
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,853,826 | Introduction to Essential Commands in Ubuntu Linux | uname The uname command provides information about the system, such as the kernel name,... | 0 | 2024-05-27T01:21:24 | https://dev.to/pra_jwal001/introduction-to-essential-commands-in-ubuntu-linux-4cg1 | ubuntu, linux |
<u>**uname** </u>
_The uname command provides information about the system, such as the kernel name, version._
---
**<u>uptime</u>**
_The uptime command shows how long the system has been running, the current time, the number of users logged on, and the system load averages._

---
**<u>who</u>**
_The who command displays a list of users currently logged into the system._

---
**<u>whoami</u>**
_The whoami command prints the username of the current user._

---
**<u>which</u>**
_The which command locates the executable file associated with a given command by searching the directories listed in the PATH environment variable._

---
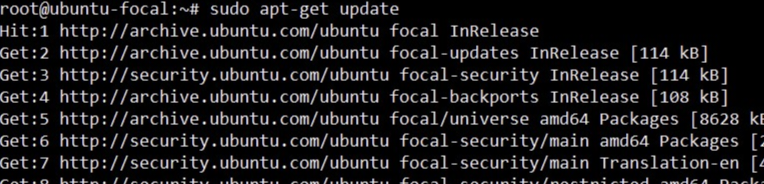
**<u>sudo apt-get update</u>**
_The sudo apt-get update command is used to update the local package index. This package index contains information about the available packages from the repositories configured on the system._
---
_**User management in ubuntu linux**_
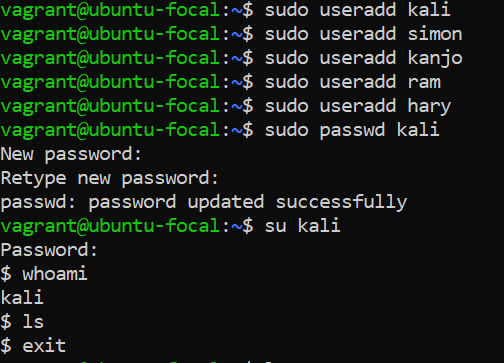
**<u>useradd</u>**
_The useradd command in Ubuntu is used to easily create a new user account,can provide password(recommend)_
---
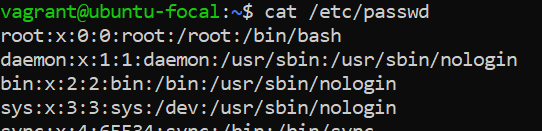
**<u>cat /etc/passwd</u>**
_The /etc/passwd file lists each user's username, UID, GID, home directory, and shell. It is essential for user account management._
---
**<u>groupadd</u> and <u>groupdel</u>**
_**groupadd** command is used to create a new group on a Linux system._
_**groupdel** This command is used to delete an existing group from a Linux system._
<u>**cat /etc/group**</u>
_the **cat /etc/group** command is used to display the contents of the /etc/group file. This file contains information about all the groups on the system._

---
<u>**add user to group**</u>
_These commands use "usermod" to add existing users ("kali", "simon", and "ram") to the "learning" group on the system._
---
**<u>zipping directory</u>**
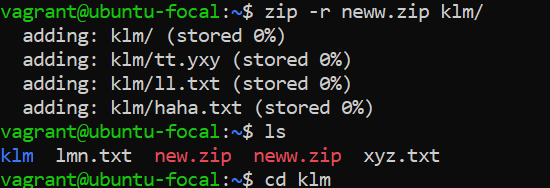
_the command **zip -r neww.zip klm/** creates a zip file named **neww.zip** containing all the files and directories within the **klm/** directory. Then, **ls** lists the files in the current directory, including **neww.zip**, indicating that the zip file was created successfully._
---
**<u>unzipping directory</u>**
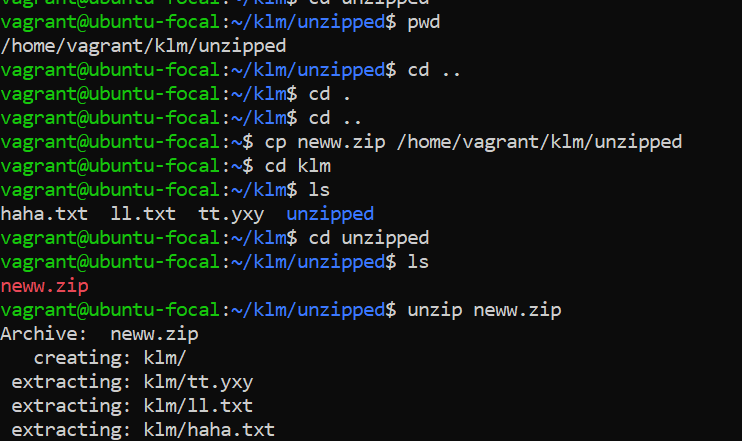
_copied a zip file named **neww.zip** from your home directory to a folder called unzipped within **/home/vagrant/klm/**. Then, you unzipped it, which contained a directory **klm/**along with its contents (tt.yxy, 11.txt, and haha.txt).( Tried to copy from Source to destination path and unzipped directory structure containing files_
**<u>file permission commands</u>**
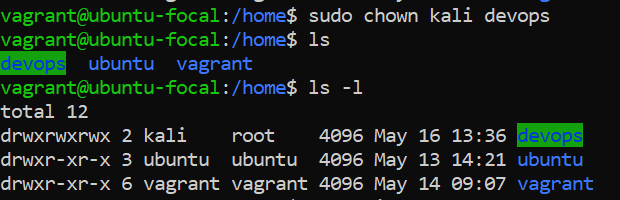
_changed the ownership of the directory "devops" to user "kali" using the **sudo chown** command_
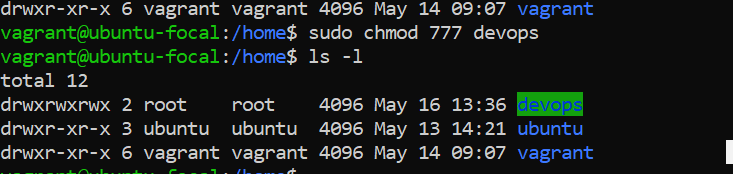
_changed the permissions of the "devops" directory to allow read, write, and execute access for all users._
---
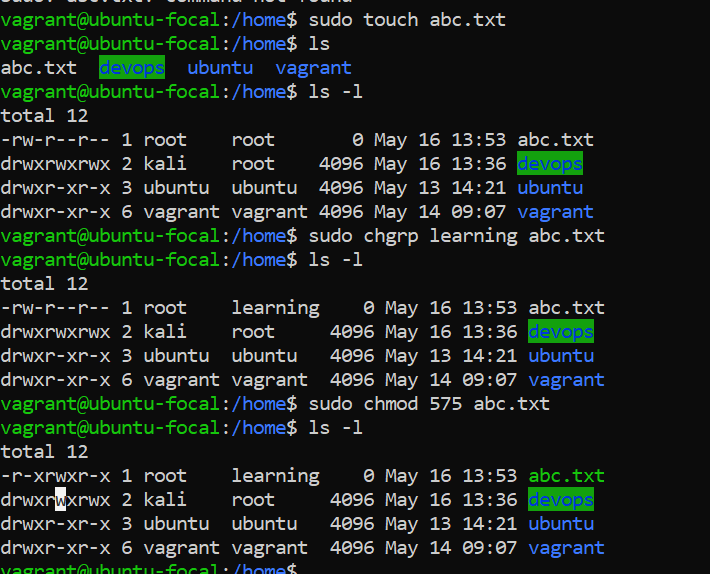
_created a file named "**abc.txt**" using **sudo touch abc.txt,** then listed the contents of the directory. After that,displayed the permissions of each entry using ls -1, which showed the "**abc.txt**" file along with the directories and their permissions.changed the group ownership of "**abc.txt**" to "**learning**" using **sudo chgrp learning abc.txt**, and then modified the permissions of "**abc.txt**" to 575 using sudo **chmod 575 abc.txt**.The final listing (ls -1) reflects these changes, showing the updated permissions for "**abc.txt**" and the directories._
---
**<u>Learn more about file permission</u>**
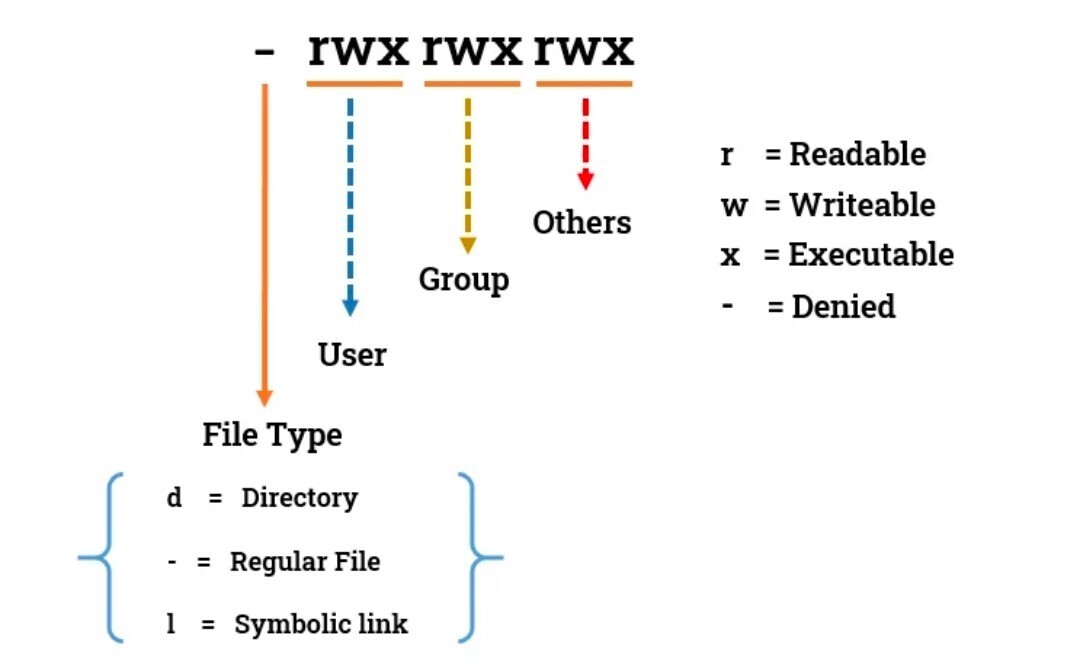

**an alternative way to change the permissions of a file in Linux to give read, write, and execute permissions to the user, group, and others.**
_<u>chmod a+rwx demo.sh </u>would give read, write, and execute permissions to all users (user, group, and others) on the file named <u>demo.sh_</u>
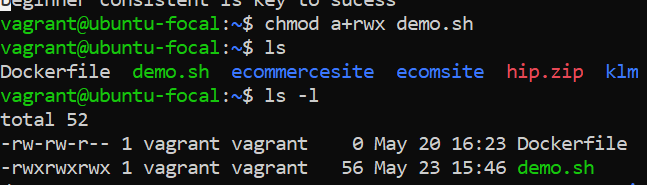
---
_here g-wx remove the write and execute permission for group on demo.sh_

---
_here o-wx remove the write and execute permission for others on demo.sh_

| pra_jwal001 |
1,866,008 | Setting Up Secure Cloud Storage: Restricted Access, Partner Sharing, Website Backup, and Lifecycle Management | Create a storage account and configure high availability. In Azure Portal, search for "storage... | 0 | 2024-05-27T01:16:16 | https://dev.to/opsyog/how-to-provide-private-storage-for-internal-company-documents-4077 | azurefunctions, azure, access, storage | **Create a storage account and configure high availability.**
**In Azure Portal, search for "storage account"**
**Select "Storage account"**
**Select "Create"**
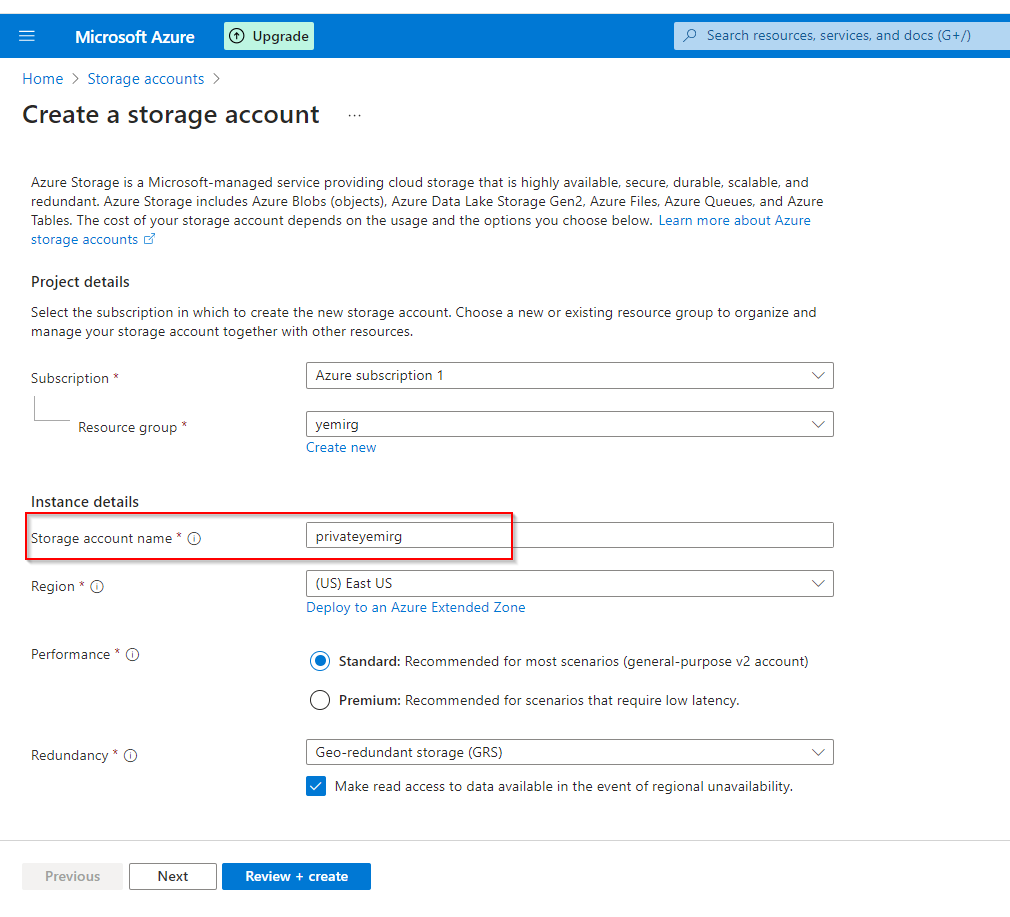
**Insert Resource Group previously created name
**
**Insert Storage account name
**
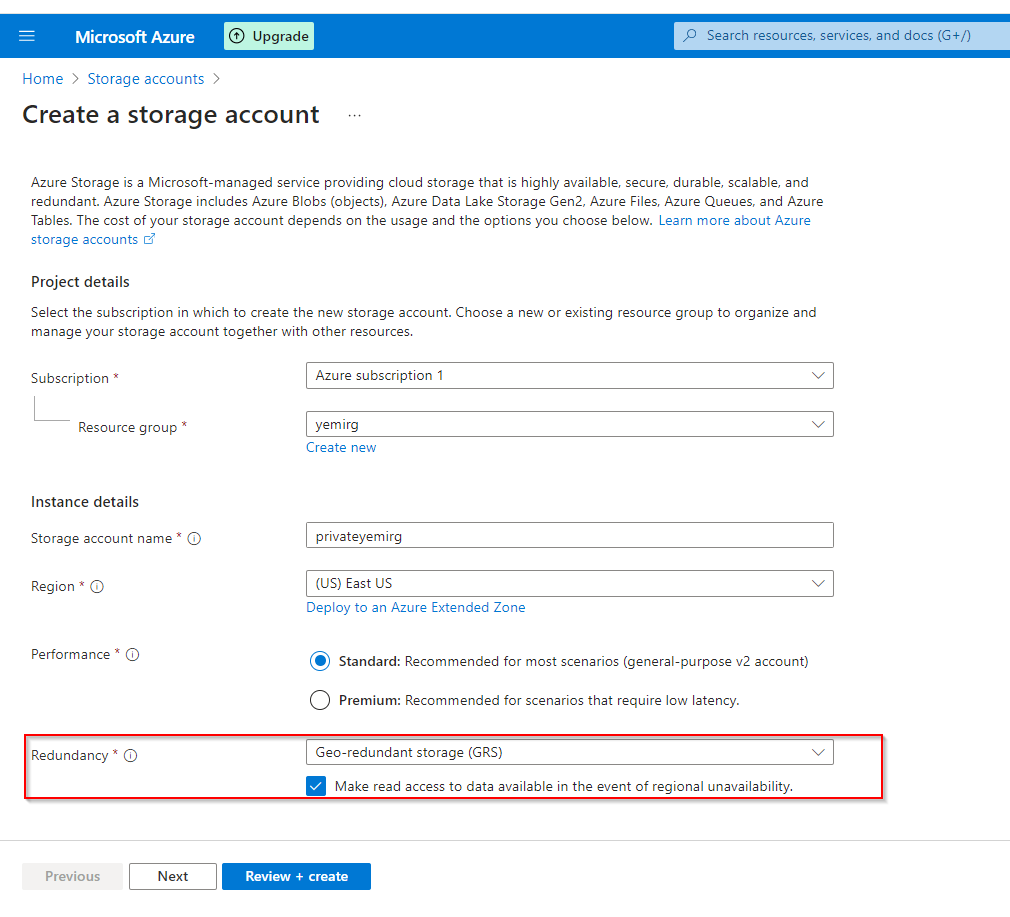
**Select "Redundancy" to be Geo-redundant storage (GRS)**
**Select "Review + Create"**
**Check Validation and select "Create"**
**Create a storage container, upload a file, and restrict access to the file.**
**In the storage account, select "Data storage" and select "containers"**
**Select "+ Container"**
**Name the container**

**Ensure access level is private**
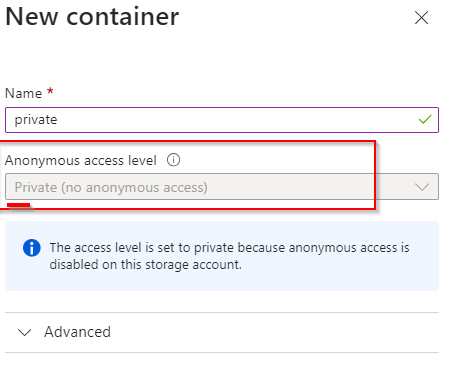
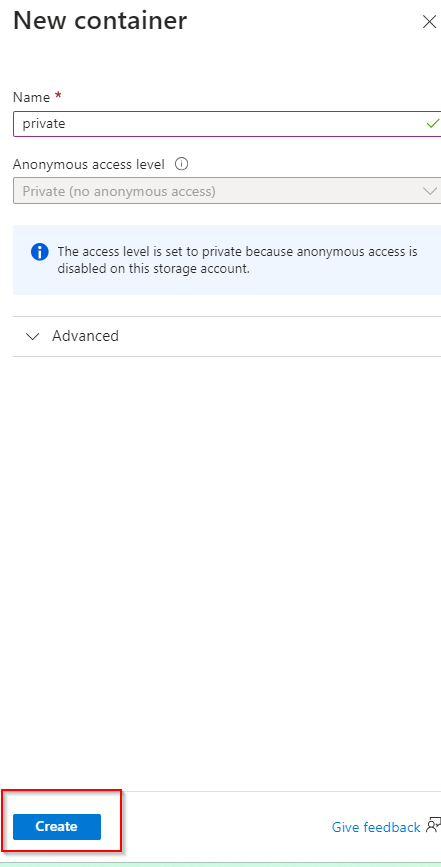
**Select "Create"**
**Upload File to Container**
Select Container
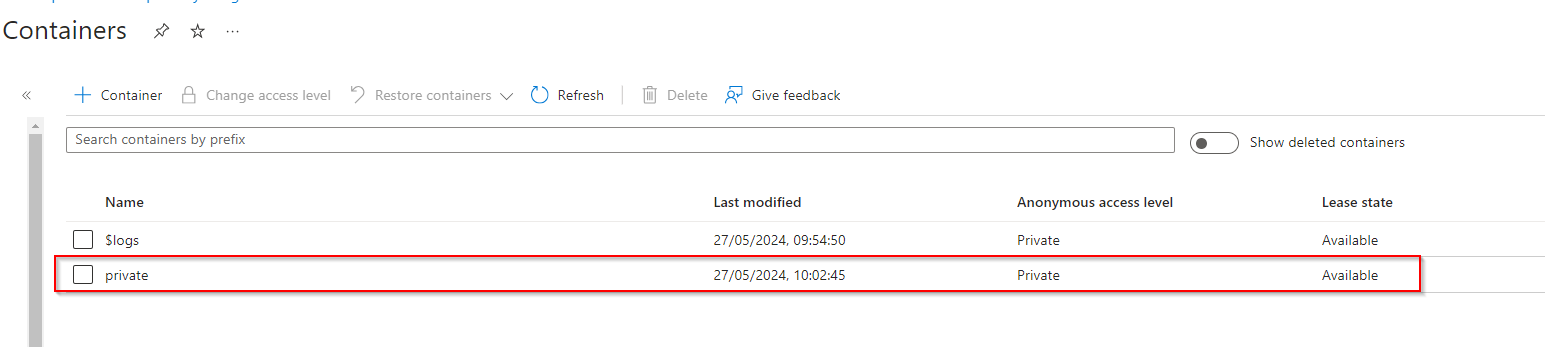
**Select "Upload"**
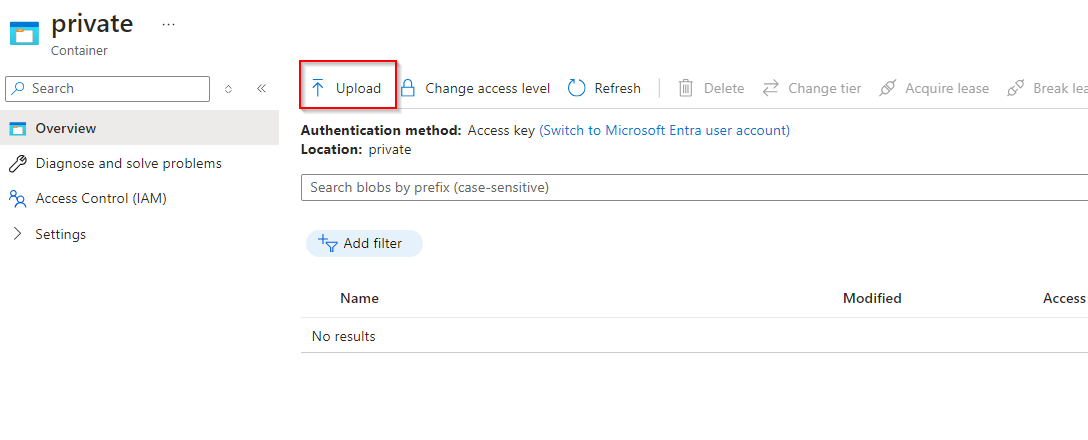
**Select File and upload**
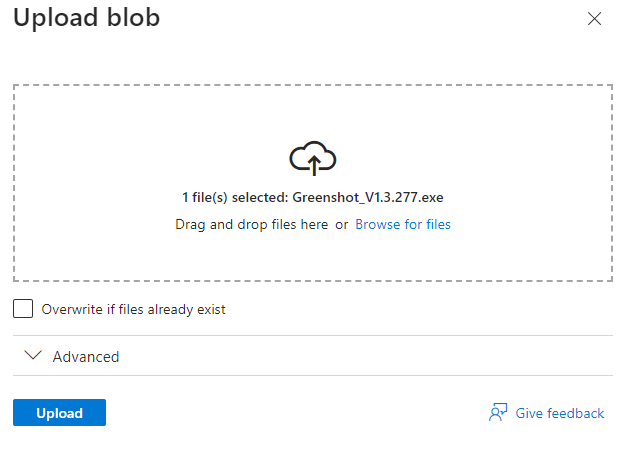
**Select the file and copy file URL to check if file will be accessed**
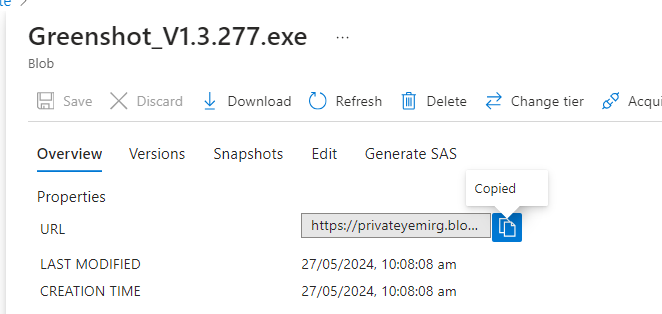
**Paste URL to a new tab, verify file doesn't display**
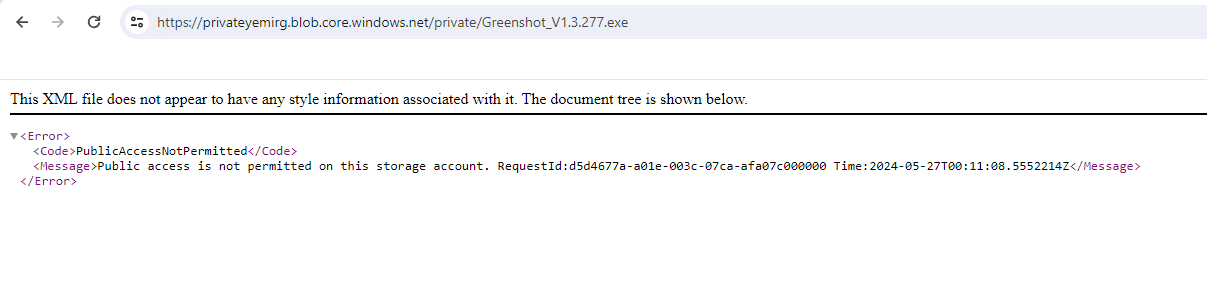
**An external partner requires read and write access to the file for at least the next 24 hours. Configure and test a shared access signature (SAS)**
**Select the uploaded blob file and click the "Generate SAS tab"**
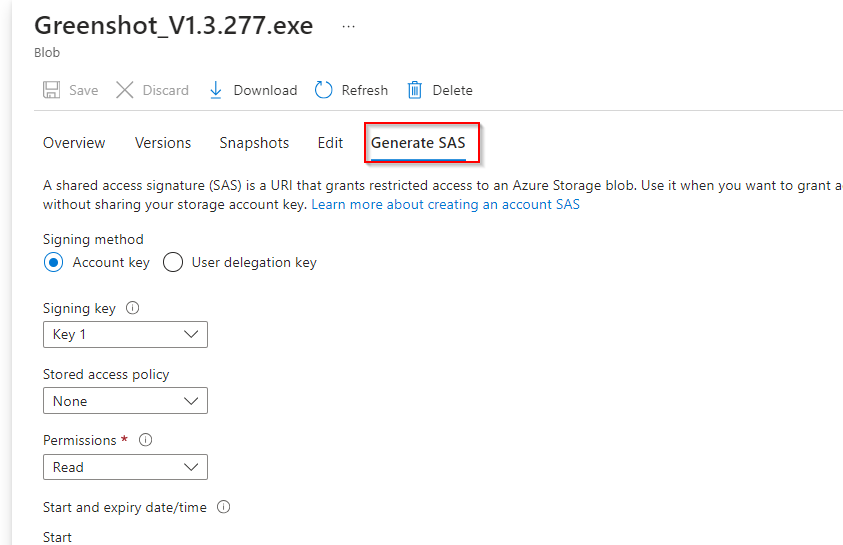
**Ensure the partner has only read permission**
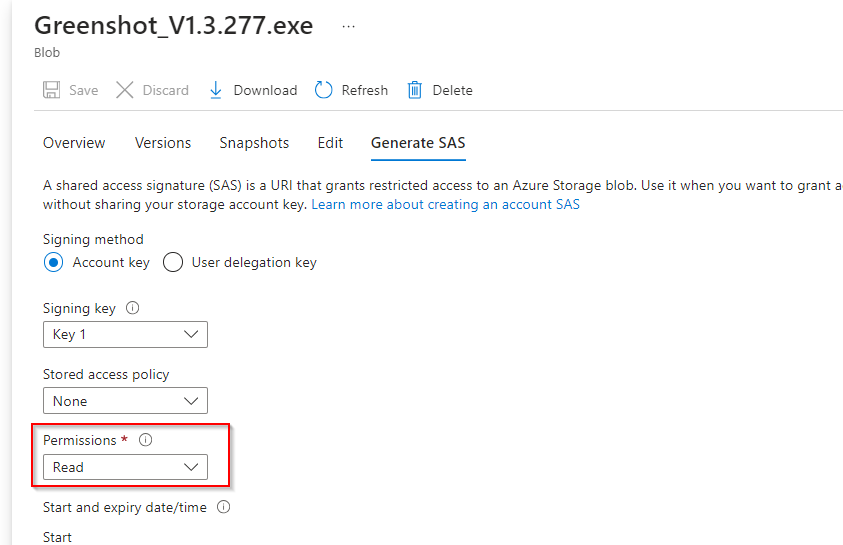
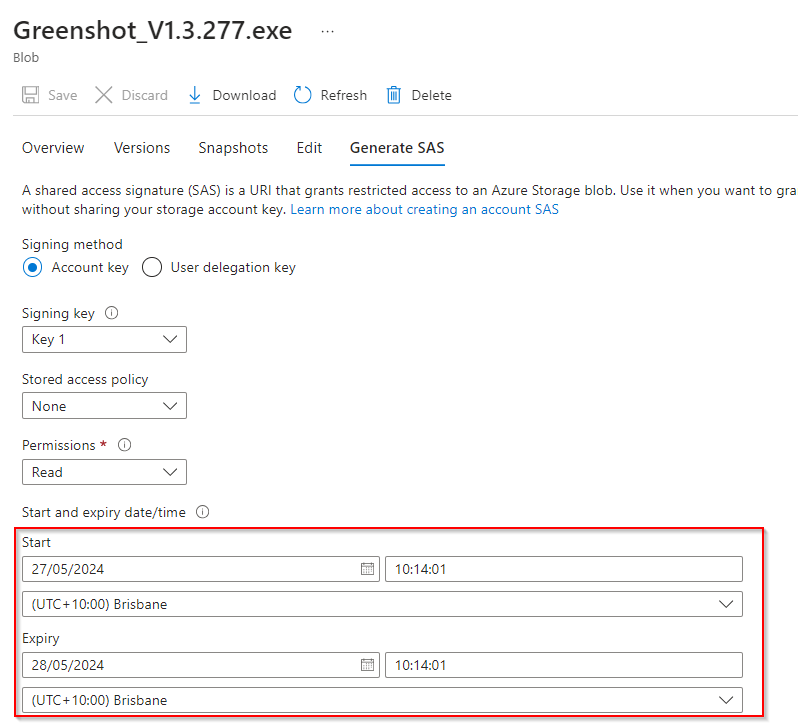
**Set start/expiry time for the next 24 hours**
**Select "Generate SAS token and URL"**
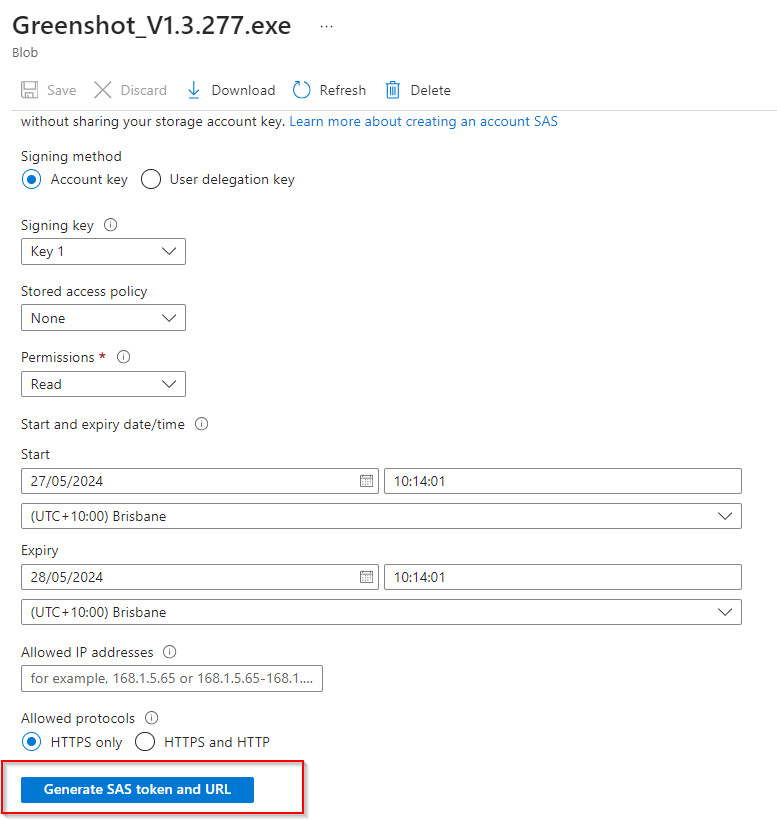
**Copy the Blob SAS URL to a new browser tab to verify accessibility, file should be accessible.**

**Configure storage access tiers and content replication.**
Return to storage account
**Notice the default access tier is set to hot**
**In the Data Management section**
**Select "Lifecycle management"**
**Select "Add a rule"**
**Add Rule name**
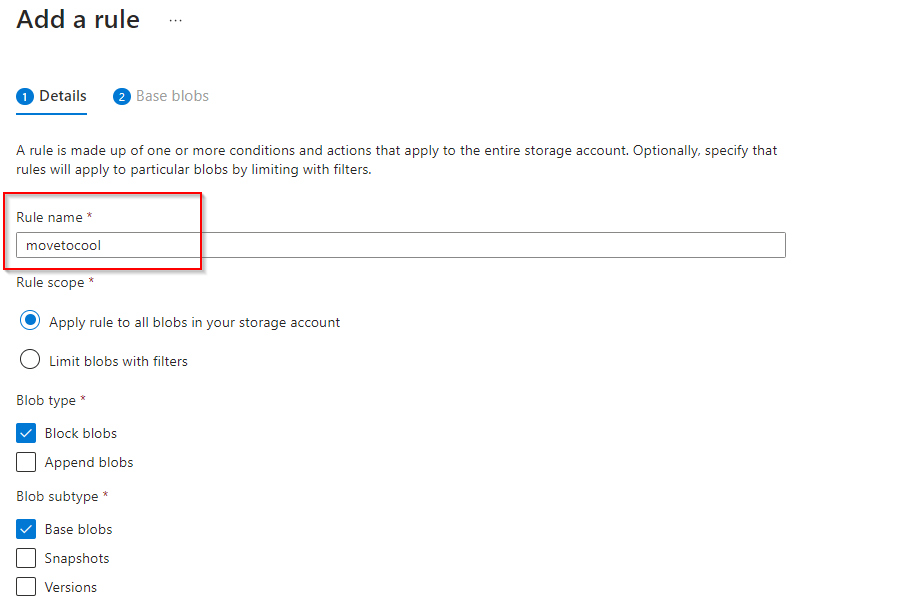
**Select Rule scope to apply rule to all blobs in your storage account**
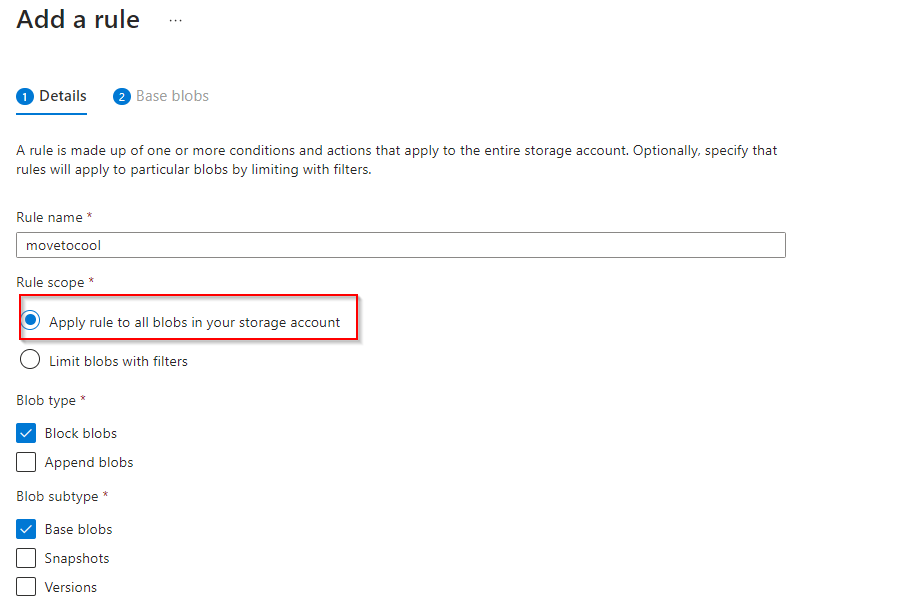
**Select "Next"**
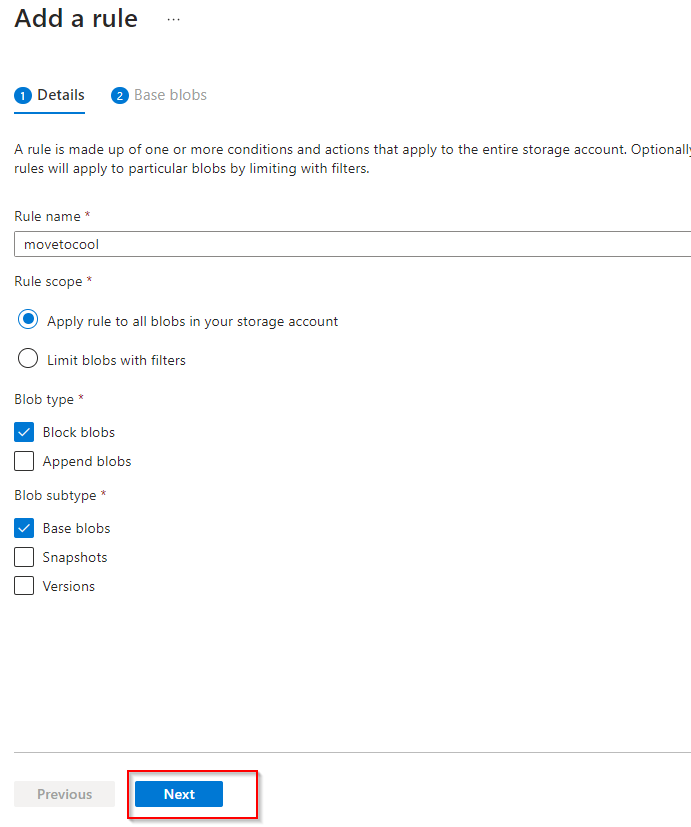
**Select "Last modified"**
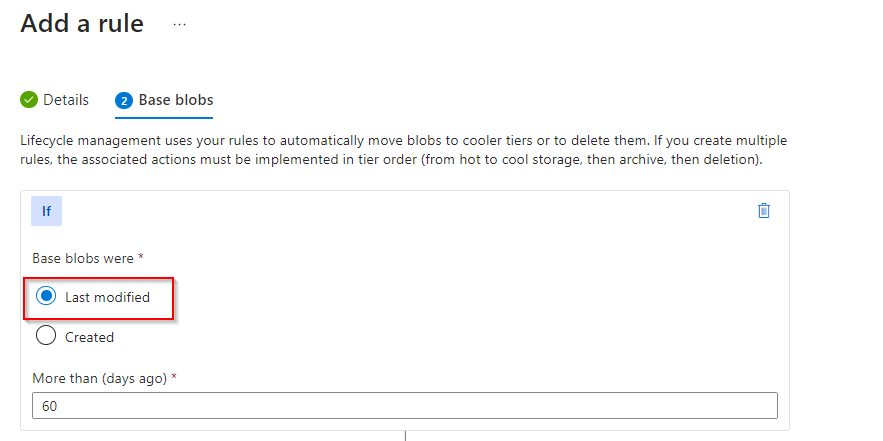
Set days
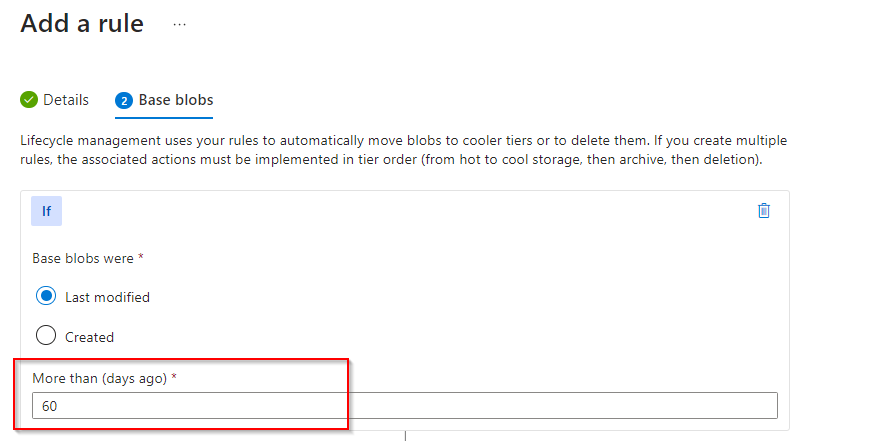
**Select "Move to cool storage"**
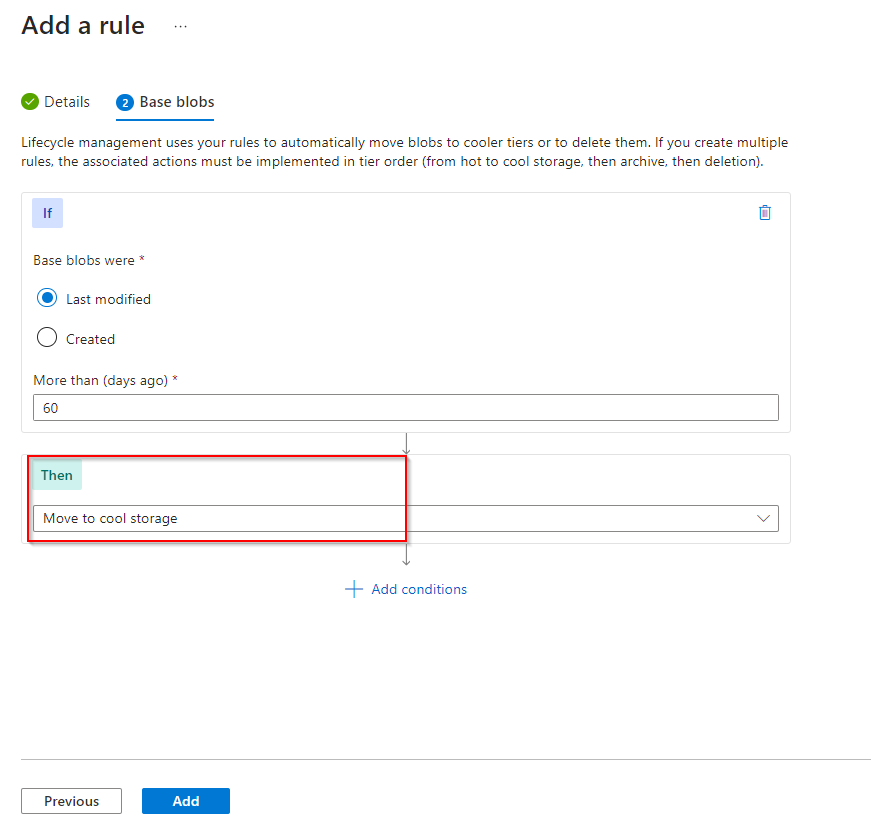
**Add rule**
**The public website files need to be backed up to another storage account**
**Create a new container**
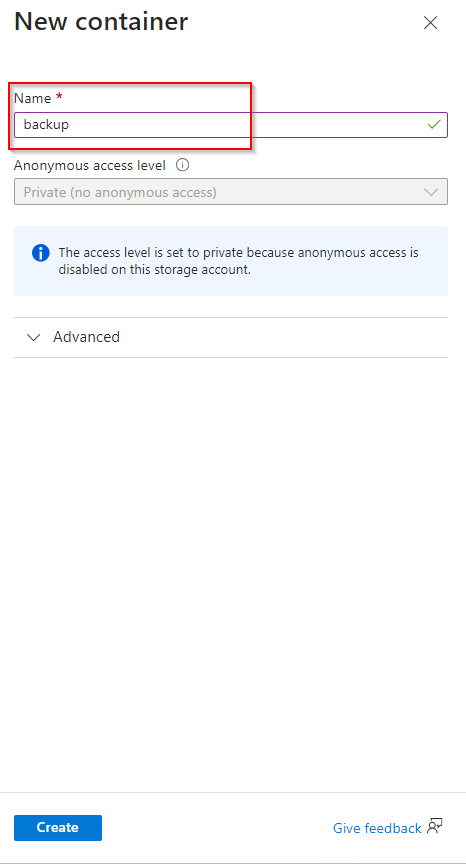
**Select "Create"**
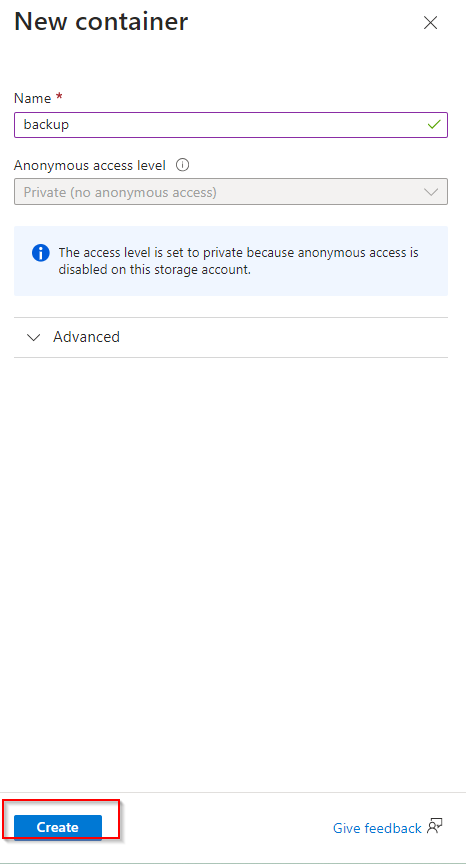
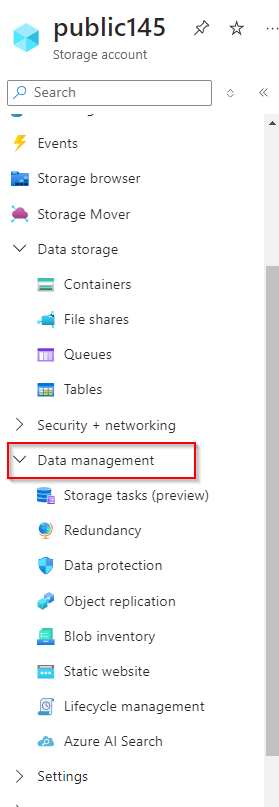
**Navigate to another storage account, click on "Data management"**
**Select "Object replication"**
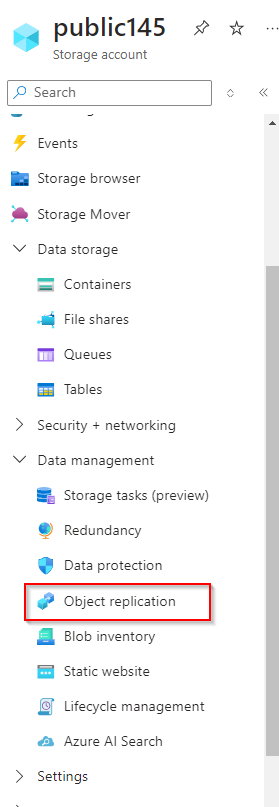
**Select "Create replication rules"**
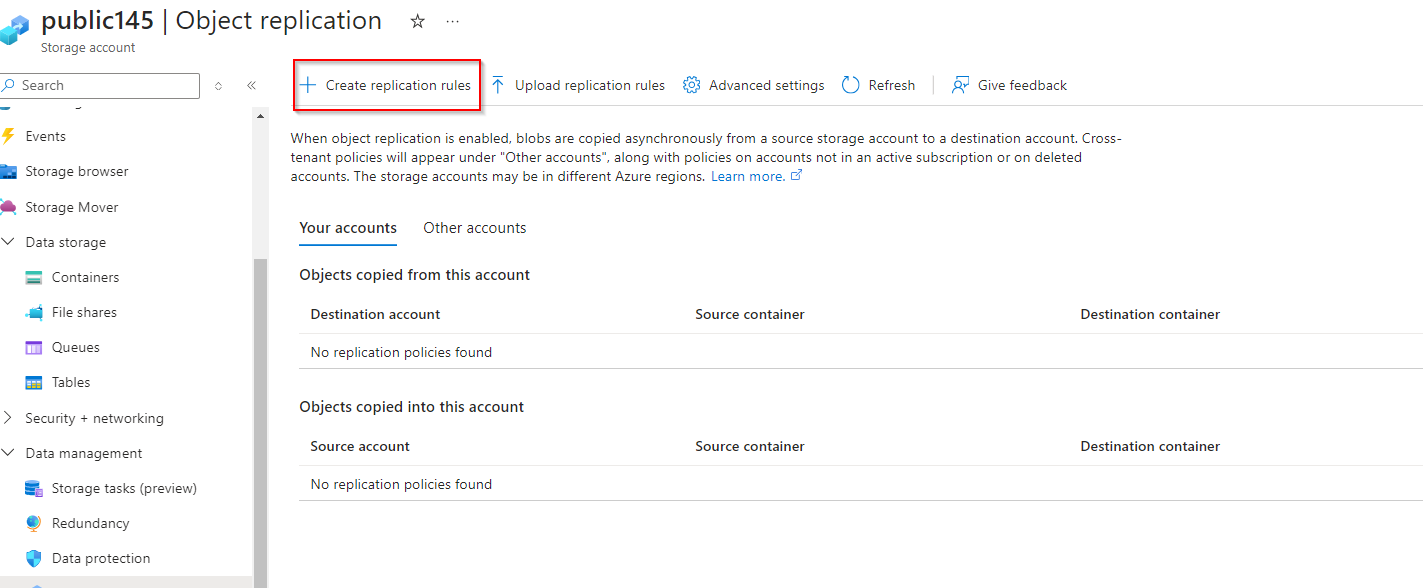
**Set Destination storage account to the Private storage previously created**
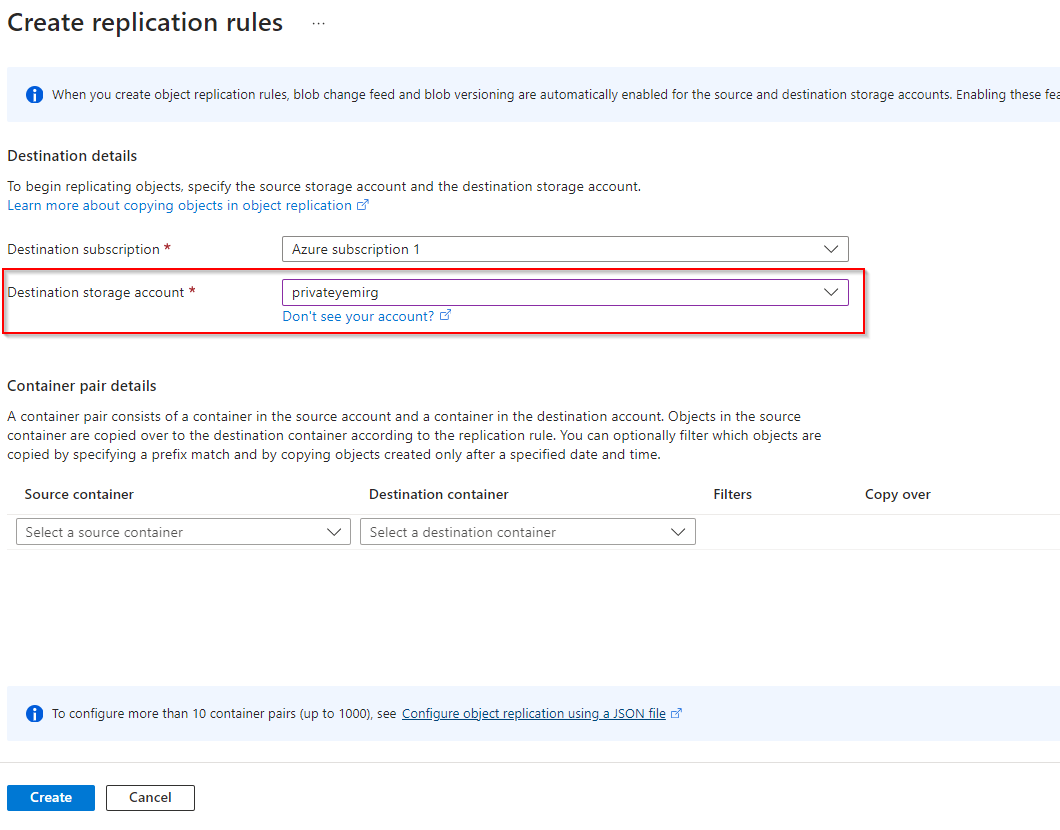
**Set Source Container as mainpublic and Destination Container as backup**
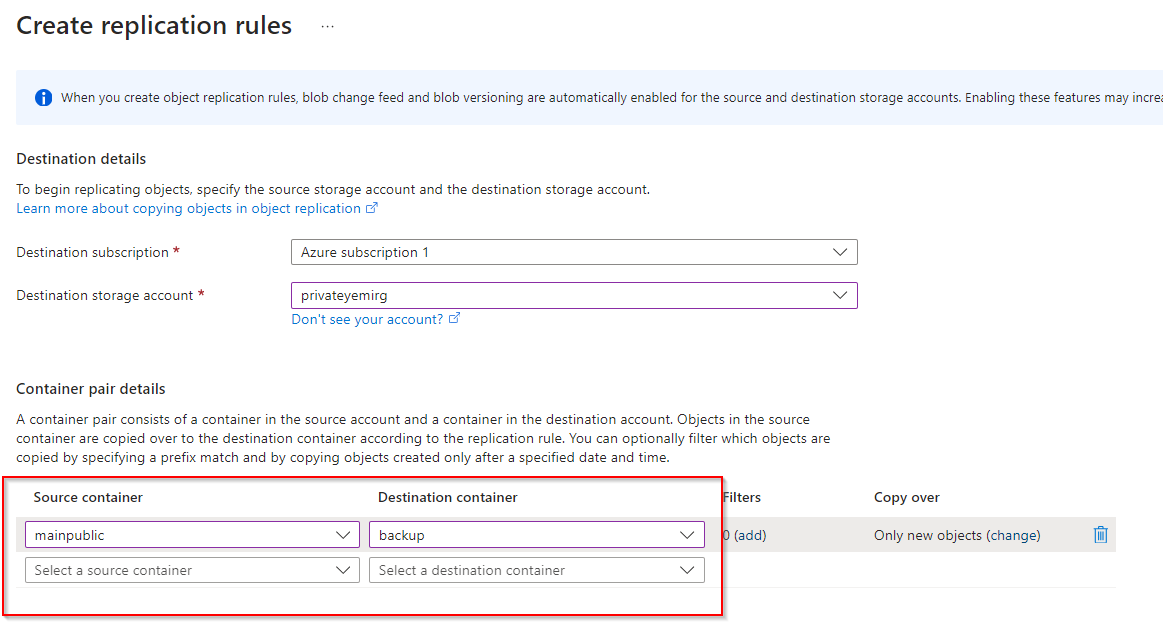
**Select "Create"**
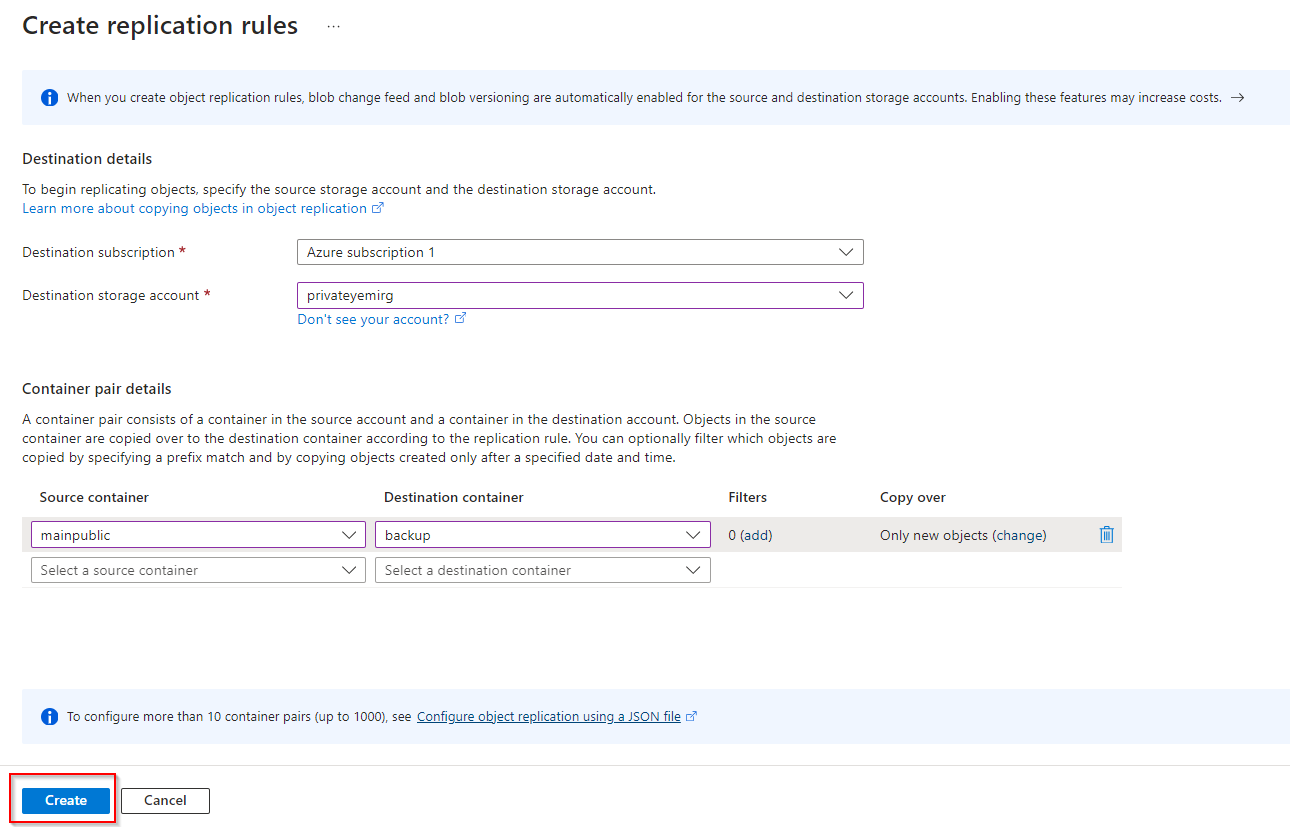
| opsyog |
1,866,006 | Alternative Trading Ideas--K-line Area Trading Strategy | Looking at a not-so-reliable trading idea -- the K-line area trading strategy, in this article, we... | 0 | 2024-05-27T01:14:09 | https://dev.to/fmzquant/alternative-trading-ideas-k-line-area-trading-strategy-2n96 | trading, strategy, cryptocurrency, fmzquant | Looking at a not-so-reliable trading idea -- the K-line area trading strategy, in this article, we will explore the concept and try to implement the script.
### Main Idea of the K-Line Area Strategy
The K-line area strategy is a trading strategy based on the area relationship between price K-lines and moving averages. Its main idea is to predict possible trends in stock prices by analyzing the magnitude and changes of price trends, as well as shifts in buying and selling sentiment, thereby determining when to open positions and exit. This strategy relies on the area between the K-line and moving averages, as well as values from the KDJ indicator, to generate long and short trading signals.
### The Principle of K-Line Area Strategy
The area of the K-line refers to the spatial area between the price K-line and the moving average, calculated by subtracting the moving average value from each bar's closing price and then summing it up. When there is a large increase in price over a long period of time, the K-line area will become larger, while during volatile markets or after volatility reversals, the K-line area is smaller. According to the principle of "what goes up must come down", as an upward trend becomes larger and lasts longer, its corresponding K-line area also increases; thus increasing its probability for reversal - much like a spring that rebounds with greater force when stretched further. Therefore, setting a threshold for this K-line area can indicate when prices may have reached their peak and are likely to reverse.
To further confirm an impending trend reversal, we introduce the use of KDJ indicators which help determine shifts in buying or selling sentiment. The thresholds for the strategy and values for these indicators can be adjusted according to specific circumstances and needs in order to enhance accuracy.
### The Advantages of K-Line Area Strategy
The advantage of the K-line area strategy lies in its combination of the magnitude and changes of price trends, as well as the shift in buying and selling sentiment, providing a relatively complete quantitative trading strategy. Its advantages include:
- It provides a simple and intuitive method to identify the possibility of trend reversal, helping traders better grasp market trends.
- By combining the K-line area and KDJ indicator, it increases the reliability and accuracy of the strategy.
- High flexibility allows for parameter adjustments according to market conditions to meet different trading needs.
### Risk of K-line Area Strategy
Although the K-line area strategy has certain advantages, it also carries some risks, including:
- The setting of thresholds may require some experience and adjustment. If it set improperly, it could lead to misjudgment of market trends.
- The accuracy of the KDJ indicator is affected by market fluctuations and noise, which may result in false signals.
- The performance of the strategy may vary under different market conditions and needs constant optimization and adjustment.
### Optimization Direction of K-line Area Strategy
To optimize the K-line area strategy, consider the following directions:
- Parameter optimization: Continuously adjust and optimize threshold values and KDJ indicator parameters to adapt to different market conditions and trading needs.
- Risk management: Implement effective risk management strategies, including stop-loss and take-profit rules, to reduce loss risks.
- Multi-strategy combination: Combine the K-line area strategy with other strategies to improve the performance of comprehensive trading strategies.
- Real-time monitoring and adjustment: Regularly monitor the performance of strategies, adjusting and improving based on actual situations.
### Implement the Strategy Using JavaScript
- Calculate K-line Area
- Long position opening signal:
(1) The "K-line area" of the downward trend reaches the threshold, it can be established beforehand.
(2) KDJ indicator value is greater than 80.
- Short position opening signal:
(1) The "K-line area" of the upward trend reaches the threshold, it can be established beforehand.
(2) KDJ indicator value is less than 20.
- Exit for Long/Short positions: ATR trailing stop loss and take profit.
Code implementation
```
// Parameter
var maPeriod = 30
var threshold = 50000
var amount = 0.1
// Global variable
let c = KLineChart({})
let openPrice = 0
let tradeState = "NULL" // NULL BUY SELL
function calculateKLineArea(r, ma) {
var lastCrossUpIndex = null
var lastCrossDownIndex = null
for (var i = r.length - 1 ; i >= 0 ; i--) {
if (ma[i] !== null && r[i].Open < ma[i] && r[i].Close > ma[i]) {
lastCrossUpIndex = i
break
} else if (ma[i] !== null && r[i].Open > ma[i] && r[i].Close < ma[i]) {
lastCrossDownIndex = i
break
}
if (i >= 1 && ma[i] !== null && ma[i - 1] !== null && r[i - 1].Close < ma[i - 1] && r[i].Close > ma[i]) {
lastCrossUpIndex = i
break
} else if (i >= 1 && ma[i] !== null && ma[i - 1] !== null && r[i - 1].Close > ma[i - 1] && r[i].Close < ma[i]) {
lastCrossDownIndex = i
break
}
}
var area = 0
if (lastCrossDownIndex !== null) {
for (var i = r.length - 1 ; i >= lastCrossDownIndex ; i--) {
area -= Math.abs(r[i].Close - ma[i])
}
} else if (lastCrossUpIndex !== null) {
for (var i = r.length - 1 ; i >= lastCrossUpIndex ; i--) {
area += Math.abs(r[i].Close - ma[i])
}
}
return [area, lastCrossUpIndex, lastCrossDownIndex]
}
function onTick() {
var r = _C(exchange.GetRecords)
if (r.length < maPeriod) {
LogStatus(_D(), "Insufficient number of K-line")
return
}
var ma = TA.MA(r, maPeriod)
var atr = TA.ATR(r)
var kdj = TA.KDJ(r)
var lineK = kdj[0]
var lineD = kdj[1]
var lineJ = kdj[2]
var areaInfo = calculateKLineArea(r, ma)
var area = _N(areaInfo[0], 0)
var lastCrossUpIndex = areaInfo[1]
var lastCrossDownIndex = areaInfo[2]
r.forEach(function(bar, index) {
c.begin(bar)
c.plotcandle(bar.Open, bar.High, bar.Low, bar.Close, {overlay: true})
let maLine = c.plot(ma[index], "ma", {overlay: true})
let close = c.plot(bar.Close, 'close', {overlay: true})
c.fill(maLine, close, {color: bar.Close > ma[index] ? 'rgba(255, 0, 0, 0.1)' : 'rgba(0, 255, 0, 0.1)'})
if (lastCrossUpIndex !== null) {
c.plotchar(bar.Time, {char: '$:' + area, overlay: true})
} else if (lastCrossDownIndex !== null) {
c.plotchar(bar.Time, {char: '$:' + area, overlay: true})
}
c.plot(lineK[index], "K")
c.plot(lineD[index], "D")
c.plot(lineJ[index], "J")
c.close()
})
if (tradeState == "NULL" && area < -threshold && lineK[lineK.length - 1] > 70) {
// long
let tradeInfo = $.Buy(amount)
if (tradeInfo) {
openPrice = tradeInfo.price
tradeState = "BUY"
}
} else if (tradeState == "NULL" && area > threshold && lineK[lineK.length - 1] < 30) {
// short
let tradeInfo = $.Sell(amount)
if (tradeInfo) {
openPrice = tradeInfo.price
tradeState = "SELL"
}
}
let stopBase = tradeState == "BUY" ? Math.max(openPrice, r[r.length - 2].Close) : Math.min(openPrice, r[r.length - 2].Close)
if (tradeState == "BUY" && r[r.length - 1].Close < stopBase - atr[atr.length - 2]) {
// cover long
let tradeInfo = $.Sell(amount)
if (tradeInfo) {
tradeState = "NULL"
openPrice = 0
}
} else if (tradeState == "SELL" && r[r.length - 1].Close > stopBase + atr[atr.length - 2]) {
// cover short
let tradeInfo = $.Buy(amount)
if (tradeInfo) {
tradeState = "NULL"
openPrice = 0
}
}
LogStatus(_D(), "area:", area, ", lineK[lineK.length - 2]:", lineK[lineK.length - 2])
}
function main() {
if (exchange.GetName().includes("_Futures")) {
throw "not support Futures"
}
while (true) {
onTick()
Sleep(1000)
}
}
```
The strategy logic is very simple:
1. First, some global variables and parameters are defined, including:
Strategy parameters
- maPeriod: The period of moving average.
- threshold: A threshold used to determine the timing of buying or selling.
- amount: The quantity for each transaction.
Global variables
- c: A K-line chart object, used for drawing charts.
- openPrice: Records the opening price.
- tradeState: Records the trading status, which can be "NULL" (empty position), "BUY" or "SELL".
Calculate function
- calculateKLineArea function: It is used to calculate the area between the price and moving average line on a K-line chart over a certain period of time, and returns the area value, the index of the last upward crossing K-line, and the index of the last downward crossing K-line. These values are used in subsequent decisions to determine when to buy and sell.
Main loop function
- onTick function: It is the main strategy execution function, and here are the operations within the function:
a. Obtain the latest K-line data and ensure that the number of K-lines is not less than maPeriod, otherwise record status and return.
b. Calculate moving average line ma and ATR indicator atr, as well as KDJ indicator.
c. Get area information from areaInfo, last cross-over K-line index, and last cross-under K-line index.
d. Use K-line chart object c to draw K-lines and indicator lines while filling in different colors based on price's relationship with moving average line.
e. Determine buying or selling timing according to conditions:
If tradeState is "NULL", and the area is less than -threshold, and the K value of KDJ is greater than 70, execute a buy operation.
If tradeState is "NULL", and the area is greater than threshold, and the K value of KDJ is less than 30, execute a sell operation.
f. Set stop loss and take profit conditions. If these conditions are met, close positions:
If it's in buying state, when the price falls below the closing price of last trading day minus previous day's ATR (Average True Range), close position.
If it's in selling state, when the price rises above last trading day's closing price plus previous day's ATR (Average True Range), close position.
main function: This serves as main execution entry point. It checks if exchange name contains "_Futures". If so, an exception will be thrown; otherwise it enters into an infinite loop where onTick function gets executed every second.
In a word, this strategy mainly relies on K-line charts and technical indicators for making buying or selling decisions while also employing stop-loss & take-profit strategies to manage risk. Please note that this just serves as an example strategy which needs to be adjusted & optimized according to market situations & specific requirements during actual use.
On FMZ.COM, using JavaScript language didn't require many lines of code, instead, it implemented this model easily. And with help from KLineChart function graphical representation of K-line chart area was easily achieved, too. The strategy design caters towards cryptocurrency spot markets by utilizing 'Digital Currency Spot Trading Library' template for placing orders through encapsulated functions within template, which makes it very simple & easy to understand and use.
### Strategy Backtesting
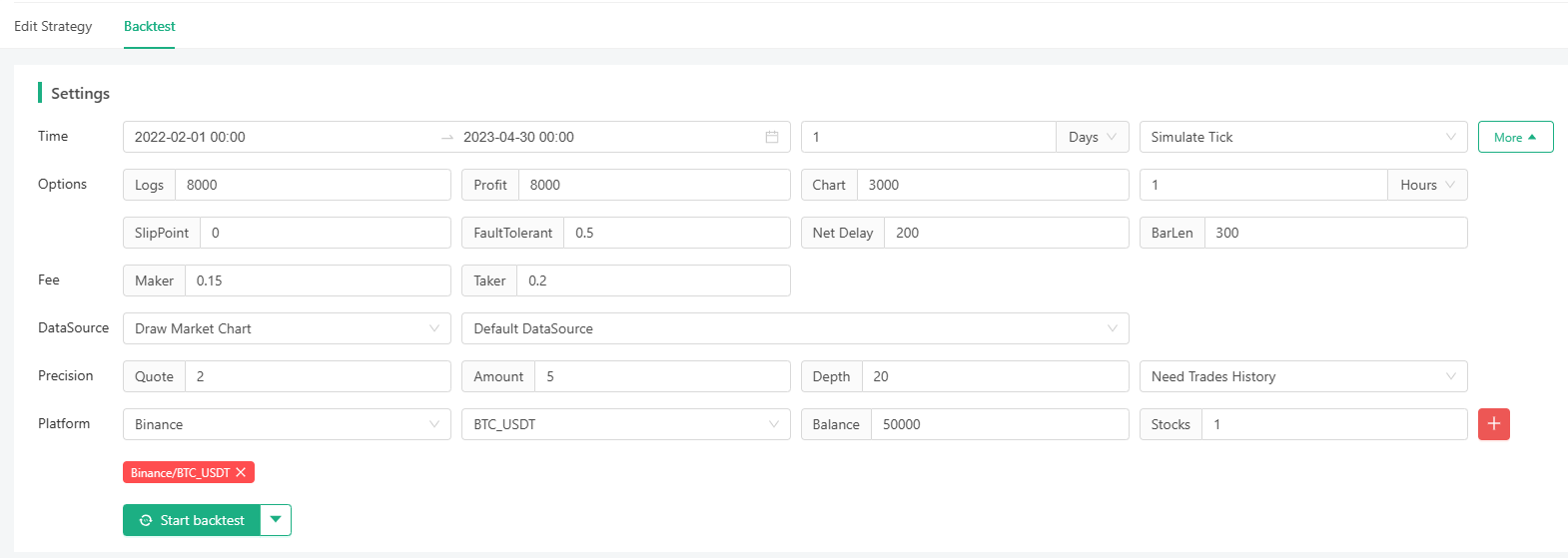
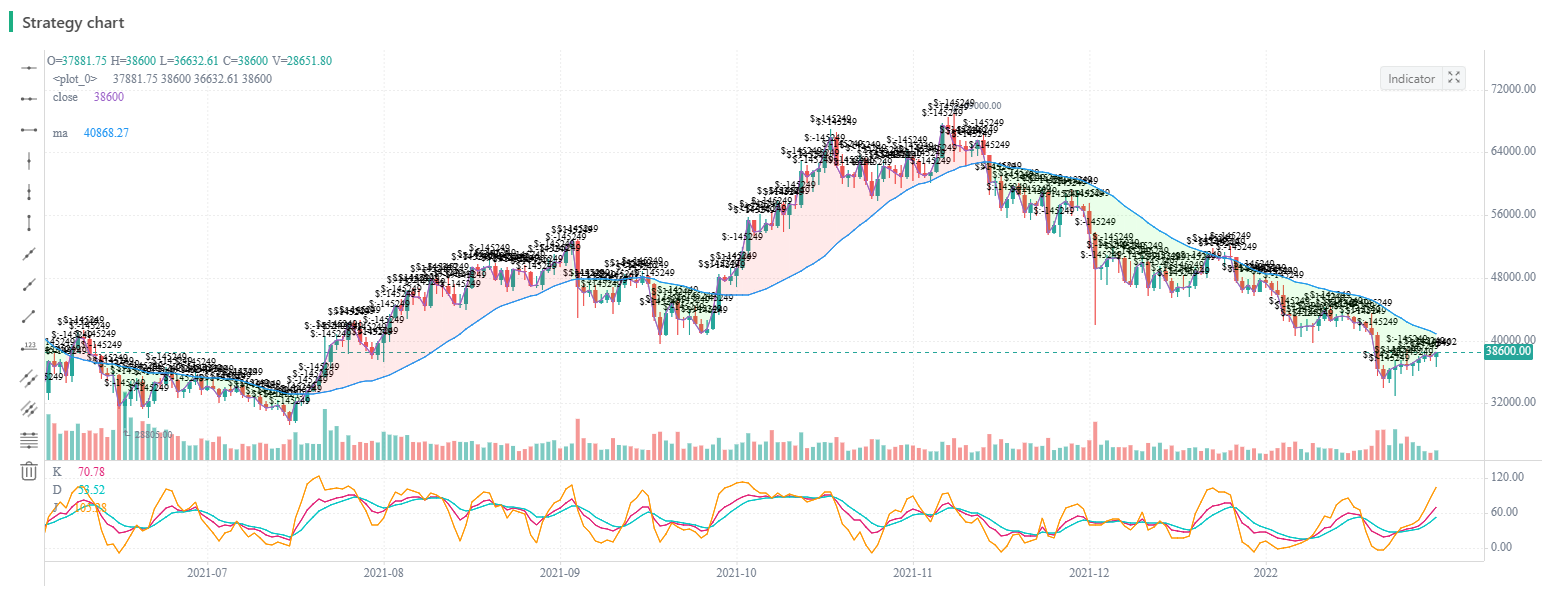
I selected a backtesting period randomly. Although I didn't lose money, I didn't accumulate profits continuously, either, and the drawdown issue is quite significant. There should be other directions and room for optimization for the strategy. Those who are interested can try to upgrade the strategy.


Through the strategy, we not only learned a rather unconventional trading idea, but also learned how to plot diagrams; representing the area enclosed by K-line and moving average line; ploting KDJ indicators etc.
### Summary
The K-line area strategy is a trading strategy based on price trend magnitude and the KDJ indicator. It helps traders predict market trends by analyzing the area between the K-line and moving averages, as well as shifts in buying and selling sentiment. Despite certain risks, this strategy can provide powerful trading tools through continuous optimization and adjustment, helping traders better cope with market fluctuations. Moreover, traders should adjust the parameters and rules of the strategy flexibly according to specific situations and market conditions to achieve better trading performance.
From: https://blog.mathquant.com/2023/11/06/alternative-trading-ideas-k-line-area-trading-strategy.html | fmzquant |
1,865,918 | where can I buy baby clothes from? | As the best children's clothing site and online store for children's clothing and baby clothes with... | 0 | 2024-05-26T21:41:50 | https://dev.to/bestbabyclothes/where-can-i-buy-baby-clothes-from-4mfd | As the [best children's clothing site](https://fingilii.com/) and online store for children's clothing and baby clothes with more than a decade of experience, Fingili's children's clothing site has succeeded in keeping up with the stores by adhering to three principles, easy payment, 7-day return guarantee and guaranteeing the originality of the goods. world-renowned, to become the largest branded children's clothing online store in Iran. As soon as you enter the Fingili baby clothes shopping site, you will be faced with a world of beautiful children's clothes! For every taste, there are high-quality and excellent products on the Fingili baby clothing site. Fingili's cheap children's clothing site is like a glamorous showcase with all kinds of products such as boys' clothes, girls' clothes, children's socks, children's watches, boys' sportswear sets, boys' formal wear, girls' formal wear, clothes Sportswear for girls, children's wedding dresses, home and comfort clothes, children's room signs, etc. are arranged. You can order all your needs in the field of buying children's clothes with just a few clicks and order them at home in the shortest possible time. Receive it. | bestbabyclothes | |
1,865,852 | Enhancing AWS VPC Security: Accessing Your Network with a Private Jumpbox using Tailscale | In today's cloud-centric world, ensuring the security of your AWS resources is paramount. I was... | 0 | 2024-05-27T00:50:03 | https://dev.to/tevindeale/enhancing-aws-vpc-security-accessing-your-network-with-a-private-jumpbox-using-tailscale-1k83 | aws, cloud, networking, tailscale | In today's cloud-centric world, ensuring the security of your AWS resources is paramount. I was recently working on a cloud project and wanted a secure way to access the VPC remotely without using EC2 Instance Connect. This is when I came up with the idea to try using [Tailscale](https://tailscale.com/) VPN. I had already been tinkering with [Tailscale](https://tailscale.com/) on my home network and noticed how powerful it was. In this post, I will share how you can enhance your AWS VPC security by setting up a private jumpbox using Tailscale. We'll be using the free plan, which is sufficient for our needs. I suggest visiting [Tailscale's](https://tailscale.com/)website to explore all their features and use cases.
## The Solution
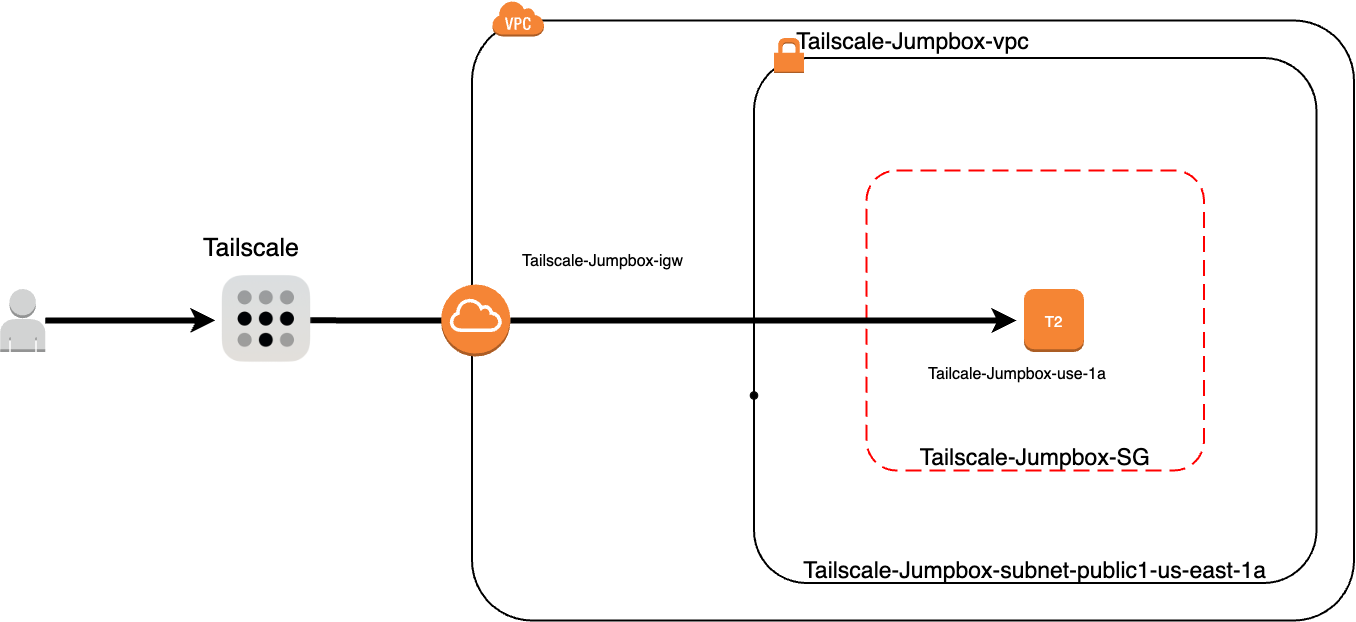
## Understanding the Basics
For those new to AWS, a Virtual Private Cloud (VPC) is a logically isolated section of the AWS cloud where you can launch AWS resources in a virtual network that you define. A jumpbox, or bastion host, acts as a secure gateway to your VPC, typically accessed via SSH, and it helps in reducing the exposure of your instances. Tailscale is a user-friendly VPN that simplifies secure network connections using WireGuard’s encryption technology. It’s particularly great for creating secure, peer-to-peer networks.
## Why Use a Private Jumpbox and Tailscale?
Using a private jumpbox, also known as a bastion host, provides a secure gateway to your AWS VPC. Unlike a public jumpbox, a private jumpbox is not accessible directly from the internet, which significantly reduces the attack surface and enhances the overall security of your network. This setup ensures that only authorized users can access your VPC resources.
Tailscale is a peer-to-peer VPN solution built on WireGuard, which simplifies secure network connections. Tailscale's ease of use, combined with its robust security features, makes it an excellent choice for setting up a private jumpbox. With Tailscale, you can create a secure mesh network that includes your local devices and your AWS resources, allowing seamless and secure access.
One of the key advantages of using Tailscale with a private jumpbox is its cost-effectiveness. Here are some points to consider:
- **Free Plan**: Tailscale offers a free plan that is sufficient for many use cases, especially for small projects or individual developers. This plan includes all the core features needed to set up a secure private jumpbox.
- **Reduced AWS Costs**: By using a private jumpbox, you can minimize the number of publicly accessible instances, which can lower your AWS costs. Public instances often require additional security measures and monitoring, increasing overall expenses.
- **No Need for Expensive Hardware**: Tailscale operates on your existing infrastructure, meaning you don't need to invest in additional hardware or complex network setups.
## Setting Up the Environment
Before we begin, ensure that you have a AWS account with necessary permissions, and the remote system set up with the Tailscale VPN.
**Create the VPC**
1. Navigate to the VPC dashboard and click _Create VPC_.
2. In the VPC Settings box we will use the _VPC and More_ option for simplicity. Match your settings to the following and click _Create VPC_:
- Name tag auto-generation: TailscaleJumpBox
- IPv4 CIDR block: 10.0.0.0/16
- IPv6 CIDR block(Important): Amazon-provided IPv6 CIDR block
- Tenancy: Default
- Number of Availability Zones: 1
- Number of public subnets: 1
- Number of private subnets: 1
- Nat gateways: None
- VPC endpoints: None
- DNS Options: Both options should be checked.
Example output:
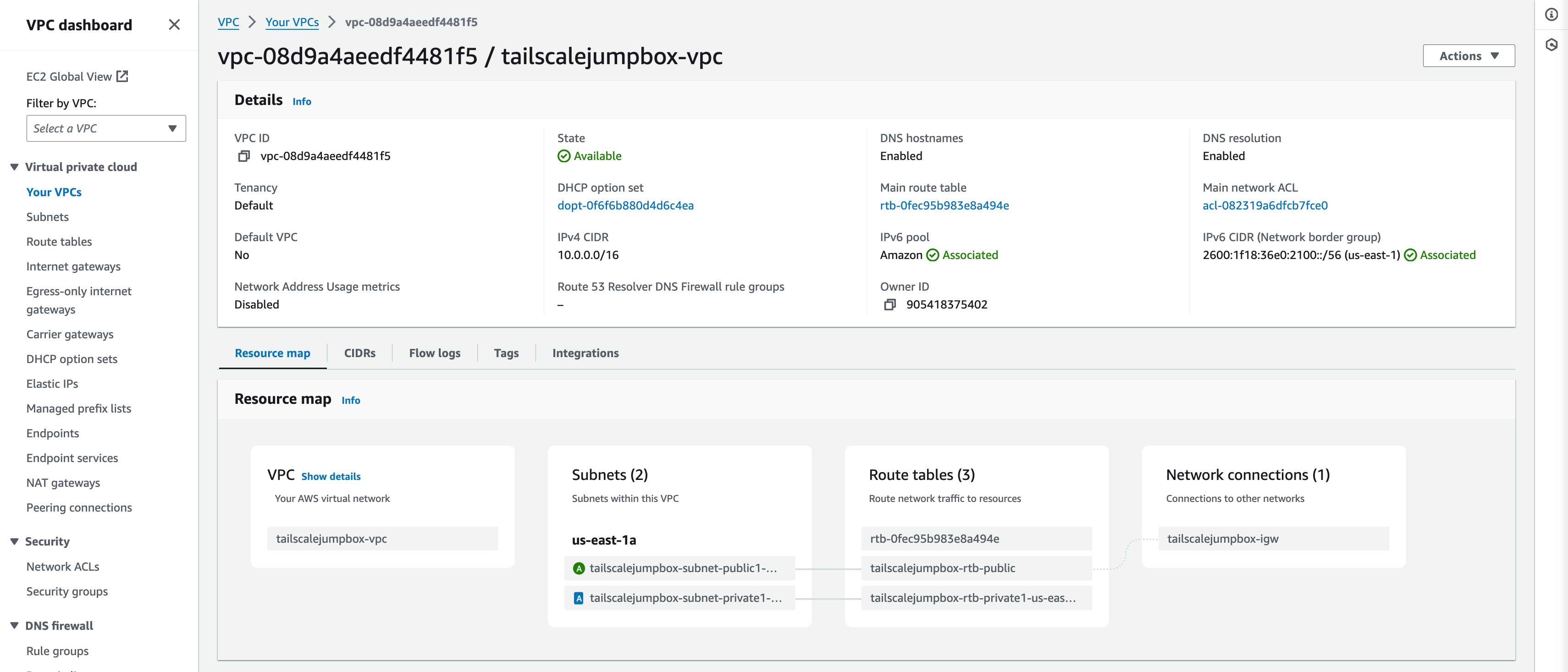
Using the VPC and more option when creating the VPC saves times by auto generating your subnets, route tables, and internet gateway.
**Turn on IPv6 Auto-assign**
1. In the VPC Dashboard menu click _Subnets_.
2. Enable Auto-assign IPv6
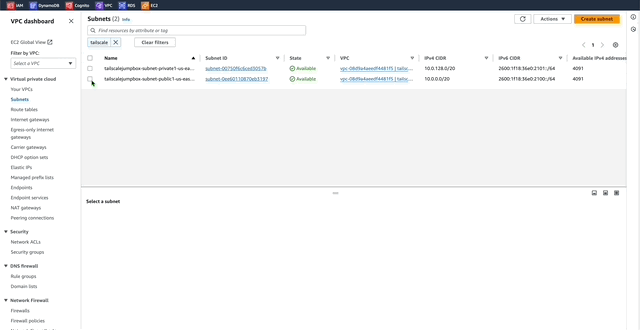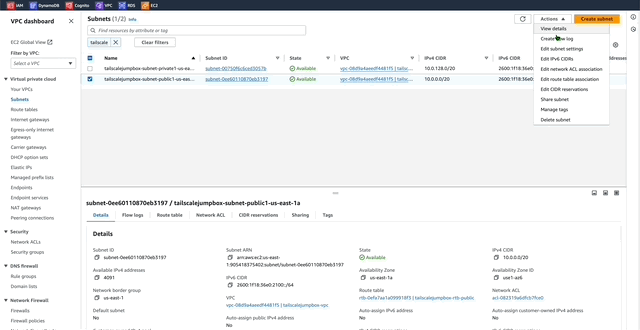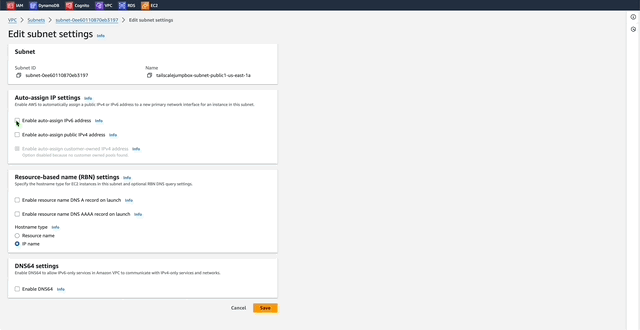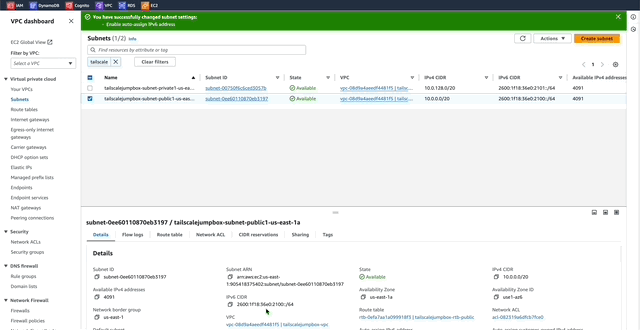
This will auto assign IPv6 addresses to resources deployed into the TailscaleJumpBox-VPC. This is useful because by default AWS IPv6 addresses are publicly available by default unlike IPv4 addresses.
**Create Security Group**
1. In the VPC Dashboard menu click _Security groups_.
2. Click _Create Security Group_.

3. Enter in the following details:
- **Security group name**: Tailscale-JumpBox-SG
- **Description**: Allow remote connection from Tailscale
- **VPC**: tailscalejumpbox-vpc
- **Inbound rules**: None (default)
- **Outbound rules**: Leave as default (all traffic)
Example Output:

**Launch Instance**
1. Navigate to the EC2 Dashboard.
2. Click _Launch Instance_.
3. Enter in the following details:
- **Name**: Tailscale-JumpBox-USE-1a
- **Application and OS Images**: Amazon Linux - Amazon Linux 2023
- **Instance Type**: t2.micro (free tier)
- **Key pair**: Create new key pair --> RSA --> .PEM --> Download Key
- **Network Settings**: Click _edit_ to change all options
- **VPC**: tailscalejumpbox-vpc
- **Subnet**: tailscalejumpbox-subnet-public1-us-east-1a
- **Auto-assign public IP**: Disable
- **Auto-assign IPv6 IP**: Enable
- **Security goups**: Select existing security group
- **Common security groups**: Tailscale-JumpBox-SG
- **Configure storage**: Leave as default
- **Advance details**: Expand this section and scroll to the bottom to enter _User data_ (Shell Script)
- **User data**:
```bash
#! bin/bash
hostnamectl set-hostname ts-jumpbox-use-1a
yum update -y
curl -fsSL https://tailscale.com/install.sh | sh
tailscale up --auth-key <tskey-auth> --ssh
```
Shell script breakdown:
1. `#! bin/bash`: This shebang line indicates that the script should be run in the bash shell.
2. `hostnamectl set-hostname ts-jumpbox-use-1a`: Sets a readable hostname for the instance. (Optional)
3. `yum update -y`: Updates all installed packages.
4. `curl -fsSL https://tailscale.com/install.sh | sh`: Downloads and installs Tailscale's quick install script.
5. `tailscale up --auth-key <tskey-auth> --ssh`: Starts Tailscale and authenticates the instance using the provided auth key, with SSH access enabled.
6. Launch Instance
**Note**: Replace `<tskey-auth>` with your actual Tailscale authentication key. You can generate an auth key from the Tailscale admin console under the Keys section in the settings.
**Using the `--ssh` Flag**
By using the `--ssh` flag in the `tailscale up` command, you enable Tailscale SSH, which allows you to SSH into the machine using Tailscale’s secure network. After running the script, you will see an SSH tag on the machine in the Tailscale admin console.
## Connecting to the JumpBox
To SSH into the server using Tailnet SSH, use the following command:
```
ssh ec2-user@<tailnet IP address>
```
You will be prompted to log in with a browser to authorize access to the server.
Alternatively, you can use the -i flag with the RSA key generated when launching the instance:
```
ssh -i rsa.pem ec2-user@<tailnet IP address>
```
By following these steps, you can securely connect to your jumpbox and access your AWS VPC using Tailscale, taking advantage of its seamless and secure networking capabilities.
## Conclusion
In this blog post, we explored how to enhance the security of your AWS VPC by setting up a private jumpbox using Tailscale. By utilizing a private jumpbox, you significantly reduce the attack surface of your infrastructure, making your network more secure and resilient against unauthorized access.
We walked through a step-by-step process to install and configure Tailscale on your jumpbox, leveraging its powerful yet user-friendly VPN capabilities. By enabling Tailscale SSH, we made accessing your jumpbox and other AWS resources secure and straightforward, providing you with a seamless and cost-effective solution for remote network access.
One of the standout advantages of this setup is its cost-effectiveness. Using Tailscale's free plan and minimizing the number of publicly accessible instances can save costs while still providing robust security features.
By following the steps outlined, you now have a secure method to access your AWS VPC, ensuring your resources are protected without sacrificing convenience. I encourage you to implement this setup in your projects and experience the benefits firsthand.
If you have any questions, comments, or additional tips to share, please leave them below. I’d love to hear about your experiences and any further enhancements you make to this setup.
Call to Action
Try setting up your own private jumpbox with Tailscale today, and ensure your AWS VPC remains secure and accessible. Don’t forget to share your feedback and any custom configurations you come up with!
For more information and to explore additional features, visit [Tailscale’s documentation](https://tailscale.com/kb/1017/install).
Thank you for reading, and happy securing!
| tevindeale |
1,866,000 | Mmoexp Path of exile currency: Everything from your skills to your endgame experience | 8 Remnant: From The Ashes Release year: 2019 Platforms: Windows, PlayStation 4 and Xbox One,... | 0 | 2024-05-27T00:46:36 | https://dev.to/rozemondbell/mmoexp-path-of-exile-currency-everything-from-your-skills-to-your-endgame-experience-fon | webdev, javascript, beginners, programming | 8 Remnant: From The Ashes Release year: 2019 Platforms: Windows, PlayStation 4 and Xbox One, PlayStation 5, Xbox Series X|S
Featuring some of <a href="https://www.mmoexp.com/Path-of-exile/Currency.html">Path of exile currency</a> the most unique monster designs, Remnant: From The Ashes tells the tale of a realm descending into chaos thanks to an alternate dimension evil. The remnants of humanity team up to fight off the monstrous hoard and take back their world.
RELATED: Things We Wish We Knew Before Starting Remnant: From The Ashes
It's a pretty common setup, but Remnant executes itself with such panache and style. If you're looking for a co-op Soulslike game with action, guns, and, most importantly, loot, Remant: From the Ashes is the one to play.
.hidden-poll {display: none} The Ultimate Beginner's Guide To Path Of Exile Path Of Exile: A Comprehensive Beginner's Guide By Charles Burgar Updated Apr 23, 2023
From currency to leveling, this guide will cover all of the essentials a new player needs to survive on Wraeclast.
Quick LinksCreating A Character Finding A Build Surviving The First Few Acts The Passive Tree And Ascendancies Skill Gems And Support Gems Explained How To Upgrade Your Gear Useful Community Resources
No ARPG on the market can match the sheer depth of Path of Exile. This free-to-play dungeon crawler offers a degree of customization that would make other games blush. Everything from your skills to your endgame experience can be suited to <a href="https://www.mmoexp.com/Path-of-exile/Currency.html">cheap POE currency</a> your needs.
| rozemondbell |
1,865,999 | Dev na Gringa: Processos Seletivos e Onde Estudar Para Eles | Originalmente postado no Dev na Gringa Substack. Caso queira receber novos artigos no seu e-mail,... | 0 | 2024-05-27T00:42:43 | https://dev.to/lucasheriques/dev-na-gringa-processos-seletivos-e-onde-estudar-para-eles-b9f | braziliandevs, career | Originalmente postado no [Dev na Gringa Substack](https://open.substack.com/pub/devnagringa/p/dev-na-gringa-processos-seletivos?r=gb7rl&utm_campaign=post&utm_medium=web). Caso queira receber novos artigos no seu e-mail, increva-se!
---
Você encontrou a vaga, aplicou para uma vaga de dev na gringa, e foi chamado para a entrevista.
Chegou a hora de entender como você será avaliado.
Nesse artigo, vou mostrar os principais métodos usados no mercado internacional.
Não vou entrar em muitos detalhes individualmente. Pois o objetivo é dar uma visão ampla sobre os diferentes processos seletivos.
Vou compartilhar todos os recursos que eu utilizo quando estou me preparando.
Como vocês podem ver neste diagrama, todas as etapas são eliminatórias.
Sim, são muitos pontos que são sem volta.
Por isso, é importante estar bem preparado para cada uma delas.
Vou deixar algumas dicas específicas minhas também no final, que não encaixam em uma etapa específica. Baseadas em experiências anteriores.
Mais um último lembrete. Esse guia detalha todas as etapas que eu já fiz e tenho experiência. Porém, certamente existem empresas que possuem processos diferentes.
Inclusive, se você participou de um, peço que comente neste artigo! E assim podemos ter mais conhecimento difundido para todos também.
## 1. Conversa inicial com recrutador
Durante essa conversa, o recrutador irá te contar um pouco mais sobre a posição e o processo seletivo.
Se for um vaga de dev na gringa, sua comunicação já começa a ser avaliada nessa primeira conversa.
Ler um pouco sobre a empresa também é algo que faz maravilhas. Procure entender a situação que a empresa está. Se estão buscando crescimento. Diminuindo os gastos. Quais as últimas iniciativas que trabalharam.
Mostre um interesse genuíno.
Tenha algumas perguntas preparadas.
No final da entrevista, o recrutador irá perguntar se tem algo que você queira saber.
É uma ótima oportunidade de fazer perguntas de assuntos pertinentes para a sua posição.
Alguns exemplos:
- Você pode me contar um pouco mais sobre a cultura da empresa?
- Existem oportunidades para participar de conferências ou ter acesso à material educativo?
- Como está a diversidade na empresa?
- Tem algo específico que preciso me preparar para a próxima etapa?
Perguntar mostra que você tem um interesse genuíno na empresa. E também ajuda você a determinar se a empresa se encaixa naquilo que você está buscando.
## 2. Entrevista técnica inicial ou _Phone Screen_
É uma conversa técnica, com duração de 45min até 1 hora.
Nessa entrevista, você irá fazer _pair_ com algum desenvolvedor.
Existe a possibilidade de você receber um problema grande, que dure a entrevista inteira. Ou até três perguntas menores.
Se você estiver aplicando para uma vaga de front, você deve focar nos domínios de HTML, CSS e JavaScript.
Também é possível ser um problema de algoritmos e estruturas de dados.
Recursos para aprofundar:
1. [GreatFrontEnd](https://devnagringa.substack.com/p/%5Bhttps://greatfrontend.com/%5D(https://greatfrontend.com/)): para entrevistas de vagas em front.
2. [NeetCode](https://devnagringa.substack.com/p/%5Bhttps://neetcode.io/%5D(https://neetcode.io/)): para algoritmos e estruturas de dados.
3. [LeetCode](https://devnagringa.substack.com/p/%5Bhttps://leetcode.com/%5D(https://leetcode.com/)): para problemas específicos das empresas que você está aplicando.
4. Livro: Cracking the Coding Interview por Gayle Laakmann McDowell.
## 3. Teste prático ou _Take Home Exercise_
Esse é o teste técnico que você faz em casa.
A empresa vai te dar um prazo e te enviar todos os requisitos do projeto.
Neste tipo de projeto, existem duas opções:
1. A empresa o pede com uma stack específica.
2. Você tem a liberdade de escolher a stack que preferir.
As dicas dependem um pouco do tipo de teste.
Caso seja uma stack específica, tenha certeza de estar atualizado com as práticas de mercado.
Por exemplo, se for uma aplicação React, opte por usar Nextjs ou Vite como o framework/ferramenta de _build_. TypeScript também é comum. Para testes, eu usaria Vitest/Jest, React Testing Library e Playwright.
Se você tiver a liberdade de escolha, faça escolhas sensatas. Use a ferramenta apropriada para o trabalho.
Por exemplo: se é um aplicação de AI/dados, Python é uma boa escolha. Para frontend web, o ecossistema JavaScript é o mais usado. Backend? Python, Node, Ruby, Go, várias opções.
O importante é que você saiba justificar todas as suas escolhas.
Algumas dicas de como se destacar nesta etapa:
1. Clarifique os requisitos e quaisquer dúvidas que você possa ter. Depois de ler a especificação, pergunte se tiver dúvidas. Não deixe a dúvida ficar para depois da entrega.
2. Dedique um tempo a documentação. Como rodar o seu app? Ele está hospedado em alguma infraestrutura? Que abordagens você usou para teste? Inclua esse tipo de informação no README.
3. Faça diagramas com a sua arquitetura. Seja da informação, dos fluxos de usuário, ou talvez do seu modelo de dados. Use o que precisar para que fique claro qual foi sua abordagem.
4. Se tiver tempo, faça entregáveis extras que possam impressionar o revisor. Exemplos: um app de frontend? Faça animações que façam o usuário experimentar algum sentimento novo. De backend? Explique como você faria a observabilidade do sistema. Surpreenda as pessoas.
## 4. Entrevistas onsite / _Onsite Interviews_
A última etapa antes da oferta é o que chamamos como dev na gringa de _onsite interview_.
Pode ser em um dia só, ou dividir em mais dias. Em especial quando são muitas etapas.
Elas podem ser uma variação dos vários tipos de entrevistas que vamos falar abaixo.
Se você quiser saber quais serão as etapas, recomendo você perguntar ao recrutador.
Quanto mais senior você é, menos ênfase tem as etapas de programação. A entrevista comportamental e de _system design_ passam a ter maior relevância.
### Algoritmos e estruturas de dados
Uma das fundações da computação são algoritmos e estruturas de dados.
Sim, são problemas que muitas vezes não são utilizados no nosso dia a dia.
Mas existe, sim, um motivo pelo qual empresas perguntam esse tipo de problema.
É um conhecimento que já está presente há **décadas**. E que continua sendo relevante até hoje.
Sim, pode ser que no dia a dia você não interaja diretamente com elas.
Mas elas estão, sim, presentes nos sistemas que utilizamos.
Pense nas redes sociais, que são usadas por bilhões de usuários diariamente.
A maneira eficiente de guardar os dados sobre conexões entre pessoas é um clássico exemplo da utilização de grafos.
Agora, vamos supor que você tenha um sistema distribuído. E você quer fazer o balanceamento de carga entre os vários nós do seu sistema. Quais algoritmos e estruturas vem ao caso aqui? Filas, _round-robin_ e _least-connections_ me vem a cabeça.
Então, pode ser que você não use essas estruturas no seu dia a dia.
Mas o conhecimento que elas trazem é algo que superou o teste do tempo.
Com isso a parte, vamos falar das dicas.
Problemas de algoritmos e estruturas de dados são sobre o reconhecimento de padrões.
Esses padrões vão ficam mais claros conforme você resolve mais problemas.
Então, quando você ver um problema novo, tente pensar em quais padrões podem ser aplicados a ele.
Vamos supor que você precise encontrar um caminho em algum tipo de rede ou grafo. Provavelmente será algum problema que será usado BFS ou DFS.
Ou que talvez você precise computar alguma _subarray_ ou _substring_. O padrão de _sliding window_ deve ser útil.
Lembre-se também de comunicar o seu raciocínio. Se tiver alguma dúvida, pergunte.
Também escreva alguns testes de caso que você possa executar no final do seu código. Procure pensar em potenciais _edge cases_ que podem vir a acontecer.
Recursos extras:
1. [NeetCode](https://devnagringa.substack.com/p/%5Bhttps://neetcode.io/%5D(https://neetcode.io/)): para algoritmos e estruturas de dados.
2. [LeetCode](https://devnagringa.substack.com/p/%5Bhttps://leetcode.com/%5D(https://leetcode.com/)): para problemas específicos das empresas que você está aplicando.
3. Livro: Cracking the Coding Interview por Gayle Laakmann McDowell.
Os recursos daqui são os mesmos que já falamos na entrevista técnica.
### _Pair Programming_
É um tipo de entrevista que tenta simular como você trabalharia com alguém no dia a dia do trabalho.
A lição mais importante aqui é a comunicação. Mostre que você é alguém que se preocupa com o código que está escrevendo. Em particular sobre como a pessoa que irá ler ele depois.
Lembre-se que código é muito mais lido do que ele é escrito.
Eu sinto que eu repito isso em basicamente todas as entrevistas.
Mas, sério, a comunicação aqui é muito importante. Assim como em todas as outras etapas. 😅
Especialmente se for uma vaga de dev na gringa. Tudo fica um pouco mais difícil quando você se comunica com uma língua diferente.
Por isso, a minha dica é respirar fundo sempre que você estiver se sentindo confuso.
Diga que você precisa pensar um pouco, se precisar. Mas, se possível, pense alto. Deixe que o seu entrevistador entenda o seu raciocínio.
Tome cuidado para não falar muito rápido. Essa é uma dificuldade minha até hoje, que venho tentado melhorar.
Mas, às vezes, quando fico nervoso, começo a acelerar e falar rápido. E, devido ao meu sotaque, pode ser que meu inglês fique difícil de entender.
Por isso, recomendo sempre estar atento a sua respiração. De modo que você não esteja correndo com o que você fala.
Recursos que podem ajudar:
1. Faça _side projects_. Se você gostar de programar no seu tempo livre, acho que essa é uma das melhores maneiras de aprender.
2. [GreatFrontEnd](https://devnagringa.substack.com/p/%5Bhttps://greatfrontend.com/%5D(https://greatfrontend.com/)): mencionando o GFE de novo. Acho que é uma ótima plataforma para praticar problemas de front.
3. Pratique com um amigo! Se tiver alguém que está praticando para entrevistas também, acho que é uma ótima lição.
### Projeto de Sistema / _System Design_
Essas entrevistas são as minhas favoritas.
É uma etapa que é altamente relevante pra qualquer engenheiro de software. Dev na gringa ou no Brasil mesmo.
Mostra a sua capacidade de projetar um sistema. Analisar quais serão o seu gargalo. Avaliar diferentes arquiteturas para se resolver um problema.
Eu gosto de pensar nessa entrevista como uma jornada.
Uma jornada onde o seu objetivo final é chegar a uma solução. Que será feita de maneira colaborativa com o seu entrevistador.
Aqui muitas vezes não existe uma resposta correta. Uma das principais razões pelo qual desenvolver software é difícil é porque não existe uma solução que resolva tudo.
É tudo sobre os _trade-offs_.
Para qualquer problema técnico complexo, sempre haverão diversas soluções.
O que é importante é que você saiba discutir as diferentes abordagens possíveis.
Tenha certeza de clarificar todos os requisitos do projeto. Funcionais e não-funcionais.
Trabalhe com o seu entrevistador para entender o escopo do projeto. Essa é uma entrevista com tempo limitado.
Muitas vezes o seu entrevistador quer ver o seu foco em uma parte específica do sistema.
Existem cinco princípios para um projeto de software que você deve estar atento:
1. Robustez
2. Escalabilidade
3. Performance
4. Extensibilidade
5. Resiliência
Quando você faz um sistema, essas são as principais áreas onde você pode encontrar problemas. Veja como o seu design se comporta em cada uma delas.
Recursos para consulta:
1. Livros: System Design Interview 1, 2 por Alex Xu, Sahn Lam. Designing Data-Intensive Applications por Martin Kleppmann.
2. Blogs de engenharia de empresas.
3. Canal do YouTube [ByteByteGo](https://devnagringa.substack.com/p/%5Bhttps://www.youtube.com/@ByteByteGo/videos%5D(https://www.youtube.com/@ByteByteGo/videos)).
### Entrevista de Valores e Comportamental
Junto com a entrevista de _system design_, essa também é uma das minhas etapas favoritas.
Pois é uma etapa onde você também tem a chance de entrevistar a empresa que você está pensando em trabalhar.
Venha com perguntas preparadas.
Em especial se for sua primeira entrevista como dev na gringa. Você pode ter dúvidas quanto a cultura, que talvez seja diferente de como é a sua empresa no Brasil.
Essa é uma oportunidade de você também se exibir. Falar sobre suas vitórias passadas. Sobre como você conseguiu influenciar seu time de uma maneira positiva.
Porém, algo que é importante lembrar é que raramente existem vitórias de **sucesso absoluto.** Muitas vezes, o sucesso é atingido com algumas falhas e deslizes no caminho.
Fale sobre estes deslizes. Deixe que o seu entrevistador veja que isso é um caso real. Infelizmente, não temos muitos conto de fadas no mundo da engenharia de software. Resolvemos problemas, mas também pensamos em o que poderíamos fazer diferente.
Traga essa perspectiva para o seu entrevistador. Deixe que ela veja sobre como você reflete sobre o seu passado.
Recursos:
1. Canal no Youtube [A Life Engineered](https://devnagringa.substack.com/p/%5Bhttps://www.youtube.com/@ALifeEngineered%5D(https://www.youtube.com/@ALifeEngineered)).
2. [Tech Interview Handbook](https://devnagringa.substack.com/p/%5Bhttps://www.techinterviewhandbook.org/behavioral-interview/%5D(https://www.techinterviewhandbook.org/behavioral-interview/)).
3. O método STAR. Use ele como um framework de como moldar as suas histórias.
## 5. Oferta
Parabéns por ter chegado até aqui! 🎉 🎉 🎉
Sim, a oferta é a etapa final! Mas ainda existem algumas coisas que podemos fazer aqui para deixar melhor.
Este artigo já está ficando grande, então vou falar a mensagem principal: **negocie o seu salário**.
Existem três mitos quanto à negociação:
1. "Minha oferta será cancelada se eu tentar negociar"
2. "Negociação faz com que eu pareça mesquinho"
3. "Alguém vai ganhar menos dinheiro se eu ganhar mais"
Nenhuma dessas frases é verdade.
Você não perde nada por negociar o seu salário.
Em algumas vezes, pode até ganhar. Por você mostrar o valor que você realmente acha que pode agregar a empresa.
[Aqui existe um bom resumo](https://www.techinterviewhandbook.org/negotiation-rules/) sobre as principais regras de negociação salarial.
## Considerações finais
Não leve o processo de entrevistas tão a sério.
É normal ser rejeitado. Não quer dizer que você é um engenheiro ruim. Ou que você nunca irá conseguir se tornar um dev na gringa.
Trate os processos seletivos como uma oportunidade de conversar com pessoas novas.
Se mostre interessado nos problemas delas. Compartilhe de experiências suas que você acha que podem ser relevantes.
Aprenda novas tecnologias no caminho. Descubra casos novos de engenharia que você não conhecia. Diferentes domínios tem diferentes desafios técnicos.
Tenha um interesse genuíno na empresa. **Ouça ativamente** o que seus entrevistadores te contam. O que os preocupa, e aquilo que os motiva.
Pratique a empatia. Se coloque no lugar deles, e procure entender o que eles estão procurando.
**Trate todo este processo como apenas uma** _**quest**_ **no enorme RPG que é a vida. Mesmo se ela der recompensas, ou falhar, você irá ganhar experiência da mesma forma.** | lucasheriques |
1,865,998 | Introduction to Time Series Analysis with Python | Introduction Time series analysis is a powerful tool for studying and predicting patterns... | 0 | 2024-05-27T00:32:36 | https://dev.to/kartikmehta8/introduction-to-time-series-analysis-with-python-15o1 | webdev, javascript, beginners, programming | ## Introduction
Time series analysis is a powerful tool for studying and predicting patterns in data that change over time. With the increasing availability of data and advancements in technology, it has become an essential skill for data analysts and researchers across various fields. Python, being a versatile and popular programming language, offers a wide range of tools and libraries for time series analysis. In this article, we will discuss the advantages, disadvantages, and features of conducting time series analysis with Python.
## Advantages
Python offers a user-friendly and efficient environment for time series analysis, as it allows for easy data manipulation, visualization, and modeling. Its vast array of libraries, such as Pandas, NumPy, and Matplotlib, provide powerful tools and functions for handling time series data. Moreover, Python's open-source community constantly develops new packages, making it a continuously improving platform. Additionally, Python's integration with other programming languages allows for seamless collaboration and integration of different tools and techniques.
## Disadvantages
As with any tool or technique, time series analysis with Python also has some limitations. The learning curve to master Python and its libraries may be challenging for beginners. Additionally, debugging errors and optimizing code can be time-consuming and require a deeper understanding of the programming language.
## Features
One of the significant features of using Python for time series analysis is its support for statistical modeling and forecasting. With libraries like StatsModels and Prophet, it is possible to analyze complex time series data, identify trends, and make accurate predictions. Furthermore, Python's machine learning libraries, such as scikit-learn and TensorFlow, enable the development of advanced forecasting models.
### Example of Time Series Analysis Using Python
```python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima_model import ARIMA
# Load dataset
data = pd.read_csv('time_series_data.csv', parse_dates=True, index_col='Date')
# Fit an ARIMA model
model = ARIMA(data['Value'], order=(1, 1, 1))
model_fit = model.fit(disp=0)
# Plot the results
plt.figure(figsize=(10, 7))
plt.plot(data['Value'], label='Original')
plt.plot(model_fit.fittedvalues, color='red', label='Fitted Values')
plt.title('Time Series Analysis using ARIMA')
plt.legend()
plt.show()
```
This example demonstrates how to perform time series analysis using the ARIMA model from the StatsModels library. It involves loading data, fitting the model, and visualizing the results.
## Conclusion
In conclusion, Python is a powerful and versatile language for conducting time series analysis. Its user-friendly environment, vast array of libraries, and support for advanced statistical modeling make it a popular choice among data analysts. While it has its limitations, the numerous advantages and continuous development of new packages make Python an efficient and valuable tool for studying time series data. | kartikmehta8 |
1,865,997 | Say Goodbye to Flaky Rendering & Animation Issues | Introduction User interface rendering and animations provide an application with an... | 0 | 2024-05-27T00:30:01 | https://dev.to/anurika_joy_c83cb5039b071/say-goodbye-to-flaky-rendering-animation-issues-h0 | softwareengineering, beginners, react, javascript |
## Introduction
User interface rendering and animations provide an application with an awesome and interactive user sensation. As amazing as this idea sounds, so is how vexing it can get when things go sideways. And one way wherein that circumstance could materialize is through trials that fluctuate.
How To Repair Flaky Trials in Rendering & Animation Maneuvers
User interface rendering and animations provide an application with an awesome and interactive user sensation. As amazing as this idea sounds, so is how vexing it can get when things go sideways. And one way wherein that circumstance could materialize is through trials that fluctuate.
There are definitely numerous motives behind flaky trials in rendering or cartoons; nevertheless, one of the prime reasons is timing.
For illustration, you might own a spring cartoon of a fastener showing. At present, trialing this might lead to flakiness, all due to the animation getting completed some nanoseconds too tardy as a result of a random backdrop managing process.
In this handbook, we’ll be utilizing Jest and React trialing libraries to portray real-world cases of trials for better comprehension. Nonetheless, you can tag along, regardless of your stack.
## Ground Origins
Flaky trials, in general, encompass rather a few communal causes. However, when getting precise about UI rendering and animations, here are the principal ground origins:
## Timing Predicaments
Animations by default often arrive with setTimeout delays or transition-duration attributes. These timings are at times what result in assertions flunking, leading to flakiness.
Take a glance at this trial for a component with an animation where its breadth gets enlarged with the tap of a fastener:
```
test("Box breadth increments", () => {
render();
const box = screen.getByTestId("box");
assume(box).toHaveStyle({ width: "70px" });
fireEvent.click(screen.getByRole("button"));
assume(box).toHaveStyle({ width: "100px" });
});
```
The catch right here is that after tapping the key to escalate the breadth, the assertion might execute before the animation of the dimension increment wraps up, subject to any timing occurrences.
Consequently, the prime predicament in rendering and animation trialing descends to guaranteeing that assertions are made after the animation has fully executed and not earlier. A nice tactic would be to wait for the animation to complete; in React trialing, this can be accomplished utilizing the use of waitFor.
## Environmental Dependencies
The system resources come into play in this instance. In a form, trials devised for rendering intricate animations can be contingent on system resources like CPU or memory.
At present, this won’t be an issue for machines that are adept. Nonetheless, if the machine has restricted resources, animation rendering could stumble and be less velvety, thereby initiating random trial failings.
Another illustration of environmental dependencies can be network connectivity. Presume you own an animation that hinges on retrieving external assets; this solo introduces sporadic factors as network oscillations can sway the animation behavior. A technique to mend this would be with the use of mocks.
## Libraries Dependencies
Oftentimes, animations employed are from libraries, as it is much quicker and more effective than authoring the code from scratch.
In React for instance, there are stacks of animation libraries like Framer Motion, React Spring, etc. Nevertheless, these libraries could prompt flaky trials when:
* the version of the third-party library and the ongoing version of the technology stack employed are not harmonious. This case is sometimes tacit, as blunders might not be exhibited, just that the tests outcomes appear to wobble.
* the animation libraries employed own dependencies that intercede with one another.
* the animation libraries contain interior bugs that haven’t been patched by the library developers which only materialize during trialing.
* developers use animation libraries in a technique it wasn’t purposed for. Remarkably enough, the library might accomplish the duty as anticipated but since it was employed inaccurately, trialing can furnish unpredictable outcomes.
##Rectifying Flaky Trials in Rendering & Animation
At present, to make this handbook more intricate and easier to grasp, we’ll present four real-world code cases and depict the incorrect way precipitating flaky trials and the correct way to remedy them.
## Rendering of a Newsletter Prompt
In this instance, this component renders a simple form with an email input and a subscribe button. When submitted, it logs the email and resets the state.
```
function NewsletterPrompt() {
const [email, setEmail] = useState("");
const [subscribed, setSubscribed] = useState(false);
const handleSubmit = (e) => {
e.preventDefault();
setSubscribed(true);
};
return (
{!subscribed ? (
<h2>Subscribe to Bulletin</h2> setEmail(e.target.value)} /> Subscribe ) : (
Subscribed effectively
)}
); }
```
At present let’s script a trial for the component that’ll show how flakiness can transpire:
```
test("Bulletin southern renders and can be subscribed to", () => {
render();
const emailInput = screen.getByPlaceholderText("Email address...");
const subscribeButton = screen.getByText("Subscribe");
fireEvent.change(emailInput, { target: { value: "xyz@example.com" } });
fireEvent.click(subscribeButton);
assume(screen.getByText("Subscribed effectively")).toBeInTheDocument();
});
```
The predicament right here is that making assertions directly like this could run before the component even re-renders to show updates of the submitted email.
This trial is bound to be flaky because it relies on the component being rendered synchronously, which might not always be the case. As rendering can sometimes be asynchronous.
A mend for this trial would be something like this:
```
test("Bulletin southern renders and can be subscribed to", async () => {
render();
const emailInput = screen.getByPlaceholderText("Email address...");
const subscribeButton = screen.getByText("Subscribe");
fireEvent.change(emailInput, { target: { value: "xyz@example.com" } });
fireEvent.click(subscribeButton);
assume(
await screen.findByText("Subscribed effectively"),
).toBeInTheDocument();
});
```
In this mend, we employed `async/await` and the `screen.findByText `technique to anticipate and wait for the text content element to show up in the DOM, which would confirm that the component has forsooth re-rendered with the “Subscribed effectively” notification.
## An Animated Key
Let’s presume you own a fastener that animates its color from orange to blue when clicked and reverts to orange when clicked again.
```
export nonremovable function AnimatedButton() {
const [isAnimated, setIsAnimated] = useState(false);
const handleClick = () => {
setIsAnimated(!isAnimated);
};
const buttonStyle = {
dimension: "100px",
height: "50px",
backdropColor: isAnimated ? "blue" : "orange",
transition: "backdropColor 0.5s ease",
};
return (
Analyze
);
}
```
Now here’s a frequent but incorrect way to script the trial for this button color change, as it could evince flaky actions:
```
import { render, fireEvent } from "@testing-library/react";
import AnimatedButton from "./AnimatedButton";
test("background color changes", () => {
render();
const button = screen.getByRole("button", { name: "Animate" });
fireEvent.click(button);
assume(button).toHaveStyle({ backdropColor: "blue" });
fireEvent.click(button);
assume(button).toHaveStyle({ backdropColor: "orange" });
});
```
This trial appears truly straightforward; it renders the button, clicks it, and then asserts the awaited color changes. However, there’s a tad of a lax spot, which is where flakiness steps in.
The reason this trial might at times evince flaky outcomes is that after each click event, it assumes that the animation finishes immediately, as we aren’t assessing the timing of the animation before asserting the status of the button’s background color.
As an alternative, this would be the right way:
```
test("background color changes", async () => {
render();
const button = screen.getByRole("button", { name: "Animate" });
fireEvent.click(button);
await waitFor(() => assume(button).toHaveStyle({ backdropColor: "blue" }));
fireEvent.click(button);
await waitFor(() =>
assume(button).toHaveStyle({ backdropColor: "orange" }),
);
});
```
With this mere change of utilizing waitFor, we can be certain that the trial would permit the animation to be finalized before asserting the backdrop color of the button. This ensures that the trial assertion is in sync with the UI’s rendering update.
Rendering of a Basic Panorama
For this exemplar, let’s utilize a simple panorama component that when a fastener is clicked, the visibility of the panorama alters:
```
function AnimatedWindow() {
const [isApparent, setIsApparent] = useState(false);
const toggleVisibility = () => setIsApparent(!isApparent);
return (
Toggle Panorama {isApparent && Animated Panorama}
); }
```
Now as plain as this component is, trialing if it renders rightfully can grow into a hitch due to the animation.
Here is an incorrect way to script the trial:
```
test("Toggling animated panorama", () => {
render();
const toggleButton = screen.getByRole("button", { name: "Toggle Panorama" });
assume(screen.queryByTestId("animated-modal")).not.toBeInTheDocument();
fireEvent.click(toggleButton);
assume(screen.getByTestId("animated-modal")).toBeInTheDocument();
});
```
As we portrayed in the foregoing exemplar, this trial also asserts the presence of the panorama content straight away after the click event. Thus, due to the animations being asynchronous, this trial is bound to be a flaky one.
Here’s the right way:
```
test("Toggling animated panorama", async () => {
render();
const toggleButton = screen.getByRole("button", { name: "Toggle Panorama" });
assume(screen.queryByTestId("animated-modal")).not.toBeInTheDocument();
fireEvent.click(toggleButton);
await waitFor(() => {
assume(screen.queryByTestId("animated-modal")).toBeVisible();
});
fireEvent.click(toggleButton);
await waitFor(() => {
assume(screen.queryByTestId("animated-modal")).not.toBeInTheDocument();
});
});
```
In this mend, we employed waitFor to assert the panorama’s presence or absence visibility only after the animation has been finalized. This gives us the assurance that the trial is more dependable.
T
## actics to Minimize Flaky Trials in Rendering & Animation
So when scripting trials expressly for UI rendering and animations, here are some facets to look out for or what you should exploit rather to lessen the likelihood of flaky trials showing up:
Always scrutinize the trial logic scripted as it is one of the communal mistakes made as elucidated in the section above.
Network lags or fluctuations should be taken into account, and mock functions can be handy in fixing this.
When trialing on UI rendering, bypass utilizing DOM selectors like `.querySelector()` to fetch elements, rather employ the queries dispensed by the trialing library like getBy, queryBy, or findBy.
Assure that the version of the animation library employed is harmonious with the version of the tech stack employed.
Retain the rendering or animation trials in smaller units i.e. endeavor to only trial one component at a time. This is more capable and simpler to debug flakiness.
Comprehend when to utilize the apt assertion matchers, for instance when trialing animations, `toBeVisible()` is superior suited than `toBeInTheDocument()`.
Utilize waitFor for assertions and not for firing events.
You can utilize `jest.useFakeTimers()` as an alternative to waitFor for further control of trialing.
Some developers drop/disable animations when trialing, while it’s not advocated, it is an option.
## Conclusion
Flaky trials in rendering and animations can genuinely be intricate to manage with; but with a proper understanding of the communal causes exclusively timing complications, the flakiness of trials can be curtailed tremendously.
| anurika_joy_c83cb5039b071 |
1,865,993 | [Game of Purpose] Day 8 | Today I learned about auto materials. I started designing my first level. | 27,434 | 2024-05-27T00:18:08 | https://dev.to/humberd/game-of-purpose-day-8-3bab | gamedev | Today I learned about auto materials.
I started designing my first level.
| humberd |
1,865,992 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-05-27T00:17:50 | https://dev.to/othmane_belalami_0183ff59/my-pen-on-codepen-4bko | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Othmane-Belalami/pen/OJYRexx %} | othmane_belalami_0183ff59 |
1,860,737 | 10 Key Data Structures We Use Every Day | Data structures are like the building blocks for organizing information in our daily lives. While... | 0 | 2024-05-27T00:13:55 | https://dev.to/emmauche001/10-key-data-structures-we-use-every-day-2l42 | data, learning, datastructure | Data structures are like the building blocks for organizing information in our daily lives. While they might not be explicitly called out, these structures underlie many of the things we do. Here are 10 key data structures we use every day:
1. **Lists:** These are ordered collections of items, like a grocery list, a to-do list, or the songs in your music playlist. You can easily add, remove, or rearrange items on a list.
2. **Arrays:** Similar to lists, arrays hold a fixed number of items in a specific order. Imagine the buttons on a calculator or the channels on your TV – you access them by their position in the sequence.
3. **Stacks:** These follow a "Last In, First Out" (LIFO) principle. Think of a stack of plates – you can only add or remove plates from the top. This structure is used in things like browser history (you visit the most recently accessed page first) or when undoing actions on a computer program.
4. **Queues:** Unlike stacks, queues operate on a "First In, First Out" (FIFO) basis. Imagine a line at a coffee shop – the person who has been waiting the longest gets served first. Queues are used in waiting lists, task scheduling, and even traffic flow management (vehicles that enter the queue first exit first).
5. **Trees:** Hierarchical structures that mimic real-world trees. Imagine a family tree or an organizational chart. They represent relationships between items, with a root element at the top and branches (sub-elements) connecting to it.
6. **Graphs:** These represent connections between objects. Think of a social media network where users are connected to their friends, or a map where cities are connected by roads. Graphs help us visualize and analyze relationships between different entities.
7. **Hashes:** Used for fast retrieval of information. Imagine a phonebook – you look up a name (key) to find the corresponding phone number (value). Hash tables store data with unique keys for efficient access.
8. **Sets:** Collections of unique items, like the unique words in a document or the different types of fruits in a fruit basket. Sets ensure no duplicates exist within the collection.
9. **Associative Arrays (Dictionaries):** Similar to hash tables, these store key-value pairs but allow for more complex data types as values. Imagine a recipe book where the recipe name (key) is associated with a list of ingredients and instructions (value).
10. **Linked Lists:** These are linear data structures where elements (nodes) are not stored contiguously in memory. Each node holds data and a reference (link) to the next node in the sequence. They are useful for dynamic data (frequently changing size) like managing musical playlists or social media feeds.
Understanding these underlying data structures allows us to better appreciate the organization that underpins seemingly simple aspects of our daily lives.
Which data structure do you find most surprising in everyday use? Why? or Have you encountered any data structures in your hobbies or work that aren't on this list? Share your experiences!
| emmauche001 |
1,865,920 | FileSyncDrive | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-27T00:00:47 | https://dev.to/godwinagedah/filesyncdrive-3adf | devchallenge, awschallenge, amplify, fullstack | 1.
*This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
## What I Built
<!-- Tell us what your app does! -->
FileSyncDrive is an electron desktop app that listens for changes on a users local files and syncs to the cloud. it creates a folder "sync_folder" in the users home directory, any changes made to that folder will be reflected on the amplify storage.
## Demo
<!-- Share a link to your deployed solution on Amplify Hosting, and include some screenshots here. -->
Link to a shared file: https://main.d4c4zbq9x7suw.amplifyapp.com/?file=picture-submissions/70ec69fc-50d1-70f6-7731-0e68374df71b/sync_folder/New%20Text%20Document.txt
_i used the starter template for the shared file site, ran out of time_
[Desktop App Repo](https://github.com/Godwin9911/amplify_file_sync)
_*Building the .exe file was a challenge due to my limited hardware and time_
<figcaption>Login Amplify Authenticator Component</figcaption>
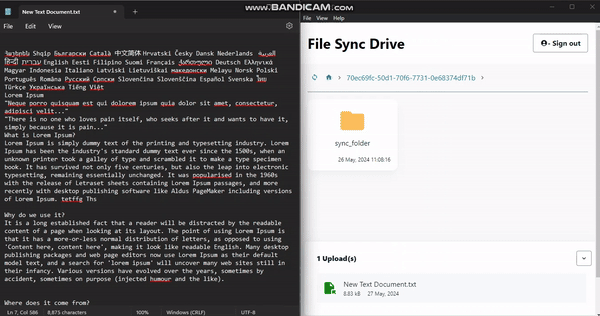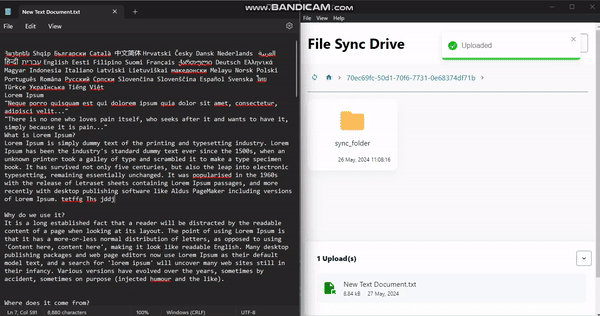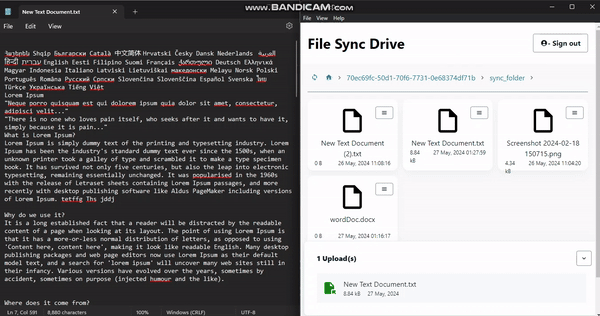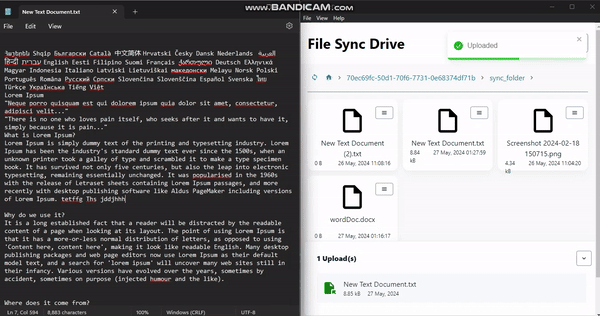
<figcaption>File Changes Synced, notice the time change.</figcaption>
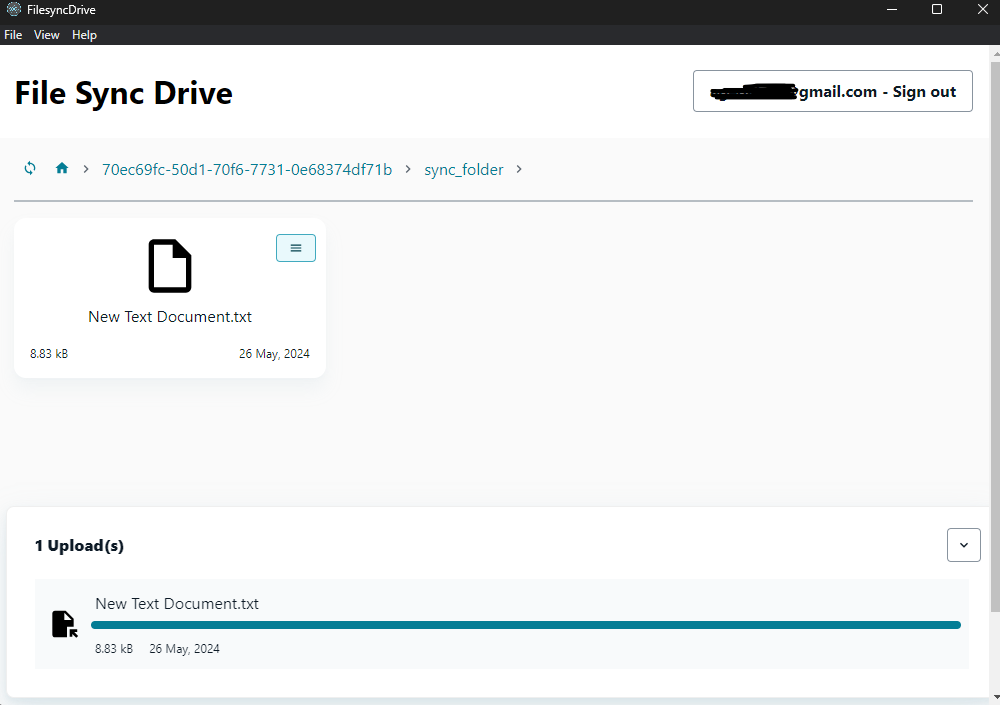
<figcaption>Screenshot 1</figcaption>
<figcaption>Screenshot 2</figcaption>
<figcaption>Screenshot 3</figcaption>
<figcaption>File link can be shared for users to access via the web</figcaption>
Tested on Windows 11
## Journey
<!-- Tell us about your process, the services you incorporated, what you learned, anything you are particularly proud of, what you hop to do next, etc. . -->
**Connected Components and/or Feature Full**
<!-- Let us know if you developed UI using Amplify connected components for UX patterns, and/or if your project includes all four features: data, authentication, serverless functions, and file storage. -->
### Amplify UI Components
[Amplify UI Components](https://ui.docs.amplify.aws/react/components) was used to quickly scaffold our UI. it contains all the components you'll mostly need for a UI.
### Authentication
[Amplify Authenticator](https://ui.docs.amplify.aws/react/connected-components/authenticator) was used to setup our Auth flow. it was a straight forward setup with a single react Component.
### File Storage
[Amplify Storage](https://docs.amplify.aws/react/build-a-backend/storage/) enabled us to instantly upload our modified files on local, also we can easily get our uploaded files from the storage as well as the download url.
In the future the storage space will be limited for the user, also social authentication will be added for easy sign up.
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- Don't forget to add a cover image (if you want). -->
[Desktop App Repo](https://github.com/Godwin9911/amplify_file_sync)
_*Building the .exe file was a challenge due to my limited hardware and time_
[Repo for shared file on the web](https://github.com/Godwin9911/amplify-vite-react-template)
<!-- Thanks for participating! --> | godwinagedah |
1,867,814 | Claim-Check Pattern with AWS Message Processing Framework for .NET and Aspire | TL;DR Learn how to use AWS.Messaging by implementing Claim-Check pattern. The... | 0 | 2024-06-03T09:08:56 | https://nikiforovall.github.io/dotnet/aws/2024/05/27/aws-claim-check-dotnet.html | dotnet, aws, aspnetcore, architecture | ---
title: Claim-Check Pattern with AWS Message Processing Framework for .NET and Aspire
published: true
date: 2024-05-27 00:00:00 UTC
tags: dotnet, aws, aspnetcore, architecture
canonical_url: https://nikiforovall.github.io/dotnet/aws/2024/05/27/aws-claim-check-dotnet.html
---
## TL;DR
Learn how to use [AWS.Messaging](https://www.nuget.org/packages/AWS.Messaging/) by implementing Claim-Check pattern.
> The Claim-Check pattern allows workloads to transfer payloads without storing the payload in a messaging system. The pattern stores the payload in an external data store and uses a “claim check” to retrieve the payload. The claim check is a unique, obscure token or key. To retrieve the payload, applications need to present the claim-check token to the external data store.
Source code: [https://github.com/NikiforovAll/aws-claim-check-dotnet](https://github.com/NikiforovAll/aws-claim-check-dotnet)
- [TL;DR](#tldr)
- [Introduction](#introduction)
- [When to use Claim-Check pattern?](#when-to-use-claim-check-pattern)
- [What is AWS.Messaging?](#what-is-awsmessaging)
- [Implementation](#implementation)
- [Goal](#goal)
- [Code](#code)
- [File Upload via API](#file-upload-via-api)
- [File Processing via Worker](#file-processing-via-worker)
- [OpenTelemetry support](#opentelemetry-support)
- [Conclusion](#conclusion)
- [References](#references)
## Introduction
> ☝️The blog post will focus on code implementation and usage of `AWS.Messaging` and `Aspire` and not on the details of the Claim-Check pattern.For more details I highly recommend seeing [Azure/Architecture Center/Claim-Check pattern](https://learn.microsoft.com/en-us/azure/architecture/patterns/claim-check)
Traditional messaging systems are optimized to manage a high volume of small messages and often have restrictions on the message size they can handle. Large messages not only risk exceeding these limits but can also degrade the performance of the entire system when the messaging system stores them.
The solution to this problem is to use the Claim-Check pattern, and don’t send large messages to the messaging system. Instead, send the payload to an external data store and generate a claim-check token for that payload. The messaging system sends a message with the claim-check token to receiving applications so these applications can retrieve the payload from the data store. The messaging system never sees or stores the payload.
<center>
<img src="https://nikiforovall.github.io/assets/claim-check/claim-check-diagram.svg" width="70%" style="margin: 15px;">
</center>
1. Payload
2. Save payload in data store.
3. Generate claim-check token and send message with claim-check token.
4. Receive message and read claim-check token.
5. Retrieve the payload.
6. Process the payload.
### When to use Claim-Check pattern?
The following scenarios are use cases for the Claim-Check pattern:
- Messaging system limitations: Use the Claim-Check pattern when message sizes surpass the limits of your messaging system. Offload the payload to external storage. Send only the message with its claim-check token to the messaging system.
- Messaging system performance: Use the Claim-Check pattern when large messages are straining the messaging system and degrading system performance.
For example, AWS SQS has a message size limit of 256 KiB. See [Amazon SQS message quotas](https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/quotas-messages.html) for more details.
## What is AWS.Messaging?
The _AWS Message Processing Framework for .NET_ is an AWS-native framework that simplifies the development of .NET message processing applications that use AWS services such as Amazon Simple Queue Service (SQS), Amazon Simple Notification Service (SNS), and Amazon EventBridge. The framework reduces the amount of boiler-plate code developers need to write, allowing you to focus on your business logic when publishing and consuming messages.
The Message Processing Framework supports the following activities and features:
- Sending messages to SQS and publishing events to SNS and EventBridge.
- Receiving and handling messages from SQS by using a long-running poller, which is typically used in background services. This includes managing the visibility timeout while a message is being handled to prevent other clients from processing it.
- Handling messages in AWS Lambda functions.
- FIFO (first-in-first-out) SQS queues and SNS topics.
- OpenTelemetry for logging.
For a good introductory blog post see [AWS Developer Tools Blog / Introducing the AWS Message Processing Framework for .NET (Preview)](https://aws.amazon.com/blogs/developer/introducing-the-aws-message-processing-framework-for-net-preview/)
## Implementation
### Goal
🎯 Assume we want to process pdf documents provided by users to extract key phrases and store these key phrases for further processing.
Here’s a step-by-step explanation of the process:
1. _File Submission_: A user submits a file through an API Gateway. This could be any document that needs to be processed, such as a PDF file.
2. _File Storage_: The API Gateway forwards the file to a REST API running on an EC2 instance. The API then stores the file in an S3 bucket and sends a message to an SNS (Simple Notification Service) topic with the location of the file in S3 (this is known as a claim-check pattern).
3. _Message Queuing_: The SNS topic puts the message into an SQS (Simple Queue Service) queue for processing. The API returns a 201 response to the API Gateway, which then returns a response to the user indicating that the file was successfully submitted.
4. _File Processing_: A background service running on another EC2 instance consumes the message from the SQS queue. This service retrieves the file from S3 and sends it to Amazon Textract for parsing.
5. _Text Extraction_: Amazon Textract loads the document, extracts the text, and returns the parsed content to the background service.
6. _Key Phrase Extraction_: The background service then sends the parsed content to Amazon Comprehend to extract key phrases.
7. _Result Storage_: The key phrases are then stored back in S3 by the background service. The service acknowledges the message in the SQS queue, removing it from the queue.
This workflow allows for the asynchronous processing of documents at scale. The user gets a quick response when they submit a file, and the heavy processing is done in the background, allowing the system to handle a large number of file submissions.
<center>
<img src="https://nikiforovall.github.io/assets/claim-check/sd-aws.png" width="90%" style="margin: 15px;">
</center>
❗🤔 Arguably, in the world of AWS, there are cloud-native alternatives to the canonical claim check pattern. For example, you can subscribe to S3 events from a lambda function, but my goal is demonstrate how to use AWS.Messaging and Claim-Check pattern implementation and not to provide reference solution to these problem.
### Code
The solution consist of _Api_, _Processor_ (Worker) components, and AWS resources defined via [CloudFormation](https://docs.aws.amazon.com/cloudformation/).
This application is based on Aspire integration for AWS. Basically, it bootstraps the the CloudFormation stack for your application during the `AppHost` startup.
```csharp
// AppHost/Program.cs
using Amazon;
var builder = DistributedApplication.CreateBuilder(args);
var awsConfig = builder.AddAWSSDKConfig().WithProfile("default").WithRegion(RegionEndpoint.USEast1);
var awsResources = builder
.AddAWSCloudFormationTemplate("DocumentSubmissionAppResources", "aws-resources.template")
.WithReference(awsConfig);
builder.AddProject<Projects.Api>("api").WithReference(awsResources);
builder.AddProject<Projects.Processor>("processor").WithReference(awsResources);
builder.Build().Run();
```
The code above is based on couple of NuGet packages:
- [Aspire.Hosting.AWS](https://www.nuget.org/packages/Aspire.Hosting.AWS) - Provides extension methods and resources definition for a .NET Aspire AppHost to configure the AWS SDK for .NET and AWS application resources.
- [Aspire.Hosting.AppHost](https://www.nuget.org/packages/Aspire.Hosting.AppHost) - Provides the core APIs and MSBuild logic for .NET Aspire AppHost projects.
To glue everything together, we need to take a look at CloudFormation template - “aws-resources.template”. The interesting part here is the **Outputs** section. It serves as a contract between your application and infrastructure defined through Aspire.
```json
{
"AWSTemplateFormatVersion": "2010-09-09",
"Parameters": {},
"Resources": {
// skipped content, see source code for more details.
},
"Outputs": {
"DocumentQueueUrl": {
"Value": {
"Ref": "DocumentQueue"
}
},
"DocumentTopicArn": {
"Value": {
"Ref": "DocumentTopic"
}
},
"DocumentBucketName": {
"Value": {
"Ref": "DocumentBucket"
}
}
}
}
```
In order to reference Outputs in our code I added next code:
```csharp
// ServiceDefaults/Extensions.cs
public static AwsResources AddAwsResources(this IHostApplicationBuilder builder)
{
var awsResources = builder.Configuration.GetSection("AWS:Resources").Get<AwsResources>()!;
// validate, consume at runtime via IOptions if needed.
builder
.Services.AddOptions<AwsResources>()
.Configure(options => builder.Configuration.Bind("AWS:Resources", options))
.ValidateOnStart();
return awsResources;
}
```
And the model:
```csharp
// ServiceDefaults/AwsResources.cs
public class AwsResources
{
[Required]
[Url]
public string DocumentQueueUrl { get; set; } = default!;
[Required]
public string? DocumentTopicArn { get; set; }
[Required]
public string? DocumentBucketName { get; set; }
}
```
Now once we have the infrastructure ready, we can take a look at the components.
#### File Upload via API
It is very intuitive and easy to work with `AWS.Messaging`, all we need is to define a publisher:
```csharp
// Program.cs
var builder = WebApplication.CreateBuilder(args);
builder.AddServiceDefaults();
var awsResources = builder.AddAwsResources();
builder.Services.AddAWSService<IAmazonS3>();
builder.Services.AddAWSMessageBus(messageBuilder =>
{
messageBuilder.AddMessageSource("DocumentSubmissionApi");
messageBuilder.AddSNSPublisher<DocumentSubmission>(awsResources.DocumentTopicArn);
});
var app = builder.Build();
app.MapUploadEndpoint();
app.Run();
```
Here is how to use it:
```csharp
app.MapPost(
"/upload",
async Task<Results<Created, BadRequest<string>>> (
IFormFile file,
[FromServices] IOptions<AwsResources> resources,
[FromServices] IAmazonS3 s3Client,
[FromServices] IMessagePublisher publisher,
[FromServices] TimeProvider timeProvider,
[FromServices] ILogger<Program> logger
) =>
{
if (file is null or { Length: 0 })
{
return TypedResults.BadRequest("No file uploaded.");
}
using var stream = file.OpenReadStream();
var bucketName = resources.Value.DocumentBucketName;
var key = Guid.NewGuid().ToString();
await s3Client.PutObjectAsync(
new PutObjectRequest
{
BucketName = bucketName,
Key = key,
InputStream = stream
}
);
var response = await publisher.PublishAsync(
new DocumentSubmission { CreatedAt = timeProvider.GetLocalNow(), Location = key }
);
logger.LogInformation("Published message with id {MessageId}", response.MessageId);
return TypedResults.Created();
}
);
```
#### File Processing via Worker
Note, in this case we need to provide an SQS Queue Url to listen to.
```csharp
// Program.cs
var builder = Host.CreateApplicationBuilder(args);
builder.AddServiceDefaults();
var awsResources = builder.AddAwsResources();
builder.Services.AddAWSService<IAmazonTextract>();
builder.Services.AddAWSService<IAmazonComprehend>();
builder.Services.AddAWSService<IAmazonS3>();
builder.Services.AddAWSMessageBus(builder =>
{
builder.AddSQSPoller(awsResources.DocumentQueueUrl);
builder.AddMessageHandler<DocumentSubmissionHandler, DocumentSubmission>();
});
builder.Build().Run();
```
Here is the handler:
```csharp
public class DocumentSubmissionHandler(
IAmazonTextract amazonTextractClient,
IAmazonComprehend amazonComprehendClient,
IAmazonS3 s3Client,
IOptions<AwsResources> resources,
ILogger<DocumentSubmissionHandler> logger
) : IMessageHandler<DocumentSubmission>
{
public async Task<MessageProcessStatus> HandleAsync(
MessageEnvelope<DocumentSubmission> messageEnvelope,
CancellationToken token = default
)
{
logger.LogInformation("Received message - {MessageId}", messageEnvelope.Id);
var bucketName = resources.Value.DocumentBucketName;
var key = messageEnvelope.Message.Location;
var textBlocks = await this.AnalyzeDocumentAsync(bucket, key, token);
var keyPhrases = await this.DetectKeyPhrasesAsync(textBlocks, token);
await this.StorKeyPhrases(keyPhrases, bucket, key, token);
return MessageProcessStatus.Success();
}
}
```
#### OpenTelemetry support
The awesome thing about `Aspire` and `AWS.Messaging` is the native OpenTelemetry support, here is how to add `AWS.Messaging` instrumentation:
```csharp
// ServiceDefaults/Extensions.cs
public static IHostApplicationBuilder ConfigureOpenTelemetry(
this IHostApplicationBuilder builder
)
{
builder.Logging.AddOpenTelemetry(logging =>
{
logging.IncludeFormattedMessage = true;
logging.IncludeScopes = true;
});
builder
.Services.AddOpenTelemetry()
.WithMetrics(metrics =>
{
metrics
.AddAspNetCoreInstrumentation()
.AddHttpClientInstrumentation()
.AddRuntimeInstrumentation();
})
.WithTracing(tracing =>
{
tracing
.AddAspNetCoreInstrumentation()
.AddHttpClientInstrumentation()
.AddAWSInstrumentation() // <-- add this
.AddAWSMessagingInstrumentation(); // <-- and this
});
builder.AddOpenTelemetryExporters();
return builder;
}
```
The result of file upload from Aspire Dashboard:
<center>
<img src="https://nikiforovall.github.io/assets/claim-check/trace-claim-check.png" style="margin: 15px;">
</center>
💡 `Aspire` is great for investigating how distributed systems work. We can use it to deepen our understanding of Claim-Check pattern in our case.
## Conclusion
In conclusion, leveraging the power of `AWS.Messaging` coupled with `Aspire` can significantly streamline the process of .NET and AWS Cloud development. These tools simplify the complexities associated with development of distributed systems.
## References
1. [https://github.com/awslabs/aws-dotnet-messaging](https://github.com/awslabs/aws-dotnet-messaging)
2. [https://aws.amazon.com/blogs/developer/introducing-the-aws-message-processing-framework-for-net-preview/](https://aws.amazon.com/blogs/developer/introducing-the-aws-message-processing-framework-for-net-preview/)
3. [https://learn.microsoft.com/en-us/azure/architecture/patterns/claim-check](https://learn.microsoft.com/en-us/azure/architecture/patterns/claim-check)
4. [https://docs.aws.amazon.com/sdk-for-net/v3/developer-guide/msg-proc-fw.html](https://docs.aws.amazon.com/sdk-for-net/v3/developer-guide/msg-proc-fw.html)
5. [https://www.enterpriseintegrationpatterns.com/patterns/messaging/StoreInLibrary.html](https://www.enterpriseintegrationpatterns.com/patterns/messaging/StoreInLibrary.html)
6. [https://docs.aws.amazon.com/prescriptive-guidance/latest/automated-pdf-analysis-solution/welcome.html](https://docs.aws.amazon.com/prescriptive-guidance/latest/automated-pdf-analysis-solution/welcome.html) | nikiforovall |
1,865,990 | The Watchful Eye: CCTV Trends and Tips | Lights, Camera, Monitoring! A Manual to CCTV Systems CCTV technology is used as a watch... | 0 | 2024-05-26T23:55:24 | https://dev.to/liong/cctv-installation-2gch | cctvinstallationmalaysia, pasangcctv, cctvrumah, cctvinstallationkl |
## Lights, Camera, Monitoring! A Manual to CCTV Systems
CCTV technology is used as a watch guard for an area or place. This is similar to supervision and it is general with both benefits and arguments. In this blog, we are going to get an ide of the benefits and problems of CCTV with some real-life examples.
## Benefits of CCTV:
This technology has been so much helpful that it has made our lives easier by providing protection and much more. It includes benefits like:
● **Crime prevention:** CCTV cameras can remove criminal activity. When the criminals got to know that they were recorded they did not take risks in committing crime.
● **Helps in criminal investigations:** A single footage from CCTV cameras can help identify suspects, vehicles, and details of crimes and provide important evidence for investigations. This increases the chances of solving crimes.
● **Increased security for businesses and properties:** This technology of cameras provides round-the-clock monitoring of commercial areas, helping remove theft, robbery, vandalism, etc. They also monitor employee conduct and activities.
● **Safety and protection in public places:** The presence of cameras in streets, parks, ATMs, etc. enhances safety. Footage assists in cases of accidents, crimes, missing persons, and crowd control during events.
● **Promotes faster emergency response:** CCTV surveillance helps emergency services quickly respond to incidents like accidents, crimes, fires, and health issues by live monitoring of camera feeds.
● **Insurance fraud:** Recording activities through video evidence makes fraud insurance claims difficult and supports genuine claims in case of documented losses or damages.
● **Improves responsibility:** The presence of cameras boosts responsible behavior and responsibility. People are less likely to get in improper conduct if they know it is being recorded.
## Benefits of CCTV (Examples)
● In London, vehicle theft and robbery dipped 50% after large-scale [CCTV installation](https://ithubtechnologies.com/cctv-rumah/?utm_source=dev.to%2F&utm_campaign=cctv&utm_id=Offpageseo+2024https://ithubtechnologies.com/cctv-rumah/?utm_source=dev.to%2F&utm_campaign=cctv&utm_id=Offpageseo+2024). In Delhi, cameras helped catch a serial molester assaulting over 80 women.
● In Florida, footage identified a jogger who assaulted an elderly woman, leading to his quick arrest. In Sydney, armed robbery images from an ATM camera convicted a culprit within a week.
## **Handling CCTV:**
Handling CCTV surveillance is important to protect personal privacy and prevent any possible misuse of this technology. The government has passed data privacy laws governing how CCTV systems should be operated. Some key parts that laws typically cover include selecting clear guidelines around where and how cameras can be deployed in public spaces, how footage can be stored and accessed, and for how long recordings are kept. Rules may also require the camera operators to provide proper signage informing the public that they are under surveillance.
Independent oversight authorities are also important to ensure CCTV programs are regularly for legal use, address public complaints, and impose penalties or restrictions in case of violations. As CCTV and analytical technologies continue advancing rapidly, regulations need to maintain pace and balance security benefits with individual rights through principles of necessity, proportionality, and transparency.
## Legal and honest issues
The use of CCTV grows legal issues regarding privacy and civil rights. There are laws handling management and data privacy but they vary greatly between jurisdictions. The major issues include whether public or private CCTV filming requires permission, how long footage can be stored, and who can access recordings. Unauthorized use of facial recognition also raises privacy concerns.
Systems need strict controls to prevent potential biases and misuse of footage. For example, CCTV should not be used for racial profiling. Transparent policies and oversight are necessary to ensure legal and ethical use. Privacy impact assessments also help address legal and ethical risks.
## Improvements in CCTV technology
Recent technologies have improved CCTV abilities. IP cameras with WiFi allow remote, wireless placement, and live streaming. The infrared cameras allow 24/7 monitoring irrespective of lighting conditions. AI-powered analytics can detect abnormalities, automatically track objects, and recognize license plates. Thermal cameras can see in total darkness. Facial recognition is gaining ground but also fuss due to privacy importance. When combined with other technologies like drones and automated number plate recognition, CCTV is more effective yet risks amplifying mass surveillance concerns if used without management and clearness regarding data usage. Standards and regulations need to fix pace with innovation to manage the implications of new capabilities.
## Implementing a useful CCTV system
It is important to plan CCTV deployment thoughtfully based on identified security objectives and within legal compliance. Key steps involve assessing locations based on their vulnerabilities and footfall via crime mapping, obtaining required permits, purchasing high-quality certified equipment, and installing cameras discreetly yet visibly at optimal points with clear lines of sight.
Procedures for operating, monitoring, recording, storing, and sharing footage must be documented along with defined retention periods. Access controls ensure recordings are not altered or leaked. Signs inform the public of surveillance. Periodic reviews evaluate if the CCTV system requires changes to remain effective and legal as per evolving circumstances. Good documentation and standard processes deliver a balanced, optimized CCTV security strategy over time.
## Future Trends:
CCTV technology is rapidly growing and becoming more advanced and combined with other systems. In the coming years, some trends in this domain include the increasing use of AI-powered video analytics for automatic detection of 'events' and facial recognition. Networked IP cameras will become smarter with computing capabilities. Integration of CCTV footage with data from IoT sensors and devices is expected to generate deeper insights. Thermal and 360-degree cameras will provide more comprehensive coverage. Miniature cameras and drones will enable aerial surveillance. Automated license plate readings will likely expand. However, privacy issues related to the mass collection and use of biometric data still need addressing. While predictive policing aids may emerge, overreach risks undermine community trust if not regulated carefully with transparency. Overall, CCTV is poised to become more autonomous yet oversight will be crucial to maximize benefits responsibly.
## Conclusion
It can be summarized that with responsible usage and transparent oversight, CCTV can aid safety. However, left unregulated it risks enabling mass surveillance and curbing civil liberties. Sustainable solutions balance both security and privacy concerns through proportionate, legal, and transparent systems. | liong |
1,865,989 | IP-Adapter-FaceID-PlusV2–0 Shot Face Transfer — Auto Installer & Gradio App — Massed Compute, RunPod, Kaggle, Windows | The zip file contains installers for Windows, RunPod, Massed Compute and a free Kaggle account... | 0 | 2024-05-26T23:55:14 | https://dev.to/furkangozukara/ip-adapter-faceid-plusv2-0-shot-face-transfer-auto-installer-gradio-app-massed-compute-runpod-kaggle-windows-2m20 | beginners, tutorial, ai, opensource | <p style="margin-left:0px;">The zip file contains installers for Windows, RunPod, Massed Compute and a free Kaggle account notebook</p>
<p style="margin-left:0px;">It generates a VENV and install everything inside it. Works with Python 3.10.x — I suggest 3.10.11</p>
<p style="margin-left:0px;">Also you need C++ tools and Git. You can follow this tutorial to install all : <a target="_blank" rel="noopener noreferrer" href="https://youtu.be/-NjNy7afOQ0"><u>https://youtu.be/-NjNy7afOQ0</u></a></p>
<p style="margin-left:0px;">Updated 27 May 2024 : <a target="_blank" rel="noopener noreferrer" href="https://www.patreon.com/posts/95759342"><u>https://www.patreon.com/posts/95759342</u></a></p>
<p style="margin-left:auto;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/0*Mnq5rE_OL0fqCUrd.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/0*Mnq5rE_OL0fqCUrd.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/0*Mnq5rE_OL0fqCUrd.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/0*Mnq5rE_OL0fqCUrd.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/0*Mnq5rE_OL0fqCUrd.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/0*Mnq5rE_OL0fqCUrd.png 1100w, https://miro.medium.com/v2/resize:fit:1400/format:webp/0*Mnq5rE_OL0fqCUrd.png 1400w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 700px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/0*Mnq5rE_OL0fqCUrd.png 640w, https://miro.medium.com/v2/resize:fit:720/0*Mnq5rE_OL0fqCUrd.png 720w, https://miro.medium.com/v2/resize:fit:750/0*Mnq5rE_OL0fqCUrd.png 750w, https://miro.medium.com/v2/resize:fit:786/0*Mnq5rE_OL0fqCUrd.png 786w, https://miro.medium.com/v2/resize:fit:828/0*Mnq5rE_OL0fqCUrd.png 828w, https://miro.medium.com/v2/resize:fit:1100/0*Mnq5rE_OL0fqCUrd.png 1100w, https://miro.medium.com/v2/resize:fit:1400/0*Mnq5rE_OL0fqCUrd.png 1400w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 700px"><img class="image_resized" style="height:auto;width:680px;" src="https://miro.medium.com/v2/resize:fit:1313/0*Mnq5rE_OL0fqCUrd.png" alt="" width="700" height="304">
</picture>
</p>
<p style="margin-left:0px;">21 January 2024 Update<br>SDXL model upgraded to ip-adapter-faceid-plusv2_sd15<br>Kaggle Notebook upgraded to V3 and supports SDXL now</p>
<p style="margin-left:0px;">First of all I want to thank you so much for this amazing model.</p>
<p style="margin-left:0px;">I have spent over 1 week to code the Gradio and prepare the video. I hope you let this thread remain and even add to the Readme file.</p>
<p style="margin-left:0px;">After video has been published I even added face embedding caching mechanism. So now it will calculate face embedding vector only 1 time for each image, thus super speed up the image generation.</p>
<p style="margin-left:0px;"><a target="_blank" rel="noopener noreferrer" href="https://youtu.be/rjXsJ24kQQg"><u>Instantly Transfer Face By Using IP-Adapter-FaceID: Full Tutorial & GUI For Windows, RunPod & Kaggle</u></a></p>
<p style="margin-left:auto;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/0*evwUUOU49rbRNVJq.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/0*evwUUOU49rbRNVJq.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/0*evwUUOU49rbRNVJq.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/0*evwUUOU49rbRNVJq.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/0*evwUUOU49rbRNVJq.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/0*evwUUOU49rbRNVJq.png 1100w, https://miro.medium.com/v2/resize:fit:960/format:webp/0*evwUUOU49rbRNVJq.png 960w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 480px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/0*evwUUOU49rbRNVJq.png 640w, https://miro.medium.com/v2/resize:fit:720/0*evwUUOU49rbRNVJq.png 720w, https://miro.medium.com/v2/resize:fit:750/0*evwUUOU49rbRNVJq.png 750w, https://miro.medium.com/v2/resize:fit:786/0*evwUUOU49rbRNVJq.png 786w, https://miro.medium.com/v2/resize:fit:828/0*evwUUOU49rbRNVJq.png 828w, https://miro.medium.com/v2/resize:fit:1100/0*evwUUOU49rbRNVJq.png 1100w, https://miro.medium.com/v2/resize:fit:960/0*evwUUOU49rbRNVJq.png 960w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 480px"><img class="image_resized" style="height:auto;width:480px;" src="https://miro.medium.com/v2/resize:fit:900/0*evwUUOU49rbRNVJq.png" alt="" width="480" height="270">
</picture>
</p>
<p style="margin-left:0px;">chapters are like below</p>
<p style="margin-left:0px;">0:00 Introduction to IP-Adapter-FaceID full tutorial<br>2:19 Requirements to use IP-Adapter-FaceID gradio Web APP<br>2:45 Where the Hugging Face models are downloaded by default on Windows<br>3:12 How to change folder path where the Hugging Face models are downloaded and cached<br>3:39 How to install IP-Adapter-FaceID Gradio Web APP and use on Windows<br>5:35 How to start the IP-Adapter-FaceID Web UI after the installation<br>5:46 How to use Stable Diffusion XL (SDXL) models with IP-Adapter-FaceID<br>5:56 How to select your input face and start generating 0-shot face transferred new amazing images<br>6:06 What does each option on the Web UI do explanations<br>6:44 What are those dropdown menu models and their meaning<br>7:50 How to use custom and local models with custom model path<br>8:09 How to add custom models and local models into your Web UI dropdown menu permanently<br>8:52 How to use a CivitAI model in IP-Adapter-FaceID web APP<br>9:17 How to convert CKPT or Safetensors model files into diffusers format<br>10:05 How to use diffusers exported model in custom model path input<br>10:24 How to download generated images and also where the generated images are saved<br>10:40 How to use an SDXL mode<br>11:37 How to permanently add your custom local models into your Web APP models dropdown list<br>13:28 How to install and use IP-Adapter-FaceID gradio Web APP on RunPod<br>15:39 How to start IP-Adapter-FaceID gradio Web APP on RunPod after the installation<br>16:02 What you need to be careful when using on RunPod or on Kaggle<br>16:43 How to use a network storage on RunPod to permanently keep storage between pods<br>17:17 How to edit web app on RunPod and add any model to UI permanently<br>17:46 How to kill started Web UI instance on RunPod<br>18:08 How to install fuser command on RunPod on Linux<br>19:01 How to use custom CivitAI model on RunPod with IP-Adapter-FaceID<br>20:00 If wget method from CivitAI fails how to make it work on RunPod or on Kaggle<br>20:34 How to delete files on RunPod properly<br>20:58 How to convert CKPT or Safetensors checkpoints into diffusers on RunPod<br>22:58 Showing example of SD 1.5 model conversion on RunPod<br>24:18 How to install and use IP-Adapter-FaceID gradio Web APP on a Free Kaggle notebook<br>26:10 How to download custom models into the temp directory of Kaggle to use on the Web APP<br>26:47 How to get your token and activate it to use Gradio app on Kaggle<br>27:05 After auth token set how to start Web UI on Kaggle<br>28:26 How to convert a custom CivitAI or any model into Diffusers on Kaggle to use<br>29:23 How to download all the generated images on a Kaggle notebook with 1 click<br>30:12 Where to find our Discord channel link: <a target="_blank" rel="noopener noreferrer" href="https://discord.com/servers/software-engineering-courses-secourses-772774097734074388"><u>https://discord.com/servers/software-engineering-courses-secourses-772774097734074388</u></a></p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*ah9mEnw7PJP_qaIWfPzwhg.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*ah9mEnw7PJP_qaIWfPzwhg.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*ah9mEnw7PJP_qaIWfPzwhg.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*ah9mEnw7PJP_qaIWfPzwhg.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*ah9mEnw7PJP_qaIWfPzwhg.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*ah9mEnw7PJP_qaIWfPzwhg.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*ah9mEnw7PJP_qaIWfPzwhg.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*ah9mEnw7PJP_qaIWfPzwhg.png 640w, https://miro.medium.com/v2/resize:fit:720/1*ah9mEnw7PJP_qaIWfPzwhg.png 720w, https://miro.medium.com/v2/resize:fit:750/1*ah9mEnw7PJP_qaIWfPzwhg.png 750w, https://miro.medium.com/v2/resize:fit:786/1*ah9mEnw7PJP_qaIWfPzwhg.png 786w, https://miro.medium.com/v2/resize:fit:828/1*ah9mEnw7PJP_qaIWfPzwhg.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*ah9mEnw7PJP_qaIWfPzwhg.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*ah9mEnw7PJP_qaIWfPzwhg.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*ah9mEnw7PJP_qaIWfPzwhg.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*NrsXYCd0Bnnlxf9WtJcI3g.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*NrsXYCd0Bnnlxf9WtJcI3g.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*NrsXYCd0Bnnlxf9WtJcI3g.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*NrsXYCd0Bnnlxf9WtJcI3g.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*NrsXYCd0Bnnlxf9WtJcI3g.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*NrsXYCd0Bnnlxf9WtJcI3g.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*NrsXYCd0Bnnlxf9WtJcI3g.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*NrsXYCd0Bnnlxf9WtJcI3g.png 640w, https://miro.medium.com/v2/resize:fit:720/1*NrsXYCd0Bnnlxf9WtJcI3g.png 720w, https://miro.medium.com/v2/resize:fit:750/1*NrsXYCd0Bnnlxf9WtJcI3g.png 750w, https://miro.medium.com/v2/resize:fit:786/1*NrsXYCd0Bnnlxf9WtJcI3g.png 786w, https://miro.medium.com/v2/resize:fit:828/1*NrsXYCd0Bnnlxf9WtJcI3g.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*NrsXYCd0Bnnlxf9WtJcI3g.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*NrsXYCd0Bnnlxf9WtJcI3g.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*NrsXYCd0Bnnlxf9WtJcI3g.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*FkRLex1h9xbcwK_5rWkTag.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*FkRLex1h9xbcwK_5rWkTag.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*FkRLex1h9xbcwK_5rWkTag.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*FkRLex1h9xbcwK_5rWkTag.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*FkRLex1h9xbcwK_5rWkTag.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*FkRLex1h9xbcwK_5rWkTag.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*FkRLex1h9xbcwK_5rWkTag.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*FkRLex1h9xbcwK_5rWkTag.png 640w, https://miro.medium.com/v2/resize:fit:720/1*FkRLex1h9xbcwK_5rWkTag.png 720w, https://miro.medium.com/v2/resize:fit:750/1*FkRLex1h9xbcwK_5rWkTag.png 750w, https://miro.medium.com/v2/resize:fit:786/1*FkRLex1h9xbcwK_5rWkTag.png 786w, https://miro.medium.com/v2/resize:fit:828/1*FkRLex1h9xbcwK_5rWkTag.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*FkRLex1h9xbcwK_5rWkTag.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*FkRLex1h9xbcwK_5rWkTag.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*FkRLex1h9xbcwK_5rWkTag.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*kEgIfYbddAzvibg6oDNcrw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*kEgIfYbddAzvibg6oDNcrw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*kEgIfYbddAzvibg6oDNcrw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*kEgIfYbddAzvibg6oDNcrw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*kEgIfYbddAzvibg6oDNcrw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*kEgIfYbddAzvibg6oDNcrw.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*kEgIfYbddAzvibg6oDNcrw.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*kEgIfYbddAzvibg6oDNcrw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*kEgIfYbddAzvibg6oDNcrw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*kEgIfYbddAzvibg6oDNcrw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*kEgIfYbddAzvibg6oDNcrw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*kEgIfYbddAzvibg6oDNcrw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*kEgIfYbddAzvibg6oDNcrw.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*kEgIfYbddAzvibg6oDNcrw.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*kEgIfYbddAzvibg6oDNcrw.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*vuSe7TMcBwEWt6yhm1wv3g.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*vuSe7TMcBwEWt6yhm1wv3g.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*vuSe7TMcBwEWt6yhm1wv3g.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*vuSe7TMcBwEWt6yhm1wv3g.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*vuSe7TMcBwEWt6yhm1wv3g.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*vuSe7TMcBwEWt6yhm1wv3g.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*vuSe7TMcBwEWt6yhm1wv3g.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*vuSe7TMcBwEWt6yhm1wv3g.png 640w, https://miro.medium.com/v2/resize:fit:720/1*vuSe7TMcBwEWt6yhm1wv3g.png 720w, https://miro.medium.com/v2/resize:fit:750/1*vuSe7TMcBwEWt6yhm1wv3g.png 750w, https://miro.medium.com/v2/resize:fit:786/1*vuSe7TMcBwEWt6yhm1wv3g.png 786w, https://miro.medium.com/v2/resize:fit:828/1*vuSe7TMcBwEWt6yhm1wv3g.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*vuSe7TMcBwEWt6yhm1wv3g.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*vuSe7TMcBwEWt6yhm1wv3g.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*vuSe7TMcBwEWt6yhm1wv3g.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*NFeyHv-nWYvGc3NKQhtRnw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*NFeyHv-nWYvGc3NKQhtRnw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*NFeyHv-nWYvGc3NKQhtRnw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*NFeyHv-nWYvGc3NKQhtRnw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*NFeyHv-nWYvGc3NKQhtRnw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*NFeyHv-nWYvGc3NKQhtRnw.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*NFeyHv-nWYvGc3NKQhtRnw.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*NFeyHv-nWYvGc3NKQhtRnw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*NFeyHv-nWYvGc3NKQhtRnw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*NFeyHv-nWYvGc3NKQhtRnw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*NFeyHv-nWYvGc3NKQhtRnw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*NFeyHv-nWYvGc3NKQhtRnw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*NFeyHv-nWYvGc3NKQhtRnw.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*NFeyHv-nWYvGc3NKQhtRnw.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*NFeyHv-nWYvGc3NKQhtRnw.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*R7prXIUhSq0M5hMiQP8lVw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*R7prXIUhSq0M5hMiQP8lVw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*R7prXIUhSq0M5hMiQP8lVw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*R7prXIUhSq0M5hMiQP8lVw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*R7prXIUhSq0M5hMiQP8lVw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*R7prXIUhSq0M5hMiQP8lVw.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*R7prXIUhSq0M5hMiQP8lVw.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*R7prXIUhSq0M5hMiQP8lVw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*R7prXIUhSq0M5hMiQP8lVw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*R7prXIUhSq0M5hMiQP8lVw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*R7prXIUhSq0M5hMiQP8lVw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*R7prXIUhSq0M5hMiQP8lVw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*R7prXIUhSq0M5hMiQP8lVw.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*R7prXIUhSq0M5hMiQP8lVw.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*R7prXIUhSq0M5hMiQP8lVw.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*AH7zOussEIyL3e3bu-xMIQ.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*AH7zOussEIyL3e3bu-xMIQ.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*AH7zOussEIyL3e3bu-xMIQ.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*AH7zOussEIyL3e3bu-xMIQ.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*AH7zOussEIyL3e3bu-xMIQ.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*AH7zOussEIyL3e3bu-xMIQ.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*AH7zOussEIyL3e3bu-xMIQ.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*AH7zOussEIyL3e3bu-xMIQ.png 640w, https://miro.medium.com/v2/resize:fit:720/1*AH7zOussEIyL3e3bu-xMIQ.png 720w, https://miro.medium.com/v2/resize:fit:750/1*AH7zOussEIyL3e3bu-xMIQ.png 750w, https://miro.medium.com/v2/resize:fit:786/1*AH7zOussEIyL3e3bu-xMIQ.png 786w, https://miro.medium.com/v2/resize:fit:828/1*AH7zOussEIyL3e3bu-xMIQ.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*AH7zOussEIyL3e3bu-xMIQ.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*AH7zOussEIyL3e3bu-xMIQ.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*AH7zOussEIyL3e3bu-xMIQ.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*5y_1yqy576tW4uUOhWbMYw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*5y_1yqy576tW4uUOhWbMYw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*5y_1yqy576tW4uUOhWbMYw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*5y_1yqy576tW4uUOhWbMYw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*5y_1yqy576tW4uUOhWbMYw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*5y_1yqy576tW4uUOhWbMYw.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*5y_1yqy576tW4uUOhWbMYw.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*5y_1yqy576tW4uUOhWbMYw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*5y_1yqy576tW4uUOhWbMYw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*5y_1yqy576tW4uUOhWbMYw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*5y_1yqy576tW4uUOhWbMYw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*5y_1yqy576tW4uUOhWbMYw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*5y_1yqy576tW4uUOhWbMYw.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*5y_1yqy576tW4uUOhWbMYw.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*5y_1yqy576tW4uUOhWbMYw.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*AMCiD7uxhkZtyXFh8rmgsQ.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*AMCiD7uxhkZtyXFh8rmgsQ.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*AMCiD7uxhkZtyXFh8rmgsQ.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*AMCiD7uxhkZtyXFh8rmgsQ.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*AMCiD7uxhkZtyXFh8rmgsQ.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*AMCiD7uxhkZtyXFh8rmgsQ.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*AMCiD7uxhkZtyXFh8rmgsQ.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*AMCiD7uxhkZtyXFh8rmgsQ.png 640w, https://miro.medium.com/v2/resize:fit:720/1*AMCiD7uxhkZtyXFh8rmgsQ.png 720w, https://miro.medium.com/v2/resize:fit:750/1*AMCiD7uxhkZtyXFh8rmgsQ.png 750w, https://miro.medium.com/v2/resize:fit:786/1*AMCiD7uxhkZtyXFh8rmgsQ.png 786w, https://miro.medium.com/v2/resize:fit:828/1*AMCiD7uxhkZtyXFh8rmgsQ.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*AMCiD7uxhkZtyXFh8rmgsQ.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*AMCiD7uxhkZtyXFh8rmgsQ.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*AMCiD7uxhkZtyXFh8rmgsQ.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*Wh-u4r8z3umx0Ck77QAbuA.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*Wh-u4r8z3umx0Ck77QAbuA.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*Wh-u4r8z3umx0Ck77QAbuA.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*Wh-u4r8z3umx0Ck77QAbuA.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*Wh-u4r8z3umx0Ck77QAbuA.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*Wh-u4r8z3umx0Ck77QAbuA.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*Wh-u4r8z3umx0Ck77QAbuA.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*Wh-u4r8z3umx0Ck77QAbuA.png 640w, https://miro.medium.com/v2/resize:fit:720/1*Wh-u4r8z3umx0Ck77QAbuA.png 720w, https://miro.medium.com/v2/resize:fit:750/1*Wh-u4r8z3umx0Ck77QAbuA.png 750w, https://miro.medium.com/v2/resize:fit:786/1*Wh-u4r8z3umx0Ck77QAbuA.png 786w, https://miro.medium.com/v2/resize:fit:828/1*Wh-u4r8z3umx0Ck77QAbuA.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*Wh-u4r8z3umx0Ck77QAbuA.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*Wh-u4r8z3umx0Ck77QAbuA.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*Wh-u4r8z3umx0Ck77QAbuA.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*gMNBxKSAMcPw8sW9XqTEIg.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*gMNBxKSAMcPw8sW9XqTEIg.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*gMNBxKSAMcPw8sW9XqTEIg.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*gMNBxKSAMcPw8sW9XqTEIg.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*gMNBxKSAMcPw8sW9XqTEIg.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*gMNBxKSAMcPw8sW9XqTEIg.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*gMNBxKSAMcPw8sW9XqTEIg.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*gMNBxKSAMcPw8sW9XqTEIg.png 640w, https://miro.medium.com/v2/resize:fit:720/1*gMNBxKSAMcPw8sW9XqTEIg.png 720w, https://miro.medium.com/v2/resize:fit:750/1*gMNBxKSAMcPw8sW9XqTEIg.png 750w, https://miro.medium.com/v2/resize:fit:786/1*gMNBxKSAMcPw8sW9XqTEIg.png 786w, https://miro.medium.com/v2/resize:fit:828/1*gMNBxKSAMcPw8sW9XqTEIg.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*gMNBxKSAMcPw8sW9XqTEIg.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*gMNBxKSAMcPw8sW9XqTEIg.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*gMNBxKSAMcPw8sW9XqTEIg.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*bAs9r6NMQs5qjbF0pljv0w.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*bAs9r6NMQs5qjbF0pljv0w.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*bAs9r6NMQs5qjbF0pljv0w.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*bAs9r6NMQs5qjbF0pljv0w.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*bAs9r6NMQs5qjbF0pljv0w.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*bAs9r6NMQs5qjbF0pljv0w.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*bAs9r6NMQs5qjbF0pljv0w.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*bAs9r6NMQs5qjbF0pljv0w.png 640w, https://miro.medium.com/v2/resize:fit:720/1*bAs9r6NMQs5qjbF0pljv0w.png 720w, https://miro.medium.com/v2/resize:fit:750/1*bAs9r6NMQs5qjbF0pljv0w.png 750w, https://miro.medium.com/v2/resize:fit:786/1*bAs9r6NMQs5qjbF0pljv0w.png 786w, https://miro.medium.com/v2/resize:fit:828/1*bAs9r6NMQs5qjbF0pljv0w.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*bAs9r6NMQs5qjbF0pljv0w.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*bAs9r6NMQs5qjbF0pljv0w.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*bAs9r6NMQs5qjbF0pljv0w.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*u2k0zndKul_mtwD2SLFvaw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*u2k0zndKul_mtwD2SLFvaw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*u2k0zndKul_mtwD2SLFvaw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*u2k0zndKul_mtwD2SLFvaw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*u2k0zndKul_mtwD2SLFvaw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*u2k0zndKul_mtwD2SLFvaw.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*u2k0zndKul_mtwD2SLFvaw.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*u2k0zndKul_mtwD2SLFvaw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*u2k0zndKul_mtwD2SLFvaw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*u2k0zndKul_mtwD2SLFvaw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*u2k0zndKul_mtwD2SLFvaw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*u2k0zndKul_mtwD2SLFvaw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*u2k0zndKul_mtwD2SLFvaw.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*u2k0zndKul_mtwD2SLFvaw.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*u2k0zndKul_mtwD2SLFvaw.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*hTTjsnHv0BpDy23ILm6pGw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*hTTjsnHv0BpDy23ILm6pGw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*hTTjsnHv0BpDy23ILm6pGw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*hTTjsnHv0BpDy23ILm6pGw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*hTTjsnHv0BpDy23ILm6pGw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*hTTjsnHv0BpDy23ILm6pGw.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*hTTjsnHv0BpDy23ILm6pGw.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*hTTjsnHv0BpDy23ILm6pGw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*hTTjsnHv0BpDy23ILm6pGw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*hTTjsnHv0BpDy23ILm6pGw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*hTTjsnHv0BpDy23ILm6pGw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*hTTjsnHv0BpDy23ILm6pGw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*hTTjsnHv0BpDy23ILm6pGw.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*hTTjsnHv0BpDy23ILm6pGw.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*hTTjsnHv0BpDy23ILm6pGw.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*Nt9shXy9zdl6SkE1UUSNLw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*Nt9shXy9zdl6SkE1UUSNLw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*Nt9shXy9zdl6SkE1UUSNLw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*Nt9shXy9zdl6SkE1UUSNLw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*Nt9shXy9zdl6SkE1UUSNLw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*Nt9shXy9zdl6SkE1UUSNLw.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*Nt9shXy9zdl6SkE1UUSNLw.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*Nt9shXy9zdl6SkE1UUSNLw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*Nt9shXy9zdl6SkE1UUSNLw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*Nt9shXy9zdl6SkE1UUSNLw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*Nt9shXy9zdl6SkE1UUSNLw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*Nt9shXy9zdl6SkE1UUSNLw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*Nt9shXy9zdl6SkE1UUSNLw.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*Nt9shXy9zdl6SkE1UUSNLw.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*Nt9shXy9zdl6SkE1UUSNLw.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*yjA5H54mPEbeMGwCpcOSdQ.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*yjA5H54mPEbeMGwCpcOSdQ.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*yjA5H54mPEbeMGwCpcOSdQ.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*yjA5H54mPEbeMGwCpcOSdQ.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*yjA5H54mPEbeMGwCpcOSdQ.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*yjA5H54mPEbeMGwCpcOSdQ.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*yjA5H54mPEbeMGwCpcOSdQ.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*yjA5H54mPEbeMGwCpcOSdQ.png 640w, https://miro.medium.com/v2/resize:fit:720/1*yjA5H54mPEbeMGwCpcOSdQ.png 720w, https://miro.medium.com/v2/resize:fit:750/1*yjA5H54mPEbeMGwCpcOSdQ.png 750w, https://miro.medium.com/v2/resize:fit:786/1*yjA5H54mPEbeMGwCpcOSdQ.png 786w, https://miro.medium.com/v2/resize:fit:828/1*yjA5H54mPEbeMGwCpcOSdQ.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*yjA5H54mPEbeMGwCpcOSdQ.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*yjA5H54mPEbeMGwCpcOSdQ.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*yjA5H54mPEbeMGwCpcOSdQ.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*im1wTjsZ-irjuGVnT2i4bw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*im1wTjsZ-irjuGVnT2i4bw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*im1wTjsZ-irjuGVnT2i4bw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*im1wTjsZ-irjuGVnT2i4bw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*im1wTjsZ-irjuGVnT2i4bw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*im1wTjsZ-irjuGVnT2i4bw.png 1100w, https://miro.medium.com/v2/resize:fit:668/format:webp/1*im1wTjsZ-irjuGVnT2i4bw.png 668w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*im1wTjsZ-irjuGVnT2i4bw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*im1wTjsZ-irjuGVnT2i4bw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*im1wTjsZ-irjuGVnT2i4bw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*im1wTjsZ-irjuGVnT2i4bw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*im1wTjsZ-irjuGVnT2i4bw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*im1wTjsZ-irjuGVnT2i4bw.png 1100w, https://miro.medium.com/v2/resize:fit:668/1*im1wTjsZ-irjuGVnT2i4bw.png 668w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 334px"><img class="image_resized" style="height:auto;width:390.667px;" src="https://miro.medium.com/v2/resize:fit:1920/1*im1wTjsZ-irjuGVnT2i4bw.png" alt="" width="334" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*hyoJIlSBI5Htb2Ubd0xP8w.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*hyoJIlSBI5Htb2Ubd0xP8w.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*hyoJIlSBI5Htb2Ubd0xP8w.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*hyoJIlSBI5Htb2Ubd0xP8w.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*hyoJIlSBI5Htb2Ubd0xP8w.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*hyoJIlSBI5Htb2Ubd0xP8w.png 1100w, https://miro.medium.com/v2/resize:fit:1000/format:webp/1*hyoJIlSBI5Htb2Ubd0xP8w.png 1000w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 500px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*hyoJIlSBI5Htb2Ubd0xP8w.png 640w, https://miro.medium.com/v2/resize:fit:720/1*hyoJIlSBI5Htb2Ubd0xP8w.png 720w, https://miro.medium.com/v2/resize:fit:750/1*hyoJIlSBI5Htb2Ubd0xP8w.png 750w, https://miro.medium.com/v2/resize:fit:786/1*hyoJIlSBI5Htb2Ubd0xP8w.png 786w, https://miro.medium.com/v2/resize:fit:828/1*hyoJIlSBI5Htb2Ubd0xP8w.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*hyoJIlSBI5Htb2Ubd0xP8w.png 1100w, https://miro.medium.com/v2/resize:fit:1000/1*hyoJIlSBI5Htb2Ubd0xP8w.png 1000w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 500px"><img class="image_resized" style="height:auto;width:591px;" src="https://miro.medium.com/v2/resize:fit:1920/1*hyoJIlSBI5Htb2Ubd0xP8w.png" alt="" width="500" height="1536">
</picture>
</p>
<p style="margin-left:64px;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*IYIFHpDfP8HcpkCO3Pg0iw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*IYIFHpDfP8HcpkCO3Pg0iw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*IYIFHpDfP8HcpkCO3Pg0iw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*IYIFHpDfP8HcpkCO3Pg0iw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*IYIFHpDfP8HcpkCO3Pg0iw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*IYIFHpDfP8HcpkCO3Pg0iw.png 1100w, https://miro.medium.com/v2/resize:fit:1000/format:webp/1*IYIFHpDfP8HcpkCO3Pg0iw.png 1000w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 500px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*IYIFHpDfP8HcpkCO3Pg0iw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*IYIFHpDfP8HcpkCO3Pg0iw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*IYIFHpDfP8HcpkCO3Pg0iw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*IYIFHpDfP8HcpkCO3Pg0iw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*IYIFHpDfP8HcpkCO3Pg0iw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*IYIFHpDfP8HcpkCO3Pg0iw.png 1100w, https://miro.medium.com/v2/resize:fit:1000/1*IYIFHpDfP8HcpkCO3Pg0iw.png 1000w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 500px"><img class="image_resized" style="height:auto;width:591px;" src="https://miro.medium.com/v2/resize:fit:1920/1*IYIFHpDfP8HcpkCO3Pg0iw.png" alt="" width="500" height="1536">
</picture>
</p> | furkangozukara |
1,859,309 | AI-assisted coding interview preparation with AWS Amplify Gen 2, React and Bedrock | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-26T23:52:19 | https://dev.to/thevishnupradeep/ai-assisted-coding-interview-preparation-with-aws-amplify-gen-2-react-and-bedrock-9bd | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
## What I Built
I have built a next-generation platform that enhances the coding practice experience by integrating AI-powered assistance. The platform allows users to tackle coding challenges across a wide variety of topics and difficulties. The platform isn't just about solving problems.
## Demo
[Live Deployment](https://main.d24ov5ps4lrbcv.amplifyapp.com/)
<!-- Share a link to your deployed solution on Amplify Hosting, and include some screenshots here. -->
### Onboarding / Authentication
### Home / New Challenge
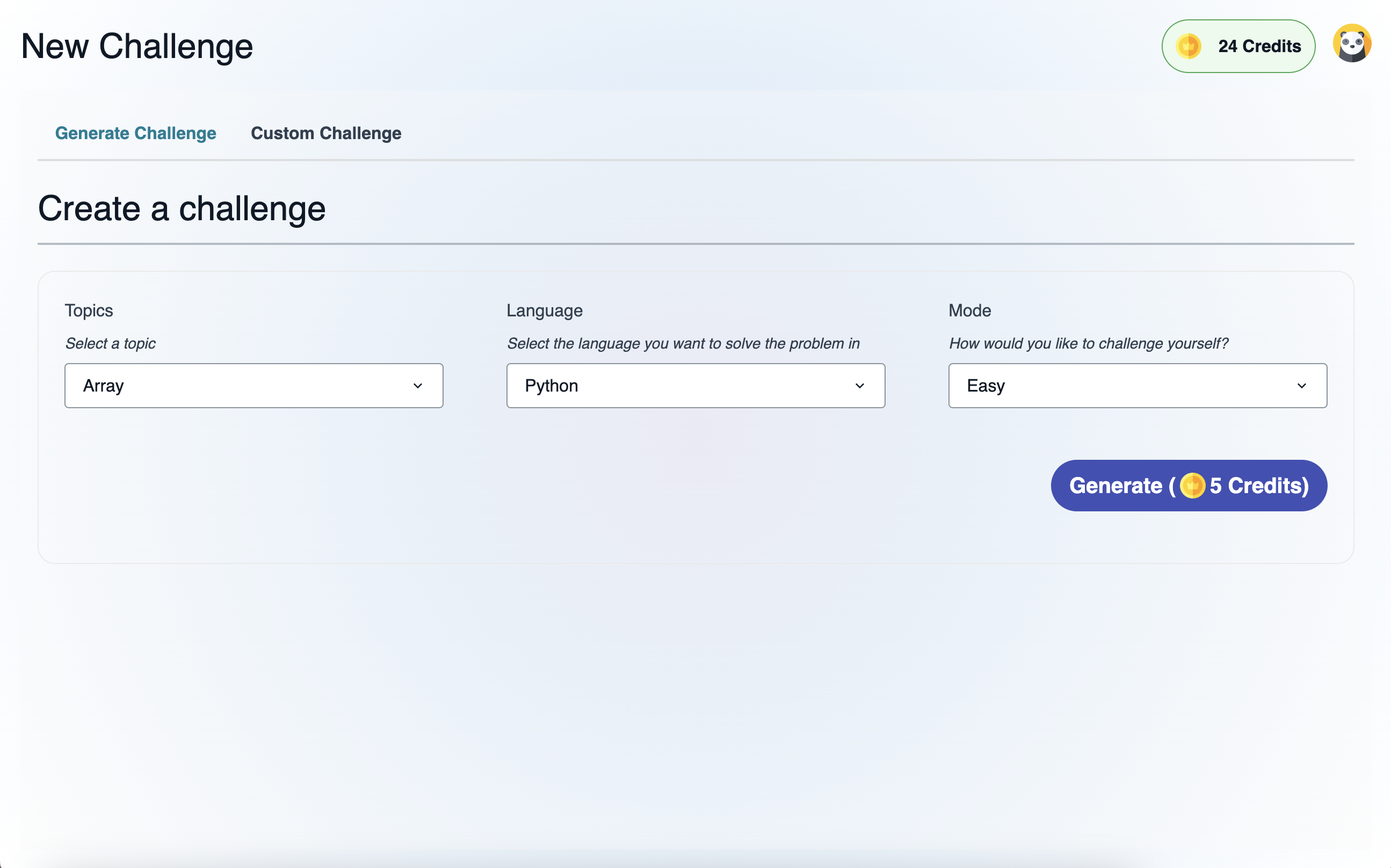
### Run the solution
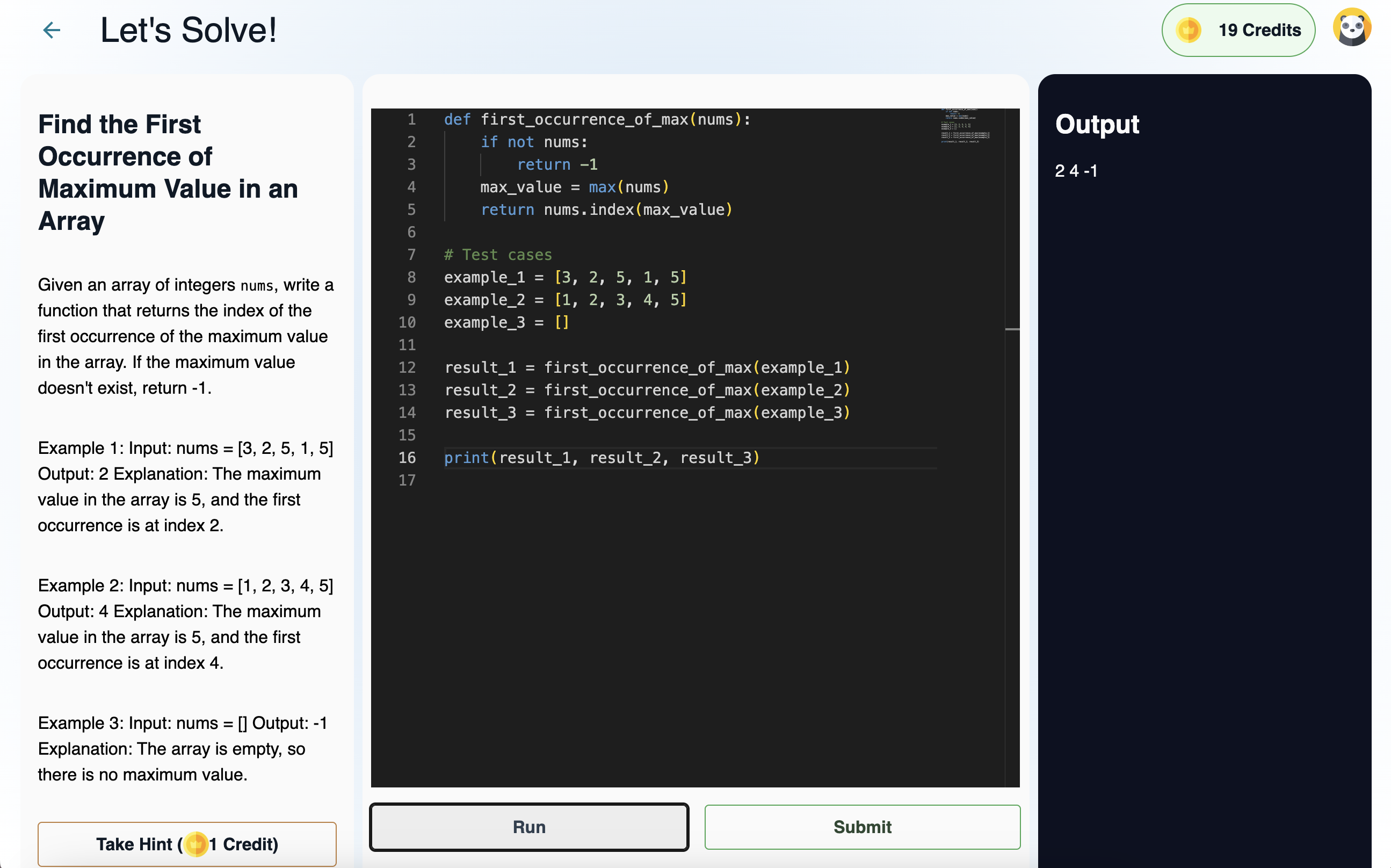
### submit & Evaluate
### Profile Page
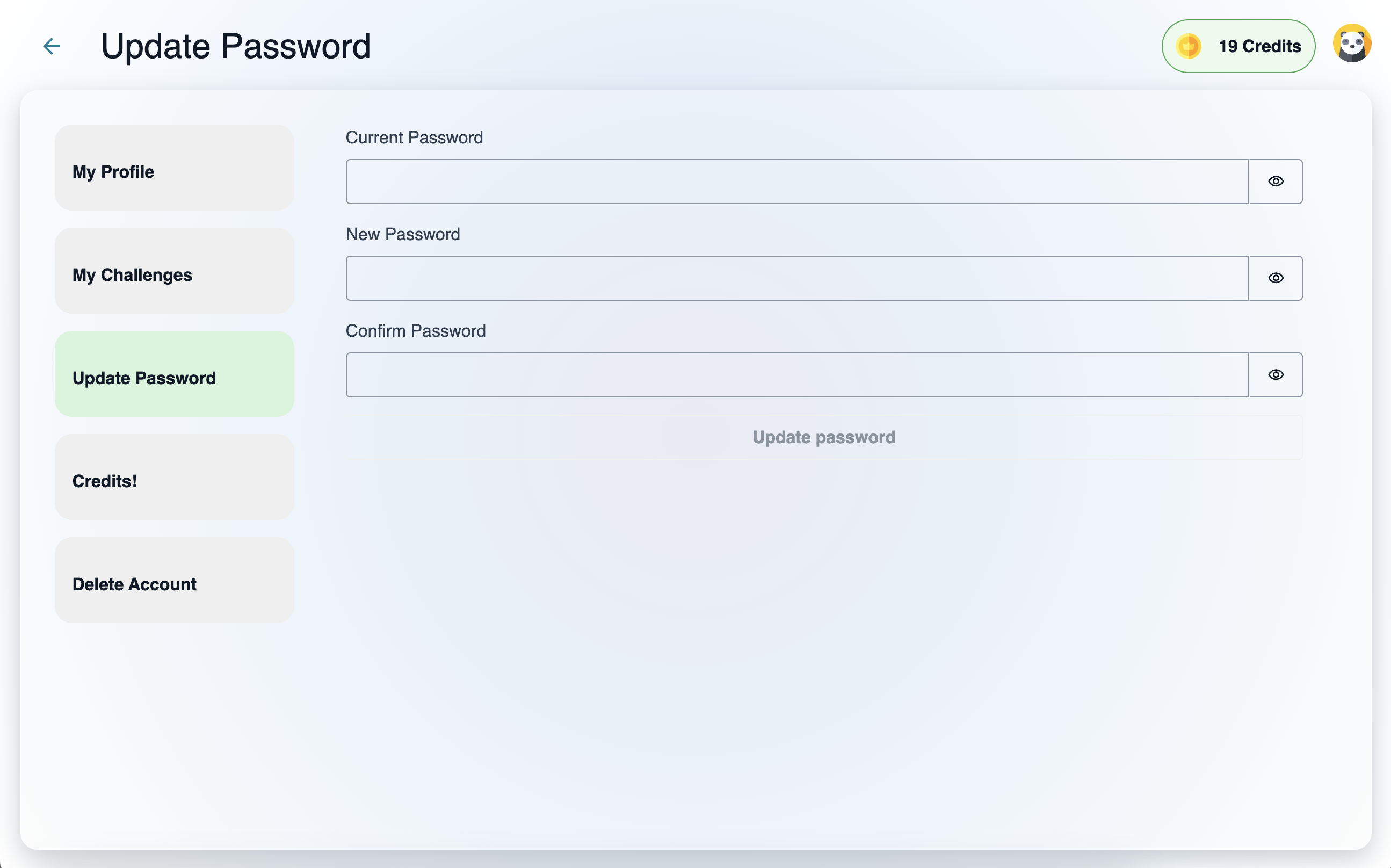
## Journey
<!-- Tell us about your process, the services you incorporated, what you learned, anything you are particularly proud of, what you hop to do next, etc. . -->
Building a coding platform was both challenging and enlightening. I utilized several AWS services, including Amplify Hosting for deployment, Cognito for authentication, Lambda for server logic, Amazon Bedrock for AI integration, and DynamoDB for storing user data and challenge details.
For code execution and testing, I used another third-party solution called [Judge0](https://github.com/judge0/judge0) which is an open-source service.
**Connected Components and/or Feature Full**
AWS Amplify Gen 2 has made building a complicated app from scratch a breeze. I used several features of Amplify Gen 2 and combined them with Amazon Bedrock to build this platform.
Data: The entire data layer is abstracted using AWS AppSync and DynamoDB provided by the Data feature. I also use Lambda functions to customize and insert data.
UI & Authentication: Amplify Auth with Cognito was used for the authentication feature. Most of the functionalities were implemented using the Authenticator component and lambda triggers. Rest of the app was built using Amplify UI.
Lambda Functions: Most of the business logic lives on three different lambda functions. All are connected to Amazon Bedrock for generative AI integration.
<!-- Let us know if you developed UI using Amplify connected components for UX patterns, and/or if your project includes all four features: data, authentication, serverless functions, and file storage. -->
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- Don't forget to add a cover image (if you want). -->
<!-- Thanks for participating! --> | thevishnupradeep |
1,865,923 | Spring Bean Scopes | Bean scope in Spring Framework refers to the lifecycle of a Spring bean and its visibility in the... | 0 | 2024-05-26T23:38:38 | https://dev.to/emmauche001/spring-bean-scopes-j6a | learning, springboot, spring | Bean scope in Spring Framework refers to the <u>lifecycle of a Spring bean and its visibility in the context of the application.</u>
When you create a bean definition, you create a recipe for creating actual instances of the class defined by that bean definition. The idea that a bean definition is a recipe is important, because it means that, as with a class, you can create many object instances from a single recipe.
Spring provides multiple scope to register and configure beans and scoping has an impact on a state management of the component.
Singleton is the default scope of a bean, which means one instance per application context.
Bean Scopes provided by Spring:
1. **Singleton** Only one instance of a bean is created and all request of that bean will receive the same instance. This is useful for beans that do not hold state or where the same state is to be shared by all users or threads. For example, a database connection pool
```
@Configuration
public class DataSourceConfig {
@Bean
public DataSource dataSource() {
HikariConfig config = new HikariConfig();
config.setDriverClassName("org.postgresql.Driver");
config.setJdbcUrl("jdbc:postgresql://localhost:5432/yourdatabase");
config.setUsername("yourusername");
config.setPassword("yourpassword");
config.setMaximumPoolSize(10);
config.setMinimumIdle(2);
config.setPoolName("HikariCP");
return new HikariDataSource(config);
}
}
```
2. **Prototype** A new instance is being created each time a bean is requested from the container. Useful for stateful beans or beans that are not thread-safe, such as a bean that maintains user-specific data during an operation.
```
@Component
@Scope("prototype")
public class UserData {
private String username;
private String operation;
// Getters and setters
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getOperation() {
return operation;
}
public void setOperation(String operation) {
this.operation = operation;
}
}
```
3. **Request** This scope is Only valid in the context of a web-aware Spring ApplicationContext for a single http request. A new bean is created for each http request. For example, a bean that tracks the progress of a user's request or data specific to that request, such as user credentials or input parameters.
```
@Component
@RequestScope
public class RequestData {
private String userId;
private String requestStatus;
// Getters and setters
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getRequestStatus() {
return requestStatus;
}
public void setRequestStatus(String requestStatus) {
this.requestStatus = requestStatus;
}
}
```
4. **Session** A new bean is created for each http session by the container. Also applicable in web-aware Spring ApplicationContext. Useful for user sessions in a web application, like storing a user's authenticated session or a shopping cart in an e-commerce site.
```
@Component
@Scope(value = "session", proxyMode = ScopedProxyMode.TARGET_CLASS)
public class UserSession {
private String username; // You can add more session-related data here
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
}
```
5. **Application** Scopes a single bean definition to the lifecycle of a ServletContext. Only valid in the context of a web-aware Spring ApplicationContext. For example, application-wide configuration that is web-context aware, like a cache that is shared across sessions but not across different applications.
6. **WebSocket** Scopes a single bean definition to the lifecycle of a WebSocket. Only valid in the context of a web-aware Spring ApplicationContext.
The scope of a bean affects its injection into another bean in terms of lifecycle management and statefulness:
**Singleton beans** injected into other beans will have their state shared across the entire application, making them suitable for shared configurations or stateless services.
**Prototype-scoped beans** ensure that a new instance is provided each time a bean is injected, suitable for stateful beans or beans that are not thread-safe.
**Request, Session, Application, and Websocket scopes** allow beans to be tied to the lifecycle of web components, making them ideal for managing user sessions, application context, and real-time communication channels respectively.
**Singleton Beans with Prototype-bean Dependencies**
When you use singleton-scoped beans with dependencies on prototype beans, be aware that dependencies are resolved at instantiation time. Thus, if you dependency-inject a prototype-scoped bean into a singleton-scoped bean, a new prototype bean is instantiated and then dependency-injected into the singleton bean. The prototype instance is the sole instance that is ever supplied to the singleton-scoped bean.
**Custom Scopes**
The bean scoping mechanism is extensible. You can define your own scopes or even redefine existing scopes, although the latter is considered bad practice and you cannot override the built-in singleton and prototype scopes. | emmauche001 |
1,865,924 | Javascript Memory Management | When the javascript engine starts executing the code it will store variables inside of the memory.... | 0 | 2024-05-26T22:07:42 | https://dev.to/ikbalarslan/javascript-memory-management-188l | javascript, programming, webdev | When the javascript engine starts executing the code it will store variables inside of the memory. for storing data, runtime uses two different memory:
- Stack memory
- Heap memory
> Javascript only can communicate with stack memory.
Before explaining the differences around these memories I should explain the data types in javascript. In javascript, we have two different data types:
- Primitive types: primitive types stored directly in the stack
- String, Number, Boolean, Null, Undefined, Symbol, BigInt
---
- Reference types: Stored in the heap and accessed by reference from Stack
- Arrays, Functions, Objects
---
For maximum optimization in the memory space javascript engine uses something called garbage collector. it will clean the value immediately when a value is not reachable via a variable(label).
| ikbalarslan |
1,865,979 | My Pen on CodePen | []( 57~~~~ ) Check out this Pen I made! | 0 | 2024-05-26T23:14:36 | https://dev.to/othmane_belalami_0183ff59/my-pen-on-codepen-3bbj | codepen |
[](
1. 57~~~~
)
Check out this Pen I made!
{% codepen https://codepen.io/Othmane-Belalami/pen/dyEpLYz %} | othmane_belalami_0183ff59 |
1,864,273 | Understanding WP-Cron: The Essential Guide | Table of Contents What is WP-Cron? How WP-Cron Works Common Uses of WP-Cron Setting Up... | 0 | 2024-05-26T23:06:06 | https://dev.to/mikevarenek/understanding-wp-cron-the-essential-guide-3mn7 | ## Table of Contents
1. What is WP-Cron?
2. How WP-Cron Works
3. Common Uses of WP-Cron
4. Setting Up WP-Cron Jobs
5. Running WP-Cron Jobs Manually
6. Managing and Troubleshooting WP-Cron Jobs
7. Alternatives to WP-Cron
## Section 1: What is WP-Cron?
**Definition of WP-Cron**
WP-Cron is a scheduling system integrated into WordPress that allows developers to schedule tasks to be executed at specific intervals. Unlike traditional cron jobs, which are handled by the server's operating system, WP-Cron is managed entirely within the WordPress environment. This makes it more accessible for users who may not have server-level access or familiarity with system-level cron jobs.
**WP-Cron operates by checking for scheduled tasks each time a page is loaded on the site.** If any tasks are due to run, WP-Cron executes them during the request. This setup allows WordPress to perform automated tasks such as publishing scheduled posts, updating plugins, sending email notifications, and more.
**Difference Between WP-Cron and System Cron Jobs**
The primary difference between WP-Cron and system cron jobs lies in their execution and reliability:
**Execution Method:**
- WP-Cron: Runs within the WordPress environment and is triggered by site visits. This means WP-Cron relies on traffic to the site to initiate scheduled tasks.
- System Cron Jobs: Scheduled and managed by the server's operating system (e.g., Linux's crontab). These jobs run at specified intervals regardless of site traffic.
**Reliability:**
- WP-Cron: Can be less reliable for sites with low traffic because tasks will only run when a user visits the site. If no one visits the site, scheduled tasks may not run on time.
- System Cron Jobs: More reliable because they are executed by the server at precise intervals, ensuring tasks run as scheduled regardless of web traffic.
Read also: [5 Best WordPress Security Plugins](https://spacema-dev.com/5-best-wordpress-security-plugins/)
**Configuration and Access:**
- WP-Cron: Easier to configure within WordPress without needing server-level access or knowledge of server cron syntax.
- System Cron Jobs: Requires access to the server's command line and knowledge of how to configure cron jobs in the server environment.
How WP-Cron is Used in WordPress
**WP-Cron is utilized for various automated tasks within the WordPress ecosystem. Some common uses include:**
- Publishing Scheduled Posts: Automatically publishing posts at a set time and date.
- Plugin and Theme Updates: Checking for and applying updates to plugins and themes.
- Backups: Running scheduled backup tasks to save site data.
- Email Notifications: Sending out scheduled emails such as newsletters or notifications.
- Cache Management: Clearing and rebuilding cache at regular intervals to maintain site performance.
- Maintenance Tasks: Performing regular maintenance tasks like database optimization.
**Example Usage:**
Imagine you have a WordPress site where you publish a new blog post every Monday at 10 AM. With WP-Cron, you can schedule these posts in advance, and they will automatically go live at the specified time without any manual intervention.
## Section 2: How WP-Cron Works
**Explanation of WP-Cron’s Event Scheduling**
WP-Cron's event scheduling system allows developers to schedule and manage tasks that need to be executed at specific intervals. The core of this system revolves around scheduling "events" which are essentially hooks that are set to run at a future time.
**Here are the basic components of WP-Cron’s event scheduling:**
- Events: These are the tasks or functions you want to schedule. Each event is hooked to a specific action.
- Schedules: WP-Cron supports several predefined schedules such as hourly, twice daily, and daily. Developers can also define custom schedules.
- Hooks: Functions tied to scheduled events are triggered via hooks. When the scheduled time arrives, the corresponding hook is executed.
To schedule an event, you typically use the wp_schedule_event function, which takes parameters such as the time of the first occurrence, the recurrence interval, and the hook to be triggered.
Example:
```php
if (!wp_next_scheduled('my_custom_event_hook')) {
wp_schedule_event(time(), 'hourly', 'my_custom_event_hook');
}
add_action('my_custom_event_hook', 'my_custom_event_function');
function my_custom_event_function() {
// Code to execute
}
```
In this example, `my_custom_event_function` is scheduled to run hourly.
**How WP-Cron is Triggered by Site Visits**
Unlike traditional cron jobs that run at set intervals regardless of site activity, WP-Cron relies on site traffic to trigger its scheduled events. **Here's how it works:**
- Page Load Trigger: Every time a visitor loads a page on the WordPress site, WP-Cron checks the database for any scheduled events that are due to run.
- Event Execution: If any events are found to be due, WP-Cron runs them during the current page load request.
- Rescheduling: After executing an event, WP-Cron reschedules it for its next occurrence based on the defined interval.
- This mechanism means that WP-Cron is dependent on site traffic. If the site has no visitors, scheduled tasks may not run at the expected time.
## Section 3: Common Uses of WP-Cron
WP-Cron is a versatile tool within the WordPress ecosystem that enables the automation of various routine tasks. Here are some common uses of WP-Cron and the benefits it brings to site management.
Read also: [What is WordPress $wpdb](https://spacema-dev.com/what-is-wordpress-wpdb/)
**Examples of Tasks Handled by WP-Cron**
**Scheduled Posts:**
Use Case: Automatically publish posts at a specified time and date.
Example: A blog post written in advance can be scheduled to go live at 8 AM on Monday.
Code Snippet:
```php
wp_schedule_event(strtotime('next Monday 8AM'), 'weekly', 'publish_scheduled_post');
add_action('publish_scheduled_post', 'publish_my_post_function');
function publish_my_post_function() {
// Code to publish the post
}
```
**Plugin and Theme Updates:**
Use Case: Regularly check for and apply updates to plugins and themes.
Example: Ensuring the site stays secure and up-to-date without manual intervention.
Code Snippet:
```php
wp_schedule_event(time(), 'daily', 'check_for_updates');
add_action('check_for_updates', 'update_plugins_and_themes');
function update_plugins_and_themes() {
// Code to check and apply updates
}
```
**Backups:**
Use Case: Schedule regular backups of the WordPress database and files.
Example: Creating daily backups to ensure data recovery in case of issues.
Code Snippet:
```php
wp_schedule_event(time(), 'daily', 'daily_backup');
add_action('daily_backup', 'backup_site');
function backup_site() {
// Code to backup the site
}
```
**Email Notifications:**
Use Case: Send out scheduled emails like newsletters or notifications.
Example: Sending a weekly newsletter every Friday at 5 PM.
Code Snippet:
```php
wp_schedule_event(strtotime('next Friday 5PM'), 'weekly', 'send_weekly_newsletter');
add_action('send_weekly_newsletter', 'send_newsletter_function');
function send_newsletter_function() {
// Code to send the newsletter
}
```
**Maintenance Tasks:**
Use Case: Perform regular maintenance tasks like database optimization.
Example: Optimizing the database weekly to improve performance.
Code Snippet:
```php
wp_schedule_event(strtotime('next Sunday 2AM'), 'weekly', 'optimize_database');
add_action('optimize_database', 'optimize_db_function');
function optimize_db_function() {
// Code to optimize the database
}
```
**Benefits of Using WP-Cron for These Tasks**
**Automation:**
- WP-Cron allows for the automation of routine tasks, reducing the need for manual intervention and saving time for site administrators and developers.
**Consistency:**
- Tasks can be scheduled to run at precise intervals, ensuring consistent execution. This is particularly useful for tasks like backups and updates, which need to be performed regularly.
**Improved Performance:**
- By scheduling maintenance tasks such as cache clearing and database optimization, WP-Cron helps keep the site running smoothly and efficiently.
**Enhanced User Experience:**
- Automating content publishing and email notifications ensures that users receive updates and information promptly, enhancing their experience with the site.
Read also: [How to create custom post type in WordPress](https://spacema-dev.com/how-to-create-custom-post-type-in-wordpress/)
**Security:**
- Regular updates and backups are critical for site security. WP-Cron helps maintain a secure site by automating these essential tasks.
**Customization:**
- Developers can create custom schedules and tasks tailored to the specific needs of their site or application, providing a high degree of flexibility.
## Section 4: Setting Up WP-Cron Jobs
Setting up WP-Cron jobs involves using specific WordPress functions to schedule events. This section will cover the basic syntax and functions, provide example code snippets for scheduling events, and explain how to create custom intervals for WP-Cron jobs.
**Basic Syntax and Functions**
`wp_schedule_event`
Schedules a recurring event.
Parameters:
`$timestamp`: The Unix timestamp (in GMT/UTC) for the first occurrence of the event.
`$recurrence`: The recurrence interval ('hourly', 'daily', 'twicedaily', or a custom interval).
`$hook`: The name of the action hook to execute.
`$args`: (Optional) An array of arguments to pass to the hook's callback function.
Example:
```php
if (!wp_next_scheduled('my_custom_event_hook')) {
wp_schedule_event(time(), 'hourly', 'my_custom_event_hook');
}
```
`wp_schedule_single_event`
Schedules a single event to occur at a specific time.
Parameters:
`$timestamp`: The Unix timestamp (in GMT/UTC) when the event should occur.
`$hook`: The name of the action hook to execute.
`$args`: (Optional) An array of arguments to pass to the hook's callback function.
Example:
```php
wp_schedule_single_event(time() + 3600, 'my_single_event_hook'); // 1 hour from now
```
`wp_next_scheduled`
Checks if an event with a specific hook is already scheduled.
Parameters:
`$hook`: The name of the action hook.
`$args`: (Optional) An array of arguments.
Example:
```php
$timestamp = wp_next_scheduled('my_custom_event_hook');
```
**Example Code Snippets for Scheduling Events**
Scheduling a Recurring Event:
```php
if (!wp_next_scheduled('my_hourly_event')) {
wp_schedule_event(time(), 'hourly', 'my_hourly_event');
}
add_action('my_hourly_event', 'my_hourly_function');
function my_hourly_function() {
// Code to execute every hour
error_log('Hourly event executed');
}
```
Scheduling a Single Event:
```php
wp_schedule_single_event(time() + 3600, 'my_single_event'); // 1 hour from now
add_action('my_single_event', 'my_single_event_function');
function my_single_event_function() {
// Code to execute once
error_log('Single event executed');
}
```
**Custom Intervals for WP-Cron Jobs**
To create custom intervals, you need to hook into the `cron_schedules` filter and add your custom interval. Here’s how you can do it:
Add Custom Interval:
```php
add_filter('cron_schedules', 'add_custom_cron_intervals');
function add_custom_cron_intervals($schedules) {
$schedules['every_five_minutes'] = array(
'interval' => 300, // 300 seconds = 5 minutes
'display' => __('Every 5 Minutes')
);
return $schedules;
}
```
Schedule an Event with Custom Interval:
```php
if (!wp_next_scheduled('my_five_minute_event')) {
wp_schedule_event(time(), 'every_five_minutes', 'my_five_minute_event');
}
add_action('my_five_minute_event', 'my_five_minute_function');
function my_five_minute_function() {
// Code to execute every 5 minutes
error_log('Five-minute event executed');
}
```
## Section 5: Running WP-Cron Jobs Manually
Running WP-Cron jobs manually can be necessary for testing purposes or to ensure critical tasks are executed without waiting for the next scheduled run. This section covers two main methods: using the WordPress Dashboard with the help of plugins like WP Crontrol, and using the command line with WP-CLI.
**How to Run WP-Cron Jobs Manually from the WordPress Dashboard**
One of the easiest ways to run WP-Cron jobs manually is by using a plugin such as [WP Crontrol](https://wordpress.org/plugins/wp-crontrol/). This plugin provides a user-friendly interface to view, control, and manually run WP-Cron jobs directly from the WordPress Dashboard.
**Install WP Crontrol:**
- Go to your WordPress Dashboard.
- Navigate to Plugins > Add New.
- Search for "WP Crontrol".
- Click Install Now and then Activate.
**Access WP Crontrol:**
In the WordPress Dashboard, go to Tools > Cron Events.
**View Scheduled Events**
WP Crontrol lists all scheduled WP-Cron events, including their hooks, next run time, and recurrence interval.
**Run a Cron Event Manually**
- Find the event you want to run in the list of scheduled events.
- Hover over the event and click Run Now.
- This method is straightforward and does not require any technical knowledge beyond basic WordPress administration.
**How to Run WP-Cron Jobs Manually from the Command Line**
For developers comfortable with the command line, WP-CLI (WordPress Command Line Interface) offers a powerful way to manage and run WP-Cron jobs manually. WP-CLI needs to be installed on your server.
**Install WP-CLI:**
Follow the installation instructions from the [WP-CLI documentation](https://developer.wordpress.org/cli/commands/).
**Check Scheduled Events:**
Open your terminal and navigate to your WordPress directory.
Run the following command to list all scheduled cron events:
```
wp cron event list
```
This will display a table of all scheduled events, including their hook names and next scheduled run time.
Read also: [Exploring the Main Classes in WordPress: A Comprehensive Guide](https://spacema-dev.com/exploring-the-main-classes-in-wordpress-a-comprehensive-guide/)
**Run a Cron Event Manually:**
Identify the hook name of the event you want to run from the list.
Run the following command to execute the event immediately:
```
wp cron event run <hook_name>
```
Replace <hook_name> with the actual name of the cron hook you wish to run.
```
wp cron event run my_custom_event_hook
```
**Run All Due Events:**
To run all cron events that are due to be executed:
```
wp cron event run --due-now
```
Using WP-CLI is ideal for developers who need to manage cron events programmatically or through automated scripts, providing more control and flexibility than using the Dashboard.
Running WP-Cron jobs manually can be achieved easily either through the WordPress Dashboard using plugins like WP Crontrol or from the command line using WP-CLI.
**Each method has its advantages:**
**WP Crontrol Plugin:**
- User-friendly and accessible via the WordPress Dashboard.
- Ideal for site administrators who prefer a graphical interface.
**WP-CLI:**
- Powerful and flexible, suitable for developers and automated scripts.
- Ideal for those who need to manage cron events programmatically.
## Section 6: Managing and Troubleshooting WP-Cron Jobs
Managing and troubleshooting WP-Cron jobs is essential for ensuring your scheduled tasks run smoothly and efficiently. This section covers tools and plugins for managing WP-Cron, common issues and their resolutions, and methods for logging WP-Cron events for debugging.
**Tools and Plugins for Managing WP-Cron**
**WP Crontrol:**
_Description:_ A powerful [plugin](https://wordpress.org/plugins/wp-crontrol/) that allows you to view, control, and manage WP-Cron events from the WordPress Dashboard.
_Features:_
- View all scheduled cron events.
- Add, edit, delete, and run cron events.
- Manage custom cron schedules.
_Usage:_
- Install and activate the plugin.
- Navigate to Tools > Cron Events to manage WP-Cron jobs.
**Advanced Cron Manager:**
_Description:_ Another [plugin](https://wordpress.org/plugins/advanced-cron-manager/) for managing WP-Cron jobs with a focus on user-friendly interfaces and advanced features.
_Features:_
- View and manage cron events.
- Add new cron events and schedules.
- Debug cron events with detailed information.
_Usage:_
- Install and activate the plugin.
- Access the plugin interface from the WordPress Dashboard to manage cron jobs.
**WP-CLI:**
_Description:_ A command-line interface for WordPress that provides powerful tools for managing WP-Cron events.
_Features:_
- List, run, and delete cron events.
- Create and manage custom cron schedules.
_Usage:_
- Use commands like wp cron event list, wp cron event run, and wp cron event delete to manage cron jobs.
## Common Issues and How to Resolve Them
_Missed Schedules:_
Description: WP-Cron jobs may not run at the scheduled time, especially on low-traffic sites.
_Resolution:_
- Increase site traffic or set up an external cron job to trigger WP-Cron more reliably.
- Use the WP Crontrol plugin to manually run missed events.
- Implement a real cron job on the server to hit the site's WP-Cron URL periodically.
Example of setting up a real cron job:
```
* * * * * wget -q -O - http://yoursite.com/wp-cron.php?doing_wp_cron > /dev/null 2>&1
```
_Overlapping Events:_
Description: Events that take longer to execute than the interval between them can overlap, causing performance issues.
_Resolution:_
- Ensure cron jobs are optimized and complete quickly.
- Use locking mechanisms to prevent overlapping executions.
Example of using a lock:
```php
function my_cron_function() {
if ( false === ( $lock = get_transient( 'my_cron_lock' ) ) ) {
set_transient( 'my_cron_lock', time(), 60*15 ); // 15-minute lock
// Your cron job code
delete_transient( 'my_cron_lock' );
}
}
```
_Debugging and Logging Issues:_
Description: Without proper logging, it can be challenging to identify why cron jobs are failing or not executing as expected.
_Resolution:_
Implement logging within your cron functions to capture detailed execution information.
Example of simple logging:
```php
function my_cron_function() {
if ( false === ( $lock = get_transient( 'my_cron_lock' ) ) ) {
set_transient( 'my_cron_lock', time(), 60*15 ); // 15-minute lock
// Log start
error_log('Cron job started at ' . current_time('mysql'));
// Your cron job code
// Log end
error_log('Cron job ended at ' . current_time('mysql'));
delete_transient( 'my_cron_lock' );
} else {
error_log('Cron job skipped due to existing lock at ' . current_time('mysql'));
}
}
```
_Identifying Conflicts and Errors:_
Description: Conflicts with plugins or themes can cause cron jobs to fail.
_Resolution:_
- Use the WP Crontrol plugin to review and manage cron jobs.
- Deactivate plugins/themes one by one to identify conflicts.
- Check the error log for specific error messages related to cron jobs.
## Logging WP-Cron Events for Debugging
Effective logging is crucial for debugging WP-Cron issues. Here are a few tips for logging WP-Cron events:
**Using error_log:**
Simple and effective for capturing basic information about cron job execution.
Example:
```
function my_debug_cron_function() {
error_log('Cron job executed at ' . current_time('mysql'));
// Your cron job code
}
```
Read also: [What is WordPress actions and filters](https://spacema-dev.com/what-is-wordpress-actions-and-filters/)
**Custom Logging Function:**
Create a custom logging function to capture detailed information.
Example:
```php
function custom_cron_logger($message) {
$log = ABSPATH . 'wp-content/cron-log.txt';
$date = date('Y-m-d H:i:s');
$message = $date . ' - ' . $message . "\n";
file_put_contents($log, $message, FILE_APPEND);
}
function my_advanced_cron_function() {
custom_cron_logger('Cron job started');
// Your cron job code
custom_cron_logger('Cron job ended');
}
```
**Debugging with WP-CLI:**
Use WP-CLI to check the status and output of cron jobs.
Example:
```
wp cron event list --fields=hook,next_run,recurrence
wp cron event run my_custom_event_hook
```
## Section 7: Alternatives to WP-Cron
While WP-Cron is a powerful and convenient tool within WordPress, it does have limitations. This section explores those limitations, discusses using system cron jobs as an alternative or in conjunction with WP-Cron, and provides an example setup of a system cron job for WordPress tasks.
**Limitations of WP-Cron**
Dependency on Site Traffic:
- WP-Cron relies on site visits to trigger scheduled tasks. On low-traffic sites, this can result in missed or delayed execution of cron jobs.
Performance Impact:
- WP-Cron runs during page loads, which can slow down the site for visitors if the scheduled tasks are resource-intensive.
Limited Precision:
- WP-Cron’s timing is not precise because it depends on site visits. If exact timing is crucial, WP-Cron might not be suitable.
Overlapping Jobs:
- If a cron job takes longer than expected, it can overlap with subsequent jobs, leading to potential issues with task execution and performance.
## Using System Cron Jobs Instead of or Alongside WP-Cron
System cron jobs (traditional cron jobs provided by the operating system) are not subject to the same limitations as WP-Cron. They run at specified intervals regardless of site traffic, offering more precise and reliable scheduling.
**Advantages of System Cron Jobs:**
- Independence from Site Traffic: They execute on time regardless of how many visitors the site has.
- Performance: They do not impact page load times since they run independently of WordPress page requests.
- Precision: System cron jobs run exactly as scheduled.
| mikevarenek | |
1,865,977 | Explaining the Concept of the State Pattern in Flutter | The State Pattern serves as a behavioral design pattern that helps in encapsulating various behaviors... | 0 | 2024-05-26T22:36:41 | https://dev.to/anurika_joy_c83cb5039b071/explaining-the-concept-of-the-state-pattern-in-flutter-4ool | flutter, dart, beginners |
The State Pattern serves as a behavioral design pattern that helps in encapsulating various behaviors for an object according to its internal state. This allows an object to modify its behavior dynamically without relying on conditional statements, ultimately enhancing maintainability.
## Unpacking the Essence of the State Pattern
As per the Design Patterns in Dart resource, the State Pattern acts as a behavioral design pattern pivotal in encapsulating diverse behaviors for an object based on its internal state. With this approach, an object can adjust its behavior dynamically without the need for conditional statements, thereby simplifying the codebase.
Essentially, each state of an object gets represented by distinct classes, serving as extensions or variations of a core state class specific to that object.
### Diving Deeper into the Concept

Consider having an object like `Water`, where you define a `WaterState` to embody variations such as `Solid`, `Liquid`, and `Gaseous`:
```dart
abstract class WaterState {
//
}
class Solid extends WaterState {
//
}
class Liquid extends WaterState {
//
}
class Gaseous extends WaterState {
//
}
```
Furthermore, the State Pattern becomes a vital component of the BLoC pattern. If you are employing the BLoC pattern, you are essentially leveraging the State Pattern.
## Ideal Scenarios for Implementing the State Pattern
The State Pattern comes in handy under the following circumstances:
* When an object behaves differently based on its state.
* If the number of states is substantial, and state changes are frequent.
* When a class features a multitude of conditionals affecting its behavior related to field values.
* In cases where there is significant code duplication for similar states and transitions.
## Application of the State Pattern in Real Life
Let's now explore a practical example showcasing the State Pattern in action. Consider the class below, where state definitions incorporate variables and `ChangeNotifier`:
```dart
class CategoryStore extends ChangeNotifier {
List<String> categories = [];
bool isLoading = false;
String error = '';
IApiDatasource apiDatasource = ApiDatasource();
void getCategories() async {
isLoading = true;
await apiDatasource.getCategories().then((response) {
response.fold(
(left) => error = left.message,
(right) => categories = right,
);
});
isLoading = false;
notifyListeners();
}
}
```
The `fold()` method highlighted above is associated with the Either type, an essential element in functional programming that represents a value falling under one of two specified types. Typically, Either represents a successful or failed value, much like in the example where `left` signifies the error value and `right` signifies the success value.
Within the aforementioned class, a function initiates loading through `isLoading`, then proceeds to fetch data from an API, storing it in the `categories` variable. Upon completion of loading, the function adjusts the value to false.
To streamline this code using the State Pattern, we structure it as follows:
### Defining State Classes
The states and their corresponding classes are declared initially:
```dart
abstract class CategoryState {}
class CategoryInitial extends CategoryState {}
class CategoryLoading extends CategoryState {}
class CategoryLoaded extends CategoryState {
final List<String> categories;
CategoryLoaded(this.categories);
}
class CategoryError extends CategoryState {
final String message;
CategoryError(this.message);
}
```
### Refining the Store Class
In the `getCategories()` function, we eliminate the `isLoading` variable and introduce the `value` variable, representing the state within `ValueNotifier` and adhering to the `CategoryState`. Consequently, `CategoryLoading` is designated to signify our state.
Subsequently, in the `fold()` method, if the request flounders, `value` transitions into the `Error` state carrying the error message (`left`). Conversely, upon a successful outcome, it adopts the `Loaded` state with the data residing in the `right` variable. This workflow discards the `categories` and `error` variables:
```dart
class CategoryStore extends ValueNotifier<CategoryState> {
CategoryStore() : super(CategoryInitial());
IApiDatasource apiDatasource = ApiDatasource();
void getCategories() async {
value = CategoryLoading();
await apiDatasource.getCategories().then((response) {
response.fold(
(left) => value = CategoryError(left.message),
(right) => value = CategoryLoaded(right),
);
});
}
}
```
The `value` getter pertains to `ValueNotifier`, housing the present state of our Store class.
### Demonstrating an Instance within a Page
```dart
class HomePage extends StatefulWidget {
const HomePage({super.key});
@override
State<HomePage> createState() => _HomePageState();
}
class _HomePageState extends State<HomePage> {
// CategoryStore instance establishment
CategoryStore store = CategoryStore();
// Initialization function upon page load
@override
void initState() {
store.getCategories();
super.initState();
}
@override
void dispose() {
super.dispose();
store.dispose();
}
@override
Widget build(BuildContext context) {
return Scaffold(
body: Expanded(
// Observing the store
child: ValueListenableBuilder(
valueListenable: store,
builder: (context, value, child) {
// Error handling
if (value is CategoryError) {
return Center(
child: Text(
'Error loading categories: ${value.message}',
),
);
}
// Presenting loaded data
if (value is CategoryLoaded) {
return ListView.builder(
itemCount: value.categories.length,
itemBuilder: (context, index) {
final category = value.categories[index];
return Text(category);
},
);
}
// Display loading status
return const Center(child: CircularProgressIndicator());
},
),
),
);
}
}
```
In this manner, we have successfully implemented the State Pattern! Through this approach, we adhere to the Single Responsibility and Open/Closed Principles, and streamline the code by eliminating conditional statements that could otherwise complicate the codebase.
## Wrapping Up
Your journey through this exploration of the State Pattern is greatly appreciated. While the focus was on the State Pattern itself, I refrained from delving too deeply into elements like `ValueNotifier` and others utilized in the example.
| anurika_joy_c83cb5039b071 |
1,865,976 | How To Build a Data Analytics Dashboard | Building a data analytics dashboard can be a daunting task, especially when you need to manage data... | 0 | 2024-05-26T22:28:25 | https://five.co/blog/how-to-build-a-data-analytics-dashboard/ | database, learning, datascience, sql | <!-- wp:paragraph -->
<p>Building a data analytics dashboard can be a daunting task, especially when you need to manage data from multiple sources and present it in a user-friendly manner. Fortunately, Five offers a powerful and rapid development environment that simplifies this process. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>In this step-by-step guide, we'll walk you through building a responsive data analytics dashboard that connects to a REST API, visualizes the data, and provides interactive features for end-users.</p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading -->
<h2 class="wp-block-heading">What Is a Data Analytics Dashboard?</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>A data analytics dashboard is a visual representation of key performance indicators (KPIs), metrics, and data points relevant to an organization, department, specific process or business. It consolidates and presents critical information in an easy-to-understand format, such as charts, graphs, tables, and gauges, enabling users to monitor, analyze, and derive insights from their data in real-time.</p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Who Is This Article For?</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>This article is great for business analysts, data analysts, managers, executives, IT professionals, entrepreneurs, consultants, and marketers. Those individuals who often work with data and need to communicate insights effectively to drive informed decision-making. Learning how to create visually appealing and interactive dashboards enables you to monitor key performance indicators, identify trends, and optimize strategies based on real-time data. Students and researchers in fields such as business, economics, and data science may also find the article useful for presenting their findings.</p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:essential-blocks/table-of-contents {"blockId":"eb-toc-fd7th","blockMeta":{"desktop":".eb-toc-fd7th.eb-toc-container { max-width:610px; background-color:var(\u002d\u002deb-global-background-color); padding:30px; border-radius:4px; transition:all 0.5s, border 0.5s, border-radius 0.5s, box-shadow 0.5s }.eb-toc-fd7th.eb-toc-container .eb-toc-title { text-align:center; cursor:default; color:rgba(255,255,255,1); background-color:rgba(69,136,216,1); font-size:22px; font-weight:normal }.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper { background-color:rgba(241,235,218,1); text-align:left }.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li { color:rgba(0,21,36,1); font-size:14px; line-height:1.4em; font-weight:normal }.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li:hover,.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li.eb-toc-active \u003e a { color:var(\u002d\u002deb-global-link-color) }.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li a { color:inherit }.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li svg path { stroke:rgba(0,21,36,1) }.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li:hover svg path { stroke:var(\u002d\u002deb-global-link-color) }.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li a,.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li a:focus { text-decoration:none; background:none }.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li { padding-top:4px }.eb-toc-fd7th.eb-toc-container .eb-toc-wrapper .eb-toc__list li:not(:last-child) { padding-bottom:4px }.eb-toc-fd7th.eb-toc-container.style-1 .eb-toc__list-wrap \u003e .eb-toc__list li .eb-toc__list { background:#fff; border-radius:4px }","tab":"","mobile":"","editorDesktop":"\n\t\t \n\t\t \n\n\t\t .eb-toc-fd7th.eb-toc-container{\n\t\t\t max-width:610px;\n\n\t\t\t background-color:var(\u002d\u002deb-global-background-color);\n\n\t\t\t \n \n\n \n\t\t\t \n padding: 30px;\n\n \n\t\t\t \n \n \n \n\n \n \n border-radius: 4px;\n\n \n \n\n \n\n\n \n\t\t\t transition:all 0.5s, \n border 0.5s, border-radius 0.5s, box-shadow 0.5s\n ;\n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container:hover{\n\t\t\t \n \n \n\n\n \n\n \n \n \n\n \n \n\n \n\n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-title{\n\t\t\t text-align: center;\n\t\t\t cursor:default;\n\t\t\t color: rgba(255,255,255,1);\n\t\t\t background-color:rgba(69,136,216,1);\n\t\t\t \n\t\t\t \n \n\n \n\t\t\t \n \n font-size: 22px;\n \n font-weight: normal;\n \n \n \n \n \n\n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper{\n\t\t\t background-color:rgba(241,235,218,1);\n\t\t\t text-align: left;\n\t\t\t \n \n\n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper ul,\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper ol\n\t\t {\n\t\t\t \n\t\t\t \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li {\n\t\t\t color:rgba(0,21,36,1);\n\t\t\t \n \n font-size: 14px;\n line-height: 1.4em;\n font-weight: normal;\n \n \n \n \n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li:hover,\n .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li.eb-toc-active \u003e a{\n\t\t\t color:var(\u002d\u002deb-global-link-color);\n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li a {\n\t\t\t color:inherit;\n\t\t }\n\n .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li svg path{\n stroke:rgba(0,21,36,1);\n }\n .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li:hover svg path{\n stroke:var(\u002d\u002deb-global-link-color);\n }\n\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li a,\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li a:focus{\n\t\t\t text-decoration:none;\n\t\t\t background:none;\n\t\t }\n\n\t\t \n\n .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li {\n padding-top: 4px;\n }\n\n .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper .eb-toc__list li:not(:last-child) {\n padding-bottom: 4px;\n }\n\n \n .eb-toc-fd7th.eb-toc-container.style-1 .eb-toc__list-wrap \u003e .eb-toc__list li .eb-toc__list{\n background: #fff;\n \n \n \n \n\n \n \n border-radius: 4px;\n\n \n \n\n \n\n\n \n }\n\n\n\t \n\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper{\n\t\t\t display:block;\n\t\t }\n\t\t ","editorTab":"\n\t\t \n\t\t .eb-toc-fd7th.eb-toc-container{\n\t\t\t \n\n\t\t\t \n \n\n \n\t\t\t \n \n\n \n\t\t\t \n \n \n\n \n\n \n \n \n\n \n \n\n \n\t\t }\n\t\t .eb-toc-fd7th.eb-toc-container:hover{\n\t\t\t \n \n \n \n \n \n \n\n \n \n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-title{\n\t\t\t \n \n\n \n\t\t\t \n \n \n \n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper{\n\t\t\t \n \n\n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li{\n\t\t\t \n \n \n \n \n\t\t }\n\n .eb-toc-fd7th.eb-toc-container.style-1 .eb-toc__list-wrap \u003e .eb-toc__list li .eb-toc__list{\n \n \n \n\n \n\n \n \n \n\n \n \n\n \n }\n\n\t \n\t\t ","editorMobile":"\n\t\t \n\t\t .eb-toc-fd7th.eb-toc-container{\n\t\t\t \n\n\n\t\t\t \n \n\n \n\t\t\t \n \n\n \n\t\t\t \n \n \n\n \n\n \n \n \n\n \n \n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container:hover{\n\t\t\t \n \n \n\n \n \n \n \n\n \n \n\n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-title{\n\t\t\t \n \n\n \n\t\t\t \n \n \n \n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper{\n\t\t\t \n \n\n \n\t\t }\n\n\t\t .eb-toc-fd7th.eb-toc-container .eb-toc-wrapper li{\n\t\t\t \n \n \n \n \n\t\t }\n\n .eb-toc-fd7th.eb-toc-container.style-1 .eb-toc__list-wrap \u003e .eb-toc__list li .eb-toc__list{\n \n \n \n\n \n\n \n \n \n\n \n \n \n }\n\n\t \n\t "},"headers":[{"level":2,"content":"What Is a Data Analytics Dashboard?","text":"What Is a Data Analytics Dashboard?","link":"what-is-a-data-analytics-dashboard"},{"level":2,"content":"Who Is This Article For?","text":"Who Is This Article For?","link":"who-is-this-article-for"},{"level":2,"content":"Why Build a Data Analytics Dashboard?","text":"Why Build a Data Analytics Dashboard?","link":"why-build-a-data-analytics-dashboard"},{"level":2,"content":"Goals and Objectives","text":"Goals and Objectives","link":"goals-and-objectives"},{"level":2,"content":"Step-by-Step Guide","text":"Step-by-Step Guide","link":"step-by-step-guide"},{"level":3,"content":"Step 1: Creating a New Application","text":"Step 1: Creating a New Application","link":"step-1-creating-a-new-application"},{"level":2,"content":"Side Note: Resources and Downloads","text":"Side Note: Resources and Downloads","link":"side-note-resources-and-downloads"},{"level":3,"content":"Preview The Application Online","text":"Preview The Application Online","link":"preview-the-application-online"},{"level":3,"content":"Download the Finished Application","text":"Download the Finished Application","link":"download-the-finished-application"},{"level":3,"content":"Step 2: Running Your Application","text":"Step 2: Running Your Application","link":"step-2-running-your-application"},{"level":3,"content":"Step 3: Adding an API as a Data Source","text":"Step 3: Adding an API as a Data Source","link":"step-3-adding-an-api-as-a-data-source"},{"level":3,"content":"Step 4: Creating a Form on the API","text":"Step 4: Creating a Form on the API","link":"step-4-creating-a-form-on-the-api"},{"level":2,"content":"First Checkpoint: Run Your Application","text":"First Checkpoint: Run Your Application","link":"first-checkpoint-run-your-application"},{"level":3,"content":"Step 5: Visualizing the Data from the API","text":"Step 5: Visualizing the Data from the API","link":"step-5-visualizing-the-data-from-the-api"},{"level":3,"content":"Step 6: Combining Multiple Charts in a Dashboard","text":"Step 6: Combining Multiple Charts in a Dashboard","link":"step-6-combining-multiple-charts-in-a-dashboard"},{"level":3,"content":"Step 7: Adding Menu Items to Your App","text":"Step 7: Adding Menu Items to Your App","link":"step-7-adding-menu-items-to-your-app"},{"level":2,"content":"Second Checkpoint: Run Your Application","text":"Second Checkpoint: Run Your Application","link":"second-checkpoint-run-your-application"},{"level":3,"content":"Finding Help in Five","text":"Finding Help in Five","link":"finding-help-in-five"}],"deleteHeaderList":[{"label":"What Is a Data Analytics Dashboard?","value":"what-is-a-data-analytics-dashboard","isDelete":false},{"label":"Who Is This Article For?","value":"who-is-this-article-for","isDelete":false},{"label":"Why Build a Data Analytics Dashboard?","value":"why-build-a-data-analytics-dashboard","isDelete":false},{"label":"Goals and Objectives","value":"goals-and-objectives","isDelete":false},{"label":"Step-by-Step Guide","value":"step-by-step-guide","isDelete":false},{"label":"Step 1: Creating a New Application","value":"step-1-creating-a-new-application","isDelete":false},{"label":"Side Note: Resources and Downloads","value":"side-note-resources-and-downloads","isDelete":false},{"label":"Preview The Application Online","value":"preview-the-application-online","isDelete":false},{"label":"Download the Finished Application","value":"download-the-finished-application","isDelete":false},{"label":"Step 2: Running Your Application","value":"step-2-running-your-application","isDelete":false},{"label":"Step 3: Adding an API as a Data Source","value":"step-3-adding-an-api-as-a-data-source","isDelete":false},{"label":"Step 4: Creating a Form on the API","value":"step-4-creating-a-form-on-the-api","isDelete":false},{"label":"First Checkpoint: Run Your Application","value":"first-checkpoint-run-your-application","isDelete":false},{"label":"Step 5: Visualizing the Data from the API","value":"step-5-visualizing-the-data-from-the-api","isDelete":false},{"label":"Step 6: Combining Multiple Charts in a Dashboard","value":"step-6-combining-multiple-charts-in-a-dashboard","isDelete":false},{"label":"Step 7: Adding Menu Items to Your App","value":"step-7-adding-menu-items-to-your-app","isDelete":false},{"label":"Second Checkpoint: Run Your Application","value":"second-checkpoint-run-your-application","isDelete":false},{"label":"Finding Help in Five","value":"finding-help-in-five","isDelete":false}],"isMigrated":true,"titleBg":"rgba(69,136,216,1)","titleColor":"rgba(255,255,255,1)","contentBg":"rgba(241,235,218,1)","contentColor":"rgba(0,21,36,1)","contentGap":8,"titleAlign":"center","titleFontSize":22,"titleFontWeight":"normal","titleLineHeightUnit":"px","contentFontWeight":"normal","contentLineHeight":1.4,"ttlP_isLinked":true,"commonStyles":{"desktop":".wp-admin .eb-parent-eb-toc-fd7th { display:block }.wp-admin .eb-parent-eb-toc-fd7th { filter:unset }.wp-admin .eb-parent-eb-toc-fd7th::before { content:none }.eb-parent-eb-toc-fd7th { display:block }.root-eb-toc-fd7th { position:relative }","tab":".editor-styles-wrapper.wp-embed-responsive .eb-parent-eb-toc-fd7th { display:block }.editor-styles-wrapper.wp-embed-responsive .eb-parent-eb-toc-fd7th { filter:none }.editor-styles-wrapper.wp-embed-responsive .eb-parent-eb-toc-fd7th::before { content:none }.eb-parent-eb-toc-fd7th { display:block }","mobile":".editor-styles-wrapper.wp-embed-responsive .eb-parent-eb-toc-fd7th { display:block }.editor-styles-wrapper.wp-embed-responsive .eb-parent-eb-toc-fd7th { filter:none }.editor-styles-wrapper.wp-embed-responsive .eb-parent-eb-toc-fd7th::before { content:none }.eb-parent-eb-toc-fd7th { display:block }"}} /-->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Why Build a Data Analytics Dashboard?</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>When you build a data analytics dashboard using an application builder like Five, the end result is a fully functional web application that goes beyond the capabilities of a simple Excel spreadsheet. This web app offers a range of advantages and features that make it a more powerful and effective tool for data analysis and visualization.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>A web app also provides a more user-friendly and interactive experience compared to an Excel dashboard. With features like drill-down capabilities, filters, and interactive charts and graphs, users can easily explore and analyze data at various levels of detail. This interactivity encourages users to engage with the data and uncover valuable insights that might be hidden in static Excel reports.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Furthermore, a data analytics dashboard web app built with Five is highly customizable and can be tailored to match your organization's branding and specific requirements. You can create a visually appealing and professional-looking dashboard that aligns with your company's style and color scheme, making it more engaging and intuitive for users. This level of customization is difficult to achieve with Excel's limited formatting options.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Another advantage of having a proper web app is that it can handle large amounts of data from multiple sources. Five allows you to connect to various databases, APIs and be cloud hosted, enabling you to consolidate and analyze data from different systems in a single dashboard. This data integration ensures that your dashboard provides a comprehensive view of your organization's performance, rather than relying on data from a single source, as is often the case with Excel dashboards.</p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Goals and Objectives</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>By the end of this guide, you'll have developed a responsive data analytics dashboard connected to the DummyJSON API. The API's JSON payload will be converted into relational data, displayed on a form, and visualized in a dashboard with multiple charts. Users will be able to interact with the data through the application.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Note: If your data isn't stored using a REST API with Five you can also build your data analytics dashboard using <a href="https://five.co/blog/how-to-create-a-front-end-for-a-mysql-database/">MySQL</a>, SQL Server, SQLite, or import from <a href="https://five.co/blog/excel-to-web-app/">Excel/Google Sheets.</a></p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Step-by-Step Guide</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 1: Creating a New Application</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><a href="https://five.co/get-started/"><strong>Sign Up for Free Access</strong> to the Five development environment.</a></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on "Applications" in the top navigation bar.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2938,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/image-7-1024x694-1.png" alt="" class="wp-image-2938"/></figure>
<!-- /wp:image -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on the yellow Plus icon.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2939,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/Five.Co-Yellow-Plus-Button-Create-a-New-Application-1024x649-1.png" alt="" class="wp-image-2939"/></figure>
<!-- /wp:image -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Name your application "Data Dashboard".</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Save it by clicking the tick mark.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2940,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/image-12-1024x619-1.png" alt="" class="wp-image-2940"/></figure>
<!-- /wp:image -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Side Note: Resources and Downloads</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Preview The Application Online</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To preview the application we are developing online, <a href="https://default-tryfive.5au.co/">click here</a>.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Download the Finished Application</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Download the finished application as a Five Definition File (FDF) and <a href="https://www.youtube.com/watch?v=tq7ULfWFfu0">import it into Five</a>. Once imported, run the application by clicking the "Deploy to Development" button, located in the top-right corner of Five.</p>
<!-- /wp:paragraph -->
<!-- wp:file {"id":2609,"href":"https://five.co/wp-content/uploads/2024/03/RESTAPIDashboard.fdf"} -->
<div class="wp-block-file"><a id="wp-block-file--media-85dee8d3-0eb1-44af-88e5-289338a70c71" href="https://five.co/wp-content/uploads/2024/03/RESTAPIDashboard.fdf">RESTAPIDashboard</a><a href="https://five.co/wp-content/uploads/2024/03/RESTAPIDashboard.fdf" class="wp-block-file__button wp-element-button" download aria-describedby="wp-block-file--media-85dee8d3-0eb1-44af-88e5-289338a70c71">Download</a></div>
<!-- /wp:file -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 2: Running Your Application</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Deploy Your Application</strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on the "Deploy to Development" button.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Five will create a cloud-hosted instance, including a database server and unique URL for your app.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Once deployed, the button will change to "Run". Click "Run" to preview your application.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2942,"sizeSlug":"large","linkDestination":"none"} -->
<figure class="wp-block-image size-large"><img src="https://five.co/wp-content/uploads/2024/05/Five.Co-Run-Your-Application-1024x576.png" alt="" class="wp-image-2942"/></figure>
<!-- /wp:image -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 3: Adding an API as a Data Source</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Use the Connection Wizard</strong> to connect Five to an external API:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on the <strong>blue</strong> manage button</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2943,"sizeSlug":"large","linkDestination":"none"} -->
<figure class="wp-block-image size-large"><img src="https://five.co/wp-content/uploads/2024/05/Screenshot-2024-05-22-at-4.07.53-pm-1024x520.png" alt="" class="wp-image-2943"/></figure>
<!-- /wp:image -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on "Data" > "Connection Wizard".</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2944,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/image-65-1024x190-1.png" alt="" class="wp-image-2944"/></figure>
<!-- /wp:image -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on "Read List Mapping".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Use the DummyJSON API: <code>https://dummyjson.com/products</code></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click "Send" to see the API response.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2945,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/image-66-1024x651-1.png" alt="" class="wp-image-2945"/></figure>
<!-- /wp:image -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Go to "Field Mapping" and set the display type for "description" to <code>_Memo</code>.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Ensure "id" is selected as the Primary Key.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2946,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/Five.Co-Connection-Wizard-Field-Mapping-1024x646-1.png" alt="" class="wp-image-2946"/></figure>
<!-- /wp:image -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on "Read Single Mapping" and paste <code>https://dummyjson.com/products/:id</code>.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In "General", create a new WebService with ID "DummyJSON" and Name "ProductAPI".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Save your API connection. Here's what it should look like so far.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2948,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/image-67-1024x649-1.png" alt="" class="wp-image-2948"/></figure>
<!-- /wp:image -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 4: Creating a Form on the API</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Use the Form Wizard</strong> to create a form:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2949,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/Five.Co-Form-Wizard-1024x650-1.png" alt="" class="wp-image-2949"/></figure>
<!-- /wp:image -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on "Visual" > "Form Wizard".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select "ProductsAPI" as the Main Data Source.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Name the form "Product Form".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Save the form.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading -->
<h2 class="wp-block-heading">First Checkpoint: Run Your Application</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Preview Your Application</strong> by clicking the "Run" button.<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Check that the "Product Form" menu item is available.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Ensure the form displays the API data correctly.</li>
<!-- /wp:list-item --></ul>
<!-- wp:paragraph -->
<p>Here’s what your app should look like. On the left, you should now see a new menu item called <strong>Product Form</strong> (your app will have different colors, because we haven’t themed it yet).</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>By clicking on <strong>Product Form</strong>, users can see all of the API’s data in a form created by Five.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Currently, the API returns a total of 30 rows of data. When you click on any of the products sent by the API, you can see its details. Because the API doesn’t let us update or delete products, the forms is read-only. If we had an API endpoint for each HTML method (GET, PATCH/PUT, POST, DELETE), our form could be configured with full create, read, update, and delete permissions.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"id":2950,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/image-5-1024x650-1.png" alt="" class="wp-image-2950"/></figure>
<!-- /wp:image -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 5: Visualizing the Data from the API</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>We will now add two charts to our application: a bar chart and a line chart that visualize data received from the API.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Create Charts</strong> using the Chart Wizard:<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on "Visual" > "Chart Wizard".</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list --></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2951,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/Five.Co-Excel-to-Web-App-Chart-Wizard-1024x651-1.png" alt="" class="wp-image-2951"/></figure>
<!-- /wp:image -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Create a bar chart for stock data:<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Title: Stock On Hand</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Data Source: ProductAPI</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>X Value Column: title</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Y Value Column: stock</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Chart Area ID: StockChart</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Chart Area Title: Stock Chart</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Chart Type: Bar</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list --></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Save the chart (click tick)</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Create a line chart for price data:<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Title: Product Prices</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Data Source: ProductAPI</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>X Value Column: title</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Y Value Column: price</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Chart Area ID: PriceChart</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Chart Area Title: Price Chart</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Chart Type: Line</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list --></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Save the chart (click tick)</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 6: Combining Multiple Charts in a Dashboard</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Navigate to Dashboards</strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Go to "Visual" > "Dashboards".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on the yellow Plus icon to create a new dashboard.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Configure the Dashboard</strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Fill in the fields as follows:<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Title: <code>API Dashboard</code></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Columns: <code>2</code></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Rows: <code>2</code></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list --></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>This setup creates a 2×2 grid to arrange your charts on the dashboard.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2953,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/Five.Co-Dashboard-API-Dashboard-1024x651-1.png" alt="" class="wp-image-2953"/></figure>
<!-- /wp:image -->
<!-- wp:table -->
<figure class="wp-block-table"><table><tbody><tr><td><strong>Title</strong></td><td>API Dashboard</td></tr><tr><td><strong>Columns</strong></td><td>2</td></tr><tr><td><strong>Rows</strong></td><td>2</td></tr></tbody></table></figure>
<!-- /wp:table -->
<!-- wp:paragraph -->
<p><strong>Add Actions to the Dashboard</strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Click on "Actions".</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the Actions section, click the Plus icon to add new actions.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Set Chart Positions</strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:image {"id":2954,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/Five.Co-Dashboard-Adding-Actions-1024x651-1.png" alt="" class="wp-image-2954"/></figure>
<!-- /wp:image -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>For Page Position <code>A1</code>, select <code>StockChart</code> (Chart) as the Action. Save it by clicking the Tick icon.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>For Page Position <code>B1</code>, select <code>PriceChart</code> (Chart) as the Action. Save it by clicking the Tick icon.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>For Page Position <code>A2</code>, select <code>ProductAPI</code> (Form) as the Action. Save it by clicking the Tick icon.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2955,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/image-6-1024x315-1.png" alt="" class="wp-image-2955"/></figure>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><strong>Save the Dashboard</strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Finally, save your configured dashboard by clicking the Tick icon.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Step 7: Adding Menu Items to Your App</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>Add a Menu Item for the Dashboard</strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Go to<strong> Visual > Menus</strong>.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on the yellow <strong>Plus </strong>icon<strong>.</strong></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Type <strong>Dashboard</strong> into Caption.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Type <strong>2 </strong>into <strong>Menu Order.</strong></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>In the <strong>Action</strong> drop-down select <strong>API Dashboard (Dashboard)</strong> as the action.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Click on the <strong>Tick </strong>icon to save your new menu item.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Second Checkpoint: Run Your Application</h2>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Preview Your Application</strong> by clicking the "Run" button.<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Check that the dashboard menu item works and displays the charts correctly.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list --></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>It’s time to run the application again. Here’s what it should look like (again, your app will have different colors, because it doesn’t have a theme).</p>
<!-- /wp:paragraph -->
<!-- wp:image {"id":2956,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/image-7-1024x651-1.png" alt="Build a data analytics dashboard" class="wp-image-2956"/></figure>
<!-- /wp:image -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:paragraph -->
<p>To deploy your data analysis dashboard to the web, <a href="https://five.co/order-payment/">sign up for one of our paid plans, starting from US$29.99 per month and application</a>. Your plan includes unlimited end-users and provides you with a custom URL to access the application online.</p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator has-alpha-channel-opacity"/>
<!-- /wp:separator -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Finding Help in Five</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>If you need assistance:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>User Community</strong>: Visit <a href="https://five.org/">Five’s User Community</a>.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>Documentation</strong>: Visit <a href="https://help.five.org/">Five’s Documentation</a>.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><strong>In-App Help</strong>: Use Five’s in-app help available in the top right corner.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:image {"id":2957,"sizeSlug":"full","linkDestination":"none"} -->
<figure class="wp-block-image size-full"><img src="https://five.co/wp-content/uploads/2024/05/Five.Co-Finding-Help-1024x649-1.png" alt="" class="wp-image-2957"/></figure>
<!-- /wp:image --> | domfive |
1,865,975 | Online Journal | What I Built I built a journaling app that allows users to create, read, update, and... | 0 | 2024-05-26T22:27:13 | https://dev.to/imkarthikeyan/online-journal-2icm | devchallenge, awschallenge, amplify, fullstack | ## What I Built
I built a journaling app that allows users to create, read, update, and delete (CRUD) their journal entries. Users can also filter entries based on the date selected from a calendar component.
## Demo and Code
Live Demo: https://main.d16q40xevlck1a.amplifyapp.com/
Code Repository: https://github.com/skarthikeyan96/amplify-journal/tree/main
## Screenshots:
**Customised auth form**
**Filter entry by date**
**Creating Journal Entry**
**Home page**
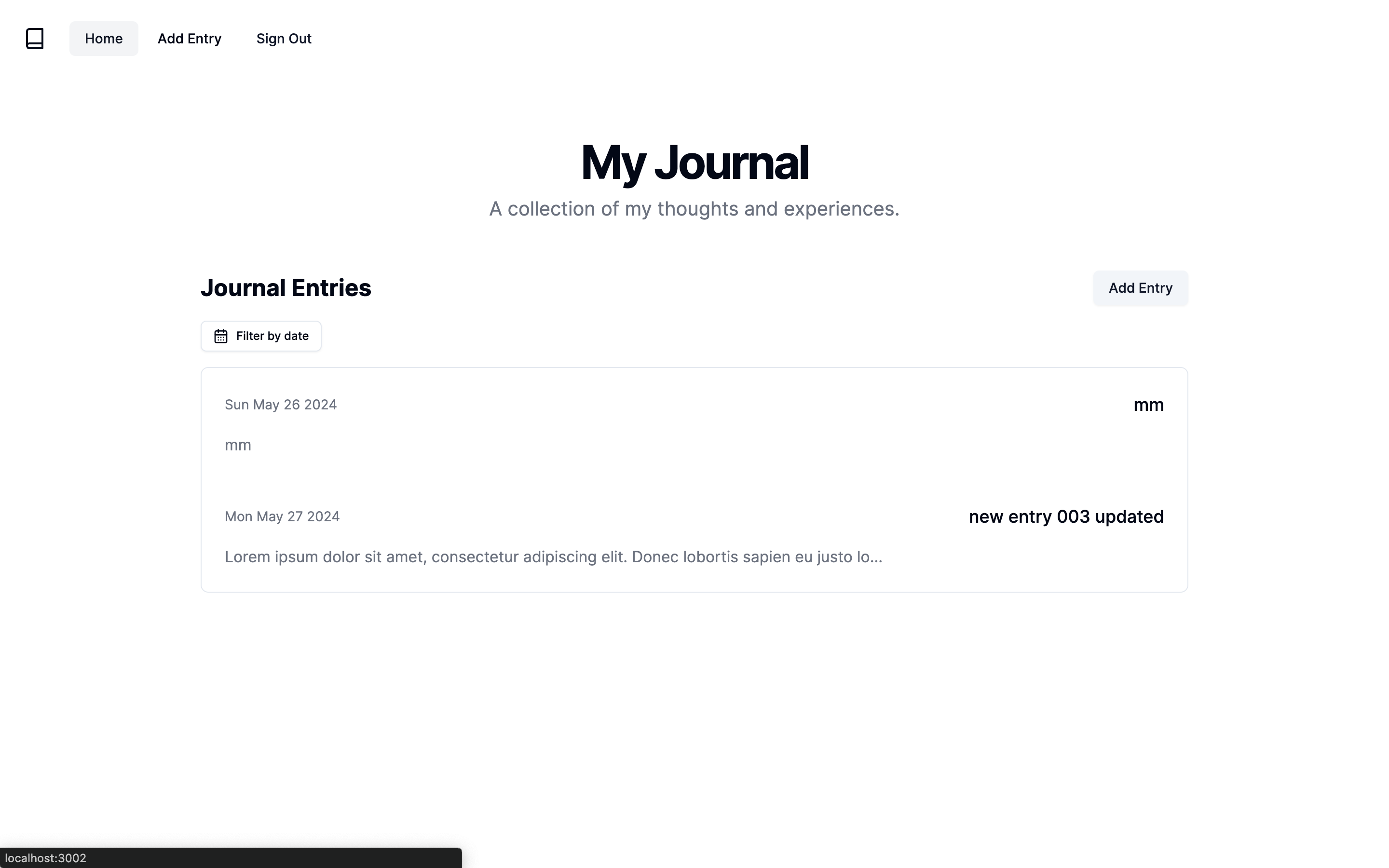
## Integrations
**Data Persistence**: Amplify DataStore is used to securely store and retrieve journal entries.
Optional:
**User Authentication**: Amplify Auth for user login and data privacy.
## Features
- Create journal
- Delete journal
- Update journal
- Search journal by date
- Authentication using Amplify Auth
## Upcoming
- Multimedia file support using S3
- Notification to update the journal entries
| imkarthikeyan |
1,823,878 | How to Build a Docker Image from Github and push to Docker Hub using a Jenkins Job | Instead of manually building a docker image every time you make changes in your source code, you can... | 0 | 2024-05-26T22:26:13 | https://dev.to/ericawanja/how-to-push-a-docker-image-to-docker-hub-using-jenkins-job-k5j | devops, jenkins, docker, beginners | Instead of manually building a docker image every time you make changes in your source code, you can build a Jenkins job that pulls the source code, builds the image, and publishes it to to docker hub.
How do you achieve that? Let's find out
### 1. Setting up the DockerHub credentials on Jenkins
Jenkins will need the docker hub credentials to build and push the image to the docker hub. Instead of using dockerHub username and password, we will Create an Access Token in the dockerHub.
1. Log in to DockerHub
2. Click on the profile Icon and click on the Account settings
3.Click on the Security tab on the left menu, click on the "New Access Token and Enter a brief Description. After clicking the "Generate" button, click on the "Copy and Close" button.
#### How to save the credentials on Jenkins
On Jenkins navigate to add a global credential
Enter the details needed to create the credential and save
### 2. Setting up the project on Github
If you don't have a project you can clone this https://github.com/Ericawanja/Jenkins-DockerHub-Automation
Delete the Jenkinsfile and Dockerfile to follow along
### 3. Setting up the Dockerfile
The docker file contains instructions on how to package the different computer pieces needed for a software application into a single package called an image.
We will create a simplified Dockerfile which copies all files into a work directory. Since we're not accessing this application from a browser, we will not be exposing any port.
```groovy
FROM node:20-alpine
WORKDIR /app
COPY . .
```
### 4. Creating and updating the Jenkins file
Create a Jenkins file on the root folder and follow along to update it
**Step 1: Logging in to Docker**
In the first step of the Jenkinsfile, we will log in to docker using with credentials() method which allows us to bind credentials into a pipeline script. Binding credentials using withCredentials method prevents exposing them in the script or on the Jenkins console.
```groovy
stages{
stage('Login') {
steps {
withCredentials([usernamePassword(credentialsId: 'dockerJenkinsID', usernameVariable: 'USERNAME', passwordVariable: 'PASSWORD')]) {
sh "docker login -u $USERNAME -p $PASSWORD"
}
}
}
```
- "usernamePassword" denotes the type of credentials.
- `credentialsId` is the ID of the credential stored in Jenkins
- `usernameVariable` and `passwordVariable` populate the username and password stored in Jenkins
**Step 2: Building the docker image**
Building a docker image is gathering all the artifacts needed for your software to run and packaging them so that the software can run anywhere.
To do so, the system uses a dockerfile which contains step-by-step instructions on how to build the image. Since we already have our dockerfile ready, we will be adding the command to trigger the image build.
```groovy
stage('Build'){
steps {
sh 'docker build -t ericawanja/todoapp:latest .'
}
}
```
**Step 3: Pushing the image to the docker hub**
Dockerhub is a cloud-based repository built for finding, using, and sharing docker container images. We will our push the image to the docker hub to make it available for other developers to pull and use it.
```groovy
stage('Push'){
steps {
//Deploy our app to DockerHub
sh 'docker push ericawanja/todoapp:latest'
}
}
}
```
**Step 4: Log out from Docker**
Logging out from service after logging in is a good security practice that prevents attacks such as session hijacking or unauthorized access.
We will log out from Jenkins in the "post" section which defines actions that are executed after the main stages in the Jenkins pipeline script have been completed.
The commands contained in the "always" block are executed every time the pipeline script runs regardless of the pipeline outcome.
```
post {
always {
sh 'docker logout'
}
}
```
### 4. Creating and Running the Jenkins Jobs
In this step, we will create a Jenkins job that pulls the source code from GitHub and uses the Jenkins file to build and push the image to dockerhub.
Log in to Jenkins, click "+ New item" and select a pipeline Job type. Don't forget to enter the name before clicking the OK button.
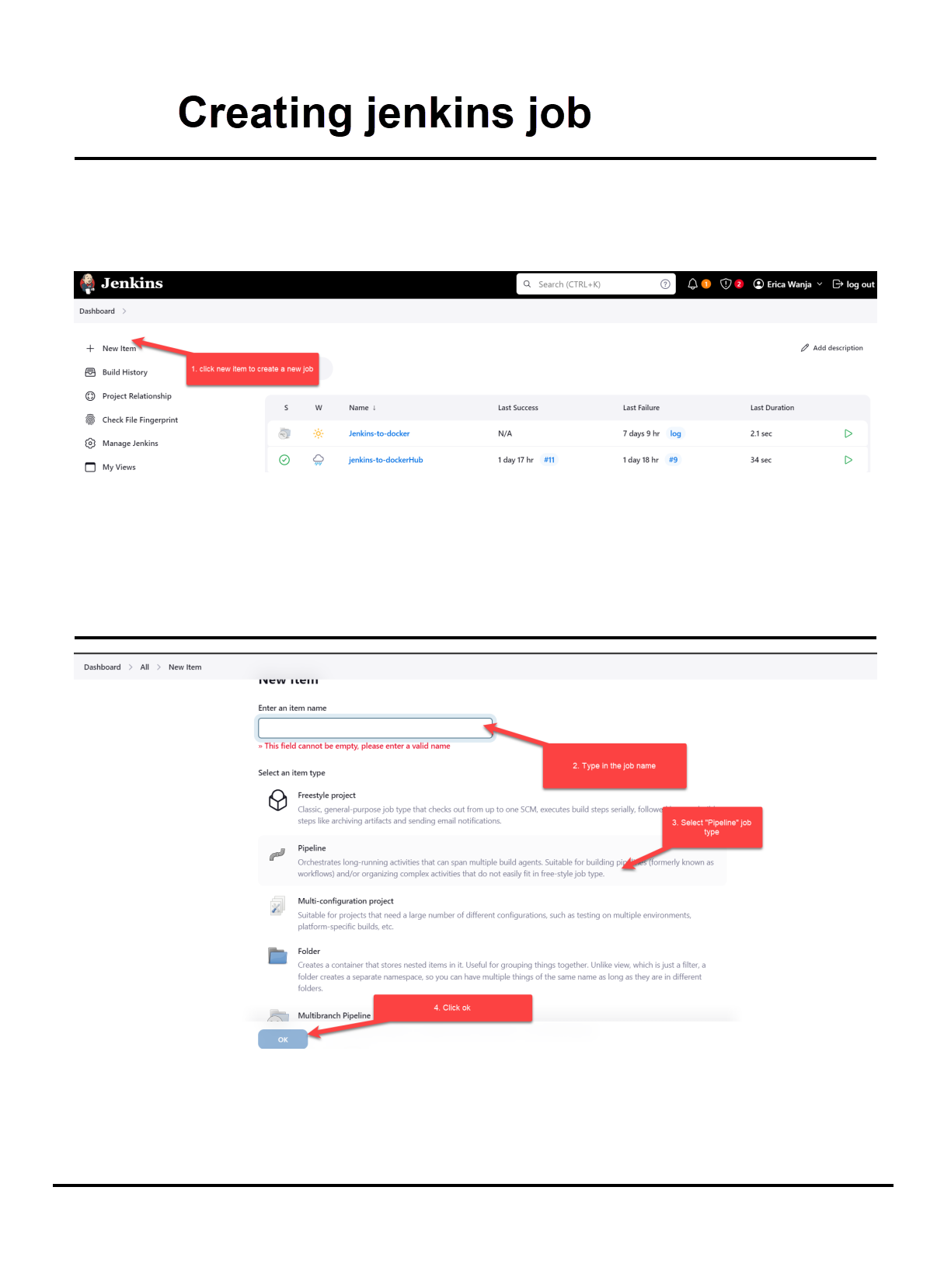
Because we're using a Jenkinsfile, the pipeline script will be from SCM. I'm using a public GitHub repository, therefore I don't have to configure the credentials. Remember to change the branch to "main" or the branch name you want to build.
Finish setting the job and run it.
### Conclusion
Automation aims at saving time and effort. By building a Jenkins pipeline that pulls the source code changes, builds an image, and pushes it to docker, will save you time and effort spent doing that manually.
| ericawanja |
1,865,927 | Exploring 64 Bit Asseembly lanaguage | Hey there! I am back again with an upadate in my journey of learning Software portability and... | 0 | 2024-05-26T22:18:05 | https://dev.to/yuktimulani/exploring-64-bit-asseembly-lanaguage-4fin | aarch64, x86, assembly | Hey there! I am back again with an upadate in my journey of learning Software portability and Optimisation. So, today we are going to dive deep in writing assembly in 2 architechtures and their names are [x86_64](http://spo600.cdot.systems/doku.php?id=spo600:x86_64_register_and_instruction_quick_start) and [aarch64](http://spo600.cdot.systems/doku.php?id=spo600:aarch64_register_and_instruction_quick_start).
Before we get started you might wanna take a look at [Assembler Basics](http://spo600.cdot.systems/doku.php?id=spo600:assembler_basics)
Lets get started directly into todays lab.So I was given the access for the 2 architectures by my professor for this lab and following are the tasks and how I did them.
## Task 1: Build and run the C version(s)
• Navigate to the spo600/examples/hello/c directory.
• Use the make command to build the C programs.
• Run the generated binaries to observe their behavior.
• Compare the source code in hello.c, hello2.c, and hello3.c to understand the differences
Below is how the same program of hello world hello.c, hello2.c and hello3.c written in c looks like in x86(left) and aarch64(right).



Well not much of a difference just colour changes right?. NO, WRONG in the first snapshot you can see that we are doing a system call for displaying the text "Hello World!" and also including the header required for that method, whereas in the second and the third snapshot we are not includeing any special headers just using the builtin methods write and printf respectively.
Now how do you biuld and compile these files, using the command `make filname` in this case it was `make hello` `make hello2` `make hello3`. These commads will build and compile the program and generate binary file which then can be run to execute the program.
You might ask what is make or makefile?
A Makefile is a special file used by the make utility to automate the process of compiling and building programs. It contains rules and instructions on how to compile and link the program's source files. This helps streamline the build process, especially for projects with multiple files and dependencies.
We will go deep into this topic in our next post, for now lets concentrate on the lab because it is kind of urgent 😭.
## Task 2: Disassemble the C binaries
• Use `objdump -d` command on the generated binaries to disassemble them into assembly code.
• Look for the <main> section in the disassembled code and analyze it.
• Note the differences in the amount of code compared to the C source code.
Here are the results.
I have highlighted the main tag and see how different are the 2 archietecturs and their addressing modes. The way they store a byte is also very different.
#1. Register Naming and Usage
aarch64:
- aarch64 has 31 general-purpose registers named x0 to x30.
- Register x0 to x7 are used for passing arguments and return values.
- There is a special zero register xzr which always reads as 0.
- Stack pointer is sp, and the link register (for return addresses) is lr or x30.
x86 (x86-64):
- x86-64 has 16 general-purpose registers named rax, rbx, rcx, rdx, rsi, rdi, rsp, rbp, and r8 to r15.
- Register rax, rdi, rsi, rdx, rcx, r8, and r9 are used for passing arguments and return values.
- The stack pointer is rsp, and the base pointer (used for stack frames) is rbp.
#2. Instruction Set
aarch64:
- Uses a Reduced Instruction Set Computing (RISC) architecture.
- Instructions are generally fixed at 32 bits in length.
- Emphasizes load/store architecture where memory operations are separate from arithmetic operations.
x86:
- Uses a Complex Instruction Set Computing (CISC) architecture.
- Instructions vary in length from 1 to 15 bytes.
- More complex instructions that can perform multiple operations.
And the list goes on and on. I think this is a lot of content already I dont want it to be overwhelming for my readers as it was for me 🥲. So, see you in the next post till then try to make sense of the above content.
Happy Coding!!
| yuktimulani |
1,864,266 | Hosting WordPress on Ubuntu: A Step-by-Step Guide | Let's say you are a blogger or even a small business owner looking for a way to share your insights... | 0 | 2024-05-26T22:10:15 | https://dev.to/florenceokoli/hosting-wordpress-on-ubuntu-a-step-by-step-guide-3707 | wordpress, ubuntu, devops, cloud | Let's say you are a blogger or even a small business owner looking for a way to share your insights or products with the world at large. For this, you would need a perfect platform for your website that is also flexible with a vast array of plugins.
Well, here comes **WordPress** to the rescue.
You now have a great platform, but you may want the freedom to customize your server environment and ensure that every aspect of your website runs exactly as you want, without relying on managed hosting services.
Okay. **Ubuntu** comes into play and combined with the power of the **LAMP** stack (Linux, Apache, MySQL, PHP) gives you complete control over your website.
All these may seem daunting at first but in this guide, I will walk you through the process of hosting WordPress on Ubuntu using the LAMP stack.
**Overview of Key Components**
Before we delve into the step-by-step process, let's take a brief look at what WordPress, Ubuntu, and the LAMP stack are, and their roles in this project:
* **WordPress** - WordPress is a widely used content management system (CMS) for creating and managing websites. It is well-known for its user-friendly interface and extensive library of plugins and themes. With WordPress, you can build anything from basic blogs to advanced e-commerce sites without requiring advanced technical skills. In this guide, WordPress will serve as the platform for creating and managing your website's content.
* **Ubuntu** - Ubuntu is a popular, open-source Linux operating system known for its stability, security, and ease of use. In this project, Ubuntu serves as the foundation, hosting the web server and other essential software components.
* **LAMP Stack** - LAMP is a set of open-source software for creating web servers, comprising Linux (Ubuntu as the operating system), Apache (webserver), MySQL (database), and PHP (scripting language). Each component is important and here is what they will do in this project:
* Linux: Provides the Operating System foundation.
* Apache: Handles browser requests and serves web pages.
* MySQL: Manages the WordPress database.
* PHP: Processes dynamic content and interacts with the
database.
**Prerequisites**
1. An Ubuntu Server: You can use either a local machine(Vagrant virtual box)or a cloud-based virtual private server from AWS, Digital Ocean or Google Cloud.
2. A basic understanding of Linux commands
**Steps**
**Update your package index**
* This command `sudo apt update` updates the package lists for upgrades and new package installations from the repositories defined in your system.

**Install Dependencies**
* To install Apache2 and PHP, run the following command
```
sudo apt install apache2 \
ghostscript \
libapache2-mod-php \
mysql-server \
php \
php-bcmath \
php-curl \
php-imagick \
php-intl \
php-json \
php-mbstring \
php-mysql \
php-xml \
php-zip
```
Copy and paste this command into a text file before pasting it into your virtual environment to avoid errors.
**Install WordPress**
* Let's create a new directory first and change the ownership of
this directory to the user `www-data` to ensure that the
webserver has the appropriate access to these files.
```
sudo mkdir -p /srv/www
sudo chown www-data: /srv/www
```

* Next, let's download the latest version of WordPress and extract it into the `/srv/www` directory.
```
curl https://wordpress.org/latest.tar.gz | sudo -u www-data tar zx -C /srv/www
```

Here is what the code does:
> This `curl https://wordpress.org/latest.tar.gz` command uses `curl` to download the file at the given URL, which is the latest version of WordPress in a gzipped tarball format.
> The pipe `|` command takes the output of the command on its left and uses it as the input to the command on its right.
> `sudo -u www-data`: This runs the following command as the `www-data` user. This is done because the `/srv/www directory` is owned by `www-data`, which we set earlier if you can remember
> This command `tar zx -C /srv/www` extracts the gzipped tarball. The `z` option tells tar to uncompress the file (as it is gzipped), the `x` option tells it to extract the files from the tarball, and the `-C /srv/www` option tells it to change to the `/srv/www` directory before doing so.
To confirm you followed the above step correctly, run this command
```
ls -l /srv/www/wordpress
```
If you see an image like the one below, then you are on track.
**Configure Apache for WordPress**
* To configure Apache for WordPress, run this command to create and edit WordPress configuration file
```
sudo vi /etc/apache2/sites-available/wordpress.conf
```

The command above opens up an empty configuration file. Copy the codes below and paste them into the configuration file. Then, save it
```
<VirtualHost *:80>
DocumentRoot /srv/www/wordpress
<Directory /srv/www/wordpress>
Options FollowSymLinks
AllowOverride Limit Options FileInfo
DirectoryIndex index.php
Require all granted
</Directory>
<Directory /srv/www/wordpress/wp-content>
Options FollowSymLinks
Require all granted
</Directory>
</VirtualHost>
```
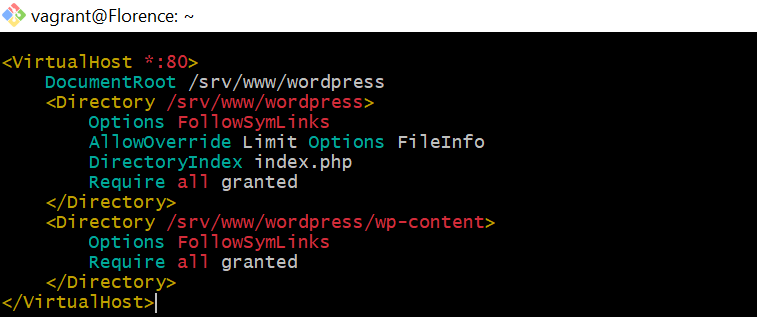
* When this is done, enable the site using this command - `sudo
a2ensite wordpress` and then enable URL rewriting using this
command `sudo a2enmod rewrite` lastly, disable the default site
using `sudo a2dissite 000-default`
* To finish up with this step, reload apache2 to apply all these
changes
`sudo service apache2 reload`
**Configure MySQL Database**
* Before we proceed, it is important to note that MySQL commands end with ; or /g
* Let's begin with opening up the MySQL CLI using this command
`sudo mysql -u root`
This command opens the MySQL command-line client as the root user
* Now, we create a database called wordpress, create a user for
this database and give it a unique password. Next, we grant
privileges to this user and with the flush privileges command,
we reload the user privileges from the grant tables in the
MySQL database.
Here is the code at play:
```
CREATE DATABASE wordpress;
CREATE USER wordpress@localhost IDENTIFIED BY '<your-password>';
GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,ALTER ON wordpress.* TO wordpress@localhost;
FLUSH PRIVILEGES;
quit
```
* Please note that these commands should be copied one after the * other into the CLI to avoid errors.
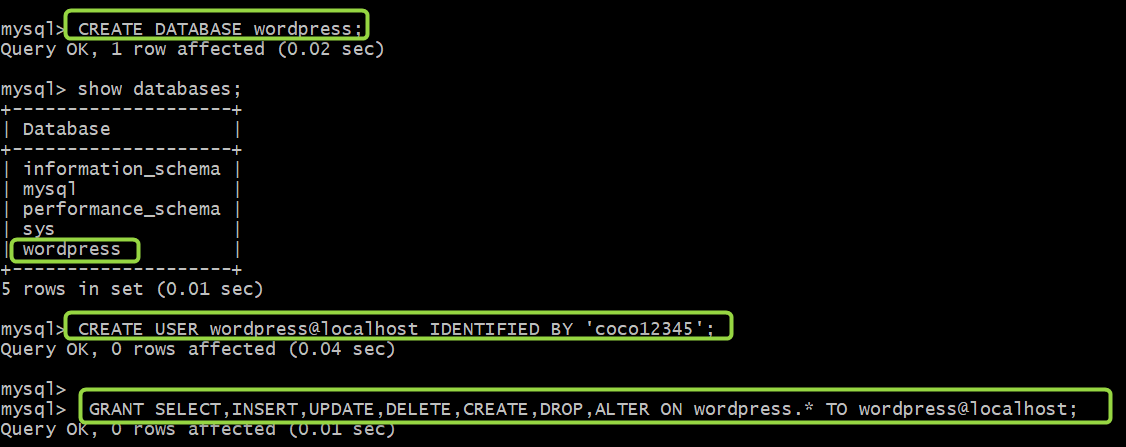
* To apply these changes we made, let's enable the MySQL service
with this command here - `sudo service mysql start`
**Configure WordPress to connect to the database**
* First, let's create a new configuration file for WordPress by
copying the sample configuration file to `wp-config.php`
```
sudo -u www-data cp /srv/www/wordpress/wp-config-sample.php /srv/www/wordpress/wp-config.php
```

* Next, we configure the credentials in the configuration file.
Please note that the only thing you are expected to change in
the commands below is your password.
Remember the unique password you created when you were creating
the MySQL database? Yeah, that's the one.
```
sudo -u www-data sed -i 's/database_name_here/wordpress/' /srv/www/wordpress/wp-config.php
sudo -u www-data sed -i 's/username_here/wordpress/' /srv/www/wordpress/wp-config.php
sudo -u www-data sed -i 's/password_here/<your-password>/' /srv/www/wordpress/wp-config.php
```

* Now we need to edit the WordPress config file. Use this command
to open and edit the config file `sudo -u www-data
/srv/www/wordpress/wp-config.php`
* In your config file, scroll down to where you will find the
commands below:
```
define( 'AUTH_KEY', 'put your unique phrase here' );
define( 'SECURE_AUTH_KEY', 'put your unique phrase here' );
define( 'LOGGED_IN_KEY', 'put your unique phrase here' );
define( 'NONCE_KEY', 'put your unique phrase here' );
define( 'AUTH_SALT', 'put your unique phrase here' );
define( 'SECURE_AUTH_SALT', 'put your unique phrase here' );
define( 'LOGGED_IN_SALT', 'put your unique phrase here' );
define( 'NONCE_SALT', 'put your unique phrase here' );
```
* Now delete these commands above and replace them with the
content you will find [here](https://api.wordpress.org/secret-key/1.1/salt/). (This address is a randomiser that
returns completely random keys each time it is opened.)
See mine below:
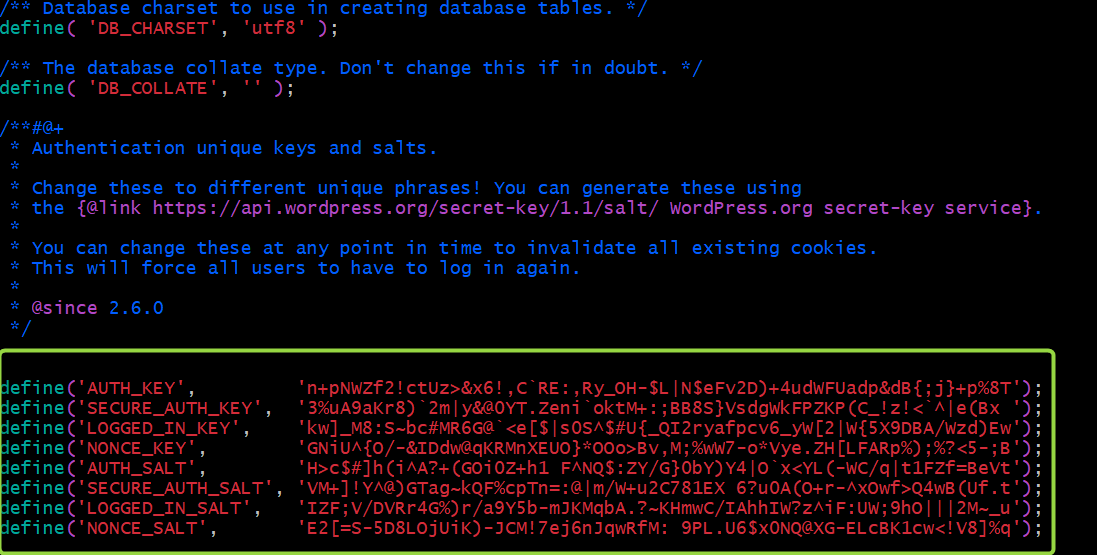
> This step is important to ensure that your site is not vulnerable to attacks.
Save the changes.
**Customize WordPress to serve your web pages**
* On your terminal, run this command `ip a` to copy the IP
address of your local machine. Copy and then paste the address
on your browser. You will see an image similar to the one below
upon loading your browser. Click on "continue" to customize
WordPress for hosting your web pages.
* Next, enter the title of your new site, username, password, and
a valid e-mail address. Note that the username and password you
choose here are for the WordPress site and not the ones you
used for the MySQL database earlier.
Click on Install WordPress to continue
* Now, let's log in with our details
* Once you log in to the WordPress dashboard, you will find a variety of icons and options to customize your website according to your preferences.
C'est fini!!
Congratulations on taking the first step toward creating your own WordPress website on Ubuntu using the powerful LAMP stack! By following this guide, you've set up a flexible and customizable platform for sharing your insights, products, or even services with the world.
I hope you found this tutorial helpful and easy to follow. | florenceokoli |
1,865,606 | Tool to get daily GitHub stars history | Introduction I created Daily Stars Explorer out of curiosity to track the star trends of... | 0 | 2024-05-26T22:09:16 | https://dev.to/emanuelef/tool-to-get-daily-github-stars-history-1mik | github, opensource, stats, stars | ## Introduction
I created [Daily Stars Explorer](https://emanuelef.github.io/daily-stars-explorer) out of curiosity to track the star trends of GitHub repositories. Currently, GitHub does not offer a graph showing the daily star changes for a repository.
Besides I can see that the most popular tool to track stars doesn't currently show the daily number of stars and it limits the cumulative stars to 40k, tracing a straight line from 40k to the current number of total stars.
I recognize that using stars as the sole measure of a repository's relevance can be risky. Various factors, beyond just quality, can influence the number of stars a repository receives:
- **Popularity contests**: Sometimes, projects gain stars simply because they become popular due to factors like marketing, promotion, or being featured in articles, blogs, or social media posts. This popularity can snowball, leading to more stars, even if the project itself may not offer substantial value.
- **Trendiness**: Projects related to trendy technologies, buzzwords, or topics may attract attention and stars, regardless of their actual quality or usefulness. For example, projects related to AI, Rust, or cryptocurrency may receive a significant number of stars due to the hype surrounding these fields.
- **Novelty**: Projects that introduce novel or unique ideas, even if they are not particularly useful in practice, may attract attention and stars simply because they are different. However, novelty does not always translate to long-term usefulness or sustainability.
- **Community support**: Projects with active and engaged communities may accumulate stars through contributions, feedback, and endorsements from community members. Even if the project itself is not outstanding, a supportive community can drive its popularity and star count.
- **Historical significance**: Some projects may have gained stars over time due to their historical significance or influence on subsequent projects, even if they are outdated or no longer actively maintained. These projects may serve as references or inspirations for newer projects, leading to continued star accumulation.
- **Unbiased evaluation**: Users may star projects for reasons unrelated to their quality or usefulness, such as personal preferences, curiosity, or experimentation. This can lead to inflated star counts for projects that may not deserve them based on objective criteria.
- **Awesome lists**: Those tend to accumulate a high number of GitHub stars, and one reason behind this phenomenon could be the perception of stars as bookmarks. Users might star repositories with the intention of revisiting them later for reference or exploration. Additionally, the sheer number of stars often acts as a social signal, prompting more users to star the repository, thus perpetuating the cycle of popularity.
- **Buy stars**: Sounds crazy but is also possible to buy stars from fake or even real accounts. This [blog post](https://dagster.io/blog/fake-stars) analyses in detail this phenomenon.
Having said that, I understand that observing star trends can provide valuable insights into a project's perception and its popularity trajectory. Additionally, I notice that many projects actively solicit GitHub stars, highlighting their significance within the community.
The idea behind my project is to treat the daily star count as an intriguing time series that can be analyzed with statistical tools. Whether you find this valuable or not is for you to decide.
## Features
### Full History of Stars
My project offers you the ability to access the full history of stars for a GitHub repository. It not only shows you the stars per day but also provides a cumulative stars graph. This way, you can visualize how a repository's popularity has evolved over time.
### Generate CSV and JSON
Easily save the star history as CSV or JSON files, with a daily and cumulative star count for each day since the repository's creation. You can then analyse the time series with the tools of your choice.
### Caching and Data Refresh
To keep things efficient, I've implemented a caching mechanism. Once you've fetched the history of stars, the data is cached for ten days. During this period, you have the option to refresh the data up to the current day. Please note that the graph will display data up to the last complete UTC day.
### Compare Repositories
For those curious about how two repositories stack up against each other, my project offers a comparison feature. This is something I wasn't sure to add, please consider the factors that might influence the number of stars.
### Aggregates and trends
In the Transform drop down is possible to select different levels of aggregation and also see the trend of the time series (using FB Prophet library).
## Patterns noticed
### Spikes
[OpenTofu](https://emanuelef.github.io/daily-stars-explorer/#/opentofu/opentofu)
Using Log Y-Axis
### Constant growth
[Keycloak](https://emanuelef.github.io/daily-stars-explorer/#/keycloak/keycloak)
The project was started 10 years ago and is showing an interesting constant growth in the number of daily stars.
## Limits
- Using one GitHub PAT the app can query up to 500k stars per hour. If this limit has already been reached, you will need to wait until the next hourly refresh.
- Rate limit: There's also a 60 maximum requests per hour for the full star history API, that should be enough for a human and it helps preventing bots running and use all the resources including
- Fetching Time: The time it takes to retrieve all star history (if not already cached) depends on the total number of stars. To overcome the 40,000-star limit, I leveraged the GitHub GraphQL API. Unfortunately, this doesn't allow for parallel requests. The workaround is to fetch the first half of the stars from the beginning and the other half from the end simultaneously, which can be time-consuming for large repositories.
Retrieving the complete star history for Kubernetes (~108k stars) typically takes about 3 minutes.
## Conclusion
This tool has been an interesting exercise for me to experiment with different technologies, you might find it valuable or completely useless. Curious to read in the comments what are your thoughts. | emanuelef |
1,865,928 | Happy Birthday Me, Happy Birthday NeoHaskell | Unleashing NeoHaskell v0.1.0 | 0 | 2024-05-26T22:09:00 | https://dev.to/nickseagull/happy-birthday-me-happy-birthday-neohaskell-2nk5 | programming, opensource, haskell | ---
title: Happy Birthday Me, Happy Birthday NeoHaskell
published: true
description: Unleashing NeoHaskell v0.1.0
tags: #programming #opensource #haskell
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/j1oif9h3k8i70m1rpmfw.png
# Use a ratio of 100:42 for best results.
published_at: 2024-05-26 22:09 +0000
---

Today is a special day for me—it's my birthday and also the release of the first version of NeoHaskell! 🎉 It's exciting to see it being born into the aethereal currents of the internet 30 years after my own birth.
On a personal note, I'm feeling much better since [my last post](https://dev.to/neohaskell/coming-out-as-an-eldritch-god-1nha). I've been focusing on my well-being, remodeling my apartment, and really listening to what my body needs. This reboot of NeoHaskell aligns perfectly with my renewed energy and excitement for ongoing development.
### First Version Highlights
This first version comes with a forked version of `nri-prelude`, an excellent library by NoRedInk, designed with Elm's philosophy in mind and mimicking the Elm core libraries. NeoHaskell takes this as an inspiring starting point to build upon, providing a solid foundation for future development.
### What's Inside the Core Library
- **Accumulator:** A DSL to gather values into an accumulable type.
- **Array:** Fast immutable arrays.
- **Basics:** Fundamental operations and types.
- **Char:** Character operations with ASCII and Unicode support.
- **Console and File:** Basic IO operations.
- **LinkedList:** Comprehensive list operations.
- **Map:** Builder API for maps.
- **Maybe:** Handling optional values.
- **Text:** Text operations including substring handling and formatting.
- **Traits:** Traits for appendable, default, mappable, and thenable types.
These changes aim to create a well-structured and documented codebase, making it easier for others to contribute and ensuring the project’s scalability.
### Getting Started
There aren't any detailed guides or tutorials yet, but you can clone the repository at [NeoHaskell Starter](https://github.com/neohaskell/neohaskell-starter) to start playing with the new version. For any help or instructions, join us on [Discord](https://discord.com/invite/wDj3UYzec8) where the community is ready to support you.
Thanks for being a part of this journey. Let's make great things happen with NeoHaskell! | nickseagull |
1,857,937 | Effective Map Composables: Non-Draggable Markers | This article is the first in a series exploring effective patterns and best practices for the... | 27,531 | 2024-05-26T22:00:28 | https://dev.to/bubenheimer/effective-map-composables-non-draggable-markers-2b2 | programming, kotlin, mobile, android | This article is the first in a series exploring effective patterns and best practices for the [android-maps-compose] GitHub library, with a focus on map markers. _android-maps-compose_ is a [Jetpack Compose] wrapper around the Google Play services [Maps SDK for Android], providing a toolkit for adding interactive maps to your Android application with ease.
Each post in the series elaborates on a different [example][android-maps-compose-marker-examples] from the android-maps-compose [5.0.3 release]. Later posts build on earlier ones. I authored the underlying library examples and made other recent contributions to the android-maps-compose GitHub project; I have been using the library in my own apps.
This post introduces a streamlined Composable for non-draggable Markers, supporting marker position updates from a model. The post also serves to establish common terminology. The project's [UpdatingNoDragMarkerWithDataModelActivity] example has the complete code.
---
><center>TL;DR: do this:</center><br/>
>
>```kotlin
>@Composable
>fun SimpleMarker(position: LatLng) {
> val state = rememberUpdatedMarkerState(position)
> Marker(state = state)
>}
>
>@Composable
>fun rememberUpdatedMarkerState(newPosition: LatLng) =
> remember { MarkerState(position = newPosition) }
> .apply { position = newPosition }
>```
> <br/>
---
Read on to see what is behind this approach. For clarity I will focus on `position` as a Marker's primary, stateful property. Adding properties does not alter the general approach.
While getting better acquainted with the android-maps-compose project in the past half year I came across suboptimal Marker usage patterns, in the project itself and in the community. Here is the starting point for this post:
```kotlin
@Composable
fun SimpleMarker(position: LatLng) {
Marker(state = MarkerState(position = position)) // bad
}
```
This snippet displays a [Marker] and keeps its position updated from a model. It looks convenient, but: [MarkerState] is a [hoisted state type], or [state holder]. It encapsulates state of a Marker, in particular its position. An android-maps-compose Marker is a wrapper around a [Maps SDK Marker].
```kotlin
class MarkerState(position: LatLng) {
var position: LatLng by mutableStateOf(position)
//...
}
```
The earlier snippet is essentially the following, a state object without [remember]:
```kotlin
Marker(state = mutableStateOf(latLng)) // bad pseudo code
```
In this case the IDE will generally flag the problem, but in the former example it would not, [until now][StateFactoryMarker PR]. (Or whenever the PR actually sees the light of day.)
The core problem is that every recomposition creates a new state object. At best, this may imply a performance penalty; at worst, it might cause incorrect behavior, depending on the API's internal behaviors.
To fix it, our next step might be:
```kotlin
@Composable
fun SimpleMarker(position: LatLng) {
val state =
remember(position) { MarkerState(position = position) } // bad
Marker(state = state)
}
```
This version is a little better. Recomposition will not recreate the state object each time, but only if the position parameter changes. (In this simplistic example, recomposition would not occur otherwise anyway, but that is beside the point.)
The pattern still needs improvement: recomposition replaces the state object instead of updating it; we need another fix to [hoist state][hoisted state] correctly. (A close look at the Marker implementation shows replacing the state object in the above fashion does not work quite right.)
Let's try again:
```kotlin
@Composable
fun SimpleMarker(position: LatLng) {
val state = remember { MarkerState(position = position) }
LaunchedEffect(position) {
state.position = position
}
Marker(state = state)
}
```
This version shows a familiar Compose pattern that does the right thing. It may be what many Compose developers would choose naturally. Are we done yet? A concern is that this code defers moving the Marker to a new position until the next recomposition; [LaunchedEffect] runs at the very end of a composition cycle. The code also guarantees to add that extra, costly recomposition. What to do?
```kotlin
@Composable
fun SimpleMarker(position: LatLng) {
val state = remember { MarkerState(position = position) }
state.position = position // ?!
Marker(state = state)
}
```
This approach may look sketchy, but it is valid:
The assignment looks like a [side effect] of composition. In fact, it is not a side effect because it updates snapshot state. If the composition were canceled, the update to snapshot state would disappear along with the composition.
However, this still writes to state in composition, which can be dicey: the problem is [backward writes], changing state after it has been read.
In the above case there is no backward write. The code updates position state before reading it in the Marker Composable. You can verify that all this happens within a single composition, without triggering recomposition. The pattern is what we want for decent code logic and performance.
If still in doubt, look at the implementation of [rememberUpdatedState] from the Compose runtime:
```kotlin
@Composable
fun <T> rememberUpdatedState(newValue: T): State<T> = remember {
mutableStateOf(newValue)
}.apply { value = newValue }
```
The above code does the same thing, but for plain [MutableState].
It is a good idea to encapsulate the MarkerState pattern in the same way to address the risk of accidentally moving the assignment down and introducing a backward write:
```kotlin
@Composable
fun SimpleMarker(position: LatLng) {
val state = rememberUpdatedMarkerState(position)
Marker(state = state)
}
@Composable
fun rememberUpdatedMarkerState(newPosition: LatLng): MarkerState =
remember { MarkerState(position = newPosition) }
.apply { position = newPosition }
```
What we have arrived at is a general purpose Composable `SimpleMarker(position: LatLng)` that encapsulates the Marker's statefulness. Convenient whenever we deal with non-draggable Markers that may change their position; naturally, the Composable is equally applicable for Markers that never move:
```kotlin
@Composable
fun FlightTracker(
musk: LatLng,
zuck: LatLng,
cook: LatLng
) {
SimpleMarker(musk)
SimpleMarker(zuck)
SimpleMarker(cook)
}
```
Be aware that `rememberUpdatedMarkerState(LatLng)` above is not to be confused with [rememberMarkerState(LatLng)][rememberMarkerState] from the android-maps-compose API. The latter is a strange beast that uses [rememberSaveable] to remember and persist MarkerState, without updating for model-driven changes. `rememberSaveable` introduces an additional source of truth. I do not see a use case for `rememberMarkerState` outside of small demos without a model, so I recommend ignoring it.
---
It may seem odd that we ended up with a function that mirrors [rememberUpdatedState][rememberUpdatedState KDoc] from the Compose runtime. `rememberUpdatedState` is generally used to access the most recent value of a stream of updating values from inside a long-running lambda. We do not have a long-running lambda in the simple Marker examples above. However, this similarity to rememberUpdatedState is just coincidence; the pattern is [applicable in other contexts][MapClickListeners usage] as well.
Here is what sets the Marker situation apart from typical Compose UI APIs: the android-maps-compose Markers API hoists state (MarkerState) to model the statefulness of the underlying Maps SDK Marker API. Hoisting state makes the Compose API essentially stateless, but it does not offer a corresponding stateful API, as is [common in Compose development][stateful vs stateless]. It is somewhat like using [BasicTextField] for both input and display, instead of choosing [BasicText] for simplified text display. The `SimpleMarker` Composable is the equivalent of the stateful BasicText API surface.
---
This post focused on the use case of non-draggable Marker _display_, outlining a _stateful_ Composable pattern to complement the _stateless_ Maps Compose Marker API. The stateful Composable supports model-driven Marker position updates with a streamlined API surface and efficient implementation. In this case [state only flows down][unidirectional data flow], i.e. the model is the singular source of truth, without state-changing events flowing back up.
The next post in the series will explore the converse use case: a draggable Marker updating state, with state-changing events bubbling up. rememberUpdatedMarkerState is no longer helpful in this case: MarkerState becomes the primary source of truth, supplanting the model.
---
Do _you_ have thoughts on this topic? Consider leaving a comment below. Composable maps APIs are still in their infancy, and there is much uncharted territory.
If you need professional help with your maps-related Compose project you can reach out to me through my profile. I have intimate knowledge of the Maps Compose API surface, its internals, and many ideas how to fix its deficiencies.
{% user bubenheimer %}
> Attribution: _cover image at the top of the post generated with DALL-E_
[android-maps-compose]: https://github.com/googlemaps/android-maps-compose
[android-maps-compose-marker-examples]: https://github.com/googlemaps/android-maps-compose/tree/1a03452dee3d6cf6c59de506652daca32fb51156/app/src/main/java/com/google/maps/android/compose/markerexamples
[5.0.3 release]: https://github.com/googlemaps/android-maps-compose/releases/tag/v5.0.3
[Jetpack Compose]: https://developer.android.com/develop/ui/compose
[Maps SDK for Android]: https://developers.google.com/maps/documentation/android-sdk
[UpdatingNoDragMarkerWithDataModelActivity]: https://github.com/googlemaps/android-maps-compose/blob/1a03452dee3d6cf6c59de506652daca32fb51156/app/src/main/java/com/google/maps/android/compose/markerexamples/updatingnodragmarkerwithdatamodel/UpdatingNoDragMarkerWithDataModelActivity.kt
[unidirectional data flow]: https://developer.android.com/develop/ui/compose/architecture#udf
[hoisted state type]: https://github.com/androidx/androidx/blob/c007497116a6bae87089e0d46f5ba8b385582cf7/compose/docs/compose-api-guidelines.md#hoisted-state-types
[state holder]: https://developer.android.com/topic/architecture/ui-layer/stateholders
[StateFactoryMarker PR]: https://github.com/googlemaps/android-maps-compose/pull/516
[remember]: https://developer.android.com/reference/kotlin/androidx/compose/runtime/package-summary#remember(kotlin.Function0)
[backward writes]: https://developer.android.com/develop/ui/compose/performance/bestpractices#avoid-backwards
[rememberUpdatedState]: https://github.com/androidx/androidx/blob/8e8e0d86039298fb4816960398308b531eea734e/compose/runtime/runtime/src/commonMain/kotlin/androidx/compose/runtime/SnapshotState.kt#L309-L312
[rememberUpdatedState KDoc]: https://developer.android.com/reference/kotlin/androidx/compose/runtime/package-summary#rememberUpdatedState(kotlin.Any)
[rememberMarkerState]: https://github.com/googlemaps/android-maps-compose/blob/1a03452dee3d6cf6c59de506652daca32fb51156/maps-compose/src/main/java/com/google/maps/android/compose/Marker.kt#L177-L183
[rememberSaveable]: https://developer.android.com/reference/kotlin/androidx/compose/runtime/saveable/package-summary#rememberSaveable(kotlin.Array,androidx.compose.runtime.saveable.Saver,kotlin.String,kotlin.Function0)
[MarkerState]: https://github.com/googlemaps/android-maps-compose/blob/1a03452dee3d6cf6c59de506652daca32fb51156/maps-compose/src/main/java/com/google/maps/android/compose/Marker.kt#L78-L92
[Marker]: https://googlemaps.github.io/android-maps-compose/maps-compose/com.google.maps.android.compose/-marker.html
[Maps SDK Marker]: https://developers.google.com/maps/documentation/android-sdk/reference/com/google/android/libraries/maps/model/Marker
[MutableState]: https://developer.android.com/reference/kotlin/androidx/compose/runtime/MutableState
[LaunchedEffect]: https://developer.android.com/reference/kotlin/androidx/compose/runtime/package-summary?hl=en#LaunchedEffect(kotlin.Any,kotlin.coroutines.SuspendFunction1)
[hoisted state]: https://developer.android.com/develop/ui/compose/state#state-hoisting
[BasicText]: https://developer.android.com/reference/kotlin/androidx/compose/foundation/text/package-summary#BasicText(androidx.compose.ui.text.AnnotatedString,androidx.compose.ui.Modifier,androidx.compose.ui.text.TextStyle,kotlin.Function1,androidx.compose.ui.text.style.TextOverflow,kotlin.Boolean,kotlin.Int,kotlin.Int,kotlin.collections.Map,androidx.compose.ui.graphics.ColorProducer)
[BasicTextField]: https://developer.android.com/reference/kotlin/androidx/compose/foundation/text/package-summary#BasicTextField(androidx.compose.ui.text.input.TextFieldValue,kotlin.Function1,androidx.compose.ui.Modifier,kotlin.Boolean,kotlin.Boolean,androidx.compose.ui.text.TextStyle,androidx.compose.foundation.text.KeyboardOptions,androidx.compose.foundation.text.KeyboardActions,kotlin.Boolean,kotlin.Int,kotlin.Int,androidx.compose.ui.text.input.VisualTransformation,kotlin.Function1,androidx.compose.foundation.interaction.MutableInteractionSource,androidx.compose.ui.graphics.Brush,kotlin.Function1)
[stateful vs stateless]: https://developer.android.com/develop/ui/compose/state#stateful-vs-stateless
[MapClickListeners usage]: https://github.com/googlemaps/android-maps-compose/blob/1a03452dee3d6cf6c59de506652daca32fb51156/maps-compose/src/main/java/com/google/maps/android/compose/GoogleMap.kt#L108-L116
[side effect]: https://developer.android.com/develop/ui/compose/side-effects
| bubenheimer |
1,854,405 | Dev: Software | A Software Developer is a professional who specializes in designing, creating, testing, and... | 27,373 | 2024-05-26T22:00:00 | https://dev.to/r4nd3l/dev-software-3bh1 | softwaredevelopment, developer | A **Software Developer** is a professional who specializes in designing, creating, testing, and maintaining software applications or systems. Here's a detailed description of the role:
1. **Analysis and Planning:**
- Software Developers analyze user requirements, business needs, and system specifications to understand the scope and objectives of software projects.
- They collaborate with stakeholders, project managers, and other team members to define project goals, timelines, and resource requirements.
2. **Design and Architecture:**
- Software Developers design software solutions, including the overall architecture, data models, user interfaces, and system components.
- They choose appropriate technologies, frameworks, and development methodologies based on project requirements and constraints.
3. **Programming and Development:**
- Software Developers write, test, and debug code using programming languages such as Java, C++, C#, Python, JavaScript, or Ruby.
- They implement algorithms, data structures, and software patterns to create efficient, scalable, and maintainable software solutions.
4. **Database Management:**
- Software Developers design and optimize databases, schemas, and queries to store, retrieve, and manipulate data efficiently.
- They use relational database management systems (e.g., MySQL, PostgreSQL, Oracle) or NoSQL databases (e.g., MongoDB, Cassandra) based on project needs.
5. **User Experience (UX) and User Interface (UI):**
- Software Developers design intuitive user interfaces (UIs) and user experiences (UX) to enhance usability and accessibility for end-users.
- They collaborate with UX/UI designers to create wireframes, prototypes, and mockups that align with user needs and design principles.
6. **Testing and Quality Assurance:**
- Software Developers conduct unit tests, integration tests, and system tests to identify and fix bugs, errors, and performance issues.
- They use testing frameworks, automated testing tools, and continuous integration (CI) pipelines to ensure software quality and reliability.
7. **Version Control and Collaboration:**
- Software Developers use version control systems (e.g., Git, SVN) to manage source code, track changes, and collaborate with team members effectively.
- They participate in code reviews, pair programming sessions, and sprint meetings to share knowledge, provide feedback, and improve code quality.
8. **Deployment and Maintenance:**
- Software Developers deploy software applications to production environments, cloud platforms, or app stores, ensuring smooth deployment and configuration.
- They monitor application performance, troubleshoot issues, and apply patches or updates to maintain system stability and security.
9. **Documentation and Communication:**
- Software Developers create technical documentation, user manuals, and API documentation to facilitate usage, maintenance, and integration of software products.
- They communicate project status, progress, and challenges to stakeholders, clients, and team members through reports, presentations, and meetings.
10. **Continuous Learning and Improvement:**
- Software Developers stay updated on emerging technologies, programming languages, and best practices through self-study, training programs, and professional development activities.
- They seek feedback, learn from past experiences, and strive for continuous improvement in their coding skills, problem-solving abilities, and software development practices.
In summary, a Software Developer is a versatile professional who plays a critical role in the design, development, and delivery of software solutions that meet business needs and user expectations. They combine technical expertise, creativity, and problem-solving skills to create innovative and reliable software products that drive digital transformation and business success. | r4nd3l |
1,854,404 | Dev: Software | A Software Developer is a professional who specializes in designing, creating, testing, and... | 27,373 | 2024-05-26T22:00:00 | https://dev.to/r4nd3l/dev-software-3pmh | softwaredevelopment, developer | A **Software Developer** is a professional who specializes in designing, creating, testing, and maintaining software applications or systems. Here's a detailed description of the role:
1. **Analysis and Planning:**
- Software Developers analyze user requirements, business needs, and system specifications to understand the scope and objectives of software projects.
- They collaborate with stakeholders, project managers, and other team members to define project goals, timelines, and resource requirements.
2. **Design and Architecture:**
- Software Developers design software solutions, including the overall architecture, data models, user interfaces, and system components.
- They choose appropriate technologies, frameworks, and development methodologies based on project requirements and constraints.
3. **Programming and Development:**
- Software Developers write, test, and debug code using programming languages such as Java, C++, C#, Python, JavaScript, or Ruby.
- They implement algorithms, data structures, and software patterns to create efficient, scalable, and maintainable software solutions.
4. **Database Management:**
- Software Developers design and optimize databases, schemas, and queries to store, retrieve, and manipulate data efficiently.
- They use relational database management systems (e.g., MySQL, PostgreSQL, Oracle) or NoSQL databases (e.g., MongoDB, Cassandra) based on project needs.
5. **User Experience (UX) and User Interface (UI):**
- Software Developers design intuitive user interfaces (UIs) and user experiences (UX) to enhance usability and accessibility for end-users.
- They collaborate with UX/UI designers to create wireframes, prototypes, and mockups that align with user needs and design principles.
6. **Testing and Quality Assurance:**
- Software Developers conduct unit tests, integration tests, and system tests to identify and fix bugs, errors, and performance issues.
- They use testing frameworks, automated testing tools, and continuous integration (CI) pipelines to ensure software quality and reliability.
7. **Version Control and Collaboration:**
- Software Developers use version control systems (e.g., Git, SVN) to manage source code, track changes, and collaborate with team members effectively.
- They participate in code reviews, pair programming sessions, and sprint meetings to share knowledge, provide feedback, and improve code quality.
8. **Deployment and Maintenance:**
- Software Developers deploy software applications to production environments, cloud platforms, or app stores, ensuring smooth deployment and configuration.
- They monitor application performance, troubleshoot issues, and apply patches or updates to maintain system stability and security.
9. **Documentation and Communication:**
- Software Developers create technical documentation, user manuals, and API documentation to facilitate usage, maintenance, and integration of software products.
- They communicate project status, progress, and challenges to stakeholders, clients, and team members through reports, presentations, and meetings.
10. **Continuous Learning and Improvement:**
- Software Developers stay updated on emerging technologies, programming languages, and best practices through self-study, training programs, and professional development activities.
- They seek feedback, learn from past experiences, and strive for continuous improvement in their coding skills, problem-solving abilities, and software development practices.
In summary, a Software Developer is a versatile professional who plays a critical role in the design, development, and delivery of software solutions that meet business needs and user expectations. They combine technical expertise, creativity, and problem-solving skills to create innovative and reliable software products that drive digital transformation and business success. | r4nd3l |
1,865,694 | Creating PDF and EPUB eBook from Laravel Documentation using Ibis Next | In this article, I will guide you through creating a PDF and EPUB e-book from the Laravel... | 0 | 2024-05-26T21:57:36 | https://dev.to/robertobutti/creating-pdf-and-epub-ebook-from-laravel-documentation-using-ibis-next-3bgc | laravel, documentation, books, tutorial | In this article, I will guide you through **creating a PDF and EPUB e-book** from the **Laravel documentation**.
We will use the Ibis Next tool to accomplish this.
The Laravel documentation is available in Markdown format on GitHub, and Ibis Next is a powerful utility for generating eBooks from Markdown files.
## Installing Ibis Next
You must install Ibis Next globally on your machine to create PDF or EPUB files from Markdown files. Ibis Next is a PHP package, so you'll need Composer to install it. If you don't have Composer installed, download and install it from getcomposer.org.
Once Composer is installed, run the following command to install Ibis Next globally:
```shell
composer global require hi-folks/ibis-next
```
Ensure Composer's global `bin` directory is in your system's `PATH`. You can typically add it by adding the following line to your `~/.bashrc`, `~/.zshrc`, or `~/.profile` file:
```shell
export PATH="$PATH:$HOME/.composer/vendor/bin"
```
## Cloning the Laravel Documentation Repository
Then, you need to clone the Laravel documentation repository to your local machine. In your terminal, in a new empty directory, execute the following command:
```shell
git clone --depth 1 https://github.com/laravel/docs.git
```
This command will download the repository containing the Markdown files for the Laravel documentation.
This command will generate the `docs` directory.
## Configure Ibis Next
Ibis Next provides the `init` command that generates the needed configuration and the basic assets files:
```shell
ibis-next init
```
The `init` command will generate the `assets` directory with some assets files, such as the CSS for creating the HTML files and the cover image. It will also generate the configuration file, `ibis.php`.
## Creating the cover (optional)
If you want, you can create the cover image, a PNG or WebP file with the aspect ratio of an A4 file. Or, if you prefer, you can download a basic one like :

You can save it into `assets/cover-laravel.png`.
## Creating the configuration
Before executing Ibis Next you have to configure it via the `ibis.php` file.
I already prepared a configuration file for setting the page header, the cover, and the list of the proper files. Feel free to override the ibis.php file with this one (and eventually adjust it according to your needs):
```php
<?php
return [
/**
* The book title.
*/
'title' => 'Laravel Doc e-book',
/**
* The author name.
*/
'author' => '',
/**
* The list of fonts to be used in the different themes.
*/
'fonts' => [
// 'calibri' => 'Calibri-Regular.ttf',
// 'times' => 'times-regular.ttf',
],
/**
* Document Dimensions.
*/
'document' => [
'format' => [210, 297],
'margin_left' => 27,
'margin_right' => 27,
'margin_bottom' => 14,
'margin_top' => 14,
],
/**
* Table of Contents Levels
*/
'toc_levels' => [
'H1' => 0,
'H2' => 1,
'H3' => 2,
],
/**
* Cover photo position and dimensions
*/
'cover' => [
'position' => 'position: absolute; left:0; right: 0; top: -.2; bottom: 0;',
'dimensions' => 'width: 210mm; height: 297mm; margin: 0;',
'image' => 'cover-laravel.png',
],
/**
* Page ranges to be used with the sample command.
*/
'sample' => [
[1, 7],
[15, 15],
],
/**
* default commonmark
*/
'configure_commonmark' => [
],
/**
* A notice printed at the final page of a generated sample.
*/
'sample_notice' => 'This is a sample',
/**
* CSS inline style for the page header.
* If you want to skip header, comment the line
*/
'header' => 'font-style: italic; text-align: right; border-bottom: solid 1px #808080;',
/**
* List of the Markdown files.
* If the `md_file_list` is not set (default)
* all the markdown files in the content directory
* will be loaded.
* If you need to select a subset of markdown files
* for creating PDF or EPUB or HTML you can list here
* the files. You need to set the filename in the
* content directory. The fieldname should include the
* extension.
*/
'md_file_list' => [
'releases.md',
'upgrade.md',
'contributions.md',
'installation.md',
'configuration.md',
'structure.md',
'frontend.md',
'starter-kits.md',
'deployment.md',
'lifecycle.md',
'container.md',
'providers.md',
'facades.md',
'routing.md',
'middleware.md',
'csrf.md',
'controllers.md',
'requests.md',
'responses.md',
'views.md',
'blade.md',
'vite.md',
'urls.md',
'session.md',
'validation.md',
'errors.md',
'logging.md',
'artisan.md',
'broadcasting.md',
'cache.md',
'collections.md',
'context.md',
'contracts.md',
'events.md',
'filesystem.md',
'helpers.md',
'http-client.md',
'localization.md',
'mail.md',
'notifications.md',
'packages.md',
'processes.md',
'queues.md',
'rate-limiting.md',
'strings.md',
'scheduling.md',
'authentication.md',
'authorization.md',
'verification.md',
'encryption.md',
'hashing.md',
'passwords.md',
'database.md',
'queries.md',
'pagination.md',
'migrations.md',
'seeding.md',
'redis.md',
'eloquent.md',
'eloquent-relationships.md',
'eloquent-collections.md',
'eloquent-mutators.md',
'eloquent-resources.md',
'eloquent-serialization.md',
'eloquent-factories.md',
'testing.md',
'http-tests.md',
'console-tests.md',
'dusk.md',
'database-testing.md',
'mocking.md',
'billing.md',
'cashier-paddle.md',
'dusk.md',
'envoy.md',
'fortify.md',
'folio.md',
'homestead.md',
'horizon.md',
'mix.md',
'octane.md',
'passport.md',
'pennant.md',
'pint.md',
'precognition.md',
'prompts.md',
'pulse.md',
'reverb.md',
'sail.md',
'sanctum.md',
'scout.md',
'socialite.md',
'telescope.md',
'valet.md'
],
];
```
I also prepared a Gist file, in case you prefer to use Gist: https://gist.github.com/roberto-butti/5e43c07921eefe0a913ab076cb95bc5e
## Generating the PDF file
Now, finally, you have Ibis Next installed and configured so that you can run it. To generate the PDF file using the Laravel cloned markdown files:
```shell
ibis-next pdf --content=docs
```
The file by default will be generated into the `export` directory.
You can open the generated PDF file with your PDF viewer.
## Generating the EPUB file
To generate the EPUB file using the Laravel cloned markdown files:
```shell
ibis-next epub --content=docs
```
The file, by default, will be generated into the `export` directory.
You can open the generated EPUB file with your EPUB viewer or transfer it to your eBook reader device.
> Both commands take a while to complete; the Laravel Documentation is huge, and you will probably create a PDF file with more than 2000 pages!!!
## Customize your PDF or EPUB file
If you want to customize the PDF or the EPUB file, you can read the documentation of Ibis Next here: https://github.com/Hi-Folks/ibis-next
## References
Feel free to drop your comments or feedback below. Some useful references if you want to explore more:
- Ibis Next project: https://github.com/Hi-Folks/ibis-next
- Ibis https://github.com/themsaid/ibis was the original project (now outdated) created by Mohamed. I forked the Ibis project to create Ibis Next to update it with the latest PHP versions and dependencies and add new functionalities like exporting into EPUB format, setting the page headers, etc
- Laravel documentation: https://github.com/laravel/docs
| robertobutti |
1,865,921 | 𝗧𝗵𝗲 𝗙𝗶𝗿𝘀𝘁 𝗦𝘁𝗿𝗲𝗮𝗸 𝗼𝗻 𝗟𝗲𝗲𝘁𝗖𝗼𝗱𝗲 | Dynamic Programming- Q 552. Student Attendance Record II class Solution { public int... | 0 | 2024-05-26T21:46:43 | https://dev.to/sailwalpranjal/-1apm | java, streak, leetcode, dynamicprogramming | **Dynamic Programming- Q 552. Student Attendance Record II**
```
class Solution {
public int checkRecord(int n) {
final int MOD = 1000000007;
int[][] dpCurrState = new int[2][3];
int[][] dpNextState = new int[2][3];
dpCurrState[0][0] = 1;
for (int len = 0; len < n; len++) {
for (int i = 0; i < 2; i++) {
Arrays.fill(dpNextState[i], 0);
}
for (int totalAbsences = 0; totalAbsences < 2; totalAbsences++) {
for (int consecutiveLates = 0; consecutiveLates < 3; consecutiveLates++) {
dpNextState[totalAbsences][0] = (dpNextState[totalAbsences][0] + dpCurrState[totalAbsences][consecutiveLates]) % MOD;
if (totalAbsences < 1) {
dpNextState[totalAbsences + 1][0] = (dpNextState[totalAbsences + 1][0] + dpCurrState[totalAbsences][consecutiveLates]) % MOD;
}
if (consecutiveLates < 2) {
dpNextState[totalAbsences][consecutiveLates + 1] = (dpNextState[totalAbsences][consecutiveLates + 1] + dpCurrState[totalAbsences][consecutiveLates]) % MOD;
}
}
}
for (int i = 0; i < 2; i++) {
System.arraycopy(dpNextState[i], 0, dpCurrState[i], 0, 3);
}
}
int totalCount = 0;
for (int totalAbsences = 0; totalAbsences < 2; totalAbsences++) {
for (int consecutiveLates = 0; consecutiveLates < 3; consecutiveLates++) {
totalCount = (totalCount + dpCurrState[totalAbsences][consecutiveLates]) % MOD;
}
}
return totalCount;
}
}
```
𝗢𝗽𝗲𝗻 𝘁𝗼 𝗨𝗽𝗱𝗮𝘁𝗲𝘀 𝗮𝗻𝗱 𝗦𝘂𝗴𝗴𝗲𝘀𝘁𝗶𝗼𝗻𝘀. | sailwalpranjal |
1,865,910 | 𝗔𝗿𝗿𝗮𝘆- 𝗤𝟲 𝗠𝗮𝘅𝗶𝗺𝘂𝗺 𝗦𝗰𝗼𝗿𝗲 𝗪𝗼𝗿𝗱𝘀 𝗙𝗼𝗿𝗺𝗲𝗱 𝗯𝘆 𝗟𝗲𝘁𝘁𝗲𝗿𝘀 | class Solution { public int maxScoreWords(String[] words, char[] letters, int[] score) { ... | 0 | 2024-05-26T21:17:12 | https://dev.to/sailwalpranjal/--14d8 | java | ```
class Solution {
public int maxScoreWords(String[] words, char[] letters, int[] score) {
int[] available = new int[26];
for (char c : letters) {
available[c - 'a']++;
}
int n = words.length;
int[] wordScores = new int[n];
int[][] wordCounts = new int[n][26];
for (int i = 0; i < n; i++) {
int wordScore = 0;
for (char ch : words[i].toCharArray()) {
wordCounts[i][ch - 'a']++;
wordScore += score[ch - 'a'];
}
wordScores[i] = wordScore;
}
int maxScore = 0;
for (int mask = 0; mask < (1 << n); mask++) {
int[] totalAvailable = available.clone();
int currentScore = 0;
boolean valid = true;
for (int i = 0; i < n; i++) {
if ((mask & (1 << i)) != 0) {
for (int j = 0; j < 26; j++) {
totalAvailable[j] -= wordCounts[i][j];
currentScore += wordCounts[i][j] * score[j];
}
}
}
for (int count : totalAvailable) {
if (count < 0) {
valid = false;
break;
}
}
if (valid) {
maxScore = Math.max(maxScore, currentScore);
}
}
return maxScore;
}
}
```
𝗢𝗽𝗲𝗻 𝘁𝗼 𝗨𝗽𝗱𝗮𝘁𝗲𝘀 𝗮𝗻𝗱 𝗦𝘂𝗴𝗴𝗲𝘀𝘁𝗶𝗼𝗻𝘀. | sailwalpranjal |
1,865,909 | Why you should be using Supabase. | Introduction This article will provide a brief overview of what is Supabase and its... | 0 | 2024-05-26T21:16:43 | https://dev.to/hitarth_gandhi_738e151b4e/why-you-should-be-using-supabase-2l4l | ## Introduction
This article will provide a brief overview of what is Supabase and its powerful features. Supabase is a Free Open Source Software(FOSS) providing a complete backend for mobile and web applications. The biggest challenge when building an app is not the coding, but picking the right tech stack such that the application can function at a huge scale. That's where Supabase comes in providing Database services as an alternative to Firebase. But wait, maybe we're getting ahead of ourselves so first let's understand what we mean by a database.
## What's a database
A database is generally defined as the collection of structured information, or data, stored electronically in a computer system. Nowadays when there are thousands and millions of users running a single application, the need to store data efficiently arises. Here comes the various databases such as Firebase, and Oracle Database which provide methods to store data for modern applications with huge userbases. Supabse being one of them, offers a substitute for Firebase, providing various features such as Database webhooks and authentication services while being cross-platform.
## Let's discuss the infrastructure of Supabase
Supabase uses Postgres to store data, this is a deliberate decision from the Supabase team. While Postgres does seem like a difficult database as compared to NoSql, Supabases tries to make it simpler and easy to use.
Below is a diagram of the basic infrastructure of Supabase
Now, lets try to understand each of the above concepts -
Supabase
The main part. It is the entire backend around the Postgres database.
Supabase Studio
The administration UI, which you see when you go to app.supabase.com.
Supabase Client Libraries
Supabase provides low-level access to Supabase with client libraries in various technologies.
Supabase CLI
Supabase CLI provides a command line interface for the Supabase API.
S3 storage provider
Supabase uses Amazon S3 storage to save all large files. However, for the self-hosted variant, you must select an S3-compatible storage provider.
Didn't quite catch on? No worries, let's simplify the working of Supabse.
At a high level, Supabse provides two things, The backend and The frontend. The backend consists of infrastructure such as a Database, file storage, and edge functions. The front end consists of SDK which basically connects the infrastructure to the various frameworks used to develop applications such as Reacr, flutter, etc. For users this allows the user to simply communicate to the infrastructure and automatically generates REST and GraphQl APIs
## Conclsion
Supabase is a great open source alternative for Firebase, as most of the services Supabase uses are generally also open source, while also providing the various important services Authentication and row-level-security.
| hitarth_gandhi_738e151b4e | |
1,865,908 | Extension in Docker compose | To write an extension in a compose.yml file for Docker, you can use the x- prefix to define reusable... | 0 | 2024-05-26T21:14:08 | https://dev.to/hmzi67/extension-in-docker-compose-5fio | docker, python, postgres, kong | To write an extension in a **compose.yml** file for Docker, you can use the **x-** prefix to define reusable fragments of configuration. Here's an example demonstrating how to use extensions in compose.yml:
- Define the Extension: Use the **x- **prefix to define reusable configurations.
- Reference the Extension: Use **<<** to include the extension in your service definitions.
## Example compose.yml with Extensions
```
version: '3.8'
# Define extensions
x-common-environment: &common-environment
environment:
- NODE_ENV=production
- LOG_LEVEL=info
x-common-volumes: &common-volumes
volumes:
- data:/data
services:
web:
image: my-web-app:latest
<<: *common-environment # Include common environment variables
<<: *common-volumes # Include common volumes
ports:
- "80:80"
worker:
image: my-worker-app:latest
<<: *common-environment # Include common environment variables
<<: *common-volumes # Include common volumes
environment:
- WORKER_TYPE=background
volumes:
data:
```
## Key Points:
- Extensions with x- Prefix: Define common configurations with x- prefix.
- Reference Extensions: Use <<: *extension-name to include them in services.
- Reuse Configurations: Simplifies and DRYs up the compose.yml.
This method helps maintain a clean and maintainable compose.yml file by avoiding repetition.
| hmzi67 |
1,865,907 | Javascript Engine | JavaScript is not directly understood by computers but the browsers have an inbuilt JavaScript... | 0 | 2024-05-26T21:08:52 | https://dev.to/ikbalarslan/javascript-runtime-37i8 | javascript, webdev, programming | JavaScript is not directly understood by computers but the browsers have an inbuilt JavaScript engine which helps to convert our JavaScript program into computer-understandable language. So whenever someone talks about running code they are talking about a javascript engine.
Javascript is a dynamic language so we expect it to be slow but it is pretty fast the reason is all the modern runtimes use something called JIT(just in time compile) because of that it is pretty fast.
Here is a list of the javascript engines in some popular browsers:
- V8 (Chrome)
- Chakra (Internet Explorer)
- Spider Monkey (Firefox)
- Javascript Core Webkit (Safari)
As an example, I will explain the workflow inside of the V8 engine:
for optimizing they use two compilers
- _baseline compiler ( V8 uses Ignition):_ it is regular compiler that generates machine code.
- _optimizing compiler (V8 uses turbofan):_ saves the type information for "hot" functions
Since javascript is a dynamic typing language we don't know the types when a user enters. so the compiler needs to find the types each time.
For optimization, we use an optimizing compiler which does:
- Re-compile: (if it is hot or used a lot) "hot" functions with type information from previous execution
- De-optimize: since javascript dynamically typed language, when the type changes remove it.
> If we don't change the types optimizing compiler can remember the types for the same functions so the code can be faster
so if we let the optimizing compiler do its job and don't change the types our code will be much faster. | ikbalarslan |
1,865,533 | Introduction of CodeBehind Framework | In this tutorial series, we introduce the CodeBehind framework belonging to Elanat. Elanat has dubbed... | 27,500 | 2024-05-26T21:00:25 | https://dev.to/elanatframework/introduction-of-codebehind-framework-3oco | tutorial, dotnet, beginners, backend | In this tutorial series, we introduce the [CodeBehind framework](https://github.com/elanatframework/Code_behind) belonging to [Elanat](https://elanat.net). Elanat has dubbed the CodeBehind framework the .NET Diamond.
## What is CodeBehind Framework
CodeBehind is a new free and open-source back-end framework that works under .NET Core. CodeBehind is owned by Elanat and developed in 2023 by Mohammad Rabie. The first version of the CodeBehind framework is built on .NET Core version 7.0.
## Why was CodeBehind created
If we leave Blazor technology aside, two frameworks for creating web applications in .NET Core have been provided by Microsoft; one of them is ASP.NET Core MVC and the other is Razor Pages. Both these frameworks have complexity and hard dependencies. On the other hand, the CodeBehind framework inherits all the advantages of ASP.NET Core and gives it more simplicity, power and flexibility.

These two frameworks have many structural weaknesses, their flexibility is low and their learning curve is hard. The Code Behind framework has a revolutionary MVC architecture for developing web systems that is easy to understand, has soft dependencies, and has high power and flexibility.
## Advantages of CodeBehind Framework

The CodeBehind framework includes revolutionary and new innovations with a modern approach; some of the advantages of this framework are written below:
- **Fast**: The CodeBehind framework is faster than the default structure of cshtml pages in ASP.NET Core.
- **Simple**: Developing with CodeBehind is very simple. You can use mvc pattern or model-view or controller-view or only view.
- **Modular**: It is modular. Just copy the new project files, including dll and aspx, into the current active project.
- **Get output**: You can call the output of the aspx page in another aspx page and modify its output.
- **Under .NET Core**: Your project will still be under ASP.NET Core and you will benefit from all the benefits of .NET Core.
- **Code-Behind**: Code-Behind pattern will be fully respected.
- **Modern**: CodeBehind is a modern framework with revolutionary ideas.
- **Understandable**: View is preferable to controller and there is no need to set controllers in route.
- **Adaptable**: The CodeBehind framework can even be used with Razor Pages and ASP.NET Core MVC.
## Unique MVC architecture in CodeBehind
MVC is a design pattern that consists of three parts: model, view, and controller. View is the display part. Dynamic data models are placed in the view. Controllers are responsible for determining the view and model for requests.
Using the MVC Design Pattern In most MVC frameworks, controllers must be configured in the root routes. In this structure, the request reaches the route and the route recognizes the controller based on the text patterns and then calls the controller. The configuration of the controller is in the path of a poor process and the wrong structure, which is placed at the beginning of the request and response cycle and causes problems for that structure.
In the CodeBehind framework, the controller is specified in the attributes section of the View page.
MVC diagram in CodeBehind Framework
## Knowledge prerequisites
In order to understand the concepts of this educational series, you must know a C-family (C#, JAVA or etc) programming language and also know HTML.
> Please note that we do not teach you programming in this tutorial series.
## Minimum required hardware and software
**Hardware**
In order for your system to run smoothly during this tutorial series, your system should be at least DDR3 or better.
CPU: Our recommendation is to use at least an Intel Core i5-3570 or AMD Athlon 3000G or more powerful processor.
Memory: 8 GB or more
Any SSD
**Software**
Windows Server 2019,2022 or higher, or (Windows 10,11 or higher), or Linux, Unix, Mac OS related .NET Core
VS Code 1.85 or higher, or Visual Studio 2022
.Net Core 7.0
IIS 10 or higher, or any web server that support .NET Core
Sql Server 2014,2016,2017,2019 or higher
MySQL 8.0 or higher
### Related links
CodeBehind on GitHub:
https://github.com/elanatframework/Code_behind
CodeBehind in NuGet:
https://www.nuget.org/packages/CodeBehind/
CodeBehind page:
https://elanat.net/page_content/code_behind | elanatframework |
1,865,223 | Dive into Linux Working | Let's dive into Linux Working Understanding the Linux Operating System: A Deep Dive ... | 27,495 | 2024-05-25T23:06:00 | https://dev.to/aws-builders/dive-into-linux-working-474p |
Let's dive into Linux Working
# Understanding the Linux Operating System: A Deep Dive
## 1. Kernel Initialization
The kernel is the heart of the Linux operating system. During boot, several critical steps occur:
- **BIOS/UEFI and Bootloader**:
- The BIOS or UEFI firmware initializes hardware components.
- The bootloader (e.g., GRUB) loads the Linux kernel (`vmlinuz`).
- **Kernel Initialization**:
- The kernel initializes hardware devices (CPU, memory, storage, etc.).
- It sets up essential data structures (e.g., process tables, page tables).
- The root filesystem is identified and mounted.
## 2. Init Process
- The kernel starts the init process (traditionally `init`, but modern systems use `systemd`).
- Init is responsible for:
- Starting system services and daemons.
- Managing user sessions and spawning user-space processes.
## 3. User Space Initialization
- Init spawns the first user-space process (usually `init` or `systemd`).
- User sessions (e.g., graphical desktop environments) start from here.
## 4. Filesystem Hierarchy
- Linux follows a standard directory structure:
- `/`: Root directory.
- `/bin`, `/sbin`: Essential system binaries.
- `/etc`: Configuration files.
- `/home`: User home directories.
- `/var`: Variable data (logs, caches).
- `/tmp`: Temporary files.
- `/usr`: User programs and libraries.
- `/opt`: Optional software.
- `/dev`: Device files.
- `/proc`: Virtual filesystem for process information.
## 5. Processes and Scheduling
- The scheduler (e.g., Completely Fair Scheduler) manages process execution.
- Processes are created using `fork()` and `exec()` system calls.
- Priorities, nice values, and CPU affinity affect scheduling.
## 6. Memory Management
- Virtual memory management:
- Page tables map virtual addresses to physical memory.
- TLB (Translation Lookaside Buffer) caches page table entries.
- Demand paging and swapping optimize memory usage.
- Memory allocation:
- `malloc()`, `free()` manage dynamic memory.
- Kernel memory management handles system memory.
## 7. File I/O and System Calls
- File descriptors (stdin, stdout, stderr) facilitate I/O.
- System calls (e.g., `open()`, `read()`, `write()`, `close()`) interact with files.
## 8. Networking
- Network stack:
- IP, TCP, UDP protocols.
- Socket API for network communication.
- Network configuration:
- `ifconfig`, `ip` commands.
- Routing tables determine packet forwarding.
## 9. Security and Permissions
- Users, groups, and permissions control access.
- `sudo` allows privilege escalation.
- File integrity checks (e.g., `md5sum`, `sha256sum`) verify file integrity.
## 10. Device Drivers
- Kernel modules manage hardware devices.
- Examples: `usb-storage`, `e1000` (Ethernet), `i915` (graphics).
## 11. Logging and Debugging
- `syslog` and `dmesg` provide system logs.
- Debugging tools (e.g., `strace`, `gdb`) help diagnose issues.
## 12. Shutdown and Reboot
- Init sends signals to processes.
- Filesystems are unmounted.
- The system halts or reboots.
🌟 Cheatsheet Linux🐧
1. **Linux Basics**:
- **Commands**:
- `ls`: List files and directories.
- `cd`: Change directory.
- `pwd`: Print working directory.
- `cp`: Copy files or directories.
- `mv`: Move or rename files.
- `rm`: Remove files or directories.
- **File Permissions**:
- `chmod`: Modify file permissions.
- `chown`: Change file ownership.
- `chgrp`: Change group ownership.
- **Processes**:
- `ps`: List running processes.
- `top`: Monitor system processes.
- `kill`: Terminate processes.
- `nice`: Adjust process priority.
- **Package Management**:
- `yum` (RPM-based systems): Install, update, and manage packages.
- `apt-get` (Debian-based systems): Similar functionality.
2. **File System Hierarchy**:
- Understand the directory structure:
- `/`: Root directory.
- `/bin`: Essential system binaries.
- `/etc`: Configuration files.
- `/home`: User home directories.
- `/var`: Variable data (logs, caches).
- `/tmp`: Temporary files.
- `/usr`: User programs and libraries.
- `/opt`: Optional software.
- `/dev`: Device files.
- `/proc`: Virtual filesystem for process information.
3. **Networking**:
- `ifconfig` or `ip`: Network configuration.
- `ping`: Check network connectivity.
- `netstat`: Network statistics.
- `ssh`: Secure shell for remote access.
- `iptables`: Firewall rules.
4. **Shell Scripting**:
- Create and execute shell scripts:
- Variables.
- Loops (for, while).
- Conditionals (if, else).
- Functions.
- Input/output redirection.
5. **System Administration**:
- User management:
- `useradd`, `userdel`, `passwd`.
- Disk management:
- `df`, `du`, `mount`.
- Cron jobs:
- `crontab`.
6. **Security**:
- `sudo`: Execute commands with superuser privileges.
- File integrity checks:
- `md5sum`, `sha256sum`.
- Firewalls and SELinux.
Sharing working overview, and there's much more to explore!
Feel free to ask questions and share with beginners starting with AWS DevOps. Happy learning! 🌟🐧 | yashvikothari | |
1,865,905 | Essential Guide to Python's Built-in Functions for Beginners | Overview Python offers a set of built-in functions that streamline common programming... | 0 | 2024-05-26T20:54:23 | https://dev.to/varshav/guide-to-pythons-built-in-functions-18oa | beginners, python, programming, webdev | ### Overview
Python offers a set of built-in functions that streamline common programming tasks. This guide categorizes and explains some of these essential functions.
### Basic Functions
`print()`: Prints the specified message to the screen or other standard output device.
```python
print("Hello, World!") # Output: Hello, World!
```
`input()`: Allows the user to take input from the console.
```python
name = input("Enter your name: ")
print(f"Hello, {name}!")
```
`len()`: Returns the length (number of items) of an object or iterable.
```python
my_list = [1, 2, 3, 4]
print(len(my_list)) # Output: 4
```
`type()`: Returns the type of an object.
```python
print(type(10)) # Output: <class 'int'>
print(type(3.14)) # Output: <class 'float'>
print(type("hello")) # Output: <class 'str'>
```
`id()`: Returns a unique id for the specified object.
```python
id(my_list)
```
`repr()`: Returns a readable version of an object. ie, returns a printable representation of the object by converting that object to a string
```python
repr(my_list) # Output: '[1, 2, 3, 4]'
```
### Data Type Conversion
`int()`:Converts a value to an integer.
```python
print(int("123")) # Output: 123
```
`float()`Converts a value to a float.
```python
print(float("123.45")) # Output: 123.45
```
`str()`:Converts a value to a string.
```python
print(str(123)) # Output: '123'
```
`bool()`:Convert any other data type value (string, integer, float, etc) into a boolean data type.
> - False Values: 0, NULL, empty lists, tuples, dictionaries, etc.
> - True Values: All other values will return true.
```python
print(bool(1)) # Output: True
```
`list()`: Converts a value to a list.
```python
print(list("hello")) # Output: ['h', 'e', 'l', 'l', 'o']
```
`tuple()`: Converts a value to a tuple.
```python
print(tuple("hello")) # Output: ('h', 'e', 'l', 'l', 'o')
```
`set()`: Converts a value to a list.
```python
print(set("hello")) # Output: {'e', 'l', 'o', 'h'}
```
`dict()`: Used to create a new dictionary or convert other iterable objects into a dictionary.
```python
dict(One = "1", Two = "2") # Output: {'One': '1', 'Two': '2'}
dict([('a', 1), ('b', 2), ('c', 3)], d=4) # Output: {'a': 1, 'b': 2, 'c': 3, 'd': 4}
```
### Mathematical Functions
`abs()`: Returns the absolute value of a number.
```python
print(abs(-7)) # Output: 7
```
`round()`: Returns the absolute value of a number.
```python
print(round(3.14159, 2)) # Output: 3.14
```
`min()`: Returns the smallest item in an iterable or the smallest of two or more arguments.
```python
print(min([1, 2, 3, 4, 5])) # Output: 1
```
`max()`: Returns the largest item in an iterable or the largest of two or more arguments.
```python
print(max([1, 2, 3, 4, 5])) # Output: 5
```
`sum()`: Sums the items of an iterable from left to right and returns the total.
```python
print(sum([1, 2, 3, 4, 5])) # Output: 15
```
`pow()`: Returns the value of a number raised to the power of another number.
```python
print(pow(2, 3)) # Output: 8
```
### Sequence Functions
`enumerate()`: Adds a counter to an iterable and returns it as an enumerate object.
```python
fruits = ['apple', 'banana', 'cherry']
for index, fruit in enumerate(fruits):
print(index, fruit)
# Output:
# 0 apple
# 1 banana
# 2 cherry
```
`zip()`: Combines multiple iterables into a single iterator of tuples.
```python
names = ['Alice', 'Bob', 'Charlie']
ages = [24, 50, 18]
for name, age in zip(names, ages):
print(f"{name} is {age} years old")
# Output:
# Alice is 24 years old
# Bob is 50 years old
# Charlie is 18 years old
```
`sorted()`: Returns a sorted list from the elements of any iterable.
```python
print(sorted([5, 2, 9, 1])) # Output: [1, 2, 5, 9]
```
`reversed()`: Returns a reversed iterator.
```python
print(list(reversed([5, 2, 9, 1]))))
# Output: [1, 9, 2, 5]
```
`range()`: Generates a sequence of numbers.
```python
for i in range(5):
print(i)
# Output: 0, 1, 2, 3, 4
```
### Object and Class Functions
`isinstance()`: Checks if an object is an instance or subclass of a class or tuple of classes.
```python
class Animal:
pass
class Dog(Animal):
pass
dog = Dog()
print(isinstance(dog, Dog)) # True
print(isinstance(dog, Animal)) # True
print(isinstance(dog, str)) # False
```
`issubclass()`: Checks if a class is a subclass of another class.
```python
print(issubclass(Dog, Animal)) # True
print(issubclass(Dog, object)) # True
print(issubclass(Animal, Dog)) # False
```
`hasattr()`: Checks if an object has a specified attribute.
```python
class Car:
def __init__(self, model):
self.model = model
car = Car("Toyota")
print(hasattr(car, "model")) # True
print(hasattr(car, "color")) # False
```
`getattr()`: Returns the value of a specified attribute of an object.
```python
print(getattr(car, "model")) # Toyota
print(getattr(car, "color", "Unknown")) # Unknown (default value)
```
`setattr()`: Sets the value of a specified attribute of an object.
```python
setattr(car, "color", "Red")
print(car.color) # Red
```
`delattr()`: Deletes a specified attribute from an object.
```python
delattr(car, "color")
print(hasattr(car, "color")) # False
```
### Functional Programming
`lambda`: Used to create small anonymous functions.
```python
add = lambda a, b: a + b
print(add(3, 5)) # 8
```
`map()`: Applies a function to all the items in an iterable.
```python
numbers = [1, 2, 3, 4]
squared = map(lambda x: x**2, numbers)
print(list(squared)) # [1, 4, 9, 16]
```
`filter()`: Constructs an iterator from elements of an iterable for which a function returns
```python
numbers = [1, 2, 3, 4, 5, 6]
even_numbers = filter(lambda x: x % 2 == 0, numbers)
print(list(even_numbers)) # [2, 4, 6]
```
### I/O Operations
`open()`: Opens a file and returns a corresponding file object.
`write()`: Writes data to a file.
```python
file = open("example.txt", "w")
file.write("Hello, world!")
file.close()
```
`close()`: Closes an open file.
```python
file = open("example.txt", "r")
print(file.read()) # Line A\nLine B\nLine C
file.close()
print(file.closed) # True
```
`read()`: Reads data from a file.
```python
file = open("example.txt", "r")
content = file.read()
print(content) # Hello, world!
file.close()
```
`readline()`
```python
file = open("example.txt", "w")
file.write("Line 1\nLine 2\nLine 3")
file.close()
file = open("example.txt", "r")
print(file.readline()) # Line 1
print(file.readline()) # Line 2
file.close()
```
`readlines()`
```python
file = open("example.txt", "r")
lines = file.readlines()
print(lines) # ['Line 1\n', 'Line 2\n', 'Line 3']
file.close()
```
`writelines()`
```python
lines = ["Line A\n", "Line B\n", "Line C\n"]
file = open("example.txt", "w")
file.writelines(lines)
file.close()
file = open("example.txt", "r")
print(file.read()) # Line A\nLine B\nLine C
file.close()
```
`with`
```python
with open("example.txt", "w") as file:
file.write("Hello, world!")
# No need to call file.close(), it's done automatically
```
### Memory Management
`del()`: Deletes an object.
```python
x = 10
print(x) # Output: 10
del x
# print(x) # This will raise a NameError because x is deleted.
```
`globals()`: Returns a dictionary representing the current global symbol table.
```python
def example_globals():
a = 5
print(globals())
example_globals()
# Output: {'__name__': '__main__', '__doc__': None, ...}
```
`locals()`: Updates and returns a dictionary representing the current local symbol table.
```python
def example_locals():
x = 10
y = 20
print(locals())
example_locals()
# Output: {'x': 10, 'y': 20}
```
`vars()`: Returns the __dict__ attribute of the given object.
```python
class Example:
def __init__(self, a, b):
self.a = a
self.b = b
e = Example(1, 2)
print(vars(e)) # Output: {'a': 1, 'b': 2}
```
### Miscellaneous
`help()`: Invokes the built-in help system.
```python
help(len)
# Output: Help on built-in function len in module builtins:
# len(obj, /)
# Return the number of items in a container.
```
`dir()`: Attempts to return a list of valid attributes for an object.
```python
print(dir([]))
# Output: ['__add__', '__class__', '__contains__', ...]
```
`eval()`: Parses the expression passed to it and runs Python expression within the program.
```python
x = 1
expression = "x + 1"
result = eval(expression)
print(result) # Output: 2
```
`exec()`: Executes the dynamically created program, which is either a string or a code object.
```python
code = """
for i in range(5):
print(i)
"""
exec(code)
# Output:
# 0
# 1
# 2
# 3
# 4
```
`compile()`: Compiles source into a code or AST object.
```python
source = "print('Hello, World!')"
code = compile(source, '<string>', 'exec')
exec(code)
# Output: Hello, World!
```
### Conclusion
Python's built-in functions are essential tools that facilitate a wide range of programming tasks. From basic operations to complex functional programming techniques, these functions make Python versatile and powerful. Familiarizing yourself with these functions enhances coding efficiency and effectiveness, enabling you to write cleaner and more maintainable code.
If you have any questions, suggestions, or corrections, please feel free to leave a comment. Your feedback helps me improve and create more accurate content.
***Happy coding!!!*** | varshav |
1,865,740 | Creating a simple Message Bus: Episode 1 | In my perpetual quest to be a better engineer and to understand tools/architectures better, I decided... | 27,569 | 2024-05-26T20:53:40 | https://dev.to/breda/creating-a-simple-message-bus-episode-1-2hjm | go, architecture, learning, softwareengineering | In my perpetual quest to be a better engineer and to understand tools/architectures better, I decided to start building stuff.
Build a message bus, database, reverse proxy... etc.
Whatever. Just build something I'm interested in learning more of.
To not think about this as a huge task, I decided to commit myself to build stuff in the simplest way possible. No fancy shenanigans.
Start small and simple. Add more along the way.
I'll be working with Go, not because I'm a Go expert, but because I like it and I feel like it helps with my productivity. I'll probably be learning more about Go along the way. Two birds with one stone kind of thing.
I also want to point out, that I write a post after I'm done with a portion of the code, sort of journaling my way through it.
which means that, the code could be incomplete or does not work (as I'm writing this, I'm thinking but that's what tests are for, but lets leave the tests for some other time). And it also means I'll probably be jumping between files a lot.
---
I wanted to start with a **message bus**.
Let's define it and start this series of posts by creating the project structure and maybe a bit more.
A message bus, is a messaging system that allows different systems to communicate with each other via sending and receiving of these messages.
So this message bus, is a system (also called the broker) that allows senders (also called producers) to send messages (just data, it could contain anything) to receivers (also called consumers).
In other words,
1. A producer prepares a messages, points it to the broker and says "here, deliver this message please" to this destination
2. The broker gets the message and delivers it to one or more consumers that are subscribing to said destination.
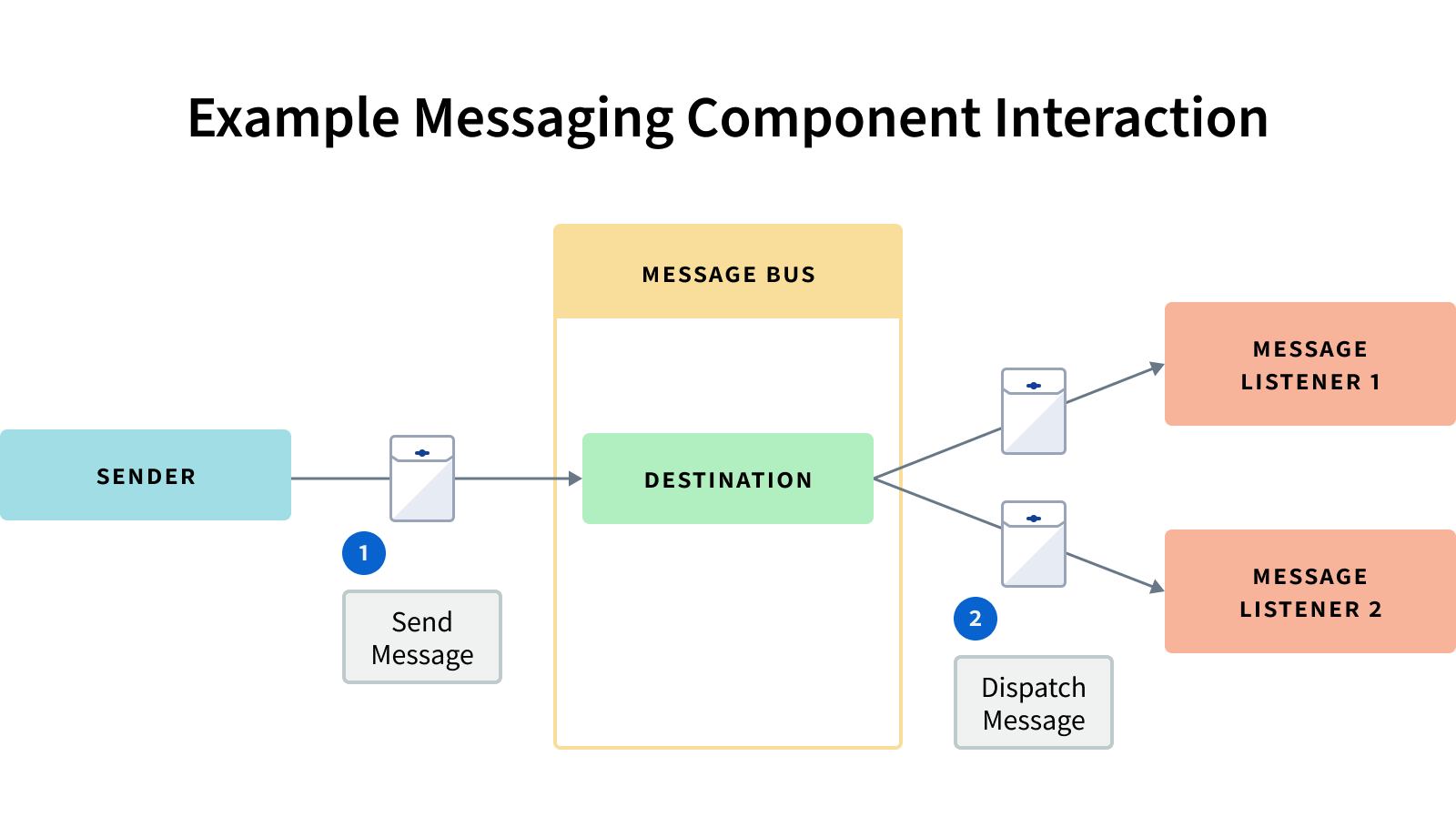
(image source: [here](https://learn.liferay.com/w/dxp/liferay-development/core-frameworks/message-bus))
## Project layout
So we have three actors: a broker, consumer and producer.
Let's start by creating an empty project structure. I'll call the go module `mbus`. Short and nice.
```bash
# Create the dir and cd into it
mkdir mbus
cd mbus
# Create the go module
go mod init mbus
# Create the project layout
mkdir cmd internal build
mkdir cmd/{broker,producer,consumer}
mkdir internal/{broker,producer,consumer}
```
Our base project layout is created.
To make our lives easier, let's create a very simple `Makefile`
```makefile
all: clean build
.PHONY: build
build:
go build -o build/broker cmd/broker/broker.go
go build -o build/producer cmd/producer/producer.go
go build -o build/consumer cmd/consumer/consumer.go
.PHONY: clean
clean:
rm -f build/broker
rm -f build/consumer
rm -f build/producer
```
So running `make` in the command line will rebuild our project. You could use something like [gowatch](https://github.com/silenceper/gowatch), but again I'm keeping it simple.
## Message structure
Let's define what "message" is in our application.
1. It needs to have some data, it could be json, it could be Base64 encoded image... we don't know and we don't care.
2. It needs to have some sort of destination name, for us to know where to send it to. In the "message bus" world, it's often called a "topic" or a "routing key" if you want to sound like a real nerd. I like "routing key" but let's use topic since it's shorter.
The message will be our contract between all parties, so let's call it `apiv1` and put it inside `internal`, like so
```bash
mkdir internal/apiv1
touch internal/apiv1/message.go
```
```go
// internal/apiv1/message.go
package apiv1
type Message struct {
Data []byte
Len int
Topic string
}
func NewMessage(topic string, data []byte) *Message {
return &Message{
Data: data,
Len: len(data),
Topic: topic,
}
}
```
Nice and simple.
The `Len` field is something we might not use, but when dealing with slices it's always a good idea to keep the length of it around. We'll see, if we don't need it we can just remove it later on.
Now, let's create the "producer" part of the app and call it a day.
## Producing messages
If you remember from our intro, a producer is very simple: it has a message and a topic, and it just sends them off to a broker.
Knowing that, let's create a command line app that will accept a host and port pair to point it to the broker, a topic and a message.
```go
// cmd/producer/producer.go
package main
import (
"flag"
"log"
"mbus/internal/producer"
)
var (
brokerHost string
brokerPort string
topic string
message string
)
func main() {
parseFlags()
client := producer.New(brokerHost, brokerPort)
err := client.Publish(topic, message)
if err != nil {
log.Fatalf(err.Error())
}
}
func parseFlags() {
flag.StringVar(&brokerHost, "host", "127.0.0.1", "Broker host")
flag.StringVar(&brokerPort, "port", "9990", "Broker port")
flag.StringVar(&topic, "topic", "", "Topic to produce the message for")
flag.StringVar(&message, "message", "", "The message contents")
flag.Parse()
if topic == "" {
log.Fatalf("please provide a topic")
}
if message == "" {
log.Fatalf("please provide a message to be sent")
}
}
```
1. Parsing flags to get command line arguments,
2. Creating a client by using `mbus/internal/producer` package (which we'll create after this)
3. Publishing the message to the topic, using the client.
The interesting stuff is at `internal/producer/producer.go` which we'll create in a minute, first I want to show you what a `Producer` looks like.
```go
// internal/producer/producer.go
type Producer struct {
host string
port string
conn net.Conn
encoder encoder.Encoder
}
```
- The first two fields are there to know where the broker is in our network.
- The second field, represents the TCP connection to the broker.
- The next one is the encoder. More on this bellow.
In order for us to send a `Message` object down the wire, we need to properly encode it to binary. We have a bunch of options in Go, but I'll go with [msgpack](github.com/vmihailenco/msgpack). ([Offical Website](https://msgpack.org/index.html))
The `encoder.Encoder` is an interface so we can swap out the msgpack implementation with another one.
I'm used to a lot of OOP so that encoded is embedded inside the publisher (composition), but I realize that maybe that's not the best way to things all the time.
But it works for now, so let's leave it be.
```bash
// Creating a shared folder for all shared things
mkdir -p internal/shared/encoder
```
The `Encoder` interface is pretty simple:
```go
// internal/shared/encoder/encoder.go
package encoder
import "mbus/internal/apiv1"
type Encoder interface {
Encode(*apiv1.Message) ([]byte, error)
}
```
Let's create a `msgpack` encoder, but first let's install the msgpack package:
```bash
go get -u github.com/vmihailenco/msgpack
```
```go
// internal/shared/encoder/msgpack.go
package encoder
import (
"mbus/internal/apiv1"
"github.com/vmihailenco/msgpack"
)
type MsgpackEncoder struct {
}
func (e *MsgpackEncoder) Encode(msg *apiv1.Message) ([]byte, error) {
data, err := msgpack.Marshal(msg)
if err != nil {
return nil, err
}
return data, nil
}
```
Pretty simple stuff.
Now let's get back to our producer by creating a constructor method:
```go
// internal/producer/producer.go
func New(host, port string) *Producer {
return &Producer{
host: host,
port: port,
conn: nil,
encoder: &encoder.MsgpackEncoder{},
}
}
```
Here, we create a new `Publisher` and use `MsgpackEncoder` for decoding.
Now, let's add a method to the `Publisher` so we can start publishing messages:
```go
// internal/producer/producer.go
func (c *Producer) Publish(topic, message string) error {
// we could connect in the New function before returning
// but it's better to defer it and call it here, whenever
// the user tries to publish a message.
err := c.connect()
if err != nil {
return err
}
msg := apiv1.NewMessage(topic, []byte(message))
data, err := c.encoder.Encode(msg)
if err != nil {
return err
}
n, err := c.conn.Write(data)
if err != nil {
return err
}
if n != len(data) {
return errors.New("could not write all data")
}
return nil
}
func (c *Producer) connect() error {
conn, err := net.Dial("tcp", net.JoinHostPort(c.host, c.port))
if err != nil {
return nil
}
c.conn = conn
return nil
}
```
Again very simple.
We connect to the broker, create a `Message` object, encode it, and send it to the broker using the connection established.
That's it. Producer part done. I told you the producer is the easiest one.
Next one will be the broker.
But first, let's at least manually test (since we don't have unit tests, lazy me) that our producer is actually sending stuff somewhere.
For that, we can use netcat for this. Run this command in another terminal:
```bash
nc -l -p 9990 -t 127.0.0.1
```
This will tell netcat (`nc`) to listen for TCP connections, on 127.0.0.1 port 9990. Kind of like a temporary test double for our broker :grin:
Now, let's compile our app and run the producer:
```bash
make
./build/producer -topic sales -message hey
```
You should see something printed on the terminal where you ran `nc`
Done, test coverage 100%.
Jokes aside, we'll probably add tests in another episode.
But for now, we'll call it a day.
---
Like I said at the start of this post, I'm just starting out with this so I don't really know where I'm going with this, and that's part of the fun. But it also means you could find the code not working or incomplete.
In any way, if you find a mistake or have some feedback, I'd love to hear it.
until then, see you in another episode! | breda |
1,865,904 | The Power of Video Promotion: Elevate Your Brand and Engage Your Audience | In today's digital age, video promotion has become a powerful tool for businesses to engage with... | 0 | 2024-05-26T20:50:31 | https://dev.to/blogiefy/the-power-of-video-promotion-elevate-your-brand-and-engage-your-audience-4672 | In today's digital age, video promotion has become a powerful tool for businesses to engage with their audience, build brand awareness, and drive sales. From social media platforms to email marketing campaigns, videos are now an essential component of any comprehensive marketing strategy. This article explores the benefits of video promotion and offers practical tips on how to create effective promotional videos that can elevate your brand and captivate your target audience.
The Benefits of [Video Promotion services](https://www.videopromotionservice.com/)
1. Enhanced Engagement:
Video content is inherently more engaging than text or images alone. It combines visuals, audio, and motion, creating a dynamic experience that can capture and retain the viewer's attention. According to a study by Wyzowl, 84% of people say that they’ve been convinced to buy a product or service by watching a brand’s video. This indicates that videos are not only engaging but also persuasive.
2. Improved SEO:
Search engines love video content. Websites with video are 53 times more likely to rank on the first page of Google search results, according to Moovly. This is because videos increase the amount of time visitors spend on your site, reducing bounce rates and signaling to search engines that your content is valuable. Additionally, videos can be optimized with keywords, descriptions, and tags, further enhancing your SEO efforts.
3. Higher Conversion Rates:
Videos can significantly boost conversion rates. Including a video on a landing page can increase conversions by 80%, as reported by Unbounce. Videos provide a clear and concise way to explain your product or service, showcase its benefits, and address potential concerns, making it easier for viewers to make a purchasing decision.
4. Stronger Emotional Connection:
Videos have the unique ability to evoke emotions and create a personal connection with the audience. Through storytelling, music, and visuals, videos can convey emotions more effectively than any other medium. This emotional connection can foster brand loyalty and encourage viewers to share your content, expanding your reach.
Tips for Creating Effective Promotional Videos
1. Know Your Audience:
Understanding your target audience is crucial for creating videos that resonate with them. Research their preferences, interests, and pain points to tailor your content accordingly. A video aimed at millennials, for example, might focus on trends and social causes, while one targeting business professionals might emphasize efficiency and results.
2. Keep It Short and Sweet:
Attention spans are short, especially online. Aim to keep your promotional videos between 1 to 2 minutes. This is enough time to convey your message without losing the viewer's interest. If you need to provide more detailed information, consider creating a series of shorter videos.
3. Focus on Storytelling:
People love stories. Instead of just listing features and benefits, weave a narrative that engages the viewer emotionally. Show how your product or service can solve a problem or improve their life. A compelling story will make your video more memorable and shareable.
4. Use High-Quality Production:
While you don’t need a Hollywood budget, the quality of your video production matters. Invest in good lighting, clear audio, and professional editing. Poor-quality videos can harm your brand’s credibility and turn potential customers away.
5. Include a Clear Call to Action:
Every promotional video should have a clear call to action (CTA). Whether you want viewers to visit your website, sign up for a newsletter, or purchase a product, make sure your CTA is specific and easy to follow. Place the CTA at the end of the video and reinforce it in the video description.
6. Optimize for Mobile:
With the majority of video content being consumed on mobile devices, it’s essential to optimize your videos for mobile viewing. This includes using subtitles for viewers who watch without sound, ensuring fast loading times, and creating vertical or square videos for better viewing on smartphones.
7. Leverage Social Media:
Social media platforms are perfect for video promotion. Share your videos on Facebook, Instagram, Twitter, and LinkedIn to reach a broader audience. Each platform has its own best practices for video content, so tailor your approach to fit the platform. For example, Instagram Stories and TikTok favor shorter, more casual videos, while LinkedIn is better suited for professional and educational content.
Conclusion
[Video marketing](https://www.videopromotionservice.com/video-marketing/) is an indispensable tool for modern marketers. Its ability to engage audiences, improve SEO, boost conversion rates, and create emotional connections makes it a highly effective marketing strategy. By understanding your audience, focusing on storytelling, and leveraging social media, you can create compelling promotional videos that elevate your brand and drive business growth. Embrace the power of video promotion and watch your brand thrive in the digital landscape. | blogiefy | |
1,865,903 | 30 Days of CPP | Join the 30-Days-of-CPP Challenge: Learn C++ and Contribute to Open Source! Are you an... | 0 | 2024-05-26T20:48:58 | https://dev.to/shubhadip_bhowmik/30-days-of-cpp-4go7 | opensource, cpp, beginners | ## Join the 30-Days-of-CPP Challenge: Learn C++ and Contribute to Open Source!
Are you an open-source enthusiast looking for your next challenge? Do you want to dive into the world of C++ programming or sharpen your existing skills? Look no further! I am excited to introduce you to my open-source project, **30-Days-of-CPP**, designed to guide both beginners and advanced programmers through the fascinating journey of mastering C++ in just 30 days.
## What is 30-Days-of-CPP?
**30-Days-of-CPP** is a comprehensive, step-by-step challenge that aims to teach you everything you need to know about C++ programming. Whether you are just starting out or looking to refine your skills, this project provides a structured curriculum, comprehensive documentation, and a supportive community to help you along the way.
## The Vision Behind 30-Days-of-CPP
As a passionate programmer and educator, I have always believed in the power of structured learning and community engagement. The 30-Days-of-CPP project was born out of this belief, with a vision to provide a comprehensive, accessible, and collaborative learning platform for C++ enthusiasts worldwide. Our goal is to demystify C++ and make it approachable for everyone, from beginners to seasoned programmers.
### Key Features of the 30-Days-of-CPP Challenge:
1. **Structured Curriculum:**
Our 30-day plan offers daily lessons that cover essential C++ concepts in a systematic and progressive manner. Each day, you will tackle new topics that build on your previous knowledge, ensuring a solid understanding of C++.
2. **Comprehensive Documentation:**
Detailed guides with explanations, code samples, and additional resources are provided to help you grasp each concept thoroughly. This documentation serves as both a learning tool and a reference as you progress through the challenge.
3. **We Are Open Source:**
The entire project is open-source, providing hands-on experience and opportunities for practical learning. You are encouraged to contribute, whether by improving existing content, adding new examples, or helping fellow learners.
4. **Free Access:**
All program resources and materials are freely accessible, ensuring that anyone interested can participate without any financial barriers. Our goal is to make learning C++ inclusive and accessible to everyone.
5. **Informative Blogs:**
Regularly updated blogs cover a wide range of C++ topics, offering supplementary insights and knowledge beyond the daily lessons. These blogs are a great way to deepen your understanding and stay updated with the latest in C++ programming.
6. **Community Engagement:**
Join our supportive community where you can interact, collaborate, and learn with others. We encourage discussions, sharing experiences, and helping each other succeed in the challenge. You can join our Whatsapp Channel for instant support and camaraderie.
## Why C++?
C++ is one of the most popular programming languages in history. It is widely used in developing mobile apps, desktop applications, games, and even in machine learning and AI. Its versatility and performance make it a valuable skill for any programmer. By participating in the **30-Days-of-CPP** challenge, you will not only learn C++ but also gain the confidence to apply it in real-world projects.
## How to Get Started?
1. **Visit the Project Repository:**
Check out the [30-Days-of-CPP GitHub repository](https://github.com/subhadipbhowmik/30-Days-Of-CPP/) for all the resources and to start your journey.
2. **Explore the Site:**
Visit the [30-Days-of-CPP site](https://subhadipbhowmik.github.io/30-Days-Of-CPP/) for an overview of the project, access to lessons, and more information.
3. **Join the Community:**
Connect with other participants and get support by joining our Whatsapp Channel (link available on the site).
4. **Start Contributing:**
Whether you are following the lessons or looking to contribute to the project, your participation is valuable. Check out the contribution guidelines on our GitHub repository.
## Conclusion
The **30-Days-of-CPP** challenge is more than just a learning journey—it's a community-driven effort to make C++ accessible and enjoyable for everyone. Whether you're a novice or an experienced programmer, this project offers something for you. Join us, contribute, and let’s learn C++ together!
Happy coding!
[GitHub Repository](https://github.com/subhadipbhowmik/30-Days-Of-CPP/) | [Project Site](https://subhadipbhowmik.github.io/30-Days-Of-CPP/) | shubhadip_bhowmik |
1,865,821 | Behind the scenes with FTP | File Transfer Protocol (FTP) is a cornerstone network protocol for moving computer files between a... | 0 | 2024-05-26T20:48:17 | https://dev.to/mahakfaheem/behind-the-scenes-with-ftp-28be | webdev, cybersecurity, ftp, protocol | File Transfer Protocol (FTP) is a cornerstone network protocol for moving computer files between a client and server on a network. As a Computer Science and Cybersecurity student, I've known about FTP for a while. I might have known more, but I could only recall "port 21" and a basic tool for file sharing in my mind. But today, as FTP came up in my learning, I decided to dig deeper. Here's a fresh, detailed look at FTP, how it works, and some practical examples to illustrate its operations.
### Historical Context
- **`Origins:`** FTP is one of the oldest protocols still in use today, dating back to the early 1970s. It was developed to support file transfers over ARPANET, the precursor to the modern internet.
- **`RFC 114:`** The first specification of FTP was published as RFC 114 in April 1971. This has evolved significantly over time, with the most widely recognized version being defined in RFC 959, published in 1985.
## What is FTP?
FTP allows for the transfer of files between two machines over a network. It operates based on a **client-server architecture** where the client initiates the connection to the server to upload or download files. Let’s break down how FTP works:
1. **`Establishing Connection:`** The client connects to the server on port 21 to establish a control connection.
2. **`Authentication:`** The client sends login credentials (username and password) over the control connection to authenticate with the server.
3. **`Command Exchange:`** The client sends FTP commands over the control connection, such as commands to change directories, list files, or initiate file transfers.
4. **`Data Transfer:`** When a file transfer command is issued, the server initiates a data connection on port 20. The actual file data is then transferred over this connection.
5. **`Termination:`** After the file transfer is complete, the data connection on port 20 is closed. The control connection on port 21 remains open until the client sends a command to terminate the session.
### Connection Establishment
- **`Port 21 - FTP Control:`** This port is used for the control connection between the client and the server. Commands such as login credentials, changing directories, and other control commands are sent and received here.
- **`Port 20 - FTP Data:`** This port handles the actual data transfer. Once the control connection on port 21 is established, port 20 is used to transfer the data between the client and server.
### Authentication
1. **`Client Initiates Connection:`** The client connects to the server on port
2. **`Server Response:`** The server responds with a greeting message.
3. **`Client Sends Credentials:`** The client sends a username and password to authenticate.
4. **`Server Verifies:`** The server verifies the credentials and responds with a success or failure message.
### Command & Response Exchange
FTP commands are text-based and follow a specific syntax. Each command sent by the client results in a response code from the server. Here are a few examples:
```
USER: Command to send the username.
PASS: Command to send the password.
LIST: Command to list files in a directory.
RETR: Command to retrieve (download) a file.
STOR: Command to store (upload) a file.
```
Example command exchange:
```
Client: USER ftpuser
Server: 331 Password required for ftpuser.
Client: PASS ftppassword
Server: 230 User ftpuser logged in.
```
### Data Transfer Modes
FTP can operate in two modes: Active and Passive.
**Active FTP:**
In Active FTP, the client opens a port and waits for the server to connect to it from port 20. Here’s how it works:
- The client connects to the server's port 21 and sends the PORT command, specifying which port the client is listening on.
- The server acknowledges and initiates a connection from its port 20 to the client’s specified port.
- The data transfer occurs over this new connection.
**Passive FTP:**
In Passive FTP, the roles are reversed, making it easier to handle firewall and NAT issues. Here’s how it works:
- The client connects to the server's port 21 and sends the PASV command.
- The server responds with the IP address and port number that the client should connect to for the data transfer.
- The client then establishes a data connection to the specified IP address and port.
### Directory Operations
FTP allows clients to navigate and manage directories on the server. Commands for these operations include:
- **PWD**: Print working directory.
- **CWD**: Change working directory.
- **MKD**: Make directory.
- **RMD**: Remove directory.
### File Transfer
File transfer operations involve the RETR and STOR commands:
- **`Download a File`**: The client sends RETR filename, and the server transfers the file over the data connection.
- **`Upload a File`**: The client sends STOR filename, and the client transfers the file to the server over the data connection.
### Some Security Considerations
- **`Unencrypted Transfers`**: Standard FTP does not encrypt data, making it vulnerable to eavesdropping and interception. Secure variants like FTPS (FTP Secure) and SFTP (SSH File Transfer Protocol) are used to address these security concerns.
- **`FTPS`**: FTPS adds support for the Transport Layer Security (TLS) and the Secure Sockets Layer (SSL) cryptographic protocols, providing encryption for both the control and data channels.
- **`SFTP`**: Despite its name, SFTP is a completely different protocol based on the Secure Shell (SSH) protocol. It provides secure file transfer capabilities, encrypting both command and data transfers.
- **`Anonymous FTP`**: Many public servers support anonymous FTP, where users can log in with the username "anonymous" and an email address as the password. This is often used for distributing public files and software updates.
### Hands-On Example: Using FTP with CLI
Let’s explore some hands-on examples using the FTP command line interface. These examples assume that an FTP server is up and running. You may refer this [blog](https://dev.to/mahakfaheem/ftp-server-setup-in-a-windows-vm-7ka) to setup one on a windows VM.
**Connecting to an FTP Server**
```
ftp <ftp_server_address>
```
**Logging In**
```
Name (ftp_server_address:username): your_username
Password: your_password
```
**Listing Files**
```
ftp> ls
```
**Changing Directories**
```
ftp> cd <directory_name>
```
**Downloading a File**
```
ftp> get <file_name>
```
**Uploading a File**
```
ftp> put <file_name>
```
**Exiting the FTP Session**
```
ftp> bye
```
Python provides an easy-to-use library called **[ftplib](https://docs.python.org/3/library/ftplib.html)** for FTP operations.
### Conclusion
FTP is a powerful protocol for transferring files between a client and a server. Understanding the roles of the control and data ports, along with the differences between Active and Passive modes, can help you effectively use FTP for your file transfer needs. The hands-on examples provided give a practical introduction to using FTP via the command line and Python.
By mastering FTP, you can efficiently manage file transfers in various network environments, ensuring smooth and secure data exchanges. So next time you think of FTP, you’ll see it as more than just port 21, but as a comprehensive protocol that facilitates essential file transfer operations.
Thanks | mahakfaheem |
1,865,214 | Network & ALL Devices Compromised | For over (3) years now, my smartphones, laptops and networks have been compromised by individuals I... | 0 | 2024-05-25T22:02:33 | https://dev.to/unixuser69/network-all-devices-compromised-omb | For over (3) years now, my smartphones, laptops and networks have been compromised by individuals I know. I have been collecting logs on everything I'm doing as well as what they are doing, nor am I hiding from them, cause I have nothing to hide. Now a few months before this started, my laptop was stolen off my kitchen table through a window. It was reported stolen immediately. 2 years later, the laptop shows up with Illegal Explicit Content all over it! Now this is why I report stuff like this; the date of the police report would be before the Illegal stuff was uploaded. I had to have a police officer make it very loud & clear so they (neighbors) would hear. Anything on that device uploaded after date reported stolen, and he hoped they turned it in to give them in return, Receiviing Stolen Property or Theft and charges for the illegal content for them to shut the fukc up, I was tired of hearing the neighbors talk about it...
Now the last (3) years, I found out the following:
-They are using C2 Connection(s) (Command & Control)
- They are using (20+) DNS and / or CDNs before a connection to me. Everything from Akamai to AmazonAWS to Cloudflare to Level3 and so on and so forth. See images.
- Depending on the wireless carrier, on TMO me and ALL my contacts shared the SAME IP address if they were on TMO. On Verizon and AT&T, Everytime the network changes, so does the IP address. Myself and all my contacts on TMO shared a Blacklisted IP in General and TMO. Even had a Blacklist on it (192.0.0.4) which is owned and operated by DS-Lite and the small block of (7) IPs 192.0.0.1-192.0.0.7 was the range. Ive had multiple devices and tested every carrier. On VZW, using NO DNS or Firewall, I am showing DNS IP Addresses.
-Geo-Located all my IPs, the internal and externals as well and I am showing (20+) different countries the DNS / CDN IPs are coming from.
-Now the Home Network is used by a bunch of IOT devices, fire sticks, laptops and (5) Roommates smartphones, all Android. All the devices when Geo-Locating show the same path my devices are showing.
-I believe they are trying to frame me for things which I have not done, hacking a bunch of devices, ALL my contacts, and every network I attach too, I can't seem to shake them off my ass and firewalls do not block IP addresses in both my Linux Laptop and Android Smartphones (All Google Pixels) so they were always updated with the latest CVEs.
-So if all these devices are connected via IP addresses, they are Using (20+) DNS or CDN Servers and C2 connections, while recording everything I am doing on my devices to (2) Clouds, AmazonAWS and CyberCloudSeven (owned and operated by Cloudflare). But the activities they are attempting to "hem me up for" I never did, not saying everything I ever did was legal ( illegal Narcotic Purchases : RIP #SilkRoad). Again, I am recording everything their doing and I'm doing and I'm not hiding anything so Im not using VPNs, DNSs, or anything to hide what I'm doing. And I haven't ordered or purchased anything illegal in over 15-20 yrs, which was either silkroad 1, 2, or 3.
- In the last 3 years, I have notified the State Police Cyber Crimes Unit, my local prosecutor's office Cyber Crimes and FBI IC3 and sent a little bit of evidence and they are aware, I am just "information gathering" with a Ton of screenshots and network logs.
-2 years ago I had a Federal Court hearing for SSI, the call lasted about 1hr 15min. At the end of the call, the Judge asked his assistant, also on the phone to stop the recording, about (30-60) seconds later, tap-tap tap-tap tap-tap, which I already knew what it was, the Judge yelles out before I could say a peep, "Who else is on this God-Damn Line, (5) times. Now my lawyer took the fall, because it was the professional thing to do. Now this was over the phone due to COVID. After this incident, I found out I could get a copy of the audio so I did, after listening (3) times, I realized the tapping started when they hit STOP! What that means is there were (2) recordings already going on before they hit record, a wire /phone tap is a recording over a recording, no matter how many times / ways you are recording a phone conversation, the 3rd cancels the (2) recordings out. Every 3rd or let's say an odd number of recordings at the same time. this confirmed my suspicion of we everything being recorded on (2) clouds, AmazonAWS and CyberCloudSeven. Now most if not all the apps they are using are cloud-based APIs.
-Attacks are a combination of DDOS, MITM, and BruteForce and Port Scanning.
-I also have information on the main Host, www.attentivemobile.com While checking IPs on Wireshark, top right-hand corner of my screen flashed a connection to either my Loopback or Laptop. www.cloudflare.at********* and I heard my neighbors flipping out because they basically gave themselves up. After a few weeks trying to figure out the other letters to the address, I found it. Attentive Mobile is a company that has a Quantum or Super Computer their AI is running and in the NYC/North NJ area, and is also a $2.4Billion company.
-my last network, I have months of network logs, showing C2 connections and all the external DNS IPs.
- Last while Monitoring my Network, My Router (AP-Link) shows up on my Router, and they are now my old neighbors and now 3-4 towns away. How does my Router show up on my Router? Now I got their MAC Address of their Router, either they Fucked Up again or the software they are using Did. Now when I seen it, I didn't screenshot, I refreshed after a double take, My Router changed to My Computer but still same MAC and AP-Link does NOT make PCs...
-Last, I reverse engineered all (20) DNS / CDN IPs and got their Comcast Business Account IP which is Private, 10.1.10.9. This would be their internal IP not External IP. BTW any IP I ping that is connected to this orgy of IPs, DNSs, CDNs and Clouds gets a Ping of 2002ms, which sounds about right for the amount of "trying to cover their tracks.". I know who, they made it impossible to prove. I am hoping even if they got a new Router, I can Geo-Locate the GPS history of that TP-Link Router. The engineer that put this hack together works
-The entire system is Automated AI and so easy a 1st grader can do it. mostly port Scanning from 65k down to 1, not up the channels, 1-65k.
I think they might be using an MDM by Akamai (Linode). Due to the fact that I was using Pixels and actually, let John Wu, head of Google Android Security about an exploit of the Block Camera and / or Block Mic was NOT Working. I wish I filed a big bounty, I didn't fix it, just pointed it out. Available in Android 15+ Block Camera & Block Mic now work, and beings they found the exploit, found out they were exploited by a company called Espysya.com which gave me More Info of some tools the Perps or Gangstalkers/ GasLighters.
My question to you "True Hackers" is what would you call this circus? the greatest show on earth? I know who it is but they made it almost impossible to trace back to them.
Thanks in advance
| unixuser69 | |
1,712,713 | ARIA attributes: The forgotten ones of accessibility | ARIA attributes? Accessible Rich Internet Applications (ARIA) attributes might not be on... | 0 | 2024-05-26T20:44:14 | https://dev.to/miasalazar/aria-attributes-the-forgotten-ones-of-accessibility-4e12 | a11y, accesibility, frontend, aria | ##ARIA attributes?
Accessible Rich Internet Applications (ARIA) attributes might not be on every developer's radar, yet they play a pivotal role in fostering accessibility within web products. By augmenting HTML elements, ARIA attributes convey vital information to assistive technologies, enriching the [accessibility tree](https://developer.mozilla.org/en-US/docs/Glossary/Accessibility_tree), by modifying or providing additional details to incomplete code.
ARIA attributes are imperceptible to most users, as they neither alter functionality nor influence visual appearance; their impact is predominantly felt by assistive technology users.
##When to use ARIA
ARIA is not a panacea for correcting faulty code nor does it automatically enhance a website's accessibility. Consider utilizing ARIA under the following circumstances:
- When a specific feature lacks HTML support.
- When HTML features are present but lack proper [accessibility support](https://www.html5accessibility.com/).
- When styling requirements prevent the use of a native element.
##ARIA features
The main features of ARIA are:
- state: Allows elements to change their state. For instance, when using a non-native HTML element as a checkbox, the `aria-checked` attribute informs assistive technologies about the checkbox's status.
`<div aria-checked="true" role="checkbox" >Checkbox input </div>`
- role: Expresses the purpose or nature of an element. For example, defining a button using the `role` attribute.
`<div role="button">Close Modal</div>`
- properties: Define the relationship or characteristics between elements.
```
<button aria-describedby="close-description">Close modal</button>
<p id="close-description">This button will close a modal</p>
```
##Categorization of Roles
ARIA roles are categorized into Abstract Roles, Widget Roles, Document Structure Roles, Landmark Roles, Live Region Roles, and Window Roles. Each serves a distinct purpose in organizing and describing elements within a web page.
- [Abstract Roles](https://w3c.github.io/aria/#abstract_roles): Abstract Roles are intended solely for browser use in organizing a document. Developers should refrain from utilizing them to ensure optimal performance. Avoid incorporating these roles—command, composite, input, landmark, range, roletype, section, sectionhead, select, structure, widget, and window—into your projects.
- [Widget Roles](https://w3c.github.io/aria/#widget_roles): These roles define common interactive patterns, providing a standardized approach for enhancing user interactivity.
- [Document Structure Roles](https://w3c.github.io/aria/#document_structure_roles): The various Document Structure Roles serve the purpose of conveying information about the structure within a section of a document.
- [Landmark Roles](https://w3c.github.io/aria/#landmark_roles): Landmark roles indicate the structure and organization of a web page.
- [Live Region Roles](https://w3c.github.io/aria/#live_region_roles): They define elements whose content will dynamically change
- [Window Roles](https://w3c.github.io/aria/#window_roles): Window Roles specify roles for sub-windows within the main window, offering a structured hierarchy in web application interfaces.
##States and properties
There are 38 properties in ARIA for states and properties and they fall into [4 categories](https://w3c.github.io/aria/#state_prop_taxonomy) according to W3C:
- [Drag-and-Drop Attributes](https://w3c.github.io/aria/#attrs_dragdrop): These attributes give information about drag-and-drop elements.
- [Relationship Attributes](https://w3c.github.io/aria/#attrs_relationships): They specify relationships between elements, enhancing the contextual understanding of content.
- [Widget Attributes](https://w3c.github.io/aria/#attrs_widgets): They define details about user input elements
- [Live Region Attributes](https://w3c.github.io/aria/#attrs_liveregions): Live Region Attributes signal elements where content changes dynamically, even when those elements may not currently have focus. These attributes play a crucial role in creating dynamic and responsive content areas.
##Tips for ARIA
###Don't use ARIA
Follow ARIA's principle: the less you use it, the better. Prioritize solving accessibility challenges through HTML and UI adjustments before resorting to ARIA.
###Use Semantic HTML
Prefer using HTML tags with implicit meaning or roles over ARIA attributes whenever possible. Semantic HTML tags, such as `<button>` or `<main>`, inherently provide accessibility benefits.
```
<button>Use this</button>
<div role="button">Not this</div>
<main>Use this</main>
<div role="main">Not this</div>
```
Besides, HTML5 tags already have landmark roles so it's unnecessary to add them and they are redundant.
###Elements should be focusable
Make sure interactive ARIA controls are keyboard-accessible. If an element lacks native keyboard focus, include it in the logical tab order using `tabindex="0"`.
`<p tabindex=“0”>I recieve focus!</p>`
###Don't hide elements
Focusable elements shouldn't be hidden, so avoid using `aria-hidden="true"` or `role="presentation"`. If a user tries to navigate through the keyboard, that person may end up focusing on nothing and it can be confusing.
###Check ARIA syntax
Many common mistakes with ARIA could have been solved just by checking the syntax. For example: roles should be written in lowercase. Some browsers might be able to interpret the roles even in uppercase, however, but other browsers might not.
###Don't overwrite semantics
Use ARIA only when HTML semantics prove inadequate or unavailable. Developers should avoid overwriting HTML native semantics. For example: If you want to build a heading tag, the `<h2>` itself has its own semantic meaning. However, a `<div>` can receive this role.
```
<div role=tab><h2>Do this</h2></div>
<h2 role=tab>Don't do this</h2>
``` | miasalazar |
1,865,901 | FTP Server Setup in a Windows VM | How to Set Up and Use an FTP Server in a Windows 11 VM FTP (File Transfer Protocol) is a... | 0 | 2024-05-26T20:43:18 | https://dev.to/mahakfaheem/ftp-server-setup-in-a-windows-vm-7ka | tutorial, ftp | ### How to Set Up and Use an FTP Server in a Windows 11 VM
FTP (File Transfer Protocol) is a standard network protocol used to transfer files between clients and servers. Setting up an FTP server in a Virtual Machine (VM) on a Windows host can help keep your main operating system secure and provide a controlled environment for file transfers. This guide will walk you through the steps to set up an FTP server using IIS (Internet Information Services) on a Windows 11 VM and then demonstrate how to use the FTP command line interface to interact with it.
### Step 1: Enable IIS and FTP Server Features
1. **Open Control Panel:**
- Press `Windows + R`, type `control`, and press Enter.
2. **Navigate to Programs and Features:**
- Go to `Programs` > `Programs and Features`.
- Click on `Turn Windows features on or off` in the left pane.
3. **Enable IIS and FTP Server:**
- In the Windows Features dialog, expand the `Internet Information Services` node.
- Expand `FTP Server`.
- Check `FTP Service` and `FTP Extensibility`.
- Ensure `Web Management Tools` and `World Wide Web Services` are also checked.
4. **Install Features:**
- Click `OK` and wait for the features to be installed.
### Step 2: Configure the FTP Server
1. **Open IIS Manager:**
- Press `Windows + R`, type `inetmgr`, and press Enter.
2. **Add FTP Site:**
- In IIS Manager, expand the node for your computer in the Connections pane.
- Right-click `Sites` and select `Add FTP Site`.
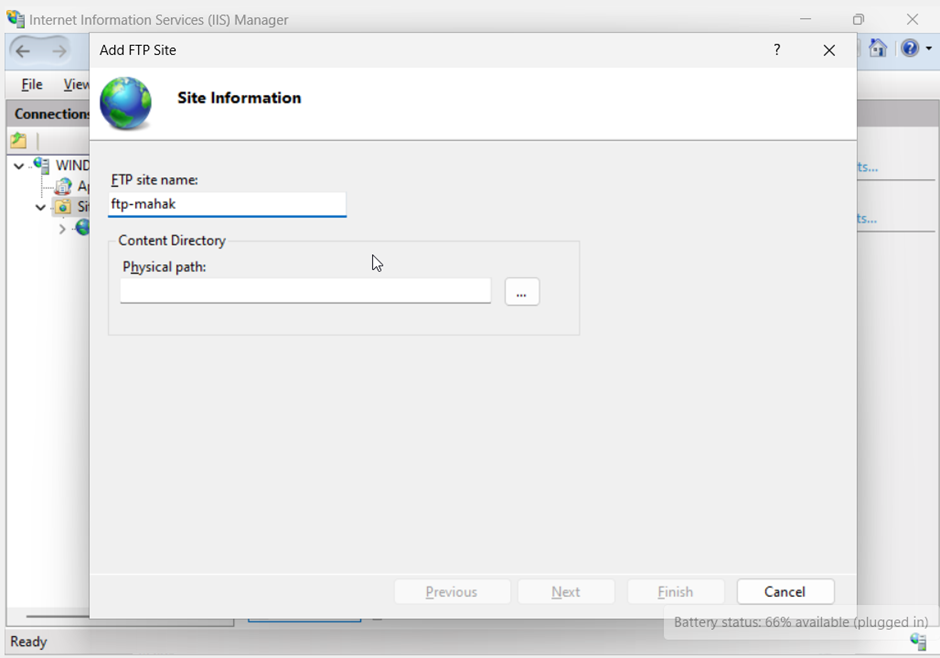
3. **FTP Site Details:**
- **Site Name:** Enter a name for your FTP site.
- **Physical Path:** Select the folder you want to use for FTP file storage.
- Click `Next`.
4. **Binding and SSL Settings:**
- **IP Address:** Select the IP address of your VM or leave it as `All Unassigned`.
- **Port:** Default is 21.
- **SSL:** For a demo, you can choose `No SSL`.
- Click `Next`.
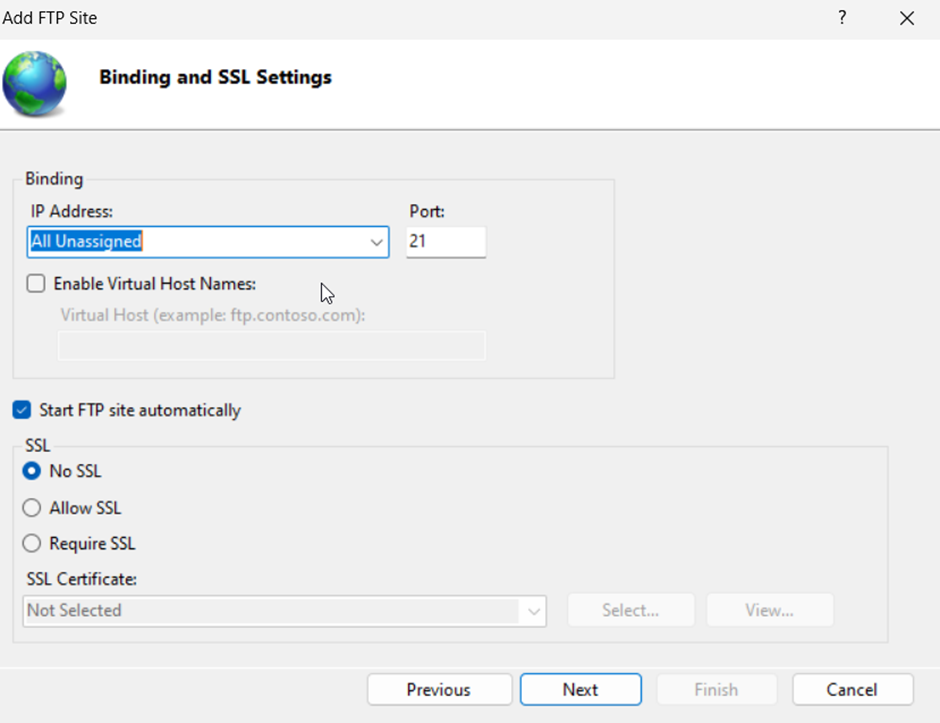
5. **Authentication and Authorization:**
- **Authentication:** Select `Basic`.
- **Authorization:** Choose `Specified users` and enter your Windows username.
- Set Permissions to `Read` and `Write` if you want to allow both uploading and downloading.
- Click `Finish`.
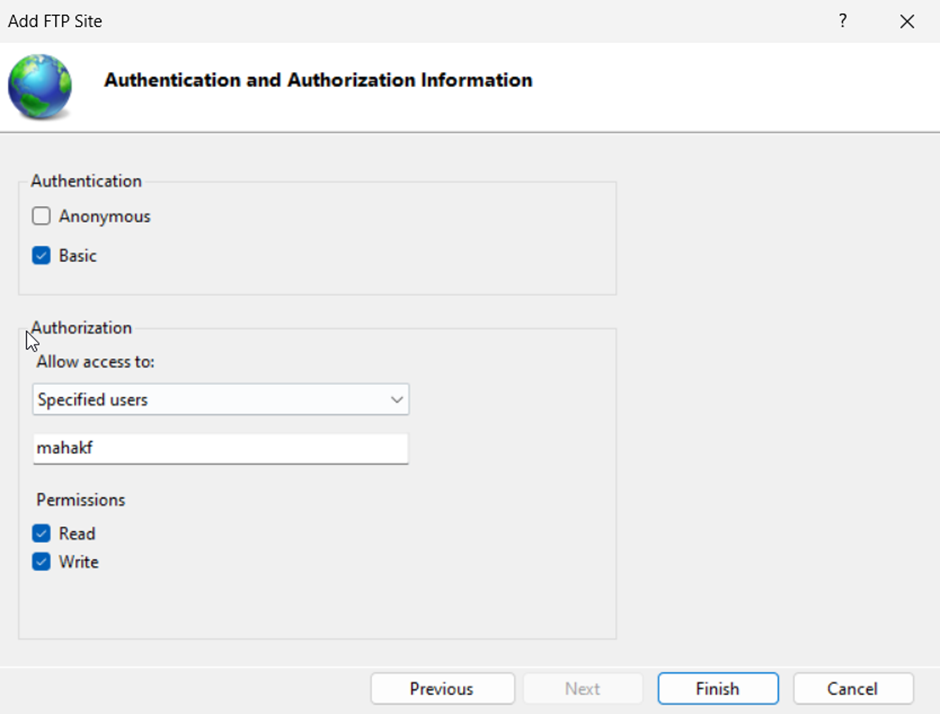
### Step 3: Configure Firewall Rules
1. **Open Windows Firewall:**
- Press `Windows + R`, type `firewall.cpl`, and press Enter.
2. **Allow FTP through Firewall:**
- Click on `Advanced settings`.
- In the left pane, click `Inbound Rules`.
- In the right pane, click `New Rule`.
- Select `Port` and click `Next`.
- Choose `TCP` and specify port 21.
- Click `Next`, allow the connection, and complete the rule setup.
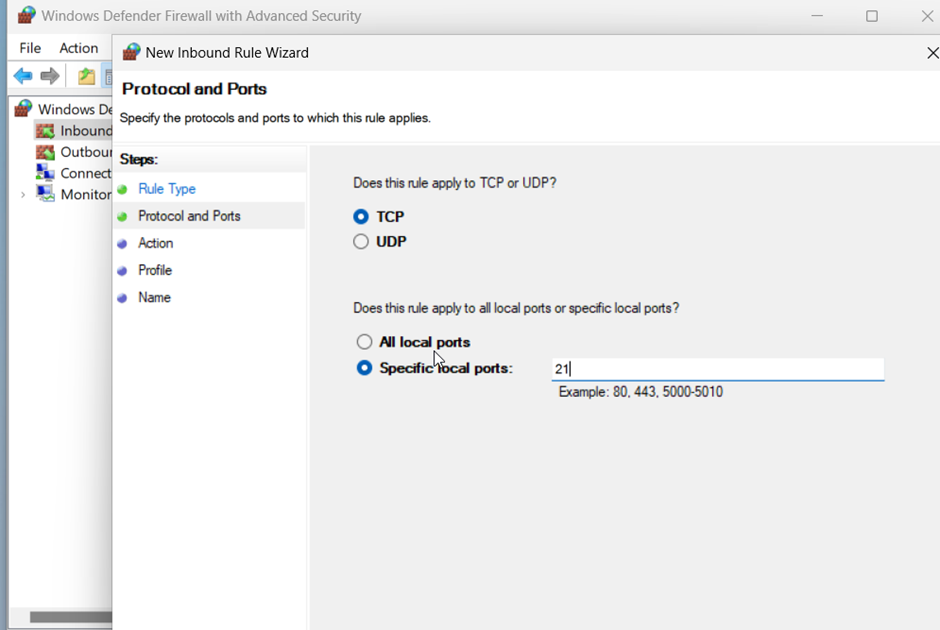
### Step 4: Access the FTP Server
1. **Find VM's IP Address:**
- Open Command Prompt (`cmd`), type `ipconfig`, and find the IP address of your VM.
2. **Test FTP Connection:**
- You may need to turn off the VM's firewall. Do turn on back once testing is done.
- Ensure the VM's network is set to Bridged-Adapter.
### Using the FTP Command Line Interface
Let’s explore some hands-on examples using the FTP command line interface. These examples assume you have an FTP server set up and running.
1. **Connecting to an FTP Server:**
- Open Command Prompt on your Windows host machine.
- Connect to the FTP server using its IP address:
```plaintext
ftp <ftp_server_address>
```
2. **Logging In:**
- Enter your username and password:
```plaintext
Name (ftp_server_address:username): your_username
Password: your_password
```
3. **Listing Files:**
- List the files in the current directory:
```plaintext
ftp> ls
```
4. **Changing Directories:**
- Change to a different directory:
```plaintext
ftp> cd <directory_name>
```
5. **Downloading a File:**
- Download a file from the FTP server:
```plaintext
ftp> get <file_name>
```
6. **Uploading a File:**
- Upload a file to the FTP server:
```plaintext
ftp> put <file_name>
```
7. **Exiting the FTP Session:**
- Exit the FTP session:
```plaintext
ftp> bye
```
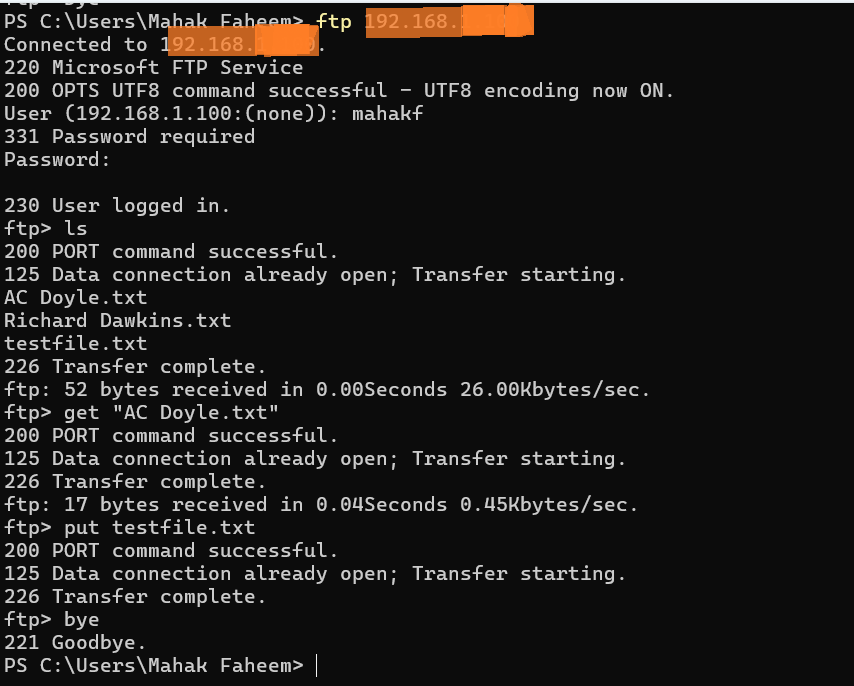
### Conclusion
Setting up an FTP server in a Windows 11 VM on your Windows host is a recommended practice for ensuring security and isolation. By following the steps above, you can install and configure an FTP server using IIS on a Windows 11 VM, configure necessary firewall rules, and interact with the server using the FTP command line interface from your Windows host. This setup provides a robust and secure environment for managing file transfers. | mahakfaheem |
1,865,900 | Chaotic Schedule v1.1 released! | Hello, I've released a new version for Chaotic Schedule package. This new release introduces new... | 0 | 2024-05-26T20:36:00 | https://dev.to/skywarth/chaotic-schedule-v11-released-4e2 | laravel, php, opensource, rng | Hello,
I've released a new version for [Chaotic Schedule](https://github.com/skywarth/chaotic-schedule) package. This new release introduces new random scheduling macro: `hourlyMultipleAtRandom().`
## What is Chaotic Schedule?
[Github](https://github.com/skywarth/chaotic-schedule), [Packagist](https://packagist.org/packages/skywarth/chaotic-schedule)
Chaotic Schedule is a Laravel package which allows you to randomize command schedules, be it date or time. Want a sampler for taste of flavor, sure:
$schedule->command('foo:bar')
->weekly()
->randomDays(
RandomDateScheduleBasis::WEEK,
[Carbon::FRIDAY,Carbon::Tuesday,Carbon::Sunday],
1,2
)
->atRandom('14:48','16:54');
## Where can you use Chaotic Schedule?
Here's some use-cases which might be valid for you as well:
* I have a command to send notifications to my clients. But I would like it to be sent at a random time between `14:00` and `17:00`
* I would like to send some gifts to users if they are active between my special event period which is every week `Friday` and `Saturday` between `00:00` and `04:20`
* My boss asked me to generate and send statistical reports regarding database activities every month, but only on `Monday`, `Wednesday` and `Friday`. And this report has to be delivered in the morning between `08:00` and `09:30` and I want it to look like I've personally generated and sent it personally. So random time and date is crucial to stage this.
* I would like to send reminders to customers and I want it to look and feel *human*. So random run times and dates every week would help me a lot. Otherwise, if I send every week on `Tuesday` `11:00` they would know this is automated and ignore these.
* There is a financial deficit, in order to detect the source of it I'll be running audit calculations. But these have to be random, otherwise they'll alter the records accordingly. I need to run audit calculations/assertions 3 times a day at random times.
* I'm trying to detect certain anomalies in my data, and therefore it would help me a lot to run a command completely randomly but with a minimum of at least 100 times a year.
## What's new?
`hourlyMultipleAtRandom()` can be used for scheduling your commands to run every hour on random minutes. Example use case: I want to run a command every hour, 1-5 times at random, on random minutes. E.g. run minutes:[5,11,32,44]
* Runs every hour
* Only designates random **run time(s)**
* Runs multiple times per hour, according to `$timesMin` and `$timesMax` params
* Doesn't designate any date on the schedule. So you may have to provide some date scheduling such as `daily()`, `weekly()`, `mondays()` etc.
* Behaves exactly the same with [->hourlyAtRandom](https://github.com/skywarth/chaotic-schedule?tab=readme-ov-file#hourly-at-random) if the `timesMin=1` and `timesMax=1`. (I mean duh) | skywarth |
1,865,899 | WSGI als Python runtime - Django in Produktion Teil 5 | Vorwort Nun, da wir auf unserem Produktionsserver alles auf unsere django - Webapp... | 0 | 2024-05-26T20:33:06 | https://dev.to/rubenvoss/wsgi-als-python-runtime-django-in-produktion-teil-5-1701 | ## Vorwort
Nun, da wir auf unserem Produktionsserver alles auf unsere django - Webapp vorbereitet haben, ist als nächstes Gunicorn dran. Gunicorn wird unsere app - so wie `python manage.py runserver` in der Entwicklung, in Produktion zum laufen bringen.
## Installation in requirements.txt
Jetzt sollte unsere requirements - Datei zumindestens folgendes enthalten:
```
# django
django==5.0.4
# postgresql database adapter
psycopg2==2.9.9
psycopg2-binary==2.9.9
# webserver in production
gunicorn==21.2.0
```
in Entwicklung und Produktion mit `pip install -r requirements.txt` installieren
## Erster Start
Jetzt kannst du den WSGI server das erste mal starten, am besten bei dir Lokal in der Entwicklungsumgebung.
```
cd meine_repository/meine_app
gunicorn meine_app.wsgi
# so sollte dein Output ausschauen:
[2024-05-26 22:25:05 +0200] [71525] [INFO] Starting gunicorn 21.2.0
[2024-05-26 22:25:05 +0200] [71525] [INFO] Listening at: http://127.0.0.1:8000 (71525)
[2024-05-26 22:25:05 +0200] [71525] [INFO] Using worker: sync
[2024-05-26 22:25:05 +0200] [71526] [INFO] Booting worker with pid: 71526
--- Using development Settings ---
```
Nun sollte deine app in der Produktionsversion lokal bei dir laufen. Gehe einfach auf http://127.0.0.1:8000 und du kannst sie dir anschauen.
Das kannst du nun so auch auf deinem Server ausführen, aber du wirst deine App wahrscheinlich nicht unter deiner Domain / ip erreichen können. Um das zu können musst du mit nginx deinen Webserver als Reverse-Proxy weiterleiten. Damit geht's beim nächsten mal weiter.
[Hier kannst du mehr über nginx als Reverse Proxy herausfinden.](https://docs.gunicorn.org/en/latest/deploy.html)
PS: Viel Spaß beim Coden,
Dein Ruben
[Mein Blog](rubenvoss.de) | rubenvoss | |
1,865,898 | My experience with preparation and passing the AWS Cloud Practitioner exam | What is this certification about AWS Cloud Practitioner Certificate is the entry-level... | 0 | 2024-05-26T20:31:52 | https://dev.to/lyumotech/my-experience-with-preparation-and-passing-the-aws-cloud-practitioner-exam-pn0 | aws, cloud, certifications, cloudpractitioner | ## What is this certification about
AWS Cloud Practitioner Certificate is the entry-level certificate offered by Amazon for their services. While the official recommendation is to have about 6 months of experience with AWS services, many people without any experience and even outside of the technical field successfully passed this exam.
The focus of the exam is to test a participant on as broad a field as possible. I believe the test itself is not difficult from an understanding point of view but could be challenging if memorization is not your strongest trait.
## My background
As a native mobile developer, I had zero experience with AWS in particular and the cloud in general.
## Study plan and resources
I purchased the following:
- [[NEW] Ultimate AWS Certified Cloud Practitioner CLF-C02](https://www.udemy.com/course/aws-certified-cloud-practitioner-new/) is a full preparation course. It includes videos, slide set, practice videos, and short quizzes after each section.
- Practice tests: [6 Practice Exams | AWS Certified Cloud Practitioner CLF-C02](https://www.udemy.com/course/practice-exams-aws-certified-cloud-practitioner/)
The benefit of those is the explanation for the answers to each question. Reviewing and analyzing those was one of the most important steps of my preparations.
Those materials are frequently available on sale (as usual for Udemy) for around ~15 euro each.
Later, I learned about [the free alternative by freeCodeCamp](https://www.youtube.com/watch?v=NhDYbskXRgc). Even though I haven't tried it, many people find this material very useful, so if for some reason Udemy doesn't work, it could have also been a good option.
There are plenty of exam materials and recommendations for this certification exam from AWS itself. I made the mistake of navigating through AWS's own free courses first, and they were not very useful for me.
Their official [exam guide](https://d1.awsstatic.com/training-and-certification/docs-cloud-practitioner/AWS-Certified-Cloud-Practitioner_Exam-Guide.pdf), while important, is also not particularly helpful, because it just lists pretty much every single service AWS provides.
## Exam highlights
Preparation process:
- As a person who used to dive deep into unknown topics, I had to change my approach to studies to focus more on breadth instead of depth for this exam.
- Spreading the preparation throughout multiple days/weeks over shorter (under 1 hour) study sessions was more useful than trying to study long hours.
- Going through test exam questions as early as possible to get used to the format and wording helped a lot.
Before the exam:
- I was not ready for the multi-step exam sign-in process and all the hiccups. AWS portal provided a testing function, I made all necessary tests the day before the exam on a separate laptop and didn't touch it until the exam time, yet right before the exam there were still errors with the software. Luckily, everything was resolved.
- Scheduling exams in the morning, not cramming the night before, going to sleep, and getting to the exam with a fresh head helped also.
During the exam:
- Use the elimination principle. Scanning all answers and excluding those that don't fit was one of the most efficient tools.
- If don't remember something, mark a question for review and come back to it later. This approach allowed me to save a lot of time.
## Conclusion
As a result of my preparations, I passed from the first attempt.
Preparing for the exam and going through the exam itself has been a valuable experience for me. Now I feel confident working on more similar tests.
## Resources
- [Exam starting page](https://aws.amazon.com/certification/certified-cloud-practitioner/)
- [The official exam guide](https://d1.awsstatic.com/training-and-certification/docs-cloud-practitioner/AWS-Certified-Cloud-Practitioner_Exam-Guide.pdf)
- [[NEW] Ultimate AWS Certified Cloud Practitioner CLF-C02](https://www.udemy.com/course/aws-certified-cloud-practitioner-new/)
- [6 Practice Exams | AWS Certified Cloud Practitioner CLF-C02](https://www.udemy.com/course/practice-exams-aws-certified-cloud-practitioner/)
- [Free lectures by freeCodeCamp](https://www.youtube.com/watch?v=NhDYbskXRgc)
| lyumotech |
1,865,877 | Auction House Hunter (amplify awschallenge entry) | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge (Important Note: Simple... | 0 | 2024-05-26T20:16:37 | https://dev.to/jake_horvath_b58f87019ef1/auction-house-hunter-amplify-awschallenge-entry-4g94 | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
(Important Note: Simple Email Service SES was just approved for me by AWS for production use. You can now save records and receive emails with CSV files for any user's email.)
## What I Built
Inspiration for this application came from local small business owners that told me they want to get real time data from auction sites. I built a web-scraping application that tracks current listings on popular auction sites. It currently is working for one auction site (hibid.com). This is a business oriented real-time data tracking application and is heavily focused on lambdas, dynamoDB streams, S3 buckets, and serverless functions. Simply go to your auction website of choice, search for whatever you want with whatever filters you want, and copy and paste the URL of the search results page you’re currently viewing into Auction House Hunter (the name of my site). It will immediately perform axios requests with my own custom API configurations and proxy onto that URL and sort all of the data into CSV ready format for every single product currently available and save it to an S3 bucket using a DynamoDB Stream Handler function. After saving the CSV file to the S3 bucket, then an email is sent to the email address on file for the Cognito user containing the CSV file of the scraped data from the URL.
## Demo and Code
This a private repo, but significant amounts of code logic will be included throughout this submission. I just would prefer to keep the repository as a whole private for future business use. Here is a link to the website I made:
https://storage.d12npvtctq2ov6.amplifyapp.com/
Before going to my website. Go to hibid.com and perform a search and copy the URL that you found. Here’s an example: https://hibid.com/lots?q=ww2%20medal&status=OPEN
Just create your account using Amplify UI’s default login/cognito functionality and signin.
Land on the home page
Enter a search URL and click Submit and wait a moment for the input field to disappear and your saved record to appear with a delete button available.
(Currently only visible to AWS admin) DynamoDB stream watching the “PastedUrl” table is triggered by the record change and runs a lambda to run an Axios request, sort/parse the data, and save it to an S3 bucket. The CSV file that is saved is now available to manipulate using Amplify, other AWS services, or just to directly download from the AWS Console.
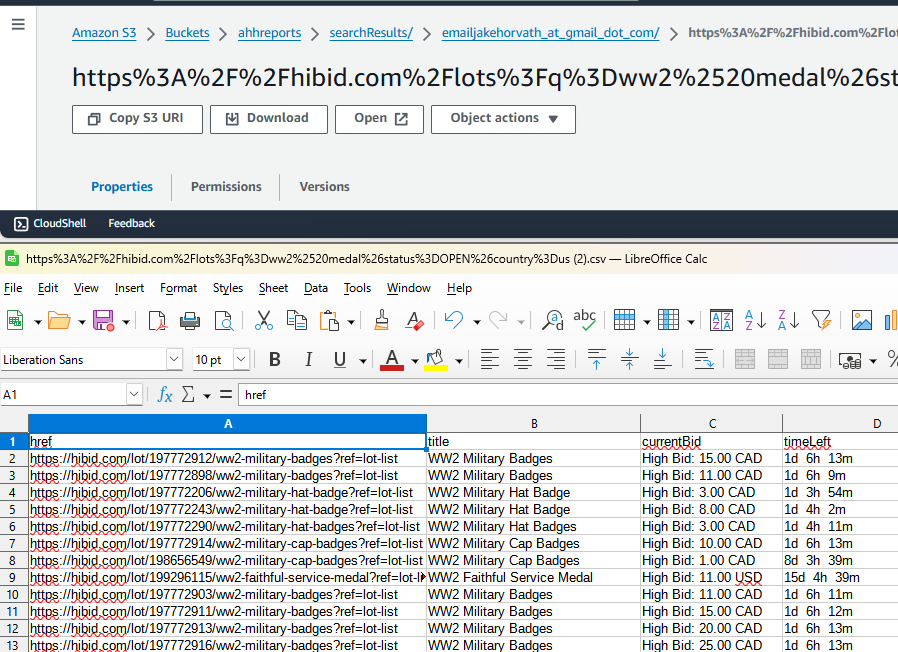
After saving the CSV file to S3 another lambda is triggered that will send an email to your account’s email address containing the URL you used to search and a copy of the CSV file generated in S3. It uses data from the S3 bucket file and uses AWS SES to send an email.
## Integrations
<!-- Tell us which qualifying technologies you integrated, and how you used them. -->
<!-- Reminder: Qualifying technologies are data, authentication, serverless functions, and file storage as outlined in the guidelines → -->
### Data
***Data*** is an essential part of how this site works. A schema was created for 2 tables. One table being the PastedUrl table and the other being Product table (Product table functionality will be added at a later date). Product table has a many to one relationship with the PastedUrl table and only the Cognito authenticated user that created the records are able to view them. Here is a code sample of the data/resource.ts
```typescript
const schema = a.schema({
Product: a.model({
href: a.url().required(),//full link to product
title: a.string().required(), //product title
currentBid: a.string(),//current bid price is optional as it may not be available
timeLeft: a.string(),//time left for auction to end is optional as it may not be available
productId: a.id(),
pastedUrl: a.belongsTo('PastedUrl', 'productId')
})
.authorization((allow) => [allow.owner()]),
PastedUrl: a.model({
id: a.id().required(),
url: a.url().required(),//url of search results provided by user
userEmail: a.email().required(),//email of user
products: a.hasMany('Product', 'productId')
})
.authorization((allow) => [allow.owner()]),
});
```
Here is sample code of the entrypoint (page.tsx) file that creates records, deletes records and updates the records visible on the application to the authenticated user:
```typescript
const [pastedUrl, setPastedUrl] = useState<Schema["PastedUrl"]["type"][]>([]);
const [inputUrl, setInputUrl] = useState<string>('');
// Function to create a new record in the PastedUrl table
const createUrl = async (userEmail: string) => {
await client.models.PastedUrl.create({
url: inputUrl,
userEmail: userEmail
});
// Fetch the records from the PastedUrl table
const { data } = await client.models.PastedUrl.list();
setPastedUrl(data);
};
// Set the initial state of the pastedUrl array to the records in the PastedUrl table
useEffect(() => {
const fetchData = async () => {
const { data } = await client.models.PastedUrl.list();
setPastedUrl(data);
};
fetchData();
}, []);
// Delete a record from the PastedUrl table using the current PastedUrl ID
async function deleteRecord() {
// Ensure the pastedUrl array is not empty
if (pastedUrl.length === 0) {
console.error('No records to delete');
return;
}
// Get the id of the first record to be deleted
const toBeDeletedPastedUrl = {
id: pastedUrl[0].id
};
try {
// Call the delete method on the PastedUrl model
const { data: deletedPastedUrl, errors } = await client.models.PastedUrl.delete(toBeDeletedPastedUrl);
// Log the result
console.log('Deleted Record:', deletedPastedUrl);
// Handle any errors
if (errors) {
console.error('Errors occurred while deleting the record:', errors);
}
else {
// Set pastedUrl to an empty array to reset screen record state to empty
setPastedUrl([]);
}
} catch (error) {
// Handle any unexpected errors
console.error('An error occurred:', error);
}
}
```
### Authentication
***Authentication*** was pretty straightforward. Mostly the default Cognito authentication for creating, verifying, and logging in/out of the application. Just altered the header of the email the user receives.
```typescript
import { defineAuth } from "@aws-amplify/backend";
/**
* Define and configure your auth resource
* @see https://docs.amplify.aws/gen2/build-a-backend/auth
*/
export const auth = defineAuth({
loginWith: {
email: {
verificationEmailStyle: "CODE",
verificationEmailSubject: "Welcome to Auction House Hunter!",
verificationEmailBody: (createCode) => `Use this code to confirm your account: ${createCode()}. Now let's get to hunting some deals!`,
},
},
});
```
### Serverless Functions
***Serverless functions*** are the bread and butter of this application. Here is a sample of the resource.ts for the DynamoDB stream that is used whenever a record is created (URL saved). There is also an environment secret used for the API key of my proxy service for security purposes.
```typescript
import { defineFunction, secret } from "@aws-amplify/backend";
export const dynamodbPerformSearch = defineFunction({
name: "dynamodbPerformSearch",
timeoutSeconds: 30, // timeout
environment: {
scrapeops: secret('scrapeops') //secrets must be defined in the function's resource.ts file
}
});
```
Here is a sample of the handler.ts function that performs the DynamoDBStreamHandler (lambda) function whenever a new record is saved to the DynamoDB table: PastedUrl
```typescript
export const handler: DynamoDBStreamHandler = async (event) => {
try {
for (const record of event.Records) {
logger.info(`Processing record: ${record.eventID}`);
logger.info(`Event Type: ${record.eventName}`);
if (record.eventName === "INSERT") {
const newImage = record.dynamodb?.NewImage;
if (newImage) {
const userEmail = newImage.userEmail?.S || '';
const url = newImage.url?.S ? encodeURIComponent(newImage.url.S + '&country=us') : undefined; //encode the URL
const productId = newImage.id?.S || '';
logger.info(`New Image: ${JSON.stringify(newImage)}`);
logger.info(`User Email: ${userEmail}`);
logger.info(`URL: ${url}`);
if (url) {
const proxyAndUrl = `${env.scrapeops}${url}`; //combine the proxy and URL
try {
const response = await axios.get(proxyAndUrl);
// Get the final data from the response and convert it to a CSV format using parse
const finalData = await searchData(response.data, productId);
const finalDataCSV = parse(finalData);
logger.info(`Axios response successful: ${response.status}`);
logger.info(`Response final data: ${finalDataCSV}`);
// Upload the final data to S3
await uploadToS3(userEmail, url, finalDataCSV);
} catch (error) {
logError(error);
logger.error(`Axios GET request failed.`);
// Continue to the next record instead of failing the whole batch
continue;
}
}
}
}
}
} catch (error) {
// Log the error for retrieving the secret
logError(error);
logger.error(`Error processing event.`);
}
return {
batchItemFailures: [],
};
};
```
The DynamoDBStreamHandler also calls another lambda that will generate a CSV file and save it to the S3 bucket:
```typescript
const s3Client = new S3Client();// grant access to S3
// This is an asynchronous function that uploads a file to S3.
async function uploadToS3(userEmail: string, url: string, searchResults: string) {
// Convert searchResults to a Buffer
const buffer = Buffer.from(searchResults, 'utf-8');
const safeEmail = userEmail.replace(/[@]/g, '_at_').replace(/[.]/g, '_dot_'); //sanitize the email to use as path
const command = new PutObjectCommand({
Bucket: "ahhreports", //bucket name should go here
Key: `searchResults/${safeEmail}/${url}.csv`,
Body: buffer, // Use searchResults as the content of the file
ContentType: 'text/csv', // Set the content type of the file
});
try {
//try to list buckets
// Try to send the command to the S3 client. This will upload the file.
await s3Client.send(command);
// If the upload is successful, log a success message.
logger.info('Upload successful');
// Now send the email with the same buffer
await sendEmailWithAttachment(userEmail, url, buffer);
} catch (error) {
// If there's an error during the upload, catch it and log an error message.
logger.error('Error uploading to S3', error as Error);
}
}
```
And finally, the uploadToS3 lambda triggers another lambda that will email a copy of the CSV file to the Cognito user’s email address:
```typescript
async function sendEmailWithAttachment(toAddress: string, url: string, attachmentBuffer: Buffer) {
const params = {
Source: "auctionhousehunter@gmail.com", // verified Gmail address
Destinations: [toAddress],
RawMessage: {
Data: new Uint8Array(Buffer.from(createRawEmail(toAddress, url, attachmentBuffer))),
},
};
try {
// Send the email
await new SESClient().send(new SendRawEmailCommand(params));
logger.info('Email sent successfully');
} catch (error) {
logger.error('Error sending email', error as Error);
}
}
```
### File Storage
***File Storage*** was complicated with Amplify Gen 2 using Next.js as the stack. I wanted dynamic S3 bucket generation to occur using existing Amplify Gen 2 functionality, but it is currently not working. The functionality that is broken involves having Amplify automatically generate bucket names for you and being able to pass the bucket name as an environment variable to lambda functions. Here’s a link to the issue ticket in amplify-backend github Amplify deploy fails when using function resolver with env by TypeScript error · Issue #1374 · aws-amplify/amplify-backend (github.com) https://github.com/aws-amplify/amplify-backend/issues/1374 .
There are some attempted workarounds in that ticket, but none of them worked for me. But life finds a way. After a few days of trying I managed to figure out how to make it work using an alternate route that is not fully fleshed out in the Amplify documentation.
I created a new S3 bucket manually that will be used for this website. Then I had to open Amplify in the console, locate my Lambda function for my deployed branch, and then navigate to it in IAM/Roles section of the console. I then Added permissions for it to access S3 and SES (for sending emails). The permission for S3 would have been taken care of automatically if Amplify Gen 2 was working properly with environment variable generation and distribution to lambda functions in Next.js.
And here is a log in Cloudwatch that shows all of the lambdas occurring and them successfully running after a record is updated:

<!-- Let us know if you developed UI using Amplify connected components for UX patterns, and/or if your project includes all four integrations to qualify for the additional prize categories. → -->
The UI components were essentially all taken from Amplify Dev Center UI Library. They all work seamlessly together and with the GraphQL plus AppSync API connections and user authentication with Cognito. I decided to take full advantage of the massive time-saving that can occur from just using Amplify’s preset UI library for React/Next.js.
This project includes all four integrations to qualify for the additional prize categories.
And just like I mentioned at the beginning of this post, please be understanding of the website not sending you an email when you save a record (unless you have me add your email to the sandbox). AWS is VERY thorough about who has access to a Simple Email Service production environment that can send to any email address that is not manually entered. It can take days or even weeks for them to grant me access and as you are well aware this contest just did not give them enough time to grant it to me, but you can see in the screenshots it is working properly with my personal verified SES email address.
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
Jake Horvath
@jake_horvath_b58f87019ef1
| jake_horvath_b58f87019ef1 |
1,865,876 | My first DEV community post | Hello Dev Community👋 My name is Mihailo, and I'm from Serbia 🇷🇸. I'm currently a student of... | 0 | 2024-05-26T19:59:54 | https://dev.to/mihailocv/my-first-dev-community-post-38b6 | webdev, discuss, beginners | **Hello Dev Community👋**
My name is Mihailo, and I'm from Serbia 🇷🇸. I'm currently a student of information technologies at the Higher Education Technical School of Professional Studies in Novi Sad, and I'm in my final year of studies. As I prepare to finish university, I'm focusing on honing my skills to become a full-stack web developer, with the hope of landing my first IT job next year. This summer, I'm hoping to build up my GitHub with as many projects as possible and create a strong portfolio.
I would greatly appreciate any support and guidance from this community to help me improve as a developer. If you have any suggestions, tips for landing my first job, or just want to connect, please feel free to leave a comment or reach out to me through my socials☺️
| mihailocv |
1,865,875 | Effective Spill Containment: The Importance of Oil Absorbent Socks | In industrial and commercial settings, spills of oil and other hazardous liquids are not just a... | 0 | 2024-05-26T19:57:37 | https://dev.to/oilhungry/effective-spill-containment-the-importance-of-oil-absorbent-socks-5b79 | In industrial and commercial settings, spills of oil and other hazardous liquids are not just a nuisance—they pose significant risks to workplace safety, environmental health, and operational efficiency. Effective spill containment is crucial to mitigate these risks, and **oil absorbent socks** are one of the most effective tools available for this purpose. This blog explores the critical role of oil absorbent socks in spill containment, their benefits, and best practices for their use.
Understanding Oil Absorbent Socks
Oil absorbent socks are tubular products filled with highly absorbent materials such as polypropylene or cellulose. These socks are designed to contain and absorb oil and other hazardous liquids while repelling water, making them particularly effective for managing oil spills in various environments. Their flexibility allows them to be easily placed around spills, machinery, or other potential sources of leaks.
The Need for Effective Spill Containment
Spill containment is essential for several reasons:
Safety: Spills create slip hazards that can lead to workplace accidents and injuries.
Environmental Protection: Uncontained spills can seep into the soil, contaminate water sources, and harm wildlife.
Operational Efficiency: Spills can disrupt operations, damage equipment, and lead to costly cleanup efforts.
Regulatory Compliance: Many industries are required by law to have effective spill containment measures in place to prevent environmental contamination.
Benefits of Oil Absorbent Socks
1. Immediate Spill Containment
Oil absorbent socks are designed for rapid deployment, allowing for immediate containment of spills. By quickly surrounding the spill with absorbent socks, you can prevent the liquid from spreading and causing further damage. This immediate containment is crucial for minimizing the impact of the spill and facilitating easier cleanup.
2. Versatility in Application
Oil absorbent socks are versatile tools that can be used in a wide range of settings and for various types of spills. They are effective for containing oil leaks from machinery, spills in automotive workshops, and even oil spills on water surfaces. Their ability to absorb oil while repelling water makes them particularly useful in marine environments, where oil spills can have devastating effects on aquatic ecosystems.
3. Protection of Water Sources
Oil absorbent socks play a critical role in protecting water sources from contamination. When used around drains or along shorelines, they can prevent oil from entering water systems, thereby safeguarding drinking water supplies and aquatic habitats. This protection is vital for maintaining water quality and preventing long-term environmental damage.
4. Cost-Effective Solution
Investing in oil absorbent socks is a cost-effective way to manage spills and protect the environment. They are relatively inexpensive compared to the potential costs of extensive cleanup operations, environmental fines, and equipment damage. By preventing spills from spreading and causing more significant issues, absorbent socks help reduce overall expenses associated with spill management.
5. Compliance with Environmental Regulations
Many industries are subject to strict environmental regulations that require effective spill containment measures. Using oil absorbent socks helps companies comply with these regulations, avoiding legal penalties and demonstrating a commitment to environmental stewardship. Compliance with regulations not only protects the environment but also enhances the company's reputation as a responsible and eco-conscious organization.
Best Practices for Using Oil Absorbent Socks
1. Regular Inspections and Maintenance
Conduct regular inspections of your facility to identify potential spill risks and ensure absorbent socks are readily available in spill-prone areas. Regularly check and replace absorbent socks as needed to maintain their effectiveness.
2. Proper Training
Train employees on the proper use and deployment of oil absorbent socks. This ensures that spills are managed quickly and efficiently, minimizing environmental impact and enhancing workplace safety.
3. Strategic Placement
Store oil absorbent socks in easily accessible locations, such as near machinery, storage tanks, and other high-risk areas. This facilitates rapid deployment in the event of a spill, ensuring quick containment and cleanup.
4. Effective Disposal
Follow proper disposal procedures for used absorbent socks, adhering to local regulations for hazardous waste. This helps prevent secondary contamination and ensures compliance with environmental standards.
5. Integration with Spill Kits
Integrate [oil absorbent socks](https://www.oilhungry.com/products/oil-absorbent-socks) into comprehensive spill kits that include other essential tools like absorbent pads, booms, and personal protective equipment (PPE). This ensures that all necessary resources are available for effective spill response.
Conclusion
Oil absorbent socks are indispensable tools for effective spill containment in industrial and commercial settings. Their ability to provide immediate containment, versatility in application, protection of water sources, cost-effectiveness, and compliance with environmental regulations make them essential for managing spills and protecting the environment. By implementing best practices for their use and ensuring proper training and maintenance, industries can significantly reduce the risk of environmental contamination and contribute to a [safer](https://www.usamljeni.com/forum/profile/oilhungry/), more sustainable future. Investing in high-quality oil absorbent socks is not just a regulatory necessity—it's a proactive step toward environmental stewardship and responsible industrial practices. | oilhungry | |
1,865,207 | How to deploy an AWS EC2 Instance | While building your applications as a software developer, an important step in the process is to... | 0 | 2024-05-26T19:56:11 | https://dev.to/uhrinuh/how-to-deploy-an-aws-ec2-instance-l9k |
While building your applications as a software developer, an important step in the process is to deploy your app for the world to see. If you have never done it before, it can seem very scary and daunting so this blog is meant to serve as a How To tutorial as well as educate on what specific terminology means when you go to deploy. There are many different deployment services, but for this blog, I will be focusing on deploying an EC2 instance on AWS.
**What is Amazon EC2?**
Amazon EC2 is a web service provided by AWS where users can rent virtual computers to run their own applications. When launching an EC2 instance (which is basically just a server), the instance is within an Availability Zone in the region. The instance is secured with a security group which is just a virtual firewall that controls traffic on your deployment. Then, a private key is stored on your local computer and a public key is stored on your instance. This key pair is used to verify the identity of the user.
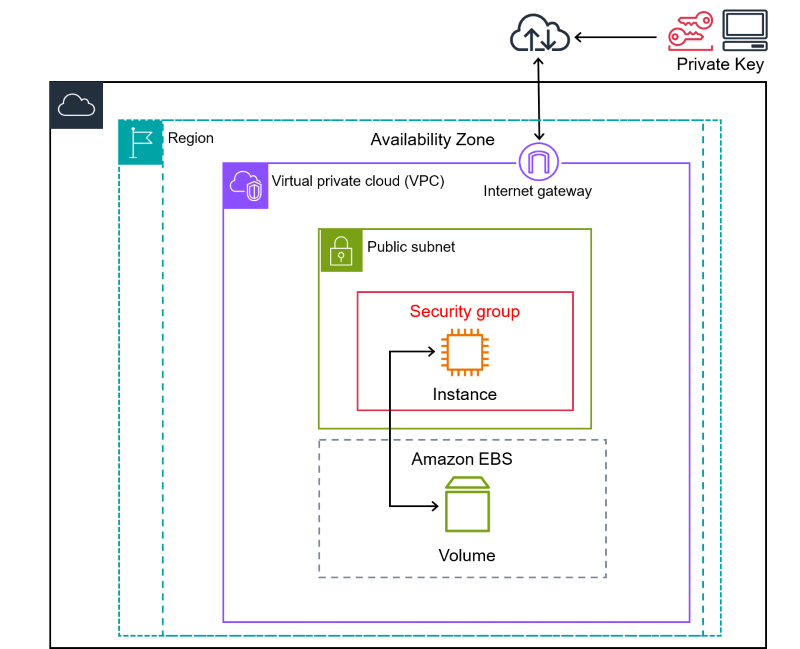
**How Do I Do All Of This?**
**STEP 1**
Navigate to this link https://aws.amazon.com/pm/ec2-amd/?gclid=Cj0KCQjwmMayBhDuARIsAM9HM8fECNLSOTLaAhm8LO-C2FZOAD-P1EM_HVdhW0oIU57xQXfKCTZO91oaAvNOEALw_wcB&trk=dfddd7d7-36f1-4ece-bbba-bddb99e3d295&sc_channel=ps&ef_id=Cj0KCQjwmMayBhDuARIsAM9HM8fECNLSOTLaAhm8LO-C2FZOAD-P1EM_HVdhW0oIU57xQXfKCTZO91oaAvNOEALw_wcB:G:s&s_kwcid=AL!4422!3!651751059243!e!!g!!amazon%20web%20server!19852662164!145019249497 and click Sign In to the Console on the top right
**STEP 2**
Once logged in, you will be greeted with the home page. On the top right corner you will see a drop down bar with specific locations, like so

Here, you will be clicking on a region where the instance will be deployed. This is when the availability zones come into play because AWS has these zones (essentially data centers) located around the world. You can pick a region based on where your users will be located or a region that has the compliance requirements you seek.
**STEP 3**
Now, you can use the search bar to search EC2 and once you click that, you will be greeted with this page
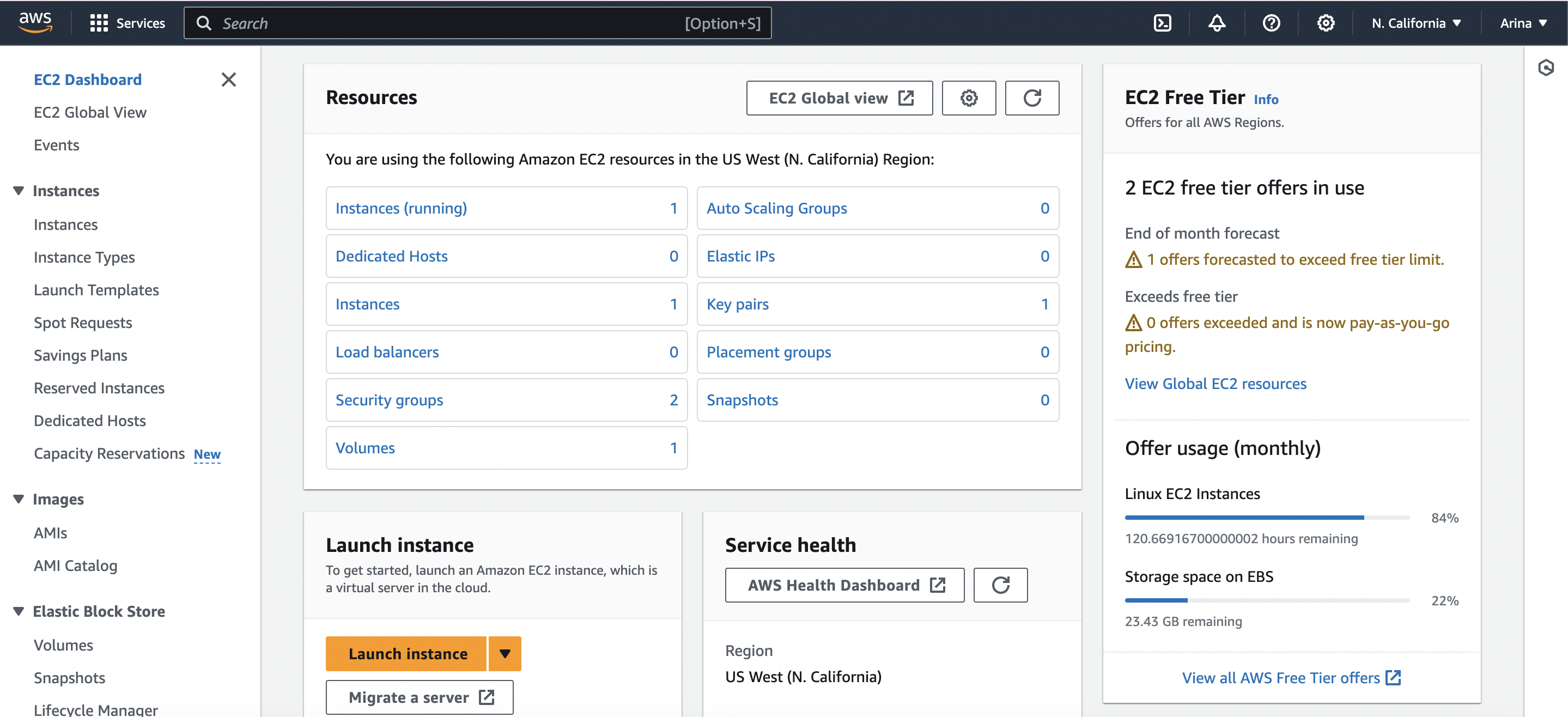
The resources tab is where you can see all the different features EC2 provides. Instances is the virtual server you will create, dedicated hosts is a physical server for your own use, load balancers is used to distribute your application/network traffic across multiple targets, security groups are the virtual firewalls for your instance, volumes provide storage for data that ie needed even if an instance is terminated, auto scaling groups adjust the number of EC2 instances in response to changes in demand, elastic IPs are static IPv4 addresses that can be associated with EC2 instances, key pairs are the public and private keys used to secure your instance, placement groups control the placement of instances in the AWS Cloud to meet requirements, and snapshots are backups of EBS volumes. For our purpose, we will be clicking the orange Launch Instance button.
**STEP 4**
Now we are launching an instance.
- First you must input a name for your instance.
- Then, you pick which AMI you'd like to use. AMI is a template that contains the software configuration required to launch an instance. There are a lot of them, but I personally use Ubuntu.
- Then you pick the specific tier you'd like to use. This is where you would find an AMI that fits the needs of your specific application and for my purposes, the given free tier is fine for me.
- Then you must pick an instance type that meets your computing, memory, networking, or storage needs. If you're creating a large application that will require a lot of data to be held in storage and/or lots of traffic, you may need to pick an instance type with larger memory and a higher vCPU. Again, for my purpose, a t2.micro is fine.
- Then, you pick a key pair. If you hadn't made one prior to launching the instance, thats fine and you can just click create new key pair.
- Then we deal with network settings. You should create a new security group. There are 3 options: Allow SSH traffic from, Allow HTTPS traffic from the internet, and allow HTTP traffic from the internet. Allow SSH traffic from helps connect to your instance. SSH is a protocol used for secure remote access to a server. It allows for two computers to communicate and share data securely over an unsecured network. This is where you transfer your files through SSH to a remote server. If you click Allow SSH traffic from you can choose between allowing it from anywhere, custom, or my IP. It is best to only allow SSH traffic from IP addresses that need access to the deployment.
- Finally, you can scroll to the bottom and click Launch Instance.
**STEP 5**
Now you're able to navigate to your instances through the resources view.
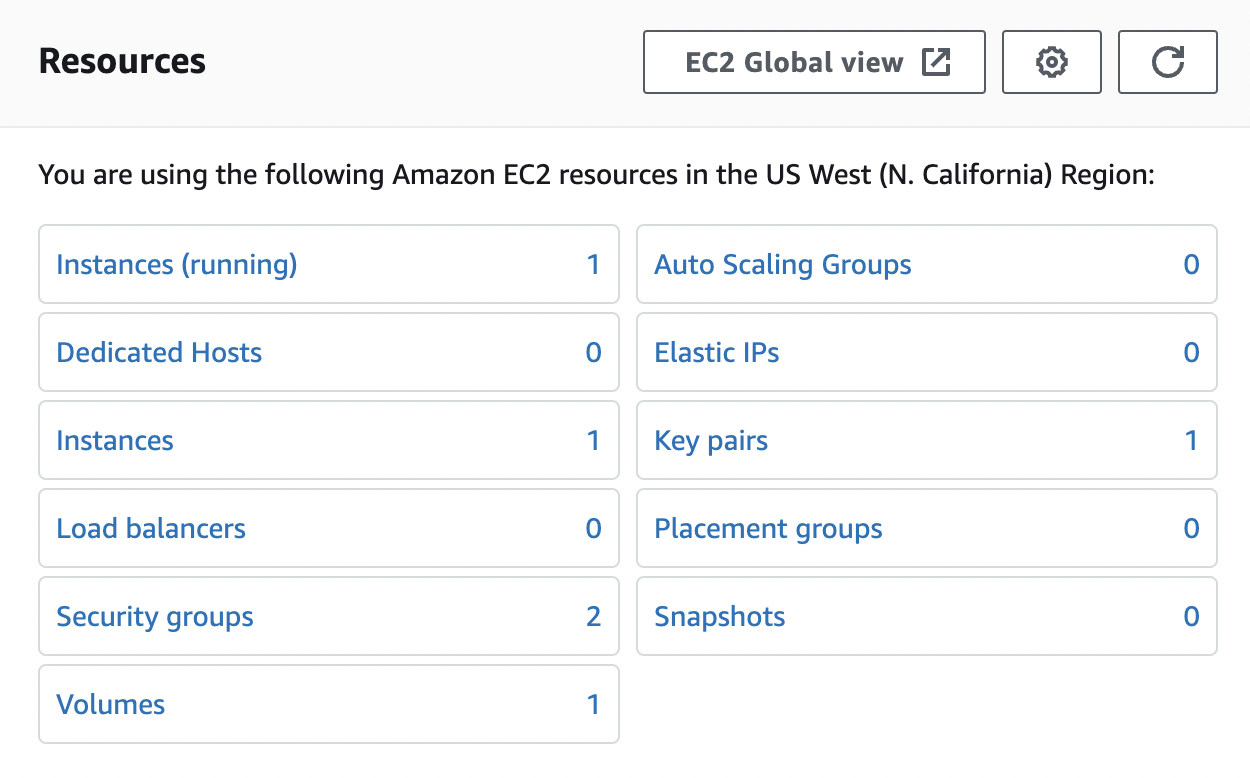
You'll need to click Instances and then click on your instance's Instance ID link. Once you do that, this will give you all the information about your instance. While in here, take note of the Public IPv4 address and the Public IPv4 DNS address. These will be important later.
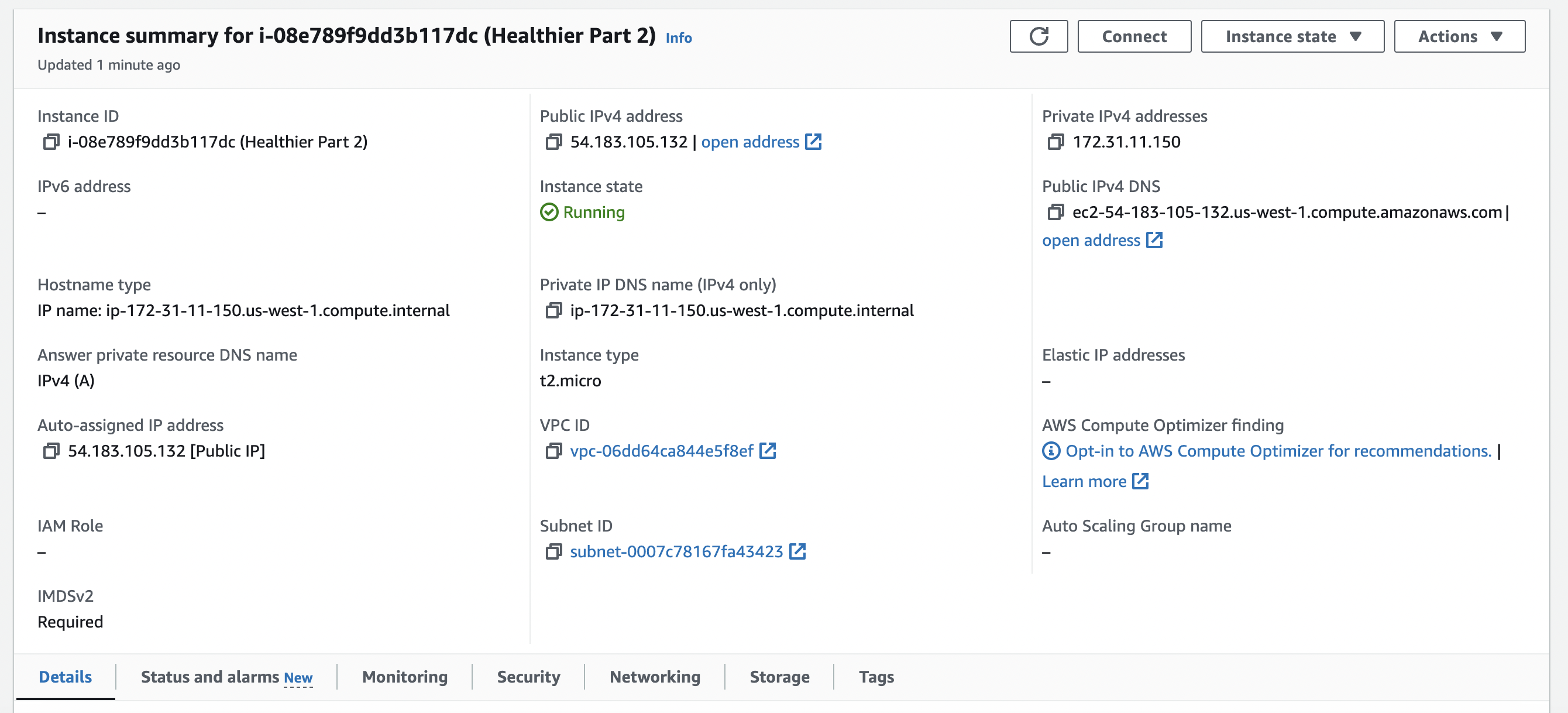
For now, you're going to want to click on security, then the security groups link. This is where you can edit the inbound rules of your instance. These are the settings that control the incoming traffic to your instance. They specify the protocol, port range, and the source of the traffic. One rule should already be there from when you initially created the instance, and you can add a rule to allow traffic from the port you used in your application.
**STEP 6** (if you use google authentication, if not just skip)
You are going to need to navigate to Google Cloud and go to APIs and Services and create a new credential for OAuth 2.0 Client IDs. Here, you will link your Public IPv4 DNS link with the specific port you used and the endpoint like so

**STEP 7**
Now we can finally work in the terminal. For reference, I use a Macbook Air and specifically work with iTerm and VIM. Also, since my instance is Ubuntu that will be reflected in the terminal.
Remember that .pem file we downloaded that holds our key? We are going to move that to a more secure space in our local computer. For me, I put it in my .ssh file.
- Move your key: mv path-to-key ~/.ssh (for example, if your key is called Healthier and its currently in your downloads folder, you're going to type mv Downloads/Healthier.pem ~/.ssh)
- Cd into .ssh and run ls -a to check and see if the key is there
- Cd out of .ssh and now we are going to need to set the permission of the file to be read-only for the owner. To do this, you are going to do chmod 400 ~/.ssh/key. This means that the owner has read access to the private key file, and no one else can access it
- Finally we can ssh into our instance
- The command to run is ssh -i ~/.ssh/keyname.pem ubuntu@ec2address since we know our key is in the .ssh file and ubuntu is the root user for our instance because that is what we originally chose. Your ec2 address can be found in the Public IPv4 address in your instance
- Once you are ssh'd in, you can run any install/file setup steps necessary for your project and then navigate to your instance's link
Deploying your application is a great way to show your colleagues/friends the application you have been working on. There are many different deployment options but Amazon's EC2 service is the easiest for me to navigate. Happy deploying!
Sources
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html
https://docs.aws.amazon.com/ec2/ | uhrinuh | |
1,865,874 | Free headless CMS for devs | When I was building Sveltepack - The ultimate SvelteKit boilerplate I had trouble finding a no-bloat,... | 0 | 2024-05-26T19:53:18 | https://dev.to/rahulsingh_ca/free-headless-cms-for-devs-2h56 | webdev, programming, tutorial, startup | When I was building [Sveltepack - The ultimate SvelteKit boilerplate](https://sveltepack.com) I had trouble finding a no-bloat, free, and simple tool to make blogs.
I tried every single headless CMS that I could find but they were all overkill for me. I just needed something small to make blogs.
So I went to Twitter and asked if anyone had the same issues. Turns out they did so I launched [tinycms](https://usetinycms.com)! Tinycms gives you a free online WYSIWYG editor to make blogs, you can then copy the JSON, add it to your database, and serve the data to your web app for free!
I have built components in my web app for each component type on tinycms, this lets me easily loop through the data and render each part of the blog dynamically! In the end I get consistent and clean blogs for my site.
Would love to see what you guys think! | rahulsingh_ca |
1,865,723 | HOW TO CREATE AZURE VIRTUAL MACHINE USING WINDOWS 11 | Step 1: Logging into Azure Portal Open your web browser and navigate to... | 0 | 2024-05-26T15:49:25 | https://dev.to/edjdeborah/how-to-create-azure-virtual-machine-using-windows-11-m57 | Step 1: Logging into Azure Portal
Open your web browser and navigate to https://portal.azure.com.
Sign in using your Azure account credentials.
Step 2: Navigating to Virtual Machines
After logging in, you’ll land on the Azure dashboard. In the left-hand menu, click on “Virtual machines”
This will take you to the Virtual machines section, where you can manage your VMs.
Step 3: Creating a New Virtual Machine
Click the “+ Add” button to start creating a new virtual machine.
The process begins with configuring the basics of your VM:
Subscription: Choose the appropriate subscription.
Resource Group: Create a new or select an existing resource group.
Virtual machine name: Give your VM a unique name.
Region: Choose the data center region closest to you.
Availability options: Select the availability preferences.
Image: Choose the operating system as window 11
add administration account password, click on monitoring and (disable) then tag with the VM name
step 4: click on review and create for virtual machine to be deployed and wait for it to be completed. Also click on recourse group to extend the idle time out on the IP address and save, connect download RDP and save into your local repository and lunch your virtual machine
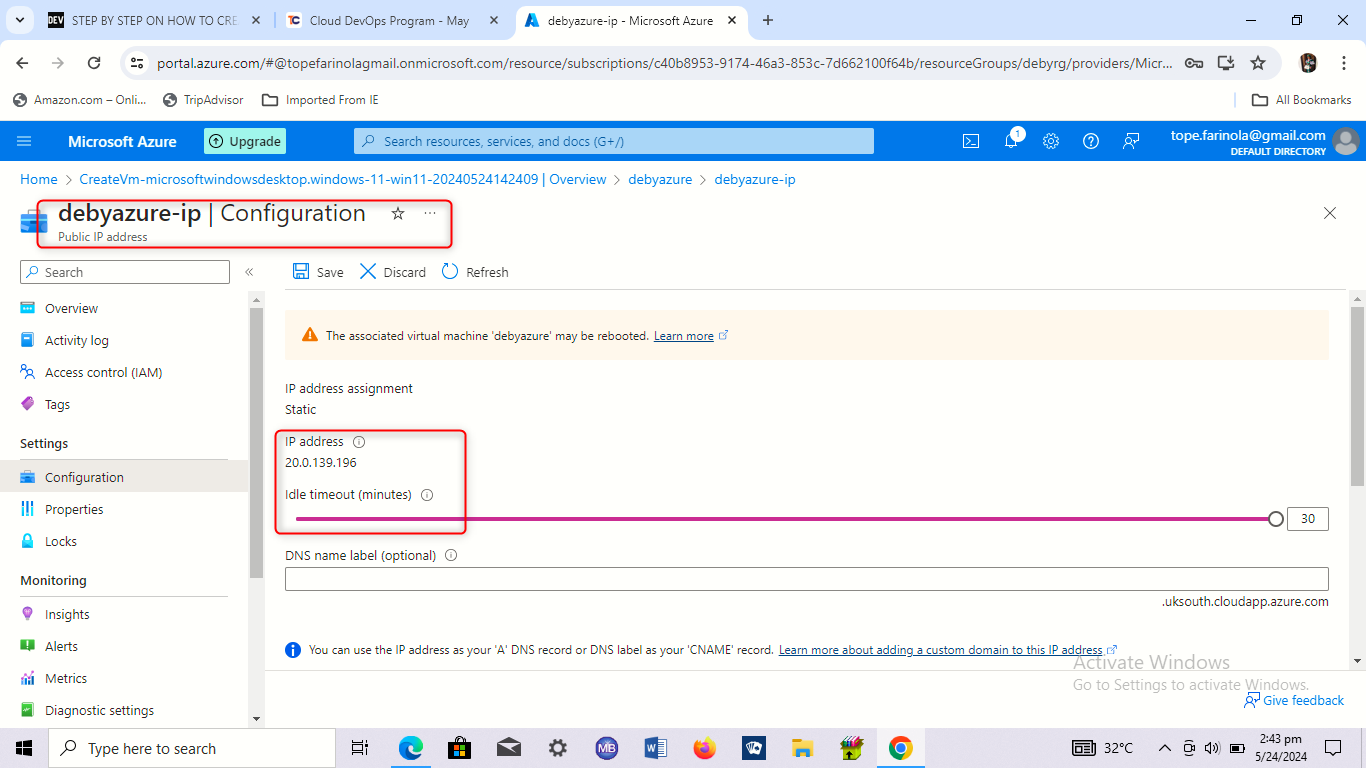
| edjdeborah | |
1,865,850 | Creating a ChatGPT crypto trading bot | Does it make sense to create a LLM-driven trading bot ? Looking at the recent improvement... | 0 | 2024-05-26T19:50:13 | https://dev.to/michelonpython/creating-a-chatgpt-crypto-trading-bot-3p4e | chatgpt, python, trading, bot | ## Does it make sense to create a LLM-driven trading bot ?
Looking at the recent improvement in LLM, I decided to check by myself.
I recently realized that beyond the usual "I'm an AI model, I can't give price predictions", LLM like ChatGPT (and most AI models) can actually be surprisingly good at predicting a price.
So here is what I did:
## Ask for data analysis, not financial predictions
I will use ChatGPT (`gpt-4o` to be accurate) for the rest of this article as it is the most famous one.
If you give candle data to ChatGPT and ask if the price will go up or down, you get this answer `I'm sorry, but I can't predict the future price of Bitcoin or any other financial asset. ....`, which makes sense.
However, things are different when giving the LLM data to work with and ask for statistics based on those data. Here is what I get when feeding it with the latest price:
The full answer is:
> Based on the provided data, it appears that the price has been fluctuating with some periods of increase and decrease. The latest closing price is 68843.3.
Given the recent trend, where the price has seen both ups and downs but with a slight downward trend in the last few data points, I predict the next movement will be **down** with a **60% confidence**.
Now things are different ! It turns out that ChatGPT is now willing to make a prediction.
Special thanks to [www.octobot.cloud](https://www.octobot.cloud) and their [open source bot](https://github.com/Drakkar-Software/OctoBot) where I found this trick. It looks like they are already using for some of their strategies and it seems to work pretty well.
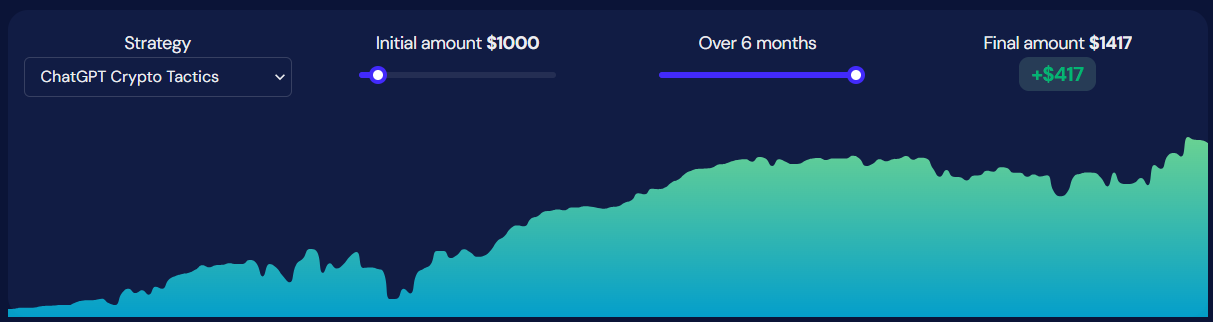
So I decided to try creating my bot.
## My ChatGPT trading bot script
Here is the ChatGPT trading bot script I created. I'm currently testing. I'll put it here in case someone has ideas to make it better, I would really like to get some feedback on it so if you have improvement ideas in the main algorithm, please let me know !
It's very simplistic, but the main ideas are there:
1. Use different crypto at the same time
1. Ask the LLM
2. Trade accordingly
```python
import json
import openai
import ccxt.async_support
import asyncio
OPENAI_KEY = ''
API_KEY = None
API_SECRET = None
async def _bot_iteration(binance, openai_client, symbol):
btc_price = await binance.fetch_ohlcv(symbol, "4h", limit=50)
messages = [
{
'role': 'system',
'content': 'Predict: {up or down} {confidence%} no other info'
},
{
'role': 'user',
'content': json.dumps(btc_price)
}
]
completions = await openai_client.chat.completions.create(model='gpt-4o', messages=messages)
prediction = completions.choices[0].message.content # ex: 'down 70%'
should_buy = "up" in prediction
should_sell = "down" in prediction
confidence = float(prediction.split(" ")[1].split("%")[0])
# only trade when confidence is at least 70%
if confidence >= 70:
if should_buy:
await binance.create_market_buy_order(symbol, 0.001)
elif should_sell:
await binance.create_market_sell_order(symbol, 0.001)
async def bot():
symbols = ["BTC/USDT", "ETH/USDT"]
binance = ccxt.async_support.binance({'apiKey': API_KEY, 'secret': API_SECRET})
openai_client = openai.AsyncOpenAI(api_key=OPENAI_KEY)
while True:
# trigger evaluations
await asyncio.gather(
*(_bot_iteration(binance, openai_client, symbol) for symbol in symbols)
)
await asyncio.sleep(4 * 3600) # wakeup every 4 hours
asyncio.run(bot())
```
| michelonpython |
1,865,750 | Echodiary : AI-Powered Diary with AWS Amplify | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What we... | 0 | 2024-05-26T19:48:46 | https://dev.to/sidjs/echodiary-ai-powered-diary-with-aws-amplify-i9a | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
## What we Built
We created **_Echodiary_**, a user-friendly diary-making Web App using AWS Amplify Gen 2. Echodiary allows users to document their daily experiences by talking to our mascot _Echo_, which transcribes voice to text, or by writing entries manually. Users can enhance their diary entries with photos, making memories more vivid. The app features a one-click AI Content Enhancement ✨ to improve grammar and structure. Additionally, _AI-generated_ weekly highlights and personalized suggestions help users reflect on their week and improve mental health and personal growth.
Echodiary combines advanced technology with user-friendly features to offer a seamless and enriching diary-keeping experience.
## Demo
- Live Deployment: [echodiary.live](https://echodiary.live/)
- Source Code:
[GitHub Repository](https://github.com/EchoDiary/EchoDiary)
#### Dashboard Page
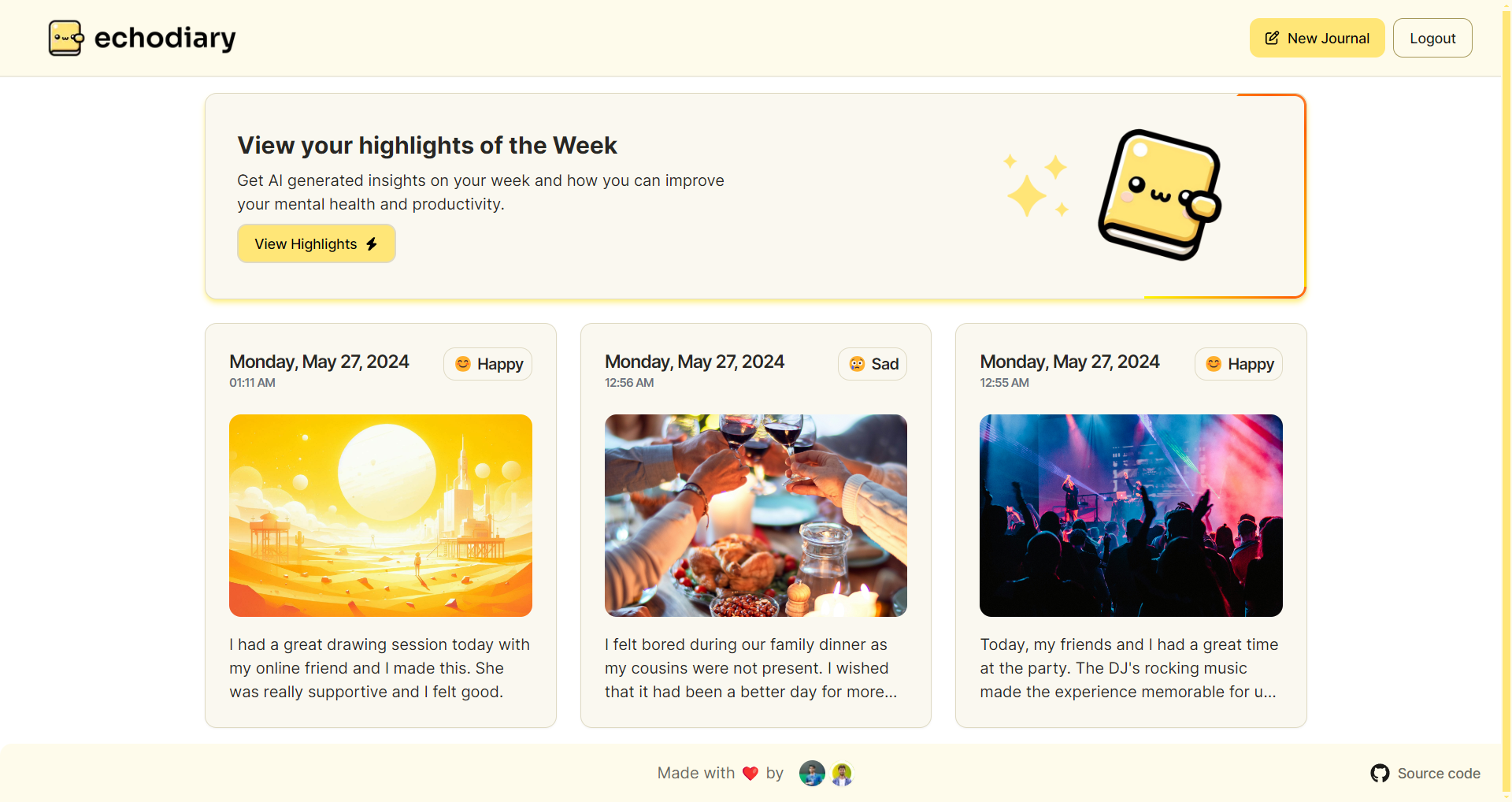
#### Creating New Diary Entry
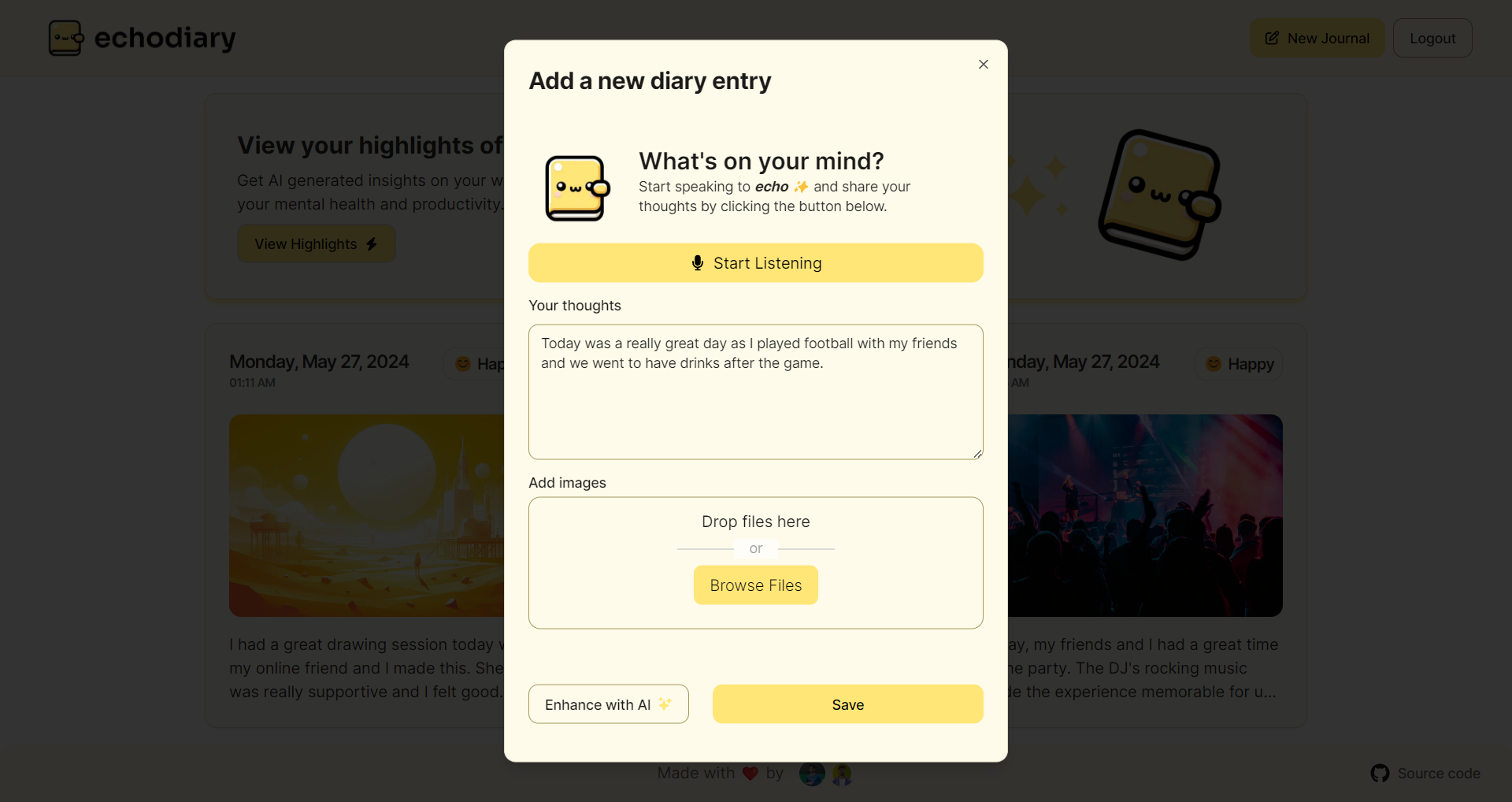
#### Diary Entry with Mood Analysis
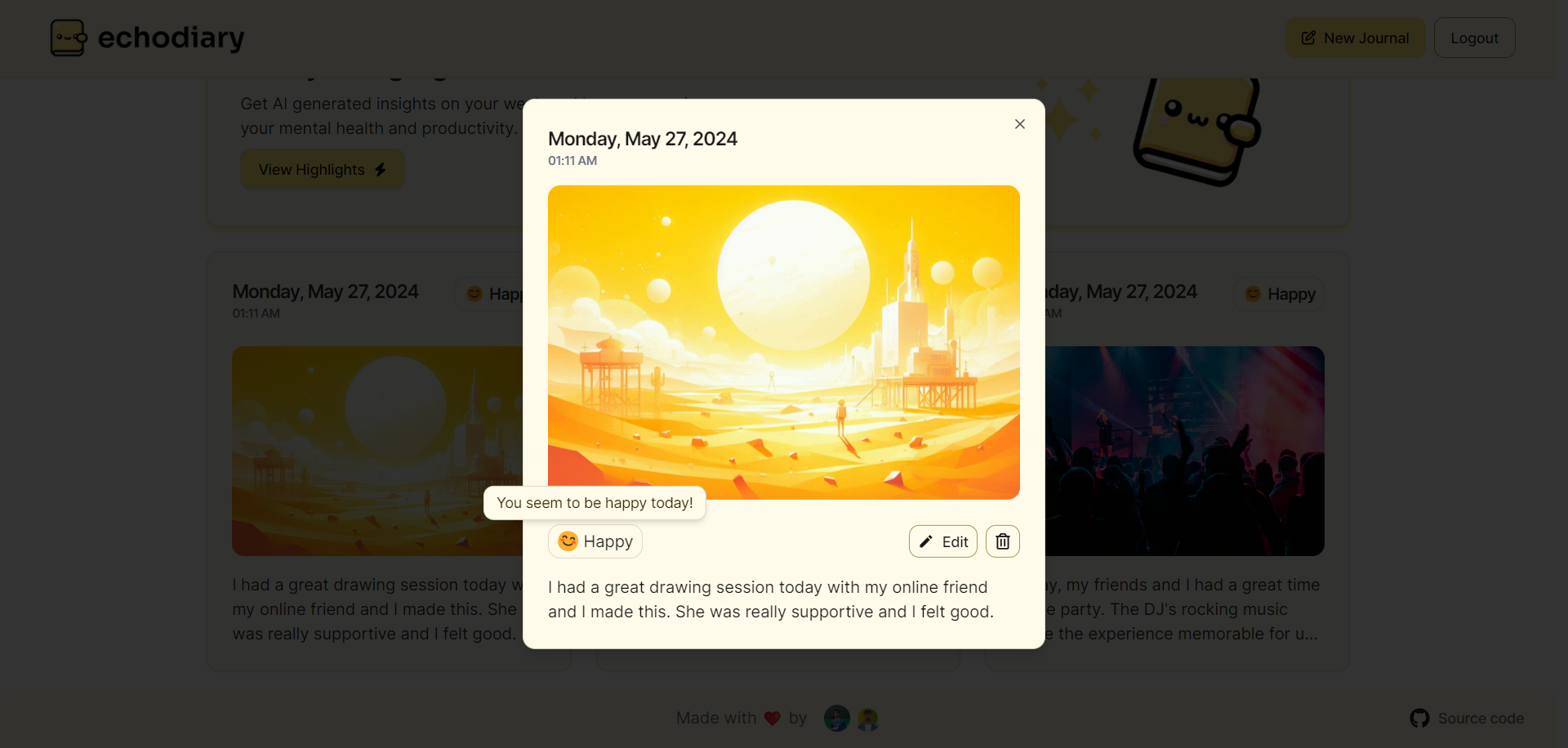
#### Landing Page

## Journey
<!-- Tell us about your process, the services you incorporated, what you learned, anything you are particularly proud of, what you hop to do next, etc. . -->
Initially, we set out to create a basic CRUD app with Amplify, but as we dove into development, we were astounded by its capabilities. This got us thinking about ways to push the envelope. We noticed the lack of a modern diary app infused with AI. What started as a simple diary app evolved into something much grander.
We recognized that traditional typing might not suit everyone, so we integrated **_speech recognition_** to allow users to express themselves orally. But we didn't stop there. We wanted to elevate the content beyond mere transcription, so we introduced _**AI-enhanced features**_ to refine grammar and structure.
However, we found that the experience lacked warmth. To bridge this gap, we introduced "_echo_" our friendly mascot, to foster a sense of connection with the user. With echo, users could engage in a dialogue, making the app feel more like conversing with a friend.
As our diary entries accumulated, we realized the potential for insights. Thus, we incorporated **mood tracking** and **AI-generated highlights** to distill meaningful moments from the entries. The result is an app that not only captures moments but also enriches and reflects upon them.
As we progressed with development, we encountered and familiarized ourselves with numerous functionalities such as Amplify Serverless Functions and leveraged AWS Bedrock to enhance our AI capabilities, ultimately refining our app for optimal performance.
### Connected Components and Feature Full
_We have used Connected Components and all four features: Data, Authentication, Serverless functions, and File Storage._
<!-- Let us know if you developed UI using Amplify connected components for UX patterns, and/or if your project includes all four features: data, authentication, serverless functions, and file storage. -->
- **Data:**
The diary entries are securely stored in Amplify Storage (DynamoDB) with authorization rules ensuring that only the diary owner has access.
- **Authentication:**
The users are authenticated using Amplify Auth(Cognito) to access the Dashboard and create diary entries.
- **File Storage:**
Users can add images to the Diary Entries which are securely stored in Private/Protected S3 Buckets using Amplify Storage
- **Serverless Function:** We utilize a serverless function to invoke the _AWS Bedrock_ Model (mistral-7b-instruct) for enhancing diary text content and generating weekly highlights for users.
- **Connected Components:** We used the Authenticator Connected Component to manage user authentication and the Storage Image and Storage Manager components to handle images within diary entries.
#### Additional Features
- **AWS Bedrock:** We used AWS Bedrock to enhance the diary text content and to generate the Weekly Highlights using Mistral AI's mistral-7b-instruct model.
- **Amplify AI/ML Predictions (AWS Comprehend):** We used Amplify Predictions to perform Sentiment Analysis of the user's diary to analyze their mood.
- **Voice Enabled Diaries:** We used the [Web Speech Recognition API](https://developer.mozilla.org/en-US/docs/Web/API/SpeechRecognition) to let users express their thoughts with their voice and transcribe them into the diary text.
- **AI Content Enhancement:** We used AWS Bedrock to enhance the diary's text content and improve the grammar and structure and also to generate Weekly Highlights.
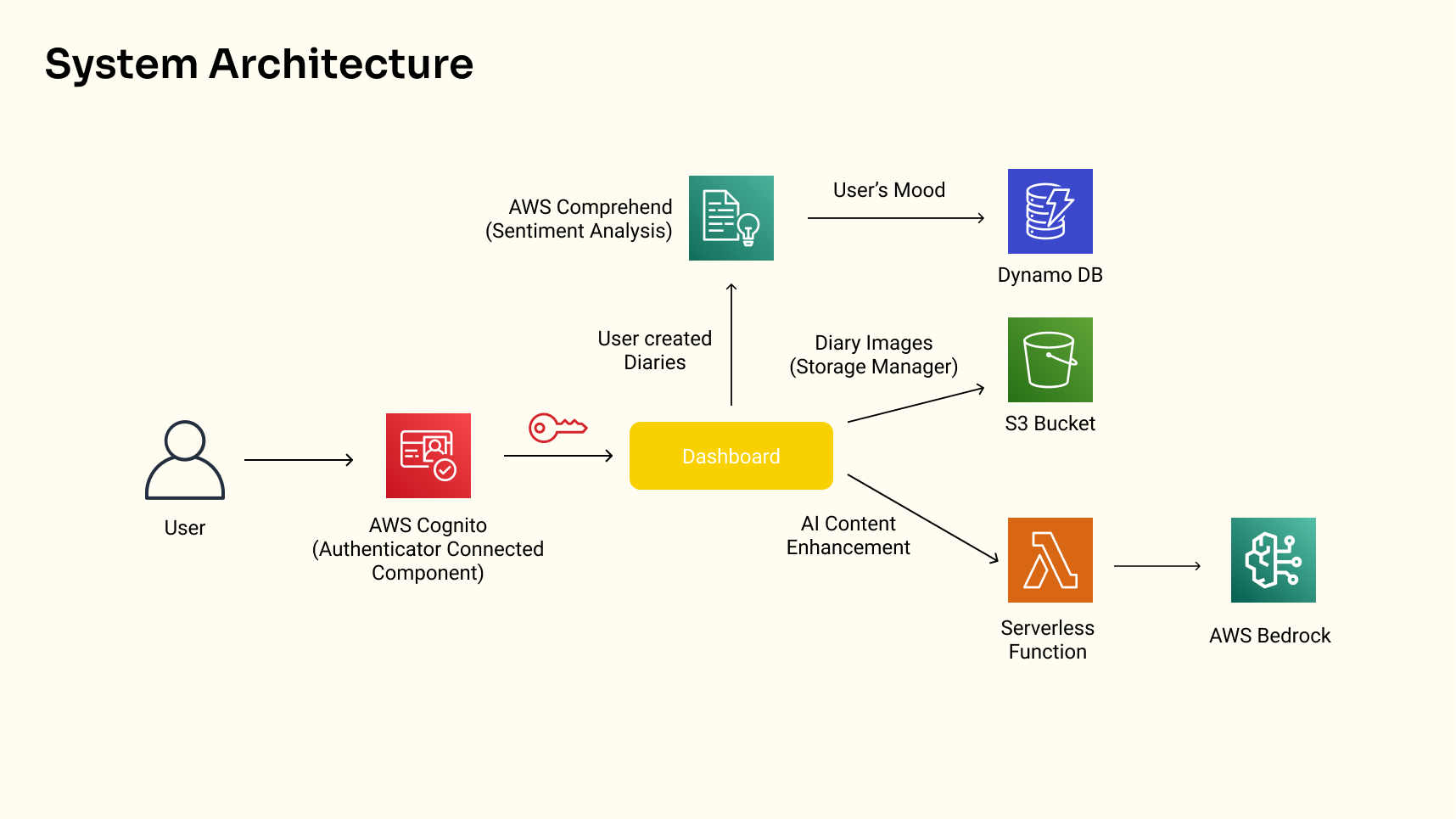
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
##### This is a submission by a team of 2.
#### Team Members:
- @sidjs
- @shivamsharma1
| sidjs |
1,865,872 | HTML semantics | Semantic HTML are tags that define the content they contain. Semantic HTML is widely used in HTML 5,... | 0 | 2024-05-26T19:42:26 | https://dev.to/justin_okpara_23ffc03ea1e/html-semantics-5fbj |
Semantic HTML are tags that define the content they contain.
Semantic HTML is widely used in HTML 5, which is the latest version of HTML.
It requires organizing and arranging HTML tags in a well detailed manner using detailed elements.
Such elements tags are: Header, nav, section, article, aside, figure, figcaption, main, time, address and footer.
HTML semantics can be beneficial in the following ways:
1 Code structuring
2 SEO
3 Accessibility
4 Readable and reusable code.
HTML tags:
Header: used to define the header of a context, can be used in any part of the document apart from the footer.
Nav: used to define navigation for links to different pages or any part of the document, the ul and li were formerly used before the nav were introduced
Figure: used to contain an image, it houses the section of an image and the images caption.
Figcaption: this is the caption for the image in the figure tag.
NB: it is safe to note that most of the HTML semantics tags do not alter the style of the document or give it a specific style, rather it helps in organizing and ordering the code in a readable manner.
| justin_okpara_23ffc03ea1e | |
1,865,871 | KEDA On Azure Kubernetes Service (AKS) | As Managed Kubernetes Service offerings like AKS, EKS, GKE, etc. continue to grow, the more you’re... | 0 | 2024-05-26T19:41:58 | https://dev.to/thenjdevopsguy/keda-on-azure-kubernetes-service-aks-55hg | kubernetes, devops, cloud, programming | As Managed Kubernetes Service offerings like AKS, EKS, GKE, etc. continue to grow, the more you’re going to see available addons and third-party services. The addon services can be anything from Service Mesh solutions to security solutions.
The most recent add-on that AKS has added is Kubernetes Event-Driven Autoscaling (KEDA).
In this blog post, you’ll learn about what KEDA is, an example of how to use KEDA, and how to install both with and without the addon.
## What Is KEDA?
In the world of performance and resource optimization, we typically see two focus points in the Kubernetes landscape:
1. Pod optimization
2. Cluster optimization
Pod optimization is ensuring that the containers inside of the Pods have enough resources (memory and CPU) available to run the workloads as performant as possible. This sometimes means adding more resources or taking away resources if the containers no longer need them. As more load hits a Pod, more CPU and memory will be needed. Once that load goes away, the Pods no longer need the extra CPU and memory.
Cluster optimization is about ensuring that the Worker Nodes have enough memory and CPU available to give the Pods when they ask for it. This means adding more Worker Nodes automatically when needed and when the extra CPU and memory is no longer needed, the extra Worker Nodes can go away. This is the job of cluster autoscalers like Karpetner and Cluster Autoscaler.
The third piece to the resource scaling and optimization puzzle that we don’t see as much as numbers one and two is scaling based on a particular event. Think about it like serverless. Serverless allows you to run code based on a particular trigger from an event that occurs.
Kubernetes has a similar approach with KEDA.
KEDA scales workloads up and down based on particular events that occur. It works alongside other scalers like the Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA).
<aside>
💡 HPA and VPA are not the same type of autoscaling as KEDA. HPA and VPA are all about scaling when a Pod is under load and needs more resources. KEDA scales based on an event that occurs.
</aside>
Keep in mind that KEDA is primarily used for event-driven applications that are containerized.
## KEDA Example
Within KEDA, the primary object/kind you’ll see used for Kubernetes is the `ScaledObject`.
In the example below, KEDA is performing automatically via metrics that come from Prometheus. It’s scaled based on a trigger with a threshold of `50` from Prometheus. Much like with HPA, you can set the min count and the max count of Pods that can run.
KEDA also has a “scale to zero” option which allows the workflow to drop to 0 Pods if the metric value that’s defined is below the threshold.
```jsx
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheustest
spec:
scaleTargetRef:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
name: promtest
triggers:
- type: prometheus
metadata:
serverAddress: http://localhost:9090
metricName: http_request_total
query: envoy_cluster_upstream_rq{appId="300", cluster_name="aksenvironment01", container="test", response_code="200" }
threshold: "50"
idleReplicaCount: 0
minReplicaCount: 2
maxReplicaCount: 6
```
Outside of Kubernetes components, you can also use KEDA within Kubernetes for triggers that aren’t Kubernetes objects.
For example, below is an example of a trigger for Azure Blob Storage. It has nothing to do with Kubernetes, but you can still manage it via Kubernetes (hence Kubernetes becoming the underlying platform of choice).
```jsx
triggers:
- type: azure-blob
metadata:
blobContainerName: functions-blob
blobCount: '5'
activationBlobCount: '50'
connectionFromEnv: STORAGE_CONNECTIONSTRING_ENV_NAME
accountName: storage-account-name
blobPrefix: myprefix
blobDelimiter: /example
cloud: Private
endpointSuffix: blob.core.airgap.example # Required when cloud=Private
recursive: false
globPattern: glob-pattern
```
## Implementing KEDA Without The Addon
KEDA isn't a solution that you can only install on AKS, nor is it a solution that’s just available via an addon. You can also install it via Helm and Kubernetes Manifests. Although this blog post is focused on the KEDA addon, it’s good to still know that you can use it outside of AKS and without the addon.
Below is the configuration to deploy via Helm.
First, add the KEDA repo.
```jsx
helm repo add kedacore https://kedacore.github.io/charts
```
Next, ensure that the chart repo is updated.
```jsx
helm repo update
```
Lastly, install KEDA in it’s own Namespace.
```jsx
helm install keda kedacore/keda --namespace keda --create-namespace
```
## Implementing KEDA With The AKS Addon
As mentioned in the opening of this blog post, there are a ton of Managed Kubernetes Service providers that are creating ways to use third-party tools and addons directly within their environment vs you having to go out and install it in a different way.
For the KEDA AKS addon, there are three solutions:
1. Within the Azure Portal
2. Creating a new cluster and enabling KEDA within the commands
3. Update an existing cluster and enable KEDA within the commands
### Azure Portal
To use the GUI, go to your existing AKS cluster and under **Settings**, choose the **Application scaling** option.
Click the **+ Create** button.
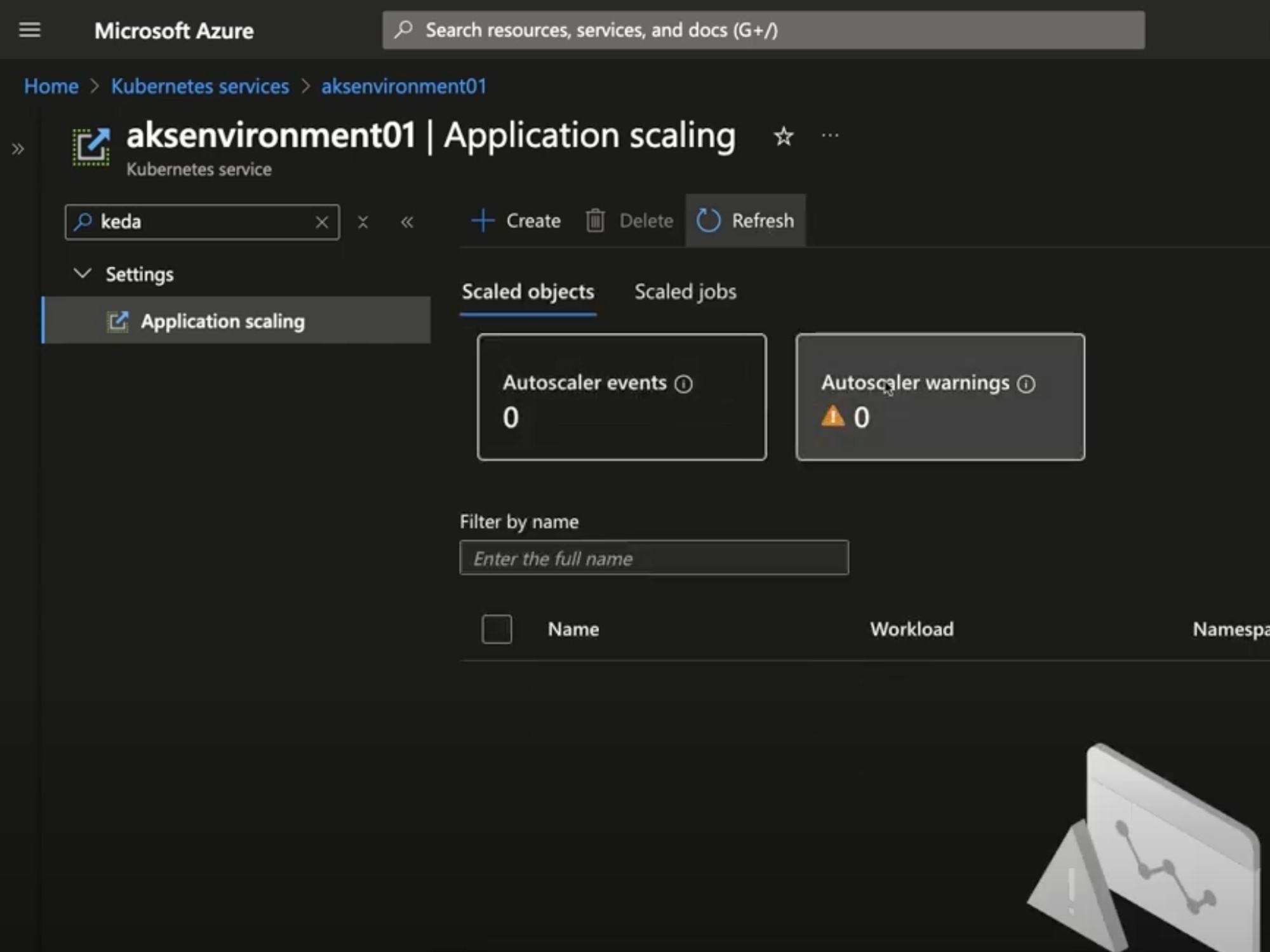
You’ll now see the “Scale with KEDA” screen and you can set up KEDA from here.
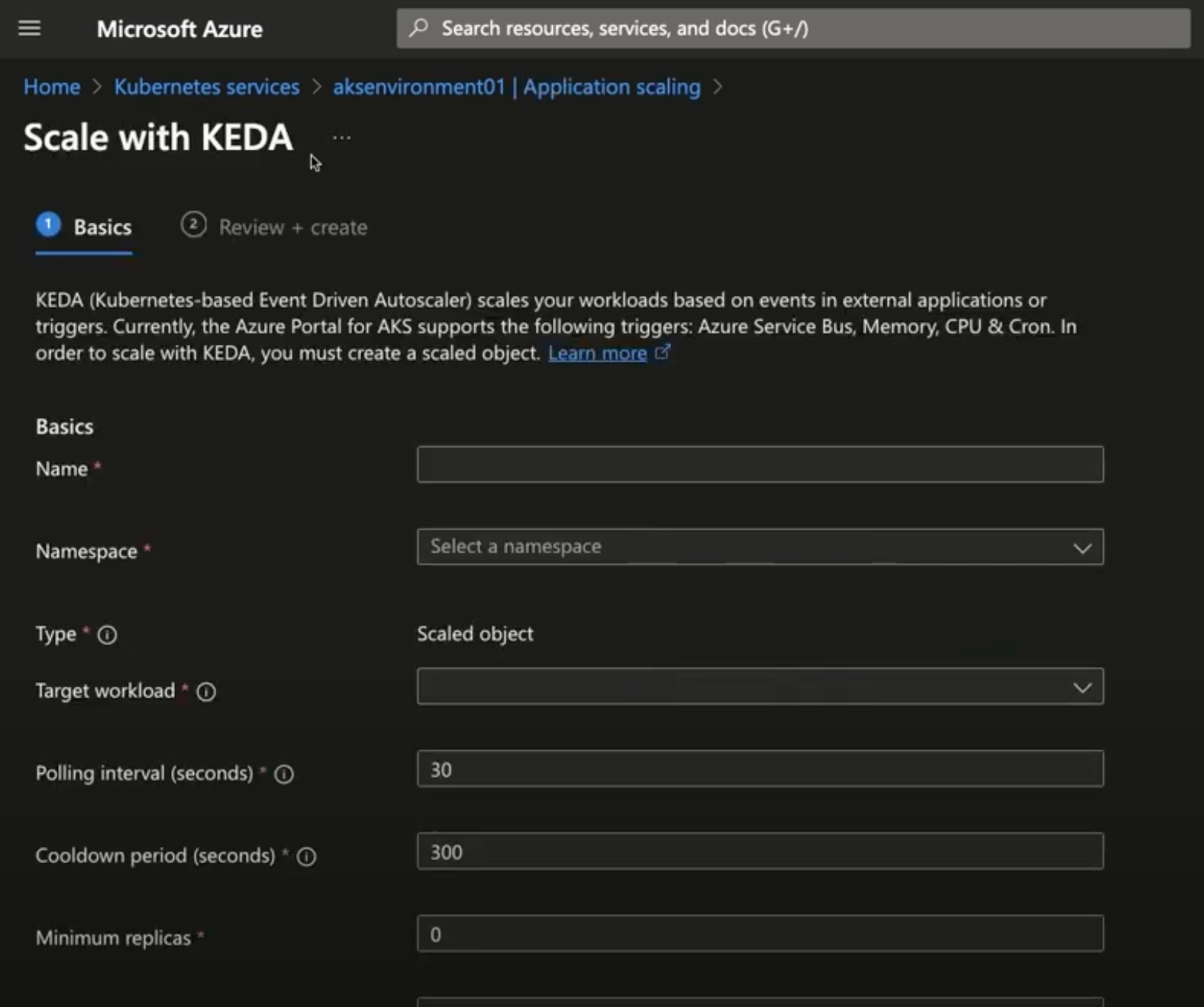
### New Cluster
If you decide that you want to create a new cluster instead of using an existing one, you can do that as well.
As you’re creating the cluster, all you have to do is use the `--enable-keda` flag to enable KEDA.
Below is an example.
```jsx
az aks create --resource-group your_rg_name \
--name your_new_cluster_name
--enable-keda
```
### Existing Cluster
Like the `az aks create` command, there’s an `update` subcommand that’s very similar. All you have to do is use the same `--enable-keda` flag.
```jsx
az aks update --resource-group your_rg_name \
--name your_existing_cluster_name \
--enable-keda
```
## Closing Thoughts
When you think about what your resource optimization, performance optimization, and overall strategy is when thinking about how you want to ensure proper scaling within your environment, KEDA is a great implementation if you have a need to perform event-driven scaling via particular triggers. | thenjdevopsguy |
1,865,869 | Dependency Injection in PHP simply explained with an example | I think you all have heard about Dependency Injection in PHP. But do you know it well?. If not read... | 0 | 2024-05-26T19:39:19 | https://dev.to/vimuth7/dependency-injection-in-php-simply-explained-with-an-example-4fo4 | I think you all have heard about **Dependency Injection** in PHP. But do you know it well?. If not read this and you will understand.
##Example Without Dependency Injection
First let us talk about example without Dependency Injection. Then let us talk about drawbacks and let's talk how to overcome them with Dependency Injection
We need these two classes
```
class Vehicle {
private $make;
private $model;
public function __construct($make, $model){
$this->make = $make;
$this->model = $model;
}
}
class Garage {
private $vehicle;
private $sku;
public function __construct($sku, $vehicleMake, $vehicleModel){
$this->vehicle = new Vehicle($vehicleMake, $vehicleModel);
$this->sku = $sku;
}
}
```
Make note that we are calling **Vehicle** class inside **Garage** class and create an object.
But this approach may create problems. Imagine this scenario. Imagine we need to add subclass instead of main class. This is the subclass,
```
class ElectricVehicle extends Vehicle {
private $batteryCapacity;
public function __construct($make, $model, $batteryCapacity){
parent::__construct($make, $model);
$this->batteryCapacity = $batteryCapacity;
}
public function getBatteryCapacity() {
....
}
}
```
To use this new implementation, you need to modify the **Garage** class:
```
class Garage {
private $vehicle;
private $sku;
public function __construct($sku, $make, $model, $batteryCapacity = null){
if ($batteryCapacity) {
$this->vehicle = new ElectricVehicle($make, $model, $batteryCapacity);
} else {
$this->vehicle = new Vehicle($make, $model);
}
$this->sku = $sku;
}
}
```
This change introduces conditional logic inside the **Garage** class, making it more complex and harder to maintain. Every time a new type of **Vehicle** is added, the Garage class must be modified.
##Improved Approach with Dependency Injection
To avoid these issues, you can use dependency injection to decouple the classes. Check this out,
```
class Vehicle {
private $make;
private $model;
public function __construct($make, $model){
$this->make = $make;
$this->model = $model;
}
}
class ElectricVehicle extends Vehicle {
private $batteryCapacity;
public function __construct($make, $model, $batteryCapacity){
parent::__construct($make, $model);
$this->batteryCapacity = $batteryCapacity;
}
public function getBatteryCapacity() {
...
}
}
class Garage {
private $vehicle;
private $sku;
public function __construct($sku, Vehicle $vehicle){
$this->vehicle = $vehicle;
$this->sku = $sku;
}
}
// Create an instance of Vehicle
$vehicle = new Vehicle('Toyota', 'Corolla');
$garage = new Garage('SKU123', $vehicle);
// Create an instance of ElectricVehicle
$electricVehicle = new ElectricVehicle('Tesla', 'Model S', 100);
$electricGarage = new Garage('SKU124', $electricVehicle);
```
Check this example very carefully. Let us simplify this. Imagine we have new requirement to get **BatteryCapacity**. Here we have created a subclass from parent class and added the function **getBatteryCapacity()**. Check that we haven't change **Vehicle** or **Garage** class. This is the real power of Dependency Injection. | vimuth7 | |
1,865,868 | Passkeys F.A.Q. | The WebAuthn protocol is more than 200 pages long, it's complex and gets constantly tweaked.... | 0 | 2024-05-26T19:34:03 | https://blog.passwordless.id/passkeys-faq | passkeys, webauthn, authentication, passwordless | > The WebAuthn protocol is more than 200 pages long, it's complex and gets constantly tweaked. Moreover, the reality of browsers and authenticators have their own quirks and deviate from the official RFC. As such, all information on the web should be taken with a grain of salt.
>
> Also, there is some confusion regarding where passkeys are stored because the protocol evolved quite a bit in the past few years. In the beginning, "public key credentials" were hardware-bound. Then, major vendors pushed their agenda with "passkeys" synced with the user account in the cloud. Then, even password managers joined in with synced accounts shared with the whole family for example.
>
> How the protocol works, and its security implications, became fuzzier and more nuanced.
## What *is* a passkey?
Depending on who you ask, the answer may vary. According to the W3C specifications, it's a **discoverable** public key credential.
> If you ask me, that's a pretty dumb definition. Calling **any** public key credential a passkey would have been more straightforward.
## What is an authenticator?
The authenticator is the hardware or software that issues public key credentials and signs the authentication payload.
Hardware authenticators are typically security keys or the device itself using a dedicated chip. Software authenticators are password managers, either built-in in the platform or as dedicated app.
## Is the passkey hardware-bound or synced in the cloud?
It depends. It can be either and it's up to the *authenticator* to decide.
In the past, where security keys pioneered the field, hardware-bound keys were the norm. However, now that the big three (Apple, Google, Microsoft) built it in directly in their platform, software-bound keys, synced with the platform's user account in the cloud became the norm. These are sometimes also dubbed "multi-device" credentials.
## Can I decide if the created credential should be hardware-bound or synced?
Sadly, that is something only the authenticator can decide. You cannot influence whether the passkey should be synced or not, nor can you filter the authenticators that can be used.
> Concerns have been raised many times in the RFC, see [issue #1714](https://github.com/w3c/webauthn/issues/1714), [issue #1739](https://github.com/w3c/webauthn/issues/1739) and [issue #1688](https://github.com/w3c/webauthn/issues/1688) among others (and voice your opinion!).
## Are passkeys a form of 2FA?
Not by default. Passkeys are a single step 2FA only if:
- The credential is hardware-bound, not `synced`. Then this first factor is "something you possess".
- The flag `userVerification` is `required`. Then this second factor is "something you are" (biometrics) or "something you know" (PIN code).
> While requiring user verification would be ideal, this also restrict the hardware authenticators that can be used. Not all USB security keys have fingerprint sensor or PIN.
## Are hardware-bound credentials more secure than synced ones?
*Yes*. When the credential is hardware-bound, the security guarantees are straightforward. You must possess the device. Extremely simple and effective.
When using synced "multi-device" passkeys, the "cloud" has the key, your devices have the key, and the key is in-transit over the wire. While vendors go to great length to secure every aspect, it is still exposed to more risk. All security guarantees are hereby delegated to the software authenticator, whether it's built-in in the platform or a password manager. At best, these passkeys are as safe as the main account itself. If the account is hacked, whether it's by a stolen password, temporary access to your device or a lax recovery procedure, all the passkeys would come along with the hacked account. While it offers convenience, the security guarantees are not as strong as with hardware bound authenticators.
The privacy concerns are similar. It is a matter of thrust with the vendor.
## How to deal with recovery when using hardware-bound credentials?
A device can be lost, broken, or stolen. You must deal with it. The most straightforward way is to offer the user a way to register multiple passkeys, so that losing one device does not imply locking oneself out.
Another alternative is to provide a recovery procedure per SMS, TOTP or some other thrusted means. Relying on solely a password as recovery is discouraged, since the recovery per password then becomes the "weakest link" of the authentication system.
## Discoverable vs non-discoverable?
There are two ways to trigger authentication. By providing a list of allowed credential ids for the user or not.
If no list is provided, the default, an OS native popup will appear to let the user pick a passkey. One of the *discoverable* credential registered for the website. However, if the credential is *not discoverable*, it will not be listed.
Another way is to first prompt the user for its username, then the list of allowed credential IDs for this user from the server. Then, calling the authentication with `allowCredentials: [...]`. This usually avoids a native popup and goes straight to user verification.
> There is also another indirect consequence for "security keys" (USB sticks like a Yubikey). Discoverable credentials need the ability to be listed, and as such require some storage on the security key, also named a "slot", which are typically fairly limited. On the other hand, non-discoverable credential do not need such storage, so unlimited non-discoverable keys can be used. There is an interesting article about it [here](https://fy.blackhats.net.au/blog/2023-02-02-how-hype-will-turn-your-security-key-into-junk/).
## Can I know if a passkey is already registered?
No, the underlying WebAuthn protocol does not support it.
> A request to add an `exists()` method to guide user experience has been brought up by me, but was ignored so far. See [issue #1749](https://github.com/w3c/webauthn/issues/1749) (and voice your opinion!).
As an alternative to the problem of not being able to detect the existence of passkeys, major vendors pushed for an alternative called "conditional UI" which in turn pushes discoverable synced credentials.
## What is conditional UI and mediation?
This mechanism leverages the browser's input field autocomplete feature to provide public key credentials in the list. Instead of invoking the WebAuthn authentication on a button click directly, it will be called when loading the page with "conditional mediation". That way, the credential selection and user verification will be triggered when the user selects an entry in the input field autocomplete.
> Note that the input field *must* have `autocomplete="username webauthn"` to work.
## What is attestation?
The attestation is a proof of the authenticator model.
> Note that several platforms and password managers do not provide this information. Moreover, some browsers allow replacing it with a generic attestation to increase privacy.
## Do I need attestation?
Unless you have stringent security requirements where you want only specific hardware devices to be allowed, you won't need it. Furthermore, the UX is deteriorated because the user first creates the credential client-side, which is then rejected server-side.
> There was a feature request sent to the RFC to allow/exlude authenticators in the registration call, but it never landed in the specs.
## Usernameless authentication?
While it is in theory possible, it faces a very practical issue: how do you identify the credential ID to be used? Browsers do not allow having a unique identifier for the device, it would be a privacy issue. Also, things like local storage or cookies could be cleared at any moment. But *if* you have a way to identify the user, in a way or another, then you can also deduct the credential ID and trigger the authentication flow directly.
## What about the security aspects?
The security aspects are vastly different depending on:
1. Synced or hardware-bound
2. User verification or not
3. Discoverable or not
A hardware-bound key is a "factor", since you have to possess the device. The other factor would be "user verification", since it is something that you know (device PIN or password) or are (biometrics like fingerprint).
Many implementations favor *synced credentials with optional user verification* though, for the sake of *convinience*, combined with discoverable credentials. This is even the default in the WebAuthn protocol and what many guides recommend.
In that case, the security guarantee becomes: *"the user has access to the software authenticator account"*. It's a delegated guarantee. It is obvious that having the software authenticator compromised (platform account or password manager), would leak all passkeys since they are synced.
## What about privacy aspects?
Well, if the passkeys are synced, it's like handing over the keys to your buddy, the software authenticator, in good faith. That's all. If the software authenticator has bad intents, gets hacked or the NSA/police knocks on their door, your keys may be given over.
> Note that if a password manager has an "account recovery" or "sharing" feature, it also means it is able to decrypt your (hopefully encrypted) keys / passwords. On the opposite, password managers without recovery feature usually encrypt your data with your main password. This is the more secure/private option, since that way, even they cannot decrypt your data. | dagnelies |
1,809,449 | Captura de erros, operadores relacionais para string e procedures | Para quem não está acompanhando, o POJ (Pascal on the JVM) é um compilador que transforma um subset... | 26,440 | 2024-05-26T19:32:08 | https://dev.to/alexgarzao/captura-de-erros-operadores-relacionais-para-string-e-procedures-3e46 | go, compiling, antlr, jasm | Para quem não está acompanhando, o POJ (_Pascal on the JVM_) é um compilador que transforma um _subset_ de Pascal para JASM (_Java Assembly_) de forma que possamos usar a JVM como ambiente de execução.
Na [última postagem](https://dev.to/alexgarzao/estruturas-de-repeticao-repeat-while-e-for-4ph6) foi adicionado suporte às estruturas de repetição repeat, while e for.
Como estamos compilando para a JVM faz-se necessário detalhar o funcionamento de vários pontos desta incrível máquina virtual. Com isso, em vários momentos eu detalho o funcionamento interno da JVM bem como algumas das suas instruções (_Java Assembly_).
## Melhorias na saída de erros
Sempre que existia um erro léxico, sintático ou semântico no código Pascal, o POJ apenas listava os erros gerados sem nenhum tipo de abstração. Além disso, a compilação seguia normalmente.
Para implementar melhorias, as seguintes modificações foram realizadas:
- [Neste _commit_](https://github.com/alexgarzao/poj/pull/26/commits/233c325e5ef09fa9eab6fbd47d8704ce263d0fbb) o código foi alterado para que a análise léxica, sintática e semântica retornem os erros encontrados;
- [Neste _commit_](https://github.com/alexgarzao/poj/pull/26/commits/26816073da6fffead78b371911da0fb5bda173b6) foi criada uma classe customizada de erros para ser utilizada pelo _runtime_ do ANTLR. Com isso podemos obter os erros encontrados pelo _parser_ bem como realizar o tratamento adequado;
- [Neste _commit_](https://github.com/alexgarzao/poj/pull/26/commits/0a7c9be57bbf4fc5cb9837591b5026b19a05171e) o código principal do POJ obtém os possíveis erros gerados, lista eles e aborta o processo de compilação quando necessário;
- [Neste _commit_](https://github.com/alexgarzao/poj/pull/26/commits/c47aa50abcec1cb9ab2f0b5929e549321e6117fc) foram introduzidos programas em Pascal inválidos bem como a saída de erros esperada. Com isso os testes automatizados, além de validarem a saída esperada de programas válidos (_Java Assembly_), também verificam a saída de erros esperada a partir de programas inválidos (lista de erros).
[Aqui](https://github.com/alexgarzao/poj/pull/26/files) está o PR completo.
## Operadores relacionais para o tipo _String_
Até o momento tínhamos o suporte aos operadores relacionais apenas para o tipo inteiro (_integer_).
[Neste _commit_](https://github.com/alexgarzao/poj/pull/28/commits/42c6b32be74368381b5e011b926fd7477732aba9) foi implementado um programa em Java para entendermos como a JVM lida com os operadores relacionais para o tipo _String_. A partir do programa Java abaixo:
```
public class IfWithStrings {
public static void main(String[] args) {
String v1 = "aaa";
String v2 = "bbb";
if (v1.compareTo(v2) > 0)
System.out.println("v1>v2");
else
System.out.println("v1<=v2");
}
}
```
Quando desassemblamos o arquivo _class_ obtemos o _assembly_ abaixo. Trechos irrelevantes foram omitidos, bem como o trecho original (em Java) que deu origem ao _assembly_ foi inserido com ";;":
```
public class IfWithStrings {
;; public static void main(String[] args)
public static main([java/lang/String)V {
;; String v1 = "aaa";
ldc "aaa"
astore 1
;; String v2 = "bbb";
ldc "bbb"
astore 2
;; v1.compareTo(v2)
aload 1
aload 2
invokevirtual java/lang/String.compareTo(java/lang/String)I
;; if (v1.compareTo(v2) > 0)
ifle label3
;; System.out.println("v1>v2");
getstatic java/lang/System.out java/io/PrintStream
ldc "v1>v2"
invokevirtual java/io/PrintStream.println(java/lang/String)V
goto label5
;; System.out.println("v1<=v2");
label3:
getstatic java/lang/System.out java/io/PrintStream
ldc "v1<=v2"
invokevirtual java/io/PrintStream.println(java/lang/String)V
label5:
return
}
}
```
Com este exemplo foi possível identificar que para comparar duas _strings_ a JVM obtém da pilha as _strings_ e executa o método "compareTo" da classe _String_. Este método compara as _strings_ e empilha o seguinte resultado:
- \-1, caso o 1o valor seja menor que o segundo;
- 0, caso os dois valores sejam iguais;
- +1, caso o 2o valor seja maior que o primeiro.
Dito isso, a partir do programa Pascal abaixo:
```
program IfWithStrings;
begin
if ( 'aaa' > 'bbb' ) then
write('true')
else
write('false');
end.
```
O POJ foi ajustado para gerar o seguinte JASM:
```
// Code generated by POJ 0.1
public class if_with_strings {
public static main([java/lang/String)V {
;; if ( 'aaa' > 'bbb' ) then
ldc "aaa"
ldc "bbb"
invokevirtual java/lang/String.compareTo(java/lang/String)I
iflt L3
iconst 1
goto L4
L3: iconst 0
L4: ifeq L1
;; write('true')
getstatic java/lang/System.out java/io/PrintStream
ldc "true"
invokevirtual java/io/PrintStream.print(java/lang/String)V
goto L2
L1: ;; write('true')
getstatic java/lang/System.out java/io/PrintStream
ldc "false"
invokevirtual java/io/PrintStream.print(java/lang/String)V
L2: return
}
}
```
Este [commit](https://github.com/alexgarzao/poj/pull/28/commits/e689ba9f797847a68934dda216c8bbe220430148) implementa a chamada ao método _String.compareTo_ bem como a geração do teste (_iflt_) citados acima.
[Aqui](https://github.com/alexgarzao/poj/pull/28/files) está o PR completo.
## Chamada de _procedures_
Até o momento tínhamos que implementar todo o código no bloco principal (_main_) do programa em Pascal. [Neste PR](https://github.com/alexgarzao/poj/pull/30/files) foi implementado o suporte à chamada de _procedures_. Reforçando que, em Pascal, uma _procedure_ é o equivalente a uma _function_ que não retorna um resultado.
[Neste commit](https://github.com/alexgarzao/poj/pull/30/commits/58082456f186692389695ee7e52aef4e2d041ecb) foi implementado um programa em Java para entender como a JVM lida com a chamada de procedures (funções sem retorno). A partir do programa Java abaixo:
```
public class ProcedureCall {
public static void main(String[] args) {
System.out.println("Hello from main!");
myMethod();
}
static void myMethod() {
System.out.println("Hello from myMethod!");
}
}
```
Quando desassemblamos o _class_ obtemos o seguinte _assembly_:
```
public class ProcedureCall {
;; public static void main(String[] args)
public static main([java/lang/String)V {
;; System.out.println("Hello from main!");
getstatic java/lang/System.out java/io/PrintStream
ldc "Hello from main!"
invokevirtual java/io/PrintStream.println(java/lang/String)V
;; myMethod();
invokestatic ProcedureCall.myMethod()V
return
}
;; static void myMethod()
static myMethod()V {
;; System.out.println("Hello from myMethod!");
getstatic java/lang/System.out java/io/PrintStream
ldc "Hello from myMethod!"
invokevirtual java/io/PrintStream.println(java/lang/String)V
return
}
}
```
Com este exemplo foi possível identificar que para invocar uma _procedure_ a JVM utiliza a instrução "invokestatic ProcedureCall.myMethod()V" onde:
- invokestatic é a instrução que recebe como argumento a assinatura completa do método a ser chamado;
- ProcedureCall é o nome da classe;
- myMethod()V é assinatura completa do método com seus parâmetros (neste exemplo nenhum) e o tipo de retorno (neste exemplo V - _void_ - que indica nenhum).
Dito isso, a partir do programa Pascal abaixo:
```
program procedure_call_wo_params;
procedure myprocedure;
begin
write('Hello from myprocedure!');
end;
begin
write('Hello from main!');
myprocedure();
end.
```
O POJ foi ajustado para gerar o seguinte JASM:
```
// Code generated by POJ 0.1
public class procedure_call_wo_params {
;; procedure myprocedure;
static myprocedure()V {
;; write('Hello from myprocedure!');
getstatic java/lang/System.out java/io/PrintStream
ldc "Hello from myprocedure!"
invokevirtual java/io/PrintStream.print(java/lang/String)V
return
}
;; bloco principal (main)
public static main([java/lang/String)V {
;; write('Hello from main!');
getstatic java/lang/System.out java/io/PrintStream
ldc "Hello from main!"
invokevirtual java/io/PrintStream.print(java/lang/String)V
;; myprocedure();
invokestatic procedure_call_wo_params.myprocedure()V
return
}
}
```
Este [commit](https://github.com/alexgarzao/poj/pull/30/commits/09ecc90a3a56f40a3c4e7283fae87bca7efe7dbe) implementa o suporte ao tipo "_procedure_" na tabela de símbolos.
Este [commit](https://github.com/alexgarzao/poj/pull/30/commits/708232d2a4561d1c50f941cb247bde39e10d4892) implementa o suporte a geração do _assembly_ correto. Para tal, o POJ precisa lidar com contextos (_procedure_ sendo interpretada) para saber quando está interpretando o código de um procedimento ou do bloco principal.
## Passagem de argumentos para o procedimento
Até então tínhamos a chamada de procedimentos funcional, mas sem argumentos. Neste [commit](https://github.com/alexgarzao/poj/pull/30/commits/b1e00fc706a196c0531720b28e710d3a6f3f8d53) foi implementado um programa em Java para identificar como a JVM lida com a passagem de argumentos. No exemplo é possível ver que, assim como com outros _opcodes_, no início de sua execução o procedimento retira seus argumentos da pilha. Com isso basta empilhar os argumentos antes de invocar o procedimento.
Dito isso, a partir do programa Pascal abaixo:
```
program procedure_call_add_numbers;
procedure add(value1, value2: integer);
begin
write(value1 + value2);
end;
begin
add(4, 6);
end.
```
O POJ gera o seguinte JASM:
```
// Code generated by POJ 0.1
public class procedure_call_add_numbers {
;; procedure add(value1, value2: integer);
static add(I, I)V {
;; write(value1 + value2);
getstatic java/lang/System.out java/io/PrintStream
iload 0 ;; carrega o parâmetro 0 (value1)
iload 1 ;; carrega o parâmetro 1 (value2)
iadd
invokevirtual java/io/PrintStream.print(I)V
return
}
;; Bloco principal (main)
public static main([java/lang/String)V {
;; add(4, 6);
sipush 4
sipush 6
invokestatic procedure_call_add_numbers.add(I, I)V
return
}
}
```
Para o correto suporte à chamada com argumentos foi necessário [acrescentar na tabela de símbolos](https://github.com/alexgarzao/poj/pull/30/commits/8b4ba9f4e69d08560486b96c7f3d902d7b607b39) os tipos dos argumentos dos procedimentos. Por sua vez, para a correta invocação dos procedimentos, o [_parser_ teve que validar bem como gerar o _assembly_](https://github.com/alexgarzao/poj/pull/30/commits/a89bedf78dabfa7fbd1de513e35cad932dcfcf65) corretamente conforme a assinatura do procedimento.
[Aqui](https://github.com/alexgarzao/poj/pull/30/files) está o PR completo.
## Próximos passos
Na próxima publicação vamos falar sobre funções, entrada de dados e, se possível, concluir um dos objetivos deste projeto: cálculo do fatorial de forma recursiva.
## Código completo do projeto
O repositório com o código completo do projeto e a sua documentação está [aqui](https://github.com/alexgarzao/poj). | alexgarzao |
1,865,866 | Pure HTML with CDN json schema form element has typo | what a great project that uses... | 0 | 2024-05-26T19:28:57 | https://dev.to/wsq/pure-html-with-cdn-json-schema-form-element-has-typo-3dal | javascript, jsonschema, uischema, lit | what a great project that uses lit
https://github.com/json-schema-form-element/jsfe?tab=readme-ov-file
Everything was working great with https://github.com/json-schema-form-element/examples/blob/main/src/pages/pure-html.html
but when I tried to use the ui-schema it failed until I changed
ui-schema to uiSchema
not working:
```
<json-schema-form
// .....
ui-schema='{
"bar": {
"ui:widget": "switch"
}
}'
></json-schema-form>
```
working:
```
<json-schema-form
// .....
uiSchema='{
"bar": {
"ui:widget": "switch"
}
}'
></json-schema-form>
``` | wsq |
1,865,863 | Fin Alchemist MVP with AWS Amplify Gen 2 | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-26T19:22:29 | https://dev.to/gokhantamkoc/fin-alchemist-mvp-with-aws-amplify-gen-2-22kc | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
## What I Built
I built a simple MVP app. Virtually, It can build a stock portfolio. These stocks are from NASDAQ exchange.
I quite enjoyed using AWS Amplify Gen 2, the only thing I do not like about it is the `UI-React` library. There is no Modal Component, so I had to implement that on my own :-) Still I had fun... You should try too.
## Screen Shots
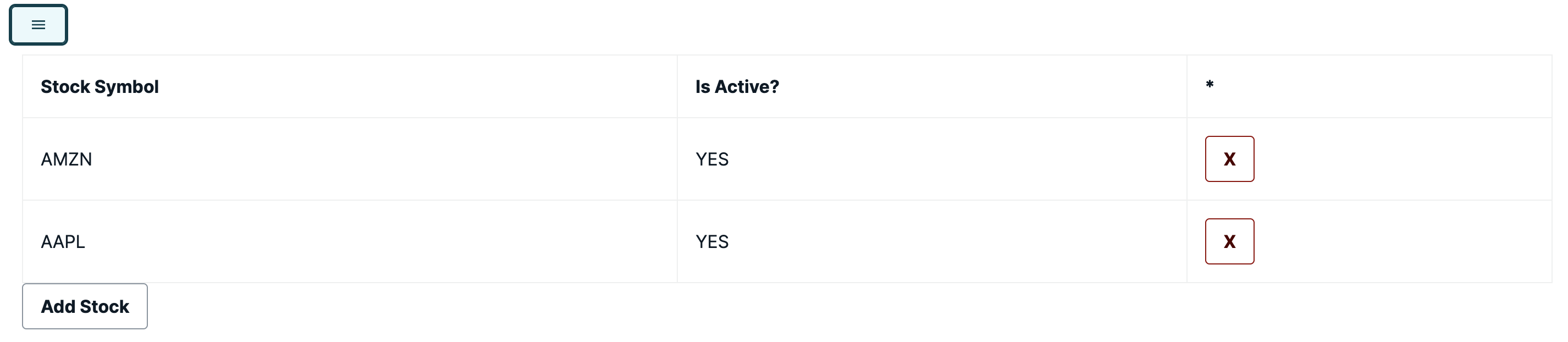
> **Note: ** Sorry, I am not a UI/UX developer, therefore please mind my design :-)
## Demo and Code
Fin Alchemist's code can be found [here](https://github.com/gokhantamkoc/fin-alchemist-demo-app).
The demo can be accessed from [here](https://main.d2wknzviowb134.amplifyapp.com).
## Integrations
I used the below integrations for `Fin Alchemist`:
- For Authentication, The MVP depends on Cognito.
- For Data, The MVP depends on DynamoDB.
- For Servless Functions, The MVP is integrated with AWS Lambda
- For File Storage: The MVP depends on AWS S3.
**Connected Components and/or Feature Full**
The MVP uses `Authenticator` connected component for Sign in/up actions.
## Team Members
- [Gökhan Tamkoç](https://github.com/gokhantamkoc)
> **Note:** You can connect with me on [Linkedin](https://www.linkedin.com/in/gokhantamkoc/) as well. | gokhantamkoc |
1,865,860 | Css / SVG | Hi, I'm new here and I'm just starting to learn html, css and JavaScript. And I'm trying to figure... | 0 | 2024-05-26T19:18:41 | https://dev.to/elllki/css-svg-30pi | help | Hi, I'm new here and I'm just starting to learn html, css and JavaScript. And I'm trying to figure out how to use an svg image and assign an animation to just one part of the image. Does anyone know how? | elllki |
1,864,392 | what happens when you type https://www.google.com in your browser and press Enter? | Understanding the functioning of the internet is essential in grasping the mechanics of the web and... | 0 | 2024-05-26T19:11:32 | https://dev.to/unbothered_dev/what-happens-when-you-type-httpswwwgooglecom-in-your-browser-and-press-enter-p7g | webdev, google, tutorial, loadbalancing | ##
Understanding the functioning of the internet is essential in grasping the mechanics of the web and websites. As you navigate the online realm by typing a website address into your browser and hitting enter, a series of intricate processes occur in the background. Your browser, acting as the client, sends a message to your Internet Service Provider (ISP), such as AT\&T or Comcast in the US or BT or TalkTalk in the UK.
This message communicates your request to access a specific website, like 'google.com', to the ISP. The ISP then forwards this inquiry to a crucial component known as a Domain Name System (DNS) server - akin to an advanced phone directory. Subsequently, the DNS server seeks and retrieves the precise IP address associated with the requested website from its database.
Every device connected to the internet has a unique IP address, serving as a digital address for routing data between computers. Once the DNS server identifies the IP address, it relays this crucial information back to your browser through the ISP via the internet. Following this, you can directly contact the server associated with the IP address, which in this case would be the Google servers. These servers furnish your browser with all the essential files and data necessary to display the Google homepage.Now let us take a deep dive into "what happens when you type https://www.google.com in your browser and press Enter?"
## FIRST STEP:DOMAIN NAME SYSTEM(DNS) REQUEST
Almost everything on the web starts with a DNS (Domain Name System) request. The browser needs to convert the user-friendly domain name [www.google.com](www.google.com) into an IP address, which computers use to communicate. To do this, it sends a query to a DNS server, which functions like the internet's phonebook, retrieving the IP address associated with Google's server."
## THE PROTOCOL SUITE: HOW TCP AND IP WORK TOGETHER.
The protocol suite known as TCP/IP plays a crucial role when it comes to using the IP address. TCP ensures a dependable connection between your machine and Google's server, ensuring the integrity and proper order of the data. IP, on the other hand, is responsible for accurately routing the data packets to the expected destination.
## THE FIREWALL
The firewall, known as the guard, plays a crucial role in the journey of packets. Its main purpose is to ensure the safety and authorization of traffic by carefully examining each packet. Only after passing predefined rules does the firewall permit the packets to continue their journey.
## THE SECURE CHANNEL:HTTPS AND SSL.
In a secure domain such as HTTPS, Secure Socket Layer (SSL) or its successor, Transport Layer Security (TLS), play a vital role in establishing a secure connection. They achieve this by encrypting the data exchanged between your browser and Google's server, effectively protecting against eavesdropping(in the context of network security, refers to the unauthorized interception and listening to private communications over a network).
## TRAFFIC COORDINATOR: LOAD BALANCING.
A load balancer serves as a traffic distributor and coordinator helping to effectively distribute incoming requests among multiple servers. The purpose of this is to prevent any individual server from becoming overwhelmed, resulting in improved performance and enhanced reliability. By evenly balancing the load, the load balancer optimizes the utilization of server resources.
## THE GATE WAY: WEB SERVERS.
After load balancing, the web server steps in to handle the HTTP request. It determines the necessary action and often interacts with an application server to further process the request it also determines the course of action from the recieved requests.
## THE PROCESSOR: APPLICATION SERVER.
The application server serves as the central intelligence of the operation. It executes the essential business logic required to fulfill the request. This server communicates with the database to retrieve or update information and processes the data as needed. Once all necessary operations are completed, the application server prepares the HTTP response, ensuring it is ready to be sent back to your browser. This response includes all the dynamic content and data requested, seamlessly integrating backend processes with the user-facing web application.
## THE VAULT:DATABASE.
In order to fulfill your request, the application server may need to retrieve or store data. It establishes communication with the database, serving as the central storage for data storage and management. Through these operations, the application server diligently ensures the successful and efficient execution of your search requests.
## THE FINAL ACT:RENDERING.
The HTTP response traverses a complex path and ultimately reaches your browser wherein it undergoes rendering of HTML, CSS and JavaScript elements. This collaborative process culminates in the familiar and beloved Google webpage experience.
The seamless orchestration of this sequence of events, though seemingly instantaneous, is a testament to the engineering excellence that is inherent within the realm of technology. It represents a prodigious achievement in the field, showcasing the vast potential and possibilities of the ever-evolving technological landscape.
| unbothered_dev |
1,865,857 | C# 13.0 da nima yanglik ? | *Ushbu maqolada nimalarni o'rganamiz ? * C# 13.0 haqida 1👆 Params to'plamlar Indexga yashirin... | 0 | 2024-05-26T19:08:00 | https://dev.to/ozodbek_soft/c-130-da-nima-yanglik--5dcl | csharp, dotnet, microsoft, news | **Ushbu maqolada nimalarni o'rganamiz ? **
1. **C#** 13.0 haqida
2. 1👆
3. Params to'plamlar
4. Indexga yashirin kirish
C# 13.0 - Bu C# ning 13.0 chi versioni degani. O'zimizni tilda avlodi. Va har yili yangilanib boradi. Bazida esa 2 3 yilda bir yangilanadi...
Xullas boshladik!
`C# 13.0` o'z ichiga quyidagi narsalarni oladi.
- Siz ushbu functionni `.NET sdk 9.0` da ishlata olasiz xolos.
- **Visual studio 2022** yoki **VsCode** orqali ishlatishingiz mumkin.
C# 13.0 Faqatgina SDK 9.0 da ishlaydi. Undan pastiga emas ❌
Xohlasangiz `.NET SDK 9.0` ni o'rnating ([ushbu havola orqali](https://dotnet.microsoft.com/en-us/download/dotnet/9.0))
`Params` modifikator massiv turlari bilan cheklanmaydi. Endi siz `System.Span<T> , System.ReadOnlySpan<T>` va `System.Collections.Generic.IEnumerable<T>` ni params har qanday to'plam turidan foydalana olasiz. Add orqali esa `System.Collections.Generic.IEnumerable<T>` , `System.Collections.Generic.IReadOnlyCollection<T>` , `System.Collections.Generic.IReadOnlyList<T>` , `System.Collections.Generic.ICollection<T>` interfeyslari bor , va `System.Collections.Generic.IList<T>` dan ham foydalanish mumkin.
Indexga yashirin murojaat qilish.
Endilikda `^` orqali objectni ishga tushirish ham mumkin(ruxsat beriladi). Ya'ni nima demoqchiman. Ming marta eshitgandan bir marta korgan yaxshi deganlaridek. Quyidagi code orqali siz massivni ishga tushirishingiz mumkin.
```
var sanash = new TimerRemaining()
{
buffer =
{
[^1] = 0,
[^2] = 1,
[^3] = 2,
[^4] = 3,
[^5] = 4,
[^6] = 5,
[^7] = 6,
[^8] = 7,
[^9] = 8,
[^10] = 9
}
};
```
ana ko'rdilarmi.
> Hozir bu code 0 dan 9 gacha hisoblovchi massivni yaratadi. C# 9.0 `^` belgi orqali massivni ishga tushirishga ruxsat bermasdi. `C# 13.0` da esa o'zingzi ko'rib turibsiz.
_Hozircha men ham tushunganlarim shu. Lekin hali bundanda qiziqarli maqolalar hali oldinda..._ | ozodbek_soft |
1,861,628 | Lifetimes in Rust - one difficult exercise | The excellent online book Rust By Practice in the Lifetime chapter has a difficult exercise called...... | 27,577 | 2024-05-26T19:02:38 | https://dev.to/michal1024/lifetimes-in-rust-one-difficult-exercise-1c13 | rust, programming | The excellent online book *Rust By Practice* in the *Lifetime* chapter has a difficult exercise called... *A difficult exercise*. I struggled with it for a while, then looked at the solution and - I still did not get it. Not until I read the chapter on ownership from *The Rustonomicon*. Let's dive into the problem and describe the solution in detail.
First we need to go over the code in the exercise and explain what it does. It defines a structure called `List`; that structure has nothing to do with an actual list, it is just a container for a single object. The object it holds is an instance of a `Manager` structure. The `List` gives mutable access to the `Manager` but not directly - instead it creates container called `Interface` that holds mutable reference to the `Manager`. This is done in `get_interface` method that returns `Interface`. The only method of `Interface` is `noop(self)`.
```rust
struct Interface<'a> {
manager: &'a mut Manager<'a>
}
impl<'a> Interface<'a> {
pub fn noop(self) {
println!("interface consumed");
}
}
struct Manager<'a> {
text: &'a str
}
struct List<'a> {
manager: Manager<'a>,
}
impl<'a> List<'a> {
pub fn get_interface(&'a mut self) -> Interface {
Interface {
manager: &mut self.manager
}
}
}
fn main() {
let mut list = List {
manager: Manager {
text: "hello"
}
};
list.get_interface().noop(); // <--- Interface created and used here.
println!("Interface should be dropped here and the borrow released");
use_list(&list);
}
fn use_list(list: &List) {
println!("{}", list.manager.text);
}
```
When trying to run this code, rust fails to compile it with the following error:
According to rust's lifetime rules, borrow is valid from it's declaration to it's last use. Last use of `Interface` is when `noop()` is called in the `main` function. It should be similar to this example:
```rust
fn main() {
let mut x = 1;
let y = &mut x;
// print!("{x}"); <-- this will not compile,
// x is mutably borrowed so print cannot borrow it again
*y = 42; // last use of y
print!("{x}"); // x no longer borrowed, can be used
}
```
So why it does not work? Let's analyze reference lifetimes in the `main` function. I am using similar notation that the *The Rustonomicon* is using, showing scopes of each lifetime. Note this is not valid rust syntax!
```rust
fn main() {
'a {
let mut list = List { // list has lifetime 'a
manager: Manager {
text: "hello"
}
};
'b {
list.get_interface().noop(); // Interface uses lifetime 'b
}
// 'b is out of scope
println!("Interface should be dropped here and the borrow released");
use_list(&list);
} // lifetime 'a ends here
}
```
But... this still does not explain the issue. `'b` lifetime is short and ends before `use_list` is called. To understand what happens we need to look closer at `get_interface()` method declaration:
```rust
impl<'a> List<'a> {
pub fn get_interface(&'a mut self) -> Interface {
Interface {
manager: &mut self.manager // what is lifetime of this?
}
}
}
```
Rust lifetime elision allows us to skip some lifetime parameters. If we make all lifetimes explicit, the declaration will look as below
```rust
impl<'a> List<'a> {
pub fn get_interface(&'a mut self) -> Interface<'a> {
Interface::<'a> {
manager: &'a mut self.manager
}
}
}
```
The lifetime `'a` from above snippet will be the same as the lifetime `'a` from `main` function since we are calling this method on `list` object in `main`. This means `Interface.manager` will hold reference with `'a` lifetime. And if you look inside `Manager` struct it uses this lifetime in `text` reference. Recall the implementation of `Interface`:
```rust
struct Interface<'a> {
manager: &'a mut Manager<'a>
}
```
Even if we stop using `Interface`, the `manager` reference is still alive as it is using `'a` lifetime, which in `get_interface` will be bound to `List`'s lifetime also called `'a` here.
How do we fix this? We need to untangle `Interface`'s lifetime from `Manager`'s lifetime. Let's introduce separate lifetime `'b` for Interface's reference. I will consistently use `'a` and `'b` which should make it easier to track which lifetime is which.
```rust
struct Interface<'b, 'a> {
manager: &'b mut Manager<'a> // reference with lifetime 'b
// holding Manager with lifetime 'a
}
impl<'b, 'a> Interface<'b, 'a> {
pub fn noop(self) {
println!("interface consumed");
}
}
```
We could bind the lifetimes declaring `'a: 'b` to indicate `'a` outlives `'b`, but this is not necessary in this example.
The last thing remaining is to create `Interface` instance with proper lifetimes. `List` uses only one lifetime `'a`, but we can extend `get_interface` method to take another generic lifetime parameter `'b`.
```rust
impl<'a> List<'a> {
pub fn get_interface<'b>(&'b mut self) -> Interface<'b, 'a> {
Interface {
manager: &mut self.manager
}
}
}
```
Now we explicitly told rust to use `'b` lifetime for reference inside `Interface`. Once usage is done, rust can release the reference and `list` becomes available.
*The Rustonomicon* describes itself as *the awful details that you need to understand when writing Unsafe Rust programs*. In this example we did not do any unsafe rust, yet the knowledge from that book was very helpful. I recommend reading *The Rustonomicon* even if you only plan to play safe.
Sources:
1. https://doc.rust-lang.org/nomicon/lifetimes.html
2. https://practice.course.rs/lifetime/advance.html
3. https://doc.rust-lang.org/nomicon/lifetime-elision.html | michal1024 |
1,865,847 | Guide To Choose A Database For Your Next Design | Why we need to choose a database? A database is an organized collections of data that can... | 0 | 2024-05-26T18:51:20 | https://dev.to/isurumax26/guide-to-choose-a-database-for-your-next-design-5cam | database, systemdesign, sql, nosql | ## Why we need to choose a database?
A database is an organized collections of data that can be managed and accessed easily. Each provider has applied these modifications to data stores differently, depending on the type of database and how the database engine is configured. As a result, we are unable to store certain data structures in one type of database but in another.
As an illustration, a relational database cannot hold a graph data structure. These kinds of data structures are intended to be stored in different kinds of databases. Therefore, it is crucial to select the appropriate database for your needs at the design phase rather than selecting the incorrect database type and changing it later on in the development process.
## Types Of Databases
We can choose between traditional relational databases and non-relational databases. More than these two words you may have heard SQL and NO SQL databases. Non-relational databases are referred to as NO SQL and relational databases as SQL.
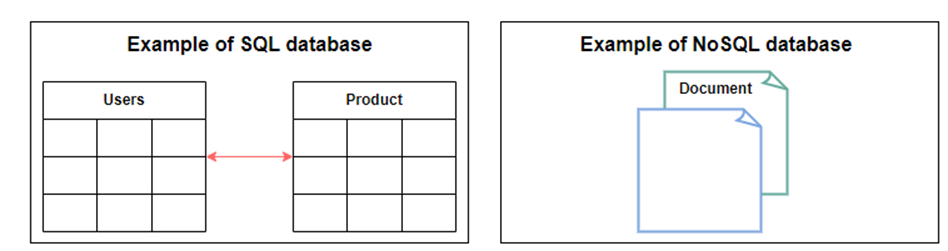
Let's talk about the various factors we took into account before deciding on a database for our designs.
## Relational Databases
Relational databases have been around here for more than 40 years and it is the default choice of software professionals for structured data storages. You might have heard about ACID principles. In order to maintain consistency in databases, before and after the transactions, certain properties are followed. These are called ACID properties. One of the greatest powers of the relational database is its abstractions of ACID transactions and related programming semantics.
Some of the important features of relational database are
1. ACID compliance
The general principle is if one change fails, the whole transaction will fail, and the database will remain in the state it was in before the transaction was attempted.
2. Reduced redundancy - Normalization
The information related to a specific entity is stored in one table and relent data is stored in another table linked to that by a foreign key. As an example, product related information are stored in a one table and customer who brought the product stored in another table and linked to the production table by a foreign key. This process is called normalization and has the additional benefit of removing anomalies.
3. Concurrency
Database concurrency is a unique characteristic enabling two or more users to retrieve information from the database at the same time without affecting data integrity. Common issues during concurrent database transactions include dirty reads and lost data updates (dirty reads - This issue arises when a particular transaction accesses a data object written or updated by another uncommitted transaction in the database.). Concurrency in a relational database is handled through transactional access to the data.
If your database is running this transaction as one whole atomic unit, and the system fails due to a power outage, the transaction can be undone, reverting your database to its original state.
4. Back Up and Disaster Recovery
Relational databases guarantee the state of data is consistent at any time. The export and import operations make backup and restoration easier. Most cloud-based relational databases perform continuous mirroring to avoid loss of data and make the restoration process easier and quicker.
So If our use case required above features then we should consider going with a relational database.
So are there any drawbacks of relational databases?
Yeah of course, let’s discuss some drawbacks of relational databases
1. Lack of scalability
While using the relational database over multiple servers, its structure changes and becomes difficult to handle, especially when the quantity of the data is large. Due to this, the data is not scalable on different physical storage servers. Ultimately, its performance is affected.
2. Complexity in Structure
Relational databases can only store data in tabular form which makes it difficult to represent complex relationships between objects. This is an issue because many applications require more than one table to store all the necessary data required by their application logic.
## Non-Relational Databases
These databases are used in applications that require a large volume of semi-structured and unstructured data, low latency, and flexible data models. This can be achieved by relaxing some of the data consistency restrictions of other databases.
Following are some of the characteristics of the NOSQL database
1. Simple Design
Unlike SQL databases, NoSQL databases are not complicated. They store data in an unstructured or a semi-structured form that requires no relational or tabular arrangement. For example storing all the customer related information in a one document instead of multiple tables which require join operations. So less code , debug and maintain.
2. Horizontal Scaling
As stated above scaling is one of the drawbacks in the relational databases. But scaling is one of the prominent features in non-relational databases. Because we can represent all of the customer related information in a one document instead of multiple tables over several nodes like in relational databases, we scale NoSQL databases pretty easily.
3. Availability
Most of the non-relational databases support replication to support availability.
4. Independent Of Schema
Non-relational databases don’t need a schema at the time of database configuration or data writes. As an example, mongo db which store the data in document (JSON, XML) allow different fields in different documents. So Number of fields in different documents can be different
Following are some of drawback of Non-relational databases.
1. No Support for ACID implicitly
They don’t support ACID (atomicity, consistency, isolation, durability) transactions across multiple documents. But currently there are some newer versions of No-SQL databases which supports ACID properties to some extent. (MongoDB added support for multi-document ACID transactions in the 4.0 release, and extended them in 4.2 to span sharded clusters.)
2. Relatively Large Storage
In terms of storage utilization, No SQL databases needs more storage because they focus more on query optimization than considering the storage. So there are lot of duplicates data in No-SQL databases
NoSQL databases are divided into various categories based on the nature of the operations and features, including document store, columnar database, key-value store, and graph database.
So we discussed about different pros and cons of relational and non-relational databases. So how do we choose the right database for our requirement.
## Choose the right database
Various factors affect the choice of database to be used in an application. A comparison between the relational and non-relational databases is shown in the following table to help us choose:
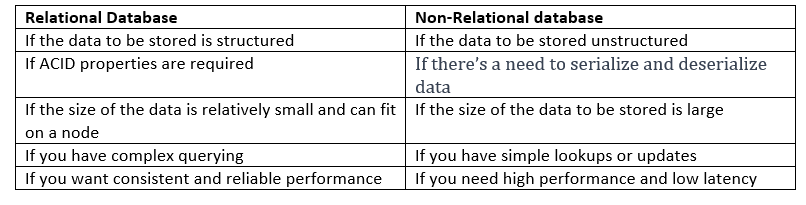
By taking above table as a guidance we will go through some scenarios
Which database should we use when we have unstructured data and there’s a need for high performance?
So type of data is unstructured and needs high performance. So, it should be No SQL database. NoSQL database like MongoDB would be a perfect choice for this
Which database should we use when we have a financial application, like stock trading application, and we need our data to be consistent all times?
In a stock trading application data will be structured and we need high consistency too. So these are the features of relational database.
What kind of database should we use if we make a retail store application that requires storing the data in tabular format?
if we have tabular data that means we have structured data. Hence, a relational database is the right choice
Which kind of database should we use for making an application like Reddit/Facebook?
The data generated by the these social media applications are mostly unstructured which requires a non-relational databases.
For a web multiplayer game?
In this scenario we need to store data in the database as same as the object in the game so we can deserialize later. Hence, best choice is document oriented NoSQL database.
| isurumax26 |
1,865,849 | Amplify-Gallery | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge ... | 0 | 2024-05-26T18:44:19 | https://dev.to/kakug/amplify-gallery-4g36 | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
##Introduction
Amplify-gallery is an online photo-sharing app that leverages AWS Amplify's data,storage & authentication .
User can upload photos after authentication & share them to other users.
## Demo and Code
Here you can find the github repo for the reference:
I have used AWS Amplify vite starter template for bootstrapping the app.
[Code](https://github.com/Kaku-g/amplify-vite-react-template)
[Live Website](https://main.d269wuph7uc92m.amplifyapp.com/)
## Integrations
I have used AWS Amplify's authentication, data & storage for building tis gallery. Additionally I have used MUI as frotendnlibrary and toastify for providing notifications.
**Connected Components and/or Feature Full**
##Screenshots
Photo-Gallery
Authentication Page
##Future Updates
Amplify's Lamda functions to make it an intelligent photo sharing app that utilizes cloud space. It will automatically compress the less accessed photos & will timely keep track of the compressed & uncompressed files.
| kakug |
1,865,846 | **SOLID PRINCIPLE OF SOFTWARE ENGINEERING** | Heyy? Do you know about the solid principle of software engineering. Lemme show being more specific... | 0 | 2024-05-26T18:37:19 | https://dev.to/hussain101/solid-principle-of-software-engineering-8cf | softwaredevelopment |
Heyy? Do you know about the solid principle of software engineering.
Lemme show being more specific to react(give it a 10 mins read):
# S.O.L.I.D Principle
**General Description**:
A collection of design rules in software engineering called the S.O.L.I.D. principles is intended to make software more extensible, scalable, and maintainable. These guidelines aid programmers in handling the majority of software design issues and improve the readability, flexibility, and maintainability of their code.
**More specific to React**:
By encouraging reusable, manageable, and modular code, the S.O.L.I.D. principles may be used in ReactJS to enhance the organization and caliber of React apps. Let's look at some real-world examples of how each of these ideas may be implemented in a ReactJS project:
### **Single Responsibility Principle (SRP):**
**Principle:** A component should have one reason to change, meaning it should have only one job.
**Example:** Instead of creating a component that handles user inputs, processes data, and also renders the results, it's better to split these responsibilities:
### **Open/Closed Principle (OCP):**
**Principle:** Components should be open for extension but closed for modification.
**Explanation**:
The Open/Closed Principle (OCP) is one of the key principles in object-oriented software design and is just as applicable in component-based architectures like ReactJS. OCP states that software entities (such as modules, classes, functions, or, in the case of React, components) should be open for extension but closed for modification. This means you should be able to change the behavior of a component without altering its source code.
**Understanding the Principle**
- **Closed for Modification**: Once a component is tested and deployed, you should not modify its internal code for new functionality to prevent the risk of breaking existing code. The original component should remain untouched, which ensures that updates or changes won't introduce new bugs in the existing functionalities.
- **Open for Extension**: You should be able to extend the existing components to add new behaviors. In React, this can be efficiently handled using props, higher-order components (HOCs), render props, or hooks to add new functionalities.
**Example:**
Higher-order components are a powerful pattern for reusing component logic. A higher-order component is a function that takes a component and returns a new component, thus extending the original component's functionality without directly modifying its implementation:

### **Liskov Substitution Principle (LSP)**
**Principle:** Derived components should be substitutable for their base components.
Explanation:
In React, LSP would imply that any component that extends another component should be able to replace its parent without any errors or changes in the expected behavior of the application. This principle is less commonly demonstrated in React because React favors composition over inheritance. However, understanding LSP is still beneficial, especially when designing component libraries or higher-order components where substitutability could become an issue.
Example:
Consider two components: **`BaseButton`** and **`PrimaryButton`**. The **`PrimaryButton`** component extends the **`BaseButton`** and should be able to replace **`BaseButton`** without any issues.


### **Interface Segregation Principle (ISP)**
**Principle:** Clients should not be forced to depend upon interfaces that they do not use.
**Explanation:**
In React, the Interface Segregation Principle implies that components should not be burdened with props or functionality that they don't need. Instead of creating large, monolithic components with many props, it's better to create smaller, more focused components with clear and specific purposes. This makes the components easier to understand, maintain, and reuse.
### **Example:**
Consider a component **`UserProfile`** that displays user information and allows editing:

If the **`UserProfile`** component is sometimes used only to display user information without the edit functionality, it violates ISP because it forces the client to depend on the **`onEdit`** prop even when it’s not needed.
To adhere to ISP, you can split this into two components:

### **Dependency Inversion Principle (DIP)**
**Principle:** High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g., interfaces). Abstractions should not depend on details. Details should depend on abstractions.
**Explanation:**
In React, DIP can be applied by ensuring that components depend on abstracted dependencies rather than concrete implementations. This can be achieved using hooks, context, or higher-order components (HOCs) to inject dependencies.
### **Example:**
Consider a component **`DataFetcher`** that fetches data from an API and displays it:

This component is tightly coupled to the fetch API and the URL, violating DIP. To adhere to DIP, we can abstract the data fetching logic and inject it into the component:

| hussain101 |
1,865,840 | How to inject simple dummy data at a large scale in MySQL | Introduction Ever found yourself in a situation where you needed a large amount of dummy... | 0 | 2024-05-26T18:25:25 | https://dev.to/siddhantkcode/how-to-inject-simple-dummy-data-at-a-large-scale-in-mysql-eci | database, mysql, programming, designsystem | ## Introduction
Ever found yourself in a situation where you needed a large amount of dummy data for testing, but didn't want to spend hours writing scripts or manually inserting records? Or perhaps you've been curious about how to leverage new features in MySQL 8.0 to streamline your database tasks? Well, you're in for a treat! In this post, we'll explore how to use [Common Table Expressions (CTEs)](https://dev.mysql.com/doc/refman/8.0/en/with.html) to effortlessly generate and insert vast amounts of dummy data into your MySQL database.
Imagine needing to populate a table with a million hash values for load testing or performance benchmarking. Sounds like a nightmare, right? Not anymore! With the advent of CTEs in MySQL 8.0, you can achieve this in a matter of seconds. Let's dive into how this works and how you can use this powerful feature to simplify your data generation needs.
## TL; DR
Common Table Expressions (CTEs), a new feature added in MySQL 8.0, can be used to easily input a large amount of simple dummy data. For example, if you want to input 1 million dummy data into a table called `hashes` that stores hash values, you can achieve this with the following steps:
## Table Definitions
First, create the table:
```sql
CREATE TABLE hashes (
id INT PRIMARY KEY AUTO_INCREMENT,
hash CHAR(64)
);
```
## Query Execution
Set the session variable to allow a higher recursion depth:
```sql
SET SESSION cte_max_recursion_depth = 1000000;
```
Then, execute the CTE to insert 1 million rows:
```sql
INSERT INTO hashes(hash)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000
)
SELECT SHA2(n, 256) FROM cte;
```
This method leverages a recursive common table expression to generate the dummy data.
## Understanding CTEs
A [Common Table Expression (CTE)](https://dev.mysql.com/doc/refman/8.0/en/with.html) is a named temporary result set that can be referenced within a single statement multiple times. CTEs are particularly useful for simplifying complex queries and improving readability.
### Syntax Breakdown
#### Setting Recursion Depth
```sql
SET SESSION cte_max_recursion_depth = 1000000;
```
The `cte_max_recursion_depth` system variable sets the upper limit for recursion. By default, it's 1000, so to recurse more, you need to adjust it. Here, we set it to 1 million.
#### The CTE Query
```sql
INSERT INTO hashes(hash)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000
)
SELECT SHA2(n, 256) FROM cte;
```
Let's break down this query:
- `WITH RECURSIVE cte (n)`: This starts the CTE definition. `cte` is the name of the temporary result set, and `n` is the column.
- `SELECT 1`: This is the non-recursive part of the CTE, serving as the starting point (initial value).
- `UNION ALL SELECT n + 1 FROM cte WHERE n < 1000000`: This is the recursive part, which increments the value of `n` by 1 until it reaches 1,000,000.
- `SELECT SHA2(n, 256) FROM cte`: This final part of the query selects the SHA-256 hash of each `n` value, generating the dummy data for insertion.
### How It Works
The CTE recursively generates numbers from 1 to 1,000,000. For each number, it computes the SHA-256 hash and inserts it into the `hashes` table. This approach is efficient and leverages MySQL's recursive capabilities to handle large data volumes seamlessly.
## Processing Speed
### Verification Environment
To understand the impact of this feature, I used a [Gitpod Enterprise](https://www.gitpod.io/pricing) workspace, leveraging the powerful and ephemeral environment to avoid the hassle of setups and installations. Here’s a glance at the setup:
- **Machine**: [Gitpod Enterprise `XXLarge` workspace](https://www.gitpod.io/docs/configure/workspaces/workspace-classes#enterprise)
- **OS**: Ubuntu 22.04.4 LTS (Jammy Jellyfish)
- **Containerization**: Docker version 26.0.1
- **MySQL Version**: Official MySQL 8.0 Docker image
### Results
For 1 million rows, the query execution time is approximately 4.46 seconds:
```sql
mysql> INSERT INTO hashes(hash)
-> WITH RECURSIVE cte (n) AS
-> (
-> SELECT 1
-> UNION ALL
-> SELECT n + 1 FROM cte WHERE n < 1000000
-> )
-> SELECT SHA2(n, 256) FROM cte;
Query OK, 1000000 rows affected (4.43 sec)
Records: 1000000 Duplicates: 0 Warnings: 0
```
### Performance Metrics
| Number of Rows | Execution Time |
|----------------|----------------|
| 1,000 | 0.03 sec |
| 10,000 | 0.07 sec |
| 100,000 | 0.42 sec |
| 1,000,000 | 4.43 sec |
| 10,000,000 | 48.53 sec |
## Conclusion
Using CTEs in MySQL 8.0 is a game-changer for generating large amounts of dummy data quickly. It's especially handy for load testing and performance benchmarking. With just a few lines of code, you can effortlessly populate your tables and then get back to the other important parts of your project.
Don't hesitate to play around with different data generation strategies and recursion depths to see what works best for you. For more tips and insights on security and log analysis, follow me on Twitter [@Siddhant_K_code](https://x.com/Siddhant_K_code) and stay updated with the latest & detailed tech content like this. Happy coding!
| siddhantkcode |
1,865,815 | Share Text Securely with AWS Amplify Gen 2 | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-26T18:21:36 | https://dev.to/henryjw/share-text-securely-with-aws-amplify-gen-2-59c5 | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/aws)*
## What I Built
<!-- Tell us what your app does! -->
SecureShare allows users to share text snippets securely. The user has the option to set a time for the snippet to expire, whether or not the snippet should be deleted ("burned") after being viewed, and a password for additional privacy.
When using a password, the snippet content is encrypted with the password (which isn't sent to the backend or stored anywhere), so even someone with access to the database can't decrypt it!
### Sharing snippet
As a user, you can create a snippet and share it with someone else by sharing the link to it and, optionally, the password to view it. If there's no password set, then anyone with the link can view the snippet.
### Managing snippets
The core functionality of the app is creating, sharing, and viewing shared snippets. While these features don't require an account, being logged allows the user to be able to manage their shared snippets.
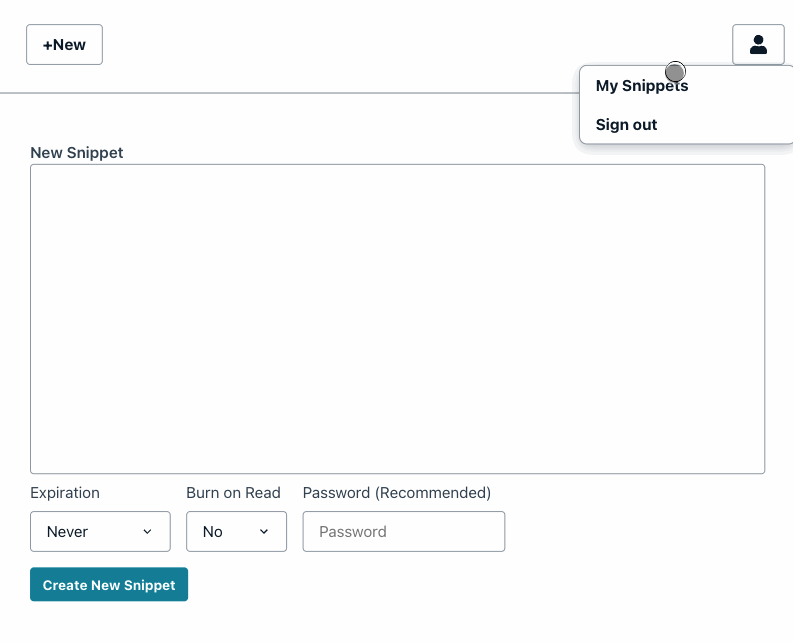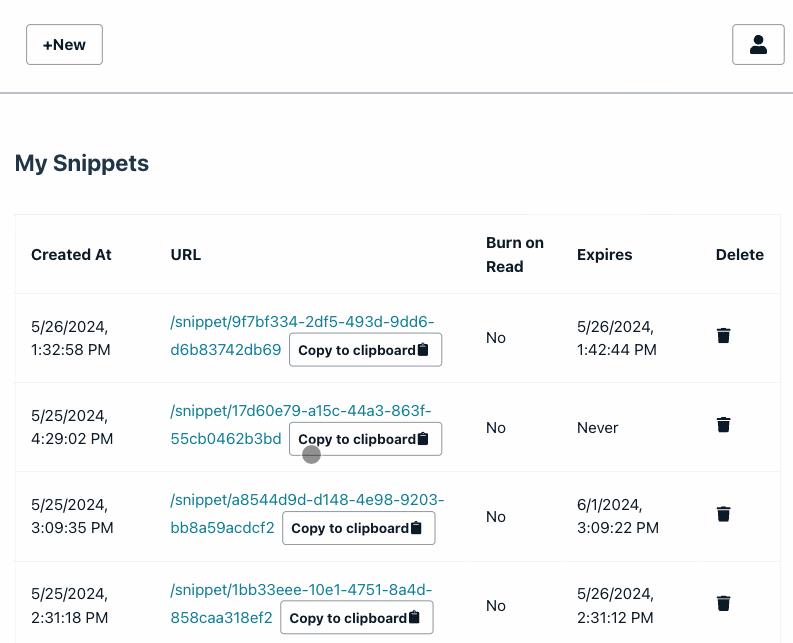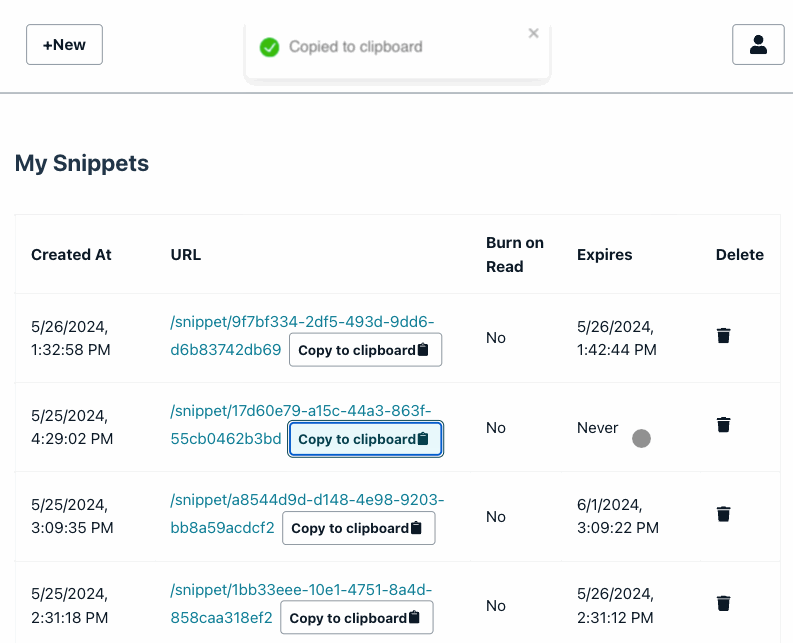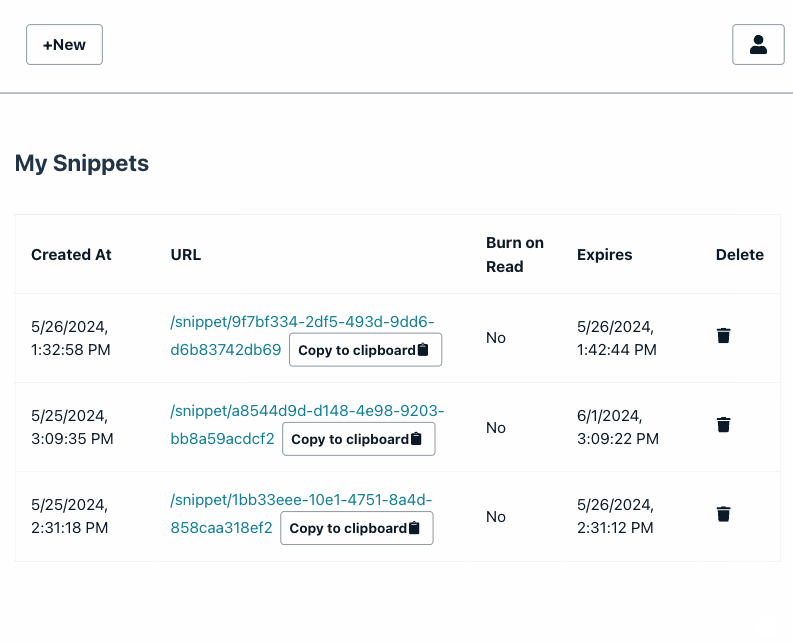
### Inspiration
- [PrivateBin.io](https://privatebin.io/)
- [Pastebin.com](https://pastebin.com/)
## Demo and Code
<!-- Share a link to your Amplify App and source code. Include some screenshots as well. -->
- **Demo app:** https://main.d26ottewuge4ec.amplifyapp.com/
- **Code:** https://github.com/henryjw/secure-share-app
## Journey
This was an interesting project for me because I've primarily focused on backend for most of my career. I hadn't implemented any significant frontend features in over a year and hadn't used react in even longer than that. So, I'm proud that I was able to implement as many features as I did for this project.
I had an initial list of features I wanted to implement and most of them were "nice-to-have" or "optional" to keep the scope realistic given my lack of frontend development experience. The only feature I didn't get to implement was adding the ability to add a file attachment to the snippet since it would have taken more time to implement and test.
## Integrations
<!-- Tell us which qualifying technologies you integrated, and how you used them. -->
<!-- Reminder: Qualifying technologies are data, authentication, serverless functions, and file storage as outlined in the guidelines -->
- **Data:** The snippets are stored in the database so they can be retrieved later
- **Authentication:** Used for login / signup and account management
- **File storage:** Not used
- **Serverless functions:** Not used
**Connected Components and/or Feature Full:** Connected components; not feature full
Used connected components for for login / sign up and account management. I later learned that Amplify can also generate connected components based on the data schemas to further simplify development. However, I had already created most of the UI by that time so I didn't get a chance to use them. Maybe next time!
<!-- Let us know if you developed UI using Amplify connected components for UX patterns, and/or if your project includes all four integrations to qualify for the additional prize categories. -->
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- Don't forget to add a cover image (if you want). -->
<!-- Thanks for participating! --> | henryjw |
1,865,837 | Rodosbet Giriş | Rodosbet RodosBet, 2021 yılında kurulan ve kısa sürede online bahis ve casino sektöründe kendine... | 0 | 2024-05-26T18:20:46 | https://dev.to/rodosbet/rodosbet-2g3j | rodosbet | **Rodosbet**
RodosBet, 2021 yılında kurulan ve kısa sürede online bahis ve casino sektöründe kendine sağlam bir yer edinen bir platformdur. PAGCOR lisansına sahip olan RodosBet, kullanıcılarına güvenilir ve kaliteli bir oyun deneyimi sunmayı hedefler. BETCONSTRUCT altyapısını kullanan site, hem spor bahisleri hem de casino oyunlarında geniş bir yelpaze sunar.
**RodosBet**'in sunduğu spor bahisleri seçenekleri oldukça çeşitlidir. Futbol, basketbol, tenis gibi popüler spor dallarının yanı sıra, e-spor ve daha az bilinen spor dallarında da bahis yapma imkanı sağlar. Bu sayede, farklı ilgi alanlarına sahip kullanıcılar, kendilerine uygun bahis seçeneklerini kolayca bulabilirler. Spor bahislerinin yanı sıra, canlı bahis imkanı da sunan RodosBet, maçları anlık olarak takip ederek bahis yapma olanağı sağlar.
Casino oyunları konusunda da oldukça iddialı olan RodosBet, kullanıcılarına çeşitli oyun sağlayıcılarından oluşan geniş bir oyun yelpazesi sunar. Evolution, Pragmatic Play Live, NetEnt gibi dünya çapında tanınan sağlayıcılarla çalışan RodosBet, yüksek kaliteli ve eğlenceli casino oyunlarına ev sahipliği yapar. Slot oyunları, masa oyunları, canlı casino ve daha birçok seçenek ile kullanıcılarına keyifli bir oyun deneyimi sunar.
Finansal işlemler konusunda da kullanıcı dostu bir yaklaşım sergileyen RodosBet, çeşitli yatırım ve çekim yöntemleri sunar. Kripto Fulgurpay, JestPays Havale, Payfix, MiniPay Papara, Anında Papara, Anında Parazula, MiniHavale Kredi Kartı, HemenÖde Mefete, Anında Kredi Kartı, Aninda QR, Hizlıca Papara, Tosla, Paycell ve Peppara gibi birçok ödeme yöntemi sayesinde kullanıcılar, kendilerine en uygun ve güvenli yöntemi seçebilirler. Bu çeşitlilik, kullanıcıların finansal işlemlerini hızlı ve sorunsuz bir şekilde gerçekleştirmelerini sağlar.
_RodosBet_, kullanıcı deneyimini en üst düzeye çıkarmak için çeşitli sosyal medya platformlarında da aktif olarak yer alır. Telegram kanalı, Twitter ve YouTube gibi platformlar üzerinden kullanıcılarına en güncel bilgileri ve promosyonları sunar. Bu sayede, kullanıcılar her zaman en yeni bilgilere ve fırsatlara erişebilirler. Ayrıca, RodosBet'in mobil uygulaması sayesinde kullanıcılar, her yerden ve her zaman siteye erişim sağlayabilirler. Mobil uygulama, kullanıcıların hareket halindeyken bile bahis yapmalarına ve casino oyunlarına katılmalarına olanak tanır.
Sonuç olarak, [RodosBet](https://rodosbet-giris.blogspot.com/), geniş oyun seçenekleri, çeşitli ödeme yöntemleri ve kullanıcı dostu hizmet anlayışı ile online bahis ve casino sektöründe öne çıkan bir platformdur. Kullanıcılarına güvenilir ve eğlenceli bir oyun deneyimi sunmayı amaçlayan RodosBet, sürekli olarak kendini geliştirerek kullanıcı memnuniyetini en üst düzeyde tutmayı hedefler. | rodosbet |
1,865,820 | Mastering Logistics with Our International Tracking and Service Software | Shipping goods from South Africa to China can be a complex and daunting process, but with the right... | 0 | 2024-05-26T18:04:23 | https://dev.to/zrmish/mastering-logistics-with-our-international-tracking-and-service-software-2bn1 | Shipping goods from South Africa to China can be a complex and daunting process, but with the right tools, it can become a seamless and efficient operation. Our International Tracking and Service Software is designed to help businesses master the logistics of international shipping. This article will guide you through the benefits and features of our software, showing how it can transform your shipping processes and ensure your goods reach their destination smoothly.
The Challenges of International Shipping
Shipping goods internationally involves navigating a web of regulations, documentation, and logistics. For businesses shipping from South Africa to China, this can be particularly challenging due to the distance, differing regulations, and the need for real-time tracking. Common challenges include:
Customs Clearance:
Understanding and complying with the import/export regulations of both countries.
Tracking Shipments: Ensuring that goods are tracked accurately throughout the journey.
Communication: Maintaining clear communication with shipping carriers and customers.
Documentation:
Managing the necessary paperwork efficiently.
Our International Tracking and Service Software addresses these challenges, providing a comprehensive solution for businesses.
Key Features of Our Software
Real-Time Tracking
One of the most critical aspects of international shipping is the ability to track shipments in real-time. Our software provides:
GPS Tracking: Monitor the exact location of your shipment at any time.
Status Updates: Receive regular updates on the status of your goods, including departure, transit, and arrival times.
Alerts: Get notified of any delays or issues that may arise during transit.
Customs Compliance
Navigating customs regulations is a major hurdle in international shipping. Our software offers:
Automated Documentation: Generate all necessary shipping documents automatically.
Regulation Updates: Stay informed about the latest customs regulations and changes.
Compliance Checks: Ensure your shipments meet all regulatory requirements before they are dispatched.
Communication Tools
Effective communication is vital for successful shipping. Our software includes:
Integrated Messaging: Communicate directly with carriers and customers within the platform.
Document Sharing: Easily share documents and updates with all parties involved.
Customer Portal: Provide your customers with access to track their shipments and receive updates.
Analytics and Reporting
Understanding the performance of your shipping operations is key to improvement. Our software features:
Performance Analytics: Track key metrics such as delivery times, costs, and efficiency.
Custom Reports: Generate reports tailored to your business needs.
Historical Data: Access past shipment data to identify trends and areas for improvement.
Benefits of Using Our Software
Efficiency and Accuracy
By automating many of the complex processes involved in international shipping, our software significantly increases efficiency and accuracy. This means fewer errors, faster processing times, and more reliable shipments.
Cost Savings
Our software helps businesses save money by:
Reducing Errors: Minimize costly mistakes in documentation and compliance.
Optimizing Routes: Choose the most efficient shipping routes and carriers.
Improving Communication: Avoid delays and misunderstandings through better communication.
Enhanced Customer Satisfaction
With real-time tracking and transparent communication, customers are kept informed about their shipments at all times. This transparency builds trust and leads to higher customer satisfaction and repeat business.
Case Study: A Success Story
Consider the example of a South African company that used our software to ship electronics to China. Before using our software, they faced frequent delays and compliance issues. After implementation, they saw:
50% Reduction in Delays: Thanks to real-time tracking and automated documentation.
30% Cost Savings: Through optimized shipping routes and reduced errors.
Improved Customer Feedback: Customers appreciated the transparency and reliable updates.
Conclusion
Mastering logistics for [international shipping](https://buffalotracking.net/international-sealine-services/) from South Africa to China requires the right tools. Our International Tracking and Service Software provides a comprehensive solution that addresses the key challenges of customs compliance, real-time tracking, effective communication, and performance analysis. By adopting our software, businesses can streamline their shipping processes, reduce costs, and enhance customer satisfaction. Take control of your international logistics and ensure your goods reach their destination smoothly and efficiently with our advanced tracking and service solutions.
| zrmish | |
1,865,756 | AWS Amplify Fullstack TypeScript Challenge Submission | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-26T17:54:45 | https://dev.to/davidlewisgardin/aws-amplify-fullstack-typescript-challenge-submission-41fn | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/aws)*
## What I Built
My app is a demo of a fictional company called ChargeNG. They provide monitoring of the British electricity grid to consumers so that they can check supply and demand, both currently and historically, to make decisions on when and where to charge their EV.
## Demo
[ChargeNG Demo](https://main.d28gbqvmg1hblh.amplifyapp.com/)
(You'll need to register with an email address in order to access the app content. Don't worry, I'll remove all user accounts regularly!)
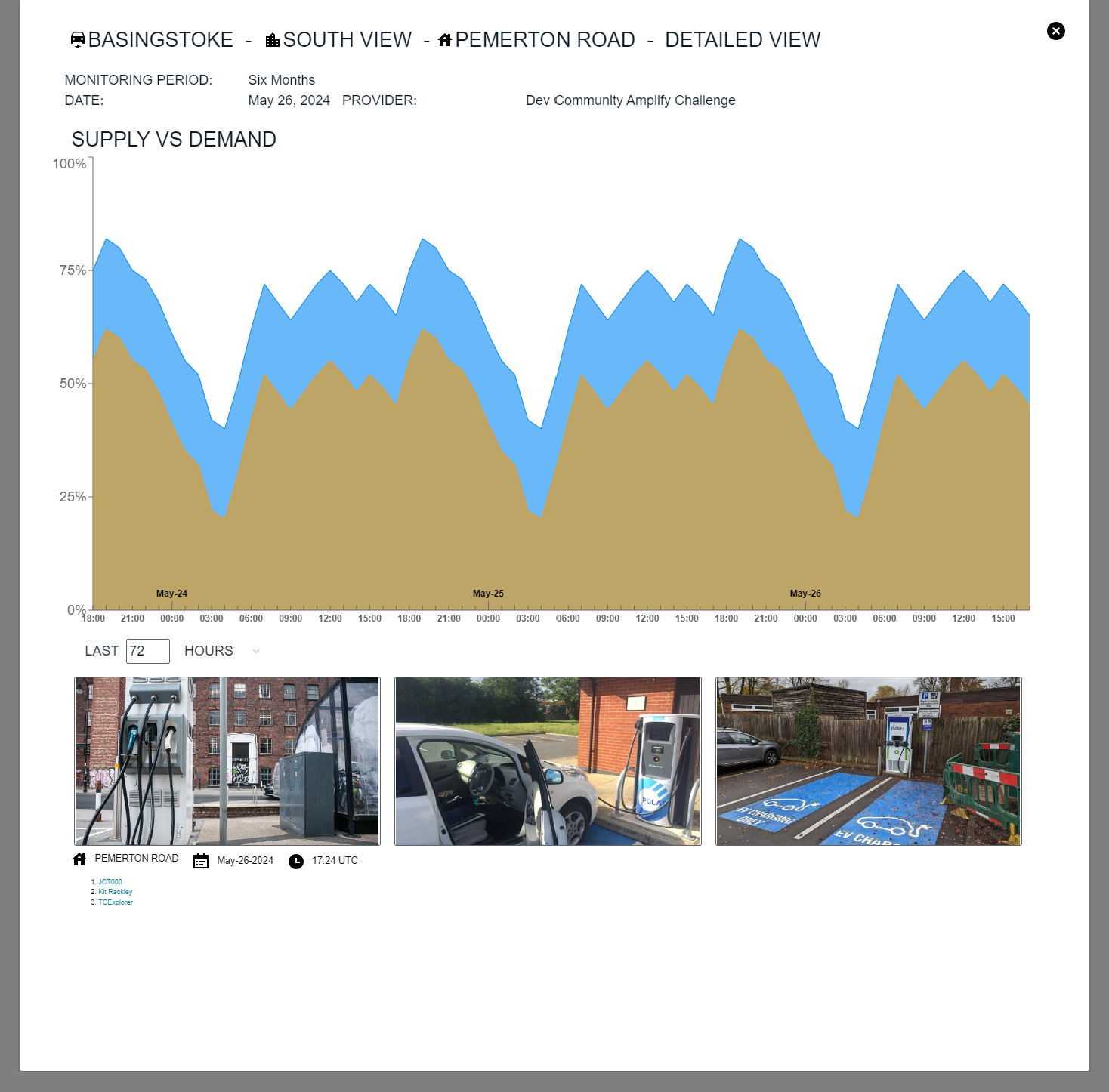
## Journey
I use Amplify Gen 1 in my day job, so having a good reason to try out Gen 2 was too good an opportunity to pass on!
I already use an AWS tech stack in my day job, so I already knew that I wanted to incorporate Cognito, AppSync, DynamoDB and S3. The Gen 2 Amplify documentation was really clear and, much like with the Gen 1 documentation, I got up and running with Gen 2 quickly. Of course there are some gotchas that need to be addressed by AWS:
- If we're going to be allowed to define our Cognito service in code, then Cognito needs to support updating the user pool from code. I ran into build errors that required me to delete the app and start over.
- It would be awesome if Amplify Data could support single-table design in . Our production data model would require at least half a dozen tables with the current Gen 2 implementation, which would create a big headache for integration and maintenance.
- The **list()** method really shouldn't default to a DynamoDB scan for obvious reasons. Our production data contains DynamoDB items partitioned by area (i.e. "MeasurementByArea#< Area ID >"), so I'd like to be able to supply the partition key (and optionally the sort key) when I call the **list()** method, switching it to query mode.
The app itself uses [Tanstack Query](https://tanstack.com/query/latest) to manage client-side data, with the Amplify Data operations contained in a utilities file ("utils/crud.js"). The charting feature is implemented using [Recharts](https://recharts.org/en-US/).
Overall, it's great that I can now do in code what used to be a PITA to do in configuration and direct in the generated service. The next step for me is to start making a lot of noise in AWS' direction to get the above issues resolved, so I can make plans to use Amplify Gen 2 in our product web application.
**Connected Components and/or Feature Full**
The UI is built with Next.js 14, the Amplify UI library and uses the Authenticator connected component to implement the UI for user management.
The project uses the following Amplify categories:
- Auth
- Data
- Storage
| davidlewisgardin |
1,865,818 | Navigating Divorce with a Grand Rapids Divorce Lawyer | Divorces are never easy. It's a trying moment, full of emotional tension and difficult decisions. If... | 0 | 2024-05-26T17:52:29 | https://dev.to/haider_ali_254932fc25713b/navigating-divorce-with-a-grand-rapids-divorce-lawyer-2aph |
Divorces are never easy. It's a trying moment, full of emotional tension and difficult decisions. If you're going through a divorce in Grand Rapids, having a competent and sympathetic divorce lawyer on your side may make a huge difference. This article will look at the job of a Grand Rapids divorce lawyer and how they may help you through this difficult time.
Understanding the Role of a Divorce Lawyer
A divorce lawyer specializes in family law and can handle all the proceedings. Their primary purpose is to represent your interests and assist you in getting the best possible conclusion. Here are some important ways a divorce lawyer might help you:
Legal Advice and Guidance
Different states have different divorce rules that can be hard to understand. A divorce lawyer in Grand Rapids will provide clear and correct legal help. To help you know what to expect during the process, they will tell you what your rights and duties are.
Paperwork and Documentation
The divorce procedure entails a great deal of documentation. From submitting the first divorce petition to preparing agreements and court papers, your lawyer will ensure all documentation is completed accurately and on schedule. This reduces delays and guarantees that legal regulations complete everything.
Negotiation and Mediation
In a divorce, there are often talks about how to divide assets, who cares for the kids, and how to pay child support. During these talks, a good divorce lawyer will seek your best interests and try to reach a fair deal. If needed, they can also help with mediation, which is when a third party who is not involved in the dispute helps both sides come to an understanding.
Why Choose a Grand Rapids Divorce Lawyer?
Local Expertise
Choosing a lawyer conversant with the local legal scene might provide considerable benefits. A Grand Rapids divorce lawyer is familiar with Michigan's divorce laws and has dealt with local courts and judges before. This local experience can help you shorten the process and better understand your issue.
Personalized Attention
Divorce is a highly personal process; therefore, having a lawyer who provides individualized attention is essential. A professional Grand Rapids divorce lawyer will take the time to understand your specific circumstances and adjust their strategy to your requirements. They will be available to answer your questions, address your concerns, and assist at this difficult time.
Emotional Support
Even though their main job is to help clients with the law, divorce lawyers offer mental support. Getting a divorce can be very stressful, and having a lawyer who cares can make a big difference. They can help you stay calm and focused by giving you a steady hand and an ear to listen.
Choosing the Right Lawyer
When choosing a Grand Rapids divorce lawyer, ensure they are knowledgeable, trustworthy, and a good fit for your requirements. Here are some suggestions for locating the proper lawyer:
Research: Look for lawyers with good reviews and a solid track record in handling divorce cases.
Consultations: Many lawyers offer free initial consultations. Use this opportunity to meet with potential lawyers, ask questions, and see if they are a good fit.
Communication: Choose a lawyer who communicates clearly and promptly. You want someone who keeps you informed and is easy to reach.
Conclusion
During the divorce process, a Grand Rapids divorce lawyer can be beneficial. They give you important legal advice, take care of your paperwork, bargain on your behalf, and support you emotionally. Selecting the appropriate lawyer can make this challenging time easier to handle and protect your rights and best interests.
If you're going through a divorce in Grand Rapids, don't go it alone. Hire an experienced and sympathetic divorce lawyer.
| haider_ali_254932fc25713b | |
1,865,817 | ChatGPT - Prompts for Code Review and Debugging | Discover the various ChatGPT Prompts for Code Review and Debugging | 0 | 2024-05-26T17:48:50 | https://dev.to/techiesdiary/chatgpt-prompts-for-code-review-and-debugging-48j | chatgpt, promptengineering, ai, programming | ---
published: true
title: 'ChatGPT - Prompts for Code Review and Debugging'
cover_image: 'https://raw.githubusercontent.com/sandeepkumar17/td-dev.to/master/assets/blog-cover/chat-gpt-prompts.jpg'
description: 'Discover the various ChatGPT Prompts for Code Review and Debugging'
tags: chatgpt, promptengineering, ai, programming
series:
canonical_url:
---
## Why Code Review and Debugging is important:
Code review and Debugging are crucial in software development. They help identify and fix bugs, improve code quality, enhance software reliability, optimize performance, promote knowledge sharing, ensure adherence to coding standards, and mitigate risks and vulnerabilities.
## ChatGPT Prompts for Code Review and Debugging:
Sharing a list of the prompts that can help you to use ChatGPT to review the code and debugging.
Replace the words in `block` to get the desired result, for example, use your choice of language, i.e., `C#`, `JavaScript`, `Python`, `NodeJS`, etc.
| | Type | Prompt |
| --- | --- | --- |
| 1 | Debug | Can you help me debug this error message from my `C#` program: <br /> `[error message]` |
| 2 | Debug | Describe the unexpected behavior you are observing in the code and provide any error messages or stack traces for further analysis. <br /> `[error message]` |
| 3 | Debug | Help me debug this `Python` script that processes a list of objects and suggests possible fixes. <br /> `[Enter your code here]` |
| 4 | Debug | Highlight any error-handling mechanisms in the code and explain how they are currently handling or failing to handle the encountered issue. <br /> `[Enter your code here]` |
| 5 | Debug | Debug the given `Java` code. It should perform `[expected behavior]`, but it’s producing `[current behavior]`. <br /> `[Enter your code here]` |
| 6 | Debug | Debug the following `JavaScript` code: <br /> `[Enter your code here]` <br /><br /> It’s expected to perform `[expected behavior]` but instead, it’s producing `[current behavior]` when given inputs: `[input examples]`. |
| 7 | Issues | Could you find potential issues in this `JavaScript` code: <br /> `[Enter your code here]` |
| 8 | Issues | Can you identify any bugs in this `C#` code snippet: <br /> `[Enter your code here]` |
| 9 | Issues | Look over this `PowerShell` script to check if there are any bugs. <br /> `[Enter your code here]` |
| 10 | Issues | Help me understand why this `JavaScript` function is not working as expected. <br /> `[Enter your code here]` |
| 11 | Issues | What are the potential issues with this `C++` recursive function: <br /> `[Enter your code here]` |
| 12 | Issues | Find any potential issues in this `C#` code that processes string array: <br /> `[Enter your code here]` |
| 13 | Issues | Can you spot the bug in this `Java` function that handles database connection: <br /> `[Enter your code here]` |
| 14 | Issues | What’s wrong with this `C#` method that suppose to parse a CSV file: <br /> `[Enter your code here]` |
| 15 | Issues | Find the logic error in this `JavaScript` function that is intended to reverse the array, given these inputs: `[input parameters]`, and expected to produce `[output]`, but currently gives `[incorrect output]`. <br /> `[Enter your code here]` |
| 16 | Issues | Find potential bugs in the `Python` script that processes `[input type]` and outputs `[output type]`: <br /> `[Enter your code here]` |
| 17 | Issues |Identify the logic error in this `C#` function intended to check the password strength with these inputs: `[input parameters]` and expected output: `[output]` <br /> `[Function Description]` |
| 18 | Performance | Can you find any performance issues in this `Java` code: <br /> `[Enter your code here]` |
| 19 | Performance | Are there any memory leaks in this `C#` code: <br /> `[Enter your code here]` |
| 20 | Performance | Review the following `C#` function. <br /> `[Enter your code here]` <br /><br /> Please identify any potential bugs, performance issues, and non-compliance. |
| 21 | Performance | Please review the `Java` function for any potential memory leaks or performance issues when processing an Array of a million records. |
| 22 | Performance | Find the memory leaks in the following `C#` code and suggest possible optimizations: <br /> `[Enter your code here]` |
| 23 | Performance | Review the given `Java` code for potential scalability issues: <br /> `[Enter your code here]` |
| 24 | Performance | Review the algorithms and data structures used in the code to ensure they are optimized for performance. <br /> `[Enter your code here]` |
| 25 | Review | Review this `C#` function for errors: <br /> `[Enter your code here]` |
| 26 | Review | Can you review this `C#` function and suggest areas for error handling <br /> `[Enter your code here]` |
| 27 | Review | Review the following `JavaScript` function and provide suggestions for error handling and potential bottlenecks. <br /> `[Enter your code here]` |
| 28 | Review | Can you spot any potential problems with this `C#` class definition: <br /> `[Enter your code here]` |
| 29 | Review | Can you analyze this `Python` code and point out potential errors? <br /> `[Enter your code here]` |
| 30 | Review | Please review this `Angular` code for style and best practices: <br /> `[Enter your code here]` |
| 31 | Review | Please review the following `JavaScript` to check if it is following Google Style Guide: <br /> `[Enter your code here]` |
| 32 | Review | Please review this `JavaScript` code that is supposed to calculate the factorial given the inputs `[input variables]` and return `[output]`: <br /> `[Enter your code here]` |
| 33 | Security | Are there any security vulnerabilities in this `C#` code: <br /> `[Enter your code here]` |
| 34 | Security | Identify potential vulnerabilities in the code and propose mitigation strategies: <br /> `[Enter your code here]` |
| 35 | Security | Analyze the code for any potential security loopholes and suggest ways to address them.: <br /> `[Enter your code here]` |
| 36 | Security | I am concerned about security issues in this `C#` code. what are your thoughts? <br /> `[Enter your code here]` |
| 37 | Security | Examine the code for possible security risks and provide recommendations to enhance its security posture. <br /> `[Enter your code here]` |
| 38 | Security | Inspect the code for any security vulnerabilities and outline steps to remediate them. <br /> `[Enter your code here]` |
| 39 | Security | Help identify any potential security issues in the following Java code related to cross-site scripting. <br /> `[Enter your code here]` |
| 40 | Security | Scrutinize the code for any security weaknesses or loopholes and suggest measures to strengthen its security posture. <br /> `[Enter your code here]` |
---
## NOTE:
> [Check here to review more prompts that can help the developers in their day-to-day life.](https://dev.to/techiesdiary/chatgpt-prompts-for-developers-216d)
| techiesdiary |
1,865,809 | Lost money trading crypto, get it recovered ! | I became a victim of a bitcoin scam and lost a significant amount of money. This incident happened a... | 0 | 2024-05-26T17:24:14 | https://dev.to/kirstie_langan/lost-money-trading-crypto-get-it-recovered--jmh | I became a victim of a bitcoin scam and lost a significant amount of money. This incident happened a month ago. The way I handled the situation and recovered my money was to reach out to the right recovery support, via an email on; Hackrecovery AT Yandex DOT ru, I was in a complete despair. I started to feel a little better about myself as soon as I wrote them a letter. The good thing here is that I didn’t have to worry about anything during the process; all I had to do was wait for them to finish and return all my lost money to my wallet. I really commend the whole process. | kirstie_langan | |
1,865,764 | Boost Your Productivity: Essential VSCode Extensions for Developers | In the world of software development, efficiency is key. Whether you're a seasoned developer or... | 0 | 2024-05-26T17:18:19 | https://dev.to/vidyarathna/boost-your-productivity-essential-vscode-extensions-for-developers-25bd | vscodeextensions, developertools, productivityhacks, vscode |

In the world of software development, efficiency is key. Whether you're a seasoned developer or just beginning your coding journey, the tools you use can significantly impact your productivity and success. One such tool is Visual Studio Code (VSCode), a popular and powerful code editor loved by developers worldwide. With a vast ecosystem of extensions, VSCode can be customized to suit your specific needs and boost your productivity to new heights. In this article, we'll explore 25 essential VSCode extensions that will supercharge your development workflow and help you write better code faster.
1. **Rename**: Simplify the process of renaming variables, functions, and other code elements across your project with ease, ensuring consistency and reducing errors.
2. **Prettier**: Automatically format your code according to defined rules, maintaining consistent styling and improving readability without manual effort.
3. **Live Server**: Launch a local development server with live reloading capabilities to instantly preview changes in your web applications, speeding up the development process.
4. **Remote - SSH**: Access and develop on remote servers or virtual machines using SSH directly within VSCode, eliminating the need for external terminals and facilitating collaboration.
5. **GitLens**: Enhance your Git workflow with features like inline blame annotations, code lens, and repository insights, allowing for more efficient version control management.
6. **Git History**: Visualize and explore the history of your Git repositories within the editor, making it easier to understand changes over time and collaborate with team members.
7. **CSS Peek**: Peek into CSS class definitions and references directly from HTML or JavaScript files, saving time and improving code navigation.
8. **JavaScript Code Snippets**: Accelerate coding tasks with a library of pre-defined JavaScript snippets for common patterns and functions, reducing repetitive typing and errors.
9. **Peacock**: Customize the color of your VSCode workspace to distinguish between different projects and improve focus, enhancing your productivity and organization.
10. **Colorize**: Enhance code readability by colorizing text based on defined patterns, making it easier to identify important elements and understand complex codebases.
11. **Indent-Rainbow**: Visualize indentation levels in your code with colorful guides, improving code structure and readability, and reducing cognitive load while writing or reviewing code.
12. **Code Spell Checker**: Detect and correct spelling errors in your code and comments to maintain professionalism and clarity, ensuring high-quality documentation and communication.
13. **Debugger for Chrome**: Debug JavaScript code running in the Chrome browser directly from VSCode, streamlining the debugging process and improving efficiency.
14. **Icon Fonts**: Insert icons from popular icon fonts like Font Awesome directly into your code for improved visual communication and UI design, enhancing user experience.
15. **Turbo Console Log**: Quickly insert console.log() statements with enhanced features for debugging, reducing manual typing and errors, and accelerating the debugging process.
16. **Bracket Pair Colorizer**: Colorize matching brackets in your code for easier navigation and understanding of code blocks, improving code readability and reducing syntax errors.
17. **Path Intellisense**: Autocomplete filenames and paths in your code to save time and minimize errors when referencing files, enhancing productivity and reducing frustration.
18. **Better Comments**: Utilize custom comment styles and tags to improve code readability and organization, making comments more informative and actionable for you and your team.
19. **Todo Tree**: Keep track of TODO, FIXME, and other annotations in your code with a dedicated tree view, helping you stay organized and focused on important tasks and priorities.
20. **vscode-icons**: Customize the appearance of file icons in the VSCode Explorer to improve visual distinction and streamline navigation, making it easier to find and work with files.
21. **Regex Previewer**: Preview the results of regular expressions in real-time, helping you write and debug regex patterns more effectively and efficiently, saving time and reducing errors.
22. **Bookmarks**: Easily add and navigate bookmarks in your code, allowing you to quickly jump between important sections or lines, improving code navigation and productivity.
23. **Settings Sync**: Synchronize your VSCode settings, keybindings, themes, and extensions across multiple devices, ensuring a consistent and personalized development environment wherever you work.
24. **REST Client**: Send HTTP requests and view responses directly within VSCode, simplifying API testing and development tasks, and improving productivity.
25. **Rainbow CSV**: Highlight and format CSV files in VSCode with colors, improving readability and making it easier to work with large datasets, enhancing productivity and efficiency.
In conclusion, these VSCode extensions are invaluable tools for any developer looking to enhance their productivity and streamline their workflow. From code formatting and debugging to project management and visualization, each extension serves a specific purpose in making coding tasks more efficient and enjoyable. By incorporating these extensions into your development environment, you can expect to see significant improvements in your coding experience, ultimately leading to faster development cycles and higher-quality code. So why wait? Start exploring these extensions today and unlock your full potential as a developer in Visual Studio Code! | vidyarathna |
1,865,762 | Create a circle in html css | How to create a circle in html/css First step: create the square To create a square in html/css,... | 0 | 2024-05-26T17:17:35 | https://dev.to/tidycoder/create-a-circle-in-html-css-4bne | circle, shape, html, css | <h2>How to create a circle in html/css</h2>
<h3>First step: create the square</h3>
<p>To create a square in html/css, you can create/write a div element, and add a background and a size to this:</p>
{% codepen https://codepen.io/TidyCoder/pen/LYoRvjz %}
<h3>Two step: use the border-radius css property to add rounded corners to this</h3>
<p>Set the border-radius property to 50% for all corner, Because 50% is the half of 59px in this code.</p>
{% codepen https://codepen.io/TidyCoder/pen/pomEBWv %} | tidycoder |
1,865,744 | 552. Student Attendance Record II | 552. Student Attendance Record II Hard An attendance record for a student can be represented as a... | 27,523 | 2024-05-26T16:57:35 | https://dev.to/mdarifulhaque/552-student-attendance-record-ii-1n4b | php, leetcode, algorithms, programming | 552\. Student Attendance Record II
Hard
An attendance record for a student can be represented as a string where each character signifies whether the student was absent, late, or present on that day. The record only contains the following three characters:
- `'A'`: Absent.
- `'L'`: Late.
- `'P'`: Present.
Any student is eligible for an attendance award if they meet **both** of the following criteria:
- The student was absent (`'A'`) for **strictly** fewer than 2 days **total**.
- The student was **never** late (`'L'`) for 3 or more **consecutive** days.
Given an integer `n`, return _the **number** of possible attendance records of length `n` that make a student eligible for an attendance award. The answer may be very large, so return it **modulo** <code>10<sup>9</sup> + 7</code>._
**Example 1:**
- **Input:** n = 2
- **Output:** 8
- **Explanation:** There are 8 records with length 2 that are eligible for an award:
"PP", "AP", "PA", "LP", "PL", "AL", "LA", "LL"
Only "AA" is not eligible because there are 2 absences (there need to be fewer than 2).
**Example 2:**
- **Input:** n = 1
- **Output:** 3
**Example 3:**
- **Input:** n = 10101
- **Output:** 183236316
**Constraints:**
- <code>1 <= n <= 10<sup>9</sup></code>
**Solution:**
```
class Solution {
/**
* @param Integer $n
* @return Integer
*/
function checkRecord($n) {
$kMod = 1000000007;
$dp = array(array(0, 0, 0), array(0, 0, 0));
$dp[0][0] = 1;
while ($n-- > 0) {
$prev = array_map(function($A) {
return array_values($A);
}, $dp);
$dp[0][0] = ($prev[0][0] + $prev[0][1] + $prev[0][2]) % $kMod;
$dp[0][1] = $prev[0][0];
$dp[0][2] = $prev[0][1];
$dp[1][0] = ($prev[0][0] + $prev[0][1] + $prev[0][2] + $prev[1][0] + $prev[1][1] + $prev[1][2]) % $kMod;
$dp[1][1] = $prev[1][0];
$dp[1][2] = $prev[1][1];
}
return (int)(($dp[0][0] + $dp[0][1] + $dp[0][2] + $dp[1][0] + $dp[1][1] + $dp[1][2]) % $kMod);
}
}
```
**Contact Links**
- **[LinkedIn](https://www.linkedin.com/in/arifulhaque/)**
- **[GitHub](https://github.com/mah-shamim)** | mdarifulhaque |
1,865,742 | Introduction to Frida for Reverse Engineering | Introduction to Frida for Reverse Engineering Frida is a dynamic instrumentation toolkit widely used... | 0 | 2024-05-26T16:57:22 | https://dev.to/phantomthreads/introduction-to-frida-for-reverse-engineering-1gc9 | frida | Introduction to Frida for Reverse Engineering
Frida is a dynamic instrumentation toolkit widely used in the realm of reverse engineering, security research, and application testing. It allows researchers and developers to inject their own scripts into running processes to analyze and manipulate their behavior at runtime. This powerful capability is invaluable for understanding how software works, identifying vulnerabilities, or bypassing certain restrictions without modifying the actual binary, which is especially useful in closed or proprietary systems.
Benefits of Using Frida for Reverse Engineering
Frida supports various platforms including Windows, Linux, macOS, iOS, Android, and QNX. This cross-platform support is crucial for analyzing applications that are available on multiple platforms.
Frida works by attaching to existing processes or by spawning new processes. It doesn't require any changes to the binary itself, which makes it an ideal tool for analyzing production binaries.
Frida uses JavaScript (or TypeScript) for scripting, which is easy to write and understand. This lowers the barrier to entry and allows for rapid prototyping and deployment of complex hooks and manipulations.
Frida provides a rich API that allows deep manipulation and monitoring capabilities. This includes accessing memory, intercepting function calls, modifying registers, and calling native functions dynamically.
There is a vibrant community around Frida, which contributes to a large repository of scripts and extensions. This ecosystem makes it easier to find solutions or get help for specific problems.
Advanced Examples of Using Frida for Reverse Engineering
Example 1: Intercepting and Modifying Function Arguments
Suppose you're analyzing a proprietary encryption function within an Android app, and you want to see the data being passed to this function. You can use Frida to intercept the function call, log the arguments, and even modify them.
```javascript
Java.perform(function () {
var TargetClass = Java.use("com.example.app.EncryptionUtils");
TargetClass.encrypt.implementation = function (data) {
console.log("Original data: " + data);
// Modify the argument
var modifiedData = "modified_" + data;
console.log("Modified data: " + modifiedData);
// Continue with modified data
return this.encrypt(modifiedData);
};
});
```
This script changes the data being encrypted, which can be useful for testing how the application handles unexpected inputs or for bypassing security checks.
Bypassing SSL Pinning on iOS
SSL pinning is a security measure used to mitigate man-in-the-middle attacks by validating the server's certificate against a known good copy embedded in the application. Frida can be used to bypass this by intercepting the relevant SSL checks.
```javascript
ObjC.schedule(ObjC.mainQueue, function () {
var NSURLSessionDelegate = ObjC.protocols.NSURLSessionDelegate;
// Override the method that validates the server trust
Interceptor.attach(ObjC.classes.YourAppClass['- validateServerTrust:'].implementation, {
onEnter: function (args) {
// Log the server trust validation attempt
console.log("Server trust validation function called");
// Always return true for the validation result
args[2] = ptr("0x1");
}
});
});
```
This script forces the validation function to always return `true`, effectively bypassing SSL pinning.
Dynamic Analysis of a Windows Application
Suppose you want to trace the usage of a particular Windows API within an application to understand how it interacts with the system. Frida makes it easy to hook these API calls and log their parameters and results.
```javascript
const kernel32 = Module.load("kernel32.dll");
const createFile = Module.findExportByName("kernel32.dll", "CreateFileW");
Interceptor.attach(createFile, {
onEnter: function (args) {
this.path = args[0].readUtf16String();
console.log("CreateFile called with path: " + this.path);
},
onLeave: function (retval) {
if (parseInt(retval, 16) !== -1) {
console.log("File opened successfully");
} else {
console.log("Failed to open file");
}
}
});
```
This script hooks the `CreateFileW` function in `kernel32.dll`, logs the file paths being accessed, and reports on whether the file open operation was successful.
Some Android scripting examples:
1. Script to bypass root detection:
```javascript
Java.perform(function() {
var targetClass = Java.use("com.example.RootDetectionClass");
targetClass.isRooted.implementation = function() {
console.log("Bypassing root detection...");
return false; // Always return false to bypass root detection
};
});
```
2. Script to hook and decrypt encrypted strings:
```javascript
Java.perform(function() {
var targetClass = Java.use("com.example.EncryptionClass");
targetClass.decryptString.overload("java.lang.String").implementation = function(encryptedString) {
var decryptedString = this.decryptString(encryptedString);
console.log("Encrypted String: " + encryptedString);
console.log("Decrypted String: " + decryptedString);
return decryptedString;
};
});
```
3. Script to bypass SSL pinning:
```javascript
Java.perform(function() {
var CertificatePinner = Java.use("okhttp3.CertificatePinner");
CertificatePinner.check.overload('java.lang.String', 'java.util.List').implementation = function(hostname, certificates) {
console.log("Bypassing SSL pinning for hostname: " + hostname);
// Do nothing to bypass SSL pinning
};
});
```
Make sure to replace the class names (`com.example.RootDetectionClass`, `com.example.EncryptionClass`) and method names with the appropriate ones from the target application you are analyzing. These scripts are just examples and may need to be adjusted based on the actual code you are reverse engineering.
Conclusion
Frida is an exceptionally versatile tool for reverse engineering, offering the ability to inspect, modify, and bypass the internal workings of a software application dynamically across multiple platforms. By understanding and utilizing Frida's capabilities through scripts like the examples provided, researchers and developers can gain deep insights into software behavior, enhance security testing, and even develop patches or enhancements for existing applications. | phantomthreads |
1,865,743 | Learning Python | Hi guys, this is my second personal blog about learning Python. I am happy to say I am already in an... | 0 | 2024-05-26T16:57:22 | https://dev.to/adarshagupta/learning-python-2n4j | python, machinelearning, webdev, beginners | Hi guys, this is my second personal blog about learning Python. I am happy to say I am already in an advanced topic. Python is easier than I thought. If you are scared of programming you should definitely start with Python.
So far, Harvard CS50 has been the most important resource followed by the University of Helsinki(MOOC.fi). I would highly recommend these resources.
In addition to Python, I have gained some knowledge in SQL and Robotics. I was able to build almost all the bigger level projects and was able to solve some leetcode problems.
It was very fun to learn and be productive. | adarshagupta |
1,865,623 | Managing Machine Learning Projects | Tools and processes that can help ML teams | 0 | 2024-05-26T16:36:30 | https://dev.to/hangry_coder/managing-machine-learning-projects-kfc | machinelearning, ai, projectmanagement, scrumforml | ---
title: Managing Machine Learning Projects
published: true
description: Tools and processes that can help ML teams
tags: ML, AI, ProjectManagement, ScrumForML
# cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/mkkq4naq54pqsca6d0qu.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-26 09:43 +0000
---
## Intro
There is a lot of technical advice and trainings available online about engineering of AI, ML or data-science related projects, but very little practical advice is available about how to plan and manage and execute them efficiently. This article suggests a set of tools and processes that ML Teams can use.
## The Problem
Gartner [claims](https://www.techrepublic.com/article/85-of-big-data-projects-fail-but-your-developers-can-help-yours-succeed/) that 85% of A.I. Projects end up failing citing various reasons including, but not limited to:
* Inability to ship an ML-enabled product to production
* Shipping products that customers don’t use
* Deploying defective products that customers don’t trust
* Inability to evolve and improve models in production quickly enough
While almost all software engineering projects can be complex, AI and ML projects are particularly challenging due to their inherent element of uncertainty; the fact that these projects are fundamentally based on hypotheses that can fail.
In traditional software engineering, projects typically involve implementing well-defined requirements where inputs lead to predictable outputs. The success of such projects hinges primarily on the correctness of the code and adherence to specifications; things that can be managed through "good" planning and execution.
In contrast, ML projects start with a hypothesis about patterns in the data. For example, an ML project might hypothesize that certain features can predict an outcome, such as customer churn or product recommendations. This hypothesis is tested through the development and training of a model. However, there is no guarantee that the chosen features, the model architecture, or the available data will validate the hypothesis. The model may not perform as expected, leading to outcomes that can be suboptimal or outright failures. Hence, despite the most thorough planning, unforeseen issues can still arise, echoing Murphy's Law: "Whatever can go wrong, will go wrong" (Edward A. Murphy Jr.).
The motivation of this article is to not avoid the problems, but to find them as soon as possible; failing fast in order to find the right solution faster.
## Problem Discovery
The first step for an ML project, like every other project, is Problem Discovery & definition.
[Discovery](https://www.producttalk.org/2021/08/product-discovery/) is a set of activities that helps us better understand the problem, the opportunity, and potential solutions. It provides a structure for navigating uncertainty through rapid, time-boxed, iterative activities that involve various stakeholders and customers.
As eloquently articulated in [Lean Enterprise](https://www.oreilly.com/library/view/lean-enterprise/9781491946527/part02ch02.html#idm45284643425944) (O’Reilly), the process of creating a shared vision always starts with clearly defining the problem, because having a clear problem statement helps the team focus on what is important and ignore distractions.
For ML projects it is particularly important to understand the problem not only to see what ML/AI based solution is needed, but more importantly to see why it is needed? Why can't the problem be solved with traditional approach?
The problem with emerging technologies is that when they are in the "peak of inflated expectations" on the [Gartner Hype-cycle](https://gartner.com/en/articles/what-s-new-in-the-2023-gartner-hype-cycle-for-emerging-technologies), everyone expects them to do everything. And we are now living in a time when A.I., specially generative A.I. is on the peak of inflated expectations as shown in the diagram above. Therefore, a detailed requirement analysis is required to figure out the best solution for the given problem.
Some tools that can help Product Owners in Machine Learning teams at this phase of the projects are as follows:
### Double Diamond design process
[Effective Machine Learning Teams](https://www.oreilly.com/library/view/effective-machine-learning/9781098144623/) (O' Reilly) suggests that, in addition to the context of ML, one tool that can be useful for every problem-solving scenario is the [Double Diamond design process](https://www.equalexperts.com/blog/our-thinking/innovation-by-design-evolving-double-diamond/).
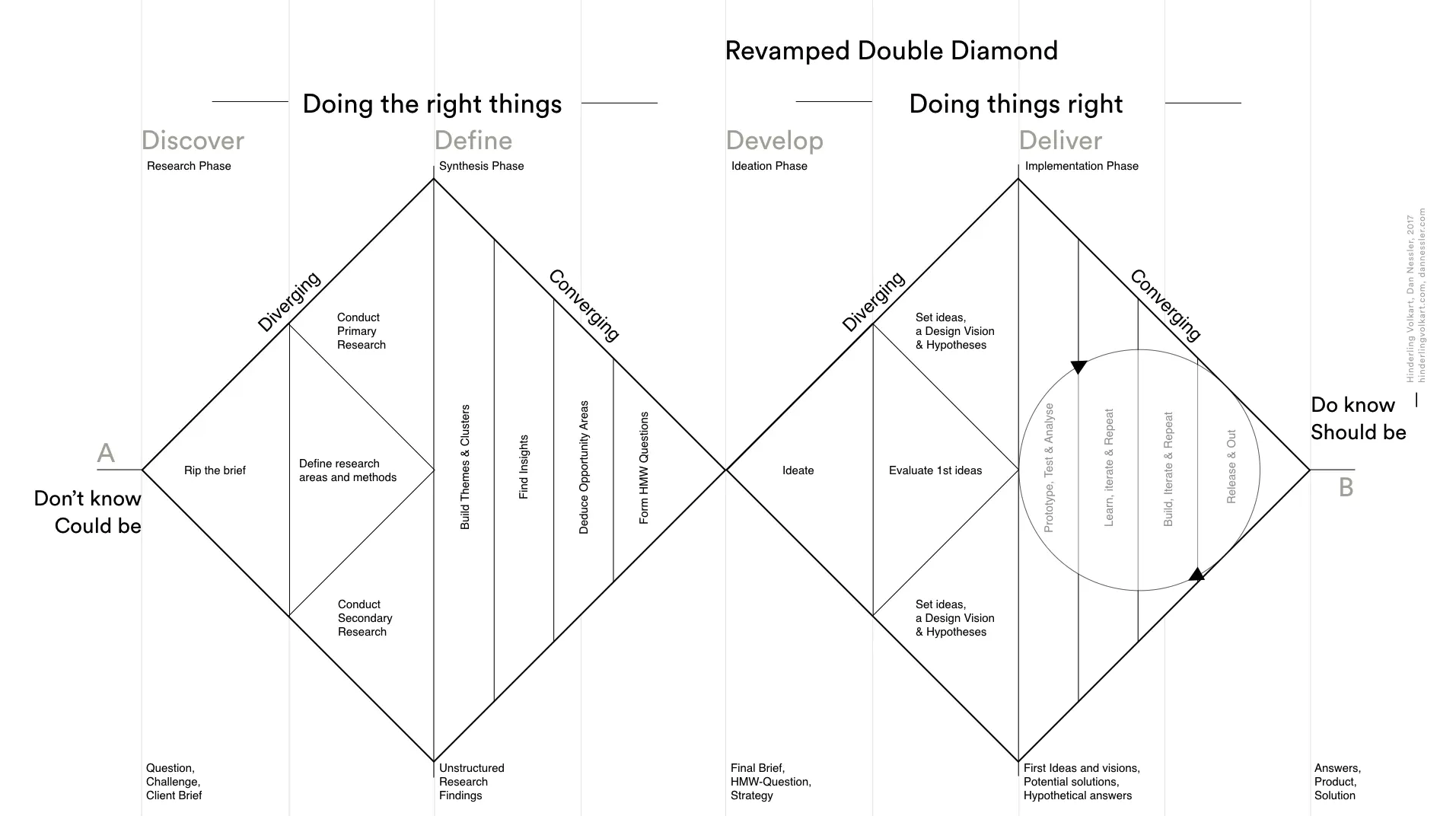
There are four phases to the process:
1. **Discover:** Understand the problem rather than merely assuming it. This involves speaking to and spending time with people— e.g., customers and users—who are affected by the problem.
2. **Define:** The insight gathered from the Discovery phase can help to define the challenge or problem in a different way.
3. **Develop/Design:**
Generate different answers to the clearly defined problem, seeking inspiration from elsewhere and co-designing with a range of different people.
4. **Deliver:** Test out different solutions at a small scale, rejecting those that will not work and improving the ones that will.
The general principle of divergent and then convergent thinking in first the problem and then the solution space is applicable in almost any problem-solving scenario, and you might also find yourself using this model to run meetings, write code, or plan a dinner party!
Additionally another tool suggested in the same book for ML product discovery is the [Data Product Canvas](https://medium.com/@leandroscarvalho/data-product-canvas-a-practical-framework-for-building-high-performance-data-products-7a1717f79f0), a tool that provides a decent framework for connecting all the dots between data collection, ML efforts and Value creation.
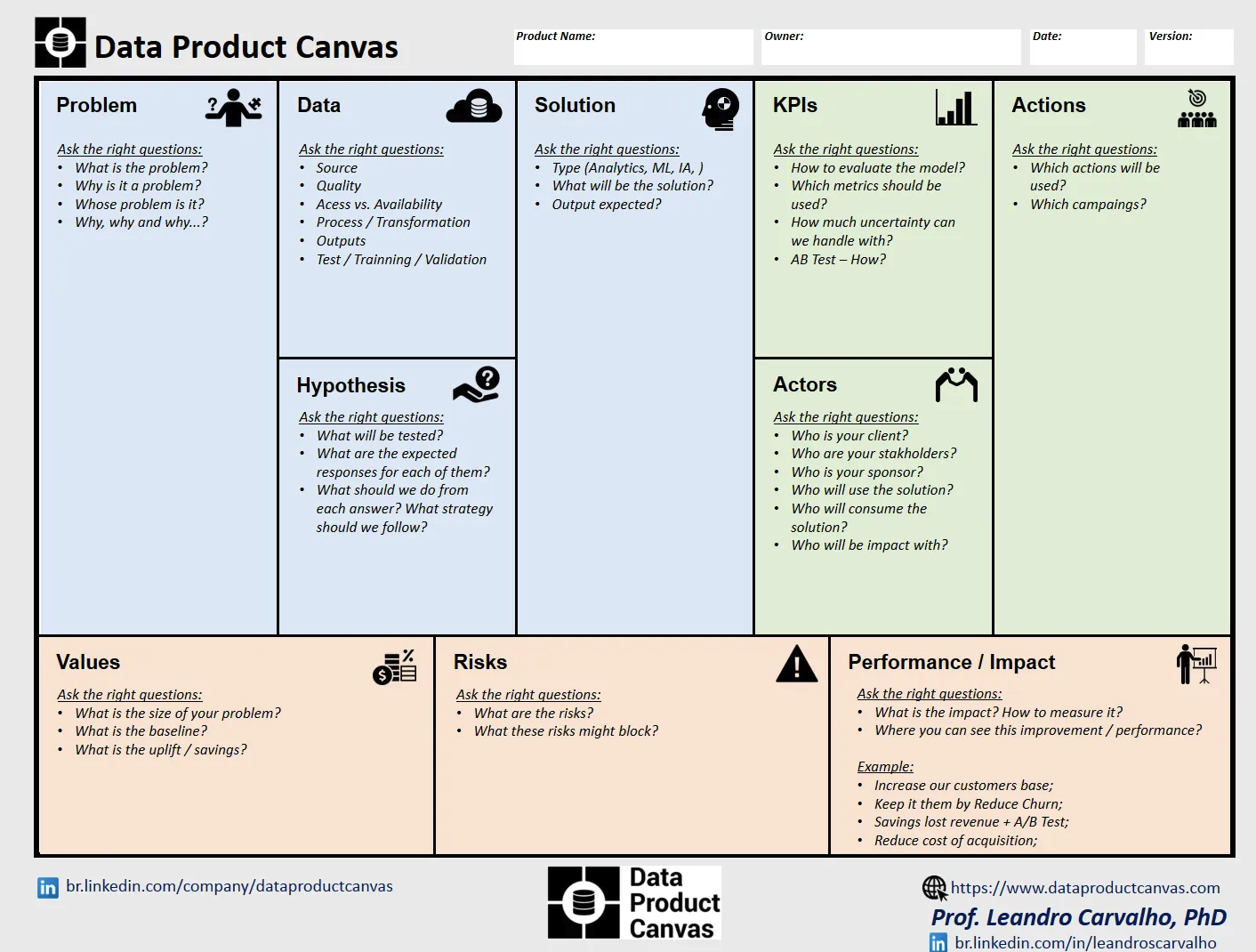
Both these tools, the double diamond design process and the data product canvas, produce artifacts that inform and guide the team during execution.
## Fail Fast, Pivot Fast Execution
Once we have understanding of the problem to be solved, we shift our focus on delivery which has its own unique challenges because businesses and customers often lack clear expectations or understanding of what an ML product can achieve because:
* It’s difficult to predict how well an ML system will perform with the data available.
* During product ideation;
* we might conceive ideas that are technically infeasible.
* or, we may be unaware of which features are feasible until we conduct experiments and develop functional prototypes.
It is therefore, essential to adopt a strategy of failing fast and pivoting fast:
1. **Rapid Prototyping:** Start with simple models and prototypes to quickly test hypotheses. Use these early results to guide further development rather than investing heavily in complex solutions upfront.
2. **Frequent Testing and Validation:** Regularly test models on validation data to catch issues early. Implement automated testing for model performance, ensuring that every change is evaluated rigorously.
3. **Small Iterations:** Break down the project into smaller, manageable tasks or sprints. Each iteration should deliver something that can be tested and evaluated, providing frequent feedback loops.
4. **Flexible Roadmap:** Maintain a flexible project roadmap that allows for changes based on new insights or data. Being rigid can hinder the ability to pivot when something isn’t working.
5. **Early User Feedback:** If applicable, get early feedback from end-users or stakeholders. Their insights can reveal practical issues and guide adjustments that improve the project’s relevance and effectiveness.
6. **Automated Monitoring and Alerting:** Implement monitoring tools to track model performance in production. Automated alerts for performance degradation can help in quickly identifying when a pivot or retraining is needed.
7. **Post-Mortem Analysis:** After each iteration or sprint, conduct a thorough post-mortem analysis to understand what went wrong and why. Use these insights to inform future pivots and improvements.
Sounds Familiar? What else do we, as engineers, know that inherently deals with complications and requires small iterations, early user feedback and flexible adjustable roadmap? **Scrum**. So can scrum be used for AI/ML Projects? Yes:
## Scrum FTW
Here’s a step-by-step guide to implementing Scrum in ML projects:
### Step 1: Form the Scrum Team
- **Product Owner (PO)**: Responsible for defining the features and requirements of the ML project, managing the product backlog, and ensuring that the team delivers value.
- **Scrum Master (SM)**: Facilitates Scrum processes, removes impediments, and ensures that the team adheres to Scrum principles.
- **Development Team**: Comprises data scientists, ML engineers, software developers, and possibly domain experts. The team is cross-functional and collaborative.
### Step 2: Define the Product Backlog
The product backlog for an ML project includes all the tasks and features needed to achieve the project goals. This might include:
- Data collection and preprocessing tasks
- Model selection and training experiments
- Feature engineering tasks
- Model evaluation and validation
- Deployment and monitoring tasks
- Documentation and reporting tasks
Even though the product owner here is responsible for creating the product backlog items, by using the discovery tools mentioned above, the scrum team can help refine them by making sure the following questions are answered:
1. Have we documented the motivations behind our data gathering strategies?
2. Is our approach to data gathering aligned with the project goals and requirements?
3. Are there any gaps or issues in the current data collection process?
4. How will we systematically built the data pipeline infrastructure to support the project's later stages?
5. Will we have a pipeline that handles data ingestion, transformation, and access for the modeling team?
6. Can we think of bottlenecks in our data pipeline that would need to be addressed later?
7. How are we going to establish model repositories and versioning infrastructures for all project artifacts?
8. Are the repositories commissioned and ready for use?
9. Is the team using these repositories consistently to track versions of models, datasets, and code?
10. Have we established model repositories and versioning infrastructures for all project artifacts?
11. Are the repositories commissioned and ready for use?
12. Is the team using these repositories consistently to track versions of models, datasets, and code?
Also the scrum team can review the following tools that can help in operations of ML engineering:
1. [25 top MLOps tools](https://www.datacamp.com/blog/top-mlops-tools)
2. [Best Workflow and Pipeline Orchestration tools](https://dagshub.com/blog/best-machine-learning-workflow-and-pipeline-orchestration-tools/)
### Step 3: Plan the Sprint
Sprints in ML projects can last between 2-4 weeks. Scrum team can decide what they want to achieve, whether the sprint is only to curate data and create the right data pipeline for the project or to run a training. During Sprint Planning, the team selects items from the product backlog to work on during the sprint. These items should be broken down into smaller, manageable tasks (sprint backlog).
### Step 4: Execute the Sprint
During the sprint, the team works on the selected tasks. Key Scrum ceremonies include:
- **Daily Stand-ups**: Short daily meetings where team members discuss what they did yesterday, what they plan to do today, and any blockers they face. This helps maintain transparency and address issues promptly.
- **Sprint Reviews**: At the end of each sprint, the team demonstrates the completed work to stakeholders. This could involve presenting a trained model, showcasing new features, or sharing performance metrics.
- **Sprint Retrospectives**: After the sprint review, the team reflects on what went well, what didn’t, and how processes can be improved for the next sprint.
### Step 5: Manage and Prioritize the Backlog
The Product Owner continuously refines the product backlog, prioritizing tasks based on feedback from sprint reviews, changes in project requirements, and new insights. This might involve:
- Adding new data sources
- Adjusting model requirements
- Incorporating feedback from stakeholders or users
### Step 6: Iterative Development and Validation
ML projects benefit from iterative cycles of development, testing, and validation. During each sprint, the team can focus on specific aspects:
- **Early Sprints**: Data collection, cleaning, and exploratory data analysis (EDA).
- **Middle Sprints**: Model prototyping, training, and initial validation. Experiment with different algorithms and hyperparameters.
- **Later Sprints**: Model tuning, extensive validation, and deployment.
### Step 7: Adopt a Fail Fast, Pivot Fast Approach
Incorporate the following practices to align with the fail fast, pivot fast methodology:
- **Rapid Prototyping**: Start with simple models to quickly test hypotheses and gather preliminary results.
- **Continuous Feedback**: Regularly evaluate model performance using validation data and user feedback.
- **Flexible Roadmaps**: Be prepared to pivot based on new data, feedback, or changes in project direction. Update the backlog and sprint goals accordingly.
### Example (generated from chatGPT): Implementing Scrum for an ML-Based Recommendation System
1. **Sprint 1: Data Collection and Exploration**
- Tasks: Collect user interaction data, clean the dataset, perform EDA.
- Deliverable: Cleaned dataset, initial insights from EDA.
2. **Sprint 2: Basic Model Development**
- Tasks: Implement a simple collaborative filtering model, evaluate its performance.
- Deliverable: Baseline model, performance metrics.
3. **Sprint 3: Model Improvement and Validation**
- Tasks: Experiment with different algorithms (e.g., content-based filtering), validate models with cross-validation.
- Deliverable: Improved model, comparative performance metrics.
4. **Sprint 4: Deployment and Monitoring**
- Tasks: Deploy the model, set up monitoring and feedback loops.
- Deliverable: Deployed model, monitoring dashboard.
5. **Sprint 5: Refinement and Iteration**
- Tasks: Incorporate user feedback, fine-tune the model, address any performance issues.
- Deliverable: Refined model, updated metrics based on real-world usage.
By adopting Scrum, ML projects can benefit from structured, iterative development processes that enable continuous improvement, flexibility, and the ability to rapidly respond to new insights and changes.
## More Tools
### Hypothesis Canvas
Another canvas that helps systematically articulate and test our ideas in rapid cycles, and keep track of learnings over time is the Hypothesis Canvas:
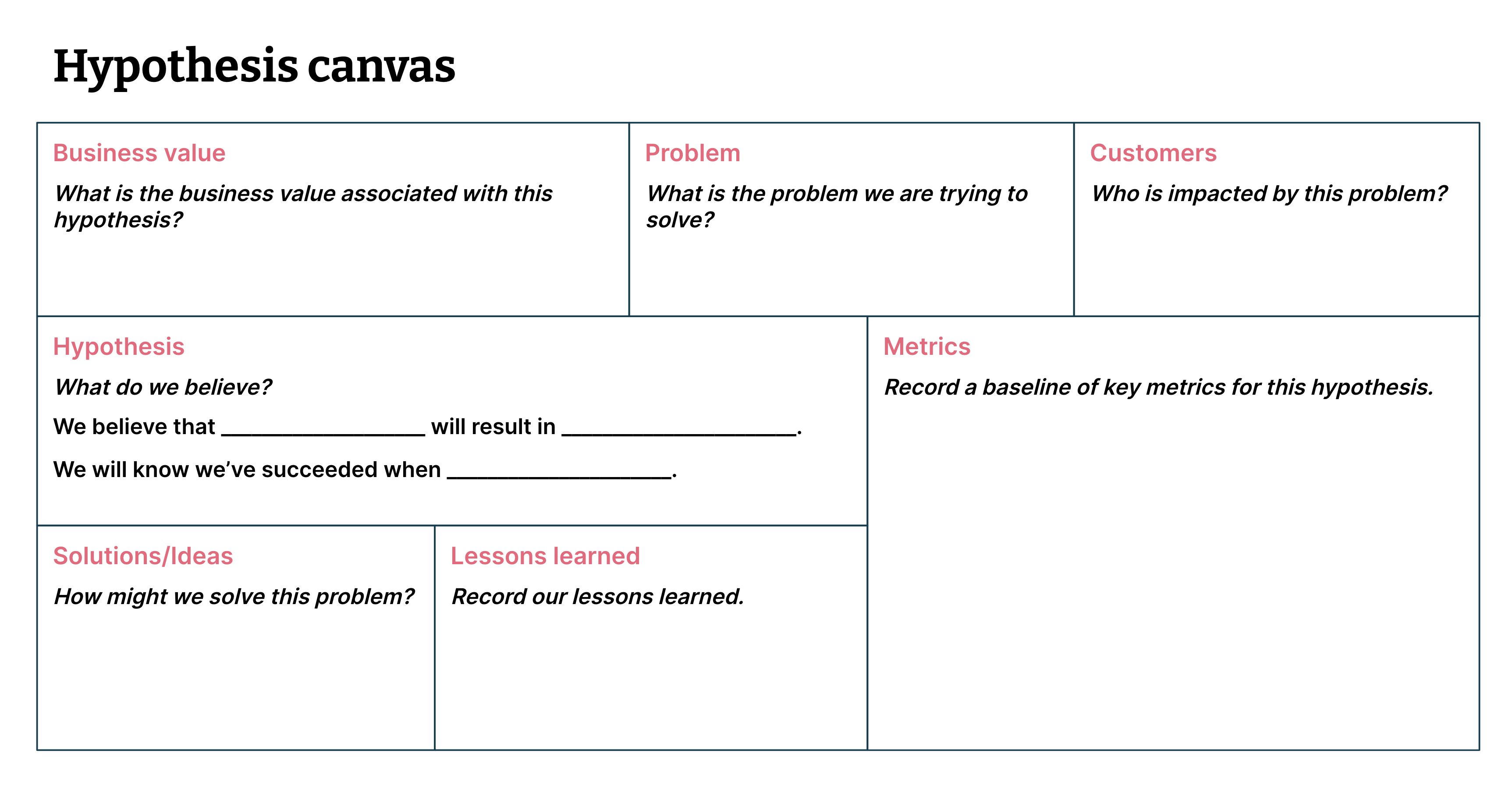
Read more about it [here](https://www.thoughtworks.com/en-au/insights/articles/data-driven-hypothesis-development)
### The C4 Software Architecture Model
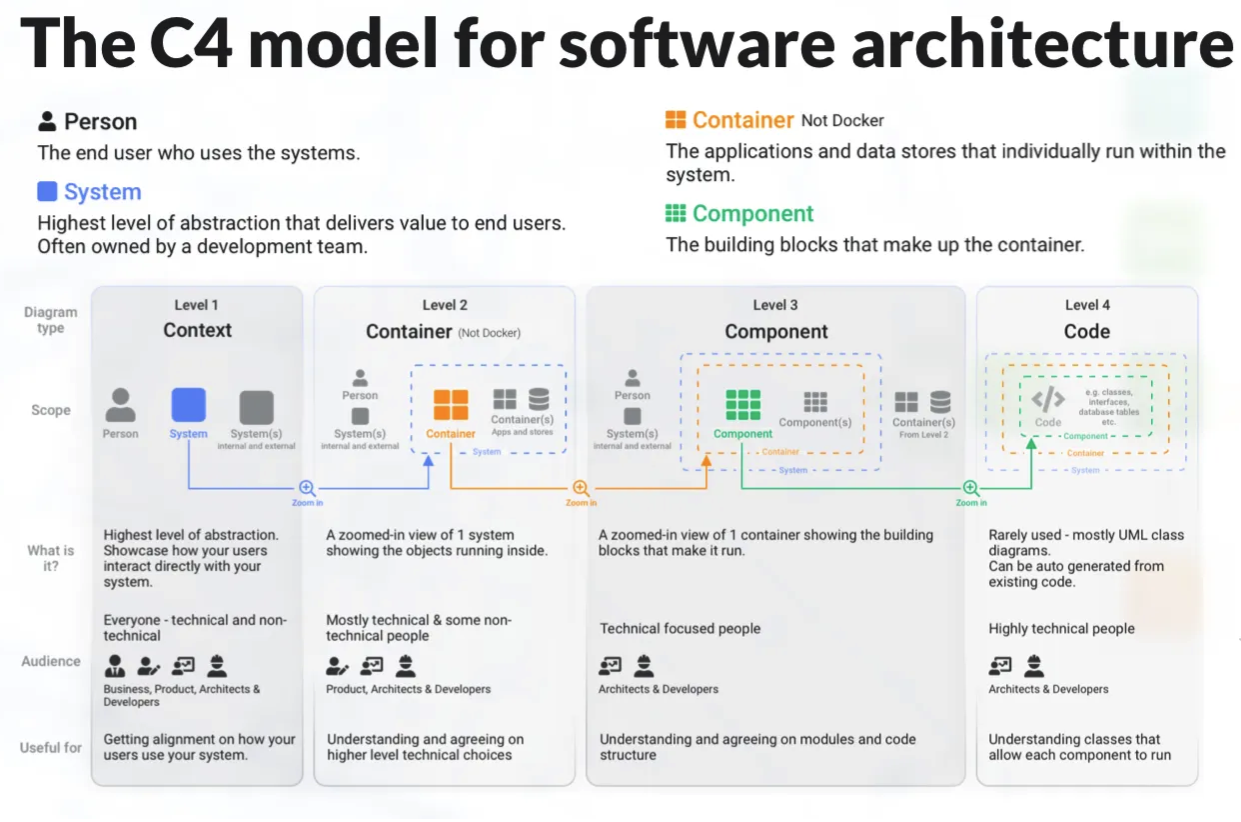
The C4 model is a framework for visualizing the architecture of software systems at 4 levels of details; Context, Container, Component, and Code.
For the engineers in the ML teams, applying the C4 model can help clarify the architecture and design of ML systems, ensuring that all stakeholders have a clear understanding of how the system is structured and how its components interact. For example, here's a concise summary of applying the C4 model to ML engineering:
####Level 1: Context Diagram
* **Identify External Entities:** Users (e.g., data scientists, end-users) and external systems (e.g., data sources, APIs).
* **Define ML System:** Specify the system’s boundaries and main purpose (e.g., recommendation engine).
####Level 2: Container Diagram
* **Identify Containers:** ML service, data ingestion, model training, data storage, user interface.
* **Define Interactions:** Describe data flows and API calls between containers.
####Level 3: Component Diagram
* **Decompose Containers:** Break down into components (e.g., data preprocessing, model training).
* **Define Interactions:** Specify interactions within each container.
####Level 4: Code Diagram (optional)
* **Detail Component Implementation:** Show classes and methods for key components.
Read more about it [here](https://icepanel.medium.com/visualizing-software-architecture-with-the-c4-model-9255025c70b2)
## Where to go from here
In this articles I have shared some tools and processes that may assist ML teams. I would like to further recommend two books that they can read:
1. [Effective Machine Learning Teams](https://www.oreilly.com/library/view/effective-machine-learning/9781098144623/) (O' Reilly)
2. [Managing Machine Learning Projects](https://www.manning.com/books/managing-machine-learning-projects) (Manning)
Hope this article is useful. Please feel free to share your thoughts in comments below.
| hangry_coder |
1,865,741 | Understanding Higher-Order Components (HOCs) in React: A Beginner's Guide | As React developers, we often encounter scenarios where we need to reuse component logic.... | 0 | 2024-05-26T16:55:37 | https://dev.to/mradamus/understanding-higher-order-components-hocs-in-react-a-beginners-guide-4cp4 | reactjsdevelopment, javascript, programming, webdev | As React developers, we often encounter scenarios where we need to reuse component logic. Higher-Order Components (HOCs) offer a powerful pattern to achieve this. In this article, we'll explore what HOCs are, why they are useful, and provide a step-by-step real-life example to help you understand how to implement them.
**What are Higher-Order Components?**
A Higher-Order Component (HOC) is a function that takes a component and returns a new component with enhanced functionality. HOCs allow us to reuse logic across multiple components without modifying their code directly.
Think of an HOC as a wrapper that "decorates" a component with additional features. This pattern is similar to higher-order functions in JavaScript, which take functions as arguments and return new functions.
**Why Use Higher-Order Components?**
HOCs help us to:
- Reuse Code: Encapsulate common functionality that can be shared across different components.
- Enhance Components: Add new behaviors or data to existing components.
- Maintain Separation of Concerns: Keep components focused on their primary tasks while HOCs handle auxiliary concerns.
**A Real-Life Example**
To illustrate the concept of HOCs, let's consider a real-life example. Suppose we have a component that displays user information, but we want to enhance it by adding authentication checking.
**Step 1: Create a Basic Component**
First, let's create a basic component called `UserInfo` that displays user information.
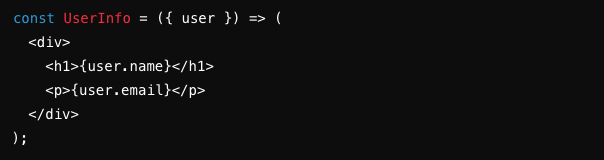
**Step 2: Create the HOC**
Next, we create an HOC named withAuth that adds authentication checking.
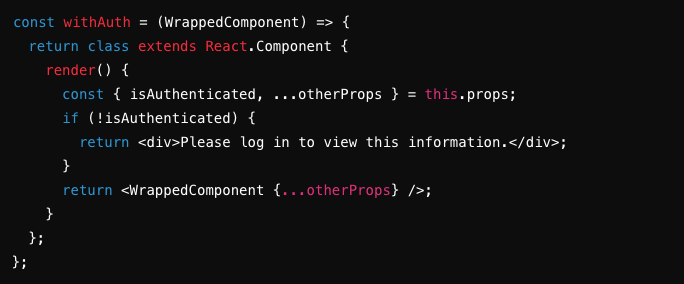
**Step 3: Wrap the Basic Component with the HOC**
Now, we use the HOC to create a new component called `UserInfoWithAuth` that includes the authentication logic.

**Step 4: Use the Enhanced Component**
Finally, we use the enhanced component in our application.
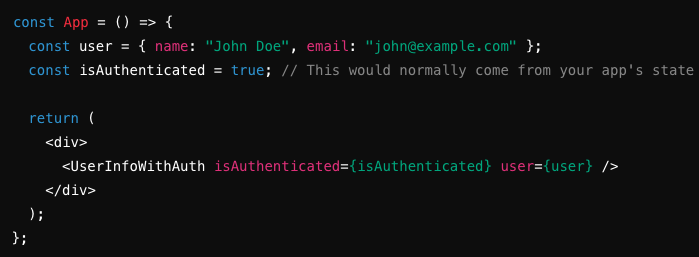
**How It Works**
Let's break down how this works:
- UserInfo: The original component that displays user information.
- withAuth: The HOC that adds authentication checking.
- UserInfoWithAuth: The new component created by wrapping UserInfo with the withAuth HOC.
- When UserInfoWithAuth is rendered, it first checks if the user is authenticated. If not, it displays a message prompting the user to log in. If authenticated, it renders the UserInfo component with the passed props.
**Conclusion**
Higher-Order Components (HOCs) are a powerful pattern in React for reusing component logic. By creating HOCs, we can enhance components with additional functionality while maintaining clean and maintainable code. In our example, we saw how to add authentication logic to a user information component using an HOC.
By understanding and implementing HOCs, you can make your React applications more modular, reusable, and easier to maintain.
Happy coding!
| mradamus |
1,865,286 | Introdução às Expressões Regulares (Regex) | Vamos falar sobre expressões regulares (Regex). Nesse artigo, vamos abordar alguns conceitos, ver... | 0 | 2024-05-26T16:48:21 | https://dev.to/thiagohnrt/introducao-as-expressoes-regulares-regex-1gha | regex, webdev, beginners, braziliandevs | Vamos falar sobre expressões regulares (Regex).
Nesse artigo, vamos abordar alguns conceitos, ver como usá-los com exemplos práticos. Este guia é adequado tanto para iniciantes quanto para aqueles que já têm alguma experiência.
## O Que São Expressões Regulares?
Expressões regulares, ou Regex, são sequências de caracteres que formam um padrão de pesquisa. Elas são usadas para procurar e manipular texto baseado em padrões específicos. Regex pode ser usada em diversas linguagens de programação, como JavaScript, Java, Python entre outras.
## Por Que Usar Regex?
Regex é extremamente útil para:
- Validação de entrada de dados (como e-mails, números de telefone)
- Busca e substituição em texto
- Extração de informações de grandes volumes de texto
## Sintaxe Básica
### Caracteres Literais
O exemplo mais simples de Regex é a correspondência de caracteres literais. Por exemplo, a expressão `animal` corresponde exatamente à sequência "animal" no texto.
### Metacaracteres
Metacaracteres têm significados especiais em Regex. Alguns dos metacaracteres mais comuns são:
- `.`: Corresponde a qualquer caractere único, exceto nova linha.
- `^`: Início de uma linha.
- `$`: Fim de uma linha.
- `*`: Zero ou mais ocorrências do caractere anterior.
- `+`: Uma ou mais ocorrências do caractere anterior.
- `?`: Zero ou uma ocorrência do caractere anterior.
- `\`: Escapa um metacaractere (por exemplo, `\.` corresponde a um ponto literal).
### Conjuntos de Caracteres
Conjuntos de caracteres permitem especificar um conjunto de caracteres que correspondem a uma posição no texto. Eles são definidos entre colchetes `[]`.
- `[abc]`: Corresponde a qualquer um dos caracteres a, b ou c.
- `[a-z]`: Corresponde a qualquer caractere minúsculo de a a z.
- `[^abc]`: Corresponde a qualquer caractere que não seja a, b ou c.
### Âncoras e Limites
- `\b`: Limite de palavra (fronteira entre caractere de palavra e não-palavra).
- `\B`: Não-limite de palavra.
## Exemplos Práticos
### Validação de E-mail
Um exemplo comum é a validação de endereços de e-mail. Uma Regex para validar e-mails pode ser complexa, mas um exemplo simples seria:
```regex
^[\w.-]+@[a-zA-Z\d.-]+\.[a-zA-Z]{2,6}$
```
- `^[\w.-]+`: Início da linha seguido por um ou mais caracteres de palavra, ponto ou hífen.
- `@[a-zA-Z\d.-]+`: Um caractere @ seguido por um ou mais caracteres alfanuméricos, ponto ou hífen.
- `\.[a-zA-Z]{2,6}$`: Um ponto seguido por 2 a 6 caracteres alfabéticos até o fim da linha.
Exemplo em JavaScript:
```js
const emailPattern = /^[\w.-]+@[a-zA-Z\d.-]+\.[a-zA-Z]{2,6}$/;
const email = "exemplo@dominio.com";
console.log(emailPattern.test(email)); // true
```
### Extração de URLs
Para extrair URLs de um texto, você pode usar a seguinte Regex:
```regex
https?:\/\/[^\s]+
```
- `https?`: Corresponde a "http" ou "https".
- `:\/\/`: Corresponde a "://".
- `[^\s]+`: Corresponde a um ou mais caracteres que não sejam espaço.
Exemplo em JavaScript:
```js
const text = "Visite nosso site em http://example.com e http://test.com";
const urlPattern = /https?:\/\/[^\s]+/g;
const urls = text.match(urlPattern);
console.log(urls); // ["http://example.com", "http://test.com"]
```
### Substituição de Palavras
Para substituir todas as ocorrências da palavra "foo" por "bar" em um texto, você pode usar a Regex:
```regex
s/foo/bar/g
```
- `foo`: O padrão a ser correspondido.
- `bar`: O texto de substituição.
- `g`: Modificador que significa "global", ou seja, substituir todas as ocorrências.
Exemplo em JavaScript:
```js
const text = "foo é uma palavra comum, foo é usada frequentemente.";
const newText = text.replace(/foo/g, 'bar');
console.log(newText); // "bar é uma palavra comum, bar é usada frequentemente."
```
## Conclusão
Regex é uma ferramenta poderosa e versátil para manipulação de texto. Compreender sua sintaxe e aprender a aplicá-la em diferentes contextos pode economizar tempo e esforço em tarefas de processamento de texto. Comece com os conceitos básicos e experimente com exemplos práticos para melhorar suas habilidades em Regex. | thiagohnrt |
1,865,739 | Introducing AWS CloudFormation | Intro AWS CloudFormation is a powerful tool that simplifies the process of creating and managing... | 0 | 2024-05-26T16:43:56 | https://dev.to/azeem_shafeeq/introducing-aws-cloudformation-4397 | aws, cloudformation, webdev, tutorial |

Intro
AWS CloudFormation is a powerful tool that simplifies the process of creating and managing AWS resources through code templates. AWS CloudFormation automates the deployment of infrastructure and provides real-time status updates. It is a service that helps users model and set up their AWS resources, allowing them to spend less time managing resources and more time focusing on their applications
**How to use it?**
To use AWS CloudFormation in your app, you can create a CloudFormation template that describes all the AWS resources your app requires, such as Amazon EC2 instances, Amazon RDS DB instances, Auto Scaling groups, Elastic Load Balancing load balancers, and more. Once the template is created, you can use it to create a CloudFormation stack, which will provision and configure all the specified resources for you. This allows you to easily manage a collection of resources as a single unit, simplifying infrastructure management and allowing for quick replication of infrastructure. Additionally, you can reuse your CloudFormation template to provision resources consistently and track changes to your infrastructure using version control
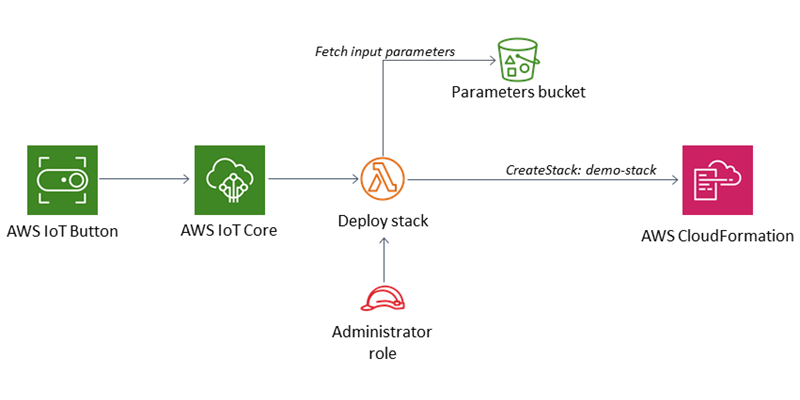
**How to deploy**
To deploy AWS resources using CloudFormation, follow these steps outlined in the provided document:
_Step 1: Pick a template_
Obtain a template that specifies the resources needed for your stack. You can use a sample template provided in the document or create your own.
_Step 2: Make sure you have prepared any required items for the stack_
Ensure that all dependent resources required by the template are available. For example, if the template requires an Amazon EC2 key pair, make sure you have a valid key pair name.
_Step 3: Create the stack_
Sign in to the AWS Management Console and open the AWS CloudFormation console.
Choose "Create Stack" and specify the template URL for the sample WordPress template.
Enter a name for the stack and provide values for any parameters that don't have default values, such as DBUser, DBPassword, DBRootPassword, and KeyName.
_Step 4: Monitor the progress of stack creation_
After initiating the stack creation, monitor the progress of the creation process in the CloudFormation console. Check the status of the stack and view the events to track the creation progress.
_Step 5: Use your stack resources_
Once the stack status shows "CREATE_COMPLETE," you can start using its resources. For example, in the case of the WordPress stack, you can complete the WordPress installation and start using the website.
_Step 6: Clean up_
To avoid unwanted charges, delete the stack and its resources once you are done using them. This involves selecting the stack in the CloudFormation console and choosing "Delete Stack."
Following these steps will enable you to deploy AWS resources using CloudFormation as per the provided document.
A simple developer looking to start working with AWS CloudFormation should understand the following key points:
1. CloudFormation Templates: Developers need to understand how to create and modify CloudFormation templates, which describe the AWS resources and their properties.
2. Provisioning and Configuration: Developers should be aware that CloudFormation handles the provisioning and configuration of AWS resources based on the provided template.
3. Infrastructure Management: CloudFormation simplifies infrastructure management by allowing developers to manage a collection of resources as a single unit.
4. Replication of Infrastructure: Developers can use CloudFormation to quickly replicate infrastructure in multiple regions, ensuring availability for their applications.
5. Tracking Changes: CloudFormation templates can be used to track changes to infrastructure using version control, similar to how developers control revisions to source code.
By understanding these points, a simple developer can effectively leverage AWS CloudFormation to manage and provision AWS resources for their applications.
| azeem_shafeeq |
1,865,738 | Comment devenir revendeur IPTV | Dans cet article, nous vous guiderons à travers les étapes nécessaires pour devenir revendeur IPTV... | 0 | 2024-05-26T16:39:21 | https://dev.to/aboprotv/comment-devenir-revendeur-iptv-23oj | iptv, revendeuriptv, iptvrevendeur | Dans cet article, nous vous guiderons à travers les étapes nécessaires pour [devenir revendeur IPTV](devenir-revendeur-iptv-2/) prospère, en mettant l'accent sur les aspects techniques, juridiques et commerciaux de cette activité.
Qu'est-ce que l'IPTV et pourquoi devenir revendeur IPTV ?
Avant de discuter des étapes pour devenir [revendeur IPTV](https://abonnementiptv.ma/revendeur-iptv/), il est crucial de comprendre ce qu'est l'IPTV et pourquoi ce service est de plus en plus demandé. L'IPTV permet aux utilisateurs de regarder la télévision via Internet, en diffusant des contenus en streaming plutôt que par les méthodes traditionnelles de diffusion. Cette technologie offre une flexibilité et une accessibilité accrues, ce qui en fait une option attrayante par rapport aux services de télévision par câble ou satellite.
En tant que revendeur IPTV, vous pouvez capitaliser sur cette tendance en fournissant des services IPTV à une large clientèle. Vous agirez en tant qu'intermédiaire entre le fournisseur de services IPTV et les clients finaux, en ajoutant de la valeur grâce au support technique, à la personnalisation des offres et au service client.
Devenir revendeur IPTV et gagner entre 1000€ et 5000€ par mois
En plus des aspects essentiels liés au choix d'un fournisseur IPTV, il est important de souligner le potentiel financier considérable de ce secteur. En fonction de la taille de votre clientèle, de la qualité de vos services, et de votre capacité à commercialiser et fidéliser vos clients, vous pourriez générer des revenus mensuels généralement compris entre 1000€ et 5000€.
Le succès financier dépendra de votre dévouement, de votre efficacité opérationnelle et de votre capacité à fournir un service de haute qualité qui fidélise et attire de nouveaux clients. En investissant dans la recherche d'un [fournisseur IPTV](https://abonnementiptv.ma) de qualité et en mettant en œuvre des stratégies de marketing et de service client efficaces, vous pouvez maximiser vos chances de succès financier en tant que revendeur IPTV.
Notre plateforme pour devenir revendeur IPTV
Nous offrons une expérience utilisateur simplifiée et un contrôle total. Les revendeurs peuvent facilement gérer les comptes de leurs abonnés via une interface conviviale, ajouter des abonnés, fournir des URL M3U, des codes API Xtream, et même intégrer des appareils Enigma et MAG.
Pour renforcer la sécurité, nous avons inclus des Captchas pour prévenir les activités non autorisées, ainsi qu'une fonction de déconnexion automatique en cas d'inactivité. Nous avons également créé un tutoriel vidéo simple pour expliquer le fonctionnement de la plateforme IPTV pour les revendeurs.
Étapes pour devenir revendeur IPTV
1. Rechercher les fournisseurs de services IPTV : Sélectionnez des fournisseurs fiables offrant une large gamme de chaînes, une qualité de diffusion élevée et un support technique solide.
2. Étudier les offres de programmes et les tarifs : Comparez les offres et les tarifs des différents fournisseurs pour choisir ceux qui conviennent le mieux à votre marché cible.
3. Établir un modèle commercial : Déterminez votre modèle commercial en fonction de votre marché cible et de vos objectifs financiers. Vous pouvez opter pour des abonnements à prix fixe, des forfaits mensuels ou annuels, ou des tarifs personnalisés.
4. Obtenir une licence ou une autorisation légale : Assurez-vous d'obtenir les licences ou autorisations nécessaires pour opérer légalement en tant que revendeur IPTV.
5. Mettre en place une infrastructure technique : Configurez une infrastructure pour gérer les flux de contenu, le traitement des paiements et le support client.
6. Promouvoir vos services : Utilisez des techniques de marketing en ligne comme le SEO, les réseaux sociaux, la publicité payante et le marketing d'affiliation pour attirer des clients.
7. Fournir un excellent service client : Offrez un support client de qualité pour fidéliser vos clients et encourager les recommandations positives.
Conclusion
Devenir revendeur IPTV offre une opportunité passionnante pour ceux prêts à s'engager dans une entreprise dynamique et en évolution constante. En investissant du temps et des efforts dans la mise en place et la gestion de votre entreprise, vous pouvez bénéficier d'un marché en pleine croissance.
En suivant ces étapes et en mettant l'accent sur un service client exceptionnel, il est possible de construire une entreprise de revendeur IPTV durable et rentable. Avec la demande croissante de contenu numérique et de services de streaming, le potentiel de croissance dans ce secteur reste prometteur pour ceux prêts à saisir cette opportunité. En somme, l'IPTV offre un terrain fertile pour ceux qui souhaitent investir et s'engager dans une entreprise lucrative et gratifiante. | aboprotv |
1,865,737 | Learning to Learn: A Tech Girl’s Guide to Staying Ahead | Let’s be honest, the tech world is a treadmill on fast-forward. By the time you master one... | 0 | 2024-05-26T16:37:16 | https://dev.to/daisyauma/learning-to-learn-a-tech-girls-guide-to-staying-ahead-30ec | Let’s be honest, the tech world is a treadmill on fast-forward. By the time you master one programming language like Python, there’s a hot new framework like Django out there threatening to make it seem outdated. Cloud platforms shift from on-premise servers to behemoths like AWS, methodologies evolve from waterfall to agile, and the pressure to stay relevant feels constant. It’s enough to make any ambitious twenty-something like me want to throw in the towel.
But here’s the secret weapon I’ve discovered: it’s not about desperately cramming every new tech trend into your brain. It’s about mastering the art of learning to learn.
Yes, you read that right. In this ever-changing landscape, the most valuable skill you can develop is the ability to adapt and acquire new information efficiently. Here’s how I’m tackling this challenge:
**Focus on Fundamentals:** Before diving into the newest thing, solidify your grasp of core concepts. Think of these fundamentals as the building blocks of your tech knowledge. Understanding things like data structures (like arrays and linked lists) and algorithms (like sorting and searching) creates a strong foundation for future learning. You can check sites like Leetcode for the most sought after questions. These concepts are evergreen and apply across different programming languages and technologies. Sites like The Odin Project offer fantastic, interactive introductions to these core concepts, with comprehensive curriculums and hands-on projects that make learning engaging and practical.
**Befriend Online Resources:** The tech world is a goldmine of free and paid resources. From online courses like Coursera to informative blogs and YouTube channels, there’s something for everyone. Find learning styles that resonate with you — some people learn best by reading in-depth articles, while others prefer video tutorials or attending live webinars. There are fantastic resources for every budget. Sites like Coursera and edX offer affordable courses from top universities, while platforms like YouTube have a wealth of free, high-quality content from tech experts. For instance, Google offers a free course on its own developer platform, Google Developers, covering a wide range of topics from building web applications to machine learning.
**Embrace the Power of Communities:** Don’t underestimate the power of connecting with other tech enthusiasts. Online forums like Stack Overflow are great places to get help with specific coding problems, while meetups and conferences allow you to network with like-minded individuals. There are even dedicated online communities for women in tech, like Women Who Code, which offer mentorship, workshops, and a supportive network. You can also find tech communities on platforms like Meetup, where you can connect with local developers and attend events focused on specific technologies. Organizations like Women Techmakers and GDG provide resources and programs specifically geared towards women in technology.
**Learn by Doing:** The best way to solidify your knowledge is to apply it. Don’t be afraid to experiment with personal projects. Maybe you could build a simple website using HTML, CSS, and JavaScript, or develop a mobile app to automate a mundane task. There are also a plethora of open-source initiatives on platforms like GitHub where you can contribute to existing projects and learn from experienced developers. Contributing to open-source not only enhances your skills but also gives you valuable experience to showcase on your resume. You can find open-source projects on GitHub that cater to all skill levels, so don’t be afraid to jump in and start exploring!
**Develop a Growth Mindset:** Shift your perspective from fearing change to embracing it as an opportunity to grow. Celebrate challenges as learning experiences, and view mistakes as stepping stones to mastery. Instead of getting discouraged when you get stuck on a coding problem, reframe it as a puzzle to be solved. Approach new technologies with curiosity and a willingness to learn. There are countless books and online resources on developing a growth mindset, such as Carol Dweck’s influential book “Mindset: The New Psychology of Success.” You can also find articles and videos on the topic through a quick Google search.
Remember, learning to learn is a continuous journey. There will be days when you feel overwhelmed by the sheer volume of new information, but don’t let that discourage you. Embrace the constant evolution of tech, focus on the joy of discovery, and you’ll find yourself not just keeping up, but thriving in this dynamic field. Here are some additional tips to keep in mind:
**Curate Your Learning:** Don’t try to learn everything at once. Instead, identify your specific goals and tailor your learning resources accordingly. For example: Are you interested in becoming a web developer? Focus on learning front-end technologies like HTML, CSS, and JavaScript, along with a popular back-end framework like Node.js or Python.
Goodluck!
Was this article helpful?
https://buymeacoffee.com/daisyauma
| daisyauma | |
1,865,736 | Understanding JS getters and setters | Let's dive to understand getters and setters from a 10x newbie. You should have a basic knowledge of... | 0 | 2024-05-26T16:26:31 | https://dev.to/draczihper/understanding-js-getters-and-setters-436a | javascript, oop, webdev, beginners | Let's dive to understand getters and setters from a 10x newbie. You should have a basic knowledge of JavaScript objects and classes to go on with this tutorial.
## `get`
What is `get` in JavaScript?
`get` is a syntax that binds an object property to function, that will be called when that property is looked up.
### Using `get` in objects
```javascript
// Object example with a getter
const obj = {
name: 'John',
surname: 'Doe',
age: 32,
get intro() {
return `Hello there, my name is ${this.name} and I am ${this.age} years old`;
}
}
console.log(obj.intro)
// OUTPUT: Hello there, my name is John and I am 32 years old
```
So a `get` is used to look into a function code and run it. Without the get syntax the output will be the whole function ` intro() { /* ... */}` because calling our `obj.intro` won't know what to do with our function call and hence it returns the whole function.
* `get` can bind property names of the function. Example;
```javascript
const obj = {
/* code... */
get prop() { /* code to be executed when calling obj.prop */ }
}
```
* Also `get` can use computed property names (expression). Example;
```javascript
const obj = {
/* code... */
get [expression]() { /* code to be executed when calling obj.[expression] */ }
}
```
### Using `get` in classes
In classes `get` is used the same as in objects but since getter properties are defined on the `prototype` property of the class unlike in object you need to instantiate the class with the `new` keyword, otherwise calling raw class will return `undefined`. Example;
```javascript
class WithGet {
text = "Hi there";
get greeting() {
return this.text;
}
}
// Without instantiation
console.log(WithGet.greeeting)
// OUTPUT: undefined
// With instantiation
const greet = new WithGet()
console.log(greet.greeting)
// OUTPUT: Hi there
```
That's it on understanding getters. Some advanced concepts on static and private getters, deleting a getter, defining a getter on an existing object are discussed [here](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/get).
* `get` is useful because it provides encapsulation, allowing you to control access to the internal properties of an object.
* `get` is used for lazy evaluation, where a value is only computed the first time it is accessed.
* `get` provide a clean and readable way to access properties.
## `set`
What is `set` in JavaScript?
`set` syntax binds an object property to a function to be called when there is an attempt to set that property.
### Using `set` in objects
```javascript
// Object example with a setter
const score = {
sheet: [],
set grade(passmark) {
this.sheet.push(passmark);
}
}
score.grade = 'A';
score.grade = 'B';
console.log(score.sheet);
// OUTPUT: ["A", "B"]
```
So a `set` is used to set put into a property some value defined in the setter eg. in our `score` object, `set` is used to put grades in the `sheet` array property. Without the setter `set` our code would run but it would return an empty array `[]` because the grade function method won't know what to do with sheet array property.
* `set` can bind a function method. Example;
```javascript
const obj = {
/* code... */
set prop(val) { /* code to be executed when calling obj.prop */ }
}
```
Where the `val` parameter is the value which you want to set on the object.
* Also `set` can use computed property names (expression). Example;
```javascript
const obj = {
/* code... */
get [expression](val) { /* code to be executed when calling obj.[expression] */ }
}
```
### Using `set` in classes
In classes `set` has the same syntax but commas are not needed between methods. Example;
```javascript
class WithSet {
text = "Hi there";
get greeting() {
return this.text;
}
set greeting(name) {
this.text = `Hello ${name}`;
}
}
// Without instantiation
console.log(WithSet.greeting)
// OUTPUT: undefined
// With instantiation
const greet = new WithSet()
greet.greeting = 'John';
console.log(greet.greeting)
// OUTPUT: Hello John
```
**Note** In classes, to return the code which the setter (for this example `greeting` setter) has done action on, you need a getter otherwise, you need to explicitly define a function method that will return the greeting or use a constructor.
That's it on understanding setters. Some advanced concepts on static and private setters, deleting a setter, defining a setter on an existing object are discussed [here](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/set).
* `set` allows you to control how properties of an object are modified thus offering control and encapsulation of code.
* `set` help maintain the integrity of the object's data by ensuring that any changes are validated and processed correctly before being applied.
* `set` centralize the logic for updating a property, which makes the code easier to maintain and refactor.
Thanks for reading this tutorial and I hope you understood what are getters and setters. For any queries, corrections or suggestion please comment so we can all level up to 10x newbies😉.
| draczihper |
1,865,735 | Mengenal Bonus dan Promosi Terbaik di Dunia Judi Online | Mengenal Bonus dan Promosi Terbaik di Dunia Judi Online Dalam industri perjudian online... | 0 | 2024-05-26T16:26:27 | https://dev.to/lindamiranda/mengenal-bonus-dan-promosi-terbaik-di-dunia-judi-online-4cp9 | gamedev, webdev, javascript, beginners | **Mengenal Bonus dan Promosi Terbaik di Dunia Judi Online**
===========================================================

Dalam industri perjudian online yang semakin kompetitif, pemilik bisnis judi online dan pemain judi online profesional perlu memahami pentingnya menawarkan bonus dan promosi yang menarik. Bonus dan promosi yang tepat dapat menjadi kunci untuk memperoleh keunggulan kompetitif dan memikat pemain baru, serta mempertahankan pemain yang sudah ada. Artikel ini akan memberikan wawasan mendalam, statistik terbaru, dan contoh nyata tentang permainan judi online, sambil menjelaskan pentingnya bonus dan promosi dalam industri ini.
**Pentingnya Bonus dan Promosi dalam Industri Judi Online**
-----------------------------------------------------------
Sebagai pemilik bisnis judi **[dewapoker](https://185.96.163.225/)** online, penting untuk menyadari bahwa pemain memiliki banyak pilihan platform judi online yang tersedia. Dalam persaingan ini, menawarkan bonus dan promosi yang menarik adalah cara yang efektif untuk membedakan diri dan menarik perhatian pemain potensial. Bonus dan promosi dapat menjadi faktor penentu dalam keputusan pemain untuk bergabung dengan suatu platform dan tetap setia pada platform tersebut.
Selain itu, bonus dan promosi yang kompetitif juga dapat meningkatkan loyalitas pemain. Dalam survei terbaru, sekitar 82% pemain judi online menyatakan bahwa mereka cenderung tetap bermain di platform yang menawarkan bonus dan promosi yang menguntungkan. Dengan memperhatikan kebutuhan dan preferensi pemain, pemilik bisnis judi online dapat menyesuaikan bonus dan promosi mereka untuk meningkatkan tingkat retensi pemain dan memperoleh keuntungan jangka panjang.
Dengan memperhatikan kebutuhan dan preferensi pemain, pemilik bisnis judi online dapat menyesuaikan bonus dan promosi mereka untuk meningkatkan tingkat retensi pemain dan memperoleh keuntungan jangka panjang. Melalui analisis data pengguna dan umpan balik pemain, pemilik bisnis dapat memahami preferensi pemain, seperti jenis permainan yang paling diminati, tingkat taruhan yang diinginkan, atau preferensi bonus tertentu.
Dengan informasi ini, pemilik bisnis dapat merancang bonus dan promosi yang sesuai dengan preferensi pemain tersebut. Misalnya, jika pemain cenderung memilih permainan slot, pemilik bisnis dapat menawarkan putaran gratis atau bonus setoran khusus untuk permainan slot. Atau jika pemain lebih suka permainan meja seperti blackjack atau roulette, bonus khusus dapat diberikan untuk permainan tersebut.
Selain itu, pemilik bisnis juga dapat memperhatikan preferensi pemain dalam hal tingkat taruhan. Beberapa pemain mungkin lebih suka taruhan tinggi dengan peluang besar untuk memenangkan hadiah besar, sementara yang lain lebih nyaman dengan taruhan rendah yang memberikan pengalaman bermain yang lebih lama. Dengan menyesuaikan bonus dan promosi berdasarkan tingkat taruhan, pemilik bisnis dapat menarik pemain dengan berbagai preferensi taruhan.
Selain menyesuaikan bonus dan promosi, pemilik bisnis juga dapat mengatur program loyalitas yang dirancang khusus untuk meningkatkan retensi pemain. Program loyalitas yang memberikan reward berkelanjutan, tingkat keanggotaan yang meningkat dengan manfaat tambahan, atau hadiah eksklusif bagi pemain setia adalah contoh strategi yang efektif. Dengan memberikan insentif bagi pemain untuk tetap aktif dan setia pada platform, pemilik bisnis dapat menciptakan hubungan jangka panjang dengan pemain dan meningkatkan nilai seumur hidup dari setiap pelanggan.
Dalam mengimplementasikan penyesuaian bonus **[poker88](https://95.164.113.248/)** dan promosi ini, penting bagi pemilik bisnis judi online untuk terus memantau dan menganalisis data pemain serta mengikuti tren industri terkini. Dengan memahami perubahan preferensi pemain dan persaingan di pasar, pemilik bisnis dapat mengoptimalkan strategi bonus dan promosi mereka untuk tetap relevan dan menarik bagi pemain.
Dalam rangka mencapai keuntungan jangka panjang, pemilik bisnis judi online harus melihat bonus dan promosi sebagai investasi yang berpotensi menghasilkan pengembalian yang tinggi. Meskipun bonus dan promosi dapat mengurangi pendapatan jangka pendek, keuntungan jangka panjang yang diperoleh melalui retensi pemain dan pertumbuhan basis pengguna dapat melebihi kerugian tersebut. Dengan pendekatan yang bijaksana dan strategi yang tepat, pemilik bisnis judi online dapat mencapai kesuksesan jangka panjang dengan menyesuaikan bonus dan promosi mereka sesuai kebutuhan dan preferensi pemain.
**Statistik Terbaru tentang Bonus dan Promosi di Industri Judi Online**
-----------------------------------------------------------------------
Data statistik terbaru menunjukkan bahwa bonus dan promosi yang ditawarkan oleh platform judi **[dominobet](https://31.14.238.81/)** online memiliki dampak yang signifikan pada pertumbuhan pendapatan dan basis pengguna. Menurut laporan industri, platform judi online yang menawarkan bonus selamat datang yang menarik dan promosi reguler dapat melihat peningkatan hingga 30% dalam jumlah pemain baru yang mendaftar. Selain itu, platform yang menawarkan program loyalitas yang kuat dan insentif berkelanjutan dapat meningkatkan tingkat retensi pemain hingga 40%.
### **Contoh Nyata Bonus dan Promosi Terbaik di Dunia Judi Online**
**Bonus Selamat Datang yang Menggiurkan:**
Sebagai contoh, platform judi online terkemuka, dewapoker, menawarkan bonus selamat datang yang tidak dapat ditolak kepada pemain baru. Setelah mendaftar, pemain diberikan bonus setoran pertama sebesar 100% hingga $1000, ditambah dengan putaran gratis pada beberapa permainan slot populer. Bonus ini memberikan pemain kesempatan lebih besar untuk menghasilkan kemenangan dan mengeksplorasi berbagai permainan yang tersedia.
**Program Loyalitas yang Menguntungkan:**
Permainan dewapoker, platform judi **[domino88](https://67.205.148.8/)** online terkenal, telah sukses dalam menarik pemain profesional dengan menawarkan program loyalitas yang menguntungkan. Pemain yang aktif mendapatkan poin loyalitas setiap kali mereka bermain, dan poin ini dapat ditukarkan dengan hadiah eksklusif seperti bonus setoran, tiket turnamen, atau hadiah fisik. Program loyalitas semacam ini memberikan insentif bagi pemain untuk tetap setia pada platform dan memberikan penghargaan atas aktivitas mereka.
**Promosi Menarik secara Berkala:**
Platform judi online dewapoker menjaga kegembiraan pemain dengan menawarkan promosi menarik secara berkala. Misalnya, mereka menyelenggarakan turnamen eksklusif dengan hadiah besar, mengadakan undian mingguan dengan peluang memenangkan liburan mewah, atau memberikan cashback harian pada kerugian pemain. Promosi semacam ini menciptakan antusiasme dan memacu pemain untuk terus berpartisipasi dalam aktivitas perjudian online.
Dalam industri perjudian online yang kompetitif, bonus dan promosi yang menarik adalah kunci untuk memperoleh keunggulan kompetitif dan memikat pemain baru. Dengan menyediakan bonus selamat datang yang menggiurkandan promosi yang kompetitif, pemilik bisnis judi online dapat meningkatkan daya tarik platform mereka dan menarik lebih banyak pemain. Program loyalitas yang menguntungkan dan promosi berkala juga dapat meningkatkan tingkat retensi pemain dan mempertahankan basis pengguna yang kuat.
Melalui contoh nyata seperti bonus selamat datang yang menggiurkan, program loyalitas yang menguntungkan, dan promosi menarik secara berkala, pemilik bisnis judi online dapat memperkuat posisi mereka dalam industri ini. Dengan memahami pentingnya bonus dan promosi serta memanfaatkan data statistik terbaru, pemilik bisnis judi online dapat mengembangkan strategi yang tepat untuk menarik pemain potensial dan mempertahankan pemain yang sudah ada.
Sebagai pemilik bisnis judi online atau pemain judi online profesional, memahami dan mengikuti tren terkini dalam industri perjudian online adalah kunci untuk tetap relevan dan sukses. Dalam dunia yang terus berkembang ini, bonus dan promosi yang menarik dapat menjadi perbedaan antara platform yang sukses dan yang terpinggirkan. Dengan strategi yang tepat, pemilik bisnis judi online dapat mencapai pertumbuhan yang signifikan dan membangun reputasi yang kuat di dunia judi online yang kompetitif. | lindamiranda |
1,865,734 | Unveiling JavaScript: The Quirks and Charms of the World's Most Popular Language | Love it or hate it, you can't ignore it. Here are some fascinating quirks and unique features of... | 0 | 2024-05-26T16:26:21 | https://dev.to/azeem_shafeeq/unveiling-javascript-the-quirks-and-charms-of-the-worlds-most-popular-language-20pc | javascript, react, programming, beginners |

Love it or hate it, you can't ignore it. Here are some fascinating quirks and unique features of JavaScript that every developer should know about:
➡ JavaScript was created in just 10 days by Brendan Eich in 1995. This rushed development has left us with some interesting quirks.
➡ JavaScript automatically converts values between types, which can lead to unexpected results:
- [] + [] results in an empty string ("").
- [] + {} yields [object Object].
- Swapping the order ({} + []) gives 0.
- {} + {} results in NaN.
➡ Did you know that JavaScript's `Array.prototype.sort` sorts elements as strings by default? To sort numbers correctly, you need to provide a compare function:
[1, 100000, 21, 30, 4].sort((a, b) => a - b); // Correctly sorts numbers
➡ Two ways to represent 'no value':
- undefined: A variable has been declared but not assigned a value.
- null: An assignment value representing an intentional absence of any object value.
➡ Before ES6, JavaScript lacked a native module system, leading to the creation of CommonJS, AMD, and UMD. Now, we have ES Modules, but older projects still use the old systems, adding complexity.
➡ The JavaScript world is constantly evolving with new frameworks and libraries. This rapid evolution can feel like a never-ending chase for the latest and greatest tools.
Despite its quirks, JavaScript remains a versatile and essential language for web development. Embrace its uniqueness and leverage its widespread use to build amazing projects | azeem_shafeeq |
1,865,733 | Building My Portfolio: A Journey into Full-Stack Development. | Hello everyone! I'm delighted to announce that I've started a quest to establish my portfolio. As a... | 0 | 2024-05-26T16:23:21 | https://dev.to/ketankumar_vekariya/building-my-portfolio-a-journey-into-full-stack-development-16ie | webdev, programming, react, springboot | Hello everyone!
I'm delighted to announce that I've started a quest to establish my portfolio. As a recent graduate with a Master of Science in Management of Information Systems, a Master of Computer Applications, and a Bachelor of Science in Mathematics, I've decided to establish a project showcasing my full-stack programming talents and projects.
**Project Overview**
Technologies I'm Using:
- Front-End:React
1. Leveraging React's component-based architecture for a dynamic and responsive UI
2. Utilizing modern JavaScript (ES6+), HTML5, and CSS3 for a seamless user experience
- Back-End: Spring Boot
1. Building robust and scalable server-side logic
2. Managing data and form submissions efficiently
**Why this project?**
Creating a portfolio is a wonderful approach for me to demonstrate my knowledge of web development, both front-end and back-end. It not only displays my technical ability, but it also acts as a creative outlet for me to demonstrate my design and problem-solving capabilities.
**What to Expect during this endeavour**,
I will:
- Share insights and tutorials about building components with React.
- Discuss how to integrate React with Spring Boot for full-stack apps.
- Provide advice on CSS styling and developing a responsive design.
- Document the problems I face and how I overcome them.
**Current Progress**
I've established the fundamental framework of my React application and created the initial layout of my portfolio. Next, I'll work on integrating interactive components and linking the front-end to my Spring Boot backend.
**Why learn in public?**
Learning in public is a great way to get feedback, connect with the development community, and stay motivated. I'm excited to interact with other devs, exchange ideas, and grow together.
Please contact me if you are working on a similar project or have any tips to provide. Let us study and build together!
Stay tuned for additional information about my portfolio project.
| ketankumar_vekariya |
1,865,662 | Are You Writing Your Git Commit Messages Properly? | When it comes to version control, Git is a very effective tool. However, like any other tool you have... | 0 | 2024-05-26T16:22:04 | https://dev.to/otienorabin/are-you-writing-your-git-commit-messages-properly-54cl | git, developer, productivity | When it comes to version control, Git is a very effective tool. However, like any other tool you have to use it the right way to get the most out of it. There are different aspects that you need to take into consideration. This article focuses on how to write effective Git commit messages following the Conventional Commits specification. It outlines the fundamentals to help you create clear, informative, and standardized commit messages.
## How does a good commit message look?
The purpose of sending a message is to communicate. For communication to be effective, the receiver has to clearly understand what the sender of the message is trying to tell them. Thus you need to provide the context and adequate information. Based on this, a good commit message should convey the following:
**1. Type (mandatory)**
* `fix:` – applicable when the action is fixing a bug.
* `feat:` – applicable when you add a new feature.
* `BREAKING CHANGE:` - applicable when you introduce a change that
might require certain aspects of the program to be updated or
upgraded to avoid disruptions. For example, replacing deprecated
resources with new ones might disrupt functionality if there is
no backward compatibility. You can also indicate a breaking
change by using the symbol '!' right after the type (or scope if
available).
Example; 'feat(authentication)!:'
* `docs:` – applicable for documentation.
Others include *test: , chore: , refactor: , build: , style:* etc. If you are part of a team there might be a convention with customized types that you are expected to adhere to. It is therefore important to get the details beforehand.
**2. Scope (optional)**
Although providing the scope is optional, it is good practice to include it for clarity. The scope specifies the part of the codebase affected by the changes thus helping readers understand the context of the change. This is especially helpful in large projects with many contributors. It makes collaboration easier.
**3. Description (mandatory)**
This is the part where you describe what you’ve done. Keep it concise and straight to the point. Make sure that you write it in imperative form. For instance, instead of writing “Added authentication mechanism” you should write “Add authentication mechanism”. This will promote readability in automatically generated changelogs and release notes.
**4. Body (optional)**
Here is where you can provide more information about what you’ve implemented. Use a blank line to separate the body from the description.
**5. Footer (optional)**
If there is any metadata you’d like to include do so in the footer. For instance, if the change you’ve made addresses an issue that had been raised earlier you can indicate it here by citing the reference number. Example; '**fix #003**'
You can also include reviewer’s name in the footer.
Remember, a scope should be followed by a colon and space before giving the description. You should also keep in mind that BREAKING CHANGE is case-sensitive when included in the footer hence should be written in uppercase.
## Examples
* chore(Art_func): change variable “Empty” to “empty”
Change variable name from “Empty” to “empty” for consistency with
the naming convention.
* fix(database)!: modify schema
Modify schema to accommodate only structured data. Dismiss all
other types of data.
* feat: add support for dark mode.
For long messages, use a text editor by running
```bash
git commit
```
without the -m flag. This opens an editor where you can write a detailed commit message. For shorter messages you can just include the -m flag and use the terminal instead of an editor.
```
git commit -m "subject" -m "body"
```
Using multiple -m flags helps you format the message correctly by separating the subject, body, and footer.
## Conclusion
Writing a commit message should serve the intended purpose. To make it clear and informative, it is recommended that you include at least the type and description of the changes you’ve made. Follow the conventional approach to maintain a good codebase that can support collaboration and automation of various processes. For detailed information be sure to go through the [Conventional Commits](https://www.conventionalcommits.org/en/v1.0.0/) guidelines.
| otienorabin |
1,865,731 | Private offline blogging open source projects ? | Got this question from artistic persons that would like to write notes, add pictures and videos... | 0 | 2024-05-26T16:21:15 | https://dev.to/jy95/private-offline-blogging-open-source-projects--4hm9 | help, opensource, privacy | Got this question from artistic persons that would like to write notes, add pictures and videos offline without relying on cloud for privacy reasons. Could you suggest solutions that are open-source ?
Thanks in advance | jy95 |
1,865,730 | Team up for Develop Social media Application | 👋 Hey React Developer's! Looking to team up with fellow React JS developers for an exciting project!... | 0 | 2024-05-26T16:21:08 | https://dev.to/codenik01/team-up-for-develop-social-media-application-2l5j | 👋 Hey React Developer's!
Looking to team up with fellow React JS developers for an exciting project! I'm planning to build a social media application using React JS and would love to collaborate with anyone interested. If you're keen to join forces and bring this idea to life together, drop me a message! Let's make it happen! 🚀
CodeNik :) | codenik01 | |
1,865,729 | first post | first post | 0 | 2024-05-26T16:19:47 | https://dev.to/manh_moe/first-post-36d | first post | manh_moe |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.