
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,909,950 | User and Group Management Script | Script Explanation The script automates the creation of users and groups on a Linux system, assigns... | 0 | 2024-07-03T10:03:30 | https://dev.to/olatunbosun_salako/user-and-group-management-script-m8n | **Script Explanation**
The script automates the creation of users and groups on a Linux system, assigns users to specified groups, sets random passwords, and logs the operations.
1. **Argument Check**

The script che... | olatunbosun_salako | |
1,909,948 | Functional Patterns: Recursions and Reduces | This is part 4 of a series of articles entitled Functional Patterns. Make sure to check out the... | 0 | 2024-07-03T10:02:16 | https://dev.to/if-els/functional-patterns-recursions-and-reduces-jhk | javascript, haskell, programming, learning | > This is part 4 of a series of articles entitled *Functional Patterns*.
>
> Make sure to check out the rest of the articles!
>
> 1. [The Monoid](https://dev.to/if-els/functional-patterns-the-monoid-22ef)
> 2. [Compositions and Implicitness](https://dev.to/if-els/functional-patterns-composition-and-implicitness-4n08)
>... | if-els |
1,909,813 | Generics: A Boon for Strongly Typed Languages | Exciting News! Our blog has a new home!🚀 Background Consider a scenario, You have two... | 0 | 2024-07-03T10:01:32 | https://canopas.com/generics-a-boon-for-strongly-typed-languages-bbb18f0ed04a | go, webdev, programming, beginners | > Exciting News! Our blog has a new **[home](https://canopas.com/blog)**!🚀
## Background
Consider a scenario, You have two glasses one with milk and the other with buttermilk. Your task is to identify between milk and buttermilk before drinking it(of course without tasting and touching!).
Hard to admit that, right?... | cp_nandani |
1,909,946 | TailwindCSS Flexbox. Free UI/UX design course | Flexbox It's time to take a look at another famous Tailwind CSS tool - flexbox. In fact,... | 25,935 | 2024-07-03T09:59:34 | https://dev.to/keepcoding/tailwindcss-flexbox-free-uiux-design-course-5fnc | tailwindcss, ui, uidesign, tutorial | ## Flexbox
It's time to take a look at another famous Tailwind CSS tool - flexbox.
In fact, flexbox itself is not a creation of Tailwind, but simply CSS, but thanks to Tailwind, we can comfortably use flexbox using the class utilities.
But enough talk, let's explain it better with examples.
## Step 1 - add headings... | keepcoding |
1,909,945 | From Homework Help to Exam Prep: Best Online Class-Taking Services | In today's fast-paced world, finding time to attend traditional classes can be challenging. Whether... | 0 | 2024-07-03T09:58:38 | https://dev.to/john_hipo/from-homework-help-to-exam-prep-best-online-class-taking-services-3bg6 | In today's fast-paced world, finding time to attend traditional classes can be challenging. Whether you’re a student juggling multiple responsibilities or a professional seeking to enhance your skills, online class-taking services offer a flexible and convenient solution. These platforms cater to various needs, from ho... | john_hipo | |
1,909,944 | Geospatial Indexing and Queries in MongoDB | MongoDB provides robust support for geospatial data and queries, allowing developers to efficiently... | 0 | 2024-07-03T09:57:29 | https://dev.to/platform_engineers/geospatial-indexing-and-queries-in-mongodb-4ojk | MongoDB provides robust support for geospatial data and queries, allowing developers to efficiently execute spatial queries on collections containing geospatial shapes and points. This blog post delves into the technical aspects of geospatial indexing and queries in MongoDB, highlighting the different types of indexes ... | shahangita | |
1,909,943 | Single Page Application: Authentication and Authorization in Angular | Introduction In a Single Page Application (SPA), each element has its own existence and... | 0 | 2024-07-03T09:54:43 | https://dev.to/starneit/single-page-application-authentication-and-authorization-in-angular-118b | webdev, javascript, programming, beginners | ###Introduction
In a Single Page Application (SPA), each element has its own existence and lifecycle, rather than being part of a global page state. Authentication and authorization can affect some or all elements on the screen.
###Authentication Process in an SPA
1. User login: Obtain an access and refresh token.
2... | starneit |
1,909,940 | What is Staking in Crypto? – Process, Benefits & Risks | Staking is a popular phenomenon in the crypto space. It allows crypto developers to secure their... | 0 | 2024-07-03T09:51:50 | https://dev.to/digivikas/what-is-staking-in-crypto-process-benefits-risks-1nli | cryptocurrency, web3, blockchain, learning | Staking is a popular phenomenon in the crypto space. It allows crypto developers to secure their networks while rewarding participants who stake their tokens. Crypto staking has lately emerged as a favored way for crypto enthusiasts and investors to make a side income from their crypto portfolio. It involves staking yo... | digivikas |
1,909,939 | Frontend Technologies | As a beginner frontend developer you most likely have heard and used technologies such as HTML, CSS... | 0 | 2024-07-03T09:51:04 | https://dev.to/goldyn/frontend-technologies-4h4b | As a beginner frontend developer you most likely have heard and used technologies such as HTML, CSS and plain JavaScript. These are the stepping stone and building blocks of frontend development.
However there is more. Concepts such as URL routing, state management, component-based architecture and much more can rea... | goldyn | |
1,909,896 | Enhancing Video to Text Transcription with AI: An Asynchronous Solution on Google Cloud Platform | Asynchronous transcription can be applied in various contexts. For developers looking to implement a... | 0 | 2024-07-03T09:50:46 | https://dev.to/stack-labs/enhancing-video-to-text-transcription-with-ai-an-asynchronous-solution-on-google-cloud-platform-59el | devops, ai, python, googlecloud | Asynchronous transcription can be applied in various contexts. For developers looking to implement a robust, scalable, and efficient transcription solution, the Google Cloud Platform (GCP) offers an ideal environment. In this article, we’ll explore an asynchronous video-to-text transcription solution built with GCP usi... | maximilien_soviche_9af134 |
1,909,938 | 19 Best Startup Directories to Promote Your Business for Free | Launching a startup is quite an exhilarating experience. You’ll face hurdles, but these tips and... | 0 | 2024-07-03T09:48:35 | https://dev.to/martinbaun/19-best-startup-directories-to-promote-your-business-for-free-32ej | startup, career, productivity | Launching a startup is quite an exhilarating experience. You’ll face hurdles, but these tips and directories will help you overcome them.
## Challenges
Getting your product in front of the right audience is a challenge you’ll run into. Your product will likely fail if you do not present it to the correct consumer base... | martinbaun |
1,909,936 | Top boarding schools in Delhi NCR | Looking for the best boarding schools in Delhi for your child? Look no further! Global Edu Consulting... | 0 | 2024-07-03T09:44:32 | https://dev.to/globaleduconsulting/top-boarding-schools-in-delhi-ncr-375e | boarding, boaardingscholsindelhi | Looking for the **[best boarding schools in Delhi](https://www.doonedu.com/boarding-schools-delhi)** for your child? Look no further! Global Edu Consulting has narrowed down the top options for you. With our extensive knowledge of boarding schools across India, we are here to guide you towards making the best choice fo... | globaleduconsulting |
1,909,935 | 10 Reasons Why Google Vertex AI is a Game Changer | In today's rapidly evolving technological landscape, artificial intelligence (AI) has become an... | 0 | 2024-07-03T09:44:30 | https://dev.to/kodexolabs/10-reasons-why-google-vertex-ai-is-a-game-changer-22ak | In today's rapidly evolving technological landscape, artificial intelligence (AI) has become an indispensable tool for businesses seeking to gain a competitive edge. With the launch of Google Vertex AI, Google has once again raised the bar for AI platforms, offering a comprehensive solution that promises to revolutioni... | kodexolabs | |
1,909,934 | Nostra Games | How does Nostra empower gaming developers to create engaging free online games with no... | 0 | 2024-07-03T09:41:14 | https://dev.to/claywinston/nostra-games-138n | mobilegames, gamedev, freeonlinegames, games | ## How does Nostra empower gaming developers to create engaging free online games with no download required for players to enjoy on the platform?
[**Nostra**](https://nostra.gg/articles/conquer-boredom-with-free-online-games.html?utm_source=referral&utm_medium=article&utm_campaign=Nostra) empowers gaming developers to... | claywinston |
1,909,933 | Next.js 15 is Here: Exploring the New Features | Next.js 15 and React 19 are set to revolutionize the web development landscape with their latest... | 0 | 2024-07-03T09:40:08 | https://dev.to/helloworldttj/nextjs-15-is-here-exploring-the-new-features-5bp3 | javascript, nextjs, react, news |
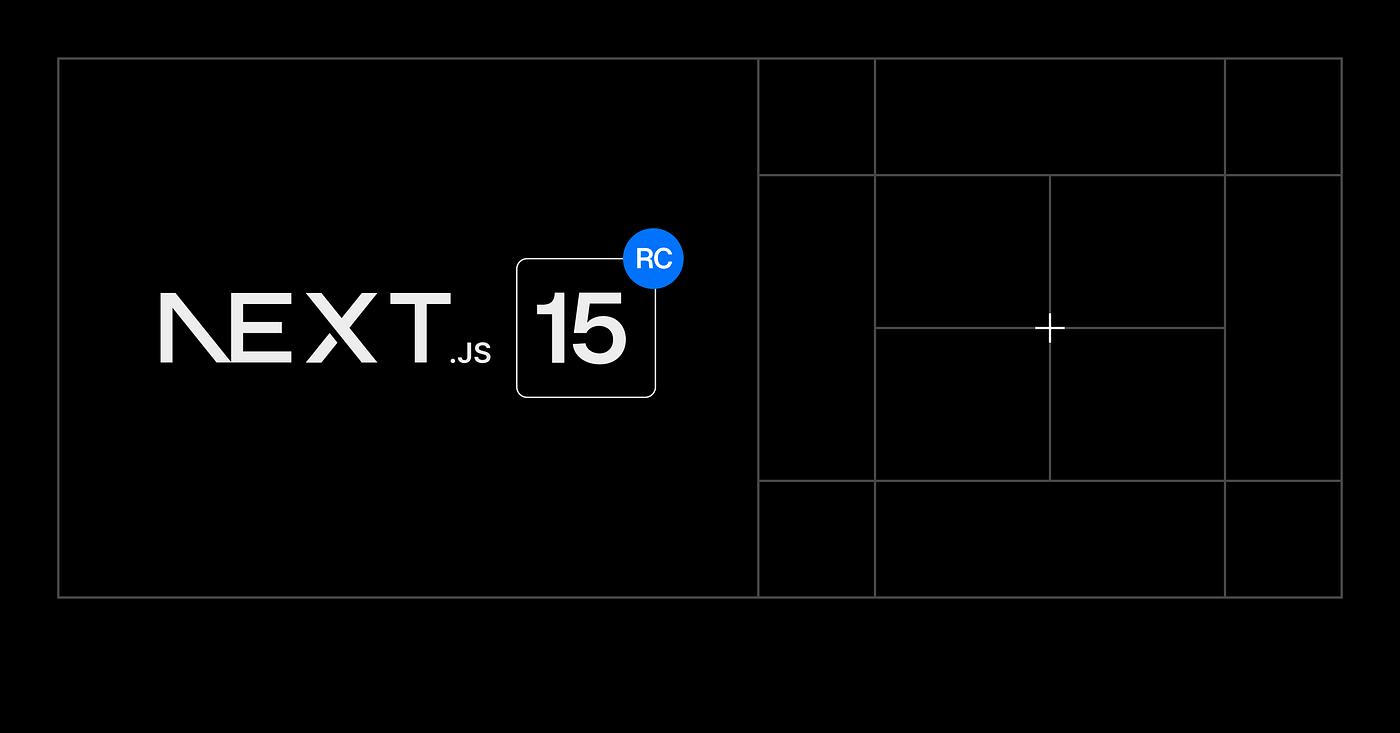Next.js 15 and React 19 are set to revolutionize the web development landscape with their latest features and improvements. In this blog post, we'll dive deep into what Next.js 15 brings to the table, how it can enhance your... | helloworldttj |
1,909,932 | Corrosion Inhibitors Market: Opportunities and Threats | According to the new market research report "Corrosion Inhibitors Market by Compound(Organic,... | 0 | 2024-07-03T09:39:59 | https://dev.to/aryanbo91040102/corrosion-inhibitors-market-opportunities-and-threats-da4 | news | According to the new market research report "Corrosion Inhibitors Market by Compound(Organic, Inorganic), Type(Water Based, Oil Based and VCI), Application, End-Use (Power Generation, Oil & Gas, Metal & Mining, Pulp & Paper, Utilities, Chemical), and Region - Global Forecast to 2026", published by MarketsandMarkets™, t... | aryanbo91040102 |
1,909,930 | How to Use Software Reviews to Predict Long-Term Software Performance? | When selecting software for your business or personal use, it's essential to consider more than just... | 0 | 2024-07-03T09:37:50 | https://dev.to/amara_nielson_bb770edefd8/how-to-use-software-reviews-to-predict-long-term-software-performance-n75 | software, softwarereview, review, rating | When selecting software for your business or personal use, it's essential to consider more than just its current features. Understanding its long-term performance is equally crucial. Software reviews can be an invaluable resource for making this prediction. Here’s a straightforward guide to using them effectively:
**1... | amara_nielson_bb770edefd8 |
1,909,929 | What Technologies Empower Cloud-Native Development, And How Do They Work Together? | The cloud has become the new normal today, but many businesses continue to use outdated, heavy-duty... | 0 | 2024-07-03T09:34:54 | https://dev.to/andrew050/what-technologies-empower-cloud-native-development-and-how-do-they-work-together-1lg3 | cloudnative, cloudcomputing | The cloud has become the new normal today, but many businesses continue to use outdated, heavy-duty computer software that is slow and prone to failure. Many companies have understood the value of the cloud and are focusing on application migration, which involves migrating legacy apps and functionality to a cloud plat... | andrew050 |
1,909,928 | Navigating the World of Mobile Development: A Journey of Self-Discovery and Growth with HNG Internship | Introduction: As a mobile developer, I've come to realize that learning to sell myself is just as... | 0 | 2024-07-03T09:32:42 | https://dev.to/big_dre007/navigating-the-world-of-mobile-development-a-journey-of-self-discovery-and-growth-with-hng-internship-352b | **Introduction**:
As a mobile developer, I've come to realize that learning to sell myself is just as important as learning to code. With the ever-evolving landscape of mobile development, it's crucial to stay up-to-date with the latest platforms and architecture patterns. In this article, I'll be sharing my knowledg... | big_dre007 | |
1,909,924 | What is CFG Scale Stable Diffusion and How to Use It? | Understanding the CFG scale in Stable Diffusion. Learning how to use it to enhance image quality in... | 0 | 2024-07-03T09:30:15 | https://dev.to/novita_ai/what-is-cfg-scale-stable-diffusion-and-how-to-use-it-n2g | Understanding the CFG scale in Stable Diffusion. Learning how to use it to enhance image quality in our blog.
## Introduction
The CFG scale, also known as the Classifier Free Guidance scale, plays a crucial role in controlling the adherence of Stable Diffusion to your text prompt, which can be used in both **[text-to-... | novita_ai | |
1,908,757 | 3. Essential Keymapping and Settings | Now I am about to write a lot of neovim configuration code, the first configuration will be settings... | 27,945 | 2024-07-03T09:29:30 | https://dev.to/stroiman/3-essential-keymapping-and-settings-3e8 | neovim, vim | Now I am about to write a lot of neovim configuration code, the first configuration will be settings that help me working with the configuration itself.
[Read more about keyboard sequences and leader keys](https://dev.to/stroiman/leader-keys-and-mapping-keyboard-sequences-3ehm)
## Open and re-source the configuration... | stroiman |
1,909,927 | Mastering MuleSoft: Your Gateway to Seamless Integration | In today's digitally-driven world, businesses rely heavily on efficient data integration to... | 0 | 2024-07-03T09:28:46 | https://dev.to/mylearnnest/mastering-mulesoft-your-gateway-to-seamless-integration-4jgg | In today's digitally-driven world, businesses rely heavily on efficient data integration to streamline operations, enhance customer experiences, and drive innovation. As companies adopt diverse applications and systems, the need for robust integration solutions becomes paramount. MuleSoft, a [leading integration platfo... | mylearnnest | |
1,909,912 | How to enhance your video quality? | Video has rapidly become a cornerstone of modern communication, whether it's through social media,... | 0 | 2024-07-03T09:27:13 | https://dev.to/alinaxiaoya/how-to-enhance-your-video-quality-1b1f | webdev, tutorial | Video has rapidly become a cornerstone of modern communication, whether it's through social media, professional presentations, or content creation for personal projects. The quality of your video can greatly influence the viewer's perception and engagement. Therefore, enhancing the quality of the video content you've a... | alinaxiaoya |
1,909,926 | How to Use Scroll Area in Next.js with Shadcn UI | In this tutorial, we will see how to implement a scroll area in Next.js 13 using the Shadcn... | 0 | 2024-07-03T09:26:31 | https://frontendshape.com/post/how-to-use-scroll-area-in-next-js-with-shadcn-ui | nextjs, shadcnui, webdev | In this tutorial, we will see how to implement a scroll area in Next.js 13 using the Shadcn UI.
Before using the scroll area in Next.js with Shadcn UI, you need to install it with npx shadcn-ui@latest and add the scroll-area component.
```
npx shadcn-ui@latest add scroll-area
# or
npx shadcn-ui@latest add
```
### Next... | aaronnfs |
1,909,925 | The Cloud Revolution Shaking Up Video Production | Hey folks, if you've been around the broadcasting scene as long as I have, you know how much the... | 0 | 2024-07-03T09:24:24 | https://dev.to/kevintse756/the-cloud-revolution-shaking-up-video-production-434g |
Hey folks, if you've been around the broadcasting scene as long as I have, you know how much the landscape has changed in recent years. The move from old analog systems to internet-driven digital workflows has turned traditional broadcasting on its head. These massive changes might seem intimidating, especially for us... | kevintse756 | |
1,908,754 | 2. Creating a Sandbox Environment | When I started creating the configuration, I already had a working configuration, that should stay... | 27,945 | 2024-07-03T09:18:01 | https://dev.to/stroiman/2-creating-a-sandbox-environment-4p06 | vim, neovim | When I started creating the configuration, I already had a working configuration, that should stay the default configuration until I was happy with the new configuration.
Fortunately, this is quite easy. By default, neovim loads the configuration from `$HOME/.config/nvim`. But you can customise this through environmen... | stroiman |
1,909,923 | Automating User Management on Linux with Bash Scripting | As a SysOps engineer, efficient user management is crucial for maintaining system security and... | 0 | 2024-07-03T09:21:38 | https://dev.to/hellowale/automating-user-management-on-linux-with-bash-scripting-1jk1 | productivity, devops, bash | As a SysOps engineer, efficient user management is crucial for maintaining system security and functionality. I've developed a bash script called create_users.sh that automates user creation, password management, group assignment, and logging on Linux systems to simplify this process. This script is designed to dynamic... | hellowale |
1,909,922 | Telemedicine Practitioners | At Telemedicine Practitioners, Barbara Grubbs provides numerous health and wellness services to both... | 0 | 2024-07-03T09:20:29 | https://dev.to/barbara_grubbs_ad2bf09ff7/telemedicine-practitioners-1dk2 | healthcare, onlinemedicalcare | At [Telemedicine Practitioners](https://www.telemedicinepractitioners.com/), Barbara Grubbs provides numerous health and wellness services to both men and women. My area of expertise encompasses medically supervised weight loss, focusing on providing safe, convenient medications to your doorstep or pharmacy to help you... | barbara_grubbs_ad2bf09ff7 |
1,909,921 | Exploring the Future of Waterproofing with Silicone Sealants | According to the new market research report “Construction Silicone Sealants Market by Type (One... | 0 | 2024-07-03T09:20:15 | https://dev.to/aryanbo91040102/exploring-the-future-of-waterproofing-with-silicone-sealants-27id | news | According to the new market research report “Construction Silicone Sealants Market by Type (One Component, two Component), Curing Type (Acetoxy, Alkoxy, Oxime), Application, End-Use Industry (Residential, Commercial, Industrial) and Region — Global Forecast to 2026”, published by MarketsandMarkets™, the global Construc... | aryanbo91040102 |
1,909,920 | Commercial Vehicle Online Platform TrucksBuses.com | When it comes to secure and comfortable transport of a group of people then the 52 seater bus becomes... | 0 | 2024-07-03T09:18:50 | https://dev.to/ravi_kumar_4131905e53bcea/commercial-vehicle-online-platform-trucksbusescom-3786 | trucks, buses, minitruck, pickup | When it comes to secure and comfortable transport of a group of people then the 52 seater bus becomes the perfect solution. Different [52 seater bus](https://www.trucksbuses.com/pc/52-seater-bus) brands have been produced by leading bus manufacturers in India to provide for the varying demand for buses in the market es... | ravi_kumar_4131905e53bcea |
1,909,867 | CSS One-Liners to Improve (Almost) Every Project | A collection of simple one-line CSS solutions to add little improvements to any web page. | 0 | 2024-07-03T09:18:50 | https://alvaromontoro.com/blog/68055/ten-css-one-liners-for-almost-every-project#limit-content-width | css, webdev, listicle | ---
title: CSS One-Liners to Improve (Almost) Every Project
published: true
description: A collection of simple one-line CSS solutions to add little improvements to any web page.
tags: css,webdev,listicle
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/vwz130pfkgx462jzw3t7.png
canonical_url: https... | alvaromontoro |
1,909,919 | How I got 50 Followers on ProductHunt in 5 Minutes using AI | Everybody who knows anything about ProductHunt, knows it's filled exclusively with marketing managers... | 0 | 2024-07-03T09:16:58 | https://ainiro.io/blog/how-i-got-50-followers-on-producthunt-in-5-minutes-using-ai | Everybody who knows anything about [ProductHunt](https://www.producthunt.com), knows it's filled exclusively with marketing managers and click leeches.
You can see this by nobody really caring about having an actual discussion, which shows by everybody asking questions. The idea behind this is to artificially inflate ... | polterguy | |
1,909,918 | Is tail call optimization truly necessary? | When I was learning about a new functional programming language, one of the first things I would... | 0 | 2024-07-03T09:16:56 | https://dev.to/mrdimosthenis/is-tail-call-optimization-truly-necessary-ojo | functional, scala | When I was learning about a new functional programming language, one of the first things I would check would be if it supports tail call optimization. My thinking was that if this feature isn't available, then the tail-recursive functions could blow the stack.
Tail call optimization is a technique that makes recursive... | mrdimosthenis |
1,909,917 | How to Apply a Magento 2 Patch | Keeping your Magento 2 store secure and up-to-date is crucial for maintaining its stability and... | 0 | 2024-07-03T09:16:49 | https://dev.to/amineyaakoubii/how-to-apply-a-magento-2-patch-5aom | magento, security, patch | Keeping your Magento 2 store secure and up-to-date is crucial for maintaining its stability and protecting it from vulnerabilities. In this guide, we’ll walk you through the steps to apply a Magento 2 patch, often referred to as a "composer patch," without actually using Composer.
## Step-by-Step Guide to Applying a M... | amineyaakoubii |
1,909,916 | Asynchronous Programming in C#: Async/Await Patterns | Asynchronous programming is nowadays common in modern software development and allows applications to... | 0 | 2024-07-03T09:15:20 | https://dev.to/wirefuture/asynchronous-programming-in-c-asyncawait-patterns-47nk | csharp, dotnet, aspdotnet, webdev | Asynchronous programming is nowadays common in modern software development and allows applications to do work without stalling the main thread. The async and await keywords in C# provide a much cleaner method for creating asynchronous code. This article explores the internals of asynchronous programming in C# including... | tapeshm |
1,909,915 | SSRF Vulnerability in HiTranslate: A Technical Breakdown | Server-side request Forgery (SSRF) is a security vulnerability that allows an attacker to induce the... | 0 | 2024-07-03T09:14:48 | https://dev.to/tecno-security/ssrf-vulnerability-in-hitranslate-a-technical-breakdown-1dpm | security, tecno, cybersecurity, bounty | Server-side request Forgery (SSRF) is a security vulnerability that allows an attacker to induce the server-side application to make HTTP requests to an arbitrary domain chosen by the attacker. This article details the discovery, exploitation, and mitigation of an SSRF vulnerability in the HiTranslate application, a po... | tecno-security |
1,906,960 | Understanding LINQ While Writing Your Own | In this article, we will learn what LINQ is and how it works behind the scenes while writing your own... | 0 | 2024-07-03T09:10:31 | https://dev.to/rasulhsn/understanding-linq-while-writing-your-own-klj | dotnet, linq, csharp | In this article, we will learn what LINQ is and how it works behind the scenes while writing your own LINQ methods.
LINQ stands for Language-Integrated Query. It is one of the most powerful tools in the .NET platform that provides an abstract way of querying data for various data sources. In other words, it abstracts ... | rasulhsn |
1,909,913 | Automating User Creation: A Streamlined Approach | Managing user accounts can be a time-consuming task, especially when dealing with frequent... | 0 | 2024-07-03T09:09:47 | https://dev.to/udoh_deborah_b1e484c474bf/automating-user-creation-a-streamlined-approach-p90 | webdev, devops, hng, bashscript | Managing user accounts can be a time-consuming task, especially when dealing with frequent onboarding. on my stage one task with https://hng.tech/internship, I took a deep dive into automating User Creation. This guide introduces a Bash script, `create_users.sh`, that automates user creation and management based on a t... | udoh_deborah_b1e484c474bf |
1,909,911 | Alight Motion vs. Other Video Editing Apps: A Comparison | When it comes to video editing on mobile devices, Alight Motion stands out as a powerful and... | 0 | 2024-07-03T09:04:23 | https://dev.to/mark_3793ebf46aad4787c3ba/alight-motion-vs-other-video-editing-apps-a-comparison-38eo | productivity | When it comes to video editing on mobile devices, Alight Motion stands out as a powerful and versatile tool. However, it's important to compare it with other popular video editing apps to understand its strengths and weaknesses. Here's a detailed comparison of Alight Motion with some other well-known video editing apps... | mark_3793ebf46aad4787c3ba |
1,864,678 | Optimizing Kubernetes Deployments: Tips and Tricks | Kubernetes has become the de facto standard for container orchestration, providing a powerful... | 27,507 | 2024-07-03T09:04:00 | https://dev.to/idsulik/optimizing-kubernetes-deployments-tips-and-tricks-5a13 | kubernetes, tips, tricks, optimization | [Kubernetes](https://kubernetes.io/) has become the de facto standard for container orchestration, providing a powerful platform for deploying, scaling, and managing containerized applications. However, optimizing Kubernetes deployments can be challenging due to the complexity of the system and the wide array of config... | idsulik |
1,909,910 | bartowski/Phi-3.1-mini-4k-instruct-GGUF-torrent | https://aitorrent.zerroug.de/bartowski-phi-3-1-mini-4k-instruct-gguf-torrent/ | 0 | 2024-07-03T09:01:19 | https://dev.to/octobreak/bartowskiphi-31-mini-4k-instruct-gguf-torrent-o1i | ai, machinelearning, chatgpt, beginners | https://aitorrent.zerroug.de/bartowski-phi-3-1-mini-4k-instruct-gguf-torrent/ | octobreak |
1,910,233 | Use the MGT SearchBox control in a SPFx solution | Proceeding with the appointments with the MGT (Microsoft Graph Toolkit) controls today I want to talk... | 0 | 2024-07-04T06:42:59 | https://iamguidozam.blog/2024/07/03/use-the-mgt-searchbox-control-in-a-spfx-solution/ | development, mgt, spfx | ---
title: Use the MGT SearchBox control in a SPFx solution
published: true
date: 2024-07-03 09:00:00 UTC
tags: Development,MGT,SPFx
canonical_url: https://iamguidozam.blog/2024/07/03/use-the-mgt-searchbox-control-in-a-spfx-solution/
---
Proceeding with the appointments with the MGT (Microsoft Graph Toolkit) controls ... | guidozam |
1,909,908 | Restaurant Bookkeeping services India | We are specialists in restaurant bookkeeping services India. With our all-inclusive accounting... | 0 | 2024-07-03T08:56:41 | https://dev.to/globalbookkeeping/restaurant-bookkeeping-services-india-1ab4 | accounting, bookkeeping, tax, payroll | We are specialists in **_[restaurant bookkeeping services India](https://globalbookkeeping.net/service/restaurant-bookkeeping)_**. With our all-inclusive accounting services for restaurants, you can guarantee success and financial transparency. Keep an advantage while improving your earnings. | globalbookkeeping |
1,909,906 | If you are a WeChat mini-program developer, WeTest penetration testing is a must | Imagine a world where your online shopping WeChat mini-program is not only user-friendly but also... | 0 | 2024-07-03T08:56:14 | https://dev.to/wetest/if-you-are-a-wechat-mini-program-developer-wetest-penetration-testing-is-a-must-2oe6 | miniprogram, softwaredevelopment, webdev, javascript |

Imagine a world where your online shopping WeChat mini-program is not only user-friendly but also secure from potential threats. In this success story, we reveal how WeTest's penetration testing service transform... | wetest |
1,909,903 | This is title | This is ordered list 1 This is ordered list 2 This is unordered list This is unordered list | 0 | 2024-07-03T08:54:09 | https://dev.to/marufhossen/this-is-title-18dd | django | 1. This is ordered list 1
2. This is ordered list 2
- This is unordered list
- This is unordered list
| marufhossen |
1,909,905 | How Amazom Dyanamo DB Works? | Amazon DynamoDB is a fully managed NoSQL database service provided by Amazon Web Services (AWS) that... | 0 | 2024-07-03T08:54:00 | https://dev.to/adish_ghimire_07ac8af0c87/how-amazom-dyanamo-db-works-25m7 | amazon, amazondynanamodb, dyanamodb, fundamentalsofdynamodb | **Amazon DynamoDB** is a fully managed NoSQL database service provided by Amazon Web Services (AWS) that offers fast and predictable performance with seamless scalability. Here’s a detailed overview of how DynamoDB works:
Key Concepts
Tables: The primary structure that holds data in DynamoDB. Each table is a collectio... | adish_ghimire_07ac8af0c87 |
1,909,902 | Master Digital Marketing with Top-notch Courses in Lucknow | Mastering the art of digital marketing is essential for individuals and businesses alike. Whether... | 0 | 2024-07-03T08:51:35 | https://dev.to/digitalearnseo/master-digital-marketing-with-top-notch-courses-in-lucknow-3g98 | digitalmarketingcourse, onlinemarketing, digitalmarketingtraining, masterindigitalmarketing | Mastering the art of digital marketing is essential for individuals and businesses alike. Whether you're a beginner or an experienced marketer, digital marketing courses in Lucknow cater to all levels of expertise. It covers many topics to ensure you receive a holistic understanding of the field.
So, Are you in Luckno... | digitalearnseo |
1,909,900 | Building .NET MAUI Barcode Scanner with Visual Studio Code on macOS | Recently, Dynamsoft released a new .NET MAUI Barcode SDK for building barcode scanning applications... | 0 | 2024-07-03T08:48:23 | https://www.dynamsoft.com/codepool/dotnet-maui-barcode-sdk-tutorial.html | dotnet, maui, csharp, android | Recently, Dynamsoft released a new **.NET MAUI Barcode SDK** for building barcode scanning applications on **Android** and **iOS**. In this tutorial, we will use **Visual Studio Code** to create a .NET MAUI Barcode Scanner from scratch. Our application will decode barcodes and QR codes from both image files and camera ... | yushulx |
1,909,899 | Running npm install on a Server with 1GB Memory using Swap | Running npm install on a server with only 1GB of memory can be challenging due to limited RAM.... | 0 | 2024-07-03T08:46:46 | https://victorleungtw.com/2024/07/03/swap/ | swap, memory, server, optimization | Running `npm install` on a server with only 1GB of memory can be challenging due to limited RAM. However, by enabling swap space, you can extend the virtual memory and ensure smooth operation. This blog post will guide you through the process of creating and enabling a swap partition on your server.
 of Django to use | Introduction Choosing the right class-based view (CBV) in Django can be streamlined by... | 0 | 2024-07-03T08:31:49 | https://dev.to/doridoro/determine-which-cbv-classed-base-view-of-django-to-use-4gf1 | django | ## Introduction
Choosing the right class-based view (CBV) in Django can be streamlined by understanding the purpose and features of each type. Django offers several built-in CBVs, each designed to handle common web application patterns efficiently. Here’s a guide to help you select the appropriate CBV for your needs:
... | doridoro |
1,909,892 | Bitcoin As A Safe Haven Asset: A Viable Option Or Not? | Introduction The idea of Bitcoin as a safe haven asset has garnered significant attention, especially... | 0 | 2024-07-03T08:27:56 | https://dev.to/cleaningmarble_667c21bf45/bitcoin-as-a-safe-haven-asset-a-viable-option-or-not-4h6f | programming, ai, discuss, datascience | Introduction
The idea of **[Bitcoin as a safe haven asset ](https://thomas-stray.com/ai-business-tools-for-starting-a-business-a-quick-8-step-guide/)**has garnered significant attention, especially during times of economic uncertainty. But what exactly makes an asset a "safe haven"? Typically, these assets maintain or ... | cleaningmarble_667c21bf45 |
1,909,891 | Phone Number Verification Bot 📞✅ | Welcome to the Phone Number Verification Bot! This Telegram bot helps you verify phone numbers,... | 0 | 2024-07-03T08:26:30 | https://dev.to/kidddevs/phone-number-verification-bot-15ia | telegram, telegrambot, dakidarts, bot | Welcome to the **[Phone Number Verification Bot](https://dakidarts.com/)**! This Telegram bot helps you verify phone numbers, providing details about the country, location, phone type, and more. Built with Python and leveraging the power of RapidAPI, this bot is here to ensure you have accurate information at your fing... | kidddevs |
1,909,889 | How to Solve RankerX Captcha using CaptchaAI | In today's digital environment, automation tools like RankerX significantly streamline SEO tasks, but... | 0 | 2024-07-03T08:25:55 | https://dev.to/media_tech/how-to-solve-rankerx-captcha-using-captchaai-53c6 | In today's digital environment, automation tools like RankerX significantly streamline SEO tasks, but they often encounter challenges such as solving captchas. This is where CaptchaAI comes into play, offering a robust solution for captcha solving services, including reCaptcha solving services and **image captcha solvi... | media_tech | |
1,909,888 | Discover How Sinopec No.5 Construction Maximizes NocoBase to Drive Informatization of Singapore's CRISP Project! | Sinopec Fifth Construction Co., Ltd., a significant player in the petrochemical industry, is using... | 0 | 2024-07-03T08:24:15 | https://dev.to/nocobase/discover-how-sinopec-no5-construction-maximizes-nocobase-to-drive-informatization-of-singapores-crisp-project-4ekf | nocode, lowcode | Sinopec Fifth Construction Co., Ltd., a significant player in the petrochemical industry, is using NocoBase as part of its digital transformation under the leadership of IT director Mr. Dong Ke. [Let's dive into the story!](https://www.nocobase.com/en/blog/SFCC)
## 1. **Background and Challenge**
Sinopec No.5 Constru... | nocobase |
1,909,877 | The Perpetual Rivalry Between iOS and Android | The mobile operating system landscape has been dominated by two giants for over a decade: iOS and... | 0 | 2024-07-03T08:22:21 | https://dev.to/klimd1389/the-perpetual-rivalry-between-ios-and-android-1okm | ios, android, devops, productivity | The mobile operating system landscape has been dominated by two giants for over a decade: iOS and Android. This rivalry is more than just a competition between Apple and Google; it embodies the ongoing debate about technology, user preferences, and innovation. Both platforms have carved out distinct identities, each wi... | klimd1389 |
1,909,841 | CRISP-DM: The Essential Methodology for Structuring Your Data Science Projects | As with any IT project, Machine Learning projects need a framework. However, classical methodologies... | 0 | 2024-07-03T08:18:39 | https://dev.to/moubarakmohame4/crisp-dm-the-essential-methodology-for-structuring-your-data-science-projects-3fk2 | machinelearning, datascience, data, datastructures | As with any IT project, Machine Learning projects need a framework. However, classical methodologies do not apply or apply very poorly to Data Science. Among the existing methodologies, CRISP-DM is the most commonly used and will be presented here. Several variants exist.
> Be careful, CRISP is a framework and not a r... | moubarakmohame4 |
1,909,840 | How do you file cuticles with a nail drill? | Utilizing a Nail Drill to File Cuticles Introduction You've probably come across a nail drill if... | 0 | 2024-07-03T08:18:05 | https://dev.to/edwin_padilla_4aa17388914/how-do-you-file-cuticles-with-a-nail-drill-29bm | nail, art, drill, bit | Utilizing a Nail Drill to File Cuticles
Introduction
You've probably come across a nail drill if you’re a nail lover. This is often a tool used to file, buff, and shape fingernails. Nonetheless, are you aware it to register cuticles that one may also use? We'll be speaking about the benefits and safety with this innova... | edwin_padilla_4aa17388914 |
1,909,838 | Unit Testing and TDD With PostgreSQL is Easy | Note: this is a repost from my personal blog: Unit Testing and TDD With PostgreSQL is Easy I... | 0 | 2024-07-03T08:14:13 | https://dev.to/vbilopav/unit-testing-and-tdd-with-postgresql-is-easy-2hej | postgressql, tdd, testing, sql | >
>Note: this is a repost from my personal blog: [Unit Testing and TDD With PostgreSQL is Easy
> ](https://vb-consulting.github.io/blog/unit-testing-postgresql/)
>
>I believe this subject matter is important and it deserves a bigger audience.
>
I keep hearing that PostgreSQL, as well as all other databases - are n... | vbilopav |
1,907,789 | Reconsider Using UUID in Your Database | Using UUIDs (Universally Unique Identifiers) as primary keys in databases is a common practice for us... | 0 | 2024-07-03T08:12:16 | https://dev.to/gisakaze/reconsider-using-uuid-in-your-database-3c4k | performance, development, database | Using UUIDs (Universally Unique Identifiers) as primary keys in databases is a common practice for us as developer, but this approach can have significant performance drawbacks. I am going to explore with you two major performance issues associated with using UUIDs as keys in your database tables.
### What are UUIDs?
... | gisakaze |
1,909,837 | The Power of Full Project Context using LLM's | I've tried integrating RAG into the DevoxxGenie plugin, but why limit myself to just some parts found... | 0 | 2024-07-03T08:10:25 | https://dev.to/stephanj/the-power-of-full-project-context-using-llms-463c | devoxxgenie, claudeai, idea, intelli | I've tried integrating RAG into the DevoxxGenie plugin, but why limit myself to just some parts found through similarity search when I can go all out?
> RAG is so June 2024 😂
Here's a mind-blowing secret: most of the latest features in the Devoxx Genie plugin were essentially 'developed' by the latest Claude 3.5 Son... | stephanj |
1,909,834 | ASTRO JS | P2 | SSG and SSR | Hello my fellow web developers, today i will be continuing my astro js series with the second part... | 0 | 2024-07-03T08:08:53 | https://dev.to/shubhamtiwari909/astro-js-p2-ssg-and-ssr-2l2l | html, javascript, webdev, tutorial | Hello my fellow web developers, today i will be continuing my astro js series with the second part where we are going to cover some more topics like SSG, SSR, and Hybrid mode. It is mostly related to how we are going to render our pages and in which mode
- [What is SSG?](#ssg)
- [What is SSR?](#ssr)
- [What is Hybrid ... | shubhamtiwari909 |
1,909,832 | 6 Most Important Used Design Principle for UX Design. | UX Principles The user comes first: One of the most important principles in UX design is... | 0 | 2024-07-03T08:07:30 | https://dev.to/iam_divs/6-most-important-used-design-principle-for-ux-design-1cln | webdev, javascript, ui, ux | UX Principles

1. The user comes first:
One of the most important principles in UX design is understanding that the user always comes first. UX design isn’t UX without user research.
2. Useful, usable, and used:... | iam_divs |
1,909,831 | The huge gap between Innovation & Accessibility | Here's why we still have a lot to do for improving accessibility in life: A blind person can take a... | 0 | 2024-07-03T08:06:20 | https://dev.to/abdermaiza/the-huge-gap-between-innovation-accessibility-22ca | a11y, webdev, beginners |
Here's why we still have a lot to do for improving accessibility in life:
- A blind person can take a picture of his kid playing in a park with a smartphone, but he probably can't book tickets on his own, as ticketing interfaces are very inaccessible these days.
- We can now pay contacless with our smartphone, but y... | abdermaiza |
1,909,830 | Published my first npm package: react-popupify! | What is react-popupify? React-Popupify is a simple and easy to use popup component... | 0 | 2024-07-03T08:06:00 | https://dev.to/viditkushwaha/react-popupify-simplify-popup-management-in-your-react-apps-4109 | react, npm, opensource, javascript | <img src="https://i.ibb.co/m6t3dQc/download-1.gif" alt="GIF">
## What is `react-popupify`?
[`React-Popupify`](https://www.npmjs.com/package/react-popupify) is a simple and easy to use popup component library for Reactjs applications. It manages popups using a singleton pattern with a central popup manager instead rel... | viditkushwaha |
1,909,829 | Custom Mailer Boxes That Wow Your Customers | Packaging has become a very important part of the marketing mix for brands in this age of increased... | 0 | 2024-07-03T08:03:37 | https://dev.to/exam-dumsp/custom-mailer-boxes-that-wow-your-customers-52p4 | mailerboxes, custommailerboxeswholesale, customprintedmailerboxes, custommailerboxeswithlogo | Packaging has become a very important part of the marketing mix for brands in this age of increased competition, and it affects the growth of customer satisfaction and brand recognition. In the extensive array of packaging solutions available, **custom mailer boxes** are the same kind that have been adopted by brand ow... | exam-dumsp |
1,909,828 | Automating User Management on Linux with Bash Scripting | Managing user accounts and permissions on a Linux system is a fundamental task for system... | 0 | 2024-07-03T08:01:39 | https://dev.to/madeblaq/automating-user-management-on-linux-with-bash-scripting-1i6a | Managing user accounts and permissions on a Linux system is a fundamental task for system administrators and DevOps teams. Automating this process can streamline operations and ensure consistency across environments. In this guide, we'll walk through how to use a Bash script (create_users.sh) to automate user and group... | madeblaq | |
1,909,827 | Top PR Firm in London: IMCWire's Proven Strategies | Expertise and Experience Our team of PR professionals brings a wealth of experience and industry... | 0 | 2024-07-03T08:00:33 | https://dev.to/vondacleveland/top-pr-firm-in-london-imcwires-proven-strategies-l4d | webdev |
Expertise and Experience
Our team of PR professionals brings a wealth of experience and industry knowledge to the table. We stay ahead of industry trends and continuously refine our strategies to deliver the best possible outcomes for our clients. Our expertise spans various sectors, allowing us to provide specializ... | vondacleveland |
1,909,825 | The Art of Packaging Custom Chocolate Boxes that Delight and Impress | How Custom Shoe Boxes Create A Memorable First Impression To the extent that first... | 0 | 2024-07-03T07:55:44 | https://dev.to/exam-dumsp/the-art-of-packaging-custom-chocolate-boxes-that-delight-and-impress-27f0 | customshoebox, customshoeboxeswholesale, wholesaleshoeboxes, customshoeboxes | # How Custom Shoe Boxes Create A Memorable First Impression
To the extent that first impressions comprise a critical aspect, packaging in a world where consumers prefer to buy products they are familiar with and can metaphorically hold in their hands means everything. Large **custom shoe boxes** step up to be the unse... | exam-dumsp |
1,908,941 | 3 Easy Steps to Setup Gmail Less Secure Apps(Django) | Introduction On your software development journey, you'll likely want to integrate email... | 0 | 2024-07-03T07:52:09 | https://dev.to/titusnjuguna/3-easy-steps-to-setup-gmail-less-secure-appsdjango-2eoe | emailintegration, gmail, lesssecureapps, webdev | ##Introduction
On your software development journey, you'll likely want to integrate email to test event-driven email sending. Pre-deployment testing of this feature requires an email client to verify functionalities.
While you might initially think you need endless bandwidth for mass testing, that's not necessarily t... | titusnjuguna |
1,909,823 | Data Science Essentials: Building a Strong Foundation | In today’s data-driven world, the demand for skilled data scientists is skyrocketing. Companies... | 0 | 2024-07-03T07:47:46 | https://dev.to/alex101112/data-science-essentials-building-a-strong-foundation-530g | ai, datascience | In today’s data-driven world, the demand for skilled data scientists is skyrocketing. Companies across various industries are seeking professionals who can analyze data, extract valuable insights, and drive decision-making processes. If you're looking to embark on a career in this exciting field, it's crucial to build ... | alex101112 |
1,909,822 | API Testing: An Essential Guide | Introduction Application Programming Interfaces (APIs) are integral to modern software architecture,... | 0 | 2024-07-03T07:47:30 | https://dev.to/keploy/api-testing-an-essential-guide-4e3m | ai, devops, opensource, css |

Introduction
Application Programming Interfaces (APIs) are integral to modern software architecture, facilitating communication between different software systems. Ensuring the reliability, security, and performance... | keploy |
1,909,818 | Install LEMP LAMP LLMP LEPP LAPP or LLPP using parameters only | This is an availability notice for my software project. Use my toolkit to automatically install on... | 0 | 2024-07-03T07:47:14 | https://dev.to/wintersysprojects/install-lemp-lamp-llmp-lepp-lapp-or-llpp-on-linux-using-parameters-only-423b | nginx, apache, lighttpd, linux | This is an availability notice for my software project.
Use my [toolkit](https://github.com/wintersys-projects/adt-build-machine-scripts) to automatically install on Ubuntu or Debian LEMP LAMP LLMP LEPP LAPP or LLPP using parameters only.
My solution currently supports Digital Ocean, Linode, Exoscale or Vultr platfo... | wintersysprojects |
1,909,821 | Oracle Cloud’s 24C Release Is Coming: Are You Prepared to Test for Success? | Oracle’s 24C release is just around the corner. The tentative Oracle 24C release date is set for... | 0 | 2024-07-03T07:44:54 | https://www.opkey.com/blog/oracle-cloud-24c-release | oracle, cloud, release | 
Oracle’s 24C release is just around the corner. The tentative Oracle 24C release date is set for July 2024. This release brings changes to the Financials, Supply Chain Management, and Human Capital Management modules... | johnste39558689 |
1,909,819 | Nepal's favorite online shopping service. Shop from Amazon, eBay, Flipkart and many more | International shopping made easy Shop from US and Indian websites We deliver right to your door steps | 0 | 2024-07-03T07:43:54 | https://dev.to/iwishbag/nepals-favorite-online-shopping-service-shop-from-amazon-ebay-flipkart-and-many-more-1oeo | International **[shopping](https://www.iwishbag.com/)** made easy Shop from US and Indian websites We deliver right to your door steps | iwishbag | |
1,909,817 | Machine Learning in Finance: Powering Predictions and Minimizing Risks with Data Science | The financial world thrives on information and calculated risks. Today, machine learning (ML) is... | 0 | 2024-07-03T07:42:52 | https://dev.to/fizza_c3e734ee2a307cf35e5/machine-learning-in-finance-powering-predictions-and-minimizing-risks-with-data-science-3fc2 | machinelearning, datascience |
The financial world thrives on information and calculated risks. Today, machine learning (ML) is transforming the way financial institutions operate, offering powerful tools for predictive analytics and risk management. Let's explore how ML is shaping the future of finance and the data science expertise needed to navi... | fizza_c3e734ee2a307cf35e5 |
1,909,810 | Automating User Managment system with Bash: in a linux environment. | Onboarding several new workers can make managing users on a Linux system a repetitious chore. This... | 0 | 2024-07-03T07:41:28 | https://dev.to/mauricemakafui/automating-user-managment-system-with-bash-in-a-linux-environment-5dj3 | Onboarding several new workers can make managing users on a Linux system a repetitious chore. This procedure may be automated to save time and lower the possibility of human mistake. This tutorial will walk you through creating a bash script that creates users, assigns them to groups, configures their home directories,... | mauricemakafui | |
1,909,816 | Effective Digital Marketing Solutions, Every Time | Digify Local is a dynamic digital marketing agency based in Texas, committed to helping businesses... | 0 | 2024-07-03T07:40:41 | https://dev.to/digifylocal/effective-digital-marketing-solutions-every-time-25li | Digify Local is a dynamic digital marketing agency based in Texas, committed to helping businesses thrive in the online world. With our deep understanding of the local market, we develop customized strategies that boost your brand's online presence and deliver concrete outcomes. Our expert team utilizes data-driven ins... | digifylocal | |
1,909,702 | Building a Cloud Development Kit (CDK) | What Exactly is a Cloud Development Kit (CDK)? Imagine you're a developer who needs to set... | 0 | 2024-07-03T07:39:46 | https://dev.to/samyfodil/building-a-cloud-development-kit-cdk-3lgd | cloudcomputing, cdk, webassembly, cloudpractitioner | ### What Exactly is a Cloud Development Kit (CDK)?
Imagine you're a developer who needs to set up a bunch of cloud resources. Traditionally, you might deal with endless lines of JSON or YAML configurations. It's precise but can get pretty tedious, right? Well, this is where a Cloud Development Kit, or CDK, comes in ha... | samyfodil |
1,909,815 | Crafting the Perfect Custom Chocolate Packaging | The Evolvement of Packaging Chocolate brands must understand the consumers’ desire for... | 0 | 2024-07-03T07:39:29 | https://dev.to/adil_qadeer_458a15a126710/crafting-the-perfect-custom-chocolate-packaging-53i5 | chocolateboxespackaging, custompackaging, customboxeswholesale, chocolateboxesforgifts | ## The Evolvement of Packaging
Chocolate brands must understand the consumers’ desire for good packaging as they prepare their marketing plans. Currently, these containers are no longer narrowly seen as just storage, but they can be used as an expressive medium by displaying art and innovative solutions.
## Up-to-Dat... | adil_qadeer_458a15a126710 |
1,909,814 | Why There’s No Need for forwardRef in React | Introduction Understanding why forwardRef exists and whether it’s truly necessary in React... | 0 | 2024-07-03T07:37:16 | https://dev.to/sharoztanveer/why-theres-no-need-for-forwardref-in-react-4fa5 | react, webdev, javascript, typescript | ## Introduction
Understanding why `forwardRef` exists and whether it’s truly necessary in React has been a complex journey. After identifying seven significant issues with `forwardRef` and recognising a simpler and superior alternative, it became evident that `forwardRef` could be removed from React without much impact... | sharoztanveer |
1,909,812 | How to Transfer SOL and SPL Tokens Using Anchor | The Anchor framework is a Rust-based framework for building Solana programs using Solana blockchain... | 0 | 2024-07-03T07:33:17 | https://dev.to/donnajohnson88/how-to-transfer-sol-and-spl-tokens-using-anchor-21ef | solidity, solana, learning, webdev | The Anchor framework is a Rust-based framework for building Solana programs using [Solana blockchain development](https://blockchain.oodles.io/solana-blockchain-development-services/?utm_source=devto). It simplifies the process of developing Solana smart contracts by providing a higher-level abstraction over Solana’s l... | donnajohnson88 |
1,909,809 | Is Unit testing really useful? | In the realm of software development, unit testing often sparks debates. While some developers swear... | 0 | 2024-07-03T07:30:27 | https://dev.to/zafar_hayat_50df31884c827/is-unit-testing-really-usefull-12c7 | In the realm of software development, unit testing often sparks debates. While some developers swear by its efficacy, others question its real-world value. This article delves into the varied opinions on unit testing based on personal experiences, rather than presenting a purely technical guide.
**The Concept of Unit ... | zafar_hayat_50df31884c827 | |
1,909,789 | Introducing Kuery Client for those who love writing SQL in Kotlin/JVM | Introducing Kuery Client for those who love writing SQL in Kotlin/JVM | 0 | 2024-07-03T07:25:50 | https://dev.to/behase/introducing-kuery-client-for-those-who-love-writing-sql-in-kotlinjvm-1g51 | kotlin, r2dbc, jdbc, spring | ---
title: Introducing Kuery Client for those who love writing SQL in Kotlin/JVM
published: true
description: Introducing Kuery Client for those who love writing SQL in Kotlin/JVM
tags: kotlin, r2dbc, jdbc, spring
---
## First of all
- Repository
- https://github.com/be-hase/kuery-client
- Document
- https://kuer... | behase |
1,909,808 | Best Practices for Reporting Errors | Effective error reporting is crucial for efficient troubleshooting and resolution. A well-documented... | 0 | 2024-07-03T07:25:20 | https://dev.to/msnmongare/best-practices-for-reporting-errors-3i1p | beginners, productivity, tutorial, ai | Effective error reporting is crucial for efficient troubleshooting and resolution. A well-documented error report can save time and resources by helping developers quickly understand and address the issue. Here are some best practices for reporting errors:
#### 1. Describe the Issue
Clearly describe what the system is... | msnmongare |
1,909,807 | 5 Things to Keep in Mind Regarding Workday Release | Keeping up with the latest releases of an enterprise resource planning (ERP) system is essential for... | 0 | 2024-07-03T07:24:44 | https://getfont.net/5-things-to-keep-in-mind-regarding-workday-release/ | workday, release | 
Keeping up with the latest releases of an enterprise resource planning (ERP) system is essential for a firm to sustain their competitive edge and operational efficiency in an ever-evolving world of these systems. Thr... | rohitbhandari102 |
1,909,543 | GraphQL Types | Field declaration By default, it's valid for any field in your schema to return null... | 27,944 | 2024-07-03T07:21:31 | https://dev.to/jacktt/graphql-types-26og | graphql | ## Field declaration
By default, it's valid for any field in your schema to return null instead of its specified type.
You can require that a particular field doesn't return null with an exclamation mark !, like so:
```graphql
type Author {
name: String! # Can't return null
books: [Book!] # This list can be null ... | jacktt |
1,909,794 | structure ideas: | Introduction Defining Telemarketer Memes: A brief introduction to what telemarketer memes are and why... | 0 | 2024-07-03T07:20:13 | https://dev.to/md_rabiulislamein42/structure-ideas-1g5g | Introduction Defining Telemarketer Memes: A brief introduction to what telemarketer memes are and why they have become popular. Purpose of the post: Explain why you are writing about the telemarketer meme and what readers can expect. Telemarketer Meme Types Text-Based Meme: An example of a meme that uses text to descri... | md_rabiulislamein42 | |
1,907,813 | Powerful AI Tools You Should Know | Hello Devs👋 Nowadays there are many AI tools available to boost your productivity but finding the... | 0 | 2024-07-03T07:19:17 | https://dev.to/dev_kiran/powerful-ai-tools-you-should-know-1gf1 | webdev, ai, productivity, programming | Hello Devs👋
Nowadays there are many AI tools available to boost your productivity but finding the most effective ones can be challenging and time-consuming.
In this article, I'll be sharing some fantastic AI tools that can significantly boost your productivity and save you a lot of time.🕧
.
In this article we will touch on Widget tests and how this package can be useful for us.
## Let's briefly go through again what exactly are ApprovalTests?
In manual c... | yelmuratoff |
1,909,785 | Interiors By Design | From meticulous preparation to faultless execution, we ensure your dream comes true. Our Kitchen... | 0 | 2024-07-03T07:14:56 | https://dev.to/interiorsbydesignuk/interiors-by-design-man | From meticulous preparation to faultless execution, we ensure your dream comes true. Our Kitchen Manufacturing procedure includes accurate planning, professional guidance, and flawless implementation. From the first design to the manufacturing stage, we collaborate closely with you the entire way. Our solid relationshi... | interiorsbydesignuk | |
1,909,784 | Get Started with ChatGPT: Free Course for All Levels | Welcome to a Free ChatGPT Course designed for all levels. Understand the benefits of learning ChatGPT... | 0 | 2024-07-03T07:14:26 | https://dev.to/alex101112/get-started-with-chatgpt-free-course-for-all-levels-mg | ai, chatgpt | Welcome to a [Free ChatGPT Course](https://www.pickl.ai/course/chatgpt-free-certification-online) designed for all levels. Understand the benefits of learning ChatGPT and get an overview of what this course offers.
## Account Setup and Basics
Learn how to create your ChatGPT account and navigate the platform. This fo... | alex101112 |
1,909,783 | AccessToken, RefreshToken | 참조:... | 0 | 2024-07-03T07:13:40 | https://dev.to/sunj/accesstoken-refreshtoken-24j0 | _참조: https://tae-jun.tistory.com/19_
_https://sokdak-sokdak.tistory.com/11_
_https://velog.io/@park2348190/JWT%EC%97%90%EC%84%9C-Refresh-Token%EC%9D%80-%EC%99%9C-%ED%95%84%EC%9A%94%ED%95%9C%EA%B0%80_ | sunj | |
1,909,781 | Spatial Reader Tech Support | Getting Support: mail: wenxian890105@qq.com or leave comment below. | 0 | 2024-07-03T07:10:01 | https://dev.to/wenxian_liu_9ca538b426cda/spatial-reader-tech-support-36h8 |
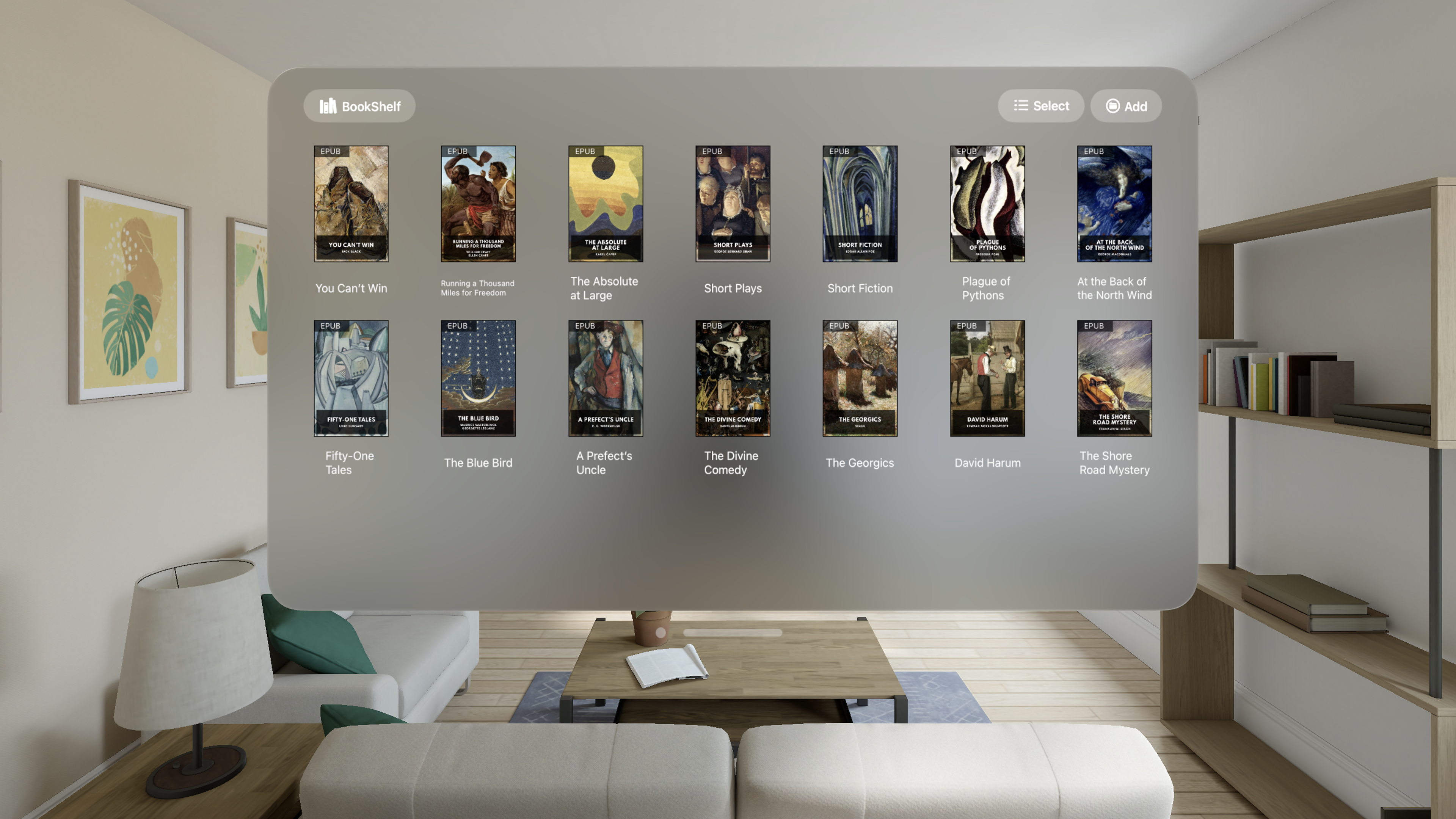Getting Support:
mail: wenxian890105@qq.com
or leave comment below. | wenxian_liu_9ca538b426cda |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.