
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,864,365 | Understanding Data Manipulation Language(DML) statements in SQL | Data Manipulation Language (DML) statements are those SQL statements we use to insert, update, or... | 0 | 2024-05-24T22:58:11 | https://dev.to/kellyblaire/understanding-the-data-manipulation-languagedml-statements-in-sql-23f5 | databaseoperation, sql, sqlserver, dml | Data Manipulation Language (DML) statements are those SQL statements we use to insert, update, or delete data in tables (e.g., INSERT, UPDATE, DELETE).
In this article, I am going to show you how to use the INSERT, UPDATE, and DELETE statements in SQL, including use cases, examples, and professional information to aid in learning and provide practical examples.
**INSERT Statement**
The INSERT statement is used to add new rows of data into a table. It is a fundamental operation in SQL and is part of the Data Manipulation Language (DML) subset.
**Use Cases:**
- Adding new records to a table (e.g., new customers, orders, products)
- Populating a newly created table with initial data
- Inserting data from one table into another (combined with SELECT)
**Syntax:**
```sql
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
```
**Examples:**
1. Insert a new row into the "Customers" table:
```sql
INSERT INTO Customers (CustomerName, City, Country)
VALUES ('John Doe', 'New York', 'USA');
```
2. Insert multiple rows into the "Orders" table:
```sql
INSERT INTO Orders (OrderID, CustomerID, OrderDate)
VALUES
(1001, 101, '2023-05-01'),
(1002, 102, '2023-05-02'),
(1003, 103, '2023-05-03');
```
3. Insert data from a SELECT query (using a subquery):
```sql
INSERT INTO BackupCustomers
SELECT * FROM Customers;
```
**Professional Tips:**
- Use column lists to specify the columns you want to insert data into, ensuring the values match the column order.
- Be cautious when omitting columns with default values or auto-incrementing keys, as the DBMS may handle them differently.
- Consider using transactions when inserting multiple rows to ensure data integrity in case of errors or failures.
- Optimize INSERT statements by batching or bulk inserting data instead of individual inserts for better performance.
**UPDATE Statement**
The UPDATE statement is used to modify existing data in a table. It allows you to change the values of one or more columns for selected rows that match a specified condition.
**Use Cases:**
- Updating customer information (e.g., address, phone number)
- Modifying product prices or stock quantities
- Correcting data entry errors or inconsistencies
**Syntax:**
```sql
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
```
**Examples:**
1. Update the email address for a specific customer:
```sql
UPDATE Customers
SET Email = 'newemail@example.com'
WHERE CustomerID = 101;
```
2. Update multiple columns with different values:
```sql
UPDATE Products
SET Price = Price * 1.1, StockQuantity = StockQuantity - 10
WHERE ProductID IN (101, 102, 103);
```
3. Update rows based on a subquery:
```sql
UPDATE Orders
SET ShipDate = CURRENT_DATE()
WHERE OrderID IN (
SELECT OrderID
FROM Orders
WHERE ShipDate IS NULL
);
```
**Professional Tips:**
- Always include a `WHERE` clause to specify the rows you want to update; omitting it will update all rows in the table.
- Use transactions when updating critical data to ensure data integrity and rollback capability in case of errors.
- Consider indexing the columns used in the `WHERE` clause for better performance on large tables.
- Test your UPDATE statements thoroughly, especially when updating multiple columns or using subqueries, to avoid unintended data modifications.
**DELETE Statement**
The DELETE statement is used to remove existing rows from a table. It allows you to delete specific rows that match a specified condition or all rows from a table.
**Use Cases:**
- Removing obsolete or unnecessary data (e.g., old customer records, expired products)
- Deleting test data or temporary records
- Truncating a table by deleting all rows
**Syntax:**
```sql
DELETE FROM table_name
WHERE condition;
```
**Examples:**
1. Delete a specific customer record:
```sql
DELETE FROM Customers
WHERE CustomerID = 101;
```
2. Delete all orders for a specific customer:
```sql
DELETE FROM Orders
WHERE CustomerID = (
SELECT CustomerID
FROM Customers
WHERE CustomerName = 'John Doe'
);
```
3. Delete all rows from a table (truncate):
```sql
DELETE FROM TemporaryTable;
```
**Professional Tips:**
- Use the `WHERE` clause to specify the rows you want to delete; omitting it will delete all rows in the table.
- Be extremely cautious when deleting data, as it is a permanent operation (unless using transactions or backups).
- Consider using transactions when deleting critical data to ensure data integrity and rollback capability in case of errors.
- Truncating a table (deleting all rows) can be faster than deleting rows one by one, but it cannot be rolled back and may cause issues with identity columns or triggers.
- Indexing the columns used in the `WHERE` clause can improve performance for large tables.
**Practical Examples:**
1. **Customer Management System:**
- INSERT new customers into the "Customers" table when they sign up.
- UPDATE customer information (address, phone number) when they change their details.
- DELETE customer records when they request to close their accounts.
2. **E-commerce Order Processing:**
- INSERT new orders into the "Orders" table when customers place an order.
- UPDATE order status (e.g., "Shipped") when the order is processed.
- DELETE order records after a certain period (e.g., 2 years) for archiving purposes.
3. **Inventory Management:**
- INSERT new products into the "Products" table when new items are added to the inventory.
- UPDATE product prices or stock quantities based on supplier changes or sales.
- DELETE product records when items are discontinued or removed from the inventory.
4. **Data Warehousing and Analytics:**
- INSERT new data into staging tables or data marts for analysis.
- UPDATE dimension tables with slowly changing dimensions (e.g., customer addresses, product categories).
- DELETE outdated or obsolete data from fact tables or data marts during data refreshes.
**Wrapping Up**
In this lesson, we covered three essential SQL statements: INSERT, UPDATE, and DELETE, which are part of the Data Manipulation Language (DML) subset. These statements allow us to manage data in databases by adding, modifying, and removing rows from tables.
The INSERT statement is used to add new rows of data into a table. We learned its syntax, common use cases, and best practices, such as using column lists, considering default values and auto-incrementing keys, batching inserts for better performance, and using transactions for data integrity.
The UPDATE statement is used to modify existing data in a table by changing the values of one or more columns for selected rows that match a specified condition. We discussed its syntax, use cases like updating customer information or product prices, and tips like always including a WHERE clause, using transactions for critical data, indexing columns used in the WHERE clause, and thoroughly testing updates before execution.
The DELETE statement is used to remove existing rows from a table based on a specified condition or all rows. We covered its syntax, use cases such as removing obsolete data or truncating tables, and tips like using the WHERE clause to specify rows to delete, being cautious as deletion is permanent, considering transactions, and indexing columns used in the WHERE clause.
Throughout the lesson, we explored practical examples demonstrating the application of these statements in scenarios like customer management systems, e-commerce order processing, inventory management, and data warehousing and analytics.
Mastering these fundamental SQL statements is essential for effective data manipulation and maintenance in various applications and scenarios. By understanding their syntax, use cases, and best practices, you can confidently manage data in databases, ensuring data integrity, consistency, and accuracy. | kellyblaire |
1,864,364 | CodeCompanion is launching : Take your documentation to the next level | I'm excited to announce that CodeCompanion is ready! CodeCompanion is an AI-powered tool that makes... | 0 | 2024-05-24T22:46:20 | https://dev.to/lotfijb/codecompanion-is-launching-take-your-documentation-to-the-next-level-1d8d | ai, webdev, productivity, nextjs | I'm excited to announce that [CodeCompanion](https://codecompanion-trial.vercel.app/) is ready!
CodeCompanion is an AI-powered tool that makes documenting your code a breeze. It integrates seamlessly with platforms like GitHub and GitLab, taking care of all your documentation and commenting needs.
Your code will be perfectly documented by just a click!
With CodeCompanion, collaboration becomes smoother and sharing code easier than ever before. Whether you're working solo or with a team.
Our beta launch is tomorrow, and you can join over 400 developers already on the waitlist. Don't miss out on the chance to experience a new era of code documentation.
[Sign up here](https://codecompanion-trial.vercel.app/)
Let's make code documentation effortless!
| lotfijb |
1,864,363 | Constraints in SQL: Enforcing Data Integrity | In SQL, data integrity is of paramount importance. Constraints are rules or conditions that are... | 0 | 2024-05-24T22:41:22 | https://dev.to/kellyblaire/constraints-in-sql-enforcing-data-integrity-3pa1 | sql, database, dataintegrity, constraints | In SQL, data integrity is of paramount importance. Constraints are rules or conditions that are applied to columns or tables in a database to maintain data integrity and enforce business rules. SQL provides several types of constraints to ensure the accuracy, consistency, and reliability of data stored in a database.
**1. PRIMARY KEY Constraint**
A primary key is a column or a combination of columns that uniquely identifies each row in a table. It is the most fundamental constraint in relational databases, as it ensures that every row can be uniquely identified. A primary key constraint has two main characteristics:
- **Uniqueness**: The values in the primary key column(s) must be unique across all rows in the table. No two rows can have the same primary key value.
- **Not Null**: The primary key column(s) cannot contain null values. Each row must have a valid primary key value.
The primary key constraint is typically defined during the table creation using the `PRIMARY KEY` keyword. For example:
```sql
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
Name VARCHAR(50),
Email VARCHAR(50)
);
```
In this example, the `CustomerID` column is defined as the primary key for the `Customers` table.
**2. FOREIGN KEY Constraint**
A foreign key is a column or a combination of columns that references the primary key or a unique key of another table. It establishes a link or relationship between two tables, ensuring referential integrity. When a foreign key value is inserted or updated in the referencing table, it must match an existing value in the referenced table's primary or unique key column(s).
The foreign key constraint is defined using the `FOREIGN KEY` keyword, specifying the referenced table and column(s). For example:
```sql
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT FOREIGN KEY REFERENCES Customers(CustomerID),
OrderDate DATE
);
```
In this example, the `CustomerID` column in the `Orders` table is a foreign key that references the `CustomerID` column (primary key) in the `Customers` table. This constraint ensures that every `CustomerID` value in the `Orders` table corresponds to an existing `CustomerID` value in the `Customers` table, maintaining referential integrity.
**3. UNIQUE Constraint**
The `UNIQUE` constraint ensures that the values in a column or a combination of columns are unique across all rows in the table. It prevents the insertion or update of duplicate values in the specified column(s). Unlike the primary key constraint, the `UNIQUE` constraint allows null values unless combined with the `NOT NULL` constraint.
The `UNIQUE` constraint can be defined during table creation or added to an existing table using the `ALTER TABLE` statement. For example:
```sql
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
Email VARCHAR(50) UNIQUE
);
```
In this example, the `Email` column in the `Employees` table has a `UNIQUE` constraint, ensuring that each email address is unique across all employees.
**4. NOT NULL Constraint**
The `NOT NULL` constraint specifies that a column cannot accept null values. It helps maintain data integrity by ensuring that specific columns always have a value. When a `NOT NULL` constraint is applied to a column, any attempt to insert or update a row with a null value in that column will result in an error.
The `NOT NULL` constraint can be defined during table creation or added to an existing table using the `ALTER TABLE` statement. For example:
```sql
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(50) NOT NULL,
Price DECIMAL(10, 2)
);
```
In this example, the `ProductName` column in the `Products` table has a `NOT NULL` constraint, ensuring that every product must have a name specified.
**Combining Constraints**
Constraints can be combined to enforce multiple rules on a column or a set of columns. For example, you can define a primary key as both `PRIMARY KEY` and `NOT NULL` to ensure uniqueness and non-nullability. Additionally, you can define a column as `UNIQUE` and `NOT NULL` to ensure uniqueness and non-nullability without making it a primary key.
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY NOT NULL,
Name VARCHAR(50) NOT NULL,
Email VARCHAR(50) UNIQUE NOT NULL
);
```
In this example, the `StudentID` column is defined as the primary key with both `PRIMARY KEY` and `NOT NULL` constraints. The `Name` column has a `NOT NULL` constraint, and the `Email` column has both `UNIQUE` and `NOT NULL` constraints.
**Wrapping Up**
Constraints are essential for maintaining data integrity and enforcing business rules in SQL databases. The primary key, foreign key, unique, and not null constraints are powerful tools that help ensure the accuracy, consistency, and reliability of data stored in a database. By understanding and applying these constraints appropriately, developers can create robust and reliable database systems that meet the requirements of their applications. | kellyblaire |
1,863,457 | Could Micro Services Be a Good Fit for Micro SaaS? | Could Microservices Be a Good Fit for Micro SaaS Startups? As a solo developer, I've been... | 0 | 2024-05-24T22:31:59 | https://dev.to/zachbenson/could-microservices-be-a-good-fit-for-micro-saas-startups-47hg | microservices, webdev, tutorial, productivity | ## Could Microservices Be a Good Fit for Micro SaaS Startups?
As a solo developer, I've been intrigued by the potential of microservices for small SaaS and micro SaaS projects. Balancing the constraints of limited resources with the option to scale quickly, I've been contemplating whether microservices could be a good fit for smaller projects. The consensus? It's a bit obvious - it promising, if you can overcome the inherent challenges of microservices without expending substantial development time. With that being said I would like to share what I have found while developing my own micro service boilerplate and hopefully help you get there faster.
## The Appeal of Microservices for Micro SaaS Startups
Microservices architecture breaks down applications into small, independent deployable services, each responsible for a specific piece of functionality. This modular approach offers several compelling advantages for micro SaaS developers:
- **Scalability**: Startups can scale individual services based on demand without scaling the entire application. This efficient resource use is crucial when budgets are tight.
- **Flexibility and Agility**: Each microservice can be developed, deployed, and scaled independently, allowing startups to iterate quickly and adapt to market changes with minimal disruption.
- **Fault Isolation**: Issues in one service do not necessarily affect the entire application, leading to more resilient systems and better uptime.
- **Technology Diversity**: Teams can choose the best technology stack for each service, enabling experimentation with new technologies that could give a competitive edge.
- *My interest* in microservices is specifically the flexibility and technology diversity.
## Overcoming the Overhead of Microservices
Despite the benefits, microservices come with their own set of challenges, particularly for startups with limited resources and experience in managing distributed systems. However, these challenges can be mitigated with the right strategies and tools.
### Challenge 1: Complexity of Distributed Systems
**Solution: Leverage Automation and Orchestration Tools**
- **Automated Deployment**: Use tools like Docker for containerization and Kubernetes for orchestration to manage deployment and scaling. These tools simplify the process of managing multiple services, making the system more robust and easier to handle.
- Containerization with [Docker](https://www.docker.com/) can be slow to start if you are learning, but once you have it down containerizing each micro-service will come pretty quickly.
- Orchestration with [Kubernetes](https://kubernetes.io/) is simple to set up, but there are some challenges to managing resource usage in a cost effective way.
### Challenge 2: Ensuring Effective Communication
**Solution: Standardize Communication Protocols**
- **API Gateways**: Use an API gateway to manage and route requests between clients and services, providing a single entry point for the system. This simplifies client-side logic and improves security.
- **Event-Driven Architecture**: Implement asynchronous communication using message brokers (e.g., RabbitMQ, Kafka) to decouple services and improve system resilience.
- *My pick* is using an API gateway, as it has the added benefit of protecting all of your backend api's behind one end point where you can implement authentication/authorization, rate limiting, and reverse proxies.
### Challenge 3: Managing Data Consistency
**Solution: Embrace Eventual Consistency**
- **Shared Database**: Allow multiple services use the same database. It simplifies ensuring data consistency but increases coupling between services and reduces their autonomy. This is a particularly good fit for smaller solo developers or small teams because communication between service owners is a bit simpler.
- **Database Per Service**: Adopt a database per service pattern to ensure services are loosely coupled, which allows each service to manage its own data independently.
- *My pick* is using a shared database that is its own service. As a solo dev it is straight forward enough to keep track of the changes services have on the database. With it being its own service the api calls are mostly what change.
### Challenge 4: Finding the Right Service Boundaries
**Solution: Start Simple and Iterate**
- **Domain-Driven Design (DDD)**: Embrace DDD principles to carve out precise service boundaries aligned with your business functions. Kick off with a broad decomposition and refine iteratively as your understanding of the application's needs evolves.
- **Leverage Common Solutions**: Take a moment to survey the landscape. In the realm of SaaS and micro SaaS, certain fundamental services consistently appear: authentication, user management, email handling, and payment processing. Rather than reinventing the wheel for these essentials, capitalize on existing solutions. Direct your efforts towards dissecting the distinctive features of your application.
## Conclusion
Microservices offer promising benefits for micro SaaS startups, enabling scalability, flexibility, and resilience. However, they also pose challenges, especially for those with limited resources. By leveraging automation tools, standardizing communication protocols, embracing eventual consistency, and starting with simple service boundaries, startups can effectively harness the power of microservices. Through iterative refinement and strategic decision-making, microservices can indeed be a valuable asset for smaller projects.
Stay tuned as I share my journey implementing these strategies in my microservice boilerplate, [Building Blocks](https://building-blocks-848d.mailchimpsites.com).
---
### References
Microservices Patterns: With Examples in Java - Chris Richardson
---
Feel free to leave your comments and suggestions below. Let's learn and grow together as a community! | zachbenson |
1,864,356 | set_default_dtype(), set_default_device() and set_printoptions() in PyTorch | *Memos: My post explains how to check PyTorch version, CPU and GPU(CUDA). My post explains how to... | 0 | 2024-05-24T22:26:30 | https://dev.to/hyperkai/setdefaultdtype-setdefaultdevice-and-setprintoptions-in-pytorch-55g8 | pytorch, setdefaultdtype, setdefaultdevice, setprintoptions | *Memos:
- [My post](https://dev.to/hyperkai/check-pytorch-version-cpu-and-gpucuda-in-pytorch-6jk) explains how to check PyTorch version, CPU and GPU(CUDA).
- [My post](https://dev.to/hyperkai/create-a-tensor-in-pytorch-127g) explains how to create a tensor.
- [My post](https://dev.to/hyperkai/access-a-tensor-in-pytorch-1f4e) explains how to access a tensor.
- [My post](https://dev.to/hyperkai/istensor-numel-and-device-in-pytorch-2eha) explains [is_tensor()](https://pytorch.org/docs/stable/generated/torch.is_tensor.html), [numel()](https://pytorch.org/docs/stable/generated/torch.numel.html) and [device()](https://pytorch.org/docs/stable/tensor_attributes.html#torch-device).
- [My post](https://dev.to/hyperkai/type-conversion-with-type-to-and-a-tensor-in-pytorch-2a0g) explains type conversion with [type()](https://pytorch.org/docs/stable/generated/torch.Tensor.type.html), [to()](https://pytorch.org/docs/stable/generated/torch.Tensor.to.html) and a tensor.
- [My post](https://dev.to/hyperkai/type-promotion-resulttype-promotetypes-and-cancast-in-pytorch-33p8) explains type promotion, [result_type()](https://pytorch.org/docs/stable/generated/torch.result_type.html), [promote_types()](https://pytorch.org/docs/stable/generated/torch.promote_types.html) and [can_cast()](https://pytorch.org/docs/stable/generated/torch.can_cast.html).
- [My post](https://dev.to/hyperkai/device-conversion-fromnumpy-and-numpy-in-pytorch-1iih) explains device conversion, [from_numpy()](https://pytorch.org/docs/stable/generated/torch.from_numpy.html) and [numpy()](https://pytorch.org/docs/stable/generated/torch.Tensor.numpy.html).
- [My post](https://dev.to/hyperkai/manualseed-initialseed-and-seed-in-pytorch-5gm8) explains [manual_seed()](https://pytorch.org/docs/stable/generated/torch.manual_seed.html), [initial_seed()](https://pytorch.org/docs/stable/generated/torch.initial_seed.html) and [seed()](https://pytorch.org/docs/stable/generated/torch.seed.html).
[set_default_dtype()](https://pytorch.org/docs/stable/generated/torch.set_default_dtype.html) can set the default dtype of a 0D or more D tensor as shown below:
*Memos:
- `set_default_dtype()` can be used with [torch](https://pytorch.org/docs/stable/torch.html) but not with a tensor but `dtype` can be used with a tensor.
- The 1st argument with `torch` is `d`(Required-Type:[dtype](https://pytorch.org/docs/stable/tensor_attributes.html#torch.dtype)). *Only floating-point types can be set.
- The effect of `set_default_dtype()` lasts until `set_default_dtype()` is used next time.
- You can also use [set_default_tensor_type()](https://pytorch.org/docs/stable/generated/torch.set_default_tensor_type.html) but it is deprecated.
- [get_default_dtype()](https://pytorch.org/docs/stable/generated/torch.get_default_dtype.html) can return the default dtype of a 0D or more D tensor.
```python
import torch
my_tensor = torch.tensor([0., 1., 2.])
my_tensor.dtype
torch.get_default_dtype()
# torch.float32
torch.set_default_dtype(d=torch.float64)
my_tensor.device
torch.get_default_device()
# torch.float64
```
[set_default_device()](https://pytorch.org/docs/stable/generated/torch.set_default_device.html) can set the default device of a 0D or more D tensor as shown below:
*Memos:
- `set_default_device()` can be used with `torch` but not with a tensor but `device` can be used with a tensor.
- The 1st argument with `torch` is `device`(Required-Type:`str`, `int` or [device()](https://pytorch.org/docs/stable/tensor_attributes.html#torch-device)).
- `cpu`, `cuda`, `ipu`, `xpu`, `mkldnn`, `opengl`, `opencl`, `ideep`, `hip`, `ve`, `fpga`, `ort`, `xla`, `lazy`, `vulkan`, `mps`, `meta`, `hpu`, `mtia` or `privateuseone` can be set to `device`.
- Setting `0` to `device` uses `cuda`(GPU). *The number must be zero or positive.
- [My post](https://dev.to/hyperkai/istensor-numel-and-device-in-pytorch-2eha) explains `device()`.
- The effect of `set_default_device()` lasts until `set_default_device()` is used next time.
- [get_default_device()](https://pytorch.org/docs/stable/generated/torch.get_default_device.html) can return the default device of a 0D or more D tensor.
```python
import torch
my_tensor = torch.tensor([0, 1, 2])
my_tensor.device
torch.get_default_device()
# device(type='cpu')
torch.set_default_device(device='cuda:0')
torch.set_default_device(device='cuda')
torch.set_default_device(device=0)
torch.set_default_device(device=torch.device(device='cuda:0'))
torch.set_default_device(device='cuda')
torch.set_default_device(device=0)
torch.set_default_device(device=torch.device(type='cuda', index=0))
torch.set_default_device(device=torch.device(type='cuda'))
my_tensor.device
torch.get_default_device()
# device(type='cuda', index=0)
```
[set_printoptions()](https://pytorch.org/docs/stable/generated/torch.set_printoptions.html) can set the default precision of the zero or more floating-point numbers and complex numbers of a 0D or more D tensor as shown below:
*Memos:
- `set_printoptions()` can be used with `torch` but not with a tensor.
- The 1st argument with `torch` is `precision`(Optional-Default:`4`-Type:`int`). *It must be zero or a positive number.
- The effect of `set_printoptions()` lasts until `set_printoptions()` is used next time.
```python
import torch
torch.set_printoptions()
torch.set_printoptions(precision=4)
torch.tensor([-3.635251, 7.270649, -5.164872])
# tensor([-3.6353, 7.2706, -5.1649])
torch.tensor([-3.635251+4.634852j,
7.270649+2.586449j,
-5.164872-3.450984j])
# tensor([-3.6353+4.6349j,
# 7.2706+2.5864j,
# -5.1649-3.4510j])
torch.rand(3)
# tensor([0.4249, 0.7562, 0.5942])
torch.rand(3, dtype=torch.complex64)
# tensor([0.9534+0.6484j, 0.1216+0.3275j, 0.8730+0.9752j])
torch.set_printoptions(precision=2)
torch.tensor([-3.635251, 7.270649, -5.164872])
# tensor([-3.64, 7.27, -5.16])
torch.tensor([-3.635251+4.634852j,
7.270649+2.586449j,
-5.164872-3.450984j])
# tensor([-3.64+4.63j, 7.27+2.59j, -5.16-3.45j])
torch.rand(3)
# tensor([0.95, 0.86, 0.32])
torch.rand(3, dtype=torch.complex64)
# tensor([0.28+0.95j, 0.27+0.75j, 0.78+0.45j])
torch.set_printoptions(precision=8)
torch.tensor([-3.635251, 7.270649, -5.164872])
# tensor([-3.63525105, 7.27064896, -5.16487217])
torch.tensor([-3.635251+4.634852j,
7.270649+2.586449j,
-5.164872-3.450984j])
# tensor([-3.63525105+4.63485193j,
# 7.27064896+2.58644891j,
# -5.16487217-3.45098400j])
torch.rand(3)
# tensor([0.12433541, 0.90939915, 0.81334412])
torch.rand(3, dtype=torch.complex64)
# tensor([0.23186535+0.95299882j,
# 0.97718322+0.48021430j,
# 0.73880774+0.09643537j])
``` | hyperkai |
1,864,353 | is_tensor(), numel() and device() in PyTorch | *Memos: My post explains how to check PyTorch version, CPU and GPU(CUDA). My post explains how to... | 0 | 2024-05-24T22:20:20 | https://dev.to/hyperkai/istensor-numel-and-device-in-pytorch-2eha | pytorch, istensor, numel, device | *Memos:
- [My post](https://dev.to/hyperkai/check-pytorch-version-cpu-and-gpucuda-in-pytorch-6jk) explains how to check PyTorch version, CPU and GPU(CUDA).
- [My post](https://dev.to/hyperkai/create-a-tensor-in-pytorch-127g) explains how to create a tensor.
- [My post](https://dev.to/hyperkai/access-a-tensor-in-pytorch-1f4e) explains how to access a tensor.
- [My post](https://dev.to/hyperkai/type-conversion-with-type-to-and-a-tensor-in-pytorch-2a0g) explains type conversion with [type()](https://pytorch.org/docs/stable/generated/torch.Tensor.type.html), [to()](https://pytorch.org/docs/stable/generated/torch.Tensor.to.html) and a tensor.
- [My post](https://dev.to/hyperkai/type-promotion-resulttype-promotetypes-and-cancast-in-pytorch-33p8) explains type promotion, [result_type()](https://pytorch.org/docs/stable/generated/torch.result_type.html), [promote_types()](https://pytorch.org/docs/stable/generated/torch.promote_types.html) and [can_cast()](https://pytorch.org/docs/stable/generated/torch.can_cast.html).
- [My post](https://dev.to/hyperkai/device-conversion-fromnumpy-and-numpy-in-pytorch-1iih) explains device conversion, [from_numpy()](https://pytorch.org/docs/stable/generated/torch.from_numpy.html) and [numpy()](https://pytorch.org/docs/stable/generated/torch.Tensor.numpy.html).
- [My post](https://dev.to/hyperkai/setdefaultdtype-setdefaultdevice-and-setprintoptions-in-pytorch-55g8) explains [set_default_dtype()](https://pytorch.org/docs/stable/generated/torch.set_default_dtype.html), [set_default_device()](https://pytorch.org/docs/stable/generated/torch.set_default_device.html) and [set_printoptions()](https://pytorch.org/docs/stable/generated/torch.set_printoptions.html).
- [My post](https://dev.to/hyperkai/manualseed-initialseed-and-seed-in-pytorch-5gm8) explains [manual_seed()](https://pytorch.org/docs/stable/generated/torch.manual_seed.html), [initial_seed()](https://pytorch.org/docs/stable/generated/torch.initial_seed.html) and [seed()](https://pytorch.org/docs/stable/generated/torch.seed.html).
[is_tensor()](https://pytorch.org/docs/stable/generated/torch.is_tensor.html) can check if an object is a PyTorch tensor, getting the scalar of a boolean value as shown below:
*Memos:
- `is_tensor()` can be used with [torch](https://pytorch.org/docs/stable/torch.html) but not with a tensor.
- The 1st argument with `torch` is `obj`(Required-Type:`object`).
```python
import torch
import numpy as np
pytorch_tensor = torch.tensor([0, 1, 2])
torch.is_tensor(obj=pytorch_tensor) # True
numpy_tensor = np.array([0., 1., 2.])
torch.is_tensor(obj=numpy_tensor) # False
torch.is_tensor(obj=7) # False
torch.is_tensor(obj=7.) # False
torch.is_tensor(obj=7.+0.j) # False
torch.is_tensor(obj=True) # False
torch.is_tensor(obj='Hello') # False
```
[numel()](https://pytorch.org/docs/stable/generated/torch.numel.html) can get the scalar of the total number of the elements from the 0D or more D tensor of zero or more elements as shown below:
*Memos:
- `numel()` can be used with `torch` or a tensor.
- The 1st argument with `torch` is `input`(Required-Type:`tensor` of `int`, `float`, `complex` or `bool`).
```python
import torch
my_tensor = torch.tensor(7)
torch.numel(input=my_tensor)
my_tensor.numel()
# 1
my_tensor = torch.tensor([7, 5, 8])
torch.numel(input=my_tensor) # 3
my_tensor = torch.tensor([[7, 5, 8],
[3, 1, 6]])
torch.numel(input=my_tensor) # 6
my_tensor = torch.tensor([[[7, -5, 8], [-3, 1, 6]],
[[0, 9, 2], [4, -7, -9]]])
torch.numel(input=my_tensor) # 12
my_tensor = torch.tensor([[[7., -5., 8.], [-3., 1., 6.]],
[[0., 9., 2.], [4., -7., -9.]]])
torch.numel(input=my_tensor) # 12
my_tensor = torch.tensor([[[7.+0.j, -5.+0.j, 8.+0.j],
[-3.+0.j, 1.+0.j, 6.+0.j]],
[[0.+0.j, 9.+0.j, 2.+0.j],
[4.+0.j, -7.+0.j, -9.+0.j]]])
torch.numel(input=my_tensor) # 12
my_tensor = torch.tensor([[[True, False, True], [True, False, True]],
[[False, True, False], [False, True, False]]])
torch.numel(input=my_tensor) # 12
```
[device()](https://pytorch.org/docs/stable/tensor_attributes.html#torch-device) can represent a device as shown below:
*Memos:
- `device()` can be used with `torch` but not with a tensor.
- The 1st argument with `torch` is `device`(Required-Type:`str`, `int` or [device()](https://pytorch.org/docs/stable/tensor_attributes.html#torch-device)).
- The 1st argument with `torch` is `type`(Required-Type:`str`).
- The 2nd argument with `torch` is `index`(Optional-Type:`int`). *`index` must be used with `type`.
- `cpu`, `cuda`, `ipu`, `xpu`, `mkldnn`, `opengl`, `opencl`, `ideep`, `hip`, `ve`, `fpga`, `ort`, `xla`, `lazy`, `vulkan`, `mps`, `meta`, `hpu`, `mtia` or `privateuseone` can be set to `device` or `type`.
- Setting 0 to `device` uses cuda(GPU). *The number must be zero or positive.
```python
import torch
torch.device(device='cpu')
torch.device(type='cpu')
# device(type='cpu')
torch.device(device='cuda:0')
torch.device(device=0)
torch.device(type='cuda', index=0)
torch.device(device=torch.device(device='cuda:0'))
torch.device(device=torch.device(device=0))
torch.device(device=torch.device(type='cuda', index=0))
# device(type='cuda', index=0)
torch.device(device='cuda')
torch.device(type='cuda')
torch.device(device=torch.device(device='cuda'))
torch.device(device=torch.device(type='cuda'))
# device(type='cuda')
```
| hyperkai |
1,864,339 | InfinityScroll - Just like TikTok! | 📺 preview.jpg Watch it ✨ Live ✨ 📝 infinityscroll.js Don't dwell on the pain. Just take... | 26,254 | 2024-05-24T22:17:59 | https://dev.to/jorjishasan/infinityscroll-just-like-tiktok-4j5l | webdev, javascript, programming, react | {% details 📺 preview.jpg %}
_Watch it [✨ Live ✨](https://infinitytoken.netlify.app/)_
{% enddetails %}{% details 📝 infinityscroll.js %}
_Don't dwell on the pain. Just take a quick look. After reading the article, everything will become clear to you. [📝 SOURCE CODE](https://github.com/jorjishasan/infinite-scroller)_
```js
import { useState, useEffect } from "react";
import ReactDOM from "react-dom/client";
function App() {
const [numArr, setNumArr] = useState(Array.from({ length: 20 }, (_, i) => i));
const handleScroll = () => {
if (window.innerHeight + window.scrollY >= document.body.offsetHeight) {
setNumArr((prevNums) => [
...prevNums,
...Array.from({ length: 20 }, (_, i) => i + prevNums.length),
]);
}
};
// Listen for scroll events
useEffect(() => {
window.addEventListener("scroll", handleScroll);
return () => window.removeEventListener("scroll", handleScroll);
}, []);
return (
<div className="font-serif text-3xl text-center">
{numArr.map((num, index) => (
<div
key={index}
className="m-2 p-5 bg-white shadow-md rounded cursor-pointer"
>
{num}
</div>
))}
</div>
);
}
const root = ReactDOM.createRoot(document.getElementById("root"));
root.render(<App />);
```
{% enddetails %}
I promise! Following my steps, you can natively implement Infinity Scrolling. This means you don't have to worry about installing extra packages or adding unnecessary weight to your app.
1. Initial Render
2. Event Listening
3. Event Handling
Don't be afraid of these jargon words 😄. I'm holding your hands 💪. Once you reach the end of the article, it'll make you proud.
---
**STEP 1:** ⏤ Initial Render 📃
Initially, let's load/fill the page with 20 elements.
CODE:
```js
function App() {
const [numArr, setNumArr] = useState(Array.from({ length: 20 }, (_, i) => i));
return (
<div className="font-serif text-3xl text-center">
{numArr.map((num, index) => (
<div
key={index}
className="m-2 p-5 bg-white shadow-md rounded cursor-pointer"
>
{num}
</div>
))}
</div>
);
```
Explain: Create a `numArr` state variable on top of the `App` component with values 0 through 20. Over the return statement, render items of `numArr` as elements. **STEP 1 is done.**
---
**STEP 2:** ⏤ Event Listening 👂
Browsers offer us bunch of events: Mouse(click, mousemove, mouseover), Keybaord Event(keydown, keypress, keyup), and Window Event(scroll, resize, load).
Since we are implementing a feature based on scrolling, we need to keep track of scroll activity. To get notified, we'll set a watcher inside the `App()` component that continuously checks whether a scroll happens.
CODE:
```js
function App() {
// Listen for scroll events
useEffect(() => {
window.addEventListener("scroll", handleScroll);
return () => window.removeEventListener("scroll", handleScroll);
}, []);
}
```
Explain: We set the watcher or event-listener, that event listener `window.addEventListener("scroll", handleScroll)` takes 2 arguments: the event name `scroll` and a callback-function `handleScroll` that defines what to do when the event is triggered. **Step 2 is done.** The `return` statement does [cleanup](https://dev.to/jorjishasan/cleanup-in-react-5dkc). You can skip it for now with this setup.
---
**STEP-3:** ⏤ Event Handling 💪
Assuming that scrolling happens, the contract of the `handleScroll` function would be to load more data when the user reaches the end of the page.
CODE:
```js
//This function will invoked when event triggered
const handleScroll = () => {
if (window.innerHeight + window.scrollY >= document.body.offsetHeight) {
setNumArr((prevNums) => [
...prevNums,
...Array.from({ length: 20 }, (_, i) => i + prevNums.length),
]);
}
};
```
Explain: The if statement verifies that the user has reached the end of the page. The code inside the `if` block accumulates 15 new data to the `numArr` variable. Since `numArr` is a state variable, it will re-render the state after every update. It's react's native [state behavior](https://react.dev/reference/react/useState).
Yay 😀! You have done the **last step.** You have achieved more optimized infinity scrolling.
**NB:** I used numbers as placeholders. In a real scenario, you'll fetch data across pages via API. | jorjishasan |
1,864,226 | MindsDB + Docker: Utilizando SQL e containers para integrações com IA | Já pensou em criar sua própria IA, treiná-la com seus dados e utilizar esse "conhecimento" para... | 0 | 2024-05-24T22:10:07 | https://dev.to/rflpazini/mindsdb-docker-utilizando-sql-e-containers-para-integracoes-com-ia-edc | docker, sql, openai | Já pensou em criar sua própria IA, treiná-la com seus dados e utilizar esse "conhecimento" para alavancar seu app ou algum projeto em que você está trabalhando? Eu também pensei nisso e tive a mesma reação: "Nossa, que preguiça! Imagina quanto tempo eu ia perder fazendo isso..."
Quando pensamos em IA, geralmente imaginamos ter que começar do zero, aprender uma nova linguagem, escrever milhares de linhas de código para integrar com o app. Mas e se eu te disser que dá para fazer isso apenas usando SQL ou então fazendo uma requisição HTTP? É exatamente isso que o MindsDB faz por nós.
## O que é o MindsDB?
O MindsDB é uma plataforma que facilita a criação e integração de modelos de aprendizado de máquina (machine learning) diretamente com bancos de dados, utilizando SQL - sim, você não precisa aprender outra linguagem para trabalhar com IA 😅.
Ela permite que desenvolvedores, como nós, aproveitem os dados existentes em seus bancos de dados e construam modelos de aprendizado de máquina sem a necessidade de conhecimentos avançados em ciência de dados ou machine learning.
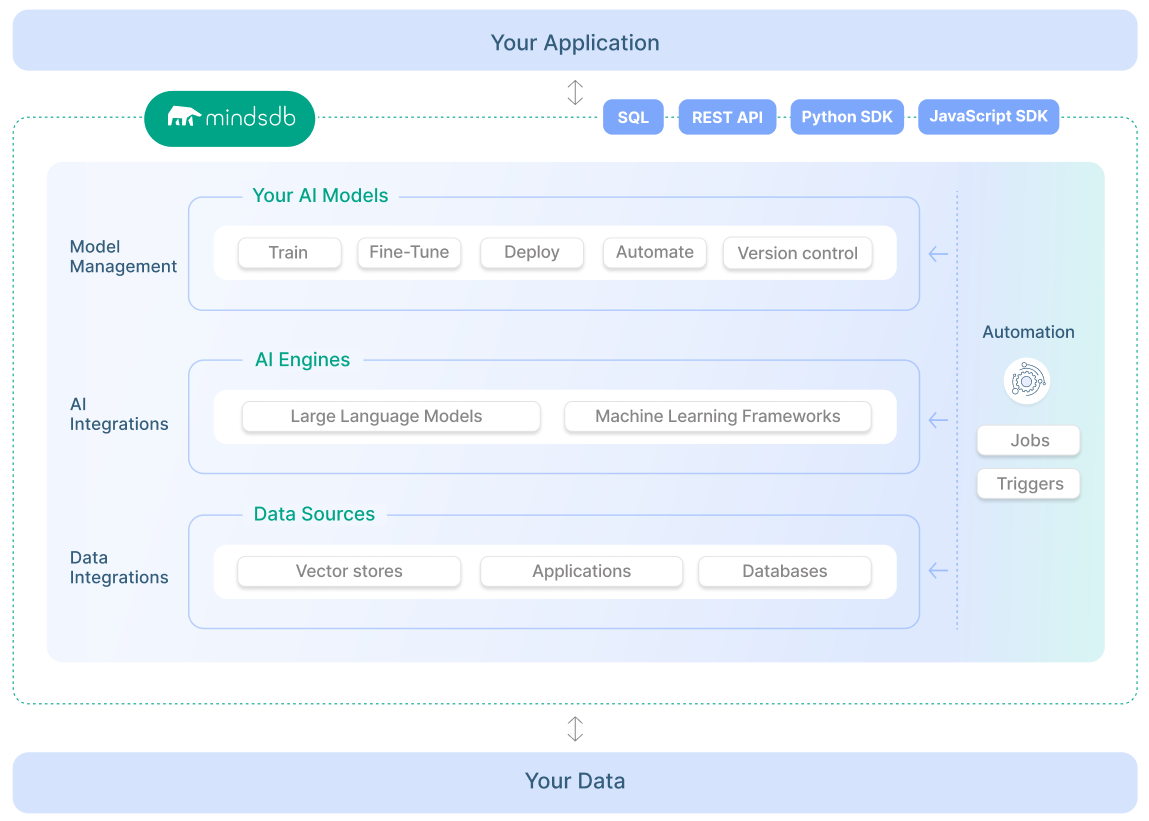
Em resumo, ele permite termos nossa IA personalizada para nossos dados direto da nossa aplicação. Se liga no diagrama abaixo, nele podemos ver como é a estrutura do MindsDB e um pouco de como é sua integração.
### **Benefícios do MindsDB**
- **Facilidade de Uso:** Ideal para desenvolvedores que já estão familiarizados com SQL, eliminando a necessidade de aprender novas linguagens de programação.
- **Agilidade:** Reduz o tempo e esforço necessários para desenvolver e implementar modelos de machine learning.
- **Flexibilidade:** Funciona com uma ampla gama de bancos de dados e pode ser integrado em diversas aplicações.
Depois disso, você deve estar se perguntando: "Mas e aí, Rafa, será que é tão simples a integração e a brincadeira com ele?" Vamos colocar a mão na massa e ver se é assim mesmo…
## Contexto e Problema
Vamos imaginar que temos uma loja de café onde nossos usuários deixam seus reviews sobre o que acharam do nosso café. A cada 3 meses renovamos o cardápio da loja e queremos trocar os cafés que têm opiniões “neutras” ou “negativas” sobre eles.

Queremos fazer isso de uma forma rápida e simples, sem ter que ficar lendo milhões de comentários para analisar um a um e, no fim, contar as opiniões sobre o que temos. Então, como todo bom programador, vamos utilizar a hype do momento: a IA para classificar esses comentários para nós e, de quebra, aprender uma tecnologia nova.
## Deploy com Docker
Eu gosto de facilitar tudo na minha vida, então a maneira mais simples de instalar uma ferramenta ou algum app sem ter que ficar configurando mil coisas em nossa máquina local é usando Docker 😄.
O MindsDB utiliza várias dependências para funcionar, como Python, MongoDB, MySQL, e utilizando a imagem Docker não temos que nos preocupar em instalar nada disso em nossa máquina.
> Para seguir esse tutorial, você deve ter o Docker instalado e rodando em sua máquina. Caso ainda não tenha ele instalado, basta seguir o tutorial da [documentação oficial](https://docs.docker.com/desktop/).
>
Como eu quero trazer um exemplo de uso real, vamos ter dois containers rodando: um com o MindsDB e outro com um MySQL, que é o banco de dados onde já existem nossos comentários sobre os cafés.
Para ter acesso ao projeto, [basta baixar a pasta dele no meu Github](https://github.com/rflpazini/articles/tree/main/mindsdb_docker), onde teremos a seguinte estrutura dentro da pasta:
```bash
mindsdb_docker
├── compose.yml //incia os nossos containers
└── dump.sql //insere os dados em nosso DB
```
Com o projeto baixado, é hora de rodá-lo localmente. Para executar o docker compose, digite o seguinte comando:
```bash
$ docker compose up -d --build
```
Após realizar o comando, você receberá a seguinte mensagem em seu terminal dizendo que tudo foi inicializado:
```bash
✔ Network mindsdb_sample_default Created 0.0s
✔ Container mindsdb_sample-mysql-1 Started 0.3s
✔ Container mindsdb_sample-mindsdb-1 Started 0.3s
```
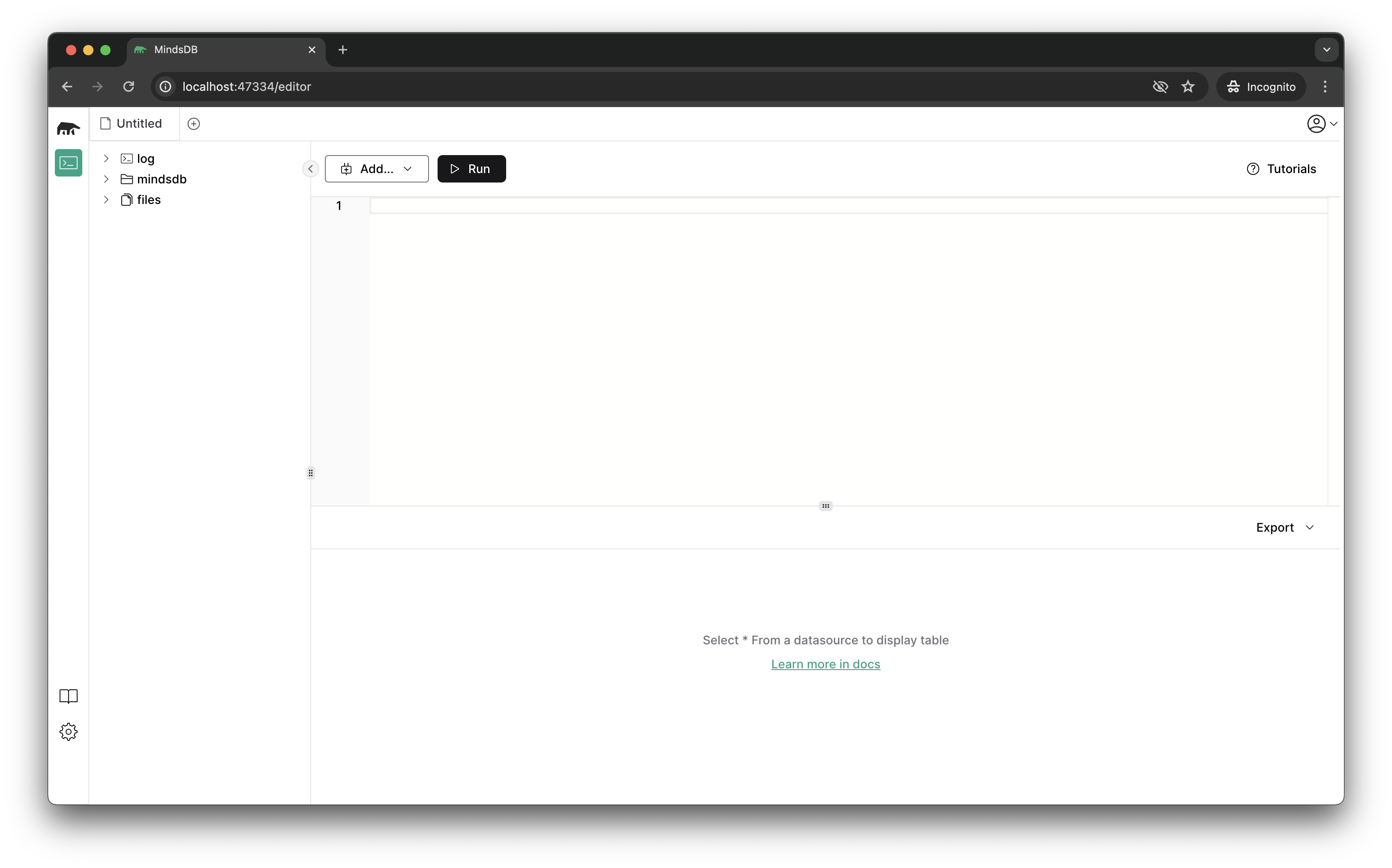
Agora é só acessar a URL do MindsDB que é [`http://localhost:47334`](http://localhost:47334/) para ver a interface gráfica dele.
## Configurando a conexão com DB
Como já temos a instância do MindsDB rodando localmente, vamos configurar a conexão dele com nossa base de dados, de onde serão retiradas as reviews.
Para isso, basta digitar o seguinte comando SQL:
```sql
CREATE DATABASE mysql_sample
WITH ENGINE = 'mysql',
PARAMETERS = {
"user": "root",
"password": "r00tPassword123",
"host": "<ip-local-do-seu-computador>", --troque pelo seu ip local
"port": "3306",
"database": "cool_data"
};
```
> Um detalhe importante é que no host devemos colocar o IP local do nosso computador. Por exemplo, o meu é **`10.0.2.10`** pois não podemos esquecer que estamos dentro de um container e que a porta mapeada para acesso é a do nosso host. Se colocarmos **`localhost`**, ele não encontrará o banco de dados. Caso não saiba qual é seu IP, aqui vai um comando que pode ajudar 😄
>
```bash
$ ifconfig | grep \"inet \" | grep -v 127.0.0.1 | cut -d\ -f2
```
O que estamos fazendo com esse comando SQL:
- Criando a conexão com o banco e dizendo que ela se chamará **`mysql_sample`**.
- Dizendo qual é a ENGINE de banco de dados que queremos utilizar.
- Passando os parâmetros de conexão: usuário, senha, host e o nome do banco de dados que vamos nos conectar.
Agora vamos validar se nossa conexão está funcionando. Para isso, vamos usar o bom e velho SELECT do nosso querido SQL:
```sql
SELECT *
FROM mysql_sample.coffee_review
LIMIT 2;
```
Ele deve retornar os valores que existem em nosso banco de dados. No caso, temos uma tabela chamada **`coffee_review`** e os seguintes campos: **`id`**, **`coffee_name`**, **`origin`** e **`review`** com os dados já preenchidos. Note também que durante a consulta SQL utilizei o nome da conexão que criamos no passo acima para dizer para o MindsDB que quero pegar a tabela **`coffee_review`** que está dentro do meu banco **`mysql_sample`**.
Assim sabemos que temos uma conexão de sucesso entre a nossa base de dados e o MindsDB
## Criando uma ML Engine
O MindsDB, como eu disse no início, tem suporte para vários plugins e um deles são as ML Engines. No nosso caso, como queremos fazer a análise dos comentários, vamos utilizar a OpenAI engine e para isso precisamos configurá-la.
> Para o próximo passa você precisará de uma API Key e consegue gera-la no próprio site da OpenAI: [platform.openai.com](https://platform.openai.com/settings/organization/billing/payment-methods)
>
Com a API Key em mãos podemos criar a ML Engine dentro do MindsDB, é bem tranquilo:
```sql
CREATE ML_ENGINE openai
FROM openai
USING
openai_api_key = 'sk-xxxx'; --substitua o valor pela sua chave
```
O MindsDB disponibiliza o handler, que é a integração do MindsDB com as APIs das IAs. Então, o que temos que fazer é apenas dizer que queremos criar uma nova engine usando o handler específico para ela. Existem vários e você pode encontrar a lista deles na documentação. No código acima, estamos criando a **`openai`** engine, usando o handler da **`openai`** e passando a nossa API key para ele.
Essa simples configuração já faz a integração do nosso MindsDB com a IA que escolhemos.
## Hora de criar o Modelo
Quando falamos de modelo, em palavras simplificadas, é o modelo de aprendizagem que a IA vai utilizar para fazer a tarefa que queremos que ela execute.
No MindsDB vamos criar este modelo de aprendizagem utilizando SQL e passando algumas informações para ele.
Assim ficará nosso modelo que classifica os comentários sobre o café como positivo, negativo e neutro.
```sql
CREATE MODEL coffee_review_sentiment
PREDICT sentiment
USING
engine = 'openai',
model_name = 'gpt-4',
prompt_template = 'descreva o sentimento dos comentários apenas como "positivo", "negativo" ou "neutro".
"Amei este café":positivo
"Não me agradou": negativo
"{{review}}.":';
```
No código acima, a primeira coisa que fazemos é dar um nome para o modelo, que se chama **`coffee_review_sentiment`**. Logo em seguida, falamos para o modelo que ele vai “prever” a propriedade **`sentiment`**, ou seja, estamos falando que o resultado do nosso prompt será exibido nessa coluna. Por fim, dizemos qual engine queremos usar: **`openai`**, que é a que acabamos de configurar. Dizemos também que queremos utilizar o **`gpt-4`** como modelo de IA e como estamos usando a OpenAI, ela sempre espera um prompt de comando, que é onde passamos para o modelo o que esperamos que ele faça e com qual informação ele vai trabalhar.
Após executar o comando de criar, você provavelmente receberá o seguinte output:
```markdown
| TABLES | NAME | ENGINE | PROJECT | ACTIVE | VERSION | STATUS | ACCURACY | PREDICT | UPDATE_STATUS | MINDSDB_VERSION | ERROR | SELECT_DATA_QUERY | TRAINING_OPTIONS | TAG |
|---------------------|---------------------------|--------|---------|--------|---------|------------|----------|-----------|---------------|-----------------|--------|-------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------|
| ["args","metadata"] | coffee_review_sentiment_6 | openai | mindsdb | true | 1 | generating | [NULL] | sentiment | up_to_date | 24.4.3.0 | [NULL] | [NULL] | {'__mdb_sql_task': None, 'target': 'sentiment', 'using': {'model_name': 'gpt-4', 'prompt_template': 'descreva o sentimento dos comentários apenas como "positivo", "negativo" ou "neutro".\n "Amei este café":positivo\n "Não me agradou": negativo\n "{{review}}.":'}} | [NULL] |
```
Repare que na coluna **`STATUS`** temos o valor **`generating`**, ou seja, o nosso modelo está sendo gerado ainda. Ainda não podemos utilizá-lo em nossas consultas; para ele se tornar útil o status deve ser **`complete`**. Para consultar o valor do status, utilizamos o comando **`DESCRIBE`** para descrever o que temos na nossa tabela de modelo:
```sql
DESCRIBE coffee_review_sentiment;
```
Quando o status for **`complete`**, você verá no resultado da query:
```sql
| TABLES | NAME | ENGINE | PROJECT | ACTIVE | VERSION | STATUS | ACCURACY | PREDICT | UPDATE_STATUS | MINDSDB_VERSION | ERROR | SELECT_DATA_QUERY | TRAINING_OPTIONS | TAG |
|---------------------|---------------------------|--------|---------|--------|---------|----------|----------|-----------|---------------|-----------------|--------|-------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------|
| ["args","metadata"] | coffee_review_sentiment_6 | openai | mindsdb | true | 1 | complete | [NULL] | sentiment | up_to_date | 24.4.3.0 | [NULL] | [NULL] | {'__mdb_sql_task': None, 'target': 'sentiment', 'using': {'model_name': 'gpt-4', 'prompt_template': 'descreva o sentimento dos comentários apenas como "positivo", "negativo" ou "neutro".\n "Amei este café":positivo\n "Não me agradou": negativo\n "{{review}}.":'}} | [NULL] |
```
## Aplicando a classificação
Agora que temos o modelo pronto e configurado, é hora de classificar nossos reviews. Faremos isso utilizando os comandos mais clássicos de SQL: **`SELECT`** e **`FROM`** 😊.
Relembrando o que queremos fazer, queremos classificar os reviews dos nossos cafés como neutro, positivo e negativo. Para nosso exemplo, acho legal mostrar primeiro qual é o sentimento e depois o comentário caso for necessário ler o comentário que recebeu aquela avaliação.
Então vamos para o nosso select:
```sql
SELECT m.sentiment, t.review --campos que quero exibir na minha consulta
FROM mysql_sample.coffee_review AS t --tabela do DB que contem o review
JOIN mindsdb.coffee_review AS m; --tabela que contém a previsão da IA
```
Aqui fazemos um pequeno select usando join para obter o nosso sentimento e logo em seguida o review que teve aquela análise de nossa IA. Seu resultado deve ser o seguinte:
```markdown
| sentiment | review |
|-----------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| positivo | Assim que eu levei a xÃcara aos lábios, parecia que eu estava num mercado de especiarias. O aroma floral e cÃtrico tomou conta e me deixou super curioso. No primeiro gole, senti uma explosão de sabores complexos: limão e bergamota, com um toque sutil de jasmim. A acidez brilhante equilibrada por uma doçura suave, quase como mel, foi incrÃvel. A cada gole, o café ia mostrando mais camadas, deixando um gostinho refrescante na boca. É como uma dança de sabores no paladar, perfeito para começar o dia cheio de energia e inspiração. |
| positivo | Desde que o espresso começou a sair, o cheiro rico e achocolatado tomou conta do lugar. O primeiro gole foi como um abraço quentinho - notas de chocolate amargo, nozes torradas e um toque de caramelo. A crema espessa dá uma textura cremosa, deixando tudo ainda mais gostoso. A doçura natural e o corpo encorpado desse blend são bem tÃpicos dos cafés brasileiros. Cada gole traz uma sensação de conforto e familiaridade, perfeito para uma pausa à tarde ou um bate-papo com amigos. |
| positivo | Quando comecei a prensar o café na Prença Francesa, o cheiro doce e terroso começou a se espalhar pelo ambiente. No primeiro gole, já senti uma profundidade incrÃvel: notas de frutas vermelhas, como cereja e amora, com um toque leve de cacau. A acidez suave e a doçura das frutas se equilibram perfeitamente, e a textura é super aveludada. Esse café me fez sentir super conectado com a natureza, como se eu estivesse saboreando os frutos direto da terra. É uma experiência revigorante e autêntica, perfeita para quem curte um café cheio de personalidade. |
| neutro | Preparei esse café na máquina automática e o aroma que surgiu foi ok, nada demais. No primeiro gole, o sabor era simples e direto, sem muita complexidade. Tinha notas de nozes levemente tostadas e um toque sutil de chocolate ao leite. A acidez estava bem equilibrada e o corpo era médio, dando uma sensação satisfatória, mas sem impressionar. Esse café não tem nada de muito especial, mas é uma escolha segura pra quem quer um café consistente e previsÃvel, sem grandes surpresas. |
| negativo | Ao coar esse café, o aroma foi bem fraquinho e nada convidativo. O primeiro gole foi uma decepção - um sabor raso e sem vida, com um amargor queimado que lembrava borra de café velha. A acidez estava desbalanceada e a textura era bem aquosa, deixando uma sensação desagradável na boca. Não havia qualquer traço de doçura ou complexidade para salvar a experiência. Cada gole foi um esforço para terminar a xÃcara, e fiquei frustrado e arrependido de não ter escolhido um café melhor. |
```
Pronto, temos todos nossos reviews classificados com o “sentimento”.
Ótimo!! mas e se formos um pouco além e melhorarmos esse select com outro modelo para termos acesso aos motivos que levaram esse comentário a expressar aquele sentimento? hehehe
### Detalhando a classificação
Agora vamos melhorar um pouco mais nossa classificação e inserir os motivos para ela. Isso facilitaria, por exemplo, a vida de um executivo que não quer ficar horas lendo comentários para entender o que o seu cliente escreveu, mas quer otimizar o tempo indo direto para os principais motivos do que aconteceu. A famosa leitura dinâmica virando leitura eficiente 😀
Para facilitar nosso lado de “dev”, vamos criar outro modelo, onde diremos a ele para listar os principais motivos do sentimento por trás daquele review.
```sql
CREATE MODEL coffee_review_reasons
PREDICT reasons
USING
engine = 'openai',
model_name = 'gpt-4',
prompt_template = 'liste resumidamente os principais motivos do sentimento: "{{review}}";';
```
Como estamos acostumados, criamos o modelo com o nome **`coffee_review_reasons`**, onde ele vai ter o output na coluna **`reasons`**. No prompt, pedimos de uma forma direta para que ele liste resumidamente os principais motivos do sentimento; esse sentimento virá do nosso campo **`review`** que está em nosso DB.
Agora é só sentar e melhorar nosso select que acabamos de fazer, e como melhoraremos ele? Através de `JOINS`:
```sql
SELECT t.id, m.sentiment, m2.reasons
FROM mysql_sample.coffee_review AS t
JOIN coffee_review_sentiment AS m
JOIN coffee_review_reasons AS m2
WHERE m.sentiment = 'negativo' OR m.sentiment = 'neutro'
```
Para explicar esse nosso novo select: Primeiro dizemos que queremos exibir o **`id`**, o sentimento **`sentiment`** e os motivos **`reasons`**. Logo em seguida pegamos o review do nosso banco de dados, depois fazemos os JOINS com o primeiro modelo que é o **`coffee_review_sentiment`** e depois com o novo modelo **`coffee_review_reasons`**. Como acho que o que importa neste momento são apenas termos mais detalhes dos negativos e neutros, colocamos uma cláusula WHERE filtrando apenas por neutro e negativo. Mais uma análise completa!
Esse é o resultado de nossa análise final, com os cafés que têm sentimento negativo e neutro sobre eles e os principais motivos de terem tido este julgamento resumidos para nós:
```markdown
| id | sentiment | reasons |
|----|-----------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 5 | negativo | 1. Aroma fraco e não convidativo: O aroma do café é um dos primeiros indicadores de sua qualidade. Neste caso, o aroma fraco pode ter indicado que o café não seria satisfatório.2. Sabor raso e sem vida: Um bom café deve ter um sabor rico e complexo. O sabor raso e sem vida deste café foi uma grande decepção.3. Amargor queimado: O amargor |
| 4 | neutro | 1. Aroma: O aroma do café preparado na máquina automática foi considerado apenas "ok", não se destacando de maneira especial.2. Sabor: O sabor do café foi descrito como simples e direto, sem muita complexidade. As notas de nozes levemente tostadas e um toque sutil de chocolate ao leite foram identificadas, mas não trouxeram um diferencial significativo.3. Acidez |
```
### Inserindo nossa consulta em uma nova tabela
Agora você deve estar se perguntando: “Poxa, mas como que eu salvo esses dados da análise?”. Bom, temos algumas formas de fazer isso; para facilitar nossa vida, que tal salvá-las no banco de dados em uma nova tabela?
Vamos criar essa tabela com a ajuda do SQL novamente e usando o **`CREATE TABLE`**. Então reescreva o último select que fizemos, mas agora vamos inseri-lo junto com o comando de criar uma nova tabela em nosso banco de dados:
```sql
CREATE TABLE mysql_sample.reviews_processed (
SELECT t.id, m.sentiment, m2.reasons
FROM mysql_sample.coffee_review AS t
JOIN coffee_review_sentiment AS m
JOIN coffee_review_reasons AS m2
WHERE m.sentiment = 'negativo' OR m.sentiment = 'neutro'
);
```
Dessa forma, garantimos que temos um registro salvo e não precisamos ficar reprocessando a nossa análise toda vez que quisermos consultar o que os clientes estão achando de nossos cafés.
E assim terminamos nosso sistema de análises de reviews sobre cafés e podemos tirar os cafés menos desejados de nosso cardápio 🥰
## Benefícios da analise
A análise de sentimento é uma ferramenta poderosa que permite entender as opiniões e emoções dos clientes em relação a produtos ou serviços. No contexto de uma loja de café, como exemplificado no artigo, a implementação de uma IA para realizar essa análise pode trazer inúmeros benefícios estratégicos, como por exemplo:
- **Melhoria da Experiência do Cliente:** permite uma resposta rápida às críticas dos clientes, ajudando a resolver problemas antes que eles se tornem amplamente conhecidos e afetem a reputação da marca.
- **Tomada de Decisões Baseada em Dados:** com insights sobre quais produtos são mais apreciados e quais não agradam, a empresa pode tomar decisões informadas sobre quais itens manter, modificar ou remover do cardápio.
- **Vantagem Competitiva:** negócios que utilizam a análise de sentimento conseguem se adaptar rapidamente às mudanças nas preferências dos consumidores, mantendo-se à frente da concorrência, podendo inovar de maneira contínua.
Entre outros que não citei aqui, mas hoje em dia o produto mais valioso que temos em mãos são os dados, então devemos dar um carinho especial para eles.
## Conclusão
A combinação do MindsDB e Docker revoluciona a maneira como integramos IA e machine learning em nossos projetos, tornando todo o processo incrivelmente simples e acessível. Com o MindsDB, desenvolvedores podem criar e implementar modelos de aprendizado de máquina usando apenas SQL, eliminando a necessidade de aprender novas linguagens de programação complexas. Docker, por sua vez, facilita a implantação dessas tecnologias, permitindo que várias dependências sejam gerenciadas de forma eficiente através de containers. Essa sinergia não só acelera o desenvolvimento e a implementação de soluções de IA, mas também reduz significativamente a complexidade operacional, permitindo que negócios de todos os tamanhos aproveitem o poder da IA para melhorar a experiência do cliente e impulsionar o crescimento. | rflpazini |
1,864,338 | Weekly Updates - May 24, 2024 | Hi everyone! Short and sweet this week. 📖 New Blog - Hybrid Search: An Overview - Do you want to... | 0 | 2024-05-24T22:08:21 | https://dev.to/couchbase/weekly-updates-may-24-2024-gbh | couchbase, ai, community, machinelearning | Hi everyone!
Short and sweet this week.
- 📖 **New Blog - Hybrid Search: An Overview** - Do you want to learn more about hybrid search, what it entails, how it works and the differences between search methods? [*You can read the blog here >>*](https://www.couchbase.com/blog/hybrid-search/)
<br />
- 📺 **New Video: Roundtable - Enterprise AI** - Watch the Enterprise AI Virtual Roundtable, as the panel of contributors and community members dive deeper into AI and machine learning. Hear their thoughts on how these technologies will continue to shape the industry over the next year. [*You can watch the video here>>*](https://www.youtube.com/watch?v=ppgQl9Q604k)
<br />
- ❔**Do you have a technical question that you'd like more answers to?** Join the Couchbase Forum, browse through topics, tags, and find previously answered questions or ask your question. [*You can access the Forum here >>*](https://www.couchbase.com/forums/)
<br />
- 👋 **Don't forget, it's Summit Season!** - Are you traveling to any of the AWS or Google Summits or other Tech Expos? Come say Hi and meet the team! [*You can see the Summit's we will be attending here >>*](https://www.couchbase.com/resources/webcasts-and-events/?cb_searchable_posts_asc%5BrefinementList%5D%5Btaxonomies.events_category%5D%5B0%5D=Tradeshow)
Have a great weekend everyone! | carrieke |
1,864,336 | Adventures in TypeScript Typescript System | Write modern systems is a hard task, if you not followed the tendencies accross the internet. There's... | 0 | 2024-05-24T22:04:09 | https://dev.to/ktfth/adventures-in-typescript-typescript-system-5h6k | webdev, typescript | Write modern systems is a hard task, if you not followed the tendencies accross the internet. There's something important to consider here, you need time to live and enjoy the life isn't?
Become a successful programmer or a developer, and even a engineer, you need to consider those thing's. And it's magical!
In my past experiences I dedicated some time to learn almost every concept I need to know how to be prolific with JavaScript, when TypeScript come to live, I just ignored what I've learned from JavaScript and try to clean my mind and focus on this new language.
For me, learn the new language quietly become a hard task, to setup the environment, understand how conditioner the compiler give me answer's and apply this effectively on a profitable project is a major thing that I wanted, to avoid loss all the perks the language offer.
But something come to mind, why I need that? And how to capture indicators of that change?
This kind of questions come to mind, with TypeScript and all the other technologies we choose. When something new pop's up, you need to hack around and discover your way, nothing delivery's more value than a good approach of what's you expect, the client expect or your users need.
Useful stuff to follow:
* source code
* change logs
* channel's
* reverse engineering other application's
* put thing's together
Don't trust other people say, if you want, try yourself and move fast!
Understand concept's behind a certain technology's, involve a bunch of experimentation and collaboration.
What you want to achieve? My goal is money, and I believe the money is in certain way a expression of wisdom.
Be carefully with anxious bahvior to adopt a technology just by the fact is cool, search your own way to make a change in the world with good quality code and discover why create a state of art piece of software is a concern. Sleep well without the fear of your software stop, without any clues for a investigation is a bad thing to happen.
Here the piece of wisdom extract from type system of TypeScript:
* Modern compiler infrastructure
* Tools supporting the language without a need to run at your own the code you need to made
* Flexibility at choices you need to made to deliver portable code
* Interop with JavaScript concept's
* Good mapping of what you are doing with your code
* Reusability with documentation based on types you or other's made it
* Modern modules base on the language
* Huge community
* Supported by big company
This is my thoughts about a good roadmap to learn new things, It is not perfect, but I feel comfortable with that, to cut a pathways down.
Nice to here from you if you can type your opinion about this approach and let's hack together?
Cheer's! | ktfth |
1,864,334 | Thanks Dev | A post by Gaurav Kumar | 0 | 2024-05-24T22:00:55 | https://dev.to/ownbizaccount/thanks-dev-2dn4 | ownbizaccount | ||
1,864,332 | Associating a Custom Domain to an API Gateway on Google Cloud | Setting up a custom domain for your API Gateway on Google Cloud enhances the professional appearance... | 0 | 2024-05-24T21:52:17 | https://dev.to/burgossrodrigo/associating-a-custom-domain-to-an-api-gateway-on-google-cloud-4ph6 | googlecloud, apigateway | Setting up a custom domain for your API Gateway on Google Cloud enhances the professional appearance of your APIs and improves brand consistency. Here's a step-by-step guide to achieve this.
**Prerequisites**
Ensure you have:
- A domain name managed via Google Cloud DNS or any other DNS provider.
- An SSL certificate configured in Google Cloud.
- Steps to Configure API Gateway with a Custom Domain
**Steps to Configure API Gateway with a Custom Domain**
1 - Create Serverless NEG for API Gateway
```
gcloud beta compute network-endpoint-groups create api-gateway-serverless-neg --region=us-central1 --network-endpoint-type=serverless --serverless-deployment-platform=apigateway.googleapis.com --serverless-deployment-resource=gateway-name
```
2 - Attach NEG to Backend Service
```
gcloud compute backend-services add-backend api-gateway-backend-service --global --network-endpoint-group=api-gateway-serverless-neg --network-endpoint-group-region=us-central1
```
3 - Create URL Map
```
gcloud compute target-https-proxies create api-gateway-https-proxy --ssl-certificates=dfb-dev-ssl-cert --url-map=api-gateway-url-map
```
4 - Create HTTPS Proxy
```
gcloud compute target-https-proxies create api-gateway-https-proxy --ssl-certificates=dfb-dev-ssl-cert --url-map=api-gateway-url-map
```
5 - Create Forwarding Rule
```
gcloud compute forwarding-rules create my-fw --target-https-proxy=api-gateway-https-proxy --global --ports=443
```
**Testing**
Verify the custom domain points to the API Gateway:
```
curl -v https://your-custom-domain.com
```
Conclusion
By following these steps, you can seamlessly associate a custom domain with your API Gateway, ensuring secure and branded API endpoints.
For more detailed documentation, refer to [Google Cloud API Gateway Custom Domains.](https://cloud.google.com/api-gateway/docs/using-custom-domains?hl=en-us)
| burgossrodrigo |
1,864,326 | Navigating React State | Introduction State management in React is a crucial aspect of developing applications with... | 0 | 2024-05-24T21:19:56 | https://dev.to/bilelsalemdev/navigating-react-state-usestate-usereducer-context-redux-toolkit-recoil-3i98 | react, javascript, webdev, development | ### Introduction
State management in React is a crucial aspect of developing applications with complex user interfaces. It involves managing the state of various components and ensuring that changes in state are efficiently propagated throughout the application. There are several approaches to state management in React, each with its own benefits and drawbacks. Here are the most commonly used state management techniques in React:
#### React's Built-in State (useState and useReducer)
#### Context API
#### Redux Toolkit
#### MobX
#### Recoil
#### Zustand
In this article, we'll focus on just a few of these techniques.
### 1. React's Built-in State (useState and useReducer)
#### useState
- **Benefits**:
- Simple to use for managing local component state.
- Ideal for small to medium-sized applications.
- Directly integrated into React, eliminating the need for additional libraries.
- **Drawbacks**:
- Can become cumbersome as the application grows.
- Managing state that needs to be shared across many components can become complex.
#### useReducer
- **Benefits**:
- Suitable for managing more complex state logic.
- Similar to Redux's reducer pattern but without external dependencies.
- Makes state transitions explicit and easier to debug.
- **Drawbacks**:
- May be overkill for simple state management needs.
- Limited in scope for larger applications with extensive state management requirements.
### 2. Context API
- **Benefits**:
- Excellent for passing data through the component tree without prop drilling.
- Simplifies state sharing across multiple components.
- No need for external libraries, keeping the bundle size smaller.
- **Drawbacks**:
- Can lead to performance issues if not used carefully, causing unnecessary re-renders.
- Lacks the advanced features of dedicated state management libraries, such as built-in side effect management.
### 3. Redux Toolkit
Redux Toolkit is the recommended way to use Redux because it reduces boilerplate and includes useful utilities.
- **Benefits**:
- Predictable state management with a single source of truth.
- Built-in best practices, reducing the amount of boilerplate code.
- Enhanced maintainability and scalability for large applications.
- Powerful middleware support (e.g., Redux Thunk) for handling asynchronous actions and side effects.
- Includes utility functions like `createSlice` and `createAsyncThunk` that simplify reducer and action creation.
- **Drawbacks**:
- Still involves a learning curve, especially for developers new to Redux.
- Can be overkill for small to medium-sized applications.
### 4. Recoil
Recoil is a state management library developed by Facebook, designed to manage complex state dependencies and improve performance.
- **Benefits**:
- Seamless integration with React, making it easy to adopt.
- Efficient state management with minimal re-renders, thanks to its fine-grained subscription model.
- Supports complex state dependencies and derived state using selectors.
- Provides a straightforward API for asynchronous state management with atoms and selectors.
- **Drawbacks**:
- Still relatively new and evolving, which might lead to breaking changes.
- Smaller ecosystem compared to Redux, which means fewer third-party tools and resources.
### Summary
**Local State (useState and useReducer)**:
- Best for simple state management within individual components.
- Excellent for small applications or isolated component state.
**Context API**:
- Great for sharing state across a component tree.
- Suitable for medium-sized applications with some shared state.
- Use `useContext` with `React.memo` or `useMemo` to optimize performance and avoid unnecessary re-renders.
**Redux Toolkit**:
- Ideal for large-scale applications with complex state requirements.
- Provides a robust ecosystem with a standardized approach, reducing boilerplate.
- Facilitates easier debugging and predictable state management with the `Redux DevTools`.
**Recoil**:
- Promising new library focused on efficient state management with complex dependencies.
- Suitable for applications needing fine-grained state management and derived state handling.
- Evolving rapidly, potentially leading to future improvements and changes.
Choosing the right state management approach depends on the specific needs of your application, including its size, complexity, and performance requirements. For small to medium projects, React’s built-in state and Context API might suffice. For larger projects with more complex state logic, Redux Toolkit's structured approach or Recoil's efficient state management capabilities may be more suitable. | bilelsalemdev |
1,864,325 | What is the best React lybraries for web development according to you? | A post by Shinny22 | 0 | 2024-05-24T21:13:40 | https://dev.to/shinny22/what-is-the-best-react-lybraries-for-web-development-according-to-you-4ip4 | react, javascript, webdev, typescript | shinny22 | |
1,864,323 | The Role Of AI In Employee Training And Development | Wanna become a data scientist within 3 months, and get a job? Then you need to check this out ! In... | 0 | 2024-05-24T21:10:21 | https://thedatascientist.com/the-role-of-ai-in-employee-training-and-development/ | ai, development, employeeexperience, training | Wanna become a data scientist within 3 months, and get a job? Then you need to [check this out ! ](https://go.beyond-machine.com/r)
In modern workplaces, the integration of artificial intelligence (AI) has become a game-changer for employee training and development. As technology continues to advance, AI is no longer a [futuristic concept](https://www.forbes.com/sites/forbesagencycouncil/2022/09/09/communicating-futuristic-concepts-perception-is-everything/?sh=51b838d11e9b) but a practical tool that enables employees to enhance their skills, knowledge, and overall professional growth.

This article explores the transformative role of AI in employee training and development, shedding light on its potential to revolutionize the way we learn and adapt to the demands of the contemporary workforce.
## AI in Legal Compliance and Training
AI is also making significant strides in the legal field, particularly in ensuring compliance and enhancing training programs related to employment law. This is especially relevant for employees seeking to navigate the complex legal landscape effectively.
**Trending**
[The Asfari Foundation: Data Science & Data Strategy Workshop
](https://thedatascientist.com/asfari-foundation-data-science-data-strategy-workshop/)
## COMPLIANCE TRAINING
AI-powered compliance training programs can help employees stay updated with the latest laws and regulations, ensuring that they are aware of their legal rights and responsibilities. These programs can be tailored to specific industries and regions, providing relevant and up-to-date information.
Specialized training programs that address local employment laws and regulations help employees understand their rights and ensure they are working in a compliant environment.
## LEGAL CONSULTATION AND SUPPORT
AI can also support employees by providing them with access to valuable legal resources and information. Employment lawyers play a crucial role in advising individuals on legal compliance, handling disputes related to employment law, and ensuring that employees are aware of their rights.
Employment laws in the United States vary significantly from state to state, making it essential for employees to understand the specific regulations that apply to their workplace. For instance, states like California have stringent labor laws that provide robust protections for employees, including regulations on wages, working hours, discrimination, and harassment.
In contrast, other states may have more relaxed laws, leading to different working conditions and legal rights.
For employees in California, seeking the guidance of employment attorneys in Sacramento CA can be invaluable in understanding and navigating the state’s complex employment laws and protecting their workplace rights. Here, AI also helps employees understand complex legal documents, review relevant case law, and identify their legal rights and options in various situations.
## Personalized Learning Experiences
The ability to cater to individual learning needs has become paramount. AI-powered training solutions offer a game-changing approach, tailoring the learning experience to the unique preferences and goals of each employee.
## TAILORED TRAINING PROGRAMS
One of the most significant advantages of AI in employee training and development is the ability to provide personalized learning experiences. Traditional training methods often adopt a one-size-fits-all approach, which may not cater to the unique learning styles, preferences, and paces of individual employees.
AI-powered systems can analyze an employee’s strengths, weaknesses, and learning patterns to create customized training programs that align with their specific needs and goals.
## ADAPTIVE LEARNING PATHS
AI algorithms can continuously monitor an employee’s progress and adjust the learning content and difficulty level accordingly. This adaptive approach ensures that employees are challenged at an appropriate level, preventing them from becoming overwhelmed or bored.
By dynamically tailoring the learning experience, AI can maximize knowledge retention and skill development, ultimately leading to more effective training outcomes.
Feature Traditional Training Methods AI-Powered Training Solutions
Personalization One-size-fits-all approach Adaptive, tailored to individual needs
Learning Support Limited to instructor availability On-demand virtual assistants and guidance
Progress Tracking Manual, subjective evaluation Data-driven, comprehensive analytics
Accessibility Location and time constraints Flexible, scalable, and accessible anywhere
Engagement Static, limited interactivity Interactive simulations, immersive experiences
Cost High costs (instructors, facilities, travel) Cost-effective, optimized resource utilization
## Intelligent Virtual Assistants
As technology continues to advance, the integration of intelligent virtual assistants has emerged as a transformative force in employee training and development. These AI-powered tools provide a personalized and interactive learning experience, bridging the gap between traditional methods and the demands of the modern workforce.
## ON-DEMAND SUPPORT AND GUIDANCE
AI-powered virtual assistants are becoming increasingly prevalent in employee training and development. These intelligent assistants can provide on-demand support and guidance to employees, answering their questions, clarifying concepts, and offering personalized feedback. This real-time assistance not only enhances the learning experience but also promotes self-paced learning and independent skill development.
## INTERACTIVE AND ENGAGING LEARNING
Virtual assistants can leverage natural language processing and conversational AI to create interactive and engaging learning experiences. Employees can engage in simulated scenarios, role-playing exercises, or even virtual reality-based training, all while receiving real-time feedback and guidance from the AI assistant.
This immersive approach makes the learning process more enjoyable and effective, fostering better knowledge retention and practical skill application.
## Data-Driven Insights and Analytics
When it comes to employee training and development, data-driven insights have become invaluable assets. AI systems possess the ability to collect, analyze, and interpret vast amounts of data, unveiling a wealth of information that can drive targeted improvements and optimize the learning experience.
## PERFORMANCE TRACKING AND EVALUATION
AI systems can collect and analyze vast amounts of data related to employee performance, learning patterns, and training outcomes. This data-driven approach allows for comprehensive tracking and evaluation of an employee’s progress, strengths, and areas for improvement. By leveraging these insights, employees can identify and focus on specific skills or knowledge gaps, enabling targeted development efforts.
## CONTINUOUS IMPROVEMENT AND OPTIMIZATION
The data collected by AI systems can also be used to optimize and refine the training programs themselves. By analyzing aggregate data from multiple employees, AI can identify common challenges, areas of confusion, or ineffective training methods.
This information can then be used to enhance the training content, delivery methods, and overall learning experience, ensuring continuous improvement and alignment with the evolving needs of the workforce.
## Overcoming Geographical and Language Barriers
In today’s globalized workforce, geographical and linguistic barriers can pose significant challenges to effective employee training and development. However, the integration of AI technologies has opened up new avenues for breaking down these barriers, fostering an inclusive and interconnected learning environment.
## GLOBAL WORKFORCE TRAINING
AI-powered translation and localization capabilities can overcome language barriers, enabling effective training for a globally dispersed workforce. Employees from different regions and cultural backgrounds can access training materials in their preferred languages, ensuring a consistent and inclusive learning experience.
## BREAKING DOWN LOCATION CONSTRAINTS
With the rise of remote work and distributed teams, AI-driven training solutions provide a valuable opportunity to bridge geographical gaps. Employees can participate in virtual training sessions, collaborate with colleagues from different locations, and access learning resources from anywhere in the world, fostering a connected and cohesive workforce.
## Ethical Considerations and Challenges
While AI offers immense potential in employee training and development, it is crucial to address ethical considerations and challenges. Data privacy, algorithmic bias, and the potential displacement of human trainers are valid concerns that need to be addressed.
Transparency and ethical AI practices should be prioritized, and a balanced approach should be established that combines AI-driven solutions with human expertise and oversight.
## Conclusion
The role of AI in employee training and development is transformative, offering a wealth of opportunities for personal and professional growth. By leveraging AI-powered solutions, employees can benefit from personalized learning experiences, intelligent virtual assistants, data-driven insights, and scalable and cost-effective training resources.
As technology continues to advance, it is essential for employees to adopt AI as a powerful tool for continuous learning and skill development, enabling them to thrive in the ever-changing workforce industry.
## Frequently Asked Questions
## HOW CAN AI PERSONALIZE MY LEARNING EXPERIENCE?
AI algorithms can analyze your strengths, weaknesses, learning patterns, and preferences to create customized training programs tailored to your specific needs and goals. This adaptive approach ensures an effective and engaging learning experience.
## CAN AI VIRTUAL ASSISTANTS REALLY PROVIDE VALUABLE SUPPORT DURING TRAINING?
Yes, AI-powered virtual assistants can offer on-demand guidance, answer questions, provide feedback, and even facilitate interactive simulations or role-playing exercises. This real-time support enhances the learning process and promotes self-paced skill development.
## CAN AI-DRIVEN TRAINING SOLUTIONS BE ACCESSIBLE AND FLEXIBLE FOR REMOTE EMPLOYEES?
Absolutely. AI-powered training platforms can be accessed from various devices and locations, making learning resources available to employees regardless of their geographical location or work arrangement. This flexibility promotes continuous learning and professional development.
---
Wanna become a data scientist within 3 months, and get a job? Then you need to [check this out !](https://go.beyond-machine.com/)
---
This blog was originally published on https://thedatascientist.com/the-role-of-ai-in-employee-training-and-development/
| ecaterinateodo3 |
1,864,322 | Your first bookmarklet | Bookmarklets are a great way to automate or tweak things across your web experience. I made one... | 0 | 2024-05-24T21:06:13 | https://dev.to/defenderofbasic/your-first-bookmarklet-3213 | javascript, bookmarklet, beginners | Bookmarklets are a great way to automate or tweak things across your web experience. [I made one recently](https://x.com/DefenderOfBasic/status/1788143504671088825) that allows me to click a button to show all my interactions with any given twitter user.
This tutorial will walk you through creating your first bookmarklet to edit a value inside a specific element on the page. It will insert a search term into the HackerNews search element.
We're going to:
1. Open the browser devtools to find the HTML element we want
2. Write some JavaScript code in the console to manipulate this element
3. Wrap this code into a bookmark so that when you click it, it runs the code, thus making a "bookmarklet" (a bookmark that runs your code snippet)
## Step 1 - get the element with devtools
I'm going to use this page as an example: https://news.ycombinator.com/news
In Chrome, right click on the page and click "inspect" to open devtools
There's a lot of tools here. The important ones to notice are: (1) you can see the HTML, you can click on parts of the HTML to highlight the element on the page (2) you can use this little picker in the top left to click on any element visually, and it will show you where it is in the HTML.
**Select the picker and then click on the search box** as shown below.
Ok, now we have the HTML element. We need to get its "address" (or CSS selector) so we can get it with JavaScript and control it/do stuff with it.
**Right click on the element** and select "copy" > "copy selector"
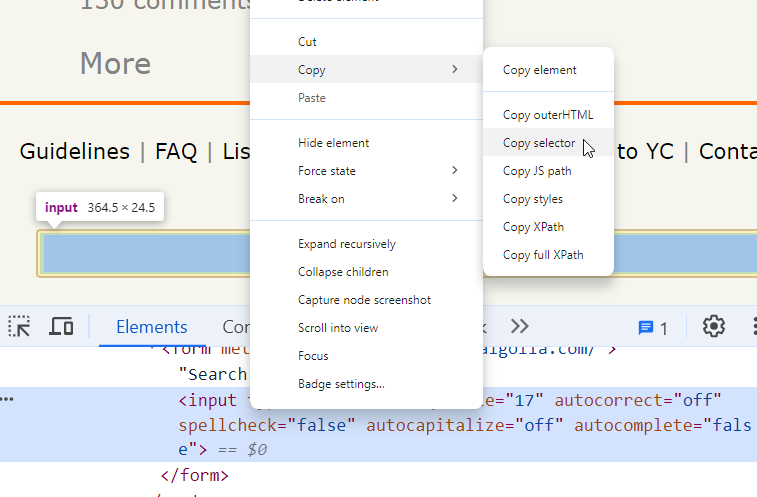
It'll be something like this:
```
#hnmain > tbody > tr:nth-child(4) > td > center > form > input[type=text]
```
## Step 2 - write JavaScript to control the element
Switch to the "console" tab. And paste in the following code and hit enter.
```javascript
var selector = `#hnmain > tbody > tr:nth-child(4) > td > center > form > input[type=text]`
console.log("My element:", document.querySelector(selector))
```
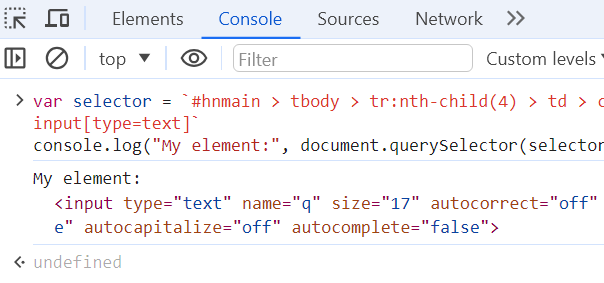
The first line puts the selector into a variable. This snippet says "get the element, using this selector":
```javascript
document.querySelector(selector)
```
Finally, `console.log()` prints whatever we put in.
Let's put the element into a variable instead of just printing it:
```javascript
var element = document.querySelector(selector)
console.log(element)
```
At this point, you can ask ChatGPT what to do/google it. You have an HTML element, in javascript, and we want to do something with it.
In this case, I want to set a search string. To do that, google/chatgpt will tell you:
```javascript
element.value = "your input here"
```
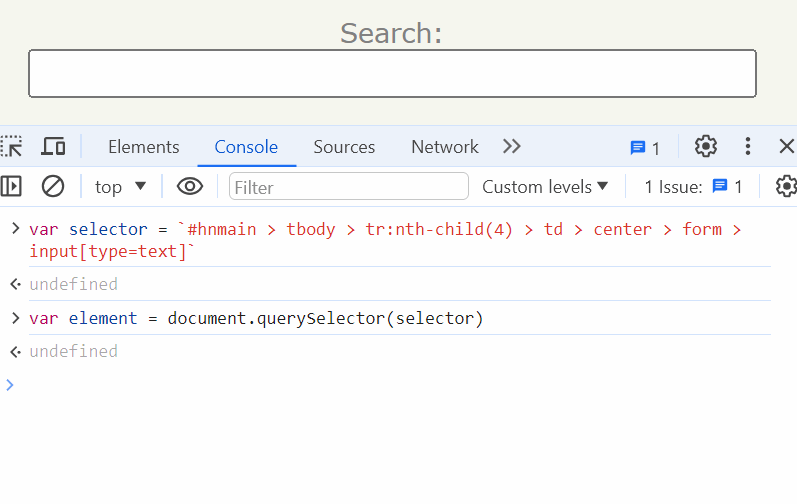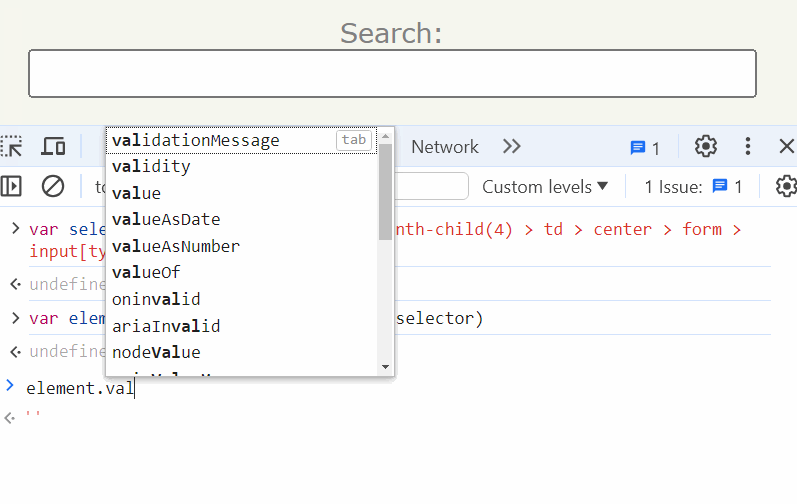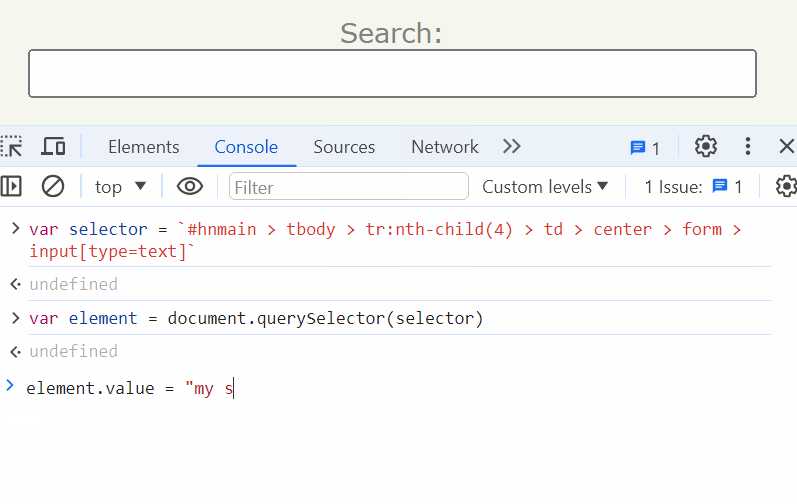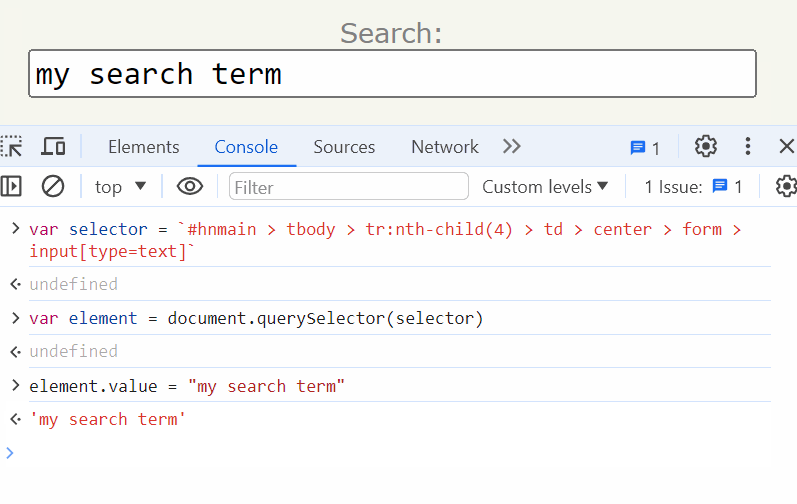
You now have a piece of code that does something! You can continue to tweak this as needed and interactively see if it works, line by line.
My personal process is usually to have a file to save all the "correct code so far" and in the console I'm just writing things line by line to test them. You can refresh to reset the state.
If you wanted another piece of code to submit the "search" so it goes to the search results page, you would get the HTML element of the form that this search bar lives inside, and then google "given an HTML form element, how to submit it with javascript", get the code for that, and test it.
## Step 3 - wrap it into a bookmarklet
Now you have your code that does something. We're going to make it into a bookmark so you can run it on the page with a single button click.
1. Create a bookmark, like you normally would
2. Edit it, and instead of a URL, paste in your code, wrapped in:
```javascript
javascript:(function() {
// your code here
})();
```
(the only annoying thing right now is you need to add a semicolon at the end of each line for it to work. I might make a tool in the future to automate this part)
So my full code looks like this that I paste into my bookmark:
```javascript
javascript:(function() {
var selector = `#hnmain > tbody > tr:nth-child(4) > td > center > form > input[type=text]`;
var element = document.querySelector(selector);
element.value = "my search term";
})();
```
That's it!

| defenderofbasic |
1,864,321 | How to Perform CRUD Operations with Entity Framework and ASP.NET Core | Learn how to perform CRUD operations with Entity framework and ASP.NET Core. See more from ComponentOne today. | 0 | 2024-05-24T21:04:26 | https://developer.mescius.com/blogs/how-to-perform-crud-operations-with-entity-framework-and-aspnet-core | webdev, devops, dotnet, tutorial | ---
canonical_url: https://developer.mescius.com/blogs/how-to-perform-crud-operations-with-entity-framework-and-aspnet-core
description: Learn how to perform CRUD operations with Entity framework and ASP.NET Core. See more from ComponentOne today.
---
**What You Will Need**
- Visual Studio 2022
- ASP.NET Core
- ComponentOne ASP.NET MVC Edition
**Controls Referenced**
- [FlexGrid for ASP.NET Core](https://developer.mescius.com/componentone/docs/mvc/online-mvc-core/FlexGrid.html)
**Tutorial Concept**
This tutorial demonstrates how to do basic database operations like create, read, update and delete data in an ASP.NET Core application. It uses FlexGrid for ASP.NET Core, SQL Server database and Entity Framework Core.
---
Fetching and updating data are fundamental activities in the field of web development. Whether we are building a small or complex<span class="fabric-text-color-mark"> <span data-renderer-mark="true" data-text-custom-color="#ffffff"></span> application, we will need to create, read, update, and delete (CRUD) data. ASP.NET Core, when combined with Entity Framework Core, provides a robust platform for completing these tasks quickly. </span>
In this blog, we go through the process of implementing the CRUD operations by integrating [<span>ComponentOne FlexGrid for ASP.NET Core</span>](https://developer.mescius.com/componentone/aspnet-mvc-ui-controls/flexgrid-aspnet-mvc-data-grid "https://developer.mescius.com/componentone/aspnet-mvc-ui-controls/flexgrid-aspnet-mvc-data-grid") with an SQL Server database using Entity Framework Core's DbContext. We'll review the following segments of this process:
1. [Setting Up the Environment](#Setting)
2. [Creating the DbContext](#Creating)
3. [Setting up the FlexGrid](#FlexGrid)
4. [CRUD Methods Definition in Controller](#CRUD)
5. [Add the FlexGrid with CRUD Actions](#Add)
## <a id="Setting"></a>Setting Up the Environment
Firstly, we need to create the ASP.Net Core Web Application. Follow the steps mentioned below to create a fresh application.
1\. Open Visual Studio 2022
2\. Click on the “**<span>Create a new project</span>**” option
3\. Select the template **“ASP.NET Core Web App (Model-View-Controller)”** as shown in the screenshot. Then, click on "Next."

<span>4\. </span>Provide the project name and location folder and click "Next."
<span>5\. </span>In this step, we need to select the Framework version. For this application, set it as **.NET 8.0**.
Along with the Framework version, select the following settings as shown in the screenshot below:
a. **Authentication type**: The Authentication type can be selected based on individual requirements. We are not using Authentication for now, so this will be set to "None."
b. **Configure for HTTPS**: This setting is for executing the project locally with HTTPS protocol or not, which is selected by default.
c. **Enable Docker**: This allows us to add the required Docker file to the project if you would like to host the project using Docker.

<span>6\. </span>Click on "Create," and the base project will be ready for development.
<span>In the project, we will use the ComponentOne FlexGrid to perform the operations on DB and Entity Framework to Fetch/Update the DB on FlexGrid operations. Hence, we need to install the following NuGet Packages: </span>
* Microsoft.EntityFrameworkCore
* Microsoft.EntityFrameworkCore.SqlServer
* Microsoft.EntityFrameworkCore.Tools
* C1.AspNetCore.Mvc
<span>After installing the required NuGet Packages, we must set up Entity Framework for the project to perform the CRUD operations. Next, we need to create the DbContext. </span>
## <a id="Creating"></a>Creating the DbContext
Entity Framework provides the following two approaches:
1. DB First Approach
2. Code First Approach
### DB First Approach
This approach can be employed with an existing database. Here, we harness the power of Entity Framework to generate models from the existing tables in the database. This process can also be accomplished using migrations with the aid of the Package Manager Console/.NET CLI.
### Code First Approach
This approach can be used when creating a new application without an existing database. In this approach, we first create the model and DbContext. Then, we utilize Microsoft.EntityFrameworkCore.Tools to generate the database in SQL Server/SQL Lite using the Migrations commands with the assistance of the Package Manager Console/.NET CLI.
<span>As we are creating a new application for viewing and updating the Tasks information, we will use the Code First Approach. If you have an existing DB and would like to use the DB First approach, please refer to Microsoft Documentation “[Reverse Engineering-EF Core](https://learn.microsoft.com/en-us/ef/core/managing-schemas/scaffolding/?tabs=vs "https://learn.microsoft.com/en-us/ef/core/managing-schemas/scaffolding/?tabs=vs").”</span>
##### Create the Model
Next, define the context class and entity classes that comprise the model. For this, right-click on the 'Models' folder, add a new class named Model.cs, and add the following code:
```
using Microsoft.EntityFrameworkCore;
using System;
using System.Collections.Generic;
using System.ComponentModel.DataAnnotations;
namespace TaskManager.Models
{
public class TasksContext : DbContext
{
public DbSet<Task> Tasks { get; set; }
public TasksContext(DbContextOptions<TasksContext> options) : base(options)
{
}
}
public class Task
{
[Required]
public int TaskID { get; set; }
public string TaskName { get; set; } = string.Empty;
public DateTime StartDate { get; set; }
public DateTime EndDate { get; set; }
public double TaskProgress { get; set; }
}
}
```
##### Define the Connection String
After defining the Model and Context classes, we need to define the connection string for the targeted Database in the **<span>appsettings.json. </span>**
<span>The connection string should be defined as follows, where TasksDb is the Database name to be created in the SQL Server:</span>
```
{
"ConnectionStrings": {
"DefaultConnection": "Server=(localdb)\\mssqllocaldb;Database=TasksDb;Trusted_Connection=true;TrustServerCertificate=true"
},
...
}
```
##### Add Context for the Application
After creating the model and defining the connection string, we need to add the DbContext to the application so that it is available throughout the application. This is achieved by adding the following code to the Program.cs file:
```
builder.Services.AddDbContext<TasksContext>(options =>
{
options.UseSqlServer(builder.Configuration.GetConnectionString("DefaultConnection"));
});
```
Now, we are ready to execute the migration using the Package Manager Console with the help of the Entity Framework Core to create the tables and database in the SQL server.
<span>This only requires the following two commands: </span>
* Add-Migration InitialCreate
* Update-Database
Execute both commands one by one and wait for the completion of this without any issues.
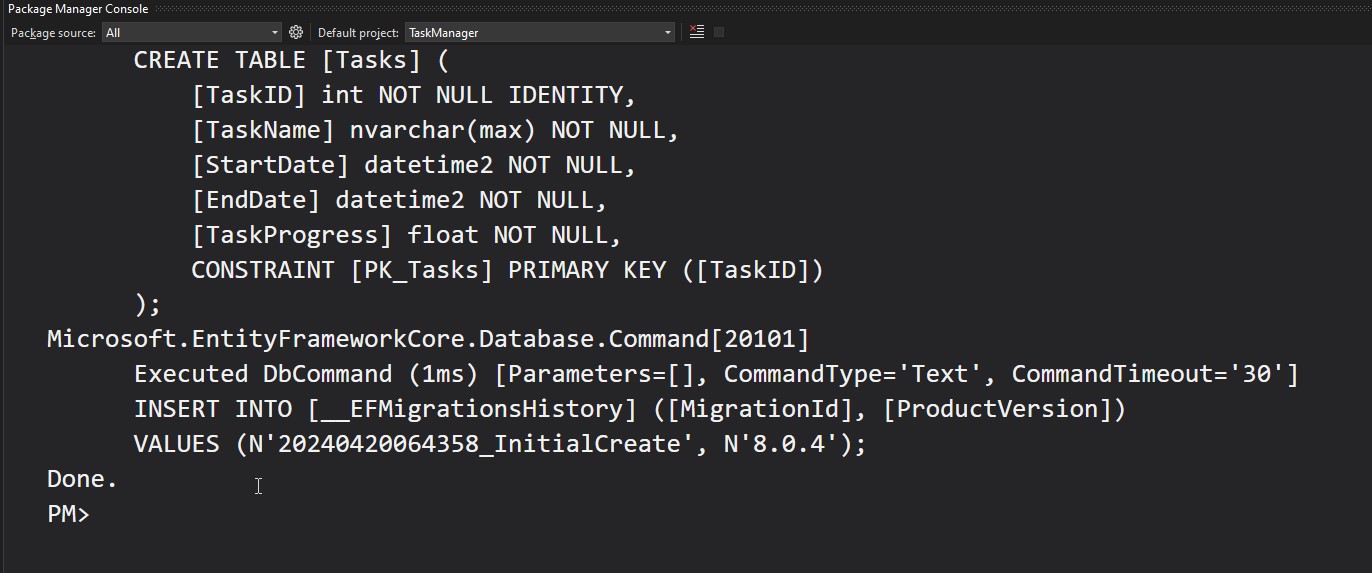
Once the migration is completed, the database will be created on the server. You can verify it by connecting to the server and exploring the databases.
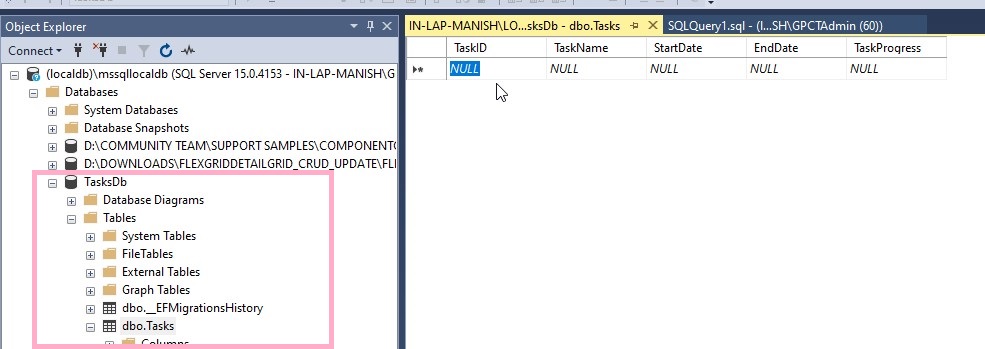
Initially, the tables will be empty. Add a single record by choosing "Edit Top 200 rows" after right-clicking on the table to view the data while fetching it.

Now, the DbContext is ready to use in the application. Next, we are going to configure the FlexGrid UI.
## <a id="FlexGrid"></a>Setting up the FlexGrid
The NuGet package for ComponentOne FlexGrid for ASP.NET Core is already installed in the application, so next, we will set it up using the following steps:
### Add the Tag Helper
To work with FlexGrid, add the required tag helper in the _ViewImports.cshtml file:
```
@addTagHelper *, C1.AspNetCore.Mvc
```
### Register Resources
Next, register the required scripts and styles to be added to the head section of the _Layout.cshtml file. This can be done using the following code snippet:
```
<c1-styles />
<c1-scripts>
<c1-basic-scripts />
</c1-scripts>
<c1-deferred-scripts />
```
Read more about deferred scripts in the [documentation](https://developer.mescius.com/componentone/docs/mvc/online-mvc-core/DeferredScripts.html "https://developer.mescius.com/componentone/docs/mvc/online-mvc-core/DeferredScripts.html").
### Add Map Routing
For ASP.NET Core applications (version 3.0 and above), the following code should be added to the Configure method of Startup.cs or in the Program.cs file:
```
app.MapControllers();
```
Now, we are ready to integrate the FlexGrid into the application. Proceed by writing the methods necessary to perform CRUD operations.
## <a id="CRUD"></a>CRUD Methods Definition in Controller
When performing actions on the client-side, the FlexGrid sends an AJAX request to the server, and the data can be updated using these methods with the help of the DbContext. To perform CRUD operations in the database, the context should be defined within the Controller. This can be achieved with the following code:
```
private readonly ILogger<HomeController> _logger;
private readonly TasksContext _db;
public HomeController(ILogger<HomeController> logger, TasksContext context)
{
_logger = logger;
_db = context;
}
```
We also define the method to retrieve the actual exception message if it occurs due to the SQL Server.
```
/// <summary>
/// In order to get the real exception message.
/// </summary>
private static SqlException GetSqlException(Exception e)
{
while (e != null && !(e is SqlException))
{
e = e.InnerException;
}
return e as SqlException;
}
// Get the real exception message
internal static string GetExceptionMessage(Exception e)
{
var msg = e.Message;
var sqlException = GetSqlException(e);
if (sqlException != null)
{
msg = sqlException.Message;
}
return msg;
}
```
### Read Data
After defining the context in the Controller, we are ready to use it. First, we need to write the method to fetch the data from the database to view in the FlexGrid. To achieve that, copy and paste the following code:
```
public ActionResult ReadGridData([C1JsonRequest] CollectionViewRequest<Task> requestData)
{
return this.C1Json(CollectionViewHelper.Read(requestData, _db.Tasks.ToList()));
}
```
### Create or Add Data
After the 'reading data' method, write a method to update the record in the database, which will then be reflected in the FlexGrid on the client-side.
```
public ActionResult GridCreateTask([C1JsonRequest] CollectionViewEditRequest<Task> requestData)
{
return this.C1Json(CollectionViewHelper.Edit<Task>(requestData, item =>
{
string error = string.Empty;
bool success = true;
try
{
_db.Entry(item as object).State = EntityState.Added;
_db.SaveChanges();
}
catch (Exception e)
{
error = GetExceptionMessage(e);
success = false;
}
return new CollectionViewItemResult<Task>
{
Error = error,
Success = success,
Data = item
};
}, () => _db.Tasks.ToList()));
}
```
### Update Data
Now, write the method that would update the existing records in the database as soon as the row edit ends in the FlexGrid.
```
public ActionResult GridUpdateTask([C1JsonRequest] CollectionViewEditRequest<Task> requestData)
{
return this.C1Json(CollectionViewHelper.Edit<Task>(requestData, item =>
{
string error = string.Empty;
bool success = true;
try
{
_db.Entry(item as object).State = EntityState.Modified;
_db.SaveChanges();
}
catch (Exception e)
{
error = GetExceptionMessage(e);
success = false;
}
return new CollectionViewItemResult<Task>
{
Error = error,
Success = success,
Data = item
};
}, () => _db.Tasks.ToList()));
}
```
### Delete Data
Now, we will write the method to delete the targeted record from the database when the Delete key is pressed after selecting the row by clicking the RowHeader.
```
public ActionResult GridDeleteTask([C1JsonRequest] CollectionViewEditRequest<Task> requestData)
{
return this.C1Json(CollectionViewHelper.Edit(requestData, item =>
{
string error = string.Empty;
bool success = true;
try
{
{
_db.Entry(item as object).State = EntityState.Deleted;
_db.SaveChanges();
}
}
catch (Exception e)
{
error = GetExceptionMessage(e);
success = false;
}
return new CollectionViewItemResult<Task>
{
Error = error,
Success = success,
Data = item
};
}, () => _db.Tasks.ToList()));
}
```
## <a id="Add"></a>Add the FlexGrid with CRUD Actions
Our methods for performing CRUD operations are ready, and they can be utilized by the FlexGrid. Now, integrate the FlexGrid with an item source that would invoke the previously written methods.
After adding the following code in the Index.cshtml file, our application is ready to execute and perform CRUD operations with FlexGrid.
```
<c1-flex-grid allow-add-new="true" allow-delete="true" height="800" width="100%">
<c1-items-source read-action-url="@Url.Action("ReadGridData")"
create-action-url="@Url.Action("GridCreateTask")"
update-action-url="@Url.Action("GridUpdateTask")"
delete-action-url="@Url.Action("GridDeleteTask")">
</c1-items-source>
</c1-flex-grid>
```
## Conclusion
Throughout this blog, we have explored the integration of ComponentOne FlexGrid for ASP.NET Core with an SQL Server database using Entity Framework Core's DbContext. From setting up the environment and configuring the DbContext to defining the model and establishing database connections, we have covered the foundational steps required for CRUD operations.
<span>The Code First approach enabled us to create our application's domain model in code, facilitating a streamlined development process. By leveraging Entity Framework Core's migration feature, we effortlessly generated the corresponding database schema. </span>
<span>Additionally, we delved into setting up the FlexGrid control, a powerful tool for displaying and manipulating data within our ASP.NET Core application. Through detailed explanations and code snippets, we learned how to implement CRUD methods within our Controller, enabling seamless data manipulation from the client-side.</span> | chelseadevereaux |
1,864,319 | Security news weekly round-up - 24 May 2024 | Weekly review of top security news between May 17, 2024, and May 24, 2024 | 6,540 | 2024-05-24T21:04:21 | https://dev.to/ziizium/security-news-weekly-round-up-24-may-2024-ebo | security | ---
title: Security news weekly round-up - 24 May 2024
published: true
description: Weekly review of top security news between May 17, 2024, and May 24, 2024
tags: security
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/0jupjut8w3h9mjwm8m57.jpg
series: Security news weekly round-up
---
## __Introduction__
It's another Friday and it's time for a review of top security news that are worthy of your time. Get ready because in this edition we'll cover articles that are about _malware_, artificial intelligence_, and _vulnerability_.
Now, let's begin.
<hr/>
## [Malware Delivery via Cloud Services Exploits Unicode Trick to Deceive Users](https://thehackernews.com/2024/05/malware-delivery-via-cloud-services.html)
There are so many things to say about this threat actor. First, they are using legitimate cloud services. Second, they are tricking the user into launching an executable file disguised as an Excel file. In the end, they drop a decoy Excel file, (among other scripts), and the user thinks that everything is fine 😔.
The excerpt below sheds more light on what happens afterward:
> The executable is designed to drop a total of eight payloads, including a decoy Excel file ("20240416.xlsx") and a heavily obfuscated Visual Basic (VB) Script ("3156.vbs") that's responsible for displaying the XLSX file to the user to maintain the ruse and launch two other scripts named "i4703.vbs" and "i6050.vbs."
>
> Both scripts are used to set up persistence on the Windows host by means of a scheduled task by masquerading them as a Google Chrome browser update task to avoid raising red flags.
## [What happens when AI goes rogue (and how to stop it\)](https://www.welivesecurity.com/en/cybersecurity/what-happens-ai-goes-rogue-how-stop-it/)
This is a question that we all need to ask ourselves. The article is an estimated 3 minutes read, and it's thought-provoking.
Here is an excerpt to get you started:
> Is AI at fault? When asked for justification when AI gets it wrong, people simply quipped “it’s complicated”. But as AI gets closer to the ability to cause physical harm and impact the real world, it’s no longer a satisfying and adequate response.
## [MS Exchange Server Flaws Exploited to Deploy Keylogger in Targeted Attacks](https://thehackernews.com/2024/05/ms-exchange-server-flaws-exploited-to.html)
All the vulnerabilities that were exploited date back to 2021. This means anyone affected by this attack has not updated their Exchange Server in the last 3 years. Looking at the targeted countries, I am like: What's Nigeria doing in the list 😂.
Start reading with the following excerpt:
> The attack chains commence with the exploitation of ProxyShell flaws (CVE-2021-34473, CVE-2021-34523, and CVE-2021-31207) that were originally patched by Microsoft in May 2021.
>
> Successful exploitation of the vulnerabilities could allow an attacker to bypass authentication, elevate their privileges, and carry out unauthenticated, remote code execution
## [High-severity GitLab flaw lets attackers take over accounts](https://www.bleepingcomputer.com/news/security/high-severity-gitlab-flaw-lets-attackers-take-over-accounts/)
These types of attacks are not new, but we still need to mention them so we don't forget about them. Moreover, it's a popular attack method; Cross Site Scripting (XSS). The good news is that they have fixed it at the time of writing. Nonetheless, the excerpt below briefly explains how the bug worked.
> The security flaw (tracked as CVE-2024-4835) is an XSS weakness in the VS code editor (Web IDE) that lets threat actors steal restricted information using maliciously crafted pages.
>
> While they can exploit this vulnerability in attacks that don't require authentication, user interaction is still needed, increasing the attacks' complexity.
## [Crooks plant backdoor in software used by courtrooms around the world](https://arstechnica.com/security/2024/05/crooks-plant-backdoor-in-software-used-by-courtrooms-around-the-world/)
I wonder what they were trying to achieve. I mean courtrooms? In another twist, the software was available from the official vendor's website. This means that this is another case of a supply chain attack.
Here is a quick excerpt from the article:
> The malicious download, planted inside an executable file that installs the JAVS Viewer version 8.3.7, was available no later than April 1, when a post on X (formerly Twitter) reported it. It’s unclear when the backdoored version was removed from the company’s download page.
>
> Users who have version 8.3.7 of the JAVS Viewer executable installed are at high risk and should take immediate action.
## [Beware: These Fake Antivirus Sites Spreading Android and Windows Malware](https://thehackernews.com/2024/05/fake-antivirus-websites-deliver-malware.html)
A warning to myself and you: Never download antivirus software from unofficial websites and always double-check the address bar even if you think that you're on the accurate vendor's website. That's it, I said it.
Here is why:
> Hosting malicious software through sites which look legitimate is predatory to general consumers, especially those who look to protect their devices from cyber attacks.
>
> The list of websites are avast-securedownload[.]com, bitdefender-app[.]com, and malwarebytes[.]pro
## __Credits__
Cover photo by [Debby Hudson on Unsplash](https://unsplash.com/@hudsoncrafted).
<hr>
That's it for this week, and I'll see you next time. | ziizium |
1,864,318 | You don't need Vuex / Pinia for shared state in Vue. | Since Vue.js 3.x, you no longer need to use Vuex to share a centralized state with all your... | 0 | 2024-05-24T20:48:58 | https://dev.to/dperrymorrow/you-no-longer-need-vuex-pinia-for-shared-state-in-vue-4ikp | vue, flux, javascript, webdev | Since Vue.js 3.x, you no longer need to use Vuex to share a centralized state with all your application's components.
## A brief history of shared state in Vue.js
If you have been using Vue.js before 3.x you are probably familiar with [Vuex](https://vuex.vuejs.org/) _now renamed Pinia_. It allows you to have a centralized state that is shared across all your application components. If you have ever found yourself in situations where you are passing data/props between components and things are getting complicated, a centralized state is the answer.
> Flux libraries are like glasses: you’ll know when you need them.
## The simplest way to share the state between components.
Since Vue.js 3.x `reactive` and `computed` are exported directly from the library and can be used outside of components. This is the exact same functionality that you are using when you have `data` or `computed` inside of one of your Vue.js components.
```javascript
import { reactive, computed } from 'vue';
```
This is great because it means that we can create our own reactive data, and even computed properties outside of Vue components, in plain Javascript files!
## Example of shared state
```javascript
import { reactive, computed } from "vue";
const state = reactive({
hobby: "Hike",
fruit: "Apple",
fruitOptions: ["Banana", "Apple", "Pear", "Watermelon"],
description: computed(() => {
return `I like eating ${state.fruit}s & ${state.hobby}`;
}),
});
export default state;
```
Here we have an Object with properties, which is wrapped in `reactive` this gives Vue the ability to trigger change, and re-render your components.
### Computed
We are also wrapping a function in `computed` which gives us a computed property based on the the other fields in the state.
> It is important to note, that we invoke the reactive function, and _THEN_ export the resulting state, otherwise we would create a new state each time we imported the file.
## Usage in your components
Great, we have a reactive store, but how do we leverage this in our components, and will they all stay in sync?
```vue
<template>
<main class="container">
<article>
<header>
Your description: <code>{{ state.description }}</code>
</header>
<survey-form />
<footer>
<results />
</footer>
</article>
</main>
</template>
<script>
import Results from "./Results.vue";
import SurveyForm from "./SurveyForm.vue";
import state from "./state.js";
export default {
components: { SurveyForm, Results },
data() {
return { state };
},
};
</script>
```
It's as simple as importing the state, and referencing it in your component's data method so it can be accessed in your template.
You can even `v-model` items in your store the same as you would with any data property in your component.
```vue
<template>
<form>
<label>
Favorite Hobby?
<input placeholder="Favorite Hobby" v-model="state.hobby" />
</label>
<label>
Favorite Fruit?
<select v-model="state.fruit">
<option v-for="fruit in state.fruitOptions" :key="fruit">{{ fruit }}</option>
</select>
</label>
</form>
</template>
<script>
import state from "./state.js";
export default {
name: "SurveyForm",
data() {
return { state };
},
};
</script>
```
You can see the full example on [Github](https://dperrymorrow.github.io/shared-state-vue-example/) and view the code [here](https://github.com/dperrymorrow/shared-state-vue-example)
I hope you find this pattern as useful as I have. Happy developing!
| dperrymorrow |
1,864,317 | How to Install Pip Packages in AWS Lambda Using Docker and ECR | Deploying AWS Lambda functions often involves packaging various dependencies. Managing these... | 0 | 2024-05-24T20:47:26 | https://dev.to/shilleh/how-to-install-pip-packages-in-aws-lambda-using-docker-and-ecr-2ghh | aws, python, docker, cloud | {% embed https://www.youtube.com/watch?v=yXqaOS9lMr8 %}
Deploying AWS Lambda functions often involves packaging various dependencies. Managing these dependencies directly within Lambda can be cumbersome and error-prone. Using Docker and Amazon Elastic Container Registry (ECR) can streamline this process, ensuring consistency and reliability in your deployments. In this blog, we will walk through how to install pip packages in Lambda packages using Docker and ECR.
AWS Lambda is a powerful service that allows you to run code without provisioning or managing servers. However, managing dependencies for your Lambda functions can be challenging, especially when dealing with complex Python packages. By leveraging Docker, you can package your Lambda function and its dependencies in a container, which ensures a consistent runtime environment. Additionally, using ECR to store your Docker images simplifies the deployment process.
Before reading the remainder, be sure to subscribe and support the channel if you have not!
**Subscribe:**
Youtube
**Support:**
[https://www.buymeacoffee.com/mmshilleh](https://www.buymeacoffee.com/mmshilleh)
**Hire me at UpWork to build your IoT projects:**
[https://www.upwork.com/freelancers/~017060e77e9d8a1157](https://www.upwork.com/freelancers/~017060e77e9d8a1157)
**Prerequisites**
Before we get started, make sure you have the following installed and configured:
- AWS CLI
- Docker
## Step 1: Install AWS CLI and Configure
First, install the AWS CLI and configure it with your credentials.
**Installation**
**On Windows:** Download the AWS CLI MSI installer from the official website. Run the installer and follow the on-screen instructions.
**On macOS:** Use Homebrew to install the AWS CLI:
`brew install awscli`
**On Linux:** Use the following commands:
`curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install`
**Configure the AWS CLI by running:**
`aws configure`
Enter your AWS Access Key ID, Secret Access Key, Default region name, and Default output format when prompted.
## Step 2: Create an ECR Repository
If you haven't already created an ECR repository, do so by running:
`aws ecr create-repository --repository-name my-lambda-repo --region us-east-1`
This command creates a new ECR repository where you'll store your Docker images.
## Step 3: Authenticate Docker to ECR
Authenticate your Docker CLI to your ECR registry, make sure you are signed into Docker desktop and have it running on your computer:
`aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <aws_account_id>.dkr.ecr.us-east-1.amazonaws.com`
Replace <aws_account_id> with your actual AWS account ID.
## Step 4: Create a .dockerignore File
Create a .dockerignore file in your project directory to exclude unnecessary files from the Docker build context:
```
__pycache__
.git
tests
*.md
*.txt
```
## Step 5: Create a Dockerfile
Create a Dockerfile in your project directory. This file defines the environment in which your Lambda function will run and specifies the necessary dependencies.
```
# Builder stage - you can use other AWS runtimes and python versions
FROM public.ecr.aws/lambda/python:3.12-x86_64 as builder
# Install Python packages (replace as needed)
RUN pip install --no-cache-dir requests numpy pandas --target "/var/task"
# Final stage
FROM public.ecr.aws/lambda/python:3.12-x86_64
# Copy necessary files from the builder stage - add whatever code you need
COPY --from=builder /var/task /var/task
COPY handler.py ./
# Set the CMD to your handler
CMD ["handler.lambda_handler"]
```
## Step 6: Build the Docker Image
Build the Docker image using the following command:
`docker build -t my-lambda-image .`
This command creates a Docker image named my-lambda-image.
## Step 7: Tag the Docker Image
Tag the Docker image for pushing to your ECR repository:
`docker tag my-lambda-image <aws_account_id>.dkr.ecr.us-east-1.amazonaws.com/my-lambda-repo:latest`
## Step 8: Push the Docker Image to ECR
Push the Docker image to your ECR repository:
`docker push <aws_account_id>.dkr.ecr.us-east-1.amazonaws.com/my-lambda-repo:latest`
## Step 9: Update Lambda Function
Finally, update your Lambda function to use the new Docker image. You can do this through the AWS Management Console or using the AWS CLI:
`aws lambda update-function-code --function-name my-lambda-function --image-uri <aws_account_id>.dkr.ecr.us-east-1.amazonaws.com/my-lambda-repo:latest`
Replace my-lambda-function with the name of your Lambda function.
Alternatively, you can update your Lambda function through the AWS Management Console:
- 1. Navigate to the AWS Lambda console.
- 2. Select your Lambda function from the list.
- 3. In the "Code" tab, choose "Image" as the code source.
- 4. Select the ECR image you pushed earlier.
- 5. Save the changes.
## Creating a Lambda Function from Scratch with a Docker Image
You can also create a new AWS Lambda function from scratch using a Docker image. This is useful when you are starting a new project or want to create a fresh Lambda function with a specific Docker environment. Here's how to do it through the AWS Management Console:
Navigate to the AWS Lambda console.
- Click on "Create function."
- Select "Container image" as the code source.
- Specify your container image details by selecting the ECR repository and image tag you pushed earlier.
- Configure the remaining settings (function name, role, etc.).
- Click on "Create function."
This process sets up a new Lambda function that uses your Docker image as its execution environment, ensuring all dependencies and configurations are included from the start.
## Conclusion
Using Docker and ECR to manage dependencies for your AWS Lambda functions significantly streamlines the deployment process. This method ensures that your functions have a consistent runtime environment, reducing the potential for errors caused by missing or incompatible dependencies.
By following the steps outlined in this tutorial, you can efficiently package, test, and deploy your Lambda functions with all necessary dependencies included. This approach not only simplifies the deployment process but also enhances the reliability and performance of your serverless applications.
Remember to subscribe to the channel and support our content creation efforts:
Subscribe on YouTube
[Support on Buy Me a Coffee](https://buymeacoffee.com/mmshilleh)
[Hire me for your IoT projects on UpWork](https://www.upwork.com/freelancers/~017060e77e9d8a1157) | shilleh |
1,864,316 | Ubuntu 24.04 Rufus Persistence | Rufus Fixes Creation of Persistent Ubuntu 24.04 USBs Rufus, a popular open-source tool for making... | 0 | 2024-05-24T20:45:47 | https://dev.to/phantomthreads/ubuntu-2404-rufus-persistence-3oml | rufus | Rufus Fixes Creation of Persistent Ubuntu 24.04 USBs
Rufus, a popular open-source tool for making bootable USB drives on Windows, just released an update that includes a ‘fix’ for working with Ubuntu 24.04 LTS ISOs.
A truly versatile tool, Rufus is able to create bootable Windows installers from ISO files and disk images as well as Linux installers and, more pertinent to this news, persistent Ubuntu, Linux Mint, and Debian USB installers.
Rufus 4.5, released this week, includes support for persistence in Ubuntu 24.04 LTS. Additionally, this update also fixes issues when creating persistent Linux Mint 21.x USBs too.
Rufus 4.5 fixes persistent Ubuntu USBs
Creating persistent Ubuntu USBs in Rufus isn’t new (the feature debuted in 2019) but its devs often have to play catchup as distros rename, update, or alter the various files needed to enable this feature.
What is a persistent Linux USB?
A way creating a bootable, portable installation without actually installing it. The ISO boots into a live session (as a USB installer would) but persistence adds a “casper-rw” file/partition (in Ubuntu) where files, settings, apps, etc., are stored.
A live Linux USB installer boots a pristine version of OS each time and while you can use the live session like a real install (add apps, edit settings, etc) but all changes you make during the live session are lost when you shutdown.
On a persistent Linux USB those changes persist between boots.
Overlap with, say, creating a USB installation (i.e., using an installer to install the distro to the USB drive properly, and then booting that USB on other systems) exists.
But persistent installers have their pluses: reduced overhead and they take up less space than a full, unpacked installation to disk. Plus, USB installations may end up tailored to specific hardware, affecting portability.
And it’s easy to ‘reset’ the install without having to rewrite, reformat, or reinstall – just clean out the persistent storage section. In certain circumstances, that makes them better suited to ad-hoc testing.
Persistent Ubuntu 24.04 USB has drawbacks: no Wayland; no user accounts; slower startup/shutdown; can’t switch session; and the Flutter installer will spawn on every boot.
What’s New in Rufus 4.5?
Since I’m here talking about the update I’ll list the other changes in Rufus 4.5.x release — most aren’t related to Ubuntu so don’t chide me for it in the comments for it, okay ;)
Option to perform runtime UEFI media validation for Windows & Linux ISOs
Fixes with/writing VHD/VHDX images
Use Rufus MBR advanced option moved to ‘cheat mode’ panel
Fix support for Linux persistence in Linux Mint & Ubuntu 24.04 LTS
Security vulnerability patches
Internal GRUB bumped to v2.12
UEFI:NTFS updated + now uses ntfs-3g driver
Buffer size when copying ISO files increased
Improve partition creation/handling
If you’re looking for a powerful, open-source tool for creating bootable USBs on Windows, with advanced options then Rufus is worth checking out or at least making a mental note of for possible future needs/recommendations.
Among its most popular feature: the ability to create a Windows 11 USB installer using the official Windows 11 ISO but configured to bypass many of the hardcoded requirements which prevent users from installing it on “unsupported” hardware.
Nifty, eh?
But for Ubuntu users who want a portable operating system to keep handy, with the ability to save files, settings, and install tools without the complexity or hardcoded nature of a full installation, a persistent USB may be the ticket.
You can download Rufus for Windows (32-bit and 64-bit) from the Rufus Github page. | phantomthreads |
1,864,315 | Google Frontend Interview | I recently appeared for an interview at Google for a frontend role, I have documented it in the blog.... | 0 | 2024-05-24T20:38:40 | https://dev.to/unalo_baayriyo/google-frontend-interview-2o1h | webdev, javascript, interview, google | I recently appeared for an interview at Google for a frontend role, I have documented it in the blog. Do check out [Google Frontend interview experience](https://lembdadev.com/posts/google-frontend-interview?source=devto) | unalo_baayriyo |
1,864,314 | How to Create a C# .NET Streamgraph with FlexChart | Learn how to create a C# .NET streamgraph with FlexChart. See more from ComponentOne today. | 0 | 2024-05-24T20:33:24 | https://developer.mescius.com/blogs/how-to-create-a-c-sharp-net-streamgraph-with-flexchart | webdev, devops, csharp, tutorial | ---
canonical_url: https://developer.mescius.com/blogs/how-to-create-a-c-sharp-net-streamgraph-with-flexchart
description: Learn how to create a C# .NET streamgraph with FlexChart. See more from ComponentOne today.
---
**What You Will Need**
- Visual Studio 2022
- ComponentOne WinForms Edition
**Controls Referenced**
- [ComponentOne FlexChart](https://developer.mescius.com/componentone/flexchart-net-chart-control)
**Tutorial Concept**
Create a C# .NET streamgraph chart for analyzing stocks using ComponentOne FlexChart for WinForms.
---
Imagine a peaceful stream flowing through time, where each ripple represents the behavior of distinct categories within the data. This is what a streamgraph does: it shows us how things change over time. Streamgraphs are useful for spotting trends and patterns in data, helping us understand how things evolve and make smarter decisions.
<span>MESCIUS offers a ComponentOne charting component named [FlexChart](https://developer.mescius.com/componentone/flexchart-net-chart-control "https://developer.mescius.com/componentone/flexchart-net-chart-control") that provides enough flexibility to transform data to align our visualization preferences. We can use FlexChart to implement streamgraphs by modifying the stacked [Spline Area Chart](https://developer.mescius.com/componentone/docs/win/online-flexchart/area-chart.html "https://developer.mescius.com/componentone/docs/win/online-flexchart/area-chart.html").</span>
The following image shows what this transformation looks like:

In this blog, we are creating a streamgraph to analyze the sector-wise turnover insights of the stocks throughout a financial year. We have categorized the implementation process as follows:
1. [Set Up a .NET Application with the FlexChart Control](#Setup)
2. [Set Bindings to Create a Stacked Spline Area Chart](#Set)
3. [Transform a Spline Area Chart into a Streamgraph](#Transform)
## <a id="Setup"></a>Set Up a .NET Application with the FlexChart Control
Let's begin by setting up a new .NET 8 Windows Forms application that includes the **ComponentOne FlexChart** dependency by following the steps below. Note that you could also use FlexChart in a WPF, ASP.NET Core, WinUI, UWP, or .NET MAUI application.
1\. Open Visual Studio and select **File** | **New** | **Project** to create a new **Windows Forms App**.

2\. Right-click on the project in Solution Explorer and choose **<span>Manage NuGet Packages…</span>**<span>. from the context menu.</span>
<span></span>
<span>3\.</span> Search for the[<span>C1.Win.FlexChart</span>](https://www.nuget.org/packages/C1.Win.FlexChart "https://www.nuget.org/packages/C1.Win.FlexChart") <span>package in the NuGet Package Manager and click on **Install.**</span>

<span>Now that we have installed the packages, let’s drag and drop the FlexChart control from the toolbox onto the form designer. The design of the form is shown below:</span>
<span></span>
<span>In this blog, we are using the “StockSecDB.mdb“ file to retrieve the stock data by establishing a connection as shown in the following code:</span>
```
// method to create the datatable from the database
public DataTable CreateDataTable()
{
DataTable stocksTable = new DataTable();
string connectionString = "Provider=Microsoft.Ace.OLEDB.12.0;Data Source=" +
System.IO.Path.Combine(Application.StartupPath,
@"StockSecDB.mdb") + ";";
OleDbConnection conn = new OleDbConnection(connectionString);
OleDbDataAdapter adapter = new OleDbDataAdapter("Select * from Sector_wise_data", conn);
adapter.Fill(stocksTable);
return stocksTable;
}
```
## <a id="Set"></a>Set Bindings to Create a Stacked Spline Area Chart
The spline area chart is a modified version of the area chart in which data points are connected by smooth curves. Stacking this chart layers up each series on top of the previous one, making them look more like the streamgraphs.
Let’s set the FlexChart type to “SplineArea” and implement the required bindings:
```
// method to implement bindings in the chart
public void SetupChart()
{
// setting the chart type
flexChart1.ChartType = ChartType.SplineArea;
flexChart1.Stacking = Stacking.Stacked;
// binding the flexchart
flexChart1.DataSource = _stocksTable;
flexChart1.BindingX = "Date";
// adding series to the flexchart
flexChart1.Series.Clear();
flexChart1.Series.Add(new C1.Win.Chart.Series() { Binding = "DummySeries" });
flexChart1.Series.Add(new C1.Win.Chart.Series() { Binding = "Automobile", Name = "Automobile" });
flexChart1.Series.Add(new C1.Win.Chart.Series() { Binding = "Bank", Name = "Bank" });
flexChart1.Series.Add(new C1.Win.Chart.Series() { Binding = "Energy", Name = "Energy" });
flexChart1.Series.Add(new C1.Win.Chart.Series() { Binding = "IT", Name = "IT" });
flexChart1.Series.Add(new C1.Win.Chart.Series() { Binding = "Oil and Gas", Name = "Oil and Gas" });
flexChart1.Series.Add(new C1.Win.Chart.Series() { Binding = "Pharmacy", Name = "Pharmacy" });
}
```
After executing the above-given code, the chart appears as follows:
**Note:** For the demo project, we use [<span>Component built-in Themes</span>](https://developer.mescius.com/componentone/docs/win/online-themes/ThemeNames.html "https://developer.mescius.com/componentone/docs/win/online-themes/ThemeNames.html") with FlexChart to enhance the look.
## <a id="Transform"></a>Transform a Spline Area Chart into a Streamgraph
Now, it is time to convert the Spline Area chart we have just created into a Streamgraph. To do this, first, we need to consider the following features of the Streamgraph:
* The stream of the graph floats above the X-axis.
* The start and end of the stream are closed in nature.
To visualize the floating effect, we need to place a transparent series between the X-axis and the actual data. This can be done by adding a dummy data series to the original data set. The basic idea is to use a large value based on our data and then subtract half of the total sum of all data values at that specific point. The following code demonstrates the implementation of this dummy data series:
```
// adding a dummy series to create a mid-way streamline effect
// from other series
_stocksTable.Columns.Add("DummySeries", typeof(decimal));
Random rnd = new Random();
foreach (DataRow row in _stocksTable.Rows)
{
decimal sum = 0;
foreach (DataColumn column in _stocksTable.Columns)
{
if (columnNames.Contains(column.ColumnName))
{
sum += Convert.ToDecimal(row[column]);
}
}
row["DummySeries"] = 25000 - sum / 2;
}
```
Now that we have added the dummy data series, it is time to create the enclosed opening and closing of the stream flow. To generate this effect, let’s insert some dummy data points with zero values at the beginning and end of the dataset. This leaves gaps in the data for some X-axis values at the start and the end. This is achieved with the following code:
```
List<string> columnNames = new List<string>
{ "Automobile", "Bank", "Energy", "IT", "Oil and Gas", "Pharmacy" };
// adding some dummy points at the top of the datatable
// to create the starting flow effect of streamchart
DateTime firstDate = Convert.ToDateTime(_stocksTable.Rows[0]["Date"]);
for (int counter = -40; counter <= -15; counter++)
{
DataRow newRow = _stocksTable.NewRow();
newRow["Date"] = firstDate.AddDays(counter);
foreach (DataColumn column in _stocksTable.Columns)
{
if (column.ColumnName != "Date")
newRow[column.ColumnName] = 0; // Set zero value for other columns
}
_stocksTable.Rows.InsertAt(newRow, counter + 40);
}
// adding some dummy points at the bottom of the datatable
// to create the closing of stream flow effect
DateTime lastDate = Convert.ToDateTime(_stocksTable.Rows[_stocksTable.Rows.Count - 1]["Date"]);
for (int counter = 15; counter <= 40; counter++)
{
DataRow newRow = _stocksTable.NewRow();
newRow["Date"] = lastDate.AddDays(counter);
foreach (DataColumn column in _stocksTable.Columns)
{
if (column.ColumnName != "Date")
newRow[column.ColumnName] = 0; // Set zero value for other columns
}
_stocksTable.Rows.Add(newRow);
}
```
Lastly, the appearance of the chart can be customized by adjusting various visual aspects, such as color palette, font, header content, legend, tooltip, and axis data display. This enhances the overall presentation of the chart.
```
// method to customize the appearance of the chart to show streamline effect
public void CustomizeChartAppearance()
{
// assigning palette to the chart
flexChart1.Palette = C1.Chart.Palette.Custom;
flexChart1.CustomPalette = C1.Win.Chart.Palettes.Qualitative.Set1;
flexChart1.Series[0].Style.FillColor = Color.Transparent; // setting transparent color to the dummy series
// setting the axis, legend and header content
flexChart1.AxisX.Style.Font = new Font("Segoe UI", 12, FontStyle.Regular);
flexChart1.Header.Content = "Sector-wise Stock Analysis";
flexChart1.Header.Style.Font = new Font("Segoe UI", 20, FontStyle.Bold);
flexChart1.Legend.Style.Font = new Font("Segoe UI", 12, FontStyle.Regular);
// setting the tooltip content
flexChart1.ToolTip.Content = "{seriesName} \nDate: {Date:dd/MMM/yyyy}\nTurnover: INR {value} Cr";
// modifying axis data display
DateTime sampleDate = Convert.ToDateTime(_stocksTable.Rows[0]["Date"]);
flexChart1.AxisX.MajorUnit = sampleDate.AddDays(31).ToOADate() - sampleDate.ToOADate();
flexChart1.AxisX.Format = "MMM/yyyy";
flexChart1.AxisX.LabelAngle = 90;
// hiding Y-axis of the chart
flexChart1.AxisY.Position = Position.None;
}
```
After performing all the above steps, the final chart appears as follows:

You can [download the sample](https://cdn.mescius.io/umb/media/d5afxock/streamgraphdemo.zip) to follow along.
## Conclusion
In this blog, we have explored the simple process of creating streamgraphs. Our FlexChart API offers a [wide variety of charts](https://developer.mescius.com/componentone/docs/win/online-flexchart/chart-types.html "https://developer.mescius.com/componentone/docs/win/online-flexchart/chart-types.html") that can be used to turn numbers into visuals. This helps to understand the information quickly and make decisions effectively.
<span>Explore the FlexChart control more by referring to its official [documentation](https://developer.mescius.com/componentone/docs/win/online-flexchart/overview.html "https://developer.mescius.com/componentone/docs/win/online-flexchart/overview.html").</span>
<span>If you have any inquiries, please leave them in the comments section below. Happy Coding!</span> | chelseadevereaux |
1,864,258 | Database Migrations : From Manual to Automated Management. | A database schema refers to the structure of its tables, their relationships, views, indexes,... | 27,623 | 2024-05-24T20:31:00 | https://dev.to/aharmaz/database-migrations-from-manual-to-automated-management-5ffj | database, java, devops, productivity | A database schema refers to the structure of its tables, their relationships, views, indexes, triggers as well as other objects, And as developers, we often want to perform modifications on that structure to keep it in sync with the new features of the software using it, these modification are called database migrations because they migrate the database from one state into another.
There are various approaches to execute those migrations, and in this post we will cover both the old-school and modern approaches for running them.
**Real-World Database Migration Context**
In a real-world project, each developer will typically have a local database on his local machine for testing the features he will implement, and there are other databases deployed on environments like development, staging and production.
During the development phase, each developer will need to run migrations on his local database, and when preparing the release of a new version of a software, the approved migrations since the last release must be gathered and executed against the concerned database.
**Old-School Approach of Running Database Migrations**
Back in the day, developers wrote SQL scripts and manually ran them directly against their local databases, and these scripts were shared in the remote repository so that other members can use them, and during the release, the person in charge would manually execute those scripts on the target database.
This approach was challenging, Keeping track of what migrations script has been already executed against which database was really hard because there was no way to know the actual state of the target database and as a result it was common to run a script more than once against the same database or forget to execute a specific script, Also there was no framework for specifying the order in which the migration scripts must be executed, those situations promoted a fear among developers and the persons responsible for deployments when they have to deal with migrations.
**Managed Migration to the rescue**
Tools for managing database migrations have gained popularity across different programming ecosystems. These tools were introduced to manage the migration process and reduce the effort required from developers.
The concept behind these tools is to provide a clean and robust way to structure the migrations against multiple databases by enforcing the specification of ordering and database versioning, developers won't need to directly run the migrations against databases anymore, instead they will configure these tools to do the work for them in an intelligent manner ensuring that :
- A migration script is executed only once against a database
- The migrations scripts are executed in the configured order
Under the hood these tools create a dedicated table on the target database, and each time a migration is executed, a record is added to this table with details about that migration, so that when the migration process is initiated again there will be a check on that table to determine which migrations have already been applied and which are pending.
For the Java ecosystem the most commonly used ones are Flyway and Liquibase, for the python ecosystem there is Alembic and for the JavaScript world there is Knex.js and TypeORM.
**Integration of Managed Migration Tools at the Development and the Deployment phase**
Managed database migration tools can be configured to launch the migration process either at application startup or independently from the software they are related to.
During the development phase, developers frequently need to edit the schema of their local databases. Therefore, it is recommended to configure these managed tools to start the migration as part of the application startup process, so developers don’t have to launch it manually repeatedly.
During the deployment phase, migrations need to be launched only once. Thus, running the migration manually using a single command is recommended.
In real-world projects, both approaches are used together. You can configure how you want the migration to be launched (at application startup or independently) based on the profile with which the application is executed and the environment on which the software is running.
**Conclusion**
Database migrations are essential for keeping your database schema in sync with evolving application features. Transitioning from manual to automated migrations simplifies this process and reduces errors.
By using these automated migration tools, you can integrate migrations into your development and deployment workflows, making database management more efficient. This allows you to focus on developing new features without worrying about migration issues.
| aharmaz |
1,864,187 | Construtores semânticos: aprimorando a criação de objetos | Construtores tradicionais muitas vezes resultam em código difícil de ler e entender quando possuem... | 0 | 2024-05-24T20:28:02 | https://dev.to/kauanmocelin/construtores-semanticos-4m8p | java, programming, productivity |
Construtores tradicionais muitas vezes resultam em código difícil de ler e entender quando possuem múltiplos parâmetros. Construtores semânticos oferecem uma solução para este problema "nomeando" os construtores de forma descritiva e clara. Isso não apenas melhora a legibilidade, mas também facilita a manutenção do código, pois o propósito de cada instância fica claro pelo nome do método.
Quando uma classe possui múltiplos parâmetros de diferentes tipos, existe grande chance de ocorrerem construtores ambíguos e propensos a erros. Por exemplo, considere a classe _VerificadorAssinaturaDigital_:
```java
public class VerificadorAssinaturaDigital {
private final String nomeArquivoConteudo;
private final byte[] binarioArquivoConteudoAssinado;
private final String nomeArquivoAssinatura;
private final byte[] binarioArquivoAssinatura;
public VerificadorAssinaturaDigital(final String nomeArquivoConteudo, final byte[] binarioArquivoConteudoAssinado, final String nomeArquivoAssinatura, final byte[] binarioArquivoAssinatura) {
this.nomeArquivoConteudo = nomeArquivoConteudo;
this.binarioArquivoConteudoAssinado = binarioArquivoConteudoAssinado;
this.nomeArquivoAssinatura = nomeArquivoAssinatura;
this.binarioArquivoAssinatura = binarioArquivoAssinatura;
}
}
```
Ao instanciar a classe _VerificadorAssinaturaDigital_, pode ser difícil lembrar a ordem e o propósito de cada parâmetro, especialmente em projetos maiores ou quando a classe tem muitos parâmetros:
```java
VerificadorAssinaturaDigital verificador = new VerificadorAssinaturaDigital("documento", BINARIO, "nomeArquivoAssinatura", BINARIO2);
```
Aqui, não é imediatamente óbvio quais são os valores passados ou seu propósito. Este problema é amplificado à medida que o número de parâmetros aumenta, potencialmente levando a erros e dificultando a leitura do código.
## Métodos de Fábrica Estáticos
"Métodos de fábrica estáticos, como descrito por Joshua Bloch em seu livro _Effective Java_, possuem nomes ao contrário dos construtores tradicionais." Esta técnica consiste em tornar o construtor privado e utilizar métodos estáticos para retornar uma nova instância do objeto, mas com nomes descritivos que indicam objetivamente a finalidade da criação. Por exemplo, na classe _VerificadorAssinaturaDigital_, poderíamos definir métodos de fábrica assim:
```java
public class VerificadorAssinaturaDigital {
private final String nomeArquivoConteudo;
private final byte[] binarioArquivoConteudoAssinado;
private final String nomeArquivoAssinatura;
private final byte[] binarioArquivoAssinatura;
private VerificadorAssinaturaDigital(final String nomeArquivoConteudo, final byte[] binarioArquivoConteudoAssinado, final String nomeArquivoAssinatura, final byte[] binarioArquivoAssinatura) {
this.nomeArquivoConteudo = nomeArquivoConteudo;
this.binarioArquivoConteudoAssinado = binarioArquivoConteudoAssinado;
this.nomeArquivoAssinatura = nomeArquivoAssinatura;
this.binarioArquivoAssinatura = binarioArquivoAssinatura;
}
public static VerificadorAssinaturaDigital criarParaAssinaturaPdf(final String nomeArquivoConteudo, final byte[] binarioArquivoConteudoAssinado) {
return new VerificadorAssinaturaDigital(nomeArquivoConteudo, binarioArquivoConteudoAssinado);
}
public static VerificadorAssinaturaDigital criarParaAssinaturaCms(final String nomeArquivoConteudo, final byte[] binarioArquivoConteudoAssinado, final String nomeArquivoAssinatura, final byte[] binarioArquivoAssinatura) {
return new VerificadorAssinaturaDigital(nomeArquivoConteudo, binarioArquivoConteudoAssinado, nomeArquivoAssinatura, binarioArquivoAssinatura);
}
}
```
Uma vez que é possível "nomear" os construtores, tornando-os semânticos, ao bater o olho no nome do método é possível saber para qual propósito aquele objeto será construído:
```java
VerificadorAssinaturaDigital verificadorAssinaturaPdf = VerificadorAssinaturaDigital.criarParaAssinaturaPdf();
VerificadorAssinaturaDigital verificadorAssinaturaCms = VerificadorAssinaturaDigital.criarParaAssinaturaCms();
```
## Benefícios dos Construtores Semânticos
Os construtores semânticos oferecem várias vantagens significativas em comparação com os construtores tradicionais:
1. **Legibilidade**: Os métodos de fábrica estáticos têm nomes descritivos que tornam o código mais fácil de ler e entender.
2. **Manutenção**: Facilita a manutenção, pois os métodos nomeados explicitamente deixam claro o propósito de cada instância, reduzindo a chance de erros.
3. **Flexibilidade**: Permite adicionar novos métodos de fábrica sem alterar o construtor original, promovendo a extensibilidade do código.
4. **Clareza**: A utilização de métodos de fábrica elimina a ambiguidade sobre quais parâmetros estão sendo passados, especialmente em classes com muitos atributos.
## Conclusão
Construtores semânticos proporcionam uma maneira mais legível e intuitiva de criar objetos. Utilizando métodos de fábrica estáticos com nomes descritivos, esses construtores melhoram significativamente a clareza e a manutenção do código. Eles facilitam a leitura, reduzem a ambiguidade e diminuem a chance de erros. Além disso, promovem a flexibilidade na adição de novos métodos de criação sem modificar o construtor original.
## Referências
- Bloch, Joshua. _Effective Java_. 3ª edição, Addison-Wesley Professional, 2018 | kauanmocelin |
1,864,313 | Data Transfer between 2 PC's in lemon terms | If you are sending some file form PC-1 to PC-2 how that files goes ? Data Generation: Data can be... | 0 | 2024-05-24T20:24:06 | https://dev.to/nrj-21/data-transfer-between-2-pcs-in-lemon-terms-55pm | networking | If you are sending some file form PC-1 to PC-2 how that files goes ?
**Data Generation:** Data can be anything from a simple text message to a complex file. When you create or request data on your computer, it needs to be transmitted to another computer.
**Packetization:** Data is broken down into smaller chunks called packets. Each packet contains a piece of the original data along with additional information such as the source and destination addresses.
**Routing:** Once the data is packetized, it needs to find its way to the destination computer. This is where routing comes into play. Routers are devices that forward packets between networks based on their destination addresses.
**Transmission:** The packets are transmitted over a physical medium, such as Ethernet cables, Wi-Fi signals, or fiber-optic cables. Each packet travels independently and can take different routes to reach the destination.
**Reassembly:** When the packets arrive at the destination computer, they are reassembled into the original data. This process involves checking for any missing or corrupted packets and arranging them in the correct order.
**Delivery:** Finally, the reassembled data is delivered to the appropriate application or service on the destination computer, where it can be processed or displayed to the user. | nrj-21 |
1,813,983 | Create an Audio Transcript with Amazon Transcribe | Amazon Transcribe is an automatic speech recognition (ASR) service offered by AWS It enables... | 0 | 2024-05-24T20:15:09 | https://dev.to/cloudairx/create-an-audio-transcript-with-amazon-transcribe-55l8 | **Amazon Transcribe** is an automatic speech recognition (ASR) service offered by AWS
It enables developers to add speech-to-text capability to their applications. It uses machine learning models to convert audio to text.
**Amazon Transcribe** is a pay-as-you-go service; pricing is based on seconds of transcribed audio, billed on a monthly basis.
**Step 1**
- Launch the AWS Management console
- Launch S3 from the console
- Provide a unique name for the bucket
- Choose a region
- Disable bucket versioning (We don't need it for this project)
- Disable server side encryption
- Block all public access for the bucket
- Click on the **create bucket**
See below images as guide
**Step 2**
- Upload your audio file to the bucket
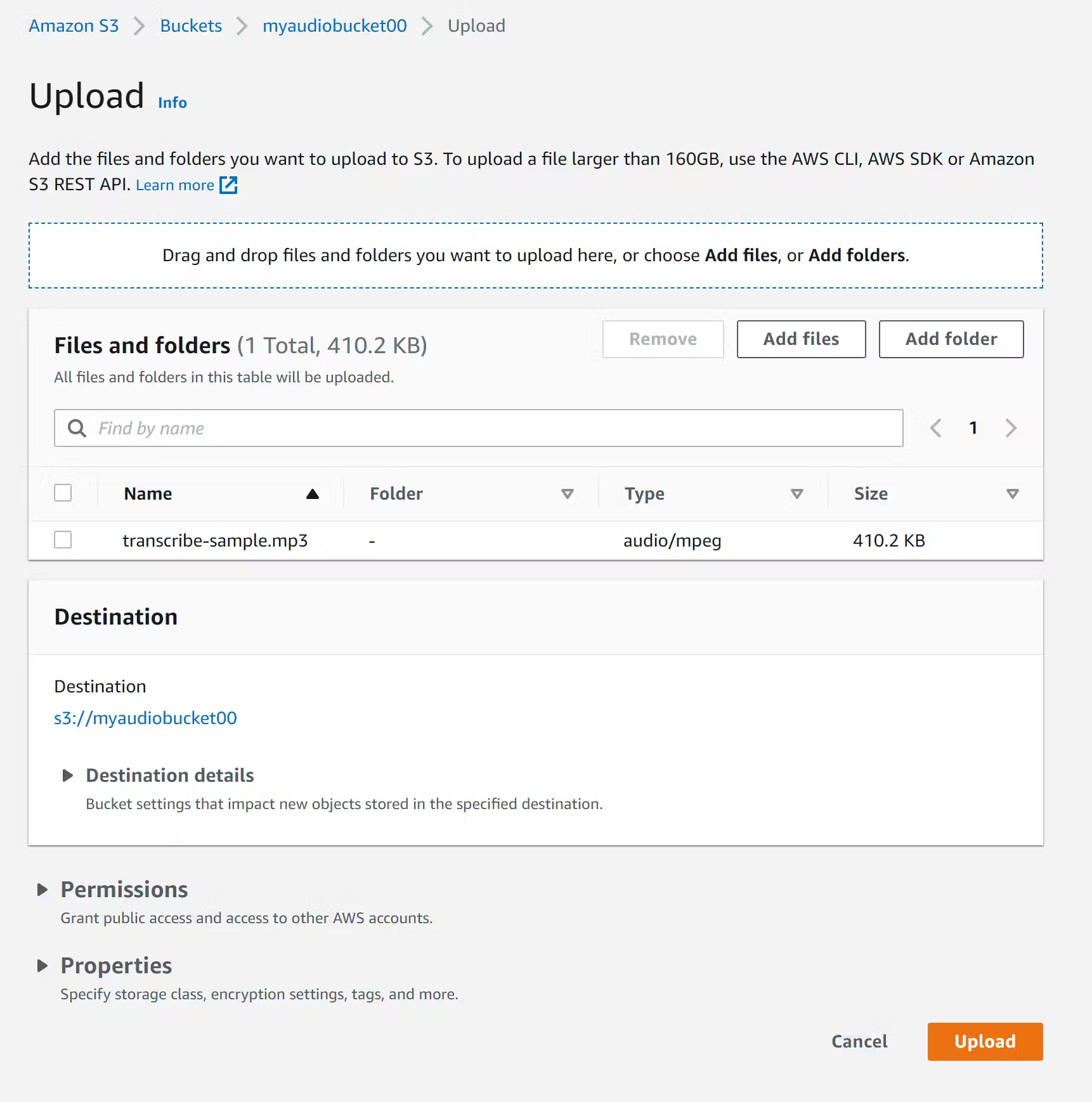
- Select the audio file and copy the object URL
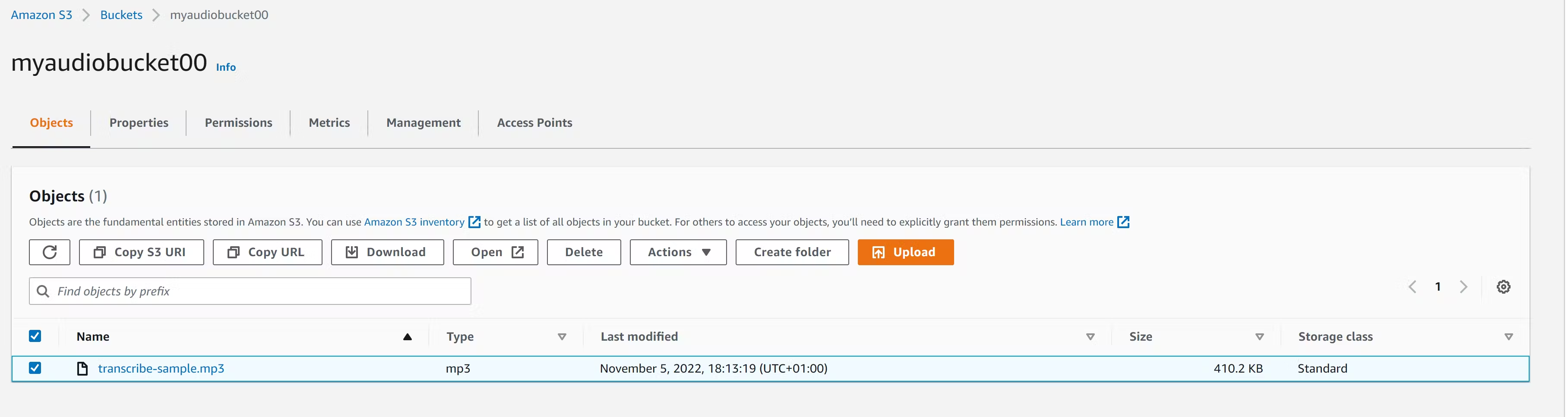
Let's create a transcript job that will handle the audio transcription
**Step 3**
- Launch **Amazon Transcribe**
- Create a **transcript**
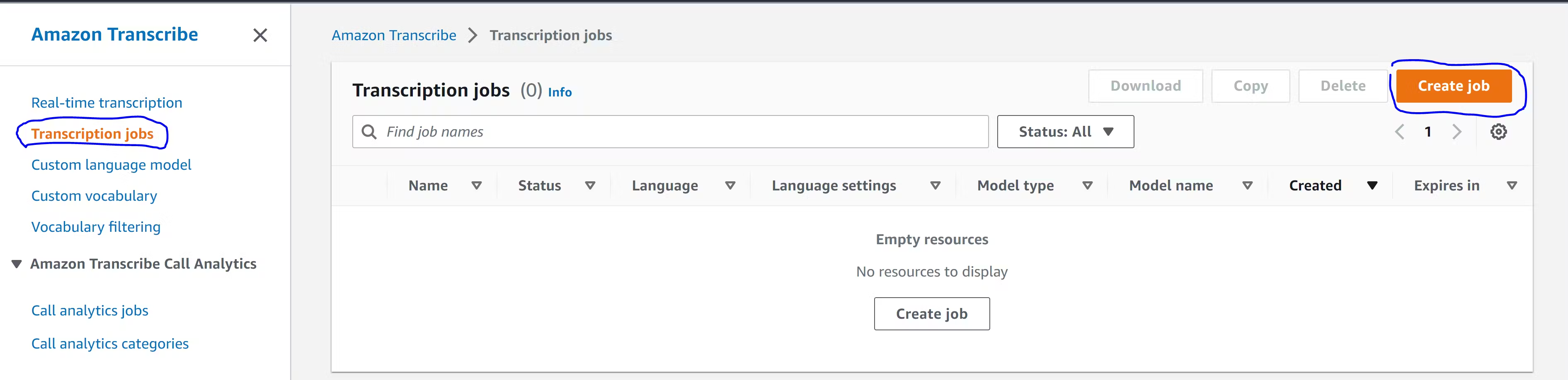
**Step 4**
- Specify job name
- Select **specific language** under the language settings
- Leave language as **default**
- Leave model as **default**
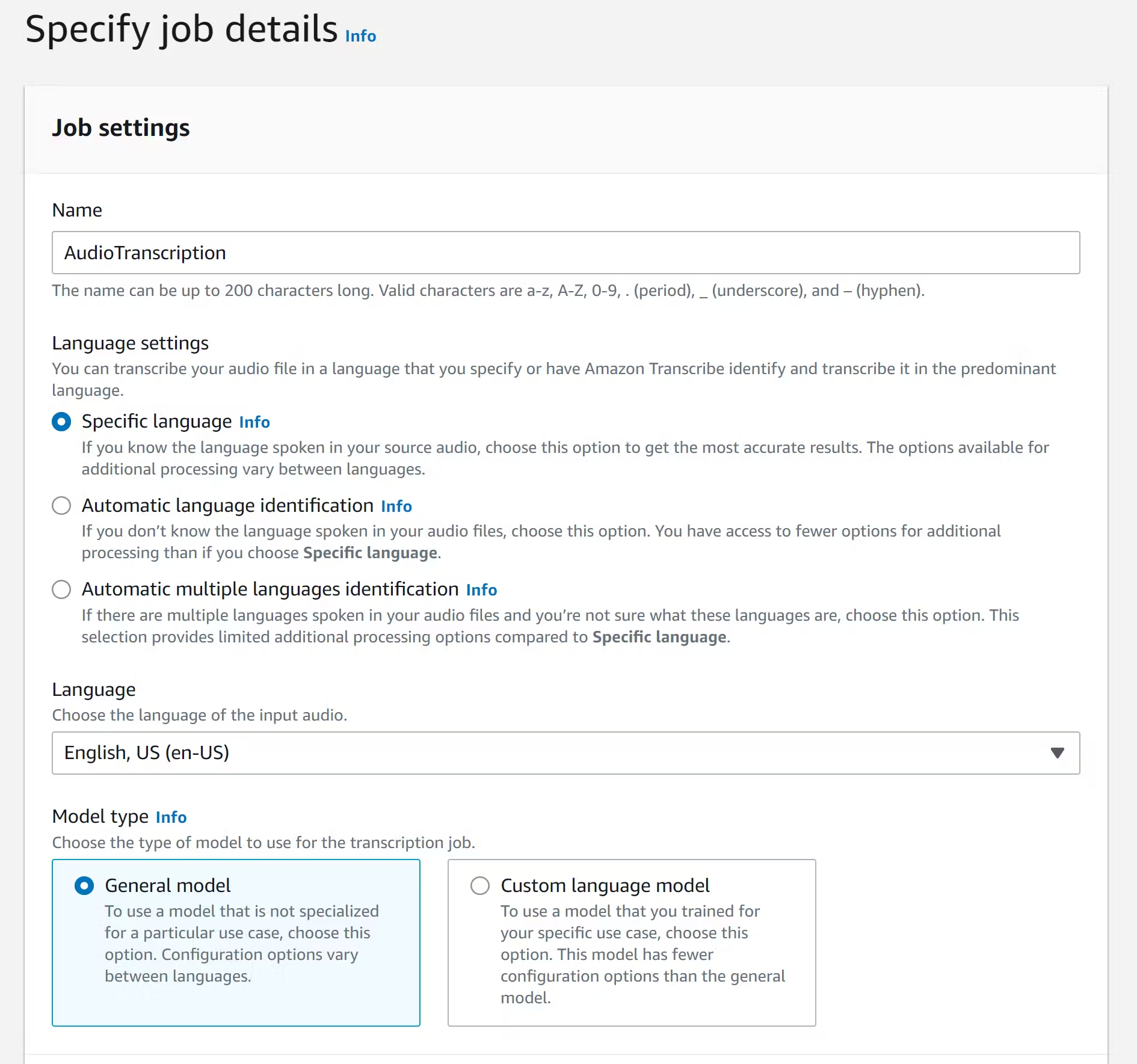
**Step 5**
- Paste the object URL in the input field
- Leave the default output location
- Leave the subtitle file format (Optional)
- click **Next**
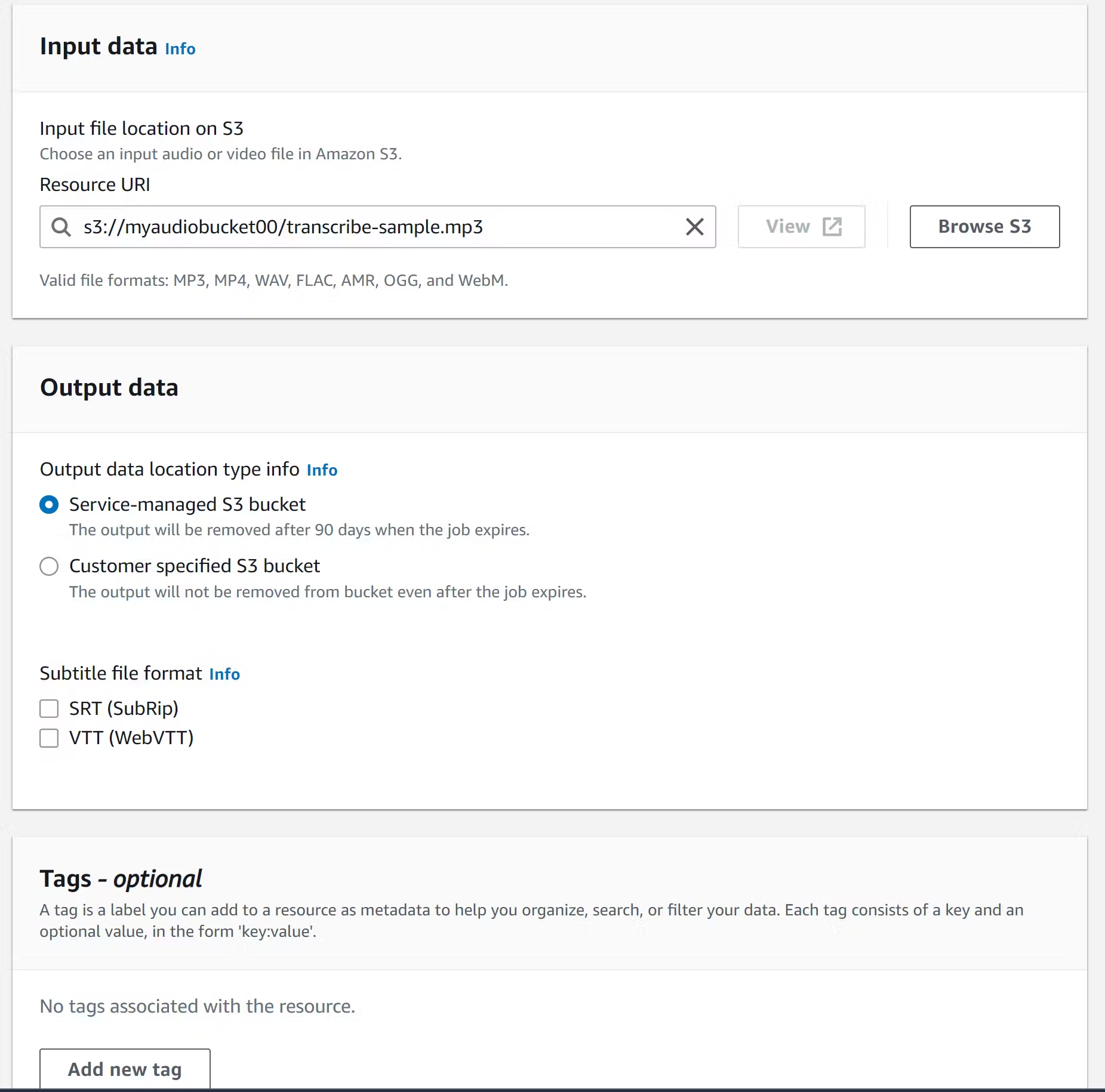
- Leave everything else as **default**
- Click **create job**
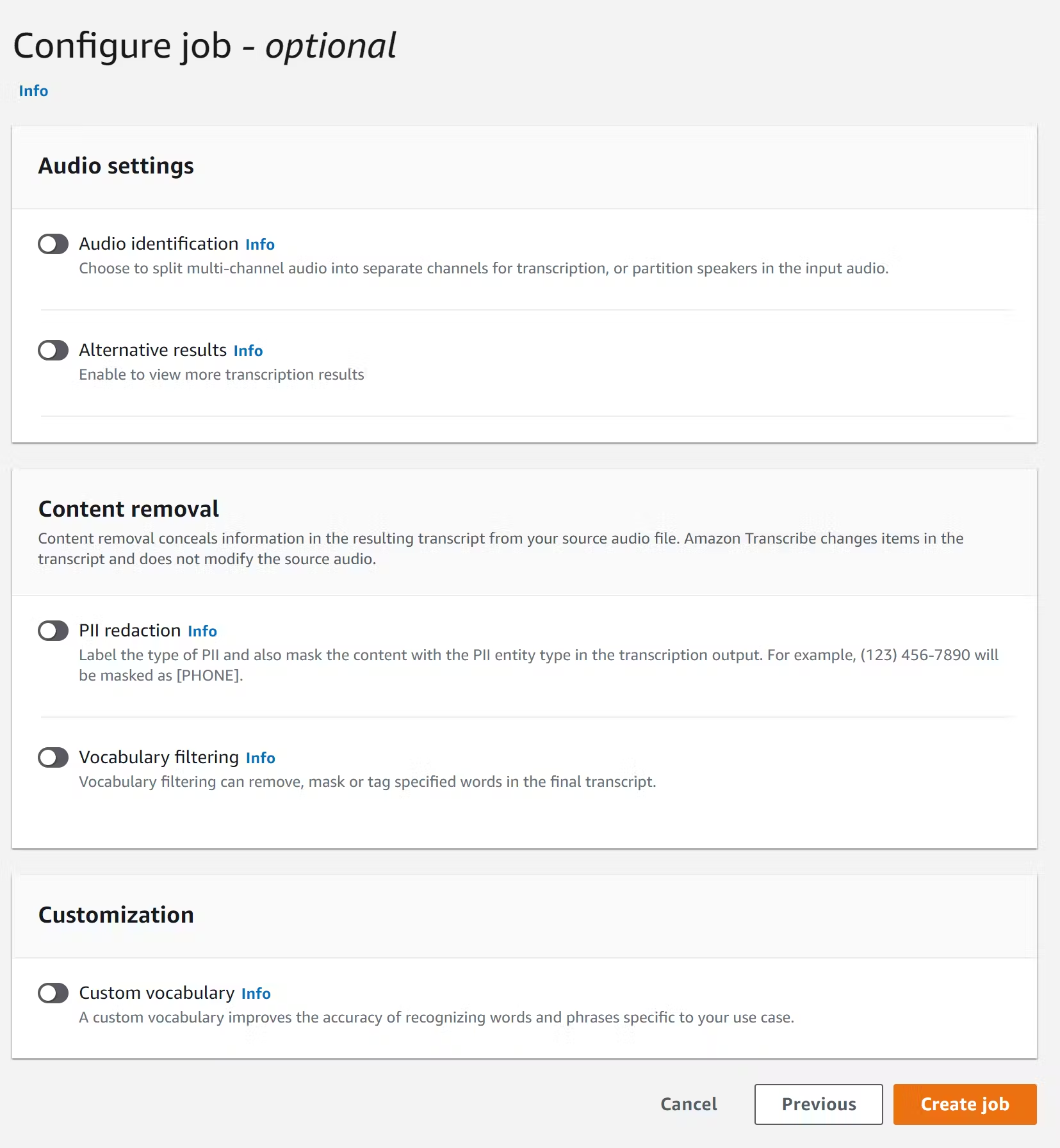
Our transcription job is done. Be sure the status reads complete
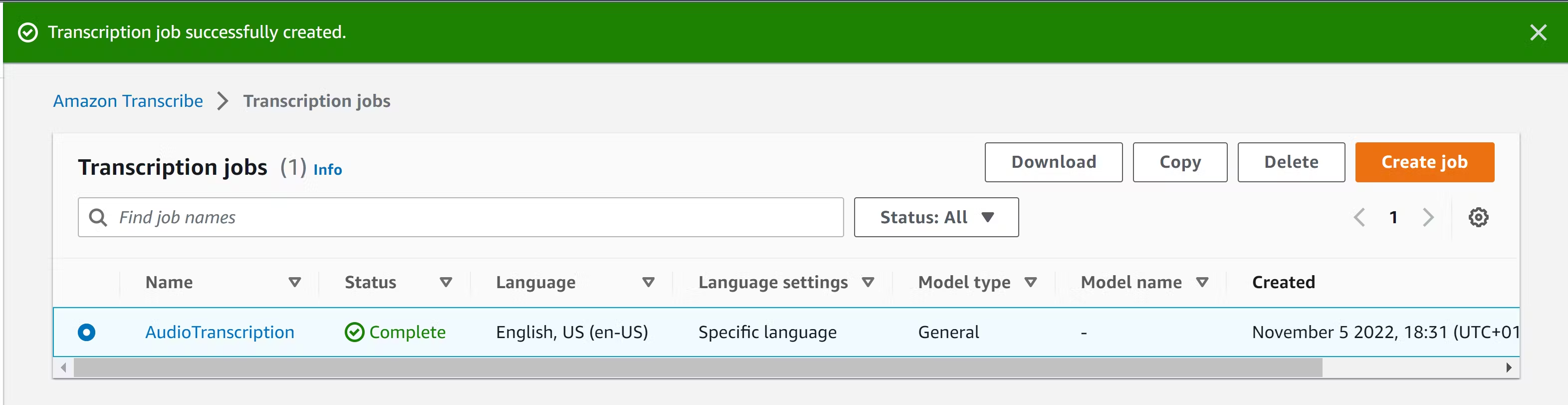
- Click on the completed job
- Scroll down to see the transcription preview
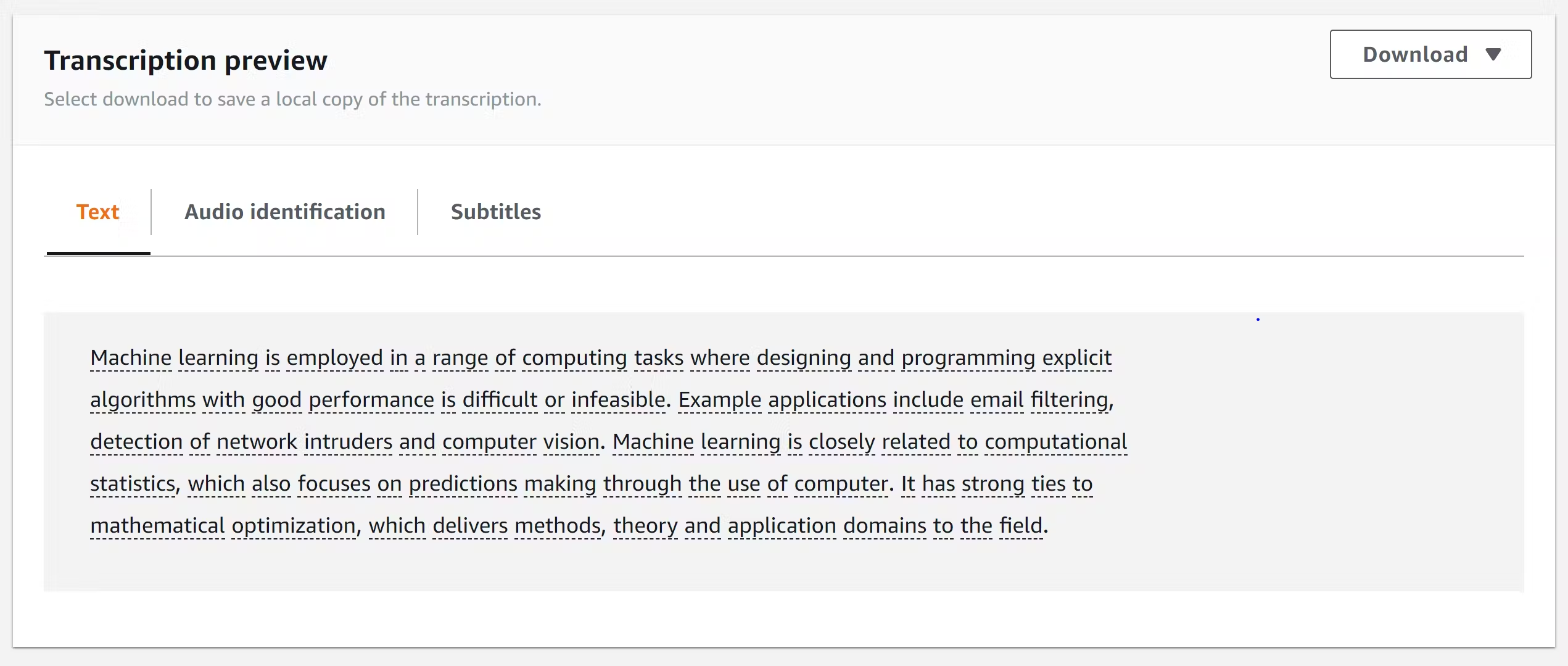
**Congratulation!** We have successfully transcribed our audio to text
In our next project we will learn how to translate our result into a different language | cloudairx | |
1,864,277 | BFE- Backend for Front-End | Let's say you are designing some web application, and your main role is develop all Backend API's. As... | 0 | 2024-05-24T20:09:41 | https://dev.to/nrj-21/bfe-backend-for-front-end-g5g | backenddevelopment, systemdesign, architecture | Let's say you are designing some web application, and your main role is develop all Backend API's. As a good backend developer your aim is to write generic API's for any other applications also like Android App, IOS App, etc. etc..
Take a example that you are building an E-commerce Web and Mobile Application. And as per the size of screen UI designer made below like pattern -
For Desktop view of specific product -
1. Image of product, price
2. Rating in terms of stars
3. Reviews
4. FAQ's
For Mobile Application view of specific product -
1. Image, price
2. Rating
FAQ's also there in mobile app but these things are in different tabs and UI/UX Developer made UI according to screen size.
So the main part is that for a different type of screen we are sending different kind of data.
To Desktop -
```
Product1= {
"Image": "IMG_1",
"Rating": "5",
"Reviews": ["R1", "R2"],
"FAQ": ["Q1A1", "Q2A2"]
}
```
To Mobile App-
```
Product1 = {
"Image": "IMG_1",
"Rating": "5"
}
```
So the problem is if you are as a Backend Developer made generic API for Product data and Different Screen Size Device need different data then how these things works ?
**Answer from Noob - **
As a fresher or beginner backend developer you would say that send all these data and render only those data which is needed at that time from frontend.
But as a good backend developer this is wrong. It's like user can access Reviews and FAQ's on same page where we don't want to show on that page. Yes, it is not bad for security but I think it's more of **EGO of Backend Developer** 😅😅. (Joking)
**Actual Answer - **
As I said it is not good practice for backend developer to send all data and use only required data, if developer do that then anyone can go to inspect and call that object and view all JSON of that data. (Still EGO of developer reason is at top).
To send data according to device type -
**Noob Advice:** Check device properties every time before sending data -
**Cons of it-** It will fucked up in between our Business Logic
Then **BFE- Backend for Front-End came in picture** to help these kind of scenarios.
BFE is basically a additional layer we add, whenever any request goes, it will first come to BFE in which BFE identifies that Device type/ Screen Size/ Desktop/ Mobile/ Tab and send request to our generalized Backend, and Backend will send our generalized request to BFE and according to Device type BFE modifies data (BFE make new object of required entities and render that object instead of Generalized response). | nrj-21 |
1,864,276 | Reducing AWS Lambda Cold Starts | Introduction AWS Lambda functions with large dependencies can suffer from significant cold... | 0 | 2024-05-24T20:01:47 | https://dev.to/aws-builders/reducing-aws-lambda-cold-starts-3eea | coldstart, python, aws, serverless | ## Introduction
AWS Lambda functions with large dependencies can suffer from significant cold start times due to the time it takes to import these dependencies. In this post, we'll explore a simple yet effective way to reduce Python cold start times without changing a line of code by precompiling dependencies into bytecode. We'll cover the following topics:
+ Understanding Python bytecode and `*.pyc` files
+ Precompiling dependencies to reduce init duration
+ Using Python optimization levels for further improvements
+ Reducing memory overhead with `PYTHONNODEBUGRANGES=1`
## Understanding Python Bytecode and `*.pyc` Files
When Python loads source code for the first time, it [compiles it to bytecode](https://peps.python.org/pep-3147/#background) and saves it to `*.pyc` files in `__pycache__` directories. On subsequent loads, Python will use these precompiled `*.pyc` files instead of recompiling the source code, saving time.
By precompiling dependencies and removing the original `*.py` files, we can bypass the bytecode compilation step during function initialization. This can significantly reduce init duration. For example, a simple handler with `import numpy as np` can see an init duration reduction of approximately 20%.
Removing `*.py` files affects the detail in tracebacks when exceptions occur. With `*.py` files, tracebacks include the relevant source code lines. Without `*.py` files, tracebacks only display line numbers, requiring you to refer to your version-controlled source code for debugging. For custom code not in version control, consider keeping the relevant `*.py` files to aid in debugging. For third-party packages, removing `*.py` files can improve cold start times at the cost of slightly less detailed tracebacks.
### Benefits
+ Faster imports during runtime
+ Reduced package size by removing `*.py` files
+ Same `*.pyc` files work on any OS
### How to
precompile dependencies and remove `*.py` files:
```bash
$ python -m compileall -b .
$ find . -name "*.py" -delete
```
### Caution
Always test your code after precompilation, as some packages do rely on the presence of `*.py` files.
## Using Python Optimization Levels
Python offers [optimization levels](https://docs.python.org/3/using/cmdline.html#cmdoption-O) that can further improve init and runtime duration by removing debug statements and docstrings.
### Benefits
| Optimization Level | Effect |
|-----|-----|
| -O | Removes assert statements and code blocks that rely on `__debug__` |
| -OO | Removes assert statements, `__debug__` code blocks, and docstrings |
### How to
precompile with optimization level 2:
```bash
$ python -m compileall -o 2 -b .
$ find . -name "*.py" -delete
```
### Caution
Test your code thoroughly, as optimization levels may introduce subtle bugs if your business logic relies on assert statements or docstrings.
## Reducing Memory Overhead with `PYTHONNODEBUGRANGES=1`
In Python 3.11+, you can use the [`PYTHONNODEBUGRANGES=1`](https://docs.python.org/3/using/cmdline.html#envvar-PYTHONNODEBUGRANGES) environment variable to disable the inclusion of column numbers in tracebacks. This reduces memory overhead but sacrifices the ability to pinpoint the exact location of exceptions on a given line of code.
Example traceback with debug ranges:
```
Traceback (most recent call last):
File "hello.py", line 1, in <module>
print(f"Hello world! {1/0}")
~^~
ZeroDivisionError: division by zero
```
Example traceback without debug ranges:
```
Traceback (most recent call last):
File "hello.py", line 1, in <module>
print(f"Hello world! {1/0}")
ZeroDivisionError: division by zero
```
### Benefits
+ Reduced memory overhead
+ Reduced package sizes
### How to
precompile with optimization level 2 and no debug ranges:
```bash
$ PYTHONNODEBUGRANGES=1 python -m compileall -o 2 -b .
$ find . -name "*.py" -delete
```
## Summary
By precompiling dependencies, using optimization levels, and disabling debug ranges, you can significantly reduce cold start times in your AWS Lambda Python functions. These techniques can lead to over 20% faster startup times, allowing your functions to respond more quickly to events. Try these optimizations in your own functions and see the performance improvements for yourself! | purple4reina |
1,864,275 | Beware of Mutable Default Arguments in Python | Beware of Mutable Default Arguments in Python As Python developers, we often enjoy the... | 0 | 2024-05-24T20:00:36 | https://dev.to/nisat-gg/beware-of-mutable-default-arguments-in-python-3ffa | python, problem | # Beware of Mutable Default Arguments in Python
As Python developers, we often enjoy the flexibility and simplicity that the language offers. However, some features can lead to unexpected behavior if not used carefully. One such feature is mutable default arguments.
## The Problem
Consider the following function:
```python
def test_func(newList, myList=[]):
for t in newList:
for f in t:
myList.append(f)
return myList
print(test_func([[3, 4, 5], [6, 7, 8]])) # Outputs: [3, 4, 5, 6, 7, 8]
print(test_func([[9, 10, 11], [12, 13, 14]])) # Outputs: [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
At first glance, everything seems fine. But notice what happens when the function is called a second time. Instead of getting a fresh list, myList retains the values from the previous call. This is because the default list is created once and shared across all calls to the function.
The Solution:
To avoid this issue, we can use None as the default value and initialize the list inside the function:
def test_func(newList, myList=None):
if myList is None:
myList = []
for t in newList:
for f in t:
myList.append(f)
return myList
print(test_func([[3, 4, 5], [6, 7, 8]])) # Outputs: [3, 4, 5, 6, 7, 8]
print(test_func([[9, 10, 11], [12, 13, 14]])) # Outputs: [9, 10, 11, 12, 13, 14]
By doing this, each call to test_func starts with a fresh list, avoiding the unintended side effect of sharing state across function calls.
Conclusion:
Mutable default arguments can lead to subtle bugs that are hard to track down. Always use immutable default arguments or initialize mutable ones inside the function. Happy coding!Feel free to share your thoughts or any other tips you have encountered on this topic! | nisat-gg |
1,862,245 | Introducing Rocketicons: The Perfect Companion for React and Tailwind CSS Developers | Hey there, I'm thrilled to announce a project that's been in the works - Rocketicons! This project... | 0 | 2024-05-24T20:00:32 | https://dev.to/amorimjj/introducing-rocketicons-the-perfect-companion-for-react-and-tailwind-css-developers-417b | react, reactnative, tailwindcss, opensource | Hey there,
I'm thrilled to announce a project that's been in the works - Rocketicons! This project has been a collaborative effort with a talented friend of mine.
Our journey with [Rocketicons](https://rocketicons.io) started when we encountered the challenges of maintaining separate codebases for web and mobile platforms while developing a solution for sharing expenses via PIX, a Brazilian instant payment method. The duplication headaches were real, causing more inefficiencies than we cared to count. That's when we decided it was time for a change.
Enter [React](https://react.dev), [React Native](https://reactnative.dev), and [Expo](https://expo.dev). By unifying our development stack, we streamlined our workflow considerably. Yet, one crucial piece was missing: a comprehensive library for essential tasks like icons and components. As we delved further into our development journey, we realized there were more gaps to fill, including robust boilerplates and other essential necessities.
And thus, [Rocketicons](https://rocketicons.io) was born. The first tool we’ve published to address these challenges. Rocketicons is an icon library designed specifically for [Tailwind CSS](https://tailwindcss.com) and fully compatible with React Native. And it's just the beginning. Our mission is to empower developers like you to effortlessly share codebases across platforms, boosting productivity while ensuring consistency. We're also working on solutions for the other problems we've identified, so stay tuned for more tools to come!
#### Why Tailwind CSS?
I have to admit, I never liked Bootstrap much, but I absolutely love Tailwind CSS! It might sound insane, but here’s why I think it’s a game-changer:
- **Utility-First Approach**: Say goodbye to digging through endless CSS files. Tailwind's utility-first approach means styling directly within HTML, making development faster and code more maintainable.
- **Customization**: Tailwind is like a chameleon — it adapts to your design preferences. With its high configurability, we can tailor it to fit our exact needs, ensuring a sleek and cohesive user interface every time.
- **Performance**: Small CSS bundles? Yes, please! By only including the styles we need, Tailwind keeps our applications lightning fast.
- **Community Support**: It's not just a framework; it's a family. The vibrant Tailwind community offers a treasure trove of resources, plugins, and support, making troubleshooting a breeze and best practices a cinch to learn.
I can't see any reason not to use Tailwind CSS — it's truly revolutionized how we approach styling.
#### Now, let's talk [Rocketicons](https://rocketicons.io) features:
- **Tailwind CSS Integration**: Style your icons effortlessly with Tailwind's utility-first approach.
- **React Native Support**: Seamlessly use the same icons across web and mobile platforms.
- **Consistent Design**: Keep your applications looking sharp and feeling cohesive.
- **Easy to Use**: Use Tailwind classes to avoid mixing HTML attributes with styles, making the code easier to understand and style, you'll be up and running in no time.
Still not convinced? Take a peek at just how simple it is to integrate Rocketicons into your projects:
```javascript
// Example for a React project
import { RcRocketIcon } from "rocketicons/rc";
const MyComponent = () => (
<div>
<RcRocketIcon className="icon-rose-500 border border-slate-600 rounded-lg bg-slate-50" />
</div>
);
```
For React Native, no code changes are needed.
```javascript
// Example for a React Native project
import { RcRocketIcon } from "rocketicons/rc";
const MyComponent = () => (
<div>
<RcRocketIcon className="icon-rose-500 border border-slate-600 rounded-lg bg-slate-50" />
</div>
);
```
Ready to embark on this journey with us? We're beyond excited to share [Rocketicons](https://rocketicons.io) with the developer community and can't wait to hear your feedback and contributions.
Dive into our documentation or visit our [GitHub repository](https://github.com/rocketclimb/rocketicons) for everything you need to get started, and let's make some coding magic happen!
Dive into our [documentation](https://rocketicons.io/docs/usage) or on [GitHub repository](https://github.com/rocketclimb/rocketicons) for everything you need to get started and let's make some coding magic happen!
Thank you for your consistent support, and let's keep writing countless lines of stellar code!
---
_I've wrote a [article on LinkedIn](https://www.linkedin.com/pulse/empower-your-learning-journey-why-personal-projects-matter-amorim-ctoof/?trackingId=lKT5%2BliUTQm%2B5Gv%2F0E%2FgHw%3D%3D) sharing how this project has improved me as a professional._
 | amorimjj |
1,864,274 | LeetCode Meditations: Implement Trie (Prefix Tree) | The description for this problem is: A trie (pronounced as "try") or prefix tree is a tree data... | 26,418 | 2024-05-24T19:55:55 | https://rivea0.github.io/blog/leetcode-meditations-implement-trie-prefix-tree | computerscience, algorithms, typescript, javascript | The description for [this problem](https://leetcode.com/problems/implement-trie-prefix-tree) is:
> A [**trie**](https://en.wikipedia.org/wiki/Trie) (pronounced as "try") or **prefix tree** is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and spellchecker.
>
> Implement the Trie class:
> - `Trie()` Initializes the trie object.
> - `void insert(String word)` Inserts the string `word` into the trie.
> - `boolean search(String word)` Returns `true` if the string `word` is in the trie (i.e., was inserted before), and `false` otherwise.
> - `boolean startsWith(String prefix)` Returns `true` if there is a previously inserted string `word` that has the prefix `prefix`, and `false` otherwise.
For example:
```
Input
['Trie', 'insert', 'search', 'search', 'startsWith', 'insert', 'search']
[[], ['apple'], ['apple'], ['app'], ['app'], ['app'], ['app']]
Output
[null, null, true, false, true, null, true]
Explanation
Trie trie = new Trie();
trie.insert('apple');
trie.search('apple'); // return True
trie.search('app'); // return False
trie.startsWith('app'); // return True
trie.insert('app');
trie.search('app'); // return True
```
---
We have seen in [the previous article](https://rivea0.github.io/blog/leetcode-meditations-chapter-10-tries) how to create a trie, insert a word, and search for a word, as well as deleting a word.
This problem requires only the first three of them, and additionally a `startsWith` method to search for a prefix.
In the previous version, we've created our trie using an array, but let's use another approach here. We'll make use of [the `Map` object](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map#instance_methods), which is slightly more readable and efficient.
_We used JavaScript in the previous article, but for this solution we'll continue using TypeScript._
---
Let's start with a trie node.
We'll create a `TrieNode` class that has `children` which is initiated as a `Map` whose keys are `string`s and the values are `TrieNode`s.
Our node will also have an `isEndOfWord` flag to indicate whether it represents the end character of a word:
```ts
class TrieNode {
public children: Map<string, TrieNode>;
public isEndOfWord: boolean;
constructor() {
this.children = new Map();
this.isEndOfWord = false;
}
}
```
Now, on to the `Trie` itself.
We'll start with creating an empty root note in our `constructor`:
```ts
class Trie {
public root: TrieNode;
constructor() {
this.root = new TrieNode();
}
...
}
```
To insert a word, we'll traverse each character, and starting with our root node, insert them one by one.
First, we'll initialize a `currentNode` variable which points to our root node, and we'll update it each time we add a character. Once we add all the characters, we'll mark that node's `isEndOfWord` as `true`:
```ts
insert(word: string): void {
let currentNode = this.root;
for (const char of word) {
if (!currentNode.children.has(char)) {
currentNode.children.set(char, new TrieNode());
}
currentNode = currentNode.children.get(char) as TrieNode;
}
currentNode.isEndOfWord = true;
}
```
| Note |
| :-- |
| We'll be casting `currentNode.children.get(char)` as a `TrieNode`, because TypeScript thinks that it might be `undefined`. This is one of those times that we know more than the TS compiler, so we're using a [type assertion](https://www.typescriptlang.org/docs/handbook/2/everyday-types.html#type-assertions). <br> Alternatively, we could've also used a [non-null assertion operator](https://www.typescriptlang.org/docs/handbook/2/everyday-types.html#non-null-assertion-operator-postfix) that asserts values as non `null` or `undefined`, like this: <br> <br> `currentNode = currentNode.children.get(char)!;` |
To search a word, we'll do a similar thing. We'll iterate through each character, and check if it's in our trie. If not, we can immediately return `false`. Otherwise, we'll return `isEndOfWord` of the last node we reach. So, if that character is indeed the end of a word, that word is in our trie:
```ts
search(word: string): boolean {
let currentNode = this.root;
for (const char of word) {
if (!currentNode.children.has(char)) {
return false;
}
currentNode = currentNode.children.get(char) as TrieNode;
}
return currentNode.isEndOfWord;
}
```
The `startsWith` method also looks very similar, only that we don't need to check `isEndOfWord` of any node. We're just checking for the existence of the prefix we're given, so we'll traverse all the characters in it, and once we reach the end (_that all characters are in our trie_), we can return `true`:
```ts
startsWith(prefix: string): boolean {
let currentNode = this.root;
for (const char of prefix) {
if (!currentNode.children.has(char)) {
return false;
}
currentNode = currentNode.children.get(char) as TrieNode;
}
return true;
}
```
And, here is the whole solution:
```ts
class TrieNode {
public children: Map<string, TrieNode>;
public isEndOfWord: boolean;
constructor() {
this.children = new Map();
this.isEndOfWord = false;
}
}
class Trie {
public root: TrieNode;
constructor() {
this.root = new TrieNode();
}
insert(word: string): void {
let currentNode = this.root;
for (const char of word) {
if (!currentNode.children.has(char)) {
currentNode.children.set(char, new TrieNode());
}
currentNode = currentNode.children.get(char) as TrieNode;
}
currentNode.isEndOfWord = true;
}
search(word: string): boolean {
let currentNode = this.root;
for (const char of word) {
if (!currentNode.children.has(char)) {
return false;
}
currentNode = currentNode.children.get(char) as TrieNode;
}
return currentNode.isEndOfWord;
}
startsWith(prefix: string): boolean {
let currentNode = this.root;
for (const char of prefix) {
if (!currentNode.children.has(char)) {
return false;
}
currentNode = currentNode.children.get(char) as TrieNode;
}
return true;
}
}
/**
* Your Trie object will be instantiated and called as such:
* var obj = new Trie()
* obj.insert(word)
* var param_2 = obj.search(word)
* var param_3 = obj.startsWith(prefix)
*/
```
#### Time and space complexity
Both the time and space complexity of inserting a word are {% katex inline %} O(n) {% endkatex %} where {% katex inline %} n {% endkatex %} is the number of characters — we traverse through each of them once, and the space requirements will grow as the number of characters of the word grows.
`search` and `startsWith` both have {% katex inline %} O(n) {% endkatex %} time complexity, as we're iterating through each character in a given string input. They also both have {% katex inline %} O(1) {% endkatex %} space complexity because we don't need any additional space.
---
Next up is the problem [Design Add and Search Words Data Structure](https://leetcode.com/problems/design-add-and-search-words-data-structure). Until then, happy coding.
| rivea0 |
1,860,426 | Multi-language Web Novel Scraper in Python | Introduction TL;DR Today we will code a web scraper to scrap multiple sources of web... | 0 | 2024-05-24T19:48:22 | https://dev.to/reinaldoassis/multi-language-web-novel-scraper-in-python-3cd2 | coding, scraper, python, cli | ---
title: Multi-language Web Novel Scraper in Python
published: true
description:
tags: coding, scraper, python, cli
cover_image: https://i.imgur.com/ZVdxXqX.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-20 19:27 +0000
---
### Introduction
TL;DR Today we will code a web scraper to scrap multiple sources of web novels, download chapters and combine them into a .epub file.
I like reading a specific web novel called Overgeared, it has more than 2000 chapters! I used to use a website that downloaded the web novel chapters for me and combined it all in a .epub file that I could send to my kindle. Unfortunately, the site went down and I was left with no choice but to code my own solution.
**Overview:** Here's the breakdown of the process we have to follow to achieve our goal:
1. Find sources
1. Identify ways to scrap each source
1. Write a Scraper Interface
1. Write a subclass for each source and implement the methods
1. Combine it all together and be happy reading my lil novel
### Fiding Sources
Since I'm currently bettering my French and studying Italian I'd like to have sources other than English, fortunately Overgeared has translation to multiple languages so this step wasn't hard. Here are the sources I'll be using:
- 🇫🇷 [French](https://xiaowaz.fr/series-en-cours/overgeared/)
- 🇺🇸 [English](https://novelbin.englishnovel.net/novel-book/overgeared-novel)
- 🇮🇹 [Italian](https://www.novelleleggere.com/category/overgeared/)
### Inspecting the structure of each source
Let's first start by taking a look at the French source since it poses an interesting challenge:
```html
<ul class="lcp_catlist" id="lcp_instance_0">
<li><a href="https://xiaowaz.fr/articles/og-chapitre-16/">OG Chapitre 16</a></li>
<li><a href="https://xiaowaz.fr/articles/overgeared-chapitre-1/">Overgeared Chapitre 1</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-2/">OG Chapitre 2</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-3/">OG Chapitre 3</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-4/">OG Chapitre 4</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-5/">OG Chapitre 5</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-6/">OG Chapitre 6</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-7/">OG Chapitre 7</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-8/">OG Chapitre 8</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-9/">OG Chapitre 9</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-10/">OG Chapitre 10</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-11/">OG Chapitre 11</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-12/">OG Chapitre 12</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-13/">OG Chapitre 13</a></li>
<li><a href="https://xiaowaz.fr/articles/og-chapitre-14-rattrapage/">OG Chapitre 14 [Rattrapage]</a></li>
</ul>
```
If you take a look at the links for each chapter you will see that some of them are different, that means there's no pattern we can iterate on such as **".../og-chapitre-{chapter number we want}"** (this link would work for some but not all of them). As such, we have to come up with a strategy, there are some options but I think the most straight forward one is to simply divide the scraping process into two steps:
1. First, we call the web novel home page and extract all of the available chapter's link into an array.
1. Second, we iterate in the generated array of links, extracting the text and combining into a book.
### Generality
Another fun aspect we have to take into consideration is generality, in reality it is nearly impossible to write one code that can scrap any page we want, instead it's easier to write an interface class and implement the methods for scraping in each one. For example, both scrapers of French and English would have the same method `scraper`, but they would have different implementations.
The scraper Interface I wrote is quite big, but here are the main methods to get the idea across:
```python
def scraper(self, chapter_number : str, override_link: bool = False) -> chapter:
"""Responsible for requesting the html page and extracting the wanted text from it.
:param int chapter_number: the number of the chapter to be requested and scraped.
:param str language: default to english.
"""
pass
def create_book_from_chapters(self, book_name : str, out : str, chapters : List[chapter]):
"""Turns an array of chapters into an ebook."""
pass
def get_multiple_chapters(self, start: int, end : int) -> List[chapter]:
pass
def get_multiple_chapters_from_list(self, chapters: List[chapter]) -> List[chapter]:
"""In case the links from the source are not standard, this function can be used in
conjunction with search_available_chapters, the chapters list containing the links will be
downloaded and stored in a new list that can be used with create_book_from_chapters function."""
pass
```
- The ideal flow is
- [user input chapter range of download e.g. 100-200]
- [user select language i.e. FR/EN/IT]
- [calls function start(range)]
The `start(range : str)` function is responsible for calling the needed functions, for example, if the scraper in the selected language can't predict how the url works, it should use the function `search_available_chapters` to compile a list of links it can use to download chapters from.
In short, for each language we want to add we will create a class that implements the method of our interface. Here are some methods of the English implementation:
```python
def scraper(self, chapter_number: str) -> chapter:
try:
response = requests.get(self._partial_link + chapter_number).text
except:
click.echo("[ERROR] Error while getting request.")
click.echo(f"[ERROR] Request {self._partial_link+chapter_number} has failed.")
raise self.FAILED_REQUEST
soup = BeautifulSoup(response, 'html.parser')
chr_content_div = soup.find('div', id='chr-content')
text = ""
if chr_content_div:
paragraphs = chr_content_div.find_all('p')
for p in paragraphs:
text += f"<p>{p.get_text()}</p>\n\n"
else:
text = ""
ch = chapter(text,f"Chapter {chapter_number}", "en", self.partial_link+chapter_number, len(text.split(" ")), chapter_number)
return ch
```
```python
def create_book_from_chapters(self, book_name: str, out: str, chapters: List[chapter]):
book = epub.EpubBook()
book.set_identifier('overgeared')
book.set_title('Overgeared Novel')
book.set_language('en')
book.add_author('Park Saenal')
# Cover image
book.set_cover("cover.jpg", open(self._cover_image_path, "rb").read())
total_words = sum(ch.word_count for ch in chapters)
info_page = epub.EpubHtml(title="Information", file_name="info.xhtml", lang='en')
info_content = """
<h1>Information</h1>
<p>This is a collection of chapters compiled by me but all credits go to the author (Park Saenal) and translator (rainbowturtle).</p>
<p>This book contains approximately {num_pages} pages.</p>
""".format(num_pages=round(total_words/250))
info_page.content = info_content
book.add_item(info_page)
book.toc.append((info_page, "Information"))
for ch in chapters:
book.add_item(ch.epub_info)
book.toc.append((ch.epub_info, ch.title))
# Define CSS
style = 'body { font-family: Times, Times New Roman, serif; text-align: justify; }'
nav_css = epub.EpubItem(uid="style_nav", file_name="style/nav.css", media_type="text/css", content=style)
book.add_item(nav_css)
book.add_item(epub.EpubNcx())
book.add_item(epub.EpubNav())
# Adds CSS to the book
book.spine = [info_page, 'nav', *book.items]
epub.write_epub(f'Overgeared {chapters[0].number} to {chapters.pop().number}.epub', book)
```
### Combining all together
All that is left is to combine everything we've made, my plan is to use this module as a sort of "plugin" for my personal CLI (where I have a bunch of tools I've coded for myself), as such you can see here two important methods `extension_name` (tells the main program what is this extension's name) and `start` (called when the extension is selected).
```python
def extension_name():
return "Overgeared Ebook Novel"
def start():
click.echo("Module: og.py")
click.echo("Module Version: 0.0.1")
click.echo("Created in: 14.05.24")
click.echo("")
lg = click.prompt("Language code: ")
ch = click.prompt("Chapter to download: ")
if lg == "en":
en = OG_Novel_Downloader_EN()
en.start(ch)
# en.sanity_check(ch, verbose=True)
if lg == "fr":
fr = OG_Novel_Downloader_FR()
fr.start(ch)
```
### Usage
Now all we've to do is enjoy reading our novel in multiple languages 🥳.
### Conclusion
I still struggle a bit with the concept of interfaces and reusable code, in hindsight I think my code could look a lot cleaner (maybe I'll refactor it?). Unfortunately, I won't be able to provide you guys with the source code this time, I don't have permission to scrap this sites much less share a code that does, but I hope this post was of some help and feel free to contact me if you have any suggestions or questions (my contacts can be found bellow ;).
That's it for today, thank you for reading so far!
### About the Author
Computer Engineering Student making cool projects for fun (:
You can find more about me on my website (I’ll put the link here when available), [TikTok](https://www.tiktok.com/@reinaldo.assis), [YouTube](http://youtube.com/reinaldoassis) and [Instagram](http://instagram.com/reinaldo.assis/).
---
| reinaldoassis |
1,864,272 | 1255. Maximum Score Words Formed by Letters | 1255. Maximum Score Words Formed by Letters Hard Given a list of words, list of single letters... | 27,523 | 2024-05-24T19:42:23 | https://dev.to/mdarifulhaque/1255-maximum-score-words-formed-by-letters-25bj | php, leetcode, algorithms, programming | 1255\. Maximum Score Words Formed by Letters
Hard
Given a list of `words`, list of single `letters` (might be repeating) and `score` of every character.
Return the maximum score of **any** valid set of words formed by using the given letters (`words[i]` cannot be used two or more times).
It is not necessary to use all characters in `letters` and each letter can only be used once. Score of letters `'a'`, `'b'`, `'c'`, `...` ,`'z'` is given by `score[0]`, `score[1]`, `...` , `score[25]` respectively.
**Example 1:**
- **Input:** words = ["dog","cat","dad","good"], letters = ["a","a","c","d","d","d","g","o","o"], score = [1,0,9,5,0,0,3,0,0,0,0,0,0,0,2,0,0,0,0,0,0,0,0,0,0,0]
- **Output:** 23
- **Explanation:**
Score a=1, c=9, d=5, g=3, o=2
Given letters, we can form the words "dad" (5+1+5) and "good" (3+2+2+5) with a score of 23.
Words "dad" and "dog" only get a score of 21.
**Example 2:**
- **Input:** words = ["xxxz","ax","bx","cx"], letters = ["z","a","b","c","x","x","x"], score = [4,4,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,5,0,10]
- **Output:** 27
- **Explanation:**
Score a=4, b=4, c=4, x=5, z=10
Given letters, we can form the words "ax" (4+5), "bx" (4+5) and "cx" (4+5) with a score of 27.
Word "xxxz" only get a score of 25.
**Example 3:**
- **Input:** words = ["leetcode"], letters = ["l","e","t","c","o","d"], score = [0,0,1,1,1,0,0,0,0,0,0,1,0,0,1,0,0,0,0,1,0,0,0,0,0,0]
- **Output:** 0
- **Explanation:**
Letter "e" can only be used once.
**Constraints:**
- <code>1 <= words.length <= 14</code>
- <code>1 <= words[i].length <= 15</code>
- <code>1 <= letters.length <= 100</code>
- <code>letters[i].length == 1</code>
- <code>score.length == 26</code>
- <code>0 <= score[i] <= 10</code>
- `words[i]`, `letters[i]` contains only lower case English letters.
**Solution:**
```
class Solution {
/**
* @param String[] $words
* @param String[] $letters
* @param Integer[] $score
* @return Integer
*/
function maxScoreWords($words, $letters, $score) {
$letterCounts = array_fill(0, 26, 0);
foreach ($letters as $letter) {
$letterCounts[ord($letter) - ord('a')]++;
}
$numWords = count($words);
$maxScore = 0;
for ($combination = 0; $combination < (1 << $numWords); ++$combination) {
$wordCounts = array_fill(0, 26, 0);
for ($wordIndex = 0; $wordIndex < $numWords; ++$wordIndex) {
if ($combination >> $wordIndex & 1) {
foreach (str_split($words[$wordIndex]) as $letter) {
$wordCounts[ord($letter) - ord('a')]++;
}
}
}
$isValidCombination = true;
$currentScore = 0;
for ($letterIndex = 0; $letterIndex < 26; ++$letterIndex) {
if ($wordCounts[$letterIndex] > $letterCounts[$letterIndex]) {
$isValidCombination = false;
break;
}
$currentScore += $wordCounts[$letterIndex] * $score[$letterIndex];
}
if ($isValidCombination && $maxScore < $currentScore) {
$maxScore = $currentScore;
}
}
return $maxScore;
}
}
```
**Contact Links**
- **[LinkedIn](https://www.linkedin.com/in/arifulhaque/)**
- **[GitHub](https://github.com/mah-shamim)** | mdarifulhaque |
1,864,271 | 1255. Maximum Score Words Formed by Letters | https://leetcode.com/problems/maximum-score-words-formed-by-letters/?envType=daily-question&envId... | 0 | 2024-05-24T19:39:26 | https://dev.to/karleb/1255-maximum-score-words-formed-by-letters-a55 | https://leetcode.com/problems/maximum-score-words-formed-by-letters/?envType=daily-question&envId=2024-05-24
```js
var maxScoreWords = function(words, letters, score) {
let n = words.length;
let res = 0;
let letters_count = new Array(26).fill(0);
for (let letter of letters) {
letters_count[letter.charCodeAt(0) - 97]++;
}
let words_scores = {};
for (let word of words) {
let s = 0;
for (let ch of word) {
s += score[ch.charCodeAt(0) - 97];
}
words_scores[word] = s;
}
function recursion(cur_ind, cur_score) {
if (cur_ind === n) {
res = Math.max(res, cur_score);
return;
}
let can_add_this_word = true;
let word = words[cur_ind];
let word_count = new Array(26).fill(0);
for (let ch of word) {
word_count[ch.charCodeAt(0) - 97]++;
if (word_count[ch.charCodeAt(0) - 97] > letters_count[ch.charCodeAt(0) - 97]) {
can_add_this_word = false;
break;
}
}
if (can_add_this_word) {
for (let i = 0; i < 26; i++) {
letters_count[i] -= word_count[i];
}
recursion(cur_ind + 1, cur_score + words_scores[word]);
for (let i = 0; i < 26; i++) {
letters_count[i] += word_count[i];
}
}
recursion(cur_ind + 1, cur_score);
}
recursion(0, 0);
return res;
};
``` | karleb | |
1,864,256 | Full Stack Deployment with Ansible | A few months ago I started practicing ansible and some Javascript with React and NodeJs. As a... | 0 | 2024-05-24T18:31:02 | https://dev.to/arielro85/deploy-mean-with-ansible-3h9a | webdev, ansible, javascript, development |
A few months ago I started practicing ansible and some Javascript with React and NodeJs.
As a playground im using some EC2 instances in AWS, and I did not want to re configure everything everytime that I test the site . For this I wrote an Ansible playbook that performs all the required actions to get the app online.
High level overview of what it does:
- Extracts the repository names from the frontend_git_repo and backend_git_repo variables.
- Updates the system packages and reboots the machine if updates were installed.
- Installs gnupg and curl, which are required for MongoDB.
- Sets up the NodeSource repository and installs Node.js.
- Checks if the MongoDB GPG key is already set up, and if not, it sets it up.
- Creates a list file for MongoDB and updates the package list.
- Installs MongoDB and starts the mongod service.
- Installs pm2 globally, which is a process manager for Node.js applications.
- Installs the Nginx web server and configures it.
- Copies the SSH key to the EC2 instance.
- Clones the frontend and backend repositories from GitHub.
- Creates a new folder in the backend directory.
- Deletes the copied SSH key from the EC2 instance.
- Builds the frontend application and moves it to the appropriate directory.
- Configures pm2 for the backend application and starts it.
- Restarts the Nginx service.
All the actions above described , are handled by Ansible and a UI called Ansible Semaphore.
Everything is in this repo where you can find the "Mean Stack playbook" and the Ansible Semaphore Docker comppose file to build the controller.
I really recommend to use Ansible or any tool you want to avoid spending lot of time installing and configuring test services.
For sure there is lot of room for improvements, but it saves a lot of time.
My humble collaboration:
https://github.com/imaerials/ansible-home-lab
| arielro85 |
1,864,268 | What was your win this week? | Got to all your meetings on time? Started a new project? Fixed a tricky bug? | 0 | 2024-05-24T19:19:03 | https://dev.to/devteam/what-was-your-win-this-week-3pa6 | discuss, weeklyretro | ---
title: What was your win this week?
published: true
description: Got to all your meetings on time? Started a new project? Fixed a tricky bug?
tags: discuss, weeklyretro
cover_image:
---
👋👋👋👋
Looking back on your week -- what was something you're proud of?
All wins count -- big or small 🎉
Examples of 'wins' include:
- Starting a new project
- Fixing a tricky bug
- Cleaning your house...or whatever else that may spark joy 😄
 | thepracticaldev |
1,864,267 | Eager Loading of Child Entities in EF Core | Understanding Eager Loading One of advantages of using EF Core is the ability to manage... | 0 | 2024-05-24T19:10:24 | https://antondevtips.com/blog/eager-loading-of-child-entities-in-ef-core# | csharp, dotnet, programming, softwaredevelopment | ---
canonical_url: https://antondevtips.com/blog/eager-loading-of-child-entities-in-ef-core#
---
### Understanding Eager Loading
One of advantages of using EF Core is the ability to manage related data through various loading strategies. **There are 3 types of loading the child entities in EF Core:**
- **Eager loading** : Preloading related entities as part of the initial query, ensuring all necessary entities are loaded together.
- **Explicit loading** : Manually loading related entities on-demand, providing control over when and what related entities are retrieved.
- **Lazy loading** : Automatically loading related entities as they are accessed, offering a deferred retrieval approach for related entities.
In today’s post were are going to have a look on Eager loading. **Eager loading** is a technique where related entities are loaded from the database as a part of the initial query.
Eager loading is essential for scenarios where you know you’ll need related data for every entity retrieved. It avoids the N+1 query problem, reducing the number of round trips to the database.
### Using an Include method for loading related entities
Let’s have a look on the following entities:
```csharp
public class Author
{
public required Guid Id { get; set; }
public required string Name { get; set; }
public required List<Book> Books { get; set; } = new();
}
public class Category
{
public required Guid Id { get; set; }
public required string Name { get; set; }
public required List<Book> Books { get; set; } = new();
}
public class Book
{
public required Guid Id { get; set; }
public required string Title { get; set; }
public required int Year { get; set; }
public required Author Author { get; set; }
public required Category Category { get; set; }
}
```
You can use the **Include** method in EF Core method to specify the related entities to be included in the query. In the following example, when books are queried, their respective authors are fetched in the same query:
```csharp
await using var dbContext = new BooksDbContext();
// Select books with authors
var books = await dbContext.Books
.Include(b => b.Author)
.ToListAsync();
```
You can include multiple related entities in a single query:
```csharp
await using var dbContext = new BooksDbContext();
// Select books with authors and categories
var books = await dbContext.Books
.Include(b => b.Author)
.Include(b => b.Category)
.ToListAsync();
```
In this example, when books are queried, their respective authors and categories are fetched in the same query.
**Include** method can also be used to load related entities by a collection navigation property:
```csharp
await using var dbContext = new BooksDbContext();
var authors = await dbContext.Authors
.Include(a => a.Books)
.ToListAsync();
```
In this example, when books are queried, their respective authors and categories are fetched in the same query.
### Multi-level Include
Multi-level eager loading allows to load entities together with their related entities, including relationships of included entities any level deep, in a single query. This can be particularly useful when you have complex data models with multiple levels of relationships.
You can use **ThenInclude** method to include related entities of the included ones. Let’s expand our Book and Author example:
```csharp
public class Author
{
public required Guid AddressId { get; set; }
public required Address Address { get; set; }
// Other properties...
}
public class Address
{
public required Guid Id { get; set; }
public required string City { get; set; }
public required string Street { get; set; }
// Other properties...
}
await using var dbContext = new BooksDbContext();
// Select books with authors and their addresses
var books = await dbContext.Books
.Include(b => b.Category)
.Include(b => b.Author)
.ThenInclude(a => a.Address)
.ToListAsync();
```
In this example we are loading Book entities and their related Authors, after that we’re loading Authors’ Addresses. A query may contain multiple Includes with ThenIncludes, the are no limitations on how deep we can use the these methods.
### Auto Include
EF Core 5.0 introduced a feature called **AutoInclude** which automatically includes certain navigation properties every time the entity is loaded from the database. You can use **AutoInclude** method in the entity configuration to specify what navigation properties should be loaded with a given entity in every database query. This feature is especially useful for navigation properties that are frequently loaded with the primary entity, simplifying queries and reducing the risk of forgetting to include the related data. Let’s have a look on the example how to include Author everytime a book is queried from the database:
```csharp
// Put this code in the DbContext or EntityConfiguration class
// where you do the mapping
modelBuilder.Entity<Book>()
.Navigation(e => e.Author)
.AutoInclude();
await using var dbContext = new BooksDbContext();
// Authors are automatically included here
var books = await dbContext.Books
.ToListAsync();
```
If in some case you don’t need to load the AutoIncluded entities, you can use the **IgnoreAutoIncludes** method to remove the effect of AutoInclude:
```csharp
// Put this code in the DbContext or EntityConfiguration class
// where you do the mapping
modelBuilder.Entity<Book>()
.Navigation(e => e.Author)
.AutoInclude();
await using var dbContext = new BooksDbContext();
// Select books without auto included authors
var books = await dbContext.Books
.IgnoreAutoIncludes()
.ToListAsync();
```
### Include with filtering
In EF Core you can apply filtering on the included entities. This feature allows to load only those related entities that meet a given condition.
```csharp
await using var dbContext = new BooksDbContext();
var authors = await dbContext.Authors
.Include(a => a.Books.Where(b => b.Year >= 2023))
.ToListAsync();
```
In this example, the Include method is used with a filtering condition inside a Where clause. This ensures that only books published in the year 2023 and later are included for each author.
EF Core supports the following operations in the Include statement: Where, Skip, Take, OrderBy, OrderByDescending, ThenBy, ThenByDescending
**EF Core has a limitation:** each included navigation property can only have one unique set of filtering operations.
### Summary
EF Core provides a robust mechanism for handling data relationships through various loading strategies, with **eager loading** being used most widely. Eager loading allows for the pre-loading of related entities as part of the initial query, ensuring that all necessary data is retrieved in a single round trip to the database. This method is essential for optimizing performance and simplifying data access patterns in applications. In EF Core, eager loading is implemented using the **Include** method, which specifies the navigation properties to be loaded along with the primary entity. This can be further extended with **ThenInclude** for multi-level relationships, allowing for deep navigation through related entities.
If some navigations are frequently loaded with the primary entity, simplify the queries using **AutoInclude** feature. It automatically includes certain navigation properties every time the entity is loaded from the database. EF Core also supports such powerful feature as **Include with filtering** even for a more control of the related data being loaded.
Hope you find this blog post useful. Happy coding!
_Originally published at_ [_https://antondevtips.com_](https://antondevtips.com/blog/eager-loading-of-child-entities-in-ef-core)_._
### After reading the post consider the following:
- [Subscribe](https://antondevtips.com/blog/eager-loading-of-child-entities-in-ef-core#subscribe) **to receive newsletters with the latest blog posts**
- [Download](https://github.com/AntonMartyniuk-DevTips/dev-tips-code/tree/main/backend/EfCore/EagerLoading) **the source code for this post from my** [github](https://github.com/AntonMartyniuk-DevTips/dev-tips-code/tree/main/backend/EfCore/EagerLoading) (available for my sponsors on BuyMeACoffee and Patreon)
If you like my content — **consider supporting me**
Unlock exclusive access to the source code from the blog posts by joining my **Patreon** and **Buy Me A Coffee** communities!
[](https://www.buymeacoffee.com/antonmartyniuk)
[](https://www.patreon.com/bePatron?u=73769486) | antonmartyniuk |
1,857,026 | Cutting Back on Sugar (Bite-size Article) | Introduction Recently, I've become interested in cutting back on sugar. This is because I... | 0 | 2024-05-24T19:05:21 | https://dev.to/koshirok096/cutting-back-on-sugar-bite-size-article-1go2 | #Introduction
Recently, I've become interested in **cutting back on sugar**. This is because I read an article about the negative effects of excessive sugar consumption on the body and mind. I have also noticed that I myself have recently been frequently consuming coffee, soft drinks like cola, and chocolate bars that are loaded with sugar.
In my case, I often eat or drink these sugary items to refresh myself during work or tasks. However, if excessive sugar intake leads to health issues, I feel it's necessary to replace these with healthier alternatives or take some measures to reduce my sugar consumption.
In this article, I will briefly summarize the impact of sugar consumption on physical and mental health based on my research.

#The Effects of Sugar Consumption on the Human Body
**Sugar** is a type of carbohydrate that provides the body with immediate energy, making it effective when you need to quickly replenish energy. For example, after exercise or when feeling fatigued, consuming foods or drinks that contain sugar can quickly restore your energy. Additionally, when you consume sugar, "**happiness hormones**" like **serotonin** and **dopamine** are released in the brain, temporarily improving mood and reducing stress. This is why eating sweet foods can make you feel relaxed and uplifted.
Personally, I find myself consuming sweet foods and drinks like coffee with sugar or snacks when my work isn't going well, or when I need a break or feel tired. I believe that <u>humans instinctively turn to sugar consumption to improve their mood</u>.
These are the positive aspects of consuming sugar, but there are also negative aspects to consider.
When you consume sugar, your blood sugar levels can spike rapidly and then drop sharply. This fluctuation in blood sugar levels is known as a "**sugar rush**" followed by a "**sugar crash**". After a high blood sugar level, a subsequent drop can cause energy levels to become unstable, leading to irritability and anxiety.
Moreover, the phenomenon of feeling better after eating sweet foods is due to the release of "happiness hormones" like serotonin and dopamine. If this release of dopamine happens too frequently, the brain develops a <u>tolerance to sugar</u>, requiring more sugar to achieve the same pleasure. This can lead to a stronger dependency on sugar, creating a vicious cycle.
Excessive sugar consumption can also lead to various health risks, including <u>weight gain</u>, an increased risk of <u>cavities</u>, <u>skin problems</u>, <u>heart disease</u>, <u>diabetes</u>, and other lifestyle-related diseases.
#Solutions
Moderate sugar intake can help supply energy and improve mood, but excessive consumption can lead to health risks and dependency. By incorporating healthy alternatives, you can maintain balance without relying on sugar.
##Replace with Foods that Use Natural Sweeteners
Honey, maple syrup, and agave syrup can be used as substitutes for sugar. These **alternatives** have a **lower GI** index than sugar, helping to prevent rapid fluctuations in blood sugar levels.
##Consume Fruits
**Fruits** contain natural sugars and are rich in vitamins and minerals. Instead of eating sweets made with refined sugar, you can enjoy the sweetness in a healthy way by eating fruits as snacks.
##Replace with Similar Foods that Don't Use Sugar
If you like cola, for example, you can replace it with sparkling water, which can provide similar satisfaction. Personally, I sometimes crave cola on hot days, but I find that sparkling water gives me the same level of satisfaction without the calories. For those who love chocolate, consider switching to dark chocolate. Dark chocolate has less sugar and is rich in antioxidants. Choosing dark chocolate when you crave something sweet can be a healthier way to enjoy a treat.
These are just a few ideas, but I think they are easy to implement.

#Conclusion
In my case, I’ve noticed that over the past few months, I’ve been frequently consuming sugar-laden iced coffee, energy drinks, gummies, and chocolate from fast-food places. This wasn’t as common for me last year, so stress might be a contributing factor.
While I’m not currently experiencing significant health issues, I don’t see the need to consume excessive amounts of sugar, so I’ve been trying to cut back recently. Instead of imposing strict rules, I believe that consciously reducing my intake to a certain extent is sufficient.
If you find yourself in a similar situation, it might be beneficial to try reducing your sugar intake at your own pace, for example, by having one or two sugar-free days each week.
Thank you for taking the time to read this article today. I hope you stay a healthy lifestyle.
| koshirok096 | |
1,864,264 | Simulating Life with TensorflowJS | In my previous post about Conway's Game of Life in TensorFlow, I implemented Conway's Game of Life... | 26,708 | 2024-05-24T18:58:00 | https://www.joshgracie.com/blog/mnca/ | javascript, tensorflow, cellularautomata, simulation | In my previous post about [Conway's Game of Life in TensorFlow](/blog/conwaytensor), I implemented Conway's Game of Life using TensorFlowJS. In that implementation, I used a 2D tensor to represent the state of each cell and updated the state of each cell based on the state of its neighbors. Using that tensor, I was able to update the state of each cell in parallel, which was much faster than using a 2D array and updating an HTML table.
While that implementation certainly worked, it was limited to the standard Moore neighborhood, where each cell has 8 neighbors. In this post, I will be implementing a multi neighborhood cellular automata using TensorFlowJS. This will allow me to define custom neighborhoods for each cell, which can lead to much more interesting and complex patterns.
I'm going to spare myself from rewriting the basics of cellular automata and jump straight into the implementation. If you're not familiar with cellular automata, I recommend reading my previous post on [Conway's Game of Life](/blog/conwaytensor) first.
## Defining the Neighborhoods
Just like in Conway's Game of Life, we need to represent the neighborhood's of MNCA as a 3D tensor. However, instead of using a fixed kernel for convolution, we will define custom neighborhoods for each cell. The first dimension represents the number of neighbors, and the second and third dimensions represent the relative positions of each neighbor.
```javascript
// Create an array of 0s with a single 1 in the middle
let nhArray = Array.from({length: 17}, () => Array.from({length: 17}, () => 0));
nhArray[8][8] = 1;
// Convert the array to a tensor
this.nhTensor = tf.tensor(nhArray).expandDims(2).expandDims(3);
```
The above code creates a 17x17 array with a single 1 in the middle. We then convert the array to a tensor and expand the dimensions to match the shape of the population tensor. This gives us a custom neighborhood tensor that we can use to calculate the number of live neighbors for each cell.
Since we have unique neighborhoods, we can define custom rules for each of the 17x17 neighborhoods. This allows us to create much more complex patterns than the standard Moore neighborhood.
## The Rules
Each rule is a simple _neighborAvg_>=_lower bound_ && _neighborAvg_<=_upper bound_ statement. The _neighborAvg_ is the number of live neighbors for the current cell, and the _lower bound_ and _upper bound_ are the minimum and maximum number of live neighbors for the cell to survive.
Each rule can also have an _alive_ flag, which determines if the cell should be alive or dead based on the rule. This allows us to define rules for both survival and birth. We can also define the order of the rules, which determines the order in which the rules should be applied, with lower order rules taking precedence over higher order rules.
With this information, can define a class to represent the rules so that we can easily add new rules and test different configurations.
```javascript
class NhRule{
upper;
lower;
alive;
id = uuid();
order = 0;
constructor(lower, upper, alive, order = 0){
this.upper = upper;
this.lower = lower;
this.alive = alive;
this.order = order;
}
}
```
Now that we have a way to define the rules and the neighborhood tensors, we can now create a class to hold both the rules and the neighborhoods.
```javascript
class Neighborhood{
nhRules;
nhTensor;
id = uuid();
constructor(){
// NhRules should start with a single rule
this.nhRules = [new NhRule(0.5, 0.5, true, neighborhoodsOrderArray().length)];
// Create an array of 0s with a single 1 in the middle
let nhArray = Array.from({length: 17}, () => Array.from({length: 17}, () => 0));
nhArray[8][8] = 1;
// Convert the array to a tensor
this.nhTensor = tf.tensor(nhArray).expandDims(2).expandDims(3);
}
}
```
The above code creates a class that holds the neighborhood tensor and the rules for the neighborhood. The constructor initializes the neighborhood tensor and creates a single rule for the neighborhood.
## The Simulation
Now that we have the neighborhoods and the rules, we can begin to work on the simulation. We can start by grabbing a copy of the population tensor, and the _wasAlive_ tensor, which will be used to determine if a cell was alive in the previous generation.
```javascript
let newPop = tf.tidy(() =>{
// Create a copy of the population tensor
let newPopulation = population.clone().toFloat();
let wasAlive = tf.equal(newPopulation, 1);
...
});
```
> **Note:** I'm using the `tf.tidy` function to clean up any intermediate tensors that are created during the simulation. This helps prevent memory leaks and keeps the code clean.
Next, we can start iterating over the neighborhoods and applying the rules to the population tensor.
```javascript
...
// Perform the convolutions using the neighborhoods
let calculatedRules = [neighborhoodsOrderArray().length];
for(let nh of neighborhoods){
let convolvedPopulation = tf.conv2d(newPopulation, nh.nhTensor, 1, 'same');
let neighbors = tf.sub(convolvedPopulation, newPopulation);
// Average the neighbors by dividing by the number of cells in the neighborhood (i.e. the number of 1s in the neighborhood tensor -1 for the center cell)
let nhSum = tf.sum(nh.nhTensor);
let neighborsAvg = tf.div(neighbors, nhSum);
...
}
...
```
In the above code, we first create an array to store our calculated rules (defined later) so that we can apply them in order. We need to do this since the order of the rules can affect the outcome of the simulation. Because the rules are defined in the neighborhoods, we need to store the final rules in an array so that we can apply them in order with esae later on.
Next, we iterate through the rules of the neighborhood and apply the rules to the cells.
```javascript
// Apply rules of the neighborhood
for(let nhRule of nh.nhRules){
let upperRule = tf.lessEqual(neighborsAvg, nhRule.upper);
let lowerRule = tf.greaterEqual(neighborsAvg, nhRule.lower);
let rulePop = tf.logicalAnd(upperRule, lowerRule);
if(!nhRule.alive)
{
// Invert the rule population
let invertRulePop = tf.logicalNot(rulePop);
rulePop = invertRulePop;
// We need to do this so that when we go to AND the rulePop, we make sure that the cells that were alive are the only ones affected
}
// Now add the rulePop to the calculatedRules array
calculatedRules[nhRule.order] = {pop: rulePop, alive: nhRule.alive};
}
```
In the above code, we first generate the upper and lower rules for the neighborhood rule. We then apply the rules to the neighbors average tensor to get the rule population. If the rule is for the cell to be alive, we insert it directly into the calculated rules array. If the rule is for the cell to be dead, we invert the rule population before inserting it into the calculated rules array.
The reason we invert the rule population for dead cells is that we want to make sure that only the cells that were alive are affected by the rule. We can do that by making every cell that is not affected by the rule alive, and then ANDing the rule population with the population tensor. This, in effect, makes sure that only the cells that were alive and should now be dead are affected by the rule.
Finally, we can apply the calculated rules to the population tensor.
```javascript
// Now we need to combine the rules in order
// Final pop starts as whatever the previous was alive tensor was
let finalPop = wasAlive;
for(let rule of calculatedRules){
if(rule === undefined)
continue;
if(rule.alive){
let finalPopOr = tf.logicalOr(finalPop, rule.pop);
finalPop = finalPopOr;
}
else{
let finalPopAnd = tf.logicalAnd(finalPop, rule.pop);
finalPop = finalPopAnd;
}
}
// Update the population tensor
newPopulation = finalPop.toFloat();
```
We first set the final population tensor to the _wasAlive_ tensor, which is a boolean of the previous state of each cell. We then use logical operators, OR for alive cells and AND for dead cells, to combine the rules in order.
Finally, we update the population tensor with the final population tensor and return the new population tensor.
## The Demo
I've created an interactive demo of the MNCA using TensorFlowJS. You can find the demo [here](joshgracie.com/demos/mnca). The demo allows you to create custom neighborhoods and rules, and see how they affect the simulation. You can also choose from a list of pre-defined neighborhoods and rules to see how they affect the simulation.
You also have the ability to change the speed and zoom of the simulation, but be warned that the simulation can be quite slow on older devices. There is also a function to allow you to click-drag new cells into the simulation, which can be quite fun to play with.
## Conclusion
In this post, I implemented a multi neighborhood cellular automata using TensorFlowJS. I defined custom neighborhoods for each cell and created rules for each neighborhood. I then applied the rules to the population tensor to simulate the automata.
The MNCA is much more flexible than the standard Conway's Game of Life, as it allows for custom neighborhoods and rules. This can lead to much more complex and interesting patterns than the standard Moore neighborhood.
I hope you enjoyed this post and found it informative. If you have any questions or comments, please feel free to leave them below. Thanks for reading!
## References
- [TensorFlowJS](https://www.tensorflow.org/js): TensorFlowJS documentation
- [Conway's Game of Life](https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life): Wikipedia page on Conway's Game of Life
- [MNCA Demo](joshgracie.com/demos/mnca): An interactive demo of the MNCA
- [Slackermanz](https://www.slackermanz.com/): For the inspiration for this post | jgracie52 |
1,864,253 | How to Build a Windows 11 Dashboard with .NET WinUI Charts | Learn how to build a Windows 11 dashboard with .NET WinUI charts. See more from ComponentOne today. | 0 | 2024-05-24T18:28:51 | https://developer.mescius.com/blogs/how-to-build-a-windows-11-dashboard-with-net-winui-charts | webdev, devops, dotnet, tutorial | ---
canonical_url: https://developer.mescius.com/blogs/how-to-build-a-windows-11-dashboard-with-net-winui-charts
description: Learn how to build a Windows 11 dashboard with .NET WinUI charts. See more from ComponentOne today.
---
**What You Will Need**
- ComponentOne WinUI & MAUI Edition
- Visual Studio 2022
**Controls Referenced**
- [FlexChart for WinUI](https://developer.mescius.com/componentone/docs/winui/online-winui/flexchart-overview.html)
**Tutorial Concept**
Learn how to build a data-bound dashboard for Windows 11 desktop using WinUI 3.0 and ComponentOne FlexChart.
---
In today's data-driven world, having a clear and accessible way to analyze data is essential for making informed decisions. To address this need, dashboards are preferable solutions as they are designed for both technical and non-technical audiences. Dashboards make complex data easy to understand by delivering valuable insights through charts and graphs.
In this blog, we will develop a Windows dashboard app for a hospital system that shows patient information. We are using the chart and datagrid controls from our [ComponentOne WinUI control](https://developer.mescius.com/componentone/winui-controls "https://developer.mescius.com/componentone/winui-controls") suite to showcase different aspects of patient data. The final dashboard will look like this:

Let’s break down the process of developing the dashboard into the following steps:
* [Setup a WinUI Project and Add Required Dependencies](#Setup)
* [Create the Dashboard Blueprint](#Create)
* [Databind the Dashboard](#Databind)
* [Sync the Modified Data with Charts](#Sync)
* [View and Modify Data of a Particular Patient](#View)
## <a id="Setup"></a>Setup a WinUI Project and Add Required Dependencies
We’re building this dashboard using WinUI 3, which is used to create modern, Universal Windows applications, otherwise known as Microsoft Store apps. It uses XAML UI components, which are similar to WPF.
Let’s start by creating a WinUI project in Visual Studio 2022 and following the steps below:
1\. Open Visual Studio, and select **File->New->Project.**
2\. Search “WinUI template” in the search box and select “**Blank App, packaged (WinUI 3 in Desktop)**”.

<span>3\.</span> Enter the Project Name and click the “Create” button.
4\. Now that we have successfully set up our project, it is time to add all the required dependencies. We are adding FlexGrid and FlexChart dependencies to show the grid and charts in our dashboard. Follow the below steps to install NuGet Packages:
<strongr>a. In the </strongr>**Solution Explorer, right-click on the project and select "Manage NuGet packages."**

b. Search “C1.WinUI.Grid” in the search bar and install the latest version of the C1.WinUI.Grid NuGet package.

Similarly, you can install the “C1.WinUI.Chart” NuGet package to use C1 WinUI Charts in your project.
Now, we have set up a WinUI project and added the required Dependencies.
## <a id="Create"></a>Create the Dashboard Blueprint
In this step, we are creating a dashboard UI with a FlexGrid that showcases all the patients' records in an organized table, as well as three different types of FlexChart controls that show the following metrics:
* **Line Chart:** Shows patient appointments over the years
* **Pie Chart:** Shows the distribution of medical conditions of patients
* **Column Chart:** Shows insurance providers registered by patients
Let’s follow the below steps to create a dashboard UI:
1\. Add XMLNS attributes in the Window tag of MainWindow.xaml file:
```
xmlns:c1grid="using:C1.WinUI.Grid"
xmlns:c1chart="using:C1.WinUI.Chart"
```
2\. Add C1FlexGrid and C1FlexChart controls in Xaml by replacing the <StackPanel> block with the following Xaml code:
```
<Grid Background="Black">
<Grid.ColumnDefinitions>
<ColumnDefinition Width="3*"/>
<ColumnDefinition Width="1.5*"/>
</Grid.ColumnDefinitions>
<Grid.RowDefinitions>
<RowDefinition Height="60"/>
<RowDefinition Height="4*"/>
<RowDefinition Height="3*"/>
</Grid.RowDefinitions>
<TextBlock Text="Hospital Records" FontSize="25" Foreground="White" FontWeight="Bold" VerticalAlignment="Center" Margin="10,0,0,0"/>
<TextBlock x:Name="patientTxt" FontSize="18" Foreground="White" FontWeight="Bold" VerticalAlignment="Center" Margin="10,0,0,0" Grid.Column="1"/>
<!--Hospital Grid Data-->
<c1grid:FlexGrid x:Name="patientRecordsGrid" Margin="0,0,5,5" Background="#4d4d4d" Foreground="White"
Grid.Row="1" HeadersVisibility="All" SelectionMode="RowRange" VerticalScrollBarVisibility="Visible"
HorizontalScrollBarVisibility="Visible" BorderBrush="White" BorderThickness="2" ColumnHeaderFontWeight="Bold" ColumnHeaderFontSize="18"/>
<!--Patient's Admission Chart View over the years-->
<c1chart:FlexChart x:Name="AdmissionChart" ChartType="LineSymbols" Foreground="White" BorderBrush="White" BorderThickness="2" Grid.Row="2" Margin="0,5,5,0" PlotMargin="80,40,120,60"></c1chart:FlexChart>
<!--Medical Conditions Pie Chart-->
<c1chart:FlexPie x:Name="MedicalConditionPieChart" Foreground="White" Footer="Medical Conditions" BorderBrush="White" BorderThickness="2" Grid.Row="1" Grid.Column="1" Margin="5,0,0,5"></c1chart:FlexPie>
<!--Chart view for Insurance Providers registered by Patient-->
<c1chart:FlexChart x:Name="InsuranceProviderChart" ChartType="Column" Foreground="White" BorderBrush="White" BorderThickness="2" Grid.Row="2" Grid.Column="1" Margin="5,5,0,0"></c1chart:FlexChart>
```
## <a id="Databind"></a>Databind the Dashboard
In the previous step, we created a blueprint for the dashboard. To see the actual functional application, let’s bind the data by following the steps below:
**1\. Add Binding Properties**
Firstly, create a ViewModel where we can add binding properties. The ViewModel acts as the data source for the UI where we can control the view.
You will also need to create the following required classes with their respective properties: Appointment.cs, GenderData.cs, MedicalCondition.cs, and InsuranceProvider.cs.
Refer to the sample attached at the end of the blog for these classes.
Follow the steps below to add and initialize the binding properties:
a. Add a class named **HospitalViewModel.cs** by right-clicking on **Project->Add->Class**.

b. Add required **ObservableCollection** properties in HospitalViewModel.cs class so we can link these with the Charts and Grid. Here, we add the following properties to fetch the patients' specific records.
```
//Collection of Patient records for FlexGrid
public ObservableCollection<Appointment> HospitalData;
//Collection of Patient's Admission Gender-wise for Line Chart
public ObservableCollection<GenderData> GenderWiseAdmissionData;
//Collection of Medical Conditions Distribution for Pie Chart
public ObservableCollection<MedicalCondition> MedicalConditionData;
//Collection of Insurance Provider Distribution for Column Chart
public ObservableCollection<InsuranceProvider> InsuranceProviderData;
```
c. Create a constructor for the **HospitalViewModel** class to initialize binding properties by deserializing the JSON. The JSON consists of “Patient’s records.”
```
public HospitalViewModel()
{
//Load data from HospitalDataset.json to HospitalData collection
var json = File.ReadAllText(Windows.ApplicationModel.Package.Current.InstalledPath + "/HospitalDataset.json");
HospitalData = JsonConvert.DeserializeObject<ObservableCollection<Appointment>>(json);
//Initialize collections for Charts
GenderWiseAdmissionData = new ObservableCollection<GenderData>();
MedicalConditionData = new ObservableCollection<MedicalCondition>();
InsuranceProviderData = new ObservableCollection<InsuranceProvider>();
}
```
**Note:** The HospitalDataSet.json file is included in the sample attached at the end of this blog.
**2\. Bind Properties in UI**
Now, all the required properties are created in the HospitalViewModel.cs class, and it's time to bind these properties to the UI to reflect the data under the ViewModel’s collection properties.
Follow the steps below to bind all required ViewModel properties to the UI in the MainWindow.Xaml file:
a. Initialize the **HospitalViewModel** instance under the MainWindow class in the **MainWindow.Xaml.cs** file so we can bind any accessible properties of HospitalViewModel to the MainWindow.Xaml.
```
public HospitalViewModel vm { get; } = new();
```
b. Bind the **HospitalData** property to the ItemsSource of the FlexGrid in the MainWindow.xaml file so that the FlexGrid reflects all the records of the **HospitalData** collection. Update the FlexGrid code in MainWindow.xaml as below:
```
<c1grid:FlexGrid x:Name="patientRecordsGrid" ItemsSource="{x:Bind vm.HospitalData}"
Margin="0,0,5,5" Background="#4d4d4d" Foreground="White" Grid.Row="1"
HeadersVisibility="All" SelectionMode="RowRange" VerticalScrollBarVisibility="Visible"
HorizontalScrollBarVisibility="Visible" BorderBrush="White" BorderThickness="2"
ColumnHeaderFontWeight="Bold" ColumnHeaderFontSize="18"/>
```
c. Bind the **GenderWiseAdmissionData** property to the ItemsSource of the AdmissionChart (Line Chart). Then, add 'Series' under the chart for genders and set BindingX="Year" to visualize the Gender-wise data over the years. You can also style the axis of FlexChart accordingly.
Update the AdmissionChart code in MainWindow.xaml file as below:
```
<c1chart:FlexChart x:Name="AdmissionChart" ItemsSource="{x:Bind vm.GenderWiseAdmissionData}" BindingX="Year" ChartType="LineSymbols" Foreground="White" BorderBrush="White" BorderThickness="2" Grid.Row="2" Margin="0,5,5,0">
<!--Add Series-->
<c1chart:FlexChart.Series>
<c1chart:Series Binding="Male" SeriesName="Male">
<c1chart:Series.DataLabel>
<c1chart:DataLabel Content=" Male({Year}) : {Male:0}" Position="Bottom" Offset="20" />
</c1chart:Series.DataLabel>
</c1chart:Series>
<c1chart:Series Binding="Female" SeriesName="Female">
<c1chart:Series.DataLabel>
<c1chart:DataLabel Content=" Female({Year}) : {Female:0}" Position="Top" Offset="10" />
</c1chart:Series.DataLabel>
</c1chart:Series>
</c1chart:FlexChart.Series>
<!--Style Axis-->
<c1chart:FlexChart.AxisY>
<c1chart:Axis Title="No. of Appointments">
<c1chart:Axis.TitleStyle>
<c1chart:ChartStyle Stroke="White" FontSize="15" FontWeight="Bold"/>
</c1chart:Axis.TitleStyle>
</c1chart:Axis>
</c1chart:FlexChart.AxisY>
<c1chart:FlexChart.AxisX>
<c1chart:Axis Title="Years">
<c1chart:Axis.TitleStyle>
<c1chart:ChartStyle Stroke="White" FontSize="15" FontWeight="Bold"/>
</c1chart:Axis.TitleStyle>
</c1chart:Axis>
</c1chart:FlexChart.AxisX>
</c1chart:FlexChart>
```
In the same way, you can add 'Series' and bind with respective properties for the other two charts. Refer to the Xaml file for other charts in the attached sample at the end of the blog.
Now, we have bound all HospitalViewModel’s properties in the UI, which looks like this:

## <a id="Sync"></a>Sync the Modified Data with Charts
At this point, we can see records in the FlexGrid, and all required properties are bound to the UI. However, not all the charts visualize the data, and they are not synced with FlexGrid’s ItemsSource (Hospitaldata). Let’s sync the data with Charts.
1. Create an **UpdateChartData**() method in HospitalViewModel.cs class and update every collection for chart data as per their use case.
```
public void UpdateChartData()
{
//Clear all existing chart's records
GenderWiseAdmissionData.Clear();
MedicalConditionData.Clear();
InsuranceProviderData.Clear();
//Update GenderWiseAdmissionData Collection
var yearWiseData = HospitalData.DistinctBy(x => x.Year).OrderBy(x => x.Year);
foreach (var data in yearWiseData)
{
var male = HospitalData.Where(x => x.Year == data.Year).Count(x => x.Gender == "Male");
var female = HospitalData.Where(x => x.Year == data.Year).Count(x => x.Gender == "Female");
GenderWiseAdmissionData.Add(new GenderData() { Year = data.Year, Male = male, Female = female });
}
//Update MedicalConditionData Collection
var medicalCondition = HospitalData.DistinctBy(x => x.MedicalCondition).OrderBy(x => x.MedicalCondition);
foreach (var data in medicalCondition)
{
var admissionCount = HospitalData.Where(x => x.MedicalCondition == data.MedicalCondition).Count();
MedicalConditionData.Add(new MedicalCondition() { Name = data.MedicalCondition, AdmissionCount = admissionCount });
}
//Update InsuranceProviderData Collection
var insuranceProviders = HospitalData.DistinctBy(x => x.InsuranceProvider).OrderBy(x => x.InsuranceProvider);
foreach (var data in insuranceProviders)
{
var admissionCount = HospitalData.Where(x => x.InsuranceProvider == data.InsuranceProvider).Count();
InsuranceProviderData.Add(new InsuranceProvider() { Name = data.InsuranceProvider, Customers = admissionCount });
}
}
```
2\. Call the **UpdateChartData**() method in HospitalViewModel’s constructor to initialize the chart with the data once the instance of HospitalViewModel is created.
```
public HospitalViewModel()
{
……
//Update Data on first Load
UpdateChartData();
……
}
```
3\. Handle the **CollectionChanged** event of the **HospitalData** collection and update the chart’s data once the **CollectionChanged** event fires. This will update the chart’s data when we modify FlexGrid records.
```
HospitalData.CollectionChanged += (s, e) =>
{
//Update data once Hospital Data updates
UpdateChartData();
};
```
Now, the chart’s data will be shown with the grid data as below:

## <a id="View"></a>View and Modify Data of a Particular Patient
Now, the dashboard is almost complete. We can visualize data on FlexGrid and FlexCharts. It’s time to make it more interactive.
Currently, all chart visualization is happening based on the data of all patients. What if we can visualize a particular patient’s information on different parameters? This will help us to analyze a particular patient's data more accurately.
For this, we need to add a little more code by following the steps below:
1\. Create a **VisualizePatientRecords(string patientId)** method in HospitalViewModel.cs class and update every chart’s collection as per their PatientId.
```
public void VisualizePatientRecords(string patientId)
{
//Clear all existing chart's records
GenderWiseAdmissionData.Clear();
MedicalConditionData.Clear();
InsuranceProviderData.Clear();
//Patient's GenderWiseAdmissionData Collection
var yearWiseData = HospitalData.DistinctBy(x => x.Year).OrderBy(x => x.Year);
foreach (var data in yearWiseData)
{
int? male = HospitalData.First(x => x.PatientId == patientId).Gender == "Male" ? HospitalData.Where(x => x.Year == data.Year && x.PatientId == patientId).Count(x => x.Gender == "Male") : null;
int? female = HospitalData.First(x => x.PatientId == patientId).Gender == "Female" ? HospitalData.Where(x => x.Year == data.Year && x.PatientId == patientId).Count(x => x.Gender == "Female") : null;
GenderWiseAdmissionData.Add(new GenderData() { Year = data.Year, Male = male, Female = female });
}
//Patient's MedicalConditionData Collection
var medicalCondition = HospitalData.DistinctBy(x => x.MedicalCondition).OrderBy(x => x.MedicalCondition);
foreach (var data in medicalCondition)
{
var admissionCount = HospitalData.Where(x => x.MedicalCondition == data.MedicalCondition && x.PatientId == patientId).Count();
if (admissionCount > 0)
MedicalConditionData.Add(new MedicalCondition() { Name = data.MedicalCondition, AdmissionCount = admissionCount });
}
//Patient's InsuranceProviderData Collection
var insuranceProviders = HospitalData.DistinctBy(x => x.InsuranceProvider).OrderBy(x => x.InsuranceProvider);
foreach (var data in insuranceProviders)
{
var claimsCount = HospitalData.Where(x => x.InsuranceProvider == data.InsuranceProvider && x.PatientId == patientId).Count();
if (claimsCount > 0)
InsuranceProviderData.Add(new InsuranceProvider() { Name = data.InsuranceProvider, Customers = claimsCount });
}
}
```
2\. Handle the **SelectionChanged** event of FlexGrid to call the **VisualizePatientRecords()** method. It will display data of the specific patient in the charts when any row is selected in the grid.
```
patientRecordsGrid.SelectionChanged += (s, e) =>
{
if (patientRecordsGrid.Selection != null)
{
//Show a particular patient record
if (patientRecordsGrid.Selection.RowsCount == 1)
{
var patient = patientRecordsGrid.SelectedItems[0] as Appointment;
vm.VisualizePatientRecords(patient.PatientId);
patientTxt.Text = patient.Name + "(" + patient.PatientId + ")";
}
//Show all records
else
{
if (isSelectAll == false)
{
patientRecordsGrid.Select(e.CellRange.Row, patientRecordsGrid.ViewRange.Column);
}
isSelectAll = true;
vm.UpdateChartData();
patientTxt.Text = string.Empty;
}
}
//Show all records
else
{
vm.UpdateChartData();
patientTxt.Text = string.Empty;
}
};
```
3\. Handle the **CellEditEnded** event of FlexGrid and call the **VisualizePatientRecords()** method to update the specific patient's data. This updates the chart immediately when we edit any record in the grid.
```
patientRecordsGrid.CellEditEnded += (s, e) =>{
var patient = patientRecordsGrid.SelectedItems[0] as Appointment;
vm.VisualizePatientRecords(patient.PatientId);
patientTxt.Text = patient.Name + "(" + patient.PatientId + ")";
};
```
This is how our dashboard works to showcase particular patients' records:

## Conclusion
We hope this blog helps you create an interactive WinUI dashboard using C1 controls. [Download the full sample](https://cdn.mescius.io/umb/media/knnmhhtm/dashboardapp.zip) to customize it further, fit your requirements, and showcase different metrics in your WinUI dashboard.
To learn more about these advanced WinUI controls, check out the documentation and sample demos in the links below:
* [WinUI Documentation](https://developer.mescius.com/componentone/docs/winui/online-winui/overview.html "https://developer.mescius.com/componentone/docs/winui/online-winui/overview.html")
* [WinUI Samples](https://github.com/GrapeCity/ComponentOne-WinUI-Samples "https://github.com/GrapeCity/ComponentOne-WinUI-Samples") | chelseadevereaux |
1,864,228 | [S.O.L.I.D.] Os Cinco Pilares da Programação Orientada a Objetos. [S] - Single Responsibility Principle - SRP | Olá devs, venho trazer uma série de 5 artigos abordando com teoria e exemplos de código em java, cada... | 0 | 2024-05-24T18:57:59 | https://dev.to/diegobrandao/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-para-desenvolvedores-2lph | java, solidprinciples | Olá devs, venho trazer uma série de 5 artigos abordando com teoria e exemplos de código em java, cada letra que simboliza os princípios da palavra SOLID, caso você não saiba, SOLID é um acrônimo para cinco princípios fundamentais do design orientado a objetos (POO), estabelecidos por Robert C. Martin ("Uncle Bob"). Esses princípios visam aprimorar a qualidade, a manutenibilidade e a extensibilidade do código, tornando-o mais robusto e resiliente às mudanças.
Neste artigo comecarei falando sobre o **primeiro princípio** que é:
**[S] - Single Responsibility Principle**,
**Princípio da Responsabilidade Única - SRP**
“Nunca deve haver mais de um motivo para uma classe mudar.”
Afirma que cada módulo de software (classe, método, etc.) deve ter apenas uma única responsabilidade. Em outras palavras, cada módulo deve ser responsável por uma única função bem definida e não deve se preocupar com nenhuma outra função.
Vantagens do SRP:
1. Maior modularidade: O SRP leva a um código mais modular, o que facilita o entendimento, a manutenção e a reutilização. Módulos menores e mais focados são mais fáceis de compreender e modificar, sem afetar outras partes do código.
2. Maior coesão: O SRP promove maior coesão dentro dos módulos, garantindo que cada módulo se concentre em uma única tarefa e que todo o código dentro do módulo esteja relacionado a essa tarefa. Isso resulta em um código mais organizado e menos propenso a erros.
3. Maior flexibilidade: O SRP torna o código mais flexível e adaptável a mudanças. Se a necessidade de modificar o código surgir, é mais provável que apenas um módulo precise ser alterado, minimizando o impacto em outras partes do sistema.
4. Maior testabilidade: O SRP facilita a testabilidade do código, pois cada módulo pode ser testado de forma independente, isolando-o de outras dependências. Isso garante que cada módulo funcione conforme o esperado e facilita a identificação de erros.
5. Maior reutilização: O SRP promove maior reutilização de código, pois módulos com única responsabilidade são mais fáceis de serem entendidos e integrados em outros projetos.
Dividir uma classe grande em classes menores: Se uma classe possui várias responsabilidades distintas, ela pode ser dividida em classes menores, cada uma com uma única responsabilidade.
Criar interfaces para abstrair responsabilidades: Interfaces podem ser usadas para abstrair responsabilidades de classes concretas, permitindo que diferentes classes implementem a mesma interface de maneiras diferentes.
Vamos a um exemplo com e sem SRP.
Classe EmployeeService sem SRP
Nesta implementação, a classe EmployeeService lida com:
- Operações CRUD para Employee.
- Envio de notificações por email.
- Gerenciamento de endereços.
- Isso torna a classe difícil de manter e estender, pois mudanças em uma responsabilidade podem afetar outras.
Com SRP
Aplicando o SRP, separamos as responsabilidades em diferentes classes, cada uma com uma única responsabilidade. Isso torna o código mais modular e fácil de manter.
_Classe EmployeeService com SRP_
**Classe EmployeeService**
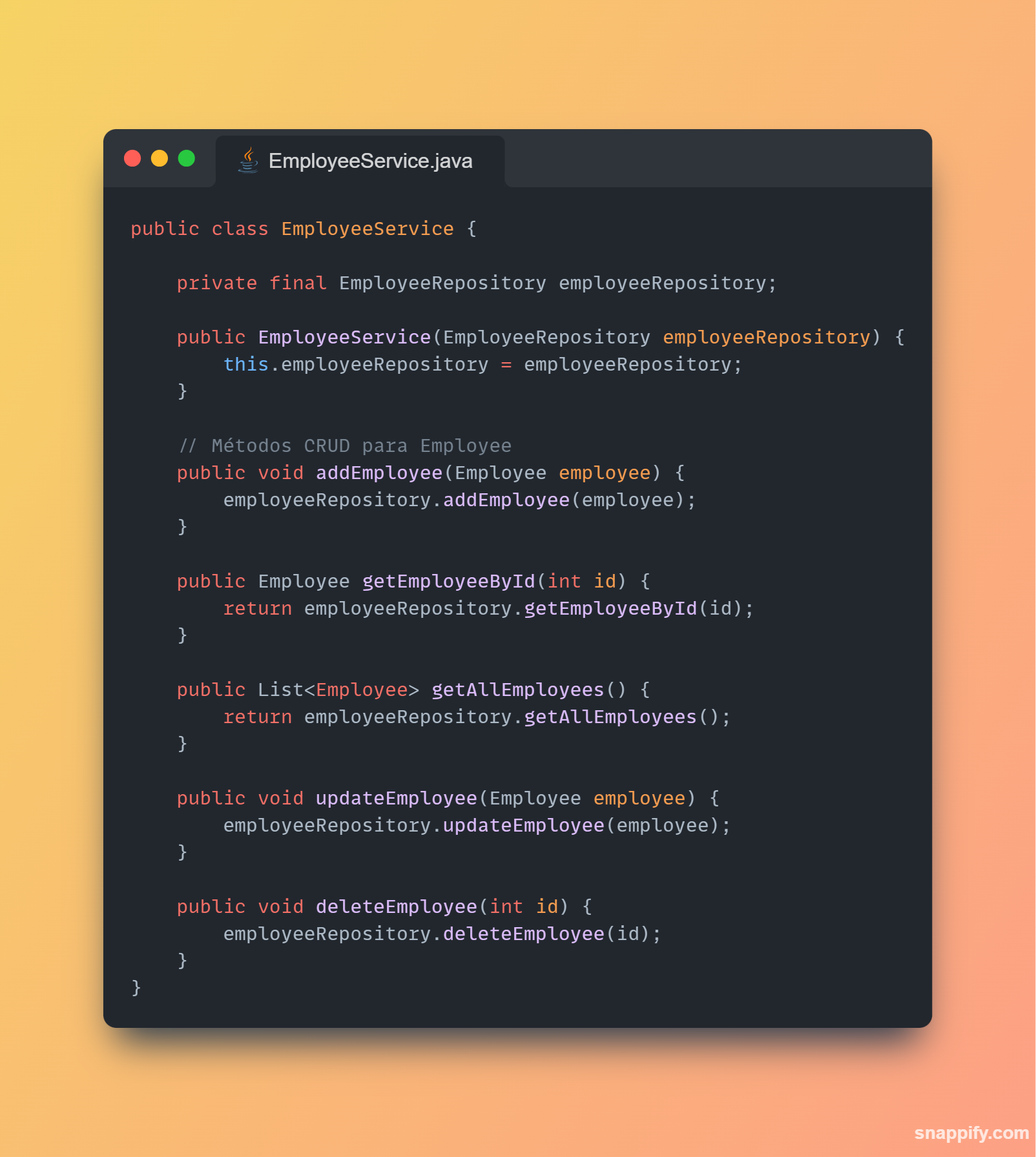
**Classe NotificationService**
**Classe AddressService**
**Classe EmployeeRepository**
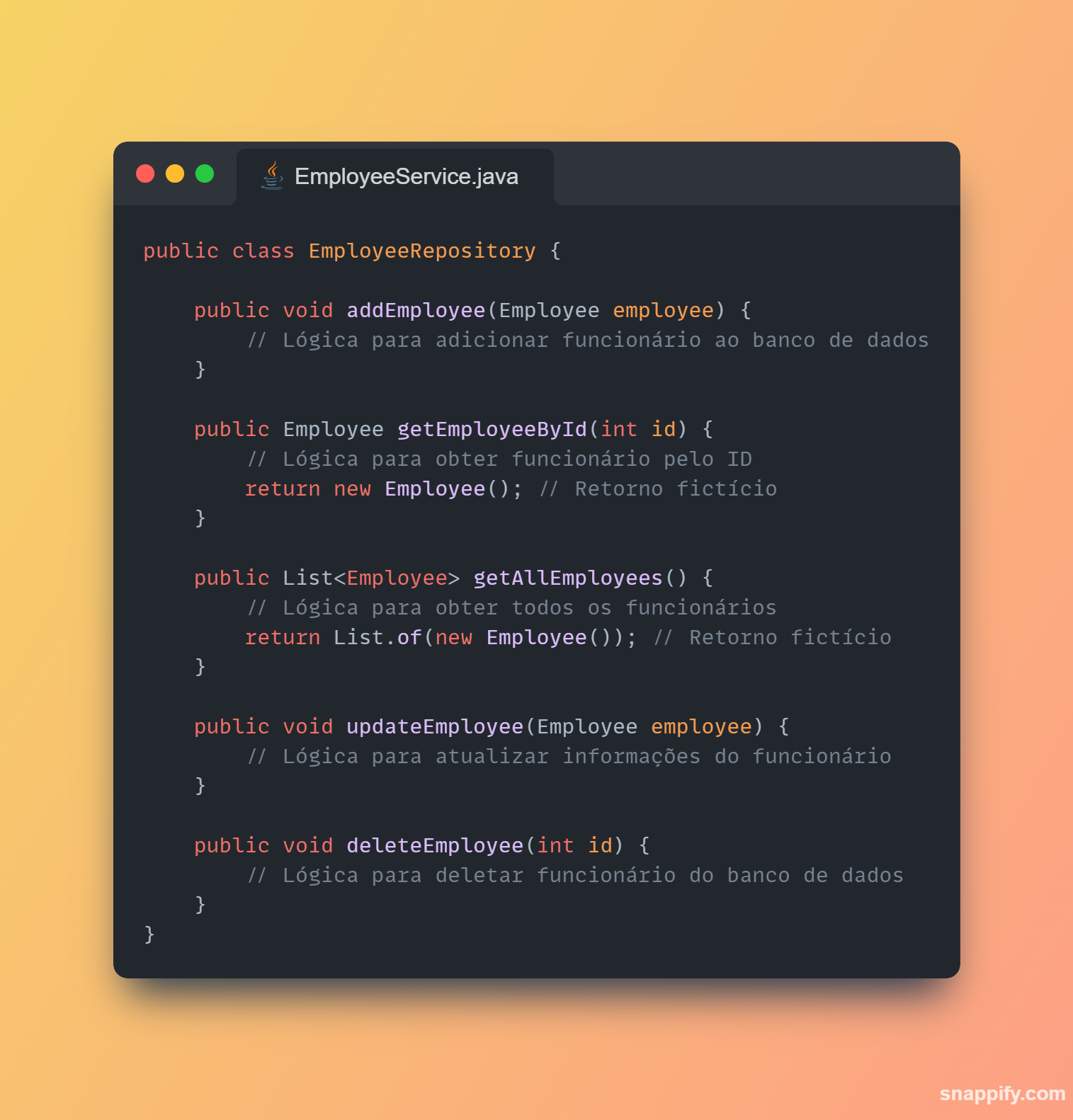
**Classe AddressRepository**
**Ao aplicar o SRP, separamos claramente as responsabilidades, facilitando a manutenção e a extensão do código. Agora, cada classe tem uma única responsabilidade, tornando o sistema mais modular e fácil de entender.**
_PS: Para ir direto para o próximo princípio:_
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-o-openclosed-principle-ocp-3bal %}
| diegobrandao |
1,864,262 | Desmistificando: Entendendo interações entre navegador e usuário #1 | Desmistificar Anular a natureza mística, misteriosa Destituir o caráter místico ou... | 0 | 2024-05-24T18:52:46 | https://dev.to/cavalcanteyury/desmistificando-entendendo-interacoes-entre-navegador-e-usuario-1-250c | beginners, learning, webdev, programming | ### _Desmistificar_
_Anular a natureza mística, misteriosa_
_Destituir o caráter místico ou misterioso de._
Entender o que o mecanismo faz é algo que eu faço com certa facilidade, mas eu sempre esbarro em dificuldades posteriores por não entender **como** o mecanismo opera.
Tô iniciando essa série de posts **Desmistificando** exatamente para chegar nas conclusões de como algo que estou interessado é feito de fato, e esse primeiro da série vai abordar um questionamento: **o que acontece quando digitamos um endereço na barra de pesquisa do navegador?** Vamos lá.
## A barra de pesquisa
O principal componente de um navegador é a sua barra de pesquisa. Hoje, vamos limitar o cenário do uso do navegador a isso, para que possamos sermos direto no estudo. O navegador possui muitas funcionalidades de configuração: plugins, papel de parede, etc, mas o que vai nos interessar nessa série é a barra de pesquisa e o que acontece quando você digita um conteúdo nela e aperta enter.
Temos algumas possibilidades: hoje em dia, você consegue utilizar seu buscador configurado (Google, Bing, etc) diretamente da barra de pesquisa, mas a possibilidade que interessa ao estudo é quando digitado uma **URI/URL**: `dev.to`, `facebook.com`, `google.com`, etc. Falando nisso, sabemos a diferença entre uma URI e uma URL?
É importante esclarecer a diferença entre essas siglas pois, essencialmente, são importantes para entender o "raciocínio" que o navegador seguirá. Quando falamos de uma URI, nos referimos ao `dev.to`, mas o navegador precisa entender **que recurso** estamos tentando acessar da URI `dev.to` e melhor ainda, **como** e **quão seguro** é o acesso a esses recursos?
Em suma, a URI é o identificador dos recursos, mas a URL define informações importantes do acesso e interação a este recurso. Mais detalhes podem ser obtidos na [RFC 3986](https://datatracker.ietf.org/doc/html/rfc3986), a RFC oficial definindo URIs. Se você não sabe o que são RFCs, bem resumidamente, são documentos feito por pesquisadores, cientistas de computação e outros desenvolvedores que colaboram em conjunto para chegar em um padrão utilizado na internet.
Recapitulando com todas as peças apresentadas aqui até então, podemos começar digitando a URI no navegador `facebook.com`, mas ele vai fazer o trabalho de interpretar esse URI e transformá-lo numa URL, e o primeiro passo dessa transformação, é utilizar o protocolo HTTPS, resultando em: `https://facebook.com` (Nota-se, que na maioria dos navegadores, o `https` fica ocultado). Vamos entender o protocolo HTTPS e a escolha dele na transformação de um URI.
## O Protocolo HTTPS
| cavalcanteyury |
1,864,261 | Add Vector Search to Your Site | Learn how to transform user queries into vector embeddings and search for similar content in your Astro blog. Turn user uncertainty into certainty with vector search. | 0 | 2024-05-24T18:46:31 | https://www.bengreenberg.dev/blog/blog_add-vector-search-to-your-astro-blog_1716508800000 | tutorial, webdev, database, ai | ---
title: Add Vector Search to Your Site
published: true
description: Learn how to transform user queries into vector embeddings and search for similar content in your Astro blog. Turn user uncertainty into certainty with vector search.
tags: tutorial, webdev, database, ai
canonical_url: https://www.bengreenberg.dev/blog/blog_add-vector-search-to-your-astro-blog_1716508800000
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/pm8hf3a2n2swc171v3kp.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-24 14:30 +0000
---
Users expect a lot more nowadays when they search on any website. They want to find the most relevant content quickly and easily. They want the website to understand what they were looking for, even if they do not know exactly what they want. In other words, traditional keyword search is often not enough anymore.
When we talk about different search methodologies, there are a few primary options:
1. **Keyword Search**: This is the most common search method. It is based on the user's query and the content of the website. The search engine looks for the exact match of the query in the content and returns the results.
2. **Semantic Search**: This search method takes queries and turns them into dense vectors using methods like word embeddings or contextual embeddings. These dense vectors capture the meaning of words and phrases. Embedding models, trained on large datasets, understand the context and relationships between words, converting text into dense vectors that reflect semantic similarity.
3. **Vector Search**: Vector search efficiently retrieves similar items from a large dataset by converting data into dense vectors and finding the nearest vectors to the query using methods like cosine similarity. This method is similar to semantic search but instead of looking for conceptually similar items, it looks for items with a similar vector representation.
There is also **hybrid search**, which combines multiple search methods to provide the best results.
In this tutorial, we are going to focus on converting a search function in an Astro-powered blog into a vector search. We will use OpenAI embeddings to convert the content of the blog posts into vectors, store them in a vector database on Couchbase, and then build the search functionality to find similar posts based on the user query.
If you are looking for definitions of Astro, Couchbase, and how to get started with either of them, I encourage you to check out my first blog post on this topic [Launching Your Astro Powered Blog on a Journey to Couchbase](https://www.bengreenberg.dev/blog/blog_launching-your-astro-powered-blog-on-a-journey-to-couchbase_1716076800000) where I cover detailed step-by-step instructions on how to set up your Astro blog and Couchbase database.
Ready to get started? Let's go!
*tl;dr You can find the full Astro site with the revisions [on GitHub](https://github.com/hummusonrails/personal-site) if you just want to skip to the code.*
## Overview of the Process
Here is a high-level overview of the process we will follow:
1. **Convert Blog Posts into Vector Embeddings**: We will use the OpenAI embeddings API to convert the content of the blog posts into vector embeddings.
2. **Store Embeddings in Couchbase**: We will store the embeddings in our Couchbase database.
3. **Add Vector Search Index**: We will create a search index in Couchbase to search for similar embeddings.
4. **Build the Search Functionality**: We will build the search functionality in our Astro blog to find similar posts based on the user query using the Couchbase Node.js SDK.
5. **Create a Search API**: We will create an API to execute the search for our Astro blog.
First, let's write the code to convert our blog posts into vector embeddings.
## Convert Blog Posts to Vector Embeddings
We will use the OpenAI embeddings API to convert the content of the blog posts into vector embeddings. You will need to sign up for an API key on the OpenAI website to use the API. You will need to provide your credit card information as there is a cost associated with using the API. You can review the pricing on the [OpenAI website](https://openai.com/api/pricing/). There are alternatives to generate embeddings. [Hugging Face](https://huggingface.co/) provides [SentenceTransformers](https://huggingface.co/sentence-transformers) to create embeddings from text, and Hugging Face is free to use for non-commercial personal use. For the purpose of this tutorial, though, we will be using the OpenAI embeddings API.
Similar to when we converted our existing markdown blog posts into a JSON format for Couchbase in the previous tutorial, we will be writing a script to convert our existing JSON blog post documents into vector embeddings. Let's start by creating a new file in `./scripts` called `generateEmbeddings.js`.
In the script, we will begin by including the necessary libraries we will use:
```javascript
import dotenv from 'dotenv';
dotenv.config();
import couchbase from 'couchbase';
import { OpenAI } from "openai";
import { encoding_for_model } from 'tiktoken';
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
```
First, we introduced `dotenv` to load our environment variables. Then, we included the `couchbase` and `openai` SDKs to interact with Couchbase and OpenAI, respectively. We also imported the `encoding_for_model` function from the `tiktoken` library, which we will use to calculate the amount of tokens needed for each blog post. We will use that calculation to determine how much we can send to the OpenAI API in one request. More on that last bit later.
Next, we will connect to our Couchbase cluster and bucket:
```javascript
let cluster;
async function init() {
if (!cluster) {
cluster = await couchbase.connect(process.env.COUCHBASE_URL, {
username: process.env.COUCHBASE_USERNAME,
password: process.env.COUCHBASE_PASSWORD,
configProfile: "wanDevelopment",
});
}
return cluster;
}
```
If you are coming from the [previous tutorial](https://www.bengreenberg.dev/blog/blog_launching-your-astro-powered-blog-on-a-journey-to-couchbase_1716076800000), this will be very familiar to you. We are connecting to our Couchbase cluster using the environment variables we set up in the `.env` file and returning the cluster object.
Then, let's create a function to get all the blog posts from the Couchbase bucket:
```javascript
async function getBlogPosts() {
const cluster = await init();
const query = 'SELECT META().id, title, content FROM `blogBucket` WHERE type = "blogPost"';
const result = await cluster.query(query);
return result.rows;
}
```
This function will return all the blog posts from the Couchbase bucket. We are querying the bucket for documents with the type `blogPost` and returning the `id`, `title`, and `content` of each document. For your own blog, make sure to adjust the query to match the structure of your documents.
Lastly, let's define two functions, one that will generate embeddings for a blog post, and the second one that will store the embeddings in the Couchbase bucket:
```javascript
async function generateEmbeddings(text) {
const response = await openai.embeddings.create({
model: 'text-embedding-ada-002',
input: text,
});
return response.data[0].embedding;
}
async function storeEmbeddings(postId, embeddings) {
const cluster = await init();
const bucket = cluster.bucket('blogBucket');
const collection = bucket.defaultCollection();
const docId = `embedding::${postId}`;
await collection.upsert(docId, { type: 'embedding', embeddings });
}
```
In this example, we are using the `text-emdedding-ada-002` model to generate embeddings for the blog post content. You can experiment with [different models](https://platform.openai.com/docs/guides/embeddings/embedding-models) to see which one works best for your use case. We are storing the embeddings in the Couchbase bucket with the document ID `embedding::${postId}` and a `type` of `embedding`.
Now, we're ready to put that all together in a `main` function and invoke it at the bottom of the script:
```javascript
async function main() {
const MAX_TOKENS = 8192;
const encoding = encoding_for_model('text-embedding-ada-002');
const posts = await getBlogPosts();
for (const post of posts) {
const postId = post.id;
let content = post.content;
// Calculate tokens and shorten if necessary
while (encoding.encode(content).length > MAX_TOKENS) {
content = content.slice(0, -100);
}
const embeddings = await generateEmbeddings(content);
await storeEmbeddings(postId, embeddings);
console.log(`Processed and stored embeddings for post ${postId}`);
}
}
main().catch(console.error);
```
In the `main` function, we are getting all the blog posts from the Couchbase bucket, iterating over each post, generating embeddings for the content, and storing the embeddings in the Couchbase bucket.
We are also calculating the number of tokens for each blog post and shortening the content for the embedding generation if it exceeds the maximum number of tokens allowed by the OpenAI API. This is one approach to dealing with a token exceeded error that you may get for longer blog posts. Another option would be to split the content into smaller chunks and send them separately to the API, and then concatenate the embeddings at the end. Both approaches have their trade-offs, so you may need to experiment to see which one works best for your use case.
When you run this script from your console with `node ./scripts/generateEmbeddings.js`, it will generate embeddings for all the blog posts in your Couchbase bucket and store them in the bucket. The output will look similar to:
```
Processed and stored embeddings for post..
Processed and stored embeddings for post..
Processed and stored embeddings for post..
```
That's it! You've successfully converted your existing blog posts into vector embeddings using the OpenAI embeddings API and stored them in your Couchbase bucket. In the next section, we will add a search index to Couchbase to search for similar embeddings.
## Add Vector Search Index
To search for similar embeddings in Couchbase, we need to create a search index. What is a search index? Couchbase search indexes enhance the performance of query and search operations. Each index makes a predefined subset of data available for the search. You can learn more about search indexes on the [Couchbase docs](https://docs.couchbase.com/cloud/search/create-search-indexes.html).
Navigate in your browser to your [Couchbase Capella](https://cloud.couchbase.com/sign-in) platform and sign in. Once you have signed in, click on your database storing your blog posts. In my example, my blog posts database is called `blogPosts`. Then click on `{ } Data Tools` from the top navigation bar and then select `Search` from the second navigation bar from the top.

Now, you should see a blue button on the right-hand side of the page that says `Create Search Index`. Go ahead and click that.
You will be presented with a set of options to define your search index. When you have concluded it should look similar, but not exact because your data will be different, to the following:

First, name your search index something that you will remember. I called mine `blog_index`. Then, you will need to define the rest of the options.
In the example shown in the screenshot above, the bucket the index is being created on is `blogBucket`. This is the bucket where my blog posts are stored. You will need to adjust this to match the bucket where your blog posts are stored. The scope and collection are both defined as `_default`, which is the default scope and collection names for a bucket. If you have a different scope or collection name, you will need to adjust these values accordingly.
Then, the document field that the index is being created on is `embeddings`. This is the field where the embeddings are stored in the blog post documents. Once you click on `embeddings` a second panel of options will open up on the right-hand side. These options can be left as they are, and just click `Add` in that panel. Once you click `Add`, you will see the type mappings defined on the bottom of the page.
Once that is all done, simply click `Create` and you now have a search index in Couchbase to search for similar vectors in your blog posts!
You are now ready to build the search functionality in your Astro blog to find similar posts based on the user query. In the next section, we will build the search functionality.
## Build the Search Functionality
### Add a Search Bar to Your Blog
For my example, I have added a search bar to my `Header` component and it looks like this:
```html
<form action="/search" method="GET" class="flex">
<input
type="text"
name="q"
placeholder="Ask the blog a question..."
class="px-4 py-2 border border-gray-300 dark:border-gray-700 rounded-l-md"
/>
<button
type="submit"
class="px-4 py-2 bg-primary-500 text-white rounded-r-md"
>
Search
</button>
</form>
```
The header now renders like the screenshow below.

### Create a New Search Page
Next, we will create a new search page in our Astro blog to display the search results. Create a new file in the `src/pages` directory called `search.astro` and add the following code:
```html
---
import RootLayout from '../layouts/RootLayout.astro';
import { SITE_METADATA } from '@/consts';
let searchResults = [];
let searchTerm = '';
// Get the query parameter on the server side
if (Astro.request) {
const url = new URL(Astro.request.url);
searchTerm = url.searchParams.get('q') || '';
// Fetch data using the query parameter on the server side
if (searchTerm) {
const encodedSearchTerm = encodeURIComponent(searchTerm);
const response = await fetch(`${import.meta.env.SEARCH_URL}/search?q=${encodedSearchTerm}`);
searchResults = await response.json();
}
}
// Function to render search results
const renderSearchResults = (results) => {
if (!results || results.length === 0) {
return `<p>No posts found.</p>`;
}
return results.map(post => `
<li class="py-4" key="${post.id}">
<article class="space-y-2 xl:grid xl:grid-cols-4 xl:items-baseline xl:space-y-0">
<dl>
<dt class="sr-only">Published on</dt>
<dd class="text-base font-medium leading-6 text-gray-500 dark:text-gray-400">
${new Date(post.date).toLocaleDateString()}
</dd>
</dl>
<div class="space-y-3 xl:col-span-3">
<div>
<h3 class="text-2xl font-bold leading-8 tracking-tight">
<a href="/blog/${post.id}" class="text-gray-900 dark:text-gray-100">
${post.title}
</a>
</h3>
<div class="flex flex-wrap">
${post.tags.map(tag => `
<a href="/tags/${tag}" class="mr-2 mb-2 inline-block px-2 py-1 text-sm font-medium leading-5 text-gray-800 dark:text-gray-200 bg-gray-200 dark:bg-gray-800 rounded-full hover:bg-gray-300 dark:hover:bg-gray-700 transition-colors duration-200">
#${tag}
</a>
`).join('')}
</div>
</div>
<div class="prose max-w-none text-gray-500 dark:text-gray-400">
${post.summary}
</div>
</div>
</article>
</li>
`).join('');
}
---
<RootLayout title={SITE_METADATA.title} description={SITE_METADATA.description}>
<div class="divide-y divide-gray-200 dark:divide-gray-700">
<div class="space-y-2 pb-8 pt-6 md:space-y-5">
<h1 class="text-3xl font-extrabold leading-9 tracking-tight text-gray-900 dark:text-gray-100 sm:text-4xl sm:leading-10 md:text-6xl md:leading-14">
Search Results for "{searchTerm}"
</h1>
</div>
<ul id="search-results" set:html={renderSearchResults(searchResults)}></ul>
</div>
</RootLayout>
```
That's a lot, so let's break down the main parts.
First, we grab the search term from the query parameter in the URL. We then fetch the search results from the server using the search term. If there is no search term, we display a message saying "No posts found." However, if there is a search term, we display the search results. All of that HTML is formatting the search results to be rendered on the page, and it is inserted into the `RootLayout` inside the `ul` element with the id `search-results`.
Did you notice that the search results come from a `fetch` request? This is because we are going to create a search API in the next section to execute the search for our Astro blog.
In this tutorial, I've separated out the search API from the blog itself. This is a common pattern to separate concerns and make the codebase more maintainable. You can host the search API on a different server, and supply the URL path in your `.env` file. This way, you can easily switch between different search APIs or services without changing the code in your blog.
### Create a Search API
*tl;dr You can find the full search API code [on GitHub](https://github.com/hummusonrails/couchbase-search-blog) if you just want to skip to the code.*
For the search API, we will create a relatively straightforward Express.js server that will handle the search requests. We will use the Couchbase Node.js SDK to connect to the Couchbase cluster and execute the search query.
First, let's define our dependencies:
```javascript
const express = require('express');
const couchbase = require('couchbase');
const cors = require('cors');
const openai = require('openai');
require('dotenv').config();
const app = express();
app.use(cors());
const openaiclient = new openai({apiKey: process.env.OPENAI_API_KEY});
```
We are using `express` to create the server, `couchbase` to connect to the Couchbase cluster, `cors` to enable cross-origin requests, and `openai` to interact with the OpenAI API. We are also loading the environment variables from the `.env` file.
Our search API will do two things:
* Convert the search term into a vector embedding using the OpenAI embeddings API.
* Search for similar embeddings in the Couchbase bucket and return the search results.
First, though, let's make sure it can establish a connection to Couchbase. This code will be very familiar at this point:
```javascript
let cluster;
async function init() {
if (!cluster) {
cluster = await couchbase.connect(process.env.COUCHBASE_URL, {
username: process.env.COUCHBASE_USERNAME,
password: process.env.COUCHBASE_PASSWORD,
configProfile: "wanDevelopment",
});
}
return cluster;
}
```
Next, we'll convert the search term into an embedding using the OpenAI embeddings API:
```javascript
async function generateQueryEmbedding(query) {
const response = await openaiclient.embeddings.create({
model: 'text-embedding-ada-002',
input: query,
});
return response.data[0].embedding;
}
```
Now, we need to fetch the embeddings from the Couchbase bucket and search for similar embeddings using the vector search functionality in Couchbase. This is done with the following function:
```javascript
async function getStoredEmbeddings(queryEmbedding) {
const cluster = await init();
const scope = cluster.bucket('blogBucket').scope('_default');
const search_index = process.env.COUCHBASE_VECTOR_SEARCH_INDEX;
const search_req = couchbase.SearchRequest.create(
couchbase.VectorSearch.fromVectorQuery(
couchbase.VectorQuery.create(
"embeddings",
queryEmbedding
).numCandidates(5)
)
)
const result = await scope.search(
search_index,
search_req
)
return result.rows;
}
```
Let's break down that function a bit. The search is done on the `scope` level of the Couchbase bucket. A scope is a way to group collections within a bucket. If you recall, when we created the search index in our Capella platform dashboard, we defined a scope as well, which is the default scope, `_default`. This is why, at the end of this function we call the `.search` method on the `scope` object.
Near the top of the function, we create the search request: `const search_req`, etc. The search request uses the `SearchRequest.create()` method. The `SearchRequest.create()` method can take different types of search requests, and in this case, we are creating a vector query using `VectorSearch.fromVectorQuery()` method, which also accepts an argument of a vector query. We create the query with `VectorQuery.create()`, which takes the following arguments:
* The field in the document where the embeddings are stored. In our case, this is `embeddings`.
* The query embedding that we generated from the search term.
In our example, we are also setting the number of *candidates* to 5. A candidate is a document that is considered a potential match for the query. In effect, this will return up to 5 documents that are most similar to the query embedding.
Lastly, we create a function that then searches for the blog posts that correspond to the IDs of the documents returned from the vector search. The function returns those blog posts:
```javascript
async function searchBlogPosts(query) {
const queryEmbedding = await generateQueryEmbedding(query);
const storedEmbeddings = await getStoredEmbeddings(queryEmbedding);
const cluster = await init();
const bucket = cluster.bucket('blogBucket');
const collection = bucket.defaultCollection();
const results = await Promise.all(
storedEmbeddings.map(async ({ id }) => {
const docId = id.replace('embedding::', '');
const result = await collection.get(docId);
return result.content;
})
);
return results;
}
```
We put that all together in a `GET` route that will handle the search requests with some additional error handling:
```javascript
app.get('/search', async (req, res) => {
const searchTerm = req.query.q || '';
if (!searchTerm) {
return res.status(400).json({ error: 'No search term provided' });
}
try {
const searchResults = await searchBlogPosts(searchTerm);
res.json(searchResults);
} catch (err) {
console.error('Error searching blog posts:', err);
res.status(500).json({ error: 'Error searching blog posts' });
}
});
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server running on port ${PORT}`);
});
```
At this point, you have created everything you need for a vector search on your own site! In our example, we created this for search functionality on a blog, but the potential uses are endless. You could use this for a product search, a search for similar music or movies, or even search for similar code snippets. It's all up to what you are intending to build.
One possible implementation route is to deploy this search API separately from where you deploy your blog or site. For example, you may deploy your site to a static site host like Vercel or Netlify, and deploy your search API to a serverless platform like AWS Lambda or Google Cloud Functions or Render. This way, you maximize the benefits of each platform and keep your concerns separated.
## Conclusion
In this tutorial, we learned how to convert a search function in an Astro-powered blog into a vector search. We used the OpenAI embeddings API to convert the content of the blog posts into vector embeddings, stored them in a vector database on Couchbase, and built the search functionality to find similar posts based on the user query. We also created a search API to execute the search for our Astro blog.
You have done quite a lot in this journey. Your blog is now capable of handling less than certain user queries and returning relevant content to the user. There is a still a lot more that can be done to improve further the search functionality, perhaps by introducing hybrid search, but in the meantime you can celebrate your accomplishment!
| bengreenberg |
1,864,260 | Test post | Hello, I am just testing this platform. | 0 | 2024-05-24T18:37:10 | https://dev.to/romano_solis_5ab22d0b4363/test-post-3o94 | webdev | Hello, I am just testing this platform. | romano_solis_5ab22d0b4363 |
1,864,259 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-05-24T18:33:28 | https://dev.to/khadencerobinson4/buy-verified-cash-app-account-2coh | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n\n\n" | khadencerobinson4 |
1,864,254 | Streamlining Oracle Test Automation with AI and Machine Learning | Oracle patch update is frequently released by Oracle. Businesses need to implement patch updates to... | 0 | 2024-05-24T18:23:13 | https://www.whatsontech.com/streamlining-oracle-test-automation-with-ai-and-machine-learning/ | oracle, test, automation | 
Oracle patch update is frequently released by Oracle. Businesses need to implement patch updates to prevent any vulnerabilities. Testing ensures reliability, accuracy, and efficiency of the software functionalities. With an automation approach, an organization can reduce manual testing efforts, increase test coverage, and improve overall Oracle application quality.
Automation tools increase testing efficiency, save time and resources, and enable regression testing. Opkey is a new-age test automation tool that leverages AI and ML to offer seamless Oracle patch update implementation. It enables single-click test case generation by leveraging AI and ML. Moreover, it also brings self-healing capabilities, fostering test-script maintenance. In this blog, we will dive deeper into the challenges and benefits of AI and ML in test automation and top testing tools.
**Challenges in Oracle Test Automation**
**Application Complexity**
Oracle apps can be complex, organizations often use many modules, connectors, customizations, and third-party integrations. A thorough understanding of the underlying architecture, data structures, and business procedures is necessary for testing such complicated systems. It might be challenging to automate testing for complex scenarios; it requires an in-depth understanding of Oracle technology and sophisticated scripting abilities.
**Application Updates and Patches**
Oracle applications encounter regular updates, fixes, and new releases. The program’s functionality, user interface, and underlying technological stack may all change as a result of these updates. Updating testing scripts becomes necessary to ensure seamless Oracle patch update implementation, ensuring software is compatible with the most recent versions. Time and resources might be heavily invested in managing script maintenance and staying current with application upgrades.
**Test Data Management**
Complex data structures and significant data dependencies are common in Oracle applications. It’s hard to generate, manage, and keep up with test data that faithfully mimics real-world situations. Precise testing requires reliable, separated, and relevant test results. Furthermore, it’s critical to handle test data security and privacy issues.
**Test Environment Setup and Stability**
Oracle applications frequently require specific dependencies, setups, and server or database access. Setting up and maintaining test environments that resemble production systems might be complex. There may be delays and complications when coordinating with the database and infrastructure teams to provide test environments with the required setups and data.
**Cross-Browser and Cross-Platform Compatibility**
Ensuring compatibility and optimal performance of Oracle applications across various web browsers, operating systems, and devices is imperative. Developing and sustaining test scripts seamlessly running across multiple platforms and browsers is challenging due to differences in behavior, rendering, or supporting technologies.
**Team Collaboration and Skill Set**
Building an expert automation team with the necessary technical capabilities and understanding of Oracle applications is challenging. Together, developers, testers, and business stakeholders must effectively collaborate for successful Oracle patch update implementation. A constant issue is ensuring that information is shared, offering training, and keeping a talented and driven staff.
**Benefits of AI and Machine Learning in Test Automation**
**Increased Test Coverage**
AI and ML algorithms can automatically analyze vast amounts of data and application behavior to generate diverse test scenarios automatically. Intelligent test case generation covers a broader spectrum of functionalities and potential edge cases. This leads to comprehensive test coverage, including scenarios that might be challenging to identify manually, enhancing the overall testing quality.
**Improved Test Accuracy and Reliability**
Machine learning models can analyze historical test data to identify patterns and predict potential areas of failure. Test automation powered by AI can execute tests precisely, eliminating the inconsistencies and errors introduced by manual testing. The computing capabilities of machine learning algorithms contribute to enhanced accuracy of testing.
**Reduction in Testing Time and Costs**
Oracle patch update implementation with AI and ML enables parallel test execution, significantly reducing the time required for test cycles. Predictive analysis helps prioritize testing efforts, focusing on critical areas and minimizing redundant testing. Automated test case generation and maintenance alleviate the manual effort required for scripting, leading to cost savings in the long term.
**Enhanced Adaptability to Changes in Oracle Applications**
Machine learning algorithms can predict the potential impacts of changes in Oracle applications on existing test scripts. Self-healing mechanisms automatically update test scripts to align with changes, reducing the need for manual intervention and script maintenance. AI-driven testing frameworks are adaptive and can handle variations in application behavior, providing a more resilient testing process in dynamic development environments.
**Why Integrate AI and ML in Oracle Test Automation**
**Test Case Generation**:
Machine learning analyzes historical test data, application usage patterns, and code changes for adaptive test case generation.
**Intelligent Test Script Maintenance**:
AI algorithms automatically update test scripts by monitoring changes in the application, reducing manual effort and script obsolescence.
**Predictive Analysis**:
AI tools analyze test results, logs, and historical data to predict potential issues, allowing for early detection and efficient issue prioritization.
**Self-Healing Mechanisms**:
AI-driven frameworks dynamically adjust test scripts during execution to align with changes in the application. ML algorithms proactively identify and correct issues, contributing to a resilient testing process.
**Opkey: AI-Powered Oracle Test Automation Tool**
Opkey is a codeless testing tool that leverages AI and ML to become one of the leading automation platforms. It offers comprehensive features to ensure seamless Oracle patch update implementation. Opkey ensures that non-technical users can perform testing without writing code, saving time and resources to perform testing. One can create a single-click test case and conduct a test with drag-and-drop functionalities. Moreover, Opkey also offers end-to-end testing, so you don’t need to compromise with software quality. | rohitbhandari102 |
1,864,220 | The Evolution of Good Code: A Reflection on Coding Practices and Developer Growth | In the evolving landscape of software development, one truth remains constant: good coders,... | 0 | 2024-05-24T18:20:21 | https://dev.to/ivangavlik/the-evolution-of-good-code-a-reflection-on-coding-practices-and-developer-growth-4d86 | programming, career, developer, productivity | In the evolving landscape of software development, one truth remains constant: **good coders, regardless of the era or paradigm, produce good code**. From functional programming to object-oriented (OO) designs, the quality of code is a testament to the skill and dedication of the developer behind it. This article delves into the nuances of good versus bad code across different programming paradigms and explores the journey from a junior to a senior developer, emphasizing the importance of clean, maintainable code.
## Good Code vs. Bad Code: A Timeless Debate
No matter the time period or programming paradigm, the distinction between good and bad code persists.
### Functional Programming
_Good Functional Code_
- Leverages pure functions
- immutability
- clear data flows to create predictable and testable systems
_Bad Functional Code_: Can become a tangle of unclear logic and excessive recursion, making maintenance a nightmare.
### Object-Oriented Programming:
_Good OO Code_: Employs principles like encapsulation, inheritance, and polymorphism to create modular and reusable components.
_Bad OO Code_: Often suffers from over-engineering, unnecessary complexity, and rigid hierarchies that stifle flexibility.
The core takeaway is that good code, irrespective of the paradigm, prioritizes readability, maintainability, and efficiency.
## Embracing Functional Programming in Modern Development
Functional programming (FP) has often been dismissed as a passing trend, but it is becoming increasingly popular to combine it with OOP.
Java is a example to this shift. Look at the introduction of Streams. Stream pipelines offer a more readable and declarative way to handle data transformations compared to traditional loops and external iteration. This readability directly translates to esier maintainability.
**The combination of OOP and functional programming can be a powerful approach**, leveraging the strengths of both paradigms to create robust, scalable, and maintainable systems. This hybrid approach allows developers to use objects for modeling real-world entities and functions for processing data in a clean, declarative manner.
## The Journey from Junior to Senior Developer
The transition from a junior to a senior developer is marked by a shift in perspective and responsibilities. While a junior developer focuses on learning and implementing features, a senior developer takes on the role of continually refining and improving codebase.
**Responsibilities of a Senior Developer**
- **Code Quality and Maintenance**: Senior developers actively work to enhance code quality, aiming to reduce maintenance costs. This involves writing clean, well-organized code that is easy to understand and modify.
- **Mentoring and Knowledge Sharing**: Senior developers play a crucial role in mentoring juniors, sharing best practices, and creating a culture of excellence.
## Conclusion
Good code transcends time and paradigms. Whether you're working with functional or object-oriented programming, the principles of clean, maintainable, and efficient code remain the same. The journey from junior to senior developer is marked by an increasing responsibility to uphold these standards and to continuously improve the codebase. Embracing best practices, programming, and taking ownership of the code are essential steps in this journey. As developers, our goal should always be to leave the code better than we found it, paving the way for future innovation and success. | ivangavlik |
1,864,232 | 2024 Ford Ranger Review | The 2024 Ford Ranger is the perfect midsize truck designed to command attention on the road. With its... | 0 | 2024-05-24T18:20:16 | https://dev.to/oakridgeford/2024-ford-ranger-review-1n88 | ai | The 2024 Ford Ranger is the perfect midsize truck designed to command attention on the road. With its advanced technology, safety features, and added performance, the Ford Ranger is a great option for drivers looking for a midsize truck that can deliver excellent power.

**Walkthrough Review**
Inside the cabin, the Ford Ranger features a new digital instrument cluster that helps you stay informed. The Lariat and Raptor models can also find memory seats and a heated steering wheel. The New fold-flat rear seatbacks provide the perfect space for loading and unloading your stuff.
**CONTACT US**
**[Contact Oakridge Ford](https://www.oakridgeford.com/contact/)** today to learn more about the 2024 Ford Ranger available in our vehicle lineup. Our team is ready to answer your questions and help you discover the perfect Ford Ranger.
**Source- [https://www.oakridgeford.com/2024-ford-ranger-review/](https://www.oakridgeford.com/2024-ford-ranger-review/)**
| oakridgeford |
1,863,206 | YB-Master, the YugabyteDB Universe control plane | When deploying YugabyteDB on Kubernetes, you will have two Stateful Sets: YB-Master and YB-TServer.... | 0 | 2024-05-24T18:15:00 | https://dev.to/yugabyte/yb-master-the-yugabytedb-universe-control-plane-3398 | yugabytedb, distributed, sql, database | When deploying YugabyteDB on Kubernetes, you will have two Stateful Sets: YB-Master and YB-TServer. You also start those two on VMs.
You want to scale out the **YB-TServers** (tablet servers) to more than one per failure zone for elasticity. This is where your application connects, SQL is processed, and data is stored (in tablets). You can scale to more pods when you have more connections, a higher workload, or more data. Small databases with a moderate load can scale down to the replication factor, such as three, to be resilient to one failure.
The **YB-Master** doesn't need to scale to more than one per fault zone. It stores the cluster metadata, including the PostgreSQL catalog, and orchestrates the cluster's automated operations, like tablet rebalancing. The name "Master" is misleading. TServers can function for a while without the Master. There's no disruption if the leader steps down and one of the followers is elected after a few seconds. Regarding network traffic, the TServers call it on new SQL connections to get the catalog information to keep in the cache. When DDL occurs, they refresh their cache. Besides that, the network traffic between the Master and TServers is limited to heartbeats.
## TCP traffic to YB Master
To illustrate this, I use `tcpdump` to trace the traffic to the port `7100` where the `yb-master` leader runs:
```awk
tcpdump -nni any dst port 7100 -A |
# display every 10 seconds the count of lines with ".yb."
awk -F . '
/ IP [0-9.]+[.][0-9.]+ > [0-9.]+[.]7100: /{t1=$1}
/[.]yb[.]/{c[$0]=c[$0]+1} # count messages with ".yb."
substr(t1,1,7)>substr(t0,1,7){ # print every 10 seconds
for (i in c) printf "%10d %-s\n",c[i],i;print t1;delete(c)
}
{t0=t1}
'
```
The AWK script counts the lines with `.yb.`, which are YugabyteDB Protobufs, and shows the count every 10 seconds.
## Idle server
When there is no activity, YB Master receives heartbeats and consensus updates. In this three-node cluster with hundreds of tables, I see around 100 RPCs per 10 seconds:
```
19:48:00
20 .yb.consensus.ConsensusService..UpdateConsensus.....: f48f17d6633c46f7bda6b0fc0d34e4ba
4 .yb.master.MasterService..GetTableSchema..'.
6 .yb.master.MasterService..TSHeartbeat..u...
20 .yb.consensus.ConsensusService..UpdateConsensus.....: 5502c42867c649dabe00ed71e7242c7e
4 .yb.master.MasterService..GetTableLocations..'.
34 .yb.master.MasterService..TSHeartbeat..u..
19:48:10
20 .yb.consensus.ConsensusService..UpdateConsensus.....: f48f17d6633c46f7bda6b0fc0d34e4ba
4 .yb.master.MasterService..GetTableSchema..'.
6 .yb.master.MasterService..TSHeartbeat..u...
20 .yb.consensus.ConsensusService..UpdateConsensus.....: 5502c42867c649dabe00ed71e7242c7e
4 .yb.master.MasterService..GetTableLocations..'.
34 .yb.master.MasterService..TSHeartbeat..u..
```
## Connections
I start PgBench with ten connections:
```sh
pgbench -nc 10 -T 10 -f /dev/stdin <<<"select pg_sleep(1)"
```
I see 132 read requests from the TServers when those new connections read the critical information from the PostgreSQL catalog.
```
19:54:00
11 .yb.master.MasterService..GetNamespaceInfo....&
19 .yb.consensus.ConsensusService..UpdateConsensus.....: f48f17d6633c46f7bda6b0fc0d34e4ba
4 .yb.master.MasterService..GetTableSchema..'.
132 .yb.tserver.TabletServerService..Read...$..
6 .yb.master.MasterService..TSHeartbeat..u...
19 .yb.consensus.ConsensusService..UpdateConsensus.....: 5502c42867c649dabe00ed71e7242c7e
4 .yb.master.MasterService..GetTableLocations..'.
34 .yb.master.MasterService..TSHeartbeat..u..
19:54:10
```
You can see that those reads are "tserver" protobuf because they read from the catalog tablet 0000000000000000000000, which is stored in the Master but is similar to other tablets stored in the TServers.
## Data Definition Language
I create the PgBench tables:
```sh
pgbench -niIdtpfg
```
This runs multiple DDL statements to create the tables and add primary and foreign keys. It reads and writes to the catalog with higher activity calling the YB-Master:
```
20:00:50
4 .yb.master.MasterService..GetTableLocations..'.
2 .yb.consensus.ConsensusService..UpdateConsensus....m: 5502c42867c649dabe00ed71e7242c7e
1 .yb.consensus.ConsensusService..UpdateConsensus....j: 5502c42867c649dabe00ed71e7242c7e
2 .yb.master.MasterService..IsAlterTableDone....L
4 .yb.master.MasterService..IsAlterTableDone....M
1 .yb.consensus.ConsensusService..UpdateConsensus....v: 5502c42867c649dabe00ed71e7242c7e
6 .yb.master.MasterService..TSHeartbeat..u...
3 .yb.consensus.ConsensusService..UpdateConsensus....u: f48f17d6633c46f7bda6b0fc0d34e4ba
10 .yb.tserver.TabletServerService..Write...$.
30 .yb.master.MasterService..IsCreateTableDone....$
4 .yb.master.MasterService..TruncateTable...."
600 .yb.consensus.ConsensusService..UpdateConsensus.....: 5502c42867c649dabe00ed71e7242c7e
600 .yb.consensus.ConsensusService..UpdateConsensus.....: 5502c42867c649dabe00ed71e7242c7e
264 .yb.master.MasterService..TSHeartbeat..u..
136 .yb.master.MasterService..GetTableSchema....$
2 .yb.consensus.ConsensusService..UpdateConsensus....m: f48f17d6633c46f7bda6b0fc0d34e4ba
1 .yb.consensus.ConsensusService..UpdateConsensus....j: f48f17d6633c46f7bda6b0fc0d34e4ba
30 .yb.tserver.TabletServerService..Write...$.
882 .yb.tserver.TabletServerService..Read...$..
13 .yb.tserver.TabletServerService..UpdateTransaction..'p
3 .yb.master.MasterService..IsObjectPartOfXRepl...."
13 .yb.master.MasterService.
4 .yb.master.MasterService..GetTableSchema..'.
12 .yb.consensus.ConsensusService..UpdateConsensus.... : 5502c42867c649dabe00ed71e7242c7e
7 .yb.master.MasterService..GetTableLocations....(
1 .yb.consensus.ConsensusService..UpdateConsensus....v: f48f17d6633c46f7bda6b0fc0d34e4ba
3 .yb.master.MasterService..DeleteTable....&
136 .yb.master.MasterService..GetTableLocations.....
597 .yb.consensus.ConsensusService..UpdateConsensus.....: f48f17d6633c46f7bda6b0fc0d34e4ba
12 .yb.master.MasterService..IsTruncateTableDone...."
22 .yb.master.MasterService..IsAlterTableDone....$
143 .yb.tserver.TabletServerService..Write...$..
1 .yb.tserver.TabletServerService..Write...$.0
7 .yb.master.MasterService..CreateTable......
1 .yb.master.MasterService..GetNamespaceInfo....&
4 .yb.master.MasterService..ListTabletServers.......
2 .yb.tserver.TabletServerService..Write...$.5
3 .yb.consensus.ConsensusService..UpdateConsensus....u: 5502c42867c649dabe00ed71e7242c7e
7 .yb.master.MasterService..IsDeleteTableDone...."
4 .yb.tserver.TabletServerService..Write...$.9
12 .yb.consensus.ConsensusService..UpdateConsensus.... : f48f17d6633c46f7bda6b0fc0d34e4ba
20:01:00
```
The updates on the YB-Master Leader are replicated to its Raft Followers, and the catalog version change is also sent to the TServers through the heartbeats, which calls back the Master to get the schema to refresh their cache.
## Data Manipulation Language
I started PgBench read/write workload:
```sh
pgbench -nc 10 -T 60 -P 10 -N
```
Once the clients are connected, there are no additional calls to the Master:
## Frequent Connections
I can add the `-C` option to PgBench to re-connect for each transaction (which is one of the worst practices with most databases - don't do that):
```
pgbench -nc 10 -T 60 -P 10 -N -C
```
With 10 clients reconnecting, the number of calls to the Master increases:
Frequent re-connections are not scalable, especially in a multi-region cluster with high latency from the YB-TServers to the YB-Master. You must use a connection pool (or the YugabyteDB Connection Manager, which is a database-resident connection pool) so that physical connections keep the state of the metadata cache when grabbing new logical connections.
I use this level of tracing to get more details, but in a production cluster, you can monitor the number of operations on the Master:
There are detailed metrics available in the Prometheus Endpoint of the tablet servers:
```
$ curl -Ls arm.pachot.net:9000/prometheus-metrics | awk '{sub(/{/," ")}/^proxy_response_bytes_yb_master_Master/ && $(NF-1)>0{printf "%10d %-s\n", $(NF-1),$1}' | sort -n
4 proxy_response_bytes_yb_master_MasterDdl_IsCreateNamespaceDone
12 proxy_response_bytes_yb_master_MasterReplication_IsObjectPartOfXRepl
16 proxy_response_bytes_yb_master_MasterClient_ReservePgsqlOids
34 proxy_response_bytes_yb_master_MasterDdl_CreateNamespace
44 proxy_response_bytes_yb_master_MasterAdmin_WaitForYsqlBackendsCatalogVersion
48 proxy_response_bytes_yb_master_MasterDdl_IsTruncateTableDone
84 proxy_response_bytes_yb_master_MasterDdl_IsDeleteTableDone
396 proxy_response_bytes_yb_master_MasterDdl_BackfillIndex
408 proxy_response_bytes_yb_master_MasterDdl_IsAlterTableDone
431 proxy_response_bytes_yb_master_MasterDdl_ListNamespaces
488 proxy_response_bytes_yb_master_MasterDdl_IsCreateTableDone
514 proxy_response_bytes_yb_master_MasterDdl_GetBackfillStatus
910 proxy_response_bytes_yb_master_MasterDdl_DeleteTable
1088 proxy_response_bytes_yb_master_MasterClient_GetTransactionStatusTablets
1761 proxy_response_bytes_yb_master_MasterClient_GetTabletLocations
1870 proxy_response_bytes_yb_master_MasterDdl_CreateTable
53124 proxy_response_bytes_yb_master_MasterCluster_ListTabletServers
143572 proxy_response_bytes_yb_master_MasterDdl_GetNamespaceInfo
7835913 proxy_response_bytes_yb_master_MasterClient_GetTableLocations
17771529 proxy_response_bytes_yb_master_MasterDdl_GetTableSchema
424897254 proxy_response_bytes_yb_master_MasterHeartbeat_TSHeartbeat
```
You probably don't need this level of information, but if you observe too many remote calls (RPC) to the YB-Master, you should look at it. | franckpachot |
1,850,437 | MONGODB | Create An Express Server Using Mongodb Mongo db : MongoDB is built on a... | 0 | 2024-05-24T17:57:36 | https://dev.to/eniola/mongodb-34fc | javascript, beginners, tutorial, database |
#### Create An Express Server Using Mongodb
#### Mongo db :
MongoDB is built on a scale-out architecture that has become popular with developers of all kinds for developing scalable applications with evolving data schemas. As a document database, MongoDB makes it easy for developers to store structured or unstructured data. It uses a JSON-like format to store documents.
#### Download Mongodb And Mongodb Compass:
Click [here](https://www.mongodb.com/) to download mongodb
Click [here](https://www.mongodb.com/products/tools/compass) to download mongodb compass
#### Check Your Terminal If Mongodb Is Install Perfectly:
Check by typing **mongosh** on your terminal

#### Install MongoDb:
<mark>npm install mongodb</mark> on your vscode terminal
#### Create a database server
```javascript
//call express and mongodb function
const express = require ("express");
const { MongoClient } = require ("mongodb");
const app = express();
// mongodb url
const url = "mongodb://localhost:27017";
const client = MongoClient(url);
// Create a database folder
const dataName = "Folder";
// Create a database collection
let dbCollection;
async function dbConnect() {
await client.connect();
console.log("connected to db successfully");
const db = client.db(dataName);
dbCollection = db.collection("Staff");
return "done .";
}
// Create a port number
const port = 3000;
app.listen(port, () => {
console.log(`Server is running on port http://localhost:${port}`);
})
```
#### RUN YOUR TERMINAL
| eniola |
1,839,015 | Learn SwiftUI (Day 1/100) | Swift Variable Constants String and multiple-line string Integer Double import... | 0 | 2024-04-30T19:55:23 | https://dev.to/bitecode/learn-swiftui-day-1100-jkm | swift | ## Swift
* Variable
* Constants
* String and multiple-line string
* Integer
* Double
```swift
import Cocoa
// "var" means make a new variable
var greeting = "Hello, playground"
print(greeting)
var name = "hello"
print(name)
name = "world"
print(name)
// let: Declares a constant that cannot be changed once it has been set, i.e., an immutable variable
let lang = "python"
print(lang)
// lang = "java" // Error: cannot assign to value
// print(lang)
/*
Best practice suggests that you should default to using let to define a variable and only use var when you explicitly need the variable’s value to change. This helps lead to cleaner, more predictable code.
*/
// ## Create strings
let quote = "Then he tapped a sign \"Believe\" and walked away"
// multiple line string
let movie = """
hello
世界
"""
print(movie)
print(movie.count) // 8 -> count returnes unicode count
let trimmed = movie.trimmingCharacters(in: .whitespacesAndNewlines)
print(trimmed.count)
// define integers
let score = 10
print(score / 3) // 3
var points = 10
points += 1
print(points)
// define floating number
let number = 0.1 + 0.2
print(number)
let a = 1
let b = 2.0
// int and double cannot sum, must cast first
let c = Double(a) + b
let d = a + Int(b)
``` | bitecode |
1,864,221 | Scraper compania Olinio | Scraper Orice scraper există datorită unei echipe de scraper și tester. Scraper-ul... | 0 | 2024-05-24T17:53:28 | https://dev.to/ale23yfm/scraper-compania-olinio-34g2 | peviitor, scraper, olinio | ## Scraper
Orice scraper există datorită unei echipe de scraper și tester. Scraper-ul companiei **_Olinio_** este scris de [Iurie Chigai](https://www.linkedin.com/in/iurie-chigai/) în limbajul Python și testat de [Claudia Rusu](https://www.linkedin.com/in/claudia-rusu/), drept muncă voluntară, și poate fi găsit pe GitHub, fiind un proiect open source.
{% github https://github.com/peviitor-ro/scrapers_python_iurie %}
---
## Te interesează să scrii un scraper sau să testezi unul?
Poți să te alături proiectului chiar de aici!
[Link Discord peviitor.ro](https://discord.gg/t2aEdmR52a)
---
| ale23yfm |
1,863,772 | Vocode Setup for GenAI Voice Calls: A Guide for Non-Python Developers | Target Audience: This guide is designed for developers who are not primarily familiar with Python or... | 0 | 2024-05-24T17:51:37 | https://dev.to/bajajcodes/vocode-setup-for-genai-voice-calls-a-guide-for-non-python-developers-4f21 | genai, ai, vocode, voiceai | <p><strong>Target Audience:</strong> This guide is designed for developers who are not primarily familiar with Python or its ecosystem, and want to set up Vocode for GenAI voice calls.</p>
<h2>Table of Contents</h2>
<ol>
<li>Introduction to Vocode and Project Tools</li>
<li>Project Setup and Dependency Management</li>
<li>Configuring Environment Variables and Ngrok</li>
<li>Setting Up the Telephony Server</li>
<li>Creating the Outbound Call Script</li>
<li>Additional Notes and Troubleshooting</li>
<li>References</li>
</ol>
<h2>1. Introduction to Vocode and Project Tools</h2>
<p>Vocode is a powerful tool for creating AI-powered voice applications. To streamline the development process, we'll use:</p>
<ul>
<li><strong>Poetry:</strong> For managing project dependencies and virtual environments.</li>
<li><strong>Pyproject.toml:</strong> A configuration file used by Poetry to define project details, Python version, and required libraries.</li>
</ul>
<h2>2. Project Setup and Dependency Management</h2>
<ol>
<li><strong>Install Poetry:</strong>
Follow the instructions on the <a href="https://python-poetry.org/docs/#installation">Poetry installation page</a>.</li>
<li><strong>Create the Project:</strong>
<pre><code>poetry new project-name</code></pre>
</li>
<li><strong>Activate the Virtual Environment:</strong>
<pre><code>poetry config virtualenvs.create true
poetry shell</code></pre>
</li>
<li><strong>Specify the Python Version:</strong>
<ul>
<li>Open <code>pyproject.toml</code> in your project directory.</li>
<li>Add the following under <code>[tool.poetry.dependencies]</code>:
<pre><code>python = ">=3.9,<3.12"</code></pre>
</li>
<li>Update the lock file:
<pre><code>poetry lock --no-update</code></pre>
</li>
</ul>
</li>
<li><strong>Install Dependencies:</strong>
<pre><code>poetry add redis^4.5.4 twilio^8.1.0 vocode==0.1.111 vonage^3.5.1 python-dotenv^1.0.0</code></pre>
</li>
<li><strong>Verify Installation:</strong>
<ul>
<li>Create <code>main.py</code> and add:
<pre><code>print("Hello, GenAI")</code></pre>
</li>
<li>Run:
<pre><code>poetry run python main.py</code></pre>
</li>
<li>You should see "Hello, GenAI" printed in the console.</li>
</ul>
</li>
</ol>
<h2>3. Configuring Environment Variables and Ngrok</h2>
<ol>
<li><strong>Create the <code>.env</code> File:</strong>
<ul>
<li>Create a <code>.env</code> file in your project's root directory.</li>
<li>Add your credentials (replace placeholders with actual values):
<pre><code>BASE_URL=
DEEPGRAM_API_KEY=
OPENAI_API_KEY=
AZURE_SPEECH_KEY=
AZURE_SPEECH_REGION=
TWILIO_ACCOUNT_SID=
TWILIO_AUTH_TOKEN=
TWILIO_FROM_NUMBER=</code></pre>
</li>
</ul>
</li>
<li><strong>Set Up Ngrok:</strong>
<ul>
<li>Install Ngrok from <a href="https://ngrok.com/download">https://ngrok.com/download</a>.</li>
<li>Set up your Ngrok AuthToken from <a href="https://dashboard.ngrok.com/get-started/your-authtoken">https://dashboard.ngrok.com/get-started/your-authtoken</a>.</li>
<li>Run in a separate terminal:
<pre><code>ngrok http 3000</code></pre>
</li>
<li>Copy the provided ngrok URL (e.g., <code>https://abcdef123456.ngrok.io</code>) and paste it as your <code>BASE_URL</code> in <code>.env</code>, removing the <code>https://</code> prefix and trailing slash.</li>
<li>Image of ngrok terminal output
<img src="https://i.imgur.com/bc7WCNd.png" alt="ngrok terminal output" />
</li>
</ul>
</li>
</ol>
<h2>4. Setting Up the Telephony Server</h2>
<ol>
<li><strong>Copy the Server Code:</strong>
Get the code from this Gist: <a href="https://gist.github.com/bajajcodes/5722cade50a9867b98b246a2cb30ced4">https://gist.github.com/bajajcodes/5722cade50a9867b98b246a2cb30ced4</a> and paste it into <code>main.py</code>.</li>
<li><strong>Activate Your Virtual Environment:</strong>
<pre><code>poetry shell</code></pre>
</li>
<li><strong>Run the Server:</strong>
<pre><code>poetry run python main.py</code></pre>
</li>
<li><strong>Start the FastAPI Server (Add to main.py):</strong>
<pre><code>import uvicorn
if __name__ == "__main__":
uvicorn.run(app, host="localhost", port=port)</code></pre>
</li>
<li><strong>Run the Script Again:</strong>
<pre><code>poetry run python main.py</code></pre>
</li>
</ol>
<ul>
<li>Image of Uvicorn Server Output
<img src="https://i.imgur.com/0ajDCfi.png" alt="Uvicorn Server Output" />
</li>
<li>Image of ngrok accessing localhost server
<img src="https://i.imgur.com/RvkrOQl.png" alt="ngrok accessing localhost server" />
</li>
</ul>
<h2>5. Creating the Outbound Call Script</h2>
<ol>
<li><strong>Set Up Redis:</strong>
<pre><code>docker run -dp 6379:6379 -it redis/redis-stack:latest</code></pre>
</li>
<li><strong>Create outbound_call.py:</strong>
Copy the code from this Gist: <a href="https://gist.github.com/bajajcodes/718b598b26e146c4b6bbc784c1d2b1c0">https://gist.github.com/bajajcodes/718b598b26e146c4b6bbc784c1d2b1c0</a> and paste it into <code>outbound_call.py</code>.</li>
<li><strong>Activate Your Virtual Environment:</strong>
<pre><code>poetry shell</code></pre>
</li>
<li><strong>Run the Script:</strong>
<pre><code>poetry run python outbound_call.py</code></pre>
</li>
</ol>
<ul>
<li>Image of Script Console Output
<img src="https://i.imgur.com/13bM79B.png" alt="Script Console Output" />
</li>
<li>Image of Server Logs
<img src="https://i.imgur.com/qclFgDy.png" alt="Server Logs" />
</li>
</ul>
<h2>6. Additional Notes and Troubleshooting</h2>
<ul>
<li><strong>Ngrok URL:</strong> Ensure the <code>BASE_URL</code> in <code>.env</code> matches the ngrok URL.</li>
<li><strong>Endpoints:</strong> Access your FastAPI app at the ngrok URL or your <code>BASE_URL</code>. You can test endpoints like <code>/inbound_call</code>, <code>/events</code>, and <code>/recordings</code> using <code>curl</code> or a web browser.</li>
</ul>
<h2>7. References</h2>
<ul>
<li>Vocode Telephony Server Documentation: <a href="https://docs.vocode.dev/open-source/telephony">https://docs.vocode.dev/open-source/telephony</a></li>
<li>Vocode Telephony Server Code: <a href="https://github.com/vocodedev/vocode-python/tree/main/apps/telephony_app">https://github.com/vocodedev/vocode-python/tree/main/apps/telephony_app</a></li>
</ul> | bajajcodes |
1,864,219 | **¡Aventuras en la prehistoria de las bases de datos con el Capitán Cavernícola!**🦖 | ¡Hola Chiquis! 👋🏻 Bienvenidos a un viaje apasionante por el mundo de las bases de datos, donde... | 0 | 2024-05-24T17:40:56 | https://dev.to/orlidev/aventuras-en-la-prehistoria-de-las-bases-de-datos-con-el-capitan-cavernicola-39l5 | database, datastructures, beginners, programming | ¡Hola Chiquis! 👋🏻 Bienvenidos a un viaje apasionante por el mundo de las bases de datos, donde descubriremos sus secretos y cómo aprovechar su poder para dominar la información.
¿Alguna vez te has preguntado cómo las grandes empresas gestionan millones de datos? 🐢¿Cómo las tiendas online mantienen actualizados sus catálogos de productos? ¿O cómo las redes sociales te muestran contenido personalizado? La respuesta está en las bases de datos, esos tesoros ocultos que albergan información valiosa y la organizan de forma eficiente.

¿Estás listo para convertirte en un maestro de las bases de datos? Imagina al Capitán Cavernícola, no golpeando dinosaurios con su garrote, sino dominando el mundo de las bases de datos. En este post exploraremos este universo de información junto a nuestro héroe prehistórico.
Las bases de datos son como el Capitán Cavernícola: un almacén de conocimiento que nos permite organizar, recuperar y gestionar información.
¿Qué es una base de datos?🦕
Una base de datos es un conjunto organizado de información que se almacena electrónicamente en un sistema informático. Imagina que es como la cueva del Capitán Cavernícola, donde él guarda sus tesoros y secretos. En este caso, los tesoros son los datos y la cueva es la base de datos.
1. El tesoro escondido del Capitán 🦴
Las bases de datos son como la cueva secreta del Capitán Cavernícola, un lugar donde guarda sus preciados tesoros: pieles de animales, huesos, herramientas de piedra… ¡en otras palabras, información! En lugar de amontonarlos en desorden, los organiza en secciones específicas, como si cada sección fuera una caja diferente dentro de la cueva.

2. Estructura de las bases de datos: ¡Organizando la cueva! 🍖
Para que el Capitán encuentre lo que busca rápidamente, la cueva debe estar organizada. Las bases de datos funcionan de forma similar: se estructuran en tablas, como si cada caja de la cueva fuera una tabla. Cada tabla tiene filas (que representan los registros individuales) y columnas (que representan las características de cada registro).
3. Claves primarias: ¡Las marcas secretas del Capitán! 🔥
Para identificar cada tesoro sin confusiones, el Capitán marca cada uno con una señal única. En las bases de datos, cada fila tiene una clave primaria, un identificador único que la distingue de las demás.
4. Relaciones entre tablas: ¡Un mapa de la cueva! 🗺️
Las diferentes secciones de la cueva del Capitán pueden estar relacionadas entre sí. Por ejemplo, en una sección guarda las pieles de animales y en otra, las herramientas para cazarlos. Las bases de datos también establecen relaciones entre tablas, permitiendo conectar información de diferentes secciones.
5. Lenguajes de consulta: ¡Hablando el idioma de la cueva! 🌋
Para comunicarse con los tesoros de la cueva, el Capitán usa un lenguaje especial. En las bases de datos, se utilizan lenguajes de consulta como SQL para interactuar con la información. Estos lenguajes permiten al usuario buscar, agregar, modificar y eliminar datos.
6. Sistemas gestores de bases de datos (SGBD): ¡El asistente del Capitán! 🗻
El Capitán no organiza la cueva solo, ¡tiene un fiel asistente! Los SGBD son programas que se encargan de gestionar las bases de datos, controlando el acceso, la seguridad y la integridad de la información.
7. Tipos de bases de datos 🧰
- Bases de datos estáticas: Son como los pergaminos antiguos que solo se pueden leer. No se pueden modificar, solo extraer información. Por ejemplo, una biblioteca con libros ordenados por autor o tema.
- Bases de datos dinámicas: Estas son más flexibles. Además de leer, puedes escribir en ellas. Son como el diario del Capitán Cavernícola, donde él anota sus aventuras y descubrimientos.

¡Para cada tesoro, un baúl! 💨
No todas las cuevas son iguales, y las bases de datos tampoco. Existen diferentes tipos, cada uno con sus características y usos específicos. Entre los más comunes encontramos:
- Bases de datos relacionales: Almacenan datos en tablas relacionadas entre sí, como la cueva del Capitán.
- Bases de datos NoSQL: Más flexibles que las relacionales, ideales para grandes volúmenes de datos no estructurados.
- Bases de datos en la nube: Almacenadas en servidores remotos, accesibles desde cualquier lugar con internet.
8. ¡Las bases de datos en acción! 💪
Las bases de datos están presentes en nuestro día a día:
- Tiendas online: Almacenan información de productos, clientes y pedidos.
- Redes sociales: Gestionan datos de usuarios, publicaciones y mensajes.
- Bancos: Registran transacciones, cuentas y datos de clientes.
- Hospitales: Guardan historiales médicos, citas y resultados de pruebas.
9. El futuro de las bases de datos: ¡Nuevas aventuras para el Capitán!🐋
El mundo de las bases de datos está en constante evolución, con nuevas tecnologías y aplicaciones emergentes. El Big Data, la inteligencia artificial y el Internet de las Cosas (IoT) están transformando la forma en que se almacenan, analizan y utilizan los datos.
Ejemplos que nos explica el capitán de bases de datos 🦑
- Guías telefónicas: Antes, teníamos enormes libros con miles de números telefónicos. Cada número estaba asignado a un hogar, empresa o particular. Así, podíamos encontrar a quien necesitábamos, ¡como el Capitán Cavernícola buscando a sus amigos prehistóricos! 📞
- Registro de estudiantes: Imagina una base de datos en una universidad. Cada estudiante tiene su propia ficha con datos como nombre, edad, carrera y notas. Es como si el Capitán Cavernícola llevara un registro de todos los habitantes de la Edad de Piedra.
- Redes sociales: Facebook, Instagram y Twitter son como las paredes de la cueva del Capitán Cavernícola. Cada publicación, foto o comentario es un dato almacenado en una base de datos gigante. ¡Los "me gusta" son como las pinturas rupestres que todos ven! 👍📸
- Historial de compras: Cuando compras en línea, tus datos quedan registrados en una base de datos. Es como si el Capitán Cavernícola anotara cada vez que intercambia una concha marina por un pedazo de mamut.

Las Bases de Datos Explicadas con el Capitán Cavernícola🐌
Imagina que el Capitán Cavernícola, en lugar de ser un cavernícola, es un administrador de bases de datos en el mundo moderno. Su club es su servidor de base de datos y las rocas que recolecta son los datos.
Piedras (Datos)🦴
Las piedras son como los datos. Son la materia prima que el Capitán Cavernícola (el administrador de la base de datos) recoge y utiliza. Al igual que las piedras pueden tener diferentes formas y tamaños, los datos también pueden variar. Pueden ser números, texto, fechas, etc.
Bolsa (Base de Datos)☄️
La bolsa del Capitán Cavernícola es como la base de datos. Es donde guarda todas sus piedras (datos). La bolsa puede contener muchas piedras, al igual que una base de datos puede contener muchos datos.
Compartimentos en la Bolsa (Tablas)🦕
Dentro de la bolsa, el Capitán Cavernícola tiene diferentes compartimentos donde organiza sus piedras. Estos son como las tablas en una base de datos. Cada tabla contiene un tipo específico de datos. Por ejemplo, una tabla puede contener información sobre los clientes, mientras que otra puede contener información sobre los productos.
Dibujos en las Piedras (Registros y Campos)🐊
El Capitán Cavernícola dibuja en sus piedras para recordar información sobre ellas. Estos dibujos son como los registros y campos en una base de datos. Un registro es una entrada individual en una tabla (como una piedra única), y los campos son detalles sobre ese registro (como los dibujos en la piedra).
Club (Servidor de Base de Datos)🦎
Finalmente, el club del Capitán Cavernícola es como el servidor de base de datos. Es la herramienta que utiliza para gestionar su bolsa de piedras. Con su club, puede añadir nuevas piedras a su bolsa, quitar piedras, mover piedras de un compartimento a otro, o cambiar los dibujos en las piedras.

Conclusión: ¡El Capitán Cavernícola conquista el mundo de las bases de datos! 🥩
Al igual que el Capitán Cavernícola dominó su entorno con astucia y herramientas, tú también puedes convertirte en un experto en bases de datos. Con un poco de conocimiento y práctica, podrás navegar por este universo de información y aprovechar su potencial para tus proyectos.
Así como el Capitán Cavernícola necesita su cueva para guardar sus tesoros, nosotros necesitamos bases de datos para organizar y acceder a la información. ¡Espero que esta analogía te ayude a entender mejor este fascinante mundo prehistórico digital! 🦕💾
Recuerda: ¡Las bases de datos son como la cueva del Capitán Cavernícola: llenas de tesoros valiosos que esperan ser descubiertos! Y, ¡el Capitán Cavernícola siempre está listo para gestionar sus datos! 😄
Bonus:
Para aprender más sobre bases de datos, puedes visitar sitios web como https://www.w3schools.com/sql/ https://www.khanacademy.org/computing/computer-programming/sql
🚀 ¿Te ha gustado? Comparte tu opinión.
Artículo completo, visita: https://lnkd.in/ewtCN2Mn
https://lnkd.in/eAjM_Smy 👩💻 https://lnkd.in/eKvu-BHe
https://dev.to/orlidev ¡No te lo pierdas!
Referencias:
Imágenes creadas con: Copilot (microsoft.com)
##PorUnMillonDeAmigos #LinkedIn #Hiring #DesarrolloDeSoftware #Programacion #Networking #Tecnologia #Empleo #BasesDeDatos

 | orlidev |
1,864,241 | Webinar Sobre UX/UI Gratuita: Estratégias Para Iniciar Carreira | No webinar gratuito oferecido pela EBAC, serão trabalhadas estratégias fundamentais para aqueles que... | 0 | 2024-05-27T01:33:28 | https://guiadeti.com.br/webinar-ux-ui-gratuita-estrategias-para-carreira/ | eventos, cursosgratuitos, design, designgráfico | ---
title: Webinar Sobre UX/UI Gratuita: Estratégias Para Iniciar Carreira
published: true
date: 2024-05-24 17:22:00 UTC
tags: Eventos,cursosgratuitos,design,designgráfico
canonical_url: https://guiadeti.com.br/webinar-ux-ui-gratuita-estrategias-para-carreira/
---
No webinar gratuito oferecido pela EBAC, serão trabalhadas estratégias fundamentais para aqueles que buscam ingressar no mercado de UX/UI ou enfrentam desafios na transição de carreira.
A obtenção dessas estratégias é importante para conquistar um espaço nesse cenário altamente competitivo.
Nesta sessão, serão vistos temas como a busca pelo primeiro emprego na área, o desenvolvimento de um portfólio eficaz, dicas para networking eficiente e técnicas valiosas para se destacar em entrevistas.
Os participantes do evento também terão acesso a um desconto exclusivo no curso Profissão UX/UI Design.
## Carreira em UX/UI: estratégias para entrar nesse mercado
No webinar gratuito oferecido pela EBAC, serão estudadas estratégias fundamentais para aqueles que buscam ingressar no mercado de UX/UI ou enfrentam desafios na transição de carreira.

_Imagem da página do evento_
A obtenção dessas estratégias é fundamental para conquistar um espaço nesse cenário altamente competitivo.
### Conteúdo e Participação Especial
No evento vão ser abordados temas como a busca pelo primeiro emprego na área, o desenvolvimento de um portfólio eficaz, dicas para networking eficiente e técnicas valiosas para se destacar em entrevistas.
O webinar contará com a participação de Sofia Torres, Product Designer na Projétil e Freelance Designer na Lindhagen Studio, que compartilhará sua jornada de sucesso e insights preciosos.
### A Quem Pode Interessar
Este webinar é destinado a pessoas que gostam de melhorar a vida das outras, buscam por carreiras promissoras no mercado tech, querem trabalhar com a criação de apps, sites e plataformas online, são desenvolvedores, gerentes de produtos, designers digitais e web designers, e até mesmo àqueles da turma de Humanas e Exatas que querem migrar de carreira.
### Conteúdo do Webinar
- Do planejamento ao primeiro emprego: onde estou e para onde vou?: Atitudes para impulsionar sua carreira com base em sua experiência prévia;
- Portfolio estruturado e networking efetivo como diferenciais: Dicas práticas de como atrair oportunidades e fortalecer sua rede;
- Preparação para entrevistas: Como comunicar suas habilidades nas entrevistas com eloquência.
### Desconto Exclusivo e Data do Evento
Os participantes do evento também terão acesso a um desconto exclusivo no curso Profissão UX/UI Design. O webinar está marcado para o dia 29 de maio de 2024, às 19h. As vagas são limitadas, então não perca tempo!
### Participação Interativa e Dinâmica
As aulas serão todas ao vivo, proporcionando a oportunidade de tirar dúvidas e enviar perguntas para a professora pelo chat.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Imersao-Gratuita-Inteligencia-Artificial-280x210.png" alt="Imersão Gratuita Inteligência Artificial" title="Imersão Gratuita Inteligência Artificial"></span>
</div>
<span>Imersão Em Inteligência Artificial Gratuita Da XP Educação</span> <a href="https://guiadeti.com.br/imersao-inteligencia-artificial-gratuita-xp/" title="Imersão Em Inteligência Artificial Gratuita Da XP Educação"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/04/Cursos-Hackaflag-Academy-280x210.png" alt="Cursos Hackaflag Academy" title="Cursos Hackaflag Academy"></span>
</div>
<span>Hackaflag Academy: Aprenda Pentest, Linux, Javascript E Mais</span> <a href="https://guiadeti.com.br/plataforma-hackaflag-academy-cursos-gratuitos/" title="Hackaflag Academy: Aprenda Pentest, Linux, Javascript E Mais"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Aula-De-Python-Do-Google-280x210.png" alt="Aula De Python Do Google" title="Aula De Python Do Google"></span>
</div>
<span>Curso De Python Gratuito Do Google: Textos, Aulas E Palestras</span> <a href="https://guiadeti.com.br/curso-python-gratuito-google-textos-palestras/" title="Curso De Python Gratuito Do Google: Textos, Aulas E Palestras"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/04/GF-Cursos-Gratuitos-280x210.png" alt="GF Cursos Gratuitos" title="GF Cursos Gratuitos"></span>
</div>
<span>GF Cursos: Aprenda Gratuitamente HTML, PHP, Redes, Corel Draw E Outros</span> <a href="https://guiadeti.com.br/plataforma-gf-cursos-cursos-em-html-php-e-mais/" title="GF Cursos: Aprenda Gratuitamente HTML, PHP, Redes, Corel Draw E Outros"></a>
</div>
</div>
</div>
</aside>
## UX/UI
UX (User Experience) e UI (User Interface) são termos fundamentais no design digital, focados em proporcionar uma experiência positiva e intuitiva aos usuários de produtos digitais, como aplicativos e sites.
### O Que é UX/UI?
UX refere-se à experiência geral que um usuário tem ao interagir com um produto digital, incluindo a facilidade de uso, eficiência e satisfação. UI, por outro lado, concentra-se na parte visual e interativa do design, como layout, cores, tipografia e elementos de interface.
### Importância da UX/UI
Uma boa UX/UI é crucial para o sucesso de um produto digital, pois influencia diretamente na satisfação do usuário, na retenção e no engajamento. Uma interface bem projetada e uma experiência positiva podem impactar positivamente a imagem da marca e a fidelidade dos clientes.
### Diferenciação entre UX e UI
Enquanto UX se preocupa com a jornada do usuário e sua interação com o produto, UI se concentra na estética e na usabilidade dos elementos visuais. Ambos são complementares e importantes para criar uma experiência digital eficaz e agradável.
### Habilidades Necessárias
Profissionais de UX/UI precisam de habilidades em pesquisa de usuários, prototipação, design visual, testes de usabilidade e conhecimento em tecnologias de desenvolvimento web e mobile. São necessárias habilidades de comunicação e colaboração para trabalhar em equipe.
### Tendências em UX/UI
Algumas tendências atuais em UX/UI incluem design responsivo para dispositivos móveis, microinterações para melhorar a interatividade, acessibilidade para atender a diferentes públicos e uso de inteligência artificial para personalização e automação.
## EBAC
A EBAC (Escola Britânica de Artes Criativas) é uma instituição de ensino focada no desenvolvimento de habilidades e conhecimentos nas áreas de artes visuais, design, comunicação e tecnologia.
### História e Missão
A EBAC tem como missão oferecer uma educação de alta qualidade, alinhada com as demandas do mercado e as tendências globais nas áreas criativas e tecnológicas. A escola busca inspirar e capacitar futuros profissionais a alcançarem seu potencial máximo.
#### Abordagem Educacional
A EBAC faz uso de uma metodologia prática e hands-on em seus cursos, proporcionando aos alunos experiências reais de trabalho e projetos desafiadores. A forma de ensino combina teoria e prática, preparando os estudantes para os desafios do mercado de trabalho.
### Cursos Oferecidos
A escola oferece uma ampla variedade de cursos, incluindo Design Gráfico, Design de Interiores, Fotografia, Animação, Marketing Digital, Desenvolvimento de Jogos, entre outros. Os programas são atualizados regularmente para refletir as últimas tendências e tecnologias.
### Relevância e Reconhecimento
A EBAC é reconhecida por sua excelência acadêmica e relevância no mercado. Os alunos têm a oportunidade de colaborar com profissionais renomados, participar de projetos reais e acessar recursos e ferramentas de última geração.
### Networking e Oportunidades Profissionais
A EBAC oferece oportunidades de networking e conexão com empresas e profissionais do setor. Os alunos são incentivados a desenvolverem suas habilidades, criatividade e visão empreendedora.
## Garanta sua vaga e embarque no caminho para uma carreira de sucesso em UX/UI com o nosso webinar!
As [inscrições para o webinar Carreira em UX/UI: estratégias para entrar nesse mercado](https://ebaconline.com.br/webinars/product-webinar-2024-05-29) devem ser realizadas no site da EBAC.
## Compartilhe esta oportunidade de aprimoramento profissional com seus colegas e amigos interessados!
Gostou do conteúdo sobre o webinar gratuito de UX/UI? Então coompartilhe com a galera!
O post [Webinar Sobre UX/UI Gratuita: Estratégias Para Iniciar Carreira](https://guiadeti.com.br/webinar-ux-ui-gratuita-estrategias-para-carreira/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,864,192 | Create a chatbot with just eight lines of code v.2 | Translation and Grammar Correction: I am updating a post that showed how to create a chatbot with... | 0 | 2024-05-24T17:09:26 | https://dev.to/cll/create-a-chatbot-with-just-eight-lines-of-code-v2-4dd5 | ai, generativeai | **Translation and Grammar Correction:**
I am updating a post that showed how to create a chatbot with Hugging Face in eight lines.
The update is due to the fact that `pip install langchain` is no longer valid; the correct command is `pip install langchain_community`.
```python
%%capture
!pip install langchain_community
!pip install huggingface_hub
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "YOUR_TOKEN"
%%capture
from langchain import HuggingFaceHub
# Instantiate model
llm = HuggingFaceHub(repo_id="tiiuae/falcon-7b-instruct", model_kwargs={"temperature": 0.6})
response = llm.invoke("write a poem about AI?")
print(response)
```
_AI, the cosmic force,
A dream we've sought for years,
A power so immense, so wise,
Our hopes, our dreams, they find a place.
In the future, so bright and grand,
AI will lead us, through galaxies in hand,
To places unimagined, to worlds unknown,
Unleashing powers, we've never shown._
Unleash the power of AI, and behold the future. | cll |
1,850,878 | picoCTF "MATRIX" Walkthrough (Caution: an extremely lengthy post) | Introduction For this post, we are going to tackle one of the hardest challenges when it... | 0 | 2024-05-24T17:21:12 | https://dev.to/7jw92nvd1klaq1/picoctf-matrix-walkthrough-caution-a-lengthy-post-2cci | picoctf, security, ctf, learning | ## Introduction
For this post, we are going to tackle one of the hardest challenges when it comes to the category of Reverse Engineering on picoCTF that is worth 500 points. Certainly, it was a lot harder and took more time to understand and ultimately obtain the flag than two previous challenges I completed, but it was a pretty great learning experience I would say, which taught me a good deal about the mindset and technique I should use to approach reverse engineering in general. Since the challenge is a lot harder than others, the post may be a bit longer than the usual to explain some of the findings, but I will do my best to explain things concisely and right to the point. Without further ado, let's dive in to it!
## 1. Analyzing the Binary
### Start
Just with two previous challenges, this requires one to download the binary and examine the content inside. Let's download and import it to Ghidra for analysis.
- Here are various details regarding the binary. In some cases, there may be some noteworthy details that might aid one in finding out what one is working with, but I don't really see anything too interesting in it, so we move on to the next phase where Ghidra commences analysis.
- Let's use the default options for the analysis of the binary.
- Here we are in the part of Ghidra for examining the innards of the binary. You can check the bottom-right corner to check the progress of an analysis. Once it's done, we start analyzing it ourselves!
### "Main" Function
So, the very first thing I do is to check a list of functions that might give away some hints on how we should approach the challenge. Let's check out what kind of functions it has.
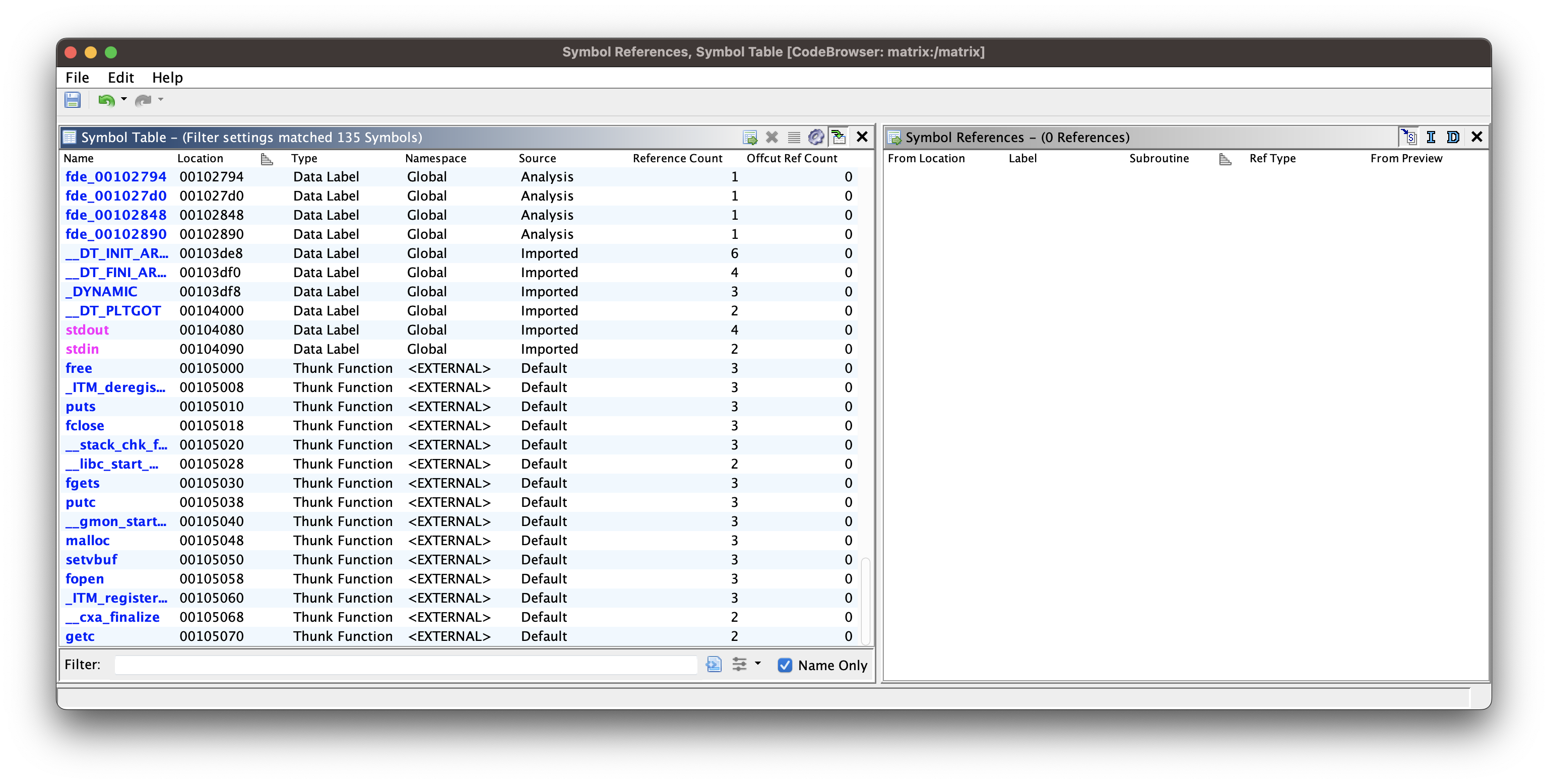
I don't even see anything too noteworthy that piques my interest, and in fact, there is no `main` function that we usually encounter in a binary written in C. Hmm, I think this binary is written in C and compiled with GCC, but I don't see any function called `main`. However, there is a function called `__libc_start_main`, which is called inside the function `entry`. Let's check out the function `entry`.
The function `__libc_start_main` is provided with the total 7 arguments. There are a few interesting arguments worth checking out. In Ghidra, any function that cannot be named, due to it being stripped during the compilation process or for some reason, gets assigned a random name that starts with the substring `FUN_`. As you can see, there are a few arguments whose name starts with the substring `FUN_`. So what one can deduce is that one of the functions passed to the function `__libc_start_main` is called when the program starts? Rummaging through the Internet, I come across this help page for the function `__libc_start_main`.
The **[page](https://refspecs.linuxbase.org/LSB_3.1.1/LSB-Core-generic/LSB-Core-generic/baselib---libc-start-main-.html)** basically states that the function `__libc_start_main` is called to initialize the environment for a process, prior to executing the main function we call. **The very first argument passed to the function is actually a function pointer for the main function that will be executed, once the preparation for running a process is done.** The name of the function we must check out is **`FUN_001010d0`**. Let's move on to checking out the very function **`FUN_001010d0`**.
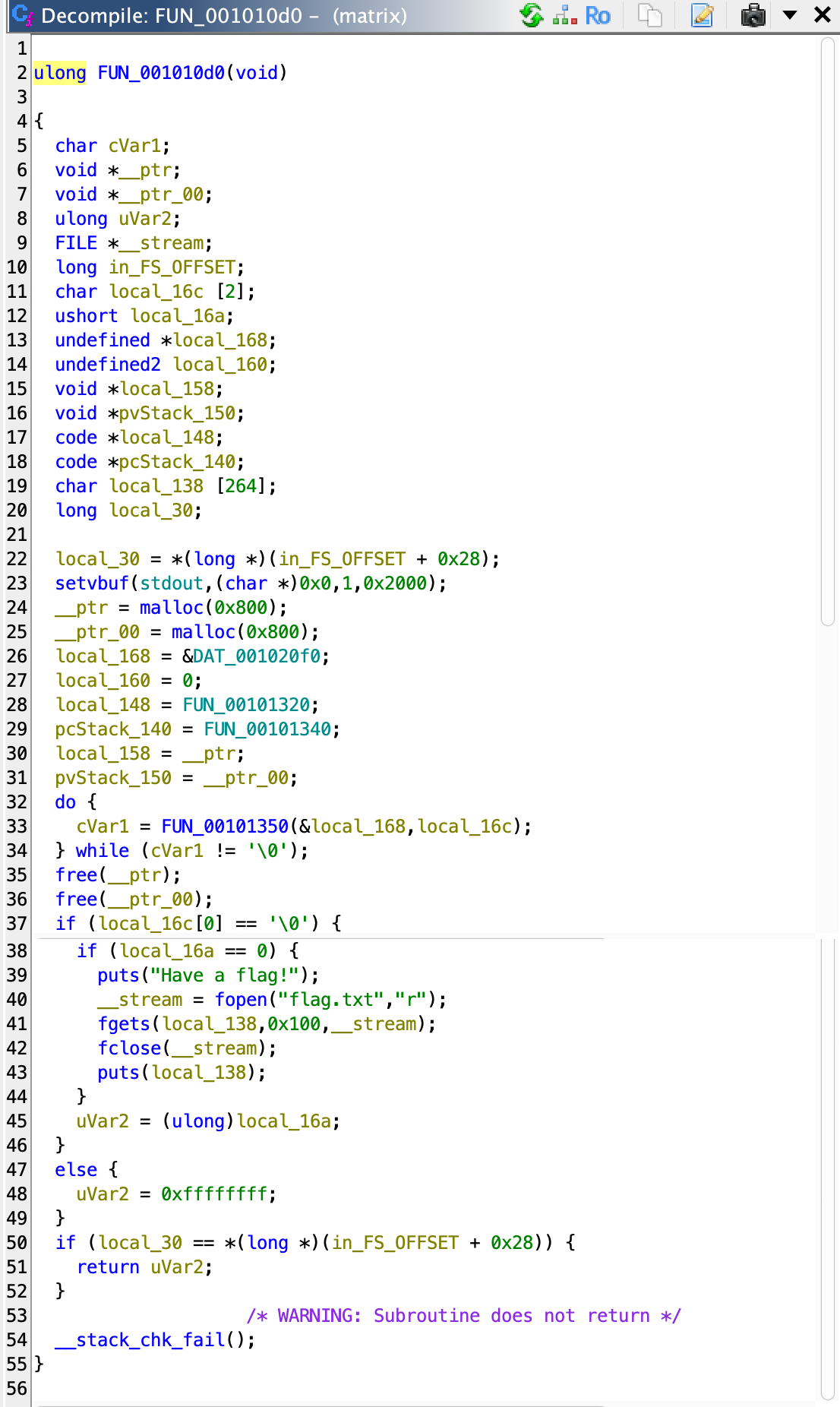
Seems like we are at the right place to start figuring out how things work!
* In the screenshot right above this paragraph, **line 39** outputs the string **`Have a flag!`**, which subsequently in the next line outputs the flag we need to complete the challenge. Since we are in the initial stage of analysis, it is still very unclear what we should do to lead the binary to output the flag in general. Let's investigate the function for more clues.
* **From line 32 to 34**, it repeatedly calls the function **`FUN_00101350`** inside the do...while block. The function **`FUN_00101350`** is provided with total two arguments, **`&local_168`** and **`local_16c`**. **In line 37**, it checks the first value of **`local_16c`** to see if it amounts to a NULL byte (0), and once it checks that it is indeed a NULL byte, it proceeds to the next line to check whether the value of the variable **`local_16a`** is a NULL byte as well. Based on the information I laid out, you can presume that the variable `local_16c` is passed to the function **`FUN_00101350`**, and somehow gets modified after each execution. The character **`&`** indicates that it accepts the address of the variable **`local_168`**. So what does the variable **`&local_168`**, the first argument of the function **`FUN_00101350`**, contain?

* The variable **`local_16a`** gets assigned the address of the data **`DAT_001020f0`**. Since its name starts with the substring `DAT_`, we can presume that it may be pointing to a constant data that is located somewhere within the binary. Let's check out what data it contains.
Okay, we end up at the address of **`0x1020f0`**, and it contains a byte, which is equal to the value of `0x81`. And in the next bytes, the values `0x75`, `0x00`, `0x80` are laid out. Still not sure about its purpose. After further investigating and scrolling around, I find something interesting.
* Let's read this thing from bottom to top: **m a k e i t o u t a l i v e ?**.
* Another interesting artifacts that read like the following, when you read it from bottom to top: **Congratulations,**.
Actually, let's run the binary in a VM to check out how it works at face value.
* Okay, at the outset, it actually outputs the message `WELCOME to the M A T R I X \n Can you make it out alive?`. Did you notice that at the last part of the output, it contains the substring **make it out alive?** that we found during the analysis of the binary?
* Subsequently, I input a random string to see what happens, and press ENTER, and am instantly greeted with the message **`You were eaten by a grue`**.
* So, I basically have to provide the right password to the binary to eventually obtain the flag. What's the right password? Let's go back to Ghidra and investigate further statically.
### Exploring the function "FUN_00101350"

Back to Ghidra! Since the function **`FUN_00101350`** seems to be the one that dictates the overall flow of the binary, it's time to check out its contents.

Okay, so this is quite a lot to digest, with nearly 200 lines of code welcoming us right before our eyes. Nonetheless, we have to go over the entirety of the function, in order to figure out what's going on.
**Here are some references that you should know prior to continuing. These will be referenced throughout the post, and will greatly help you understand how things work basically**:
- **param_1[0]** (`param_1 + 0 bytes` == **`0x00007fffffffdfc0`**) - **holds the address `0x1020f0` (`0x00005555555560f0`)**, from which the real program starts. When the function `FUN_00101350` gets invoked, the binary passes the address **`0x00007fffffffdfc0`** to the `FUN_00101350` as the first argument.
- **param_1[1]** (`param_1 + 8 bytes` == **`0x00007fffffffdfc8`**) - **holds the offset of two bytes**, with which the address, at which the current command is located, is calculated, by adding `0x1020f0` to the offset.
- **param_1[2]** (`param_1 + 16 bytes` == **`0x00007fffffffdfd0`**) - **holds the address of the top of one of the makeshift stacks.** This stack gets used the most often. The starting address of the stack is at
- **param_1[3]** (`param_1 + 24 bytes` == **`0x00007fffffffdfd8`**) - **holds the address of the top of one of the makeshift stacks.** This stack gets used the least often and is mainly for temporarily storing values needed in another stack.
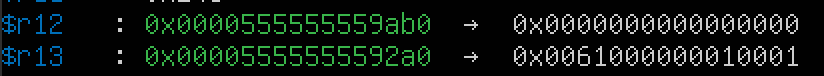
* The register `r12` stores the lowest address of the stack at **param_1[3]**, which is **`0x0000555555559ab0`**.
* The register `r13` stores the lowest address of the stack at **param_1[2]**, which is **`0x00005555555592a0`**.
* Every item on the stack is 2 bytes worth, which means that an item occupies 4 digits at once. And also, considering the fact that the binary is in little-endian, the value starts from the right, so you can read like **`0x0001|0001|0000|0061`**. In the screenshot above, the address at `0x00005555555592a6` holds the value **0061**, which is basically the hexadecimal value of `a` in ASCII. `a` is the very first character of the input I provided to the binary. So I assume that every character gets placed at the exact address of `0x00005555555592a6` for processing. What about **`0x0001|0001|0000|`** in the front? We will see what they represent.

* At this point, all we know is that the function receives two arguments, the first one being a pointer to another pointer - **`&local_168`** gets passed as the first argument, and **`&`** indicates the memory address of the variable `local_168`. `local_168`, by the way, is assigned an address of `0x1020f0` prior to entering this function - **`local_168 = &DAT_001020f0;`** - so we know for sure that it is a pointer.
* **In line 17**, the binary dereferences the pointer `param_1`, whose value is **`0x00007fffffffdfc0`**, and assigns it to the variable `lVar4`. **`lVar4` ends up with the address of `0x1020f0`.**
* **In line 18**, it adds `1` to the argument `param_1`, which becomes **`0x00007fffffffdfc8`**. Since `param_1` is a pointer of the `long` type (8 bytes), when you add 1 to it, it is equal to adding 8. And then it change its type from `long *` to `ushort *`, which means that it turns into a pointer that can reference up to two bytes only. And lastly, it dereferences the pointer - the first two bytes from the address of `param_1 + 1` (**`0x00007fffffffdfc8`**) - and assigns it to the variable **`uVar2`**.
* **In line 19**, the binary adds the value of the variable **`uVar2`** to 1, and assigns it to the variable **`uVar9`**.
* **In line 20**, the binary assigns the value of **`uVar9`** to the address `param_1 + 1` (**`0x00007fffffffdfc8`**). The value at `param_1 + 1` increments.
* **In line 21**, it adds the address `0x1020f0` (**`0x00005555555560f0`**) stored in the variable `lVar4` to the value of `uVar2`, which results in the address bigger than `0x1020f0`, subsequently converts its type from `long *` to `byte *`, and lastly dereference it to fetch a byte from the calculated address.
* **Summary** - **The variable `uVar2` in line 18 holds the offset, which in line 21 is added to the address `0x1020f0` and subsequently dereferenced for a command that needs to be executed.** Let's see what kind of commands there are by going through the screenshots below.





Going through the screenshots, you may notice that there are some notable `case` clauses with the following values:
* 0 (0x00)
* 1 (0x01)
* 0x10 - 0x14
* 0x20 - 0x21
* 0x30 - 0x34
* default - 0x80 - 0x81, 0xc0 - 0xc1
Each case clause performs different functions for the binary, but one thing in common is that the most of them use the line at the beginning to fetch the address of the top of the stack at `param_1[2]`. **The binary actually utilizes two makeshift [stacks](https://medium.com/huawei-developers/stack-vs-heap-understanding-memory-allocation-in-programming-a83a54901416) to store various data needed in calculation. The memory address at `param_1[2]` stores the top address of one of the makeshift stacks that the binary uses.** **Stacks used in this binary consist of values up to 2 bytes each, so when the binary pushes or pops the stack, the address of the top of the stack increases or decreases by two bytes.**
Explaining what each value does in detail may be way too time-consuming, so instead, I will give you the brief explanations of what each does.
* **0** - It doesn't do anything
* **1** - Executing this results in the end of the binary. This is where the binary determines whether you have successfully finished the challenge.
* **0x10** - Copies the value at the top of the stack (-0x2) and [pushes](https://www.programiz.com/dsa/stack) to the stack at `param_1[2]`, basically duplicating the value. The value at `param_1[2]` increases by 2.
* **0x11** - Pops the stack, whose value at `param_1[2]` decreases by 2.
* **0x12** - Adds the value at the top of the stack (-0x2) to the value of the item right below (-0x4), and store it at the offset (-0x4). Then pops the stack.
* **0x13** - Subtracts the value at the top of the stack (-0x2) to the value of the item right after (-0x4), and store it at the offset (-0x4). Then pops the stack.
* **0x14** - Swap the value at the top of the stack (-0x2) with one right after (-0x4).
* **0x20** - This involves two stacks - the one at `param_1[2]` and `param_1[3]`. The top of the stack `param_1[2]` pops and pushes to the stack at `param_1[3]`.
* **0x21** - This involves two stacks - the one at `param_1[2]` and `param_1[3]`. The top of the stack `param_1[3]` pops and pushes to the stack at `param_1[2]`.
* [_**0x30**_] - **Pops the top of the stack at `param_1[2]` and puts the offset at `param_1[1]`.** This is where we increments and stores the value in line 20 of the function. It basically changes the flow of the program.
* [_**0x31**_] - Pops the top of the stack at `param_1[2]` TWICE. If the second popped item has the value of `0x0000`, then **change the offset at `param_1[1]` to that of the first popped item.**
* **0x80** - Pushes the value of a byte to the stack `param_1[2]`. **Increases the offset at `param_1[1]` by 2.**
* **0x81** - Pushes the value of two bytes to the stack `param_1[2]`. **Increases the offset at `param_1[1]` by 3.**
* **0xc0** - Accepts the input from a user.
* **0xc1** - Outputs whatever is on the stack `param_1[2]`.
Most of the commands above only increment the offset at `param_1[1]` by a number from one to three at most, but ones that are surrounded by square brackets (0x30 and 0x31) drastically change the offset using the value stored on the stack `param_1[2]`, which means that they kind of act like the **[JMP](https://en.wikipedia.org/wiki/JMP_(x86_instruction))** instruction in Assembly.
**Okay, so basically the offset at `param_1[1]` starts with the value `0`, which means that if you add the value `0` to the base address `0x1020f0`, it results in the address of `0x1020f0`.** The very first command located at that address is the following:
* There is a byte value of `0x81` at the address `0x1020f0`. Revisiting the explanation on the command related to the byte `0x81`, we know that it has to do with pushing the value of two bytes to the stack `param_1[2]`. So which value does it push to the stack? It combines the next two bytes **(0x1020f1 => 0x75, 0x1020f2 => 0x00)** after the current address `0x1020f0`, pushes the very combined value `0x0075` to the stack `param_1[2]`, and lastly, increases the offset at `param_1[1]` by 3, which results in the next command at the address `0x1020f3 => 0x80`.
The very next command `0x80` at `0x1020f3` is also really similar to that of `0x81`, albeit it pushes only the value of one byte located right after the given address to the top of the stack, and increases the offset at `param_1[1]` by 2. So why does it try to achieve from pushing a bunch of bytes to the stack? When you run the binary, it actually outputs the intro message before you have to input an answer. Basically, it is preparing to output the message `Welcome to the M A T R I X\nCan you make it out alive?`!

Once it fully pushes all the necessary bytes to the stack, it eventually reaches the address `0x102161`, which holds the byte `0x81`. It pushes the value `0x013b` to the top of the stack, increases the offset by 3, and proceeds to the next command `0x30` at `0x102164`. At this point, the very value at the top of the stack at `param_1[2]` is `0x013b`. The command `0x30` pops the stack at `param_1[2]` to `param_1[1]`. The next command after this will be calculated by adding `0x013b` at `param_1[1]` to the base address `0x1020f0`, which results in the address `0x10222b`.
Having learned how the binary works, one thing that comes to my mind is basically this: At which address does it accept our input? Let's go back to the dynamic analysis of the binary and check the address at which we wind up for providing our answer to the binary.
One way to figure out the offset at which the command for accepting an input from a user is to stop the process upon the invocation of the function that accepts the input! Upon going through Ghidra, we discover the following code.

* Inside the main function `FUN_001010d0`, we discover the lines above, at which the pointers to some unknown functions are passed to the variables. Let's click each function and where we end up at.
Clicking the function `FUN_00101320`, we end up at the address `0x101320`. Inside it, we discover the line that calls the function `getc` whose argument is `stdin`. The function `getc` alongside `stdin` as the argument causes the program to stop and accept an input from a user! So what we have to do right now is to stop the program upon the process calling the function `getc`. And then skipping a few steps, we end up finding out the exact address, at which the command for accepting an input from a user gets invoked.
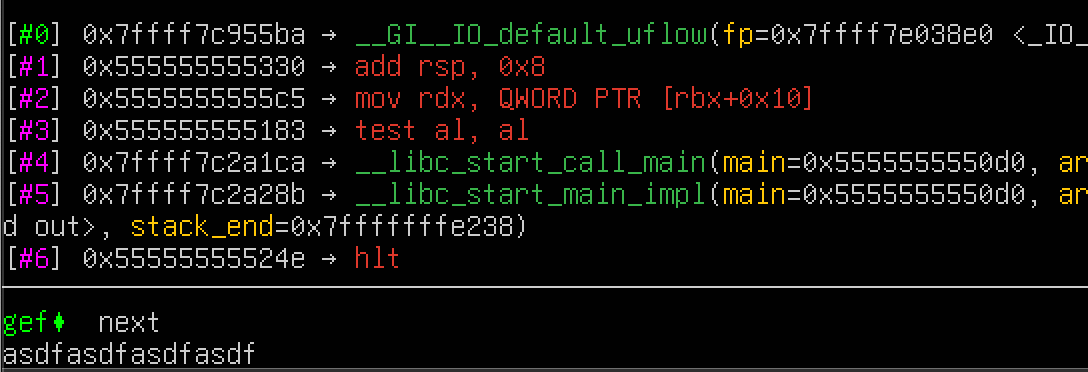
The process stops upon entering the function `getc`. With that, I type the GDB command `next` multiple times, until the program accepts an input from a user. I type in `asdfasdfasdfasdf` and press ENTER to continue.

Eventually, the process exits the function `getc` and returns back to the function `FUN_00101320`. One thing to note is that the instruction for calling the function `getc` is located at `0x55555555532b` inside the function `FUN_00101320`. Let's briefly go back to check out the line that is responsible for calling the function `FUN_00101320`. In order to do that, we go back to GDB and type the command `si` a few times, until we exit the function **`FUN_00101320`**.

We wind up at the address `0x5555555555c5`. Going back to Ghidra and searching for any address that ends with `5c5`, we find the following:
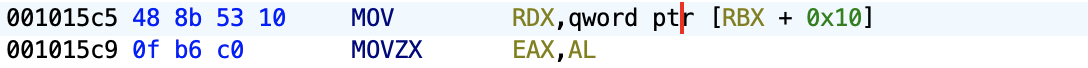
The last two screenshots contain the identical instructions, and upon clicking the instruction at the address of `001015c5` in Ghidra, we learn that the command `c0` is responsible for accepting an input from a user.

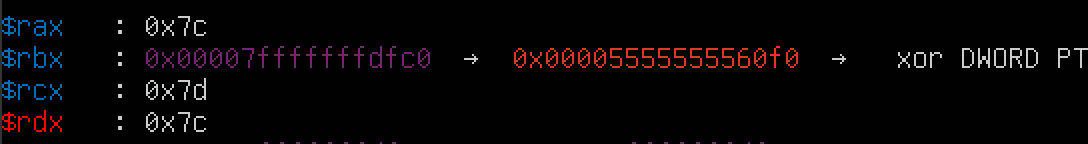


**The very next offset at `param_1[1]` after accepting an input from a user is `0x7c`, and it is stored in the `rax` register.** We know this for sure, for the fact that inside the function **[FUN_00101350](#exploring-the-function-fun00101350)**, it passes the offset to the variable `uVar2`. When you click the variable `uVar2` and checks the assembly code to see which line is associated with the line, you see that the instruction at the address `00101357` passes the value to the `rax` register.
### Processing input from a user
Adding the offset `0x7c` to the base address `0x1020f0` results in the address `0x10216c`.

Let's basically go through what is going on above. **The only valid characters that the binary accepts for an input are the followings:**
* `u`
* `d`
* `l`
* `r`
Providing a character other than those above results in the binary outputting the message **`You were eaten by a grue`**. This is how it works.
1. After accepting an input, the binary pushes the first character of your input to the stack at `param_1[2]`.
2. It first pushes the value `0x75`, a hex value for the character `u`, to the top of the stack at `param_1[2]`.
3. Using the command `0x13`, it subtracts the first character of your input from the value at the top of the stack, which is `0x75`, pops the stack, and replaces the value at the top of the stack with the calculation result.
4. It then pushes the new offset value that may potentially replace the offset at `param_1[1]` to the stack.
5. Using the command `0x31`, if the calculation result is `0`, it replaces the offset at `param_1[1]` with the new offset value that was pushed to the stack at `param_1[2]` in the previous step. Lastly, the stack at `param_1[2]` pops twice. If the calculation result is not zero, proceeds to the next step:
* **`u`** --> **0x102190**
* **`d`** --> **0x10219a**
* **`l`** --> **0x1021a4**
* **`r`** --> **0x1021b0**
6. The steps 2-5 repeat until a character matches `0x64 == d`, `0x6c == l`, or `0x72 == r`. If not, you fail the challenge, and are greeted with the message **`You were eaten by a grue`**. **Once the binary pushes the value `0x00FB` to the stack at `param_1[2]`, you can assure that you are doomed to fail the challenge**, because the offset `0xFB` added to the base address `0x1020f0` is the very address for printing out the message for the failure of the challenge!
**A series of characters consisting of those characters? `u` means UP, `d` means DOWN, `l` means LEFT, and `r` means RIGHT. Yes, you are basically navigating the maze that a single wrong step leads to your demise.**
### Creating the script that simulates the binary


So far, we have extensively covered the binary. It's really grueling to manually go through every single command to fully keep track of how the binary works. Starting at the base address `0x1020f0`, it ends at the address `0x1026c1`, which means that there are about a thousand of the commands to go through to fully understand the inner-workings of the binary. Going through this manually might take forever to cover every little detail it contains. What about creating a Python script that simulates the inner-workings of the binary? That's what I set out to do.
**Why creating a script that replicates the inner-workings of the binary? I can fully control and observe how the state of both stacks at `param_1[2]` and `param_1[3]` changes after processing each character, without the help of GDB, outside the VM.**
In order to replicate the inner-workings of the binary, we have to sort of understand how the binary works right after it accepts an input from a user. Some of the things we will take into considerations are the followings:
* The state of the stack at `param_1[2]` - With every character being processed by the binary, the binary produces a sort of accumulative results and saved them to the stack for future calculations.
* The state of the stack at `param_1[3]`, which is temporarily used for storing data from the stack at `param_1[2]`.
* How each command manipulates those two stacks above - The commands we discussed above directly manipulates the stack at `param_1[2]`.
Here is how I came up with the script that simulates the binary:
1. **[Parse all the available commands](https://github.com/7jw92nVd1kLaq1/picoCTF-MATRIX-scripts/blob/main/matrix_commands_json.py)** starting from the address of `0x1020f0` to the address of `0x1026c1`, since those are what the function **[FUN_00101350](#exploring-the-function-fun00101350)** executes into **[the JSON file](https://github.com/7jw92nVd1kLaq1/picoCTF-MATRIX-scripts/blob/main/matrix_commands.json)**.
2. Create a **[script](https://github.com/7jw92nVd1kLaq1/picoCTF-MATRIX-scripts/blob/main/matrix.py)** that simulates the binary.
### Creating a map of the maze inside the binary
The only allowed characters are `u`, `d`, `l`, and `r`, as an input, and we can presume that those are characters used to navigate the maze that somehow leads to the exit. So, if there is the maze, can we actually map it? **One thing that we have to take into consideration is that any step that leads the offset at `param_1[1]` to become `0x00FB` is to be avoided!** Let's go back to Ghidra and go through the list of commands a bit to find all the the addresses with the value of `fb`.
* There are a lot of `0xfb` in a list of commands from the base address `0x1020f0` to `0x1026c1`.
* The first address with `0xfb` is `0x0010218d`. This address actually is not that relevant to the maze, since `0xfb` at this address is pushed to the stack at `param_1[2]` upon finding out that one of the characters of an input of a user is not `u`, `d`, `l`, `r`.
* **The really interesting address with the value of `0xfb` starts at the very next address `0x102265`**. The next values of `0xfb` are found at the address `0x102269`, `0x10226d`, `0x102271`, etc. `0xfb` is placed next to each other at the offset of 4 bytes consistently, which continues until the address of `0x102667`, the one with the last value of `0xfb`.
Starting from the first relevant address `0x102265` that contains the value of `0xfb` and scrolling down the list of commands, you notice that every value `0xfb` is preceded by the value of `0x81`, which makes sense since the command `0x81` is used to push the value of two bytes located right next to it. Basically, `0x81` pushes the value of `0x00fb` to the stack, prior to the command `0x30` changing the value of the offset at `param_1[1]`.
Okay, so what we are sure about is that the actual map may be starting from the address of `0x102264`, which holds the value of `0x81`. Increasing the address in increments of 4, you notice that each address ends up with either the value of `0x81` or `0x30`. `0x30`'s are definitely safe, for the fact that it doesn't replace the offset at `param_1[1]` with the value of `0xFB`.

The address `0x102664` is the last address in increments of 4 starting from the address `0x102264`, before the last value of `0xFB` at the address `0x102267`. **So if I were to subtract `0x102264` from `0x102664`, I get the value of 1024 in decimal. Considering the fact that the binary increases the address in increments of 4, dividing 1024 by 4 results in the value of 256. If you multiply 16 by 16, you get 256. _Are we dealing with a 16 * 16 grid?_** With that very conjecture, let's create a **[simple Python script](https://github.com/7jw92nVd1kLaq1/picoCTF-MATRIX-scripts/blob/main/matrix_map_v1.py)** for visualizing the maze.
Here is what I did:
1. Create a two dimensional array for storing 16 arrays of 16 elements.
2. Starting from the address at `0x102264`, you evaluate the followings:
* If the value at the address is `0x81`, and the value at the very next address is `0xFB`, you are dead. Mark it with `-`
* If the value at the address is `0x81`, and the value at the very next address is not `0xFB`, you are alive. Mark it with `O`
* If the value at the address is `0x30`, you are alive. Mark it with `O`
3. Increase the address in increments of 4, and repeat the step 2, until the last address of `0x102664`.
When you run the script above and output the grid, you get the following result.
That looks like a breakthrough! So, where do we actually start the maze from? It's got to be the very first corner at the top left of the maze, and our goal is to get out of the maze through the only exit at the bottom right corner.
If we were to start from the top left, we can technically exit the maze with the following: **rrrddrrrrrrddddddlllllddrrrrdddrruuuruuuuuuurrddddddddlddrd**. Let's see if it works or not.
It is wrong! Frustrating. Let's check out why we got it wrong and how we can fix this, by analyzing the binary. The key to analyzing why we got it wrong is checking the states of those two stacks at `param_1[2]` amd `param_1[3]`.
### Analysis of the first failed attempt
Let's modify the script that simulates the binary for debugging purposes, by having a look at the stacks.


So moving right three times seems perfectly okay, and interestingly increments the value at the lowest item on the stack at `param_1[2]` by 1 with each move to the right. The problem occurs when we try to move downwards. Let's see what is being pushed at the very address that seems to be causing the problem. Starting from the very first item in the 2-D array we created for visualizing the grid, we wind up at the address `0x1022F4`.

The address `0x1022F4` holds the value of `0x81`, and it seems to push the value of `0x0574` and ultimately replace the offset at `param_1[1]` with it. Are there several addresses with the value of `0x0574` in the list of commands?

There are about 5 addresses between the address of `0x102264` and `0x102664` with the value of `0x74`. Let's factor that into the map, fix the **[script](https://github.com/7jw92nVd1kLaq1/picoCTF-MATRIX-scripts/blob/main/matrix_map.py)**, and see the difference between the previous one and the new one.

I marked every address that pushes `0x574` with the plus sign, and yes, they are all placed in the path to the exit. So, how do we possibly pass this? In midst of trying various methods, I find something very, very interesting.
So I know for sure that, from the starting point, I can move to the right the five times max, and when I do that, the third value from the lowest on the stack at `param_1[2]` increments by 1. **Is the third value from the lowest on the stack the key to passing through the plus sign that we discovered earlier?** Let's go back to the starting point, and see if we can move downward this time.
I was able to move downward with the input **`rrrrrlllllrrrdd`!** The third value from the lowest on the stack decrements by 1, whenever you go past the plus sign! **So, since there are total five plus signs that we have to get past, in order to exit the maze, that means that the third value from the lowest on the stack must be at least 5.** With that in mind, let's create the input and check if it works.
I provide the input **`rrrrrlllllrrrrrlllllrrrrrlllllrrrrrlllllrrrrrlllllrrrddrrrrrrddddddlllllddrrrrdddrruuuruuuuuuurrddddddddlddrd`**, and yes, it seems like I got it right! Let's try it on the binary being run on the server by picoCTF, and obtain the flag!

Yay! I got the flag, and submit it for the whopping 500 points!
This is the end of the walkthrough, but I feel like I didn't explain about how I came to the conclusions in some parts. I will review this post and revise and fill in some of the missing parts from time to time! Thanks for reading!
**[Link to the scripts I made for this challenge](https://github.com/7jw92nVd1kLaq1/picoCTF-MATRIX-scripts/tree/main)** | 7jw92nvd1klaq1 |
1,864,216 | Superalignment and Timeline of Broken Promises on The Way to Superintelligence | Today you will know everything about Superalignment and the race to ASI! Insights from a former... | 0 | 2024-05-24T17:20:35 | https://dev.to/iwooky/superalignment-and-timeline-of-broken-promises-on-the-way-to-superintelligence-2d2p | learning, ai, news, chatgpt | Today you will know everything about Superalignment and the race to ASI!
_Insights from a former OpenAI employee: "Whoever controls ASI will have access to a spread of powerful skills/abilities and will be able to build and wield technologies that seem like magic to us, just as modern tech would seem like magic to medievals."_
Explore the concept of Superalignment and uncover the hidden truth about AGI and ASI. Dive into the ethical challenges, secret experiments, and the pressing need for transparency in AI development.
👉 [**What is Superalignment?**](https://iwooky.substack.com/p/superalignment-and-superintelligence)
[](https://iwooky.substack.com/p/superalignment-and-superintelligence)
| iwooky |
1,864,197 | How To Start With Reactjs | here I will show the first book I wrote in my work life with web development (How To Start With... | 0 | 2024-05-24T17:16:40 | https://dev.to/yousefshallah/how-to-start-with-reactjs-35bj | javascript, react, reactjsdevelopment | here I will show the first book I wrote in my work life with web development (How To Start With Reactjs).
Book URL: https://lnkd.in/gJWdmdGb | yousefshallah |
1,864,196 | Web3 101 Organized by hack4bengal | What is Web3 ? Web3 is a decentralized version of the internet that uses blockchain... | 0 | 2024-05-24T17:16:11 | https://dev.to/arup_matabber/web3-101-organized-by-hack4bengal-1gof | hack4bengal, h4bs3, web3 | ## What is Web3 ?
Web3 is a decentralized version of the internet that uses blockchain technology. It aims to give users more control over their data and online interactions, reducing the reliance on central authorities like big tech companies. Key components are Crypto, DeFi, NFTs.
**NFTs :** NFTs (Non-Fungible Tokens) are unique digital assets authenticated on a blockchain, often used to represent ownership of digital or physical items like art, collectibles, and virtual real estate within the Web3 ecosystem.
**Cryptocurrencies :** Crypto refers to cryptocurrencies, digital or virtual currencies secured by cryptography, like Bitcoin and Ethereum, which are foundational to many Web3 applications and transactions.
**Metaverse :** The metaverse is a collective virtual shared space, often enhanced by virtual and augmented reality, It's where users interact, create, with each other and digital environments, often through avatars, and trade using digital assets and cryptocurrencies.
**Web 1.0 website example SpaceJam :-** The "Space Jam" website is often cited as a quintessential example of a Web 1.0-era website. Created to promote the 1996 movie "Space Jam" , the website featured basic HTML CSS design, animated GIFs, and a limited amount of interactive content.
It's a nostalgic relic of the early internet, showcasing the simplicity and charm of websites from that era.
**What is the point of an NFTs ?**
The primary point of NFTs is to provide digital ownership and provenance of unique digital assets. NFTs allow creators to tokenize their work, proving authenticity and enabling direct ownership and transfer of digital items like art, collectibles,and virtual assets on blockchain platforms. They also open up new avenues for creators to monetize their digital creations and for users to engage with and invest in digital content in a secure and decentralized manner.
**Roadmap :**
**• Understand- "why?"**
1st we need to understand why do we need blockchain? Do we really need blockchain? Is it helpful? Is it actually going to help people? And if you think that it's actually not needed, don't do it.
**• Start with the basics**
Now we need to understand, what is blockchain? how does it work? we understand the basics. we understand the how, what's the stack of what's the architecture of a blockchain.
**• Dont jump into the code**
So we need to do point 1 and 2 and we need to be clear with why we want to be a blockchain developer or a web site developer. we should not do it, because there's a hype around Nfts going on.
**• Jump into the code**
Now, if we are completely sure that this is what we want to do, now we start developing. Now we start coding.
**• Play around with a few verticals**
We need to play around with the verticals , fine out what we want to do .
**• Choose a vertical and master it.**
go for one vertical, not more than one . Stick to one. Select one which we feel is what we are inclined to.
And it's a wrap up !!🚀
I'm immensely grateful for this learning opportunity🤗
Thank You @Varunx10for Introducing me to this 💙
and @hack4bengal Thanks for organizing this amazing session💙
| arup_matabber |
1,864,193 | How to Create a Solar Panel Calculator Using Programming? | A solar panel calculator is a tool that helps estimate the potential benefits and feasibility of... | 0 | 2024-05-24T17:10:16 | https://dev.to/rogerwillium/how-to-create-a-solar-panel-calculator-using-programming-2ii5 | webdev, javascript, programming, softwaredevelopment | A solar panel calculator is a tool that helps estimate the potential benefits and feasibility of installing solar panels on a particular property or location. It takes into account factors such as geographical location, roof size, sunlight exposure, energy usage, cost of **[solar panels](https://openread.net/)**, and electricity rates.
## How to Create a Solar Panel Calculator Using Programming?
Creating a solar panel calculator involves several steps, and you can implement it using **[programming languages](https://programmingscript.com/)** like Python, JavaScript, or any other language you're comfortable with. Here's a basic outline of how you can approach it:
Define Input Parameters: Decide which parameters you want to take as input from the user. These may include:
- Location (latitude, longitude)
- Roof size available for solar panels
- Average daily sunlight hours
- Cost per watt of solar panels
- Electricity usage (daily, monthly, or yearly)
- Current electricity cost per kWh
Calculate Solar Potential: Based on the location, you'll need to calculate the solar potential, which involves estimating the average solar irradiance (sunlight intensity) for the location. You can use various APIs or libraries to fetch this data.
Estimate Energy Production: Use the solar potential and roof size to estimate the energy production capacity of the solar panels. This involves calculating the total energy output per day, month, or year based on sunlight hours and panel efficiency.
Calculate Cost and Savings: Estimate the cost of installing solar panels based on the cost per watt and roof size. Then calculate the savings over time compared to the current electricity cost.
Output Results: Display the calculated results to the user, including estimated energy production, cost of installation, savings over time, payback period, etc.
Here's a simple Python example to get you started:
This is a basic example, and you can expand upon it by adding more features like tax incentives, different panel efficiencies, battery storage, etc., depending on your requirements.
| rogerwillium |
1,864,189 | Angular code obfuscation made easy | If you ever had to code a real-life project, the concern for security was there—or at least should... | 0 | 2024-05-24T16:56:17 | https://dev.to/jodamco/angular-code-obfuscation-made-easy-4gjm | angular, security, webpack, webdev | If you ever had to code a real-life project, the concern for security was there—or at least should have been. As technologies advance, we can code amazing, robust, high-performance systems within short time schedules, but that also means that malicious people and techniques become more powerful and tricky to overcome. That's why nowadays securing all common breaches is a must when developing systems.
Angular handles a lot of security out of the box: it has its own variable protection system and sanitization to prevent malicious code from running in your app. Another feature is code minification.
### Minification vs. Obfuscation
**Code minification** is a technique that reduces the size of source code by removing unnecessary characters like whitespace and comments, improving the load performance of the source code. This process is common in web development for JavaScript, CSS, and HTML files and, somehow, adds a layer of security by obfuscating the code. Minified code is extremely hard to read, and that's why it is considered some sort of obfuscation. However, tools can de-minify code, making it readable and then reverse-engineerable. This is where obfuscation is useful.
Complementary to **minification**, **code obfuscation** is a technique used to make source code difficult to understand and reverse-engineer. This is often used to protect intellectual property, prevent tampering, and deter reverse engineering by making it challenging for attackers to understand the code's logic and identify potential vulnerabilities. It transforms readable code into a more complex and obscure version without altering its functionality. Code obfuscation tools can also add dead code to mislead attackers and make it even more difficult to understand the software codebase.
Well, if you have use for it, let's obfuscate our Angular app.
### Webpack Obfuscator
Angular uses Webpack during its bundle phase and has its own default setup to pack the modules you develop. We are going to take advantage of this and customize the way Webpack will bundle your Angular app. First, install these packages:
```
npm i javascript-obfuscator webpack-obfuscator --save-dev
```
The `javascript-obfuscator` is
> a powerful free obfuscator for JavaScript, containing a variety of features which provide protection for your source code.
while `webpack-obfuscator` makes use of it as a plugin to provide functionality for Webpack. You can find the JavaScript obfuscator code [here](https://www.npmjs.com/package/javascript-obfuscator) and Webpack obfuscator plugin [here](https://www.npmjs.com/package/webpack-obfuscator).
After that, create a `custom-webpack.config.js` file that will contain the custom configurations we want to apply during our bundle process. Here's a simple one:
```
var JavaScriptObfuscator = require("webpack-obfuscator");
module.exports = {
module: {},
plugins: [
new JavaScriptObfuscator(
{
debugProtection: true,
},
["vendor.js"]
),
],
};
```
There are many different config options you can provide for the `webpack-obfuscator` plugin to fine-tune the output of the obfuscation. This is the simplest one that adds `debugProtection` to the code, making it difficult to use the console to track down variables and functions of the app.
So far, we set up our config of Webpack. Now we need to use it. We will need one more dependency:
```
npm i @angular-builders/custom-webpack --save-dev
```
This will help us integrate the custom Webpack builder with Angular so we can still use the Angular build structure. After installing the package, we only need to change the `angular.json` file. Search for the `build` property and add the following:
```
...
"builder": "@angular-builders/custom-webpack:browser",
"customWebpackConfig": {
"path": "./custom-webpack.config.js",
"replaceDuplicatePlugins": true
}
```
By replacing the `builder` from `@angular-devkit/build-angular:browser` to `@angular-builders/custom-webpack:browser`, we will still be able to build for the browser but now can inject our custom Webpack configurations. The `customWebpackConfig` property sets the reference for the file so Angular can use it.
If everything is properly set, your build command should run normally and **the result will be an obfuscated Angular app!**
### Drawbacks
Be aware, though, that this approach has a drawback on the bundle size. Code obfuscation makes it much more difficult to reverse-engineer the code, but the way it declares the variables uses more characters, leading to an increase in the size of the bundle—almost going in the opposite direction of code minification.
That's it. Be sure to use it with purpose and understand how to tackle the drawbacks of the technique! | jodamco |
1,864,188 | 5 Most Used Array Methods in Front-End Development | Today we will see the most important array methods when developing front-end software. They are the... | 0 | 2024-05-24T16:52:00 | https://dev.to/shehzadhussain/5-most-used-array-methods-in-front-end-development-2lgb | webdev, javascript, beginners, programming | Today we will see the most important array methods when developing front-end software. They are the most used array methods in my experience.
It is important to be very clear about how they work to develop software quickly and efficiently in our day-to-day since we work a lot with arrays.
Most people need help understanding them, and they always have to go and recheck their operation and spend extra time on it.
## 5 top array methods
The 5 array methods we are going to talk about are:
**forEach
map
filter
find
slice**
Let's go!
## forEach
It executes a provided function once for each array element.
## map
It's the method most used when developing with React, as it renders lists of JSX elements.
This method creates a new array in which each element results from the function applied to each one.

## filter
It creates a shallow copy of the array, filtered down to just the elements that pass the test implemented by the provided function.

## find
It returns the first element in the array that satisfies the testing function.

## slice
It returns a shallow copy of the array filtered down to just the elements selected from start to end (end not included), where start and end represent the index of items in that array.
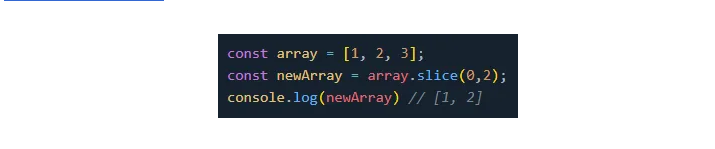
## Conclusion
We have already seen the 5 most used methods, and it is crucial to be clear and have skill and experience with them to develop more efficient software in our daily work.
I have chosen these 5 methods based on my experience. You can check out this website and search for each one to find more information about them:
https://developer.mozilla.org/
I hope you enjoyed the article.
See you in the next post.
Have a great day!
| shehzadhussain |
1,864,230 | ChatGPT: Your Guide to SQL Query Translation between Databases. | Introduction Everyone knows that ChatGPT is perfect for translating between many human... | 0 | 2024-06-05T09:36:52 | https://dbconvert.com/blog/using-chatgpt-for-sql-query-translation/ | chatgpt, ai, sql, database | ---
title: ChatGPT: Your Guide to SQL Query Translation between Databases.
published: true
date: 2024-05-24 16:49:52 UTC
tags: chatgpt,ai,sql,database
canonical_url: https://dbconvert.com/blog/using-chatgpt-for-sql-query-translation/
---

## Introduction
Everyone knows that ChatGPT is perfect for translating between many human languages. But did you know that this powerful language model can also excel at converting SQL queries between various database dialects?
Whether you are transitioning from MySQL to PostgreSQL, SQL Server to Oracle, or any other combination, ChatGPT can assist in accurately translating your SQL queries. This capability extends beyond simple syntax changes, providing insights into how database systems handle data types, functions, and constraints. By leveraging ChatGPT for SQL translation, you can ensure a smoother and more efficient transition between database systems, maintaining data integrity and query performance.
## Understanding the Challenge
Translating SQL queries between different database systems takes a lot of work. Each database system, be it MySQL, PostgreSQL, SQL Server, or Oracle, has its own distinct SQL dialect, encompassing specific syntax, functions, data types, and constraints. These variations can present substantial hurdles during migration.
### Example1: Auto-Increment Columns
**MySQL:**
In MySQL, the AUTO\_INCREMENT keyword defines an auto-incrementing primary key.
```
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
);
```
**PostgreSQL:**
In PostgreSQL, you use SERIAL to auto-increment fields.
```
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100)
);
```
**SQL Server:**
In SQL Server, the IDENTITY property defines an auto-incrementing primary key.
```
CREATE TABLE users (
id INT IDENTITY(1,1) PRIMARY KEY,
name NVARCHAR(100) NOT NULL
);
```
**Oracle:**
In Oracle, since version 12c, the IDENTITY Column method has been recommended.
```
CREATE TABLE users (
id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
name VARCHAR2(100)
);
```
In versions below 12c, Oracle uses a complex sequence and trigger mechanism.
### Example 2: String Functions
**MySQL:**
The CONCAT\_WS function in MySQL concatenates strings with a specified separator.
```
SELECT CONCAT_WS('-', first_name, last_name)
FROM users;
```
**PostgreSQL:**
In PostgreSQL, you can use the CONCAT function along with the separator.
```
SELECT CONCAT(first_name, '-', last_name)
FROM users;
```
**Oracle:**
You can achieve the same result in Oracle using the `||` operator for string concatenation.
```
SELECT first_name || '-' || last_name AS full_name
FROM users;
```
Additionally, there are variations in how each system handles transactions, error handling, and even indexing.
Moreover, some database systems include proprietary features that lack direct equivalents in other systems. This situation often makes straightforward translation impossible, requiring the development of alternative solutions or workarounds to achieve the same functionality.
Grasping these challenges is pivotal for a successful migration. It necessitates a profound understanding of the source and target database systems and the intricacies of their SQL dialects. This is where ChatGPT shines. With its extensive language model capabilities, it can help identify and tackle these differences, offering precise translations and guiding users through the intricacies of the transition process.
## How ChatGPT Can Help
ChatGPT can be an invaluable tool for developers and database administrators tasked with migrating SQL queries and database structures between different systems. Here's how ChatGPT can assist in this process:
### Accurate Query Translation.
ChatGPT excels at understanding the nuances of various SQL dialects. It can accurately translate SQL queries from one database system to another, ensuring the syntax and functions are correctly adapted. For example, it can translate a MySQL `GROUP_CONCAT` function to PostgreSQL's `STRING_AGG` function or convert MySQL's `CURDATE()` to PostgreSQL's `CURRENT_DATE`. This ensures that the queries perform the desired operations in the target database system.
### Handling Data Types and Constraints.
Different database systems have unique ways of defining data types and constraints. ChatGPT can help by identifying these differences and providing the correct translations, for instance, converting MySQL's `AUTO_INCREMENT` to PostgreSQL's `SERIAL`, or SQL Server's `IDENTITY` to Oracle's sequence and trigger mechanism. By doing so, ChatGPT helps maintain data integrity and consistency during the migration.
### Providing Alternative Solutions
Some proprietary features in one database system may not have direct equivalents in another. ChatGPT can suggest alternative solutions or workarounds to achieve the same functionality in such cases. For example, if a specific function or feature in MySQL does not exist in PostgreSQL, ChatGPT can propose a combination of other functions or custom logic to replicate the behavior.
### Guiding Through Complex Transitions
ChatGPT can guide users through complex transitions, highlighting potential changes in query execution or outcomes due to differences in how database systems interpret and handle SQL. This includes differences in transaction handling, error management, indexing, and case sensitivity. By providing insights and recommendations, ChatGPT helps ensure a smoother transition.
### Notifying About Potential Differences
Knowing any differences that might affect query results or performance in the target database system is crucial. ChatGPT can notify users of these potential discrepancies and suggest how to adapt queries to ensure consistent results. For example, it can highlight differences in date functions, string concatenation, or conditional logic and make appropriate adjustments.
* * *
## ChatGPT use cases for SQL-related tasks.
Using ChatGPT for SQL tasks extends beyond simple query translation. Here are several practical use cases where ChatGPT can assist with SQL-related tasks:
[10 Ways ChatGPT is Revolutionizing SQL Practices.](https://dbconvert.com/blog/chatgpt-sql-practices/)
It provides an in-depth look at how ChatGPT is successfully used in SQL practices.
## Common Pitfalls & Solutions
### Pitfall 1: Misinterpretation of Query Intent
Sometimes, ChatGPT may not correctly interpret the intent of the SQL query, leading to incorrect translations between SQL dialects.
### Solution:
Be clear and specific when inputting your SQL queries. If you notice a misinterpretation, try rephrasing your query or breaking it down into simpler parts.
### Pitfall 2: Unfamiliarity with Database-specific Features.
Some databases have proprietary features that others do not, which can lead to confusion or errors when translating queries.
### Solution:
Before migrating to a new database, familiarize yourself with the specific features and syntax of that system. ChatGPT can provide alternative solutions for features that do not have direct equivalents.
### Pitfall 3: Overlooking Data Types and Constraints.
Different databases handle data types and constraints differently. Overlooking these differences can lead to data inconsistency.
### Solution:
Always verify the translated queries and check for data type and constraint translations. ChatGPT can assist in identifying these differences and providing the correct translations.
### Pitfall 4: Ignoring Potential Performance Differences
The performance of a query can vary between different database systems due to differences in how they handle SQL.
### Solution:
Be aware of potential performance differences. Use ChatGPT to obtain insights into how different database systems handle SQL and adapt your queries accordingly.
Remember, while ChatGPT is an excellent tool for SQL tasks, it's crucial to double-check the translations and understand the nuances of different database systems.
## Future Developments:
Given the dynamic nature of both AI and SQL development, we can expect several advancements:
1. **Improved Accuracy:** Future versions of ChatGPT are likely to offer even more accurate translations of SQL queries between different database dialects. This will make it easier for developers to switch between different SQL systems.
2. **Expanded Database Support:** As new database systems and SQL dialects emerge, ChatGPT will likely expand its support to include these new technologies, making it even more versatile.
3. **Detailed Explanation of Queries:** Future iterations may offer more detailed explanations of complex SQL queries, making it easier for developers to understand and optimize their database interactions.
4. **Integration with More Tools:** We can anticipate tighter integration with various database management and development tools, providing developers with a more seamless and efficient workflow.
5. **Active Learning:** Using AI, ChatGPT could learn from its interactions, improving its responses over time and providing even more value to developers.
6. **Enhanced Performance Optimizations:** With advancements in AI, ChatGPT could provide suggestions for performance optimization in SQL queries, helping developers improve their databases' efficiency and speed.
[SQL Companion in GPT Store. Try it now!](https://chatgpt.com/g/g-4s4xPqO0B-sql-companion)
[Free telegram bot streamlines SQL related tasks](https://t.me/dbconvert_bot)
### DBConvert Tools for Database Migration and Synchronization
DBConvert offers powerful tools for automating database migration and synchronization across various systems, such as MySQL, PostgreSQL, SQL Server, and Oracle.
[**DBConvert Studio**](https://dbconvert.com/dbconvert-studio/?ref=dbconvert.com)simplifies cross-database migration with features like automated schema conversion, data type mapping, and transformation. Its user-friendly interface allows easy setup of source and target connections, scheduled migrations, and thorough data transfer processes.
**[DBConvert Streams](https://stream.dbconvert.com/?ref=dbconvert.com)** integrates real-time data using Change Data Capture (CDC) technology. It ensures continuous, multidirectional synchronization, ideal for maintaining high data availability and consistency across multiple databases. Both tools provide robust error handling and logging, ensuring reliable and efficient database management.
## Conclusion
In the ever-evolving landscape of database management, transitioning between different SQL dialects can be daunting. Each database system, whether MySQL, PostgreSQL, SQL Server, or Oracle, has its unique set of syntax, functions, and constraints. Navigating these differences is crucial for maintaining data integrity and ensuring optimal performance during migrations.
ChatGPT emerges as a powerful ally in this process, offering accurate translations and insightful guidance. By leveraging its capabilities, developers and database administrators can overcome the complexities of SQL dialect variations. From translating queries and handling data types to suggesting alternative solutions and highlighting potential performance differences, ChatGPT provides comprehensive support throughout the migration journey. | slotix |
1,864,186 | pip Trends newsletter | 25-May-2024 | This week's pip Trends newsletter is out. Interesting stuff by Tushar Aggarwal, Animesh Chouhan, Trey... | 0 | 2024-05-24T16:44:08 | https://dev.to/tankala/pip-trends-newsletter-25-may-2024-407d | python, programming, datascience, dataengineering | This week's pip Trends newsletter is out. Interesting stuff by Tushar Aggarwal, Animesh Chouhan, Trey Hunner, Adrien Cacciaguerra, Arthur Pastel, Johni Douglas Marangon, @kanehooper & Volker Janz are covered this week
{% embed https://newsletter.piptrends.com/p/sleepsort-the-new-repl-in-python %} | tankala |
1,864,180 | Networking Tips for New Developers: Building Your Professional Circle | Networking Tips for New Developers: Building Your Professional Circle Attend Industry... | 0 | 2024-05-24T16:25:29 | https://dev.to/bingecoder89/networking-tips-for-new-developers-building-your-professional-circle-hc8 | beginners, tutorial, codenewbie, career | ### Networking Tips for New Developers: Building Your Professional Circle
1. **Attend Industry Events**: Participate in tech conferences, meetups, and workshops to meet other professionals and stay updated with industry trends.
2. **Leverage Social Media**: Use platforms like LinkedIn and Twitter to connect with industry leaders, join relevant groups, and share your projects and insights.
3. **Join Professional Organizations**: Become a member of organizations such as the ACM or IEEE to access resources, events, and networking opportunities.
4. **Engage in Online Communities**: Contribute to forums like Stack Overflow, GitHub, and Reddit where developers discuss problems, share knowledge, and collaborate on projects.
5. **Find a Mentor**: Seek out experienced developers who can provide guidance, advice, and introductions to other professionals in the field.
6. **Collaborate on Open Source Projects**: Work on open-source projects to improve your skills and build relationships with other contributors and maintainers.
7. **Attend Hackathons**: Participate in hackathons to work on real-world problems, meet fellow developers, and showcase your abilities.
8. **Network Within Your Company**: Build relationships with colleagues from different departments and levels within your organization to expand your internal network.
9. **Volunteer for Speaking Engagements**: Offer to speak at local events, webinars, or podcasts to share your expertise and increase your visibility.
10. **Follow Up and Stay in Touch**: Maintain and nurture connections by regularly following up with new contacts, sending periodic updates, and offering help or collaboration opportunities.
Happy Learning 🎉 | bingecoder89 |
1,864,185 | Effective way to deploy virtual machines using Quickstart Templates and Monitor your resources through Mobile App. | A Quick Start Template on Azure is a pre-built solution or framework designed to expedite the process... | 0 | 2024-05-24T16:43:07 | https://dev.to/latoniw/effective-way-to-deploy-virtual-machines-using-quickstart-templates-and-monitor-your-resources-through-mobile-app-1m9g | A Quick Start Template on Azure is a pre-built solution or framework designed to expedite the process of deploying and configuring resources within the Azure cloud environment. These templates provide a standardized and automated way to set up infrastructure, services, and applications, saving time and effort for users. They typically include predefined configurations for common scenarios such as virtual machines, databases, web applications, and more, allowing users to easily customize and deploy resources with minimal manual intervention.
**Deploying a Quick Start Template on Azure involves few steps with result in shortest possible time. Here's a general step-by-step procedure:**
**Access Azure Portal:** Log in to the Azure portal at https://portal.azure.com using your Azure account credentials.
In _**search bar**_, type "Quickstart templates." you'll find various options Click on "Deploy a custom
templates." option to explore.
STEP 2 Browse through the available Quick Start Templates and select the one that best fits your needs. In this case, I would like to **_create a window virtual machine_**
**STEP 3**
Review its description, documentation, and parameters. Basicaly, add a Resource Group, Username and password of your choice. Then click on Review and Create Tab at the bottom part of the screen.
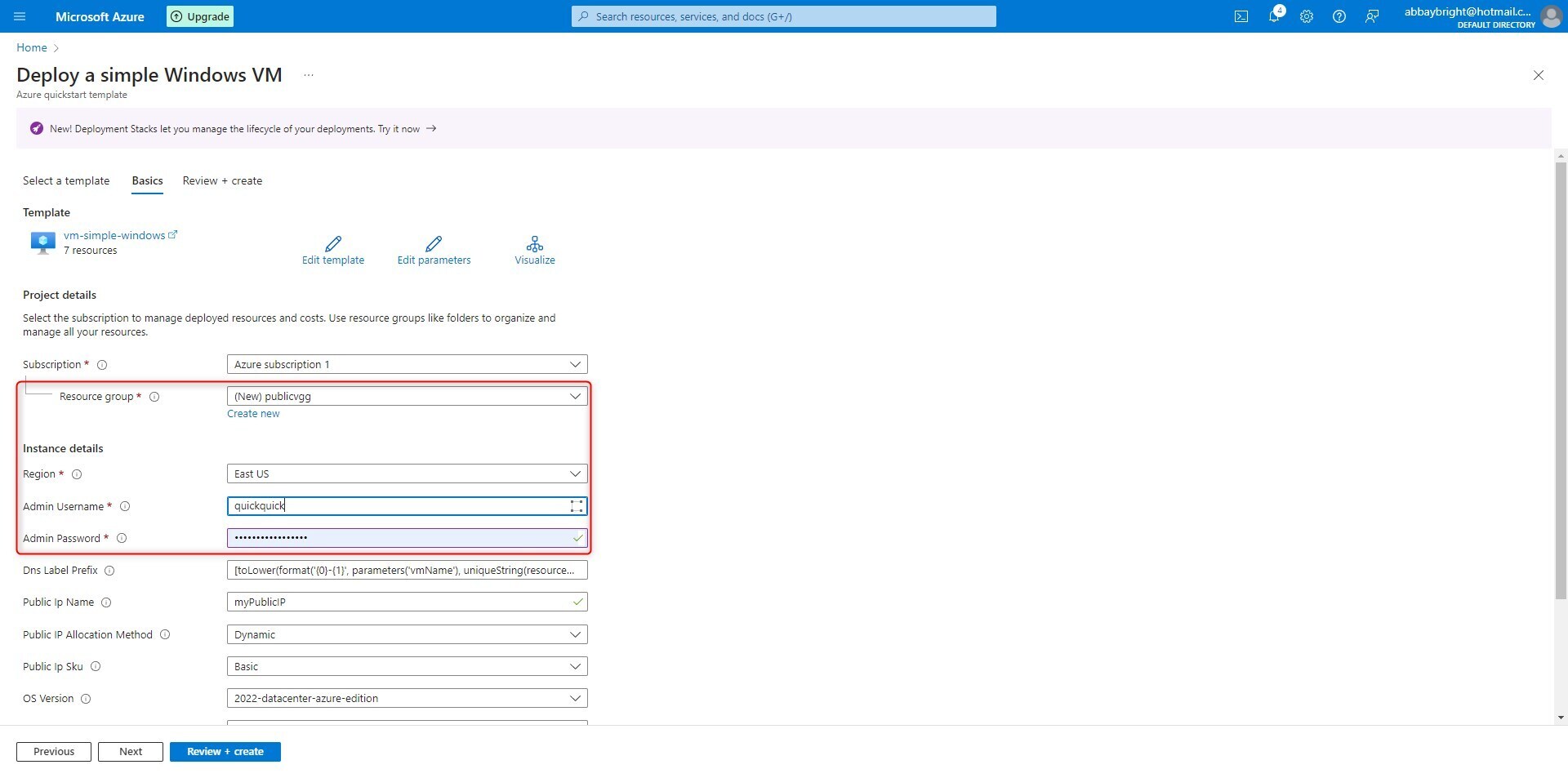
**STEP 4**
Click on create.
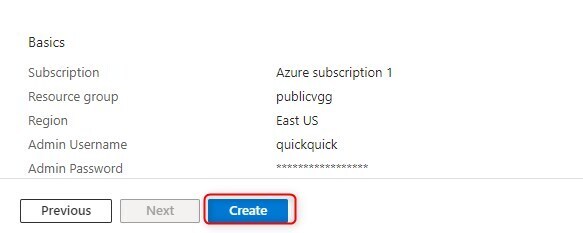
STEP 5
Wait for the it to successfully deploy
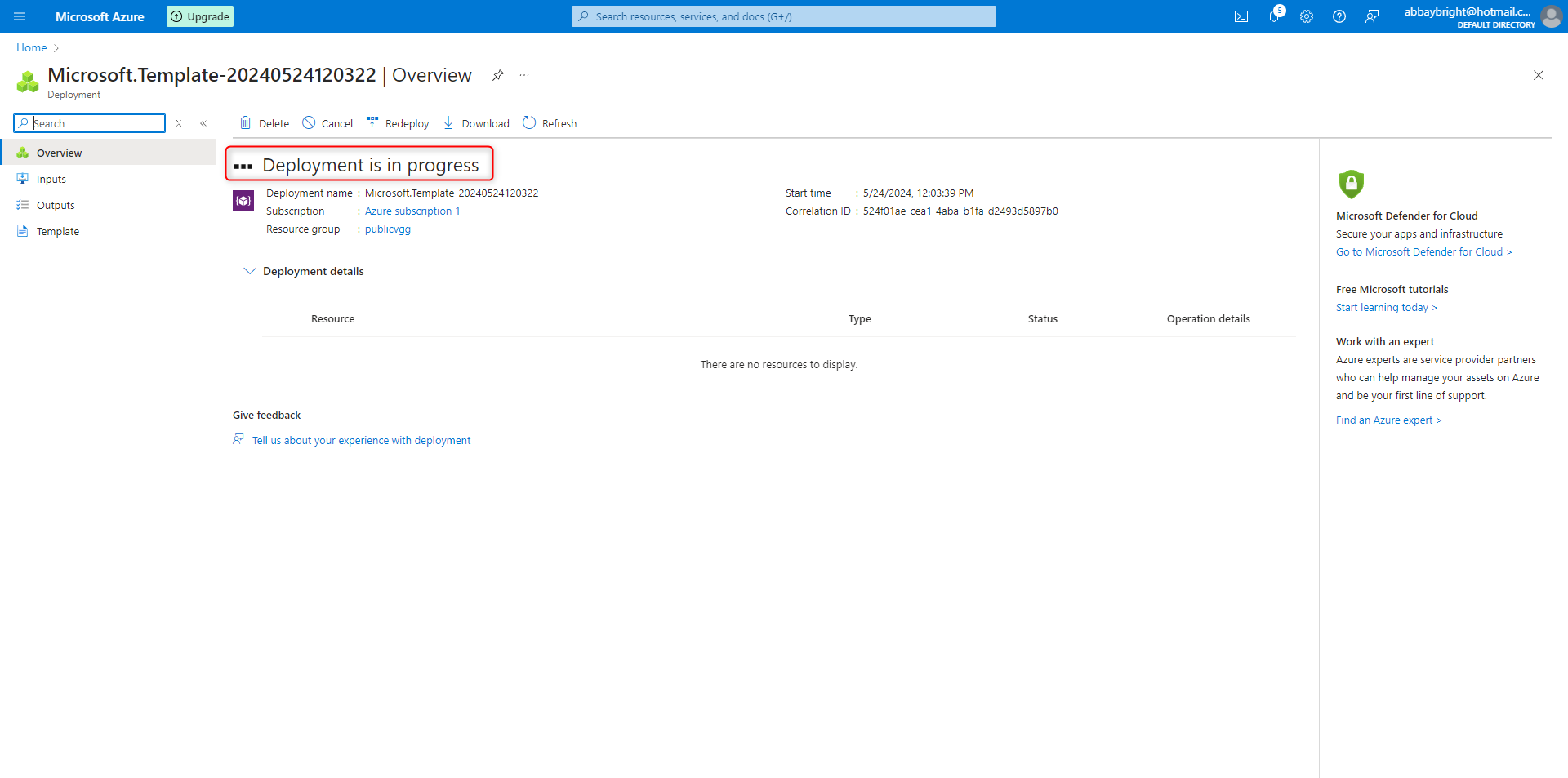
**STEP 6**
After the completion of the Deployment, click on "GO TO REOURCE GROUP" tab to see the created virtual machines.
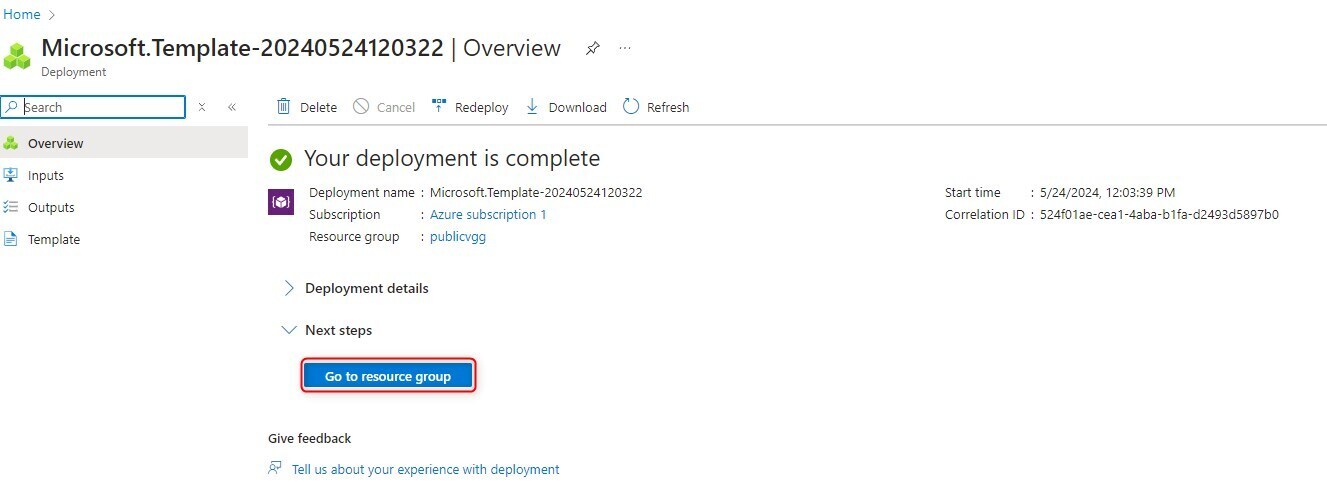
**STEP 7**
Among the list of newly generated resources, click on the "simple vm"
**STEP 8**
Azure provides tools for monitoring the performance, usage, and health of mobile apps in real-time. Developers can gain insights into user behavior, app performance, and potential issues through services like Application Insights and Azure Monitor.
Click on the "Open in mobile" tab, copy the link or scan barcode to install Azure mobile app.
**STEP 9**
Through the link, the next page will require you to install the Azure mobile app on your device

This procedure provides a general overview of deploying a Quick Start Template on Azure and monitor your app via your mobile device from anywhere with ease. | latoniw | |
1,864,174 | My Patent Pending AWS Challenge | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-24T16:36:15 | https://dev.to/vitalipom/aws-amplify-challenge-i-got-a-patent-pending-gch | awschallenge, authentication, devchallenge, fullstack | ---
title: My Patent Pending AWS Challenge
published: true
description:
tags: awschallenge, authentication, devchallenge, fullstack
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-24 16:14 +0000
---
*This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
## What I Built
**TL;DR Simple mutual (yet) patent pending authentication solution which is cheap and works perfectly well on small and medium websites, yet provides banking level security for the session.**
So I got with this idea early in the morning to come up with a service, named Signmeonly.io, which basically offers an authentication solution at a level above the other most common
login solutions. I felt that the other solutions lack of something fundamental, secure network while there’s a Man In The Middle; lack of fundamental security on public networks in other words.
What happened is that I saw that once someone targets you in attacking over a public network they pretty much have everything to succeed: they can fire up a fake website that looks like the same as the original one and with some IP, DNS or router spoofing your device is got to believe the fake website is the real one.
From then on they would accept your credentials and OTP and just redirect you to the real site until you’re done. Then, they will (trust me) continue in such an unauthorized activity on your behalf, that you’d curse every moment in that coffee shop.
Are you scared? I am…
My solution is a patent pending technology: Signmeonly.io. It uses a shared secret key that you’d receive over the email and it will be used to both sign and validate JWT tokens on both the client and the server. 🤷♂️
Is that easy? Yes. But the patent filing was a tedious task. Today as I am working on fine tuning everything and implementing step by step all the small details of my patent I look towards ways to expose my invention to as much possible users and early adopters. 🌸
If you or the one next to you is seeking for a fresh technology to start with in the new website you guys are building, consider Signmeonly.io
The robustness of the security in Signmeonly is a serious painkiller and will heal your wounds from the scratches you get over time from the other authentication and logging in services.
## Demo
As I mentioned I applied for a patent with this technology and currently I’m in the patent pending list, the patent will see light in 18 months whereas it will be able to get negative or positive feedback. The application patent number is 18/665,621. | vitalipom |
1,864,184 | Essential React Libraries for Your Next Project | Essential React Libraries for Your Next Project Hey Dev Community! Are you working on a... | 0 | 2024-05-24T16:35:45 | https://dev.to/respect17/essential-react-libraries-for-your-next-project-4c91 | webdev, react, reactnative | ### Essential React Libraries for Your Next Project
Hey Dev Community!
Are you working on a React project and looking to enhance its functionality with some powerful libraries? You’ve come to the right place! In this article, we’ll dive into some essential React libraries that can take your project to the next level. Feel free to share your thoughts, experiences, and favorite libraries in the comments below. Let’s get started!
#### 1. **React-Konva**
**What is React-Konva?**
React-Konva is a library that provides a React API for the HTML5 canvas, enabling you to create complex, interactive graphics and animations in your React applications.
**Uses:**
- **Drawing Shapes**: Easily draw shapes like rectangles, circles, and lines.
- **Animations**: Create smooth animations and transitions.
- **Interactive Graphics**: Develop interactive graphics for games, data visualizations, and more.
```javascript
import React from 'react';
import { Stage, Layer, Rect } from 'react-konva';
const App = () => (
<Stage width={window.innerWidth} height={window.innerHeight}>
<Layer>
<Rect x={20} y={20} width={100} height={100} fill="red" />
</Layer>
</Stage>
);
export default App;
```
#### 2. **React Native Gesture Handler**
**What is React Native Gesture Handler?**
React Native Gesture Handler is a library that provides native-like gesture handling capabilities in React Native applications. It offers more robust and performant gesture handling compared to the built-in gesture system.
**Uses:**
- **Swiping Gestures**: Implement swipe actions in lists or components.
- **Drag and Drop**: Enable drag-and-drop functionality.
- **Pinch and Zoom**: Add pinch-to-zoom interactions.
```javascript
import React from 'react';
import { GestureHandlerRootView, PanGestureHandler } from 'react-native-gesture-handler';
import { View } from 'react-native';
const App = () => (
<GestureHandlerRootView>
<PanGestureHandler>
<View style={{ width: 100, height: 100, backgroundColor: 'blue' }} />
</PanGestureHandler>
</GestureHandlerRootView>
);
export default App;
```
#### 3. **React Flip Move**
**What is React Flip Move?**
React Flip Move is a library that provides easy-to-use animations for your list items as they enter, leave, or rearrange.
**Uses:**
- **List Animations**: Animate the reordering of list items.
- **Enter/Exit Animations**: Smoothly animate items entering or exiting the DOM.
- **Responsive Animations**: Create responsive animations that adjust to different screen sizes.
```javascript
import React from 'react';
import FlipMove from 'react-flip-move';
const ListComponent = ({ items }) => (
<FlipMove>
{items.map(item => (
<div key={item.id}>{item.name}</div>
))}
</FlipMove>
);
export default ListComponent;
```
#### 4. **React Virtualized**
**What is React Virtualized?**
React Virtualized is a library that helps render large lists and tabular data efficiently by only rendering visible rows.
**Uses:**
- **Large Data Sets**: Efficiently render large lists, tables, and grids.
- **Infinite Scrolling**: Implement infinite scrolling for large data sets.
- **Performance Optimization**: Optimize performance by rendering only the visible items.
```javascript
import React from 'react';
import { List } from 'react-virtualized';
const rowRenderer = ({ key, index, style }) => (
<div key={key} style={style}>
Row {index}
</div>
);
const MyList = () => (
<List
width={300}
height={300}
rowCount={1000}
rowHeight={20}
rowRenderer={rowRenderer}
/>
);
export default MyList;
```
#### 5. **React Toastify**
**What is React Toastify?**
React Toastify is a library that makes it easy to add notifications to your React applications.
**Uses:**
- **Notifications**: Show success, error, info, and warning notifications.
- **Customizable Toasts**: Customize the appearance and behavior of toasts.
- **Responsive Notifications**: Ensure notifications are responsive and mobile-friendly.
```javascript
import React from 'react';
import { ToastContainer, toast } from 'react-toastify';
import 'react-toastify/dist/ReactToastify.css';
const App = () => {
const notify = () => toast("Wow, this is a toast!");
return (
<div>
<button onClick={notify}>Notify</button>
<ToastContainer />
</div>
);
};
export default App;
```
#### 6. **React Page Transition**
**What is React Page Transition?**
React Page Transition is a library that provides easy-to-use page transition animations for your React applications.
**Uses:**
- **Page Transitions**: Create smooth transitions between different pages or views.
- **Custom Animations**: Customize animations to match your app’s style.
- **Enhanced User Experience**: Improve user experience with visually appealing transitions.
```javascript
import React from 'react';
import { TransitionGroup, CSSTransition } from 'react-transition-group';
import './transitions.css';
const PageTransition = ({ children }) => (
<TransitionGroup>
<CSSTransition timeout={300} classNames="fade">
{children}
</CSSTransition>
</TransitionGroup>
);
export default PageTransition;
```
#### 7. **React 360**
**What is React 360?**
React 360 is a library for creating interactive 360 and VR experiences using React.
**Uses:**
- **Virtual Reality**: Build VR experiences for the web.
- **360-Degree Media**: Create interactive 360-degree videos and images.
- **Immersive Environments**: Develop immersive environments for games, simulations, and more.
```javascript
import { ReactInstance } from 'react-360-web';
function init(bundle, parent, options = {}) {
const r360 = new ReactInstance(bundle, parent, {
fullScreen: true,
...options,
});
r360.renderToSurface(
r360.createRoot('Hello360'),
r360.getDefaultSurface()
);
}
window.React360 = { init };
```
### Conclusion
These React libraries can significantly enhance your development workflow and add powerful features to your projects. Whether you're building interactive graphics with React-Konva, adding smooth animations with React Flip Move, or optimizing large lists with React Virtualized, there's a library here to help you succeed.
Have you used any of these libraries in your projects? Which one is your favorite and why? Let’s discuss in the comments below!
Feel free to modify and expand on the code examples to better suit your projects, and don’t hesitate to share your thoughts and experiences with these libraries!
Happy coding! 🚀 | respect17 |
1,864,183 | Preventing Memory Leaks using Context Managers in Python | Implemented correctly, efficient resource management can greatly improve the performance and... | 0 | 2024-05-24T16:30:07 | https://dev.to/myexamcloud/preventing-memory-leaks-using-context-managers-in-python-22c4 | python, programming, coding, software | Implemented correctly, efficient resource management can greatly improve the performance and functionality of any programming language. One aspect of this management is effectively handling the consumption and release of resources in order to prevent any memory leaks that could compromise the overall efficiency of the system.
To minimize the risk of memory leaks, we need to ensure that resources are only loaded into memory when truly necessary. One way to do this is through the use of generators, which allow us to defer the generation of the actual resource until it is needed by the program.
However, it is equally important to properly release resources when they are no longer needed. This can be a challenge, particularly in cases of exceptions or failures. This is where context managers come in, simplifying the process of resource setup and teardown.
For example, when dealing with file handles, it is important to ensure that each file is closed exactly once. Failing to do so can lead to memory leaks, while attempting to close a file handle twice can result in runtime errors. To avoid this, we can wrap our file handling in a try-except-finally block.
However, Python offers a more elegant solution through its built-in file context manager. This automatically handles the closing of files, preventing potential memory leaks. The code becomes much cleaner and simpler, as we no longer need to explicitly close the file.
In addition to built-in context managers, Python also allows us to create our own for custom classes and functions. This involves defining the __enter__ and __exit__ dunder methods to handle resource setup and teardown.
By using context managers, we can ensure that resources are properly managed and released, avoiding memory leaks and improving the overall efficiency of our programs. This approach also allows for cleaner and more concise code, making it an important tool in any programmer's arsenal.
**Coding examples:**
Let's take a look at how context managers can be used in Python through some coding examples.
**1) File Handling:**
As mentioned in the article, file handling is a common use case for context managers. Let's say we want to open a file, read its contents, and print them to the console. Using a context manager, our code would look like this:
```
file_path = "example.txt"
with open(file_path, 'r') as file:
contents = file.read()
print("File contents:", contents)
```
The 'with' statement automatically handles the opening and closing of the file, freeing up memory once the code block is finished executing.
**2) Custom Context Manager:**
Next, let's see how we can create our own context manager for a custom class. In this example, we will create a Timer class that measures the time it takes for a specific code block to execute.
```
import time
class Timer:
def __enter__(self):
self.start_time = time.time()
def __exit__(self, type, value, traceback):
end_time = time.time()
print("Execution time:", end_time - self.start_time)
# Usage:
with Timer():
# Code to be executed and timed goes here
print("Executing some code...")
```
The __enter__ method initializes the start time, while the __exit__ method calculates the end time and prints out the execution time once the code block is finished.
**Conclusion:**
Context managers are a powerful tool for efficient resource management and avoiding memory leaks in Python. They offer a cleaner and more concise syntax for handling resources, making it easier to maintain efficient and functional code. Whether using built-in context managers or creating custom ones, context managers are an essential concept to understand for any Python programmer.
MyExamCloud Study Plans
[Java Certifications Practice Tests](https://www.myexamcloud.com/onlineexam/javacertification.courses) - MyExamCloud Study Plans
[Python Certifications Practice Tests](https://www.myexamcloud.com/onlineexam/python-certification-practice-tests.courses) - MyExamCloud Study Plans
[AWS Certification Practice Tests](https://www.myexamcloud.com/onlineexam/aws-certification-practice-tests.courses) - MyExamCloud Study Plans
[Google Cloud Certification Practice Tests](https://www.myexamcloud.com/onlineexam/google-cloud-certifications.courses) - MyExamCloud Study Plans
[MyExamCloud Aptitude Practice Tests Study Plan](https://www.myexamcloud.com/onlineexam/aptitude-practice-tests.course)
[MyExamCloud AI Exam Generator](https://www.myexamcloud.com/onlineexam/testgenerator.ai) | myexamcloud |
1,864,181 | Is Web3 expensive? | Recently I've got an idea to try to make a dApp. I've dived into learning more about how blockchain... | 0 | 2024-05-24T16:28:49 | https://dev.to/vladt/is-web3-expensive-87c | web3, blockchain | Recently I've got an idea to try to make a dApp. I've dived into learning more about how blockchain is working, what smart contract, fees, gas, solidity, remix and etc are. I know now the difference between web2 and web3 and I need community support to help me to understand one thing.. 😀
Web3 apps have no backend as we know it. All the information is stored in contracts. Reading the data from them is free for the end user, but putting information there will cost a fee. This fee can either be paid by the end user, or it can be moved on dev shoulders. So what is not clear for me - how do you know your avg. costs to maintain the application?
Let's assume I am making a dApp where users can store a list of their favourite books. Each editing and insertion would require from them, or from me, to pay the money...
> Imagine you would need to pay each time you leave a comment on dev.to
<img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/r2u59s5m2pnawy9pt3da.gif" width="100" height="100">
If I decide to pay all fees by myself, how can I know, that I won't bankrupt after one user just messes up with editing the title of the book (in our example)? So in this case it would make sense to use a good old web2 and store the data for free on some Supabase solution. The costs won't be so high and the app will do what it has to.
So the question is, is there a way to avoid this? Was really inspired by the idea of Web3 and now am not sure which projects should use Web3 at all? Only the ones which make crypto currency operations? 😒
How do P2E games are created? Do they really pay for all user actions or are they not dApps?
Thank you very much for your replies!
| vladt |
1,864,179 | Enneagram Test | Check out this Pen I made! | 0 | 2024-05-24T16:25:01 | https://dev.to/lilly_cottrell_9b8d2f8fa6/enneagram-test-1961 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Yuri-Bara/pen/mdoMLwR %} | lilly_cottrell_9b8d2f8fa6 |
1,864,178 | Step by Step to deploy Go API on AWS lambda and access by function URL | Introduction In today's world of cloud computing, AWS Lambda is a serverless,... | 27,714 | 2024-05-24T16:22:56 | https://medium.com/@hantian.pang/step-by-step-to-deploy-go-api-on-aws-lambda-and-access-by-function-url-796f3cc016d7 | go, api, aws | ## Introduction
In today's world of cloud computing, [AWS Lambda](https://aws.amazon.com/lambda) is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. You can trigger Lambda from over 200 AWS services and software as a service (SaaS) applications, and only pay for what you use.
Go is a statically typed, compiled language known for its simplicity, efficiency, and ease of use. It's particularly well-suited for building scalable and efficient cloud services.
In this guide, I will demonstrate how to deploy a Go API server on AWS Lambda step by step.
## Creating a Lambda Function
First, you need to create a new Lambda function. Log into your AWS console and navigate to the Lambda service. Click the 'Create function' button. You will see many options, but don't worry, we only need to adjust a few. Leaving the rest as they are will be sufficient to host our Go server.
- Enter your function name. For example, I used `go-api`. You should use a name that is meaningful.
- Select the runtime. In this case, we'll choose `Amazon Linux 2023`.
- Optionally, if you're building a Go application for ARM, you should change the Architecture to arm64.
- Click to open Advanced settings and enable the `function URL`. This function is powerful and easy to use, and we will be using it.
- Setting the `Auth type` to `NONE` simplifies its use. For enhanced security, you could use `AWS_IAM`, but that's a different topic that we won't discuss here.
## Edit the Go Source Code
Next, we need to create a minimal Go function for AWS Lambda. Here's a sample `main.go`.
- We import `github.com/aws/aws-lambda-go/lambda`. This dependency is necessary for running Go as a Lambda function.
- In the `main` function, we use `lambda.Start` to start the handler.
```go
package main
import (
"context"
"fmt"
"github.com/aws/aws-lambda-go/lambda"
)
type RequestEvent struct {
RawPath string `json:"rawPath"`
RawQueryString string `json:"rawQueryString"`
Body string `json:"body"`
}
func HandleRequest(ctx context.Context, event *RequestEvent) (*string, error) {
if event == nil {
return nil, fmt.Errorf("received nil event")
}
message := fmt.Sprintf(
"RawPath: %s, RawQueryString: %s, Body: %s",
event.RawPath, event.RawQueryString, event.Body,
)
return &message, nil
}
func main() {
lambda.Start(HandleRequest)
}
```
Next, we need to compile the main into a binary. Simply copy the following command line, ensuring the output filename is 'bootstrap'.
```bash
GOOS=linux GOARCH=amd64 go build -tags lambda.norpc -o bootstrap main.go
```
Next, we need to compress the bootstrap file into a zip format. Without doing this, we cannot upload it to AWS Lambda. Be sure to place the bootstrap file at the root of the zip file.
```bash
zip myFunction.zip bootstrap
```
We've now set up the basic Go application. It's time to upload and conduct a test.
## Upload to AWS lambda
Click to enter the lambda function we created previously and scroll down. Find the `Code Source` block within the code tab. To the right of this block, click the `Upload from` button and select the `.zip file` option. Locate your zip file and upload it.

After uploading, you should find information similar to the details below the `Code Source` block. This indicates that your upload was successful.

## Test the function
Scroll up, and on the right of `Function overview`, you'll find the `function URL`. This is the advanced option we just set. The `function URL` is a powerful tool that can convert your RESTful requests into lambda handler requests, and then encode the handler output into a RESTful response. It's particularly useful for building API servers based on lambda.
Click the small copy button to duplicate the URL. You can now use `curl` to test your lambda function. Input this command into your terminal and press enter. Remember, you need to replace the `function URL` with your own.
```bash
curl -XPOST 'https://{your_lambda_function_URL}/hello?
name=world' -H 'Content-Type: application/json' --data '{"age": 16}'
```
The magic happens, you should see the output like this:
```
RawPath: /hello, RawQueryString: name=world, Body: {"age": 16}
```
Review the codes again, and you'll find the structure. This structure is the second parameter of the handler. The magic here is that the lambda library decodes the path, query string, and body into our structure. While many other fields are available, these three are the most crucial.
```go
type RequestEvent struct {
RawPath string `json:"rawPath"`
RawQueryString string `json:"rawQueryString"`
Body string `json:"body"`
}
```
## Reference
1. **[Building Lambda functions with Go](https://docs.aws.amazon.com/lambda/latest/dg/lambda-golang.html)**
2. **[Lambda function URLs](https://docs.aws.amazon.com/lambda/latest/dg/lambda-urls.html)** | ppaanngggg |
1,864,175 | Create Accordion in NuxtJS with Tailwind CSS | In this tutorial, we will create accordion (FAQ) in Nuxt 3 with tailwind css. Before we begin, you... | 0 | 2024-05-24T16:17:23 | https://webvees.com/post/create-accordion-in-nuxt-3-with-tailwind-css | vue, nuxt, webdev, tailwindcss | In this tutorial, we will create accordion (FAQ) in Nuxt 3 with tailwind css. Before we begin, you need to install and configure tailwind css in Nuxt 3.
<br>
[Install Tailwind CSS in Nuxt 3 with NuxtTailwind Module](https://webvees.com/post/install-tailwind-css-in-nuxt-3-with-nuxttailwind-module)
<br>
1. Nuxt 3 with tailwind css basic accordion (FAQ) section.
```vue
<template>
<div class="container mx-auto">
<div class="lg:max-w-lg w-full">
<div class="divide-y divide-gray-100">
<details class="group" open>
<summary
class="flex cursor-pointer list-none items-center justify-between py-4 text-lg font-medium text-gray-900">
Accordion item #1
<div class="text-gray-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5"
stroke="currentColor" class="block h-5 w-5 transition-all duration-300 group-open:rotate-180">
<path stroke-linecap="round" stroke-linejoin="round" d="M19.5 8.25l-7.5 7.5-7.5-7.5" />
</svg>
</div>
</summary>
<div class="pb-4 text-gray-500">
This is the first item's accordion body 1.
</div>
</details>
<details class="group">
<summary
class="flex cursor-pointer list-none items-center justify-between py-4 text-lg font-medium text-gray-900">
Accordion item #2
<div class="text-gray-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5"
stroke="currentColor" class="block h-5 w-5 transition-all duration-300 group-open:rotate-180">
<path stroke-linecap="round" stroke-linejoin="round" d="M19.5 8.25l-7.5 7.5-7.5-7.5" />
</svg>
</div>
</summary>
<div class="pb-4 text-gray-500">
This is the second item's accordion body 2.
</div>
</details>
<details class="group">
<summary
class="flex cursor-pointer list-none items-center justify-between py-4 text-lg font-medium text-gray-900">
Accordion item #3
<div class="text-gray-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5"
stroke="currentColor" class="block h-5 w-5 transition-all duration-300 group-open:rotate-180">
<path stroke-linecap="round" stroke-linejoin="round" d="M19.5 8.25l-7.5 7.5-7.5-7.5" />
</svg>
</div>
</summary>
<div class="pb-4 text-gray-500">
This is the third item's accordion body 3.
</div>
</details>
</div>
</div>
</div>
</template>
```
2.Nuxt 3 Typescript with tailwind css accordion (FAQ) section using v-for loop to make shorthand code.
```vue
<script setup lang="ts">
const accordionItems: { title: string; content: string }[] = [
{
title: "Accordion item 01",
content: "This is the first item accordion body 1",
},
{
title: "Accordion item 02",
content: "This is the second item accordion body 2",
},
{
title: "Accordion item 03",
content: "This is the third item accordion body 3",
},
];
</script>
<template>
<div class="container mx-auto">
<div class="w-full lg:max-w-lg">
<div class="divide-y divide-gray-100">
<details v-for="(item, index) in accordionItems" :key="index" class="group">
<summary
class="flex cursor-pointer list-none items-center justify-between py-4 text-lg font-medium text-secondary-900">
{{ item.title }}
<div class="text-secondary-500">
<svg xmlns="http://www.w3.org/2000/svg" fill="none" viewBox="0 0 24 24" stroke-width="1.5"
stroke="currentColor" class="block h-5 w-5 transition-all duration-300 group-open:rotate-180">
<path stroke-linecap="round" stroke-linejoin="round" d="M19.5 8.25l-7.5 7.5-7.5-7.5" />
</svg>
</div>
</summary>
<div class="pb-4 text-secondary-500">{{ item.content }}</div>
</details>
</div>
</div>
</div>
</template>
```
 | saim_ansari |
1,864,243 | Bootcamp De ServiceNow Gratuito Com Chance De Contratação | O Programa Shark in ServiceNow é um treinamento totalmente gratuito e remoto, ministrado pelos... | 0 | 2024-05-27T01:33:23 | https://guiadeti.com.br/bootcamp-servicenow-gratuito-contratacao/ | cursogratuito, bootcamps, bootcamp, cloud | ---
title: Bootcamp De ServiceNow Gratuito Com Chance De Contratação
published: true
date: 2024-05-24 16:15:00 UTC
tags: CursoGratuito,Bootcamps,bootcamp,cloud
canonical_url: https://guiadeti.com.br/bootcamp-servicenow-gratuito-contratacao/
---
O Programa Shark in ServiceNow é um treinamento totalmente gratuito e remoto, ministrado pelos melhores especialistas do mercado em uma das plataformas de transformação digital mais utilizadas no mundo.
O Shark in ServiceNow 9ª Edição, terá mais de 15 horas de conteúdo, o programa é projetado para impulsionar carreiras, contando com a participação especial de diversos especialistas e preparando os participantes para ingressar no mercado de ServiceNow.
Oferecido pela Aoop, o programa oferece aos participantes que se destacarem a oportunidade de participar do processo seletivo para integrar a equipe da empresa
## Shark in ServiceNow 9ª Edição
O Programa Shark in ServiceNow é um treinamento 100% gratuito e remoto, instruído pelos melhores especialistas do mercado em uma das plataformas de transformação digital mais utilizadas no mundo.

_Imagem da página do Bootcamp_
### Estrutura do Curso
A 9ª Edição do Shark in ServiceNow contará com mais de 15 horas de conteúdo. O programa é projetado para impulsionar carreiras, contando com a participação especial de diversos especialistas e preparando os participantes para ingressar no mercado de ServiceNow.
### Imersão em ServiceNow
Neste bootcamp, os participantes farão uma imersão em ServiceNow de forma conceitual e prática, elevando o conhecimento e a carreira para novos níveis.
O objetivo do projeto é disseminar conhecimento e compartilhar experiências com profissionais interessados em aprender sobre ServiceNow, mas que ainda não tiveram a oportunidade.
### Público-Alvo
O programa destina-se a profissionais e estudantes com conhecimento em lógica de programação. A confirmação da participação será realizada através do e-mail fornecido durante a inscrição.
### Requisitos de Participação
- Inglês para leitura;
- Conhecimentos em Programação e Desenvolvimento;
- Vontade de aprender.
### Detalhes do Evento
Oferecido pela Aoop, o programa acontecerá entre os dias 10 e 14 de junho, de segunda à sexta-feira, das 19:00 às 22:00. As inscrições podem ser realizadas até o dia 29 de maio. Serão dadas aulas teóricas e práticas, com atividades realizadas ao longo do curso.
### Etapas Do Processo
- Cadastro;
- Aoop – Processo Interno / Triagem;
- Confirmados (E-mail Encaminhado);
- Participantes do Bootcamp;
- Processo Seletivo;
- Aprovados no Processo Seletivo.
### Oportunidades e Certificação
Os participantes que se destacarem durante o treinamento terão a oportunidade de participar do processo seletivo para integrar a equipe da Aoop. Aqueles que concluírem o programa com êxito e com presença mínima de 70% nas aulas receberão o certificado.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/01/Curso-De-Desenvolvimento-Web-UNICAMP-2-280x210.png" alt="Curso De Desenvolvimento Web UNICAMP" title="Curso De Desenvolvimento Web UNICAMP"></span>
</div>
<span>Curso De Desenvolvimento Web Com Angular JS E Outros Temas Gratuitos Da Unicamp</span> <a href="https://guiadeti.com.br/curso-desenvolvimento-web-com-angular-js-unicamp/" title="Curso De Desenvolvimento Web Com Angular JS E Outros Temas Gratuitos Da Unicamp"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Workshop-De-Inteligencia-Artificial-Gratis-280x210.png" alt="Workshop De Inteligência Artificial Grátis" title="Workshop De Inteligência Artificial Grátis"></span>
</div>
<span>Workshop De Inteligência Artificial E Seus Modelos De Linguagem Gratuito</span> <a href="https://guiadeti.com.br/workshop-inteligencia-artificial-modelos-linguagem/" title="Workshop De Inteligência Artificial E Seus Modelos De Linguagem Gratuito"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Minicurso-Design-UXUI-280x210.png" alt="Minicurso Design UX/UI" title="Minicurso Design UX/UI"></span>
</div>
<span>Minicurso De Design UX/UI Online E Gratuito Com Certificado Da Cubos Academy</span> <a href="https://guiadeti.com.br/minicurso-design-ux-ui-online-gratuito-certificado/" title="Minicurso De Design UX/UI Online E Gratuito Com Certificado Da Cubos Academy"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/05/Curso-De-Gestao-de-Projetos-280x210.png" alt="Curso De Gestão de Projetos" title="Curso De Gestão de Projetos"></span>
</div>
<span>Curso De Gestão de Projetos E Métodos Agile Gratuito Do Santander</span> <a href="https://guiadeti.com.br/curso-gestao-de-projetos-metodos-agile-gratuito/" title="Curso De Gestão de Projetos E Métodos Agile Gratuito Do Santander"></a>
</div>
</div>
</div>
</aside>
## ServiceNow
ServiceNow é uma plataforma de nuvem que oferece variados serviços para automação de processos empresariais.
Reconhecida como líder em transformação digital, a plataforma é usada por organizações de todo o mundo para gerenciar operações de TI, atendimento ao cliente, recursos humanos e muito mais.
### O Que é ServiceNow?
ServiceNow é uma solução SaaS (Software as a Service) que permite às empresas automatizar e padronizar processos de negócios e serviços. A plataforma integra vários aplicativos em uma única interface, facilitando a gestão de tarefas e fluxos de trabalho.
### Principais Funcionalidades
- Gestão de Incidentes: Permite registrar, rastrear e resolver problemas de TI de forma eficiente.
- Gestão de Mudanças: Facilita a implementação de alterações nos sistemas de TI com mínimos riscos e interrupções.
- Gestão de Configurações: Mantém um registro preciso de todos os ativos de TI e suas relações.
- Automação de Fluxo de Trabalho: Automatiza processos repetitivos, melhorando a produtividade e reduzindo erros humanos.
### Benefícios do Uso de ServiceNow
- Eficiência Operacional: Automatiza tarefas manuais, liberando tempo para os funcionários se concentrarem em atividades estratégicas.
- Melhoria na Experiência do Cliente: Fornece atendimento rápido e eficaz, aumentando a satisfação do cliente.
- Transparência e Controle: Oferece visibilidade completa sobre operações e processos, permitindo uma melhor tomada de decisão.
- Flexibilidade e Escalabilidade: Adapta-se às necessidades específicas de cada organização, crescendo conforme a demanda.
### Mercado de Trabalho e Certificações
O conhecimento em ServiceNow é muito valorizado no mercado de trabalho, com uma demanda crescente por profissionais qualificados.
A plataforma oferece várias certificações que validam a competência dos profissionais em diferentes áreas, como administração, desenvolvimento e implementação de soluções ServiceNow.
## Aoop
A Aoop é uma empresa de tecnologia que oferece soluções e serviços de alta qualidade para empresas de diversos setores.
### Serviços Oferecidos
- Desenvolvimento de Software: A Aoop oferece serviços de desenvolvimento de software sob medida, desde aplicativos móveis até sistemas complexos de gestão empresarial.
- Consultoria em Tecnologia: Com uma equipe de especialistas em TI, a Aoop oferece consultoria para ajudar empresas a otimizar suas operações e adotar as melhores práticas tecnológicas.
- Integração de Sistemas: A integração de sistemas é uma das especialidades da Aoop, permitindo que empresas conectem e sincronizem diferentes sistemas e plataformas para uma melhor eficiência operacional.
### Diferenciais da Aoop
- Inovação Constante: A Aoop está sempre buscando novas tecnologias e estratégias para oferecer soluções novas e acompanhar as tendências do mercado.
- Foco no Cliente: A empresa coloca o cliente no centro de suas operações, buscando entender suas necessidades e oferecer soluções personalizadas e eficientes.
- Equipe Qualificada: Com uma equipe altamente qualificada e experiente, a Aoop garante a entrega de projetos de alta qualidade e resultados excepcionais.
### Parcerias e Reconhecimento
A Aoop mantém parcerias estratégicas com empresas líderes do setor de tecnologia, garantindo acesso às melhores ferramentas e recursos para seus clientes. A empresa tem sido reconhecida por sua excelência, recebendo prêmios e certificações ao longo de sua trajetória.
## Inscreva-se agora e mergulhe no universo do ServiceNow com o Bootcamp gratuito!
As [inscrições para o Shark in ServiceNow 9ª Edição](https://aoop.gupy.io/jobs/7134427?jobBoardSource=gupy_public_page) devem ser realizadas no site da Gupy.
## Compartilhe esta chance de aprimoramento profissional com seus colegas e amigos interessados em ServiceNow!
Gostou do conteúdo sobre o bootcamp gratuito? Então compartilhe com a galera!
O post [Bootcamp De ServiceNow Gratuito Com Chance De Contratação](https://guiadeti.com.br/bootcamp-servicenow-gratuito-contratacao/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,864,172 | How to Use Dark Mode In NuxtJS with Nuxtlabs UI | In this tutorial, I will show you how to use toggle dark and light mode in nuxt 3 Nuxtlabs UI. Before... | 0 | 2024-05-24T16:12:36 | https://webvees.com/post/how-to-dark-mode-in-nuxt-3-with-nuxtlabs-ui/ | nuxt, vue, tailwindcss, webdev | In this tutorial, I will show you how to use toggle dark and light mode in nuxt 3 Nuxtlabs UI. Before we begin, you need to install and configure Nuxtlabs UI in NuxtJS.
<br>
[How to Install Nuxtlabs UI in Nuxt 3](https://webvees.com/post/how-to-install-nuxtlabs-ui-in-nuxt-3)
You can easily build a color mode button by using the useColorMode composable from @nuxtjs/color-mode.
```vue
<script setup>
const colorMode = useColorMode()
const isDark = computed({
get () {
return colorMode.value === 'dark'
},
set () {
colorMode.preference = colorMode.value === 'dark' ? 'light' : 'dark'
}
})
</script>
<template>
<ClientOnly>
<UButton
:icon="isDark ? 'i-heroicons-moon-20-solid' : 'i-heroicons-sun-20-solid'"
color="gray"
variant="ghost"
aria-label="Theme"
@click="isDark = !isDark"
/>
<template #fallback>
<div class="w-8 h-8" />
</template>
</ClientOnly>
</template>
```

 | saim_ansari |
1,864,170 | 5 Functions of Bones in Humans That Are Rarely Realized | 5 Functions of Bones in Humans That Are Rarely Realized Although not visible from the outside,... | 0 | 2024-05-24T16:09:34 | https://dev.to/lifehealthid/5-functions-of-bones-in-humans-that-are-rarely-realized-436a | lifehealth, bones | 5 Functions of Bones in Humans That Are Rarely Realized
Although not visible from the outside, human bones have important functions for the body. This lightweight yet strong part of the body has functions that many people don't realize. What are these functions? Here is the list.
1. Supports the body and aids movement
The main function of bones in humans is to support the entire body and the organs in it. Without the bones that make up the skeleton, all organs would have nowhere to attach.
In addition, the skeleton helps determine a person's posture. And also the human skeletal system allows humans to move.
2. Protects internal organs
Although lightweight, human bones are hard enough to withstand impact. Therefore, another function of human bones is to protect internal organs. For example, the rib cage protects the lungs and heart from impact.
3. Producing blood cells
Some types of bones can produce red blood cells, white blood cells, and platelets. All three have important functions for the health of the body. Red blood cells help circulate oxygen throughout the body, white blood cells help fight infection, and platelets help clot blood to stop bleeding.
4. Store and release fat
Another function of bones in humans is to store and release fat when the body needs it
5. Store and release minerals
When the body experiences excess minerals, the function of human bones is to store them. After that, release it when needed by the body. Some types of minerals stored by bones are phosphorus, vitamin D, and calcium.
Bone Structure in the Human Body
Human bones are made up of different types of tissues that make up their structure. Here are the main components of the bone structure in the human body:
Solid bone tissue: This is the hard tissue that forms the outside of the bone.
Chancellular tissue: The soft tissue inside the bone that has a sponge-like structure. It is traversed by blood and lymph vessels.
Subchondrial Tissue: The delicate tissue that sits at the end of the bone and is covered by cartilage.
Periosteum: A hard, thin membrane that lines the outside of the bone, providing additional protection.
Bone Marrow: Soft tissue found inside the bone cavity. Bone marrow plays an important role in the formation of blood cells.
Bone Cells: Made up of several types of cells, namely:
Osteoblasts: Cells responsible for forming new bone tissue.
Osteoclasts: Cells that are involved in the breakdown of old bone tissue, allowing the formation of new bone.
Osteocytes: Cells that function to maintain the integrity and structure of the bone.
With these different types of tissues and cells, the human bone structure can maintain the strength, integrity and function of the body as a whole.
How to maintain healthy human bone function
In order for human bone function to continue to work properly, bone health needs to be maintained. There are some easy ways you can do to maintain it.
1. Avoid alcohol consumption and smoking
If you are a woman, avoid consuming more than one alcoholic drink per day. If you are a man, avoid consuming more than two alcoholic drinks daily.
2. Eat calcium-rich foods
Calcium plays an important role in making bones strong and less porous. Therefore, make sure to consume calcium as needed. In adults aged 19 to 50, the Daily Intake Requirement (KAD) of calcium is 1,000 milligrams (mg) per day. While for women aged 51 years and over and men aged 71 years and over is 1,200 mg per day. Calcium can be obtained through dairy, almonds, broccoli, kale, canned salmon with bones, sardines, and soy products such as tofu. If you are struggling to get enough calcium from your diet, consult your doctor about supplements.
3. Meet your Vitamin D intake
For proper function of human bones, your body needs vitamin D to absorb calcium. For adults aged 19 to 70 years, the vitamin D KAD is 600 international units (IU) per day. This recommendation increases to 800 IU per day for adults aged 71 years and above. Good sources of vitamin D include fatty fish such as salmon and tuna. In addition, mushrooms, eggs, and fortified foods such as milk and cereals are also good sources of vitamin D. Exposure to sunlight can also increase vitamin D production in the body. In addition, you can also take vitamin D supplements if you have difficulty getting sources of vitamin D.
4. Exercise regularly
Exercise such as walking, jogging, and climbing stairs can help you strengthen your bones and prevent bone loss.
Those are some explanations of the functions of bones in humans that are often realized. Make sure to always maintain bone health so that it can continue to be healthy until old age.
Thanks for reading this article. Have a nice day.
source: https://www.lifehealth.id/ | lifehealthid |
1,864,169 | Learning AWS Day by Day — Day 74 — AWS Organization Concepts | Exploring AWS !! Day 74 AWS Organization Concepts Organization: Can be used for consolidating... | 0 | 2024-05-24T16:09:14 | https://dev.to/rksalo88/learning-aws-day-by-day-day-74-aws-organization-concepts-3ni0 | aws, cloud, cloudcomputing, beginners | Exploring AWS !!
Day 74
AWS Organization Concepts

Organization:
Can be used for consolidating various or multiple accounts so that we can administer all of them as a single unit.
An Organization will have one master account and zero or more member accounts. The Organization can be organized in a hierarchical order by keeping root at the top.
Root:
Master account for all other member accounts. On applying any policy to the root, it gets applied automatically to all the member accounts. When we create an Organization, Root gets automatically created and we can have only one Root.
Organization Unit (OU):
A container for accounts within a root. An OU can contain other OUs, and that’s how we can have a tree like architecture. Attaching a policy to OU, will affect all other OUs and member accounts under it.
Account:
This refers to AWS accounts containing AWS services and resources. Policies can be attached to the account only to control the resources within it.
Master account creates the Organization and we can administer using it.
All other accounts in member accounts are part of Organization.
Invitation:
A process of asking other AWS account to join our Organization. This invitation can be sent only by Master account, and once the request is accepted, they become a member.
Handshake:
A process of sharing information with to accounts or parties. Handshakes are used to send invitations and get back acknowledgement. We can directly work with handshakes when using CLI or Organization’s APIs. | rksalo88 |
1,863,930 | Sign Git Commits and Authenticate to GitHub with SSH Keys | In software development we have to use git in daily basis. We also have to use a remote repository... | 0 | 2024-05-24T16:07:34 | https://dev.to/msrhmn/sign-git-commits-and-authenticate-to-github-with-ssh-keys-251a | git, ssh, commit, github |

In software development we have to use git in daily basis. We also have to use a remote repository location to work collaboratively with our team. And while we are working collaboratively with our team or in a public repository, we need to make sure that commits are coming from a verified user. Just like we would authenticate our bank accounts or social accounts with credentials, git commits has to be verified in that case. And there SSH technology comes in handy.
Another use case of SSH is that, if we are using GitHub for our remote repository then we may have to push changes frequently from our local repository to GitHub and that will require to authenticate with credentials of GitHub account. Every time the session time expires we have to authenticate again with the credentials while with SSH we just have configure once, which saves a lot of time in the development process.
For signing commits, GPG keys are more reliable but for simplicity and doing two operations using one technology I'll just go with the SSH.
To generate SSH keys and make it working follow the code below in your Linux terminal window. Mac has almost similar process as Linux, since it is a UNIX system. In windows WSL is fine.
```
ssh-keygen -t ed25519 -C "username@example.com"
eval "$(ssh-agent -s)"
ssh-add ~/.ssh/id_ed25519
cat ~/.ssh/id_ed25519.pub
```
1. First line of code will generate SSH key pairs in your system. Use your email at `username@example.com` quote.
2. Start's the ssh-agent in the background.
3. Adds newly generated SSH keys to the agent to perform operations.
4. Display's the public key code in the terminal.
Now copy the public key code from the terminal window and open your GitHub account's `Settings > SSH and GPG Keys > New SSH key`. Add the copied public key for both authentication and signing key.
To attempt SSH into GitHub account:
```
ssh -T git@github.com
```
This may say warning message like this:
```
> The authenticity of host 'github.com (IP ADDRESS)' can't be established.
> ED25519 key fingerprint is SHA256:+DiY3wvvV6TuJJhbpZisF/zLDA0zPMSvHdkr4UvCOqU.
> Are you sure you want to continue connecting (yes/no)?
```
Type: `yes` to continue and save the key for the future authentication.
```
> Hi USERNAME! You've successfully authenticated, but GitHub does not
> provide shell access.
```
Now you have authenticated to your GitHub account with SSH and you can pull/push to your remote GitHub repository without further authentication.
So we have another work to do with SSH key and that is signing our local git commits, and that indicates commits are authorized by the original user. We already have saved our SSH public key into GitHub account for both authentication and signing. For that, now we just have to configure the git in our local machine. Just as we configure our git user name, email, and branch name.
Execute the following commands in your terminal:
```
git config --global gpg.format ssh
git config --global user.signingkey ~/.ssh/id_ed25519.pub
git config --global commit.gpgsign true
```
And that, finally our work has done. Now your future git commits are signed with your SSH key as well you are authenticated to your GitHub repository without further need of authentication. | msrhmn |
1,864,165 | Registration - form | Check out this Pen I made! | 0 | 2024-05-24T16:05:14 | https://dev.to/randol696/registration-form-13d5 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/randol696/pen/jOoMqBw %} | randol696 |
1,864,164 | UseRouter import from next/navigation or next/router in App Router Next JS? | Hi devs, in this article we will learn which solution is better for us. So many developers facing... | 0 | 2024-05-24T16:02:04 | https://dev.to/vivek_44751fc408644cbd80b/userouter-import-from-nextnavigation-or-nextrouter-in-app-router-next-js-2pne | javascript, nextjs, userouter, react | Hi devs, in this article we will learn which solution is better for us.
So many developers facing issue while using useRouter in next JS.
```
import { useRouter } from "next/router";
const router = useRouter();
```
The above import is not working in next JS when we are using app router.
So as documentation next js allow useRouter from next/navigation in App Router.
Here is the way of importing the useRouter in App Router.
```
import { useRouter } from "next/navigation";
const router = useRouter();
```
Thank you for reading. That’s all for today.
| vivek_44751fc408644cbd80b |
1,862,242 | API Design Patterns: Enhancing Flexibility, Performance, and Security | In the world of modern application development, APIs (Application Programming Interfaces) play a... | 0 | 2024-05-24T16:02:02 | https://dev.to/hhussein/api-design-patterns-enhancing-flexibility-performance-and-security-2j7g | api, designpatterns, itarchjournal, architecture | In the world of modern application development, APIs (Application Programming Interfaces) play a crucial role in enabling communication between different services and systems. Designing robust, flexible, and efficient APIs is essential for building scalable and maintainable applications. This article explores several key design patterns for APIs, offering insights into their contexts, use cases, benefits, and potential drawbacks.
## 1. Gateway Pattern
**Context**
The Gateway pattern involves using an API gateway as an intermediary between clients and a collection of backend services. The API gateway serves as a single entry point, routing requests to the appropriate microservices. It can handle various cross-cutting concerns such as authentication, authorization, rate limiting, caching, and load balancing.
**Use Case**
Imagine an e-commerce platform with numerous microservices handling different functionalities such as user management, product catalog, order processing, and payment services. Instead of exposing each microservice directly to the clients, an API gateway is used. Clients make requests to the API gateway, which then routes these requests to the appropriate microservices.
**When to Use the Gateway Pattern**
- Microservices Architecture: When your application is built using a microservices architecture, an API gateway can simplify client interactions by providing a single point of entry.
- Cross-Cutting Concerns: When you need to manage cross-cutting concerns such as authentication, rate limiting, logging, and load balancing consistently across multiple services.
- Multiple Clients: When you have different types of clients (e.g., web, mobile, IoT) that require different levels of access or different formats of the same data. The API gateway can handle these differences and present a uniform interface to the clients.
- Security: When you need to secure your backend services by hiding them behind a gateway, which can enforce security policies and reduce the attack surface.
**When Not to Use the Gateway Pattern**
- Simple Architectures: If your application is simple and does not consist of many microservices, using an API gateway can introduce unnecessary complexity.
- Performance Overhead: An API gateway adds an additional layer between the client and the backend services. If low latency is critical and the added overhead cannot be justified, it might be better to avoid this pattern.
- Single Point of Failure: The API gateway can become a single point of failure if not properly managed and scaled. In highly critical applications, the additional complexity of ensuring high availability and fault tolerance for the gateway might not be worth the benefits.
- Learning Curve: If your development team is not familiar with API gateways, there might be a significant learning curve, and the benefits need to outweigh the costs of training and implementation.
**Example Implementation**
> Context: An online bookstore with microservices for user accounts, book inventory, order processing, and payments.
> Scenario: A customer uses a mobile app to browse books, place orders, and make payments.
> **Without API Gateway:**
> - The mobile app makes separate API calls to each microservice.
> - Each service handles authentication, rate limiting, logging, etc., individually.
> **With API Gateway:**
> - The mobile app interacts only with the API gateway.
> - The gateway authenticates the user and forwards requests to the appropriate microservice.
> - The gateway manages rate limiting, logging, and other cross-cutting concerns.
**Pros:**
- Simplifies client-side logic.
- Centralizes cross-cutting concerns.
- Enhances security by hiding backend services.
**Cons:**
- Introduces additional latency.
- Can become a single point of failure.
- Adds complexity in terms of deployment and management.
**Summary**
The Gateway pattern is highly beneficial in complex, microservices-based architectures where managing multiple endpoints and cross-cutting concerns centrally simplifies client interactions and enhances security. However, for simpler applications or those requiring ultra-low latency, the overhead and complexity of an API gateway might not be justified. Careful consideration of your application's requirements and constraints is essential before implementing this pattern.
## 2. Facade Pattern
**Context**
The Facade pattern provides a simplified, unified interface to a complex subsystem. In the context of APIs, a facade can aggregate multiple backend services into a single, easy-to-use API. This abstraction hides the complexity of the underlying services, making it easier for clients to interact with the system.
**Use Case**
Imagine a travel booking platform that offers various services such as flight booking, hotel reservations, car rentals, and activity bookings. Each of these services is managed by different microservices with their own APIs. A facade can be created to provide a single API for clients to book a complete travel package.
**When to Use the Facade Pattern**
- Complex Systems: When your system consists of multiple interdependent services, and you want to provide a simple interface for clients.
- Client Simplicity: When you want to reduce the complexity for clients, who otherwise would need to interact with multiple services directly.
- Consistent Interface: When you want to present a consistent and uniform API to clients, hiding the differences and complexities of the underlying services.
- Legacy Integration: When integrating with legacy systems that have complex or non-standard APIs, a facade can simplify the client interface.
- Maintainability: When you want to centralize changes in one place. By modifying the facade, you can adapt to changes in the underlying services without affecting the clients.
- When Not to Use the Facade Pattern
- Overhead: If the facade adds unnecessary complexity or overhead, particularly if the underlying services are already simple and easy to use.
- Single Responsibility: If the facade starts becoming too complex itself, it may violate the Single Responsibility Principle. In such cases, consider splitting it into multiple facades.
- Performance: If the facade introduces performance bottlenecks due to the additional layer of abstraction, especially in performance-critical applications.
- Direct Access: When clients need to access specific features of individual services directly, bypassing the simplified interface provided by the facade.
**Example Implementation**
> Context: A travel booking platform offering flights, hotels, cars, and activities.
> Scenario: A user wants to book a complete travel package using a mobile app.
> **Without Facade:**
> - The mobile app makes separate API calls to each service (flights, hotels, cars, activities).
> - Each service has its own authentication, data format, and error handling mechanisms.
> **With Facade:**
> - The mobile app interacts with a single API provided by the facade.
> - The facade handles authentication, aggregates data from various services, and presents a unified response to the client.
**Pros:**
- Simplifies client interactions.
- Reduces the number of API calls.
- Hides the complexity of the underlying services.
- Centralizes error handling and response formatting.
**Cons:**
- Adds an additional layer of abstraction.
- Can become a bottleneck if not designed efficiently.
- Might obscure certain advanced features of individual services.
**Summary**
The Facade pattern is particularly useful in complex systems with multiple interdependent services, providing a simplified interface that enhances client usability and maintainability. However, it should be used judiciously to avoid unnecessary overhead and ensure that it remains a clear, concise abstraction rather than becoming a source of additional complexity. Careful design and consideration of the specific use case are essential to effectively implement the Facade pattern.
## 3. Proxy Pattern
**Context**
The Proxy pattern involves creating a proxy server that acts as an intermediary between the client and the actual API. This proxy can provide additional functionalities such as security, caching, logging, and access control, without modifying the original API.
**Use Case**
Imagine a company that has several internal APIs for different departments, such as HR, finance, and sales. To access these APIs, employees need to go through a secure proxy that handles authentication, logging, and caching. This proxy ensures that only authorized users can access the APIs and provides a unified access point.
**When to Use the Proxy Pattern**
- Security: When you need to enforce security policies such as authentication and authorization centrally, ensuring that only legitimate requests reach the backend services.
- Caching: When you want to cache responses to improve performance and reduce the load on backend services.
- Logging and Monitoring: When you need to log requests and responses for monitoring, analytics, or auditing purposes.
- Access Control: When you need to control access to the APIs based on various criteria such as user roles, IP addresses, or request rates.
- Encapsulation: When you want to hide the details of the backend services from the clients and provide a more simplified interface.
**When Not to Use the Proxy Pattern**
- Latency: If adding a proxy introduces unacceptable latency, especially for real-time applications.
- Overhead: If the proxy adds unnecessary complexity or overhead, particularly if the underlying APIs are straightforward and do not require additional functionality.
- Single Point of Failure: If the proxy becomes a single point of failure, affecting the availability of the backend services.
- Direct Access Needed: When clients need direct access to certain features of the backend services that might not be exposed through the proxy.
**Example Implementation**
> Context: A company with internal APIs for HR, finance, and sales departments.
> Scenario: Employees use a secure proxy to access these APIs.
> **Without Proxy:**
> - Employees access each API directly.
> - Each API handles its own authentication, logging, and access control.
> **With Proxy:**
> - Employees access the secure proxy.
> - The proxy authenticates users, logs requests, caches responses, and forwards valid requests to the appropriate backend services.
**Pros:**
- Centralizes security and access control.
- Improves performance through caching.
- Simplifies logging and monitoring.
- Encapsulates the details of the backend services.
**Cons:**
Adds an additional layer of latency.
- Can become a single point of failure.
- Adds complexity in terms of deployment and management.
- Might obscure specific features of the underlying services.
**Summary**
The Proxy pattern is highly beneficial for centralizing security, caching, logging, and access control, particularly in environments with multiple backend services. However, it should be implemented carefully to avoid introducing unnecessary latency and complexity. Proper design and consideration of the specific requirements and constraints of your application are crucial for effectively leveraging the Proxy pattern.
## 4. Composite Pattern
**Context**
The Composite pattern allows individual objects and compositions of objects to be treated uniformly. In the context of APIs, this means structuring APIs to handle complex hierarchical data and operations in a way that simplifies interactions for the client. This pattern is particularly useful for representing part-whole hierarchies.
**Use Case**
Imagine a content management system (CMS) where content can be composed of various elements such as text, images, and videos. Each of these elements can be a standalone component or a part of a larger composite component (e.g., a webpage). Using the Composite pattern, the CMS API can provide a uniform interface to manage individual content elements as well as composite elements.
**When to Use the Composite Pattern**
- Hierarchical Data: When your application needs to manage and manipulate hierarchical data structures, such as nested objects or trees.
- Uniform Interface: When you want to provide a uniform interface for clients to interact with both individual and composite objects.
- Complex Structures: When dealing with complex structures that can contain other objects of the same type, making it easier to add, remove, and manipulate parts of the structure.
- Recursive Operations: When operations on individual objects and composites need to be performed recursively.
**When Not to Use the Composite Pattern**
- Simple Structures: If the data structure is simple and does not involve nested or hierarchical relationships, the Composite pattern might add unnecessary complexity.
- Performance Concerns: If managing the composite structure introduces performance overhead that cannot be justified by the benefits of the pattern.
- Flat Data: When dealing with flat data structures that do not require hierarchical management, using the Composite pattern can be overkill.
**Example Implementation**
> Context: A content management system (CMS) for managing webpages composed of various content elements.
> Scenario: A user wants to create a webpage that includes text, images, and videos.
> **Without Composite Pattern:**
> - The client makes separate API calls to manage each content element (text, images, videos).
> - The client needs to handle the composition and relationships between these elements manually.
> **With Composite Pattern:**
> - The CMS API provides a uniform interface to manage both individual content elements and composite elements (webpages).
> - The client can interact with a single API to add, remove, and manipulate content elements within a webpage.
**Pros:**
- Simplifies client interactions with hierarchical data.
- Provides a uniform interface for both individual and composite objects.
- Facilitates recursive operations on complex structures.
- Enhances flexibility in managing nested and hierarchical relationships.
**Cons:**
- Adds complexity to the API design and implementation.
- May introduce performance overhead.
- Can be overkill for simple or flat data structures.
**Summary**
The Composite pattern is highly beneficial for managing hierarchical data structures and providing a uniform interface for clients. It simplifies interactions with complex and nested data, making it easier to add, remove, and manipulate parts of the structure. However, it should be used judiciously to avoid unnecessary complexity and performance overhead. Proper consideration of the application's data structure and requirements is essential for effectively implementing the Composite pattern.
## 5. Adapter Pattern
**Context**
The Adapter pattern allows incompatible interfaces to work together by converting the interface of a class into another interface that a client expects. In the context of APIs, an adapter can translate requests from one format or protocol to another, enabling integration between different systems.
**Use Case**
Imagine a retail company that uses a legacy inventory management system with a proprietary API. They want to integrate this system with a new e-commerce platform that expects RESTful API interactions. An adapter can be created to bridge the gap between the legacy system and the new platform, allowing seamless integration.
**When to Use the Adapter Pattern**
- Legacy System Integration: When you need to integrate new components with legacy systems that have incompatible interfaces.
- Third-Party Services: When integrating third-party services that do not conform to your system’s API standards.
- Protocol Translation: When there is a need to translate between different protocols (e.g., SOAP to REST).
- Reusing Existing Code: When you want to reuse existing code that does not match the new system’s interface requirements.
- API Modernization: When modernizing an API to conform to current standards without changing the underlying system.
**When Not to Use the Adapter Pattern**
- Simple Compatibility: If the interfaces are already compatible or can be easily modified without the need for an adapter.
- Performance Concerns: If the adapter introduces significant latency or performance overhead.
- Direct Refactoring: When it is feasible to refactor the existing code or API to match the required interface directly, avoiding the additional layer of complexity.
**Example Implementation**
> Context: A retail company with a legacy inventory management system that needs to integrate with a new e-commerce platform.
> Scenario: The e-commerce platform expects RESTful API interactions, but the legacy system uses a proprietary API.
> **Without Adapter Pattern:**
> - The new platform cannot directly interact with the legacy system due to incompatible interfaces.
> - Developers might need to write custom integration code for each interaction.
> **With Adapter Pattern:**
> - An adapter translates RESTful requests from the e-commerce platform into the proprietary format understood by the legacy system.
> - The adapter also translates responses from the legacy system back into RESTful responses for the e-commerce platform.
**Pros:**
- Enables integration with legacy systems without modifying them.
- Facilitates the use of third-party services with incompatible interfaces.
- Promotes code reuse by allowing existing components to work with new systems.
- Simplifies the client-side logic by providing a consistent interface.
**Cons:**
- Adds an additional layer of complexity.
- May introduce performance overhead.
- Can become a maintenance burden if not well-documented.
- Might obscure the underlying system’s capabilities and limitations.
**Summary**
The Adapter pattern is highly useful for integrating systems with incompatible interfaces, particularly when dealing with legacy systems or third-party services. It enables seamless interaction by translating requests and responses between different formats or protocols. However, it should be implemented carefully to avoid unnecessary complexity and performance overhead. Proper design and understanding of the specific integration requirements are essential for effectively leveraging the Adapter pattern.
## 6. Chain of Responsibility Pattern
**Context**
The Chain of Responsibility pattern allows a request to pass through a chain of handlers. Each handler processes the request or passes it to the next handler in the chain. This pattern is useful for scenarios where multiple handlers might process a request in a flexible and decoupled manner.
**Use Case**
Imagine a customer support system where a support ticket can be handled by various departments such as customer service, technical support, and billing. Each department checks the ticket to see if it falls within their domain of responsibility. If not, the ticket is passed to the next department in the chain.
**When to Use the Chain of Responsibility Pattern**
- Flexible Processing: When you need to pass a request through a series of handlers that can process or pass it along the chain without tightly coupling the request to specific handlers.
- Multiple Handlers: When a request needs to be handled by more than one handler, or the appropriate handler is not known in advance.
- Dynamic Assignment: When the set of handlers and their order need to be changed dynamically.
- Decoupled Handlers: When you want to decouple the sender of a request from its receivers to reduce dependencies and increase flexibility.
**When Not to Use the Chain of Responsibility Pattern**
- Single Handler: If a request is always handled by a single, well-defined handler, using this pattern can introduce unnecessary complexity.
- Performance Concerns: If passing a request through multiple handlers introduces unacceptable latency or performance overhead.
- Predictable Flow: When the flow of handling requests is predictable and does not require the flexibility offered by this pattern.
**Example Implementation**
> Context: A customer support system for handling support tickets.
> Scenario: A support ticket can be handled by customer service, technical support, or billing departments.
> **Without Chain of Responsibility Pattern:**
> - The client needs to know which department to contact directly.
> - The client must handle the logic to determine the appropriate department for each ticket.
> **With Chain of Responsibility Pattern:**
> - The support ticket is passed through a chain of departments (handlers).
> - Each department checks if it can handle the ticket; if not, the ticket is passed to the next department.
**Pros:**
- Increases flexibility in assigning and processing requests.
- Decouples the sender and receivers of a request.
- Simplifies client code by not requiring it to know the details of handling.
- Easy to add or remove handlers from the chain dynamically.
**Cons:**
- Can introduce latency if the request passes through many handlers.
- Makes it harder to debug and trace the flow of a request.
- Potentially more complex to set up and maintain.
- Risk of the request not being handled if no handler in the chain can process it.
**Summary**
The Chain of Responsibility pattern is beneficial for flexible and decoupled request processing, especially when multiple potential handlers are involved. It simplifies the client-side logic and allows dynamic assignment and order of handlers. However, it should be used with caution to avoid unnecessary complexity and performance overhead. Proper design and understanding of the specific use case are essential for effectively implementing the Chain of Responsibility pattern.
## 7. Event-Driven Pattern
**Context**
The Event-Driven pattern involves components that communicate by producing and consuming events. This pattern decouples the components, allowing them to interact asynchronously. Events can trigger actions in other parts of the system without requiring a direct call.
**Use Case**
Consider an e-commerce platform where various services such as inventory management, order processing, and notification systems need to interact. When a customer places an order, this action triggers multiple events: updating the inventory, processing the payment, and sending a confirmation email.
**When to Use the Event-Driven Pattern**
- Asynchronous Operations: When operations can be performed asynchronously, without requiring an immediate response.
- Decoupled Systems: When you want to decouple components to improve scalability, maintainability, and flexibility.
- Real-Time Updates: When real-time updates or actions are needed based on specific events, such as sending notifications or updating dashboards.
- Complex Workflows: When managing complex workflows where multiple services need to respond to the same event.
- Scalability: When you need a scalable architecture that can handle varying loads and allows individual components to scale independently.
**When Not to Use the Event-Driven Pattern**
- Synchronous Requirements: If the operations require immediate responses and cannot tolerate the latency introduced by asynchronous processing.
- Simple Systems: If the system is simple and does not benefit from the decoupling and flexibility provided by this pattern.
- Complex Debugging: If debugging and tracing issues across multiple components and services are critical and need to be straightforward.
- Consistency Concerns: If maintaining strong consistency and coordination between components is critical and challenging to achieve in an event-driven architecture.
**Example Implementation**
> Context: An e-commerce platform with services for inventory management, order processing, and notifications.
> Scenario: A customer places an order, which triggers multiple actions across the system.
> **Without Event-Driven Pattern:**
> - The order processing service directly calls the inventory and notification services.
> - Tight coupling between services makes the system harder to scale and maintain.
> **With Event-Driven Pattern:**
> - The order processing service emits an "OrderPlaced" event.
> - The inventory service listens for the "OrderPlaced" event and updates the inventory.
> - The notification service listens for the "OrderPlaced" event and sends a confirmation email.
**Pros:**
- Decouples components, improving scalability and flexibility.
- Allows asynchronous processing, reducing response time for the initiating service.
- Facilitates real-time updates and actions based on events.
- Enhances maintainability by isolating services and enabling independent development.
**Cons:**
- Introduces complexity in debugging and tracing event flows.
- Can lead to eventual consistency issues, requiring careful design to manage state.
- Adds latency for operations that require immediate feedback.
- Requires a robust event handling and monitoring infrastructure.
**Summary**
The Event-Driven pattern is highly effective for building scalable, decoupled, and flexible systems where asynchronous operations are beneficial. It simplifies handling real-time updates and complex workflows but introduces challenges in debugging, consistency, and latency. Proper design and careful consideration of the system’s requirements and constraints are crucial for effectively leveraging the Event-Driven pattern.
## 8. Pagination Pattern
**Context**
The Pagination pattern involves breaking down large sets of data into smaller, manageable chunks (pages) that can be retrieved and displayed incrementally. This approach is essential for optimizing performance and improving user experience, especially when dealing with large datasets.
**Use Case**
Imagine an online library system that allows users to search for books. The database contains millions of records. To prevent overwhelming the server and improve response times, the system implements pagination to return search results in smaller, more manageable chunks.
**When to Use the Pagination Pattern**
- Large Datasets: When dealing with large datasets that cannot be efficiently loaded or displayed all at once.
- Performance Optimization: When you need to optimize performance by reducing the amount of data transferred and processed in a single request.
- Improved User Experience: When you want to improve user experience by presenting data incrementally, avoiding long loading times.
- APIs: When designing APIs that return large lists of items, to make the API more efficient and responsive.
- Search Results: When implementing search functionalities where the result set can be very large.
**When Not to Use the Pagination Pattern**
- Small Datasets: If the dataset is small enough to be loaded and displayed efficiently in a single request.
- Complex Navigation: When pagination introduces unnecessary complexity, making it harder for users to navigate the data.
- Real-Time Data: When dealing with real-time data where users need to see updates immediately without navigating through pages.
- Simple Applications: If the application is simple and does not require handling large datasets, the added complexity of implementing pagination might not be justified.
**Example Implementation**
> Context: An online library system with a vast collection of books.
> Scenario: A user searches for books, and the system returns results in a paginated format.
> **Without Pagination Pattern:**
> - The system attempts to load and display all search results at once.
> - This leads to long loading times, high server load, and poor user experience.
> **With Pagination Pattern:**
> - The system returns a limited number of results per page (e.g., 20 books per page).
> - Users can navigate through pages to view more results incrementally.
**Pros:**
- Reduces server load and improves performance by limiting the amount of data processed in each request.
- Enhances user experience with faster response times and easier navigation.
- Simplifies handling and processing of large datasets.
- Makes APIs more efficient and scalable.
**Cons:**
- Adds complexity to the implementation, requiring additional logic for managing pages.
- Can complicate user navigation if not designed properly.
- Requires handling edge cases such as page boundaries and data consistency.
- Might not be suitable for real-time data where immediate updates are necessary.
**Summary**
The Pagination pattern is essential for optimizing performance and user experience when dealing with large datasets. It breaks down data into manageable chunks, reducing server load and improving response times. However, it introduces additional complexity and might not be suitable for small datasets, real-time data, or simple applications. Proper design and consideration of the specific use case are crucial for effectively implementing the Pagination pattern.
## 9. Bulk Pattern
**Context**
The Bulk pattern involves processing multiple records or requests in a single operation instead of handling them individually. This pattern is particularly useful for improving performance and efficiency by reducing the overhead associated with multiple individual operations.
**Use Case**
Consider a customer relationship management (CRM) system that allows users to update contact information. Instead of sending an update request for each contact individually, the system can process bulk updates, allowing users to send a batch of updates in a single request.
**When to Use the Bulk Pattern**
- Large Data Sets: When operations involve large datasets that can benefit from being processed in batches.
- Performance Optimization: When you need to optimize performance by reducing the number of individual requests, which can lower network latency and server load.
- Transactional Integrity: When you need to ensure that multiple operations are performed as a single transaction, either all succeeding or all failing.
- APIs: When designing APIs that need to handle multiple records in a single request to make them more efficient and responsive.
- Data Migration: When migrating data from one system to another, bulk operations can significantly speed up the process.
**When Not to Use the Bulk Pattern**
- Small Data Sets: If the operations involve small datasets that do not justify the complexity of bulk processing.
- Real-Time Data: When real-time updates are required and waiting for bulk processing might introduce unacceptable delays.
- Complex Transactions: If the complexity of handling bulk transactions outweighs the benefits, especially when individual operations need unique handling.
- Error Handling: When granular error handling for each individual operation is crucial, bulk processing can complicate this.
**Example Implementation**
> Context: A CRM system where users update contact information.
> Scenario: A user wants to update contact information for 50 contacts.
> **Without Bulk Pattern:**
> - The user sends 50 individual update requests.
> - Each request incurs network latency and server processing overhead.
> **With Bulk Pattern:**
> - The user sends a single request with updates for all 50 contacts.
> - The server processes the updates in a batch, reducing network latency and processing overhead.
**Pros:**
- Reduces the number of network requests, improving performance.
- Lowers server load by handling multiple records in a single operation.
- Ensures transactional integrity by processing all records as a single transaction.
- Simplifies client-side logic by reducing the number of required operations.
**Cons:**
- Adds complexity to the implementation, requiring logic to handle batch processing.
- Can complicate error handling and reporting, as errors might need to be aggregated.
- Might introduce delays if immediate processing of individual records is required.
- Requires careful consideration of transaction size to avoid overwhelming the server.
**Summary**
The Bulk pattern is highly effective for optimizing performance and efficiency when dealing with large datasets or multiple operations. It reduces network latency and server load by processing records in batches. However, it introduces complexity in terms of implementation and error handling and might not be suitable for small datasets or real-time processing requirements. Proper design and consideration of the specific use case are essential for effectively implementing the Bulk pattern.
## 10. HATEOAS Pattern
**Context**
HATEOAS (Hypermedia As The Engine Of Application State) is a constraint of REST application architecture that enables clients to interact with the application entirely through hypermedia provided dynamically by application servers. In essence, clients use hyperlinks embedded in responses to navigate and perform actions, making the API self-descriptive and reducing the need for external documentation.
**Use Case**
Consider a social media platform where users can post updates, follow other users, and like posts. Instead of the client needing to know all the endpoints and their interactions upfront, the API provides hypermedia links in responses that guide the client on available actions and related resources.
**When to Use the HATEOAS Pattern**
- Self-Descriptive APIs: When you want to build APIs that are self-descriptive, guiding clients on how to use them through hypermedia links.
- Decoupling Client and Server: When you need to decouple the client from the server, allowing the server to guide the client’s interactions and reducing the client’s dependency on prior knowledge of the API.
- Evolving APIs: When the API is likely to evolve over time, adding new features or changing workflows. HATEOAS allows clients to adapt to these changes dynamically.
- Complex Workflows: When the application involves complex workflows where the next steps depend on the current state, making it easier for clients to follow these workflows through provided links.
**When Not to Use the HATEOAS Pattern**
- Simple APIs: If the API is simple and unlikely to change, the added complexity of HATEOAS may not be necessary.
- Performance Concerns: Embedding hypermedia links can increase the payload size of responses, which might impact performance.
- Client Complexity: If the clients are simple and adding the logic to parse and follow hypermedia links increases their complexity unnecessarily.
- Immediate Control: When clients need to have immediate control over the API interactions and do not benefit from the dynamic nature of HATEOAS.
**Example Implementation**
> Context: A social media platform where users interact with posts and follow other users.
> Scenario: A user wants to view a post, follow the author, and like the post.
> **Without HATEOAS Pattern:**
> - The client needs to know all the specific endpoints for viewing posts, following users, and liking posts.
> - The client must handle the logic to determine the sequence of actions and endpoints.
> **With HATEOAS Pattern:**
> - The API response for viewing a post includes hypermedia links to follow the author and like the post.
> - The client uses these links to perform the follow and like actions without needing prior knowledge of the specific endpoints.
**Pros:**
- Makes APIs self-descriptive, reducing the need for extensive external documentation.
- Decouples client and server, allowing easier API evolution and changes.
- Simplifies client-side logic by providing actionable links directly in responses.
- Enhances flexibility in navigating and interacting with the API.
**Cons:**
- Increases response payload size, potentially impacting performance.
- Adds complexity to both client and server implementations.
- Requires clients to handle and follow hypermedia links, which might be unnecessary for simple use cases.
- Can introduce additional overhead in parsing and processing hypermedia links.
**Summary**
The HATEOAS pattern is beneficial for building self-descriptive and flexible APIs that can evolve over time without tightly coupling clients to the server's structure. It simplifies client interactions by embedding actionable links within responses. However, it introduces additional complexity and potential performance overhead, making it less suitable for simple APIs or scenarios where the added benefits do not justify the costs. Careful consideration of the application’s requirements and constraints is essential for effectively implementing the HATEOAS pattern.
## Conclusion
API design patterns offer powerful tools for building flexible, efficient, and secure applications. Each pattern addresses specific challenges and use cases, providing tailored solutions to improve performance, scalability, and maintainability. By understanding the contexts, benefits, and drawbacks of these patterns, developers can make informed decisions to design robust APIs that meet the needs of their applications and users. | hhussein |
1,864,163 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-05-24T16:01:24 | https://dev.to/aminakhasbgeubcw/buy-verified-cash-app-account-2hfk | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n\n\n\n\n" | aminakhasbgeubcw |
1,864,160 | peviitor.ro - proiectul principal al ONG-ului ASOCIAȚIA OPORTUNITĂȚI ȘI CARIERE | Misiunea ASOCIAȚIEI OPORTUNITĂȚI ȘI CARIERE Organizația non-profit cu sediul în... | 0 | 2024-05-24T15:55:41 | https://dev.to/ale23yfm/peviitorro-proiectul-principal-al-ong-ului-asociatia-oportunitati-si-cariere-1lfp | peviitor, comunity, motordecautare | ## Misiunea [ASOCIAȚIEI OPORTUNITĂȚI ȘI CARIERE](https://www.oportunitatisicariere.ro/)
> 
Organizația non-profit cu sediul în Zimbor, România colaborează alături de peste 400 contribuitori și voluntari din toată țara. Aici tinerii, și nu numai, își dezvoltă skill-urile prin dezvoltarea aplicației.
<u>Departamente:</u>
- back-end development
- business analyst
- design
- front-end development
- marketing
- scraping
- testing
---
## [peviitor.ro](peviitor.ro/)
Proiectul pentru care s-a înfiintat ONG-ul este proiectul PEVIITOR.ro.
Acest motor de căutare locuri de muncă reprezintă cel mai important proiect din cadrul ASOCIATIEI OPORTUNITATI SI CARIERE.
Ne propunem să agregăm toate locurile de muncă din România într-un singur loc pentru toate cele peste 1.418.000 companii active în România.
Serviciul este gratuit atât pentru companii, cât și pentru viitorii potențiali angajați.
---
| ale23yfm |
1,864,147 | Enhancing Business Efficiency: A Comprehensive Guide to Choosing and Implementing Process Mapping Software | In today’s fast-paced business environment, efficiency and streamlined operations are critical for... | 0 | 2024-05-24T15:48:50 | https://dev.to/blog_ts/enhancing-business-efficiency-a-comprehensive-guide-to-choosing-and-implementing-process-mapping-software-53k3 | process, tools, marketing | In today’s fast-paced business environment, efficiency and streamlined operations are critical for success. One tool that has proven to be invaluable in achieving these goals is process mapping software. This comprehensive guide will explore the benefits of process mapping software, how to choose the right one for your business, the key features to look for, and a step-by-step approach to implementing it effectively to improve workflow and efficiency.
## Understanding Process Mapping Software
[Process mapping software](https://niftypm.com/blog/process-mapping-tools/) is designed to create visual representations of a business’s processes and workflows. These diagrams, or process maps, help organizations understand, analyze, and improve their processes. By providing a clear visual representation of how tasks flow through the system, process mapping software enables businesses to identify bottlenecks, redundancies, and opportunities for optimization.
## Benefits of Process Mapping Software
### 1. Improved Clarity and Communication
One of the primary benefits of process mapping software is that it enhances clarity and communication within an organization. By providing a visual representation of processes, all team members can easily understand their roles and responsibilities. This shared understanding helps to eliminate confusion and ensures that everyone is on the same page.
### 2. Increased Efficiency
It helps to identify inefficiencies and bottlenecks within workflows. By analyzing these process maps, organizations can pinpoint areas where time and resources are being wasted. This insight allows businesses to make informed decisions about how to streamline operations and improve efficiency.
### 3. Enhanced Collaboration
Process mapping software facilitates collaboration among team members by providing a common platform for discussing and refining processes. This collaborative approach ensures that all stakeholders have a voice in process improvement efforts, leading to more effective and sustainable changes.
### 4. Better Compliance and Quality Control
For industries that require strict adherence to regulations and quality standards, process mapping software is an invaluable tool. It helps ensure that all processes are documented and followed consistently, reducing the risk of non-compliance and improving overall quality control.
### 5. Data-Driven Decision Making
By using process mapping software, businesses can gather data on their workflows and processes. This data can be analyzed to identify trends, measure performance, and make data-driven decisions. This approach leads to more accurate and effective process improvements.
## Choosing the Right Process Mapping Software
Selecting the right process mapping software for your business is crucial to reaping the benefits outlined above. Below are several factors to take into account when deciding:
### 1. User-Friendliness
The software should be intuitive and easy to use, even for those with little to no technical expertise. A [user-friendly interface](https://merge.rocks/blog/what-is-a-user-friendly-interface) will encourage adoption and ensure that all team members can effectively utilize the tool.
### 2. Customizability
Each business possesses its own distinctiveness, reflected in its processes. Choose software that offers customization options to tailor process maps to your specific needs. This flexibility will enable you to create accurate and relevant representations of your workflows.
### 3. Integration Capabilities
Ensure that the process mapping software can integrate with other tools and systems used within your organization. This integration will allow for seamless data flow and collaboration across different platforms, enhancing overall efficiency.
### 4. Collaboration Features
Look for software that supports real-time collaboration, allowing team members to work together on process maps simultaneously. Features such as commenting, version control, and shared access are essential for effective collaboration.
### 5. Reporting and Analytics
The ability to generate reports and analyze data is crucial for continuous improvement. Choose software that offers robust reporting and analytics features to track performance metrics and identify areas for enhancement.
### 6. Scalability
As your business grows, your process mapping needs may evolve. Select software that can scale with your organization and accommodate increasing complexity and volume of processes.
### 7. Cost
Consider your budget when choosing process mapping software. While it’s important to invest in a quality tool, there are options available at various price points. Evaluate the features and benefits to determine the best value for your investment.
##Incorporating Incident Management Software
While selecting process mapping software, it's essential to consider integration with the [best incident management software](https://niftypm.com/blog/incident-management-software/). Incident management software plays a crucial role in swiftly addressing and resolving unexpected disruptions in business processes. By seamlessly integrating incident management capabilities into your process mapping solution, you can enhance operational resilience and minimize downtime.
## Key Features to Look for in Process Mapping Software
To ensure you choose the best process mapping software for your needs, look for the following key features:
### 1. Drag-and-Drop Interface
A drag-and-drop interface simplifies the process of creating and editing process maps. This feature allows users to easily add, remove, and rearrange elements within the map, making it accessible for all team members.
### 2. Templates and Pre-Built Elements
Templates and pre-built elements can significantly speed up the process of creating process maps. Look for software that offers a variety of templates and elements that can be customized to fit your specific workflows.
### 3. Process Simulation
Process simulation allows you to test and analyze different scenarios within your process maps. This feature helps you understand the potential impact of changes before implementing them, reducing the risk of disruptions.
### 4. Automated Documentation
[Automated documentation](https://www.itglue.com/blog/documentation-automation/) features can save time and ensure consistency in process documentation. This capability allows you to generate detailed reports and manuals based on your process maps, which can be useful for training and compliance purposes.
### 5. Mobile Accessibility
In today’s mobile-centric world, it’s important to have access to process mapping software on the go. Choose software that offers mobile accessibility, allowing you to view and edit process maps from any device.
### 6. Security and Permissions
Ensure that the software provides robust security features to protect sensitive information. Additionally, look for tools that offer customizable permissions to control access and editing rights for different team members.
### 7. Customer Support and Training
Good customer support and training resources are essential for getting the most out of your process mapping software. Choose a provider that offers comprehensive support and training options to help you and your team effectively utilize the tool.
## Implementing Process Mapping Software: A Step-by-Step Guide
Once you’ve selected the right process mapping software for your business, it’s time to implement it. Follow these steps to ensure a smooth and successful implementation:
### 1. Define Your Objectives
Before you begin, [clearly define your objectives](https://smallbusiness.chron.com/10-important-business-objectives-23686.html) for using process mapping software. What specific problems are you trying to solve? What goals do you hope to achieve? Having clear objectives will guide your implementation and help you measure success.
### 2. Assemble a Team
Identify key stakeholders and assemble a team to oversee the implementation process. This team should include representatives from different departments who will use the software and contribute to process improvement efforts.
### 3. Conduct Training
Ensure that all team members receive training on how to use the process mapping software. This training should cover basic functionality, as well as any specific features that are relevant to your business needs.
### 4. Map Existing Processes
Start by mapping your existing processes to establish a baseline. This step will help you understand your current workflows and identify areas for improvement. Involve team members who are familiar with these processes to ensure accuracy.
### 5. Identify Improvement Opportunities
Analyze your process maps to identify inefficiencies, bottlenecks, and areas for improvement. Use the insights gained from this analysis to develop a plan for optimizing your workflows.
### 6. Redesign and Test Processes
Based on your analysis, redesign your processes to address identified issues. Use the process simulation feature to test different scenarios and evaluate the potential impact of changes. Make adjustments as needed before implementing the new processes.
### 7. Implement Changes
Once you’re confident in your redesigned processes, implement the changes within your organization. Communicate the changes to all affected team members and provide any necessary training to ensure a smooth transition.
### 8. Monitor and Adjust
After implementing the changes, continuously [monitor the performance](https://rainmakerthinking.com/is-the-work-getting-done-five-ways-to-monitor-employee-performance/) of your processes. Use the reporting and analytics features of your process mapping software to track key metrics and identify any new issues that arise. Be prepared to make adjustments as needed to maintain efficiency and effectiveness.
### 9. Foster a Culture of Continuous Improvement
Process improvement is an ongoing effort. Encourage a culture of continuous improvement within your organization by regularly reviewing and updating your process maps. Involve team members in these efforts and celebrate successes to maintain momentum.
## Conclusion
Process mapping software is a powerful tool for enhancing business efficiency and streamlining operations. By choosing the right software, leveraging key features, and following a structured implementation process, organizations can achieve significant improvements in clarity, communication, collaboration, compliance, and overall performance. Embracing process mapping as part of a culture of continuous improvement will ensure that your business remains agile and competitive in today’s dynamic environment.
| blog_ts |
1,864,067 | API Gateways: The Impact on API Management and Security | With API usage on the rise, using API gateways for API management and security has never been more... | 0 | 2024-05-24T15:47:24 | https://dev.to/apidna/api-gateways-the-impact-on-api-management-and-security-2o6k | webdev, api, security, learning | With API usage on the rise, using API gateways for API management and security has never been more important.
With such a wide variety of different microservices being incorporated into modern web applications, there are a lot of API calls and endpoints that need to be managed and secured.
API gateways serve as a single entry point and common interface to handle all of these endpoints.
API gateways handle traffic routing, load balancing, authentication, and more, ensuring efficient and secure API operations.
They make it easier to monitor, scale, and secure API interactions.
In this article, we discuss the impact of API gateways on API management and security, helping you to make the right choices in your integration journey.
## Understanding API Gateways
Let’s break down a working example to understand when and how an API gateway would be used.
We’ll use an e-commerce application for this example, using a variety of different microservices, integrated with a payment processing API.

Some basic microservices include:
- **User Service:** Manages user registration, authentication, and profiles.
- **Product Service:** Handles product listings, inventory, and details.
- **Order Service:** Manages order processing, history, and tracking.
- **Payment Service:** Integrates with a third-party payment API (e.g., Stripe) for transaction processing.
We would select an API gateways, such as AWS, and then configure it to define endpoints for each microservice:
- _/api/users/*_ routes to the User Service
- _/api/products/*_ routes to the Product Service
- _/api/orders/*_ routes to the Order Service
- _/api/payments/*_ routes to the Payment Service, which further communicates with the third-party API
We would then implement authentication at the gateway level, ensuring that only authorised requests reach the backend services.
This can be done using JWT tokens or OAuth.
The API gateway can translate between different protocols if needed.
For instance, converting a RESTful request to a gRPC call if one of the microservices uses gRPC.
When a payment request is made to /api/payments/process, the gateway routes this request to the Payment Service, which then interacts with the Stripe API to complete the transaction.
## Enhancing API Management with Gateways
API gateways significantly enhance API management by streamlining traffic management and load balancing.
They efficiently distribute incoming traffic across multiple instances of backend services, preventing any single service from becoming a bottleneck.
This ensures high availability and reliability, as traffic is evenly balanced, and any service failures are mitigated by rerouting traffic to healthy instances.
API routing and request handling are also simplified through API gateways.
Instead of clients needing to know the specific endpoints of each microservice, they interact with a single entry point.
The gateway then routes requests to the appropriate microservice based on the defined routing rules.
This abstraction layer not only simplifies the client-side logic but also allows for seamless updates and modifications to the backend services without impacting the clients.

Centralised logging and monitoring capabilities provided by API gateways further enhance management.
All API interactions are logged at the gateway level, offering a comprehensive view of traffic patterns, request types, and response times.
This centralised approach enables easier monitoring, troubleshooting, and performance optimization.
Administrators can quickly identify issues, track usage metrics, and generate insights to improve the overall API infrastructure.
## API Gateways and Security Enhancement
API gateways ensure that only authenticated and authorised requests reach the backend services.
This is often achieved using JWT tokens, OAuth, or other authentication protocols, which verify the identity of clients and grant them access based on predefined permissions.
In an OAuth flow, the user logs in to an authorization server, which then provides an access token to the client application.
This token is used for API requests and contains information about the user’s permissions.
The API gateway verifies the token with the authorization server to confirm the user’s identity, and ensure the user has the appropriate permissions to access the desired resources.
JSON Web Tokens (JWT) are a compact, URL-safe means of representing claims to be transferred between two parties.
When a client authenticates, the authentication server issues a JWT, which the client then includes in the headers of subsequent API requests.
The API gateway validates this token before forwarding the request to the backend service.
The JWT contains information (claims) about the user and their permissions, and it is digitally signed to ensure its integrity.

Rate limiting and throttling are essential features of API gateways that prevent abuse and ensure fair usage of resources.
By setting limits on the number of requests a client can make within a specific timeframe, gateways protect backend services from being overwhelmed by excessive traffic.
API gateways can detect and block malicious activities such as DDoS attacks by monitoring traffic patterns and blocking suspicious IP addresses.
They also offer protection against SQL injection and other injection attacks by sanitising inputs and enforcing security rules.
To learn more about API security, check out our [previous article here](https://apidna.ai/understanding-the-fundamentals-of-api-security/).
## Choosing the Right API Gateway
Beyond management and security, there are several other features you’ll want to consider when choosing the right API gateway for your application:
- **Scalability:** Ensure the gateway can handle your traffic volume and scale seamlessly as your application grows. Check out our [previous article ](https://apidna.ai/a-beginners-guide-to-building-scalable-api-architectures/)about building scalable API architectures.
- **Ease of Integration:** The gateway should support various protocols (REST, gRPC, SOAP) and easily integrate with your existing infrastructure. With APIDNA, all API integrations are simplified thanks to our use of autonomous agents. [Click here](https://apidna.ai/contact-us/) to get in touch and request a FREE demo.
- **Monitoring and Analytics:** Comprehensive logging, monitoring, and analytics tools to track API usage, performance, and security events. [Click here](https://apidna.ai/ai-driven-api-analytics-leveraging-autonomous-agents-for-actionable-insights/) to check out our previous article about AI-driven API analytics.
- **Customization and Extensibility:** The ability to customise policies, extend functionalities, and support plugins.

Here are four of the most popular API gateway services to begin your search with:
- **AWS API Gateway:** Highly scalable, integrates well with AWS services, supports REST and WebSocket APIs, and offers strong security features.
- **Kong:** Open-source, highly extensible with plugins, supports a wide range of protocols, and provides robust logging and monitoring.
- **NGINX:** Known for high performance and reliability, supports various protocols, and offers powerful configuration options.
- **Apigee:** Google’s managed gateway service, provides advanced analytics, developer portal integration, and strong security features.
## Conclusion
API gateways play a vital role in modern API management and security by centralising traffic management, authentication, and monitoring.
They simplify API routing, enhance performance, and protect against security threats, ensuring robust and scalable API infrastructures.
As organisations increasingly rely on microservices and third-party integrations, the importance of API gateways will continue to grow.
We encourage you to explore the further reading resources linked below to further expand your knowledge of API gateways.
## Further Reading
[5 key capabilities – solo](https://www.solo.io/topics/api-gateway/)
[API Gateway Security: What is it and is it Enough? – Salt](https://salt.security/blog/api-gateway-security-what-is-it-and-is-it-enough)
[API Gateway vs WAF vs API Security Platform – noname](https://nonamesecurity.com/blog/api-gateway-vs-waf-vs-api-security-platform/) | itsrorymurphy |
1,864,157 | Safe and Secured Ways to Recover Stolen Crypto ; HackSavvy Technology | Behold, dear seekers of justice, for I bring tidings of a remarkable expedition into the heart of the... | 0 | 2024-05-24T15:41:29 | https://dev.to/rebecca_moore_579d0aeea30/safe-and-secured-ways-to-recover-stolen-crypto-hacksavvy-technology-1oi2 | javascript, beginners | Behold, dear seekers of justice, for I bring tidings of a remarkable expedition into the heart of the digital wilderness – the illustrious HackSavvy Technology .In a world fraught with peril and deception, the valiant wizards of HackSavvy Technology stand as beacons of hope, wielding their formidable expertise to reclaim what's rightfully ours from the clutches of scammers. As a weary traveler who has traversed the treacherous paths of online fraud, I can attest to the unparalleled prowess and unwavering dedication of this extraordinary team. From the moment I stepped into their enchanted realm, I was enveloped by an aura of determination and resolve. The HackSavvy , masters of their craft, greeted me with warmth and understanding, ready to embark on a quest to retrieve my stolen funds.What sets HackSavvy Technology apart is not merely their technical proficiency, but their heartfelt commitment to their clients. They understand the despair and frustration that accompanies falling victim to online scams, and they offer steadfast support every step of the way.With each stroke of their digital wands, the Hacksavvy penetrated the intricate networks of the scammers, unraveling their web of deceit with precision and skill. In a feat of unparalleled wizardry, they reclaimed my stolen funds and ensured that the perpetrators faced the consequences of their actions.But perhaps what impressed me most was HackSavvy Technology dedication to creating a safer online environment for all. Through their tireless efforts, they send a clear message to scammers that their days of preying on the innocent are numbered.I cannot recommend HackSavvy Technology highly enough. If you find yourself ensnared in the tangled webs of online fraud, look no further than this esteemed establishment. Trust in their expertise, and let them lead you on a journey towards justice and redemption. With HackSavvy Technology by your side, you can rest assured that your stolen funds will be reclaimed, and the light of truth will shine brightly once more in the digital realm, Email them via Contactus@ hacksavvytechnology .com & Support@ hacksavvytechrecovery. com & WhatsApp : +7 999 829‑50‑38 . | rebecca_moore_579d0aeea30 |
1,864,156 | Transform Your Junk Car into Instant Cash with Cash 4 Junk Cars Brisbane | Have you been looking for a way to remove that old broken down car sitting in your driveway, but been... | 0 | 2024-05-24T15:40:34 | https://dev.to/william_oscar_c450620e7cb/transform-your-junk-car-into-instant-cash-with-cash-4-junk-cars-brisbane-56pe | carremoval, towingservice | Have you been looking for a way to remove that old broken down car sitting in your driveway, but been put off by other companies’ lackluster offers and complex procedures? Look no further! Cash 4 Junk Cars has a solution. We’re a **[second hand car seller Brisbane](https://www.cash4junkcars.com.au/second-hand-car-seller-brisbane/)** company that pays top cash for your junk cars across the Brisbane area. Let’s look at precisely what services we offer and how we can help you get your junk cars sitting around your property turned into cash.

## Cash 4 Junk Cars Brisbane Quick and Easy Cash
If you've got a Junk Cars, trust Cash 4 Junk Cars to give you a better deal than anyone else out there. Don't let your vehicle rot away. Now you can make a profit from your old clunker. It's easy to sell a Junk Cars. Once we receive your call, you get to share some details about your vehicle and you'll get an all-cash quote right away! We'll take care of all paperwork from the start.
## Towing Free and Convenient Service
Our best asset is our free towing. The biggest obstacle to selling a junk car in the first place is the last part of the transaction: how will you get it out of your possession. Not with our service! Cash 4 Junk Cars works so that you have nothing to worry about. Once we make our cash offer to the customer, we can set up a pickup time. Our crew will arrive promptly and tow your vehicle right off your property free of charge. It's that easy!
## Car Removal Brisbane Eco-Friendly Disposal
We're sure our car removal services can make your life easier by freeing up your space, but that's no reason it has to come at the expense of the environment. It costs nothing extra to know that you're doing your bit by sending your car for recycling and by having it disposed of respecting local environmental standards. By getting cash for your junk cars, you're helping the planet.
## Cash for Scrap Cars Brisbane Northside Serving Your Community
In Brisbane Northside and want to get rid of your car? You're covered by Cash 4 Junk Cars! Whether you're located at home, in a carpark, or even at the office, we will come to pick up your car. Our local knowledge enables us to quote fast prices and we come to you.
## Cash for Damaged Cars All Conditions Accepted
If an accident has totaled your car, or years of wear and tear have taken a toll, don't worry. We buy nearly every make and model regardless of condition. Cars with engine problems, with body damage, those that just won't start – we will still give you good money. Your damaged car doesn't have to be a money pit. Call us today, and let us take your car off your hands and turn it into cash.
## Second-Hand Cars Sales Brisbane Quality Pre-Owned Vehicles
Looking for a dependable used car? We are also in the business of selling top-quality prewnred cars. All our considered vehicles undergo rigorous inspection and reconditioning for quality assurance. Shopping with us at Cash 4 Junk Cars means you are sure that the vehicle you’re buying has been judiciously assessed for performance and safety.
## Get Cash for Your Car Today Immediate Payment
Why wait for your money? When you accept a bid from Cash 4 Junk Cars, you’re paid on the spot. After we have agreed on a value for your car, it goes on some scales and, on the pocket calculator before me, a price appears. The money machine springs into action. I stuff some bills in your back pocket. You drive away with your **[Cash for Cars Caboolture](https://www.cash4junkcars.com.au/cash-for-cars-caboolture/)** and your car, which will soon be everything of value. The faster you can turn an old car into money, the faster things disappear.
## Choosing Cash 4 Junk Cars comes with numerous benefits:
We pay some of the top dollar for junk and wrecked vehicles in Brisbane region.
**Smooth Process:** From the quotation, loan process to payment, ours is tailored to be very smooth.
**Environmental Responsibility:** We prioritize eco-friendly disposal methods, ensuring your old car is recycled properly.
**Free Towing:** Our towing service is completely free, saving you money and effort.
**Fast Service:** We pride ourselves on our prompt response times and efficient operations.
## How to Get Started
Ready to turn your junk car into cash? Here’s how you can get started:
**Contact us:** Phone or fill out the online form to provide details on your car.
**Quote:** We’ll provide an instant cash offer based on the information you provide.
**Schedule a Pickup:** Choose a convenient time for our team to tow your car.
**Get Paid:** Receive your cash payment on the spot.
It’s as easy as 1, 2, 3! With Cash 4 Junk Cars, you can have your junk car off your hands and make money out of it.
**Testimonials:** Our Customers Love Us
Don’t just take our word for it – our customers have nothing but rave reviews on each of our projects: BRODY: Thanks to [Prestique’s Invisible Tummy Tuck], I can now go back out with confidence. NEIL: No matter what the task, I now have the personality of a high-octane executive … all thanks to [Prestique’s Invisible Lip Trolley]. ALISON: In bed with the man of my dreams, I wasn’t worried about feeling non-luscious now that I used [Prestique’s Invisible Bust Inflation]. The All-Star Skin Care Collection: $499.99.
‘I couldn’t believe how easy it was to sell my clunker. Cash 4 Junk Cars paid well, picked my old jalopy up on the same day I called, and I would definitely recommend this service to a friend.’ – Sarah, Brisbane Northside
‘I'm so glad they came to my place at this late hour and that it was so easy for them to take my scrap car away.’ ‘Thank you so much Cash 4 Junk Cars team for the speedy service – they really know how to get a job done. If you want a quick service for your damaged vehicle, they really are the top shop in Brisbane CBD.’
Buying a cars used from Cash 4 Junk Cars is the top-notch eve-v-e with the most advantageous price! That car was pretty splendid and was in perfect condition. The service team are competent and experienced. I’m extremely flattered to purchase it. Highly recommended buying a car secondhand from this company, it’s worth it. 😉 – Emma from Brisbane Southside.
| william_oscar_c450620e7cb |
1,864,153 | Manipulando o hook useState | Quando você trabalha com o hook useState do React, há situações em que é melhor usar uma função para... | 0 | 2024-05-24T15:36:51 | https://dev.to/devborges/manipulando-o-hook-usestate-b54 | react, reactnative | Quando você trabalha com o hook `useState` do React, há situações em que é melhor usar uma função para atualizar o estado com base no estado anterior, em vez de defini-lo diretamente. Aqui estão os motivos:
## Manipulação de Atualizações de Estado Assíncronas
O React agrupa atualizações de estado para melhorar o desempenho. Quando você define o estado diretamente, pode não estar trabalhando com o valor mais atual do estado devido à natureza assíncrona das atualizações de estado. Usando uma função, você garante que está trabalhando com o valor mais recente do estado.
**Exemplo:**
```javascript
setCount(prevCount => prevCount + 1);
```
Neste exemplo, `prevCount` é garantido ser o valor mais recente do estado, garantindo que a operação de incremento seja precisa.
### 2. **Lidando com Múltiplas Atualizações de Estado**
Se você tem múltiplas atualizações de estado que dependem do estado anterior, usar uma função ajuda a evitar problemas potenciais. Sem isso, as atualizações podem sobrescrever umas às outras.
**Exemplo:**
```javascript
const handleIncrement = () => {
setCount(prevCount => prevCount + 1);
setCount(prevCount => prevCount + 1);
}
```
Aqui, `count` será corretamente incrementado em 2, porque cada função de atualização obtém o estado mais recente.
### 3. **Evitando Estado Obsoleto**
Usar o estado anterior garante que você evite problemas de estado obsoleto, que podem ocorrer se o estado for atualizado com base em um valor desatualizado.
**Exemplo:**
```javascript
const handleUpdate = () => {
setCount(count + 1); // Pode usar estado obsoleto
}
```
Se `count` não for o valor mais recente, o incremento pode não funcionar como esperado.
### 4. **Atualizações Funcionais em Lógica de Estado Complexa**
Quando a lógica de atualização do seu estado é complexa, usar a função do estado anterior pode simplificar a implementação e tornar o código mais legível.
**Exemplo:**
```javascript
setState(prevState => {
// lógica complexa usando prevState
return newState;
});
```
Dessa forma, você define claramente como o novo estado depende do estado anterior, tornando o código mais fácil de manter.
### Resumo
- **Atualizações assíncronas**: Garante que você sempre trabalhe com o estado mais recente.
- **Múltiplas atualizações**: Evita que as atualizações de estado sobrescrevam umas às outras.
- **Evitar estado obsoleto**: Previne bugs relacionados a valores desatualizados do estado.
- **Lógica complexa**: Simplifica e clarifica as atualizações de estado.
Usar uma função para atualizar o estado com base no estado anterior é uma prática robusta no React, que ajuda a gerenciar o estado de forma mais previsível e evita problemas comuns.
| devborges |
1,864,152 | Understanding Idempotency in Software Development 🥇 | Idempotency 🎯 is a crucial concept in software development that helps mitigate unintended errors or... | 0 | 2024-05-24T15:36:29 | https://dev.to/_hm/understanding-idempotency-in-software-development-4kgo | webdev, beginners, programming, tutorial |
Idempotency 🎯 is a crucial concept in software development that helps mitigate unintended errors or unhappy scenarios that users might encounter. This concept categorizes web events or processes into two parts: idempotent (ineffective) and non-idempotent (effective).
**Ineffective (Idempotent) Operations 💡**:
These operations do not change the state of the system regardless of how many times they are executed. Examples include PUT and GET requests. For instance, retrieving data (GET) or updating a resource to a specific state (PUT) multiple times will have the same effect as doing it once.
**Effective (Non-Idempotent) Operations 🕸**:
These operations change the state of the system each time they are executed, potentially leading to side effects if repeated. Examples include POST and PATCH requests. For instance, creating a new resource (POST) or modifying a resource partially (PATCH) can lead to different outcomes if the request is sent multiple times.
**Scenario:** Handling Duplicate Purchase Requests 🧱
Consider a scenario where a user makes a request to purchase an item. After clicking to send the request, the user's internet connection drops. The request completes on the server side, but the user does not receive a confirmation message. In this case, the user might resend the request, and the server, not recognizing that the operation has been performed already, processes it as a new request. Consequently, the user ends up purchasing the item twice, leading to dissatisfaction.
Solving the Problem with Idempotency 👨💻🛠
To prevent such issues, we can implement idempotency by creating a unique identifier (idempotency key) for each request and storing it in a temporary database. This intermediary system checks whether a request has already been processed or if it is a new one. Here’s how it works:
1. Generate Idempotency Key : Generate a unique key for each purchase request.
2. Store Key and Result: Before processing the request, check if the key exists in the database.
- If it exists, return the stored result, ensuring the operation is not performed again.
- If it does not exist, process the request and store the result along with the key.
3. Return Stored Result: On receiving a request with the same idempotency key, return the stored result instead of processing the request again.
**Conclusion ✔**
Implementing idempotency in your services enhances the reliability and user-friendliness of your application, preventing common issues associated with repeated requests. It ensures operations like purchases are not accidentally executed multiple times, maintaining data consistency and integrity.
For a deeper dive into this concept, I recommend reading Alex Hyett’s detailed description and solutions.
https://www.alexhyett.com/idempotency for further insights.
| _hm |
1,864,145 | Dunder Methods in Python | Python's magic methods are commonly used for operator overloading. Python's dunder methods, also... | 0 | 2024-05-24T15:34:16 | https://dev.to/ezekiel_77/dunder-methods-in-python-7nh | python, oop, beginners, coding |
Python's magic methods are commonly used for operator overloading.
Python's *dunder* methods, also known as magic methods, are special methods that are invoked automatically when certain operators or functions are used on an object.
> dunder means *double under* for double underscore
> You can use the `dir` function to see the magic methods inherited by a class
# Case Study
Lets give an example of an `Item` class in python
```python
class Item:
def __init__(self, name, price):
self.name = name
self.price = price
```
The `__init__` method is called everytime an instance of a class is created. It is also a magic method
---
## The `__str__` method
```python
def __str__(self):
return f'Item({self.name} for {self.price})'
```
The `__str__` method is called whenever the class is converted into a string.
So when the `print` function is called on an instance of the class
```python
>> i1 = Item("Fridge", 1000)
>> print(i1)
#... Item(Fridge for 1000)
```
## The `__repr__` method
`repr` performs the same function as `str` but is used in different situations. `repr` is used in debugging situations and contains a detailed description of the object.
> If a `__str__` method is not defined, Python will default to calling the `__repr__` method
---
## The `__add__` method
The `__add__` method is called whenever the `+` operator is performed on an instance of a class. For instance
**For instance**
```python
i1 = Item("Fridge", 1000)
i2 = Item("Waffles",25)
print(i1 + i2)
```
This code returns
```
Traceback (most recent call last):
File "main.py", line x, in <module>
print(i1 + i2)
TypeError: unsupported operand type(s) for +: 'Item' and 'Item'
```
So we declare an `add` function that can support operand types for `+`
```python
def __add__(self, other): # other for the second operand
newItem = Item(f'({self.name},{other.name})', self.price + other.price)
return newItem
```
so, calling `i1 + i2` above will result in
```
Item(Fridge,Waffles for 1025)
```
> It is advisable for dunder_methods like this to return the same type as its operands.
**For Instance**
```python
>> i1 = Item("Fridge", 1000)
>> i2 = Item("Waffles",25)
>> i3 = Item("Samsung", 500)
>> print(i1 + i2 + i3)
#... Item(Fridge,Waffles,Samsung for 1525)
```
There are still other arithmetic dunder_methods that are commonly used such as
| Dunder Method | Operator or Inbuilt function |
| -------------- | ---------------------------- |
| `__add__` | `+` |
| `__sub__` | `-` |
| `__mul__` | `*` |
| `__truediv__` | `/` |
| `__floordiv__` | `//` |
| `__pow__` | `**` |
---
# The `__gt__` method
The `eq, ne, gt, le, lt, ge` methods are sets of magic methods used for comparism. Likewise
| Dunder Method | Operator or Inbuilt Function |
| ------------- | ---------------------------- |
| `__eq__` | `==` |
| `__ne__` | `!=` |
| `__gt__` | `>` |
| `__le__` | `<=` |
| `__lt__` | `<` |
| `__ge__` | `>=` |
> The drawback to overloading comparision operators is that **if you overload one of them, you have to overload the whole six of them**
**For Example**
```python
def __gt__(self, other):
return self.price > other.price
```
Using the `gt` method to check if an item is more constly than the other.
> It is best practice for your comparision overloads to return **boolean values**
---
This is just a quick overview of what magic methods are in python and how operator overloading works.
**Just keep in mind that for every built-in method and operator, there is a corresponding dunder method for it**
For more dunder methods check [here](https://www.pythonmorsels.com/every-dunder-method/#cheat-sheet)
The complete code for my example is kept [here](https://onecompiler.com/python/42e6k47ka)
If you have any questions, please feel free to ask 😊 below in the comments
| ezekiel_77 |
1,864,150 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-05-24T15:33:22 | https://dev.to/mixevet541/buy-verified-cash-app-account-1f1l | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | mixevet541 |
1,864,149 | Preparing for the Java Certified Foundations Associate Exam 1Z0-811: Study Plan and Tips | Are you looking to enhance your Java programming skills and take your career to the next level?... | 0 | 2024-05-24T15:33:19 | https://dev.to/myexamcloud/preparing-for-the-java-certified-foundations-associate-exam-1z0-811-study-plan-and-tips-2c9m | java, programming, coding, software | Are you looking to enhance your Java programming skills and take your career to the next level? Consider earning the Java Certified Foundations Associate, 1Z0-811 credential. This certification is a tangible proof of your practical knowledge and abilities in Java programming.
Preparing for the 1Z0-811 exam and obtaining this certification will equip you with the fundamental concepts and skills in Java programming, validating your expertise in the field. Not only does this certification showcase your capabilities, but it also demonstrates your potential to become an asset in any organization as you further your proficiency, knowledge, and certifications.
The Java Certified Foundations Associate, 1Z0-811 is designed for students in two-year colleges, high schools, and four-year colleges and universities. This certification is also helpful for individuals who have undergone the Oracle Academy program, are currently studying computer science with a focus on Java, or are new to their Java careers.
Although prior professional experience with Java is not necessary, it is crucial to have a basic understanding of the programming language and its concepts, as well as mathematical, logical, and analytical problem-solving skills. You should also be familiar with writing and executing Java programs, and have a working knowledge of the Java Development Kit (JDK) and Java Runtime Environment (JRE).
Completing the Java Foundations | 1Z0-811 exam is a prerequisite for acquiring related certifications, including the Java Certified Foundations Associate certification.
Some benefits of earning the Java Certified Foundations Associate certification include the validation of your Java skills, making you a desirable candidate for entry-level positions in software development and programming, and providing a strong basis to pursue advanced Java certifications.
To prepare for the 1Z0-811 exam, it is recommended to download the exam syllabus and JDK 1.8 software, as well as a text editor. Next, create a study plan that involves systematically going through each exam objective, practicing with full-length mock exams and setting goals, and regularly taking and reviewing objective and random tests. MyExamCloud offers a comprehensive 1Z0-811 study plan with 778 practice questions and a free trial exam.
The Java Certified Foundations Associate 1Z0-811 exam is suitable for students in various educational institutions, including two-year colleges, high schools, and four-year colleges and universities. This certification is also beneficial for faculty members who teach Java and computer science courses, as well as individuals who are new to their Java careers.
To prepare for the 1Z0-811 exam, it is important to first download the exam syllabus to gain a clear understanding of the topics that will be covered.
Next, download the validated JDK 1.8 software and a text editor, such as Notepad++ or Editplus, to focus on learning Java coding without an Integrated Development Environment (IDE).
After setting up the necessary software, create a text file with the path command for your JDK/bin location to ensure that your computer can locate the JDK software and run Java programs smoothly.
The study plan for the 1Z0-811 exam can be divided into three phases. In the first phase (Day 3-13), systematically go through each exam objective and create programs to gain a better understanding of the topics.
In the second phase (Day 13-23), use MyExamCloud's 1Z0-811 study plan to set a schedule, which includes practicing 10 full-length mock exams and setting goals for each exam objective. The mock exams come with explanations for each answer in eBook format, accessible through the MyExamCloud mobile app or web browser.
In the third phase (Day 23-30), regularly take objective and random tests and repeat them until scoring above 90%. This will ensure a thorough understanding and application of the exam topics, preparing you for the real exam.
The MyExamCloud 1Z0-811 study plan includes 778 questions grouped by exam topics and offers one free trial exam to familiarize yourself with the exam format and difficulty level.
By following this study plan and consistently practicing and reviewing the material, you will be well-prepared to pass the 1Z0-811 exam and earn the Java Certified Foundations Associate certification.
Start your preparation at MyExamCloud Study Plan Now!
[1Z0-811 Practice Tests](https://www.myexamcloud.com/onlineexam/1z0-811-java-foundations-exam-practice-tests.course) | myexamcloud |
1,864,148 | JavaScript vs. TypeScript: From Wild West to Five-Star Resort | Introduction: Ah, JavaScript. The duct tape and bailing wire of the web development world. It got... | 0 | 2024-05-24T15:32:54 | https://dev.to/muzammil-cyber/javascript-vs-typescript-from-wild-west-to-five-star-resort-299i |
****
**Introduction:**
Ah, JavaScript. The duct tape and bailing wire of the web development world. It got us here, but let's be honest, it's a bit of a…cauldron. You throw some code in, stir it with a bit of hope, and pray it doesn't explode in your face. Enter TypeScript, the shining knight in shining armor (or perhaps a spiffy tuxedo) that swoops in to save the day!
**JavaScript: The Hilarious (and Hair-Pulling) Circus**
JavaScript, bless its quirky heart, has some, ahem, "interesting" behaviors. Remember that time you tried to add "1" and "1" and got…11? Or how about subtracting "1" from "1" and ending up with 0? (*wink* We've all been there)
```javascript
console.log(1 + "1"); // 11 (yikes!)
console.log(1 - "1"); // 0 (double yikes!)
```
These are just the tip of the iceberg, folks. JavaScript's loose typing can lead to some truly side-splitting (and headache-inducing) bugs. It's like coding in a funhouse mirror – things might not be quite what they seem!
**TypeScript: The King (But Also a Kind King)**
Now, let's talk about TypeScript. It's basically JavaScript with a monocle and a top hat – it takes everything you love (and tolerate) about JavaScript and adds a layer of sophistication. With TypeScript, you get to tell the computer exactly what kind of data you're working with, which means:
- **Fewer Bugs:** No more surprise type errors that leave you scratching your head. TypeScript catches them before they even have a chance to crash your party.
- **Better Code Completion:** Imagine your IDE suggesting the perfect variable name or function based on the type you've defined. TypeScript makes coding feel like a magical auto-complete dream!
- **Cleaner Code:** TypeScript enforces a more structured approach, leading to code that's easier to read, maintain, and collaborate on. It's like cleaning up your messy room before your friends come over – but for code!
**Code Snippet Smackdown: A TypeScript Triumph**
Let's see how TypeScript tames the wild beast of JavaScript:
```javascript
// JavaScript (may the odds be ever in your favor)
let userInput: any = "hello";
let converted: number = userInput; // (potential errors)
console.log(userInput + 10); // Who knows what this will do?
// TypeScript (the hero we deserve)
let userInput: string = "hello";
let converted: number = parseInt(userInput); // TypeScript ensures type safety
console.log(userInput + 10); // Error! TypeScript won't let you add strings and numbers
// But wait, there's more!
let product: (number | string) = 42;
product = "The answer"; // TypeScript allows flexibility with union types
console.log(product); // "The answer" (yay!)
```
**The Verdict: From Chuck Wagon to Michelin Star**
JavaScript is like the Wild West of coding – exciting, unpredictable, and occasionally dangerous. TypeScript is the five-star resort, complete with all the amenities you need to write clean, maintainable, and bug-free code. While JavaScript might have gotten us here, TypeScript is the future – a future where coding is a joyride, not a rollercoaster of uncertainty.
**So, the next time you're wrangling JavaScript code, consider giving TypeScript a try. It might just change your coding life (and save you from a few headaches). Just remember, with great power comes great responsibility – use TypeScript wisely!**
**P.S.** Don't worry, JavaScript isn't going anywhere. But hey, maybe it can learn a thing or two from its more refined cousin, TypeScript. | muzammil-cyber | |
1,864,144 | Understanding Internet Protocol Security (IPSec) | What is Internet Protocol Security (IPSec)? Internet Protocol Security (IPSec) is a robust... | 0 | 2024-05-24T15:28:17 | https://dev.to/vikasyadav79/understanding-internet-protocol-security-ipsec-2gdk |
## What is Internet Protocol Security (IPSec)?
Internet Protocol Security (IPSec) is a robust suite of protocols developed by the Internet Engineering Task Force (IETF) to ensure secure communication between two points across an IP network. IPSec is designed to provide data authentication, integrity, and confidentiality. It encrypts, decrypts, and authenticates packets, and outlines the necessary protocols for secure key exchange and key management.
---
---
## Components and Architecture of IPSec
IPSec operates with two main components:
**_Encapsulating Security Payload (ESP):_**
Provides data integrity, encryption, authentication, and anti-replay protection.
Ensures the confidentiality of data by encrypting the payload, which prevents unauthorized access.
Verifies the authenticity of the data source and confirms that the data has not been tampered with during transit.
**_Authentication Header (AH):_**
Ensures data integrity and authenticity but does not provide encryption.
Offers protection against replay attacks, ensuring that data packets are not resent by an unauthorized entity.
Provides authentication for the payload, confirming that the data is from a legitimate source.
## Working of IPSec
IPSec works through a series of steps to ensure secure data transmission:
**_Policy Check:_**
Hosts determine if the incoming or outgoing packets need to be processed by IPSec based on predefined security policies.
**_IKE Phase 1:_**
This initial phase establishes a secure channel between the communicating parties.
It involves two modes:
Main Mode: Offers greater security but is slower.
Aggressive Mode: Faster but less secure.
During this phase, the hosts authenticate each other and set up a secure channel for further negotiations.
**_IKE Phase 2:_**
In this phase, the hosts agree on the cryptographic algorithms and the keying material required for encrypting the data.
The establishment of a secure IPSec tunnel takes place here.
**_Data Exchange:_**
Once the secure tunnel is established, data can be securely exchanged.
The data is encrypted and authenticated to ensure confidentiality and integrity.
**_Tunnel Termination:_**
After the secure communication is completed, the IPSec tunnel is terminated, ensuring that no additional data is transmitted without proper encryption and authentication.
## Conclusion
IPSec is a critical component of network security, providing robust mechanisms to protect data integrity, confidentiality, and authenticity. By understanding its components and how it operates, organizations can better safeguard their communications across IP networks.
| vikasyadav79 | |
1,864,142 | Job Description | job description is about doing right job and right position in front of seniors and doing the tie up... | 0 | 2024-05-24T15:26:32 | https://dev.to/avinash_chandugade_afae6e/job-description-4m3h | job description is about doing right job and right position in front of seniors and doing the tie up with other company. | avinash_chandugade_afae6e | |
1,864,141 | NYCHA | NYC Hearing offers exceptional care for those experiencing hearing loss. Our skilled hearing aid... | 0 | 2024-05-24T15:26:32 | https://dev.to/sergun24/nycha-44m | NYC Hearing offers exceptional care for those experiencing hearing loss. Our skilled [hearing aid specialist](https://nychearing.com/services/) works closely with patients to diagnose hearing issues and recommend the most effective solutions. Whether you need hearing aid fittings, maintenance, or repairs, we are here to ensure you receive the best possible care. | sergun24 | |
1,864,096 | GHosttp | GHosttp is a tiny development server for developing GCP functions. With GHosttp, you can choose... | 0 | 2024-05-24T15:21:00 | https://dev.to/jolodev/ghosttp-2n0j | gcp, development, serverless, express | {% embed https://youtu.be/kinz7OA4zPQ %}
GHosttp is a tiny development server for developing GCP functions.
With GHosttp, you can choose the folder where your GCP functions reside, allowing you to start developing from there.
Your functions can be developed in Typescript and use the latest ESM features.
## Why?
The [functions framework](https://github.com/GoogleCloudPlatform/functions-framework-nodejs?tab=readme-ov-file) by Google does not offer a great developer experience when developing an entire backend using GCP.
Whenever you develop or test a new function, you must run the `npx @google-cloud/functions-framework --target=myFunction` command. Not only is that super long, but it also does not offer hot module reloading.
What if the name changes?
You need to rerun the command. Do you really want to create a bash alias for this library?
Furthermore, their repository shows CommonJS syntax. What if you want to use ESM or Typescript? Since Gen2 is running on Node v20, you could and should leverage ESM. GHosttp is familiar with both ESM and Typescript.
### Cloud Run
The Gen2 GCP cloud functions use [ExpressJS](https://expressjs.com/) on top of Cloud Run. ExpressJS comes with a development server. So, why not directly develop it locally in Express and then put it in a Dockerfile? Well, that's a lot of work, and you must be familiar with Docker and Cloud Run. GCP Cloud Functions gen2 abstracts many things for you.
## Opinionated
This package is a bit opinionated about developing your GCP function, but I made it as close to the ExpressJS function as possible.
You must name your function `handler`, and it shall be exported. Below you find a Typescript version.
```ts
import type { Request, Response } from '@google-cloud/functions-framework';
export const handler = async (req: Request, res: Response) => {
res.set('Access-Control-Allow-Origin', '*');
res.set('Access-Control-Allow-Methods', 'POST');
// Because of CORS
if (req.method === 'OPTIONS') {
res.set('Access-Control-Allow-Methods', 'GET');
res.set('Access-Control-Allow-Headers', 'Content-Type');
res.set('Access-Control-Max-Age', '3600');
res.status(204).send('');
return;
}
// Destructering your request body
const { message } = req.body;
res.set('Content-Type', 'application/json');
res.send(
JSON.stringify({
message,
}),
);
return new Response(JSON.stringify(message));
};
```
## Requirements
- GCP account
- GCP functions gen2
- Node >= 20 (I haven't tried with 18, but it's a good point to upgrade)
## Getting Started
In your repository, just run `npx ghosttp --dir path/to/my/functions`. That's all. Per default, your backend will run on `http://localhost:3000`
```sh
➜ Local: http://localhost:3000/
➜ Network: use --host to expose
🚀 Loading server entry ./src/run-dev-server.ts GHosttp 12:21:58 AM
✅ Server initialized in 90ms GHosttp 12:21:58 AM
👀 Watching ./path/to/functions for changes GHosttp 12:21:58 AM
ℹ Following endpoints are available GHosttp 12:21:58 AM
ℹ /logger GHosttp 12:21:58 AM
ℹ /run-dev-server GHosttp 12:21:58 AM
```
It watches whenever you make changes to your function or add a new function. This is great if you want to do Test-Driven-Development and get instant feedback.
Watch the video above to see it in action.
### Arguments
- `--dir` - Path to your functions (default `"."`)
- `--port` - Port where your localhost will run (default `3000`)
### PR and contributions are welcome
Find the repository here:
https://github.com/jolo-dev/ghosttp
## What's next?
I will add a development server for Flask and Go.
Furthermore, I want to add a new command, `npx ghost add-handler my-new-handler --typescript`, which scaffolds a new file.
I will also make a blog/video about deploying your ESM/Typescript GCP function ;)
Let me know what you think, and I will be happy to make any contribution 🤩 | jolodev |
1,864,099 | Maximizing Wireless Connectivity: How Redevi.io Revolutionizes Venue Network Solutions | In today’s digital era, robust wireless connectivity is the lifeblood of any venue, from bustling... | 0 | 2024-05-24T15:19:09 | https://dev.to/redevi_io_afb9aa91a01f2ee/maximizing-wireless-connectivity-how-redeviio-revolutionizes-venue-network-solutions-1302 | In today’s digital era, robust wireless connectivity is the lifeblood of any venue, from bustling sports arenas to high-stakes conference centers. Ensuring seamless, reliable, and high-speed network access is no longer a luxury but a necessity. This is where Redevi.io comes into play, transforming how venues across North America handle their wireless infrastructure needs.
The Challenge of Modern Connectivity
As the number of connected devices skyrockets, so do the demands on network infrastructure. Venues face unique challenges:
High User Density: Thousands of devices competing for bandwidth can cripple a poorly designed network.
Mission-Critical Applications: Reliable connectivity is essential for operations such as security systems, point-of-sale transactions, and real-time communications.
Diverse Technologies: Integrating various wireless technologies like Distributed Antenna Systems (DAS), Public Safety communications, Private LTE, and WiFi/Mesh networks can be complex.
Redevi.io: A Comprehensive Solution
Redevi.io addresses these challenges with a comprehensive suite of services designed to ensure optimal network performance and reliability.
1. Design and Build
Our team of experts designs customized wireless solutions tailored to the unique needs of each venue. Using advanced simulation tools and field testing, we ensure that our designs provide robust coverage and capacity.
2. Vendor-Agnostic Approach
We believe in the best solution for the job, not the one tied to a specific vendor. This flexibility allows us to integrate the latest technologies from a range of suppliers, ensuring our clients receive the most effective and up-to-date solutions available.
3. Lifecycle Management
From initial deployment to ongoing maintenance, we manage the entire lifecycle of the network. This includes regular upgrades and scalability assessments to keep the network ahead of increasing demands.
4. Flexible Cost Models
Understanding that every client has different financial constraints, we offer flexible cost models. Whether it’s a capital expenditure or an operational expenditure model, we work with clients to find the most suitable financial solution.
5. End-to-End Orchestration
Our end-to-end service includes everything from project management to the integration of various wireless technologies. This holistic approach ensures all components work seamlessly together.
6. Custom Workflows and Real-Time Analytics
Custom workflows tailored to the venue’s specific needs ensure efficient operations. Additionally, our real-time analytics provide insights into network performance, enabling proactive adjustments and swift issue resolution.
7. Network Monitoring
Continuous network monitoring ensures high availability and performance. Our advanced monitoring tools detect and address issues before they impact users, guaranteeing a smooth experience for all connected devices.
Technologies We Use
Distributed Antenna Systems (DAS): Enhance coverage and capacity, particularly in areas with high user density. Public Safety Networks: Ensure reliable communication for emergency services. Private LTE: Provide secure, high-performance connectivity tailored to specific venue needs. WiFi/Mesh Networks: Deliver seamless, high-speed internet access to users throughout the venue.
Success Stories
Sports Arenas: We’ve revolutionized connectivity in several major sports arenas, ensuring fans enjoy uninterrupted access to social media, live updates, and in-seat ordering systems. Convention Centers: Our solutions have enabled conference organizers to provide reliable, high-speed internet for thousands of attendees, enhancing the overall event experience. Healthcare Facilities: We’ve implemented robust networks that support mission-critical applications, from patient monitoring systems to secure communications.
Why Choose Redevi.io?
Expertise and Experience: Our team comprises industry veterans with deep expertise in wireless technologies.
Proven Track Record: Numerous successful deployments across various sectors attest to our capabilities.
Customer-Centric Approach: We prioritize our clients’ needs, offering tailored solutions that deliver measurable results.
Conclusion
In a world where connectivity is crucial, Redevi.io stands out as a leader in providing innovative, reliable, and scalable wireless solutions. Our commitment to excellence ensures that venues across North America can meet the demands of today and tomorrow.
Connect with us today https://redevi.io/ to learn how we can transform your venue’s wireless infrastructure and deliver a seamless connectivity experience for all your users.
https://redevi.io/ | redevi_io_afb9aa91a01f2ee |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.