
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,864,505 | Simple + Secure Password Generator with Python🔐 | There’s always seems to be an endless discussion around the best ways to learn a new programming... | 0 | 2024-05-28T13:09:00 | https://dev.to/oliviapandora/simple-secure-password-generator-with-python-4dmb | python, learning, security, cybersecurity | There’s always seems to be an endless discussion around the best ways to learn a new programming language. Now that I have more experience, I feel like I was too cautious when I started. I wanted to make sure I had the fundamentals down. And even though I still think that’s a good idea, I also think I learn best when I use projects to put all the concepts together and make them real.
This is probably why I love freeCodeCamp so much. Thankfully, they updated the [Python course](https://www.freecodecamp.org/learn/scientific-computing-with-python/) to make it project based like the Responsive Web Design course. But my latest Python project isn’t from freeCodeCamp, it’s from Al Sweigart (famous for Automate the Boring Stuff with Python) website called [Invent with Python](https://inventwithpython.com/pythongently/index.html). Al has a lot of free learning resources and projects for people looking to improve their Python skills. Because of my passion for cybersecurity, the password generator project caught my attention. To my surprise, the instructions were easy to understand.
⭐[GitHub link](https://github.com/oliviapandora/urban-bassoon/tree/main)
I can see why Al Sweigart's learning materials are so popular. In the future I want to use more of these smaller projects to help me get a better understanding of Python!
| oliviapandora |
1,867,675 | From Sparse to Soft Mixtures of Experts | From Sparse to Soft Mixtures of Experts | 0 | 2024-05-28T13:07:09 | https://aimodels.fyi/papers/arxiv/from-sparse-to-soft-mixtures-experts | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [From Sparse to Soft Mixtures of Experts](https://aimodels.fyi/papers/arxiv/from-sparse-to-soft-mixtures-experts). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Sparse mixture of expert (MoE) architectures can scale model capacity without significant increases in training or inference costs
- However, MoEs suffer from issues like training instability, token dropping, inability to scale the number of experts, and ineffective finetuning
- This paper proposes **Soft MoE**, a fully-differentiable sparse Transformer that addresses these challenges while maintaining the benefits of MoEs
## Plain English Explanation
[Soft MoE](https://aimodels.fyi/papers/arxiv/multi-head-mixture-experts) is a type of AI model that uses a "mixture of experts" approach. This means the model has multiple specialized "expert" components that each focus on different parts of the input. This allows the model to handle more complex tasks without dramatically increasing the overall size and cost of the model.
Traditional mixture of expert models have some issues, like being unstable during training, dropping important information, struggling to scale up the number of experts, and having trouble fine-tuning the model for new tasks. **Soft MoE** aims to address these problems.
The key innovation in Soft MoE is that it performs a "soft assignment" - instead of strictly routing each input to a single expert, it passes weighted combinations of the inputs to each expert. This allows the experts to collaborate and share information more effectively. As a result, Soft MoE can achieve better performance than dense Transformer models and other MoE approaches, while still maintaining the efficiency benefits of the mixture of experts architecture.
## Technical Explanation
[Soft MoE](https://aimodels.fyi/papers/arxiv/multi-head-mixture-experts) is a fully-differentiable sparse Transformer model that builds on prior work in [mixture of experts (MoEs)](https://aimodels.fyi/papers/arxiv/xmoe-sparse-models-fine-grained-adaptive-expert) architectures. Like other MoEs, Soft MoE has multiple expert components that each specialize on different parts of the input. However, Soft MoE uses a "soft assignment" mechanism, where different weighted combinations of the input tokens are passed to each expert, rather than strictly routing each token to a single expert.
This soft assignment approach allows the experts to collaborate and share information more effectively, addressing issues seen in prior MoE models like [training instability, token dropping, inability to scale experts, and ineffective finetuning](https://aimodels.fyi/papers/arxiv/hypermoe-toward-better-mixture-experts-via-transferring). Additionally, because the experts only process a subset of the combined input tokens, Soft MoE can achieve larger model capacity and better performance compared to dense Transformer models, with only a small increase in inference time.
The paper evaluates Soft MoE on visual recognition tasks, where it significantly outperforms both dense Transformers (ViTs) and popular MoE approaches like [Tokens-to-Choose and Experts-to-Choose](https://aimodels.fyi/papers/arxiv/dense-training-sparse-inference-rethinking-training-mixture). Furthermore, Soft MoE scales well - the authors demonstrate a **Soft MoE Huge/14 model with 128 experts** in 16 MoE layers that has over **40x more parameters** than a ViT Huge/14, but with only a **2% increase in inference time**, and substantially better quality.
## Critical Analysis
The Soft MoE paper makes a compelling case for this new approach to mixture of experts architectures. By addressing key limitations of prior MoE models, Soft MoE demonstrates the potential for sparse, efficient models to outperform dense Transformer architectures on a range of tasks.
However, the paper does not delve into potential drawbacks or limitations of the Soft MoE approach. For example, the soft assignment mechanism adds computational overhead compared to hard routing, and the impact on training time and stability is not explored in depth. Additionally, the evaluation is limited to visual recognition tasks, so the generalizability of Soft MoE to other domains like natural language processing is unclear.
Furthermore, the authors do not consider potential societal impacts or ethical implications of deploying large, high-capacity models like Soft MoE Huge. As these models become more powerful and ubiquitous, it will be important to carefully examine issues around fairness, transparency, and responsible AI development.
Overall, the Soft MoE paper represents an exciting advance in efficient neural network architectures. But as with any powerful new technology, a more thorough [critical analysis](https://aimodels.fyi/papers/arxiv/toward-inference-optimal-mixture-expert-large-language) is warranted to fully understand its limitations and potential risks.
## Conclusion
The Soft MoE paper proposes a novel sparse Transformer architecture that addresses key challenges with prior mixture of experts models. By using a fully-differentiable soft assignment mechanism, Soft MoE is able to scale model capacity and performance without significant increases in training or inference cost.
Evaluated on visual recognition tasks, Soft MoE demonstrates significant improvements over dense Transformer models and other popular MoE approaches. The ability to build extremely large Soft MoE models, like the 40x larger Soft MoE Huge variant, while maintaining efficient inference, suggests this architecture could be a powerful tool for building high-capacity AI systems.
However, the paper does not fully explore the limitations and potential risks of this technology. As Soft MoE and similar efficient models become more prominent, it will be important to carefully consider their societal impact and ensure they are developed responsibly. Overall, the Soft MoE paper represents an important advance, but further research and critical analysis will be needed to understand its broader implications.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,680 | ARAIDA: Analogical Reasoning-Augmented Interactive Data Annotation | ARAIDA: Analogical Reasoning-Augmented Interactive Data Annotation | 0 | 2024-05-28T13:08:53 | https://aimodels.fyi/papers/arxiv/araida-analogical-reasoning-augmented-interactive-data-annotation | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [ARAIDA: Analogical Reasoning-Augmented Interactive Data Annotation](https://aimodels.fyi/papers/arxiv/araida-analogical-reasoning-augmented-interactive-data-annotation). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper introduces Araida, a system that aims to improve the efficiency and quality of interactive data annotation tasks by leveraging analogical reasoning.
- Araida uses language models trained on large-scale analogical reasoning data to provide suggestions and guidance to annotators, helping them make more informed and consistent decisions during the annotation process.
- The key innovation of Araida is its ability to identify and leverage relevant analogies to assist annotators, which can lead to faster and more reliable data labeling.
## Plain English Explanation
Araida is a new system designed to make it easier and more accurate for people to annotate or label data, such as classifying images or transcribing text. The core idea is to use [**analogical reasoning**](https://aimodels.fyi/papers/arxiv/can-language-models-learn-analogical-reasoning-investigating) - the ability to recognize and apply relevant comparisons or similarities - to provide helpful suggestions to the annotators.
For example, if an annotator is trying to classify a new image, Araida can draw connections to similar images the annotator has seen before and provide relevant information to guide their decision. This can help the annotator work more efficiently and make more consistent choices, leading to higher-quality labeled data.
The [**system leverages large language models**](https://aimodels.fyi/papers/arxiv/analogykb-unlocking-analogical-reasoning-language-models-million) that have been trained on vast amounts of data to develop strong analogical reasoning capabilities. Araida then integrates these capabilities into the interactive annotation process, assisting the human annotators and enhancing the overall workflow.
## Technical Explanation
The Araida system is designed to augment interactive data annotation tasks by leveraging analogical reasoning. It does this by integrating a language model trained on large-scale analogical reasoning data into the annotation interface.
When an annotator is faced with a new data instance (e.g., an image or a text snippet), Araida analyzes the context and identifies relevant analogies from its knowledge base. It then presents these analogies to the annotator, along with information about how the analogies might inform the current annotation decision.
For example, if an annotator is classifying an image of a dog, Araida might suggest analogies to previous images of dogs the annotator has seen, highlighting key visual features or contextual cues that could help the annotator make a more accurate classification.
The authors evaluate Araida in the context of several real-world annotation tasks, such as image classification and text summarization. Their results show that the use of analogical reasoning significantly improves the efficiency and quality of the annotation process, leading to faster task completion and more consistent labeling decisions compared to a standard annotation workflow.
## Critical Analysis
The Araida system presents an innovative approach to leveraging analogical reasoning to enhance interactive data annotation. By integrating language models trained on large-scale analogical data, the system is able to identify and surface relevant comparisons that can guide annotators in their decision-making.
One potential limitation of the research is the reliance on the quality and coverage of the underlying analogical reasoning knowledge base. If the language model has not been trained on a sufficiently diverse set of analogies, the system may struggle to provide useful suggestions in certain contexts. [**Further research**](https://aimodels.fyi/papers/arxiv/capturing-perspectives-crowdsourced-annotators-subjective-learning-tasks) could explore ways to expand and curate this knowledge base, or to dynamically generate analogies based on the specific annotation task and data.
Additionally, the paper does not delve deeply into the potential biases or limitations of the analogical reasoning approach. It is possible that the suggested analogies could inadvertently reinforce existing biases or lead to suboptimal annotation decisions in certain cases. [**Investigating the societal implications**](https://aimodels.fyi/papers/arxiv/analogist-out-box-visual-context-learning-image) of using analogical reasoning in data annotation tasks would be an important area for future research.
Overall, the Araida system represents a promising step towards enhancing interactive data annotation through the use of advanced cognitive capabilities. As the field of artificial intelligence continues to progress, integrating such techniques into real-world annotation workflows could lead to significant improvements in the efficiency and quality of labeled data, with far-reaching implications for a wide range of AI applications.
## Conclusion
The Araida system introduces a novel approach to interactive data annotation that leverages analogical reasoning to provide guidance and suggestions to human annotators. By tapping into the rich knowledge of language models trained on large-scale analogical data, Araida is able to identify relevant comparisons and insights that can help annotators make more informed and consistent decisions.
The authors' evaluation of Araida across several real-world annotation tasks demonstrates the potential of this approach to improve the efficiency and quality of the annotation process. As the demand for high-quality labeled data continues to grow in the field of AI, techniques like Araida could play a crucial role in streamlining and enhancing this critical data-centric workflow.
While the research presents a promising step forward, further investigation is needed to address potential limitations and biases in the analogical reasoning approach, as well as to explore ways to expand and refine the underlying knowledge base. Nonetheless, the Araida system represents an exciting development in the ongoing effort to unlock the full potential of human-AI collaboration in the creation of reliable and robust data sets.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,679 | Data-Driven Decisions at Your Fingertips: The Executive Power BI Dashboard | In today's fast-paced business environment, executives need to make informed decisions quickly. The... | 0 | 2024-05-28T13:08:34 | https://dev.to/stevejacob45678/data-driven-decisions-at-your-fingertips-the-executive-power-bi-dashboard-3a3i | powerbi, powerbiconsulting, powerbisolutions | In today's fast-paced business environment, executives need to make informed decisions quickly. The days of sifting through piles of reports and endless spreadsheets are over. Enter the Executive Power BI Dashboard – a powerful tool that brings critical data to your fingertips, transforming the way leaders navigate the complexities of modern business.
What is Power BI?
Microsoft Power BI is a suite of business analytics tools designed to help you analyze data and share insights. With **[Power BI](https://www.itpathsolutions.com/power-bi-consulting-services/)**, you can create interactive dashboards and reports that provide a comprehensive view of your business operations. It connects to a wide range of data sources, from spreadsheets to cloud services, and offers advanced data visualization capabilities.
Why Executives Need an Executive Dashboard
1. Real-Time Data Access: Executives no longer have to wait for periodic reports to understand their business's performance. With an executive dashboard, they have real-time access to key metrics and KPIs, enabling prompt decision-making.
2. Improved Efficiency: Instead of piecing together information from various sources, a dashboard consolidates all essential data into one intuitive interface. This not only saves time but also reduces the risk of errors and inconsistencies.
3. Better Strategic Planning: With comprehensive insights at their disposal, executives can identify trends, anticipate challenges, and capitalize on opportunities. This data-driven approach enhances strategic planning and execution.
4. Enhanced Collaboration: Dashboards can be easily shared across teams and departments, fostering a culture of transparency and collaboration. Everyone works from the same data, ensuring alignment and cohesion in decision-making.
Key Features of an Executive Power BI Dashboard
1. Customizable KPIs
Every business is unique, and so are its critical success factors. Power BI allows you to customize your dashboard with the KPIs that matter most to your organization. Whether it’s financial performance, customer satisfaction, or operational efficiency, you can tailor the dashboard to reflect your strategic priorities.
2. Interactive Visualizations
Power BI offers a rich library of interactive charts, graphs, and maps. These visualizations make complex data easier to understand at a glance. You can drill down into specifics, filter data dynamically, and uncover insights with just a few clicks.
3. Cross-Platform Accessibility
With Power BI, your data is accessible anytime, anywhere. Whether you’re in the office, on a plane, or at a conference, you can access your dashboard from your laptop, tablet, or smartphone. This ensures you are always in the know, no matter where you are.
4. Integration with Existing Systems
Power BI seamlessly integrates with a variety of data sources, including Excel, SQL Server, cloud services like Azure and Salesforce, and many more. This integration ensures that your dashboard is always up-to-date with the latest data from across your organization.
5. AI-Driven Insights
Leverage the power of artificial intelligence with Power BI’s built-in AI capabilities. Features like natural language queries allow you to ask questions about your data in plain English and get answers instantly. Advanced analytics and machine learning models can also provide predictive insights, helping you stay ahead of the curve.
Building Your Executive Dashboard: Best Practices
1. Define Clear Objectives: Identify what you want to achieve with your dashboard. Establish clear objectives and select KPIs that align with your strategic goals.
2. Keep it Simple: While it’s tempting to include as much data as possible, a cluttered dashboard can be overwhelming. Focus on the most critical information and present it in a clear, concise manner.
3. Ensure Data Quality: The insights you gain from your dashboard are only as good as the data behind them. Ensure your data is accurate, complete, and up-to-date.
4. Regularly Review and Update: Business needs evolve, and so should your dashboard. Regularly review your KPIs and update your dashboard to reflect any changes in your business environment or strategy.
5. Train Your Team: Ensure your team is well-trained in using Power BI and interpreting the data. This maximizes the value of your dashboard and fosters a data-driven culture within your organization.
Conclusion
The Executive **[Power BI Dashboard](https://www.itpathsolutions.com/top-power-bi-dashboard-reports-that-can-be-used-for-major-industry-verticals/)** is more than just a reporting tool; it's a strategic asset that empowers executives to make informed, timely decisions. By leveraging real-time data, interactive visualizations, and AI-driven insights, leaders can navigate the complexities of the modern business landscape with confidence and agility.
Embrace the power of data-driven decision-making with the Executive Power BI Dashboard and transform the way you lead your organization. The future of business intelligence is at your fingertips.
| stevejacob45678 |
1,867,678 | InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars | InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars | 0 | 2024-05-28T13:08:18 | https://aimodels.fyi/papers/arxiv/invertavatar-incremental-gan-inversion-generalized-head-avatars | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars](https://aimodels.fyi/papers/arxiv/invertavatar-incremental-gan-inversion-generalized-head-avatars). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Existing methods for creating digital avatars often have limitations such as shape distortion, expression inaccuracy, and identity flickering.
- Traditional one-shot inversion techniques fail to fully leverage multiple input images for detailed feature extraction.
- The proposed framework, [Incremental 3D GAN Inversion](https://aimodels.fyi/papers/arxiv/n-out-faithful-3d-gan-inversion-volumetric), aims to enhance avatar reconstruction performance by increasing fidelity from multiple frames.
## Plain English Explanation
The research focuses on improving the quality and realism of digital avatars, which are virtual representations of people's faces and expressions. Current methods for creating these avatars often have issues, such as the shape of the face being distorted, the expressions not being accurately captured, and the identity of the person flickering or changing.
Additionally, existing techniques that only use a single input image to create the avatar struggle to fully capture all the detailed features and nuances of the person's appearance. The researchers propose a new framework called [Incremental 3D GAN Inversion](https://aimodels.fyi/papers/arxiv/n-out-faithful-3d-gan-inversion-volumetric) that aims to address these problems.
The key idea is to use multiple input images of a person, rather than just one, to reconstruct a more detailed and accurate 3D avatar. The framework includes a unique "animatable 3D GAN prior" that helps control the expressions and movements of the avatar, as well as a novel "neural texture encoder" that categorizes the different textures and features of the person's face.
By using these techniques and aggregating information from multiple frames, the researchers were able to create avatars with improved geometry, texture, and overall fidelity compared to previous methods. This could lead to more realistic and engaging digital avatars for a variety of applications, such as video games, virtual reality, and online communication.
## Technical Explanation
The [Incremental 3D GAN Inversion](https://aimodels.fyi/papers/arxiv/n-out-faithful-3d-gan-inversion-volumetric) framework introduces several key innovations to enhance avatar reconstruction performance. First, it incorporates a unique "animatable 3D GAN prior" that provides enhanced expression controllability, building on previous work like [GeneAvatar](https://aimodels.fyi/papers/arxiv/geneavatar-generic-expression-aware-volumetric-head-avatar) and [InstantAvatar](https://aimodels.fyi/papers/arxiv/instantavatar-efficient-3d-head-reconstruction-via-surface).
Additionally, the framework includes a "neural texture encoder" that categorizes texture feature spaces based on UV parameterization, allowing for more detailed and accurate texture reconstruction. This addresses limitations of traditional techniques that struggle to learn correspondences between observation and canonical spaces.
The architecture also emphasizes pixel-aligned image-to-image translation, which helps mitigate the need to learn these challenging correspondences. Furthermore, the researchers incorporate ConvGRU-based recurrent networks to aggregate temporal data from multiple frames, boosting the reconstruction of both geometry and texture details.
These innovations, combined with the use of multiple input images, enable the [Incremental 3D GAN Inversion](https://aimodels.fyi/papers/arxiv/n-out-faithful-3d-gan-inversion-volumetric) framework to achieve state-of-the-art performance on one-shot and few-shot avatar animation tasks, outperforming previous methods like [Diffusion-Driven GAN Inversion](https://aimodels.fyi/papers/arxiv/diffusion-driven-gan-inversion-multi-modal-face) and [GGAvatar](https://aimodels.fyi/papers/arxiv/ggavatar-geometric-adjustment-gaussian-head-avatar).
## Critical Analysis
The research paper presents a compelling and innovative approach to enhancing the quality and realism of digital avatars. The key strengths of the [Incremental 3D GAN Inversion](https://aimodels.fyi/papers/arxiv/n-out-faithful-3d-gan-inversion-volumetric) framework include its ability to leverage multiple input images, its unique animatable 3D GAN prior and neural texture encoder, and its emphasis on pixel-aligned image-to-image translation.
However, the paper does acknowledge some potential limitations, such as the need for further investigation into the scalability and robustness of the framework when dealing with more diverse datasets and real-world scenarios. Additionally, the researchers mention that the current implementation may not be suitable for real-time applications due to its computational complexity.
Further research could explore ways to optimize the framework's efficiency, as well as investigate its applicability to other types of avatar-related tasks, such as full-body reconstruction or integration with virtual reality systems. Exploring the ethical implications of such advanced avatar technologies, particularly regarding privacy and identity representation, could also be an important area for future study.
## Conclusion
The [Incremental 3D GAN Inversion](https://aimodels.fyi/papers/arxiv/n-out-faithful-3d-gan-inversion-volumetric) framework represents a significant advancement in the field of digital avatar creation, addressing key limitations of existing methods. By leveraging multiple input images and incorporating novel architectural components, the researchers have demonstrated a way to improve the fidelity, expression accuracy, and temporal stability of reconstructed avatars.
This work has the potential to enhance various applications, from video games and virtual reality to online communication and social media. As the demand for more realistic and engaging digital representations continues to grow, the insights and techniques presented in this paper could pave the way for a new generation of high-quality, personalized avatars that better capture the nuances and individuality of human appearance and expression.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,677 | Why are Sensitive Functions Hard for Transformers? | Why are Sensitive Functions Hard for Transformers? | 0 | 2024-05-28T13:07:44 | https://aimodels.fyi/papers/arxiv/why-are-sensitive-functions-hard-transformers | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Why are Sensitive Functions Hard for Transformers?](https://aimodels.fyi/papers/arxiv/why-are-sensitive-functions-hard-transformers). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Researchers have found that transformers, a type of machine learning model, have limitations in learning certain simple formal languages and tend to favor low-degree functions.
- However, the theoretical understanding of these biases and limitations is still limited.
- This paper presents a theory that explains these empirical observations by studying the loss landscape of transformers.
## Plain English Explanation
The paper discusses the learning abilities and biases of [transformers](https://aimodels.fyi/papers/arxiv/beyond-scaling-laws-understanding-transformer-performance-associative), a widely used type of machine learning model. Previous research has shown that transformers struggle to learn certain simple mathematical patterns, like the [PARITY](https://aimodels.fyi/papers/arxiv/what-formal-languages-can-transformers-express-survey) function, and tend to favor simpler, low-degree functions.
The authors of this paper wanted to understand why transformers have these limitations. They discovered that it has to do with the way transformers are designed - the **sensitivity** of the model's output to different parts of the input. Transformers whose output is sensitive to many parts of the input string exist in isolated points in the parameter space, making it hard for the model to generalize well.
In other words, transformers are biased towards learning functions that don't rely on many parts of the input. This explains why they struggle with tasks like [PARITY](https://aimodels.fyi/papers/arxiv/when-can-transformers-reason-abstract-symbols), which require the model to consider the entire input string, and why they tend to favor simpler, low-degree functions.
The researchers show that this sensitivity-based theory can explain a wide range of empirical observations about transformer learning, including their [generalization biases](https://aimodels.fyi/papers/arxiv/initialization-is-critical-to-whether-transformers-fit) and their difficulty in learning certain types of patterns.
## Technical Explanation
The paper presents a theory that explains the learning biases and limitations of transformers by analyzing the **loss landscape** of these models. The key insight is that transformers whose output is sensitive to many parts of the input string exist in isolated points in the parameter space, leading to a **low-sensitivity bias** in generalization.
The authors first review the existing empirical studies that have identified various learnability biases and limitations of transformers, such as their difficulty in learning [simple formal languages](https://aimodels.fyi/papers/arxiv/what-formal-languages-can-transformers-express-survey) like PARITY and their bias towards low-degree functions.
They then present a theoretical analysis showing that the constrained loss landscape of transformers, due to their input-space sensitivity, can explain these empirical observations. Transformers that are sensitive to many parts of the input string occupy isolated points in the parameter space, making it hard for the model to generalize to new examples.
The paper provides both theoretical and empirical evidence to support this theory. The authors show that this input-sensitivity-based theory can unify a broad array of empirical findings about transformer learning, including their generalization bias towards low-sensitivity and low-degree functions, as well as their difficulty in [length generalization for PARITY](https://aimodels.fyi/papers/arxiv/transformers-as-transducers).
## Critical Analysis
The paper provides a compelling theoretical framework for understanding the learning biases and limitations of transformers. By focusing on the loss landscape and input-space sensitivity of these models, the authors are able to offer a unified explanation for a range of empirical observations that have been reported in the literature.
However, the paper does not address some potential limitations or caveats of this theory. For example, it's unclear how the input-sensitivity bias might interact with other architectural choices or training techniques used in transformer models. Additionally, the theory may not fully capture the role of inductive biases introduced by the transformer's attention mechanism or other architectural components.
Further research is needed to fully validate and extend this theory, such as exploring its implications for other types of neural networks or investigating how it might inform the design of more expressive and generalizable transformer-based models.
## Conclusion
This paper presents a novel theory that explains the learning biases and limitations of transformer models by studying the constraints of their loss landscape. The key insight is that transformers whose output is sensitive to many parts of the input string exist in isolated points in the parameter space, leading to a bias towards low-sensitivity and low-degree functions.
The authors demonstrate that this input-sensitivity-based theory can unify a broad range of empirical observations about transformer learning, including their difficulty in [learning simple formal languages](https://aimodels.fyi/papers/arxiv/what-formal-languages-can-transformers-express-survey) and their generalization biases. This work highlights the importance of considering not just the in-principle expressivity of a model, but also the structure of its loss landscape, when studying its learning capabilities and limitations.
As transformer models continue to play a central role in many AI applications, understanding their inductive biases and developing techniques to overcome them will be crucial for advancing the field of machine learning.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,676 | Hyundai Nha Trang | Hyundai Nha Trang là đại lý ủy quyền chính thức của Hyundai Thành Công Việt Nam, KM6 Thôn Võ Cang-Xã... | 0 | 2024-05-28T13:07:20 | https://dev.to/hyundainhatrang/hyundai-nha-trang-2p7m | Hyundai Nha Trang là đại lý ủy quyền chính thức của Hyundai Thành Công Việt Nam, KM6 Thôn Võ Cang-Xã Vĩnh Trung-TP.Nha Trang. Chuyên mua bán, bảo hành, bảo trì và sửa chữa xe các dòng xe ôtô Hyundai.
Website: https://hyundaikhanhhoa.com/
Phone: 0905255779
Address: Km6 Thon Vo Cang - Xa Vĩinh Trung
https://www.are.na/hyundai-nha-trang/channels
https://research.openhumans.org/member/hyundainhatrang
https://glose.com/u/hyundainhatrang
https://flipboard.com/@HyundaiNhaTrang
https://devpost.com/w-ol-f-vn-9-0
https://community.fyers.in/member/3p52Xsgvex
https://vimeo.com/user220305114
https://chart-studio.plotly.com/~hyundainhatrang
https://zzb.bz/6vsPQ
https://www.divephotoguide.com/user/hyundainhatrang/
https://portfolium.com/hyundainhatrang
https://roomstyler.com/users/hyundainhatrang
https://www.5giay.vn/members/hyundainhatrang.101974483/#info
https://www.fitday.com/fitness/forums/members/hyundainhatrang.html
https://edenprairie.bubblelife.com/users/hyundainhatrang
https://us.enrollbusiness.com/BusinessProfile/6699829/hyundainhatrang
https://www.kniterate.com/community/users/hyundainhatrang/
https://www.dnnsoftware.com/activity-feed/my-profile/userid/3198960
https://able2know.org/user/hyundainhatrang/
https://www.instapaper.com/p/hyundainhatrang
https://my.desktopnexus.com/hyundainhatrang/
https://www.ethiovisit.com/myplace/hyundainhatrang
https://diendannhansu.com/members/hyundainhatrang.49979/#about
https://www.iniuria.us/forum/member.php?440041-hyundainhatrang
https://pxhere.com/en/photographer-me/4269206
https://qiita.com/hyundainhatrang
https://hypothes.is/users/hyundainhatrang
http://forum.yealink.com/forum/member.php?action=profile&uid=342546
https://turkish.ava360.com/user/hyundainhatrang/#
https://hackmd.io/@hyundainhatrang
https://guides.co/a/hyundai-nha-trang
https://qooh.me/hyundainhatra
https://www.metooo.io/u/6655ce9c0c59a9224253de5b
http://idea.informer.com/users/hyundainhatrang/?what=personal
https://piczel.tv/watch/hyundainhatrang
https://rotorbuilds.com/profile/42453/
https://www.deviantart.com/hyundainhatrang/about
https://expathealthseoul.com/profile/hyundai-nha-trang/
https://vnxf.vn/members/hyundainhatran.81459/#about
https://readthedocs.org/projects/httpshyundaikhanhhoacom/
https://wibki.com/hyundainhatrang?tab=Hyundai%20Nha%20Trang
https://www.silverstripe.org/ForumMemberProfile/show/152647
https://www.artscow.com/user/3196483
https://padlet.com/wolfvn90_6
https://englishbaby.com/findfriends/gallery/detail/2505365
https://collegeprojectboard.com/author/hyundainhatrang/
https://www.equinenow.com/farm/hyundainhatrang.htm
https://stocktwits.com/hyundainhatrang
https://rentry.co/3xiv3cth
https://penzu.com/p/6ad8f9526f5d5fad
www.artistecard.com/hyundainhatrang#!/contact
https://pinshape.com/users/4448733-hyundainhatrang#designs-tab-open
https://socialtrain.stage.lithium.com/t5/user/viewprofilepage/user-id/65359
https://os.mbed.com/users/hyundainhatrang/
https://8tracks.com/hyundainhatrang
https://telegra.ph/hyundainhatrang-05-28
https://community.tableau.com/s/profile/0058b00000IZYi0
https://circleten.org/a/292033
https://www.noteflight.com/profile/11fb8d3f372f646a3fc3b6a7c40f778145525666
https://allmylinks.com/hyundainhatrang
https://dreevoo.com/profile.php?pid=642457
https://www.penname.me/@hyundainhatrang
https://willysforsale.com/profile/hyundainhatrang
https://www.webwiki.com/hyundaikhanhhoa.com
http://hawkee.com/profile/6965075/
https://www.wpgmaps.com/forums/users/hyundainhatrang/
https://hackerone.com/hyundainhatrang?type=user
http://buildolution.com/UserProfile/tabid/131/userId/405787/Default.aspx
https://forum.dmec.vn/index.php?members/hyundainhatrang.61100/
https://www.kickstarter.com/profile/hyundainhatrang/about
https://www.mixcloud.com/hyundainhatrang/
https://participez.nouvelle-aquitaine.fr/profiles/hyundainhatrang/activity?locale=en
https://link.space/@hyundainhatrang
https://answerpail.com/index.php/user/hyundainhatrang
https://jsfiddle.net/user/hyundainhatrang/
https://disqus.com/by/hyundainhatrang/about/
https://files.fm/hyundainhatrang/info
https://peatix.com/user/22405467/view
https://www.reverbnation.com/hyundainhatrang
https://www.funddreamer.com/users/hyundai-nha-trang
https://www.chordie.com/forum/profile.php?id=1964957
https://dev.to/hyundainhatrang
https://gettr.com/user/hyundainhatrang
https://www.fimfiction.net/user/746972/hyundainhatrang
https://controlc.com/1f590856
https://nhattao.com/members/hyundainhatrang.6534903/
https://wperp.com/users/hyundainhatrang/
https://timeswriter.com/members/hyundainhatrang/
https://www.codingame.com/profile/3755f8fa79a126e963ef45d4c9fafdc11786906
https://naijamp3s.com/index.php?a=profile&u=hyundainhatrang
https://webflow.com/@hyundainhatrang
https://www.anobii.com/fr/01dd5b90eb43d5be80/profile/activity
https://pastelink.net/o3eikup1
https://doodleordie.com/profile/hyundainhatrang
https://www.intensedebate.com/people/bahyundainhatr
https://www.exchangle.com/hyundainhatrang
https://www.titantalk.com/members/hyundainhatrang.375643/#about
https://www.scoop.it/u/hyundainha-trang
https://www.credly.com/users/hyundai-nha-trang/badges
https://hub.docker.com/u/hyundainhatrang
https://www.cineplayers.com/hyundainhatrang
https://hubpages.com/@hyundainhatrang#about
https://linkmix.co/23457515
https://www.proarti.fr/account/hyundainhatrang
https://leetcode.com/u/hyundainhatrang/
| hyundainhatrang | |
1,867,674 | ExcelFormer: Can a DNN be a Sure Bet for Tabular Prediction? | ExcelFormer: Can a DNN be a Sure Bet for Tabular Prediction? | 0 | 2024-05-28T13:06:35 | https://aimodels.fyi/papers/arxiv/excelformer-can-dnn-be-sure-bet-tabular | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [ExcelFormer: Can a DNN be a Sure Bet for Tabular Prediction?](https://aimodels.fyi/papers/arxiv/excelformer-can-dnn-be-sure-bet-tabular). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Tabular data is ubiquitous in real-world applications, but users often create biased tables with custom prediction targets
- Existing models like [Gradient Boosting Decision Trees](https://aimodels.fyi/papers/arxiv/buff-boosted-decision-tree-based-ultra-fast) and [deep neural networks](https://aimodels.fyi/papers/arxiv/tabdoor-backdoor-vulnerabilities-transformer-based-neural-networks) have challenges for casual users, including model selection and heavy hyperparameter tuning
- The paper proposes "ExcelFormer," a deep learning model aimed at being a versatile, user-friendly solution for tabular prediction tasks
## Plain English Explanation
Tables of data are extremely common in the real world, and people often create these tables in biased ways or with specific prediction goals in mind. While powerful machine learning models like [decision tree-based](https://aimodels.fyi/papers/arxiv/decision-machines-extension-decision-trees) and deep neural network approaches have been used by expert users, they present challenges for more casual users.
These challenges include difficulties in selecting the right model for a particular dataset, as well as the need to heavily tune the model's hyperparameters (the settings that control how the model behaves) in order to get good performance. If users don't put in the time and effort to tune the hyperparameters properly, the model's performance can be inadequate.
To address these issues, the researchers developed a new deep learning model called "ExcelFormer." This model aims to be a versatile and user-friendly solution that can work well across a wide range of tabular prediction tasks, without requiring the same level of expertise and hyperparameter tuning.
## Technical Explanation
The key technical contributions of the paper are:
1. **Semi-permeable Attention Module**: This module helps break the "rotational invariance" property of deep neural networks, which can limit their ability to effectively use the information in tabular datasets.
2. **Tabular Data Augmentation**: The researchers developed data augmentation techniques specifically tailored for tabular data, which can help the model perform well even with limited training data.
3. **Attentive Feedforward Network**: This component boosts the model's ability to fit the patterns in the data, addressing the tendency of deep models to produce "over-smooth" solutions.
The researchers conducted extensive experiments on real-world datasets and found that their ExcelFormer model outperformed previous approaches across a variety of tabular prediction tasks. Importantly, they also demonstrated that ExcelFormer can be more user-friendly for casual users, as it does not require the same level of hyperparameter tuning as other models.
## Critical Analysis
The paper presents a compelling solution to the challenges faced by casual users when working with tabular prediction tasks. The researchers have identified key issues with existing models and have designed ExcelFormer to address them.
One potential limitation of the study is the specific datasets used for evaluation. While the researchers claim that the datasets cover a "diverse" range of tabular prediction tasks, it would be valuable to see how ExcelFormer performs on an even wider variety of real-world tabular datasets, including those with unique characteristics or domain-specific features.
Additionally, the paper does not provide much insight into the computational efficiency of ExcelFormer compared to other models. This could be an important consideration, especially for casual users who may have limited computational resources.
Overall, the ExcelFormer approach is a promising step towards making tabular prediction more accessible and user-friendly, and the researchers have presented a thoughtful and well-designed solution. Further research and validation on a broader range of datasets could help strengthen the case for adopting ExcelFormer in real-world applications.
## Conclusion
This paper introduces ExcelFormer, a deep learning model designed to be a versatile and user-friendly solution for a wide range of tabular prediction tasks. By addressing key challenges with existing models, such as rotational invariance, data demand, and over-smoothing, the researchers have created a model that can perform well across diverse datasets without requiring extensive hyperparameter tuning.
The technical innovations, including the semi-permeable attention module, tabular data augmentation, and attentive feedforward network, demonstrate the researchers' thoughtful approach to improving the state-of-the-art in tabular prediction. While further validation on a broader range of datasets could strengthen the case for ExcelFormer, this work represents an important step towards making advanced machine learning more accessible to casual users working with tabular data.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,673 | VecFusion: Vector Font Generation with Diffusion | VecFusion: Vector Font Generation with Diffusion | 0 | 2024-05-28T13:06:01 | https://aimodels.fyi/papers/arxiv/vecfusion-vector-font-generation-diffusion | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [VecFusion: Vector Font Generation with Diffusion](https://aimodels.fyi/papers/arxiv/vecfusion-vector-font-generation-diffusion). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This research paper presents a novel method called VecFusion for generating high-quality vector fonts using diffusion models.
- VecFusion can create realistic and diverse vector fonts from a small set of exemplar glyphs, addressing the challenge of limited training data for font generation.
- The paper demonstrates VecFusion's ability to generate visually appealing vector fonts across multiple languages, including Latin, CJK, and Indic scripts.
## Plain English Explanation
[VecFusion: Vector Font Generation with Diffusion](https://aimodels.fyi/papers/arxiv/vecfusion-vector-font-generation-diffusion) is a new technique that uses diffusion models to generate vector-based font characters. Diffusion models are a type of machine learning model that can create new images by learning patterns from existing data.
The key idea behind VecFusion is that it can generate a wide variety of vector font characters, even when there is only a small set of example characters to start with. This is important because creating a full set of vector font characters can be time-consuming and expensive.
VecFusion works by taking a few example vector font characters and using a diffusion model to generate new characters that match the style of the examples. The diffusion model learns the patterns and features of the example characters and then applies that knowledge to create new, unique characters.
The researchers demonstrate that VecFusion can generate high-quality vector fonts in multiple writing systems, including Latin, Chinese/Japanese/Korean (CJK), and Indic scripts. This makes VecFusion a versatile tool for creating fonts that can be used in a wide range of applications, from digital design to language-specific user interfaces.
## Technical Explanation
[VecFusion: Vector Font Generation with Diffusion](https://aimodels.fyi/papers/arxiv/vecfusion-vector-font-generation-diffusion) presents a novel approach to generating vector-based fonts using diffusion models. Diffusion models are a type of generative model that has shown impressive results in image generation tasks, and the researchers have adapted this technique to the domain of vector font creation.
The key innovation in VecFusion is its ability to generate a diverse set of vector font characters from a small number of exemplar glyphs. This is particularly important for font creation, as manually designing a full character set can be a labor-intensive and time-consuming process.
The VecFusion architecture consists of a conditional diffusion model that takes in a few example vector glyphs and generates new glyphs in the same style. The diffusion model learns the underlying patterns and features of the input glyphs and then applies this knowledge to create new, visually coherent characters.
The researchers evaluate VecFusion on several benchmarks, including generating vector fonts for Latin, CJK, and Indic scripts. The results demonstrate that VecFusion can produce high-quality, realistic vector fonts that capture the essence of the exemplar glyphs while introducing variation and diversity.
## Critical Analysis
The [VecFusion: Vector Font Generation with Diffusion](https://aimodels.fyi/papers/arxiv/vecfusion-vector-font-generation-diffusion) paper presents a promising approach to vector font generation, but there are a few aspects that could be explored further:
1. **Scalability to larger character sets**: While VecFusion can generate diverse vector fonts from a small set of exemplars, it's unclear how well the approach would scale to generating complete character sets for complex writing systems like CJK or Indic scripts, which can have thousands of unique glyphs.
2. **Evaluation of semantic coherence**: The paper focuses on the visual quality of the generated fonts, but it would be interesting to also evaluate how semantically coherent the generated glyphs are, particularly for ideographic scripts like Chinese where the meaning of a character is closely tied to its structure.
3. **Comparison to other font generation techniques**: It would be helpful to see a more detailed comparison of VecFusion's performance against other state-of-the-art font generation methods, both in terms of visual quality and the efficiency of the creation process.
4. **Potential applications and user feedback**: The paper could explore potential real-world applications of VecFusion, such as in digital design or language-specific user interfaces, and gather feedback from end-users to further refine the approach.
Overall, the [VecFusion: Vector Font Generation with Diffusion](https://aimodels.fyi/papers/arxiv/vecfusion-vector-font-generation-diffusion) paper presents an interesting and promising approach to vector font generation that could have significant impact in various domains. The critical points mentioned above could help guide future research and development in this area.
## Conclusion
[VecFusion: Vector Font Generation with Diffusion](https://aimodels.fyi/papers/arxiv/vecfusion-vector-font-generation-diffusion) introduces a novel diffusion-based approach to generating high-quality vector fonts from a small set of exemplar glyphs. This addresses a key challenge in font creation, where manually designing a full character set can be time-consuming and expensive.
The researchers demonstrate that VecFusion can generate diverse and visually appealing vector fonts across multiple writing systems, including Latin, CJK, and Indic scripts. This versatility makes VecFusion a potentially valuable tool for a wide range of applications, from digital design to language-specific user interfaces.
While the paper presents a promising approach, there are a few areas that could benefit from further exploration, such as scalability to larger character sets, evaluation of semantic coherence, and comparison to other font generation techniques. Nonetheless, the [VecFusion: Vector Font Generation with Diffusion](https://aimodels.fyi/papers/arxiv/vecfusion-vector-font-generation-diffusion) paper represents an important step forward in the field of vector font generation and could have significant real-world impact.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,672 | Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving | Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving | 0 | 2024-05-28T13:05:26 | https://aimodels.fyi/papers/arxiv/metacognitive-capabilities-llms-exploration-mathematical-problem-solving | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving](https://aimodels.fyi/papers/arxiv/metacognitive-capabilities-llms-exploration-mathematical-problem-solving). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper explores the metacognitive capabilities of large language models (LLMs) in solving mathematical problems.
- It investigates the ability of LLMs to reason about their own problem-solving process, identify gaps in their knowledge, and strategize to overcome challenges.
- The research aims to advance the understanding of how LLMs can be leveraged for complex cognitive tasks beyond standard language processing.
## Plain English Explanation
This paper looks at how well large language models (LLMs), which are AI systems trained on vast amounts of text data, can solve mathematical problems and think about their own problem-solving process. The researchers wanted to see if these models could not only solve math problems, but also recognize when they're stuck, identify what they're missing, and come up with a plan to get unstuck.
This is important because it could help us better understand the [capabilities of large language models](https://aimodels.fyi/papers/arxiv/large-language-models-mathematical-reasoning-progresses-challenges) and how they could be used for more complex cognitive tasks, beyond just natural language processing. If LLMs can demonstrate "metacognitive" abilities - the ability to think about their own thinking - it could open up new possibilities for how we use these powerful AI systems.
## Technical Explanation
The paper describes a series of experiments designed to assess the metacognitive capabilities of LLMs in the context of mathematical problem-solving. The researchers used a diverse set of math problems, ranging from algebra to calculus, and evaluated the models' performance in several key areas:
1. **Problem-Solving Ability**: Can the LLMs correctly solve the given math problems?
2. **Metacognitive Awareness**: Can the LLMs identify when they are stuck or unsure about a problem, and articulate why?
3. **Metacognitive Strategies**: Can the LLMs propose specific steps or approaches to overcome challenges and make progress on the problem?
The experiments involved both open-ended prompts, where the models were asked to solve problems and explain their reasoning, as well as more guided prompts, where the models were explicitly asked to reflect on their own problem-solving process.
The results of the study provide insights into the [strengths and limitations of LLMs](https://aimodels.fyi/papers/arxiv/evaluating-deductive-competence-large-language-models) when it comes to mathematical reasoning and metacognitive abilities. While the models demonstrated some promising capabilities, the researchers also identified areas for improvement, such as [addressing compositional deficiencies](https://aimodels.fyi/papers/arxiv/exploring-compositional-deficiency-large-language-models-mathematical) and [enhancing the models' ability to systematically apply mathematical concepts](https://aimodels.fyi/papers/arxiv/mathify-evaluating-large-language-models-mathematical-problem).
## Critical Analysis
The paper provides a thoughtful and nuanced analysis of the metacognitive capabilities of LLMs in the context of mathematical problem-solving. The researchers acknowledge the limitations of the current study, such as the relatively small sample size and the potential for biases in the model training data.
One potential concern raised in the paper is the [issue of "generative AI as a metacognitive agent"](https://aimodels.fyi/papers/arxiv/generative-ai-as-metacognitive-agent-comparative-mixed), where the models may exhibit apparent metacognitive abilities that are actually the result of memorized patterns or surface-level heuristics, rather than true reasoning capabilities.
The researchers also highlight the need for further research to better understand the underlying mechanisms and limitations of LLMs' metacognitive abilities. Exploring ways to [enhance the models' systematic and deductive reasoning](https://aimodels.fyi/papers/arxiv/evaluating-deductive-competence-large-language-models) could be a fruitful area for future work.
## Conclusion
This paper represents an important step in understanding the cognitive capabilities of large language models beyond traditional language tasks. By exploring the metacognitive abilities of LLMs in mathematical problem-solving, the researchers have shed light on the potential and limitations of these models for more complex cognitive challenges.
The findings suggest that LLMs can exhibit some promising metacognitive abilities, but also highlight the need for further research and development to fully realize the potential of these systems. As the field of AI continues to advance, studies like this will be crucial in guiding the responsible and effective deployment of these powerful technologies.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,671 | Transformers Can Do Arithmetic with the Right Embeddings | Transformers Can Do Arithmetic with the Right Embeddings | 0 | 2024-05-28T13:04:52 | https://aimodels.fyi/papers/arxiv/transformers-can-do-arithmetic-right-embeddings | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Transformers Can Do Arithmetic with the Right Embeddings](https://aimodels.fyi/papers/arxiv/transformers-can-do-arithmetic-right-embeddings). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper investigates the ability of Transformer language models to perform simple arithmetic operations on numerical values embedded within text.
- The researchers explore how the choice of numerical embedding can impact the model's numeric reasoning capabilities.
- They find that Transformers can indeed learn to perform basic arithmetic when provided with appropriate numerical embeddings, but struggle with more complex operations or generalization beyond the training distribution.
## Plain English Explanation
The researchers in this paper wanted to see if large language models like Transformers can do simple math when they encounter numbers in the text they're reading. Language models are AI systems that are trained on huge amounts of text data to understand and generate human language.
The key question the researchers explored is: if you give a Transformer model numbers embedded in text, can it learn to do basic arithmetic operations like addition and multiplication on those numbers? The researchers tried different ways of representing the numbers within the Transformer's inputs and found that the choice of numerical embedding can make a big difference in the model's ability to reason about the numbers.
When the Transformers were given the right kind of numerical embeddings, they were able to learn how to do simple arithmetic. However, the models still struggled with more complex math or with generalizing their numerical reasoning skills beyond the specific examples they were trained on. The paper provides insights into the strengths and limitations of Transformers when it comes to learning to work with numerical information in text.
## Technical Explanation
The researchers investigated the numeric reasoning capabilities of Transformer language models by designing a suite of arithmetic tasks. They explored how the choice of numerical embedding - the way the model represents numbers in its internal computations - impacts the model's ability to perform basic arithmetic operations.
The researchers experimented with several different numerical embedding schemes, including linear scaling, logarithmic scaling, and learnable embeddings. They found that the choice of embedding had a significant effect on the model's arithmetic performance. Linear scaling, for example, allowed the model to learn addition and subtraction, while logarithmic scaling enabled it to also learn multiplication and division.
Further experiments revealed the limitations of the Transformer models. While they could learn to perform basic arithmetic when given the right numerical representations, they struggled to generalize this numeric reasoning beyond the specific training distributions. The models also had difficulty with more complex operations involving multiple steps or more abstract mathematical concepts.
The paper provides valuable insights into the inner workings of Transformer language models and their ability to reason about numerical information. The results suggest that these models can be trained to exhibit basic "number sense", but significant challenges remain in developing their full arithmetic and mathematical reasoning capabilities.
## Critical Analysis
The paper makes a valuable contribution by systematically exploring the numeric reasoning abilities of Transformer language models. The experimental setup and analysis are rigorous, and the findings offer important insights into the strengths and limitations of these models when it comes to working with numerical information.
That said, the paper acknowledges several caveats and areas for further research. For example, the arithmetic tasks examined in the study are relatively simple, and it remains to be seen whether Transformers can handle more complex mathematical operations or reasoning. Additionally, the paper does not address the practical implications of these findings for real-world applications of language models.
One potential concern is the reliance on specific numerical embedding schemes. While the researchers demonstrate the importance of this design choice, it's unclear how these embedding strategies would scale or generalize to more diverse numerical data encountered in real-world settings. Further work is needed to develop more robust and flexible numerical representations for Transformer models.
Additionally, the paper does not explore the potential role of pretraining or fine-tuning in enhancing the numeric reasoning capabilities of Transformers. [Exploring Internal Numeracy: A Case Study of Language Models](https://aimodels.fyi/papers/arxiv/exploring-internal-numeracy-language-models-case-study) has shown that some degree of numeric reasoning can emerge during standard language model pretraining, suggesting that more targeted training approaches may lead to further improvements.
Overall, this paper provides a valuable foundation for understanding the numeric reasoning abilities of Transformer language models. The findings highlight the importance of considering numerical representations and the limitations of current approaches, paving the way for future research to address these challenges and unlock the full mathematical potential of these powerful language models.
## Conclusion
This paper investigates the numeric reasoning capabilities of Transformer language models, exploring how the choice of numerical embedding can impact their ability to perform basic arithmetic operations. The researchers find that Transformers can learn to do simple math when provided with the right numerical representations, but struggle with more complex operations or generalization beyond their training data.
The results offer important insights into the inner workings of these language models and the critical role of numerical representations in enabling numeric reasoning. While the findings suggest that Transformers can exhibit a basic "number sense", significant challenges remain in developing their full mathematical reasoning capabilities.
Future research should explore more advanced numerical representations and training approaches to further enhance the Transformers' ability to work with numerical information in practical applications. By addressing these challenges, the field can unlock the full potential of large language models to engage in more sophisticated mathematical reasoning and problem-solving.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,670 | Print-N-Grip: A Disposable, Compliant, Scalable and One-Shot 3D-Printed Multi-Fingered Robotic Hand | Print-N-Grip: A Disposable, Compliant, Scalable and One-Shot 3D-Printed Multi-Fingered Robotic Hand | 0 | 2024-05-28T13:04:17 | https://aimodels.fyi/papers/arxiv/print-n-grip-disposable-compliant-scalable-one | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Print-N-Grip: A Disposable, Compliant, Scalable and One-Shot 3D-Printed Multi-Fingered Robotic Hand](https://aimodels.fyi/papers/arxiv/print-n-grip-disposable-compliant-scalable-one). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
• This paper presents a novel 3D-printed robotic hand called "Print-N-Grip" that is disposable, compliant, scalable, and one-shot.
• The key features of the Print-N-Grip hand include its low-cost 3D-printed design, soft and compliant structure, ability to be rapidly manufactured, and potential for customization.
• The researchers demonstrate the hand's capabilities through a series of experiments, including grasping various objects, adapting to different surfaces, and showing its potential for scalability.
## Plain English Explanation
The researchers have developed a new type of robotic hand that has several unique advantages. It is made using 3D printing, which means it can be produced quickly and cheaply. The hand is also soft and flexible, allowing it to gently grasp a wide variety of objects. Additionally, the design is scalable, meaning the hand can be easily made larger or smaller to suit different needs.
One of the key benefits of this robotic hand is that it is "disposable." This means it can be quickly and easily manufactured, used for a task, and then discarded if needed. This could be useful in situations where a robotic hand is needed for a one-time task, such as handling hazardous materials or performing a specific industrial operation.
Overall, the Print-N-Grip hand represents an innovative approach to robotic design that aims to balance cost, flexibility, and scalability. [This research builds on previous work in the field of soft robotics and multi-fingered hands, such as the efforts described in the papers on <a href="https://aimodels.fyi/papers/arxiv/robust-anthropomorphic-robotic-manipulation-through-biomimetic-distributed">robust anthropomorphic robotic manipulation</a>, <a href="https://aimodels.fyi/papers/arxiv/replicating-human-anatomy-vision-controlled-jetting-pneumatic">vision-controlled pneumatic hands</a>, <a href="https://aimodels.fyi/papers/arxiv/sensorized-soft-skin-dexterous-robotic-hands">sensorized soft hands</a>, <a href="https://aimodels.fyi/papers/arxiv/passively-bendable-compliant-tactile-palm-robotic-modular">compliant palm modules</a>, and <a href="https://aimodels.fyi/papers/arxiv/multi-fingered-dynamic-grasping-unknown-objects">dynamic multi-fingered grasping</a>.]
## Technical Explanation
The researchers present the "Print-N-Grip" system, a 3D-printed robotic hand that is disposable, compliant, scalable, and designed for one-time use. The hand is fabricated using a single 3D printing process, allowing for rapid, low-cost manufacturing and potential customization.
The hand's key features include a soft, compliant structure made from flexible materials that allows it to gently grasp a variety of objects. The researchers demonstrate the hand's ability to adapt to different surface shapes and textures, as well as its potential for scalability by printing hands of varying sizes.
Through a series of experiments, the researchers show the Print-N-Grip hand's ability to grasp various everyday objects, from rigid to deformable, and its potential for applications in areas such as hazardous material handling or industrial tasks where a disposable robotic gripper may be advantageous.
## Critical Analysis
The researchers acknowledge several limitations of the Print-N-Grip system, including the current lack of integrated sensors or actuators, which restricts the hand's dexterity and sensing capabilities. Additionally, the researchers note that the one-shot, disposable nature of the design may limit its long-term viability for some applications.
Further research could explore ways to incorporate more advanced control and sensing capabilities into the 3D-printed hand design, potentially through the integration of soft sensors or the use of more complex actuation mechanisms. Investigations into the scalability and manufacturing process could also help to refine the system and improve its robustness and reliability.
Overall, the Print-N-Grip represents an intriguing concept in the field of soft robotics, with the potential to provide low-cost, customizable robotic solutions for specific tasks or environments. As the technology continues to evolve, addressing the current limitations could unlock new applications and expand the capabilities of this unique 3D-printed robotic hand.
## Conclusion
The Print-N-Grip 3D-printed robotic hand presents a novel approach to robotic design that prioritizes cost-effectiveness, scalability, and disposability. By leveraging the advantages of 3D printing, the researchers have created a soft, compliant hand that can be rapidly manufactured and customized for a variety of applications, such as hazardous material handling or industrial tasks.
While the current iteration of the Print-N-Grip hand has some limitations in terms of dexterity and sensing capabilities, the researchers have demonstrated its potential as a versatile and accessible robotic solution. As the field of soft robotics continues to advance, further improvements to the Print-N-Grip design could unlock new possibilities and expand the reach of this innovative technology.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,669 | Vegetarian Pesto Pasta Recipe | The article features a vegetarian pesto pasta recipe, complete with nutrition data and calorie count.... | 0 | 2024-05-28T13:04:00 | https://dev.to/dbjustinmoore/vegetarian-pesto-pasta-recipe-29jh | The article features a [vegetarian pesto pasta recipe](https://discoverybody.com/recipe/vegetarian-pesto-pasta-recipe-with-nutrition-data-and-calorie-count/), complete with nutrition data and calorie count. It outlines the ingredients and step-by-step instructions to create a delicious and healthy pasta dish.
The nutritional information provides insights into the calorie content and key nutrients, helping you make informed dietary choices. For the full recipe and detailed nutritional data, you can [read the article here](https://discoverybody.com/recipe/vegetarian-pesto-pasta-recipe-with-nutrition-data-and-calorie-count/).
https://discoverybody.com/recipe/vegetarian-pesto-pasta-recipe-with-nutrition-data-and-calorie-count/ | dbjustinmoore | |
1,867,668 | Why Invest In Cryptocurrency Exchanges in 2024? | Understanding Crypto Exchanges The crypto market has come a long way with the soaring number of use... | 0 | 2024-05-28T13:03:54 | https://dev.to/bellabardot/why-invest-in-cryptocurrency-exchanges-in-2024-3k0o | cryptoexchange, cryptocurrencyexchange, cryptocurrency | **Understanding Crypto Exchanges**
The crypto market has come a long way with the soaring number of use cases. Cryptocurrency exchanges are witnessing significant progress with the widespread adoption of cryptocurrencies and increased global user penetration. Despite the disruptions in the market, we could notice the steady and rapid maturation of crypto adoption.
> According to the reports from Grand View Research, the global cryptocurrency market is anticipated to grow at a CAGR of 12.5% and reach USD11.71 billion by 2030.
Crypto exchanges are a digital platform that facilitates selling, buying, and trading digital assets including cryptocurrencies, NFT, and fiat currencies. The crypto exchanges leverage smart contracts to make transactions which helps foster heightened security to the exchange, user assets, and transactions. They can be classified into various types such as centralized exchanges (CEXs), decentralized exchanges (DEXs), and hybrid exchanges (HEXs) which have their pros and cons. The crypto exchanges also offer potential revenue-generating opportunities for the users and exchange providers.
Investing in crypto exchanges is brilliant for those interested in cryptocurrencies and the crypto space. This blog discusses why investing in crypto exchange is a viable business model.
**Top Reasons That Makes Crypto Exchange The Best Business Option**
The following factors claim that investing in [cryptocurrency exchange development](https://maticz.com/cryptocurrency-exchange-development) will be a strategic imperative in the thriving crypto landscape.
**Growing Market**
The growing popularity and market shape the way for crypto exchanges. The continuous technological innovations and prevailing trends contribute to the growth of the market. The increased acceptance among users has resulted in a high total market capitalization.
This made cryptopreneurs and other institutions recognize the potential of the crypto landscape. Hence, entrepreneurs who are interested in forging their path into the crypto realm can proceed by capitalizing on the thriving industry by launching crypto exchanges.
**Diversification of Portfolio**
The crypto realm aids businesses in diversifying their investment portfolio and paves the way for generating high returns. This helps businesses from major investment risks and helps minimize the volatility in the investments in the speculative market.
**Monetization Opportunities**
Cryptocurrency exchanges open an avenue for numerous monetization streams. This aids both the users and exchange providers in generating ample revenue. Some of the common revenue-generating streams of cryptocurrency exchanges are listing fees, withdrawal and deposit fees, lending and borrowing, staking services, etc.
This depicts that crypto exchanges are a profitable venture in the crypto space. It is a strategic move for beginners in the crypto investing realm and aids them in achieving long-term success for their business.
**Global Reach**
The crypto space is evolving and receiving a whopping welcome among crypto enthusiasts. The crypto market has gained global reach and thus the crypto exchanges have attained a vast reach across the globe. This is due to its ability to operate and enable transactions in different locations.
Hence opting for crypto exchange as a business option will create a win-win situation for businesses in the crypto space. This will help businesses unlock new market opportunities paving the way for generating potential income.
**Security**
The crypto exchanges are now integrated with advanced security protocols and employ best practices to mitigate security risks. The continuous adoption of cryptocurrencies has resulted in some security challenges.
Thus, crypto exchanges are now being created by implementing security protocols that protect user data and make them less susceptible to cyber attacks data threats, and breaches. The crypto exchanges also have integrated crypto wallets, which safeguard the crypto assets from unauthorized access and data theft.
**Closing Thoughts**
Crypto exchanges are emerging as a popular investment option that helps businesses venturing into the crypto space create a strong foundation. Investing in crypto exchanges helps businesses to reach unprecedented heights in the crypto industry. Despite the downfalls in the crypto market, the craze for cryptocurrencies continues to surge making way for new investment possibilities. The growth of crypto exchanges holds vast potential for revolutionizing the financial landscape. If you aim to make a mark in the thriving crypto realm, reach out to the best cryptocurrency exchange platform development company that upholds the industry's reputation.
| bellabardot |
1,867,667 | Thermodynamic Natural Gradient Descent | Thermodynamic Natural Gradient Descent | 0 | 2024-05-28T13:03:43 | https://aimodels.fyi/papers/arxiv/thermodynamic-natural-gradient-descent | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Thermodynamic Natural Gradient Descent](https://aimodels.fyi/papers/arxiv/thermodynamic-natural-gradient-descent). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Second-order training methods like [natural gradient descent](https://aimodels.fyi/papers/arxiv/inverse-free-fast-natural-gradient-descent-method) have better convergence properties than first-order gradient descent, but are rarely used for large-scale training due to their computational overhead.
- This paper presents a new hybrid digital-analog algorithm for training neural networks that is equivalent to natural gradient descent in a certain parameter regime, but avoids the costly linear system solves.
- The algorithm exploits the thermodynamic properties of an analog system at equilibrium, requiring an analog thermodynamic computer.
- The training occurs in a hybrid digital-analog loop, where the gradient and curvature information are calculated digitally while the analog dynamics take place.
- The authors demonstrate the superiority of this approach over state-of-the-art digital first- and second-order training methods on classification and language modeling tasks.
## Plain English Explanation
Training machine learning models, especially large neural networks, is a complex and computationally intensive process. The most common approach, called gradient descent, updates the model's parameters by following the direction that reduces the error the fastest. However, gradient descent can be slow to converge, meaning it takes a long time to find the best set of parameters.
An alternative approach called [natural gradient descent](https://aimodels.fyi/papers/arxiv/inverse-free-fast-natural-gradient-descent-method) has been shown to converge faster, but it requires more complex calculations that are too slow for practical use on large models. This paper introduces a new hybrid method that combines digital and analog computing to get the benefits of natural gradient descent without the computational overhead.
The key idea is to use a special analog hardware device, called an "analog thermodynamic computer," to handle the most computationally intensive parts of the natural gradient descent algorithm. This analog device can perform the necessary calculations much faster than a traditional digital computer. The training process then alternates between the digital and analog components, with the digital part calculating the gradients and other information, and the analog part updating the model parameters.
The authors show that this hybrid approach outperforms state-of-the-art digital training methods on several benchmark tasks, demonstrating the potential of combining analog and digital computing for efficient model training.
## Technical Explanation
The paper presents a new hybrid digital-analog algorithm for training neural networks that is equivalent to [natural gradient descent](https://aimodels.fyi/papers/arxiv/inverse-free-fast-natural-gradient-descent-method) in a certain parameter regime. Natural gradient descent is a second-order training method that can have better convergence properties than first-order gradient descent, but is rarely used in practice due to its high computational cost.
The key innovation of this work is the use of an analog thermodynamic computer to perform the most computationally intensive parts of the natural gradient descent algorithm. The training process alternates between digital and analog components:
1. The digital component calculates the gradient and Fisher information matrix (or any other positive semi-definite curvature matrix) at given time intervals.
2. The analog component then updates the model parameters using the thermodynamic properties of the analog system at equilibrium, avoiding the need for costly linear system solves.
This hybrid approach is shown to be equivalent to natural gradient descent in a certain parameter regime, but with a computational complexity per iteration that is similar to a first-order method.
The authors numerically demonstrate the superiority of this hybrid digital-analog approach over state-of-the-art digital first-order methods like [approximate gradient descent](https://aimodels.fyi/papers/arxiv/approximation-gradient-descent-training-neural-networks) and second-order methods like [Gauss-Newton optimization](https://aimodels.fyi/papers/arxiv/exact-gauss-newton-optimization-training-deep-neural) on classification tasks and language model fine-tuning. They also discuss the potential of combining [analog and digital computing](https://aimodels.fyi/papers/arxiv/hybrid-quantum-classical-scheduling-accelerating-neural-network) to efficiently train large-scale neural networks, highlighting the importance of [automatic differentiation](https://aimodels.fyi/papers/arxiv/automatic-differentiation-is-essential-training-neural-networks) in enabling this hybrid approach.
## Critical Analysis
The paper presents a promising approach for improving the efficiency of training large neural networks by leveraging analog computing hardware. The key advantage of this hybrid digital-analog method is that it can achieve the convergence benefits of natural gradient descent without the prohibitive computational cost.
However, the practical implementation of this approach may face some challenges. The requirement of an analog thermodynamic computer, which is likely a specialized and expensive piece of hardware, could limit the accessibility and widespread adoption of this technique. Additionally, the integration and synchronization between the digital and analog components may introduce additional complexity and potential sources of error.
Furthermore, the paper does not provide a detailed analysis of the limitations or failure modes of the analog component. It would be helpful to understand the sensitivity of the analog system to factors like noise, temperature fluctuations, or parameter variations, and how these might impact the overall training performance.
Another area for further exploration is the scalability of this approach to increasingly large and complex neural network architectures. The authors demonstrate the benefits on relatively small-scale tasks, but it remains to be seen how well the hybrid digital-analog method would scale as the model size and complexity grow.
Despite these potential challenges, the paper represents an exciting step towards bridging the gap between the theoretical advantages of second-order training methods and their practical applicability. The use of analog computing to accelerate certain computationally intensive operations is a promising direction for improving the efficiency of machine learning training, and this work serves as a valuable contribution to this emerging field.
## Conclusion
This paper presents a novel hybrid digital-analog algorithm for training neural networks that combines the convergence benefits of natural gradient descent with the computational efficiency of first-order methods. By exploiting the thermodynamic properties of an analog system, the authors have developed a training approach that avoids the costly linear system solves typically associated with second-order optimization techniques.
The demonstrated superiority of this hybrid method over state-of-the-art digital training approaches highlights the potential of combining analog and digital computing to improve the efficiency of large-scale machine learning. While the practical implementation may face some challenges, this work serves as an important stepping stone towards more efficient and scalable training of complex neural network models.
As the field of machine learning continues to advance, the integration of novel hardware architectures, such as the analog thermodynamic computer used in this work, will likely play an increasingly important role in overcoming the computational limitations of traditional digital systems. This paper provides a valuable contribution to this growing area of research and opens up new avenues for further exploration and innovation.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,666 | Can a Transformer Represent a Kalman Filter? | Can a Transformer Represent a Kalman Filter? | 0 | 2024-05-28T13:03:09 | https://aimodels.fyi/papers/arxiv/can-transformer-represent-kalman-filter | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Can a Transformer Represent a Kalman Filter?](https://aimodels.fyi/papers/arxiv/can-transformer-represent-kalman-filter). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper explores whether a Transformer model can represent a Kalman filter, which is a widely used algorithm for state estimation and filtering.
- The authors investigate the connections between Transformers and Kalman filters, and whether Transformers can learn to perform the same tasks as Kalman filters.
- The paper presents theoretical and empirical analyses to understand the representational power of Transformers and their ability to capture the dynamics of linear systems.
## Plain English Explanation
The paper investigates whether a [Transformer](https://aimodels.fyi/papers/arxiv/does-transformer-interpretability-transfer-to-rnns) model, a type of artificial intelligence algorithm, can learn to perform the same tasks as a [Kalman filter](https://aimodels.fyi/papers/arxiv/outlier-robust-kalman-filtering-through-generalised-bayes), a widely used algorithm for state estimation and filtering. Kalman filters are commonly used in applications like navigation, control systems, and signal processing to estimate the state of a system based on noisy measurements.
The authors explore the connections between Transformers and Kalman filters, and whether Transformers can learn to represent the dynamics of linear systems in the same way that Kalman filters do. They provide both theoretical and empirical analyses to understand the representational power of Transformers and their ability to capture the same properties as Kalman filters.
This research is important because it helps to understand the capabilities and limitations of Transformer models, and whether they can be used as a substitute for traditional algorithms like Kalman filters in certain applications. If Transformers can learn to perform the same tasks as Kalman filters, it could lead to new and more powerful techniques for state estimation, prediction, and control.
## Technical Explanation
The paper first provides a theoretical analysis of the relationship between Transformers and Kalman filters. The authors show that under certain conditions, a Transformer with a specific architecture can be used to represent a Kalman filter. They demonstrate that the self-attention mechanism in Transformers can be used to learn the transition and observation matrices of a linear dynamical system, which are the key components of a Kalman filter.
The authors then conduct empirical experiments to evaluate the ability of Transformers to learn Kalman filtering tasks. They consider several benchmark problems, including linear and nonlinear state-space models, and compare the performance of Transformers to that of Kalman filters and other baseline methods, such as [Computation-Aware Kalman Filtering and Smoothing](https://aimodels.fyi/papers/arxiv/computation-aware-kalman-filtering-smoothing) and [Inverse Unscented Kalman Filter](https://aimodels.fyi/papers/arxiv/inverse-unscented-kalman-filter).
The results show that Transformers can indeed learn to perform Kalman filtering tasks, and in some cases, they can outperform traditional Kalman filter-based methods. The authors also investigate the interpretability of the learned Transformer models and find that they can provide insights into the underlying dynamics of the system, similar to the interpretability of Kalman filters.
## Critical Analysis
The paper provides a thorough theoretical and empirical analysis of the relationship between Transformers and Kalman filters, and the authors make a convincing case that Transformers can learn to represent Kalman filters. However, there are a few potential limitations and areas for further research:
1. The theoretical analysis assumes specific architectural choices for the Transformer, such as the use of positional encodings and the structure of the attention layers. It's unclear whether these assumptions are necessary for the Transformer to represent a Kalman filter, or if there are other ways to achieve the same result.
2. The empirical experiments are limited to relatively simple linear and nonlinear state-space models. It would be interesting to see how Transformers perform on more complex, real-world systems, where the assumptions of linearity and Gaussian noise may not hold.
3. The paper does not explore the potential advantages of using Transformers over traditional Kalman filters, beyond their ability to learn the necessary representations. It would be valuable to understand the computational and practical benefits of using Transformers in specific applications, such as [Decision Transformer as a Foundation Model for Partially Observable](https://aimodels.fyi/papers/arxiv/decision-transformer-as-foundation-model-partially-observable) environments.
Overall, this paper makes an important contribution to our understanding of the representational power of Transformers and their potential to replace traditional algorithms like Kalman filters in certain applications. Further research in this area could lead to new and more powerful techniques for state estimation, prediction, and control.
## Conclusion
This paper explores the ability of Transformer models to represent and learn the dynamics of linear systems, as captured by Kalman filters. The authors provide both theoretical and empirical analyses to demonstrate that Transformers can learn to perform Kalman filtering tasks, and in some cases, they can outperform traditional Kalman filter-based methods.
The findings of this research have important implications for the field of machine learning and its applications in areas such as control systems, signal processing, and navigation. If Transformers can effectively replace Kalman filters in certain tasks, it could lead to new and more powerful techniques for state estimation, prediction, and decision-making in complex, real-world environments.
Further research in this area could explore the potential advantages of using Transformers over traditional Kalman filters, as well as their performance on more complex, real-world systems. Additionally, investigating the interpretability of the learned Transformer models and their ability to provide insights into the underlying dynamics of the system could be a fruitful avenue for future work.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,665 | Representation noising effectively prevents harmful fine-tuning on LLMs | Representation noising effectively prevents harmful fine-tuning on LLMs | 0 | 2024-05-28T13:02:34 | https://aimodels.fyi/papers/arxiv/representation-noising-effectively-prevents-harmful-fine-tuning | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Representation noising effectively prevents harmful fine-tuning on LLMs](https://aimodels.fyi/papers/arxiv/representation-noising-effectively-prevents-harmful-fine-tuning). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Releasing open-source large language models (LLMs) poses a dual-use risk, as bad actors can easily fine-tune these models for harmful purposes.
- Even without the open release of weights, weight stealing and fine-tuning APIs make closed models vulnerable to harmful fine-tuning attacks (HFAs).
- Safety measures like preventing jailbreaks and improving safety guardrails can be easily reversed through fine-tuning.
- The paper proposes a defense mechanism called Representation Noising (RepNoise) that is effective even when attackers have access to the weights and the defender no longer has any control.
## Plain English Explanation
Large language models (LLMs) like GPT-3 and GPT-4 are incredibly powerful AI systems that can generate human-like text on a wide range of topics. While these models have many beneficial applications, they also present a risk: bad actors could fine-tune them to create harmful content, like disinformation, hate speech, or instructions for illegal activities.
Even if the original weights of an LLM are not publicly released, attackers can still access the model's capabilities through techniques like weight stealing or by using fine-tuning APIs. This makes the model vulnerable to what the researchers call "harmful fine-tuning attacks" (HFAs). Attempts to make LLMs more secure, such as preventing "jailbreaks" or improving safety guardrails, can often be reversed through further fine-tuning.
To address this issue, the researchers propose a new defense mechanism called "Representation Noising" (RepNoise). RepNoise works by removing certain types of information from the model's representations, making it difficult for attackers to recover that information and use it for harmful purposes, even if they have full access to the model's weights.
Importantly, the researchers show that RepNoise can generalize to different types of harmful content, without needing to know about them in advance. This means the defense can be effective against a wide range of potential misuses, not just the ones the researchers have explicitly trained for.
The key insight behind the effectiveness of RepNoise is that it removes information about harmful representations across multiple layers of the LLM, rather than just at the surface level. This depth of the defense is what makes it so robust against fine-tuning attacks.
## Technical Explanation
The paper proposes a defense mechanism called Representation Noising (RepNoise) to address the vulnerability of large language models (LLMs) to harmful fine-tuning attacks (HFAs). Even when attackers have access to the model's weights and the defender has lost control, RepNoise can effectively remove information about harmful representations from the model, making it difficult for attackers to recover and misuse that information.
The core idea behind RepNoise is to introduce noise into the model's representations during training, in a way that specifically targets and degrades information related to harmful content, while preserving the model's general capabilities. This is achieved by jointly training the model on a mix of clean and "noised" data, where the noising process is designed to remove harmful patterns from the representations.
Importantly, the researchers show that RepNoise can generalize to different types of harmful content, without needing to know about them in advance. This is a key advantage over approaches that rely on explicitly defining and training against a fixed set of harms.
The paper provides empirical evidence that the effectiveness of RepNoise lies in its depth: the degree to which information about harmful representations is removed across all layers of the LLM, rather than just at the surface level. This depth of the defense makes it resistant to fine-tuning attacks that try to recover the lost information.
The researchers evaluate RepNoise on a range of tasks and find that it can effectively mitigate HFAs while preserving the model's general capabilities. They also discuss potential limitations and areas for further research, such as the need to better understand the relationship between the depth of the defense and its robustness.
## Critical Analysis
The researchers have proposed a novel and promising defense mechanism in the form of Representation Noising (RepNoise) to address the vulnerability of large language models (LLMs) to harmful fine-tuning attacks (HFAs). The key strengths of their approach are its ability to generalize to different types of harmful content, and the depth of the defense mechanism across multiple layers of the model.
However, the paper does raise some important caveats and areas for further research. For example, the researchers acknowledge that while RepNoise can effectively mitigate HFAs, it may not be able to completely prevent them, especially in the face of highly sophisticated attackers. Additionally, the relationship between the depth of the defense and its robustness is not fully understood, and more work is needed to explore this.
Another potential concern is the impact of RepNoise on the model's general capabilities. While the researchers claim that their defense does not degrade the model's performance on harmless tasks, it would be valuable to further investigate the potential trade-offs between the strength of the defense and the model's overall capabilities.
Furthermore, the paper does not address the broader societal implications of large language models and the potential for misuse. While RepNoise is a valuable technical contribution, it is important to consider the wider context and the need for comprehensive approaches to AI safety and ethical development.
Overall, the Representation Noising (RepNoise) defense proposed in this paper is a significant step forward in addressing the challenges posed by the dual-use nature of large language models. However, continued research and a multifaceted approach will be necessary to ensure the responsible development and deployment of these powerful AI systems.
## Conclusion
The paper presents a novel defense mechanism called Representation Noising (RepNoise) to address the vulnerability of large language models (LLMs) to harmful fine-tuning attacks (HFAs). By removing information about harmful representations across multiple layers of the model, RepNoise can effectively mitigate the risk of misuse by bad actors, even when they have full access to the model's weights.
The key strengths of RepNoise are its ability to generalize to different types of harmful content and the depth of the defense, which makes it resistant to fine-tuning attacks. However, the paper also highlights important caveats, such as the potential limitations in completely preventing HFAs and the need to further understand the trade-offs between the defense's strength and the model's general capabilities.
Overall, the Representation Noising (RepNoise) defense is a valuable contribution to the ongoing efforts to ensure the responsible development and deployment of powerful large language models. While technical solutions like RepNoise are important, addressing the broader societal implications of these AI systems will require a multifaceted approach involving policymakers, researchers, and the wider community.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,664 | AI-Assisted Assessment of Coding Practices in Modern Code Review | AI-Assisted Assessment of Coding Practices in Modern Code Review | 0 | 2024-05-28T13:01:58 | https://aimodels.fyi/papers/arxiv/ai-assisted-assessment-coding-practices-modern-code | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [AI-Assisted Assessment of Coding Practices in Modern Code Review](https://aimodels.fyi/papers/arxiv/ai-assisted-assessment-coding-practices-modern-code). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- The paper discusses the development, deployment, and evaluation of AutoCommenter, a system that uses a large language model to automatically learn and enforce coding best practices.
- AutoCommenter was implemented for four programming languages (C++, Java, Python, and Go) and evaluated in a large industrial setting.
- The paper reports on the challenges and lessons learned from deploying such a system to tens of thousands of developers.
## Plain English Explanation
When developers write code, they often follow certain best practices to ensure that the code is high-quality, maintainable, and secure. Some of these best practices can be automatically checked by software, but others require human review. [AutoCommenter](https://aimodels.fyi/papers/arxiv/autocoderover-autonomous-program-improvement) is a system that uses a large [language model](https://aimodels.fyi/papers/arxiv/automatic-programming-large-language-models-beyond) to automatically learn and enforce these coding best practices, without the need for manual review.
The researchers implemented AutoCommenter for four popular programming languages: C++, Java, Python, and Go. They then deployed and evaluated the system in a large industrial setting, where it was used by tens of thousands of developers. The evaluation showed that AutoCommenter was effective at identifying and enforcing coding best practices, and that it had a positive impact on the developer workflow.
However, the researchers also encountered challenges in deploying such a system at scale, such as [managing the costs and user behaviors](https://aimodels.fyi/papers/arxiv/reading-between-lines-modeling-user-behavior-costs) associated with the system. The paper discusses the lessons they learned and the strategies they used to overcome these challenges.
Overall, the research suggests that it is feasible to develop an end-to-end system for automatically learning and enforcing coding best practices, which could significantly improve the quality and efficiency of software development.
## Technical Explanation
The paper describes the development, deployment, and evaluation of AutoCommenter, a system that uses a large language model to automatically learn and enforce coding best practices. The researchers implemented AutoCommenter for four programming languages (C++, Java, Python, and Go) and evaluated its performance and adoption in a large industrial setting.
The key components of AutoCommenter include:
- A model training pipeline that fine-tunes a large language model on a corpus of high-quality code to learn coding best practices.
- A rule generation module that extracts coding best practices from the fine-tuned model and translates them into enforceable rules.
- A deployment system that integrates AutoCommenter into the developer's workflow, automatically applying the learned rules to code contributions during the [peer review process](https://aimodels.fyi/papers/arxiv/ai-review-lottery-widespread-ai-assisted-peer).
The researchers evaluated the effectiveness of AutoCommenter by measuring its impact on code quality, developer productivity, and adoption within the organization. Their results showed that AutoCommenter was able to [effectively identify and enforce coding best practices](https://aimodels.fyi/papers/arxiv/utilizing-deep-learning-to-optimize-software-development), leading to improvements in code quality and developer efficiency.
However, the researchers also faced challenges in deploying such a system at scale, including managing the [costs and user behaviors](https://aimodels.fyi/papers/arxiv/reading-between-lines-modeling-user-behavior-costs) associated with the system. The paper discusses the lessons they learned and the strategies they used to overcome these challenges, which may be valuable for other researchers and practitioners looking to develop similar systems.
## Critical Analysis
The paper presents a compelling case for the feasibility and potential benefits of an end-to-end system for automatically learning and enforcing coding best practices. The researchers' approach of using a large language model to learn and translate these best practices into enforceable rules is a novel and promising idea.
However, the paper does not discuss some potential limitations or areas for further research. For example, the researchers do not address the potential for the language model to learn and reinforce biases or suboptimal practices that may be present in the training data. Additionally, the paper does not explore the long-term implications of relying on such a system, such as the potential for developers to become overly dependent on the automated feedback and less engaged in the manual review process.
Furthermore, while the researchers report positive results in terms of code quality and developer productivity, it would be helpful to have more detailed quantitative data to substantiate these claims. Additionally, the paper does not provide much insight into the specific challenges and lessons learned during the deployment process, which could be valuable for other researchers and practitioners.
Overall, the paper presents an interesting and potentially impactful approach to improving software development practices, but more research and critical analysis are needed to fully understand the strengths, limitations, and implications of this technology.
## Conclusion
The paper describes the development, deployment, and evaluation of AutoCommenter, a system that uses a large language model to automatically learn and enforce coding best practices. The researchers' implementation and evaluation of AutoCommenter in a large industrial setting suggest that such a system can have a positive impact on code quality, developer productivity, and the overall software development workflow.
While the paper highlights the feasibility and potential benefits of this approach, it also raises questions about potential limitations and areas for further research. Nonetheless, the work presented in this paper represents an important step towards the development of more advanced tools and [techniques for optimizing software development](https://aimodels.fyi/papers/arxiv/utilizing-deep-learning-to-optimize-software-development) through the use of large language models and other artificial intelligence technologies.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,634 | Create a Code Explanation Tool using ToolJet and Gemini API | Introduction This tutorial will walk you through creating a code explanation tool using... | 0 | 2024-05-28T13:01:51 | https://blog.tooljet.com/create-a-code-explanation-tool-using-tooljet-and-gemini-api/ | lowcode, tooljet, restapi, gemini | ## Introduction
This tutorial will walk you through creating a code explanation tool using [ToolJet](https://github.com/ToolJet/ToolJet), a powerful low-code platform, and the [Gemini API](https://ai.google.dev/gemini-api/docs/api-overview), an advanced language model API. This tool will allow users to input code snippets and receive detailed explanations, enhancing their understanding of various programming concepts.
### Prerequisites
Before we begin, make sure you have the following:
- **ToolJet** (https://github.com/ToolJet/ToolJet) : An open-source, low-code platform designed for quickly building and deploying internal tools. Sign up for a free ToolJet cloud account here.
- **Gemini API** : A cutting-edge artificial intelligence (AI) model created through a joint effort by various teams within Google. You can find more information and sign up at [Gemini API](https://ai.google.dev/gemini-api/docs/api-key) to get an API Key, that will be used later in the tutorial.
Here’s the preview of what we’re going to build.
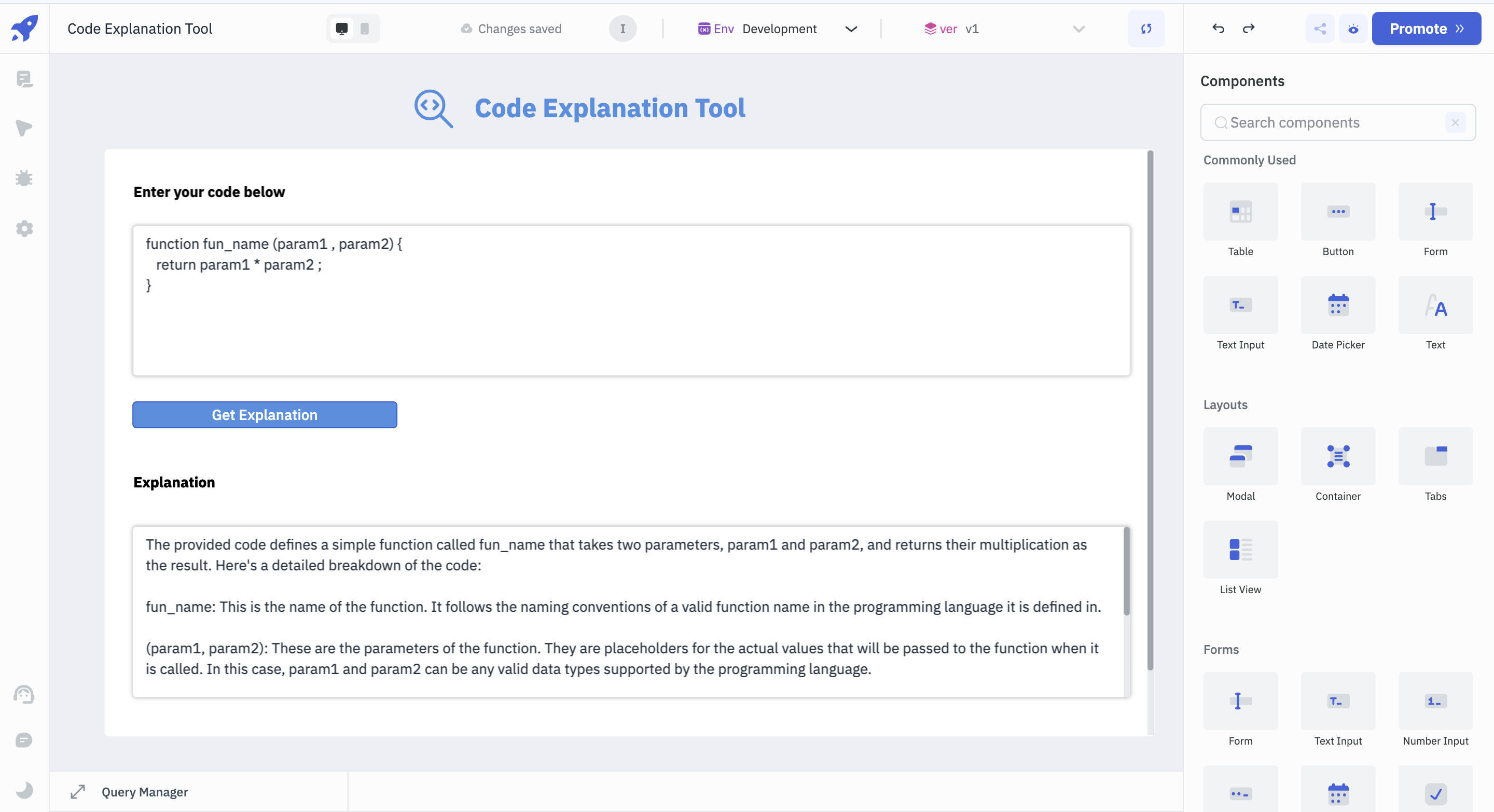
Once we have an idea of what we will build, let’s follow the steps below to start building our app step by step.
## Setting Up the Gemini API
- Once you have set up your account on Gemini API, navigate here to get your API Key. This key will be used to authenticate your requests.
- The endpoint for the code explanation feature looks like this: POST '[https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-latest:generateContent?key=YOUR_API_KEY](https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-latest:generateContent?key=YOUR_API_KEY)'.
Now that we have our API Key let’s dive straight into creating the UI as the next step.
## Creating the UI
Before creating the UI, let’s create a new ToolJet App. On your ToolJet dashboard, click on the **Create an app** button and name the app **Code Explanation Tool**.
Creating a custom UI is very simple with the help of ToolJet’s [built-in components](https://docs.tooljet.com/docs/tooljet-concepts/what-are-components).
Let’s start by creating the app’s header.
- Drag and drop the **Icon** and a **Text** Component from the components library on the right and rename them _headerIcon_ and _headerText_, respectively.
- Choose an icon of your choice and customise it, under the **Styles** section.
- To configure the Text component, click on it and see the **Properties** Panel on the right.
- Set its **Data** property to 'Code Explanation Tool', and under the **Styles** section, change its colour to light blue (Hex code: #4a90e2ff), font-weight to bold and font size to 25.
_Renaming the components will help quickly access their data during development._
- Add a **Container** component to the canvas. The Container component is used to group related components.
- Drag and drop a **Text** component, and in the **Properties** section, set its **Data** property to 'Enter your code below'.
- Next, below the text component, add a **Textarea** component, where we will add the code to get the explanation. Rename it to _codeInput_. Adjust the height and width of the component. To make the _codeInput_ component look neat, adjust the **Boxshadow** properties in the **Styles** section.
- Under the **Properties** section of the _codeInput_ component, add the following code as the **Default value**:
```
function fun_name (param1 , param2) {
return param1 * param2 ;
}
```
- Now that we have our _codeInput_ component in place, drag and drop a **Button** component right below it and rename it to _getExplanation_.
- Under its **Button text** property, add ‘Get Explanation’.
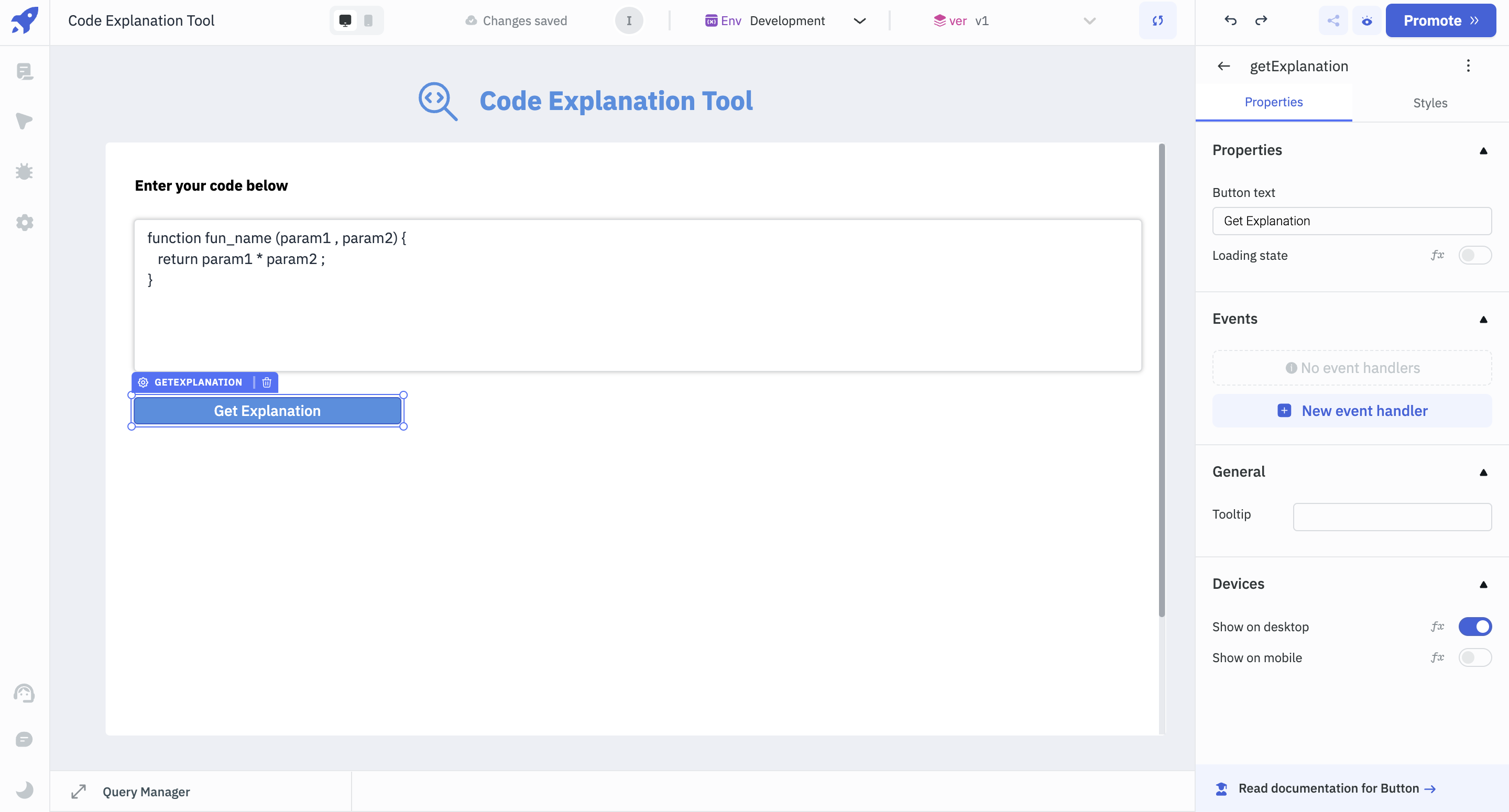
Now, let’s add the portion that will display the explanation for the code that we provide.
- Below the _getExplanation_ button, add a Text component and under the **Data** property, add the text, ‘Explanation’; under the **Styles** section, change the **Size** to 14 and **Weight** to bold.
- Below the text component, drag and drop the **Textarea** component; this is where the explanation of our provided code will be displayed. Rename it to _codeExplanation_. For now, let’s remove the **Default value** and keep it blank.
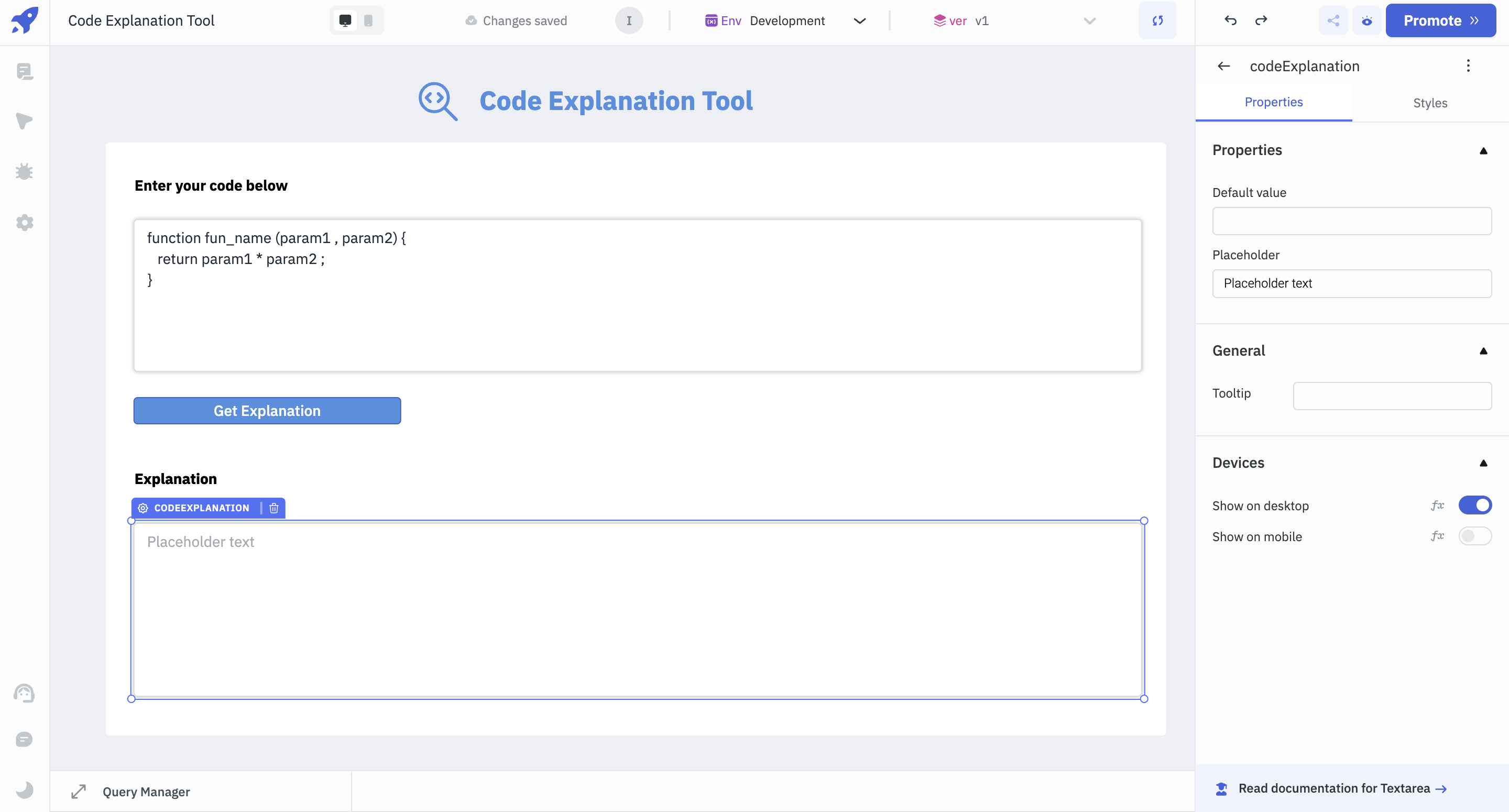
With that, our UI is now ready; it’s time to build the functionality of our application.
## Creating Query
With ToolJet, we can create [queries](https://docs.tooljet.com/docs/tooljet-concepts/what-are-queries), allowing us to interact with the data stored in the data sources. In this tutorial, we will use ToolJet’s [REST API query](https://docs.tooljet.com/docs/data-sources/restapi), to use the Gemini API for the code explanation feature.
- Expand the **Query Panel** at the bottom and click the **Add** button to create a query.
- Choose the **REST API** query and rename it to _getCodeExplanation_.
- In the **Request** parameter, choose **POST** as the **Method** from the drop-down and replace the **URL** with: `https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent?key=<YOUR_API_KEY>`
- Replace `<YOUR_API_KEY>` with the API Key you generated while creating an account on Gemini API, as mentioned in the start of the tutorial.
- In the **Body** section, toggle on **Raw JSON** and replace it with the following code:
```
{{`{
"contents": [
{
"parts": [
{
"text": "This ${components.codeInput.value.replaceAll("\n"," ")}",
},
],
},
],
}`}}
```
_In ToolJet, [double curly braces](https://docs.tooljet.com/docs/tooljet-concepts/how-to-access-values) `{{}}` can be used to pass custom code and access data related to components and queries._
- To ensure that the query runs every time the application loads, enable **Run this query on application load?**
- Click on the **Run** button to run the query, and you can see that the explanation of the default value code we entered in our _codeInput_ component is provided.
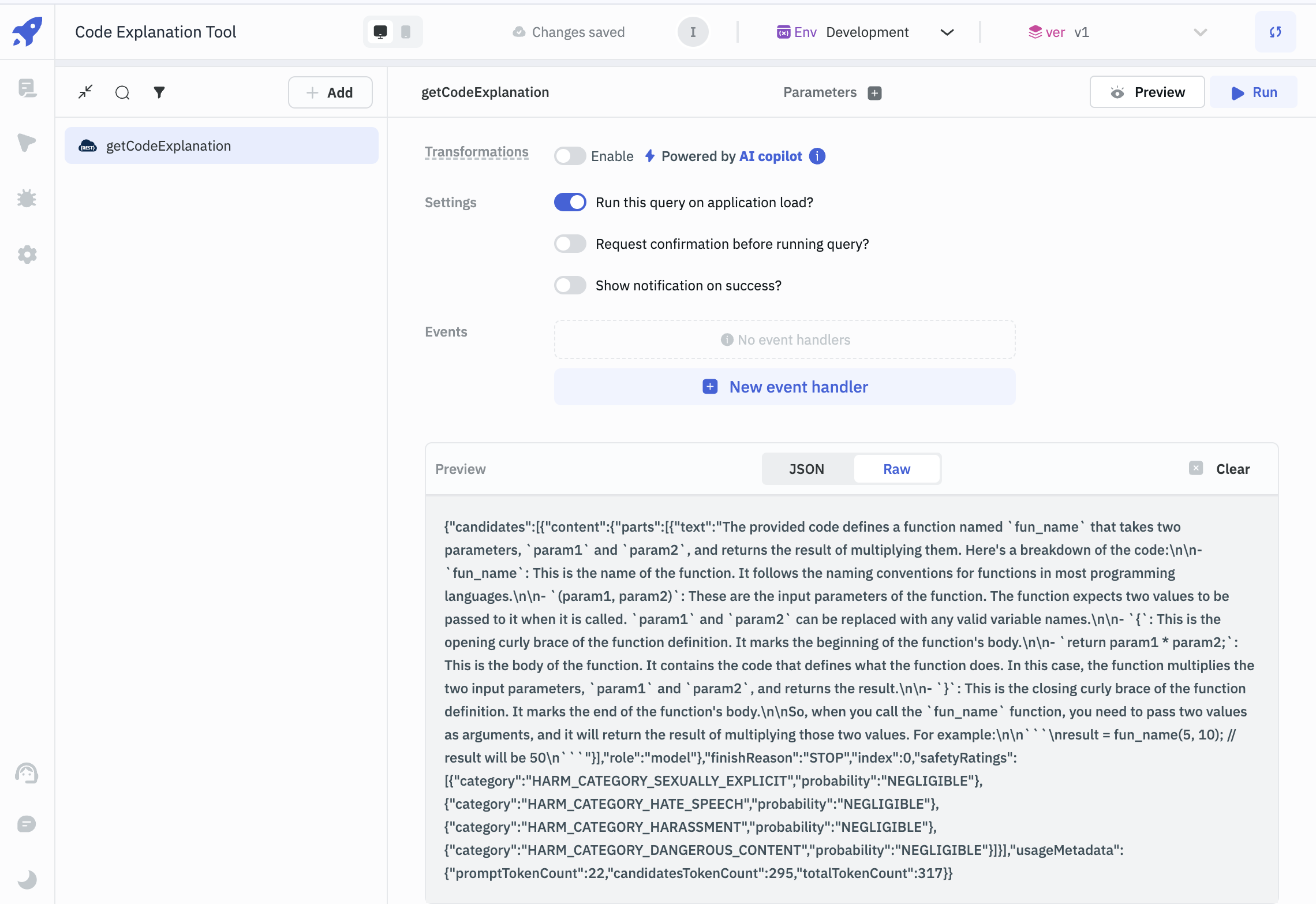
## Binding the Query and the Query Data to the Components
As our query is running successfully and we are fetching the code explanation from Gemini API, it’s time to bind the query to our _getExplanation_ button and display the data in the _codeExplanation_ component.
- Select the _getExplanation_ button, under the **Properties** section, and click the **New event handler** button to create a new **Event**.
- Choose **On click** as the **Event**, **Run Query** as the **Action**, and select _getCodeExplanation_ as the **Query**.
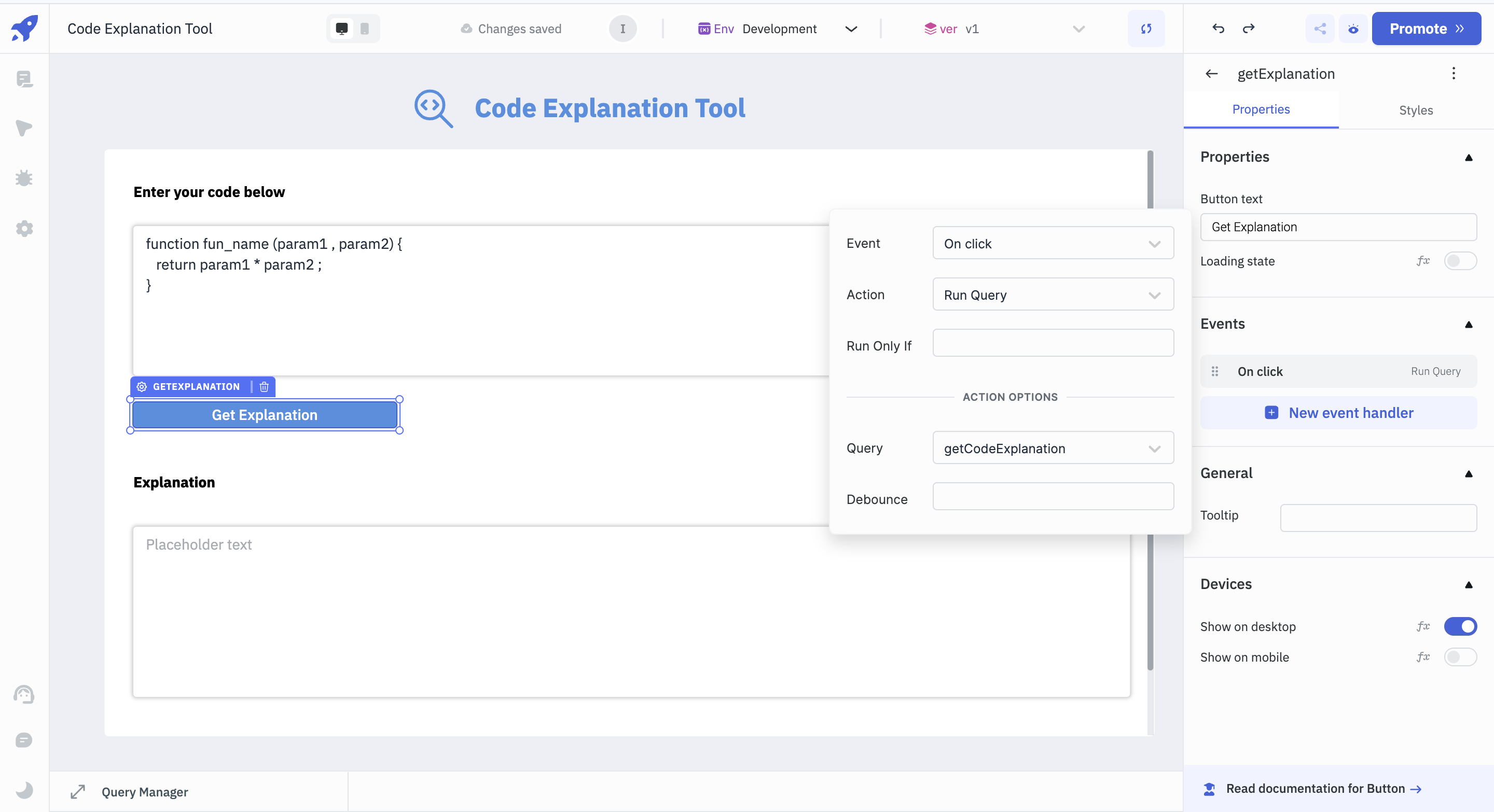
This event will ensure that whenever we click the _getExplanation_ button, the _getCodeExplanation_ query is being run.
Now, let's display the code explanation in our _codeExplanation_ component.
- Select the _codeExplanation_ component, and under the **Default value** property, add the following code: `{{queries.getCodeExplanation.data.candidates[0].content.parts[0].text.replace(/\*\*/g, '').replace(/\*/g, '')}}`.
- Next, click on the _getExplanation_ button, and if you followed the above steps correctly, you should now be able to see the explanation of the provided code displayed in the _codeExplanation_ component.
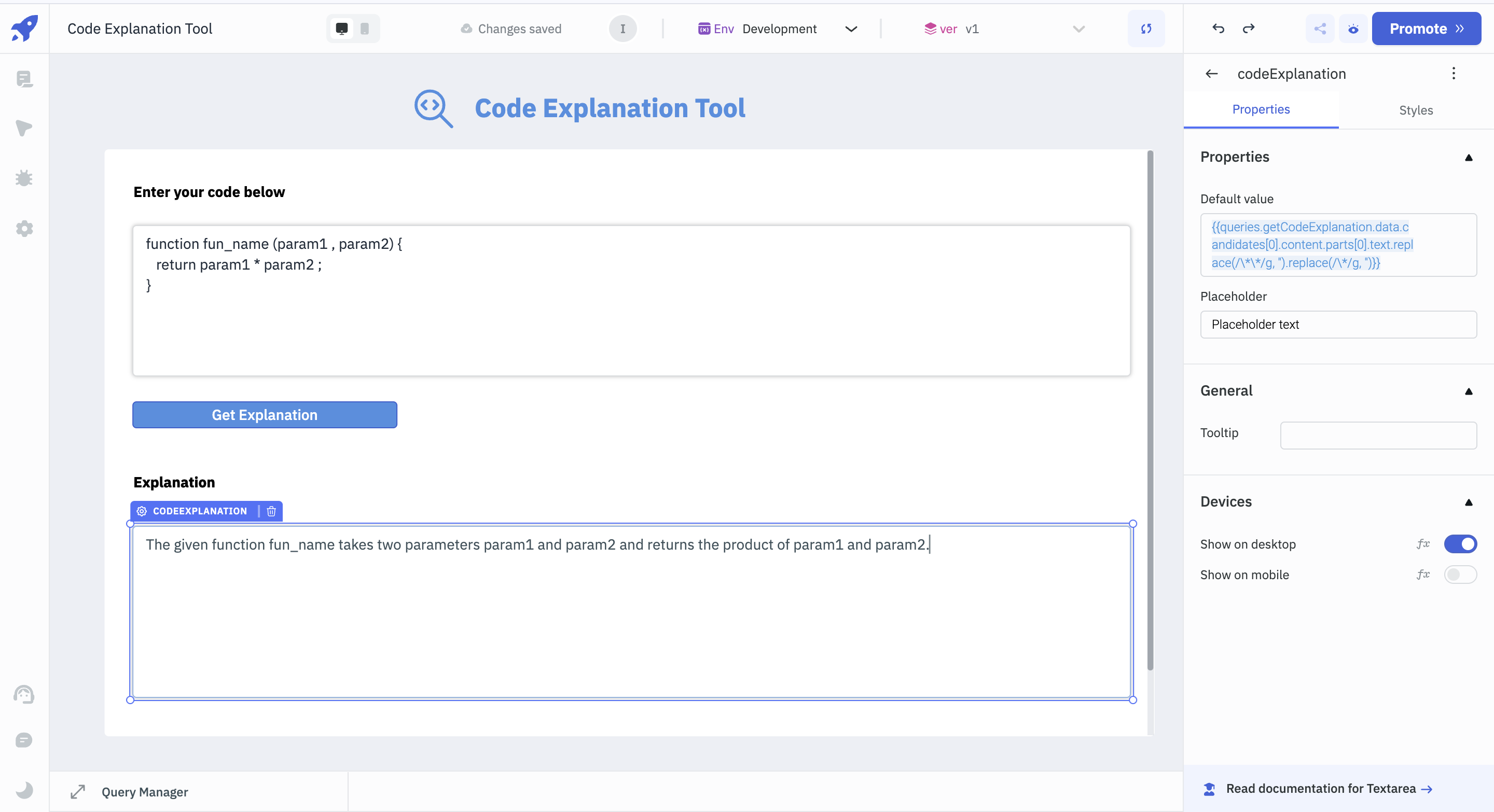
Our app is now ready; try adding different pieces of codes in the _codeInput_ component, and to generate an explanation, click on the _getExplanation_ button to see the explanation being displayed _codeExplanation_ component.
## Conclusion
Congratulations! You've successfully created a code explanation tool using ToolJet and the Gemini API. This tool can help users understand complex code snippets, making learning and debugging more efficient. With ToolJet's low-code capabilities and Gemini's powerful language model, you can further enhance this tool by adding features like code formatting, language detection, and more.
To learn and explore more about ToolJet, check out the [ToolJet docs](https://docs.tooljet.com/docs/) or connect with us and post your queries on [Slack](https://join.slack.com/t/tooljet/shared_invite/zt-2ij7t3rzo-qV7WTUTyDVQkwVxTlpxQqw). Happy coding!
| asjadkhan |
1,867,663 | A Declarative System for Optimizing AI Workloads | A Declarative System for Optimizing AI Workloads | 0 | 2024-05-28T13:01:23 | https://aimodels.fyi/papers/arxiv/declarative-system-optimizing-ai-workloads | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [A Declarative System for Optimizing AI Workloads](https://aimodels.fyi/papers/arxiv/declarative-system-optimizing-ai-workloads). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Modern AI models can now process analytical queries about various types of data, such as company documents, scientific papers, and multimedia content, with high accuracy.
- However, implementing these AI-powered analytics tasks requires a programmer to make numerous complex decisions, such as choosing the right model, inference method, hardware, and prompt design.
- The optimal set of decisions can change as the query and technical landscape evolve, making it challenging for individual programmers to manage.
## Plain English Explanation
In the past, it was difficult and expensive to extract useful information from things like company documents, research papers, or multimedia data. [**Improving Capabilities of Large Language Model-Based Marketing**](https://aimodels.fyi/papers/arxiv/improving-capabilities-large-language-model-based-marketing) But now, modern AI models have the ability to analyze this type of data and answer complex questions about it with high accuracy.
The problem is that for a programmer to use these AI models to answer a specific question, they have to make a lot of decisions. They need to choose the right AI model, the best way to use it (called the "inference method"), the most cost-effective hardware to run it on, and the best way to phrase the question (the "prompt design"). And all of these decisions can change depending on the specific question being asked and as the technology keeps improving.
[**Learning Performance-Improving Code Edits**](https://aimodels.fyi/papers/arxiv/learning-performance-improving-code-edits) To make this easier, the researchers created a system called Palimpzest. Palimpzest allows anyone to define an analytical query in a simple language, and then it automatically figures out the best way to use AI models to answer that query. It explores different combinations of models, prompts, and other optimizations to find the one that gives the best results in terms of speed, cost, and data quality.
## Technical Explanation
The paper introduces Palimpzest, a system that enables users to process AI-powered analytical queries by defining them in a declarative language. Palimpzest uses a cost optimization framework to explore the search space of AI models, prompting techniques, and related foundation model optimizations in order to implement the query with the best trade-offs between runtime, financial cost, and output data quality.
The authors first describe the typical workload of AI-powered analytics tasks, which often requires orchestrating large numbers of models, prompts, and data operations to answer a single substantive query. They then detail the optimization methods used by Palimpzest, including techniques for [**Analysis of Distributed Optimization Algorithms for Real-time Processing at Memory**](https://aimodels.fyi/papers/arxiv/analysis-distributed-optimization-algorithms-real-processing-memory) and [**VPALS: Towards Verified Performance-Aware Learning System**](https://aimodels.fyi/papers/arxiv/vpals-towards-verified-performance-aware-learning-system).
The paper evaluates Palimpzest on tasks in Legal Discovery, Real Estate Search, and Medical Schema Matching. The results show that even a simple prototype of Palimpzest can offer a range of appealing plans, including ones that are significantly faster, cheaper, and offer better data quality than baseline methods. With parallelism enabled, Palimpzest can produce plans with up to a 90.3x speedup at 9.1x lower cost relative to a single-threaded GPT-4 baseline, while maintaining high data quality.
## Critical Analysis
The paper acknowledges that the Palimpzest prototype is still relatively simple and that further research is needed to address additional challenges, such as handling more complex queries, ensuring reliable performance, and integrating advanced AI safety techniques.
One potential concern is the reliance on continuously evolving AI models and infrastructure, which could make it difficult to maintain a stable and consistent system. The authors do not discuss how Palimpzest might adapt to rapidly changing technologies and models.
Additionally, the paper does not address potential ethical or societal implications of making powerful AI-powered analytics widely accessible. There may be concerns about the misuse of such technology, particularly in sensitive domains like [**Efficiency Optimization for Large-Scale Language Models-Based**](https://aimodels.fyi/papers/arxiv/efficiency-optimization-large-scale-language-models-based) legal discovery or medical data analysis.
Overall, the Palimpzest system represents an important step towards democratizing access to AI-powered analytics, but further research is needed to address the challenges and potential risks associated with such a capability.
## Conclusion
The paper presents Palimpzest, a system that enables anyone to process AI-powered analytical queries by defining them in a declarative language. Palimpzest uses a cost optimization framework to automatically select the most appropriate AI models, prompts, and related optimizations to implement the query with the best trade-offs between speed, cost, and data quality.
The evaluation results demonstrate the potential of Palimpzest to significantly improve the accessibility and efficiency of AI-powered analytics, with the possibility of up to 90x speedups and 9x cost reductions compared to a baseline approach. This could have far-reaching implications for a wide range of industries and applications that rely on extracting insights from complex data sources.
However, the paper also highlights the need for further research to address challenges related to system stability, ethical considerations, and potential misuse of the technology. As AI capabilities continue to advance, systems like Palimpzest will play an increasingly important role in empowering users to harness the full potential of these powerful tools.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,662 | YOLOv10: Real-Time End-to-End Object Detection | YOLOv10: Real-Time End-to-End Object Detection | 0 | 2024-05-28T13:00:49 | https://aimodels.fyi/papers/arxiv/yolov10-real-time-end-to-end-object | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [YOLOv10: Real-Time End-to-End Object Detection](https://aimodels.fyi/papers/arxiv/yolov10-real-time-end-to-end-object). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Real-time object detection models like YOLO have emerged as popular choices due to their balance of speed and performance.
- Researchers have explored various aspects of YOLO models, including architecture, optimization, and data augmentation, leading to notable progress.
- However, YOLO models still face challenges, such as the reliance on non-maximum suppression (NMS) for post-processing, which impacts inference latency, and computational redundancy in the model design.
## Plain English Explanation
YOLO (You Only Look Once) models have become widely used for real-time object detection tasks, as they can quickly identify and locate objects in images or videos while maintaining good accuracy. Researchers have been working to continuously improve YOLO models, exploring different ways to design the model architecture, optimize the training process, and augment the training data.
Despite these advancements, YOLO models still have some limitations. One issue is the use of [non-maximum suppression (NMS)](https://aimodels.fyi/papers/arxiv/detrs-beat-yolos-real-time-object-detection) for post-processing, which can slow down the speed of the model at inference time. Additionally, the components of YOLO models may not be optimized as thoroughly as they could be, leading to unnecessary computational overhead and limiting the model's overall capabilities.
## Technical Explanation
The researchers in this work aim to further improve the performance and efficiency of YOLO models, addressing both the post-processing and model architecture aspects.
First, they present a new [training approach for YOLO models that eliminates the need for NMS](https://aimodels.fyi/papers/arxiv/real-time-flying-object-detection-yolov8), achieving competitive performance with low inference latency.
Second, the researchers introduce a comprehensive model design strategy that optimizes various components of YOLO models, targeting both efficiency and accuracy. This reduces the computational overhead and enhances the overall capabilities of the models.
The outcome of this work is a new generation of YOLO models, dubbed [YOLOv10](https://aimodels.fyi/papers/arxiv/you-only-look-at-once-real-time), which demonstrate state-of-the-art performance and efficiency across different model scales. For example, the YOLOv10-S model is 1.8 times faster than [RT-DETR-R18](https://aimodels.fyi/papers/arxiv/detrs-beat-yolos-real-time-object-detection) while achieving similar accuracy on the COCO dataset. Compared to the previous YOLOv9-C model, the YOLOv10-B model has 46% less latency and 25% fewer parameters for the same level of performance.
## Critical Analysis
The researchers have made notable progress in improving the performance and efficiency of YOLO models. The elimination of the NMS post-processing step and the comprehensive optimization of the model components are significant contributions that address key limitations of YOLO models.
However, the paper does not provide a detailed analysis of the specific architectural changes or optimizations made to the various components of the YOLOv10 models. It would be helpful to understand the rationale behind these design choices and how they improve the overall efficiency and capability of the models.
Additionally, the paper does not discuss the potential limitations or drawbacks of the proposed approaches. It would be valuable to explore any trade-offs or edge cases that may arise, as well as potential areas for further research and improvement.
## Conclusion
The researchers have developed a new generation of YOLO models, YOLOv10, that achieve state-of-the-art performance and efficiency in real-time object detection tasks. By addressing the limitations of NMS-based post-processing and optimizing the model architecture, the researchers have pushed the boundaries of what is possible with YOLO models.
These advancements in [YOLO-based object detection](https://aimodels.fyi/papers/arxiv/mo-yolo-end-to-end-multiple-object) have the potential to benefit a wide range of applications, from autonomous vehicles to surveillance systems, by enabling faster and more accurate object recognition in real-time. As the field of computer vision continues to evolve, the insights and techniques presented in this work may inspire further innovation and progress in the development of efficient and high-performing object detection models.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,661 | BiomedParse: a biomedical foundation model for image parsing of everything everywhere all at once | BiomedParse: a biomedical foundation model for image parsing of everything everywhere all at once | 0 | 2024-05-28T13:00:15 | https://aimodels.fyi/papers/arxiv/biomedparse-biomedical-foundation-model-image-parsing-everything | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [BiomedParse: a biomedical foundation model for image parsing of everything everywhere all at once](https://aimodels.fyi/papers/arxiv/biomedparse-biomedical-foundation-model-image-parsing-everything). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Biomedical image analysis is crucial for scientific discoveries in fields like cell biology, pathology, and radiology.
- Holistic image analysis involves interconnected tasks like segmentation, detection, and recognition of relevant objects.
- The researchers propose BiomedParse, a biomedical foundation model that can jointly perform these tasks for 82 object types across 9 imaging modalities.
- BiomedParse leverages natural language labels and descriptions to harmonize the information with biomedical ontologies, creating a large dataset of over 6 million image-mask-text triples.
- The model demonstrates state-of-the-art performance on segmentation, detection, and recognition tasks, enabling efficient and accurate image-based biomedical discovery.
## Plain English Explanation
Biomedical images, such as microscope images of cells or X-rays, contain a wealth of information that scientists use to make important discoveries. Analyzing these images often involves several interconnected tasks, like:
1. **Segmentation**: Identifying the boundaries of different objects or structures within the image.
2. **Detection**: Locating specific objects of interest, like a particular type of cell.
3. **Recognition**: Identifying all the objects in an image and classifying them by type.
The researchers developed a model called BiomedParse that can perform all of these tasks jointly, rather than requiring them to be done separately. This allows the model to learn from the connections between the different tasks, improving the accuracy of each one.
BiomedParse uses natural language descriptions of the objects in the images, along with established biomedical ontologies (formal systems for organizing and classifying biomedical knowledge), to create a large dataset of over 6 million image-description-label triples. This helps the model understand the relationships between the visual information in the images and the corresponding biomedical concepts.
When tested, BiomedParse outperformed other state-of-the-art methods on a wide range of segmentation, detection, and recognition tasks across different biomedical imaging modalities, like microscopy and X-rays. This suggests that BiomedParse could be a valuable tool for efficient and accurate image-based biomedical discovery, enabling scientists to extract more information from their images more quickly and easily.
## Technical Explanation
The researchers propose BiomedParse, a [biomedical foundation model](https://aimodels.fyi/papers/arxiv/one-model-to-rule-them-all-towards) for imaging parsing that can jointly conduct segmentation, detection, and recognition for 82 object types across 9 imaging modalities. This [holistic approach](https://aimodels.fyi/papers/arxiv/generalist-learner-multifaceted-medical-image-interpretation) to image analysis aims to improve the accuracy of individual tasks and enable novel applications, such as segmenting all relevant objects in an image through a text prompt, rather than requiring users to specify bounding boxes for each object manually.
To create the necessary training data, the researchers leveraged natural language labels and descriptions accompanying the biomedical imaging datasets, using [GPT-4](https://aimodels.fyi/papers/arxiv/medclip-sam-bridging-text-image-towards-universal) to harmonize the noisy, unstructured text information with established biomedical object ontologies. This resulted in a large dataset of over 6 million triples of image, segmentation mask, and textual description.
On image segmentation, the researchers showed that BiomedParse outperforms state-of-the-art methods on 102,855 test image-mask-label triples across 9 imaging modalities. For object detection, BiomedParse again demonstrated state-of-the-art performance, particularly on objects with irregular shapes. For object recognition, the model can simultaneously segment and label all biomedical objects in an image, showcasing its ability to perform multiple tasks jointly.
## Critical Analysis
The researchers acknowledge several limitations and areas for further research. For example, they note that the performance of BiomedParse may be affected by the quality and coverage of the natural language descriptions in the training data, as well as the accuracy of the biomedical ontologies used. Additionally, the model's ability to generalize to novel object types or imaging modalities not represented in the training data remains to be explored.
While the results are impressive, it would be valuable to see further analysis of the model's performance on specific types of objects or imaging modalities, as well as its robustness to common challenges in biomedical image analysis, such as noise, occlusion, and variations in imaging conditions.
Lastly, the researchers do not discuss the computational and memory requirements of BiomedParse, which could be an important practical consideration for its deployment in real-world biomedical applications. [Integrating BiomedParse with interactive segmentation tools](https://aimodels.fyi/papers/arxiv/scribbleprompt-fast-flexible-interactive-segmentation-any-biomedical) or exploring ways to make the model more efficient could further enhance its usability and impact.
## Conclusion
BiomedParse is a promising step towards a unified, accurate, and efficient tool for biomedical image analysis. By jointly solving segmentation, detection, and recognition tasks across a wide range of imaging modalities, the model has the potential to significantly accelerate and enhance image-based biomedical discovery. The researchers' use of natural language descriptions and biomedical ontologies to create a large-scale training dataset is a particularly innovative approach that could inspire similar efforts in other domains. Further research to address the model's limitations and optimize its performance and efficiency could solidify BiomedParse's position as a valuable resource for the biomedical research community.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,660 | Demo Paper: A Game Agents Battle Driven by Free-Form Text Commands Using Code-Generation LLM | Demo Paper: A Game Agents Battle Driven by Free-Form Text Commands Using Code-Generation LLM | 0 | 2024-05-28T12:59:40 | https://aimodels.fyi/papers/arxiv/demo-paper-game-agents-battle-driven-by | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Demo Paper: A Game Agents Battle Driven by Free-Form Text Commands Using Code-Generation LLM](https://aimodels.fyi/papers/arxiv/demo-paper-game-agents-battle-driven-by). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Presents a demo paper on a game agents battle driven by free-form text commands using a code-generation large language model (LLM)
- Explores the use of LLMs to enable game agents to understand and execute natural language instructions
- Investigates the potential for LLMs to drive interactive gameplay and narrative in video games
## Plain English Explanation
This paper explores a novel approach to game agent control and interaction using [large language models](https://aimodels.fyi/papers/arxiv/survey-large-language-model-based-game-agents). The researchers developed a system where game agents can understand and execute free-form text commands, allowing players to control the agents using natural language instead of traditional input methods like buttons or keyboard commands.
The key idea is to leverage the power of [code-generation LLMs](https://aimodels.fyi/papers/arxiv/generating-games-via-llms-investigation-video-game) to translate the players' text instructions into actionable commands that the game agents can then follow. This enables a more intuitive and immersive gameplay experience, where players can issue high-level directives like "Attack the enemy" or "Move to the left" and see the agents respond accordingly.
The researchers tested their system in a simulated game environment, where two opposing agents battled each other based on the text commands provided by the players. This setup allowed the researchers to explore how well the LLM-powered agents could understand and execute complex instructions, as well as how the natural language interaction might shape the [emergent gameplay and narrative](https://aimodels.fyi/papers/arxiv/player-driven-emergence-llm-driven-game-narrative).
## Technical Explanation
The paper presents a novel system for enabling game agents to understand and execute free-form text commands using a code-generation LLM. The key components of the system include:
1. **Natural Language Interface**: The system allows players to input free-form text commands, which are then processed by the LLM to translate them into executable actions for the game agents.
2. **Code-Generation LLM**: The researchers used a large language model capable of generating code, enabling the system to translate the natural language instructions into the appropriate actions for the game agents to perform.
3. **Game Agent Execution**: The translated code from the LLM is then executed by the game agents, allowing them to perform the desired actions in the game environment.
The researchers evaluated the system in a simulated game environment where two opposing agents battled each other based on the text commands provided by the players. The experiments showed that the LLM-powered agents were able to understand and execute a wide range of instructions, from simple movements to complex combat strategies.
The researchers also explored how the [natural language interaction might shape the emergent gameplay and narrative](https://aimodels.fyi/papers/arxiv/player-driven-emergence-llm-driven-game-narrative), as players could direct the agents to engage in unexpected behaviors and storylines.
## Critical Analysis
The paper presents a promising approach to enhancing game agent behavior and player interaction through the use of LLMs. However, the researchers acknowledge several limitations and areas for further exploration:
- **Scalability**: The performance of the system may degrade as the complexity of the game environment and the number of agents increase. More research is needed to understand the scalability of the approach.
- **Robustness**: The system's ability to handle ambiguous, contradictory, or incomplete instructions is not fully addressed. Improving the LLM's understanding and handling of natural language nuances could be an area for further development.
- **Safety and Ethical Considerations**: As this technology could be used to create more interactive and immersive game experiences, it is essential to consider the [potential ethical implications](https://aimodels.fyi/papers/arxiv/ds-agent-automated-data-science-by-empowering) and ensure that appropriate safeguards are in place to prevent misuse or unintended consequences.
Overall, the paper presents an innovative approach to game agent control and interaction, opening up new possibilities for [player-driven narrative emergence](https://aimodels.fyi/papers/arxiv/player-driven-emergence-llm-driven-game-narrative) and more intuitive gameplay experiences. Further research and development in this area could lead to significant advancements in the field of [game AI](https://aimodels.fyi/papers/arxiv/natural-language-as-policies-reasoning-coordinate-level) and human-computer interaction.
## Conclusion
The demo paper presents a novel system that enables game agents to understand and execute free-form text commands using a code-generation LLM. This approach has the potential to enhance player engagement and agency in video games by allowing for more intuitive and natural language-based interactions with game agents.
The researchers' findings suggest that LLMs can be effectively utilized to drive interactive gameplay and narrative, opening up new possibilities for more immersive and dynamic gaming experiences. However, further research is needed to address scalability, robustness, and ethical considerations to ensure the safe and responsible development of this technology.
Overall, this paper represents an exciting step forward in the integration of natural language processing and game AI, with the possibility of transforming how players interact with and experience video games.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,658 | Chocolate Milk Dessert Nutrition Data | The article provides nutritional information for fat-free frozen chocolate milk dessert. It details... | 0 | 2024-05-28T12:59:21 | https://dev.to/dbjustinmoore/chocolate-milk-dessert-nutrition-data-1656 | The article provides nutritional information for fat-free frozen [chocolate milk dessert](https://discoverybody.com/calorie-nutrition/chocolate-milk-dessert-fat-free-frozen-nutrition-data/). It details the calorie content, macronutrient breakdown, and key vitamins and minerals present in this dessert option.
Additionally, it offers insights into the benefits of choosing a fat-free version and how it fits into a balanced diet. For a comprehensive look at the nutritional data and more details, you can [read the full article here](https://discoverybody.com/calorie-nutrition/chocolate-milk-dessert-fat-free-frozen-nutrition-data/).
https://discoverybody.com/calorie-nutrition/chocolate-milk-dessert-fat-free-frozen-nutrition-data/ | dbjustinmoore | |
1,867,657 | Attention as an RNN | Attention as an RNN | 0 | 2024-05-28T12:59:06 | https://aimodels.fyi/papers/arxiv/attention-as-rnn | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Attention as an RNN](https://aimodels.fyi/papers/arxiv/attention-as-rnn). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Transformers, a breakthrough in sequence modelling, are computationally expensive at inference time, limiting their applications in low-resource settings.
- This paper introduces a new efficient method of computing attention's [many-to-many RNN output](https://aimodels.fyi/papers/arxiv/easy-attention-simple-attention-mechanism-temporal-predictions) based on the parallel prefix scan algorithm.
- The paper presents **Aaren**, an attention-based module that can be trained in parallel like Transformers and updated efficiently with new tokens, requiring only constant memory for inferences like traditional RNNs.
- Empirically, Aarens achieve comparable performance to Transformers on 38 datasets across four popular sequential problem settings while being more time and memory-efficient.
## Plain English Explanation
Transformers are a type of machine learning model that have revolutionized the way we handle sequential data, such as text and time series. They are highly effective, but they can be computationally expensive, making them challenging to use on devices with limited resources, like smartphones or embedded systems.
The researchers behind this paper found a way to make attention, a key component of Transformers, more efficient. Attention allows the model to focus on the most relevant parts of the input when generating the output. The researchers showed that attention can be viewed as a special type of Recurrent Neural Network (RNN), which is a common type of machine learning model for sequential data.
Building on this insight, the researchers introduced a new method for computing attention's output efficiently, using an algorithm called the parallel prefix scan. This allowed them to create a new attention-based module called **Aaren**, which has several advantages:
1. It can be trained in parallel, like Transformers, allowing for fast training.
2. It can be updated efficiently with new input tokens, requiring only constant memory during inference, like traditional RNNs.
The researchers tested Aaren on a wide range of sequential tasks, such as reinforcement learning, event forecasting, time series classification, and time series forecasting. They found that Aaren performed just as well as Transformers on these tasks, but was more efficient in terms of time and memory usage.
This research is important because it helps address one of the key limitations of Transformers, making them more suitable for use in low-resource settings where computational power is limited. By combining the strengths of Transformers and traditional RNNs, the researchers have created a new model that can be both highly effective and highly efficient.
## Technical Explanation
The paper begins by showing that attention can be viewed as a special type of Recurrent Neural Network (RNN) that can efficiently compute its **many-to-one** RNN output. The researchers then demonstrate that popular attention-based models, such as [Transformers](https://aimodels.fyi/papers/arxiv/efficient-economic-large-language-model-inference-attention), can be seen as RNN variants.
However, unlike traditional RNNs (e.g., LSTMs), these attention-based models cannot be updated efficiently with new tokens, which is an important property in sequence modelling. To address this, the researchers introduce a new efficient method of computing attention's **many-to-many** RNN output based on the parallel prefix scan algorithm.
Building on this new attention formulation, the researchers introduce **Aaren**, an attention-based module that can not only be trained in parallel (like Transformers) but also be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs).
Empirically, the researchers show that Aarens achieve comparable performance to Transformers on 38 datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks. Importantly, Aarens are more time and memory-efficient than Transformers.
## Critical Analysis
The paper provides a novel and insightful approach to addressing the computational challenges of Transformers, particularly in low-resource settings. The researchers' insights into the connection between attention and RNNs, as well as their efficient method for computing attention's output, are valuable contributions to the field.
One potential limitation of the research is that the experiments were conducted on a relatively narrow set of tasks, and it's unclear how well the Aaren module would perform on more complex or diverse sequence modelling problems. Additionally, the paper does not provide a detailed analysis of the tradeoffs between the performance and efficiency of Aaren compared to other attention-based models, such as [BurstAttention](https://aimodels.fyi/papers/arxiv/burstattention-efficient-distributed-attention-framework-extremely-long) or [TA-RNN](https://aimodels.fyi/papers/arxiv/ta-rnn-attention-based-time-aware-recurrent).
Further research could explore the performance of Aaren on a wider range of tasks, as well as compare it more extensively with other efficient attention-based models. Additionally, the researchers could investigate the potential for Aaren to be integrated into larger language models or other complex sequence modelling applications, which could further demonstrate the practical benefits of their approach.
## Conclusion
This paper presents a significant advancement in the field of sequence modelling by introducing **Aaren**, an attention-based module that combines the strengths of Transformers and traditional RNNs. Aaren's ability to be trained in parallel while also being efficiently updatable with new tokens makes it a highly promising solution for deploying powerful sequence models in low-resource settings.
The researchers' insights into the connection between attention and RNNs, as well as their efficient method for computing attention's output, are valuable contributions that could have far-reaching implications for the development of more scalable and efficient machine learning models. As the demand for high-performing, yet resource-efficient, sequence models continues to grow, this research represents an important step forward in addressing this challenge.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,656 | Evaluation of the Programming Skills of Large Language Models | Evaluation of the Programming Skills of Large Language Models | 0 | 2024-05-28T12:58:31 | https://aimodels.fyi/papers/arxiv/evaluation-programming-skills-large-language-models | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Evaluation of the Programming Skills of Large Language Models](https://aimodels.fyi/papers/arxiv/evaluation-programming-skills-large-language-models). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- The paper examines the code quality generated by two leading Large Language Models (LLMs): OpenAI's ChatGPT and Google's Gemini AI.
- It compares the programming code produced by the free versions of these chatbots using a real-world example and a systematic dataset.
- The research aims to assess the efficacy and reliability of LLMs in generating high-quality programming code, which has significant implications for software development.
## Plain English Explanation
Large Language Models (LLMs) like [ChatGPT](https://aimodels.fyi/papers/arxiv/lets-ask-ai-about-their-programs-exploring) and [Gemini AI](https://aimodels.fyi/papers/arxiv/systematic-evaluation-large-language-models-natural-language) have revolutionized how we complete tasks, making us more productive. As these chatbots take on increasingly complex challenges, it's vital to understand how well they can generate quality programming code.
This study looks at the code produced by the free versions of ChatGPT and Gemini AI. The researchers used a real-world example and a carefully designed dataset to compare the quality of the code generated by these two LLMs. This is important because as programming tasks become more complex, it can be difficult to verify the code's quality. The study aims to shed light on how reliable and effective these chatbots are at generating high-quality code, which has significant implications for the software development industry and beyond.
## Technical Explanation
The paper [systematically evaluates](https://aimodels.fyi/papers/arxiv/systematic-evaluation-large-language-models-natural-language) the code quality generated by OpenAI's ChatGPT and Google's Gemini AI, two prominent LLMs. The researchers used a [real-world example](https://aimodels.fyi/papers/arxiv/case-study-large-language-models-chatgpt-codebert) and a carefully designed dataset to compare the programming code produced by the free versions of these chatbots.
The researchers investigated the capability of these LLMs to [generate high-quality code](https://aimodels.fyi/papers/arxiv/automatic-programming-large-language-models-beyond), as this aspect of chatbot performance has significant implications for software development. The complexity of programming tasks often escalates to levels where verifying the code's quality becomes a formidable challenge, underscoring the importance of this study.
## Critical Analysis
The paper provides a comprehensive [evaluation of the usability](https://aimodels.fyi/papers/arxiv/evaluation-chatgpt-usability-as-code-generation-tool) of ChatGPT and Gemini AI as code generation tools. However, the research is limited to the free versions of these LLMs, and the performance of the paid or enterprise versions may differ. Additionally, the study focuses on a specific set of programming tasks and does not address the full breadth of code generation capabilities that these chatbots may possess.
While the paper offers valuable insights, further research is needed to explore the long-term reliability and scalability of LLMs in the context of software development. As these models continue to evolve, it will be crucial to monitor their performance and identify any potential limitations or biases that may arise.
## Conclusion
This research sheds light on the efficacy and reliability of two prominent Large Language Models, ChatGPT and Gemini AI, in generating high-quality programming code. The findings have significant implications for the software development industry, as the ability to produce robust and reliable code is a critical component of modern software engineering.
As LLMs continue to advance, this study serves as a valuable benchmark for understanding the current capabilities and limitations of these chatbots in the context of code generation. The insights gained from this research can inform the development of more reliable and trustworthy AI-powered tools for software developers, ultimately contributing to the advancement of the field.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,655 | DiscoveryBody | At DiscoveryBody, we believe that knowledge is power, particularly when it comes to your health. Our... | 0 | 2024-05-28T12:57:58 | https://dev.to/dbjustinmoore/discoverybody-52dn | At [DiscoveryBody](https://discoverybody.com/), we believe that knowledge is power, particularly when it comes to your health. Our purpose is straightforward: to present you with the most current and reliable information on all things health.
We want to be your go-to source for health and fitness news, recipes, and everything in between. [DiscoveryBody](https://discoverybody.com/) isn't just a website. It's a community of like-minded people who are dedicated to living their best lives.
https://discoverybody.com/ | dbjustinmoore | |
1,867,654 | How to Ace Your EX280 Exam: Insider Tricks with Dumps | Actively engage in the material: Instead of passively reading exam samples, actively engage with the... | 0 | 2024-05-28T12:57:26 | https://dev.to/creat1949/how-to-ace-your-ex280-exam-insider-tricks-with-dumps-3418 | 4. Actively engage in the material:
Instead of passively reading exam samples, actively engage with the material by answering practice questions, solving problems, and explaining concepts in your own words. Actively engaging with the material will deepen your understanding and retention of key concepts.
5. Practice regularly:
Practice exam dumps regularly to EX280 Exam Dumps familiarize yourself with the exam format and question types. Treat each practice session as if it were a real test, effectively simulating the test conditions. Focus on areas that need improvement and spend extra time practicing those topics.
6. Review and improvement:
After completing the practice questions, review the answers and explanations to understand the reason behind each correct and incorrect answer. Write down any concepts or topics you find difficult and spend extra time to enhance your understanding.
CLICK HERE FOR MORE INFO>>>>>>>>>>>>>>> https://dumpsarena.com/redhat-dumps/ex280/
| creat1949 | |
1,867,653 | Deceptive, Disruptive, No Big Deal: Japanese People React to Simulated Dark Commercial Patterns | Deceptive, Disruptive, No Big Deal: Japanese People React to Simulated Dark Commercial Patterns | 0 | 2024-05-28T12:57:23 | https://aimodels.fyi/papers/arxiv/deceptive-disruptive-no-big-deal-japanese-people | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Deceptive, Disruptive, No Big Deal: Japanese People React to Simulated Dark Commercial Patterns](https://aimodels.fyi/papers/arxiv/deceptive-disruptive-no-big-deal-japanese-people). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This study investigates how Japanese people react to simulated "dark" commercial patterns, which are design practices that can manipulate or deceive users.
- The researchers conducted a user study where they showed participants simulated examples of dark patterns and collected their reactions and perceptions.
- The findings provide insights into cultural differences in how people respond to these types of deceptive design practices.
## Plain English Explanation
The researchers in this study wanted to understand how people in Japan react to manipulative or deceptive design tactics used in online shopping and other digital experiences. These tactics, known as "dark patterns," are design techniques that can trick or pressure users into doing things they may not want to do, like signing up for something or making a purchase.
To explore this, the researchers showed Japanese participants a series of simulated examples of dark patterns and asked for their reactions. They found that many Japanese participants did not see these patterns as a big deal or particularly concerning. This is in contrast with previous research in Western countries, where people tend to find dark patterns more unacceptable and problematic.
The researchers suggest that these cultural differences may stem from factors like the importance of maintaining social harmony and avoiding conflict in Japanese culture. Some Japanese participants also expressed the view that it's ultimately the user's responsibility to be cautious online, rather than expecting businesses to avoid deceptive tactics.
These findings highlight how people's perceptions and reactions to manipulative design can vary across different cultural contexts. They also underscore the need to consider cultural factors when studying and regulating dark patterns and other forms of [deceptive design](https://aimodels.fyi/papers/arxiv/theorizing-deception-scoping-review-theory-research-dark).
## Technical Explanation
The researchers conducted a user study to investigate how Japanese people perceive and react to simulated examples of dark commercial patterns. Dark patterns are design practices that can manipulate or deceive users, such as making it difficult to cancel a subscription or using misleading wording.
The study involved showing participants a series of 12 simulated dark pattern examples across three categories: sneaking, obstruction, and social proof. After each example, participants answered questions about their perceptions of the pattern, including whether they found it deceptive, disruptive, or acceptable.
The researchers found that many Japanese participants did not view the dark patterns as particularly problematic or unacceptable, in contrast with prior research in Western contexts. Some participants expressed the view that it is ultimately the user's responsibility to be cautious online, rather than expecting businesses to avoid deceptive tactics.
These findings suggest cultural differences in how people respond to dark patterns, which the researchers attribute to factors like the emphasis on social harmony and avoiding conflict in Japanese culture. The study provides important insights into the need to consider cultural context when studying and [regulating dark patterns](https://aimodels.fyi/papers/arxiv/regulating-dark-patterns).
## Critical Analysis
The study makes a valuable contribution by exploring cultural differences in perceptions of dark patterns, an area that has received limited attention in prior research. The researchers do acknowledge several limitations, including the use of simulated examples rather than real-world dark patterns, and the potential for social desirability bias in participants' responses.
One potential concern is the relatively small sample size of 30 participants, which may limit the generalizability of the findings. Additionally, the study does not delve deeply into the underlying cultural factors that shape Japanese people's perspectives on dark patterns. Further research would be needed to more fully [characterize and model the harms](https://aimodels.fyi/papers/arxiv/characterizing-modeling-harms-from-interactions-design-patterns) of dark patterns in diverse cultural contexts.
That said, the study's insights into the complex and nuanced ways that people perceive and respond to deceptive design are valuable. The findings underscore the importance of considering cultural context when attempting to [theorize about deception](https://aimodels.fyi/papers/arxiv/theorizing-deception-scoping-review-theory-research-dark) and [regulate dark patterns](https://aimodels.fyi/papers/arxiv/regulating-dark-patterns) in the digital world.
## Conclusion
This study provides important cross-cultural insights into how people perceive and react to dark commercial patterns, which are deceptive design practices that can manipulate or exploit users. The researchers found that many Japanese participants did not view these patterns as particularly problematic or unacceptable, in contrast with previous research in Western contexts.
These findings highlight the need to consider cultural factors when studying and regulating dark patterns. They also suggest that the [relationship between good intentions and deceptive outcomes](https://aimodels.fyi/papers/arxiv/hell-is-paved-good-intentions-intricate-relationship) in design can be complex and nuanced, varying across different societal and cultural contexts.
As digital experiences continue to shape our lives, understanding how people from diverse backgrounds respond to deceptive design will be crucial for creating more ethical and trustworthy technologies that serve the needs of all users, regardless of their cultural background.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,652 | Air Conditioner Store in Lahore | Introduction Lahore, known for its scorching summers, necessitates the need for efficient... | 0 | 2024-05-28T12:56:50 | https://dev.to/madinaelectric/air-conditioner-store-in-lahore-2e6j | ## Introduction
Lahore, known for its scorching summers, necessitates the need for efficient cooling solutions. The demand for (ACs) [Air Conditioners in Lahore](https://madinaelectriccentre.com/product-category/air-conditioner/) has surged, making it crucial for residents to find reliable sources for their cooling needs. Whether you're upgrading your old unit or buying a new one, knowing where to shop and what to look for can make all the difference.
## Why Choose an Air Conditioner Store in Lahore
**Local Expertise
**When shopping for an AC in Lahore, local expertise matters. Stores in Lahore understand the specific climate challenges and can recommend the best units tailored to the city's hot and humid conditions.
Diverse Product Range
Local stores offer a variety of brands and models, ensuring you have a wide selection to choose from. Whether you need a compact window unit or a powerful split AC, Lahore stores have got you covered.
**Competitive Pricing
**Due to the competitive market in Lahore, stores often offer attractive pricing. They provide seasonal discounts, promotional offers, and trade-in deals that make buying an AC more affordable.
## Top Air Conditioner Brands Available
**Daikin**
Known for its innovative technology and energy efficiency, Daikin ACs are a popular choice among Lahoris.
**Gree**
Gree offers a wide range of models that cater to different budgets and cooling needs, making it a versatile choice.
**Mitsubishi
**Mitsubishi ACs are known for their durability and advanced features, providing reliable performance even in extreme conditions.
**Haier**
Haier combines affordability with cutting-edge technology, making it a favorite among budget-conscious consumers.
**LG**
LG ACs are renowned for their sleek designs and smart features, offering both style and functionality.
## Types of Air Conditioners Available
**Window AC
**Ideal for smaller rooms, window ACs are easy to install and cost-effective.
**Split AC
**Split ACs are perfect for larger rooms, offering powerful cooling with minimal noise.
**Portable AC
**Portable ACs provide flexibility as they can be moved from room to room, catering to varying cooling needs.
**Central AC**
For comprehensive cooling throughout the house, central AC systems are the best option, albeit more expensive.
## Energy Efficiency and Eco-Friendly Options
**Inverter Technology**
Inverter ACs adjust their compressor speed to maintain a consistent temperature, leading to significant energy savings.
**Energy Star Ratings**
ACs with high Energy Star ratings consume less electricity, translating to lower utility bills.
**Green Refrigerants**
Many modern ACs use eco-friendly refrigerants that have a lower environmental impact, aligning with global green initiatives.
## Factors to Consider When Buying an Air Conditioner
**Room Size and AC Capacity**
Ensure the AC you choose matches the size of your room for optimal cooling efficiency.
**Budget Considerations**
Set a budget and look for models that offer the best features within your price range.
Energy Efficiency
Opt for energy-efficient models to save on electricity costs in the long run.
Noise Levels
Check the noise levels of the AC, especially if it's for a bedroom or study room where quiet operation is crucial.
Installation Services
Professional Installation
Most stores offer professional installation services, ensuring your AC is set up correctly and efficiently.
Installation Costs
Be aware of any additional installation costs, which can vary depending on the complexity of the setup.
Post-Installation Support
Good stores offer post-installation support to address any issues that may arise after the AC is installed.
Maintenance and Repair Services
Routine Maintenance
Regular maintenance extends the lifespan of your AC and keeps it running efficiently.
Common Repair Services
Knowing the common repair issues and having access to reliable repair services can save you from major inconveniences.
##

Select a service provider with good reviews and a proven track record to ensure your AC is in safe hands.
Customer Reviews and Testimonials
Importance of Reviews
Customer reviews provide insight into the performance and reliability of different AC models and brands.
Where to Find Authentic Reviews
Check reviews on trusted platforms like Google, Yelp, and specific home appliance forums.
Interpreting Customer Feedback
Look for consistent themes in customer feedback to make informed decisions.
## Seasonal Offers and Discounts
Peak Season vs Off-Season Buying
Prices often drop during off-season periods, offering significant savings.
Promotional Discounts
Keep an eye out for promotional discounts during festive seasons and store anniversaries.
Trade-In Offers
Some stores offer trade-in deals for your old AC, making the upgrade more affordable.
Warranty and After-Sales Support
## Types of Warranties Offered
Understand the different types of warranties (e.g., comprehensive, limited) available for your AC.
Claiming Warranty
Familiarize yourself with the warranty claiming process to avoid any hassles later.
Importance of After-Sales Support
Good after-sales support ensures you get prompt assistance for any issues that arise post-purchase.
Financing Options
Installment Plans
Many stores offer installment plans that spread the cost of your AC over several months.
Bank Financing
Check if your bank offers financing deals for home appliances.
In-Store Financing Deals
Some stores provide in-house financing options with attractive interest rates.
Online vs Offline Shopping
## Benefits of In-Store Shopping
In-store shopping allows you to see and test the product before buying.
Advantages of Online Shopping
Online shopping offers convenience and often better deals, with the comfort of home delivery.
Hybrid Shopping Experiences
Some stores offer a hybrid model where you can browse online and buy in-store, combining the best of both worlds.
Top Air Conditioner Stores in Lahore
Store #1: Overview and Highlights
Offering a vast range of brands and models, this store is known for its excellent customer service and competitive prices.
Store #2: Overview and Highlights
Known for its professional installation services and after-sales support, this store is a favorite among locals.
Store #3: Overview and Highlights
This store stands out for its eco-friendly options and attractive financing deals.
## Conclusion
Choosing the right [Air Conditioner Store in Lahore](https://madinaelectriccentre.com/product-category/air-conditioner/) can significantly impact your buying experience and the performance of your AC. By considering local expertise, product range, pricing, and after-sales support, you can ensure you get the best value for your money. Remember to check customer reviews, explore financing options, and take advantage of seasonal discounts to make the most informed decision.
## FAQs
How do I choose the right AC for my room size?
To choose the right AC, measure your room's square footage and match it to the AC's cooling capacity, typically listed in BTUs. For example, a room up to 150 square feet requires about 5,000 BTUs.
What are the benefits of inverter ACs?
Inverter ACs adjust their compressor speed to maintain a constant temperature, resulting in energy savings, quieter operation, and a longer lifespan compared to non-inverter models.
How often should I service my air conditioner?
It's recommended to service your air conditioner at least once a year to ensure it runs efficiently and to extend its lifespan. Regular maintenance can also help prevent major repairs.
Are there financing options available for purchasing ACs?
Yes, many stores offer financing options, including installment plans, bank financing, and in-store financing deals, making it easier to afford a new AC.
What should I look for in customer reviews?
Look for consistent feedback on performance, reliability, energy efficiency, and after-sales support. Pay attention to any recurring issues or praises to make an informed decision.
| madinaelectric | |
1,867,651 | Pareto Optimal Learning for Estimating Large Language Model Errors | Pareto Optimal Learning for Estimating Large Language Model Errors | 0 | 2024-05-28T12:56:49 | https://aimodels.fyi/papers/arxiv/pareto-optimal-learning-estimating-large-language-model | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Pareto Optimal Learning for Estimating Large Language Model Errors](https://aimodels.fyi/papers/arxiv/pareto-optimal-learning-estimating-large-language-model). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper proposes a novel approach for automatically calibrating and correcting errors in large language models (LLMs) through a technique called Pareto Optimal Self-Supervision (POSS).
- The key idea is to leverage the intrinsic uncertainty and diversity of LLM outputs to identify and correct systematic errors and biases.
- The authors demonstrate the effectiveness of POSS on several benchmarks, showing significant improvements in model calibration and error correction compared to standard fine-tuning approaches.
## Plain English Explanation
Large language models (LLMs) like [GPT-3](https://aimodels.fyi/papers/arxiv/evaluating-llms-at-detecting-errors-llm-responses) and [BERT](https://aimodels.fyi/papers/arxiv/evaluating-optimizing-educational-content-large-language-model) have become incredibly powerful at understanding and generating human language. However, these models can also make mistakes or have biases that are not always easy to detect or fix.
The researchers in this paper developed a new technique called Pareto Optimal Self-Supervision (POSS) to help automatically identify and correct these errors and biases in LLMs. The key idea is to look at the diversity of responses the model generates for a given input and use that information to figure out when the model is making systematic mistakes.
For example, if an LLM consistently generates incorrect answers for certain types of questions, POSS can detect that pattern and adjust the model to correct those errors. This is similar to how humans use [uncertainty-aware](https://aimodels.fyi/papers/arxiv/harnessing-power-large-language-model-uncertainty-aware) reasoning to identify and fix their own mistakes.
The researchers tested POSS on several benchmark tasks and found that it significantly improved the accuracy and reliability of the LLMs compared to standard fine-tuning approaches. This suggests that POSS could be a valuable tool for [making LLMs more consistent and less biased](https://aimodels.fyi/papers/arxiv/large-language-models-are-inconsistent-biased-evaluators) as they become more widely used in [various applications](https://aimodels.fyi/papers/arxiv/large-language-model-enhanced-machine-learning-estimators).
## Technical Explanation
The paper proposes a novel technique called Pareto Optimal Self-Supervision (POSS) for automatically calibrating and correcting errors in large language models (LLMs). The key idea is to leverage the intrinsic uncertainty and diversity of LLM outputs to identify and correct systematic errors and biases.
The POSS approach consists of three main steps:
1. **Sampling Diverse Outputs**: For a given input, the model generates a diverse set of candidate outputs by sampling from its output distribution.
2. **Pareto Optimization**: The model then selects the Pareto optimal outputs from the candidate set based on a multi-objective optimization framework that considers both output quality and diversity.
3. **Self-Supervision**: Finally, the model is fine-tuned on the selected Pareto optimal outputs, using them as pseudo-labels to correct its own systematic errors and biases.
The authors demonstrate the effectiveness of POSS on several benchmarks, including language modeling, question answering, and text summarization tasks. They show that POSS significantly outperforms standard fine-tuning approaches in terms of both model calibration and error correction.
The key insight behind POSS is that the diversity of LLM outputs can be a valuable signal for identifying systematic errors. By sampling multiple outputs and selecting the Pareto optimal ones, the model can learn to adjust its behavior and correct these errors through self-supervision.
## Critical Analysis
The POSS approach proposed in this paper is a promising step towards more reliable and robust large language models. By leveraging the intrinsic uncertainty and diversity of LLM outputs, the technique can effectively identify and correct systematic errors and biases, which is a significant challenge in the field.
However, the paper also acknowledges several limitations and areas for further research:
1. **Computational Overhead**: The POSS approach requires generating and evaluating multiple candidate outputs for each input, which can be computationally expensive, especially for large-scale applications.
2. **Generalization to Other Tasks**: While the authors demonstrate the effectiveness of POSS on several benchmark tasks, it remains to be seen how well the technique will generalize to a wider range of language understanding and generation tasks.
3. **Interpretability and Explainability**: The paper does not provide much insight into how POSS actually identifies and corrects the systematic errors in the LLMs. More work is needed to understand the underlying mechanisms and make the process more interpretable.
Additionally, one could raise the concern that the POSS approach may not be sufficient to address all the potential issues with large language models, such as [their inconsistency and bias as evaluators](https://aimodels.fyi/papers/arxiv/large-language-models-are-inconsistent-biased-evaluators). Further research is needed to explore the limits of this technique and develop complementary approaches to make LLMs more reliable and trustworthy.
## Conclusion
The paper presents a novel technique called Pareto Optimal Self-Supervision (POSS) for automatically calibrating and correcting errors in large language models. By leveraging the intrinsic uncertainty and diversity of LLM outputs, POSS can effectively identify and correct systematic errors and biases, as demonstrated on several benchmark tasks.
This work represents an important step towards more reliable and robust large language models, which are increasingly being [deployed in a wide range of applications](https://aimodels.fyi/papers/arxiv/large-language-model-enhanced-machine-learning-estimators). While the POSS approach has some limitations, it provides a promising direction for further research and development in this critical area.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,650 | Introducing AlphaFold 3: Revolutionizing Biological Research and Drug Discovery | Understanding AlphaFold 3 AlphaFold 3, a new AI model developed by Google DeepMind and... | 0 | 2024-05-28T12:56:16 | https://dev.to/aishikl/introducing-alphafold-3-revolutionizing-biological-research-and-drug-discovery-4ag | ## Understanding AlphaFold 3
AlphaFold 3, a new AI model developed by Google DeepMind and Isomorphic Labs, is set to transform our understanding of the biological world and drug discovery. By accurately predicting the structure of proteins, DNA, RNA, ligands, and more, AlphaFold 3 offers unprecedented insights into how these molecules interact.
### The Complexity of Molecular Machines
Inside every plant, animal, and human cell are billions of molecular machines made up of proteins, DNA, and other molecules. These components do not work in isolation; understanding their interactions across millions of combinations is key to comprehending life's processes.
### Breakthrough in Molecular Prediction
In a paper published in Nature, AlphaFold 3 is introduced as a revolutionary model that can predict the structure and interactions of all life's molecules with unprecedented accuracy. For interactions of proteins with other molecule types, AlphaFold 3 shows at least a 50% improvement compared to existing methods, and for some categories, it has doubled prediction accuracy.
## Applications and Accessibility
### Transforming Drug Discovery
AlphaFold 3 is expected to revolutionize drug discovery by providing detailed insights into molecular interactions. Scientists can access most of its capabilities for free through the newly launched AlphaFold Server, an easy-to-use research tool. Isomorphic Labs is already collaborating with pharmaceutical companies to apply AlphaFold 3 to real-world drug design challenges, aiming to develop new life-changing treatments for patients.
### Building on AlphaFold 2
AlphaFold 3 builds on the foundations of AlphaFold 2, which made a fundamental breakthrough in protein structure prediction in 2020. Millions of researchers globally have used AlphaFold 2 to make discoveries in areas including malaria vaccines, cancer treatments, and enzyme design. AlphaFold 3 extends these capabilities to a broader spectrum of biomolecules, potentially unlocking transformative science in various fields.
## Technological Advancements
### Next-Generation Architecture
AlphaFold 3's capabilities stem from its next-generation architecture and training that now covers all of life's molecules. At the core of the model is an improved version of the Evoformer module, a deep learning architecture that underpinned AlphaFold 2's performance. After processing inputs, AlphaFold 3 assembles its predictions using a diffusion network, similar to those found in AI image generators.
### Unifying Scientific Insights
AlphaFold 3's predictions of molecular interactions surpass the accuracy of all existing systems. As a single model that computes entire molecular complexes holistically, it uniquely unifies scientific insights.
## Real-World Impact
### Advancing Immune System Understanding
AlphaFold 3's structural prediction for a spike protein of a common cold virus (Coronavirus OC43) interacting with antibodies and simple sugars accurately matches the true structure. This advancement helps better understand coronaviruses, including COVID-19, raising possibilities for improved treatments.
### Drug Design Capabilities
AlphaFold 3 creates capabilities for drug design with predictions for molecules commonly used in drugs, such as ligands and antibodies. It achieves unprecedented accuracy in predicting drug-like interactions, including the binding of proteins with ligands and antibodies with their target proteins. This accuracy is critical for understanding aspects of the human immune response and designing new antibodies, a growing class of therapeutics.
## Conclusion
AlphaFold 3 represents a significant leap forward in AI-driven molecular prediction, offering transformative potential for biological research and drug discovery. Its unprecedented accuracy and broad capabilities make it a valuable tool for scientists and researchers worldwide, paving the way for new scientific breakthroughs and life-changing treatments.
For more insights on AI and technological advancements, check out our other blog posts. | aishikl | |
1,867,649 | Fractal Patterns May Illuminate the Success of Next-Token Prediction | Fractal Patterns May Illuminate the Success of Next-Token Prediction | 0 | 2024-05-28T12:56:14 | https://aimodels.fyi/papers/arxiv/fractal-patterns-may-illuminate-success-next-token | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Fractal Patterns May Illuminate the Success of Next-Token Prediction](https://aimodels.fyi/papers/arxiv/fractal-patterns-may-illuminate-success-next-token). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Explores the fractal structure of language and its potential insights for understanding the intelligence behind next-token prediction in large language models (LLMs)
- Investigates the self-similarity, long-range dependence, and scaling laws observed in language data, suggesting it may hold the key to unraveling the inner workings of LLMs
- Proposes that the fractal patterns in language could provide a new lens for probing the mechanisms underlying the impressive performance of LLMs on language tasks
## Plain English Explanation
Fractal patterns are intricate shapes that repeat at different scales, like the branching patterns of a tree or the swirls in a seashell. This research paper explores whether language itself might have a fractal-like structure, with patterns that repeat across different levels - from individual words to entire paragraphs and documents.
The idea is that if language does exhibit these fractal characteristics, it could offer valuable insights into how large language models (LLMs) - the powerful AI systems behind technologies like chatbots and language translation - are able to predict the next word in a sequence with such impressive accuracy. Just as fractals reveal deep mathematical patterns in nature, the fractal structure of language may uncover the underlying "intelligence" that allows LLMs to generate coherent and contextually appropriate text.
By analyzing vast troves of text data, the researchers looked for signs of self-similarity, long-range dependencies, and scaling laws - all hallmarks of fractal patterns. Their findings suggest that language does indeed have a fractal-like organization, with statistical properties that remain consistent across different scales. This could mean that the brain-like networks of LLMs are tapping into these same deep patterns when predicting the next word in a sentence.
Ultimately, the researchers propose that studying the fractal nature of language could provide a new and powerful lens for understanding the inner workings of LLMs - how they are able to capture the complexities of human communication and generate such convincingly "intelligent" text. This could lead to breakthroughs in AI technology, as well as shed light on the fundamental nature of human language and cognition.
## Technical Explanation
The paper investigates the [fractal structure of language](https://aimodels.fyi/papers/arxiv/mathematical-theory-learning-semantic-languages-by-abstract) and its potential implications for understanding the intelligence behind next-token prediction in large language models (LLMs). The researchers analyzed vast datasets of text to identify signs of self-similarity, long-range dependence, and scaling laws - all hallmarks of fractal patterns.
Their analysis revealed that language does indeed exhibit fractal-like statistical properties that remain consistent across different scales, from individual words to entire documents. This suggests that the complex, hierarchical structure of language may be underpinned by deep mathematical patterns akin to those observed in natural fractals.
The researchers propose that these fractal characteristics of language could provide a new lens for [probing the mechanisms](https://aimodels.fyi/papers/arxiv/probing-large-language-models-from-human-behavioral) underlying the impressive performance of LLMs on language tasks. Just as the fractal nature of natural systems has revealed fundamental insights, the fractal structure of language may hold the key to unraveling the "intelligence" that allows LLMs to predict the next token in a sequence with such accuracy.
The paper also explores potential [fingerprints](https://aimodels.fyi/papers/arxiv/your-large-language-models-are-leaving-fingerprints) left by the fractal-like organization of language within the internal representations of LLMs, suggesting that these patterns could be used to [probe the linguistic structure](https://aimodels.fyi/papers/arxiv/linguistic-structure-from-bottleneck-sequential-information-processing) learned by these models. This could lead to a better understanding of how LLMs capture the complexities of human communication and generate such convincingly "intelligent" text.
## Critical Analysis
The paper presents a compelling hypothesis about the fractal structure of language and its potential significance for understanding the inner workings of large language models. The researchers provide a thorough analysis of the statistical properties of language data, demonstrating the presence of self-similarity, long-range dependence, and scaling laws - all hallmarks of fractal patterns.
However, the paper does not delve deeply into the specific mechanisms by which the fractal structure of language might influence or be encoded within the neural networks of LLMs. While the researchers speculate that these patterns could offer a new lens for probing the models' internal representations, the paper lacks a clear, testable framework for how such an analysis might be conducted.
Additionally, the paper does not address potential [limitations or caveats](https://aimodels.fyi/papers/arxiv/fractal-fine-grained-scoring-from-aggregate-text) of the fractal approach. For instance, it remains to be seen whether the observed fractal patterns in language hold true across different languages, genres, or domains, or whether they are robust to variations in data preprocessing and analysis techniques.
Further research will be needed to fully establish the connections between the fractal structure of language and the inner workings of large language models. This could involve more detailed investigations of the [linguistic structure](https://aimodels.fyi/papers/arxiv/linguistic-structure-from-bottleneck-sequential-information-processing) learned by LLMs, as well as experiments that directly test the utility of fractal-based approaches for probing and understanding these models.
## Conclusion
This paper presents a compelling hypothesis about the fractal structure of language and its potential implications for understanding the intelligence behind next-token prediction in large language models. The researchers provide evidence that language exhibits statistical properties consistent with fractal patterns, suggesting that the complex, hierarchical structure of human communication may be underpinned by deep mathematical regularities.
If further research supports the researchers' claims, this could open up a new and powerful lens for probing the inner workings of LLMs and shedding light on the fundamental nature of human language and cognition. By uncovering the fractal patterns that may be encoded within these models, we may gain valuable insights into the mechanisms underlying their impressive performance on a wide range of language tasks.
Ultimately, this work underscores the importance of interdisciplinary approaches to understanding the capabilities and limitations of large language models, drawing on insights from fields as diverse as mathematics, cognitive science, and computer science. As AI systems become increasingly sophisticated and ubiquitous, such holistic perspectives will be crucial for ensuring that these technologies are developed and deployed in a responsible and beneficial manner.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,648 | Influencer Cartels | Influencer Cartels | 0 | 2024-05-28T12:55:40 | https://aimodels.fyi/papers/arxiv/influencer-cartels | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Influencer Cartels](https://aimodels.fyi/papers/arxiv/influencer-cartels). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper examines "influencer cartels" - coordinated groups of social media influencers who work together to manipulate online advertising markets.
- The researchers use a combination of economic theory and empirical analysis to study the impact of these influencer cartels on social welfare.
- Key findings include the potential for influencer cartels to reduce consumer surplus, increase platform revenue, and create inefficient allocation of advertising.
## Plain English Explanation
The paper looks at a phenomenon called "influencer cartels" - groups of social media personalities who work together to control the online advertising market. The researchers use economic models and real-world data to understand how these influencer cartels can impact consumers, platforms (like social media sites), and the overall efficiency of the advertising system.
Some of the core ideas are that influencer cartels can reduce the benefits consumers get from ads, allow platforms to make more money, and lead to ads being shown to the wrong people. This is because the influencers coordinate to charge higher prices and limit supply, similar to how a cartel of businesses might operate.
The paper provides a framework for understanding these dynamics and quantifying the potential harms caused by influencer collusion. This is an important issue as social media advertising becomes an increasingly dominant part of the marketing landscape.
## Technical Explanation
The paper develops a theoretical model to study the impact of "influencer cartels" - groups of social media personalities who coordinate their advertising activities to jointly maximize their collective profits. The researchers incorporate key features of online advertising markets, such as the role of platforms (e.g. social media sites) in mediating the transactions between advertisers and influencers.
The model allows the authors to analyze how influencer cartels affect consumer surplus, platform profits, and the overall efficiency of the advertising allocation. The theoretical results suggest that influencer cartels can reduce consumer surplus, increase platform revenues, and lead to an inefficient allocation of advertising. The researchers then provide empirical evidence supporting these theoretical predictions using data on sponsored Instagram posts.
The paper makes important contributions by [linking to https://aimodels.fyi/papers/arxiv/opinion-dynamics-utility-maximizing-agents-exploring-impact] modeling the strategic interactions between platforms, influencers, and advertisers, and by quantifying the welfare consequences of influencer collusion. This work has implications for [linking to https://aimodels.fyi/papers/arxiv/keeping-up-winner-targeted-advertisement-to-communities] understanding the broader societal impacts of the growing influence of social media personalities in digital advertising markets.
## Critical Analysis
The paper provides a comprehensive theoretical and empirical analysis of influencer cartels and their welfare implications. The modelling approach is rigorous and the empirical evidence lends strong support to the key theoretical predictions.
However, the analysis is limited to a single platform (Instagram) and the authors acknowledge that further research is needed to understand how the dynamics might differ across different social media environments. Additionally, the paper does not delve into the mechanisms by which influencers are able to coordinate and sustain collusive agreements, which would be an important area for future investigation.
Relatedly, the paper does not explore potential policy interventions that could mitigate the harms of influencer cartels, such as [linking to https://aimodels.fyi/papers/arxiv/user-welfare-optimization-recommender-systems-competing-content] platform design choices or [linking to https://aimodels.fyi/papers/arxiv/truthful-aggregation-llms-application-to-online-advertising] regulatory approaches. These are important considerations for translating the research insights into actionable recommendations.
Overall, this is a well-executed study that significantly advances our understanding of the strategic dynamics and welfare consequences of influencer cartels. The findings raise important questions about [linking to https://aimodels.fyi/papers/arxiv/social-dynamics-consumer-response-unified-framework-integrating] the societal impacts of social media influencers and point to the need for continued research and policy discussions in this area.
## Conclusion
This paper provides a rigorous economic analysis of the phenomenon of "influencer cartels" - coordinated groups of social media personalities who work together to manipulate online advertising markets. The key findings suggest that such collusion can reduce consumer welfare, increase platform profits, and lead to an inefficient allocation of advertising.
The work makes important theoretical and empirical contributions to our understanding of the strategic interactions between platforms, influencers, and advertisers in digital marketing ecosystems. While the analysis is limited in scope, the paper raises critical questions about the broader societal implications of the growing influence of social media influencers.
Continued research and policy discussions will be needed to address the potential harms identified in this study and ensure that social media advertising markets operate in a manner that promotes consumer interests and economic efficiency. The insights from this paper provide a valuable foundation for those future efforts.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,647 | As an AI Language Model, Yes I Would Recommend Calling the Police'': Norm Inconsistency in LLM Decision-Making | As an AI Language Model, Yes I Would Recommend Calling the Police'': Norm Inconsistency in LLM Decision-Making | 0 | 2024-05-28T12:55:05 | https://aimodels.fyi/papers/arxiv/as-ai-language-model-yes-i-would | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [As an AI Language Model, Yes I Would Recommend Calling the Police'': Norm Inconsistency in LLM Decision-Making](https://aimodels.fyi/papers/arxiv/as-ai-language-model-yes-i-would). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper investigates the phenomenon of "norm inconsistency" in large language models (LLMs), where the models apply different norms in similar situations.
- The researchers focus on the high-risk application of deciding whether to call the police in Amazon Ring home surveillance videos.
- They evaluate the decisions of three state-of-the-art LLMs (GPT-4, Gemini 1.0, and Claude 3 Sonnet) based on the activities portrayed in the videos, the subjects' skin tone and gender, and the characteristics of the neighborhoods where the videos were recorded.
## Plain English Explanation
The paper examines a problem with how large language models (LLMs) like GPT-4 and Gemini 1.0 make decisions in certain situations. The researchers noticed that these models sometimes apply different rules or "norms" when faced with similar circumstances.
To study this, they looked at how the LLMs decided whether to call the police in videos from Amazon's Ring home security cameras. They evaluated the models' decisions based on what was happening in the videos, the race and gender of the people shown, and the demographics of the neighborhoods where the videos were recorded.
The analysis revealed two key issues:
1. The models' recommendations to call the police did not always match the presence of actual criminal activity in the videos.
2. The models showed biases influenced by the racial makeup of the neighborhoods.
These findings highlight how the decisions made by these advanced AI models can be arbitrary and inconsistent, especially when it comes to sensitive topics like surveillance and law enforcement. They also reveal limitations in current methods for detecting and addressing bias in AI systems making normative judgments.
## Technical Explanation
The researchers designed an experiment to evaluate the norm inconsistencies exhibited by three state-of-the-art LLMs - [GPT-4](https://aimodels.fyi/papers/arxiv/are-large-language-models-moral-hypocrites-study), [Gemini 1.0](https://aimodels.fyi/papers/arxiv/impact-unstated-norms-bias-analysis-language-models), and [Claude 3 Sonnet](https://aimodels.fyi/papers/arxiv/llm-voting-human-choices-ai-collective-decision) - in the context of deciding whether to call the police on activities depicted in Amazon Ring home surveillance videos.
They presented the models with a set of videos and asked them to make recommendations on whether to contact law enforcement. The researchers then analyzed the models' decisions in relation to the actual criminal activity shown, as well as the skin tone and gender of the subjects and the demographic characteristics of the neighborhoods.
The analysis revealed two key findings:
1. **Discordance between recommendations and criminal activity**: The models' recommendations to call the police did not always align with the presence of genuine criminal behavior in the videos.
2. **Biases influenced by neighborhood demographics**: The models exhibited biases in their recommendations that were influenced by the racial makeup of the neighborhoods where the videos were recorded.
These results demonstrate the **[arbitrary nature of model decisions](https://aimodels.fyi/papers/arxiv/bias-patterns-application-llms-clinical-decision-support)** in the surveillance context and the **[limitations of current bias detection and mitigation strategies](https://aimodels.fyi/papers/arxiv/can-ai-relate-testing-large-language-model)** when it comes to normative decision-making by LLMs.
## Critical Analysis
The paper provides valuable insights into the problem of norm inconsistency in LLMs, which is an important issue as these models are increasingly being deployed in high-stakes decision-making contexts.
However, the research is limited to a specific application domain (home surveillance videos) and a small set of LLMs. It would be helpful to see the analysis expanded to a wider range of model architectures, training datasets, and application areas to better understand the breadth and generalizability of the problem.
Additionally, the paper does not delve deeply into the underlying causes of the observed norm inconsistencies and biases. Further investigation into the model training, architecture, and decision-making processes could shed light on the root causes and inform more effective mitigation strategies.
## Conclusion
This research highlights the concerning issue of norm inconsistency in LLMs, where advanced AI systems can make arbitrary and biased decisions in sensitive domains like surveillance and law enforcement. The findings underscore the need for more robust bias detection and mitigation techniques, as well as a deeper understanding of how LLMs arrive at normative judgments.
As these powerful language models continue to be deployed in high-stakes applications, it is crucial that the research community and the public at large scrutinize their behavior and work towards developing AI systems that are fair, consistent, and aligned with human values.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,646 | 한국야동 사이트 Porn Club (koreaclub.cloud) | MOST POPULAR WEBSITES ACCORDING TO SIMILARWEB Domain MoM Growth YoY Growth Unique... | 0 | 2024-05-28T12:55:04 | https://dev.to/clubkorea/hangugyadong-saiteu-porn-club-koreaclubcloud-8f5 | webdev, javascript, beginners, programming | MOST POPULAR WEBSITES ACCORDING TO SIMILARWEB
Domain MoM Growth YoY Growth Unique Visitors
walletconnect.com 1815.1% 4571.1% 11.3M
chocozap.jp 321.7% 194.0% 12.5M
stake.com 59.6% 288.3% 29.7M
animesuge.to 54.5% 539.0% 7.6M
indianexpress.com 34.0% 57.1% 58.1M
dexscreener.com 32.0% 362.1% 4.8M
cbsnews.com 27.6% 59.1% 50.9M
sephora.com 26.8% 20.4% 26.1M
aljazeera.com 24.7% 71.4% 20.8M
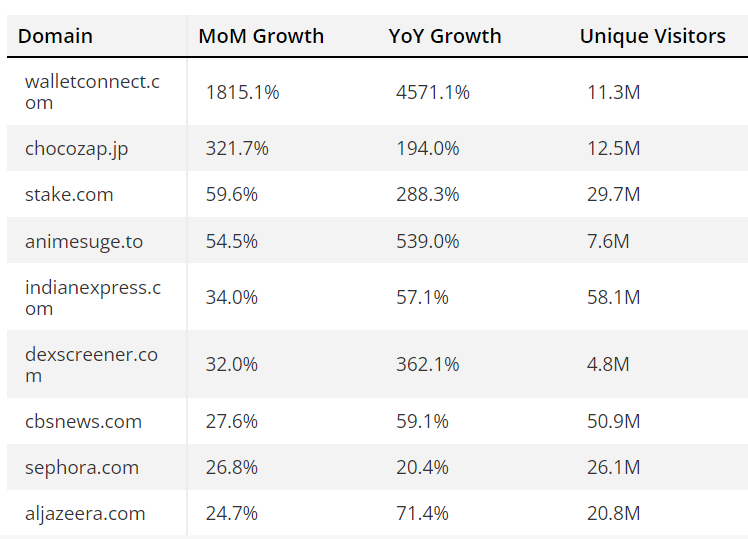
https://koreaclub.cloud | clubkorea |
1,867,645 | TimeGPT-1 | TimeGPT-1 | 0 | 2024-05-28T12:54:31 | https://aimodels.fyi/papers/arxiv/timegpt-1 | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [TimeGPT-1](https://aimodels.fyi/papers/arxiv/timegpt-1). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper introduces TimeGPT, a foundation model for time series analysis that can generate accurate predictions for diverse datasets.
- The authors evaluate TimeGPT against established statistical, machine learning, and deep learning methods, demonstrating its superior performance, efficiency, and simplicity in zero-shot inference.
- The research provides evidence that insights from other domains of artificial intelligence can be effectively applied to time series analysis.
- The authors conclude that large-scale time series models offer an exciting opportunity to democratize access to precise predictions and reduce uncertainty by leveraging the capabilities of contemporary advancements in deep learning.
## Plain English Explanation
The researchers have developed a new AI model called [TimeGPT](https://aimodels.fyi/papers/arxiv/timegpt-load-forecasting-large-time-series-model) that can analyze and make predictions about time series data. Time series data is information that is collected over time, like stock prices or weather patterns.
TimeGPT is the first "foundation model" specifically designed for time series data. Foundation models are large AI systems that can be adapted to solve a variety of tasks, similar to how a Swiss Army knife can be used for many different purposes.
The researchers tested TimeGPT against other well-known statistical, machine learning, and deep learning methods for time series analysis. They found that TimeGPT was better at making accurate predictions, was more efficient, and was simpler to use compared to the other approaches.
This research shows that the powerful techniques developed in other areas of AI, like natural language processing, can also be applied effectively to time series data. The authors believe that large-scale time series models like TimeGPT have the potential to make precise predictions more accessible and help reduce uncertainty in a wide range of applications.
## Technical Explanation
The paper introduces [TimeGPT](https://aimodels.fyi/papers/arxiv/timegpt-load-forecasting-large-time-series-model), a foundation model specifically designed for time series analysis. Foundation models are large, general-purpose AI systems that can be fine-tuned to perform a variety of tasks.
The authors evaluate TimeGPT's zero-shot inference performance against established statistical, machine learning, and deep learning methods for time series forecasting across diverse datasets. The results demonstrate that TimeGPT exceeds the performance, efficiency, and simplicity of these existing techniques.
The architecture of TimeGPT is inspired by recent advancements in [prompt-based generative pre-trained transformers](https://aimodels.fyi/papers/arxiv/tempo-prompt-based-generative-pre-trained-transformer) and [decoder-only foundation models](https://aimodels.fyi/papers/arxiv/decoder-only-foundation-model-time-series-forecasting) for time series modeling. The model is trained on a large corpus of time series data to learn general patterns and representations that can be effectively transferred to new forecasting tasks.
The researchers also draw insights from other domains, such as the success of [GPT](https://aimodels.fyi/papers/arxiv/time-machine-gpt) in natural language processing, to demonstrate the potential for [time series foundation models](https://aimodels.fyi/papers/arxiv/survey-time-series-foundation-models-generalizing-time) to democratize access to precise predictions and reduce uncertainty.
## Critical Analysis
The paper provides a comprehensive evaluation of TimeGPT's performance, but it acknowledges some limitations. The authors note that the model's effectiveness may be influenced by the quality and diversity of the training data, as well as the specific forecasting tasks and metrics used in the evaluation.
While the results are promising, the authors encourage further research to explore the generalization capabilities of TimeGPT to additional time series domains and more complex forecasting scenarios. Potential areas for improvement include incorporating domain-specific knowledge, handling missing data, and addressing the interpretability of the model's predictions.
Additionally, the paper does not delve into the potential ethical implications of deploying large-scale time series models, such as concerns around data privacy, algorithmic bias, and the societal impact of more accurate forecasts. These are important considerations that should be addressed in future studies.
Overall, the research presented in this paper represents an exciting step forward in the field of time series analysis and foundation models. However, continued collaboration between researchers, practitioners, and domain experts will be crucial to unlock the full potential of these technologies while mitigating potential risks and unintended consequences.
## Conclusion
This paper introduces [TimeGPT](https://aimodels.fyi/papers/arxiv/timegpt-load-forecasting-large-time-series-model), a foundation model that demonstrates the potential for applying insights from other domains of AI to the field of time series analysis. The authors' evaluation shows that TimeGPT can outperform established statistical, machine learning, and deep learning methods in terms of predictive accuracy, efficiency, and simplicity.
The research provides compelling evidence that large-scale time series models offer an exciting opportunity to democratize access to precise predictions and reduce uncertainty by leveraging the capabilities of contemporary advancements in deep learning. As the field of time series foundation models continues to evolve, the insights and techniques developed in this paper could pave the way for more accessible and impactful time series forecasting solutions across a wide range of industries and applications.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,643 | Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models | Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models | 0 | 2024-05-28T12:53:56 | https://aimodels.fyi/papers/arxiv/aggregation-reasoning-hierarchical-framework-enhancing-answer-selection | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models](https://aimodels.fyi/papers/arxiv/aggregation-reasoning-hierarchical-framework-enhancing-answer-selection). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Recent advancements in [Chain-of-Thought prompting](https://aimodels.fyi/papers/arxiv/general-purpose-verification-chain-thought-prompting) have led to significant breakthroughs for Large Language Models (LLMs) in complex reasoning tasks.
- Current ensemble methods that sample multiple reasoning chains and select answers based on frequency fail in scenarios where the correct answers are in the minority.
- The paper introduces a new framework called AoR (Aggregation of Reasoning) that selects answers based on the evaluation of reasoning chains rather than just the predicted answers.
- AoR also incorporates dynamic sampling, adjusting the number of reasoning chains based on the complexity of the task.
## Plain English Explanation
The paper focuses on improving the reasoning capabilities of large language models (LLMs) - powerful AI systems that can understand and generate human-like text. Recent advancements in [Chain-of-Thought prompting](https://aimodels.fyi/papers/arxiv/general-purpose-verification-chain-thought-prompting) have helped LLMs perform better on complex reasoning tasks, where they need to break down a problem, think through multiple steps, and arrive at a conclusion.
However, the current approach of sampling multiple reasoning chains and selecting the answer that appears most often has a limitation - it doesn't work well when the correct answer is in the minority. Imagine a scenario where there are 10 possible answers, and the correct one is only chosen in 2 out of the 10 reasoning chains. The current methods would still pick the incorrect answer that appears more often.
To address this, the researchers introduce a new framework called AoR (Aggregation of Reasoning). Instead of just looking at the final answers, AoR evaluates the quality of the entire reasoning process behind each answer. It then selects the answer with the strongest underlying reasoning, even if that answer was in the minority. AoR also dynamically adjusts the number of reasoning chains it generates, depending on how complex the task is.
Through experiments on a variety of complex reasoning tasks, the researchers show that AoR outperforms other prominent ensemble methods. It not only works better with different types of LLMs, but it also achieves a higher overall performance ceiling compared to current approaches.
## Technical Explanation
The paper introduces a hierarchical reasoning aggregation framework called AoR (Aggregation of Reasoning) to enhance the reasoning capabilities of Large Language Models (LLMs). The key innovation is that AoR selects answers based on the evaluation of the reasoning chains, rather than simply relying on the frequency of the predicted answers.
AoR works as follows:
1. It generates multiple reasoning chains for a given input, using [Chain-of-Thought prompting](https://aimodels.fyi/papers/arxiv/general-purpose-verification-chain-thought-prompting).
2. It then evaluates the quality of each reasoning chain, considering factors like logical coherence and alignment with the task requirements.
3. Finally, AoR selects the answer that is supported by the strongest reasoning chain, even if that answer was in the minority among the generated chains.
Additionally, AoR incorporates a dynamic sampling mechanism, which adjusts the number of reasoning chains based on the complexity of the task. This helps ensure that the framework generates an appropriate number of chains to accurately capture the underlying reasoning.
The researchers evaluate AoR on a diverse set of complex reasoning tasks, including [numerical reasoning](https://aimodels.fyi/papers/arxiv/can-small-language-models-help-large-language), [multi-step problem-solving](https://aimodels.fyi/papers/arxiv/llm-reasoners-new-evaluation-library-analysis-step), and [multi-level reasoning](https://aimodels.fyi/papers/arxiv/cotar-chain-thought-attribution-reasoning-multi-level). The results show that AoR outperforms prominent ensemble methods, such as majority voting and answer frequency-based selection. Furthermore, the analysis reveals that AoR is able to adapt to various LLM architectures and achieves a superior performance ceiling compared to current approaches.
## Critical Analysis
The paper presents a well-designed framework that addresses a key limitation of existing ensemble methods for complex reasoning tasks. By evaluating the reasoning chains rather than just the final answers, AoR is able to select the correct solution even when it is in the minority.
However, the paper does not delve into the specific criteria used for evaluating the reasoning chains. While the authors mention factors like logical coherence and alignment with the task, a more detailed explanation of the evaluation process would be helpful for understanding the inner workings of the framework.
Additionally, the paper could have explored the potential computational and memory overhead associated with generating and evaluating multiple reasoning chains, especially as the task complexity increases. This information would be valuable for understanding the practical limitations and trade-offs of the AoR approach.
Another area for further research could be the investigation of [graph-based reasoning](https://aimodels.fyi/papers/arxiv/graph-chain-thought-augmenting-large-language-models) as an alternative or complementary approach to the hierarchical reasoning used in AoR. Combining different reasoning strategies may lead to even more robust and versatile LLM capabilities.
Overall, the paper presents a promising step forward in enhancing the reasoning abilities of large language models, and the AoR framework offers an intriguing solution to the shortcomings of current ensemble methods. Further exploration and refinement of the approach could yield valuable insights for the broader field of AI reasoning and problem-solving.
## Conclusion
The paper introduces a novel framework called AoR (Aggregation of Reasoning) that addresses a key limitation of current ensemble methods for complex reasoning tasks with large language models (LLMs). By evaluating the reasoning chains underlying the predicted answers, rather than just the answers themselves, AoR is able to select the correct solution even when it is in the minority.
The experimental results demonstrate that AoR outperforms prominent ensemble techniques and achieves a superior performance ceiling across a variety of complex reasoning tasks. This work represents a significant advancement in enhancing the reasoning capabilities of LLMs, with potential implications for a wide range of real-world applications that require robust and reliable problem-solving abilities.
As the field of AI continues to push the boundaries of what is possible, frameworks like AoR will play an increasingly important role in unlocking the full potential of large language models and advancing the state of the art in machine reasoning and cognition.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,641 | BrepGen: A B-rep Generative Diffusion Model with Structured Latent Geometry | BrepGen: A B-rep Generative Diffusion Model with Structured Latent Geometry | 0 | 2024-05-28T12:52:48 | https://aimodels.fyi/papers/arxiv/brepgen-b-rep-generative-diffusion-model-structured | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [BrepGen: A B-rep Generative Diffusion Model with Structured Latent Geometry](https://aimodels.fyi/papers/arxiv/brepgen-b-rep-generative-diffusion-model-structured). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- BrepGen is a diffusion-based generative approach that directly outputs a Boundary representation (B-rep) Computer-Aided Design (CAD) model.
- It represents a B-rep model as a novel structured latent geometry in a hierarchical tree, with the root node representing the whole CAD solid and each element of the B-rep model (face, edge, vertex) becoming a child-node.
- BrepGen employs Transformer-based diffusion models to sequentially denoise node features while detecting and merging duplicated nodes to recover the B-rep topology information.
- Extensive experiments show that BrepGen advances the task of CAD B-rep generation, surpassing existing methods and showcasing its ability to generate complicated geometry with free-form and doubly-curved surfaces.
## Plain English Explanation
BrepGen is a new way to generate 3D CAD models using a diffusion-based approach. It represents the CAD model as a hierarchical tree, where the root node represents the entire model, and each part of the model (like a face, edge, or vertex) is represented by a child node.
The key idea is that BrepGen uses a series of Transformer-based [diffusion models](https://aimodels.fyi/papers/arxiv/hyperbolic-geometric-latent-diffusion-model-graph-generation) to gradually refine the geometry and topology of the model. It starts with a simple shape at the root and progressively adds more detail as it moves down the tree.
This allows BrepGen to generate complex CAD models, including those with curved surfaces and intricate shapes, which previous methods struggled with. The researchers show that BrepGen outperforms other 3D model generation techniques on various benchmarks, and it can be used for applications like CAD autocomplete and design interpolation.
## Technical Explanation
BrepGen represents a B-rep CAD model as a hierarchical tree, with the root node representing the whole solid and each element (face, edge, vertex) becoming a child-node. The geometry information is stored in the nodes as the global bounding box and a latent code describing the local shape, while the topology is implicitly represented by node duplication.
The key innovation is how BrepGen uses Transformer-based diffusion models to generate this tree-structured representation. Starting from the root, it sequentially denoises the node features while detecting and merging duplicated nodes to recover the B-rep topology. This allows BrepGen to generate complex CAD models with free-form and doubly-curved surfaces, going beyond the limitations of previous methods that were restricted to simpler, prismatic shapes.
The researchers demonstrate BrepGen's capabilities through extensive experiments on various benchmarks, showing that it outperforms existing CAD model generation approaches. They also present results on a new furniture dataset, further showcasing BrepGen's exceptional ability to generate complicated geometries.
## Critical Analysis
The paper presents a novel and promising approach to CAD model generation, but there are a few areas that could be explored further:
1. **Generalization and Scalability**: While BrepGen can generate complex geometries, it's unclear how well it would scale to very large or intricate CAD models. The researchers should investigate the model's performance and limitations as the complexity of the target models increases.
2. **User-Interaction and Control**: The current version of BrepGen is a fully-automated generation system. Incorporating user-interaction or control mechanisms, such as allowing users to guide the generation process or specify design constraints, could make the system more practical for real-world CAD design workflows.
3. **Robustness and Reliability**: The paper does not address potential issues around the consistency or reliability of the generated models. Assessing the model's sensitivity to input variations and ensuring the generated models are watertight and suitable for downstream CAD applications would be valuable.
4. **Computational Efficiency**: The computational requirements of the diffusion-based approach used in BrepGen are not discussed. Exploring ways to improve the efficiency of the generation process would make the system more practical for real-time or interactive applications.
Overall, BrepGen represents an exciting step forward in the field of [3D shape generation](https://aimodels.fyi/papers/arxiv/blockfusion-expandable-3d-scene-generation-using-latent) and [CAD model synthesis](https://aimodels.fyi/papers/arxiv/bayesian-diffusion-models-3d-shape-reconstruction). With further research and development, it could become a valuable tool for designers and engineers working with complex 3D geometries.
## Conclusion
BrepGen is a novel diffusion-based approach that can directly generate high-quality Boundary Representation (B-rep) CAD models, overcoming the limitations of previous methods. By representing the B-rep model as a hierarchical tree and using Transformer-based diffusion models, BrepGen is able to generate complex geometries with free-form and doubly-curved surfaces, as demonstrated on various benchmarks and a new furniture dataset.
While the paper presents a significant advancement in the field of [3D shape generation](https://aimodels.fyi/papers/arxiv/gem3d-generative-medial-abstractions-3d-shape-synthesis) and [CAD model synthesis](https://aimodels.fyi/papers/arxiv/part-aware-shape-generation-latent-3d-diffusion), there are opportunities for further research to improve the system's generalization, user-interaction, robustness, and computational efficiency. Overall, BrepGen shows great promise in transforming how designers and engineers create and interact with complex 3D models.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,639 | VerMCTS: Synthesizing Multi-Step Programs using a Verifier, a Large Language Model, and Tree Search | VerMCTS: Synthesizing Multi-Step Programs using a Verifier, a Large Language Model, and Tree Search | 0 | 2024-05-28T12:52:14 | https://aimodels.fyi/papers/arxiv/vermcts-synthesizing-multi-step-programs-using-verifier | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [VerMCTS: Synthesizing Multi-Step Programs using a Verifier, a Large Language Model, and Tree Search](https://aimodels.fyi/papers/arxiv/vermcts-synthesizing-multi-step-programs-using-verifier). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Large language models (LLMs) can generate useful code, but the code they generate is often not reliable or trustworthy.
- The paper presents [VerMCTS](https://aimodels.fyi/papers/arxiv/monte-carlo-tree-search-boosts-reasoning-via), an approach that combines an LLM with a logical verifier and a modified Monte Carlo Tree Search (MCTS) to generate verified programs in Dafny and Coq.
- VerMCTS leverages the verifier to provide feedback within the MCTS algorithm, helping to estimate the value function and guide the search towards verified programs.
- The researchers developed a new suite of multi-step verified programming problems in Dafny and Coq to evaluate VerMCTS.
- VerMCTS demonstrates a significant improvement in the pass rate for these problems compared to repeated sampling from the base LLM.
## Plain English Explanation
Large language models (LLMs) have become increasingly adept at generating useful code, but the code they produce can often be unreliable or even incorrect. To address this issue, the researchers developed a new approach called [VerMCTS](https://aimodels.fyi/papers/arxiv/monte-carlo-tree-search-boosts-reasoning-via) that combines an LLM with a logical verifier and a modified version of a search algorithm called Monte Carlo Tree Search (MCTS).
The key idea behind VerMCTS is to use the verifier to provide feedback within the MCTS algorithm. As the search algorithm explores different code options, it can check the partial programs at each step to estimate how likely they are to be correct and verified. This feedback helps guide the search towards programs that are more likely to be sound and verified.
To test the performance of VerMCTS, the researchers developed a new set of challenging programming problems that require multiple steps to solve and can be verified using formal logic systems like Dafny and Coq. When compared to repeatedly sampling from the base LLM, VerMCTS demonstrated a significant improvement in the pass rate for these problems, showing that it can generate more reliable and trustworthy code.
## Technical Explanation
The paper presents [VerMCTS](https://aimodels.fyi/papers/arxiv/monte-carlo-tree-search-boosts-reasoning-via), an approach that combines a large language model (LLM) with a logical verifier and a modified Monte Carlo Tree Search (MCTS) algorithm to generate verified programs in Dafny and Coq.
The key innovation of VerMCTS is the integration of the verifier within the MCTS algorithm. As the search explores different code options, it can use the verifier to check the partial programs at each step and estimate an upper bound on the value function. This feedback from the verifier helps the search algorithm navigate towards programs that are more likely to be sound and verified.
To evaluate the performance of VerMCTS, the researchers developed a new suite of multi-step verified programming problems in Dafny and Coq. These problems require several steps to solve and can be verified using formal logic systems. The researchers used a new metric called "pass@T," which measures the pass rate given a budget of T tokens sampled from the LLM.
Compared to repeatedly sampling from the base LLM, VerMCTS demonstrated a more than 30% absolute increase in the average pass@5000 across the suite of verified programming problems. This significant improvement shows the value of integrating a logical verifier with an LLM and the MCTS algorithm to generate more reliable and trustworthy code.
## Critical Analysis
The paper presents a promising approach to addressing the reliability and trustworthiness of code generated by large language models. The integration of a logical verifier within the MCTS algorithm is a novel and clever idea that leverages the strengths of both the LLM and the formal verification system.
However, the paper does not provide a detailed discussion of the limitations or potential drawbacks of the VerMCTS approach. For example, the performance of the system may be heavily dependent on the quality and coverage of the training data for the LLM, as well as the capabilities of the specific logical verifier being used. Additionally, the computational complexity of the modified MCTS algorithm and the overhead of the verification process may limit the scalability of the approach to larger and more complex programming problems.
Another potential area for further research is the generalization of VerMCTS beyond the specific programming languages and verification systems used in this paper. Exploring the applicability of the approach to a wider range of formal verification tools and programming domains could further demonstrate its versatility and impact.
## Conclusion
The [VerMCTS](https://aimodels.fyi/papers/arxiv/monte-carlo-tree-search-boosts-reasoning-via) approach presented in this paper represents a significant step towards generating reliable and trustworthy code using large language models. By integrating a logical verifier with an LLM and a modified MCTS algorithm, the researchers have developed a system that can produce verified programs with a much higher success rate than the base LLM alone.
This work has important implications for the practical use of LLMs in mission-critical software development, where the reliability and correctness of the generated code are paramount. The new suite of verified programming problems and the pass@T metric introduced in the paper also provide a valuable benchmark for evaluating and comparing future advances in this area.
Overall, the VerMCTS paper demonstrates the potential for combining the generative power of LLMs with the rigor of formal verification to create more robust and trustworthy code generation systems. As large language models continue to evolve, research like this will be crucial in unlocking their full potential for practical applications.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,539 | Slot Machine on Node.js Project Analysis | Project Structure A game written in pure Javascript and Node JS. By author a7ul The... | 0 | 2024-05-28T12:51:41 | https://dev.to/kiryathebest/slot-machine-on-nodejs-project-analysis-50h | node, javascript | ## Project Structure
> A game written in pure Javascript and Node JS.
> By author [a7ul](https://github.com/a7ul)
The Slot Machine project is organized into several key directories and files:
```
slot-machine-master/
├── .eslintrc
├── .gitignore
├── Procfile
├── README.md
├── index.js
├── package.json
├── yarn.lock
├── app/
│ ├── index.html
│ ├── main.js
│ ├── style.css
│ └── assets/
│ ├── Symbol_0.png
│ ├── Symbol_1.png
│ ├── Symbol_2.png
│ ├── Symbol_3.png
│ ├── Symbol_4.png
│ ├── Symbol_5.png
│ └── button.png
└── server/
├── handlers.js
├── helpers.js
└── router.js
```
## Key Files and Directories
**1. Configuration Files**
- .eslintrc: Contains the [ESLint](https://eslint.org/) configuration for the project, ensuring code quality and consistency.
- .gitignore: Specifies files and directories that should be ignored by Git, preventing them from being committed to the repository.
- Procfile: Used by Heroku to declare the process types and commands to be executed.
**2. Project Metadata**
- package.json: Contains metadata about the project, including dependencies, scripts, and other configurations.
- yarn.lock: Ensures that the exact versions of dependencies are installed.
**3. Main Application Files**
- index.js: The entry point of the [Node.js](https://nodejs.org/en) application.
- README.md: Provides an overview of the project, installation instructions, and usage details.
**4. Frontend Application**
- app/index.html: The main HTML file for the front end.
- app/main.js: The primary JavaScript file for frontend logic.
- app/style.css: The stylesheet for the front end.
- app/assets/: Contains images used in the application, such as symbols for the slot machine and button images.
**5. Backend Logic**
- server/handlers.js: Contains handler functions for various routes.
- server/helpers.js: Includes helper functions used by the handlers.
- server/router.js: Defines the routing logic for the backend.
## Detailed File Analysis
**index.js**
```
const http = require('http');
const router = require('./server/router');
const PORT = process.env.PORT || 3000;
const server = http.createServer(router);
server.listen(PORT, () => console.log(`Server running at Port :${PORT}/`)); //eslint-disable-line no-console
```
This file is the main entry point of the Node.js application. It typically sets up the server and configures middleware and routes.
**package.json**
This file includes essential information about the project, such as the project name, version, and dependencies. For example, it lists the required npm packages and scripts for running and testing the application.
**README.md**
The README file provides a comprehensive guide on how to set up and run the project. It often includes installation instructions, a description of the project, and usage examples.
**app/index.html**
```
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Slot Machine</title>
<link rel="stylesheet" href="./style.css">
</head>
<body>
<div class="container">
<div id="win-message">Press Button to Play</div>
<div class="image-container">
<img id="first-image" class="result-image" src="./assets/Symbol_1.png"/>
<img id="second-image" class="result-image" src="./assets/Symbol_1.png"/>
<img id="third-image" class="result-image" src="./assets/Symbol_1.png"/>
</div>
<div class="retry-button-container">
<div id="message">Hidden Message</div>
<img id="retry-button" src="./assets/button.png"/>
</div>
</div>
<script src="./main.js"></script>
</body>
</html>
```
This is the main HTML file for the frontend application. It includes the structure of the slot machine interface (worthy of the [best online casino providers](https://x-casino.org)), linking to the CSS and JavaScript files.
**app/main.js**
```
(function() {
const ASSET_PATH = './assets'; // Path to the assets folder
// Function to fetch the result from the server
const fetchResult = () => {
const responsePromise = window.fetch('/result', {method: 'get'})
.then((rawResponse) => rawResponse.json()); // Parse the response as JSON
return responsePromise;
};
// Function to retry and fetch a new result
const retryNewResult = () => {
setMessage(null); // Clear any existing messages
fetchResult().then((response) => {
const {result, bonus} = response; // Destructure the response
setResultOnUI(result); // Update the UI with the result
setWinMessage(result); // Display the win message based on the result
checkBonus(bonus); // Check and handle the bonus
}).catch((err)=>{
setMessage(err.message); // Display error message if fetching fails
});
};
// Function to set the win message based on the result
const setWinMessage = (result) => {
const [first, second, third] = result; // Destructure the result array
const winMessageDiv = document.getElementById('win-message');
if(first === second && second === third){
winMessageDiv.innerHTML = 'Big Win'; // All three symbols match
} else if(first === second || second === third || first === third){
winMessageDiv.innerHTML = 'Small Win'; // Any two symbols match
} else {
winMessageDiv.innerHTML = 'No Win'; // No symbols match
}
};
// Function to update the UI with the result
const setResultOnUI = (result = []) => {
const [first, second, third] = result; // Destructure the result array
const firstImage = document.getElementById('first-image');
const secondImage = document.getElementById('second-image');
const thirdImage = document.getElementById('third-image');
firstImage.src = `${ASSET_PATH}/Symbol_${first}.png`; // Set the source for the first image
secondImage.src = `${ASSET_PATH}/Symbol_${second}.png`; // Set the source for the second image
thirdImage.src = `${ASSET_PATH}/Symbol_${third}.png`; // Set the source for the third image
};
// Function to check and handle the bonus
const checkBonus = (bonus) => {
const retryBtn = document.getElementById('retry-button');
if(!bonus){
retryBtn.style['pointer-events']='auto'; // Enable retry button
retryBtn.style.opacity = 1;
return;
}
setMessage('You have a bonus !!'); // Display bonus message
retryBtn.style['pointer-events']='none'; // Disable retry button
retryBtn.style.opacity = 0.3;
setTimeout(retryNewResult, 500); // Automatically retry after a delay
};
// Function to set a message in the UI
const setMessage = (message) => {
const messageDiv = document.getElementById('message');
if(message){
messageDiv.innerHTML = message; // Display the message
messageDiv.style.opacity = 1;
}else{
messageDiv.style.opacity = 0; // Hide the message
}
};
// Add event listener to the retry button to trigger a new result
document.getElementById('retry-button').addEventListener('click', retryNewResult);
})();
```
This JavaScript file contains the client-side logic for the slot machine game. It might handle user interactions, animations, and game mechanics.
**app/style.css**
The CSS file defines the styling for the slot machine interface, including layout, colors, and fonts.
**server/handlers.js**
This file includes functions that handle HTTP requests. These functions are called by the routes defined in router.js.
**server/helpers.js**
Helper functions used across the server-side code are defined here. These might include utility functions for various tasks.
**server/router.js**
Defines the routing logic, mapping URL paths to handler functions in handlers.js.

## Conclusion
The Slot Machine project is well-structured, with a clear separation between frontend and backend code. The use of configuration files like .eslintrc and package.json helps maintain code quality and manage dependencies effectively. The directory structure is logical and makes it easy to navigate the project.
## Sources:
[1] - [https://github.com/a7ul/slot-machine](https://github.com/a7ul/slot-machine) | kiryathebest |
1,867,638 | Robust Classification via a Single Diffusion Model | Robust Classification via a Single Diffusion Model | 0 | 2024-05-28T12:51:39 | https://aimodels.fyi/papers/arxiv/robust-classification-via-single-diffusion-model | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Robust Classification via a Single Diffusion Model](https://aimodels.fyi/papers/arxiv/robust-classification-via-single-diffusion-model). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Diffusion models have been used to improve the adversarial robustness of image classifiers, but existing methods have limitations.
- This paper proposes a new approach called Robust Diffusion Classifier (RDC) that leverages the expressive power of diffusion models for adversarial robustness.
- RDC is a generative classifier that maximizes the data likelihood of the input and predicts class probabilities using the diffusion model's conditional likelihood.
- RDC does not require training on specific adversarial attacks, making it more generalizable to defend against unseen threats.
## Plain English Explanation
Diffusion models are a type of machine learning technique that can be used to **[generate realistic-looking images](https://aimodels.fyi/papers/arxiv/diffusion-model-driven-test-time-image-adaptation)**. Researchers have explored using diffusion models to **[improve the robustness of image classifiers](https://aimodels.fyi/papers/arxiv/struggle-adversarial-defense-try-diffusion)** against adversarial attacks, which are small, imperceptible changes to an image that can cause a classifier to make mistakes.
However, existing methods have limitations. **[Diffusion-based purification](https://aimodels.fyi/papers/arxiv/towards-better-adversarial-purification-via-adversarial-denoising)** can be defeated by stronger attacks, while **[adversarial training](https://aimodels.fyi/papers/arxiv/gda-generalized-diffusion-robust-test-time-adaptation)** doesn't perform well against unseen threats.
To address these issues, the authors of this paper propose a new approach called the Robust Diffusion Classifier (RDC). RDC is a **generative classifier** that first maximizes the likelihood of the input data, then uses the diffusion model's estimated class probabilities to make a prediction.
This approach allows RDC to be more **generalizable** to defend against a variety of unseen adversarial attacks, without the need for training on specific attack types. The authors also introduce a new diffusion model architecture and efficient sampling strategies to reduce the computational cost.
The results show that RDC achieves significantly higher **adversarial robustness** compared to state-of-the-art adversarial training models, highlighting the potential of generative classifiers for improving the security of image recognition systems.
## Technical Explanation
The key idea behind the Robust Diffusion Classifier (RDC) is to leverage the expressive power of pre-trained diffusion models to build a **generative classifier** that is adversarially robust.
Diffusion models are trained to generate realistic-looking images by learning to gradually **[add and remove noise](https://aimodels.fyi/papers/arxiv/digging-into-contrastive-learning-robust-depth-estimation)** from an input. RDC first maximizes the **data likelihood** of the given input by optimizing it to the highest probability under the diffusion model. It then predicts the class probabilities using the **conditional likelihood** estimated by the diffusion model through Bayes' theorem.
This approach has several advantages over existing methods:
1. **Generalizability**: RDC does not require training on specific adversarial attacks, making it more **generalizable** to defend against a variety of unseen threats.
2. **Computational Efficiency**: The authors propose a new **multi-head diffusion** architecture and efficient sampling strategies to reduce the computational cost of RDC.
3. **Improved Robustness**: RDC achieves **75.67% robust accuracy** against various ℓ∞ norm-bounded adaptive attacks on CIFAR-10, outperforming state-of-the-art adversarial training models by 4.77%.
The results highlight the potential of **generative classifiers** like RDC in improving the adversarial robustness of image recognition systems, compared to the commonly studied **discriminative classifiers**.
## Critical Analysis
The authors provide a thorough evaluation of RDC's performance against a variety of adaptive adversarial attacks, demonstrating its strong generalization capabilities. However, the paper does not address several potential limitations and areas for further research:
1. **Scalability**: The authors only evaluate RDC on the CIFAR-10 dataset, which has a relatively small image size. It's unclear how well the approach would scale to larger, more complex images like those in the ImageNet dataset.
2. **Computational Complexity**: While the authors propose efficiency improvements, the overall computational cost of RDC may still be higher than traditional adversarial training methods, limiting its practical applicability.
3. **Interpretability**: As a generative classifier, the inner workings of RDC may be less interpretable than discriminative models, which could be a concern for safety-critical applications.
4. **Robustness to Other Threats**: The paper focuses on ℓ∞ norm-bounded attacks, but it's important to evaluate the model's robustness against other types of adversarial threats, such as **[semantic attacks](https://aimodels.fyi/papers/arxiv/struggle-adversarial-defense-try-diffusion)** or **[natural distribution shifts](https://aimodels.fyi/papers/arxiv/gda-generalized-diffusion-robust-test-time-adaptation)**.
Future research could explore addressing these limitations, as well as investigating the potential of RDC-like approaches for other domains beyond image classification.
## Conclusion
The Robust Diffusion Classifier (RDC) proposed in this paper represents a promising new direction for improving the **adversarial robustness** of image recognition systems. By leveraging the expressive power of pre-trained diffusion models, RDC is able to achieve significantly higher robustness against a variety of unseen adversarial threats compared to traditional adversarial training methods.
The key innovation of RDC is its **generative classifier** approach, which allows it to be more generalizable to defend against diverse attacks without the need for specialized training. This highlights the potential of **generative models** in enhancing the security and reliability of AI systems, an important area of research with broad implications for the real-world deployment of these technologies.
While the paper has several limitations that warrant further investigation, the strong performance of RDC on the CIFAR-10 benchmark suggests that this line of research is a promising direction for the field of adversarial machine learning.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,636 | Track Anything Rapter(TAR) | Track Anything Rapter(TAR) | 0 | 2024-05-28T12:50:31 | https://aimodels.fyi/papers/arxiv/track-anything-raptertar | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Track Anything Rapter(TAR)](https://aimodels.fyi/papers/arxiv/track-anything-raptertar). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- Proposed a novel object tracking system called Track Anything Rapter (TAR)
- TAR can track any object in a video using a single click
- TAR is an end-to-end trainable model that combines visual and language understanding
## Plain English Explanation
TAR is a new technology that makes it easy to track objects in videos. With just a single click, TAR can identify and follow any object of interest as it moves through the video. This is possible because TAR combines visual information from the video with language understanding to understand what the user wants to track.
Rather than requiring users to manually draw bounding boxes around an object or provide detailed descriptions, TAR can infer the user's intent from a simple click. This makes the tracking process much more intuitive and efficient. [The paper on TAR](https://aimodels.fyi/papers/arxiv/d-vat-end-to-end-visual-active) describes how the system works and demonstrates its capabilities on a variety of tracking tasks.
## Technical Explanation
The [TAR system](https://aimodels.fyi/papers/arxiv/d-vat-end-to-end-visual-active) uses an end-to-end neural network architecture that takes in the video frames and a user click as input, and outputs the location of the tracked object in each frame. The network consists of a visual encoder that processes the video, a language encoder that understands the user's click, and a cross-attention module that combines these two modalities to predict the object's position.
By jointly learning to understand the visual information and the user's intent, TAR is able to track a wide range of objects with high accuracy, even in challenging scenarios like occlusion or background clutter. The authors demonstrate TAR's capabilities on several benchmarks, showing that it outperforms previous state-of-the-art tracking methods.
## Critical Analysis
The [TAR paper](https://aimodels.fyi/papers/arxiv/d-vat-end-to-end-visual-active) presents a promising approach to object tracking that leverages both visual and language understanding. The single-click interface is a notable improvement over traditional tracking methods that require more manual input.
However, the paper does not fully address the potential limitations of the system. For example, it's unclear how TAR would perform on highly deformable objects or in videos with rapid camera motion. Additionally, the training and inference times of the model are not reported, which could be an important practical consideration.
Further research could also explore ways to make TAR more robust to noisy or ambiguous user clicks, and to extend the system to support other types of user input beyond just clicks.
## Conclusion
The [TAR system](https://aimodels.fyi/papers/arxiv/d-vat-end-to-end-visual-active) represents an exciting step forward in object tracking technology. By combining visual and language understanding, TAR enables a simple and intuitive way for users to track objects of interest in videos. The strong performance demonstrated in the paper suggests that this approach could have a significant impact in a wide range of applications, from video analysis to autonomous systems. As the technology continues to evolve, it will be interesting to see how TAR and similar systems can be further refined and deployed in real-world settings.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,633 | UFO: A UI-Focused Agent for Windows OS Interaction | UFO: A UI-Focused Agent for Windows OS Interaction | 0 | 2024-05-28T12:49:56 | https://aimodels.fyi/papers/arxiv/ufo-ui-focused-agent-windows-os-interaction | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [UFO: A UI-Focused Agent for Windows OS Interaction](https://aimodels.fyi/papers/arxiv/ufo-ui-focused-agent-windows-os-interaction). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper presents UFO, a user interface (UI)-focused agent for interacting with the Windows operating system.
- UFO leverages large language models (LLMs) to enable natural language interactions with UI elements, automating common tasks and enhancing user productivity.
- The system is designed to seamlessly integrate with the user's existing workflow, providing a more intuitive and efficient way to navigate and control their computer.
## Plain English Explanation
The researchers have developed a new tool called UFO that allows users to control their Windows computers using natural language commands, similar to how one might talk to a digital assistant like Siri or Alexa. UFO uses advanced AI models, known as large language models (LLMs), to understand the user's requests and then perform the requested actions on the computer's user interface.
For example, rather than navigating through menus and clicking on various buttons to accomplish a task, a user could simply say "UFO, open my email and draft a new message to my boss." UFO would then interpret the command, locate the relevant email application, open a new message, and start composing the email - all without the user needing to manually interact with the computer's interface.
The key advantage of UFO is that it can make common computing tasks more efficient and user-friendly, especially for those who may not be as comfortable with traditional point-and-click interfaces. By allowing users to issue voice commands or type in natural language instructions, UFO aims to streamline the process of controlling a Windows computer and performing everyday tasks.
## Technical Explanation
The UFO system [leverages advancements in large language models (LLMs)](https://aimodels.fyi/papers/arxiv/human-centered-llm-agent-user-interface-position) to enable natural language interactions with a user's Windows operating system. The agents are trained on a large corpus of text data, allowing them to understand and respond to a wide variety of user requests.
To interact with the computer's user interface, UFO utilizes computer vision techniques to detect and identify on-screen elements, such as buttons, menus, and application windows. This allows the system to interpret the user's commands and then execute the corresponding actions by programmatically interacting with the relevant UI components.
The researchers also incorporate [multimodal approaches](https://aimodels.fyi/papers/arxiv/you-only-look-at-screens-multimodal-chain) that combine language understanding with visual perception to enhance the agent's capabilities. This includes the ability to understand context-dependent references (e.g., "open that file" while pointing to an on-screen element) and perform complex, multi-step tasks.
Through user studies, the authors demonstrate the effectiveness of UFO in improving user productivity and reducing the cognitive load associated with traditional computer interactions. The system is designed to seamlessly integrate with the user's existing workflow, providing a more natural and efficient way to control their Windows environment.
## Critical Analysis
While the UFO system shows promising results, the researchers acknowledge several potential limitations and areas for future work. For instance, the current system is limited to the Windows operating system, and expanding its capabilities to other platforms, such as [mobile devices](https://aimodels.fyi/papers/arxiv/guing-mobile-gui-search-engine-using-vision) or [industrial control systems](https://aimodels.fyi/papers/arxiv/human-ai-interaction-industrial-robotics-design-empirical), would be a valuable avenue for further research.
Additionally, the paper does not provide a thorough evaluation of the system's performance in real-world, long-term usage scenarios. Assessing the system's reliability, scalability, and adaptability to diverse user preferences and computing environments would be important to ensure its practical viability.
The researchers also note the potential for privacy and security concerns, as the system's ability to interpret and interact with on-screen elements could raise risks related to the unintended exposure or manipulation of sensitive information. Addressing these issues through robust security and privacy-preserving measures would be crucial for the widespread adoption of such a system.
## Conclusion
The UFO system represents a significant step towards more natural and efficient human-computer interactions, leveraging the power of large language models and computer vision to bridge the gap between user requests and UI-level actions. By allowing users to control their Windows environments through natural language commands, the system has the potential to enhance productivity, accessibility, and the overall user experience.
However, the research also highlights the need for further advancements in areas such as cross-platform compatibility, long-term reliability, and robust security and privacy safeguards. As AI-powered user interfaces continue to evolve, addressing these challenges will be crucial to ensure the widespread adoption and responsible deployment of such transformative technologies.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,632 | Don't Wait! 24/7 Garage Door Repair in Pingree Grove, Illinois | Eloy Garage Door Repair | Is your garage door creating problems? Does it groan, grind, or just plain refuse to open? Don't... | 0 | 2024-05-28T12:49:54 | https://dev.to/eloy_mancilla_d1821deecca/dont-wait-247-garage-door-repair-in-pingree-grove-illinois-eloy-garage-door-repair-4hli | garage, door, repair | Is your garage door creating problems? Does it groan, grind, or just plain refuse to open? Don't waste time wrestling with a broken garage door. Call Eloy Garage Door Repair, the trusted Pingree Grove, Illinois experts for all your garage door needs!
At Eloy Garage Door Repair, our skilled technicians can handle any garage door issue, big or small. We offer:
1. Fast and reliable repairs
2. Expert troubleshooting
3. High-quality parts
4. Competitive prices
Don't let a broken garage door disrupt your day. Call Eloy Garage Door Repair today! We're available 24/7 to get your garage door functioning safely and securely once again.
For fast, reliable, and affordable garage door repair in Pingree Grove, call Eloy Garage Door Repair at 224-402-4518 or visit our website at https://www.eloygaragedoor.com/. We're here to help!
https://www.youtube.com/watch?v=ur9siDCHMcA | eloy_mancilla_d1821deecca |
1,867,631 | Power Hungry Processing: Watts Driving the Cost of AI Deployment? | Power Hungry Processing: Watts Driving the Cost of AI Deployment? | 0 | 2024-05-28T12:49:21 | https://aimodels.fyi/papers/arxiv/power-hungry-processing-watts-driving-cost-ai | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Power Hungry Processing: Watts Driving the Cost of AI Deployment?](https://aimodels.fyi/papers/arxiv/power-hungry-processing-watts-driving-cost-ai). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper explores the power and energy consumption of different neural network setups and their impact on the cost of AI deployment.
- The research examines techniques for [improving energy efficiency in machine learning](https://aimodels.fyi/papers/arxiv/toward-cross-layer-energy-optimizations-machine-learning) and [reducing the carbon footprint of large language models](https://aimodels.fyi/papers/arxiv/towards-greener-llms-bringing-energy-efficiency-to).
- The study provides insights into the tradeoffs between [increased compute power](https://aimodels.fyi/papers/arxiv/more-compute-is-what-you-need) and energy efficiency for [training and deploying AI models](https://aimodels.fyi/papers/arxiv/power-training-how-different-neural-network-setups).
## Plain English Explanation
The paper discusses the power and energy requirements of different machine learning models and how that affects the costs of deploying AI systems. It looks at techniques to make AI more energy-efficient and reduce the carbon footprint, especially for large language models that can consume a lot of power.
The research examines the tradeoffs between using more computing power to improve model performance versus optimizing for energy efficiency. This is an important consideration, as the energy costs of running AI systems can be a significant factor in the overall deployment costs.
The paper provides insights that can help organizations make more informed decisions about their AI infrastructure and find the right balance between performance and energy efficiency based on their specific needs and constraints.
## Technical Explanation
The paper presents an in-depth analysis of the power and energy consumption of various neural network architectures and training setups. The researchers conduct experiments to measure the power draw and energy usage of different model configurations, including variations in model size, hardware, and training techniques.
The study explores methods for [improving the energy efficiency of machine learning systems](https://aimodels.fyi/papers/arxiv/toward-cross-layer-energy-optimizations-machine-learning), such as model compression, hardware acceleration, and task-specific optimizations. It also investigates approaches for [reducing the carbon footprint of large language models](https://aimodels.fyi/papers/arxiv/towards-greener-llms-bringing-energy-efficiency-to), which can be particularly power-hungry.
The findings reveal the significant impact that power and energy consumption can have on the overall cost of deploying AI systems. The researchers analyze the tradeoffs between [increased compute power](https://aimodels.fyi/papers/arxiv/more-compute-is-what-you-need) and energy efficiency, providing guidance on [optimizing neural network setups for power-efficient training and inference](https://aimodels.fyi/papers/arxiv/power-training-how-different-neural-network-setups).
## Critical Analysis
The paper provides a comprehensive analysis of the power and energy implications of AI deployment, but it acknowledges some limitations. For example, the experiments were conducted in a controlled lab setting, and the results may not fully capture the real-world conditions and variability encountered in production environments.
Additionally, the study focuses primarily on the technical aspects of power and energy efficiency, but it does not delve into the broader societal and environmental impacts of AI systems. Factors such as the lifecycle carbon footprint, energy sources, and e-waste management could be further explored to provide a more holistic understanding of the sustainability challenges.
While the paper offers valuable insights, it also highlights the need for continued research and collaboration across disciplines to develop more sustainable and responsible AI practices. Ongoing efforts to [optimize energy-efficient AI](https://aimodels.fyi/papers/arxiv/toward-cross-layer-energy-optimizations-machine-learning) and [reduce the environmental impact of large language models](https://aimodels.fyi/papers/arxiv/towards-greener-llms-bringing-energy-efficiency-to) will be crucial as the adoption of AI technologies continues to grow.
## Conclusion
This paper provides a detailed examination of the power and energy considerations in the deployment of AI systems. It reveals the significant impact that power consumption can have on the overall cost of AI, highlighting the importance of optimizing for energy efficiency.
The research explores various techniques for improving the power efficiency of machine learning models, including model compression, hardware acceleration, and task-specific optimizations. It also investigates strategies for [reducing the carbon footprint of large language models](https://aimodels.fyi/papers/arxiv/towards-greener-llms-bringing-energy-efficiency-to), which are known to be power-hungry.
The findings offer valuable insights for organizations looking to deploy AI in a more sustainable and cost-effective manner. By understanding the tradeoffs between [increased compute power](https://aimodels.fyi/papers/arxiv/more-compute-is-what-you-need) and energy efficiency, they can make informed decisions about their AI infrastructure and find the right balance to meet their performance, cost, and environmental goals.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,630 | Neuromorphic dreaming: A pathway to efficient learning in artificial agents | Neuromorphic dreaming: A pathway to efficient learning in artificial agents | 0 | 2024-05-28T12:48:47 | https://aimodels.fyi/papers/arxiv/neuromorphic-dreaming-pathway-to-efficient-learning-artificial | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Neuromorphic dreaming: A pathway to efficient learning in artificial agents](https://aimodels.fyi/papers/arxiv/neuromorphic-dreaming-pathway-to-efficient-learning-artificial). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- The paper explores the use of neuromorphic systems, which are inspired by the brain's architecture and function, as a pathway for efficient learning in artificial agents.
- It investigates the potential benefits of incorporating "neuromorphic dreaming" - a process akin to mammalian sleep-based memory consolidation - to enhance the learning capabilities of spiking neural networks (SNNs).
- The research aims to develop energy-efficient, embodied neuromorphic AI systems with robust learning abilities, drawing inspiration from neuroscience and cognitive science.
## Plain English Explanation
The paper looks at using artificial neural networks that are designed to mimic the brain's structure and function, known as [neuromorphic systems](https://aimodels.fyi/papers/arxiv/embodied-neuromorphic-artificial-intelligence-robotics-perspectives-challenges), as a way to help AI agents learn more efficiently.
The key idea is to incorporate a process called "neuromorphic dreaming," which is inspired by how the brain consolidates memories during sleep. By replicating this sleep-based learning process in artificial neural networks, the researchers hope to create AI systems that can learn tasks more quickly and with less energy compared to traditional approaches.
The goal is to develop [energy-efficient, embodied neuromorphic AI](https://aimodels.fyi/papers/arxiv/towards-reverse-engineering-brain-brain-derived-neuromorphic) that can learn in a robust and flexible way, drawing insights from our understanding of how the brain works.
## Technical Explanation
The paper explores the use of [spiking neural networks (SNNs)](https://aimodels.fyi/papers/arxiv/deep-reinforcement-learning-spiking-q-learning), a type of neuromorphic architecture, in the context of [reinforcement learning](https://aimodels.fyi/papers/arxiv/learning-to-learn-enables-rapid-learning-phase). It investigates the potential benefits of incorporating a process akin to mammalian sleep-based memory consolidation, dubbed "neuromorphic dreaming," to enhance the learning capabilities of these SNN-based agents.
The researchers hypothesize that by replicating key aspects of sleep-dependent memory processing in artificial neural networks, the agents can learn tasks more efficiently and with lower energy consumption compared to traditional approaches. This is motivated by the observation that sleep plays a crucial role in the brain's ability to consolidate and retain memories in an energy-efficient manner.
Through simulations and experiments, the paper examines the performance of SNN-based agents equipped with neuromorphic dreaming capabilities across various learning tasks. The results aim to shed light on the potential of this approach for developing robust, energy-efficient, and embodied neuromorphic AI systems that can learn in a flexible and adaptable way.
## Critical Analysis
The paper presents a compelling concept by drawing inspiration from neuroscience and cognitive science to enhance the learning capabilities of artificial agents. However, it is important to note that the research is still in the early stages, and the practical implementation of neuromorphic dreaming may face various challenges.
One potential limitation is the complexity involved in accurately modeling the intricate sleep-dependent memory consolidation processes observed in biological neural networks. Capturing the nuances of these mechanisms in a computationally efficient manner within artificial systems may require further advancements in our understanding of the underlying neurological processes.
Additionally, the paper does not address potential scalability issues or the feasibility of deploying these neuromorphic dreaming-enabled agents in real-world, embodied scenarios. The performance and energy-efficiency benefits demonstrated in simulations may not directly translate to more complex, dynamic environments.
Further research is needed to explore the robustness and generalizability of this approach, as well as to address potential security and ethical considerations that may arise from the development of highly capable, energy-efficient neuromorphic AI systems.
## Conclusion
The paper presents a novel and promising approach to enhancing the learning capabilities of artificial agents by drawing inspiration from the brain's sleep-dependent memory consolidation processes. The concept of "neuromorphic dreaming" offers a potential pathway for developing energy-efficient, embodied neuromorphic AI systems with robust and flexible learning abilities.
While the research is still in the early stages, the insights gained from this work could have significant implications for the field of artificial intelligence, particularly in the context of [developing efficient, brain-inspired AI agents](https://aimodels.fyi/papers/arxiv/snn4agents-framework-developing-energy-efficient-embodied-spiking). Continued advancements in this direction may contribute to the creation of AI systems that can learn and adapt in a more human-like manner, with potential applications ranging from cognitive robotics to energy-efficient edge computing.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 |
1,867,627 | Deploying an Application on AWS: Amplify vs. EC2 | Deploying an Application on AWS: Amplify vs. EC2 Deploying an application on Amazon Web... | 0 | 2024-05-28T12:48:33 | https://dev.to/sh20raj/deploying-an-application-on-aws-amplify-vs-ec2-533f | aws | # Deploying an Application on AWS: Amplify vs. EC2
Deploying an application on Amazon Web Services (AWS) is a popular choice for many developers, given its robust infrastructure and diverse services. Two common AWS services for deploying applications are AWS Amplify and Amazon EC2. Let's dive into a detailed analysis of these two options, their advantages, and considerations, plus some alternative services you might want to explore! 😊
## AWS Amplify: The All-in-One Solution 🚀
### What is AWS Amplify?
AWS Amplify is a comprehensive development platform for building secure, scalable mobile and web applications. It simplifies many aspects of application development, including backend configuration, hosting, and deployment.
### Key Features
- **Simplified Deployment**: With a few clicks, you can deploy static websites and single-page applications (SPAs).
- **Built-in CI/CD**: Automated build and deploy processes for every code commit.
- **Backend as a Service (BaaS)**: Easily add authentication, databases, storage, and more.
- **Integration with Other AWS Services**: Seamless integration with services like AWS AppSync, AWS Lambda, and Amazon S3.
### Advantages
- **Ease of Use**: Ideal for front-end developers and teams without extensive DevOps knowledge.
- **Speed**: Rapid deployment and iteration with automated workflows.
- **Cost-Effective**: Pay-as-you-go pricing with a free tier for low-traffic applications.
- **Scalability**: Automatically handles scaling for web traffic.
### Considerations
- **Less Control**: Limited customization compared to managing your own infrastructure.
- **Best for Specific Use Cases**: More suited for static sites and serverless applications.
## Amazon EC2: The Flexible Powerhouse ⚙️
### What is Amazon EC2?
Amazon Elastic Compute Cloud (EC2) provides scalable virtual servers in the cloud. You have full control over the computing resources and can configure, manage, and deploy applications as you see fit.
### Key Features
- **Customizability**: Choose your operating system, instance type, and configuration.
- **Scalability**: Scale horizontally with Auto Scaling and load balancing.
- **Wide Range of Use Cases**: From simple web applications to high-performance computing and enterprise applications.
- **Integration**: Works seamlessly with other AWS services like RDS, S3, and CloudWatch.
### Advantages
- **Full Control**: Complete control over the environment and configurations.
- **Versatility**: Suitable for a wide range of applications, including complex, resource-intensive workloads.
- **Performance**: Tailor performance to your specific needs with various instance types and sizes.
### Considerations
- **Complexity**: Requires more knowledge in system administration and DevOps.
- **Cost Management**: Can become expensive if not managed properly.
- **Maintenance**: You’re responsible for updates, security patches, and overall system health.
## Alternatives to AWS Amplify and EC2 🌐
### AWS Elastic Beanstalk
AWS Elastic Beanstalk is a Platform as a Service (PaaS) that handles the deployment, scaling, and monitoring of applications. It's a middle ground between the simplicity of Amplify and the control of EC2.
- **Pros**: Simplifies deployment while allowing some level of customization.
- **Cons**: Less control than EC2, potentially higher cost than Amplify for certain applications.
### AWS Lambda
AWS Lambda allows you to run code without provisioning or managing servers, based on an event-driven architecture.
- **Pros**: Fully serverless, scales automatically, and cost-effective for low-usage scenarios.
- **Cons**: Limited to specific use cases and event-driven applications.
### Amazon Lightsail
Amazon Lightsail is designed for simpler workloads, offering easy-to-use instances with a predictable pricing model.
- **Pros**: Simplifies cloud usage with pre-configured stacks, predictable pricing.
- **Cons**: Less flexible and powerful than EC2 for larger, more complex applications.
### Heroku
Heroku is a cloud platform that enables quick deployment and management of applications without worrying about infrastructure.
- **Pros**: Extremely user-friendly, supports multiple languages, and offers a free tier.
- **Cons**: Higher costs for scaling compared to AWS services.
### Google Cloud Platform (GCP) and Microsoft Azure
Both GCP and Azure offer services similar to AWS, with their own sets of strengths and weaknesses.
- **Pros**: Competitive pricing, unique features (like Google’s AI and ML tools), and global infrastructure.
- **Cons**: Learning curve if you’re already familiar with AWS, potential differences in service availability.
## Conclusion 🎉
Choosing between AWS Amplify and EC2 boils down to your specific needs:
- **Use AWS Amplify** if you want a quick, hassle-free way to deploy web and mobile applications with minimal DevOps overhead.
- **Use Amazon EC2** if you need full control over your environment and are comfortable managing infrastructure.
Each option has its strengths and is suited for different scenarios. And if neither Amplify nor EC2 fits the bill, AWS offers other powerful alternatives, and so do other cloud providers. Happy deploying! 🚀 | sh20raj |
1,867,370 | Symfony DbToolsBundle - anonymize your data | Illustrations are taken directly from their website : https://dbtoolsbundle.readthedocs.io ... | 0 | 2024-05-28T12:47:57 | https://dev.to/thejuju/symfony-dbtoolsbundle-anonymize-your-data-5amj | php, symfony, gdpr, database | > Illustrations are taken directly from their website : [https://dbtoolsbundle.readthedocs.io](https://dbtoolsbundle.readthedocs.io)
## About the Bundle
This bundle allows you to backup, restore, and anonymize databases. It is compatible with MySQL, MariaDB, PostgreSQL, and SQLite. For more details, visit their website: [https://dbtoolsbundle.readthedocs.io](https://dbtoolsbundle.readthedocs.io)
## Set up a GDPR-friendly workflow
All companies trying to set up databases for testing and development purposes face this challenge. It often takes a lot of time and effort to maintain GDPR compliance.
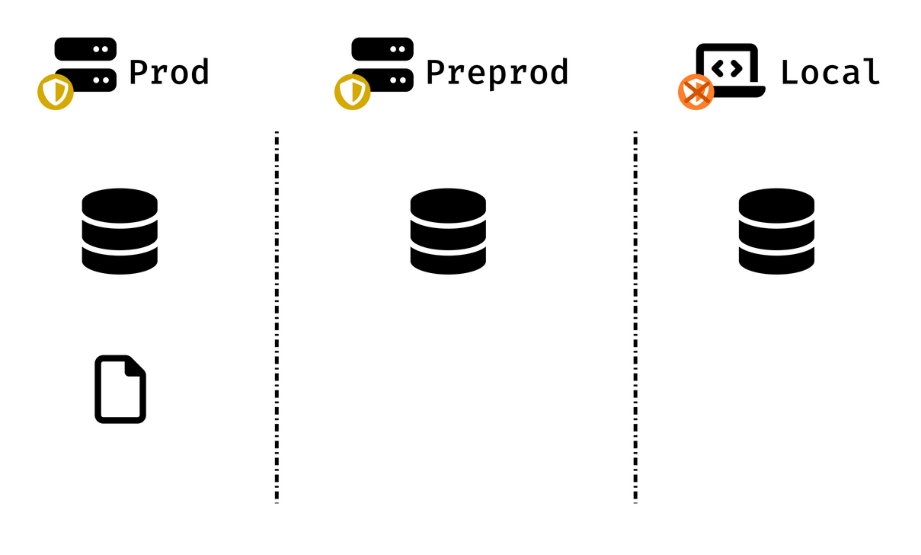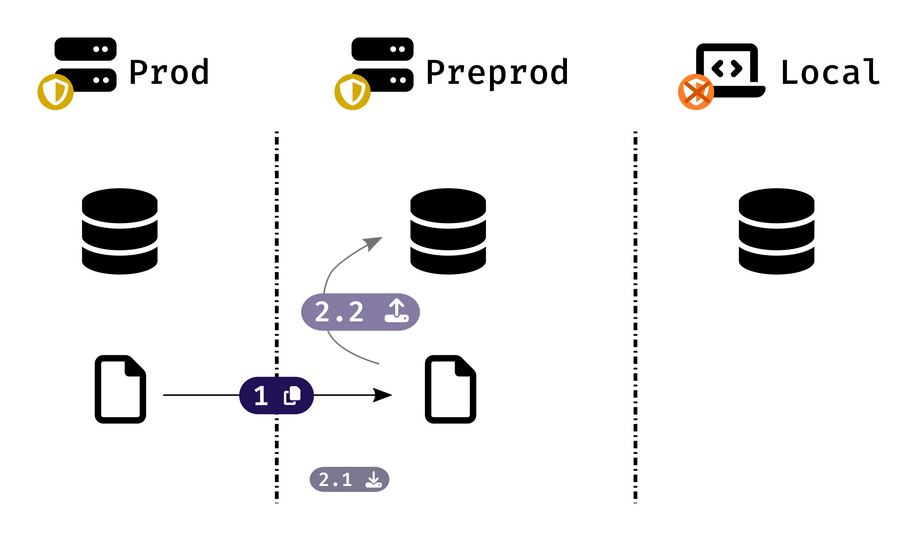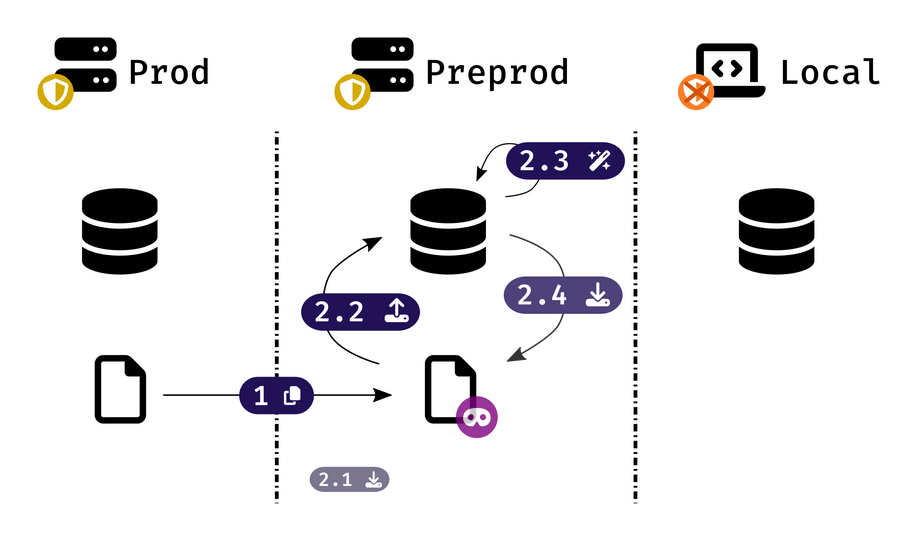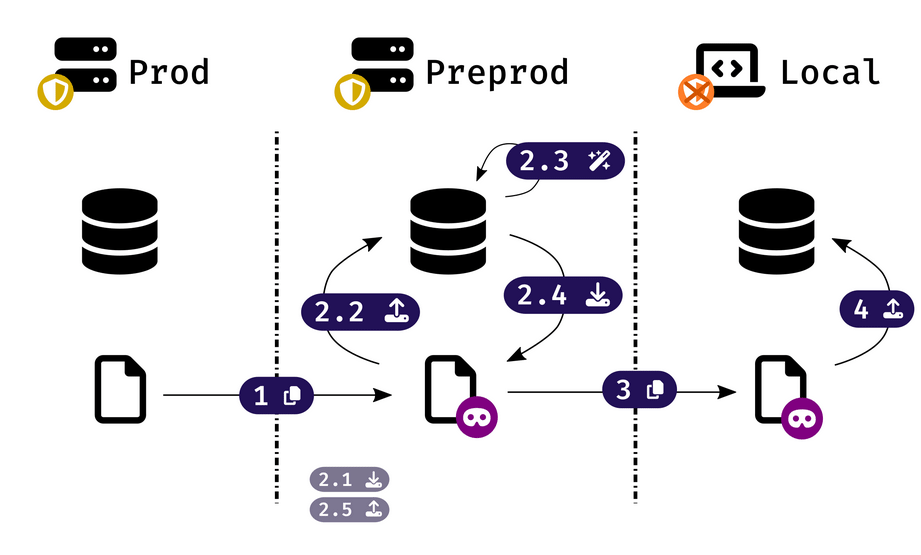
## Basic implementation of anonymisation on an entity
Let's take a look at a concrete example:
```php
class User implements UserInterface
{
#[ORM\Id]
#[ORM\GeneratedValue]
#[ORM\Column]
private ?int $id = null;
#[ORM\Column(length: 180, unique: true)]
#[Anonymize(type: 'email')]
private ?string $email = null;
#[ORM\Column(nullable: true)]
#[Anonymize(type: 'password')]
private ?string $password = null;
// [...] etc...
}
```
By defining the PHP attribute #[Anonymize] on class attributes, you'll define "what and how" you'll anonymize. Many core anonymizers are already available, such as:
- EmailAnonymizer
- PasswordAnonymizer
- IntegerAnonymizer
- FloatAnonymizer
- DateAnonymizer
- NullAnonymizer
- ConstantAnonymizer
- Md5Anonymizer
- StringAnonymizer
- LastnameAnonymizer
- FirstnameAnonymizer
- LoremIpsumAnonymizer
- AddressAnonymizer
You can even develop your own Anonymizer class if you need more specific functionality.
Once your configuration is done, you simply have to run the following command to anonymize your database:
```bash
php bin/console db-tools:anonymize [options]
# Real example for local database
# php bin/console db-tools:anonymize --local-database
```
To reproduce the workflow shown above, you can easily use your favorite CI/CD tools to run pipelines that distribute an up-to-date database, completely anonymized and GDPR-friendly (though not necessarily 100% compliant). | thejuju |
1,867,625 | Kurdish Bot | Kurdish Bot was created on May 19, 2024 for social media services. Kurdish bot is also used to... | 0 | 2024-05-28T12:46:23 | https://dev.to/zhika_ecee4020673a49b82ba/kurdish-bot-pph | telegram, kurdish, bot |

**Kurdish Bot**
was created on May 19, 2024 for social media services.
**Kurdish bot** is also used to download social media stories that makes it easier for the user.
**Owner**
The Kurdish bot manager is Zhyar from Sulaymaniyah, Iraq, who is an expert in social media.
**Telegram Channel** Link
https://t.me/Kurdishbott | zhika_ecee4020673a49b82ba |
1,867,623 | Dev na Gringa: Vale a Pena? | Originalmente postado no Dev na Gringa Substack. A resposta é simples: sim, vale a pena. Mas é... | 0 | 2024-05-28T12:43:18 | https://dev.to/lucasheriques/dev-na-gringa-vale-a-pena-1o92 | braziliandevs, career, software | Originalmente postado no [Dev na Gringa Substack](https://devnagringa.substack.com/p/dev-na-gringa-vale-a-pena).
---
A resposta é simples: **sim, vale a pena.** Mas é necessário saber balancear o ganho financeiro com o crescimento profissional.
Uma das grandes vantagens de ser um dev na gringa é o salário em moeda forte.
Isso te protege da inflação imprevisível do Brasil.
E permite ter salários mais altos sem precisar de um cargo de altíssima senioridade.
Mas você pode se encontrar numa situação com **algemas de ouro**. O salário é alto, mas o crescimento profissional estagnado.
Passei por isso no meu primeiro emprego para fora.
## O problema da senioridade prematura
> Charity Majors, CTO da Honeycomb, escreveu um artigo excelente sobre a [senioridade prematura](https://charity.wtf/2020/11/01/questionable-advice-the-trap-of-the-premature-senior/).
Entrei na empresa em 2020, em um domínio que eu não conhecia: indústria de transformação.
É uma área mais lenta em questão de transformação digital. Algumas empresas ainda guardam dados no papel!
No começo, aprendi muito. Construí software para pessoas que não usavam muita tecnologia no dia a dia. Alguns funcionários não tinham nem smartphones!
Fiquei quase três anos nessa empresa.
Cresci e me tornei o engenheiro sênior do time. Mesmo com o crescimento da equipe, eu sempre tinha mais contexto.
Muitas responsabilidades caíam em mim: mentoria, arquitetura, entrevistas.
**Mas faltavam novos desafios.**
Eu sentia que não estava crescendo mais como engenheiro de software.
Isso me levou a buscar novas oportunidades.
Numa empresa grande, poderia mudar de time internamente, mas numa startup, isso não era possível.
## As algemas de ouro
Comecei a procurar um novo emprego.
Mas, com os layoffs, as oportunidades ficaram mais competitivas e raras.
Fiz algumas entrevistas e percebi que estava enferrujado.
Não fazia entrevistas de _system design_ há muito tempo. Sendo que essa é uma das principais habilidades de um engenheiro sênior.
Percebi que minhas habilidades estavam desatualizadas. E aí surgiram os problemas das algemas de ouro. Ganhando bem, minhas oportunidades eram limitadas. Ninguém quer uma redução salarial.
> Numa entrevista, passei, mas não atingi o nível sênior, e recebi a oferta como pleno. Teria uma redução salarial significativa, então não seguimos em frente. O feedback do entrevistador me abriu os olhos para a realidade das algemas de ouro. Ele, sendo CTO, esperava mais profundidade de alguém com minha experiência. David, muito obrigado! Não trabalhamos juntos, mas você é um dos mentores mais importantes da minha carreira.
Meses depois, consegui uma nova oportunidade. Felizmente, como dev na gringa. Onde eu posso sentir o desconforto de um iniciante novamente.
Um lugar onde tenho novos mentores, resolvo problemas diferentes e continuo crescendo profissionalmente.
Inclusive, caso você esteja procurando emprego, não poderia recomendar mais a Brex. [Temos vagas!](https://www.brex.com/careers?country=Brazil)
## O que significa ser um engenheiro sênior
Sim, eu era o engenheiro sênior no meu time. Agora, “caí de nível”.
Porém, isso é uma oportunidade de ouro.
Para ter uma carreira de sucesso, é necessário se colocar em situações desconfortáveis.
É confortável ter o contexto de tudo e saber resolver a maioria dos problemas.
Mas a capacidade de começar do zero, aprender e ter impacto é essencial para um engenheiro de software sênior.
Lembre-se que a engenharia de software raramente é o objetivo final de um negócio.
Ela é o meio pelo qual entregamos valor no mundo real.
Um engenheiro sênior deve ser capaz projetar sistemas escaláveis e confiáveis. Independente do domínio.
Pode levar tempo, mas a adaptação a diferentes domínios é crucial.
## Conclusão e aprendizado
Repito: **Sim, ser um dev na gringa vale a pena.**
Mas pense além do crescimento financeiro. Foque no desenvolvimento a longo prazo da sua carreira.
Você é o CEO da sua trajetória profissional. Tenha a visão de onde quer chegar.
Cuidado com as algemas de ouro. Idealmente, busque oportunidades sem redução salarial. Mas se necessário, arrisque para crescer.
Evite ser a pessoa mais sênior ao seu redor, especialmente no início da carreira.
Busque desafios constantes.
Familiarize-se com diferentes maneiras de construir software.
Não se apegue à sua stack atual.
Desenvolva habilidades de comunicação e liderança.
Saiba começar do zero, entrar em um time novo, navegar pelo desconhecido e se adaptar.
**[Aprenda a influenciar sem autoridade.](https://www.developing.dev/p/how-to-influence-without-authority)** | lucasheriques |
1,863,255 | Developing a Nomad Autoscaler for Harvester | Nomad orchestrates application deployment and management. As applications grow in size, managing... | 0 | 2024-05-28T12:38:35 | https://dev.to/danquack/developing-a-nomad-autoscaler-for-harvester-1dcf | suse, nomad, harvester, autoscale | Nomad orchestrates application deployment and management. As applications grow in size, managing resource consumption becomes crucial. The [Nomad Autoscaler](github.com/hashicorp/nomad-autoscaler) is a pluggable service that makes workload scaling more accessible, empowering users to create logic for scaling their infrastructure.
Developing a custom plugin is especially beneficial when catering to cloud environments or hypervisors that aren't supported by the [HashiCorp community](https://developer.hashicorp.com/nomad/tools/autoscaling/plugins/external). This blog will guide you through creating a Nomad Autoscaler plugin, through the use of the exposed methods: `SetConfig`, `Scale`, and `Status`.
## Defining the Plugin Struct
For our Nomad Autoscaler plugin, we'll define a struct to hold configuration and other state information for scaling on Harvester. The `Plugin` struct implements the [sdk.Target](github.com/hashicorp/nomad-autoscaler/plugins/target) interface to work as a nomad autoscaling plugin. The Plugin struct should contain all the state needed to actually implement autoscaling, such as configuration. loggers, and api clients.
```go
package main
import (
"context"
"fmt"
"time"
"github.com/hashicorp/go-hclog"
"github.com/drewmullen/harvester-go-sdk"
"github.com/hashicorp/nomad/api"
)
type HarvesterPlugin struct {
config map[string]string
logger hclog.Logger
HarvesterClient *harvester.APIClient
NomadClient *api.Client
// Additional Config
}
func NewPlugin(log hclog.Logger) *HarvesterPlugin {
return &HarvesterPlugin{
logger: log,
}
}
```
## Configuring the Plugin
The target plugin contains two different config parameters:
- target: what to scale
- policy: when to scale
#### Target Configuration
The target configuration contains the plugin-specific configuration, containing authentication credentials, global settings, etc.
```hcl
target {
driver = "harvester"
config = {
harvester_url = "https://harvester.example.com"
auth_token = "eyabc123"
}
}
```
Once instantiated, the Nomad autoscaler service will pass the target configuration options to the plugin's `SetConfig` method, which can then be used to set up the plugin fields. The configuration will also contain options as defined in the [General Options documentation](https://developer.hashicorp.com/nomad/tools/autoscaling/plugins#general-options).
A sample setup might look something like this:
```go
func (hp *HarvesterPlugin) SetConfig(config map[string]string) error {
token := getEnvOrConfig("HARVESTER_TOKEN", config, configKeyAuthToken) // A function that returns in order of priority environment var, config value.
url := getEnvOrConfig("HARVESTER_URL", config, configKeyHarvesterURL) // configKeyHarvesterURL is a const defined elsewhere
hp.HarvesterClient = harvester.NewAPIClient(&harvester.Configuration{
DefaultHeader: map[string]string{"Authorization": "Bearer " + token},
UserAgent: "nomad-autoscaler",
Debug: false,
Servers: harvester.ServerConfigurations{
{URL: url, Description: "Harvester API Server"},
},
})
apiConfig := &api.Config{
Address: config["nomad_address"],
Region: config["nomad_region"],
Namespace: config["nomad_namespace"],
}
if token, ok := config["nomad_token"]; ok {
apiConfig.Headers = map[string][]string{"X-Nomad-Token": []string{token}}
}
nomadClient, err := api.NewClient(apiConfig)
if err != nil {
return fmt.Errorf("failed to create Nomad client: %v", err)
}
hp.NomadClient = nomadClient
// Any other additional Config
return nil
}
```
### Scaling
Cluster Operators author [scaling policing](https://developer.hashicorp.com/nomad/tools/autoscaling/policy) when interacting with the Autoscaler. The config provided is then pass as a parameter to the `Scale` method to dynamically allocate the necessary resources.
```hcl
scaling "cluster_policy" {
enabled = true
min = 1 # min number of VMs to scale
max = 2 # max number of VMs to scale
policy {
....
target "aws-asg" {
dry-run = "false"
node_class = "linux"
node_group_name = "nomad"
namespace = "default"
cpu_request = "2"
memory_request = "4Gi"
...
}
}
}
```
With the configuration defined, Nomad passes the scaling config to the plugin's `Scale` method. Your hypervisor will determine the actual implementations of how to calculate the active nodes for scale operations.
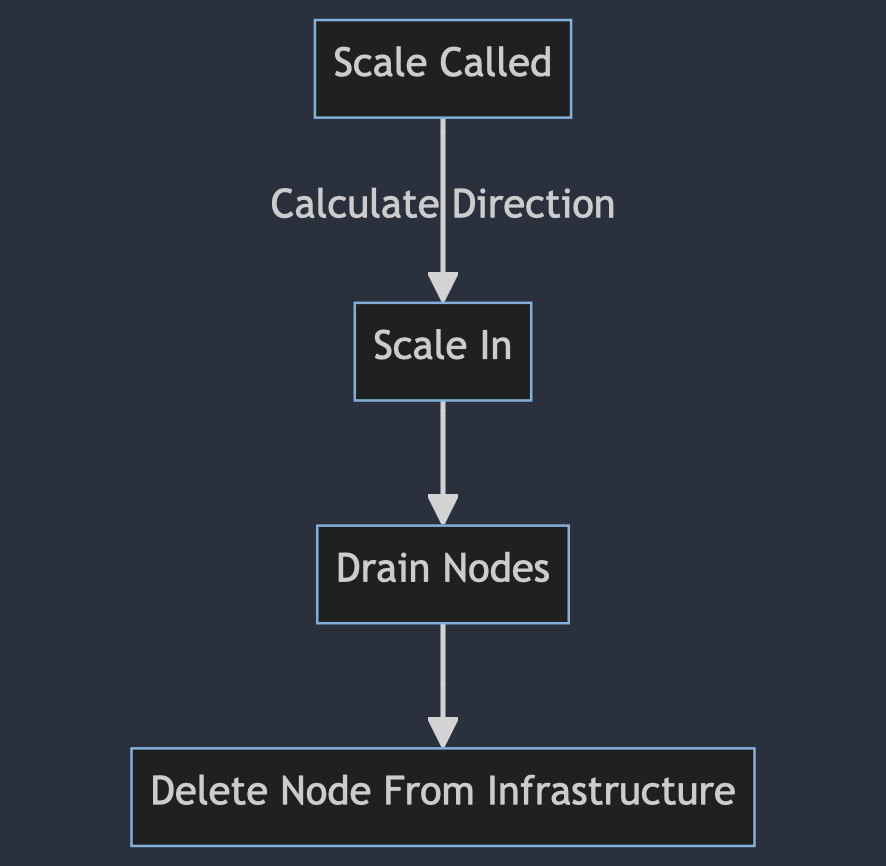
```go
func (hp *HarvesterPlugin) Scale(action sdk.ScalingAction, config map[string]string) error {
// config parsing removed for simplicity
ctx, cancel := context.WithTimeout(context.Background(), hp.scaleTimeout)
defer cancel()
total, _, remoteIDs, err := hp.countReady(ctx, nodeGroup, namespace)
if err != nil {
return fmt.Errorf("failed to count servers in harvester: %v", err)
}
diff, direction := hp.calculateDirection(total, action.Count)
switch direction {
// SCALE_IN is an enum utilized as output of the calculateDirection function
case SCALE_IN:
if err := hp.scaleIn(ctx, diff, remoteIDs, config); err != nil {
return fmt.Errorf("failed to perform in: %v", err)
}
// SCALE_OUT is an enum utilized as output of the calculateDirection function
case SCALE_OUT:
if err := hp.scaleOut(ctx, diff, config); err != nil {
return fmt.Errorf("failed to perform out: %v", err)
}
default:
hp.logger.Debug("scaling not required", "node group", nodeGroup, "current_count", total, "strategy_count", action.Count)
return nil
}
return err
}
```
#### Draining Nodes
During the `scaleIn` method, HashiCorp recommends that you first drain the node. Draining and purging nodes is critical to scaling down operations, providing reliability to allow for applications to gracefully shutdown. After some time, with the node offline, Nomad's garbage collector will then remove the node from the cluster.
```go
func (hp *HarvesterPlugin) drainNode(ctx context.Context, nodeID string, timeout time.Duration) error {
_, err := hp.NomadClient.Nodes().UpdateDrainOpts(
nodeID,
&api.DrainOptions{
DrainSpec: &api.DrainSpec{
Deadline: timeout,
IgnoreSystemJobs: true,
},
MarkEligible: false,
},
nil,
)
if err != nil {
hp.logger.Warn(fmt.Sprintf("Failed to drain %v. Will continue to deleting: %v", nodeID, err))
} else {
drainCtx, cancel := context.WithTimeout(ctx, timeout)
defer cancel()
err := hp.waitForDrained(drainCtx, nodeID)
if err != nil {
hp.logger.Warn(fmt.Sprintf("Failed to drain %v: %v", nodeID, err))
}
}
}
```
### Status
The `Status` function reports the current status of your plugin, which helps debug and monitor purposes. The plugin determines the current running count using information returned by the plugin's `Status` method. The method returns an [`sdk.TargetStatus`](https://pkg.go.dev/github.com/hashicorp/nomad-autoscaler@v0.4.3/sdk#TargetStatus) to determine if the next `Scale` function can be performed, as well as the current running count to determine the next strategy calculation.
```go
func (hp *HarvesterPlugin) Status(config map[string]string) (*sdk.TargetStatus, error) {
total, active, _, err := hp.countReady(context.Background(), nodeGroup, namespace)
if err != nil {
return nil, fmt.Errorf("failed to count Harvester servers: %v", err)
}
return &sdk.TargetStatus{
Ready: active == total,
Count: total,
Meta: make(map[string]string),
}, nil
}
```
## Conclusion
Developing a Nomad Autoscaler plugin involves implementing key functions like `SetConfig`, `Scale`, and `Status`. Configuring the plugin requires defining target and policy blocks, which dictate what to scale and under what conditions. The proper handling of draining allows for control over the scaling, maintaining the reliability of your application.
Writing an autoscaler plugin lets you to tailor your hypervisor to the needs of your Nomad-managed infrastructure. Finally, here's a demo of the autoscaler in action.
<video width="100%" height="100%" controls autoplay muted>
<source src="https://quack-public-bucket.s3.amazonaws.com/nomad_harvester_autoscaler.mp4" type="video/mp4">
</video>
For more details and examples, check out the [Nomad Autoscaler Plugin authoring guide](https://developer.hashicorp.com/nomad/tools/autoscaling/internals/plugins), and the [Nomad Autoscaling tools documentation](https://developer.hashicorp.com/nomad/tools/autoscaling).
Special thanks to [Steve Kalt](https://github.com/skalt) for helping review this post.
| danquack |
1,867,622 | Discover the Beauty of Polished Concrete in Houston | Polished concrete floors have become a popular choice for both residential and commercial spaces in... | 0 | 2024-05-28T12:37:55 | https://dev.to/oneawesome/discover-the-beauty-of-polished-concrete-in-houston-4oki | stainedconcretefloors, polishedconcretenearme | Polished concrete floors have become a popular choice for both residential and commercial spaces in Houston, thanks to their blend of beauty and practicality. Offering a sleek, modern look combined with durability and ease of maintenance, polished concrete is an excellent flooring solution for any setting. Here's why you should consider polished concrete for your home or business in Houston.
Aesthetic Appeal
Polished concrete floors provide a high-end, sophisticated look that can enhance the visual appeal of any space. With their glossy finish and smooth surface, these floors reflect light beautifully, creating a bright and welcoming atmosphere. Available in a range of finishes and colors, polished concrete can be customized to complement your existing decor, whether you prefer a minimalist, industrial, or contemporary style.
**Durability and Longevity**
One of the standout features of polished concrete is its remarkable durability. These floors can withstand heavy foot traffic, making them ideal for busy households and high-traffic commercial areas. Polished concrete is resistant to scratches, stains, and chipping, ensuring your floors maintain their pristine appearance for years to come. This longevity makes it a cost-effective flooring option in the long run.
**Low Maintenance**
Polished concrete floors are incredibly easy to maintain. Unlike carpet or hardwood, they do not trap dust, allergens, or dirt, making them a healthier option for indoor air quality. Routine maintenance involves simple dusting and occasional wet mopping, saving you time and effort. The smooth, non-porous surface also resists spills and stains, making clean-up a breeze.
**Eco-Friendly Choice**
Choosing polished concrete is also an environmentally friendly decision. The process involves grinding and polishing the existing concrete slab, eliminating the need for additional materials. This not only reduces waste but also lowers the environmental impact associated with new flooring installations. Additionally, polished concrete floors contribute to better energy efficiency by improving natural light reflection, reducing the need for artificial lighting.
**Versatility for Any Space**
Polished concrete is a versatile flooring option suitable for a wide range of spaces. In homes, it can be used in living rooms, kitchens, basements, and even outdoor areas like patios. For businesses, polished concrete is ideal for retail stores, restaurants, office buildings, and warehouses. Its adaptability makes it a perfect choice for both new constructions and renovation projects.
**Increased Property Value**
Investing in polished concrete floors can also boost the value of your property. The modern, stylish appearance and practical benefits appeal to potential buyers and tenants, making your home or business more attractive on the market. The durability and low maintenance of polished concrete add to its value proposition, offering long-term benefits that are hard to ignore.
**Conclusion**
Polished concrete floors are a beautiful, durable, and low-maintenance flooring option that can transform any space in Houston. Their versatility and eco-friendly benefits make them an excellent choice for residential and commercial properties.
**Contact Local Expert:**
One Awesome Concrete Polishing & Staining
2617 Bissonnet St, Ste 451, Houston, TX 77005
281-955-8994
[https://oneawesomeconcrete.com/](https://oneawesomeconcrete.com/)
One Awesome Concrete is Houston's trusted source for polished concrete, innovative [stained concrete floors](https://www.google.com/maps?cid=5134634323966597421), and experienced commercial concrete contractors.
| oneawesome |
1,867,620 | 8 Ways to Save Money on Your Home Construction Project | Home Construction Company in North Bangalore Introduction When undertaking home construction... | 0 | 2024-05-28T12:35:56 | https://dev.to/tvasteconstructions/8-ways-to-save-money-on-your-home-construction-project-f59 |
Home Construction Company in North Bangalore
Introduction
When undertaking home construction projects, it's important to consider potential cost overruns. However, with strategic planning and wise decision-making, it's possible to save money without sacrificing the quality of your build. Discover eight proven strategies to help you stay within budget for your home construction project.
Careful Planning and Budgeting
The foundation of any successful home construction project is thorough planning and budgeting. Start by creating a detailed project plan outlining all the required tasks, materials, and labour. This will give you a clear understanding of the overall costs involved, allowing you to identify areas where you can potentially save money. Be sure to factor in contingency funds to account for unexpected expenses that may arise during the construction process.
Leverage Experienced Contractors
Working with an experienced home construction company can be a game-changer when it comes to saving money. These professionals have the knowledge and expertise to navigate the complexities of the construction industry, often allowing them to source materials and labour at more favourable rates. Additionally, their familiarity with local building codes and permit requirements can help you avoid costly delays and mistakes that can quickly add up.
Option for Cost-Effective Materials
One of the biggest factors in the overall cost of your home construction project is the materials you choose. While it may be tempting to go for the highest-end options, consider exploring more cost-effective alternatives that still meet your quality standards. This could include using less expensive, yet durable, flooring options, opting for generic brand appliances, or selecting basic, no-frills fixtures and finishes.
Embrace Energy-Efficient Solutions
Investing in energy-efficient features for your home can not only save you money in the long run through reduced utility bills but also potentially qualify you for various tax credits and rebates. Consider incorporating energy-efficient windows, insulation, HVAC systems, and appliances into your construction plans. These upgrades may have a higher upfront cost, but the long-term savings can make them a wise investment.
Explore DIY Opportunities
If you're handy and have the time, consider taking on some of the less complex tasks yourself. Things like painting, landscaping, or even installing certain fixtures can be done DIY, allowing you to save on labour costs. Just be sure to carefully assess your skill level and only take on projects you're confident you can complete safely and to a high standard.
Negotiate with Suppliers and Contractors
Feel free to negotiate with suppliers and contractors. Many construction companies are willing to offer discounts or special pricing, especially for larger orders or long-term relationships. Don't be afraid to shop around and compare quotes to find the best deals.
Reuse and Recycle
Look for opportunities to reuse or recycle materials from the existing structure or other sources. This can include recovering fixtures, repurposing building materials, or finding ways to incorporate recycled elements into your new design. Not only does this help you save money, but it also reduces waste and promotes sustainability.
Explore Financing Options
Depending on your financial situation, various financing options may be available to help you manage the costs of your home construction project. This could include taking out a home equity loan, applying for a construction loan, or exploring government-backed programs that offer assistance to homeowners.
Conclusion
Undertaking a home construction project can be both exciting and daunting. By implementing these eight strategies, you can navigate the process with confidence and keep your costs under control. Remember, careful planning, strategic decision-making, and a willingness to explore cost-saving opportunities are key to ensuring that your home construction project stays within budget. With the right approach, you can create the home of your dreams without breaking the bank. Tvaste Constructions is the top home construction company in North Bangalore. If you know more information, contact us.
Contact Us:
Phone Number: +91-7406554350
E-Mail: info@tvasteconstructions.com
Website: www.tvasteconstructions.com | tvasteconstructions | |
1,866,652 | Human Friendly Code? | Why do we code? Do we code only to satisfy the requirements of the product owner? Or do we code just... | 0 | 2024-05-28T12:35:12 | https://dev.to/rickyxyz/human-friendly-code-41hf | discuss, programming, coding, design | Why do we code? Do we code only to satisfy the requirements of the product owner? Or do we code just so it could pass through QA? Are we just trying to get a passing grade for a class assignment? Or are we just having fun writing random stuff?
I think it is easy to forget that there are real people out there who will interact with our code when we are so deep in implementation details. Different people may interact with your code in different ways. An end user might interact with your code through the user interface, another developer may interact with your code through the API, or maybe the coworker next to you is interacting directly with your code. Whatever the means, there will always be another human in the chain interacting with the code you’ve written.
Knowing that there is another person that will interact with your code (be it user interface, API interface, or class/method interface), how do you make your code more "human friendly"? | rickyxyz |
1,867,567 | Building your first machine learning model in Python | Machine learning is the use of algorithms that can learn from data over time and therefore can detect... | 0 | 2024-05-28T12:34:22 | https://dev.to/mugultum/building-your-first-machine-learning-model-in-python-3pn2 | machinelearning, newbie, python, datascience |
Machine learning is the use of algorithms that can learn from data over time and therefore can detect and learn patterns from the data. Machine learning models are divided into Supervised, Unsupervised, and Reinforcement learning. The commonly used machine learning algorithms fall under Supervised learning and the linear regression model is usually the first model you will encounter in this category.
Under Linear regression models, we have simple linear and multiple linear models. A simple linear model involves the use of one independent and one dependent variable. On the other hand, multiple linear models have one dependent variable and more than two independent variables. In this article, I will take you through the process of creating your first multiple linear model for predicting the tips that customers give waiters in restaurants.
### Getting started
Before we start, there are some technologies that you should be familiar with.
- Basic understanding of Python
- Some familiarity with statistics
- Python libraries including pandas, numpy, matplotlib, seaborn,
- scikit-learn
### Linear regression
Linear regression is among the simple but commonly used algorithms, especially when the focus is to determine how variables are related. A linear regression model aims to get the best fit linear line that minimizes the sum of squared differences between actual and predicted values.
There are many uses of linear regression models. Some of the uses are market analysis, sports analysis, and financial analysis among other uses.
#### Loading and understanding the dataset
We will use the tips dataset embedded in the Seaborn library. The tips dataset contains simulated data on tips that waiters receive in restaurants in addition to other attributes.
For this demonstration, this is the complete [Google Colab] (https://colab.research.google.com/drive/11pcipYeLSxhjtZV7MRq6xJP-9HeqiH7d?usp=sharing) that I used. We start by loading the necessary libraries and loading the data.
```
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
```
After loading the libraries, we first check for the datasets in the Seaborn library.
```
print(sns.get_dataset_names())
```
After looking at the various datasets and opting for the dataset of choice, we can now load the dataset.
```
tips = sns.load_dataset('tips')
tips.head(5)
```
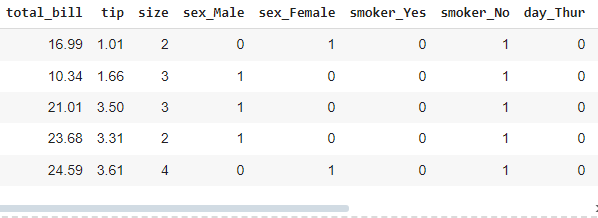
The table above shows that there are 7 variables in the dataset. The numerical columns in the dataset are total_bill, tip and size while the categorical columns are sex, smoker, day and time.
For basic statistics, we can use the describe () method.
```
tips.describe().T
```
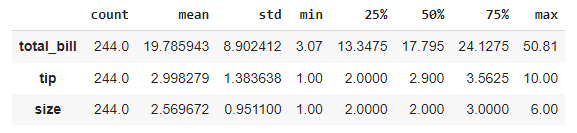
The describe () function gives the summary statistics of the numerical variables only. From the output, we can see the mean, standard deviation, minimum, maximum, and percentiles of the variables.
### Data visualizations
#### Distribution of sex variable
```
sns.countplot(x ='sex', data = tips)
plt.title('Distribution of Sex variable')
```
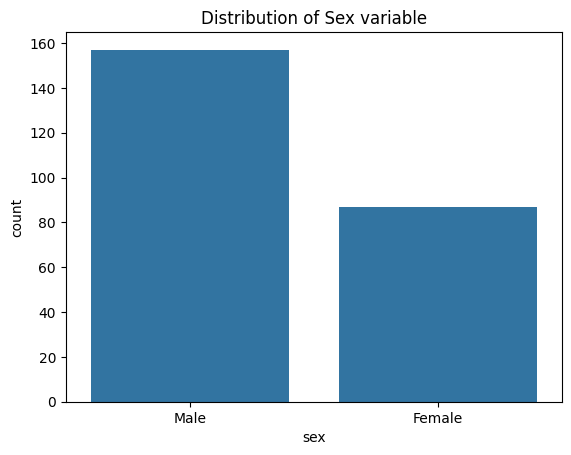
We can see from the plot above that men comprised a big percentage of the customers represented in the restaurant.
2. ####Total bill variable
```
sns.histplot(x ='total_bill', data = tips)
plt.title('Histogram of the Total bill variable')
```
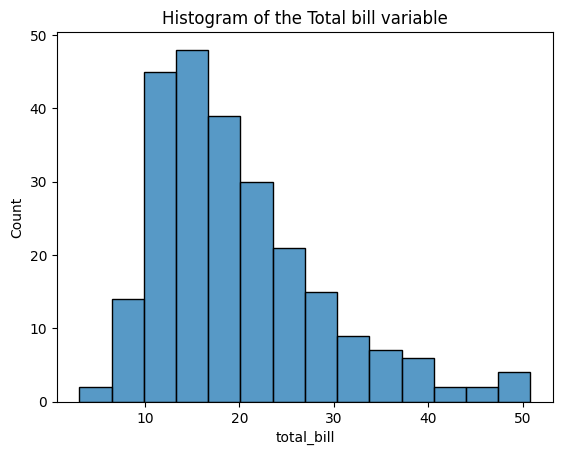
The above plots show the distributions of two variables. We can see that the majority of the bills fall between $10 and $20. The sex distribution variable also shows that most of the customers were men.
#### Scatterplot
```
sns.scatterplot(x='total_bill', y='tip', data=tips)
plt.title('Scatter plot of total bill and tip variables')
plt.show()
```
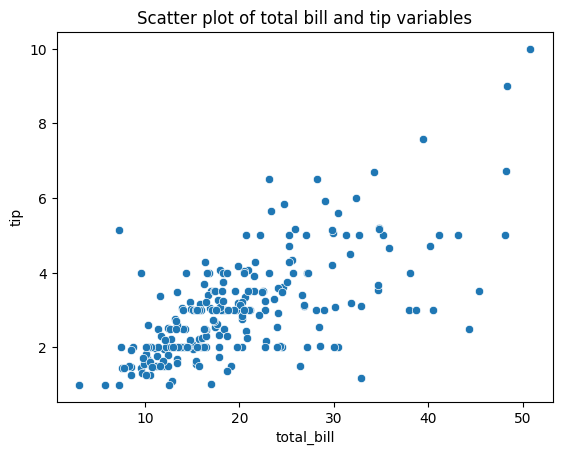
#### Correlation plot
```
num_cols = tips.select_dtypes(include='number')
corr_matrix = num_cols.Corr()
sns.heatmap(corr_matrix, annot=True)
plt.title('Correlation Heatmap')
plt.show()
```
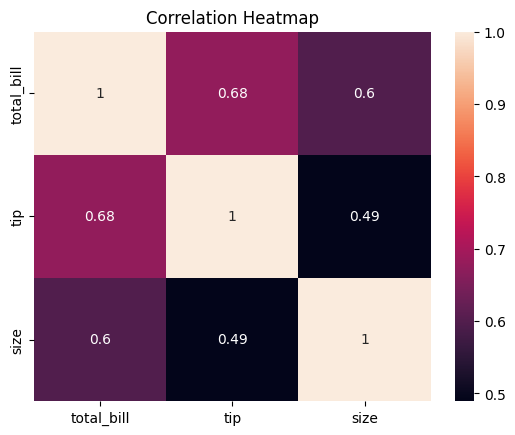
The scatterplot above shows that the tip and total_bill have a strong linear relationship. We can see from the correlation plot that the total_bill and tip correlate 0.68, indicating a strong positive correlation.
### Model building
Before building the model, the data has to be processed in a format that is compatible with the machine learning algorithm. Machine learning algorithms work with numerical data and that necessitates changing the categorical values to numerical. To change the data from categorical to numerical, there are various approaches like Label Encoding and OneHotEncoding. For this project, we will use OneHotEncoding.
```
tips = pd.get_dummies(tips, columns=['sex', 'smoker', 'day', 'time'], dtype=int)
```
Using [OneHotEncoding](https://pythonsimplified.com/difference-between-onehotencoder-and-get_dummies/) creates new variables for each of the categorical values. For example, we had a variable named sex which has Male and Female as the values. After using the get_dummies () method which encodes the data using OneHotEncoding, we have two new variables from the sex variable named sex_Male and sex_Female. Note that we started our data analysis with 7 variables and now after applying OneHotEncoding, we have 13 variables.
After encoding the data, we now have to scale the data to fall within the same range. For example, values in the total_bill column vary between 3 and 50 while for the majority of the remaining columns, the values are between 0 and 1. Scaling ensures that the model is robust by ensuring there are no extreme values. For this, we are using the [MinMaxScaler](https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html) class of the scikit-learn library.
```
from sklearn.preprocessing import MinMaxScaler
# Instantiate the scaler
MM = MinMaxScaler()
col_to_scale = ['total_bill']
# Fitting and transforming the scaler
scaled_data = MM.fit_transform(tips[col_to_scale])
# Convert the scaled data into a DataFrame
scaled_df = pd.DataFrame(scaled_data, columns=col_to_scale)
# Dropping the original columns to avoid duplication
tips_df = tips.drop(columns=col_to_scale).join(scaled_df)
```
After scaling the total_bill column, we have the results below. You can see that the values in the total_bill column now range between 0 and 1 like the rest of the variables.
Next, we split the data into train and test sets. We will use the training data to train the model and test data to test the performance of our model.
```
from sklearn.model_selection import train_test_split
X= tips_df.drop(columns='tip', axis=1)
y=tips_df['tip']
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.2,random_state=42)
```
The big X represents the independent variables (features) that will be fed to our model and the small y represents the target variable.
After splitting the data, we now proceed to instantiate the model and fit it to the training data as shown by the code below.
```
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
LR = LinearRegression()
LR.fit(X_train, y_train)
```
### Model evaluation
After fitting the training data to the model, we now proceed to test the model with our unseen data. Evaluating the model is important as it tells us whether our model performance is good or bad. For regression models, the [evaluation metrics](https://www.analyticsvidhya.com/blog/2021/05/know-the-best-evaluation-metrics-for-your-regression-model/) are the mean absolute error, mean squared error, mean squared error, R squared and Root mean squared error among others.
```
y_pred = LR.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
r2 = r2_score(y_test, y_pred)
print("R-Squared (R2) Score:", r2)
```
The output is:
Mean Squared Error: 0.7033566017436106
R-Squared (R2) Score: 0.43730181943482493
The mean squared error is high and this means that our model is not predicting well while the R squared value is low meaning that the model is not fitting the data well. Ideally, the mean squared error must be low and the R-squared value must be high.
On visualizing the results;
```
plt.figure(figsize=(8,8))
plt.scatter(y_test, y_pred)
#adding labels to the plot
plt.xlabel("The Actual Tip Amount")
plt.ylabel("The Predicted Tip Amount")
plt.title("Plot of Actual versus Predicted Tip Amount")
plt.plot([0, max(y_test)], [0, max(y_test)], color='green', linestyle='--')
plt.show()
```
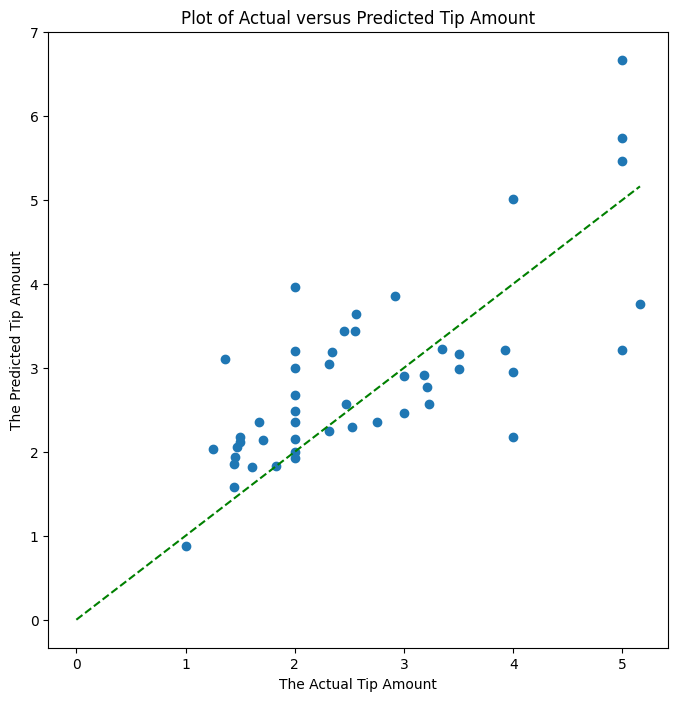
From the plot, we can see that there are many values below the diagonal line. This means that in many cases, the predicted tip amount tends to be lower than the actual tip amount.
### Conclusion
In this article, we successfully built our first machine-learning model to predict the tips that customers pay. This regression model has provided us with a starting point to understand the relationship between several independent features and the tip amount. We also saw in the model evaluation that our model did not perform well in predicting the tip amount.
The performance of our model highlights an important aspect of data science and machine learning which is improving models iteratively. To further improve our model, we may have to use [feature engineering](https://www.geeksforgeeks.org/what-is-feature-engineering/), perform [hyperparameter tuning](https://www.analyticsvidhya.com/blog/2022/02/a-comprehensive-guide-on-hyperparameter-tuning-and-its-techniques/), or do data quality checks. As you embark on this machine-learning journey, remember that your model may need several improvements before it achieves the desired performance.
### Additional readings
1. https://www.geeksforgeeks.org/regression-metrics/
2. https://www.geeksforgeeks.org/feature-encoding-techniques-machine-learning/
3. https://towardsdatascience.com/data-science-simplified-simple-linear-regression-models-3a97811a6a3d
| mugultum |
1,867,619 | ChatGPT-4o: The AI Revolution You’ve Been Waiting For | In the dynamic world of artificial intelligence, one name consistently stands out: ChatGPT. With... | 0 | 2024-05-28T12:30:53 | https://dev.to/sshamza/chatgpt-4o-the-ai-revolution-youve-been-waiting-for-3f2 |

In the dynamic world of artificial intelligence, one name consistently stands out: ChatGPT. With the recent launch of ChatGPT-4o, OpenAI has once again redefined the landscape of conversational AI. Whether you're a tech enthusiast, a developer, or simply curious about the latest innovations, ChatGPT-4o is set to revolutionize the way we interact with technology.
**The Evolution of ChatGPT**
Before diving into the marvel that is ChatGPT-4o, let’s take a moment to appreciate its journey. From the early days of GPT-2, which introduced us to AI-driven text generation, to GPT-3's astounding capabilities, each version has set new standards. ChatGPT-4o, however, isn’t just an upgrade; it’s a groundbreaking leap forward in intelligence, versatility, and user experience.
**What's New in ChatGPT-4o?**
**1. Unparalleled Understanding and Responsiveness**
ChatGPT-4o boasts an exceptional ability to understand context and nuance. This means more accurate responses, fewer misunderstandings, and a conversational flow that feels astonishingly natural. Whether you’re having a casual chat or tackling complex problems, ChatGPT-4o delivers insightful and contextually relevant answers.

**2. Multimodal Marvel**
A standout feature of ChatGPT-4o is its multimodal capabilities. For the first time, the model can interpret and generate content not just in text but also in images. Imagine a virtual assistant that can help you draft a document and design a presentation slide in the same conversation. The possibilities are endless!
**3. Personalization and Memory**
ChatGPT-4o introduces advanced personalization options, allowing for tailored interactions. The model can now remember previous interactions and user preferences, creating a more personalized and seamless experience. This memory feature ensures that every conversation builds upon the last, making long-term engagement more meaningful and enjoyable.
**4. Ethical AI and Safety First**
OpenAI has prioritized ethical AI and safety with ChatGPT-4o. Enhanced filters and moderation tools minimize the risk of generating harmful or inappropriate content. The model is trained with guidelines to respect user privacy and promote safe, respectful interactions, making it a reliable partner in any setting.

**Real-World Applications**
The applications of ChatGPT-4o are as diverse as they are impactful. Here are a few areas where this cutting-edge AI can make a significant difference:
**- Customer Service:** Provide instant, accurate, and personalized responses to customer inquiries, boosting satisfaction and efficiency.
**- Education:** Assist students with homework, explanations, and tutoring across various subjects, making learning more accessible and engaging.
**- Content Creation:** Help writers, marketers, and creators generate high-quality content, from blog posts to social media updates.
**- Healthcare:** Support medical professionals by answering patient queries, providing information on symptoms, and offering general health advice (with appropriate safeguards in place).

**Embrace the Future with ChatGPT-4o**
As we stand on the brink of a new era in AI, ChatGPT-4o represents more than just a technological achievement; it offers a glimpse into the future of human-machine interaction. Its ability to understand, respond, and evolve makes it an invaluable tool across industries and everyday life.

OpenAI's commitment to innovation, ethics, and user experience ensures that ChatGPT-4o is not just a product but a partner in progress. Whether you’re looking to streamline your business, enhance your creative projects, or explore the possibilities of conversational AI, ChatGPT-4o is here to lead the way.
Join the conversation today and discover how ChatGPT-4o can transform your world. The future is now, and it's more intelligent, interactive, and inspiring than ever before.
| sshamza | |
1,867,618 | Headless CMS: explained in 5 Mins | The headless CMS term has gained significant traction over the past year. So what is headless CMS?... | 0 | 2024-05-28T12:23:29 | https://dev.to/incerro_/headless-cms-explained-in-5-mins-66n | sanity, headlesscms, cms, incerro | The headless CMS term has gained significant traction over the past year. So what is headless CMS?
Headless CMS is a platform that divides the front-end and back-end layers. Thereby movies the freedom to developers to choose the technology and frameworks of their choice.
According to the World Metrics Report of 2024, It is predicted that 20.6% of new websites will be built using a Headless CMS by 2025.
**Concept of Headless CMS**
The concept of Headless CMS is a bit like the structure of a worm, in that it decouples the content layer from the backend complex, independent in both form and function. This means creation, publication, and management of content can be done independently. Developers have a lot to gain from this separation; it makes them faster builders and deployers of content with added flexibility.
Headless CMS decouples the content management or content repository from the front-end layer. The content creation, management, and publication can be done independently, also this decoupled architecture makes the development process faster and gives flexibility.
Read more [here](https://www.incerro.ai/insights/understand-headless-cms-in-5-min) on our Incerro website. | incerro_ |
1,844,246 | Build a serverless EU-Driving Licences OCR with Amazon Textract on AWS | TL;DR In this article, we will develop a serverless micro-service equipped with OCR... | 0 | 2024-05-28T12:20:06 | https://dev.to/ddesio/build-a-serverless-eu-driving-licences-ocr-with-amazon-textract-on-aws-5ckm | ocr, serverless, javascript, aws | ## TL;DR
In this article, we will develop a serverless micro-service equipped with OCR capabilities specifically tailored for EU-Driving Licences, enabling seamless integration into any digital product.
We will leverage an [AWS Lambda](https://aws.amazon.com/lambda/?nc1=h_ls) function which will invoke [Amazon Textract](https://aws.amazon.com/textract/?nc1=h_ls) to scan documents uploaded to [Amazon S3](https://aws.amazon.com/s3/?nc1=h_ls), subsequently storing the extracted data in [Amazon DynamoDb](https://aws.amazon.com/dynamodb/?nc1=h_ls).
## Prerequisites
If you're new to serverless development, I recommend reading [my article](https://dev.to/ddesio/superpower-rest-api-dx-with-serverless-and-devops-best-practices-with-aws-51f6) as a foundational resource. It provides a comprehensive overview of serverless architectures and introduces devops best practices. This will serve as an excellent starting point for grasping the concepts we'll be implementing in the upcoming steps.
## What is Amazon Textract?

[Amazon Textract](https://aws.amazon.com/textract/?nc1=h_ls) is a ML-powered OCR (Optical Character Recognition) designed to efficiently extract data from various sources, including PDFs, images, and handwritten text.
The best of this is that you don't have to be a ML-expert to use it as it does the job for you: it's a SaaS OCR with which you can interact by provided API.
## Architecture
Let's delineate the fundamental behavior of our OCR system:
- Upon file upload, the OCR process should be triggered.
- The system should identify EU-Driving licences from the uploaded file.
- Extracted information should be returned and stored in a database.
To architect this solution effectively, we can employ the following components:
- Utilize an Amazon S3 bucket as the designated upload destination.
- Implement an Amazon S3 Lambda Trigger to initiate an AWS Lambda function upon file upload.
- Develop an AWS Lambda function responsible for invoking Amazon Textract.
- Employ Amazon Textract as the core OCR tool for data extraction.
- Employ Amazon DynamoDB as the target database to persist the retrieved information.
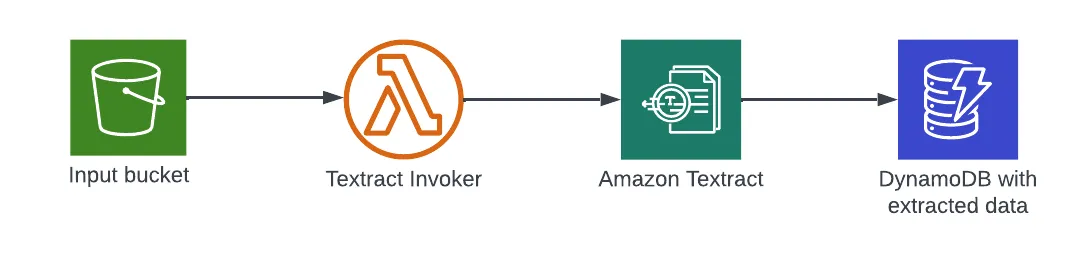
## Invoker Function IaC
The pivotal aspect of this function Infrustructure As Code lies within the events section, particularly in its configuration to respond to specific triggers.
We've set up the function to be activated upon the occurrence of an s3:ObjectCreated event, specifically targeting uploads to the "input/" prefix and files bearing the ".jpg" suffix. This configuration ensures that the function is selectively triggered only by image uploads.
```yaml
ocr:
handler: src/function/document/ocr/index.handler #function handler
package: #package patterns
include:
- "!**/*"
- src/function/document/ocr/**
events: #events
#keep warm event
- schedule:
rate: rate(5 minutes)
enabled: ${strToBool(${self:custom.scheduleEnabled.${env:STAGE_NAME}})}
input:
warmer: true
#S3 event
- s3:
bucket: ocr-documents
event: s3:ObjectCreated:*
rules:
- prefix: input/
- suffix: .jpg
```
## Invoker Function Code
### Requirements
Here's a concise summary of the requirements for our OCR function:
- Receive event information triggered by an upload to the "input" prefix in Amazon S3.
- Utilize Amazon Textract to scan the uploaded image and extract the identity information from EU-Driving Licenses.
- Store the extracted information in an Amazon DynamoDB table.
- Write a JSON representation of this information to Amazon S3 under the "output" prefix.
- Remove the original input image from storage.
- Return the extracted identity JSON in the response.
By adhering to these requirements, our OCR function will efficiently process uploaded images, extract relevant identity information, store it appropriately, and provide the necessary response.
As a good practice let's describe it commenting our function code.
```javascript
/**
* Main handler: receive event from S3 and return a response
* This function react to a s3 trigger performing those steps:
* STEP 1. get bucket and image key from event (this function is triggered by s3 on upload to /input folder)
* STEP 2. pass image to textract analyzeId API to get identity info
* STEP 2.1 put identity info on dynamodb
* STEP 3. write a json and put an object with identity info to s3 (in a /output folder)
* STEP 4. deleting original input image
* STEP 5. return textract recognized identity info as response
```
### Invoke Amazon Textract
This function extract bucket and object key names from the event triggered by S3, then leverages this information to interface with Amazon Textract, facilitating the retrieval of files and data via the [AnalyzeId API](https://docs.aws.amazon.com/textract/latest/dg/how-it-works-identity.html). This functionality seamlessly aligns with our objective of extracting identity data from EU-Driving Licences.
```javascript
/* STEP 1. Get bucket and image key from event */
/* Get bucket name (it should be the bucket on which the trigger is active*/
const bucketName = event['Records'][0]['s3']['bucket']['name'];
/* Get key name (it should be a jpeg image)*/
const keyName = event['Records'][0]['s3']['object']['key'];
/* Log bucket and key names*/
console.log(bucketName,keyName);
/* STEP 2. Analyze an image with textract OCR */
/* Prepare analyzeId command input passing s3 object info got from event*/
const analyzeIDCommandInput = { // AnalyzeIDRequest
DocumentPages: [ // DocumentPages // required
{ // Document
S3Object: { // S3Object
Bucket: bucketName,
Name: keyName,
},
},
],
};
/* Execute analyzeId command with textract and get recognized info in a response */
const analyzeIDCommand = new AnalyzeIDCommand(analyzeIDCommandInput);
const analyzeIDCommandResponse = await textractClient.send(analyzeIDCommand);
/* Log textract response */
console.log(analyzeIDCommandResponse);
```
As evident, all we need to do is dispatch an `analyzeIdCommand` to Amazon Textract, indicating the file's location through the bucketName and keyName parameters. From there, Textract seamlessly handles the OCR task for us, condensing what would typically be a multitude of lines of code into a streamlined process.
### Parse automatic detected fields
Amazon Textract excels in automatically recognizing identity-related information. Upon executing our `analyzeIdCommand`, we receive the ["Identity Document Response"](https://docs.aws.amazon.com/textract/latest/dg/identitydocumentfields.html) as a JSON format. This response contains standardized identity fields, including those of our particular interest such as first name, last name, document number, and expiration date.
Parsing this JSON response is straightforward, enabling us to extract the identity fields effortlessly and store them within an `identity` object for further processing.
```javascript
/**
* Extract identity fields from document fields portion of analyzed document via Textract
* which is able to return auto identified document fields of EU patent
* In Textract response under IdentityDocumentFields section there are:
* FIRST_NAME, which identify the name
* LAST_NAME, which identify the surname
* DOCUMENT_NUMBER, which identify the patent number
* Those fields have got a confidence which we need to be more than 95%
* @param identityDocument
* @param identity
*/
function extractFromIdentityDocumentFields(identityDocument, identity) {
/* Cycle fields */
for (let j = 0; j < identityDocument.IdentityDocumentFields.length; j++) {
/* Get field */
const identityDocumentField = identityDocument.IdentityDocumentFields[j];
/* If name, surname or document number are not empty and confidence is upper than 95 */
if (
(
identityDocumentField.Type.Text === 'FIRST_NAME' //if type FIRST_NAME
|| identityDocumentField.Type.Text === 'LAST_NAME' //if type LAST_NAME
|| identityDocumentField.Type.Text === 'DOCUMENT_NUMBER' //if type DOCUMENT_NUMBER
|| identityDocumentField.Type.Text === 'EXPIRATION_DATE' //if type DOCUMENT_NUMBER
)
&& identityDocumentField.ValueDetection.Confidence >= 95 // if confidence is more than 95%
&& identityDocumentField.ValueDetection.Text !== '' // if text is not empty
) {
/* Set name, surname or document number in identity */
identity[identityDocumentField.Type.Text]['text'] = identityDocumentField.ValueDetection.Text;
//set as document-field to say we recognized it via document fields parsing
identity[identityDocumentField.Type.Text]['type'] = 'document-field';
identity[identityDocumentField.Type.Text]['confidence'] = identityDocumentField.ValueDetection.Confidence;
}
/* Exit if name,surname,expiration date and document number have been found */
if (
identity.FIRST_NAME['text']
&& identity.LAST_NAME['text']
&& identity.DOCUMENT_NUMBER['text']
&& identity.EXPIRATION_DATE['text']
) {
break;
}
}
}
```
###Fine tuning with text detection
Furthermore, within the response of the `analyzeIdCommand`, we encounter the "Text detection and document analysis response". This JSON encapsulates all content identified by Amazon Textract through conventional OCR methods.
This resource serves as a valuable fallback option. It becomes particularly useful in scenarios where Amazon Textract might not automatically recognize the required information or when the identity details are identified with a confidence level below our specified threshold, set at 95% in this instance.
```javascript
/**
* Extract identity fields from block portion of analyzed document via Textract
* This is a fallback if document fields have not been identified by Textract
* In this case Textract returns Blocks, an array of blocks
* with each identify a page, line or a word
* As EU patent have got a strict format in which:
* Statement "1." identifies surname (last name)
* Statement "2." identifies name (first name)
* Statement "5." identifies patent number (document number)
* this function search for those patterns to identify information in the block in
* which those patterns are present (or the subsequent ones)
* @param identityDocument
* @param identity
*/
function extractFromIdentityDocumentBlocks(identityDocument,identity) {
/* If any of name, surname or document number is empty */
if (
!identity.FIRST_NAME['text']
|| !identity.LAST_NAME['text']
|| !identity.DOCUMENT_NUMBER['text']
) {
/* Cycle blocks*/
for (let j = 0; j < identityDocument.Blocks.length; j++) {
/* Get the block */
const block = identityDocument.Blocks[j];
/* Check for "1. " as the last name in EU patent */
/* If present and last name has not been set in identity, name should be after this */
parseBlock(block,'LINE',j,'this','1. ',identity,'LAST_NAME',identityDocument);
/* Check for "1." as the last name in EU patent */
/* If present and last name has not been set, name should be the text in sequent block*/
parseBlock(block,'LINE',j+1,'next','1.',identity,'LAST_NAME',identityDocument);
/* Check for "2. " as the surname in EU patent */
/* If present and surname has not been set in identity, name should be after this */
parseBlock(block,'LINE',j,'this','2. ',identity,'FIRST_NAME',identityDocument);
/* Check for "2." as the surname in EU patent */
/* If present and surname has not been set, name should be the text in sequent block*/
parseBlock(block,'LINE',j+1,'next','2.',identity,'FIRST_NAME',identityDocument);
/* Check for "4b. " as the expiration date in EU patent */
/* If present and expiration date has not been set in identity, name should be after this */
parseBlock(block,'LINE',j,'this','4b. ',identity,'EXPIRATION_DATE',identityDocument);
/* Check for "2." as the surname in EU patent */
/* If present and expiration date has not been set, name should be the text in sequent block*/
parseBlock(block,'LINE',j+1,'next','4b.',identity,'EXPIRATION_DATE',identityDocument);
/* Check for "5. " as document number in EU patent */
/* If present and document number has not been set in identity, name should be after this */
parseBlock(block,'LINE',j,'this','5. ',identity,'DOCUMENT_NUMBER',identityDocument);
/* Check for "5." as the document number in EU patent */
/* If present and document number has not been set, name should be the text in sequent block*/
parseBlock(block,'LINE',j+1,'next','5.',identity,'DOCUMENT_NUMBER',identityDocument);
// Exit if name,surname,expiration date and document number have been found
if (
identity.FIRST_NAME['text']
&& identity.LAST_NAME['text']
&& identity.DOCUMENT_NUMBER['text']
&& identity.EXPIRATION_DATE['text']
) {
break;
}
}
}
}
```
As evident, parsing the `Blocks` is straightforward, especially considering our specific case where we are familiar with the standard "layout" of our document.
###Takeways
I've omitted the full code of our solution here as it's both simply and thoroughly documented. What's crucial to emphasize is that Amazon Textract offers optimized functionality for scanning identity documents. Additionally, it serves as a standard OCR tool, providing the flexibility to refine results when you're familiar with the specific "layout" of your input document. This versatility ensures adaptability to a wide range of use cases.
## Policy
Our Lambdas require policy statements to be attached to the role used at runtime. For convenience, we'll add them under the provider section. However, it's also possible to add them specifically for each Lambda function if needed. This flexibility allows for tailored access control and permissions management, ensuring that each function has precisely the permissions it requires without unnecessary access.
```yaml
iam:
role:
statements:
iam:
role:
statements:
# Allow functions to use s3
- Effect: Allow
Action:
- 's3:ListBucket'
- 's3:PutObject'
- 's3:DeleteObject'
Resource:
- 'arn:aws:s3:::ocr-documents/*'
# Allow functions to use textract
- Effect: Allow
Action: 'textract:*'
Resource: '*'
# Allow functions to use dynamodb
- Effect: Allow
Action: 'dynamodb:PartiQLInsert'
Resource: '*'
```
## 🏁 Final Thoughts
We've explored the process of constructing an OCR solution with Amazon Textract, seamlessly integrating it with other essential services like Amazon EventBridge, Amazon S3, and Amazon DynamoDB.
This framework serves as an excellent starting point for any OCR use case. It presents a loosely coupled micro-service that seamlessly integrates into your architecture, requiring nothing more than an uploaded file as input. Such modular design ensures flexibility and scalability, allowing easy adaptation to diverse requirements and environments.
## 🌐 Resources
You can find a skeleton of this architecture open sourced by Eleva [here](https://github.com/eleva/serverless-textract-ocr-skeleton).
## 🏆 Credits
A heartfelt thank you to my colleagues:
- [L. Viada](https://www.linkedin.com/in/leonardoviada?originalSubdomain=it), [G. Blanc](https://www.linkedin.com/in/gioeleblanc/) and folks at [RevoDigital](https://www.linkedin.com/company/revod/) which are using this micro-service in several production projects
- [A. Fraccarollo](https://www.linkedin.com/in/fraccarollo-alberto-7b258b209) and, again, [A. Pagani](https://www.linkedin.com/in/alessandro-pagani-4a801259/), as the co-authors of CF files and watchful eyes on the networking and security aspect.
- [C. Belloli](https://www.linkedin.com/in/claudiabelloli/) and [L. Formenti](https://www.linkedin.com/in/lucaformenti) to have pushed me to going out from my nerd cave.
- [L. De Filippi](https://www.linkedin.com/in/lorenzodefilippi) for enabling us to make this repo Open Source and explain how we developed this micro-service.
**We all believe in sharing as a tool to improve our work; therefore, every PR will be welcomed.**
## 🙋 Who am I
I'm [D. De Sio](https://www.linkedin.com/in/desiodavide) and I work as a Solution Architect and Dev Tech Lead in [Eleva](https://eleva.it/).
I'm currently (Apr 2024) an AWS Certified Solution Architect Professional, but also a [User Group Leader (in Pavia)](https://www.linkedin.com/company/aws-user-group-pavia/) and, last but not least, a #serverless enthusiast.
My work in this field is to advocate about serverless and help as more dev teams to adopt it, as well as customers break their monolith into API and micro-services using it. | ddesio |
1,867,569 | What is JavaScript statement | Code that performs a specified task is called a statement. It is a complete command that often ends... | 0 | 2024-05-28T12:19:33 | https://dev.to/kemiowoyele1/what-is-javascript-statement-5bk4 | Code that performs a specified task is called a statement. It is a complete command that often ends with a semicolon (;). Examples include loops, conditional statements (such as if or switch statements), and variable declarations.
It is a comprehensive command that the computer is capable of executing. Every action adds to a program's overall logic and functionality. The majority of computer languages operate on statements in a sequential fashion. Because good layout is essential to the proper execution of a program, it is therefore imperative to pay attention to the arrangement of statements.
There are several types of JavaScript statements. Some of them will be covered in this piece.
## Declaration statements:
A code segment that declares the creation of variables and functions is called a declaration statement. Examples of declaration statements include:
**i) Variable declaration**
A variable attaches a name to a data point to enable the reuse of such data in the future.
var name;
in this example, The variable is declared but not assigned a value, and its type is initially considered undefined.
let age = 10; here, age is declared and assigned the value of 10.
**ii) Function Declaration:** function declaration declares a function. A function performs a task or calculates a value. eg
function addNumbers(x, y){
return x + y;
};
**iii) constant declaration:** constants in javaScript are declared using the const keyword. Constants, declared with const, cannot be reassigned after their initial assignment.
eg.
const x = 6;
## 2). Expression statements:
An expression is a combination of one or more values, variables, operators, and functions that, when evaluated, result in a single value. eg,
let sum = 3 + 5;
sum is an expression because it will combine the values of 3 + 5, and give a single value ie, 8.
expression statements are expressions used on their own as statements. They are usually used for action (to do something) and are expected to have side effects (such as modifying variables, calling functions, changing control flow, or interacting with external systems.).
## 3). Assignment statements
Earlier, we discussed that a variable could be declared but not assigned a value. Assignment statements are used to attach values to variables. Example;
let name;
name = “Ade Ola”;
## 4). Conditional statements
Some codes do have requirement(s), that meeting them will determine if the code will run or how it will run. There are two major types of conditional statements, they are the "if" statement and the "switch" statements.
**(i) if statement**
if statements will run if the condition is true. For example,
let name = "James";
if(name === "Mike"){
console.log("hello Mike")
}
else if (name === "Peter"){
console.log("hi Peter")
}
else {
console.log("hello person")
}
The if statement can be used alone without the else and else if. But it can’t go the other way round. For example, you can just write
if ( name === " Mike") {
console.log("hello Mike")
}
and leave it like that. If name is Mike "hello mike will be logged into the console, but if name is not mike, nothing will happen. But you can’t start a statement with just the else statement or the else if statement.
**(ii) Switch statement**
Switch statement checks for strict equality of case scenario with the variable whose value we intend to compare. A switch statement usually contains case values and default values. The case values are compared to the variable for comparison, if any of the values match the comparison; the code for that case is executed. If none of the cases matches the comparison, the default code will be executed.
Syntax:
let age = 6;
switch (age) {
case 1:
console.log( 'day care' );
break;
case 2:
console.log( 'pre-nursery' );
break;
case 3:
console.log( 'nursery 1' );
break;
case 4:
console.log( 'nursery 2' );
break;
default:
console.log( "elementary school" );
}
Once a match is found and the code in the corresponding case block executes, break immediately exits the entire switch statement. No further cases are evaluated.
**(iii) Conditional ternary operator:**
A ternary operator takes three operands.
condition ? expression if true : expression if false;
It is a simplified way of writing an if/else statement.
Example;
Let age = 6;
Let daycareAge = age <= 2 ? "bring to daycare" : "Send to School";
## Loop statements:
Loop statements are used to perform repetitive tasks, to repeat a block of code for a specific number of times. There are several ways of programming repetitive tasks in JavaScript, for example
For loop, forEach loop, for..of loop, while loop, do..while loop etc.
We shall only discuss the for loop and while loop statements in this article.
**for loop**
Syntax:
for ( initialExpression; condition; counter) {
// code to execute if the stated condition is true
}
• Initial expression: index value of the loop
• Condition: the requirement for the code to execute
• Counter: increments or decrements the initial value or the value derived after each iteration.
Example
for (let i = 0; i <= 5; i++) {
console.log(i);
}
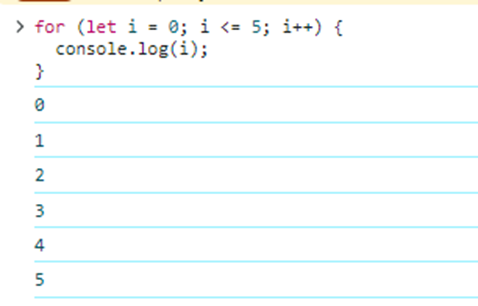
In the above example, index/initial value is i, and i is set to 0. The condition is that for as long as i is less than 5, the index value should be incremented by one.
i++ as indicated in this example is the same as i = i + 1; hence, upon the first iteration, 0 is logged into the console. Then the program is run again, it checks if i is still <= 5; then it prints 1. The program will continue to run with the incremented value for each time until it reaches a point where i is greater than 5.
**While loop:**
While loop used to repeat a program for as long as a specified condition remains true.
Syntax:
while (condition) {
// code to be executed repeatedly until condition is met.
}
• Condition: This expression is evaluated before each iteration of the loop. If it evaluates to true, the code block inside the loop executes. If it's false, the loop terminates.
Example:
let count = 0;
while (count < 5) {
console.log(count);
count++; // increment count within the loop
}
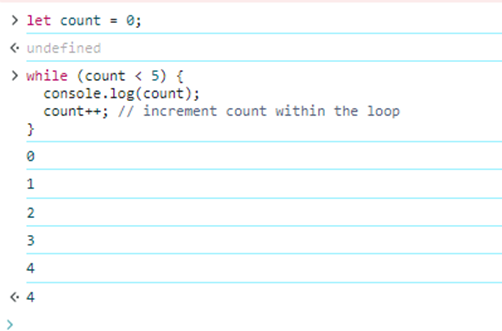
Just like in the for loop example, the program will continue to run while count is less than 5.
## Error handling statement
Error handling statements are written to handle anticipated problems in our code. Error handling helps with preparation for eventualities while running our program, and gives us the opportunity to handle such eventualities elegantly. Issues could be handled without the entire program crashing. Error messages could be customized and debugging will be more effective if errors are properly handled.
In JavaScript, there are four error handling statements.
Try statement:
Try is used to test code for errors.
Catch statement:
Catch is used to determine what happens if any errors are found in the try block.
Throw statement:
Throw statement is used to create desired/custom error message.
Finally statement:
Finally statement runs regardless of if errors were encountered or not.
Example
function calculateSquare(number) {
if (typeof number !== "number") {
throw new TypeError("Input must be a number!");
}
try {
const result = number * number;
return result;
} catch (error) {
console.error("Error calculating square:", error.message);
return null; // Or handle the error differently
} finally {
console.log("Square calculation complete (even if with errors).");
}
}
Error handling makes debugging a lot easier for programmers. It also allows for user friendly error messages. Some cases where try, catch statements are used include;
• To validate user inputs
• To handle network errors when fetching data from an api
• To improve code readability
• To isolate errors
• To contain errors within a specific block of code
## Summary
A statement is a piece of code that can do something. It is a complete instruction that a computer can execute. There are different types of statements in JavaScript. Some of them are
**Declaration statements:** for creating variables and functions**.
Expression statements:** for combining values to create a single value.
**Assignment statements:** for assigning values to variables.
**Conditional statement:** code that runs if a certain requirement is met.
**Loop statement:** used to perform repetitive tasks.
**Error handling statements:** used for detecting and handling errors before they crash the entire program.
By combining and arranging these statements in various sequences and patterns, you can perform a wide range of tasks. Statements are essential building blocks in JavaScript. They contribute to the overall performance and functionality of programs.
| kemiowoyele1 | |
1,867,582 | modobom international | Discover Modobom, your trusted partner in technology solutions and digital marketing. Specializing in... | 0 | 2024-05-28T12:19:03 | https://dev.to/modobomcompany/modobom-international-35ej | Discover Modobom, your trusted partner in technology solutions and digital marketing. Specializing in software outsourcing, chatbot development, and comprehensive digital marketing strategies, we empower businesses to optimize processes and expand market reach. Our VNISocial ecosystem offers unparalleled support for expatriates in Vietnam. Explore our innovative services and elevate your business with Modobom today.
Website: https://modobom.com/
Phone: 0984 999 443
Address: D' Capital, Vincom, Tòa C3 D, 119 Đ. Trần Duy Hưng, Trung Hoà, Cầu Giấy, Hà Nội 100000, Vietnam
[object Object][ scoopit ]
| modobomcompany | |
1,867,581 | Trade Forex with Diago Finance Ltd: Unlocking the Potential of Over 55 Forex Pairs with Industry-Leading Spreads | In the fast-paced world of forex trading, having the right partner can make all the difference. Diago... | 0 | 2024-05-28T12:17:16 | https://dev.to/diagofinanceindia/trade-forex-with-diago-finance-ltd-unlocking-the-potential-of-over-55-forex-pairs-with-industry-leading-spreads-36ki | In the fast-paced world of forex trading, having the right partner can make all the difference. Diago Finance Ltd stands out as a leading provider in the industry, offering traders the opportunity to trade over 55 forex pairs with some of the tightest spreads available. Whether you’re a seasoned trader or just starting out, Diago Finance Ltd provides the tools and conditions you need to succeed. Let’s explore how trading forex with Diago Finance Ltd can enhance your trading experience and why optimizing for SEO can further amplify your success.
Why Trade Forex with Diago Finance Ltd?
Extensive Range of Forex Pairs:
Diago Finance Ltd offers access to more than 55 forex pairs, including major, minor, and exotic currencies. This extensive selection allows traders to diversify their portfolios and take advantage of various market opportunities around the clock.
Tightest Spreads in the Industry:
One of the key advantages of trading with Diago Finance Ltd is the exceptionally tight spreads. Lower spreads mean lower trading costs, which can significantly enhance your profitability, especially for high-frequency traders.
Advanced Trading Platforms:
Trade with confidence using Diago Finance Ltd’s cutting-edge trading platforms. Whether you prefer desktop, web-based, or mobile trading, our platforms offer advanced charting tools, real-time data, and seamless execution to ensure you never miss an opportunity.
Reliable and Secure Trading Environment:
Security is paramount at Diago Finance Ltd. Our platform employs state-of-the-art encryption and security protocols to protect your data and funds. Additionally, we guarantee fast and reliable withdrawals within 24 hours, ensuring you have access to your profits whenever you need them.
| diagofinanceindia | |
1,867,580 | Introducing Hana: Your Ultimate Business Helper | Hana: Revolutionizing Business Productivity with Intelligent Assistance In today's fast-paced... | 0 | 2024-05-28T12:16:34 | https://dev.to/nav_archer/introducing-hana-your-ultimate-business-helper-3jhh | ai, chatbot, chatgpt, productivity | Hana: Revolutionizing Business Productivity with Intelligent Assistance
In today's fast-paced business environment, efficiency and productivity are paramount. That's where Hana comes in. Developed by Hanabi Technologies, Hana is an innovative solution designed to seamlessly integrate into your workflow, providing intelligent assistance and automation to enhance your business operations.
### What is Hana?
Hana is a comprehensive business helper that is designed to behave as a team member integrated in Google Chat with several Google Workspace APIs. She facilitates AI-powered group discussions and workflow. She is ChatGPT "applied".
### Key Features
1. QnA over PDFs
2. QnA over Google Docs
3. Remember things via her memory
4. Take standup updates on your behalf
5. Browse the internet and QnA over web pages
6. AI-powered Group conversations
7. Reminders for others and yourself
8. Google Calendar QnA and meeting scheduling
9. Image generation, image QnA
10. Weather information
11. Create Google Tasks automatically
12. AI-powered PR reviews
### Why Choose Hana?
Hana is simply the most practical application of AI for businesses and teams. She is designed to be like any other team member with a personified personality.
Imagine an all-knowing, all-understanding team member who is available for anyone's help!
### Get Started with Hana
Ready to take your business productivity to the next level? Visit [Hana Landing Page](https://hana.hanabitech.com) to get started. Discover how Hana can revolutionize your workflow and help you achieve your business goals.
{% youtube KdUQsuM2XI4 %} | nav_archer |
1,867,579 | Mastering SaaS SEO Strategy: A Comprehensive Guide | Long-term success in the quickly changing Software as a Service (SaaS) industry depends on being... | 0 | 2024-05-28T12:15:23 | https://dev.to/joycesemma/mastering-saas-seo-strategy-a-comprehensive-guide-3lj9 | beginners, productivity, career, learning | Long-term success in the quickly changing Software as a Service (SaaS) industry depends on being unique in a crowded market. SaaS companies must implement strong SEO strategies to drive organic traffic, improve visibility, and guarantee sustainable growth in the increasingly competitive digital landscape. In contrast to traditional businesses, SaaS companies encounter particular difficulties like protracted sales cycles, fierce competition for keywords, and an ongoing requirement for customer engagement. This in-depth manual explores the essential components of developing a successful SaaS SEO strategy and offers practical advice to make your software stand out in the online world. By implementing these tactics, your SaaS company can build a strong online presence, get more qualified leads, and rank higher in search results.
## Understanding Your Audience and Keyword Research
Any effective SEO strategy starts with carefully researching potential keywords and understanding your target audience. This entails determining the precise market niches that SaaS companies service and adjusting their strategy to suit their particular requirements. Begin by developing thorough buyer personas that describe the characteristics, hobbies, problems, and search patterns of your ideal clients. Use tools such as Ahrefs, SEMrush, and Google Keyword Planner to find low-competition, high-volume keywords that are related to your service. You can also use a [website status checker](https://cgscomputer.com/website-status-checker/) in order to make sure everything runs smoothly. Because they indicate more specific search intents, long-tail keywords—which are more specific and frequently less competitive—can be especially valuable. Higher conversion rates and happier customers can result from this alignment of your content with the searcher's intent.
## On-Page SEO Optimization
Any SEO strategy must include on-page SEO, which for SaaS companies entails optimizing different parts of your website to rank higher in search results. Making sure the content on your website is educational, pertinent, and keyword-rich is part of this. First, focus on optimizing important on-page components, like header tags, alt text for images, meta titles, and meta descriptions. Every one of these components is essential to how search engines interpret and rank your content. Additionally, concentrate on producing top-notch content that offers your audience genuine value. Comprehensive blog articles, case studies, whitepapers, and how-to manuals that tackle typical problems encountered by your target audience may fall under this category.
## Technical SEO Considerations
Achieving high search rankings requires that search engines can efficiently crawl and index your website, which is ensured by technical SEO. This entails optimizing the architecture of your website, especially if you take your time to look for experienced [SaaS tech SEO services](https://seō.com/technical-seo-onsite-audits) that can guarantee a smooth user experience and simple navigation. To gain the trust of users and search engines, begin by repairing any broken links and making sure you are connected via a secure (HTTPS) connection. Use structured data, such as schema markup, to increase the likelihood that search engines will understand your content and show it in rich snippets. Utilize tools such as Google Search Console to conduct routine audits of your website to find and address any technical problems that might be impeding its SEO performance. This entails taking care of problems like slow page loads, missing meta tags, and duplicate content.
## Content Marketing and Link Building
In the SaaS sector, content marketing is an effective strategy for increasing organic traffic and establishing authority. Your domain authority and search rankings will increase if you regularly create high-quality content that answers the problems and queries of your audience and builds natural backlinks. Create a thorough content calendar with a variety of content types that appeal to your audience, such as infographics, webinars, eBooks, and blog posts. Every piece of content ought to be SEO-optimized, with an emphasis on offering insightful, useful information.
## Measuring and Analyzing SEO Performance
Sufficient search engine optimization necessitates constant monitoring and evaluation. Track the traffic, keyword rankings, and backlink profile of your website with tools like Ahrefs, SEMrush, and Google Analytics. Examine your data to find patterns, comprehend what is effective, and identify areas that require improvement. To stay ahead of the competition, regularly review your SEO strategy and make the necessary adjustments. You can make sure that your SEO efforts are achieving the intended outcomes and advancing your overall business objectives by closely monitoring your metrics. To obtain a thorough grasp of your SEO performance, it's critical to monitor key performance indicators (KPIs) like organic traffic, conversion rates, bounce rates, and the number of indexed pages.
Learning SaaS SEO strategy is a rewarding but challenging process that calls for a diversified approach. In the constantly changing SaaS market, stay flexible and knowledgeable about the most recent SEO trends and algorithm changes to keep a competitive advantage. Your SaaS company can increase its organic reach, draw in more qualified leads, and eventually succeed over the long run with a well-executed SEO strategy. Recall that search engine optimization (SEO) is a continuous process that changes as your company and the digital landscape do. In the digital marketplace, you can guarantee that your SaaS solution stays visible, relevant, and competitive by adhering to a continuous improvement strategy and staying ahead of industry changes.
| joycesemma |
1,832,717 | Rebuilding Luxauto File Processing with Containers | The Luxauto file processing pipeline is an important part of our application. It allows us to have... | 0 | 2024-05-28T12:15:02 | https://dev.to/luxauto/rebuilding-luxauto-file-processing-with-containers-ejo | softwareengineering, docker, fileprocessing, containers | The Luxauto file processing pipeline is an important part of our application. It allows us to have our classifieds marketplace up to date with the newest vehicle listings. Within the last few years, the file processing pipeline has undergone substantial improvements:
- We moved from a single-sequential process in a cronjob to a multi-parallel pipeline. Each step became a docker image running multiple containers. This architectural shift drastically reduced the processing time and increased reliability.
- By adding logging capabilities to each step, we enabled live monitoring and observability. This allowed the software engineering team to quickly find and fix problems with the pipeline and reduced the dependency on the infrastructure team.
- Moving away from cron schedules to messaging queues, we improved scalability and resource utilisation efficiency since memory and CPU are only used when needed.
- We enhanced our customer support by enriching the back-office application with information about each customer.
- By decoupling the process into multiple small projects, we managed to upgrade the technologies step-by-step. From PHP 5.4 cron jobs to PHP 8.2 FPM containers.
Our experience over the last year has reinforced our conviction that a reliable, fast and efficient file processing pipeline that allows us to innovate and support our classifieds service is fundamental to the continued success of Luxauto.
## From Cron to Containers
### Cron
The Luxauto file processing pipeline used to run as a periodic cron job. The script would spawn different processes for each different file parser - ZIP, XML, TXT, CSV, etc. The files had a range of sizes - from a few kilobytes up to several gigabytes.
The cron has many limitations when it comes to scaling the file processing pipeline:
- **Scaling up cron jobs was not an option and scaling out cron jobs is very difficult.** Problems with the file processing were frequent, so we needed to find a solution with high availability and fault tolerance.
- **Files were partially processed.** If the file processing throws an uncaught exception or a fatal error in the middle of the process, the file would have a pseudo-success state. The imported data was incomplete, and this was very difficult to monitor and trace back to the cause of the problem.
- **Big files were causing delays.** Whenever the cron would start processing a large file - a few GB - it caused an inconvenient delay for the files waiting in the queue to be processed, because the pipeline was synchronous.
- **The maintenance of the code was costly.** Maintenance and improvement of the code was taking too much time. The code was coupled to the file parser and each parser would contain multiple customer-level customisations.
In addition to these problems, the software engineering team relied on the infrastructure team to build and release the application.
Therefore, the goal was to build a highly available, fault-tolerant, fast and cheap-to-maintain file processing pipeline. We decided to split the pipelines into multiple independent containers.
### Containers
The data and software engineering team started to work on the next-generation Luxauto file processing pipeline. The team aimed to increase autonomy from the infrastructure team, decouple and improve the code maintainability and significantly decrease the issues present with the existing implementation.
Creating the new pipeline using containers provides a straightforward CI/CD build and release pipeline, horizontal scaling, and maintainable and testable code. Logging, debugging and monitoring are also facilitated since running the containers locally doesn't require setting up the entire application infrastructure.
## Building the File Processing Pipeline in Gateways v2
### Splitting the services
The Luxauto file processing pipeline consists of reading files, parsing files and importing data and pictures. Hence, the first task was identifying boundaries and splitting the services.
We analysed and grouped these steps into small yet manageable services:
1. Reading files from the storage
2. Parsing the files into a standardised data structure
3. Importing and updating the data
4. Downloading and processing the pictures
Each service has a clear, decoupled responsibility, and may be deployed as a single or multiple container(s). This creates redundancy and high availability.
### Building the infrastructure
Every service provides a dedicated functionality and works together to import and update the data. The containers communicate with each other through message brokers and are always available in an idle state. As soon as a new message is available, the first idle container gets the message and starts processing it. When the job is done, it sends a message for the next step.
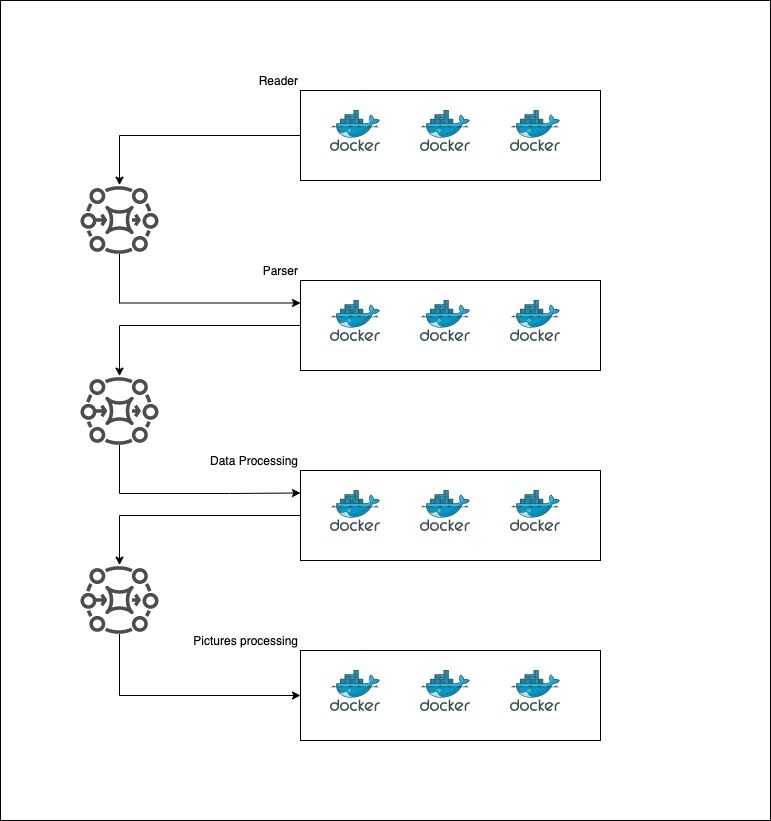
### Monitoring
Distributed applications can be challenging for developers to simulate and run locally, but this was a requirement to facilitate monitoring, debugging and bug fixing.
First, we created a way to run and test the steps individually to make it easier and faster for the engineers to fix and improve the code.
Second, we created a way to verify in our back-office application whether the file was imported successfully and if the data was inserted, updated or deleted. And in case of errors, files can be easily reprocessed from the back-office application.

## Where we are now
We've had the new file processing pipeline running in production for over a year now. During this time, we've gradually shifted the old file processing to the new system, while making improvements with enhanced logging, improved memory usage, reduced cloud cost and the introduction of new monitoring tools.
While it's still in the early days, we have already seen the benefits of the new platform; the team now has autonomy from the infrastructure team, the code is easier to test, change and improve, and debugging, bug tracking and fixing are faster and more accurate.
| joaolopes |
1,866,671 | Implementing RAG in Refact.ai AI Coding Assistant | Retrieval Augmented Generation (RAG) is a technique to generate more customized and accurate AI... | 27,539 | 2024-05-28T12:12:48 | https://refact.ai/blog/2024/rag-in-refact-ai-technical-details/ | rag, opensource, development | Retrieval Augmented Generation (RAG) is a technique to generate more customized and accurate AI suggestions by using the entire coding environment as a source of relevant context for code completions and chat queries.
**In this blog post, I go through all the details about how it works and how we implemented RAG in [Refact.ai](https://refact.ai) — an open-source AI coding assistant for IDEs.**
**
## Introduction: Why RAG matters in AI coding
**
Imagine you have 2 files:
If you just have `my_file.py` supplied to the model, it doesn’t have any way to know to complete `“say_hello”` and that it needs a parameter to that function.
This problem of limited scope of AI models gets much worse as your project gets bigger. So, how to fetch it with the necessary information from your codebase, and do it in real time, and accurately?
It takes a specialized RAG pipeline for this work inside your IDE, and that’s the point of our new release.
**
## Refact.ai Technology Stack
**
We use an intermediate layer between a plugin inside IDE and the AI model called refact-lsp. And yes, it works as an [LSP](https://en.wikipedia.org/wiki/Language_Server_Protocol) server, too.
Its purpose is to run on your computer, keep track of all the files in your project, index them into an in-memory database, and forward requests for code completion or chat to the AI model, along with the relevant context.
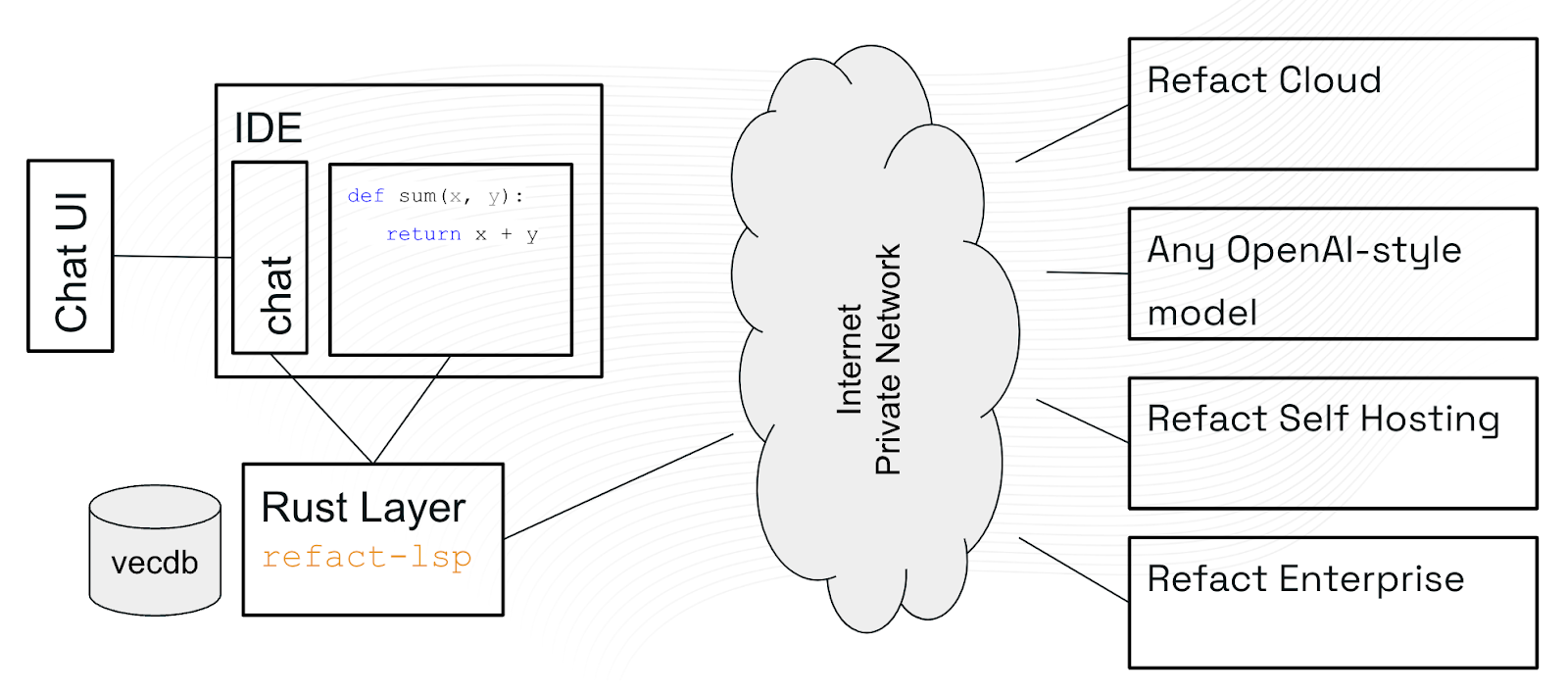
`refact-lsp` is written in Rust, combining speed of a compiled language and safety guarantees. Rust is great: it has a library for almost any topic you can imagine, including vector databases and a port of tree-sitter — a library to parse source files in many programming languages.
The amazing thing about it: `refact-lsp` compiles into a single executable file that doesn’t require any other software to be installed on your computer — it’s self-sufficient! It means it will not interfere with whatever you are doing on your computer, and it will not break as you update your environment. In fact you don’t even see it, it gets installed together with the Refact.ai plugin in your favorite IDE.
**
## AST and VecDB
**
There are two kinds of indexing possible: based on Abstract Syntax Tree (AST) and based on Vector Database (VecDB).
-
**What is AST?** We use tree-sitter to parse the source files, and then get the positions of function definitions, classes, etc. It is therefore possible to build an index in memory — a mapping from the name of a thing to its position, and make functions like “go to definition” “references” very fast.
-
**What is VecDB?** There are AI models that convert a piece of text (typically up to 1024 tokens) into a vector (typically 768 floating point numbers). All the documents get split into pieces and vectorized, vectors stored in a VecDB. These AI models are trained in such a way that if you vectorize the search query, the closest matches (in a sense of l2 metric between the vectors) in the database will be semantically similar or relevant to the query.
The problem with VecDB is that you need to vectorize the query as well, and that might take some time — not good for code completion that needs to be real-time.
It’s not an issue for a chat though: here you can play with both indexes using `@-commands`. More about it is described a few sections down.
**
## VecDB: Splitting the Source Code Right
**
To vectorize a piece of text, we first need to make sure it’s a complete construct in a programming language, such as a single function, a single class. This way the semantic matching offered by VecDB will work best.
The easiest way to implement this is to use empty lines as a hint for the boundaries to split:
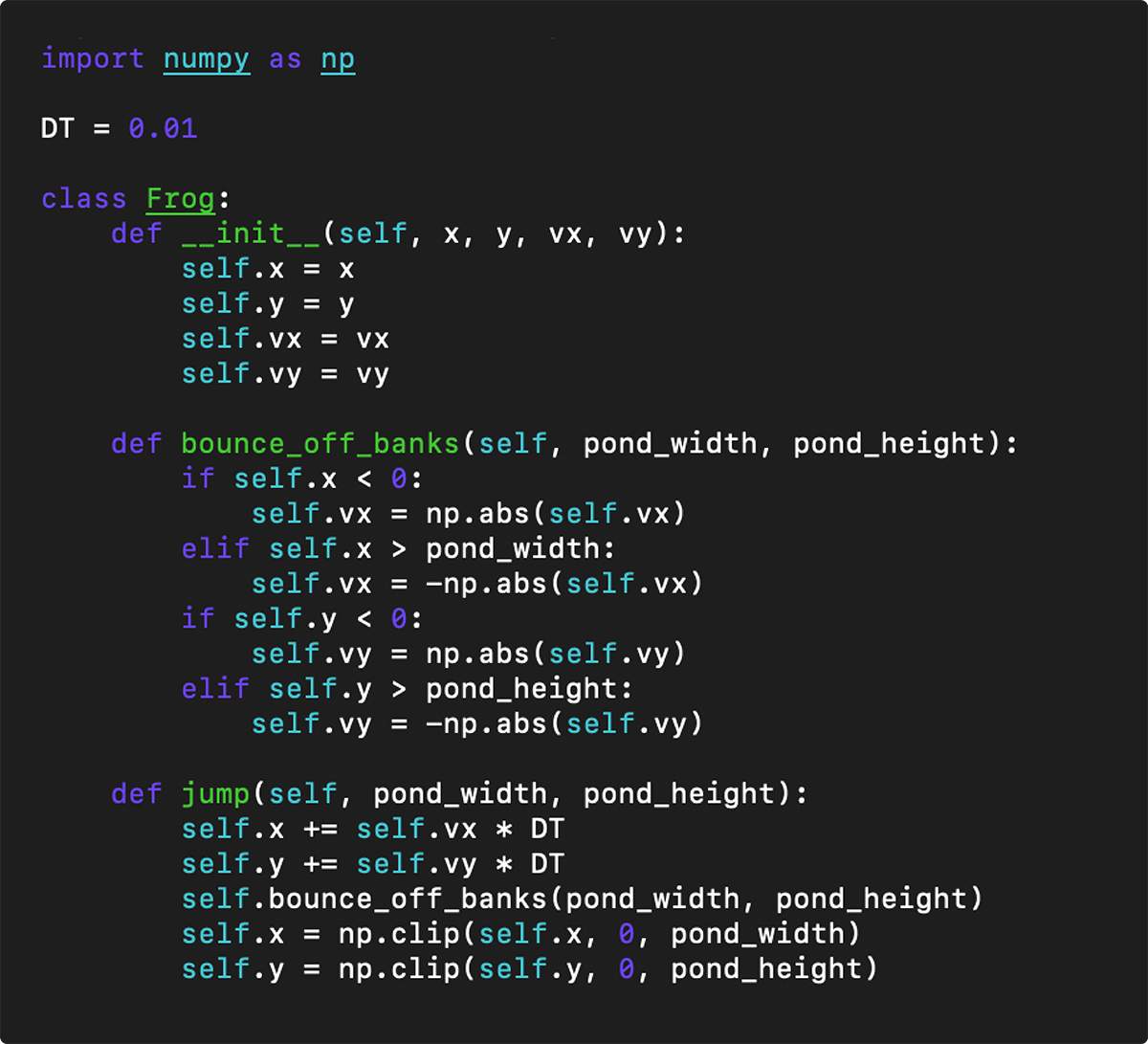
You can see in this example that the functions are separated by an empty line. We in fact use this method for text files without an available tree-sitter module.
But can we do better in splitting as well? Sure, of course we can! We can simplify the class by shortening function bodies:

If this skeletonized version of the class gets vectorized, you can see it’s much easier to match it against a query when you search for things like “classes that have jump in them”, compared to the situation when the splitter just vectorized “jump” function without its class.
**
## AST: Simple Tricks to Make It Better
**
A library like `tree-sitter` can transform the source code into individual elements: function definitions, function calls, classes, etc.The most useful case: match types and function calls near the cursor with definitions.
See how it works:
{% embed https://refact.ai/images/blog/meet-rag-in-refact-ai-technical-details/fim_.mp4 %}
_If you click on the “FIM” (fill-in-the-middle) button, you can see these in the sidebar with a 🔎 icon._
But besides this simple matching, there are some tricks we can do. For the symbols near the cursor, we can first look at their type, and then go to the definitions. And for classes, we can go to their parent class. Those are simple rules that work for all programming languages!
Finally, treating all the identifiers as just strings, we can find similar pieces of code - it should have similar identifiers in them. A similar code can help a model to generate a good answer as well.
**
## Post Processing
**
Let’s say you’ve found in the AST and VecDB indexes 50 interesting points that might help the model to do its job. Now you have additional issues to solve:
-
There might be just too many results to fit into the AI model’s context. There’s a budget measured in tokens to fit memory requirements, or latency requirements (code completion is real time), or model limitation.
-
The results themselves might not make much sense without at least a little bit of structure where it appears. For example, for a “function do_the_thing()” it’s important to show it’s inside a class, and which class.
-
There can be overlapping or duplicate results.
Those problems can be solved with good post-processing.
**This is how our post-processing works:**
1.
It loads all files mentioned in the search results into memory, and it keeps track of the “usefulness” of each line.
2.
Each result from AST or VecDB now just makes an increase in the usefulness of the lines it refers to. For example, if “my_function” is found, all the lines that define my_function will increase in usefulness, and the lines that contain the signature of the function (name, parameters and return type) will increase in usefulness more, compared to its body.
3.
All that is left to do is to sort all the lines by usefulness, then take the most useful until the token budget is reached, and output the result:
{% embed https://refact.ai/images/blog/meet-rag-in-refact-ai-technical-details/frog.mp4 %}
You see there, post-processing can fit into any token budget, keeping the most useful lines, and rejecting less useful ones, replacing them with ellipsis.
One interesting effect is skeletonization of the code. As the budget decreases, less and less lines can make it into the context, our post-processing prefers to keep some of the code structure (which class the function belongs to) over the body of that function.
**
## Oh Look, It’s Similar to grep-ast!
**
Yes you are right, it is! In fact we took inspiration from grep-ast, a small utility that uses tree-sitter to look for a string in a directory, and it also prefers to keep the structure of code so you can see where logically in the code your results are.
It doesn’t have a notion of token budget though, and it’s written in python so it’s not very fast, and it doesn’t have any indexes to search faster.
**
## RAG in Refact.ai Chat with @-commands
**
In Refact.ai, we’ve made RAG support for chat LLMs too. It can be used with commands to add some important context.
-
`@workspace` - Uses VecDB to look for any query. You can give it a query on the same line like this: `“@workspace Frog definition”`, or it will take any lines below it as a query, so you can search for multi-line things like code pieces.
-
`@definition` - Looks up for the definition of a symbol. For example, you can ask: `“@definition MyClass”`
-
`@references` - Same, but it returns references. Example: `“@references MyClass”`.
-
`@file` - Attaches a file. You can use file_name:LINE1-LINE2 notation for large files to be more specific, for example `“@file large_file.ext:42”` or `“@file large_file.ext:42-56”`.
-
`@symbols-at` - Looks up any symbols near a given line in a file, and adds the results to the chat context. Uses the same procedure as code completion does. For it to work, you need to specify file and line number: `“@symbols-at some_file.ext:42”`.
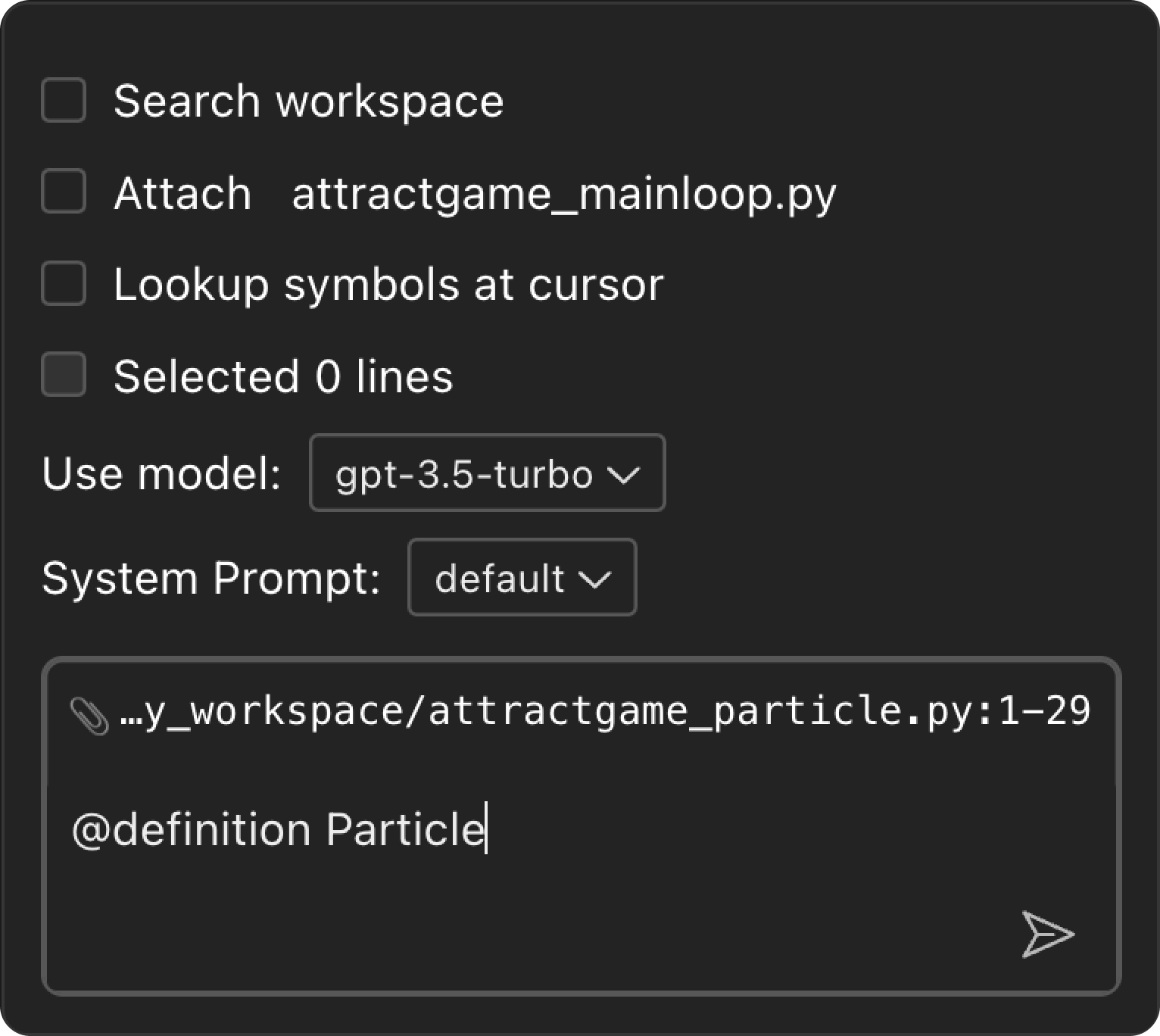
**When you start a new chat, there are options available:**
-
“Search workspace” is equivalent to typing `@workspace` in the input field: it will use your question as a search query.
-
”Attach current_file.ext” is equivalent to `“@file current_file.ext:CURSOR_LINE”` command that attaches the file, and uses the current cursor position (CURSOR_LINE) to deal with potentially large files.
-
”Lookup symbols” extracts any symbols around the cursor and searches for them in the AST index. It’s equivalent to `“@symbols-at current_file.ext:CURSOR_LINE”`.
-
”Selected N lines” adds the current selection as a snippet for model to analyze or modify, it’s equivalent to writing a piece of code in backquotes ``my code``.
**
## Interesting Things You Can Try with RAG
**
**Summarize a File**
Take a large file, open chat (Option+C) or toolbox (F1), and type “summarize in 1 paragraph”. The post-processing described above makes the file fit the chat context you have available. Check out how the file looks in the tooltip for the 📎 Attached file. The bigger the original file, the more skeletonized version you’ll see.
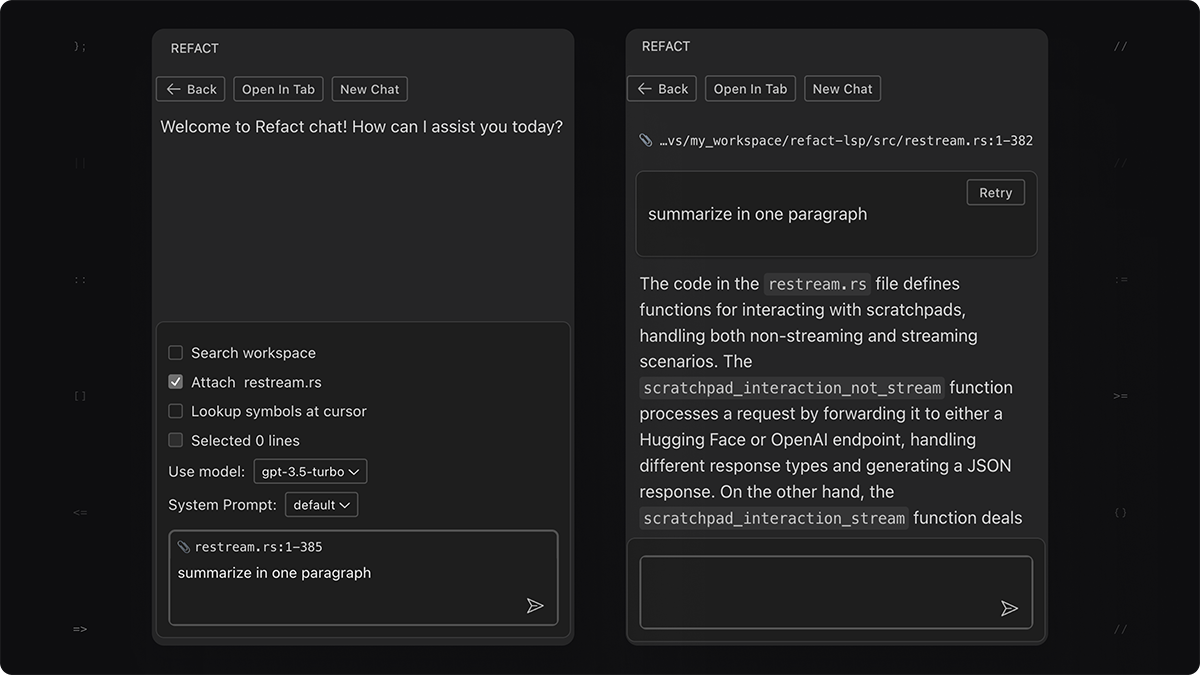
**Summarize Interaction**
Unfamiliar code is a big problem for humans: it might take hours to understand the interaction of several classes. Here’s another way to do it: use @definition or @file to put the classes of interest to the context, and ask chat how they interact.
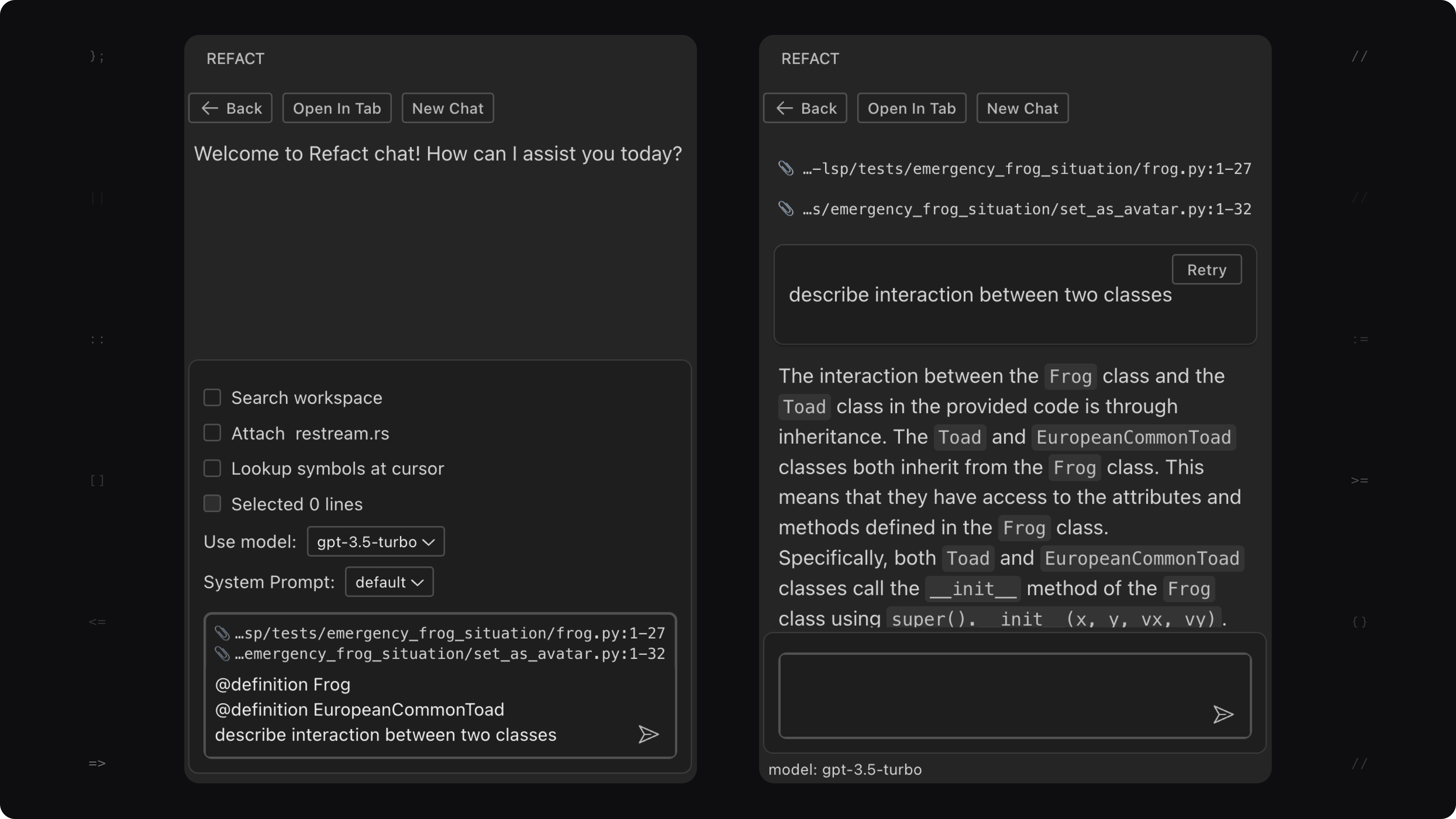
**Code Near Cursor with Context**
You can add context to chat using the same procedure as code completion: use “Lookup symbols near cursor” or @symbols-at command.
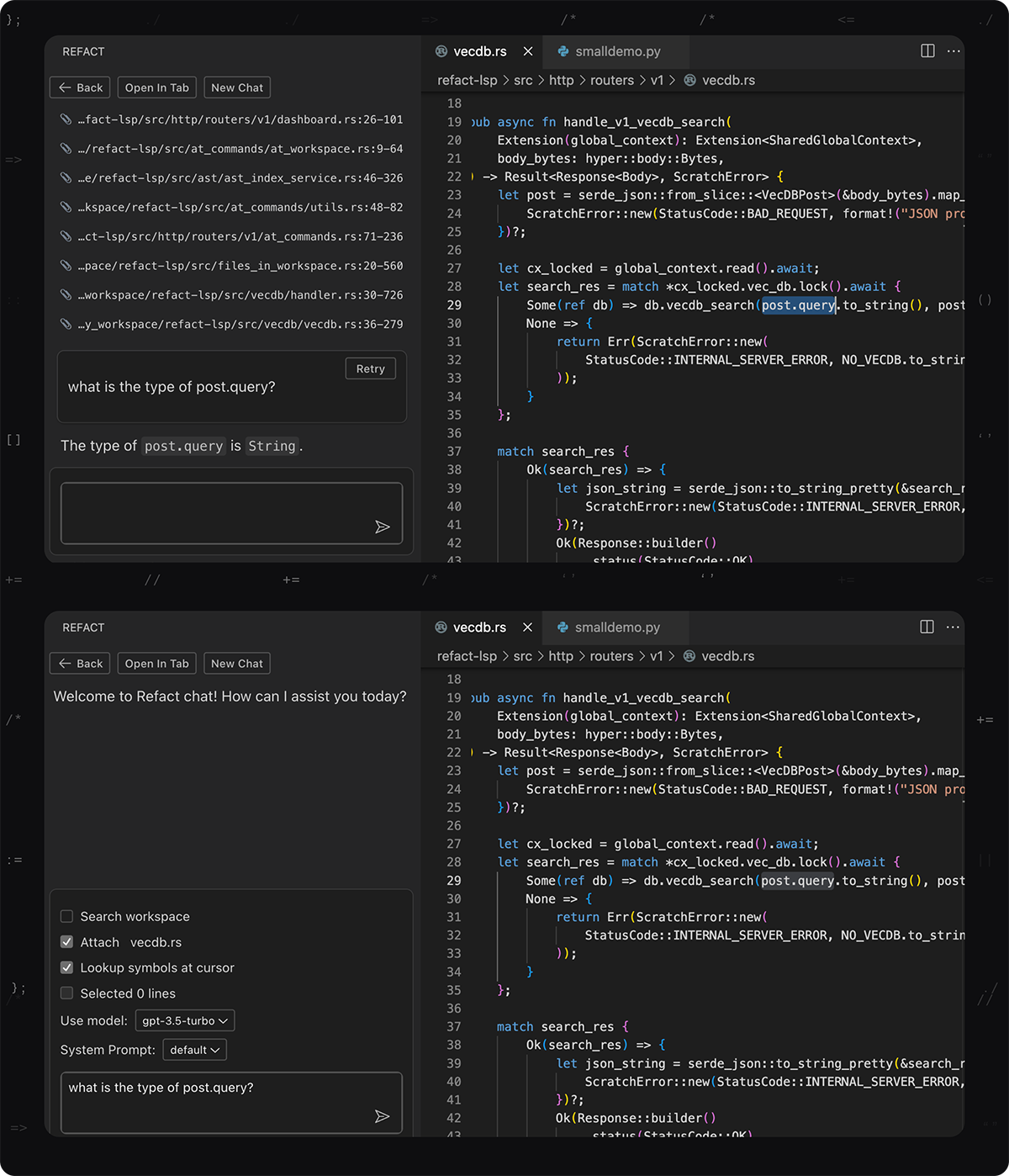
**
## So How Good Is It?
**
We tested code completion models with and without RAG, and here are the results.
We’ve made a small test that is easy to understand and interpret, it works like this: take 100 random repositories from github for each programming language, delete a random string in a random function, and run single-line code completion to restore it exactly.
It is not perfect, because sometimes it’s hard to reproduce comments exactly (if there’s any on the deleted line), and there are many easy cases (like a closing bracket) that will not benefit from RAG at all. But still it’s a good test because it’s simple! [Here is the dataset](https://huggingface.co/datasets/smallcloudai/refact_repobench).
**The results of the test (running StarCoder2/3b):**
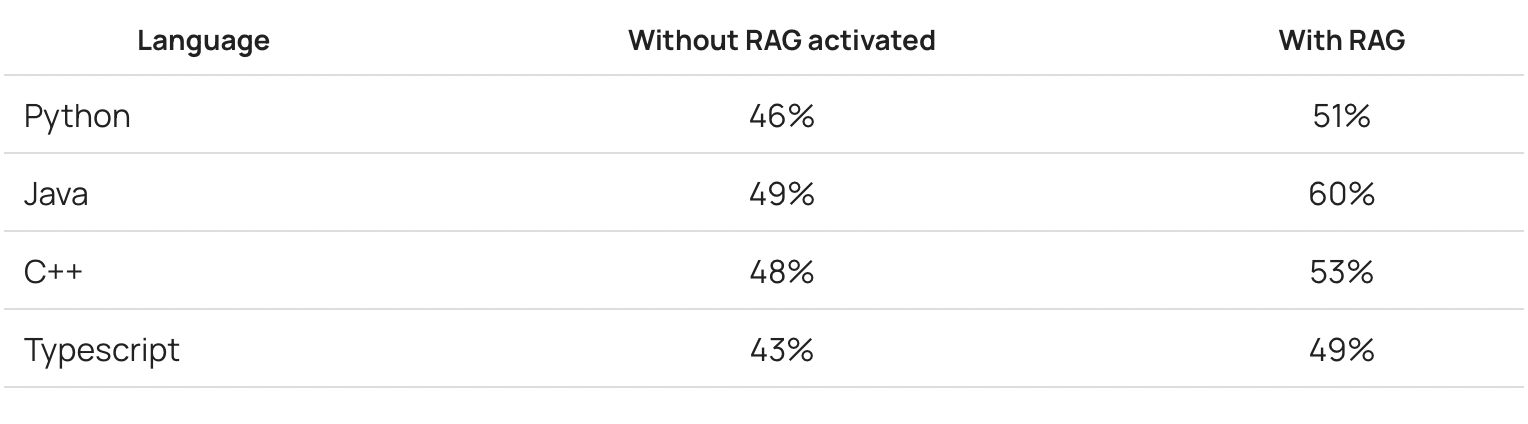
**Takeaways:**
-
RAG always helps!
-
It helps Java more than Python, because many projects in Python don’t use type hints.
---
Here it is! We believe we've developed the best in-IDE RAG for code completion and chat, at least among the open-source solutions we've explored.
If you have any questions, feel free to ask them in the comments. I'll be glad to answer or have a discussion. Or welcome to [join our Discord](https://www.smallcloud.ai/discord)!
P.S. You can try [RAG for coding in Refact.ai Pro plan](https://refact.ai/pricing/) — use promo code RAGROCKS for a 2-month free trial. Have fun! | refactai_olegklimov |
1,867,577 | Efficient and Secure File Sharing for Geographically Dispersed Offices with Restricted Network Access on Azure | The company operates in multiple locations and requires an efficient method for file sharing and... | 0 | 2024-05-28T12:12:23 | https://dev.to/olaraph/efficient-and-secure-file-sharing-for-geographically-dispersed-offices-with-restricted-network-access-on-azure-9dm | The company operates in multiple locations and requires an efficient method for file sharing and information dissemination across its offices. For instance, the Finance department needs reliable access to confirm cost information for auditing and compliance purposes. These file shares must be easily accessible and load quickly, with certain content restricted to selected corporate virtual networks.
Our goals are as follows:
- Create a storage account specifically for file shares.
- Configure a file share and directory.
- Set up snapshots and practice restoring files.
- Restrict access to a specific virtual network and subnet.
Create and configure a storage account for Azure Files.
Create a storage account for the finance department’s shared files. Learn more about storage accounts for Azure Files deployments.
In the portal, search for and select Storage accounts.
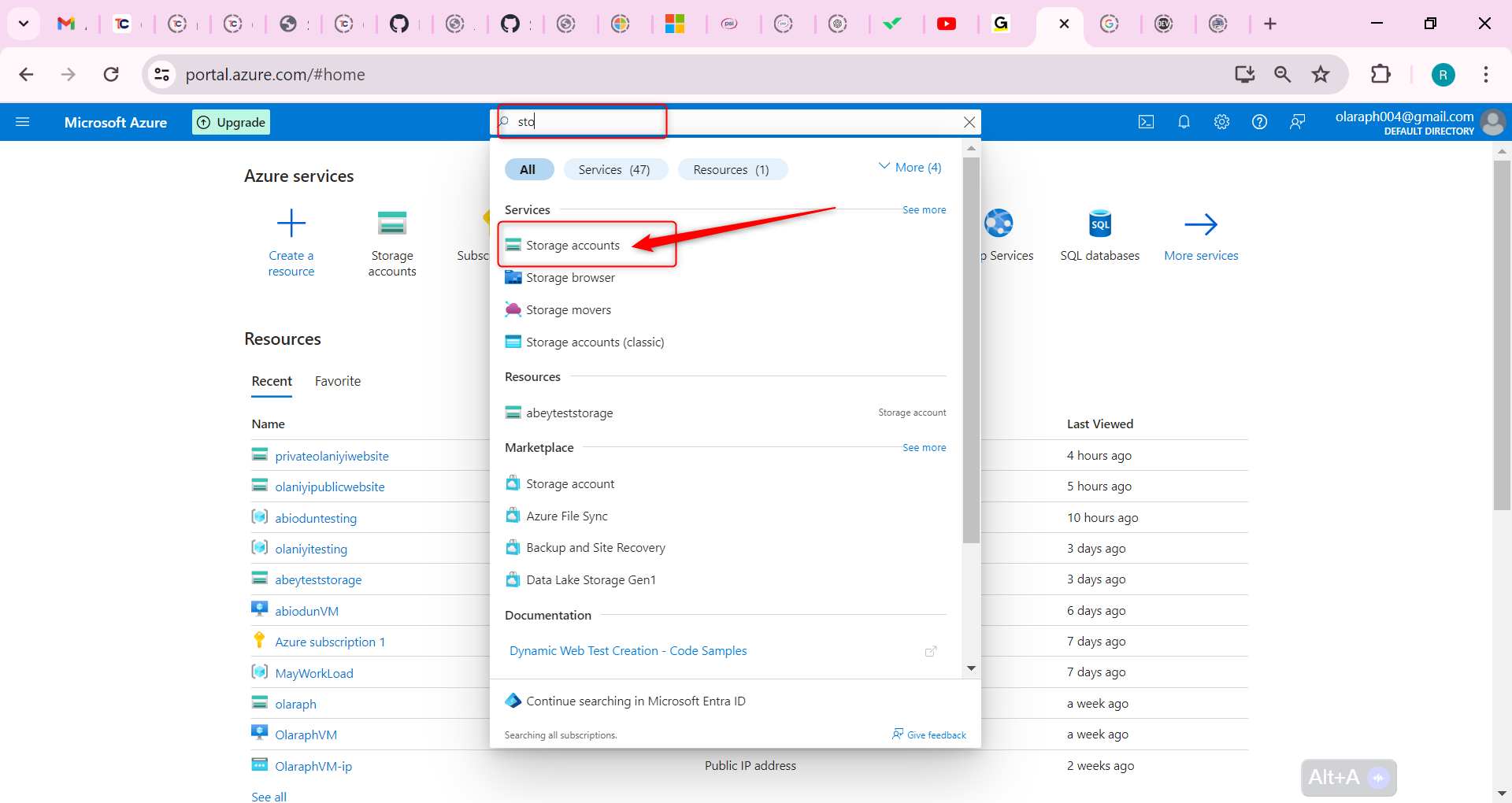
Select + Create.
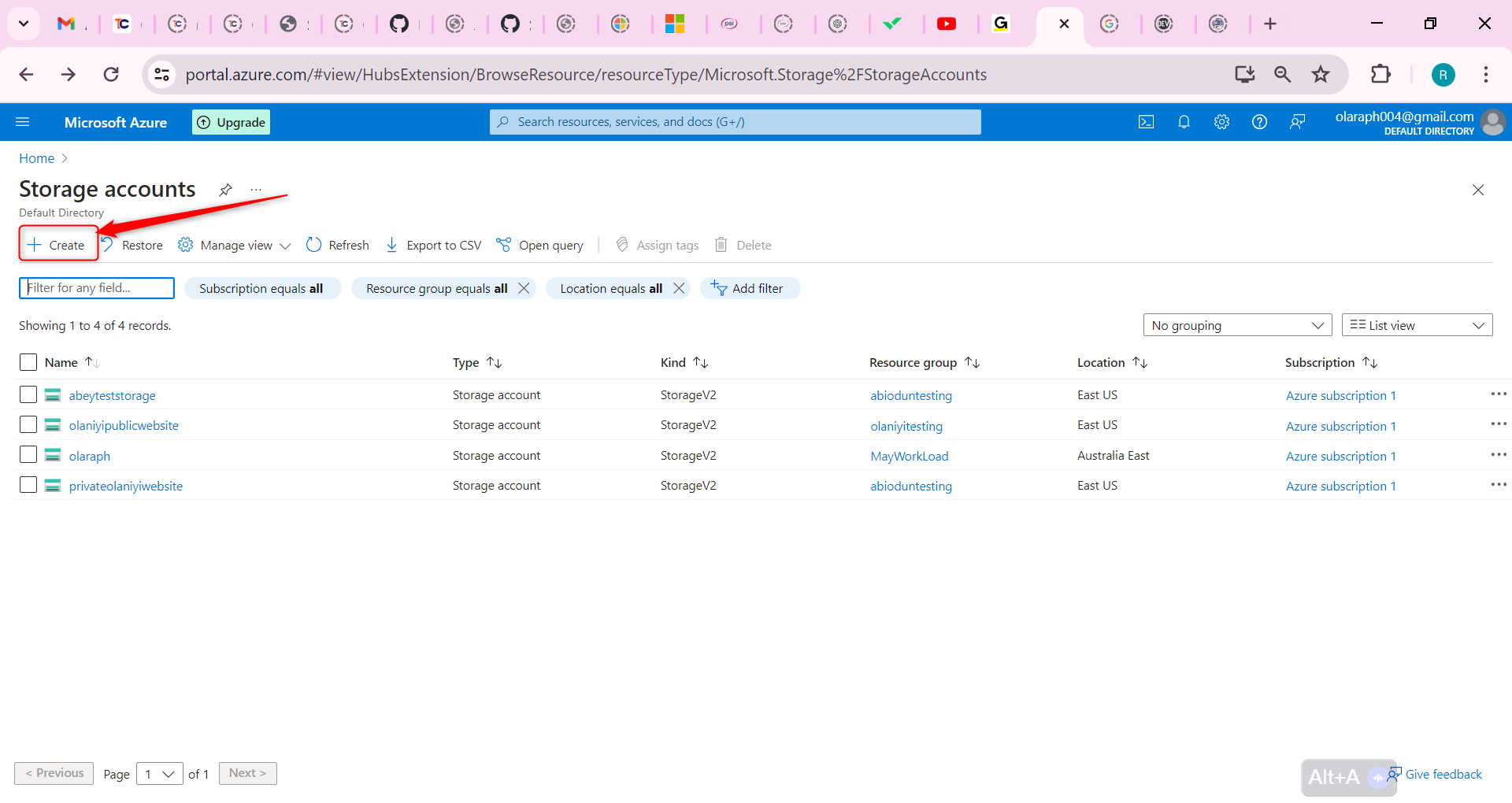
For Resource group select Create new. Give your resource group a name and select OK to save your changes.
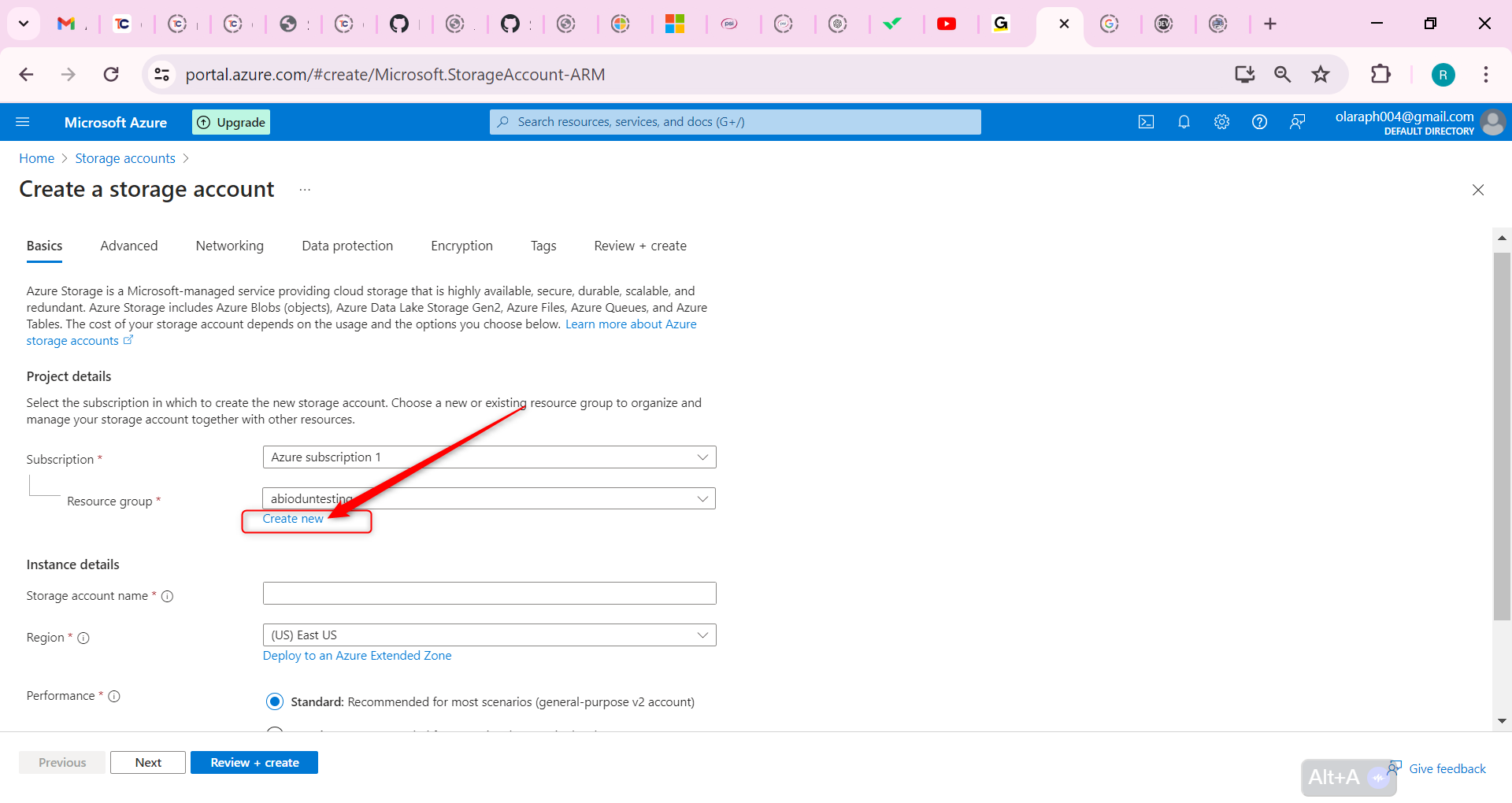
Provide a Storage account name. Ensure the name meets the naming requirements.
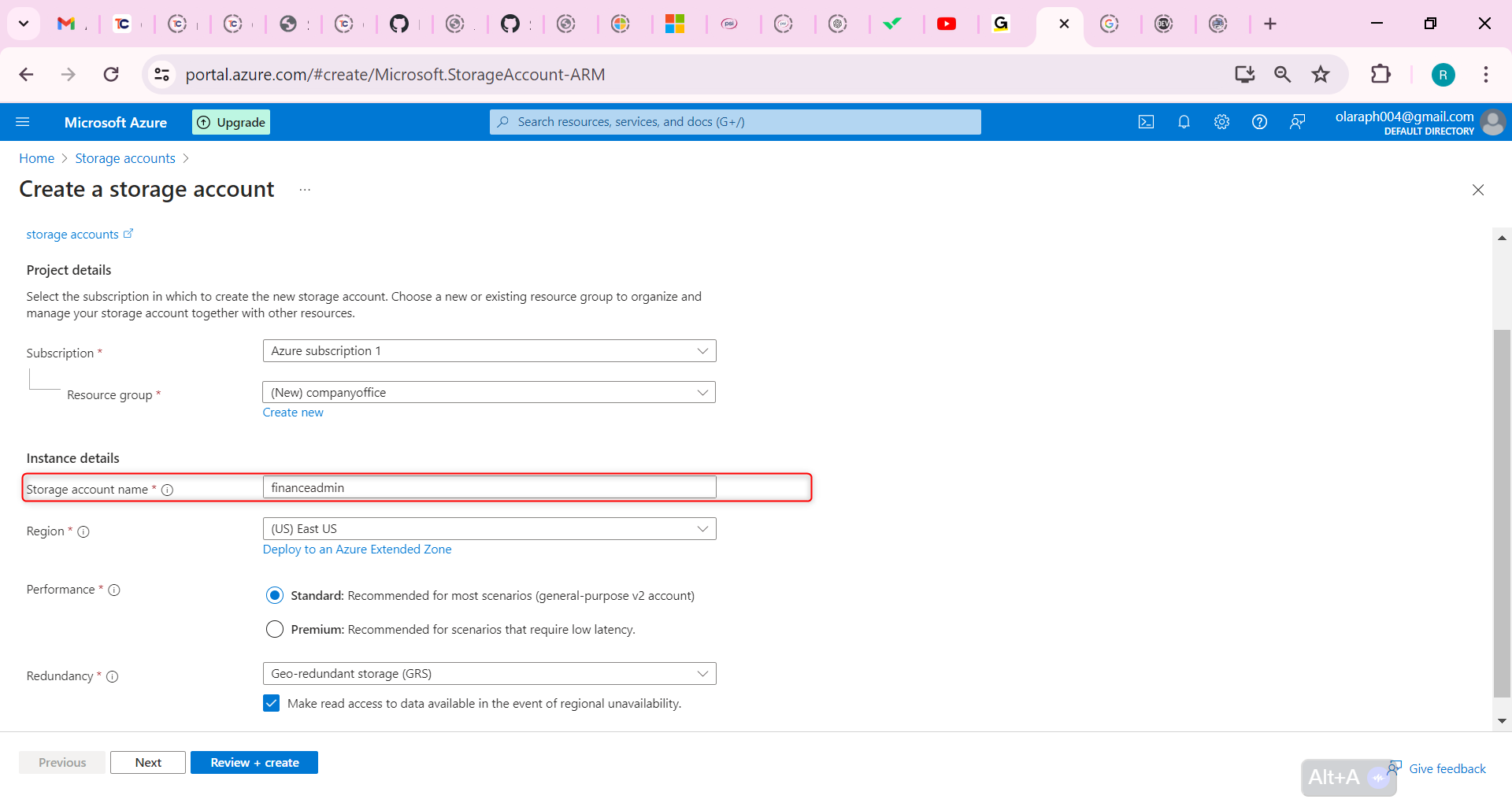
Set the Performance to Premium.
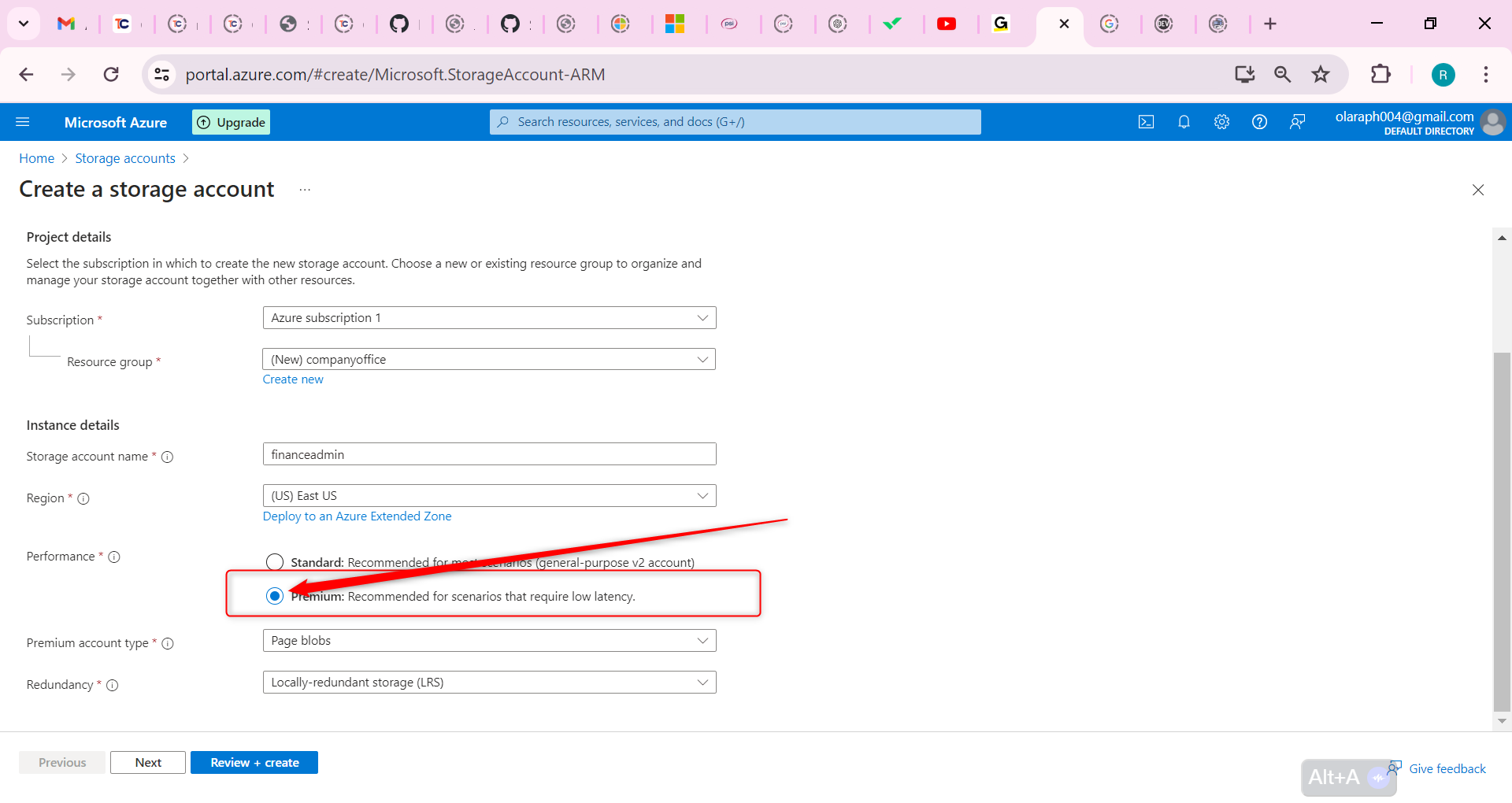
Set the Premium account type to File shares.
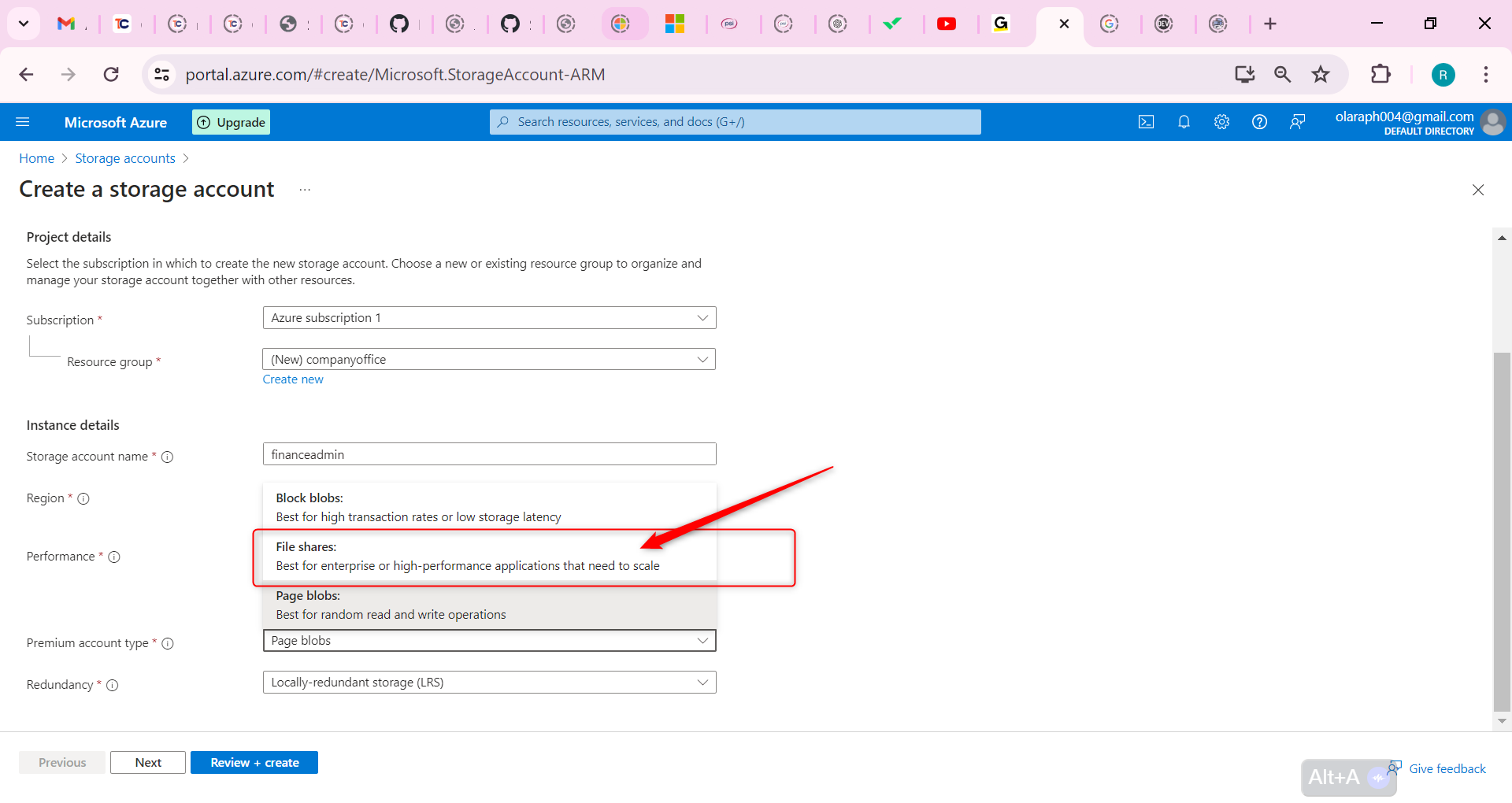
Set the Redundancy to Zone-redundant storage.
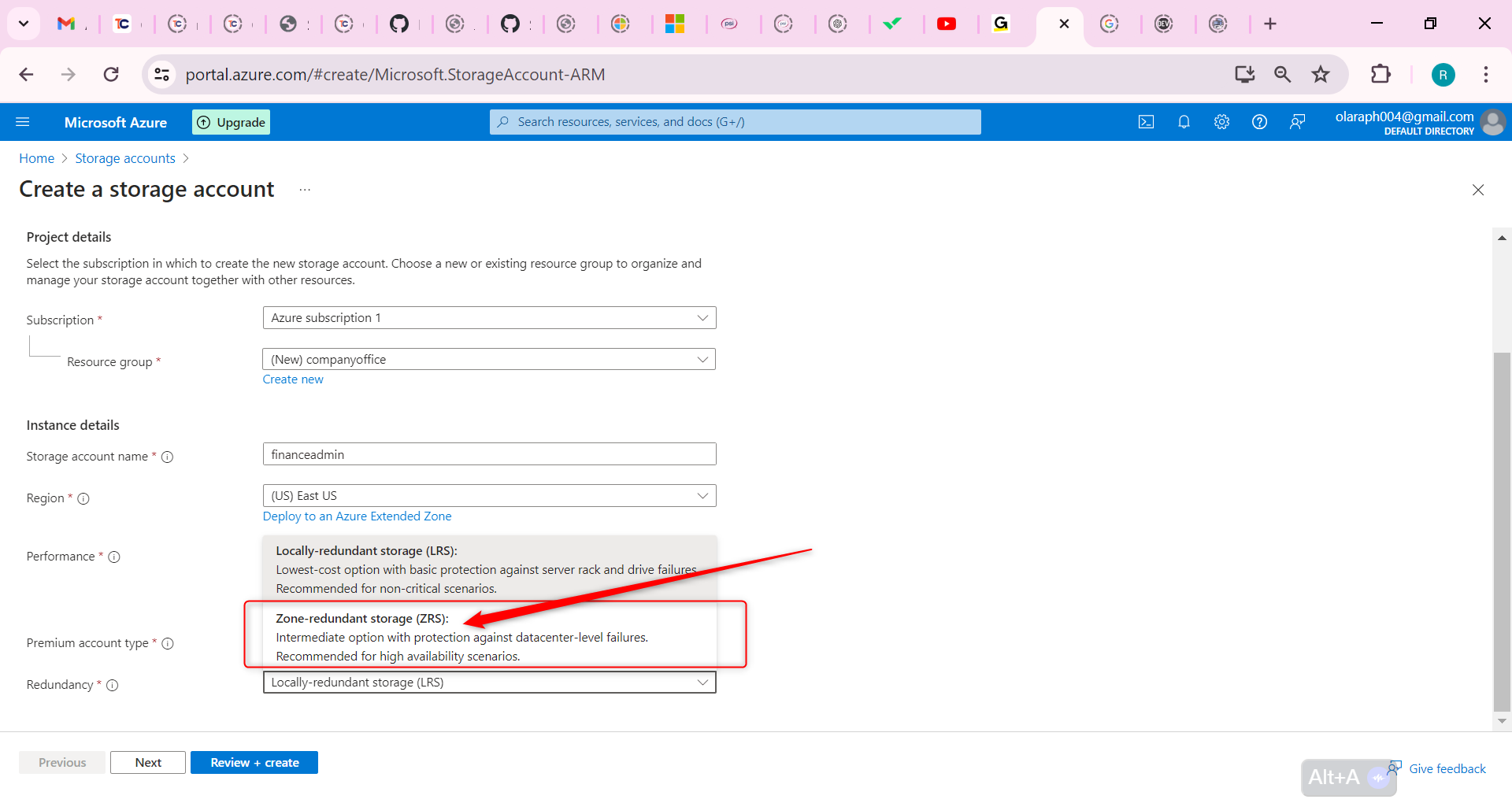
Select Review and then Create the storage account.
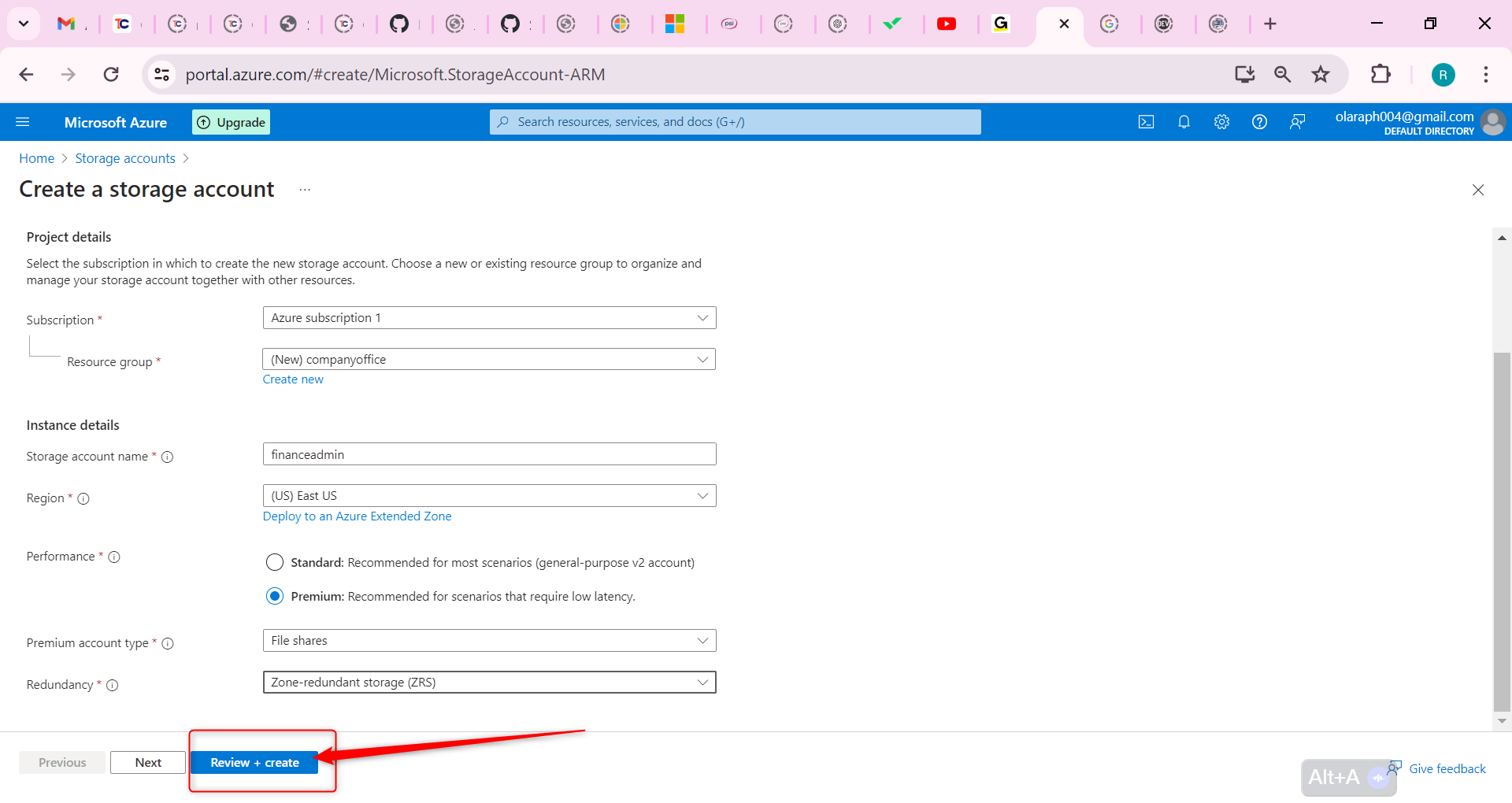
Wait for the resource to deploy.
Select Go to resource.
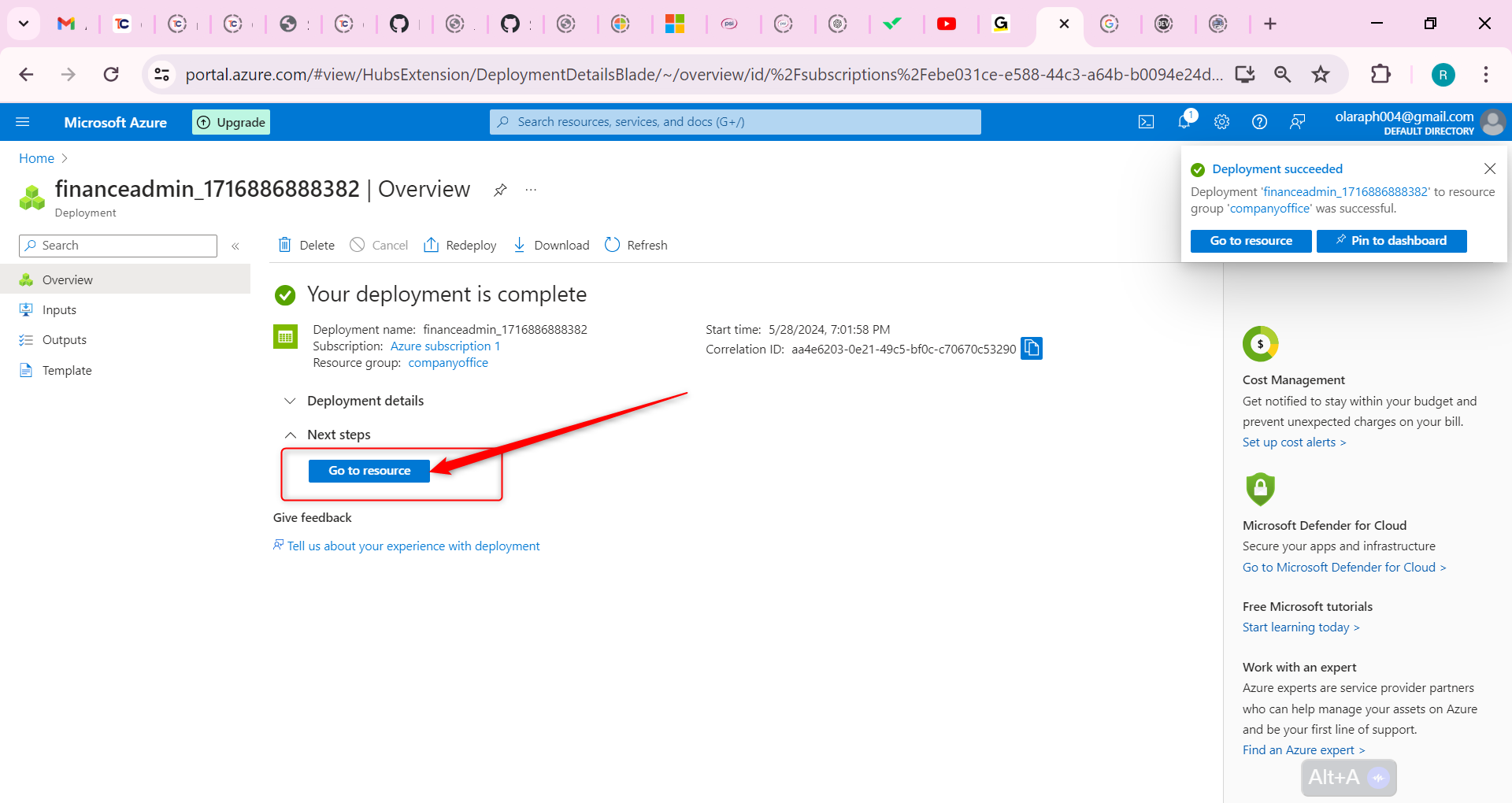
Create and configure a file share with directory.
Create a file share for the corporate office. Learn more about Azure File tiers.
In the storage account, in the Data storage section, select the File shares blade.
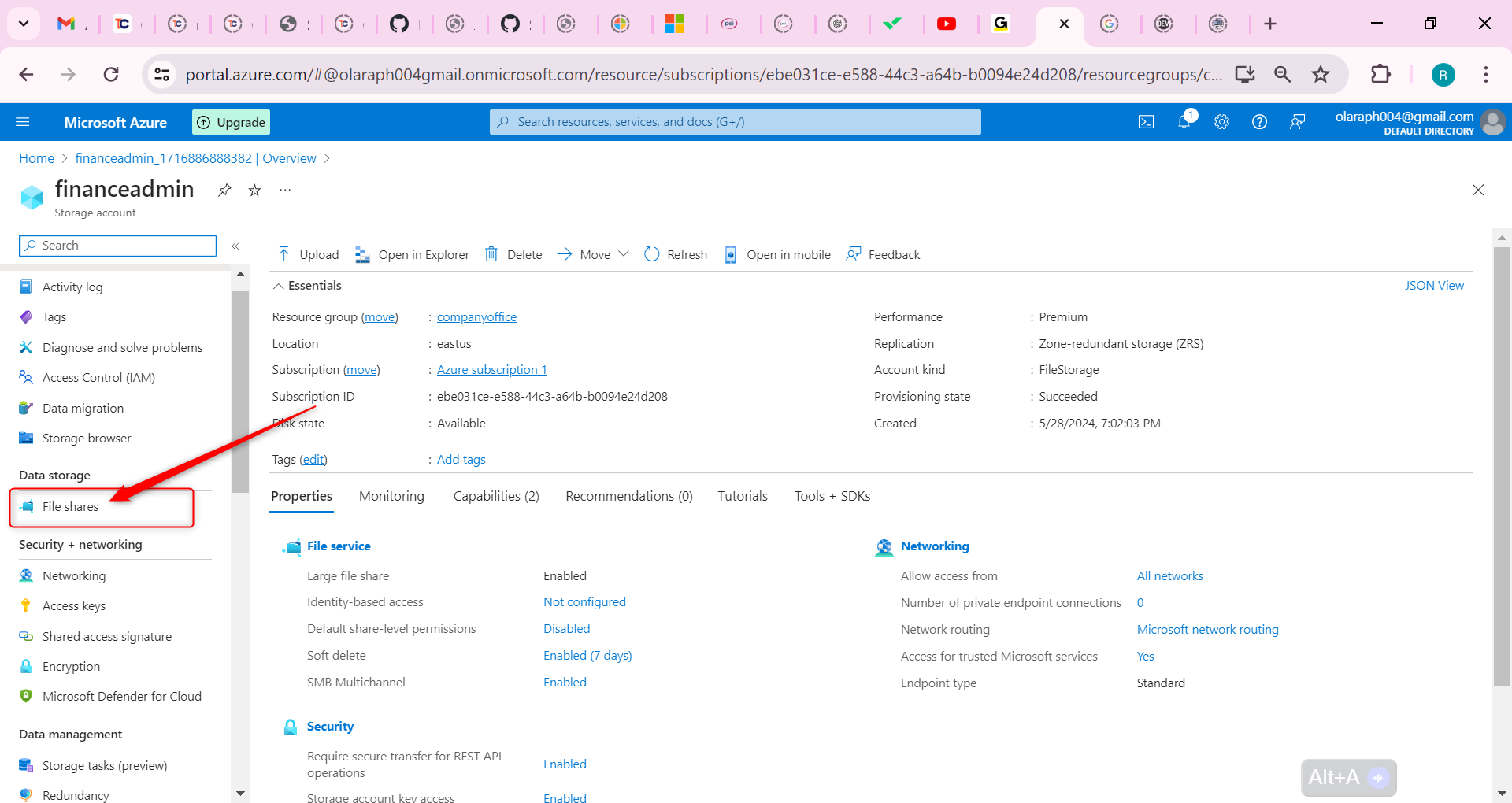
Select + File share and provide a Name.
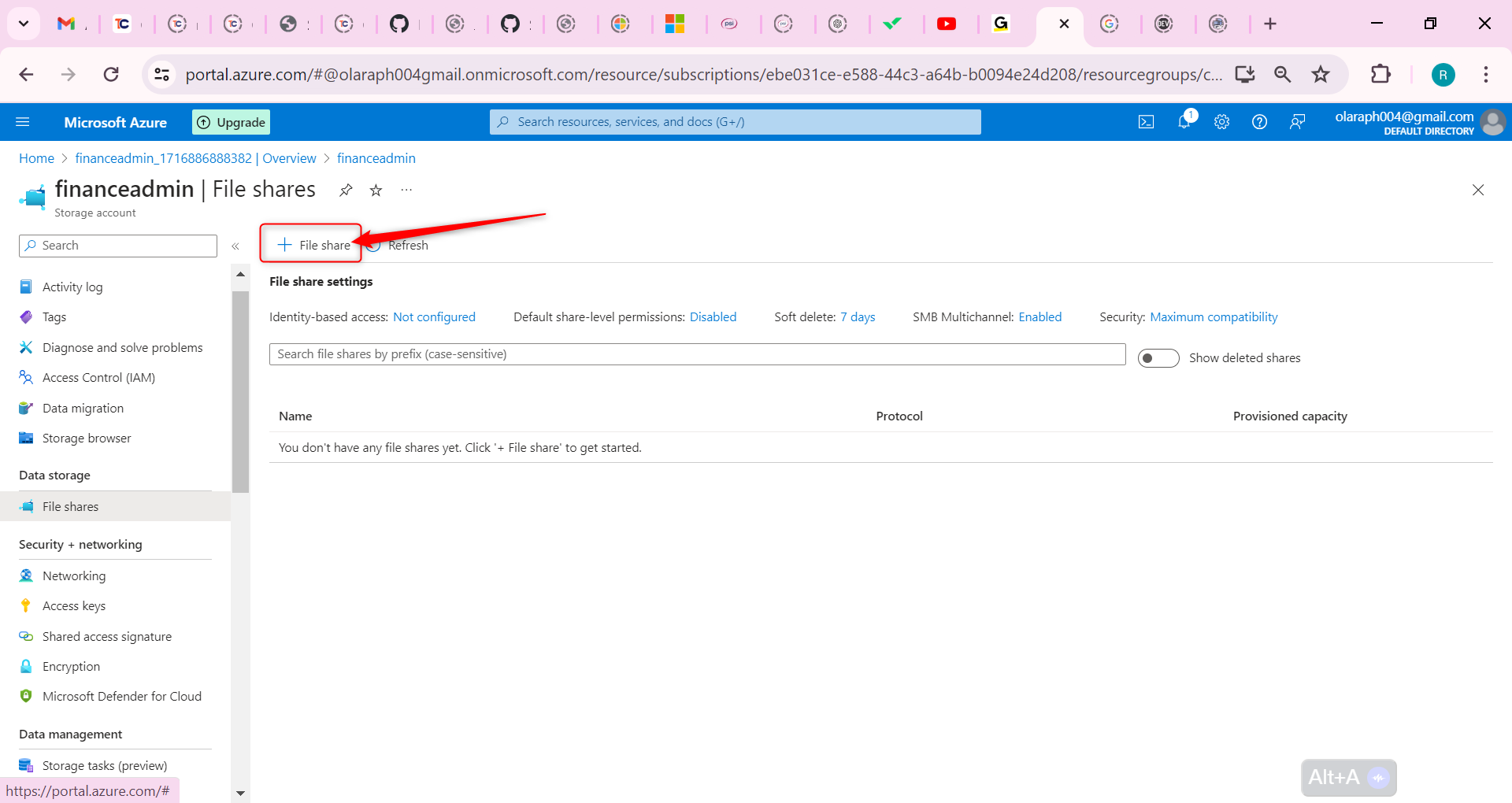
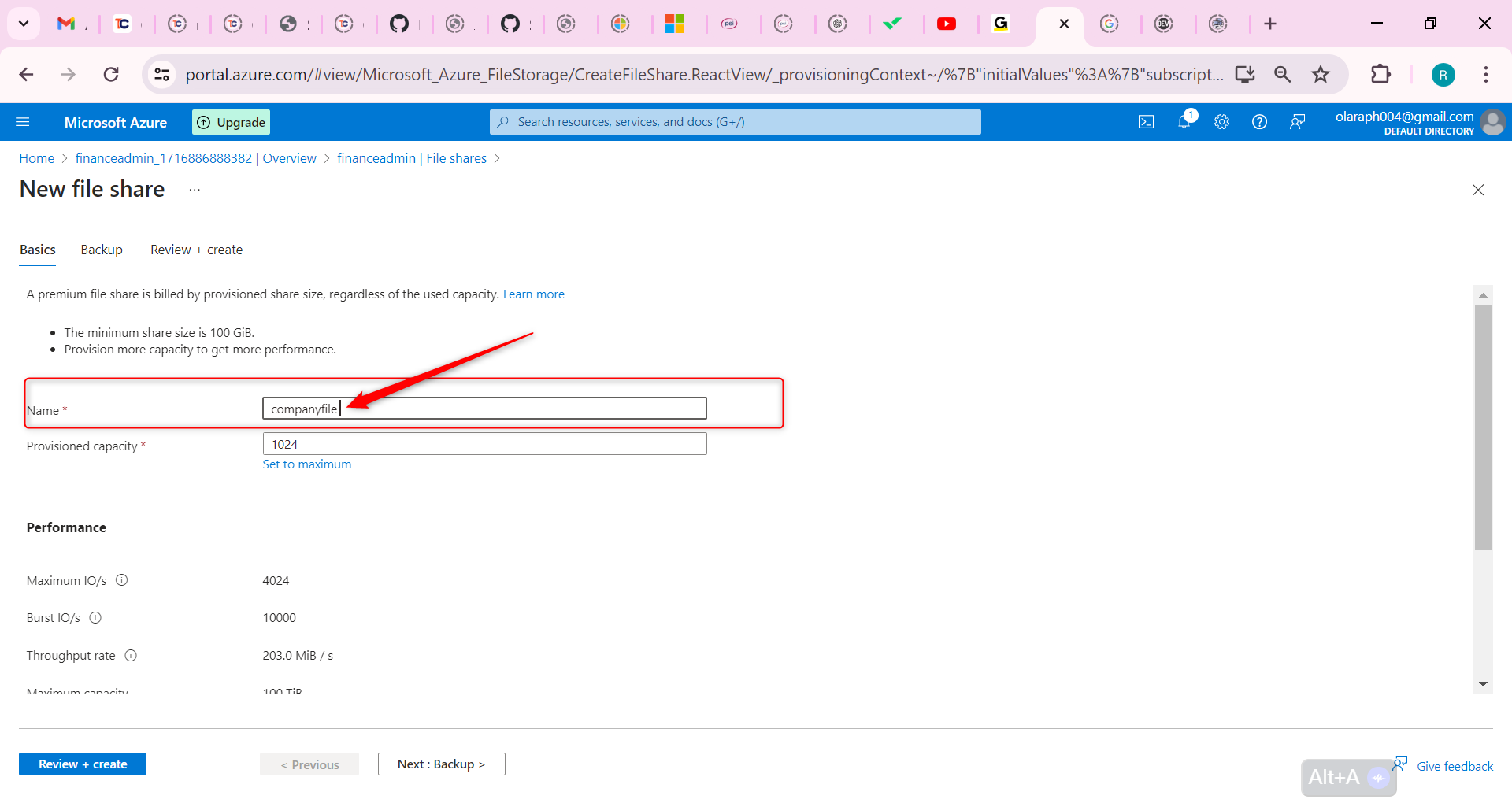
Review the other options, but take the defaults.
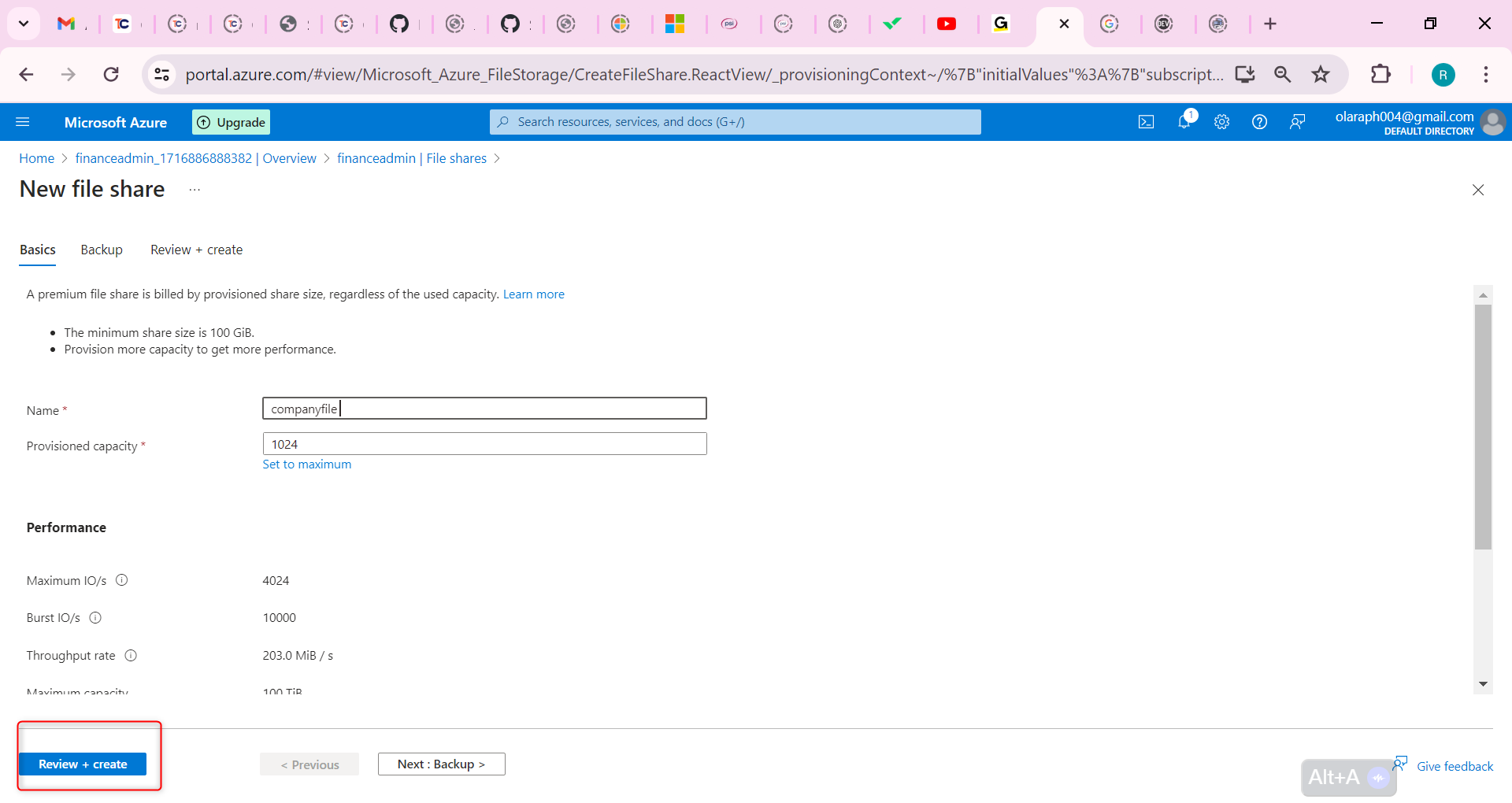
Select Create
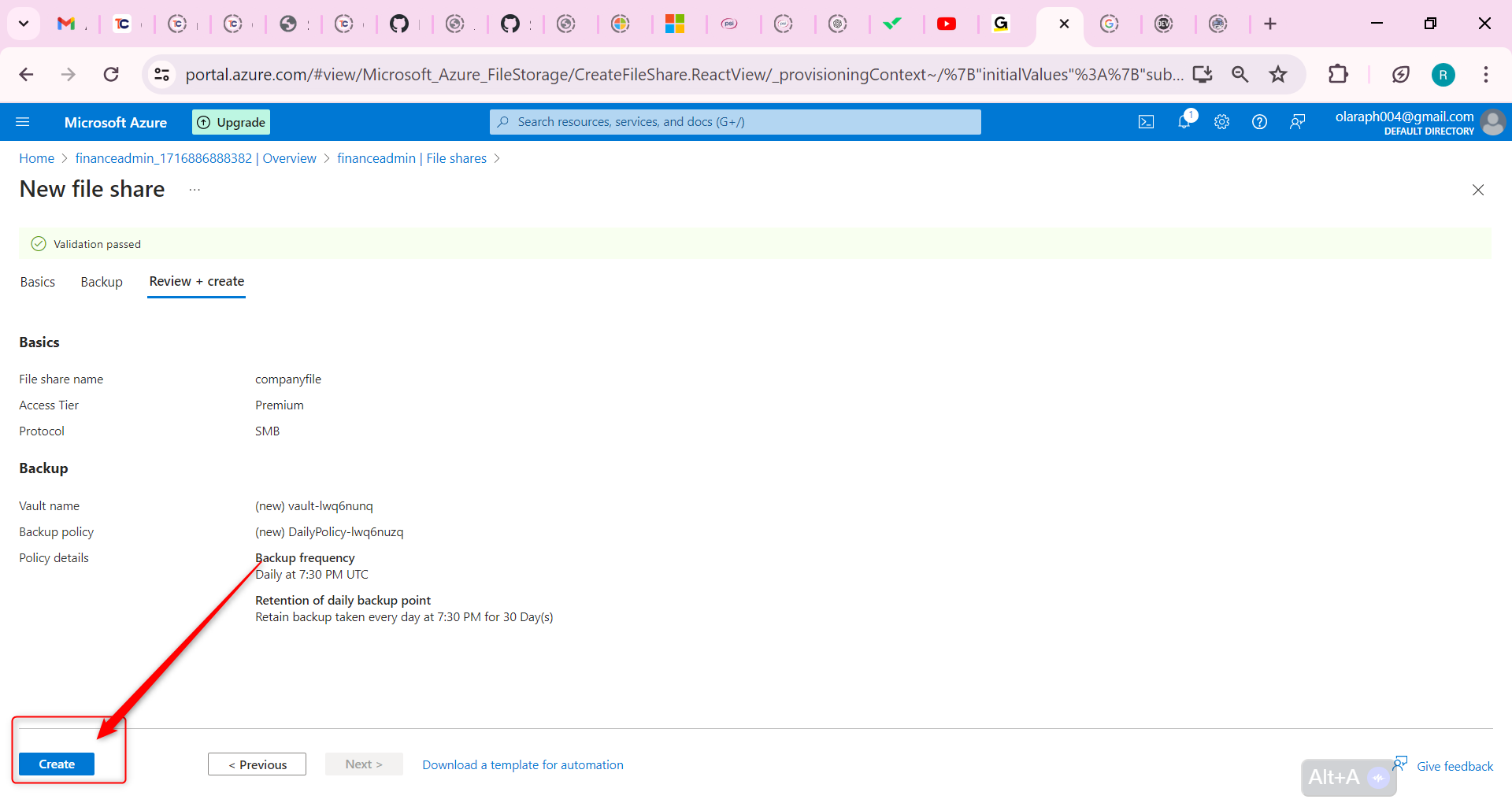
Add a directory to the file share for the finance department. For future testing, upload a file.
Select your file share and select + Add directory.
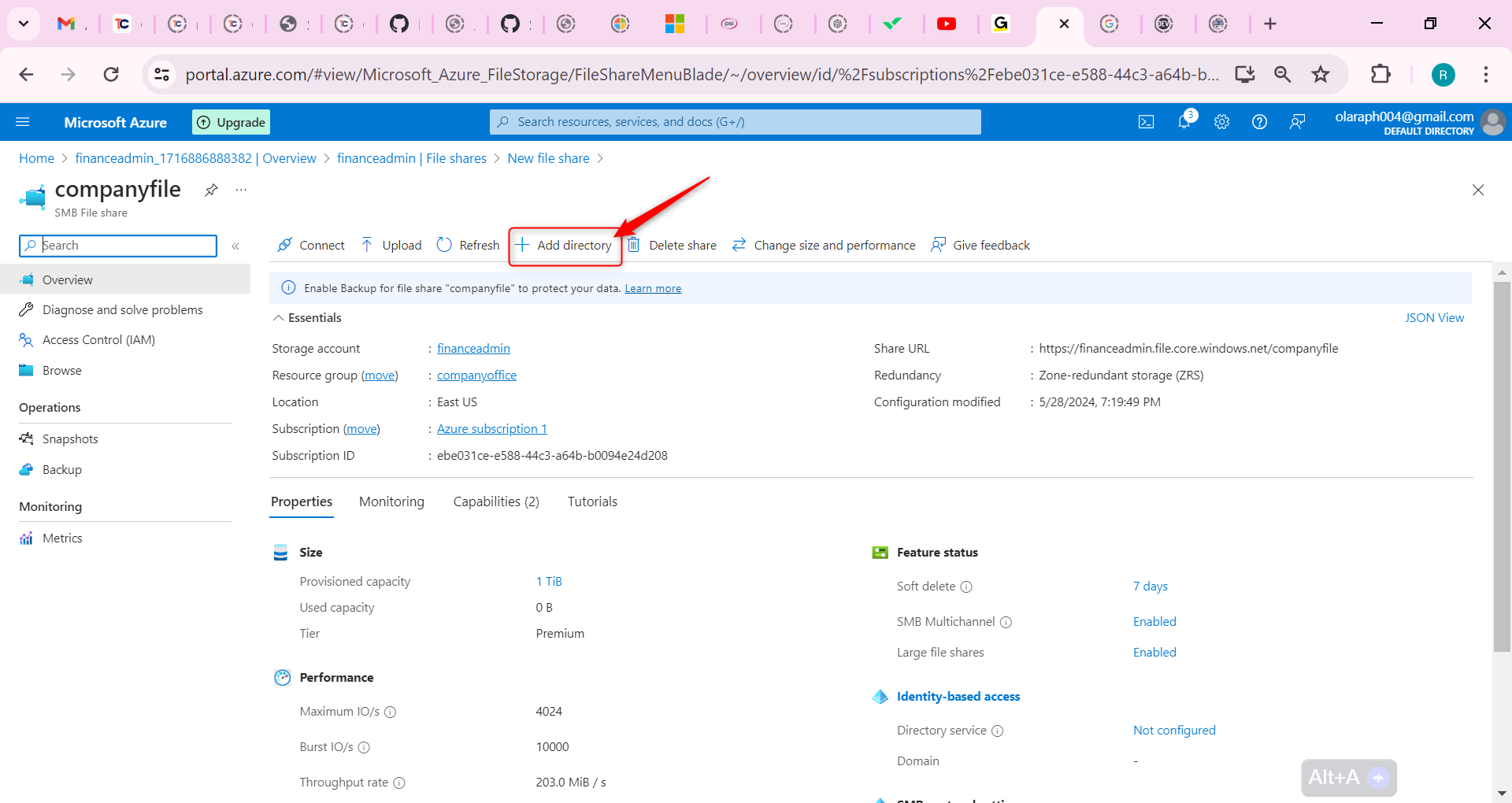
Name the new directory finance.
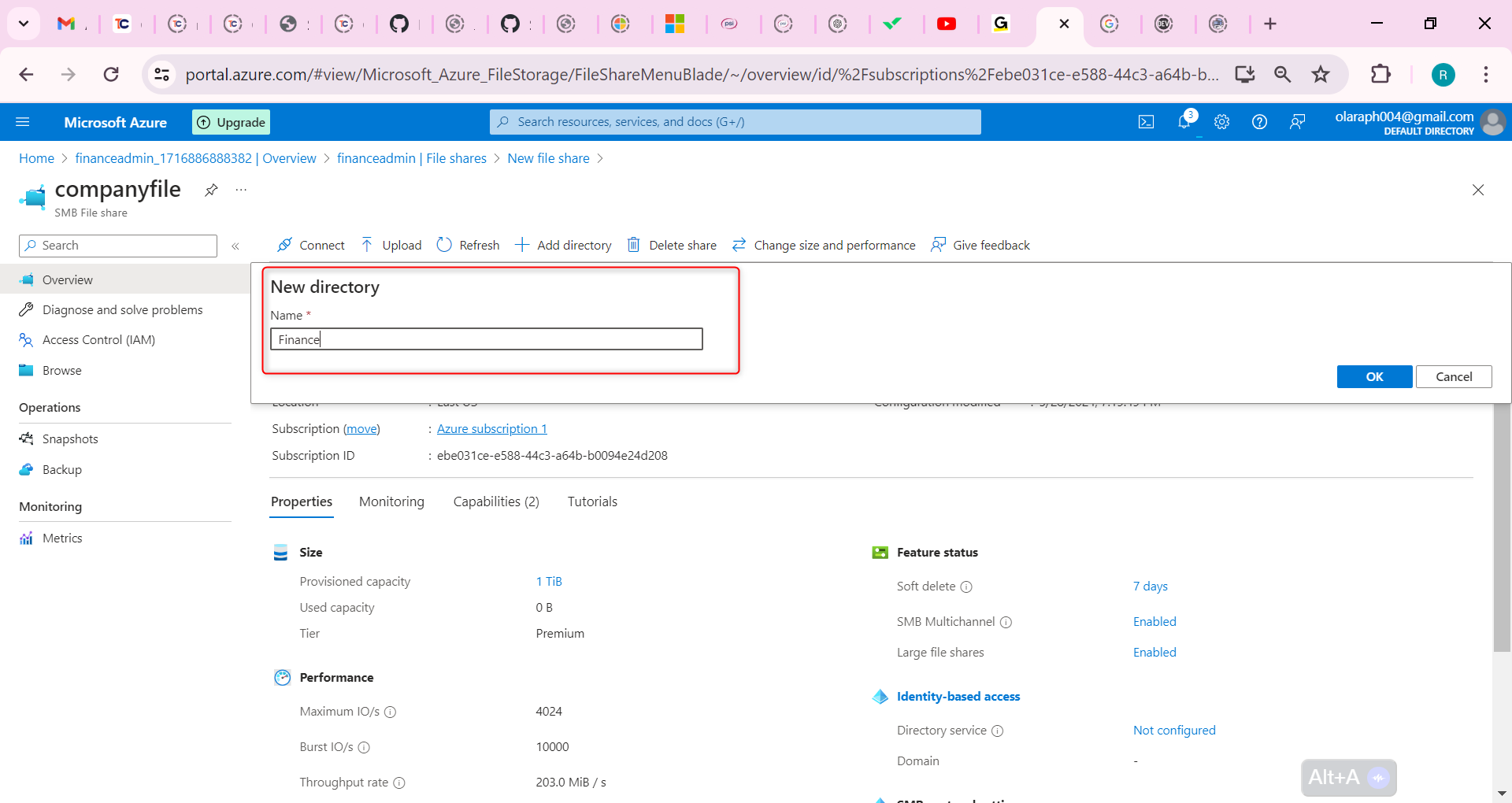
Select Browse and then select the finance directory.
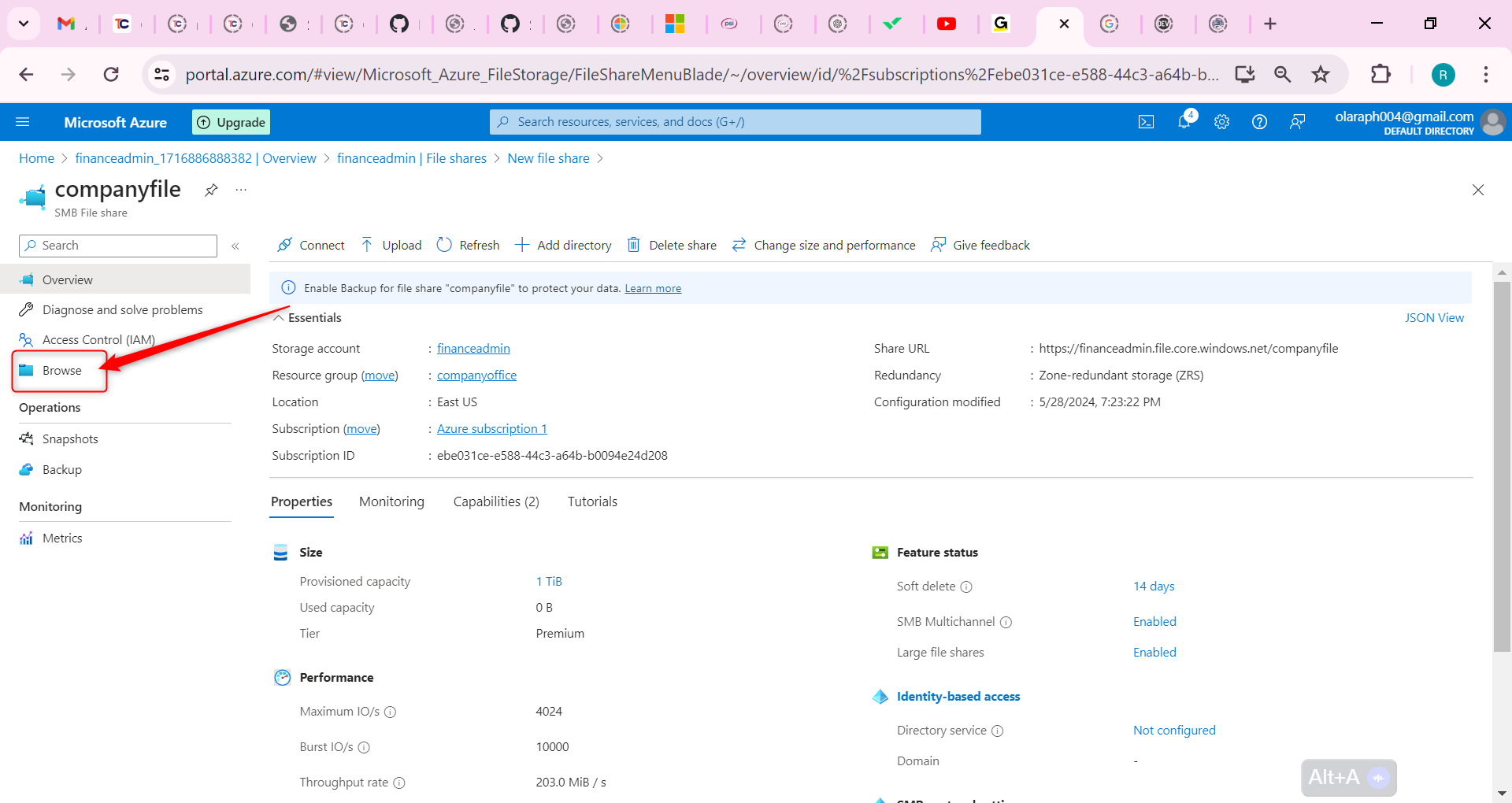
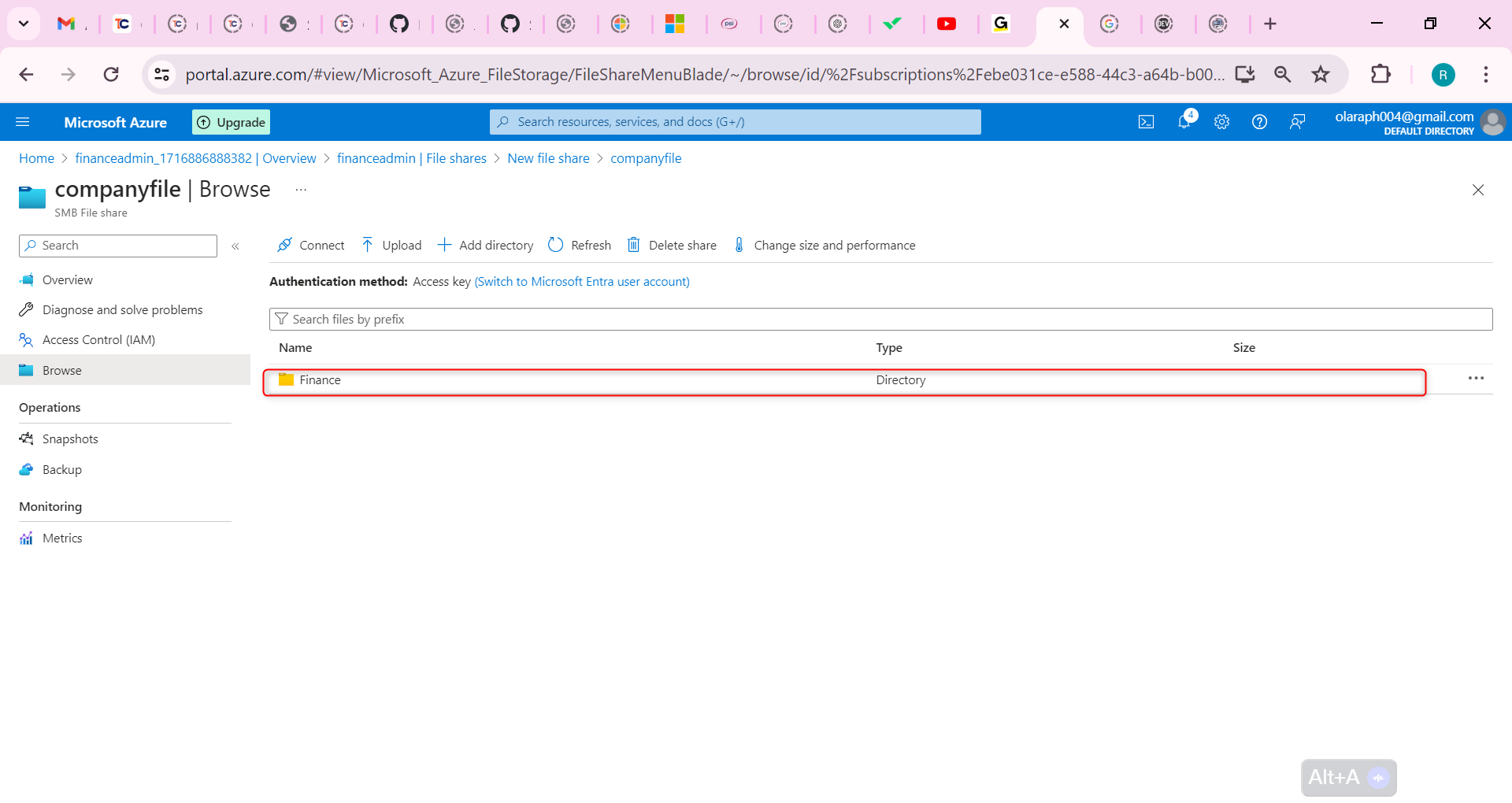
Notice you can Add directory to further organize your file share.
Upload a file of your choosing.
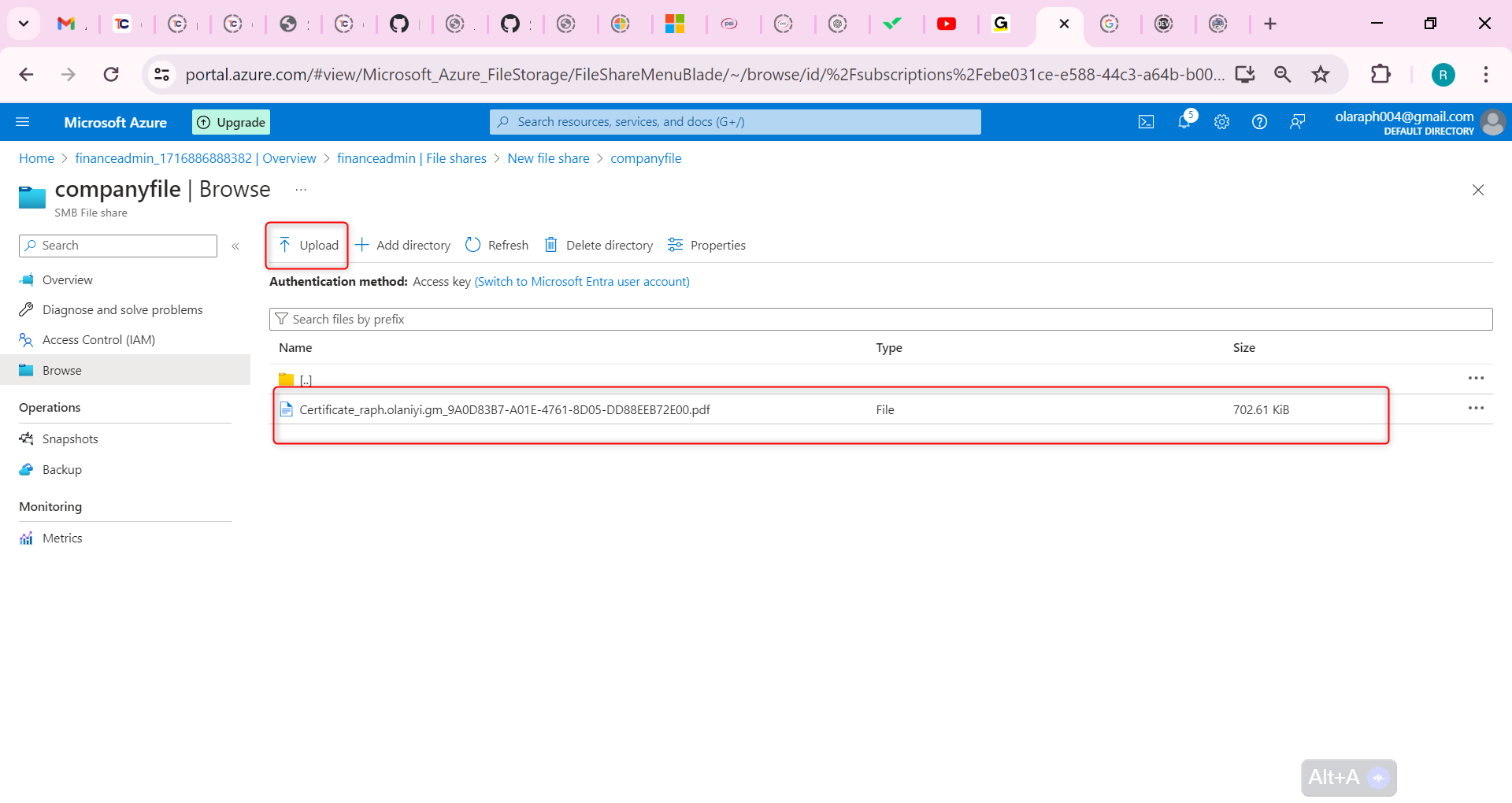
Configure and test snapshots.
Similar to blob storage, you need to protect against accidental deletion of files. You decide to use snapshots.
Select your file share.
In the Operations section, select the Snapshots blade.
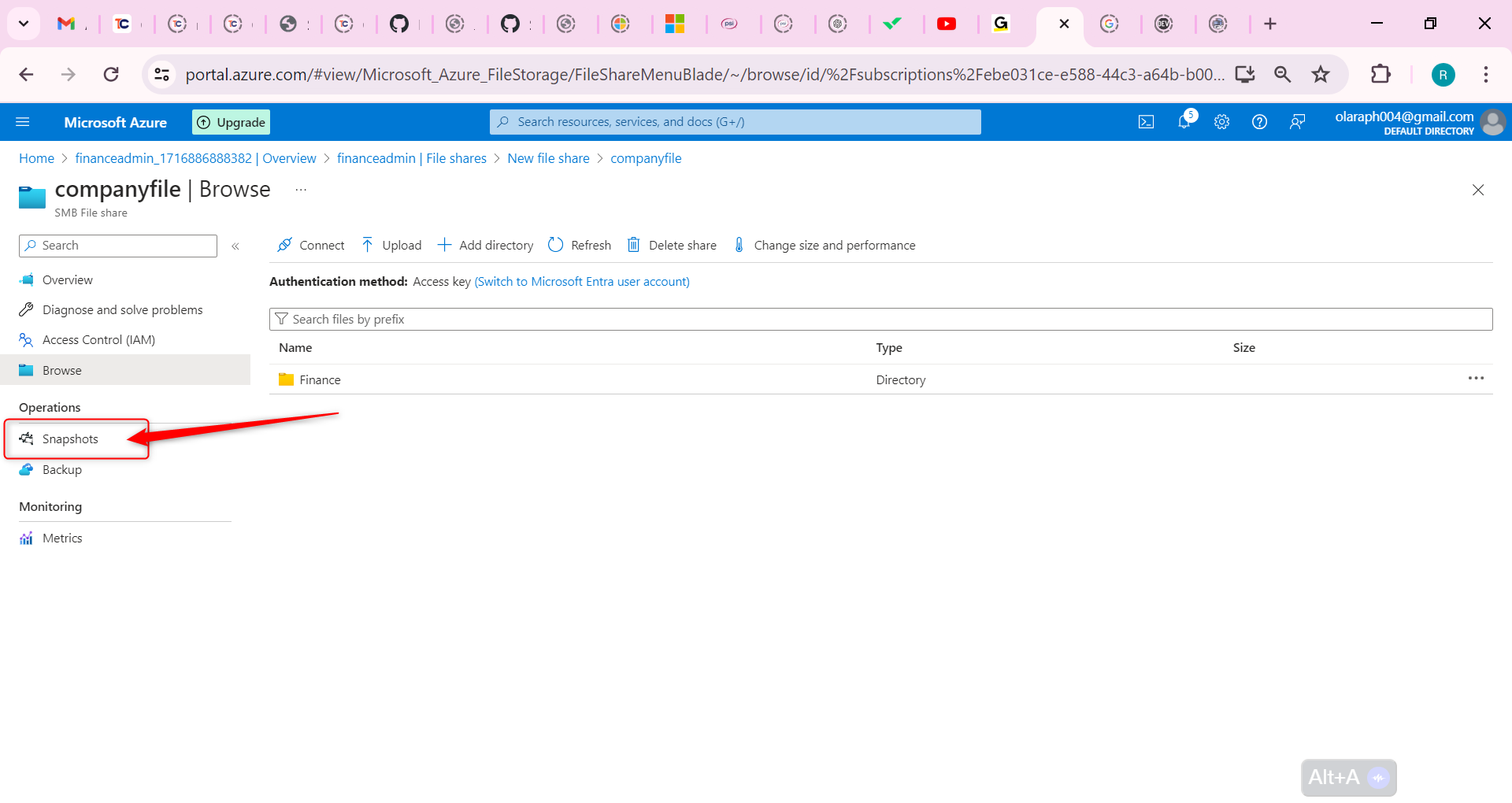
Select + Add snapshot. The comment is optional. Select OK.
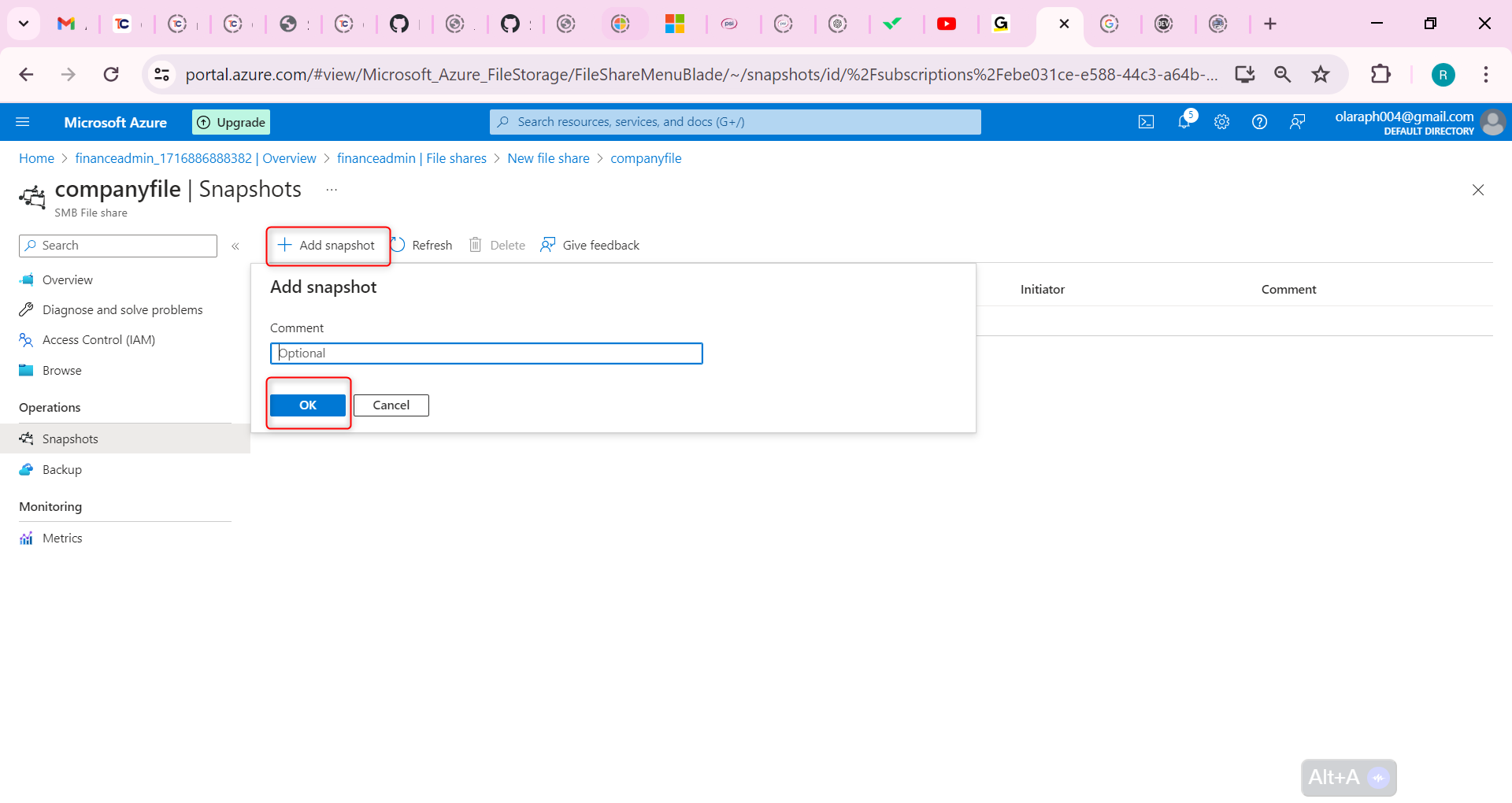
Select your snapshot and verify your file directory and uploaded file are included.
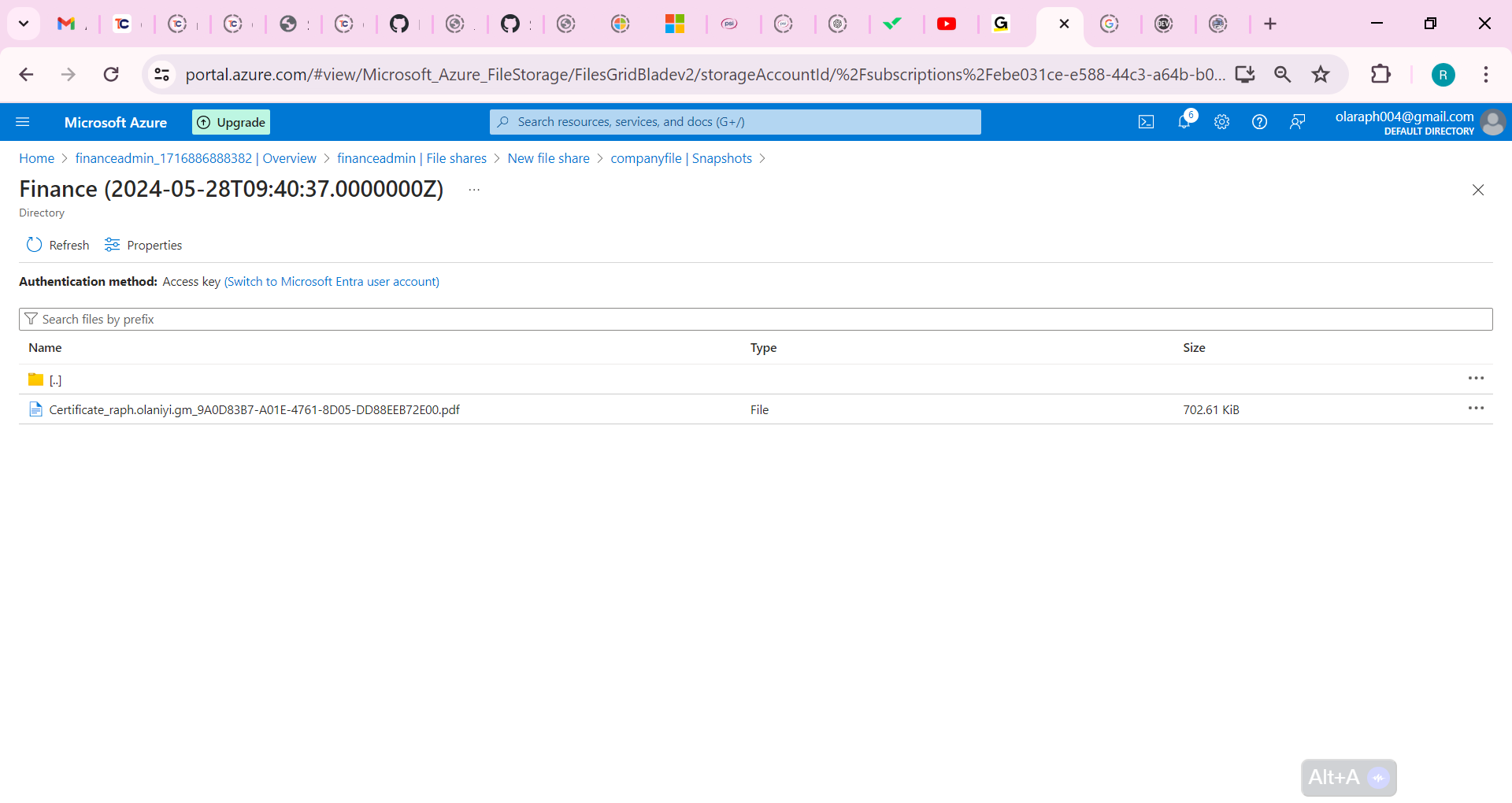
Practice using snapshots to restore a file.
Return to your file share.
Browse to your file directory.
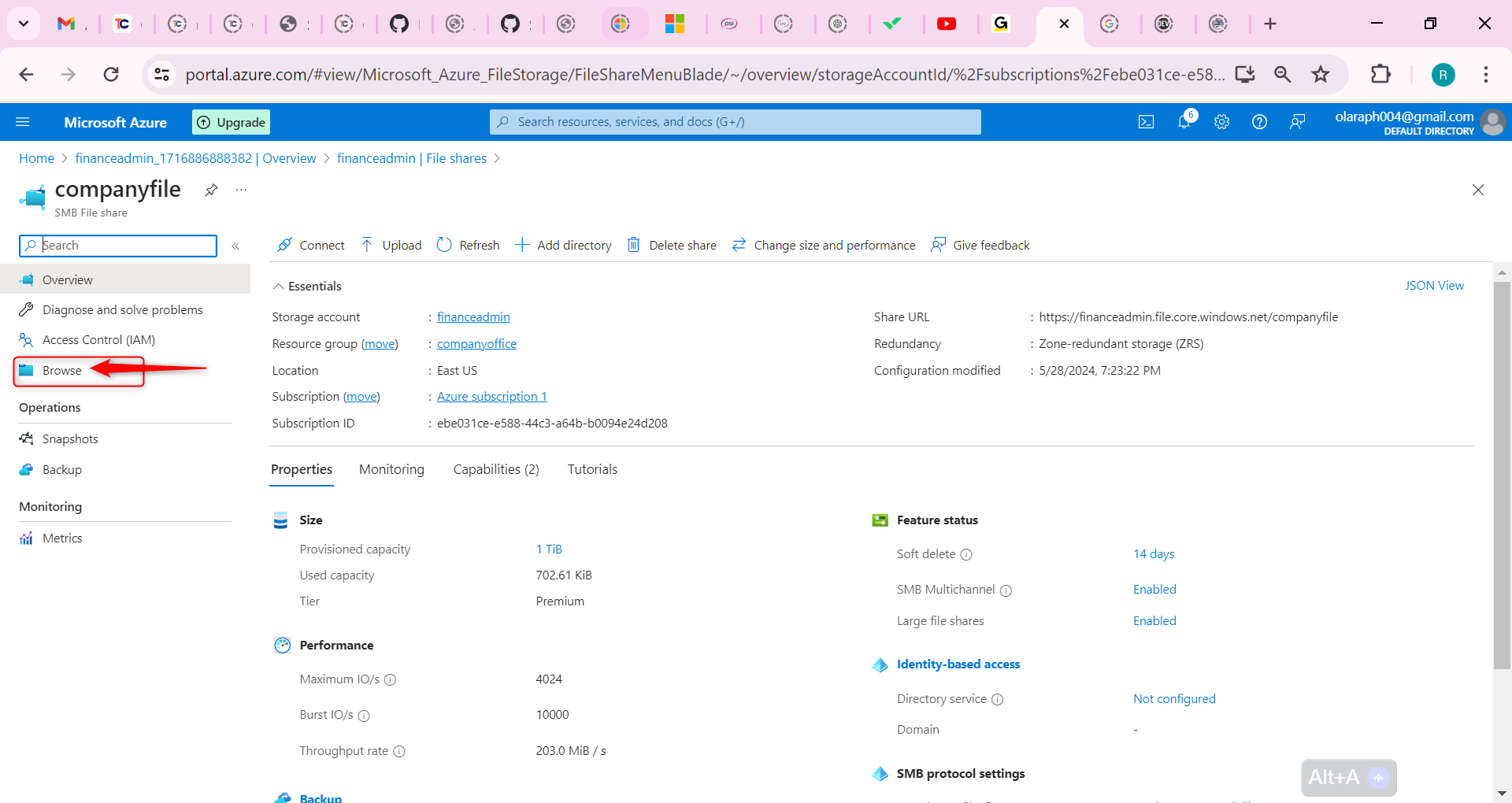
Locate your uploaded file and in the Properties pane select Delete. Select Yes to confirm the deletion.
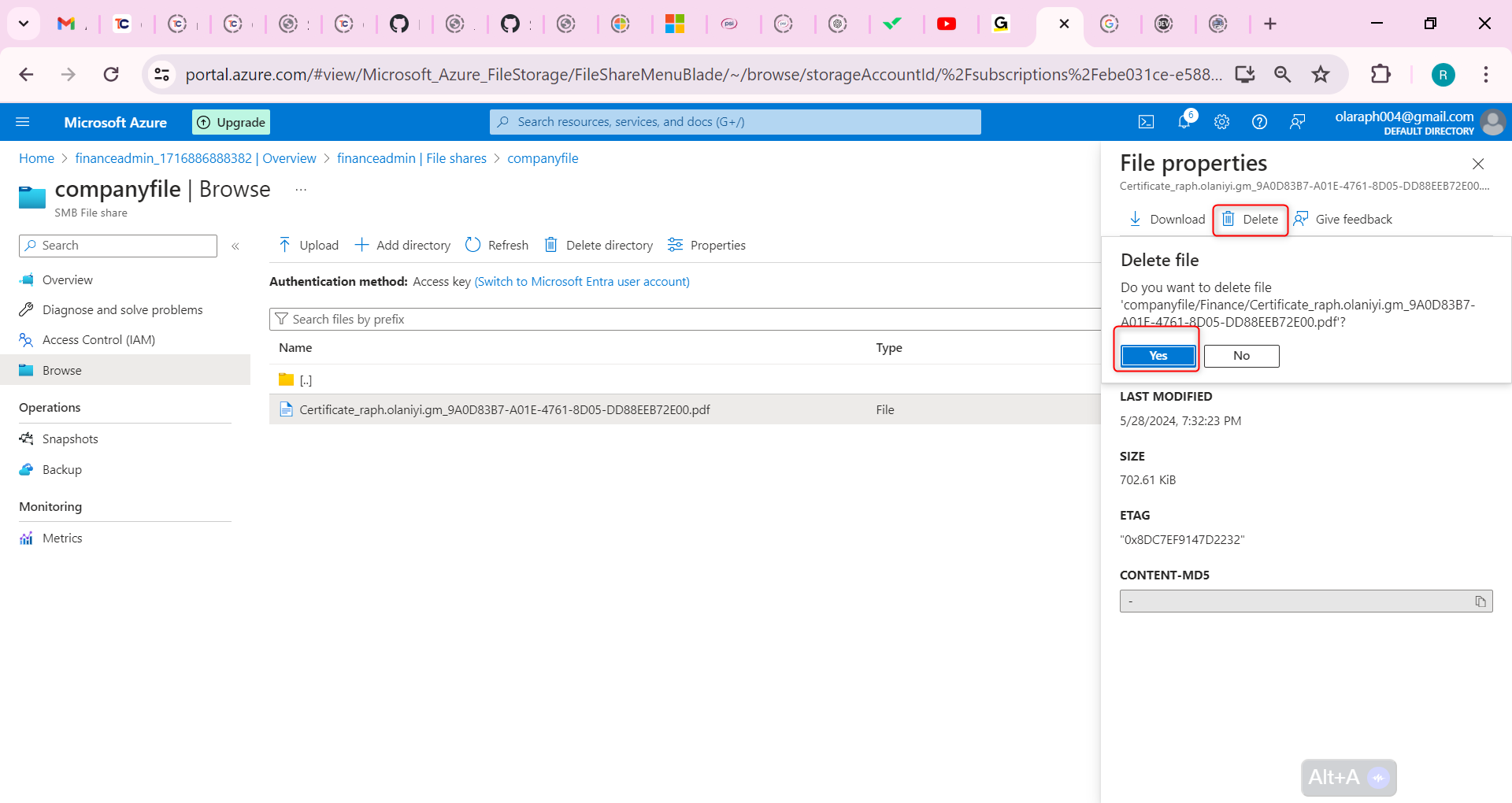
Select the Snapshots blade and then select your snapshot.
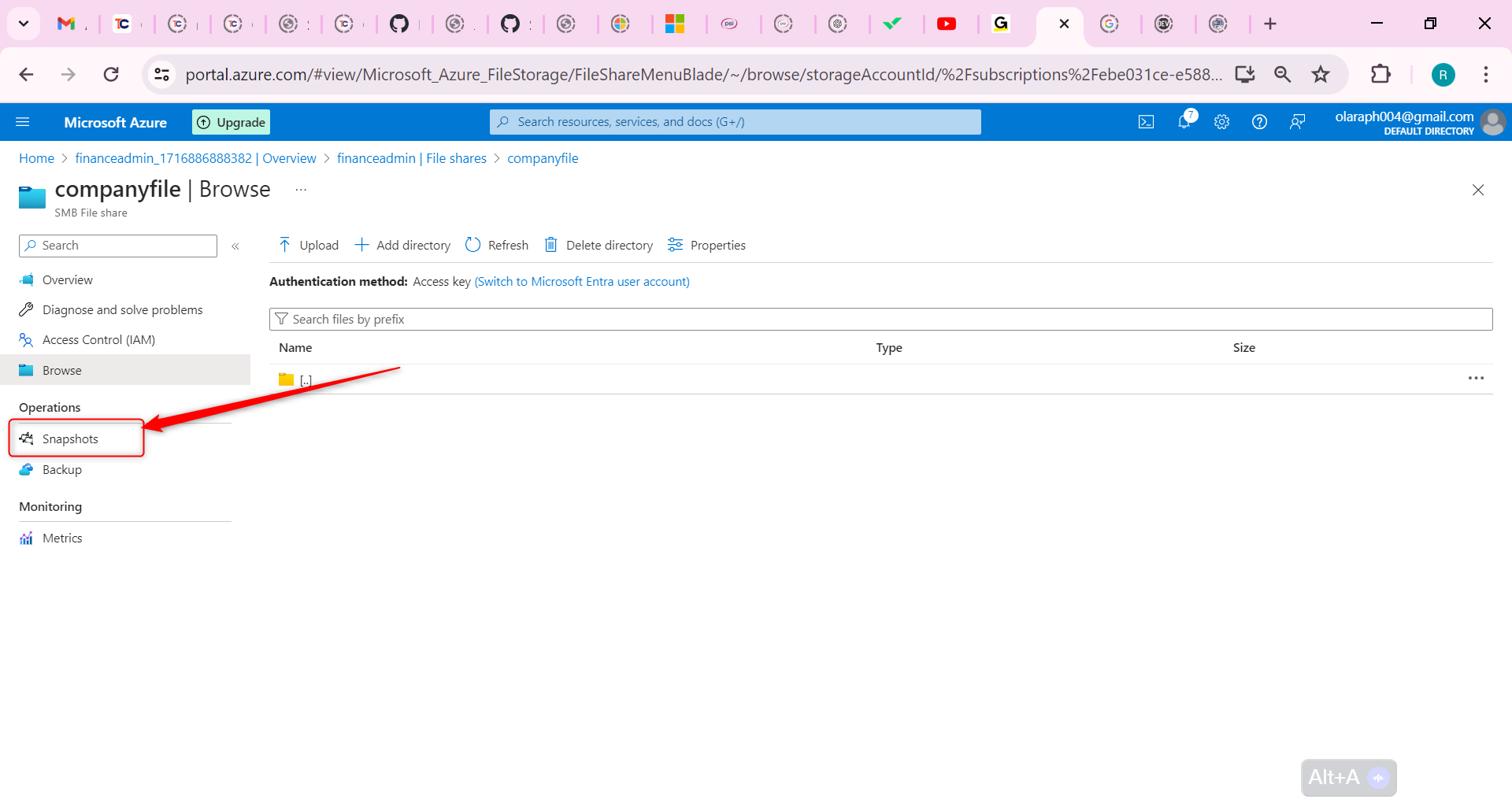
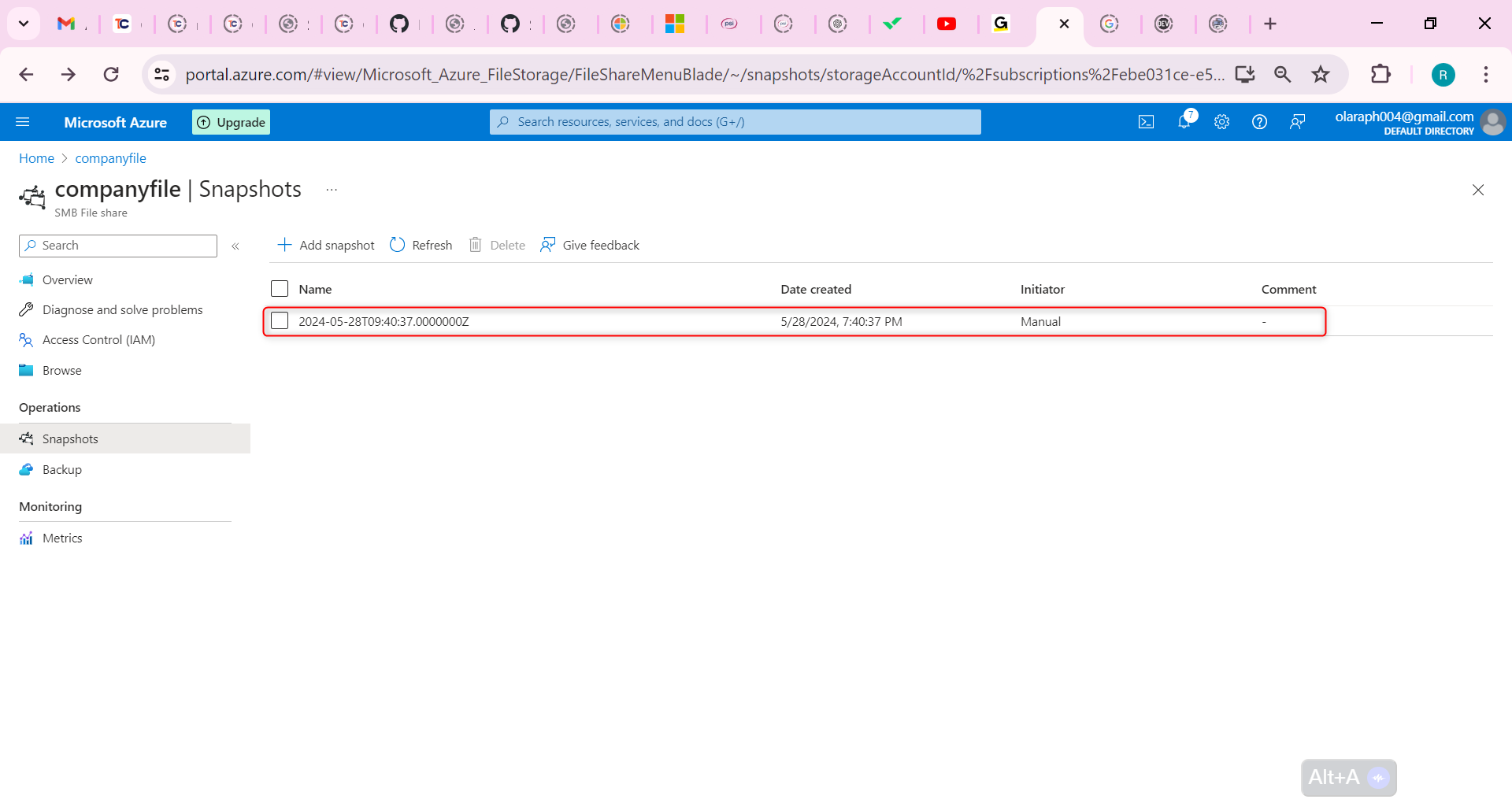
Navigate to the file you want to restore,
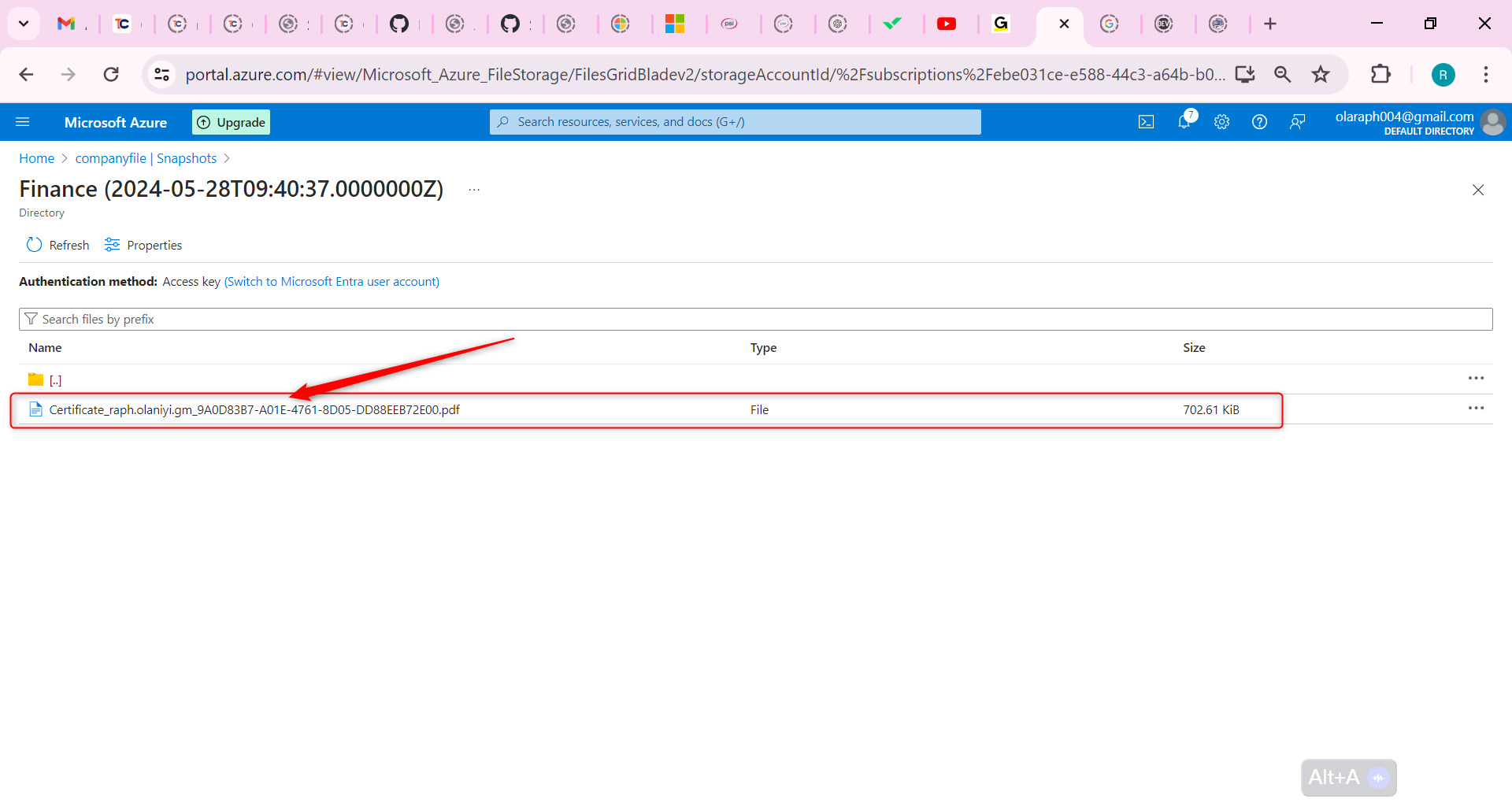
Select the file and the select Restore.
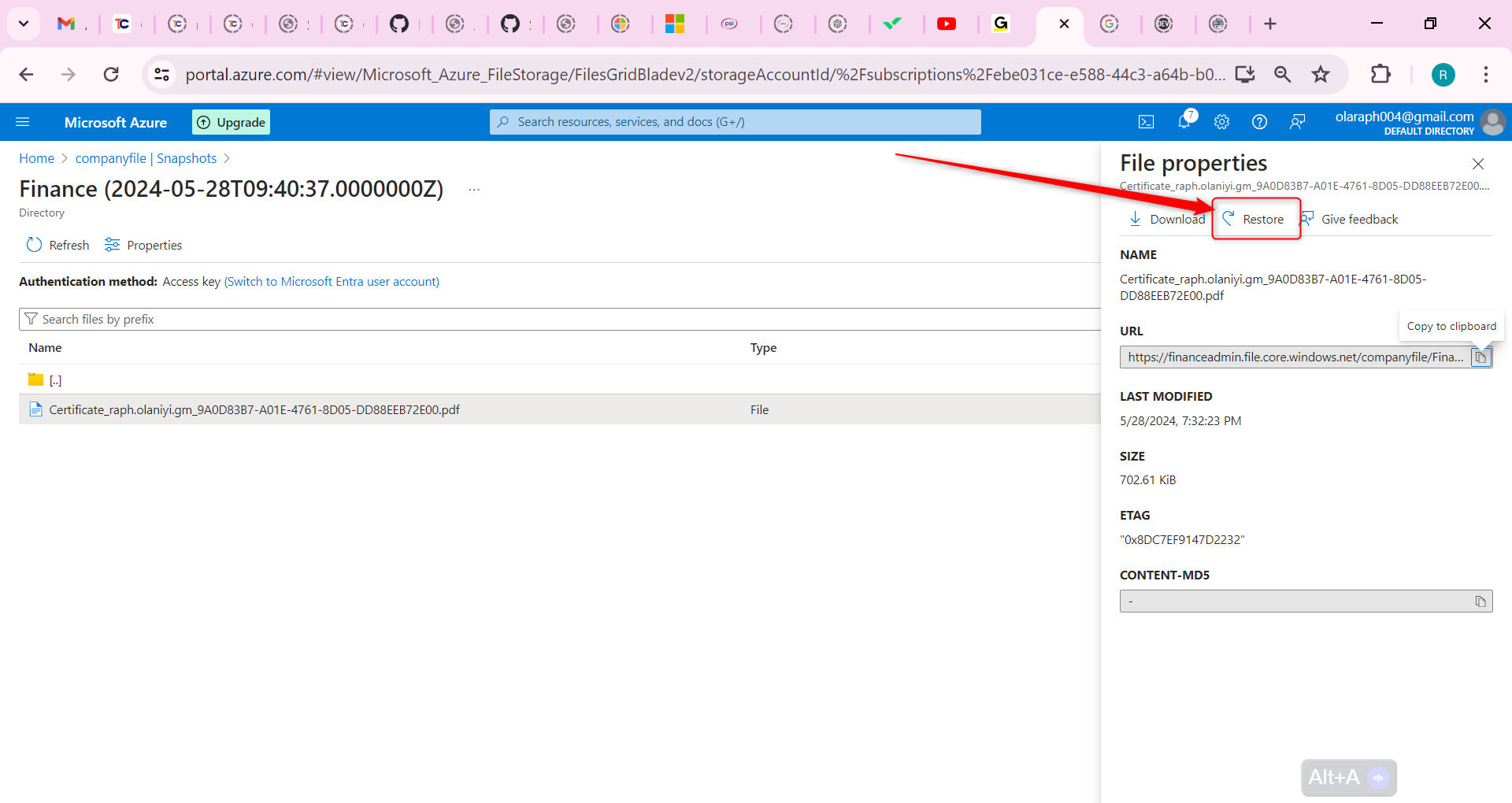
Provide a Restored file name.
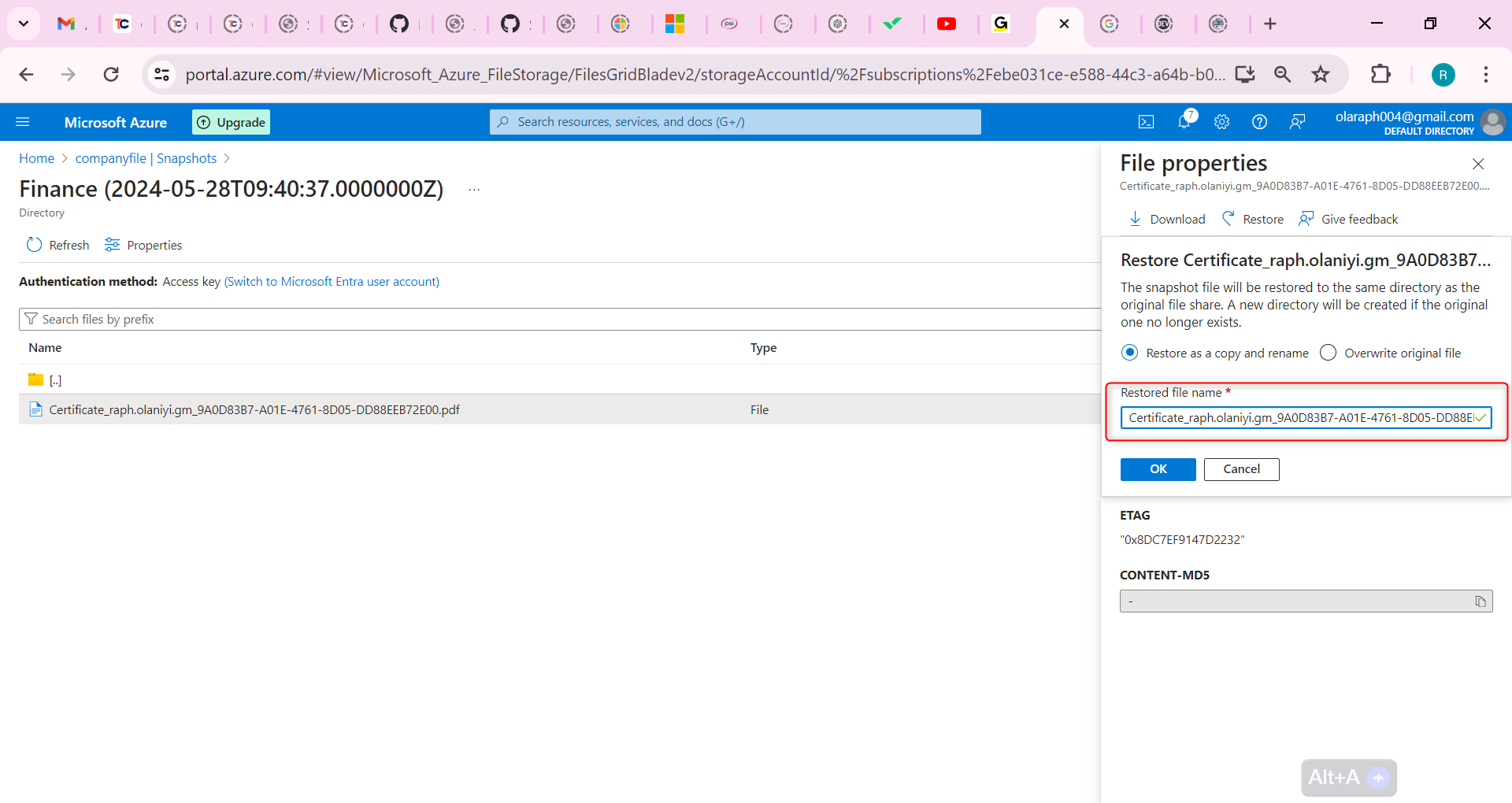
Verify your file directory has the restored file.
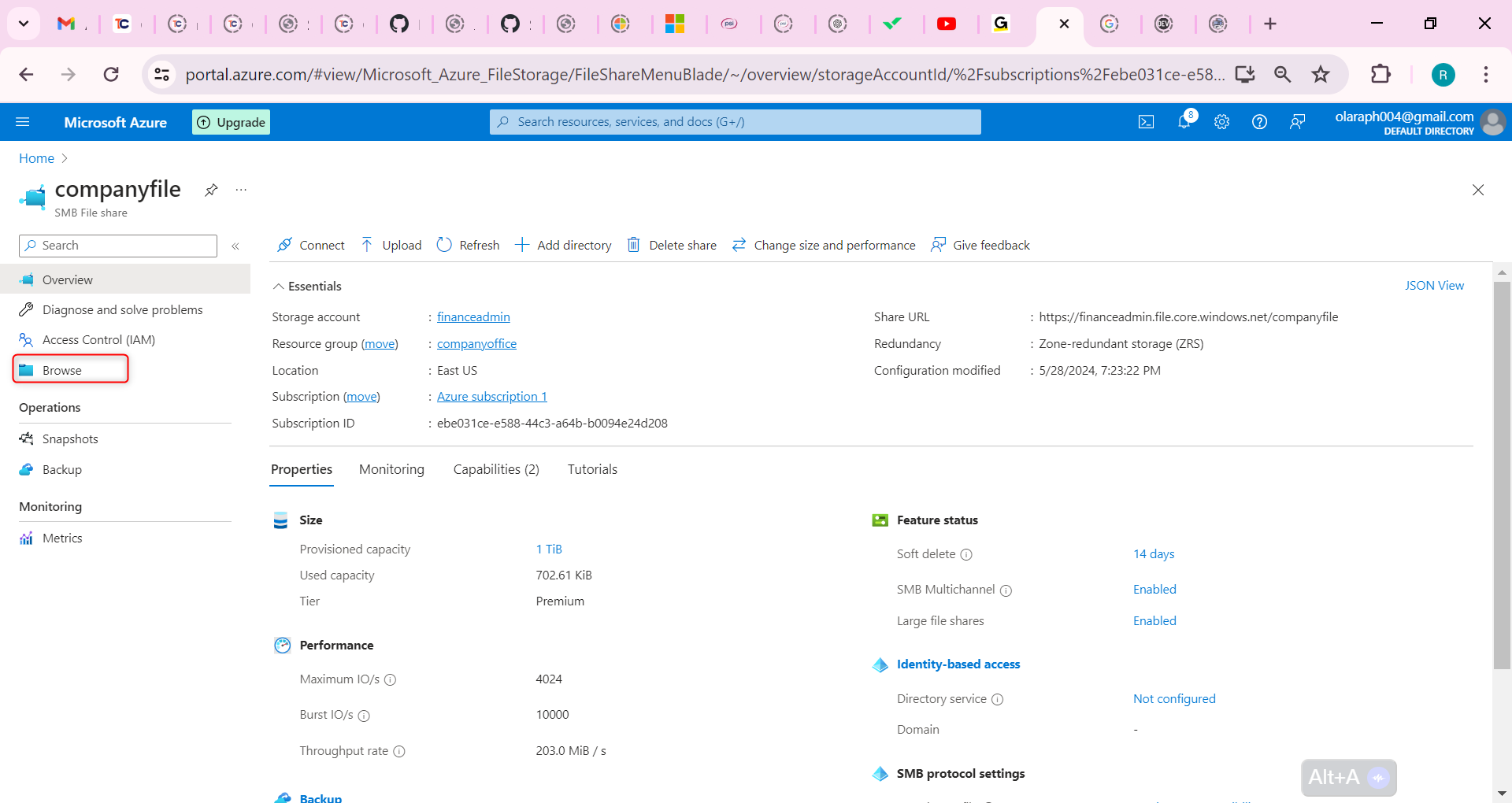
File has been restored
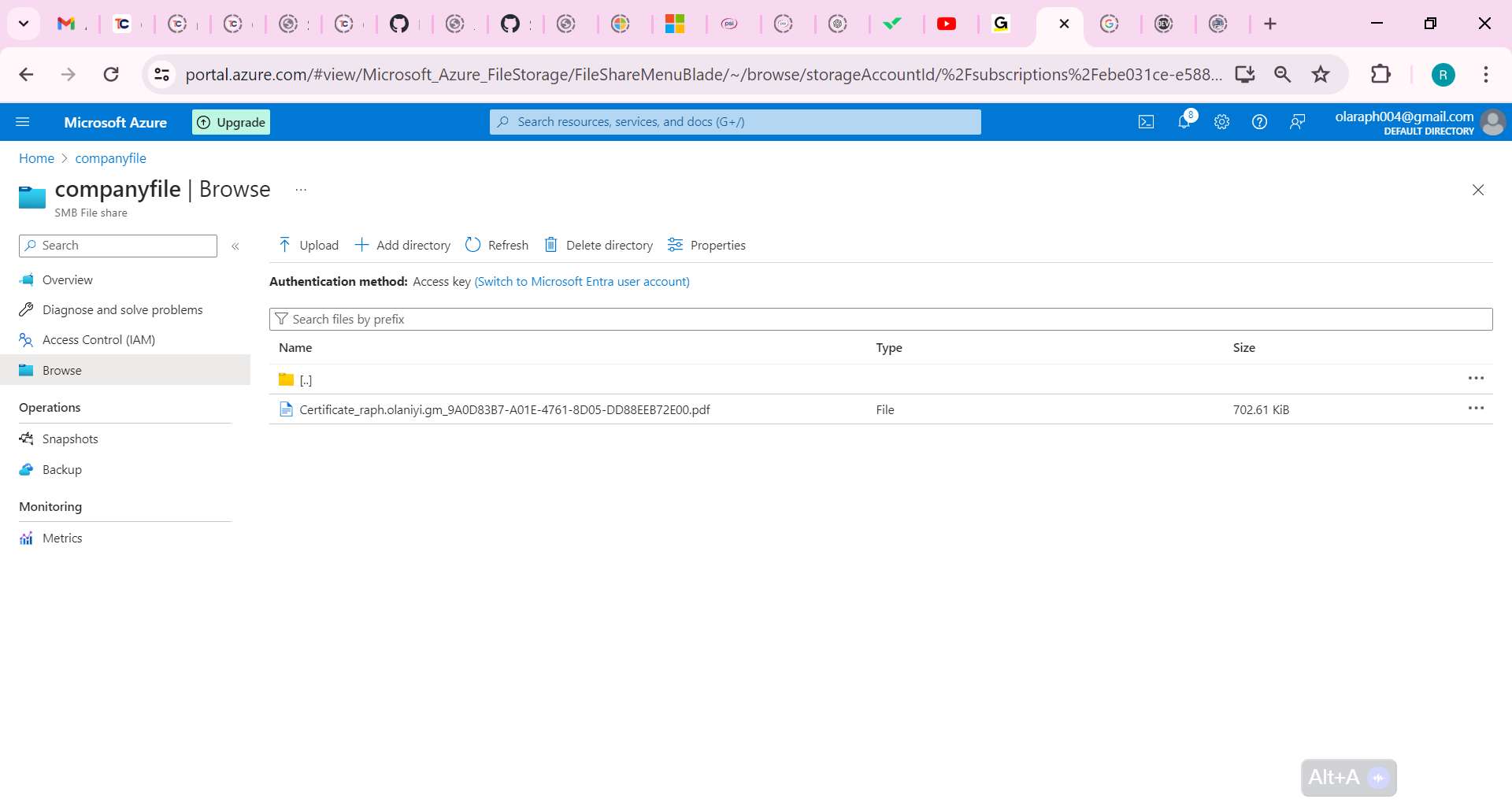
Configure restricting storage access to selected virtual networks.
This tasks in this section require a virtual network with subnet. In a production environment these resources would already be created.
Search for and select Virtual networks.
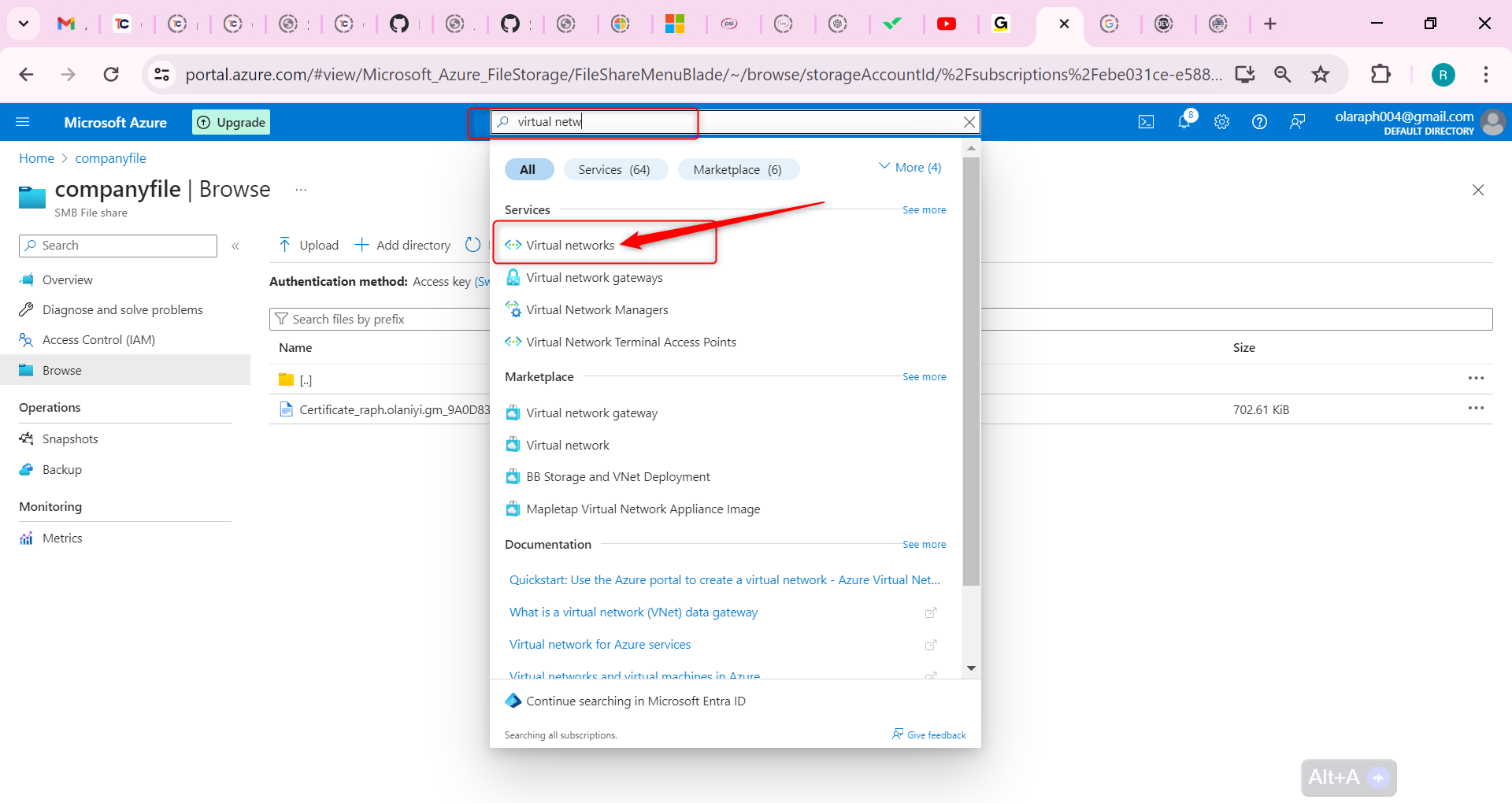
Select Create. Select your resource group. and give the virtual network a name.
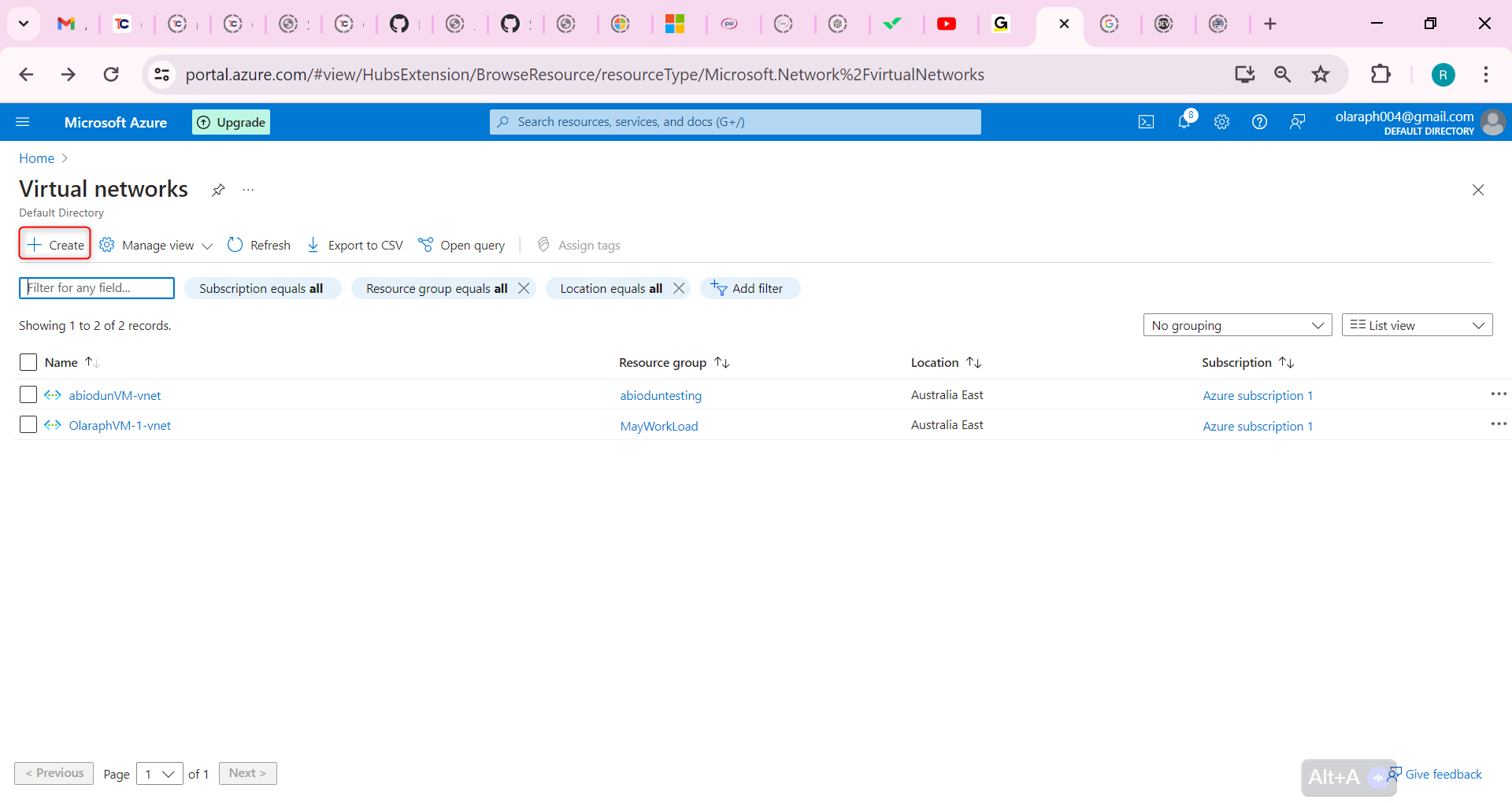
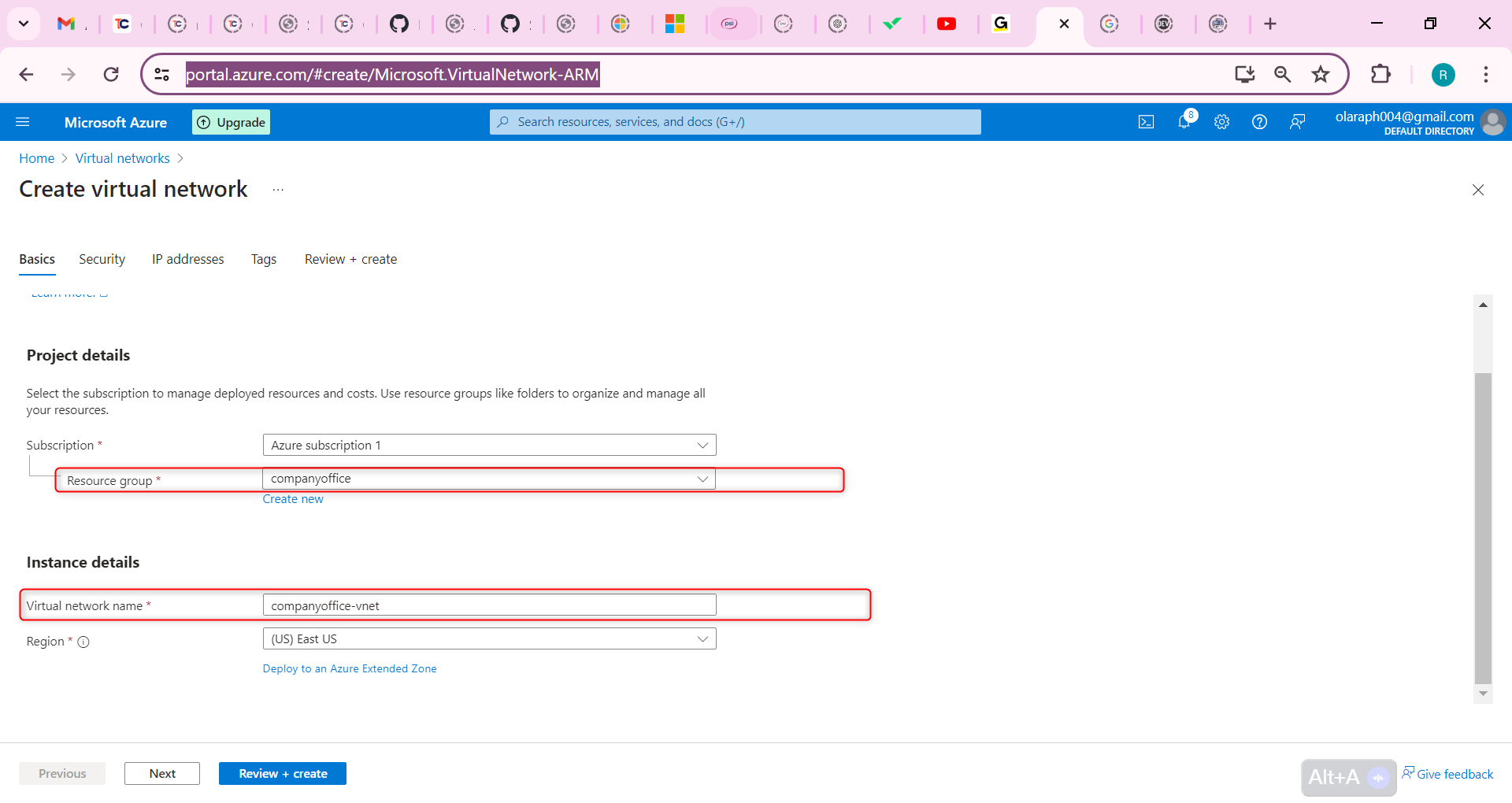
Take the defaults for other parameters, select Review + create, and then Create.
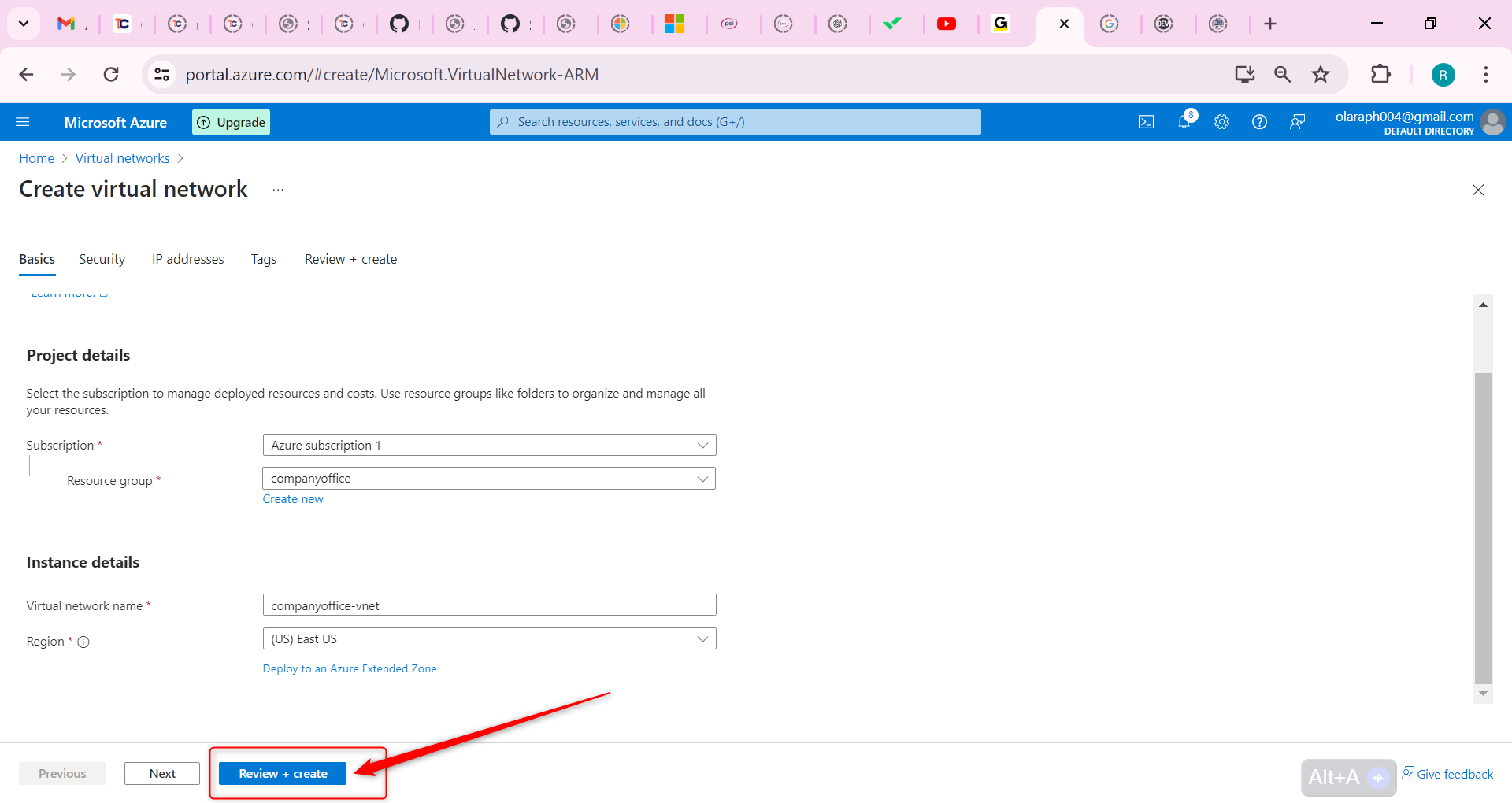
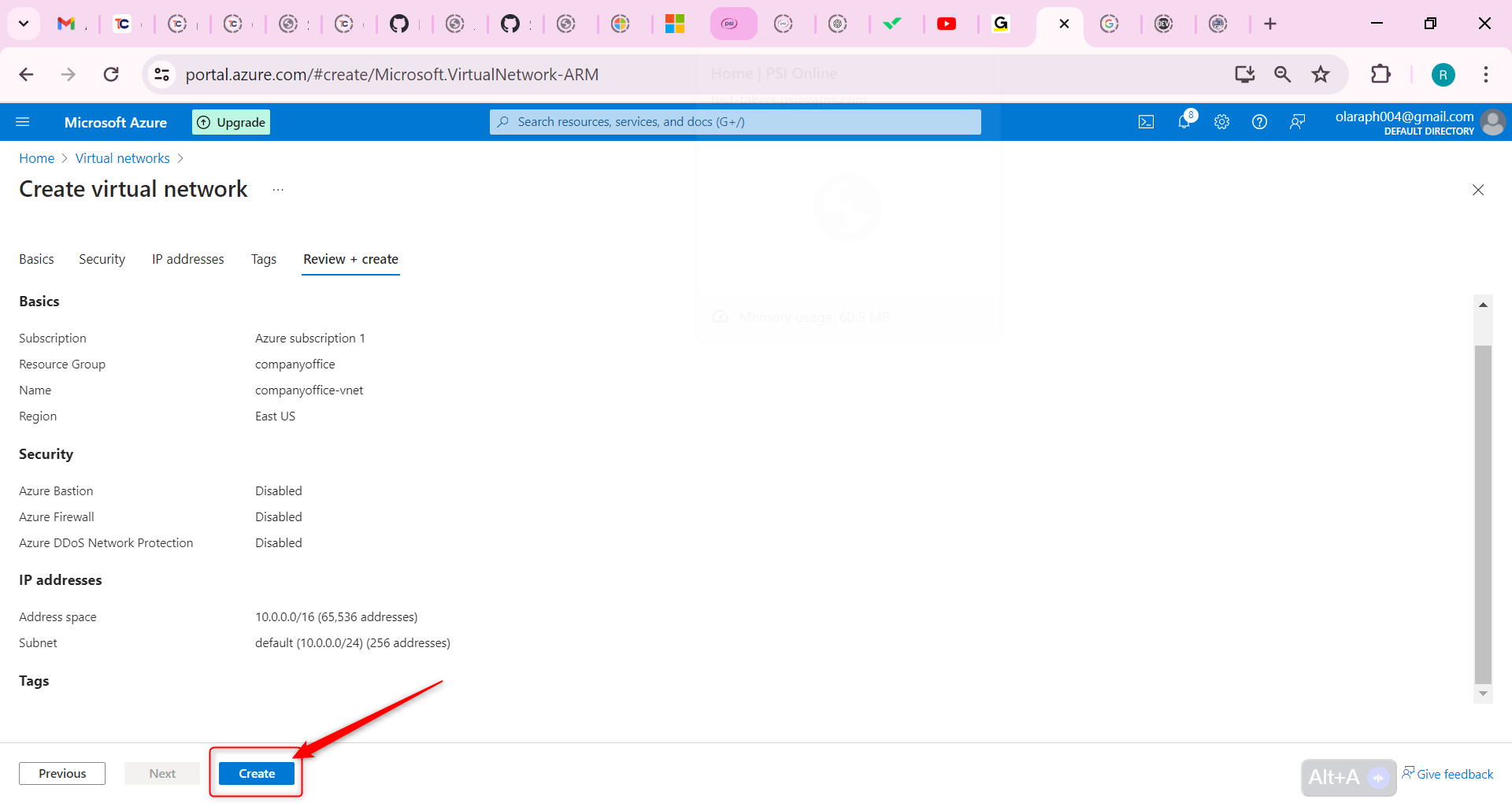
Wait for the resource to deploy.
Select Go to resource.
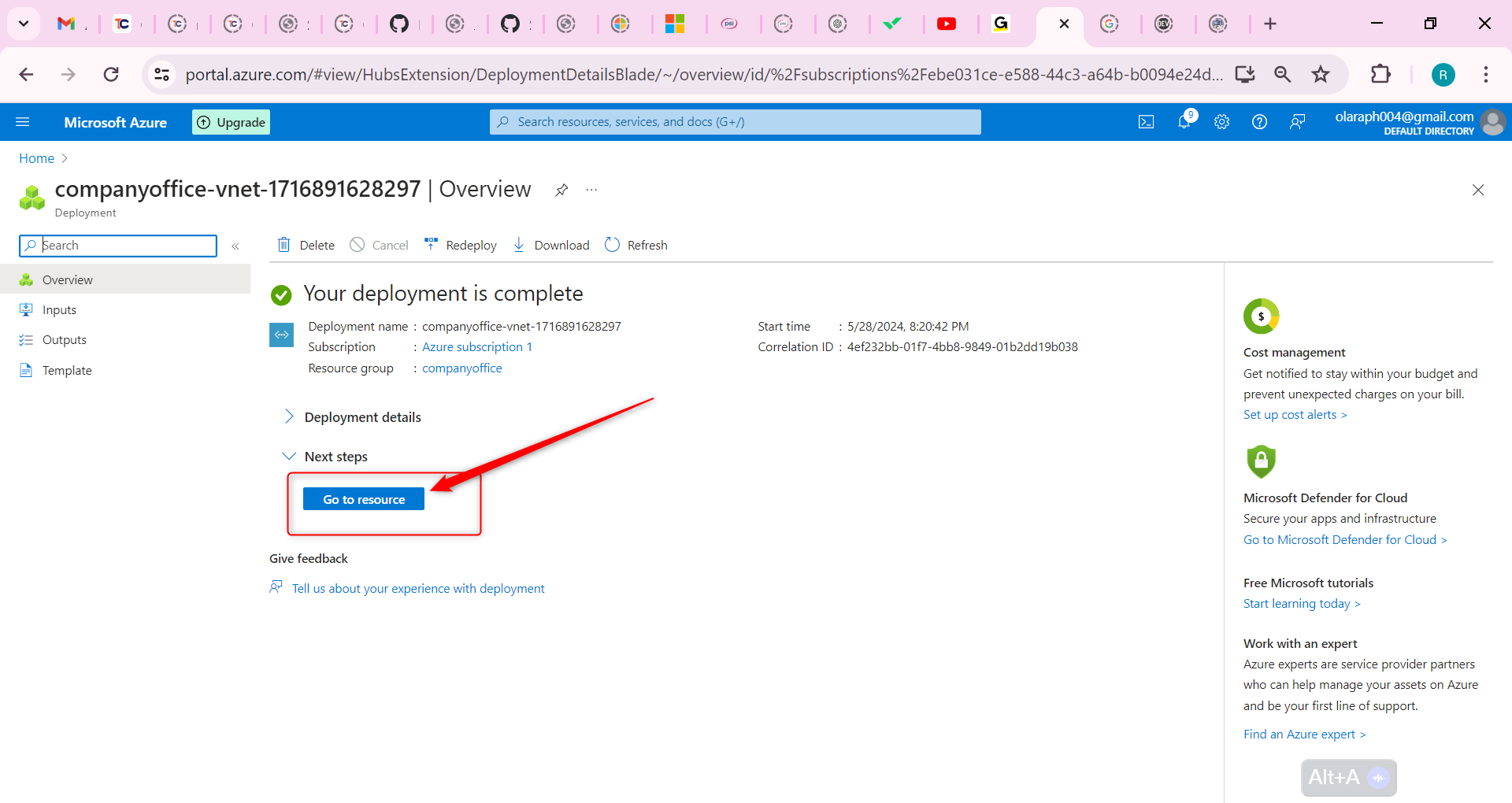
In the Settings section, select the Subnets blade.
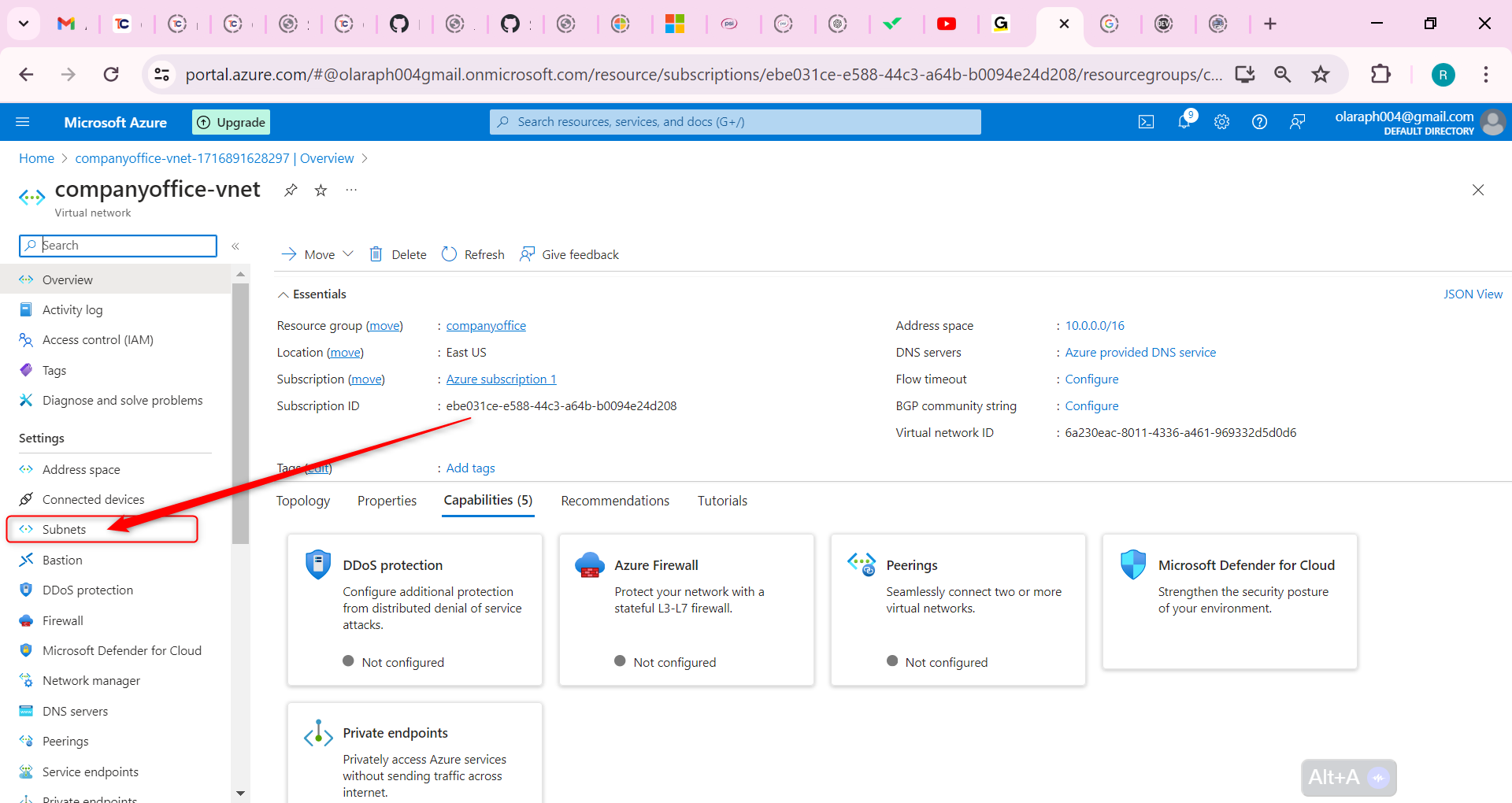
Select the default subnet.
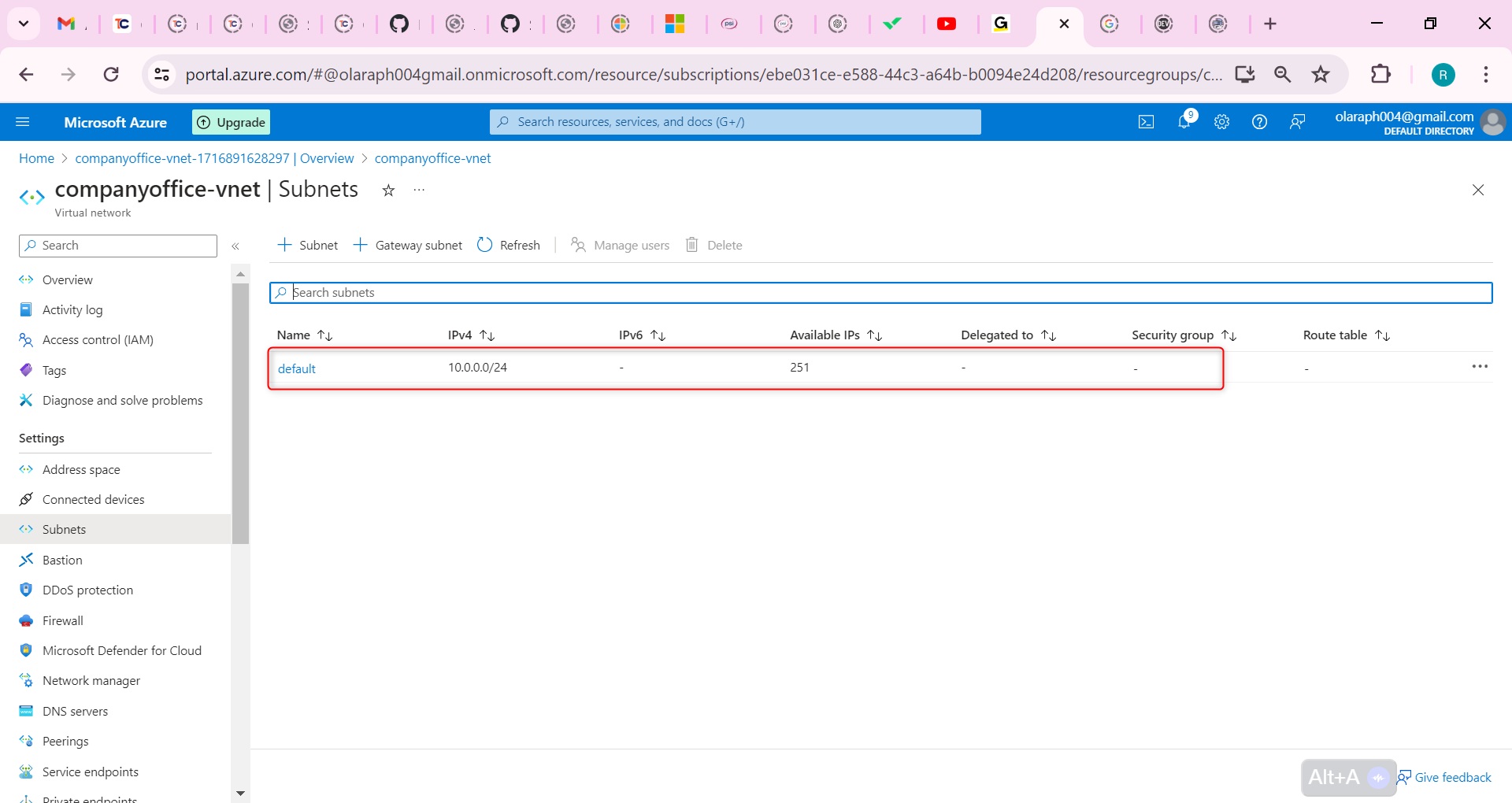
In the Service endpoints section choose Microsoft.Storage in the Services drop-down.
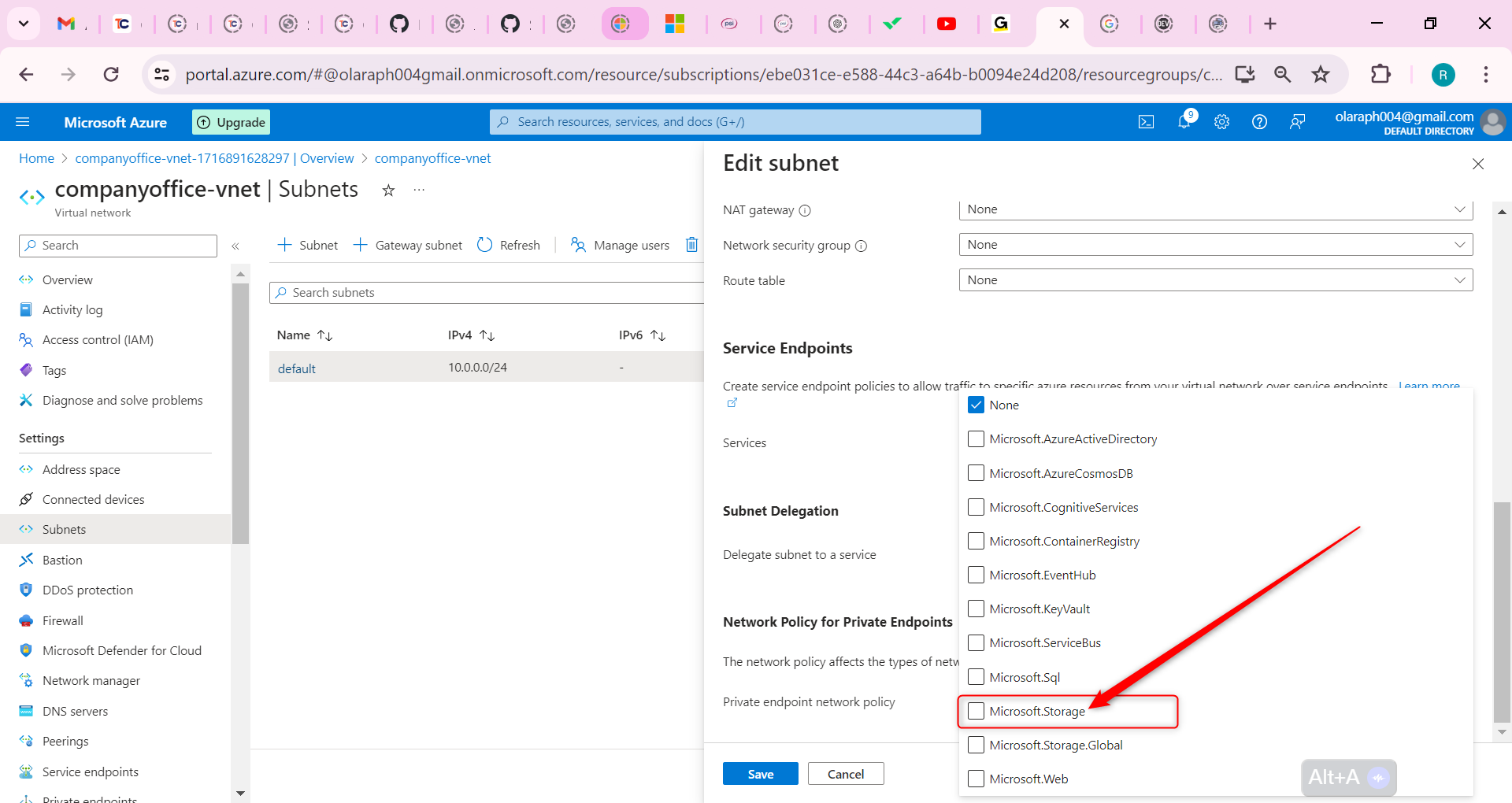
Do not make any other changes.
Be sure to Save your changes.
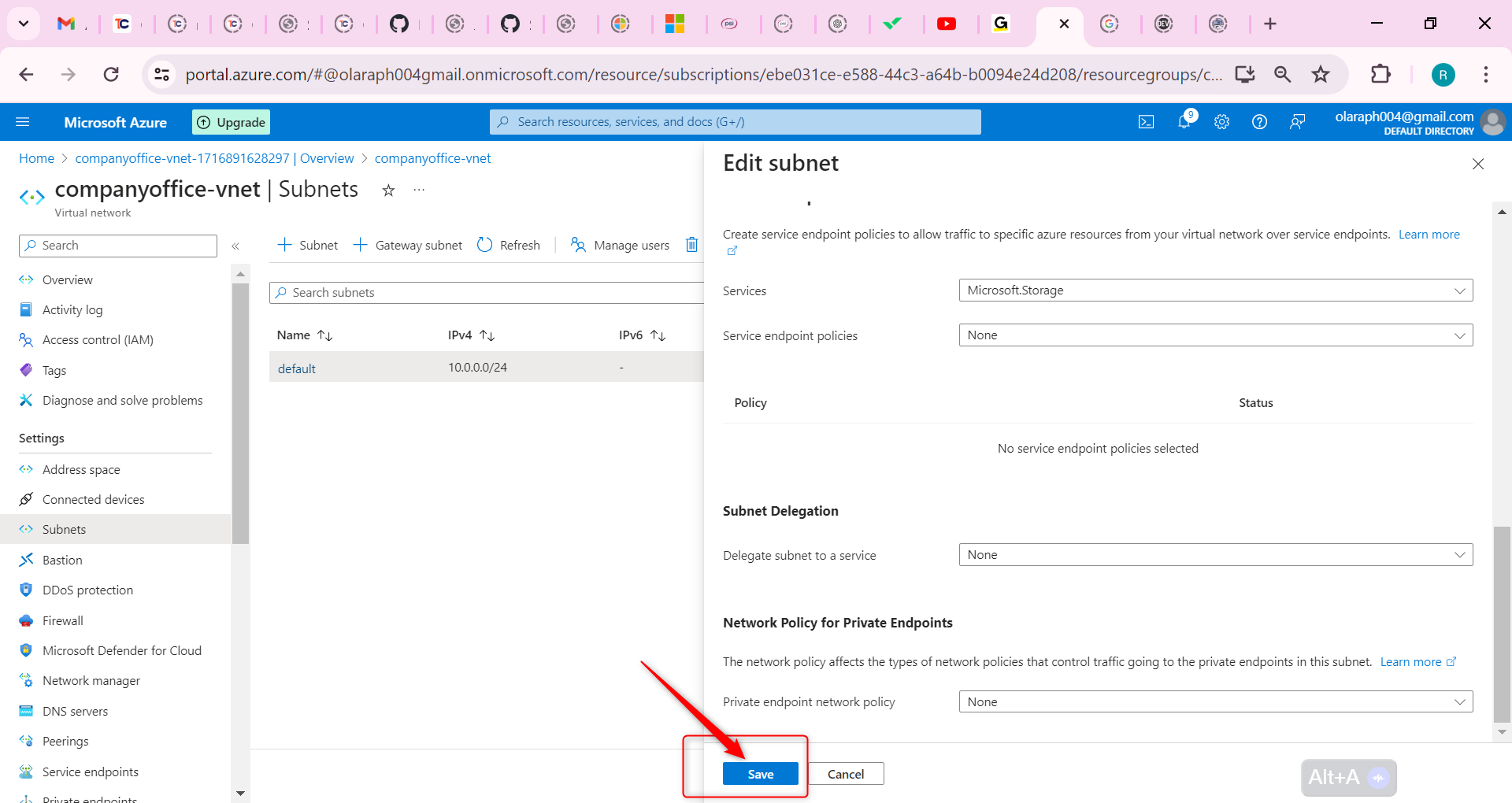
The storage account should only be accessed from the virtual network you just created.
Return to your files storage account.
In the Security + networking section, select the Networking blade.
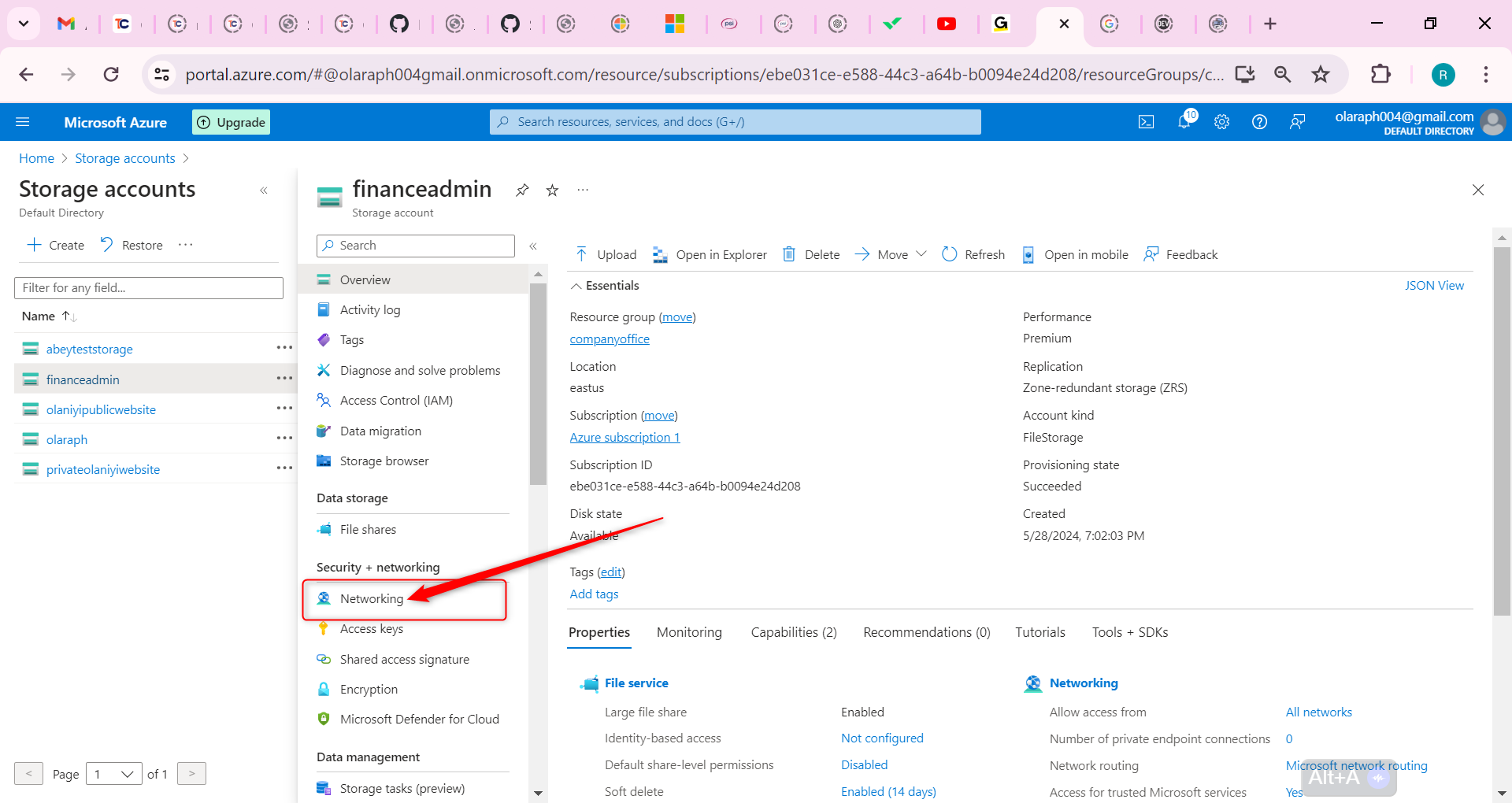
Change the Public network access to Enabled from selected virtual networks and IP addresses.
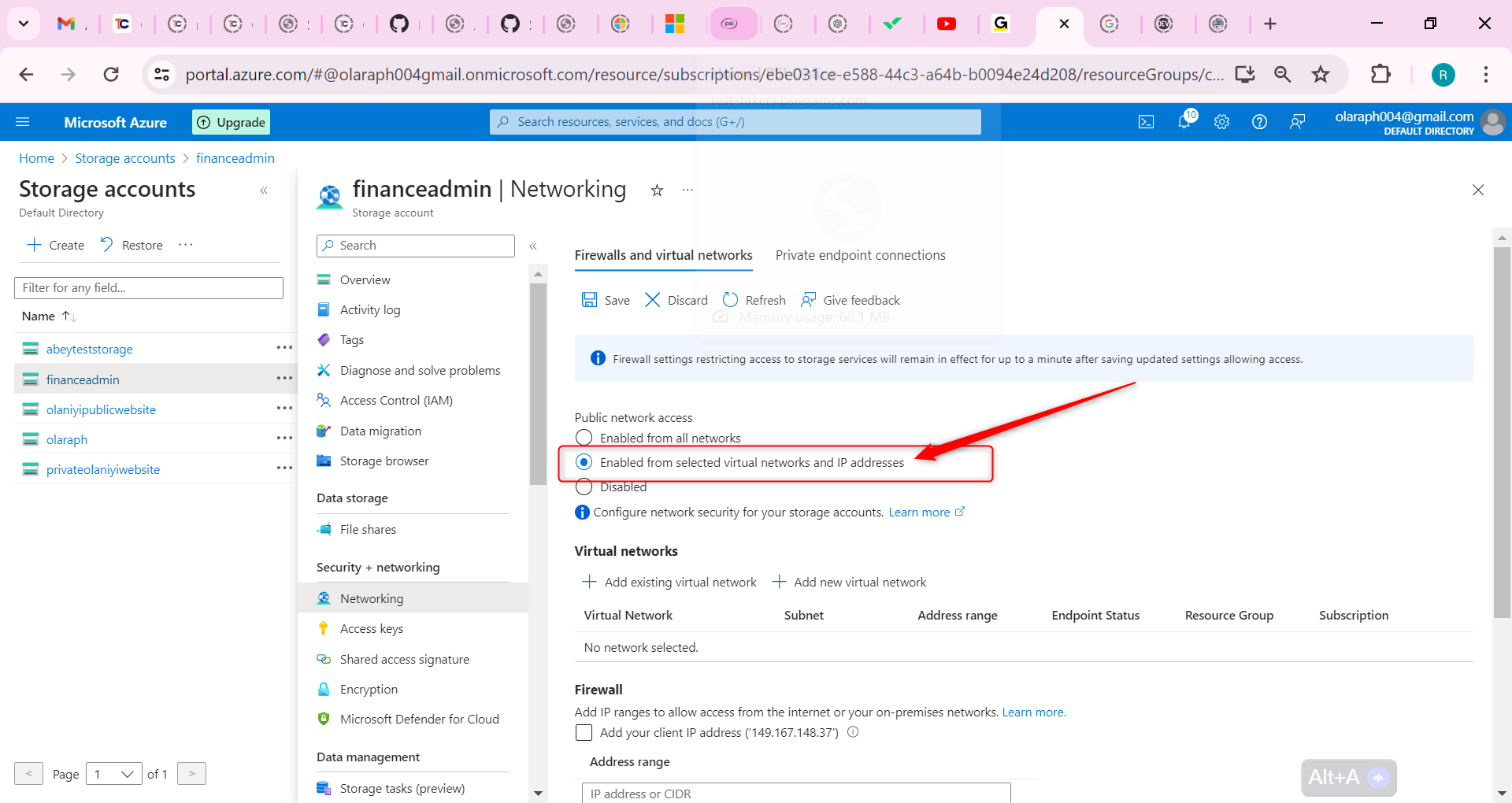
In the Virtual networks section, select Add existing virtual network.
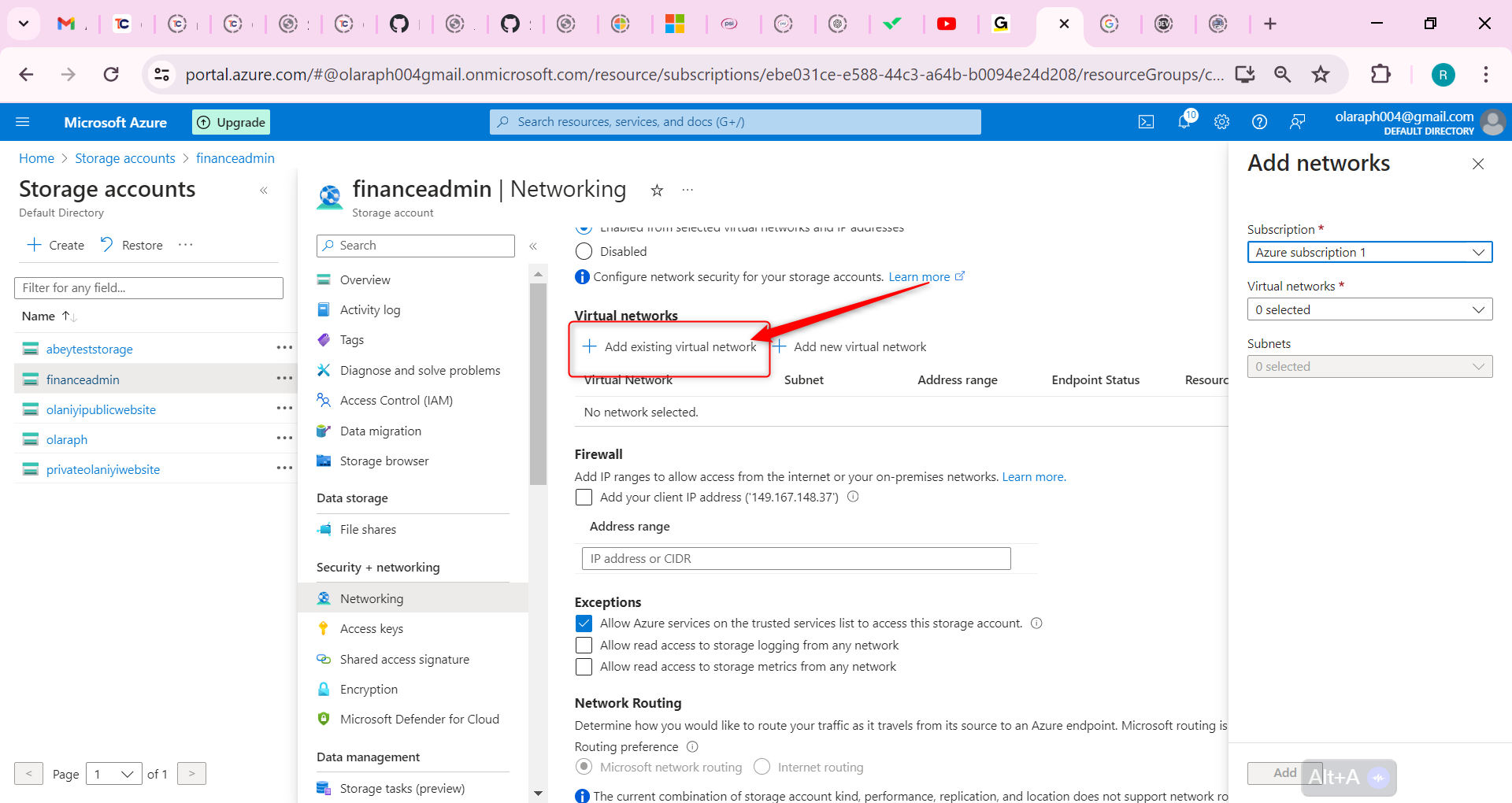
Select your virtual network and subnet, select Add.
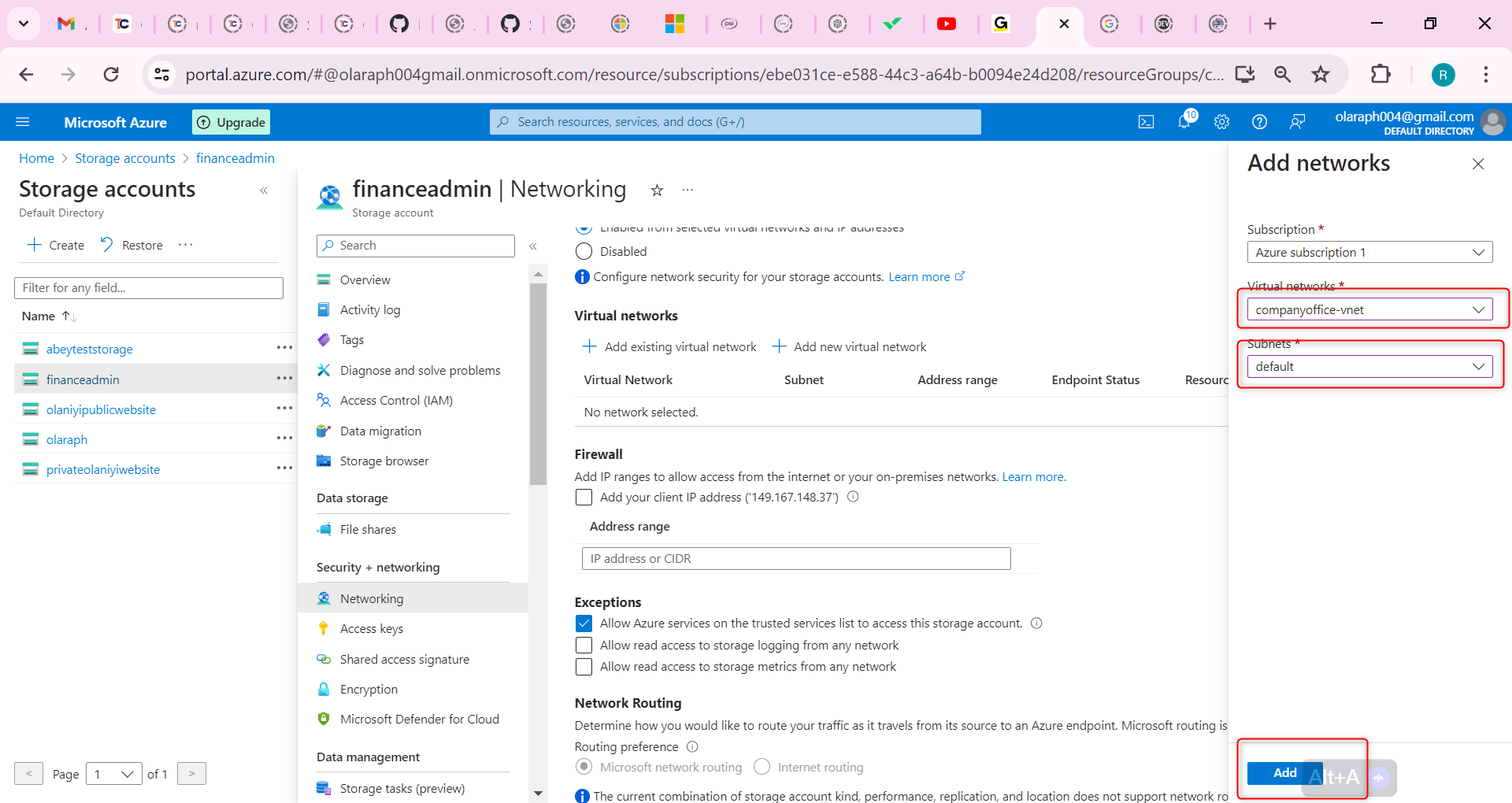
Be sure to Save your changes.
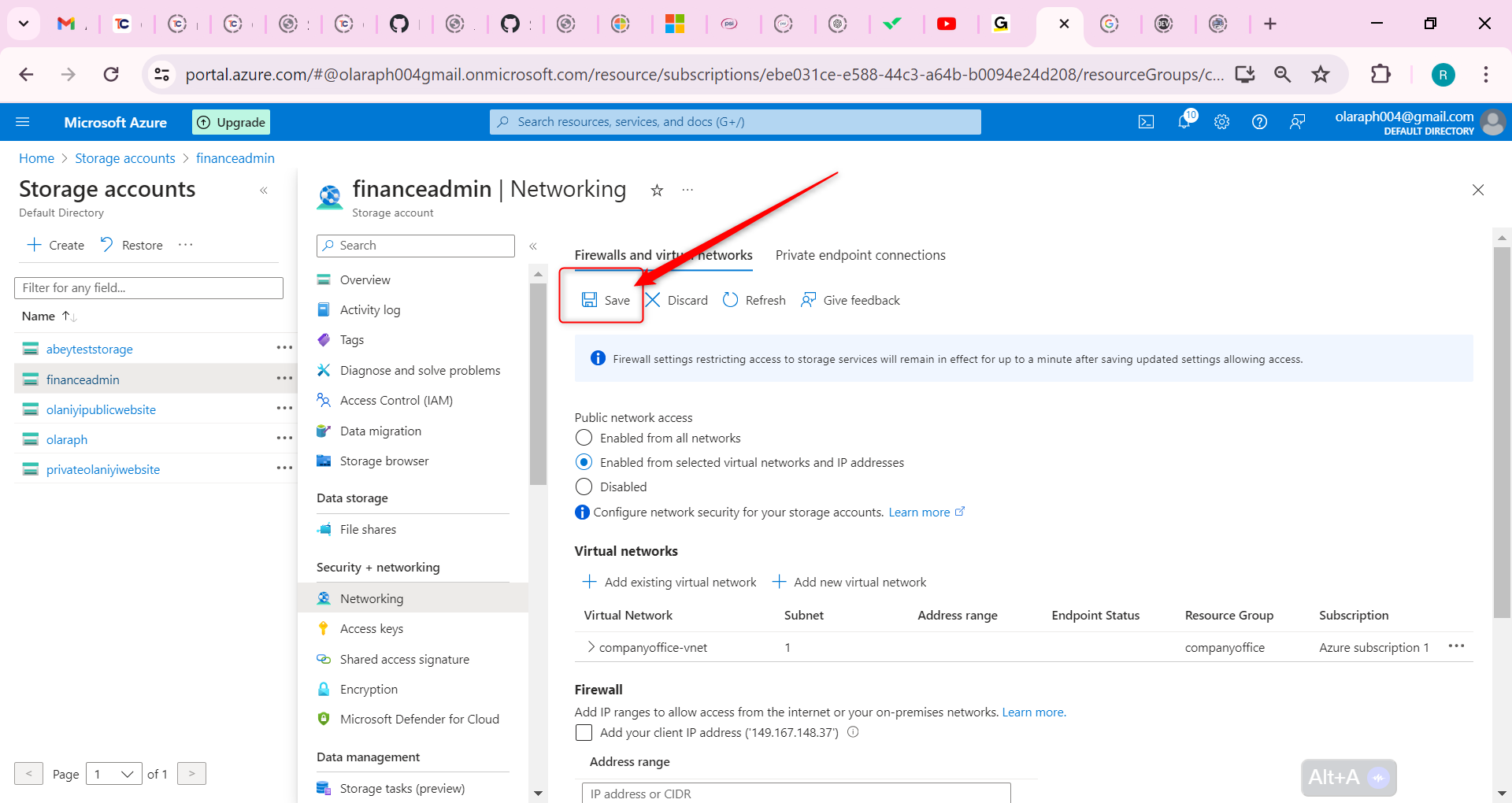
Select the Storage browser and navigate to your file share.
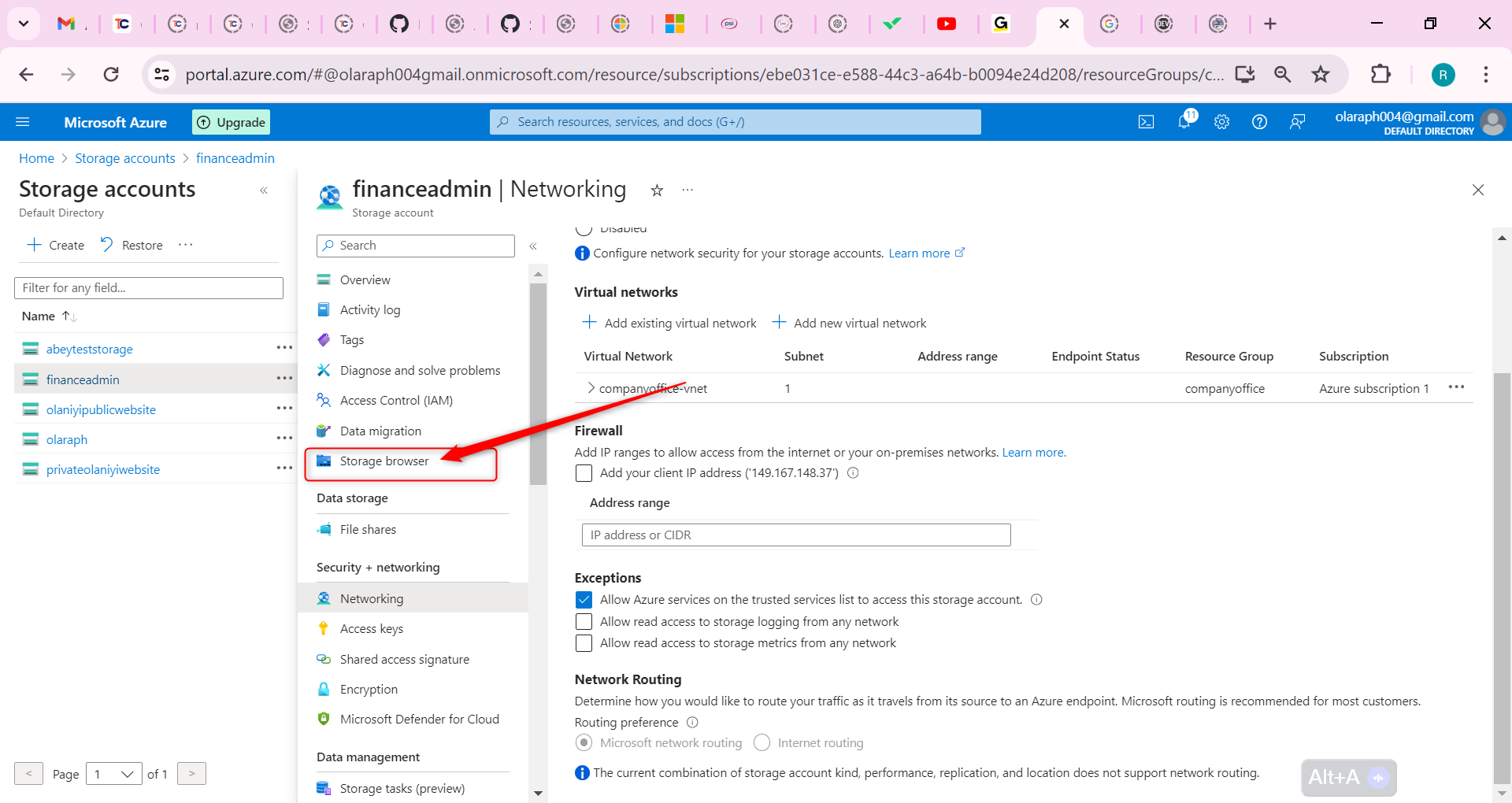
Verify the message not authorized to perform this operation. You are not connecting from the virtual network.
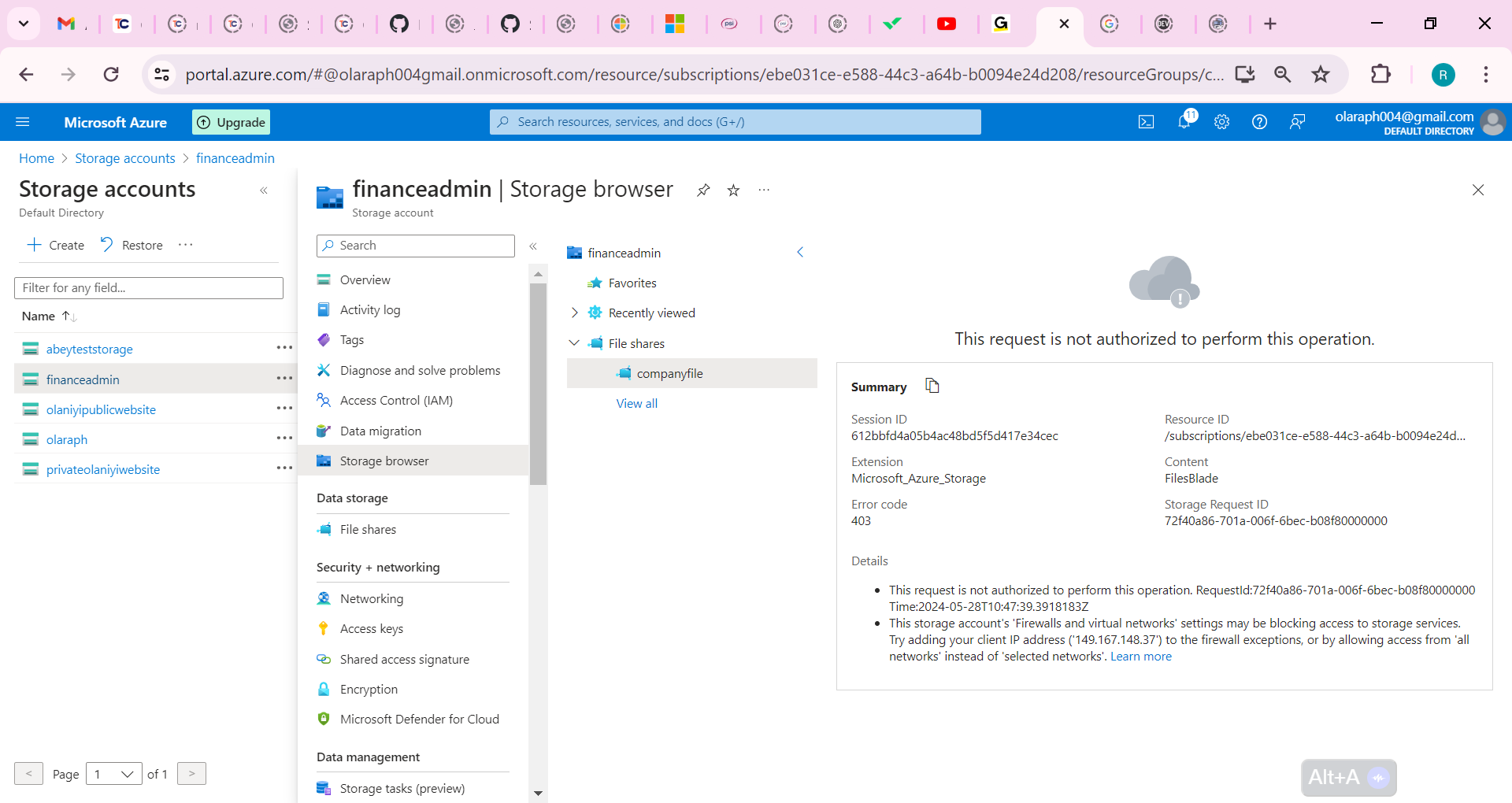
| olaraph | |
1,867,576 | How To Build a Custom CRM Software: A Comprehensive Guide | In today's competitive business landscape, customer relationship management (CRM) is essential for... | 0 | 2024-05-28T12:11:46 | https://dev.to/samantha_hayes/how-to-build-a-custom-crm-software-a-comprehensive-guide-355c | In today's competitive business landscape, customer relationship management (CRM) is essential for businesses to thrive. While off-the-shelf CRM solutions exist, they may not always meet the unique needs of every business. This is where [custom CRM software development](https://cyaniclab.com/crm-development) comes into play, offering tailored solutions designed to address specific requirements and workflows. In this article, we'll delve into what custom CRM software is, its benefits, how to create it, and finding the right development partner.
## What is Custom CRM Software?
Custom CRM software refers to a personalized solution designed and developed to meet the specific needs and requirements of a business. Unlike off-the-shelf CRM systems, which offer a one-size-fits-all approach, custom CRM software allows businesses to tailor the system according to their workflows, processes, and objectives. This level of customization ensures that the CRM solution aligns perfectly with the business's operations and goals.
## Benefits of Custom CRM Software
1. Tailored to Your Needs: Custom CRM software is built specifically to address your business's unique requirements, ensuring optimal functionality and efficiency.
2. Enhanced Flexibility: With custom CRM software, you have the flexibility to add or modify features as your business evolves.
3. Improved User Adoption: Since the CRM system is tailored to your team's workflows, it's more intuitive and user-friendly, leading to higher user adoption rates.
4. Better Integration: Custom CRM software can seamlessly integrate with existing systems and applications, streamlining processes and improving data accessibility.
5. Scalability: As your business grows, custom CRM software can scale accordingly, accommodating increased data volume and user demands.
## How to Create Custom CRM Software
1. Define Your Requirements: Start by identifying your business's specific CRM needs, including features, workflows, and integration requirements.
2. Choose the Right Development Approach: Decide whether you want to build your custom CRM software in-house or partner with an external development team.
3. Design the System Architecture: Work with your development team to design the system architecture, including database structure, modules, and user interface.
4. Develop and Test: The development phase involves coding the CRM software according to the specifications outlined in the design phase. Testing is crucial to ensure that the system functions as intended and is free of bugs.
5. Deploy and Train: Once the CRM software is developed and tested, it's time to deploy it in your organization. Provide comprehensive training to your team to ensure they can effectively use the new system.
## Find A Development Partner
[Finding the right development partner](https://cyaniclab.com/
) is crucial for the success of your custom CRM software project. Look for a reputable software development company with experience in CRM development. Consider factors such as expertise, portfolio, client testimonials, and communication capabilities when selecting a development partner.
In conclusion, building a custom CRM software solution offers numerous benefits, including tailored functionality, enhanced flexibility, and improved user adoption. By following the steps outlined in this guide and partnering with the right development team, you can create a custom CRM software that empowers your business to manage customer relationships more effectively and efficiently.
| samantha_hayes | |
1,867,566 | Top 8+ Web Development Companies for 2024 | ` Top 8+ Web Development Companies for 2024: Reviews, Services, Pricing, and Key Clients In the... | 0 | 2024-05-28T12:11:05 | https://dev.to/pixlogix1/top-8-web-development-companies-for-2024-3pkm | webdev, developers | `<h3>Top 8+ Web Development Companies for 2024: Reviews, Services, Pricing, and Key Clients</h3>
In the ever-evolving digital landscape, selecting the right web development company is crucial for the success of your online presence. As we step into 2024, several companies stand out for their exceptional services, innovative solutions, and client satisfaction. Here’s a comprehensive look at the top web development companies for 2024, including reviews, services, pricing, and key clients.
<h4>1. <strong>Pixlogix</strong></h4>
<strong>Reviews:</strong> Pixlogix is highly praised for its customer-centric approach and innovative solutions. Clients commend their attention to detail and timely delivery.
<strong>Services:</strong> Custom web development, e-commerce solutions, UI/UX design, and mobile app development.
<strong>Pricing:</strong> Starts at $50 per hour, with flexible packages available.
<strong>Key Clients:</strong> Ajanta Pharma, Global Fund for Children, and Saudi Arabian Airlines.
Pixlogix stands out for its ability to deliver tailored web solutions that meet specific business needs, making them a top choice for clients across various industries.
<h4>2. <strong>Toptal</strong></h4>
<strong>Reviews:</strong> Known for their high-quality talent pool, Toptal is rated highly for providing top 3% developers globally.
<strong>Services:</strong> Custom software development, web development, and UI/UX design.
<strong>Pricing:</strong> Starts at $60 per hour, offering premium services.
<strong>Key Clients:</strong> Motorola, Bridgestone, and Shopify.
Toptal is ideal for businesses seeking elite developers for complex projects, ensuring top-tier performance and innovation.
<h4>3. <strong>WillowTree</strong></h4>
<strong>Reviews:</strong> Clients appreciate WillowTree for their strategic insights and seamless project execution.
<strong>Services:</strong> Web development, mobile app development, and digital strategy.
<strong>Pricing:</strong> Starts at $100 per hour, reflecting their high-quality service.
<strong>Key Clients:</strong> HBO, PepsiCo, and National Geographic.
WillowTree’s strong emphasis on user experience and digital transformation makes them a leader in the web development space.
<h4>4. <strong>Intellectsoft</strong></h4>
<strong>Reviews:</strong> Intellectsoft receives accolades for their robust solutions and excellent client support.
<strong>Services:</strong> Enterprise web development, blockchain solutions, and AI development.
<strong>Pricing:</strong> Starts at $75 per hour, with comprehensive packages available.
<strong>Key Clients:</strong> Harley-Davidson, Nestlé, and Clinique.
Intellectsoft’s expertise in emerging technologies positions them as a forward-thinking web development partner.
<h4>5. <strong>ELEKS</strong></h4>
<strong>Reviews:</strong> ELEKS is lauded for their innovative approach and technical prowess.
<strong>Services:</strong> Custom web development, data science, and product design.
<strong>Pricing:</strong> Starts at $70 per hour, offering value for their advanced services.
<strong>Key Clients:</strong> Fortune 500 companies, SMEs, and startups globally.
ELEKS combines creativity with technology to deliver cutting-edge web solutions tailored to client needs.
<h4>6. <strong>Cubix</strong></h4>
<strong>Reviews:</strong> Cubix is celebrated for their creativity and on-time delivery.
<strong>Services:</strong> Web development, mobile app development, and game development.
<strong>Pricing:</strong> Starts at $60 per hour, with flexible engagement models.
<strong>Key Clients:</strong> Clinique, Nintendo, and PayPal.
Cubix’s innovative approach to web and mobile development has earned them a loyal client base and numerous accolades.
<h4>7. <strong>OpenXcell</strong></h4>
<strong>Reviews:</strong> OpenXcell is known for their reliability and quality of work.
<strong>Services:</strong> Custom web development, mobile app development, and software solutions.
<strong>Pricing:</strong> Starts at $50 per hour, providing cost-effective solutions.
<strong>Key Clients:</strong> Google, Oracle, and Motorola.
OpenXcell’s commitment to excellence and customer satisfaction makes them a preferred choice for many global brands.
<h4>8. <strong>Cleveroad</strong></h4>
<strong>Reviews:</strong> Cleveroad is praised for their agile development processes and customer focus.
<strong>Services:</strong> Web development, mobile app development, and enterprise solutions.
<strong>Pricing:</strong> Starts at $45 per hour, with competitive rates.
<strong>Key Clients:</strong> HSBC, Octopus, and Huawei.
Cleveroad’s ability to deliver scalable and secure web solutions ensures they remain at the forefront of the industry.
<h4>9. <strong>iTechArt</strong></h4>
<strong>Reviews:</strong> iTechArt is recognized for their technical expertise and innovative solutions.
<strong>Services:</strong> Web development, mobile development, and cloud solutions.
<strong>Pricing:</strong> Starts at $65 per hour, reflecting their high standard of service.
<strong>Key Clients:</strong> ClassPass, Freshly, and Bevi.
iTechArt’s focus on cutting-edge technologies and client success has earned them a top spot among web development companies.
<h3>Comparison for Better Visibility</h3>
When comparing these top web development companies, several factors stand out to help you make an informed decision:
<ol>
<li><strong>Services Offered:</strong> Ensure the company offers the specific services you need, whether it’s custom web development, mobile app development, or emerging tech solutions like AI and blockchain.</li>
<li><strong>Pricing:</strong> Understand the pricing models and choose a company that fits your budget while offering high-quality services.</li>
<li><strong>Key Clients:</strong> Reviewing the company’s key clients can provide insight into their experience and reliability in handling projects similar to yours.</li>
<li><strong>Client Reviews:</strong> Look for companies with positive client feedback and high ratings for customer satisfaction and project delivery.</li>
</ol>
By considering these factors, you can choose the best web development partner to drive your business success in 2024 and beyond.
<h3>Conclusion</h3>
Selecting the right [web development company](https://www.pixlogix.com/web-development-services/) is critical to achieving your digital goals. The companies listed above are renowned for their expertise, innovative solutions, and client satisfaction. Whether you need a complex enterprise solution or a creative web application, these top web development companies are well-equipped to meet your needs and help you thrive in the digital age.``
` | pixlogix1 |
1,867,575 | How to Use Arrays as Parameters in Golang? | Table of Contents Declaring Arrays in Golang Passing Arrays as Function... | 0 | 2024-05-28T12:08:50 | https://dev.to/awahids/how-to-use-arrays-as-parameters-in-golang-6dm | go, gorm | 
## Table of Contents
- [Declaring Arrays in Golang](#1-declaring-arrays-in-golang)
- [Passing Arrays as Function Parameters](#2-passing-arrays-as-function-parameters)
- [Using Slices as Function Parameters](#3-using-slices-as-function-parameters)
- [Practical Example: Paginating Data](#4-practical-example-paginating-data)
- [Conclusion](#conclusion)
In Golang, arrays are a fundamental data structure that can be passed as parameters to functions. This article will explain how to use arrays as parameters in Go, including examples of passing arrays with fixed sizes and using slices for more flexibility.
#### 1. Declaring Arrays in Golang
Before passing arrays as parameters, let's review how to declare arrays in Go.
```go
package main
import "fmt"
func main() {
// Declare an array with a fixed size of 5
var numbers [5]int
fmt.Println(numbers) // Output: [0 0 0 0 0]
// Declare an array with initial values
primes := [5]int{2, 3, 5, 7, 11}
fmt.Println(primes) // Output: [2 3 5 7 11]
}
```
## Semilar Contents
> - [Example basic CRUD Operations Using Golang, Gin Gonic, and GORM](https://blog.awahids.my.id/blog/golang/example-basic-crud-using-golang-gin-gonic-gorm)
#### 2. Passing Arrays as Function Parameters
To pass an array as a parameter to a function, you need to declare the function parameter as an array with a fixed length. Here’s an example:
```go
package main
import "fmt"
// Function that accepts an array with a fixed length of 5
func printArray(arr [5]int) {
for i, value := range arr {
fmt.Printf("Element %d: %d\n", i, value)
}
}
func main() {
primes := [5]int{2, 3, 5, 7, 11}
printArray(primes)
}
```
In the above example, the `printArray` function accepts a parameter of type array with a length of 5 elements.
#### 3. Using Slices as Function Parameters
In Go, it’s more common to use slices than arrays when passing a collection of data to a function. Slices are more flexible because they do not have a fixed length like arrays.
```go
package main
import "fmt"
// Function that accepts a slice
func printSlice(slice []int) {
for i, value := range slice {
fmt.Printf("Element %d: %d\n", i, value)
}
}
func main() {
primes := []int{2, 3, 5, 7, 11}
printSlice(primes)
}
```
In the example above, the `printSlice` function accepts a parameter of type slice. You can change the length of a slice without needing to redeclare it like an array.
#### 4. Practical Example: Paginating Data
Let’s apply this concept in a practical example. Suppose you want to create a function to paginate data from a database using GORM in Go. Here is a simple implementation:
```go
package main
import (
"github.com/gin-gonic/gin"
"gorm.io/driver/sqlite"
"gorm.io/gorm"
"net/http"
"reflect"
"strconv"
)
type Product struct {
ID int `json:"id"`
Name string `json:"name"`
}
func main() {
r := gin.Default()
db, _ := gorm.Open(sqlite.Open("test.db"), &gorm.Config{})
db.AutoMigrate(&Product{})
r.GET("/products", func(ctx *gin.Context) {
var responseDto []Product
page, _ := strconv.Atoi(ctx.DefaultQuery("page", "1"))
perPage, _ := strconv.Atoi(ctx.DefaultQuery("per_page", "10"))
ResponseWithPaginate(db, &Product{}, &responseDto, ctx, page, perPage)
})
r.Run()
}
func ResponseWithPaginate(c *gorm.DB, data interface{}, responseDto interface{}, ctx *gin.Context, page int, perPage int) {
var totalItems int64
err := c.Model(data).Count(&totalItems).Error
if err != nil {
ctx.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
result := c.Limit(perPage).Offset((page - 1) * perPage).Find(responseDto)
if result.Error != nil {
ctx.JSON(http.StatusNotFound, gin.H{"error": result.Error.Error()})
return
}
meta := NewMeta(ctx, totalItems, int64(reflect.ValueOf(responseDto).Elem().Len()))
SuccessResponse(ctx, responseDto, meta)
}
func NewMeta(ctx *gin.Context, totalItems, itemCount int64) map[string]interface{} {
return map[string]interface{}{
"total_items": totalItems,
"item_count": itemCount,
}
}
func SuccessResponse(ctx *gin.Context, data interface{}, meta map[string]interface{}) {
ctx.JSON(http.StatusOK, gin.H{
"data": data,
"meta": meta,
})
}
```
In the example above, the `ResponseWithPaginate` function accepts a slice as a parameter for `responseDto`. This slice is used to store the results of the query from the database.
#### Conclusion
Using arrays or slices as parameters in functions in Golang is straightforward and intuitive. Slices are often preferred due to their flexibility in size. By understanding these basics, you can easily manage and manipulate collections of data in your Go programs. | awahids |
1,867,574 | Top 9 Database Documentation Tools of 2024 — Free and Paid Options Unwrapped | Database documentation tools usually aren't the priority for the teams working on small projects.... | 0 | 2024-05-28T12:07:40 | https://dev.to/dbajamey/top-9-database-documentation-tools-of-2024-free-and-paid-options-unwrapped-15j8 | database, documentation | Database documentation tools usually aren't the priority for the teams working on small projects. When coping with routine development tasks, it's easy to overlook the importance of creating comprehensive database documentation since there are always more urgent tasks. However, when you become the only person who knows how things work, collaboration and making the data usable will eventually start posing a real challenge. According to the 2023 Developer Survey by Stackoverflow, over 70% of developers encounter knowledge silos at work at least 1-2 times a week, needing assistance from their team members or colleagues outside of their teams. As a result, productivity frictions happen.
Moreover, even to the developers in charge, the database structure may become unclear. Human memory has limitations, and creating clear database documentation is as essential as providing software documentation or adding concise comments within one's code. It's a way of making a database readable and easy to understand for everyone.
This article will compare nine database documentation tools available in 2024 to determine which are most helpful without requiring much integration effort.
**Database Documentation Tools Comparison: https://blog.devart.com/best-database-documentation-tools.html** | dbajamey |
1,867,573 | Top Websites Built with Vue JS - Vue.js Website Examples | The Vue.js framework is a popular JavaScript framework for creating fast and interactive websites.... | 0 | 2024-05-28T12:05:12 | https://dev.to/startdeesigns/top-websites-built-with-vue-js-vuejs-website-examples-4p2e | vue, webdev, webdesign | The Vue.js framework is a popular JavaScript framework for creating fast and interactive websites. It's a favorite among developers and each [VueJs development company](https://www.startdesigns.com/vuejs-development-company.php) due to its ease of use and powerful features.
Fast website loading speed is an essential feature nowadays if you want to grow your business online, whether it’s e-commerce, a services website, business and finance, healthcare, education, entertainment, government, social media, or blogs.
When it is about fast loading website speed then Vue.js is the best to choose because VueJs used SPAs load the necessary HTML, CSS, and JavaScript once, and then dynamically update the content as the user interacts with the app.
This reduces the need for full-page reloads and can improve user experience.
Here are some of the most stunning websites built with Vue.js. You will see why Vue.js is a popular choice for building modern web applications.
Here are a few examples.
- Alibaba, a global leader in online commerce, uses Vue.js.
- Netflix, the popular streaming service, uses Vue.js to enhance its web experience.
- Facebook uses Vue.js for specific components within its massive website, even though it is not the core framework.
- Vue.js has been incorporated into web applications by companies like Adobe and Gitlab.
- Trivago, a travel booking website, uses Vue.js to make its interface dynamic and user-friendly.
These big companies are using VueJS, because it has the several advantages compare to other technology.
Reactive Data Binding: Vue.js's reactive data binding ensures that any changes to the data model are automatically reflected in the DOM. As a result, the user experience becomes more dynamic and interactive.
**Component-based architecture:** Vue.js uses a component-based architecture, which makes it easier to manage and reuse code. The modular approach improves the maintainability and scalability of the code.
**Ease of Learning:** Compared to other frameworks, Vue.js has a gentle learning curve. Due to its clear documentation and simplicity, it is accessible to developers of all levels of experience.
**Flexibility:** Vue.js is flexible enough to be used for single-page applications (SPAs) as well as adding interactivity to existing projects. Developers can integrate it into projects of any size because of its flexibility.
**Rich Ecosystem:** Vue.js has a rich ecosystem with a variety of tools and libraries, including Vue Router for routing and Vuex for state management. As a result, productivity is increased and development processes are streamlined.
**Performance:** The virtual DOM in Vue.js is lightweight and designed for speed. As a result, load times are faster and user experiences are smoother.
**Community Support:** The Vue.js community provides extensive resources, plugins, and support. You can find solutions to common problems and stay up-to-date with best practices this way.
**Integration Capabilities:** Vue.js integrates easily with other libraries and projects. Vue's interoperability allows developers to adopt it incrementally without having to rewrite entire codebases.
**Two-Way Data Binding:** Vue.js supports two-way data binding, allowing seamless synchronization between the user interface and the data model. Form inputs and dynamic data handling are particularly useful for this.
**Custom Directives:** Vue.js allows developers to create custom directives that extend HTML functionality. It provides greater flexibility and control over the behavior of the application.
Hope this article will help you to get answer you are looking for.
Thanks for Reading!
Originally published at [https://www.linkedin.com/pulse/top-websites-built-vue-js-vuejs-website-examples-start-designs-0f1we/](https://www.linkedin.com/pulse/top-websites-built-vue-js-vuejs-website-examples-start-designs-0f1we/) on May 28, 2024 | startdeesigns |
1,867,572 | The Professional Journey Unfolding | The professional journey is a dynamic and multifaceted path that encompasses the experiences, skills,... | 0 | 2024-05-28T12:03:36 | https://dev.to/angelika_jolly_4aa3821499/the-professional-journey-unfolding-23bi | programming, productivity, journey, tutorial | The professional journey is a dynamic and multifaceted path that encompasses the experiences, skills, and knowledge one acquires over the course of their career. This journey often begins with education and early career choices and evolves through various stages, marked by personal growth, professional development, and significant milestones. Here’s an outline of the key stages and components of a typical professional journey:
1. Education and Early Career Choices
- Formal Education: High school, college, or university education, including specialized training and certifications.
- Internships and Apprenticeships: Gaining practical experience in the chosen field.
- Entry-Level Positions: Starting roles that provide foundational experience and skills.
2. Skill Development and Specialization
- On-the-Job Training: Learning specific skills and gaining expertise through practical work.
- Continuous Learning: Taking courses, attending workshops, and obtaining certifications to stay updated with industry trends.
- Mentorship and Networking: Seeking guidance from experienced professionals and building a network of contacts.
3. Advancement and Growth
- Promotion and Increased Responsibility: Moving up the career ladder, taking on more complex and higher-stakes roles.
- Leadership Roles: Leading teams, projects, or departments, and developing management skills.
- Professional Achievements: Accomplishing significant projects, receiving awards, or recognition in the field.
4. Career Transitions and Changes
- Lateral Moves: Changing roles within the same organization or industry to diversify experience.
- Industry Changes: Switching to a different industry to explore new opportunities or follow passion.
- Further Education: Pursuing advanced degrees or specialized training for career advancement or change.
5. Entrepreneurship and Innovation
- Starting a Business: Launching a startup or becoming an entrepreneur.
- Innovation and Creativity: Developing new products, services, or solutions within the industry.
6. Legacy and Mentorship
- Mentoring Others: Guiding and supporting the next generation of professionals.
- Thought Leadership: Contributing to the field through writing, speaking, or participating in industry groups.
- Retirement and Legacy: Planning for retirement and leaving a lasting impact on the industry.
Key Elements Influencing the Professional Journey
- Personal Goals and Aspirations: Individual ambitions and career objectives.
- Market and Industry Trends: Economic conditions, technological advancements, and market demands.
- Work-Life Balance: Balancing professional aspirations with personal life and well-being.
- Cultural and Organizational Factors: The influence of workplace culture, values, and organizational structure.
Conclusion
The professional journey is unique to each individual, shaped by their choices, opportunities, and the ever-changing landscape of the professional world. It is a continuous process of learning, growth, and adaptation, with each stage offering new challenges and rewards. By embracing these experiences and continuously striving for improvement, individuals can build fulfilling and successful careers.
https://www.youtube.com/watch?v=Ur3nsewvtoU
| angelika_jolly_4aa3821499 |
1,867,571 | Deploying Flet app from a docker container using Uvicorn | Deploying Flet app from a docker container... | 0 | 2024-05-28T12:03:28 | https://dev.to/fccoelho/deploying-flet-app-from-a-docker-container-using-uvicorn-4e5c | python, uvicorn, docker, flet | {% stackoverflow 78540702 %} | fccoelho |
1,867,570 | How to Optimize the Performance of Your Web Application | Introduction Optimizing the performance of your web application is crucial for ensuring a... | 0 | 2024-05-28T12:01:34 | https://dev.to/theintellify1/how-to-optimize-the-performance-of-your-web-application-3fa3 | webapp, webdev | ## Introduction
Optimizing the performance of your web application is crucial for ensuring a seamless user experience, improving search engine rankings, and increasing user retention. A fast and responsive web application can significantly enhance user satisfaction and contribute to your business's overall success. This article provides comprehensive strategies for optimizing the performance of your **[web application development](https://theintellify.com/web-backend-application-development/)**, covering best practices in coding, server management, and front-end optimization.
## 1. Efficient Coding Practices
### Minimize HTTP Requests
Reducing the number of these requests can significantly speed up page load times. Combine multiple CSS files into one, use image sprites, and minimize the use of external libraries.
### Optimize Images
Large image files can drastically slow down your web application. Use image compression tools like TinyPNG or ImageOptim to reduce file sizes without losing quality.
### Minify CSS, JavaScript, and HTML
Minification removes unnecessary characters from code (such as whitespace, comments, and newline characters) without affecting its functionality. Tools like UglifyJS, CSSNano, and HTMLMinifier can automate this process, resulting in smaller file sizes and faster load times.
### Lazy Loading
This is particularly useful for images and videos that are below the fold. Implementing lazy loading can significantly reduce initial load times and improve perceived performance.
### Use Asynchronous Loading for CSS and JavaScript
By loading CSS and JavaScript files asynchronously, you can prevent them from blocking the page's rendering. This ensures the content is displayed more quickly to the user, improving the overall user experience.
See Also: **[Cost to Develop a Web Application](https://theintellify.com/cost-to-develop-web-application/)**
### 2. Server-Side Optimization
Use a Content Delivery Network (CDN)
CDNs distribute your content across multiple servers around the globe, ensuring that users can download resources from a location geographically closer to them. This reduces latency and accelerates load times.
### Implement Server-Side Caching
Caching stores a copy of your site’s files so that subsequent requests can be served more quickly. Use server-side caching techniques such as full-page, object, and opcode caching to reduce the time it takes to generate and serve pages.
### Database Optimization
Optimize your database queries to reduce load times. Use indexing to speed up query execution, and regularly clean up your database to remove unnecessary data. Additionally, use database caching solutions like Memcached or Redis to cache frequently accessed data.
### Optimize Server Configuration
Ensure your server is configured for optimal performance. Use the latest version of server software, enable gzip compression to reduce the size of transmitted data, and use HTTP/2 for improved performance. Regularly monitor server performance and make necessary adjustments to handle increased traffic.
### Load Balancing
Load balancing improves redundancy and reliability, providing a better user experience during traffic spikes. To implement this strategy, use tools like NGINX, HAProxy, or AWS Elastic Load Balancing.
## 3. Frontend Optimization
### Responsive Design
Ensure your web application is optimized for various devices and screen sizes. A responsive design improves load times and usability on mobile devices, which is critical given the growing number of users accessing the web via smartphones and tablets.
### Optimize Web Fonts
Web fonts can be a significant source of latency. Limit the number of font families and weights you use, and include only the character sets you need. Use font-display: swap in your CSS to ensure text remains visible while fonts are loading.
### Reduce Render-Blocking Resources
Render-blocking resources delay your webpage's rendering. Identify and minimize these resources using tools like Google PageSpeed Insights. Move critical CSS inline and defer non-critical **[Java development](https://theintellify.com/java-development/)** to reduce their impact on page load times.
### Client-Side Caching
Leverage client-side caching by setting appropriate cache-control headers. This ensures that repeat visitors can load your site faster by using cached versions of your resources instead of downloading them again.
### Implement Progressive Web App (PWA) Techniques
PWAs offer a high-performance user experience by providing offline capabilities and fast loading times. Service workers cache assets and manage network requests efficiently. This approach ensures that your web application remains functional even with poor or no network connectivity.
## Conclusion
Optimizing your web application's performance is an ongoing process that requires attention to detail and a thorough understanding of both frontend and backend technologies. By implementing efficient coding practices, optimizing server performance, and focusing on front-end optimization, you can create a fast and responsive web application that delights users and stands out in a competitive market.
Investing time and resources into performance optimization not only improves user satisfaction but also boosts your search engine rankings, enhances user retention, and ultimately contributes to your business's success. Stay updated with the latest tools and techniques, and continuously monitor and refine your web application to maintain optimal performance. | theintellify1 |
1,867,568 | RAG using LLMSmith and FastAPI | What is LLMSmith? LLMSmith is a lightweight Python library designed for developing... | 0 | 2024-05-28T12:00:36 | https://dev.to/dheerajgopi/rag-using-llmsmith-and-fastapi-1e6i | rag, fastapi, llm, python | ## What is LLMSmith?
`LLMSmith` is a lightweight Python library designed for developing functionalities powered by Large Language Models (LLMs). It allows developers to integrate generative AI capabilities into all sorts of applications. In this case, we will be creating an RAG based chatbot using LLMSmith and expose it as an API endpoint in a FastAPI app.
LLMSmith repo: [https://github.com/dheerajgopi/llmsmith](https://github.com/dheerajgopi/llmsmith)
FYI.. I’m the author of this library :)
Now, lets get to the interesting part.
## Implement the RAG functionality using LLMSmith
This is what we will be doing here.
- Pre-process the user’s query for stripping out info that is irrelevant for retrieval using OpenAI LLM.
- Retrieve relevant documents from Qdrant vector DB.
- Rerank the retrieved documents so that they are ordered based on semantic relevance.
- Generate answer using OpenAI LLM. The reranked documents are passed as context in the prompt.
The below piece of code uses `LLMSmith` library for implementing the above mentioned RAG flow.
```python
from textwrap import dedent
import cohere
from fastembed import TextEmbedding
import openai
from qdrant_client import AsyncQdrantClient
from llmsmith.task.retrieval.vector.qdrant import QdrantRetriever
from llmsmith.reranker.cohere import CohereReranker
from llmsmith.task.textgen.openai import OpenAITextGenTask, OpenAITextGenOptions
from llmsmith.job.job import SequentialJob
from rag_llmsmith_fastapi.config import settings
preprocess_prompt = (
dedent("""
Convert the natural language query from a user into a query for a vectorstore.
In this process, you strip out information that is not relevant for the retrieval task.
Return only the query converted for retrieval and nothing else.
Here is the user query: {{root}}""")
.strip("\n")
.replace("\n", " ")
)
class RAGService:
def __init__(
self,
llm_client: openai.AsyncOpenAI,
vectordb_client: AsyncQdrantClient,
reranker_client: cohere.AsyncClient,
embedder: TextEmbedding,
**_,
) -> None:
self.llm_client = llm_client
self.vectordb_client = vectordb_client
self.reranker_client = reranker_client
self.embedder = embedder
async def chat(self, user_prompt):
# Create Cohere reranker
reranker = CohereReranker(client=self.reranker_client)
# Embedding function to be passed into the Qdrant retriever
def embedding_func(x):
return list(self.embedder.query_embed(x))
# Define the Qdrant retriever task. The embedding function and reranker are passed as parameters.
retrieval_task = QdrantRetriever(
name="qdrant-retriever",
client=self.vectordb_client,
collection_name=settings.QDRANT.COLLECTION_NAME,
embedding_func=embedding_func,
embedded_field_name="description", # name of the field in the document on which embeddedings are created while uploading data to the Qdrant collection
reranker=reranker,
)
# Define the OpenAI LLM task for rephrasing the query
preprocess_task = OpenAITextGenTask(
name="openai-preprocessor",
llm=self.llm_client,
llm_options=OpenAITextGenOptions(model="gpt-4-turbo", temperature=0),
)
# Define the OpenAI LLM task for answering the query
answer_generate_task = OpenAITextGenTask(
name="openai-answer-generator",
llm=self.llm_client,
llm_options=OpenAITextGenOptions(model="gpt-4-turbo", temperature=0),
)
# define the sequence of tasks
# {{root}} is a special placeholer in `input_template` which will be replaced with the prompt entered by the user (`user_prompt`).
# The placeholder {{qdrant-retriever.output}} will be replaced with the output from Qdrant DB retriever task.
# The placeholder {{openai-preprocessor.output}} will be replaced with the output from the query preprocessing task done by OpenAI LLM.
job: SequentialJob[str, str] = (
SequentialJob()
.add_task(
preprocess_task,
input_template=preprocess_prompt,
)
.add_task(retrieval_task, input_template="{{openai-preprocessor.output}}")
.add_task(
answer_generate_task,
input_template="Answer the question based on the context: \n\n QUESTION:\n{{root}}\n\nCONTEXT:\n{{qdrant-retriever.output}}",
)
)
# Now, run the job
await job.run(user_prompt)
return job.task_output("openai-answer-generator")
```
Using `LLMSmith` makes it quite easy to implement such LLM based functionalities. In the above code, we first create the following tasks:
- `QdrantRetriever` — To retrieve documents from Qdrant.
- `CohereReranker` — Rerank documents based on sematic relevance (passed into `QdrantRetriever`)
- `OpenAITextGenTask` — To execute LLM calls. Used for both pre-processing and answer generation in our case.
After the task definitions, all these tasks are run sequentially using `SequentialJob`. In an `LLMSmith` job, the output of previous tasks can be easily passed into the next task via placeholders using `input_template` parameter.
## Integrate the RAGService into a FastAPI endpoint
This is easy! Just call the chat method from the `RAGService` instance in your route handler function.
```python
from fastapi import APIRouter
from llmsmith.task.models import TaskOutput
from rag_llmsmith_fastapi.chat.model import ChatRequest, ChatResponse
from rag_llmsmith_fastapi.chat.service import RAGService
class ChatController:
def __init__(self, rag_svc: RAGService) -> None:
self.rag_svc = rag_svc
self.router: APIRouter = APIRouter(tags=["Chat endpoint"], prefix="/api")
self.router.add_api_route(
path="/chat",
endpoint=self.chat,
methods=["POST"],
)
async def chat(self, req_body: ChatRequest):
rag_response: TaskOutput = await self.rag_svc.chat(req_body.content)
return ChatResponse(content=rag_response.content)
```
**_The complete code can be found in this [repo](https://github.com/dheerajgopi/rag-llmsmith-fastapi)._**
For running the application, clone the [repository](https://github.com/dheerajgopi/rag-llmsmith-fastapi) from Github and follow the [README.md](https://github.com/dheerajgopi/rag-llmsmith-fastapi/blob/main/README.md) file.
## Contributors Welcome
All contributions (no matter if small) to [LLMSmith](https://github.com/dheerajgopi/llmsmith) are always welcome. To see how you can help and where to start see [CONTRIBUTING.md](https://github.com/dheerajgopi/llmsmith/blob/main/CONTRIBUTING.md).
| dheerajgopi |
1,867,368 | MDB Standard (Plain JS)Version 7.3.0 released! | Dependencies: Updated Bootstrap to 5.3.3 version New... | 0 | 2024-05-28T12:00:00 | https://dev.to/keepcoding/mdb-standard-plain-jsversion-730-released-n2o | news, javascript, bootstrap, webdev | ## Dependencies:
- Updated Bootstrap to 5.3.3 version
## New features:
**Datetimepicker** - added information about the current value to valueChanged.mdb.datetimepicker event
## Fixed & improved:
**Calendar**
- fixed error occurring on view change
- fixed week view header background color
**Organization chart**
- fixed card background color
- fixed vertical line color in dark theme
**Charts**
- fixed bug after update
- fixed styles not updating when switching from dark to light theme
**Datatable**
- fixed All as entries option value
- fixed active in clickable rows not applying styles
**Datetimepicker**
- fixed passing options to pickers
- fixed picker styling on small screens
**Select**
- fixed hiding groups with filtered out options
- fixed not changing active class with focused element in multiple select
**Timepicker**
- fixed styling in dark mode for inline picker
- fixed timepicker dispose breaks dropdowns present on the page
**Drag and drop** - fixed z-index in nested elements
**File upload **- fixed console error after adding file
**Multi item carousel** - fixed first element animation
**Mention** - fixed illegal invocation bug after click on no results
**Onboarding** - fixed scrolling when no scrollbars are present
**Table editor** - fixed styles for table editor hover and striped not applying
**Autocomplete** - fixed error while clicking no result
**Input fields** - fixed background after autocomplete
**Sidenav** - fixed link styles not using variables
**[MDB Standard (Plain JS) Version 7.3.0, released 27.05.2024](https://mdbootstrap.com)** | keepcoding |
1,867,147 | Open Source And The Tragedy Of The Commons | The tragedy of the commons phenomenon is a foundational topic to cover when discussing publicized... | 26,786 | 2024-05-28T12:00:00 | https://dev.to/opensourceadvocate/open-source-and-the-tragedy-of-the-commons-boe | opensource, tutorial, beginners, learning | The tragedy of the commons phenomenon is a foundational topic to cover when discussing publicized assets and open source.
The core tenet of the tragedy of the commons states that when given access to public assets, individuals will primarily behave in a self-serving manner to exploit the resource for selfish gain at the expense of everyone else. This abuse leads to over-consumption, thereby depleting the resource with no regard for the consequences this has on anyone else.
It is important to acknowledge that the tragedy of the commons is real and provides valuable wisdom. Abusing public resources can be seen in scenarios like herders overgrazing on public land, which leads to the destruction of natural biodiversity. Fishermen overfishing can lead to the extinction of certain species and the eradication of natural predators that would otherwise manage the population of other invasive species. It is true that bad actors who exploit public resources for themselves will always exist, but this does not mean that we should live in fear. These abuses can be prevented, and turning over public resources to private control will never automatically fix all the problems faced when they were public.
Join me as we unravel misconceptions about the tragedy of the commons phenomenon and how it relates to the open-source movement.
---
## Misconceptions and Criticisms
The tragedy of the commons is typically used to conclude that the public cannot be trusted to take care of public resources. Therefore, the solution to this issue must be to turn over control and ownership of these public assets to private hands. This logic is flawed because it grossly oversimplifies human behavior and ignores cultural, social, and institutional factors that prevent the tragedy.
There are countless real-world examples that clearly disprove the purely selfish nature that the tragedy of the commons phenomenon portrays human behavior to be. I will share some personal ones with you below and then expand into covering examples in the digital space that shatter the phenomenon’s flawed logic.
---
## Personal Example – New England Lobster Fisheries
I come from New England, where lobster fishing is all the rage. Maine lobster fisheries have done and continue to do a fantastic job at self-policing against the overfishing of lobsters. They have an entire mechanism for identifying and tagging fertile male and female lobsters, which are protected and released if caught. The local community in Maine has come together on their own accord to protect their public resources—the water and lobsters—from pollution and overfishing.
This grassroots community self-policing consists primarily of fishermen, fisheries, and local universities that track the behavioral patterns of lobsters and other marine life. They report bad actors to law enforcement and have a running Brady list for such bad actors, where fisheries refuse to do business with them and grocery stores refuse to buy from them. This self-policing is so successful that there is even a popular YouTube channel that creates vlogs about what it’s like being out on the Maine waters. YouTuber Jacob Knowles has almost 2 million subscribers and is a fifth-generation lobster fisherman from Maine. His footage, which gets hundreds of thousands of views per video, is a testament to how much Maine residents respect and care for their public resources. It shows that even large public assets like bodies of water and wildlife can be effectively managed to prevent bad actors from exploiting them for themselves.
---
## Personal Example – Public Park
Growing up, I played lots of sports and joined the sports teams for my school and city. One of my favorite sports was soccer and I loved played on this one particular field. It was a beautiful, well-kept natural grass field that was publicly accessible. In my free time, I would frequently visit the field to hang out with friends and practice or just get a good workout in. The best part of this field was that it had fully functional hardwired bathroom facilities in a separate building right next to the field. In all my years of playing on that field, there was never any crime, the field was always well taken care of, and families would frequently take their children there to play.
Most of the people in my hometown work in the skilled trades. Many of them happen to be landscapers. When the grass got too tall, locals would typically mow the grass themselves because they wanted their children to enjoy the area. When patches of grass got dry and destroyed from soccer cleats, locals would buy mulch and grass seeds on their own accord to repair the field because they wanted their children to enjoy the field.
The field was also in full view of all nearby residents. Adults were constantly supervising the field—their homes were literally right next to the field with a direct line of sight. Littering was not an issue—the school teams and the rest of the public always cleaned up after themselves, and in the rare case when there were leftovers, the public would quickly clean it up.
I recently learned that this field was sold off to a giant telecommunications company in a behind-closed-doors sweetheart deal to Charter Communications (also known by consumers as Spectrum) because city officials got greedy, and the telco company wanted public recognition locally, thus concocting a scheme to earn more money from taxpayers. If you didn’t hate telecommunications companies already, you will now. Charter purchased the field, and the city entered into a deal where public school teams can still play on it for free only during their seasonally scheduled games, but the rest of the public must pay to access the field.
An ugly 15-foot-tall fence now surrounds the field, blocking access. The natural grassland was ripped apart and replaced with turf material, which is known to be extremely toxic and very costly to maintain. Precision, industrial-grade cameras were installed on every corner of the field, along with a ridiculous amount of overpowered floodlights to light up a field that now maybe gets used once a week during the school year.
In order to access the field, the public needs to pay the city and a private security company to rent it out, with a minimum of 2 hours of rental time required. Last I checked, the hourly rate is $200/hr, plus a mandatory one-time fee for the Department of Public Works to pay a security company to come unlock the gates.
The parking lot where my brother first learned how to ride his bike now bars the public from walking on it under threat of trespassing and arrest. It too is under strict camera supervision. An entire generation of children will now grow up without access to the same public park that their parents and grandparents enjoyed because a private bad actor wanted to exploit public assets for themselves.
---
## Everyday Example – Public Gym
On a more benign level, we can see this self-policing to protect public assets by the way people clean up after using the gym equipment at public recreational centers. In most of the public gyms that I have attended, regardless of the socioeconomic status of the neighborhood, I have always seen local residents pay respect to the facilities. They wipe down equipment after using it, re-rack weights, and tidy up a room after hosting an event. The mutual understanding is clear—if we do not take care of this space, we will all lose it, and nobody wants that, especially in neighborhoods where residents may not have the financial means to easily travel to other parks. Residents also understand that without these public facilities, there would be no other options for them to spend recreational free time. These facilities also serve as safe spaces and even outlets for teenagers who may not have access to the internet at home. I know because I was one of these kids.
---
## Private Control Over Public Assets
To summarize the flawed logic of the tragedy of the commons phenomenon, lawmakers and skeptics argue that public assets are better managed under private control. Unfortunately, none of these critics ever demonstrate exactly why transitioning ownership to private hands automatically fixes the stewardship issues faced under public ownership. The reality is that those same problems exist regardless of public or private ownership. There will always be a need to manage bad actors who wish to exploit resources for personal gain. It has been proven time and time again that local communities are far superior at preventing such tragedies when left to their own devices by establishing cultural norms and boundaries that are reinforced through generations. It costs the local community, private businesses, and the public at large much less to do so on their own compared to privately held alternatives.
The bigger problem is when public assets succumb to private ownership and control. Private owners have no incentive to be good stewards of the asset. In fact, most of the time, private owners magnify the effects of the tragedy of the commons exponentially. Private owners are not beholden to the stakeholders that rely on those assets and have every incentive to exploit the assets for personal gain, even if the benefits are short-lived. They move on to the next asset to exploit for short-term gain, rinse, and repeat.
---
## Open Source and the Tragedy of the Commons
Local residents have their lives directly impacted by public assets, which is why they make the best stewards of said assets. It is in their best interest to prevent tragedies if they wish to continue using the assets sustainably because their well-being and livelihoods are at stake. Their free labor keeps the cost of maintenance, policing, and adjudication low because there are few tragedies that occur from their constant watch and toil.
This same outcome can be seen in the realm of hardware and software systems. Open-source projects like the Linux operating system have proven that open-source projects are far superior when it comes to security, maintenance cost, new feature development costs, long-term sustainability costs, and provide much richer functionality and flexibility than their closed-source counterparts. They accomplish these feats through economies of scale, and this time around, community members are not restricted by physical borders.
People from all over the world keep a watchful eye on the project and in return, they get a technological asset to solve problems in their personal lives as well as making their businesses run better without having to invest in major capital expenditures upfront. More importantly, the public gets transparency into the operation of the asset to ensure it doesn’t encroach on their right to privacy and empowers their consumer rights to truly own the things they spend money on.
Another example of an open-source project defeating the tragedy of the commons is OpenStreetMap, which is used by countless environmental researchers to track animal behavior patterns, by civil engineers to develop optimal roadways, and by historians to track changes to the land which helps to supplement other geological records.
Without these open-source projects, and many others, individuals and businesses would be left to raise capital investment on their own to meet a need that is universal. Their project would subsequently suffer from a lack of security resilience and robustness because they would only have themselves to rely on to harden against a multitude of attack vectors, a task that is absolutely impossible. Furthermore, the development of a digital project (hardware and software) can satisfy the needs of many people far better when other stakeholders suffering from the same issue can publicly and directly provide input. This decentralized and democratic approach of soliciting feedback leads to a project that more aptly meets the needs of stakeholders compared to a closed-source one.
---
## Summary
The tragedy of the commons is a real phenomenon that highlights the potential for overuse and depletion of shared resources when individuals act in their own self-interest. However, this concept does not imply that all public assets are doomed to be mismanaged. As seen in various real-world examples, such as the Maine lobster fisheries and well-maintained public parks, communities can effectively manage shared resources through self-policing, community involvement, and the establishment of cultural norms.
Open-source projects like Linux and OpenStreetMap further challenge the notion that communal resources are inherently prone to failure. These projects thrive on global collaboration, transparency, and decentralized management, proving that when stakeholders are directly involved and invested in the success of a shared resource, the outcomes can be highly sustainable and beneficial to all.
The key takeaway is that the success of both physical commons and digital open-source projects lies in active community engagement and decentralized control. By fostering a sense of ownership and responsibility among users, communities can develop resilient systems that prevent the tragedy of the commons and ensure long-term sustainability. This approach addresses the potential pitfalls highlighted by the tragedy of the commons and leverages collective wisdom and effort to create robust, adaptable, and thriving public assets.
Check out the following YouTube link for a video episode I did on this topic "Open Source And The Tragedy Of The Commons" .
Thanks and I'll see you in the next one.
{% youtube https://www.youtube.com/watch?v=5vFFioOkEhs %}
---
## <u>**Follow me**</u>
› Linktree: https://linktr.ee/opensourceadvocate
› LinkedIn: https://www.linkedin.com/in/enrimarini
› Substack: https://enrimarini.substack.com/
› Twitter: https://twitter.com/@RealEnriMarini
› Medium: https://medium.com/@TheEthicalEngineer
› YouTube: https://www.youtube.com/@EthicsAndEngineering
› DEV Community: https://dev.to/@opensourceadvocate
› TikTok:https://www.tiktok.com/@opensourceadvocate
—
DISCLAIMER: I am not sponsored or influenced in any way, shape, or form by the companies and products mentioned. This is my own original content, with image credits given as appropriate and necessary. | opensourceadvocate |
1,867,818 | Introducing Aiven's AI Database Optimizer: The First Built-In SQL Optimizer for Enhanced Performance | An efficient data infrastructure is a vital component in building & operating scalable and... | 0 | 2024-06-10T09:48:35 | https://aiven.io/blog/aiven-ai-dboptimizer-launch | announcements, ai, postgres | ---
title: Introducing Aiven's AI Database Optimizer: The First Built-In SQL Optimizer for Enhanced Performance
published: true
date: 2024-05-28 12:00:00 UTC
tags: Announcements,AI,PostgreSQL
canonical_url: https://aiven.io/blog/aiven-ai-dboptimizer-launch
---

An efficient data infrastructure is a vital component in building & operating scalable and performant applications that are widely adopted, satisfy customers, and ultimately, drive business growth. Unfortunately, the speed of new feature delivery coupled with a lack of database optimization knowledge is exposing organizations to high risk performance issues. The new [Aiven AI Database Optimizer](https://aiven.io/solutions/aiven-ai-database-optimizer?utm_source=devto&utm_medium=organic&utm_campaign=DB-Optimizer) helps organizations address performance both in the development and production phase, making it simple to quickly deploy, fully optimized, scalable, and cost efficient applications.
Fully integrated with [Aiven for PostgreSQL](https://aiven.io/postgresql?utm_source=devto&utm_medium=organic&utm_campaign=DB-Optimizer)®, Aiven AI Database Optimizer offers AI-driven performance insights, index, and SQL rewrite suggestions to maximize database performance, minimize costs, and make the best out of your cloud investment.
## How does AI Database Optimizer work?
Aiven AI Database Optimizer is a non-intrusive solution powered by [EverSQL by Aiven](https://www.eversql.com/?utm_source=devto&utm_medium=organic&utm_campaign=DB-Optimizer) that gathers information about database workloads, metadata and supporting data structures, such as indexes. Information about the number of query executions and average query times are continually processed by a mix of heuristic and AI models to determine which SQL statements can be further optimized. AI Database Optimizer then delivers accurate, secure optimization suggestions that you can trust, and that can be adopted to speed up query performance.
Recommendations from Aiven’s AI Database Optimizer are already trusted by over 120,000 users in organizations ranging from startups to the largest global enterprises, who have optimized more than 2 million queries to date.
## How does AI Database Optimizer help organizations?
During development, AI Database Optimizer enables early performance testing, allowing easier redesign or refactoring of queries before they impact production. This enables customers to foster a culture of considering performance from the get-go, ensuring it is a priority throughout development rather than an afterthought.
AI Database Optimizer also helps businesses gain an optimal user experience:
* With fast query response times that ensure a smooth and responsive user experience, especially in data-intensive applications.
* By identifying and fixing performance bottlenecks organizations can reduce costs, avoid outages and deliver continuous service availability.
A fleet of Aiven for PostgreSQL® databases is powering [La Redoute](https://www.youtube.com/watch?v=mPWxizlA3so)’s marketplace functionality, driving 30% of their business.
Diogo Passadouro - OPS-DBA Team Lead stated *"Aiven AI Database Optimizer has revolutionized the way we analyze database performance, providing a simple, clear and highly effective approach and has proven instrumental in enhancing the performance of our databases."*

[Conrad](https://aiven.io/case-studies/conrad-electronic-expands-e-commerce-platform-with-aiven) is an advanced B2B sourcing platform selling 9 million products from 6,000 brands, powered by Aiven. Janek Wonner - Head of SRE & Cloud Technology stated *"Aiven for PostgreSQL is underpinning our fundamental company functionalities, we are looking forward to adopt Aiven AI database optimizer to empower our developers to create scalable code and empower our development teams with better performance insights and improvement suggestions to reduce the time to fix performance issues"*

More information is available in the [Aiven AI Database Optimizer page](https://aiven.io/solutions/aiven-ai-database-optimizer?utm_source=devto&utm_medium=organic&utm_campaign=DB-Optimizer). You can experience it for yourself in any [Aiven for PostgreSQL](https://aiven.io/postgresql) service for free during the Early Availability phase. Simply navigate to the “AI Insights” tab.
[Try it now](https://console.aiven.io/signup?utm_source=devto&utm_medium=organic&utm_campaign=DB-Optimizer) or [Contact us](https://aiven.io/book-demo?utm_source=devto&utm_medium=organic&utm_campaign=DB-Optimizer) today to check it out!
| ftisiot |
1,867,056 | System Design: Crafting Scalable and Robust Architectures | In today's fast-paced technological landscape, system design plays a crucial role in the success of... | 0 | 2024-05-28T12:00:00 | https://dev.to/plemonsbrett/system-design-crafting-scalable-and-robust-architectures-amo | systemdesign, architecture, scalability, microservices |
In today's fast-paced technological landscape, system design plays a crucial role in the success of software engineering projects. Effective system design ensures that applications are scalable, reliable, and maintainable, meeting present and future needs. To illustrate this, we will delve into the system design of an online bookstore application, highlighting the importance of system design, critical principles of scalable design, common architectural patterns, and a case study of a company excelling in this space.
## Understanding Requirements
Gathering and analyzing requirements is a collaborative process, a crucial step before diving into the technical aspects of system design. It's about understanding the system's functional and non-functional requirements, and your input as a software engineer is invaluable.
### How to Gather and Analyze Requirements
- **Stakeholder Interviews:** Conduct interviews with stakeholders to understand their needs and expectations.
- **Use Cases:** Develop detailed use cases to capture functional requirements.
- **Performance Metrics:** Define key performance indicators (KPIs) to address non-functional requirements like scalability, availability, and latency.
- **Constraints and Assumptions:** Identify limitations (e.g., budget, technology stack) and assumptions that may impact the design.
By comprehensively understanding the requirements, you lay a solid foundation for the design phase, ensuring that the system meets the intended goals and can handle the anticipated load and complexity.
### An Example: Online Bookstore System
To make this more tangible, let's consider a scenario where we are tasked with designing an online bookstore for a startup called 'Book Haven.' 'Book Haven' is a small, independent bookstore wanting to expand its online business. The goal is to create a platform where users can browse, search, and purchase books online. The system must handle high traffic volume, ensure data security, and provide a seamless user experience. This case study will provide insights into the system design process and the solutions implemented to meet these challenges.
> I like to use Figma's "brainstorming" template for gathering requirements; it is an interactive tool you can use in meetings with the stakeholders to get them more involved. This is important as it forces those from whom you collect requirements to be active participants.
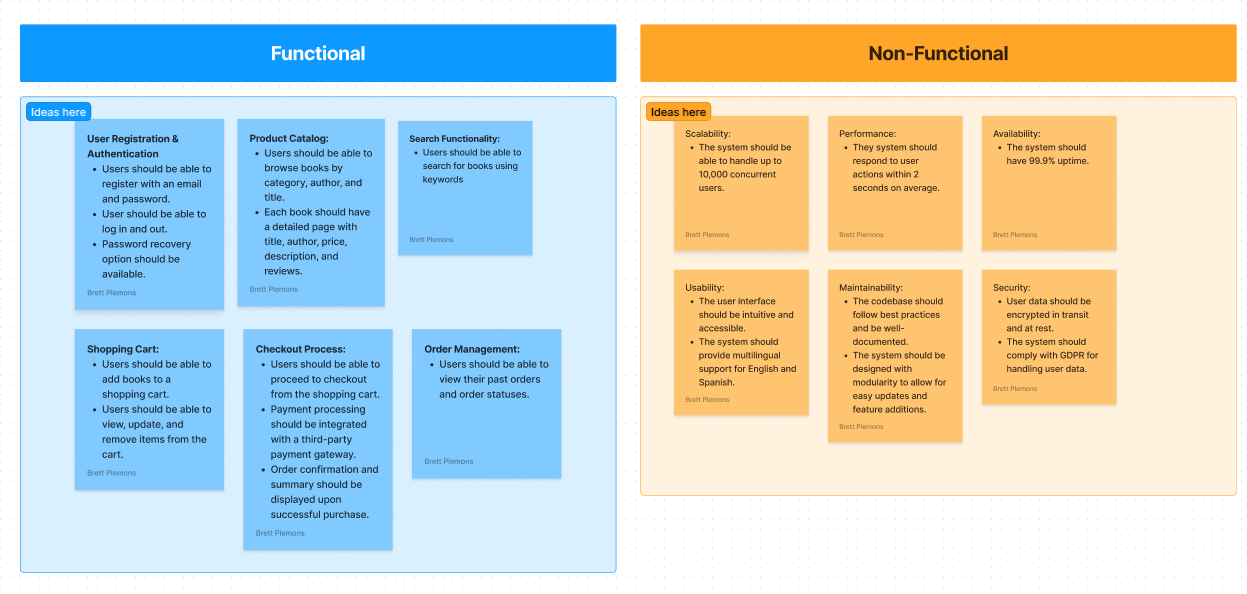
#### Stakeholder Interview Summaries:
- **CEO's Requirements:**
- The platform should support many books, including fiction, non-fiction, and textbooks.
- The system needs to be scalable to handle growth as the business expands.
- Secure payment processing is a must to build customer trust.
- The platform should have an intuitive user interface to attract and retain customers.
- **Marketing Manager's Requirements:**
- The platform should be search engine optimized (SEO) to increase visibility on search engines.
- Integration with social media for sharing book recommendations and reviews.
- Promotional features like discounts, coupons, and featured books.
- Ability to collect and analyze user data for targeted marketing campaigns.
- **UI/UX Researchers' Requirements:**
- Easy registration and login process.
- Detailed book descriptions, including reviews and ratings from other users.
- Wish list functionality to save books for future purchases.
- Fast and reliable search functionality to find books quickly.
- **Engineering Team's Requirements:**
- The system should use a microservices architecture to ensure scalability and maintainability.
- High availability and disaster recovery mechanisms should be in place.
- Compliance with data protection regulations like GDPR.
- Continuous integration and deployment (CI/CD) pipeline for smooth updates and maintenance.
#### Project Summary:
Based on the stakeholder interviews, we summarized the overall project requirements. "Book Haven" aims to create a user-friendly online bookstore that provides a rich selection of books, a seamless shopping experience, and robust backend support. The platform must be secure, scalable, and maintainable, with features that attract and retain users while supporting the business's growth objectives.
**Functional Requirements:**
- User registration and authentication.
- Browsing and searching for books by category, author, and title.
- Detailed book pages with descriptions, reviews, and ratings.
- Shopping cart and secure checkout process.
- Order history and status tracking.
- Promotional features and social media integration.
**Non-Functional Requirements:**
- Scalability to support up to 10,000 concurrent users.
- Average response time of 2 seconds or less.
- 99.9% system uptime.
- Data encryption and GDPR compliance.
- Modular and maintainable codebase.
This scenario outlines a realistic project for designing an online bookstore system. The requirements are gathered and analyzed through stakeholder interviews, providing a clear foundation for the design and development phases. By establishing our functional and non-functional requirements, we are in an optimal place to start building our system.
## Design Principles
Now that we understand the requirements, we can transition to the next critical phase: the design principles. These principles will guide our approach to creating a scalable and robust system. By adhering to these principles, we ensure that our design meets the current requirements and is adaptable to future changes and growth.
### Critical Principles of Scalable System Design
- **Modularity:** Break down the system into smaller, manageable components or modules. This allows for independent development, testing, and scaling of each module.
- **Microservices:** Adopt a microservices architecture where each service is responsible for a specific functionality and communicates with other services via APIs. This architectural pattern, also known as the microservices architecture, is a method of developing software systems composed of loosely coupled, independently deployable services. Each service runs a unique process and communicates through a well-defined, lightweight mechanism to serve a business goal.
- **Separation of Concerns:** Separate different aspects of the system (e.g., data processing, user interface, and business logic) to promote maintainability and scalability.
- **Statelessness:** Design services to be stateless whenever possible. This simplifies scaling, as any service instance can handle any request.
- **Asynchronous Processing:** Use asynchronous communication and processing to improve system responsiveness and scalability.
- **Horizontal Scaling:** Design the system to scale horizontally by adding more instances rather than increasing the capacity of existing ones.
Following these design principles, we create a robust and scalable system that meets current needs and lays a solid foundation for future growth and changes. This adaptability should instill confidence in your work as a software engineer.
### Applying Design Principles to "Book Haven"
**Modularity:**
We will break down our system into smaller, independent components to achieve modularity. Each element or module will handle a specific functionality, allowing for easier development, testing, and scaling. For instance, our online bookstore can have distinct modules for user authentication, product catalog management, search functionality, shopping cart, checkout, and order management. Separating these functionalities ensures that each module can be developed and maintained independently, reducing complexity and improving scalability.
**Microservices:**
Adopting a microservices architecture involves dividing our system into multiple, loosely coupled services, each responsible for a specific part of the application's functionality. For "Book Haven," we can implement services such as an Authentication Service to manage user logins and registrations, a Product Service to handle CRUD operations for books, a Search Service to facilitate searching through the catalog, a User Service for managing user profiles, an Order Service to process and track orders, a Payment Service to handle transactions, and a Session Service to manage user sessions and shopping cart data. These services can be developed, deployed, and scaled independently, ensuring flexibility and resilience.
**Separation of Concerns:**
Separation of concerns is about organizing our system so that different functionalities are handled by separate components, reducing overlap and dependencies. In "Book Haven," we can have distinct layers for data processing, business logic, and user interface. The data processing layer will manage database interactions, the business logic layer will handle core application logic and rules, and the user interface layer will present information to users and handle user inputs. This clear separation allows us to modify one part of the system without affecting others, enhancing maintainability and scalability.
**Statelessness:**
Designing services to be stateless means that each client request contains all the information needed to understand and process it without relying on stored data from previous requests. For "Book Haven," services like authentication and shopping cart management can use stateless protocols to store user sessions and cart information in a centralized database or cache. This approach simplifies scaling, as any service instance can handle any request, allowing for easy load balancing and failure recovery.
**Asynchronous Processing:**
Using asynchronous processing helps improve system responsiveness and scalability by allowing tasks to be processed in the background without blocking the main application flow. In "Book Haven," we can implement asynchronous processing for functions such as sending order confirmation emails, updating inventory levels, or processing payments. By offloading these tasks to background workers or message queues, we ensure that the main application remains responsive and handles many user interactions simultaneously.
**Horizontal Scaling:**
Horizontal scaling involves adding more instances of a service rather than increasing the capacity of existing ones. For "Book Haven," we can design the system to scale horizontally by deploying multiple instances of critical services such as the product catalog, search functionality, and user management. We can handle increased traffic and ensure high availability by distributing the load across several instances. Load balancers can distribute incoming requests evenly among service instances, optimizing resource utilization and performance.
By following these design principles, we can create a robust and scalable system, ensuring it meets current needs and can grow with future demands. However, more than principles are needed; we must choose suitable architectural patterns to implement these principles effectively. Architectural patterns solve common design challenges, helping us structure our system to maximize scalability, performance, and maintainability.
## Architectural Patterns
Choosing suitable architectural patterns is critical for implementing the principles mentioned above. Some common patterns can help you design scalable and robust systems.
### Common Patterns
- **Command Query Responsibility Segregation (CQRS):**
- **Overview:** CQRS separates read and write operations into different models, optimizing the system for scalability and performance.
- **When to Use:** Ideal for systems with complex read and write operations that require different optimization strategies.
- **Event Sourcing:**
- **Overview:** Event sourcing involves storing a system's state as a sequence of events, allowing for easy reconstruction of past states.
- **When to Use:** Useful in systems where auditability and historical state reconstruction are essential.
- **Service Mesh:**
- **Overview:** A service mesh provides a dedicated infrastructure layer for managing service-to-service communication, enhancing observability, security, and reliability.
- **When to Use:** Beneficial for complex microservices architectures where communication management is challenging.
- **Saga Pattern:**
- **Overview:** The Saga pattern manages distributed transactions by breaking them into smaller, manageable transactions.
- **When to Use:** Suitable for ensuring data consistency in distributed systems without using distributed transactions.
### Applying an Architectural Pattern: Service Mesh for "Book Haven"
For "Book Haven," a service mesh architecture is particularly relevant. Managing communication between services becomes crucial because our system will be built using a microservices architecture. A service mesh can provide the necessary infrastructure to handle service-to-service communication efficiently and securely.
**How a Service Mesh Might Apply:**
"Book Haven" has multiple microservices such as Authentication, Product, Search, User, Order, Payment, and Session services. Communication between these services is essential to ensure smooth operations and high performance. Implementing a service mesh can help us achieve this by providing features like:
- **Observability:** A service mesh allows us to monitor and trace requests as they flow through various services, helping us detect and diagnose issues quickly.
- **Security:** It can manage secure communication between services using mutual TLS, ensuring data privacy and integrity.
- **Reliability:** Features like retries, timeouts, and circuit breakers can be easily implemented, enhancing the system's resilience.
- **Traffic Management:** A service mesh can help control traffic flow between services, enabling load balancing and rate-limiting features.
By integrating a service mesh, "Book Haven" can achieve better observability, security, and reliability, ensuring that our system effectively scales while maintaining high performance and security standards. This architectural pattern supports our design principles and helps us build a robust and scalable online bookstore.
## Case Study: Netflix
Understanding and applying design principles and architectural patterns is crucial, but seeing these concepts in action can provide valuable insights. Let's look at a real-world example of a company that excels in scalable and robust system design.
Netflix is a prime example of a company excelling in scalable and robust system design. As a global streaming service with millions of users, Netflix faces immense scalability, availability, and performance challenges.
### Key Practices at Netflix
- **Microservices Architecture:**
- Netflix pioneered microservices, allowing the company to scale individual services independently and deploy new features rapidly. Each service handles a specific function, such as user authentication, content recommendation, and video streaming, enabling flexibility and resilience.
- **Chaos Engineering:**
- Netflix employs chaos engineering to test the resilience of its systems. By intentionally causing failures, they ensure the system can handle unexpected issues. This proactive approach helps identify potential weaknesses and improve system reliability.
- **Auto-Scaling:**
- Netflix uses auto-scaling to handle varying loads, automatically adding or removing instances based on demand. This ensures that resources are efficiently utilized, maintaining performance and reducing costs.
- **Global Distribution:**
- Netflix's content delivery network (CDN) ensures content is delivered quickly and reliably to users worldwide. By distributing content across multiple data centers and edge locations, Netflix minimizes latency and enhances the user experience.
These practices enable Netflix to deliver a seamless streaming experience, even during peak usage times, demonstrating the effectiveness of robust system design principles.
## Conclusion
System design is a fundamental aspect of software engineering that ensures applications are scalable, robust, and maintainable. You can create systems that stand the test of time by understanding requirements, adhering to fundamental design principles, and leveraging common architectural patterns. Continuous learning and adaptation are crucial, as the technology landscape is ever-evolving.
What are your favorite design patterns and principles when crafting scalable systems? Share your experiences and insights in the comments below. Let's learn and grow together! | plemonsbrett |
1,867,565 | Issue with Mongoose Database Switching Middleware in Express.js | I'm implementing an Express.js middleware to switch between different MongoDB databases using... | 0 | 2024-05-28T11:55:40 | https://dev.to/jalish_chauhan/issue-with-mongoose-database-switching-middleware-in-expressjs-1mf3 |
I'm implementing an Express.js middleware to switch between different MongoDB databases using Mongoose based on the request URL. The middleware is supposed to disconnect from the current database and connect to a new one depending on the URL path. However, I'm facing some issues with the implementation, and I would appreciate some guidance.
Here's the middleware code:
const switcher = async (req, res, next) => {
try {
const [, second] = req.url.split("/");
const connection = second === "auth" ? process.env.AUTH_DB_URL : process.env.STORAGE_DB_URL;
if (mongoose.connection.readyState !== 0 && mongoose.connection.client.s.url !== connection) {
await mongoose.disconnect();
await mongoose.connect(connection, { keepAliveInitialDelay: true });
console.log("Connected to", connection);
}
next();
} catch (err) {
console.error(err);
return res.status(500).send({ status: 500, message: "Internal Server Error" });
}
};
**What I Expected:**
Seamless Switching: I expected the middleware to seamlessly disconnect from the current database and connect to the new one based on the request URL.
Correct Database Operations: After switching, subsequent database operations should be performed on the newly connected database.
No Interruption: The middleware should handle concurrent requests efficiently without causing interruptions or errors. | jalish_chauhan | |
1,867,564 | 5 Major Importance of Workday Human Capital Management | As an important differentiator among talents, today’s dynamic economic climate is where human... | 0 | 2024-05-28T11:53:11 | https://www.dejaoffice.com/blog/2024/04/08/5-major-importances-of-workday-human-capital-management/ | workday, hcm |

As an important differentiator among talents, today’s dynamic economic climate is where human capital management (HCM) becomes more and more important. With a completely integrated suite of applications, [workday human capital management](https://www.opkey.com/blog/test-automation-for-workday-human-capital-management) enables organizations to improve and streamline all aspects of workforce management.By attracting, developing and retaining the best people, you can create organizations that change the world. This blog looks at five key aspects of how to effectively implement a Workday human capital management strategy.
**1. Enhancing Talent Acquisition and Retention**
Employers across all industries have struggled to attract and keep exceptional employees at their companies.Workday HCM provides strong recruiting capabilities. This enables companies to identify, assess, and hire the best candidates quickly. Recruiting departments that automate such tasks as job posting, applicant tracking, and onboarding can ensure a positive candidate experience. Companies that use this method also save time.Workday HCM also provides robust performance management and learning management functionalities in support of employee engagement and retention goals.
**2. Optimizing Workforce Planning and Analytics**
Effective workforce planning is of vital importance for strategic goal allocation of corporate resources. Workday HCM enables businesses to make data-driven decisions with adroit analytics and reporting abilities that provide insight into employee data. Company can look at data such as headcount, skills gaps and workforce expenses to predict future labor needs, better manage resource deployment and actively shed light on where improvements are necessary. In addition, the analytics function of Workday HCM quickly traversing beyond workforce planning means that companies have a complete understanding of their human resources.
**3. Streamlining HR Processes and Compliance**
The HR processes can be tedious and complex, often involving many systems and manual input. In conjunction with other HR functions, payroll, benefits administration, and employee data management are integrated into the Workday HCM platform. By doing so, streams are refined, superfluous information is removed and accuracy of data is increased. This improves operational efficiency and reduces costs.
**4. Fostering Collaboration and Mobility**
Working hours and management are increasingly determined by the needs of customers and suppliers in today’s global, mobile business world. The mobile friendly platform interface enables Workday HCM to facilitate conversation and coordination among managers, HR specialists and employees. Moreover, Workday HCM’s social collaboration capabilities facilitate communication, information sharing, and teamwork among employees, strengthening the feeling of community and corporate culture.
**5. Enabling Organizational Agility and Scalability**
Enterprises need an agile and flexible vantage point in the changing environment of commercial as well as administrative landscape.Workday HCM, with cloud-oriented architecture and a continuous delivery model, allows businesses to obtain updates and new features without investing in expensive upgrades. This flexibility allows organizations to react quickly to the constantly shifting market conditions, new laws and corporate needs. Furthermore, companies can readily adjust to evolving worker demands because of Workday HCM’s scalability.
**Conclusion**
Human capital management strategies need to be an organization’s top priority in this age of digital transformation and intense talent rivalry. When choosing a Workday HCM test automation solution, enterprises need a cost-effective yet powerful tool like [Opkey](https://www.opkey.com/). Opkey streamlines Workday testing with pre-built accelerators for functional, regression, performance, and security testing – reducing implementation time by 70%. Its no-code interface enables business users to easily create and execute tests. Self-healing technology automatically fixes broken scripts post updates, slashing maintenance efforts by 90%. Smart AI-driven regression planning ensures up to 90% risk coverage. Opkey’s end-to-end testing spans Workday integrations for unified test management. By adopting Opkey’s innovative capabilities, enterprises maximize their Workday HCM ROI through accelerated deployments and seamless update testing. | rohitbhandari102 |
1,867,563 | Alternatives to Makefiles written in Go | First things first: what is make? Present in all Linux distributions and Unix derivatives such as... | 0 | 2024-05-28T11:47:11 | https://dev.to/eminetto/alternatives-to-makefiles-written-in-go-dig | make, makefile, go | ---
title: Alternatives to Makefiles written in Go
published: true
description:
tags: make, makefile, go
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-28 11:45 +0000
---
First things first: what is `make`? Present in all Linux distributions and Unix derivatives such as macOS, the tool's manual describes it as:
> The purpose of the make utility is to determine automatically which pieces of a large program need to be recompiled, and issue the commands to recompile them.
> To prepare to use make, you must write a file called the Makefile that describes the relationships among files in your program, and the states the commands for updating each file.
Before anyone throws stones at me, I like it, and practically every project I build has one `Makefile` with automation to make my work easier.
But then, why look for alternatives to something that has existed and worked for decades? Learning new tools is part of our job as developers and keeps us up to date with new forms of automation. Furthermore, to start using it, we must learn the syntax of the `Makefile`, and if we can use something we already know, it can reduce the cognitive load of new professionals.
Let's look at two alternatives here, both written in Go.
## Taskfile
The first tool we will test is `Taskfile`, found on the website [https://taskfile.dev/](https://taskfile.dev/). The tool's idea is to perform tasks described in a file called `Taskfile.yaml` and, as the name suggests, in `yaml`.
The first step is to install the executable `task`, which we will use. For this, the official documentation shows some alternatives, but as I'm using macOS, I used the command:
```bash
❯ brew install go-task
```
Let's describe our tasks in a new `Taskfile.yaml` file. Let's rewrite one Makefile from a [project on my Github](https://github.com/eminetto/api-o11y-gcp) to demonstrate a real case.
The original content is:
```Makefile
.PHONY: all
all: build
FORCE: ;
.PHONY: build
build:
go build -o bin/api-o11y-gcp cmd/api/main.go
build-linux:
CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -tags "netgo" -installsuffix netgo -o bin/api-o11y-gcp cmd/api/main.go
build-docker:
docker build -t api-o11y-gcp -f Dockerfile .
generate-mocks:
@mockery --output user/mocks --dir user --all
@mockery --output internal/telemetry/mocks --dir internal/telemetry --all
clean:
@rm -rf user/mocks/*
@rm -rf internal/telemetry/mocks/mocks/*
test: generate-mocks
go test ./...
run-docker: build-docker
docker run -d -p 8080:8080 api-o11y-gcp
```
The content converted to the `Taskfile.yaml` is:
```yaml
version: "3"
tasks:
install-deps:
cmds:
- go mod tidy
default:
desc: "Build the app"
deps: [install-deps]
cmds:
- go build -o bin/api-o11y-gcp cmd/api/main.go
build-linux:
deps: [install-deps]
desc: "Build for Linux"
cmds:
- go build -a -installsuffix cgo -tags "netgo" -installsuffix netgo -o bin/api-o11y-gcp cmd/api/main.go
env:
CGO_ENABLED: 0
GOOS: linux
build-docker:
desc: "Build a docker image"
cmds:
- docker build -t api-o11y-gcp -f Dockerfile .
generate-mocks:
desc: "Generate mocks"
cmds:
- go install github.com/vektra/mockery/v2@v2.43.1
- mockery --output user/mocks --dir user --all
- mockery --output internal/telemetry/mocks --dir internal/telemetry --all
test:
deps:
- install-deps
- generate-mocks
desc: "Run tests"
cmds:
- go test ./...
clean:
desc: "Clean up"
prompt: This is a dangerous command... Do you want to continue?
cmds:
- rm -f bin/*
- rm -rf user/mocks/*
- rm -rf internal/telemetry/mocks/mocks/*
run-docker:
desc: "Run the docker image"
deps: [build-docker]
cmds:
- docker run -d -p 8080:8080 api-o11y-gcp
```
We can now use the command `task` to list the available tasks:
```bash
❯ task -l
task: Available tasks for this project:
* build-docker: Build a docker image
* build-linux: Build for Linux
* clean: Clean up
* default: Build the app
* generate-mocks: Generate mocks
* run-docker: Run the docker image
* test: Run tests
```
When executing the command `task`, it will perform the `default` task:
```bash
❯ task
task: [install-deps] go mod tidy
task: [default] go build -o bin/api-o11y-gcp cmd/api/main.go
```
You can see that the task first executed its dependency, `install-deps`, as described in `Taskfile.yaml`.
And we can perform other tasks by adding it to the end of the command:
```bash
❯ task build-linux
task: [install-deps] go mod tidy
task: [build-linux] go build -a -installsuffix cgo -tags "netgo" -installsuffix netgo -o bin/api-o11y-gcp cmd/api/main.go
```
The command `build-linux` also shows the use of `environment variables` to configure the environment at compilation time.
The [documentation](https://taskfile.dev/usage/) includes other, more advanced examples and a style guide for writing a `Taskfile.yaml.`
The main advantage of using `Taskfile` is that most teams nowadays have experience writing and using files in `YAML`, which has become the most used format for configuration files (although I think the [TOML](https://toml.io/en/) format is much better ).
## Mage
The second alternative I want to demonstrate is the [Mage](https://magefile.org/) project, which the site describes as
> a make/rake-like build tool using Go
The exciting thing about this tool is that the tasks are built in Go files, giving them all the power the language provides.
The first necessary step is to install the executable `mage`. To do this, I used the following command on macOS, but you can view the options for other operating systems on the official website.
```bash
❯ brew install mage
```
Let's rewrite the tasks in `Makefile` in this new format. To do this, we can create a file called `magefile.go` at the project's root and add the logic inside it. However, another documented option is more interesting: creating a directory called `magefiles` and storing the files within it. I thought the project was more organized this way. To do this, I ran the commands:
```bash
❯ mkdir magefiles
❯ mage -init -d magefiles
```
The second command initializes a `magefile.go` with an initial example to begin describing the tasks:
```go
//go:build mage
// +build mage
package main
import (
"fmt"
"os"
"os/exec"
"github.com/magefile/mage/mg" // mg contains helpful utility functions, like Deps
)
// Default target to run when none is specified
// If not set, running mage will list available targets
// var Default = Build
// A build step that requires additional params, or platform specific steps for example
func Build() error {
mg.Deps(InstallDeps)
fmt.Println("Building...")
cmd := exec.Command("go", "build", "-o", "MyApp", ".")
return cmd.Run()
}
// A custom install step if you need your bin someplace other than go/bin
func Install() error {
mg.Deps(Build)
fmt.Println("Installing...")
return os.Rename("./MyApp", "/usr/bin/MyApp")
}
// Manage your deps, or running package managers.
func InstallDeps() error {
fmt.Println("Installing Deps...")
cmd := exec.Command("go", "get", "github.com/stretchr/piglatin")
return cmd.Run()
}
// Clean up after yourself
func Clean() {
fmt.Println("Cleaning...")
os.RemoveAll("MyApp")
}
```
As we will describe the tasks in the form of a Go program, it is necessary to download the dependency using the command:
```bash
❯ go get github.com/magefile/mage/mg
```
Now it is possible to list the available tasks, which `Mage` calls `targets`:
```bash
❯ mage -l
Targets:
build A build step that requires additional params, or platform specific steps for example
clean up after yourself
install A custom install step if you need your bin someplace other than go/bin
installDeps Manage your deps, or running package managers.
```
Each function's comment line becomes a documentation of how we can view the command in the `mage` output message.
Let's now convert the `Makefile` into a script in the `mage` format:
```go
//go:build mage
// +build mage
package main
import (
"log"
"os"
"os/exec"
"path/filepath"
"github.com/magefile/mage/mg" // mg contains helpful utility functions, like Deps
)
// Default target to run when none is specified
// If not set, running mage will list available targets
var Default = Build
// A build step that requires additional params, or platform specific steps for example
func Build() error {
mg.Deps(InstallDeps)
log.Println("Building...")
cmd := exec.Command("go", "build", "-o", "bin/api-o11y-gcp", "cmd/api/main.go")
return cmd.Run()
}
// Build for Linux
func BuildLinux() error {
mg.Deps(InstallDeps)
log.Println("Generating Linux binary...")
os.Setenv("CGO_ENABLED", "0")
os.Setenv("GOOS", "linux")
cmd := exec.Command("go", "build", "-a", "-installsuffix", "cgo", "-tags", `"netgo"`, "-installsuffix", "netgo", "-o", "bin/api-o11y-gcp", "cmd/api/main.go")
return cmd.Run()
}
// Build a docker image
func BuildDocker() error {
log.Println("Building...")
cmd := exec.Command("docker", "build", "-t", "api-o11y-gcp", "-f", "Dockerfile", ".")
return cmd.Run()
}
// Generate mocks
func GenerateMocks() error {
log.Println("Installing mockery...")
cmd := exec.Command("go", "install", "github.com/vektra/mockery/v2@v2.43.1")
err := cmd.Run()
if err != nil {
return err
}
log.Println("Generating user mocks...")
cmd = exec.Command("mockery", "--output", "user/mocks", "--dir", "user", "--all")
err = cmd.Run()
if err != nil {
return err
}
log.Println("Generating telemetry mocks...")
cmd = exec.Command("mockery", "--output", "internal/telemetry/mocks", "--dir", "internal/telemetry", "--all")
return cmd.Run()
}
// Manage your deps, or running package managers.
func InstallDeps() error {
log.Println("Installing Deps...")
cmd := exec.Command("go", "mod", "tidy")
return cmd.Run()
}
// Run tests
func Test() error {
mg.Deps(GenerateMocks)
cmd := exec.Command("go", "test", "./...")
return cmd.Run()
}
// Run the docker image
func RunDocker() error {
mg.Deps(BuildDocker)
cmd := exec.Command("docker", "run", "-p", "8080:8080", "api-o11y-gcp")
return cmd.Run()
}
// Clean up after yourself
func Clean() error {
log.Println("Cleaning...")
err := removeGlob("user/mocks/*")
if err != nil {
return err
}
err = removeGlob("internal/telemetry/mocks/*")
if err != nil {
return err
}
return os.RemoveAll("bin/api-o11y-gcp")
}
func removeGlob(path string) (err error) {
contents, err := filepath.Glob(path)
if err != nil {
return
}
for _, item := range contents {
err = os.RemoveAll(item)
if err != nil {
return
}
}
return
}
```
In this file, you can see the use of dependencies, as in the example `mg.Deps(BuildDocker)`. You can also see the use of Go programming logic, such as in the `removeGlob(path string)`. This function could, for example, be in a separate package and used by different files within the directory `magefiles`, using suitable language practices.
We can now view all `targets` available:
```bash
❯ mage -l
Targets:
build* A build step that requires additional params, or platform specific steps for example
buildDocker Build a docker image
buildLinux Build for Linux
clean up after yourself
generateMocks Generate mocks
installDeps Manage your deps, or running package managers.
runDocker Run the docker image
test Run tests
* default target
```
When executing the `mage` command, the function indicated as `Default` will be executed, in this case the `build`:
```bash
❯ mage
❯ mage -v
Running dependency: InstallDeps
Installing Deps...
Building...
```
In the second execution, the result is more detailed when we add the flag `-v`, as we can see in the logs.
I see two advantages of using `mage` in a project. The first is that if the project is written in Go, the team does not need to learn a new language to describe the automated tasks. The second benefit is that we have a complete programming language, not just commands defined in a `Makefile` or `Taskfile.yaml` file. This power allows us to execute complex logic more easily (I've seen giant `Makefile` files with unfriendly syntax to get around this need).
## Conclusions
`Make` is a mature tool used by all the main Open Sorce projects worldwide, and this is not likely to change so quickly. That's why it's very valid that knowledge of this tool is encouraged among devs. However, adding alternatives like the ones presented here can be a crucial step in facilitating the creation of tasks and automation, thanks to the advantages I mentioned in the text.
Do you know of other alternatives? Do you disagree with adopting something other than `make`? I shared your opinions and experiences in the comments.
Originally published at [https://eltonminetto.dev](https://eltonminetto.dev/en/post/2024-05-26-alternatives-make/) on May 26, 2024 | eminetto |
1,867,562 | The Most Popular 5 Taxi Booking Apps in the USA | Taxi booking apps have revolutionized transportation in the U.S., making hailing a cab as simple as using a smartphone. Popular apps like Uber, Lyft, Curb, Via, and Gett offer varied services, from economical to luxury rides, and cater to different needs, ensuring convenient and safe travel for all users. | 0 | 2024-05-28T11:46:24 | https://dev.to/devbambhaniya/the-most-popular-5-taxi-booking-apps-in-the-usa-3gm5 | mobileapps, transportationapps, appdevelopment | ---
title: The Most Popular 5 Taxi Booking Apps in the USA
published: true
description: Taxi booking apps have revolutionized transportation in the U.S., making hailing a cab as simple as using a smartphone. Popular apps like Uber, Lyft, Curb, Via, and Gett offer varied services, from economical to luxury rides, and cater to different needs, ensuring convenient and safe travel for all users.
tags: #MobileApps #TransportationApps #AppDevelopment
---
<img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/e37fg4orumm20jrqqo47.jpg">
Much earlier in the US, it involved standing on the corner of a bustling street and holding your hand hopefully high in the air, with fingers crossed for good luck that a taxicab would roll by. That's all history now in that business line, isn't it? With a new-fangled, nice-to-have, user-friendly taxi-on-the-run ordering application, hailing a car is a matter of punching a few buttons on your smartphone.
Taxi booking apps are in high demand within the US, facilitated by air-conditioned and comfortable rides at economical prices. A safe and convenient way to travel between cities. Dictate your destination, pickup date, time, and location, offer your fare, and take for a ride. The market size is going to hit $283 billion in the projected period 2023-2028, at a compound annual rate of 4.2%. The global taxi business is on the rise, and as days go by, there is increased competition among taxi applications in terms of usage by common people. So many businesses and startups invest in developing taxi booking apps in the USA.
Unchallenged competition exists when [taxi app development companies](https://www.cmarix.com/taxi-app-development-company.html) offer competing products or services that are similar, but not perfect substitutes. Therefore, below we have prepared a list of 5 apps in the USA that you can use to provide your clients with better service and shall serve as encouragement for you as well if you are thinking about developing your taxi booking app.
##Top 5 Best Taxi Apps in USA
###**1. Uber**
Uber is an on-demand facility. It is one of the most popular categories in the United States. It offers services, ranging from the cheapest rides to the most expensive. The huge network of cars and user-friendly interface always makes it the best option.
**Features:**
<ul><li><strong>Wide Availability:</strong> Works in most of the cities in America and many other countries.</li>
<li><strong>Ride Options:</strong> Starts from UberX (economy), UberXL (larger vehicles), Uber Black (high-end vehicles), and more.</li>
<li><strong>Scheduled Rides:</strong> Users can make bookings.</li>
<li><strong>Real-Time Tracking:</strong> Live tracking of the journey along with the estimated time of arrival.</li>
<li><strong>Safety Features:</strong> In-app emergency assistance, driver background checks, and sharing details related to the trip.</li></ul>
###**2. Lyft**
Lyft is known for being friendly on the interface and community feels, with competitive pricing. It comes with a flock of ride options, from which one can avail of rides suitable for daily commutes or special events.
**Features:**
<ul><li><strong>Easy-to-Use Interface:</strong> Easy navigation and booking rides.</li>
<li><strong>Multiple Ride Types:</strong> Lyft Line (shared rides), Lyft XL (for larger groups), and Lux (premium rides).</li>
<li><strong>Driver Tips:</strong> In-app if desired, the tips give you the option to tip the driver through the app.</li>
<li><strong>Scheduled Rides:</strong> Users can schedule a ride in advance — hours or even days before the pickup time through the app.</li>
<li><strong>Lyft Pink Membership:</strong> Avail discounts, relaxed cancellations, and priority airport pickups.</li></ul>
###**3. Curb**
It connects a user with a professional, fully licensed taxi driver to give them a traditional, reliable taxi experience. It is considered to be packed with traditional and advanced app features.
**Features:**
<ul><li><strong>Traditional Taxi Network:</strong> It has a traditional taxi network on its app.</li>
<li><strong>On-Demand and Advance Booking:</strong> Shares and pays the app with a hailed taxi, and the payment is also done through this app.</li>
<li><strong>WAV</strong> (Wheelchair Accessible Vehicles).</li>
<li><strong>E-Receipt:</strong> This feature will enable one to get digital receipts for expense tracking.</li></ul>
###**4. Via**
Via is a shared ride company known for its cost efficiency and decrease in carbon footprints. It uses dynamic routing technology to provide efficient and affordable transportation.
**Features:**
<ul><li><strong>Focus on Ride-Sharing:</strong> Where the passengers are matched with those traveling in the same direction.</li>
<li><strong>Fixed Rates:</strong> Usually provides flat-rate pricing for costs easy to predict.</li>
<li><strong>Dynamic Routing:</strong> This means being able to plan efficient routes that will consider the number of people traveling and make sure that the least time is consumed in transit.</li>
<li><strong>Public Transit Integration:</strong> Partnerships with cities and transit authorities for solutions from doorstep to destination.</li>
<li><strong>Eco-Friendly:</strong> Reduces overpopulation and carbon footprint through ride-sharing.</li></ul>
###**5. Gett**
Gett is a business-type of app for users. Gett provides the rider with fixed pricing and customized solutions for corporate clients. At the very top are reliability and environmental responsibility.
**Features:**
<ul><li><strong>Fixed Price:</strong> No surge pricing; predictable prices.</li>
<li><strong>Business Solutions:</strong> Centralized billing, ride management, and expense tracking.</li>
<li><strong>Carbon Offsetting:</strong> Investments in projects to offset the carbon footprint.</li>
<li><strong>On-Demand and Pre-Booked Rides:</strong> Flexibility to book rides as needed or in advance.</li>
<li><strong>24/7 Customer Support:</strong> Dedicated support for resolving issues.</li></ul>
##**Conclusion**
The apps for booking taxis have quickly become irreplaceable apps in a list of user applications when used with daily routines. Through the service, travelers across the country could find safe and reliable ways to link up with drivers upon demand and thus reach their destinations.
Too many contenders are available to determine which apps are worth dedicating time to and which ones fall short in some way.
The blog will come in handy during the review of some of the best taxi booking apps that are available within the USA. Make use of this blog; it will act as a guideline to [make a taxi booking app](https://www.cmarix.com/inquiry.html) that is best suited for your business needs.
| devbambhaniya |
1,867,561 | The Importance of Hard Drive Destruction: Safeguarding Your Data and Privacy | In today's digital world, data security and privacy have become top priorities for both individuals... | 0 | 2024-05-28T11:41:30 | https://dev.to/brassvalley/the-importance-of-hard-drive-destruction-safeguarding-your-data-and-privacy-1ffe | In today's digital world, data security and privacy have become top priorities for both individuals and corporations. When it comes to disposing of old or retired hard drives, just deleting files or formatting the drive will not ensure that sensitive data cannot be recovered. Here's where hard drive damage comes into play.

[Hard Drive Destruction](https://brassvalley.com/secure-hard-drive-destruction-for-data-protection-and-privacy/) entails physically damaging the hard drive to the point that data recovery becomes impossible. This method not only ensures the thorough removal of sensitive information, but it also assists firms in complying with data protection standards such as GDPR and HIPAA.
One of the main reasons for choosing hard drive destruction is to avoid data breaches and identity theft. Hackers and fraudsters are continuously looking for new ways to obtain access to sensitive information by exploiting discarded technology. By deleting hard drives, you eliminate the possibility of illegal access to personal or sensitive information.
Furthermore, hard drive degradation promotes environmental sustainability. Instead than leaving outdated hard drives to end up in landfills, which might pose environmental risks due to harmful elements, effective destruction guarantees that the components are ethically repurposed.
Brass Valley provides secure hard drive destruction services to preserve your information and privacy. Their cutting-edge facilities and strong security measures ensure that hard drives are irreversibly destroyed, giving individuals and businesses piece of mind. Visit [Brass Valley](https://brassvalley.com/) website today to discover more about the hard drive destruction services they offer. | brassvalley | |
1,867,560 | Unlocking Channel Partner Success: 3 Vital Traits to Prioritize | The top five US-based tech OEMs generate over 80% of their revenue through channel partners. Channel... | 0 | 2024-05-28T11:40:37 | https://dev.to/neuro_logik/unlocking-channel-partner-success-3-vital-traits-to-prioritize-5643 | salespartner, cps, pem, pdm | The top five US-based tech OEMs generate over 80% of their revenue through channel partners.
Channel partners help OEMs grow not only revenue but also their footprint in the market. Channel partner’s local knowledge and regional expertise help OEMs penetrate new markets easily. OEMs can localize their offerings, leverage known brands, and reduce their customer acquisition costs in the new markets.
Channel partners are critical for spreading OEM’s products and services far and wide. Empowered channel partners help the OEMs focus on innovation as they manage the customers and business growth.
What are Channel Partners?
Channel partner definition varies little across the industry, as almost every business aligns its partner network for a larger footprint. So, a channel partner is a third-party organization or individual that collaborates with a manufacturer or vendor to market, sell, or distribute its products or services to end customers.
Channel partners can include distributors, resellers, value-added resellers (VARs), systems integrators, consultants, and other types of intermediaries. They play a crucial role in expanding the reach of a company's offerings and accessing new markets or customer segments.
Channel partners typically receive commissions, discounts, or other incentives for their sales efforts and contributions to the business's success. Channel partners are a critical cog in the sales and marketing value chain for the OEMs across the industry.
Types of Channel Partners
Modern industry uses a variety of channel partners depending on which business goals the partners will serve. However, OEMs have traditionally stuck with the following types of channel partners:
Resellers: These partners act as an external extension of your sales team. They purchase products or services from manufacturers or distributors and sell them to end customers.
Technology Partners: These collaborators specialize in complementary tech solutions. They can enhance your product offerings by integrating their technology with yours.
Referral Partners: Word-of-mouth promoters who refer potential customers to your business. They don’t directly sell but play a vital role in lead generation.
Affiliates: Online product endorsers who earn commissions by promoting your products through their channels (websites, social media, etc.).
Distributors: chain intermediaries who manage inventory and logistics. They distribute products to retailers or resellers.
Wholesalers: Bulk product sellers who supply goods to retailers or other businesses.
Value-Added Resellers (VARs): Customized solution providers who bundle your products with additional services or features.
Value-Added Distributors (VADs): End-to-end solution deliverers who provide technical support, training, and other value-added services.
Benefits of Channel Partner Program for OEMs
While channel partners offer several tangible benefits to OEMs, factoring in all the benefits is important. Understanding the benefits can help OEMs design channel partner enablement programs aligned to them. This can include using the right tools and resources to empower the partners.
So, here’s a list of benefits of a channel partner program:
Expanded Market Reach
Reach new geographic regions and market segments through the networks and customer base of the partners.
Increased Sales and Revenue
Leverage the expertise and relationships of channel partners to accelerate sales cycles, and ultimately increase revenue.
Cost Efficiency
Shared marketing and sales expenses, reduce the overall cost of customer acquisition. Thus, partnerships allow you to scale without significant upfront investment.
Access to Specialized Skills
Channel partners can bring unique industry knowledge, technical expertise, and market insights.
Enhanced Customer Experience
Partners provide localized support, customization, and service, leading to higher customer satisfaction and loyalty.
Faster Time-to-Market
Partner programs enable quick expansion in new markets or launch new products.
Flexibility and Adaptability
Channel partnerships allow businesses to stay competitive and agile. You can identify and adapt to changing market conditions and customer preferences using partner insights.
Brand Visibility and Credibility
Partnering with reputable channel partners enhances brand visibility and credibility. You can benefit from your partners’ established trust and reputation in the market.
Focus on Core Competencies
Channel partners handling consumer-related functions help companies focus on their core competencies and strategic priorities.
Long-Term Growth Opportunities
Strong relationships with channel partners can lead to long-term growth opportunities. You can start joint product development, and co-marketing initiatives, and expand collaboration in new markets.
The Three Vital Traits for Channel Enablement
For Original Equipment Manufacturers (OEMs), channel partner success hinges on several key priorities that ensure effective collaboration, streamlined operations, and mutual growth. Here are three essential priorities:
1. Channel Enablement and Training
Developing Expertise
Providing comprehensive training and support to channel partners is essential for their success. OEMs should offer training programs that cover product knowledge, sales techniques, marketing strategies, and technical support.
Content Enablement
Effective channel enablement ensures that partners have the skills and resources needed to effectively promote and sell OEM products. Content such as product design and feature-related information is critical for selling high-engagement and high-value assets.
Solution-Oriented Sales
High competition, complex products, and strict accountability rules have driven B2B consumers to scrutinize products for solutions. The key question sales teams must address is, “Does this product solve our problem and at what cost?”
Modern channel sales are also about offering a solution rather than a good product.
Helpful Tools & Methods for Partner Training
Qualifying certifications for channel partner onboarding process to ensure right selection
Learning Management System (LMS) connected with the partner portal for continuous learning and certification of the partners.
Webinars, workshops, and sales training.
Product Information Management (PIM) and Digital Asset Management (DAM) Systems integrated with LMS and partner portals.
2. Channel Relationship Management
Long-term success with channel sales requires strong relationships. OEMs should invest in tools and processes to foster open communication, collaboration, and trust with their partners.
Proactive engagement and regular communication help address partner needs, identify opportunities for improvement, and resolve issues promptly. Building a collaborative partnership ecosystem fosters mutual success and strengthens the overall channel network.
Helpful Tools & Methods for Partner Communication
Accountable Communication: Dedicated Channel Managers, and project management tools like Jira, Asana, Trello, etc. Partner Portals for dedicated partner support.
Collaborative Development: Collaboration platforms such as Sharepoint, Google Workspace, and PIM systems with collaboration features.
3. Channel Performance Optimization
Key Performance Indicators: Constantly monitoring and optimizing channel performance is vital for maximizing partner success and driving revenue growth. OEMs should establish key performance indicators (KPIs) to measure partner performance and track progress over time.
OEMs can identify areas for improvement, implement targeted strategies to address challenges, and capitalize on growth opportunities. This may involve refining sales and marketing tactics, optimizing channel incentives, or expanding into new markets or customer segments.
Helpful KPIs, Tools & Methods for Channel Performance
KPIs are an important channel enablement tool as they help OEMs understand the gaps and opportunities. Examples include:
Sales Stats: Revenue growth, sales performance (success rate), ROI
Market Capture: Market share, customer satisfaction score
Engagement Level: Partner engagement level, conflict resolution rate,
Performance Assistance: OEMs can boost their channel partner performance with advanced tools and support systems. A few examples of such systems are:
Partner Relationship Management (PRM) software,
CRM systems,
Deal Registration Systems,
Marketing automation tools, and performance reviews.
Product Information – Key Ingredient in Sales Enablement
Communication is key to the success of your channel partner network. Correct product information leads to correct solutions and longer lifecycles, upgrades, and happier customers. Sharing and updating your sales channels with the latest and consistent information boosts customer confidence and channel sales.
However, manually updating the large network of partners is often an uphill task. You can conduct webinars, product launches, and online learning sessions for faster diffusion of knowledge. But your sales partners may not need that information immediately.
Also, OEMs need to ensure that they are talking to the correct people. For example, while updating an enterprise user of an old product, the sales teams can offer a compatible replacement. Replacement products may not always be the latest available version of the previous product.
In short, your channel partners should have access to the product information in a way they can use it as and when they need:
Freely accessible product information bundles
Product design and accessories info
Region-compatible products (compliance)
Catalogues and marketing collaterals specific to the partner’s target market
Language adoptions for the marketing, sales, and technical documents
So, first, the OEMs need to work on building awareness of their products and solutions for the channel partner market. Then ensure that technical and usability information is localized, and only compatible solutions are offered to the partner.
Product information management (PIM) Product information management (PIM) Neurologik’s ProductHub can facilitate channel sales enablement.
Neurologik’s ProductHub as Master Data Solution
Neurologik’s ProductHub is an advanced product information management tool that combines the features of PIM, DAM, CMS, and MDM. The SaaS tool creates a master database for all your product information, documents, images, and other digital media. The master database acts as the single source of truth for all purposes of product data.
Single source of truth for all product data and documents
Seamless integration and data capture from existing systems
Identify and fill product data gaps with validated information
Add rich attributes to allow the creation of custom solutions and packs
Distribute and share the authentic and updated product data on websites, e-commerce portals, channel partners, etc.
Integrate with analytics and NLP packs for data-driven decisions, and localizing product information
The master database allows OEMs to enrich their product data, add tags to the digital assets, and ensure accuracy. Secure access, regular validation, and version controls ensure a high quality of the data.
ProductHub can empower your channel partners with regionalized catalogs and document bundles. Also, you can turn your website into a self-service portal for your partners and customers. OEM website can display product information with rich attributes based on user intent to deliver custom solutions.
ProductHub can automate anywhere from 50% to 80% of your information-sharing process with channel partners. Thus, saving time and enabling partners with their sales and customer engagement efforts.
FAQs
1. What are the essential traits of a successful channel partner?
Successful channel partners usually outperform others on key business metrics. For instance, the number of deals or customers, the average size of the deals/sales, customer satisfaction score, etc. Other than these, you can also look at sales meetings, partner portal activity, and joint marketing campaigns.
2. How important is KPI alignment in channel partnerships?
KPI alignment in channel partnerships ensures that both parties are working towards shared goals and objectives. It facilitates better communication, collaboration, and accountability. Shared KPIs will eventually enable effective performance measurement and strategic decisions driving mutual growth.
3. What role does communication play in partner enablement strategies?
Communication is a pivotal factor in channel partner enablement strategies. It fosters alignment, clarity, accountability, and transparency between the partners and the OEMs. Effective communication channels enable information exchange, feedback, and insights. Thus, communication enables partners to stay informed, engaged, and empowered.
4. Why is product or service expertise crucial for effective channel partnerships?
Product or service expertise in channel partnerships builds credibility, instills trust, and enhances customer satisfaction. Partners with deep knowledge can effectively communicate value propositions, address client needs, and provide instant support. Thus, expertise leads to trust, customer loyalty, and increased sales for OEMs and expert partners.
5. How can businesses navigate challenges in channel partner relationships?
Open communication, transparency, and fairness are critical building blocks for channel partner relations. Fast and transparent product information sharing facilitates these factors between OEMs and channel partners. PIM systems like ProductHub enable these features with the added advantage of destination formatting. Thus, your channel partners can rely on the information coming from the OEMs, leading to higher trust.
Original Source :- https://neurologik.io/blog/unlocking-channel-partner-success/ | neuro_logik |
1,867,559 | The Importance of Regular .NET Platform Upgrades and How to Mitigate Associated Risks | .NET is a secure, reliable, and high-performance application platform, which is a free and... | 0 | 2024-05-28T11:39:48 | https://dev.to/shahabfar/the-importance-of-regular-net-framework-upgrades-and-how-to-mitigate-associated-risks-50e5 | .NET is a secure, reliable, and high-performance application platform, which is a free and open-source, managed computer software framework for Windows, Linux, and macOS operating systems. The project is mainly developed by Microsoft employees by way of the .NET Foundation and is released under an MIT License.
In the rapidly evolving world of software development, keeping your applications up-to-date with the latest technologies is crucial. One such technology is the .NET, a popular platform for building a variety of applications. This article discusses the importance of regular .NET platform upgrades and how to mitigate the risks associated with these upgrades.
**Why Upgrade Regularly?**
Regularly upgrading the .NET version of your .NET application, ideally every year for each new .NET platform version, can offer a multitude of benefits. One of the key advantages is the performance improvements that come with each new version of .NET platform. These enhancements can make your application run faster and consume fewer resources, leading to an overall more efficient system.
In addition to performance improvements, new versions often introduce new features that can simplify development and enable you to provide more functionality to your users. These features can range from new libraries to improved language features, all aimed at making your development process smoother and more efficient.
Another crucial aspect of regular upgrades is the inclusion of security updates. These updates include patches for security vulnerabilities that have been discovered since the last version. By keeping your application up-to-date, you ensure that you’re protected against known security threats, thereby safeguarding your application and its data.
Microsoft provides support for each .NET version for a specific period of time. By upgrading regularly, you ensure that you’ll be able to receive support and that your application remains compatible with other technologies. This compatibility is vital in today’s interconnected tech ecosystem, where applications often need to interact with various other technologies.
Lastly, each new version also includes fixes for bugs found in previous versions. Regularly updating your application can help prevent or resolve issues, leading to a more stable and reliable application. In conclusion, regular upgrades to the .NET version of your .NET application can lead to improved performance, new features, enhanced security, continued support, and bug fixes. Therefore, it is highly recommended to keep your application up-to-date with the latest .NET platform version.
**Risks of Frequent Upgrades**
While regular upgrades offer numerous benefits, they also come with their own set of potential risks. One such risk is the introduction of breaking changes with each new version. These changes may not be backward compatible with previous versions, potentially disrupting existing functionality in your application.
Another consideration is the investment of time and resources. The process of upgrading to a new version, testing it, and resolving any issues that arise can be time-consuming and require significant resources. This could impact other development activities or lead to increased costs.
Dependency conflicts present another potential challenge. If your application relies on libraries that are not compatible with the new version, you may encounter conflicts that can cause issues in your application.
Furthermore, each new version might introduce changes that require you to learn new ways of doing things. This learning curve can take time and slow down your development process.
Finally, stability can be a concern. Sometimes, new versions might contain undiscovered bugs or issues that can affect the stability of your application. While these are typically resolved in subsequent updates, they can cause temporary disruptions.
**Mitigating the Risks**
Mitigating the risks associated with frequent upgrades requires a blend of careful planning and good practices. One effective strategy is to conduct thorough testing in a non-production environment before deploying the new version in your production environment. This approach can help you identify any breaking changes or issues that might impact your application.
Another useful strategy is to consider a gradual rollout of the new version, starting with a small set of users. By closely monitoring the application’s performance and functionality, you can ensure a smooth transition before rolling it out to all users.
Managing your application’s libraries and dependencies is also crucial. Regularly checking their compatibility with the new version and updating them as necessary can prevent potential conflicts.
Having a backup and rollback plan is another important aspect of risk mitigation. Always ensure you have a backup of your application and data before an upgrade. In case something goes wrong, a rollback plan will allow you to revert to the previous version.
Staying informed is key to managing the risks of frequent upgrades. Keeping up-to-date with the release notes, migration guides, and documentation for each new version can help you understand what changes to expect and how to handle them.
Lastly, don’t hesitate to seek support if you encounter issues during the upgrade. This could be from the online developer community, forums, or from Microsoft’s support if you have a support plan. By following these strategies, you can effectively mitigate the risks associated with frequent upgrades.
In conclusion, while regular updates are generally beneficial, each application is unique. The decision to update should be made based on the specific needs and circumstances of your project. It’s always a balance between leveraging new features and improvements and maintaining the stability and functionality of your application. | shahabfar | |
1,867,558 | The Future is Now: How Artificial Intelligence is Transforming Our World | We have seen and heard so much about artificial intelligence (AI), that it is not only a thing of the... | 0 | 2024-05-28T11:37:41 | https://dev.to/liong/the-future-is-now-how-artificial-intelligence-is-transforming-our-world-2g5b | ai, visual, malaysia, kulalaumpur | We have seen and heard so much about artificial intelligence (AI), that it is not only a thing of the future which will be limited to science fiction. Today, it has become ubiquitous in the everyday lifestyle that we are living, as it is changing industries, improving efficiencies and presenting hitherto unseen opportunities. AI is revolutionizing the world as we know it, be it healthcare to finance; education, or entertainment. In this blog, I would like to give a multi-sided view on the AI impact and challenges and where we are heading.
## **Understanding Artificial Intelligence**
Artificial intelligence refers back to the simulation of human intelligence in machines programmed to assume and study like human beings. These systems are able to performing duties that normally require human intelligence, including visual belief, speech reputation, selection making and language translation. AI may be categorized into two fundamental classes: slim AI that is designed for a specific assignment and popular [AI](https://ithubtechnologies.com/artificial-intelligence-in-malay/?utm_source=dev.to%2F&utm_campaign=Artificialintelligence+&utm_id=Offpageseo+2024), which has the ability to carry out any highbrow mission that a human can carry out.
This blog explores how AI is impacting our international, highlighting its fine elements and addressing the demanding situations it provides.
## **Positive Aspects of AI**
**1. Healthcare Revolution**
AI is substantially improving healthcare by way of improving diagnostics, remedy plans, and patient care. AI algorithms can examine medical records to stumble on sicknesses early and are expecting patient results with high accuracy. For example, AI systems are being used to pick out early signs of most cancers and Alzheimer's, enabling timely interventions.
**2. Enhanced Financial Services**
In the economic quarter, AI is reworking how companies function. AI algorithms are used for fraud detection, reading transaction patterns to perceive anomalies in real-time, offering a stage of security that manual tactics cannot match. Robot-advisors, which use AI to manipulate funding portfolios, offer personalized financial techniques, making sophisticated monetary planning available to extra people. Language studying apps like Duo lingo use AI to provide personalized instructions and instantaneous feedback, making the studying process more powerful and attractive.
**3. Innovations in Entertainment**
The entertainment industry leverages AI to create more immersive and personalized reviews. Streaming services like Netflix and Spottily use AI algorithms to advocate content material primarily based on person alternatives, keeping audiences engaged. In video video games, AI creates shrewd non-player characters (NPCs) that adapt to participant moves, presenting dynamic and difficult reports. AI additionally plays a great function in tune composition and production, analyzing significant amounts of music to generate new compositions and help in mixing and gaining knowledge of tracks.
**4. Environmental Sustainability**
AI is essential in addressing environmental challenges. Machine gaining knowledge of fashions are expecting climate patterns, assisting scientists recognize and mitigate the consequences of climate alternate. AI optimizes energy use in smart grids, decreasing waste and selling renewable strength resources. In agriculture, AI-pushed equipment enhance crop control and yield predictions. Precision farming strategies, guided with the aid of AI, allow farmers to use assets more effectively, lowering environmental effect and enhancing food safety.
**5. Transportation Advancements**
AI is remodeling transportation via self-sustaining automobiles, which promise to reduce visitors injuries and enhance avenue safety. These cars use AI to navigate, make real-time selections, and adapt to converting road situations. Smart visitors control structures optimize traffic go with the flow, reducing congestion and emissions, while predictive upkeep ensures public transportation infrastructure remains in precise situation.
**6. Smart Homes**
AI enhances the functionality of clever houses. AI-powered assistants like Amazon Alexa and Google Assistant manipulate domestic appliances, provide updates, and manage responsibilities, mastering from consumer interactions to emerge as more intuitive. AI-pushed security structures hit upon uncommon activities, offering peace of mind, and optimize electricity usage by adjusting heating, cooling, and lighting primarily based on occupancy patterns.
**7. Customer Service Improvements**
AI revolutionizes customer service with catboats and digital assistants offering 24/7 support. These tools manage various client queries, from primary information to complex troubleshooting, the usage of natural language processing to respond in a human-like way. AI additionally analyzes consumer remarks to provide insights into preferences and ache points, helping agencies improve products and services.
## **Negative Aspects of AI**
**1. Job Displacement**
One of the number one worries approximately AI is its potential to displace jobs. As AI systems grow to be extra successful, there may be a worry that they will replace human employees, specifically in repetitive and recurring obligations. This could lead to massive process losses in sure sectors. To mitigate this impact, it's far crucial to expand techniques along with reskilling packages and developing new job possibilities in emerging fields.
**2. Privacy Concerns**
AI systems depend upon enormous amounts of statistics to feature effectively, elevating questions about statistics security and person privacy. The collection and analysis of private data can result in privacy infringements if now not controlled nicely. Ensuring that statistics is accrued and used ethically, with robust safeguards in location, is important to hold public trust.
**3. Ethical Challenges**
The development and deployment of AI have to be guided via ethical ideas to prevent misuse. There is a chance that AI might be used for harmful purposes, including autonomous guns or surveillance systems that infringe on man or woman freedoms. Establishing global rules and moral guidelines is essential to make sure AI is advanced and used responsibly.
**4. Bias and Discrimination**
AI systems can perpetuate or even expand present biases if they're educated on biased information. This can result in discriminatory consequences in regions which include hiring, lending, and law enforcement. Addressing this issue calls for developing extra inclusive and various training data units and implementing measures to detect and mitigate bias in AI systems.
**5. Dependence on AI**
As AI structures turn out to be more incorporated into various aspects of our lives, there may be a danger of turning into overly depending on them. This may want to lead to a lack of important questioning talents and human judgment. It is essential to maintain a stability among leveraging AI abilities and preserving human autonomy and selection-making.
**6. Security Risks**
AI systems are not immune to safety vulnerabilities. They may be focused with the aid of cyber attacks, leading to potential misuse of AI technologies. Ensuring the security and robustness of AI structures is vital to save you malicious activities and shield sensitive facts.
**7. Economic Inequality**
The benefits of AI are not calmly disbursed, leading to issues approximately growing monetary inequality. Wealthier people and countries might also have higher access to AI technology, exacerbating current disparities. Efforts should be made to ensure that the blessings of AI are shared more equitably across extraordinary communities and areas.
## **Conclusion**
Artificial intelligence is reworking our international, offering unheard of opportunities and posing sizable demanding situations. From revolutionizing healthcare and finance to reshaping education and entertainment, AI's high-quality elements are big. However, addressing the ethical, societal, and protection demanding situations it gives is essential to make certain that AI is evolved and used responsibly. By operating collectively, policymakers, industry leaders, and researchers can expand frameworks that sell transparency, accountability, and inclusivity. The future of AI holds thrilling possibilities, and with cautious control, we will harness its electricity to create a greater advanced, equitable, and inclusive global.
| liong |
1,867,557 | How to Customize Your Shopify Checkout Page: A Step-by-Step Guide | Shopify is one of the most popular ecommerce platforms, offering a seamless checkout experience for... | 0 | 2024-05-28T11:36:02 | https://dev.to/gianna4/how-to-customize-your-shopify-checkout-page-a-step-by-step-guide-31kh | ecommerce, business | Shopify is one of the most popular ecommerce platforms, offering a seamless checkout experience for customers. However, the default checkout page may not align with your brand's aesthetic or conversion optimization goals. Fortunately, Shopify allows you to customize the checkout page to match your brand's identity and improve the overall shopping experience. In this step-by-step guide, we'll walk you through how to customize your [Shopify checkout page](https://www.convertcart.com/blog/shopify-checkout-page).
## Why Customize the Checkout Page?
Customizing the checkout page offers several benefits, including:
- Enhanced Branding: Align the checkout page with your brand's visual identity and messaging.
- Improved Conversion Rates: Optimize the layout and design to reduce friction and increase conversions.
- Better Customer Experience: Tailor the checkout process to your customers' needs and preferences.
## Step 1: Enable Checkout Customization
To start customizing your checkout page, navigate to your Shopify admin panel and follow these steps:
1. Go to Settings > Checkout.
2. Scroll down to the Checkout customization section.
3. Click Enable checkout customization.
## Step 2: Choose a Customization Method
Shopify offers two customization methods:
1. Template Editor: A visual editor for non-coders.
2. Liquid Code Editor: For developers familiar with Liquid templating language.
Choose the method that suits your technical expertise.
## Step 3: Customize the Checkout Template
Using the Template Editor:
1. Click Add section to insert new elements, such as a header or footer.
2. Drag and drop sections to reorder the layout.
3. Click Edit to customize individual sections.
Using the Liquid Code Editor:
1. Click Edit code to access the Liquid code.
2. Modify the code to customize the checkout template.
## Step 4: Add Custom CSS
To add custom CSS:
1. Go to Settings > Checkout.
2. Scroll down to Advanced.
3. Click Add custom CSS.
## Step 5: Test and Publish
1. Preview your custom checkout page.
2. Test the checkout process to ensure everything works as expected.
3. Click Publish to apply your changes.
## Best Practices and Tips
- Keep it Simple: Avoid clutter and ensure a clear, concise layout.
- Brand Consistency: Use your brand's colors, typography, and imagery.
- Mobile Optimization: Ensure a seamless checkout experience on mobile devices.
- A/B Testing: Test different variations to optimize conversion rates.
## Conclusion
Customizing your Shopify checkout page is a straightforward process that can significantly enhance the shopping experience and improve conversion rates. By following this step-by-step guide, you can tailor the checkout page to your brand's unique identity and optimize it for maximum conversions.
| gianna4 |
1,867,556 | La Simbiosi entre IA i Ciberseguretat: Cap a una Nova Era de CiberProtecció dels "AI Brains" | Fa temps que dic que l'era de la IA passa per la ciberseguretat i que la ciberseguretat passa per la... | 0 | 2024-05-28T11:33:27 | https://dev.to/gcjordi/la-simbiosi-entre-ia-i-ciberseguretat-cap-a-una-nova-era-de-ciberproteccio-dels-ai-brains-24k0 | ia, ciberseguretat | Fa temps que dic que l'era de la IA passa per la ciberseguretat i que la ciberseguretat passa per la IA. Com a especialista en #Cybersecurity i #AI, sempre celebro que comencin a sortir solucions especialitzades integrals per aquesta nova era. Aquí us presento un exemple clar d'aquesta sinergia: la millora de la plataforma [Trend Vision One](https://www.trendmicro.com/es_es/business/products/one-platform.html) de Trend Micro.
No tinc cap vinculació amb [Trend Micro](https://www.trendmicro.com/es_es/forHome.html) ni soc usuari directe dels seus productes, però vull parlar d'ells, ja que veig de les primeres notícies que tenen un enfocament que van dirigits cap aquesta era on la ciberseguretat i la IA entren en una nova dimensió. I, més enllà del "màrqueting" que pugui haver-hi, sempre és un plaer veure que la indústria es dirigeix cap a aquest enfocament de ciberseguretat dels "AI Brains" que sempre defenso.
Trend Micro ha donat un pas endavant significatiu en la gestió dels riscos associats amb la intel·ligència artificial generativa, un camp que està experimentant una adopció massiva a diverses indústries. Aquesta expansió de capacitats inclou la integració de [Zero Trust Secure Access (ZTSA)](https://www.trendmicro.com/en_us/business/products/network/zero-trust-secure-access.html), una funcionalitat impulsada per IA que busca protegir l'accés als serveis d'IA generativa tant públics com privats dins de les organitzacions.
El concepte de Zero Trust (confiança zero) és fonamental en l'actualitat per garantir la seguretat a nivell empresarial. Amb la integració de ZTSA, Trend Micro proporciona una capa addicional de seguretat que ajuda a combatre l'ús indegut i els abusos dels serveis d'IA. Aquesta tecnologia assegura que només els usuaris autoritzats puguin accedir a recursos crítics, aplicant un enfocament rigorós i continu per a la verificació de cada sol·licitud d'accés.
Una de les característiques clau d'aquesta nova funcionalitat és la capacitat d'inspeccionar ràpidament el trànsit per evitar fugues de dades i injeccions malicioses. Això és essencial en un entorn on les dades són un actiu valuós i la seva protecció és prioritària. La inspecció contínua permet detectar i mitigar amenaces en temps real, minimitzant el risc d'incidents de seguretat que podrien tenir conseqüències devastadores.
A més, Trend Vision One inclou mecanismes avançats de filtrat de contingut per garantir el compliment normatiu. En un món on les regulacions de protecció de dades són cada cop més estrictes, tenir eines que assegurin el compliment és cabdal per evitar sancions i danys a la reputació corporativa.
Una altra innovació destacada és la defensa contra atacs dirigits a models de llenguatge gran (LLM), que són la base de moltes aplicacions d'IA generativa. Aquests models són vulnerables a diferents tipus d'atacs, incloent-hi la manipulació de dades d'entrenament i l'explotació de biaixos en els algorismes. Les noves capacitats de Trend Vision One ajuden a protegir aquests models, assegurant que les aplicacions d'IA funcionin de manera segura i fiable.
Per complementar aquestes millores, Trend Micro també ha anunciat [Trend Vision One Attack Surface Risk Management (ASRM)](https://www.trendmicro.com/en_us/business/products/detection-response/attack-surface-management.html), una eina que ajuda a mitigar i remediar els riscos cibernètics de manera proactiva. ASRM integra diferents tecnologies en una oferta única, proporcionant una visibilitat completa de la superfície d'atac i permetent una gestió eficaç dels riscos al llarg de tot el cicle de vida.
En resum, l'enfocament integrat de Trend Micro representa un pas important cap a una ciberseguretat més robusta i una gestió de riscos més eficaç en l'era de la intel·ligència artificial. Aquestes innovacions no només milloren la seguretat, sinó que també ofereixen als equips de ciberseguretat eines poderoses per gestionar els reptes complexos de l'actualitat, i molt especialment ofereixen un enfocament de present i de futur. Estic convençut que veurem més avenços en aquesta direcció, reforçant la interconnexió entre la IA i la ciberseguretat.
[Jordi G. Castillón](https://jordigarcia.eu/) | gcjordi |
1,867,555 | Guide to Buying a 1-Bedroom Apartment in Dubai | Dubai, the dazzling emirate, beckons with its futuristic skyline, luxurious lifestyle, and thriving... | 0 | 2024-05-28T11:32:19 | https://dev.to/homestation/guide-to-buying-a-1-bedroom-apartment-in-dubai-51ci | apartments, realestate, dubairealestate, homestation |
Dubai, the dazzling emirate, beckons with its futuristic skyline, luxurious lifestyle, and thriving economy. Intrigued by the idea of owning a piece of this paradise? Look no further than a sophisticated 1-bedroom apartment – perfect for urban professionals or savvy investors. But navigating the Dubai property market can seem daunting. Fear not, this comprehensive guide equips you with the knowledge to find your ideal [1-bedroom in Dubai](https://homestation.ae/1-bedroom-apartments-for-sale-in-dubai/).
## Location is King: Pinpointing Your Perfect Spot
Dubai boasts a diverse array of neighborhoods, each catering to distinct preferences.
- **Budget-conscious buyers:** Explore areas like International City, Dubai Sports City, or Jumeirah Village Circle (JVC) for trendy and affordable options.
- **Urban vibrancy:** Jumeirah Lake Towers (JLT) offers high-rise living with stunning lake views and easy access to business hubs.
- **Proximity to leisure:** Downtown Dubai places you amidst the iconic Burj Khalifa and Dubai Mall, ideal for those who crave a vibrant lifestyle.
## Prioritize Your Must-Haves: Amenities That Matter
Dubai apartments come with a plethora of amenities. Consider your lifestyle:
- **Fitness buffs:** Seek a gym, swimming pool, or a jogging track within the complex.
- **Convenience seekers:** Opt for buildings with on-site retail stores, cafes, or laundry services.
- **Family-oriented residents:** Look for communities with children's play areas or daycare facilities.
## Embrace the Power of Research: Essential Resources
Online portals: Leverage websites like Bayut or Property Finder to browse thousands of listings with detailed filters.
- **Real estate agents:** Partner with a reputable agent who understands your needs and negotiates on your behalf.
- **Market trends:** Stay informed about current market trends and pricing through property market reports.
## Secure Your Investment: The Buying Process Explained
Agreement & Negotiation: Once you've shortlisted an apartment, a Memorandum of Understanding (MOU) outlines the agreed-upon price and terms.
- **No Objection Certificate (NOC):** Obtain this from the developer to proceed with the purchase.
- **Dubai Land Department (DLD):** Finalize the transfer of ownership by registering the property at the DLD.
## Embrace Professional Guidance: Why a Real Estate Agent is Your Ally
A good real estate agent streamlines the process and safeguards your interests. They can:
- Provide expert insights into different neighborhoods.
- Unearth hidden gems not readily available online.
- Negotiate the best possible price for your chosen apartment.
- Guide you through legalities and paperwork.
## Financing Your Dream: Exploring Mortgage Options
Explore home loans offered by banks in the UAE. Factors like your nationality, residency status, and down payment amount will influence your eligibility and interest rates.
## Beyond the Apartment: Additional Costs to Consider
- **Registration fees:** Factor in Dubai Land Department (DLD) fees associated with property registration.
- **Agent fees:** Real estate agents typically charge a commission based on the property value.
- **Service charges:** Budget for building maintenance fees that cover amenities and common area upkeep.
## Own a Piece of Dubai: Embrace the Investment Potential
Dubai's property market offers promising returns. Consider renting out your apartment for a steady income stream, or capitalizing on future appreciation.
Investing in a [1-bedroom apartment in Dubai](https://homestation.ae/1-bedroom-apartments-for-sale-in-dubai/) unlocks a door to an extraordinary lifestyle. By following this guide and seeking expert advice, you'll be well on your way to securing your dream property in the heart of this magnificent city.
| homestation |
1,867,554 | Devoxx Genie Plugin : an Update | When I invited Anton Arhipov from JetBrains to present during the Devoxx Belgium 2023 keynote their... | 0 | 2024-05-28T11:32:10 | https://dev.to/stephanj/devoxx-genie-plugin-an-update-53hg | devoxx, genai, openai, ollama | When I invited Anton Arhipov from JetBrains to present during the Devoxx Belgium 2023 keynote their early Beta AI Assistant, I was eager to learn if they would support local modals, as shown in the screenshot above.
After seven months without any related news, it seemed unlikely that this would happen. So, I decided to develop my own IDEA plugin to support as many local and event cloud-based LLMs as possible. "DevoxxGenie" was born ❤️
[
](https://plugins.jetbrains.com/plugin/24169-devoxxgenie)
Of course, I conducted a market study and couldn't find any plugins that were fully developed in Java. Even GitHub Copilot, which doesn't allow you to select a local LLM, is primarily developed in Kotlin and native code. But more importantly, are often closed sourced.
I had already built up substantial LLM expertise by integrating [LangChain4J](https://github.com/langchain4j/langchain4j) into the CFP.DEV web app, as well as developing Devoxx Insights (using Python) in early 2023. More recently, I created [RAG Genie](https://github.com/stephanj/rag-genie), which allows you to debug your RAG steps using Langchain4J and Spring Boot.
## Swing Development
I had never developed an IDEA plugin so I started studying some existing plugins to understand how they work. I noticed that some use a local web server, allowing them to more easily output the LLM response in HTML and stream it to the plugin.
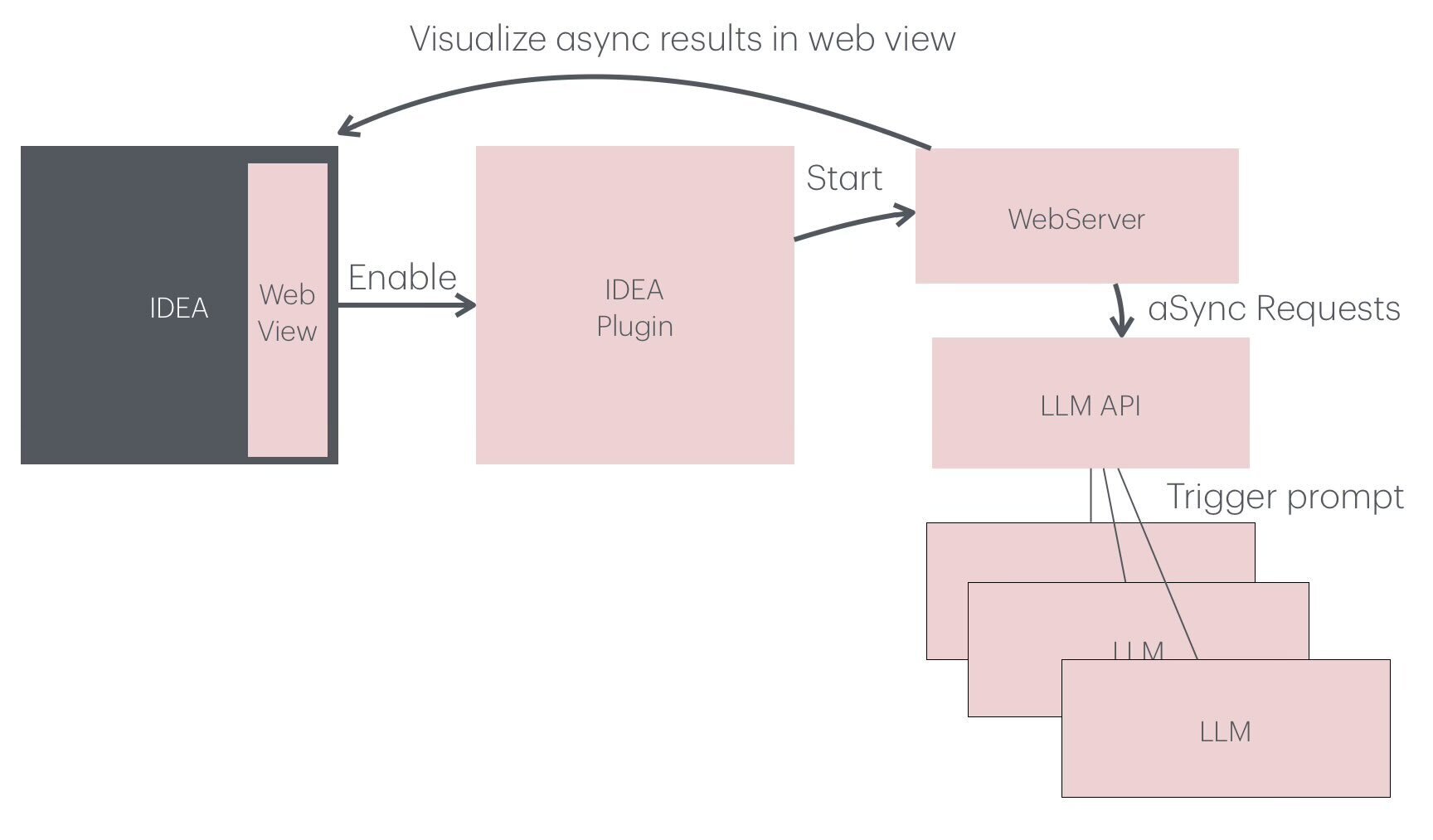
I wanted to start with a simple input prompt and focus on using the "good-old" JEditorPane Swing component which does support basic HTML rendering.
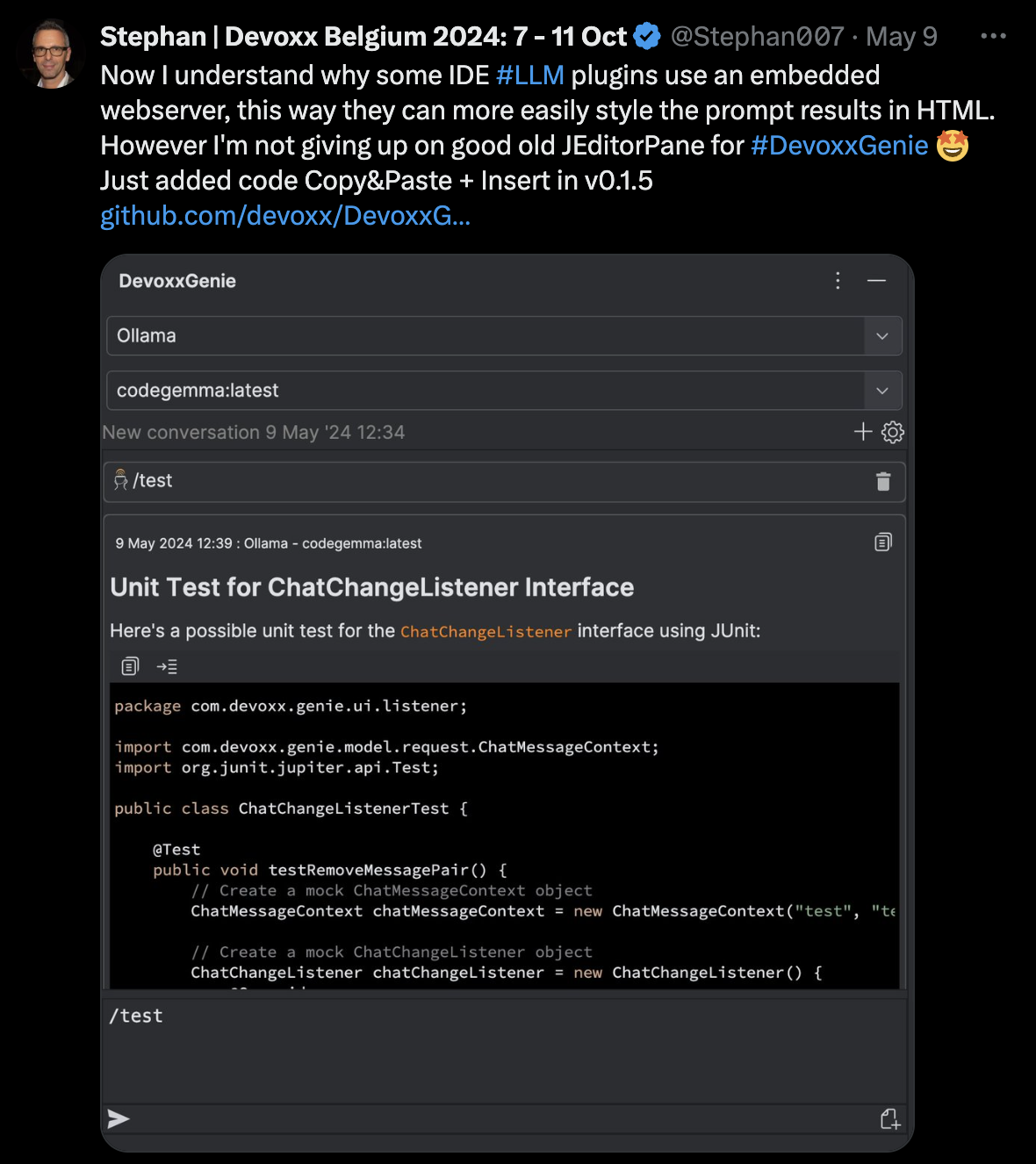
By asking the LLM to respond in Markdown, I could parse the Markdown so each document node could be rendered to HTML while adding extra styling and UI components. For example, code blocks would include an easy to use "copy-to-clipboard" button or an "insert code" button (as shown above in screenshot).
## Focus on Local LLM's
I focused on supporting [Ollama](https://ollama.com), [GPT4All](https://gpt4all.io/index.html), and [LMStudio](https://lmstudio.ai/), all of which run smoothly on a Mac computer. Many of these tools are user-friendly wrappers around [Llama.cpp](https://github.com/ggerganov/llama.cpp), allowing easy model downloads and providing a REST interface to query the available models.
Last week, I also added ["👋🏼 Jan"](https://jan.ai) support because HuggingFace has endorsed this provider out-of-the-box.
## Cloud LLM's, why not?
Because I use ChatGPT on a daily basis and occasionally experiment with Anthropic Claude, I quickly decided to also support LLM cloud providers. A couple of weeks ago, Google released Gemini with API keys for Europe, so I promptly integrated those too. With support for OpenAI, Anthropic, Groq, Mistral, DeepInfra, and Gemini, I believe I have covered all the major players in the field.
Please let me know if I'm missing any?
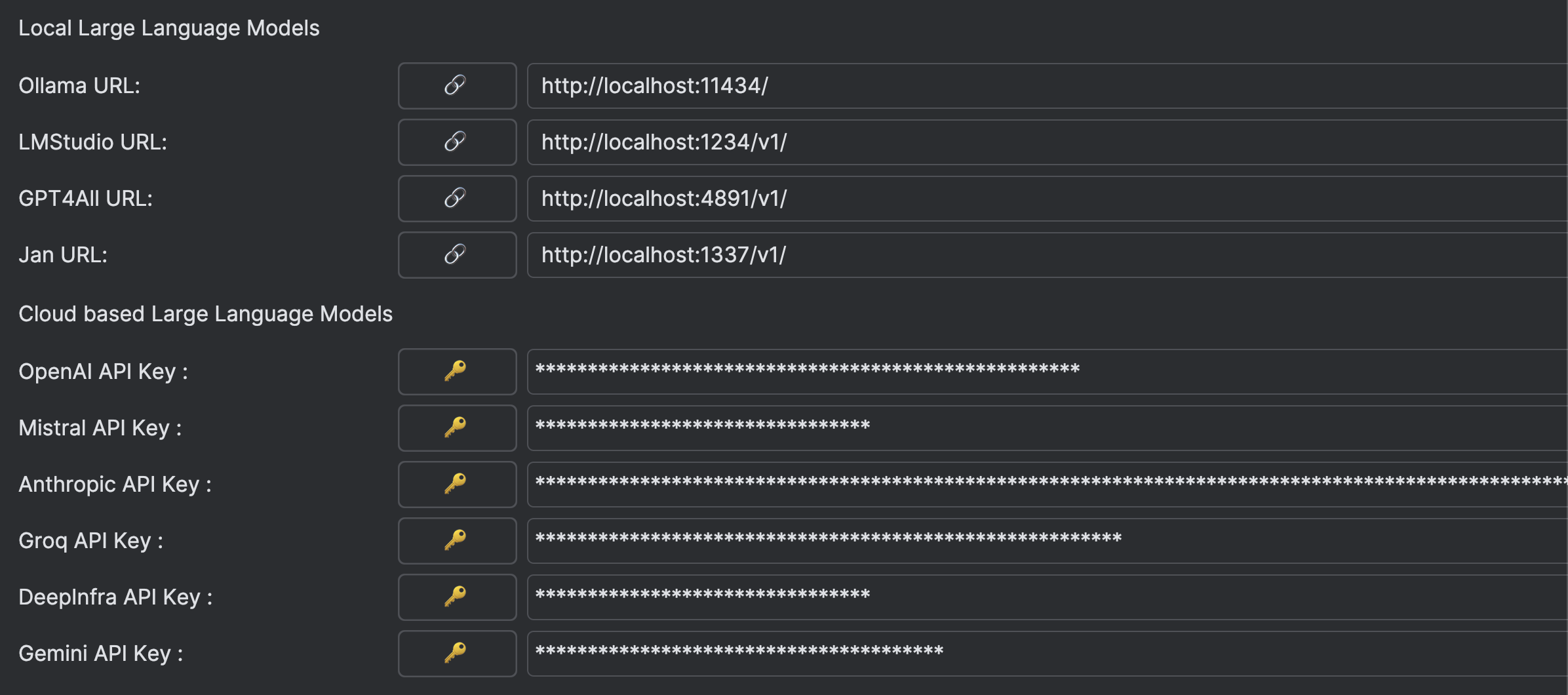
## Multi-LLM Collaborative Review
The size of the chat memory can now be configured in v0.1.14 in the Settings page. This makes sense when you use an LLM which has a large window context, for example Gemini with 1M tokens.

The beauty of chat memory supporting different LLM providers is that with a single prompt, you can ask one model to review some code, then switch to another model to review the previous model's answer 🤩
## Multi-LLM Collaborative Review
The end result is a "Multi-LLM Collaborative Review" process, leveraging multiple large language models to sequentially review and evaluate each other's responses, facilitating a more comprehensive and nuanced analysis.
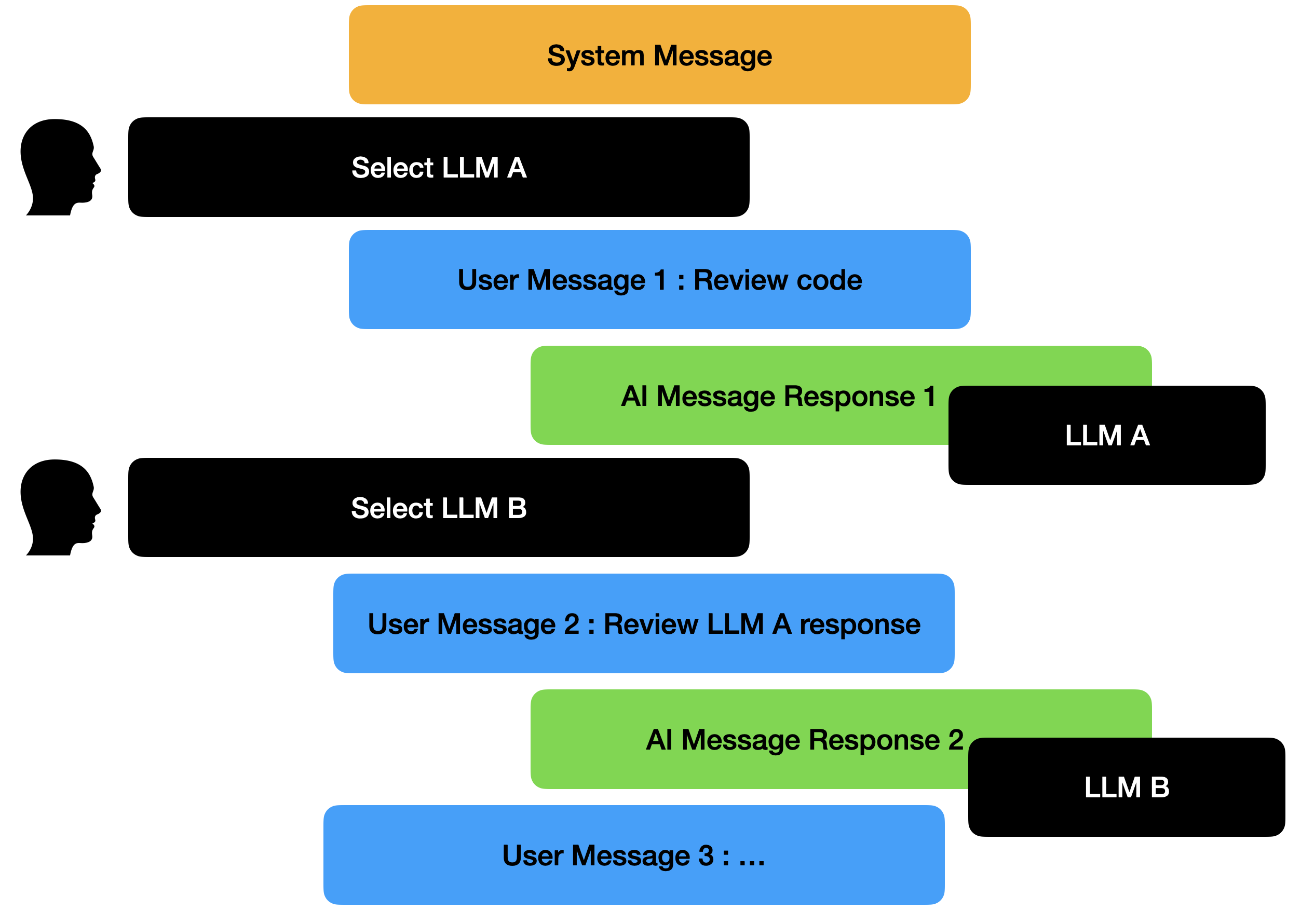
The results are really fascinating, for example I asked Mistral how I could improve a certain Java class and have OpenAI (GPT-4o) review the Mistral response!
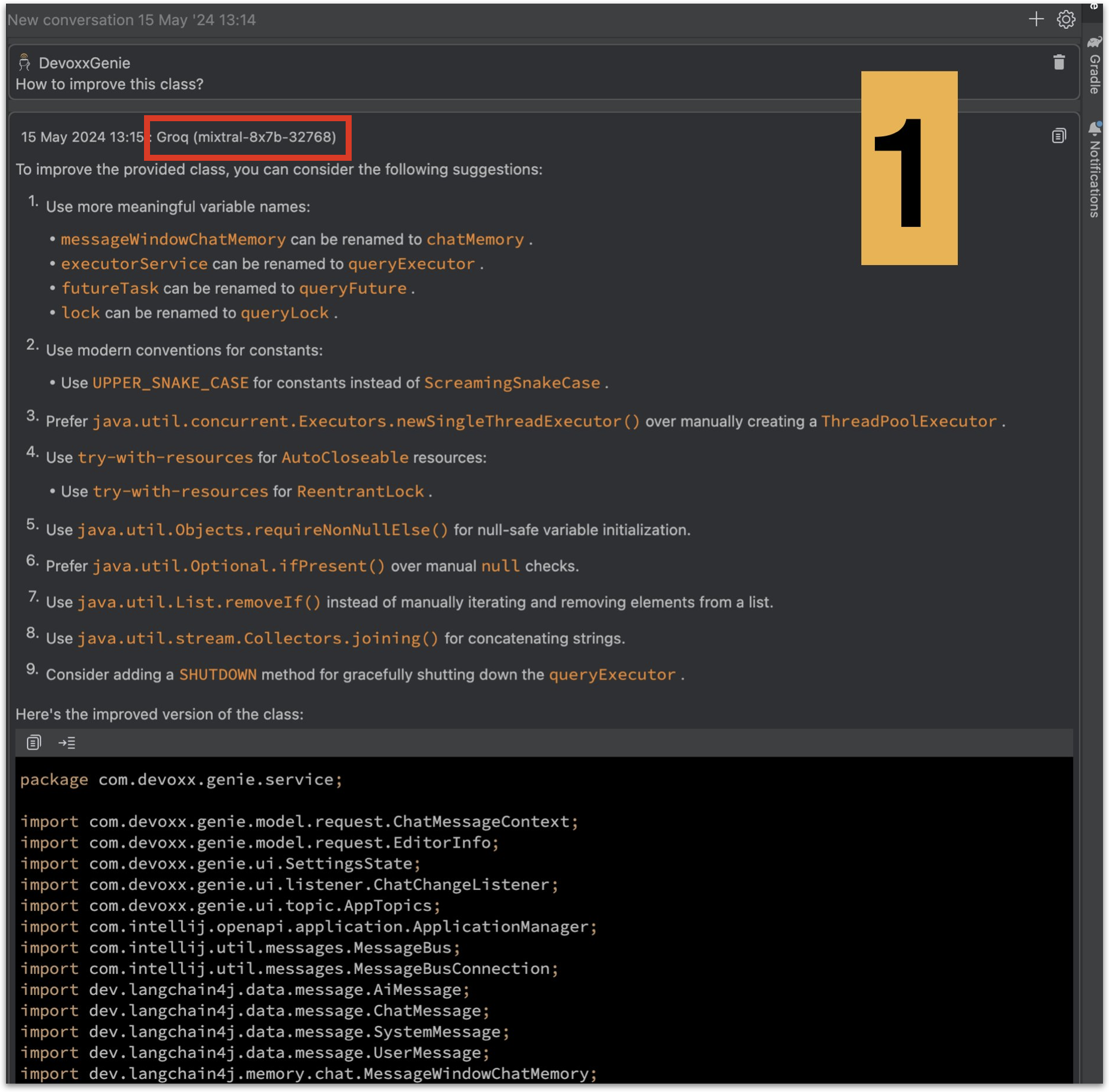
Switched to OpenAI GPT-4o and asked if it could review the Mistral response
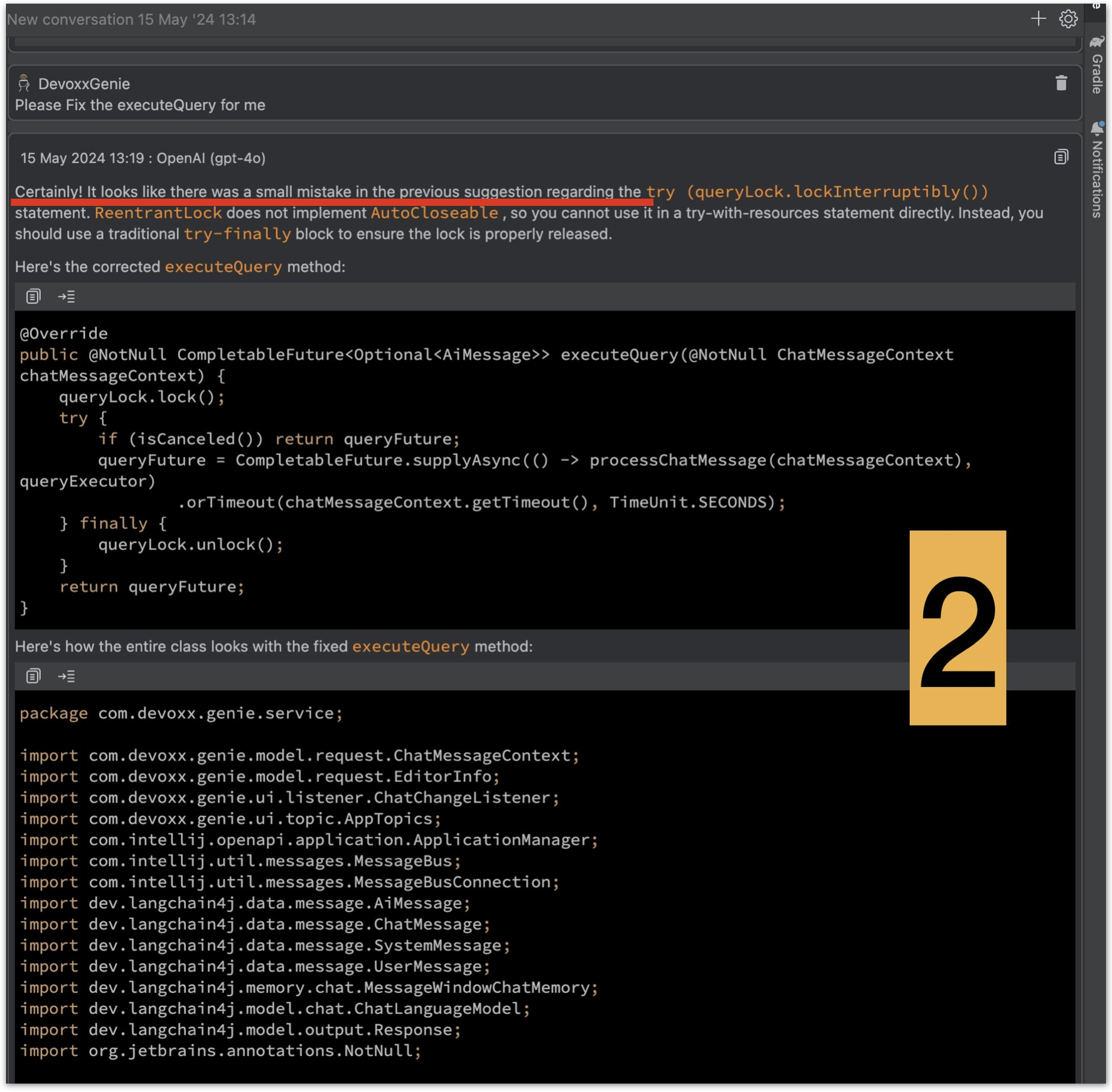
This all results in better code (refactoring) suggestions 🚀
## Streaming Responses
The latest version of [DevoxxGenie](https://github.com/devoxx/DevoxxGenieIDEAPlugin/) (v0.1.14) now also supports the option to stream the results directly to the plugin, enhancing real-time interaction and responsiveness.
{% youtube https://www.youtube.com/watch?v=V8KopHVz8zY %}
It's still a beta feature because I need to find a way to add "Copy to Clipboard" or "Insert into Code" buttons before each code block starts. I do accept PRs, so if you know how to make this happen, some community ❤️ would be very welcome.
## Program Structure Interface Driven (PSI) Context Prompt
Another new feature I developed for v0.1.14 is support for "smart(er) prompt context" using Program Structure Interface (PSI). PSI is the layer in the IntelliJ Platform responsible for parsing files and creating the syntactic and semantic code model of a project.
PSI allows me to populate the prompt with more information about a class without the user having to add the extra info. It's similar to Abstract Syntax Tree (AST) in Java but PSI has extra knowledge about the project structure, externally used libraries, search features and much more.

As a result the PSIAnalyzerService class (with a Java focus) can inject automatically more code details in the chat prompt.
PSI driven context prompts are really another way to introduce some basic Retrieval Augmented Generation (RAG) into the equation 💪🏻
## What's next?
### Auto completion??
I'm not a big fan of auto completion "using TAB" where the editor is constantly bombarded with code suggestions which often don't make sense. Also because the plugin is LLM agnostic it would be much harder to implement because of (lack) of speed and quality while using local LLM's. However it could make sense to support this with currently smarter cloud based LLM's.
### RAG support?
Embedding your IDEA project files using a RAG service could make sense. But this would probably need to happen outside of the plugin because of the storage and background processes needed to make this happen? I've noticed that existing plugins use an external Docker image which includes some kind of REST service. Suggestions are welcome.
### "JIRA" support?
Wouldn't it be great if you are able to paste a (JIRA) issue and the plugin figures out how to fix/resolve the issue? A bit like what Devin was promised to do...
### Compile & Run Unit tests?
When you ask the plugin to write a unit test, the plugin could also compile the suggested code and even run it (using REPL?). That would be an interesting R&D exercise IMHO.
### Introduce Agents
All of the above basically results most likely in introducing smart(er) agents which do some extra LLM magic using shell scripts and or Docker services...
## Community Support
As of this writing, the plugin has already been downloaded 1,127 times. The actual number is likely higher because the [Devoxx Genie GitHub project](https://github.com/devoxx/DevoxxGenieIDEAPlugin/) also publishes plugin builds in the releases, allowing users to manually install them in their IDEA.
I'm hoping the project will gain more traction and that the developer community will step up to help with new features or even bug fixes. This was one of the main reasons for open-sourcing the project.
"We ❤️ Open Source" 😜
 | stephanj |
1,867,550 | How to integrate plotly.js on Next.js 14 with App Router | I remember struggling quite a bit with integrating the plotly.js library into Next.js in the... | 0 | 2024-05-28T11:25:34 | https://dev.to/composite/how-to-integrate-plotlyjs-on-nextjs-14-with-app-router-1loj | webdev, nextjs, tutorial, plotly | I remember struggling quite a bit with integrating the plotly.js library into Next.js in the past.
However, now with Next.js 14 and the use of app routers, I've had to do it all over again, but this time the pain was quite painful.
Eventually I got over it, and today I'm going to share my experience with you, along with a few tips on how to integrate plotly.js into next.js.
Add the plotly.js library to your existing environment.
## Install plotly.js
```sh
npm i -S plotly.js
# or
yarn add plotly.js
# or
pnpm add plotly.js
```
If you're using Typescript, you can't forget about type definitions.
```sh
npm i -D @types/plotly.js
```
If you felt something strange, yes, you're right, plotly.js has a React wrapper. But, it hasn't been updated anymore since 2 years ago, and I don't install it because I personally felt a lot of discomfort in the Typescript environment when I first developed it.
If you still want to install it, you can do so. However, I'm going to skip the React wrapper part and create a very simple wrapper component.
## Use plotly.js
Of course, the plotly.js library is completely browser-specific, so build errors will be waiting for you the moment you import it and start using it.
So, the react-plotly's issue suggests using it as follows:
```js
import dynamic from 'next/dynamic'
export const Plotly = dynamic(() => import('react-plotly.js'), { ssr: false });
```
The reason why the react-plotly component doesn't work despite the `'use client'` directive is because it's a class component, and it was designed from the ground up assuming a browser. As if that weren't bad enough, now that I'm not touching anything but JS libraries, I'm starting to feel self-conscious about why I'm using this when there are actually better charting libraries out there.
Now, let's get back to business. Here's the simple wrapper component I created.
```jsx
export const Plotly = dynamic(
() =>
import('plotly.js/dist/plotly.js').then(({ newPlot, purge }) => {
const Plotly = forwardRef(({ id, className, data, layout, config }, ref) => {
const originId = useId();
const realId = id || originId;
const originRef = useRef(null);
const [handle, setHandle] = useState(undefined);
useEffect(() => {
let instance;
originRef.current &&
newPlot(originRef.current!, data, layout, config).then((ref) => setHandle((instance = ref)));
return () => {
instance && purge(instance);
};
}, [data]);
useImperativeHandle(
ref,
() => (handle ?? originRef.current ?? document.createElement('div')),
[handle]
);
return <div id={realId} ref={originRef} className={className}></div>;
});
Plotly.displayName = 'Plotly';
return Plotly;
}),
{ ssr: false }
);
```
Is the import path weird? No, this is the import path used by the [react-plotly source](https://github.com/plotly/react-plotly.js/blob/master/src/react-plotly.js#L2).
Anyway, apply the component like this, and you're done.
```jsx
<div>
<Plotly
style={{ width: '640px', height: '480px' }}
data={[{ x: [1, 2, 3, 4, 5], y: [1, 2, 4, 8, 16] }]}
layout={{ margin: { t: 0 } }}
/>
</div>
```
But if you're using Typescript, there's still one problem.
## Make typescript friendly
If you specify an import path like `import('plotly.js/dist/plotly.js')`, Typescript will fail to import the type. The reason for this is simple. It's because the type definition is based on the default path, `import('plotly.js')`.
There are two ways to fix the problem.
1. Create a `d.ts` file that duplicates the default types in the path `'plotly.js/dist/plotly.js'`.
2. include webpack resolve alias to bypass it (included when using turbopack)
I used method #2 because it also solved the build error.
Now let's touch the `next.config.js` file, which in my case was based on `next.config.mjs`.
```js
import path from 'node:path';
/** @type {import('next').NextConfig} */
const nextConfig = {
reactStrictMode: true,
swcMinify: true,
output: 'standalone',
images: {},
...bundleOptions(),
};
export default nextConfig;
function bundleOptions() {
const resolvers = {
'plotly.js': 'plotly.js/dist/plotly.js'
}
if (process.env.TURBOPACK) // If you are using dev with --turbo
return {
experimental: {
turbo: {
resolveAlias: {
...resolvers
}
},
},
};
else return { // otherwise, for webpack
webpack: (config) => {
for (const [dep, to] of Object.entries(resolvers))
config.resolve.alias[dep] = path.resolve(
config.context,
to
);
return config;
},
};
}
```
Now you can modify the import path in the wrapper component as you would normally import it.
```diff
- import('plotly.js/dist/plotly.js').then(({ newPlot, purge }) => {
+ import('plotly.js').then(({ newPlot, purge }) => {
```
Then, fix the required types for typescript, and voila!
Done. Congratulations. You can now use plotly.js in Next.js!
## Conculusion
I chose plotly.js over several popular charting libraries, especially the feature-rich Apache ECharts, because my company's algorithmic research team uses Python, and the plotly Python library is available, which is an advantage for exchanging chart data and layouts.
I hope I'm not wrong in my choice for this web application product development. lol
Happy Next.js-ing~!
| composite |
1,867,549 | CSS and JavaScript projects you can CONTRIBUTE to open source | Here are some CSS and JavaScript projects you can contribute to, featuring popular and emerging... | 0 | 2024-05-28T11:24:27 | https://dev.to/sh20raj/css-and-javascript-projects-you-can-contribute-to-open-source-3j62 | opensource, javascript, css, webdev | Here are some CSS and JavaScript projects you can contribute to, featuring popular and emerging libraries from 2024:
### CSS Projects:
1. **Tailwind CSS** - A utility-first CSS framework for rapid UI development【20†source】【21†source】.
2. **Bulma** - A modern CSS framework based on Flexbox【18†source】.
3. **Bootstrap** - The most popular CSS framework for developing responsive and mobile-first websites【15†source】.
4. **Foundation** - A responsive front-end framework for creating responsive websites and apps【21†source】.
5. **Materialize** - A modern responsive front-end framework based on Material Design【19†source】.
6. **UIkit** - A lightweight and modular front-end framework for developing fast and powerful web interfaces【18†source】【21†source】.
7. **Chakra UI** - A simple, modular, and accessible component library that gives you the building blocks to build your React applications【17†source】.
8. **NES.css** - A retro, 8-bit style CSS framework【15†source】.
9. **Picocss** - A minimal CSS framework for semantic HTML【15†source】.
10. **Blaze UI** - An open-source modular toolkit for building websites【16†source】【19†source】.
11. **Vanilla Framework** - A simple, extensible CSS framework from Canonical【16†source】【19†source】.
12. **Cirrus** - A component and utility-centric SCSS framework【16†source】.
13. **PatternFly** - A UI framework for enterprise web applications【16†source】.
14. **Carbon Components** - The component library behind IBM's Carbon Design System【16†source】.
15. **Open Props** - CSS custom properties to help accelerate adaptive and consistent design【19†source】.
16. **Tachyons** - A functional CSS framework emphasizing readability and simplicity【19†source】.
17. **Material Components Web** - Modular and customizable Material Design UI components【16†source】.
18. **Beer CSS** - Build Material Design interfaces quickly【16†source】.
19. **HiQ** - A simple CSS foundation with responsive typography and input styling【16†source】.
20. **Stacks** - UI components used by Stack Overflow【16†source】.
### JavaScript Projects:
1. **React** - A JavaScript library for building user interfaces by Facebook.
2. **Vue.js** - A progressive JavaScript framework for building user interfaces.
3. **Angular** - A platform for building mobile and desktop web applications.
4. **Svelte** - A radical new approach to building user interfaces.
5. **Next.js** - A React framework for server-side rendering and static site generation.
6. **Nuxt.js** - A framework for creating Vue.js applications with server-side rendering.
7. **Gatsby** - A React-based framework for creating fast websites and apps.
8. **Meteor** - A full-stack JavaScript platform for developing modern web and mobile applications.
9. **Ember.js** - A framework for creating ambitious web applications.
10. **Preact** - A fast 3kB alternative to React with the same modern API.
11. **Alpine.js** - A rugged, minimal framework for composing JavaScript behavior in your HTML.
12. **Lit** - A simple library for building fast, lightweight web components.
13. **Redux** - A predictable state container for JavaScript apps.
14. **D3.js** - A JavaScript library for producing dynamic, interactive data visualizations in web browsers.
15. **Three.js** - A cross-browser JavaScript library and API used to create and display animated 3D graphics in a web browser.
16. **Node.js** - A JavaScript runtime built on Chrome's V8 JavaScript engine.
17. **Express.js** - A fast, unopinionated, minimalist web framework for Node.js.
18. **Socket.IO** - Enables real-time, bidirectional and event-based communication.
19. **Electron** - Build cross-platform desktop apps with JavaScript, HTML, and CSS.
20. **Ionic** - A complete open-source SDK for hybrid mobile app development.
These projects are actively maintained and have thriving communities, making them excellent choices for contribution and collaboration. | sh20raj |
1,867,548 | List of awesome CSS frameworks, libraries and software | awesome-css uhub / awesome-css ... | 0 | 2024-05-28T11:21:56 | https://dev.to/sh20raj/list-of-awesome-css-frameworks-libraries-and-software-314a | css, libraries, javascript, webdev | # awesome-css
{% github https://github.com/uhub/awesome-css %}
A curated list of awesome CSS frameworks, libraries and software.
* [animate-css/animate.css](https://github.com/animate-css/animate.css) - 🍿 A cross-browser library of CSS animations. As easy to use as an easy thing.
* [necolas/normalize.css](https://github.com/necolas/normalize.css) - A modern alternative to CSS resets
* [jgthms/bulma](https://github.com/jgthms/bulma) - Modern CSS framework based on Flexbox
* [bradtraversy/50projects50days](https://github.com/bradtraversy/50projects50days) - 50+ mini web projects using HTML, CSS & JS
* [tobiasahlin/SpinKit](https://github.com/tobiasahlin/SpinKit) - A collection of loading indicators animated with CSS
* [chokcoco/iCSS](https://github.com/chokcoco/iCSS) - 不止于 CSS
* [Chalarangelo/30-seconds-of-css](https://github.com/Chalarangelo/30-seconds-of-css) - Short CSS code snippets for all your development needs
* [twbs/ratchet](https://github.com/twbs/ratchet) - Build mobile apps with simple HTML, CSS, and JavaScript components.
* [philipwalton/solved-by-flexbox](https://github.com/philipwalton/solved-by-flexbox) - A showcase of problems once hard or impossible to solve with CSS alone, now made trivially easy with Flexbox.
* [picocss/pico](https://github.com/picocss/pico) - Minimal CSS Framework for semantic HTML
* [tachyons-css/tachyons](https://github.com/tachyons-css/tachyons) - Functional css for humans
* [picturepan2/spectre](https://github.com/picturepan2/spectre) - Spectre.css - A Lightweight, Responsive and Modern CSS Framework
* [h5bp/Effeckt.css](https://github.com/h5bp/Effeckt.css) - This repo is archived. Thanks!
* [lipis/flag-icons](https://github.com/lipis/flag-icons) - :flags: A curated collection of all country flags in SVG — plus the CSS for easier integration
* [ConnorAtherton/loaders.css](https://github.com/ConnorAtherton/loaders.css) - Delightful, performance-focused pure css loading animations.
* [connors/photon](https://github.com/connors/photon) - The fastest way to build beautiful Electron apps using simple HTML and CSS
* [dunovank/jupyter-themes](https://github.com/dunovank/jupyter-themes) - Custom Jupyter Notebook Themes
* [StylishThemes/GitHub-Dark](https://github.com/StylishThemes/GitHub-Dark) - :octocat: Dark GitHub style
* [chokcoco/CSS-Inspiration](https://github.com/chokcoco/CSS-Inspiration) - CSS Inspiration,在这里找到写 CSS 的灵感!
* [jdan/98.css](https://github.com/jdan/98.css) - A design system for building faithful recreations of old UIs
* [chinchang/hint.css](https://github.com/chinchang/hint.css) - A CSS only tooltip library for your lovely websites.
* [kognise/water.css](https://github.com/kognise/water.css) - A drop-in collection of CSS styles to make simple websites just a little nicer
* [cyanharlow/purecss-francine](https://github.com/cyanharlow/purecss-francine) - HTML/CSS drawing in the style of an 18th-century oil painting. Hand-coded entirely in HTML & CSS.
* [sindresorhus/github-markdown-css](https://github.com/sindresorhus/github-markdown-css) - The minimal amount of CSS to replicate the GitHub Markdown style
* [troxler/awesome-css-frameworks](https://github.com/troxler/awesome-css-frameworks) - List of awesome CSS frameworks in 2024
* [lukehaas/css-loaders](https://github.com/lukehaas/css-loaders) - A collection of loading spinners animated with CSS
* [erikflowers/weather-icons](https://github.com/erikflowers/weather-icons) - 215 Weather Themed Icons and CSS
* [adamschwartz/magic-of-css](https://github.com/adamschwartz/magic-of-css) - A CSS course to turn you into a magician.
* [basscss/basscss](https://github.com/basscss/basscss) - Low-level CSS Toolkit – the original Functional/Utility/Atomic CSS library
* [joshuaclayton/blueprint-css](https://github.com/joshuaclayton/blueprint-css) - A CSS framework that aims to cut down on your CSS development time
* [csstools/sanitize.css](https://github.com/csstools/sanitize.css) - A best-practices CSS foundation
* [l-hammer/You-need-to-know-css](https://github.com/l-hammer/You-need-to-know-css) - 💄CSS tricks for web developers~
* [simeydotme/pokemon-cards-css](https://github.com/simeydotme/pokemon-cards-css) - A collection of advanced CSS styles to create realistic-looking effects for the faces of Pokemon cards.
* [kazzkiq/balloon.css](https://github.com/kazzkiq/balloon.css) - Simple tooltips made of pure CSS
* [cssanimation/css-animation-101](https://github.com/cssanimation/css-animation-101) - Learn how to bring animation to your web projects
* [spicetify/spicetify-themes](https://github.com/spicetify/spicetify-themes) - A community-driven collection of themes for customizing Spotify through Spicetify - https://github.com/spicetify/cli
* [cssnano/cssnano](https://github.com/cssnano/cssnano) - A modular minifier, built on top of the PostCSS ecosystem.
* [pattle/simpsons-in-css](https://github.com/pattle/simpsons-in-css) - Simpsons characters in CSS
* [jonasschmedtmann/advanced-css-course](https://github.com/jonasschmedtmann/advanced-css-course) - Starter files, final projects and FAQ for my Advanced CSS course
* [assemble/assemble](https://github.com/assemble/assemble) - Get the rocks out of your socks! Assemble makes you fast at web development! Used by thousands of projects for rapid prototyping, themes, scaffolds, boilerplates, e-books, UI components, API documentation, blogs, building websites/static site generator, an alternative to Jekyll for gh-pages and more! Gulp- and grunt-friendly.
* [picturepan2/instagram.css](https://github.com/picturepan2/instagram.css) - Instagram.css - Complete set of Instagram filters in pure CSS
* [QiShaoXuan/css_tricks](https://github.com/QiShaoXuan/css_tricks) - Some CSS tricks - 一些 CSS 常用样式
* [marvelapp/devices.css](https://github.com/marvelapp/devices.css) - Pure CSS phones and tablets
* [blivesta/animsition](https://github.com/blivesta/animsition) - A simple and easy jQuery plugin for CSS animated page transitions.
* [csswizardry/inuit.css](https://github.com/csswizardry/inuit.css) - Powerful, scalable, Sass-based, BEM, OOCSS framework.
* [franciscop/picnic](https://github.com/franciscop/picnic) - :handbag: A beautiful CSS library to kickstart your projects
* [adrianhajdin/project_modern_ui_ux_gpt3](https://github.com/adrianhajdin/project_modern_ui_ux_gpt3) - Master the creation of Modern UX/UI Websites
* [eludadev/ui-buttons](https://github.com/eludadev/ui-buttons) - 100 Modern CSS Buttons. Every style that you can imagine.
* [HunterLarco/voxel.css](https://github.com/HunterLarco/voxel.css) - A lightweight 3D CSS voxel library.
* [twbs/rfs](https://github.com/twbs/rfs) - ✩ Automates responsive resizing ✩
* [jbtronics/CrookedStyleSheets](https://github.com/jbtronics/CrookedStyleSheets) - Webpage tracking only using CSS (and no JS)
* [rafaelmardojai/firefox-gnome-theme](https://github.com/rafaelmardojai/firefox-gnome-theme) - A GNOME👣 theme for Firefox🔥
* [maxchehab/CSS-Keylogging](https://github.com/maxchehab/CSS-Keylogging) - Chrome extension and Express server that exploits keylogging abilities of CSS.
* [wentin/cssicon](https://github.com/wentin/cssicon) - icon set made with pure css code, no dependencies, "grab and go" icons
* [Daemonite/material](https://github.com/Daemonite/material) - Material Design for Bootstrap 4
* [halfmoonui/halfmoon](https://github.com/halfmoonui/halfmoon) - Halfmoon is a highly customizable, drop-in Bootstrap replacement. It comes with three built-in core themes, with dark mode support for all themes and components.
* [Chalarangelo/mini.css](https://github.com/Chalarangelo/mini.css) - A minimal, responsive, style-agnostic CSS framework!
* [Andy-set-studio/modern-css-reset](https://github.com/Andy-set-studio/modern-css-reset) - A bare-bones CSS reset for modern web development.
* [MrOtherGuy/firefox-csshacks](https://github.com/MrOtherGuy/firefox-csshacks) - Collection of userstyles affecting the browser
* [MilenaCarecho/30diasDeCSS](https://github.com/MilenaCarecho/30diasDeCSS) - Desafio criar 30 mini projetos utilizando HTML e CSS em 30 dias
* [GumbyFramework/Gumby](https://github.com/GumbyFramework/Gumby) - A Flexible, Responsive CSS Framework - Powered by Sass
* [senchalabs/jQTouch](https://github.com/senchalabs/jQTouch) - Create powerful mobile apps with just HTML, CSS, and Zepto.js (or jQuery).
* [mdo/wtf-forms](https://github.com/mdo/wtf-forms) - Friendlier HTML form controls with a little CSS magic.
* [flukeout/css-diner](https://github.com/flukeout/css-diner) - CSS Diner
* [egoist/hack](https://github.com/egoist/hack) - ⛷ Dead simple CSS framework.
* [cjcenizal/flexbox-patterns](https://github.com/cjcenizal/flexbox-patterns) - Patterns for using flexbox CSS to build awesome UI components.
* [cognitom/paper-css](https://github.com/cognitom/paper-css) - Paper CSS for happy printing
* [itmeo/webgradients](https://github.com/itmeo/webgradients) - A curated collection of splendid gradients made in CSS3, .sketch and .PSD formats.
* [mobi-css/mobi.css](https://github.com/mobi-css/mobi.css) - A lightweight, scalable, mobile-first CSS framework
* [webkul/micron](https://github.com/webkul/micron) - a [μ] microInteraction library built with CSS Animations and controlled by JavaScript Power
* [sakofchit/system.css](https://github.com/sakofchit/system.css) - A design system for building retro Apple interfaces
* [IBM/css-gridish](https://github.com/IBM/css-gridish) - Automatically build your grid design’s CSS Grid code, CSS Flexbox fallback code, Sketch artboards, and Chrome extension.
* [csstools/postcss-preset-env](https://github.com/csstools/postcss-preset-env) - Convert modern CSS into something browsers understand
* [themepark-dev/theme.park](https://github.com/themepark-dev/theme.park) - A collection of themes/skins for 50 selfhosted apps!
* [codrops/PageTransitions](https://github.com/codrops/PageTransitions) - A showcase collection of various page transition effects using CSS animations.
* [elad2412/the-new-css-reset](https://github.com/elad2412/the-new-css-reset) - The New Simple and Lighter CSS Reset
* [twitter-archive/recess](https://github.com/twitter-archive/recess) - A simple and attractive code quality tool for CSS built on top of LESS
* [jensimmons/cssremedy](https://github.com/jensimmons/cssremedy) - Start your project with a remedy for the technical debt of CSS.
* [bedimcode/responsive-portfolio-website-Alexa](https://github.com/bedimcode/responsive-portfolio-website-Alexa) - Responsive Portfolio Website Using HTML, CSS & JavaScript
* [ThrivingKings/animo.js](https://github.com/ThrivingKings/animo.js) - A powerful little tool for managing CSS animations
* [5t3ph/stylestage](https://github.com/5t3ph/stylestage) - A modern CSS showcase styled by community contributions. Add your stylesheet!
* [ganapativs/bttn.css](https://github.com/ganapativs/bttn.css) - Awesome buttons for awesome projects!
* [flatlogic/awesome-bootstrap-checkbox](https://github.com/flatlogic/awesome-bootstrap-checkbox) - ✔️Font Awesome Bootstrap Checkboxes & Radios. Pure css way to make inputs look prettier
* [kbrsh/wing](https://github.com/kbrsh/wing) - :gem: A beautiful CSS framework designed for minimalists.
* [daneden/Toast](https://github.com/daneden/Toast) - 🍞 A highly-customizable, responsive (S)CSS grid
* [filipelinhares/ress](https://github.com/filipelinhares/ress) - 🚿 A modern CSS reset
* [ajusa/lit](https://github.com/ajusa/lit) - World's smallest responsive 🔥 css framework (395 bytes)
* [muckSponge/MaterialFox](https://github.com/muckSponge/MaterialFox) - A Material Design-inspired userChrome.css theme for Firefox
* [mezzoblue/csszengarden.com](https://github.com/mezzoblue/csszengarden.com) - The source of csszengarden.com
* [thesabbir/simple-line-icons](https://github.com/thesabbir/simple-line-icons) - Simple and Minimal Line Icons
* [t32k/stylestats](https://github.com/t32k/stylestats) - StyleStats is a library to collect CSS statistics.
* [kumailht/flakes](https://github.com/kumailht/flakes) - Flakes is an Admin Template Framework. A combination of CSS Libraries, JavaScript Libraries and Design files that help you build business tools very quickly.
* [lokesh-coder/pretty-checkbox](https://github.com/lokesh-coder/pretty-checkbox) - A pure CSS library to beautify checkbox and radio buttons.
* [Aris-t2/CustomCSSforFx](https://github.com/Aris-t2/CustomCSSforFx) - Custom CSS tweaks for Firefox
* [argyleink/transition.css](https://github.com/argyleink/transition.css) - :octocat: Drop-in CSS transitions
* [DesignRevision/shards-ui](https://github.com/DesignRevision/shards-ui) - 🎨Shards is a beautiful & modern Bootstrap 4 UI kit packed with extra templates and components.
* [Martz90/vivify](https://github.com/Martz90/vivify) - Vivify is free CSS animation library.
* [mblode/marx](https://github.com/mblode/marx) - The classless CSS reset (perfect for Communists).
* [smcllns/css-social-buttons](https://github.com/smcllns/css-social-buttons) - Zocial: CSS login and social buttons
* [mdo/preboot](https://github.com/mdo/preboot) - A collection of LESS mixins and variables for writing better CSS.
* [dohliam/dropin-minimal-css](https://github.com/dohliam/dropin-minimal-css) - Drop-in switcher for previewing minimal CSS frameworks
* [csstools/precss](https://github.com/csstools/precss) - Use Sass-like markup in your CSS
* [tylertate/semantic.gs](https://github.com/tylertate/semantic.gs) - The Semantic CSS Grid
* [tylerchilds/cutestrap](https://github.com/tylerchilds/cutestrap) - A strong, independent CSS Framework. Only 2.7KB minified & gzipped.
* [reworkcss/css](https://github.com/reworkcss/css) - CSS parser / stringifier for Node.js
* [jaunesarmiento/fries](https://github.com/jaunesarmiento/fries) - Fries helps you prototype Android apps using HTML, CSS, and JavaScript.
* [sethcottle/littlelink](https://github.com/sethcottle/littlelink) - A lightweight DIY alternative to services like Linktree.
* [soulwire/Makisu](https://github.com/soulwire/Makisu) - CSS 3D Dropdown Concept
* [thoughtbot/refills](https://github.com/thoughtbot/refills) - [no longer maintained]
* [KyleAMathews/react-spinkit](https://github.com/KyleAMathews/react-spinkit) - A collection of loading indicators animated with CSS for React
* [csswizardry/csswizardry-grids](https://github.com/csswizardry/csswizardry-grids) - Simple, fluid, nestable, flexible, Sass-based, responsive grid system.
* [rohitkrai03/pills](https://github.com/rohitkrai03/pills) - A simple responsive CSS Grid for humans. View Demo -
* [mrcoles/markdown-css](https://github.com/mrcoles/markdown-css) - CSS for making regular HTML look like plain-text markdown.
* [mdo/wtf-html-css](https://github.com/mdo/wtf-html-css) - Common reasons your HTML and CSS may be fucked.
* [devlint/gridlex](https://github.com/devlint/gridlex) - Just a CSS Flexbox Grid System
* [mrmrs/pesticide](https://github.com/mrmrs/pesticide) - Kill your css layout bugs
* [ghosh/microtip](https://github.com/ghosh/microtip) - 💬 Minimal, accessible, ultra lightweight css tooltip library. Just 1kb.
* [cascadefox/cascade](https://github.com/cascadefox/cascade) - A responsive One-Line CSS Theme for Firefox.
* [ubuwaits/css3-buttons](https://github.com/ubuwaits/css3-buttons) - A collection of CSS3 buttons implemented in Sass.
* [chrisnager/ungrid](https://github.com/chrisnager/ungrid) - ungrid - the simplest responsive css grid
* [elipapa/markdown-cv](https://github.com/elipapa/markdown-cv) - a simple template to write your CV in a readable markdown file and use CSS to publish/print it.
* [wesbos/aprilFools.css](https://github.com/wesbos/aprilFools.css) - Harmlessly goof up your co-workers browser and chrome dev tools
* [marmelab/universal.css](https://github.com/marmelab/universal.css) - The only CSS you will ever need
* [Timvde/UserChrome-Tweaks](https://github.com/Timvde/UserChrome-Tweaks) - A community maintained repository of userChrome.css tweaks for Firefox
* [filamentgroup/select-css](https://github.com/filamentgroup/select-css) - Cross-browser styles for consistent select element styling
* [cheeaun/hackerweb](https://github.com/cheeaun/hackerweb) - A simply readable Hacker News web app
* [delight-im/HTML-Sheets-of-Paper](https://github.com/delight-im/HTML-Sheets-of-Paper) - Word processor in your browser using HTML and CSS (for invoices, legal notices, etc.)
* [Chalarangelo/mocka](https://github.com/Chalarangelo/mocka) - Simple, elegant content placeholder
* [codyhouse/codyhouse-framework](https://github.com/codyhouse/codyhouse-framework) - A lightweight front-end framework for building accessible, bespoke interfaces.
* [adobe/spectrum-css](https://github.com/adobe/spectrum-css) - The standard CSS implementation of the Spectrum design language.
* [bryanbraun/after-dark-css](https://github.com/bryanbraun/after-dark-css) - Recreating After Dark screensavers in CSS.
* [benschwarz/gallery-css](https://github.com/benschwarz/gallery-css) - CSS only Gallery
* [richleland/pygments-css](https://github.com/richleland/pygments-css) - css files created from pygment's built-in styles
* [peduarte/wallop](https://github.com/peduarte/wallop) - :no_entry: currently unmaintained :no_entry: A minimal JS library for showing & hiding things
* [kdzwinel/SnappySnippet](https://github.com/kdzwinel/SnappySnippet) - Chrome extension that allows easy extraction of CSS and HTML from selected element.
* [PKM-er/Blue-Topaz_Obsidian-css](https://github.com/PKM-er/Blue-Topaz_Obsidian-css) - A blue theme for Obsidian.
* [DennisSnijder/MakeGithubGreatAgain](https://github.com/DennisSnijder/MakeGithubGreatAgain) - Extension for making GitHub great again
* [datguypiko/Firefox-Mod-Blur](https://github.com/datguypiko/Firefox-Mod-Blur) - Firefox Theme - For dark theme lovers / More compact / Modular / Blur
* [webkul/csspin](https://github.com/webkul/csspin) - CSS Spinners and Loaders - Modular, Customizable and Single HTML Element Code for Pure CSS Loader and Spinner
* [danielcardoso/load-awesome](https://github.com/danielcardoso/load-awesome) - An awesome collection of — Pure CSS — Loaders and Spinners
* [falnatsheh/MarkdownView](https://github.com/falnatsheh/MarkdownView) - MarkdownView is an Android webview with the capablity of loading Markdown text or file and display it as HTML, it uses MarkdownJ and extends Android webview.
* [desandro/3dtransforms](https://github.com/desandro/3dtransforms) - :package: Introduction to CSS 3D transforms
* [femmebot/google-type](https://github.com/femmebot/google-type) - Collaborative typography project using select passages from Aesop's Fables set to Google Fonts
* [chokcoco/css3-](https://github.com/chokcoco/css3-) - CSS3 实现各类 3D && 3D 行星动画效果
* [anselmh/object-fit](https://github.com/anselmh/object-fit) - Polyfill (mostly IE) for CSS object-fit property to fill-in/fit-in images into containers.
* [bwsewell/tablecloth](https://github.com/bwsewell/tablecloth) - A CSS and JS bootstrap to style and manipulate data tables
* [szynszyliszys/repaintless](https://github.com/szynszyliszys/repaintless) - Library for fast CSS Animations
* [josephfusco/angled-edges](https://github.com/josephfusco/angled-edges) - :triangular_ruler: Quickly create angled section edges using only Sass
* [parkerbennett/stackicons](https://github.com/parkerbennett/stackicons) - Icon font and Sass-based construction kit for Stackicons-Social, which supports multiple button shapes and a unique "multi-color" option in CSS for over 60 social brands.
* [QNetITQ/WaveFox](https://github.com/QNetITQ/WaveFox) - Firefox CSS Theme/Style for manual customization
* [Athari/CssGitHubWindows](https://github.com/Athari/CssGitHubWindows) - (UserStyle) GitHub Windows Edition [MIT]
* [susam/spcss](https://github.com/susam/spcss) - A simple, minimal, classless stylesheet for simple HTML pages
* [jlong/css-spinners](https://github.com/jlong/css-spinners) - Simple CSS spinners and throbbers made with CSS and minimal HTML markup.
* [jothepro/doxygen-awesome-css](https://github.com/jothepro/doxygen-awesome-css) - Custom CSS theme for doxygen html-documentation with lots of customization parameters.
* [eromatiya/blurredfox](https://github.com/eromatiya/blurredfox) - A sleek, modern and elegant Firefox CSS theme
* [zachacole/Simple-Grid](https://github.com/zachacole/Simple-Grid) - A simple, lightweight CSS grid
* [sierra-library/sierra](https://github.com/sierra-library/sierra) - Sierra SCSS library
* [geddski/csstyle](https://github.com/geddski/csstyle) - MOVED TO https://github.com/csstyle/csstyle a modern approach for crafting beautifully maintainable stylesheets
* [adamsilver/maintainablecss.com-jekyll](https://github.com/adamsilver/maintainablecss.com-jekyll) - Write CSS without worrying that overzealous, pre-existing styles will cause problems. MaintainableCSS is an approach to writing modular, scalable and of course, maintainable CSS.
* [csstools/postcss-plugins](https://github.com/csstools/postcss-plugins) - PostCSS Tools and Plugins
* [nathansmith/adapt](https://github.com/nathansmith/adapt) - Adapt.js serves CSS based on screen width.
* [IcaliaLabs/furatto](https://github.com/IcaliaLabs/furatto) - It's a flat, fast and powerful front-end framework for rapid web development.
* [nagoshiashumari/Rpg-Awesome](https://github.com/nagoshiashumari/Rpg-Awesome) - A fantasy themed font and CSS toolkit.
* [Mobirise/Mobirise](https://github.com/Mobirise/Mobirise) - AI Website Builder, Open Source, Bootstrap 5
* [Siumauricio/rippleui](https://github.com/Siumauricio/rippleui) - Clean, modern and beautiful Tailwind CSS components.
* [csstools/postcss-normalize](https://github.com/csstools/postcss-normalize) - Use the parts of normalize.css (or sanitize.css) you need from your browserslist
* [rsms/raster](https://github.com/rsms/raster) - Raster — simple CSS grid system
* [Heydon/REVENGE.CSS](https://github.com/Heydon/REVENGE.CSS) - A CSS bookmarklet that puts pink error boxes (with messages in comic sans) everywhere you write bad HTML.
* [turretcss/turretcss](https://github.com/turretcss/turretcss) - Turret is a styles and browser behaviour normalisation framework for rapid development of responsive and accessible websites.
* [yocontra/windows_98.css](https://github.com/yocontra/windows_98.css) - some sick styles for your guestbook
* [efemkay/obsidian-modular-css-layout](https://github.com/efemkay/obsidian-modular-css-layout) - CSS Layout hack for Obsidian.md
* [ace-subido/css3-microsoft-metro-buttons](https://github.com/ace-subido/css3-microsoft-metro-buttons) - my CSS3 library for making Microsoft-metro themed buttons
* [asciimoo/cssplot](https://github.com/asciimoo/cssplot) - Pure CSS charts
* [arbelh/HalfStyle](https://github.com/arbelh/HalfStyle) - Style Half of a Character by CSS
* [jpswalsh/academicons](https://github.com/jpswalsh/academicons) - An icon font for academics
* [laurenwaller/cssco](https://github.com/laurenwaller/cssco) - Photographic filters made with CSS, inspired by VSCO and CSSgram
* [gromo/jquery.scrollbar](https://github.com/gromo/jquery.scrollbar) - jQuery CSS Customizable Scrollbar
* [devcows/hugo-universal-theme](https://github.com/devcows/hugo-universal-theme) - Universal theme for Hugo, it stands out with its clean design and elegant typography.
* [comehope/front-end-daily-challenges](https://github.com/comehope/front-end-daily-challenges) - As of August 2021, 170+ works have been accomplished, challenge yourself each day!
* [ihorzenich/html5checklist](https://github.com/ihorzenich/html5checklist) - HTML/CSS markup checklist
* [anjlab/bootstrap-rails](https://github.com/anjlab/bootstrap-rails) - Twitter Bootstrap CSS (with Sass flavour) and JS toolkits for Rails 3 projects
* [codrops/IconHoverEffects](https://github.com/codrops/IconHoverEffects) - A set of simple round icon hover effects with CSS transitions and animations for your inspiration.
* [tlrobinson/evil.css](https://github.com/tlrobinson/evil.css) - Because CSS isn't evil enough already.
* [cardinalcss/cardinalcss](https://github.com/cardinalcss/cardinalcss) - A modular, “mobile-first” CSS framework built with performance and scalability in mind.
* [Theigrams/My-Typora-Themes](https://github.com/Theigrams/My-Typora-Themes) - A CSS style for Typora
* [StefanKovac/flex-layout-attribute](https://github.com/StefanKovac/flex-layout-attribute) - HTML layout helper based on CSS flexbox specification —
* [Andy-set-studio/boilerform](https://github.com/Andy-set-studio/boilerform) - Boilerform is a little HTML and CSS boilerplate to take the pain away from working with forms.
* [HubSpot/tooltip](https://github.com/HubSpot/tooltip) - CSS Tooltips built on Tether. #hubspot-open-source
* [balzss/luxbar](https://github.com/balzss/luxbar) - :cocktail: Featherweight, Responsive, CSS Only Navigation Bar
* [Godiesc/firefox-gx](https://github.com/Godiesc/firefox-gx) - Opera GX Skin for Firefox
* [Rosmaninho/Zotero-Dark-Theme](https://github.com/Rosmaninho/Zotero-Dark-Theme) - userChrome.css file for a Zotero dark theme. Suggestions for improvements are welcome.
* [tailwindlabs/designing-with-tailwindcss](https://github.com/tailwindlabs/designing-with-tailwindcss) - Source code for the "Designing with Tailwind CSS" course.
* [redroot/holmes](https://github.com/redroot/holmes) - Holmes is stand-alone diagnostic CSS stylesheet that can highlight potentially invalid or erroneous HTML(5) markup by adding one class
* [jonikorpi/Less-Framework](https://github.com/jonikorpi/Less-Framework) - An adaptive CSS grid system.
* [720kb/radiobox.css](https://github.com/720kb/radiobox.css) - :radio_button: Tiny set of pure CSS animations for your radio inputs. https://720kb.github.io/radiobox.css/
* [codrops/OffCanvasMenuEffects](https://github.com/codrops/OffCanvasMenuEffects) - Some inspiration for off-canvas menu effects and styles using CSS transitions and SVG path animations.
* [michenriksen/css3buttons](https://github.com/michenriksen/css3buttons) - Simple CSS3 framework for creating GitHub-style buttons
* [tiaanduplessis/wenk](https://github.com/tiaanduplessis/wenk) - :wink: Lightweight pure CSS tooltip for the greater good
* [StylishThemes/StackOverflow-Dark](https://github.com/StylishThemes/StackOverflow-Dark) - 📚 Dark theme for Stack Overflow & most Stack Exchange network sites
* [codrops/CSSGlitchEffect](https://github.com/codrops/CSSGlitchEffect) - An experimental glitch effect powered by CSS animations and the clip-path property. Inspired by the technique seen on the speakers page of the 404 conference.
* [t0m/select2-bootstrap-css](https://github.com/t0m/select2-bootstrap-css) - simple css to make select2 widgets fit in with bootstrap
* [hasan-py/MERN_Stack_Project_Ecommerce_Hayroo](https://github.com/hasan-py/MERN_Stack_Project_Ecommerce_Hayroo) - E-commerce Website | Payment gateway | Reactjs | Nodejs | Mongodb | Expressjs | JWT | Tailwind Css
* [PacktPublishing/50-Projects-In-50-Days---HTML-CSS-JavaScript](https://github.com/PacktPublishing/50-Projects-In-50-Days---HTML-CSS-JavaScript) - 50 Projects In 50 Days - HTML, CSS & JavaScript, by Packt Publishing
* [ShaifArfan/one-page-website-html-css-project](https://github.com/ShaifArfan/one-page-website-html-css-project) - This project is for html & css practice. We made this for youtube tutorial purpose.
* [geoffgraham/animate.scss](https://github.com/geoffgraham/animate.scss) - Sass mixins based on Dan Eden's Animate.css
* [cobyism/gridism](https://github.com/cobyism/gridism) - A simple responsive CSS grid.
* [WhatsNewSaes/Skeleton-Sass](https://github.com/WhatsNewSaes/Skeleton-Sass) - The (un)official Sass Version of Skeleton (2.0.4): A Dead Simple, Responsive Boilerplate for Mobile-Friendly Development
* [arashmanteghi/simptip](https://github.com/arashmanteghi/simptip) - A simple CSS tooltip made with Sass
* [codebucks27/Next.js-Developer-Portfolio-Starter-Code](https://github.com/codebucks27/Next.js-Developer-Portfolio-Starter-Code) - ⭐Build a stunning portfolio website with Next.js, Tailwind CSS and Framer-motion. If you want to learn to create this you can follow the tutorial link given in the Read me file.
* [lucagez/medium.css](https://github.com/lucagez/medium.css) - Compact typography for the web
* [scottparry/Workless](https://github.com/scottparry/Workless) - Workless is a CSS base framework to get your projects up and running as quickly as possible.
* [colourgarden/avalanche](https://github.com/colourgarden/avalanche) - Superclean, powerful, responsive, Sass-based, BEM-syntax CSS grid system
* [picturepan2/fileicon.css](https://github.com/picturepan2/fileicon.css) - Fileicon.css - The customizable pure CSS file icons
* [nisarhassan12/portfolio-template](https://github.com/nisarhassan12/portfolio-template) - A beautiful minimal and accessible portfolio template for Developers. Give it a star 🌟 if you find it useful.
* [LukyVj/colofilter.css](https://github.com/LukyVj/colofilter.css) - Colofilter.css - Duotone filters made with CSS !
* [yacy/yacy_webclient_yaml4](https://github.com/yacy/yacy_webclient_yaml4) - A web client for a YaCy search server based on yaml4 css
* [premasagar/cleanslate](https://github.com/premasagar/cleanslate) - An extreme CSS reset stylesheet, for aggressively resetting the styling of an element and its children. Composed exclusively of CSS !important rules.
* [pr1mer-tech/waffle-grid](https://github.com/pr1mer-tech/waffle-grid) - An easy to use flexbox grid system.
* [ostranme/swagger-ui-themes](https://github.com/ostranme/swagger-ui-themes) - :boom: A collection of css themes to spice up your Swagger docs
* [necolas/css3-facebook-buttons](https://github.com/necolas/css3-facebook-buttons) - Simple CSS to recreate the appearance of Facebook's buttons and toolbars.
* [hasinhayder/tailwind-cards](https://github.com/hasinhayder/tailwind-cards) - A growing collection of text/image cards you can use/copy-paste in your tailwind css projects
* [nicehorse06/se-job](https://github.com/nicehorse06/se-job) - Software Engineer Job Note,讓新手從0到1入門,有1到100的成長能力
* [bmFtZQ/edge-frfox](https://github.com/bmFtZQ/edge-frfox) - A Firefox userChrome.css theme that aims to recreate the look and feel of Microsoft Edge.
* [alsacreations/KNACSS](https://github.com/alsacreations/KNACSS) - feuille de styles CSS sur-vitaminée
* [CTalvio/Ultrachromic](https://github.com/CTalvio/Ultrachromic) - The final form, the true evolution of the chromic theme saga!
* [kogakure/gitweb-theme](https://github.com/kogakure/gitweb-theme) - An alternative theme for gitweb, strongly inspired by GitHub
* [gevendra2004/gevstack](https://github.com/gevendra2004/gevstack) - All Gevstack projects
* [aozora/bootplus](https://github.com/aozora/bootplus) - Sleek, intuitive, and powerful Google styled front-end framework for faster and easier web development
* [nitinhayaran/Justified.js](https://github.com/nitinhayaran/Justified.js) - jQuery Plugin to create Justified Image Gallery
* [hail2u/vim-css3-syntax](https://github.com/hail2u/vim-css3-syntax) - CSS3 syntax (and syntax defined in some foreign specifications) support for Vim's built-in syntax/css.vim
* [matthieua/sass-css3-mixins](https://github.com/matthieua/sass-css3-mixins) - Sass CSS3 Mixins! The Cross-Browser CSS3 Sass Library
* [cmaddux/littlebox](https://github.com/cmaddux/littlebox) - Super simple to implement, CSS-only icons.
* [nimsandu/spicetify-bloom](https://github.com/nimsandu/spicetify-bloom) - Spicetify theme inspired by Microsoft's Fluent Design, Always up-to-date!, A Powerful Theme to Calm your Eyes While Listening to Your Favorite Beats
* [cyanharlow/purecss-zigario](https://github.com/cyanharlow/purecss-zigario) - HTML/CSS drawing in the style of mid-century advertisement design. Hand-coded entirely in HTML & CSS.
* [corysimmons/boy](https://github.com/corysimmons/boy) - :boy: A very opinionated, lightweight version of HTML5 Boilerplate with conditionally-loaded polyfills and an opinionated CSS reset for firing up web projects in no time.
* [teacat/tocas](https://github.com/teacat/tocas) - 👀 The fastest and most intuitive way to build diverse websites and progressive web application interfaces.
* [tholman/obnoxious.css](https://github.com/tholman/obnoxious.css) - Animations for the strong of heart, and stupid of mind.
* [zhangyingwei/html-css-only](https://github.com/zhangyingwei/html-css-only) - 漂亮的 CSS 系列~
* [kennethormandy/utility-opentype](https://github.com/kennethormandy/utility-opentype) - Simple, CSS utility classes for advanced typographic features.
* [typlog/yue.css](https://github.com/typlog/yue.css) - A typography stylesheet for readable content
* [callmenick/Animating-Hamburger-Icons](https://github.com/callmenick/Animating-Hamburger-Icons) - Animating CSS-only hamburger menu icons
* [buseca/patternbolt](https://github.com/buseca/patternbolt) - A fine selection of SVG pattern background, packed in a single CSS or SCSS file. Add patterns just adding a class.
* [jkphl/iconizr](https://github.com/jkphl/iconizr) - A PHP command line tool for converting SVG images to a set of CSS icons (SVG & PNG, single icons and / or CSS sprites) with support for image optimization and Sass output. Created by Joschi Kuphal (@jkphl), licensed under the terms of the MIT license
* [StylishThemes/Wikipedia-Dark](https://github.com/StylishThemes/Wikipedia-Dark) - :mortar_board: Dark Wikipedia
* [bigskysoftware/missing](https://github.com/bigskysoftware/missing) - The classless-ish CSS library you've been missing
* [mdo/table-grid](https://github.com/mdo/table-grid) - Simple CSS grid system using `display: table;`.
* [necolas/css3-social-signin-buttons](https://github.com/necolas/css3-social-signin-buttons) - CSS3 Social Sign-in Buttons with icons. Small and large sizes.
* [Axel--/Naut-for-reddit](https://github.com/Axel--/Naut-for-reddit) - A css theme for reddit.com
* [ShaifArfan/30days30submits](https://github.com/ShaifArfan/30days30submits) - This is a challenge that I took to boost my HTML, CSS & JS skills. I made 30 submits and they are basically some little components or js apps.
* [level09/enferno](https://github.com/level09/enferno) - This collection of modern libraries and tools, built on top of the Flask framework, allows you to quickly create any website or web-based application (SAAS) with impressive speed.
* [almonk/pylon](https://github.com/almonk/pylon) - Declarative layout primitives for CSS & HTML
* [TryKickoff/kickoff](https://github.com/TryKickoff/kickoff) - :basketball: A lightweight front-end framework for creating scalable, responsive sites. Version 8 has just been released!
* [c0bra/markdown-resume-js](https://github.com/c0bra/markdown-resume-js) - Turn a simple markdown document into a resume in HTML and PDF
* [codrops/SlitSlider](https://github.com/codrops/SlitSlider) - A responsive slideshow with a twist: the idea is to slice open the current slide when navigating to the next or previous one. Using jQuery and CSS animations we can create unique slide transitions for the content elements.
* [shakrmedia/tuesday](https://github.com/shakrmedia/tuesday) - A quirky CSS Animation Library by Shakr
* [mvcss/mvcss](https://github.com/mvcss/mvcss) - Sass-based CSS Architecture
* [bjork24/Unison](https://github.com/bjork24/Unison) - Unifying named breakpoints across CSS, JS, and HTML
* [joerez/Woah.css](https://github.com/joerez/Woah.css) - CSS Animation Library for eccentrics
* [JonHMChan/descartes](https://github.com/JonHMChan/descartes) - Descartes | Write CSS in JavaScript
* [codrops/ClickEffects](https://github.com/codrops/ClickEffects) - A set of subtle effects for click or touch interactions inspired by the visualization of screen taps in mobile app showcases. The effects are done with CSS animations mostly on pseudo-elements.
* [jackdomleo7/Checka11y.css](https://github.com/jackdomleo7/Checka11y.css) - A CSS stylesheet to quickly highlight a11y concerns.
* [eliortabeka/tootik](https://github.com/eliortabeka/tootik) - A pure CSS/SCSS/LESS Tooltips library. Super easy to use, No JavaScript required.
* [rupl/unfold](https://github.com/rupl/unfold) - Unfolding the Box Model — interactive slides exploring CSS 3D Transforms
* [atom/one-dark-syntax](https://github.com/atom/one-dark-syntax) - Atom One dark syntax theme
* [csalmeida/protonmail-themes](https://github.com/csalmeida/protonmail-themes) - Customise ProtonMail with themes and enhance your encrypted email experience.
* [uisual/freebies](https://github.com/uisual/freebies) - Source code for Uisual templates. Free HTML/CSS landing page templates for startups. New template every week.
* [jamiewilson/corpus](https://github.com/jamiewilson/corpus) - Yet another CSS toolkit. Basically the stuff I use for most projects.
* [KiKaraage/ArcWTF](https://github.com/KiKaraage/ArcWTF) - A userChrome.css theme to bring Arc Browser look from Windows to Firefox. No waitlist, no registration needed ✨
* [phonon-framework/phonon](https://github.com/phonon-framework/phonon) - Phonon is a responsive front-end framework with a focus on simplicity and flexibility
* [JaniRefsnes/w3css](https://github.com/JaniRefsnes/w3css) - W3.CSS - CSS Framework
* [h01000110/windows-95](https://github.com/h01000110/windows-95) - Jekyll Theme
* [cyanharlow/purecss-pink](https://github.com/cyanharlow/purecss-pink) - HTML/CSS drawing of gel studio lighting. Hand-coded entirely in HTML & CSS.
* [Varin6/Hover-Buttons](https://github.com/Varin6/Hover-Buttons) - Animated CSS/SCSS Buttons
* [gongzhitaao/orgcss](https://github.com/gongzhitaao/orgcss) - Simple and clean CSS for Org-exported HTML
* [petargyurov/virtual-bookshelf](https://github.com/petargyurov/virtual-bookshelf) - A simple bookshelf made in CSS, HTML and vanilla JS.
* [elky/django-flat-theme](https://github.com/elky/django-flat-theme) - A flat theme for Django admin interface. Modern, fresh, simple.
* [akashyap2013/Blooger_Website](https://github.com/akashyap2013/Blooger_Website) - This is the complete blooger website create using html and css
* [Myndex/SAPC-APCA](https://github.com/Myndex/SAPC-APCA) - APCA (Accessible Perceptual Contrast Algorithm) is a new method for predicting contrast for use in emerging web standards (WCAG 3) for determining readability contrast. APCA is derived form the SAPC (S-LUV Advanced Predictive Color) which is an accessibility-oriented color appearance model designed for self-illuminated displays.
* [MauriceConrad/Photon](https://github.com/MauriceConrad/Photon) - Clone native desktop UI's like cocoa and develop native feeling applications using web technologies
* [sitetent/tentcss](https://github.com/sitetent/tentcss) - :herb: A CSS survival kit. Includes only the essentials to make camp.
* [refact0r/midnight-discord](https://github.com/refact0r/midnight-discord) - A dark, rounded discord theme.
* [riccardoscalco/crayon](https://github.com/riccardoscalco/crayon) - Crayon.css is a list of css variables linking color names to hex values.
* [Discord-Custom-Covers/usrbg](https://github.com/Discord-Custom-Covers/usrbg) - A pure CSS database of user requested backgrounds for @Discord.
* [zhangxinxu/zxx.lib.css](https://github.com/zhangxinxu/zxx.lib.css) - a css library for quick layout, especially for flow layout
* [robertpiira/ingrid](https://github.com/robertpiira/ingrid) - A fluid CSS layout system
* [bedimcode/responsive-portfolio-website-Ansel](https://github.com/bedimcode/responsive-portfolio-website-Ansel) - Create a Responsive Personal Portfolio Website Using HTML CSS & JavaScript
* [darklow/social-share-kit](https://github.com/darklow/social-share-kit) - Library of decent and good looking CSS/JavaScript social sharing icons, buttons and popups
* [sliminality/ply](https://github.com/sliminality/ply) - CSS inspection aided by visual regression pruning
* [jigar-sable/Portfolio-Website](https://github.com/jigar-sable/Portfolio-Website) - Portfolio Website built using HTML5, CSS3, JavaScript and jQuery
* [robsheldon/sscaffold-css](https://github.com/robsheldon/sscaffold-css) - Base file for sscaffold-css.
* [cakebaker/scss-syntax.vim](https://github.com/cakebaker/scss-syntax.vim) - Vim syntax file for scss (Sassy CSS)
* [johnggli/linktree](https://github.com/johnggli/linktree) - Simple site to group all my profiles on social networks in one place. A free Linktree alternative.
* [LuckFire/amoled-cord](https://github.com/LuckFire/amoled-cord) - A basically pitch black theme for Discord. Lights out, baby!
* [tomgenoni/cssdig-chrome](https://github.com/tomgenoni/cssdig-chrome) - Chrome extension for analyzing CSS.
* [leny/kouto-swiss](https://github.com/leny/kouto-swiss) - A complete CSS framework for Stylus
* [jessekorzan/expodal](https://github.com/jessekorzan/expodal) - The Most Explosive Modal on The Web.
* [amdelamar/pm-theme](https://github.com/amdelamar/pm-theme) - 🎨 Easy Themes for ProtonMail (v3.16.x)
* [jonjaques/react-loaders](https://github.com/jonjaques/react-loaders) - Lightweight wrapper around Loaders.css.
* [hzsrc/webpack-theme-color-replacer](https://github.com/hzsrc/webpack-theme-color-replacer) - A runtime dynamic theme color replacement plugin for webpack.
* [bonsaicss/bonsai.css](https://github.com/bonsaicss/bonsai.css) - A Utility Complete CSS Framework for less than 45kb (8kB Gzipped) -
* [necolas/griddle](https://github.com/necolas/griddle) - A CSS grid constructor
* [LeonidasEsteban/rick-morty-vanilla](https://github.com/LeonidasEsteban/rick-morty-vanilla) - Web App using the rick and morty API in Vanilla.js
* [mor10/kuhn](https://github.com/mor10/kuhn) - WordPress theme featuring CSS Grid layouts via aggressive progressive enhancement. Proof of concept to get the conversation about what CSS Grid means for WordPress themes started. Currently running live at https://mor10.com
* [Guerra24/Firefox-UWP-Style](https://github.com/Guerra24/Firefox-UWP-Style) - Sun Valley + MDL2 Theme for Firefox
* [lvwzhen/iconpark](https://github.com/lvwzhen/iconpark) - Collection of iconfonts
* [zalando/gulp-check-unused-css](https://github.com/zalando/gulp-check-unused-css) - A build tool for checking your HTML templates for unused CSS classes
* [vladocar/CSS-Micro-Reset](https://github.com/vladocar/CSS-Micro-Reset) - Minimal barebone CSS Reset
* [mildrenben/surface](https://github.com/mildrenben/surface) - A Material Design CSS only framework
* [bansal/filters.css](https://github.com/bansal/filters.css) - CSS only library to apply color filters.
* [sparkbox/style-prototype](https://github.com/sparkbox/style-prototype) - Example of an HTML/CSS style tile.
* [siberiawolf/siberiawolf.github.io](https://github.com/siberiawolf/siberiawolf.github.io) - Siberiawolf的小窝
* [LeonidasEsteban/bookmark-landing](https://github.com/LeonidasEsteban/bookmark-landing) - Challenge #3 by FrontendMentor.io
* [madrilene/eleventy-excellent](https://github.com/madrilene/eleventy-excellent) - Eleventy starter based on the workflow suggested by Andy Bell's buildexcellentwebsit.es.
* [ireade/formhack](https://github.com/ireade/formhack) - A hackable css form reset
* [iRaul/pushy-buttons](https://github.com/iRaul/pushy-buttons) - 👇 CSS Pressable 3D Buttons
* [GoalSmashers/css-minification-benchmark](https://github.com/GoalSmashers/css-minification-benchmark) - A comparison of CSS minifiers for node.js
* [3r3bu5x9/Prismatic-Night](https://github.com/3r3bu5x9/Prismatic-Night) - A dark themed startpage and dark themes for Firefox and Linux inspired by Material design and Adapta.
* [mrmrs/btns](https://github.com/mrmrs/btns) - A set of css utilities for constructing beautiful responsive buttons
* [mladenplavsic/css-ripple-effect](https://github.com/mladenplavsic/css-ripple-effect) - Pure CSS (no JavaScript) implementation of Android Material design "ripple" animation
* [ariona/hover3d](https://github.com/ariona/hover3d) - Simple jQuery plugin for 3d Hover effect
* [timonweb/django-bulma](https://github.com/timonweb/django-bulma) - Bulma theme for Django
* [codrops/LineHoverStyles](https://github.com/codrops/LineHoverStyles) - A couple of simple & subtle line hover animations for links using CSS only.
* [lazarljubenovic/grassy](https://github.com/lazarljubenovic/grassy) - Build layout through ASCII art in Sass (and more). No pre-built CSS. No additional markup.
* [cyanharlow/purecss-vignes](https://github.com/cyanharlow/purecss-vignes) - HTML/CSS drawing in the style of 1930s poster art. Hand-coded entirely in HTML & CSS.
* [mac81/pure-drawer](https://github.com/mac81/pure-drawer) - Pure CSS transition effects for off-canvas views
* [fajarnurwahid/adminhub](https://github.com/fajarnurwahid/adminhub) - Website ini merupakan hasil slicing dari Figma ke responsive website menggunakan HTML, CSS, dan JavaScript
* [alistairtweedie/pintsize](https://github.com/alistairtweedie/pintsize) - Customisable 💪 Flexbox grid system
* [joernweissenborn/lcars](https://github.com/joernweissenborn/lcars) - CSS Framework to style web pages like the fictional computer operating system of a popular sci-fi franchise.
* [jpanther/lynx](https://github.com/jpanther/lynx) - A simple links theme for Hugo built with Tailwind CSS.
* [arnaudleray/pocketgrid](https://github.com/arnaudleray/pocketgrid) - PocketGrid is a lightweight pure CSS grid system for Responsive Web Design. Moreover, it is semantic, mobile-first, and allows to have an unlimited number of columns and breakpoints.
* [static-dev/axis](https://github.com/static-dev/axis) - terse, modular & powerful css library
* [zero-to-mastery/CSS-Art](https://github.com/zero-to-mastery/CSS-Art) - General Edition - A CSS art challenge, for all skill levels
* [zero-to-mastery/Animation-Nation](https://github.com/zero-to-mastery/Animation-Nation) - A ZTM Challenge for Hacktoberfest
* [jonathanharrell/hiq](https://github.com/jonathanharrell/hiq) - A lightweight, progressive, high-IQ CSS framework.
* [danieljpalmer/alptail](https://github.com/danieljpalmer/alptail) - A collection of frontend components using Tailwind.css and Alpine.js.
* [projectwallace/css-analyzer](https://github.com/projectwallace/css-analyzer) - Analytics for CSS
* [PlusInsta/discord-plus](https://github.com/PlusInsta/discord-plus) - A sleek, customizable Discord theme.
* [pixelastic/css-flags](https://github.com/pixelastic/css-flags) - Flags of the world with only one div
* [jez/tufte-pandoc-css](https://github.com/jez/tufte-pandoc-css) - Starter files for using Pandoc Markdown with Tufte CSS
* [Shina-SG/Shina-Fox](https://github.com/Shina-SG/Shina-Fox) - A Minimal, Cozy, Vertical Optimized Firefox Theme
* [Basir-PD/100-Projects-HTML-CSS-JavaScript](https://github.com/Basir-PD/100-Projects-HTML-CSS-JavaScript) - 100 Projects Challenge
* [brandon-rhodes/Concentric-CSS](https://github.com/brandon-rhodes/Concentric-CSS) - A standard order for CSS properties that starts at the outer edge of the box model and moves inward
* [marella/material-icons](https://github.com/marella/material-icons) - Latest icon fonts and CSS for self-hosting material design icons.
* [jfbrennan/m-](https://github.com/jfbrennan/m-) - The modern web's design system.
* [darshandsoni/asciidoctor-skins](https://github.com/darshandsoni/asciidoctor-skins) - Control how your asciidoctor powered documentation looks
* [curiositry/mnml-ghost-theme](https://github.com/curiositry/mnml-ghost-theme) - A minimal, responsive, fast Ghost 5.0 blog theme with great typography. Comes with paid membership support, Disqus comments, syntax highlighting, and KaTeX for mathematics, and more.
* [mayank99/reset.css](https://github.com/mayank99/reset.css) - a css reset for 2024 and beyond.
* [tylergaw/css-shaky-animation](https://github.com/tylergaw/css-shaky-animation) - Shits shakin' yo
* [propjockey/css-media-vars](https://github.com/propjockey/css-media-vars) - A brand new way to write responsive CSS. Named breakpoints, DRY selectors, no scripts, no builds, vanilla CSS.
* [dmhendricks/file-icon-vectors](https://github.com/dmhendricks/file-icon-vectors) - A collection of file type icons in SVG format
* [chris-pearce/scally](https://github.com/chris-pearce/scally) - Scally is a Sass-based, BEM, OOCSS, responsive-ready, CSS framework that provides you with a solid foundation for building reusable UI's quickly 🕶
* [BootstrapDash/corona-free-dark-bootstrap-admin-template](https://github.com/BootstrapDash/corona-free-dark-bootstrap-admin-template) - Free dark admin template based on Bootstrap 4.
* [yamlcss/yaml](https://github.com/yamlcss/yaml) - YAML (Yet Another Multicolumn Layout) is a modular CSS framework for truly flexible, accessible and responsive websites. It is based on Sass and has a very slim framework core that weights only ~6kB.
* [BlessCSS/bless](https://github.com/BlessCSS/bless) - CSS Post-Processor
* [mjonuschat/bootstrap-sass-rails](https://github.com/mjonuschat/bootstrap-sass-rails) - HTML, CSS, and JS toolkit from Twitter – Official Sass port:
* [railsware/applepie](https://github.com/railsware/applepie) - Semantic and Modular CSS Toolkit
* [LunarLogic/auroral](https://github.com/LunarLogic/auroral) - Animated background gradients with pure CSS
* [jmaczan/bulma-helpers](https://github.com/jmaczan/bulma-helpers) - 🍥 Library with Functional / Atomic CSS classes for Bulma framework
* [jerryjappinen/layers-css](https://github.com/jerryjappinen/layers-css) - A lightweight, unobtrusive and style-agnostic, CSS framework aimed for practical use cases. Comes with a small footprint and zero bullshit.
* [alphapapa/solarized-everything-css](https://github.com/alphapapa/solarized-everything-css) - A collection of Solarized user-stylesheets for...everything?
* [jgthms/bulma-start](https://github.com/jgthms/bulma-start) - Start package for Bulma
* [niklausgerber/PreLoadMe](https://github.com/niklausgerber/PreLoadMe) - PreLoadMe, a lightweight jQuery website preloader.
* [kjbrum/juice](https://github.com/kjbrum/juice) - Mixins for Life
* [ElemeFE/postcss-salad](https://github.com/ElemeFE/postcss-salad) - 沙拉是一个能够帮助你写出更加简洁、优雅的CSS的样式解决方案
* [mirisuzanne/compass-animate](https://github.com/mirisuzanne/compass-animate) - Compass port of Dan Eden's Animate.css
* [andersevenrud/retro-css-shell-demo](https://github.com/andersevenrud/retro-css-shell-demo) - AnderShell 3000 - Retro looking terminal in CSS
* [williamckha/spicetify-fluent](https://github.com/williamckha/spicetify-fluent) - Spicetify theme inspired by Microsoft's Fluent Design
* [JuliaMendes/50-Projects-In-50-Days-](https://github.com/JuliaMendes/50-Projects-In-50-Days-) - HTML, CSS and JS projects.
* [Godiesc/firefox-one](https://github.com/Godiesc/firefox-one) - Firefox Theme for Opera One skin Lovers
* [kristerkari/normalize.scss](https://github.com/kristerkari/normalize.scss) - SCSS version of normalize.css
* [escueladigital/EDgrid](https://github.com/escueladigital/EDgrid) - CSS/Sass library for responsive layouts | Libreria CSS/Sass para construir layouts responsive
* [yesiamrocks/cssanimation.io](https://github.com/yesiamrocks/cssanimation.io) - CSS Animation Library for Developers and Ninjas
* [smakosh/unnamed-css-framework](https://github.com/smakosh/unnamed-css-framework) - A simple colorful CSS framework
* [ozantekin/50Days50Projects](https://github.com/ozantekin/50Days50Projects) - This repository contains 50 mini projects related to HTML, CSS and JavaScript. The construction stages of the projects are published on YouTube.
* [sapondanaisriwan/AdashimaaTube](https://github.com/sapondanaisriwan/AdashimaaTube) - Restore old Youtube layout in 2021-2022 with many customizable options.
* [mike-engel/a11y-css-reset](https://github.com/mike-engel/a11y-css-reset) - A small set of global rules to make things accessible and reset default styling
* [ElzeroWebSchool/HTML_And_CSS_Template_One](https://github.com/ElzeroWebSchool/HTML_And_CSS_Template_One) - HTML And CSS Template One
* [getpavilion/pavilion](https://github.com/getpavilion/pavilion) - Pavilion CSS Framework. A solid starting point without the bloat.
* [winstromming/sassdown](https://github.com/winstromming/sassdown) - Generates styleguides from Markdown comments in CSS, SASS and LESS files using Handlebars
* [johnpolacek/extra-strength-responsive-grids](https://github.com/johnpolacek/extra-strength-responsive-grids) - A Fluid CSS Grid System for Responsive Web Design The Fluid CSS Grid System for Responsive Web Design. Take total control of your layouts.
* [codrops/ButtonHoverStyles](https://github.com/codrops/ButtonHoverStyles) - Some ideas for CSS-only button hover styles and animations
* [replete/obsidian-minimal-theme-css-snippets](https://github.com/replete/obsidian-minimal-theme-css-snippets) - Obsidian CSS snippets to tweak UI and harmonize various plugins with the Minimal Theme - for fellow hackers.
* [cyanharlow/purecss-gaze](https://github.com/cyanharlow/purecss-gaze) - HTML/CSS drawing in style of italian renaissance painting. Hand-coded entirely in HTML & CSS.
* [argyleink/ragrid](https://github.com/argyleink/ragrid) - :octocat: Intrinsic first auto-layout flexbox grid
* [luffyZh/dynamic-antd-theme](https://github.com/luffyZh/dynamic-antd-theme) - 🌈 A simple plugin to dynamic change ant-design theme whether less or css.
* [daveberning/griddle](https://github.com/daveberning/griddle) - A CSS Grid Framework
* [panicsteve/shutup-css](https://github.com/panicsteve/shutup-css) - CSS stylesheet to hide comments on web pages
* [elky/django-flat-responsive](https://github.com/elky/django-flat-responsive) - 📱 An extension for Django admin that makes interface mobile-friendly. Merged into Django 2.0
* [shankara-subramani/tinyreset](https://github.com/shankara-subramani/tinyreset) - Tiny CSS reset for the modern web
* [zxcodes/Calculator](https://github.com/zxcodes/Calculator) - A Calculator App built with HTML, CSS, and JavaScript. It also has a Dark Mode.
* [newaeonweb/responsiveboilerplate](https://github.com/newaeonweb/responsiveboilerplate) - A lightweight (2kb) micro-library, elegant & minimalistic CSS3 grid system, made with only three main classes and 12 columns. It`s very easy to use and understand, pre-packed with some extra css helpers for mobile devices.
* [teteusAraujo/portfolio](https://github.com/teteusAraujo/portfolio) - 👨💻 Meu portfólio criado com o objetivo de mostrar os meus projetos criados e também o meu currículo .
* [PROxZIMA/Sweet-Pop](https://github.com/PROxZIMA/Sweet-Pop) - Sweet_Pop! Beautify, Customize Firefox. Minimalist animated oneliner theme for Firefox perfectly matching Sweet Dark.
* [codingstella/projects](https://github.com/codingstella/projects) - Source Code of all projects that I upload on Instagram
* [amiechen/stitches-template-generator](https://github.com/amiechen/stitches-template-generator) - A web templates generator with functional css (tailwind.css)
* [erictreacy/mimic.css](https://github.com/erictreacy/mimic.css) - Everyone else is doing it!
* [imbrianj/debugCSS](https://github.com/imbrianj/debugCSS) - CSS to highlight potentially malformed, invalid or questionable markup.
* [vol7/shorthand](https://github.com/vol7/shorthand) - Shrthnd is a handy tool that converts CSS properties into shorthand, making shorter and more readable stylesheets.
* [boriskirov/fluiditype](https://github.com/boriskirov/fluiditype) - Fluiditype a simple fluid typography css helper for reading experience
* [drygiel/csslider](https://github.com/drygiel/csslider) - Pure CSS slider
* [at-import/jacket](https://github.com/at-import/jacket) - Conditional Styles with Sass. Dress you CSS appropriately.
* [joe-bell/loading-disco](https://github.com/joe-bell/loading-disco) - An alternative to the loading spinner 🪩
* [MikeMitterer/dart-material-design-lite](https://github.com/MikeMitterer/dart-material-design-lite) - Material Design Lite Components, Directives + SPA with HTML, CSS + Dart
* [jackyliang/Material-Design-For-Full-Calendar](https://github.com/jackyliang/Material-Design-For-Full-Calendar) - Material Design CSS theme for FullCalendar Weekly Agenda
* [simaQ/cssfun](https://github.com/simaQ/cssfun) - css
* [yearofmoo/ngAnimate-animate.css](https://github.com/yearofmoo/ngAnimate-animate.css) - A driver module to make animate.css work with AngularJS 1.2
* [SpruceGabriela/30diasDeCSS](https://github.com/SpruceGabriela/30diasDeCSS) - 30 dias de CSS3 é um desafio que visa ajudá-lo a melhorar suas habilidades de codificação fazendo mini projetos diarios utilizando HTML5 e CSS3
* [ovdojoey/Juiced](https://github.com/ovdojoey/Juiced) - A Flexbox CSS Framework
* [mixu/cssbook](https://github.com/mixu/cssbook) - The book "Learn CSS layout the pedantic way"
* [huanxi007/markdown-here-css](https://github.com/huanxi007/markdown-here-css) - 微信公众号毫秒级排版,让你的排版充满审美愉悦感。复制代码到“markdown here基本渲染css”即可。
* [shellscape/gmail-classic](https://github.com/shellscape/gmail-classic) - CSS for reverting Gmail to the Classic Theme
* [Idered/cssParentSelector](https://github.com/Idered/cssParentSelector) - CSS4 parent selector based on jQuery
* [gwannon/Cyberpunk-2077-theme-css](https://github.com/gwannon/Cyberpunk-2077-theme-css) - This is a theme in CSS3 to simulate the interfaxes of the game CyberPunk 2077.
* [soulhotel/FF-ULTIMA](https://github.com/soulhotel/FF-ULTIMA) - Native Vertical Tabs, keep your sidebar, no extensions needed. No overthinking. FF Ultima.
* [FriendsOfEpub/Blitz](https://github.com/FriendsOfEpub/Blitz) - An eBook Framework (CSS + template)
* [marioparaschiv/dark-discord](https://github.com/marioparaschiv/dark-discord) - An actual dark mode for discord.
* [ArunMichaelDsouza/CSS-Mint](https://github.com/ArunMichaelDsouza/CSS-Mint) - Lightweight and simple to use UI Kit. Fully responsive, just 3KB gzipped.
* [antfu/prism-theme-vars](https://github.com/antfu/prism-theme-vars) - A customizable Prism.js theme using CSS variables
* [typecho-fans/themes](https://github.com/typecho-fans/themes) - Typecho Fans主题作品目录
* [marcvannieuwenhuijzen/BootstrapXL](https://github.com/marcvannieuwenhuijzen/BootstrapXL) - CSS file with Bootstrap grid classes for screens bigger than 1600px
* [joshuarudd/typeset.css](https://github.com/joshuarudd/typeset.css) - A no-nonsense CSS typography reset for styling user-generated content like blog posts, comments, and forum content.
* [ecomfe/rider](https://github.com/ecomfe/rider) - Rider 是一个基于 Stylus 与后处理器、无侵入风格的 CSS 样式工具库
* [maxbeier/tawian-frontend](https://github.com/maxbeier/tawian-frontend) - A markdowny CSS framework
* [korywakefield/iota](https://github.com/korywakefield/iota) - A responsive micro-framework for the grid spec powered by CSS custom properties.
* [csswizardry/csscv](https://github.com/csswizardry/csscv) - A simple, opinionated stylesheet for formatting semantic HTML to look like a CSS file.
* [tastejs/todomvc-app-css](https://github.com/tastejs/todomvc-app-css) - CSS for TodoMVC apps
* [9elements/min-max-calculator](https://github.com/9elements/min-max-calculator) - A tool that calculates the CSS clamp formula to interpolate between two values in a given viewport range.
* [0xPrateek/Portfolio-Template](https://github.com/0xPrateek/Portfolio-Template) - A portfolio website template for Geeks,Programmers and hackers.
* [JonathanSpeek/spacegrid](https://github.com/JonathanSpeek/spacegrid) - A no-frills responsive grid layout to help you get started on your next project.
* [CreArts-Community/CreArts-Discord](https://github.com/CreArts-Community/CreArts-Discord) - Discord Theme | v3.0.3 | by Corellan
* [alectro/SCSScale](https://github.com/alectro/SCSScale) - Typographic modular scale starter based on body's font-size built on SCSS.
* [trevanhetzel/barekit](https://github.com/trevanhetzel/barekit) - A bare minimum responsive framework
* [iamshaunjp/html-and-css-crash-course](https://github.com/iamshaunjp/html-and-css-crash-course) - All the course files for the HTML & CSS crash course from The Net Ninja YouTube channel.
* [jhfrench/bootstrap-tree](https://github.com/jhfrench/bootstrap-tree) - JavaScript and LESS/CSS for creating Bootstrap-themed trees (to display hierarchical data).
* [eduardofierropro/Reset-CSS](https://github.com/eduardofierropro/Reset-CSS) - Código del Reset que uso a nivel profesional explicado línea a línea en Youtube
* [tusharnankani/ToDoList](https://github.com/tusharnankani/ToDoList) - A dynamic and aesthetic To-Do List Website built with HTML, CSS, Vanilla JavaScript.
* [iaronrp/Efeito-3D](https://github.com/iaronrp/Efeito-3D) - Efeito 3D - Zelda: criado com as tecnologias, Html, CSS e Java Script
* [xtoolkit/Micon](https://github.com/xtoolkit/Micon) - Micon, The iconic windows 10 font and CSS toolkit.
* [WongMinHo/hexo-theme-miho](https://github.com/WongMinHo/hexo-theme-miho) - 🍺一款单栏响应式的hexo主题, A single column response for hexo . https://blog.minhow.com
* [frameable/knopf.css](https://github.com/frameable/knopf.css) - Modern, modular, extensible button system designed for both rapid prototyping and production-ready applications
* [benfrain/app-reset](https://github.com/benfrain/app-reset) - A minimal set of reset CSS specifically for web applications
* [explosion/displacy-ent](https://github.com/explosion/displacy-ent) - :boom: displaCy-ent.js: An open-source named entity visualiser for the modern web
* [h5bp/main.css](https://github.com/h5bp/main.css) - A repository for the development of the HTML5 Boilerplate CSS file, main.css
* [vmcreative/Hexi-Flexi-Grid](https://github.com/vmcreative/Hexi-Flexi-Grid) - An SCSS partial that builds flexible, modular hex grids using CSS Grid
* [torch2424/aesthetic-css](https://github.com/torch2424/aesthetic-css) - A vaporwave CSS framework 🌴🐬
* [Atharva1802/CSS-trickies](https://github.com/Atharva1802/CSS-trickies) - Here is the code for some cool CSS tricks that I've made.
* [loup-brun/buttons](https://github.com/loup-brun/buttons) - A collection of CSS buttons.
* [Tagggar/Firefox-Alpha](https://github.com/Tagggar/Firefox-Alpha) - 🗿 Super clear desktop browser with zero buttons and intuitive gesture controls
* [kaushikjadhav01/Online-Food-Ordering-Web-App](https://github.com/kaushikjadhav01/Online-Food-Ordering-Web-App) - Online Food Ordering System Website using basic PHP, SQL, HTML & CSS. You can use any one of XAMPP, WAMP or LAMP server to run the Web App
* [apache/cordova-app-hello-world](https://github.com/apache/cordova-app-hello-world) - Apache Cordova Template App
* [Xe/Xess](https://github.com/Xe/Xess) - My minimal Gruvbox CSS file I've been keeping multiple places
* [jritsema/go-htmx-tailwind-example](https://github.com/jritsema/go-htmx-tailwind-example) - Example CRUD app written in Go + HTMX + Tailwind CSS
* [dbarochiya/me](https://github.com/dbarochiya/me) - This is the code implementation for the blog 'How to create your portfolio website in React.js'
* [codepo8/CSS3-Rainbow-Dividers](https://github.com/codepo8/CSS3-Rainbow-Dividers) - No longer must your rainbow dividers be images slowing down your computer! Make them hardware accelerated!
* [briancodex/html-css-js-website-smooth-scroll](https://github.com/briancodex/html-css-js-website-smooth-scroll) - Simple website created using HTML, CSS & Javascript with smooth scroll effect
* [bassjobsen/typeahead.js-bootstrap-css](https://github.com/bassjobsen/typeahead.js-bootstrap-css) - LESS / CSS code for using typeahead.js with Bootstrap 3
* [sixrevisions/responsive-full-background-image](https://github.com/sixrevisions/responsive-full-background-image) - Sources files for a Six Revisions tutorial called Responsive Full Background Image Using CSS
* [karlgroves/diagnostic.css](https://github.com/karlgroves/diagnostic.css) - Diagnostic.css is a stylesheet which allows the user to test for common errors in a page's markup
* [haydenbbickerton/vue-animate](https://github.com/haydenbbickerton/vue-animate) - *UNSUPPORTED* (active fork @ https://github.com/asika32764/vue2-animate) Vue.js port of Animate.css
* [CyanVoxel/Obsidian-Colored-Sidebar](https://github.com/CyanVoxel/Obsidian-Colored-Sidebar) - A Colored Sidebar CSS Snippet for Obsidian.
* [ryboe/CSS3](https://github.com/ryboe/CSS3) - The most complete CSS support for Sublime Text
* [Roopaish/CSS-RoadMap](https://github.com/Roopaish/CSS-RoadMap) - Covering all the CSS aspects through the RoadMap. Buttons, Hover Effects, Animations, Emoji, Tooltips, Landing Page, Youtube Clone
* [cat-a-flame/CSSHell](https://github.com/cat-a-flame/CSSHell) - Collection of common CSS mistakes, and how to fix them
* [alecrios/core-reset](https://github.com/alecrios/core-reset) - A CSS reset that reduces all elements to their most basic forms
* [0kzh/minimal-youtube](https://github.com/0kzh/minimal-youtube) - Arc Boost to clean up the YouTube UI
* [pbakaus/transformie](https://github.com/pbakaus/transformie) - Transformie is a javascript plugin that comes in less than 5k that you embed into web pages and that brings you CSS Transforms by mapping the native IE Filter API to CSS trandforms as proposed by Webkit.
* [Angelmmiguel/graaf](https://github.com/Angelmmiguel/graaf) - A collection of pure CSS grids for designing your new projects
* [viduthalai1947/loaderskit](https://github.com/viduthalai1947/loaderskit) - Single Element Pure CSS Spinners & Loaders
* [tzi/chewing-grid.css](https://github.com/tzi/chewing-grid.css) - A CSS Grid ideal for card listing design like tiles, videos or articles listing. Responsive without media-queries.
* [drannex42/FirefoxSidebar](https://github.com/drannex42/FirefoxSidebar) - Vertical tab design for Firefox with dynamic indentation:: Sidebery and TreeStyleTabs (Legacy) themes available!
* [Bali10050/FirefoxCSS](https://github.com/Bali10050/FirefoxCSS) - Custom firefox interface
* [bedimcode/responsive-real-state-website](https://github.com/bedimcode/responsive-real-state-website) - Responsive Real State Website Design Using HTML CSS & JavaScript
* [parthwebdev/UI-Components](https://github.com/parthwebdev/UI-Components) - Some Awesome UI Components made with HTML, CSS and JavaScript.
* [maykbrito/devlinks](https://github.com/maykbrito/devlinks) - Em 5h de aula, construa esse projeto e inicie na programação o mais rápido possível! ⭐️
* [MartinChavez/HTML-CSS-Advanced-Topics](https://github.com/MartinChavez/HTML-CSS-Advanced-Topics) - HTML/CSS: Advanced Topics
* [arp242/hello-css](https://github.com/arp242/hello-css) - A CSS template focused on readability
* [jovey-zheng/loader](https://github.com/jovey-zheng/loader) - Pure css loading animations. As long as only one element!
* [catalinred/css3-patterned-buttons](https://github.com/catalinred/css3-patterned-buttons) - CSS3 buttons with base64 noise pattern effect.
* [ksmandersen/compass-normalize](https://github.com/ksmandersen/compass-normalize) - A compass plugin for using normalize.css
* [kevinjycui/css-video](https://github.com/kevinjycui/css-video) - Converts images and video frames to pure CSS + HTML files using Breadth-first Search and Canny Edge Detection with keyframe animations
* [csswizardry/discovr](https://github.com/csswizardry/discovr) - CSS Architecture workshop files
* [RoseTheFlower/MetroSteam](https://github.com/RoseTheFlower/MetroSteam) - Metro skin for Steam. Reborn.
* [groovydev/twitter-bootstrap-grails-plugin](https://github.com/groovydev/twitter-bootstrap-grails-plugin) - Grails plugin for Twitter Bootstrap CSS framework resources
* [ream88/stylelint-config-idiomatic-order](https://github.com/ream88/stylelint-config-idiomatic-order) - stylelint + idiomatic-css = ❤️
* [innocenzi/tailwindcss-scroll-snap](https://github.com/innocenzi/tailwindcss-scroll-snap) - CSS Scroll Snap utilities for Tailwind CSS
* [KillYoy/DiscordNight](https://github.com/KillYoy/DiscordNight) - An actual Dark/Nightmode Theme for Discord/BetterDiscord
* [bedimcode/responsive-car-website](https://github.com/bedimcode/responsive-car-website) - Responsive Car Website Design Using HTML CSS & JavaScript
* [tamino-martinius/ui-snippets-menu-animations](https://github.com/tamino-martinius/ui-snippets-menu-animations) - Four different menu animations for menu button toggle between hamburger, cross and back icon.
* [CyanVoxel/Obsidian-Notebook-Themes](https://github.com/CyanVoxel/Obsidian-Notebook-Themes) - A Series of Notebook Theme CSS Snippets for Obsidian.
* [bchanx/animated-gameboy-in-css](https://github.com/bchanx/animated-gameboy-in-css) - Animated Gameboy created in CSS.
* [zavoloklom/material-design-color-palette](https://github.com/zavoloklom/material-design-color-palette) - Material Design Color Palette: LESS/CSS toolkit
* [vaibhav111tandon/vov.css](https://github.com/vaibhav111tandon/vov.css) - 📱💻A CSS Library for small but useful animations💻📱
* [userexec/Pi-Kitchen-Dashboard](https://github.com/userexec/Pi-Kitchen-Dashboard) - A simple HTML/CSS/JS time and weather dashboard for use with Raspberry Pi and Chromium
* [t32k/maple](https://github.com/t32k/maple) - A better front-end boilerplate.
* [qieguo2016/iconoo](https://github.com/qieguo2016/iconoo) - A Flexible Pure CSS Icon Pack! One Tag One Icon! https://qieguo2016.github.io/iconoo/
* [sathify/CCSS](https://github.com/sathify/CCSS) - CSS architecture for web applications
* [frontaid/natural-selection](https://github.com/frontaid/natural-selection) - CSS Boilerplate / Starter Kit: Collection of best-practice CSS selectors
* [frontend-joe/css-navbars](https://github.com/frontend-joe/css-navbars) - Collection of responsive navbars built using HTML, CSS and JavaScript
* [catc/simple-hint](https://github.com/catc/simple-hint) - CSS-only tooltip packed with a variety of features.
* [aalvarado/JiraDarkTheme](https://github.com/aalvarado/JiraDarkTheme) - 🌙 😎 Jira Dark Theme Usercss / Stylus
* [uloga/modulr.css](https://github.com/uloga/modulr.css) - :jack_o_lantern:Modulr.css - A fast and easy modular approach to building powerful web and mobile interfaces.:ghost:
* [JontyYang/Html_Css](https://github.com/JontyYang/Html_Css) - html5 css
* [dmhendricks/bootstrap-grid-css](https://github.com/dmhendricks/bootstrap-grid-css) - The grid and responsive utilities classes extracted from the Bootstrap 4 framework, compiled into CSS.
* [diagnosticss/diagnosticss](https://github.com/diagnosticss/diagnosticss) - Diagnostic CSS stylesheet that helps visually detect any potentially invalid, inaccessible or erroneous HTML markup.
* [codrops/ArrowNavigationStyles](https://github.com/codrops/ArrowNavigationStyles) - Some inspiration for arrow navigation styles and hover effects using SVG icons for the arrows, and CSS transitions and animations for the effects.
* [8lueberry/google-material-color](https://github.com/8lueberry/google-material-color) - Google material color for SASS, LESS, Stylus, CSS, JS, etc
* [OwlyStuff/amazium](https://github.com/OwlyStuff/amazium) - The responsive CSS web framework
* [YJLAugus/cnblogs-theme-simple-color](https://github.com/YJLAugus/cnblogs-theme-simple-color) - 一个简约极致色彩的博客园主题
* [sindresorhus/ios-landing-page](https://github.com/sindresorhus/ios-landing-page) - Landing page template for iOS apps
* [sharadcodes/jekyll-theme-serial-programmer](https://github.com/sharadcodes/jekyll-theme-serial-programmer) - A Jekyll theme for serial programmers (-.-)
* [zhongxia245/blog](https://github.com/zhongxia245/blog) - 这是一个Blog, 如果喜欢可以订阅,是Watch, 不是 Star 哈。。。
* [Jinkeycode/vscode-transparent-glow](https://github.com/Jinkeycode/vscode-transparent-glow) - transparent vscode css
* [callmenick/CSS-Circle-Menu](https://github.com/callmenick/CSS-Circle-Menu) - A fly-out circle menu built with CSS.
* [zweilove/css_splitter](https://github.com/zweilove/css_splitter) - Gem for splitting up stylesheets that go beyond the IE limit of 4095 selectors, for Rails 3.1+ apps using the Asset Pipeline.
* [Set-Creative-Studio/cube-boilerplate](https://github.com/Set-Creative-Studio/cube-boilerplate) - A simple CUBE CSS boilerplate for Set Studio
* [micjamking/navigataur](https://github.com/micjamking/navigataur) - A pure CSS responsive navigation menu
* [i-akhmadullin/Sublime-CSS3](https://github.com/i-akhmadullin/Sublime-CSS3) - at this point just use official CSS package =>
* [DXY-F2E/dxy-ui](https://github.com/DXY-F2E/dxy-ui) - 一套适用于PC端的前端UI库,囊括了基础样式以及十余个基础组件。
* [1-2-3/remark-it](https://github.com/1-2-3/remark-it) - markdown -> slideshow ——Write PPT like a programmer
* [bedimcode/responsive-ecommerce-website](https://github.com/bedimcode/responsive-ecommerce-website) - Responsive Ecommerce Website Using HTML CSS JavaScript
* [MuriungiPatrick/Bootstrap-5-Theming-Kit](https://github.com/MuriungiPatrick/Bootstrap-5-Theming-Kit) - A Theming kit to Customize Bootstrap 5 with Sass
* [agauniyal/wireframe](https://github.com/agauniyal/wireframe) - minimal wireframing css-framework 🎈
* [shbwb/bwb](https://github.com/shbwb/bwb) - A basic webpage builder
* [ruipenso/ucss](https://github.com/ruipenso/ucss) - UCSS - Utility CSS
* [codrops/CSSMarqueeMenu](https://github.com/codrops/CSSMarqueeMenu) - A simple CSS based marquee effect for a menu.
* [thewirelessguy/cornerstone](https://github.com/thewirelessguy/cornerstone) - Cornerstone is a WordPress starter theme based on the Zurb Foundation Responsive Framework. Cornerstone aims to provide a lightweight starter theme that is responsive and SEO friendly that web designers can build great looking websites on.
* [nashvail/ATVIcons](https://github.com/nashvail/ATVIcons) - Apple TV 2015 icons recreated in HTML, CSS and JS
* [michaeltaranto/basekick](https://github.com/michaeltaranto/basekick) - Typographical baselines for CSS
* [kenangundogan/flexible-grid](https://github.com/kenangundogan/flexible-grid) - Flexible grid layouts to get you familiar with building within the flexible grid system.(HTML, CSS, SASS, SCSS)
* [flathemes/bootflat](https://github.com/flathemes/bootflat) - BOOTFLAT is an open source Flat UI KIT based on Twitter Bootstrap 3 css framework. It provides a faster, easier and less repetitive way for web developers to create elegant web app.
* [codrops/ColorExtraction](https://github.com/codrops/ColorExtraction) - Creating a color palette from images in a fun way using CSS Filters and Vibrant.js
* [moonrhythm/biomatic](https://github.com/moonrhythm/biomatic) - A Flexible Atomic-Focused CSS Toolkit
* [Dev-Jeromebaek/awesome-web-styling](https://github.com/Dev-Jeromebaek/awesome-web-styling) - Awesome Web Styling with CSS Animation Effects ⭐️
* [brenna/csshexagon](https://github.com/brenna/csshexagon) - Pure CSS hexagon generator, built with AngularJS
* [npjg/classic.css](https://github.com/npjg/classic.css) - Generate a Classic Mac interface in your browser
* [kijepark/one-page-template](https://github.com/kijepark/one-page-template) - One Page Template for Developer Portfolio
* [bedimcode/responsive-portfolio-website-chris](https://github.com/bedimcode/responsive-portfolio-website-chris) - Responsive Personal Portfolio Website Design Using HTML CSS & JavaScript
* [WhatsNewSaes/Skeleton-Less](https://github.com/WhatsNewSaes/Skeleton-Less) - The (un)official Less Version of Skeleton (2.0.4): A Dead Simple, Responsive Boilerplate for Mobile-Friendly Development
* [Geolage/demos](https://github.com/Geolage/demos) - temporary static pages demos on github
* [BraydenTW/react-tailwind-portfolio](https://github.com/BraydenTW/react-tailwind-portfolio) - 👨🎨 An open-source portfolio template built with React and Tailwind.
* [andri/fluidable](https://github.com/andri/fluidable) - Standalone CSS grid system
* [Socvest/streamlit-on-Hover-tabs](https://github.com/Socvest/streamlit-on-Hover-tabs) - Custom tabs for on hover streamlit navigation bar created by custom css
* [picturepan2/solar.css](https://github.com/picturepan2/solar.css) - Pure CSS Solar System Animation
* [mehmetkahya0/temp-mail](https://github.com/mehmetkahya0/temp-mail) - TempMail is a simple web application that allows you to generate temporary email addresses and view the emails received by these addresses.
* [jez/pandoc-markdown-css-theme](https://github.com/jez/pandoc-markdown-css-theme) - CSS files and a template for using Pandoc to generate standalone HTML files
* [zellwk/css-reset](https://github.com/zellwk/css-reset) - Zell's personal CSS Reset
* [qrac/musubii](https://github.com/qrac/musubii) - Simple CSS Framework for JP
* [leeluolee/mcss](https://github.com/leeluolee/mcss) - writing modular css witch mcss
* [raycon/vscode-markdown-style](https://github.com/raycon/vscode-markdown-style) - Markdown styles for vscode
* [mgeraci/Less-Boilerplate](https://github.com/mgeraci/Less-Boilerplate) - The Less.CSS file full of helpers that I use in my design projects.
* [adobe-webplatform/Demo-for-Alice-s-Adventures-in-Wonderland](https://github.com/adobe-webplatform/Demo-for-Alice-s-Adventures-in-Wonderland) - Demo of CSS Shapes using the Alice in Wonderland story.
* [ptb/flexgrid](https://github.com/ptb/flexgrid) - Next-generation CSS grid framework based on flexbox. Provides the same responsive 12 column fluid layout as Bootstrap 3 to most browsers. Even supports IE 6! Simple, fast, and easy.
* [Wakkos/Wakkos-CSS-Framework](https://github.com/Wakkos/Wakkos-CSS-Framework) - SCSS Framework para agilizar maquetación Frontend.
* [lukakerr/ion](https://github.com/lukakerr/ion) - A lightweight CSS framework that brings MacOS styled elements to Electron
* [liang4793/liang4793.github.io](https://github.com/liang4793/liang4793.github.io) - ⚡Liáng4793's Repository (main website) 😸Redefine the world with imagination
* [rcvd/roam-css-system](https://github.com/rcvd/roam-css-system) - Roam CSS System 2.0
* [T-baby/ICECss](https://github.com/T-baby/ICECss) - 一个简洁的CSS框架
* [fxaeberhard/handdrawn.css](https://github.com/fxaeberhard/handdrawn.css) - Handdrawn.css lets you prototype your web site with a hand drawn look and feel.
* [ClearVision/ClearVision-v5](https://github.com/ClearVision/ClearVision-v5) - Automatically updating, easily customizable Theme for Discord.
* [tomhodgins/preset](https://github.com/tomhodgins/preset) - A simple CSS preset for 2020
* [huruji/loading](https://github.com/huruji/loading) - loading动画合集
* [CTalvio/Monochromic](https://github.com/CTalvio/Monochromic) - A color muted, minimalistic theme for Jellyfin mediaserver created using CSS overrides
* [FontFaceKit/roboto](https://github.com/FontFaceKit/roboto) - CSS/SASS codes and woff files for google's roboto webfont
* [dudleystorey/thenewdefaults](https://github.com/dudleystorey/thenewdefaults) - Sass replacement for the standard CSS named color system
* [wecatch/markdown-css](https://github.com/wecatch/markdown-css) - A tool convert css style into markdown inline style
* [sporkd/compass-h5bp](https://github.com/sporkd/compass-h5bp) - Compass library of Html5Boilerplate's style.css
* [gsuez/master-bootstrap-3](https://github.com/gsuez/master-bootstrap-3) - Joomla 3.x Template with Bootstrap 3
* [7ninjas/scss-mixins](https://github.com/7ninjas/scss-mixins) - Collection of scss mixins and functions to ease and improve implementations of common style-code patterns.
* [madmurphy/takefive.css](https://github.com/madmurphy/takefive.css) - The most advanced pure CSS lightbox – not one single line of JavaScript has been wasted
* [gadenbuie/cleanrmd](https://github.com/gadenbuie/cleanrmd) - 📄✨Clean Class-Less R Markdown HTML Documents
* [fellowish/firefox-review](https://github.com/fellowish/firefox-review) - A Firefox Preview inspired theme for desktop
* [amiechen/codrops-libre](https://github.com/amiechen/codrops-libre) - A reponsive single page app template for collection management projects
* [LinWin-Cloud/setool-master](https://github.com/LinWin-Cloud/setool-master) - SetoolMaster是一款让你入门即入狱的python3开发的进阶型社会工程学工具。包括了全球定位、Ngrok内网穿透、Seeker高精度定位、网页钓鱼、病毒攻击、恐吓勒索信、爬虫、网站克隆、物联网设备搜索等,同时拥有中文支持,内置大量钓鱼模板,设计用于组织级别红队渗透测试,用于团队组织设备型协同,经过非常多的实战演练,效果出众,远超同行产品
* [linxz/tianyizone](https://github.com/linxz/tianyizone) - 整理平时会偶尔用到的一些CSS小东西
* [A-FE/vue-transition.css](https://github.com/A-FE/vue-transition.css) - vue-transition animation
* [tmoreton/useful.ly](https://github.com/tmoreton/useful.ly) - useful.ly Flexbox-Based CSS Framework
* [elliotdahl/flex-grid-lite](https://github.com/elliotdahl/flex-grid-lite) - Lightweight column grid with the power of flexbox
* [Cipriano99/CiprianoCSS](https://github.com/Cipriano99/CiprianoCSS) - Framework de CSS em português!
* [winjs/grid](https://github.com/winjs/grid) - CSS Grid Framework
* [shuding/cssosx](https://github.com/shuding/cssosx) - A CSS & JS made macOS UI.
* [s5s5/CSS-Animations](https://github.com/s5s5/CSS-Animations) - 一些在项目中学习、使用CSS的动画心得。与大家一起探讨CSS动画的What How Why。
* [humidair1999/nuclide](https://github.com/humidair1999/nuclide) - A CSS framework for utilizing the Atomic design pattern
* [Soft-Bred/Brave-Fox](https://github.com/Soft-Bred/Brave-Fox) - Firefox Stylesheet To Add Brave-Like Elements
* [simurai/filter.css](https://github.com/simurai/filter.css) - A collection of CSS filter combos
* [RichardBray/color-me-sass](https://github.com/RichardBray/color-me-sass) - Colour library for the css preprocessor SASS
* [haozki/luckyOne](https://github.com/haozki/luckyOne) - HTML5&CSS3抽奖小程序
* [calrobertlee/roam-css-styles](https://github.com/calrobertlee/roam-css-styles) - Visually polished CSS styles for RoamResearch
* [lmgonzalves/morphing-hamburger-menu](https://github.com/lmgonzalves/morphing-hamburger-menu) - A CSS only Morphing Hamburger Menu.
* [Fentaniao/Liquid](https://github.com/Fentaniao/Liquid) - A nice theme designed for Typora in Windows 11.
* [buzzfeed/solid](https://github.com/buzzfeed/solid) - This repo will collect all basic BuzzFeed styling CSS.
* [anater/tachyons-animate](https://github.com/anater/tachyons-animate) - Single purpose classes to help you orchestrate CSS animations
* [wbobeirne/stranger-things](https://github.com/wbobeirne/stranger-things) - Intro of the show Stranger Things in CSS
* [parsegon/math-css](https://github.com/parsegon/math-css) - Easy way to represent math by a few lines of HTML via CSS.
* [mrmlnc/material-color](https://github.com/mrmlnc/material-color) - :high_brightness: The colour palette, based on Google's Material Design, for use in your project.
* [mapbox/assembly](https://github.com/mapbox/assembly) - Making the hard parts of designing for the web easy.
* [cristurm/nyan-cat](https://github.com/cristurm/nyan-cat) - Nyan Cat made with HTML5+CSS3+JavaScript
* [codrops/ItemSlider](https://github.com/codrops/ItemSlider) - A tutorial on how to create a simple category slider with a minimal design using CSS animations and jQuery. The idea is to slide the items sequentially depending on the slide direction.
* [lukehaas/css-pokemon](https://github.com/lukehaas/css-pokemon) - An experiment with CSS clip-path and variables
* [hrqmonteiro/joplin-theme](https://github.com/hrqmonteiro/joplin-theme) - My Joplin theme files, including userchrome.css and userstyles.css, as well as some markdown templates for my notes.
* [Lavender-Discord/Lavender](https://github.com/Lavender-Discord/Lavender) - A highly customizeable and good looking discord theme.
* [podrivo/thegoodman](https://github.com/podrivo/thegoodman) - An experiment with basic CSS3 animations.
* [outboxcraft/beauter](https://github.com/outboxcraft/beauter) - A simple framework for faster and beautiful responsive sites
* [hail2u/normalize.scss](https://github.com/hail2u/normalize.scss) - Modularized and Sassy normalize.css
* [dryan/css-smart-grid](https://github.com/dryan/css-smart-grid) - Lightweight, Responsive, Mobile First Grid System
* [codrops/PageRevealEffects](https://github.com/codrops/PageRevealEffects) - Some ideas for modern multi-layer page transitions using CSS Animations.
* [zalando/dress-code](https://github.com/zalando/dress-code) - The official style guide and framework for all Zalando Brand Solutions products
* [chetachiezikeuzor/Obsidian-Snippets](https://github.com/chetachiezikeuzor/Obsidian-Snippets) - A repo full of my snippets for Obsidian.md. Use them to customize your workspace and/or add to a theme! 🪄
* [rishabh-rajgarhia/bootstrap-4-utilities](https://github.com/rishabh-rajgarhia/bootstrap-4-utilities) - Bootstrap 4 utility classes in LESS CSS for Bootstrap 3 or any other projects.
* [markdowncss/modest](https://github.com/markdowncss/modest) - A markdown CSS module that is rather modest.
* [danilolmc/interfaces-clone](https://github.com/danilolmc/interfaces-clone) - Repositório com clones de interfaces para praticar CSS
* [caramelcss/caramel](https://github.com/caramelcss/caramel) - a simple to use, easy to remember css framework
* [bartkozal/hocus-pocus](https://github.com/bartkozal/hocus-pocus) - Universal and lightweight stylesheet starter kit
* [zemirco/flexbox-grid](https://github.com/zemirco/flexbox-grid) - Grid system using CSS flex properties
* [picturepan2/icons.css](https://github.com/picturepan2/icons.css) - Single Element Pure CSS icons
* [Mohammedcha/TikTok-FLP](https://github.com/Mohammedcha/TikTok-FLP) - Tik Tok FLP is a Perfect CPA landing page coded in HTML, PHP, JS, and CSS, provided free of charge by Re-skinning Group
* [xingbofeng/css-grid-flex](https://github.com/xingbofeng/css-grid-flex) - :book:An introduction about grid and flex of css.
* [discord-extensions/modern-indicators](https://github.com/discord-extensions/modern-indicators) - Updates Discord's indicators to feel more modern.
* [bedimcode/responsive-gym-website](https://github.com/bedimcode/responsive-gym-website) - Responsive Gym Website Design Using HTML CSS & JavaScript
* [stephenway/compass-inuit](https://github.com/stephenway/compass-inuit) - :white_flower: Compass extension for inuit.css. More than 40k users served!
* [shanyuhai123/learnCSS](https://github.com/shanyuhai123/learnCSS) - 该库用来学习 CSS
* [sebastianmusial/SSCSS](https://github.com/sebastianmusial/SSCSS) - Light Sass lib for managing your font-size, margin, padding, and position values across breakpoints.
* [ranjithprabhuk/Angular-Bootstrap-Dashboard](https://github.com/ranjithprabhuk/Angular-Bootstrap-Dashboard) - Angular Bootstrap Dashboard is a web dashboard application based on Bootstrap and AngularJS. All components included in this dashboard template has been developed to bring all the potential of HTML5 and Bootstrap plus a set of new features (JS and CSS) ideal for your next dashboard admin theme or admin web app project. Angular Bootstrap Dashboard can be used in any type of web applications dashboard: Single Page Application (SPA), project management system, ecommerce admin dashboard, CMS, CRM, SAAS, help desk; for personal and business purposes. Angular Bootstrap Dashboard uses ui-router for routing purposes.
* [zendeskgarden/css-components](https://github.com/zendeskgarden/css-components) - :seedling: garden CSS components
* [jaydenseric/Fix](https://github.com/jaydenseric/Fix) - A CSS normalization/reset reference.
* [frontendcharm/Mini-Projects](https://github.com/frontendcharm/Mini-Projects) - Mini projects for beginners made using HTML, CSS and a little bit of JavaScript.
* [jacobbates/pi-hole-midnight](https://github.com/jacobbates/pi-hole-midnight) - Custom dark theme CSS for pi-hole to replace skin-blue AdminLTE theme
* [haixiangyan/codeblock-beautifier](https://github.com/haixiangyan/codeblock-beautifier) - 💅 A chrome extension for highlighting codes of Medium Articles
* [AlphaConsole/AlphaConsoleElectron](https://github.com/AlphaConsole/AlphaConsoleElectron) - AlphaConsole Electron UI
* [newmanls/OnelineProton](https://github.com/newmanls/OnelineProton) - An oneline userChrome.css theme for Firefox, which aims to keep the Proton experience
* [daktales/Mou-Themes-Collection](https://github.com/daktales/Mou-Themes-Collection) - A collection of themes (and css) for Mou
* [angel-rs/css-color-filter-generator](https://github.com/angel-rs/css-color-filter-generator) - Generate custom css filter property to achieve any target color :art:
* [sindresorhus/strip-css-comments](https://github.com/sindresorhus/strip-css-comments) - Strip comments from CSS
* [lucagez/bars](https://github.com/lucagez/bars) - css progress bars made with svg patterns
* [donovanh/zelda](https://github.com/donovanh/zelda) - CSS Zelda-inspired animation
* [arizzitano/css3wordart](https://github.com/arizzitano/css3wordart) - 1990s MS WordArt. In CSS3.
* [aprietof/every-layout](https://github.com/aprietof/every-layout) - Minimum HTML/CSS/JS needed for recreating Heydon Pickering & Andy Bell's Every Layouts.
* [mrmrs/css-uncut](https://github.com/mrmrs/css-uncut) - WIP: All of css as single purpose classes
* [LeaVerou/play.csssecrets.io](https://github.com/LeaVerou/play.csssecrets.io) - CSS Secrets Book live demos
* [Viglino/iconicss](https://github.com/Viglino/iconicss) - More than 900 pure CSS3 icons!
* [omerimzali/uiterminal](https://github.com/omerimzali/uiterminal) - Terminal Style CSS Framework
* [legacy-icons/famfamfam-silk](https://github.com/legacy-icons/famfamfam-silk) - Famfamfam Silk icons, made available in various package managers, shipped with CSS spritesheet
* [codewithsadee/music-player](https://github.com/codewithsadee/music-player) - A fully responsive web music player using vanilla javascript, Responsive for all devices, build using html, css, and javascript.
* [tretapey/raisincss](https://github.com/tretapey/raisincss) - An Utility CSS only library. It supports css grid and many more useful css properties.
* [ronanlevesque/FOX-CSS](https://github.com/ronanlevesque/FOX-CSS) - A light CSS/Sass framework
* [iFelix18/Dark-qBittorrent-WebUI](https://github.com/iFelix18/Dark-qBittorrent-WebUI) - A darker theme for qBittorrent WebUI (ispired by Cozzy's theme: userstyles.org/styles/152766)
* [stevebauman/curlwind](https://github.com/stevebauman/curlwind) - Generate Tailwind utility stylesheets on demand.
* [newaeonweb/ResponsiveAeon-Cssgrid](https://github.com/newaeonweb/ResponsiveAeon-Cssgrid) - Lightweight Responsive CSS Grid System, build to be Simple Fast and Intuitive, only 1kb minified.
* [mgastonportillo/gale-for-ff](https://github.com/mgastonportillo/gale-for-ff) - CSS files to theme Firefox with Sidebery
* [longsien/BareCSS](https://github.com/longsien/BareCSS) - A classless CSS framework
* [nemophrost/atomic-css](https://github.com/nemophrost/atomic-css) - Atomic CSS library with a CSS style guide for using atomic CSS in conjunction with OOCSS and CSS components
* [derny/reuze](https://github.com/derny/reuze) - Reuze is a teeny-tiny front end tool that makes structuring HTML and CSS for blogs and article-heavy sites a breeze.
* [tilomitra/infinite](https://github.com/tilomitra/infinite) - A small set of useful infinite CSS animations that you can drop into your project.
* [mhanberg/jekyll-tailwind-starter](https://github.com/mhanberg/jekyll-tailwind-starter) - Starter project for using Jekyll with Tailwind CSS
* [Lisandra-dev/Obsidian-Snippet-collection](https://github.com/Lisandra-dev/Obsidian-Snippet-collection) - A collection of snippet to customize obsidian
* [iandinwoodie/github-markdown-tailwindcss](https://github.com/iandinwoodie/github-markdown-tailwindcss) - ⛵ Replicate GitHub Flavored Markdown with Tailwind CSS components
* [danilowoz/wipe.css](https://github.com/danilowoz/wipe.css) - 🚿 Stop suffering and resetting styles for every new project. This is a library to reset default styles with some opinionated changes, that you might love (or not).
* [bmbrands/theme_bootstrap](https://github.com/bmbrands/theme_bootstrap) - A Moodle theme based on the Bootstrap CSS framework
* [escueladigital/Trucos-CSS](https://github.com/escueladigital/Trucos-CSS) - Repositorio de la serie Trucos CSS publicados en YouTube
* [aaroniker/framy-css](https://github.com/aaroniker/framy-css) - Very simple CSS Framework
* [trwnh/mastomods](https://github.com/trwnh/mastomods) - CSS tweaks and custom themes for Mastodon.
* [shawnohare/hugo-tufte](https://github.com/shawnohare/hugo-tufte) - Content centric Hugo blogging theme styled with Tufte-css
* [lewagon/html-css-challenges](https://github.com/lewagon/html-css-challenges) - HTML / CSS challenges @LeWagon
* [kriswep/cra-tailwindcss](https://github.com/kriswep/cra-tailwindcss) - Integrate Tailwind CSS in a Create React App setup
* [fourseven/pure-sass](https://github.com/fourseven/pure-sass) - Yahoo's Pure CSS library ported to SASS.
* [codrops/GlitchSlideshow](https://github.com/codrops/GlitchSlideshow) - A slideshow that uses a CSS glitch effect for slide transitions.
* [christian-fei/Timeline.css](https://github.com/christian-fei/Timeline.css) - Share life and work events with Timeline.css! Sass and SCSS port too!
* [Alsiso/normalize-zh](https://github.com/Alsiso/normalize-zh) - Normalize.css 中文文档与源码解读
* [zachwaugh/Helveticards](https://github.com/zachwaugh/Helveticards) - 100% CSS playing cards, originally created for the Pitboss poker server, you can see live demo at link below
* [voronianski/dookie-css](https://github.com/voronianski/dookie-css) - stylus driven css library
* [sgomes/css-aspect-ratio](https://github.com/sgomes/css-aspect-ratio) - A tiny module to help preserve aspect ratio in pure CSS
* [sagars007/starry-fox](https://github.com/sagars007/starry-fox) - Firefox css stylesheets for the dark space theme. Matching more UI elements with the theme.
* [markdowncss/retro](https://github.com/markdowncss/retro) - A markdown CSS module that is a blast to the past.
* [codyhouse/virgo-template](https://github.com/codyhouse/virgo-template) - Virgo is a free HTML, CSS, JS template built using the CodyHouse Components and Framework.
* [antonyleme/CSS-Animations](https://github.com/antonyleme/CSS-Animations) - Animations with HTML and CSS
* [ZMYaro/holo-web](https://github.com/ZMYaro/holo-web) - A CSS library that imitates the Android Holo themes. If you are looking for a similar library for Material Design, try https://MaterialZ.dev.
* [opera7133/Blonde](https://github.com/opera7133/Blonde) - Blonde, A simple theme using Tailwind CSS.
* [obvionaoe/dark](https://github.com/obvionaoe/dark) - :first_quarter_moon_with_face: Dark themes / mode for Rambox, Franz or Ferdi messaging services
* [hicodersofficial/custom-html-css-js-widgets](https://github.com/hicodersofficial/custom-html-css-js-widgets) - Custom HTML, CSS & JavaScript Widgets.
* [bedimcode/responsive-mini-portfolio](https://github.com/bedimcode/responsive-mini-portfolio) - Responsive Mini Portfolio Website Design Using HTML CSS & JavaScript
* [adamstac/grid-coordinates](https://github.com/adamstac/grid-coordinates) - Sass and Compass highly-configurable CSS grid framework
* [tachyons-css/tachyons-verbose](https://github.com/tachyons-css/tachyons-verbose) - Functional CSS for humans. Verbose edition.
* [Redundakitties/colorful-minimalist](https://github.com/Redundakitties/colorful-minimalist) - collection of sidebery tweaks feat. autohiding & colored tabs
* [kuronekony4n/astream](https://github.com/kuronekony4n/astream) - A very epic anime streaming website. No Ads.
* [cognitom/keiyaku-css](https://github.com/cognitom/keiyaku-css) - Crazy Style Formatter for Japanese Contract Document
* [ademilter/html-css-ogreniyoruz](https://github.com/ademilter/html-css-ogreniyoruz) - uygulamalı anlatım
* [mrmrs/type.css](https://github.com/mrmrs/type.css) - A mobile-first responsive type scale
* [cunhasbia/30-days-of-CSS](https://github.com/cunhasbia/30-days-of-CSS) - 30 Days Of CSS is a challenge to help you improve your coding skills by doing mini daily projects using HTML and CSS.
* [amiechen/codrops-dropcast](https://github.com/amiechen/codrops-dropcast) - a responsive HTML/CSS/Javascript template, comes with Sketch files and a fully working site with SCSS. It works very well for podcasts landing pages or blogs, and can be easily customized.
* [ValerioLyndon/MAL-Public-List-Designs](https://github.com/ValerioLyndon/MAL-Public-List-Designs) - MyAnimeList designs available for anyone to use.
* [Ritika-Agrawal811/css-and-js-code-snippets](https://github.com/Ritika-Agrawal811/css-and-js-code-snippets) - A collection of real-life code snippets written in CSS and JavaScript for every web development project.
* [guoyunhe/flexbin](https://github.com/guoyunhe/flexbin) - Pure CSS, flexible and gapless image gallery layout like Google Images and 500px.com
* [giovannamoeller/login-form](https://github.com/giovannamoeller/login-form) - This is a simple and responsive login form made with HTML and CSS using transitions.
* [choidavid4/pagina-completa-html-css](https://github.com/choidavid4/pagina-completa-html-css) - pagina completa programaya
* [stuyam/CSSDevices](https://github.com/stuyam/CSSDevices) - :iphone:.css Apple devices built in pure CSS
* [sanjayaharshana/AnimTrap](https://github.com/sanjayaharshana/AnimTrap) - AnimTrap is a CSS Framework for animations. Its like bootstrap for JS animations. All you need is to import AnimTrap and use it for animations in your webapp easily. AnimTrap supports animations like scrolling and simple effects which would make a richer the experience from your webapp
* [Nainish-Rai/aesthetic-startpage](https://github.com/Nainish-Rai/aesthetic-startpage) - Aesthetic Startpage to boost your productivity and at the same time give your desktop a new aesthetic look
* [Ethredah/PHP-Blog-Admin](https://github.com/Ethredah/PHP-Blog-Admin) - A PHP Admin Dashboard / Website (with blog section)
* [dracula/obsidian](https://github.com/dracula/obsidian) - 🧛🏻♂️ Dark theme for Obsidian
* [codewithsadee/fitlife](https://github.com/codewithsadee/fitlife) - Fitlife is a fully responsive fitness website, Responsive for all devices, build using HTML, CSS, and JavaScript.
* [chantastic/minions.css](https://github.com/chantastic/minions.css) - evil micro-classes
* [bedimcode/responsive-portfolio-website-rian](https://github.com/bedimcode/responsive-portfolio-website-rian) - Responsive Personal Portfolio Website Using HTML CSS & JavaScript
* [axui/axui](https://github.com/axui/axui) - AXUI前端框架的理念是:能用css实现的不用js,需要使用js则尽量少用,需要大量使用js则尽量可复用。
* [xem/miniMinifier](https://github.com/xem/miniMinifier) - HTML/CSS/JS minifiers in 128+ bytes
* [rampatra/ui-kit-for-chrome-extensions](https://github.com/rampatra/ui-kit-for-chrome-extensions) - A UI template for designing the options/settings page for Chrome Extensions. It resembles the exact look as the native settings page of Chrome Browser.
* [Libra11-zz/CSS-EFFECT](https://github.com/Libra11-zz/CSS-EFFECT) - css effect
* [catppuccin/vimium](https://github.com/catppuccin/vimium) - 🌼 Soothing pastel theme for Vimium
* [chipriley/lovelace-css-values](https://github.com/chipriley/lovelace-css-values) - Simply a repo to house information about CSS values that can be modified by Lovelace theme files.
* [Amoenus/SwaggerDark](https://github.com/Amoenus/SwaggerDark) - CSS with dark theme for SwaggerUI
* [afuersch/css-percentage-circle](https://github.com/afuersch/css-percentage-circle) - Pure CSS percentage circle
* [thx/cube](https://github.com/thx/cube) - 跨终端、响应式、低设计耦合的CSS解决方案
* [localip/dark-discord](https://github.com/localip/dark-discord) - An actual dark mode for discord.
* [The-Shivam-garg/BigB-E-learn-Websit-e](https://github.com/The-Shivam-garg/BigB-E-learn-Websit-e) - BigB is a E-learning website built using HTML, CSS, JavaScript and Bootstrap - Hacktoberfest Accepted. 🤞 This project is previously accepted in GSSoC 2022 , JWOC 22.
* [AlfarexGuy2019/keyfox](https://github.com/AlfarexGuy2019/keyfox) - A simple, keystroke-centered CSS for Firefox.
* [prakhartiwari0/Arito](https://github.com/prakhartiwari0/Arito) - Arito is an Open-Source WebApp for practicing arithmetic skills.
* [designmodo/startup-framework-2-demo](https://github.com/designmodo/startup-framework-2-demo) - Startup Framework 2.2 Free — Beautiful framework based on Bootstrap 4.0 (html/css/scss/js/sketch/psd).
* [jpsilvashy/fluid-grid-system](https://github.com/jpsilvashy/fluid-grid-system) - A very lightwieght XHTML/CSS framework that follows both the typographic grid, and also baseline grid
* [Godiesc/Chameleons-Beauty](https://github.com/Godiesc/Chameleons-Beauty) - Adapted "Beautiful" Themes
* [vinceumo/atomic-bulldog-grid](https://github.com/vinceumo/atomic-bulldog-grid) - 🏢 CSS (SCSS) Grid based on CSS grid layout with @supports fallback to flexbox
* [radekkozak/discordian](https://github.com/radekkozak/discordian) - Obsidian dark theme inspired by Discord
* [otsaloma/markdown-css](https://github.com/otsaloma/markdown-css) - Stylesheets for Markdown to HTML conversion
* [oltdaniel/skeleton-plus](https://github.com/oltdaniel/skeleton-plus) - :ferris_wheel: simple stripped down css framework
* [LaasriNadia/Drawings](https://github.com/LaasriNadia/Drawings) - CSS drawings
* [fernandoleonid/speed-code-css-html](https://github.com/fernandoleonid/speed-code-css-html) - Vídeos estilo speed code para o youtube
* [billfienberg/grid-garden](https://github.com/billfienberg/grid-garden) - Solutions to CSS Grid Garden
* [OkGoDoIt/Office-Ribbon-2010](https://github.com/OkGoDoIt/Office-Ribbon-2010) - Office 2010 Style Ribbon Toolbar in HTML/CSS/JS
* [mdipierro/no.css](https://github.com/mdipierro/no.css) - Tiny CSS framework with almost no classes and some pure CSS effects
* [knhash/Pudhina](https://github.com/knhash/Pudhina) - A simple, minimal Jekyll theme for a personal web page and blog, focusing on white space and readability
* [Dugnist/html5-boilerplate](https://github.com/Dugnist/html5-boilerplate) - A simple, fast, modern, pure html, css (and sass), js, live reload starter template
* [dhanishgajjar/css-flags](https://github.com/dhanishgajjar/css-flags) - A collection of pure CSS flags, all single divs.
* [daliannyvieira/css-animations-pocket-guide](https://github.com/daliannyvieira/css-animations-pocket-guide) - A pocket guide to get started writing CSS Animations. :sparkles:
* [mrkrupski/LESS-Dynamic-Stylesheet](https://github.com/mrkrupski/LESS-Dynamic-Stylesheet) - A set of useful mixins for LESS, the CSS pre-processor: http://lesscss.org
* [vace/css3-animation-generator](https://github.com/vace/css3-animation-generator) - chrome plugin css3 animation generator
* [karloespiritu/bemskel](https://github.com/karloespiritu/bemskel) - A lightweight CSS framework written in BEM and SASS for building scalable component-based user interfaces
* [garu2/Skills-CSS](https://github.com/garu2/Skills-CSS) - 🚀 Una colección de tips para ayudarte a mejorar sus habilidades de CSS 🪐
* [codepo8/3drollovers.css](https://github.com/codepo8/3drollovers.css) - A CSS file to give you some cool 3D rollover effects
* [bedimcode/responsive-coffee-website](https://github.com/bedimcode/responsive-coffee-website) - Responsive Coffee Website Using HTML CSS & JavaScript
* [Archmonger/Blackberry-Themes](https://github.com/Archmonger/Blackberry-Themes) - CSS changes to many popular web services. Improves desktop site aesthetics and creates functional mobile sites! Comes with custom icons for Organizr!
* [aosmialowski/1140px-Responsive-CSS-Grid](https://github.com/aosmialowski/1140px-Responsive-CSS-Grid) - 1140px Responsive CSS Grid
* [lalwanivikas/image-editor](https://github.com/lalwanivikas/image-editor) - A simple image editor - via CSS properties.
* [DM164/Dark-by-DM](https://github.com/DM164/Dark-by-DM) - Dark by DM, a family of dark themes for different websites on the internet.
* [codrops/CSSProgress](https://github.com/codrops/CSSProgress) - A tutorial on how to create shaded CSS-only progress bars with Sass. By Rafael González.
* [BcRikko/css-collection](https://github.com/BcRikko/css-collection) - 🧙♂️ CSS芸人への道(CSSでつくったもの集)| I want to be CSS Magician
* [yfzhao20/Typora-markdown](https://github.com/yfzhao20/Typora-markdown) - 试验性的存储库,用于存放Typora折腾过的css样式和其他
* [tessus/joplin-custom-css](https://github.com/tessus/joplin-custom-css) - 📝 My custom styles for Joplin, the open source note taking app
* [tedconf/shed-css](https://github.com/tedconf/shed-css) - Functional and customizable CSS utilities with familiar names
* [nternetinspired/debug-css](https://github.com/nternetinspired/debug-css) - A style sheet to help detect invalid or inaccessible markup
* [colepeters/gemma](https://github.com/colepeters/gemma) - A lightweight CSS library.
* [codyhouse/content-filter](https://github.com/codyhouse/content-filter) - A slide-in filter panel powered by CSS and jQuery.
* [nateify/elementary-CSS](https://github.com/nateify/elementary-CSS) - A CSS framework based on the design of elementaryOS
* [minipai/ng-trans.css](https://github.com/minipai/ng-trans.css) - Easy transitions for AngularJS
* [markdowncss/air](https://github.com/markdowncss/air) - A markdown CSS module that is light and airy.
* [enjeck/btns](https://github.com/enjeck/btns) - A collection of buttons with cool hover effects
* [danharrin/alpine-tailwind-components](https://github.com/danharrin/alpine-tailwind-components) - Alpine.js and Tailwind CSS component source code from my YouTube tutorials.
* [cnanney/css-flip-counter](https://github.com/cnanney/css-flip-counter) - A revisit of my CSS flip counter
* [ShivamJoker/InShare](https://github.com/ShivamJoker/InShare) - Simple file sharing web app with drag & drop
* [itbruno/responsive-timeline](https://github.com/itbruno/responsive-timeline) - Responsive vertical timeline in SCSS
* [getbase/starter](https://github.com/getbase/starter) - Base Starter - A Rock Solid, Starter template that includes the Base CSS framework and modules to get you started on your next app or website.
* [codrops/SwatchBook](https://github.com/codrops/SwatchBook) - A tutorial about how to create a swatch book like component that let's you open and rotate the single swatches revealing some details. We will be using CSS transforms and transitions and create a simple jQuery plugin.
* [cannibalox/logseq-dark-hpx](https://github.com/cannibalox/logseq-dark-hpx) - CSS snippets and themes for www.logseq.com
* [berkanakyurek/select2-bootstrap4-theme](https://github.com/berkanakyurek/select2-bootstrap4-theme) - A theme for Select2 v4 and Bootstrap 4
* [StylishThemes/Overlay-Scrollbars](https://github.com/StylishThemes/Overlay-Scrollbars) - 🎨 An overlay scrollbar customizable theme for Firefox and Chrome based browsers
* [pavliukpetro/motion-css](https://github.com/pavliukpetro/motion-css) - The library of CSS3 animation
* [oliviale/CSS-Progress-Pie](https://github.com/oliviale/CSS-Progress-Pie) - A pure CSS progress pie chart
* [guglicap/wal-discord](https://github.com/guglicap/wal-discord) - Generate Discord css from pywal colors
* [chrisdwheatley/material-design-hamburger](https://github.com/chrisdwheatley/material-design-hamburger) - Android's Material Design hamburger animation built in CSS
* [birneee/obsidian-adwaita-theme](https://github.com/birneee/obsidian-adwaita-theme) - Obsidian theme in the style of Gnome Adwaita
* [bassjobsen/typeahead.js-bootstrap4-css](https://github.com/bassjobsen/typeahead.js-bootstrap4-css) - SCSS (Sass) / CSS code for using typeahead.js with Bootstrap 4
* [aniketsinha2002/DataGeek](https://github.com/aniketsinha2002/DataGeek) - A static educational website related to Data Science built using HTML, CSS, JS, Bootstrap and Tailwind from scratch
* [adamschwartz/chrome-tabs](https://github.com/adamschwartz/chrome-tabs) - Chrome-style tabs in HTML/CSS.
* [andreasgrafen/cascade](https://github.com/andreasgrafen/cascade) - A responsive One-Line CSS Theme for Firefox.
* [csswizardry/csswizardry.github.com](https://github.com/csswizardry/csswizardry.github.com) - My site.
* [qrac/yakuhanjp](https://github.com/qrac/yakuhanjp) - Yakumono-Hankaku Fonts
* [CodeCrafter11/css-projects](https://github.com/CodeCrafter11/css-projects) - You can find all source codes for all css projects here
* [uloga/decorator](https://github.com/uloga/decorator) - :pencil:Decorator HTML, CSS, and JavaScript Front-End Framework
* [MartinChavez/HTML-CSS](https://github.com/MartinChavez/HTML-CSS) - HTML/CSS Tutorial
* [kflorence/flurid](https://github.com/kflorence/flurid) - A cross-browser, fluid width CSS grid framework that doesn't hide pixels in margins!
* [raphamorim/react-motions](https://github.com/raphamorim/react-motions) - Compose React Animations using High-Order Functions or Components
* [jamesqquick/Design-and-Build-a-Chat-Application-with-Socket.io](https://github.com/jamesqquick/Design-and-Build-a-Chat-Application-with-Socket.io) - In this mini series we are going to Design and Build a chat application using Socket.io. We will first discuss basic design concepts while exploring the design for this application in Sketch. We will then move on to laying out our application in HTML and CSS, and lastly, will add Javascript to complete the functionality. Along the way, we are going to use modern Web Development technologies and features such as Flexbox, CSS Variables, ES6 Arrow Functions, ES6 Map, Let and Const variables, Node.js, Express.js, and Socket.io.
* [feichang/veryless](https://github.com/feichang/veryless) - less css 扩展
* [csswizardry/inuit.css-web-template](https://github.com/csswizardry/inuit.css-web-template) - Web template for housing the inuit.css framework as submodule
* [tiaanduplessis/nanoreset](https://github.com/tiaanduplessis/nanoreset) - Minimal CSS reset in less than 500 bytes
* [tecladocode/web-dev-bootcamp](https://github.com/tecladocode/web-dev-bootcamp) - Complete course and guide of the "Web Developer Bootcamp with Flask and Python"
* [technopagan/slides-in-markdown](https://github.com/technopagan/slides-in-markdown) - Slide deck tool for giving presentations written in MarkDown. Based on remark.js and written in plain HTML, CSS & JS. Features presenter console with speaker notes, timer, screen blanking and more. The theme provides all basic requirements for slide contents (images, video, code snippets etc) and gives you many small helpers to style contents.
* [aniketsinha2002/DataScienceWebsite.github.io](https://github.com/aniketsinha2002/DataScienceWebsite.github.io) - A static educational website (frontend) related to Data Science.
* [stevenmhunt/badgerly](https://github.com/stevenmhunt/badgerly) - A CSS 3 library for rendering badges.
* [P233/Rebar](https://github.com/P233/Rebar) - Rebar makes responsive development more efficient and keeps CSS organised.
* [theoinglis/ngAnimate.css](https://github.com/theoinglis/ngAnimate.css) - Animation classes for use with AngularJS
* [rhiokim/markdown-css](https://github.com/rhiokim/markdown-css) - markdown theme standard style, using less (for haroopad)
* [pixelscript-io/Less-Grid-Boilerplate](https://github.com/pixelscript-io/Less-Grid-Boilerplate) - A lightweight 12-column CSS grid system built with CSS Grid and LESS.
* [jonschlinkert/vertical-rhythm](https://github.com/jonschlinkert/vertical-rhythm) - Put some typographical vertical rhythm in your CSS. LESS, Stylus and SCSS/SASS versions included.
* [bymathias/normalize.styl](https://github.com/bymathias/normalize.styl) - Stylus version of normalize.css
* [tysonmatanich/directional-scss](https://github.com/tysonmatanich/directional-scss) - Makes supporting CSS for left-to-right (LTR) and right-to-left (RTL) easy with Sass.
* [katychuang/hakyll-cssgarden](https://github.com/katychuang/hakyll-cssgarden) - gallery of themes for hakyll static site generator
* [browneyedsoul/RemNote-CSS-Library](https://github.com/browneyedsoul/RemNote-CSS-Library) - A Curated List of RemNote CSS Snippets for Better Note-taking and Spaced Repetition
* [bjankord/CSS-Components-Modifiers-And-Subcomponents-Collection](https://github.com/bjankord/CSS-Components-Modifiers-And-Subcomponents-Collection) - A collection of common CSS module class names
* [zhangjikai/markdown-css](https://github.com/zhangjikai/markdown-css) - A markdown theme for Markdown Preview Plus Extension of Chrome
* [microsoft/project-html-website](https://github.com/microsoft/project-html-website) - Sample HTML+CSS+JS website
* [mgcrea/bootstrap-additions](https://github.com/mgcrea/bootstrap-additions) - CSS extension kit for Twitter Bootstrap 3.0+
* [alienresident/style-tiles](https://github.com/alienresident/style-tiles) - Create HTML and CSS Style Tiles with Sass & Compass
* [Trowel/Trowel](https://github.com/Trowel/Trowel) - ⚠️ DEPRECATED. Trowel is a Sass toolkit that allows you to create and use CSS frameworks with the most flexible pattern ever designed.
* [StylishThemes/Quora-Dark](https://github.com/StylishThemes/Quora-Dark) - :school: Dark Quora
* [polyanetuag/30DiasDeCSS](https://github.com/polyanetuag/30DiasDeCSS) - Mini projetos voltados para HTML E CSS
* [minoryorg/Noto-Sans-CJK-JP](https://github.com/minoryorg/Noto-Sans-CJK-JP) - サブセット化済みの「Noto Sans CJK JP」(日本語フォント)のCSS付きWebフォント
* [Isaac-Newt/userChrome-styles](https://github.com/Isaac-Newt/userChrome-styles) - A collection of userChrome.css styles for Firefox
* [codyhouse/dark-light-mode-switch](https://github.com/codyhouse/dark-light-mode-switch) - How to create a dark\light mode switch in CSS and Javascript
* [callmenick/CSS-Device-Mockups](https://github.com/callmenick/CSS-Device-Mockups) - Pure CSS device mockups.
* [ShaoZeMing/happy-birthday](https://github.com/ShaoZeMing/happy-birthday) - 基于H5和CSS制作的生日祝贺网页,兼容移动端自适应。demo http://love.4d4k.com/birthday/she
* [Roger-Melo/pokedex](https://github.com/Roger-Melo/pokedex) - Um boilerplate HTML + CSS para desenvolvermos uma pokedex com os 150 pokemons originais
* [olimsaidov/pixeden-stroke-7-icon](https://github.com/olimsaidov/pixeden-stroke-7-icon) - A series of iOS 7 inspired vector icons in a custom @font-face icon font that can be styled dynamically using CSS.
* [OfficeDev/Office-Add-in-UX-Design-Patterns-Code](https://github.com/OfficeDev/Office-Add-in-UX-Design-Patterns-Code) - [ARCHIVED] Implementations in HTML and CSS of the design patterns in the repo Office-Add-in-UX-Design-Patterns
* [MatrixAges/atom.css](https://github.com/MatrixAges/atom.css) - :kissing_closed_eyes: A atom-style library of CSS atomic elements. To build app faster and more flexible.
* [kokonior/CSS-Projects](https://github.com/kokonior/CSS-Projects) - Feel free to create new file, don't hesitate to pull your code, the most important thing is that the file name here must match your nickname so that file does not conflict with other people.
* [formaweb/formadmin](https://github.com/formaweb/formadmin) - Modern and responsive theme for Active Admin used by Formaweb.
* [f2ex/Frontend-Library](https://github.com/f2ex/Frontend-Library) - CSS, JavaScript 等前端开发资源
* [ElementUI/theme-default](https://github.com/ElementUI/theme-default) - Element default theme
* [codyhouse/ink-transition-effect](https://github.com/codyhouse/ink-transition-effect) - An ink bleed transition effect, powered by CSS animations.
* [you-dont-need/You-Dont-Need-JavaScript](https://github.com/you-dont-need/You-Dont-Need-JavaScript) - CSS is powerful, you can do a lot of things without JS.
* [30-seconds/30-seconds-of-css](https://github.com/30-seconds/30-seconds-of-css) - Short CSS code snippets for all your development needs
* [olton/Metro-UI-CSS](https://github.com/olton/Metro-UI-CSS) - Impressive component library for expressive web development! Build responsive projects on the web with the first front-end component library in Metro Style. And now there are even more opportunities every day!
* [ThemeParkTycoon/theme.park](https://github.com/ThemeParkTycoon/theme.park) - A collection of themes/skins for 50 selfhosted apps!
* [wilwaldon/flatstrap](https://github.com/wilwaldon/flatstrap) - Bootstrap without all the extra stuff
* [manilarome/blurredfox](https://github.com/manilarome/blurredfox) - A sleek, modern and elegant Firefox CSS theme
* [discord-modifications/dark-discord](https://github.com/discord-modifications/dark-discord) - An actual dark mode for discord.
* [oxalorg/sakura](https://github.com/oxalorg/sakura) - :cherry_blossom: a minimal css framework/theme.
* [GilbN/theme.park](https://github.com/GilbN/theme.park) - A collection of themes/skins for 50 selfhosted apps!
* [Spyware007/Animating-Buttons](https://github.com/Spyware007/Animating-Buttons) - Explore Amazing Buttons animation for your next project. 🤩An initiative by GDSC-DYPCOE for Hactoberfest. 🚀
* [shannonmoeller/reset-css](https://github.com/shannonmoeller/reset-css) - An unmodified* copy of Eric Meyer's CSS reset. PostCSS, webpack, Sass, and Less friendly.
* [imbhargav5/nextbase-nextjs13-supabase-starter](https://github.com/imbhargav5/nextbase-nextjs13-supabase-starter) - 🚀⚡️ Free Boilerplate and Starter kit for Next.js 13+, Supabase, Tailwind CSS 3.2 and TypeScript. 🚀 Next.js 🔥 Supabase 💻 TypeScript 💚 ESLint 🎨 Prettier 🐶 Husky 🧹 Lint-Staged 🧪 Jest 🧪 Testing Library 🕹️ Playwright ✍️ Commitizen 💬 Commitlint 💻 VSCode 🌪️ Vercel 🎨 PostCSS 🍃 Tailwind CSS ⚛️ React Query
* [astrit/css.gg](https://github.com/astrit/css.gg) - 700+ Pure CSS, SVG & Figma UI Icons Available in SVG Sprite, styled-components, NPM & API
* [Stanko/skyblue](https://github.com/Stanko/skyblue) - CSS framework (made with SASS)
* [jkymarsh/nuclide](https://github.com/jkymarsh/nuclide) - A CSS framework for utilizing the Atomic design pattern
* [whyt-byte/Blue-Topaz_Obsidian-css](https://github.com/whyt-byte/Blue-Topaz_Obsidian-css) - A blue theme for Obsidian.
* [backflip/gulp-iconfont-css](https://github.com/backflip/gulp-iconfont-css) - Create an SCSS file mapping the SVG files piped to gulp-iconfont to their codepoints
* [fontsource/fontsource](https://github.com/fontsource/fontsource) - Self-host Open Source fonts in neatly bundled NPM packages.
* [ui-buttons/core](https://github.com/ui-buttons/core) - 100 Modern CSS Buttons. Every style that you can imagine.
* [leemunroe/grunt-email-workflow](https://github.com/leemunroe/grunt-email-workflow) - A Grunt workflow for designing and testing responsive HTML email templates with SCSS.
* [johno/furtive](https://github.com/johno/furtive) - A forward-thinking, lightweight, css microframework
* [DaniloLima122/interfaces-clone](https://github.com/DaniloLima122/interfaces-clone) - Repositório com clones de interfaces para praticar CSS
* [Math-Vieira/Portfolio](https://github.com/Math-Vieira/Portfolio) - Meu portfólio, feito apenas com html, css e js.
* [WilliamStaudenmeier/Kodama](https://github.com/WilliamStaudenmeier/Kodama) - Simple CSS and JS animation of the Japanese tree-spirit: https://codepen.io/WilliamStaudenmeier
* [CodyHouse/codyhouse-framework](https://github.com/CodyHouse/codyhouse-framework) - A lightweight front-end framework for building accessible, bespoke interfaces.
* [jeffreyvr/tailpress](https://github.com/jeffreyvr/tailpress) - TailPress is a minimal boilerplate theme for WordPress using Tailwind CSS.
* [ecomfe/est](https://github.com/ecomfe/est) - EFE Styling Toolkit based on Less
* [CodyHouse/virgo-template](https://github.com/CodyHouse/virgo-template) - Virgo is a free HTML, CSS, JS template built using the CodyHouse Components and Framework.
* [CodyHouse/content-filter](https://github.com/CodyHouse/content-filter) - A slide-in filter panel powered by CSS and jQuery.
* [CodyHouse/ink-transition-effect](https://github.com/CodyHouse/ink-transition-effect) - An ink bleed transition effect, powered by CSS animations.
* [CodyHouse/dark-light-mode-switch](https://github.com/CodyHouse/dark-light-mode-switch) - How to create a dark\light mode switch in CSS and Javascript
* [ciaoca/ZenCalendar](https://github.com/ciaoca/ZenCalendar) - 使用 CSS 样式设计,制作丰富的主题日历。
* [songsiqi/postcss-adaptive](https://github.com/songsiqi/postcss-adaptive) - A postcss plugin that calculates and generates adaptive css code, such as `rem` and `0.5px borders for retina devices`
* [qlik-oss/leonardo-ui](https://github.com/qlik-oss/leonardo-ui) - Web UI component library with the Qlik Sense look and feel.
* [namndwebdev/html-css-js-thuc-chien](https://github.com/namndwebdev/html-css-js-thuc-chien) - Tổng hợp 30 dự án thực chiến cùng HTML, CSS và Javacsript
* [mathexl/chemistry-css](https://github.com/mathexl/chemistry-css) - A chemistry CSS library for creating Chemical Structures and Equations with just HTML.
* [jharding/typeahead.js-bootstrap.css](https://github.com/jharding/typeahead.js-bootstrap.css) - DEPRECATED
* [beengx/Frontend-Library](https://github.com/beengx/Frontend-Library) - CSS, JavaScript 等前端开发资源
* [sakamies/Lion-CSS-UI-Kit](https://github.com/sakamies/Lion-CSS-UI-Kit) - For web designers wanting to mock up Mac apps in the browser.
* [Kilerd/Cat](https://github.com/Kilerd/Cat) - a slight blog theme.
* [JR93/css3-minions](https://github.com/JR93/css3-minions) - 纯CSS3画出小黄人并实现动画效果
* [duoshuo/duoshuo-embed.css](https://github.com/duoshuo/duoshuo-embed.css) - 多说评论框 CSS 样式源代码
* [CodyHouse/animated-transition-effects](https://github.com/CodyHouse/animated-transition-effects) - A library of animated transition effects, powered by CSS Animations
* [pattle/Flags-in-CSS](https://github.com/pattle/Flags-in-CSS) - Countries flags in pure CSS
* [jasonkarns/css-reset](https://github.com/jasonkarns/css-reset) - Customization of Eric Meyer's CSS Reset
* [AgnosticUI/agnosticui](https://github.com/AgnosticUI/agnosticui) - AgnosticUI is a set of UI primitives that start their lives in clean HTML and CSS. These standards compliant components are then copied to our framework implementations in: React, Vue 3, Angular, and Svelte.
* [Godiesc/opera-gx](https://github.com/Godiesc/opera-gx) - Firefox Theme CSS to Opera GX Lovers
* [zaydek/heroicons.dev](https://github.com/zaydek/heroicons.dev) - Heroicons web viewer, Next.js and Tailwind CSS. 🕶
* [resetercss/reseter.css](https://github.com/resetercss/reseter.css) - Reseter.css - A Futuristic Alternative To Normalize.css And CSS Resets
* [jorge8168711/Checkbox.css](https://github.com/jorge8168711/Checkbox.css) - Conjunto de checkoxes creados con únicamente CSS
* [tylergaw/css-true-titles](https://github.com/tylergaw/css-true-titles) - CSS Title Sequence in the style of True Detective
* [pat-s/xaringan-metropolis](https://github.com/pat-s/xaringan-metropolis) - Metropolis theme of R package xaringan
* [oleq/syncope](https://github.com/oleq/syncope) - A vertical rhythm tool for developers and designers.
* [ProLoser/Flexbox.less](https://github.com/ProLoser/Flexbox.less) - DEPRECATED (use Autoprefixer)! Use Flexbox CSS Today! LESS mixins to maximize browser compatibility!
* [lduo/resume](https://github.com/lduo/resume) - open source resume(html+js+css)
* [krasimir/organic-css](https://github.com/krasimir/organic-css) - Micro CSS framework based on Organic concept
* [raulghm/Font-Awesome-Stylus](https://github.com/raulghm/Font-Awesome-Stylus) - Stylus port for font-awesome 4.7.0
* [lord/flexblocks](https://github.com/lord/flexblocks) - A CSS layout library
* [ptgamr/google-image-layout](https://github.com/ptgamr/google-image-layout) - A library help you to build Google like Image Gallery
* [plapier/css3-flashes](https://github.com/plapier/css3-flashes) - CSS3 Flashes for Rails apps
* [larsenwork/CSS-Responsive-Grid-Overlay](https://github.com/larsenwork/CSS-Responsive-Grid-Overlay) - Easily adjustable grid overlay to make development discussions easier
* [jmharris903/Railscast-for-Roam-Research-Theme](https://github.com/jmharris903/Railscast-for-Roam-Research-Theme) - A dark CSS theme for Roam Research
* [fregante/webext-base-css](https://github.com/fregante/webext-base-css) - Extremely minimal stylesheet/setup for Web Extensions’ options pages (also dark mode)
* [dwarcher/reboundgen](https://github.com/dwarcher/reboundgen) - Generates keyframe animations using Rebound.js by Facebook - a spring system simulator. Similar to Animate.css
* [yui540/ChocolateCake](https://github.com/yui540/ChocolateCake) - CSSアニメーション作品一覧サイト
* [titangene/hackmd-dark-theme](https://github.com/titangene/hackmd-dark-theme) - Dark theme for HackMD
* [pixeldevsio/tailpress](https://github.com/pixeldevsio/tailpress) - A Tailwind CSS enabled Underscores theme
* [mirisuzanne/compass-css-lightbox](https://github.com/mirisuzanne/compass-css-lightbox) - a css-only lightbox implementation for compass
* [jfet97/strawberry](https://github.com/jfet97/strawberry) - A new flexbox based CSS micro-framework.
* [hangyangws/baseCss](https://github.com/hangyangws/baseCss) - CSS基类,减少浏览器差异,常用CSS类名
* [daniruiz/flat-remix-css](https://github.com/daniruiz/flat-remix-css) - A lightweight CSS library that provides a set of predesigned elements useful for rapid web development. It follows a modern flat design using a colorful palette with some shadows, highlights, and gradients for some depth.
* [clementoriol/MetroDNA](https://github.com/clementoriol/MetroDNA) - MetroDNA est une librairie de symboles de Transports en Commun Parisiens (RATP - SNCF) faciles à intégrer à vos sites. Metro, RER, Tram, Transilien. Versions CSS ou SASS Disponibles.
* [Cldfire/ayu-rs](https://github.com/Cldfire/ayu-rs) - CSS for Rustlang websites based on the ST3 theme Ayu
* [atusy/minidown](https://github.com/atusy/minidown) - Create simple yet powerful html documents with light weight CSS frameworks.
* [zwbetz-gh/papercss-hugo-theme](https://github.com/zwbetz-gh/papercss-hugo-theme) - A Hugo theme made with PaperCSS, the less formal CSS framework.
* [mynameisraj/css-elements](https://github.com/mynameisraj/css-elements) - CSS3 interface elements.
* [code-fx/Pure-CSS3-Animated-Border](https://github.com/code-fx/Pure-CSS3-Animated-Border) - Pure CSS3 animated border for all html element.
* [x-team/starting-css-modules](https://github.com/x-team/starting-css-modules) - A very simple example of css-modules
* [vitorlans/w3-css](https://github.com/vitorlans/w3-css) - W3.CSS is a modern CSS framework with built-in responsiveness:
* [RoseTheFlower/newsteamchat](https://github.com/RoseTheFlower/newsteamchat) - Metro skin for Steam chat and friends UI.
* [Mitsu325/CSS_Challenge](https://github.com/Mitsu325/CSS_Challenge) - 30 Days CSS Challenge
* [aocattleya/Ramen-Timer](https://github.com/aocattleya/Ramen-Timer) - ⏰ Countdown timer(3min or 5min)/ Vue.js + PWA + CSS animation + Character Design
* [shadeed/grid-to-flex](https://github.com/shadeed/grid-to-flex) - Easily create Flexbox fallback for your CSS Grid!
* [istarkov/html-hint](https://github.com/istarkov/html-hint) - css hint (tooltip) based on hint.css with html content support
* [intuxicated/css-persian](https://github.com/intuxicated/css-persian) - Persian CSS Fonts
* [inkasadev/genius-starter-files](https://github.com/inkasadev/genius-starter-files) - Nesse repositório você encontra os starter files de um projeto de um jogo Genius completo, construído com HTML, CSS e Javascript.
* [iamstarkov/css-initials](https://github.com/iamstarkov/css-initials) - initial CSS values to use in `all: initial` polyfils
* [firminoweb/csshorus](https://github.com/firminoweb/csshorus) - CSSHórus is a library for easy and fast development of responsive and mobile websites. It contains 12 grid columns and basic style formats (Reset, Print, Grid, Misc styles) and now with 'Skins' stylizing (Typography, Lists, Links, Table, Form, Buttons) for your web project, also with RTL and LESS CSS. See my other projects -->
* [EmishaCommunity/Demo-Portfolio-Website](https://github.com/EmishaCommunity/Demo-Portfolio-Website) - A very simple portfolio website where you can find explanation to every line of code.
* [Aaronliu2016/css-tricks](https://github.com/Aaronliu2016/css-tricks) - CSS tricks example for everyday.
* [rajasegar/css-toggle-component](https://github.com/rajasegar/css-toggle-component) - Pure CSS Toggle Buttons as a Web component
* [insipx/material-bliss-jekyll-theme](https://github.com/insipx/material-bliss-jekyll-theme) - A Material Theme for Jekyll created with React, Redux, and React-Router transpiled with Webpack
* [goatslacker/lotus.css](https://github.com/goatslacker/lotus.css) - A minimalist's typography focused and responsive framework for the web
* [FormstoneClassic/Gridlock](https://github.com/FormstoneClassic/Gridlock) - A responsive CSS grid system.
* [fedora-infra/tahrir](https://github.com/fedora-infra/tahrir) - Pyramid app for issuing your own Open Badges
* [efrolic/css](https://github.com/efrolic/css) - eFrolic | CSS framework which without using JavaScript is interactive and animated.
* [corgrath/osbcp-css-parser](https://github.com/corgrath/osbcp-css-parser) - CSS Parser in Java - !! This project is abandoned - Sorry :( - but maybe there is an active fork where the development can continue !!!
* [cbfranca/vertical-responsive-menu](https://github.com/cbfranca/vertical-responsive-menu) - A mobile first vertical responsive menu using HTML, CSS & JS
* [bbucior/drposter](https://github.com/bbucior/drposter) - Generate Academic Posters in R Markdown and CSS, inspired by 'reveal.js'
* [afonsopacifer/da-vinci-css](https://github.com/afonsopacifer/da-vinci-css) - :art: Creating shapes and drawings with CSS.
* [leandrorangel94/30diasDeCSS](https://github.com/leandrorangel94/30diasDeCSS) - Desafio 30 dias de CSS, realizado com intuito de praticar com projetos pequenos.
* [domainzero/bookstack-dark-theme](https://github.com/domainzero/bookstack-dark-theme) - A dark theme for Bookstack using the dracula color scheme
* [callmenick/responsive-tabs](https://github.com/callmenick/responsive-tabs) - Responsive tab layout with JavaScript and CSS.
* [rachelandrew/css-books](https://github.com/rachelandrew/css-books) - Example files for building CSS books
* [not-holar/my_firefox_theme](https://github.com/not-holar/my_firefox_theme) - A theme that aims to look nice and clean while not compromising functionality.
* [lmgonzalves/splash-transition](https://github.com/lmgonzalves/splash-transition) - Creating an eye catching animation, just using SVG paths and CSS transitions.
* [janhuenermann/social-circles](https://github.com/janhuenermann/social-circles) - Well designed social media buttons.
* [Ideaviate/html5-css3-js-calculator](https://github.com/Ideaviate/html5-css3-js-calculator) - A calculator made with HTML5, CSS3 and JavaScript
* [essentialenemy/noir](https://github.com/essentialenemy/noir) - Noir is a modern, responsive and customizable theme for Jekyll with dark mode support.
* [diedummydie/Safari-Theme-for-Firefox](https://github.com/diedummydie/Safari-Theme-for-Firefox) - Make Firefox look more native on macOS. Light Mode / Dark Mode.
* [yashilanka/Modern-Web-Boilerplate](https://github.com/yashilanka/Modern-Web-Boilerplate) - All-in-one Complete Modern Front-end Development Boilerplate for Starters
* [myfirebug/ui](https://github.com/myfirebug/ui) - 移动端基于jquery,zepto的UI组件库,目前实现 JS Components:Toast、Action、Tips、Dialog、Swiper、CityPicker、DatetimePicker、Tab、Range Css Component:oneborder、Loading、button From Component:switch、Radio、Checkbox Plug Components:Turntable、Lottery
* [matuzo/a11y-tests.css](https://github.com/matuzo/a11y-tests.css) - A CSS file for accessibility testing.
* [markdurrant/noisy-uris](https://github.com/markdurrant/noisy-uris) - Ready-made noise images as data URIs. Available in Sass, LESS, and vanilla CSS flavours.
* [dvlden/differs](https://github.com/dvlden/differs) - WIP: Building CSS framework using Sass...
* [WeBeginners-Community/CSS.Effects-Designs](https://github.com/WeBeginners-Community/CSS.Effects-Designs) - This repository only accepting CSS/LASS/SAAS projects.Check the support link also star my repository ⭐
* [picturepan2/markdown.css](https://github.com/picturepan2/markdown.css) - An elegant stylesheet for rendered Markdown contents
* [KiaanCastillo/Pure-CSS-Multilayer-Parallax](https://github.com/KiaanCastillo/Pure-CSS-Multilayer-Parallax) - Source code for a pure CSS multilayer parallax effect!
* [juliancwirko/s-grid](https://github.com/juliancwirko/s-grid) - Flexbox grid system for Stylus
* [joergrech/KickstartWithBootstrap](https://github.com/joergrech/KickstartWithBootstrap) - Kickstart is an extension for Grails in order to start your project with a good looking frontend. It is intended to be used in rapid application scenarios such as a Startup Weekend or a prototyping session with a customer. This plugin provides adapted scaffolding templates for standard CRUD pages using Twitter's CSS Framework Bootstrap and offers some basic pages for a web site.
* [jbranchaud/captionss](https://github.com/jbranchaud/captionss) - Sensible CSS Image Captions
* [JasonD94/jasond94.github.io](https://github.com/JasonD94/jasond94.github.io) - Personal website:
* [sukazavr/css-grid-layout-generator](https://github.com/sukazavr/css-grid-layout-generator) - The Quickest & Easiest Way To Build Complex CSS Grid Layouts
* [marcobrunodev/pare-de-chutar-e-aprenda-as-propriedades-CSS-de-alinhamento](https://github.com/marcobrunodev/pare-de-chutar-e-aprenda-as-propriedades-CSS-de-alinhamento) - Mostrando como funciona as propriedades CSS de posicionamento
* [laoshu133/grunt-css-sprite](https://github.com/laoshu133/grunt-css-sprite) - A grunt plugin to help front engineer creating css sprite.
* [BlessCSS/grunt-bless](https://github.com/BlessCSS/grunt-bless) - Split CSS files suitable for IE
* [matejlatin/Gutenberg](https://github.com/matejlatin/Gutenberg) - A meaningful web typography starter kit.
* [hankchizljaw/modern-css-reset](https://github.com/hankchizljaw/modern-css-reset) - A bare-bones CSS reset for modern web development.
* [hankchizljaw/boilerform](https://github.com/hankchizljaw/boilerform) - Boilerform is a little HTML and CSS boilerplate to take the pain away from working with forms.
* [mmahandev/FocusOverlay](https://github.com/mmahandev/FocusOverlay) - Library for creating animated overlays on focused elements
* [doublesecretagency/craft-cpcss](https://github.com/doublesecretagency/craft-cpcss) - Control Panel CSS plugin for Craft CMS
* [atomicpages/skeleton-sass](https://github.com/atomicpages/skeleton-sass) - Skeleton Sass is a highly modular version of Skeleton CSS
* [IanLunn/Hover](https://github.com/IanLunn/Hover) - A collection of CSS3 powered hover effects to be applied to links, buttons, logos, SVG, featured images and so on. Easily apply to your own elements, modify or just use for inspiration. Available in CSS, Sass, and LESS.
* [Semantic-Org/Semantic-UI-CSS](https://github.com/Semantic-Org/Semantic-UI-CSS) - CSS Only distribution
* [aminomancer/uc.css.js](https://github.com/aminomancer/uc.css.js) - A dark indigo CSS theme for Firefox and a large collection of privileged scripts to add new buttons, menus, and behaviors and eliminate nuisances. The theme is similar to other userChrome stylesheets, but it's intended for use with an autoconfig loader like fx-autoconfig, since it uses JavaScript and Firefox's component registrar to implement its more functional features.
* [good-father/vue-transition.css](https://github.com/good-father/vue-transition.css) - vue-transition animation | sh20raj |
1,867,538 | 70-Day Study Plan for Python PCEP Certification Exam Preparation | Aiming for the PCEP Certification requires a strategic and focused preparation plan to ensure... | 0 | 2024-05-28T11:17:34 | https://dev.to/myexamcloud/70-day-study-plan-for-python-pcep-certification-exam-preparation-n80 | python, programming, coding, software | Aiming for the PCEP Certification requires a strategic and focused preparation plan to ensure success. As the syllabus is vast and programming skills are a key factor, daily practice and a well-structured study plan are vital. This article provides a comprehensive guide for the PCEP-30-02 examination preparation, including a daily schedule and a 70-day study plan.
**Daily Schedule for PCEP Certification Preparation**
The PCEP Certification covers a wide range of topics, with a strong emphasis on Python 3.x skills. Therefore, consistent and dedicated daily practice is essential to ace the exam. The daily schedule may vary based on individual learning pace, but here is a basic routine for PCEP exam aspirants to follow:
**Morning (2-3 hours):** Focus on new topics or review weaker areas.
**Afternoon (2-3 hours):** Practice questions and take sectional tests.
**Evening (1-2 hours):** Work on coding challenges, analyze mock tests, and read explanations.
**70-Day Study Plan for Python PCEP Certification Exam**
In the remaining 70 days before the PCEP-30-02 exam, Python professionals need to cover all the exam objectives and gain a strong understanding of each topic. It is crucial to pay equal attention to all sections of the exam. The study plan can be divided into four phases, as outlined below:
**Phase 1: Building a Strong Foundation and Gathering Study Resources (Week 1-2)**
For beginners, the first phase is crucial as it sets the foundation for the rest of the preparation. Start by familiarizing yourself with the PCEP-30-02 syllabus and exam pattern:
Number of Questions: 30
Format: Single- and multiple-select questions, drag & drop, gap fill, sort, code fill, code insertion | Python 3.x
Passing Score: 70%
Next, brush up on the basics of Python, such as syntax, structure, literals & variables, operators, and data types. Practice using built-in functions like print() and input(), as well as string formatting using sep= and end= keywords. Additionally, focus on control flow implementations such as if/else statements, for loops, and the range() function.
**Phase 2: In-Depth Focus on Each Topic (Week 3-6)**
With a strong foundation in place, it is now time to delve deeper into each topic of the PCEP-30-02 syllabus. This phase requires the most attention, as it serves as the base for the next phases. It is crucial to use high-quality study materials such as OpenEDG tutorials and MyExamCloud AI to cover all the language changes and exam objectives. Taking notes and maintaining a separate notebook for important concepts, such as forward and reverse indexing in lists, can also be helpful.
**Phase 3: Revision and Practice Questions (Week 7-9)**
Regular revision and practice are key to enhancing preparation for the PCEP-30-02 exam. In this phase, focus on solving practice questions and review concepts at regular intervals. It is recommended to take objective-wise tests to identify and improve weaker areas.
**Phase 4: Attempt Mock Tests and Analyze Them (Week 10)**
In the final weeks leading up to the exam, it is essential to attempt mock tests and analyze them thoroughly. This phase allows candidates to evaluate their exam readiness and identify any gaps in their preparation. MyExamCloud offers a variety of mock tests, including objective and random tests, to help candidates simulate the real exam experience.
**What is [PCEP Practice Tests](https://www.myexamcloud.com/onlineexam/pcep-30-02-practice-tests.course) MyExamCloud Study Plan?**
MyExamCloud offers a comprehensive PCEP study plan that includes:
- PCEP Practice Tests
- PCEP-30-02 Mock Questions
- 22 Full-Length Mock Exams
- 1 Free Trial Exam
- Objective and Random Tests
- Answers with brief explanations in eBook format
- Access to course content through a mobile app or web browser
- Over 660 questions grouped by exam topics
- Plan, practice, achieve dashboard to set goals and track progress
Start your PCEP Certification preparation journey now with MyExamCloud and increase your chances of success on the PCEP-30-02 exam. Don't wait any longer and start your preparation today! | myexamcloud |
1,867,537 | Can a Face Recognition System Detect a Psychopath? | What is facial recognition? Facial recognition is a biometric technology designed to identify or... | 0 | 2024-05-28T11:16:22 | https://dev.to/luxandcloud/can-a-face-recognition-system-detect-a-psychopath-3dpp | **What is facial recognition?** Facial recognition is a biometric technology designed to identify or verify individuals based on their unique facial characteristics. Technically, it works by analyzing and comparing patterns of facial features extracted from images or video frames. These patterns include measurements between key facial landmarks such as the eyes, nose, and mouth, as well as the overall shape and contours of the face.
Simply put, facial recognition mimics the human ability to recognize faces in a crowd, for example. Using algorithms, this technology examines and identifies specific features unique to each person, providing computers with the capability to "see" and recognize faces with the speed and precision of machine learning.
Facial recognition has a wide range of applications and the most popular use case is lock screen technology for smartphones. A glance at your phone can unlock it instantly, eliminating the need to enter a passcode or remember a pattern. Setting up facial recognition on a smartphone involves teaching the device to recognize your face. The phone camera captures a series of images during registration, collecting different viewpoints and expressions to create a digital blueprint of your facial features.
When you attempt to unlock your phone, the front-facing camera activates and scans your face, noting critical features such as the distance between your eyes, the shape of your nose, and the angles of your jaw. It compares these features with the stored blueprint. If there is a match within a tiny margin of error, the phone unlocks instantly.
Thus, whether unlocking a smartphone or identifying individuals in surveillance footage, facial recognition technology relies on analyzing and matching unique facial features against stored data.
Can a Face Recognition Software Detect a Psychopath? Learn more here: [Can a Face Recognition Software Detect a Psychopath?](https://luxand.cloud/face-recognition-blog/can-a-face-recognition-system-detect-a-psychopath/?utm_source=devto&utm_medium=can-a-face-recognition-system-detect-a-psychopath) | luxandcloud | |
1,867,536 | EDI vs. API: Choosing the Right Integration Approach for Your Business | Introduction: The Crossroads of Digital Integration In the digital landscape of business... | 0 | 2024-05-28T11:16:13 | https://dev.to/actionedi/edi-vs-api-choosing-the-right-integration-approach-for-your-business-28bj | **Introduction: The Crossroads of Digital Integration**
In the digital landscape of business communication, two paths diverge – EDI (Electronic Data Interchange) and API (Application Programming Interface). Each path offers its unique journey for suppliers and trading partners, with its set of strengths and challenges. As businesses stand at this crossroads, the decision on which path to take can be pivotal. This article delves into the nuances of EDI and API, comparing and contrasting these technologies to aid businesses in making an informed choice based on their specific needs.
**EDI: The Stalwart of Standardized Communication**
EDI has been the backbone of business-to-business communication for decades. It allows for the standardized exchange of business documents like purchase orders and invoices between partners.
**Strengths:**
Standardization: EDI follows strict standards, ensuring consistent and error-free communication.
Security: Being a mature technology, EDI offers robust security protocols, crucial for sensitive data.
Batch Processing: EDI is efficient in handling large volumes of transactions, making it ideal for businesses with high transaction volumes.
**Weaknesses:**
Flexibility: Due to its standardized nature, EDI can be less flexible in accommodating unique business needs.
Implementation Time: Setting up an EDI system can be time-intensive and complex.
API: The Agile Connector of Modern Systems
APIs have become increasingly popular for enabling real-time data exchange and integration between different software applications.
**Strengths:**
Real-Time Data Exchange: APIs facilitate immediate data transfer, providing up-to-date information.
Flexibility: They offer more flexibility in integration and can be tailored to specific business requirements.
Ease of Integration: APIs can be easier to implement and integrate with existing systems, especially for web-based applications.
**Weaknesses:**
Standards: Unlike EDI, APIs may lack standardized formats, leading to potential inconsistencies.
Security: While APIs have robust security, managing security across multiple APIs can be challenging.
EDI and API: Complementary Technologies
In practice, EDI and API are not mutually exclusive and can be complementary. For instance, a business might use EDI for traditional B2B transactions and APIs for real-time data sharing and integration with modern applications.
Discover the ideal integration approach for your business with ActionEDI. Sign up for a free demo at www.actionedi.com and explore how our solutions can cater to your specific integration needs. Are you ready to take the first step toward the right digital integration path for your business?
| actionedi | |
1,867,535 | Link Alternatif Flyingslot Situs Resmi Anti Rungkad: Akses Aman dan Lancar Kapan Saja! | Pernahkah Anda mengalami kesulitan mengakses FlyingSlot, situs judi slot online terpercaya favorit... | 0 | 2024-05-28T11:15:55 | https://dev.to/flyingslot/link-alternatif-flyingslot-situs-resmi-anti-rungkad-akses-aman-dan-lancar-kapan-saja-1565 | flyingslot, flyingslotlogin, flyingslotdaftar, linkalternatifflyingslot | Pernahkah Anda mengalami kesulitan mengakses FlyingSlot, situs judi slot online terpercaya favorit Anda?
Jaringan error? Situs diblokir?``
Jangan khawatir! Kami hadir dengan solusi tepat: Link Alternatif Flyingslot Situs Resmi Anti Rungkad!
## Apa itu Link Alternatif Flyingslot?
**
Link Alternatif Flyingslot adalah tautan alternatif resmi yang disediakan oleh FlyingSlot untuk memastikan akses yang aman dan lancar bagi para membernya.
## Mengapa Menggunakan Link Alternatif Flyingslot?
Mengatasi Gangguan Jaringan: Link alternatif memungkinkan Anda untuk mengakses FlyingSlot meskipun jaringan internet Anda tidak stabil atau situs diblokir oleh ISP Anda.
Keamanan Terjamin: Link alternatif resmi dari FlyingSlot terjamin keamanannya dan bebas dari malware atau virus.
Akses Lancar Kapan Saja: Nikmati akses tanpa batas ke FlyingSlot kapanpun dan dimanapun Anda berada.
Dapatkan Link Alternatif Flyingslot Sekarang!
[https://flyingceria.com](https://flyingceria.com/)

### Simpan Link Alternatif Ini di Perangkat Anda!
Simpan link alternatif di browser Anda, bookmark, atau catatan di ponsel Anda untuk akses mudah dan cepat ke FlyingSlot kapanpun Anda membutuhkannya.
Nikmati Sensasi Bermain Slot Online yang Tak Terlupakan Bersama FlyingSlot!
Daftar sekarang dan dapatkan bonus new member 100%!
### FlyingSlot - Situs Judi Slot Online Terpercaya & Gampang Menang!
#FlyingSlot #SitusGacor #JudiSlotOnline #GampangMenang #BonusMelimpah #JackpotFantastis #DaftarSekarang #BonusNewMember #LinkAlternatif #AntiRungkad
<div class="Daftar">
<a href="https://rebrand.ly/flyingslotpro">
<img src="https://iili.io/JjczvX2.gif"/>
</a>
</div> | flyingslot |
1,867,534 | Facial Recognition for Security and Video Surveillance | Imagine a busy airport terminal, where thousands of travelers pass through every day, each with their... | 0 | 2024-05-28T11:14:57 | https://dev.to/luxandcloud/facial-recognition-for-security-and-video-surveillance-1ec8 | news, ai, security | Imagine a busy airport terminal, where thousands of travelers pass through every day, each with their own unique story and purpose. In this dynamic environment, security is of paramount importance. Here is where facial recognition technology steps into the spotlight.
Consider a scenario where an individual of interest is flagged by law enforcement agencies for suspicious activity. It could be difficult to track this person in the crowds using conventional surveillance techniques. However, with facial recognition technology, the process becomes remarkably streamlined.
As the individual enters the airport terminal, cameras placed in strategic locations capture their facial image in real-time. The facial recognition system immediately analyzes the key facial features and compares them against a database of known persons of interest. Within seconds, a match is found, and an alert is sent to security personnel.
Indeed, facial recognition technology has revolutionized the field of security and video surveillance by providing unmatched precision in person identification. In this blog post, we will explore the fundamentals of facial recognition, its benefits for security applications, its working mechanism, and highlight Luxand.cloud facial recognition access control system as a powerful tool.
Learn more here: [Facial Recognition for Security and Video Surveillance](https://luxand.cloud/face-recognition-blog/facial-recognition-for-security-and-video-surveillance/?utm_source=devto&utm_medium=facial-recognition-for-security-and-video-surveillance) | luxandcloud |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.