feature. The best part is that there is 24/7 support in Squarespace!
Now, for those who don’t like to work on their website, there’s a Squarespace mobile app as well. The best thing is that Squarespace supports multiple pages. In fact, at times, it can support up to 1,000 pages. | shariqahmed525 |
1,869,059 | Refactoring function signature maintaining backward compatibility | Have you ever see yourself with a function (or method, depending on programming language) that has... | 0 | 2024-05-29T14:09:56 | https://dev.to/schirrel/refactoring-function-signature-maintaining-backward-compatibility-mnp | javascript, development, programming, code | Have you ever see yourself with a function (or method, depending on programming language) that has too many arguments and would be a lot better to switch to a single `options`/`params`/`item` object?
This can be stressfull or painfull depending on all the regressions or usages of this functions. Even sometimes it can be a blind spot to how much that function is being used.
**But no fear my friend, Rest Operators are here to save you! 🦸**

Imagine you have an add to cart function:
```js
const addItemToCart = (productId, quantity, size) => {
// ommited for god's sake
}
```
Time (and developers) goes by and we need to add more items to it, but it have so many usages that a refactor will be a hell of a work... After some years this function found itself as
```js
const addItemToCart = (productId, quantity, size, hasPromotion, addedFrom, cartId, someOtherInfo) => {
}
```
You wish you could change to a simple `const addItemToCart = (itemData) => ` but that will make a simple task grows to a hell of a regressions and files to update, right?
Well let's start a painless refactor:
1 - of course change the functions arguments to be a single one:
```js
const addItemToCart = (itemData) => {
}
```
2 - let convert this argument to use [Rest Operators](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/rest_parameters):
```js
const addItemToCart = (...itemData) => {
}
```
3 last but not least let's apply conditional validation to use the arguments data:
```js
const addItemToCart = (...itemData) => {
let item = {};
if (typeof itemData[0] === 'object') {
item = itemData[0];
else {
const [
productId,
quantity,
size,
hasPromotion,
addedFrom,
cartId,
someOtherInfo
] = itemData;
item = {
productId,
quantity,
size,
hasPromotion,
addedFrom,
cartId,
someOtherInfo
};
}
}
```
And now all old keeps working and you can start write new function call with a prettier code 😉 | schirrel |
1,869,057 | Processing Two-Dimensional Arrays | Nested for loops are often used to process a two-dimensional array. Suppose an array matrix is... | 0 | 2024-05-29T14:05:10 | https://dev.to/paulike/processing-two-dimensional-arrays-17mc | java, programming, learning, beginners | Nested **for** loops are often used to process a two-dimensional array.
Suppose an array **matrix** is created as follows:
`int[][] matrix = new int[10][10];`
The following are some examples of processing two-dimensional arrays.
_Initializing arrays with input values_. The following loop initializes the array with user input values:
`java.util.Scanner input = new Scanner(System.in);
System.out.println("Enter " + matrix.length + " rows and " +
matrix[0].length + " columns: ");
for (int row = 0; row < matrix.length; row++) {
for (int column = 0; column < matrix[row].length; column++) {
matrix[row][column] = input.nextInt();
}
}`
_Initializing arrays with random values_. The following loop initializes the array with random values between **0** and **99**:
`for (int row = 0; row < matrix.length; row++) {
for (int column = 0; column < matrix[row].length; column++) {
matrix[row][column] = (int)(Math.random() * 100);
}
}`
_Printing arrays_. To print a two-dimensional array, you have to print each element in the array using a loop like the following:
`for (int row = 0; row < matrix.length; row++) {
for (int column = 0; column < matrix[row].length; column++) {
System.out.print(matrix[row][column] + " ");
}
System.out.println();
}`
_Summing all elements_. Use a variable named **total** to store the sum. Initially **total** is **0**. Add each element in the array to total using a loop like this:
`int total = 0;
for (int row = 0; row < matrix.length; row++) {
for (int column = 0; column < matrix[row].length; column++) {
total += matrix[row][column];
}
}`
_Summing elements by column_. For each column, use a variable named **total** to store its sum. Add each element in the column to **total** using a loop like this:
```
for (int column = 0; column < matrix[0].length; column++) {
int total = 0;
for (int row = 0; row < matrix.length; row++)
total += matrix[row][column];
System.out.println("Sum for column " + column + " is "
+ total);
}
```
_Which row has the largest sum?_ Use variables **maxRow** and **indexOfMaxRow** to track the largest sum and index of the row. For each row, compute its sum and update **maxRow** and **indexOfMaxRow** if the new sum is greater.
```
int maxRow = 0;
int indexOfMaxRow = 0;
// Get sum of the first row in maxRow
for (int column = 0; column < matrix[0].length; column++) {
maxRow += matrix[0][column];
}
for (int row = 1; row < matrix.length; row++) {
int totalOfThisRow = 0;
for (int column = 0; column < matrix[row].length; column++)
totalOfThisRow += matrix[row][column];
if (totalOfThisRow > maxRow) {
maxRow = totalOfThisRow;
indexOfMaxRow = row;
}
}
System.out.println("Row " + indexOfMaxRow
+ " has the maximum sum of " + maxRow);
```
_Random shuffling_. How do you shuffle all the elements in a two-dimensional array? To accomplish this, for each element **matrix[i][j]**, randomly generate indices **i1** and **j1** and swap **matrix[i][j]** with **matrix[i1][j1]**, as follows:
`for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[i].length; j++) {
int i1 = (int)(Math.random() * matrix.length);
int j1 = (int)(Math.random() * matrix[i].length);
// Swap matrix[i][j] with matrix[i1][j1]
int temp = matrix[i][j];
matrix[i][j] = matrix[i1][j1];
matrix[i1][j1] = temp;
}
}` | paulike |
1,867,750 | Automate repetitive tasks with the Pinion code generator | Written by Joseph Mawa✏️ When working with certain design patterns, your project will almost always... | 0 | 2024-05-29T14:04:06 | https://blog.logrocket.com/automate-repetitive-tasks-pinion-code-generator | webdev, javascript | **Written by [Joseph Mawa](https://blog.logrocket.com/author/josephmawa/)✏️**
When working with certain design patterns, your project will almost always follow a specific structure. Manually setting up these projects can be daunting and tedious. You can save yourself time by using code generators for these repetitive tasks.
Code generators are tools you can use to automate repetitive tasks such as generating boilerplate code. They increase productivity by freeing up time so that you can focus on more productive areas of your project. A code generator can generate configuration files, create directories, and set up necessary tooling. These tools include linters, testing frameworks, compilers, and more.
There are several code generation tools in the JavaScript ecosystem, including Pinion, Yeoman, Plop, and Hygen. In this article, we will focus on the Pinion code generator toolkit and how to use it to automate repetitive tasks.
## What is a code generator?
Generators remove low-level, tedious, repetitive tasks such as creating directories and setting up development tools like linters, testing frameworks, compilers, and transpilers so that you focus on more productive activities like building and shipping products. Code generators also ensure you follow best practices and consistent style and structure in your project, making your project easy to maintain.
Code generators typically depend on user preferences to ensure that the generated code aligns with the developer's needs. These preferences can be specified via the command line.
There are several third-party code generators developed using tools such as Yeoman. However, there is no one-size-fits-all code generator. The existing code generators may not meet your project requirements, coding style, or licensing requirements, especially when building enterprise projects. You also need to take into account the long-term maintenance and potential security issues such packages may pose.
To meet your project requirements, you might need to develop your own generator using tools like Yeoman, Hygen, Plop, or Pinion. In this article, we will focus on Pinion.
## An introduction to Pinion
Pinion is a free, open source, MIT-licensed toolkit for creating code generators. It is a lightweight Node.js package. Though you need to use TypeScript to create code generators with Pinion, you can use Pinion in any project — including those that don't use Node.js or JavaScript.
If you want to use Pinion in a non-JavaScript or non-TypeScript project, you will need to first install the supported Node.js version and initialize the project using the `npm init --yes` command before installing Pinion.
Pinion is type-safe, fast, composable, and has a minimal API. Therefore, you can learn it fairly quickly. But unlike other similar tools like Yeoman, Plop, and Hygen, Pinion is relatively new.
## Using the Pinion code generator toolkit
In this section, you will learn how to use Pinion to automate repetitive tasks. Pinion is available in the npm package registry, so, you can install it like so:
```bash
npm install --save-dev @featherscloud/pinion
```
In the code above, we installed Pinion as a development dependency because you will almost always use code generators in a development environment.
With Pinion, you can create a code generator anywhere in your project and execute the generator from the command line. For example, if your code generator is in the `generator/generate-blog-template.ts` file, you can execute it using the command below:
```typescript
npx pinion generator/generate-blog-template.ts
```
Instead of typing the path to your code generator each time you want to run it, you can add a script with a meaningful name to your `package.json` file as demonstrated in the example below. It will ensure that anybody contributing to your project can use your code generator without having to learn Pinion or even knowing what tool you're using:
```javascript
{
...
"scripts": {
"generate-blog-template": "npx pinion generator/generate-blog-template.ts",
},
...
}
```
If you have the above script in your `package.json` file, you can now execute it like so:
```bash
npm run generate-blog-template
```
A typical Pinion code generator has two primary components: a TypeScript interface that defines the context, and a `generate` function that you must export from your generator. The `generate` function wraps the context and renders the template.
The example below shows a basic generator that creates a basic blog post template. Notice how we use a template literal to declare the template:
```javascript
import { PinionContext, toFile, renderTemplate } from "@featherscloud/pinion";
// An empty Context interface
interface Context extends PinionContext {}
// The file content as a template string
const blogPostTemplate = (): string =>
`# Blog title
## Introduction
## Conclusion
`;
const getFormattedDate = (): string => {
const date = new Date();
const yyyy = date.getFullYear();
const mm = date.getMonth().toString().padStart(2, "0");
const dd = date.getDate().toString().padStart(2, "0");
return `${yyyy}-${mm}-${dd}`;
};
// A function export that wraps the context and renders the template
export const generate = (init: Context) => {
return Promise.resolve(init).then(
renderTemplate(blogPostTemplate, toFile(`${getFormattedDate()}.md`))
);
};
```
Running the above generator will create a blog post template in Markdown format. It will use today's date in the [`yyyy-mm-dd.md` format](https://blog.logrocket.com/handling-date-strings-typescript/#template-literal-types) to name the generated file. In a real-world project, you will most likely get the file’s name from the user.
### How to create templates in Pinion
Unlike other code generators, Pinion doesn't have a separate templating language. It uses template strings (template literals) to create templates. A template string is a built-in feature of JavaScript and TypeScript. Therefore, it doesn't introduce learning overhead like code generators that use other templating languages.
You can create a template and write it to a file or inject it into an existing file. In the example below, I am creating a simple blog post template and rendering it to a new Markdown file. Notice how I'm dynamically adding the date to the front matter and using the date to create the file name:
```javascript
import { PinionContext, toFile, renderTemplate } from "@featherscloud/pinion";
interface Context extends PinionContext {}
const getFormattedDate = (): string => {
const date = new Date();
const yyyy = date.getFullYear();
const mm = date.getMonth().toString().padStart(2, "0");
const dd = date.getDate().toString().padStart(2, "0");
return `${yyyy}-${mm}-${dd}`;
};
const blogPostTemplate = () => `---
layout: blog-post-layout.liquid
title: Blog post 1
date: ${getFormattedDate()}
tags: ['post']
---
## Introduction
Your introduction
## Conclusion
Your conclusion
`;
export const generate = (init: Context) => {
return Promise.resolve(init).then(
renderTemplate(blogPostTemplate, toFile(`${getFormattedDate()}.md`))
);
};
```
In the above example, I am using the `toFile` helper function. The other file-related helper functions include `file` and `fromFile`. You can read about them in the [Pinion documentation](https://feathers.cloud/pinion/api#file).
You can execute the above generator using the following command. It will create a new Markdown blog post template:
```typescript
npx pinion path/to/generator/file.ts
```
### How to handle user inputs
Sometimes, a static template isn't enough to automate repetitive tasks. To create a more tailored template, try adding user input for customization.
In Pinion, you can use the `prompt` task to prompt user inputs from the command line. Internally, Pinion uses the `Inquirer` package to receive user input.
Remember that in the previous section, we created a simple blog post template and used today's date to name it. Instead of always creating a template with the same filename, blog post title, and author, let's dynamically get this information from the user, as shown in the example below:
```javascript
import {
PinionContext,
renderTemplate,
toFile,
prompt,
} from "@featherscloud/pinion";
interface Context extends PinionContext {
filename: string;
blogPostTitle: string;
author: string;
}
const getFormattedDate = (): string => {
const date = new Date();
const yyyy = date.getFullYear();
const mm = date.getMonth().toString().padStart(2, "0");
const dd = date.getDate().toString().padStart(2, "0");
return `${yyyy}-${mm}-${dd}`;
};
const blogPostTemplate = ({ blogPostTitle, author }: Context) => `---
layout: blog-post-layout.liquid
title: ${blogPostTitle}
author: ${author}
date: ${getFormattedDate()}
tags: ['post']
---
## Introduction
Your introduction
## Conclusion
Your conclusion
`;
export const generate = (init: Context) =>
Promise.resolve(init)
.then(
prompt((context) => {
return {
filename: {
type: "input",
message: "What is the filename?",
when: !context.filename,
},
blogPostTitle: {
type: "input",
message: "What is the title of your blog post?",
when: !context.blogPostTitle,
},
author: {
type: "input",
message: "What is the name of the author?",
when: !context.author,
},
};
})
)
.then(
renderTemplate(
blogPostTemplate,
toFile(({ filename }) => [
"posts",
`${filename}-${getFormattedDate()}.md`,
])
)
);
```
When you execute the above generator as before, you will be prompted for the filename, blog post title, and the author’s name before creating the blog post template.
### How to compose code generators
One of the benefits of using Pinion is that the generators you create are composable. For example, you may have a code generator for creating a project README template, a separate one for creating a project code of conduct template, and a third for creating a project license.
You can compose the three generators in another generator. In the example below, I am composing the three in a generator that initializes an npm project:
```javascript
import { PinionContext, exec, prompt } from "@featherscloud/pinion";
import { generate as generateCodeOfConduct } from "./code-of-conduct";
import { generate as generateLicense } from "./license";
import { generate as generateReadme } from "./readme";
interface Context extends PinionContext {
projectName: string;
}
export const generate = (init: Context) => {
return Promise.resolve(init)
.then(
prompt((context) => {
return {
projectName: {
type: "input",
message: "What is your project name?",
when: !context.projectName,
},
};
})
)
.then(generateReadme)
.then(generateLicense)
.then(generateCodeOfConduct)
.then((ctx) => ({ ...ctx, cwd: `${ctx.cwd}/${ctx.projectName}` }))
.then(exec("npm", ["init", "--yes"]))
.then((ctx) => {
return { ...ctx, cwd: ctx.pinion.cwd };
});
};
```
The above generator will prompt you for the project name. It will then create a project README, a license, and a code of conduct file in Markdown format before initializing the directory as an npm project.
## Comparing Pinion with other code generator tools
Pinion is a relatively new code generator toolkit in the JavaScript ecosystem. In this section, we will compare Pinion and some more mature and battle-tested code generation tools.
Though our focus will primarily be on their features, we will also highlight their npm download statistics, GitHub stars, issues (open and closed), and maintenance. Keep in mind that a high star count doesn't guarantee that a package is secure, feature-rich, or of better quality than the others. Additionally, metrics can change over time, and an actively maintained project today may become unmaintained in a few months. You should thoroughly investigate before using a package in an enterprise project.
One of the benefits of using Pinion over other code generation tools like Hygen, Yeoman, and Plop is its templating language. With Pinion, you use plain JavaScript/TypeScript template strings to write templates. If you know JavaScript/Typescript, then you already know Pinion's templating language; there is no learning curve.
A typical Pinion template is a template string that looks like the following:
```javascript
const readme = ({ organization }) =>
`# ${organization}
This is a readme
Copyright © 2024 ${organization} developers
`
```
Other code generation tools use third-party templating languages. For example, Plop uses handlebars and Hygen uses EJS. These templating languages have their own syntax. Therefore, unless you're already familiar with their syntax, they introduce a learning curve.
Assuming you want to use Hygen instead of Pinion, you will have to translate the above template to EJS so that it looks like this:
```javascript
---
to: app/readme.md
---
# <%= organization %>
This is a readme
Copyright © 2024 <%= organization %> developers
```
The above code may look simple for basic “Hello, World!” templates, but you need an intermediate to advanced level of familiarity with EJS to write more complex templates.
Furthermore, as highlighted above, Pinion forces you to use TypeScript when writing code generators; TypeScript introduces type safety that reduces hard-to-debug errors. The other tools do not have this benefit.
Yeoman is one of the most popular and battle-tested code generation tools in the JavaScript ecosystem. It has a whole ecosystem of tools and code generators developed by the community. Therefore, if you are looking to build a code generator using Yeoman, there is a chance that someone has built a similar Yeoman code generator.
On the other hand, Pinion, as well as Hygen, and Plop do not have an extensive collection of community-built code generators like Yeoman. You will almost always have to bootstrap your code generator from scratch. However, they’re much easier to pick up than Yeoman:
| | **Pinion** | **Yeoman** | **Hygen** | **Plop** |
| -------- | ----------- | ---------- | --------- | ----- |
| Templating language | Typestring template string | Handlebars, EJS, Jade | EJS | Handlebars |
| Active maintenance | Yes | Yes | Yes | Yes | | Type safety | Yes | No | No | No |
| Documentation | Good | Good | Good | Good | | License | MIT | BSD-2-Clause | MIT | MIT |
| Pricing | Free | Free | Free | Free |
| Community support | Good | Good | Good | Good | | GitHub stars | 65 | 3.8k | 5.5k | 6.9k |
| Open GitHub issues | 3 | 97 | 79 | 43 |
| Closed GitHub issues | 3 | 491 | 192 | 248 |
## Conclusion
Code generator toolkits like Pinion are useful for automating repetitive tasks like creating a new project that follows a specific design pattern. By eliminating the more mundane development tasks, these tools help increase your development speed and reduce the time to production.
Pinion distinguishes itself as a fast, flexible, and type-safe toolkit, licensed under MIT and developed in TypeScript. It supports creating and executing code generators in TypeScript, using built-in JavaScript/TypeScript template string for its templating language.
---
##[LogRocket](https://lp.logrocket.com/blg/javascript-signup): Debug JavaScript errors more easily by understanding the context
Debugging code is always a tedious task. But the more you understand your errors, the easier it is to fix them.
[LogRocket](https://lp.logrocket.com/blg/javascript-signup) allows you to understand these errors in new and unique ways. Our frontend monitoring solution tracks user engagement with your JavaScript frontends to give you the ability to see exactly what the user did that led to an error.
[](https://lp.logrocket.com/blg/javascript-signup)
LogRocket records console logs, page load times, stack traces, slow network requests/responses with headers + bodies, browser metadata, and custom logs. Understanding the impact of your JavaScript code will never be easier!
[Try it for free](https://lp.logrocket.com/blg/javascript-signup).
| leemeganj |
1,869,055 | Watch Wrestling - Watch WWE | WWE Raw | Smackdown Live Free | Watch Wrestling - Watch WWE | WWE Raw | Smackdown Live Free Watch Wrestling is available to stream... | 0 | 2024-05-29T14:04:03 | https://dev.to/watch_wrestling_c1c84c23e/watch-wrestling-watch-wwe-wwe-raw-smackdown-live-free-10lg | webdev, watchwrestling, javascript, wwe | Watch Wrestling - Watch WWE | WWE Raw | Smackdown Live Free
Watch Wrestling is available to stream quickly and in great definition for free
online.hd free in high quality. WWE Raw, WWE SmackDown, WWE Main Event, and WWE
NXT where you can watch Wrestling without any sign up or registration fast servers.
<a href="https://watchwrestlling.com/">Watch Wrestling</a>
| watch_wrestling_c1c84c23e |
1,869,054 | Angular Series Part 2 From Basics to Advanced: Exploring Angular’s ngOnChanges | Understanding Angular's ngOnChanges: A Comprehensive Guide ... | 0 | 2024-05-29T14:01:32 | https://dev.to/chintanonweb/angular-series-part-2-from-basics-to-advanced-exploring-angulars-ngonchanges-3d9m | webdev, javascript, angular, typescript | # Understanding Angular's `ngOnChanges`: A Comprehensive Guide
{% embed https://www.youtube.com/embed/TSmj3yvC6jM %}
## Introduction
Angular, a powerful front-end framework, offers numerous lifecycle hooks to manage component behavior. Among these hooks, `ngOnChanges` is particularly important as it allows developers to react to changes in component input properties. Understanding how to use `ngOnChanges` effectively can significantly improve the efficiency and performance of Angular applications. This article will dive deep into the `ngOnChanges` lifecycle hook, providing step-by-step examples and covering various scenarios to ensure a thorough grasp of its usage.
## What Is `ngOnChanges`?
`ngOnChanges` is a lifecycle hook in Angular that is called whenever there are changes to input properties of a component. It allows you to act upon those changes and is useful for tasks that need to be executed when input values change.
### How Does `ngOnChanges` Work?
The `ngOnChanges` method is triggered when Angular sets or resets data-bound input properties. It receives a `SimpleChanges` object, which contains the current and previous values of the input properties.
### Syntax
```typescript
ngOnChanges(changes: SimpleChanges): void {
// logic to handle changes
}
```
## Setting Up an Angular Project
Before diving into `ngOnChanges`, let's set up a basic Angular project. This will help us to follow along with the examples.
### Step 1: Create a New Angular Project
Run the following command to create a new Angular project:
```bash
ng new ngOnChangesDemo
cd ngOnChangesDemo
```
### Step 2: Generate a New Component
Generate a new component that we'll use to demonstrate `ngOnChanges`:
```bash
ng generate component demo
```
## Implementing `ngOnChanges`
Let's implement `ngOnChanges` in our newly created component to see how it works in practice.
### Example 1: Basic Usage of `ngOnChanges`
First, let's set up a parent component that will pass data to the `DemoComponent`.
#### Parent Component Template (app.component.html)
```html
<app-demo [inputValue]="parentValue"></app-demo>
<button (click)="changeValue()">Change Value</button>
```
#### Parent Component Class (app.component.ts)
```typescript
import { Component } from '@angular/core';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
parentValue: number = 0;
changeValue() {
this.parentValue = Math.floor(Math.random() * 100);
}
}
```
#### Child Component Template (demo.component.html)
```html
<p>Input Value: {{ inputValue }}</p>
```
#### Child Component Class (demo.component.ts)
```typescript
import { Component, Input, OnChanges, SimpleChanges } from '@angular/core';
@Component({
selector: 'app-demo',
templateUrl: './demo.component.html',
styleUrls: ['./demo.component.css']
})
export class DemoComponent implements OnChanges {
@Input() inputValue: number;
ngOnChanges(changes: SimpleChanges) {
for (let propName in changes) {
let change = changes[propName];
let cur = JSON.stringify(change.currentValue);
let prev = JSON.stringify(change.previousValue);
console.log(`${propName}: currentValue = ${cur}, previousValue = ${prev}`);
}
}
}
```
### Explanation
In this example:
- `DemoComponent` receives an input property `inputValue`.
- Whenever `inputValue` changes, the `ngOnChanges` method logs the current and previous values to the console.
- The parent component (`AppComponent`) has a button to change `parentValue`, demonstrating how `ngOnChanges` responds to changes in input properties.
### Example 2: Handling Multiple Input Properties
Let's extend the example to handle multiple input properties.
#### Parent Component Template (app.component.html)
```html
<app-demo [inputValue]="parentValue" [anotherValue]="parentAnotherValue"></app-demo>
<button (click)="changeValue()">Change Values</button>
```
#### Parent Component Class (app.component.ts)
```typescript
import { Component } from '@angular/core';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
parentValue: number = 0;
parentAnotherValue: string = 'Initial Value';
changeValue() {
this.parentValue = Math.floor(Math.random() * 100);
this.parentAnotherValue = 'Changed Value ' + Math.floor(Math.random() * 100);
}
}
```
#### Child Component Template (demo.component.html)
```html
<p>Input Value: {{ inputValue }}</p>
<p>Another Value: {{ anotherValue }}</p>
```
#### Child Component Class (demo.component.ts)
```typescript
import { Component, Input, OnChanges, SimpleChanges } from '@angular/core';
@Component({
selector: 'app-demo',
templateUrl: './demo.component.html',
styleUrls: ['./demo.component.css']
})
export class DemoComponent implements OnChanges {
@Input() inputValue: number;
@Input() anotherValue: string;
ngOnChanges(changes: SimpleChanges) {
for (let propName in changes) {
let change = changes[propName];
let cur = JSON.stringify(change.currentValue);
let prev = JSON.stringify(change.previousValue);
console.log(`${propName}: currentValue = ${cur}, previousValue = ${prev}`);
}
}
}
```
### Explanation
In this extended example:
- `DemoComponent` now has two input properties: `inputValue` and `anotherValue`.
- The `ngOnChanges` method logs changes to both properties.
- The parent component (`AppComponent`) changes both input values when the button is clicked, showcasing how `ngOnChanges` handles multiple property changes.
## Common Scenarios and Best Practices
### Scenario 1: Initial Value Setting
`ngOnChanges` is also called when the component is initialized if there are any input properties.
#### Example
If the parent component initially sets values for the inputs:
```html
<app-demo [inputValue]="42" [anotherValue]="'Hello'"></app-demo>
```
`ngOnChanges` will log these initial values when the component is first rendered.
### Scenario 2: Ignoring Unnecessary Changes
In some cases, you might want to ignore certain changes or perform actions only on specific changes.
#### Example
```typescript
ngOnChanges(changes: SimpleChanges) {
if (changes['inputValue']) {
let cur = JSON.stringify(changes['inputValue'].currentValue);
let prev = JSON.stringify(changes['inputValue'].previousValue);
console.log(`inputValue: currentValue = ${cur}, previousValue = ${prev}`);
}
}
```
### Scenario 3: Deep Change Detection
`ngOnChanges` performs shallow comparison. For deep objects, additional logic is required.
#### Example
```typescript
import { isEqual } from 'lodash';
ngOnChanges(changes: SimpleChanges) {
if (changes['complexObject']) {
let cur = changes['complexObject'].currentValue;
let prev = changes['complexObject'].previousValue;
if (!isEqual(cur, prev)) {
console.log(`complexObject has changed.`);
}
}
}
```
### Best Practices
1. **Minimize Heavy Processing:** Avoid performing heavy computations in `ngOnChanges`. Delegate them to other methods if necessary.
2. **Use Immutable Data Structures:** This helps in efficiently detecting changes.
3. **Combine with Other Lifecycle Hooks:** Use `ngOnInit` and `ngDoCheck` for initialization and custom change detection logic.
## FAQ Section
### What Is `ngOnChanges` Used For?
`ngOnChanges` is used to detect and respond to changes in input properties of a component. It is essential for tasks that need to react to input value changes dynamically.
### When Is `ngOnChanges` Called?
`ngOnChanges` is called before `ngOnInit` when the component is initialized and whenever any data-bound input properties change.
### How Does `ngOnChanges` Differ from `ngDoCheck`?
`ngOnChanges` is triggered automatically by Angular when input properties change, while `ngDoCheck` is called during every change detection cycle and can be used for custom change detection.
### Can `ngOnChanges` Be Used with All Input Properties?
Yes, `ngOnChanges` can be used with all input properties defined with the `@Input` decorator.
### What Is `SimpleChanges`?
`SimpleChanges` is an object that contains the current and previous values of the input properties. It is passed as an argument to the `ngOnChanges` method.
## Conclusion
Mastering `ngOnChanges` is crucial for developing dynamic and responsive Angular applications. By understanding its usage, handling multiple input properties, and applying best practices, developers can effectively manage component behavior based on changing inputs. This comprehensive guide provides the foundation needed to utilize `ngOnChanges` proficiently in your Angular projects. | chintanonweb |
1,869,053 | Using AT Commands in Linux | POST UPDATE Our article explains how the "at" command can be used to schedule tasks for future... | 0 | 2024-05-29T14:00:40 | https://dev.to/giftbalogun/using-at-commands-in-linux-2aa1 | POST UPDATE
Our article explains how the "at" command can be used to schedule tasks for future execution on a Linux system. Some few essential to note.
- Time Expressions: An example is provided in which one could write “teatime” for 4 PM using an informal form of time easily recognized by "at".
- Interactive Scheduling: An explanation of the process of scheduling tasks interactively using the at prompt is given in this article in addition to other related topics.
- Creating Shell Scripts: Instructions for creating a shell script, making it executable, and then scheduling it using an at command.
Learn more: https://everythingdevops.dev/how-to-schedule-future-processes-in-linux-using-at/ | giftbalogun | |
1,868,979 | Zaman (NTP) Sunucusu Politikası | Network Time Protocol (NTP), bilgisayar sistemleri arasında saat senkronizasyonu sağlamak için olan... | 0 | 2024-05-29T13:20:39 | https://dev.to/dogacakinci/politikalar-ntp-server-tanimlama-306j | Network Time Protocol (NTP), bilgisayar sistemleri arasında saat senkronizasyonu sağlamak için olan bir ağ protokolüdür.
# Politikayı Oluşturma ve Ayarlama
Domain eklentimizde Nesne Ekle kısmına tıklayıp açılan arayüzden nesnemizin tipini seçip nesnemize bir ad veriyoruz ve ekle butonuna tıklıyoruz.
Daha sonra Obje Türlerinden Politikaları seçtiğimizde eklediğimiz politikayı görebiliriz.
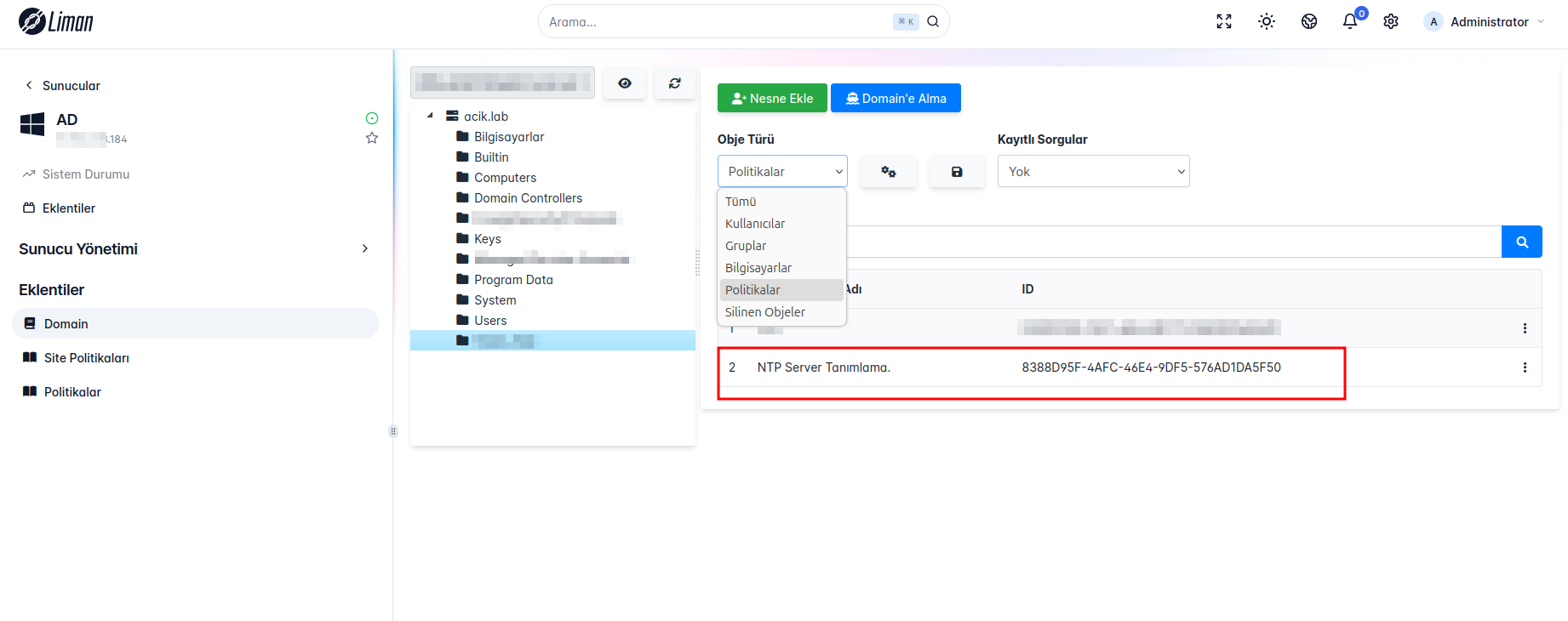
### Site Adresleri
Eklediğimiz politikanın üstüne tıkladıktan sonra açılan arayüzden Makine' yi seçip ve ordan da "Zaman (NTP) Sunucusu" na gelip "Site Adresleri" kısmından istelinen değişiklikler yapılabilir. Site Adresi Aktif hale getirildiğinde belirttiğiniz domain site adresleri NTP sunucu olarak kullanılacaktır. Bu sisteminizin zaman bilgisini bu NTP sunucularından senkronize edeceği anlamına gelir.
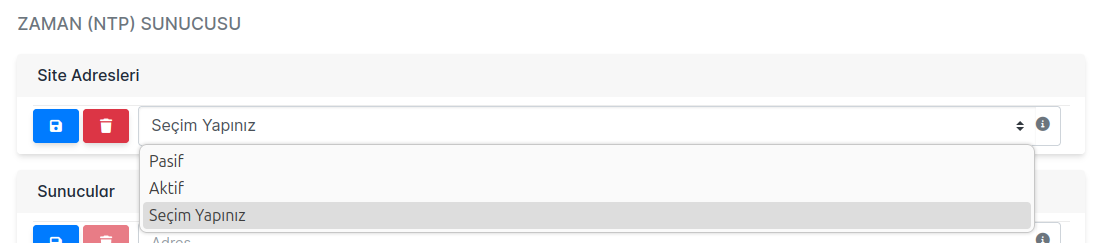
### Sunucular
Yine aynı yerden "Sunucular" kısmına Domain Controller(DC) IP adresi girilir ve kaydet simgesine tıklanıldığında politika kaydedilmiş olucaktır.
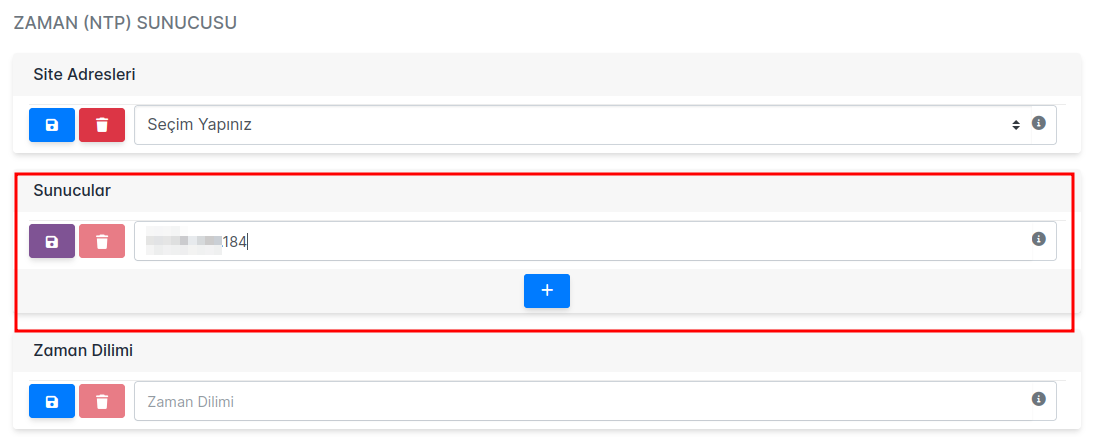
### Zaman Dilimi
Bu alan, sistemin kullanacağı zaman dilimini belirlemek için kullanılır. Zaman dilimi seçildiğinde, NTP sunucusu bu zaman dilimine göre sistem saatini senkronize eder.
```
timedatectl list-timezones
```
komutu ile yazabileceğimiz zaman dilimlerini görebiliriz
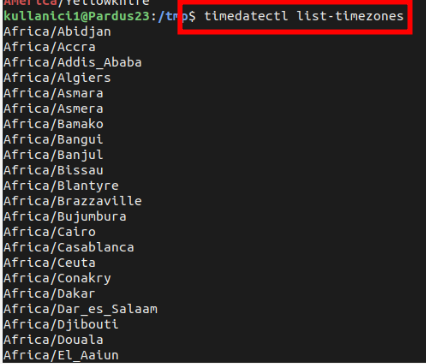

# Politika Çalışması ve Kontrolü
### Sunucular
İstemci tarafında
```
gpupdate -v
```
komutunu çalıştırdığımızda "Politika Sonucu: Başarılı" mesajını görüyorsak politikamızın başarılı bir şekilde uygulandığını görmüş oluruz.
Daha sonrasında da
```
timedatectl
```
komutunu çalıştırdığımızda karşımıza çıkan "NTP service: active" mesajından NTP Servisimizin aktif olduğunu ve aynı zamanda da görünen IP adresinin başta "Zaman (NTP) Sunucusu" na girdiğimiz IP bilgisi ile aynı olduğunu görebiliriz.
### Zaman Dilimi
İstemci tarafında
```
gpupdate -v
```
komutunu çalıştırdığımızda "Politika Sonucu: Başarılı" mesajını görüyorsak politikamızın başarılı bir şekilde uygulandığını görmüş oluruz.
Daha sonrasında da çalıştırdığımız
```
timedatectl
```
komutunun çıktısındaki Time Zone ile başta girdiğimiz Time Zone' un aynı olduğunu teyit edebiliriz.
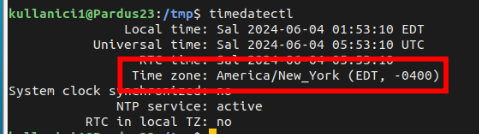
| dogacakinci | |
1,869,051 | How to track your GitHub todos and accomplishments | Have you ever seen a GitHub notification, made a mental note to circle back, and then later forgot... | 0 | 2024-05-29T13:56:56 | https://www.beyonddone.com/blog/posts/github-todos-and-accomplishments | github, taskmanagement, productivity | Have you ever seen a GitHub notification, made a mental note to circle back, and then later forgot where it happened or couldn’t find it? Ever get pulled away to attend standup and froze when you were asked what you did and what you still need to do?
Rest assured that you are not alone. These are challenges faced by many software engineers. Thankfully there are solutions. I’ll list the Github todos and accomplishments most software engineers want to track before presenting three solutions.
## Github todos and accomplishments
Here is a short list of GitHub events and the todo action required from the software engineer:
- Pull request reviewed, changed requested — Make changes.
- Pull request reviewed, approved — Look it over, perhaps test again, and merge.
- Pull request reviewed, commented — Address the comments.
- Pull request in need of review — Request reviews in GitHub and/or some other communication medium.
- Pull request with failing status check — Investigate what is breaking the status check and fix it.
- Request for pull request review — Review the pull request.
- Issue assigned — Work to resolve the issue.
- Open Issue — Manage moving the open issue forward by responding to comments.
- Mention — Respond to messages directed to them with a reaction or comment.
In addition, there are GitHub accomplishments that the software engineer should remember for standup and their own reference:
- Pull requests reviewed, commented, approved, opened, and merged
- Repos and issues created
- Comments and discussions
## Option #1 Watch your email inbox or phone
The first alternative is to configure GitHub notifications so that you receive notifications to your phone and email inbox.
### Advantages:
- Real-time notifications when things happen.
### Disadvantages:
- If there are more than just a few of these notifications, it can be easy to lose or forget about them, especially when they’re mixed with your other email and text messages.
- The software engineer still has to devise some sort of system for marking when items are completed. This could be with email filters, tags, or deletion.
## Option #2 GitHub Notifications
The second alternative is to look at the GitHub Notifications page. The filter option allows the software engineer to view only notifications of interest and decrease the noise on the page. There is also the ability to mark items done. For this option to work, the software engineer needs to look at the Notifications page daily and manually mark items as “done” as they complete them.
### Advantages
- Built and supported by GitHub.
### Disadvantages
- Very manual. The software engineer needs to mark things like open pull requests as “done” to remove them from the main Notifications view even when they’re obviously done, such as is the case for merged pull requests.
- Requires the software engineer to use the GitHub Notifications page as their task management system. Might be ok if all their work is within the walls of Github, but if they do things in other platforms such as Jira, Slack, or Confluence, it means they’re juggling several different task management systems.
## Option #3 BeyondDone App
The final option is the BeyondDone app, which allows you to see all your GitHub todos and accomplishments in one view.
BeyondDone goes beyond what is offered through the GitHub platform in many ways. GitHub todo items are automatically marked done and transferred to an Activity page, where it is organized by date or time. In addition, these items are included in an automatically generated standup update ready for your next standup. The Todos page displays the status checks for your pull requests, so you know when there is a failing build to investigate.
Beyond the GitHub platform, BeyondDone aggregates your todos and activity from Jira and Confluence. Github activity related to Jira tickets is grouped. You can add your todos and accomplishments when you have items that don’t currently have a BeyondDone integration. I’ve used these to remind myself to resolve Slack conversations or capture work not covered by a Jira ticket.
I use BeyondDone daily, which has turbocharged my ability to stay on top of things and sell myself better in standup and meetings with my supervisor.
I encourage you all to [sign up today](https://www.beyonddone.com?utm_source=devto&utm_medium=blog). There’s a 30-day free trial with no payment information required.
| sdotson |
1,869,050 | Integrating AI into Your Software Development Workflow | In the dynamic realm of contemporary business, enterprises incessantly strive to refine their... | 0 | 2024-05-29T13:56:30 | https://dev.to/danieldavis/integrating-ai-into-your-software-development-workflow-2n2f | In the dynamic realm of contemporary business, enterprises incessantly strive to refine their operations, elevate productivity, and outpace rivals. A pivotal strategy in this quest involves the integration of Artificial Intelligence (AI) into workflow processes.
By seamlessly embedding AI capabilities across various phases of development, businesses can attain unprecedented levels of efficiency, precision, and scalability. This article explores the integration of AI into workflows, highlighting its benefits and providing a unique technical implementation example.
## The Way AI Changing E-commerce
[How AI is changing e-commerce](https://redwerk.com/blog/how-ai-is-changing-ecommerce/) finds its application in e-commerce through diverse avenues, including Tailored product suggestions derived from user actions and preferences and proactive inventory management to prevent stock shortages and excess inventory.
[Artificial intelligence](https://www.entrepreneur.com/topic/artificial-intelligence) is steadily integrating into our daily routines. Generative AI instantly creates content, while predictive AI forecasts future trends. Deep learning generates human-like personalities, and ChatGPT is widely recognized. Big data has gained prominence.
This expansion extends to e-commerce, too, where AI is opening up fresh possibilities for customer understanding, interaction, and vital process automation.
## Improving Software Development Workflows Using Generative AI
### Automating Code Generation
Generative AI substantially boosts software development workflows, mainly through automating code generation. By training on extensive codebases, generative AI models can produce new code snippets tailored to specific needs or patterns. It accelerates development, especially for repetitive tasks or standard code segments.
### Natural Language Processing (NLP)
Generative AI can enhance natural language processing abilities within software development. For instance, it can automatically create documentation, generate test cases, or aid in requirements gathering by analyzing and summarizing textual data.
### Automating Design
Generative AI aids in streamlining the design process by producing mock-ups, layouts, or even complete user interfaces aligned with design guidelines and specifications. It facilitates more efficient collaboration between designers and developers and enables quicker design iterations.
### Testing and Debugging
Generative AI can aid in software testing and debugging. For instance, it can automatically create test cases based on code coverage metrics or identify and resolve common bugs and vulnerabilities in the code.
### Workflow Enhancement
Generative AI can optimize [software development](https://issuu.com/infilontecnology/docs/software_development_ac7021c36c6d02) workflows by analyzing data from different sources, including version control systems, project management tools, and code repositories. It can offer insights and suggestions for enhancing team collaboration, task prioritization, and resource allocation.
### Tailored User Experiences
Generative AI can create customized user experiences in software applications. For instance, it can generate dynamic content like recommendations or personalized messages, adapting to user interactions and preferences.
## Advantages of Employing Generative AI in Software Development
**Enhanced Efficiency:** Generative AI automates repetitive tasks and optimizes workflows, enabling developers to concentrate on creative and high-impact tasks and improving productivity.
**Accelerated Development:** Generative AI expedites the development cycle by automating laborious tasks like code generation and testing, facilitating quicker release cycles.
**Enhanced Code Integrity:** Generative AI helps produce cleaner and more manageable code by adhering to best practices and identifying potential issues at the outset of the development process.
**Boosted Ingenuity:** Generative AI empowers developers to delve into fresh ideas and methodologies by generating alternative solutions or design concepts grounded in existing data and patterns.
## Challenges and Factors to Consider
Despite its benefits, using Generative AI in software development comes with some challenges:
**Content Quality:** The content produced by Generative AI models may vary in quality, often needing manual review and adjustments to meet specific standards.
**Ethical and Legal Issues:** Generative AI raises moral and legal concerns, such as copyright violations and biases in the generated content, requiring careful management and mitigation.
**Integration and Acceptance:** Incorporating Generative AI into current development workflows may require substantial alterations to tools, procedures, and team roles, which may pose hurdles to acceptance.
## Integrating Generative AI: Best Practices
1. **Incremental Implementation:** Initiate the integration process by identifying specific tasks or areas within the development cycle where Generative AI can provide substantial value.
Starting with small-scale experiments and prototypes enables teams to assess its effectiveness before expanding its scope across broader applications.
2. **Cross-disciplinary Collaboration:** Foster collaboration among developers, designers, and AI specialists to leverage their diverse expertise and ensure that Generative AI is seamlessly integrated into the workflow. This collaborative approach facilitates the alignment of AI-generated content with the project's objectives and quality standards, enhancing its overall effectiveness.
3. **Continuous Learning and Adaptation:** Recognize that Generative AI models require ongoing training and refinement to maintain their relevance and efficacy. Allocate resources and establish continuous learning, monitoring, and optimization processes to keep pace with evolving project requirements and technological advancements.
4. **Ethical Considerations and Governance:** Develop robust ethical guidelines and governance frameworks to govern the responsible and ethical use of Generative AI. Address concerns related to data privacy, bias mitigation, and copyright infringement to uphold moral standards and build trust among stakeholders and end-users.
5. **Education and Skill Development:** Provide comprehensive education and training programs to equip developers and other stakeholders with the knowledge and skills to leverage Generative AI effectively. Empowering teams with a deep understanding of AI capabilities and integration methodologies fosters informed decision-making and promotes successful implementation within the development workflow.
## Conclusion
Generative AI can revolutionize software development workflows by automating tasks, boosting productivity, and enhancing creativity. Integrating it requires considering its benefits, challenges, and best practices. Developers can harness its power to innovate and accelerate software development.
| danieldavis | |
1,869,049 | Newbie feedback | Good afternoon all. I've recently started playing around with C-Sharp, and whilst i understand very... | 0 | 2024-05-29T13:55:11 | https://dev.to/newbiedev24/newbie-feedback-2dbg | feedback, csharp, beginners | Good afternoon all.
I've recently started playing around with C-Sharp, and whilst i understand very little of it, i have found for the most part the dev community is great, and that google and stack overflow is in fact a friend.
I am currently putting the finishing touches to my first application a .Net Framework 4.8 Web Application, i have no intention of publishing the application itself for others, its purely for my own ends, but i was wondering where is the best place to publish the source code for feedback purposes and where the best places are to seek such feedback, if i am to learn or get better feedback is critical.
Many thanks.
ND24 | newbiedev24 |
1,869,048 | WeatherIcon | Check out this Pen I made! | 0 | 2024-05-29T13:53:41 | https://dev.to/chensov/weathericon-3jj | codepen | Check out this Pen I made!
{% codepen https://codepen.io/senche/pen/LYoxNZd %} | chensov |
1,869,047 | Multidimensional Arrays | Data in a table or a matrix can be represented using a two-dimensional array. You can use a... | 0 | 2024-05-29T13:52:24 | https://dev.to/paulike/multidimensional-arrays-38po | java, programming, learning, beginners | Data in a table or a matrix can be represented using a two-dimensional array. You can use a two-dimensional array to store a matrix or a table. For example, the following table that lists the distances between cities can be stored using a two-dimensional array named **distances**.
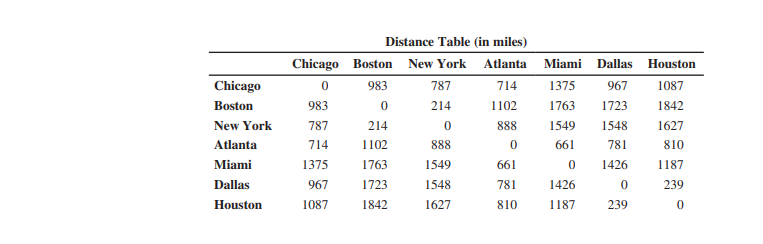
`double[][] distances = {
{0, 983, 787, 714, 1375, 967, 1087},
{983, 0, 214, 1102, 1763, 1723, 1842},
{787, 214, 0, 888, 1549, 1548, 1627},
{714, 1102, 888, 0, 661, 781, 810},
{1375, 1763, 1549, 661, 0, 1426, 1187},
{967, 1723, 1548, 781, 1426, 0, 239},
{1087, 1842, 1627, 810, 1187, 239, 0},
};`
An element in a two-dimensional array is accessed through a row and column index. How do you declare a variable for two-dimensional arrays? How do you create a two-dimensional array? How do you access elements in a two-dimensional array? This section addresses these issues.
## Declaring Variables of Two-Dimensional Arrays and Creating
Two-Dimensional Arrays
The syntax for declaring a two-dimensional array is:
`elementType[][] arrayRefVar;`
or
`elementType arrayRefVar[][]; // Allowed, but not preferred`
As an example, here is how you would declare a two-dimensional array variable **matrix** of **int** values:
`int[][] matrix;`
or
`int matrix[][]; // This style is allowed, but not preferred`
You can create a two-dimensional array of 5-by-5 **int** values and assign it to **matrix** using this syntax:
`matrix = new int[5][5];`
Two subscripts are used in a two-dimensional array, one for the row and the other for the column. As in a one-dimensional array, the index for each subscript is of the **int** type and starts from **0**, as shown below (a).

To assign the value **7** to a specific element at row **2** and column **1**, as shown above (b), you can use the following syntax:
`matrix[2][1] = 7;`
It is a common mistake to use **matrix[2, 1]** to access the element at row **2** and column **1**. In Java, each subscript must be enclosed in a pair of square brackets.
You can also use an array initializer to declare, create, and initialize a two-dimensional array. For example, the following code below in (a) creates an array with the specified initial values, as shown above (c). This is equivalent to the code below in (b).

## Obtaining the Lengths of Two-Dimensional Arrays
A two-dimensional array is actually an array in which each element is a one-dimensional array. The length of an array **x** is the number of elements in the array, which can be obtained using **x.length. x[0], x[1]**, . . . , and **x[x.length-1]** are arrays. Their lengths can be obtained using **x[0].length, x[1].length**, . . . , and **x[x.length-1].length**. For example, suppose **x = new int[3][4]**, **x[0]**, **x[1]**, and **x[2]** are one-dimensional arrays and each contains four elements, as shown below. **x.length** is **3**, and **x[0].length, x[1].length**, and **x[2].length** are **4**.
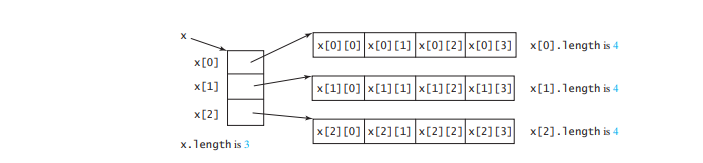
## Ragged Arrays
Each row in a two-dimensional array is itself an array. Thus, the rows can have different lengths. An array of this kind is known as a _ragged array_. Here is an example of creating a ragged array:
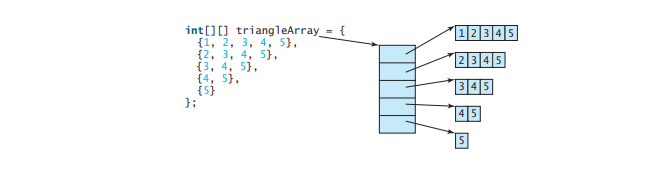
As you can see, **triangleArray[0].length** is 5, **triangleArray[1].length** is 4, **triangleArray[2].length** is 3, **triangleArray[3].length** is 2, and **triangleArray[4].length** is 1.
If you don’t know the values in a ragged array in advance, but do know the sizes—say, the same as before—you can create a ragged array using the following syntax:
`int[][] triangleArray = new int[5][];
triangleArray[0] = new int[5];
triangleArray[1] = new int[4];
triangleArray[2] = new int[3];
triangleArray[3] = new int[2];
triangleArray[4] = new int[1];`
You can now assign values to the array. For example,
`triangleArray[0][3] = 50;
triangleArray[4][0] = 45;`
The syntax **new int[5][]** for creating an array requires the first index to be specified. The syntax **new int[][]** would be wrong. | paulike |
1,869,046 | I made a tool to launch a blog in minutes. time-saving & fully customizable! | I noticed a need for a blogging tool that gives full control over customization, UI quality,... | 0 | 2024-05-29T13:50:56 | https://dev.to/bandhanimish/i-made-a-tool-to-launch-a-blog-in-minutes-time-saving-fully-customizable-4lm1 | blog, productivity, react | I noticed a need for a blogging tool that gives full control over customization, UI quality, effortless content editing and saves time during setup. BlogCode offers a hassle-free way to add a blog, empowering developers to focus on what they do best.
After chatting with a developer friend who was also dissatisfied with his current blogging tool, I decided to create an MVP. I created a demo of a new tool designed to launch blogs in minutes, offering a clean and simple interface along with effortless content editing.
Here's what sets this tool apart:
- **Speedy Setup:** Get your blog up and running in minutes.
- **Beautiful UI:** A clean and modern design to make your content shine.
- **Customization:** Full control over the look and feel of your blog.
- **Effortless Content Editing:** Intuitive and straightforward content management.
I shared the demo with my friend, and he loved it. His feedback was overwhelmingly positive.
I hope this tool helps others streamline their blogging process and create beautiful, customized blogs without the usual headaches.
If you are looking to start a blog or are unhappy with current blogging tools, give BlogCode a try & share your thoughts.
[BlogCode](getblogcode.netlify.app)
Its still under Launch discount, hurry up. | bandhanimish |
1,869,044 | CSS Image Styling Help? | Hi All, Looking for some styling help if possible. When making the browser smaller, it adds gaps... | 0 | 2024-05-29T13:47:07 | https://dev.to/louis_mason_c489f98477918/css-image-styling-help-1g6p | css, help, elementor, wordpress | Hi All,
Looking for some styling help if possible. When making the browser smaller, it adds gaps above and below the image element. How could I make it that no matter the size it will cover the image on the second column in the section.
I'm using elementor in Wordpress.
Please see video below:
[Link to desktop recording](https://youtu.be/1LV6OMNve8Q) | louis_mason_c489f98477918 |
1,869,042 | Using Cronjob for Periodic Task in Linux | You work on your machine or server everything repeating same task everything the Cronjob should be... | 0 | 2024-05-29T13:46:29 | https://dev.to/giftbalogun/using-cronjob-for-periodic-task-in-linux-1el8 | You work on your machine or server everything repeating same task everything the Cronjob should be used, it enables your code, security check and updates to take place at any time you setup for it. In this article, discover how to:
- schedule routine tasks on Linux using
- the structure of crontab files for precise timing of jobs
- the structure of crontab files for precise timing of jobs
- Maximize productivity by automating updates, backups, and more with cron.
All here: https://everythingdevops.dev/how-to-schedule-a-periodic-task-with-cron/ | giftbalogun | |
1,869,040 | Automate Docker Dependency Update. | POST UPDATE The article discusses the importance of managing dependencies in software projects,... | 0 | 2024-05-29T13:45:20 | https://dev.to/giftbalogun/automate-docker-dependency-update-b9k | POST UPDATE
The article discusses the importance of managing dependencies in software projects, which are external libraries needed for an application to function properly. Here are some critical points:
It highlights the difficulties developers face, such as “dependency mismatch” bugs and the complexity of managing multiple codebases, which can lead to “dependency hell.
The focus is on using WhiteSource _Renovate_, a tool that automates dependency updates for Docker projects by checking and updating dependency declaration files and creating pull requests automatically.
It provides a step-by-step guide on how to configure Renovate for Docker projects, including setting up a GitHub personal access token and creating a _docker-compose.yml_ file to run the Renovate Docker image.
Details here: https://everythingdevops.dev/automating-dependency-updates-for-docker-projects/ | giftbalogun | |
1,866,910 | Buy Verified Paxful Account | Buy Verified Paxful Account There are several compelling reasons to consider purchasing a... | 0 | 2024-05-27T19:36:01 | https://dev.to/robert_miller_3916c1653f0/buy-verified-paxful-account-2ooi | Buy Verified Paxful Account
There are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.
https://dmhelpshop.com/product/buy-verified-paxful-account/
Moreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.
https://dmhelpshop.com/product/buy-verified-paxful-account/
Lastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.
Buy US verified paxful account from the best place dmhelpshop
Why we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.
https://dmhelpshop.com/product/buy-verified-paxful-account/
If you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-
Email verified
Phone number verified
Selfie and KYC verified
SSN (social security no.) verified
Tax ID and passport verified
Sometimes driving license verified
MasterCard attached and verified
Used only genuine and real documents
100% access of the account
All documents provided for customer security
What is Verified Paxful Account?
In today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.
In light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.
For individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.
Verified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.
But what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.
Why should to Buy Verified Paxful Account?
There are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.
Moreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.
Lastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.
What is a Paxful Account
Paxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.
In line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.
https://dmhelpshop.com/product/buy-verified-paxful-account/
Is it safe to buy Paxful Verified Accounts?
Buying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.
PAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.
This brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.
https://dmhelpshop.com/product/buy-verified-paxful-account/
How Do I Get 100% Real Verified Paxful Accoun?
Paxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.
However, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.
In this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.
Moreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.
Whether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.
Benefits Of Verified Paxful Accounts
Verified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.
Verification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.
Paxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.
Paxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.
What sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.
How paxful ensure risk-free transaction and trading?
Engage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.
With verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.
Experience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.
In the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.
Examining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from dmhelpshop.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.
How Old Paxful ensures a lot of Advantages?
Explore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.
Businesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.
Experience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.
Paxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.
Why paxful keep the security measures at the top priority?
In today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.
Safeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.
Conclusion
Investing in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.
The initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.
In conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.
Moreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.
Contact Us / 24 Hours Reply
Telegram:dmhelpshop
WhatsApp: +1 (980) 277-2786
Skype:dmhelpshop
Email:dmhelpshop@gmail.com | robert_miller_3916c1653f0 | |
1,869,039 | Background and Foreground Jobs in Lunix | POST UPDATE You have a Linux Operation System or Server running and still not familiar with... | 0 | 2024-05-29T13:44:09 | https://dev.to/giftbalogun/background-and-foreground-jobs-in-lunix-2a76 | POST UPDATE
You have a Linux Operation System or Server running and still not familiar with background and foreground jobs or task, then this is for you. Learn to efficiently manage foreground and background processes in Linux. Discover how to:
- Run commands in the background with &, freeing up the shell.
- Bring background jobs to the foreground with _fg_.
- Pause jobs with CTRL + Z and resume with _bg_
- Keep jobs running after closing the terminal using _nohup_ or _disown4_.
More here: https://everythingdevops.dev/linux-background-and-foreground-process-management/ | giftbalogun | |
1,869,038 | Is Confluence giving you headaches? Migrate to a Smoother Knowledge Base Manager with XWiki (Free Webinar!) | Join our free upcoming webinar and discover a smoother, more efficient way to manage your knowledge... | 0 | 2024-05-29T13:41:46 | https://dev.to/lorina_b/is-confluence-giving-you-headaches-migrate-to-a-smoother-knowledge-base-manager-with-xwiki-free-webinar-elm | Join our free upcoming webinar and discover a smoother, more efficient way to manage your knowledge base with XWiki, the leading open-source alternative.
Level up your knowledge management with:
🚀Effortless Migration: Ditch the hassle! Our enhanced Confluence Migrator (Pro) makes switching to XWiki a breeze.
🚀Tailored Experience: Take control with automated setup and a wider range of configuration options for a migration that fits your needs. ️
🚀Live Demo & Expert Insights: Witness XWiki's latest migration advancements and powerful macros in action. Plus, get your questions answered by our Confluence migration specialist, Ștefana Nazare, in a live Q&A.
Walk away with:
✅ A clear understanding of XWiki's advantages as a robust open-source alternative.
✅Practical knowledge to migrate your Confluence data seamlessly.
✅Valuable resources to keep your wiki thriving after the switch.
📆 Date: May 30, 2024
⏰ Time: 16:00 CET (Central European Time)
Stop managing your wiki, start optimizing it!
Register today and learn about a more efficient future for your knowledge base: https://xwiki.com/en/webinars/easiest-migration-from-confluence-to-xwiki
#XWiki #ConfluenceMigration #OpenSource #webinar #confluence #kbm | lorina_b | |
1,869,037 | Understanding the Importance of Professional Plumbing Installation in New Lenox | Plumbing systems are of critical importance to every homeowner in our area. Installation without... | 0 | 2024-05-29T13:40:24 | https://dev.to/dankelly1/understanding-the-importance-of-professional-plumbing-installation-in-new-lenox-3c0g | Plumbing systems are of critical importance to every homeowner in our area. Installation without professional guidance can result in a host of problems down the line ranging from minor leaks that cause an increment in water bills, to significant malfunctions causing flooding and structural damage. This article aims to enlighten New Lenox residents on the key benefits and reasons for professional plumbing installation.
Ensuring Safety and Compliance
Safety should always be paramount when considering service installations. Certified professionals adhere to local codes and regulations when performing plumbing installations in New Lenox. They know the details of these rules concerning system installations, ensuring built structures are compliant with safety rules established by ordinances or homeowners associations.
Proper Fittings and Sizing
Utilizing a professional plumber's expertise guarantees that your new installation will fit perfectly into your home’s existing piping system. An experienced plumber will make sure all pipes, fittings, valves, and devices are securely installed with proper fittings. Moreover, they efficiently handle different pipe sizes having varying diameters ensuring a seamless installation process.
Minimized Risk of Damages
With access to specialized tools and extensive training, professionals ensure a high standard for each [New Lenox plumbing installation](https://www.home8.org/IL/New-Lenox/Expert-Plumbing-Service-New-Lenox/) task carried out avoiding negative impacts on property due to errors. Therefore it reduces the risk of future leakages or breaks due to incorrect handling during the fitting process which could lead to costly repairs or replacements later.
Longevity of Your System’s Life
A poorly installed plumbing system tends to wear out faster than one professionally constructed. The knowledge of material quality, application specifics, local water characteristics brought by professional teams means higher longevity for your newly installed pipelines making this long-term investment worthwhile.
Time-Saving and Efficient Service
Despite many DIY tutorials available online, installing pipes may prove more complex than anticipated especially when dealing with unique case scenarios not covered in general instructions. A professional plumber, having faced a variety of installation situations, can perform the task swiftly and correctly, thereby saving you time.
Seamless After-Service
A trusted professional plumbing company often provides after-service support to their customers. Thus, if any issue arises post-installation, they are quick to solve any problem extending their service warranty period.
Choosing a reliable professional service for your New Lenox plumbing installation is pivotal. It assures safety and compliance with local codes, guarantees proper fittings and sizes needed in your home’s specific piping system, minimizes risks of damages that could lead to unnecessary costs, prolongs the longevity of your system’s life through quality material usage and experienced techniques during fitting processes.
What's more, it saves considerable time while enhancing efficiency during the fitting procedure; ensuring customers can rest easy with warranties and efficient after-service assistance offered by the reliable installing company. Understanding these key benefits ensures that you make an informed decision about investing wisely into the plumbing infrastructure in your home which ultimately adds value to your property.
**[Expert Plumbing Service](https://www.expertplumbers.com/)**
Address: [1333 S Schoolhouse Rd Unit 340A, New Lenox, IL 60451 ](https://www.google.com/maps?cid=17566594220891879877)
Phone: 815-310-1033 | dankelly1 | |
1,869,036 | Wholesale Jerseys | From Stitch to Stitches: Unveiling the World of Baseball Jersey Makers Baseball, with its... | 0 | 2024-05-29T13:40:06 | https://dev.to/samwalker1122/wholesale-jerseys-4age | ## From Stitch to Stitches: Unveiling the World of Baseball Jersey Makers
Baseball, with its rich history and passionate fan base, has a uniform as iconic as the game itself: the jersey. But have you ever wondered where these jerseys come from? This article delves into the world of baseball jersey makers, exploring the craftsmanship, technology, and industry forces that shape these treasured pieces of fan gear.
**The Jersey Journey: From Design to Production**
The life of a baseball jersey begins with a spark of creativity. Designers translate team colors, logos, and player names into detailed specifications. These specs then reach the hands of skilled patternmakers, who meticulously craft templates for each jersey component.
**The Manufacturing Mix: Traditional Techniques and Modern Advancements**
**[Baseball jersey maker](https://thegeniusfit.com/
)** often blends traditional techniques with modern advancements. Sewing machines guided by experienced hands stitch intricate seams, ensuring durability and a clean finish. Embroidery machines, programmed with precise patterns, meticulously recreate logos and lettering.
Technology plays a crucial role in modern jersey production. Computer-aided design (CAD) software allows for faster and more precise pattern creation. Direct-to-garment (DTG) printing offers a faster and more cost-effective way to personalize jerseys, especially for small orders.
**Licensed vs. Unlicensed: Navigating the Legal Landscape**
Baseball jerseys fall into two categories: licensed and unlicensed. Licensed jerseys are produced by manufacturers authorized by Major League Baseball (MLB) to use official team logos and trademarks. These jerseys adhere to strict quality standards and often come at a premium price.
Unlicensed jerseys, on the other hand, are produced by manufacturers without official MLB authorization. These jerseys often offer lower prices but may not guarantee the same level of quality or accuracy in logos and designs.
**The Global Reach of Baseball Jersey Production**
**[wholesale jerseys](https://thegeniusfit.com/nba-jersey/)** production is a global industry. Countries like China, Vietnam, and the Dominican Republic have become major hubs due to their lower labor costs and established manufacturing infrastructure. However, concerns about labor practices and environmental regulations have led to calls for more transparency and ethical production practices.
**Looking Ahead: Sustainability and Customization in the Future**
The future of baseball jersey production is likely to be shaped by two key trends: sustainability and customization.
* **Sustainability:** Consumers are increasingly concerned about the environmental impact of clothing production. Manufacturers are exploring eco-friendly materials like recycled polyester and organic cotton. Additionally, ethical labor practices are becoming a key consideration for both manufacturers and consumers.
* **Customization:** The demand for personalized jerseys with custom names and numbers is on the rise. This trend is driven by fan desire to express their individuality and support for specific players.
**Conclusion:**
Baseball jersey makers play a vital role in bringing the spirit of the game to life. From the initial design to the final stitch, their work ensures that fans can proudly wear their team's colors and celebrate the players they admire. As the industry evolves, expect to see a growing focus on ethical production, sustainable practices, and innovative techniques to meet the ever-changing demands of passionate baseball fans. | samwalker1122 | |
1,869,035 | The Ultimate beginners guide to open source – part 1 | An open source project is one where the source code is visible to everyone and where developers are... | 0 | 2024-05-29T13:38:49 | https://dev.to/dunsincodes/the-ultimate-beginners-guide-to-open-source-part-1-2la9 | beginners, opensource, career, development | An open source project is one where the source code is visible to everyone and where developers are welcome to contribute. React(made by facebook), WordPress, and Node.js are two instances of open source projects.
**<u>People who engage in open source projects include the following:</u>**
- **Owner**: Who created or launched the initiative; this could be a company or a person.
- **Contributor**: A person who asks for changes to the project in order to improve it.
- **Maintainer**: Someone who makes decisions for the project, such as whether a pull request is acceptable or an issue is valid, and who generates ideas; this is most frequently a contributor and the owner.
- **Users**: This group of individuals that use the project, as the name implies.
**Myths in Open source:**
- You must be familiar with every tool used: If a project uses React, Redux, and Tailwind it you can know react and just redux, you can contribute with what you know until you master the rest.
- You must be a programmer: You can contribute to design and documentation without having any programming experience.
- You must be an expert: There is always something you can contribute to the project, regardless of the degree of your expertise.
**Ways to contribute to a project:**
- Fix a bug you found
- Read the documentation and if anything is confusing, help improve it
- Propose a feature you want added
- Help improve the design
- Translate the documentation to your language
How to contribute to a project:
- Fork the project

- Read the readme file

- Use the project by going to the url or downloading the app and suggest improvement, this gives you first hand experience on what users may need as you're putting yourself in their shoes

- Look at existing issues and see what you can work on.
Looking for a project to practice try this [Practice Project](https://github.com/dun-sin/code-magic)
_**Thanks for reading, let me know what you think about this and if you would like to see more, if you think i made a mistake or missed something, don't hesitate to comment**_
[check out part 2](https://dev.to/dunsincodes/the-ultimate-beginners-guide-to-open-source-part-2-defeating-the-fear-of-contributing-1olj) | dunsincodes |
1,869,045 | Spheron's Matchmaking Mechanisms: Connecting GPU Users and Providers | In today's rapidly evolving digital landscape, the demand for GPU resources is skyrocketing –... | 0 | 2024-05-29T18:05:52 | https://blog.spheron.network/spherons-matchmaking-mechanisms-connecting-gpu-users-and-providers | spheron, web3, blockchain, decentralization | ---
title: Spheron's Matchmaking Mechanisms: Connecting GPU Users and Providers
published: true
date: 2024-05-29 13:36:55 UTC
tags: Spheron,Web3,Blockchain,decentralization
canonical_url: https://blog.spheron.network/spherons-matchmaking-mechanisms-connecting-gpu-users-and-providers
---

In today's rapidly evolving digital landscape, the demand for GPU resources is skyrocketing – particularly given the ongoing surge in AI and machine learning applications. Traditional centralized GPU markets are struggling to keep pace with this demand, leading to increased costs and limited access.
To address these growing resource needs, Spheron has created a groundbreaking global compute network that ensures the efficient, cost-effective, and equitable distribution of GPU resources. Now, anyone can earn passive returns by lending their excess GPU power to Spheron Network – and become a vital part of the decentralized AI revolution!

Spheron’s decentralized market connects you to a worldwide user base that's ready to utilize providers’ excess compute power, no matter where they are. Let’s break down how it works.
## Spheron’s Decentralized Compute Network
At the heart of Spheron's protocol lies the Decentralized Compute Network (DCN), a distributed framework where independent providers supply GPU and compute resources. This network ensures resilience, scalability, and accessibility, catering to the diverse needs of AI and ML projects. Central to the DCN is the Matchmaking Engine, which is designed to efficiently connect GPU users with providers.
## Matchmaking Engine: Enabling Efficient, Automated Resource Allocation
Spheron's Matchmaking Engine is tasked with the essential role of orchestrating the dynamic allocation of GPU resources between deployment requests and provider nodes. This mechanism leverages the Actively Validated Services (AVS) framework from EigenLayer, which incorporates a sophisticated consensus algorithm to match deployment requests with the most suitable providers.
How it Works:
**Provider Registration:** Providers begin by registering their compute specs, region, tier, and other relevant details on the Provider Registry.
**Provider Lookup and Bidding:** When a user initiates a deployment request, the matchmaking engine broadcasts a PROVIDER_LOOKUP event. Providers that meet the deployment criteria submit their bids, detailing their capacity and pricing.
**Consensus-Based Matching:** The matchmaking algorithm evaluates these bids based on predefined parameters, such as geographic proximity, price, uptime, and reputation. Once a quorum is reached, the optimal provider is selected, and the matched order is updated in the Task Manager contract.
**Lease Creation and Deployment:** Following the provider selection, the Deployment Order contract establishes a lease with the provider, initiating the deployment process. The provider then configures and activates the server, with all relevant deployment details made available to the user.
**Payment and Settlement:** Once a user chooses a provider to deploy their workloads, all pertinent details are shared on-chain, marking the beginning of payment settlement based on the pricing set by the provider.
In addition to the above steps, Provider Nodes are also responsible for maintaining their node activity and chain state synchronization. Specific responsibilities include:
**Deployment Management:** Provider Nodes are responsible for the continuous management of deployments, including the initiation (CREATE_LEASE), update (UPDATE_LEASE), and termination (CLOSE_LEASE) of services. Each action is meticulously recorded on the blockchain, ensuring transparency and traceability.
**Synchronization and Reliability:** To maintain operational alignment with the network, Provider Nodes run RPC / Sequencer nodes to synchronize with the latest chain state. This synchronization is critical for participating in the bidding process and for ensuring the timely and successful execution of deployments.
Together, the above steps ensure the continual exchange of available GPU resources with end users within a seamless, low-cost environment.
## Spheron’s Matchmaking Engine Benefits All Ecosystem Participants
Spheron's Matchmaking Engine provides multiple benefits to GPU providers and end users alike by offering a more transparent, cost-effective, and efficient alternative to traditional service providers like AWS or Google Cloud.
Key benefits include:

## Welcome to the Future of Decentralized Compute
Spheron’s Matchmaking Engine allows anyone to play a vital role in the decentralized AI revolution, benefiting providers with new revenue streams and users with on-demand, customizable options. This approach current market constraints while catalyzing innovation and development in AI and machine learning – at a lower cost and higher performance levels than existing solutions.
Whether you want to access unlimited GPU power instantly and affordably or get paid to lend out your extra computing power, Spheron invites you to participate in a cutting-edge global compute network that is dynamic, scalable, and ready for tomorrow.
 today and unlock your full earning potential!
| spheronstaff |
1,869,033 | Payroll Processing software | A post by hr365 india | 0 | 2024-05-29T13:33:49 | https://dev.to/hr365india/payroll-processing-software-2gii |
 | hr365india | |
1,869,032 | Different Testing Techniques | 1.Boundary value analysis is a software testing technique used to evaluate boundary conditions of... | 0 | 2024-05-29T13:33:43 | https://dev.to/s1eb0d54/different-testing-techniques-4ipf | learning, testing | 1.**Boundary value analysis** is a software testing technique used to evaluate boundary conditions of input values. It focuses on testing values at the boundaries rather than the center of the input domain. This approach helps identify errors related to boundary conditions that may not be detected through other testing methods.
In boundary value analysis, test cases are designed to include values at the lower and upper boundaries of valid input ranges, as well as just inside and just outside these boundaries. By testing these critical points, testers can uncover potential issues such as off-by-one errors or incorrect handling of edge cases.
Consider a system that accepts values between 1 and 100. Instead of testing all values from 1 to 100, BVA selects values at the boundaries (1, 2, 99, 100) and just beyond (0, 101). This ensures that boundary conditions, where errors are often found, are thoroughly tested.
_Here's a diagram illustrating BVA_
```
|<--Valid Range-->|
| |
---|-----------------|---
0 100 101
```
In this _example_, values at the edges of the valid range (0, 1, 100, 101) are tested to ensure that the system behaves correctly and handles boundary conditions appropriately. By focusing on boundary values, BVA efficiently identifies potential issues, improving the quality and reliability of software systems.
2.**Decision table testing** is a systematic technique used to test the behavior of software systems based on different combinations of input conditions. It involves creating a table that represents all possible combinations of inputs and their corresponding outputs or actions. This approach helps ensure thorough test coverage, especially in complex systems with multiple conditions influencing behavior.
Here's an _example_ diagram illustrating decision table testing:
| Conditions | Condition 1 | Condition 2 | Condition 3 |
|------------|--------------|--------------|--------------|
| Case 1 | True | True | False |
| Case 2 | False | True | True |
| Case 3 | True | False | True |
| Case 4 | True | True | True |
| Actions | Action 1 | Action 2 |
|------------|------------|------------|
| Case 1 | Do A | Do B |
| Case 2 | Do C | Do D |
| Case 3 | Do E | Do F |
| Case 4 | Do G | Do H |
Test cases are derived from this table, covering each combination of conditions to ensure all scenarios are evaluated. Decision table testing enhances test efficiency and effectiveness by systematically addressing various input conditions and their outcomes.
3.**Use case testing** is a methodology used to validate the functionality of a software system based on its specified use cases. It involves designing test cases that simulate real-world scenarios or interactions with the system to ensure that it behaves as expected. Each use case represents a specific sequence of actions performed by a user or external system, along with the expected outcomes.
Test cases in use case testing are derived from these use cases, covering both typical and exceptional scenarios to validate the system's behavior comprehensively. This approach helps testers understand how users will interact with the system and ensures that it meets their requirements and expectations.
By focusing on real-world usage scenarios, use case testing enhances the relevance and effectiveness of testing efforts, leading to the discovery of potential issues early in the development lifecycle. It also facilitates communication between stakeholders by aligning testing activities with the intended functionality of the system.
_For example_, consider a banking application with a "Transfer Funds" feature. A use case for this feature could involve a user transferring money from one account to another.
Test cases derived from this use case might include scenarios such as:
Successful transfer: A user transfers funds between their accounts within the allowed limit.
Insufficient funds: A user tries to transfer an amount exceeding their account balance.
Invalid account: A user attempts to transfer funds to a non-existent account.
Network failure: Transfer fails due to network issues during the transaction.
Confirmation message: Ensuring that the user receives a confirmation message after a successful transfer.
4.**LCSAJ (Linear Code Sequence and Jump) testing** is a structural testing technique that focuses on validating the execution paths of a program by examining linear sequences of code and the associated jumps. It aims to verify that all possible linear code sequences are executed at least once during testing. This approach helps identify potential errors in the control flow of the program, such as missing or unreachable code segments.
An _example_ of LCSAJ testing involves analyzing a program's control flow graph to identify linear code sequences and associated jumps. Test cases are designed to ensure that each identified sequence is executed, covering all possible paths through the program.
Here's a simplified diagram illustrating LCSAJ testing:
```
Start
|
v
Sequence 1
|
v
Jump 1
|
v
Sequence 2
|
v
Jump 2
|
v
Sequence 3
|
v
End
```
In this example, LCSAJ testing would verify that all sequences (Sequence 1, Sequence 2, and Sequence 3) are executed, along with the associated jumps (Jump 1 and Jump 2), to achieve comprehensive coverage of the program's control flow. | s1eb0d54 |
1,869,031 | Multi-Tech Powerhouse: Intensive Filter Himenviro | Demystifying Fabric Filters: A Comprehensive Guide to Their... | 0 | 2024-05-29T13:33:29 | https://dev.to/marketing_intensivfilterh/multi-tech-powerhouse-intensive-filter-himenviro-4jpd | webdev, ai, productivity | Demystifying Fabric Filters: A Comprehensive Guide to Their Functionality
https://www.intensiv-filter-himenviro.com/info/blogs/demystifying-fabric-filters-a-comprehensive-guide-to-their-functionality
Also Check- [air pollution control equipments](https://www.intensiv-filter-himenviro.com/)
[dust collector](https://www.intensiv-filter-himenviro.com/)
In the realm of industrial air pollution control, fabric filters play a pivotal role in ensuring cleaner and safer environments. As industries strive to meet stringent emission regulations and maintain sustainable practices, understanding the functionality of fabric filters becomes imperative. In this comprehensive guide, we delve into the intricate world of fabric filters, unraveling their mechanisms, benefits, and significance in the context of air quality management.
**Understanding Fabric Filters:
**
Fabric filters, also known as baghouse filters, are one of the most widely adopted methods for controlling particulate matter emissions from industrial processes. They are designed to capture and remove suspended particles, such as dust, fumes, and pollutants, from gas streams. This filtration process is crucial not only for compliance with environmental regulations but also for safeguarding public health and preserving the integrity of surrounding ecosystems.
**The Mechanism Behind Fabric Filters:
**
Fabric filters operate on the principle of physical filtration, utilizing a matrix of fabric bags or tubes to capture particulate matter. The polluted gas stream is directed through the fabric bags, while the particles are trapped on the surface or within the fabric's intricate pore structure. The clean gas is then released back into the atmosphere.
**Benefits of Fabric Filters:
**
Fabric filters offer a range of benefits that make them a preferred choice for many industries:
High Efficiency: Fabric filters exhibit remarkable particle removal efficiency, even for sub-micron particles, ensuring compliance with stringent emission standards.
Versatility: They can effectively handle various particulate types, sizes, and concentrations, making them suitable for diverse industrial applications.
Low Pressure Drop: Fabric filters typically maintain low pressure drop, resulting in energy savings and reduced operating costs.
Modularity: The modular design of fabric filter systems allows for easy scalability and adaptation to changing process conditions.
Durability: With proper maintenance, fabric filters can have a long service life, contributing to sustainable air pollution control solutions.
**Types of Fabric Filters:
**
Fabric filters come in various configurations, tailored to specific industrial needs:
Pulse-Jet Fabric Filters: These filters use compressed air pulses to dislodge particles from the fabric surface, ensuring continuous and efficient operation.
Reverse Air Fabric Filters: Reverse air fabric filters employ a reverse flow of air to clean the fabric surface, making them suitable for applications with sticky or agglomerative particulates.
Shaker-Type Fabric Filters: Shaker-type filters mechanically agitate the fabric to remove accumulated particles, offering simple and cost-effective solutions.
**Significance in Air Quality Management:
**
The implementation of fabric filters significantly contributes to air quality management by reducing airborne pollutants that pose health risks to both humans and the environment. Their ability to efficiently capture even the smallest particles ensures cleaner emissions and healthier communities.
**Conclusion:
**
Fabric filters, with their intricate mechanisms and diverse applications, stand as stalwarts in the battle against air pollution. Their role in ensuring regulatory compliance, safeguarding public health, and promoting sustainable industrial practices is undeniable. As industries continue to prioritize environmental responsibility, a thorough understanding of fabric filters and their functionality becomes a cornerstone of effective air pollution control strategies.
In an age where air quality is a global concern, fabric filters emerge as champions of cleaner skies and a healthier world.
| marketing_intensivfilterh |
1,869,030 | Distributed Tracing with Jaeger for Debugging Microservices in Kubernetes | Debugging microservices-based applications can be a complex task due to the distributed nature of... | 0 | 2024-05-29T13:33:15 | https://dev.to/platform_engineers/distributed-tracing-with-jaeger-for-debugging-microservices-in-kubernetes-2b4e | Debugging microservices-based applications can be a complex task due to the distributed nature of these systems. Distributed tracing is a technique used to monitor and debug microservices by tracking requests as they propagate through the system. In this blog post, we will explore how to use Jaeger, an open-source distributed tracing system, to debug microservices in Kubernetes.
## Jaeger Overview
Jaeger is an open-source distributed tracing system developed by Uber. It provides a way to monitor and debug microservices by tracking requests as they propagate through the system. Jaeger uses a client-server architecture, where the client libraries are integrated into the microservices, and the server component is responsible for collecting, storing, and visualizing the trace data.
## Jaeger provides several key features for debugging microservices:
1. Distributed context propagation: Jaeger automatically propagates context information between microservices, allowing you to trace requests across service boundaries.
2. Trace visualization: Jaeger provides a web UI for visualizing traces, making it easy to identify performance bottlenecks and debug errors.
3. Service dependency analysis: Jaeger provides a service dependency graph, allowing you to understand the relationships between microservices and identify potential issues.
4. Performance metrics: Jaeger provides performance metrics for each microservice, allowing you to monitor the health and performance of your system.
## Setting up Jaeger in Kubernetes
Setting up Jaeger in Kubernetes involves deploying the Jaeger server component and integrating the Jaeger client libraries into your microservices. Here are the steps to set up Jaeger in Kubernetes:
1. Deploy the Jaeger server component: You can use the official Jaeger Helm chart to deploy the Jaeger server component in Kubernetes. Here's an example Helm command to deploy Jaeger:
```bash
helm install my-jaeger jaegertracing/jaeger --namespace my-namespace
```
2. Integrate the Jaeger client libraries into your microservices: You can use one of the many Jaeger client libraries to integrate Jaeger into your microservices. Here's an example of how to use the Jaeger Go client library to instrument a Go microservice:
```go
package main
import (
"fmt"
"log"
"net/http"
"github.com/opentracing/opentracing-go"
"github.com/opentracing/opentracing-go/ext"
"github.com/opentracing/opentracing-go/log"
jaeger "github.com/uber/jaeger-client-go"
jaegercfg "github.com/uber/jaeger-client-go/config"
)
func main() {
// Create a new Jaeger tracer
cfg := jaegercfg.Configuration{
ServiceName: "my-service",
Sampler: &jaeger.ProbabilisticSampler{
SamplingRate: 1.0,
},
Reporter: &jaeger.LoggingReporter{},
}
tracer, _, err := cfg.NewTracer()
if err != nil {
log.Fatal(err)
}
defer tracer.Close()
// Create a new HTTP server
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
// Create a new span for the HTTP request
span := tracer.StartSpan("handle-request")
defer span.Finish()
// Set the span tags and logs
span.SetTag("http.method", r.Method)
span.SetTag("http.url", r.URL.String())
span.LogFields(
log.String("event", "request"),
log.String("user-agent", r.UserAgent()),
)
// Process the HTTP request
fmt.Fprintf(w, "Hello, world!")
})
// Start the HTTP server
log.Println("Starting HTTP server on :8080...")
log.Fatal(http.ListenAndServe(":8080", nil))
}
```
3. View the traces in the Jaeger UI: Once you have deployed the Jaeger server component and integrated the Jaeger client libraries into your microservices, you can view the traces in the Jaeger UI. You can access the Jaeger UI by running the following command:
```bash
kubectl port-forward svc/my-jaeger-query 16686:16686 -n my-namespace
```
This will forward traffic from port 16686 on your local machine to the Jaeger query service in Kubernetes. You can then access the Jaeger UI by opening a web browser and navigating to <http://localhost:16686>.
## Debugging Microservices with Jaeger
Once you have set up Jaeger in Kubernetes, you can use it to debug microservices by tracing requests as they propagate through the system. Here are some examples of how to use Jaeger to debug microservices:
1. Identify performance bottlenecks: You can use the Jaeger UI to identify performance bottlenecks by viewing the trace data for each microservice. You can sort the traces by duration and identify the slowest requests.
2. Debug errors: You can use the Jaeger UI to debug errors by viewing the trace data for failed requests. You can see which microservices were involved in the request and identify the root cause of the error.
3. Analyze service dependencies: You can use the Jaeger UI to analyze service dependencies by viewing the service dependency graph. You can see which microservices are dependent on each other and identify potential issues.
4. Monitor performance metrics: You can use the Jaeger UI to monitor performance metrics for each microservice. You can see the number of requests, response times, and error rates for each microservice.
## Conclusion
Distributed tracing is an essential tool for debugging microservices-based applications in [platform engineering](www.platformengineers.io). Jaeger is an open-source distributed tracing system that provides a way to monitor and debug microservices by tracking requests as they propagate through the system. | shahangita | |
1,865,064 | What is Local-first Web Development? | Introduction Imagine having full control over your data on every web app you use, like... | 0 | 2024-05-29T13:31:53 | https://dev.to/alexanderop/what-is-local-first-web-development-3mnd | webdev, pwa, localfirst, vue |
## Introduction
Imagine having full control over your data on every web app you use, like Twitter or Instagram. Even better, think about using your apps offline and having them sync up automatically once you're back online. What if you could easily switch apps and take your data with you? This is what Local-First Web Development is all about. Now that browsers and devices are more powerful, we can avoid backends, loading delays, and network errors. In this blog post, the first of a series, I'll explain the basics of Local-First Web Development and how it benefits users.
## The Traditional Web Application
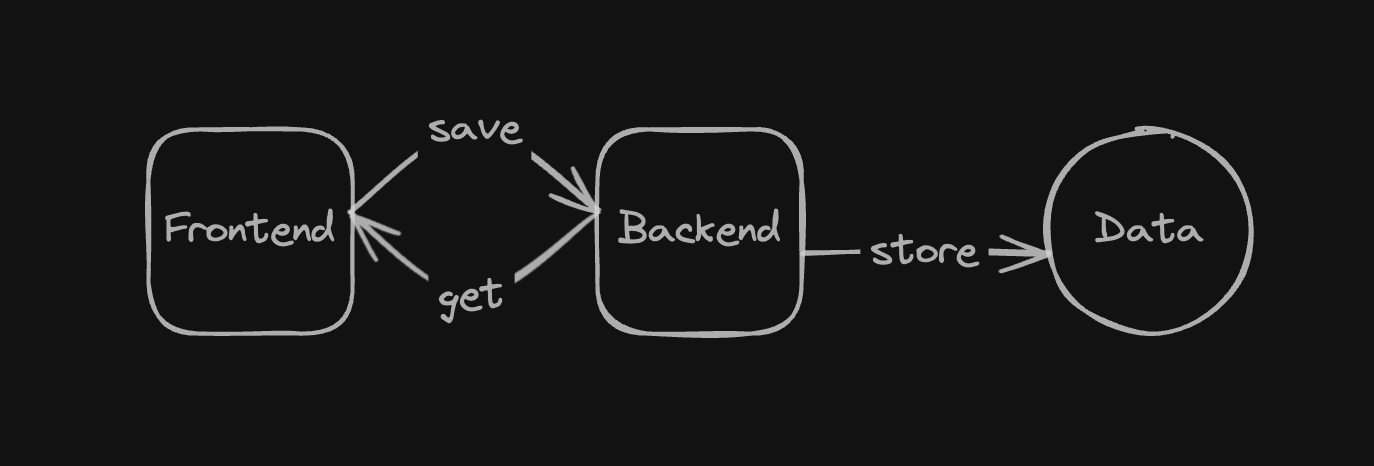
In traditional web apps, the frontend always relies on a backend for operations. Saving something? You'll likely see a loading spinner and might run into errors if the backend is down or if you're offline. Although modern frameworks like Nuxt speed up the initial website load with server-side rendering, the apps often slow down afterward. All your data is typically stored in the cloud, which means it's not really yours. If the app shuts down, you might lose access to your data, and downloading all your data isn't usually straightforward.
## What is Local-First?
Local-First is similar to offline-first. Like mobile apps on your phone, a local-first web app works offline. Here’s what makes an app truly local-first:
- **Instant Access:** You can get to your work right away, no waiting for data to load or sync.
- **Device Independence:** You can access your data from any device.
- **Network Independence:** You don't need an internet connection for basic tasks.
- **Effortless Collaboration:** The app supports easy collaboration, even offline.
- **Future-Proof Data:** Your data is safe over time, even as software changes.
- **Built-In Security:** Security and privacy are a priority.
- **User Control:** You own and control your data.
Not everything can be offline, like deleting your account, because that needs real-time backend communication to avoid errors.
For more on what a local-first app needs, check out [Ink & Switch: Seven Ideals for Local-First Software](https://www.inkandswitch.com/local-first/#seven-ideals-for-local-first-software).
## Types of Local-First Applications
There are two main types:
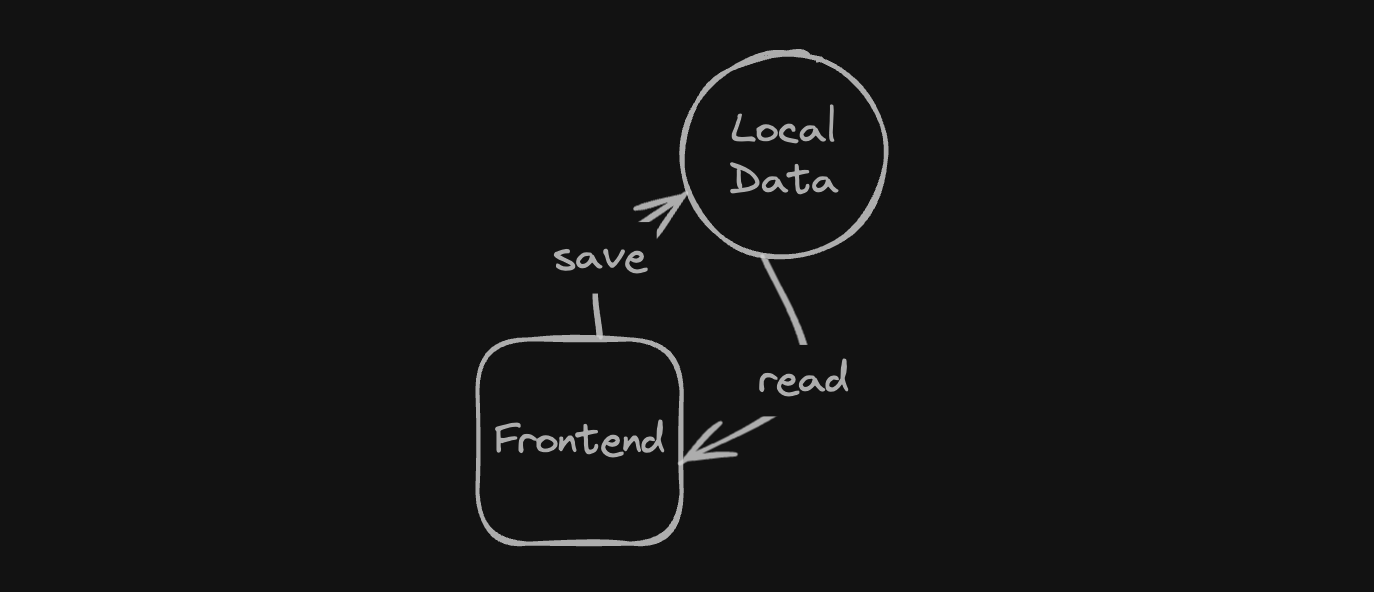
- **Local-Only Applications:** These apps don't sync data to the cloud. Data stays on your device. You can transfer data by exporting and importing it between devices. This is simpler but might not feel as smooth.
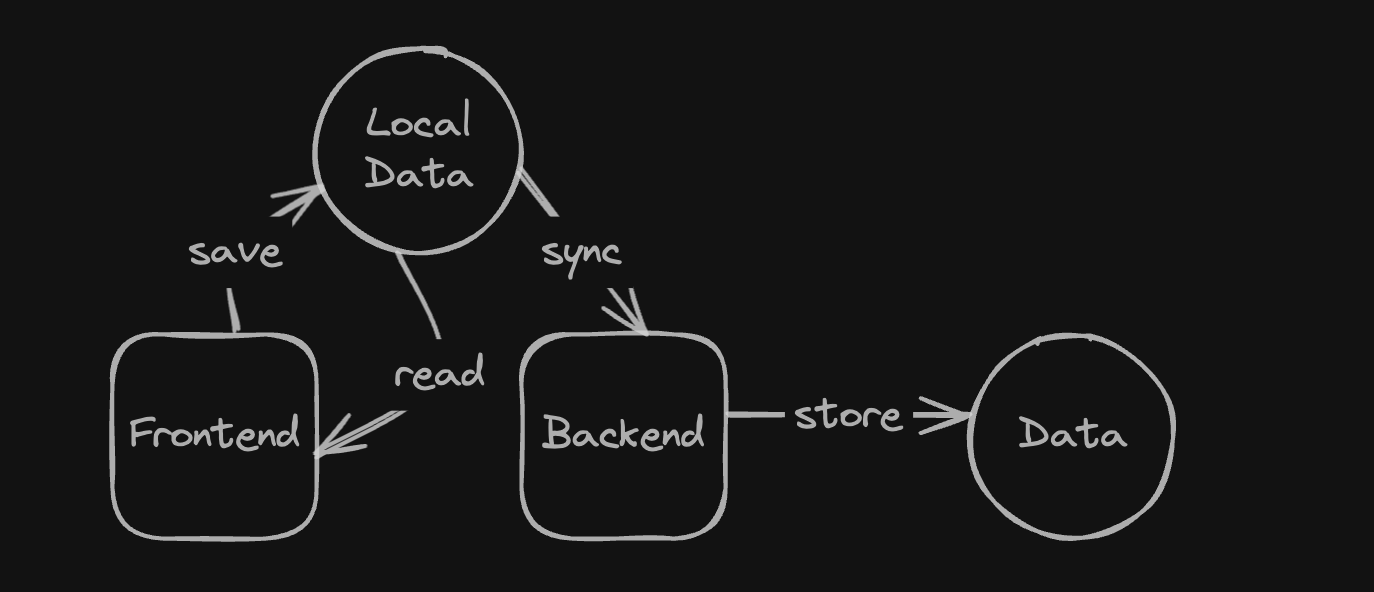
- **Sync-Enabled Applications:** These apps automatically sync your data to a cloud database. This can enhance user experience but adds complexity for developers.
## Challenges with Sync-Enabled Applications
Consider a note app used by multiple people. If someone edits a note offline and later syncs it, this could cause merge conflicts. Managing these requires special algorithms and data types. I'll talk more about this in the series.
Even for single-user apps, syncing local data with the cloud requires additional logic.
## How to Build Local-First Apps
Here are some key steps to build local-first apps, focusing on using Vue:
1. **Turn Your Vue SPA into a PWA**
Make your Vue Single Page Application (SPA) a Progressive Web App (PWA). This lets users interact with it like a native app.
2. **Manage Storage Properly**
Using localStorage alone isn't enough. We need better storage solutions.
3. **Implement Syncing and Authentication**
For syncing apps, you must handle user authentication to manage and secure data across devices.
4. **Ensure Security**
Encrypt sensitive user data stored in the browser to protect it.
I'll cover these topics in more detail throughout the series.
## Additional Resources
If you're interested in learning more about local-first applications, here are some resources:
1. **Website:** A good starter site with many follow-up topics - [Local First Web](https://localfirstweb.dev/)
2. **Podcast:** The awesome Local First podcast - [Local First FM](https://www.localfirst.fm/)
3. **Discord:** Join the Local First community on Discord - [Local First Discord](https://discord.com/invite/ZRrwZxn4rW)
## Summary
This series aims to be both informative and practical as we explore local-first applications. I'm excited to share what I've learned about local-first development and hope you find it useful. This is just the beginning!
| alexanderop |
1,869,027 | How to Read Excel XLSX Files from a URL Using JavaScript | Learn how to read Excel XLSX files from a URL using JavaScript. See more from SpreadJS today. | 0 | 2024-05-29T13:31:26 | https://developer.mescius.com/blogs/how-to-read-excel-xlsx-files-from-a-url-using-javascript | webdev, devops, javascript, tutorial | ---
canonical_url: https://developer.mescius.com/blogs/how-to-read-excel-xlsx-files-from-a-url-using-javascript
description: Learn how to read Excel XLSX files from a URL using JavaScript. See more from SpreadJS today.
---
**What You Will Need**
- Visual Studio Code
- [SpreadJS Release Files](https://developer.mescius.com/spreadjs/download)
**Controls Referenced**
- [SpreadJS - JavaScript Spreadsheet Component](https://developer.mescius.com/spreadjs)
- [Documentation](https://developer.mescius.com/spreadjs/docs/overview) | [Demos](https://developer.mescius.com/spreadjs/demos)
**Tutorial Concept**
Fetch and read Excel files from a URL into a JavaScript spreadsheet application.
---
[SpreadJS, our JavaScript spreadsheet API](https://developer.mescius.com/spreadjs "https://developer.mescius.com/spreadjs"), contains pure JavaScript logic for importing and exporting Excel XLSX files built right into its API with no dependencies on Microsoft Excel. This is very useful when you need to make your application platform independent. While we currently feature a live demo highlighting SpreadJS’ versatility in [opening and saving files from various formats on a user’s system](https://developer.mescius.com/spreadjs/demos/features/spreadjs-file-format/overview/ "https://developer.mescius.com/spreadjs/demos/features/spreadjs-file-format/overview/"), the JavaScript API also supports the direct import of Excel files from specified URLs. In this blog, we'll explore how to leverage the SpreadJS JavaScript spreadsheet API to effortlessly import and read Excel files from designated URLs.

## Read Excel XLSX Files from a URL in a JavaScript Application
1. [Create a JavaScript Spreadsheet Application](#Create)
2. [](https://grapecity.atlassian.net/wiki/spaces/UMT/pages/3635478718/REWRITE+How+to+Read+Excel+XLSX+Files+from+a+URL+Using+JavaScript#fetch-xlsx "#fetch-xlsx")[Fetch XLSX from the URL and Return the File as a Blob](#Fetch)
3. [](https://grapecity.atlassian.net/wiki/spaces/UMT/pages/3635478718/REWRITE+How+to+Read+Excel+XLSX+Files+from+a+URL+Using+JavaScript#read-xlsx "#read-xlsx")[Read the Excel File Blob and Import it to the JS Spreadsheet Instance](#Read)
<div style="background: #dfe2e6; padding: 15px;">
[Download the sample application and follow along with the blog.](https://cdn.mescius.io/umb/media/5bxny5wf/sjs-read-xlsx-from-url.zip)
</div>
## <a id="Create"></a>Create a JavaScript Spreadsheet Application
Start by creating a simple HTML file and include the needed SpreadJS release files, including:
* **Main SJS Library**: spread.sheets.all.x.x.x.min.js
* **Plug-Ins**:
* gc.spread.sheets.io – provides import/export Excel support
* spread.sheets.charts.x.x.x.min.js – provides chart support
* spread.sheets.shapes.x.x.x.min.js – provides shape support
* **CSS Spreadsheet Theme:**
* spread.sheets.excel2013white.css - [several SpreadJS themes to choose from!](https://developer.mescius.com/spreadjs/docs/features/styletheme#site_main_content-doc-content_title "https://developer.mescius.com/spreadjs/docs/features/styletheme#site_main_content-doc-content_title")
The code below references the **v17.0.8** build of SpreadJS. Be sure to update the version numbers based on the version you download.
```
<!doctype html>
<html lang="en" style="height:100%;font-size:14px;">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<!-- SpreadJS Release Files -->
<link rel="stylesheet" type="text/css" href="SpreadJS.Release.17.0.8/SpreadJS/css/gc.spread.sheets.excel2013lightGray.17.0.8.css" />
<script src="SpreadJS.Release.17.0.8/SpreadJS/scripts/gc.spread.sheets.all.17.0.8.min.js" type="text/javascript"></script>
<script src="SpreadJS.Release.17.0.8/SpreadJS/scripts/plugins/gc.spread.sheets.io.17.0.8.min.js" type="text/javascript"></script>
<script src="SpreadJS.Release.17.0.8/SpreadJS/scripts/plugins/gc.spread.sheets.shapes.17.0.8.min.js" type="text/javascript"></script>
<script src="SpreadJS.Release.17.0.8/SpreadJS/scripts/plugins/gc.spread.sheets.charts.17.0.8.min.js" type="text/javascript"></script>
</head>
<body>
</body>
</html>
```
Next, add a script to initialize the SpreadJS Workbook component and a div element to contain it. For this blog, we will also need an Input Type to specify the XLSX URL and an Input Button Type to invoke the import of the Excel file.
```
<!doctype html>
<html lang="en" style="height:100%;font-size:14px;">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<!-- SpreadJS Release Files -->
<link rel="stylesheet" type="text/css" href="SpreadJS.Release.17.0.8/SpreadJS/css/gc.spread.sheets.excel2013lightGray.17.0.8.css" />
<script src="SpreadJS.Release.17.0.8/SpreadJS/scripts/gc.spread.sheets.all.17.0.8.min.js" type="text/javascript"></script>
<script src="SpreadJS.Release.17.0.8/SpreadJS/scripts/plugins/gc.spread.sheets.io.17.0.8.min.js" type="text/javascript"></script>
<script src="SpreadJS.Release.17.0.8/SpreadJS/scripts/plugins/gc.spread.sheets.shapes.17.0.8.min.js" type="text/javascript"></script>
<script src="SpreadJS.Release.17.0.8/SpreadJS/scripts/plugins/gc.spread.sheets.charts.17.0.8.min.js" type="text/javascript"></script>
<script type="text/javascript">
window.onload = function () {
// Initialize the JavaScript spreadsheet instance
var workbook = new GC.Spread.Sheets.Workbook(document.getElementById("ss"));
</script>
</head>
<body>
<!-- JS spreadsheet workbook host element -->
<div class="container">
<div id="ss" style="width:75%;height:600px"></div>
<div class="options">
<H3>Import URL</H3>
<!-- Input type for URL -->
<input id="importURL" value="/media/bwyhahmx/profit-loss-statement.xlsx" />
<!-- Button to invoke XLSX
import-->
<button id="loadFromURL">Import Excel from URL</button>
</div>
</div>
</body>
</html>
```
The JavaScript spreadsheet UI component can now be seen in the browser.

<div style="background: #dfe2e6; padding: 15px;">
**License Information**
No license key is needed to use SpreadJS locally, but a Hostname License is required when deploying a web page displaying SpreadJS. [Check out the documentation](https://developer.mescius.com/spreadjs/docs/getstarted/trial_SpreadJS "https://developer.mescius.com/spreadjs/docs/getstarted/trial_SpreadJS") for license information.
</div>
## <a id="Fetch"></a>Fetch XLSX from the URL and Return the File as a Blob
Implement a click event listener to capture button clicks and retrieve the URL inputted by the user. Utilize the [Fetch API](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API/Using_Fetch "https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API/Using_Fetch") to establish a fetch request within the event, retrieving the Excel Workbook data from the provided link in blob format.
```
<script type="text/javascript">
window.onload = function () {
// Initialize the JavaScript spreadsheet instance
var workbook = new GC.Spread.Sheets.Workbook(document.getElementById("ss"));
// Fetch XLSX from URL and Return the File as a Blob
document.getElementById('loadFromURL').addEventListener('click', function () {
var url = document.getElementById("importURL").value;
fetch(url)
.then(res => res.blob()) // returns URL data a blob
.then((blob) => {
console.log(blob);
});
})
}
</script>
```
<div style="background: #dfe2e6; padding: 15px;">
**Import Note**
When developing web apps that fetch resources from external domains, you may encounter CORS errors like "_No 'Access-Control-Allow-Origin' header._"

The [moesif CORS browser extension](https://chrome.google.com/webstore/detail/moesif-orign-cors-changer/digfbfaphojjndkpccljibejjbppifbc?hl=en-US "https://chrome.google.com/webstore/detail/moesif-orign-cors-changer/digfbfaphojjndkpccljibejjbppifbc?hl=en-US") can bypass these restrictions during local development, but [server-side solutions or CORS headers are needed for production readiness](https://medium.com/@dtkatz/3-ways-to-fix-the-cors-error-and-how-access-control-allow-origin-works-d97d55946d9 "https://medium.com/@dtkatz/3-ways-to-fix-the-cors-error-and-how-access-control-allow-origin-works-d97d55946d9").
</div>
We are now able to return the URL as a blob. We can see this by writing it to the browser console.
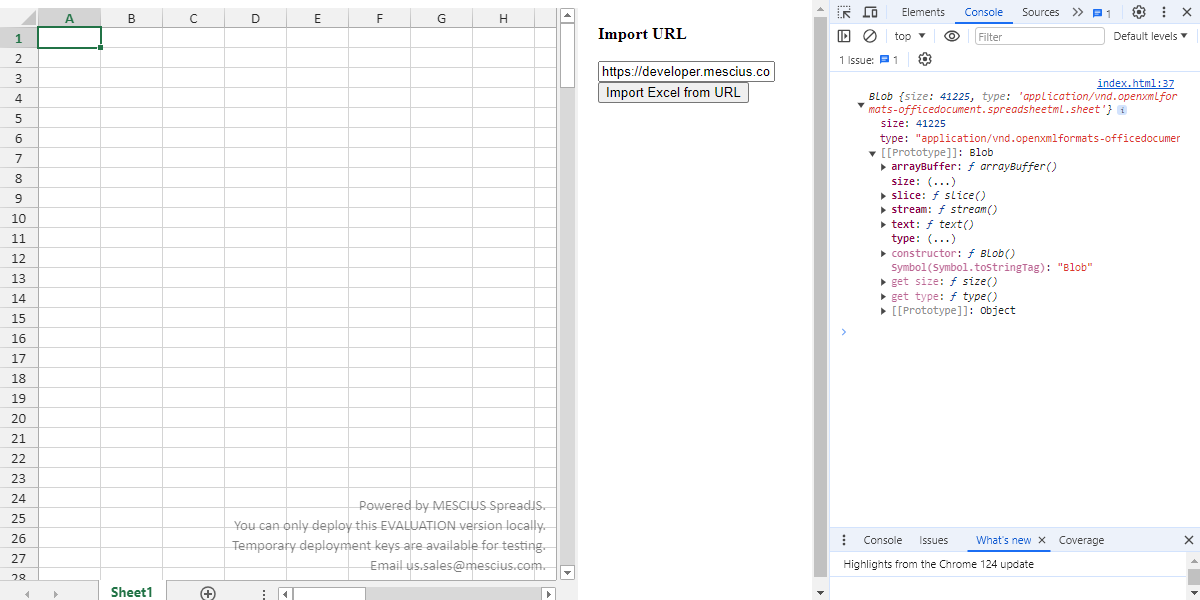
## <a id="Read"></a>Read the Excel File Blob and Import It to the JS Spreadsheet Instance
Now that we can fetch the Excel file’s data from its URL and return the file's data as a blob, our final step is to read the XLSX blob and import it to the JavaScript spreadsheet workbook instance. We can accomplish this using the SpreadJS [**import** method](https://developer.mescius.com/spreadjs/api/classes/GC.Spread.Sheets.Workbook#import "https://developer.mescius.com/spreadjs/api/classes/GC.Spread.Sheets.Workbook#import") within the fetch request.
```
<script type="text/javascript">
window.onload = function () {
// Initialize the JavaScript spreadsheet instance
var workbook = new GC.Spread.Sheets.Workbook(document.getElementById("ss"));
// Fetch XLSX from URL and Return the File as a Blob
document.getElementById('loadFromURL').addEventListener('click', function () {
var url = document.getElementById("importURL").value;
fetch(url)
.then(res => res.blob()) // returns URL data a blob
.then((blob) => {
// Import the Excel file blob to the JS workbook
workbook.import(blob);
});
})
}
</script>
```
Users can now import and edit Excel files in a web app from a URL. [Check out our other blog that covers how to add additional client-side importing and exporting capabilities](https://developer.mescius.com/blogs/how-to-import-export-excel-xlsx-using-javascript "https://developer.mescius.com/blogs/how-to-import-export-excel-xlsx-using-javascript").
## JavaScript Spreadsheet Components
This article only scratches the surface of the full capabilities of [**SpreadJS**](https://developer.mescius.com/spreadjs),our JavaScript spreadsheet component. Review the [documentation](https://developer.mescius.com/spreadjs/docs/overview "https://developer.mescius.com/spreadjs/docs/overview") to see some of the many available features, and check out our [online demos](https://developer.mescius.com/spreadjs/demos/ "https://developer.mescius.com/spreadjs/demos/") to see the features in action and interact with the sample code. Integrating a spreadsheet component into your applications allows you to customize your users' experience and provide them with familiar spreadsheet functionality without referring them to an external program. To learn more about SpreadJS, check out this video:
{% embed https://youtu.be/jACaSv6JVAc %} | chelseadevereaux |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.