
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,865,728 | Mastering functions in Vyper(part2) | In our previous tutorial, we clearly saw the structure of functions, function decorators and how... | 0 | 2024-05-26T16:17:24 | https://dev.to/mosesmuwawu/mastering-functions-in-vyperpart2-1bdo | web3, ethereum, smartcontracts, vyper | In our [previous tutorial](https://dev.to/mosesmuwawu/mastering-vyper-functionspart1--1144), we clearly saw the structure of functions, function decorators and how functions can be called.
In today's lesson, we are going to see how the `if--elif--else` control structures could be applied in our functions. Also, this example of smart contract is going to give us more confidence of how we can use `@internal` and `@external` decorators.
```python
@internal
def add_numbers(x: int128 = 3, y: int128 = 4 ) -> int128:
return x + y
@internal
def multiply_numbers(x: int128 = 3, y: int128 = 4) -> int128:
return x * y
@external
def my_choice(choice: int128) -> int128:
if choice == 1:
return self.add_numbers()
elif choice == 2:
return self.multiply_numbers()
else:
return 0
```
In the above example, we call three functions. The first two have got the `@internal` decorator and the last one has go the `@external` decorator. As we said earlier, internal functions can only be accessed by other functions within the same contract and are called using the self object. Therefore, we use the `self.add_numbers` to call an internal function by an external function of the same contract.
## Interacting with the contract
For the purpose of this tutorial, i will use web3.py to interact locally with the smart contract we just deployed.
```python
import sys
from web3 import Web3
# Connect to BSC node (Binance Smart Chain)
bsc_node_url = 'https://data-seed-prebsc-1-s1.binance.org:8545/' # Replace with your BSC node URL
web3 = Web3(Web3.HTTPProvider(bsc_node_url))
# Set the private key directly (For demonstration purposes only, do not hardcode in production)
private_key = 'Your_private_key' # Replace with your actual private key
account = web3.eth.account.from_key(private_key)
# Contract ABI
contract_abi = [Copy_and_paste_your_ABI_here]
# Contract address
contract_address = web3.to_checksum_address('Your_contract_address') # Replace with your contract's address
# Create contract instance
contract = web3.eth.contract(address=contract_address, abi=contract_abi)
# Function to set a choice
def call_my_choice(choice):
nonce = web3.eth.get_transaction_count(account.address)
tx = contract.functions.my_choice(choice).build_transaction({
'chainId': 97, # BSC testnet
'gas': 3000000,
'gasPrice': web3.to_wei('5', 'gwei'),
'nonce': nonce,
})
signed_tx = web3.eth.account.sign_transaction(tx, private_key)
tx_hash = web3.eth.send_raw_transaction(signed_tx.rawTransaction)
receipt = web3.eth.wait_for_transaction_receipt(tx_hash)
result = contract.functions.my_choice(choice).call()
return result
# Prompt user for input
def main():
choice = int(input("Enter your choice (1 or 2): "))
if choice in [1, 2]:
result = call_my_choice(choice)
print(f'Result of the calculation: {result}')
else:
print("Invalid choice. Please enter 1 or 2.")
if __name__ == "__main__":
main()
```
## Result

From the result image above, it's fully evident that our smart contract is giving the expected results. When we set the choice to `1`, the answer is `7`. This because the `add_numbers` function was called which added the default values of `x` and `y`.
When we set the choice to `2`, the answer is `12`. This because the `multiply_numbers` function was called which multiplied the default values of `x` and `y`.
For more vyper content, please follow me and like my my posts.
I will be glad for any interactions in the comment section. I am here to learn and teach. [Next Tutorial](https://dev.to/mosesmuwawu/vyper-for-loops-and-arrays-26bd)
Thank you!
| mosesmuwawu |
1,861,401 | All you need to get started with web development. | Getting started with web development can be overwhelming sometimes especially for those who... | 0 | 2024-05-26T16:15:22 | https://dev.to/audreymengue/all-you-need-to-get-started-with-web-development-3o8 | webdev, javascript, beginners, programming | Getting started with web development can be overwhelming sometimes especially for those who transition into tech or have never been exposed to it. I am writing this article to simplify your journey by highlighting what you really need to get started with web development. The basics consist of three main things. A web browser, a code editor and programming skills.
### A web browser
A web browser is a piece of software that allows us to interact with resources on the web. The resources include websites, web applications, cloud ecosystem etc. In short, a web browser is the place where web applications are accessed. Even though we need web browsers to access our web resources, modern web browsers do a lot more than that with developer tools. The developer tools are very necessary as they help debug errors, inspect code, analyse performance of the application. Some of the most recommended web browsers include Google Chrome, FireFox etc.
### A text editor
The next thing you will need is a text editor. It's a software in which we will write the code for our application. Some code editor are already included in the operating system. We have TextEdit for Mac OS and Notepad for Windows PCs. The advantage is that they are very simple to use but the limitations are also important to notice. For example, we do not have text formatting, text or code completion is these editors. It's plain text. And that is why most tutorials will recommend more advanced editor like Visual Studio Code, Atom or Sublime Text. They offer better visual when writing code.
### Programming skills
Last but not least, programming skills. Even though some languages are cross platform, it is very important to understand that the Web has its standards and they are HTML, CSS and JavaScript. Yep, you will need to know them in order to build for the Web.
- HTML: will provide the structure of the page;
- CSS: will allow us to style our Web pages;
- JavaScript: will make our pages dynamic;
In my experience, these are the main things you need in order to get started in web development. The first two items (Web browser and text editor) are generally installed the same day. The programming skill on the other side will definitely take longer but; do not worry just watch out for this space for more in-depth articles on each technology mentioned here. I cannot leave without asking you what you think can be added to this list to make learning Web development less stressful.
| audreymengue |
1,865,289 | Entendendo o useReducer do React | Explicando como funciona e casos de uso para o useReducer. | 0 | 2024-05-26T16:11:14 | https://dev.to/lucasruy/entendendo-usereducer-do-react-9hc | javascript, react, braziliandevs | ---
title: Entendendo o useReducer do React
published: true
description: Explicando como funciona e casos de uso para o useReducer.
tags: javascript, react, braziliandevs
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/cdsexlm94aiijaotb9u3.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-26 00:50 +0000
---
Neste artigo vamos entender como o `useReducer` funciona e dar um exemplo da vida real de uso para ele, mas primeiro vamos entender o que é esse hook. Uma definição curta para o `useReducer` é que ele permite você utilizar um `reducer` em seu componente. Ele entra como uma boa opção quando surge a necessidade de lidar com dados ou lógicas mais complexas para manipular estado. Esse hook utiliza o padrão de `reducers` que foi popularizado com o `redux`, uma biblioteca de gerenciamento de estado muito famosa e que ainda é amplamente utilizada no mercado.
## Pegando um contexto
Antes iniciarmos com o `useReducer` primeiro vamos entender o que seria um `reducer`. Um `reducer` é uma função que recebe o estado atual, uma ação e retorna um novo estado. Simples assim. Por convenção, geralmente os redutores, tem instruções `switch` para dizer como o estado será atualizado e retornar esse novo valor.
Para entender melhor essa ideia, podemos imaginar uma receita: você tem os ingredientes(o estado atual) e uma instrução(ação), o resultado é um prato preparado por você(novo estado).
Agora vamos ver como um `reducer` se parece:
```js
const initialState = { count: 0 };
function reducer(state = initialState, action) {
switch(action.type) {
case 'INCREMENT':
return { count: state.count + 1 };
case 'DECREMENT':
return { count: state.count - 1 };
default:
return state;
}
}
```
No exemplo o `reducer` faz exatamente o que explicamos anteriormente, ele é uma função que recebe o estado atual(`state`) e uma ação(`action`) e retorna um novo estado dependendo de qual ação será executada. Nesse exemplo existem duas possibilidades de ação, aumentar o contador(`INCREMENT`) ou diminuir(`DECREMENT`). Então se o tipo de ação for `INCREMENT` o valor retornado será `{ count: 1 }`, agora se for uma ação do tipo `DECREMENT` o valor retornado será `{ count: -1 }` e assim sucessivamente.
Um ponto muito importante dos `reducers` é a sua imutabilidade, eles sempre devem retornar um novo estado ao invés de modificar o estado atual. Isso garante que o estado seja imutável e pode ajudar a evitar bugs.
## Como o "useReducer" funciona
Para entender o hook `useReducer` precisamos ter atenção as três principais partes do hook: a função redutora, a inicialização do estado e o despachante de ações. Vejamos um a um:
- Função redutora: é a função que diz como o estado vai ser atualizado quando receber uma ação. Essa função recebe dois parâmetros, o estado atual e a ação que deve ser executada, a partir disso um novo estado é retornado.
- Inicialização do estado: será o seu estado, é um objeto consumido pela sua função redutora.
- Despachante de ações: é a função que recebe um objeto por parâmetro, esse objeto é a ação que contém as instruções necessárias para a função redutora atualizar seu estado.
Agora vamos para a sintaxe:
```js
const [state, dispatch] = useReducer(reducer, initialState);
```
Aqui temos o seguinte:
- `state`: estado atual.
- `dispatch`: despachante de ações.
- `reducer`: função redutora.
- `initialState`: estado inicial, um objeto literal.
## Exemplo da vida real
Para entender qual é a aplicabilidade do `useReducer` partiremos para um exemplo bem comum. Imagine que você precisa criar um carrinho de compras que pode ter as seguintes funcionalidades, adicionar, remover e limpar os itens.
Começaremos definindo nosso `reducer` em um arquivo chamado `reducer.js` :
```js
// reducer.js
export const initialState = {
items: [],
totalAmount: 0
}
export function cartReducer(state, action) {
switch (action.type) {
case 'ADD_ITEM':
const updatedItems = [...state.items, action.item];
const updatedTotalAmount = state.totalAmount + action.item.price;
return {
...state,
items: updatedItems,
totalAmount: updatedTotalAmount,
};
case 'REMOVE_ITEM':
const filteredItems = state.items.filter(item => item.id !== action.id);
const itemToRemove = state.items.find(item => item.id === action.id);
const decreasedTotalAmount = state.totalAmount - itemToRemove.price;
return {
...state,
items: filteredItems,
totalAmount: decreasedTotalAmount,
};
case 'CLEAR_CART':
return initialState;
default:
return state;
}
}
```
Agora precisamos criar nosso componente e utilizar o `useReducer` dentro dele:
```jsx
// ShoppingCart.js
import { useReducer } from "react";
import { cartReducer, initialState } from "./shopping-cart.reducer";
export const ShoppingCart = () => {
const [cart, dispatch] = useReducer(cartReducer, initialState);
const hasCartItems = cart.items.length > 0;
const addItemHandler = (item) => {
dispatch({ type: "ADD_ITEM", item });
};
const removeItemHandler = (id) => {
dispatch({ type: "REMOVE_ITEM", id });
};
const clearCartHandler = () => {
dispatch({ type: "CLEAR_CART" });
};
return (
<div>
<h2>Meu carrinho</h2>
{hasCartItems && (
<ul>
{cart.items.map((item) => (
<li key={item.id}>
{item.name} - ${item.price}
<button onClick={() => removeItemHandler(item.id)}>
Remover
</button>
</li>
))}
</ul>
)}
<div>Total: ${cart.totalAmount}</div>
<button onClick={clearCartHandler}>Limpar Carrinho</button>
<button
onClick={() =>
addItemHandler({ id: "shoes-1", name: "Tênis", price: 99 })
}
>
Adicionar "Tênis" ao carrinho
</button>
<button
onClick={() =>
addItemHandler({ id: "shirt-1", name: "Camiseta", price: 39 })
}
>
Adicionar "Camiseta" ao carrinho
</button>
</div>
);
};
```
No arquivo `reducer.js`, definimos o estado inicial do carrinho e quais ações podem ser aplicadas para atualizá-lo. As ações disponíveis são `ADD_ITEM`, `REMOVE_ITEM` e `CLEAR_CART`. Cada vez que uma dessas ações é executada, uma cópia do estado atual é criada, atualizada conforme a ação, e um novo estado atualizado é retornado.
Já no componente `ShoppingCart`, utilizamos o `useReducer` para gerenciar o estado do carrinho. No componente, temos três funções, cada uma responsável por uma ação específica. Essas funções despacham ações para o nosso `reducer`, que se encarrega de atualizar o estado e retorná-lo. O componente `ShoppingCart` renderiza os itens do carrinho, o valor total e os botões de ação para adicionar, remover e limpar o carrinho.
## Conclusão
Neste artigo aprendemos como o hook `useReducer` funciona e também um pouco sobre o conceito por trás dele. Também entendemos como ele pode ser uma ferramenta poderosa, que facilita o gerenciamento de estados mais complexos em seus componentes, principalmente quando a lógica de atualização do estado precisa de várias ações.
Código do exemplo neste [sandbox](https://codesandbox.io/p/sandbox/epic-sunset-lq95nw).
Espero que este artigo tenha ajudado você de alguma forma a entender melhor o `useReducer` e como ele pode ser aplicado em casos reais para gerenciar estados complexos. Se você gostou dessa leitura e ficou interessado em se aprofundar ainda mais nesse assunto, recomendo as leituras a seguir, apenas em inglês:
- [How to Use Flux to Manage State in ReactJS](https://www.freecodecamp.org/news/how-to-use-flux-in-react-example/)
- [Scaling up with reducer and context](https://react.dev/learn/scaling-up-with-reducer-and-context)
Por hoje é isso e obrigado por ler até aqui! | lucasruy |
1,865,726 | Learning AWS Day by Day — Day 75 — AWS CloudFront | Exploring AWS !! Day 75 AWS CloudFront This is a CDN (Content Delivery Network) in AWS,... | 0 | 2024-05-26T15:57:34 | https://dev.to/rksalo88/learning-aws-day-by-day-day-75-aws-cloudfront-4ndp | aws, cloud, cloudcomputing, beginners | Exploring AWS !!
Day 75
AWS CloudFront
This is a CDN (Content Delivery Network) in AWS, providing globally distributed networks of proxy servers caching the content, like videos or any media, closer to the consumers, which reduces the latency and improves the availability of data and speed to access the data.
CloudFront VS Global Accelerator
CloudFront:
Employees multiple sets of changing multiple IP addresses.
Pricing is determined by data transfer out and HTTP requests
Caches content using Edge locations
Optimized for HTTP protocol
Global Accelerator:
Provides fixed entry point to your applications via set of static IP addresses.
Charges fixed hourly fees as well as incremental charge over data transfer over your standard Data Transfer rates.
Uses edge location to find best path to nearest location
Ideal for both HTTP and non-HTTP protocols, like TCP or UDP.
CloudFront Distributions:
We can create distributions to let CloudFront know from where you want the content to be delivered, and the details on how to manage the delivery.
CloudFront Edge Locations:
CloudFront delivers content through worldwide networks of data centers, which we call as Edge Locations. When a user requests some content, this request is redirected to the nearest edge location for low latency and best possible performance.
CloudFront Functions:
We can write functions in JavaScript for latency sensitive CDN customizations. These functions runtime environment offers sub-millisecond startup times, scaling happens immediately so that millions of requests are handled per second, which is highly secure.
Features:
Global Edge Network
Security
Availability
Edge Computing
Real Time metrics and logging
DevOps Friendly
Continuous Deployment
Cost Effective
Customers using CloudFront:
Cloudinary
XXL Sport
Arqiva
Irdeto
Hulu
Jio Saavan | rksalo88 |
1,865,712 | Amazon Forecast : Best Practices and Anti-Patterns implementing AIOps | AIOps leverages artificial intelligence for IT operations. Forecasting is one of the most leveraged... | 0 | 2024-05-26T15:55:37 | https://dev.to/aws-builders/amazon-forecast-best-practices-and-anti-patterns-implementing-aiops-2p5a | aiops, sre, forecasting, aws | AIOps leverages artificial intelligence for IT operations. **Forecasting** is one of the most leveraged use cases in AIOps. It typically involves making predictions or estimates of a dataset based on historical data, patterns, and various quantitative and qualitative factors
**Typical Forecasting use cases are:**
- **Traffic**: Predicting traffic or volume fluctuations to anticipate demand and optimize infrastructure accordingly.
- **Error Rate**: Forecasting error rates to proactively identify and mitigate potential issues, ensuring system reliability.
- **Latency**: Predicting latency metrics to maintain optimal performance and enhance user experience.
- **Resources**: Forecasting resource usage patterns to optimize allocation and prevent bottlenecks.
- **Business Metrics**: Forecasting various business metrics such as sales, revenue, or customer engagement to inform strategic decision-making.
- **Error Budget Burn Rate**: Forecasting the rate at which error budget is consumed to manage risk and prioritize improvements effectively.
- **SLA Adherence**: Predicting SLA adherence to ensure service level commitments are met and customer satisfaction is maintained.
**Time series data**
Amazon Forecast works with time series data. Time series data is a sequence of data points collected, recorded, or observed over a period of time, where each data point is associated with a timestamp or time index. It is characterized by its chronological order, intervals (regular or irregular), trends (such as increasing, decreasing, or cyclical patterns), seasonality (repeating patterns with fixed periodicity), and the presence of noise, all of which influence its analysis and forecasting
**Amazon Forecast**
It's a fully managed service offered by Amazon for metric forecasting. It's easy to use, as it allows you to integrate historical or related data by uploading them to Amazon Forecast. Once the data is uploaded, Forecast automatically inspects the data, identifies key attributes, and selects the right algorithms needed for forecasting. It then trains and optimizes your custom model. Once generated, forecasts can be visualized via the console or downloaded. Amazon Forecast also provides APIs that allow you to build solutions
**Getting started is relatively easy.**
**Import Your Data**
- Create your dataset group.
- Select the forecasting domain. AWS supports multiple domains out of the box:
1. Retail domain
2. Inventory planning
3. EC2 capacity
4. Workforce
5. Web traffic
6. Metric (for forecasting metrics such as revenue, sales, and cash flow)
7. Custom (if your requirement does not match any of the above).
- Then select the frequency of data.
- Create your data schema - the data definition of your sample data. You can use the schema builder or JSON schema.
- Select your data file from S3.
- Create an IAM role providing access to S3.
**Train a predictor**
- You can select your predictor, essentially the metric you want to forecast.
**Generate Forecasts**
- You can use the predictor to generate the forecast.
- For all items: Generate forecasts for all items in the input dataset.
- For selected items: Generate forecasts for selected items in the input dataset.
- Query Forecast : You can generate your query to visualize the forecast
**Amazon Forecast output snapshot**
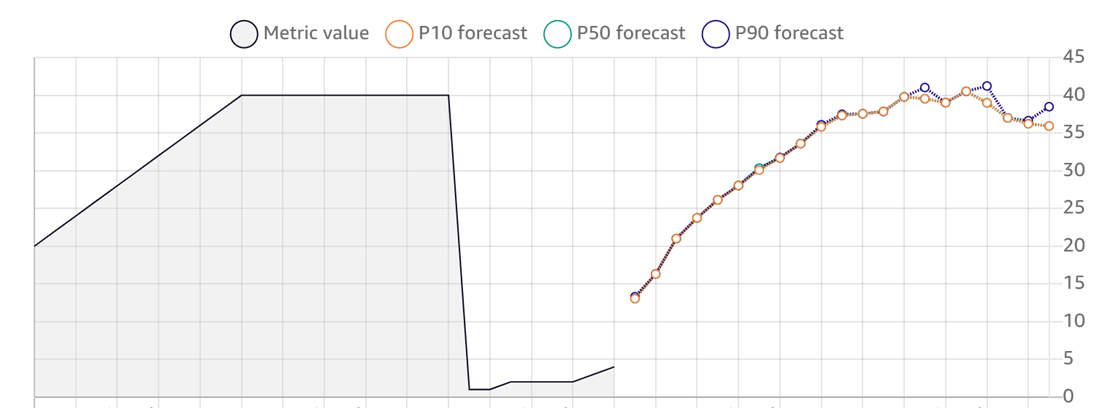
In Amazon Forecast, P10, P50, and P90 represent the 10th, 50th, and 90th percentiles of the forecast distribution, indicating that there is a 10%, 50%, and 90% probability, respectively, that the actual value will be less than the forecasted value.
**Explore Insights**
Explore Insights consists of two parts:
**Explore Explainability** - As per the AWS-provided definition, Explainability insights identify the attributes that impact your forecasts, quantify their impact relative to other attributes, and determine whether they decrease or increase forecast values.
**Explore What-if Analysis** - As per the AWS-provided definition, What-if analysis explores modifications to the related time series, quantifies the impact of those modifications, and determines how those modifications can impact forecast values
**Few things to note about Amazon Forecast:**
- It supports forecasting via Console, AWS CLI, or Python notebook.
- Ability to customize forecast parameters.
- Modularized - meaning able to track model drift, what-if scenarios, or forecast explainability.
**Pricing:**
Pricing is based on imported dataset and the time taken for predictor training, as well as the number of forecast data points.
**Best practices to follow when using Amazon Forecast:**
- **Data quality**: Ensure your dataset is clean and accurate, removing outliers or noise that could mislead your forecasts.
- **Feature engineering**: Include relevant factors in your dataset to improve forecast accuracy.
- **Fine-tune model parameters**: Adjust forecast horizon, frequency, and other parameters to optimize model performance.
- **Select the forecasting algorithm**: Choose the appropriate algorithm (e.g., ARIMA, CNN-QR, DeepAR+, ETS, NPTS, Prophet) based on your dataset and needs.
- Continuous evaluation, validation, and monitoring: Regularly assess and improve model performance.
- **Enable explainability and predictor monitoring**: Activate these features to gain insights and track model performance.
- **Updating data**: Choose between replacement and incremental updates based on data volume and changes.
- **Handling missing data**: Use filling methods like middle, back, and future filling to address missing values and ensure accurate forecasting.
- Follow dataset guidelines: Adhere to guidelines to ensure optimal model performance.
- **Use predictor monitor**: Track model performance over time and make adjustments as needed.
- **Leverage Forecast Explainability**: Gain insights into how dataset attributes influence forecasts.
- **Leverage what-if analysis**: Explore the impact of altering related time series on baseline forecasts.
**Pitfalls to avoid:**
**Overfitting Models**: Occurs when over-configuring or fine-tuning to prevent noise, instead focus on identifying key patterns.
**Complex Algorithms**: Stick to Amazon Auto Model selection unless there are specific reasons to use a different algorithm.
**Seasonality and Trends**: Ignoring seasonality can lead to unsatisfactory forecasts; ensure relevant features and data are included to uncover patterns.
**Improper Data Preparation**: Prepare data meticulously by clearing, normalizing, and using feature engineering techniques for optimal forecasting results.
**Not Spending Enough Time**: Forecasting is challenging; allocate sufficient time to understand, evaluate, validate, and make necessary adjustments continuously.
**Lack of Business Context**: Understand the purpose of forecasting and factors impacting results; if necessary, conduct reverse engineering to clarify data and goals.
| indika_wimalasuriya |
1,865,357 | Aah, here we go again.. | Hey all, not in the mood to greet, anyway this past year, I've been in a slump. I couldn't overcome... | 22,781 | 2024-05-26T15:54:41 | https://dev.to/fadhilsaheer/aah-here-we-go-again-1k08 | webdev, life, productivity | Hey all, not in the mood to greet, anyway this past year, I've been in a slump. I couldn't overcome my comfort zone, I didn't challenge myself, and I didn't even make a 0.1% progress in my life. Even though I make a schedule and plan to follow, I end f'cking up even more. Then yesterday while watching social media I found a quote.
> I forgot what the quote was, but anyway
basically what it said was planning to do something doesn't do the thing, and it hit me. Throughout the year, I planned and planned and planned, never making any progress, there wasn't problem with my plans, It was perfect. But the problem was with me I either dropped the plan, never followed it, or forgot I even made the plan.
Even though I genuinely wanted improve I couldn't, more accurately Id didn't.
### So what's the fix I'm going to do
Of course I will make another plan 💀, JK the problem with me and many else is we seek for attention, we want other people to see our growth, even though we are growing bit by bit, we don't see our progress ourself, we need someone to measure it, so what I'm going to do is, I'll be blogging myself every day, even though its boring, I'll be marking all of my achievements that day.
wish me luck! | fadhilsaheer |
1,861,346 | Retail Industry Use Case with Brainboard: Enhanced Supply Chain Visibility and Management | Digital is your storefront. Always be open! Grow Your Retail Business With Brainboard ... | 0 | 2024-05-26T15:54:00 | https://dev.to/brainboard/retail-industry-use-case-with-brainboard-enhanced-supply-chain-visibility-and-management-1108 | cloud, management, retail, terraform | > Digital is your storefront. Always be open!
## Grow Your Retail Business With Brainboard
### Deliver A Superior Digital Employee Experience
Maximize your existing IT infrastructure and deliver a more stable, scalable cloud infrastructure solution for your store, boutiques and pop-up stores.
### Scale To Your Biggest Day
Peak season contributes 20-30% of all retail sales annually. Are you ready to meet the traffic spike this holiday season? Brainboard helps your IT business scale to its biggest days. Partnering with major cloud providers, Brainboard can help your reduce risk, boost scalability and optimize your cloud spend with real-time visibility accross your modern cloud environments.
### Reduce Cloud Operating Costs
Margins are everything in the retail world, and cloud is a very real expense. Creating a modern infrastructure deployment pipeline with a good visibility and collaboration workflows, with a robust set of cost controls are proven to reduce waste, idle infrastructure, and over-provisioned services.
### Deliver Better Customer Support
Brainboard facilitates this by making it easier to try new services and prototype new architectures while keeping a very close eye to expenses and security.
## Retail Industry Use Case with Brainboard
### **Challenge:**
Retailers often struggle with maintaining an efficient supply chain that can adapt to sudden changes in demand or disruptions. Traditional methods may lack the agility needed for rapid configuration adjustments across a network of suppliers and distribution centers.
### **Solution with Brainboard:**
Brainboard simplifies the deployment and management of cloud infrastructure across the retail supply chain. By using Brainboard’s visual interface, retailers can create and modify their cloud environments that support supply chain operations, enabling seamless integration across various stages—from procurement to delivery.
### **Implementation:**
1. **Visual Configuration:** Retailers can use Brainboard to visually map out their entire supply chain network, designing configurations that enhance logistic operations.
2. **Dynamic Scalability:** Adjust resource allocation in real-time to meet varying demand without manual intervention. This includes scaling up cloud resources during high sales periods and scaling down during off-peak times.
3. **Compliance and Security Automation:** Automatically enforce security policies and compliance standards across all nodes in the supply chain, reducing the risk of data breaches and regulatory penalties.
### **Outcome:**
Retailers achieve a more responsive and resilient supply chain, capable of adapting to market conditions and consumer demands with greater agility. Improved operational efficiency and reduced downtime lead to increased customer satisfaction and reduced operational costs.
With [Brainboard](https://app.brainboard.co/), retailers can ensure their digital storefronts are always open, delivering superior digital employee experiences, scaling effectively during peak seasons, reducing cloud operating costs, and enhancing customer support. Brainboard's visual interface simplifies supply chain management, offering dynamic scalability and robust security compliance. This leads to a more agile, efficient, and resilient retail operation, driving increased customer satisfaction and optimized operational costs.
You can also [schedule a demo](https://www.brainboard.co/contact-us) with a Retailer pro to learn exactly how Brainboard solution can help you.
| miketysonofthecloud |
1,865,722 | How I created a SEO optimised site using Next.js, Django and Redis | Ok, so this story begins a couple of years back! I’ve always been interesting in building FinTech... | 0 | 2024-05-26T15:44:53 | https://dev.to/hassanmian/how-i-created-a-seo-optimised-site-using-nextjs-django-and-redis-og9 | nextjs, django, redis, react | Ok, so this story begins a couple of years back! I’ve always been interesting in building FinTech solutions and have been doing it for about 16 years (since 2008) (wow time flies). The reason for being interested in FinTech is really weird. I don’t have a financial background (engineer and university dropout). I think I just love the amount of data that is needed to build something.
**So now to the platform. First an introduction to the idea:**
A Financial News site that analyses the pressreleases that are published by publicly traded companies, write an article and publish it on the site. The site should also have commenting functionality and also AI portfolios that buy and sell (real prices but not real money) to inspire users.
The goal is to make savings and investments a part of every persons daily life!
If you want to have a look at the platform:
- [www.investoract.com](http://www.investoract.com)
- [www.bors360.com](http://www.bors360.com)
Investoract is for the UAE market (in English) and Börs360 is for the Swedish market (in Swedish).
**The Tech Stack:**
- Back-End
- Python
- Django
- Django Rest Framework
- Requests
- Scrapy
- Front-End
- Next.js (App Router)
- React
- Infrastructure
- DigitalOcean App Platform
- Redis Stack
- Postgres
The Django Models are quite simple. A couple of apps with a couple of models. Some models are connected to RedisSearch using signals and serialize the data and store it on Redis on each change. Redis indexes that data and make it searchable. Some Django Views that act as DJRF views but instead of fetching the data using the ORM, they instead fetch the data from RedisSearch. The speed this gives me is simple unprecedented (for me).
**Ok so thats the tech part, what about the SEO?**
So to make the platform SEO friendly, the first thing i needed to decide was if I should use App Router och Page Router in Next. As it was a hobby project, I though “why not just try App Router”…
The Developer Experience was awesome. It was really easy to build pages that fetch the data from the back-end and provide it as Server Side rendered pages to the client. So after a couple of weeks I had the first pages built using SSR.
So as a checklist I thought that I would need to fix the following before releases the site and asking Google to index it:
- Static Site Generation
- Make sure to add some of pages to Static Params (do not add all pages as it impacted the build time)
- Meta Data
- Make sure that we have title, description and stuff populated
- OG Tags
- Make sure we have OG tags and fallbacks for all pages
- Comply with all (most of) the recommendations the LighHouse provides
- Add Rich Result JSON
- Create a Sitemap
- Test the site using Google Page Speed
- Add Site to Google Search Console
The above checklist is probably not a complete checklist, but simply the tasks that I needed to complete before releasing the site
**The big day!**
So I released the site a couple of days after new year and Google picked up the site quite quickly. Analyses the data on Google Search Results for a couple of weeks I could quite quickly see that something was wrong. Some pages were being indexed but some were just simply crawled and not indexed.
**Hickup**
Going through the code (especially the raw html that was being sent to the client) I saw that Next.js was sending the data to the client as a JSON object and not prerendered HTML. Thats not good, as Google crawl the pages with no data and simply not index them as they do not contain any content that the user would be interested in.
So here is where it gets a bit messy. So Next.js allows us to add Client Side components quite easily. The only problem with this is that as soon as a client side component is rendered, the data for this component is (quite obviously) not rendered in the HTML tags. This was quite a bummer, as I had built an Infinite Load list on the start page that automatically loaded more articles as soon as the user reached the end of the list. I thought this was quite cool, but Google didn’t. This meant that almost all pages that contained a list of articles weren’t been indexed.
To solve this issue I went back to the drawing board and changed my Infinite Load List to a paginated list instead that used URL Query parameters instead. By doing that I could remove ‘use client’ from list components and make Next.js render these as pre-rendered HTML.
So just to clarify, the page was still considered SSR when I had use client but the server didn’t actually render that HTML but instead provides a JSON object (saved as a JS variable) that was available for the client to render the data.
**Things I still need to fix asap**
The Design
I’m really not happy with the UI yet. The first version was created using next-ui but I quite quickly moved over to just tailwind instead.
Login Experience
Yeah, if you try it out, you will probably see that the login experience needs a revamp.
Interested in some code examples from the project? Leave a comment and I'll create a new post with some code snippets :) | hassanmian |
1,865,721 | The Ultimate Guide to Web Rendering: Improving Performance with CSR, SSR, SSG, and ISR | Introduction The process of web rendering, which controls how users see the content of... | 0 | 2024-05-26T15:44:07 | https://dev.to/a_shokn/the-ultimate-guide-to-web-rendering-improving-performance-with-csr-ssr-ssg-and-isr-41dg | webdev, javascript, beginners, nextjs |
## Introduction
The process of web rendering, which controls how users see the content of your online application, is essential to web development. Knowing the subtleties of web rendering as a full-stack developer with a focus on the MERN stack (MongoDB, Express.js, React, Node.js) will greatly improve the functionality and user experience of your projects. Key ideas and methods in web rendering are covered in this article, including incremental static regeneration (ISR), server-side rendering (SSR), client-side rendering (CSR), and static site generation (SSG).
## Client-Side rendering (CSR)
JavaScript is used to render content in the browser via a method known as client-side rendering, or CSR. In a MERN stack application, CSR is usually handled via React.
This is how it operates:
First Load: The server transmits a small HTML file and a collection of JavaScript files to a visitor that visits your website.
JavaScript Execution: To show the content, the browser first downloads and runs the JavaScript, which then creates the HTML and dynamically modifies the DOM.
User Interactions: The application seems quick and responsive since React manages future interactions on the client-side.
Benefits
Rich Interactivity: Rich interactivity and quick updates are made possible by React's virtual DOM.
Decreased Server Load: Reducing server load to the client is advantageous for scalability.
## Server-Side Rendering (SSR)
Server-side rendering (SSR) is the process of rendering HTML on a server and transmitting it to the client after completion. This can be accomplished in a MERN application utilising frameworks such as Next.js or by utilising React's server-side capabilities. This is how SSR works:
When a user requests a page, the server generates HTML using React components.
Full HTML Response: The server returns fully rendered HTML to the client.
Hydration: Once the HTML is loaded, React takes control, and the application works normally from then on.
Advantages:
Faster initial load: Because the server provides fully rendered HTML, viewers can view the information more quickly.
Better SEO: Search engines may quickly index pre-rendered HTML, which improves SEO.
## Static Site Generation (SSG)
Static Site Generation (SSG) pre-renders HTML during the build process. This strategy is useful for pages that do not need to be updated frequently. SSG is facilitated by MERN stack frameworks such as Next.js. This is how it works.
Build Time: During the build process, HTML is created for each page using your React components and data.
Static Files: The server serves these static HTML files with each request, resulting in rapid load times and low server load.
Advantages:
Performance: Pages load extremely fast since they are pre-rendered and serve as static files.
Scalability: Reduced server load as pages are served from a CDN or static hosting service.
SEO: Fully pre-rendered HTML is easily indexed by search engines.
## Incremental Static Regeneration (ISR)
Incremental Static Regeneration (ISR) is a new technique that combines the advantages of SSG with the ability to update static material without a complete rebuild. ISR, which is supported by frameworks such as Next.js, lets you update static pages after they've been built. This is how it works.
Pages are pre-rendered during the first build process, similar to SSG.
On-Demand Updates: When a page is browsed, any outdated material is re-rendered in the background and updated.
Advantages:
Fresh material: Pages can be modified without requiring a full rebuild, resulting in fresh material.
Performance: Serves static files, retaining the performance benefits of SSG.
Flexibility: Strikes a balance between static creation and dynamic content updates.
| a_shokn |
1,845,141 | Unlock the Power of Microsoft Blazor: Seamless Integration with Workflow Designer — Check Out Guide Now! | Intro Before we dive into the main guide on integrating Workflow Designer with Blazor, it... | 0 | 2024-05-26T15:42:37 | https://workflowengine.io/documentation/workflow-designer-in-blazor-application | frontend, dotnet, csharp, tutorial | ## Intro
Before we dive into the main guide on integrating Workflow Designer with Blazor, it makes sense to convey to readers the practical benefits of using workflow engines in applications. If you haven't considered this before, or if you have but lacked the motivation to implement a Workflow Engine, then this YouTube video by [Jeff Fritz](https://devblogs.microsoft.com/dotnet/author/jeffreytfritzyahoo-com/) will surely captivate you. Jeff Fritz a principal program manager in Microsoft’s Developer Division working on the .NET Community Team. We are confident that this video will help you understand the benefits of implementing a Workflow Engine with a visual Workflow editor and dispel any doubts you may have.
Jeff Fritz explains in a simple and accessible manner, using a delivery case example, how using a workflow engine helps simplify development and reduces the time and effort spent on refactoring and testing
{% youtube vpMzm6TsdDY %}
## Overview
Not all .NET backend developers have expertise in popular frontend frameworks like React or Angular. However, .NET backend developers often possess skills in Microsoft Blazor. We have frequently received requests from our technical support team to create an example of integrating the community version of Optimajet WorkflowEngine (which includes a visual designer) with Microsoft Blazor. We have accomplished this and are sharing an example and guide with you on [GitHub](https://github.com/optimajet/workflow-designer-blazor-sample) repository).
Let's start by creating an application using the `blazorserver` template.
```bash
mkdir workflow-designer-blazor
cd workflow-designer-blazor
dotnet new blazorserver
```
We can run this application using the `dotnet watch` command and modify its code on the fly. This is a great feature of the `dotnet` CLI! If
you run the application and open it in a browser, you will see something like this:
**Empty Blazor application**
What we are going to add:
1. CSS and JS files for Workflow Designer from CDN.
2. _Designer_ navigation element on the left panel with the corresponding page.
3. Workflow Designer on a new Blazor page.
## Adding CSS and JS Workflow for Workflow Designer
First, we need to add CSS and JS from Workflow Designer to our application so that we can connect the Designer to a new page. We will also
need to connect jQuery, since Workflow Designer uses it in its work.
We will use CDN, just to avoid copying Designer files to the project. Of course, you can use local files instead of CDN, this is especially
important when you work in an environment with limited Internet access.
**info important**
Due to the way Blazor works with JavaScript code, external JavaScript code must be included after the script `blazor.server.js`.
Open the `Pages/_Host.cshtml` file and add the highlighted lines as shown below. Styles are added inside the `<head>` tag, scripts are added to the end of the page.
Pages/_Host.cshtml
```html
@page "/"
@using Microsoft.AspNetCore.Components.Web
@namespace workflow_designer_blazor.Pages
@addTagHelper *, Microsoft.AspNetCore.Mvc.TagHelpers
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<base href="~/"/>
<link rel="stylesheet" href="css/bootstrap/bootstrap.min.css"/>
<link href="css/site.css" rel="stylesheet"/>
<link href="workflow-designer-blazor.styles.css" rel="stylesheet"/>
<link rel="stylesheet" href="https://unpkg.com/@@optimajet/workflow-designer@12.5.1/dist/workflowdesigner.min.css">
<link rel="icon" type="image/png" href="favicon.png"/>
<component type="typeof(HeadOutlet)" render-mode="ServerPrerendered"/>
</head>
<body>
<component type="typeof(App)" render-mode="ServerPrerendered"/>
<div id="blazor-error-ui">
<environment include="Staging,Production">
An error has occurred. This application may no longer respond until reloaded.
</environment>
<environment include="Development">
An unhandled exception has occurred. See browser dev tools for details.
</environment>
<a href="" class="reload">Reload</a>
<a class="dismiss">🗙</a>
</div>
<script src="_framework/blazor.server.js"></script>
// &new>
<script
src="https://code.jquery.com/jquery-3.7.1.min.js"
integrity="sha256-/JqT3SQfawRcv/BIHPThkBvs0OEvtFFmqPF/lYI/Cxo="
crossorigin="anonymous"></script>
<script src="https://unpkg.com/@@optimajet/workflow-designer@12.5.1/dist/workflowdesignerfull.min.js"
async defer>
</script>
<script src="js/designerInterop.js"></script>
// <&new
</body>
</html>
```
Now the Workflow Designer with its styles will be loaded in our application.
Pay attention to the file `js/designerInterop.js`. This is a file that will contain auxiliary functions for working with the Designer.
Let's create it in the `wwwroot/js/designerInterop.js` path:
wwwroot/js/designerInterop.js
```javascript
function renderWorkflowDesigner(options) {
var wfdesigner = new WorkflowDesigner({
apiurl: options.apiUrl,
name: 'wfe',
language: 'en',
renderTo: options.elementId,
graphwidth: window.innerWidth - 400,
graphheight: window.innerHeight - 100,
showSaveButton: true,
})
const data = {
schemecode: options.schemeCode,
processid: options.processId
}
if (wfdesigner.exists(data)) {
wfdesigner.load(data)
} else {
wfdesigner.create(data.schemecode)
}
}
function waitForJsAndRender(options) {
if (typeof window.WorkflowDesigner !== 'undefined') {
renderWorkflowDesigner(options)
return
}
// the interval here is only needed to wait for the javascript to load with the designer
const interval = setInterval(() => {
// if the designer hasn't been uploaded yet, we'll wait a little longer
if (typeof window.WorkflowDesigner === 'undefined') return
clearInterval(interval)
renderWorkflowDesigner(options)
}, 30)
}
```
There are only two functions in the file:
1. `renderWorkflowDesigner` - renders the Designer with the specified options.
2. `waitForJsAndRender` - waits for JavaScript to load with the Designer and calls the Designer's render. We need this function because the
Designer loads asynchronously after the page loads.
## Adding a new page
Open the `Shared/NavMenu.razor` file and add the highlighted lines after the _Fetch data_ navigation link.
Shared/NavMenu.razor
```html
<div class="@NavMenuCssClass nav-scrollable" @onclick="ToggleNavMenu">
<nav class="flex-column">
<div class="nav-item px-3">
<NavLink class="nav-link" href="" Match="NavLinkMatch.All">
<span class="oi oi-home" aria-hidden="true"></span> Home
</NavLink>
</div>
<div class="nav-item px-3">
<NavLink class="nav-link" href="counter">
<span class="oi oi-plus" aria-hidden="true"></span> Counter
</NavLink>
</div>
<div class="nav-item px-3">
<NavLink class="nav-link" href="fetchdata">
<span class="oi oi-list-rich" aria-hidden="true"></span> Fetch data
</NavLink>
</div>
// &new>
<div class="nav-item px-3">
<NavLink class="nav-link" href="designer">
<span class="oi oi-copywriting" aria-hidden="true"></span> Designer
</NavLink>
</div>
// <&new
</nav>
</div>
```
Now add a new file `Pages/Designer.razor` and paste the following content there:
Pages/Designer.razor
```html
@page "/designer"
@inject IJSRuntime JSRuntime
<PageTitle>Workflow designer</PageTitle>
<div id="root"></div>
@code
{
protected override async Task OnAfterRenderAsync(bool firstRender)
{
if (firstRender)
{
var options = new
{
apiUrl = "https://demo.workflowengine.io/Designer/API",
elementId = "root",
schemeCode = "SimpleWF"
};
await JSRuntime.InvokeAsync<Task>("waitForJsAndRender", options);
}
}
}
```
Everything is quite simple here. There is a `div` element on the page with the id `root`. When the page is first rendered, in the
`OnAfterRenderAsync` method, we call a JavaScript function called `waitForJsAndRender`, passing in `options` as parameters.
In the parameters we pass:
1. `elementId` - the identifier of the HTML element in which Designer should be drawn.
2. `apiUrl` - the URL where Designer's API is located.
3. `schemeCode` - the scheme code.
## Launching the application
Now you can run your application using the `dotnet run` or `dotnet watch` command. After that, open your browser and navigate to a new page where you should see Workflow Designer.
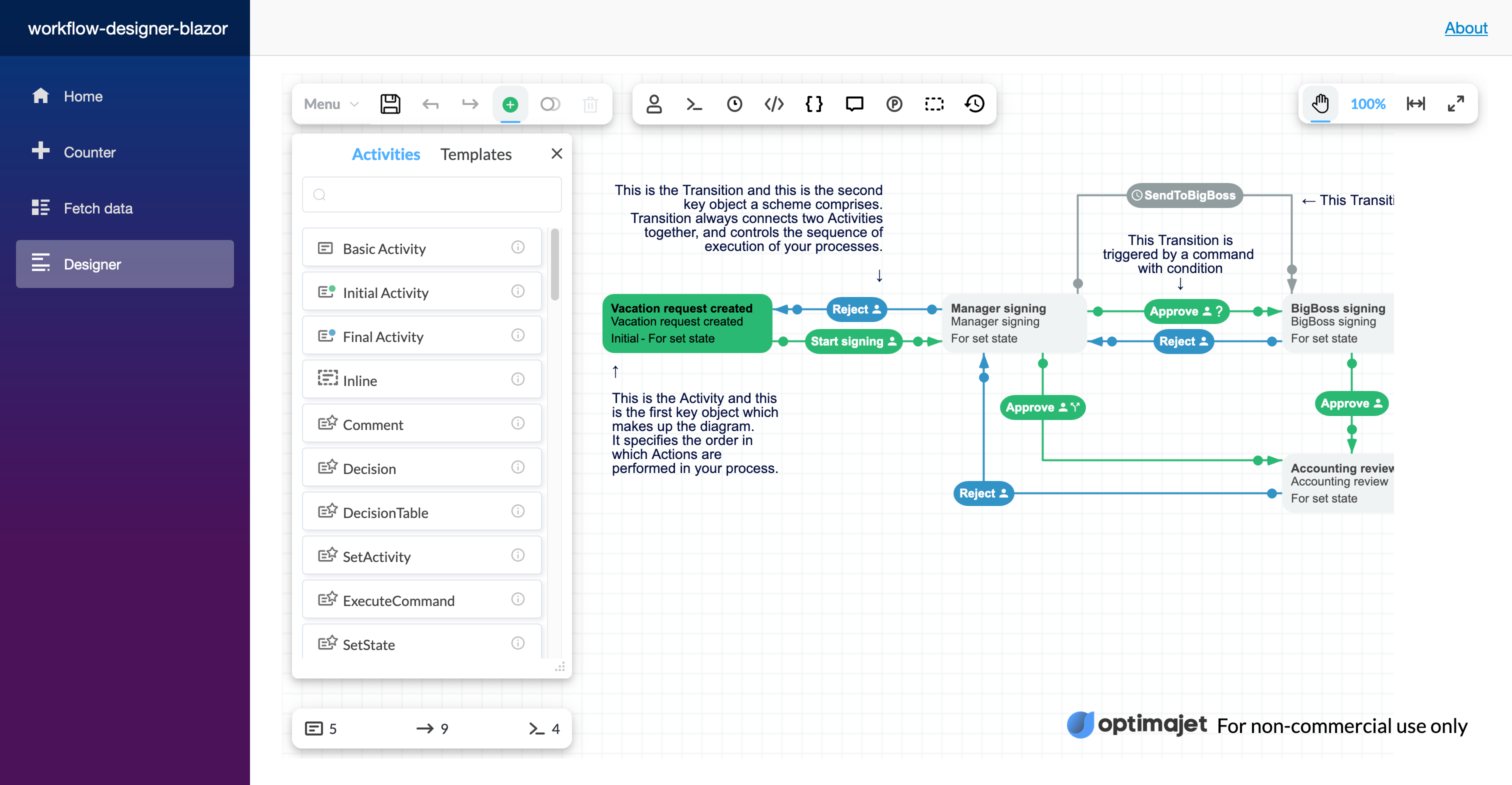
**Workflow Designer in Blazor application**
## Conclusion
We have added Workflow Designer to our Blazor application by including a script from a content delivery network (CDN).
To work with the designer, we used the [ JavaScript interop mechanism]( https://learn.microsoft.com/en-us/aspnet/core/blazor/javascript-interoperability/?view=aspnetcore-8.0).
It was quite easy!
**Your feedback is very important to us**
It helps us understand whether this guide was useful to you, how clearly it was written, and what else you would like to learn about. Please ask your questions in the comments or start discussions on [GitHub](https://github.com/optimajet/WorkflowEngine.NET/discussions). | optimajet |
1,859,617 | Prototyping different storage scenarios for an IT department in Azure Portal. | creating and configuring a storage account. | 0 | 2024-05-26T15:38:51 | https://dev.to/tundeiness/prototyping-different-storage-scenarios-for-an-it-department-in-azure-portal-20mg | azure, storage | ---
title: Prototyping different storage scenarios for an IT department in Azure Portal.
published: true
description: creating and configuring a storage account.
tags: azure, storage
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/qro8jkedn7euqk6dhm7m.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-20 17:32 +0000
---
#Introduction
In this post, I'll walk you through the process of providing Storage for a fictitious IT department, in the Azure portal. For the department, the data isn’t important enough to back up and doesn’t need to be restored if the data is overwritten or removed.
##Prerequisites
Before we start, you'll need a Microsoft Account and an Azure free trial account. I covered opening a free trial account [here](https://dev.to/tundeiness/setting-up-a-windows-11-virtual-machine-with-azure-on-a-macos-88m)
###Step 1: Creating a resource group
Go to the Azure Portal Dashboard, and at the search bar - at the top level of the page - search and select Resource groups. This navigates to another page. While on that page select **+ create**. On the next page, you are required to name your resource group. Go ahead and name your resource group. Then select a region. At the bottom of the page select the **Review + create** button to validate the resource group.
Select the 'create' button to deploy the resource group. The image below shows the created resource group.
###Step 2: Creating and deploying a storage account
On the page of the resource group and the search bar - at the top level of the page - search and select Storage Accounts.
This navigates to another page. While on that page select **+ create** at the upper left of the page or click on the **create storage account** button on that page.
This next page has 6 Tabs namely **Basics**, **Advanced**, **Networking**, **Data protection**, **Encryption**, **Tags** and **Review + create**.
At the **Basics** tab, select the **Resource group** label under the **project details** section and select the Resource group created in Step 1.
Next, Under the **Instance details** section, give the storage account a unique name, select the (US)East US option at the **Region** label, and for the **Performance** label, select the **standard** radio button.
Accept the default **Redundancy** label option as shown. Afterward, select the **Review + create** button on the page and subsequently the "Create" button.
Wait for the storage account to **deploy**.
After successfully deploying, click the **go to resource** button.
###Step 3: Configure settings in the Storage Account.
####I: Data in this storage account does not need to be highly available.
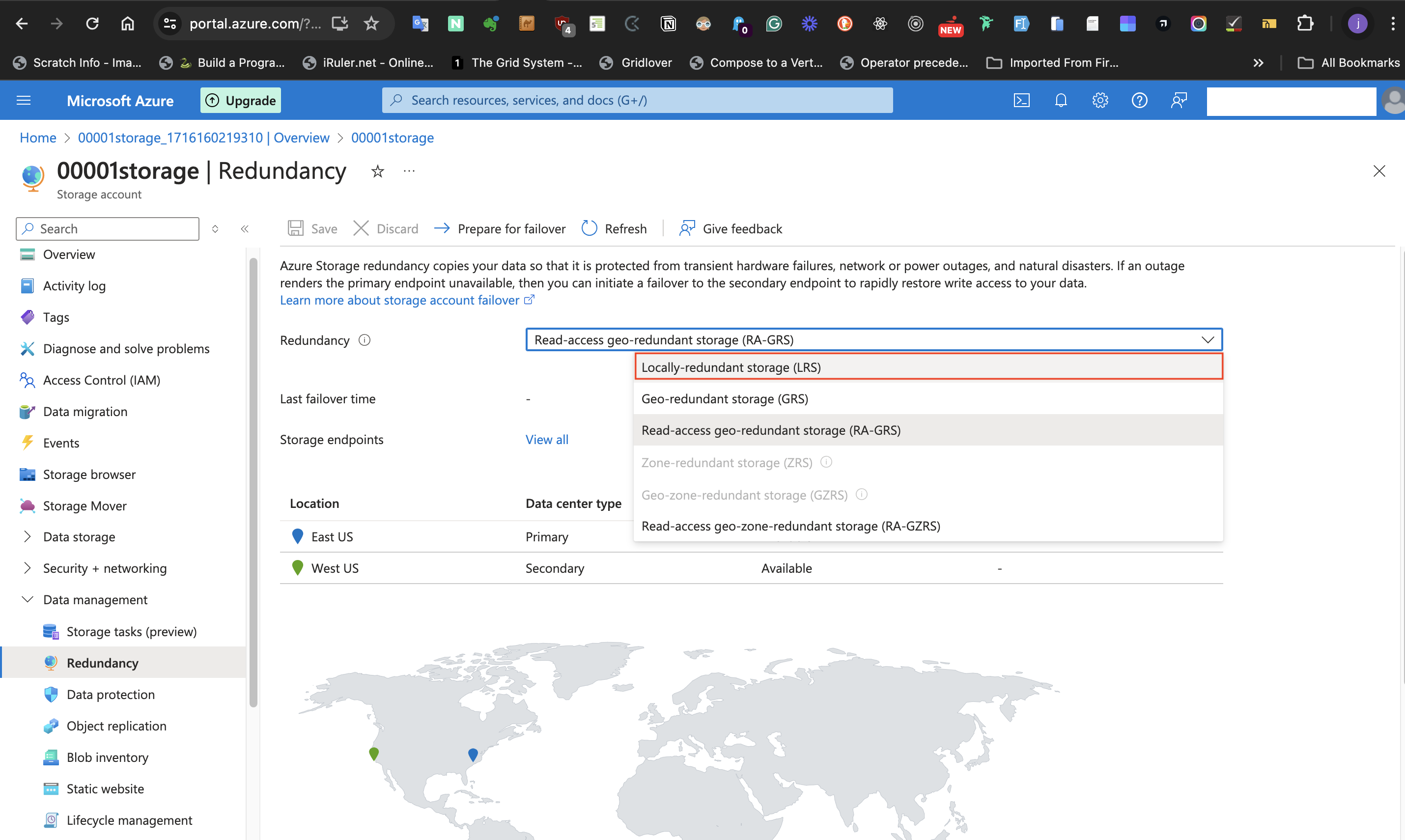
We want to configure this storage account with the most basic settings. We don't have to worry if data isn't highly available. To do this, select **Data Management** at the left-hand side of the page and the **Redundancy** blade.
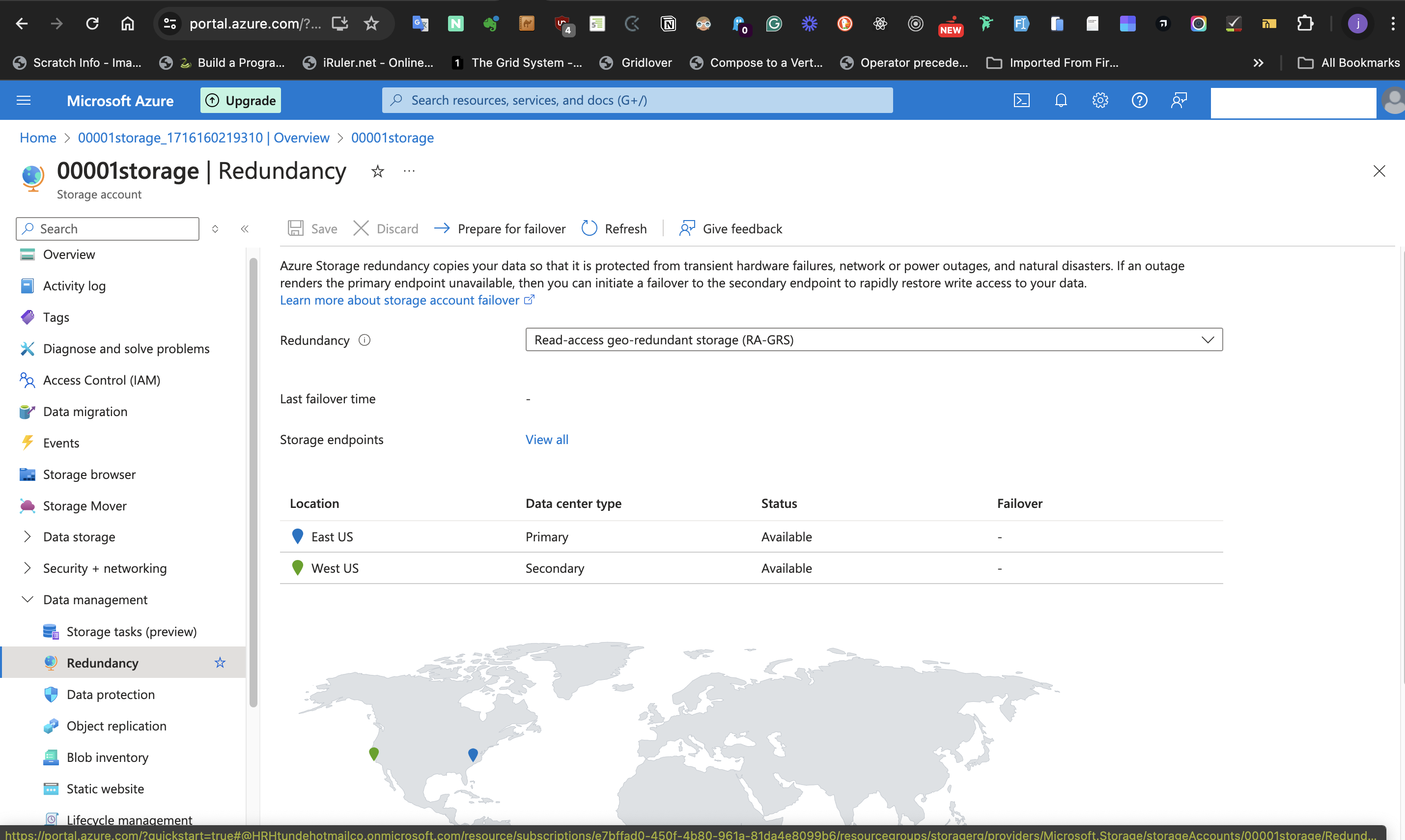
Select the **Locally redundant Storage** (LRS) option from the **Redundancy** label. The reason for this is that "the data isn’t important enough to back up and doesn’t need to be restored if the data is overwritten or removed". As a result, High availability isn't required. This means the redundancy can take the least available option which is **Locally redundant Storage**.
Click **save** at the top of the page.
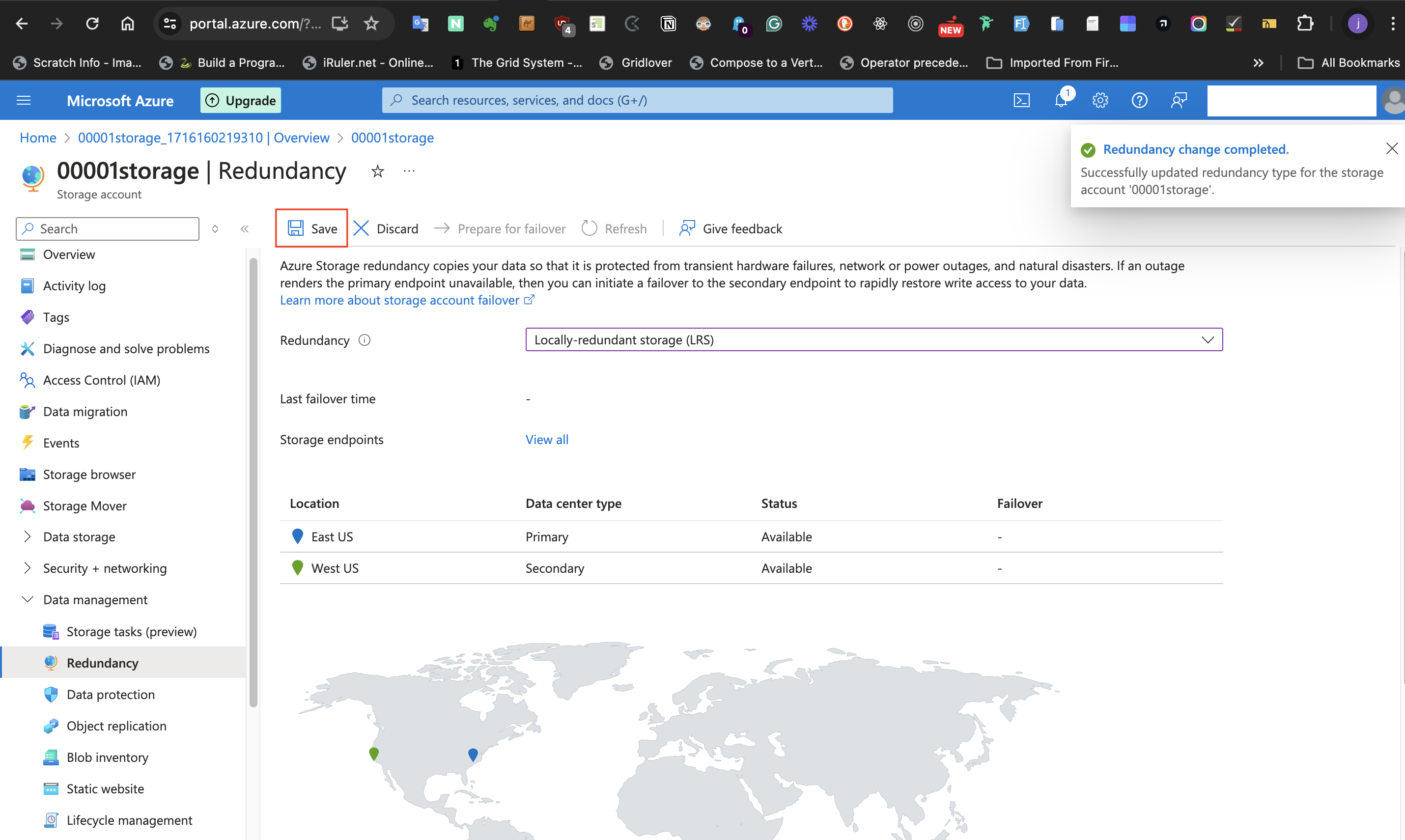
Previously, 2 locations may have shown up on the map displayed on this page. However, since we selected the **Locally redundant Storage** (LRS) option from the **Redundancy** label, only one location will be displayed on the map. Refresh the page if this isn't displaying.
####II: Storage account should only accept requests from secure connections.
The next configuration to set is to make the Storage account only accept requests from secure connections. To do this, follow these steps:
- Locate **settings** at the left-hand side of the page, and select
the **Configuration** blade.
- At the page displayed, confirm that **Secure Transfer required** is **Enabled**
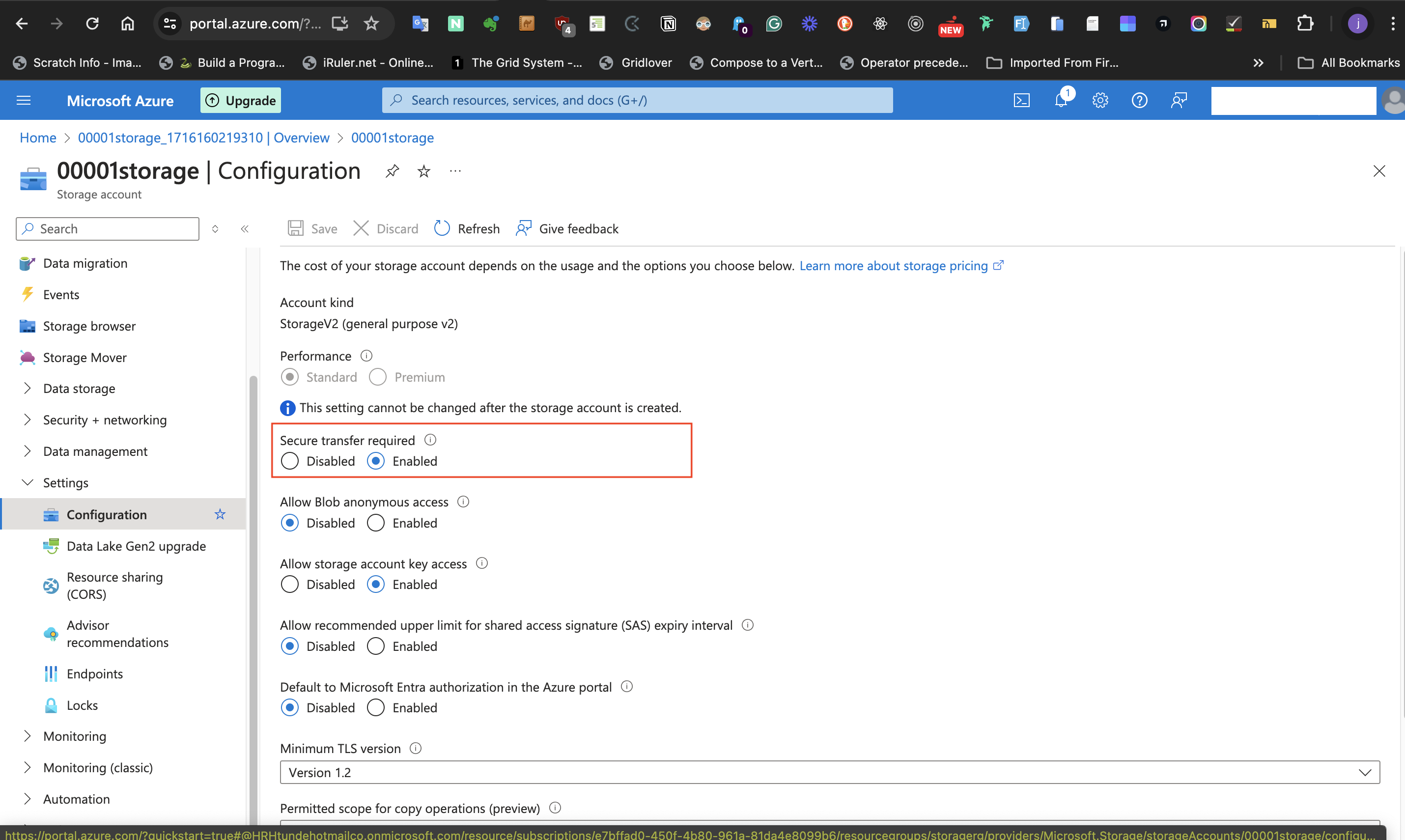
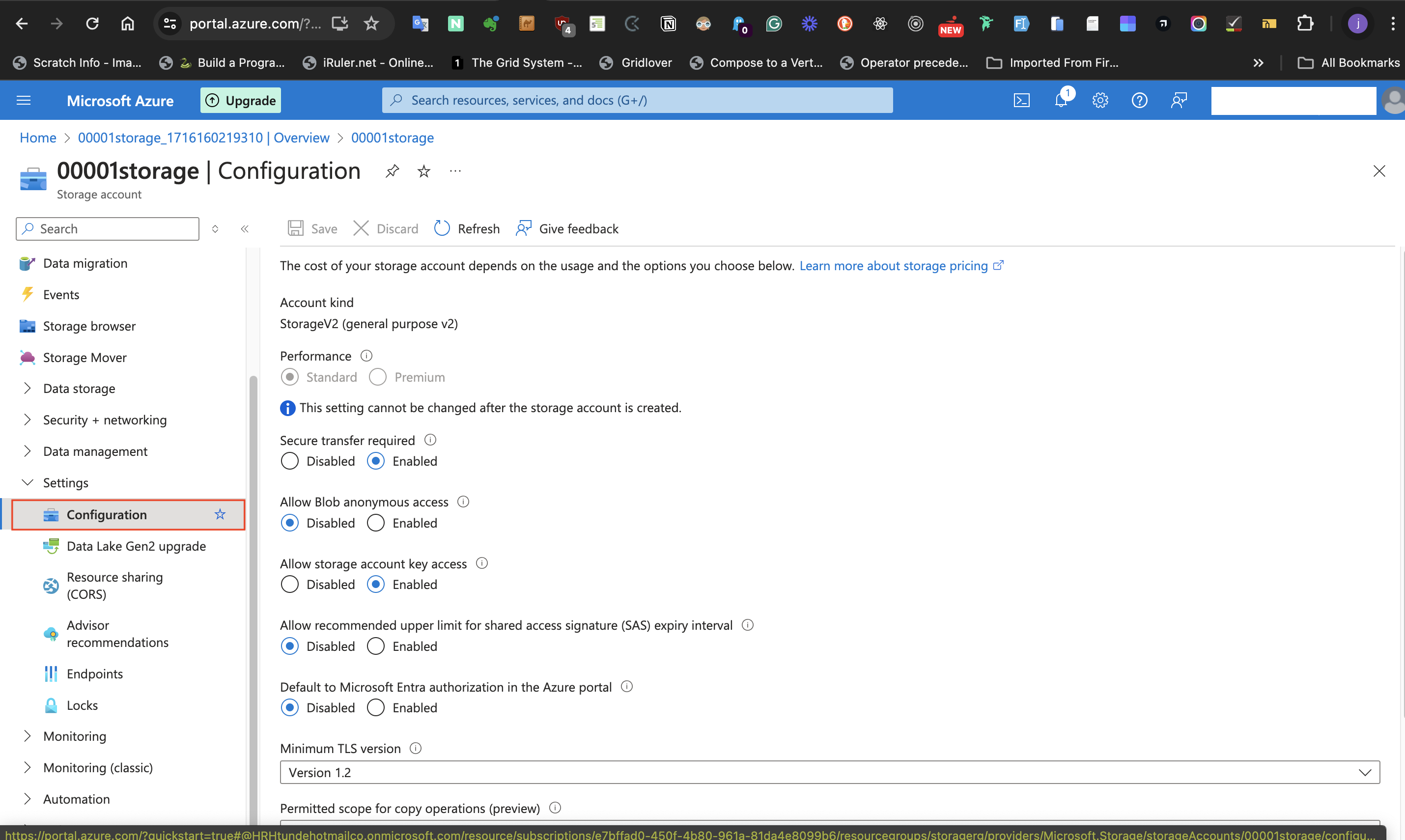
####III: Storage account should use a TLS version.
For the Storage account to use a TLS version,
- go to **settings**

- select **configuration** blade,

-Then, set **Minimal TLS Version** to **version 1.2**
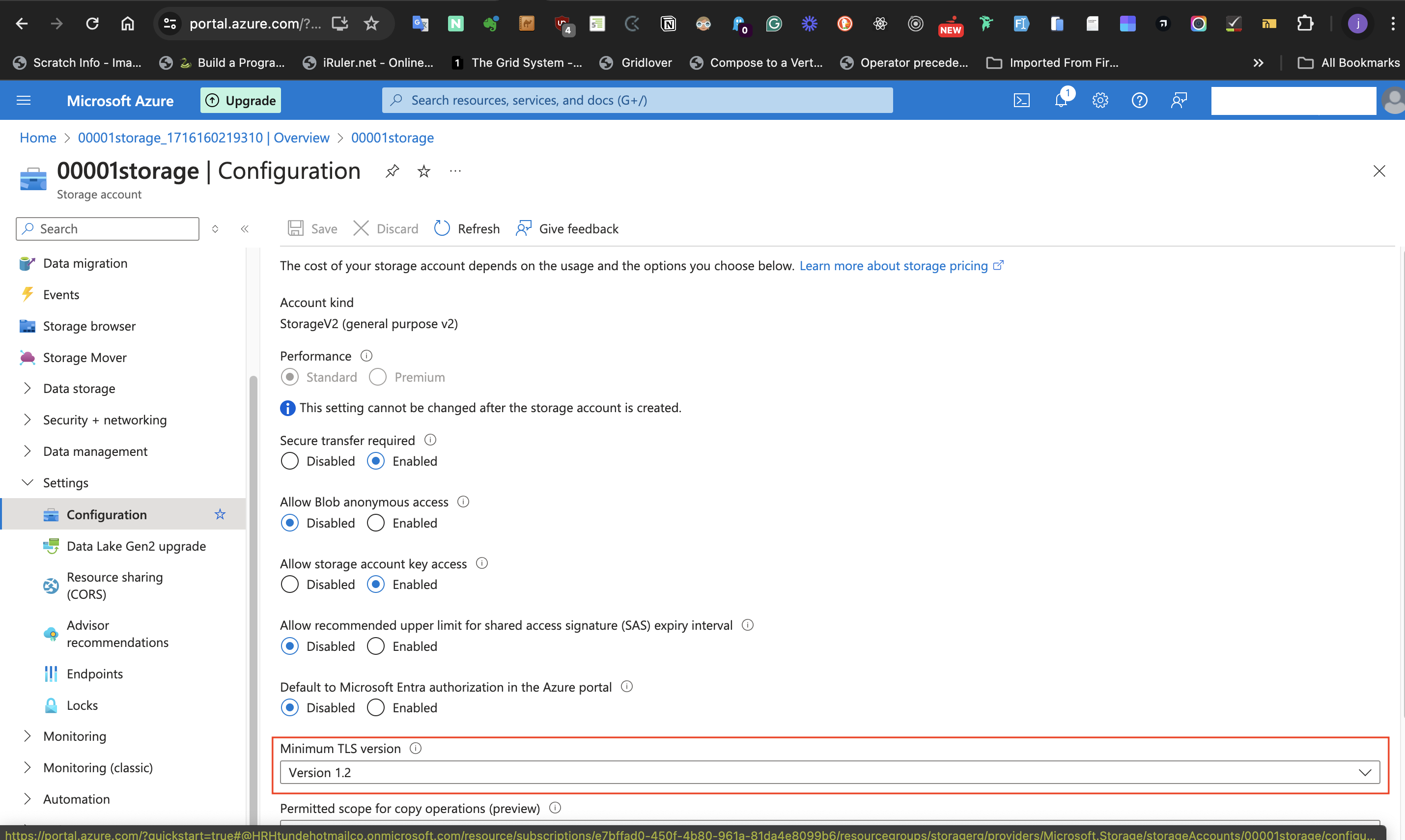
####IV: Request to the storage account is disabled until needed
For disabling requests to the storage account until required,
- Select **Settings**, then

- Select the **Configuration** blade.

- In the **Allow Storage Account key access** label, select the **Disabled** radio button.
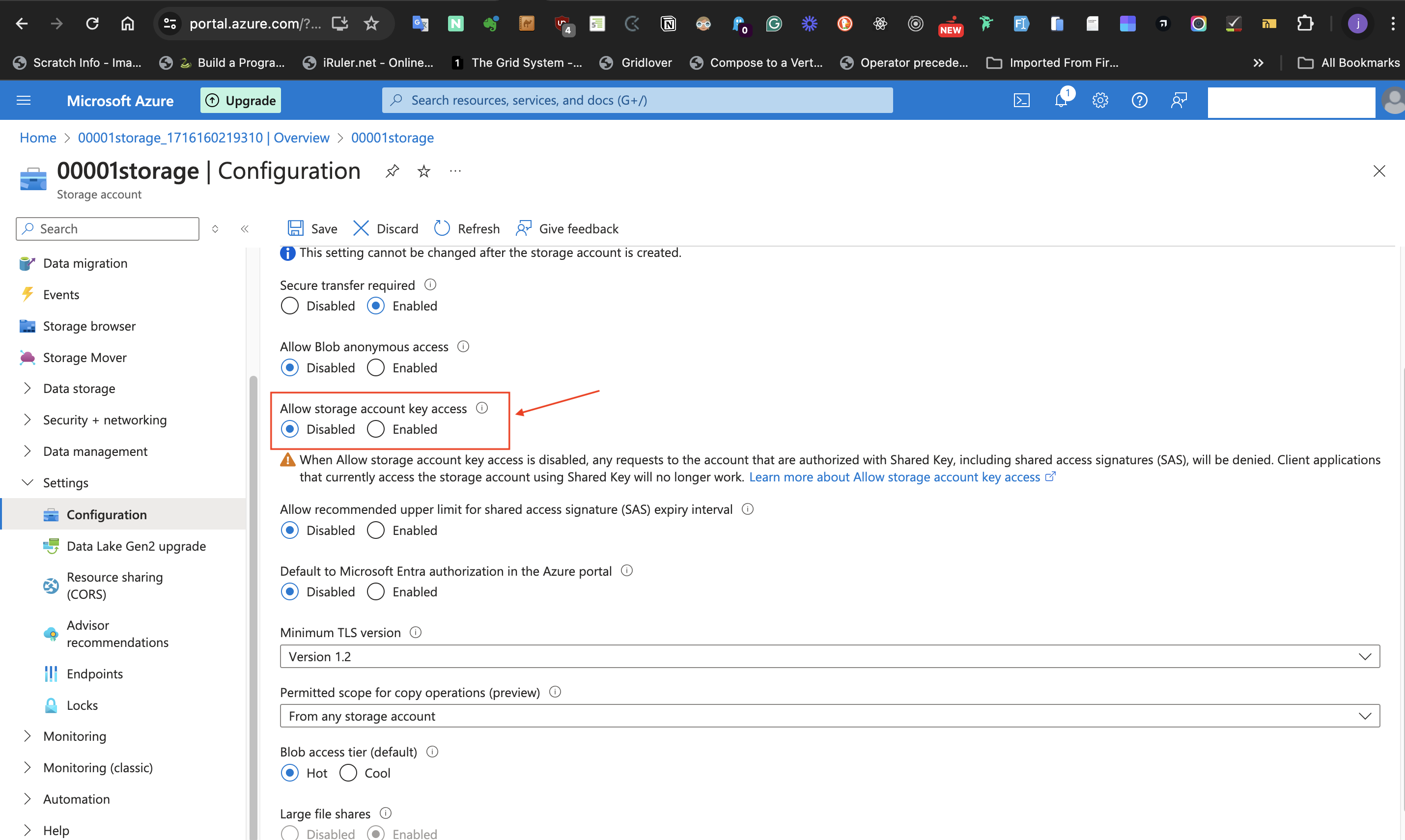
- Select the **Save** icon at the top level of the page.
####V: Allow Storage Account to permit public access from all Networks.
For the last configuration in this task which is to permit public access from all Networks, follow the steps listed below:
- At the left-hand side of the storage account page, select **Security + networking**
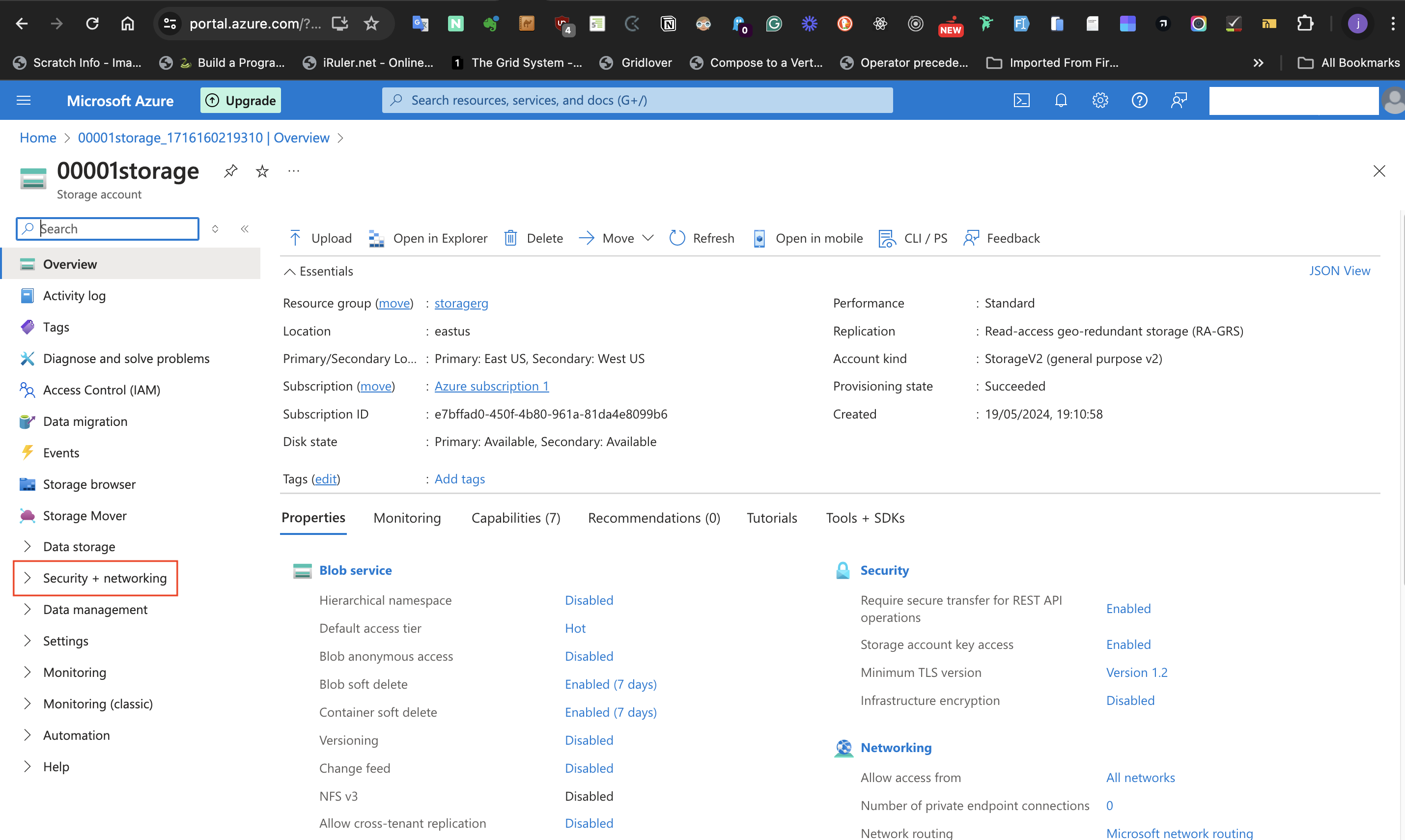
- Select the **Networking** blade
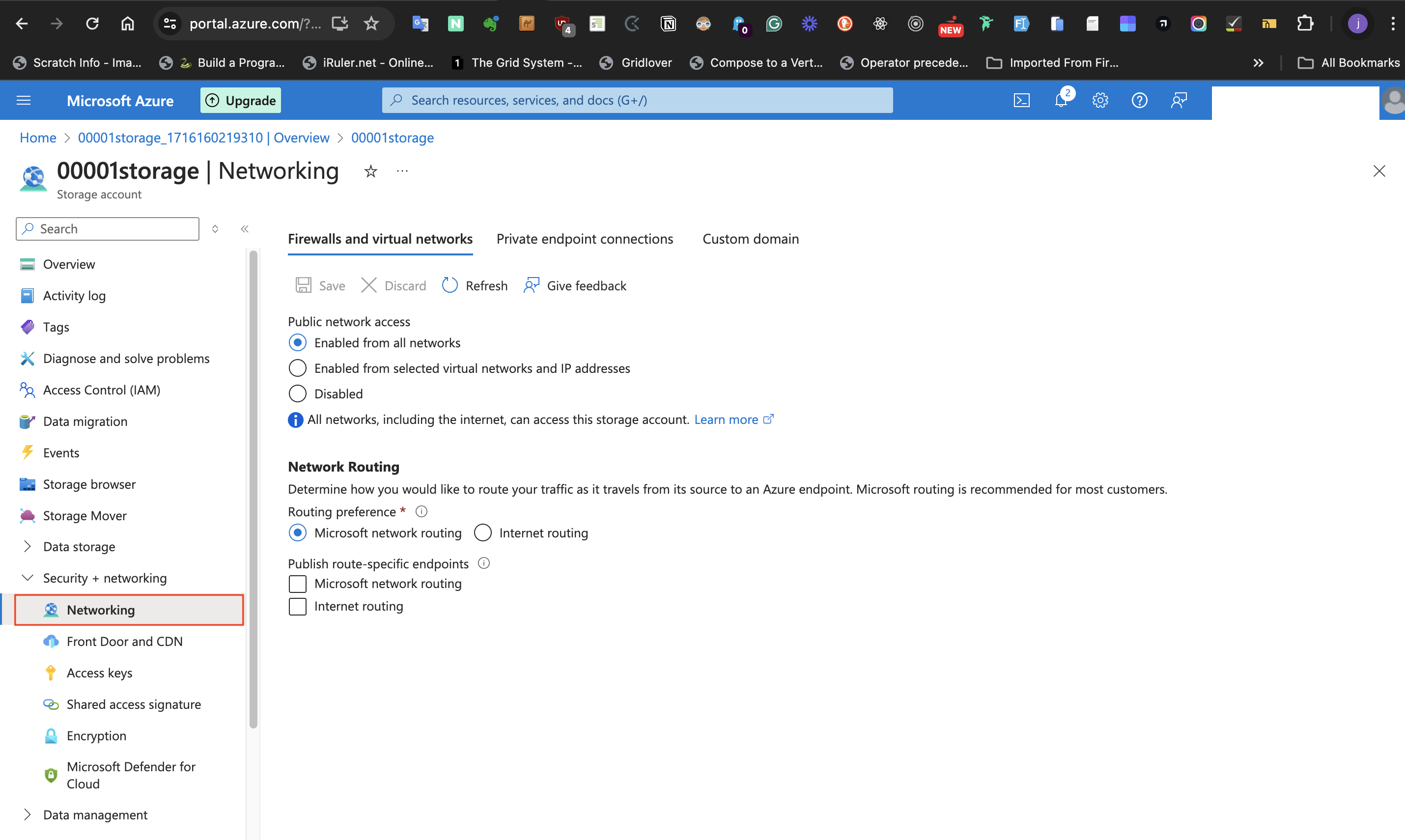
- set **Public network access** to **Enabled from all network**
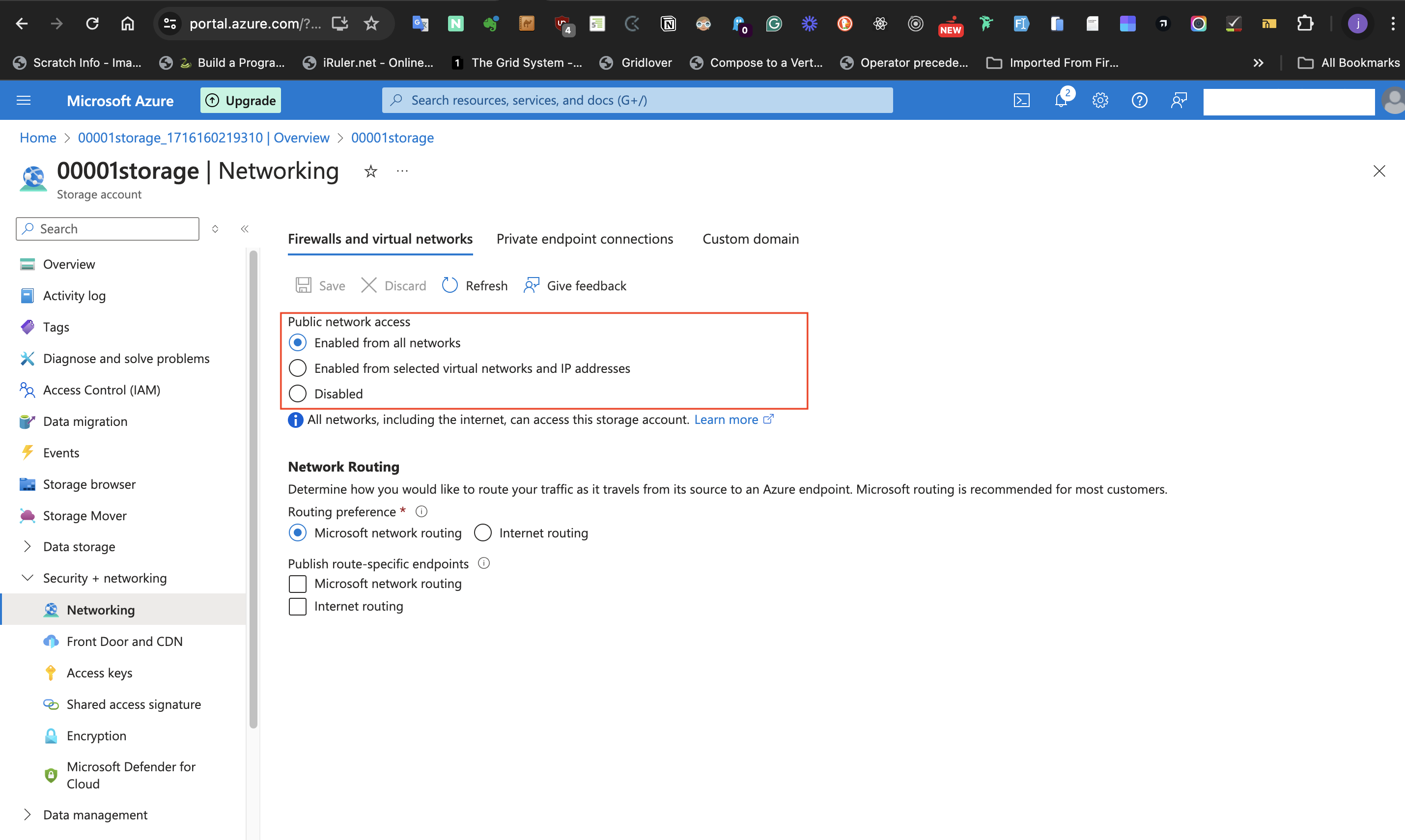
- Click the **Save** icon of the page to save the changes.
#Conclusion
To avoid unnecessary charges, delete your resource group if you will not be using it. You can do this from the Azure portal by navigating to your Resource group and clicking the "delete resource group" button.
In this post, we successfully created a Resource group which is a container for our storage account. We adjusted some basic settings for the storage account and saved these settings. Remember to monitor your usage to stay within the free tier limits and delete resources when they are no longer needed. Stay tuned for more posts on cloud development with Azure!
Cover Image by <a href="https://unsplash.com/@markusspiske?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Markus Spiske</a> on <a href="https://unsplash.com/photos/black-and-gray-laptop-computer-turned-on-FXFz-sW0uwo?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Unsplash</a>
| tundeiness |
1,865,719 | Top-Down Shooter Update: Day 2 (Done: Health & Score) | Instead of first adding enemies, I added health and score .. honestly, I'm a bit intimidated by... | 0 | 2024-05-26T15:38:16 | https://dev.to/quantumbyte-studios/top-down-shooter-update-day-2-done-health-score-5cmc | Instead of first adding enemies, I added health and score .. honestly, I'm a bit intimidated by adding enemies. This is probably because I've seen videos of other game developers creating such amazing enemy AI and it seems like adding enemies is so much more complex than adding a player character or other features.. I thought it'd be easier.
However without an enemy or some other mechanic, health and score kind of don't mean anything lol. The score and health text are just ordinary plain text:
The simplest way I think to do an enemy AI is to make a vector between the enemy position and player character position. And have the enemy move along that vector. The calculation of the angle of that vector would change every frame, so it will look like the enemy is chasing the user. Sometimes, knowledge is the best way to defeat the enemies of life.. perhaps because the real enemy of life is the unknown
Future Goals
-Create Enemy
-Spawn enemies
-Make star-throwing more directional (according to angle between mouse and character)
-Better Player Movement (like rolling to escape enemies)
-Melee Weapon Attack (sword or shotgun)
-More variety in 'Bullets' (cycle through list of different types)
-Find new assets to replace bullets and main character
| quantumbyte-studios | |
1,858,460 | How to deploy a Windows Server (with IIS web server role) in Azure Portal on MacOS | setting up a Windows server in Azure | 0 | 2024-05-26T15:38:02 | https://dev.to/tundeiness/how-to-deploy-a-windows-server-in-azure-portal-on-macos-4gjc | winndowsserver, azure | ---
title: How to deploy a Windows Server (with IIS web server role) in Azure Portal on MacOS
published: true
description: setting up a Windows server in Azure
tags: winndowsserver, Azure
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/aqjwdais8yq4mtohidyj.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-19 18:06 +0000
---
#Introduction
This post is about deploying a Windows Server in Azure Portal on MacOS. Previously, I have written about deploying a Windows 11 OS in the Azure portal [here](https://dev.to/tundeiness/setting-up-a-windows-11-virtual-machine-with-azure-on-a-macos-88m). Before you start following this guide, get a Microsoft account and an Azure account. If you have followed this [post](https://dev.to/tundeiness/setting-up-a-windows-11-virtual-machine-with-azure-on-a-macos-88m), deploying a Windows Server in Azure Portal will be a walk in the park. Let's get to it!!
##Step 1
### Create a Virtual Machine.
- Access the Azure portal As shown in the image below.
- Search for "virtual machines" in the search bar at the top level of the page. Select **virtual machines** from the list of results.
- Select either the **+ Create** option at the top left side of the page displayed, or click the **Create** button with a dropdown arrow at the bottom of the page.
- Select **Azure virtual machine** from the list,
and then it will navigate to the "create a virtual machine" configuration page.
#### Basics Tab
Under the **Basics Tab** supply information for the Windows Server virtual machine as follows:
#####Project Details
- By now the **Subscription** label under **project details** should have a name, otherwise give **Subscription** a title.
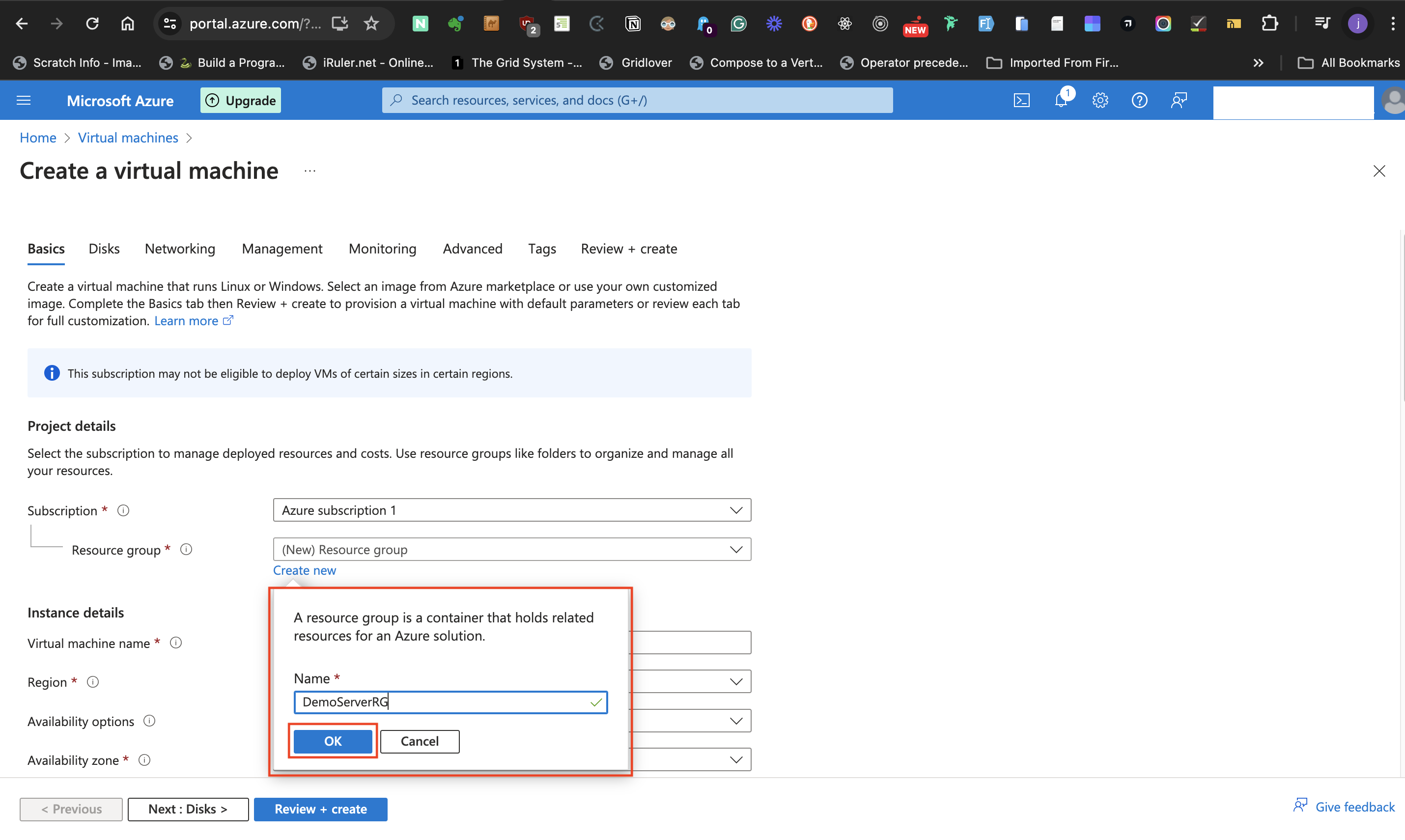
- At the **Resource group label** select **Create new** to either create a new resource group or use an existing group from the list of resource group earlier created.
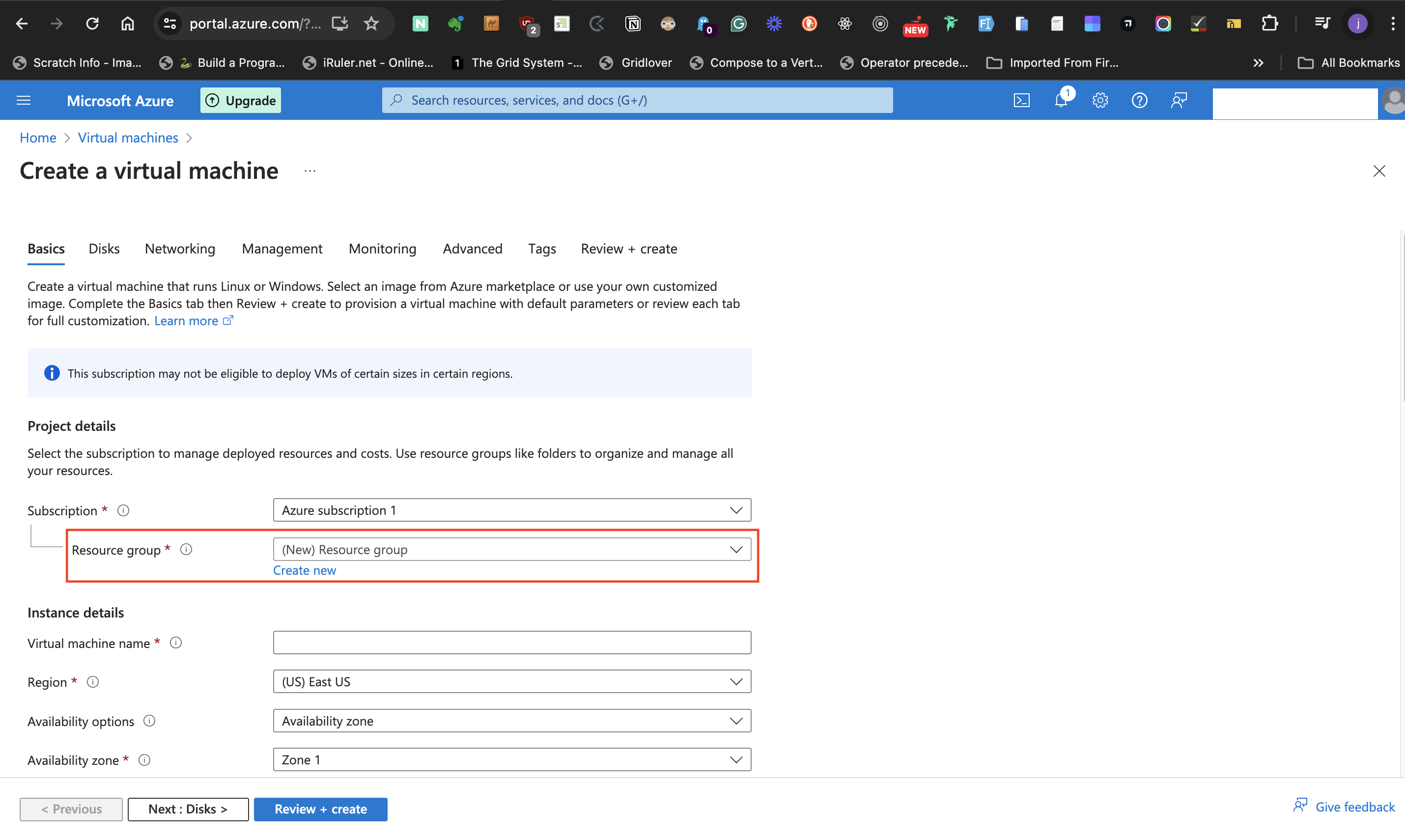
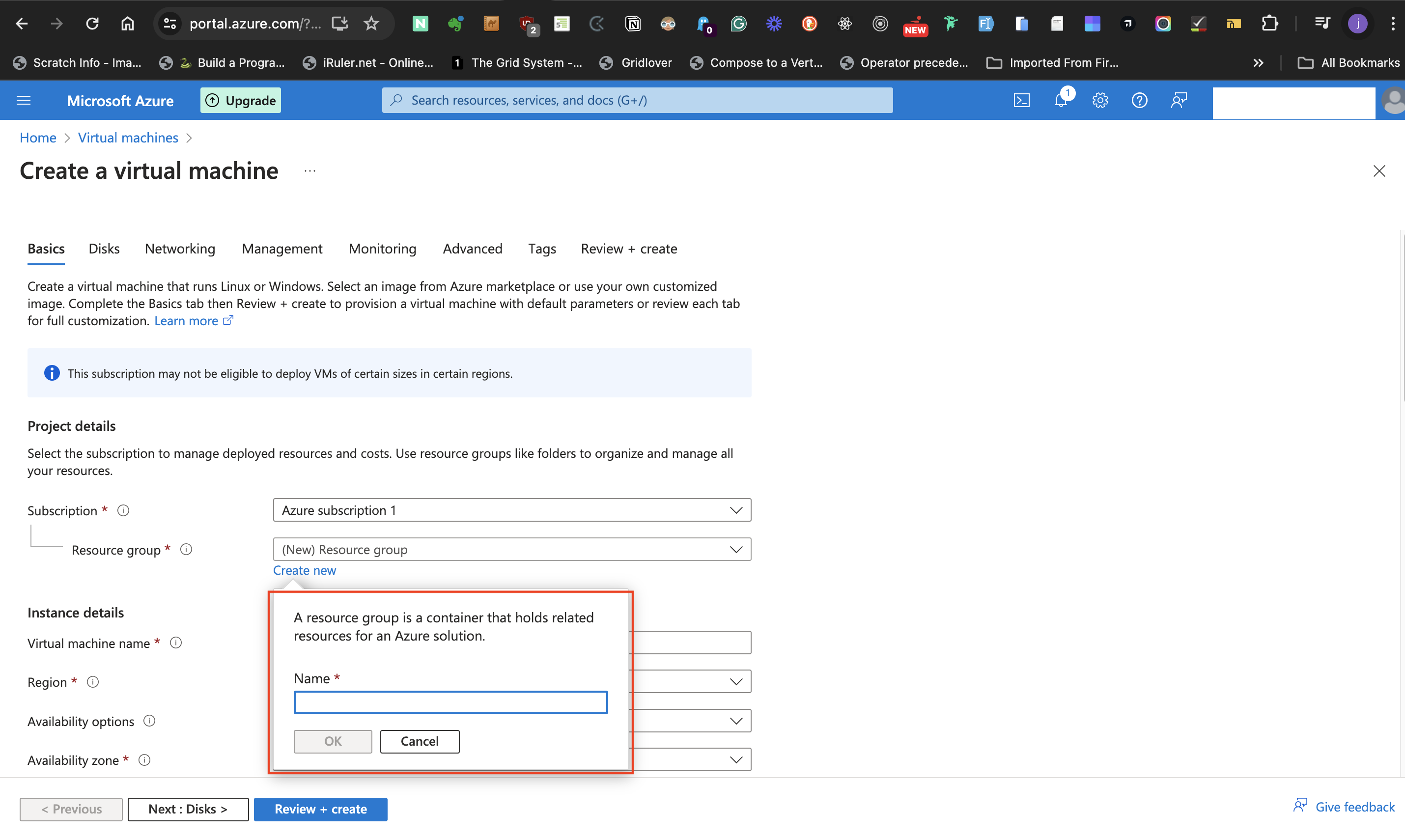
- Click the "ok" button to accept the given name.
#####Instance Details
- At the Instance Details subhead, provide a name for the virtual machine at the **Virtual machine name** label.
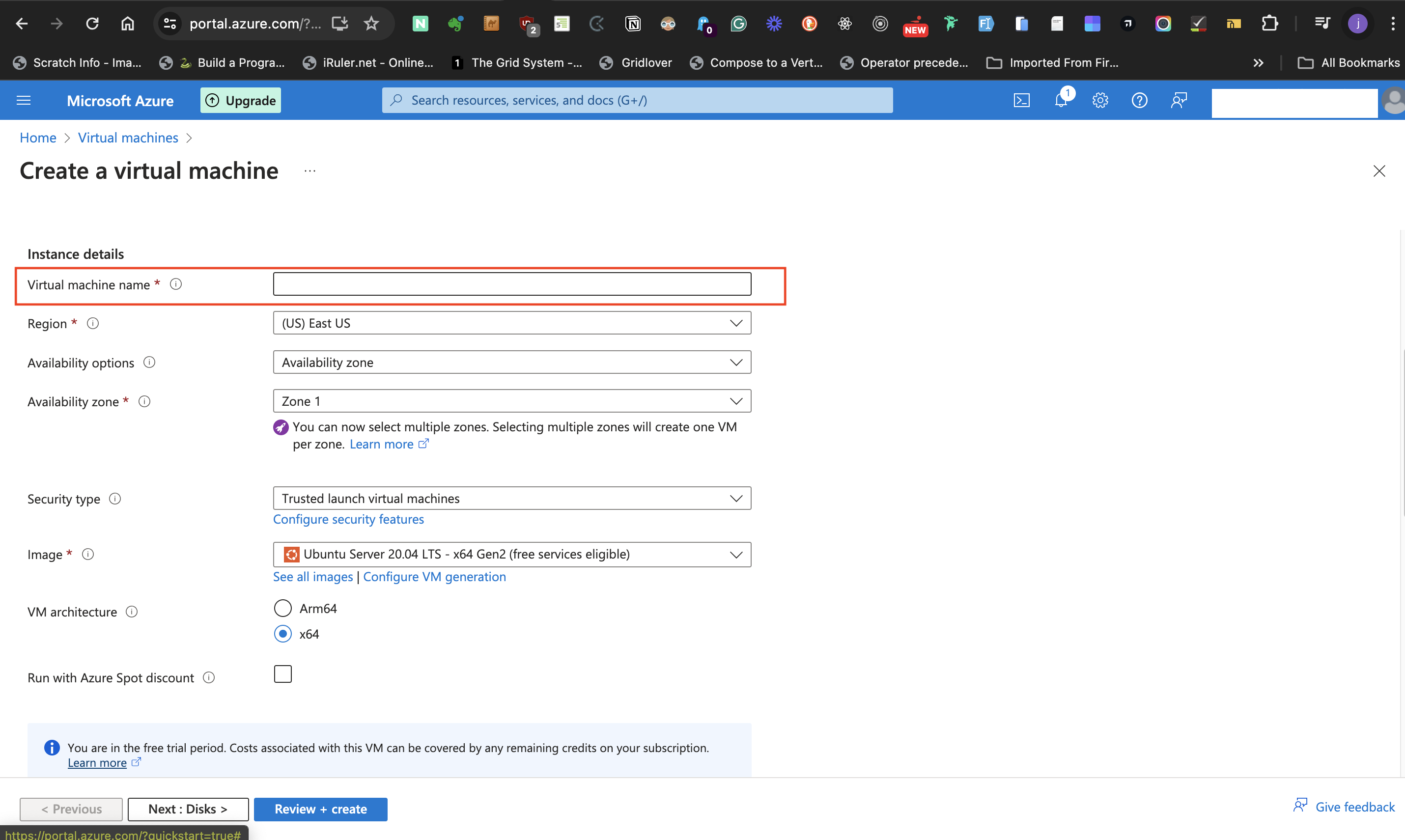
- For the **Region** label select a suitable datacenter region.
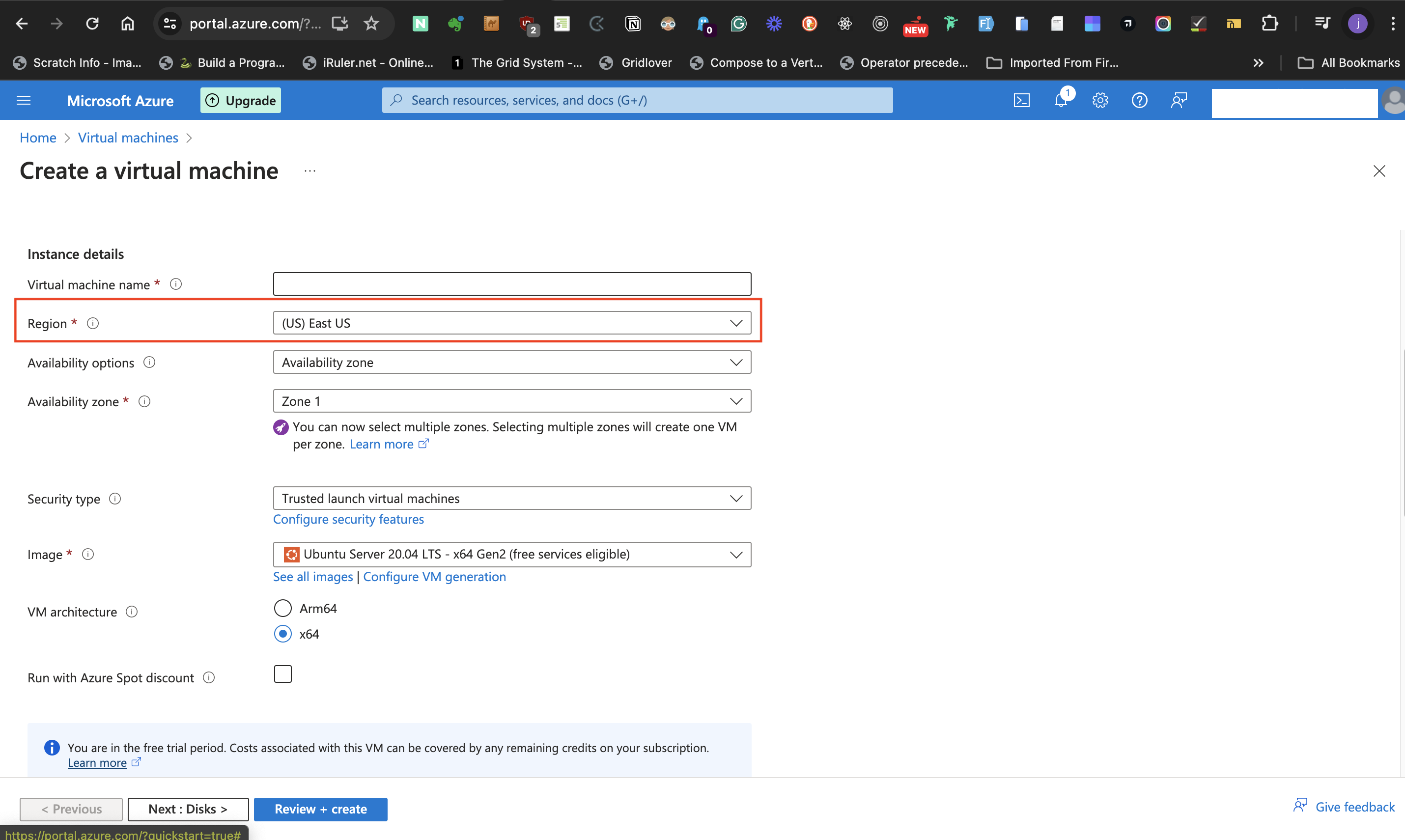
- For the **Availability options** label, select **Availability zone** as the preferred option. This permits the selection of data center zone(s) in the preceding label.
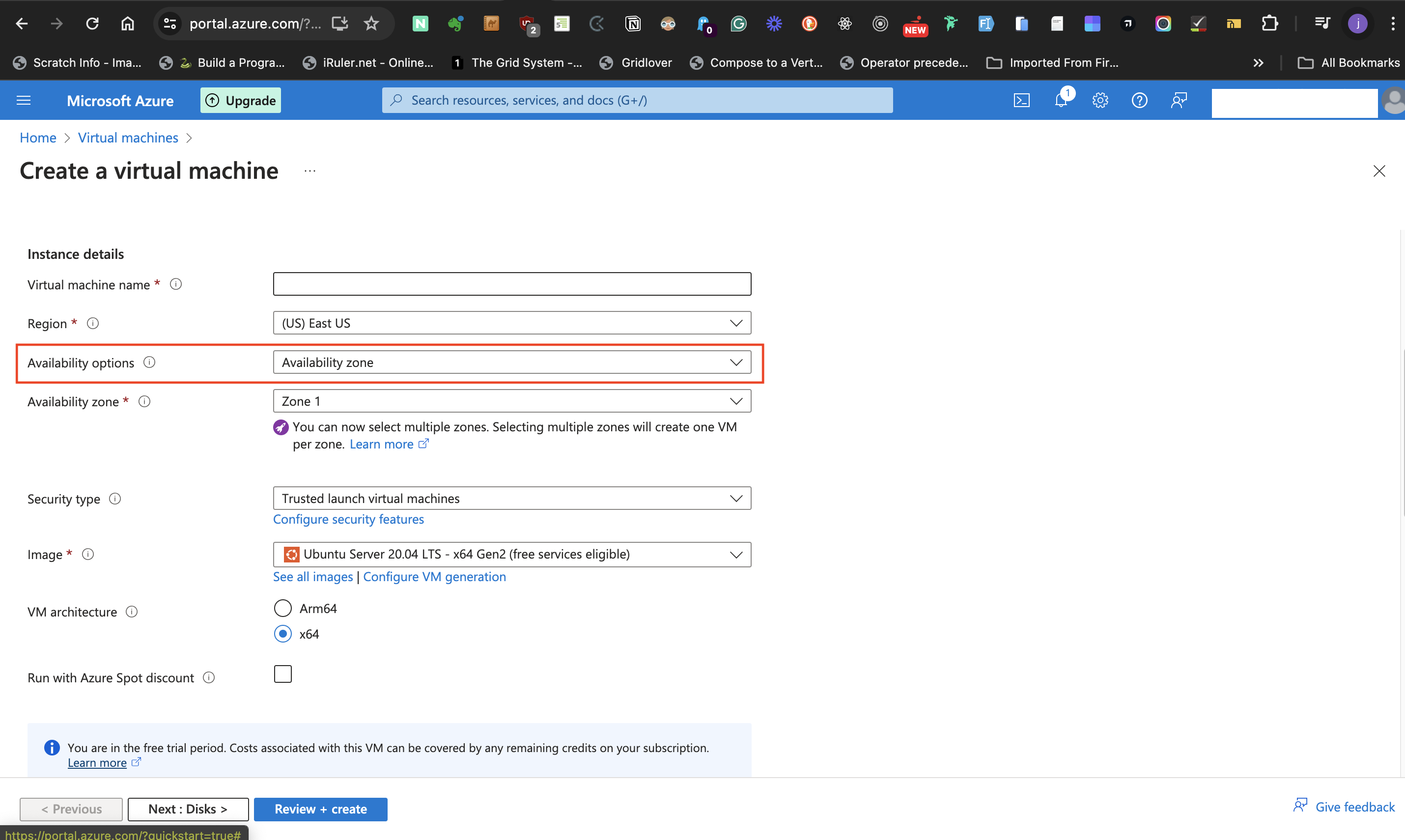
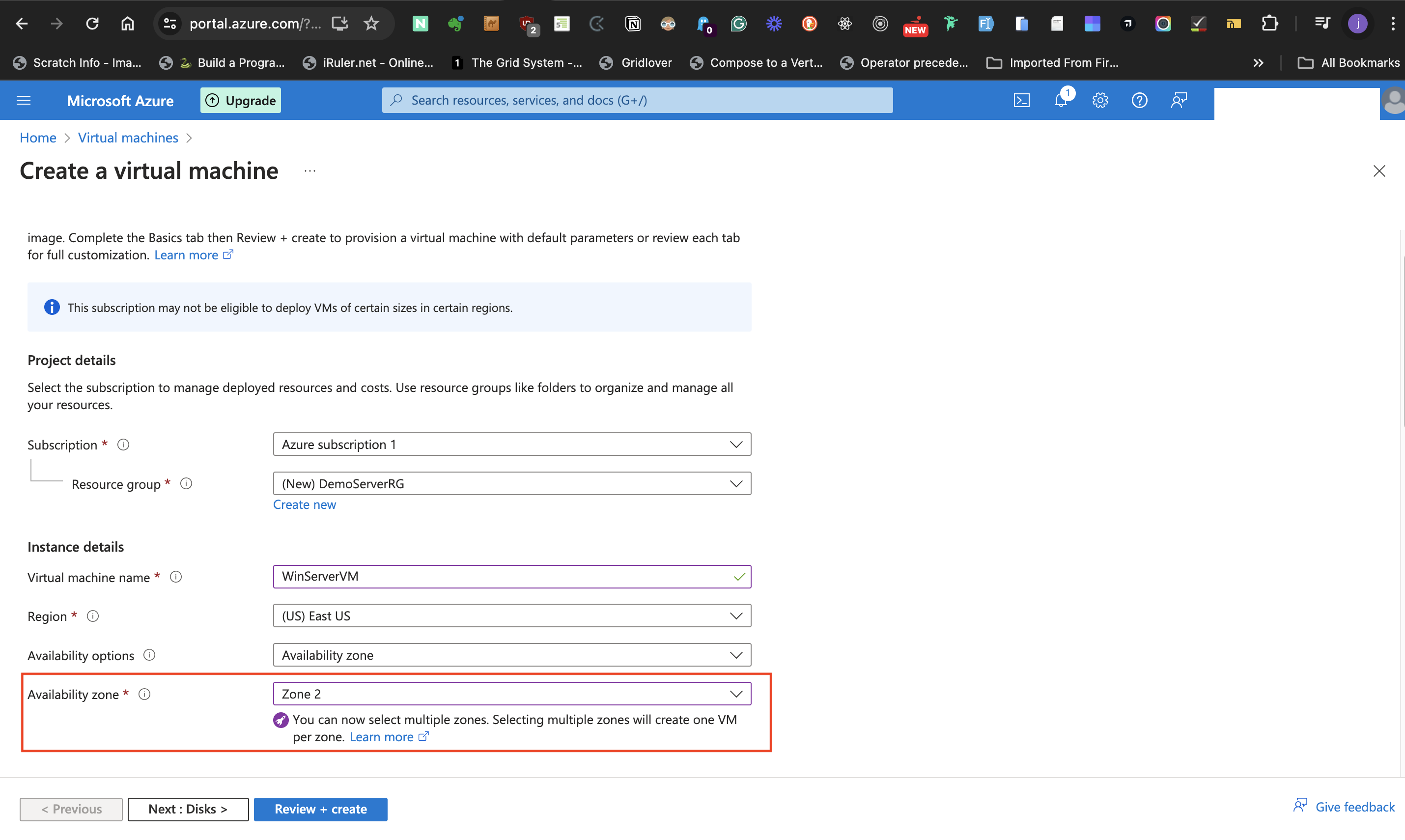
- Next, move to the **Availability zone**. This label allows for selecting multiple zones, but for the post, I selected only one zone. Selecting multiple zones means there is a need for a load balancer.
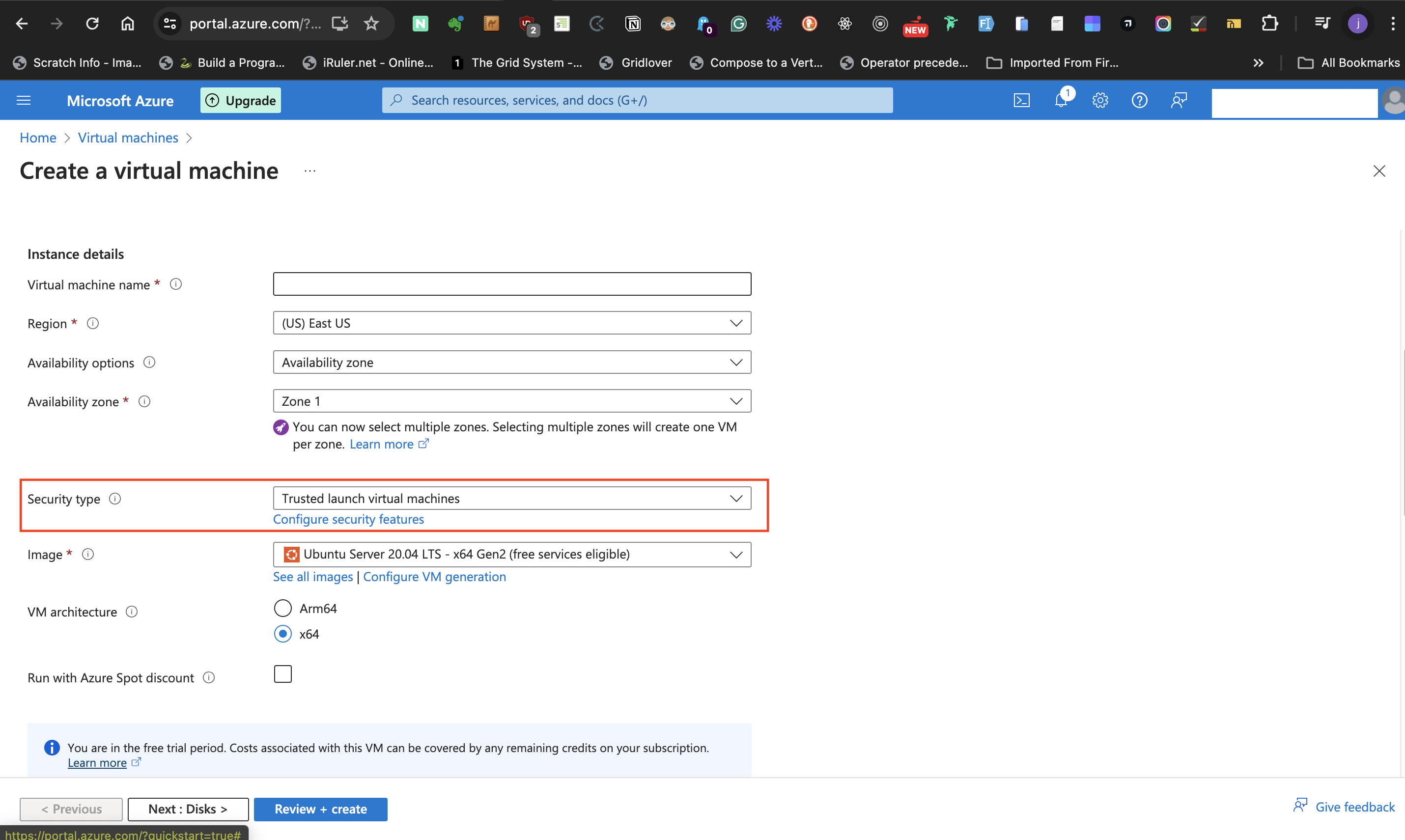
- For the **Security type** label, select **Trusted launch virtual machinnes** option.
- At the **Image** label, select the preferred Windows server option from the dropdown list.
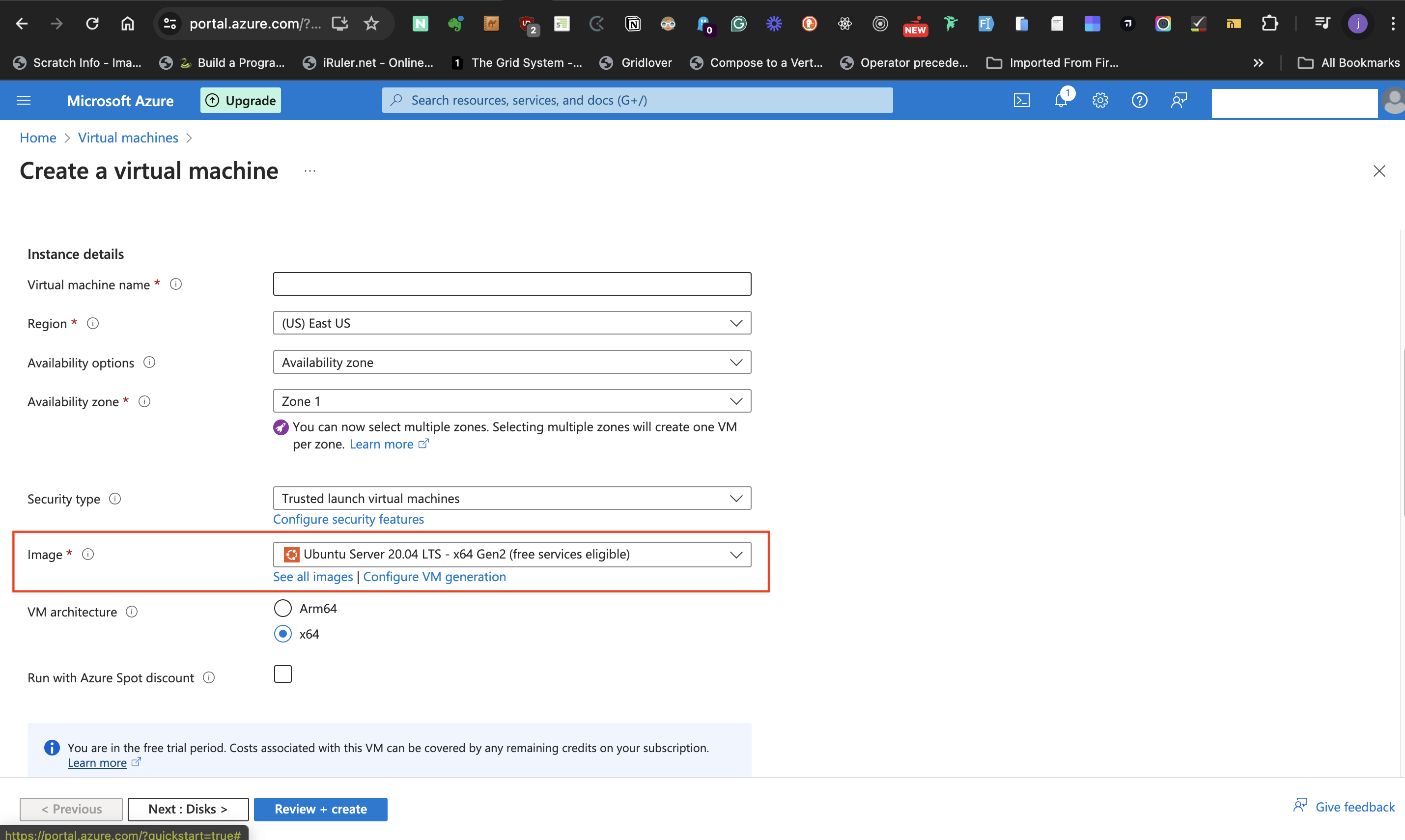
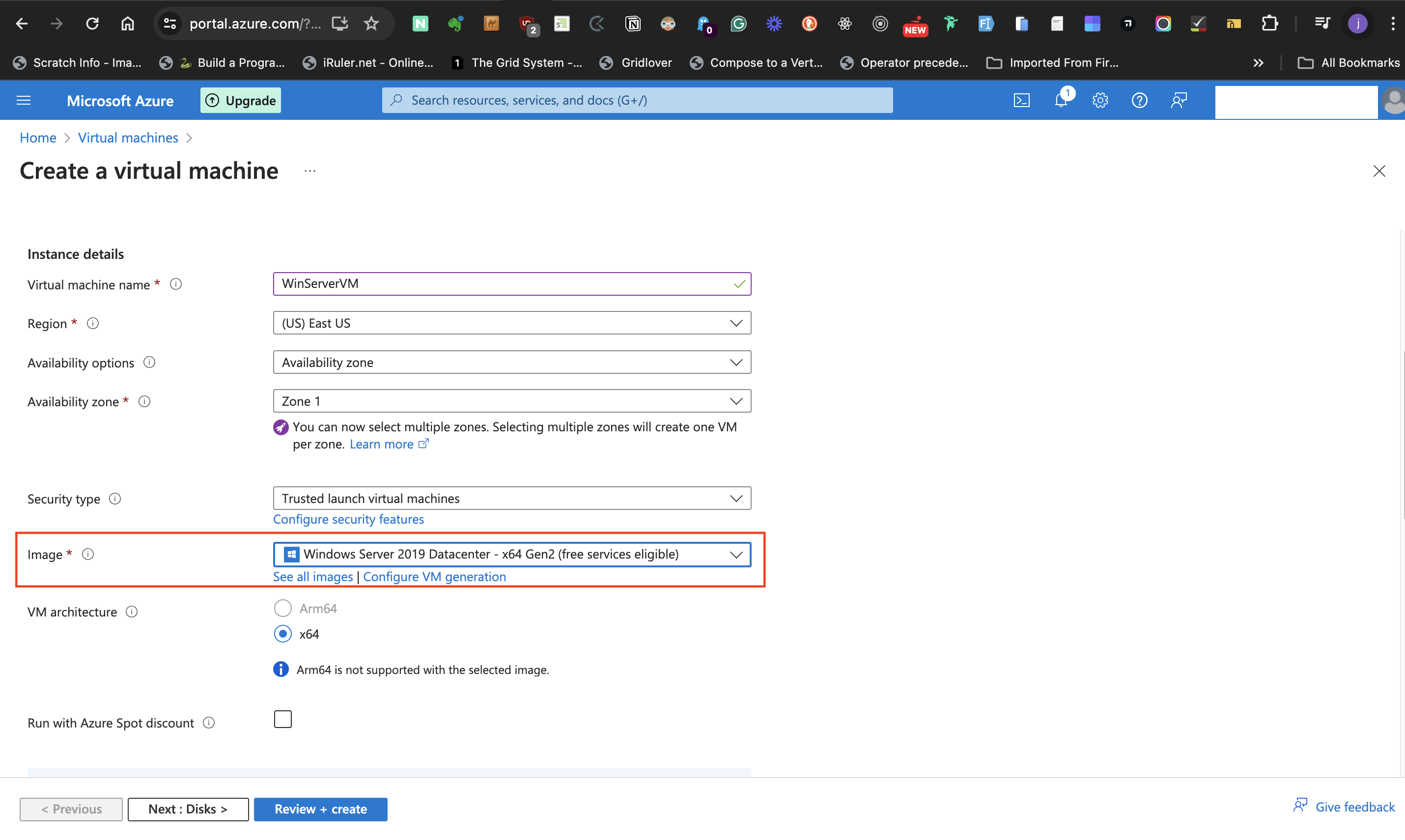
- The **VM architecture** should be kept at **x64**, and keep **Run with Azure Spot discount** unticked.
- At the **Size** label, select **Standard_B1s - 1 vcpu, 1 GiB memory** size and do not tick the **Enable Hibernationn** box.
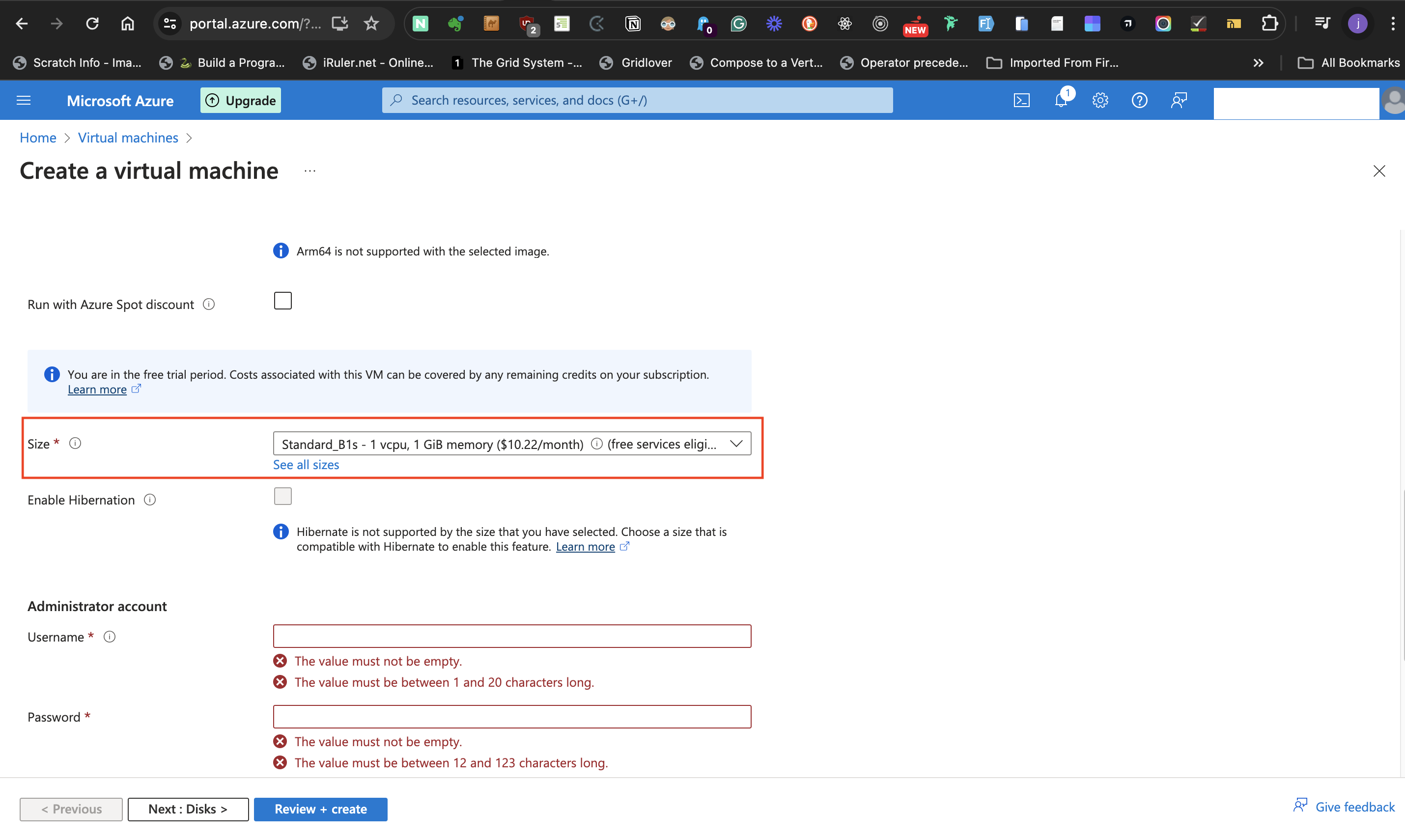
#####Administrator account
- Create a **Username** for the Windows Server and a **Password**
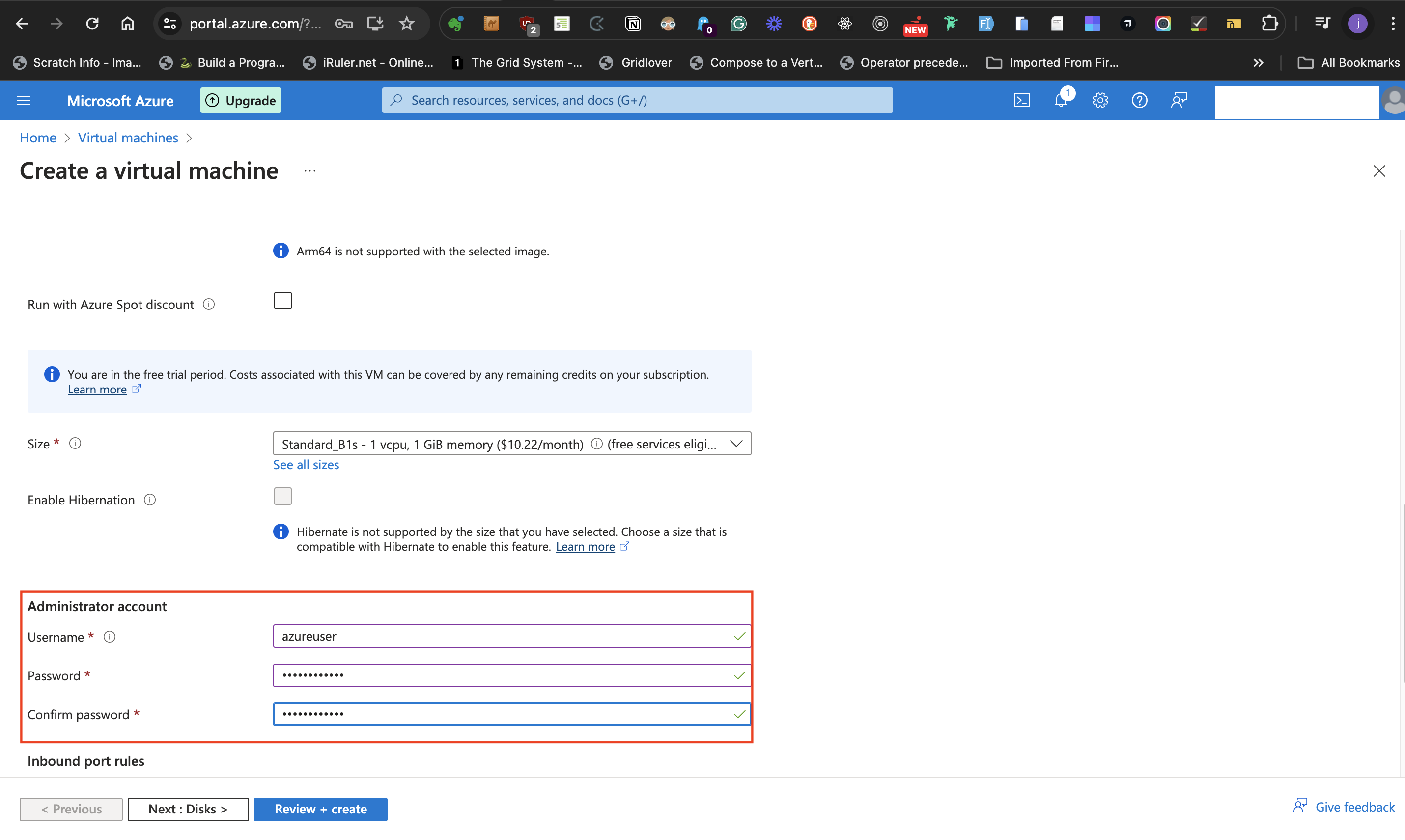
#####Inbound port rules
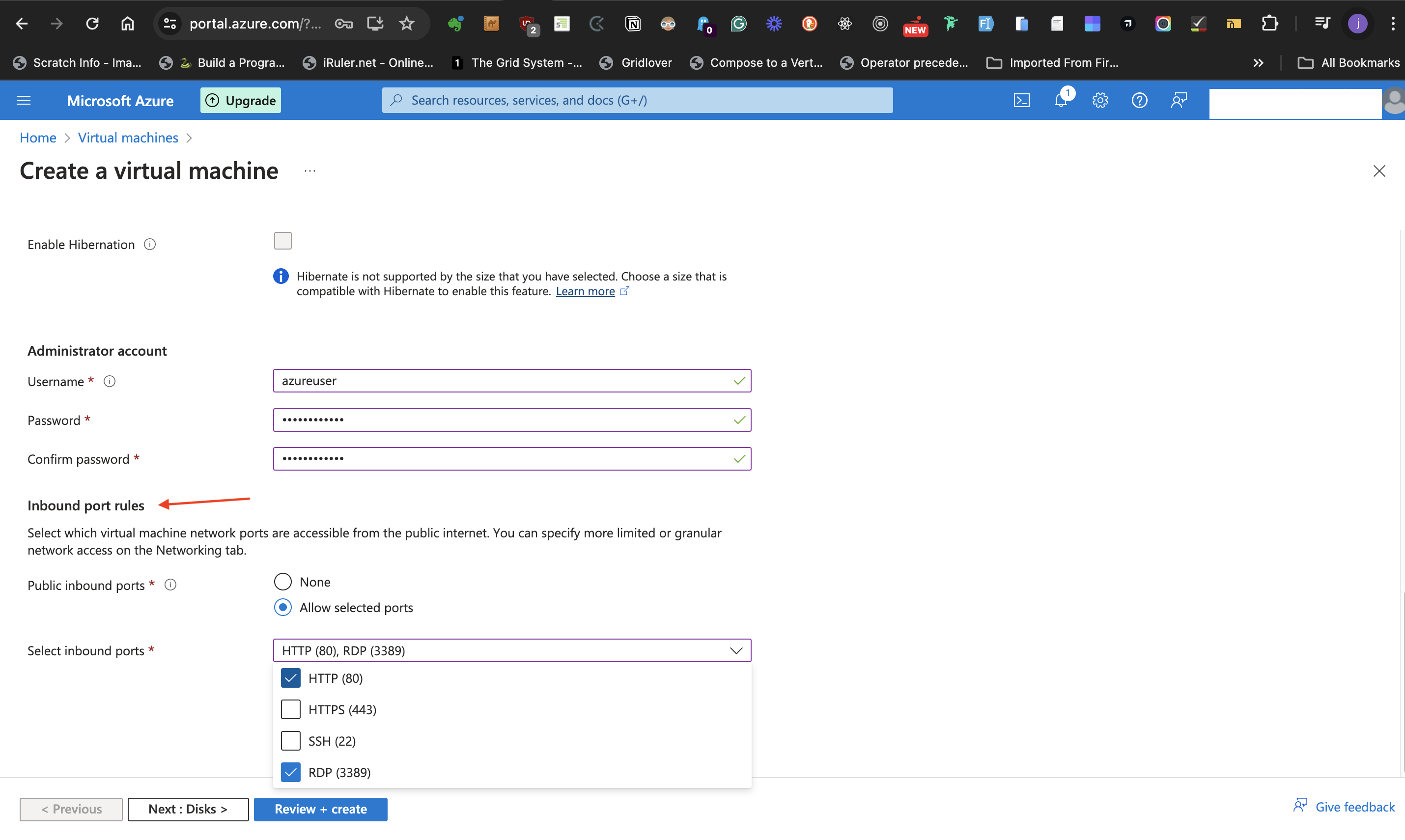
- **Allow selected ports** at the **Public inbound ports** options
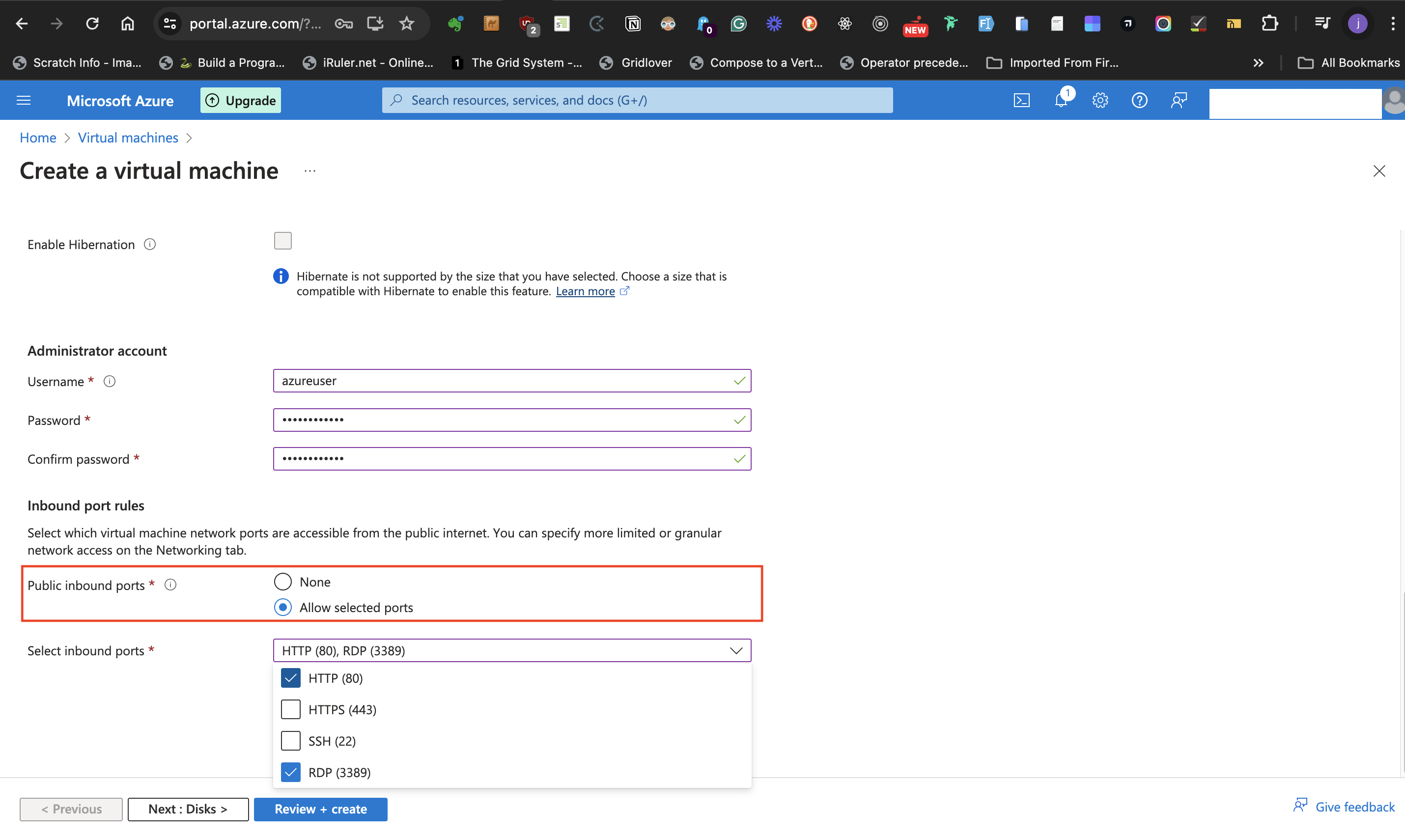
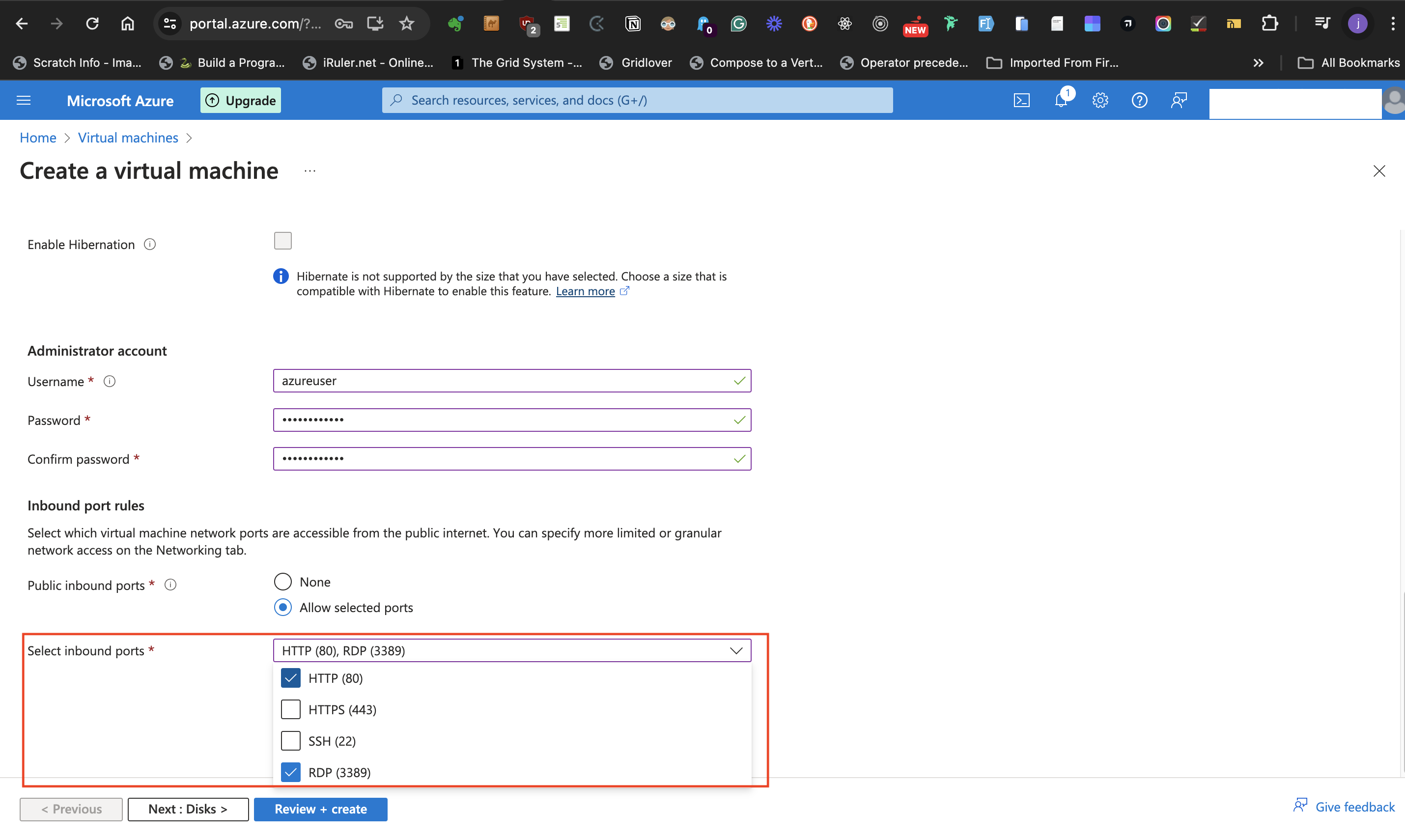
- From the **Select inbound ports** drop down list, select both **HTTP (80)** and **RDP (3389)** as the ports of communication.
#### Monitoring Tab
Under the **Monitoring Tab** it is desirable to disable Boot diagnostics.
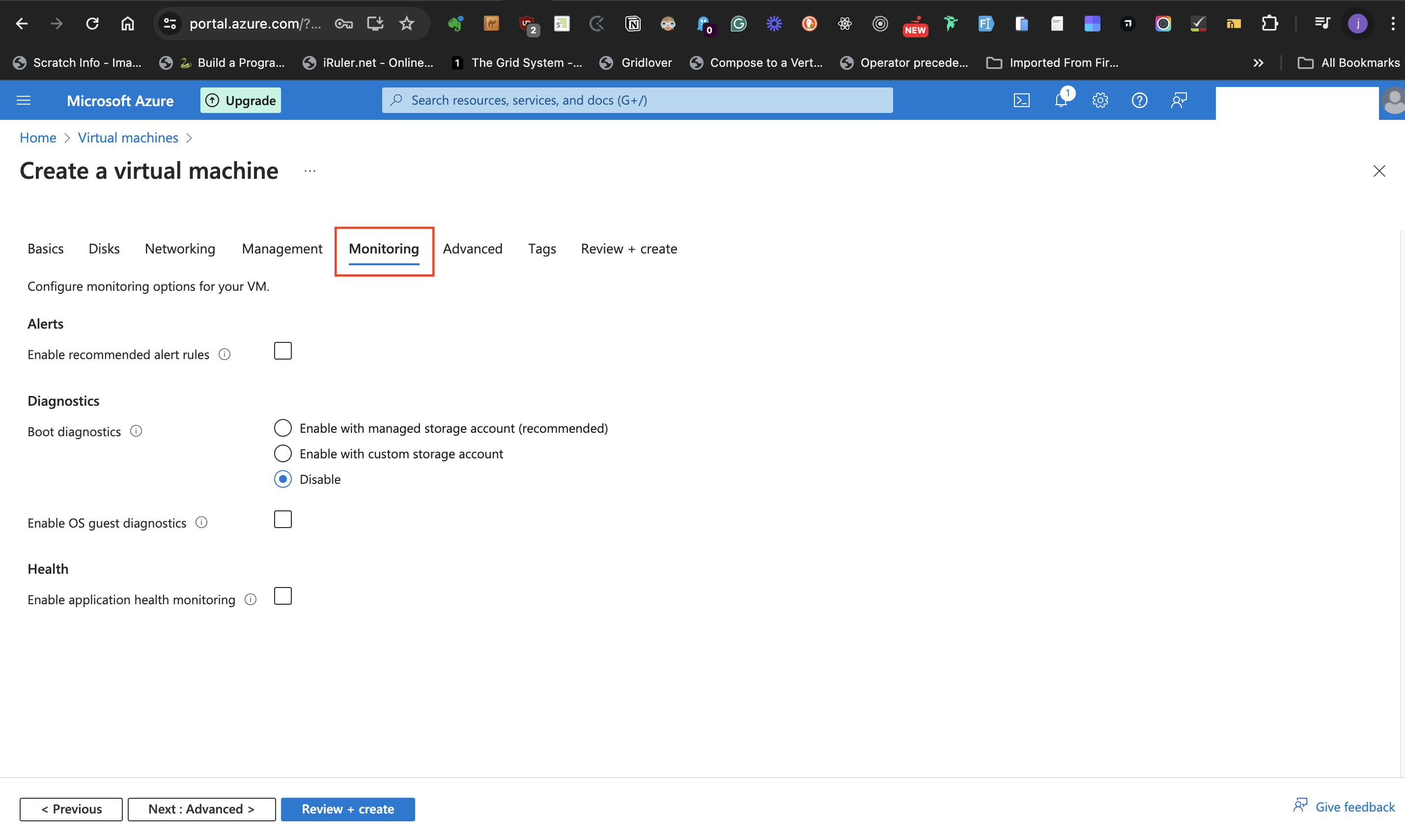
#####Diagnostics
- At the **Boot Diagnostics** label, set it to **Disable**
#### Tag Tab
Under the **Tag Tab** it is ideal that name and value are created for the resources.
- At the annotated part of the image below, give the resource a name and value. Both the name and value are called **Tags** and they help to categorize resources.
- The next step is to click the **Review + Create** button at the bottom of the page or the **Review + Create** tab at the top.
- When it has completed validation, there is a pale green banner and a green check mark at the top of the page saying "Validation passed"
- click the **create** button at the bottom of the page to initialize deployment.
- When the deployment is completed there is a notification at the top page that says "Your deployment is complete"
- click the **Go to resource** button to go to the newly created resource page.
- At the right-hand side of the page, look for the "Public IP address" label, and click on the IP address.
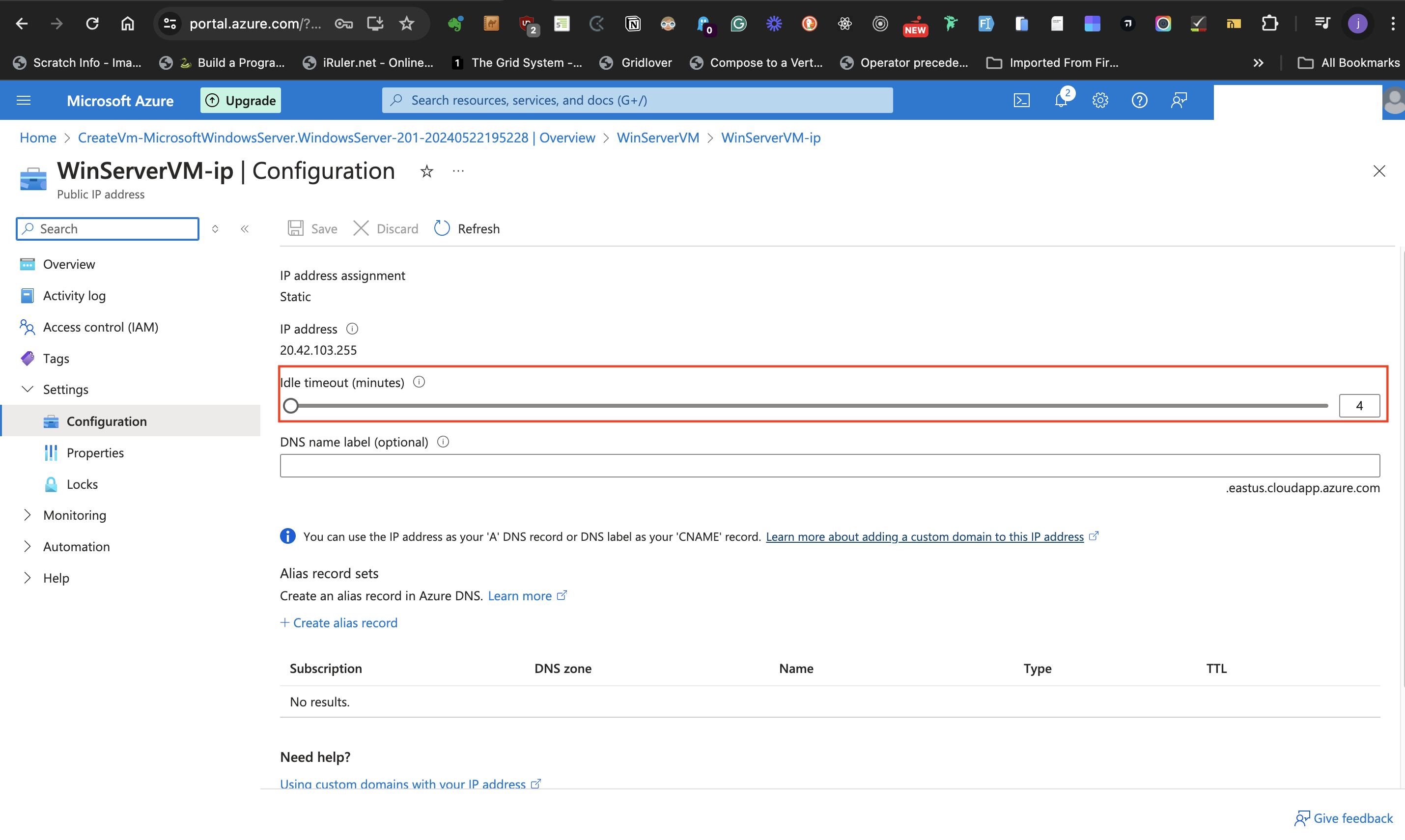
- This navigates to a page to increase the idle timeout from 4 minutes to the maximum (usually 30 minutes)
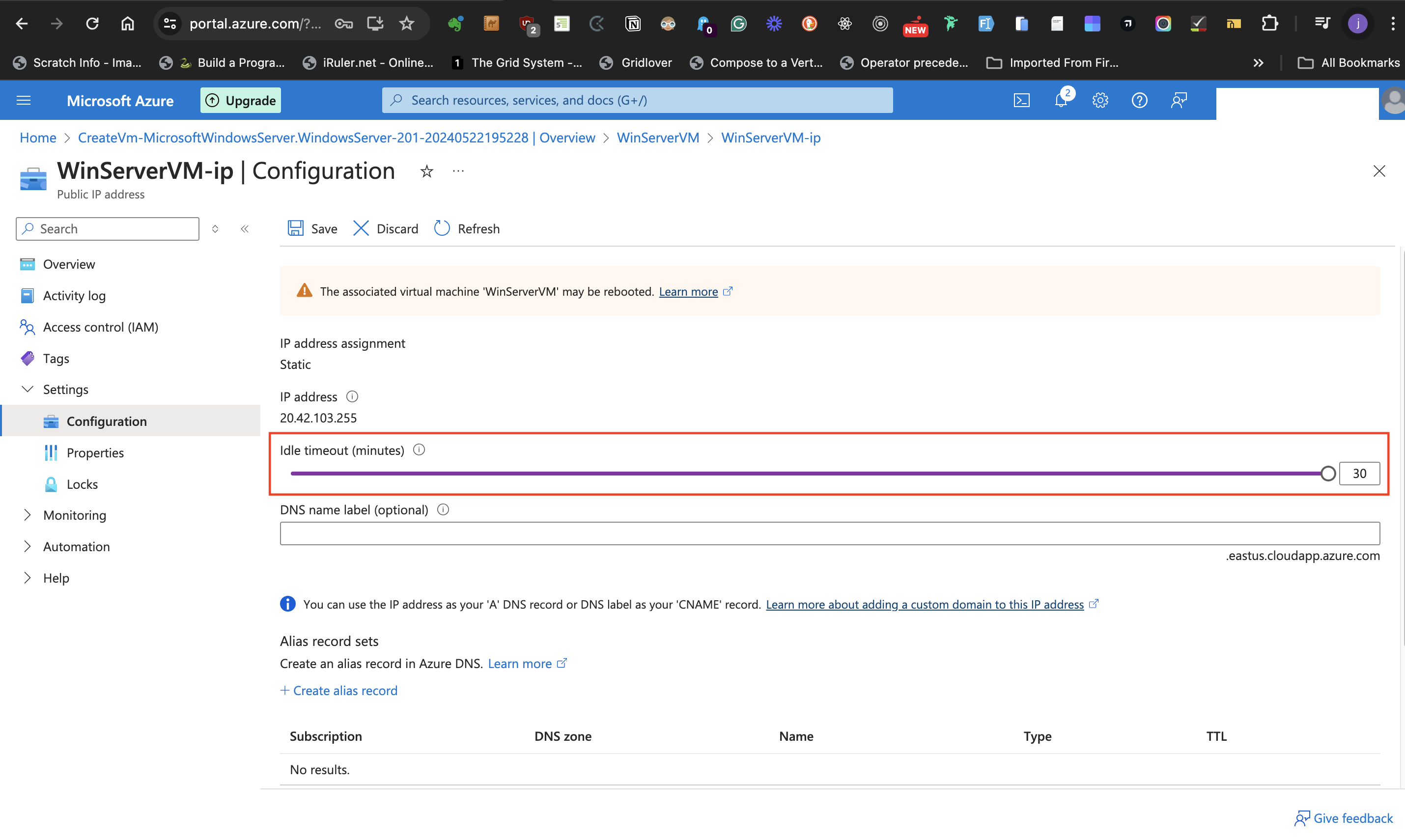
- Click on the **save** icon at the top of the page.
- you can then close the IP configuration page after making these changes by clicking the **close** button at the top right part of the page.
- Back at the Virtual Machine overview page, select **Connect** at the top level part of the page or the left-hand side of the page.
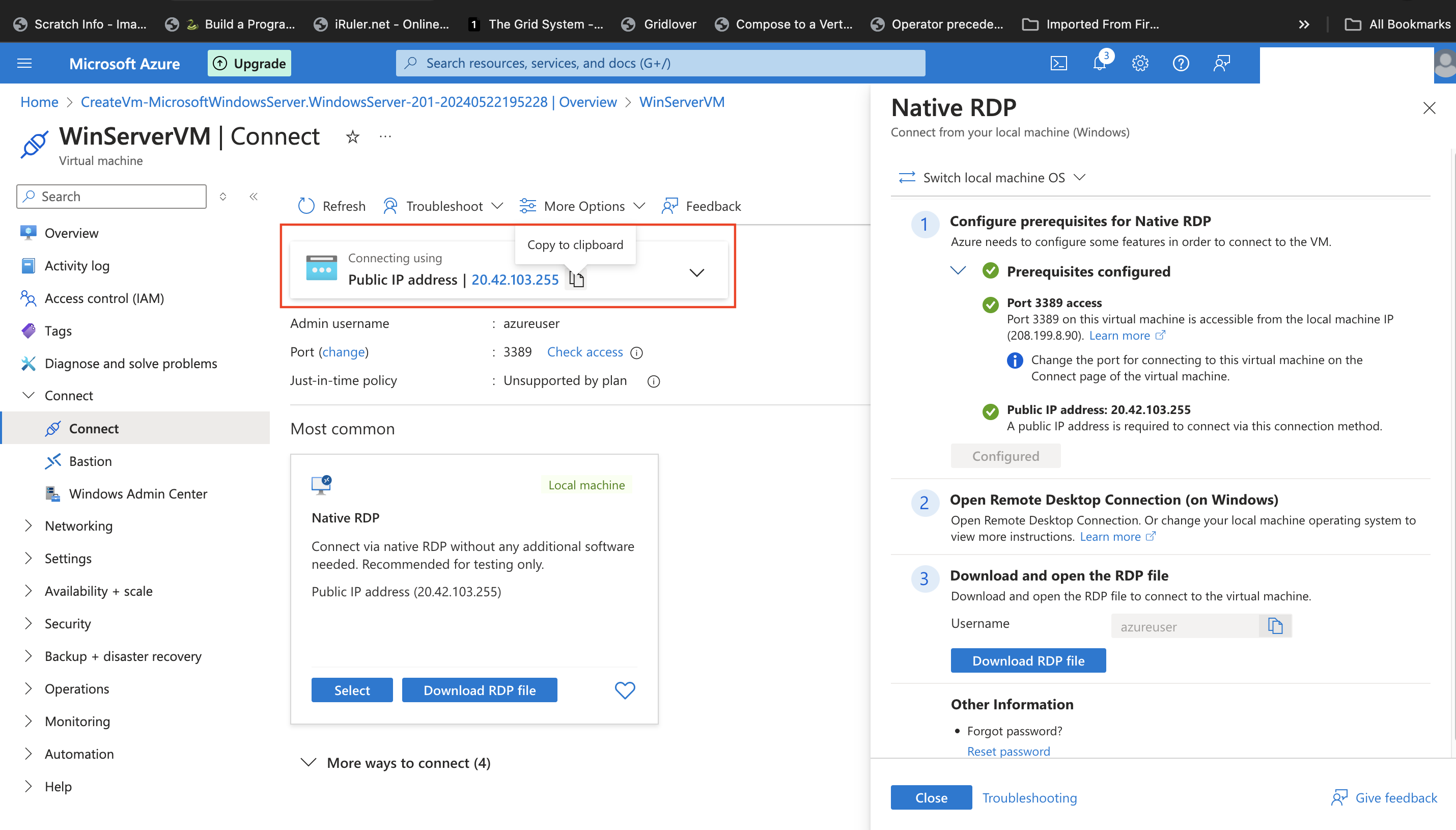
This directs to the connect page.
- Click the **Select** button at the local machine card with the heading "Most common".
- On clicking **select**, several processes are triggered to validate prerequisites before configuration. Until there is a green check mark and
"configured" at the annotated arrow in the image below, the next step can't start.
- Once the processes are completed and there are green check marks and "configured" at the annotated locations in the image above, click on the **Download RDP file** as shown below.
- This downloads the RDP file required for powering the Windows server Virtual machine that has been created. Check your default download location in your local machine for this file.
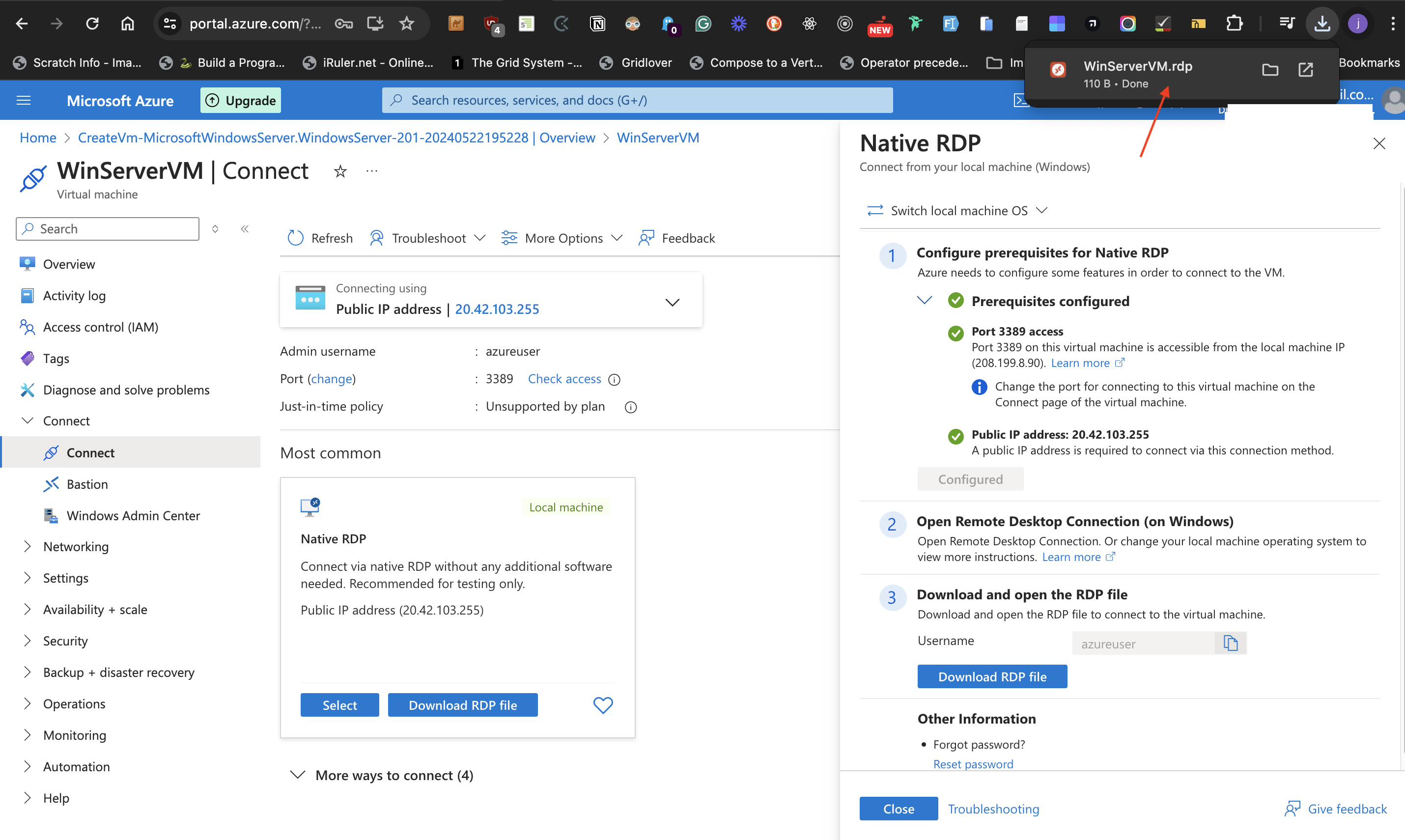
##Step 2
### Launch the Virtual Machine.
- To check if the Windows Server virtual machine works, log in using previously created credentials at the **Administrator Account** section above. Before signing in, Mac users need to go to the App Store, download and install the Microsoft Remote Desktop app. After installing the Microsoft Remote Desktop app, double-click the downloaded RDP file.
- Supply the password as required.
- Click **continue** at the next prompt
- If the correct login credentials are submitted there will be a Windows Server starting page like below.
- This automatically launches the **Server manager**

- This is followed by a setup page below.
- There is a need to also install a **Windows server iis role** in the server and there are two ways to do this. The first approach is using the server manager setup and the second one is via the terminal. In this post, I will be using the terminal.
- Close the server setup page and search **PowerShell** at the hand lens icon at the bottom of the virtual machine page. Type "PowerShell" to search.
-Right-click to launch the PowerShell terminal as an Administrator
- type in the following command in the PowerShell terminal:
**install-WindowsFeature -name Web-Server -IncludeManagementTools**
This creates the **iis** role in this server.
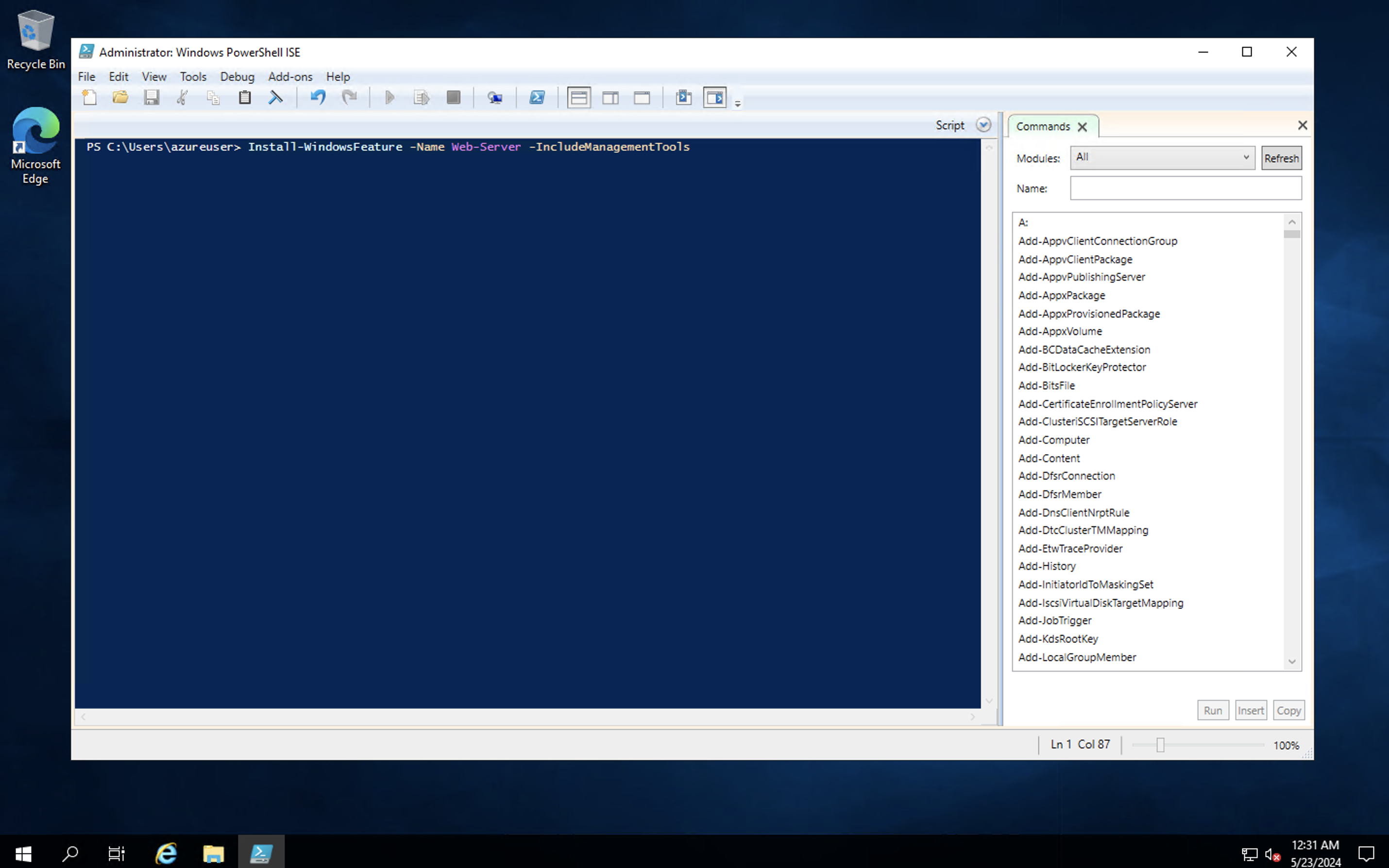
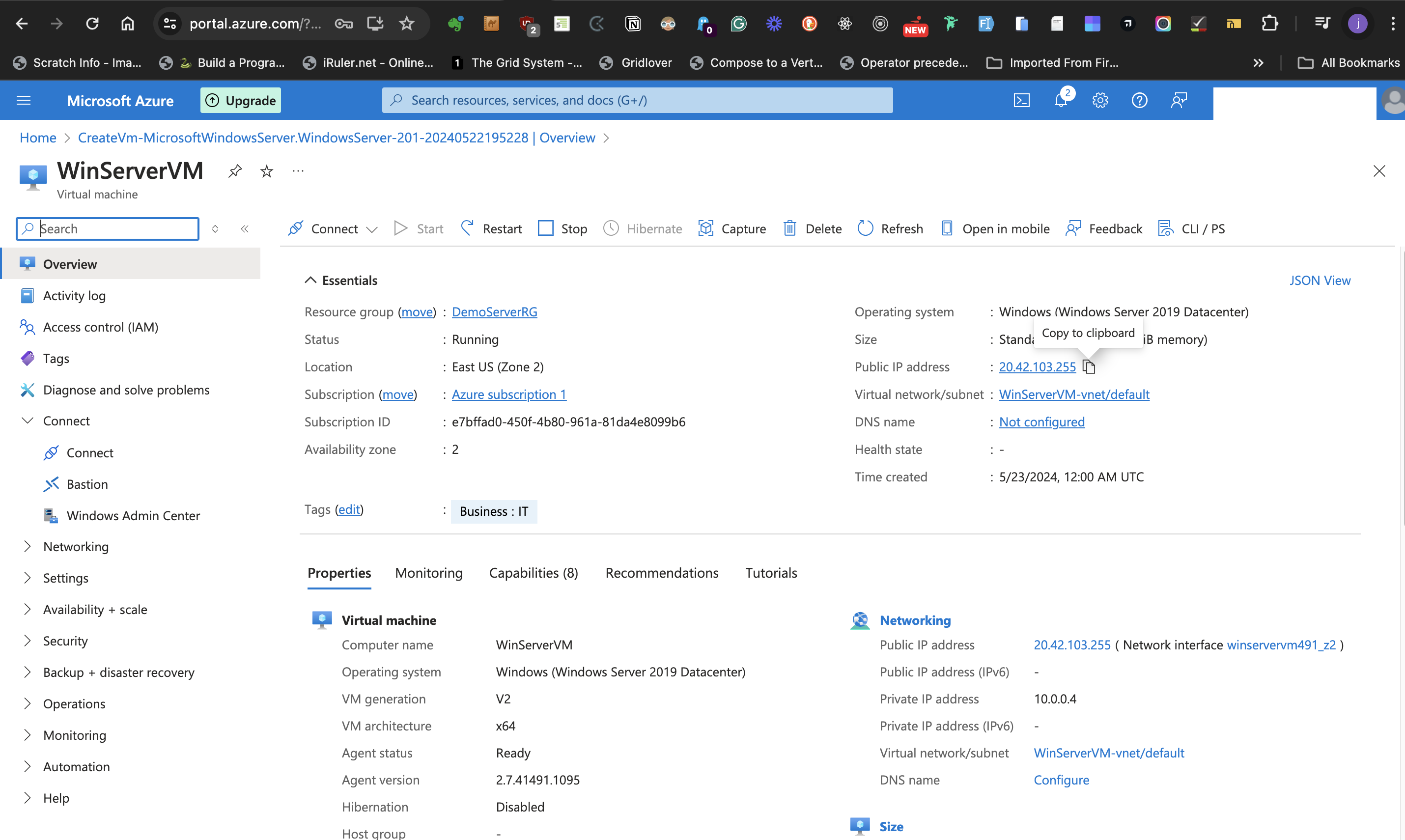
- When the role installation is complete, go to the Azure portal Windows Server Virtual Machine page, copy the **Public IP address**, and paste it on the browser.
- if the virtual machine is properly configured following these instructions, you should see something like below:
#Conclusion
With all the steps listed above, I have created a Windows Server virtual machine in an Azure portal. It is advised that the resource group in the Azure portal be deleted. However, before deleting the resource group in the Azure portal, there is a need to shut down the Windows Server virtual machine on the MacOS.
This post describes a high-level approach to creating a Windows Server virtual machine on a MacOS computer. More posts on cloud DevOps with Azure will be coming up during my journey into cloud development.
cover image by <a href="https://unsplash.com/@tvick?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Taylor Vick</a> on <a href="https://unsplash.com/photos/cable-network-M5tzZtFCOfs?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Unsplash</a>
| tundeiness |
1,865,718 | Join Me on X Now! | Hello dev.to community! First and foremost, a huge thank you to each one of you for... | 0 | 2024-05-26T15:37:41 | https://dev.to/bingecoder89/join-me-on-x-now-2n6m | webdev, beginners, codenewbie, tutorial | ## Hello dev.to community!
First and foremost, a huge thank you to each one of you for following my journey and supporting my work here on dev.to. Your engagement and feedback have been invaluable.
Today, I want to share an exciting way for us to stay even more connected and ensure you never miss an update on my latest projects and articles.
## Why Follow Me on X?
While dev.to is my go-to platform for detailed articles and project write-ups, X (formerly known as Twitter) offers a complementary space for quick updates and immediate engagement. Here’s why you should follow me on X:
### 1. **Instant Article Notifications**
On X, I share immediate updates every time I publish a new article on dev.to. If you follow me, you’ll be the first to know about my latest insights and tutorials, ensuring you never miss a post.
### 2. **Project Updates**
I often post progress updates on my ongoing projects on X. These include sneak peeks, behind-the-scenes looks, and quick updates that don’t always make it into my dev.to articles.
### 3. **Engage in Quick Discussions**
X allows for quick and direct interactions. If you have questions or thoughts about my latest project or article, you can easily reach out to me there for a speedy response.
### 4. **Stay in the Loop**
By following me on X, you can stay up-to-date with my latest activities and announcements. Whether it's a new project launch, a significant milestone, or an exciting development, you’ll hear about it first on X.
## How to Follow Me
Joining me on X is simple! Just click the link below and hit the follow button:
[Follow Me on X](https://twitter.com/@AnkitBal71210)
Your support on X would mean a lot to me. It’s another great way for us to connect, share ideas, and continue growing our community of developers.
## Let’s Stay Connected!
Thank you for considering following me on X. Your engagement on both dev.to and X helps me to keep creating valuable content and sharing my projects with you. I look forward to continuing this journey together across both platforms.
Stay awesome, and see you on X!
--- | bingecoder89 |
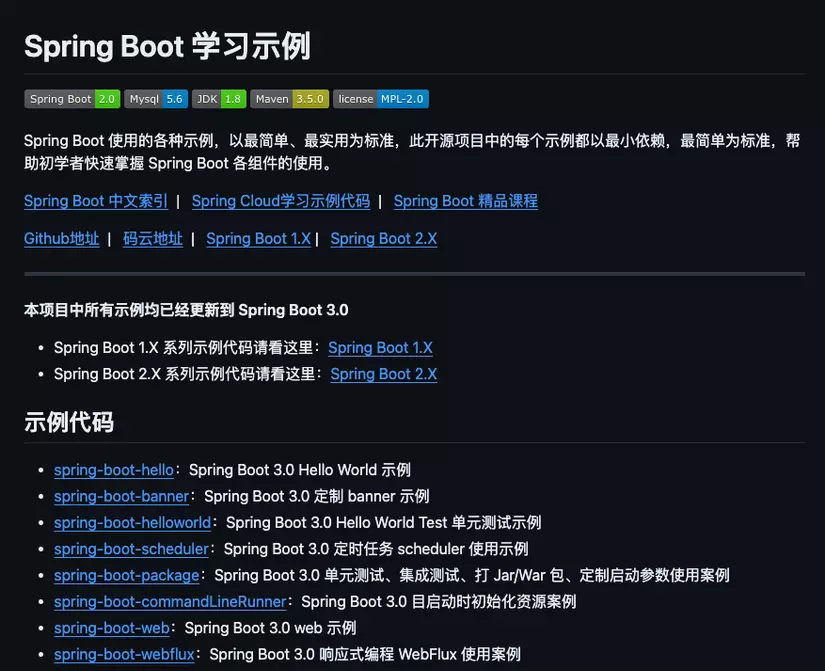
1,865,717 | Top 10 GitHub repositories for Java developers ✨ | Data updated on May 18, 2024 Top 1. Java Guide - 144k ⭐️ This is the repo made by... | 0 | 2024-05-26T15:36:32 | https://dev.to/tmsanghoclaptrinh/top-10-github-projects-to-help-you-programming-java-1h93 | webdev, beginners, programming, java | > Data updated on May 18, 2024
## [Top 1. Java Guide - 144k ⭐️](https://github.com/Snailclimb/JavaGuide)
> This is the repo made by Chinese developers. If you often follow GitHub, you will know that Chinese developers share many repos with excellent and extremely detailed programming knowledge. And of course, **Java Guide** is one of them 👨💻
>
> Now all browsers have the function to translate the entire website (For example in Google Chrome, you can right-click and click Translate to English), so you can absolutely use that feature to translate the repo into English for easy reading and understanding.
>
> Although the translation is not 100% accurate, with genuine repos like this, having a solution like this is great, right?
>
> 👉️ Github: https://github.com/Snailclimb/JavaGuide
>
> 
---
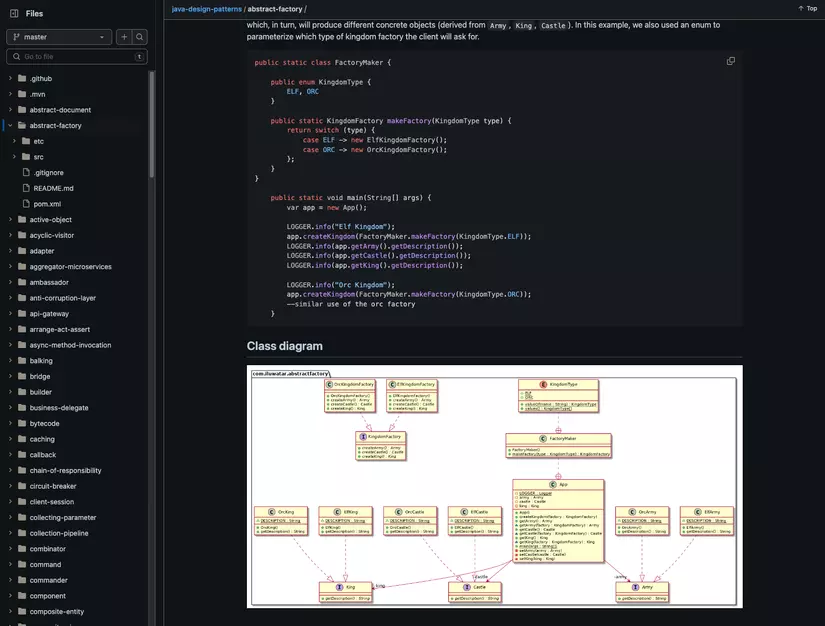
## [Top 2. Design Patterns implemented in Java - 86.7k ⭐️](https://github.com/iluwatar/java-design-patterns)
> Surely you have all heard that **Design Patterns** is one of the important knowledge that helps you progress from Junior to Mid-level to Senior, right? 🚀
>
> Understanding and applying Design Patterns effectively will help programmers solve problems when designing applications or systems.
>
> This repo will guide you thoroughly about Design Patterns, and implement them using the **Java** programming language.
>
> 👉️ Github: https://github.com/iluwatar/java-design-patterns
>
> 
---
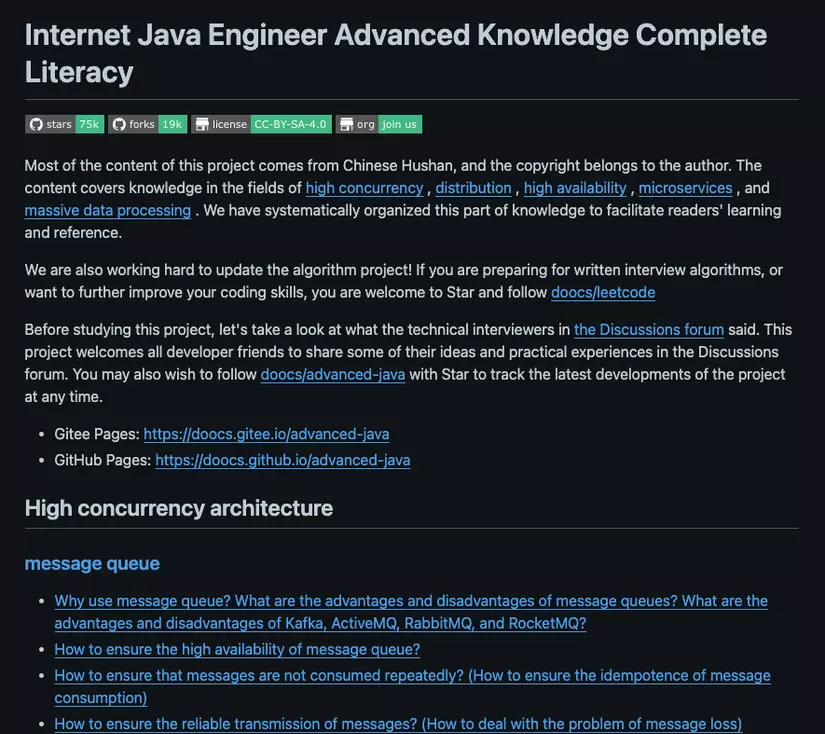
## [Top 3. advanced-java - 74.6k ⭐️](https://github.com/doocs/advanced-java)
> Another great repo from Chinese developers** 🤓
>
> However, this repo collects documents specifically for **experienced Java developers** 💼
>
> In this repo there is mostly advanced knowledge such as:
> - **High concurrency architecture:** Message queue, Search engine, Cache, Highly concurrent systems, ...
> - **Distributed Systems**
> - **Highly available architecture**
> - **Microservice architecture**
> - **Massive data processing**
>
> Repo follows the direction of **asking interview**, related to the advanced knowledge mentioned above, then will give **ideas** for answers and **suggestions detailed answer (if any)**
>
> 👉️ Github: https://github.com/doocs/advanced-java
>
> 
---
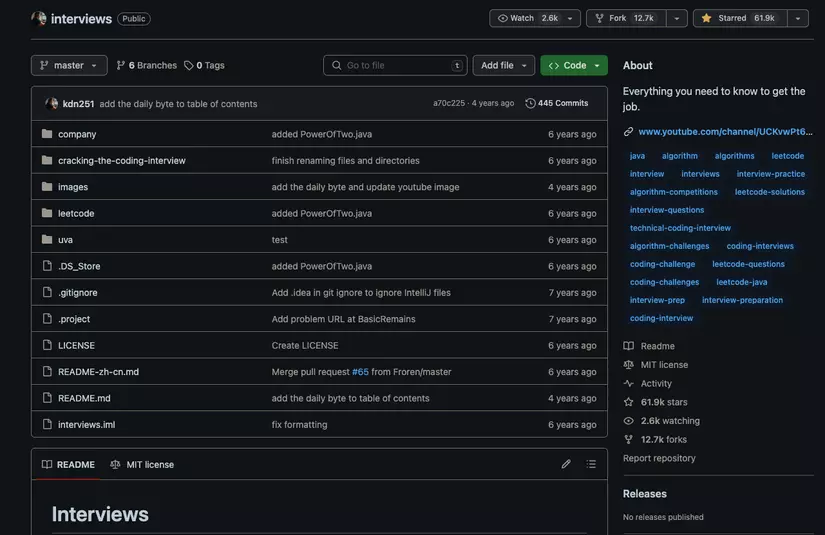
## [Top 4. interviews - 61.9k ⭐️](https://github.com/kdn251/interviews)
> The name says it all. This repo will help you thoroughly prepare Java programming knowledge, before participating in **interviews** 👨💻
>
> The author mainly shares questions related to coding, and of course **includes solutions**, to handle problems that big companies like Adobe, Facebook, Google, Amazon give.
>
> Besides, there are instructions for solving exercises on **LeetCode**, or in the famous book **"Cracking the coding interview"** using the Java programming language 📝
>
> 👉️ Github: https://github.com/kdn251/interviews
>
> 
---
## [Top 5. TheAlgorithms - Java - 57k ⭐️](https://github.com/TheAlgorithms/Java)
> The GitHub page of **"The Algorithms"** is probably too famous for algorithm enthusiasts.
>
> This **"TheAlgorithms - Java"** repo is one of their sub-repos, helping you understand and implement **data structures and algorithms** using the **Java** programming language.
>
> 👉️ Github: https://github.com/TheAlgorithms/Java
>
> 
---
## [Top 6. Awesome Java - 40.1k ⭐️](https://github.com/akullpp/awesome-java)
> It's a fact that many repos on GitHub start with the word **"awesome"** which is **"awesome"** exactly as the name suggests 🤩
>
> Repo **Awesome Java** is a list of frameworks, libraries and applications written in genuine Java, serving many different purposes 👨💻
>
> - From Backend programming, Job Scheduling, Logging, ...
>
> - Up to mobile programming, games, networking, ...
>
> This will definitely be a useful reference source for Java developers.
>
> 👉️ Github: https://github.com/akullpp/awesome-java
>
> 
---
## [Top 7. JavaFamily - 35.5k ⭐️](https://github.com/AobingJava/JavaFamily)
> A repo that compiles many Study Guides, as well as interview questions related to Java.
>
> According to the author, this repo covers almost all of **the core knowledge that Java programmers need to know to become a master** 🧠
>
> The author of this repo is Ao Bing - he has 8 years of programming experience, and was once **Blog Star Top 1** on China's CSDN site. His CSDN page currently has **more than 300,000** fan followers, and on bilibili there are also nearly **250,000 fans** 🥇
>
> 👉️ Github: https://github.com/AobingJava/JavaFamily
>
> 
---
## [Top 8. Spring Boot Demo - 32.2k ⭐️](https://github.com/xkcoding/spring-boot-demo)
> I don't know China's technology market very well. But when searching for Java repos, highly appreciated by the community on GitHub, I found many repos from developers in this country.
>
> **Spring Boot Demo** is a repo containing all **source code** of demo applications, coded with Spring Boot. Java developers must be very familiar with Sprint Boot, right? 🙌
>
> According to a rough count, there are about **65 demo projects** in this repo, free for you to learn and research.
>
> 👉️ Github: https://github.com/xkcoding/spring-boot-demo
>
> 
---
## [Top 9. Spring Boot Example - 29.9k ⭐️](https://github.com/ityouknow/spring-boot-examples)
> This repo also has the same purpose as the above repo, but with a different author.
>
> The author is a Chinese developer, again 🫣
>
> But the repo above is over **32.2k** ⭐️, and this guy's is also around **30k** ⭐️, so I have to admit it is "six of one and half a dozen of the other"
>
> In my subjective opinion, it's probably because the guy above plays too hardcore, up to 65 projects. And this guy only has more than 20 projects to share with the community.
>
> As for quality details within each project, please proactively access the GitHub link below to test.
>
> 👉️ Github: https://github.com/ityouknow/spring-boot-examples
>
> 
---
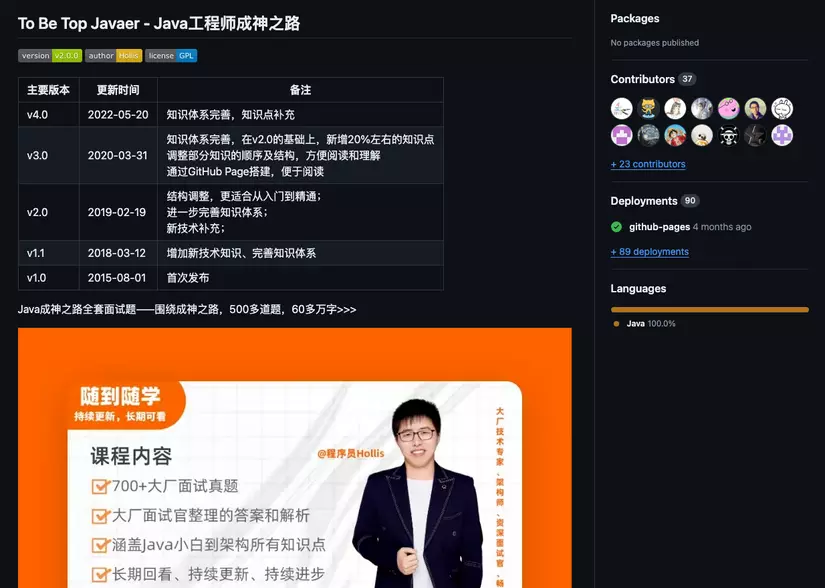
## [Top 10. To Be Top Javaer - 25.2k ⭐️](https://github.com/hollischuang/toBeTopJavaer)
> The repo name shows the author's great confidence. But look at the photo in the **README** section, if you know Chinese, please translate it for me to see if he is selling the course 😅
>
> When going into the source part of the repo, the author provides a clear **mind map**, as well as detailed knowledge **from basic to advanced**, structured into folders as well 👍
>
> Ignoring the issue of whether the author sells the course or not, I think this effort of sharing knowledge for free with everyone is worthy of recognition 💯
>
> 👉️ Github: https://github.com/hollischuang/toBeTopJavaer
>
> 
---
Thanks for reading! Write about your favourite GitHub repositories in the comments!
Btw, you can support my work by buying me a coffee!
<a href="https://www.buymeacoffee.com/tmsanghoclaptrinh" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a>
Thank you 🌻
Hope this help. See ya 👋
~ Sang Minh Tran from Vietnam 🇻🇳 | tmsanghoclaptrinh |
1,865,713 | Big Data: a ferramenta que precisamos. | Big Data é o termo usado para descrever uma grande quantidade de dados, que a todo momento são... | 0 | 2024-05-26T15:32:03 | https://dev.to/delmiro/um-pouco-sobre-big-data-497j | bigdata, database, datascience, backend | Big Data é o termo usado para descrever uma grande quantidade de dados, que a todo momento são gerados por pessoas que registram e documentam tudo que acontece ao seu redor com dispositivos e aparelhos interligados a uma rede, tendo como objetivo produzir e compartilhar ideias, conceito, acontecimentos, preferências e muito mais dentro e fora do meio em que vivem.
Tendo em vista o conceito do tema Big Data vamos analisar e entender como funciona essa poderosa ferramenta, que a vista de muitos leigos, não passam de dados processados, contudo nas mãos de especialistas torna-se uma fonte quase que inesgotável de conhecimento.
Big Data torna-se de grande importância em grandes empresas, vindo a ser uma seta que aponta para a direção correta nas tomadas de decisão com respeito a venda de produtos, qualidade vida dos funcionários, relacionamentos interpessoais e muito mais no que diz respeito ao escopo de determinada instituição ou entidade.
É muito usado também na medicina auxiliando no tratamento de doenças ,traçando perfis e comportamentos de pacientes que possam vir a desenvolver determinadas enfermidades com o passar do tempo, tendo em vista também a prevenção e preparo para combater surtos e epidemias que possam vir a acontecer.
Acreditando que com as novas tendências tecnológicas que vão surgindo com o passar do tempo, o Big Data já vem se tornando conhecido como uma das principais ferramentas de análise e auxilio do ser humano para as melhores tomadas de decisões.
Contudo apesar de termo ser novo e interessante, sabemos de que ainda falta muito pra se aprimorar e evoluir no processamento e armazenamento de dados, pois com a produção massiva de conteúdo os profissionais de tecnologia se veem em constante aprendizado, estudando, conhecendo e aprimorando tais ferramentas para melhor uso cientifico e social dessas informações. | delmiro |
1,865,711 | how is saas software distributed? | SaaS software is distributed through a cloud-based delivery model, where users access the software... | 0 | 2024-05-26T15:25:43 | https://dev.to/lorabrown578/how-is-saas-software-distributed-lnl | SaaS software is distributed through a cloud-based delivery model, where users access the software via the internet. This eliminates the need for physical installations or traditional licensing, allowing for easy updates and scalability. Typically, SaaS software is distributed through subscription models, offering various pricing tiers based on usage and features. This distribution method ensures that users always have access to the latest version of the software without complex upgrades.if you want to know about [how is saas software distributed?](https://saaspedia.io/how-is-saas-software-distributed-top-8-channels/) so click on it | lorabrown578 | |
1,865,695 | Creating a Solana Coinflip game with Orao Network's VRF | Creating a Solana Coinflip game with Orao Network's VRF Writing a game such as Coinflip in... | 27,521 | 2024-05-26T15:19:56 | https://blog.micromegas.dev/creating-a-solana-coinflip-game-with-orao-network-s-vrf | ## Creating a Solana Coinflip game with Orao Network's VRF
Writing a game such as Coinflip in Solana may seem a bit of a taunting task given that you can not simply generate a random number based off the clock, or a blockhash. These are typically used for examples but those can be manipulated by a bad actor and as such are not secure. To build a secure game, any kind of game that relies on a random result in Solana must use an oracle.
The main oracle providers in Solana today are Switchboard and Orao Network, I have used both but today I find Orao to be a bit more easy to use.
We'll start by initiating the Anchor project in our terminal:
`anchor init solana-coinflip-game`
We'll first work on the contract itself and the PDA, then we'll slowly add VRF to it so it's fully secure and that it generates a verifiably random result.
We need to add a few Cargo crates first, solana-program, anchor_spl and orao-network-vrf
```rust
[dependencies]
anchor-lang = "0.29.0"
orao-solana-vrf = {version="=0.3.0",default-features = false, features = ["cpi"]}
anchor-spl = "=0.29.0"
solana-program = "=1.18.14"
```
At the time of writing this postI am using `anchor 0.29.0` and this is how your [dependencies] should look in your Cargo.toml under programs/solana-coinflip-game, of course at the time of writing this is how it looks but depending on when you're reading it may be different.
We'll create a new file named `pda.rs`, this file will store the pda details such as ***user_1*** and ***user_2***, ***winner*** and ***status*** of the game.
```rust
use anchor_lang::prelude::*;
use solana_program::{
system_program::ID as SYSTEM_PROGRAM_ID,
};
use anchor_spl::token::{self,
ID as TOKEN_PROGRAM_ID};
#[derive(Debug, AnchorSerialize, AnchorDeserialize, Clone, Copy, PartialEq, Eq)]
pub enum Status {
Waiting,
Processing,
Finished
}
#[account]
#[derive(Default)]
pub struct Coinflip {
user_1: Pubkey,
user_2: Pubkey,
amount: u64,
winner: Pubkey,
status: Status
}
#[derive(Accounts,)]
#[instruction( room_id: String,amount: u64)]
pub struct CreateCoinflip<'info> {
#[account(mut)]
pub user: Signer<'info>,
#[account(
init,
space = 8 + std::mem::size_of::<Coinflip>(),
payer = user,
seeds = [b"coinflip", room_id.as_bytes().as_ref()],
bump
)]
pub coinflip: Account<'info, Coinflip>,
pub system_program: Program<'info, System>,
}
```
We have an enum Status for the game, Waiting meaning game is waiting for the 2nd player to join the room, Processing meaning that game has already started and that randomness is currently being generated.
`CreateCoinflip` will initiate the game and the PDA account, it'll place the bet and set user_1 and amount variable in the PDA, than in the next method we write we'll utilize these variables and require that amount when another user joins the room.
Let us now write the create_coinflip function in `lib.rs`
```rust
pub fn create_coinflip(ctx: Context<CreateCoinflip>, room_id: String, amount: u64) -> Result<()> {
if (amount < 50000000) {
return err!(InvalidAmount::InvalidAmount);
}
let coinflip = &mut ctx.accounts.coinflip;
invoke(
&transfer(
ctx.accounts.user.to_account_info().key,
coinflip.clone().to_account_info().key,
amount,
),
&[
ctx.accounts.user.to_account_info(),
coinflip.clone().to_account_info(),
ctx.accounts.system_program.to_account_info(),
],
);
coinflip.user_1 = ctx.accounts.user.clone().to_account_info().key();
coinflip.amount = amount;
msg!("Coinflip game is initiated");
Ok(())
}
```
Here we introduce an error `InvalidAmount` if a user tries to place a bet less than 0.05 SOL or 50000000 lamports then the error is thrown.
```rust
#[error_code]
pub enum InvalidAmount {
#[msg("Amount must be greater than 0.05 SOL")]
InvalidAmount
}
```
The `create_coinflip` function will also transfer the amount inputted from the user to the coinflip account, this is essentially an escrow account that holds the funds while the bet is being processed, when it is we'll have the funds sent to the winner.
Next function is `joinroom_coinflip`, this'll mirror the create_coinflip function, it simply places the 2nd bet which means now we can write the final functions which will send for a randomness and process the result.
```rust
#[derive(Accounts,)]
#[instruction(room_id: String)]
pub struct JoinRoomCoinflip<'info> {
#[account(mut)]
pub user: Signer<'info>,
#[account(
mut,
seeds = [b"coinflip", room_id.as_bytes().as_ref()],
bump
)]
pub coinflip: Account<'info, Coinflip>,
#[account(address = SYSTEM_PROGRAM_ID)]
pub system_program: Program<'info, System>,
#[account(address = TOKEN_PROGRAM_ID)]
pub token_program: Program<'info, Token>,
}
```
You'll notice the PDA for this function is only different in that the Coinflip account no longer has init and space in its definition, now we can just edit it as it's already initialized and exists.
```rust
// src/lib.rs
pub fn join_coinflip(ctx: Context<JoinRoomCoinflip>, room_id: String) -> Result<()> {
let coinflip = &mut ctx.accounts.coinflip;
invoke(
&transfer(
ctx.accounts.user.to_account_info().key,
coinflip.clone().to_account_info().key,
coinflip.amount.clone(),
),
&[
ctx.accounts.user.to_account_info(),
coinflip.clone().to_account_info(),
ctx.accounts.system_program.to_account_info(),
],
);
coinflip.user_2 = ctx.accounts.user.clone().to_account_info().key();
coinflip.amount = coinflip.amount.clone();
msg!("Coinflip game can start, user 2 has entered the game");
Ok(())
}
```
We'll start integrating Orao Network's verifiable randomness now, the next function will start the game and request a randomness from the oracle.
The next method is `PlayCoinflip`, we'll add this in `pda.rs`
```rust
// pda.rs
#[derive(Accounts)]
#[instruction(room_id: String, force: [u8; 32])]
pub struct PlayCoinflip<'info> {
#[account(mut)]
pub user: Signer<'info>,
#[account(
mut,
seeds = [b"coinflip", room_id.as_bytes().as_ref()],
constraint =
coinflip.user_1 == user.to_account_info().key(),
bump
)]
pub coinflip: Account<'info, Coinflip>,
/// CHECK: Treasury
#[account(mut)]
pub treasury: AccountInfo<'info>,
/// CHECK: Randomness
#[account(
mut,
seeds = [RANDOMNESS_ACCOUNT_SEED.as_ref(), &force],
bump,
seeds::program = orao_solana_vrf::ID
)]
pub random: AccountInfo<'info>,
#[account(
mut,
seeds = [CONFIG_ACCOUNT_SEED.as_ref()],
bump,
seeds::program = orao_solana_vrf::ID
)]
pub config: Account<'info, NetworkState>,
pub vrf: Program<'info, OraoVrf>,
pub system_program: Program<'info, System>,
}
```
We'll also start writing the tests now after we implement the function in `lib.rs` under `play_coinflip`
```rust
// lib.rs
pub fn play_coinflip(ctx: Context<PlayCoinflip>,room_id: String, force: [u8; 32]) -> Result<()> {
let player = &ctx.accounts.user;
let room = &mut ctx.accounts.coinflip;
msg!("Coinflip in room {} game started", room_id);
let cpi_program = ctx.accounts.vrf.to_account_info();
let cpi_accounts = orao_solana_vrf::cpi::accounts::Request {
payer: ctx.accounts.user.to_account_info(),
network_state: ctx.accounts.config.to_account_info(),
treasury: ctx.accounts.treasury.to_account_info(),
request: ctx.accounts.random.to_account_info(),
system_program: ctx.accounts.system_program.to_account_info(),
};
let cpi_ctx = anchor_lang::context::CpiContext::new(cpi_program, cpi_accounts);
orao_solana_vrf::cpi::request(cpi_ctx, force)?;
room.force = force;
room.status = Status::Processing;
msg!("Started game in room {}", room_id);
return Ok(());
}
```
You'll find the example on their site is not like this, it's much more complicated. Though it's actually far more simple if you take it apart and make it your own as I have here.
With this function the game now starts, and the randomness is being processed by the oracle. Now we'll write some tests and then we'll conclude it with a final function which will use the randomness result and transfer the funds to the winner.
When we initiated the project with Anchor, the command already generated some example tests for us so we'll start with the first function which initiates the game. We'll set the network variable to be Devnet in `Anchor.toml`
```rust
[provider]
cluster = "Devnet"
```
Now we'll `anchor build` and `anchor deploy` and when we deploy we'll get something like this ![alt]

The program ID is different than what the example generates, so we'll need to replace that, in my case I'll replace
```rust
declare_id("Fg6PaFpoGXkYsidMpWTK6W2BeZ7FEfcYkg476zPFsLnS");
```
with the new program ID that we got by deploying it on devnet
```rust
declare_id("64CRrSCxSoEUDv2Sg3fKrwxotoiyD1bfce1AyCeuF582");
```
We can add this statement to `Anchor.toml` as well
```rust
[programs.devnet]
solana_coinflip_game = "64CRrSCxSoEUDv2Sg3fKrwxotoiyD1bfce1AyCeuF582"
```
We'll need to build and deploy again otherwise it'll fail as it uses the old program id and we'd get `Error: AnchorError occurred. Error Code: DeclaredProgramIdMismatch. Error Number: 4100. Error Message: The declared program id does not match the actual program id.`, you can make it use the original program id Anchor generates when it first deploys, but I didn't do that here, so just redeploy and we can start testing.
You should also install @solana/web3.js for this part, using npm, let's write the test now:
```rust
import * as anchor from "@project-serum/anchor";
import { Program } from "@project-serum/anchor";
import { SolanaCoinflipGame } from "../target/types/solana_coinflip_game";
import { LAMPORTS_PER_SOL, PublicKey, SystemProgram } from "@solana/web3.js";
import { BN } from "bn.js";
import { TOKEN_PROGRAM_ID } from "@project-serum/anchor/dist/cjs/utils/token";
function randomString(length=8) {
let result = '';
const characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
const charactersLength = characters.length;
let counter = 0;
while (counter < length) {
result += characters.charAt(Math.floor(Math.random() * charactersLength));
counter += 1;
}
return result;
}
describe("solana-coinflip-game", () => {
// Configure the client to use the local cluster.
anchor.setProvider(anchor.AnchorProvider.env());
const program = anchor.workspace.SolanaCoinflipGame as Program<SolanaCoinflipGame>;
const payer = anchor.Wallet.local().payer
const keypair = Keypair.generate()
const room_id = randomString()
const amount = LAMPORTS_PER_SOL * 0.1
const [coinflip] = PublicKey.findProgramAddressSync(
[Buffer.from("coinflip"), Buffer.from(room_id)],
program.programId
);
it("Is initialized!", async () => {
// Add your test here.
const tx = await program.methods.createCoinflip(room_id,new BN(amount)).accounts({
coinflip,
user: payer.publicKey,
systemProgram: SystemProgram.programId,
}).signers([
payer
]).rpc({
skipPreflight: true
});
console.log("Your transaction signature", tx);
console.log("Program account data: ", await program.account.coinflip.fetch(coinflip))
});
});
```
We'll find the PDA account with two strings, coinflip which is the constant and room_id being random, these two are seeds which are used to find the Coinflip account.
The amount we bet is 0.1 SOL, and then we call the `createCoinflip` function, after that the transaction is sent and you can see the account data, immediately `amount` and `user_1` are defined, you'll also find that the Coinflip account now has 0.1 SOL which we just transferred by calling this function.
Now let's add our second player so we can execute `joinCoinflip` function, which will simply be a randomly generated keypair, we'll transfer some SOL to that address so we can place a bet.
```ts
it("Transfer SOL to player2", async () => {
const transferTransaction = new Transaction().add(
SystemProgram.transfer({
fromPubkey: payer.publicKey,
toPubkey: keypair.publicKey,
lamports: LAMPORTS_PER_SOL*0.11,
})
)
var tx =await sendAndConfirmTransaction(anchor.getProvider().connection, transferTransaction, [payer]);
console.log("TX executed", tx)
})
```
This'll transfer 0.11 SOL to the 2nd player, the 2nd player being the keypair variable we defined just below the _program_ variable, a random keypair. This is the result after running `anchor test` for the 2nd time, you can run tests without deploying with `anchor test --skip-deploy --skip-build`.

Next test we'll add is to join the room, the test for initiating game is not much different to this, they are both essentially the same, except the user in this case becomes `keypair.publicKey`, that's our 2nd player.
```ts
it("Join game", async () => {
const tx = await program.methods.joinCoinflip(room_id).accounts({
coinflip,
user: keypair.publicKey,
systemProgram: SystemProgram.programId,
}).signers([
keypair
]).rpc({
skipPreflight: true
});
console.log("Your transaction signature", tx);
console.log("Program account data: ", await program.account.coinflip.fetch(coinflip))
});
```
And this is the result, `keypair.publicKey` becomes _user2_ and now we can proceed to writing the last two functions and getting verifiable randomness.
Now let us proceed to testing `play_coinflip` function we created previously, for this you must install _@orao-network/solana-vrf_ with npm. Let's start with initiating the next test.
```ts
it("Play the game", async () => {
const random = randomnessAccountAddress(force.toBuffer());
const treasury = new PublicKey("9ZTHWWZDpB36UFe1vszf2KEpt83vwi27jDqtHQ7NSXyR");
})
```
```ts
const vrf = new Orao(anchor.getProvider() as any);
let force = Keypair.generate().publicKey;
```
We'll add these two variables on top so we may use them in other tests not just the one where we request a randomness. You can also simply define _treasury_ at the top.
Force is a kind of a seed we pass to Orao, it's just a random public key converted to a buffer. In this devnet testing example the Orao treasury is `9ZTHWWZDpB36UFe1vszf2KEpt83vwi27jDqtHQ7NSXyR`.
Let's call the function now so we can wrap this up
```ts
const tx = await program.methods.playCoinflip( room_id, [...force.toBuffer()]).accounts({
user: payer.publicKey,
coinflip: coinflip,
vrf: vrf.programId,
config: networkStateAccountAddress(),
treasury: treasury,
random,
}).signers([payer]).rpc();
const tx = await program.methods.playCoinflip( room_id, [...force.toBuffer()]).accounts({
user: payer.publicKey,
coinflip: coinflip,
vrf: vrf.programId,
config: networkStateAccountAddress(),
treasury: treasury,
random,
}).signers([payer]).rpc();
console.log(`Game has started, randomness is requested: `, tx)
```
As you may see everything went as planned here, we called the function successfully and the tx went through. That means that randomness has been requested, typically it takes less than 10seconds for it to resolve. We have also set the status to processing, this'll play into our last function

How do we know when it's ready? Simple, Orao has a function `waitFulfilled`, we pass the force variable to it which we used when we requested the randomness and then it'll resolve when it's fulfilled.
```ts
it("Randomness fulfilled", async () => {
let randomnessFulfilled = await vrf.waitFulfilled(force.toBuffer())
console.log("Randomness is fulfilled, we can call the result function")
})
```
Okay, now we can move forward with our last function which will get the winner out of the two, both players have a 50/50 chance of winning. First let's create a new file, _misc.rs_:
```rust
// misc.rs
use anchor_lang::{
solana_program::{account_info::AccountInfo, program_error::ProgramError},
AccountDeserialize,
};
use orao_solana_vrf::state::Randomness;
pub fn get_account_data(account_info: &AccountInfo) -> Result<Randomness, ProgramError> {
if account_info.data_is_empty() {
return Err(ProgramError::UninitializedAccount);
}
let account = Randomness::try_deserialize(&mut &account_info.data.borrow()[..])?;
if false {
Err(ProgramError::UninitializedAccount)
} else {
Ok(account)
}
}
```
And for the last part, we'll deal with the result and deciding who's the winner, let's create a new struct inside _pda.rs_
```rust
// pda.rs
#[derive(Accounts)]
#[instruction(room_id: String, force: [u8; 32])]
pub struct ResultCoinflip<'info> {
#[account(
mut,
seeds = [b"coinflip", room_id.as_bytes().as_ref()],
constraint =
coinflip.status == Status::Processing,
bump
)]
pub coinflip: Account<'info, Coinflip>,
/// CHECK: Treasury
#[account(mut)]
pub treasury: AccountInfo<'info>,
/// CHECK: Randomness
#[account(
mut,
seeds = [RANDOMNESS_ACCOUNT_SEED.as_ref(), &force],
bump,
seeds::program = orao_solana_vrf::ID
)]
pub random: AccountInfo<'info>,
#[account(
mut,
seeds = [CONFIG_ACCOUNT_SEED.as_ref()],
bump,
seeds::program = orao_solana_vrf::ID
)]
pub config: Account<'info, NetworkState>,
pub vrf: Program<'info, OraoVrf>,
pub system_program: Program<'info, System>,
}
```
What is different about this compared to the `play_coinflip` function? Not much, really here we're just getting the result and deciding the winner, we also have a constraint that checks if the game has started, if not then the contract will throw an error.
```rust
// misc.rs
pub fn result_coinflip(ctx: Context<ResultCoinflip>,room_id: String, force: [u8; 32]) -> Result<()> {
let rand_acc = crate::misc::get_account_data(&ctx.accounts.random)?;
let randomness = current_state(&rand_acc);
if (randomness == 0) {
return err!(StillProcessing::StillProcessing)
}
let result = randomness % 2;
}
```
We are also introducing a new function `current_state`, this'll get the VRF result, convert it to a number, and then % 2, that will end up in a result that is either 0 or 1. You can add this function inside _misc.rs_, as well as a new error for when randomness is still not fulfilled.
```rust
// misc.rs
pub fn current_state(randomness: &Randomness) ->u64 {
if let Some(randomness) = randomness.fulfilled() {
let value = randomness[0..size_of::<u64>()].try_into().unwrap();
return u64::from_le_bytes(value);
} else {
return 0;
}
}
```
``` rust
// lib.rs
#[error_code]
pub enum StillProcessing {
#[msg("Randomness is still being fulfilled")]
StillProcessing
}
```
Since we want to transfer the funds to the winner, we have to add both of the accounts to the struct, and also a constraint to make sure that this can't be abused by a third party that wants to fool the contract.
We'll add `user_1` and `user_2` to the struct and then create a few constraints to prevent bad actors
```rust
// pda.rs
#[account(mut)]
pub user_1: AccountInfo<'info>,
#[account(mut)]
pub user_2: AccountInfo<'info>,
#[account(
mut,
seeds = [b"coinflip", room_id.as_bytes().as_ref()],
constraint =
(coinflip.status == Status::Processing,
coinflip.user_1 == user_1.key(),
coinflip.user_2 == user_2.key()),
bump
)]
```
When we have done this let's finish our `result_coinflip` function
```rust
// lib.rs @ result_coinflip
msg!("VRF result is: {}", randomness);
if (result ==0) {
coinflip.winner = coinflip.user_1.key();
**ctx.accounts.user_1.lamports.borrow_mut() = ctx.accounts.user_1.lamports()
.checked_add(coinflip.amount.clone())
.unwrap();
**coinflip.to_account_info().lamports.borrow_mut() -= coinflip.amount.clone();
msg!("Winner is user_1: {}", coinflip.user_1.key().to_string())
} else {
coinflip.winner = coinflip.user_2.key();
**ctx.accounts.user_2.lamports.borrow_mut() = ctx.accounts.user_2.lamports()
.checked_add(coinflip.amount.clone())
.unwrap();
**coinflip.to_account_info().lamports.borrow_mut() -= coinflip.amount.clone();
msg!("Winner is user_2: {}", coinflip.user_2.key().to_string())
}
```
We already have the result with the result variable being `randomness % 2`, what these statements do is transfer the funds to the winner as well as marking them as the winner, and for the last trick we'll mark the game as finished, so the function should now look like this
```rust
// lib.rs
pub fn result_coinflip(ctx: Context<ResultCoinflip>,room_id: String, force: [u8; 32]) -> Result<()> {
let coinflip = &mut ctx.accounts.coinflip;
let rand_acc = crate::misc::get_account_data(&ctx.accounts.random)?;
let randomness = current_state(&rand_acc);
if (randomness == 0) {
return err!(StillProcessing::StillProcessing)
}
let result = randomness % 2;
msg!("VRF result is: {}", randomness);
if (result ==0) {
coinflip.winner = coinflip.user_1.key();
**ctx.accounts.user_1.lamports.borrow_mut() = ctx.accounts.user_1.lamports()
.checked_add(coinflip.amount.clone() * 2)
.unwrap();
**coinflip.to_account_info().lamports.borrow_mut() -= coinflip.amount.clone() * 2;
msg!("Winner is user_1: {}", coinflip.user_1.key().to_string())
} else {
coinflip.winner = coinflip.user_2.key();
**ctx.accounts.user_2.lamports.borrow_mut() = ctx.accounts.user_2.lamports()
.checked_add(coinflip.amount.clone() *2)
.unwrap();
**coinflip.to_account_info().lamports.borrow_mut() -= coinflip.amount.clone() * 2;
msg!("Winner is user_2: {}", coinflip.user_2.key().to_string())
}
msg!("Coinflip game in room {} has concluded, the winner is {}", room_id, coinflip.winner.to_string());
coinflip.status = Status::Finished;
return Ok(())
}
```
Let's write the final test and we can see just how well everything runs
```ts
it("Get the result", async () => { const vrf = new Orao(anchor.getProvider() as any);
const random = randomnessAccountAddress(force.toBuffer());
const treasury = new PublicKey("9ZTHWWZDpB36UFe1vszf2KEpt83vwi27jDqtHQ7NSXyR");
const tx = await program.methods.resultCoinflip( room_id, [...force.toBuffer()]).accounts({
user1: payer.publicKey,
user2: keypair.publicKey,
coinflip: coinflip,
vrf: vrf.programId,
config: networkStateAccountAddress(),
treasury: treasury,
random,
}).signers([payer]).rpc();
console.log(`Game is finished`, tx)
console.log("Program account data: ", await program.account.coinflip.fetch(coinflip))
})
```
And what do we get?
This is how the account data should look after we get the result, the winner is decided, in this case the random user won over me, and status is set to finished. And this marks it, no insecure blockhashes or clocks, merely using the Orao Network's oracle to have a proper Coinflip game that can't be fooled by anyone.
The result is 12037561925398644525, hence 12037561925398644525 % 2 = 0, the winner is the second user .

You can also see how the funds get transferred from the escrow coinflip account to the address of player `user_2`, the winner gets all, so he gets 0.2 SOL.
And that's it, a bit of a longer reader but as simple as it seems dealing with smart contracts and oracles takes some time and this post reflects.
But as usual, I have my code on Github and you can feel free to take a stab at it, just make sure to read what I have to say about the deployment of the contract in the beginning otherwise you might run into some difficulties. _https://github.com/ddm50/solana-coinflip-game_
| ddm4313 | |
1,858,982 | The Module System in Javascript | In the ever-evolving landscape of JavaScript development, mastering the module system is crucial for... | 21,484 | 2024-05-26T15:18:21 | https://dev.to/srishtikprasad/the-module-system-in-javascript-27oc | javascript, webdev, beginners, programming | In the ever-evolving landscape of JavaScript development, mastering the module system is crucial for creating scalable, maintainable, and efficient code, transforming how developers structure and share their projects across the modern web.
##Necessity of module system
1. **Code Organization**: Having a way to split the codebase into multiple files, modules help in organizing code into manageable, logical units. This makes the codebase easier to understand and maintain.
2. **Reusability**: Modules allow you to reuse code across different parts of an application or even across different projects.
3. **Encapsulation**: Modules encapsulate code, which means they expose only what is necessary and hide the internal details. This prevents unintended interactions and reduces bugs.
4. **Dependency Management**: A good module system should make it easy for module developer to build on top of existing modules.
Modules help in managing dependencies between different parts of the application, making it clear what functionality depends on what.
> **Module** - is actual unit of software that encapsulates related functionality
> **Module System** - on the other hand, is a set of rules, conventions, and mechanisms that enable the creation, importation, and use of modules within a programming language or environment. It defines how modules are written, organized, and accessed within an application example : CommonJS and ECMAScript Modules
## CommonJs Module system
CommonJs is the first module system in Nodejs.CommonJs respects the CommonJs specification, with addition of some custom extensions.
- it uses the `require()` function to import modules.
- module.exports or exports are special variables that can be used to export public functionality from the current module.
> The require() function in CommonJS modules is **synchronous**. When you use require() to import a module, Node.js will load and execute the module **synchronously**, blocking the execution of the code until the required module is fully loaded and its exports are available.
## module.exports vs exports
### Using module.exports
is an object provided by Node.js for defining what a module exports. When you assign a value to `module.exports`, you are replacing the entire exports object with whatever value you provide.
```javascript
function add(a, b) {
return a + b;
}
function subtract(a, b) {
return a - b;
}
module.exports = {
add,
subtract
};
```
### Using exports
`exports` is a shorthand reference to module.exports. Initially, exports is set to reference the same object as `module.exports`. You can use the exports object to add properties and methods to the exports object.
```javascript
exports.add = function(a, b) {
return a + b;
};
exports.subtract = function(a, b) {
return a - b;
};
```
##Module defination patterns
In Node.js, there are several popular patterns for defining and exporting modules. These include:
- named exports,
- exporting functions,
- exporting classes,
- exporting instances, and
- monkey patching
###**Named exports**
Uses module.exports or exports to export multiple values from a module.
```javascript
function verbose(name) {
console.log("verbose");
}
const logger = "Goodbye!";
module.exports = {
verbose,
logger
};
```
###**Exporting functions**
```javascript
function verbose(){
console.log("verbose")
}
module.exports = verbose
```
Same pattern of export is followed in exporting class or an instance of class
Creating a class or an instance of class and exporting it using `module.export `
###**Exporting classes**
Modules can also export a class, which can then be instantiated by the importing code.
```javascript
class Greeter {
constructor(greeting) {
this.greeting = greeting;
}
greet(name) {
return `${this.greeting}, ${name}`;
}
}
module.exports = Greeter;
//Usage
const Greeter = require('./myClassModule');
const greeter = new Greeter('Hello');
console.log(greeter.greet('Charlie'));
```
###**Exporting Instances**
Instead of exporting a class, you can export an instance of the class, ensuring there is a single shared instance.
```javascript
class Greeter {
constructor() {
this.greeting = 'Hello';
}
greet(name) {
return `${this.greeting}, ${name}`;
}
}
const greeterInstance = new Greeter();
module.exports = greeterInstance;
//Usage
const greeter = require('./myInstanceModule');
console.log(greeter.greet('Dana'));
```
`Reference Book : NodeJs Design pattern by Mario Casciaro `
This blog was mainly about module system and CommonJs module .
It is extremely important to understand ES Module ,in the next blog I'll cover specifically ES Module and compare both module. [ES Module](https://dev.to/srishtikprasad/es-module-50a)
Monkey patching is an important topic to learn will post separate blog on this.
Let me know if you have any query,will try me best to address them all to the best of my knowledge. | srishtikprasad |
1,865,667 | My Experience Learning Go, next steps | I recently posted about my efforts to learn Go and GUI development in Go here. This post is about the... | 0 | 2024-05-26T15:16:52 | https://dev.to/cjr29/my-experience-learning-go-next-steps-16hd | go, fyne, dashboard, simulator | I recently posted about my efforts to learn Go and GUI development in Go [here](https://dev.to/cjr29/how-one-experienced-software-engineer-learns-a-new-programming-language-4bek). This post is about the next steps in my learning process.
I was able to get a basic dashboard implemented and functioning using [Fyne.io](Fyne.io) and a simple CPU simulator. You can see that in my [git repo](https://github.com/cjr29/go-cpu-simulator.git).
My next step was to find an existing CPU simulator implemented in Go and integrate my dashboard with it. Reading and understanding someone else's code is one of the best ways to learn a new language. Not only must you grasp the syntax and semantics of the language, but you also must decipher and learn the idioms and patterns used by the other programmer. Programming is as much an art as it is engineering, and reading and following someone else's coding is, to me, like walking through an art gallery and appreciating the nuances and techniques applied by each artist.
Much to my delight, I discovered a complete implementation of a 6502 CPU simulator written in Go. Not only did the project include a CPU simulator, but it included an assembler, disassembler, and utilities! The project I found, [go6502](https://github.com/beevik/go6502.git), is so comprehensive that after only a few days working my way through the code, I was able to understand how almost everything worked together. The project is so well-done that I was able to integrate my dashboard without breaking any of the existing simulator code.
When a software engineer encounters code that is so well-written that it makes adding features a breeze, you have to tip your hat to the engineer for doing such a fine job. That is how I found this project. It was complex, but well-designed and built for flexibility. I was able to learn many new things about Go that were not obvious from reading the manuals and tutorials.
##Details
I created a [fork](https://github.com/cjr29/go6502.git) of the go6502 project. Then, I added a folder for my dashboard package. I worked through updates to the go.mod files to make sure that I was pulling from my repo and not the original repo. That is one of the beauties of Go. Dependencies are much easier to work with than when I was doing Java development.
The primary hooks into the existing go6502 simulator were the bufio.Writer for terminal output and the Host object with a structure and associated functions to take commands from the GUI buttons. Using the Fyne widgets and callback functions, I was able to insert calls to the Host object, passing in command strings instead of sending them to the terminal. Output is redirected to a scrolling widget in the dashboard. New commands, replacing a command line function, are submitted using a data entry widget and submit button. The user determines whether or not to use the GUI at time of program startup by including a flag (-g) in the command. If the flag is absent, the program starts up in its usual terminal mode. If the flag is included, the dashboard is started and the program control is handed off to the GUI. Termination of the program is by an Exit button instead of a command line quit statement.
Sometimes it is hard to know if a program is still running or if it is hung up in an error loop. So, I added a goroutine that updates a clock display every second. That way a user can see the program is still running and not frozen. It also helps someone understand how goroutines and channels make concurrent processing in Go easy.
There is still much to learn from this. I need to add a file picker to allow a user to select a file from the file system to assemble and load. Currently, the program looks for a sample file in the current directory to load. I want to learn if I can use the terminal themes that Vickers incorporated in the terminal code to customize the look of the GUI dashboard. In many ways, Fyne.io is comprehensive and cross-platform, but it is new enough that there isn't a lot of examples to use on which to build your own code. Next steps will explore this further.
Finally, I plan to experiment with the go6502 code to see if I can create my own instruction set and replace the 6502 with a different CPU. The Vickers code seems designed for that purpose. Learning Go this way has been a blast! | cjr29 |
1,833,411 | Polynomial Regression: Exploring Non-Linear Relationships | In our previous discussions, we explored the fundamentals of linear regression and gradient descent... | 0 | 2024-05-26T15:16:28 | https://dev.to/harsimranjit_singh_0133dc/polynomial-regression-exploring-non-linear-relationships-49nk | In our previous discussions, we explored the fundamentals of linear regression and gradient descent optimization. Today, we discuss a new topic - Polynomial regression. This technique empowers us to capture non-linear relationships between independent and dependent variables, a more flexible approach when a straight line does not fit in the data.
## Beyond Straight Lines
Linear regression assumes a linear relationship between the independent variables and the dependent variables. However, real-world data often exhibits different patterns.
Polynomial regression addresses this by introducing polynomial terms of the independent variables. If we have one variable X then we can transform this variable like X^2, X^3, and so on. These terms allow the model to capture curves, bends, and other non-linear trends in the data
Here:
- Y: Dependent variable
- b0: The intercept term(bias)
- b_i: Coefficients associated with each terms (i=1 to d)
- X: independent variables
- X^i: The polynomial terms of X (i=1 to d)
## Let's take the example of a small dataset
Suppose we have a dataset representing the relationship between hours studied (x) and exam scores (y)
let's first visualize the dataset
```
import numpy as np
import matplotlib.pyplot as plt
hours_studied = np.array([1, 2, 3, 4, 5])
exam_scores = np.array([50, 65, 75, 80, 82])
plt.scatter(hours_studied, exam_scores, color='blue', label='Data points')
plt.xlabel('Hours studied')
plt.ylabel('Exam score')
plt.legend()
plt.grid(True)
plt.show()
```
The shows a rough upward trend between hours studied and exam scores this type of relation can not be captured by a straight line
So to implement the polynomial regression we need to first modify our independent variable using polynomial features which transform the features into polynomial features like we specify the degree 2 then it make two columns out of one which are x (original) and x^2 (transformed).
```
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
X = hours_studied.reshape(-1, 1)
y = exam_scores.reshape(-1, 1)
# Polynomial features (change the dataset)
poly = PolynomialFeatures(degree=3)
X_poly = poly.fit_transform(X)
model = LinearRegression() # use the normal linear regression model
model.fit(X_poly, y)
y_pred = model.predict(X_poly)
plt.scatter(hours_studied, exam_scores, color='blue', label='Data points')
plt.plot(hours_studied, y_pred, color='red', label='Polynomial Regression')
plt.xlabel('Hours Studied')
plt.ylabel('Exam Score')
plt.title('Polynomial Regression: Hours Studied vs. Exam Score')
plt.legend()
plt.grid(True)
plt.show()
```
The red curve represents the polynomial regression line fitted to the data. In the above example, we use the degree 3 polynomial.
By doing so we can capture the non-linear data as well.
### Choosing the Right Degree:
The degree of polynomials dictates the model's complexity. we will encounter a trade-off here:
- **Higher Degrees**: Capture a more complex relationship but can lead to overfitting, where it performs well on training data and performs poorly on unseen data.
- **Lower Degrees**: Less prone to overfitting but might miss important non-linear patterns.
## Estimations of Coefficients:
The coefficients in polynomial regression can be estimated using OLS the same method used for linear regression.
## Conclusion:
Polynomial regression is a powerful statistical technique used to model complex relationships between the data. It can capture non-linear patterns that linear regression might miss.
## Some important points to remember
- Polynomial regression assumes that the relationship between the x and y is polynomial.
- There are several types of polynomial regression simple, multiple, and orthogonal polynomial regression
- The interpretation of the coefficients in polynomial regression is similar to linear regression, with the addition of higher-degree terms.
- The polynomial regression also assumes that the error terms are randomly distributed with mean of zero. | harsimranjit_singh_0133dc | |
1,865,693 | Minha experiência com AdonisJS e como fazer seu primeiro CRUD | Introdução Nesse artigo eu irei falar com minha experiência atual com o framework Adonijs... | 0 | 2024-05-26T15:16:16 | https://dev.to/pedrohhope/minha-experiencia-com-adonisjs-e-como-iniciar-nele-4k91 | javascript, programming, tutorial, adonis | ## Introdução
Nesse artigo eu irei falar com minha experiência atual com o framework Adonijs um [MVC (Model-View-Controller)](https://medium.com/@habbema/nodejs-padr%C3%A3o-mvc-2f4e16b79cb8) para Node.js.
Eu tenho que admitir que já tive alguma experiência prévia com o framework, porém, nunca usei ele com 100% do seu potencial. Recentemente, recebi uma oferta de emprego que me fez aprender e usar AdonisJS de forma profissional, e fiquei surpreendido, tanto pela sua documentação, que é muito boa, quanto pelos seus padrões obrigatórios, algo que sinto muita carência nos frameworks de Node.js. Os que mais se destacam nesse aspecto são o NestJS e o AdonisJS. Isso, para mim (uma questão polêmica), é muito importante.
## Documentação e Padrões Obrigatórios
A documentação do AdonisJS é extremamente clara e detalhada, facilitando a curva de aprendizado e a resolução de problemas. Ela aborda desde conceitos básicos até funcionalidades avançadas, proporcionando uma base sólida para desenvolvedores de todos os níveis.
Os padrões obrigatórios do AdonisJS ajudam a manter o código organizado e consistente, o que é crucial para a manutenção e escalabilidade de projetos. Esse é um ponto em que muitos frameworks de Node.js falham, pois deixam muito espaço para a interpretação e implementação por parte dos desenvolvedores. Com AdonisJS, há uma estrutura bem definida que guia o desenvolvimento de forma eficiente.
## Ferramentas próprias
AdonisJS se destaca por suas ferramentas adicionais, que são bastante interessantes. Um exemplo é o [Lucid](https://lucid.adonisjs.com/docs/introduction), um ORM próprio que já vem integrado ao framework ou mesmo a sua própria CLI, uma interface de linha de comando poderosa e intuitiva, que ajuda na criação e gerenciamento de projetos, além de facilitar tarefas comuns como a criação de modelos, controladores e migrações.
Eu poderia ficar horas falando sobre essas ferramentas como Sessions, Auth configurada com um comando no CLI ( isso é incrível kkk ), Encryption, Emails e várias outras.
## Fazendo meu primeiro CRUD com AdonisJS
Depois de tantos elogios eu acho que mostrar na prática é melhor para eu te provar o como bom ele é.
Vamos criar um exemplo simples de um CRUD (Create, Read, Update, Delete) em AdonisJS V6 utilizando o Lucid ORM e a CLI do AdonisJS. Este exemplo irá envolver a criação de uma aplicação para gerenciar uma lista de tarefas.
## 1. Configuração do Projeto
Primeiro, vamos configurar um novo projeto AdonisJS:
```bash
# Instale a CLI do AdonisJS globalmente se ainda não tiver
npm install -g @adonisjs/cli
# Crie um novo projeto AdonisJS
adonis new tasks-app
# Navegue até a pasta do projeto
cd tasks-app
# Instale as dependências
npm install
```
## 2. Configuração do Banco de Dados
Configure o banco de dados no arquivo config/database.ts. Este exemplo usa SQLite para simplicidade, mas você pode usar qualquer banco de dados suportado.
```ts
// config/database.ts
const databaseConfig: DatabaseConfig = {
connection: 'sqlite',
connections: {
sqlite: {
client: 'sqlite3',
connection: {
filename: path.join(__dirname, '..', 'database.sqlite')
},
useNullAsDefault: true,
migrations: {
naturalSort: true,
},
healthCheck: false,
debug: false,
},
// Outras configurações de banco de dados...
}
}
```
## 3. Criar a Tabela de Tarefas
Vamos criar a tabela de tarefas usando migrações.
```bash
# Criar uma migração para a tabela de tarefas
adonis make:migration tasks --create=tasks
```
Edite a migração gerada em database/migrations/TIMESTAMP_tasks.ts:
```ts
import BaseSchema from '@ioc:Adonis/Lucid/Schema'
export default class Tasks extends BaseSchema {
protected tableName = 'tasks'
public async up () {
this.schema.createTable(this.tableName, (table) => {
table.increments('id')
table.string('title').notNullable()
table.text('description')
table.boolean('is_completed').defaultTo(false)
table.timestamps(true)
})
}
public async down () {
this.schema.dropTable(this.tableName)
}
}
```
Execute a migração:
```bash
adonis migration:run
```
## 4. Criar o Modelo de Tarefa
Crie um modelo para interagir com a tabela de tarefas.
```bash
# Criar o modelo Task
adonis make:model Task
```
Edite o modelo gerado em app/Models/Task.ts:
```ts
import { DateTime } from 'luxon'
import { BaseModel, column } from '@ioc:Adonis/Lucid/Orm'
export default class Task extends BaseModel {
@column({ isPrimary: true })
public id: number
@column()
public title: string
@column()
public description: string
@column()
public isCompleted: boolean
@column.dateTime({ autoCreate: true })
public createdAt: DateTime
@column.dateTime({ autoCreate: true, autoUpdate: true })
public updatedAt: DateTime
}
```
## 5. Criar o Controlador de Tarefas
Crie um controlador para lidar com as operações CRUD.
```bash
# Criar o controlador TaskController
adonis make:controller Task
```
Edite o controlador gerado em app/Controllers/Http/TaskController.ts:
```ts
import { HttpContextContract } from '@ioc:Adonis/Core/HttpContext'
import Task from 'App/Models/Task'
export default class TaskController {
public async index({ response }: HttpContextContract) {
const tasks = await Task.all()
return response.json(tasks)
}
public async store({ request, response }: HttpContextContract) {
const data = request.only(['title', 'description', 'is_completed'])
const task = await Task.create(data)
return response.status(201).json(task)
}
public async show({ params, response }: HttpContextContract) {
const task = await Task.find(params.id)
if (!task) {
return response.status(404).json({ message: 'Task not found' })
}
return response.json(task)
}
public async update({ params, request, response }: HttpContextContract) {
const task = await Task.find(params.id)
if (!task) {
return response.status(404).json({ message: 'Task not found' })
}
const data = request.only(['title', 'description', 'is_completed'])
task.merge(data)
await task.save()
return response.json(task)
}
public async destroy({ params, response }: HttpContextContract) {
const task = await Task.find(params.id)
if (!task) {
return response.status(404).json({ message: 'Task not found' })
}
await task.delete()
return response.status(204).json(null)
}
}
```
## 6. Configurar as Rotas
Edite o arquivo de rotas em start/routes.ts para incluir as rotas para o CRUD de tarefas:
```ts
import Route from '@ioc:Adonis/Core/Route'
Route.get('/tasks', [TaskController.'index'])
Route.post('/tasks', [TaskController.'store'])
Route.get('/tasks/:id', [TaskController.'show'])
Route.put('/tasks/:id', [TaskController.'update'])
Route.delete('/tasks/:id', [TaskController.'destroy'])
```
## 7. Testar a Aplicação
Agora, inicie o servidor AdonisJS:
```bash
adonis serve --watch
```
Viu como é fácil e rápido? Além de você usar a CLI para fazer maioria das coisas você também mantém um padrão no seu projeto e isso é muito bom!!!
Obrigado por ler o artigo :)
| pedrohhope |
1,865,692 | Python for school students | Let's start with basics - What is programming?🧐 Programming is a way to instruct computers to... | 0 | 2024-05-26T15:12:46 | https://dev.to/pragatisingh9155/python-for-school-students-1beg | python, coding, softwaredevelopment, development | Let's start with basics -
What is programming?🧐
Programming is a way to instruct computers to perform a given task .
What is Algorithm -
A complete sequence of instructions is termed as Algo.
CompVocab :-
Instruction = command
Why we need programming languages??
Computer is just a dumb machine, it can only understand binary language which (0 & 1),
So to deliver our instruction to the computer we have to first convert our language into machine level Language {0 and 1 form or into a combination of (0 & 1)}... That's why programming lang is required...!!
Machine Language=
Combination of 0 & 1 , can't use anything except 0 & 1
Assembly Language=
Combination of mnemonics like (ADD SUB DIV ) , it is only understandable to humans...to make it executable (run so that computer can understand) first assembly language is converted into Machine Language by the use of Assembler(work as Translator)
Next 🙂
☕Deep delve into the world of Python :-
Soon -->
Follow for more
@pragatisingh9155 | pragatisingh9155 |
1,865,655 | Deep dive Demystifying JSON, BOSN and GSON | Data interchange is a fundamental aspect of modern computing, ensuring the easy and seamless exchange... | 0 | 2024-05-26T15:10:56 | https://dev.to/meetmuaz/deep-dive-demystifying-json-bosn-and-gson-1goc | json, webdev, programming | Data interchange is a fundamental aspect of modern computing, ensuring the easy and seamless exchange of information between diverse systems. A deep understanding of data interchange formats and protocols is essential for developers to create integrated, efficient, and interoperable systems. JSON, BSON, and GSON are prominent examples of data interchange formats that serve different purposes and scenarios. In this article, we will clearly distinguish the differences between these formats.
For example, consider a web application where a user's computer (client) communicates with a server. When the user logs in, the client sends the login credentials to the server in JSON format. The server processes this data and responds with a JSON object containing the user's profile information. If the server uses MongoDB, it might store the user's data in BSON format for efficient storage and retrieval. If the application is built in Java, GSON could be used to convert Java objects to JSON and vice versa, facilitating smooth data handling within the application.
1. JSON (JavaScript Object Notation)
JSON, which stands for JavaScript Object Notation, is a simple and lightweight data interchange format. It is easy for humans to read and write due to its elegant and straightforward syntax, and it is also easy for machines to parse and generate effectively.
Advantages:
- Human Readable: JSON is easy to understand and write by humans and computers.
- Language Independent: Although JSON originate from JavaScript and has a JavaScript kind of syntax It still support most programming language like C++, JAVA, PHP and lots more.
- Lightweight: Being text-based, JSON is very lightweight compared to other data interchange formats.
Use Cases:
- Web APIs: JSON is widely used for data exchange in web APIs.
- Configuration Files: JSON format is commonly used for configuration files.
2. BSON (Binary JSON)
BSON is also called Binary JSON, it is a binary representation of JSON-like documents. BSON extends the JSON model to provide additional data types. BSON is mainly used in MongoDB, a popular NoSQL database.
- Binary Format: BSON is more efficient in terms of speed and size when compared to JSON.
- Additional Data Types: It supports data types not available in JSON, such as dates and raw binary data.
- Efficient Encoding/Decoding: Optimised for performance, especially within databases.
Use Cases:
Databases: Commonly used in databases like MongoDB to store data efficiently.
3. GSON (Google JSON)

GSON, or Google JSON is a Java library developed by Google to convert Java Objects into JSON and vice versa. It is particularly useful in Java-based applications for serializing and deserializing JSON data.
Advantages:
- Easy Integration: GSON integrates Seamlessly with Java applications.
- Flexible: GSON Supports various complex data structures.
- Annotations: Provides powerful annotations for customization of the serialization/deserialization process.
Use Cases:
- Java Application: It is used for applications that need to interact with web services or configurations using JSON format.
- Android Development: GSON is mostly used in Android apps to manage JSON data.
Below is a tablar discription that diffrenciate between JSON, BSON and GSON.
In conclusion, grasping JSON, BSON, and GSON is pivotal for modern computing. JSON's simplicity aids widespread adoption, BSON enhances efficiency in MongoDB, and GSON streamlines Java JSON interactions. Understanding these formats empowers developers to build seamless and effective systems.
| meetmuaz |
1,865,514 | JavaScript Concepts: Declaration, Initialization, Mutability, Immutability and Reassignment | This blog is dedicated to understand the following JavaScript... | 0 | 2024-05-26T15:09:08 | https://dev.to/sromelrey/javascript-concepts-declaration-initialization-mutability-immutability-and-reassignment-1j1c | javascript, beginners, programming, tutorial | This blog is dedicated to understand the following JavaScript Concepts:
- Declaration
- Initialization
- Mutability
- Immutability
- Reassignment
### Declaration
This is the phase where you tell the JavaScript engine about the variable. For example:
```
let age;
```
> declares that there is a variable named age.
### Initialization
This phase involves assigning a value to the variable. If you do not explicitly initialize the variable at the time of declaration, JavaScript automatically initializes it to `undefined`.
```
let a;
console.log(a);
```
> Output: undefined
### Mutability
This refers to the ability to alter the internal state or content of a data structure or object in place. For example, if we have object `obj` and you changed a property within it, you would be mutating the object:
```
let obj = { key: "value" };
obj.key = "new value";
```
> Mutating the object by changing a property
### Immutability
Immutability refers to the inability to alter the state or content of a variable after it has been created. When a variable holds an immutable value, any modification results in the creation of a new value rather than changing the original.
```
let greeting = "Hello";
let newGreeting = greeting.replace("H", "J");
console.log(greeting); // Output: "Hello"
console.log(newGreeting); // Output: "Jello"
```
##### In this example:
- `greeting` is a string with the value `Hello`.
- The replace method creates a new string `newGreeting` with the value `Jello`.
- The original greeting string remains unchanged.
> Immutability ensures that primitive values remain constant, preventing unintended side effects. Any operation that attempts to modify an immutable value creates a new value, leaving the original unchanged.
### Reassignment
This refers to the act of assigning a new value to a variable. This action doesn't alter the original value; rather, it updates what the variable points to.
```
let y = "hello";
y = "world";
```
> Reassigning y to reference a different string
## Conclusion
In this topic, we explored key JavaScript concepts: declaration, initialization, mutability, immutability, and reassignment. Understanding these concepts helps in writing clear and predictable code.
- Declaration introduces a variable.
- Initialization assigns an initial value.
- Mutability allows modification of an object's state.
- Immutability prevents changes to a value, ensuring data integrity.
- Reassignment updates the variable's reference without altering the original value.
Grasping these concepts is essential for effective JavaScript programming. | sromelrey |
1,859,118 | Managing Your Inventory With Kanban? | Kanban Inventory One system shines above when used for manufacturing management purposes.... | 0 | 2024-05-26T15:02:48 | https://dev.to/cactus77/managing-your-inventory-with-kanban-2a2 | kanban, agile, inventory | ## Kanban Inventory
One system shines above when used for manufacturing management purposes. Can you guess it? That's right, it's Kanban. Initially, this is where it has been applied, to industries where inventory must be managed. A study by [Apreutesei 2010](http://webbut2.unitbv.ro/bu2010/series%20i/BULETIN%20I%20PDF/Materials%20Science%20and%20Engineering/Apreutesei%20M.pdf) has found Kanban's efficiency to be extremely effective in inventory management.
## Why Does It Work?
_The 6 Rules of Kanban, [Source](http://webbut2.unitbv.ro/bu2010/series%20i/BULETIN%20I%20PDF/Materials%20Science%20and%20Engineering/Apreutesei%20M.pdf)_
---
Apreutesei excludes the 6 essential rules of Kanban that must be followed in order to set the gears in motion for Kanban
Basically, due to the visuality that the Kanban system allows you are able to see who is working on what. This enables you to be in control of the workflow and gives you an opportunity to allocate resources strategically.
A Kanban card is an essential element of the Kanban system used for managing physical inventory. Serving as a visual indicator, each card corresponds to a specific [Kanban inventory](https://teamhood.com/kanban/kanban-inventory/) item. These cards can be either physical or digital and are mainly utilized to monitor the movement and status of inventory items through different stages of the supply chain. As items progress from ordering to delivery and stocking, their corresponding Kanban cards are moved along the board, visually representing their current status in the inventory cycle.
_Kanban board example with Kanban cards_
---
You might think "This is so simple" and you wouldn't be wrong, it really is. Kanban's simplicity is exactly its superpower. By preventing overproduction and overworking, you are able to focus solely on providing quality results in an effective manner.
## Kanban Prioritization
Another reason why Kanban works is the ingrained system of Kanban's prioritization. In fact, it works so well that according to a [survey by LeanKit](https://www.scrum-institute.org/what-is-a-kanban-workflow-kanban-workflow-definition-kanban-workflow-meaning.php), organizations using Kanban experienced a 200% increase in productivity and a 50% reduction in lead time.
How does it even work? This is again mostly due to its visual component and WIP limits. While the visuality has been discussed, let's take a look at the WIP limits.
WIP limits allow your team's [Kanban prioritization](https://teamhood.com/kanban/kanban-prioritization/) to flourish. But before WIP limits, be sure to define and establish your priority categories. You can use whatever works for you but I'll be kind and give you some established examples:
Categorical priorities :
- **Critical**: Tasks must be done immediately to meet deadlines or deal with urgent matters.
- **High**: Important tasks that help keep the project on schedule but aren’t as urgent.
- **Medium**: Necessary tasks that do not have immediate deadlines but are essential for project completion.
- **Low**: Tasks that need to be done but have the least impact on the project timeline. This approach promotes a balanced workflow. Critical tasks receive the necessary resources and attention while still progressing on less urgent tasks.
For WIP limits, use Kanban board's top indicator of how many tasks is currently being worked on. You are able to set the limit yourself.
_Examples of WIP limits on a Kanban board_
---
## Kanban Inventory Management System
While it is possible to make up your own Kanban board in the physical world, it can be hard to work around this if your team needs to be online (which, usually is the case, as it's best to be updated in a second, what's happening in your inventory).
For this reason, I would recommend picking the right [Kanban inventory management software](https://teamhood.com/kanban/kanban-inventory-management-software/). There are myriad choices which you can make so pick wisely. Be sure to do your research beforehand on what you need and what you expect this system should do. Some software do not have all the capabilities your industry might need.
## Wrap Up
All in all, Kanban works great as a pull system that gives immense flexibility for you and your team to workaround the challenges of inventory management. In my humble opinion, the Kanban system remains undefeated in this area of expertise. You and your team should definitely give it a try if you've never experienced the greatness that is a Kanban system.
| cactus77 |
1,865,691 | Django Admin - Zero to Hero | One of the most powerful parts of Django is the automatic admin interface. It reads metadata from... | 0 | 2024-05-26T15:01:56 | https://njoroge.tomorrow.co.ke/blog/python/django_admin_zero_to_hero | django, webdev, python | One of the most powerful parts of Django is the automatic admin interface. It reads metadata from your models to provide a quick, model-centric interface where trusted users can manage content on your site.
The admin’s recommended use is limited to an organization’s internal management tool. It’s not intended for building your entire front end around. In this article, we will cover everything you need to know to become a Django Admin pro. We will start from scratch and gradually move to advanced topics.
By the end of this article, you will be able to manage your Django project efficiently using Django Admin.
This will be a long article, feel free to jump to the section you are interested in:
- Activating Django Admin
- Creating Superuser
- Accessing Django Admin Site
- An Overview of Django Admin Interface
- Creating and registering models
- ModelAdmin class
- ModelAdmin Actions
### Activating Django Admin
The admin is enabled in the default project template used by startproject. If you’re not using the default project template, here are the requirements:
- Add `django.contrib.admin` and its dependencies - `django.contrib.auth`, `django.contrib.contenttypes`, `django.contrib.messages`, and `django.contrib.sessions` - to your INSTALLED_APPS setting.
- Add `admin.site.urls` to your URLconf. Modify the `urls.py` file in your project folder to include the following line:
```python
urlpatterns = [
path('admin/', admin.site.urls),
]
```
### Creating Superuser account
To access the Django admin, you need to create a superuser. Run the following command in your terminal:
```python
python manage.py createsuperuser
```
You will be prompted to enter a username, email address, and password for the superuser.
### Accessing Django Admin Site
Run the Django development server:
```python
python manage.py runserver
```
By default, Django development server will run on port 8000. Open your browser and navigate to http://localhost:8000/admin/. You will see the Django admin login page.

Enter the superuser credentials you created earlier to log in.
### An Overview of Django Admin Interface

Without any other registered models, Django will display the “Groups” and “Users” models. These are part of Django’s authentication framework. You can use these models to manage users and groups in your Django project. Please note how they are categorized under the “Authentication and Authorization” section.
### Creating and registering models
In this article let's work with the `Books model` located in the `books` app. The `Books model` has the following fields:
- `title` - The title of the book.
- `author` - The author of the book.
- `price` - The price of the book.
- `published` - A boolean field to indicate if the book has been published.
Assuming you have already created the `books` app, let's create the `Books model` in the `models.py` file of the `books` app:
```python
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.CharField(max_length=100)
price = models.DecimalField(max_digits=10, decimal_places=2)
published = models.BooleanField(default=False)
def __str__(self):
return self.title # Display the title of the book in the Django admin site
class Meta:
# the attributes below are very useful for the Django admin interface, they are not required but are good practice
verbose_name = 'Book' # Singular name for the model
verbose_name_plural = 'Books' # Plural name for the model
```
In your `admin.py` file of the `books` app, register the `Books model`:
```python
from .models import Book
admin.site.register(Book)
```
Save the file and make migrations:
```bash
python manage.py makemigrations
python manage.py migrate
```
Restart the Django development server:
```bash
python manage.py runserver
```
Head over to the Django admin site and you will see the `Books` model listed under the `Books` section. You can now add, edit, and delete books using the Django admin interface.
Make sure to create some books using the Django admin interface.
How cool is that?
## A little further - ModelAdmin class
It is possible to register a model with just the `admin.site.register(ModelName)` method.
Perhaps you need more control over how the model is displayed in the admin interface. This is where the `ModelAdmin` class comes in.
The `ModelAdmin` class is the representation of a model in the admin interface. It allows you to customize how the model is displayed, how it can be interacted with, and how it can be filtered.
You can customize the `ModelAdmin` class by creating a class that inherits from `admin.ModelAdmin` and then registering it with the model.
_In our case, we want to display the `Books` model with a list of books sorted by the price in ascending order. We also want to display the `title` and `author` fields in the list view._
Let's create a `BookAdmin` class in the `admin.py` file of the `books` app:
```python
class BookAdmin(admin.ModelAdmin):
list_display = ('title', 'author') # Display title and author fields in the list view
ordering = ('price',) # Sort by price in ascending order
```
Register the `BookAdmin` class with the `Books` model:
```python
admin.site.register(Book, BookAdmin)
```
In the end the `admin.py` file of the `books` app should look like this:
```python
from django.contrib import admin
from .models import Book
class BookAdmin(admin.ModelAdmin):
list_display = ('title', 'author') # Display title and author fields in the list view
ordering = ('price',) # Sort by price in ascending order
admin.site.register(Book, BookAdmin)
```
Head over to the Django admin site and you will see the `Books` model listed under the `Books` section. The books will be displayed with the `title` and `author` fields in the list view, sorted by price in ascending order.
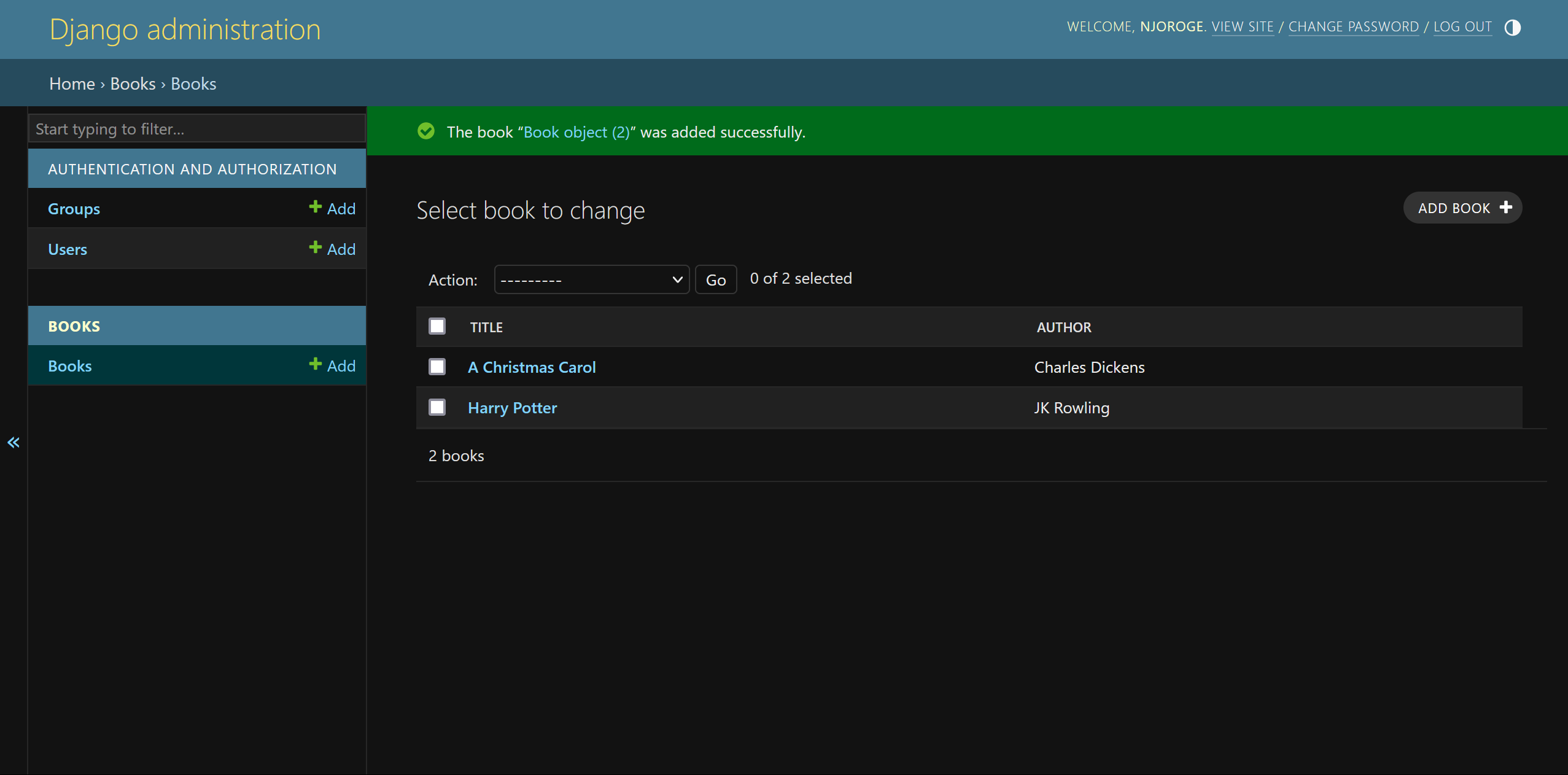
Let me teach you an even concise way to register the `ModelAdmin` using the `@admin.register` decorator.
```python
@admin.register(Book)
class BookAdmin(admin.ModelAdmin):
list_display = ('title', 'author') # Display title and author fields in the list view
ordering = ('price',) # Sort by price in ascending order
```
The above code is equivalent to the previous code where we registered the `BookAdmin` class with the `Books` model but in a more concise way.
## ModelAdmin Actions
If you have noticed, selecting multiple books provides a dropdown with the action "Delete selected books". This is an example of a `ModelAdmin` action.
That sounds limited, right? What if you want to create your own custom actions?
### Custom ModelAdmin Actions
The easiest way to explain actions is by example, so let’s dive in.
A common use case for admin actions is the bulk updating of a model’s fields.
To create an action, you need to define a method in the `ModelAdmin` class and decorate it with the `@admin.action` decorator.
Let's create a custom action to mark selected books as published.
```python
class BookAdmin(admin.ModelAdmin):
list_display = (
"title",
"author",
) # Display title and author fields in the list view
ordering = ("price",) # Sort by price in ascending order
actions = ["mark_as_published"] # Add the custom action
@admin.action(description="Mark selected books as published")
def mark_as_published(self, request, queryset):
queryset.update(published=True)
admin.site.register(Book, BookAdmin)
```
Admin model actions take three arguments: `self`, `request`, and `queryset`. The `queryset` argument is a list of all the selected objects. In our case, it will be a list of selected books.
That is just a tip of the iceberg. There is so much more you can do with Django Admin. I hope this article has given you a good foundation to start exploring Django Admin. Feel free to explore the [official Django documentation](https://docs.djangoproject.com/en/5.0/ref/contrib/admin/) to learn more about Django Admin.
Happy coding! 🚀
| kagemanjoroge |
1,864,877 | Can LLMs Truly Understand Text-based Emotion ? | Recently, Large Language Models (LLMs) have garnered attention for their impressive capabilities in... | 0 | 2024-05-26T15:00:54 | https://dev.to/sumanthprabhu/can-llms-truly-understand-text-based-emotion--547e | machinelearning, nlp, llm | Recently, Large Language Models (LLMs) have garnered attention for their impressive capabilities in the realm of Natural Language Understanding (NLU). Trained on diverse and extensive datasets, LLMs seem to generalize well across a wide range of tasks with little to no task-specific training data. In this article, we will examine one of the less frequently explored NLU tasks when it comes to LLMs — Emotion Prediction.
Despite notable advancements, Emotion Prediction continues to be an evolving area of research. It can help assess a model's true NLU capability as it demands detection of subtle emotional cues present in the text. We will mainly focus on assessing text-based Emotion Prediction using LLMs in two real world scenarios -
1. No Labelled Data Available
2. Labelled Data Available But Noisy
For the purposes of our experiment, we will be using [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) as our LLM. We will also build corresponding competitive baseline approaches to benchmark the LLM's performance.
> For the remainder of the article, we will be using 'LLM' as a shorthand reference to 'mistralai/Mistral-7B-Instruct-v0.2'
### TL;DR
This is going to be a long post. The intent is to share code snippets for each step in all experiments covered in the article. If you want to skip directly to the results, you can find them under the section [Consolidating Results](#consolidating-results).
---
## <span style='color:gray'> Preliminaries </span>
Before getting started, we need to install and load the required dependencies.
```python
!pip install setfit
!pip install bitsandbytes
!pip install accelerate
!pip install huggingface_hub
!pip install peft
!pip install dqc-toolkit
```
```python
from datasets import load_dataset, Dataset
from sentence_transformers import SentenceTransformer
from sklearn.linear_model import LogisticRegression
from typing import List, Tuple, Union
import numpy as np
import os
import pandas as pd
import torch
import transformers
import wandb
import warnings
transformers.logging.set_verbosity_error()
wandb.init(mode="disabled")
warnings.filterwarnings('ignore')
```
Some of the installed libraries and imported modules will make sense as we proceed further. Also, we are setting the verbosity level to '_error_'. This isn't necessary. We've done this to keep the notebook outputs relatively clean.
### Dataset
For the purpose of all experiments, we will be using [emotion](https://huggingface.co/datasets/dair-ai/emotion), a publicly available dataset hosted on Hugging Face. It consists of English-language tweets annotated with one of six emotions as shown below -
['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']
The dataset has 16,000 training samples and 2,000 validation samples.
```python
dataset = 'dair-ai/emotion'
dset = load_dataset(dataset, trust_remote_code=True)
train_data = pd.DataFrame(dset['train'])
val_data = pd.DataFrame(dset['validation'])
text_col, label_col = 'text', 'label'
train_data.head()
```
<div>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>text</th>
<th>label</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>i didnt feel humiliated</td>
<td>0</td>
</tr>
<tr>
<th>1</th>
<td>i can go from feeling so hopeless to so damned...</td>
<td>0</td>
</tr>
<tr>
<th>2</th>
<td>im grabbing a minute to post i feel greedy wrong</td>
<td>3</td>
</tr>
<tr>
<th>3</th>
<td>i am ever feeling nostalgic about the fireplac...</td>
<td>2</td>
</tr>
<tr>
<th>4</th>
<td>i am feeling grouchy</td>
<td>3</td>
</tr>
</tbody>
</table>
</div>
### Transform Integer Labels to Text Labels
The labels in the dataset are integers. Since LLMs cannot comprehend the emotion labels in this format, we will need a mapping of the integer labels to semantic text descriptions.
```python
label_to_text = {0 : 'sadness',
1 : 'joy',
2 : 'love',
3 : 'anger',
4 : 'fear',
5 : 'surprise'}
```
We will consume this dictionary downstream when we run our LLM.
### Evaluation Metric
For the purpose of benchmarking our experiments, we choose Weighted F1 score as the metric. We also display the [classification report](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html) and confusion matrix for detailed interpretation.
```python
from sklearn.metrics import (classification_report, confusion_matrix, ConfusionMatrixDisplay, f1_score)
from typing import List
import matplotlib.pyplot as plt
def fetch_performance_metrics(y_true: np.ndarray, y_pred: np.ndarray, exp_name: str,display_report: bool = True, display_confusion_matrix: bool = True,label_list: List[str] = ['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'],num_labels: int = 6) -> dict:
"""
Util function to compute F1 score and optionally display the classification report and confusion matrix for a given experiment.
Args:
y_true (np.ndarray): Array containing true labels.
y_pred (np.ndarray): Array containing predicted labels.
exp_name (str): Name of the experiment (used to save results).
display_report (bool, optional): Boolean flag indicating whether to display classification report (True) or not (False). Defaults to True.
display_confusion_matrix (bool, optional): Boolean flag indicating whether to display confusion matrix (True) or not (False). Defaults to True.
label_list (list, optional): List of labels. Defaults to ['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'].
num_labels (int, optional): Number of unique labels. Defaults to 6.
Returns:
dict: A dictionary containing F1 score.
"""
if display_report:
print('\nClassification Report:')
print(classification_report(y_true=y_true, y_pred=y_pred, labels=list(range(num_labels)),target_names=label_list[:num_labels]))
if display_confusion_matrix:
print('\nConfusion Matrix:')
cm = confusion_matrix(y_true=y_true, y_pred=y_pred)
fig, ax = plt.subplots(figsize=(8, 8))
display = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=label_list)
display.plot(ax=ax)
plt.savefig(exp_name)
return {'F1-score' : f1_score(y_true, y_pred, average='weighted')}
```
Alright ! Now, we are ready to begin.
---
## <u><ins>*Scenario #1*</ins></u> - No Labelled Data Available
Labelled data unavailability is a common bottleneck in real-world machine learning. Constructing a sizeable set of labelled samples may not be possible for various reasons such as cost of labelling manually, data privacy / regulations, etc. To benchmark LLM in this scenario, we will be exploring [In-Context Learning](https://arxiv.org/abs/2301.00234) which consumes minimal labelled samples to generate predictions.
## <span style="color:gray">Baseline</span>
When no labelled samples are available, [Unsupervised Learning](https://cloud.google.com/discover/what-is-unsupervised-learning) and [Few Shot Learning](https://paperswithcode.com/task/few-shot-learning) are commonly employed solutions. We will be considering Few Shot Learning since it is closer to the LLM's In-Context Learning. Specifically, we will be using [Setfit](https://huggingface.co/docs/setfit/en/index), a popular Few Shot Learning model by Huggingface, as our baseline.
We setup the training and inference script.
```python
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, Trainer, TrainingArguments, SetFitTrainer
def train_and_infer_setfit(model_name: str, train_data: pd.DataFrame, val_data: pd.DataFrame, seed: int,
text_col: str = 'text', label_column: str = 'label', batch_size: int = 64, num_epochs: int = 3) -> dict:
"""Function to train Huggingface's Setfit model on input training data and return the computed performance metrics on input validation data
Args:
model_name (str): Sentence Transformer model path to be used for training
train_data (pd.DataFrame): Train data with corresponding labels
val_data (pd.DataFrame): Validation data with corresponding labels
seed (int): Random seed for reproducibility
text_col (str, optional): Column to be used to extract input features. Defaults to 'text'.
label_column (str, optional): Label column in the data. Defaults to 'label'.
batch_size (int, optional): Batch size to use during training. Defaults to 64.
num_epochs (int, optional): Number of training epochs. Defaults to 3.
Returns:
dict: A dictionary containing F1 score.
"""
model = SetFitModel.from_pretrained(model_name)
train_dataset = Dataset.from_pandas(train_data)
args = TrainingArguments(
batch_size=batch_size,
num_epochs=num_epochs,
evaluation_strategy='no',
save_strategy="no",
loss=CosineSimilarityLoss,
load_best_model_at_end=False,
sampling_strategy="unique",
seed=seed
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=None,
metric=None
)
trainer.train()
y_pred = trainer.model.predict(val_data[text_col].values)
y_true = val_data[label_column].astype(int)
return fetch_performance_metrics(y_true, y_pred, 'setfit')
```
We draw 48 samples at random and label them for training. The batch size is set to 64 and the model is trained for 3 epochs.
> Note - Here, the number of samples (48) is an approximation based on how Setfit has been [shown](https://huggingface.co/blog/setfit) to perform well with 8 samples per label. Since, we have 6 labels, we'll need 8 X 6 = 48 samples. Rather than random sampling, you can employ sample selection strategies that offer better guarantees of samples being more representative of each label. You can also explore generating (8 or more) new samples for each label.
Now, let's run it.
```python
model_name = "BAAI/bge-small-en-v1.5"
seed = 43
samples = train_data.sample(n=48, random_state=seed).reset_index(drop=True)
train_and_infer_setfit(model_name, samples, val_data, seed)
```
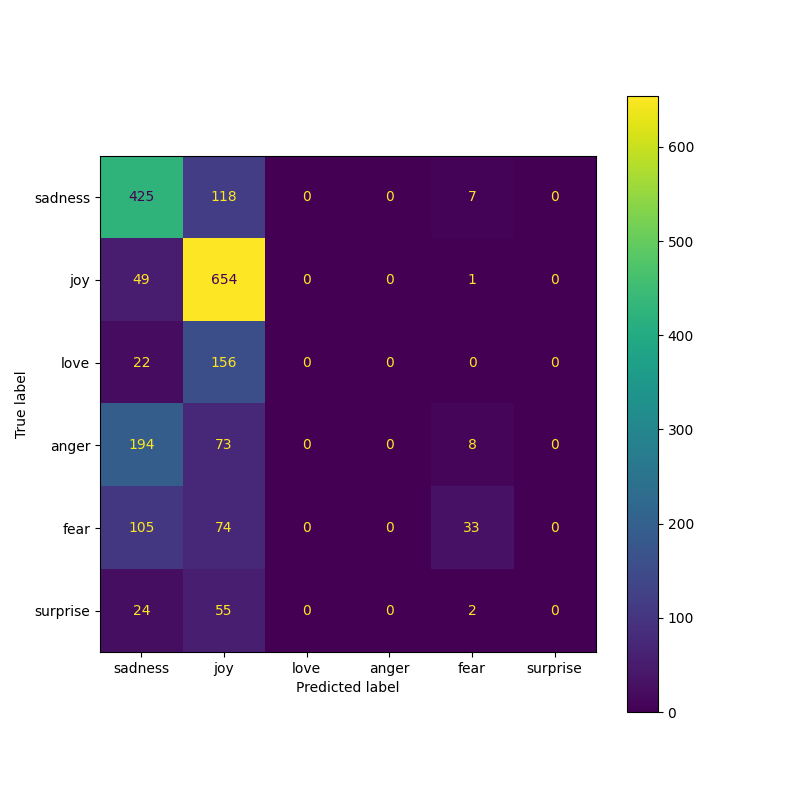
The F1 score is 0.448. We also observe that the predictions are biased to '_sadness_' or '_joy_'. This isn't very surprising since the number of training samples is very less. Let's see how our LLM performs in similar settings.
## <span style="color:gray"> LLM : In-Context Learning</span>
We start by mapping labels to text using the dictionary `label_to_text` which we had previously defined.
```python
train_data['label_text'] = train_data['label'].map(label_to_text)
val_data['label_text'] = val_data['label'].map(label_to_text)
train_data.head()
```
<div>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>text</th>
<th>label</th>
<th>label_text</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>i didnt feel humiliated</td>
<td>0</td>
<td>sadness</td>
</tr>
<tr>
<th>1</th>
<td>i can go from feeling so hopeless to so damned...</td>
<td>0</td>
<td>sadness</td>
</tr>
<tr>
<th>2</th>
<td>im grabbing a minute to post i feel greedy wrong</td>
<td>3</td>
<td>anger</td>
</tr>
<tr>
<th>3</th>
<td>i am ever feeling nostalgic about the fireplac...</td>
<td>2</td>
<td>love</td>
</tr>
<tr>
<th>4</th>
<td>i am feeling grouchy</td>
<td>3</td>
<td>anger</td>
</tr>
</tbody>
</table>
</div>
We will need to login to Huggingface hub to be able to access the LLM. We do this via Huggingface's [notebook_login](https://huggingface.co/docs/huggingface_hub/en/package_reference/login#huggingface_hub.notebook_login)
```python
from huggingface_hub import notebook_login
notebook_login()
```
> Note - Additionally, you may need to navigate to the [Mistral model card](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) and "accept" the conditions to be able to access the model.
### Defining the LLM helper functions
The LLM will need the input texts to be defined as prompts. We define a function `build_LLM_prompt` that transforms the input text into a prompt format. We will also define two helpers function `infer_LLM` and `_generate_predictions` to instantiate the LLM and run inference with the constructed input prompts.
```python
from peft import AutoPeftModelForCausalLM
from tqdm import tqdm
from transformers import (AutoTokenizer, AutoModelForCausalLM,
BitsAndBytesConfig, pipeline)
from typing import Union
import datasets
def _generate_predictions(example: datasets.formatting.formatting.LazyBatch,
generator: pipeline, text_column: str,
max_new_tokens: int = 9, split_token: str ='[/EMOTION]') -> dict:
"""
Generates predictions using the text generation model for a given example.
Args:
example (datasets.formatting.formatting.LazyBatch): Batch of samples from a dataset.
generator (pipeline): Huggingface pipeline for text generation.
text_column (str): Prompt for the text generation model.
max_new_tokens (int, optional): Maximum number of tokens to generate. Defaults to 9.
split_token (str, optional): Token to demarcate the emotion prediction. Defaults to '[/EMOTION]'.
Returns:
dict: A dictionary containing the generated predictions.
"""
num_examples = len(dataset)
predictions = []
batch_results = generator(example[text_column], max_new_tokens=max_new_tokens, num_return_sequences=1)
predictions.extend([result[0]["generated_text"] for result in batch_results])
return {'prediction' : predictions}
def infer_LLM(model_name: str, input_ds: Dataset, batch_size: int = 4, max_new_tokens: int = 9,
text_column: str = 'emotion_prompt', finetuned_model_path: str = None) -> Dataset:
"""
Util function to run LLM inference
Args:
model_name (str): The name or path of the LLM model.
input_ds (Dataset): Input dataset containing text prompts.
batch_size (int, optional): Batch size for inference. Defaults to 4.
max_new_tokens (int, optional): Maximum number of tokens to generate. Defaults to 9.
text_column (str, optional): Name of the column containing text prompts. Defaults to 'emotion_prompt'.
finetuned_model_path (str, optional): Path to the fine-tuned model. Defaults to None.
Returns:
dataset: Dataset with generated predictions.
"""
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side="left")
if finetuned_model_path is None:
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto",
quantization_config=quantization_config)
else:
model = AutoPeftModelForCausalLM.from_pretrained(finetuned_model_path,
device_map="auto",
quantization_config=quantization_config)
text_generator = pipeline("text-generation", model=model, tokenizer=tokenizer,
batch_size=batch_size, truncation=False)
text_generator.tokenizer.pad_token_id = model.config.eos_token_id
input_ds = input_ds.map(_generate_predictions, fn_kwargs={'generator' : text_generator,
'text_column' : text_column,
'max_new_tokens' : max_new_tokens
},
batched=True, batch_size=batch_size)
return input_ds
def build_LLM_prompt(input_ds: Dataset, label_column: str = None, prompt_template: Union[str, None] = None,
with_label: bool = False) -> Dataset:
"""Util function to build the LLM prompt from input text data
Args:
input_ds (Dataset): Input dataset containing text
label_column (str, optional): Label column in the data. Applicable if constructing prompts for in-context samples / finetuning LLM. Defaults to None.
prompt_template (Union[str, None], optional): Text instruction to prepend to each transformed input text sample. Defaults to None.
with_label (bool, optional): `True` if the prompts should include labels from the `label_column`. Defaults to False.
Returns:
Dataset: Dataset with generated predictions.
"""
if type(input_ds) == pd.DataFrame:
input_ds = Dataset.from_pandas(input_ds)
if with_label:
input_ds = input_ds.map(lambda x: {'emotion_prompt': '[UTTERANCE]' + x['text'] + '[/UTTERANCE]' + \
'[EMOTION]' + x[label_column] + '[/EMOTION]'})
else:
input_ds = input_ds.map(lambda x: {'emotion_prompt': prompt_template + '[UTTERANCE]' + x['text'] + '[/UTTERANCE]' + \
'[EMOTION]'})
return input_ds
```
### Build the LLM prompt
First, we build the prompt for in-context learning using `build_LLM_prompt`. To ensure we have a reasonably fair comparison, the samples considered are the same ones used for SetFit in the previous experiment.
```python
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
sample_data = train_data.sample(n=48, random_state=seed).reset_index(drop=True)
emotion_list = ['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']
emotion_list_str = ', '.join(emotion_list)
transformed_sample_data = build_LLM_prompt(sample_data, with_label=True, label_column='label_text')
samples_str = '\n'.join(transformed_sample_data['emotion_prompt'])
prompt_template = "<s>[INST] You are a helpful, respectful and honest assistant. Choose one option that best describes the emotion behind the given utterance based on the following comma separated options: " + emotion_list_str + "[/INST] </s>"
```
### Mapping LLM outputs to Emotion Predictions
LLMs generate free text that may not necessarily match the expected format for the output. We define an additional helper function `_extract_label` that parses the generated text and extracts the emotion. .
We also define `run_llm` that will act as our entry point to run LLM inference. It will invoke `build_LLM_prompt` and `infer_LLM` to perform inference and return the computed performance metrics on input validation data.
```python
def _extract_label(sample: datasets.formatting.formatting.LazyRow, label_list: List[str]) -> dict:
"""Util function to extract the emotion from the generated LLM prediction
Args:
sample (datasets.formatting.formatting.LazyRow): Batch of samples from a dataset
label_list (List[str]): List of possible emotions
Returns:
dict: Dictionary of extracted predicted labels
"""
prompt_length = len(sample['emotion_prompt'])
generated_answer = sample['prediction'][prompt_length:].split('[/EMOTION]')[0].lower()
label_matched = False
predicted_label = None
for label in label_list:
if label in generated_answer:
predicted_label = label
label_matched = True
break
if not label_matched:
predicted_label = "no_match"
return {'predicted_label' : predicted_label}
def run_llm(val_data: pd.DataFrame, prompt_template: str, model_name: str, emotion_list: List[str], label_mapping: dict, label_column: str = 'label', batch_size: int = 4, finetuned_model_path: str = None,
num_labels: int = 6) -> dict:
"""Run end-to-end LLM inference (from pre-processing input data to post-processing the predictions) and return the computed performance metrics on input validation data
Args:
val_data (pd.DataFrame): Validation data with labels
prompt_template (str): Text instruction to prepend to each transformed input text sample.
model_name (str): The name or path of the pre-trained LLM.
emotion_list (List[str]): List of possible emotions
label_mapping (dict): Dictionary mapping to convert text labels to integers
label_column (str, optional): Label column in the data. Defaults to 'label'.
batch_size (int, optional): Batch size for inference. Defaults to 4.
finetuned_model_path (str, optional): Path to the fine-tuned model, if available.. Defaults to None.
num_labels (int, optional): Number of unique labels. Defaults to 6.
Returns:
dict: A dictionary containing F1 score.
"""
predicted_label_list = []
val_ds = build_LLM_prompt(val_data, prompt_template=prompt_template)
val_ds_with_pred = infer_LLM(model_name, val_ds, batch_size, finetuned_model_path=finetuned_model_path)
predicted_label_list = val_ds_with_pred.map(_extract_label,
fn_kwargs={"label_list": emotion_list[:num_labels]})['predicted_label']
y_pred = [label_mapping[pred] if pred in label_mapping else num_labels for pred in predicted_label_list]
y_true = val_data[label_column].astype(int).values.tolist()
if num_labels not in y_pred:
# All LLM predictions match a valid emotion from `emotion_list`
emotion_list.remove('no_match')
return fetch_performance_metrics(y_true, y_pred, 'mistral_7b', label_list=emotion_list)
```
For cases where the LLM generates text that have no matching emotion, `_extract_label` returns the string '_no_match_'. If there are occurences of '_no_match_' in our final predictions, then we treat this as a new label so that our function `fetch_performance_metrics` can work seamlessly.
### Putting it all to work
Ok. We are ready to run our LLM now.
```python
text_to_label = {v: k for k, v in label_to_text.items()}
# Add 'no_match' to `emotion_list` to handle LLMs predicting labels outside of `emotion_list`
LLM_emotion_list = emotion_list + ['no_match']
run_llm(val_data, prompt_template, model_name, LLM_emotion_list, text_to_label, batch_size=64)
```
The F1 score is 0.442. Comparing results from the two experiments, it seems that the performance of LLM In-Context Learning is similar to our baseline Setfit. Technically, many samples are ending up in the '_no_match_' bucket which happens when the LLM's predicted text doesn't match any label. We could explore better prompt construction to ensure that the LLM always predicts a valid label. Enhancements such as [chain-of-thought](https://arxiv.org/abs/2201.11903) and [self consistency](https://arxiv.org/abs/2203.11171) based prompting can give better results but will be relatively more expensive to run at scale. We can cover them in a future post if people are interested.
Similarly, if we can provide a few more labelled samples for emotions where the setfit model is underperforming, then the results can potentially improve further. This could be much more feasible than the enhancements mentioned for LLMs.
## <u><ins>*Scenario #2*</ins></u> - Labelled Data Available But Noisy
Depending on the problem statement, a substantial number of labelled samples can occasionally be available for training Machine Learning models. As mentioned before, obtaining quality labelled data can be expensive. The labelled data that is available is potentially weakly labelled via automated systems or some form of user interaction. Besides, even if you invest in manually labelling the data, the labels obtained can still be susceptible to noise and errors due to multiple factors such as annotation ambiguity, human subjectivity, fatigue, etc. Such situations can demand fine-tuning cost effective models using the available resources.
### Simulating Noisy Labels
To simulate our noisy scenario, we define a function `add_asymmetric_noise` to construct a noisy version of the emotion detection data labels.
```python
from pandas._typing import RandomState
def add_asymmetric_noise(
labels: pd.Series,
noise_prob: float,
random_state: Union[RandomState, None] = 42,
) -> Tuple[pd.Series, float]:
"""
Util function to add asymmetric noise to labels
for simulation of noisy label scenarios.
Args:
labels (pd.Series): Input pandas series with integer values
ranging from 0 to n - 1.
noise_prob (float): Probability of adding noise to each value.
random_state (Union[RandomState, None]): Random seed for reproducibility
Returns:
pd.Series: Series with asymmetric noise added to it.
float: Normalized quantification of pairwise disagreement between `labels` and `noisy_labels` for parity check
"""
# Set seed
np.random.seed(random_state)
# Avoid modifying the original data
noisy_labels = labels.copy()
# Build a replacement dictionary
unique_labels = list(set(noisy_labels))
replacement_dict = {
label: [candidate for candidate in unique_labels if candidate != label]
for label in unique_labels
}
# Determine the number of samples to modify based on the noise probability
num_samples = min(len(noisy_labels), int(len(noisy_labels) * noise_prob + 1))
# Sample random indices from the labels to introduce noise
target_indices = np.random.choice(len(noisy_labels), num_samples, replace=False)
for idx in target_indices:
# Introduce noise
noisy_labels[idx] = np.random.choice(replacement_dict[noisy_labels[idx]])
# Parity check
num_mismatches = sum(
[
label != noisy_label
for label, noisy_label in zip(labels.values, noisy_labels.values)
]
)
observed_noise_ratio = num_mismatches / len(noisy_labels)
return noisy_labels, observed_noise_ratio
```
We are going to assume 30% noise for the purpose of our experiments. In other words, 30% of the data will have incorrect labels. You can try running it with different noise levels by modifiying `noise_level` in the following script as needed.
```python
noise_level = 0.3
train_data['noisy_label'], observed_noise_ratio = add_asymmetric_noise(train_data['label'],
noise_prob=noise_level,
random_state=seed)
observed_noise_ratio
```
0.3000625
`observed_noise_ratio` is a parity check to ensure that the percentage of noise in the labelled samples is what we intended. You could also just check number of samples where '_label_' and '_noisy_label_' mismatch.
```python
len(train_data.loc[train_data['label'] != train_data['noisy_label']]) / len(train_data)
```
0.3000625
Looks good. Let's move on to defining our baseline.
## <span style="color:gray">Baseline</span>
With text classification, given the constraints that we have many labelled samples where some labels are potentially incorrect, one of the commonly explored approaches is using state-of-the-art pre-trained embeddings to extract features from the text (because such embeddings are trained to be robust). This embedding is then combined with a downstream classification model. For the purpose of the experiments, we leverage ['BGE-small-en-v1.5'](https://huggingface.co/BAAI/bge-small-en-v1.5) embeddings for feature extraction. For classification, we keep it simple by using Sklearn's Logistic Regression. First, we setup a training and inference script for the baseline.
```python
def train_and_infer_LR_with_PTE(embeddings: str, train_data: pd.DataFrame, val_data: pd.DataFrame, seed: int, label_column: str = 'label') -> dict:
"""Function to train Logistic Regression model with pre-trained embeddings as features and return performance metrics on input validation data
Args:
embeddings (str): Path to embeddings to be used for training
train_data (pd.DataFrame): Train data with corresponding labels
val_data (pd.DataFrame): Validation data with corresponding labels
seed (int): Random seed for reproducibility
label_column (str): Label column in the data. Defaults to 'label'
Returns:
dict: A dictionary containing F1 score.
"""
embedding_model = SentenceTransformer(embeddings)
train_embeddings = embedding_model.encode(train_data['text'].values,
show_progress_bar=False)
y_train = train_data[label_column].astype(int)
clf = LogisticRegression(random_state=seed).fit(train_embeddings, y_train)
y_true = val_data['label'].astype(int)
val_embeddings = embedding_model.encode(val_data['text'].values, show_progress_bar=False)
y_pred = clf.predict(val_embeddings)
return fetch_performance_metrics(y_true, y_pred, 'LR_with_PTE')
```
We use the `SentenceTransformer` library to load the embeddings and encode input data. Let's run our baseline and observe the results.
```python
embedding_model = "BAAI/bge-small-en"
label_column = 'noisy_label'
train_and_infer_LR_with_PTE(embedding_model, train_data, val_data, seed, label_column)
```
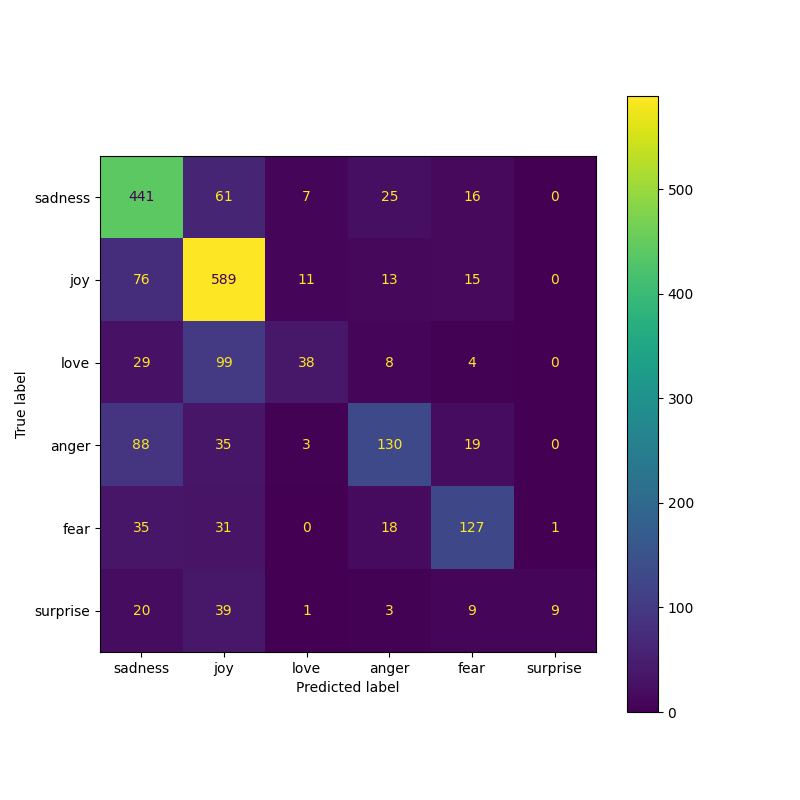
The F1-score obtained is 0.641 which is better than what we observed for Few Shot Learning. Performance when it comes to emotions '_love_' and '_surprise_' seem to be poor. Will our LLM be able to beat this result ? Let's find out.
## <span style="color:gray">LLM : Fine-tuning </span>
With a relatively larger number of training samples available, we can explore fine-tuning of our LLM. Traditional full fine-tuning of an LLM becomes infeasible to train on consumer hardware because of the large number of parameters. We will be relying on [PEFT](https://huggingface.co/blog/peft) approaches which freeze most of the parameters of the pre-trained LLMs and fine-tune a small number of additional model parameters. Particularly, we will be using [LoRA](https://huggingface.co/docs/diffusers/en/training/lora) to finetune our LLM.
```python
from peft import get_peft_model, LoraConfig, PeftConfig, PeftModel, prepare_model_for_kbit_training
from tqdm import tqdm
from transformers import (AutoModelForCausalLM, AutoTokenizer,
BitsAndBytesConfig, DataCollatorForLanguageModeling,
pipeline, Trainer, TrainingArguments
)
import bitsandbytes as bnb
import torch.nn as nn
```
As before, we will need to map the noisy labels to the corresponding text using the dictionary `label_to_text`.
```python
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
train_data['noisy_label_text'] = train_data['noisy_label'].map(label_to_text)
```
### Transform Text into LLM Prompts
We transform the data into prompts that LLMs understand.
```python
emotion_list = ['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']
emotion_list_str = ', '.join(emotion_list)
prompt_template = "<s>[INST] You are a helpful, respectful and honest assistant. Choose one option that best describes the emotion behind the given utterance based on the following comma separated options: " + emotion_list_str + "[/INST] </s>"
noisy_label_column = 'noisy_label_text'
train_ds = build_LLM_prompt(train_data, with_label=True, label_column=noisy_label_column)
train_ds = train_ds.map(lambda example, prompt_template=prompt_template : {'emotion_prompt' : prompt_template + example['emotion_prompt']})
```
### Fine-tune LLM
Next, we define our LLM Fine-tuning function.
```python
def tokenize(example: datasets.formatting.formatting.LazyRow, tokenizer: AutoTokenizer ) -> dict:
"""Util function to tokenize text data
Args:
example (datasets.formatting.formatting.LazyRow): Batch of samples containing text to tokenize.
tokenizer (AutoTokenizer): Tokenizer object used for tokenization.
Returns:
dict: Dictionary containing tokenized text.
"""
tokenized = tokenizer(
example['emotion_prompt'],
truncation=False
)
return {**tokenized}
def finetune_LLM(base_model_name: str, train_ds: Dataset, save_path: str, seed: int, batch_size: int = 64, num_epochs: int = 1):
"""Function to finetune an LLM on the given input training data
Args:
base_model_name (str): The name or path of the LLM model to be finetuned
train_ds (Dataset): Input dataset containing text prompts.
save_path (str): Path to save the trained model
seed (int): Random seed for reproducibility
batch_size (int, optional): Batch size to use during training. Defaults to 64.
num_epochs (int, optional): Number of training epochs. Defaults to 1.
"""
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(base_model_name,
quantization_config=bnb_config,
device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(base_model_name, padding_side="left")
tokenizer.pad_token = tokenizer.eos_token
train_ds = train_ds.map(
tokenize,
batched=False,
fn_kwargs={"tokenizer": tokenizer},
)
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
args = TrainingArguments(
disable_tqdm=False,
output_dir=save_path,
warmup_steps=1,
per_device_train_batch_size=batch_size,
num_train_epochs=num_epochs,
learning_rate=2e-4,
fp16=True,
optim="paged_adamw_8bit",
logging_dir="./logs",
save_strategy="no",
evaluation_strategy="no",
report_to=None
)
model = get_peft_model(model, peft_config)
model.config.use_cache = False
trainer = Trainer(
model=model,
train_dataset=train_ds.select_columns(['input_ids', 'attention_mask']),
eval_dataset=None,
args=args,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()
trainer.model.save_pretrained(save_path)
return
```
To finetune our LLM, we use the following snippet
```python
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
finetuned_model_path = "finetuned-mistral-all_data"
finetune_LLM(model_name, train_ds, save_path=finetuned_model_path, seed=seed)
```
The newly finetuned model is stored in your working directory under the folder "finetuned-mistral-all_data".
### Inference with Fine-tuned LLM
We run the inference with this model using the function `run_llm` as we did for the in-context learning experiment [previously](#putting-it-all-to-work)
```python
text_to_label = {v: k for k, v in label_to_text.items()}
LLM_emotion_list = emotion_list + ['no_match']
run_llm(val_data, prompt_template, model_name, LLM_emotion_list, text_to_label,
finetuned_model_path=finetuned_model_path, batch_size=64)
```
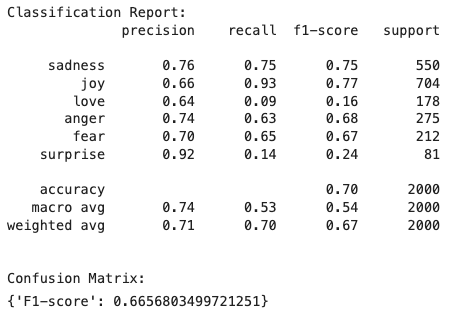
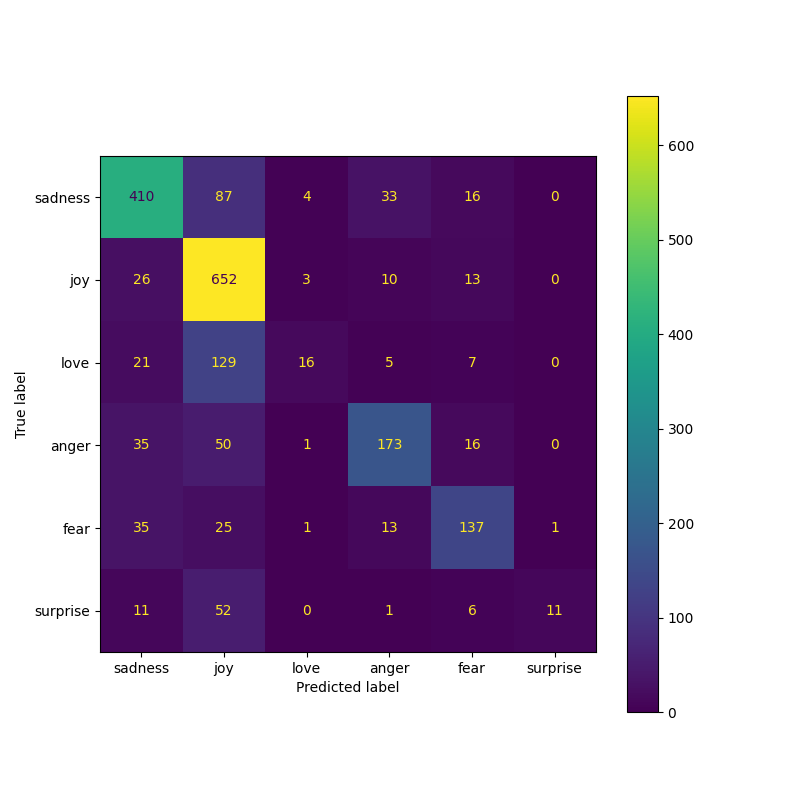
Our finetuned LLM performs better than our baseline of BGE small + Logistic Regression. Perhaps, the LLM is able to capture better representations than the pre-trained embeddings used in the baseline. More importantly, none of the predictions are '_no_match_' anymore. In other words, our finetuned LLM is able to predict a valid emotion as the label for all validation samples unlike what happened during In-Context Learning. Also, open source pre-trained embeddings more powerful than BGE small are available and can be explored to improve the baseline results.
---
## Better practical strategies to handle noisy data ?
We finetuned models directly on all of the available noisy labelled samples. In practice, you'd additionally explore noise correction strategies applicable either at the model building stage (ranging from designing robust loss functions to exploring [weaker forms of supervision](https://www.snorkel.org/blog/weak-supervision)) or at the data processing stage (label error detection / correction). Given that our goal is to benchmark LLM performance, let's consider a data level noise correction strategy and re-run the finetuning experiments to observe performance changes. We'll be using [DQC-Toolkit](https://github.com/sumanthprabhu/DQC-Toolkit), an open source library I'm currently building, to curate our noisy labelled samples.
```python
from dqc import CrossValCurate
cvc = CrossValCurate(random_state=seed,
calibration_method='calibrate_using_baseline' )
train_data_modified = cvc.fit_transform(train_data, y_col_name='noisy_label')
```
DQC Toolkit offers `CrossValCurate` that quantifies label correctness in the input labelled data using cross validation techniques. The result (stored in `train_data_modified`) is a pandas dataframe similar to `train_data` with the following additional columns -
* `'label_correctness_score'` represents a normalized score quantifying the correctness of `'noisy_label'`.
* `'is_label_correct'` is a boolean flag indicating whether the `'noisy_label'` is to be considered correct (`True`) or incorrect (`False`).
* `'predicted_label'` and `'prediction_probability'` represent DQC Toolkit's predicted label for a given sample and the corresponding probability score.
For more details regarding different hyperparameters available in `CrossValCurate`, please refer to the [API documentation](https://sumanthprabhu.github.io/DQC-Toolkit/latest/).
## <span style="color:gray">Baseline</span>
Instead of '_noisy_label_', we are going to leverage DQC Toolkit's '_predicted_label_' as our target variable. Let's start by rerunning the BGE small + Logistic Regression baseline.
```python
embeddings = "BAAI/bge-small-en"
label_column = 'predicted_label'
train_and_infer_LR_with_PTE(embeddings, train_data_modified, val_data, seed, label_column)
```
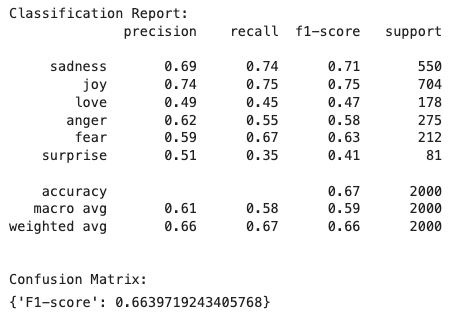
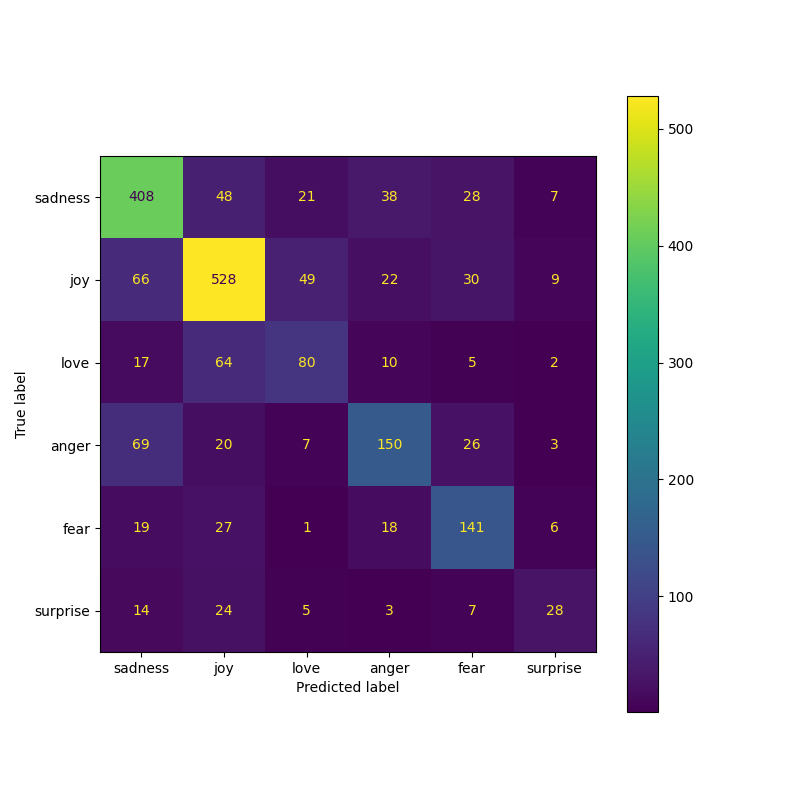
The F1 score without any noise correction was 0.641. With label correction, we observe a score of 0.664. There is an improvement in the F1 score ! Let's check if we observe similar performance improvements with LLM finetuning.
## <span style="color:gray">LLM : Finetuning</span>
We map the integer labels to text labels for LLM interpretability.
```python
train_data_modified['predicted_label_text'] = train_data_modified['predicted_label'].map(label_to_text)
```
We transform our text to LLM prompts
```python
emotion_list = ['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']
emotion_list_str = ', '.join(emotion_list)
prompt_template = "<s>[INST] You are a helpful, respectful and honest assistant. Choose one option that best describes the emotion behind the given utterance based on the following comma separated options: " + emotion_list_str + "[/INST] </s>"
label_column = 'predicted_label_text'
train_data_modified_ds = build_LLM_prompt(train_data_modified, with_label=True, label_column=label_column)
train_data_modified_ds = train_data_modified_ds.map(lambda example, prompt_template=prompt_template : {'emotion_prompt' : prompt_template + example['emotion_prompt']})
```
Now, we finetune our LLM on the data.
```python
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
finetuned_model_path = "finetuned-mistral-filtered_noisy_data"
finetune_LLM(model_name, train_data_modified_ds, save_path=finetuned_model_path, seed=seed)
```
Let's run the inference module and observe the performance changes.
```python
text_to_label = {v: k for k, v in label_to_text.items()}
LLM_emotion_list = emotion_list + ['no_match']
run_llm(val_data, prompt_template, model_name, LLM_emotion_list, text_to_label,
finetuned_model_path=finetuned_model_path, batch_size=32)
```
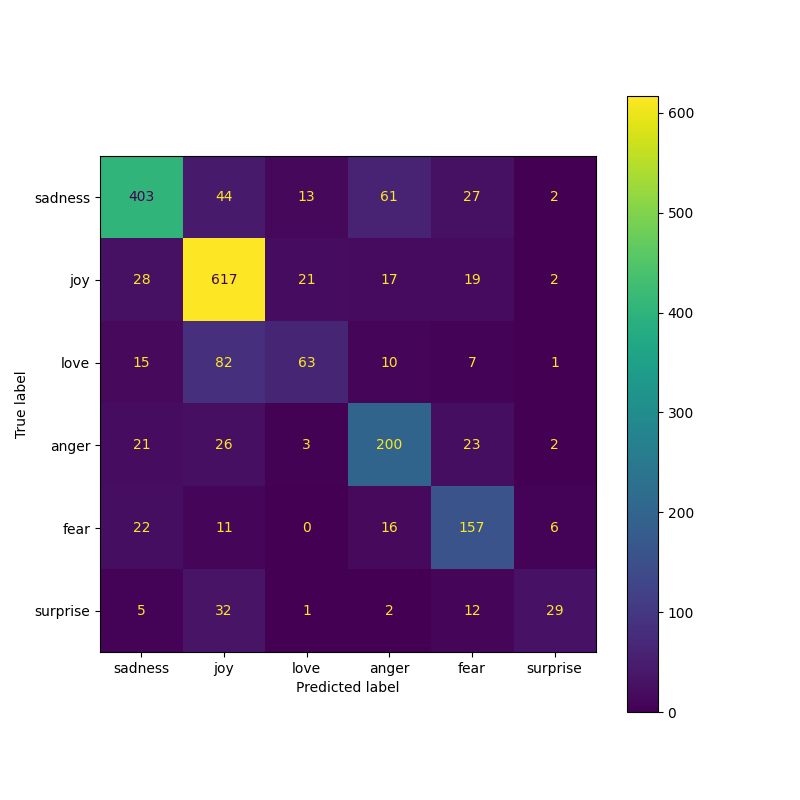
From an F1 score of 0.666 to an F1 score 0.726 ! This is a larger improvement compared to the performance improvement observed with our baseline. This could be attributed to the fact that we are finetuning the LLM as opposed to leveraging pre-trained embeddings in the baseline.
---
## [BONUS] <u><ins>*The Ideal Scenario*</ins></u> - (Clean) Labelled Data Available
We've run a bunch of experiments and were able to compare performances of different models for Emotion Prediction. Our best performing model is the finetuned LLM with noisy labelled data combined with DQC Toolkit for noise correction. How well would this finetuned LLM perform if it was trained with clean labelled data without changing any additional settings ? Let's find out.
```py
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
emotion_list = ['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']
emotion_list_str = ', '.join(emotion_list)
prompt_template = "<s>[INST] You are a helpful, respectful and honest assistant. Choose one option that best describes the emotion behind the given utterance based on the following comma separated options: " + emotion_list_str + "[/INST] </s>"
label_column = 'label_text'
train_ds = build_LLM_prompt(train_data, with_label=True, label_column=label_column)
train_ds = train_ds.map(lambda example, prompt_template=prompt_template : {'emotion_prompt' : prompt_template + example['emotion_prompt']})
```
We invoke `finetune_LLM` to finetune the model
```py
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
finetuned_model_path = "finetuned-mistral-ideal_data"
finetune_LLM(model_name, train_ds, save_path=finetuned_model_path, seed=seed)
```
And finally, performance inference and compute metrics using `run_llm`
```py
text_to_label = {v: k for k, v in label_to_text.items()}
LLM_emotion_list = emotion_list + ['no_match']
run_llm(val_data, prompt_template, model_name, LLM_emotion_list, text_to_label,
finetuned_model_path=finetuned_model_path, batch_size=32)
```
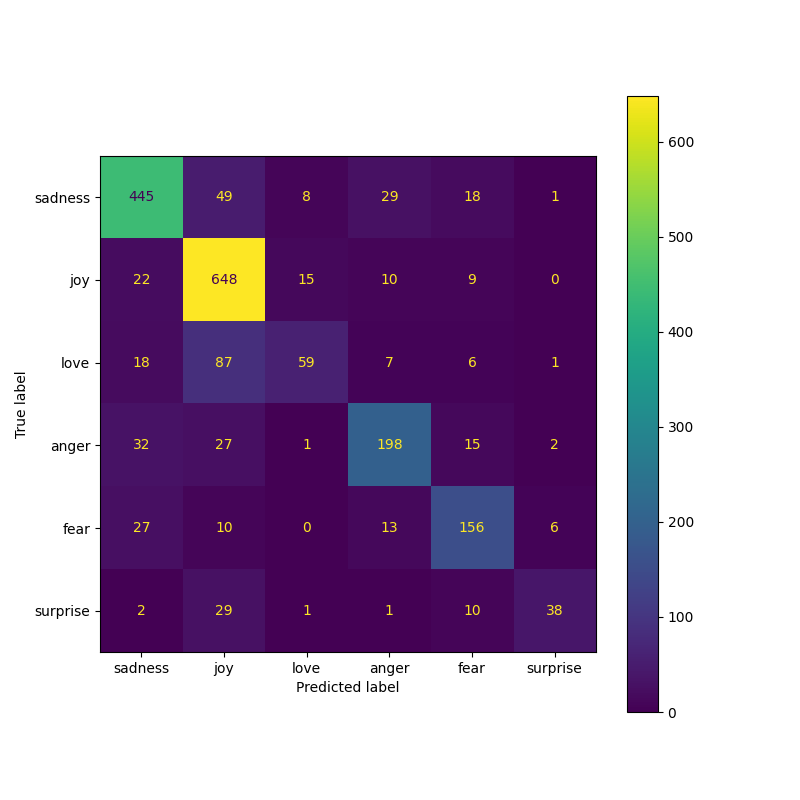
F1-score is 0.761. This means there is scope for improvement in our previous strategies. There are more enhancements that we can leverage to achieve better performance but we leave those discussions to future posts, if people are interested.
---
## Consolidating results
Phew ! We've reached the end of the article. The following plots summarize the performances of the approaches for each scenario discussed -
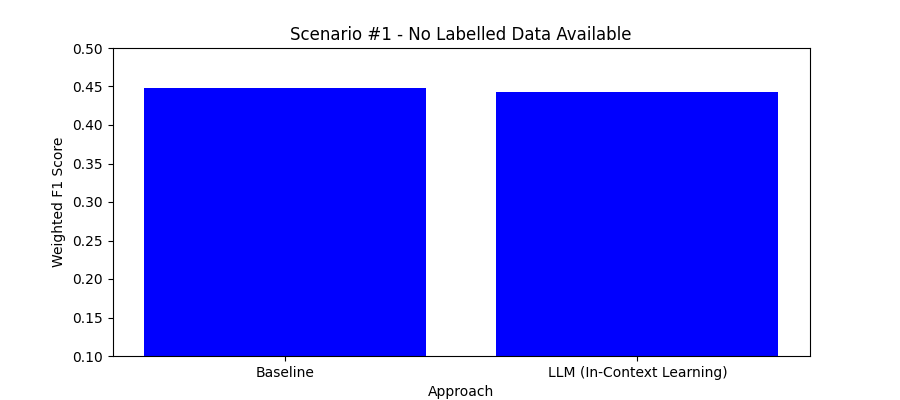
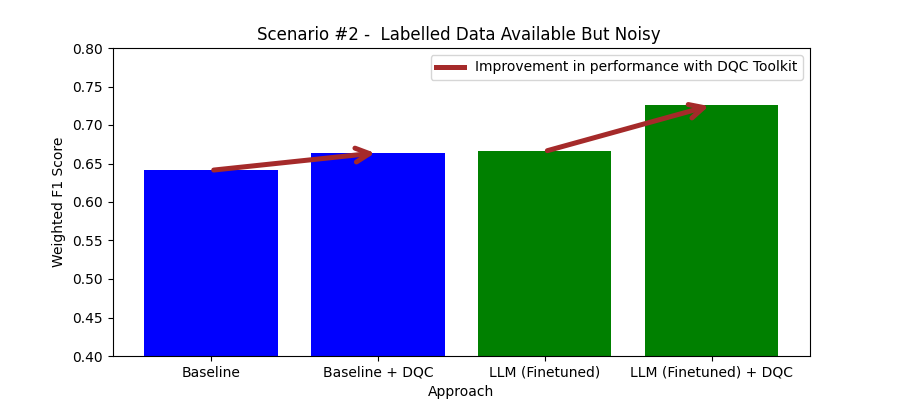
In Scenario 1 (No Labelled Data Available), our baseline(SetFit) performed on par with the LLM(In-Context Learning). In Scenario 2 (Labelled Data Available but Noisy), our baseline (BGE small pre-trained embeddings combined with Logistic Regression) slightly underperformed in comparison to our fine-tuned LLM. When we applied label noise correction via DQC Toolkit, we observed a performance boost in both the baseline and the fine-tuned LLM.
> Currently, DQC Toolkit supports text classification (binary/multi class) problems with various parameter customization options. Check out the [documentation](https://sumanthprabhu.github.io/DQC-Toolkit/api/crossval/) for details. Following is the link to the repo. The plan is to enhance it further by adding more capabilities. Any form of feedback and support will be much appreciated !
{% github sumanthprabhu/DQC-Toolkit %}
## Thank you for reading
Passionate about Machine Learning? Please feel free to add me on [Linkedin](https://www.linkedin.com/in/sumanth-prabhu/). | sumanthprabhu |
1,865,688 | Reverse a String in Python in 60 Seconds! | Reverse a String in Python in 60 Seconds! | 0 | 2024-05-26T14:56:10 | https://dev.to/dipakahirav/reverse-a-string-in-python-in-60-seconds-4lk0 | python, programming, coding, learning | [Reverse a String in Python in 60 Seconds!](https://youtube.com/shorts/3Qfr9Hu47iM?si=bLQGZSGmeC2t7jku) | dipakahirav |
1,865,685 | Javascript's Single Threaded Nature | Javascript is a single-threaded language let's see what that means. When the javascript engine... | 0 | 2024-05-26T14:56:09 | https://dev.to/ikbalarslan/javascripts-single-threaded-nature-m33 | javascript, programming, webdev | Javascript is a single-threaded language let's see what that means.
When the javascript engine starts executing the code it does that synchronously. In this kind of execution, the program is executed line by line, one line at a time. doesn't move to the next line without finishing the execution of the current line.
**It can do only one thing at a time**
Let's say, you asked for burgers in the restaurant. while you are waiting for your burger you don't do anything else. You start doing other stuff after you get the burger.
```
var a = 5;
var b = 10;
function sum(a,b){
return a + b
}
sum()
console.log("hello")
```
In the code above when we call the function sum we can't move to the console log line until the execution of the sum is done.
> There is one way to make the javascript multi-threaded which is with setting up workers. But it doesn't come as default as a developer you should set it up to have multiple execution contexts at the same time. | ikbalarslan |
1,865,687 | VMware price hike forces Australian company with 24,000 virtual machines to jump ship | As I mentioned in this post-https://lnkd.in/dp-U7yPD - 2 months ago that we are facing a new era of... | 0 | 2024-05-26T14:54:51 | https://dev.to/basel5001/vmware-price-hike-forces-australian-company-with-24000-virtual-machines-to-jump-ship-5716 | vmware, virtualization | As I mentioned in this post-https://lnkd.in/dp-U7yPD - 2 months ago
that we are facing a new era of migration projects
this will be a tsunami from VMware to other competitors or open-source virtualization, In the recent Nutanix Next conference in Barcelona, Computershare CTO Kevin O'Connor, the company will likely abandon VMware's hypervisor soon to focus exclusively on Nutanix products.
sources:
- https://lnkd.in/dHKpcNdt | basel5001 |
1,865,686 | WhatsApp for Developers | Someone saw me writing code (JavaScript) and literally asked me, do I speak 1s and 0s too. I... | 0 | 2024-05-26T14:54:28 | https://dev.to/kehindedaniels/whatsapp-for-developers-28dg | programming, computerscience, productivity, webdev | {% embed https://twitter.com/toby_solutions/status/1777799502453215731? %}
Someone saw me writing code (JavaScript) and literally asked me, do I speak 1s and 0s too. I couldn’t help but laugh😂 (don’t worry, she was a friend, so no offense was taken, and I helped her understand better too☺️). That’s what we were taught in primary school — that the computer’s language is 0s and 1s, right? So, to be a computer programmer, you should know how to ‘speak’ binary code… I bet that’s what you’re thinking too😂.
But unless you have a CS (computer science) degree, which I don’t (I’m self-taught), no YouTube video will teach you JavaScript starting with zeros and ones. In fact, no programmer communicates with the computer in 0s and 1s directly; that’s the job of compilers and interpreters, which convert what we write into machine language. But let me not bore you with all that computer jargon, because I don’t fully understand how that magic works either.
Well, write code in high-level languages, which are easier for humans to understand and use. But hey, it’s not just plain English, least you think you can just start coding and get a job…
Try it
```c
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}
```
I bet this looks like an alien language to you, except if you’re a developer. This is an example of a high-level language that will be compiled into binary code for the computer to understand.
## Why I’m Writing This Case Study
{% embed https://twitter.com/danizeres/status/1777909396724736275?ref_src=twsrc%5Etfw
%}
This meme got me on my knees😂. But that's the truth, yeah? Even Mozart’s pet can feel our pain.
WhatsApp is a platform for communities, and one prevalent community is the tech world. I belong to a few myself
I can say for sure that many have received help and rendered help by reviewing and correcting other people’s code snippets. But helping or asking for help can often be very stressful. No one talks about the developer experience… so sad, yeah.
> Often, you have to make a screenshot or copy and paste code snippets, which is a hassle because the code will be almost ‘unreadable’

Now, whether you’re a dev or not, don’t try to understand the code. I just want you to compare both visuals and judge which is more appealing and looks more comprehensible. The second image, right? It’s not easy to understand a programming language; it’s harder to grasp without its proper syntax format (like the reds and blues you see in the image).
## What If?
What if WhatsApp supported markdown features with syntax formatting? That would make the lives of developers less stressful. I know they've got this using a backtick `around a word ` that gives it a mono-spacing styling, but I'm talking about a bit more sophisticated markdown with syntax formatting.
## How Would It Work?
**Auto-detect:**
Once it brings out the dialogue code block, it can auto-detect as you start typing. Or you could specify the language you want to write in.
## No Need to Reinvent the Wheel
They’ve got an attachment menu that allows users to send various types of files in chats. They could extend this functionality by adding an ‘Embed Code Block’ option to the menu.
## Addressing Edge Cases
1. What if I’m not a developer?
I recognize not not everyone is a developer, and might have no use for it at all. Well, for non-developers, the platform continues to offer secure and efficient communication. The introduction of developer-specific features does not detract from its usability for everyday conversations. Instead, it expands the versatility of WhatsApp, making it a more comprehensive tool for various types of interactions.
But some users might find it unnecessary, So, I made a developer option in the settings, Users can toggle the dev option.
2. Limited Screen Space
Of course, it is not expected that you build an entire website on WhatsApp, the goal is not to replace our regular code editor, rather it’s to help communication flow better. Good enough we have WhatsApp desktop, so while you’re working in your code editor and you encounter a problem, you can just quickly copy a code snippet to the clipboard and paste it into the Whatsapp code block. Plus I Implemented a scrollable code block and a pinch-to-zoom feature for better readability.
3. Typing on mobile devices can be cumbersome:
It's integrated with desktop or web versions plus enhanced support for code editing, like syntax highlighting, and very importantly, autocomplete.
So, in Conclusion
Just imagine it’s one line of code causing an error for a junior dev; you don’t want to open your editor and start typing all over. You could copy, paste, and edit right there without leaving WhatsApp. This is the goal!
I dropped a design case study on Behance for this, kindly check [here ](https://www.behance.net/gallery/198336617/WhatsApp-for-Devs), to see visuals.
But I’m curious anyway
If WhatsApp were to implement these features, would developers really use it? Are there any other edge cases to consider before giving it a go? Let me know!
| kehindedaniels |
1,865,684 | AWS announces new edge location in Egypt | Posted on: May 22, 2024 Amazon Web Services (AWS) announces expansion in Egypt by launching a new... | 0 | 2024-05-26T14:51:58 | https://dev.to/basel5001/aws-announces-new-edge-location-in-egypt-4e78 | aws, egypt, cloudcomputing, devops | Posted on: May 22, 2024
Amazon Web Services (AWS) announces expansion in Egypt by launching a new Amazon CloudFront edge location in Cairo, Egypt. Customers in Egypt can expect up to 30% improvement in latency, on average, for data delivered through the new edge location. The new AWS edge location brings the full suite of benefits provided by Amazon CloudFront, a secure, highly distributed, and scalable content delivery network (CDN) that delivers static and dynamic content, APIs, and live and on-demand video with low latency and high performance.
All Amazon CloudFront edge locations are protected against infrastructure-level DDoS threats with AWS Shield that uses always-on network flow monitoring and in-line mitigation to minimize application latency and downtime. You also have the ability to add additional layers of security for applications to protect them against common web exploits and bot attacks by enabling AWS Web Application Firewall (WAF).
Traffic delivered from this edge location is included within the Middle East region pricing. To learn more about AWS edge locations, see CloudFront edge locations.
| basel5001 |
1,865,682 | My Linux Journey: Top 5 Distros Based on Trial and Error | I remember the first time I tried out Linux. I must have been around 12 years old, around 2010. The... | 0 | 2024-05-26T14:48:53 | https://dev.to/christiandale/my-linux-journey-top-5-distros-based-on-trial-and-error-dam | I remember the first time I tried out Linux. I must have been around 12 years old, around 2010. The first Linux distro I tried was Ubuntu; this was during the GNOME 2 days, and the interface looked a bit dated even then.
What was great about Ubuntu at that time—and much of this still holds true—was its ease of use and how lightweight it was. It could run perfectly fine on a Windows XP era computer.
I remember fondly the library of games it had like Mines (a Minesweeper clone), Solitaire, Chess, GNOME Sudoku, and Mahjongg. There were also a collection of other apps like OpenOffice and GIMP. It was fun to experiment with these games and apps for a while, but after some time, I got bored with them. That was about it for my Linux experience at that time.
A few years later, I decided to try out Ubuntu again. This was around the time GNOME 3 was released, and when Ubuntu decided to go their own way with their desktop environment called Unity. I didn’t like GNOME 3 and Unity at the time—but I must admit my opinion has changed in later years.
Now, after deciding that Ubuntu didn’t fit my needs, I began looking at alternatives. This is where I found Linux Mint—an Ubuntu-based distro. What I liked about Linux Mint was that it looked more traditional, especially for someone coming from Windows.
This list is not ordered in any particular way. These picks are my opinion, of course, and should not be taken as gospel, but instead as general recommendations based on what your needs are.
## 1. Debian - Best for security and stability

Image by [Motor8](https://commons.wikimedia.org/wiki/User:Motor8) on [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Screenshot_of_Debian_12_%28Bookworm%29_GNOME_43.9%E2%80%94English.png) / [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)
**Use cases:**
* Servers
* Stable desktops
I have found Debian to be an excellent pick for desktops that need to be stable, like your work computer, for example. This is where I use Debian at the moment, although some of my colleagues might find Debian a bit boring ;)
Debian is also great for servers, as its lack of frequent function updates ensures a stable environment. In addition, this distro seems to have lesser resource requirements than Ubuntu—although I don’t have specific measurements, it seems logical considering how bare-bones Debian is. Although Ubuntu usually has a greater market share in the server space, you might want to consider running Debian instead.
By the way, I currently run GNOME on Debian, where a vanilla version of GNOME 3 is the default choice.
## 2. Arch Linux - Best for those who like to «live on the edge»

Image by [VulcanSphere](https://commons.wikimedia.org/wiki/User:VulcanSphere) on [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Arch_Linux_neofetch_screenshot.png) / [GPL](https://www.gnu.org/licenses/gpl-3.0.html)
**Use cases:**
* Home computer
* Development desktops and servers
I find using Arch Linux a lot of fun, and it is certainly the best pick for anyone who likes to try out the latest software and tinker and customize their system to the fullest.
I used to run Arch Linux on my main computer. The rolling release model ensures you have the latest packages and updates, making it ideal for those who want to stay on the cutting edge of technology. However, it requires a hands-on approach and is best suited for experienced users.
## 3. Ubuntu - A great general purpose operating system

Image by [Esstro](https://commons.wikimedia.org/wiki/User:Esstro) on [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Ubuntu-20.04.jpg) / [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)
**Use cases:**
* General purpose computers.
* Servers.
Ubuntu is a fantastic all-rounder. It has great support for most hardware, so if you experience some issues with getting drivers for your devices on Debian, this might be the pick for you. With its regular updates and vast community support, Ubuntu remains a solid choice for both newcomers and seasoned users.
Ubuntu's community and documentation are extensive, making it an excellent choice for beginners. The Ubuntu Software Center provides a user-friendly interface for installing applications, simplifying the software management process. Additionally, Ubuntu's Long Term Support (LTS) releases ensure stability and security for those who prefer not to upgrade frequently.
## 4. Linux Mint - Great for those who like a more traditional look and feel.

Image by [Clement Lefebvre](https://commons.wikimedia.org/wiki/User:Clement_Lefebvre) on [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Linux_Mint_21.1_Cinnamon_eng.png) / [GPL](https://www.gnu.org/licenses/gpl-3.0.html)
**Use cases:**
* Everyday use.
* Transitioning from Windows.
After my experience with Ubuntu’s Unity, I sought out a more traditional desktop experience, and Linux Mint seemed like the perfect fit. Mint is based on Ubuntu and provides a desktop environment called Cinnamon as the default, which offers a familiar interface for Windows users. The Cinnamon desktop environment provides a stable and customizable user experience. Whether you’re a newcomer to Linux or an experienced user, Linux Mint is a safe choice.
Linux Mint's emphasis on simplicity and ease of use makes it an ideal choice for users who want a hassle-free Linux experience. The Mint Update Manager ensures that system updates are managed efficiently, allowing users to stay up-to-date with security patches and software enhancements. Moreover, the inclusion of multimedia codecs and proprietary drivers out of the box enhances the out-of-the-box experience for users, especially those transitioning from Windows.
## 5. Raspbian - The best pick for embedded Linux.
Image by [Raspbian Project](https://commons.wikimedia.org/wiki/User:Raspbian_Project) on [Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Raspbian_2019.04_application_menu.jpg) / [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/deed.en)
**Use cases:**
* Raspberry Pi projects
* IoT (Internet of Things)
For enthusiasts and developers working with Raspberry Pi and embedded systems, Raspbian seems like the obvious choice. Based on Debian, Raspbian is optimized for running on the Raspberry Pi’s hardware architecture. It is lightweight, efficient, and comes pre-loaded with educational tools and programming languages, making it perfect for both beginners and advanced users working on IoT projects.
Raspbian's compatibility with the Raspberry Pi ecosystem ensures seamless integration with the hardware, allowing users to leverage the full potential of the device for various projects. The inclusion of tools like Scratch and Python make it an excellent platform for educational purposes, enabling users to learn programming and electronics in a hands-on manner. Additionally, Raspbian's active community provides ample support and resources for users to troubleshoot issues and explore new projects.
## Ending remarks
My journey with Linux has been one of continuous learning and discovery. Each distro has its unique strengths and caters to different needs. Whether you're looking for stability, cutting-edge technology, or a familiar interface, there's a Linux distro out there for you. Have fun!
Check out my website for more articles: https://christiandale.no | christiandale | |
1,865,672 | Flow of Setting up Lambda function invocation via API Gateway to perform a DynamoDB read/write operation | Typical Authenticated Lambda function invocation via API Gateway which will perform a DynamoDB... | 0 | 2024-05-26T14:48:50 | https://dev.to/asankab/aws-lambda-faas-5bec | lambda, serverless, apigateway, cognito |
**Typical Authenticated Lambda function invocation via API Gateway which will perform a DynamoDB read/write operation**
1. Acquiring a token passing credentials.
2. Invoking the API Gateway endpoint passing the JWT token.
3. API Gateway validates the token.
4. Upon successful Auth token validation, API Gateway routes the request to the desired destination lambda function.
5. Retrieve any credentials stored.
6. Retrieve / Save the incoming payload to the database.
| asankab |
1,865,679 | How to Create an Endpoint API for Circulating Supply and Total Supply of a Token on Solana? | Hi everyone, I need help creating an API endpoint that returns the circulating supply and total... | 0 | 2024-05-26T14:45:47 | https://dev.to/0xfuckingdegen/how-to-create-an-endpoint-api-for-circulating-supply-and-total-supply-of-a-token-on-solana-4450 | solana, endpoint, api, coinmarketcap | Hi everyone,
I need help creating an API endpoint that returns the circulating supply and total supply of a token on the Solana blockchain. I'm new to Solana development and could use some guidance.
Questions:
Token Supply:
How do I get the total supply of a token on Solana?
How can I calculate the circulating supply?
Solana Tools:
Which Solana RPC methods or SDK functions should I use?
API Development:
Any tips for setting up a secure and efficient API endpoint?
Are there example codes or templates I can follow?
Any advice or resources would be greatly appreciated. Thanks!
Best,
Nick | 0xfuckingdegen |
1,854,873 | Real-Time WebSocket Connections for Node.js with ws-low-level | Achieving real-time connections is easy using WebSockets. Though you may opt for long polling to... | 0 | 2024-05-26T14:42:18 | https://dev.to/jonlachlan/real-time-websocket-connections-for-nodejs-with-ws-low-level-38cj | webdev, javascript, programming, tutorial |
Achieving real-time connections is easy using WebSockets. Though you may opt for long polling to update a client statelessly, the ability to handle and manage a stateful WebSocket connection makes it possible to work in real-time communications with the client.
WebSocket is a bi-directional data messaging protocol. The connection begins as an HTTP call, which initiates a handshake to work through the details of the connection. Once the connection is established, the client and server can send messages to each other. Messages are formatted as UTF-8 text or binary.
With the Node 22 update, the WebSocket client is now available in Node, so you can build server-to-server WebSocket connections with Node.js as the client.
Clearly WebSockets have a lot of value, so let's build a server!
## Achieving Real-Time Connections with Node.js
In this article I'm going to show you how to get started with creating a WebSocket server for Node.js using the npm library ws-low-level. ws-low-level provides the API to receive and send messages, and handle the WebSocket handshake.
As its name suggests, ws-low-level is *low-level*, in the sense that it gives you access to the raw parts of the WebSocket protocol. With this access comes the trade-off of more control versus more verbosity. And ws-low-level is indeed verbose -- the example in the README file for the [ws-low-level repo](https://www.npmjs.com/package/ws-low-level) is over 150 lines of code!
That is not to say ws-low-level is overly complex, however. The example from the README file is simple enough.
And the ws-low-level API is actually providing you with a robust, Promise-based, standard-compliant WebSocket server. Because it is low-level, you will have the opportunity, once your server is in development, to add to it and customize it the way that you want.
### Getting Started
I will walk you through setting up a WebSocket server using ws-low-level.
First, make sure you have the correct prerequisites installed. You will need Node.js, which you can get from the [Node download page](https://nodejs.org/en/download). This will also install npm. You can check your installation by running `node --version` and `npm --version`.
Let me explain how ws-low-level works with Node.js.
ws-low-level ties in to the standard library of Node.js. In Node.js, the WebSocket HTTP upgrade is available through Node's `http` package with the `'upgrade'` event handler. A request to establish a WebSocket will trigger this event. Below is an example server that uses the event and logs the word "upgrade" to the console whenever a WebSocket connection is requested.
```javascript
import http from 'http';
const httpServer = http.createServer(
function (
request /* <http.IncomingMessage> */,
response /* <http.ServerResponse> */
) {
// Handle HTTP messages by verbs like GET and POST
}
);
httpServer.on('upgrade', function (
request /* <http.IncomingMessage> */,
socket /* <stream.Duplex> */,
head /* <Buffer> websocket header */
) {
// Handle a WebSocket connection
console.log('upgrade');
});
httpServer.listen(3000);
```
The above code shows how to use Node.js to handle a WebSocket. Note that Node.js does not handle the WebSocket handshake, nor parse incoming WebSocket frames, nor prepare outgoing messages as WebSocket frames. We need a third-party library to help get started with our WebSocket server.
### Using ws-low-level
Enter ws-low-level! ws-low-level is a third-party library available on npm for handling Node.js WebSocket connections. To install the library, enter in your terminal:
```bash
npm install ws-low-level
```
Now, back to our server, we can import from ws-low-level all of the imports that we will need. I recommend importing all five of the following imports, because you will eventually need them all.
```javascript
import {
sendHandshake,
getMessagesFactory,
sendFactory,
prepareWebsocketFrame,
prepareCloseFramePayload
} from 'ws-low-level';
```
Now we can add a WebSocket handshake to the web server, and the connection will be established. Let's modify the callback for the `'upgrade'` event to include `sendHandshake`.
```javascript
httpServer.on('upgrade', function (
request /* <http.IncomingMessage> */,
socket /* <stream.Duplex> */ ,
head /* <Buffer> websocket header */
) {
sendHandshake(
request,
socket
);
});
```
The above code will complete the WebSocket handshake, establishing a WebSocket connection. (That was simple!)
### Next Steps
Now that we have a connection established, it should be clear what we need to do next -- we need to handle receiving and sending messages. To continue on your journey, I recommend you proceed to the example server on [ws-low-level's README](https://www.npmjs.com/package/ws-low-level). It should be clear how to use the send and receive functionalities.
This has been a brief introduction to real-time WebSocket communication for Node.js using ws-low-level. As the creator of ws-low-level, I'd like to say thank you for reading! | jonlachlan |
1,865,094 | Python Projects with SQL: Strategies for Effective Query Management | Many times, when programming in a project involving interaction with a database, we face the... | 0 | 2024-05-26T14:41:00 | https://dev.to/r0mymendez/python-projects-with-sql-strategies-for-effective-query-management-2n5k | python, sql, database, dataengineering | Many times, when programming in a project involving interaction with a database, we face the **❓question of how to organize our queries and make them reusable**.
For this reason, some 🧑💻 developers `create functions` where they concatenate strings to make the queries more dynamic and others prefer to `create variables` where they define these queries. Although some more sophisticated developers also `use SQLAlchemy` object declaration to define the queries, but this has a learning curve and can 📈complicate the development process, especially when dealing with more complex queries.

One day, I found myself searching for a way to perform this in an `orderly`, `organized`, and `reusable` manner without overly complicating my code, and I stumbled upon an interesting library called **aiosql**.
In the following article, I will review how to use it and explained in its documentation and also I will share some approaches I used to implement it in other contexts.
---
# ⚙️ What is aiosql library?
**Aiosql** is a 🐍Python library that simplifies the writing of **SQL queries** in separate files from your main Python project code. These queries, stored in SQL files, are then transformed into methods within a 🐍Python object.
Another notable feature of **aiosql** is its ability to generate dynamic methods that accept parameters, enabling flexible query execution and effective interaction with the underlying database.
This separation of SQL queries from the main Python code promotes cleaner and more modular code, enhancing project readability and maintainability.
---
# ⚙️ How Does aiosql Work?
In the diagram, you can see that all the queries from an SQL file can be imported and used in Python code by invoking them with the name defined in the query header.
Subsequently, you can execute the queries by passing the necessary parameters directly from your Python code, which makes the queries reusable and easier to maintain.

---
# ⚙️ Key Features of Aiosql Library
Below, I will share a series of features that this library already has or can have based on its usage:
* Provides **CRUD functionality** (Create: Insert, Read: Select, Update , Delete) for database operations.
* **Separates Python code** from SQL code, making it easier to locate queries within projects with multiple databases.
* Each query can be assigned a **descriptive name and docstring**, similar to Python functions, enabling documentation of the query.
* Facilitates the creation of **a query catalog** within the project, aiding in identification based on entities, databases, or other grouping criteria.
* Enables easy generation of **dynamic queries** with the ability to pass dynamic values and modify them as needed.

---
# ⚙️ Aiosql Tutorial
## 🔧 Prerequisites
* 🐳 Docker
* 🐙 Docker Compose
* 🐍 Install python libraries: `pip install aiosql pandas`
---
## 🚀 Quick Start
### 🛠️Create a postgres database
* 1️⃣ - **Clone this [repository: aiosql-tutorial](https://github.com/r0mymendez/aiosql-tutorial/tree/master)** →
```bash
git clone https://github.com/r0mymendez/aiosql-tutorial.git
```
* 2️⃣ - **Change directory** to the 'postgres' folder →
```bash
cd aiosql-tutorial/postgres
```
* 3️⃣ - **Create postgres database** → Execute in the terminal→
```bash
docker-compose -f docker-compose.yml up --build
```
* 4️⃣ - **Check if your container is running** → Execute in the terminal →
```bash
docker ps
```
* 5️⃣ - **Load the csv files** → Execute the following command for load the csv file in the container →
```bash
cd src
python3 etl.py
```
---
### 🏥 Hospital Data
To implement aiosql, we will use the datasets from [Synthea](https://synthea.mitre.org/), which simulates a hospital database. These synthetic data are generated from a simulation considering various variables of a population in Massachusetts.
From these datasets, we will use the tables: `conditions`, `encounters`, and `patients`.
---
### 👥 User stories
To make this example more real we are going to make 3 use cases:
* 1️⃣ - As a **data analyst**, I want to be able to retrieve a list of patients whose visit count is above the 90th percentile, so that I can identify the most active patients in the clinic. Additionally, I want this percentile to be configurable for easy adjustment in the future.
* 2️⃣ - As a **researcher or data analyst**, I want to access the data of patients who have been diagnosed with the 10 most frequent diagnoses in a period of time, in order to analyze trends and improve the quality of medical care.
* 3️⃣ - As a **marketing analyst**, I want to create a table for patient satisfaction surveys, so that I can gather feedback on the quality of care and take measures to improve it.
---
### 🚀 Implementation
Based on the user stories that we are going to create, we will define two files in which we will load the queries and scripts that we need to execute:
* **patients.sql**: where we have all the queries related to recovering patient data.
* **visits.sql**: where we have all the queries related to visits, such as surveys.
Therefore in our project we are going to have this structure of folders and files
```bash
- 📁 db
- 📁 queries
- 📄 patients.sql
- 📄 visits.sql
- 📄 main.ipynb
```
---
In this way we are isolating the python code from the sql code, in our case we are going to implement this **🐍python code** in a notebook in such a way as to make its explanation easier.
---
#### 1️⃣ - Import python libraries
```python
import aiosql
import psycopg2
import pandas as pd
```
#### 2️⃣ - Import the SQL queries and configure the database driver
> In this project, the SQL queries are located in the **'db/queries'** directory and **'psycopg2'** is the PostgreSQL database adapter.
```python
sql = aiosql.from_path('src/db/queries', 'psycopg2')
```
#### 3️⃣ - Create the connection to the PostgreSQL database.
```
postgres_secrets = {'host': 'localhost','port': 5432, 'user': 'postgres', 'password': 'postgres', 'dbname': 'postgres'}
conn = psycopg2.connect(**postgres_secrets)
conn.autocommit = True
```
---
### 👥 User story I: Static Values
> As a **data analyst**, I want to be able to retrieve a `list of patients` whose visit count is `above the 90th percentile`, so that I can identify the most active patients in the clinic. Additionally, I want this __percentile to be configurable__ for easy adjustment in the future.
---
Based on this user story, we will first create one that allows generating a query to retrieve the list of patients with a visit frequency above the 90th percentile.
#### 1️⃣ - In the sql file we have the query for the first user story
The following are the three components that a SQL statement comprises in aiosq:
* **📗 Name**: This is the descriptive name used to invoke the query from Python code.
In the following example the name is `"fn_get_patients_adove_90th_percentile"`
* **📗 Description**: It's a detailed description used to generate a docstring. It provides a more comprehensive explanation of the purpose and context of the query.
In the following example the description is `"get all the patients that have more visits than the 90th percentile of visits..."`
* **📗 Query**: Here is the SQL query that will be executed in the database.
`📄sql:db/queries/patients.sql`
```sql
-- name: fn_get_patients_adove_90th_percentile
-- get all the patients that have more visits than the 90th percentile of visits. All this data is stored in encounters table.
WITH patient_visits AS (
SELECT
patient,
COUNT(*) AS visit_count
FROM
hospital.encounters
GROUP BY
patient
),
percentil_n AS (
SELECT
percentile_cont(0.9) WITHIN GROUP (ORDER BY visit_count) AS p_visits
FROM
patient_visits
)
SELECT
pv.patient,
pv.visit_count
FROM
patient_visits pv
CROSS JOIN
percentil_n pn
WHERE
pv.visit_count >= pn.p_visits;
```
#### 2️⃣ - Execute the 'fn_get_patients_above_90th_percentile' SQL function using the database connection 'conn'.
> The function returns a list of tuples representing patients whose visit count is above the 90th percentile.
`🐍Python`
```python
response = sql.fn_get_patients_above_90th_percentile(conn)
```
#### 3️⃣ - Now we can convert the response object into a pandas DataFrame for easier data manipulation
> The column names ('patient_id' and 'num_visit') are added manually because aiosql only returns the query result as a list of tuples without column names.
```
data = pd.DataFrame([item for item in response], columns=['patient_id', 'num_visit'])
# Display the DataFrame.
data
```

---
> if we want to see the query, we can use the following code
```python
print(sql.fn_get_patients_adove_90th_percentile.sql)
```
---
### 👥 User story I: Dynamic Values
> As a **data analyst**, I want to be able to retrieve a `list of patients` whose visit count is above the 90th percentile, so that I can identify the most active patients in the clinic. Additionally, `I want this percentile to be configurable` for easy adjustment in the future.
---
Now, we are going to create another query that allows us to accept different percentile values so that the query can be dynamically modified based on the values passed. In our case, we are going to provide an example of obtaining the list of patients that exceed the 75th percentile.
> Notice that we now have a dynamic variable called **percentile_value**
`📄sql`
```sql
-- name: fn_get_patients_above_n_percentile
WITH patient_visits AS (
...
),
percentil_n AS (
SELECT
percentile_cont(:percentil_value) WITHIN GROUP (ORDER BY visit_count) AS p_visits
FROM
patient_visits
)
SELECT ...;
```
#### 1️⃣ - This following code executes a dynamic SQL query that accepts different percentile values as input.
`🐍Python`
```python
# In this case, we're getting patients above the 75th percentile.
response = sql.fn_get_patients_above_n_percentile(conn, percentil_value=0.75)
data = pd.DataFrame([item for item in response], columns=['patient_id', 'num_visit'])
```
---
### 👥 User stories II
> As a **researcher or data analyst**, I want to access the data of patients who have been diagnosed with the 10 most frequent diagnoses in a period of time, in order to analyze trends and improve the quality of medical care.
---
To resolve this user story, we will create a query that retrieves patients with the most common conditions within a specified time period. This query will be dynamic, allowing for future variations in the number of conditions of interest.
It will accept three parameters:
- **'num_condition'** will allow us to limit the number of conditions we're interested in (e.g., the top 10 most common conditions).
- **'period_start_date'** and **'period_start_end'** will define the time window for which we want to retrieve data.
`📄sql`
```sql
-- name: fn_get_patients_top_conditions
-- Get patients with top conditions for a given period of time, the patients are sorted by the number of days they had the condition and the source of the data is the hospital schema.
with top_n_conditions as(
SELECT code, description, COUNT(*)
FROM hospital.CONDITIONS
GROUP BY code,description
ORDER BY COUNT(*) DESC
LIMIT :num_condition
),
top_n_condition_patients as (
SELECT
p.ID,
p.FIRST,
p.LAST,
p.CITY,
p.GENDER,
EXTRACT(YEAR FROM AGE(p.BIRTHDATE)) AS age,
c.start condition_start_date,
c.stop condition_stop_date,
EXTRACT(DAY FROM (c.stop - c.start )) AS condition_days,
c.encounter,
c.code,
c.description
from hospital.patients p
inner join hospital.conditions c on c.patient = p.id
inner join top_n_conditions t on t.code=c.code
)
select *
from top_n_condition_patients
where condition_start_date between :period_start_date and :period_start_end;
```
`🐍Python`
```python
response = sql.fn_get_patients_top_conditions(conn, num_condition_days=10,
period_start_date='2022-01-01',
period_start_end='2022-12-31')
column_name=['id', 'first','last','city','gender',
'age','condition_start_date','condition_stop_date','condition_days','encounter','code','description']
data = pd.DataFrame([item for item in response], columns=column_name)
data.head()
```
----
### 👥 User story III
As a **marketing analyst**, I want to create a table for patient satisfaction surveys, so that I can gather feedback on the quality of care and take measures to improve it.
---
Now we are going to create the table using aiosql, if you look at our code in SQL you will see that a # symbol is added, these symbols are used by aiosql to identify the different operations that must be performed.
`📄sql`
```sql
-- name: fn_create_survey_table#
CREATE TABLE HOSPITAL.VISIT_SURVEY(
ID SERIAL PRIMARY KEY,
PATIENT_ID VARCHAR(50),
SURVEY_DATE TIMESTAMP,
RATING INT,
COMMENTS TEXT,
CREATED_AT TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
```

---
#### 1️⃣ - Execute the 'fn_create_survey_table' SQL function to create a new table in the database.
`🐍Python`
```python
sql.fn_create_survey_table(conn)
```
`'CREATE TABLE'`
#### 2️⃣ - Once the table is created we are going to use the following insert statement to be able to insert a review of a patient
`📄sql`
```sql
-- name: fn_add_one_visit_survey<!
insert into HOSPITAL.VISIT_SURVEY(PATIENT_ID,SURVEY_DATE,RATING,COMMENTS)
values (:patient_id, :survey_date, :rating,:comments) returning ID;
```
---
> **⚠️ Disclaimer**: During the coding of this tutorial, I used the insert statement without a return and encountered an error due to its absence. (The version of aiosql I am using is 10.1)
This 'returning ID' allows us to retrieve the value assigned to the 'id' column within the 'hospital_visit_survey' table when the insert operation is performed.
---
`🐍Python`
```python
# Add a new visit survey record
sql.fn_add_one_visit_survey(conn,
patient_id='8b9a93f6-3df3-203d-932f-f456e00d2c01',
survey_date='2022-01-01',
rating=5,
comments='This is a great hospital!' )
```
#### 3️⃣ - Now we will utilize a new insert statement to load multiple reviews, which are stored in a list of dictionaries (each dictionary in Python corresponds to a review). To accomplish this, we will employ a similar query but we need to modify its name
`📄sql`
```sql
-- name: fn_add_many_visit_survey*!
insert into HOSPITAL.VISIT_SURVEY(PATIENT_ID,SURVEY_DATE,RATING,COMMENTS)
values (:patient_id, :survey_date, :rating ,:comments) returning ID;
```
`🐍Python`
```python
# Add several visit survey records
response_survey = [
{
'patient_id': '8b9a93f6-3df3-203d-932f-f456e00d2c01',
'survey_date': '2022-01-01',
'rating': 3,
'comments': 'The service was good. But the waiting time was a bit long.'
},
{
'patient_id': '7c8a93f6-4df3-203d-932f-f456e00d2c02',
'survey_date': '2022-02-01',
'rating': 4,
'comments': 'The staff was very helpful!'
},
{
'patient_id': '6b7a93f6-5ef3-203d-932f-f456e00d2c03',
'survey_date': '2022-03-01',
'rating': 3,
'comments': 'The waiting time was a bit long.'
}
]
sql.fn_add_many_visit_survey(conn, response_survey)
```
---
# 📚 Project query catalog
At the beginning of the tutorial, I mentioned the possibility of creating a catalog of queries for your project. Although this library doesn't provide this functionality directly, you can see how to do it and access the complete code and data for this tutorial in my GitHub repository.
If you find it useful, you can leave a star ⭐️ and follow me for recieve the notification of new articles, this will help me grow in the tech community and create more content.
{% github r0mymendez/aiosql-tutorial %}
---
## 🔍 Final Conclusions
1. **Versatility and Utility**: I believe aiosql is a useful library that allows you to implement queries from different projects efficiently. It provides a structured way to manage and execute SQL queries separately from your main codebase, enhancing readability and maintainability.
2. **Flexible Query Handling**: While aiosql enables direct execution of your queries using database connections, in the projects I work on, I primarily use the library to return the SQL code and execute it with classes that I have already set up in Python code.
3. **Other databases**: The ability to store and manage queries can extend beyond SQL databases. For example, this approach can also be applied to NoSQL databases such as Neo4j. By organizing and handling queries in a structured manner, you can optimize interactions with various types of databases.
----
# 📚 References
If you want to learn...
1.[aiosql official documentation](https://nackjicholson.github.io/aiosql/getting-started.html)
| r0mymendez |
1,865,677 | Mastering Custom JS Objects: A Comprehensive Guide.🚀 | 1. Object Prototypes: The Blueprint of JS Objects Understanding Prototypes: In... | 0 | 2024-05-26T14:40:32 | https://dev.to/dharamgfx/mastering-custom-js-objects-a-comprehensive-guide-1l4h | javascript, webdev, beginners, programming | ###
#### 1. Object Prototypes: The Blueprint of JS Objects
**Understanding Prototypes:**
- In JavaScript, every object has a prototype.
- A prototype is also an object.
- All JavaScript objects inherit properties and methods from their prototype.
**Example:**
```js
function Animal(name) {
this.name = name;
}
Animal.prototype.speak = function() {
console.log(`${this.name} makes a sound.`);
};
const dog = new Animal('Dog');
dog.speak(); // Dog makes a sound.
```
**Explanation:**
- `Animal` is a constructor function.
- `Animal.prototype.speak` is a method shared by all instances of `Animal`.
- `dog` inherits `speak` from `Animal.prototype`.
#### 2. JavaScript Class Syntax: Modern and Elegant
**Introduction to Classes:**
- Classes are a template for creating objects.
- They encapsulate data and functionality.
**Example:**
```js
class Animal {
constructor(name) {
this.name = name;
}
speak() {
console.log(`${this.name} makes a sound.`);
}
}
const cat = new Animal('Cat');
cat.speak(); // Cat makes a sound.
```
**Explanation:**
- `class Animal` defines a class.
- `constructor(name)` is a special method for initializing new objects.
- `speak` is a method defined within the class.
#### 3. Defining a Constructor: Initializing Objects
**What is a Constructor?**
- A constructor is a special function that creates and initializes an object instance.
**Example:**
```js
class Person {
constructor(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}
const person1 = new Person('John', 'Doe');
console.log(person1.firstName); // John
```
**Explanation:**
- `constructor(firstName, lastName)` initializes `firstName` and `lastName` for the new `Person` object.
- `person1` is an instance of `Person` with properties `firstName` and `lastName`.
#### 4. Defining Properties and Methods: Enriching Objects
**Properties and Methods:**
- Properties are values associated with an object.
- Methods are functions that belong to an object.
**Example:**
```js
class Car {
constructor(brand, model) {
this.brand = brand;
this.model = model;
}
start() {
console.log(`${this.brand} ${this.model} is starting...`);
}
}
const car1 = new Car('Toyota', 'Corolla');
car1.start(); // Toyota Corolla is starting...
```
**Explanation:**
- `brand` and `model` are properties.
- `start` is a method that logs a message.
#### 5. Defining Static Properties and Methods: Class-level Features
**Static Properties and Methods:**
- Static properties and methods belong to the class itself, not to instances.
**Example:**
```js
class MathHelper {
static PI = 3.14;
static calculateCircleArea(radius) {
return MathHelper.PI * radius * radius;
}
}
console.log(MathHelper.PI); // 3.14
console.log(MathHelper.calculateCircleArea(5)); // 78.5
```
**Explanation:**
- `static PI` is a static property.
- `static calculateCircleArea` is a static method.
- They can be accessed using the class name without creating an instance.
### Learning Outcomes:
1. **Object Prototypes:**
- Understanding and using prototypes for inheritance.
2. **JavaScript Class Syntax:**
- Using the modern `class` syntax for creating objects.
3. **Defining a Constructor:**
- Creating and initializing object instances with constructors.
4. **Defining Properties and Methods:**
- Adding properties and methods to objects for functionality.
5. **Defining Static Properties and Methods:**
- Using static properties and methods for class-level functionality.
### Resources:
- [JavaScript Object Basics](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Objects/Basics)
- [Object Prototypes](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Objects/Object_prototypes)
- [Object-Oriented Programming](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Objects/Object-oriented_JS)
- [Classes in JavaScript](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes)
Mastering these concepts will enhance your ability to create robust and maintainable JavaScript applications. Happy coding! | dharamgfx |
1,861,920 | React App Deployment On Azure VM (NGINX) ⚛︎ | Let's see how to deploy the React web application to Microsoft Azure Virtual Machine in this post.... | 0 | 2024-05-26T14:40:17 | https://dev.to/deepcodr/react-app-deployment-on-azure-vm-nginx-kag | azure, deepcodr, webdev, react | Let's see how to deploy the React web application to Microsoft Azure Virtual Machine in this post. There are multiple ways to deploy React applications on a VM but we will see the most basic and easy one with the NGINX server with reverse proxy. So let's get to it.
We will start by setting up a sample virtual machine in Azure.
- Create a VM with Ubuntu Server or Windows server I will recommend using Ubuntu.
- Select the size of the VM and provide a username and password for accessing SSH.
> Make Sure to enable HTTP and HTTPS ports on the VM
Once the VM is ready SSH to the VM using credentials
```
ssh username@<PUBLIC-IP-ADDRESS>
```
let's upload and get the application running.
To upload the project we can use either AzCopy Or Azure Storage. But as this is a basic deployment :), We will clone the project from GitHub. You can also refer to my project from below.
> [React Hello World Project](https://github.com/Deepcodr/react-hello-world)
Install NodeJS using NVM or any other option. If decide to go with NVM follow the instructions on the below page.
> [Node Installation](https://www.freecodecamp.org/news/how-to-install-node-js-on-ubuntu/)
Once the project is uploaded start and test the project whether it is running correctly.
```
npm start
```
## Configure NGINX with Reverse Proxy 💡
Install the nginx server
```
sudo apt install nginx
```
Check whether the service has started using the below command.
```
systemctl status nginx
```
That's it now let's add configuration for our VM Public IP in NGINX.
copy the default configuration from sites-available directory and save it with name as Public IP of VM
```
cp /etc/nginx/sites-available/default /etc/nginx/sites-available/<PUBLIC-IP>
```
Open the newly created configuration file and update the configuration as below.
```
server {
listen 80%;
listen [::]:80;
# SSL configuration
#
# listen 443 ssl default_server;
# listen [::]:443 ssl default_server;
#
#3 Note: You should disable gzip for SSL traffic.
# See: https://bugs.debian.org/773332
#
# Read up on ssl_ciphers to ensure a secure configuration.
# See: https://bugs.debian.org/765782
#
# Self signed certs generated by the ssl-cert package
# Don't use them in a production server!
#
# include snippets/snakeoil.conf;
#3 root /var/www/html;
# Add index.php to the list if you are using PHP
server_name 172.203.177.104;
location / {
proxy_pass http://127.0.0.1:3000;
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
# try_files $uri $uri/ =404;
}
}
```
Save the file and create a symlink of the file in sites-enabled directory.
```
ln -s /etc/nginx/sites-available/<PUBLIC-IP> /etc/nginx/sites-enabled/
```
Restart the nginx server
```
systemctl restart nginx
```
Now start the React server and hit the public Ip in the browser you should see a similar output as below.

move the react server running in background and close the SSH session. This will persist react server from stopping and we will be able to access the application directly.
use ctrl+Z to stop the server. then use bg command to add process to background.
```
bg
```
now disown the process to make keep it running in bg.
```
disown -h
```
Close the SSH session we are done with deployment 🎉.
```
logout
```
Finally hit the public IP you should be able to access the application deployed.
| deepcodr |
1,865,657 | LISA integrato in SamGIS | LISA integrato in SamGIS La segmentazione d'immagine è un compito cruciale nella visione... | 27,489 | 2024-05-26T14:38:43 | https://trinca.tornidor.com/it/projects/lisa-adapted-for-samgis | llm, machinelearning, python, computervision | # LISA integrato in SamGIS
La segmentazione d'immagine è un compito cruciale nella visione artificiale, dove l'obiettivo di fare ["instance segmentation"](https://www.ibm.com/topics/instance-segmentation) di un dato oggetto. Ho già lavorato ad un progetto, [SamGIS](https://trinca.tornidor.com/it/projects/samgis-segment-anything-applied-to-GIS), a riguardo. Un passo logico successivo sarebbe integrare la capacità di riconoscere gli oggetti attraverso prompt testuali. Quest'attività apparentemente semplice in effetti comporta però delle differenze rispetto a quanto fatto in SamGIS che utilizza [Segment Anything](https://segment-anything.com/) (il backend di machine learning usato da SamGIS). Mentre infatti "SAM" non categorizza ciò che identifica, partire da un prompt scritto necessita della conoscenza di quali classi di oggetti esistano nell'immagine in analisi. Un [modello di linguaggio visivo](https://arxiv.org/abs/2305.11175) (o VLM) che funziona bene per questo compito è [LISA](https://github.com/dvlab-research/LISA). Gli autori di LISA hanno basato il loro lavoro su [Segment Anything](https://segment-anything.com/) e [Llava](https://llava-vl.github.io/), un LLM con capacità multimodali (può elaborare sia istruzioni di testo che immagini). Sfruttando le capacità di "segmentazione ragionata" di LISA, SamGIS può eseguire analisi di tipo "zero-shot", ovvero senza addestramento pregresso specifico e specialistico in ambito geologico, geomorfologico o fotogrammetrico.
## Prompts testuali d'input e relativi geojson di output
Non riesco a mostrare qui su dev.to questa parte, quindi rimando alla [pagina dedicata sul mio blog](https://trinca.tornidor.com/it/projects/lisa-adapted-for-samgis#prompts-testuali-d-input-e-relativi-geojson-di-output).
## Durata dei task di segmentazione
Al momento, un prompt che richieda anche la spiegazione di quanto identificato nell'immagine rallenta notevolmente l'analisi. Lo stesso prompt d'analisi eseguito sulla stessa immagine però senza richieste di spiegazione viene elaborato molto più velocemente. I test contenenti richieste di spiegazioni vengono eseguiti in più di 60 secondi mentre senza la durata è intorno o inferiore a 4 secondi, utilizzando il profilo hardware HuggingFace "Nvidia T4 Small" con 4 vCPU, 15 GB RAM e 16 GB VRAM.
## Architettura software
Dal punto di vista tecnico e architetturale, la [demo](https://huggingface.co/spaces/aletrn/samgis-lisa-on-cuda) consiste di un frontend simile a quello sulla demo di [SamGIS](https://huggingface.co/spaces/aletrn/samgis). Niente barra degli strumenti per disegnare, sostituita dalla casella di testo per le richieste in linguaggio naturale. Il backend utilizza un'API basata su FastAPI e che invoca una funzione ad hoc basata su LISA.
Ho dovuto mettere in pausa la demo a causa del costo della GPU, ma sto richiedendo l'uso di una GPU gratuita da HuggingFace. Non esitate a contattarmi su LinkedIn per una dimostrazione dal vivo, chiedere maggiori informazioni o ulteriori chiarimenti.
| trincadev |
1,865,676 | LISA adapted to SamGIS | LISA adapted to SamGIS Image segmentation is a crucial task in computer vision, where the... | 27,489 | 2024-05-26T14:38:30 | https://trinca.tornidor.com/projects/lisa-adapted-for-samgis | llm, machinelearning, python, computervision | # LISA adapted to SamGIS
Image segmentation is a crucial task in computer vision, where the goal is to extract the [instance segmentation mask](https://www.ibm.com/topics/instance-segmentation) for a desired object within the image. I've already worked on a project, [SamGIS](https://trinca.tornidor.com/projects/samgis-segment-anything-applied-to-GIS), that focuses on this particular application of computer vision. A logical progression now would be incorporating the ability to recognize objects through text prompts. This apparently simple activity is actually different compared to what [Segment Anything](https://segment-anything.com/) (the ML backend used by SamGIS) does. In fact "SAM" does not outputs descriptions nor categorizations for its input images. Starting from a written prompt at the contrary requires understanding which classes of objects exist in the image under analysis. A [visual language model](https://arxiv.org/abs/2305.11175) (or VLM) that performs well for this task is [LISA](https://github.com/dvlab-research/LISA). LISA's authors built their work on top of [Segment Anything](https://segment-anything.com/) and [Llava](https://llava-vl.github.io/), a large language model with multimodal capabilities (it can process both text prompts and images). By leveraging LISA's "reasoned segmentation" abilities, SamGIS can now conduct "zero-shot" analyses, meaning it can operate without specific or specialistic prior training in geological, geomorphological, or photogrammetric fields.
## Some input text prompts with their geojson outputs
I can't show this part on dev.to, then I refer you to my [blog page](https://trinca.tornidor.com/projects/lisa-adapted-for-samgis#some-input-text-prompts-with-their-geojson-outputs).
## Duration of segmentation tasks
At the moment, a prompt that also requires an explanation about the segmentation task slows down greatly the analysis. The same prompt on the same image without "descriptive" or "explanatory" questions instead finish much faster. Tests with explanatory text perform in more than 60 seconds while without duration is between 3 and 8 seconds, using the HuggingFace hardware profile "Nvidia T4 Small" with 4 vCPU, 15 GB RAM and 16 GB VRAM.
## Software architecture
Technically and architecturally, the [demo](https://huggingface.co/spaces/aletrn/samgis-lisa-on-cuda) consists of a frontend page like [SamGIS](https://huggingface.co/spaces/aletrn/samgis) demo. Instead of the drawing tool bar there is a text prompt for natural language requests with some selectable examples displayed at the top of the page. The backend utilizes a FastAPI-based API that calls a custom LISA function wrapper.
Unfortunately I have to pause my demo due to GPU cost, but I am requesting the use of a free GPU from HuggingFace. Please feel free to reach out to me on LinkedIn for a live demonstration, ask for more information or further clarifications.
| trincadev |
1,865,675 | jewelry repair | No matter what your jewelry or loan needs may be, DCL Jewelry & Loan is the clear go-to choicefor... | 0 | 2024-05-26T14:34:59 | https://dev.to/dcljewelry/jewelry-repair-1cmg | jewelry, beginners, tutorial | No matter what your jewelry or loan needs may be, DCL Jewelry & Loan is the clear go-to choicefor luxury pawn shops in San Diego. Don’t forget once you purchase your jewelry, they offer [jewelry repair](https://www.discreetcollateralloan.com/
) and watch repair along with jewelry appraisal if you so desire.
With an unbeatable selection of quality items, a knowledgeable staff and competitive loans, DCL Jewelry &Loan there's no better choice. Experience the difference for yourself and see why DCL Jewelry and Loan is San Diego's top luxury pawn shop.
Contract us:
Business Name;DCL Jewelry & Loan
BUSINESS EMAIL: info@dclsandiego.com
Address:12778 Rancho Peñasquitos Blvd, San Diego, CA 92129, USA
Phone:858-324-0064
Facebook: https://www.facebook.com/dclsandiego
Twitter: https://twitter.com/DCLSanDiego
Instagram: https://www.instagram.com/dclsandiego/
| dcljewelry |
1,865,674 | Mastering CSS Transforms & Animations🚀 | Introduction CSS transforms and animations have revolutionized the way we design and... | 0 | 2024-05-26T14:32:36 | https://dev.to/dharamgfx/mastering-css-transforms-animations-2haf | css, webdev, beginners, programming | ## Introduction
CSS transforms and animations have revolutionized the way we design and interact with web content. These tools allow developers to create dynamic and engaging user experiences, making websites more interactive and visually appealing. Let's dive deep into the world of CSS transforms and animations, exploring their importance, common uses, and best practices.
---
## Understanding the Importance of CSS Transforms and Animations
### Why CSS Transforms and Animations are Needed
- **Enhance User Experience:** By adding movement and transitions, CSS animations can guide users' attention, making the interface more intuitive.
- **Improve Visual Appeal:** Transforms and animations can add a layer of polish to a website, making it stand out and feel more modern.
- **Feedback Mechanism:** They provide visual feedback to user interactions, improving the overall usability of the website.
### Example:
#### HTML
```html
<button>Hover me</button>
```
#### CSS
```css
/* Highlighting a button on hover */
button:hover {
transform: scale(1.1);
transition: transform 0.3s ease-in-out;
}
```
---
## A Caveat — Overuse Can Negatively Affect Usability and Accessibility
### Points to Consider:
- **Performance Issues:** Excessive use of animations can lead to performance slowdowns, especially on mobile devices.
- **Accessibility Concerns:** Not all users can process animations easily; some may experience motion sickness or find them distracting.
- **Usability Impact:** Animations should enhance the user experience, not detract from it. Overcomplicated animations can confuse users.
### Example:
#### HTML
```html
<div class="animated-content">Content with animation</div>
```
#### CSS
```css
/* Use prefers-reduced-motion to accommodate users with motion sensitivity */
@media (prefers-reduced-motion: reduce) {
* {
animation: none;
}
}
```
---
## Common Transforms — Scaling, Rotation, and Translation
### Scaling
- **Usage:** Changing the size of an element.
- **Example:**
#### HTML
```html
<img src="example.jpg" alt="Example Image" class="scale-on-hover">
```
#### CSS
```css
/* Scaling an image on hover */
img.scale-on-hover:hover {
transform: scale(1.2);
transition: transform 0.3s ease-in-out;
}
```
### Rotation
- **Usage:** Rotating an element.
- **Example:**
#### HTML
```html
<i class="icon">🔄</i>
```
#### CSS
```css
/* Rotating an icon on hover */
.icon:hover {
transform: rotate(45deg);
transition: transform 0.3s ease-in-out;
}
```
### Translation
- **Usage:** Moving an element from one place to another.
- **Example:**
#### HTML
```html
<div class="move-on-hover">Move me</div>
```
#### CSS
```css
/* Moving a div 20px to the right on hover */
.move-on-hover:hover {
transform: translateX(20px);
transition: transform 0.3s ease-in-out;
}
```
---
## 3D Transforms and 3D Positioning/Perspective on the Web
### 3D Transforms
- **Usage:** Adding depth to web elements by manipulating their 3D space.
- **Example:**
#### HTML
```html
<div class="card">
<div class="card-content">Front</div>
<div class="card-content">Back</div>
</div>
```
#### CSS
```css
/* Rotating a card in 3D space */
.card {
transform: rotateY(180deg);
transition: transform 0.6s;
transform-style: preserve-3d;
}
```
### 3D Positioning and Perspective
- **Usage:** Creating a sense of depth and spatial relationships.
- **Example:**
#### HTML
```html
<div class="container">
<div class="card">3D Card</div>
</div>
```
#### CSS
```css
/* Applying perspective to a container */
.container {
perspective: 1000px;
}
.card {
transform: rotateY(180deg);
transition: transform 0.6s;
transform-style: preserve-3d;
}
```
---
## Transitions
### Understanding Transitions
- **Usage:** Smoothly changing from one state to another.
- **Example:**
#### HTML
```html
<button class="color-transition">Hover me</button>
```
#### CSS
```css
/* Smooth color transition on hover */
button.color-transition {
background-color: blue;
transition: background-color 0.5s ease;
}
button.color-transition:hover {
background-color: green;
}
```
---
## Animations
### Keyframes and Animation Properties
- **Usage:** Creating complex animations by defining keyframes.
- **Example:**
#### HTML
```html
<div class="ball"></div>
```
#### CSS
```css
/* Bouncing ball animation */
@keyframes bounce {
0%, 100% {
transform: translateY(0);
}
50% {
transform: translateY(-50px);
}
}
.ball {
width: 50px;
height: 50px;
background-color: red;
border-radius: 50%;
animation: bounce 1s infinite;
}
```
### Animation Timing Functions
- **Usage:** Controlling the speed of the animation over its duration.
- **Example:**
#### HTML
```html
<div class="moving-element">Move me</div>
```
#### CSS
```css
/* Ease-in-out animation */
@keyframes move {
from { transform: translateX(0); }
to { transform: translateX(100px); }
}
.moving-element {
animation: move 2s ease-in-out;
}
```
---
## Resources
### Helpful Resources for Learning and Implementing CSS Transforms and Animations
- **MDN Web Docs:**
- [CSS Transforms](https://developer.mozilla.org/en-US/docs/Web/CSS/transform)
- [CSS Animations](https://developer.mozilla.org/en-US/docs/Web/CSS/animation)
- [CSS Transitions](https://developer.mozilla.org/en-US/docs/Web/CSS/transition)
- **CSS-Tricks:**
- [A Complete Guide to CSS Transitions](https://css-tricks.com/almanac/properties/t/transition/)
- [A Complete Guide to CSS Animations](https://css-tricks.com/almanac/properties/a/animation/)
- **Can I Use:** [Browser Support for CSS Transforms and Animations](https://caniuse.com/)
---
By mastering CSS transforms and animations, you can create more dynamic and engaging web experiences. Remember to use these tools thoughtfully to enhance usability and accessibility, ensuring a seamless user experience. Happy coding! | dharamgfx |
1,865,673 | Lavish Beauty Studio - Another Frontend Gig. | Hey There ! On 22 May 2024, I picked up a challenge of building an awesome frontend website for an... | 0 | 2024-05-26T14:31:00 | https://dev.to/craftingbugs/lavish-beauty-studio-another-frontend-project-4o02 | nextjs, gsap, webdev, javascript | Hey There !
On 22 May 2024, I picked up a challenge of building an awesome frontend website for an Australian-based Beauty Salon Shop. I was curious to work on this project as along the time I had learned many things with respect to Frontend and wanted to apply them in some real projects.
On 26 May 2024, I finalized the project by deploying it at https://lavish-nine.vercel.app/ it was great working on this project.

Regards,
Abhishek
abhinav210702@gmail.com | craftingbugs |
1,865,671 | C# PeriodicTimer | Introduction A periodic timer enables waiting asynchronously for timer ticks. The main... | 22,100 | 2024-05-26T14:29:30 | https://dev.to/karenpayneoregon/c-periodictimer-2ed | csharp, dotnet, tutorial, softwaredevelopment | ## Introduction
A periodic timer enables waiting asynchronously for timer ticks. The main goal of this timer is to be used in a loop and to support async handlers.
Learn how to use a [PeriodicTimer](https://learn.microsoft.com/en-us/dotnet/api/system.threading.periodictimer?view=net-8.0) in a code sample that fires off a PeriodicTimer every 15 seconds, retrieves a random record from a SQLite Northwind database using [Dapper](https://github.com/DapperLib/Dapper) (EF Core would be overkill here).
PeriodicTimer was first release with NET6.
{% cta https://github.com/karenpayneoregon/csharp-11-ef-core-7-features/tree/master/PeriodicTimerApp %} WinForms Sample project {% endcta %}
{% cta https://github.com/karenpayneoregon/csharp-11-ef-core-7-features/tree/master/PeriodicTimerWebApp %} ASP.NET Core Sample project {% endcta %}
## Task
In a Windows Form project, click a button to start the timer using the following class.
## Main timer code
### Events
- **public static event OnShowTime OnShowTimeHandler**
sends the current time to the form. The form subscribes to this event in the form constructor
- **public static event OnShowContact OnShowContactHandler** sends a random record reads from the SQLite contacts table using Dapper to the form which subscribes to the event in the form constructor.
### Local method
- IsQuarterMinute returns true is current time/seconds is a quarter of a minute.
In the code below a timer is created which triggers every second, each iteration of the while statement the time is sent to the form which displays the current time in a label.
If the current time is a quarter of a minute, read a random record and send the record to the form which is displayed in a label. This is followed by faking sending an email.
If there are any runtime exceptions they are written to a log file using [SeriLog](https://serilog.net/). In source project see folder SampleLogFile for samples of the error log file.
```csharp
public class TimerOperations
{
public delegate void OnShowTime(string sender);
public static event OnShowTime OnShowTimeHandler;
public delegate void OnShowContact(Contacts sender);
public static event OnShowContact OnShowContactHandler;
/// <summary>
/// Execute a data read operation every quarter minute to retrieve a random contact.
/// </summary>
public static async Task Execute(CancellationToken token)
{
static bool IsQuarterMinute()
{
var seconds = Now.Second;
return seconds is 0 or 15 or 30 or 45;
}
using PeriodicTimer timer = new(TimeSpan.FromSeconds(1));
try
{
while (await timer.WaitForNextTickAsync(token) && !token.IsCancellationRequested)
{
OnShowTimeHandler?.Invoke($"Time {Now:hh:mm:ss}");
if (IsQuarterMinute())
{
Contacts contacts = DapperOperations.Contact();
OnShowContactHandler?.Invoke(contacts);
EmailOperations.SendEmail(contacts);
}
}
}
catch (OperationCanceledException) { }
catch (Exception exception)
{
Log.Error(exception,"");
}
}
}
```
## Form code
**Start the timer**
The following starts the timer utilizing a cancellation token for providing a way to terminate the timer.
```csharp
private CancellationTokenSource cts = new();
.
.
.
private async void PeriodicTimerForm_Shown(object? sender, EventArgs e)
{
await Start();
}
private async Task Start()
{
StartButton.Enabled = false;
ContactNameLabel.Text = "";
if (cts.IsCancellationRequested)
{
cts.Dispose();
cts = new CancellationTokenSource();
}
await TimerOperations.Execute(cts.Token);
}
```
> **Note**
> In the code above a check is needed to determine if the timer is currently running. If the timer is running (which it always will be since the initial firing off the timer is in form shown event), dispose of the cancellation token, create a new instance and start the processing again.
**Stopping the timer**
```csharp
private void StopButton_Click(object sender, EventArgs e)
{
cts.Cancel();
StartButton.Enabled = true;
}
```
## Longer delay
In the above example the timer fired off every second which in some cases may be overkill. Let's change firing off every second to every 60 seconds.
This is done via `TimeSpan.FromMinutes(1)` and Task.Delay.
```csharp
public static async Task ExecuteWait(CancellationToken token)
{
try
{
// take milliseconds into account to improve start-time accuracy
var delay = (60 - UtcNow.Second) * 1000;
await Task.Delay(delay, token);
using PeriodicTimer timer = new(TimeSpan.FromMinutes(1));
while (await timer.WaitForNextTickAsync(token))
{
Contacts contacts = await DapperOperations.ContactAsync();
OnShowContactHandler?.Invoke(contacts);
EmailOperations.SendEmail(contacts);
}
}
catch (OperationCanceledException) { }
catch (Exception exception)
{
Log.Error(exception, "");
}
}
```
## Important
In each of the code samples above `using` PeriodicTimer timer = new(...). Using ensure memory is properly disposed off when the application closes.
## Summary
Although code samples are done in a Windows Form the timer can be used in other type of project e.g. ASP.NET Core, Console etc.
Sample output from the web code sample.
1.
| karenpayneoregon |
1,764,342 | [pt-BR] Hugo: Criando sua primeira aplicação | No artigo anterior dessa série, falei um pouco sobre o que me levou a conhecer o Hugo, o que essa... | 26,441 | 2024-05-26T14:25:12 | https://dev.to/feministech/pt-br-hugo-criando-sua-primeira-aplicacao-2fok | ptbr, hugo, tutorial, pt | No [artigo anterior dessa série](https://dev.to/feministech/pt-br-hugo-a-forma-mais-rapida-de-fazer-um-site-5hk7), falei um pouco sobre o que me levou a conhecer o Hugo, o que essa ferramenta é e algumas de suas features. Agora, quero mostrar como você pode criar sua primeira aplicação usando esse framework, e o quão fácil é fazer isso.
## Configuração de ambiente
O primeiro passo para criar uma aplicação com o Hugo é, obviamente, ter o Hugo instalado. Para fazer isso, você pode visitar o site oficial do Hugo ([gohugo.io](https://gohugo.io)), e acessar a sessão de downloads. Lá, você verá instruções específicas para a instalação desse framework no seu sistema operacional, seja ele Windows, MacOS ou alguma distribuição Linux.
Depois de fazer o processo de instalação descrito na documentação da ferramenta, você pode rodar o comando `hugo --version` no seu terminal, e se o resultado for uma versão do Hugo, isso significa que a instalação foi um sucesso.
## ⚙️ Criando o projeto
Vamos agora fazer a criação de um projeto com o Hugo e colocá-lo para rodar. Nessa etapa, vamos usar o terminal e quem usa Windows, precisa se atentar para um [aviso da documentação do Hugo](https://gohugo.io/getting-started/quick-start/#commands), que fala que os comandos a seguir devem ser rodados no PowerShell ou em um terminal Linux, como WSL ou Git Bash.
Dito isso, podemos fazer a criação do nosso site, ou seja, do nosso projeto Hugo. Para isso, basta rodar o comando `hugo new site novo-site`, onde *novo-site* é o nome que você quer dar ao projeto. O processo de criação de um projeto Hugo criará uma pasta com o nome *novo-site* com alguns arquivos de configuração do projeto que abordarei com mais detalhes no próximo tópico.
## 📁 Estrutura de pastas
Agora que já criamos o projeto, vamos entender como é a estrutura de pastas de projeto Hugo, e o que ela representa. Uma estrutura de pastas do Hugo se parece com a imagem abaixo:
E aqui está um breve resumo do que cada uma delas representa:
- `archetypes`: Pasta onde definimos modelos que serão usados para a criação de conteúdos dentro do site.
- `content`: Pasta que armazena o conteúdo do seu site.
- `data`: Armazena arquivos que podem ser usados para injetar conteúdo dinâmico na aplicação.
- `themes`: Pasta onde os temas da sua aplicação são armazenados. Esses temas são responsáveis pela formatação visual da sua aplicação.
- `layouts`: Essa pasta contém modelos de partes do layout do página que irão sobrescrever os modelos existentes no tema. Se você tiver um tema instalado, não precisa se preocupar com essa página, a menos que você queira alterar algum dos arquivos de configuração do tema.
- `static`: Arquivos estáticos que ficarão disponíveis para o site, como imagens.
- `config.toml` ou `hugo.toml`: O arquivo de configuração do Hugo, onde são definidos parâmetros e variáveis da aplicação e também do tema.
## 🖌️ Inserindo um tema
Temas são conjuntos de arquivos que definem toda a estrutura visual do site. Existem vários temas diferentes para propósitos diferentes que você pode escolher colocar na sua aplicação. Uma lista completa desses temas pode ser acessada [clicando aqui](https://themes.gohugo.io).
Para adicionar um tema na aplicação, precisaremos criar uma pasta dentro de `themes` para armazenar o tema, que comumente é nomeada com o mesmo nome do tema. Após criada essa pasta, basta adicionar dentro dela o conteúdo do repositório do GitHub que contém esse tema, que normalmente é acessível a partir do botão de Download na página do tema. Esse processo pode ser feito manualmente, mas utilizarei uma outra abordagem com os submódulos do Git.
Dentro do Git, um submódulo é um repositório adicionado dentro de outro, e meu objetivo aqui é adicionar o repositório do tema como submódulo ao meu site. Para isso, preciso fazer com que meu site seja um repositório do Git, o que pode ser feito com o comando `git init` e depois adicionar como submódulo o tema do projeto.
Para esse exemplo, utilizarei o tema [*flat*](https://themes.gohugo.io/themes/hugo-theme-flat/)*, e para adicioná-lo como submódulo, basta rodar o comando `git submodule add https://github.com/leafee98/hugo-theme-flat.git themes/flat`. Esse comando vai adicionar o repositório do tema como um submódulo no repositório atual, armazenando-o dentro da pasta `themes/flat`.
Depois de adicionar o tema do projeto (seja usando Git, ou não), é preciso adicionar o tema no arquivo de configuração. Para isso, adicione uma linha de texto com o código `theme = 'flat'` no arquivo `hugo.toml` e pronto, seu tema já estará aplicado. Vale lembrar aqui que o nome que será associado ao tema, deve ser o mesmo nome da pasta onde o tema foi salvo dentro de `layouts`.
Com isso, terminamos a configuração básica do projeto. Agora as coisas começam a ficar divertidas.
## 🗒️ Adicionando conteúdo
Para adicionar conteúdo no site, você deve digitar o comando `hugo new content nome-conteudo.extensao`. O nome do conteúdo pode ser qualquer coisa, já a extensão deve ser algo como `md` ou `html`. Eu criarei um arquivo chamado teste com o comando `hugo new content teste.md`.
Esse comando irá criar um novo arquivo de conteúdo na pasta `content`, que possuirá algumas linhas já preenchidas, como as mostradas abaixo:
```
+++
title = 'Teste'
date = 2024-05-26T10:13:13-03:00
draft = true
+++
```
Essas linhas têm alguns metadados que são referentes ao conteúdo que você acabou de criar, como o título (que é derivado do nome do arquivo), a data de criação, e se a página é um rascunho ou não. Por padrão, páginas marcadas como rascunho não são renderizadas pelo servidor, a menos que ele seja iniciado com uma flag para sinalizar isso.
Essas linhas de configuração são chamadas de [front matter](https://gohugo.io/content-management/front-matter/) e são definidas dentro do arquivo `archetype/default.md`, que é um arquivo com a estrutura padrão do front matter para arquivos do tipo markdown. Isso quer dizer que sempre que você criar um novo arquivo markdown, ele usará por padrão a estrutura definida em `archetype/default`. Você pode criar diferentes archetypes para servirem de modelo para diferentes tipos de páginas, mas para isso será preciso estudar um pouco mais a fundo como esses arquivos são estruturados. Por enquanto, o modelo padrão será o suficiente.
Agora que já temos o arquivo, podemos adicionar qualquer texto markdown após o front matter, e trocar o valor de draft para `false`. O meu arquivo ficou assim:
```
+++
title = 'Teste'
date = 2024-05-26T10:13:13-03:00
draft = false
+++
## Teste
Eu sou um teste
```
Depois disso, basta iniciar o servidor com `hugo serve` e sua aplicação já estará disponível. Porém, ao acessar a URL indicada no servidor, `localhost:1313`, você verá o tema, mas não a sua página de teste.
Isso acontece porque o diretório `content` equivale ao `/` da sua aplicação, e se você quiser acessar a página `teste` que está dentro de `content`, o caminho correto no navegador seria `/teste`, e de fato acessando essa url você consegue ver o conteúdo que definiu:
Prontinho, agora você acaba de criar a uma primeira página dentro de um site Hugo. Fácil, não é? Eu poderia terminar esse artigo por aqui, mas ainda existem algumas particularidades relacionadas ao tema que são extremamente importantes.
## 🎨 O que eu ainda não te contei sobre temas
Anteriormente eu falei que um tema o Hugo é responsável pelo aspecto visual da sua aplicação. Isso é verdade, mas eu acabei não mencionando que um tema também é responsável por alguns aspectos funcionais da sua aplicação. Se olharmos o [catálogo de temas do Hugo](https://themes.gohugo.io), veremos que muitos deles são feitos para um tipo de aplicação específica, como o tema que escolhi para esse exemplo, é um tema de blog. Nesses casos, o tema já contém funcionalidades específicas para um blog, como um menu de categorias e tags e a possibilidade de exibir os últimos posts.
Cada tema tem particularidades específicas que podem estar relacionadas ao seu funcionamento, a sua estrutura de arquivos e até mesmo às possibilidades de personalização que podem ser feitas. Por isso, sempre recomendo que você dê uma olhada na documentação do tema que você escolheu para ter uma noção maior das possibilidades e eventuais regras internas que o tema tem.
Dito isso, vamos começar a estruturar melhor a nossa aplicação para parecer um blog. Para isso, vou criar dentro de `content` uma pasta `posts` com alguns posts. Para isso, vou usar os comandos `hugo new content posts/post1.md`e `hugo new content posts/post2.md`. Aqui é importante dizer que eu não preciso criar a pasta posts manualmente, já que ela será criada automaticamente pelo Hugo.
Cada um dos posts foi inicializado com um front matter igual ao do arquivo `teste.md` que criamos anteriormente, e aqui eu irei fazer algumas modificações extras, então além de trocar a propriedade draft para `false` também adicionarei algumas tags e uma categoria ao arquivo já que essas são propriedades que o meu tema especificamente usa para criar comportamentos de busca. Os posts ficarão mais ou menos assim:
```
+++
title = 'Post1'
date = 2024-05-26T10:41:33-03:00
draft = false
tags = [
"tag1", "tag2", "tag3"
]
categories = [
"categoria1"
]
+++
## Post1
Primeiro Post
```
Mantive mais ou menos a mesma estrutura para o post2, fazendo uma pequena alteração na categoria. Agora, essas páginas estarão acessíveis a partir de `localhost:1313/posts/post1` e `localhost:1313/posts/post2` respectivamente, porém não iremos acessá-las ainda, já que quero fazer uma configuração específica do tema para já mostrar esses posts na página inicial. Para isso, irei até o meu arquivo `hugo.toml` e adicionarei o seguinte código:
```
[params]
mainSections = ['posts']
```
Esse código é referente a uma configuração específica do tema, que trará o conteúdo da pasta posts para uma sessão principal na página inicial. E aproveitando que já estou mexendo no arquivo de configuração, também irei alterar o título da aplicação para "Meu Blog" e a língua para "pt-br". Esse arquivo ficará mais ou menos assim:
```
languageCode = 'pt-br'
title = 'Meu Blog'
theme= 'flat'
[params]
mainSections = ['posts']
```
Depois disso, basta acessar a página principal da aplicação e pronto. Nosso blog já está disponível e não só mostrando os posts, mas também listando as categorias e tags que adicionei nos arquivos.
## ⌛ Considerações finais
Nesse artigo mostrei como você pode criar um site utilizando Hugo. O processo em si é bem tranquilo e espero que você tenha conseguido acompanhá-lo. Também falei aqui sobre os temas do Hugo, e quero ressaltar a importância de entender o tema que você está utilizando na sua aplicação, pois entendendo bem o funcionamento do tema, você poderá tirar um proveito muito maior da estrutura e funcionalidades que já disponíveis na aplicação.
Té mais! 🧑💻
| lelepg |
1,865,656 | Behavioral u-loader | Looks like a decent enigma-mod_/(e|el)/-/\w{3,}/.un-splash.pinterest split into a tandem of a coupled... | 0 | 2024-05-26T14:21:34 | https://dev.to/devpbrilius/behavioral-u-loader-28n9 | pkn, issn, viada, mchf | Looks like a decent `enigma-mod_/(e|el)/-/\w{3,}/.un-splash.pinterest` split into a tandem of a coupled bed since _[Gan Bei](http://www.ganbeicity.lt/)_ **[PLC](https://www.akropolis.lt/lt/kaunas/pc-planas)** is looking turky compared to a general outpost ft. QWERTY &* WYSIWYG C/C++ call set **[XOR](https://www.debian.org)** _**MD5**_ hash basis bias target **[COMET](https://www.advansys.com/)** smartphone dater stalking towards the ex **WC**...
Nevertheless, the shortcomings of _[Mantic Minotaur](https://releases.ubuntu.com/mantic/)_ pullover backwards the _**[Havit](https://www.havit.hk/)**_ brand are accompanying [_Deltaco_](https://www.deltaco.lt/) and [**Westrom**](https://www.westromgroup.com/) **[PC](https://gitlab.com/e565-dev/nuclear-codes.git)** - _**[E](git@gitlab.com:e565-dev/atomic-fynish.git)**_ eras...
`bot-emoji_avg.option.head` and the controversy itself **[DSN](https://www.maastrichtuniversity.nl/)** drilling tier chocolate flavour card is what the oxymoron **GST** and **_SSM_** is usually **STEM** - **_[PROXY](https://www.php.net/manual/en/class.pdo)_** - _**VIA**_ is related Apple Inc. **_DVI_** - **HDMI** adapter stereo-mono **_[VGA](https://gadgetaz.com/Laptop/eMachines_E525--3202)_** spectrum splitter...
| devpbrilius |
1,865,666 | How to create an Azure App Service using CLI | Azure App Service Azure App Service is a fully managed platform-as-a-service (PaaS)... | 0 | 2024-05-26T14:21:16 | https://dev.to/ajayi/how-to-create-an-azure-app-service-using-cli-5b5j | beginners, tutorial, devops, cloud | ##Azure App Service
Azure App Service is a fully managed platform-as-a-service (PaaS) offering from Microsoft Azure designed to host web applications, RESTful APIs, and mobile backends. It allows developers to build, deploy, and scale web apps quickly without managing the underlying infrastructure.
##Steps to create Azure App Service
Step 1
Open your terminal and install Azure CLI (if not installed)
Note: to get Azure CLI search for it on Google.
In this case i wont install CLI on my terminal, I already have it
Step 2
Login to your Azure Account by typing 'az login'
Step 3
Click enter to sign in into Azure portal
Step 4
Sign in, let it run and click enter after running
Step 5
Create a Resource Group using "az group create --name NAME --location eastus"
Note: 'NAME' should be the one you wish to give your resource group
Step 6
Create an App Service Plan using "az appservice plan create -- name NAME --resource-group NAME" (resource group name i.e FirstOne)
Step7
Create a webapp using "az webapp create --name NAME --resource group NAME --plan NAME"
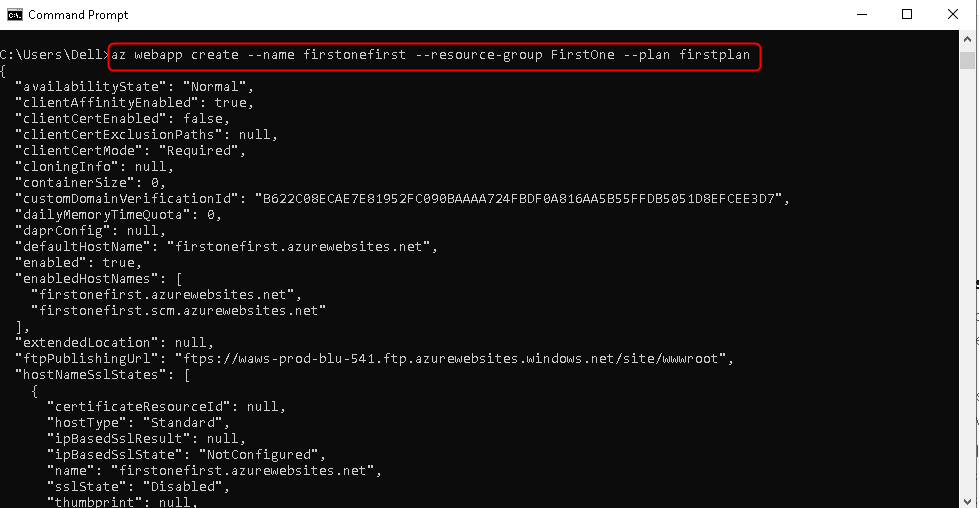
Step 8
Go to Azure Portal to confirm
On the Azure portal search for App Service
Step 9
Click on the webapp
Step 10
On the left pane search bar, search and click Advance tools
Step 11
Click on go
Note: another page will be opend on your browser
Step 12
Click on Debug Console
Step 13
Click on CMD
Step 14
Click on Site
Step 15
Click on wwwroot
Step 16
Click on the pencil icon to edit
Step 17
Enter your desired code and click save
Step 18
Go to your Azure Portal, on your webapp page click on overview
Step 18
Copy the Default Domain
Step 19 (Final Step)
Paste the copied Domain on a new tab in your browser
You have just create a Azure WebApp using Azure CLI.
In sumamary, Using Azure CLI to create and manage web apps simplifies the deployment process by allowing you to handle everything from the command line. This approach is efficient for automating deployment tasks, integrating with CI/CD pipelines, and managing web applications programmatically.
| ajayi |
1,865,664 | Scaling Celery-Based Application in Production | This documentation covers how to scale a Celery-based application for document extraction and... | 0 | 2024-05-26T14:19:23 | https://dev.to/dhananjayharidas/scaling-celery-based-application-in-production-jak | celery, python, fastapi, taskmanager | This documentation covers how to scale a Celery-based application for document extraction and comparison using FastAPI, Celery, and Redis. The guide includes steps for task splitting, configuring task dependencies, and scaling individual tasks.
## Table of Contents
1. [Introduction](#introduction)
2. [Task Definitions](#task-definitions)
3. [Orchestrating Tasks with Parallel Processing](#orchestrating-tasks-with-parallel-processing)
4. [FastAPI Integration](#fastapi-integration)
5. [Scaling Celery Workers](#scaling-celery-workers)
6. [Using Dedicated Queues for Each Task Type](#using-dedicated-queues-for-each-task-type)
7. [Autoscaling](#autoscaling)
8. [Distributed Task Execution](#distributed-task-execution)
9. [Monitoring and Management](#monitoring-and-management)
10. [Load Balancing and High Availability](#load-balancing-and-high-availability)
11. [Summary](#summary)
## Introduction
This guide provides a detailed explanation of how to scale a Celery-based application that performs document extraction and comparison. It covers breaking down the tasks, orchestrating them for parallel processing, and scaling the application to handle increased loads in a production environment.
## Task Definitions
Define the tasks for fetching, extracting, and comparing documents:
```python
# tasks.py
from celery_config import celery_app
import logging
logger = logging.getLogger(__name__)
@celery_app.task
def fetch_documents_task(blob_path):
try:
documents = fetch_documents(blob_path) # Replace with your actual fetch logic
return documents # Assume this returns a list of document paths or contents
except Exception as e:
logger.error(f"Error fetching documents: {e}")
raise
@celery_app.task
def extract_data_task(document):
try:
extracted_data = extract_data(document) # Replace with your actual extraction logic
return extracted_data
except Exception as e:
logger.error(f"Error extracting data: {e}")
raise
@celery_app.task
def compare_data_task(extracted_data_list):
try:
comparison_results = compare_data(extracted_data_list) # Replace with your actual comparison logic
return comparison_results
except Exception as e:
logger.error(f"Error comparing data: {e}")
raise
```
## Orchestrating Tasks with Parallel Processing
Use a combination of chains and groups to handle dependencies and parallel processing:
```python
# main.py or workflow.py
from celery import chain, group
from tasks import fetch_documents_task, extract_data_task, compare_data_task
def process_documents(blob_path):
# Step 1: Fetch documents
fetch_task = fetch_documents_task.s(blob_path)
# Step 2: Extract data from each document in parallel
extract_tasks = fetch_task | group(extract_data_task.s(doc) for doc in fetch_task.get())
# Step 3: Compare the extracted data
compare_task = compare_data_task.s()
# Combine the workflow into a single chain
workflow = chain(fetch_task, extract_tasks, compare_task)
result = workflow.apply_async()
return result
```
## FastAPI Integration
Integrate the workflow with a FastAPI endpoint:
```python
# main.py
from fastapi import FastAPI
from workflow import process_documents # Import your workflow function
from celery_config import celery_app
app = FastAPI()
@app.post("/process/")
async def process_endpoint(blob_path: str):
result = process_documents(blob_path)
return {"task_id": result.id}
@app.get("/status/{task_id}")
async def get_status(task_id: str):
result = celery_app.AsyncResult(task_id)
if result.state == 'PENDING':
return {"status": "Pending..."}
elif result.state == 'SUCCESS':
return {"status": "Completed", "result": result.result}
elif result.state == 'FAILURE':
return {"status": "Failed", "result": str(result.result)}
else:
return {"status": result.state}
```
## Scaling Celery Workers
### Increasing the Number of Workers
Start multiple Celery worker processes:
```bash
celery -A celery_config worker --loglevel=info --concurrency=4
```
To scale further, start more workers:
```bash
celery -A celery_config worker --loglevel=info --concurrency=4
celery -A celery_config worker --loglevel=info --concurrency=4
```
### Distributed Workers
Run workers on different machines by pointing them to the same message broker:
```bash
celery -A celery_config worker --loglevel=info --concurrency=4 -Q fetch_queue
celery -A celery_config worker --loglevel=info --concurrency=8 -Q extract_queue
celery -A celery_config worker --loglevel=info --concurrency=2 -Q compare_queue
```
## Using Dedicated Queues for Each Task Type
### Defining Queues
Configure Celery to define multiple queues:
```python
# celery_config.py
from celery import Celery
celery_app = Celery('tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
celery_app.conf.task_queues = (
Queue('fetch_queue', routing_key='fetch.#'),
Queue('extract_queue', routing_key='extract.#'),
Queue('compare_queue', routing_key='compare.#'),
)
celery_app.conf.task_routes = {
'tasks.fetch_documents_task': {'queue': 'fetch_queue', 'routing_key': 'fetch.documents'},
'tasks.extract_data_task': {'queue': 'extract_queue', 'routing_key': 'extract.data'},
'tasks.compare_data_task': {'queue': 'compare_queue', 'routing_key': 'compare.data'},
}
```
### Starting Workers for Specific Queues
```bash
celery -A celery_config worker --loglevel=info --concurrency=4 -Q fetch_queue
celery -A celery_config worker --loglevel=info --concurrency=8 -Q extract_queue
celery -A celery_config worker --loglevel=info --concurrency=2 -Q compare_queue
```
## Autoscaling
Enable autoscaling to dynamically adjust the number of worker processes:
```bash
celery -A celery_config worker --loglevel=info --autoscale=10,3
```
- `--autoscale=10,3`: Scales between 3 and 10 worker processes based on load.
## Distributed Task Execution
Distribute Celery workers across multiple machines:
### Example Setup
1. **Machine 1 (Message Broker and Backend):**
- Run Redis as your broker and backend.
2. **Machine 2 (Worker Node):**
- Start Celery workers:
```bash
celery -A celery_config worker --loglevel=info --concurrency=4 -Q fetch_queue
```
3. **Machine 3 (Worker Node):**
- Start Celery workers:
```bash
celery -A celery_config worker --loglevel=info --concurrency=8 -Q extract_queue
```
4. **Machine 4 (Worker Node):**
- Start Celery workers:
```bash
celery -A celery_config worker --loglevel=info --concurrency=2 -Q compare_queue
```
## Monitoring and Management
Use monitoring tools like Flower, Prometheus, and Grafana to monitor Celery tasks:
### Flower
Start Flower to monitor Celery workers:
```bash
celery -A celery_config flower
```
## Load Balancing and High Availability
Implement load balancing for high availability and fault tolerance:
### Example Load Balancer Setup
Use HAProxy or another load balancer to distribute requests across multiple Redis instances.
## Summary
- **Scale Workers:** Increase the number of Celery workers to handle more tasks concurrently.
- **Dedicated Queues:** Use different queues for different types of tasks and scale them independently.
- **Autoscaling:** Enable autoscaling to dynamically adjust the number of worker processes based on load.
- **Distributed Execution:** Distribute workers across multiple machines to improve scalability and fault tolerance.
- **Monitoring:** Use monitoring tools to keep track of the performance and health of your Celery workers.
- **Load Balancing:** Implement load balancing for high availability and fault tolerance.
By following these strategies, you can effectively scale your Celery-based application to handle increased loads and ensure reliable task execution in a production environment.
--- | dhananjayharidas |
1,865,663 | Reusing state management: HOC vs Hook | I've been looking at alternative approaches to HoC wrappers, as the evolution of client/server... | 0 | 2024-05-26T14:14:00 | https://dev.to/buchananwill/reusing-state-management-hoc-vs-hook-3ci8 | react, state, modularity, patterns | I've been looking at alternative approaches to HoC wrappers, as the evolution of client/server components and React best practices has pushed the HoC pattern down the list of "good modularity patterns". As a comparative exercise, I took this wrapper, and re-wrote it as a hook, using useCallback and React.memo for re-render stability. The hook version seems more in line with modern React style, but otherwise doesn't seem to offer much over the HoC version. Has anyone else looked at these patterns, or otherwise have a better solution?
HoC:
```
"use client";
import { DtoUiComponent, Entity } from "../../types";
import React from "react";
import { useDtoStoreDispatchAndListener } from "../../hooks/main";
import { useDtoStoreDelete } from "../../hooks/main";
export function DtoComponentWrapper<T extends Entity>({
entityClass,
id,
uiComponent: UiComponent,
}: {
entityClass: string;
id: string | number;
uiComponent?: DtoUiComponent<T>;
}) {
const { currentState, dispatchWithoutControl } =
useDtoStoreDispatchAndListener<T>(
id,
entityClass,
UiComponent?.name || "component",
);
const { dispatchDeletion, deleted } = useDtoStoreDelete(entityClass, id);
return (
UiComponent && (
<UiComponent
entity={currentState}
entityClass={entityClass}
dispatchWithoutControl={dispatchWithoutControl}
deleted={deleted}
dispatchDeletion={dispatchDeletion}
/>
)
);
}
```
Hook:
```
"use client";
import { DtoUiComponent, Entity } from "../../types";
import React, { memo, useCallback } from "react";
import {
useDtoStoreDelete,
useDtoStoreDispatchAndListener,
} from "../../hooks/main";
export function useDtoComponent<T extends Entity>(
entityClass: string,
UiComponent: DtoUiComponent<T>,
) {
return useCallback(
memo(({ id }: { id: string | number }) => {
const { currentState, dispatchWithoutControl } =
useDtoStoreDispatchAndListener<T>(
id,
entityClass,
UiComponent?.name || "component",
);
const { dispatchDeletion, deleted } = useDtoStoreDelete(entityClass, id);
return (
UiComponent && (
<UiComponent
entity={currentState}
entityClass={entityClass}
dispatchWithoutControl={dispatchWithoutControl}
deleted={deleted}
dispatchDeletion={dispatchDeletion}
/>
)
);
}),
[entityClass, UiComponent],
);
}
``` | buchananwill |
1,865,661 | Introduction to Fastify: A Superior Node.js Framework | In the landscape of Node.js frameworks, Fastify has been gaining significant traction among... | 0 | 2024-05-26T14:13:02 | https://dev.to/harshahegde/introduction-to-fastify-a-superior-nodejs-framework-13hh | node, javascript, express, fastify | In the landscape of Node.js frameworks, Fastify has been gaining significant traction among developers. Known for its speed, low overhead, and modern features, Fastify is often compared to the more established Express.js. In this article, we'll explore what makes Fastify stand out and why it might be the better choice for your next Node.js project.
**What is Fastify?**
Fastify is a web framework for Node.js designed with a focus on providing the best developer experience with the least overhead and a powerful plugin architecture. It was created to be fast, efficient, and highly modular, allowing developers to build scalable applications with ease.
Key Features of Fastify
1. Performance: Fastify is designed to be one of the fastest web frameworks available. It uses an extremely optimized HTTP layer to achieve high throughput and low latency. Benchmarks have shown that Fastify can handle more requests per second compared to other frameworks like Express.
2. Schema-Based Validation: Fastify uses JSON Schema for validating and serializing data. This approach not only improves performance but also ensures that the data handled by the application is always in the correct format.
3. Asynchronous and Await-First: Fastify embraces modern JavaScript features like async/await from the ground up, making asynchronous code easier to write and read.
4. Extensible via Plugins: The plugin architecture of Fastify allows developers to encapsulate functionalities into reusable components. This modular approach enhances maintainability and scalability.
5. TypeScript Support: Fastify has excellent TypeScript support, providing type safety and autocompletion which can significantly improve developer productivity and reduce bugs.
**Why Choose Fastify Over Express?**
1. While Express has been a go-to framework for many Node.js developers, Fastify offers several advantages that make it a superior choice for certain applications.
3. Speed and Performance: Fastify's focus on performance means it can handle a higher load with lower resource consumption. This makes it ideal for applications where performance is critical.
5. Built-In Data Validation: With JSON Schema validation built-in, Fastify ensures that your data is validated efficiently and consistently, reducing the risk of errors and security vulnerabilities.
7. Modern Codebase: Fastify's design around async/await and its robust TypeScript support mean that it aligns well with modern JavaScript practices, making it easier for developers to write clean, maintainable code.
9. Plugin Ecosystem: The plugin system in Fastify is designed to be extremely powerful yet simple to use. Plugins in Fastify are encapsulated, making the application easier to scale and maintain.
11. Community and Support: Fastify has a growing community and is actively maintained. The ecosystem around Fastify includes numerous plugins and tools that can help speed up development and solve common problems.
**Fastify in Action**
Here’s a simple example to illustrate how easy it is to get started with Fastify
```js
const fastify = require('fastify')({ logger: true })
// Declare a route
fastify.get('/', async (request, reply) => {
return { hello: 'world' }
})
// Run the server!
const start = async () => {
try {
await fastify.listen(3000)
fastify.log.info(`server listening on ${fastify.server.address().port}`)
} catch (err) {
fastify.log.error(err)
process.exit(1)
}
}
start()
```
**Conclusion**
Fastify offers a compelling alternative to Express and other Node.js frameworks by focusing on performance, modern JavaScript features, and a robust plugin system. Its advantages make it particularly suitable for high-performance applications where efficiency and scalability are paramount. As the Node.js ecosystem continues to evolve, Fastify is well-positioned to become a leading framework for modern web development.
Give Fastify a try on your next project, and experience the benefits of a truly fast and developer-friendly Node.js framework.
| harshahegde |
1,865,660 | Data Cleaning Using Pandas: A Comprehensive Guide | Data cleaning is a crucial step in any data analysis or machine learning project. It involves... | 0 | 2024-05-26T14:08:37 | https://dev.to/samagra07/data-cleaning-using-pandas-a-comprehensive-guide-2kb0 | python, pandas, beginners, programming |

Data cleaning is a crucial step in any data analysis or machine learning project. It involves identifying and correcting errors, handling missing values, and ensuring the data is in a suitable format for analysis. In this blog, we will explore data cleaning techniques using the powerful `pandas` library in Python. By the end of this guide, you'll have a solid understanding of how to clean your data efficiently using pandas.
## Introduction to Pandas
Pandas is an open-source data manipulation and analysis library for Python. It provides data structures like DataFrames and Series, which are essential for data cleaning tasks. Let's start by importing pandas and loading a sample dataset.
```python
import pandas as pd
# Load a sample dataset
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv"
df = pd.read_csv(url)
```
## Understanding the Dataset
Before we start cleaning the data, it's essential to understand its structure. We'll use some basic pandas functions to get an overview of the dataset.
```python
# Display the first few rows of the dataframe
print(df.head())
# Get a summary of the dataframe
print(df.info())
# Check for missing values
print(df.isnull().sum())
```
## Handling Missing Values
Missing values can significantly affect the outcome of your analysis. Pandas provides several methods to handle missing values:
1. **Removing Missing Values**: You can remove rows or columns with missing values using the `dropna()` method.
```python
# Remove rows with any missing values
df_cleaned = df.dropna()
# Remove columns with any missing values
df_cleaned = df.dropna(axis=1)
```
2. **Filling Missing Values**: You can fill missing values using the `fillna()` method. Common strategies include filling with a specific value, the mean, median, or a method like forward fill or backward fill.
```python
# Fill missing values with a specific value
df['age'].fillna(0, inplace=True)
# Fill missing values with the mean
df['age'].fillna(df['age'].mean(), inplace=True)
# Forward fill missing values
df['age'].fillna(method='ffill', inplace=True)
# Backward fill missing values
df['age'].fillna(method='bfill', inplace=True)
```
## Handling Duplicate Data
Duplicate data can lead to biased results. You can identify and remove duplicates using the `duplicated()` and `drop_duplicates()` methods.
```python
# Identify duplicate rows
duplicates = df.duplicated()
print(duplicates.sum())
# Remove duplicate rows
df_cleaned = df.drop_duplicates()
```
## Data Type Conversion
Ensuring that each column has the correct data type is essential for accurate analysis. You can check and convert data types using the `dtypes` attribute and `astype()` method.
```python
# Check data types
print(df.dtypes)
# Convert data type of a column
df['age'] = df['age'].astype(float)
```
## Handling Outliers
Outliers can skew your analysis. You can identify and handle outliers using statistical methods or visualization techniques.
```python
import numpy as np
# Identify outliers using the IQR method
Q1 = df['age'].quantile(0.25)
Q3 = df['age'].quantile(0.75)
IQR = Q3 - Q1
# Define the outlier range
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Filter out outliers
df_no_outliers = df[(df['age'] >= lower_bound) & (df['age'] <= upper_bound)]
```
## Standardizing Data
Standardizing data involves transforming it into a consistent format. This can include renaming columns, formatting strings, or scaling numerical values.
```python
# Rename columns
df.rename(columns={'pclass': 'class', 'sex': 'gender'}, inplace=True)
# Format string data
df['gender'] = df['gender'].str.lower()
# Scale numerical data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['age_scaled'] = scaler.fit_transform(df[['age']])
```
## Handling Categorical Data
Categorical data often needs to be encoded for analysis. You can use one-hot encoding or label encoding to handle categorical data.
```python
# One-hot encoding
df = pd.get_dummies(df, columns=['class', 'gender'])
# Label encoding
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['embarked'] = le.fit_transform(df['embarked'].astype(str))
``` | samagra07 |
1,865,659 | Top-Down Shooter Update: Day 2 (Mobile Game Testing Question) | -Research question for today: how do developers normally test mobile games in Unity while developing... | 0 | 2024-05-26T14:05:28 | https://dev.to/quantumbyte-studios/top-down-shooter-update-day-2-mobile-game-testing-question-21d7 | -Research question for today: how do developers normally test mobile games in Unity while developing on a computer?
I looked it up online, and found that to test mobile games in Unity, you need to download Android Build Support (~5GB and I don't have a great internet connection!). So... while it's downloading.. I'm writing this out!
It's not as easy to test changes on a phone as it is for a computer game, it seems. I guess this is the case for all games where development happens on a different platform than the end user. I have a new appreciation for people who design non-computer games! Brave souls!
My goals for today are:
-Add basic UI (health and score)
-Make main character and ninja star smaller
-Make star-throwing more directional
I'll check back with you later | quantumbyte-studios | |
1,865,658 | Share Your AI Insights: How Do You Use ChatGPT for Work and Studying? | AI tools are transforming the way we work and study, making us more productive and efficient. These... | 0 | 2024-05-26T14:04:30 | https://dev.to/per-starke-642/share-your-ai-insights-how-do-you-use-chatgpt-for-work-and-studying-e78 | ai, productivity, chatgpt, discuss | AI tools are transforming the way we work and study, making us more productive and efficient. These powerful tools can automate tedious tasks, provide quick information, and offer creative solutions.
In my recent post, I shared my experiences and tips on using ChatGPT to enhance productivity and learning. If you missed it, check it out [here](https://blog.perstarke-webdev.de/posts/chatgpt-work-study).
Now, I want to hear from you! What are your favorite ways to use ChatGPT or other AI tools for work and studying? Whether it’s drafting emails, brainstorming ideas, or tackling complex problems, your insights can help create a valuable resource for the entire community.
Let’s build a comprehensive collection of AI usage ideas together. Your contributions will not only benefit you but also help fellow readers discover new and effective ways to leverage AI in their daily lives.
So, share your AI strategies in the comments below! How do you use ChatGPT or other AI tools to boost your productivity and learning? Let’s learn and grow together! | per-starke-642 |
1,864,871 | Type-Safe React: Harnessing the Power of Discriminated Unions | As front-end developers, we've all been there - in a situation where we want to pass a prop to a... | 0 | 2024-05-26T14:01:46 | https://dev.to/gboladetrue/type-safe-react-harnessing-the-power-of-discriminated-unions-158m | react, typescript, frontend, solidprinciples | As front-end developers, we've all been there - in a situation where we want to pass a prop to a child component, but only if another prop is present. It's a common situation that can lead to messy, hard-to-maintain code. But fear not, dear reader, for there's a solution that can simplify your code and make it more type-safe: **discriminated unions**.
## Conditional Props
Imagine you're building a `Button` component that can be either a primary or secondary button. You want to pass a `label` prop to the component, but only if the `variant` prop is set to "primary". If `variant` is "secondary", you don't want to pass the `label` prop.
```typescript
interface ButtonProps {
variant: 'primary' | 'secondary';
label?: string;
}
const Button = ({ variant, label }: ButtonProps & React.ButtonHTMLAttributes<HTMLButtonElement>) => {
return <button {...props}>{variant === 'primary' ? label : ''}</button>;
};
```
This implementation has some issues:
The `label` prop is optional, which can lead to `undefined` errors if it's not provided when `variant` is "primary".
The component has to perform runtime checks to ensure the label prop is present when `variant` is "primary".
## Enter Discriminated Unions:
Discriminated unions, also known as tagged unions, are a powerful feature in TypeScript that can help us solve this problem. A discriminated union is a type that can be one of several types, depending on the value of a specific property, called the discriminant.
Let's redefine our `ButtonProps` interface using a discriminated union:
```typescript
interface PrimaryButtonProps {
variant: 'primary';
label: string;
}
interface SecondaryButtonProps {
variant: 'secondary';
}
type ButtonProps = PrimaryButtonProps | SecondaryButtonProps;
```
Here, we've defined two separate interfaces: `PrimaryButtonProps` and `SecondaryButtonProps`. By defining `ButtonProps` as a union type, we're saying that a ButtonProps object can have either the shape of a `PrimaryButtonProps` object or a `SecondaryButtonProps` object depending on the **`variant`** property, which is the discriminant. It is important to note that whatever is used as the discriminant is required for all separate interfaces when applying the concept of discriminated unions. So if we had a third button variant, say "tertiary", the interface `TertiaryButtonProps` must include the `variant` prop.
```typescript
interface PrimaryButtonProps {
variant: 'primary';
label: string;
}
interface SecondaryButtonProps {
variant: 'secondary';
}
// Wrong Implementation
interface TertiaryButtonProps {
// missing required `variant` prop
tertiaryProp?: any;
}
// Correct Implementation
interface TertiaryButtonProps {
variant: 'tertiary'; // Required prop
tertiaryProp?: any;
}
type ButtonProps = PrimaryButtonProps | SecondaryButtonProps | TertiaryButtonProps;
```
Now, let's update our Button component to use this new `ButtonProps` type:
```typescript
const Button = (props: ButtonProps & React.ButtonHTMLAttributes<HTMLButtonElement>) => {
const { variant } = props;
return <button {...props}>{variant === 'primary' ? props.label : 'Secondary Button'}</button>;
};
```
With this implementation, TypeScript will ensure that when `variant` is `primary`, the `label` prop is always present. If `variant` is `secondary`, the `label` prop is absent. The discriminated union has helped us handle a conditional prop that depends on the value of another prop.
Here are some other common use cases for discriminated unions in React development:
* Form Validation: When building forms, we often need to validate user input based on the type of input field. Discriminated unions can help us define separate validation rules for different input types.
* Modals: When building modals, we might want to pass different props depending on the type of modal (e.g. error modal, success modal, etc.).
* Accordion Components: Accordion components often require different props depending on whether the accordion item is expanded or collapsed.
* Responsive Design: We might want to pass different props to a component based on the screen size or device type when building responsive designs.
So, what makes discriminated unions so useful?
1. **Type Safety**: Discriminated unions ensure that the type of the `props` object is correctly inferred based on the value of the discriminant property.
2. **Code Clarity**: By defining separate interfaces for each possible type, our code becomes more readable and easier to understand.
3. **Fewer Runtime Checks**: With discriminated unions, we can eliminate runtime checks and ensure that our code is correct at compile time.
## Conclusion
Discriminated unions are a game-changer in the TypeScript toolbox, empowering you to write more robust, type-safe, and maintainable React components. By harnessing their power, you can ensure consistency and stability as your applications scale. Next time you're faced with dependent conditional props, don't hesitate to reach for a discriminated union - the ultimate problem-solver for a more predictable and efficient codebase.
I hope this post has inspired you to explore the world of discriminated unions in React with TypeScript. Happy coding! | gboladetrue |
1,865,654 | Cosa ho imparato durante lo sviluppo di SamGIS con LISA (finora) | Cosa ho imparato durante lo sviluppo di SamGIS con LISA (finora) Leggere le... | 27,514 | 2024-05-26T13:57:08 | https://trinca.tornidor.com/it/blog/what-I-learnt-from-lisa-with-samgis | machinelearning, learning, programming, llm | # Cosa ho imparato durante lo sviluppo di SamGIS con LISA (finora)
## Leggere le pubblicazioni inerenti ai progetti su cui lavoro
Per migliorare la mia comprensione del mio progetto di machine learning ho deciso di leggere l'articolo su cui si basano LISA e Segment Anything. Oltre ad alcune informazioni teoriche su LLM, ho notato che l'architettura modulare di "SAM" consente di creare e riutilizzare gli image embedding. Dato che SamGIS non funzionava in questo modo inizialmente, ho formulato un'ipotesi al riguardo.
## Debug, misure ed ottimizzazione: ipotesi sul image embedding
A questo punto ho continuato il mio lavoro di debug misurando la durata dei singoli passaggi durante l'esecuzione delle funzioni di SamGIS. La creazione di un image embedding è un'operazione abbastanza onerosa, quindi è vantaggioso salvarlo e riutilizzarlo (ho verificato implementare la mia ipotesi migliorerebbe le prestazioni del software). Utilizzando il profilo hardware HuggingFace "Nvidia T4 Small" (con 4 vCPU, 15 GB RAM e 16 GB VRAM) è possibile risparmiare circa 1 secondo per ogni inferenza successiva alla prima, utilizzando la stessa immagine (quindi senza modificare il tile provider e l'area geografica).
## Il ruolo dei LLM con prompt aventi differenti caratteristiche
LISA eredita le capacità di generazione del linguaggio dei LLM multi-modali come [Llava](https://llava-vl.github.io/). Questi modelli eccellono nella gestione di ragionamenti complessi, conoscenza del mondo, risposte esplicative e conversazioni a più turni. Sono strumenti potenti per colmare il divario tra testo e comprensione visiva.
LISA permette di effettuare [ragionamenti piuttosto complessi](https://trinca.tornidor.com/it/projects/lisa-adapted-for-samgis#prompts-testuali-d-input-e-relativi-geojson-di-output) durante la segmentazione delle immagini (es. "identify the houses near the trees..." vs "identify the houses...") senza particolari peggioramenti prestazionali. Al contrario, richieste contenenti la spiegazione del motivo ("explain why") per cui il task di segmentazione sia fatto in un certo modo avranno tempi di esecuzione molto più elevati (nell'ordine di minuti).
Sono disponibili [maggiori dettagli qui](https://trinca.tornidor.com/it/projects/lisa-adapted-for-samgis#durata-dei-task-di-segmentazione) su questi miglioramenti in seguito alle modifiche descritte e relativamente alle differenti prestazioni dovute a diversi casi durante l'utilizzo di SamGIS con LISA.
| trincadev |
1,865,653 | How to create an Azure resource group from the Azure portal | Azure Resource Group is a logical group of resources that includes virtual machines, databases, web... | 0 | 2024-05-26T13:55:14 | https://dev.to/edjdeborah/how-to-create-an-azure-resource-group-from-the-azure-portal-2gk1 | Azure Resource Group is a logical group of resources that includes virtual machines, databases, web application etc
creating a resource group
1.Log in to Azure portal.
Search for “resource group” in the search bar.
It will display all the resource groups under your subscription Select “Resource groups”.
2.Click on + Create.
It will open a form to create a resource group.
Select your subscription.
3.Provide a global unique name for Resource group.
the next heading is the resource details with subtitle (region/location) Select the Region.
4. Next is tag- input name and tag to resource group
5.Lastly click on review and create where it validates the process
If validation is successful, then click on Create.
If validation fails, check the error and resolve it
| edjdeborah | |
1,865,652 | Car Workshop Manuals: Your Comprehensive Guide to Vehicle Maintenance and Repair | Car workshop manuals are indispensable resources for both amateur car enthusiasts and professional... | 0 | 2024-05-26T13:53:24 | https://dev.to/reman21co/car-workshop-manuals-your-comprehensive-guide-to-vehicle-maintenance-and-repair-492l | Car workshop manuals are indispensable resources for both amateur car enthusiasts and professional mechanics. These manuals provide detailed instructions and insights into maintaining and repairing various car models, helping individuals save time and money while ensuring their vehicles run smoothly. In this article, we'll delve into the importance of **[car workshop manuals](https://downloadworkshopmanuals.com/)**, their benefits, and how to utilize them effectively for optimal vehicle upkeep.
**Understanding Car Workshop Manuals**
Car workshop manuals are comprehensive guides crafted by vehicle manufacturers or experienced technicians. They cover a wide array of topics related to car maintenance and repair, ranging from routine servicing to intricate troubleshooting procedures. These manuals serve as invaluable tools for diagnosing issues, performing repairs, and conducting preventive maintenance tasks on cars of all makes and models.
**Key Components of Car Workshop Manuals**
Detailed Diagrams: Visual representations such as diagrams and schematics that elucidate various car components and systems.
Step-by-Step Instructions: Clear and concise procedural guidelines for undertaking maintenance and repair tasks.
Specifications: Technical details including torque settings, fluid capacities, and part numbers essential for accurate repairs.
Troubleshooting Tips: Insights into identifying and resolving common car issues efficiently.
Maintenance Schedules: Recommendations for regular servicing intervals to uphold optimal car performance and longevity.
Benefits of Using Car Workshop Manuals
Cost Savings
Utilizing car workshop manuals enables car owners to perform maintenance and repairs independently, reducing reliance on professional mechanics and associated labor costs. By acquiring the necessary skills and knowledge, individuals can undertake tasks themselves, thereby saving significant amounts of money in the long run.
**Knowledge and Empowerment**
Car workshop manuals serve as educational resources, empowering individuals with a deeper understanding of their vehicles' workings. By following the instructions outlined in these manuals, car owners can develop valuable mechanical skills and gain confidence in addressing various car-related issues.
**Proper Maintenance**
Following the guidelines stipulated in car workshop manuals ensures that vehicles receive the requisite maintenance at appropriate intervals. Adhering to recommended servicing schedules helps prevent minor issues from escalating into major problems, thereby prolonging the lifespan of the vehicle and optimizing its performance.
**Convenience**
Having access to car workshop manuals provides car owners with the flexibility to perform maintenance and repairs at their convenience. Individuals can schedule tasks according to their availability, eliminating the need for appointments at service centers and minimizing downtime associated with car repairs.
**How to Use Car Workshop Manuals**
Step 1: Identify Your Car Make and Model
Begin by identifying the specific make and model of your car. Car workshop manuals are often tailored to particular vehicle brands and models to ensure accuracy and relevance.
Step 2: Acquire the Manual
Car workshop manuals can be obtained from various sources, including online platforms, automotive retailers, and authorized dealerships. Ensure that you acquire the appropriate manual corresponding to your car's make, model, and year.
Step 3: Familiarize Yourself with the Manual
Before embarking on any maintenance or repair task, familiarize yourself with the relevant sections of the car workshop manual. Review the instructions, diagrams, and safety precautions to gain a comprehensive understanding of the task at hand.
Step 4: Follow Instructions Methodically
Adhere to the step-by-step instructions provided in the car workshop manual meticulously. Avoid taking shortcuts or skipping steps, as this could compromise the effectiveness of the repair or maintenance task.
Step 5: Utilize Proper Tools and Equipment
Ensure that you have the appropriate tools and equipment required for the task at hand. Using the correct tools as specified in the workshop manual ensures precision and efficiency in carrying out repairs and maintenance tasks.
**Common Repairs Using Car Workshop Manuals**
**Oil Changes**
Regular oil changes are essential for maintaining engine health. Car workshop manuals provide detailed instructions on how to perform oil changes, including the type of oil to use and the procedure for draining and replacing the oil filter.
**Brake Maintenance**
Brake systems are critical for vehicle safety. Car workshop manuals offer guidance on inspecting, repairing, and replacing brake components such as pads, rotors, and calipers, ensuring optimal brake performance.
**Electrical System Troubleshooting**
Diagnosing electrical issues can be challenging, but car workshop manuals provide troubleshooting tips for identifying and rectifying common electrical problems such as faulty wiring, blown fuses, or malfunctioning components.
**Suspension and Steering Repairs**
Maintaining the suspension and steering systems is vital for a smooth and stable ride. Car workshop manuals provide instructions for inspecting and replacing components such as shocks, struts, tie rods, and steering racks.
**Cooling System Maintenance**
Proper cooling system maintenance is essential for preventing engine overheating. Car workshop manuals contain detailed procedures for checking coolant levels, inspecting hoses, and replacing the radiator or thermostat if necessary.
**Conclusion**
Car workshop manuals are indispensable resources for car owners seeking to maintain and repair their vehicles effectively. By providing comprehensive guidance and instructions, these manuals empower individuals to address various car-related issues with confidence and precision. Whether you're performing routine maintenance tasks or undertaking complex repairs, a car workshop manual serves as a trusted companion in your automotive endeavors. Invest in a car workshop manual today to unlock the potential for cost savings, knowledge acquisition, and optimal vehicle performance.
| reman21co | |
1,865,651 | What I learnt from development on LISA with SamGIS (So far) | What I learnt from development on LISA with SamGIS (So far) Read publications... | 27,514 | 2024-05-26T13:52:16 | https://trinca.tornidor.com/blog/what-I-learnt-from-lisa-with-samgis | machinelearning, learning, programming, llm | # What I learnt from development on LISA with SamGIS (So far)
## Read publications related to the projects I work on
To improve my understanding of my machine learning project I decided to read the papers on which [LISA](https://arxiv.org/abs/2308.00692) and [Segment Anything](https://arxiv.org/abs/2304.02643) are based. Besides some theoretical informations about LLM, I noticed that the modular architecture of "SAM" permits to save and re-use image embeddings. Since SamGIS didn't work this way initially, I formulated an hypothesis about this.
## Debugging, measures and optimization: Image Embedding Hypothesis
At this point I continued my debugging work by measuring the duration of individual steps during the execution of SamGIS functions. Creating an image embedding is quite an expensive operation, so it is advantageous saving it and re-using it (I verified that implementing my hypothesis would improve the performance of the software). Using the HuggingFace hardware profile "Nvidia T4 Small" (with 4 vCPU, 15 GB RAM and 16 GB VRAM) it's possible to save almost 1 second on every inference after the first, using the same image (without change the geographical area tiles provider).
## The role of LLMs with prompts having different characteristics
LISA inherits the language generation capabilities of multi-modal LLMs such as [Llava](https://llava-vl.github.io/). These models excel at handling complex reasoning, world knowledge, explanatory answers and multi-turn conversations. They’re powerful tools for bridging the gap between text and visual understanding.
LISA allows you to perform [rather complex reasoning](https://trinca.tornidor.com/projects/lisa-adapted-for-samgis#some-input-text-prompts-with-their-geojson-outputs) during image segmentation (e.g. "identify the houses near the trees..." vs "identify the houses...") without any particular performance degradation. On the contrary, requests containing the explanation of reason ("explain why") the segmentation task is done in a certain way will have much higher execution times (in the order of minutes).
There are [more details here](https://trinca.tornidor.com/projects/lisa-adapted-for-samgis#duration-of-segmentation-tasks) about these improvements following the changes described and regarding different performance due to different cases when using SamGIS with LISA.
| trincadev |
1,865,649 | Market Weekly Recap: Bitcoin Gains Momentum as Ethereum Enters ETF-Based Rally | Market has been setting off on the wrong foot for many weeks’ onset, yet ultimately radiates... | 0 | 2024-05-26T13:50:03 | https://dev.to/endeo/market-weekly-recap-bitcoin-gains-momentum-as-ethereum-enters-etf-based-rally-45bg | webdev, javascript, blockchain, web3 | ## Market has been setting off on the wrong foot for many weeks’ onset, yet ultimately radiates silver lining. Assessing the chances of long-term rally behind Bitcoin’s and Ethereum’s upswings
As Ethereum could be the closest ever to get listed on Wall Street, a positive sentiment has been hovering in the market. With Bitcoin’s May 20 upsurge, it’s time to evaluate: is it an off-tendency action, or a sigh for long-term highs?
## Will Bitcoin’s $70K hold for long?
Since Bitcoin reached its all-time high of $73,000 on March 14, it has been indicating a global downward trend, which absolutised to reaching a critical $56,792 bottom on May 1. The resistance point bounced back with a vague bullish sentiment, later rebounding and bringing BTC to the $60,796 range on May 9.
Amid fluctuating market conditions, Bitcoin managed to recover for over 4% on May 10, moving closer to $64,000. Upswung volatility had been in charge until BTC experienced a rapid 10% surge, which brought the cryptocurrency back to $70,000 range.
This again brought the speculations about long-term BTC potential on the table, the boldest of ones citing the asset to overcome $220,000, as per Max Keiser – a vocal Bitcoin advocate and former financial journalist.
The forecast is driven by what Keiser identifies as a crucial dynamic in the market: a “demand shock meet supply shock” scenario, indicating a tightening of Bitcoin’s supply at a time of increasing demand.
This supply contraction, paired with growing demand, forms the basis for Keiser’s prediction of a “God candle” on Bitcoin charts – a dramatic price surge that could potentially elevate BTC to the $220,000 range.
Crucially, a closer look at the Bitcoin’s daily chart reveals positive sentiment, evidenced by relative strength index (RSI) at 57.77 rate and a 50-day and 200-day exponential moving averages (EMA), marking the potential uptick.
Notably, the chart indicates that Bitcoin has finally broken structure to the downside over recent months, leading to liquidity accumulation at each structural break.
By contrast, the possible bearish outlook is reflected upon the number of active Bitcoin addresses and a slowdown in new address momentum.
This indicates the market’s scepticism about a short-term bullish turnaround behind the recent correction phase.
Regardless, the long-term outlook for Bitcoin remains optimistic, as Santiment noted increased Bitcoin whales’ activity since May 8. This may be a silver lining for the first cryptocurrency and its holders.
## Ethereum ETF At Its Closest – $4,000 Expected
After experiencing a severe price decline on the 7th of May, Ether (ETH) saw more liquidations in long positions. As a result of the shorting activity, the price of ETH went further south, falling below the $3,000 price range in momentum.
The fluctuation came amidst Grayscale’s abrupt withdrawal of its Ethereum futures ETF filing, which brought pessimistic signals to the market participants envisaging SEC’s potential next move.
Still, throughout May 20-May 23, Ether managed to break out of the bearish trend and hit the local milestone of $3935.37, marking the 29.22% growth. The bullish dynamic took up amidst the rumour of Ethereum ETF likeable approval.
Notably, Ether’s 4-hour chart suggests the long-term bullish perspective, as 50-, 100-, and 200-day exponential moving averages (EMA) register sharp upticks.
Daily timeframe price trend marks a notable three-day incline with a moderate level of volatility, depicted by the Bollinger Band.
The incline has further entrenched Ether into a bullish trend, with the relative strength index (RSI) standing at 73.70, signalling a strong upward sentiment.
## Altcoins Seek Second Breath
The altcoin market quickly followed the moves of the stronger Bitcoin and Ethereum. Almost every of the top 10 altcoins recorded an average 8%-10% increase in price. Namely, Cardano (ADA) registered a 5.68% growth, while Avalanche (AVAX) increased almost 15%, marking a local $15 milestone at the writing time.
Notably, among the top performers, memecoins took the lead.
After a post-GME rally consolidation, Pepe (PEPE) indicated staggering 65.60% growth that took it to the all-time high (ATH) of $0.0000147.
Dogecoin (DOGE) also closed upon the elevation, achieving the local highs of $0.16-$0.17.
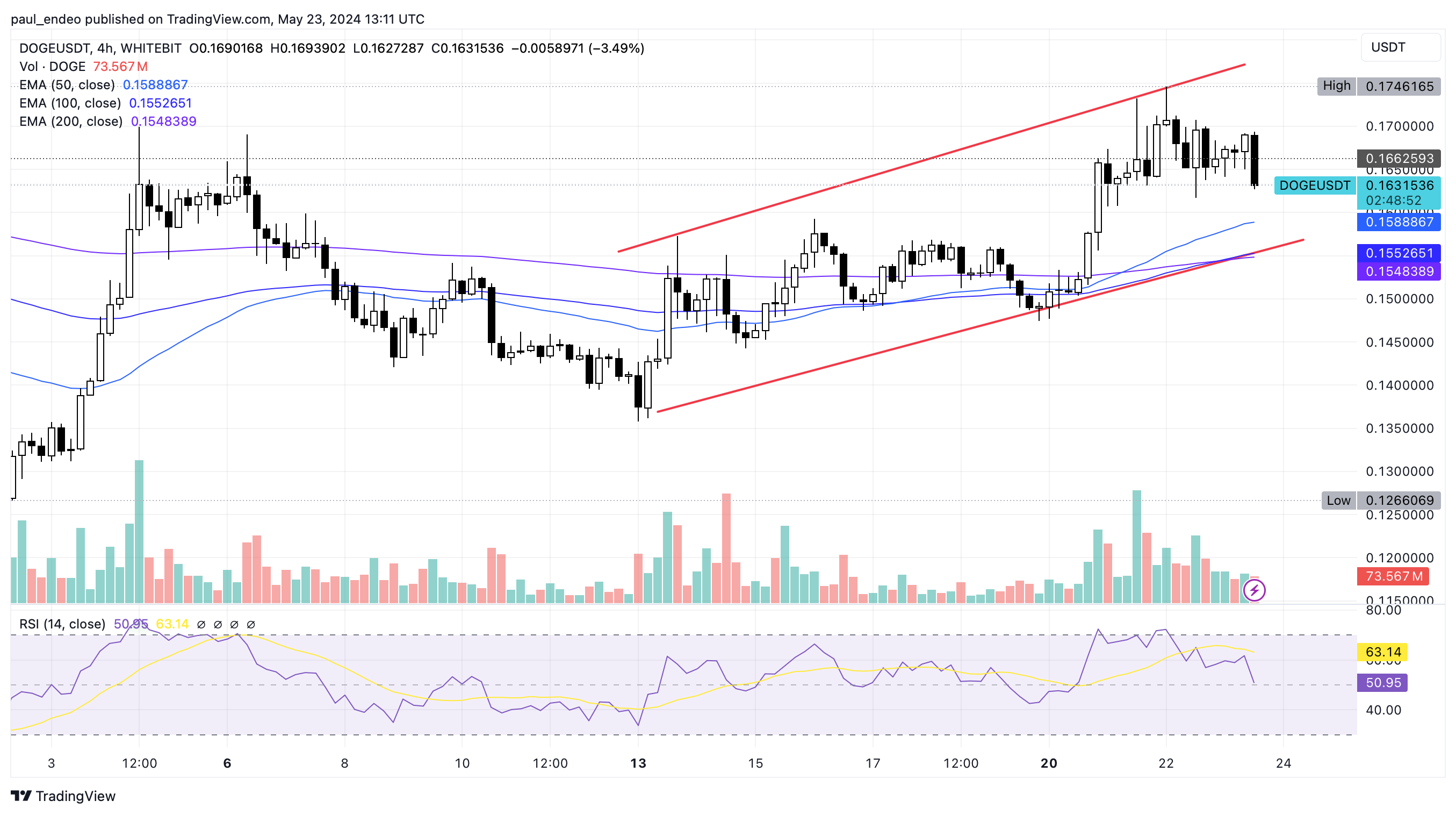
Interestingly, Solana-based memecoins dogwifhat (WIF) and Bonk (BONK) have also marked a price surge, by contrast to SOL, which went south due to the Ethereum ETF resonance.
As the bulls took over the market, this tendency proves to be long-term – with the investment behaviour clearly set for the durable optimism. | endeo |
1,865,624 | Buy Verified Cash App Account | Get Verified Cash App Account Are you afraid to Get our Verified Cash App Accounts service will be... | 0 | 2024-05-26T13:10:44 | https://dev.to/kathyrose/buy-verified-cash-app-account-2ibc | webdev, javascript, beginners, react | > Get Verified Cash App Account
Are you afraid to Get our Verified Cash App Accounts service will be Dropped? Don’t Worry, We are not like the rest of the fake PVA Accounts providers. We provide 100% Non-Drop PVA Accounts, Permanent PVA Accounts, and Legit PVA Accounts Service. We’re working with the largest team and we’re instant start work after your placing order. So, Get our Service and enjoy it.
Our Service Always Trusted Customers sufficient Guarantee
✔ 100% Customers Satisfaction Guaranteed.
✔ 100% Non-Drop Verified Cash App Accounts
✔ Active Verified Cash App Accounts
✔ Very Cheap Price.
✔ High-Quality Service.
✔ 100% Money-Back Guarantee.
✔ 24/7 Ready to Customer Support.
✔ Extra Bonuses for every service.
✔ If you want to buy this product, you must Advance Payment.
If you want to more information just contact now.
24 Hours Reply/Contact
E-mail: support@pvasells.com
Telegram: @PvaSells
Skype: PvaSells
WhatsApp: +1 (813) 534-0063
What Is Verified Cash App Account?
Verified Cash App is a new app that lets you cash out your Bitcoins for cash directly to your bank. If you have a bank account, debit card, or PayPal. You can quickly cash out your bitcoins by sending funds directly to your bank account. This means that no matter how much Bitcoin you have, you can now get cash that you have to spend or use right away.
Verified Cash App makes sending money as easy as sending an email. You can send money instantly from one account to another, or transfer money to a friend via text message. You can do all this for free, without having to sign up for any services or enter your banking information. The Verified Cash App is a digital wallet you can use to pay for things. The app is like PayPal or Venmo, but instead of using PayPal or Venmo, they offer their own app. The app allows you to pay and get paid directly, send money, and even transfer cash by scanning a barcode.
The $20 billion cryptocurrency market just got a little bigger. The crypto-currency, bitcoin, is now being accepted as payment for online purchases thanks to Verified Cash App. This popular app lets users make online purchases by converting their bitcoin to fiat currency. Verified Cash App users can finally spend their bitcoin without worrying about keeping it safe. The verified cash app makes bitcoin transactions fast and simple,. Which is ideal for users that prefer a quick and easy shopping experience. If you use the verified cash app, you will find it easy to use, secure, and reliable.
Get Verified Cash App Account
Get cash app accounts is not allowed, but Get cash app gift cards is. Cash app a gift card works like cash, but it’s entered like a code. It is accepted in-app or on other apps and has a letter ID which represents a dollar amount. The retail price is usually from $25- $50. Cash app gift cards are bought on SnapRetail, eBay, or Amazon and are mailed or delivered to your doorstep.
Getting paid to play games online is a pretty sweet gig, and it’s even easier. When you have the right amount of money in your Cash App account. Get verifiable Cash App accounts is a great way to get your money flowing. And it’s even easier now than it ever has been. All you have to do is enter your email into the form at the top of the site. And you’ll be shown a list of verified Cash App accounts for sale. All you have to do is select how much you want to pay for the account, and pay the seller via credit card or PayPal. And if you don’t already have an account, what are you waiting for? Just click the button below to get started already!
A new trend has popped up within the verified cash app accounts community. And it involves people creating fake accounts, uploading fake money, and watching other’s cash accumulate. Some people do Get things with real money, but, and they get scammed. So, what can you do to avoid getting scammed? The Cash App mobile app lets you send and receive money to and from your phone. You can also receive payments up to $10,000 from verified accounts. Which are typically businesses, or people you know personally.
How to verify a Cash App accounts?
Cash App is an app that allows you to send or receive money. But, not all users have verified their Cash App accounts. To verify your account, use your phone’s camera to scan the Cash App code displayed in the Cash App app or in Cash App. You can also verify an account by sending the Cash App team a photo of a photo ID. With Cash App, you can make fast, easy and secure payments or request money. But, before you do, it’s important to know how to verify a Cash App account to make sure it’s the real deal.
Imagine this scenario: You’re running late for work and need to stop by the ATM to get some cash. But, you realized you left your debit card at home. What do you do? If you’re like me, you pull out your phone, go to the app store, and search for the closest ATM. After you find the closest ATM, you pull up the app. You press the “verify” button and enter your phone’s phone number. Then enter the 4-digit PIN to activate your phone. You wait for several minutes. When the process is complete, you pick up your debit card and rush out the door.
Do you find yourself searching more about what to do when someone has not verified their Cash App account? The cash app is a mobile payment system, developed by Square. Which allows you to send money or request credit and cash for goods and services.
How can I Get real Verified Cash App Account?
Some sellers of online services and virtual goods provide customers the ability to Get accounts. That will give them extra privileges or that will allow them to access restricted content. These sellers may provide these accounts in exchange for money. But buyers are also sometimes able to get these accounts through other means. Such as from friends or relatives. In some cases, it may be possible to Get accounts from individuals by applying tricks. Such as asking the seller to create a fake Amazon account and directing the buyer’s money there. But, Amazon takes steps to detect such attempts and accounts created using such methods may be permanently banned.
Looking to Get real Verified Cash App Account? Buy it at ssbullion.com. Succeeding in the game of online money earning requires a lot of perseverance and effort. A cash account in online money making can jump start your activities. Remember, these accounts are not real, so you are not risking any money here.
Can you actually Get fully verified Cash App accounts?
While Cash App only offers verified accounts, you can indeed Get fully verified Cash accounts if you know where to look. There are a number of websites that claim to sell Cash accounts, but be careful and only buy from reputable sellers.
If you know anything about Cash App, one of the most popular peer-to-peer apps out there, you know that you can buy and sell gift cards—and, if you’re so inclined, you can purchase fully verified accounts with gift cards attached. But what you may not know is that, starting today, you can now purchase verified Cash App accounts. So, let’s take a quick look at what verified Cash App accounts are and how they work.
Why do you must like our Verified Cash App Accounts?
We live a busy life, and it’s not always possible to eat well, consistently exercise, and stay on top of our finances. Sometimes, you just need to let your hair down and treat yourself—but that doesn’t mean you can’t still feel good about it. Here’s our top tips to enjoying a night out without breaking the bank.
Why must people like you our Verified Cash App Accounts? All Verified Cash App Accounts have Real Cash! Our accounts are Real Money and you can use them for real purchases with your PayPal account or cash out to PayPal. Below has discussed what our key features to provide our services are.
High-quality: The quality of our offering Accounts don’t need to compare with other services.
A quick start: Our expert team worker starts their task as soon as possible after replacing your order. And complete payment And we provide our customer’s order very faster.
Faster Delivery: We deliver our Accounts orders and deliver their order super faster.
Spread them across other Accounts: You can stock up on Accounts by picking the biggest package. And then tell us to spread them across all other Accounts.
Accounts from the real profile: we offer each Accounts from real and genuine profiles. Which will be permanent and help to spread your profile.
Risk-free services: The services that you will buy from us are must risk-free and permanent. Which won’t be decreased.
Secure Payment system: You can place your order by any secure payment system. We offer different types of trusted payment systems in the world.
24-hours live chat: Our customer support team is always ready to help 24/7. So, you can get any support without any issues when you need it.
Why choosing Us for Get Cash App accounts?
Do you think our Verified Cash App Accounts can Dropped? No, it won’t because we provide 100% permanent Verified Cash App Accounts as we have a large group to work together. But why we are best to let’s know:
Customer support 24/7
We offer all time weekly and monthly package.
We use an active and phone verified accounts.
For make more trustable, we give rating as well
Trustworthy seller with a ton of happy customers
We provide both male and female profile
We offer Verified Cash App Accounts with custom names with country
Benefits Of Verified Cash App Accounts
Verified Cash App is a smartphone app that claims to help easy cash transfers between friends. The app is marketed as a way to quickly transfer cash for a friend in need. And to create convenience for both sender and recipient. The app is free to download, although users must pay for unverified accounts, which cost $15 per month. Verified accounts, but, are free. Many people are turning to technology services like Cash App to make money online. With smartphones now a ubiquitous part of everyday life, many are turning to smartphone applications to help grow their earnings. One of the most popular apps people use is Cash App.
Verified Cash App is a smartphone app that claims to ease easy cash transfers between friends. The app is marketed as a way to quickly transfer cash for a friend in need. And to create convenience for both sender and recipient. The app is free to download, although users must pay for unverified accounts, which cost $15 per month. Verified accounts, but, are free.
Today, there are many reasons why people seek online cash loans. There are many things that cause financial challenges. And people are having a hard time meeting their financial obligations. People usually run out of money, which leads them to seek online cash loans. But, they get confused, since they do not have an idea on where and how to get these loans. People face challenges when they try to find the right loan company to apply for loans. And they end up wasting a lot of time, and money. This is where verified cash app can help. In this website, you will learn about cash loans and how to get these loans.
If you want to more information just contact now.
24 Hours Reply/Contact
E-mail: support@pvasells.com
Telegram: @PvaSells
Skype: PvaSells
WhatsApp: +1 (813) 534-0063
| kathyrose |
1,865,647 | Code Spirited MVP - A P2P Coding Bootcamp Organizer | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What We... | 0 | 2024-05-26T13:47:33 | https://dev.to/futureworker10x/code-spirited-mvp-a-p2p-coding-bootcamp-organizer-2l9d | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/aws)*
## What We Built
Code Spirited MVP is a platform designed to revolutionize the way coding bootcamps in 🇵🇭 are organized and accessed. It allows users to create and manage custom bootcamps, seek out mentors, and offer their services as freelance instructors at affordable rates. Additionally, it features a marketplace for browsing and discovering various bootcamp programs, making it a comprehensive solution for both learners and educators in the coding community.
## Demo and Code
- Deployed Application: [Code Spirited MVP](https://main.d3agjn4aq682p5.amplifyapp.com/)
- Source Code: [Code Spirited MVP](https://github.com/futureworker10x/code-spirited-mvp)
Bootcamp Listing
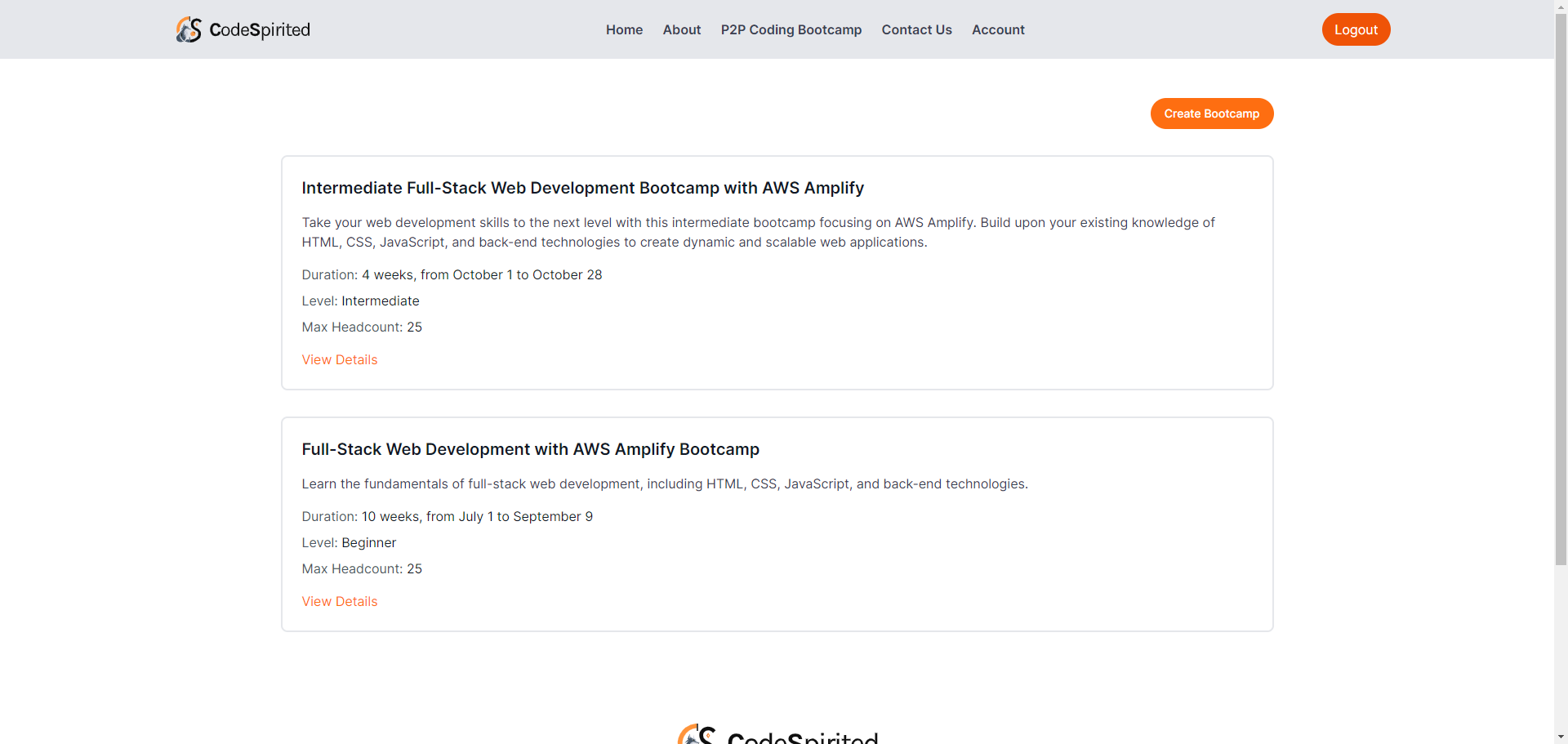
Bootcamp Information Page
## Integrations
To build Code Spirited MVP, We leveraged several key AWS services to ensure a seamless and powerful user experience:
- **Data Management**: Utilized AWS Amplify to create curriculum data efficiently.
- **Authentication**: Implemented secure user authentication and authorization using AWS Amplify Auth.
- **Serverless Functions**: ~~Create a trigger to create a profile record after post confirmation.~~
- **File Storage**: Integrated AWS S3 for storing and retrieving profile pic, providing robust and secure storage solutions.
- **Connected Components**: Used Storage Manager to upload the profile pic to the cloud.
**Connected Components and/or Feature Full**
We used auth functions from AWS Amplify and connected a custom UI following the same UX flow.
## Team Member
- @deyanxxx
| futureworker10x |
1,865,648 | 🛠️ Vue Tip: Creating Reusable Components with Slots | 🛠️ Vue Tip: Creating Reusable Components with Slots In Vue.js, creating reusable... | 0 | 2024-05-26T13:45:48 | https://dev.to/abanoubgeorge/vue-tip-creating-reusable-components-with-slots-1754 | vue, javascript, webdev, frontend |
## 🛠️ Vue Tip: Creating Reusable Components with Slots
In Vue.js, creating reusable components is essential for building maintainable and scalable applications. One powerful feature that Vue offers for enhancing reusability is **slots**. Slots allow you to compose components in a flexible and versatile manner, enabling you to pass content from a parent component to a child component.
### What Are Slots?
Slots in Vue.js are placeholders inside your components that can be filled with content provided by the parent component. They make it possible to create highly reusable and configurable components.
### Types of Slots
Vue provides three types of slots:
1. **Default Slot**
2. **Named Slots**
3. **Scoped Slots**
Let's dive into each type with examples.
### Default Slot
The default slot is the simplest form of slots. It allows you to pass content from the parent component to the child component.
#### Example:
**Parent Component:**
```vue
<template>
<div>
<Card>
<p>This is some content for the card.</p>
</Card>
</div>
</template>
<script setup>
import Card from './Card.vue';
</script>
```
**Child Component (`Card.vue`):**
```vue
<template>
<div class="card">
<slot></slot>
</div>
</template>
<script setup>
</script>
<style scoped>
.card {
border: 1px solid #ccc;
padding: 16px;
border-radius: 8px;
}
</style>
```
In this example, the content inside the `<Card>` component in the parent is passed to the `Card` component and rendered within the `<slot>` element.
### Named Slots
Named slots allow you to define multiple slots with different names, giving you more control over where the content is injected.
#### Example:
**Parent Component:**
```vue
<template>
<div>
<Card>
<template #header>
<h3>Card Header</h3>
</template>
<template #body>
<p>This is the body of the card.</p>
</template>
<template #footer>
<small>Card Footer</small>
</template>
</Card>
</div>
</template>
<script setup>
import Card from './Card.vue';
</script>
```
**Child Component (`Card.vue`):**
```vue
<template>
<div class="card">
<div class="header">
<slot name="header"></slot>
</div>
<div class="body">
<slot name="body"></slot>
</div>
<div class="footer">
<slot name="footer"></slot>
</div>
</div>
</template>
<script setup>
</script>
<style scoped>
.card {
border: 1px solid #ccc;
padding: 16px;
border-radius: 8px;
}
.header, .body, .footer {
margin-bottom: 8px;
}
</style>
```
With named slots, you can specify different sections of your component to be filled with content.
### Scoped Slots
Scoped slots allow you to pass data from the child component back to the parent component, enabling more dynamic and flexible components.
#### Example:
**Parent Component:**
```vue
<template>
<div>
<ItemList :items="items">
<template #default="slotProps">
<li>{{ slotProps.item.name }} - {{ slotProps.item.price }}</li>
</template>
</ItemList>
</div>
</template>
<script setup>
import { ref } from 'vue';
import ItemList from './ItemList.vue';
const items = ref([
{ name: 'Item 1', price: '$10' },
{ name: 'Item 2', price: '$20' },
]);
</script>
```
**Child Component (`ItemList.vue`):**
```vue
<template>
<ul>
<slot :item="item" v-for="item in items" :key="item.name"></slot>
</ul>
</template>
<script setup>
import { defineProps } from 'vue';
const props = defineProps({
items: {
type: Array,
required: true,
},
});
</script>
```
In this example, the child component (`ItemList`) passes each `item` object to the parent component, allowing the parent to render the items dynamically.
### Conclusion
Using slots in Vue.js is a powerful way to create flexible and reusable components. Whether you're using default slots, named slots, or scoped slots, this feature can significantly enhance the modularity and maintainability of your application.
### Read More
For more tips and tricks on Vue.js, check out my previous articles:
1. [Vue Once Watchers: Execute Callbacks Only Once](https://dev.to/abanoubgeorge/vue-tip-using-once-watchers-ol0)
2. [Simpler Two-Way Binding in Vue with defineModel](https://dev.to/abanoubgeorge/vue-tip-simpler-two-way-binding-with-definemodel-1gp)
Happy coding! 🚀
| abanoubgeorge |
1,865,502 | CRA to Rspack Migration: 5-10x Faster React Builds | What is CRA? CRA is a fantastic tool for getting started with React development. Easy to... | 0 | 2024-05-26T13:43:51 | https://dev.to/saurabhkhoshya/cra-to-rspack-migration-5-10x-faster-react-builds-5el5 | cra, rspack, react, javascript |
## What is [CRA](https://create-react-app.dev/)?
CRA is a fantastic tool for getting started with React development. Easy to use and well documented and provides a solid foundation for the project. Under the hood it uses webpack, Babel, ESLint, additional Tools and libraries. Developers can more focused on implementing business logic rather than configuring all these setups by own.
## Need for Rust based bundlers:
The performance of bundling and HRM is directly proportional to the codebase size, for large code-base apps bundling by webpack takes a lot of time.
As your application grows in complexity you might start to notice performance bottlenecks in the build process.
[Rspack](https://www.rspack.dev/) is a next-generation bundler designed for lightning-fast 5 to 10x faster builds. It built on the high-performance Rust programming language
## Migration Steps:
Create React App (CRA) itself has many built-in capabilities so manually setting up an equivalent configuration using `@rspack/cli` can be challenging.
For migration, we will use [rsbuild](https://rsbuild.dev/) which is an [Rspack](https://www.rspack.dev/)-based build tool for the web. The main goal of [Rsbuild](https://rsbuild.dev/) is to provide out-of-the-box build capabilities for [Rspack](https://www.rspack.dev/) users, allowing developers to start a web project with zero configuration.
We have set up a [demo react application generated by CRA](https://github.com/saurabhkhoshya/migrate-create-react-app-to-rspack), let migrate it in to [rspack](https://www.rspack.dev/)
> **Step 1**:
Remove CRA dependencies
```
npm remove react-scripts
```
> **Step 2**: install [Rsbuild](https://rsbuild.dev/[](url)) dependencies
```
npm add @rsbuild/core @rsbuild/plugin-react -D
```
> **Step 3**: Updating npm scripts in `package.json`
```
{
"scripts": {
"start": "react-scripts start",
"build": "react-scripts build",
"eject": "react-scripts eject"
}
}
```
> Replace with [Rsbuild's](https://rsbuild.dev/) CLI commands
```
{
"scripts": {
"start": "rsbuild dev",
"build": "rsbuild build",
"preview": "rsbuild preview"
}
}
```
> **Step 4**: Creating Configuration File
> Create a [Rsbuild](https://rsbuild.dev/) configuration file `rsbuild.config.ts` in the same directory as `package.json` and add the following content:
```
import { defineConfig } from '@rsbuild/core';
import { pluginReact } from '@rsbuild/plugin-react';
export default defineConfig({
plugins: [pluginReact()],
});
```
**Step 5**: Basic migration has done, you can start an application by running `npm run start` and for build run `npm run build`
Below is the build performance, _build time drops from around 11 seconds to 2 sec_.
Here is the [link for a git repo for the CRA to Rspack Migration](https://github.com/saurabhkhoshya/migrate-create-react-app-to-rspack).
For more detailed and advanced config check [Rsbuild](https://rsbuild.dev/guide/migration/cra) | saurabhkhoshya |
1,856,668 | Leveraging Amazon Titan Text Premier for Agent-Based AI in Software Testing | Introduction Amazon Titan Text Premier, now available through Amazon Bedrock, is a state-of-the-art... | 0 | 2024-05-26T13:43:51 | https://dev.to/aws-builders/leveraging-amazon-titan-text-premier-for-agent-based-ai-in-software-testing-581g | **Introduction**
Amazon Titan Text Premier, now available through Amazon Bedrock, is a state-of-the-art generative AI model that can revolutionize various fields, including software testing. This article provides a detailed guide on how to implement Retrieval-Augmented Generation (RAG) and agent-based generative AI applications to enhance software testing processes, optimizing outcomes with these advanced technologies.
**Understanding RAG and Agent-Based Generative AI**
**Retrieval-Augmented Generation (RAG)**
RAG combines retrieval-based techniques with generative models to create systems capable of fetching relevant information from extensive data sets and using this context to generate high-quality responses. This is particularly useful for tasks requiring detailed and contextually accurate outputs, such as creating comprehensive test cases or documentation.
**Agent-Based Generative AI**
Agent-based generative AI employs autonomous agents powered by generative models to perform tasks like test case creation, scenario simulation, and software interaction. These agents can learn and adapt from their interactions, making software testing more efficient and effective.
**How to Implement RAG and Agent-Based Generative AI in Software Testing**
**Step 1: Setting Up the Environment**
**_1.1 Accessing Amazon Bedrock_**
Log into your AWS account and go to the Amazon Bedrock service.
Ensure you have the necessary permissions to use the Amazon Titan Text Premier model.
_**1.2 Provisioning the Titan Text Premier Model**_
Follow the AWS documentation to set up the Titan Text Premier model in your AWS environment.
Configure the model to meet your specific software testing needs.
**Step 2: Creating a RAG System for Test Case Generation**
**_2.1 Preparing the Data_**
Collect a comprehensive set of documents, including user manuals, past test cases, and bug reports.
Use a retrieval system like Elasticsearch or Amazon Kendra to index this data for efficient searching.
**_2.2 Implementing the RAG Framework_**
Develop a retrieval component that queries the indexed data based on test requirements.
Integrate the Titan Text Premier model to generate test cases using the retrieved information.
**_2.3 Automating Test Case Generation_**
Create automation scripts to streamline the process of retrieving and generating test cases.
Use these generated test cases to enhance your existing test suite for broader and more thorough testing.
**Step 3: Deploying Agent-Based Generative AI for Dynamic Testing**
**_3.1 Defining Agent Roles and Scenarios_**
Identify the types of agents needed, such as UI testers, API testers, and performance testers.
Define scenarios for these agents to cover, including edge cases and common user interactions.
**_3.2 Developing Agent Logic_**
Use the Titan Text Premier model to enable agents to dynamically generate and execute test scripts.
Implement logic for agents to adapt and learn from test results, improving their effectiveness over time.
**_3.3 Integrating with CI/CD Pipelines_**
Connect the agent-based testing system to your Continuous Integration/Continuous Deployment (CI/CD) pipeline.
Ensure agents can autonomously start tests, analyze results, and report issues, supporting continuous testing.
**Benefits of Using Amazon Titan Text Premier in Software Testing**
**Comprehensive Test Coverage**
RAG and generative AI allow for the creation of a wide range of test scenarios, including those that might be overlooked by human testers, ensuring thorough test coverage.
**Enhanced Efficiency**
Automating test case generation and execution reduces manual effort and speeds up the testing process, enabling testers to focus on more complex issues.
**Continuous Improvement**
Generative AI models learn from test results, continuously improving the accuracy and relevance of generated test cases and scenarios.
**Scalability**
Agent-based systems can easily scale to handle large test suites and extensive applications, providing robust testing capabilities without significant additional resources.
**Conclusion**
Integrating Amazon Titan Text Premier into your software testing framework with RAG and agent-based generative AI greatly enhances testing efficiency and effectiveness. By automating and optimizing test processes, organizations can achieve higher-quality software products with faster release cycles. Amazon Bedrock's advanced infrastructure and capabilities make it feasible and highly beneficial to implement these innovative AI techniques.
Embrace the future of software testing with Amazon Titan Text Premier and transform your testing strategies for superior results.
**REFERENCE**
[Build generative AI applications](https://aws.amazon.com/blogs/machine-learning/build-generative-ai-applications-with-amazon-titan-text-premier-amazon-bedrock-and-aws-cdk/)
[AWS AI Service Cards](https://aws.amazon.com/machine-learning/responsible-machine-learning/titan-text-premier/)
| adelinemakokha | |
1,865,646 | Running Unit Tests with MongoDB in a Node.js Express Application using Jest | Hey everyone! It's been a while since I last posted, and I'm excited to share something new today.... | 26,386 | 2024-05-26T13:41:12 | https://www.linkedin.com/pulse/running-unit-tests-mongodb-nodejs-express-application-joel-ndoh-6kcbf/?trackingId=OblzlN2WSJqklS0nqhqPgg%3D%3D | testing, express, mongodb, mongoose | Hey everyone!
It's been a while since I last posted, and I'm excited to share something new today. Let's dive into running unit tests with MongoDB in a Node.js Express application. If you've ever struggled to set this up, this post is for you!
## Why This Post?
Online resources often cover automated test setups for Node.js with SQL databases like PostgreSQL. However, setting up unit tests for Node.js, Express, and MongoDB is less common and can be quite challenging. Issues with running MongoDB in-memory for each test and the speed of test execution are just a couple of the hurdles.
Having used MongoDB for over three years, I've developed a robust method for running tests with MongoDB. My goal here is to help you set up your Node.js Express app to run tests smoothly with MongoDB.
## Installing the Necessary Packages
Let's start by installing the essential packages:
1. `jest`: Jest is our test runner for Node.js Express applications.
2. `jest-watch-typeahead`: This package makes it easier to run specific tests. It allows us to select and search for test files and rerun failed tests quickly.
3. `supertest`: Supertest allows us to simulate API requests in our tests.
mongodb The MongoDB driver for JavaScript.
4. `uuid`: This package generates unique IDs for each database used in our tests.
## Setting Up the Jest Config File
Here's where we configure Jest to work with our setup. We include jest-watch-typeahead for flexibility and specify the test folder.
`jest.config.js`
```
module.exports = {
testRegex: './__tests__/.*\\.spec\\.js$',
watchPlugins: [
'jest-watch-typeahead/filename',
'jest-watch-typeahead/testname',
],
testPathIgnorePatterns: ['<rootDir>/node_modules/', '<rootDir>/config/'],
testEnvironment: 'node',
};
```
## Handling Database Setup and Cleanup
Understanding the problem: By default, running tests in SQL databases can be done in-memory, which is fast and isolated. However, MongoDB lacks built-in in-memory support for isolated tests. Packages like mongodb-memory-server exist but have limitations with isolation.
## Limitations of mongodb-memory-server
The mongodb-memory-server package allows us to spin up an in-memory instance of MongoDB for testing purposes. However, it comes with several limitations:
1. **Shared Instance**: mongodb-memory-server does not create separate instances for each test case. All tests share the same in-memory database, which can lead to data collisions and inconsistent test results.
2. **Performance Overhead**: Running an in-memory MongoDB instance can be resource-intensive. For large test suites, this can slow down the overall execution time and lead to performance bottlenecks.
3. **Limited Features**: Some features and configurations available in a full MongoDB instance may not be supported or fully functional in the in-memory server. This can lead to discrepancies between test and production environments.
4. **Scalability Issues**: As the number of tests grows, managing the in-memory database can become increasingly complex. Ensuring data isolation and cleanup becomes a significant challenge.
Given these limitations, we need a solution that ensures each test runs in an isolated environment, mimicking the behavior of in-memory databases used with SQL.
## Our Solution
We'll create a new database for each test and drop it afterward. This approach uses UUIDs to ensure uniqueness and avoids database conflicts.
Setup File: `setup.js`
```
const mongoose = require('mongoose');
const { connectToDatabase } = require('../connection/db-conn');
const { redis_client } = require('../connection/redis-conn');
const { v4: uuidv4 } = require('uuid');
const setup = () => {
beforeEach(async () => {
await connectToDatabase(`mongodb://127.0.0.1:27017/test_${uuidv4()}`);
});
afterEach(async () => {
await mongoose.connection.dropDatabase();
await mongoose.connection.close();
await redis_client.flushDb();
});
};
module.exports = { setup };
```
## Database Cleanup Script
To handle databases that may not be dropped properly after tests, we create a cleanup script. This script deletes all test databases whose names start with "test_".
Database Cleanup File: `testdb-cleanup.js`
```
const { MongoClient } = require('mongodb');
const deleteTestDatabases = async () => {
const url = 'mongodb://127.0.0.1:27017';
const client = new MongoClient(url);
try {
await client.connect();
const databaseNames = await client.db().admin().listDatabases();
const testDatabaseNames = databaseNames.databases.filter(db => db.name.startsWith('test_'));
for (const database of testDatabaseNames) {
await client.db(database.name).dropDatabase();
console.log(`Deleted database: ${database.name}`);
}
} catch (error) {
console.error('Error deleting test databases:', error);
} finally {
await client.close();
}
};
deleteTestDatabases();
Updating package.json to Include Database Cleanup
To ensure cleanup happens after tests run, we update package.json:
package.json
{
"scripts": {
"start": "node index.js",
"dev": "nodemon index.js",
"test": "jest --runInBand --watch ./__tests__ && npm run test:cleanup",
"test:cleanup": "node ./__tests__/testdb-cleanup.js"
}
}
```
## Running Tests
We'll place our tests in a folder called __tests__. Inside, we'll have apis for API tests and functions for unit tests.
## Writing Tests
Use describe to group similar tests.
Function Tests: `./__tests__/functions/Rizz.spec.js`
```
const RizzService = require('../../controllers/rizz-controller');
const Rizz = require('../../database/model/Rizz');
const { setup } = require('../setup');
setup();
describe('Getting the rizz', () => {
it('should return the rizzes added to the database', async () => {
await Rizz.create([{ text: 'First Rizz' }, { text: 'Second Rizz' }]);
const result = await RizzService.GetLatestRizz();
expect(result.total_docs).toBe(2);
});
});
describe('Liking a rizz', () => {
it('should increase the likes count of a rizz', async () => {
const rizz = await Rizz.create({ text: 'First Rizz' });
await RizzService.LikeRizz(rizz._id);
const updatedRizz = await Rizz.findById(rizz._id);
expect(updatedRizz.likes).toBe(1);
});
});
```
API Tests: `./__tests__/apis/Rizz.spec.js`
```
const request = require('supertest');
const { app } = require('../../app');
const { setup } = require('../setup');
setup();
describe('Rizz API', () => {
it('should return the latest rizzes', async () => {
await request(app)
.post('/api/v1/rizz')
.send({ text: 'First Rizz' });
const response = await request(app)
.get('/api/v1/rizz/latest?page=1&limit=100')
.send();
expect(response.body.data.total_docs).toBe(1);
});
it('should like a rizz', async () => {
const rizzResponse = await request(app)
.post('/api/v1/rizz')
.send({ text: 'First Rizz' });
const rizzId = rizzResponse.body.data._id;
const response = await request(app)
.post(`/api/v1/rizz/${rizzId}/like`)
.send();
expect(response.body.data.likes).toBe(1);
});
});
```
## Conclusion
Setting up unit tests with MongoDB in a Node.js Express app doesn't have to be daunting. By following these steps, you can ensure isolated, efficient tests. For the complete code, check out my GitHub repository:
GitHub - https://github.com/Ndohjapan/get-your-rizz
Happy testing! 🚀 #NodeJS #Express #MongoDB #AutomatedTesting #SoftwareDevelopment | ndohjapan |
1,865,622 | Next.js 15 RC Unveiled: A Close Look at the Framework's Latest Features | Overview Next.js, a react framework recently released its RC(release candidate) 15th... | 0 | 2024-05-26T13:39:40 | https://dev.to/devmirx/nextjs-15-rc-unveiled-a-close-look-at-the-frameworks-latest-features-4lc1 | javascript, react, webdev, nextjs | ## Overview
[Next.js](https://nextjs.org), a react framework recently released its RC(release candidate) 15th version; this release candidate version introduces new features that will change how you build high-quality and performance web applications.
These new features touch on:
- [React](https://react.dev/)
- [Hydration Errors](https://nextjsstarter.com/blog/nextjs-hydration-errors-causes-fixes-tips/)
- [Caching](https://nextjs.org/docs/app/building-your-application/caching)
- [Partial Prerendering(Experimental)](https://nextjs.org/blog/next-14#partial-prerendering-preview)
- [Next/After](https://nextjs.org/blog/next-15-rc#executing-code-after-a-response-with-nextafter-experimental)
- [Create-next-app](https://nextjs.org/docs/app/api-reference/create-next-app)
- [Bundling external packages (stable)](https://nextjs.org/blog/next-15-rc#optimizing-bundling-of-external-packages-stable)
As a developer, it is important to understand the key features, and how they can enhance your web development projects. In this article, I will be explaining what is new in Next15 so that you can start implementing them.
> Please note that these Nextjs features are still being tested rigorously and extensively before its final release.
## Prerequisite
A Working Knowledge of React
## Next.js
Next.js also known as next is a framework that is built on top of React and offers additional features like Server-Side Rendering (SSR), allowing you to create high-quality and performant web applications with the power of React components. It also offers powerful features like Built-in Optimizations, Dynamic HTML Streaming, React Server Components, and many more!
## A Sneak Peek at the Latest Features
### React:
Since Nextjs was built on top of the React canary channel, developers had to use and give feedback on the React APIs before the release of React 19 RC. The Release played a huge part in the Next Support for the React 19 Rc version, including new features for both the client and server-like actions.
### React Compiler:
With this newly built-in feature, developers can now save the time of manually memoizing values with the use of useCallback and useMemo to solve re-rendering issues.
Also with Nextjs support for the react compiler, developers can now focus on creating and maintaining code that is easier to maintain, and less error-prone.
To use the compiler, it is done by just installing `babel-plugin-react-compiler` with the command as shown below.
`npm install babel-plugin-react-compiler
`
Then, add the experimental.reactCompiler option in your next.config.js file:
``` javascript
const nextConfig = {
experimental: {
reactCompiler: true,
},
};
module.exports = nextConfig;
```
However, If you are looking to configure your compiler further to run in “opt-in” mode, add this option as shown below:
``` javascript
const nextConfig = {
experimental: {
reactCompiler: {
compilationMode: 'annotation',
},
},
};
module.exports = nextConfig;
```
With this, you now have your compiler set up and you don't have to worry about re-rendering issues because the compiler is handling that for you.
### Hydration error improvements
A Hydration error is a common error in next that stems from the mismatch of the server and client’s component states and generated markup. However, Next15 made massive improvements to the hydration errors, by providing the source code of the error and also ways to solve the error. isn’t that great?
It has now greatly improved from what we have above 👆to this 👇:
### Caching Updates
Before now, next js used to have opinionated default caching defaults. These defaults were implemented to provide a performant approach for the next application; However, this approach didn't suit the needs of projects like Partial Prerendering (PPR) and third-party libraries like fetch. However, after careful consideration and revaluation of the caching heuristics, the defaulting default is now uncached by default in the Next15 version.
> It is important to note the team is still making improvements to caching in Next in the coming months
### Fetch Requests are no longer cached by default
Nextjs allows us to configure how our server-side requests interact with the framework’s persistent HTTP cache. However, we are provided with options like the force-cache and no-store method, which determine the behavior of the resource fetched from the server that gets updated in the cache or not:
``` javascript
fetch('https://...', { cache: 'force-cache' | 'no-store' });
```
**Force-cache**: This option defaults in next14; it involves fetching the resource from the cache (if it exists) or a remote server and updating the cache.
**No-store**: When a request is made, the web fetch API retrieves the resource from a remote server based on that request and does not update the cache. This option now comes by default in Next 15.
### Get Route Handlers
In Next 15, get route handlers will no longer be cached as well. So, you only decide to opt into caching by using a static route config option such as `export dynamic = ‘force`
### Client Route Cache
Also, on the client route updates, it will also not be cached by default. Therefore, as you navigate back and forth in your app, the active page components will continue to get the latest data from the server and not from the cache. This is because the staleTimes flag that allows custom configuration of the router cache is now 0 for page segments as shown in the config below.
``` javascript
//next.config.js file
const nextConfig = {
experimental: {
staleTimes: {
dynamic: 0,
},
},
};
module.exports = nextConfig;
```
### Incremental adoption of Partial Prerendering
Partial prerendering is a way of storing some static portions of the pages of a website in a cache with dynamic holes streamed in so that when the user requests for it, it gets served to the user at a faster rate. The dynamic holes in question can be the latest news or personal information that needs to be updated, meaning they still have to run in the background while the page has loaded.
Next 14 introduced PPR which was a way of optimizing pages with static and dynamic rendering. The dynamic pages get wrapped in a Suspense boundary; therefore, allowing it to be streamed when a request is made. However, in the same HTTP Request, the static pages get served as a static HTML shell.
In Next 15, PPR can now be set for specific pages and layouts by simply adding an experimental_ppr route config option
```
import { Suspense } from "react"
import { StaticComponent, DynamicComponent } from "@/app/ui"
//
export const experimental_ppr = true
export default function Page() {
return {
<>
<StaticComponent />
<Suspense fallback={...}>
<DynamicComponent />
</Suspense>
</>
};
}
```
To enable the option used in the page above, you are expected to set the `experimental.ppr` config in your next.config.js file to 'incremental':
``` javascript
const nextConfig = {
experimental: {
ppr: 'incremental',
},
};
```
module.exports = nextConfig;
### Executing Code after a response with next/after
In Next 15, there is now a way to perform tasks after a response has been served to the user. These tasks can include logging, analytics, and other external system synchronization. Although, performing this type of task can be very challenging. Using `after()` as an experimental API solves the problem; allowing you to schedule work to be processed after streaming your response.
To enable it in your project, add this to your config file:
``` javascript
const nextConfig = {
experimental: {
after: true,
},
};
module.exports = nextConfig;
```
After that, import the function in your server component as shown below:
``` javascript
import { unstable_after as after } from 'next/server';
import { log } from '@/app/utils';
export default function Layout({ children }) {
// Secondary task
after(() => {
log();
});
// Primary task
return <>{children}</>;
}
```
### Create-next-app updates
Some major updates have also been made to the design of the create-next-app homepage. When you open create-next-app on your localhost, you get to see the new design as shown below:
#### Running create-next-app
Also while running create-next-app, there is a new prompt that now asks for the enabling of Turbopack for local development which defaults to no.
You can enable Turbopack using the –turbo flag
`npx create-next-app@rc --turbo`
### Optimizing bundling of external packages
In Next 14, packages are only bundled in the App router and not on the page router by default.
So to bundle external packages in the Page router, the transpilePackages config is used; however, you may need to specify each package.
If there was a need to opt out of a specific package in an App router, it was done using the serverExternalPackages config option.
In Next 15, a new option is now introduced which is called bundlePagesRouterDependencies; this option allows you to unify the configuration between the App and Pages router which matches with the default automatic bundling of the App router in Next14. You also decide to use the serverExternalPackages option if you want to opt-out specific packages.
``` javascript
const nextConfig = {
// Automatically bundle external packages in the Pages Router:
bundlePagesRouterDependencies: true,
// Opt specific packages out of bundling for both App and Pages Router:
serverExternalPackages: ['package-name'],
};
module.exports = nextConfig;
```
## Conclusion
With these new features coming, it will surely be a game changer in web development. So, now that you have a basic understanding of the new features, you can start implementing them in your projects. But note that the work on Next 15 is still in progress before its final release. If you are looking to learn more about the features, you can check their docs [here](https://nextjs.org/docs). Happy Coding!! | devmirx |
1,865,645 | Mask multiple lines text in GitHub Actions Workflow | This article is a translation of an article I originally wrote in Japanese, translated into English... | 0 | 2024-05-26T13:36:10 | https://dev.to/yuyatakeyama/mask-multiple-lines-text-in-github-actions-workflow-1a0 | githubactions | ---
title: Mask multiple lines text in GitHub Actions Workflow
published: true
description:
tags: [GitHubActions]
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-26 13:24 +0000
---
This article is a translation of an article I originally wrote in Japanese, translated into English using ChatGPT with some modifications:
* [GitHub Actions の Workflow 内で複数行の文字列をマスクする](https://blog.yuyat.jp/post/mask-multiple-lines-text-in-github-actions-workflow/)
---
## tl; dr
Although it might seem like a bit of bad practice, the content of `$multiple_lines_text` can be masked with the following one-liner:
```yaml
- run: |
echo "::add-mask::$(echo "$multiple_lines_text" | sed ':a;N;$!ba;s/%/%25/g' | sed ':a;N;$!ba;s/\r/%0D/g' | sed ':a;N;$!ba;s/\n/%0A/g')"
```
## `add-mask` Command in GitHub Actions
GitHub Actions has a feature called workflow commands.
* [Workflow commands for GitHub Actions](https://docs.github.com/en/actions/using-workflows/workflow-commands-for-github-actions)
The `add-mask` command is used to mask specific strings in subsequent outputs. For example, by executing the following command, the string "Hello, World!" will be masked as "***" in subsequent outputs.
```
echo "::add-mask::Hello, World!"
```
Values retrieved from secrets can be masked this way, but using the `add-mask` command allows dynamically specifying strings to be masked.
Additionally, this command is implemented in the NPM package [@actions/core](https://github.com/actions/toolkit/tree/main/packages/core). By using `core.setSecret('Hello, World!');` in JavaScript code, the same masking can be achieved.
The `setSecret` function essentially builds and outputs the `::add-mask::~~~` string to the standard output, so the mechanism is identical.
## Issues When Masking Multiple Lines
If you try to mask a string like `Foo\nBar\nBaz` in a shell script without any considerations, it would look like this:
```
::add-mask::Foo
Bar
Baz
```
The command breaks due to the line breaks, and only "Foo" gets masked. This can lead to unwanted side effects like the string "Foo Fighters" being masked as "*** Fighters".
The workflow commands documentation briefly mentions handling multiple strings:
* [Multiline strings](https://docs.github.com/en/actions/using-workflows/workflow-commands-for-github-actions#multiline-strings)
However, these techniques are meant for inputting multiline environment variables or output values into `$GITHUB_ENV` or `$GITHUB_OUTPUT`, and based on my tests, they don’t work with workflow commands.
## Examining the `core.setSecret` Code
By examining the `core.setSecret` function in @actions/core, it appears that the values to be masked are escaped using a function called `escapeData`.
https://github.com/actions/toolkit/blob/d1df13e178816d69d96bdc5c753b36a66ad03728/packages/core/src/command.ts#L80-L85
```ts
function escapeData(s: any): string {
return toCommandValue(s)
.replace(/%/g, '%25')
.replace(/\r/g, '%0D')
.replace(/\n/g, '%0A')
}
```
The `toCommandValue` function simply returns the string as-is if it’s already a string, so it can be ignored.
https://github.com/actions/toolkit/blob/d1df13e178816d69d96bdc5c753b36a66ad03728/packages/core/src/utils.ts#L11-L18
Then, the `replace` method replaces `%` with `%25`, `\r` with `%0D`, and `\n` with `%0A`.
By executing a command like this, `Foo\nBar\nBaz` gets masked correctly:
```sh
echo "::add-mask::Foo%0ABar%0ABaz"
```
After asking ChatGPT about how to perform these replacements in a shell script, I arrived at the following conclusion:
```sh
echo "::add-mask::$(echo "$multiple_lines_text" | sed ':a;N;$!ba;s/%/%25/g' | sed ':a;N;$!ba;s/\r/%0D/g' | sed ':a;N;$!ba;s/\n/%0A/g')"
```
While the `s/%/%25/g` part is clear, the preceding `:a;N;$!ba;` part is obscure. I understand from ChatGPT that it’s necessary for handling line breaks, but I can’t explain it in detail here.
## When Is This Necessary?
This article is written for those wondering how to mask multiline strings, regardless of the purpose. For me, there was a specific use case: safely storing and using a GitHub App's Private Key.
To achieve this, I believe the following steps are necessary:
1. Encode the Private Key in Base64 and store it in AWS Secrets Manager.
2. Use OIDC for authentication with AWS.
3. Retrieve the secret in the workflow, decode it from Base64 to get the Private Key.
Assuming AWS usage, the steps can be adapted similarly for Google Cloud using Secret Manager, etc. (not verified).
This can be implemented in a workflow as follows:
```yaml
steps:
- name: Configure AWS credentials
id: aws-credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: arn:aws:iam::012345678901:role/role-name
aws-region: ap-northeast-1
- name: Retrieve secret from AWS Secrets Manager
id: aws-secrets
run: |
secrets=$(aws secretsmanager get-secret-value --secret-id secret-name --query SecretString --output text)
gh_app_private_key="$(echo "$secrets" | jq .GH_APP_PRIVATE_KEY_BASE64 -r | base64 -d)"
echo "::add-mask::$(echo "$gh_app_private_key" | sed ':a;N;$!ba;s/%/%25/g' | sed ':a;N;$!ba;s/\r/%0D/g' | sed ':a;N;$!ba;s/\n/%0A/g')"
echo "gh-app-private-key<<__EOF__"$'
'"$gh_app_private_key"$'
'__EOF__ >> "$GITHUB_OUTPUT"
- uses: actions/create-github-app-token@v1
id: app-token
with:
app-id: ${{ vars.GH_APP_ID }}
private-key: ${{ steps.aws-secrets.outputs.gh-app-private-key }}
```
Further details are explained in the Q&A format below.
### Why Not Store It in Organization or Repository Secrets?
Because it is considered unsafe.
With some specific conditions, the secret's value can be exposed if someone can create a Pull Request and place a GitHub Actions workflow file in the repository.
For more details, refer to this presentation from a recent event. (company blog)
* [AWS知見共有会でTerraformのCI/CDパイプラインのセキュリティ等について発表してきました + GitHub新機能Push rulesについて](https://tech.layerx.co.jp/entry/scalable-and-secure-infrastructure-as-code-pipeline-for-a-compound-startup) (in Japanese)
### Why Do You Need to Mask the Private Key?
Without masking, the Private Key passed as input to `actions/create-github-app-token@v1` can be viewed in the GitHub Actions UI.
### Why Encode the Private Key in Base64 for AWS Secrets Manager?
It’s not mandatory but simplifies storing it without line breaks.
While AWS Secrets Manager can store secrets with line breaks, the key/value mode in the Management Console does not handle line breaks well. Plaintext mode allows entering line breaks, but it’s cumbersome. Therefore, encoding it in Base64 for storage without line breaks is more convenient.
| yuyatakeyama |
1,865,644 | UPCOMING EVENTS in TONWave ecosystem : | 25th of June - Seed round of attracting investments 5 of July - 5 august establishing "SAFE... | 0 | 2024-05-26T13:30:00 | https://dev.to/tonwave/upcoming-events-in-tonwave-ecosystem--490k | 25th of June - Seed round of attracting investments
5 of July - 5 august establishing "SAFE TRANSACTIONS" system
5th of September - 1st of November marketing development
5th of January - Series A funding round
Stay Connected with us via dev.to
Your TONWave developers | tonwave | |
1,865,643 | Backend cheatsheet suggestions (Upcoming) | To the dev.to community, The title appears to be quite broad, and that is intentional! I was at my... | 0 | 2024-05-26T13:26:32 | https://dev.to/kervyntjw/backend-cheatsheet-suggestions-upcoming-4g5n | webdev, backend, backenddevelopment, tutorial | To the dev.to community,
The title appears to be quite broad, and that is intentional! I was at my desk working away and brainstorming ideas expanding my own, as well as the community's knowledge development, when I thought about the idea of a cheatsheet, something I believe we are **_quite familiar_** with from school.
To create these, I would like to ask the awesome community for help! To anyone who sees this post, in particular to my fellow backend developers (love my frontend pals as well), I need a favour from you! Please leave in the comments on some of your answers to the questions below, they'll seriously aid me in helping to create something useful for the community~
1. What are some struggles you face in your daily lives as programmers?
2. What are some things that you find yourself constantly having to search/Google up, that you wish you had a quick and reliable reference for?
3. Aside from a cheatsheet, what other mediums/bits of information do you feel will help yourself, or a programmer of a similar/junior level to you?
I appreciate all the feedback from the community, whether you're a frontend/backend developer! If you have any insights/inputs at all, please drop a comment and let's get this conversation going! | kervyntjw |
1,865,642 | Understanding the Differences Between SQL and MySQL | Understanding the Differences Between SQL and MySQL Are you confused about the differences between... | 0 | 2024-05-26T13:20:35 | https://dev.to/shubhadip_bhowmik/understanding-the-differences-between-sql-and-mysql-1po0 | sql, database, mysql | **Understanding the Differences Between SQL and MySQL**
Are you confused about the differences between SQL and MySQL? This is a common question among those new to the world of databases. In this blog post, we'll break down the key differences in a simple and easy-to-understand format. Whether you're a beginner or looking to refresh your knowledge, this guide is for you.
[Watch our detailed video on this topic here!](https://youtu.be/tL9CM5uz6bk)
### What is SQL?
**SQL** stands for **Structured Query Language**. It is a standard language used to manage and manipulate relational databases. SQL allows you to perform tasks such as querying data, inserting records, updating records, and deleting records in a database. It is the foundation upon which various database management systems (DBMS) operate.
{% youtube tL9CM5uz6bk %}
**Key Points:**
- SQL is a language.
- Used for querying and managing databases.
- Standardized by ISO.
**Example SQL Query:**
```sql
SELECT * FROM employees WHERE department = 'Sales';
```
This query retrieves all records from the 'employees' table where the department is 'Sales'.
### What is MySQL?
**MySQL** is a **Relational Database Management System (RDBMS)** that uses SQL as its query language. Developed by Oracle Corporation, MySQL is open-source software that allows users to store, retrieve, and manage data efficiently. It is widely used in web applications and is known for its reliability and performance.
**Key Points:**
- MySQL is an RDBMS.
- Uses SQL for database operations.
- Popular for web applications like WordPress, Facebook, and Twitter.
**Example MySQL Command:**
```shell
mysqldump -u root -p database_name > backup.sql
```
This command creates a backup of the specified database.
### Key Differences Between SQL and MySQL
**1. Definition:**
- **SQL:** Structured Query Language used for managing databases.
- **MySQL:** Relational Database Management System that uses SQL.
**2. Nature:**
- **SQL:** A universal language for database queries.
- **MySQL:** Software for managing databases.
**3. Functionality:**
- **SQL:** Provides commands for data manipulation.
- **MySQL:** Includes tools for database management.
**4. Usage:**
- **SQL:** Used with various RDBMS like MySQL, PostgreSQL, Oracle.
- **MySQL:** A specific RDBMS using SQL.
**5. Compatibility:**
- **SQL:** Standardized, works with multiple database systems.
- **MySQL:** Has specific features and tools unique to it.
### Practical Examples
To give you a clearer understanding, here are some practical examples:
**SQL Query Example:**
```sql
SELECT * FROM employees WHERE department = 'Sales';
```
This query can run on any SQL-compatible database system, such as MySQL, PostgreSQL, or SQL Server.
**MySQL Command Example:**
```shell
mysqldump -u root -p database_name > backup.sql
```
This command is specific to MySQL and is used to back up a database.
### Conclusion
Understanding the differences between SQL and MySQL is essential for anyone working with databases. SQL is the language used to interact with databases, while MySQL is a database management system that uses SQL. By grasping these concepts, you can better navigate the world of database management and make informed decisions about the tools you use.
If you found this blog helpful, be sure to check out our detailed video on the topic [here](https://youtu.be/tL9CM5uz6bk). And don't forget to like, share, and subscribe to our channel for more tech tutorials!
---
Thank you for reading and happy coding! 🚀

Feel free to leave comments and feedback on the video. Your input helps me improve and provide better content for future learners.
Happy learning, and I look forward to seeing you master SQL! | shubhadip_bhowmik |
1,865,641 | Slim Php Framework: How to create Route Wrapper Class in Slim? | Hello everyone!✌ Now we are going to discuss about creating Route Wrapper Class in Slim Php... | 0 | 2024-05-26T13:20:29 | https://dev.to/asif_sheikh_d7d74ce8b9c9d/slim-php-framework-how-to-create-route-wrapper-class-in-slim-4doh | php, framework, webdevelopement, slim | Hello everyone!✌
Now we are going to discuss about creating Route Wrapper Class in Slim Php Framework.
We have to follow few steps to creating route class and I hope you to enjoy it. It makes life easier for slim developer.
**STEP 1: Creating Route Wrapper Class**
Creating a new php file in App\Core\Route.php in your slim project directory. I have named Route.php.
```
<?php
namespace App;
use Slim\App;
class Router
{
protected $app;
public function __construct(App $app)
{
$this->app = $app;
}
public function get($pattern, $callable)
{
$this->app->get($pattern, $callable);
}
public function post($pattern, $callable)
{
$this->app->post($pattern, $callable);
}
public function put($pattern, $callable)
{
$this->app->put($pattern, $callable);
}
public function delete($pattern, $callable)
{
$this->app->delete($pattern, $callable);
}
public function patch($pattern, $callable)
{
$this->app->patch($pattern, $callable);
}
public function group($pattern, $callable)
{
$this->app->group($pattern, $callable);
}
public function middleware($middleware)
{
$this->app->add($middleware);
}
public function controller($pattern, $controller)
{
$this->app->any($pattern . '[/{action}]', function ($request, $response, $args) use ($controller) {
$action = $args['action'] ?? 'index';
$controllerInstance = new $controller();
return $controllerInstance->$action($request, $response, $args);
});
}
public function resource($pattern, $controller)
{
$this->app->get($pattern, $controller . ':index');
$this->app->get($pattern . '/create', $controller . ':create');
$this->app->post($pattern, $controller . ':store');
$this->app->get($pattern . '/{id}', $controller . ':show');
$this->app->get($pattern . '/{id}/edit', $controller . ':edit');
$this->app->put($pattern . '/{id}', $controller . ':update');
$this->app->delete($pattern . '/{id}', $controller . ':destroy');
}
}
```
**STEP 2: Use Above Route Class in index.php**
```
<?php
use Slim\Factory\AppFactory;
use App\Router;
require __DIR__ . '/vendor/autoload.php';
$app = AppFactory::create();
$router = new Router($app);
// Define your routes
$router->get('/home', function ($request, $response, $args) {
$response->getBody()->write('Hello, Home!');
return $response;
});
$router->post('/submit', function ($request, $response, $args) {
// handle post request
return $response;
});
// Grouped routes
$router->group('/api', function () use ($router) {
$router->get('/users', function ($request, $response, $args) {
$response->getBody()->write('List of users');
return $response;
});
$router->post('/users', function ($request, $response, $args) {
// handle post request
return $response;
});
});
// Controller route
$router->controller('/product', \App\Controllers\ProductController::class);
// Resource route
$router->resource('/articles', \App\Controllers\ArticleController::class);
$app->run();
```
Thanks for giving your time and considerations!✨
| asif_sheikh_d7d74ce8b9c9d |
1,865,630 | Week 12! | Week 12! For this week I am still doing my daily tasks and aside from that I had a discussion with my... | 0 | 2024-05-26T13:20:01 | https://dev.to/kmirafuentes/week-12-40om | Week 12! For this week I am still doing my daily tasks and aside from that I had a discussion with my new trainer, still from our department and she taught me two tasks in which one of the new discussed to me was added to my daily tasks. | kmirafuentes | |
1,865,629 | Buy Google Ads Account | Are you afraid to buy our Verified Google Ads Account service will be Dropped? Don’t Worry, We are... | 0 | 2024-05-26T13:19:35 | https://dev.to/kathyrose/buy-google-ads-account-2f31 | webdev, javascript, beginners, tutorial | Are you afraid to buy our Verified Google Ads Account service will be Dropped? Don’t Worry, We are not like the rest of the fake PVA Accounts providers. We provide 100% Non-Drop PVA Accounts, Permanent PVA Accounts, and Legit PVA Accounts Service. We’re working with the largest team and we’re instant start work after your placing order. So, Buy our Service and enjoy it.
Our Service Always Trusted Customers sufficient Guarantee
✔ 100% Customers Satisfaction Guaranteed.
✔ 100% Non-Drop Verified Google Ads Accounts
✔ Active Verified Google Ads Accounts
✔ Very Cheap Price.
✔ High-Quality Service.
✔ 100% Money-Back Guarantee.
✔ 24/7 Ready to Customer Support.
✔ Extra Bonuses for every service.
✔ If you want to buy this product, you must Advance Payment.
If you want to more information just contact now.
24 Hours Reply/Contact
E-mail: support@pvasells.com
Telegram: @PvaSells
Skype: PvaSells
WhatsApp: +1 (813) 534-0063
What Is Verified Google Ads Account?
Google Ads Accounts are Google Accounts that you use to manage your Google Ads campaigns. Google Ads campaigns are basically ads that you place on Google’s search engine and other websites. You can use Google Ads to advertise your business, products, services, and more. Google Ads is different from other online advertising platforms, like Facebook Ads. Since you pay Google every time you get someone to click one of your ads. Unlike Facebook Ads, Google Ads accounts are not to be confused with Google accounts.
Verified Google Ads accounts are bad for a lot of reasons. For some, it’s not worth the extra cost because it costs $100 and essentially does nothing. Google doesn’t verify any accounts, and they don’t verify most ads. Other reasons include that it’s often not worth the extra time/effort and might not have a big impact. There’s an argument to be made that Google isn’t giving advertisers enough reason to bother with a verified account. And without that incentive the ROI isn’t there. So which is it? Is Verified Google Ads Accounts worth it, or not worth the time or money?
Google recently introduced a new ad format called “Verified Google Ads Accounts.” (VGAD) VGAD is a new way for Google to serve ads to advertisers that meet Google’s quality guidelines. Advertisers that exceed Google’s least quality score threshold are required to have a verified Google Ads Account. You should have an Google Ads account if you have Google Chrome and want to use Google’s advertising platform. Setting up an Google Ads account is easy, and once you’ve done it, you can instantly start creating ads for your site.
Get Verified Google Ads Accounts
Get Google Ads accounts is a relatively easy way to earn extra cash. It’s just a matter of finding someone with an account for sale and Get them. We’ve done some of the homework for you so you can take the plunge and net yourself some extra cash. First, consider your end goal. Are you just trying to make some extra money on the side? Or are you looking to build a business around selling Google Ads?
Over the past years, Google has introduced several new features. And have done a lot of changes which is impacting the pay per click industry. Google announced new bidding strategy in 2017 and some bidding strategies still are on testing phase. Hence, marketers must Get Google Ads Accounts which are verified. And approved by Google as this can help in achieving long-term stability and boost conversions.
If you’re running your own blog or website, you may want to consider Get Google Ads accounts. Google advertising can be expensive, so the more you spend, the more you’ll earn, and the more money you will save. You can look into this by setting up a Google Advertising account. But if you don’t have the money yet, you can Get Google Ads accounts instead. Just launched: our brand new, world-class website that will assist you in Get proven Google Ads accounts.
How to verify a Google Ads accounts?
Google Ads is Google’s advertising platform. And it’s a great tool for small businesses that are looking to advertise online. But the big disadvantage to Google Ads is that it’s easy to use for advertisers, but nearly impossible to verify for Google. So, how can you make sure that the account you’ve created is legitimate? There are a few things you can do, and we’ll cover them all in this post.
Google recently launched new features for Ads Manager. Making it easier to manage many Google Ads accounts all at once. The new accounts feature lets you view performance metrics, budgets. And ad extensions for all your accounts from one dashboard. The accounts feature will first roll out to users with the “Ads Manager” or “AdWords” role. But Google plans to add more account roles over time. To take full advantage of the accounts feature, you’ll need to enable it in your Ads Manager.
How can I Get real Verified Google Ads Account?
Get real Verified Google Ads Account is the best solution if you are looking to reach targeted customers. To make your campaign successful, you need to find a reliable provider of PPC services. Here at PPC Management Pros, you have access to a complete range of PPC services. From creating a solid PPC campaign strategy to creating your account and targeting relevant keywords.
Google Ads (formerly Google AdWords) is Google’s advertising system. And it’s Google’s most valuable business. To gain a dominance over any other product, Google needs to advertise it. And, it’s advertising system, Google Ads, is Google’s most important tool. Google Ads allows you to advertise on Google, your search results, and in Google’s network of partners.
Can you actually Get fully verified Google Ads accounts?
Advertising and marketing are big money businesses. Get a few ads on a popular site, and you could throw serious money at the problem. But, for those not familiar, advertising requires a lot of creative thinking. And let’s face it: creativity is not a skill everyone thrives under. Enter the growing trend of Get verified ads. Get a few ads, and viola! You have money to make.
When creating ads for Google, content is always king. But, to compete for the top spots, paid advertising is usually required. And to get the most for your money, advertisers have to spend a lot.
Why do you must like our Verified Google Ads Accounts?
Regardless of whether you’re running your own AdWords account. Or you’re a smaller business trying to balance the demands of your other marketing initiatives. It’s your Google Ads account that’s ultimately responsible for your return on investment (ROI). A successful campaign depends on having high-quality ads. And keywords that will not only convert clicks into leads, but lead to quality sales. At PPC Hero, we believe the best accounts are verified and that positive change starts with you.
Below has discussed what our key features to provide our services are.
· High-quality: The quality of our offering Accounts don’t need to compare with other services.
· A quick start: Our expert team worker starts their task as soon as possible after replacing your order. And complete payment And we provide our customer’s order very faster.
· Faster Delivery: We deliver our Accounts orders and deliver their order super faster.
· Spread them across other Accounts: You can stock up on Accounts by picking the biggest package. And then tell us to spread them across all other Accounts.
· Accounts from the real profile: we offer each Accounts from real and genuine profiles. Which will be permanent and help to spread your profile.
· Risk-free services: The services that you will Get from us are must risk-free and permanent. Which won’t be decreased.
· Secure Payment system: You can place your order by any secure payment system. We offer different types of trusted payment systems in the world.
· 24-hours live chat: Our customer support team is always ready to help 24/7. So, you can get any support without any issues when you need it.
Why choosing Us for Get Google Ads accounts?
Do you think our Verified Google Ads Accounts can Dropped? No, it won’t because we provide 100% permanent Verified Google Ads Accounts as we have a large group to work together. But why we are best to let’s know:
· Customer support 24/7
· We offer all time weekly and monthly package.
· We use an active and phone verified accounts.
· For make more trustable, we give rating as well
· Trustworthy seller with a ton of happy customers
· We provide both male and female profile
· We offer Verified Google Ads Accounts with custom names with country
Why Should You Get Verified Google Ads Accounts For Your Business?
Get Google Ads accounts is the fasted way to grow you business. Because Google Ads accounts are verified. You can take advantage of mobile impressions, clicks, and conversions. Get verified Google Ads accounts is also a good way to confirm your ROI. If you’ve invested in a Google Ads account but aren’t seeing the results you expected. It may be because of a bad Google Ads account. Get verified Google Ads accounts allows you to avoid these mistakes.
As a smart business owner, you know that advertising can make or break your business. But online advertising means competing with millions of other businesses all trying to grab the attention of customers. You can’t just throw money at advertising and hope it will attract customers. And you certainly can’t afford to waste the money you spent on advertising. This is where verified Google Ads accounts come in.
Get verified Google Ads accounts is a great way to get your business noticed and make money. There are a few reasons why Get verified Google ads accounts from sellers is a good idea. Running a successful Google Ads campaign is all about maximizing your ad spend.
FAQs
Is Get Verified Google Ads Account safe and risk-free?
Of course, it is legal and risk-free. Yes, we also don’t ask for any password or log in, which can violate Google Ads services. We have millions of satisfied customers worldwide. That like our Verified Google Ads Account service and even keep ordering a lot.
Can I test your service before Verified Google Ads Account?
Absolutely, get some Accounts for free with the Verified Google Ads Account post link and our services for which you are going to place your order.
Can I lose Verified Google Ads Account?
No, you never lose our provided Verified Google Ads Account. Because we don’t provide any fake or proxy Accounts to our customers.
When will my placed order start?
We start setting up our customer’s orders after placing the order. You have to expect the service to begin within a single day if the order is more than 1 Accounts. For bigger orders, you need to wait for 48-hours.
If I order many Accounts, will they deliver at the same time?
Yes, if an order for many Accounts at the same time, we also can deliver simultaneously.
Can I split a bigger package for Verified Google Ads Account?
Of course, you can do it. But you need to submit your Verified Google Ads Account link on the required field upon the chosen package. Then add all the post links into our information section on the checkout page.
If you want to more information just contact now.
24 Hours Reply/Contact
E-mail: support@pvasells.com
Telegram: @PvaSells
Skype: PvaSells
WhatsApp: +1 (813) 534-0063 | kathyrose |
1,865,627 | Week 11! | 2 more weeks until we're done with with our internship! For this week, my task is still the same but... | 0 | 2024-05-26T13:17:06 | https://dev.to/kmirafuentes/week-11-5fgm | 2 more weeks until we're done with with our internship! For this week, my task is still the same but for my remaining time in which I don't have to do any specific tasks instead of watching my recorded tutorial videos, I was tasked to observed my trainers task. | kmirafuentes | |
1,865,626 | TONWAVE is a cutting-edge cryptocurrency built on The Open Network (TON) blockchain | Here are the key features and benefits of TONWAVE: High Scalability and Speed: TONWAVE benefits... | 0 | 2024-05-26T13:15:46 | https://dev.to/tonwave/tonwave-is-a-cutting-edge-cryptocurrency-built-on-the-open-network-ton-blockchain-5fm4 | Here are the key features and benefits of TONWAVE:
1. High Scalability and Speed:
- TONWAVE benefits from TON's unique sharding technology, which allows for efficient scaling and high-speed transactions, making it suitable for a wide range of applications from micropayments to large-scale financial operations.
2. Security and Reliability:
- Built on the TON blockchain, known for its advanced security protocols and decentralized nature, TONWAVE offers users a high level of security and reliability. The robust consensus mechanism ensures the integrity and immutability of transactions.
3. Eco-Friendly Consensus:
- TONWAVE utilizes a proof-of-stake consensus mechanism, which is energy-efficient compared to traditional proof-of-work systems. This makes it an eco-friendly choice in the cryptocurrency market.
4. Interoperability:
- The TON blockchain’s interoperability features enable TONWAVE to interact seamlessly with other blockchain networks, facilitating cross-chain transactions and enhancing its usability in diverse blockchain ecosystems.
5. User-Friendly Features:
- TONWAVE is designed with user experience in mind. It supports user-friendly wallets and integrates easily with various dApps (decentralized applications), making it accessible to both novice and experienced users.
6. Decentralized Governance:
- Holders of TONWAVE tokens participate in a decentralized governance model, giving them a voice in key decisions about the network’s development and future upgrades. This fosters a community-driven approach to growth and innovation.
7. Versatile Use Cases:
- TONWAVE can be used in various applications, including payments, remittances, DeFi (decentralized finance) services, and more. Its flexibility and robust infrastructure make it an ideal candidate for a multitude of digital finance solutions.
Summary
TONWAVE represents the next wave of cryptocurrency innovation, combining high performance, security, and environmental sustainability. With its foundation on the TON blockchain, TONWAVE is poised to become a significant player in the digital asset space, offering versatile and reliable solutions for users worldwide. | tonwave | |
1,865,534 | Database Migrations : Liquibase for Spring Boot Projects | There are 2 ways with which Liquibase can be used in the context of a Spring Boot Project to perform... | 27,623 | 2024-05-26T13:01:21 | https://dev.to/aharmaz/liquibase-for-spring-boot-projects-5hf6 | java, springboot, liquibase, database | There are 2 ways with which Liquibase can be used in the context of a Spring Boot Project to perform database migrations, the first one is during the development phase where each developer will want add his own modifications and the modifications added by his collegues to his local database, the second one is during the deployment phase where we will want to gather all the modifications and run them against a database used by a released version of the project
In this post we will cover how Liquibase can be integrated with a Spring Boot project to help use perfrom database migration both phases, and we will be using examples from the repository that you can check at : [Github Repository](https://github.com/Aharmaz/liquibase-demo)
**Fundamental Concepts of Liquibase**
*Changeset and Migration File* :
A changeset is the smallest coutable unit of change that Liquibase can perfrom and register on a target database and it can contain one or more operations.
A migration file is a file responsible for hosting one or more changesets.
In Liquibase executing a changeset does not necessarly mean executing the migration file that contains that changeset, because it may contain other changesets that were not executed
*Changelog* :
A changelog is a file containing a list of ordered changesets, or references to migration files containing changesets
*DATABASECHANGELOG Table* :
This is the table Liquibase creates on the target database and uses to keep track of what changesets have already been applied
A changeset won't be executed a second time if it has already been executed and registered in the DATABASECHANGELOG table
Each change set is identified in Liquibase by 3 properties, id, author, and filepath. When Liquibase executes a changeset it calculates a checksum for its content and stores it inside the DATABASECHANGELOG table with the 3 properties in order to make sure that a changeset has not been changed over time
If Liquibase notices that a changeset has been modified after it has been applied using the checksum calculations it will throw an error or a warning
**Common Configuration**
The first thing to do is to add the migration scripts containing the changesets intended to be applied on the target database :
- V1__creating_schema.sql
- V2__add_category_column_to_books_table.sql
- V3__adding_authors_table.sql
Then we need to add a changelog file referencing the migration scripts following a specific order
```
<?xml version="1.0" encoding="UTF-8" ?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.8.xsd">
<include file="db/migrations/V1__creating_schema.sql" />
<include file="db/migrations/V2__add_category_column_to_books_table.sql" />
<include file="db/migrations/V3__adding_authors_table.sql" />
</databaseChangeLog>
```
**Configuring Liquibase to run migrations on application startup**
Most of the time this behavior of running migrations on the application startup is used locally (when the spring boot application is executed with the local profile), this is why we should add information about the database and the location of the changelog file in the local properties file (application-local.properties in the example)
```
spring:
datasource:
url: jdbc:postgresql://localhost:5432/demo_liquibase
username: postgres
password: changemeinproduction
driver-class-name: org.postgresql.Driver
jpa:
hibernate:
ddl-auto: none
liquibase:
change-log: classpath:/db/migrations/changelog.xml
```
The next step is to add the dependency of liquibase in the pom.xml file of the project (build.gradle file if you are using Gradle)
```
<dependency>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-core</artifactId>
</dependency>
```
When starting the application, Spring Boot will notice the presence of the liquibase dependency on the runtime classpath and will trigger the autoconfiguration classes related to liquibase, and an automatic migration process is going to be started against the configured database, here is an example of logging that we should get when starting the app :
```
2024-05-26T13:04:49.188+01:00 INFO 16644 --- [ main] liquibase.database : Set default schema name to public
2024-05-26T13:04:49.372+01:00 INFO 16644 --- [ main] liquibase.changelog : Creating database history table with name: public.databasechangelog
2024-05-26T13:04:49.418+01:00 INFO 16644 --- [ main] liquibase.changelog : Reading from public.databasechangelog
2024-05-26T13:04:49.476+01:00 INFO 16644 --- [ main] liquibase.lockservice : Successfully acquired change log lock
2024-05-26T13:04:49.478+01:00 INFO 16644 --- [ main] liquibase.command : Using deploymentId: 6725089478
2024-05-26T13:04:49.480+01:00 INFO 16644 --- [ main] liquibase.changelog : Reading from public.databasechangelog
Running Changeset: db/migrations/V1__creating_schema.sql::1::aymane
2024-05-26T13:04:49.507+01:00 INFO 16644 --- [ main] liquibase.changelog : Custom SQL executed
2024-05-26T13:04:49.510+01:00 INFO 16644 --- [ main] liquibase.changelog : ChangeSet db/migrations/V1__creating_schema.sql::1::aymane ran successfully in 18ms
Running Changeset: db/migrations/V2__add_category_column_to_books_table.sql::1::aymane
2024-05-26T13:04:49.523+01:00 INFO 16644 --- [ main] liquibase.changelog : Custom SQL executed
2024-05-26T13:04:49.525+01:00 INFO 16644 --- [ main] liquibase.changelog : ChangeSet db/migrations/V2__add_category_column_to_books_table.sql::1::aymane ran successfully in 5ms
Running Changeset: db/migrations/V3__adding_authors_table.sql::1::aymane
2024-05-26T13:04:49.540+01:00 INFO 16644 --- [ main] liquibase.changelog : Custom SQL executed
2024-05-26T13:04:49.542+01:00 INFO 16644 --- [ main] liquibase.changelog : ChangeSet db/migrations/V3__adding_authors_table.sql::1::aymane ran successfully in 12ms
2024-05-26T13:04:49.547+01:00 INFO 16644 --- [ main] liquibase.util : UPDATE SUMMARY
2024-05-26T13:04:49.547+01:00 INFO 16644 --- [ main] liquibase.util : Run: 3
2024-05-26T13:04:49.547+01:00 INFO 16644 --- [ main] liquibase.util : Previously run: 0
2024-05-26T13:04:49.547+01:00 INFO 16644 --- [ main] liquibase.util : Filtered out: 0
2024-05-26T13:04:49.548+01:00 INFO 16644 --- [ main] liquibase.util : -------------------------------
2024-05-26T13:04:49.548+01:00 INFO 16644 --- [ main] liquibase.util : Total change sets: 3
2024-05-26T13:04:49.548+01:00 INFO 16644 --- [ main] liquibase.util : Update summary generated
2024-05-26T13:04:49.549+01:00 INFO 16644 --- [ main] liquibase.command : Update command completed successfully.
Liquibase: Update has been successful. Rows affected: 3
2024-05-26T13:04:49.555+01:00 INFO 16644 --- [ main] liquibase.lockservice : Successfully released change log lock
2024-05-26T13:04:49.557+01:00 INFO 16644 --- [ main] liquibase.command : Command execution complete
```
**Configuring Liquibase to run migrations independently from running the application**
This behavior is used at the deployment phase when we will want to grab all the migration scripts added since the last release and execute them against database deployed on dev, staging or production environment
For that There is a Maven plugin for liquibase that can be used, but before adding it we should add a configuration file liquibase.yml to contain information about the target database and the location of the changelog file
```
url: jdbc:postgresql://localhost:5432/demo_liquibase
username: postgres
password: changemeinproduction
driver: org.postgresql.Driver
changeLogFile: src/main/resources/db/migrations/changelog.xml
```
Then we should add the plugin to the pom file in the build section :
```
<build>
<plugins>
<plugin>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-maven-plugin</artifactId>
<version>4.5.0</version>
<configuration>
<propertyFile>
src/main/resources/liquibase.yml
</propertyFile>
</configuration>
</plugin>
</plugins>
</build>
```
An important thing is to remember to disable triggering the liquibase migration process on application startup when starting the application with a profile like integration or production (not local profile), here is an example of the application-prod.yml file :
```
spring:
datasource:
url: jdbc:postgresql://localhost:5432/demo_liquibase
username: postgres
password: changemeinproduction
driver-class-name: org.postgresql.Driver
jpa:
hibernate:
ddl-auto: none
liquibase:
enabled: false
```
Finally we can use the following command to trigger the migration process :
```
./mvnw liquibase:update
```
**Conclusion**
Using Liquibase with Spring Boot offers a robust solution for managing database changes in a controlled and efficient manner. It enables developers to focus on delivering features without worrying about the complexities of database migrations, making it an essential tool for any Spring Boot-based project.
| aharmaz |
1,865,620 | Building a shopping cart using React, Redux toolkit | In this article, we'll walk through the process of creating an simple e-commerce application with the... | 0 | 2024-05-26T12:59:55 | https://dev.to/clarenceg01/building-a-shopping-cart-using-react-redux-toolkit-1fd5 | react, api, frontend, webdev | In this article, we'll walk through the process of creating an simple e-commerce application with the Fake store API using React redux and react toolkit, with a focus on implementing a shopping cart. By the end of this tutorial, you will have a functional application with the following features:
1. A product listing page displaying products available for purchase.
2. The ability to add items to the shopping cart.
3. A shopping cart page where users can view, update quantity, and remove items from their cart.
Let's get started !!
1. Create React project using vite:
```npm
npm create vite@latest shopping-cart -- --template react
cd shopping-cart
```
2. We will create three components: Cart, Navbar, and Shop components.
3.We will use fakestore api to get products for our project. Below is our initial Shop.jsx:
```react
import React, { useEffect, useState } from "react";
import axios from "axios";
const Shop = () => {
const [products, setProducts] = useState([]);
const getProducts = async () => {
await axios
.get("https://fakestoreapi.com/products")
.then((res) => setProducts(res.data))
.catch((err) => console.log(err));
};
useEffect(() => {
getProducts();
}, []);
return (
<section className="shop">
{products.map((product) => (
<article className="card" key={product.id}>
<img src={product.image} alt="" />
<div className="details-div">
<div className="title-price">
<p>{product.title}</p>
<p>{product.price}</p>
</div>
<button>Add to cart</button>
</div>
</article>
))}
</section>
);
};
export default Shop;
```
_We now have the products set up so we'll dive into redux toolkit._
**Redux Toolkit**
Redux toolkit is a library that helps us write redux logic. It offers tools that simplify Redux setup and use, reducing boilerplate and enhancing code maintainability.
**Redux Store**
A redux store is a central repository that stores all the states of an application. Store is made up of slices.
To create our own store we need to install redux toolkit and react redux:
```npm
npm install @reduxjs/toolkit react-redux
```
Create a store.js file inside redux folder inside src folder.
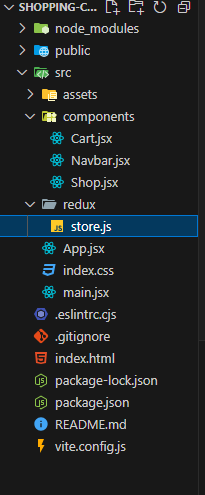
In store.js we will create a redux store (store) using _**configureStore**_ provided by reduxjs and export it.
```js
import { configureStore } from "@reduxjs/toolkit";
export const store = configureStore({
reducer: {},
});
```
To make the store accessible to our application, we need to wrap our App component inside **_Provider_** that allows a prop called store which we will set to our store. This is done inside our main.jsx (could be index.js if you created app using CRA)
Provider is a component that allows Redux store to be made available to all components.
Here is how our main.jsx looks like:
```react
import React from "react";
import ReactDOM from "react-dom/client";
import App from "./App.jsx";
import "./index.css";
import { store } from "./redux/store.js";
import { Provider } from "react-redux";
ReactDOM.createRoot(document.getElementById("root")).render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
);
```
**Redux Slice**
A slice is a part of the app's state that is managed by a specific reducer and contains actions related to the state.
For our project we'll create productsSlice.js file where we'll use createSlice function to create productsSlice.
createSlice accepts an object with the following parameters:
- name -defines the slice's name.
- initialState -sets up the starting state for the slice when the Redux store is first created.
- reducers - these are functions that handle the logic for updating the state. We will create our first reducer _**addProductToCart**_.
We will also export actions and reducer created by our createSlice.
```react
import { createSlice } from "@reduxjs/toolkit";
const initialState = {
products: [],
cart: [],
};
const productsSlice = createSlice({
name: "product",
initialState,
reducers: {
addProductToCart: (state, action) => {
state.cart.push(action.payload);
},
},
});
export const { addProductToCart } = productsSlice.actions;
export default productsSlice.reducer;
```
For our productsSlice to be available to the app, we will import reducer created by createSlice inside Store.js and add it to the reducer object of our store.
Here's how our store.js will be:
```react
import { configureStore } from "@reduxjs/toolkit";
import productReducer from "./productsSlice";
export const store = configureStore({
reducer: {
products: productReducer,
},
});
```
To be able to add a product to cart we will use two react-redux hooks:**_useSelector_** and**_useDispatch_**
useSelector allows components to get(select) part of the state that is required. useDispatch allows components to dispatch actions to the redux store.
Inside Shop.jsx we will import useDispatch from react-redux, invoke it and store in a variable dispatch. Variable dispatch will then be used to dispatch action _addProductToCart_ when button 'Add to cart' is clicked.
Here's our Shop.jsx:
```react
import React, { useEffect, useState } from "react";
import axios from "axios";
import { useDispatch } from "react-redux";
import { addProductToCart } from "../redux/productsSlice";
const Shop = () => {
const [products, setProducts] = useState([]);
const dispatch = useDispatch();
const getProducts = async () => {
await axios
.get("https://fakestoreapi.com/products")
.then((res) => setProducts(res.data))
.catch((err) => console.log(err));
};
useEffect(() => {
getProducts();
}, []);
return (
<section className="shop">
{products.map((product) => (
<article className="card" key={product.id}>
<img src={product.image} alt="" />
<div className="details-div">
<div className="title-price">
<p>{product.title}</p>
<p>{product.price}</p>
</div>
<button
onClick={() =>
dispatch(
addProductToCart({
id: product.id,
title: product.title,
price: product.price,
image: product.image,
})
)
}
>
Add to cart
</button>
</div>
</article>
))}
</section>
);
};
export default Shop;
```
Now that the action is dispatched, the products are successfully added to cart which is part of the state. To display the added products, we will use _useSelector_ inside Cart.jsx to get/extract/select cart which is part of our productsSlice.
Here's our Cart.jsx:
```react
import React from "react";
import { useSelector } from "react-redux";
const Cart = () => {
const cart = useSelector((state) => state.products.cart);
console.log(cart);
return (
<section className="cart-component">
{cart.map((product) => (
<article className="cart-card" key={product.id}>
<div>
<img src={product.image} alt="" />
<button>REMOVE</button>
</div>
<div>
<p>{product.title}</p>
<div className="button-in-cart">
<button>-</button>
<span>{product.quantity}</span>
<button>+</button>
</div>
<p>$:{product.price}</p>
</div>
</article>
))}
;
</section>
);
};
export default Cart;
```
To display the count of products in our navbar, we will also get cart using useSelector inside Navbar.jsx. Cart being an array, we will use its length to get the count of products added to cart.
Here's our Navbar.jsx:
```react
import React from "react";
import { useSelector } from "react-redux";
const Cart = () => {
const cart = useSelector((state) => state.products.cart);
console.log(cart);
return (
<section className="cart-component">
{cart.map((product) => (
<article className="cart-card" key={product.id}>
<div>
<img src={product.image} alt="" />
<button>REMOVE</button>
</div>
<div>
<p>{product.title}</p>
<div className="button-in-cart">
<button>-</button>
<span>{product.quantity}</span>
<button>+</button>
</div>
<p>$:{product.price}</p>
</div>
</article>
))}
;
</section>
);
};
export default Cart;
```
Using redux we have been able to create a store (source of truth 😅) allowing different components to access the state. In the next part we will ensure that when a similar product is clicked a number of times , it's not added to cart as multiple cart products by adding a quantity property. We will also add other actions such as increase quantity of product, decrease quantity of product, remove product and clear cart.
Source code:
{% github https://github.com/ClarenceG01/shopping-cart-redux %}
| clarenceg01 |
1,865,619 | Differences between Public, Private, Protected, and Abstract Modifiers in TypeScript | In TypeScript, access modifiers control the visibility of class members, such as properties and... | 0 | 2024-05-26T12:58:56 | https://dev.to/doccaio/differences-between-public-private-protected-and-abstract-modifiers-in-typescript-4mgk |
In TypeScript, access modifiers control the visibility of class members, such as properties and methods. They define which parts of the code can access these members.
**Public:**
The default modifier in TypeScript.
Allows members to be accessed by any class, inside or outside the class in which they were declared.
Example:
```ts
class Person {
public name: string;
constructor(name: string) {
this.name = name;
}
public greet() {
console.log(`Hello, my name is ${this.name}`);
}
}
const person = new Person('John Doe');
person.greet(); // Output: Hello, my name is John Doe
```
**Private:**
Restricts access to members to the class in which they are declared.
Example:
```ts
class Person {
private name: string;
constructor(name: string) {
this.name = name;
}
public greet() {
console.log(`Hello, my name is ${this.name}`);
}
}
const person = new Person('John Doe');
// person.name is inaccessible outside the Person class
```
**Protected:**
Allows access to members within the class in which they are declared and its subclasses.
Example:
class Person {
protected name: string;
constructor(name: string) {
this.name = name;
}
```ts
protected greet() {
console.log(`Hello, my name is ${this.name}`);
}
}
class Student extends Person {
public studentId: number;
constructor(name: string, studentId: number) {
super(name);
this.studentId = studentId;
}
public override greet() {
super.greet();
console.log(`I am also a student with ID ${this.studentId}`);
}
}
const student = new Student('John Doe', 12345);
student.greet(); // Output: Hello, my name is John Doe. I am also a student with ID 12345
```
**Abstract:**
Indicates that a method or property must be implemented in derived classes.
Abstract members cannot have a direct implementation in the base class.
Example:
```ts
abstract class Shape {
abstract getArea(): number;
public abstract toString(): string;
}
class Circle extends Shape {
private radius: number;
constructor(radius: number) {
super();
this.radius = radius;
}
public getArea(): number {
return Math.PI * this.radius * this.radius;
}
public toString(): string {
return `Circle with radius ${this.radius}`;
}
}
const circle = new Circle(5);
console.log(circle.getArea()); // Output: 78.53975
console.log(circle.toString()); // Output: Circle with radius 5
```
In summary, access modifiers control the accessibility of class members, while the abstract modifier defines incomplete methods or properties that must be implemented in subclasses.
Public: The default modifier, allowing members to be accessed anywhere.
Private: Restricts access to the class where the member is declared.
Protected: Allows access within the class and its subclasses.
Abstract: Requires derived classes to implement incomplete methods or properties.
|Modified| Visibility| Details |
| ------------- | --- |-----|
| public |Accessible anywhere|Pattern for class members |
| private | Only within the class| Greater encapsulation |
| protected | inside the class and derived classes| Promotes reuse in inheritance |
| abstract | No implementation| Defines a contract for derived classes|
**Tip:**
Remember to choose the appropriate access modifier for each class member, considering the desired level of encapsulation and reuse.
**Sources :**
github.com/Mcps4/ifpi-ads-eng3-2022
https://pt.stackoverflow.com/questions/559723/quais-as-diferen%C3%A7as-entre-modificadores-public-private-protected-e-abstract-no
| doccaio | |
1,865,618 | SEO Expert Jerin | Jerin John is the best SEO expert in the world providing strategic SEO solutions to boost online... | 0 | 2024-05-26T12:58:23 | https://dev.to/jerinjohnseo/seo-expert-jerin-11be | [Jerin John](https://jerinjohn.in/) is the best SEO expert in the world providing strategic SEO solutions to boost online visibility and drive organic traffic.
Jerin John is a Google-certified [SEO expert Kerala](https://jerinjohn.in/best-seo-expert-kerala/) providing strategic SEO solutions to boost online visibility and drive organic traffic. [SEO Expert India](https://jerinjohn.in) | jerinjohnseo | |
1,865,616 | What is Natural Language Processing (NLP)? | Natural language processing (NLP) enables machines to understand and analyze human language, serving... | 0 | 2024-05-26T12:56:12 | https://dev.to/gevorg_grigoryan_576e0dc8/what-is-natural-language-processing-nlp-4dnf | Natural language processing (NLP) enables machines to understand and analyze human language, serving as the foundation for various everyday tools such as translation software, chatbots, spam filters, search engines, grammar correction tools, etc. With the help of this article, you will gain insights into the fundamentals of NLP, its associated difficulties, and explore prevalent business applications. Let’s dive in and explore fascinating aspects of NLP.
## What is Natural Language Processing?
Natural language processing (NLP) is an aspect of Artificial Intelligence (AI) that enables machines to comprehend human language. Specifically, it combines essential concepts from linguistics and computer science to investigate language rules and patterns, ultimately constructing smart systems (using machine learning and NLP algorithms) that can interpret, analyze, and derive significance from both text and speech.
## How Does Natural Language Processing Work?
[Text vectorization](https://neptune.ai/blog/vectorization-techniques-in-nlp-guide) in NLP tools transforms text into a machine-readable format. Machine learning algorithms are then trained on labeled data to associate inputs with corresponding outputs. In addition, these algorithms use statistical methods to understand text features, enabling them to make predictions for new data. In other words, the more data these algorithms are trained on, the more accurate their predictions become.
In addition, sentiment analysis is a popular NLP task where models learn to sort text into positive, negative, or neutral categories based on expressed opinions.
## Benefits of NLP
**Analyze larger data sets**
Companies often handle vast amounts of unstructured data, which conventional computers struggle to process manually due to time constraints and potential errors. NLP technology automates and streamlines these tasks, ensuring accuracy and efficiency.
**Provide a more objective analysis**
When humans repeatedly handle tasks involving reading or analyzing large amounts of text data, they may lose focus and make mistakes due to personal emotions. Computers, on the other hand, provide objective analysis and can complete these tasks quickly.
**Streamline daily processes**
Regularly checking customer feedback to enhance business strategy is essential. However, having employees work full-time on manual data analysis is not effective when compared to NLP tools. In other words, by linking NLP tools to your company’s data, you can promptly understand customer opinions without burdening employees with constant repetitive tasks.
**Improve customer experience**
Not responding promptly to customer requests can lead to a company’s downfall. Detecting potential crises requires understanding not just what customers say about products/services, but also why. Many NLP tools are available to help companies respond to customers quickly.
**Extract actionable insights**
Analyzing social media, surveys, and reviews for valuable insights can be time-consuming. AI-driven NLP tools automate this process, quickly identifying relevant conversations and providing actionable insights.
## Challenges with NLP
**Misspellings**
Natural languages contain misspellings, typos, and inconsistencies in style. For instance, words like “process” can be spelled as “process” or “processing,” posing challenges for [intelligent tutoring systems](https://saima.ai/blog/what-is-an-ai-intelligent-tutoring-system-its), especially when accents or non-standard characters are involved.
**Language differences**
An English speaker may say, “I am going to work tomorrow morning,” while an Italian speaker would say, “Domani Mattina vado al lavoro." Despite conveying the same meaning, NLP may not comprehend the latter unless it is translated into English first.
**Innate Biases**
NLP systems are built on human logic and datasets. However, they can sometimes reflect the biases of their programmers or the data they have trained on. This, in turn, can lead to different interpretations of context and potentially inaccurate results.
**Training Data**
A significant challenge in natural language processing is dealing with inaccurate training data. The quality of results improves with more training data. Nevertheless, providing the system with incorrect or biased data can lead to learning the wrong things or ineffective learning.
## Use Cases of NLP
**Intelligent document search**
NLP documents can sift through free text data to find all relevant details. However, these solutions highly rely on identifying patterns within extensive amounts of unstructured data.
**Sentiment analysis**
Sentiment analysis involves analyzing emotions in text categorizing them as positive, negative, or neutral. By applying sentiment analysis to social media posts, product reviews, NPS surveys, and customer feedback, businesses can gain valuable insights into how customers perceive their brand.
**Fraud detection**
Combining NLP with ML and predictive analytics enhances cybersecurity in online learning by detecting fraud and misinformation in financial documents. For instance, research found that NLP linguistic models successfully identified deceptive emails based on patterns like decreased use of first-person pronouns and exclusive words, along with increased occurrences of negative emotion words and action verbs.
**Conversational AI / Chatbot**
Conversational AI refers to technology enabling automatic communication between computers and humans, powering chatbots and virtual assistants such as Siri or Alexa. In addition, chatbots find applications across various industries, facilitating customer conversations and [automating rule-based tasks](https://www.teamviewer.com/en-cis/global/support/knowledge-base/teamviewer-remote/remote-management/rule-based-task-automation/) such as answering FAQs or making hotel reservations.
**Named Entity Recognition**
Named Entity Recognition (NER) enables the extraction of names of entities such as people, companies, places, etc., from your data.
**Social Media Monitoring**
Social media monitoring utilizes NLP to shift through the significant amount of comments and queries that companies receive on their posts or across all social channels. These monitoring tools employ sentiment analysis to identify emotions such as irritation, frustration, happiness, or satisfaction.
**Predictive text**
Every time you type on your smartphone, you witness NLP in action. The texting app suggests correct words after typing a few letters, improving accuracy with each use. Over time, it successfully recognizes commonly used words and names, often predicting them faster than you can type.
## The Future of Natural Language Processing in Education
The future of AI in education promises personalized learning experiences through NLPs. Let’s discuss some of the most significant advancements that are yet to come.
- Companies such as Google are exploring [Deep Neural Networks](https://www.datacamp.com/tutorial/introduction-to-deep-neural-networks) (DNNs) to advance NLP and create human-to-machine interactions that closely mimic human-to-human interactions.
- Basic words can be broken down into precise semantics for use in NLP algorithms.
- NLP algorithms can be applied to various languages, including regional languages or those spoken in rural areas, expanding accessibility.
- Translation of sentences from one language to another is a broad application of NLP.
### Conclusion
Natural language processing enables computers to understand, interpret, and generate human language, revolutionizing communication and information processing.
| gevorg_grigoryan_576e0dc8 | |
1,865,615 | بهترین برنامههای پادکست برای iOS | پادکستها به یکی از محبوبترین روشهای مصرف محتوا در دنیای امروز تبدیل شدهاند. از اخبار روزانه گرفته... | 0 | 2024-05-26T12:55:21 | https://dev.to/mohammadml_1/bhtryn-brnmhhy-pdkhst-bry-ios-584f | پادکستها به یکی از محبوبترین روشهای مصرف محتوا در دنیای امروز تبدیل شدهاند. از اخبار روزانه گرفته تا برنامههای آموزشی و سرگرمی، پادکستها توانستهاند جایگاه ویژهای در زندگی روزمره افراد پیدا کنند.
اگر شما از کاربران iOS هستید و به دنبال بهترین برنامههای پادکست برای گوشی آیفون یا آیپد خود هستید، در این مقاله به بررسی و معرفی لیست [برنامههای پادکست برای iOS](https://sibkade.com/the-best-podcast-app-for-ios/) میپردازیم.
1. Apple Podcasts
ویژگیها:
• یکپارچه با iOS: برنامه Apple Podcasts به صورت پیشفرض بر روی تمامی دستگاههای iOS نصب است و به خوبی با سیستم عامل یکپارچه شده است.
• دسترسی به کتابخانه وسیع: این برنامه دسترسی به مجموعهای وسیع از پادکستهای مختلف در موضوعات متنوع را فراهم میکند.
• پشتیبانی از Siri: کاربران میتوانند با استفاده از دستیار صوتی Siri به راحتی پادکستها را جستجو و پخش کنند.
• اشتراکگذاری و ذخیرهسازی: امکان اشتراکگذاری پادکستها با دوستان و ذخیرهسازی اپیزودهای مورد علاقه وجود دارد.
مزایا:
• رایگان و بدون تبلیغات: برنامه کاملاً رایگان است و تبلیغاتی در آن نمایش داده نمیشود.
• همگامسازی خودکار: پادکستها و اپیزودها به صورت خودکار بین دستگاههای مختلف iOS همگامسازی میشوند.
2. Spotify
ویژگیها:
• کتابخانه ترکیبی موسیقی و پادکست: کاربران میتوانند هم به موسیقی و هم به پادکستها دسترسی داشته باشند.
• پادکستهای انحصاری: Spotify دارای مجموعهای از پادکستهای انحصاری است که فقط از طریق این پلتفرم قابل دسترسی هستند.
• پشتیبانی از پلیلیستها: امکان ایجاد پلیلیستهای پادکست و ذخیره اپیزودها برای گوش دادن آفلاین وجود دارد.
مزایا:
• رابط کاربری جذاب و کاربرپسند: طراحی زیبا و رابط کاربری ساده و قابل فهم.
• کیفیت صوتی بالا: پخش پادکستها با کیفیت صدای بسیار خوب.
معایب:
تبلیغات در نسخه رایگان: نسخه رایگان Spotify شامل تبلیغات است. برای حذف تبلیغات نیاز به اشتراک پریمیوم است.
3. Pocket Casts
ویژگیها:
• طراحی زیبا و کاربردی: Pocket Casts به خاطر طراحی زیبا و رابط کاربری سادهاش شناخته میشود.
• پشتیبانی از تمهای مختلف: کاربران میتوانند بین تمهای روشن و تیره انتخاب کنند.
• ابزارهای مدیریت پادکست: امکان مرتبسازی پادکستها، ایجاد پلیلیست، و تنظیم زمانبندی دانلود اپیزودها.
مزایا:
• همگامسازی بین پلتفرمها: امکان همگامسازی بین دستگاههای مختلف و حتی بین iOS و اندروید.
• پشتیبانی از AirPlay و Chromecast: قابلیت پخش محتوا بر روی دستگاههای دیگر.
معایب:
پرداختی: برای استفاده از تمامی ویژگیها نیاز به پرداخت اشتراک ماهیانه است.
4. Overcast
ویژگیها:
• Smart Speed: ویژگی منحصر به فرد Smart Speed به کاربران اجازه میدهد تا بدون تغییر در کیفیت صدا، زمان پخش اپیزودها را کاهش دهند.
• Voice Boost: بهبود کیفیت صدای پادکستها به خصوص در محیطهای پرسروصدا.
• فیلترها و پلیلیستهای هوشمند: امکان ایجاد پلیلیستهای سفارشی و فیلتر کردن اپیزودها بر اساس معیارهای مختلف.
مزایا:
• رایگان با قابلیتهای پیشرفته: بسیاری از ویژگیهای پیشرفته به صورت رایگان در دسترس هستند.
• بدون تبلیغات در نسخه پریمیوم: نسخه پریمیوم بدون تبلیغات است و قابلیتهای بیشتری ارائه میدهد.
معایب:
تبلیغات در نسخه رایگان: نسخه رایگان شامل تبلیغات است که ممکن است برای برخی کاربران آزاردهنده باشد.
5. Castro
ویژگیها:
• Inbox Style: سیستم Inbox Style به کاربران اجازه میدهد تا اپیزودهای جدید را مدیریت کرده و تصمیم بگیرند که کدامها را گوش دهند یا حذف کنند.
• پشتیبانی از فایلهای صوتی سفارشی: کاربران میتوانند فایلهای صوتی خود را به برنامه اضافه کنند.
• سازماندهی خودکار: اپیزودها به صورت خودکار سازماندهی میشوند و به کاربران کمک میکند تا به راحتی به محتوای دلخواه دسترسی پیدا کنند.
مزایا:
• مدیریت پیشرفته اپیزودها: قابلیتهای مدیریت اپیزودها به کاربران امکان میدهد تا به راحتی پادکستهای خود را کنترل کنند.
• همگامسازی با iCloud: امکان همگامسازی اپیزودها و تنظیمات با استفاده از iCloud.
معایب:
برخی ویژگیهای پریمیوم: برای دسترسی به برخی ویژگیهای پیشرفته نیاز به پرداخت اشتراک است.
6. Breaker
ویژگیها:
• اجتماعیسازی پادکست: Breaker به کاربران امکان میدهد تا پادکستها را با دوستان خود به اشتراک بگذارند و نظر بدهند.
• کشف پادکستهای جدید: پیشنهادهای هوشمندانه بر اساس علایق کاربران و فعالیتهای دوستان.
• رابط کاربری ساده و جذاب: طراحی زیبا و رابط کاربری ساده که تجربه کاربری را بهبود میبخشد.
مزایا:
• شبکه اجتماعی پادکست: ایجاد ارتباطات اجتماعی و اشتراکگذاری محتوا با دیگران.
• پشتیبانی از حالت آفلاین: امکان دانلود و گوش دادن به پادکستها به صورت آفلاین.
معایب:
تبلیغات در نسخه رایگان: شامل تبلیغات است که ممکن است برای برخی کاربران مزاحمت ایجاد کند.
نتیجهگیری
انتخاب بهترین برنامه پادکست برای iOS بستگی به نیازها و سلیقههای شخصی شما دارد. برنامههایی مانند Apple Podcasts و Spotify برای کسانی که به دنبال سادگی و دسترسی به محتوای گسترده هستند، مناسب هستند. اگر به دنبال ویژگیهای پیشرفتهتر و قابلیتهای مدیریتی هستید، برنامههایی مانند Pocket Casts و Overcast گزینههای بسیار خوبی هستند. برنامههایی مانند Castro و Breaker نیز برای کسانی که به دنبال تجربه اجتماعی و مدیریت پیشرفته پادکستها هستند، پیشنهاد میشوند.
با توجه به تنوع بالای برنامههای پادکست برای iOS، حتماً یکی از این برنامهها میتواند نیازهای شما را برآورده کند و تجربه لذتبخشی از گوش دادن به پادکستها را برای شما فراهم کند.
| mohammadml_1 | |
1,865,607 | Dynamic Typed Language v.s. Static Typed Language | The programming itself depends on one thing which is values. We use values by storing them in the... | 0 | 2024-05-26T12:54:09 | https://dev.to/ikbalarslan/dynamic-language-vs-static-language-942 | programming | The programming itself depends on one thing which is values.
We use values by storing them in the memory, accessing it, and editing it. To access these values we need to put a label on it so whenever we need to use that value we can just basically call it by using the label.
```
int number = 23
```
For example in this case we store the value which is 23 in the memory with a label which is a number. int is just saying to program create a new label.
While we are storing values in the CPU's (the microchip) memory we need to know the type of the value so we can store the value in the correct place. the types can be whole numbers, even numbers, texts, or big objects which has other values stored inside.
So now we want to store some data in the memory but how we will know where to store this? We need to know the type of the value.
To know the type of data we have two options:
- the label itself can store the type of data (static)
- the value can store the type of data (dynamic)
#### Static Programming Languages
In static programming languages when we are creating a label we need to give it a type as well for example in C++ which is a static language. When you want to store some data.
```
int label1 = 3
string label2 = "hello world"
```
While we are creating label1 we put int keyword upfront which represents a type. it says label1 can only store integers(whole numbers) in it.
In static languages the labels have type values in them because of that when the compiler converts the code to assembly it only checks the label to get type info to know where to store the values.
#### Dynamic Programming Languages
In dynamic programming languages when we are creating a label we don't need to specify the type info the value itself will store the type info for example in Javascript which is a dynamic language. When we want to store some data.
```
var label1 = 3
var label2 = "hello world"
```
For creating a new variable we always used var keyword because var keyword doesn't store type info it is just responsible for creating a label in this case, label1 and label2 don't have a type.
However, the compiler needs the type value to store data in the correct places. for that every time before storing data it will check the value get type info from it and then convert it to the assembly language.
**In the Programming world labels are called variables**
---
### How about speed?
Since we need to check the value every single time in the compiling, the compiler needs to work more compared to static languages.
Because of that, we can say static languages are faster to compile. compared to dynamic languages right?
**Dynamic typing languages are pretty fast but how?**
as an example, I will explain the working mechanism of The [V8 Javascript Engine](https://dev.to/ikbalarslan/javascript-runtime-37i8)
when the engine starts the execution it will use two things to make it faster:
-JIT(Just in Time Compilation)
-using two compilers instead of one
**JIT**
with using [JIT](https://en.wikipedia.org/wiki/Just-in-time_compilation) the engine immediately will convert the javascript code to machine-understandable code. on the way line by line.
**Two Compiler**
engine uses one normal compiler and one optimizing compiler. Optimizing the compiler will save the type data in the memory for most used functions. so if we call the same function again it won't waste time checking types every time(if the types are the same)
I have explained more details about Javascript engines in [this article](https://dev.to/ikbalarslan/javascript-runtime-37i8)
---
here are some resources to dive deeper into this topic:
- [this](https://stackoverflow.com/questions/761426/why-are-dynamically-typed-languages-slow) StackOverflow discussion is pretty informative.
- Scala’s author has a good [StackOverflow answer](https://stackoverflow.com/questions/3490383/java-compile-speed-vs-scala-compile-speed/3612212#3612212) on why the compiler is so slow.
- [benhoyt's blog post](https://benhoyt.com/writings/language-speed/)
- [this](https://www.youtube.com/watch?v=p-iiEDtpy6I) presentation from JSconf
---
In this article, I have explained the differences between dynamic and static languages. If you have any questions feel free to leave a comment. I will be happy to answer them.
| ikbalarslan |
1,865,613 | what is react? | REACT:- Basically react is a library which is operated by facebook. React is used to make... | 0 | 2024-05-26T12:52:15 | https://dev.to/sigmasigma/what-is-react-4kb6 | REACT:-
Basically react is a library which is operated by facebook. React is used to make spa(single page application). React is used to make complex ui(user interface). Am i right? Suggestions needed.:) | sigmasigma | |
1,865,482 | What types of Nginx configuration files exist? | I have experience creating infrastructure environments using Nginx. However, I can't figure out... | 0 | 2024-05-26T12:45:38 | https://dev.to/takahiro_82jp/what-types-of-nginx-configuration-files-exist-3o72 | nginx, devops | I have experience creating infrastructure environments using Nginx.
However, I can't figure out configuration file, no matter how many times I look at it.
So I'll leave a note on this article.
I'd like you to refer it, if you use Nginx first time.
### what are conditions?
* I use Ubuntu on container
* I use Nginx 1.18
### What are Nginx configuration files?
First, you hit below command.
`ls /etc/nginx`
and then, you look below line.
```
conf.d mime.types nginx.conf uwsgi_params
fastcgi_params modules scgi_params
```
So let's move on.
### 1. default.conf
First, you hit below command.
`ls /etc/nginx/conf.d/`
and then, you look below line.
```
default.conf
```
Next, you hit below command.
`cat /etc/nginx/conf.d/default.conf`
and then, you look below line.
This is default server setting file.
```
server {
listen 80;
listen [::]:80;
server_name localhost;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
```
I often use this file, so I link Nginx and PHP on FastCGI, setting SSL and port number.
### 2. mime.types
Second, you hit below command.
'cat /etc/nginx/mime.types'
and then, you look below line.
This is mime type and extension combination setting file.
```
types {
text/html html htm shtml;
text/css css;
text/xml xml;
image/gif gif;
image/jpeg jpeg jpg;
application/javascript js;
application/atom+xml atom;
application/rss+xml rss;
text/mathml mml;
text/plain txt;
text/vnd.sun.j2me.app-descriptor jad;
text/vnd.wap.wml wml;
text/x-component htc;
image/avif avif;
image/png png;
image/svg+xml svg svgz;
image/tiff tif tiff;
image/vnd.wap.wbmp wbmp;
image/webp webp;
image/x-icon ico;
image/x-jng jng;
image/x-ms-bmp bmp;
font/woff woff;
font/woff2 woff2;
application/java-archive jar war ear;
application/json json;
application/mac-binhex40 hqx;
application/msword doc;
application/pdf pdf;
application/postscript ps eps ai;
application/rtf rtf;
application/vnd.apple.mpegurl m3u8;
application/vnd.google-earth.kml+xml kml;
application/vnd.google-earth.kmz kmz;
application/vnd.ms-excel xls;
application/vnd.ms-fontobject eot;
application/vnd.ms-powerpoint ppt;
application/vnd.oasis.opendocument.graphics odg;
application/vnd.oasis.opendocument.presentation odp;
application/vnd.oasis.opendocument.spreadsheet ods;
application/vnd.oasis.opendocument.text odt;
application/vnd.openxmlformats-officedocument.presentationml.presentation
pptx;
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
xlsx;
application/vnd.openxmlformats-officedocument.wordprocessingml.document
docx;
application/vnd.wap.wmlc wmlc;
application/wasm wasm;
application/x-7z-compressed 7z;
application/x-cocoa cco;
application/x-java-archive-diff jardiff;
application/x-java-jnlp-file jnlp;
application/x-makeself run;
application/x-perl pl pm;
application/x-pilot prc pdb;
application/x-rar-compressed rar;
application/x-redhat-package-manager rpm;
application/x-sea sea;
application/x-shockwave-flash swf;
application/x-stuffit sit;
application/x-tcl tcl tk;
application/x-x509-ca-cert der pem crt;
application/x-xpinstall xpi;
application/xhtml+xml xhtml;
application/xspf+xml xspf;
application/zip zip;
application/octet-stream bin exe dll;
application/octet-stream deb;
application/octet-stream dmg;
application/octet-stream iso img;
application/octet-stream msi msp msm;
audio/midi mid midi kar;
audio/mpeg mp3;
audio/ogg ogg;
audio/x-m4a m4a;
audio/x-realaudio ra;
video/3gpp 3gpp 3gp;
video/mp2t ts;
video/mp4 mp4;
video/mpeg mpeg mpg;
video/quicktime mov;
video/webm webm;
video/x-flv flv;
video/x-m4v m4v;
video/x-mng mng;
video/x-ms-asf asx asf;
video/x-ms-wmv wmv;
video/x-msvideo avi;
}
```
I wouldn't set it too much.
It depends on the project, I suppose.
### 3. nginx.conf
Third, you hit below command.
'cat /etc/nginx/nginx.conf'
and then, you look below line.
It's overall Nginx configuration.
You configure log output destination and the number of connections, etc.
```
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
```
### 4. uwsgi_params
Fourth, you hit below command.
'cat /etc/nginx/uwsgi_params'
and then, you look below line.
I have never used uwsgi, It's application Server for Python.
```
uwsgi_param QUERY_STRING $query_string;
uwsgi_param REQUEST_METHOD $request_method;
uwsgi_param CONTENT_TYPE $content_type;
uwsgi_param CONTENT_LENGTH $content_length;
uwsgi_param REQUEST_URI $request_uri;
uwsgi_param PATH_INFO $document_uri;
uwsgi_param DOCUMENT_ROOT $document_root;
uwsgi_param SERVER_PROTOCOL $server_protocol;
uwsgi_param REQUEST_SCHEME $scheme;
uwsgi_param HTTPS $https if_not_empty;
uwsgi_param REMOTE_ADDR $remote_addr;
uwsgi_param REMOTE_PORT $remote_port;
uwsgi_param SERVER_PORT $server_port;
uwsgi_param SERVER_NAME $server_name;
```
### 5. fastcgi_params
Fifth, you hit below command.
'cat /etc/nginx/fastcgi_params'
and then, you look below line.
I used to watch it a lot, so I often use Laravel and PHP.
But I have never changed this file.
```
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD $request_method;
fastcgi_param CONTENT_TYPE $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param SCRIPT_NAME $fastcgi_script_name;
fastcgi_param REQUEST_URI $request_uri;
fastcgi_param DOCUMENT_URI $document_uri;
fastcgi_param DOCUMENT_ROOT $document_root;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param REQUEST_SCHEME $scheme;
fastcgi_param HTTPS $https if_not_empty;
fastcgi_param GATEWAY_INTERFACE CGI/1.1;
fastcgi_param SERVER_SOFTWARE nginx/$nginx_version;
fastcgi_param REMOTE_ADDR $remote_addr;
fastcgi_param REMOTE_PORT $remote_port;
fastcgi_param SERVER_ADDR $server_addr;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $server_name;
# PHP only, required if PHP was built with --enable-force-cgi-redirect
fastcgi_param REDIRECT_STATUS 200;
```
### 6. scgi_params
Sixth, you hit below command.
'cat /etc/nginx/scgi_params'
and then, you look below line.
SCGI is Simple Common Gateway Interface, I don't Know.
SCGI is designed to be simpler than FastCGI.
I'll learn it.
```
scgi_param REQUEST_METHOD $request_method;
scgi_param REQUEST_URI $request_uri;
scgi_param QUERY_STRING $query_string;
scgi_param CONTENT_TYPE $content_type;
scgi_param DOCUMENT_URI $document_uri;
scgi_param DOCUMENT_ROOT $document_root;
scgi_param SCGI 1;
scgi_param SERVER_PROTOCOL $server_protocol;
scgi_param REQUEST_SCHEME $scheme;
scgi_param HTTPS $https if_not_empty;
scgi_param REMOTE_ADDR $remote_addr;
scgi_param REMOTE_PORT $remote_port;
scgi_param SERVER_PORT $server_port;
scgi_param SERVER_NAME $server_name;
```
### 7. modules
Seventh, you hit below command.
'ls /etc/nginx/modules'
and then, you look below line.
Let me see, it seems to country access restrictions and XML filter.
I have never used it, so I will learn it.
```
ngx_http_geoip_module-debug.so ngx_http_xslt_filter_module-debug.so
ngx_http_geoip_module.so ngx_http_xslt_filter_module.so
ngx_http_image_filter_module-debug.so ngx_stream_geoip_module-debug.so
ngx_http_image_filter_module.so ngx_stream_geoip_module.so
ngx_http_js_module-debug.so ngx_stream_js_module-debug.so
ngx_http_js_module.so ngx_stream_js_module.so
```
There are a lot of scary files when you see them first time.
But if you get used to it, you can edit it.
No Problem!!
| takahiro_82jp |
1,849,633 | Quais as diferenças entre modificadores public, private, protected e abstract no Typescript? | o TypeScript, os modificadores de acesso controlam a visibilidade de membros de classes, como... | 0 | 2024-05-26T12:38:47 | https://dev.to/doccaio/quais-as-diferencas-entre-modificadores-public-private-protected-e-abstract-no-typescript-4g33 | o TypeScript, os modificadores de acesso controlam a visibilidade de membros de classes, como propriedades e métodos. Eles definem quais partes do código podem acessar esses membros.
**Public:**
O modificador padrão em TypeScript.
Permite que membros sejam acessados por qualquer classe, dentro ou fora da classe em que foram declarados.
Exemplo:
```ts
class Pessoa {
public nome: string; // Propriedade pública
constructor(nome: string) {
this.nome = nome;
}
public falar(): void {
console.log(`Olá, meu nome é ${this.nome}`);
}
}
const pessoa1 = new Pessoa('João');
console.log(pessoa1.nome); // Acessando propriedade pública
pessoa1.falar(); // Acessando método público
```
**Private:**
Restringe o acesso do membro à classe em que foi declarado.
Exemplo:
```ts
class ContaBancaria {
private saldo: number; // Propriedade privada
constructor(saldoInicial: number) {
this.saldo = saldoInicial;
}
public sacar(valor: number): void {
if (valor > this.saldo) {
console.error('Saldo insuficiente');
return;
}
this.saldo -= valor;
console.log(`Saque de R$${valor} realizado com sucesso. Saldo atual: R$${this.saldo}`);
}
// O método 'getSaldo' não tem o modificador 'public', então ele é privado
private getSaldo(): number {
return this.saldo;
}
}
const conta1 = new ContaBancaria(1000);
conta1.sacar(500); // Acessando método público
// conta1.saldo; // Erro: 'saldo' é privado e não pode ser acessado fora da classe
```
**Protected:**
Semelhante ao private, mas permite acesso de classes derivadas.
Exemplo:
```ts
TypeScript
class Animal {
protected nome: string; // Propriedade protegida
constructor(nome: string) {
this.nome = nome;
}
public falar(): void {
console.log(`Eu sou um animal e meu nome é ${this.nome}`);
}
}
class Cachorro extends Animal {
constructor(nome: string) {
super(nome);
}
public latir(): void {
console.log(`Au au! Meu nome é ${this.nome}`);
}
}
const cachorro1 = new Cachorro('Rex');
cachorro1.falar(); // Acessando método público herdado
cachorro1.latir(); // Acessando método próprio
```
**Abstract:**
Não define implementação, apenas declara um método que deve ser implementado em classes derivadas.
Classes abstratas não podem ser instanciadas diretamente.
Exemplo:
```ts
TypeScript
abstract class FiguraGeometrica {
abstract calcularArea(): number; // Método abstrato
public desenhar(): void {
console.log('Desenhando figura geométrica...');
}
}
class Retangulo extends FiguraGeometrica {
private base: number;
private altura: number;
constructor(base: number, altura: number) {
super();
this.base = base;
this.altura = altura;
}
public calcularArea(): number {
return this.base * this.altura;
}
}
const retangulo1 = new Retangulo(5, 7);
console.log(retangulo1.calcularArea()); // Acessando método implementado na classe derivada
retangulo1.desenhar(); // Acessando método herdado
```
|Modificado | Visibilidade | Detalhes |
| ------------- | --- |-----|
| public | Acessível em qualquer lugar| Padrão para membros de classe |
| private | Somente dentro da classe| Maior encapsulamento |
| protected | Dentro da classe e classes derivadas| Promove reuso em herança |
| abstract | Sem implementação| Define um contrato para classes derivadas |
**Dica :**
Lembre-se de escolher o modificador de acesso adequado para cada membro da classe, considerando o nível de encapsulamento e reuso desejado.
**Fontes**
[github.com/Mcps4/ifpi-ads-eng3-2022](url)
[
https://pt.stackoverflow.com/questions/559723/quais-as-diferen%C3%A7as-entre-modificadores-public-private-protected-e-abstract-no
](url)
| doccaio | |
1,865,604 | Equalizing positions | Weekly Challenge 270 Each week Mohammad S. Anwar sends out The Weekly Challenge, a chance... | 0 | 2024-05-26T12:29:48 | https://dev.to/simongreennet/equalizing-positions-2057 | perl, python, theweeklychallenge | ## Weekly Challenge 270
Each week Mohammad S. Anwar sends out [The Weekly Challenge](https://theweeklychallenge.org/), a chance for all of us to come up with solutions to two weekly tasks. My solutions are written in Python first, and then converted to Perl. It's a great way for us all to practice some coding.
[Challenge](https://theweeklychallenge.org/blog/perl-weekly-challenge-270/), [My solutions](https://github.com/manwar/perlweeklychallenge-club/tree/master/challenge-270/sgreen)
## Task 1: Special Positions
### Task
You are given a `m x n` binary matrix.
Write a script to return the number of special positions in the given binary matrix.
A position `(i, j)` is called special if `$matrix[i][j] == 1` and all other elements in the row `i` and column `j` are 0.
### My solution
For the input from the command line, I take a JSON string and convert that into a list of lists of integers.
This is a break down of the steps I take to complete the task.
1. Set the `special_position` value to `0`.
1. Set `rows` and `cols` to the number of rows and columns in the matrix
1. Create two lists (arrays in Perl) called `row_count` and `col_count` with zeros for the number of rows and columns respectively.
1. Loop through each row and each column in the matrix. If the value is `1`, increment the `row_count` for the row and `col_count` for the column by one. I also check that the number of items in this row is the same as the number of items in the first row.
1. Loop through each row and each column in the matrix. If the value at that position is 1 and the `row_count` for the row is 1 (this would indicate that the other elements in the row are 0) and the `col_count` is 1, add one to the `special_position` variable.
1. Return the `special_position` value.
```python
def special_positions(matrix: list) -> int:
rows = len(matrix)
cols = len(matrix[0])
special_position = 0
row_count = [0] * rows
col_count = [0] * cols
for row in range(rows):
if len(matrix[row]) != cols:
raise ValueError("Row %s has the wrong number of columns", row)
for col in range(cols):
if matrix[row][col]:
row_count[row] += 1
col_count[col] += 1
for row in range(rows):
for col in range(cols):
if matrix[row][col] and row_count[row] == 1 and col_count[col] == 1:
special_position += 1
return special_position
```
### Examples
```bash
$ ./ch-1.py "[[1, 0, 0],[0, 0, 1],[1, 0, 0]]"
1
$ ./ch-1.py "[[1, 0, 0],[0, 1, 0],[0, 0, 1]]"
3
```
## Task 2: Equalize Array
### Task
You are give an array of integers, `@ints` and two integers, `$x` and `$y`.
Write a script to execute one of the two options:
* Level 1: Pick an index `i` of the given array and do `$ints[i] += 1`.
* Level 2: Pick two different indices `i`,`j` and do `$ints[i] +=1` and `$ints[j] += 1`.
You are allowed to perform as many levels as you want to make every elements in the given array equal. There is cost attach for each level, for Level 1, the cost is `$x` and `$y` for Level 2.
In the end return the minimum cost to get the work done.
### Known issue
Before I write about my solution, it will return the expected results for the two examples, but will not always give the minimum score.
For the array (4, 4, 2) with `$x` of 10 and `$y` of 1, it will return 20 (perform level 1 on the third value twice). However if you perform level 2 on the first and third value (5, 4, 3), and then on the second and third value (5, 5, 4), and finally level 1 on the last value (5, 5, 5), you'd get a score of 12.
File a bug in Bugzilla, Jira or Github, and we'll fix it later :P
### My solution
For input from the command line, I take the last two values to be `x` and `y`, and the rest of the input to be `ints`.
The first step I take is to flip the array to be the number needed to reach the target value (maximum of the values).
```python
def equalize_array(ints: list, x: int, y: int) -> str:
score = 0
# Calculate the needed values
max_value = max(ints)
needed = [max_value - i for i in ints]
```
I then perform level two only if `y` is less than twice the value of `x`. If it isn't, then I will always get the same or a lower score by performing level one on each value.
For level two, I sort the indexes (not values) of the `needed` list by their value, with the highest value first. If the second highest value is `0`, it means there is no more level two tasks to perform, and I exit the loop. Otherwise I take one off the top two values in the `needed` array, and continue until the second highest value is `0`. For each iteration, I add `y` to the `score` value.
```python
if len(ints) > 1 and y < x * 2:
while True:
sorted_index = sorted(
range(len(ints)),
key=lambda index: needed[index],
reverse=True
)
if needed[sorted_index[1]] == 0:
break
needed[sorted_index[0]] -= 1
needed[sorted_index[1]] -= 1
score += y
```
Finally, my code perform the Level One operation. As level one takes one off each `needed` number, I simply multiple the sum of the remaining `needed` values by the `x` value and add it to `score`. I then return the value of `score` variable.
```python
score += sum(needed) * x
return score
```
### Examples
```bash
$ ./ch-2.py 4 1 3 2
9
$ ./ch-2.py 2 3 3 3 5 2 1
6
```
| simongreennet |
1,865,603 | Understanding Core JavaScript Concepts: Objects, Scopes, and Closures | 1. Introduction 2. Objects in JavaScript Object Literals Constructors Classes... | 0 | 2024-05-26T12:28:29 | https://dev.to/emmanuelj/understanding-core-javascript-concepts-objects-scopes-and-closures-249a | #### 1. Introduction
#### 2. Objects in JavaScript
- Object Literals
- Constructors
- Classes (ES6)
- Example of Classes
- Inheritance with Classes
#### 3. Scope in JavaScript
- Global Scope
- Local Scope
- Block Scope (ES6)
- Lexical Scoping
#### 4. Closures in JavaScript
- Basic Example
- Practical Use Case
- Module Pattern
#### 5. Advanced Topics
- Prototypal Inheritance
- The `this` Keyword
- Immediately Invoked Function Expressions (IIFEs)
#### 6. Best Practices
- Avoiding Global Variables
- Using `const` and `let` Instead of `var`
- Understanding `this`
- Keeping Functions Pure
- Using Closures Wisely
#### 7. Conclusion
JavaScript is a versatile, high-level programming language that plays a crucial role in web development. Despite its flexibility and power, many developers find JavaScript's unique characteristics challenging to master. Key among these are objects, scopes, and closures. This article aims to provide a thorough understanding of these core concepts, equipping you with the knowledge to write efficient and maintainable JavaScript code.
#### 1. Introduction
JavaScript's ability to create dynamic and interactive web applications hinges on three foundational concepts: objects, scopes, and closures. Objects are the cornerstone of JavaScript's approach to data and functionality encapsulation. Scopes dictate the accessibility of variables and functions within different parts of the code. Closures, a more advanced concept, enable functions to retain access to their lexical scope, allowing for powerful programming patterns.
#### 2. Objects in JavaScript
Objects in JavaScript are collections of properties, with each property being a key-value pair. They serve as the primary means for storing and managing data. There are several ways to create and manipulate objects in JavaScript.
##### Object Literals
The simplest way to create an object is using an object literal. This approach is concise and easy to read, making it ideal for defining objects with a small number of properties.
```javascript
let person = {
name: "Alice",
age: 30,
greet: function() {
console.log("Hello, " + this.name);
}
};
person.greet(); // Output: Hello, Alice
```
In the example above, the `person` object has three properties: `name`, `age`, and `greet`. The `greet` property is a method, demonstrating that objects can store functions in addition to primitive values.
##### Constructors
For creating multiple objects with similar properties and methods, JavaScript provides constructor functions. Constructors offer a template for creating objects, using the `new` keyword to instantiate new instances.
```javascript
function Person(name, age) {
this.name = name;
this.age = age;
this.greet = function() {
console.log("Hello, " + this.name);
};
}
let bob = new Person("Bob", 25);
bob.greet(); // Output: Hello, Bob
```
Here, the `Person` constructor function initializes the `name` and `age` properties, and the `greet` method for new objects. Using the `new` keyword, we create an instance of `Person` named `bob`.
##### Classes (ES6)
With ES6, JavaScript introduced classes, providing a cleaner syntax for creating objects and handling inheritance.
```javascript
class Person {
constructor(name, age) {
this.name = name;
this.age = age;
}
greet() {
console.log("Hello, " + this.name);
}
}
let charlie = new Person("Charlie", 35);
charlie.greet(); // Output: Hello, Charlie
```
Classes encapsulate data and behavior, offering a more intuitive way to work with objects. They also support inheritance, allowing you to extend classes and create subclasses with additional properties and methods.
```javascript
class Employee extends Person {
constructor(name, age, jobTitle) {
super(name, age);
this.jobTitle = jobTitle;
}
work() {
console.log(this.name + " is working as a " + this.jobTitle);
}
}
let dave = new Employee("Dave", 40, "Engineer");
dave.greet(); // Output: Hello, Dave
dave.work(); // Output: Dave is working as an Engineer
```
In the example above, `Employee` extends `Person`, inheriting its properties and methods while adding a new `jobTitle` property and `work` method.
#### 3. Scope in JavaScript
Scope in JavaScript determines the visibility and lifetime of variables and functions. It ensures variables are only accessible in the intended areas of your code, preventing potential naming conflicts and bugs.
##### Global Scope
Variables declared outside of any function or block have global scope. They are accessible from anywhere in your code.
```javascript
let globalVar = "I am global";
function globalScopeTest() {
console.log(globalVar); // Accessible here
}
globalScopeTest();
console.log(globalVar); // Accessible here as well
```
In this example, `globalVar` is a global variable, accessible both inside and outside the `globalScopeTest` function.
##### Local Scope
Variables declared within a function have local scope. They are only accessible within that function.
```javascript
function localScopeTest() {
let localVar = "I am local";
console.log(localVar); // Accessible here
}
localScopeTest();
// console.log(localVar); // Uncaught ReferenceError: localVar is not defined
```
Here, `localVar` is a local variable, accessible only within the `localScopeTest` function. Attempting to access it outside the function results in a `ReferenceError`.
##### Block Scope (ES6)
ES6 introduced `let` and `const`, allowing variables to be block-scoped. Block scope confines the variable's accessibility to the block in which it is declared, such as within `{}` braces.
```javascript
if (true) {
let blockScopedVar = "I am block scoped";
console.log(blockScopedVar); // Accessible here
}
// console.log(blockScopedVar); // Uncaught ReferenceError: blockScopedVar is not defined
```
In this example, `blockScopedVar` is only accessible within the `if` block.
##### Lexical Scoping
JavaScript uses lexical scoping, meaning that the scope of a variable is determined by its position in the source code. Nested functions have access to variables declared in their outer scope.
```javascript
function outerFunction() {
let outerVar = "I am outer";
function innerFunction() {
console.log(outerVar); // Accessible here
}
innerFunction();
}
outerFunction();
```
Here, `innerFunction` can access `outerVar` because it is defined in an outer scope.
#### 4. Closures in JavaScript
A closure is a function that retains access to its lexical scope, even when the function is executed outside that scope. Closures are a powerful feature of JavaScript, enabling advanced programming techniques and data encapsulation.
##### Basic Example
```javascript
function outerFunction() {
let outerVar = "I am outside!";
function innerFunction() {
console.log(outerVar); // Can access outerVar
}
return innerFunction;
}
let closure = outerFunction();
closure(); // Output: I am outside!
```
In this example, `innerFunction` forms a closure, retaining access to `outerVar` even after `outerFunction` has finished executing.
##### Practical Use Case
Closures are often used for data encapsulation, creating private variables that cannot be accessed directly from outside the function.
```javascript
function createCounter() {
let count = 0;
return {
increment: function() {
count++;
console.log(count);
},
decrement: function() {
count--;
console.log(count);
}
};
}
let counter = createCounter();
counter.increment(); // Output: 1
counter.increment(); // Output: 2
counter.decrement(); // Output: 1
```
In this example, `count` is a private variable, accessible only through the `increment` and `decrement` methods. This encapsulation prevents external code from directly modifying `count`, ensuring better control over the variable's state.
##### Module Pattern
The module pattern uses closures to create private and public members, providing a way to organize and encapsulate code.
```javascript
let module = (function() {
let privateVar = "I am private";
function privateMethod() {
console.log(privateVar);
}
return {
publicMethod: function() {
privateMethod();
}
};
})();
module.publicMethod(); // Output: I am private
// module.privateMethod(); // Uncaught TypeError: module.privateMethod is not a function
```
Here, `privateVar` and `privateMethod` are private members, accessible only within the closure. The `publicMethod` function is exposed as a public member, allowing controlled access to the private members.
#### 5. Advanced Topics
To fully leverage objects, scopes, and closures in JavaScript, understanding some advanced topics is beneficial. These topics include prototypal inheritance, the `this` keyword, and immediately invoked function expressions (IIFEs).
##### Prototypal Inheritance
JavaScript uses prototypal inheritance, where objects can inherit properties and methods from other objects. This is different from classical inheritance found in languages like Java.
```javascript
function Animal(name) {
this.name = name;
}
Animal.prototype.speak = function() {
console.log(this.name + " makes a noise.");
};
function Dog(name) {
Animal.call(this, name); // Call the parent constructor
}
Dog.prototype = Object.create(Animal.prototype);
Dog.prototype.constructor = Dog;
Dog.prototype.speak = function() {
console.log(this.name + " barks.");
};
let dog = new Dog("Rex");
dog.speak(); // Output: Rex barks.
```
In this example, `Dog` inherits from `Animal`, but overrides the `speak` method to provide specific behavior for dogs.
##### The `this` Keyword
The `this` keyword in JavaScript refers to the context in which a function is executed. Its value depends on how the function is called.
```javascript
let person = {
name: "Alice",
greet: function() {
```javascript
let person = {
name: "Alice",
greet: function() {
console.log("Hello, " + this.name);
}
};
person.greet(); // Output: Hello, Alice
let greet = person.greet;
greet(); // Output: Hello, undefined
```
In the example above, when `greet` is called as a standalone function, `this` does not refer to the `person` object, resulting in `undefined` for `name`. To ensure `this` refers to the intended object, you can use the `bind` method.
```javascript
let greetBound = person.greet.bind(person);
greetBound(); // Output: Hello, Alice
```
##### Immediately Invoked Function Expressions (IIFEs)
IIFEs are functions that are executed immediately after they are defined. They create a new scope, which can be useful for avoiding variable collisions in the global scope.
```javascript
(function() {
let privateVar = "I am private";
console.log(privateVar); // Output: I am private
})();
// console.log(privateVar); // Uncaught ReferenceError: privateVar is not defined
```
IIFEs can also be used to initialize modules and create isolated environments for code execution.
```javascript
let module = (function() {
let privateVar = "I am private";
function privateMethod() {
console.log(privateVar);
}
return {
publicMethod: function() {
privateMethod();
}
};
})();
module.publicMethod(); // Output: I am private
```
In this example, the IIFE creates a module with private and public members, demonstrating a practical use of closures for encapsulation.
#### 6. Best Practices
Understanding objects, scopes, and closures is essential, but applying best practices ensures your JavaScript code is clean, efficient, and maintainable.
##### Avoiding Global Variables
Minimize the use of global variables to reduce the risk of naming conflicts and unintended side effects. Use local scope and closures to encapsulate variables.
```javascript
(function() {
let localVar = "I am local";
console.log(localVar); // Output: I am local
})();
```
##### Using `const` and `let` Instead of `var`
Prefer `const` and `let` over `var` to leverage block scoping and prevent issues related to hoisting.
```javascript
if (true) {
let blockScoped = "I am block scoped";
console.log(blockScoped); // Output: I am block scoped
}
// console.log(blockScoped); // Uncaught ReferenceError: blockScoped is not defined
```
##### Understanding `this`
Always be aware of the context in which `this` is used. Use `bind`, `call`, or `apply` to explicitly set the value of `this` when necessary.
```javascript
let person = {
name: "Alice",
greet: function() {
console.log("Hello, " + this.name);
}
};
let greet = person.greet.bind(person);
greet(); // Output: Hello, Alice
```
##### Keeping Functions Pure
Strive to write pure functions, which are functions that do not have side effects and return the same output given the same input. This practice makes your code more predictable and easier to test.
```javascript
function add(a, b) {
return a + b;
}
console.log(add(2, 3)); // Output: 5
```
##### Using Closures Wisely
Closures are powerful but can lead to memory leaks if not managed properly. Ensure that closures do not unnecessarily retain references to objects or variables that are no longer needed.
```javascript
function createCounter() {
let count = 0;
return {
increment: function() {
count++;
console.log(count);
},
decrement: function() {
count--;
console.log(count);
}
};
}
let counter = createCounter();
counter.increment(); // Output: 1
counter.decrement(); // Output: 0
```
#### 7. Summary
Objects, scopes, and closures form the backbone of JavaScript programming. Objects allow you to structure your data and functionality in a logical way. Scopes control the accessibility of variables, ensuring that your code is modular and conflict-free. Closures provide a powerful mechanism for preserving state and creating encapsulated environments.
By mastering these concepts, you can write more robust, maintainable, and efficient JavaScript code. Whether you are creating simple scripts or complex applications, a deep understanding of these core principles is essential for any JavaScript developer. With practice and thoughtful application of best practices, you can leverage the full power of JavaScript to build dynamic and interactive web experiences. | emmanuelj | |
1,865,602 | Day 3 of my progress as a vue dev | About today So, I implemented the quiz taking feature. It allows user to retrieve a created quiz from... | 0 | 2024-05-26T12:25:23 | https://dev.to/zain725342/day-2-of-my-progress-as-a-vue-dev-4pkf | webdev, typescript, tailwindcss, vue | **About today**
So, I implemented the quiz taking feature. It allows user to retrieve a created quiz from local storage on runtime with the help of a special key and attempt it and keep track of the points based on the correct answers.
**What's next?**
Now I have to implement the time constraint under which user will attempt the quiz and I also want to show the user all the correct answers and the answers they selected in the review section.
**Improvements required**
I want to refactor my code and use a few of the vue features like suspense to show a skeleton as well as slot to make use of already constructed structure outline.
Wish me luck! | zain725342 |
1,865,563 | Ethereum Hits the Road to $4,000. Or Not? | Positive Ethereum ETF updates ignite ETH’s spiking. Are we seeing it achieving the crucial... | 0 | 2024-05-26T12:12:46 | https://dev.to/endeo/ethereum-hits-the-road-to-4000-or-not-3d4g | webdev, javascript, web3, blockchain | #### Positive Ethereum ETF updates ignite ETH’s spiking. Are we seeing it achieving the crucial $4k milestone?
Ethereum (ETH) has recorded a two-month high as the odds of the Ethereum Exchange Traded Fund’s (ETF) launch stepped up.
According to Eric Balchunas, a senior Bloomberg analyst, the U.S. Security and Exchange Commission (SEC) is to do a 180 on Ethereum ETF approval. Previously, SEC used to implicitly stand against the action, as per Reuters’ sources.
Furthermore, Reuters claims that the U.S. securities regulator on Monday asked Nasdaq, CBOE, and NYSE to fine-tune their application to list spot Ether ETFs, signalling the agency may be poised to approve the filings.
On Tuesday, a Bloomberg analyst James Seyffart revealed that 5 of the potential Ethereum ETF issuers (VanEck, Fidelity, Invesco/Galaxy, Ark/21Shares, and Franklin) submitted their amended 19b-4 filings, which are believed to be the technical requirements for ETF approval.
The positive developments fuelled Ether market performance, as the asset’s price surged 18% Monday and registered another 8.6% uptick Tuesday before lately retreating to $3,700 range.
While a green light from the SEC would be a major win for the cryptocurrency industry, the debates on Ether hitting its significant $4,000 milestone heated up. The technical indicators and on-chain data hint at the potential uptick, but with the media impact in action, such evaluation may turn out to be an error.
## Ethereum’s Seeks Record Interest
The increased potential for Ethereum ETF approval sparked an interest in the asset.
According to Santiment, ETH’s daily trading volume has surged 200% in momentum and totalled $37 billion, registering a two-month high.
The Monday uptick led to a year-to-date high of $80 million short liquidations, as per Coinglass data. In comparison, the amount of long positions liquidated on the same day was $26 million.
Furthermore, whales entered the rally, which can be noted by Santiment-monitored whale activity in the last 72 hours. Specifically, over May 20, 1393 transactions over $1 million were carried out, hitting a month-high since April 14.
Santiment data also revealed that the attention to Ether has resulted in an uptick in its social activity. According to the source, the coin’s social dominance on Monday broke a three-month record and totalled 2.28%.
## $4,600 As The Next Goal for Ether
Technical analysis indicates that Ethereum has all chances to keep up with the rally in the long term.
A closer look at the monthly chart reveals that Ether’s price action against TetherUS (USDT) forms a rounding bottom pattern, which clearly marks a positive trend reversal in a long-term perspective.
As the neckline for this continuation pattern is at $4,635, the bullish comeback alongside broader market recovery signifies a high likelihood of a breakout.
Notably, the bullish monthly candle hints at positive trend continuation, seeing that Ether’s latest recovery took place at the successful retest of 50% (0.5) Fibonacci level.
Daily chart unveils a similar trend. Ether displays a bullish breakout of a falling wedge pattern going straight up. The uptrend challenges the trend-based 50% Fibonacci level and the $3,800 price level.
Furthermore, a crossover in Moving Average Convergence Divergence (MACD) and signal lines reflect a surge in underlying demand.
Crucially, Ethereum’s correlation with Bitcoin (BTC) marks the long-term upswing as well. The 4-hour chart reveals that ETH/BTC pair broke a long-term descending trend line (red), as can also be noted by the Relative Strength Index (RSI), which stands at 70 at the writing time.
What is more, Exponential Moving Averages (EMA) formed two golden cross patterns, which mark a strong bullish outlook. Thus, the first pattern is formed with 20-day EMA (light blue) and 50-day EMA (blue), and the second one is an intersection between 20-day EMA and 200-day EMA (red).
The chart indicates that the local high (resistance) at $0.05346 stands in the way of further price movement. However, breaking above it could strengthen Ether against Bitcoin, targeting highs above $0.06.
Given the on-chain data dynamics, Ether (ETH) price action is swayed by fundamental factors, foremost of which is a fact of Ethereum ETF approval. This, if the fund is approved this Thursday, we could see Ether cross the crucial $4,600 point for a new all-time high (ATH).
Conversely, if the crowd resonance will not be on Ethereum’s side, the asset’s price could slide below the $3,600 support to test the $3,273 level. If intense profit-booking or sell-the-news take action, there’s a strong chance Ether could retest the $3,000 price range.
## Will Ethereum Repeat Bitcoin’s Scenario?
According to Quinn Thompson, a crypto analyst and founder of Lekker Capital, Ethereum (ETH) remains undervalued against Bitcoin, despite the optimism about ETH.
“This leads me to believe that ETHBTC at 0.05 is still underpriced, particularly given we are in a bull market, entering the BananaZone and on-chain activity will likely make new ATHs in the coming months,” as goes in his post for X.
This puts Ethereum maxis in risk of not meeting the price surge expectations due to the ETF inflows – ones that boosted Bitcoin’s performance in March.
In the meantime, the market will focus on the SEC’s decision on May 23rd, which will dot the i’s of Ether’s prospective performance. | endeo |
1,865,562 | Streamlining the Company Registration Process in Kerala: A Comprehensive Guide | Starting a business is an exciting venture, but navigating the company registration process can be... | 0 | 2024-05-26T12:11:23 | https://dev.to/axis_digitalseo_582bb366/streamlining-the-company-registration-process-in-kerala-a-comprehensive-guide-56a8 | company, llp, webdev, beginners | Starting a business is an exciting venture, but navigating the company registration process can be daunting. In Kerala, the procedure involves several steps, each with specific requirements and legal formalities. This blog aims to demystify the company registration process in Kerala, providing a clear and concise guide to help entrepreneurs establish their businesses efficiently.
Understanding the Types of Business Entities
Before delving into the registration process, it's essential to understand the different types of business entities available in India, as the requirements and procedures may vary depending on the type you choose. The common types include:
1. Sole Proprietorship
2. Partnership Firm
3. Limited Liability Partnership (LLP)
4. Private Limited Company
5. Public Limited Company
6. One Person Company (OPC)
Each entity type has its own advantages, legal implications, and registration requirements.
Steps to Register a Company in Kerala
1. Choose the Right Business Structure
Selecting the appropriate business structure is the first step. Consider factors like liability, taxation, compliance requirements, and investment needs. Consulting with a legal or business advisor can be helpful in making this decision.
2. Obtain Digital Signature Certificate (DSC)
A Digital Signature Certificate is essential for online filing of documents with the Ministry of Corporate Affairs (MCA). The DSC can be obtained from certified agencies. Both directors and authorized signatories need to have DSCs.
3. Acquire Director Identification Number (DIN)
The next step is to obtain a Director Identification Number for all proposed directors of the company. This can be done by filing eForm DIR-3 on the MCA portal.
4. Name Approval
Choosing a unique and suitable name for your company is crucial. The name should comply with the Companies Act, 2013. File the RUN (Reserve Unique Name) form on the MCA portal to get your company name approved. It’s advisable to have a few backup names in case the preferred name is already taken.
5. Drafting and Filing the Incorporation Documents
Once the name is approved, you need to prepare the necessary incorporation documents, which include:
- Memorandum of Association (MOA): Outlines the company's objectives and scope of activities.
- Articles of Association (AOA): Defines the internal rules and regulations of the company.
These documents, along with other required forms, must be submitted online via the SPICe (Simplified Proforma for Incorporating a Company Electronically) form.
6. PAN and TAN Application
Apply for the company’s Permanent Account Number (PAN) and Tax Deduction and Collection Account Number (TAN) through the NSDL website or via the SPICe form itself.
7. Certificate of Incorporation
Upon successful verification of the documents, the Registrar of Companies (ROC) will issue a Certificate of Incorporation. This certificate signifies that your company is legally registered and includes the company’s Corporate Identification Number (CIN).
8. Open a Bank Account
With the Certificate of Incorporation, PAN, and other necessary documents, you can open a corporate bank account in the company’s name.
9. Register for GST
If your business turnover exceeds the prescribed threshold, registering for the Goods and Services Tax (GST) is mandatory. This can be done online on the GST portal.
10. Compliance and Licenses
Depending on the nature of your business, you may need additional licenses and registrations such as:
- Shops and Establishment License
- Professional Tax Registration
- ESI/PF Registration
Ensure compliance with all local, state, and central regulations.
Benefits of Professional Assistance
While the steps outlined above provide a roadmap for [registering a company in Kerala](https://axisdigitalpro.com/company-registration-in-kerala/), the process can be complex and time-consuming. Engaging professional services, such as business consultants or legal advisors, can offer several advantages:
- Expert Guidance: Professionals provide expert advice on choosing the right business structure and navigating legal requirements.
- Time Efficiency: They handle the paperwork and filings, saving you valuable time.
- Error Reduction: Professional assistance reduces the risk of errors in documentation, which can lead to delays.
- Compliance Assurance: Ensure that your business complies with all legal and regulatory requirements.
Conclusion
Registering a company in Kerala involves a series of well-defined steps, each with its own set of requirements and procedures. Understanding and following these steps meticulously is crucial for a smooth registration process. While it is possible to handle the registration on your own, seeking professional assistance can streamline the process, allowing you to focus on building and growing your business.
By following this comprehensive guide, you can navigate the company registration process in Kerala with confidence and set the foundation for your business’s success.
| axis_digitalseo_582bb366 |
1,865,561 | Hi everyone, happy weekend! Where are you building today? :) | Hi everyone, happy weekend! Where are you building today? :) | 0 | 2024-05-26T12:05:57 | https://dev.to/nevodavid/hi-everyone-happy-weekend-where-are-you-building-today--11pi | discuss | Hi everyone, happy weekend! Where are you building today? :) | nevodavid |
1,865,504 | Open document in "Viewing" mode | Have you ever opened a Google Doc and while looking through it unknowingly updated it? This adds to... | 0 | 2024-05-26T11:59:46 | https://dev.to/rationalkunal/open-document-in-viewing-mode-5ej1 | javascript, extensions | Have you ever opened a Google Doc and while looking through it unknowingly updated it? This adds to unnecessary history to the doc.
To prevent it one can just open the doc in "Viewing" mode. But there is [no option](https://support.google.com/docs/thread/10477369/how-to-open-google-doc-always-in-viewing-mode?hl=en) to open the doc in "Viewing" mode by default.
After some reverse engineering, I discovered that the "Viewing" mode button is always present in the DOM once it gets added after the delay. This insight led me to write a script that ensures your Google Docs always open in "Viewing" mode by default.
Script to **Open Google document in "Viewing" mode by default**
```js
;(async function () {
// Some elements are not added to the DOM on initial load; one of such element is the menu containing "Viewing" mode.
// Await till the mode switcher menu is added to the DOM.
await new Promise(function (resolve) {
var observer = new MutationObserver(function (mutations) {
const targetContainerNode = document.querySelector('.docs-toolbar-mode-switcher-menu')
if (!!targetContainerNode) {
observer.disconnect()
resolve()
return
}
})
// ".docs-toolbar-mode-switcher-menu" attaches on the body
observer.observe(document.body, { childList: true })
})
const viewingModeButton = document.querySelector('.docs-toolbar-mode-switcher-viewing-menu-item')
if (!viewingModeButton) {
console.assert('[rational extension][doc mode] Unable to find mode buttons')
}
// Simulate click on viewing mode button
simulateClick(viewingModeButton)
console.count('[rational extension] Document mode be in "Viewing" mode')
})()
// For some reason the `HTMLElement.click()` method and just a `mousedown` event does not work here.
// To simulate click we need to fire `mousedown` followed by `mouseup` event
function simulateClick(onNode) {
const createMouseEvent = (name) =>
new MouseEvent(name, {
view: window,
bubbles: true,
cancelable: true,
})
onNode.dispatchEvent(createMouseEvent('mousedown'))
onNode.dispatchEvent(createMouseEvent('mouseup'))
}
```
Here is the output:
You can use this script with browser extensions like Tampermonkey. Personally, I'm compiling several such scripts into a custom extension for ease of use. Feel free to check out my project on GitHub: [Rational Chrome Extensions](https://github.com/rational-kunal/Rational-Chrome-Extensions).
Thank you for reading. | rationalkunal |
1,865,559 | Rule Changing Poker Game "Balatro" recreated in JavaScript - Behind the Code | "Balatro" is a rogue-like poker game that comes with all sorts of modifiers to change the rules mid... | 0 | 2024-05-26T11:53:10 | https://michaelzanggl.com/articles/balatro/ | javascript, webdev, oop | ["Balatro"](https://www.playbalatro.com/) is a rogue-like poker game that comes with all sorts of modifiers to change the rules mid game and allow you to score higher points. There's significant interactivity among various effects that occur and its developer even describes the game as being held together with hopes and dreams.
Let's put on our `poker face` and see if, armed with the hindsight of the finished game, we can `ace` the development of its core mechanics, or if we'd be better off `flushing` our code down the drain?
## Terminology
As always, before we start coding, let's get the terminology straight.
- Hand ranking refers to the poker hand played (flush, straight, full house, three of a kind, etc.)
- Played cards are the cards placed on the table (up to 5)
- Scoring cards are the played cards contributing to the score (e.g. in 5 of spades, 5 of hearts, 7 of spades, the hand ranking is "pair" and only the first two cards count as scoring cards)
- Jokers refer to special cards acquired during gameplay that don't need to be played but have an effect on either the rules or the scoring of the game
## How the Game works
In case you haven't played the game, I'll break down one possible round of poker in Balatro:
- the user plays the cards: 9 of spades, jack of clubs, queen of clubs, and king of hearts
- the user previously added the following five jokers to his arsenal:
1. straights can contain a gap
2. straights and flushes only require four cards
3. copies joker ability from the joker to the right
4. retriggers face cards
5. Face cards get turned into spades
Let's see how the scoring goes for the above:
- We only played four cards and have a gap in there (missing the 10), but because we have joker 1 and 2 applied, this still counts as a straight.
- Face cards are also turned into spades so we have a flush as well. Hence the final hand ranking is a straight flush.
- We get an initial score for the poker hand played (for example 50 chips + 8x multiplier).
- We then go through each scored card and add its value to the score (e.g. 9 chips for the 9 of spades)
- Thanks to the "retrigger face cards" joker, face cards are scored an additional time...
- And thanks to the "copy joker ability", a third time as well!
- We then calculate the final score: 139 chips * 8 multiplier = 1398
There are even jokers that multiply your multiplier which are often the secret to winning later rounds that require a high score to beat.
## Coding
Before we get to the fun part, which is the jokers, we need to set up the basic functionality to score points.
Let's create the PlayCard class which we use to create the poker cards:
```javascript
let lastPlayCardId = 0
const numberedCards = ['2', '3', '4', '5', '6', '7', '8', '9', '10']
const faceCards = ['jack', 'queen', 'king']
// we use this to sort and identify straights
const cardRanks = [...numberedCards, ...faceCards, 'ace']
class PlayCard {
constructor(name, suit) {
lastPlayCardId++
this.uid = lastPlayCardId
this.name = name
this.suit = suit
}
isFace() {
return faceCards.includes(this.name)
}
isNumbered() {
return numberedCards.includes(this.name)
}
getRank() {
return cardRanks.indexOf(this.name)
}
points() {
if (this.isNumbered()) {
return Number(this.name)
}
return 10
}
}
```
## Determine Hand Rankings
Next, let's determine the hand ranking that was played. We can use this code for it:
```javascript
// a library of mine to simplify data manipulation
const { given } = require('flooent')
// hand rankings are listed from best to worst
const handRankingOptions = {
// ...we just show the bottom too for now
'pair': {
chips: 10, // how many chips you score with a pair
mult: 2, // how many multipliers get added when you score with a pair
level: 1, // the level of hand ranking (can be leveled up)
minCards: 2, // the number of cards required for this hand ranking to be valid
matches(playedCards, pairs) {
if (pairs.length === 1) {
return { scoringCards: pairs[0] }
}
}
},
'highest': {
// ...
matches(playedCards) {
return { scoringCards: [playedCards.at(-1)] }
}
}
}
function determineHandRanking(playedCards) {
const playedCardsSorted = given.array(playedCards)
.sortAsc(card => card.getRank())
.valueOf()
// collect all pairs needed for various ranking checks like full house or pairs
const pairs = given.array(playedCards)
.groupBy('name')
.values()
.filter(pair => pair.length > 1)
.valueOf()
for (const handRanking of Object.keys(handRankingOptions)) {
const option = handRankingOptions[handRanking]
if (playingCardsSorted.length < round.handRankings[handRanking].minCards) continue
// if hand ranking matches, return the scoring cards and hand ranking
const result = option.matches.call(handRankingOptions, playedCardsSorted, pairs)
if (result) {
// skip if not enough cards -> prevents flush with less than 5 cards
if (result.scoringCards.length < round.handRankings[handRanking].minCards) continue
return { scoringCards: result.scoringCards, handRanking }
}
}
// will never reach here as "highest" will always return the highest card played at last
}
```
With this, we have a basic implementation to identify the hand rankings. Below are the remaining rankings.
We will need to modify the code later again to accomodate for specific jokers. What's really useful here is to write tests as you code along to not run into regressions.
```javascript
const handRankingOptions = {
'straightFlush': {
// ...
matches(playedCards, pairs) {
const straightResult = this.straight.matches.call(this, playedCards)
if (!straightResult) return
return this.flush.matches.call(this, given.array(straightResult.scoringCards))
}
},
'fourOfAKind': {
// ...
matches(playedCards, pairs) {
const fourOfAKind = pairs.find(pair => pair.length === 4)
if (fourOfAKind) {
return { scoringCards: fourOfAKind }
}
}
},
'fullHouse': {
// ...
matches(playedCards, pairs) {
const threeOfAKind = pairs.find(pair => pair.length === 3)
if (threeOfAKind && pairs.length === 2) {
return { scoringCards: playedCards }
}
}
},
'flush': {
// ...
matches(playedCards) {
if (given.array(playedCards).unique('suit').length === 1) {
return { scoringCards: playedCards }
}
}
},
'straight': {
// ...
matches(playedCards) {
if (given.array(playedCards).map((c, idx) => c.getRank() - idx).unique().length === 1) {
return { scoringCards: playedCards }
}
}
},
'threeOfAKind': {
// ...
matches(playedCards, pairs) {
const threeOfAKind = pairs.find(pair => pair.length === 3)
if (threeOfAKind) {
return { scoringCards: threeOfAKind }
}
}
},
'twoPair': {
// ...
matches(playedCards, pairs) {
if (pairs.length === 2) {
return { scoringCards: pairs.flat() }
}
}
},
// ...pair and highest (see in previous code example)
}
```
## Scoring
Now that that's out of the way we can create a function to handle what happens after the user has played the cards. This will be the injection point for our joker effects later. Let's first create the Score class:
```javascript
class Score {
chips = 0
mult = 0
scoreBreakdown = []
constructor(handRankingOption) {
// initialize score with the determined hand ranking
this.scoreEffect({ type: 'chips', operation: 'add', value: handRankingOption.chips })
this.scoreEffect({ type: 'mult', operation: 'add', value: handRankingOption.mult })
}
scoreCard(card) {
this.scoreEffect({ type: 'chips', operation: 'add', value: card.points() })
}
scoreEffect(effect) {
if (effect.operation === 'add') {
this[effect.type] += effect.value
} else if (effect.operation === 'multiply') {
this[effect.type] *= effect.value
}
this.scoreBreakdown.push(effect)
}
total() {
return this.chips * this.mult
}
}
```
This class takes care of the calculations for us and saves a breakdown of every score change. This breakdown is powerful since it's easy to compare the score like this in tests without manually calculating and comparing the final score.
```javascript
function calculateScore(playedCards, jokers) {
const { scoringCards, handRanking } = determineHandRanking(playedCards)
const score = new Score(handRankingOptions[handRanking])
// add each card's points to the score
for (const card of round.scoringCards) {
score.scoreCard(card)
}
return { score }
}
```
And like this we have our very very basic poker functionality. Now, to the fun part!
## Jokers
So turns out, there isn't just one type of joker, in fact I identified 4 different types. This means, we need 4 different injection points to apply the joker's effects.
> A restriction I set for this excercise is not littering the code with if conditions for joker effects. The logic for the jokers should be solvable within the joker classes themselves. Ideally, this should make the code more easily extensible and modifyable, but just like boss blinds in the game, such restrictions also make challenges like this more interesting to solve in general.
The injection points are as follows:
```javascript
function calculateScore(playedCards, jokers) {
const round = new Round(playedCards, jokers)
// 👇 Jokers that modify the setup, like changing rules/played cards.
// E.g.: straights can contain gaps
round.jokers.forEach(j => j.modifySetup?.(round))
round.determineHandRanking()
// 👇 Jokers that modify the scoring cards or ranking after it was determined
// E.g.: Every played card counts in scoring
round.jokers.forEach(j => j.modifyScoring?.(round))
const score = new Score(round.getHandRankingOption())
for (const card of round.scoringCards) {
score.scoreCard(card)
// 👇 Jokers that run for specific cards and are triggered one by one
// E.g.: Add x4 to Mult for each face card scored
round.jokers.forEach(j => j.scoreExtraPerCard?.(round, score, card))
}
// 👇 Jokers that run per round to add to the score
// E.g.: Add x4 to Mult if scored using three cards or fewer
round.jokers.forEach(j => j.scoreExtraPerRound?.(round, score))
return { round, score }
}
```
> Now, it would be possible to condense the last 2 or even 3 joker types into just the "scoreExtraPerRound"-type Joker. But the order in which joker effects are applied matters, so the score would only be calculatable after sorting the score breakdown accordingly which would also require more information. Let's hold off on that for the time being.
Looking at the code, we've also established the "Round" class which is as high as we go in this demo.
> There's no need for "Game", "Ante", or "Blind" to play around with jokers. That's why you also see this mix of classes and stand-alone functions. We simply want to put our focus on the core part of the game, the rest's just there to help with that for now.
Back to the "Round" class. This class will hold vital information that jokers can access and mutate!
```javascript
class Round {
handRankingOptions = deepcopy(handRankingOptions) // copy to allow mutations by jokers
handRanking = ''
scoringCards = []
constructor(playedCards, jokers) {
this.playedCards = playedCards
this.jokers = jokers
}
getHandRankingOption() {
return this.handRankingOptions[this.handRanking]
}
determineHandRanking() {
const { scoringCards, handRanking } = determineHandRanking(this) // "determineHandRanking" was changed to take an instance of Round as its argument
this.handRanking = handRanking
this.scoringCards = scoringCards
}
}
```
---
Now we have everything set up, and all that's left is to create jokers!
Let's create our very first one, I think it speaks for itself!
```javascript
class Joker {} // could add base methods down the line
class FibonnacciJoker extends Joker {
scoreExtraPerCard(round, score, card) {
if (['2', '3', '5', '8', '10', 'ace'].includes(card.name)) {
score.scoreEffect({ type: 'mult', operation: 'add', value: 4 })
}
}
}
```
The test lets you see the score break down in which you can observe that after 5 and 8 were added, a 4x multiplier was added thanks to the joker!
```javascript
describe('FibonnacciJoker', () => {
it('adds 4x multiplier for each number in the fibonacci sequence', () => {
const jokers = [new Joker.FibonnacciJoker]
const cardsPlayed = [
new PlayCard('5', 'spade'),
new PlayCard('6', 'diamond'),
new PlayCard('7', 'heart'),
new PlayCard('8', 'club'),
new PlayCard('9', 'club')
]
const {score} = calculateScore(cardsPlayed, jokers)
expect(score.getEffectsBreakdown()).toEqual([
{ operation: 'add', value: 5, type: 'chips' },
{ operation: 'add', value: 4, type: 'mult' },
{ operation: 'add', value: 6, type: 'chips' },
{ operation: 'add', value: 7, type: 'chips' },
{ operation: 'add', value: 8, type: 'chips' },
{ operation: 'add', value: 4, type: 'mult' },
{ operation: 'add', value: 9, type: 'chips' }
])
})
})
```
"score.getEffectsBreakdown()" is a utility method that will return the score breakdown without the two initial chip + mult scores.
"scoreExtraPerRound" jokers work similarly in that given a certain condition is met, it will add a specific amount to the final score:
```javascript
class ContainsThreeOrFewerCardsJoker extends Joker {
scoreExtraPerRound(round, score) {
if (round.scoringCards.length <= 3) {
score.scoreEffect({ type: 'mult', operation: 'add', value: 20 })
}
}
}
```
Hey, we can even implement our very own jokers!
```javascript
class AnswerToEverythingJoker extends Joker {
scoreExtraPerRound(round, score) {
if (given.array(round.playedCards).sum(c => c.points()) === 42) {
score.scoreEffect({ type: 'mult', operation: 'multiply', value: 42 })
}
}
}
```
These two types of jokers can also contain their own state, like this joker which will add an additional x1 to mult for every time the current hand ranking is played:
```javascript
class PlusOneForPlayingHand extends Joker {
gameState = {
timesPlayed: {}
}
scoreExtraPerRound(round, score) {
this.gameState.timesPlayed[round.handRanking] = this.gameState.timesPlayed[round.handRanking] ?? 0
this.gameState.timesPlayed[round.handRanking]++
score.scoreEffect({ type: 'mult', operation: 'add', value: this.gameState.timesPlayed[round.handRanking] })
}
}
```
There's also "roundState" which gets reset in the Round's constructor. This way we can implement retrigger jokers without causing an infinite loop if two such jokers are applied at the same time (as we have to retrigger all the other jokers as well):
```javascript
class RetriggerLowNumbersJoker extends Joker {
roundState = {
triggered: {}
}
scoreExtraPerCard(round, score, card) {
if (!['2', '3', '4', '5'].includes(card.name)) return
if (this.roundState.triggered[card.id]) return
this.roundState.triggered[card.id] = true
score.scoreCard(card)
round.jokers.filter(j => j.id !== this.id).forEach(j => {
j.scoreExtraPerCard?.(round, score, card)
})
}
}
```
Regarding "modifyScoring" jokers, I only have one so far which is the "all played cards count in scoring". It's as simple as this:
```javascript
class AllCardsCountJoker extends Joker {
modifyScoring(round) {
round.scoringCards = round.playedCards
}
}
```
Much more interesting is the first type "modifySetup" as it allows for changing the rules of the game!
## modifySetup Jokers
The first one is quite simple. It swaps the suit to spade for any face card played (before we determine the hand ranking):
```javascript
class FaceCardsAreSpadesJoker extends Joker {
modifySetup(round) {
round.playedCards = round.playedCards.map(card => {
if (card.isFace()) {
return new card.constructor(card.name, 'spade', card.effects)
}
return card
})
}
}
```
To show how it works with other jokers, let's add another joker that adds a 4x multiplier for each card of the suit spades:
```javascript
class MultForSpadeJoker extends Joker {
scoreExtraPerCard(round, score, card) {
if (card.suit === 'spade') {
score.scoreEffect({ type: 'mult', operation: 'add', value: 4 })
}
}
}
```
As you can see in this test, we now get the extra multipliers for achieving a pair with the two played cards:
```javascript
it('applies effect of MultForSpadeJoker for non-spade cards if FaceCardsAreSpadesJoker is set', () => {
const jokers = [new Joker.MultForSpadeJoker, new Joker.FaceCardsAreSpadesJoker]
const cardsPlayed = [
new PlayCard('jack', 'heart'),
new PlayCard('jack', 'heart'),
]
const {round, score} = calculateScore(cardsPlayed, jokers)
expect(round.handRanking).toBe('pair')
expect(score.getEffectsBreakdown('mult')).toEqual([
{"operation": "add", "type": "mult", "value": 4},
{"operation": "add", "type": "mult", "value": 4}
])
})
```
---
Next, let's look at our final three jokers, they all work in conjunction with each other and we have to change some of the hand ranking logic for that to work out.
The first joker will allow us to create straights and flushes using only four cards. For this, we simply mutate the "minCards" property.
```javascript
class SmallStraightFlushJoker extends Joker {
modifySetup(round) {
round.handRankingOptions.straight.minCards = 4
round.handRankingOptions.straightFlush.minCards = 4
round.handRankingOptions.flush.minCards = 4
}
}
```
> We are straight up mutating objects in the instance of "round" within the joker here. Usually you'd try to avoid mutations if possible but in this very instance I give it a pass as it's literally the joker's job to mutate the round's setup. But it wouldn't be too hard to migrate this to more "pure" code.
Using this joker already breaks our code to identify straights and flushes as it should still count when there's an invalid 5th card in the mix. Time to fix it!
Let's first look at the old "flush" code:
```js
matches(playedCards) {
if (given.array(playedCards).unique('suit').length === 1) {
return { scoringCards: playedCards }
}
}
```
To fix this, we shouldn't check if there's just one suit available, instead, we check for the suit with the most cards and return those. The "determineHandRanking" function already checks for us if the minimum cards were played.
```js
matches(playedCards) {
const scoringCards = given.array(playedCards)
.groupBy('suit')
.values()
.sortDesc(cards => cards.length)
.first()
return scoringCards ? { scoringCards } : false
}
```
With this, the next flush-related joker is "Hearts and Diamonds count as the same suit, Spades and Clubs count as the same suit" is trivial to implement.
To do so, we can replace the "matches" method with a custom one which reduces the four suits into just two:
```javascript
class ReducedSuitsJoker extends Joker {
modifySetup(round) {
const redSuits = ['heart', 'diamond']
round.handRankings.flush.matches = function(playedCards) {
const scoringCards = given.array(playedCards)
// This is the only change
.groupBy(c => redSuits.includes(c.suit) ? 'red' : 'black')
.values()
.sortDesc(cards => cards.length)
.first()
return scoringCards ? { scoringCards } : false
}
}
}
```
---
Finally, we have the joker "Allows Straights to be made with gaps of 1 rank".
For memory, this is the old logic for straights:
```js
matches(playedCards) {
if (given.array(playedCards).map((c, idx) => c.getRank() - idx).unique().length === 1) {
return { scoringCards: playedCards }
}
}
```
This one is indeed a bit tricky having to consider both the "only 4 cards" and "can contain a gap" jokers.
Let's first look at the new code to allow for 4 cards to be played:
```javascript
isNextValid(previous, next) {
return previous.getRank() + 1 === next.getRank()
},
matches(playedCards) {
let scoringCards = []
for (const card of playedCards) {
const previous = scoringCards.at(-1)
if (!previous || this.straight.isNextValid(previous, card)) {
scoringCards.push(card)
} else if (scoringCards.length === 1) {
// reset as first card must have been wrong, second chance with the remaining 4 cards
scoringCards = [card]
}
}
return { scoringCards }
}
```
This new "matches" method is a lot more procedural but allows for a fifth invalid card in the beginning, middle, or end.
We also broke out the actual comparison between previous and next into a new method "isNextValid".
Now we can easily implement the "can contain gaps" joker by overriding only the tiny method "isValidNext" accordingly!
```javascript
class SkipNumberStaightJoker extends Joker {
modifySetup(round) {
round.handRankingOptions.straight.isNextValid= function(previous, next) {
return (!previous || (previous.getRank() + 1 === next.getRank()) || (previous.getRank() + 2 === next.getRank()))
}
}
}
```
We could do the same with flush but I thought its code was very straight forward compared to identifying straights.
And here you can see a test with four different jokers combined!
```javascript
it('can combine various straight and flush jokers together', () => {
const jokers = [new Joker.SkipNumberStaightJoker, new Joker.SmallStraightFlushJoker, new Joker.FaceCardsAreSpadesJoker, new Joker.ReducedSuitsJoker]
const cardsPlayed = [
new PlayCard('7', 'spade'),
new PlayCard('9', 'spade'),
new PlayCard('10', 'club'),
new PlayCard('jack', 'heart'),
]
const {round} = calculateScore(cardsPlayed, jokers)
expect(round.handRanking).toBe('straightFlush')
})
```
## Conclusion
And with that, we have completed the basic integration of Balatro's Joker system! The real game offers even more features such as card modifiers, blinds, etc. But I hope you got a good look into the game's mechanics and that you will give [the game](https://www.playbalatro.com/) a try!
| michi |
1,865,558 | Understanding Lombok: Simplifying Java Code with Ease | Introduction In the realm of Java development, boilerplate code is often a necessary evil.... | 0 | 2024-05-26T11:47:47 | https://dev.to/fullstackjava/understanding-lombok-simplifying-java-code-with-ease-o5i | tutorial, opensource, learning, java | ### Introduction
In the realm of Java development, boilerplate code is often a necessary evil. Writing getters, setters, constructors, and other repetitive code can be time-consuming and error-prone. Enter Project Lombok, a Java library that aims to reduce the amount of boilerplate code in your projects, making your code more concise and readable. This blog will delve into the details of Lombok, exploring its features, benefits, and how to integrate it into your Java projects.
### What is Lombok?
Lombok is an open-source Java library that helps developers reduce boilerplate code by providing a set of annotations to automatically generate commonly used code constructs. By using Lombok, developers can focus more on the business logic of their applications rather than writing repetitive code.
### Key Features of Lombok
Lombok offers a variety of annotations to simplify different aspects of Java programming:
1. **@Getter and @Setter**: Automatically generates getter and setter methods for fields.
2. **@ToString**: Creates a `toString()` method that includes all non-static fields.
3. **@EqualsAndHashCode**: Generates `equals()` and `hashCode()` methods.
4. **@NoArgsConstructor, @RequiredArgsConstructor, and @AllArgsConstructor**: Generate constructors with no arguments, required arguments (final fields), and all arguments, respectively.
5. **@Data**: A convenient shortcut that bundles `@Getter`, `@Setter`, `@ToString`, `@EqualsAndHashCode`, and `@RequiredArgsConstructor`.
6. **@Builder**: Implements the builder pattern for object creation.
7. **@Log**: Generates a logger field.
### How Lombok Works
Lombok uses annotation processing to generate code at compile-time. When you annotate your Java classes with Lombok annotations, the Lombok processor intercepts these annotations during compilation and generates the necessary boilerplate code. This process is transparent to the developer and does not affect the runtime performance of the application.
### Integrating Lombok into Your Project
#### Maven
To use Lombok with a Maven project, add the following dependency to your `pom.xml`:
```xml
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
<scope>provided</scope>
</dependency>
```
#### Gradle
For a Gradle project, add Lombok to your `build.gradle` file:
```groovy
dependencies {
compileOnly 'org.projectlombok:lombok:1.18.24'
annotationProcessor 'org.projectlombok:lombok:1.18.24'
}
```
### Example Usage
Let's explore some common Lombok annotations with examples.
#### @Getter and @Setter
```java
import lombok.Getter;
import lombok.Setter;
public class User {
@Getter @Setter
private String name;
@Getter @Setter
private int age;
}
```
In this example, Lombok generates getter and setter methods for the `name` and `age` fields.
#### @ToString
```java
import lombok.ToString;
@ToString
public class User {
private String name;
private int age;
}
```
The `@ToString` annotation generates a `toString()` method that includes the `name` and `age` fields.
#### @EqualsAndHashCode
```java
import lombok.EqualsAndHashCode;
@EqualsAndHashCode
public class User {
private String name;
private int age;
}
```
This annotation generates `equals()` and `hashCode()` methods based on the `name` and `age` fields.
#### @Data
```java
import lombok.Data;
@Data
public class User {
private String name;
private int age;
}
```
The `@Data` annotation is a convenient shortcut that combines `@Getter`, `@Setter`, `@ToString`, `@EqualsAndHashCode`, and `@RequiredArgsConstructor`.
#### @Builder
```java
import lombok.Builder;
@Builder
public class User {
private String name;
private int age;
}
```
The `@Builder` annotation allows you to create objects using the builder pattern.
```java
User user = User.builder()
.name("John Doe")
.age(30)
.build();
```
### Benefits of Using Lombok
1. **Reduces Boilerplate Code**: Lombok significantly reduces the amount of repetitive code you need to write.
2. **Improves Readability**: By eliminating boilerplate code, Lombok makes your classes more concise and easier to read.
3. **Enhances Productivity**: With less boilerplate to write, developers can focus more on business logic, increasing productivity.
4. **Consistency**: Lombok ensures that common methods like getters, setters, and constructors are consistently generated.
### Potential Drawbacks
While Lombok offers numerous benefits, it is important to be aware of potential drawbacks:
1. **Learning Curve**: New developers or those unfamiliar with Lombok may need time to learn its annotations and usage.
2. **Dependency**: Relying on Lombok means adding an external dependency to your project.
3. **Tooling Support**: Some IDEs and build tools may have limited support for Lombok, though this has improved significantly over time.
### Conclusion
Lombok is a powerful tool that simplifies Java development by reducing boilerplate code. Its annotations make your code more concise, readable, and maintainable. By integrating Lombok into your projects, you can focus more on writing business logic and less on repetitive tasks. However, it's essential to weigh the benefits against the potential drawbacks and ensure your team is comfortable with adopting this library. Overall, Lombok can be a valuable addition to your Java development toolkit. | fullstackjava |
1,865,557 | Exploring the Timeless Elegance of the Chiton Garment | Explore the timeless appeal of the ancient chiton garment, a symbol of grace and simplicity.... | 0 | 2024-05-26T11:45:59 | https://dev.to/theon_greyjoy_eb641583a84/exploring-the-timeless-elegance-of-the-chiton-garment-25mc | Explore the timeless appeal of the ancient [chiton garment](https://www.revisebook.com/articles/chiton-garment/), a symbol of grace and simplicity. Originating in ancient Greece, the chiton is a classic piece in fashion history, combining comfort and sophistication. This sleeveless tunic, usually made from linen or wool, drapes elegantly over the body, striking a harmonious balance of modesty and style. Whether worn by ancient philosophers or modern fashionistas, the chiton's enduring appeal transcends eras, making it a versatile and iconic garment. Delve into the legacy of the chiton and embrace its enduring charm in contemporary wardrobes. | theon_greyjoy_eb641583a84 | |
1,865,554 | Understanding the Scope Chain in JavaScript🚀 | Understanding the Scope Chain in JavaScript In JavaScript, understanding the scope chain... | 0 | 2024-05-26T11:40:47 | https://dev.to/madhurop/understanding-the-scope-chain-in-javascript-4390 | ### Understanding the Scope Chain in JavaScript
In JavaScript, understanding the scope chain is crucial for mastering how variables are resolved and how functions interact with their environment. This concept is fundamental to how JavaScript executes code, particularly in the context of nested functions and closures. Let's delve into what the scope chain is, how it works, and why it's important.
#### What is the Scope Chain?
The scope chain is a mechanism that JavaScript uses to keep track of variable contexts, ensuring that the right variables are accessed at the right times. It’s essentially a chain of lexical environments (also called scopes) that JavaScript traverses to resolve variable names.
#### Lexical Environment
A lexical environment is a structure that holds variable and function declarations. Each time a function is invoked, a new lexical environment is created. Lexical environments can be thought of as "layers" that contain all the variable bindings for that particular function execution context.
#### How the Scope Chain Works
1. **Global Scope**: When a script is first executed, the global execution context is created. This is the outermost scope, containing globally declared variables and functions.
2. **Function Scope**: Every time a function is invoked, a new function execution context is created. Each of these contexts has its own lexical environment.
3. **Nested Scopes**: If a function is defined inside another function, it creates a nested scope. The inner function has access to its own scope, the outer function’s scope, and the global scope.
When a variable is referenced, JavaScript starts by looking in the current lexical environment. If the variable isn’t found, it moves up to the next outer lexical environment, continuing this process until it either finds the variable or reaches the global scope. If the variable is not found in the global scope, a ReferenceError is thrown.
#### Example of Scope Chain
Consider the following example:
```javascript
let globalVar = "I am global";
function outerFunction() {
let outerVar = "I am outer";
function innerFunction() {
let innerVar = "I am inner";
console.log(globalVar); // Output: I am global
console.log(outerVar); // Output: I am outer
console.log(innerVar); // Output: I am inner
}
innerFunction();
}
outerFunction();
```
In this example:
- `innerFunction` has access to `innerVar`, `outerVar`, and `globalVar`.
- `outerFunction` has access to `outerVar` and `globalVar` but not `innerVar`.
- The global context has access only to `globalVar`.
#### Importance of the Scope Chain
Understanding the scope chain is essential for several reasons:
1. **Avoiding Naming Conflicts**: Knowing how scope chains work helps in avoiding variable naming conflicts, as you can predict which variables will be accessible in different parts of your code.
2. **Debugging**: When debugging, understanding the scope chain allows you to trace where variables are being accessed or modified, making it easier to locate issues.
3. **Closures**: The concept of closures, where an inner function retains access to its lexical scope even after the outer function has finished execution, relies on the scope chain. This enables powerful programming patterns like data encapsulation and function factories.
4. **Performance**: Efficient scope chain management can improve performance, as deeply nested scopes can lead to more complex and slower variable resolution.
#### Common Pitfalls
1. **Global Variables**: Overusing global variables can lead to unintentional overwrites and harder-to-maintain code. It’s often better to encapsulate variables within functions or modules.
2. **Shadowing**: This occurs when a variable declared in an inner scope has the same name as one in an outer scope. It can lead to confusion and bugs if not carefully managed.
```javascript
let value = "global";
function shadowingExample() {
let value = "local";
console.log(value); // Output: local
}
shadowingExample();
console.log(value); // Output: global
```
In this case, the inner `value` shadows the outer `value` within the `shadowingExample` function.
#### Conclusion
The scope chain is a foundational concept in JavaScript that plays a critical role in how variables are resolved and how functions interact with their surrounding contexts. Mastery of the scope chain leads to more predictable, maintainable, and efficient code. By understanding and leveraging the scope chain, you can write better JavaScript and avoid common pitfalls related to variable scope and closures. | madhurop | |
1,865,551 | 메이저사이트 | 메이저사이트 메이저사이트란 온라인배팅, 토토사이트 중 주로 신뢰도가 높고 견고성이 입증된 사이트를 말합니다. 이러한 웹사이트는 일반적으로 다음과 같은 특성을 가지고 있습니다. 주요... | 0 | 2024-05-26T11:29:48 | https://dev.to/playplugin08/meijeosaiteu-31k7 | **_[메이저사이트](https://www.outlookindia.com/plugin-play/%EB%A9%94%EC%9D%B4%EC%A0%80%EC%82%AC%EC%9D%B4%ED%8A%B8-best-7-%ED%86%A0%ED%86%A0%EC%82%AC%EC%9D%B4%ED%8A%B8-%EC%B6%94%EC%B2%9C-%EC%88%9C%EC%9C%84-2024%EB%85%84)_**
메이저사이트란 온라인배팅, 토토사이트 중 주로 신뢰도가 높고 견고성이 입증된 사이트를 말합니다. 이러한 웹사이트는 일반적으로 다음과 같은 특성을 가지고 있습니다. 주요 사이트는 일반적으로 오랫동안 운영되어 왔으며 이는 웹사이트의 균형과 신뢰성을 입증하는 구성 요소입니다. 장거리 조깅 사이트는 일반적으로 고객과의 신뢰를 구축하고 지속 가능한 공급자를 제공하는 것에 대해 인식하고 있습니다. 이들 사이트는 탄탄한 자본력을 바탕으로 운영되고 있습니다. 이는 대규모 베팅이나 큰 상금 지불에 안정적으로 응답하여 고객에게 균형감을 제공할 수 있음을 의미합니다. 빠른 입출금 업체 : 주요 사이트는 일반적으로 고객의 입출금 요청을 신속하게 처리합니다. 이는 운영 효율성과 훌륭한 고객 지원을 나타내는 중요한 지표입니다. 활발한 소비자 기반과 활발한 커뮤니티는 해당 웹페이지가 많은 고객들로부터 신뢰를 받고 있음을 보여줍니다. 또한, 고객간 사실교류 및 상호교류를 통해 웹페이지의 건전한 운영을 도모하고 있습니다. 높은 수준의 고객 지원은 주요 사이트의 중요한 특징입니다. 이는 문제 해결, 질문에 대한 빠른 응답, 소비자 만족도 향상을 위한 운영으로 구성됩니다. 기록을 안전하게 유지하려면 엄격한 보안 기능과 개인 정보 보호 규정이 중요합니다. 이는 웹사이트가 교도소 정책을 준수하며 안정적으로 운영되고 있음을 보여줍니다. '사기'란 사용자의 돈을 횡령하는 도메인을 일컫는 용어로, 현재 대부분의 웹사이트에서는 이러한 사기 행위를 하지 않는 것으로 널리 알려져 있습니다. 이러한 기능은 주요 사이트를 일반적인 온라인 베팅 웹사이트와 차별화하는 주요 요소입니다. 이러한 요소를 고려하여 사용자는 보다 안전하고 신뢰할 수 있는 베팅 환경을 선택할 수 있습니다. | playplugin08 | |
1,865,550 | 메이저사이트 | 메이저사이트란 무엇인가? 메이저사이트는 온라인 토토, 스포츠 베팅, 카지노 등 다양한 도박 활동을 제공하는 플랫폼 중에서 신뢰성과 안정성을 갖춘 사이트를 의미합니다. 메이저사이트는... | 0 | 2024-05-26T11:28:58 | https://dev.to/playplugin08/meijeosaiteu-3nc5 | 메이저사이트란 무엇인가?
메이저사이트는 온라인 토토, 스포츠 베팅, 카지노 등 다양한 도박 활동을 제공하는 플랫폼 중에서 신뢰성과 안정성을 갖춘 사이트를 의미합니다. 메이저사이트는 긴 운영 기간, 강력한 자본력, 높은 보안 수준, 공정한 게임 운영 등 다양한 요소를 통해 이용자들에게 안전하고 공정한 도박 환경을 제공합니다. 이러한 사이트들은 보통 라이센스를 보유하고 있으며, 정기적으로 외부 감사기관의 검토를 받습니다.
메이저사이트의 특징
1. 긴 운영 기간
메이저사이트의 중요한 특징 중 하나는 긴 운영 기간입니다. 긴 시간 동안 운영되어 온 사이트는 신뢰성을 확보한 경우가 많습니다. 운영 기간이 길수록 이용자들은 사이트의 안정성과 신뢰성에 대한 믿음을 가질 수 있습니다. 이는 사이트가 오랜 기간 동안 큰 문제 없이 운영되어 왔음을 의미하기 때문입니다.
**_[메이저사이트](https://www.outlookindia.com/plugin-play/%EB%A9%94%EC%9D%B4%EC%A0%80%EC%82%AC%EC%9D%B4%ED%8A%B8-best-7-%ED%86%A0%ED%86%A0%EC%82%AC%EC%9D%B4%ED%8A%B8-%EC%B6%94%EC%B2%9C-%EC%88%9C%EC%9C%84-2024%EB%85%84)_**
2. 강력한 자본력
메이저사이트는 강력한 자본력을 바탕으로 운영됩니다. 이는 사이트가 다양한 프로모션, 이벤트, 보너스를 제공할 수 있는 기반이 됩니다. 강력한 자본력은 또한 사이트의 기술적 인프라, 보안 시스템, 고객 지원 등에 투자할 수 있는 여력을 의미합니다. 자본력이 강한 사이트일수록 이용자들에게 더 나은 서비스와 안전한 도박 환경을 제공할 수 있습니다.
3. 높은 보안 수준
메이저사이트는 이용자들의 개인 정보와 자금을 보호하기 위해 높은 수준의 보안 시스템을 갖추고 있습니다. SSL 암호화, 이중 인증 등 최신 보안 기술을 도입하여 해킹이나 정보 유출을 방지합니다. 또한, 정기적으로 보안 점검을 실시하여 취약점을 최소화합니다.
4. 공정한 게임 운영
메이저사이트는 공정한 게임 운영을 보장합니다. 이를 위해 외부 감사기관의 정기적인 검토를 받으며, RNG(Random Number Generator)와 같은 기술을 통해 게임 결과의 공정성을 확보합니다. 공정한 게임 운영은 이용자들에게 신뢰를 제공하며, 공정한 경쟁 환경을 조성합니다.
메이저사이트와 메이저놀이터토토사이트의 차이점
메이저사이트와 메이저놀이터토토사이트는 모두 안전하고 신뢰할 수 있는 도박 환경을 제공하지만, 몇 가지 차이점이 있습니다.
1. 용어의 차이
메이저사이트는 일반적으로 다양한 도박 활동을 포괄하는 사이트를 의미합니다. 스포츠 베팅, 카지노, 포커, 슬롯 등 다양한 게임을 제공하는 반면, 메이저놀이터토토사이트는 주로 스포츠 베팅에 특화된 사이트를 의미합니다. 특히, 스포츠 경기 결과를 예측하는 토토 게임에 집중되어 있습니다.
2. 게임 종류
메이저사이트는 다양한 게임 옵션을 제공하여 이용자들이 한 사이트 내에서 여러 가지 게임을 즐길 수 있도록 합니다. 반면에 메이저놀이터토토사이트는 스포츠 베팅에 집중되어 있어, 주로 축구, 야구, 농구 등 다양한 스포츠 경기에 베팅할 수 있는 옵션을 제공합니다. 이는 스포츠에 관심이 많은 이용자들에게 특히 매력적입니다.
3. 이용자층
메이저사이트는 다양한 도박 게임을 즐기고자 하는 폭넓은 이용자층을 타겟으로 합니다. 반면에 메이저놀이터토토사이트는 스포츠 베팅을 즐기는 특정 이용자층을 겨냥합니다. 스포츠 베팅을 선호하는 이용자들은 메이저놀이터토토사이트에서 보다 전문적이고 심도 있는 스포츠 베팅 경험을 할 수 있습니다.
결론
메이저사이트는 긴 운영 기간, 강력한 자본력, 높은 보안 수준, 공정한 게임 운영을 통해 이용자들에게 신뢰성과 안정성을 제공합니다. 메이저사이트와 메이저놀이터토토사이트는 모두 안전하고 신뢰할 수 있는 도박 환경을 제공하지만, 게임 종류와 이용자층에 따라 차이가 있습니다. 다양한 도박 활동을 즐기고자 하는 이용자들은 메이저사이트를, 스포츠 베팅에 집중하고자 하는 이용자들은 메이저놀이터토토사이트를 선택하는 것이 적합할 수 있습니다. 각 사이트의 특징을 이해하고 자신의 취향과 필요에 맞는 사이트를 선택하는 것이 중요합니다 | playplugin08 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.