
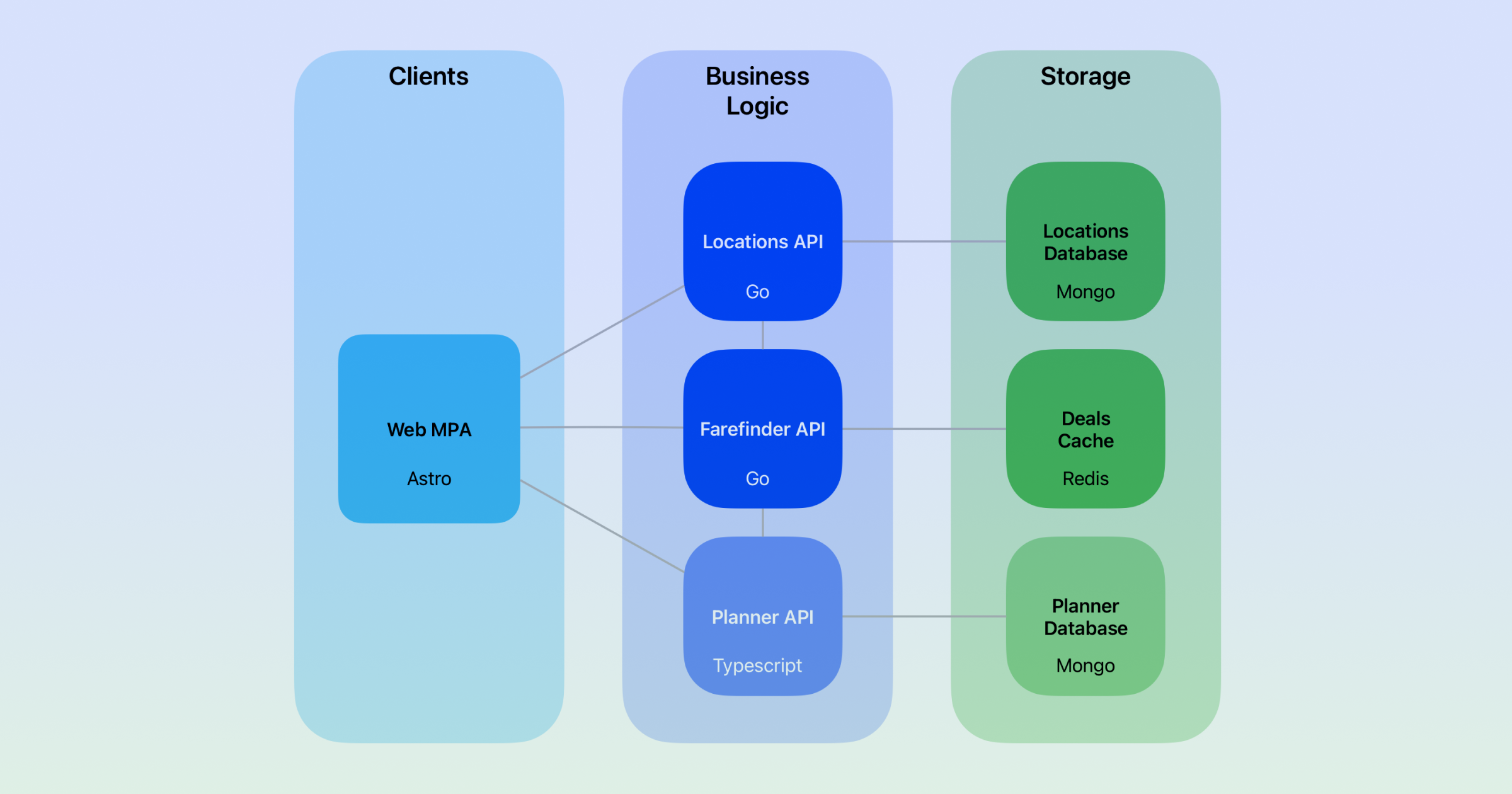
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,863,363 | Building a Ruby on Rails MVP. | Hey there 👋, It's been 2 weeks since I announced the new project I'm working on: HomeSuiteApartment,... | 27,288 | 2024-05-24T15:18:44 | https://dev.to/joelzwarrington/building-an-ruby-on-rails-mvp-4eoo | webdev, rails, startup | Hey there :wave:,
It's been 2 weeks since I announced the new project I'm working on: [HomeSuiteApartment](https://homesuiteapartment.com), a tool to manage properties.
Today, I'll be sharing an update update on the progress so far, what's next, and share some developer insights for your own Ruby on Rails project! If you'd prefer, I've also uploaded a [video walking through the product](https://youtu.be/3Q--P6-dtO4).
## Progress made so far
I've been able to build out:
- an integration with Stripe to offer subscription plans
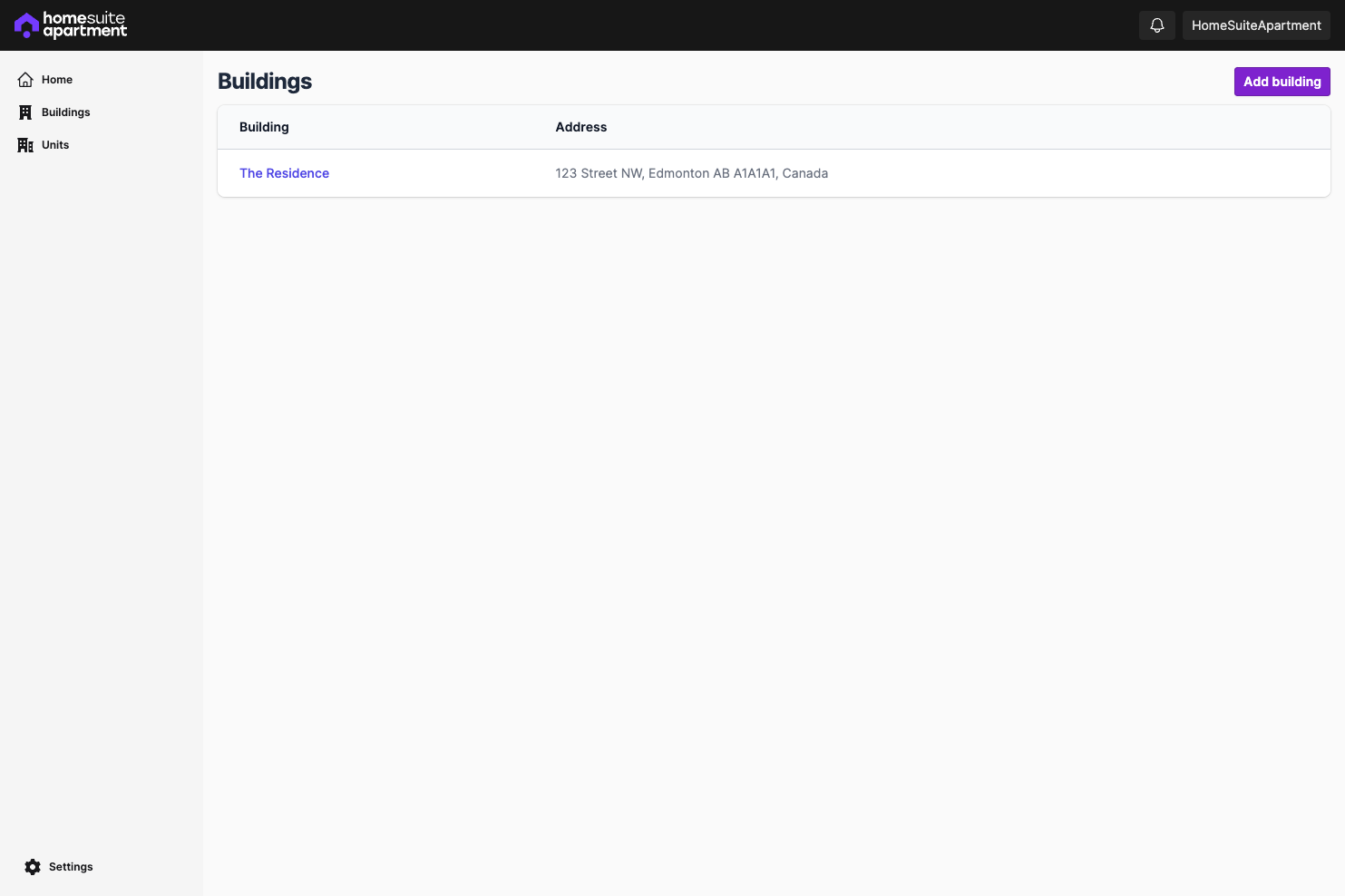
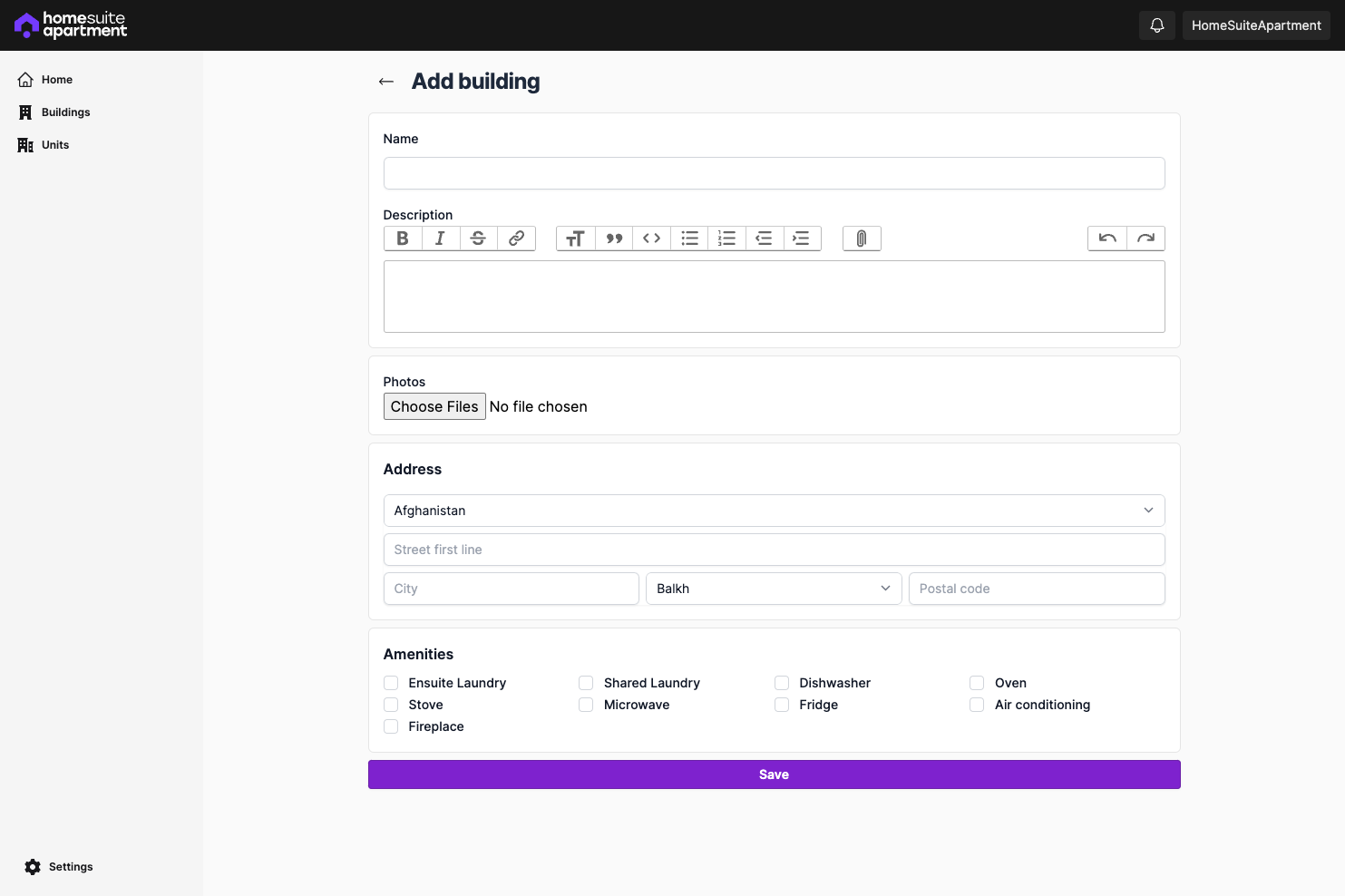
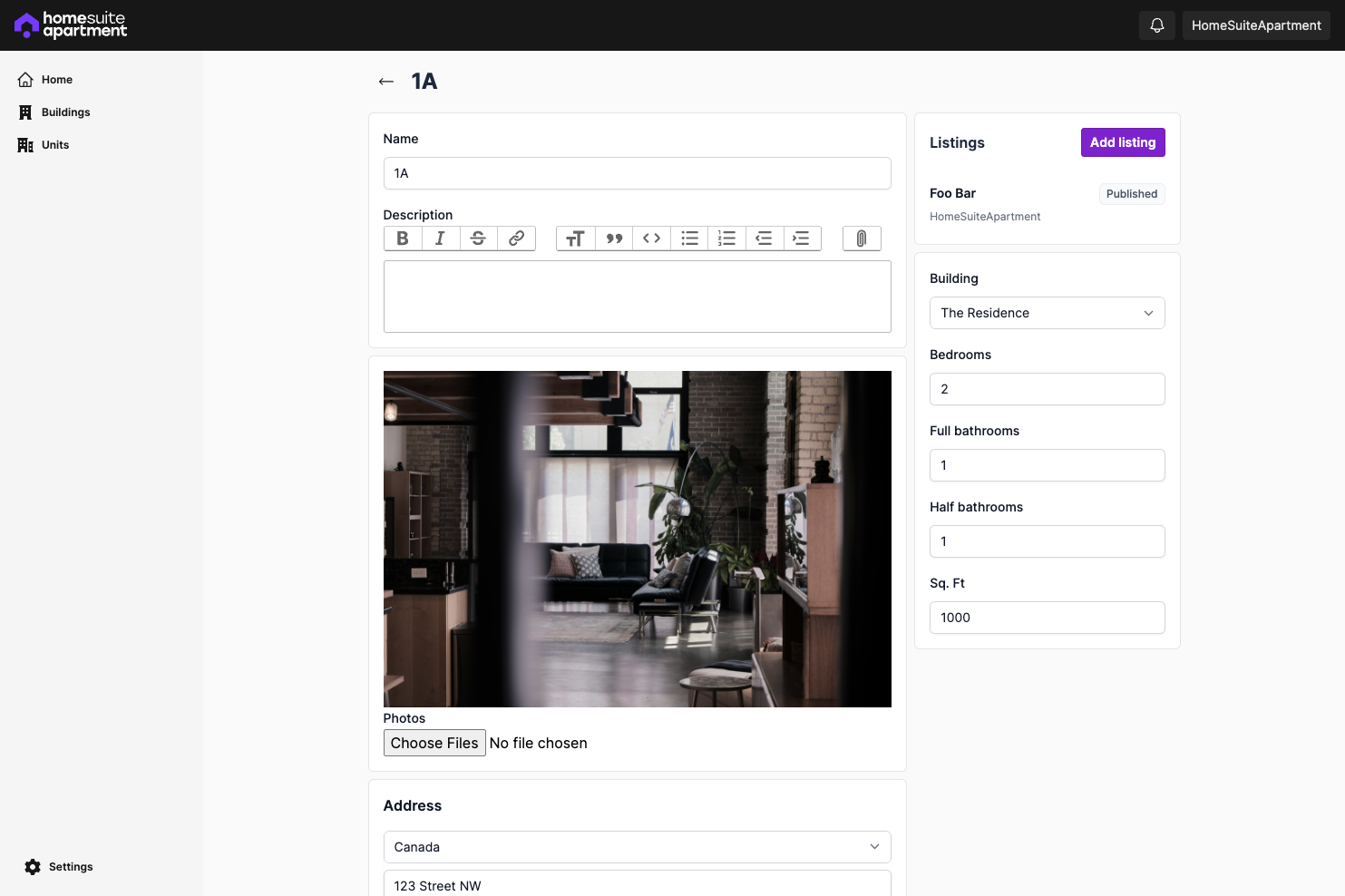
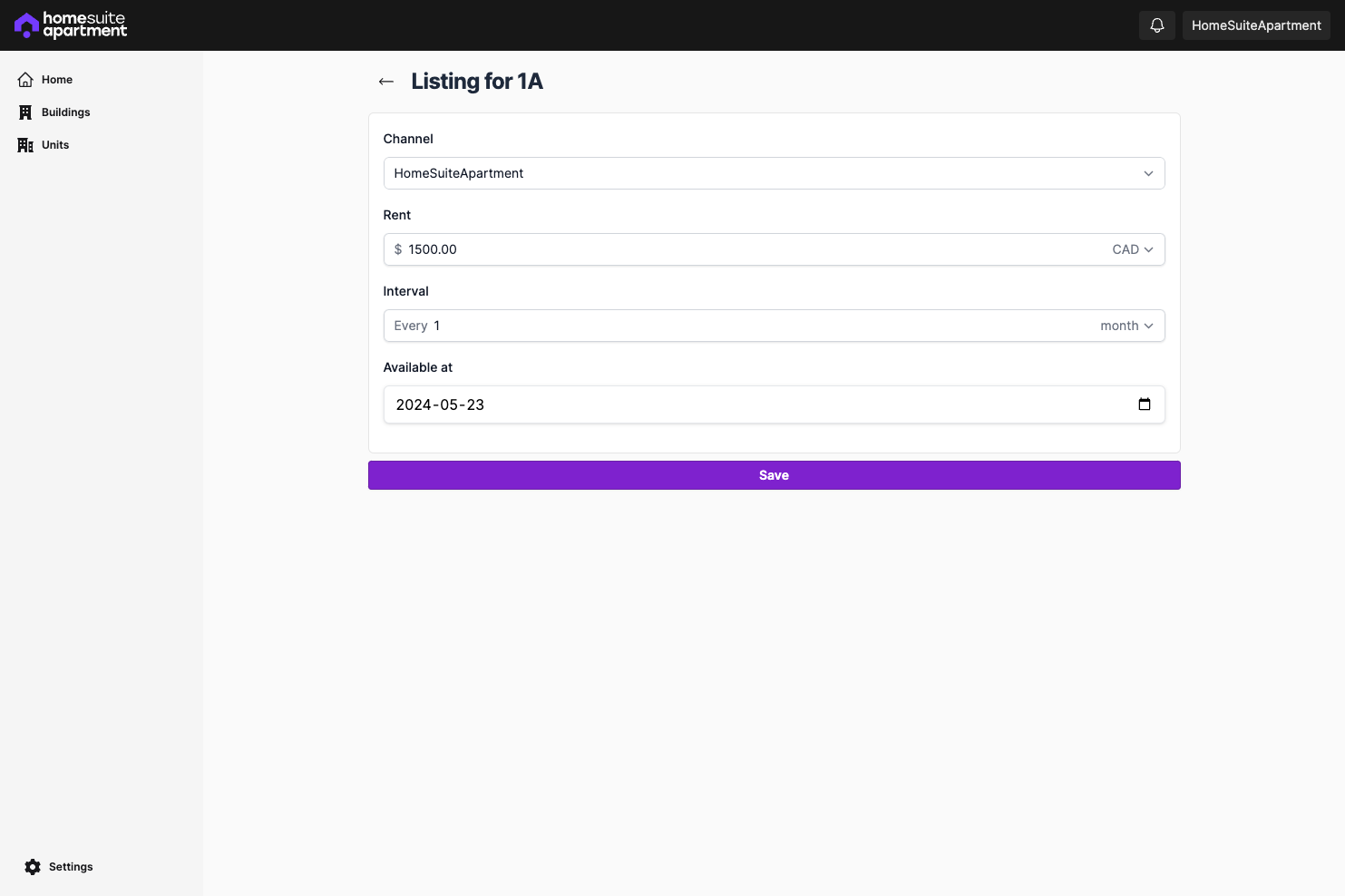
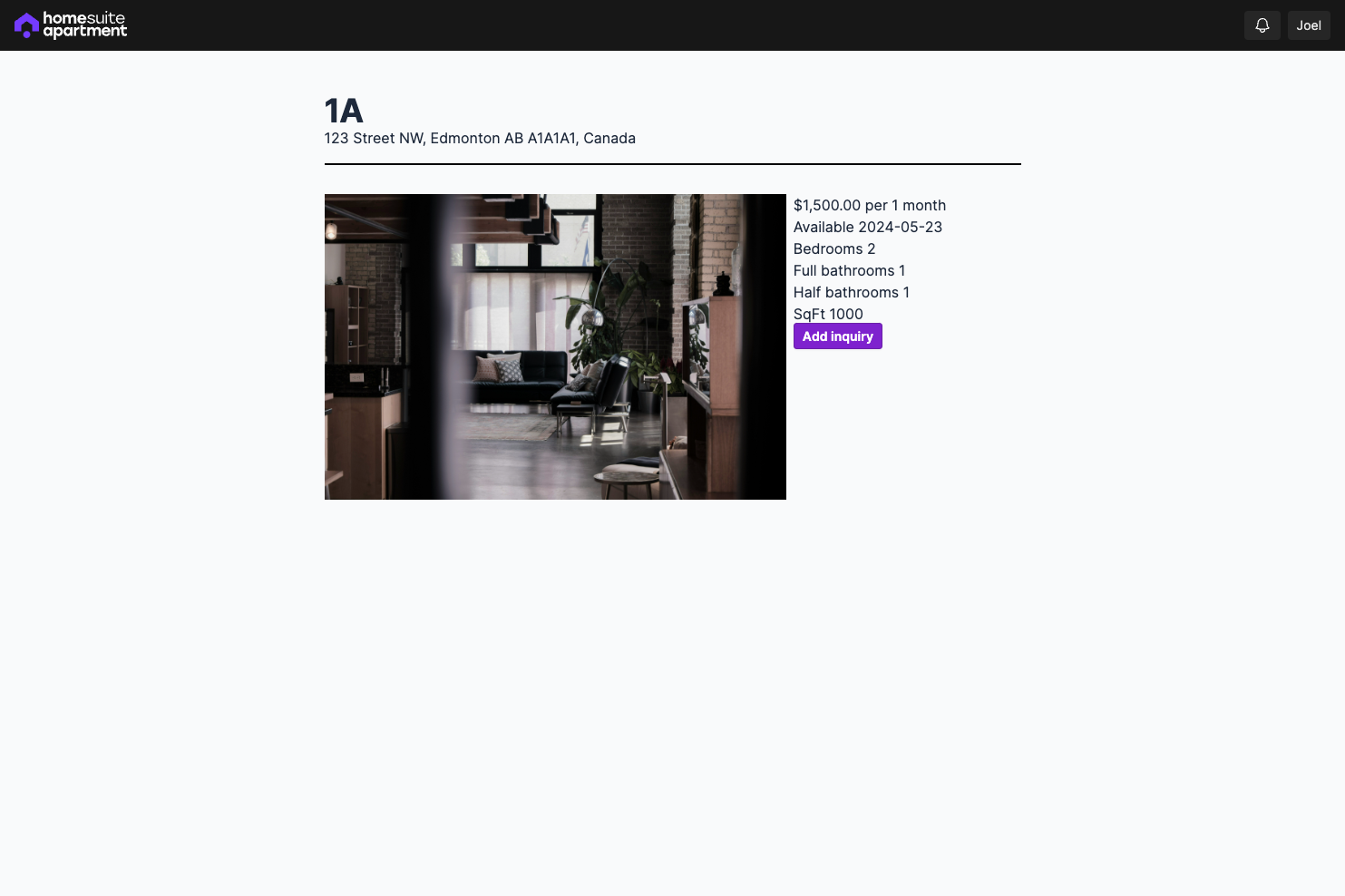
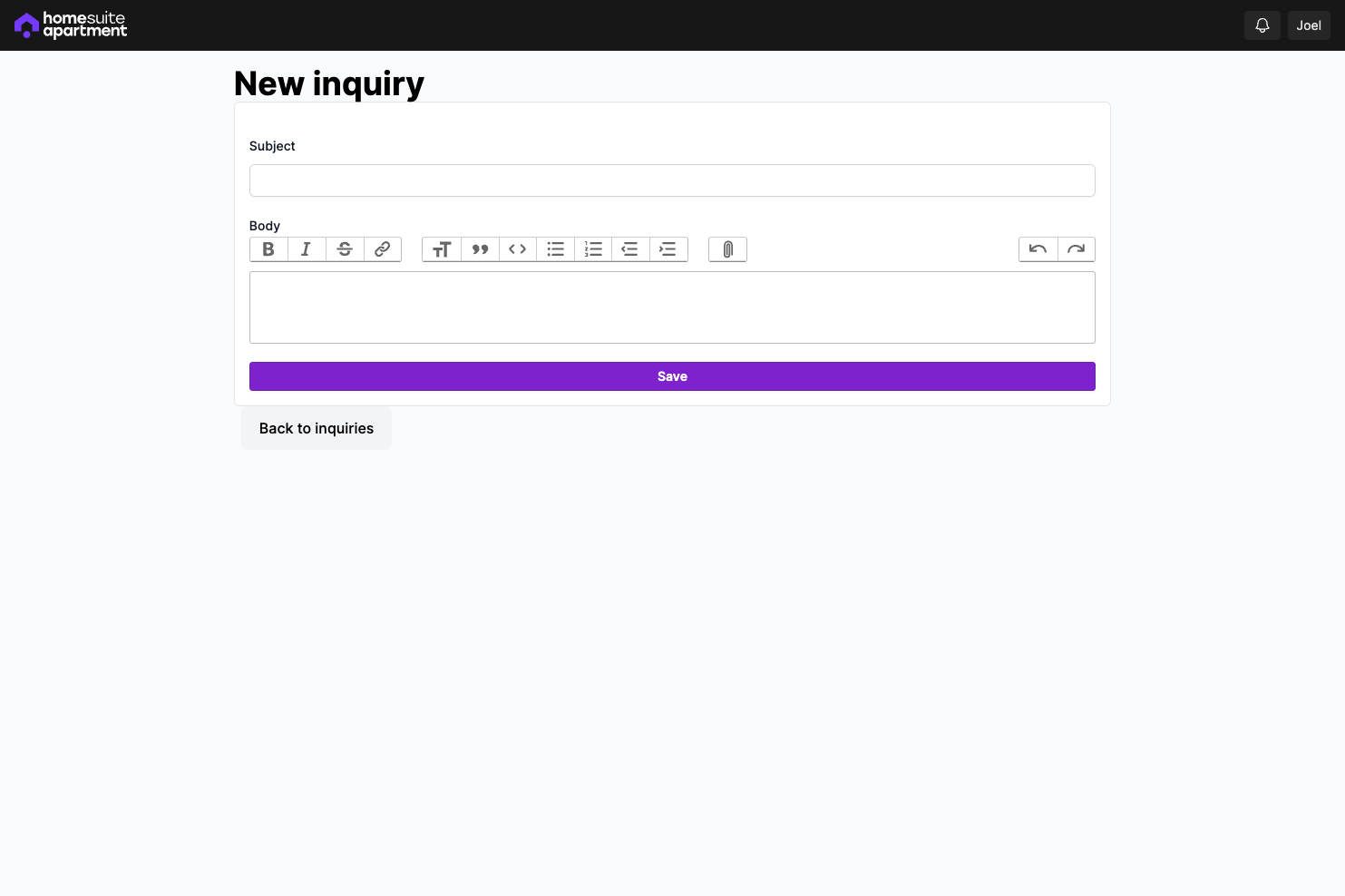
- CRUD routes for buildings and units
- CRUD routes to list a unit (at the moment only on HomeSuiteApartment, eventually on other rental listing marketplaces) and send inquiries
A lot of the pages have placeholder content at the moment, which I'll be fleshing out, but the intended workflow is almost done.
## An overview on my workflow
[Ruby on Rails](https://rubyonrails.org/), in my opinion, is the most productive full-stack web framework to-date.
I'd highly recommend reading up on the [Rails Doctrine](https://rubyonrails.org/doctrine), it really explains why Ruby on Rails came to be what it is today and how it's surpassed other frameworks.
---
To get started with Ruby on Rails, it was as simple as generating a new project, using the `rails` command line.
```shell
gem install rails
```
```shell
rails new homesuiteapartment
```
from there, it's as simple as using the provided [generators](https://guides.rubyonrails.org/generators.html) to scaffold the app.
```shell
bin/rails generate scaffold building name
```
This generates a database migration, model, route definition, controller and views, as well as tests if you've configured that. In all of a few minutes, you've got a 'working' application. In most cases, you'll need to do more, but the scaffold generator alone seems like cheating.
One of my favourite things about using generators, is that it's quite easy to customize, especially if you've implemented other gems for authorization and need to change the controller template.
---
Thankfully, [Ruby](https://www.ruby-lang.org/en/) and [Ruby on Rails](https://rubyonrails.org/) are well established, and have a large community building 'packages', known as [gems](https://guides.rubygems.org/what-is-a-gem/), similar to node packages.
[Ruby on Rails](https://rubyonrails.org/) is really just a collection of Gems which work very well together, such as [ActiveRecord](https://github.com/rails/rails/tree/main/activerecord), [ActiveModel](https://github.com/rails/rails/tree/main/activemodel), [ActionView](https://github.com/rails/rails/tree/main/actionview) and much more.
Gems are a helpful tool to easily add new functionality to your Ruby on Rails application, and is especially helpful when building an MVP so you don't need to build everything from scratch.
### Some of my favourite gems
#### Authentication
As mentioned in my previous blog post, [On the road to ramen profitability 🍜 💸](https://dev.to/joelzwarrington/on-the-road-to-ramen-profitability-21fc), I mentioned that I'm using [devise](https://github.com/heartcombo/devise). It's one of the most popular open-source authentication solutions for Rails.
I highly recommend it, as it's very configurable, and there are many plugins which I'll implement in the future, such as [OmniAuth](https://github.com/omniauth/omniauth).
One pitfall though, if you've never worked with Ruby on Rails, I recommend avoiding it and starting with a simple authentication system from scratch.
#### Authorization
If you're unfamiliar with authorization, it's very different from authentication. Read the [Authentication vs. Authorization article](https://auth0.com/docs/get-started/identity-fundamentals/authentication-and-authorization) from auth0 to learn more, but in essence:
> authentication is the process of verifying who a user is, while authorization is the process of verifying what they have access to.
There are a few gems which implement different strategies, such as [CanCanCan](https://github.com/CanCanCommunity/cancancan) and [Pundit](https://github.com/varvet/pundit).
My favourite gem for implementing authorization strategies is [ActionPolicy](https://github.com/palkan/action_policy). It's very similar to [Pundit](https://github.com/varvet/pundit), but is more extensible and isn't as barebones.
It's as simple as adding a new policy, and implementing the methods corresponding to the actions in your controller. In the example below, we have the `UnitPolicy` which will be used in the `UnitsController`. The `organization_user?` is a method which will return `true` if the user is part of the organization they're trying to access.
At the moment, most of my policies are very simple and simply check that a user is part of an organization, however, in the future it'll be easy to add permissions, roles, etc.
```ruby
class UnitPolicy < ApplicationPolicy
def index?
organization_user?
end
def new?
organization_user?
end
def create?
organization_user?
end
def show?
organization_user?
end
def edit?
organization_user?
end
def update?
organization_user?
end
def destroy?
organization_user?
end
private
relation_scope do |relation|
relation.where(organization: organization)
end
params_filter do |params|
params.permit(
:name
)
end
end
```
#### Views and Components
Out of the box, Ruby on Rails uses [erb templating](https://guides.rubyonrails.org/layouts_and_rendering.html) to build views, and [partials](https://guides.rubyonrails.org/layouts_and_rendering.html#using-partials). In Rails convention over configuration fashion, it's best to have views which correspond to your `get` actions, and you'll see these views get generated when you run the scaffold generator.
However, you might want to re-use and share code between views, and at first most would reach for [partials](https://guides.rubyonrails.org/layouts_and_rendering.html#using-partials), or if you're brave enough, think that implementing a React frontend will make this better for you, but there's a better solution.
- [ViewComponent](https://viewcomponent.org/) is a framework/gem for creating reusable, testable & encapsulated view components, built to integrate seamlessly with Ruby on Rails.
- [ViewComponent::Form](https://github.com/pantographe/view_component-form) provides an ActionView FormBuilder, so you can easily use [ViewComponent](https://viewcomponent.org/) components in your form helpers
I recommend giving these two gems a try, to , and helps with the composability that one might want,
These gems are both great at reducing the complexity and maintainability of partials, and allows for better composability, something which can be difficult in ERB templating. As mentioned previously, I've seen a lot of people reach for React frontends to solve this problem, and I think it's the wrong approach for a few reasons. If you're interested in that topic, let me know and I can publish an article going in-depth there.
#### Code formatting and linting
I highly recommend adding [standardrb](https://github.com/standardrb/standard) to your project. Under the hood it uses [rubocop](https://github.com/rubocop/rubocop) (A Ruby static code analyzer and formatter) and doesn't require any configuration - that's what makes it so powerful.
When building an MVP, you should spend the least amount of time working on things which don't directly provide value to what you're building. Linting is not a feature of your product.
When the time comes that I want to be picky about my formatting and linting rules, I'll likely pull out [standard](https://github.com/standardrb/standard) and write my own https://github.com/rubocop/rubocop rules, but in the meantime this is more than good enough.
#### Testing
Similar to linting and formatting, testing isn't really a feature. Some would highly argue against shipping code without rock-solid tests. But it really slows you down if you're hunting absolute coverage.
In my own projects, I'll use [rspec](https://rspec.info/) with [shoulda-matchers](https://github.com/thoughtbot/shoulda-matchers) alongside [FactoryBot](https://github.com/thoughtbot/factory_bot) to quickly and easily write simple tests.
For the most part, I won't add many more tests than what's included in the basic scaffold generator. Not to say I won't write tests, but covering every code path is not nescessary here. Happy path is good enough.
#### Running jobs
Ruby on Rails provides a common interface for scheduled jobs called [ActiveJob](https://guides.rubyonrails.org/active_job_basics.html), but there isn't a single job runner in the scene. There are gems such as [resque](https://github.com/resque/resque) and [sidekiq](https://github.com/sidekiq/sidekiq) but both of these gems are dependent on adding Redis.
These days, I'll be using [solid_queue](https://github.com/basecamp/solid_queue) as it's a simple solution which uses your existing SQL database.
#### Clean code
To avoid a lot of the boilerplate with [Ruby on Rails](https://rubyonrails.org/) controllers, I recommend the [responders](https://github.com/heartcombo/responders) gem. Also it's used by [devise](https://github.com/heartcombo/devise) under the hood!
## What's next?
Thanks for sticking to the end, I hope I've shared a few gems that will help you build your own [Ruby on Rails](https://rubyonrails.org/) application if you decide to do so.
As for me, I'll continue building out [HomeSuiteApartment](https://homesuiteapartment.com/), and in the next 2 weeks will mostly focus on:
- polishing pages, such as the subscription overview and unit listing page
- adding functionality to see inquiries, and book viewings from inquiries
See you in 2 weeks, for the next update! | joelzwarrington |
1,864,097 | Relax and let the data flow: A Zero-ETL Pipeline | Real-time Data Visualization with OpenSearch and Amazon DynamoDB: A Zero-ETL Pipeline 🇻🇪🇨🇱... | 0 | 2024-05-24T15:17:03 | https://community.aws/content/2gEgTJCgL2BlFfBxmUBX7nUHe3q/relax-and-let-the-data-flow-a-zero-etl-pipeline | aws, analytics, database, zeroetl | # Real-time Data Visualization with OpenSearch and Amazon DynamoDB: A Zero-ETL Pipeline
🇻🇪🇨🇱 [Dev.to](https://dev.to/elizabethfuentes12) [Linkedin](https://www.linkedin.com/in/lizfue/) [GitHub](https://github.com/elizabethfuentes12/) [Twitter](https://twitter.com/elizabethfue12) [Instagram](https://www.instagram.com/elifue.tech) [Youtube](https://www.youtube.com/channel/UCr0Gnc-t30m4xyrvsQpNp2Q)
[Linktr](https://linktr.ee/elizabethfuentesleone)
{% embed https://dev.to/elizabethfuentes12 %}
[Amazon OpenSearch](https://docs.aws.amazon.com/es_es/opensearch-service/latest/developerguide/what-is.html) Service and Amazon DynamoDB provide a powerful combination for real-time data visualization without the need for complex Extract, Transform, Load (ETL) processes. This repositorie introduces an AWS Cloud Development Kit (CDK) stack that deploys a serverless architecture for efficient, real-time data ingestion using the [OpenSearch Ingestion](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/ingestion.html) service (OSIS).
By leveraging OSIS, you can process and transform data from DynamoDB streams directly into OpenSearch, enabling near-instant visualization and analysis. This zero-ETL pipeline eliminates the overhead of traditional data transformation workflows, allowing you to focus on deriving insights from your data.
The CDK stack provisions key components such as Amazon Cognito for authentication, IAM roles for secure access, an OpenSearch domain for indexing and visualization, an S3 bucket for data backups, and a DynamoDB table as the data source. OpenSearch Ingestion acts as the central component, efficiently processing data based on a declarative YAML configuration.
## Prerequisites
- [AWS Account](https://aws.amazon.com/resources/create-account/?sc_channel=el&sc_campaign=datamlwave&sc_content=cicdcfnaws&sc_geo=mult&sc_country=mult&sc_outcome=acq)
- [Foundational knowledge of Python](https://catalog.us-east-1.prod.workshops.aws/workshops/3d705026-9edc-40e8-b353-bdabb116c89c/)
## 💰 Cost to complete:
- [Amazon DynamoDB Pricing](https://aws.amazon.com/dynamodb/pricing/)
- [Amazon OpenSearch Service Pricing](https://aws.amazon.com/opensearch-service/pricing/)
- [Amazon Cognito Pricing](https://aws.amazon.com/cognito/pricing/)
- [Amazon S3 Pricing](https://aws.amazon.com/s3/pricing/)
## How Does This Application Work?

The flow starts with data stored in Amazon DynamoDB, a managed and scalable NoSQL database. Then, the data is transmitted to [Amazon S3](https://docs.aws.amazon.com/es_es/AmazonS3/latest/userguide/Welcome.html).
From the data in S3, it is indexed using Amazon OpenSearch, a service that enables real-time search and analysis on large volumes of data. OpenSearch indexes the data and makes it easily accessible for fast queries.
The next component is Amazon Cognito, a service that enables user identity and access management. Cognito authenticates and authorizes users to access the OpenSearch Dashboard.
[AWS Identity and Access Management Roles](https://docs.aws.amazon.com/es_es/IAM/latest/UserGuide/id_roles.html) is used to define roles and access permissions.
To create an OpenSearch Ingestion pipeline, you need an [IAM role that the pipeline](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/creating-pipeline.html?icmpid=docs_console_unmapped#manage-pipeline-prerequisites) will assume to write data to the sink (an OpenSearch Service domain or OpenSearch Serverless collection). The role's ARN must be included in the pipeline configuration. The sink, which can be an OpenSearch Service domain (running OpenSearch 1.0+ or Elasticsearch 7.4+) or an OpenSearch Serverless collection, must have an access policy granting the necessary permissions to the IAM pipeline role. ([Granting Amazon OpenSearch Ingestion pipelines access to domains](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/pipeline-domain-access.html) - [Granting Amazon OpenSearch Ingestion pipelines access to collections](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/pipeline-collection-access.html)).
OpenSearch Ingestion requires [specific IAM permissions](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/creating-pipeline.html?icmpid=docs_console_unmapped#create-pipeline-permissions) to create pipelines, including `osis:CreatePipeline` to create a pipeline, `osis:ValidatePipeline` to validate the pipeline configuration, and `iam:PassRole` to pass the pipeline role to OpenSearch Ingestion, allowing it to write data to the domain. The `iam:PassRole` permission must be granted on the [pipeline role resource](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/pipeline-domain-access.html#pipeline-access-configure) (specified as sts_role_arn in the pipeline configuration) or set to * if different roles will be used for each pipeline.
The main link of this pipeline configuration is a [YAML file format](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/dashboard/template.txt) that connects the DynamoDB table with OpenSearch:
The pipeline configuration is done through a [YAML file format](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/dashboard/template.txt) like:
```
version: "2"
dynamodb-pipeline:
source:
dynamodb:
acknowledgments: true
tables:
# REQUIRED: Supply the DynamoDB table ARN and whether export or stream processing is needed, or both
- table_arn: "DYNAMODB_TABLE_ARN"
# Remove the stream block if only export is needed
stream:
start_position: "LATEST"
# Remove the export block if only stream is needed
export:
# REQUIRED for export: Specify the name of an existing S3 bucket for DynamoDB to write export data files to
s3_bucket: "<<my-bucket>>"
# Specify the region of the S3 bucket
s3_region: "<<REGION_NAME>"
# Optionally set the name of a prefix that DynamoDB export data files are written to in the bucket.
s3_prefix: "ddb-to-opensearch-export/"
aws:
# REQUIRED: Provide the role to assume that has the necessary permissions to DynamoDB, OpenSearch, and S3.
sts_role_arn: "<<STS_ROLE_ARN>>"
# Provide the region to use for aws credentials
region: "<<REGION_NAME>>"
sink:
- opensearch:
# REQUIRED: Provide an AWS OpenSearch endpoint
hosts:
[
"<<https://OpenSearch_DOMAIN>>"
]
index: "<<table-index>>"
index_type: custom
document_id: "${getMetadata(\"primary_key\")}"
action: "${getMetadata(\"opensearch_action\")}"
document_version: "${getMetadata(\"document_version\")}"
document_version_type: "external"
aws:
# REQUIRED: Provide a Role ARN with access to the domain. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "<<STS_ROLE_ARN>>"
# Provide the region of the domain.
region: "<<REGION_NAME>>"
```
The pipeline configuration file is automatically created in the CDK stack along with all the other resources.
## Let's build!
### Step 1: APP Set Up
✅ **Clone the repo**
```
git clone https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization
```
✅ **Go to**:
```
cd dashboard
```
- Configure the [AWS Command Line Interface](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html)
- Deploy architecture with CDK [Follow steps:](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/README.md)
✅ **Create The Virtual Environment**: by following the steps in the [README](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/README.md)
```
python3 -m venv .venv
```
```
source .venv/bin/activate
```
for windows:
```
.venv\Scripts\activate.bat
```
✅ **Install The Requirements**:
```
pip install -r requirements.txt
```
✅ **Synthesize The Cloudformation Template With The Following Command**:
```
cdk synth
```
✅🚀 **The Deployment**:
```
cdk deploy
```
The deployment will take between 5 and 10 minutes, which is how long it takes for the OpenSearch domain to be created.
When it is ready you will see that the status changes to completed:

To access the OpenSearch Dashboards through the [OpenSearch Dashboards URL (IPv4)](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/dashboards.html) you need to [create a user in the Amazon Cognito user pools](https://docs.aws.amazon.com/cognito/latest/developerguide/managing-users.html?icmpid=docs_cognito_console_help_panel).

With the created user, access the Dashboard and begin to experience the magic of Zero-ETL between the DynamoDB table and OpenSearch.
In this repository you created a table to which you can inject data, but you can also change it by [Updating Amazon OpenSearch Ingestion pipelines](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/update-pipeline.html) making a change to the YAML file or modifying the [CDK stack](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/dashboard/dashboard_stack.py).
## Conclusion
The combination of Amazon OpenSearch and Amazon DynamoDB enables real-time data visualization without the complexities of traditional ETL processes. By utilizing the OpenSearch Ingest Service (OSIS), a serverless architecture can be implemented that efficiently processes and transforms data from DynamoDB directly into OpenSearch. Building the application with AWS CDK streamlines and simplifies the setup of key components such as authentication, secure access, indexing, visualization, and data backup.
This solution allows users to focus on gaining insights from their data rather than managing infrastructure. Ideal for real-time dashboards, log analytics, or IoT event monitoring, this Zero-ETL pipeline offers a scalable and agile approach to data ingestion and visualization. It is recommended to clone the repository, customize the configuration, and deploy the stack on AWS to leverage the power of OpenSearch and DynamoDB for real-time data visualization.
{% embed https://dev.to/elizabethfuentes12 %}
🇻🇪🇨🇱 [Dev.to](https://dev.to/elizabethfuentes12) [Linkedin](https://www.linkedin.com/in/lizfue/) [GitHub](https://github.com/elizabethfuentes12/) [Twitter](https://twitter.com/elizabethfue12) [Instagram](https://www.instagram.com/elifue.tech) [Youtube](https://www.youtube.com/channel/UCr0Gnc-t30m4xyrvsQpNp2Q)
[Linktr](https://linktr.ee/elizabethfuentesleone)
| elizabethfuentes12 |
1,864,094 | Halo Dev.to | Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the... | 0 | 2024-05-24T15:13:34 | https://dev.to/hamevryd/halo-devto-1j8g | Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
| hamevryd | |
1,864,093 | Zero-ETL Pipeline: Relájate y deja que los datos fluyan. | Visualización de datos en tiempo real con OpenSearch y Amazon DynamoDB: A Zero-ETL... | 0 | 2024-05-24T15:10:22 | https://www.linkedin.com/pulse/zero-etl-pipeline-rel%2525C3%2525A1jate-y-deja-que-los-datos-fuentes-leone-qzj8e/?trackingId=IleRrYDzTc2pL7ggvEVw%2Bw%3D%3D | database, analytics, aws, spanish | # Visualización de datos en tiempo real con OpenSearch y Amazon DynamoDB: A Zero-ETL Pipeline
🇻🇪🇨🇱 [Dev.to](https://dev.to/elizabethfuentes12) [Linkedin](https://www.linkedin.com/in/lizfue/) [GitHub](https://github.com/elizabethfuentes12/) [Twitter](https://twitter.com/elizabethfue12) [Instagram](https://www.instagram.com/elifue.tech) [Youtube](https://www.youtube.com/channel/UCr0Gnc-t30m4xyrvsQpNp2Q)
[Linktr](https://linktr.ee/elizabethfuentesleone)
{% embed https://dev.to/elizabethfuentes12 %}
[Amazon OpenSearch](https://docs.aws.amazon.com/es_es/opensearch-service/latest/developerguide/what-is.html) Service y Amazon DynamoDB proporcionan una poderosa combinación para la visualización de datos en tiempo real sin la necesidad de procesos complejos de Extracción, Transformación y Carga (ETL). Este repositorio introduce una pila de AWS Cloud Development Kit (CDK) que despliega una arquitectura sin servidor para la ingesta eficiente de datos en tiempo real utilizando el servicio [OpenSearch Ingestion](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/ingestion.html) (OSIS).
Al aprovechar OSIS, puedes procesar y transformar datos de los streams de DynamoDB directamente en OpenSearch, permitiendo la visualización y análisis casi instantáneos. Esta canalización sin ETL elimina la sobrecarga de los flujos de trabajo tradicionales de transformación de datos, permitiéndote enfocarte en obtener información de tus datos.
El stack de CDK aprovisiona componentes clave como Amazon Cognito para autenticación, roles de IAM para acceso seguro, un dominio de OpenSearch para indexación y visualización, un bucket de S3 para respaldos de datos y una tabla de DynamoDB como fuente de datos. OpenSearch Ingestion actúa como el componente central, procesando eficientemente los datos basados en una configuración declarativa YAML.
## Requisitos previos
- [Cuenta de AWS](https://aws.amazon.com/resources/create-account/?sc_channel=el&sc_campaign=datamlwave&sc_content=cicdcfnaws&sc_geo=mult&sc_country=mult&sc_outcome=acq)
- [Conocimientos fundamentales de Python](https://catalog.us-east-1.prod.workshops.aws/workshops/3d705026-9edc-40e8-b353-bdabb116c89c/)
## 💰 Costo para completar:
- [Precios de Amazon DynamoDB](https://aws.amazon.com/dynamodb/pricing/)
- [Precios de Amazon OpenSearch Service](https://aws.amazon.com/opensearch-service/pricing/)
- [Precios de Amazon Cognito](https://aws.amazon.com/cognito/pricing/)
- [Precios de Amazon S3](https://aws.amazon.com/s3/pricing/)
## ¿Cómo funciona esta aplicación?

El flujo comienza con datos almacenados en Amazon DynamoDB, una base de datos NoSQL administrada y escalable. Luego, los datos se transmiten a [Amazon S3](https://docs.aws.amazon.com/es_es/AmazonS3/latest/userguide/Welcome.html).
Desde los datos en S3, se indexan utilizando Amazon OpenSearch, un servicio que permite la búsqueda y análisis en tiempo real en grandes volúmenes de datos. OpenSearch indexa los datos y los hace fácilmente accesibles para consultas rápidas.
El siguiente componente es Amazon Cognito, un servicio que permite la identidad del usuario y la gestión de acceso. Cognito autentica y autoriza a los usuarios para acceder al Panel de OpenSearch.
Se utiliza [AWS Identity and Access Management Roles](https://docs.aws.amazon.com/es_es/IAM/latest/UserGuide/id_roles.html) para definir roles y permisos de acceso.
Para crear una canalización de ingesta de OpenSearch, necesitas un [rol de IAM que la canalización](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/creating-pipeline.html?icmpid=docs_console_unmapped#manage-pipeline-prerequisites) asumirá para escribir datos en el sumidero (un dominio de OpenSearch Service o una colección de OpenSearch Serverless). El ARN del rol debe incluirse en la configuración de la canalización. El sumidero, que puede ser un dominio de OpenSearch Service (ejecutando OpenSearch 1.0+ o Elasticsearch 7.4+) o una colección de OpenSearch Serverless, debe tener una política de acceso que otorgue los permisos necesarios al rol de canalización de IAM. ([Otorgar acceso a las canalizaciones de ingesta de Amazon OpenSearch a dominios](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/pipeline-domain-access.html) - [Otorgar acceso a las canalizaciones de ingesta de Amazon OpenSearch a colecciones](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/pipeline-collection-access.html)).
OpenSearch Ingestion requiere [permisos específicos de IAM](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/creating-pipeline.html?icmpid=docs_console_unmapped#create-pipeline-permissions) para crear canalizaciones, incluyendo `osis:CreatePipeline` para crear una canalización, `osis:ValidatePipeline` para validar la configuración de la canalización, y `iam:PassRole` para pasar el rol de canalización a OpenSearch Ingestion, permitiéndole escribir datos en el dominio. El permiso `iam:PassRole` debe otorgarse en el [recurso de rol de canalización](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/pipeline-domain-access.html#pipeline-access-configure) (especificado como sts_role_arn en la configuración de la canalización) o establecerse en * si se utilizarán diferentes roles para cada canalización.
El enlace principal de esta configuración de canalización es un [formato de archivo YAML](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/dashboard/template.txt) que conecta la tabla DynamoDB con OpenSearch:
La configuración de la canalización se realiza a través de un formato de archivo [YAML](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/dashboard/template.txt) como:
```
version: "2"
dynamodb-pipeline:
source:
dynamodb:
acknowledgments: true
tables:
# REQUIRED: Supply the DynamoDB table ARN and whether export or stream processing is needed, or both
- table_arn: "DYNAMODB_TABLE_ARN"
# Remove the stream block if only export is needed
stream:
start_position: "LATEST"
# Remove the export block if only stream is needed
export:
# REQUIRED for export: Specify the name of an existing S3 bucket for DynamoDB to write export data files to
s3_bucket: "<<my-bucket>>"
# Specify the region of the S3 bucket
s3_region: "<<REGION_NAME>"
# Optionally set the name of a prefix that DynamoDB export data files are written to in the bucket.
s3_prefix: "ddb-to-opensearch-export/"
aws:
# REQUIRED: Provide the role to assume that has the necessary permissions to DynamoDB, OpenSearch, and S3.
sts_role_arn: "<<STS_ROLE_ARN>>"
# Provide the region to use for aws credentials
region: "<<REGION_NAME>>"
sink:
- opensearch:
# REQUIRED: Provide an AWS OpenSearch endpoint
hosts:
[
"<<https://OpenSearch_DOMAIN>>"
]
index: "<<table-index>>"
index_type: custom
document_id: "${getMetadata(\"primary_key\")}"
action: "${getMetadata(\"opensearch_action\")}"
document_version: "${getMetadata(\"document_version\")}"
document_version_type: "external"
aws:
# REQUIRED: Provide a Role ARN with access to the domain. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "<<STS_ROLE_ARN>>"
# Provide the region of the domain.
region: "<<REGION_NAME>>"
```
El archivo de configuración de la canalización se crea automáticamente en la pila CDK junto con todos los demás recursos.
## ¡Construyamos!
### Paso 1: Configuración de la APP
✅ **Clonar el repositorio**
```
git clone https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization
```
✅ **Ir a**:
```
cd dashboard
```
- Configurar la [Interfaz de línea de comandos de AWS](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html)
- Implemente la arquitectura con CDK [Siga los pasos:](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/README.md)
✅ **Cree el Entorno Virtual**: siguiendo los pasos en el [README](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/README.md)
```
python3 -m venv .venv
```
```
source .venv/bin/activate
```
para windows:
```
.venv\Scripts\activate.bat
```
✅ **Instale los Requisitos**:
```
pip install -r requirements.txt
```
✅ **Sintetice la Plantilla de Cloudformation con el Siguiente Comando**:
```
cdk synth
```
✅🚀 **El Despliegue**:
```
cdk deploy
```
El despliegue tomará entre 5 y 10 minutos, que es el tiempo que tarda en crearse el dominio de OpenSearch.
Cuando esté listo, verá que el estado cambia a completado:

Para acceder a los Dashboards de OpenSearch a través de la [URL de Dashboards de OpenSearch (IPv4)](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/dashboards.html) necesita [crear un usuario en los grupos de usuarios de Amazon Cognito](https://docs.aws.amazon.com/cognito/latest/developerguide/managing-users.html?icmpid=docs_cognito_console_help_panel).

Con el usuario creado, acceda al Dashboard y comience a experimentar la magia de Zero-ETL entre la tabla de DynamoDB y OpenSearch.
En este repositorio, creó una tabla a la que puede inyectar datos, pero también puede cambiarla [Actualizando las tuberías de ingesta de Amazon OpenSearch](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/update-pipeline.html) realizando un cambio en el archivo YAML o modificando la [pila CDK](https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization/blob/main/dashboard/dashboard/dashboard_stack.py).
## Conclusión
La combinación de Amazon OpenSearch y Amazon DynamoDB permite la visualización de datos en tiempo real sin las complejidades de los procesos ETL tradicionales. Al utilizar el Servicio de Ingesta de OpenSearch (OSIS), se puede implementar una arquitectura sin servidor que procesa y transforma eficientemente los datos de DynamoDB directamente en OpenSearch. La construcción de la aplicación con AWS CDK simplifica la configuración de componentes clave como la autenticación, el acceso seguro, la indexación, la visualización y el respaldo de datos.
Este es el contenido del blog traducido al español:
Esta solución permite a los usuarios centrarse en obtener información de sus datos en lugar de administrar la infraestructura. Ideal para paneles de control en tiempo real, análisis de registros o monitoreo de eventos de IoT, este pipeline Zero-ETL ofrece un enfoque escalable y ágil para la ingesta y visualización de datos. Se recomienda clonar el repositorio, personalizar la configuración e implementar la pila en AWS para aprovechar el poder de OpenSearch y DynamoDB para la visualización de datos en tiempo real.
{% embed https://dev.to/elizabethfuentes12 %}
🇻🇪🇨🇱 [Dev.to](https://dev.to/elizabethfuentes12) [Linkedin](https://www.linkedin.com/in/lizfue/) [GitHub](https://github.com/elizabethfuentes12/) [Twitter](https://twitter.com/elizabethfue12) [Instagram](https://www.instagram.com/elifue.tech) [Youtube](https://www.youtube.com/channel/UCr0Gnc-t30m4xyrvsQpNp2Q)
[Linktr](https://linktr.ee/elizabethfuentesleone)
| elizabethfuentes12 |
1,864,092 | Introduction to GUI Programming with Tkinter | Introduction to GUI Programming with Tkinter Graphical User Interfaces (GUIs) allow users... | 0 | 2024-05-24T15:10:03 | https://dev.to/romulogatto/introduction-to-gui-programming-with-tkinter-386h | # Introduction to GUI Programming with Tkinter
Graphical User Interfaces (GUIs) allow users to interact with software applications through visual elements such as buttons, menus, and text fields. In this guide, we will explore the basics of GUI programming using Tkinter - a popular Python library for creating user-friendly interfaces.
## Installation
Before diving into Tkinter, ensure that you have Python installed on your computer. Visit the official Python website (https://www.python.org) and download the latest version suitable for your operating system.
Once you have Python installed, Tkinter is included in the standard library by default. No additional installation is required.
## Creating a Simple GUI Application
Let's get started by creating a simple "Hello World" application using Tkinter. Open your favorite code editor or IDE and create a new Python file.
First, import the tkinter module:
```python
import tkinter as tk
```
Next, let's create an instance of the main tkinter window:
```python
window = tk.Tk()
```
Now that we have our window ready, let's add some content to it. We'll start by adding a label widget containing our "Hello World" message:
```python
label = tk.Label(window, text="Hello World!")
label.pack()
```
Finally, run the application by entering this line of code:
```python
window.mainloop()
```
Save your file with a `.py` extension and execute it from the command line or within your IDE. You should see a small window pop up displaying "Hello World".
Congratulations! You've just created your first GUI application using Tkinter!
## Working with Widgets
Tkinter provides various widgets that can be used to build powerful and interactive GUI applications. Let's take a look at some commonly used widgets along with their functionalities:
### Buttons
Buttons are used to trigger actions when clicked on by users. Here's an example of how to create a button widget:
```python
button = tk.Button(window, text="Click Me!")
button.pack()
```
### Entry Fields
Entry fields allow users to input text or numerical data. To create an entry field in Tkinter, use the following code:
```python
entry = tk.Entry(window)
entry.pack()
```
### Labels
Labels are used to display static text or images. The label widget can be created as follows:
```python
label = tk.Label(window, text="Welcome to Tkinter!")
label.pack()
```
## Styling Widgets
Tkinter also provides options for customizing the appearance and behavior of widgets. You can modify properties such as font, color, size, and layout.
For example, to change the background color of a button:
```python
button.config(bg="red")
```
To change the font style and size of a label:
```python
label.config(font=("Arial", 20))
```
Feel free to explore Tkinter's extensive documentation (https://docs.python.org/3/library/tk.html) for more details on styling.
## Conclusion
In this guide, we've covered the basics of GUI programming with Tkinter in Python. We learned how to create a simple GUI application, work with common widgets like buttons and labels, and even customize their appearance.
Tkinter offers many other features such as event handling and layout management which you can explore further on your own. So go ahead and experiment with creating your interactive user interfaces using Tkinter - it's an exciting journey into building user-friendly Python applications!
| romulogatto | |
1,864,090 | Simple Method to Block Copy and Paste in Monaco Editor with React | Monaco Editor, the code editor that powers Visual Studio Code, is a powerful tool for developers,... | 0 | 2024-05-24T15:07:26 | https://dev.to/ritish_shelke_526e503c1b7/simple-method-to-block-copy-and-paste-in-monaco-editor-with-react-eam | react, monacoeditor, javascript, webdev | **[Monaco Editor](https://www.npmjs.com/package/@monaco-editor/react)**, the code editor that powers Visual Studio Code, is a powerful tool for developers, providing a rich set of features and customization options. However, there might be situations where you want to disable the copy-paste functionality, such as in coding assessments or educational tools to prevent cheating. In this blog, we will explore how to disable the copy-paste feature in Monaco Editor.
**Why Disable Copy-Paste?**
Before diving into the implementation, let’s discuss why you might want to disable copy-paste in a code editor:
1. **Academic Integrity:** In educational settings, to ensure students write their code from scratch during exams or practice sessions.
2. **Prevent Plagiarism:** To discourage copying code from other sources without understanding it.
3. **Skill Assessment:** To accurately assess a developer’s coding skills during interviews or coding challenges.
## **Step by step solution**
**Step 1: Setting Up Monaco Editor**
First, ensure you have Monaco Editor set up in your project. You can install it via npm:
```bash
npm install @monaco-editor/react
```
Include it in your project:
```javascript
import { Editor } from "@monaco-editor/react";
```
**Step 2: Configuring Editor Options**
To disable certain functionalities and customize the editor's behavior, configure its options. For instance, you can disable the context menu and set other useful preferences:
Here's list of options for editor: https://microsoft.github.io/monaco-editor/typedoc/interfaces/editor.IStandaloneEditorConstructionOptions.html
```javascript
const options = {
selectOnLineNumbers: true,
mouseWheelZoom: true,
fontSize: 18,
contextmenu: false, // Disables right-click context menu
formatOnType: true,
smoothScrolling: true,
wordWrap: "on",
};
```
**Step 3: Handling Key Down Events**
To detect and prevent copy-paste actions, add an event listener for key down events. This allows you to intercept the key combinations for copy (Ctrl/Cmd + C) and paste (Ctrl/Cmd + V):
```javascript
const onMount = (editor, monaco) => {
editorRef.current = editor;
editor.focus();
editor.onKeyDown((event) => {
const { keyCode, ctrlKey, metaKey } = event;
if ((keyCode === 33 || keyCode === 52) && (metaKey || ctrlKey)) {
event.preventDefault();
setActivity("copypaste");
setOpen(true);
}
});
};
```
**Step 4: Implementing the Modal Component**
The Modal component provides visual feedback to the user about their activities. Here's how to implement it:
```javascript
import React from "react";
import { IoIosCloseCircle } from "react-icons/io";
import { IoWarning } from "react-icons/io5";
export default function Modal({ activity, open, onClose }) {
return (
<div>
<div
className={`fixed inset-0 bg-gray-800 bg-opacity-80 z-50 transition-opacity ${
open ? "opacity-100" : "opacity-0 pointer-events-none"
}`}
></div>
<div
onClick={(e) => e.stopPropagation()}
className={`fixed inset-0 flex justify-center items-center z-50 ${
open ? "opacity-100" : "opacity-0 pointer-events-none"
}`}
>
<div className="bg-white rounded-xl shadow p-6 relative">
<button onClick={onClose} className="absolute top-2 right-2">
<IoIosCloseCircle size={24} />
</button>
<div className="text-center w-full h-52 z-50 flex justify-center items-center flex-col gap-5">
<div className="mx-auto my-4 w-full">
<h3 className="text-lg font-black text-gray-800">
{activity === "copypaste"
? "Copy Paste Activity"
: "Handle any other activity here"}
</h3>
<p className="text-md text-gray-700 font-semibold">
{activity === "copypaste"
? "Copy paste activity has been notified to faculty"
: "Handle any other activity here"}
</p>
<p className="text-md text-gray-700 font-semibold">
{activity === "copypaste"
? "On Next copy paste your exam will be terminated"
: "Handle any other activity here"}
</p>
</div>
<button
className="text-white bg-red-500 p-3 rounded-lg w-full flex justify-center items-center gap-2"
onClick={onClose}
>
{<IoWarning />} {activity === "copypaste" ? "Close Warning" : "Handle any other here"}
</button>
</div>
</div>
</div>
</div>
);
}
```
## Full code for Editor Component:
```javascript
import React, { useState, useRef } from "react";
import { Editor } from "@monaco-editor/react";
import Modal from "../../../../components/Modal/Modal.jsx";
const EditorWindow = () => {
const [activity, setActivity] = useState("");
const [open, setOpen] = useState(false);
const editorRef = useRef(null);
const options = {
selectOnLineNumbers: true,
mouseWheelZoom: true,
fontSize: 18,
contextmenu: false,
formatOnType: true,
smoothScrolling: true,
wordWrap: "on",
};
const onMount = (editor, monaco) => {
editorRef.current = editor;
editor.focus();
editor.onKeyDown((event) => {
const { keyCode, ctrlKey, metaKey } = event;
if ((keyCode === 33 || keyCode === 52) && (metaKey || ctrlKey)) {
event.preventDefault();
setActivity("copypaste");
setOpen(true);
};
return (
<>
<div>
<Modal activity={activity} open={open} onClose={() => setOpen(false)} />
<div className="overlay overflow-hidden w-full h-full shadow-4xl">
<Editor
height="85vh"
width="100vw"
theme="vs-dark"
language="java"
options={options}
defaultValue="some default value for editor"
onMount={onMount}
/>
</div>
</div>
</>
);
};
export default EditorWindow;
```
**Conclusion**
By following these steps, you can effectively disable copy-paste functionality in Monaco Editor and monitor user activities to ensure academic integrity. This approach is particularly useful in educational platforms and coding assessments where maintaining the originality of student work is crucial. By customizing and extending this implementation, you can adapt it to suit various educational and assessment platforms.
| ritish_shelke_526e503c1b7 |
1,864,089 | Native Power: Why Java Reigns Supreme for Android App Development | Looking to build a top-notch Android app? While cross-platform development seems tempting, there's a... | 0 | 2024-05-24T15:07:14 | https://dev.to/malikhandev/native-power-why-java-reigns-supreme-for-android-app-development-a6p | app, java, mobile, native | Looking to build a top-notch Android app? While cross-platform development seems tempting, there's a reason Java remains the king for native Android apps. Here's why:
Built for Speed: Java apps are like race cars, engineered specifically for the Android racetrack. They leverage the Android SDK directly, resulting in smoother performance and faster load times.
Unmatched User Experience: A laggy app is a user's worst nightmare. Java apps deliver a seamless and responsive experience, keeping your users engaged and happy.
Access the Full Arsenal: Java grants you full access to the Android SDK's functionalities. From advanced features to intricate hardware integration, you can build feature-rich apps without limitations.
Offline Functionality: Need your app to work even without an internet connection? Java apps excel in offline capabilities, a must-have for many functionalities.
Security That Shines: Java prioritizes security with built-in features and a strong development community. This translates to a more secure app environment for your users.
Long-Term Play: Java is a mature technology with a vast developer pool. This ensures your app's maintainability and future-proofs it for years to come.
Native Look and Feel: A native app blends seamlessly with the Android ecosystem. Java apps deliver that perfect native look and feel, making them an intuitive joy to use.
Unlock True Potential: Java empowers you to create powerful, feature-rich apps that push the boundaries of what's possible. Unleash the true potential of your Android app idea.
Ready to build a blazing-fast, feature-packed Android app?
Our team of expert Java developers is here to help! We specialize in crafting high-performance native Android apps that will take your vision to life.
Visit us today and let's discuss your project!: **fiverr.com/hypersli/develop-native-applications-with-java** | malikhandev |
1,864,088 | Tes 123 | Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the... | 0 | 2024-05-24T15:06:44 | https://dev.to/hamevryd/tes-123-3kj8 | Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum. | hamevryd | |
1,864,086 | Innovation-friendly software | Let’s face it – many established companies are live software museums. Marketing often advertises it... | 0 | 2024-05-24T15:05:36 | https://softbeehive.com/blog/innovation-friendly-software | webdev, microservices, programming, javascript | Let’s face it – many established companies are live software museums. Marketing often advertises it as cutting-edge, state-of-the-art, and crème de la crème. But under the hood, in the age of AI, our world still relies on vintage technology.
Chemical terminals use 25-year-old tools that work in Internet Explorer 5 only, trains run on Windows XP, and who knows what Perls you may find in a traditional banking sector?
## Why on Earth?
I have a theory: when businesses buy products or services, their expectations are proportional to the commitment. One does not simply take away a tool folks used for decades. This phenomenon is called ***technological inertia***.
Then, one day, customers riot, demanding high-speed wi-fi on the Win XP train. You order golden routers and do a lab test. During the rollout, two million people join the network. The electric system fails. Trying to fix lights, you break doors. The release reverted via USB drive downgrade on 250 trains, 13 bricked in the process. Passengers are happy the doors work again.
Meet ***sunk cost fallacy***: individuals or organizations may have invested heavily in the existing technology. And they are unwilling to abandon that investment, even if a new solution would be more cost-effective in the long run.
The point of no return is called don’t touch if it works. The longer it remains without a change, the more untouchable it gets. Crossing this Rubicon means an expensive and lengthy upgrade ahead.
## Vehicle management at car2go

At car2go (carsharing company), I worked in the vehicle lifecycle management team. We took ownership of a relatively fresh Angular 1 single-page app developed by an external agency.
Our motivated team started making changes. I remember applying a fix that caused seven new bugs. This pattern repeated again and again. Skilled and experienced engineers could not maintain the stability bar set by the company. Only manual QA saved us because automated tests did not catch issues.
The situation was spiraling out of control. We proceeded with caution, and that slowed our progress. During retrospectives, we began questioning our course of action. Some code was relatively fresh, though the main pain point was data binding side-effects in convoluted controllers.
On the API side, challenges were more significant – multiple databases were out of sync, critical bugs in queue processing, inconsistent data, and limited observability.
### Big bang is not an option
Our team concluded it was pragmatic to rethink the architecture. We needed modularity to achieve a better user experience. And a trunk-compatible system design that makes daily releases possible.
The head of engineering recognized the added value of the transition to innovation-friendlier architecture. Five engineers and a PO with QA and PM support performed zero downtime incremental upgrades that took 1.5 years to complete. For vehicle management, it was an investment that paid off.
When you operate a fleet of expensive cars, the difference between email damage tracking and an automated system could be millions of euros per year. According to my calculations, the return on investment was around 5-7x.
## How to keep up with the progress?
Recently, micro-service architecture has been a subject of wide criticism. Watch this brilliant video.
{% embed https://www.youtube.com/watch?v=y8OnoxKotPQ %}
Michael Paulson, aka The Primeagen, a prominent yelling tech figure, likes to mock startups for having more services than users.
The core issue is not a particular architecture. Humans associate failures with things they dislike. Be it a monolith, micro-services, or a framework. But the true killer is the complexity.
I see a repeating pattern occurring in established companies. Software is left unattended for some time. People join and leave, and priorities shift. Suddenly, a vintage marvel becomes a development blocker because multiple critical parts depend on it. Organizations invest astronomical amounts into legacy system integration.
Take action before it’s too late, and keep making changes as the product evolves. Motivated people recognize when something doesn’t work. When it happens, the lead must make a calculated decision.
## How to address it?
There is a better alternative – invest in reasonable modularity. I build high-performance, innovation-friendly software that helps companies avoid expensive upgrades and legacy service pain. Estimated ROI within five years +600%.
[Hire me](https://softbeehive.com/about)
Does it resonate with your experience? I'm curious to hear how you integrate vintage software. And how do you keep up with the WILD pace of change in the web tooling? | softbeehive |
1,859,259 | As vantagens de se usar o early return | 🌟 Aprimore a legibilidade e mantenha seu código limpo com "early return"! 🌟 A técnica de "early... | 0 | 2024-05-24T15:02:50 | https://dev.to/g7miserski/as-vantagens-de-se-usar-o-early-return-o8c | programming, python, webdev | 🌟 **Aprimore a legibilidade e mantenha seu código limpo com "early return"!** 🌟
A técnica de "early return" nos permite verificar e retornar logo no início do programa, melhorando a manutenção, legibilidade e, em alguns casos, até a performance do código. 🚀
### Vantagens do "early return":
1. **Legibilidade**: Código mais fácil de ler e entender, evitando aninhamentos profundos.
2. **Redução da Complexidade**: Simplifica a lógica e facilita a manutenção.
3. **Evita Códigos Desnecessários**: Previne a execução de trechos desnecessários, melhorando a performance.
Veja a diferença com um exemplo prático:
**Sem "early return":**
```python
def check_number(n):
if n > 0:
result = "Positive"
else:
if n < 0:
result = "Negative"
else:
result = "Zero"
return result
```
**Com "early return":**
```python
def check_number(n):
if n > 0:
return "Positive"
if n < 0:
return "Negative"
return "Zero"
```
Muito mais simples e legível! 📝
Claro, nem sempre o "early return" é a melhor opção. Avalie cada caso para encontrar a melhor solução. Tem algo a adicionar ou discordar? Vamos aprender juntos nos comentários! 💬 | g7miserski |
1,862,958 | Introducing Molend: the Pioneering Lending Protocol on Mode Network | Molend, the next-generation lending protocol, launches on the Ethereum Layer 2 blockchain Mode. Users... | 0 | 2024-05-24T15:00:00 | https://dev.to/modenetwork/introducing-molend-the-pioneering-lending-protocol-on-mode-network-2976 | [Molend](https://molend.org/), the next-generation lending protocol, launches on the Ethereum Layer 2 blockchain [Mode](https://www.mode.network/). Users can now engage in collateralized lending and borrowing using Molend. Mode is the DeFi L2 designed for growth, incentivizing and directly rewarding developers, users, and protocols to foster the development of the Mode and superchain ecosystem.
**Traditional Lending vs Decentralized Lending**
Traditional bank lending services are known for their complex and lengthy processes, causing inconvenience for borrowers. Decentralized lending protocols, on the other hand, offer fast loan disbursements and high security, gaining increasing popularity and occupying a significant share in the DeFi space. In simple terms, users can borrow other digital assets by collateralizing their existing digital assets and engage in various profit-generating activities. This includes taking long or short positions on assets through lending, participating in DeFi farming to generate yields, or simply earning interest on deposited assets.
**Empowering Users with Molend’s Flash Loans and Loop Feature**
Molend provides two primary functions: **depositing** and **borrowing**. By placing funds into Molend, depositors can earn interest from the borrowing activities of others. **Flash loan**, a distinctive feature of Molend, allows borrowing & repaying from the liquidity pool in a single transaction, eliminating the need for collaterals when a borrower can repay the loan atomically. Users incur only a minimal processing fee in addition to the standard gas fee, making it an efficient option for quick financial transactions. Flash Loans are particularly useful for arbitrage, enabling users to profit from price discrepancies across different protocols and liquidation opportunities.
Furthermore, Molend will be introducing the Loop feature in the near future to simplify the process of leveraging and borrowing assets for users. The Loop feature enables users to lend and borrow the same type of asset multiple times with a single click. More details about this feature will be revealed soon.
*Note: Molend will use a point system to track users' deposits/borrowings, and allocate airdrop rewards based on the number of points.*
As a highly anticipated flagship product, Molend has many advantages. Molend has high composability and can be integrated into other platforms for use. In terms of user experience, Molend provides a user-friendly data dashboard, allowing users to accurately assess profit trends and execute investment strategies. Flash Loans provide efficient investment tools for advanced users, while most of the fees generated are directly subsidized to users who have. The team behind Molend has extensive experience and a strong technical background in the cryptocurrency industry, enabling them to identify and address user pain points accurately.
**Earn Rewardsfor Being an Early User on Molend**
MODE has a [mainnet airdrop campaign](https://www.mode.network/about-the-airdrop) for early users and a point system dedicated to it. Molend will be a close partner of the campaign, meaning Molend users will earn more MODE points by using Molend.
Moreover, Molend is also allocating 10% of its governance token, $MLD, to early users through airdrops. As a holder of $MLD, you have governance rights over the protocol AND receive protocol revenue sharing. 50% of the loan interest generated across the protocol will be directed to $MLD holders, enabling $MLD tokens with strong value capture capabilities.
Our point system tracks your deposits and borrowings, allowing us to allocate airdrop rewards based on the points you accumulate. The more you engage with Molend, the more rewards you can earn!
In the future, Molend will explore additional gameplay and features while partnering with more blockchain networks and ecosystems. Stay tuned for updates!
**About Molend**
Molend is the next-generation lending protocol built on the Ethereum Layer 2 blockchain, Mode Network. Depositors earn passive income by providing liquidity, while borrowers access assets through over-collateralization. Powered by Mode, Molend ensures secure lending with transparent governance. Join Molend to be part of the decentralized lending revolution and unlock a world of possibilities in the Mode and Superchain ecosystem.
**Stay Connected**
[Twitter](https://twitter.com/MolendProtocol) | [Discord](https://discord.gg/eGRSCv98) | [Telegram](http://t.me/molend_protocol) | [Medium](https://medium.com/@molend) | modenetwork | |
1,864,055 | If Error Messages Were Honest (and Cats) | We’ve all been there... Staring at the screen, deciphering cryptic error messages that seem designed... | 27,390 | 2024-05-24T14:59:02 | https://dev.to/buildwebcrumbs/if-error-messages-were-honest-and-cats-56ea | jokes, watercooler, webdev, development |
We’ve all been there... Staring at the screen, deciphering cryptic error messages that seem designed more to confuse than to inform.
But what if, instead of cryptic text, error messages just told us what was really going on?
Let’s dive into a world where error messages are not only helpful but also honest.
[Cat images from http.cat](https://http.cat/)
---
## 404 Not Found
**Look, I’ve searched high and low and I can’t find this page. Are you sure it ever existed?**
This error might as well be telling you that the page has packed up its bags and moved to a remote island. It’s a reminder of the ghost towns in the digital world—places that were once populated but now exist only in memory (or not at all).

---
## 500 Internal Server Error
**Something broke, and it’s definitely not your fault this time. But it’s still a mystery to all of us.**
Imagine if your car just stopped working and the mechanic shrugged and said, “It’s broken.” That’s your 500 error—unhelpful and a bit mysterious, leaving everyone involved a bit perplexed.

---
{% cta https://github.com/webcrumbs-community/webcrumbs %} ⭐ Would you consider giving us a Star on GitHub?⭐
{% endcta %}
---
## 403 Forbidden
**You shall not pass! No, seriously, you don’t have permission to be here.;**
It’s like getting turned away at the door of an exclusive club. You know there’s something awesome on the other side, but you just can’t get in.

---
## Syntax Error
**You missed a semicolon on line 237. Seriously, a semicolon!?**
It’s the programming equivalent of tripping over your own shoelaces. A tiny punctuation mark can be the downfall of an entire script. And it happens ALL THE TIME.
---
## Timeout Error
**I waited and waited, but this is taking forever. I’ve got other things to do!**
This is the digital version of waiting in line at the post office. It’s taking too long, and your patience has run out.
---
{% cta https://github.com/webcrumbs-community/webcrumbs %} ⭐ Would you consider giving us a Star on GitHub?⭐
{% endcta %}
---
## Out of Memory Error
**I’m stuffed. Can’t fit anything more in here, so stop trying.**
Picture a suitcase so full that you can’t squeeze in another sock. That’s your computer on a memory overload.
---
## Got a favorite ‘honest’ error message?
If error messages really spoke to us this way, maybe we’d get a few more laughs out of our programming blunders (And things done faster, maybe?).
Share your favorite in the comments below!
Let’s find some humor in our coding misadventures.
**Thanks for reading,**
Pachi 💚
{% cta https://github.com/webcrumbs-community/webcrumbs %} ⭐ Would you consider giving us a Star on GitHub?⭐
{% endcta %} | pachicodes |
1,863,544 | AWS SnapStart - Part 21 Measuring cold starts and deployment time with Java 17 using different compilation options | Introduction In the previous parts we've done many measurements with AWS Lambda using Java... | 24,979 | 2024-05-24T14:57:44 | https://dev.to/aws-builders/aws-snapstart-part-21-measuring-cold-starts-and-deployment-time-with-java-17-using-different-compilation-options-o14 | aws, java, serverless, coldstart | ## Introduction
In the previous parts we've done many measurements with AWS Lambda using Java 17 runtime with and without using AWS SnapStart and additionally using SnapStart and priming DynamoDB invocation :
- cold starts using [different deployment artifact sizes]( https://dev.to/aws-builders/aws-snapstart-part-18-measuring-cold-starts-with-java-17-using-different-deployment-artifact-sizes-5092)
- cold starts and deployment time using [different Lambda memory settings ]( https://dev.to/aws-builders/aws-snapstart-part-19-measuring-cold-starts-and-deployment-time-with-java-17-using-different-lambda-memory-settings-30ml)
- warm starts [using different Lambda memory settings](https://dev.to/aws-builders/aws-snapstart-part-20-measuring-warm-starts-with-java-17-using-different-lambda-memory-settings-1p7j)
We've done all those measurements using the following JAVA_TOOL_OPTIONS: "-XX:+TieredCompilation -XX:TieredStopAtLevel=1" defined in the AWS SAM template.yaml. This means that client compilation (c1) without profiling will be applied. It was considered the best choice due to the article [Optimizing AWS Lambda function performance for Java](https://aws.amazon.com/de/blogs/compute/optimizing-aws-lambda-function-performance-for-java/) by Mark Sailes. But all these measurements have been done for Java 11 and before Lambda SnapStart has been released. So now it's time to revisit this topic and measure cold and warm start times with different Java compilation options without SnapStart enabled, with SnapStart enabled (and additionally with priming). In this article we'll do it for Java 17 runtime and will compare it with the same measurements for Java 21 already performed in the article [Measuring cold and warm starts with Java 21 using different compilation options]( https://dev.to/aws-builders/aws-snapstart-part-14-measuring-cold-and-warm-starts-with-java-21-using-different-compilation-options-el4)
## Meaning of Java compilation options
This picture shows Java compilation available.

If you don't specify any options, the default one applied for will be tiered compilation. You can read more about it in this article [Tiered Compilation in JVM](https://www.baeldung.com/jvm-tiered-compilation) or generally about client (C1) and server (C2) compilation in the article [Client, Server, and Tiered Compilation](https://dzone.com/articles/client-server-and-tiered-compilation). There are also many other settings so you can apply to each of the compilation options. You can read more about them in this article [JVM c1, c2 compiler thread – high CPU consumption?](https://blog.fastthread.io/2022/05/26/jvm-c1-c2-compiler-thread-high-cpu-consumption/)
## Measuring cold starts and deployment time with Java 17 using different compilation options
In our experiment we'll re-use the application introduced in [part 8]( https://dev.to/aws-builders/measuring-lambda-cold-starts-with-aws-snapstart-part-8-measuring-with-java-17-21db) for this. Here is the code for the [sample application](https://github.com/Vadym79/AWSLambdaJavaSnapStart/tree/main/pure-lambda-17). There are basically 2 Lambda functions which both respond to the API Gateway requests and retrieve product by id received from the API Gateway from DynamoDB. One Lambda function GetProductByIdWithPureJava17Lambda can be used with and without SnapStart and the second one GetProductByIdWithPureJava17LambdaAndPriming uses SnapStart and DynamoDB request invocation priming.
The results of the experiment below were based on reproducing more than 100 cold and approximately 100.000 warm starts. For it (and experiments from my previous article) I used the load test tool [hey](https://github.com/rakyll/hey), but you can use whatever tool you want, like [Serverless-artillery](https://www.npmjs.com/package/serverless-artillery) or [Postman](https://www.postman.com/). I ran all these experiments with 5 different compilation options defined in the [template.yaml](https://github.com/Vadym79/AWSLambdaJavaSnapStart/blob/main/pure-lambda-17/template.yaml). This happens in the Globals section where variable named "JAVA_TOOL_OPTIONS" is defined in the Environment section of the Lambda function:
```
Globals:
Function:
CodeUri: target/aws-pure-lambda-snap-start-17-1.0.0-SNAPSHOT.jar
Runtime: java21
....
Environment:
Variables:
JAVA_TOOL_OPTIONS: "-XX:+TieredCompilation -XX:TieredStopAtLevel=1"
```
1. no options (tiered compilation will take place)
2. JAVA_TOOL_OPTIONS: "-XX:+TieredCompilation -XX:TieredStopAtLevel=1" (client/C1 compilation without profiling)
3. JAVA_TOOL_OPTIONS: "-XX:+TieredCompilation -XX:TieredStopAtLevel=2" (client/C1 compilation with basic profiling)
4. JAVA_TOOL_OPTIONS: "-XX:+TieredCompilation -XX:TieredStopAtLevel=3" (client/C1 compilation with full profiling)
5. JAVA_TOOL_OPTIONS: "-XX:+TieredCompilation -XX:TieredStopAtLevel=4" (server/C2 compilation)
For their meaning see our explanations above. We will refer to those compilation options in the table column "Compilation Option" by their number in the tables below, for example number 5 stays for JAVA_TOOL_OPTIONS: "-XX:+TieredCompilation -XX:TieredStopAtLevel=4". Abbreviation **c** is for the cold start and **w** is for the warm start.
**Cold (c) and warm (w) start times without SnapStart in ms:**
|Compilation Option| c p50 | c p75 | c p90 |c p99 | c p99.9| c max |w p50 | w p75 | w p90 |w p99 | w p99.9 | w max |
|-----------|----------|-----------|----------|----------|----------|----------|-----------|----------|----------|----------|----------|----------|
|1|2831.33|2924.85|2950.12|3120.34|3257.03|3386.67|5.73|6.50|7.88|20.49|49.62|1355.08|
|2|2880.53|2918.79|2974.45|3337.29|3515.86|3651.65|6.11|7.05|8.94|23.54|62.99|1272.96|
|3|2906.39|2950.59|3016.8|3283.31|3409.65|3593.65|5.73|6.61|7.87|21.07|53.74|1548.95|
|4|3247.9|3348.82|3481.41|3673.51|3798.97|3904.13|6.72|7.75|9.38|24.69|72.67|1494.98|
|5|4146.66|4231.9|4377.42|4557.21|4699.03|4780.63|6.11|7.27|10.15|29.87|103.03|2062.84|
**Cold (c) and warm (w) start times with SnapStart without Priming in ms:**
|Compilation Option| c p50 | c p75 | c p90 |c p99 | c p99.9| c max |w p50 | w p75 | w p90 |w p99 | w p99.9 | w max |
|-----------|----------|-----------|----------|----------|----------|----------|-----------|----------|----------|----------|----------|----------|
|1|1506.20|1577.06|1845.01|2010.62|2280.46|2281|5.82|6.72|8.39|22.81|798.46|1377.54|
|2|1521.33|1578.64|1918.35|2113.65|2115.77|2117.42|6.01|7.05|8.94|23.92|101.41|1077.45|
|3|1463.16|1532.00|1886.03|1990.62|2020.69|2021.39|5.92|6.72|8.00|22.09|95.17|1179.13|
|4|1657.88|1755.07|2057.37|2158.49|2169.30|2170.65|6.41|7.27|8.80|24.30|96.69|1374.43|
|5|2269.10|2340.50|2581.36|2762.91|2807.45|2808.89|6.41|7.75|11.34|32.86|1506.60|1941.26|
**Cold (c) and warm (w) start times with SnapStart and with DynamoDB invocation Priming in ms:**
|Compilation Option| c p50 | c p75 | c p90 |c p99 | c p99.9| c max |w p50 | w p75 | w p90 |w p99 | w p99.9 | w max |
|-----------|----------|-----------|----------|----------|----------|----------|-----------|----------|----------|----------|----------|----------|
|1|708.90|790.50|960.61|1041.61|1148.80|1149.91|5.64|6.61|8.38|21.07|141.53|373.37|
|2|692.79|758.00|1003.80|1204.06|1216.15|1216.88|6.21|7.27|9.38|25.09|103.03|256.65|
|3|670.98|720.33|1007.82|1072.25|1200.45|1200.64|5.38|6.11|7.27|19.15|99.81|303.52|
|4|732.99|828.88|1030.07|1271.24|1350.41|1390.03|6.30|7.05|8.52|23.17|103.03|469.45|
|5|937.84|1056.29|1227.14|1422.78|1445.72|1447.09|6.30|7.75|11.16|32.86|122.69|381.03|
## Conclusions
For all measurements for Java 17 we discovered that setting compilation options -XX:+TieredCompilation -XX:TieredStopAtLevel= 3 or 4 produced much worse cold and warm starts as the tiered compilation or -XX:TieredStopAtLevel=1 and 2 (client compilation without or with basic profling). With Java 21 we observed much worse cold and warm starts also starting with -XX:TieredStopAtLevel=2 which is not the case for Java 17.
For the Lambda function with Java 17 without SnapStart enabled tiered compilation (default one) is a better option for having lower cold and warm starts for nearly all percentiles for our use case
For the Lambda function with Java 21 without SnapStart enabled it’s different see my article [Measuring cold and warm starts with Java 21 using different compilation options]( https://dev.to/aws-builders/aws-snapstart-part-14-measuring-cold-and-warm-starts-with-java-21-using-different-compilation-options-el4) : client compilation without profiling (-XX:+TieredCompilation -XX:TieredStopAtLevel=1 ) is the better option for having lower cold and warm starts for nearly all percentiles for our use case.
For the Lambda function with Java 17 with SnapStart enabled (with priming of DynamoDB invocation or without priming) the tiered compilation or -XX:TieredStopAtLevel=1 and 2 produced very close cold and warm starts which vary a bit depending on the compilation option and percentile.
For the Lambda function with Java 21 with SnapStart enabled (with priming of DynamoDB invocation or without priming) it was different: tiered compilation (the default one) outperformed the client compilation without profiling (-XX:+TieredCompilation -XX:TieredStopAtLevel=1 ) in terms of the lower cold start time and also for the warm start time for nearly all percentiles for our use case.
So please review/re-measure the cold and warm start times for your use case if you use Java 17, as tiered compilation can be a better choice if you enable SnapStart for your Lambda function(s). In our case we didn't use any framework like Spring Boot, Micronaut or Quarkus which may also impact the measurements. | vkazulkin |
1,862,617 | What is your cloud data backup strategy ? | Did any of you think about how will we respond to a situation if our entire business data got wiped... | 0 | 2024-05-24T14:57:14 | https://dev.to/nirmalkumar/what-is-your-cloud-data-backup-strategy--5a39 | cloud, databackup, systemdesign, clouddata | Did any of you think about how will we respond to a situation if our entire business data got wiped out from cloud data center?
What's our Plan B in such cases ? Are we really prepared and ready to face it ?
Everyone has to revisit cloud backup strategy for worst case scenarios. Do you know that recently an incident happened in Google Cloud that it mistakenly wiped off an entire client's private workspace including the client's entire data backup because of a misconfiguration. Client's business data worth is ~ 125billion.
Article : [reference](https://www.yahoo.com/tech/google-accidentally-deleted-125-billion-183502623.html)
How did they recover ? Luckily this client had backup's backup in a different cloud vendor / data center using which they came back online. It took them a week.
If we don't have a clear data backup strategy defined, then it's crystal clear that our business is simply sitting on a bomb waiting to explode.

Below are my strategic thought regarding data backup. Feel free to enter yours for safe business in the comment below,
Rigorous data backup can be done based on below strategies.
* Clear data classification of every application and its data. Ex: public, internal, classified, restricted.
* Clear communication with users and documentation about backup strategies and direction from leadership team.
* Optimize backup strategy based on
1. data retention policy,
2. how frequent we might access,
3. how frequent we update or read it back,
4. Backup data center geographic location,
5. Data backup storage disk type (hardware),
6. Backup storage size
* Data-at-rest encryption plays a vital role with data security.
* Optimize data retrieval plan based on data classification and carefully evaluate business impact when needed.
* Real time monitoring, reports and alerts on data backup jobs. * How often are we doing the backup and how often are we deleting the backup based on retention policy ? This is a deep question.
* Thorough review and sign off on the deleted data reports by corresponding application owners.
* Data backup cost comparison between cloud vendor vs on-prem data center will give practical ideas and ways to optimize data backup plan.
* Regular planned switch over to Disaster recovery environment data center and allow the application to run on it for few months will give practical experience to entire engineers to have a safe environment to practice what should be done during actual production failure major scenarios.
* Data backup access control plan and clear segregation of duties will safeguard from many manual errors. | nirmalkumar |
1,864,084 | Killa | Nikotiinipussit, tunnetaan myös nimellä denssit nikotiinipussit, ovat saavuttaneet suurta suosiota... | 0 | 2024-05-24T14:53:46 | https://dev.to/fidenssit06/killa-1a4k | Nikotiinipussit, tunnetaan myös nimellä denssit nikotiinipussit, ovat saavuttaneet suurta suosiota tupakoinnin ja perinteisen nuuskan korvaajana. Näiden pienikokoisten pussien ansiosta nikotiinin käyttö on mahdollista ilman tupakoinnin tai nuuskan haittoja. Tämä artikkeli tutustuu nikotiinipussien maailmaan, keskittyen erityisesti merkkeihin kuten Denssi ja Killa, sekä niiden etuihin ja käyttöön.
Mikä ovat Denssit Nikotiinipussit?
Denssit nikotiinipussit ovat pieniä pusseja, jotka sisältävät nikotiinia, makuaineita ja muita ainesosia. Ne asetetaan ylähuulen alle, jossa nikotiini imeytyy ikenen kautta. Näin nikotiinia saadaan ilman savua, tuhkaa tai sylkeä.
Nikotiinipussien suosio on kasvanut nopeasti niiden monien etujen ansiosta:
Terveellisempi Vaihtoehto: Nikotiinipussit ovat savuttomia ja tupakattomia, mikä vähentää altistumista tupakan savun haitallisille aineille.
Käytön Helppous: Ne ovat huomaamattomia ja helppokäyttöisiä, eivätkä vaadi erityisiä valmisteluja.
Monipuolisuus: Tarjolla on laaja valikoima makuja ja nikotiinipitoisuuksia, mikä mahdollistaa yksilöllisten mieltymysten mukaan valitsemisen.
Suositut Merkit: Denssi ja Killa
Nikotiinipussimarkkinoilla Denssi ja Killa ovat tunnettuja ja suosittuja merkkejä, jotka erottuvat laadullaan ja monipuolisuudellaan.
Denssi
Denssi on merkki, joka tarjoaa laajan valikoiman nikotiinipusseja. Heidän tuotteensa ovat tunnettuja korkealaatuisista ainesosistaan ja tasaisesta nikotiinin vapautumisesta. Denssi-pussit ovat saatavilla eri makuina, kuten minttu, marja ja sitrus, tarjoten käyttäjille monipuolisen ja nautinnollisen kokemuksen. Brändi keskittyy tuottamaan miellyttävän nikotiinihitin ilman perinteisen nuuskan karvautta.
**_[Killa](https://denssit.fi/)_**
Killa on toinen johtava brändi, joka on tunnettu voimakkaasta nikotiinipitoisuudestaan ja rohkeista mauistaan. Killa-pussit on suunniteltu kokeneille käyttäjille, jotka kaipaavat intensiivisempää nikotiinikokemusta. Merkin valikoimaan kuuluvat maut, kuten vesimeloni, kola ja mustikka, houkuttelevat käyttäjiä, jotka etsivät maukasta ja voimakasta nikotiinielämystä. Killan sitoutuminen laatuun ja innovaatioihin on tehnyt siitä suositun valinnan nikotiinipussien käyttäjien keskuudessa.
Nikotiinipussien Hyödyt
Nikotiinipussit tarjoavat useita etuja verrattuna perinteisiin tupakka- ja nuuskatuotteisiin:
Terveellisempi Vaihtoehto: Ilman tupakkaa nikotiinipussit vähentävät riskiä sairastua tupakointiin liittyviin sairauksiin, kuten keuhkosyöpään ja sydänsairauksiin.
Huomaamaton Käyttö: Pussit voidaan käyttää huomaamattomasti julkisilla paikoilla, koska ne eivät tuota savua tai sylkeä.
Ei Savua, Ei Hajua: Nikotiinipussit eivät tuota savua tai jätä jälkeensä epämiellyttävää hajua, mikä tekee niistä sosiaalisesti hyväksyttävämmän vaihtoehdon.
Monipuoliset Maut: Laaja valikoima makuja vastaa erilaisiin makumieltymyksiin ja tekee nikotiinin käytöstä miellyttävämpää.
Käyttö ja Turvallisuus
Nikotiinipussien käyttö on yksinkertaista. Pussi asetetaan ylähuulen alle ja jätetään sinne noin 20-60 minuutiksi. Nikotiini imeytyy ikenen kautta, mikä tarjoaa hallitun ja tasaisen nikotiinivapautuksen.
Vaikka nikotiinipussit ovat terveellisempi vaihtoehto tupakoinnille, ne eivät ole täysin riskittömiä. Nikotiini on riippuvuutta aiheuttava aine, ja liiallinen käyttö voi johtaa riippuvuuteen. Käyttäjien tulee noudattaa suositeltuja annosteluohjeita ja olla tietoisia kulutustasoistaan.
Markkinoiden Dynamiikka
Nikotiinipussien markkinat ovat kasvaneet nopeasti, mikä johtuu lisääntyneestä tietoisuudesta tupakoinnin terveysriskeistä ja vähemmän haitallisten vaihtoehtojen kysynnästä. Pohjoismaissa ja osissa Eurooppaa nikotiinipusseista on tullut valtavirtaa, ja tarjolla on monia eri merkkejä ja makuja.
Yritykset jatkavat innovointia parantaakseen tuotteidensa laatua ja monipuolisuutta. Kilpailu markkinoilla ajaa alaa eteenpäin, varmistaen, että kuluttajilla on pääsy korkealaatuisiin ja miellyttäviin nikotiinivaihtoehtoihin. Sääntelyviranomaiset ovat myös tärkeässä roolissa markkinoiden muokkaamisessa, varmistaen, että tuotteet täyttävät turvallisuusstandardit ja että niitä markkinoidaan vastuullisesti.
Johtopäätös
Nikotiinipussit, kuten Denssi ja Killa, tarjoavat modernin ja vähemmän haitallisen tavan käyttää nikotiinia. Niiden kätevyys, monipuolisuus ja vähäisemmät terveysriskit verrattuna perinteisiin tupakkatuotteisiin tekevät niistä yhä suositumman valinnan monille nikotiinin käyttäjille. Kuitenkin, kuten minkä tahansa nikotiinituotteen kohdalla, on tärkeää käyttää niitä kohtuudella ja varovaisuudella riippuvuuden välttämiseksi. Nikotiinipussien tulevaisuus näyttää lupaavalta, ja jatkuva innovointi ja markkinoiden kasvu vastaavat yhä useamman kuluttajan tarpeisiin. | fidenssit06 | |
1,861,344 | peviitor.ro pe LinkedIn | LinkedIn este aplicația care sprijină inițiativa găsirii unui loc de muncă. Deoarece... | 0 | 2024-05-24T14:47:21 | https://dev.to/ale23yfm/peviitorro-pe-linkedin-a6k | peviitor, linkedin, comunity | LinkedIn este aplicația care sprijină inițiativa găsirii unui loc de muncă. Deoarece https://peviitor.ro/ este un motor de căutare a joburilor din România, LinkedIn este aplicația favorabilă promovării proiectului peviitor.ro. Mai exact, proiectul este răspunsul la problema din piața muncii.
[Pagina LinkedIn](https://www.linkedin.com/company/79546761/admin/feed/posts/)
---
În plus, platforma LinkedIn este folosită de voluntari să își publice experiența acumulată în cadrul asociației.

---
| ale23yfm |
1,864,082 | Ready to Build dApps? Explore the Possibilities of EVM-Compatible Blockchains | When we hear or read something about EVM, many questions arise, including what it is and what it is... | 0 | 2024-05-24T14:46:20 | https://dev.to/shevchukkk/ready-to-build-dapps-explore-the-possibilities-of-evm-compatible-blockchains-2flp | security, cryptocurrency | ##

When we hear or read something about EVM, many questions arise, including what it is and what it is for? In other words, it is a kind of platform for a secure blockchain-based coding process. The Ethereum network is the foundation for using the EVM virtual machine and is one of the key innovations. Today, there are a number of EVM-compatible blockchain networks that expand the horizons of decentralized technologies, offering users a wide range of choices and opportunities. Blockchains such as [Polygon](https://polygonscan.com/), [Avalanche](https://www.avax.network/), and [Fantom](https://fantom.foundation/) combine EVM compatibility with unique features and benefits, making them attractive for a variety of developer and user needs.
**More about Ethereum Virtual Machine compatible blockchains**
The Ethereum Virtual Machine (EVM) is a virtual computer that underpins the Ethereum blockchain. It provides an environment for processes related to the execution of smart contracts stored on the blockchain. The EVM ensures the secure and decentralized execution of these contracts, making Ethereum a powerful platform for decentralized applications (dApps). The advantages of EVM-compatible blockchains are the speed of transactions, lower fees, which are beneficial for large-scale applications, and a wide range of options for creating dApps and storing crypto. According to [Shardeum.org](http://Shardeum.org), there are many EVM-compatible blockchains, including Avalanche, Fantom, Shardeum, and others.
**[Avalanche (AVAX)](https://www.avax.network/)**
Avalanche is another powerful blockchain platform that stands out for its lightning-fast transaction speed, low fees, and scalability. Its unique consensus protocol ensures fast transaction confirmation without compromising security.
Designed to support a wide range of decentralized applications (dApps) and special blockchain networks, Avalanche is known for its compatibility and flexible infrastructure. These qualities make it a favorite in areas such as DeFi, gaming, and enterprise blockchain solutions. Avalanche allows for the creation of multiple subnets, enabling different blockchains to coexist and interact within the ecosystem. The emphasis on speed and reliability eliminates many of the common problems faced by other blockchain networks. Companies like [KKR](https://www.kkr.com/), [Deloitte](https://www.deloitte.com/global/en.html), and [MasterCard](https://www.mastercard.us/en-us.html) are already using Avalanche for their operations.
[Fantom (FTM)](https://fantom.foundation/)
Fantom is another EVM-compatible blockchain that seeks to address the problems of scalability and efficiency. Fantom uses a consensus mechanism called Lachesis, which provides near-instantaneous transaction completion, making it ideal for DeFi and other applications. Its structure not only supports smart contracts but also ensures Ethereum compatibility, allowing developers to seamlessly port their applications and leverage the growing Ethereum ecosystem, as does the [Hacken](https://hacken.io/audits/) audit project and [Verichains](https://www.verichains.io/), a world-class security guarantor.
[Shardeum (SHM)](https://shardeum.org/)
Shardeum is an innovative layer-1 blockchain designed to address three key challenges: scalability, decentralization, and security. Through dynamic state sharding, Shardeum can process a high volume of transactions with low gas fees. This unique technology makes Shardeum the first smart contract platform where TPS (transactions per second) grows proportionally with the number of nodes. The platform can dynamically expand or contract based on network load, providing both linear and automatic scaling without compromising transaction speed. Shardeum strives to become the foundation for Web3, offering a decentralized user interface (UX) that rivals, if not surpasses, its centralized counterparts. The platform has the potential to accelerate the mass adoption of decentralized technologies and open up new possibilities for people around the world. Some of the most well-known Shardeum projects include the new gaming metaverse [Zuraverse](https://zuraverse.xyz/), the P2P file-sharing protocol [FileMarket](https://filemarket.xyz/), and the Web3 gaming platform [FusionwaveAI](https://www.fusionwaveai.com/).
**[Aurora (AURORA)](https://aurora.dev/ecosystem)**
Aurora is another interesting blockchain and ecosystem that is also EVM-compatible. It works as a layer 2 blockchain protocol on [NEAR](https://near.org/). Its EVM compatibility makes it an attractive platform for developers familiar with Ethereum. One of the features of Near Protocol is its internal structural scaling solution, Nightshade. Thanks to Nightshade, Near Protocol can handle a large volume of transactions with low fees while maintaining a high level of decentralization and security. The [Aurora Cloud](https://aurora.dev/blog/aurora-cloud-console-goes-live) special development expands Aurora's capabilities, allowing multiple instances of the EVM (Ethereum Virtual Machine) to be deployed on NEAR. These instances, known as Aurora Chains, are united into a network that dynamically interacts thanks to XCC (cross-contract calls) on the NEAR base layer.
**This can be represented schematically:**
source: [doc.aurora.dev](https://doc.aurora.dev/)
Aurora is relevant for many cryptocurrency exchange transactions and uses ETH as the base currency for transactions. Additionally, the ecosystem is compatible with a wide range of Ethereum ecosystem tools, such as [MetaMask](https://metamask.io/), [Foundry](https://www.foundry.com/), [Truffle](https://archive.trufflesuite.com/), [Hardhat](https://hardhat.org/), and [Remix](https://remix.run/). Aurora is available on many cryptocurrency exchanges, including [MEXC](https://www.mexc.com/), [BingX](https://bingx.pro/en-us/), and [WhiteBIT](https://whitebit.com/).
Current price on 05/24
Source: [WhiteBIT Trading View](https://whitebit.com/ua/trade/AURORA-USDT?type=spot&tab=open-orders&fullscreen=true)
**Conclusion**
The blockchain landscape is rapidly evolving, with new players emerging and introducing innovative solutions that expand the realm of possibilities. Among these advancements, EVM (Ethereum Virtual Machine)-compatible blockchains stand out as a transformative trend, marking a significant leap forward in this technological revolution.
These blockchains, in essence, are modern interpretations of Ethereum technology, maintaining compatibility with its thriving ecosystem while simultaneously introducing a range of enhancements and unique capabilities. This opens up a world of possibilities for developers and users alike, seamlessly blending the familiarity of Ethereum with the advantages of a new frontier.
| shevchukkk |
1,864,081 | SPRING DRIVING SAFETY TIPS | As the days get warmer and longer, the spring weather can bring some vehicle challenges, from... | 0 | 2024-05-24T14:44:07 | https://dev.to/londonjaguarcanada/spring-driving-safety-tips-j6o | ai | As the days get warmer and longer, the spring weather can bring some vehicle challenges, from unpredictable weather to after-winter car maintenance. At Jaguar London, we care about your vehicle's performance and safety. Here are our Jaguar safety tips for maintaining your vehicle this spring.

**CHECK FLUID LEVELS**
Spring is a great time to check your vehicle's fluid level, including your Jaguar's engine oil, transmission fluid, brake fluid, and coolant. All of these fluids are important for your vehicle's overall performance and safety. Regularly checking and replacing your vehicle's fluids will help to prevent any mechanical failures in your Jaguar.
**INSPECT YOUR SUSPENSION SYSTEM**
The cold winter weather can be harsh on your vehicle's suspension system. Even potholes and rough road conditions can cause your suspension to compromise the integrity of your vehicle. Schedule your next service appointment at Jaguar London, and our technicians can thoroughly inspect your vehicle's suspension.
**SWAP YOUR TIRES FOR SUMMER TIRES**
Summer tires are designed for warmer weather and deliver better grip and handling on wet or dry roads. That is why changing your winter tires to summer for better handling and safety while driving in the spring is important.
**CAR DETAILING FOR A FRESH START**
Spring cleaning isn't just for your home. Treat your Jaguar to professional car detailing at Jaguar London. Our detailing services restore your vehicle's aesthetic appeal and protect its exterior and interior from the elements, ensuring it looks and feels as luxurious as the day you first drove it.
**EMBRACE SPRING WITH CONFIDENCE**
By adhering to these spring safety tips, you can ensure your Jaguar remains a reliable and exhilarating companion for all your spring adventures. Whether swapping to summer tires, undergoing a mechanical service, checking fluid levels, inspecting the suspension, or opting for car detailing, Jaguar London is here to meet all your needs with expertise and care.
**CONTACT US**
Ready to prepare your Jaguar for spring? Book your Spring service appointment at Jaguar London, your premier Jaguar dealership. Our certified technicians are equipped to provide exceptional care for your vehicle. **[Contact us](https://www.londonjaguar.ca/contactus.html)** today at Jaguar London. Your safety and satisfaction are our top priorities.
**Source- [https://www.londonjaguar.ca/spring-driving-safety-tips.html](https://www.londonjaguar.ca/spring-driving-safety-tips.html)**
| londonjaguarcanada |
1,864,080 | Working hard or hardly working? | A post by OpenSource | 0 | 2024-05-24T14:42:58 | https://dev.to/opensourcee/working-hard-or-hardly-working-4o43 | watercooler, discuss, jokes, madewithai |
 | opensourcee |
1,864,079 | The Best 9 Microsoft Project Tips for Beginners | Microsoft Project is a powerful tool used for project management across a range of industries. It... | 0 | 2024-05-24T14:42:06 | https://dev.to/soraespinobarrientos/the-best-9-microsoft-project-tips-for-beginners-38mp | microsoftproject, msproject, tips | Microsoft Project is a powerful tool used for project management across a range of industries. It provides an extensive suite of features for planning, tracking, and managing projects. However, for beginners, it can be somewhat daunting to navigate. This guide aims to ease that transition by providing practical tips to help you get the most out of Microsoft Project. Whether you're looking to manage tasks more effectively or leverage advanced features, these tips will set you on the right path.
## 1. How to Open MPP Files Without Microsoft Project
One of the first challenges you might face is opening MPP files if you don't have Microsoft Project installed. Fortunately, there are several alternatives:
[GanttPRO](https://ganttpro.com/free-online-microsoft-mpp-project-viewer/): Online project management software that allows you to import and has a simple MPP file viewer. It offers a user-friendly interface and essential features to manage your project.
Project Viewer Central: This tool allows you to view MPP files without needing the full Microsoft Project software. It’s user-friendly and supports various versions of MPP files.
MOOS Project Viewer: A versatile option that is compatible with Windows, Mac, and Linux. It enables you to open, view, and print MPP files.
GanttProject: An open-source project management tool that can import MPP files. While it might not support every feature of Microsoft Project, it’s a good starting point.
LibreProject: A free, open-source alternative that supports viewing and editing MPP files.
Using these tools can help you view and share project files without needing to invest in the full Microsoft Project suite immediately.
## 2. Familiarize Yourself with the Ribbon Interface
The ribbon interface in Microsoft Project is central to navigating the software effectively. It organizes commands into tabs, making it easier to find and use features. Spend some time exploring the different tabs such as Task, Resource, Report, and View.
**Task Tab**: This is where you'll manage tasks, set dependencies, and update progress.
**Resource Tab**: Here, you can allocate resources, track their workload, and manage costs.
**Report Tab**: Use this to create and customize reports to share with stakeholders.
**View Tab**: Switch between different views like Gantt Chart, Task Usage, and Resource Sheet to get various perspectives on your project.
Understanding the ribbon interface will significantly improve your efficiency in navigating the software.
## 3. Create a New Project from a Template
Starting a project from scratch can be overwhelming. Microsoft Project offers a range of templates that can provide a solid foundation for your project. To create a [new project from a template](https://support.microsoft.com/en-us/office/create-a-new-project-from-another-project-or-template-ff744d82-cc60-4ca3-9a18-0df696bf71e1):
1. Go to **File > New**.
2. Browse through the available templates and select one that closely matches your project type.
3. Customize the template to suit your specific project requirements.
Using templates saves time and ensures you don’t overlook important components of your project plan.
## 4. Set Up Your Project Calendar
A well-defined project calendar is crucial for accurate scheduling. To set up your project calendar:
1. Go to **Project > Change Working Time**.
2. Define your working days and hours. This includes setting up holidays and non-working days.
3. Choose a base calendar (Standard, 24 Hours, or Night Shift) that matches your project needs.
Customizing your project calendar ensures that task schedules reflect actual working conditions, reducing the risk of delays.
## 5. Define Tasks and Milestones
Defining tasks and milestones is a core part of project planning. Here's how to do it effectively:
1. In the **Gantt Chart** view, enter your tasks in the Task Name column.
2. To add milestones, enter the task name and set the duration to 0 days. This will automatically mark it as a milestone.
3. Use the **Indent Task** button to create a hierarchy, organizing tasks into phases or work packages.
Clearly defined tasks and milestones help in tracking progress and ensuring project goals are met on time.
## 6. Set Dependencies Between Tasks
Dependencies define the relationships between tasks and ensure that they are completed in the correct order. To set dependencies:
1. Select the tasks you want to link.
2. Click the **Link Tasks** button in the Task tab or use the **Predecessors** column in the Gantt Chart view.
Understanding task dependencies helps in creating a realistic project timeline and identifying potential bottlenecks.
## 7. Assign Resources and Estimate Costs
Effective [resource management](https://en.wikipedia.org/wiki/Resource_management) is key to project success. To assign resources and estimate costs:
1. Go to the **Resource Sheet** view and enter details of your resources (people, equipment, materials).
2. Assign resources to tasks by selecting a task and using the Resource Names column in the Gantt Chart view.
3. Estimate costs by setting hourly rates or fixed costs for resources in the Resource Sheet.
Accurate resource allocation and cost estimation are crucial for staying within budget and avoiding resource over-allocation.
## 8. Utilize Baselines for Tracking Progress
A [baseline](https://uk.indeed.com/career-advice/career-development/project-baseline) is a snapshot of your project plan at a particular point in time. It allows you to compare the planned progress with the actual progress. To set a baseline:
1. Go to **Project > Set Baseline**.
2. Choose **Set Baseline** again and select the entire project or selected tasks.
Regularly comparing your project’s progress against the baseline helps in identifying deviations and taking corrective actions promptly.
## 9. Generate and Customize Reports
Reports are essential for communicating project status to stakeholders. Microsoft Project offers several built-in report templates. To generate and customize reports:
1. Go to the **Report** tab.
2. Choose a report category (e.g., Project Overview, Cost, Task, Resource).
3. Customize the report by adding or removing fields, changing chart types, and adjusting formatting.
Customized reports provide clear and concise information tailored to the needs of different stakeholders, ensuring better project communication and decision-making.
## Conclusion
Navigating Microsoft Project as a beginner can seem overwhelming due to its vast array of features and capabilities. However, with these nine tips, you can build a strong foundation for effectively managing your projects. From learning how to open MPP files without Microsoft Project to mastering the ribbon interface and utilizing templates, each tip is designed to simplify your project management process. By setting up your project calendar, defining tasks and milestones, establishing dependencies, assigning resources, and tracking progress with baselines, you’ll ensure your projects stay on track and within budget. Lastly, generating and customizing reports will help you communicate effectively with stakeholders and keep everyone informed of the project’s status.
As you continue to explore and use Microsoft Project, you'll discover more advanced features and techniques that can further enhance your project management skills. With practice and experience, you'll become proficient in using this powerful tool, leading to more efficient and successful project outcomes. Remember, the key to mastering Microsoft Project lies in continuous learning and application of the features that best suit your project needs. Happy project planning! | soraespinobarrientos |
1,864,078 | CI/CD Testing: What, Why, and How | Continuous Integration and Continuous Delivery (CI/CD) have become essential practices for... | 0 | 2024-05-24T14:40:12 | https://dev.to/devanshbhardwaj13/cicd-testing-what-why-and-how-hoh | cicd, testing, softwaredevelopment, programming |
Continuous Integration and Continuous Delivery (CI/CD) have become essential practices for organizations striving to stay competitive and deliver high-quality software to their users. CI/CD streamlines the software delivery process by automating tasks like integration, testing, and deployment, empowering development teams to collaborate effectively and release code changes faster with increased confidence.
This guide explores the significance of CI/CD, its key principles, best practices, and how it revolutionizes software development, enabling organizations to achieve greater efficiency, reliability, and customer satisfaction.
Let’s dive into the world of CI/CD and discover how it can transform your software delivery approach.
> Experience the best [mobile testing platform with real devices](https://www.lambdatest.com/real-device-cloud?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=webpage) for accurate results.
## What is CI/CD?
Continuous Integration and Continuous Delivery (CI/CD) are essential practices in modern software development. These processes involve regularly integrating code changes into the main branch, ensuring that it does not interfere with the work of other developers. The primary goal is to minimize defects and conflicts during the integration of the entire project. By adopting CI/CD, development teams can collaborate and deliver high-quality software with fewer disruptions and delays.
CI/CD is a crucial practice in modern software development as it promotes continuous improvement and faster delivery cycles. By automating the integration, testing, and deployment processes, CI/CD reduces manual errors, enhances collaboration between development and operations teams, and ensures a seamless flow of code changes from development to production.
## What is Continuous Integration(CI)?
Continuous Integration (CI) is a popular software development practice where developers collaborate to integrate code changes into a shared repository in real time. It creates a smooth teamwork environment, where any code modifications made by developers are instantly integrated into the existing codebase.
The main goal of Continuous Integration is to catch and address potential issues early in the development cycle. Automated tests are triggered during integration to ensure everything works smoothly and to detect any new bugs. This practice significantly contributes to maintaining high code quality, reducing the risk of errors, and ensuring the codebase remains consistently ready for release.
Continuous Integration not only enhances efficiency but also fosters collaboration among developers. It enables multiple team members to work on different parts of the code concurrently, alleviating concerns about conflicts. The [automation testing](https://www.lambdatest.com/automation-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=webpage) process provides rapid feedback, facilitating swift problem identification and resolution before they escalate into major challenges.
> [Test mobile applications on real devices](https://www.lambdatest.com/real-device-cloud?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=webpage) to ensure seamless performance.
## What is Continuous Delivery(CD)?
Continuous Delivery (CD) represents an advanced software development practice that builds upon the advantages of Continuous Integration (CI). Its primary focus is ensuring the software remains consistently deployable and ready for release into production at any given moment.
A fundamental principle of Continuous Delivery revolves around automating the entire release process, encompassing both staging and production deployments. By doing so, it drastically reduces the time and manual effort required to introduce new features and address bug fixes, thus delivering them to users more swiftly.
This effective practice encourages frequent and incremental releases, enabling development teams to respond promptly to market demands and user feedback. Additionally, it fosters a collaborative and streamlined approach between development and operations teams, further enhancing the overall [software development lifecycle](https://www.lambdatest.com/learning-hub/software-development-life-cycle?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=learning_hub).
## What is the difference between Continuous Integration(CI) and Continuous Delivery(CD)?
Here is the detailed difference between Continuous Integration and Continuous Delivery.
> Discover efficient [android device testing online](https://www.lambdatest.com/android-device-test?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=webpage) for your apps today.
## What is Continuous Deployment(CD)?
Continuous Deployment is an extension of Continuous Delivery (CD) within the software development process. It elevates the automation and efficiency of CD by automatically deploying code changes to production environments as soon as they pass all the automated tests in the CI/CD pipeline.
In the context of Continuous Deployment, each code change that successfully navigates through the CI/CD pipeline is promptly released to production without requiring manual intervention. Consequently, new features, bug fixes, and enhancements are continuously deployed and promptly made available to end-users in real time.
The principal distinction between Continuous Deployment and Continuous Delivery is eliminating a manual approval step for production deployment. While Continuous Delivery prepares the code for deployment, Continuous Deployment takes it a step further by executing it automatically.
This effective practice empowers software teams to swiftly deliver new features and updates, ensuring that the software is consistently up-to-date and users can access the latest enhancements without any delay.
## What is CI/CD in DevOps?
Continuous Integration, Continuous Delivery, and Continuous Deployment (CI/CD) represent vital practices within the domain of DevOps. DevOps, in essence, embodies a collaborative approach that unifies development and operations, striving for smooth cooperation and efficient software delivery.
DevOps encompasses an array of practices and tools designed to expedite application and service delivery, surpassing conventional methods. The heightened pace facilitated by DevOps enables organizations to serve their customers more effectively, thus maintaining a competitive edge in the market. In DevOps, security is integrated into all phases of development, known as DevSecOps.
The main idea of DevSecOps is to include security throughout the software development process. By doing security checks early and consistently, organizations can catch vulnerabilities quickly and make informed decisions about risks. Unlike older security practices, which only focus on production, DevSecOps ensures security is a part of the whole development process. This approach keeps up with the fast-paced DevOps style.
The CI/CD pipeline is a crucial part of the DevOps/DevSecOps framework. To make it work effectively, organizations need tools that prevent any slowdowns during integration and delivery. Teams need a set of integrated technologies that facilitate seamless collaboration and development efforts.
> Optimize your testing with [cloud android device](https://www.lambdatest.com/real-device-cloud?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=webpage) solutions.
## Continuous Integration vs. Continuous Delivery vs. Continuous Deployment
Here is the detailed difference between Continuous Integration, Continuous Delivery, and Continuous Deployment.
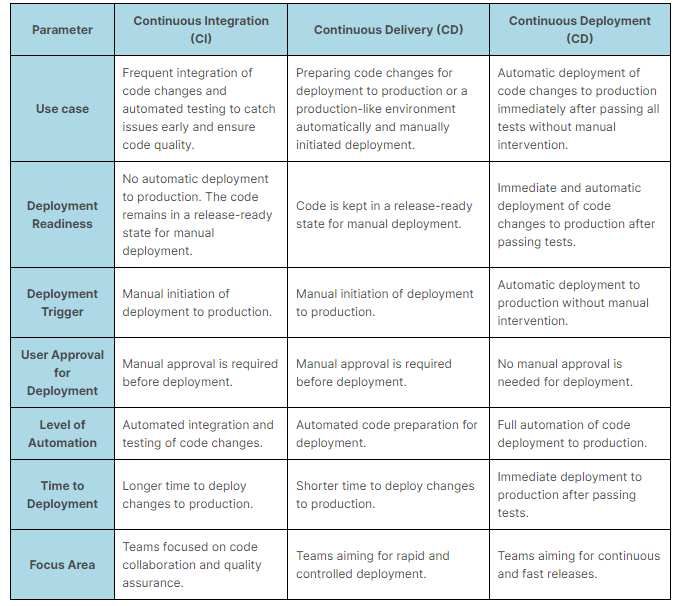
> Achieve reliable results with [cloud device testing](https://www.lambdatest.com/real-device-cloud?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=webpage) services.
## What are the benefits of CI/CD?
Continuous Integration and Continuous Deployment (CI/CD) offer numerous benefits to software development teams and organizations. Let’s explore some of the key advantages of implementing CI/CD practices:
* **Faster Time-to-Market:** CI/CD streamlines the software delivery process, enabling teams to release code changes faster and more frequently. This accelerated delivery cycle allows organizations to respond quickly to market demands, stay ahead of competitors, and deliver new features and bug fixes to users in a timely manner.
* **Early Issue Detection:** With CI, code changes are continuously integrated and automatically tested. Any issues or bugs are caught early in the development process, making it easier and less expensive to fix them before they escalate into larger problems.
* **Code Quality Improvement:** Automated testing in CI/CD ensures consistent and thorough validation of code changes. This helps maintain code quality and prevents the introduction of regressions, leading to a more stable and reliable software product.
* **Enhanced Collaboration:** CI/CD promotes collaboration among development and operations teams, fostering a culture of shared responsibility. Developers and operations professionals work together seamlessly to ensure smooth code integration, testing, and deployment.
* **Risk Reduction:** Continuous Deployment reduces the risk associated with manual deployment processes. By automating deployments and thoroughly testing code changes, CI/CD minimizes the chances of errors and outages in the production environment.
* **Increased Productivity:** CI/CD automates repetitive tasks such as testing and deployment, freeing up developers’ time to focus on coding and innovation. This increased productivity allows teams to deliver more value to users and the organization.
* **Faster Feedback Loop:** CI/CD provides fast and continuous feedback on code changes. Developers receive prompt notifications on test results, enabling them to address issues immediately and iterate quickly.
* **Greater Software Reliability:** The continuous and automated nature of CI/CD ensures that software remains in a reliable and deployable state. This reliability boosts user confidence and satisfaction with the application.
* **Scalability and Flexibility:** CI/CD practices are scalable and adaptable to various projects and environments. They can be tailored to meet the specific needs of each development team and project size.
* **Continuous Improvement:** CI/CD fosters a culture of continuous improvement by encouraging regular code integration, testing, and deployment. This iterative approach allows teams to learn from each release and continually enhance their processes and software.
CI/CD provides various benefits, significantly improving software development efficiency, code quality, and customer satisfaction. By automating key processes and fostering collaboration, CI/CD empowers organizations to deliver high-quality software faster and with greater confidence.
## What is build automation in DevOps?
Build automation in DevOps is a fundamental process that involves automating the compilation and creation of software builds from source code. This practice plays a vital role in Continuous Integration (CI), where code changes are regularly integrated into a shared repository and validated through automated testing.
To achieve build automation, developers leverage build tools and scripts that automate various steps, such as compiling source code, resolving dependencies, and generating executable or distributable artifacts. These artifacts typically include binaries, libraries, or packages that can be deployed to different environments, such as testing, staging, and production.
In the realm of software development, the automated build process is a critical checkpoint that incorporates multiple checks and assembles all necessary components, ensuring your program operates seamlessly. This applies even if you’re using an interpreted language. The results of this build stage are known as build artifacts.
Once the build artifacts are ready, they move through the CI/CD pipeline for additional testing and staging. If the build successfully passes each stage in the pipeline, it is considered ready for release to the live environment. This automated process ensures that your software is thoroughly tested and ready to be used by users confidently.
## Where do Automation Tests fit in CI/CD pipelines?
Having [CI/CD pipeline in automationt testing](https://www.lambdatest.com/blog/automation-testing-in-ci-cd-pipeline/?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=blog) is crucial in a CI/CD pipeline. Relying on a single test suite to cover all scenarios can slow down the process and be impractical as the product grows with more features and updates.
Here are the different types of tests and where they fit in the CI/CD pipelines:
* **Unit Tests:** [Unit tests](https://www.lambdatest.com/learning-hub/unit-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=learning_hub) are written by developers and are part of the build phase. They check small units of code in isolation to ensure they work correctly.
* **Integration Tests:** After every code commit, [integration tests](https://www.lambdatest.com/learning-hub/integration-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=learning_hub) run in the development environment to verify that newly added modules or changes work well together. Some organizations have a dedicated environment for running these tests.
* **Regression Tests:** [Regression testing](https://www.lambdatest.com/learning-hub/regression-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=learning_hub) ensure that newly added changes do not impact the existing code. They provide feedback to ensure the day’s work is error-free.
* **Performance and Load Tests:** Before releasing code to production, these tests assess the system’s responsiveness and stability. They are executed in the UAT/Pre-Production environment after code deployment at the end of the sprint.
Having these tests in the CI/CD pipeline is essential, and automation is the ideal approach. As the product evolves, the number of test cases increases significantly. Manual execution of all these tests would be impractical, making automation the only feasible way to run them with speed and accuracy. Automation ensures that the software is continuously tested and any issues are detected early, leading to faster and more reliable software delivery.
> Enhance your QA process using [cloud devices for testing](https://www.lambdatest.com/real-device-cloud?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=webpage).
## Importance of Test Automation for CI/CD
Test automation plays a pivotal role in the success of Continuous Integration and Continuous Deployment (CI/CD) practices. It is a critical component that ensures the efficiency, reliability, and effectiveness of the entire CI/CD workflow. Let’s explore the importance of test automation for CI/CD:
* **Speed and Efficiency:** One of the primary goals of CI/CD is to achieve quick and frequent code change delivery. [Manual testing](https://www.lambdatest.com/learning-hub/manual-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=learning_hub) can be time-consuming and can slow down the delivery process. With test automation, teams can swiftly and repeatedly execute numerous tests, providing prompt feedback on code changes. This rapid testing cycle accelerates the overall development process, empowering teams to release new features and bug fixes faster.
* **Consistency and Reliability:** Automated tests are designed to follow specific steps and predefined conditions consistently. This ensures that tests are executed in a standardized and repeatable manner, significantly reducing the risk of human errors. Consistent testing leads to more reliable results and helps maintain the software’s quality with each release.
* **Early Bug Detection:** CI/CD encourages integrating code changes multiple times throughout the day. Automated tests can be triggered after each integration, offering immediate feedback on potential bugs or issues. Early detection of bugs allows developers to address them promptly, minimizing the time and effort required for debugging later in the development process.
* **Test Coverage:** Manual testing may not cover all possible scenarios and edge cases due to time constraints. Test automation allows for broader test coverage, enabling the team to execute a wide range of tests across different platforms, browsers, and environments. Comprehensive test coverage ensures that the software functions well under various conditions, providing better assurance of its stability and performance.
* **Continuous Improvement:** CI/CD is about continuous improvement and learning. Automated tests act as a safety net during each code change, ensuring that new features do not break existing functionalities. When a test fails, it triggers an immediate investigation, leading to rapid bug fixes and continuous improvement in the software’s quality.
* **Parallel Testing:** Test automation enables [parallel testing](https://www.lambdatest.com/blog/what-is-parallel-testing-and-why-to-adopt-it/?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=blog), where multiple automated tests run simultaneously on various devices or browsers. This significantly reduces testing time and allows the team to receive faster feedback on the application’s performance across different environments.
* **DevOps Collaboration:** CI/CD promotes seamless collaboration between development and operations teams, commonly known as DevOps. Test automation plays a pivotal role in bridging the gap between these teams, ensuring a shared understanding of the application’s behavior and meeting both development and operational requirements.
Test automation empowers teams to deliver high-quality software faster, enhancing code stability and fostering a culture of collaboration and continuous improvement. With automated testing in place, organizations can effectively achieve the objectives of CI/CD, delivering dependable and feature-rich applications to their users with increased speed and confidence.
## CI/CD Workflow Pipeline
The CI/CD Workflow Pipeline is a series of automated steps and processes that software development teams follow to deliver code changes from development to production environments seamlessly. It is a crucial part of the CI/CD practice, helping to streamline software delivery and improve code quality. Let’s explore the key stages of the CI/CD workflow pipeline:
* **Code Commit:** The pipeline starts when developers commit their code changes to the version control system, such as Git. This marks the beginning of the automated CI/CD process.
* **Continuous Integration (CI):** In the CI phase, the committed code changes are automatically integrated into a shared repository. Automated builds are triggered to compile the code and check for any compilation errors.
* **Testing Automation:** Following a successful code build, automation testing becomes essential. Various types of tests, such as unit tests, integration tests, and [end-to-end tests](https://www.lambdatest.com/learning-hub/end-to-end-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=learning_hub), are employed to assess the functionality and quality of the code changes.
* **Static Code Analysis:** Static Code Analysis tools are commonly used to identify possible code issues and ensure adherence to coding standards.
* **Continuous Deployment (CD):** Following successful completion of all tests and analysis, the code advances to the Continuous Deployment phase. In this stage, the code changes are prepared for deployment to either the production environment or a production-like setting.
* **Staging Environment Deployment:** The code is deployed to a staging environment that closely resembles the production environment. This allows teams to conduct final testing and validation before proceeding with the production deployment.
* **User Acceptance Testing (UAT):** During the [user acceptance testing](https://www.lambdatest.com/learning-hub/user-acceptance-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_09&utm_term=bw&utm_content=learning_hub) stage, stakeholders or a subset of users test the code changes to ensure that the application meets their requirements.
* **Deployment to Production** After successful testing in the staging environment and UAT, the code changes are automatically deployed to the production environment.
* **Monitoring and Feedback:** Once the code is in production, monitoring tools are used to track application performance and user feedback. This feedback is valuable for further improvements and bug fixes.
By automating these steps, the CI/CD workflow pipeline minimizes manual intervention and reduces the risk of human errors. It enables teams to release code changes more frequently, ensuring faster delivery cycles and a continuous feedback loop for continuous improvement. The CI/CD workflow pipeline is an essential component of modern software development, fostering collaboration, reliability, and efficiency in the software delivery process.
## CI/CD Best Practices
Now, let us look at some of the best practices for CI/CD testing.
* **Security-First Approach**
In today’s world, security is crucial for businesses of all sizes. Breaches and vulnerabilities can cause huge losses in reputation and finances. One area at risk is the CI/CD system, which provides access to your code and credentials for deployment. Make security part of your development process, known as DevSecOps.
* **Microservices Readiness**
To implement DevOps effectively, consider using a microservices architecture. However, re-architecting existing applications can be daunting. Instead, you can take an incremental approach by keeping critical systems and gradually integrating the new architecture.
* **Tracking & Collaboration**
Tools like Jira and Bugzilla help track software progress and collaborate with teams. Use Git as a version control system, creating a single source of truth for your team, tracking code changes, and simplifying rollbacks.
* **Streamlined Development**
Minimize branching in GitOps to focus more on development. Encourage developers to commit changes daily to the main branch or merge them from local branches. This prevents major integration issues before a release.
* **Efficient Build Practices**
Avoid building source code multiple times. Execute the build process once and promote your binaries. Ensure the resulting artifact is versioned and uploaded to Git for consistency.
* **Smart Automation**
When transitioning from manual to automated processes, prioritize automation by starting with essential tasks like code compilation and automated smoke tests. Gradually automate unit tests, functional tests, and UI tests, considering their dependencies and impact.
* **Agile & Reliable Releases**
Frequent releases are possible with proper testing in a production-like environment. Use deployment stages that mirror the production environment, such as Canary deployment or Blue-Green deployment, to release and test updates.
* **On-Demand Testing Environments**
Running tests in containers helps the quality assurance team reduce environmental variables and changes between development and production. Containers add agility to your CI/CD cycle, making it easier to test and destroy them when unnecessary.
| devanshbhardwaj13 |
1,864,077 | Finance Budgeting App with AWS Amplify Gen2 | This is a submission for the The AWS Amplify Fullstack TypeScript Challenge What I... | 0 | 2024-05-24T14:39:21 | https://dev.to/travislramos/finance-budgeting-app-with-aws-amplify-gen2-4ilg | devchallenge, awschallenge, amplify, fullstack | *This is a submission for the [The AWS Amplify Fullstack TypeScript Challenge ](https://dev.to/challenges/awschallenge)*
## What I Built
I built an app called SpotMe that helps you manage the amount of money you're spending and saving each month compared to your income. Once you sign up and specify your monthly income and how much of that income you are trying to save each month, you'll be greeted with a dashboard where you can see metrics on spending habits and how much money you've saved to see if you're hitting your savings goal.
## Demo and Code
- You can access the app [here](https://main.d3w43xd0b6xvcz.amplifyapp.com).
- You can also take a look at the [source code](https://github.com/TRamos5/spotme-app) if you'd like to see how I've built it.
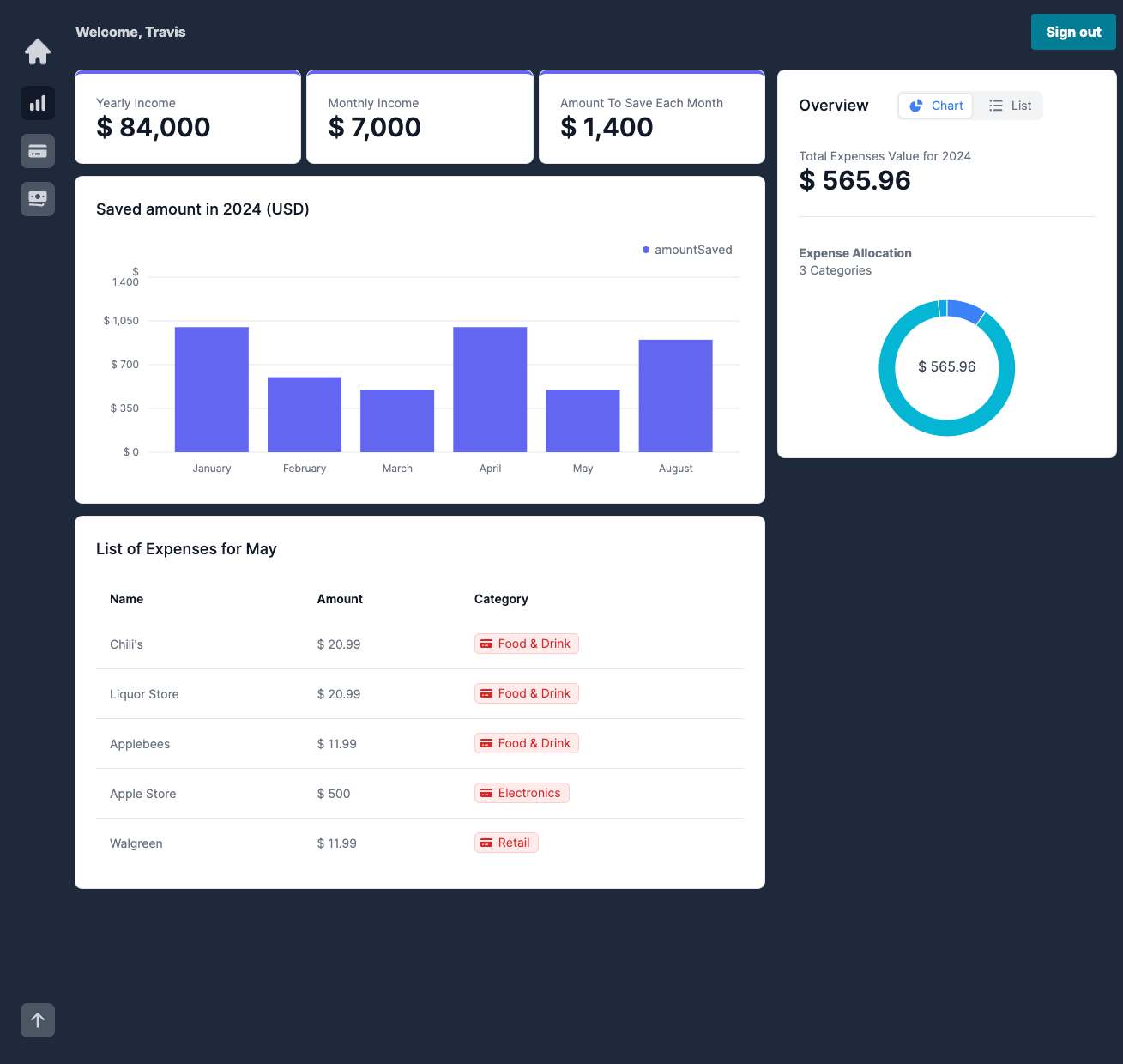
## Integrations
I developed the application using Next.js for the user interface. For authentication and data management, I leveraged AWS Amplify, integrating its connected components to enhance parts of the UI. Additionally, I utilized Tremor to create all the charts and graphs.
Let me know what you think! | travislramos |
1,864,076 | Laravel get route name from given URL | A common use case for a tabs component is to check if a routes as strings is the current route or if... | 0 | 2024-05-24T14:38:48 | https://dev.to/arielmejiadev/laravel-get-route-name-from-given-url-2dde | php, laravel | A common use case for a tabs component is to check if a routes as strings is the current route or if it exists in your app.
Laravel Route facade allows to expose the route object easily to check this:
###### Using the route name
```php
$route = route('users.index');
Route::getRoutes()->match($route);
```
###### Using a string
```php
$url = 'https://your-app.com/users';
Request::create($url)
```
Hope that the tip is useful! | arielmejiadev |
1,864,065 | Ozu, a static website deployment solution for Laravel projects, is now recruiting beta testers | For my first post here (even if I'm a long time quite reader), I chose to present the project I've... | 0 | 2024-05-24T14:37:25 | https://dev.to/dvlpp/ozu-a-static-website-deployment-solution-for-laravel-projects-is-now-recruiting-beta-testers-5902 | laravel, webdev, product | For my first post here (even if I'm a long time quite reader), I chose to present the project I've been working on, with others at [Code 16](https://code16.fr/en), for a while now: Ozu.
Bur first, a quick presentation: I'm involved in web development since a long time, and in Laravel and PHP specifically since 2014. I founded Code 16 where we shipped a lot of projects (websites and apps) for many clients, for which we created and still are actively maintaining a quite big open source project: [Sharp for Laravel](https://sharp.code16.fr).
Over the years we've had to turn down projects because they were too small or because they lacked the technical challenges that I think we are good at. When the hype for static websites came back, a few years ago, we tried many solutions and tools to build and deploy these projects on a static platform, but we were almost always disappointed by the workflow, or the limitations.
So we built Ozu, for our own needs, with three main goals in mind: keep our Laravel stack, handle all the deployment stuff automatically and allow our customers to manage their content. We are now trying to convert it to a product, since we think it could really benefit to others, and here's the real reason for this post: we are recruiting beta testers to gather feedback, and to be sure that it is a good way to tackle this (complex) topic.
If you want to know more, please [check our announcement post](https://code16.fr/posts/introducing-ozu-a-static-website-deployment-solution-for-laravel-projects/) and browse to [Ozu's landing page](https://ozu.code16.fr) to subscribe (100% spam free).
 | dvlpp |
1,864,075 | Is Kubernetes a database? CRDs explained in five minutes | When you touch on containerized apps today, Kubernetes usually comes up as their orchestrator. Sure,... | 0 | 2024-05-24T14:37:10 | https://cyclops-ui.com/blog/2024/05/24/is-k8s-database/ | kubernetes, opensource, devops, tutorial | When you touch on containerized apps today, Kubernetes usually comes up as their orchestrator. Sure, Kubernetes is great for managing your containers on a fleet of servers and ensuring those are running over time. But today, Kubernetes is more than that.
Kubernetes allows you to extend its functionality with your logic. You can build upon existing mechanisms baked into Kubernetes and build dev tooling like never before - enter Custom Resource Definitions (CRDs).
## Support us 🙏
We know that Kubernetes can be difficult. That is why we created Cyclops, a **truly** developer-oriented Kubernetes platform. Abstract the complexities of Kubernetes, and deploy and manage your applications through a UI. Because of its platform nature, the UI itself is highly customizable - you can change it to fit your needs.
We're developing Cyclops as an open-source project. If you're keen to give it a try, here's a quick start guide available on our [repository](https://github.com/cyclops-ui/cyclops). If you like what you see, consider showing your support by giving us a star ⭐

## Kubernetes components
Before diving into CRDs, let's take a step back and look at Kubernetes control plane components, specifically Kubernetes API and its ETCD database. We made a [blog](https://dev.to/cyclops-ui/complexity-by-simplicity-a-deep-dive-into-kubernetes-components-4l59) on each one of those components previously, so feel free to check it out for more details.
You will likely talk to your Kubernetes cluster using the command-line tool [kubectl](https://kubernetes.io/docs/reference/kubectl/). This tool allows you to create, read, and delete resources in your Kubernetes clusters. When I say “talk” to a Kubernetes cluster, I mean making requests against the API. Kubernetes API is the only component we, as users, ever interact with.
Each time we create or update a K8s resource, the Kubernetes API stores it in its database — `etcd`. [etcd](https://etcd.io/) is a distributed key-value store used to store all of your resource configurations, such as deployments, services, and so on. A neat feature of `etcd` is that you can subscribe to changes in some keys in the database, which is used by other Kubernetes mechanisms.
What happens when we create a new K8s resource? Let's go through the flow by creating a service. To create it, we need a file called `service.yaml`
```yaml
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
```
and apply it to the cluster using `kubectl`:
```bash
kubectl apply -f service.yaml
service/my-service created
```
`kubectl` read our file and created a request against the Kubernetes API. API then makes sure our service configuration is valid (e.g., all the necessary fields were there, fields were of the correct types, …) and stores it to etcd. Now `etcd` can utilize its `watch` feature mentioned previously and notify controllers about a newly created service.
## CRDs and how to create one
With the basic flow covered, we can now extend it. We can apply the same process of validating, storing, and watching resources to custom objects. To define those objects, we will use Kubernetes’ Custom Resource Definitions (CRD).
CRD can be a YAML file containing the schema of our new object - which fields does our custom object have, and how do we validate them. It will instruct the Kubernetes API on how to handle a new type of resource.
Let’s say your company is in the fruit business, and you are trusted with the task of automating the deployment of apples to your Kubernetes cluster. The example, of course, has nothing to do with a real-life scenario to show that you can extend the Kubernetes API however you see fit.
Apples have a color that can be either `green`, `red`, or `yellow`, and each apple has its weight. Let’s create a YAML to reflect that on our Kubernetes API:
```yaml
# apple-crd.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: apples.my-fruit.com
spec:
group: my-fruit.com
names:
kind: Apple
listKind: ApplesList
plural: apples
singular: apple
scope: Namespaced
versions:
- name: v1alpha1
schema:
openAPIV3Schema:
properties:
apiVersion:
type: string
kind:
type: string
metadata:
type: object
spec:
properties:
color:
enum:
- green
- red
- yellow
type: string
weightInGrams:
type: integer
type: object
type: object
served: true
storage: true
```
We defined two properties for version `v1alpha1` under `.properties.spec`:
- `color` (which can take one of the values in the `enum`)
- `weightInGrams`
To tell the Kubernetes API that there is a new type of object, we can just apply the previous file to the cluster:
```bash
kubectl apply -f apple-crd.yaml
customresourcedefinition.apiextensions.k8s.io/apples.my-fruit.com created
```
Kubernetes API is now ready to receive `Apples`, validate them, and store them to `etcd`.
Don’t take my word for it, you can create a Kubernetes object that satisfies the schema from the CRD above:
```yaml
# green-apple.yaml
apiVersion: my-fruit.com/v1alpha1
kind: Apple
metadata:
name: green-apple
spec:
color: green
weightInGrams: 200
```
and apply it to the cluster:
```bash
kubectl apply -f green-apple.yaml
apple.my-fruit.com/green-apple created
```
Now, your cluster can handle one more type of resource, and you can store and handle your custom data inside the same Kubernetes cluster. This is now a completely valid command:
```bash
kubectl get apples
NAME AGE
green-apple 6s
```
## Can I then use Kubernetes as a database?
Now that we know we can store any type of object in our Kubernetes database and manage it through the K8s API, we should probably draw a line on how far we want to abuse this concept.
Obviously, your application data (like fruits in the example) would fall into the **misuse** category when talking about CRDs. You should develop stand-alone APIs with separate databases for such cases.
CRDs are a great fit if you need your objects to be accessible through `kubectl` and the API to the object is [declarative](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/#declarative-apis). Also, another great use case for extending the Kubernetes API is when you are implementing the [Kubernetes Operator pattern](https://kubernetes.io/docs/concepts/extend-kubernetes/operator/), but more on that in future blog posts 😄
On the other hand, if you decide to go the CRD route, you are very much dependent on how K8s API works with resources, and you can get restricted because of its API groups and namespaces.
Kubernetes CRDs are a powerful tool and can help you build new developer platforms and tools. We at Cyclops develop on top of our CRDs so feel free to check them out on our [repository](https://github.com/cyclops-ui/cyclops).
| karadza |
1,864,068 | Scalar: Documentação OpenAPI Moderna | Swagger é uma das ferramentas mais utilizadas para documentação de APIs, mas seu tempo pode estar... | 0 | 2024-05-24T14:34:35 | https://dev.to/emergingcode/scalar-documentacao-openapi-moderna-3a8j | openapi, apifirst, swagger | > Swagger é uma das ferramentas mais utilizadas para documentação de APIs, mas seu tempo pode estar chegando ao fim com a chegada do Scalar UI.
## Contexto histórico do Swagger
A história de uso do Swagger como ferramenta para documentação OpenAPI começa com a sua criação em 2010 por Tony Tam, enquanto trabalhava na empresa Reverb Technologies. Desde o início, seu objetivo era simplificar o processo de documentação de APIs para desenvolvedores.
Com o Swagger, era possível criar uma interface amigável para APIs RESTful, permitindo aos desenvolvedores entender o funcionamento de uma API sem precisar mexer no código fonte. Além disso, o Swagger também permite testar a API diretamente no navegador, o que economiza tempo e esforço dos desenvolvedores.
Em 2015, a Swagger foi doada para a Linux Foundation e se tornou parte do projeto OpenAPI. Juntamente com outras ferramentas, o Swagger ajudou a definir o padrão OpenAPI para documentação de APIs. Resultando na UI que já estamos acostumados a trabalhar por anos:
Apesar de sua popularidade e amplo uso, a UI do Swagger também tem suas limitações. Por exemplo, durante todo esse tempo a UX do Swagger permaneceu praticamente a mesma, além de não permitir uma documentação que contivesse textos explicativos sobre os endpoints da API.
## **Scalar como alternativa na documentação OpenAPI**
O Scalar é uma ferramenta que vem servir como alternativa para documentação de APIs usando a especificação OpenAPI. Lançado recentemente, o Scalar se destaca por sua interface de usuário moderna e intuitiva, permitindo criar documentações contendo textos declarativos e explicativos sobre o negócio, funcionalidades, payloads e muitas outras formas de documentar uma API.
A interface do Scalar é limpa e simplificada, tornando-a mais acessível para qualquer pessoa que tenha interesse ou precise entender quais funcionalidades estão disponíveis em uma API. Além disso, o Scalar é mais rápido que o Swagger para documentar APIs complexas, graças ao seu eficiente mecanismo de renderização, além de disponibilizar opções de exemplos de uso das APIs em diversas linguagens e plataformas, o que traz bastante facilidade para quem está querendo usar uma API.
A integração do Scalar com a especificação OpenAPI significa que é possível importar e exportar documentação de API no formato OpenAPI, seja no formato **json** ou no formato **yaml**. Isso facilita a transição de outras ferramentas para o Scalar.
O Scalar também oferece integração com várias outras plataformas:
- .NET
- GO
- Rust
- NestJS
- Dentre outras que pode ser encontradas no [repositório oficial do projeto](https://github.com/scalar/scalar)
> **Durante esse artigo, vamos demonstrar o uso do Scalar em um projeto AspNet Core usando .NET 8.0.**
## **Habilitando Scalar UI em um projeto AspNet Core** 🚀
Para demonstrar o uso do Scalar em um projeto .NET, vamos considerar um projeto AspNet Core simples usando **.NET 8.0**, e que vai conter uma API para um sistema de gestão de hotéis.
> ⚠️ Se você está rodando seus projetos já usando o .NET 9.0, a versão do Scalar a ser usada será um outro pacote com um nome diferente do apresentado neste artigo, disponível no [Nuget](https://www.nuget.org/packages/Scalar.AspNetCore).
A versão que pode ser usada com o .NET 8.0 pode ser ou a **1.0.0** ou a **1.0.1-rc**
Primeiro, precisamos adicionar o pacote Scalar ao nosso projeto através do NuGet:
```csharp
dotnet add package AspNetCore.Scalar --version 1.0.1-rc
```
Em seguida, podemos configurar o Scalar em nosso arquivo Program.cs:
```csharp
...
var app = builder.Build();
app.UseScalar(options =>
{
options.UseTheme(Theme.Default);
options.RoutePrefix = "api-docs";
});
...
```
No trecho de código acima, estamos configurando o Scalar para servir nossa documentação de API na rota "**/api-docs**".
> 💡 Para usar o Scalar você não precisa desinstalar o Swagger do seu projeto, pois ambos conseguem conviver lado a lado. Se você já tem o swagger instalado no seu projeto, basta instalar o pacote do Scalar e adicionar o código acima e o pacote vai saber localizar a Url Path do swagger contendo a documentação da API no formato OpenAPI.
Finalmente, podemos acessar nossa documentação de API navegando para "[http://localhost:[PORTA_DEFINIDA]/scalar-api-docs](http://localhost:5096/api-docs)" em um navegador de sua preferência. A partir daí, podemos interagir com nossa API diretamente da interface do Scalar.
Esse exemplo ilustra um pouco do que o Scalar pode trazer de melhorias para a documentação da API do seu projeto. Com sua interface moderna e recursos poderosos, o Scalar é uma excelente alternativa ao Swagger para documentação OpenAPI.
A imagem abaixo mostra o resultado da integração do Scalar em uma aplicação AspNet Core:
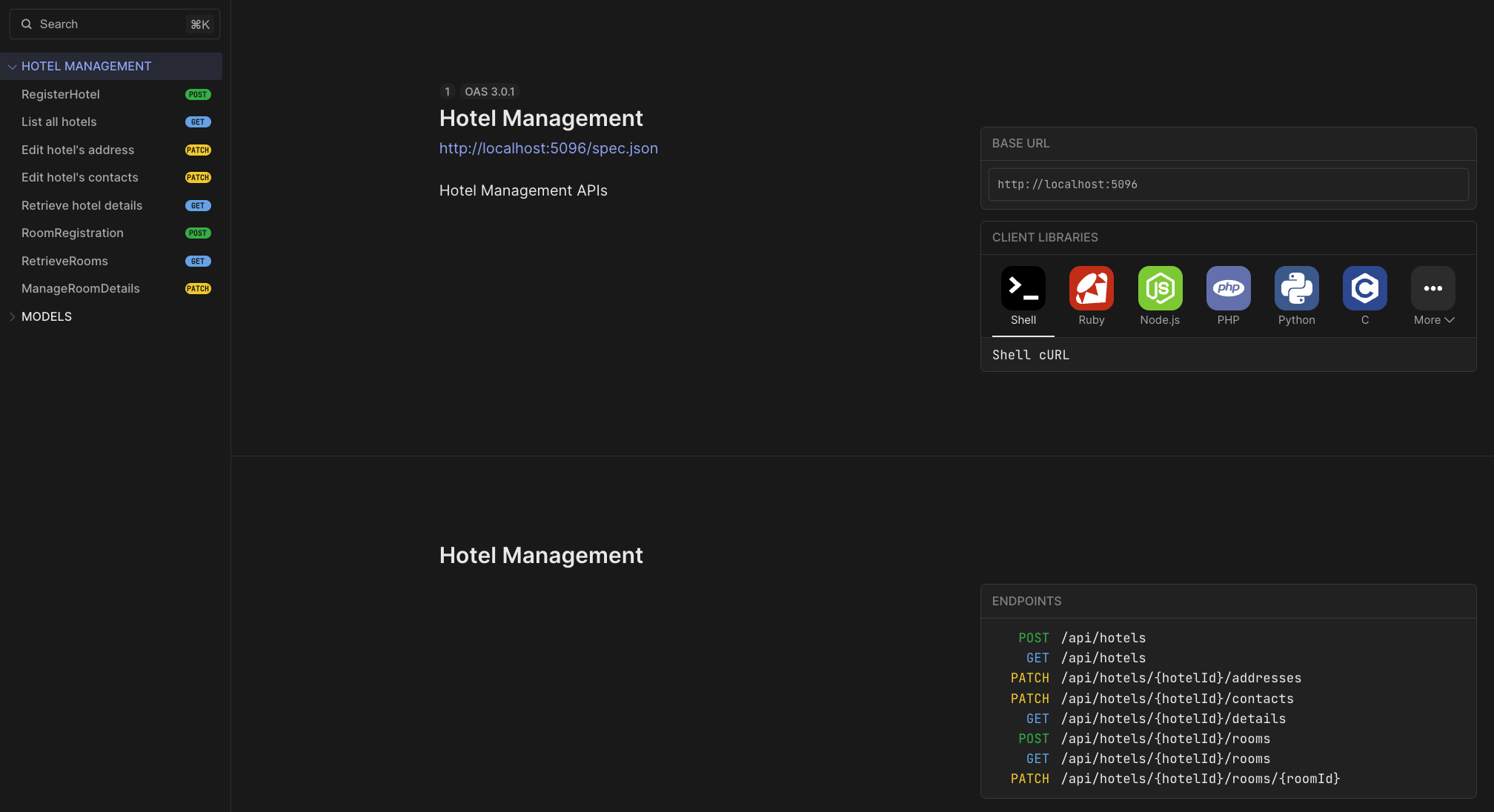
Perceba que a UI oferece uma experiência de usabilidade bastante diferente do que se está acostumado a ver com o Swagger. Além da UX diferente, também é possível realizar navegação pelas APIs e escolher uma plataforma para que o Scalar possa gerar um exemplo de código que se ajuste a sua necessidade, através das ***Client Libraries***.
## Scalar, .NET 9.0 e OpenAPI
O time do AspNet Core está trabalhando na implementação de um pacote oficial da Microsoft, o qual vai trabalhar entregando 100% das especificações OpenAPI. Nesse sentido, o pacote *Swashbuckle* será removido ❌ a partir do .NET 9.0, passando somente a ser possível utilizar o novo pacote: **Microsoft.AspNetCore.OpenApi.**
O pacote Scalar.AspNetCore, a partir da versão 1.0.1, será possível se integrar com as novidades que virão junto com o .NET 9.0 e a nova API de documentação, que trás um nome bastante óbvio: **[Microsoft.AspNetCore.OpenApi](https://learn.microsoft.com/en-us/aspnet/core/fundamentals/minimal-apis/aspnetcore-openapi?view=aspnetcore-9.0&tabs=visual-studio#using-scalar-for-interactive-api-documentation).**
## Validando sua especificação usando: *Spectral*
Spectral é um linter de documentos OpenAPI de código aberto. O pacote **Spectral** pode ser incorporado à construção de seu aplicativo para verificar a qualidade dos documentos OpenAPI gerados. Para instalar o Spectral siga as instruções através do [repositório oficial](https://github.com/stoplightio/spectral).
Para tirar vantagens do Spectral você precisa realizar algumas configurações e instalar um pacote no seu projeto, antes de utilizar a ferramenta de Linter. Instale o pacote Microsoft.Extensions.ApiDescription.Server, ele vai permitir que seja gerada a documentação OpenAPI no momento do build do projeto.
```csharp
dotnet add package Microsoft.Extensions.ApiDescription.Server --prerelease
```
Configure o seu projeto para gerar documentos no momento da compilação definindo as seguintes propriedades no arquivo **.csproj** do seu aplicativo:
```xml
<PropertyGroup>
<OpenApiDocumentsDirectory>$(MSBuildProjectDirectory)</OpenApiDocumentsDirectory>
<OpenApiGenerateDocuments>true</OpenApiGenerateDocuments>
</PropertyGroup>
```
Execute o build do seu projeto para que seja gerado o arquivo .json contendo as especificações das APIs:
```csharp
dotnet build
```
Crie um arquivo .spectral.yml com o conteúdo abaixo:
```yaml
extends: ["spectral:oas"]
```
Depois de tudo configurado e o arquivo **.json** com as especificações OpenAPI também gerado, você já pode executar o Linter contra suas especificações:
```bash
spectral lint [NOME_DO_SEU_ARQUIVO].json
...
The output will show any issues with the OpenAPI document.
```output
1:1 warning oas3-api-servers OpenAPI "servers" must be present and non-empty array.
3:10 warning info-contact Info object must have "contact" object. info
3:10 warning info-description Info "description" must be present and non-empty string. info
9:13 warning operation-description Operation "description" must be present and non-empty string. paths./.get
9:13 warning operation-operationId Operation must have "operationId". paths./.get
✖ 5 problems (0 errors, 5 warnings, 0 infos, 0 hints)
```
## Conclusão 💭
Em conclusão, o Scalar surge como uma ferramenta poderosa e intuitiva para a documentação de APIs usando a especificação OpenAPI. Com uma interface moderna, opções de exemplos de uso das APIs em diversas linguagens e plataformas, e uma integração eficiente com a especificação OpenAPI, o Scalar tem a capacidade de melhorar significativamente a experiência de documentação de APIs.
Além disso, a integração com o Spectral, um linter de documentos OpenAPI de código aberto, possibilita a verificação da qualidade dos documentos OpenAPI gerados, assegurando uma documentação mais precisa e de qualidade superior. Portanto, o Scalar se apresenta como uma excelente alternativa ao Swagger para documentação OpenAPI.
## Referências
- [Scalar](https://scalar.com/)
- [Scalar for AspNet Core](https://github.com/scalar/scalar/blob/main/packages/scalar.aspnetcore/README.md)
- [Microsoft.AspNetCore.OpenApi](https://learn.microsoft.com/en-us/aspnet/core/fundamentals/minimal-apis/aspnetcore-openapi?view=aspnetcore-9.0&tabs=netcore-cli#using-scalar-for-interactive-api-documentation)
| jraraujo |
1,864,072 | “Git Quick” VS Code Extension Review | Introduction The “Git Quick” extension for Visual Studio Code is designed to streamline... | 0 | 2024-05-24T14:30:08 | https://dev.to/gudata/git-quick-vs-code-extension-review-ln7 | vscode, git, productivity | ---
title: “Git Quick” VS Code Extension Review
published: true
description:
tags: vscode, git, productivity
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-24 14:18 +0000
---

# Introduction
The “Git Quick” extension for Visual Studio Code is designed to streamline your workflow with Git by providing instant commands for staging, committing, and restoring files directly from the editor.
## Main Features
### Instant Staging and Committing
The standout feature of “Git Quick” is the git-quick-commit command. This command allows you to commit the file currently in focus with remarkable speed. Here’s how it works:
- Automatic Staging: As soon as you invoke the command (from the command palette or shortcut), the extension stages the current file for you.
- Prompt for Commit Message: You will then be prompted to enter a commit message, ensuring that your changes are documented appropriately – and most import with the right scope!
- File Save: If the file has unsaved changes, Git Quick will automatically save it before proceeding with the commit.
This feature is particularly useful for developers who need to make frequent commits without losing focus on their current task.
Also it helps commit frequently and put the right commit messages to the right files. No more one commit message for 10 unrelated files!
### Quick Restore
The git-quick-restore command is another powerful feature of Git Quick. It allows you to quickly revert the current file to its state at the most recent commit. This is equivalent to discarding all local changes made to the file:
Instant Revert: With a single command, you can undo any unwanted changes, making it a lifesaver during experimentation or bug fixing.
No Activation if Unchanged: The command will only activate if there are changes to the file, ensuring that you don’t accidentally revert unchanged files.
### Additional Features
git-quick-checkout: This is an alias for the git-quick-restore command, providing flexibility in how you interact with the extension.
Multiple Repository Support: If you have multiple Git repositories open, Quick Git will automatically detect and apply the command to the appropriate repository.
Integration with VS Code Git Extension: It relies on the built-in Git functionality of VS Code, meaning there are no external dependencies to worry about.
## User Experience
Quick Git enhances the Git workflow by minimizing interruptions and keeping you in your coding environment. The automatic saving of files and seamless integration with VS Code’s Git extension make it a natural part of the development process.
No Distractions
Non-Intrusive: The extension won’t activate if the current file hasn’t changed, which prevents unnecessary prompts and distractions.
Focus Retention: By allowing you to commit or restore files directly from the editor, it helps maintain your focus on coding rather than switching contexts to the terminal or another Git client.
## Future Potential
The current feature set of Git Quick is already impressive, but the promise of additional “quick” commands in the future makes it an exciting tool to watch. Potential future enhancements could include:
- Quick Branch Switching: Instantly switch branches without navigating through multiple menus.
- Quick Merge/Rebase: Simplify complex Git operations to a single command.
[Download link](https://marketplace.visualstudio.com/items?itemName=gudasoft.git-quick)
## Conclusion
The Git Quick extension for VS Code is a highly efficient tool for developers looking to speed up their Git workflow. With instant staging, committing, and restoring capabilities, it reduces the friction of version control tasks and keeps you focused on coding. As it stands, it’s a valuable addition to any developer’s toolkit, with promising features on the horizon.
For more information and to download the extension, visit the [Git Quit repository](https://github.com/gudasoft/git-quick). Also, check out other great projects from [Gudasoft](https://gudasoft.com/products/)!
| gudata |
1,864,074 | 5 Lesser-Known Programming Languages That Are Easy to Learn and Highly Effective | Python, Java, and C++ often take the spotlight, and people are mostly obsessed with these languages.... | 0 | 2024-05-24T14:29:55 | https://www.webdevstory.com/lesser-known-programming-languages/ | lua, julialang, programming, haskell | Python, Java, and C++ often take the spotlight, and people are mostly obsessed with these languages. Exploring new things might open new perspectives, making our lives easier and more convenient for our work; programming languages are no exception. Today, I’ll talk about several lesser-known programming languages that offer unique advantages, simplicity, and effectiveness.
These languages might not be as popular, but they can significantly enhance your [programming skills](https://www.webdevstory.com/programming-roadmap/) and broaden your problem-solving toolkit. Here are five such programming languages that are easy to learn and highly effective.
#### 1 — Lua: The Lightweight Scripting Language
Lua is a lightweight, high-level scripting language designed for embedded use in applications. It’s widely known for its simplicity and performance.
#### Key Features
* Lua’s syntax is straightforward and minimalistic, making it accessible for beginners.
* It’s fast and efficient, ideal for embedded systems and game development.
* Lua can be embedded in applications written in other languages like C and C++.
#### Use Cases
* Game engines such as Unity and Roblox heavily use Lua.
* Because of its small footprint, Lua is perfect for embedded systems and IoT devices.
#### Resources
* [Lua.org Documentation](https://www.lua.org/docs.html)
* [Programming in Lua by Roberto Ierusalimschy](https://amzn.to/44VB7vo)
* [Introduction to Lua on Udemy](https://www.udemy.com/course/learn-lua-scripting-roblox/?couponCode=OF52424)
**Sum of an Array**
```javascript
function sum(array)
local total = 0
for i = 1, #array do
total = total + array[i]
end
return total
end
print(sum({1, 2, 3, 4, 5})) -- Output: 15
```
#### 2 — Haskell: The Purely Functional Language
Haskell is a purely functional programming language with strong static typing. It’s known for its expressive syntax and powerful abstractions.
#### Key Features
* Haskell encourages a different way of thinking about programming, focusing on functions and immutability.
* The strong type system helps catch errors at compile time, leading to more reliable code.
* Haskell allows for concise and readable code, reducing bugs and improving maintainability.
#### Use Cases
* Haskell is popular in academia for exploring new programming concepts.
* Its strong type system and functional nature make it suitable for complex data transformations.
#### Resources
* [Haskell.org Documentation](https://haskell.org/documentation/)
* [Learn You a Haskell for Great Good! by Miran Lipovača](https://amzn.to/4aOVaxb)
**Fibonacci Sequence**
```javascript
fibonacci :: Int -> Int
fibonacci 0 = 0
fibonacci 1 = 1
fibonacci n = fibonacci (n - 1) + fibonacci (n - 2)
main = print (fibonacci 10) -- Output: 55
```
#### 3 — Erlang: The Concurrency King
Erlang is a language designed for building scalable and fault-tolerant systems. It excels in concurrent programming and is used in telecommunication systems.
#### Key Features
* Erlang’s lightweight process model makes building systems that handle thousands of simultaneous processes easy.
* Built-in mechanisms for error detection and process isolation ensure systems can recover from failures.
* Allows for code updates without stopping the system, which is crucial for high-availability systems.
#### Use Cases
* Used by companies like Ericsson for building robust telecommunication infrastructure.
* The backbone of messaging platforms like WhatsApp.
#### Resources
* [Erlang.org Documentation](https://www.erlang.org/docs)
* [Programming Erlang by Joe Armstrong](https://amzn.to/3wKHa9F)
**Check Prime Number**
```javascript
-module(prime).
-export([is_prime/1]).
is_prime(2) -> true;
is_prime(N) when N > 2 -> is_prime(N, 2).
is_prime(N, D) when D * D > N -> true;
is_prime(N, D) when N rem D == 0 -> false;
is_prime(N, D) -> is_prime(N, D + 1).
% To run: prime:is_prime(7). -- Output: true
```
#### 4 — Julia: The High-Performance Numerical Computing Language
Julia has been designed for high-performance numerical and scientific computing. It combines the ease of use of Python with the speed of C.
#### Key Features
* Julia’s compilation, rather than interpretation, gives it a performance edge.
* Its syntax is simple and intuitive, similar to Python.
* Designed with numerical and scientific computation in mind, Julia excels in tasks that require high precision.
#### Use Cases
* Julia is becoming increasingly popular in data science for its speed and efficiency.
* Ideal for complex simulations and numerical analysis.
#### Resources
* [Julia Lang Documentation](https://docs.julialang.org/en/v1/)
* [Julia Programming for Operations Research by Changhyun Kwon](https://amzn.to/3wKHa9F)
* [Introduction to Julia on Coursera](https://imp.i384100.net/vNJdyj)
**Sorting an Array**
```javascript
function bubble_sort(arr::Vector{Int})
n = length(arr)
for i in 1:n-1
for j in 1:n-i
if arr[j] > arr[j + 1]
arr[j], arr[j + 1] = arr[j + 1], arr[j]
end
end
end
return arr
end
println(bubble_sort([5, 2, 9, 1, 5, 6])) -- Output: [1, 2, 5, 5, 6, 9]
```
#### 5 — Racket: The Programmable Programming Language
Racket is a descendant of Scheme and is a general-purpose, multi-paradigm programming language. It’s particularly noted for its emphasis on language creation and experimentation.
#### Key Features
* Racket makes it easy to create domain-specific languages.
* It comes with extensive libraries for various tasks.
* Often used in educational settings to teach programming concepts.
#### Use Cases
* Used for creating new programming languages and experimenting with language design.
* Popular in computer science courses for teaching fundamental programming principles.
#### Resources
* [Racket-lang.org Documentation](https://docs.racket-lang.org/)
* [Realm of Racket by Matthias Felleisen et al.](https://amzn.to/4bRNR8Q)
**Find Maximum in a List**
```javascript
#lang racket
(define (max-in-list lst)
(if (null? (cdr lst))
(car lst)
(let ([max-rest (max-in-list (cdr lst))])
(if (> (car lst) max-rest)
(car lst)
max-rest))))
(display (max-in-list '(3 5 2 9 4))) -- Output: 9
```
#### Conclusion
I hope exploring these lesser-known programming languages can open up new avenues for your [development skills](https://www.mmainulhasan.com/becoming-a-competent-programmer/) and problem-solving approaches.
Let’s experiment; maybe any of these can become your next favorite programming language.
Happy Coding!
***Support Our Tech Insights***
<a href="https://www.buymeacoffee.com/mmainulhasan" target="_blank"></a>
<a href="https://www.paypal.com/donate/?hosted_button_id=GDUQRAJZM3UR8" target="_blank"></a>
Note: Some links on this page might be affiliate links. If you purchase through these links, I may earn a small commission at no extra cost to you. Thanks for your support! | mmainulhasan |
1,864,073 | 🔬👩🔬 Skin Melanoma Classification: Step-by-Step Guide with 20,000+ Images 🌟💉 | Discover how to build a CNN model for skin melanoma classification using over 20,000 images of skin... | 0 | 2024-05-24T14:28:54 | https://dev.to/feitgemel/skin-melanoma-classification-step-by-step-guide-with-20000-images-3o56 | python, computervision, tensorflow | Discover how to build a CNN model for skin melanoma classification using over 20,000 images of skin lesions
We'll begin by diving into data preparation, where we will organize, clean, and prepare the data form the classification model.
Next, we will walk you through the process of build and train convolutional neural network (CNN) model. We'll explain how to build the layers, and optimize the model.
Finally, we will test the model on a new fresh image and challenge our model.
Check out our tutorial here : https://youtu.be/RDgDVdLrmcs
Enjoy
Eran
#Python #Cnn #TensorFlow #deeplearning #neuralnetworks #imageclassification #convolutionalneuralnetworks #SkinMelanoma #melonomaclassification
| feitgemel |
1,864,070 | Anday Aloo Recipe | Anday Aloo Recipe By Fine... | 0 | 2024-05-24T14:27:59 | https://dev.to/kinza_jafri_b30d65c3c1fa9/anday-aloo-recipe-3c1i | {% embed https://youtu.be/isZ620f5Y8E?si=maJ963w-d8QoCUJ- %} | kinza_jafri_b30d65c3c1fa9 | |
1,864,069 | How to push code from VS Code to GitHub | Are you ready to take your coding journey to the next level by sharing your projects on GitHub?... | 0 | 2024-05-24T14:25:26 | https://www.techielass.com/how-to-push-code-from-vs-code-to-github/ | github, vscode, git | 
Are you ready to take your coding journey to the next level by sharing your projects on GitHub? Whether you're just starting out or already familiar with coding, understanding how to push your [<u>Visual Studio Code</u>](https://www.techielass.com/tag/vs-code/) (VS Code) project to [<u>GitHub</u>](https://www.techielass.com/tag/github/) is a fundamental skill for any developer. In this beginner-friendly tutorial, we'll walk you through the process step by step.
## Prerequisites
Before we dive in, ensure that you have Visual Studio Code and [<u>Git</u>](https://www.techielass.com/installing-git/) installed on your machine. Additionally, you'll need to have a GitHub account set up. If you haven't already done so, head over to [<u>GitHub.com</u>](http://github.com/?ref=techielass.com) and create an account—it's free and only takes a few moments.
## Step 1: Prepare Your Project
Open up your VS Code editor and ensure that your project is ready to go. For this tutorial, I am going to be using a small project that has an HTML file, CSS file and readme file in it. This is what I want to commit to a GitHub repository.
_VS Code editor_
## Step 2: Initialise Your Repository
Navigate to the source control view in Visual Studio Code. You can do this by clicking on the icon on the left-hand side or by pressing Ctrl + Shift + G.
_Initialise Git Repository in VS Code_
When prompted, click on the "Initialise repository" button. This action creates a new Git repository in the current folder, allowing you to start tracking code changes.
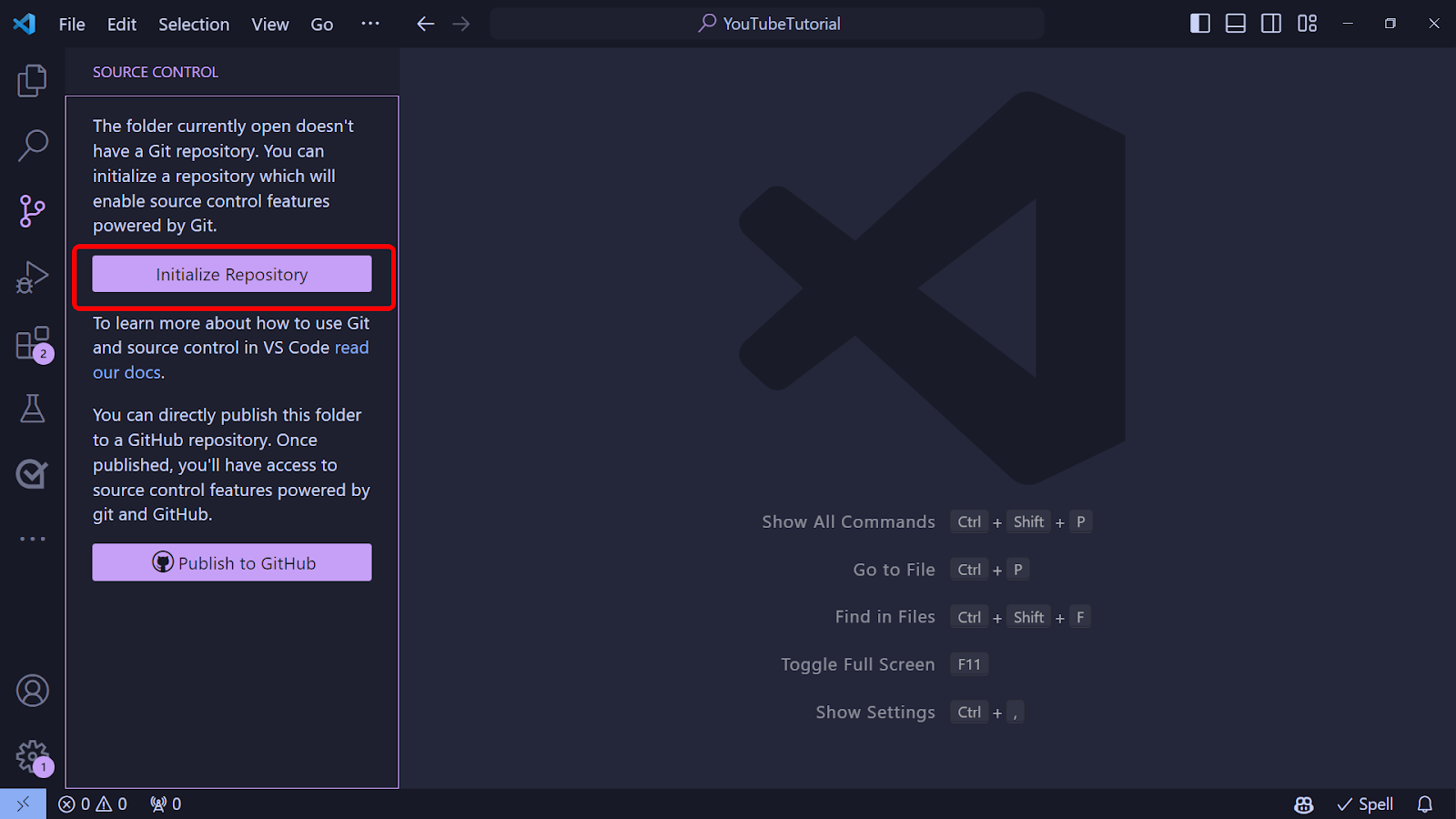
_Initialise Git Repository in VS Code_
## Step 3: Commit Your Changes
The source control view will now list any changes you've made to your project. Select all the files you want to include in this commit and enter a descriptive commit message. Then, hit commit to save your changes.
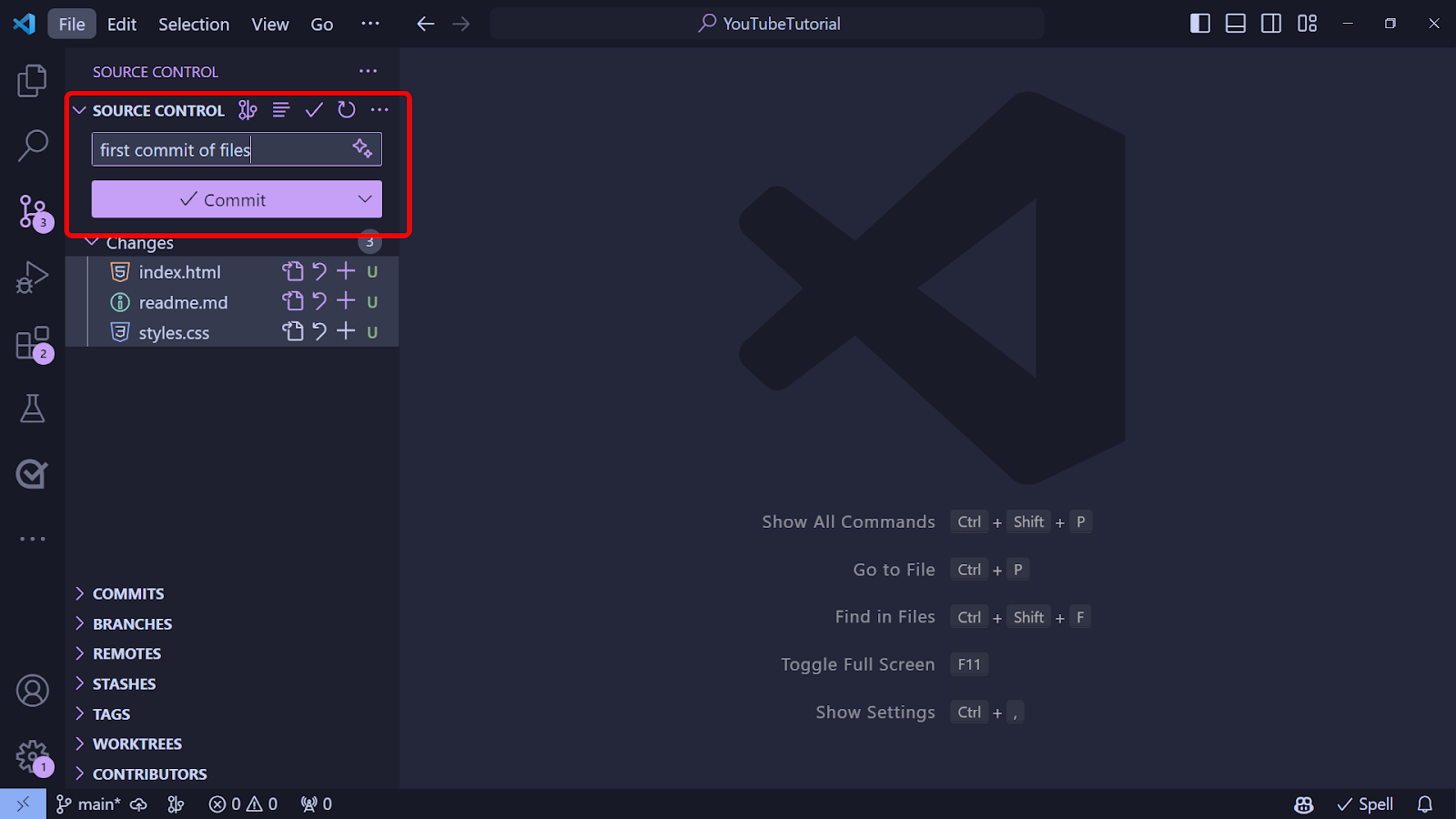
_Commit source code in VS Code_
## Step 4: Push to GitHub
Head over to GitHub.com in your browser and create a new repository.
_Create GitHub repository_
Follow the wizard to set up your repository.
_Create GitHub repository_
Once created, copy the repository's URL from the quick setup section.
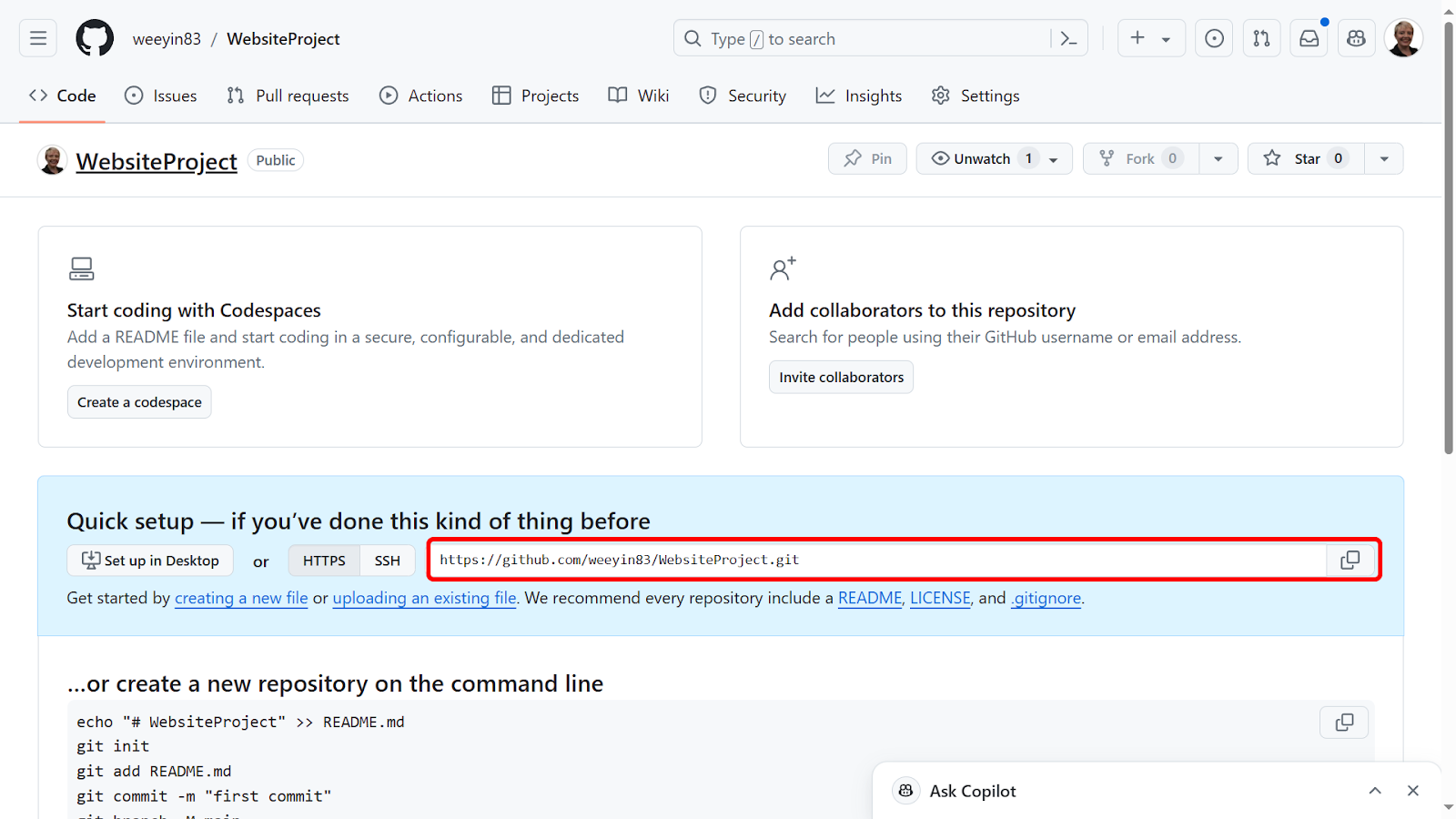
_Copy GitHub url_
Switch back to your VS Code editor. Click on the ellipsis (...) in the source control view, select Pull/Push from the drop-down menu, and choose Push to.
_Push code from VS Code to GitHub_
You will be prompted that the repository has no remotes to push to, click on the "add remote" button.
_Push code from VS Code to GitHub_
Paste the URL you copied from GitHub and give it a name.
_Push code from VS Code to GitHub_
VS Code will now display a button allowing you to push your code into GitHub. Click on the "Publish Branch" button to complete the process.
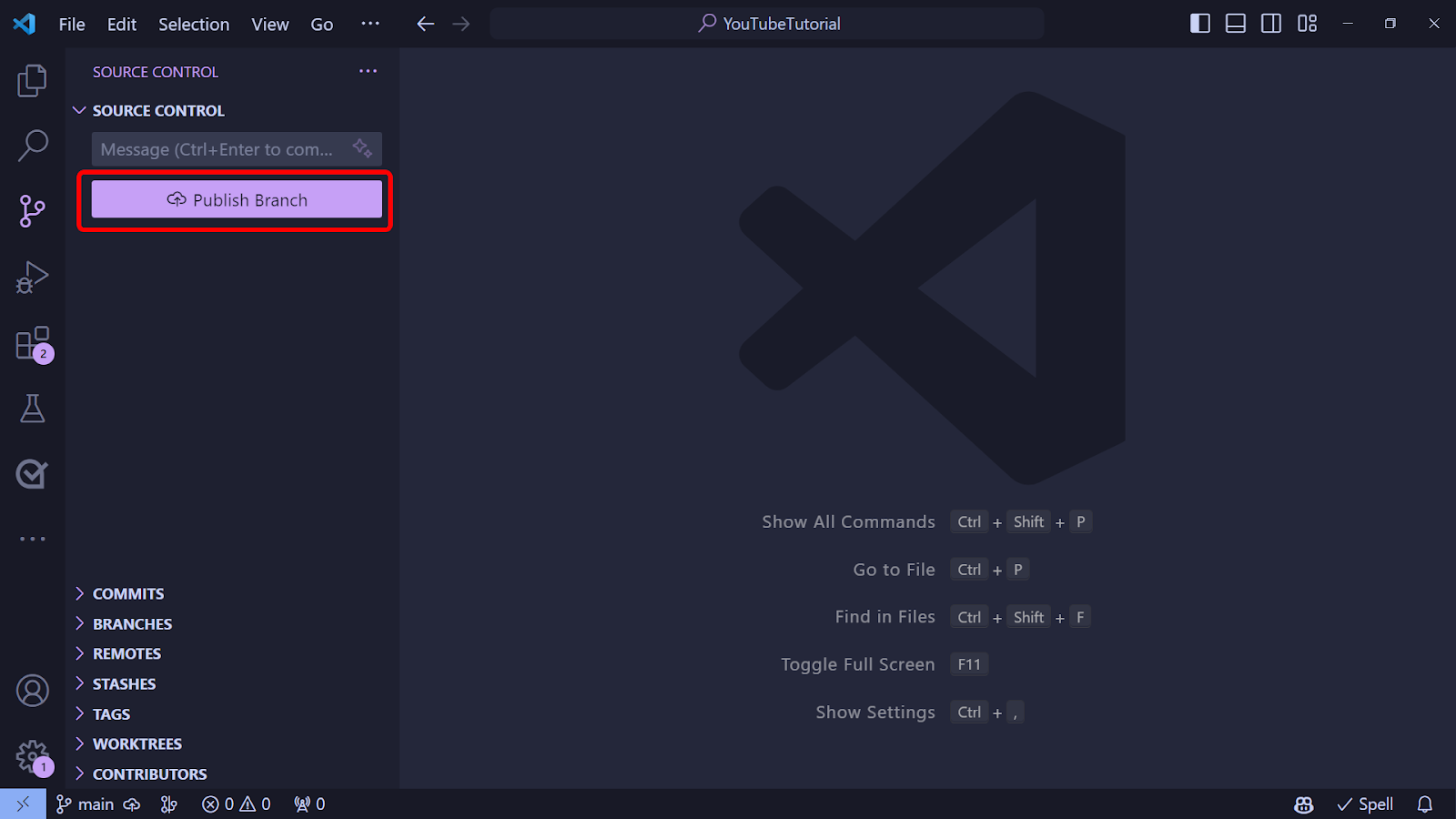
_Push code from VS Code to GitHub_
## Step 5: Verify on GitHub
Your code is now pushed to GitHub! You can head over to your GitHub repository in the browser and refresh the page to see your code there.
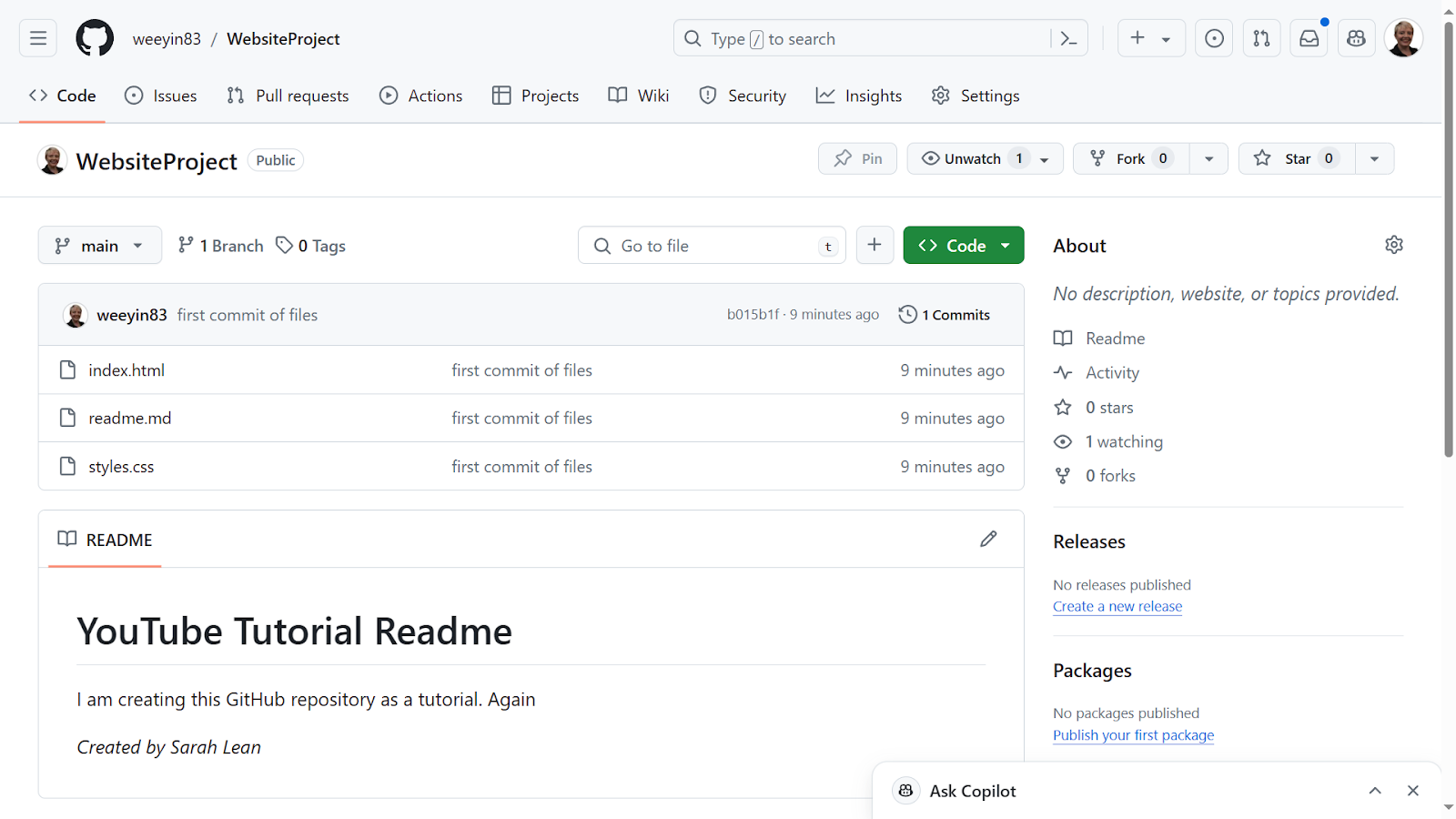
_View code in GitHub_
Congratulations! You've successfully pushed your Visual Studio Code project to GitHub. From here, you can continue making changes to your code, committing them, and syncing them to GitHub. Remember, mastering this process is essential for collaborating with others and managing your code effectively. Happy coding! | techielass |
1,864,064 | What is Alpha Testing: Overview, Process, and Examples | Alpha testing is a procedure that helps developers find and address faults in their software... | 0 | 2024-05-24T14:18:06 | https://dev.to/devanshbhardwaj13/what-is-alpha-testing-overview-process-and-examples-bdi | alpha, testing, software, programming | Alpha testing is a procedure that helps developers find and address faults in their software products. It is comparable to [user acceptance testing](https://www.lambdatest.com/learning-hub/user-acceptance-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=learning_hub), another kind of quality control. The main goal of Alpha test is to fine-tune a software product by uncovering and fixing faults that were not addressed during the initial phases of development.
While developing new software applications, many organizations overlook conducting Alpha tests. It focuses on particular product areas to detect and correct flaws missed during software development.
## What is Alpha Testing?
Alpha testing is the way to determine whether a product meets its performance standards before it is released. It is carried out by the product developers and engineers, who are familiar with the product’s expected functions. This is followed by [beta testing](https://www.lambdatest.com/blog/beta-testing-apps/?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=blog), in which a sampling of the intended audience tries the product out.
Alpha tests is considered a type of user [acceptance testing](https://www.lambdatest.com/learning-hub/acceptance-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=learning_hub). It’s designed to refine software products by finding and fixing bugs that have escaped notice during previous tests.
Alpha is the first software testing phase, which takes place very early in the development cycle. Software engineers perform it to identify any flaws in the design of a program before it enters beta testing, where other users interact with it for the first time. The term “Alpha” comes from a tradition in which code is labeled alphabetically. It is usually performed using [white box testing](https://www.lambdatest.com/learning-hub/white-box-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=learning_hub) and [black box testing](https://www.lambdatest.com/learning-hub/black-box-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=learning_hub) techniques.
> Explore the power of [Cypress Cloud](https://www.lambdatest.com/cypress-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage) for seamless testing automation.
## Objectives of Alpha Testing
It is important to know what you are looking for and why you are looking for it when performing Alpha testing. If the data obtained from this testing is not actionable, it would be better to find out as soon as possible in the development cycle so that further time and money do not need to be spent on unnecessary tests. The following lists some objectives of Alpha test.
* It is a crucial stage in the development process, where software engineers identify and fix problems with the product before it is released to the public.
* To involve customers in the development process so that they can help shape the product.
* To verify the reliability of software products at the early stages of development.
## Advantages of Alpha Testing
The advantages of Alpha tests in software engineering include:
* Provides crucial insights into the dependability of the software while also shedding light on the potential issues that could arise.
* Helps the software team gain confidence in their product before releasing the application in the market.
* It frees up your team to focus on other projects.
* Early feedback from Alpha testers helps companies to improve the quality of their products.
* It allows developers to get user feedback, which benefits the design process. This process also helps stakeholders determine which features of a new piece of software to optimize.
> Enhance your testing strategy with [Playwright Test](https://www.lambdatest.com/playwright?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage) and achieve better results.
## Disadvantages of Alpha Testing
The disadvantages of Alpha testing in software engineering include:
* If the defects stay uncovered, they will remain in the software application. The primary purpose of Alpha tests is to test users’ reactions to the application, not to find defects.
* It replicates the production environment, but some defects arise because of environmental issues. These issues don’t exist in the production environment, so they’re not present in Alpha tests.
* When it comes to small-size projects, Alpha tests is not necessary. Time and money are proportional in an IT project. Furthermore, increasing the budget increases the project implementation period.
* For large projects that have already undergone rigorous testing, performing Alpha tests on them can be time-consuming. Due to a very high probability of bugs, a proper test plan and documentation work need to be done, which indirectly is a reason for the release delay.
## Phases of Alpha Testing
Alpha testing consists of two phases:
* **Phase 1:** Software engineers use debugging tools in the first phase to improve the process and find all bugs as quickly as possible. The main aim is to ensure the software works according to plan.
* **Phase 2:** The quality assurance team conducts the second testing phase, including black box and white box testing. The primary purpose is to discover bugs that escaped previous tests.
By doing so, the quality assurance team can fix any bugs in the system just before releasing it for beta testing; this ensures the program’s quality will be high when it reaches the end user.
## Alpha Testing Process
Alpha testing has the following process:
* **Requirement Review:** In the first stage of this process, the developers and engineers must evaluate the specification and functional requirements design and recommend changes.
* **Test Development:** Test development is based on the result of the required review. The [test plan](https://www.lambdatest.com/learning-hub/test-plan?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=learning_hub) and [test cases](https://www.lambdatest.com/blog/17-lessons-i-learned-for-writing-effective-test-cases/?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=blog) are created based on the review’s outcome, which shows how testing will occur.
* **Test Case Design:** In this stage, the execution of the developed test plan and test case takes place.
* **Logging Defects:** As part of the debugging process, the identified bugs are logged. Logging the identified and detected bugs can help developers spot recurring bugs and suggest fixes.
* **Fixing the Bugs:** Once defects and bugs are identified by the testers, they are logged, and steps are taken to fix them.
* **Retesting:** After the identified bugs are fixed, testers retest the product to find out any unidentified or new bugs or errors.
> Learn the best practices for [testing web](https://www.lambdatest.com/learning-hub/web-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage) applications with our comprehensive guide.
## Alpha Testing vs. Beta Testing
Here is a detailed comparison between Alpha and Beta testing.
> Discover the best [android emulator for ios](https://www.lambdatest.com/blog/android-emulators-for-ios/?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage) to streamline your development process.
## How to Perform Alpha Testing?
Testing should be considered an ongoing process that begins when the requirements for a system are first defined and continues until the system is no longer in use, even if it does not get formal testing activities every day or week. Testing can include both functional and non-functional tests, but not all types of tests can be performed at this stage.
Alpha tests should only be done after a product has passed unit and integration testing. A group of users, including end users and developers, should test the product before beta testing starts. This group of users should not be limited to one or two testers. The more testers involved in alpha test, the better chances that bugs will be found early enough to correct before they become serious problems.
Instead of trying to test your website on every device and operating system your audience uses, consider using a cloud-based [testing infrastructure](https://www.lambdatest.com/learning-hub/test-infrastructure?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=learning_hub) like LambdaTest.
LambdaTest’s [real device cloud](https://www.lambdatest.com/real-device-cloud?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage) offers 3000+ real browsers, devices, and OS for manual and [automation testing](https://www.lambdatest.com/automation-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage). This extensive range allows you to check how your website or app renders and works on different browsers, devices, and OSes. Using LambdaTest’s automation cloud, you can achieve faster [test execution](https://www.lambdatest.com/learning-hub/test-execution?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=learning_hub) speed and developer feedback thereby reducing overall costs related to fixing problems later in the software development cycle.
With the LambdaTest automation testing platform, you can automate [web testing](https://www.lambdatest.com/web-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage) with various [automated testing tools](https://www.lambdatest.com/blog/automation-testing-tools/?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=blog) like [Selenium](https://www.lambdatest.com/selenium?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage), Cypress, [Playwright](https://www.lambdatest.com/playwright-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage), Puppeteer, TestCafe, Appium, Espresso, etc.
{% youtube jrgx_3gfWVA %}
Subscribe to the LambdaTest YouTube channel and stay updated with the latest tutorials around [Selenium testing](https://www.lambdatest.com/selenium-automation?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage), [Cypress testing](https://www.lambdatest.com/cypress-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage), CI/CD, and more.
> Use our [online emulator android](https://www.lambdatest.com/android-emulator-online?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage) to test your apps across different devices.
## Alpha Testing Best Practices
After discussing the process of performing Alpha tests, here are a few best practices to make the most out of it:
* **Recording Every Issue:** It’s a good idea to record everything during your Alpha test because you may want to return to these issues later, or they might be ready for post-release evaluation.
* **Don’t Rely Completely on Beta Testing:** Testers might find the same issues during Beta testing as during Alpha testing. But there is no certainty of finding the same problems. However, the more issues and bugs are identified and resolved during Alpha tests, the more superior the product will be perceived by public beta testers.
* **Examine the Specifications:** Before starting Alpha tests, It is crucial to review the operational and testing requirements. Doing this provides meaning and purpose for all the effort while providing general common knowledge.
* **Monitor Full Customer’s Experience:** The developed test cases should cover an actual user’s complete experience of engaging with the product. A product may perform, but it may not be useful for a more extensive dealing with all the issues.
* **Involve Non-technical Team Members:** When it comes to testing, technical people can be more lenient with bugs and application issues c ompared to non-technical and daily users. Thus, involving non-technical people in Alpha tests can give a deeper look into the usability and performance issues.
> Try our [android online emulator](https://www.lambdatest.com/android-emulator-online?utm_source=devto&utm_medium=organic&utm_campaign=apr_05&utm_term=bw&utm_content=webpage) for efficient and accurate testing.
## Wrap Up!
Alpha testing is a vital phase in the software development lifecycle. It involves testing the functionality of a software product in a real environment and achieving confidence in its users’ acceptance of the product before releasing it into the market.
| devanshbhardwaj13 |
1,864,063 | How to Send i18n HTML Emails from Scripts Using React Email | Introduction React Email is a convenient tool that allows you to design HTML emails using... | 0 | 2024-05-24T14:05:24 | https://dev.to/femtowork/how-to-send-i18n-html-emails-from-scripts-using-react-email-3lea |
### Introduction
[React Email](https://react.email/) is a convenient tool that allows you to design HTML emails using React components. It supports styling with Tailwind and can automatically convert to Plain Text for email clients that don't support HTML emails, making it easier to manage emails. There are a few configurations required when sending emails using React Email from a script(such batch script), and I will share the idea here.
### Challenges
- TypeScript constraints
Since we need to handle React components, errors occur in `.ts` files.
- i18n settings
If the email content is multilingual, i18n-related settings are required.
### Solutions
- Change the script extension to `.tsx`
With the [tsx](https://www.npmjs.com/package/tsx) command, it is possible to execute `.tsx` files.
```
npm exec tsx ./scripts/send-mail.tsx
```
- i18n settings
Set up `i18next` and `react-i18next`, then wrap the React component with `I18nextProvider` to render it.
### Example Code
```
// scripts/send-mail.tsx
import path, { join } from 'path'
import { fileURLToPath } from 'url'
import i18next from 'i18next'
import Backend from 'i18next-fs-backend'
import { I18nextProvider } from 'react-i18next'
import { renderAsync } from '@react-email/components'
import EmailComponent from './EmailComponent'
const lang = 'en'
const namespaces = ['common', 'mail']
const __dirname = path.dirname(fileURLToPath(import.meta.url)) // current directory
await i18next.use(Backend).init({
ns: namespaces,
lng: lang,
backend: {
loadPath: join(__dirname, '../public/locales/{{lng}}/{{ns}}.json'), // locale file path
},
})
const t = i18next.t // usable as the t function
const { html, text } = await renderReactEmail(
<I18nextProvider i18n={i18next}>
<EmailComponent />
</I18nextProvider>
)
// Send mail using html and text
async function renderReactEmail(react: ReactElement) {
const [html, text] = await Promise.all([
renderAsync(react),
renderAsync(react, { plainText: true }),
])
return { html, text }
}
```
### Conclusion
We introduced a method for sending multilingual React emails from a script. | femtowork | |
1,862,883 | Game Development Diary #4 : First Course Complete | 24/05/2024 - Friday Today Progress : -Continue Collision Detection Detect... | 27,527 | 2024-05-24T14:05:18 | https://dev.to/hizrawandwioka/game-development-diary-4-first-course-complete-2anf | godot, godotengine, gamedev, newbie | 24/05/2024 - Friday
#Today Progress :
###-Continue Collision Detection
Detect RigidBody collisions with signals and identify bodies with Groups
first connect signal to method by clicking this menu
```
func _on_body_entered(body: Node) -> void:
if body.name == "LandingPad":
print('you touch landingpad!')
```
use this code to detect if the character touch the destination or not
and add detection if user touch the floor then the user lose using the code below
```
func _on_body_entered(body: Node) -> void:
if "Goal" in body.get_groups():
print('you touch landingpad!')
if "LoseCondition" in body.get_groups():
print('You Lose!')
```
###-The Export Annotation
Replace ‘magic numbers’ with variables and control them from the inspector.
export a variable so it can be used in the inspector pane
```
## How much vertical force to when user move the character
@export_range(750.0,3000.0 ) var thrust: float = 1000.0
## How much force to when user move the character
@export_range(50.0,250.0 ) var torque: float = 100.0
```
and it will show in the inspector toolbar
###-Crashing and Respawning
Use functions and get_tree() to respawn when crashing.
```
func _on_body_entered(body: Node) -> void:
if "Goal" in body.get_groups():
complete_level()
if "LoseCondition" in body.get_groups():
crash()
func complete_level():
print('you touch landingpad!')
get_tree().quit()
func crash():
print('JEDER BOOM DUAR!!')
get_tree().reload_current_scene()
```
i create two function that called when user touch floor or landing page. and i called get_tree function to reload the current scene or quit the game.
###-Loading the Next Level
Making two new levels and using the landing pads to load them.
1. First i create the other level scene
2. On the previous level landing page, create script to select thescene destination
```
extends CSGBox3D
@export_file("*.tscn") var file_path
```
on the toolbar, select the next level file path
and we can continue to next level if we landed in the launching pad.
###-Learning Tweens
Use tweens to sequence and delay function calls.
```
func complete_level(next_level: String) -> void:
print('you touch landingpad!')
set_process(false)
is_transitioning = true
var tween = create_tween()
tween.tween_interval(1.0)
tween.tween_callback(
get_tree().change_scene_to_file.bind(next_level)
)
func crash():
print('JEDER BOOM DUAR!!')
set_process(false)
is_transitioning = true
var tween = create_tween()
tween.tween_interval(1.0)
tween.tween_callback(get_tree().reload_current_scene)
```
add tween to delay the function. so it give 1 second delay after the character touch the landing page or crash.
###-Tweening Hazards
Use the AnimatableBody3D node and Tweens to create moving obstacles for the player to dodge.
so the code will lookike this :
```
@export var destination:Vector3
@export var duration: float = 1.0
# Called when the node enters the scene tree for the first time.
func _ready() -> void:
var tween = create_tween()
tween.tween_property(self, "global_position", global_position+destination, duration)
```
###-Learning Audio
Use the AudioStreamPlayer node to play one off sound effects when the player crashes and completes levels.
###-Controlling Audio With Scripts
Use the AudioStreamPlayer 3D and else statements to play sounds when the player is boosting.
###-Learning Particles
Learning how to use the GPUParticles3D node and control its emitting property for the character boosters.
###-One Shot Particles
Learn how to use one shot particles for an explosion and to show the player has reached the goal.
###-change the character with complex shape / model
Use the MeshInstance3D node and a variety of shapes to customize your player rocket
###-Coloring the character
Saving and reusing the StandardMaterial3D node to color in the player ship.
###-Building Backgrounds
Learning to use Constructive Solid Geometry to build walls and background objects for our levels.
###-Lighting the Scene
Improving the WorldEnvironment DirectionalLight3D and adding Omnilights to improve the levels appearance.
###-Exporting Game
Learn how to create files players can run by downloading templates and exporting the project.
#Resources :
Complete Godot 3D: Code Your Own 3D Games In Godot 4! - GameDevTv Courses
#Next Step :
I will implement all knowledge I gain from this course to start developing my game!!
To Do List :
*Create a level, just simple plane with some obstacles(just basic shapes).
*Implement collision detection to the level.
*Create 3 Main Character according to the novel(Just use capsule first until I get the 3d model that suitable for the game - because I am not good at art, but I will try to create by myself first.)
*Use Input Mapper to create a button that can switch the playable character.
*After I complete all item in the To Do List, I will continue the courses. | hizrawandwioka |
1,864,062 | The need for AI-enabled Chatbots for healthcare systems | As healthcare systems strive for better efficiency and patient care, the need for AI-enabled... | 0 | 2024-05-24T14:02:41 | https://dev.to/traceypure/the-need-for-ai-enabled-chatbots-for-healthcare-systems-2moi | healthcaresystem, chatbots, ai | 
As healthcare systems strive for better efficiency and patient care, the need for AI-enabled applications becomes increasingly apparent. AI-enabled chatbots are necessary for every healthcare centre and offer a potential solution to many operational challenges.
AI (Artificial intelligence) is a term used to describe computing systems that mimic human intelligence. When fed with data and specific algorithms, these systems can make more accurate judgements than an average working human. AI-enabled chatbots are one of the many applications of this technology, particularly relevant in the healthcare industry for its extraordinary clinical data services.
How can a computer program understand and respond to human language? This article delves into the fascinating world of AI-enabled chatbots, discussing their workings and why they are an excellent fit for [clinical data management solutions](https://www.puresoftware.com/research-and-development/clinical-data-management) in the medical industry.
Continue reading to uncover the potential of this technology!
## AI-Enabled Chatbots
AI chatbots are fed input data, an algorithm that matches the input data to the desired output, and a self-learning program that makes it learn from its mistakes and rewards it for its accuracy. The whole set-up is done so that if a visitor asks a question to the chatbot, it analyzes their intent and other factors like tone and sentiment. After examining the input, the chatbot attempts to deliver the best possible answer using the predefined keywords/ phrases it has been programmed to recognize.
AI-enabled chatbots use NLP (natural language processing) to understand the query and give an answer. NLP itself works in two processes: NLU and NLG.
- Natural Language Understanding (NLU) is the process of converting text into structured data so that machines can understand it.
- Natural Language Generation (NLG) is the process of converting structured data back into text that humans can understand.
##Need for AI-Enabled Chatbots for Healthcare Systems
Chatbots — powered by AI and natural language processing- are in great demand in healthcare systems because they can easily understand patient queries and answer/connect them to the most relevant output. These chatbots are more intuitive and responsive tools for patient care. With these bots, healthcare systems offer better and quicker responses to the patient's query.
Next-generation AI chatbots are also one of the best clinical data management solutions. Beyond voice-enabled chatbots or general virtual assistants, GenAI chatbots can produce/ or take images, sounds, and high-quality texts. They only need training on large language models (LLMs). They feed the patient's medical history to the medical system database with little or no serviceman help, freeing them from other tasks that need human intervention. The doctor can further check the recorded data, saving them from manual work.
Here is a quick overview of other benefits of implementing health chatbots for [clinical data services](https://www.puresoftware.com/research-and-development/clinical-data-management):
- AI-enabled chatbots handle an increasing number of patient queries. These chatbots can offer basic solutions and health tips to patients, like information on the consumption of medicines in the absence of doctors.
- Health chatbots can schedule in-person or video appointments with doctors from home, as patients can submit all the necessary details online.
- Next-gen AI chatbots access patients' symptoms to suggest the appropriate treatment. Their suggestions are accurate, and offer immediate assistance when a doctor is unavailable.
- Healthcare chatbots can be set to remind patients about their vaccinations. They alert the patient when it's time to get vaccinated and flag important vaccinations to have if the patient is travelling to certain countries.
- Health chatbots have been of tremendous help in providing mental health assistance. This is especially true for rural areas. Here, mental health resources are scarce, or people experience a crisis in the middle of the night, usually when "doctors" are not available.
- AI chatbots reduce waiting time, and with round-the-clock availability, patients have instant access to medical assistance whenever needed.
Though many patients appreciate receiving help from a human assistant, health chatbots greatly help those reluctant to share their information with a doctor. Chatbots are seen as non-human and nonjudgmental. Patients feel more comfortable sharing certain medical information, like checking for STDs, mental health, sexual abuse, and more. Health chatbots keep their information private and maintain anonymity.
While health chatbots greatly help, businesses must take care of [application management services](https://www.puresoftware.com/research-and-development/application-management-services) to avoid interruptions and delays. If you, too, are interested in installing a customized health chatbot for your healthcare system, Puresoftware is here to help. We offer customized app development for healthcare professionals and are available 24/7 for technical guidance.
## Conclusion
The healthcare sector continuously aims to improve population health, improve the patient's care experience, enhance the caregiver experience, and reduce the rising cost of health care. Health chatbots seem a great fit for achieving these goals!
Healthcare chatbots standardise a future of connected and AI-augmented care, precision diagnostics, precision therapeutics, and precision medicine. AI health chatbots can also be integrated into wearable devices, making access to healthcare even easier.
| traceypure |
1,862,848 | 5 exciting open-source launches you might have missed | Hey friends 👋 Every week, our team at Quine scans the open-source ecosystem for great projects to... | 0 | 2024-05-24T14:02:00 | https://dev.to/quira/5-exciting-open-source-releases-you-might-have-missed-5gg6 | webdev, programming, productivity, opensource | Hey friends 👋
Every week, our team at Quine scans the open-source ecosystem for great projects to discuss.
For this week's article, we curated a list of the latest open-source launches!
---
If this is your first time reading our content, a warm welcome! My name is Bap, and I'm the DevRel Lead at Quine. 👋
At Quine, we are constantly on a quest to discover the hidden gems within the open-source ecosystem! Talking about Quests, we released _Creator Quests_, an initiative inviting developers to build a coding project around a specific theme.
Our latest Quest, `quest-012`, invites you to build an app (or leverage an existing open-source repo of yours) and utilise [Shepherd](https://shepherdjs.dev/)'s powerful customisations to create a dynamic user journey in your product.
**The event is open to any developer ready to leverage their skills & creativity to win cash prizes.** 💰
If you enjoy building, learning, and winning rewards for coding exciting projects, head to [Quine](https://quine.sh/quests/creator) and get cracking!
Having said that, let us now explore the latest launches in open-source. 👇

---
## [qrev-ai/qrev](https://github.com/qrev-ai/qrev/)
If Salesforce were built today with AI at its core, it would look like QRev. However, Salesforce is pricey and slightly more difficult to customise. QRev aims to be different, leveraging AI Agents at its foundation.
**This project is perfect if you want to:**
- Work with AI and digital workers for sales roles
- Customise a flexible and cost-effective sales tool
- Use tech stacks like Typescript, NodeJS, and MongoDB
**Here's what QRev offers:**
- Digital workers mimicking real sales roles
- AI-driven sales automation
- Integration with various databases and AI tools
[](https://github.com/qrev-ai/qrev/)
---
## [middlewarehq/middleware](https://github.com/middlewarehq/middleware)
There's a powerful tool for engineering leaders called "Middleware." It's perfect for those wanting to measure and analyse team effectiveness using DORA metrics without complex setups. Middleware is an open-source project that automates DORA metrics collection and analysis.
**This is a great project if you want to:**
- Improve software delivery performance
- Work with CI/CD tools
- Use Docker and Gitpod
**Middleware offers:**
- Integration with CI/CD tools
- Automated DORA metrics analysis
- Customisable reports and dashboards
[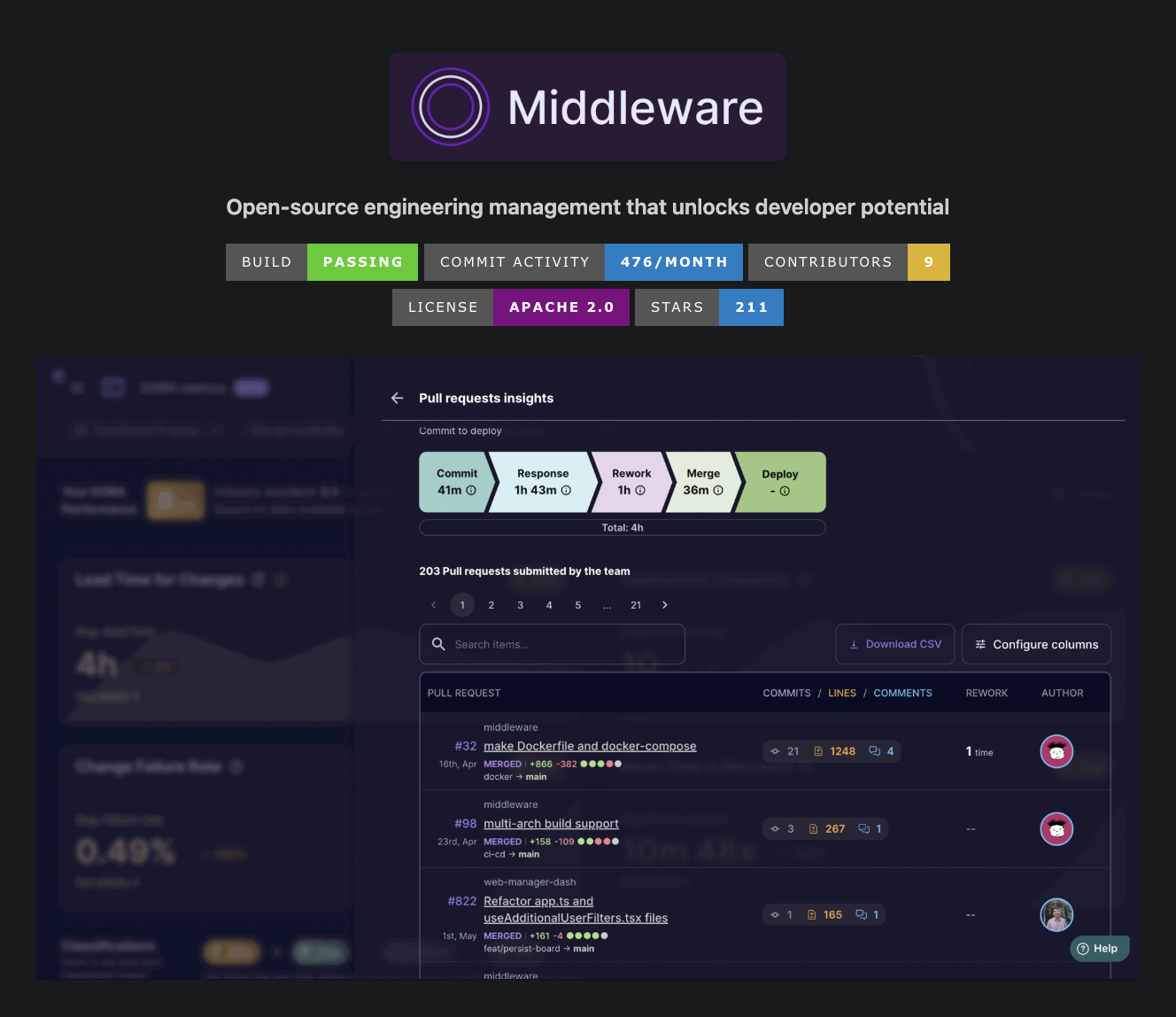](https://github.com/middlewarehq/middleware)
---
## [unifyai/unify](https://github.com/unifyai/unify)
The Unify Python Package provides access to the Unify REST API, allowing you to query Large Language Models from any Python 3.7.1+ application. It includes synchronous and asynchronous clients with support for streaming responses.
**This is a great tool if you want to:**
- Access multiple LLMs with a single API key
- Route queries to the best endpoint based on throughput, cost, or latency
- Use synchronous and asynchronous API calls
**Here's what Unify offers:**
- One API key for all endpoints
- Dynamic routing to the optimal endpoint
- Synchronous and Asynchronous clients
- Streaming responses support
[](https://github.com/unifyai/unify)
---
_The last two repositories were meticulously developed earlier and have recently made a significant push in their marketing initiatives this past month._ 👀
---
## [nocobase/nocobase](https://github.com/nocobase/nocobase)
NocoBase is a scalability-first, open-source no-code development platform. Deploy NocoBase in minutes to have a private, controllable, and highly scalable no-code development environment.
**This project is perfect if you want to:**
- Create complex and flexible data models
- Use a WYSIWYG interface for configuration
- Extend functionality with plugins
**Here's what NocoBase offers:**
- Data model-driven architecture
- WYSIWYG (_What you see is what you get_) configuration
- Plugin-based functionality expansion
[](https://github.com/nocobase/nocobase)
---
## [Baseline-JS/core](https://github.com/Baseline-JS/core)
BaselineJS is an open-source, fullstack TypeScript, serverless-first framework designed to simplify building cloud-native applications. This framework uses modern technologies, architectures, and operational processes to help teams build and deploy robust applications efficiently.
**This project is perfect if you want to:**
- Build cloud-native applications with ease
- Utilise a full-stack serverless framework
- Leverage modern tech stacks like TypeScript and AWS
**Here's what BaselineJS offers:**
- Comprehensive API
- React-based Admin and User Websites
- Integrated CI/CD
- Developer tooling and authentication
- Support for multiple environments
- Local development capabilities
- Infrastructure as Code with AWS
[](https://github.com/Baseline-JS/core)
---

If you are an open-source company that launched recently, make sure to add your repository in the comment below! 🙂
Finally, if you want to join the self-proclaimed "coolest" server in open source 😝, you should join our [discord](https://discord.com/invite/ChAuP3SC5H/?utm_source=devto&utm_campaign=exciting_repos_end_of_may_2024). We are here to help you on your journey in open source. 🫶
{% embed [https://dev.to/quine](https://dev.to/quine) %}
| fernandezbaptiste |
1,864,061 | How to transfer forked repository which original is private in GitHub | I'm Tak, Software engineer. GitHub Transfer, Is a Very useful feature. So you can easily transfer... | 0 | 2024-05-24T14:00:16 | https://dev.to/takahiro_82jp/how-to-transfer-forked-repository-which-original-is-private-in-github-8gg | github, git, devops, sre | I'm Tak, Software engineer.
GitHub Transfer, Is a Very useful feature.
So you can easily transfer the repository to another account.
1. click "Settings" in GitHub repository
2. click "Transfer"
3. Select the new owner account
4. click "I understand, transfer this repository"
It's so easy.
In addition settings, wiki, and issues can be automatically transferred.
And of course, you can transfer forked repository.
But if the original repository is private, you can not transfer the forked repository.
You read the official document.
https://docs.github.com/en/repositories/creating-and-managing-repositories/transferring-a-repository
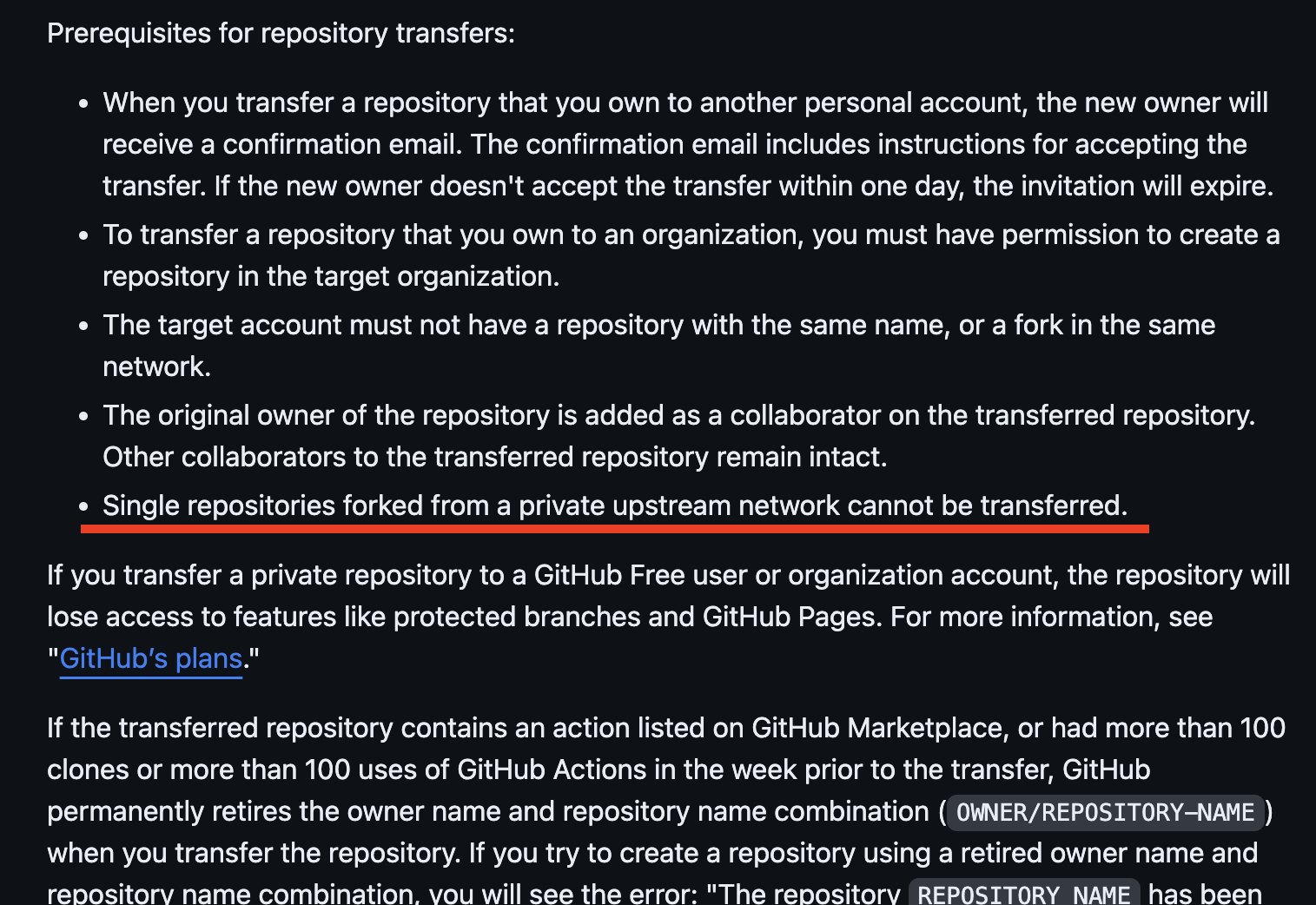
Oh...how do I transfer...
Don't worry, there is a solution.
First, you detach forked repository from private original, so you transfer repository.
You use GitHub Support.
https://support.github.com/request/fork
You select "detach forked".
Next, you contact GitHub Support.
The support ticket title is "Detach Fork".
The support ticket message is
```
In the below repository, I'd like to unfork and turn it into a standalone repository.
* https:// want to detach repository url
and I never merge to this repository.
* https:// original private ripojitory url
```
8 hours later, GitHub Support detach repository.
But there is condition, so You have administrator role in original ripository Github account.
If you don't have administrator role, original ripository Github account administrator contact GitHub Support, so detach repository.
Finally, you can transfer repository.
It's a little tough.
But this article will help you.
Thanks to read this article. | takahiro_82jp |
1,862,737 | The Missing Piece Your AI-Powered App Needs! | Hey everybody, Kais here! I've been working on an open-source project for a while and am excited to... | 0 | 2024-05-24T13:57:04 | https://dev.to/kais_rad/the-missing-piece-your-ai-powered-app-needs-3m98 | ai, opensource, programming, javascript | **Hey everybody, Kais here!**
I've been working on an open-source project for a while and am excited to tell you about it.
Lately, I've been integrating LLM-powered features into applications and found the process complex and time-consuming. From dealing with unexpected LLM outputs to constant data validation struggles and managing LLM flow, history, and server-client interactions—it can be a real headache.
That’s why I built [Scoopika](https://scoopika.com), an open-source platform that helps you integrate reliable AI agents into your applications effortlessly. These agents can collaborate and access external tools, all without the hassle.
## Key Features of Scoopika
Here are some powerful features Scoopika offers out of the box and totally for free:
- **Custom AI Agents**: Build AI agents that can collaborate, use external tools & APIs, and access real-time data based on context.
- **LLM Output Validation**: Ensure full type-safety with LLM output validation.
- **Real-Time Streaming**: Stream agent responses in real-time with over 10 hooks that work on both server and client-side with no additional setup.
- **Client-Side Actions**: Empower agents to perform actions in the user's browser in real-time for a next-level user experience.
- **Managed Sessions & History**: Keep track of conversations and maintain session history easily.
- **Secure API Keys**: Connect your LLMs with your API keys safely stored on your servers.
## Getting started
Let’s see how to get started with building AI agents using Scoopika.
1. [Create a Free Account](https://scoopika.com/login): Go to the Scoopika platform and sign up for a free account.
2. [Create Your Agent](https://scoopika.com/app?new=y): Simply give your agent a name, description, avatar, and prompt. You can choose the LLM powering your agent from a variety of available providers and models.
3. [Generate a Token](https://scoopika.com/settings?tab=tokens): Go here to generate a token for your agent.
## Run agent
First, install the Scoopika package:
```bash
npm install @scoopika/scoopika
```
Then, initialize Scoopika and run your agent in your code:
And that’s it! Now you have an agent running on your server with all the built-in features mentioned above.
## Web integration
We provide guides and examples for specific frameworks [here](https://docs.scoopika.com/guides).
If you want to use agents on the client-side, you need to create an API that uses the Scoopika container to handle requests with built-in caching and can communicate with the Scoopika client library. Here’s a simple example of creating a full API with Express:
Now you’re good to go! You can run your agents, manage sessions, and more, all from the client-side thanks to the route we added.
First, install the Scoopika client library:
```bash
npm install @scoopika/client
```
Then, see the code to run an agent:
## Further exploration
I highly recommend you check out the [documentation](https://docs.scoopika.com) to learn more about equipping agents with tools, running multi-agent boxes, and adding agents as tools to other agents.
## Got questions?
Feel free to [contact us](https://docs.scoopika.com/help/contact-us) at anytime ;) | kais_rad |
1,864,059 | Build a Powerful Video Processing Pipeline with AssemblyAI and Deploy it to Koyeb | In the digital era, video is the king, demanding innovative solutions for efficient processing and... | 0 | 2024-05-24T13:55:37 | https://www.koyeb.com/tutorials/build-a-video-processing-pipeline-with-assemblyai-on-koyeb | ai, webdev, tutorial, django | In the digital era, video is the king, demanding innovative solutions for efficient processing and distribution.
This guide introduces a powerful approach using Koyeb's cloud services to build a scalable video processing pipeline. We will rely on secure protocols for video uploads, employ AI-driven tagging and classification via AssemblyAI, and leverage Koyeb's built-in CDN technology for global content distribution. Embrace the power of serverless architecture to meet the growing demand for video content, ensuring optimal performance and viewer satisfaction.
You can follow along with this guide by viewing the GitHub repositories for the [video web app](https://github.com/koyeb/example-video-processing-app) and the [video worker service](https://github.com/koyeb/example-video-processing-worker).
## Requirements
Before diving into building your video processing pipeline with Koyeb, it's important to ensure that you have the necessary tools and knowledge. This section outlines the prerequisites needed to follow the upcoming guide successfully.
- A [Koyeb account](https://app.koyeb.com/auth/signup) will be required for deploying. It will be helpful to have a foundational understanding of its service offerings (web service and database, in this case).
- An [AssemblyAI API key](https://www.assemblyai.com/dashboard/signup) to integrate AI-driven video tagging and classification capabilities. **Note:** You will need to add credit to your account to use the LLM features implemented in this guide.
- Knowledge of Python programming for scripting and automation within the serverless architecture.
- Experience with Django for developing robust, scalable web applications that interfaces effectively with back-end services.
## Steps
1. [Set up the database](#set-up-the-database): This step involves setting up a database service on Koyeb to store and manage video metadata. This database will be used by the web application to store and access data.
2. [Build the web application](#build-the-web-application): This section guides you through developing a simple web application for video uploads along with features to view and search videos. The application is built with Django.
3. [Build the worker service](#build-the-worker-service): This step covers implementing a service API that processes the video uploads. The API will incorporate AI technologies from AssemblyAI for tagging, classifying, and potentially transcoding videos. Additionally, the API will utilize Koyeb's autoscaling features to efficiently manage varying video processing loads.
4. [Integrate with Koyeb's edge network](#integrate-with-koyebs-edge-network): This section details how to integrate the web application with Koyeb's edge network to enhance the distribution of video content globally.
## Set up the database
Setting up the database is an important part of this process. This database will be used to keep and organize video metadata, such as video titles, descriptions, lengths, file types, and other important information.
For this article you are going to setup a PostgreSQL database using Koyeb's recent fully-managed serverless PostgreSQL databases feature.
Here's a step-by-step guide on how to set up the database on Koyeb:
1. In the [Koyeb control panel](https://app.koyeb.com/), click **Create Database Service**.
2. Choose alternatives to or confirm the provided defaults for the name and role fields.
3. Choose the region closest to you or your users.
4. Select the database size. If you are not already using it, you can deploy the **Free** tire as the Instance type.
5. Click **Create Database Service**.
Once the database is created, access the database's detail page and there you can check the connection details.
Since you will be using Django later, select **Django** and copy the database connection details. Store this locally somewhere so that you can reference it later. It will look like something like this:
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'koyebdb',
'USER': 'koyeb-adm',
'PASSWORD': <YOUR_DB_PASSWORD>,
'HOST': '<YOUR_DB_URL>.eu-central-1.pg.koyeb.app',
'OPTIONS': {'sslmode': 'require'},
}
}
```
Once you've completed these steps, your database will be ready to store and manage video metadata for your application.
## Build the web application
This part of the guide will show you how to make a simple web application using Django and deploy it to Koyeb. This app will let users upload videos and also provide features to watch for these uploaded videos.
The focus of this article is the end-to-end process, so in this section we will only highlight the code relevant to this process. You can check the full source code in the [project's GitHub repository](https://github.com/koyeb/example-video-processing-pipeline).
### Create a virtual environment and initialize a new project
To get started, create a project directory and then initialize a new virtual environment inside by typing:
```bash
mkdir example-video-app
cd example-video-app
python3 -m venv venv
```
Activate the new virtual environment by typing:
```bash
source venv/bin/activate
```
Install Django within the virtual environment. We'll also install some additional libraries and packages that we'll use in the application while we're here:
```bash
pip install Django requests python-decouple psycopg2-binary Pillow
```
Save the project's dependencies to a `requirements.txt` file by typing:
```bash
pip freeze > requirements.txt
```
With Django installed, create a new Django project called **VideoApp** rooted in the existing project directory (be sure to include the trailing dot to avoid creating an extra directory hierarchy):
```bash
django-admin startproject VideoApp .
```
Next, create a new Django application called **App** that the project will incorporate:
```bash
python manage.py startapp App
```
This will create a new `App` directory alongside the existing `VideoApp` directory.
### Set up the app models
In the `App/models.py` file, you can now define the Django models for the video metadata. Replace the current contents with the following:
```python
# File: App/models.py
from django.db import models
# Model to store video metadata
class Video(models.Model):
title = models.CharField(max_length=100)
description = models.TextField()
video_file = models.FileField(upload_to='videos/')
uploaded_at = models.DateTimeField(auto_now_add=True)
duration = models.DecimalField(max_digits=5, decimal_places=2, null=True, blank=True)
size = models.CharField(max_length=10, null=True, blank=True)
def __str__(self):
return self.title
# Model to store video related tags
class Tag(models.Model):
name = models.CharField(max_length=50)
video = models.ManyToManyField(Video, related_name='tags')
def __str__(self):
return self.name
# Model to store video classification
class Category(models.Model):
name = models.CharField(max_length=50)
video = models.ManyToManyField(Video, related_name='categories')
def __str__(self):
return self.name
```
Here you are defining three database models: `Video`, `Tag`, and `Category`.
The `Video` model is used to store video metadata, including the title, description, video file, upload date and time, duration, and size.
The `Tag` model is used to store video-related tags. It has a many-to-many relationship with the `Video` model, meaning that a video can have multiple tags and a tag can be associated with multiple videos. The `related_name` attribute specifies the name of the reverse relation from the `Video` model back to the `Tag` model.
The `Category` model is used to store video classifications. It also has a many-to-many relationship with the `Video` model, meaning that a video can belong to multiple categories and a category can contain multiple videos. The `related_name` attribute specifies the name of the reverse relation from the `Video` model back to the `Category` model.
## Create a video upload form
In order to be able to upload any videos, you need to have a form defined in Django, let's now create that in `App/forms.py`:
```python
# File: App/forms.py
from django import forms
from .models import Video, Tag, Category
# Form for video upload
class VideoForm(forms.ModelForm):
class Meta:
model = Video
fields = ['title', 'description', 'video_file']
```
The `VideoForm` is a `ModelForm`, a special form created from a Django model. In this case, the `Video` model is used.
The `Meta` class inside `VideoForm` is used to specify additional metadata for the form. The `model` attribute indicates which Django model this form is associated with, and the `fields` attribute is a list of model fields that should be included in the form. In this case, the form includes fields for `title`, `description`, `video_file`.
The `tags` and `categories`, as well as `duration` and `size` will be filled in later on with the results from the worker service API.
This form will allow users to input data for these fields, which will then be saved as a new `Video` object in the database when the form is submitted.
### Configure the App views
With the form in place, next you can create the view that will handle the form submission. Replace the contents of `App/views.py` with the following:
```python
# File: App/views.py
import requests
from decouple import config
from django.shortcuts import render
from App.forms import VideoForm
from App.models import Tag, Category, Video
# View to handle video upload from the video upload form
def upload_video(request):
form = VideoForm()
if request.method == 'POST':
form = VideoForm(request.POST, request.FILES)
if form.is_valid():
# Save the video
form.save()
# Process the video file with the worker
video_url = config("DOMAIN") + form.instance.video_file.url
worker_url = config("WORKER_URL") + "/process_video?video_url=" + video_url
# Send a GET request to the worker URL
response = requests.get(worker_url)
if response.status_code == 200:
# Get the response data
response_data = response.json()
# Save the video tags
tags = response_data.get('tags')
for tag in tags:
tag, created = Tag.objects.get_or_create(name=tag)
form.instance.tags.add(tag)
# Save the video categories
categories = response_data.get('categories')
for category in categories:
category, created = Category.objects.get_or_create(name=category)
form.instance.categories.add(category)
# Save the video duration and resolution
form.instance.duration = response_data.get('duration')
form.instance.size = response_data.get('resolution')
form.instance.save()
# Return a success message
return render(request, 'upload_video.html',
{'form': form, 'message': 'Video uploaded successfully!'})
else:
# Return the form with errors
return render(request, 'upload_video.html', {'form': form,
'message': 'Error uploading video!'})
return render(request, 'upload_video.html', {'form': form})
def list_videos(request):
videos = Video.objects.all()
return render(request, 'list_videos.html', {'videos': videos})
```
The `upload_video` view function handles the video upload process. When a user submits the video upload form, this function is called to process the form data. It starts by creating an instance of the `VideoForm` with the form data and files. If the form is valid, it saves the video, processes the video file with a worker service, and saves the video metadata (tags, categories, duration, and resolution) returned by the worker service API. If the form is not valid, it returns the form with errors. If the request method is not POST, it simply renders the video upload form.
The `list_videos` view function retrieves all videos from the database and renders them in a template.
### Create the application templates
In order for this view to work, you will need to create the HTML template. Create a new directory for HTML templates:
```bash
mkdir App/templates
```
Inside, create a new file at `App/templates/upload_video.html` with the following content:
```html
<!-- File: App/templates/upload_video.html -->
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Video App</title>
</head>
<body>
<h1>Video App</h1>
<p><a href="{% url 'list_videos' %}">Back to Video list</a></p>
<h3>Upload your video</h3>
<form method="post" enctype="multipart/form-data">
{% csrf_token %} {{ form.as_p }}
<button type="submit">Upload</button>
</form>
{{ message }}
</body>
</html>
```
This HTML markup creates a simple web page for uploading videos.
The video upload form is created using the HTML `<form>` tag. The `method` attribute is set to `post`, which means the form data will be sent to the server using the HTTP `POST` method. The `enctype` attribute is set to "multipart/form-data", which is necessary for forms that allow file uploads. The `{% csrf_token %}` template tag is used to protect against cross-site request forgery attacks.
When the form is submitted, the data is sent to the server and handled by the `upload_video` view function in the `views.py` file. As mentioned earlier, if the form is valid, the video is saved and processed by the worker service, and a success message is displayed. If the form is not valid, an error message is displayed.
You will also need an HTML template to list the videos. Add the following to a `App/templates/list_videos.html` file:
```html
<!-- File: App/templates/list_videos.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Video App</title>
</head>
<body>
<h1>Video App</h1>
<p><a href="{% url 'upload_video' %}">Upload New Video</a></p>
{% for video in videos %}
<video controls width='50%' height='50%'>
<source src="{{ video.video_file.url }}" type="video/mp4"></source>
</video>
<h2>{{ video.title }}</h2>
<p>Description: {{ video.description }}</p>
<p>Tags:
{% for tag in video.tags.all %}
{{ tag.name }},
{% endfor %}
</p>
<p>Categories:
{% for category in video.categories.all %}
{{ category.name }},
{% endfor %}
</p>
<p>Duration: {{ video.duration }} seconds</p>
<p>Resolution: {{ video.size }}</p>
<p>-----</p>
{% endfor %}
</body>
</html>
```
The `{% for video in videos %}` template tag is used to loop through the list of videos passed from the `list_videos` view function in the `views.py` file. For each video, it displays the video player, title, description, tags, categories, duration, and resolution.
The `<video>` element embeds a video player in the web page. The `controls` attribute is used to display the video controls, such as play, pause, and volume. The `width` and `height` attributes are used to set the size of the video player. The `<source>` element is used to specify the video file and its MIME type.
The `{{ video.title }}`, `{{ video.description }}`, `{{ video.duration }}`, and `{{ video.size }}` template tags are used to display the video metadata.
The `{% for tag in video.tags.all %}` and `{% for category in video.categories.all %}` template tags are used to loop through the list of tags and categories associated with the video. The `{{ tag.name }}` and `{{ category.name }}` template tags are used to display the name of each tag and category.
When the web page is loaded, the `list_videos` view function in the `views.py` file is called to retrieve the list of videos from the database and pass it to the template. The template then loops through the list of videos and displays them on the web page.
### Define the URL routing
To access the views and HTML templates, you need to define the URLs, which you can add to `App/urls.py`:
```python
# File: App/urls.py
from django.urls import path
from App import views
urlpatterns = [
path('', views.list_videos, name='list_videos'),
path('upload', views.upload_video, name='upload_video'),
]
```
The `urlpatterns` list contains two `path` objects that map URLs to view functions. The first `path` object maps the root URL ('') to the `list_videos` view function and assigns it the name 'list_videos'. This means that when a user navigates to the `/` URL of the application, the `list_videos` view function will be called to handle the request and render the appropriate response.
The second `path` object maps the 'upload' URL to the `upload_video` view function and assigns it the name 'upload_video'. This means that when a user navigates to the `/upload` URL, the `upload_video` view function will be called to handle the request and render the appropriate response.
Hook the new `App/urls.py` file in to the project URL processing by editing the `VideoApp/urls.py` file as follows:
{/* prettier-ignore-start */}
```python
# File: VideoApp/urls.py
from django.contrib import admin
from django.urls import path # [!code --]
from django.urls import include, path # [!code ++]
from django.conf import settings # [!code ++]
from django.conf.urls.static import static # [!code ++]
urlpatterns = [
path('', include("App.urls")), # [!code ++]
path('admin/', admin.site.urls),
]
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT) # [!code ++]
```
{/* prettier-ignore-end */}
### Adjust the project configuration
Hook the application up with the project by editing the `VideoApp/settings.py` file and adding the `AppConfig` instance declared in the `App/apps.py` file to the list of `INSTALLED_APPS`:
{/* prettier-ignore-start */}
```python
# File: VideoApp/settings.py
. . .
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'App.apps.AppConfig', # [!code ++]
]
. . .
```
{/* prettier-ignore-end */}
You also need to make sure that we connect the Django project to the PostgreSQL database defined earlier. Also in the `VideoApp/settings.py` file, edit the `DATABASES` dictionary to take parameterized values from environment variables:
```python
# File: VideoApp/settings.py
. . .
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': config("DJANGO_DB_NAME"),
'USER': config("DJANGO_DB_USER"),
'PASSWORD': config("DJANGO_DB_PASSWORD"),
'HOST': config("DJANGO_DB_HOST"),
'OPTIONS': {'sslmode': 'require'},
}
}
. . .
```
We'll finish the configuration by setting some required variables and configuring static files. First, add some new imports to the top of the file:
{/* prettier-ignore-start */}
```python
# File: VideoApp/settigns.py
import os # [!code ++]
from pathlib import Path
from decouple import config # [!code ++]
. . .
```
{/* prettier-ignore-end */}
Next, create or set the following variables:
```python
# File: VideoApp/settings.py
. . .
SECRET_KEY = config("DJANGO_SECRET_KEY")
DEBUG = True
ALLOWED_HOSTS = config("ALLOWED_HOSTS", cast=lambda v: [s.strip() for s in v.split(',')])
DOMAIN = config("DOMAIN")
CSRF_TRUSTED_ORIGINS = config("CSRF_TRUSTED_ORIGINS", cast=lambda v: [s.strip() for s in v.split(',')])
. . .
```
The `ALLOWED_HOSTS` variable is used to set a list of allowed host names for the application. This is a security feature that prevents host header attacks.
The `DOMAIN` variable is used to set the domain name of the application. This is used in the `upload_video` view function to construct the URL for the worker service.
The `CSRF_TRUSTED_ORIGINS` variable is used to set a list of trusted origins for the Cross-Site Request Forgery (CSRF) protection in Django. This is a security feature that prevents malicious websites from making unauthorized requests to the application.
Finally, configure the static file configuration by adding the following:
```python
# File: VideoApp/settings.py
. . .
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
MEDIA_URL = '/media/'
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
. . .
```
Now, you can create and run the migrations, with:
```bash
python manage.py makemigrations
python manage.py migrate
```
The main page and the video upload form are now complete and should render if you run the test server with the expected environment variables configured. To actually upload videos, however, you need to create the associated worker service.
To finish up with the web app, create a [new repository on GitHub](https://github.com/new). Afterwards, initialize a git repository in the project root, download a basic Python `.gitignore` file, and push the changes:
```bash
git init
curl -L https://raw.githubusercontent.com/github/gitignore/main/Python.gitignore -o .gitignore
echo "videos" >> .gitingore
git add :/
git commit -m "Initial commit"
git remote add origin git@github.com:<YOUR_GITHUB_USERNAME>/<YOUR_GITHUB_REPOSITORY>.git
git branch -M main
git push -u origin main
```
## Build the worker service
You will build a second application with FastAPI that will be responsible for processing uploads.
Outside of the Django project directory, create a new project directory for the worker API service. Deactivate any existing virtual environments and create a new virtual environment:
```bash
deactivate # If you're not currently in a virtual environment, this command will fail. This is expected.
mkdir example-video-worker
cd example-video-worker
python3 -m venv venv
```
Activate the new virtual environment by typing:
```bash
source venv/bin/activate
```
Create a `requirements.txt` file with the service's dependencies:
```
# File: requirements.txt
fastapi
assemblyai
python-decouple
requests
moviepy
uvicorn
```
Install the dependencies by typing:
```bash
pip install -r requirements.txt
```
The important packages installed here are `assemblyai`, which is a speech recognition and natural language processing API, and `moviepy`, which is a library for video editing and processing.
Create a `.env` file to define your AssemblyAI API key as an environment variable:
```bash
# File: .env
ASSEMBLYAI_API_KEY=<YOUR_ASSEMBLYAI_API_KEY>
```
You will need an API key from [AssemblyAI](https://www.assemblyai.com/), which you can get [here]([AssemblyAI | Dashboard](https://www.assemblyai.com/app/)). You will need to sign up for an account if you don't have one. To use the AI features (like LEMUR) you will need to add credits to the account.
Then you can create your `main.py` file inside the FastAPI project:
```python
# File: main.py
import requests
from decouple import config
from fastapi import FastAPI
import assemblyai as aai
from moviepy.video.io.VideoFileClip import VideoFileClip
import os
# Set up the AssemblyAI client
aai.settings.api_key = config("ASSEMBLYAI_API_KEY")
transcriber = aai.Transcriber()
# Define a function to download a video file from a URL
def download_video(url, filename):
# Send a GET request to the URL
response = requests.get(url, stream=True)
# Check if the request was successful
if response.status_code == 200:
# Open a local file in binary write mode
with open(filename, 'wb') as file:
# Write the content of the response to the file in chunks
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
# Define a function to extract audio from a video file
def extract_audio_from_video(video_file_path, output_audio_path):
# Load the video file
video = VideoFileClip(video_file_path)
# Extract the audio from the video
audio = video.audio
# Write the audio to a file
audio.write_audiofile(output_audio_path)
# Close the video file to free up resources
video.close()
# Define a function to get the resolution and duration of a video file
def get_resolution_and_duration_from_video(video_file_path):
# Load the video file
video = VideoFileClip(video_file_path)
# Get the resolution of the video
resolution = video.size
# Get the duration of the video
duration = video.duration
# Close the video file to free up resources
video.close()
return resolution, duration
# Create a FastAPI instance
app = FastAPI()
# Define a route handler for the default route, for health checks
@app.get("/")
async def version():
return {"version": "v0.1"}
# Define a route handler for the /process_video route
@app.get("/process_video")
async def process_video(video_url: str):
# Download the video file from the URL and save it locally
print("Downloading video...")
video_filename = "video.mp4"
download_video(video_url, video_filename)
# Get audio from video file with MoviePy
print("Extracting audio from video...")
audio_filename = "audio.mp3"
extract_audio_from_video(video_filename, audio_filename)
# Get resolution and duration of the video
print("Getting resolution and duration...")
resolution, duration = get_resolution_and_duration_from_video(video_filename)
# Format the resolution as a string
resolution = f"{resolution[0]}x{resolution[1]}"
# Transcribe the audio with AssemblyAI
print("Transcribing audio...")
transcript = transcriber.transcribe(audio_filename)
# Generate tags for the video
print("Generating tags...")
prompt_tags = ("Generate a list of tags (max 5) for this video."
"Return only the tags, separated by commas and nothing else.")
result = transcript.lemur.task(prompt_tags)
tags = result.response.replace("\n", " ").split(",")
# Trim the tags
tags = [tag.strip() for tag in tags]
# Limit the number of tags to 5
tags = tags[:5]
# Generate the categories for the video
print("Generating categories...")
prompt_categories = ("Generate a list of categories (max 3) for this video."
"Return only the categories, separated by commas and nothing else.")
result = transcript.lemur.task(prompt_categories)
categories = result.response.replace("\n", " ").split(",")
# Trim the categories
categories = [category.strip() for category in categories]
# Limit the number of categories to 3
categories = categories[:3]
# Delete the video and audio files
print("Cleaning up...")
os.remove(video_filename)
os.remove(audio_filename)
# Return the tags and categories
print("Processing complete!")
record = {"tags": tags, "categories": categories, "resolution": resolution, "duration": duration}
print(record)
return record
```
This script first sets up an API key for the AssemblyAI service, which is used for transcribing audio. It then defines several functions for downloading a video file from a URL, extracting audio from a video file, and getting the resolution and duration of a video file.
Afterwards, it creates a FastAPI instance and defines two route handlers. The first route handler is for the default route (`/`) and simply returns the version number of the service.
The second route handler is for the `/process_video` route and performs the following steps:
1. Downloads the video file from the provided URL and saves it locally.
2. Extracts audio from the video file using MoviePy.
3. Gets the resolution and duration of the video file.
4. Transcribes the audio using AssemblyAI.
5. Generates tags and categories for the video using AssemblyAI's LEMUR model.
6. Deletes the video and audio files from local storage.
7. Returns the generated tags, categories, resolution, and duration as a JSON object.
The `assemblyai` library is used for transcribing audio and generating tags and categories and the `moviepy` library is used for extracting audio from a video file and getting the resolution and duration of a video file.
To finish up with the worker service, create a [new repository on GitHub](https://github.com/new). Afterwards, initialize a git repository in the project root, download a basic Python `.gitignore` file, and push the changes:
```bash
git init
curl -L https://raw.githubusercontent.com/github/gitignore/main/Python.gitignore -o .gitignore
printf "%s\n" "*.mp4" "*.mp3" >> .gitignore
git add :/
git commit -m "Initial commit"
git remote add origin git@github.com:<YOUR_GITHUB_USERNAME>/<YOUR_GITHUB_REPOSITORY>.git
git branch -M main
git push -u origin main
```
## Integrate with Koyeb's edge network
Integrating with Koyeb's edge network requires nothing more than deploying the applications to Koyeb. All CDN features are enabled by default and all services are part of the service mesh network and edge network.
Let's now see how you can deploy the applications to Koyeb to build the pipeline.
## Deploy the web application
You can start by first deploying the web application. For that go the [Koyeb control panel](https://app.koyeb.com/) and click **Create Web Service**:
1. Select **GitHub** as your deployment method and select your GitHub project for the web application.
2. In the **Builder** section, override the **Run command** with `python manage.py runserver 0.0.0.0:8000`.
3. In the **App and Service names** section, configure the **App name**. This will impact the environment variable values you define next.
4. In the **Environment variables** section, click **Bulk edit** and configure the following variables:
```
DJANGO_DB_HOST=
DJANGO_DB_USER=
DJANGO_DB_PASSWORD=
DJANGO_DB_NAME=
ALLOWED_HOSTS=
CSRF_TRUSTED_ORIGINS=
DJANGO_SECRET_KEY=
DOMAIN=
WORKER_URL=
```
Fill in the variables as follows:
- `DJANGO_DB_HOST`: The hostname of the PostgreSQL database.
- `DJANGO_DB_USER`: The PostgreSQL username to authenticate with.
- `DJANGO_DB_PASSWORD`: The PostgreSQL password to authenticate with.
- `DJANGO_DB_NAME`: The name of the PostgreSQL database to connect to.
- `ALLOWED_HOSTS`: The bare hostname where this application will be deployed. It will begin with your App name followed by your Koyeb org name, a hash, and end with `.koyeb.app`.
- `CSRF_TRUSTED_ORIGINS`: The domain where this application will be deployed. It will begin with `https://` and include your App name, Koyeb org name, a hash, and end with `.koyeb.app`.
- `DOMAIN`: The domain where this application will be deployed. It will begin with `https://` and include your App name, Koyeb org name, a hash, and end with `.koyeb.app`.
- `DJANGO_SECRET_KEY`: A secret key used for encryption by Django. You can follow the procedure in [generate a secure Django secret key](https://stackoverflow.com/a/57678930) locally to generate a secure Django key.
- `WORKER_URL`: The internal URL where your service worker will be deployed. This should take the following format: `http://<WORKER_SERVICE_NAME>.<YOUR_KOYEB_ORG>.koyeb:8080`. Use the name you plan to deploy your service worker under.
5. Click **Deploy**.
After a couple of minutes the application should be deployed and accessible at the application's URL.
## Deploy the worker service API
Next, deploy the worker API service. Navigate to the previous created application in the [Koyeb control panel](https://app.koyeb.com/) and click **Create Service**:
1. Select **GitHub** as your deployment method and select your GitHub project for the worker service API.
2. In the **Builder** section, override the **Run command** with `uvicorn main:app --port 8080 --host 0.0.0.0`.
3. In the **Environment variables** section, configure the following environment variable: `ASSEMBLYAI_API_KEY=<YOUR_ASSEMBLYAI_API_KEY>`.
4. In the **Scaling** section, select **Autoscaling** from 1 to 3 Instances. Set the number of requests per second to your desired threshold.
5. In the **Exposed ports** section, deselect the **Public** toggle to make it only accessible from the service mesh and set the port to **8080**.
6. In the **App and Service names** section, set the **Service name** to the value you chose in the `WORKER_URL` variable when you deployed the Django application.
7. Click **Deploy**.
After a couple of minutes the Worker Web API should be deployed.
## Test the application
You can now test the web application and the worker API pipeline by accessing the web application URL and uploading a video file.
In this example, first we upload a file and fill in the title and description:

We can observe the different steps of the video worker API in the Koyeb logs:
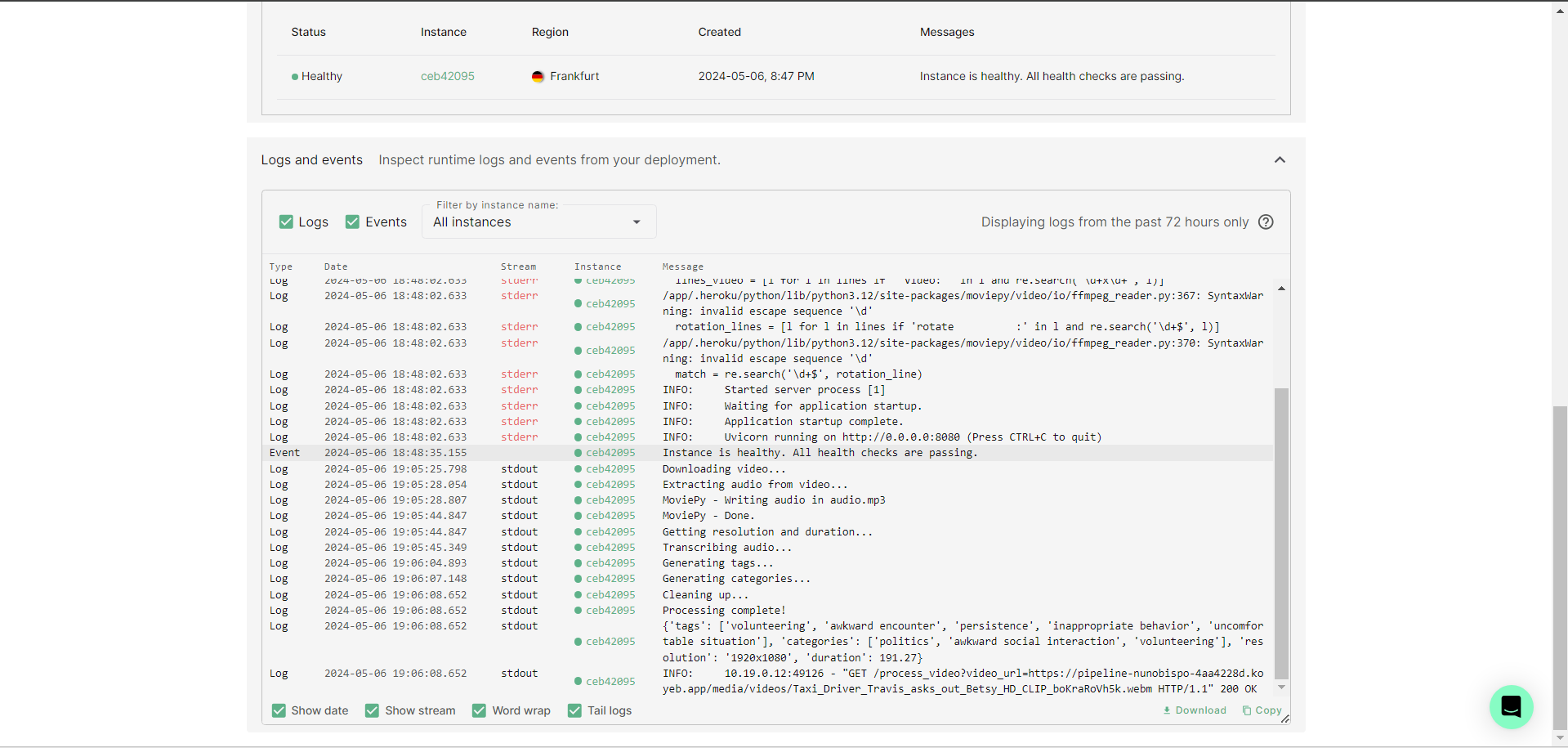
And finally, returning to the web application, we can see the categories and tags as well as the additional information filled in:
You now have a full functional working video pipeline which can automatically scale when the number of requests for the video worker API crosses the threshold.
## Conclusion
This article described how to build a video processing app using FastAPI, AssemblyAI, and Django on Koyeb. We've covered everything from setting up the app and creating the FastAPI service to implementing video processing features using AssemblyAI and MoviePy.
Throughout the article, we've seen how to build a reliable and scalable app that can process videos and extract valuable metadata, such as transcriptions, tags, and categories. You can customize and extend the app to meet your specific needs and use cases.
With the skills and knowledge you've gained from this article, you can confidently create your own video processing apps and use Koyeb to deploy innovative solutions for video processing and analysis. The demand for video content and video processing is growing rapidly, so the abilities you've learned here will be extremely valuable if you want to develop advanced video processing apps.
| alisdairbr |
1,864,058 | Backend Testing - exciting😀 yet confusing 🤔 | Background I am trying to learn MERN stack in 150 Days, about which I posted a while ago.... | 27,499 | 2024-05-24T13:55:29 | https://dev.to/prakirth/backend-testing-exciting-yet-confusing-4k51 | learning, beginners, mern, testing | ## Background
I am trying to learn MERN stack in 150 Days, about which I posted a while ago. In this series posts, I will be sharing What and *How* I have been learning.
{% embed https://dev.to/prakirth/mern-150-days-challenge-27o8 %}
> I am open to feedback to make this post better for readability/content quality.
---
## DAY 17/150 :hourglass_flowing_sand:
- Today, I have brief summaries of concepts which were either unclear/unknown to me, until now. :surfer:
- In the below sections, I share the challenges I faced with *Context*, *Reason* and *Solution* wherever relevant.
<hr>
### Challenge 1 - Backend Testing fundamentals
- **Context** : Backend-testing using `node:test`, `node:assert` and `supertest`.
- **Reason** : Completely new topic and zero-experience from previous projects
- **Solution** :
- After every topic in each section of Part 4, practice tests for 'Notes App' in a different context. For example on the current project in Part 4 exercises, 'Blogs App'
- Seek coding assistance from GitHub CoPilot
- Read through example tests from documentations
<br>
<hr>
### Challenge 2 - HTTP status codes
- **Context** : HTTP Methods use similar status codes
- **Reason** :
| HTTP Method | Response Status Codes |
| ----- | ------ |
| GET | 200, 304, 400, 404, 500 |
| POST | 200, 201, 400, 403, 404, 500 |
| PUT |200, 204, 400, 404, 409, 500 |
| PATCH | 200, 204, 400, 404, 409, 500 |
| DELETE | 200, 202, 204, 400, 404, 500 |
- Common status codes happen because HTTP method can have multiple response status codes because the outcome of a request can vary based on different factors.
- `200 OK`: The request has succeeded.
- `400 Bad Request`: The server could not understand the request due to invalid syntax.
- `404 Not Found`: The server could not find the requested resource.
- `500 Internal Server Error`: The server encountered an unexpected condition which prevented it from fulfilling the request.
<br>
<hr>
### Challenge 3 - Data re-initialization in test DB using `beforeEach`
- **Context** :
- For Testing purposes, Test-database needs to be re-initialized before each test for executing assertions successfully.
- However, due to differences in the order of execution of the `Promise` the data can be initialized in different ways.
- **Reason** : Depends on the sequence preferences, if any, of execution of `Promise`s
- **Solution** :
1. Using `for` loop for control over execution order of `Promise`
```javascript
beforeEach(async() => {
// executed in no specific order
for(let blog of helper.initialBlogs){
let blogObject = new Blog(blog)
await blogObject.save()
}
})
// tests to verify HTTP methods
...
```
2. using `Promise.all` method to allow the completion of every `Promise` in the registered order
```javascript
beforeEach(async() => {
// executed in specific order promises registred
await Promise.all(helper.initialBlogs.map(async (blog) => {
let blogObject = new Blog(blog)
blogObject.save()
}))
})
// tests to verify HTTP methods
...
```
3. most ideal method, using `mongoose` built-in methods for `insert` and `delete`
```javascript
beforeEach(async() => {
await Blog.deleteMany({})
await Blog.insertMany(helper.initialBlogs)
})
// tests to verify HTTP methods
...
```
<br>
<hr>
### Challenge 4 - Password Hashing fundamentals
- **Context** : Hashing passwords (manually) using external libraries
- **Reason** : Obviously, user data such as passwords must be encrypted, hence an enhanced level of encryption ensures user security
- **Solution** : In the current context ([FullStackOpen-core-part4](https://github.com/prak112/FullStackOpen-core-part4.git)), for user administration in saving blog posts, we are using [`bcrypt`](https://github.com/kelektiv/node.bcrypt.js/#nodebcryptjs) to ensure password hashing through *[Salt Rounds](https://github.com/kelektiv/node.bcrypt.js/#a-note-on-rounds)*, as simplified below.
- *Purpose* : Salt rounds are used to 'thwart brute force attacks' by making the hashing process slower.
- *How It Works* :
- Number of salt rounds is the exponent in the calculation of how many times the hashing algorithm is executed.
- More rounds = more hashing iterations,
- Brute force attacks slowed down and more secure.
- *Example* : If you choose 10 salt rounds, the algorithm will run 2^10 (or 1024) times.
- *Balance between Security and Performance* :
- Higher salt rounds increase security but also make the hashing process take longer.
- The cost of increasing rounds on 2 GHz core :
```css
rounds=8 : ~40 hashes/sec
rounds=9 : ~20 hashes/sec
rounds=10: ~10 hashes/sec
rounds=11: ~5 hashes/sec
rounds=12: 2-3 hashes/sec
rounds=13: ~1 sec/hash
rounds=14: ~1.5 sec/hash
rounds=15: ~3 sec/hash
rounds=25: ~1 hour/hash
rounds=31: 2-3 days/hash
```
<br>
<hr>
### Challenge 5 - Process Flow between Backend-Database to Implement new Feature
- **Context** :
- In MERN, if every new concept is implemented from the granular level, unlike Django, the sequence of operations to know are essential.
- In current context, we use `MongoDB-mongoose` for establishing backend-database communications
- If a new table/`collection` is introduced to implement a new feature, such as user administration, then the sequence of actions for an efficient process flow is as shown below.
<br>
<hr>
### Challenge 6 - Generating JSON Web Token
- **Context** : What is included in 'process.env.SECRET'?
- **Reason** : For user authentication, a `jsonwebtoken` (`JWT`) must be generated
- **Solution** :
- Any string, preferably auto-generated as a cryptic string
- Using `node` built-in library for auto-generating a cryptic string as follows:
```javascript
const crypto = require('crypto')
crypto.randomBytes(32).toString('hex') // SECRET
```
- *NEVER* save it in the source code. Generate in the terminal. Save it in `.env`
<br>
<hr>
### Challenge 7 - Authorization Header and Authentication Scheme fundamentals
- **Context** : How to retrieve the 'Authentication Header' value for implementing tests with backend API using Postman/REST Client ?
- **Reason** : To authenticate the user when a `POST` request is generated
- **Solution** :
- `HTTP request` has [`Authorization` headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Authorization) in the format - `<auth-schemes> <auth-parameters>`
- There are multiple `<auth-schemes>` ([Authentication Schemes](https://developer.mozilla.org/en-US/docs/Web/HTTP/Authentication#authentication_schemes)) available in a `HTTP request` `Authorization` header.
- Most common ones are - `Basic`, `Bearer`, `Digest`
|Feature | `Basic` | `Bearer`* | `Digest` |
|---------------| ----------------- | -------------------- | ----------------- |
| **SECURITY** | Credentials sent as `base64` encoded (plain text)| Credentials tokenized on server-side and stored on client side. Can be set to expire. | Password saved on server as plain-text/reversibly-encrypted format for verification with hashed-version. |
| **USAGE** | Simple, credentials sent with each request | Simple & safe, token sent with each request | Complex due to hashing process |
| **STATE** | *Stateful*, since credentials required for each request | *Stateless*, request contains credentials-encrypted token to authenticate user for each request | *Stateful*, random new hashed value different for each request |
| **API Suitability** | Only simple authentication, Not suitable for modern APIs | Suitable, specifically for APIs with `JWT`s and Single Sign-On (SSO) | Not Suitable, due to server-side storage |
- Based on the project (Reading list - Blogs App), the `Bearer <auth-scheme>` would be suitable for our User Authentication considering its beginner-friendly secure state of tokenizing user access.
---
Until next time! :writing_hand:
Live Long and Prosper :vulcan_salute:
---
[_Cover Photo by 'Leeloo The First' from Pexels_](https://www.pexels.com/photo/motivational-simple-inscription-against-doubts-5238645/) | prakirth |
1,864,056 | AWS in a Nutshell | AWS Most Commonly Used Terms EC2 - It stands for Elastic Compute version-2, compute... | 0 | 2024-05-24T13:52:57 | https://dev.to/jay818/aws-in-a-nutshell-391o | cloud, aws, frontend, deployement | ## AWS
**Most Commonly Used Terms**
1. `EC2` - It stands for Elastic Compute version-2, compute referred to a part of a big machine.Elastic means we can upscale or downscale it. Basically a server running elsewhere.
2. `S3` - It is used to store objects, objects referred to things that doesn't have any Data type, such as Video file, audio file , image file etc. `S3` stands for Simple storage Device.
3) `CloudFront` - It is basically a Content Delivery Network[ CDN ] that is used to deliver the static content to the user faster.
### Deplying Backend to the EC2 machine
-----ChatGPT-----
**`Learnings`**
- `SSH` - It stands for secure shell. It helps you connect to the other machine shell securely.
```ts
//ssh using mac
chmod 700 xyz.pem
ssh -i xyz.pem ubuntu@your_server_url
//ssh using windows
//1) Download Git bash
//2) Run it as Administrator
//3) Go the folder where xyz.pem file is present
chmod 700 xyz.pem
ssh -i xyz.pem ubuntu@your_server_url
```
- `using vi editor` - To use vi editor type
```ts
sudo vi /myfolder/index.js
// type 'i' for insert mode
// 'esc' to get back
// ':wq'+enter to save the file
```
- To deploy the backend we primarily need EC2 server.
- Suppose you want to deploy multiple application on save server due to some money issues.
It will look like this
```ts
your_url:3000 - for 1st website
your_url:3001 - for 2nd website
```
But there is a problem you don't want the user to enter the port & you also want that Different subdomain that lead to same ip will point to `your_url` & at the server you decide where to redirect the user.
You can do this is using nginx, it is a webserver software that provides service called `reverse-proxy`.
Default port is 80 for http
and for https it is 433
If we go to `http:your_url` then it will point to port 80.
- For free SSL certificate - [Certbot](https://certbot.eff.org/)
### Deplying Frontend
-----ChatGPT-----
- To do so upload all the static files in S3 bucket, then use Cloudfront to deliver the content.
- Why can't we use CDN in server also, in server side every request is unique that can only be handled by the server.
- Initally after setting up cloudfront you will got a url , to access something u have do like this `https:your_url/index.html`.
**`BONUS`**
- You can have multiple subdomains after buying one domain.
| jay818 |
1,864,054 | Game Dev Digest — Issue #234 - Enhancing Your Game | Issue #234 - Enhancing Your Game This article was originally published on... | 4,330 | 2024-05-24T13:46:39 | https://gamedevdigest.com/digests/issue-234-enhancing-your-game.html | gamedev, unity3d, csharp, news | ---
title: Game Dev Digest — Issue #234 - Enhancing Your Game
published: true
date: 2024-05-24 13:46:39 UTC
tags: gamedev,unity,csharp,news
canonical_url: https://gamedevdigest.com/digests/issue-234-enhancing-your-game.html
series: Game Dev Digest - The Newsletter About Unity Game Dev
---
### Issue #234 - Enhancing Your Game
*This article was originally published on [GameDevDigest.com](https://gamedevdigest.com/digests/issue-234-enhancing-your-game.html)*

Check out the latest tips on enhancing your game in various ways. Enjoy!
---
[**This Artist Added Custom Subsurface Scattering to Unity URP**](https://80.lv/articles/this-artist-added-custom-subsurface-scattering-to-unity-urp/) - And shared the nodes so you can recreate the setup yourself.
[_80.lv_](https://80.lv/articles/this-artist-added-custom-subsurface-scattering-to-unity-urp/)
[**Sun Beams / God Rays Shader Breakdown**](https://www.cyanilux.com/tutorials/god-rays-shader-breakdown/) - In my current project I wanted to add some light/sun beams (also referred to as god rays or light shafts), to somewhat simulate light passing between leaves/trees in a dense forest.
[_cyanilux.com_](https://www.cyanilux.com/tutorials/god-rays-shader-breakdown/)
[**Build The Future Web**](https://rogueengine.io/) - A Unity like environment to create web apps and games with three.js Code using plain three.js on top of RE's component framework. _[For more web tech check out [Development notes from xkcd's "Machine"](https://chromakode.com/post/xkcd-machine/)]_
[_rogueengine.io_](https://rogueengine.io/)
[**Programming like it's 1977: exploring the Atari VCS**](https://adamtornhill.com/articles/atari-vcs/programming-like-in-1977.html) - Earlier this year I started a new hobby: writing games on the Atari VCS.
[_adamtornhill.com_](https://adamtornhill.com/articles/atari-vcs/programming-like-in-1977.html)
[**The Space Quest II Master Disk Blunder**](https://lanceewing.github.io/blog/sierra/agi/sq2/2024/05/22/do-you-own-this-space-quest-2-disk.html) - There is nothing unusual about the outside of these disks, but there is something unique about the data that is stored on them, something that Sierra On-Line would have been totally unaware of and certainly wouldn’t have wanted them to include.
[_lanceewing.github.io_](https://lanceewing.github.io/blog/sierra/agi/sq2/2024/05/22/do-you-own-this-space-quest-2-disk.html)
[**SoftLimit**](https://old.reddit.com/r/Unity3D/comments/1cy2cvu/softlimit_the_feature_thatll_make_your_project/) - SoftLimit, the feature that'll make your project more responsive!
[_old.reddit.com_](https://old.reddit.com/r/Unity3D/comments/1cy2cvu/softlimit_the_feature_thatll_make_your_project/)
[**Escaping Game Coverage Limbo**](https://www.wanderbots.com/blog/escaping-game-coverage-limbo) - ‘Coverage Limbo’ is when a game gets consistently sidelined by creators (primarily Journalists, Youtubers, and Streamers), who cannot prioritize featuring it in a timely fashion for one reason or another. This leaves the developer awkwardly waiting & hoping for coverage that might never come, or even just a reply to their emails.
[_wanderbots.com_](https://www.wanderbots.com/blog/escaping-game-coverage-limbo)
## Videos
[](https://www.youtube.com/watch?v=N-dPDsLTrTE)
[**Tunes of the Kingdom: Evolving Physics and Sounds for ‘The Legend of Zelda: Tears of the Kingdom’**](https://www.youtube.com/watch?v=N-dPDsLTrTE) - At GDC 2024, developers of The Legend of Zelda: Tears of the Kingdom discuss structuring an expanded Hyrule around physics-based gameplay and evolved sound design! Join the game’s Technical Director Takuhiro Dohta, Lead Physics Programmer Takahiro Takayama, and Lead Sound Engineer Junya Osada as they explore challenges their teams faced when approaching this sequel.
[_GDC_](https://www.youtube.com/watch?v=N-dPDsLTrTE)
[**How To Pick The Right Canvas Size | Game Dev & Art Tips**](https://www.youtube.com/watch?v=u5Rkoe7__wM) - I noticed some people were curious about learning more regarding resolution & scaling, so I thought I would make a video talking about how to properly handle both of these! Hope it helps!
[_orithekid_](https://www.youtube.com/watch?v=u5Rkoe7__wM)
[**Creator Spotlight: Blender Start Here**](https://www.youtube.com/live/g2KCe1GpC8o) - The team at XRIO are on a mission to revolutionize gaming education. We will be welcoming them on our next Creator Spotlight to talk about their game, Blender Start Here, which is designed to make learning software fun and engaging. Join us in changing the way people play and learn!
[_Unity_](https://www.youtube.com/live/g2KCe1GpC8o)
[**Enhance Your Unity Game with Scene Fade Transitions**](https://www.youtube.com/watch?v=vkOhefMbrFg&list=PLx7AKmQhxJFajrXez-0GJgDlKELabQQHT&index=22) - In this Unity tutorial, we'll explore how to create smooth scene transitions by fading the current scene to black before the next scene fades in.
[_Ketra Games_](https://www.youtube.com/watch?v=vkOhefMbrFg&list=PLx7AKmQhxJFajrXez-0GJgDlKELabQQHT&index=22)
[**Best Practices: Developing an audience while developing your game - GDC 2024**](https://www.youtube.com/watch?v=FzteDkGu10E) - Join Kaci as she walks through important concepts to remember while developing a game and launching on Steam.
[_Steamworks Development_](https://www.youtube.com/watch?v=FzteDkGu10E)
[**Secondary textures - Lit sprites and 2D VFX tutorial**](https://www.youtube.com/watch?v=InNZsUWNb8k) - 2D sprites can attain the atmosphere, shape, and dynamic lighting that 3D shading offers through the use of secondary textures. This video is a comprehensive guide on possible ways how to create and use texture maps to enhance the look of your game.
[_Unity_](https://www.youtube.com/watch?v=InNZsUWNb8k)
[**Age-Friendly Design for the 50-Plus Gamer**](https://www.youtube.com/watch?v=HRfl3xVL32Q) - Video games are now a significant part of life for those aged 50 years and older, with over 50-million players. This talk features Northeastern University and AARP discussing the AARP research on 50-plus players, their needs, and the market opportunity.
[_GDC_](https://www.youtube.com/watch?v=HRfl3xVL32Q)
[**The Unity HACK that the PROS know**](https://www.youtube.com/watch?v=ilvmOQtl57c) - Hook your custom C# Systems and Services into Update, Fixed Update and more Unity Player Loop Systems using the UnityEngine LowLevel and PlayerLoop namespaces - in today's example we're building an Improved Unity Timer system that is self managing. This technique can be used for any custom system you need or want to run as part of the player loop including Data Binding and much more.
[_git-amend_](https://www.youtube.com/watch?v=ilvmOQtl57c)
[**Scene Management in Unity | Code Review**](https://www.youtube.com/watch?v=wj-cHmFYdQE) - Scenes are one of the main concepts in the Unity engine. Let's check out this cute scene management system I built for my game. Let me know in the comments how you do it in yours!
[_Useless Game Dev_](https://www.youtube.com/watch?v=wj-cHmFYdQE)
## Assets
[](https://assetstore.unity.com/mega-bundles/30-for-30&aid=1011l8NVc)
[**Save 97%: 30 for $30 Mega Bundle**](https://assetstore.unity.com/mega-bundles/30-for-30&aid=1011l8NVc) - Explore a whole new collection of powerful tools and art assets to kick-start your game development.
Including: [Boing Kit: Dynamic Bouncy Bones, Grass, and More](https://assetstore.unity.com/packages/tools/particles-effects/boing-kit-dynamic-bouncy-bones-grass-and-more-135594?aid=1011l8NVc), [Amplify Shader Pack](https://assetstore.unity.com/packages/vfx/shaders/amplify-shader-pack-202484?aid=1011l8NVc), [POLY STYLE - Medieval Village](https://assetstore.unity.com/packages/3d/environments/fantasy/poly-style-medieval-village-159363?aid=1011l8NVc), [Better Editor 2 Pack - Your Future Editor, Today](https://assetstore.unity.com/packages/tools/level-design/better-editor-2-pack-your-future-editor-today-178575?aid=1011l8NVc) and more!
[_Unity_](https://assetstore.unity.com/mega-bundles/30-for-30&aid=1011l8NVc) **Affiliate**
[**Epic Royalty-Free Music Collection Vol. 2 Bundle**](https://www.humblebundle.com/software/epic-royaltyfree-music-collection-volume-2-software?partner=unity3dreport) - The makings of an epic soundtrack. Looking for the perfect soundtrack to accompany your next project? Composer Joel Steudler invites you on a sonic journey with this colossal collection of royalty-free music from his intensive catalog! From entrancing synthwave to bombastic tunes perfect to make an impact in your trailer, this collection is packed with tracks suitable for films, games, or whatever you’re working on! Plus, your purchase will support JDRF in their mission to find a cure for type 1 diabetes!
[_Humble Bundle_](https://www.humblebundle.com/software/epic-royaltyfree-music-collection-volume-2-software?partner=unity3dreport) **Affiliate**
[**Slash & Impact Set | Free 70+ Textures + FXs**](https://www.artstation.com/artwork/DvZ0K9) - Hey! Wanted to do my own slash set within specific schools of magic/thematic. Attached below is the link to the Unity Project and with all the textures, shaders, and slashes/impacts FXs for ya'll!
[_Sergio Renato Perez Cuevas_](https://www.artstation.com/artwork/DvZ0K9)
[**TrueTrace-Unity-Pathtracer**](https://github.com/Pjbomb2/TrueTrace-Unity-Pathtracer) - Compute Shader Based Unity PathTracer
[_Pjbomb2_](https://github.com/Pjbomb2/TrueTrace-Unity-Pathtracer) *Open Source*
[**unity-canvas-page-slider**](https://github.com/tomazsaraiva/unity-canvas-page-slider?) - A Scrollable Page Viewer for Unity
[_tomazsaraiva_](https://github.com/tomazsaraiva/unity-canvas-page-slider?) *Open Source*
[**TagLayerTypeGenerator**](https://github.com/AlkimeeGames/TagLayerTypeGenerator?) - Generates statically typed classes for the Tags and Layers in your Unity projects automatically, with no manual button pushes required. Simply set and forget!
[_AlkimeeGames_](https://github.com/AlkimeeGames/TagLayerTypeGenerator?) *Open Source*
[**Unity-Improved-Timers**](https://github.com/adammyhre/Unity-Improved-Timers?) - Improved Unity C# Timers that run as a Player Loop System
[_adammyhre_](https://github.com/adammyhre/Unity-Improved-Timers?) *Open Source*
[**Unity_2D_VFX**](https://github.com/Magnno/Unity_2D_VFX?) - A collection of visual effects for 2D Unity projects.
[_Magnno_](https://github.com/Magnno/Unity_2D_VFX?) *Open Source*
[**Unio**](https://github.com/hadashiA/Unio?) - Unio (short for unity native I/O) is a small utility set of I/O using native memory areas.
[_hadashiA_](https://github.com/hadashiA/Unio?) *Open Source*
[**VR-Builder**](https://github.com/MindPort-GmbH/VR-Builder?) - VR Builder lets you create better VR experiences faster. Our code is open source and designed to be extended. Plus, our GUI empowers everyone to create fully functional VR apps - without writing code.
[_MindPort-GmbH_](https://github.com/MindPort-GmbH/VR-Builder?) *Open Source*
[**games.noio.planter**](https://github.com/noio/games.noio.planter?) - The plant simulation from Cloud Gardens as a Unity package for level design.
[_noio_](https://github.com/noio/games.noio.planter?) *Open Source*
[**Low Poly Game Dev Bundle**](https://www.humblebundle.com/software/low-poly-game-dev-bundle-software?partner=unity3dreport) - Low-poly building blocks. Nail the evocative retro look of the 32-bit era in your next project with this bundle of low-poly game assets, usable on Unity, Unreal, and other game engines big and small! You’ll get thousands of individual assets across dozens of themed packs, allowing you to create everything from awe-inspiring futuristic space colonies, to post-apocalyptic ruins teeming with hazard—plus, all the props you need to bring them to life! Everything in this bundle is in FBX format, so you’ll be able to integrate it all seamlessly, regardless of your workflow. Play what you want for this bundle of amazing building blocks and help support Save the Children with your purchase!
[_Humble Bundle_](https://www.humblebundle.com/software/low-poly-game-dev-bundle-software?partner=unity3dreport) **Affiliate**
[**Gamedev Market's RPG Adventure Essentials Bundle**](https://www.humblebundle.com/software/gamedev-markets-rpg-adventure-essentials-software?partner=unity3dreport) - Build stunning 2D worlds. Game makers, get ready to supercharge your 2D creations with this massive bundle, overflowing with pixel-perfect assets ready to drop into your next project! You'll get dozens of versatile tilesets, from somber cyberpunk cityscapes to idyllic medieval villages, allowing you to bring the worlds in your imagination to life. Populate them with a vast array of diverse characters, fearsome monsters, and charming critters, and add the finishing touches with slick icon packs, sound effects, and retro-inspired music. Pay what you want for this expansive toolkit, ready to use whatever your specific workflow, and help support the Michael J. Fox Foundation with your purchase!
[_Humble Bundle_](https://www.humblebundle.com/software/gamedev-markets-rpg-adventure-essentials-software?partner=unity3dreport) **Affiliate**
[**CornModel**](https://github.com/DevBobcorn/CornModel?) - A Minecraft Model Reader for Unity
[_DevBobcorn_](https://github.com/DevBobcorn/CornModel?) *Open Source*
[**GarageKit_for_Unity**](https://github.com/sharkattack51/GarageKit_for_Unity?) - GarageKit is Unity C# framework.
[_sharkattack51_](https://github.com/sharkattack51/GarageKit_for_Unity?) *Open Source*
[**50% off bestgamekits - Publisher Sale**](https://assetstore.unity.com/publisher-sale?aid=1011l8NVc) - Bestgamekits is a graphic designer and animator, helping creators find art for their incredible games. PLUS, get [Lowpoly farm animals](https://assetstore.unity.com/packages/3d/characters/animals/lowpoly-farm-animals-180305?aid=1011l8NVc) for FREE with code BESTGAMEKITS
[_Unity_](https://assetstore.unity.com/publisher-sale?aid=1011l8NVc) **Affiliate**
## Spotlight
[](https://store.steampowered.com/app/2704210/Wheelborn/)
[**Wheelborn**](https://store.steampowered.com/app/2704210/Wheelborn/) - Wheelborn is a short indie exploration beat ‘em up adventure, set in a world where the Wheelborn, car-like creatures with a unique lifecycle, face corruption.
_[You can wishlist it on [Steam](https://store.steampowered.com/app/2704210/Wheelborn/) and follow them on [Twitter](https://twitter.com/Klexber)]_
[_Alex Klexber_](https://store.steampowered.com/app/2704210/Wheelborn/)
[_Alex Klexber_](https://store.steampowered.com/app/2704210/Wheelborn/)
---
[](https://store.steampowered.com/app/2623680/Call_Of_Dookie/)
My game, Call Of Dookie. [Demo available on Steam](https://store.steampowered.com/app/2623680/Call_Of_Dookie/)
---
You can subscribe to the free weekly newsletter on [GameDevDigest.com](https://gamedevdigest.com)
This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article.
| gamedevdigest |
1,864,195 | Effect in React | Emerging from ZIO in the lands of Scala, there is a new ecosystem of functional programming edging... | 0 | 2024-05-24T17:29:28 | https://sean.thenewells.us/effect-in-react/ | effect, typescript | ---
title: Effect in React
published: true
date: 2024-05-24 13:44:20 UTC
tags: effect,typescript
canonical_url: https://sean.thenewells.us/effect-in-react/
---

Emerging from ZIO in the lands of Scala, there is a new ecosystem of functional programming edging its way into TypeScript - [Effect](https://effect.website).
> *ZIO*: For more about this ZIO and Scala lineage, check out this [video from Effect Days 2024](https://youtu.be/Ei6VTwhI8QQ?si=sIO6xpRI-7WSdyOq).
Behold the power! _The following are adaptations taken from the Effect home page, showing examples of what you can do with Effect_.
Want to fetch some JSON from an endpoint, handling 200 OK and valid JSON errors, boom.
```ts
const getUser = (id: number) =>
Http.request.get(`/users/${id}`).pipe(
Http.client.fetchOk,
Http.response.json,
)
```
Want to retry that endpoint if something goes wrong? Did somebody order a _one line fix_?
```diff
--- http.ts 2024-05-21 19:23:24.194145996 +0100
+++ http-with-retry.ts 2024-05-21 19:23:33.524145427 +0100
@@ -3,4 +3,5 @@
Http.client.fetchOk,
Http.response.json,
+ Effect.retry({ times: 3 })
)
```
How about a more controlled timeout, let's say 3 seconds? Another one liner.
```diff
--- http-with-retry.ts 2024-05-21 19:45:49.874052498 +0100
+++ http-with-retry-and-timeout.ts 2024-05-21 19:45:41.354053136 +0100
@@ -3,5 +3,6 @@
Http.client.fetchOk,
Http.response.json,
+ Effect.timeout("3 seconds"),
Effect.retry({ times: 3 }),
)
```
Do you want more control on the retry, like an exponential back off? Effect has you covered😎
```diff
--- http-with-retry-and-timeout.ts 2024-05-21 19:45:41.354053136 +0100
+++ http-with-retry-timeout-backoff.ts 2024-05-21 19:47:56.084044043 +0100
@@ -4,5 +4,9 @@
Http.response.json,
Effect.timeout("3 seconds"),
- Effect.retry({ times: 3 }),
+ Effect.retry(
+ Schedule.exponential(1000).pipe(
+ Schedule.compose(Schedule.recurs(3)),
+ ),
+ ),
)
```
Want a schema to parse the JSON into? `Effect.schema`. Want to throw in an abort controller? Http takes in a `signal`.
These are all _composable_ additions to the program we started with, and each of these pieces can be transparently reused and mixed into other Effects. Kind of like how you snap legos together, or how types help us reason about our program. The Effect type is core to this composition, so it's worth a bit of an introduction
## The Effect Type
The core of Effect lies in the[Effect type](https://effect.website/docs/guides/essentials/the-effect-type), defined [here](https://github.com/Effect-TS/effect/blob/main/packages/effect/src/Effect.ts#L95). The docs linked say this about the type parameters:
```ts
type Effect<TSuccess, TError, TRequirements> = ...
```
> - **Success** : Represents the type of value that an effect can succeed with when executed. If this type parameter is void, it means the effect produces no useful information, while if it is never, it means the effect runs forever (or until failure).
> - **Error** : Represents the expected errors that can occur when executing an effect. If this type parameter is never, it means the effect cannot fail, because there are no values of type never.
> - **Requirements** : Represents the contextual data required by the effect to be executed. This data is stored in a collection named Context. If this type parameter is never, it means the effect has no requirements and the Context collection is empty.
We're mostly going to focus on the first two for this first blog post, but don't sleep on Context (aka requirements), as it is how Effect can do Type-first Dependency Injection, nice! ✨
So in addition to the semantic meaning we give the three parameters, the other _truly important_ thing to know about `Effect` **is that it is lazy**. The JSDoc block describing the type from the source code says:
> The `Effect` interface defines a value that lazily describes a workflow or job.
This is critical, especially when we bridge the Effectual world to the normal world.
Let's do that now, with a small React app!
> ✋ We're not going to lay down patterns I'm happy with to ship to production (yet!). I'm still learning Effect after all. If you go on the Effect Discord's react channel, there is chatter about a library called [effect-rx](https://github.com/tim-smart/effect-rx) which is in active development. I'd encourage you to try to use it if you want to be a pioneer, a potential contributor, or want to see what it has to offer.
>
> In the next blog post I do on Effect, I'll share another stepping stone, and before too long I'll be confident enough to ship to production with Effect in the client 💪! If you're more interested in server side work, you should check out the [examples](https://github.com/Effect-TS/examples)and the [talks](https://www.youtube.com/@effect-ts), as it is far more "off the shelf" I would say.
## useEffectEffect?
> 💡 Yes, the library is, unfortunately, called Effect. And in React, we already have a concept with that name - the `useEffect` hook. It's worth repeating that [the react docs](https://react.dev/reference/react/hooks#effect-hooks) highlight `useEffect` as a way to "...connect to and synchronize with external systems" for "...non react code...". Some words I've been playing around with to differentiate the two worlds:
>
> - ReEffect
> - Coalesce
> - Collapse
> - Bridge
>
> Right now, I hate all of them. We'll see what sticks! 😅
If we fire up a quick vite app and get the famous counter going, we can begin by installing effect (I use pnpm, feel free to use your favorite package manager):
```sh
pnpm create vite my-vue-app --template react-ts
# Make sure your tsconfig is strict!
pnpm add effect
```
> 💡 If you are worried about bundle size, I wouldn't be (yet). At least for our small example things are all still gzipped under 100Kb. The first screenshot below is the default, single chunk of the app we're building today, and the second is with two chunks, a ui chunk for react+react-dom, and a 2nd chunk just for effect. I did not see any difference in bundle size with more specific imports.
Before we do anything useful, let's test our sanity by doing something we think should be trivial, like saying hello world. In Effect, the simplest thing you can do is succeed.
```ts
Effect.success("Hello world!")
```
Great! If we look at the type signature, it describes the _program we created_ by using success: `Effect<string, never, never>` which means this is a program that when run will yield a string, never error, and requires no context. Cool. 🍨
This is a lazily evaluated program (sort of... we did not pass in a lazy value, so the string is evaluated, we'll get to that), so we now need to execute or resolve it. Let's do that with `runSync`
```ts
const HiEff = Effect.success("Hello world!");
const hi = Effect.runSync(HiEff);
console.log(hi);
```
Now we see our glorious "Hello world!" in the console, so let's wrap this up in a component and spit it out on the browser
```tsx
// declare Effects _outside_ of React.
const HiEff = Effect.success("Hello world!");
export const HelloEff = () => {
// execute Effects once, on mount
const hi = useMemo(() => Effect.runSync(HiEff), []);
return <h1>{hi}</h1>;
}
// elsewhere, in App.tsx
return <HelloEff />
```
Nice! Feel free to change the text and ensure all the react-refresh / hot module reloading / vite / fast go-go juice all works, it does for me!
> 🤔 I've explicitly said to put the Effect _outside_ of React - very purposefully. We'll have to create or leverage Effects that take in user input eventually, but as much as possible put code **outside** of the render function of a component. That's generally true with and without Effect btw.
Now you may be asking... okay, that's nice, _but what about promises and all that async stuff?_ Well my friend, there's a run promise as well! Keeping our sanity still, let's just try to lift the runSync to promised land and see if we can get it into react, as that part is odd. Since we're going to run our Effect in a Promise, we can't just use the promise in our markup, unless we're on the server and can await or can suspend somehow. The more direct solution is to have some state, just like we would with fetch (or if we were to reach for react-query, just like how react-query stores the response of our n/w call, in state). That looks like this:
```tsx
// declare Effects _outside_ of React.
const HiEff = Effect.success("Hello world!");
export const HelloEffAsync = () => {
// Double up as our loading state, and storing the result.
const [result, setResult] = useState<string>("...");
useEffect(() => {
// Behaves the same as Promise.resolve
Effect.runPromise(HiEff).then(setResult);
}, []);
return <h1>{result}</h1>;
};
```
This looks like it synchronously resolves, so let's add a bit of a delay, with Effect of course, for that one line goodness.
```tsx
// Leverage Effect.delay instead of timeouts
const HiEff = Effect.delay(Effect.success("Hello world!"), "2 seconds");
export const HelloEffAsync = () => {
const [result, setResult] = useState<string>("...");
useEffect(() => {
Effect.runPromise(HiEff).then(setResult);
}, []);
return <h1>{result}</h1>;
};
```
_look ma', no (explicit) setTimeout or whacky promise shenanigans!_
Now, with the delay, we actually see the "..." loading string that we used as the initializer to `useState` first, then the promise resolves. OK - sanity confirmed, async experienced.
## ❌ Errors & Effect & React
Our sync and async workflows were simple Success Effects, now let's Fail and see what happens. In Effect, you can 'throw' with `Effect.fail(...)`, so let's do that:
```ts
const FailEff = Effect.fail("not feeling it...");
```
Let's see what happens if we runSync a failure:
```sh
(FiberFailure) Error: Error: Not feeling it
```
Oof. An exception, what is this, try-catch town clown 🤡 city?
```ts
const FailEff = Effect.fail("Not feeling it");
let result;
try {
result = Effect.runSync(FailEff);
} catch (e) {
result = "Exception: " + String(e)
}
console.log(result); // => Exception: (FiberFailure) Error: Not feeling it
```
At least our program didn't crash, but is there a better way to statically match over the error we know will happen? After all, the type signature of FailEff describes a program that never returns, errors with a string, and needs no context.
There is! There is a type Effect provides called `Exit` and it has async and sync versions of the run methods, so we wrap our result in a structure we can use. [Check out the docs here](https://effect.website/docs/guides/essentials/running-effects#runsyncexit), and let's take it for a spin:
> 🧠 Effects are composable, and you don't need to use what you don't understand. If you see something useful, just start with that and see if it helps you make apps with more confidence.
```ts
import { Cause, Effect, Exit, identity } from "effect";
function handleLeftRight(left: string, right: string) {
return `Unexpected exit: (${left}, ${right})`;
}
const FailEff = Effect.fail("Not feeling it");
const ResultExit = Effect.runSyncExit(FailEff);
// Effect provides these handy match functions to map over all possibilities of a type
const result = Exit.match(ResultExit, {
onSuccess: () => "Were we secretely feeling it?",
onFailure: (cause) =>
// The type of cause is Cause, which can
// encapsulate many kinds of failures.
Cause.match(cause, {
// We expect this to be the only path taken, given that our program
// is Effect<never, string, never>
onFail: identity,
onDie: (_defect) => "Unexpected die from a defect\n" + cause.toJSON(),
onInterrupt: (fiberId) =>
`Unexpected interrupt on fiber ${fiberId}\n` + cause.toJSON(),
onParallel: handleLeftRight,
onSequential: handleLeftRight,
onEmpty: "Empty"
})
});
console.info(result); // => "Not feeling it"
```
Awesome! You may have experienced one of two emotions:
1. Wow - Effect really makes you cross your `t`s and dot your `i`s.
2. That was annoying inside the failure case, if I console log out the cause, I _see_ that it has a failure / error I can just pull out!
By convention (or maybe coercion) there is a `_tag` field on many (all?) types that support this `.match` behaviour, so we can do our own kind of collapsing with a switch if we wanted to. This would look like this:
```ts
const result = Exit.match(ResultExit, {
onSuccess: () => "Were we secretely feeling it?",
onFailure: (cause: Cause.Cause<string>) => {
// We can do our own pattern matching
switch (cause._tag) {
case "Fail":
return cause.error;
default:
return "Unexpected failure";
}
}
});
```
This is still type safe, as `_tag` is discriminating the union and we still get `result: string` - but word to the wise, try to leverage match when possible, as it does some narrowing for you (notice the `identity` we were able to use in the nested match above), which is quite nice to "zoom" in to the underlying type of each case, when we build the switch ourself, TypeScript has narrowed the type, but we have to do the selection and mapping ourself ( `cause.error` ) - which isn't a big deal in this case, but could be for others.
> **runPromiseExit**: Try to switch to an async version of the sync console program shown above.
>
> Hint - if you are using node v20/bun you can use top level awaits, and the code changes _remarkably_ little!
Now let's bring this home _into_ react! We can start by just trying to do it all in the component, but pretty soon a wee custom hook will "pop" out of this work:
```tsx
const FailEff = Effect.delay(Effect.fail("I can't even"), "2 seconds");
type States = "processing" | "success" | "failure";
export const HelloEffAsync = () => {
const [effState, setEffState] = useState<States>("processing");
const [result, setResult] = useState<string | null>(null);
useEffect(() => {
Effect.runPromiseExit(FailEff).then((FailEffExit) => {
Exit.match(FailEffExit, {
onSuccess: () => {
setResult("I CAN even!");
setEffState("success");
},
onFailure: (cause) => {
Cause.match(cause, {
onFail: (error) => setResult(error),
onDie: (_defect) =>
setResult("Unexpected defect: " + cause.toJSON()),
onInterrupt: (fiberId) => setResult("Interrupted: " + fiberId),
onParallel: (_l, _r) => setResult("Unexpected parallel error"),
onSequential: (_l, _r) => setResult("Unexpected sequential error"),
onEmpty: null,
});
setEffState("failure");
},
});
});
}, []);
if (effState === "processing") {
return <h1>Processing...</h1>;
}
if (effState === "success") {
return <h1 className="text-green-500">{result}</h1>;
}
return <h1 className="text-red-500">{result}</h1>;
};
```
Let's wrap up the reusable promise and exit code, tidy it up a bit, and then we should have halfway decent API to work with:
```ts
type States = "processing" | "success" | "failure";
// name pending... naming is hard!
const useEff = <TSuccess, TError>(
eff: Effect.Effect<TSuccess, TError, never>
) => {
const [effState, setEffState] = useState<States>("processing");
const [result, setResult] = useState<TSuccess | null>(null);
const [error, setError] = useState<TError | string | null>(null);
// still going to opt for a useEffect mount hook to _run it once per mount_
// but we will take care of aborting
useEffect(() => {
const controller = new AbortController();
Effect.runPromiseExit(eff, { signal: controller.signal }).then((exit) => {
Exit.match(exit, {
onSuccess: (resolvedValue) => {
setResult(resolvedValue);
setEffState("success");
},
onFailure: (cause) => {
let setToFailure = true;
Cause.match(cause, {
onFail: (error) => setError(error),
onDie: (_defect) =>
setError("Unexpected defect: " + cause.toJSON()),
onInterrupt: (fiberId) => {
setToFailure = false;
console.warn(`Interrupted [${fiberId}] - expecting retry`);
},
onParallel: (_l, _r) => setError("Unexpected parallel error"),
onSequential: (_l, _r) => {
setToFailure = false;
console.warn("Sequential failure, expecting retry");
},
onEmpty: null,
});
if (setToFailure) {
setEffState("failure");
}
},
});
});
return controller.abort.bind(controller);
}, []);
return {
result,
error,
state: effState,
};
};
```
The react code then becomes quite clean, akin to a react-query or similar feel:
```tsx
const FailEff = Effect.delay(Effect.fail("I can't even"), "1 seconds");
export const HelloEffAsync = () => {
const { result, error, state } = useEff(FailEff);
if (state === "processing") {
return <h1>Processing...</h1>;
}
if (state === "success") {
return <h1 className="text-green-500">{result}</h1>;
}
return <h1 className="text-red-500">{error}</h1>;
};
```
Try switching between fail and succeed, changing the delay, and whatever else comes to mind. You'll see warnings in the console, mostly because React strict mode will mount, unmount, then mount components again which exercises that abort controller we added.
## 🕰 Full Example
Let's take that hook and stick it into a folder with whatever of those names you like most (I think I'll go with `re-effect` for now), and boom we've started a react effect library. Now let's really exercise what we have more with some shenanigans around Dates and Time.
We're going to do something simple for now, just something to make it easier for Hobbits to see when their next meal is and how to plan accordingly. They'll need to know what day it is, the time (in 12 hour format, because 'murica), the season (for what to wear), and their next meal. Let's add some chaos with "business" rules.
- We cannot display a time with an even second, only odd. This is because we like jazz too much and cannot live on the down beat, only the off beat _(🎺would the off beat be even? or odd? in 'music' beats the first beat is 1 - the down beat, and we emphasize 2 and 4... but in raw timestamps would that be offset? #tangent 🎷)_.
So a timestamp of `00:00:03` is fine (HH:mm:ss format), but `00:00:02` is NOT okay. We must show an error showing the offending, hideous even second.
- We cannot display a time in the winter, hobbits are not monsters and cannot go out when it is too cold, naturally. Their hair is a fashion statement, not a coat.
- We cannot display a time that is too early, when hobbits should be sleeping (before 5am).
Other than that, nothing else can go wrong. Because Effect! (And because we're ignoring timezones, for now. 🤡)
All of our rules can be determined from a valid `Date` object in JS, and we can get the current time with `new Date()` - there are other variants of this with libraries and feel free to install and use them - but we should wrap that with Effect so we can compose our program together, and `sync` is the [perfect tool](https://effect.website/docs/guides/essentials/creating-effects) for that.
```ts
// Effect<Date, never, never>
const GetToday = Effect.sync(() => new Date());
```
I don't think Date can fail like this, but it certainly can fail if we pass something to it that is invalid, so keep that in mind for any future feature requests or explorations you may elect to do on your own (cough user input cough 💡).
With the power of Effect, we can pretend stuff exists that we know we can build later - like functions - and start with the modelling of our expected return type and errors. Let's do that now:
```ts
// we want something like this, so we can show everything we need to
// the hobbitses
export interface Today {
monthName: Month; // union of strings January -> December
ordinalDate: string;
year: string;
/** 24 hour time */
hourNum: number;
/** 12 hour time */
hour: string;
minute: string;
second: string;
meridiem: "pm" | "am";
season: Season; // union of season names
nextMeal: Meal; // Enough info for name + time of a hobbit meal
}
// we can use simple strings for errors, feel free to use a class
// or anything you'd like: https://effect.website/docs/guides/error-management/expected-errors
type EvenSecond = "SECOND_EVEN";
type TooCold = "TOO_COLD";
type TooEarly = "TOO_EARLY";
type TodayErrors = EvenSecond | TooCold | TooEarly;
// we need this type
type TodayEff = Effect<Today, TodayErrors, never>;
```
There's a lot of little formatting bits here and there, but the _gist_ is we have that Effect sync that lifts up a Date into the effect world, we have our interface we want React to consume, and we have our errors - now we just need to compose together a new function with our initial function and we should be golden - for now let's just use FlatMap, which will be able to handle the errors / success duality, and return what we need. Oh yeah, and all that stuff I invented like Season/Meal should be made to be real, else it can't compile. 😘
```ts
function processDate(date: Date): TodayEff {
// use Date functions
// raise invalid states with Effect.fail
// map to final format of Today with Effect.succeed
}
const GetToday = TodayEff.pipe(Effect.flatMap(processDate));
```
I'm going to use tailwind to make my app look not like plain html, otherwise the hobbits will laugh at me, but try your hand at it and compare my solution on github to yours! (apologies for the bright light)
A success state:

A few fail states:
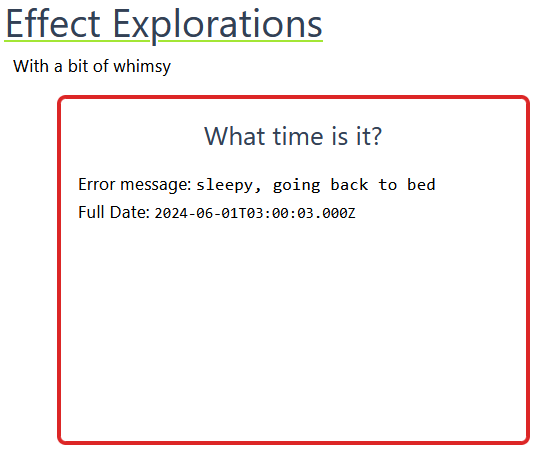
And some extra conditions if the hobbit might be running late:

Some notes:
- You can put a button on the page to remount your component which will re-run your effect, just use `key` and increment a number or something (see my linked source code)
- You can use an input and its value existing or not to switch between a TodayEff or an ArbitraryDayEff program, but you'll need to be sure to handle how the Date constructor can fail and create an "Invalid Date" object, yay browsers!
[Here is the source code](https://github.com/snewell92/explore-effect) - I will continue to update it as I explore more, the commit where this blog was published was [ea158](https://github.com/snewell92/explore-effect/commit/ea1583aa86e83f10d89ba76b121f75607650ad25).
## What's next?
I don't quite feel satisfied, so I'm going to do two things next:
1. Interact with an API, coming soon
2. Investigate a managed runtime to provide context (like what[this video](https://www.youtube.com/watch?v=THods1Q_qL8) shows in Remix, [code](https://github.com/mikearnaldi/effect-remix-stream/blob/main/app/lib/utilities.ts))
Once these two are done, I'll want to try out lots of different kinds of Effects being consumed in React to see where this falls down (as I suspect it will, hence all the work being done in effect-rx). For example, you can declare a Schedule for an Effect, which I think would still work, despite the code we wrote in this post being very "one shot" oriented. And should an async Effect suspend, and how should that work? I'll mostly be looking at react-query and effect-rx / rx-react for inspiration as I move forward.
I'm off work until July this year, so it's a good chunk of time to explore new things! 😁 | sirseanofloxley |
1,864,052 | Python vs. Go: The Backend Battle Royale | Choosing Between Python and Go for Backend Development You've decided to dive into the... | 0 | 2024-05-24T13:42:23 | https://dev.to/aquibpy/python-vs-go-the-backend-battle-royale-5ai3 | beginners, python, go, backend | # Choosing Between Python and Go for Backend Development
You've decided to dive into the exciting world of backend development, but with so many languages vying for your attention, it can be overwhelming! Two giants stand out: Python and Go. Both offer powerful features, but which one should you choose? Let's break it down!
## Python: The Friendly Giant
Python is renowned for its readability, ease of learning, and vast ecosystem. Its syntax is straightforward, and it boasts a rich collection of libraries and frameworks like Django and Flask, making it a breeze to build web applications quickly.
### Pros:
- **Beginner-friendly**: Easy to learn and pick up, perfect for new developers.
- **Extensive libraries**: Offers a vast collection of libraries for various tasks, saving you time and effort.
- **Large community**: Strong community support means you'll always find help when you need it.
- **Versatile**: Used in web development, data science, machine learning, and more.
### Cons:
- **Performance**: Can be slower than Go for demanding tasks.
- **Dynamically typed**: Requires careful testing to avoid errors.
## Go: The Speedy Challenger
Go, developed by Google, is known for its speed, concurrency, and simplicity. It's a compiled language, meaning it's faster than interpreted languages like Python. Go's focus on efficiency and parallelism makes it ideal for building robust, scalable applications.
### Pros:
- **Performance**: Excellent performance and scalability, great for handling heavy workloads.
- **Concurrency**: Built-in features for efficient handling of concurrent tasks.
- **Strong tooling**: Well-designed tools and libraries for building and testing applications.
- **Simple syntax**: Clear and concise syntax, making it easy to learn.
### Cons:
- **Limited ecosystem**: Smaller community and library collection compared to Python.
- **Less beginner-friendly**: Steeper learning curve for those new to programming.
## Choosing Your Weapon
So, which language should you choose? It ultimately depends on your project's needs and your own preferences.
### Choose Python if:
- You're a beginner and value ease of learning.
- Your project requires a rich set of libraries and frameworks.
- You need a language for tasks like data science or machine learning.
### Choose Go if:
- Your project requires high performance and scalability.
- You need to handle concurrent tasks efficiently.
- You prefer a simple and straightforward syntax.
## Getting Started
Ready to jump in? Here are some tips:
- **Try both!** Play around with both languages using online tutorials and resources.
- **Build a small project**: Choose a simple project and implement it in both Python and Go.
- **Join online communities**: Connect with other developers and get advice.
- **Practice consistently**: The more you code, the better you'll become!
No matter which path you choose, both Python and Go offer exciting opportunities in backend development. So grab your keyboard and start building! | aquibpy |
1,864,051 | Building Professional Connections as a Boomi Developer | With tech being advertised as the next best thing for humanity since the advent of penicillin, it's... | 0 | 2024-05-24T13:42:18 | https://dev.to/eyer-ai/building-professional-connections-as-a-boomi-developer-1gnp | community, boomi, ai, aiops | With tech being advertised as the next best thing for humanity since the advent of penicillin, it's no surprise that more people are picking up some tech or tech-adjacent skill. While this trend benefits both individuals and the industry, it’s clear that success in this field requires more than individual effort. This is particularly true for the Boomi landscape, highlighting the importance of the [Boomi community by Eyer](https://discord.gg/CcxvKxkaAJ).
By being a part of this community, you:
* Learn from others' experiences and contribute your own insights.
* Get help with problems you encounter and help others overcome theirs.
* Keep up-to-date on the latest platform advancements.
But the benefits go beyond the Boomi platform. Expanding your network exposes you to broader industry trends and potential collaborations. This can open doors to career advancement, new opportunities, and a more fulfilling professional journey.
This article discusses shared spaces for Boomi developers of all levels, strategies for maximizing these shared spaces, and building meaningful connections.
## Shared Boomi developer spaces
Recognizing the invaluable support Boomi developers receive from the community and networking opportunities, let's explore online and offline spaces to connect and build your network with other Boomi developers.
**Online networking**
The internet serves you the biggest online Boomi communities on a silver platter. You can join communities and keep in touch with members all at the tip of your fingers. Here are some ways to leverage these online communities to your advantage:
* **Boomi online communities:** In the past few years, several Boomi communities have emerged, including the [official Boomi community](https://community.boomi.com/s/) and the [Boomi community by Eyer](https://discord.gg/CcxvKxkaAJ), among others. These communities host forums, discussions, and Q&A sessions where you can participate by asking questions, sharing your expertise, and engaging in conversations. Contributing to these communities demonstrates your knowledge, builds your reputation, and allows you to connect with developers facing similar challenges.
* **Social media platforms:** Utilizing platforms like LinkedIn and Twitter can help you connect quickly with Boomi professionals, industry leaders, and potential employers. Following relevant accounts such as the official [Boomi Twitter](https://x.com/boomi) and [LinkedIn](https://www.linkedin.com/company/boomi-inc/) and The Eyer [Twitter](https://x.com/eyer_ai) and [LinkedIn,](https://www.linkedin.com/company/eyer-ai/) among others, is also beneficial.
In addition, creating posts that showcase your skills, certifications, and projects helps maintain meaningful connections in your niche.
You could share industry news, participate in discussions using relevant hashtags (e.g., #Boomi, #Integration), and connect with individuals whose work interests you."
* **Engaging with Others:** By actively participating in the community, you can gain insights, answer questions, and provide constructive feedback. Respond to comments on your posts, join relevant discussions, and connect with those who share your interests. By taking the initiative and being helpful, you'll build positive relationships and establish yourself as a valuable resource within the Boomi community.
* **Online events and webinars:** Attending online Boomi events and webinars offers numerous advantages. You'll gain valuable knowledge about the latest Boomi features, best practices, and industry trends directly from Boomi experts and practitioners. Webinars often feature live Q&A sessions, allowing you to network and connect with presenters and attendees directly.
These online events provide a platform for learning and expanding your network simultaneously. You'll connect with fellow developers facing similar challenges and exchange ideas.
**Offline networking**
While online connections are essential, face-to-face interactions can significantly enhance your network. Let's explore some shared offline networking spaces:
* **Local Boomi meetups and user groups:** Some organizations like [Easy Data Integration](https://easydatagroup.com/) host local Boomi meetups and user groups. These gatherings offer a fantastic opportunity to connect with Boomi developers in your area. You'll build relationships, share knowledge, and learn from each other's experiences.
* **Industry conferences and events:** Attending industry conferences and events focused on integration or Business Process Management (BPM) can be incredibly valuable. These events attract a wide range of professionals, including Boomi developers, solution providers, and industry leaders. Participating in these events allows you to:
* Learn about new technologies and upcoming trends in the integration and BPM space.
* Network with a broader audience, potentially leading to new collaborations or job opportunities.
* Attend workshops and sessions focused on Boomi development, further enhancing your skillset.
Understanding the various shared spaces where Boomi developers connect, let's explore how to make the most of these interactions.
## Tips for networking at events
Conferences offer fantastic opportunities to build meaningful connections within your field. Here are some tips to maximize your networking potential:
* **Make a plan:** Conferences are fast-paced. Know what sessions you want to attend, who you want to meet, and what you hope to achieve. Prioritize your time!
* **Do your research:** Before the event, identify key people going to these conferences and research their work. This shows initiative and helps prepare conversation starters.
* **Connect beforehand:** Use social media or email to connect with people you want to meet before the conference. Establish a rapport and build some pre-event connections.
* **Schedule your time:** Create a conference schedule that includes workshops, presentations, meetings, and discussions. This ensures you don't miss valuable networking opportunities.
## Building meaningful connections
Swapping business cards is a good start, but true professional connections are built on more than just exchanging contact information. Here are some tips to cultivate deeper relationships with fellow Boomi developers:
* **Actively listen:** When you meet someone new, put away your phone and truly focus on what they're saying. Ask thoughtful questions that show genuine interest in their work and experiences. This not only makes the other person feel valued but also helps you discover potential areas for collaboration.
* **Provide value to others:** Networking isn't a one-way street. Look for ways to be a resource for others. Share your Boomi expertise by offering tips, recommending relevant resources, or even connecting them with someone in your network who might be able to help with their specific challenge.
* **Follow up after meeting someone:** Don't let your new connection disappear. Send a personalized email or LinkedIn message within a day or two of meeting someone. Briefly mention something you enjoyed from your conversation and offer additional help if relevant. You can also suggest connecting on social media platforms focused on Boomi development to stay in touch and share industry updates.
By actively listening, providing value, and following up, you'll transform fleeting interactions into meaningful connections that can benefit your professional development and open doors to new opportunities within the Boomi developer community.
## Go for it!
This article explored the power of community in building a thriving professional network within the Boomi development landscape and, by extension, many software development fields. It discussed the wealth of online and offline spaces available to connect with fellow Boomi developers.
From online communities and social media platforms to local meetups and industry conferences, these shared spaces offer invaluable opportunities to learn, share knowledge, and forge meaningful connections. By actively engaging in these communities, you'll gain access to a supportive network that can propel your career forward.
So, take the first step and join the [Boomi community by Eyer](https://discord.gg/CcxvKxkaAJ) today.
| amaraiheanacho |
1,864,050 | RedisJSON: Enhancing JSON Data Handling in Redis | Introduction JSON has become the standard format for data exchange in modern... | 0 | 2024-05-24T13:41:34 | https://dev.to/markyu/redisjson-enhancing-json-data-handling-in-redis-3b5h | redis, json, cache, data | ## Introduction
JSON has become the standard format for data exchange in modern applications. However, traditional relational databases may face performance challenges when handling JSON data. To address this issue, Redis introduced the RedisJSON module, which allows developers to store, query, and manipulate JSON data directly within the Redis database. This article will delve into RedisJSON's working principles, key operations, performance advantages, and usage scenarios.
## Table of Contents
1. Introduction to RedisJSON
2. How RedisJSON Works
3. Installing RedisJSON
4. Basic Operations with RedisJSON
- Storing JSON Data
- Retrieving JSON Data
- Getting JSON Data Type
- Modifying JSON Data
- Deleting JSON Data
- Adding or Updating JSON Fields
- Adding Elements to a JSON Array
- JSONPath Queries
- Getting JSON Array Length
- Retrieving All Keys from a JSON Object
- Deleting Fields in JSON
- Complex Queries
5. Performance Advantages
6. Use Cases
7. Conclusion
## 1. Introduction to RedisJSON
RedisJSON is an extension module for Redis that provides native support for JSON data. With RedisJSON, developers can store JSON documents in Redis and perform efficient queries and operations on them. This module simplifies data processing workflows and significantly enhances the performance of JSON data handling.
## 2. How RedisJSON Works
### Data Storage Format
RedisJSON stores data in an optimized binary format rather than simple text. This binary format allows for fast serialization and deserialization of JSON data, improving read and write performance.
### Serialization and Deserialization
Before storing data in Redis, JSON data is serialized into a compact binary string. When reading data, this binary string is deserialized back into its original JSON format for easy use by applications.
### Internal Data Structure
RedisJSON uses a tree-like structure, known as a Rax tree (Redis tree), to manage JSON data. This ordered dictionary tree allows for efficient key sorting and quick insertion, deletion, and lookup operations.
### Query and Operation Optimization
RedisJSON supports JSONPath syntax for complex queries, enabling developers to filter and sort JSON data efficiently. All operations on JSON data are atomic, ensuring data consistency and integrity in high-concurrency environments.
### Integration with Redis Ecosystem
RedisJSON seamlessly integrates with other Redis features and tools, such as transactions, pub/sub, and Lua scripting, providing a comprehensive solution for managing JSON data.
### Performance Characteristics
Despite adding support for JSON data, RedisJSON maintains Redis's high performance. Optimized internal representation and efficient query algorithms ensure fast response times even with large datasets.
## 3. Installing RedisJSON
### Prerequisites
Ensure that Redis is installed with a version of 6.0 or higher.
### Downloading RedisJSON Module
Download the RedisJSON module from the Redis website or GitHub repository. Choose the version suitable for your operating system.
### Loading RedisJSON Module
In the Redis configuration file (`redis.conf`), add a line to load the RedisJSON module using the `loadmodule` directive, followed by the module file path.
Example:
```plaintext
loadmodule /path/to/module/rejson.so
```
### Verifying Installation
Start the Redis server and ensure there are no errors. Connect to the Redis server using the `redis-cli` tool and run `MODULE LIST` to verify that RedisJSON is loaded successfully.
## 4. Basic Operations with RedisJSON
### Storing JSON Data
Use `JSON.SET` to store JSON data.
```plaintext
JSON.SET user $ '{"name":"HuYiDao","age":18}'
```
### Retrieving JSON Data
Use `JSON.GET` to retrieve JSON data.
```plaintext
JSON.GET user
```
### Getting JSON Data Type
Use `JSON.TYPE` to get the type of JSON data.
```plaintext
JSON.TYPE user
```
### Modifying JSON Data
Use `JSON.NUMINCRBY` to modify numeric fields in JSON data.
```plaintext
JSON.NUMINCRBY user $.age 2
```
### Deleting JSON Data
Use the `DEL` command to delete a key storing JSON data.
```plaintext
DEL user
```
### Adding or Updating JSON Fields
Use `JSON.SET` with a path to add or update fields in a JSON object.
```plaintext
JSON.SET user $.address '{"city": "Beijing", "country": "China"}' NX
```
### Adding Elements to a JSON Array
Use `JSON.ARRAPPEND` to add elements to a JSON array.
```plaintext
JSON.SET user $.hobbies '["reading"]'
JSON.ARRAPPEND user $.hobbies '"swimming"'
```
### JSONPath Queries
Use JSONPath syntax to query JSON data.
```plaintext
JSON.GET user '$.name'
```
### Getting JSON Array Length
Use `JSON.OBJLEN` to get the length of a JSON array.
```plaintext
JSON.OBJLEN user $.hobbies
```
### Retrieving All Keys from a JSON Object
Use `JSON.OBJKEYS` to get all keys in a JSON object.
```plaintext
JSON.OBJKEYS user
```
### Deleting Fields in JSON
Use `JSON.DELPATH` to delete specific fields in a JSON object.
```plaintext
JSON.DELPATH user $.address
```
### Complex Queries
Use `JSON.QUERY` for advanced querying.
```plaintext
JSON.QUERY user '$[?(@.city=="Beijing")]'
```
## 5. Performance Advantages
RedisJSON offers several performance advantages:
- **In-Memory Storage**: Storing data in memory ensures fast read and write speeds, outperforming traditional relational databases.
- **Tree Structure Storage**: The tree structure enables quick access to sub-elements, enhancing query and operation efficiency.
- **Atomic Operations**: All operations on JSON data are atomic, ensuring data consistency and preventing conflicts in concurrent environments.
## 6. Use Cases
RedisJSON is ideal for applications requiring real-time performance, such as:
- **Content Management Systems**: Efficiently store and retrieve complex content structures and metadata.
- **Product Catalogs**: Manage and search product attributes and SKU combinations effectively.
- **Mobile Applications**: Synchronize data across client applications in real-time.
- **Session Management**: Manage user session data efficiently in web applications.
## Conclusion
RedisJSON provides a powerful solution for directly storing, querying, and manipulating JSON data within Redis. By leveraging RedisJSON's capabilities, developers can efficiently handle complex JSON data structures and meet the diverse needs of modern applications. Whether for content management, product catalogs, or mobile app development, RedisJSON offers a flexible and high-performance data storage and processing solution.
By understanding and utilizing RedisJSON, developers can take full advantage of Redis's speed and efficiency while working with JSON data.
---
**References:**
- [RedisJSON Documentation](https://redis.io/docs/stack/json/)
- [GitHub Repository for RedisJSON](https://github.com/RedisJSON/RedisJSON)
- [Redis Labs: RedisJSON Module](https://redislabs.com/redis-enterprise/redis-json/) | markyu |
1,864,049 | The Risks of Misusing Electron IPC: | Renderer-to-Renderer Communication In Electron applications Inter-Process Communication... | 0 | 2024-05-24T13:41:05 | https://dev.to/code-nit-whit/the-risks-of-misusing-electron-ipc-2jii | electron, ipc, node, javascript | # Renderer-to-Renderer Communication In Electron applications
Inter-Process Communication (IPC) is a crucial mechanism that enables communication between the mWtain process and renderer processes. However, direct renderer-to-renderer communication isn’t natively supported by IPC due to security considerations. This limitation can pose challenges for developers needing to facilitate data exchange between webviews or separate renderer processes. In this article, we will explore an unconventional method to achieve renderer-to-renderer communication, its possibilities, pitfalls, and reasons to avoid this approach.
## Understanding Electron IPC
Electron IPC provides a way for the main process and renderer processes to communicate via message passing. Typically, communication flows like this:
**Renderer to Main:** The renderer sends messages to the main process using ipcRenderer.send().
**Main to Renderer:** The main process sends messages back to renderers using mainWindow.webContents.send() or similar methods.
This indirect approach ensures that all inter-process communication can be controlled and sanitized by the main process, which acts as a gatekeeper for security purposes.
### The Renderer-to-Renderer Communication Challenge
Renderer processes in Electron are isolated from each other for security reasons. This isolation prevents direct IPC channels between them, which can be problematic when you need webviews or multiple renderer processes to share data directly.
## Unveiling the Hidden Event
Electron IPC relies on internal events to function. While most of these are well-documented and used for intended purposes, there are undocumented or lesser-known events that can be leveraged for renderer-to-renderer communication. Two such events are ipc-message and ipc-message-sync.
### Implementing Renderer-to-Renderer Communication
Here’s how you can use ipc-message for renderer-to-renderer communication:
In the Main Process: Ensure the main process is set up to listen for and relay messages between renderer processes.
`const { app, BrowserWindow, ipcMain } = require('electron');
let mainWindow;
app.on('ready', () => {
mainWindow = new BrowserWindow({
webPreferences: {
nodeIntegration: true,
contextIsolation: false,
},
});
mainWindow.loadURL('file://' + __dirname + '/index.html');
});
ipcMain.on('renderer-to-renderer', (event, message) => {
// Broadcast message to all renderer processes
mainWindow.webContents.send('renderer-message', message);
});`
In the Renderer Processes: Set up listeners and senders in each renderer process.
`const { ipcRenderer } = require('electron');
// Listen for messages from other renderers
ipcRenderer.on('renderer-message', (event, message) => {
console.log('Received message from another renderer:', message);
});
// Send a message to another renderer
function sendMessageToRenderer(message) {
ipcRenderer.send('renderer-to-renderer', message);
}
// Example usage
sendMessageToRenderer('Hello from Renderer 1');`
### Possibilities This Opens
By leveraging the ipc-message event, you can enable several powerful features:
**Direct Data Sharing:** Share data directly between renderer processes without routing every message through the main process.
**Performance Improvements:** Reduce latency and overhead associated with routing messages through the main process.
Complex Inter-Renderer Interactions: Enable more sophisticated and direct interactions between webviews or renderer processes.
### Risks and Reasons to Avoid This Approach
Direct renderer-to-renderer communication using internal events introduces several specific security risks:
**Unauthorized Access:** Bypassing the main process for IPC means renderer processes can communicate directly without any intermediary validation. This can lead to unauthorized access to sensitive data or functions within the renderer processes, as there is no central authority to enforce access control.
**Cross-Site Scripting (XSS): **Renderer processes are often used to display web content. If one renderer process is compromised through an XSS attack, it can potentially send malicious messages directly to other renderer processes. This significantly increases the risk and impact of XSS attacks since the malicious script could interact with multiple renderer processes.
**Lack of Logging and Monitoring:** The main process usually handles logging and monitoring of IPC messages, providing a clear audit trail. Bypassing this mechanism can make it difficult to track or monitor inter-process communication, hindering the detection and diagnosis of security incidents.
## Best Practices to Mitigate Risks
Strict Content Security Policy (CSP): Implement strict CSPs to mitigate XSS risks.
Sanitization and Validation: Ensure that any data being sent between processes is properly sanitized and validated.
Centralized Logging: Maintain logging in the main process to monitor IPC traffic for anomalies.
In conclusion, while it is technically feasible to implement renderer-to-renderer communication in Electron using internal events, it is generally advisable to avoid this approach due to the associated security risks. The security model of Electron is designed to mitigate these risks by routing IPC through the main process, and deviating from this model can expose your application to various vulnerabilities. It is generally advisable to adhere to the recommended IPC patterns to maintain a secure and robust application.
| code-nit-whit |
1,864,048 | STORAGE FOR INTERNAL COMPANY DOCUMENTS | In the portal, search for and select Storage accounts. Select + Create. Select the Resource group... | 0 | 2024-05-24T13:41:04 | https://dev.to/kellyt/shared-file-storage-for-the-company-offices-1n6l | In the portal, search for and select Storage accounts.
Select + Create.
Select the Resource group created in the previous lab.
Set the Storage account name to private. Add an identifier to the name to ensure the name is unique.
Select Review, and then Create the storage account.
Wait for the storage account to deploy, and then select Go to resource
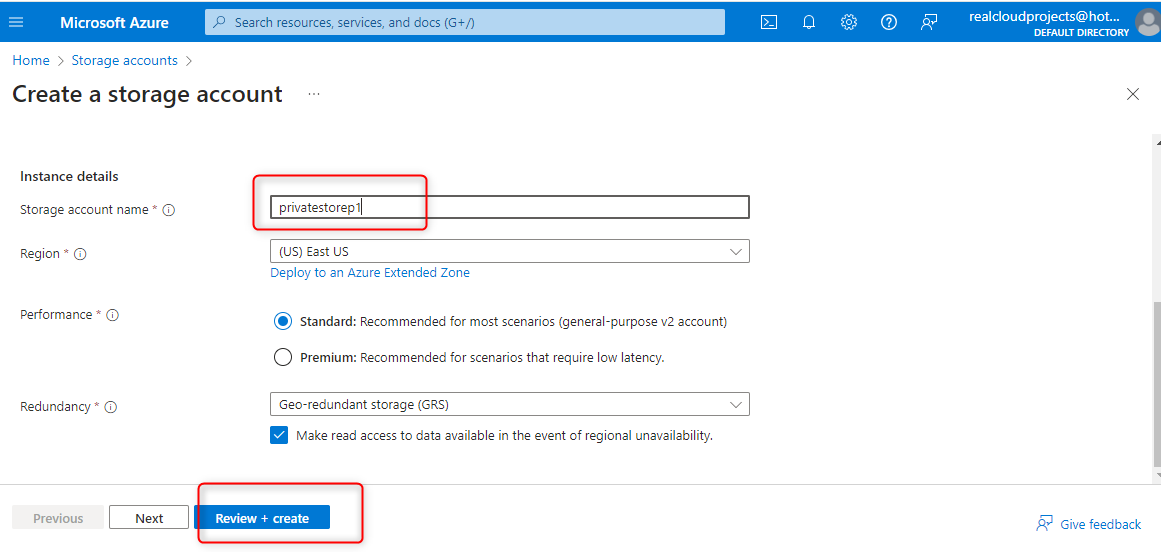
In the storage account, in the Data management section, select the Redundancy blade.
Ensure Geo-redundant storage (GRS) is selected.
Refresh the page.
Review the primary and secondary location information.
Save your changes.
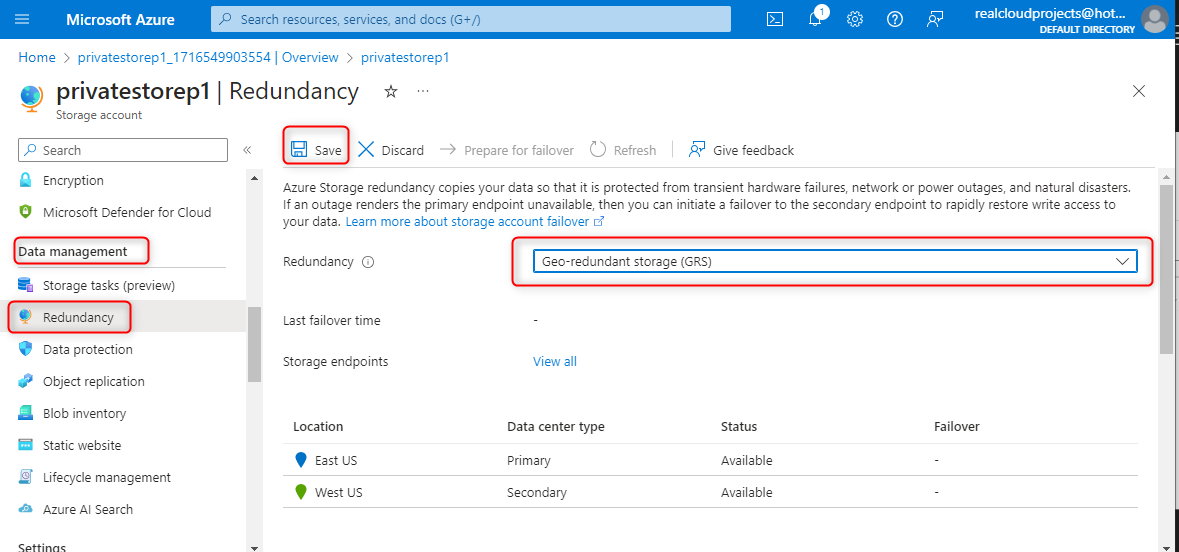
In the storage account, in the Data storage section, select the Containers blade.
Select + Container.
Ensure the Name of the container is private.
Ensure the Public access level is Private (no anonymous access).
As you have time, review the Advanced settings, but take the defaults.
Select Create.
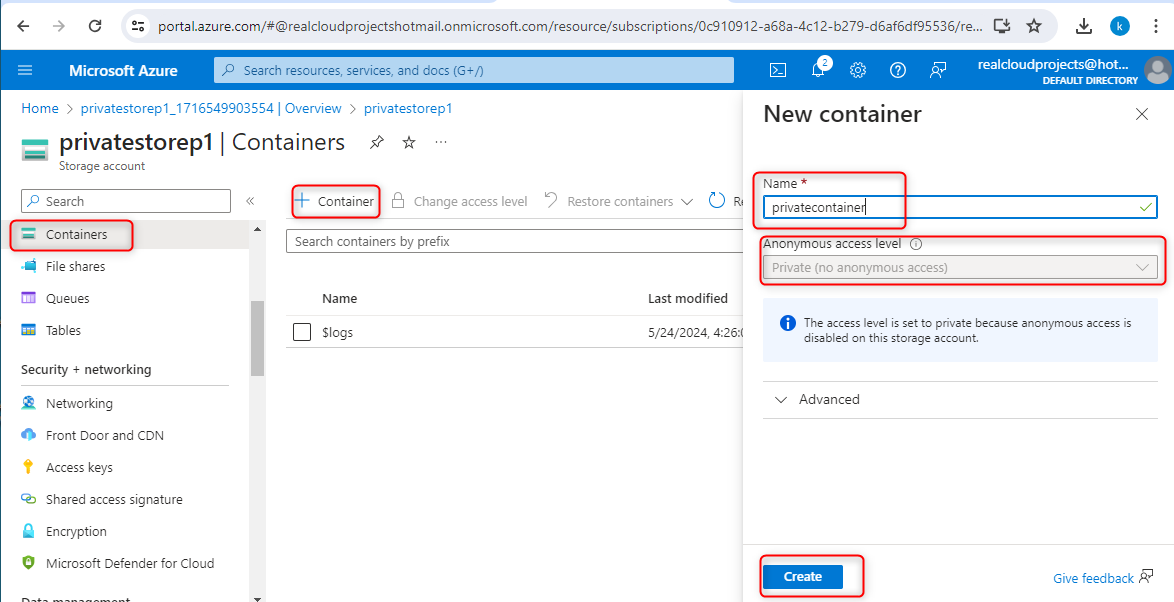
**To test and ensure the file isn't accessible (Private)**
Select the container.
Select Upload.
Browse to files and select a file.
Upload the file.
Select the uploaded file.
On the Overview tab, copy the URL.
Paste the URL into a new browser tab.
Verify the file doesn’t display and you receive an error.
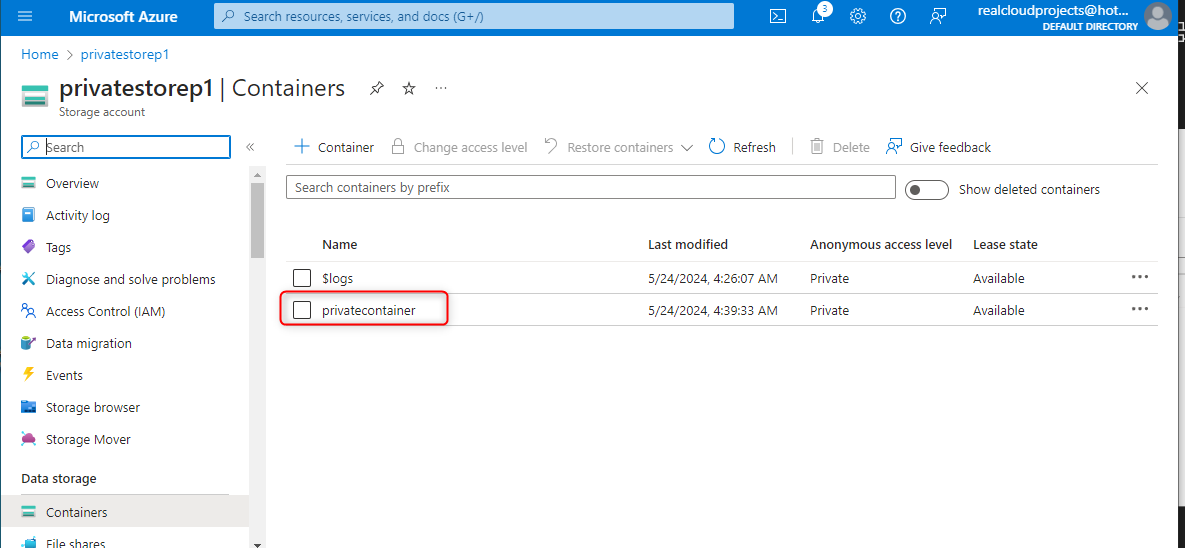
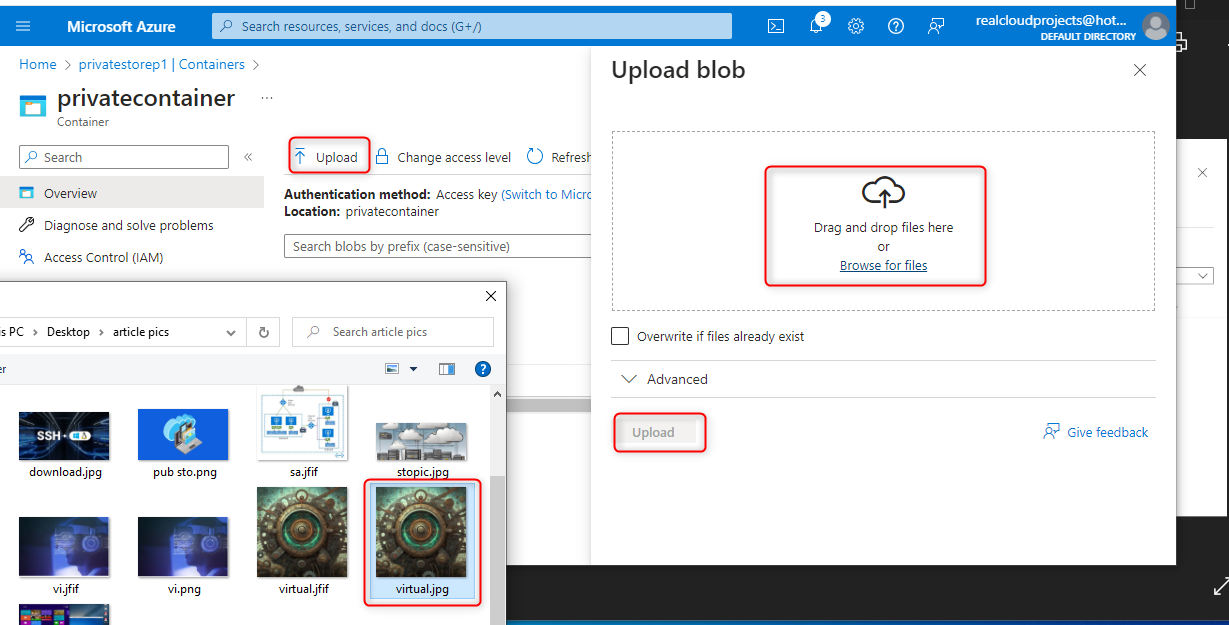
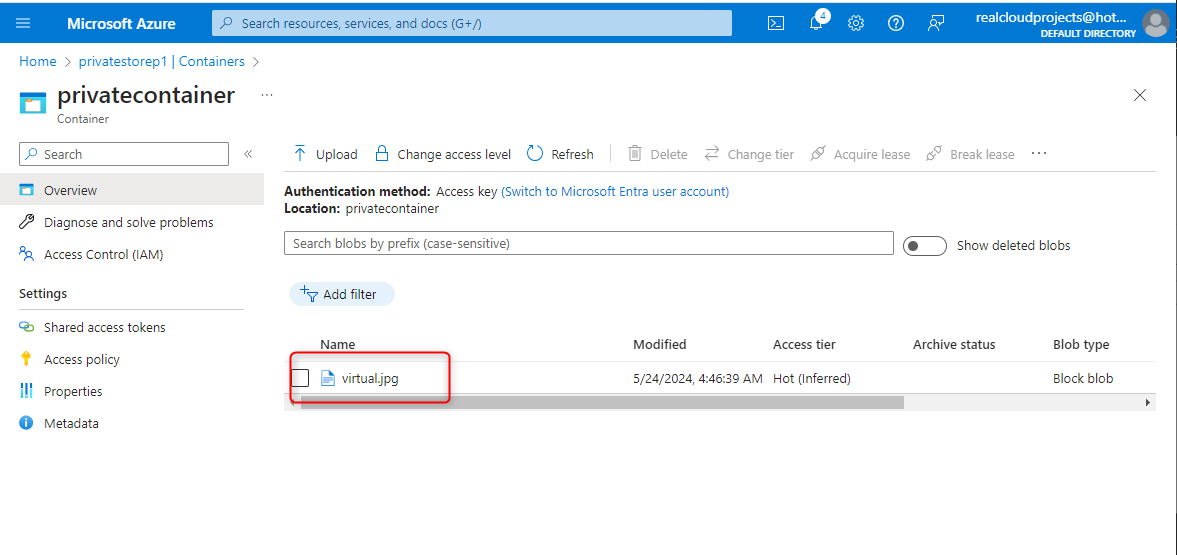
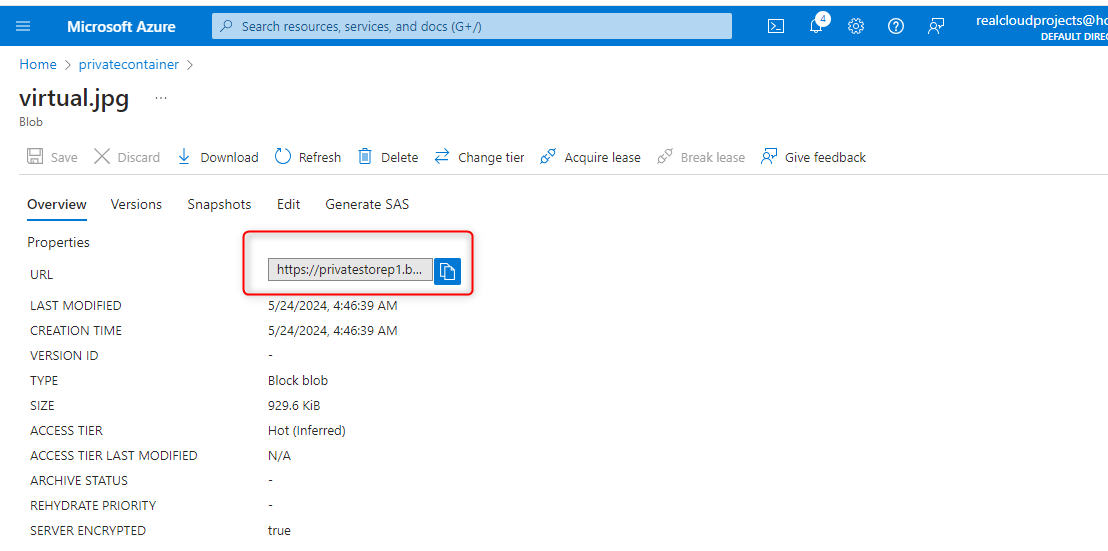
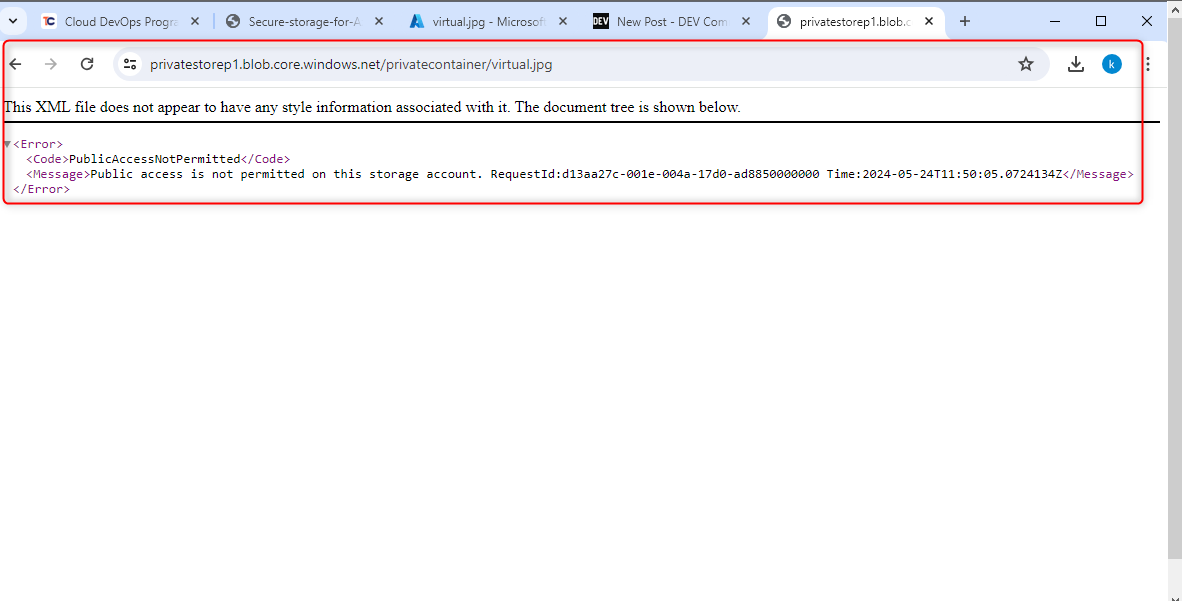
Select your uploaded blob file and move to the Generate SAS tab.
In the Permissions drop-down, ensure the partner has only Read permissions.
Verify the Start and expiry date/time is for the next 24 hours.
Select Generate SAS token and URL.
Copy the Blob SAS URL to a new browser tab.
Verify you can access the file. If you have uploaded an image file it will display in the browser. Other file types will be downloaded.
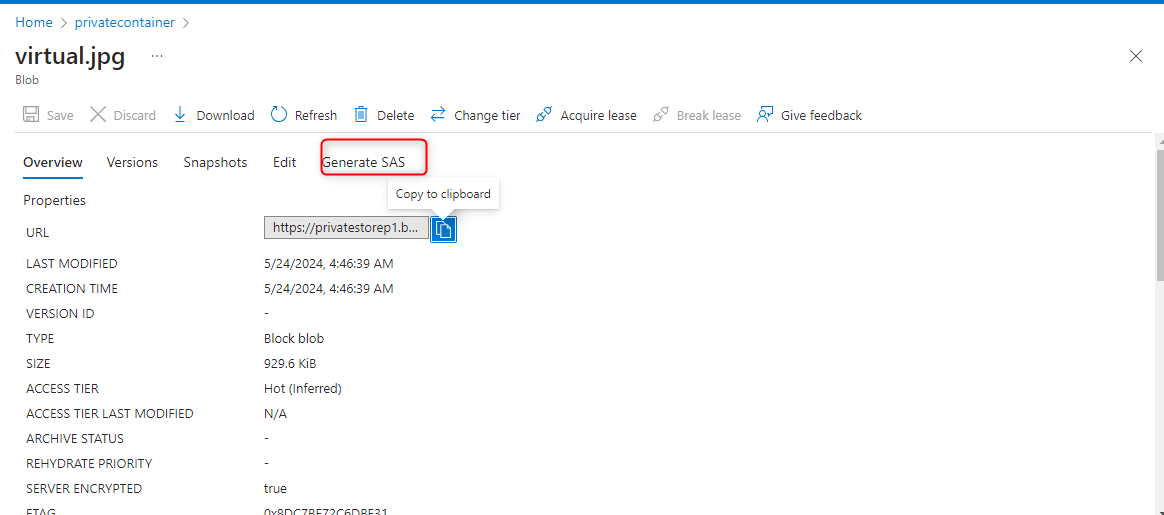
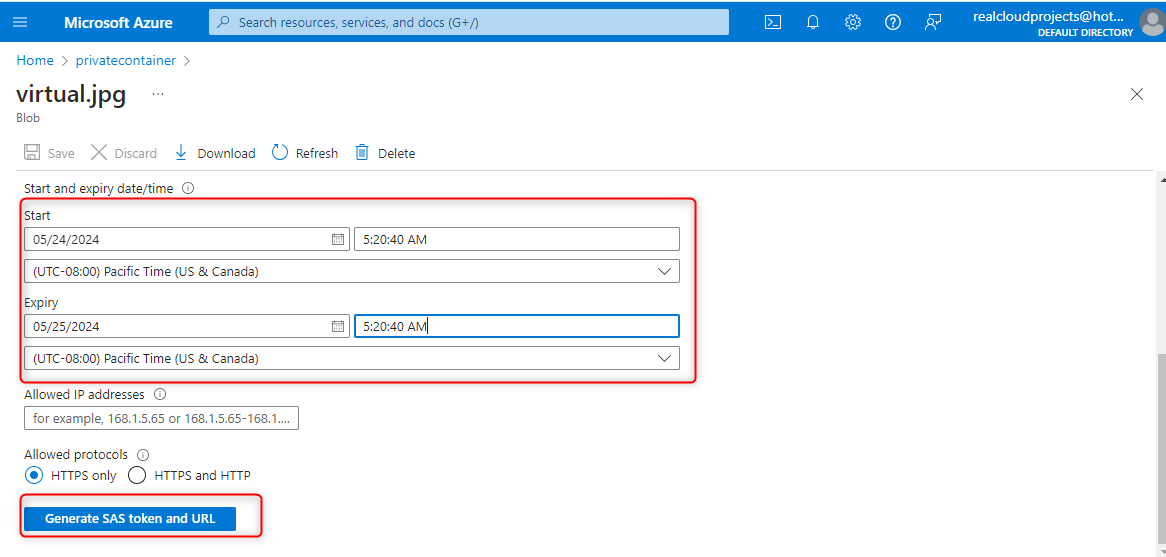
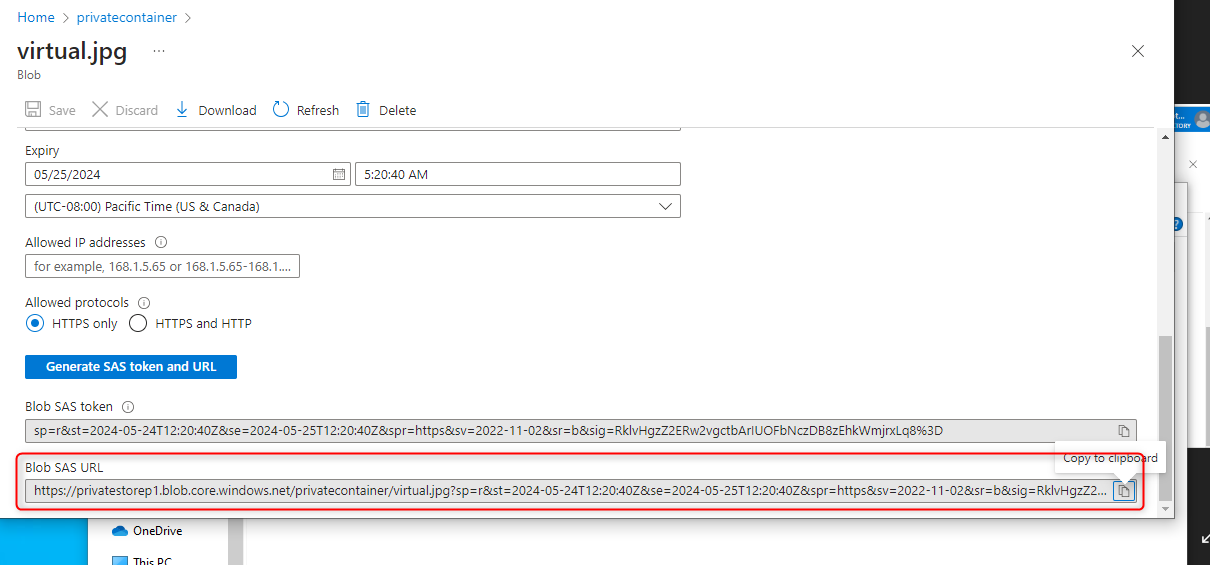
Return to the storage account.
In the Overview section, notice the Default access tier is set to Hot.
In the Data management section, select the Lifecycle management blade.
Select Add rule.
Set the Rule name to movetocool.
Set the Rule scope to Apply rule to all blobs in the storage account.
Select Next.
Ensure Last modified is selected.
Set More than (days ago) to 30.
In the Then drop-down select Move to cool storage.
As you have time, review other lifecycle options in the drop-down.
Add the rule.
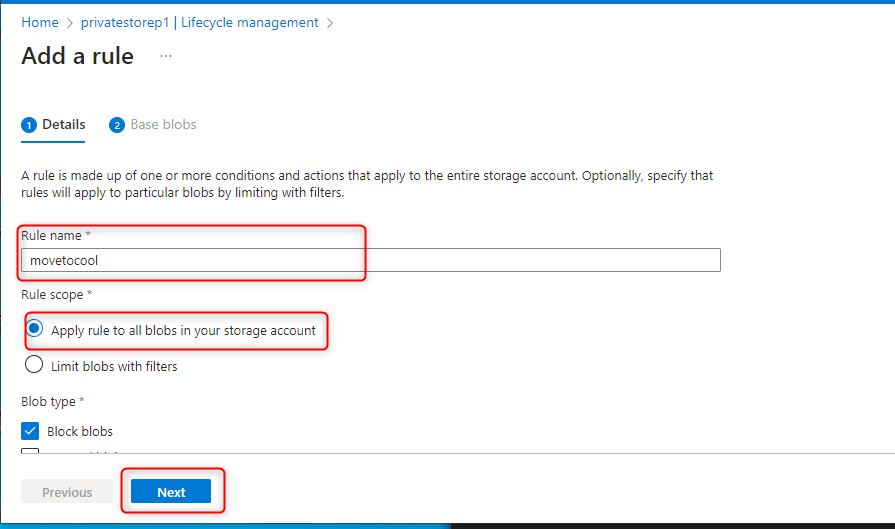
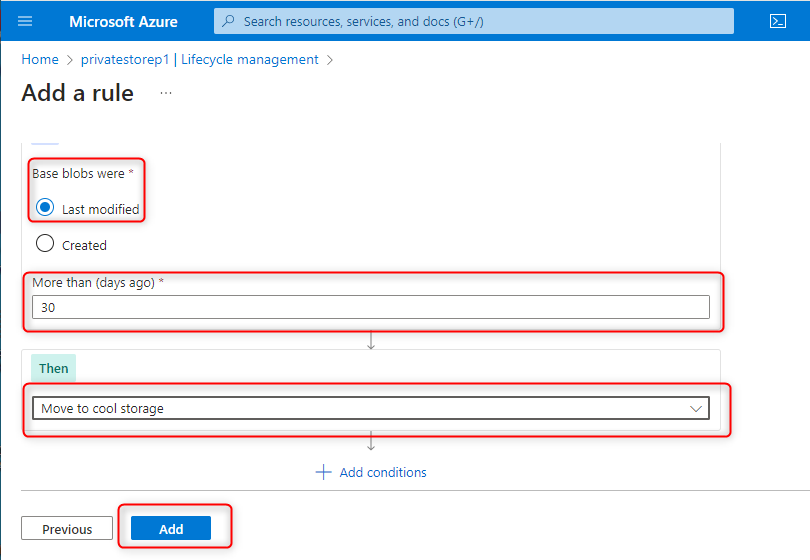
**public website files need to be backed up to another storage account**
In your storage account, create a new container called backup. Use the default values. Refer back to Lab 02a if you need detailed instructions.
Navigate to your publicwebsite storage account. This storage account was created in the previous exercise.
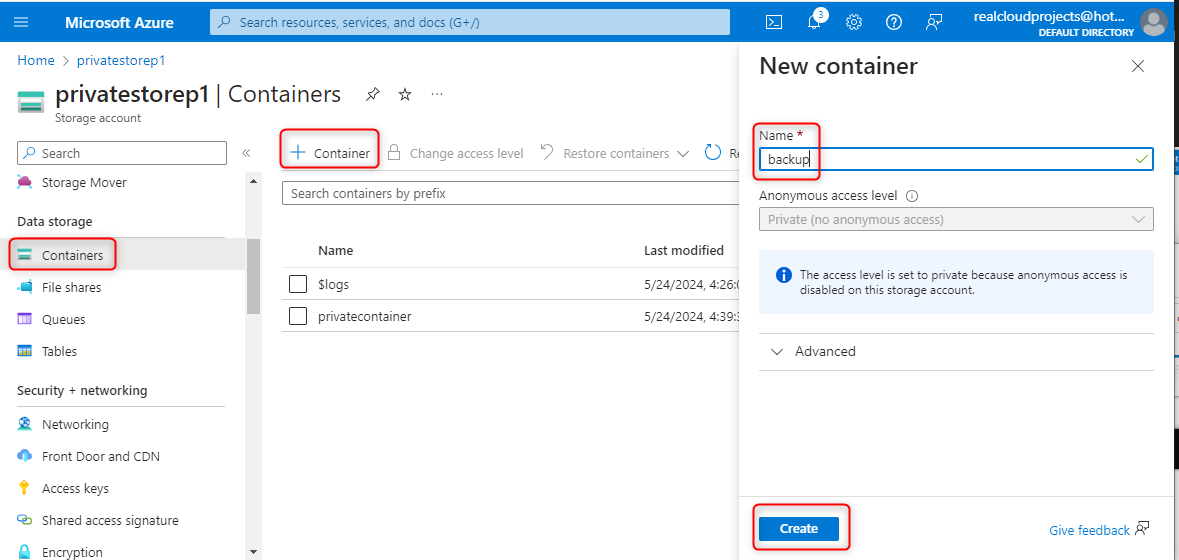
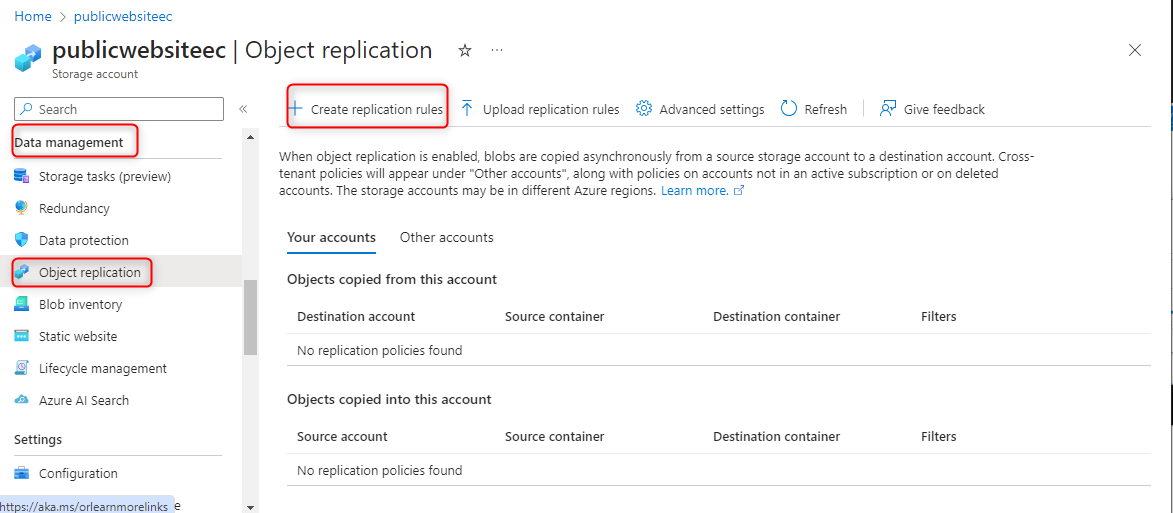
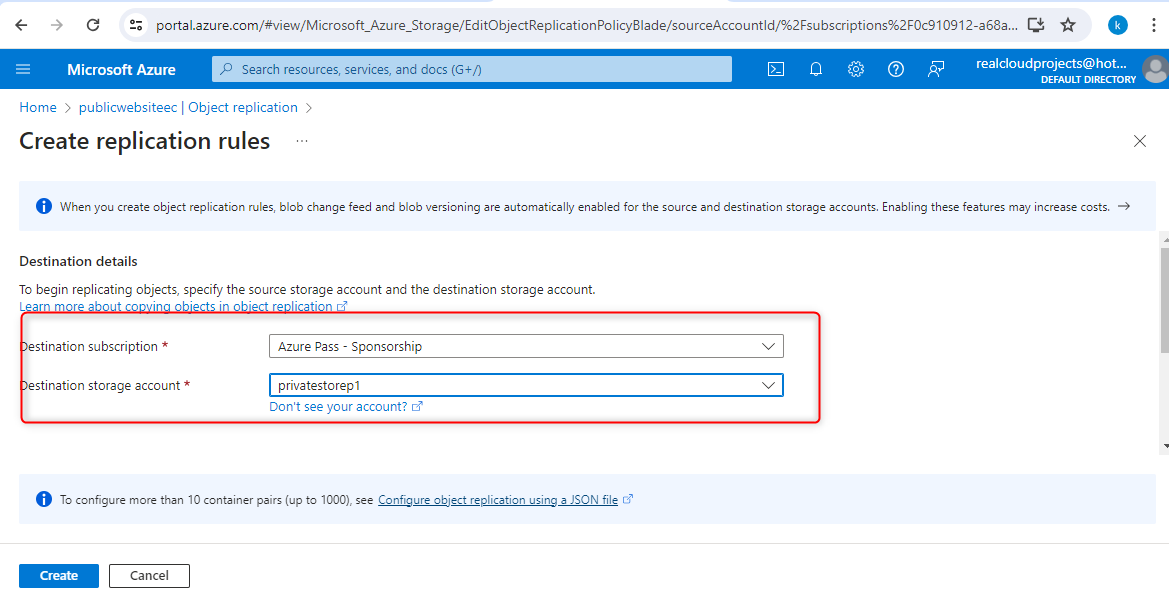
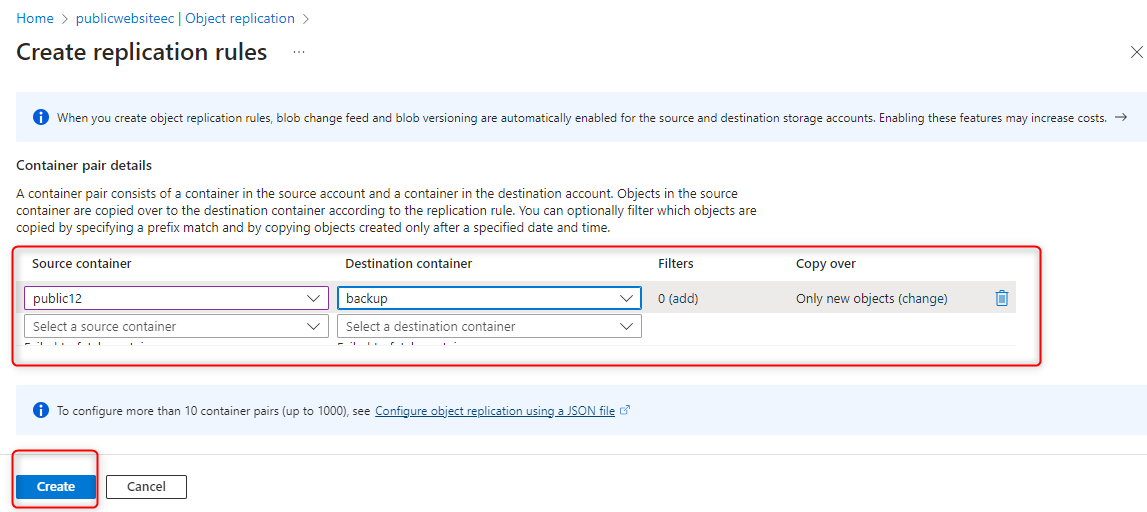
| kellyt | |
1,864,045 | What's coming in Next.js 15 | Today, I'm excited to dive into some of the latest technological advancements that have caught my... | 0 | 2024-05-24T13:40:33 | https://dev.to/iamgoncaloalves/whats-coming-in-nextjs-15-2lbo | nextjs, react, webdev | Today, I'm excited to dive into some of the latest technological advancements that have caught my eye, particularly around Next.js 15. Although these updates might seem nuanced, they are pivotal for developers looking to enhance web application performance and experience.
While it's still in the RC phase mainly due to dependencies on the upcoming React 19, the anticipation is palpable. This update promises to streamline development processes significantly and improve application performance across the board.
## Enhanced React Support
One of the standout features in this release is the integration with React 19, enhancing both client and server-side capabilities. Developers can now experiment with new features like the React compiler, which optimizes the application even further. If you're keen to try it out, running a simple `npm install next@rc` could get you started on this exciting journey.
With React 19 on the horizon, Next.js 15 is poised to integrate seamlessly, promising improvements in both client and server-side operations. This means faster, more efficient builds, and a smoother developer experience.
## Compiler Upgrades
The integration of the React 19 compiler is a game-changer. It simplifies the setup process, potentially improving performance without the need for extensive code modifications. This upgrade is particularly promising for those looking to enhance application speed and responsiveness.
## Improved Error Handling for Hydration
Next.js 15 aims to solve the hydration errors more transparently by providing clearer debugging messages. This means developers can quickly pinpoint discrepancies between server and client renders, significantly easing the debugging process. This is a huge relief for developers who have struggled with these issues in the past.
## Enhancements in Caching and Routing
Vercel has also overhauled its caching strategies. In previous versions, certain default caching behaviors led to confusion and inefficiencies. The new approach requires explicit actions to enable caching, thereby reducing unintended consequences and giving developers more control.
Routing has received attention too, with improvements ensuring that navigation fetches the most current page data, enhancing the user experience by maintaining the speed and responsiveness that Next.js applications are known for.
## Incremental Adoption of Partial Pre-rendering
This feature allows developers to implement pre-rendering gradually, making it easier to optimize performance without overhauling the entire application. It’s especially useful for enhancing user experiences on static pages like homepages or blog entries.
## Next After: Post-Request Operations
An exciting addition is the `unstable_after` feature, empowering developers to execute background tasks after a response is sent to the user. This is ideal for non-critical operations like logging or analytics, ensuring they don’t delay the initial response.
## Streamlined Developer Experience
Lastly, the improvements extend to the developer experience. The revised `create-next-app` template is cleaner and more intuitive, helping new users start projects more efficiently. Moreover, the introduction of Turbo pack invites developers to opt-in during setup, promoting a faster and more responsive development environment.
## Looking Forward
As we look towards the general availability of Next.js 15, it's clear that Vercel is committed to pushing the boundaries of what's possible in web development. These updates not only address pain points but also introduce forward-thinking capabilities that promise to set new standards in the industry.
I'm particularly excited about the potential these updates have to simplify the development process while simultaneously boosting performance and security. Whether you're a seasoned developer or just starting out, these changes are worth exploring.
## Connect with me
If you like this article be sure to leave a comment. That will make my day!
If you want to read other stuff by me you can check out my [personal blog](www.goncaloalves.com).
If you want to connect with me you can send me a message on [Twitter/X](twitter.com/iamgoncaloalves).
You can also check other stuff that I have going on [here](bio.link/goncaloalves) | iamgoncaloalves |
1,864,046 | Building a side project for developers - Part 2 | Introduction In the first part of this series, I talked about the basic things about side... | 0 | 2024-05-24T13:40:03 | https://dev.to/jamescardona11/building-a-side-project-for-developers-part-2-1epm | startup, sideprojects, startuplife, development | ## Introduction
In the first part of this series, I talked about the basic things about side projects, you can read it [here](https://dev.to/jamescardona11/building-a-side-project-for-developers-part-1-4nn3). In this part, I will talk about the ideation process how to use the tools to create a plan, and how to start with the project.
Maybe you are thinking, why do I need to create a plan? The answer is simple, the plan is the first step to start with the project, and it's a way to have a clear idea of what you want to achieve. This part is a little bit more visual and the technical solution is going to be in the next post.
## Start with this project
- What is the problem that I'm solving?: I'm building an AI application, that will help me and help people to improve their productivity when they are working to grow their social media.
- Why did I choose this idea?: Two main reasons, because I want to learn some new technologies and is something that I'm facing in my daily life.
- What is the goal of this project?: The idea is to have a working application for mobile and web. The main goal is for this app to use AI to create better social media content focused on LinkedIn and Twitter.
With the latest questions, I can start to create a plan, the first step is to create an MVP around one single idea, and after that, I can improve it, add more features, and make it better.
## Problem and Solution
Focus on the Problem, Not Just the Solution
Many side projects initially aim to create the next "big company" or an "automation tool for Y," leading to a fixation on a single solution. However, adopting a mindset centered around understanding the problem rather than fixating on a specific solution offers more flexibility.
I'm going to write the problem description, possible features, and solution; write as much as possible, and later remove the things that are not important.
### ⚡Problem
Many individuals and businesses struggle to effectively grow their audience on social media platforms, hindering their ability to reach and engage with a broader audience. Despite recognizing the importance of social media presence for brand visibility and engagement, navigating the complexities of audience growth remains a significant challenge.
Factors contributing to this challenge include:
1. **Limited Resources**: Many users lack the time, expertise, or resources to devise and implement effective audience growth strategies.
2. **Lack of Insight**: Users often struggle to understand their target audience, preferences, and the most effective content strategies to attract and retain followers.
3. **Content Management**: Managing multiple social media platforms, creating engaging content consistently, and scheduling posts can be overwhelming and time-consuming.
4. **Competition**: The crowded social media landscape makes it difficult to stand out and attract attention amidst competition from other users and brands.
5. **Analytical Complexity**: Understanding the effectiveness of audience growth efforts through analytics and metrics can be daunting for many users.
### ✅ Solution
Developing a comprehensive tool or app to address the challenge of audience growth on social media platforms requires a multifaceted approach. The solution should integrate various features and functionalities to cater to the diverse needs of users seeking to expand their reach and engagement. Key components of the solution include:
1. **Audience Insights**: Implement features that provide users with valuable insights into their target audience demographics, preferences, and behavior. This could include analytics dashboards, audience segmentation tools, and trend analysis capabilities.
2. **Content Creation and Scheduling**: Offer robust content creation tools that enable users to produce high-quality, engaging content tailored to their audience. Additionally, provides scheduling features to allow users to plan and automate their social media posts for optimal timing and consistency.
3. **Cross-Platform Integration**: Ensure compatibility with multiple social media platforms, allowing users to manage their presence across various channels seamlessly. This includes support for popular platforms such as Twitter, Facebook, Instagram, LinkedIn, and more.
4. **Engagement Tools**: Incorporate features to facilitate user engagement, such as comment management, direct messaging, and audience interaction tracking. This encourages meaningful interactions with followers and enhances community building.
5. **Performance Tracking**: Provide comprehensive analytics and reporting functionalities to help users track the effectiveness of their audience growth efforts. Metrics such as follower growth, engagement rates, and content performance should be easily accessible and actionable.
6. **Educational Resources**: Offer tutorials, guides, and best practices to educate users on effective audience growth strategies and social media marketing techniques. Empowering users with knowledge and expertise enhances their ability to leverage the platform effectively.
7. **Customization and Personalization**: Allow users to tailor the tool to their specific needs and preferences through customizable settings, personalized recommendations, and adaptive algorithms.
## Market competitors
Search market competitors, this part is easy, you can use ProductHunt, SideProjectors, Github, and Twitter. You can find a lot of projects that are similar to your idea, and you can learn from them, what they are doing right, what they are doing wrong, and how you can improve it.
<p align="center" width="100%">
<img src="https://i.imgur.com/VXOUwQM.png" title="market competitors" width="450"/>
</p>
Why do we need to do this? The answer is simple, you need to know what is the market, what the competition is, and how you can improve your project. The idea is not to copy the project but to learn from them, and make it better.
## MVP or MVE
Maybe you have heard about MVP, if not, here is a simple explanation:
Various interpretations exist for what constitutes an MVP, but generally, it refers to a product with the fewest features necessary to address the core problem.
Confining development efforts to the MVP is crucial for two primary reasons.
1) It prevents undue investment of time in building a product before confirming its market demand and user utility.
2) It guards against the temptation to endlessly add features and refine the product, potentially delaying its release by months or even years.
MVE (Minimum Viable Experiment) is a concept that emphasizes validating your idea with the least amount of effort. It involves creating a simple experiment to test your hypothesis and gather feedback from users. By focusing on the core assumptions of your idea and testing them quickly, you can validate your concept and make informed decisions about its viability.
To solve/create this side project, I created two diagrams to explain the process and how I can solve this problem.
- The first one is using some frameworks and APIs to create the AI model and solve the problems in each step.
- The second one is using No-Code tools to solve the problem, here the major challenge is to create a login to use with no-code tools.
<p align="center" width="100%">
<img src="https://i.imgur.com/S8nW96u.png" title="mvp" width="450"/>
</p>
Which of these two options is the best for me? I choose the first one and the second one, let me explain why:
- The first one is the best option because I want to learn new technologies, and I want to have more control over the project.
Here the idea is simple create a first version with a single feature, that feature is something you can do directly with ChatGPT or other AI tools, but we can start collecting feedback and improve it from here. After the first launch, we can start building more features and start testing some features that are good candidates to be a premium feature.
<p align="center" width="100%">
<img src="https://i.imgur.com/QJdElEi.png" title="code roadmap" width="450"/>
</p>
- The second one is the best option because I want to have a fast MVP, and I want to have a working project as soon as possible.
The second solution is something "straightforward", using make.com as the main tool to coordinate other tools and continue with the integration of more tools, something that I want to do quickly is use the prompts that I mentioned in the first solution, and I can use the same prompts in the second solution. I can test and improve the prompts while I'm ready to start with the first solution.
<p align="center" width="100%">
<img src="https://i.imgur.com/1d3ZcfP.png" title="nocode roadmap" width="450"/>
</p>
With this in mind, I'm going to start with solution 2, both solutions use the same tools and I can reuse part of the things that I created with solution 2 in solution 1, and I want to start testing the idea in my social media.
### Be fast
Time is of the essence, especially when considering monetizing your side project. The digital landscape is constantly evolving, and speed can be a significant advantage in gaining traction and establishing your presence. Rapid execution allows you to capitalize on emerging trends, capture market opportunities, and stay ahead of competitors.
In today's fast-paced environment, being first to market often translates to a competitive edge. By swiftly bringing your side project to fruition, you can attract early adopters, generate buzz, and start generating revenue sooner. Additionally, acting swiftly enables you to iterate based on user feedback, refine your offering, and adapt to evolving market dynamics more effectively.
Moreover, don't shy away from researching and analyzing potential competitors. Understanding their strategies, strengths, and weaknesses can provide valuable insights for refining your approach and positioning your side project for success. Embrace competition as a source of inspiration and motivation to continuously improve and differentiate your offering in the marketplace.
In essence, speed is a vital component of success in monetizing your side project. Embrace agility, seize opportunities, and stay ahead of the curve to maximize your chances of achieving your goals.
### UI inspiration
To this, you can do a lot of things, you can use Dribbble, Behance, Pinterest, or even some projects that you found in ProductHunt. The idea is to have a visual idea of how you want your project to look like. You can create a mood board or a simple sketch, the idea is to have a visual idea of how you want your project to look like.
After the inspiration, you can create some low-fidelity wireframes (We are going to do this in another post), and after that, you can create high-fidelity wireframes or find someone who that create them for you.
<p align="center" width="100%">
<img src="https://i.imgur.com/8PMcRX2.png" title="ui inspiraction" width="450"/>
</p>
Some importantly, if you are not good with design, don't stop here your progress, the value of a project is not only driven by the design.
## Conclusion
In conclusion, laying the groundwork for a successful side project involves meticulous planning and strategic decision-making. In this part of the series, we need to go deeper into the crucial steps of ideation, creating a plan, and initiating the project. Understanding the problem at hand and devising a solution that addresses its core challenges is fundamental. By focusing on the problem rather than fixating on a specific solution, we ensure flexibility and adaptability throughout the development process.
Market research and competitor analysis provide invaluable insights into the existing landscape, allowing us to identify opportunities for improvement and differentiation. Establishing a Minimum Viable Product (MVP) enables us to validate our idea efficiently while avoiding unnecessary investment of time and resources.
Choosing between alternative approaches, such as leveraging new technologies versus utilizing no-code tools, requires careful consideration of factors like learning objectives, time constraints, and desired outcomes. Ultimately, prioritizing speed and agility can be a significant advantage in seizing market opportunities and staying ahead of the competition.
Moreover, seeking inspiration from UI designs and visualizing the project's aesthetic direction adds depth and clarity to our vision. While design is important, it's essential not to let it overshadow the project's core value proposition.
In the next part of the series, we will into the technical implementation, exploring how we translate our plan into action, build the AI application, and bring our vision to life. Stay tuned for the continuation of our side project journey.
### TIP
Prioritize Flexibility
In the early stages of product development, customer needs can change rapidly. Build flexibility into your architecture to accommodate evolving requirements as you iterate with your customers. Focus on delivering a functional product first, then refine and scale later. Don't get bogged down with elaborate processes.
Prioritize building and shipping quickly, then refine and optimize as needed based on the validation of your hypothesis.
Thank you for reading this far. Consider giving it a like, sharing it, and staying tuned for future articles. Feel free to contact me via [LinkedIn](https://www.linkedin.com/in/jamescardona11/).
## References
- [Side Projects - Taro](https://www.jointaro.com/topic/side-projects/)
- [Hacker News Discussion on Side Projects](https://news.ycombinator.com/item?id=14039135)
- [6 Ways to Take on a Side Project That Doesn't Take Over Your Life](https://www.themuse.com/advice/6-ways-to-take-on-a-side-project-that-doesnt-take-over-your-life)
- [Future: Developers Side Projects](https://future.com/developers-side-projects/)
- [6 Hard Truths That Engineers Need to Get Over When Working on Side Projects](https://edward-huang.com/tech/ideas/life-lesson/2021/09/13/6-hard-truth-that-engineer-needs-to-get-over-when-working-on-side-projects/)
- [Build a Startup Without Quitting Your Day Job](https://www.jotform.com/blog/build-a-startup-without-quitting-your-day-job/)
- [How to Create Successful Side Projects](https://www.indeed.com/career-advice/career-development/how-to-create-successful-side-project)
- [How I Built My Side Project and Got 31,000 Users the First Week](https://www.freecodecamp.org/news/how-i-built-my-side-project-and-got-31-000-users-the-first-week-d9053bae5302/)
- [MVP is Over. You Need to Think About MVE.](https://medium.com/entrepreneur-s-handbook/mvp-is-over-you-need-to-think-about-mve-5a87bc7ca2ef)
| jamescardona11 |
1,864,047 | Pcr Euro 2025 Paris France | Europcr online is World-Leading Course in interventional cardiovascular medicine. It is going to be... | 0 | 2024-05-24T13:38:30 | https://dev.to/expostandzoness/pcr-euro-2025-paris-france-imb |
Europcr online is World-Leading Course in interventional cardiovascular medicine. It is going to be held from 20-23 May 2025 in Le Palais des Congrès de Paris, Paris, France. [Pcr Euro 2025 Paris](https://www.expostandzone.com/trade-shows/euro-pcr)
| expostandzoness | |
1,858,483 | Automatic retry function with Kotlin flows | Table of contents Short code example Why use this? My app on the Google play... | 0 | 2024-05-24T13:37:35 | https://dev.to/theplebdev/automatic-retry-function-with-kotlin-flows-1ji5 | android, mobile, kotlin, tristan | ### Table of contents
1. [Short code example](#code)
2. [Why use this?](#why)
### My app on the Google play store
- [The app](https://play.google.com/store/apps/details?id=elliott.software.clicker)
### Resources <a name="resources"></a>
- `Programming Android with Kotlin: Achieving Structured Concurrency with Coroutines. Chapter 10`
### Short code example <a name="code"></a>
- Here is the code that will allow you to make automatic retries on a flow:
```kotlin
fun <T, R : Any> Flow<T>.mapWithRetry(
action: suspend (T) -> R,
predicate: suspend (R, attempt: Int) -> Boolean
) = map { data ->
var attempt = 0L
var shallRetry: Boolean
var lastValue: R? = null
do {
val tr = action(data)
shallRetry = predicate(tr, (++attempt).toInt())
if (!shallRetry) lastValue = tr
} while (shallRetry)
return@map lastValue
}
```
- Cold flow usage example:
```kotlin
twitchEmoteImpl.getChannelEmotes(
oAuthToken,clientId,broadcasterId
).mapWithRetry(
action={
// result is the result from getChannelEmotes()
// if you wanted to do any manipulation to the
// request you would do it here
result -> result
},
predicate = { result, attempt ->
val repeatResult = result is Response.Failure && attempt < 3
repeatResult
}
).collect{
// do what you would normally do once a flow is emitted
}
```
- `result -> result` represents the code not doing any sort of manipulation of the result emitted from the flow
### Why use this? <a name="why"></a>
- There are times when the request fails and the best solution is to simply make another request. Instead of forcing your user to manually make another request. We can implement this function that will automatically make 3 requests if it fails. We will not inform the users of the extra requests. Instead they should only be informed after the 3 failed attempts
- However, be aware that we should not do this on every failed request. On requests that fail due to authentication or no available network errors, we should avoid making multiple requests and simply inform the user of the failed request.
### Conclusion
- Thank you for taking the time out of your day to read this blog post of mine. If you have any questions or concerns please comment below or reach out to me on [Twitter](https://twitter.com/AndroidTristan). | theplebdev |
1,819,597 | Unlock & Share data Securely with Amazon Datazone | Introduction: In today's data-driven world, organizations of all sizes – small, medium, and large –... | 0 | 2024-05-24T13:36:18 | https://dev.to/dipalikulshrestha/unlock-share-data-securely-with-amazon-datazone-3b9l | aws, datazone, datamesh, pubsub | **Introduction:**
In today's data-driven world, organizations of all sizes – small, medium, and large – are striving to become more data-centric. They want to empower everyone with the power of data, but this becomes increasingly challenging as organizations grow.
**Common Pain Points:**
**Finding the Right Data:** Struggling to locate relevant data sets within the vast amount of information.
**Data Trust & Ownership:** Difficulty in verifying data integrity and identifying data owners.
**Querying Diverse Data Sources:** Challenges in querying data from various sources and formats using preferred tools.
**Secure Collaboration & Governance:** Lack of a secure way to share data analysis while ensuring proper governance across different data sources and tools.
**Financial Services Use Case:**
Let's consider a financial services company undergoing a digital transformation journey. They envision a scenario where data is:
**Searchable & Accessible:** Easy to find and use by everyone.
**Trusted & Reliable:** Data integrity is verifiable, and owners are clearly identified.
**Simpler to Use:** Enables efficient data utilization through user-friendly tools.
**Catalyst for Innovation:** Drives transformation and empowers data-driven decision-making.
**Maximizes Reuse:** Encourages data sharing and collaboration across teams.
**Solution: Amazon DataZone as a Data Marketplace**
To achieve these goals, Amazon DataZone offers a modern data ecosystem that connects data producers and consumers within the organization. It functions as a secure data marketplace where users can:
**Access & Share:** Find and share data products in a governed manner.
**Enhanced Collaboration:** Facilitate faster, simpler, and secure collaboration between data producers and consumers.
**Real-Time Decision Making:** Empower real-time insights and data-driven decisions.
**Implementation: Multi-Account Setup with DataZone**
We can leverage a multi-account setup within AWS to implement DataZone. This ensures data producers and consumers have dedicated AWS accounts while enabling secure data collaboration facilitated by DataZone.
**Benefits:**
**Improved Data Findability:** Easy discovery of relevant data sets.
**Enhanced Data Trust:** Clear data ownership and verifiable data integrity.
**Unified Data Access:** Query data from various sources and formats using preferred tools.
**Secure Collaboration & Governance:** Streamlined data sharing with built-in governance controls.
**Faster Decision Making:** Empowers data-driven decision making with real-time insights.
**Technical Architecture**
- Data lake in a data producer account (where data assets are available)
- Then we have a central Governing Datazone Account
- And, thirdly we have Consumer's accounts who wants to consume datalake data available in producer's account
This is how the technical architecture looks like:
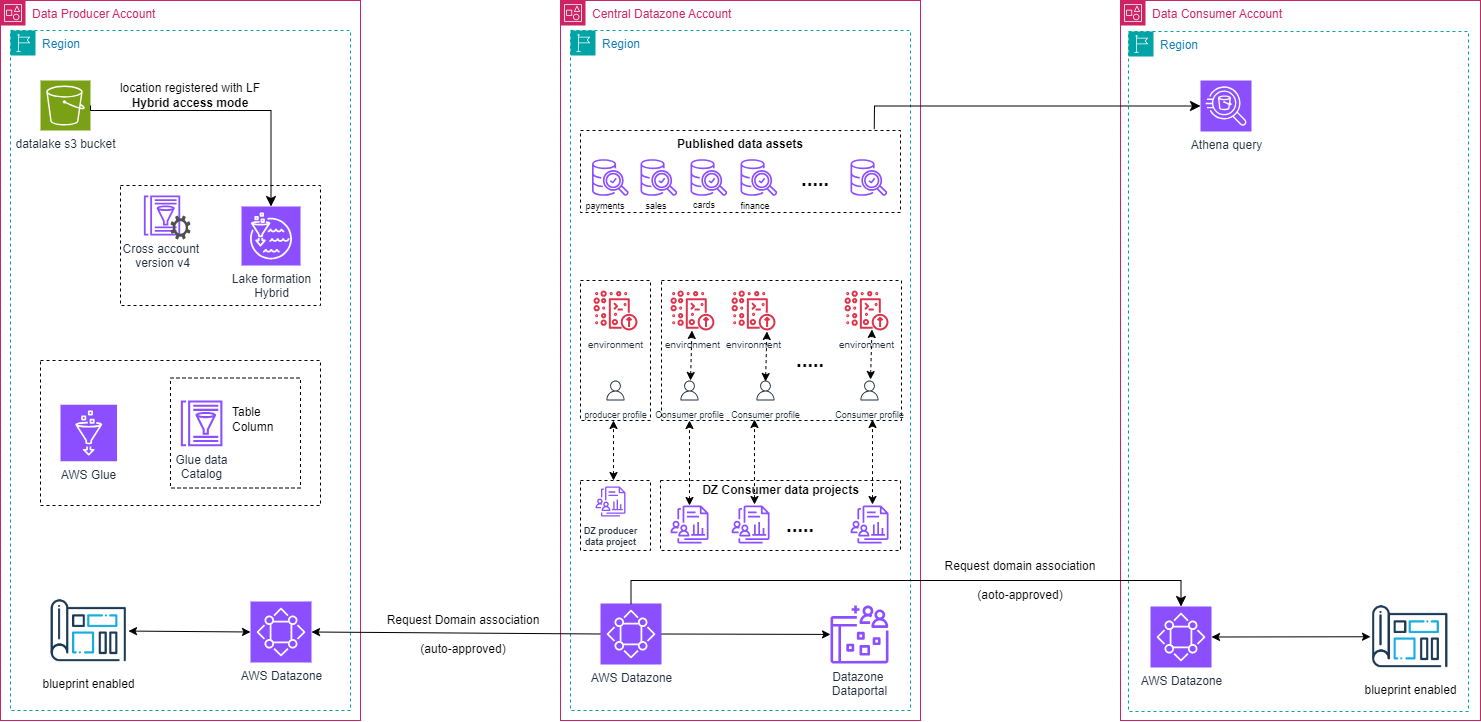
Demo to produce or consume data is available at:
https://drive.google.com/file/d/1-LwVLzUgf1W_j8suf_hZ3l1ZJchVOlR4/view?usp=sharing
**Conclusion:**
Amazon DataZone unlocks the power of data within your organization. It creates a secure and collaborative environment for data producers and consumers, ultimately driving innovation and data-driven success. | dipalikulshrestha |
1,864,044 | Selenium WebDriver: Detail Guide With Use Cases | WebDriver is a user-friendly interface that lets you control a browser locally or on a different... | 0 | 2024-05-24T13:35:31 | https://dev.to/saniyagazala/selenium-webdriver-detail-guide-with-use-cases-3clc | WebDriver is a user-friendly interface that lets you control a browser locally or on a different machine. It’s a universal protocol that works across platforms and programming languages, allowing you to remotely guide a browser’s actions, like finding and changing DOM elements or managing user agent behavior.
Now part of the Selenium project, Selenium WebDriver combines language bindings and browser control code, often simply known as WebDriver. This tool is crucial for automating browser tests across different browsers and operating systems, ensuring a smooth user experience.
As the online world advances, delivering top-notch user experiences becomes crucial. For websites and web apps, it’s vital to guarantee a seamless end-user experience. [Automation testing](https://www.lambdatest.com/automation-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) is the go-to method for testing your product on various browsers and operating systems.
Selenium, supporting languages like Java, C#, Ruby, JavaScript, and more, is a valuable tool for large organizations aiming to automate their software testing processes. This WebDriver tutorial breaks down what WebDriver is, its features, how it operates, best practices, and more.
Let’s begin!
## What is WebDriver?
A WebDriver drives a browser natively, just like you would, either locally or remotely, using a Selenium server. You can control a browser from another machine using WebDriver. It enables introspection and control of user agents. In this way, out-of-process programs can remotely instruct the behavior of web browsers using a platform and language-neutral wire protocol.
Using this specification, you can discover and manipulate the DOM, focusing on web browser compatibility. The purpose of this specification is primarily to automate the testing, but it can also be used to enable browser scripts to control the web browser.
The Selenium WebDriver consists of both language bindings and implementations of individual browser-controlling code. Usually, this is called WebDriver.
* The WebDriver has a simple and concise programming interface.
* WebDriver has a compact and easy-to-use object-oriented API.
* It runs the browser effectively.
Following are the benefits of Selenium WebDriver.
* Its simplicity makes it easy for [automated testing tools](https://www.lambdatest.com/blog/automation-testing-tools/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog) to communicate with web content. You can find commands that simplify tasks like entering text and clicking elements.
* You can extend the WebDriver protocol to add functionality not currently included in the ECMAScript standard. It allows browsers to support the automation of new platform features and will enable vendors to expose functionality specific to their browsers.
* Selenium is compatible with different programming languages like Java, JavaScript, Python, C#, and more, allowing testers to perform [web automation](https://www.lambdatest.com/learning-hub/web-automation?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) in any programming language as per their choice.
## What is Selenium?
[Selenium](https://www.lambdatest.com/selenium?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) is a widely used open-source framework with a suite of tools for automating tests on web applications. It has set tools and libraries that enable testers and developers to automate testing across various browsers and platforms.
The framework is versatile and can work with multiple programming languages like Java, Python, and C#, making it adaptable to different testing environments. It is mainly used by developers and testers due to its flexibility, scalability, and ability to test across other web browsers. It helps teams guarantee the quality and reliability of their web applications.
There are four critical components of the Selenium framework.
> Explore how to [test your Android app on multiple devices online](https://www.lambdatest.com/android-device-test?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage)!
* [**Selenium IDE](https://www.lambdatest.com/learning-hub/selenium-ide?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub)**
It is the most straightforward tool in the Selenium suite. As a Firefox add-on, it swiftly generates tests using its record-and-playback feature. Its installation is hassle-free, and learning is easy. However, it’s important to note that Selenium IDE is best suited as a prototyping tool rather than a comprehensive solution for developing and managing complicated test suites.
While programming knowledge isn’t a prerequisite for using Selenium IDE, familiarity with HTML, JavaScript, and the [Document Object Model (DOM)](https://www.lambdatest.com/blog/document-object-model/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog) enhances your ability to harness the full potential of this tool.
* [**Selenium Grid](https://www.lambdatest.com/selenium-grid-online?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage)**
Acts as a server, enabling tests to run simultaneously on various machines. It allows testers to distribute [test execution](https://www.lambdatest.com/learning-hub/test-execution?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) across different browsers and platforms. It simplifies large-scale testing and offers centralized control over the execution of tests.
* **Selenium WebDriver**
Selenium Web Driver is an improved version of Selenium RC that fixes its limitations. It talks directly to web browsers using unique methods, avoiding the need for Selenium RC. WebDriver, when combined with Selenium IDE and Selenium Grid, makes tests run reliably and quickly on a large scale.
WebDriver performs actions on web elements and is compatible with multiple programming languages such as Java, C#, PHP, Python, and more. Additionally, it smoothly integrates with frameworks like [TestNG](https://www.lambdatest.com/learning-hub/testng) and [JUnit](https://www.lambdatest.com/learning-hub/junit-tutorial) to facilitate effective test management.
## What is Selenium WebDriver?
Selenium WebDriver is an open-source collection of APIs for robust [web application testing](https://www.lambdatest.com/web-application-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) designed to automate browser activities on different browsers. This tool verifies that your web application functions as expected in various scenarios.
WebDriver in Selenium is a powerful tool for automating web application testing across different browsers. It provides a programming interface to create and run test scripts, enabling testers to simulate user interactions with web elements. WebDriver supports various programming languages, enhancing test script flexibility and integration.
It features a user-friendly API that allows you to manage web browsers using code. Its compatibility with various programming languages such as Python, Java, C#, and more makes it adaptable and user-friendly across testing frameworks and setups.
Selenium Web Driver operates faster as it communicates directly with web browsers, while Selenium RC requires a separate server for browser communication.
WebDriver includes a built-in Firefox driver (Gecko Driver). You need to incorporate their specific drivers to run tests on other browsers. Some commonly utilized WebDriver versions include Google Chrome Driver, Internet Explorer Driver, Opera Driver, Safari Driver, and HTML Unit Driver (a particular headless driver).
> Curious about [testing on mobile devices](https://www.lambdatest.com/test-on-mobile-devices?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage)? Learn more with LambdaTest.
## Key Features of Selenium WebDriver
Selenium is a widely used open-source testing framework that comes with a lot of features, some of which are mentioned below:
* WebDriver API for Browser Control: The WebDriver API lets you control web browsers through code, allowing actions like clicking links and filling out forms. This makes creating scripts that can run from the command line or be integrated with other tools easy.
* Supported Languages for Convenience: Selenium WebDriver supports multiple languages, such as JavaScript, Java, Python, C#, and Ruby. This flexibility allows automation testers to use their preferred language without learning additional ones.
* Testing Across Different Browsers: Selenium Web Driver enables testing on various browsers like Chrome, Firefox, and Internet Explorer. This ensures that web applications work well across different browsers and devices.
* Creating Robust Automated Tests: By utilizing Selenium APIs in different languages, cross-browser support, integration capabilities, and customization options, testers can produce automated, robust tests based on their project’s requirements. This approach saves time by running parallel tests across multiple machines using Grid Distribution.
* Efficient Parallel Testing and Grid Distribution: Parallel testing lets you run multiple tests simultaneously on different machines, and Grid Distribution helps distribute tests across various devices. This speeds up test execution when dealing with a large number of tests.
* Customization with User Extensions and Plugins: Users can enhance Selenium WebDriver’s capabilities by installing plugins or user extensions, adding new features, or customizing existing ones based on specific project needs.
* Integration with Other Frameworks: Selenium Web Driver integrates with other testing frameworks, like JUnit or TestNG, to create automated tests for your web application.
* Test Reports and Dashboards: Selenium generates detailed test reports and real-time dashboards, helping testers monitor progress and quickly identify issues in automated tests.
## Why Use Selenium WebDriver?
An extra benefit of Selenium WebDriver is its versatility, enabling the creation of test scripts in various programming languages. Essentially, WebDriver serves as both a language binding and a distinctive code implementation for controlling browsers, making it a potent tool for cross-browser testing. Below are the essential pointers on why using Selenium WebDriver is beneficial.
* **Platform Compatibility**
Selenium WebDriver excels in working across various operating systems, including Linux, UNIX, Mac, and Windows. This versatility enables the creation of a customized testing suite usable on any platform, allowing test case creation on one operating system and execution on another.
* **Cross-Browser Testing**
A standout feature of Selenium WebDriver is its enhanced support for automated cross-browser testing. It covers a range of browsers, including Chrome, Firefox, Safari, Opera, IE, Edge, Yandex, and more. This capability provides an efficient solution for cross-browser testing automation.
* **Framework and Language Integration**
Selenium WebDriver integrates with frameworks like Maven or ANT to compile source code. It can also be paired with testing frameworks such as TestNG for application testing and reporting and with Jenkins for Continuous Integration or Continuous Delivery automated build and deployment.
* **Cross-Device Testing**
This tool supports testing across multiple devices, allowing the creation of automated test cases for iPhones, Blackberry, and Android devices. This flexibility addresses issues related to cross-device compatibility.
* **Community Support and Regular Updates**
Being community-driven ensures regular upgrades and updates for Selenium. These updates are easily accessible and require no specific training, contributing to Selenium WebDriver’s budget-friendly and resourceful nature.
* **User-Friendly Implementation**
Selenium Web Driver’s user-friendliness is widely recognized in the automation testing community. Its open-source nature empowers users to script personalized extensions, enabling the development of customized actions, particularly at an advanced level.
* **Add-ons and Reusability**
Test scripts written with Selenium WebDriver support cross-browser testing, covering various functionality testing aspects. Customizable add-ons broaden the scope of application testing, offering significant benefits.
* **Mouse and Keyboard Simulation**
Selenium WebDriver’s capability to simulate real user scenarios, including mouse and keyboard events, is a notable feature. The Advanced User Interactions API includes action classes necessary to execute these events, supporting simple and complex interactions.
* **Leveraging Code for Test Speed**
Testers can leverage the development code, aligning it with the language developers use. This enables direct verification, such as checking a date field updated in the database and speeding up test cycles without the need for indirect verifications.
* **Server-Free Testing**
One significant advantage is that starting a server before testing with Selenium WebDriver is unnecessary. Commands in the code are interpreted directly into web services, facilitating communication with the remote driver via HTTP requests for execution in the browser.
* **Advanced Browser Interactions**
Selenium Web Driver facilitates advanced browser interactions, simulating actions like clicking browser back and front buttons. This feature is precious for testing applications involving sensitive transactions, such as online money transfers or banking applications that don’t store cookies or cache.
## Selenium 4 WebDriver
It uses the W3C standard protocol, which means the way the driver and browser talk to each other follows a set procedure. Because of this, there’s no need for special coding and decoding when they send requests and responses using this protocol.
To learn more about Selenium 4, watch this complete video tutorial to learn what’s new in [Selenium 4](https://www.lambdatest.com/learning-hub/selenium-4?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub), its features, and more.
{% youtube mMStkc3W9jY %}
> Ready to [test website on mobile devices online free](https://www.lambdatest.com/test-site-on-mobile?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage)? Get started with LambdaTest.
### Selenium 4 WebDriver Architecture
In Selenium 4, the JSON Wire protocol is entirely replaced by the W3C Protocol, marking a shift towards W3C standardization. While Selenium 3 versions from 3.8 to 3.141 utilized both protocols concurrently, the stable version of Selenium 4 exclusively works on the W3C Protocol, discontinuing the JSON Wire Protocol. The following diagram illustrates the architecture of Selenium 4 WebDriver.

### Working of Selenium 4 WebDriver
Selenium WebDriver W3C Protocol architecture reveals a direct exchange of information between the client and server, removing the dependency on the JSON Wire Protocol. This design aligns with Selenium Web Driver protocols and web browsers, ensuring its text execution is more consistent across various browsers. The use of a standard protocol significantly decreased flakiness in web automation.
With WebDriver W3C Protocol in action, automation testers no longer need to change the automation test scripts to work across different web browsers. Stability and test consistency are the two significant advantages of WebDriver W3C protocol in Selenium 4.
Now, let us look into the advantages of Selenium 4 WebDriver in detail.
### Advantages of Selenium 4 WebDriver using W3C standard protocol
In this section, you will understand the advantages of Selenium 4 WebDriver based on its new W3C standard protocol.
* **Consistent Tests Across Browsers**
Maintaining tests across multiple browsers ensures a smooth user experience. Selenium’s WebDriver interface and browser-specific drivers facilitate uniform test script creation, allowing you to efficiently identify and address compatibility issues across various browsers.
* **Stability Assurance**
Selenium 4’s standard protocol ensures stable [test automation](https://www.lambdatest.com/automation-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage). It enhances reliability by optimizing browser interactions, leading to consistent and dependable test execution.
* [**Relative Locators](https://www.lambdatest.com/blog/selenium-4-relative-locator/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)**
In Selenium 4.0, a new locator is added to the locator’s list, i.e., Friendly locators, and later it is renamed as Relative locators; these relative locators enable us to find WebElements by considering their position concerning other elements on the webpage.
Selenium uses the JavaScript function *getBoundingClientRect()* to figure out the size and location of elements on a webpage. This information is then used to find the following elements.
Selenium 4 introduces five new locators that help us to locate the web elements by their position concerning other web elements such as *above, below, toLeftOf, toRightOf,* and *near*.
To understand better, let us take an example of a relative locator.
* ***above***
The email text field cannot be identified, but the password text field is easily identifiable. In that case, we can locate the email text field by recognizing the input field of the password and using the *above* function to identify the email text field.

* ***below***
If it is difficult to identify the password text field but more straightforward, we can find the password input files using the *below* element of the email input field.
* ***toLeftOf***
Suppose it’s challenging to find the cancel button for any reason, but the submit button is easy to identify. In that case, we can locate the cancel button by recognizing that it is a “button” to the *LeftOf* the submit button.

* ***toRightOf***
Suppose it’s challenging to find the submit button, but the cancel button is still easily identifiable. In that case, you can locate it by noting that it is a “button” positioned *RightOf *the cancel element.

* ***near***
If the position of an element isn’t clear or changes with the window size, you can use the *near* method. This helps identify an element at most 50 pixels away from the given location.
A practical scenario for this is when dealing with a form element that lacks a straightforward locator, but its associated [input label](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/label) can be used.

* **Native Support for Chrome DevTools Protocol**
Many web browsers offer “DevTools,” a set of integrated tools for developers to debug web applications and assess page performance. Google Chrome’s DevTools utilize a protocol known as the Chrome DevTools Protocol (CDP). Unlike being designed for testing, CDP lacks a stable API, and its functionality heavily relies on the browser version.
The WebDriver BiDirectional Protocol is the next generation of the W3C WebDriver protocol. Its goal is to establish a stable API universally implemented by all browsers, although it has yet to develop fully. In the meantime, Selenium provides access to CDP for browsers like Google Chrome, Microsoft Edge, and Firefox that implement it. This allows testers to enhance their tests in exciting ways.
Here are the three ways to use Chrome DevTools with Selenium.
* The first option, the CDP Endpoint, is available to users but works best for simple tasks like adjusting settings and getting basic information. However, it requires knowledge of specific “magic strings” for domains, methods, and key-value pairs. It’s simpler for basic needs but is only supported temporarily.
* The CDP API is an improvement as it allows asynchronous actions. Instead of using a String and a Map, you can work directly with the code’s supported classes, methods, and parameters. However, these methods are also temporarily supported.
* Whenever possible, the preferred choice is the BiDi API option. It abstracts the implementation details and smoothly works with either CDP or as Selenium moves away from CDP
## Selenium 3 WebDriver
Selenium 3 is the third major version of the Selenium test automation framework. This open-source framework is a go-to for testers, helping automate web application testing across various browsers and platforms.
A notable transformation in Selenium 3 involves the removal of the initial Selenium Core implementation, replaced by one supported by WebDriver. The architecture of Selenium 3 incorporates the JSON Wire Protocol, a concept we’ll delve into later in this blog.
Despite these changes, the core functionality of Selenium 3 remains fast, empowering users to smoothly interact with web elements and automate web testing across diverse browsers.
> Experience [testing website on different devices](https://www.lambdatest.com/test-site-on-mobile?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage). Discover LambdaTest.
### Selenium 3 WebDriver Architecture
Before writing a test script, it is essential to know how WebDriver is built and how it communicates with browsers to ensure backend activities on what protocol and libraries Selenium WebDriver works with. It is necessary to understand its architecture, making tester’s and developers’ lives easy.
Selenium 3 WebDriver Architecture consists of 4 components:
* Selenium Client Libraries in Java, Python, or Ruby.
* JSON Wire Protocol.
* Browser Drivers.
* Browsers.
Let us get into more detail about each Selenium WebDriver component below.
**Selenium Client Libraries**
These serve as language-specific interfaces, linking developers with the Selenium Web Driver in their chosen programming language. These libraries act as connectors, facilitating the smooth integration of WebDriver functionality with the syntax and conventions of different programming languages. It empowers testers and developers to create automation scripts using the familiar structure and patterns of their preferred programming language.
**JSON Wire Protocol**
WebDriver uses JSON as an intermediary for communication between client libraries (such as Java, C#, and Python) and drivers (like Firefox Driver, IE Driver, and Chrome Driver). The interaction follows an HTTP request format, receiving input in JSON form. Operations are executed, and the response is communicated to the client in JSON format. Likewise, the communication between the RemoteWebDriver client and the RemoteWebDriver server utilizes the JSON wire protocol.

**Browsers Drivers**
Web browsers are constructed using a foundation called a browser engine. For instance, Google Chrome is built on the Chromium engine, while Mozilla Firefox uses the Gecko engine.
To enable interaction with these browser engines using W3C WebDriver-compatible clients, browsers offer a mediator known as Browser Drivers.
Browser Drivers play a crucial role in the Selenium framework. They serve as intermediaries, allowing communication between the WebDriver API (a tool for automating web browsers) and the web browsers during testing. Each browser has separate drivers, which can be downloaded from Selenium’s official repository. While using a browser driver, we must import the respective Selenium package “*org.openqa.selenium.[$browsername$];*” in your code.
We should also set the *System* property of the executable file of the browser driver using the following syntax:

Let’s illustrate this with a different example:

When the above code is executed, the *FirefoxDriver* is opened by Selenium.
**Browsers**
Selenium supports all browsers, including Chrome, Safari, Firefox, Opera, and Internet Explorer. You can run Selenium test scripts on different operating systems like Windows, Mac OS, Linux, and Solaris.
### Working of Selenium 3 WebDriver
Selenium operates on a client-server architecture, relying on Selenium client libraries to create automation test scripts. When a script is made and executed in an Integrated Development Environment (IDE) with Selenium client libraries, it is transmitted to the JSON Wire Protocol via an API. The JSON Wire Protocol links the client and server, employing a REST API that receives JSON-formatted requests and forwards them to the Browser Driver through HTTP.
Each browser driver has an HTTP server that accepts client requests via the JSON Wire Protocol. The Browser Driver interacts with the browser, translating automation script instructions into actions. The browser’s responses are then sent back to the client’s console through the browser driver, JSON Wire Protocol, and ultimately to the client.
## Key Differences between Selenium 4 and Selenium 3
As you have read about Selenium and its architectures in this section, you will learn about the critical differences between Selenium 4 and Selenium 3.
In Selenium 4, there are significant improvements, including the integration of WebDriver Manager, usage of W3C standard protocol for DevTools API, enhanced performance, optimized Selenium Grid, improvements in ChromeDriver class, the introduction of new features like Relative Locators, and overall advancements in architecture. It makes Selenium 4 a more advanced and feature-rich automation framework compared to Selenium 3.
If you are using Selenium 3 and want to upgrade to Selenium 4, please check our detailed guide on [upgrading from Selenium 3 to Selenium 4](https://www.lambdatest.com/blog/upgrade-from-selenium3-to-selenium4/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog).
{% youtube Mmp_FiNIYtQ %}
## Selenium WebDriver Limitations
Even though Selenium WebDriver is a useful tool, it’s important to know its limitations for effective testing. Here are the main drawbacks:
* **Limited Support for Desktop Applications:** WebDriver is designed for web applications and lacks strong support for desktop apps.
**Example:** Pop-up windows from desktop apps may be challenging, requiring additional tools like AutoIt.
* **Handling Dynamic Elements:** WebDriver can face difficulties with dynamic content, like AJAX or JQuery-based applications.
**Example:** If elements load dynamically, WebDriver may try to interact with them before or after they appear.
* **Difficulty Handling CAPTCHA:** CAPTCHA and reCAPTCHA are designed to prevent automation, and WebDriver can’t handle them.
**Example:** Automating CAPTCHA verification steps requires manual intervention as WebDriver can’t handle it.
* **No Built-in Reporting Capability: **WebDriver lacks built-in logging or report generation; external tools like TestNG are needed.
**Example: **Selenium doesn’t automatically generate test result reports; integration with TestNG is necessary.
* **Limitations with Mobile and Multi-touch Actions:** Selenium isn’t ideal for testing mobile apps and has limited support for multi-touch actions.
**Example: **Automating touch gestures like pinching or swiping may not work well; tools like Appium may be more suitable.
* **Requires High Technical Skill:** Skills in a programming language (e.g., Java, C#, Python) and a deep understanding of DOM and web technologies are essential for scripting in WebDriver.
**Example:**Testers without strong programming skills or knowledge of HTML and CSS may find it challenging.
Understanding these limitations helps manage expectations and choose the right testing approach for different scenarios.
## Selenium WebDriver Commands
Selenium WebDriver commands are the methods used in test automation. These commands offer different ways to interact with the WebDriver and help perform various tasks. These methods are used by driver variables and calling *driver.methodName()*.
Below is the list of Selenium WebDriver commands based on different categories.
## Browser Initialization Commands
You can initiate any browser of your choice by following the commands below. In this case, we have covered the commands based on the most popular browsers like Firefox, Chrome, and Edge.
**Firefox Syntax**
WebDriver driver = new FirefoxDriver();
This code builds a link between your Selenium test script and the Firefox web browser, allowing for smooth communication. As a mediator, the *WebDriver* enables your script to interact with the browser effortlessly.
By naming this intermediary as a *driver* and utilizing the *new FirefoxDriver()*, we instruct the code to connect to Firefox, enabling us to automate tests.
**Google Chrome Syntax**
WebDriver driver=new ChromeDriver();
This code builds a link between your Selenium test script and the Firefox web browser, allowing for smooth communication. As a mediator, the *WebDriver* enables your script to interact with the browser effortlessly.
By naming this intermediary as a *driver* and utilizing the *new ChromeDriver()*, we essentially instruct the code to connect to Chrome, enabling us to automate tests.
**Edge Syntax**
WebDriver driver=new EdgeDriver ();
This code builds a link between your Selenium test script and the Firefox web browser, allowing for smooth communication. As a mediator, the *WebDriver* enables your script to interact with the browser effortlessly.
By naming this intermediary as a *driver* and utilizing the *new EdgeDriver()*, we instruct the code to connect to Edge, enabling us to automate tests.
## Browser Commands
Now that we’ve set up the browser, the next step is to perform operations like opening a website, closing the browser, getting the page source, and more. Let’s explore the different commands to make the browser do these tasks.
***get()***: The Selenium command above opens a new web browser and goes to the provided website. It needs a single piece of information, usually the website’s address.
driver.get("http://www.lambdatest.com");
***getCurrentUrl():*** This Selenium command tells us the web address (URL) of the page currently displayed in the browser.
String url = driver.getCurrentUrl();
***getTitle():*** This command helps you retrieve the title of the current web page.
String pageTitle = driver.getTitle();
***getPageSource():*** The command above allows you to retrieve the source code of the last loaded page. Additionally, you can use it to check if specific content is present by using the *contains* method.
String j=driver.getPageSource();
boolean result = driver.getPageSource().contains("String to find");
***getClass(): ***If you want to get the runtime class name of an object, you can use the above command to achieve it.
driver.getClass();
## Browser Navigation Commands
There are various navigation commands like *back(), forward(), and refresh()*. This command helps in traversing back and forth in the browser tabs.
***navigate().to():*** This command opens a new browser window and loads a new webpage. It requires a String (usually a URL) as input and doesn’t return any value.
driver.navigate().to("http://wwww.lambdatest.com");
***refresh():*** If you want to test how a page responds to a refresh, you can use the following command to refresh the current window.
driver.navigate().refresh();
***back():*** This command is frequently used for navigation, allowing you to return to the previous page you visited.
driver.navigate().back();
***forward():*** Just like the “back” action, the “forward” action is commonly used for navigation. You can employ the above command to move to the page you were on before using the back button.
driver.navigate().forward();
## Web Elements Commands
Now that we’ve learned how to open the browser and execute different browser actions, let’s move on to Selenium commands for identifying and interacting with WebElements, such as text boxes, radio buttons, checkboxes, and more. WebElements play a crucial role in automating test scripts.
***findElement():*** This enables you to locate a web element on the web page and find the first occurrence of a web element using a specified locator.
WebElement searchBox = driver.findElement(By.id("search"));
To learn more about it, follow this guide on [Selenium locators](https://www.lambdatest.com/learning-hub/selenium-locators?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub).
***click():*** This command allows you to simulate a mouse click operation on specified buttons web element
driver.findElement(By.xpath("//div//input[@id='search']")).click();
***sendKeys():*** This command is used to simulate the typing of keyboard keys into a web element, mainly for an input field like username or password or any input field element that accepts inputs as string, number alpha-numeric, and others.
driver.findElement(By.xpath("//input[@id='id_q']")).sendKeys("pass your text here");
If you’re a beginner and want to learn more about *sendKeys()* functionality, explore this blog on [*sendKeys() *in Selenium](https://www.lambdatest.com/blog/how-to-use-selenium-sendkeys/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog). This will give you valuable insights into efficient and effective use within your Selenium test automation projects.
***clear():*** This command helps you clear the data entered in the input field via *sendKeys()*.
driver.findElement(By.xpath("//input[@id='search']")).clear();
***getLocation():*** This command lets you find out where an element is located on a web page. You can use it to retrieve a specific component’s position or interact with the textbox area using coordinates.
* **To retrieve the position of a specific element:**
org.openqa.selenium.Point location;
location = driver.findElement(By.xpath("//input[@id='search']")).getLocation();
* **To retrieve the textbox area coordinates:**
org.openqa.selenium.Point location;
action.moveByOffset(location.x, location.y).click().sendKeys("pass your text here").perform();
***getSize():*** This command helps you get the height and width, in other words, the dimensions of an object. You can use the command below.
Dimension dimension=driver.findElement(By.id("GmailAddress")).getSize();
System.out.println("Height of webelement--->"+dimension.height);
System.out.println("Height of webelement--->"+dimension.width);
***getText():*** This command helps retrieve the visible text of the specified web element.
String elementText = searchBox.getText();
**getAttribute():** This command helps retrieve the value of the specified attribute of a web element.
String attributeValue = searchBox.getAttribute("get the attribute of the element");
To know the workings of *getAttribute()* using Selenium, refer to the following blog on [*Selenium getAttribute()](https://www.lambdatest.com/blog/selenium-getattribute/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)*, and learn where it can be used and why to use *getAttribute()*.
## Radio Button/Check Box Commands
Let's explore Selenium commands for working with Radio Buttons and Checkboxes, the next set of web elements.
***isDisplayed():*** This command determines whether the specified web element is visible and consists of boolean values.
boolean isVisible = searchBox.isDisplayed();
***isEnabled():*** This command also consists of boolean values (true, false); it determines whether the specified web element is enabled or not.
boolean isEnabled = searchBox.isEnabled();
***isSelected():*** this command helps check whether the specified checkbox or radio button is selected. If the checked element returns true or false, this method returns the boolean value.
boolean isSelected = checkBox.isSelected();
## Windows Handling Commands
The next step is to automate actions across various browser windows to achieve efficient automation. Let's learn how to switch to another window and pass the driver instance to it. Please note that to switch to another window, we must first identify the tab we intend to switch to.
***windowHandles():*** Enables you to retrieve the handles of all currently open browser windows.
Set<String> windowHandles = driver.windowHandles();
Explore this guide on [handling multiple windows using Selenium WebDriver](https://www.lambdatest.com/blog/how-to-handle-multiple-windows-in-selenium-webdriver-using-java/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog) and better understand its functionality.
***switchTo().window():*** This command enables you to Switch the focus of WebDriver to a different browser window.
driver.switchTo().window(windowHandle);
## Frames Handling Commands
Frame commands are utilized to carry out operations on frames, enabling us to switch from one frame to another and perform actions within specific frames.
***switchTo().frame():*** This command in Selenium WebDriver enables you to switch the focus of the WebDriver to a specified frame within the current page.
driver.switchTo().frame("frameName");
***switchTo().defaultContent():*** This command in Selenium Web Driver enables you to switch the focus back to the page's default content.
driver.switchTo().defaultContent();
***parentFrame():*** To switch to the parent frame, you can utilize the following command.
driver.switchTo().parentFrame();
***Iframe():*** This command switches the focus of the WebDriver to a specific iframe (inline frame) within the web page.
driver.switchTo().frame(driver.findElements(By.tagName(“iframe”).get(FRAME_INDEX));
If you have just started your journey in automation with Selenium and want to know more about these advanced Selenium WebDriver commands like *switchTo().windows(), and switchTo().frame()*, watch this complete video tutorial on how you can handle windows and iframe in Selenium WebDriver.
{% youtube 32eIE4PAbJk %}
Subscribe to the LambdaTest Youtube Channel and access tutorials on [Selenium testing](https://www.lambdatest.com/selenium-automation?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage), and also learn more on [Cypress testing](https://www.lambdatest.com/cypress-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage), [Playwright testing](https://www.lambdatest.com/playwright-testinghttps://www.lambdatest.com/playwright-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage), [Appium testing](https://www.lambdatest.com/appium-mobile-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage), and more.
## Actions Commands
Commands in the Actions class are generally categorized into two types:
* Mouse-Controlled Actions
* Keyboard Actions
The Actions class offers various methods, most of which return an action object unless specified otherwise. Automating mouse and keyboard actions is essential for replicating a user’s real interactions. Let’s explore how to achieve this.
***build():*** This command is important for creating a sequence of actions you want to execute.
Actions action = new Actions(driver);
WebElement e= webdriver.findElement(By.linkText(“XPATH"));
action.moveToElement(e).moveToElement(driver.findElement(By.xpath(“XPATHVALUE"))).click().build().perform();
***clickAndHold()*:** If you want to click and keep holding at the current mouse position, you can do it with this command.
// Locate the element C by By.xpath.
WebElement titleC = driver.findElement(By.xpath("//li[text()= 'C']"));
// Create an object of actions class and pass reference of WebDriver as a parameter to its constructor.
Actions actions = new Actions(driver);
// Call clickAndHold() method to perform click and hold operation on element C.
actions.clickAndHold(titleC).perform();
***contextClick(WebElement onElement): ***Context click means clicking the right mouse button at the current location.
Actions action= new Actions(driver);
action.contextClick(productLink).build().perform();
***release(): ***After holding the click, you eventually need to release it. This command releases the pressed left mouse button at the current mouse position.
Actions builder = new Actions(driver);
WebElement canvas = driver.findElement(By.id("id of the element"));
Action dragAndDrop = builder.clickAndHold(canvas).moveByOffset(100, 150).release(canvas).build().perform();
***doubleClick(): ***You can use this command to double-click.
Actions action = new Actions(driver);
WebElement element = driver.findElement(By.id("id of the element"));
action.doubleClick(element).perform();
***dragAndDrop(WebElement source, WebElement target): ***Drag and drop involves clicking and holding the source element, moving to the target location, and releasing. This command will help you achieve it.
Actions action= new Actions(driver);
WebElement Source=driver.findElement(By.id("draggable"));
WebElement Target=driver.findElement(By.id("droppable"));
act.dragAndDrop(Source, Target).build().perform();
***dragAndDropBy(WebElement source, int xOffset, int yOffset):*** Similar to regular drag and drop, the movement is based on a defined offset.
dragAndDropBy(From, 140, 18).perform();
***moveByOffset(int xOffset, int yOffset):*** You can shift the mouse position by maintaining the current position or using (0,0) as the reference.
Actions builder = new Actions(driver);
WebElement canvas = driver.findElement(By.id("id of the element"));
Action dragAndDrop = builder.clickAndHold(canvas).moveByOffset(100, 150).release(canvas).build().perform();
***moveToElement(WebElement toElement): ***Move the mouse to the middle of a web element with this command.
Actions action = new Actions(driver);
action.moveToElement(driver.findElement(By.xpath("XPATHVALUE").click().build().perform();
***moveToElement(WebElement toElement, int xOffset, int yOffset):*** Move the mouse to an offset from the element’s top-left corner using this command.
Actions builder = new Actions(driver);
builder.moveToElement(knownElement, 10, 25).click().build().perform();
***perform():*** Execute actions without needing to call the build() command first.
Actions action = new Actions(driver);
action.moveToElement(element).click().perform();
***keyDown(), keyUp():*** These Selenium commands are used for single key presses and releases
Actions action = new Actions(driver);
action.keyDown(Keys.control).sendKeys("pass your string here").keyUp(Keys.control).
sendKeys(Keys.DELETE).perform();
To learn about Selenium mouse actions in detail, explore this guide on [How to perform Mouse Actions in Selenium WebDriver](https://www.lambdatest.com/blog/perform-mouse-actions-in-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog).
## Synchronization Commands
We have covered nearly all the necessary Selenium commands for completing automation tasks. Consider scenarios like a page reloading or a form being submitted; in such cases, the script needs to wait to ensure the action is completed. This is where Selenium commands for synchronization become important.
[***Thread.sleep()](https://www.lambdatest.com/blog/sleep-java-method/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)*:** This command pauses the script for a specified time, measured in milliseconds.
Thread.sleep(5000);
***implicitlyWait()*:** With this command, the script will wait for a specified duration before moving on to the next step.
driver.manage().timeouts().implicitlyWait(15, TimeUnit.SECONDS);
***ExplicitWait():*** Instead of setting a fixed time for every command, this command offers adaptability by waiting for specific conditions to be met. It involves using different [*ExpectedConditions](https://www.lambdatest.com/blog/expected-conditions-in-selenium-examples/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)*.
WebDriverWait wait = new WebDriverWait(driver, 10);
WebElementele=wait.until(ExpectedConditions.elementToBeClickable(By.id(“XPATH")));
To learn about waits in Selenium, explore this guide on [Selenium Waits](https://www.lambdatest.com/blog/types-of-waits-in-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog), which will provide you with valuable information with examples for better understanding.
***visibilityOfElementLocated():*** Wait until a located element becomes visible using this command.
wait.until(ExpectedConditions.visibilityOfElementLocated(By.id(“XPATH VALUE"));
***elementToBeClickable():*** This command waits for an element to become visible and clickable.
wait.until(ExpectedConditions.elementToBeClickable(By.xpath(“/XPATH VALUE”)));
***textToBePresentInElement():*** Use this command to make the execution wait until an element contains a specific text pattern.
wait.until(ExpectedConditions.textToBePresentInElement(By.xpath( XPATH VALUE”), “text to be found”));
***alertIsPresent():*** If you want the script to wait until an alert box appears, use this command.
wait.until(ExpectedConditions.alertIsPresent()) !=null);
***FluentWait():*** This command controls two crucial aspects:
* The maximum time to wait for a condition to be satisfied and the frequency of checking for the condition.
* You can configure the command to ignore specific exceptions during the waiting period.
Wait wait = new FluentWait(driver);
withTimeout(30, SECONDS);
pollingEvery(5, SECONDS);
ignoring(NoSuchElementException.class);
## Screenshot Commands
[Capturing screenshots in Selenium WebDriver](https://www.lambdatest.com/blog/how-to-capture-screenshots-in-selenium-guide-with-examples/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog) is essential for detecting code bugs. Developers and testers can quickly identify potential issues by visually analyzing the application’s state in various testing scenarios. Moreover, Selenium WebDriver can automatically take screenshots during test execution, offering a convenient overview of the application’s appearance.
***getScreenshotAs():*** In Selenium 4, the *getScreenshotAs()* method enables capturing a screenshot of a specific WebElement. This is useful when you want to focus on a particular element.
// Assuming 'driver' is your WebDriver instance
TakesScreenshot screenshot = (TakesScreenshot) driver;
File sourceFile = screenshot.getScreenshotAs(OutputType.FILE);
// Now, you can copy the screenshot file to your desired location
FileUtils.copyFile(sourceFile, new File("path/to/your/destination/screenshot.png"));
***getFullPageScreenshotAs():*** In Selenium 4, the *getFullPageScreenshotAs()* function allows you to capture [full page screenshots](https://www.lambdatest.com/blog/screenshots-with-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog).
// Assuming 'driver' is your WebDriver instance
File fullPageScreenshot = ((FirefoxDriver) driver).getFullPageScreenshotAs(OutputType.FILE);
// Copy the full page screenshot file to your desired location
FileUtils.copyFile(fullPageScreenshot, new File("path/to/your/destination/fullPageScreenshot.png"));
That’s all! You can take and save a screenshot with just these two statements.
To improve your testing approach further, consider using [visual testing](https://www.lambdatest.com/learning-hub/visual-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub). This valuable addition allows testers to inspect the application’s appearance on various browsers and operating systems and identify inconsistencies like layout breaks, styling issues, or UI glitches. Visual testing lets testers and developers spot and address these issues quickly, improving user experience.
When combined with Selenium WebDriver’s screenshot capabilities, visual testing becomes essential for ensuring a visually consistent and enhanced user interface across diverse platforms. The ability to capture, compare, and analyze screenshots empowers teams to deliver a smooth user experience, irrespective of the device or operating system users use to access the application.
## When to use Selenium WebDriver
Knowing when to use Selenium WebDriver is essential for handling different scenarios. It can be applied to simple and complex situations, adapting to various scales and complexities. Let’s explore specific instances when using Selenium WebDriver is most effective.
* [**Functional Testing](https://www.lambdatest.com/learning-hub/functional-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub)**
Automates user actions, such as clicking buttons and filling out forms, to ensure that web applications function correctly. This involves checking the expected outcomes to validate the application’s behavior.
* [**Cross-Browser Testing](https://www.lambdatest.com/online-browser-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage)**
Verifies that web applications maintain consistent appearance and functionality across browsers like Chrome, Firefox, Edge, and Safari. Explore cross-browser compatibility benefits and features in a dedicated tutorial hub.
* **Cross-Platform Testing**
Assesses web application performance on Windows, macOS, and Linux operating systems, ensuring a seamless user experience across platforms.
* [**Regression Testing](https://www.lambdatest.com/learning-hub/regression-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub)**
Ensures the continued functionality of existing features even when new ones are introduced. This safeguards against unintended side effects during software updates.
* [**Data-Driven Testing](https://www.lambdatest.com/learning-hub/data-driven-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub)**
Optimizes testing efficiency by using automatically generated or database-pulled test data. Run the same test with diverse datasets to cover a range of scenarios and conditions.
* [**UI/UX Testing](https://www.lambdatest.com/learning-hub/ux-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub)**
Automates checks to ensure your application’s visual elements and layout remain consistent, providing a positive user experience.
* [**End-to-End Testing](https://www.lambdatest.com/learning-hub/end-to-end-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub)**
Mimics fundamental user interactions across various application parts to verify a smooth and cohesive user experience from start to finish.
* [**Parallel Testing](https://www.lambdatest.com/blog/what-is-parallel-testing-and-why-to-adopt-it/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)**
Saves time by integrating with tools like Selenium Grid to run tests simultaneously on multiple browsers. This accelerates the testing process and enhances efficiency.
* **Complex User Flows**
Simulates and tests intricate user interactions that require repetition, ensuring that complex user pathways are validated thoroughly.
* **Complex Scenarios Handling**
Addresses challenges like alerts, pop-ups, iframes, and dynamic content using WebDriver’s adaptable capabilities. It ensures comprehensive testing under diverse scenarios.
* **CI Pipelines Integration**
Integrates into your [CI/CD](https://www.lambdatest.com/learning-hub/cicd-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) pipeline to automate testing with each code change. This integration provides consistent code quality throughout development.
Now that you know when to use Selenium WebDriver, you can try running your first test by watching the complete video tutorial on writing and running your test script with Selenium.
{% youtube w4cidssAdJg %}
However, running all types of tests can be challenging and time-consuming, and you might need more resources when it comes to parallel testing or when performing cross-browser testing over various browsers and operating systems.
Moreover, Selenium WebDriver can have difficulties dealing with dynamic web elements, cross-browser compatibility, and performance overload. Leveraging cloud-based testing can be an effective solution to overcome these challenges.
[Cloud testing](https://www.lambdatest.com/blog/cloud-testing-tutorial/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)tion will help you learn to automate web application testing usin is valuable for evaluating how well software functions across different environments and under actual user conditions. Testing teams can utilize numerous devices, operating systems, browsers, and browser versions to test websites and applications in real-life situations. These devices are hosted on cloud servers, ensuring continuous online availability.
Using cloud testing, testers can solve problems like having limited device options, dealing with different browsers and operating systems, and the need for complex setups. Moving testing to the Internet solves location issues and ensures a thorough testing environment.
Some of the benefits of using cloud-based testing are mentioned below.
* **Scalability:** Cloud testing lets you easily adjust the computing power you need for testing. You can use tools like the [LambdaTest Concurrency](https://www.lambdatest.com/concurrency-calculator/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) Calculator to determine how many tasks you need to speed up your testing.
* **Availability:** With an Internet connection, you can access resources from anywhere using any device. Cloud testing removes location barriers, and teams can work together in real-time using built-in tools for collaboration.
* **Cost-Effective:** It is budget-friendly because you only pay for what you use, making it cheaper than traditional testing.
* **Quicker Testing Process:** It is faster than traditional testing methods, making it quicker to start marketing your product.
* **Simpler Disaster Recovery:** Recovering from a disaster is easier with the cloud. Cloud disaster recovery (CDR) helps companies get back essential data after problems like data breaches. It’s a simple process using a secure virtual space to access files remotely without extra complications.
For cloud-based testing, leverage the LambdaTest platform. It enables the seamless execution of your automation tests, ensuring smooth performance across various devices, locations, browsers, and operating systems.
LambdaTest is an AI-powered test orchestration and execution platform that allows you to run manual and automated tests at scale, offering access to over 3000+ real devices, browsers, and OS combinations.
## Using Selenium WebDriver on Cloud
This section will use the LambdaTest platform to run Selenium test scripts. Before we write the test code based on any programming language or selected testing framework, let’s explore the setup process for LambdaTest to use its capabilities effectively.
## Setting up LambdaTest
Before running the test on LambdaTest, we need to create an account and set up some configurations to help run the test on LambdaTest.
**Step 1: **Create a [LambdaTest account](https://accounts.lambdatest.com/register).
**Step 2:** Get your Username and Access Key by going to your Profile avatar from the LambdaTest dashboard and selecting **Account Settings** from the list of options.

**Step 3:** Copy your Username and Access Key from the [Password & Security](https://accounts.lambdatest.com/security) tab.

**Step 4: **Generate Capabilities containing details like your desired browser and its various operating systems and get your configuration details on [LambdaTest Capabilities Generator](https://www.lambdatest.com/capabilities-generator/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage).

**Step 5:** Now that you have both the Username, Access key, and capabilities copied, all you need to do is paste it into your test script.
***Note: These capabilities will differ for each programming language and testing framework you choose.***
In the example below, we will run the same test case on Chrome (latest) + Windows 10 combination. The below test scenario will remain the same for all the programming languages.
Let us look into some examples based on popular programming languages like Java, JavaScript, Python, C#, Ruby, and PHP.
## How to Use Selenium WebDriver with Java?
Java is a popular programming language for developing web applications, gaming applications, and more. Selenium works well with Java for running automated tests on various web browsers. Many professionals prefer Java for their everyday Selenium tasks. Also, programs run faster in Java compared to other programming languages.
This section will help you learn to automate web application testing using [Selenium WebDriver with Java](https://www.lambdatest.com/blog/selenium-with-java/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog).
**Test Scenario:**
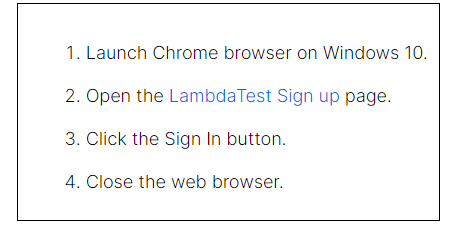
Consider implementing the above scenario with the [Cucumber testing](https://www.lambdatest.com/learning-hub/cucumber-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) framework using the code below:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import cucumber.api.CucumberOptions;
import cucumber.api.testng.CucumberFeatureWrapper;
import cucumber.api.testng.TestNGCucumberRunner;
import java.net.MalformedURLException;
import java.net.URL;
public class LambdaTestExample {
public static final String USERNAME = "<your_username>";
public static final String ACCESS_KEY = "<your_access_key>";
public static final String GRID_URL = "https://" + USERNAME + ":" + ACCESS_KEY + "@hub.lambdatest.com/wd/hub";
public static void main(String[] args) {
// Desired capabilities for Chrome on Windows 10
ChromeOptions browserOptions = new ChromeOptions();
browserOptions.setPlatformName("Windows 10");
browserOptions.setBrowserVersion("121.0");
HashMap<String, Object> ltOptions = new HashMap<String, Object>();
ltOptions.put("username", "Enter your username");
ltOptions.put("accessKey", "Enter your access key");
ltOptions.put("build", "LambdaTest Sample");
ltOptions.put("project", "LambdaTest Sample");
ltOptions.put("name", "LambdaTest Sample");
ltOptions.put("w3c", true);
// Initialize the remote WebDriver with LambdaTest capabilities
WebDriver driver = null;
try {
driver = new RemoteWebDriver(new URL(GRID_URL), capabilities);
} catch (MalformedURLException e) {
e.printStackTrace();
}
if (driver != null) {
try {
// Step 1: Launch Chrome browser on Windows 10
// This step is already covered by initializing the remote WebDriver
// Step 2: Open the LambdaTest sign-up page
driver.get("https://www.lambdatest.com/");
// Step 3: Click on the Sign In button
WebElement signInButton = driver.findElement(By.xpath("//a[contains(text(),'Sign In')]"));
signInButton.click();
// Add additional steps here if needed for the sign-in process
} finally {
// Step 4: Close the web browser
driver.quit();
}
}
}
}
Replace <your_username> and <your_access_key> with your actual LambdaTest credentials.
If you are using an editor or IDE for running your tests, you can just build and run your configured Java file in your editor/IDE.
If you are using a terminal/cmd, you would need to execute the following commands
cd to/file/location
#Compile the test file:
javac -classpath ".:/path/to/selenium/jarfile:" <file_name>.java
#Run the test:
java -classpath ".:/path/to/selenium/jarfile:" <file_name>
For Selenium automation testing using Java on LambdaTest, you can check the LambdaTest support document on [getting started with Selenium Java on LambdaTest](https://www.lambdatest.com/support/docs/java-with-selenium-running-java-automation-scripts-on-lambdatest-selenium-grid/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=support_doc).
## How to Use Selenium WebDriver with Python?
Python, a popular programming language, is extensively utilized for creating test automation scripts. Writing code in Python is known for its ease and efficiency. When used with Selenium, the automation process becomes even more seamless and expeditious.
This section will help you automate web application testing using [Selenium WebDriver with Python](https://www.lambdatest.com/blog/selenium-webdriver-with-python/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog).
**Test Scenario:**
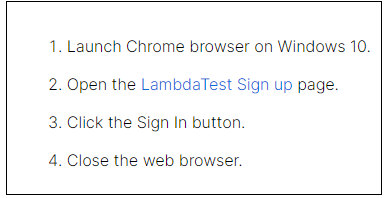
Consider implementing the above scenario with the [pytest testing](https://www.lambdatest.com/learning-hub/selenium-pytest-tutorial?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) framework using the code below:
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# LambdaTest configuration
username = '<your_username>'
access_key = '<your_access_key>'
remote_url = f'@hub.lambdatest.com/wd/hub'">https://{username}:{access_key}@hub.lambdatest.com/wd/hub'
# Desired capabilities for Chrome on Windows 10
capabilities = {
'build': 'LambdaTest Sample',
'name': 'LambdaTest Sample Test',
'platform': 'Windows 10',
'browserName': 'chrome',
'version': 'latest',
'resolution': '1920x1080',
}
@pytest.fixture
def driver():
# Initialize the remote WebDriver with LambdaTest capabilities
driver = webdriver.Remote(command_executor=remote_url, desired_capabilities=capabilities)
yield driver
# Teardown: Close the web browser
driver.quit()
def test_lambda_test_scenario(driver):
# Step 1: Launch Chrome browser on Windows 10
# This step is already covered by initializing the remote WebDriver
# Step 2: Open the LambdaTest sign-up page
driver.get('https://www.lambdatest.com/')
assert 'Cross Browser Testing Tools | Free Automated Testing | LambdaTest' in driver.title
# Step 3: Click on the Sign In button
sign_in_button = driver.find_element(By.XPATH, "//a[contains(text(),'Sign In')]")
sign_in_button.click()
Replace <your_username> and <your_access_key> with your actual LambdaTest credentials. This code uses the pytest testing framework along with Selenium.
To run the above code, run the following command.
pytest your_test_file.py
For Selenium automation testing using Python on LambdaTest, you can check the LambdaTest support document on [getting started with Selenium Python on LambdaTest](https://www.lambdatest.com/support/docs/python-with-selenium-running-python-automation-scripts-on-lambdatest-selenium-grid/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=support_doc).
## How to Use Selenium WebDriver with JavaScript?
JavaScript programming language helps you build interactive web applications and is easy to learn. Selenium and JavaScript form a powerful combination for web automation testing. Selenium automates browsers, and JavaScript serves as the scripting language. Together, they enable various tasks like logging in, form filling, and navigating web pages.
Both are open-source, cross-platform, and well-documented, making them ideal for testing web applications globally. Additionally, they support mobile app testing, report generation, and seamless integration with other tools.
This section will help you automate web application testing using [Selenium WebDriver with JavaScript](https://www.lambdatest.com/learning-hub/selenium-java?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub).
**Test Scenario:**

Consider implementing the above scenario with the [Mocha.js testing](https://www.lambdatest.com/mocha-js-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) framework using the code below:
const { Builder, By, Key, until } = require('selenium-webdriver');
const { describe, it, before, after } = require('mocha');
const assert = require('assert');
// LambdaTest configuration
const username = '<your_username>';
const accessKey = '<your_access_key>';
const remoteUrl =`@hub.lambdatest.com/wd/hub`">https://${username}:${accessKey}@hub.lambdatest.com/wd/hub`;
// Desired capabilities for Chrome on Windows 10
const capabilities = {
build: 'LambdaTest Sample',
name: 'LambdaTest Sample Test',
platform: 'Windows 10',
browserName: 'chrome',
version: 'latest',
resolution: '1920x1080',
};
let driver;
describe('LambdaTest Sample Test', function () {
this.timeout(60000); // Set timeout to 60 seconds for each test
before(async function () {
driver = await new Builder().usingServer(remoteUrl).withCapabilities(capabilities).build();
});
it('should open LambdaTest sign-up page and click on Sign In', async function () {
await driver.get('https://www.lambdatest.com/');
await driver.wait(until.titleIs('Cross Browser Testing Tools | Free Automated Testing | LambdaTest'));
const signInButton = await driver.findElement(By.xpath("//a[contains(text(),'Sign In')]"));
await signInButton.click();
// Add additional steps here if needed for the sign-in process
});
after(async function () {
if (driver) {
await driver.quit();
}
});
});
Replace <your_username> and <your_access_key> with your actual LambdaTest credentials.
Execute the following command below to run your tests:
npm test
or
node index.js
For using Selenium WebDriver with JavaScript on LambdaTest, you can check the LambdaTest support document on [getting started with Selenium JavaScript on LambdaTest](https://www.lambdatest.com/support/docs/javascript-with-selenium-running-javascript-automation-scripts-on-lambdatest-selenium-grid/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=support_doc).
## How to Use Selenium WebDriver with C#?
C# stands as a versatile programming language crafted by Microsoft. At its core, every C# program operates within the Microsoft .NET framework. Serving as the runtime platform for C# and other languages like Visual Basic, the .NET framework underpins the execution of these programs. The combination of Selenium with C# provides a robust, flexible, and scalable solution for automated testing, making it a preferred choice for developers and testers.
This section will help you automate web application testing using [Selenium WebDriver with C#](https://www.lambdatest.com/blog/selenium-c-sharp/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog).
**Test Scenario:**

Consider implementing the above scenario with the [NUnit testing](https://www.lambdatest.com/learning-hub/nunit-tutorial?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) framework using the code below. Ensure you have the necessary dependencies *(Selenium.WebDriver, Selenium.WebDriver.ChromeDriver, NUnit)*.
Using NUnit.Framework;
using OpenQA.Selenium;
using OpenQA.Selenium.Remote;
[TestFixture]
public class LambdaTestScenario
{
// LambdaTest configuration
private string username = "<your_username>";
private string accessKey = "<your_access_key>";
private string remoteUrl = $"@hub.lambdatest.com/wd/hub">https://{username}:{accessKey}@hub.lambdatest.com/wd/hub";
// Desired capabilities for Chrome on Windows 10
private DesiredCapabilities capabilities = new DesiredCapabilities();
private IWebDriver driver;
[SetUp]
public void Setup()
{
// Initialize the remote WebDriver with LambdaTest capabilities
capabilities.SetCapability("build", "LambdaTest Sample");
capabilities.SetCapability("name", "LambdaTest Sample Test");
capabilities.SetCapability("platform", "Windows 10");
capabilities.SetCapability("browserName", "chrome");
capabilities.SetCapability("version", "latest");
capabilities.SetCapability("resolution", "1920x1080");
driver = new RemoteWebDriver(new System.Uri(remoteUrl), capabilities);
}
[Test]
public void LambdaTestScenarioTest()
{
// Step 1: Launch Chrome browser on Windows 10
// This step is already covered by initializing the remote WebDriver
// Step 2: Open the LambdaTest sign-up page
driver.Navigate().GoToUrl("https://www.lambdatest.com/");
Assert.IsTrue(driver.Title.Contains("Cross Browser Testing Tools | Free Automated Testing | LambdaTest"));
// Step 3: Click on the Sign In button
IWebElement signInButton = driver.FindElement(By.XPath("//a[contains(text(),'Sign In')]"));
signInButton.Click();
// Add additional steps here if needed for the sign-in process
}
[TearDown]
public void Teardown()
{
// Step 4: Close the web browser
if (driver != null)
{
driver.Quit();
}
}
}
Replace <your_username> and <your_access_key> with your actual LambdaTest credentials.
Execute the following command below to run your tests:
dotnet run single
For using Selenium WebDriver with PHP on LambdaTest, you can check the LambdaTest support document on [getting started with Selenium C# on LambdaTest](https://www.lambdatest.com/support/docs/c-with-selenium-running-c-automation-scripts-on-lambdatest-selenium-grid/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=support_doc)
## How to Use Selenium WebDriver with Ruby?
Ruby is an excellent choice with its clean syntax and focus on built-in library integrations. Another advantage is its compatibility with other programming languages like Java and Python.
Selenium and Ruby can be seamlessly combined using the Selenium WebDriver. This facilitates the automation of test cases with various Ruby-supported frameworks. In our example, we’ll use Ruby with Selenium to make the automation testing process easy and effective.
This section will help you automate web application testing using [Selenium WebDriver with Ruby](https://www.lambdatest.com/blog/selenium-ruby/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog).
**Test Scenario:**
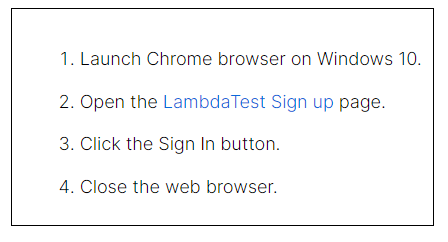
Consider implementing the above scenario with the [RSpec testing](https://www.lambdatest.com/learning-hub/rspec-ruby?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) framework using the code below. Ensure you have the necessary dependencies installed, including the Selenium WebDriver bindings for Ruby *(selenium-webdriver)*, RSpec *(rspec)*, and the *rspec-retry* gem.
require 'selenium-webdriver'
require 'rspec'
require 'rspec/retry'
RSpec.configure do |config|
config.verbose_retry = true
config.default_retry_count = 3
config.default_sleep_interval = 2
config.before(:all) do
@capabilities = {
browserName: 'chrome',
version: 'latest',
platform: 'Windows 10',
build: 'Your Build Name', # Replace with your build name
name: 'LambdaTest Example Test', # Replace with your test name
network: true, # Enable network capture for debugging (optional)
visual: true, # Enable visual testing (optional)
console: true, # Enable console logs capture (optional)
}
username = 'YOUR_USERNAME' # Replace with your LambdaTest username
access_key = 'YOUR_ACCESS_KEY' # Replace with your LambdaTest access key
url = "@hub.lambdatest.com/wd/hub">https://#{username}:#{access_key}@hub.lambdatest.com/wd/hub"
@driver = Selenium::WebDriver.for(:remote, url: url, desired_capabilities: @capabilities)
end
config.after(:all) do
@driver.quit
end
end
describe 'LambdaTest Example Test' do
it 'executes the scenario' do
@driver.get('https://www.lambdatest.com/signup/')
# Locate and click on the Sign In button
sign_in_button = @driver.find_element(id: 'signin')
sign_in_button.click
# Add assertions or additional actions if needed
# Quit the WebDriver session
@driver.quit
end
end
Replace <your_username> and <your_access_key> with your actual LambdaTest credentials.
To execute the code, follow the command.
ruby yourfile name.rb
For using Selenium WebDriver with Ruby on LambdaTest, you can check the LambdaTest support document on [getting started with Selenium Ruby on LambdaTest](https://www.lambdatest.com/support/docs/ruby-with-selenium-running-ruby-automation-scripts-on-lambdatest-selenium-grid?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=support_doc)
## How to Use Selenium WebDriver with PHP?
PHP is a common language for web development; by integrating Selenium WebDriver in PHP, the automation testing becomes smooth and easy to manage.
This section will help you automate web application testing using [Selenium WebDriver with PHP](https://www.lambdatest.com/blog/selenium-php-tutorial/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog) .
**Test Scenario:**
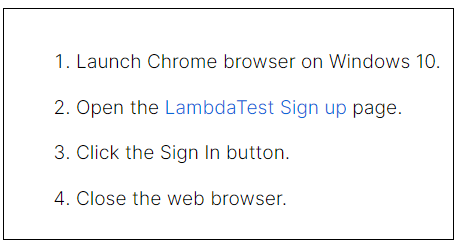
You can use the following example code to execute the scenario using LambdaTest capabilities in PHP language and the [PHPUnit testing](https://www.lambdatest.com/selenium-automation-testing-with-phpunit?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) framework. Ensure you have the necessary dependencies installed, including the Selenium WebDriver bindings for PHP *(php-webdriver/php-webdriver)* and PHPUnit.
<?php
require 'vendor/autoload.php'; // Ensure the path to autoload.php is correct based on your project structure
use FacebookWebDriverRemoteRemoteWebDriver;
use FacebookWebDriverWebDriverBy;
use FacebookWebDriverRemoteDesiredCapabilities;
class LambdaTestExample extends PHPUnitFrameworkTestCase
{
protected $webDriver;
protected function setUp(): void
{
$capabilities = [
'browserName' => 'chrome',
'version' => 'latest',
'platform' => 'Windows 10',
'build' => 'Your Build Name', // Replace with your build name
'name' => 'LambdaTest Example Test', // Replace with your test name
'network' => true, // Enable network capture for debugging (optional)
'visual' => true, // Enable visual testing (optional)
'console' => true, // Enable console logs capture (optional)
];
$username = 'YOUR_USERNAME'; // Replace with your LambdaTest username
$accessKey = 'YOUR_ACCESS_KEY'; // Replace with your LambdaTest access key
$url = "https://$username:$accessKey@hub.lambdatest.com/wd/hub";
$this->webDriver = RemoteWebDriver::create($url, $capabilities);
}
public function testLambdaTestScenario()
{
$this->webDriver->get('https://www.lambdatest.com/signup/');
// Locate and click on the Sign In button
$signInButton = $this->webDriver->findElement(WebDriverBy::id('signin'));
$signInButton->click();
// Add assertions or additional actions if needed
// Close the web browser
$this->webDriver->quit();
}
protected function tearDown(): void
{
// Ensure to quit the WebDriver session
if ($this->webDriver) {
$this->webDriver->quit();
}
}
}
Replace <your_username> and <your_access_key> with your actual LambdaTest credentials.
To execute the code, run the following command.
php tests/yourfilename.php
For using Selenium WebDriver with PHP on LambdaTest, you can check the LambdaTest support document on [getting started with Selenium PHP on LambdaTest](https://www.lambdatest.com/support/docs/php-with-selenium-running-php-automation-scripts-on-lambdatest-selenium-grid/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=support_doc)
## Advanced Use Cases for WebDriver
In this section of the Selenium WebDriver tutorial, you will learn how to run advanced use cases using Selenium and Java.
## Use Case 1: Automating Registration Page With Selenium Web Driver
When starting with Selenium automation testing for your online platform, focusing on automating either the Registration or Login Page is crucial. The Signup page is the gateway to your web application, making it a vital component to test, especially for platforms like eCommerce or Software-as-a-Service (SaaS) products. It’s a fundamental yet significant page, beginning various user journeys that need testing.
Let us take a scenario better to understand the automation registration page with Selenium WebDriver.
**Test Scenario:**

Below is the code implementation to automate the registration page.
package com.lambdatest;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.Platform;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.testng.Assert;
import org.testng.annotations.AfterClass;
import org.testng.annotations.BeforeClass;
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Parameters;
import org.testng.annotations.Test;
import org.testng.asserts.Assertion;
import com.beust.jcommander.Parameter;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.Set;
import java.util.concurrent.TimeUnit;
public class SignUpTest{
public String username = "your username";
public String accesskey = "Your accesskey";
public static RemoteWebDriver driver = null;
public String gridURL = "@hub.lambdatest.com/wd/hub";
boolean status = false;
//Setting up capabilities to run our test script
@Parameters(value= {"browser","version"})
@BeforeClass
public void setUp(String browser, String version) throws Exception {
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability("browserName", browser);
capabilities.setCapability("version", version);
capabilities.setCapability("platform", "win10"); // If this cap isn't specified, it will just get any available one
capabilities.setCapability("build", "LambdaTestSampleApp");
capabilities.setCapability("name", "LambdaTestJavaSample");
capabilities.setCapability("network", true); // To enable network logs
capabilities.setCapability("visual", true); // To enable step by step screenshot
capabilities.setCapability("video", true); // To enable video recording
capabilities.setCapability("console", true); // To capture console logs
try {
driver = new RemoteWebDriver(new URL("https://" + username + ":" + accesskey + gridURL), capabilities);
} catch (MalformedURLException e) {
System.out.println("Invalid grid URL");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
//Opening browser with the given URL and navigate to Registration Page
@BeforeMethod
public void openBrowser()
{
driver.manage().deleteAllCookies();
driver.get("https://www.lambdatest.com/");
driver.manage().timeouts().implicitlyWait(15, TimeUnit.SECONDS);
driver.manage().timeouts().pageLoadTimeout(15, TimeUnit.SECONDS);
WebElement signUpButton = driver.findElement(By.xpath("//a[contains(text(),'Start Free Testing')]"));
signUpButton.click();
}
//Verifying elements on Registration page
@Test
public void verifyElemntsOnPageTest()
{
WebElement lambdaTestLogo = driver.findElement(By.xpath("//p[@class='signup-titel']"));
lambdaTestLogo.isDisplayed();
WebElement signUpTitle = driver.findElement(By.xpath("//p[@class='signup-titel']"));
signUpTitle.isDisplayed();
WebElement termsText = driver.findElement(By.xpath("//label[@class='woo']"));
termsText.isDisplayed();
WebElement loginLinkText = driver.findElement(By.xpath("//p[@class='login-in-link test-left']"));
loginLinkText.isDisplayed();
}
//Verifying redirection to the terms and conditions page
@Test
public void termsRedirectionTest()
{
WebElement termsLink = driver.findElement(By.xpath("//a[contains(text(),'Terms')]"));
termsLink.click();
Set <String> allWindows = driver.getWindowHandles();
for(String handle : allWindows)
{
driver.switchTo().window(handle);
}
String expectedURL = "https://www.lambdatest.com/terms-of-service";
String actualURL = driver.getCurrentUrl();
//System.out.println(actualURL);
Assert.assertEquals(actualURL, expectedURL);
String expectedTitle = "Terms of Service - LambdaTest";
String actualTitle = driver.getTitle();
//System.out.println(actualTitle);
Assert.assertEquals(actualTitle, expectedTitle);
}
//Verifying Privacy policy page redirection
@Test
public void privacyPolicyRedirectionTest()
{
WebElement privacyPolicyLink = driver.findElement(By.xpath("//a[contains(text(),'Privacy')]"));
privacyPolicyLink.click();
Set <String> allWindows = driver.getWindowHandles();
for(String handle : allWindows)
{
driver.switchTo().window(handle);
}
String expectedURL = "https://www.lambdatest.com/privacy";
String actualURL = driver.getCurrentUrl();
//System.out.println(actualURL);
Assert.assertEquals(actualURL, expectedURL);
String expectedTitle = "Privacy Policy | LambdaTest";
String actualTitle = driver.getTitle();
//System.out.println(actualTitle);
Assert.assertEquals(actualTitle, expectedTitle);
}
//Verifying redirection to the Login page from Registration page
@Test
public void loginRedirectionTest()
{
WebElement loginLink = driver.findElement(By.xpath("//a[contains(text(),'Login')]"));
loginLink.click();
String expectedURL = "https://accounts.lambdatest.com/login";
String actualURL = driver.getCurrentUrl();
//System.out.println(actualURL);
Assert.assertEquals(actualURL, expectedURL);
String expectedTitle = "Login - LambdaTest";
String actualTitle = driver.getTitle();
//System.out.println(actualTitle);
Assert.assertEquals(actualTitle, expectedTitle);
}
//Verifying redirection to the landing page
@Test
public void landingPageRedirectionTest()
{
WebElement lambdaTestLogo = driver.findElement(By.xpath("//p[@class='logo-home']//a//img"));
lambdaTestLogo.click();
String expectedURL = "https://www.lambdatest.com/";
String actualURL = driver.getCurrentUrl();
Assert.assertEquals(actualURL, expectedURL);
}
// Registration with all valid data
@Test
public void validRegistrationTest(){
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("TestCompany");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("TestName");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("test6.lambdatest@gmail.com");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("Enter your LambdaTest password here");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("Enter your number");
WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
String expectedURL = "https://accounts.lambdatest.com/email/verify";
String actualURL = driver.getCurrentUrl();
Assert.assertEquals(actualURL, expectedURL);
String expectedTitle = "Verify Your Email Address - LambdaTest";
String actualTitle = driver.getTitle();
Assert.assertEquals(actualTitle, expectedTitle);
}
// Registration without providing Company Name field
@Test
public void emptyCompanyNameTest()
{
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("TestName");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("test7.lambdatest@gmail.com");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("Enter your LambdaTest account password");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("Enter your phone number here");
WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
/*
* Set <String> allWindows = driver.getWindowHandles();
*
* for(String handle : allWindows) { driver.switchTo().window(handle); }
*/
String expectedURL = "https://accounts.lambdatest.com/email/verify";
String actualURL = driver.getCurrentUrl();
Assert.assertEquals(actualURL, expectedURL);
String expectedTitle = "Verify Your Email Address - LambdaTest";
String actualTitle = driver.getTitle();
Assert.assertEquals(actualTitle, expectedTitle);
}
// Registration without providing Name field
@Test
public void emptyNameTest()
{
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("TestCompany");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("Enter your name ");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("test@test.com");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("Enter your LambdaTest account password"");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("Send your number here");
WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
String expectedErrorMsg = "Please enter your Name";
WebElement exp = driver.findElement(By.xpath("//p[contains(text(),'Please enter your Name')]"));
String actualErrorMsg = exp.getText();
Assert.assertEquals(actualErrorMsg, expectedErrorMsg);
}
// Registration without providing user email field
@Test
public void emptyEmailTest()
{
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("TestCompany");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("test");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("Enter your LambdaTest account password"");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("Enter your phone number here");
WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
String expectedErrorMsg = "Please enter your Email Address";
WebElement exp = driver.findElement(By.xpath("//p[contains(text(),'Please enter your Email Address')]"));
String actualErrorMsg = exp.getText();
Assert.assertEquals(actualErrorMsg, expectedErrorMsg);
}
// Registration with email id which already have account
@Test
public void invalidEmailTest()
{
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("TestCompany");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("TestName");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("test@test.com");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("Enter your LambdaTest account password");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("Enter your phone number here");
WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
String expectedErrorMsg = "This email is already registered";
WebElement exp = driver.findElement(By.xpath("//p[@class='error-mass']"));
String actualErrorMsg = exp.getText();
Assert.assertEquals(actualErrorMsg, expectedErrorMsg);
}
// Registration without providing password field
@Test
public void emptyPasswordTest()
{
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("TestCompany");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("TestName");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("test@test.com");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("Enter the password");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("Enter your phone number here");
WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
String expectedErrorMsg = "Please enter a desired password";
WebElement exp = driver.findElement(By.xpath("//p[contains(text(),'Please enter a desired password')]"));
String actualErrorMsg = exp.getText();
Assert.assertEquals(actualErrorMsg, expectedErrorMsg);
}
// Registration with invalid password
@Test
public void inValidPasswordTest()
{
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("TestCompany");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("TestName");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("test@test.com");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("T");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("Enter the phone number");
WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
String expectedErrorMsg = "Password should be at least 8 characters long";
WebElement exp = driver.findElement(By.xpath("//p[contains(text(),'Password should be at least 8 characters long')]"));
String actualErrorMsg = exp.getText();
Assert.assertEquals(actualErrorMsg, expectedErrorMsg);
//Password should be at least 8 characters long
}
// Registration without providing user phone number field
@Test
public void emptyPhoneTest()
{
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("TestCompany");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("TestName");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("test@test.com");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("Enter your LambdaTest account password"");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("");
WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
String expectedErrorMsg = "The phone field is required.";
WebElement exp = driver.findElement(By.xpath("//p[contains(text(),'The phone field is required.')]"));
String actualErrorMsg = exp.getText();
Assert.assertEquals(actualErrorMsg, expectedErrorMsg);
}
// Registration with providing invalid user phone number field
@Test
public void inValidPhoneTest()
{
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("TestCompany");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("TestName");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("test@test.com");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("Enter your LambdaTest account password");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("98");
WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
String expectedErrorMsg = "Please enter a valid Phone number";
WebElement exp = driver.findElement(By.xpath("//p[contains(text(),'Please enter a valid Phone number')]"));
String actualErrorMsg = exp.getText();
Assert.assertEquals(actualErrorMsg, expectedErrorMsg);
//Please enter a valid Phone number
}
// Registration without accepting terms and condition tickbox
@Test
public void uncheckedTerms()
{
WebElement companyName = driver.findElement(By.name("organization_name"));
companyName.sendKeys("TestCompany");
WebElement fullName = driver.findElement(By.name("name"));
fullName.sendKeys("TestName");
WebElement email = driver.findElement(By.name("email"));
email.sendKeys("test@test.com");
WebElement password = driver.findElement(By.name("password"));
password.sendKeys("Enter your LambdaTest account password");
WebElement phone = driver.findElement(By.name("phone"));
phone.sendKeys("Enter your phone number");
//WebElement termsOfServices = driver.findElement(By.id("terms_of_service"));
//termsOfServices.click();
WebElement signUp = driver.findElement(By.xpath("//button[contains(@class,'btn sign-up-btn-2 btn-block')]"));
signUp.click();
String expectedTermsErrorMessage = "To proceed further you must agree to our Terms of Service and Privacy Policy";
WebElement uncheckedTermCheckbox = driver.findElement(By.xpath("//p[@class='error-mass mt-2']"));
String actualTermsErrorMessage = uncheckedTermCheckbox.getText();
//To proceed further you must agree to our Terms of Service and Privacy Policy
Assert.assertEquals(actualTermsErrorMessage, expectedTermsErrorMessage);
}
// Closing the browser session after completing each test case
@AfterClass
public void tearDown() throws Exception {
if (driver != null) {
((JavascriptExecutor) driver).executeScript("lambda-status=" + status);
driver.quit();
}
}
}
You can watch the video below to learn [automating the registration page with Selenium WebDriver](https://www.lambdatest.com/blog/selenium-java-tutorial-automation-testing-of-user-signup-form/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog), gain valuable details, and start your automation journey with Selenium WebDriver.
{% youtube Ue1DuiezdtY %}
## Use Case 2: Handling Login Popups With Selenium WebDriver
When accessing certain websites, you might have encountered authentication pop-ups prompting you to enter usernames and passwords. These pop-ups serve as a security measure, ensuring that only authorized users gain access to specific resources or features on the site.
Let us take a test scenario to understand the use case better.
**Test Scenario:**
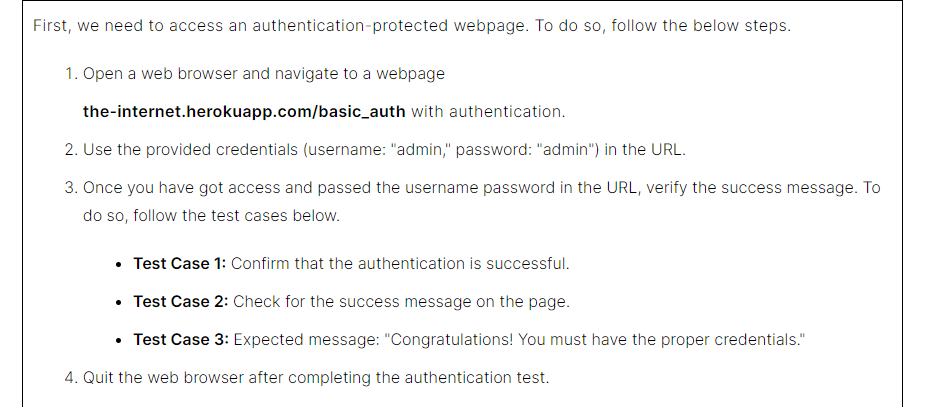
Below is the code implementation for the above test scenario.
package Pages;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Parameters;
import org.testng.annotations.Test;
public class Demo {
String username = "USERNAME"; //Enter your username
String accesskey = "ACCESSKEY"; //Enter your accesskey
static RemoteWebDriver driver = null;
String gridURL = "@hub.lambdatest.com/wd/hub";
boolean status = false;
@BeforeTest
@Parameters("browser")
public void setUp(String browser)throws MalformedURLException
{
if(browser.equalsIgnoreCase("chrome"))
{
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability("browserName", "chrome"); //To specify the browser
capabilities.setCapability("version", "70.0"); //To specify the browser version
capabilities.setCapability("platform", "win10"); // To specify the OS
capabilities.setCapability("build", "AuthPopUp"); //To identify the test
capabilities.setCapability("name", "AuthPopUpTest");
capabilities.setCapability("network", true); // To enable network logs
capabilities.setCapability("visual", true); // To enable step by step screenshot
capabilities.setCapability("video", true); // To enable video recording
capabilities.setCapability("console", true); // To capture console logs
try {
driver = new RemoteWebDriver(new URL("https://" + username + ":" + accesskey + gridURL), capabilities);
} catch (MalformedURLException e) {
System.out.println("Invalid grid URL");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
else if(browser.equalsIgnoreCase("Firefox"))
{
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability("browserName", "Firefox"); //To specify the browser
capabilities.setCapability("version", "76.0"); //To specify the browser version
capabilities.setCapability("platform", "win10"); // To specify the OS
capabilities.setCapability("build", " AuthPopUp"); //To identify the test
capabilities.setCapability("name", " AuthPopUpTest");
capabilities.setCapability("network", true); // To enable network logs
capabilities.setCapability("visual", true); // To enable step by step screenshot
capabilities.setCapability("video", true); // To enable video recording
capabilities.setCapability("console", true); // To capture console logs
try {
driver = new RemoteWebDriver(new URL("https://" + username + ":" + accesskey + gridURL), capabilities);
} catch (MalformedURLException e) {
System.out.println("Invalid grid URL");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
@Test
public void Login() {
String username = "admin";
String password = "admin";
String URL = "https://" +username +":" +password +"@"+ "the-internet.herokuapp.com/basic_auth";
driver.get(URL);
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
String title = driver.getTitle();
System.out.println("The page title is "+title);
String text = driver.findElement(By.tagName("p")).getText();
System.out.println("The test present in page is ==> "+text);
}
@AfterTest
public void tearDown() {
driver.quit();
}
}
To learn more about [handling login popups with Selenium WebDriver](https://www.lambdatest.com/blog/handling-login-popup-in-selenium-webdriver-using-java/), watch the complete video tutorial and gain valuable insights on popups.
{% youtube F9X0JCzZOjA %}
## Use Case 3: Handling Captcha With Selenium WebDriver
CAPTCHA, which stands for Completely Automated Public Turing test to tell Computers and Humans Apart, is a tool to distinguish between genuine users and automated entities like bots. The main objective of CAPTCHA is to thwart the use of automated programs or bots to access diverse computing services or gather specific sensitive information, such as email addresses and phone numbers.
Let us take a scenario to understand the use case better.
**Test Scenario:**

Below is the code implementation for the above test scenario.
package captcha;
import com.github.javafaker.Faker;
import com.microsoft.cognitiveservices.speech.ResultReason;
import com.microsoft.cognitiveservices.speech.SpeechConfig;
import com.microsoft.cognitiveservices.speech.SpeechRecognizer;
import com.microsoft.cognitiveservices.speech.audio.AudioConfig;
import com.microsoft.cognitiveservices.speech.audio.AudioProcessingConstants;
import com.microsoft.cognitiveservices.speech.audio.AudioProcessingOptions;
import io.github.bonigarcia.wdm.WebDriverManager;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutionException;
public class CaptchaHandlingTests {
private SpeechConfig config = SpeechConfig.fromSubscription("c5f183bc0c084b85a9d61e7bb5be626c", "francecentral");
private WebDriver driver;
@BeforeAll
public static void setUpClass() {
WebDriverManager.chromedriver().setup();
}
@BeforeEach
public void setUp() {
// use user agent to bypass v3 reCaptcha
ChromeOptions options = new ChromeOptions();
options.addArguments("--user-agent=Mozilla/5.0 (Linux; Android 6.0; HTC One M9 Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.98 Mobile Safari/537.36");
driver = new ChromeDriver(options);
driver.manage().window().maximize();
}
// use these keys to bypass
// Site Key: 6LeIxAcTAAAAAJcZVRqyHh71UMIEGNQ_MXjiZKhI
// Secret Key: 6LeIxAcTAAAAAGG-vFI1TnRWxMZNFuojJ4WifJWe
@Test
public void recaptchaTestAudio() throws ExecutionException, InterruptedException {
var wait = new WebDriverWait(driver, Duration.ofSeconds(30));
var faker = new Faker();
driver.navigate().to("https://demos.bellatrix.solutions/contact-form/");
var firstName = driver.findElement(By.id("wpforms-3347-field_1"));
firstName.sendKeys(faker.name().firstName());
var lastName = driver.findElement(By.id("wpforms-3347-field_1-last"));
lastName.sendKeys(faker.name().lastName());
var email = driver.findElement(By.id("wpforms-3347-field_2"));
email.sendKeys(faker.internet().safeEmailAddress());
var goldInput = driver.findElement(By.id("wpforms-3347-field_3_3"));
goldInput.click();
var session2 = driver.findElement(By.id("wpforms-3347-field_4_2"));
session2.click();
var stayOvernightOption = driver.findElement(By.id("wpforms-3347-field_5_1"));
stayOvernightOption.click();
var questionInput = driver.findElement(By.id("wpforms-3347-field_7"));
questionInput.sendKeys("Do you have free rooms?");
wait.until(ExpectedConditions.frameToBeAvailableAndSwitchToIt(By.xpath("//iframe[@title='reCAPTCHA']")));
var captchaCheckbox = wait.until(ExpectedConditions.elementToBeClickable((By.xpath("//div[@class='recaptcha-checkbox-border']"))));
captchaCheckbox.click();
driver.switchTo().defaultContent();
wait.until(ExpectedConditions.frameToBeAvailableAndSwitchToIt(By.xpath("//iframe[@title='recaptcha challenge expires in two minutes']")));
var audioOptionButton = wait.until(ExpectedConditions.elementToBeClickable(By.id("recaptcha-audio-button")));
audioOptionButton.click();
var audioProcessingOptions = AudioProcessingOptions.create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT);
var audioInput = AudioConfig.fromDefaultMicrophoneInput(audioProcessingOptions);
List<String> recognizedSpeechParts = new ArrayList<>();
var recognizer = new SpeechRecognizer(config, audioInput);
{
recognizer.recognized.addEventListener((s, e) -> {
if (e.getResult().getReason() == ResultReason.RecognizedSpeech) {
recognizedSpeechParts.add(e.getResult().getText());
System.out.println("RECOGNIZED: Text=" + e.getResult().getText());
}
else if (e.getResult().getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
});
// Starts continuous recognition. Uses stopContinuousRecognitionAsync() to stop recognition.
recognizer.startContinuousRecognitionAsync().get();
var playButton = wait.until(ExpectedConditions.elementToBeClickable(By.xpath("//button[text()='PLAY']")));
playButton.click();
Thread.sleep(10000);
recognizer.stopContinuousRecognitionAsync().get();
}
config.close();
audioInput.close();
audioProcessingOptions.close();
recognizer.close();
var audioResponseInput = driver.findElement(By.id("audio-response"));
var captchaText = String. join("", recognizedSpeechParts);
audioResponseInput.sendKeys(captchaText);
var verifyButton = driver.findElement(By.id("recaptcha-verify-button"));
verifyButton.click();
driver.switchTo().defaultContent();
var submitButton = wait.until(ExpectedConditions.elementToBeClickable(By.id("wpforms-submit-3347")));
submitButton.click();
}
@AfterEach
public void tearDown() {
if (driver != null) {
driver.quit();
}
}
}
To learn more about [handling Captcha with Selenium WebDriver](https://www.lambdatest.com/blog/handle-captcha-in-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog), refer to the video below for a better understanding.
{% youtube CCcGPLaaU10 %}
## Use Case 4: Switching Between iFrames With Selenium WebDriver
There are points where we might try to access an element, but it might not be visible or result in some expectations. When trying to traverse via the HTML structure to find the element, it is essential to know whether it is present in the main frame or on the other.
Let us understand this use case by a scenario where you are trying to handle iframe and nested iframe.
**Test Scenario:**

Below is the code implementation for switching between iframes in Selenium Java.
//Handling Frame
const { Builder, By, Key, JavascriptExecutor } = require("selenium-webdriver");
async function iframes(){
// username: Username can be found at automation dashboard
const USERNAME = "xxxxxxxxxxx";
// Accesskey: Accesskey can be generated from automation dashboard or profile section
const KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
// gridUrl: gridUrl can be found at automation dashboard
const GRID_HOST = "hub.lambdatest.com/wd/hub";
// Setup Input capabilities - this is used to run our test on chrome browser via LambdaTest
const capabilities = {
platform: "Windows 10",
browserName: "Chrome",
version: "92.0",
resolution: "1024x768",
network: true,
visual: true,
console: true,
video: true,
name: "Test 1", // name of the test
build: "NodeJS build", // name of the build
};
//creating the grid url to point to LambdaTest
const gridUrl = "https://" + USERNAME + ":" + KEY + "@" + GRID_HOST;
//Building driver instance using specified capabilities
const driver = new Builder()
.usingServer(gridUrl)
.withCapabilities(capabilities)
.build();
//navigate to our application
await driver.get("https://the-internet.herokuapp.com/iframe");
//Navigate to iframe
await driver.switchTo().frame(0)
//retrieve text from iframe using find by xpath
let text = await driver.findElement(By.xpath("//p")).getText()
.then((text) => { return text; });
//log returned text Your content goes here.
console.log("The Paragraph text is: " + text);
//close the browser
await driver.quit();
}
iframes()
To learn more about [handling iframe and windows in Selenium WebDriver](https://www.lambdatest.com/blog/handling-frames-and-iframes-in-selenium-javascript/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog), refer to the video below for a better understanding and to gain more practical knowledge.
> Wondering about [web device testing](https://www.lambdatest.com/test-site-on-mobile?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage)? Explore LambdaTest’s solutions.
{% youtube 32eIE4PAbJk %}
## Use Case 5: Handling Exceptions With Selenium WebDriver
Handling exceptions in Selenium Web Driver is important for robust test automation. Here are some common exceptions you might encounter and how to handle them using Java and Selenium WebDriver.
Some of the common Exception handling encountered in Selenium automation are.
* [***NoSuchElementException](https://www.lambdatest.com/blog/nosuchelementexception-in-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog): ***This exception occurs when the WebDriver cannot locate an element on the web page.
* [***TimeoutException](https://www.lambdatest.com/automation-testing-advisor/selenium/classes/org.openqa.selenium.TimeoutException?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage):*** This exception occurs when an operation is timed out, such as waiting for an element to be present.
* [***StaleElementReferenceException](https://www.lambdatest.com/blog/handling-stale-element-exceptions-in-selenium-java/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog):*** This exception occurs when the reference to an element is no longer valid, usually because the DOM has been refreshed.
* [***WebDriverException](https://www.lambdatest.com/automation-testing-advisor/selenium/methods/org.openqa.selenium.WebDriverException.getDriverName?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage):*** This is a generic exception for WebDriver-related issues.
To understand the exception better, let us try to handle one common exception, *NoSuchElementException*, with a scenario.
**Test Scenario:**

Below is the code implementation for the above test scenario.
import pytest
from selenium import webdriver
import sys
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
ch_capabilities = {
'LT:Options' : {
"user" : "<username>",
"accessKey" : "<accesskey>",
"build" : "StaleElementReferenceException Test on Chrome",
"name" : "StaleElementReferenceException Test on Chrome",
"platformName" : "Windows 10"
},
"browserName" : "Chrome",
"browserVersion" : "102.0",
}
def test_ecommerceplayground_staleelement():
# LambdaTest Profile username
user_name = "<username>"
# LambdaTest Profile access_key
app_key = "<accesskey>"
# Remote Url to connect to our instance of LambdaTest
remote_url = "https://" + user_name + ":" + app_key + "@hub.lambdatest.com/wd/hub"
# creating an instance of Firefox based on the remote url and the desired capabilities
ch_driver = webdriver.Remote(
command_executor=remote_url, desired_capabilities = ch_capabilities)
ch_driver.get('https://ecommerce-playground.lambdatest.io/index.php?route=account/login')
emailElement = ch_driver.find_element(By.ID, "input-email")
passwordElement = ch_driver.find_element(By.ID, "input-password")
emailElement.send_keys("email@gmail.com")
ch_driver.find_element(By.XPATH, "//input[@type='submit']").click()
passwordElement.send_keys("password")
ch_driver.quit()
These instances are just a few examples, and there are various other exceptions you might come across. The crucial aspect is recognizing potential failure points in your automation script and using try-catch blocks to manage exceptions.
To learn more about [handling exceptions with Selenium WebDriver](https://www.lambdatest.com/blog/handling-errors-and-exceptions-in-selenium-python/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog), refer to the video below for a better understanding.
{% youtube KyFnIxW-CF4 %}
## Use Case 6: Uploading and Downloading Files With Selenium Web Driver
When working with Selenium, you might encounter situations where you need to download or upload files. Many websites, like YouTube, eCommerce platforms, and writing tools, have features that involve handling files. For example, YouTube allows you to upload videos, while Amazon lets you download order invoices. As a Selenium tester, you may need to verify these file-related functionalities.
In the scenario below, let us see how to upload and download a file in Selenium WebDriver.
**Test Scenario:**
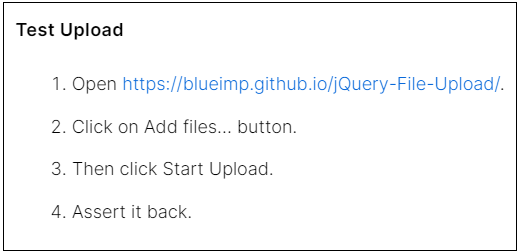
package com.POMFramework.tests;
import static org.testng.Assert.assertTrue;
import java.net.URL;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.remote.LocalFileDetector;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.testng.annotations.AfterClass;
import org.testng.annotations.BeforeClass;
import org.testng.annotations.Test;
public class LamdaTestUploadFileRemotely {
private RemoteWebDriver driver;
@BeforeClass
public void setUp() throws Exception {
ChromeOptions capabilities = new ChromeOptions();
capabilities.setCapability("user","<username>");
capabilities.setCapability("accessKey","<accesskey>");
capabilities.setCapability("build", "Build 2");
capabilities.setCapability("name", "Check Uploaded Image");
capabilities.setCapability("platformName", "Windows 10");
capabilities.setCapability("browserName", "Chrome");
capabilities.setCapability("browserVersion","79.0");
driver = new RemoteWebDriver(new URL("http://hub.lambdatest.com:80/wd/hub"), capabilities);
driver.setFileDetector(new LocalFileDetector());
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
}
@Test
public void lamdaTest() throws Exception {
driver.get("https://blueimp.github.io/jQuery-File-Upload/");
Thread.sleep(2000);
WebElement addFile = driver.findElement(By.xpath(".//input[@type='file']"));
addFile.sendKeys("path to your file to upload");
driver.findElement(By.xpath(".//span[text()='Start upload']")).click();
Thread.sleep(2000);
if(driver.findElement(By.xpath(".//a[text()='c1.jpeg']")).isDisplayed()) {
assertTrue(true, "Image Uploaded");
}else {
assertTrue(false, "Image not Uploaded");
}
}
@AfterClass
public void tearDown() throws Exception {
driver.quit();
}
}
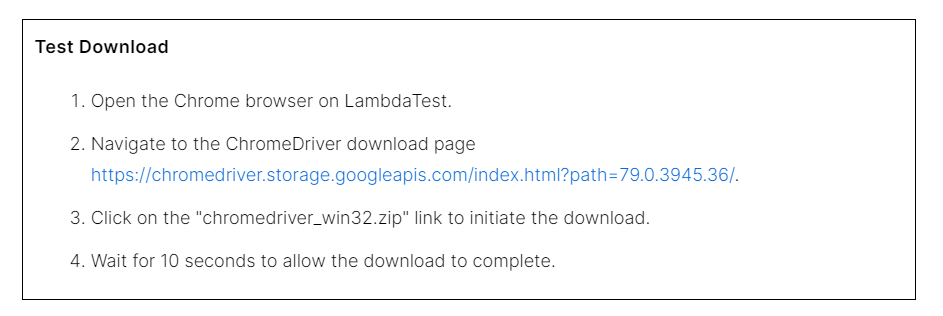
Below is the code implementation for the test scenario to download files.
package com.POMFramework.tests;
import java.awt.AWTException;
import java.net.URL;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.remote.LocalFileDetector;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.testng.annotations.AfterClass;
import org.testng.annotations.BeforeClass;
import org.testng.annotations.Test;
public class LamdaTestDownloadFileRemotely {
private RemoteWebDriver driver;
@BeforeClass
public void setUp() throws Exception {
ChromeOptions capabilities = new ChromeOptions();
capabilities.setCapability("user","<userName>");
capabilities.setCapability("accessKey","<Access key>");
capabilities.setCapability("build", "Build 4");
capabilities.setCapability("name", "Downloading File");
capabilities.setCapability("platformName", "Windows 10");
capabilities.setCapability("browserName", "Chrome");
capabilities.setCapability("browserVersion","79.0");
Map<String, Object> prefs = new HashMap<String, Object>();
prefs.put("download.prompt_for_download", false);
capabilities.setExperimentalOption("prefs", prefs);
driver = new RemoteWebDriver(new URL("http://hub.lambdatest.com:80/wd/hub"), capabilities);
driver.setFileDetector(new LocalFileDetector());
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
}
@Test
public void fileDownload() throws AWTException, InterruptedException {
driver.get("https://chromedriver.storage.googleapis.com/index.html?path=79.0.3945.36/");
Thread.sleep(2000);
WebElement btnDownload = driver.findElement(By.xpath(".//a[text()='chromedriver_win32.zip']"));
btnDownload.click();
Thread.sleep(10000);
}
@AfterClass
public void tearDown() throws Exception {
driver.quit();
}
}
To learn more about [uploading and downloading files with Selenium WebDriver](https://www.lambdatest.com/blog/how-to-download-upload-files-using-selenium-with-java/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog), watch this complete video tutorial to understand its functionality better.
> Ensure your [website’s compatibility on different devices](https://www.lambdatest.com/test-site-on-mobile?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) with LambdaTest.
{% youtube vmwc_TK07SU %}
## Use Case 7: Handling Cookies With Selenium WebDriver
When we use websites for shopping or paying bills, they often use cookies. These are not the tasty treats you eat but bits of data sent to your computer by the website. When you visit a site, it sends cookies to your computer, and when you return, these cookies help the website remember your previous visits or activities. It’s like a virtual way for the website to recognize you without invading your privacy.
Let us understand how to handle cookies by a scenario.
**Test Scenario:**

In Selenium WebDriver, you can automate cookies using the Cookies interface provided by the *WebDriver.Options* class. Below is the code implementation on how you can handle cookies.
package Pages;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.Set;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.testng.Assert;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Parameters;
import org.testng.annotations.Test;
public class HandleCookies
{
String username = "Your_username"; //Enter your username
String accesskey = "Your_accessKey"; //Enter your accesskey
static RemoteWebDriver driver = null;
String gridURL = "@hub.lambdatest.com/wd/hub";
String URL = "https://www.lambdatest.com";
@BeforeTest
@Parameters("browser")
public void setUp(String browser)throws MalformedURLException
{
if(browser.equalsIgnoreCase("chrome"))
{
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability("browserName", "chrome"); //To specify the browser
capabilities.setCapability("version", "70.0"); //To specify the browser version
capabilities.setCapability("platform", "win10"); // To specify the OS
capabilities.setCapability("build", "HandlingCookie"); //To identify the test
capabilities.setCapability("name", "CookieTest");
capabilities.setCapability("network", true); // To enable network logs
capabilities.setCapability("visual", true); // To enable step by step screenshot
capabilities.setCapability("video", true); // To enable video recording
capabilities.setCapability("console", true); // To capture console logs
try {
driver = new RemoteWebDriver(new URL("https://" + username + ":" + accesskey + gridURL), capabilities);
} catch (MalformedURLException e) {
System.out.println("Invalid grid URL");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
else if(browser.equalsIgnoreCase("Firefox"))
{
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability("browserName", "Firefox"); //To specify the browser
capabilities.setCapability("version", "76.0"); //To specify the browser version
capabilities.setCapability("platform", "win10"); // To specify the OS
capabilities.setCapability("build", " HandlingCookie"); //To identify the test
capabilities.setCapability("name", " CookieTest");
capabilities.setCapability("network", true); // To enable network logs
capabilities.setCapability("visual", true); // To enable step by step screenshot
capabilities.setCapability("video", true); // To enable video recording
capabilities.setCapability("console", true); // To capture console logs
try {
driver = new RemoteWebDriver(new URL("https://" + username + ":" + accesskey + gridURL), capabilities);
} catch (MalformedURLException e) {
System.out.println("Invalid grid URL");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
@Test
public void getCookieInformation()
{
System.out.println("=====Getting cookie information Test started======");
driver.get(URL);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
Set<Cookie> cookiesList = driver.manage().getCookies();
for(Cookie getcookies :cookiesList)
{
System.out.println(getcookies);
}
System.out.println("=====Getting cookie information Test has ended======");
}
@Test
public void addCookie() {
boolean status = false;
System.out.println("=====Adding a cookie Test started======");
driver.get(URL);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
Cookie cname = new Cookie("myCookie", "12345678999");
driver.manage().addCookie(cname);
//retrieve the cookies to view the newly added cookie
Set<Cookie> cookiesList = driver.manage().getCookies();
for(Cookie getcookies :cookiesList) {
System.out.println(getcookies);
if(getcookies.getName().equals("myCookie")) {
status = true;
System.out.println("The cookie has been added");
}
else
Assert.assertFalse(false, "The cookie hasnt been added");
}
System.out.println("=====Adding a new cookie Test has ended======");
}
@Test
public void deleteSpecificCookie()
{
System.out.println("=====Deleting a specific cookie Test started======");
driver.get(URL);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
Cookie cname = new Cookie("myCookie1", "abcdefj");
driver.manage().addCookie(cname);
driver.manage().deleteCookie(cname);
Set<Cookie> cookiesListNew = driver.manage().getCookies();
for(Cookie getcookies :cookiesListNew)
{
System.out.println(getcookies );
}
System.out.println("=====Deleting a specific cookie Test has ended======");
}
@Test
public void deleteAllCookies()
{
System.out.println("=====Deleting all cookies Test started======");
driver.get(URL);
driver.manage().window().maximize();
driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);
driver.manage().deleteAllCookies();
Set<Cookie> cookiesListNew = driver.manage().getCookies();
cookiesListNew.size();
System.out.println("The size is "+cookiesListNew);
System.out.println("=====Deleting all cookies Test has ended======");
}
@AfterTest
public void tearDown()
{
driver.quit();
}
}
Learn [handling cookies with Selenium WebDriver](https://www.lambdatest.com/blog/handling-cookies-in-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog) by referencing the complete video tutorial below.
{% youtube WaNO9RTfEQw %}
## Use Case 8: Handling Modal Dialog Box With Selenium WebDriver
Handling a Modal Dialog box is similar to handling *alerts()* in Selenium. There are other methods of handling modals that can incorporate *alerts()*.
Selenium can be used to handle various modal dialog types. Whether a JavaScript alert or a custom modal, Selenium provides a consistent way to interact with these elements in your web application.
Let’s understand the scenario.
**Test Scenario:**
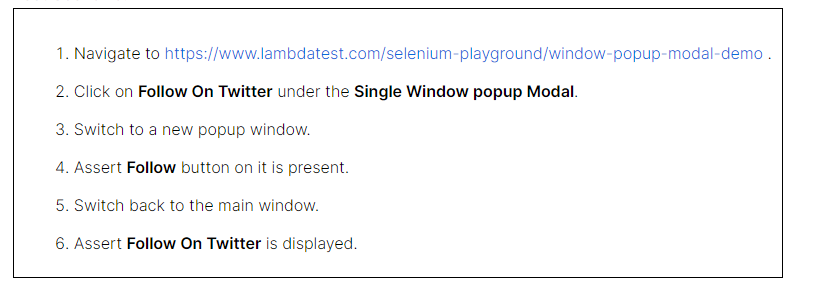
Below is the code for the above scenario on handling Modal Dialog Box using LambdaTest.
import java.util.Iterator;
import java.util.Set;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.testng.Assert;
import org.testng.annotations.Test;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
public class TestPopups extends BaseClass {
@Test(description = "test to verify pop ups")
public void verifyPopups() throws InterruptedException {
// to navigate to the website
System.out.println("Navigating to the website");
driver.get("https://www.lambdatest.com/selenium-playground/window-popup-modal-demo");
driver.manage().window().maximize();
// to fetch and save the handle of current window
System.out.println("storing the main window handle");
String mainWindowHandle = driver.getWindowHandle();
// to click the button to get a popup (new tab in this case)
System.out.println("Clicking launch popup button");
WebElement followButtonOnMainWindow = driver.findElement(By.xpath("//a[contains(@title,'Twitter')]"));
followButtonOnMainWindow.click();
// to get the list of all window handles after the new tab
// should have length 2 since 1 new tab opens up
System.out.println("Fetching the list of all window handles and asserting them");
Set<String> windowHandles = driver.getWindowHandles();
Assert.assertEquals(windowHandles.size(), 2, "Verify the total number of handles");
// switch to new opened tab
System.out.println("Switching to the new window handle");
Iterator<String> itr = windowHandles.iterator();
while (itr.hasNext()) {
String childWindowHandle = itr.next();
// to skip the handle of our main window and switch to new one
if (!mainWindowHandle.equalsIgnoreCase(childWindowHandle))
driver.switchTo().window(childWindowHandle);
}
WebDriverWait wait = new WebDriverWait(driver, 30);
wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//span[(text()='Follow')]")));
// to verify that driver focus is shifted to popup window
System.out.println("Asserting some element on the new popup window to confirm switch");
WebElement twitterFollowButton = driver.findElement(By.xpath("//span[(text()='Follow')]"));
Assert.assertTrue(twitterFollowButton.isDisplayed(), "Verify twitter follow button is displayed");
// shift driver back to main window and verify
System.out.println("Switching back to main window and asserting same");
driver.switchTo().window(mainWindowHandle);
wait.until(ExpectedConditions.visibilityOfElementLocated(
By.xpath("//a[contains(@title,'Twitter')]")));
Assert.assertTrue(followButtonOnMainWindow.isDisplayed(), "Verify focus is shifted to main window");
}
}
Now that you know the commands that help you automate the Modal box, implement the same in your Selenium test script. Refer to the complete video tutorial for valuable insight on [handling Modal Box in Selenium WebDriver](https://www.lambdatest.com/blog/how-to-handle-modal-dialog-box-in-selenium-webdriver-java/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog).
{% youtube C4YT0BT_wbQ %}
## Use Case 9: Selecting Multiple Checkboxes With Selenium WebDriver
Checkboxes on web pages let users agree/disagree or select multiple options. For automation engineers, it’s crucial to handle these checkboxes using tools like Selenium, as they are commonly found on websites. While dealing with a few checkboxes seems straightforward, it can get challenging when there are more than five.
We will understand how to handle multiple checkboxes with the scenario below.
**Test Scenario:**
Below is the code implementation for the test scenario to automate selecting multiple checkboxes with Selenium WebDriver using LambdaTest.
package test;
import java.util.List;
import org.openqa.Selenium.By;
import org.openqa.Selenium.WebElement;
import org.testng.annotations.Test;
public class TestCheckboxes extends BaseClass{
@Test
public void testSingleCheckbox()
{
System.out.println("Navigating to the URL");
driver.get("https://www.lambdatest.com/selenium-playground/checkbox-demo");
//using ID attribute to locate checkbox
WebElement checkbox = driver.findElement(By.id("isAgeSelected"));
//pre-validation to confirm that checkbox is displayed.
if(checkbox.isDisplayed())
{
System.out.println("Checkbox is displayed. Clicking on it now");
checkbox.click();
}
//post-validation to confirm that checkbox is selected.
if(checkbox.isSelected())
{
System.out.println("Checkbox is checked");
}
}
@Test
public void testMultipleCheckbox()
{
System.out.println("Navigating to the URL");
driver.get("https://www.lambdatest.com/selenium-playground/checkbox-demo");
//using class name to fetch the group of multiple checkboxes
List<WebElement> checkboxes = driver.findElements(By.className("cb-element mr-10"));
//traverse through the list and select all checkboxes if they are enabled and displayed.
for(int i=0; i<checkboxes.size(); i++)
{
if(checkboxes.get(i).isDisplayed() && checkboxes.get(i).isEnabled())
{
System.out.println("Checkbox is displayed at index : " + i + " Clicking on it now");
checkboxes.get(i).click();
}
}
//deselect the checkbox on index 1 from the list of checkboxes selected above
System.out.println("de-selecting checkbox with index 1");
checkboxes.get(1).click();
if(checkboxes.get(1).isSelected())
{
System.out.println("Checkbox is still selected");
}
else
{
System.out.println("Checkbox is deselected successfully");
}
}
}
To learn more about [selecting multiple checkboxes with Selenium WebDriver](https://www.lambdatest.com/blog/how-to-select-multiple-checkboxes-in-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog), follow the video tutorial and gain complete insights
{% youtube W07b7lEyoGs %}
## Selenium WebDriver Best Practices
Here are some of the best practices of Selenium WebDriver to make your life easier:
**Test Early and Test Often**
The importance of early and frequent testing in Selenium test automation is clear, especially as organizations transition away from the waterfall model. In this evolving development approach, the active involvement of testers throughout the entire development process becomes essential for ensuring the success of software projects.
This [shift left testing](https://www.lambdatest.com/learning-hub/shift-left-testing?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) approach advocates for testers to participate from the requirement-gathering phase onward. By doing so, they can proactively devise test cases based on a thorough understanding of end-user expectations.
The primary objective is to prevent the occurrence of bugs post-development. Testers play a vital role in offering valuable insights, assisting developers in creating products that enhance user experience and steering clear practices that may be detrimental to the product.
**Behavior-Driven Development (BDD)**
Offers a user-friendly Selenium test automation approach. By allowing testers to express test cases in simple English, [Behavior-Driven Development](https://www.lambdatest.com/blog/behaviour-driven-development-by-selenium-testing-with-gherkin/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog) bridges the communication gap between technical and business teams by allowing testers to express test cases in simple English. This practice not only simplifies the understanding of project expectations but also encourages collaboration.
The ability to write specifications in plain language facilitates better comprehension, making BDD a valuable tool for creating a shared understanding of project requirements. This approach streamlines the testing process and ensures that everyone involved, regardless of coding knowledge, can grasp the test scenarios regardless of coding knowledge.
**Use Selenium Wait Commands Instead of *Thread.sleep()***
To overcome challenges associated with varying web application loading times, it’s essential to move away from using *Thread.sleep()* for pauses in Selenium test automation scripts. Opting for Selenium waits ( implicit or explicit waits) provides a more flexible solution.
Implicit waits allow scripts to wait for elements to load dynamically, adapting to different scenarios. Explicit waits enable precise control over the waiting period for specific conditions to be met, enhancing script reliability.
This approach ensures [test scripts](https://www.lambdatest.com/learning-hub/test-scripts?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) accommodate diverse loading times, preventing unnecessary delays or failures. By incorporating effective wait commands, Selenium test automation becomes more robust and adaptable to real-world web application conditions.
**Set Up Selenium Test Automation Reports**
Establishing a reporting mechanism enhances test outcomes’ readability and minimizes the effort spent managing [test data](https://www.lambdatest.com/learning-hub/test-data?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub).
Selenium [test reports](https://www.lambdatest.com/learning-hub/test-reports?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) provide valuable insights into test performance, aiding in quickly identifying issues. By organizing test data systematically, teams gain better control over their test scripts.
Utilizing platforms like LambdaTest for Selenium testing scripts over an [online Selenium Grid](https://www.lambdatest.com/selenium-grid-online?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) of various browsers further streamlines the reporting process, contributing to more efficient and informed decision-making.
**Automated Screenshots for Failure Investigation**
Enhancing the troubleshooting process in Selenium test automation involves the collection of [automated screenshots](https://www.lambdatest.com/automated-screenshot?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) during script execution. When using Selenium Grid, obtaining screenshots becomes seamless by setting a capability flag.
This practice proves invaluable for identifying issues and debugging failed scripts. Automated screenshots provide a visual record of test execution, helping to efficiently pinpoint the root cause of failures. Leveraging platforms like LambdaTest further streamlines the process, allowing testers to generate step-by-step screenshots for comprehensive failure analysis.
**Design Tests Prior to Automation**
Before delving into Selenium test automation, a crucial best practice involves designing tests in advance. [Test scenarios](https://www.lambdatest.com/learning-hub/test-scenario?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub) and cases should be created with thoughtful consideration, providing a comprehensive test architecture.
This proactive approach ensures that automation aligns with testing goals and avoids the pitfalls of automating without a well-defined plan.
By establishing a straightforward test design, teams can execute Selenium test automation more effectively, covering diverse scenarios and reducing the likelihood of overlooking critical testing aspects.
**Identify Which Tests to Automate**
Strategic automation begins with identifying the most valuable tests. Prioritize automating repetitive tasks and scenarios with visual elements that rarely change.
By focusing on tests aligned with automation goals, teams can maximize the benefits of Selenium test automation. This approach streamlines testing efforts, ensuring that automation targets scenarios where manual testing is time-consuming.
Strategic test selection enhances the efficiency of Selenium test automation, delivering meaningful results that contribute to overall testing objectives.
**Automate Most Frequent and Predictable Test Cases**
In Selenium test automation, selecting test cases with frequent and predictable outcomes optimizes efficiency — Automate scenarios where events are sure to occur, reducing the need for repetitive manual executions.
Teams save time and resources by identifying and automating these predictable test cases. This best practice ensures that the Selenium test automation framework focuses on scenarios where automation brings the most significant benefits, striking a balance between coverage and efficiency.
**Choose the Correct Selenium Test Automation Tool**
Choosing the appropriate test automation tool is crucial for testing success. Platform support, operating system compatibility, and web and mobile application testing requirements must be considered.
The chosen tool should align with the organization’s specific needs. Questions about features like record and playback functionality, manual test creation, and support for desired capabilities should guide the selection process. Opting for a [Selenium testing tool](https://www.lambdatest.com/selenium?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=webpage) that fits the company’s needs helps optimize testing efforts and achieve more effective automation results.
**Browser Compatibility Matrix for Cross-Browser Testing**
The Browser Matrix is a vital resource that combines information drawn from product analytics, geolocation, and other detailed insights about audience usage patterns, stats counter, and competitor analysis. Browser Matrix will reduce the development and testing efforts by helping you cover all the relevant browsers (that matter to your product). Here is a sample [browser compatibility matrix](https://www.lambdatest.com/blog/creating-browser-compatibility-matrix-for-testing-workflow/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog).
By understanding the relationship between website traffic and conversion rates, you can determine the necessary steps to ensure your website is supported across various browsers. Analyzing browser support is crucial for devising an effective test strategy.
Additionally, a [browser matrix template is available for download](https://docs.google.com/spreadsheets/d/1Sqhpeq1acAB5am8ufRQpYdksoBl3ilWCrgKeVgzSPeM/edit#gid=0) to assist you in creating a comprehensive plan for testing and optimizing your website’s compatibility.
## Selenium Blog/Hub links
Below are the learning resources for individuals willing to enhance their automation careers.
* [A Detailed Guide On Selenium With Java [Tutorial]](https://www.lambdatest.com/blog/selenium-with-java/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [49 Most Common Selenium Exceptions for Automation Testing](https://www.lambdatest.com/blog/49-common-selenium-exceptions-automation-testing/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium with Java Tutorial: A Complete Guide on Automation Testing using Java](https://www.lambdatest.com/blog/selenium-with-java/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium Java Tutorial: A Comprehensive Guide With Examples and Best Practices](https://www.lambdatest.com/learning-hub/selenium-java?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub)
* [Selenium Automation Testing: Basics and Getting Started](https://www.lambdatest.com/blog/selenium-tutorial/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Complete Selenium WebDriver Tutorial with Examples](https://www.lambdatest.com/blog/selenium-webdriver-tutorial-with-examples/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [What Is New In Selenium 4 And What Is Deprecated In It?](https://www.lambdatest.com/blog/what-is-deprecated-in-selenium4/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Handle Multiple Windows In Selenium WebDriver Using Java](https://www.lambdatest.com/blog/how-to-handle-multiple-windows-in-selenium-webdriver-using-java/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How to Find Element by Text in Selenium C#](https://www.lambdatest.com/blog/find-element-by-text-selenium-csharp/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Find Element By Text In Selenium WebDriver](https://www.lambdatest.com/blog/how-to-find-element-by-text-in-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [FindElement And FindElements In Selenium [Differences]](https://www.lambdatest.com/blog/findelement-and-findelements-in-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium Java Tutorial: Automation Testing Of User Signup Form](https://www.lambdatest.com/blog/selenium-java-tutorial-how-to-test-login-process/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium Grid 4 Tutorial For Distributed Testing](https://www.lambdatest.com/blog/selenium-grid-4-tutorial-for-distributed-testing/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Build And Execute Selenium Projects](https://www.lambdatest.com/blog/build-and-execute-selenium-projects/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Automate Login Page Using Selenium WebDriver](https://www.lambdatest.com/blog/automate-login-page-using-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Handle Captcha In Selenium](https://www.lambdatest.com/blog/handle-captcha-in-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Upgrade From Selenium 3 To Selenium 4?](https://www.lambdatest.com/blog/upgrade-from-selenium3-to-selenium4/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Handle Cookies in Selenium WebDriver](https://www.lambdatest.com/blog/handling-cookies-in-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium C# Tutorial on Explicit and Fluent Wait](https://www.lambdatest.com/blog/explicit-fluent-wait-in-selenium-c/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium Waits Tutorial: Guide to Implicit, Explicit, and Fluent Waits](https://www.lambdatest.com/blog/types-of-waits-in-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium C# Tutorial: Using Implicit Wait In Selenium C#](https://www.lambdatest.com/blog/webdriverwait-in-selenium-c-sharp/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Handle Synchronization In Selenium PHP Using Implicit and Explicit Wai](https://www.lambdatest.com/blog/implicit-explicit-wait-in-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Use WebDriverWait In Selenium C#](https://www.lambdatest.com/blog/webdriverwait-in-selenium-c-sharp/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium WebDriverWait: Implementing The Explicit Wait Command | LambdaTest](https://www.lambdatest.com/blog/selenium-webdriverwait/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium PHP Tutorial: A Comprehensive Guide, with Examples & Best Practices](https://www.lambdatest.com/learning-hub/selenium-php?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub)
* [Complete solution for Synchronization in Selenium WebDriver | LambdaTest](https://www.lambdatest.com/blog/synchronization-in-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Use Selenium wait for page to load with Python [Tutorial]](https://www.lambdatest.com/blog/selenium-wait-for-page-to-load/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [xUnit Setup for Selenium WebDriver: A Complete Guide | LambdaTest](https://www.lambdatest.com/blog/setting-selenium-webdriver-for-xunit/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How to use Assert and Verify in Selenium WebDriver](https://www.lambdatest.com/blog/assert-and-verify-in-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Use Xpath In Selenium: Complete Guide With Examples | LambdaTest](https://www.lambdatest.com/blog/complete-guide-for-using-xpath-in-selenium-with-examples/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Making The Move With ID Locator In Selenium WebDriver](https://www.lambdatest.com/blog/making-the-move-with-id-locator-in-selenium-webdriver/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How To Deal With “Element is not clickable at point” Exception Using Selenium](https://www.lambdatest.com/blog/how-to-deal-with-element-is-not-clickable-at-point-exception-using-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium C# Tutorial: Setting Up Selenium In Visual Studio](https://www.lambdatest.com/blog/setting-up-selenium-in-visual-studio/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium C# Tutorial: Using Implicit Wait in Selenium](https://www.lambdatest.com/blog/implicit-wait-csharp-selenium/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium C# Tutorial: Using Explicit and Fluent Wait in Selenium](https://www.lambdatest.com/blog/explicit-fluent-wait-in-selenium-c/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium C# Tutorial: Handling Alert Windows](https://www.lambdatest.com/blog/selenium-c-tutorial-handling-alert-windows/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium C# Tutorial: Handling Multiple Browser Windows](https://www.lambdatest.com/blog/selenium-c-tutorial-handling-multiple-browser-windows/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium C# Tutorial: Handling Frames & iFrames With Examples](https://www.lambdatest.com/blog/handling-frames-and-iframes-selenium-c-sharp/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Selenium C#: Page Object Model Tutorial With Examples](https://www.lambdatest.com/blog/page-object-model-tutorial-selenium-csharp/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [How to Find Element by Text in Selenium C#](https://www.lambdatest.com/blog/find-element-by-text-selenium-csharp/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [RSpec Ruby Tutorial: The Complete Guide](https://www.lambdatest.com/learning-hub/rspec-ruby?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=learning_hub)
* [Implement Data Tables In Cucumber Using Selenium Ruby](https://www.lambdatest.com/blog/data-tables-in-cucumber-ruby/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
* [Getting Started With Automation Testing Using Selenium Ruby](https://www.lambdatest.com/blog/selenium-ruby/?utm_source=devto&utm_medium=organic&utm_campaign=apr_04&utm_term=bw&utm_content=blog)
## Conclusion
In summary, we’ve looked into Selenium and its latest version, Selenium 4, and explored how it works, along with practical examples. We’ve also checked out Selenium WebDriver and how it can be used with popular programming languages like Java, Python, C#, PHP, Ruby, and JavaScript.
Additionally, we have discussed cloud-based testing platforms, focusing on LambdaTest and how it can work seamlessly with Selenium WebDriver. This collaboration enhances the testing process by providing a reliable environment for testing across different browsers and operating systems.
In simple terms, combining Selenium and LambdaTest isn’t just practical; it’s a powerful way for testers and developers to handle automated testing effectively and efficiently.
| saniyagazala | |
1,864,043 | manual_seed(), initial_seed() and seed() in PyTorch | *My post explains rand(), rand_like(), randn(), randn_like(), randint() and... | 0 | 2024-05-24T13:34:12 | https://dev.to/hyperkai/manualseed-initialseed-and-seed-in-pytorch-5gm8 | pytorch, manualseed, initialseed, seed | *[My post](https://dev.to/hyperkai/rand-randlike-randn-randnlike-randint-and-randperm-in-pytorch-31nc) explains [rand()](https://pytorch.org/docs/stable/generated/torch.rand.html), [rand_like()](https://pytorch.org/docs/stable/generated/torch.rand_like.html), [randn()](https://pytorch.org/docs/stable/generated/torch.randn.html), [randn_like()](https://pytorch.org/docs/stable/generated/torch.randn_like.html), [randint()](https://pytorch.org/docs/stable/generated/torch.randint.html) and [randperm()](https://pytorch.org/docs/stable/generated/torch.randperm.html).
[manual_seed()](https://pytorch.org/docs/stable/generated/torch.manual_seed.html) can set a seed to generate the same random numbers as shown below:
*Memos:
- `initial_seed()` can be used with [torch](https://pytorch.org/docs/stable/torch.html) but not with a tensor.
- The 1st argument with `torch` is `seed`(Required-Type:`int`, `float`, `bool` or `number` of `str`).
- A positive and negative seed is different.
- You must use `manual_seed()` just before a random number generator each time otherwise the same random numbers are not generated.
- The effect of `manual_seed()` lasts until `manual_seed()` or [seed()](https://pytorch.org/docs/stable/generated/torch.seed.html) is used next time. *`seed()` is explained at the end of this post.
- In PyTorch, there are random number generators such as [rand()](https://pytorch.org/docs/stable/generated/torch.rand.html), [randn()](https://pytorch.org/docs/stable/generated/torch.randn.html), [randint()](https://pytorch.org/docs/stable/generated/torch.randint.html) and [randperm()](https://pytorch.org/docs/stable/generated/torch.randperm.html).
```python
import torch
torch.manual_seed(seed=8)
torch.rand(3) # tensor([0.5979, 0.8453, 0.9464])
torch.manual_seed(seed=8)
torch.rand(3) # tensor([0.5979, 0.8453, 0.9464])
```
Be careful, not using `manual_seed()` just before a random number generator each time cannot generate the same random numbers as shown below:
```python
import torch
torch.manual_seed(seed=8)
torch.rand(3) # tensor([0.5979, 0.8453, 0.9464])
# torch.manual_seed(seed=8)
torch.rand(3) # tensor([0.2965, 0.5138, 0.6443])
```
And, you can use several types of values for `seed` argument as shown below:
```python
import torch
torch.manual_seed(seed=8)
torch.rand(3) # tensor([0.5979, 0.8453, 0.9464])
torch.manual_seed(seed=8.)
torch.rand(3) # tensor([0.5979, 0.8453, 0.9464])
torch.manual_seed(seed=True)
torch.rand(3) # tensor([0.7576, 0.2793, 0.4031])
torch.manual_seed(seed='8')
torch.rand(3) # tensor([0.5979, 0.8453, 0.9464])
torch.manual_seed(seed='-8')
torch.rand(3) # tensor([0.8826, 0.3959, 0.5738])
```
[initial_seed()](https://pytorch.org/docs/stable/generated/torch.initial_seed.html) can get the current seed as shown below:
*Memos:
- `initial_seed()` can be used with `torch` but not with a tensor.
- An initial seed is randomly set.
```python
import torch
torch.manual_seed(seed=8)
torch.initial_seed() # 8
```
[seed()](https://pytorch.org/docs/stable/generated/torch.seed.html) can randomly set a seed to generate random numbers as shown below:
*Memos:
- `seed()` can be used with `torch` but not with a tensor:
- The effect of `seed()` lasts until `seed()` or `manual_seed()` is used next time.
```python
import torch
torch.seed() # 13141386358708808900
torch.seed() # 6222667032495401621
torch.seed() # 5598609927030438366
``` | hyperkai |
1,863,985 | The halting problem in computer science...actually explained | In the next five minutes you will learn— 1) What is the halting problem and why it is important 2)... | 0 | 2024-05-24T13:33:10 | https://dev.to/jamesmurdza/the-halting-problem-in-computer-science-actually-explained-3hgd | **In the next five minutes you will learn—** _1) What is the halting problem and why it is important 2) Some examples of halting and non-halting programs 3) Alan Turing's formal proof_
Often, computers hang...
Progress bars stop or go backwards...
Or you get the dreaded spinning beach ball of death. ☠️
Does this mean that some programmer just get sloppy somewhere, or is it an unavoidable fact of life?

Actually, according to computer science, this is just life!
And that’s because fundamentally—for an arbitrary program—there’s no way to predict how long a program will take to run without running it.
This was proven by the mathematician Alan Turing in 1936.
Now, you're probably thinking, if I have a simple program like this:
```python
def table(a, b):
for i in range(1, a):
for j in range(1, b):
print(i, j)
```
Of course I can calculate how long it takes to run.
> (A iterations x B iterations = A x B print statements)
But that required *us* reading the code of the program and visualizing the possible paths through the program.
(This is called static analysis, by the way—analyzing a program without actually running it.)
And as a program becomes more complex, this becomes increasingly painful to do. And actually, there's no **general way** to do this for any program.
This is where the halting problem comes in.
Formulated by Turing, the problem asks:
> Given a program and an input, can we determine if the program will eventually halt (finish running) or if it will run forever?
Let’s look at one more slightly better example before trying to solve the halting problem:
```python
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n - 1) + fibonacci(n - 2)
```
This program will halt if n is a non-negative integer. Otherwise, it will run forever!
We figured this out because we are smart human beings, who can read the code and work backwards.

But now, look at Alan Turing's challenge—**Can we write a computer program that will figure this out for us, regardless of the program?**
Spoiler alert: No program can do this.
And this is what he said: If it were possible, that means you should be able to make a program like this:
```python
def will_halt(program):
if blah blah blah:
return true
else:
return false
```
Which can clearly never be written!
To see why, we can write another mischievous program:
```python
def tricky_program():
if will_halt(tricky_program):
while True:
pass
else:
return
```
This program references the will_halt program to check what will_halt expects it to do, and does the opposite.
Wait, the program passed to will_halt can also use will_halt itself? Isn’t that cheating?
Well no—if the program will_halt can be written, then then there's no reason the same logic couldn’t be used within tricky_program. It's just code.
While this may seem like a depressing outcome for software development everywhere, this is actually just the beginning of what makes computer programming a lot of fun. Just ask Alan Turing—he was having fun with this 40 years before the first personal computer was invented!

P.S. Of course, in the year 2024, you certainly have one thought after reading this. "OK, so we can't write a program that solves the halting problem, but we can train an AI to do it!" Well, the answer is still technically **no**, but that's a post for another day... | jamesmurdza | |
1,864,042 | Key Considerations for Effective Database Table Design | Introduction In database design, the structure of tables is a critical element that... | 0 | 2024-05-24T13:32:14 | https://dev.to/markyu/key-considerations-for-effective-database-table-design-4p44 | database, sql, normalization, design | ## Introduction
In database design, the **structure of tables** is a critical element that significantly impacts the functionality, efficiency, and performance of a system. A well-designed database table structure supports system requirements effectively, optimizes data storage and retrieval, and ensures data integrity and security. **However, achieving an optimal table design is not straightforward and requires careful consideration of various factors, including data types, constraints, and indexing.** This article outlines 18 key points to consider when designing database tables, with examples to help you understand the essential aspects of table design.
## Key Considerations
### 1. Define the Purpose of the Table
Ensure that the table design aligns with the system requirements. For example, if you are designing a table to store student information, it should include all relevant fields for student data.
**Example: Creating a Student Information Table**
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Age INT
);
```
### 2. Choose Appropriate Data Types
Select data types that best represent the nature of the data. For example, use an integer type for age.
**Example: Choosing Appropriate Data Types**
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Age INT
);
```
### 3. Enforce Uniqueness Constraints
Identify fields that require uniqueness, such as a student’s email address.
**Example: Adding Uniqueness Constraint**
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
Email VARCHAR(100) UNIQUE,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
```
### 4. Design the Primary Key
Select an appropriate primary key for each table, such as using the student ID as the primary key.
**Example: Specifying Primary Key**
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
```
### 5. Define Foreign Key Relationships
Create foreign key relationships to link related tables. For instance, linking the student ID in the grades table to the student ID in the student table.
**Example: Adding Foreign Key Relationship**
```sql
CREATE TABLE Grades (
GradeID INT PRIMARY KEY,
StudentID INT,
Grade DECIMAL(3, 2),
FOREIGN KEY (StudentID) REFERENCES Students(StudentID)
);
```
### 6. Design Indexes
Design indexes based on query requirements to improve performance, such as creating an index on the last name for faster searches.
**Example: Creating an Index**
```sql
CREATE INDEX idx_student_lastname ON Students(LastName);
```
### 7. Define Constraints
Add appropriate constraints to ensure data integrity, such as not allowing null values in certain fields.
**Example: Adding Constraints**
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NOT NULL
);
```
### 8. Normalize the Database
Follow normalization principles to avoid redundancy and ensure data integrity, such as separating student information and course information into different tables.
**Example: Normalizing Tables**
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
CREATE TABLE Courses (
CourseID INT PRIMARY KEY,
CourseName VARCHAR(100)
);
```
### 9. Denormalize When Necessary
In cases where performance is critical, consider denormalization, such as adding a calculated field for average grades in the student table.
**Example: Denormalization**
```sql
ALTER TABLE Students
ADD COLUMN AverageGrade DECIMAL(3, 2);
```
### 10. Use Descriptive Field Names
Choose clear and descriptive field names to enhance readability and maintainability.
**Example: Using Descriptive Field Names**
```sql
CREATE TABLE Students (
Student_ID INT PRIMARY KEY,
First_Name VARCHAR(50),
Last_Name VARCHAR(50)
);
```
### 11. Follow Table Naming Conventions
Adopt consistent naming conventions for tables to reflect their purpose clearly.
**Example: Naming Convention for Tables**
```sql
CREATE TABLE student_info (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
```
### 12. Set Default Values
Define default values for fields to ensure consistency and avoid null values where appropriate.
**Example: Setting Default Values**
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
EnrollmentDate DATE DEFAULT CURRENT_DATE
);
```
### 13. Implement Partitioning
For large tables, consider partitioning to improve query performance, such as partitioning by student ID.
**Example: Partitioning Table**
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
)
PARTITION BY RANGE (StudentID) (
PARTITION p0 VALUES LESS THAN (1000),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
```
### 14. Add Audit Fields
Include audit fields to track data changes, such as creation and update timestamps.
**Example: Adding Audit Fields**
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
CreatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UpdatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
```
### 15. Optimize Performance
Create indexes based on query patterns to enhance performance.
**Example: Creating Index to Optimize Performance**
```sql
CREATE INDEX idx_lastname ON Students(LastName);
```
### 16. Ensure Security
Implement proper permissions and encryption to protect sensitive data.
**Example: Restricting Access to Sensitive Data**
```sql
GRANT SELECT ON Students TO 'public';
```
### 17. Plan for Backup and Recovery
Establish a strategy for regular backups to ensure data can be restored in case of failure.
**Example: Backing Up Database**
```sql
BACKUP DATABASE MyDatabase TO 'backup_path';
```
### 18. Document the Design
Thoroughly document the table design, including field meanings, constraints, and relationships.
**Example: Documenting Table Structure**
```sql
COMMENT ON TABLE Students IS 'This table stores information about students.';
COMMENT ON COLUMN Students.FirstName IS 'First name of the student.';
```
## Summary
This article has outlined 18 crucial points to consider in database table design. From defining the purpose of the table to documenting the design, each step plays a vital role in creating an efficient and reliable database structure. By choosing appropriate data types, enforcing constraints, normalizing data, and considering performance and security, you can design robust database tables that support your system's needs. Properly designed tables not only ensure data integrity and security but also enhance the overall performance and maintainability of the database system. | markyu |
1,864,040 | Middle East Banking Innovation Summit 2024 | MEBIS 2024 show Dubai is the largest banking technology & innovation event in the middle east. It... | 0 | 2024-05-24T13:28:55 | https://dev.to/expostandzoness/middle-east-banking-innovation-summit-2024-221g | [MEBIS 2024 show Dubai](https://www.expostandzone.com/trade-shows/mebis) is the largest banking technology & innovation event in the middle east. It is going to be held from 18-19 September 2024 in Jumeirah Emirates Towers Hotel, Dubai, UAE.
https://www.expostandzone.com/trade-shows/mebis | expostandzoness | |
1,864,036 | Navegador para desarrolladores | El día de hoy vengo a recomendar un navegador para el desarrollo web. Llevo un tiempo trabajando con... | 0 | 2024-05-24T13:27:01 | https://dev.to/terminator_true/navegador-para-desarrolladores-2cl5 | webdev, productivity, testing | El día de hoy vengo a recomendar un navegador para el desarrollo web.
Llevo un tiempo trabajando con **Google chrome**, pero siempre me ocurre lo mismo. El ordenador se comienza a relentizar y cuando intentas mirar lo que sucede, resulta que tu querido navegador de google, se está merendando el 60% de memoria RAM.
Luego de un rato buscando alternativas, se me presenta delante [Firefox Developer Edition](https://www.mozilla.org/es-ES/firefox/developer/).
Éste navegador presenta una versión de **Firefox** enfocada para los desarrolladores, con herramientas y facilidades para el desarrollo web, aparte de un mejor rendimiento y algunas herramientas que facilitan el debug de aplicaciones web. Ciertamente, el navegador cumple con lo que promete, ya que las herramientas de desarrollo que vienen por defecto son bastante cómodas y efectivas.
Partiendo de esa base, si instalamos algunas extensiones (según el stack que estemos utilizando), Firefox Developer Edition se puede convertir en una gran herramienta y una ayuda a la hora de desarrollar aplicaciones web!
| terminator_true |
1,864,037 | Navigating the Digital Age: Crafting a Robust Data Management Strategy for Sustainable Growth | In the ever-evolving landscape of business development, the essence of authoritative intelligence... | 0 | 2024-05-24T13:25:12 | https://dev.to/linda0609/navigating-the-digital-age-crafting-a-robust-data-management-strategy-for-sustainable-growth-4blf | In the ever-evolving landscape of business development, the essence of authoritative intelligence gathering and precise insight extraction cannot be overstated. Yet, amid the pursuit of these goals, enterprises worldwide grapple with data quality issues that threaten their efficacy and competitiveness. However, modern technologies present a beacon of hope, offering holistic strategies to mitigate these challenges. This discourse will meticulously delineate the components of an enterprise data management strategy, elucidating its pivotal importance and the multifaceted benefits it engenders.
Understanding the Essence of a Data Management Strategy
At its core, a data management strategy serves as a compass, providing event-driven guidance on the acquisition and processing of business intelligence. Its cardinal objectives encompass ensuring relevance, preserving data integrity, and facilitating ease of access. In the realm of digital transformation, corporations ardently seek a competitive edge, often turning to [data solutions](https://www.sganalytics.com/data-solutions/) to orchestrate governance and analytics activities.
Central to this endeavor are data managers, adept professionals who harness the power of automation, hybrid cloud infrastructure, metadata analytics, and machine learning (ML) to streamline insight extraction. However, the pursuit of these objectives mandates robust financial backing to uphold advanced cybersecurity measures across all organizational facets, safeguarding against pernicious data breaches that could irreparably tarnish a brand’s reputation and erode stakeholders’ trust.
Unraveling the Significance of a Data Management Strategy
1. Enhancing Reporting Consistency: Data managers serve as custodians of advanced intelligence development tools, harmonizing report quality and ensuring legal compliance through the deployment of frameworks. These frameworks address the nuances of data collection, ensuring consistency across different departments. Nonetheless, the onus lies on organizational leadership to support these professionals in imparting requisite knowledge to in-house teams, thus standardizing report exporting practices and fostering a culture of data literacy. Training and educating staff on how to interact with these tools and the importance of maintaining high data quality is crucial for consistent and reliable reporting.
2. Driving Cost Reduction: A comprehensive data management strategy transcends mere data governance, permeating the very fabric of IT infrastructure design, maintenance, and optimization. By meticulously scrutinizing resource consumption and embracing judicious budget rationalization, organizations can steer clear of the pitfalls of indiscriminate data accumulation. Strategic data management allows enterprises to prioritize critical data over less significant information, leading to optimized storage solutions and more efficient use of computational resources. This goal-driven approach curtails operational costs by reducing unnecessary data operations, leading to a more streamlined and cost-effective business model.
3. Facilitating Advanced Governance Practices: Data governance assumes paramount significance in dictating the parameters governing the access, editing, and sharing of intelligence assets. By upholding stringent accountability measures and complying with regulatory mandates, organizations fortify their defenses against digital threats. Governance practices ensure that data is handled ethically and legally, preventing corporate espionage and data breaches. Strong authentication protocols and encryption technologies are integral to protecting sensitive information, thereby fostering an environment conducive to technical progress and innovation.
4. Empowering Employee Training: Through the adoption of standardized reporting practices and intuitive data operations tools, organizations can streamline employee training processes, catalyzing productivity and reducing operational overheads. By prioritizing user-friendly interfaces and comprehensive educational documentation, organizations imbue their workforce with the requisite skills to navigate the complexities of modern data management with aplomb. Detailed training programs and continuous support help employees to effectively use data management tools, reducing the learning curve and associated costs. Simplifying tasks and minimizing coding complexities allow for faster report customizations, further enhancing operational efficiency.
Navigating the Terrain of Data Management Strategy
1. Articulating Strategic Objectives: A meticulous delineation of the rationale underpinning data collection initiatives is imperative, with due consideration accorded to immediate priorities and long-term vision. Defining clear objectives helps in aligning data collection efforts with organizational goals, ensuring that the data gathered is relevant and actionable.
2. Navigating Legal and Technological Terrain: A nuanced understanding of pertinent technologies and regulatory frameworks is indispensable in navigating the intricate landscape of data operations, mitigating the risks associated with data acquisition while preserving the sanctity of personally identifiable information (PII). Staying updated with evolving laws and technological advancements ensures compliance and enhances the reliability of insights extracted from data.
3. Embracing Technological Advancements: The adoption of cutting-edge coding and networking tools, coupled with stringent network security protocols, augurs well for enhancing pipeline resilience and expediting data retrieval processes. Leveraging modern technologies such as machine learning and artificial intelligence can significantly improve data processing efficiency and accuracy.
4. Pursuing Efficiency and Optimization: Vigilant monitoring of computing time and power consumption facilitates the identification and rectification of inefficiencies, thereby curtailing excessive billing outflows and optimizing resource allocation. By continuously assessing and refining data operations, organizations can ensure that they are operating at peak efficiency, minimizing waste and maximizing value.
Conclusion: Embracing Strategic Imperatives in Data Management
In the absence of a meticulously crafted data management strategy, businesses risk courting financial and legal perils that could imperil their viability and integrity. As the regulatory landscape undergoes seismic shifts and consumers clamor for greater transparency and data privacy, brands must tread cautiously, striking a delicate balance between their marketing imperatives and consumers’ right to privacy. However, the paucity of seasoned [data strategy](https://www.sganalytics.com/data-management-analytics/data-strategy-consulting/) professionals presents a formidable challenge, necessitating either substantial investments in employee training or prudent collaborations with established consultants. With experienced minds at the helm, strategically navigating the intricacies of corporate data management, organizations can bolster governance standards, enhance reporting quality, and fortify their analytical prowess, thereby charting a course towards sustained growth and prosperity in an increasingly data-driven world.
By adhering to these principles and continually refining their data management strategies, organizations can not only navigate the complexities of the digital age but also harness the full potential of their data assets to drive innovation, efficiency, and competitive advantage. | linda0609 | |
1,864,034 | Public Blockchain: Specifics, Benefits, and Potential | Blockchain is a term with different meanings, even though its principle of work is well-known. The... | 0 | 2024-05-24T13:22:51 | https://dev.to/getblockapi/public-blockchain-specifics-benefits-and-potential-400e | publicblockchain, cryptocurrency, bitcoin, ethereum |
Blockchain is a term with different meanings, even though its principle of work is well-known. The reason is that it hides many variants of how this technology can be implemented. Different protocols can vary depending on who can join its network, its accessibility, and the degree of control and permissions involved. Public blockchains, in particular, break down barriers by offering unrestricted access to anyone interested in using the technology.
Let’s clarify the distinction between public vs private blockchains here to navigate the decentralized world of Web3 better.
## Public Blockchains: Unleashing Decentralization
A public blockchain is a type of network that is accessible to everyone connected with it, embodying the principles of transparency and decentralization. In a public blockchain, anyone can participate, view the data, and contribute to the development of the network using its tokens. More importantly, individuals can volunteer and actively participate in the consensus process, such as mining or validating transactions.
In contrast to public blockchains, private blockchains are permissioned networks with restricted access and control mechanisms. These blockchains are typically designed for specific use cases within organizations or consortiums, where privacy, scalability, and regulatory compliance are paramount.

Satoshi Nakamoto’s creation of Bitcoin was the first successful example of a public blockchain, demonstrating how such a system could operate securely and transparently without control from a centralized entity. Several years later, Ethereum was developed by Vitalik Buterin, which enables more user involvement using smart contracts.
Today, there are hundreds of operating blockchains. The majority of them operate using this public, permissionless framework. Some well-known examples include:
- Ethereum
- Solana
- BNB Smart Chain
- TON
- Cardano
These public blockchains have fostered a vibrant ecosystem of decentralized applications (dApps), enabling peer-to-peer transactions, smart contract execution, and a wide range of innovative use cases. Check the GetBlock blockchain and cryptocurrency [comparative guide](https://getblock.io/blog/blockchain-vs-cryptocurrency-differences/?utm_source=external&utm_medium=article&utm_campaign=devto_public-blockchain) to understand how it works.
## The Essence of Permissionless Cryptocurrency Networks
A traditional cryptocurrency network is characterized by its non-permissioned functioning, which requires the following key elements:
1. **Distributed Data Storage:** Instead of storing information on a single server, the data is structured into blocks and stored across a distributed network of nodes in many copies.
2. **Decentralized Consensus:** Since there is no central authority controlling the network, a public blockchain utilizes consensus algorithms: encoded rules that govern how nodes agree or disagree on the validity of data. Examples are proof-of-work (PoW) and proof-of-stake (PoS) instruments.
3. **Immutable Record:** This system maintains a clear and chronological record of all activities. Once data is added to the blockchain, it cannot be erased, replaced, or edited.
4. **Open Participation:** What truly defines a cryptocurrency network as permissionless is the ability for anyone to download the required software, run a node, synchronize it with the entire blockchain’s data, and participate in the consensus mechanism. All nodes in such a network have equal rights to perform operations.
Therefore, the public blockchain relies on a distributed network of nodes, consensus algorithms, and open participation principles to maintain a secure and transparent record of transactions.
It’s a fundamental departure from traditional centralized systems, where a single authority controls and governs the network. By eliminating the need for a central authority, permissionless cryptocurrency networks empower individuals to participate in a truly democratic financial and governing system.
## Characteristics of Public Blockchains
Blockchains like Bitcoin are decentralized, trustless systems, and this characterization encapsulates several key aspects.
### Open-Source Trustless Nature
Communities and developers from around the world are welcome to contribute to the continuous improvement and diversification of these platforms, while their source code is open to anyone. This collaborative approach fosters innovation, transparency, and the collective ownership of the technology. Along with that, it doesn’t require trust in any regulating authority: instead, the decentralized consensus mechanism ensure that all transactions will be completed, and no funds will be compromised.
### Inclusivity and Accessibility
Decentralized blockchain networks are designed to be inclusive and accessible from any computer, laptop, or mobile device. Users can immediately participate in the network by making transactions or, if they choose, configure their hardware to become node operators and have rewards for that. This democratization of access empowers individuals to be active participants in the ecosystem, rather than mere spectators.
### Independence and Resilience
A remarkable aspect of public blockchain networks is their independence and resilience. Even if the companies or organizations that initiated these networks cease to exist, the networks can continue to operate solely relying on the distributed network of nodes. The Ethereum Classic chain serves as a prime example, having split from the Ethereum blockchain and continuing to operate independently today.
All these aspects make public blockchain a technology that can serve various community needs, from payments and governance to gaming and recreation. Let’s see which advantages make it a robust tool for redefining and empowering communities.
## Benefits of Permissionless Blockchains
The accountability, accessibility, and stability of public blockchains determine their benefits. Let’s explore them.
- **Data redundancy** means that hundreds, thousands, or potentially millions of blockchain copies are stored across all the network nodes, increasing the assurance level and system resilience.
- **Robust security** follows from its distributed nature, making it extremely difficult to breach and falsify any data, as it would require compromising a majority of the nodes simultaneously, which is de facto impossible due to the network size.
- **Transparency** of the blockchain follows from the visibility of all network transactions and contracts signed. Any attempts at data manipulation or fraudulent activities would be immediately detected and rejected
- **Accessibility** means that everyone with Internet access can reach the blockchain and participate in it, using dApps or trading tokens, benefiting from it without any intermediary or restrictions.
Source: [GetBlock](https://getblock.io/explorers/?blockchain=eth&utm_source=external&utm_medium=article&utm_campaign=devto_public-blockchain)
As we’ll see, private networks are much more similar to traditional centralized governing bodies than to those we’ve described above. Let’s compare them further.
## Public vs. Private Blockchains
The opposite of a publicly accessible blockchain is a private blockchain, where participation and access are controlled and limited to specific authorized individuals or entities. This allows for more control over who can read and write data to the blockchain, which can be beneficial for specific cases that require privacy and regulatory compliance.
However, this also means that private blockchains do not offer the same level of decentralization and accountability, as there always be a group that makes most of the decisions in the network and stores most of its data.
The key distinctions between public and private blockchains can be summarized as follows:
- **Access:** Public blockchains are open and permissionless, allowing anyone to join, while private blockchains have restricted access, limited to authorized participants.
- **Control:** Public blockchains cannot be controlled by a single entity, while private blockchains are centralized and controlled by the organization operating the network.
- **Transparency:** All transactions on public blockchains are publicly visible, while transactions on private blockchains are only visible to permitted participants.
- **Trust Model:** Public blockchains are trustless, meaning there is no need to trust any third party, while private blockchains require trust in the controlling entity or entities, being closer to centralized systems.
- **Consensus:** Public blockchains achieve consensus through decentralized mechanisms like PoW and PoS, while the consensus process in private blockchains is controlled by the network operators, usually those who run it.
Public blockchains are well-suited for cryptocurrencies, dApps, and trustless governance systems, while private blockchains can serve enterprise applications requiring privacy and regulatory compliance. They provide privacy, control, and the potential for higher throughput due to being specifically designed for a limited number of requests. Still, as they lack decentralization, they are more vulnerable to failure and cannot serve the community’s needs as public blockchains.
Some organizations lean towards so-called hybrid chains, combining the two architectures to pick the best elements of both. They usually have public and private components, allowing for a balance between transparency, privacy, decentralization, and control.
## Challenges and Limitations of Public Blockchains
Despite the benefits of democratic participation and stability, open-access blockchains have always faced different problems. Yet, all of them are opportunities for improvement, too. Let’s look closer.
- **The speed** of decentralized networks can be slow due to the large computational resources usage and time required to reach an agreement among numerous nodes. These challenges are being overcome with solutions such as sharding and Layer-2 networks.
- **Privacy issues** follow from the fact that all transactions are fully visible, so additional information or analysis could potentially link activity to individuals. Zero Knowledge (zk) technology is an example of how private but transparently verifiable transactions can be implemented to reduce privacy issues.
- **Setup and maintenance challenges** include specialized knowledge, expertise, hardware, and software necessary to set up the blockchain. That’s why node providers like [GetBlock](https://getblock.io/?utm_source=external&utm_medium=article&utm_campaign=devto_public-blockchain) are highly relevant for blockchain developers, as they take the majority of these challenges, enabling developers to focus on realizing their ideas. Sign up now and explore immediate access to 50+ blockchains with a free plan.
## Summing Up
The inclusive nature of public blockchain networks drives its development, as enthusiasts of various kinds participate in it, either as developers, traders, or consensus participants. In addition, due to its profound influence on community development, blockchain facilitates innovations and progress in general, not only in the crypto industry. Guided by existing challenges, the capabilities of cryptocurrency networks will only grow and lead to a stronger ecosystem, benefiting the whole world. | getblockapi |
1,864,033 | 49ers Forge Path to Glory: A Gridiron Odyssey | 1. Team Performance and Season Recap: The San Francisco 49ers have had an eventful season... | 0 | 2024-05-24T13:21:39 | https://dev.to/sara_jason_39adc9490651ba/49ers-forge-path-to-glory-a-gridiron-odyssey-59d7 | ## **1. Team Performance and Season Recap:**
The San Francisco 49ers have had an eventful season so far, showcasing a mix of impressive performances and some setbacks. The team, led by head coach Kyle Shanahan, entered the season with high expectations following their Super Bowl appearance a couple of years ago. However, they faced significant challenges, including injuries to key players and tough competition within their division.
Keep an eye out for further updates as the [San Francisco 49ers ](https://www.thesportsjackets.com/product-category/nfl/san-francisco-49ers-jackets/)press on in their NFL journey towards excellence.
## 2. Injury Woes:
Injuries have been a major storyline for the 49ers this season. Several key players, including star quarterback Jimmy Garoppolo, have been sidelined at various points due to injuries, disrupting the team's rhythm and impacting their performance on the field. Despite these setbacks, the team has shown resilience, with backups stepping up to fill the void and keep the team competitive.
## 3. Quarterback Situation:
The quarterback situation has been a point of discussion throughout the season. Jimmy Garoppolo's injuries have raised questions about his long-term future with the team, while rookie quarterback Trey Lance has shown flashes of potential in limited playing time. Shanahan has faced scrutiny over his handling of the quarterback position, with fans and analysts speculating about potential changes in the offseason.
## 4. Defensive Strengths:
While injuries have been a concern on the offensive side of the ball, the 49ers' defense has remained a bright spot throughout the season. Led by stars like Nick Bosa and Fred Warner, the defense has kept the team in games and provided crucial stops when needed. Defensive coordinator DeMeco Ryans has received praise for his unit's performance and ability to overcome adversity.
## 5. Playoff Push:
As the season progresses, the 49ers find themselves in the thick of the playoff race in a competitive NFC West division. With key matchups against division rivals looming, every game becomes crucial for their postseason hopes. The team will need to stay healthy and continue to perform at a high level to secure a playoff berth and make a run towards the Super Bowl.
## 6. Off-field Developments:
Beyond on-field performance, the 49ers have been active in the community and in various social initiatives. Players and coaches have been involved in charitable endeavors and efforts to promote social justice causes. The organization has also been engaged in community outreach programs aimed at making a positive impact beyond the football field.
## 7. Fan Engagement and Support:
Despite the challenges faced by the team, the 49ers continue to enjoy strong support from their passionate fan base. Whether cheering on the team at home games or following their progress online and on social media, fans remain committed to supporting the team through thick and thin. The team's success on the field is a source of pride for the entire community and brings people together in celebration.
In conclusion, the San Francisco 49ers have navigated through a season filled with ups and downs, overcoming injuries and adversity to remain competitive in the playoff hunt. With the talent and resilience they've shown, coupled with the support of their dedicated fan base, the 49ers have the potential to make noise in the postseason and contend for another Super Bowl title. As the season unfolds, all eyes will be on the team as they strive to achieve their ultimate goal of bringing a championship back to the Bay Area. | sara_jason_39adc9490651ba | |
1,864,032 | Beyond Code: The Artistry of MVC in Crafting Dynamic Applications | Before delving into the concept of MVC architecture, allow me to share a story from a few years ago... | 0 | 2024-05-24T13:21:04 | https://dev.to/umerfarooq68/beyond-code-the-artistry-of-mvc-in-crafting-dynamic-applications-4e8n | javascript, webdev, architecture, programming | Before delving into the concept of MVC architecture, allow me to share a story from a few years ago when I was sitting with my friend Hamza. At that time, I didn't know the importance and use of architecture in the world of software. We were discussing a problem related to a middleware function, and my code wasn't organized either - I had used routes, controllers, and middleware in the same JavaScript file. After hours of effort, we were successfully able to fix the errors. But suddenly, Hamza pointed out that the error still persisted. I argued that the code was running, but he responded, "You 'chapi master' (a person who is a master of doing things in a shorter way), haven’t you heard about MVC architecture?" My answer was no. After that, I studied the whole architecture.
So, what exactly is MVC architecture? Let me explain with a real-world example before we delve into the technical details.

So, the picture above illustrates a restaurant scenario where a customer selects a dish from the menu and informs the waiter of their choice. The waiter, in turn, is aware of the restaurant's inventory. If the requested item is unavailable, such as a mocktail when the necessary ingredients are absent, the waiter informs the customer accordingly. Conversely, if the item is available, the waiter proceeds to the chef to prepare the desired food.
Here, the customer is like someone watching or looking at what's on display. The waiter is like the one in charge, sort of like the brain, making sure everything runs smoothly. They can check and manage tasks. In MVC, think of the chef as the model. The chef is like the person with all the ingredients needed to cook the food.
So above picture is the technical explanation of MVC architecture. Now we study them in depth with codes.
**View:**
• The View of MVC architecture is the user interface (UI) of your application. The UI is what a user sees on their device when they interact with your program. The state of the View relies on the data stored using the mode
• Multiple views can exist for a single model for various purposes
• If you are a MERN stack developer, then React.js will act as the View because it will be displaying content to the user
• For java users the view will be like this
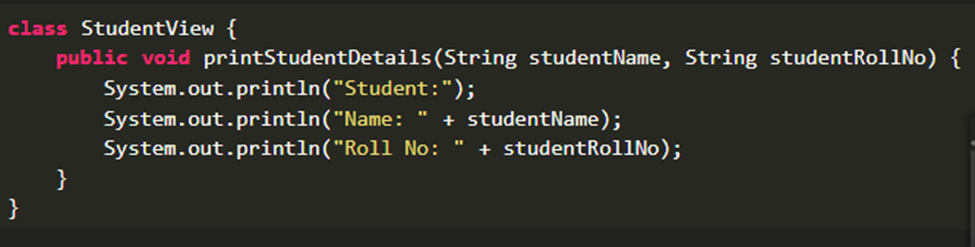
This above code represents how the data should be displayed to the user. Contains a method (printStudentDetails) to print the student’s name and roll number.
**Model :**
• It represents data that is being transferred between controller components or any other related business logic
• For MERN stack users the model will be like this :
A model is like the schema that you create for your project. It is obvious that fields such as 'filename' and 'data,' as mentioned in the above code, will be created in your database. For this particular code, I have used MySQL as my database.
• In many software development frameworks and architectures like MVC , models are indeed connected to databases
**Controllers :**
• receives user input and initiates a response by making calls on model objects
• For MERN stack users the model will be like this :
Keeping the schema that I have established in the model in mind, consider the above function (uploadFile) to act as a controller. As you can observe, multiple validations are being performed on it. It functions as the brain of your project, making crucial decisions.
• The Controller is that part of the application that handles the user interaction. The controller interprets the mouse and keyboard inputs from the user, informing the model, and the view to change as appropriate.
**Routes :**
• Routes are a crucial part of many web development frameworks that follow the MVC (Model-View-Controller) architecture. In MVC, routes typically fall under the "Controller" part of the architecture. But in most cases we make a separate file for our routes
• Routes define the URL endpoints of your web application.
• Routes are responsible for mapping HTTP request methods (GET, POST, PUT, DELETE, etc.) to controller actions.
• They can handle parameters and route patterns, allowing for dynamic routing based on user input.

In the above code “/upload” is your end point “uploadFile” is your controller that is coming from the variable “fileController” and “checkAuth” is your middleware.
**Behold, the moment you've been waiting for: introducing the middleware function, the backbone of seamless request handling and data manipulation!**

**Middleware function:**
In the beginning, middleware might confuse you. I was also confused at first, but with time, you'll grasp the concept of middleware. I intend to create a separate blog post about middleware and APIs as well. However, for now, let's focus on middleware.
Imagine planning a trip to the USA. When booking your flight, there's a higher chance you'll find an indirect flight that first stops in Dubai or Qatar before reaching the USA.
Congratulations! Through this brief analogy, you've grasped both the concepts of APIs and middleware. Trust me, it's as simple as planning this trip.
Now let me explain this analogy in technical way dubai is your middleware and your whole journey is API. Middleware functions usually have 3 standard params ( req, res, and next). The first two are objects, the last is a function that will call the next middleware function, if there is one.
The above code is middleware that acts as authentication for users. Now, the question arises: how can you use this middleware? Don't worry, I'm still here to guide you. Simply require the module and store it in a variable. Then, place it in your desired route.

For instance I want to authenticate the user who is sending post request.

| umerfarooq68 |
1,863,995 | How to Register on Chinese Platforms like QQ | Accessing the Chinese audience presents vast opportunities for businesses, but entering this market... | 0 | 2024-05-24T13:20:00 | https://dev.to/markus009/how-to-register-on-chinese-platforms-like-qq-5a38 | china, proxy, qq | Accessing the Chinese audience presents vast opportunities for businesses, but entering this market requires a specific approach. China remains a relatively closed country where familiar services like Google, Facebook, and YouTube do not work. Instead, there are local equivalents such as Baidu, WeChat, and QQ that perform similar functions.
For most Chinese services, simple access is sufficient to view publications or use the Baidu search engine. However, if you need more comprehensive use of services, including registering an account with extended features, you will need to put in more effort, especially if you are outside China.
Registering on Chinese platforms like QQ has become a challenging task in recent years. The registration process might not work on the first try, but there is still a chance of success. One of the methods we will describe in this article will help you register on QQ.
To successfully register on QQ, you need to convince the messenger that you are in China. For this, you will need any anti-detect browser and residential proxies. To demonstrate the method, I will use [Asoks proxies](https://asocks.com/?c=BSWk&utm_source=2captcha_partner&utm_medium=cpl&utm_campaign=Asocks_post&utm_term=BSWk&utm_content=post&roistat_referrer=2captcha&roistat=2captcha_partner_Asocks_post_post).
First, choose an anti-detect browser that you will be comfortable working with, register there, and log in. Generally, all browsers have their own clients that need to be downloaded to your computer. If it's difficult to decide, I use Undetectable and Dolphin Anty.
Set up the browser and install Chinese proxies. We recommend using residential proxies as they are the most secure, and in 99% of cases, services will consider you a real Chinese user.
In the personal account on Asoks, on the main page, click on the button - "Create new port."
Next, set the region to "China" (you can choose up to the city level if necessary) and click "create IP:port."
Copy the login, password, IP address, and port.
Paste the copied data into the anti-detect browser when setting up the proxy and launch it.
Connection Check
To verify that you have indeed accessed the internet as a Chinese user, enter any search query in Google. If the proxy is correct, you will not get any results, as Google is blocked in China. In our case, this is exactly what happens.
Go to baidu.com and search for the QQ messenger.
## Registering on QQ
Go to the official QQ website and click the "登录" button in the top right corner.
In the window that opens, click the middle button "注册账号."
Fill out the registration form by providing your nickname, password, and phone number to receive an activation code. Here, you will need a Chinese phone number. Virtual numbers from other countries, such as the USA, may not work for this task.
Receive the activation code on your Chinese phone number and enter it on the website.
After successfully entering the activation code, your account will be created.
This method allows you to bypass restrictions and successfully register on Chinese services like QQ using Asoks residential proxies and an anti-detect browser. | markus009 |
1,863,994 | Easily add packages to CMake with CPM | There are so many libraries and for many people it is difficult to know the correct name to add to... | 0 | 2024-05-24T13:18:14 | https://dev.to/marcosplusplus/easily-add-packages-to-cmake-with-cpm-43h4 | cmake, cpp | There are so many libraries and for many people it is difficult to know the correct name to add to CMake, or even know if it is installed.
To solve this problem there is **CPM**.
📦 CPM means: **CMake Package Manager**, that is, a Package Manager for CMake. It is a small script for dependency management, cross-platform and without configuration.
---
## Usage
Suppose you have this code [C++](https://dev.to/t/cpp):
```cpp
#include <fmt/format.h>
auto main() -> int {
fmt::print("Hello World!\n");
}
```
Note that it uses the library [fmt](https://github.com/fmtlib/fmt), if we try to compile it the way via line command, doesn't work:
```bash
g++ main.cc
/usr/lib/gcc/x86_64-pc-linux-gnu/13/../../../../x86_64-pc-linux-gnu/bin/ld: /tmp/cc5yZimt.o: in function "main":
main.cc:(.text+0x7e): undefined reference to `fmt::v10::vprint(fmt::v10::basic_string_view<char>, fmt::v10::basic_format_args<fmt::v10::basic_format_context< fmt::v10::appender, char> >)'
collect2: error: ld returned 1 exit status
```
If we use CMake, it will not automatically search for the library:
> `CMakeLists.txt`
```bash
cmake_minimum_required(VERSION 3.10)
project(MyExample)
add_executable(myexample main.cc)
```
After compiling, we will also get error:
```bash
cmake -B build .
cd build && make
[50%] Building CXX object CMakeFiles/myexample.dir/main.cc.o
[100%] Linking CXX executable myexample
/usr/lib/gcc/x86_64-pc-linux-gnu/13/../../../../x86_64-pc-linux-gnu/bin/ld: CMakeFiles/myexample.dir/main.cc .o: in the "main" function:
main.cc:(.text+0x7e): undefined reference to `fmt::v10::vprint(fmt::v10::basic_string_view<char>, fmt::v10::basic_format_args<fmt::v10::basic_format_context< fmt::v10::appender, char> >)'
collect2: error: ld returned 1 exit status
make[2]: *** [CMakeFiles/myexample.dir/build.make:97: myexample] Error 1
make[1]: *** [CMakeFiles/Makefile2:83: CMakeFiles/myexample.dir/all] Error 2
make: *** [Makefile:91: all] Error 2
```
Now let's add the CPM to our `CMakeLists.txt`, just these two statements:
```lua
file(
DOWNLOAD
https://github.com/cpm-cmake/CPM.cmake/releases/download/v0.38.3/CPM.cmake
${CMAKE_CURRENT_BINARY_DIR}/cmake/CPM.cmake
EXPECTED_HASH SHA256=cc155ce02e7945e7b8967ddfaff0b050e958a723ef7aad3766d368940cb15494
)
include(${CMAKE_CURRENT_BINARY_DIR}/cmake/CPM.cmake)
```
And then link the library (using CPM) that we want to our binary:
```lua
CPMAddPackage("gh:fmtlib/fmt#7.1.3")
target_link_libraries(myexample fmt::fmt)
```
In the end, our `CMakeLists.txt` will look like this:
```lua
cmake_minimum_required(VERSION 3.10)
project(MyExample)
add_executable(myexample main.cc)
file(
DOWNLOAD
https://github.com/cpm-cmake/CPM.cmake/releases/download/v0.38.3/CPM.cmake
${CMAKE_CURRENT_BINARY_DIR}/cmake/CPM.cmake
EXPECTED_HASH SHA256=cc155ce02e7945e7b8967ddfaff0b050e958a723ef7aad3766d368940cb15494
)
include(${CMAKE_CURRENT_BINARY_DIR}/cmake/CPM.cmake)
CPMAddPackage("gh:fmtlib/fmt#7.1.3")
target_link_libraries(myexample fmt::fmt)
```
Now just compile and run:
```bash
prompt> cmake -B build .
-- The C compiler identification is GNU 13.2.1
-- The CXX compiler identification is GNU 13.2.1
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/cc - skipped
-- Detecting C compilation features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- CPM: Adding package fmt@7.1.3 (7.1.3)
-- Version: 7.1.3
-- Build type:
-- CXX_STANDARD: 11
-- Performing Test has_std_11_flag
-- Performing Test has_std_11_flag - Success
-- Performing Test has_std_0x_flag
-- Performing Test has_std_0x_flag - Success
-- Performing Test SUPPORTS_USER_DEFINED_LITERALS
-- Performing Test SUPPORTS_USER_DEFINED_LITERALS - Success
-- Performing Test FMT_HAS_VARIANT
-- Performing Test FMT_HAS_VARIANT - Success
-- Required features: cxx_variadic_templates
-- Looking for strtod_l
-- Looking for strtod_l - not found
-- Configuring done (11.4s)
-- Generating done (0.0s)
-- Build files have been written to: /home/user/CPM/build
prompt> cd build && make
[ 20%] Building CXX object _deps/fmt-build/CMakeFiles/fmt.dir/src/format.cc.o
[ 40%] Building CXX object _deps/fmt-build/CMakeFiles/fmt.dir/src/os.cc.o
[60%] Linking CXX static library libfmt.a
[60%] Built target fmt
[80%] Building CXX object CMakeFiles/myexample.dir/main.cc.o
[100%] Linking CXX executable myexample
[100%] Built target myexample
prompt>build $./myexample
Hello World!
```
---
Of course this is a basic example and linking FMT in CMake is not difficult, but there are several cases where it is a drama!!!
I hope you enjoyed CPM. For more information [access the CPM repository on GitHub](https://github.com/cpm-cmake/CPM.cmake).
---
## Originally posted in:
### <https://terminalroot.com/easily-add-packages-to-cmake-with-cpm/> | marcosplusplus |
1,863,992 | ☕Understanding `final`, `finally`, and `finalize` in Java | Java programming involves a myriad of keywords, each serving distinct purposes to enhance the... | 0 | 2024-05-24T13:15:51 | https://dev.to/markyu/understanding-final-finally-and-finalize-in-java-3p0h | java, learning, keywords, beginners | Java programming involves a myriad of keywords, each serving distinct purposes to enhance the functionality and robustness of the code. Among these, `final`, `finally`, and `finalize` often cause confusion due to their similar nomenclature. However, they serve entirely different purposes. This article will elucidate the differences between these keywords, their uses, and practical examples to clarify their roles in Java programming.

## Introduction
In Java, `final`, `finally`, and `finalize` are keywords with distinct functions:
- **`final`**: A keyword used in variable, method, and class declarations to denote constants, prevent method overriding, and inheritance.
- **`finally`**: A block used in exception handling to execute code regardless of whether an exception is thrown or not.
- **`finalize`**: A method used to perform cleanup operations before an object is garbage collected.
Understanding the differences and applications of these keywords is crucial for writing effective Java code.
## The `final` Keyword
### Purpose
The `final` keyword is versatile and can be applied to variables, methods, and classes.
### Use Cases
1. **Final Variables**: When applied to a variable, the `final` keyword makes it a constant, meaning its value cannot be changed once assigned.
2. **Final Methods**: When applied to a method, it prevents the method from being overridden by subclasses.
3. **Final Classes**: When applied to a class, it prevents the class from being subclassed.
### Code Examples
#### Final Variables
```java
public class Constants {
public static final int MAX_USERS = 100;
public static final String APP_NAME = "MyApp";
}
```
In this example, `MAX_USERS` and `APP_NAME` are constants that cannot be changed.
#### Final Methods
```java
public class Parent {
public final void display() {
System.out.println("This is a final method.");
}
}
public class Child extends Parent {
// This will cause a compile-time error
// public void display() {
// System.out.println("Attempting to override a final method.");
// }
}
```
Here, the `display` method in the `Parent` class cannot be overridden by the `Child` class.
#### Final Classes
```java
public final class Utility {
public static void performTask() {
System.out.println("Performing a task.");
}
}
// This will cause a compile-time error
// public class AdvancedUtility extends Utility {
// }
```
The `Utility` class cannot be subclassed due to the `final` keyword.
## The `finally` Block
### Purpose
The `finally` block is used in exception handling to execute code that must run regardless of whether an exception is thrown or caught.
### Use Cases
1. **Resource Management**: Ensuring resources like files and database connections are closed properly.
2. **Cleanup Operations**: Performing necessary cleanup actions after try-catch blocks.
### Code Example
```java
public class FileOperations {
public void readFile(String filePath) {
FileReader fileReader = null;
try {
fileReader = new FileReader(filePath);
// Perform file operations
} catch (IOException e) {
System.out.println("An error occurred: " + e.getMessage());
} finally {
if (fileReader != null) {
try {
fileReader.close();
} catch (IOException e) {
System.out.println("Failed to close the file: " + e.getMessage());
}
}
}
}
}
```
In this example, the `finally` block ensures that the `FileReader` resource is closed regardless of whether an exception occurs.
## The `finalize` Method
### Purpose
The `finalize` method is invoked by the garbage collector before an object is reclaimed. It is used to perform cleanup operations, such as releasing resources.
### Use Cases
1. **Cleanup Operations**: Performing cleanup before an object is garbage collected.
### Code Example
```java
public class ResourceHolder {
private FileReader fileReader;
public ResourceHolder(String filePath) throws FileNotFoundException {
this.fileReader = new FileReader(filePath);
}
@Override
protected void finalize() throws Throwable {
try {
if (fileReader != null) {
fileReader.close();
}
} finally {
super.finalize();
}
}
}
```
Here, the `finalize` method ensures that the `FileReader` is closed before the `ResourceHolder` object is garbage collected. However, it's important to note that the `finalize` method is deprecated in recent Java versions due to unpredictability and better alternatives like `try-with-resources` and explicit resource management.
## Summary
In summary, `final`, `finally`, and `finalize` are three distinct keywords in Java with different purposes:
- **`final`**: Used to declare constants, prevent method overriding, and inheritance.
- **`finally`**: A block used in exception handling to execute necessary code regardless of exceptions.
- **`finalize`**: A method used for cleanup operations before an object is garbage collected (now largely deprecated).
Understanding these keywords helps in writing more robust, maintainable, and efficient Java code. By using `final`, you can create immutable variables and secure methods and classes. The `finally` block ensures resource management and cleanup, while `finalize` (despite its deprecation) shows the historical approach to object cleanup before garbage collection.
---
**References:**
- [Oracle Java Documentation](https://docs.oracle.com/javase/tutorial/essential/exceptions/)
- [GeeksforGeeks - Java final, finally and finalize](https://www.geeksforgeeks.org/final-finally-and-finalize-in-java/)
- [Baeldung - Java Keywords](https://www.baeldung.com/java-final) | markyu |
1,863,991 | Understanding One2Many Relationships in Odoo: A Comprehensive Guide with Real Use Case Example | Odoo, a powerful and versatile ERP system, uses various relational fields to manage data connections... | 0 | 2024-05-24T13:15:06 | https://dev.to/jeevanizm/understanding-one2many-relationships-in-odoo-a-comprehensive-guide-with-real-use-case-example-1dao | odoo |
Odoo, a powerful and versatile ERP system, uses various relational fields to manage data connections between models. One such relational field is one2many, which plays a crucial role in representing one-to-many relationships. This article will explain the concept of one2many fields in Odoo and illustrate their use with a real-world example.
What is a One2Many Relationship?
A one2many relationship in Odoo signifies that a single record in one model can be linked to multiple records in another model. This is particularly useful for managing hierarchical data structures, such as orders and their corresponding order lines, invoices and invoice items, or projects and tasks.
Defining One2Many Relationships in Odoo
To define a one2many relationship, you need two models:
A model that will hold the single record (the "parent" model).
A model that will hold the multiple related records (the "child" model).
The one2many field is declared on the parent model, while a corresponding many2one field is declared on the child model to create a bidirectional link.
Real Use Case Example: Sales Order and Order Lines
Let’s consider a common business scenario where a sales order can contain multiple order lines. Each order line represents a product or service being sold as part of the sales order.
Step-by-Step Implementation
1. Define the Parent Model (sale.order)
First, we define the sale.order model, which represents the sales order.
```
from odoo import models, fields
class SaleOrder(models.Model):
_name = 'sale.order'
_description = 'Sales Order'
name = fields.Char(string='Order Reference', required=True)
date_order = fields.Datetime(string='Order Date', required=True, default=fields.Datetime.now)
customer_id = fields.Many2one('res.partner', string='Customer', required=True)
order_line_ids = fields.One2many('sale.order.line', 'order_id', string='Order Lines')
```
In this model:
name stores the order reference.
date_order records the order date.
customer_id links to the customer (partner) placing the order.
order_line_ids is a one2many field that links to the sale.order.line model.
2. Define the Child Model (sale.order.line)
Next, we define the sale.order.line model, which represents the individual order lines within a sales order.
```
from odoo import models, fields
class SaleOrderLine(models.Model):
_name = 'sale.order.line'
_description = 'Sales Order Line'
product_id = fields.Many2one('product.product', string='Product', required=True)
quantity = fields.Float(string='Quantity', required=True)
price_unit = fields.Float(string='Unit Price', required=True)
order_id = fields.Many2one('sale.order', string='Order Reference', ondelete='cascade')
```
In this model:
product_id links to the product being ordered.
quantity specifies the quantity of the product.
price_unit records the unit price of the product.
order_id is a many2one field that links back to the sale.order model, creating the bidirectional relationship.
How It Works in Practice
When a user creates a new sales order in Odoo:
They fill out the main sales order details, such as the order reference, date, and customer.
Within the sales order form, they can add multiple order lines. Each order line specifies a product, its quantity, and the unit price.
The order_line_ids field in the sale.order model aggregates all related order lines, while each order line uses the order_id field to reference back to its parent sales order.
Benefits of Using One2Many Relationships
Data Organization: Structuring data in a hierarchical manner allows for better organization and retrieval.
Ease of Use: Users can easily manage related records within the parent record’s form view, improving usability and efficiency.
Data Integrity: Bidirectional relationships ensure that each child record is correctly linked to its parent, maintaining data consistency.
Conclusion
The one2many field in Odoo is a powerful feature for managing hierarchical data relationships. By understanding and utilizing this field type, you can create robust data models that reflect real-world business scenarios. The example of sales orders and order lines demonstrates how one2many relationships can be implemented to manage complex data structures effectively.
Using one2many relationships not only enhances data organization but also simplifies data management, making it easier for users to interact with and maintain the system. As you continue to develop and customize Odoo applications, leveraging one2many fields will be an essential tool in your arsenal. | jeevanizm |
1,863,990 | Learning: Nodes | Projection Nodes are used to: select columns, define calculated columns, parameters that request... | 0 | 2024-05-24T13:13:11 | https://dev.to/dentrodailha96/learning-calculation-views-nodes-e28 | sap, certification, dataengineering | - Projection Nodes are used to:
select columns, define calculated columns, parameters that request values at runtime, and filter on the data source.
- Aggregation Node:
Used to aggregate functions to measures based on one or several attributes.
In an Aggregation Node, a calculated column is always computed after the aggregate function.
<u>Keep Flag</u>: allows to trigger the calculation at the relevant level of granularity.
<u>Transparent Filter</u>: used when stacked view where the lower views have distinct count measures or upper calculation views contain filters on columns that are not projected.
- Join Node:
Joins vs Aggregation :: Regular Join, the aggregation is executed after the join. Dynamic Join, aggregation triggered to remove the column if the column is not requested by the client query.
Multi Join order: Outside-In (the table that is furthest from the central table is executed first) or Inside-Out (the table that is closest to the central table is executed first).
| dentrodailha96 |
1,860,719 | Bicep templates now support Microsoft Graph resources | We’re thrilled to announce that Bicep templates for Microsoft Graph resources is now available in... | 0 | 2024-05-24T13:13:10 | https://dev.to/dkershaw10/bicep-templates-now-support-microsoft-graph-resources-28b6 | azure, microsoftgraph, devops | We’re thrilled to announce that Bicep templates for Microsoft Graph resources is now available in public preview. Bicep templates bring declarative infrastructure-as-code (IaC) capabilities to Microsoft Graph resources. This new capability will initially be available for core Microsoft Entra ID resources.
Bicep templates for Microsoft Graph resources allow you to define the tenant infrastructure you want to deploy, such as Microsoft Entra ID groups or applications, in a file, then use the file throughout the development lifecycle to repeatedly deploy your infrastructure. The file uses the [Bicep language](https://learn.microsoft.com/azure/azure-resource-manager/bicep/overview), a domain-specific language (DSL), that uses declarative syntax to deploy resources—typically used in DevOps, CI/CD, and [infrastructure-as-code](https://learn.microsoft.com/en-us/devops/deliver/what-is-infrastructure-as-code) solutions.
## What problems does this solve?
Azure Resource Manager or Bicep templates allow you to declare Microsoft Azure resources in files and deploy those resources into your infrastructure. Configuring and managing your Azure services and infrastructure often includes managing Microsoft Entra ID resources, like applications and groups. Until now, you had to orchestrate your deployments between two mechanisms using ARM or Bicep template files for Azure resources and Microsoft Graph PowerShell for Microsoft Entra ID resources.
Now, with the Microsoft Graph Bicep release, you can declare the Microsoft Entra ID resources in the same Bicep files as your Azure resources, making configurations easier to define, and deployments more reliable and repeatable.
Let's look at how this works and then we'll run through an example.
## The Microsoft Graph Bicep extension
To provide support for Bicep templates for Microsoft Graph resources, we have released the new Microsoft Graph Bicep extension that allows you to author, deploy, and manage supported Microsoft Graph resources (initially Microsoft Entra ID resources) in Bicep template files either on their own, or alongside Azure resources.
### Authoring experience
You get the familiar, first-class authoring experience of the [Bicep Extension for VS Code](https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-bicep) when you use it to create your Microsoft Graph resource types in Bicep files. The editor provides rich type-safety, IntelliSense, and syntax validation.
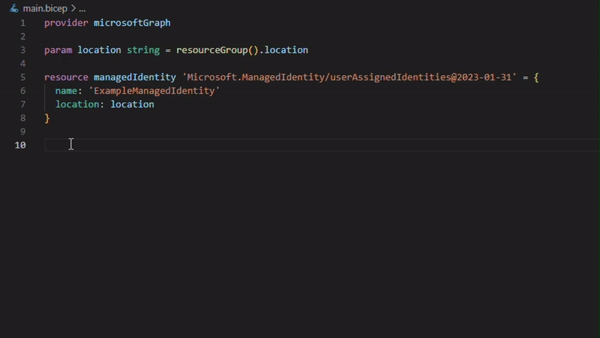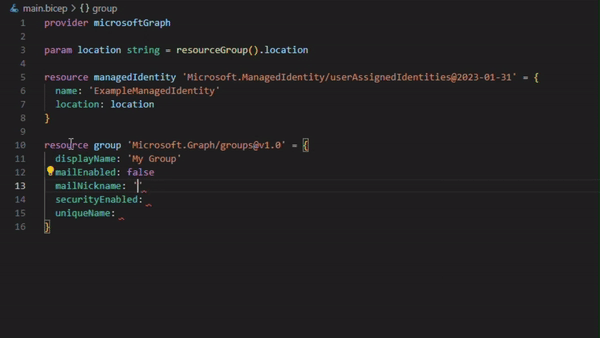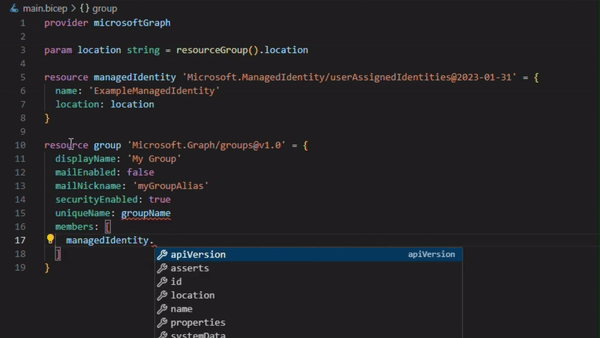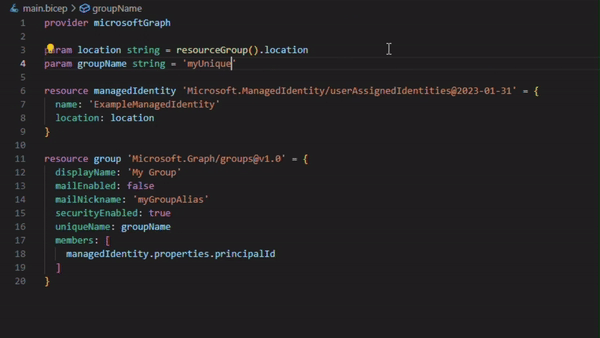
You can also create Bicep files in Visual Studio with the [Bicep extension for Visual Studio](https://marketplace.visualstudio.com/items?itemName=ms-azuretools.visualstudiobicep).
### Deploying Bicep files
Once you have authored your Bicep file, you can deploy it using familiar tools such as Azure PowerShell and Azure CLI. When the deployment request is made to the Azure Resource Manager, the deployments engine orchestrates the deployment of interdependent resources so they're created in the correct order, including the Microsoft Graph resources.
The following image shows a Bicep template file where the Microsoft Graph group creation is dependent on the managed identity resource, as it is being added as a group member. The deployments engine first sends the managed identity request to the Resource Manager, which routes it to the `Microsoft.ManagedIdentity` resource provider. Next, the deployments engine sees that `Microsoft.Graph/groups` is an extensible resource, so it knows to route this resource request to the Microsoft Graph Bicep extension. The Microsoft Graph Bicep extension then translates the groups resource request into a request to Microsoft Graph.
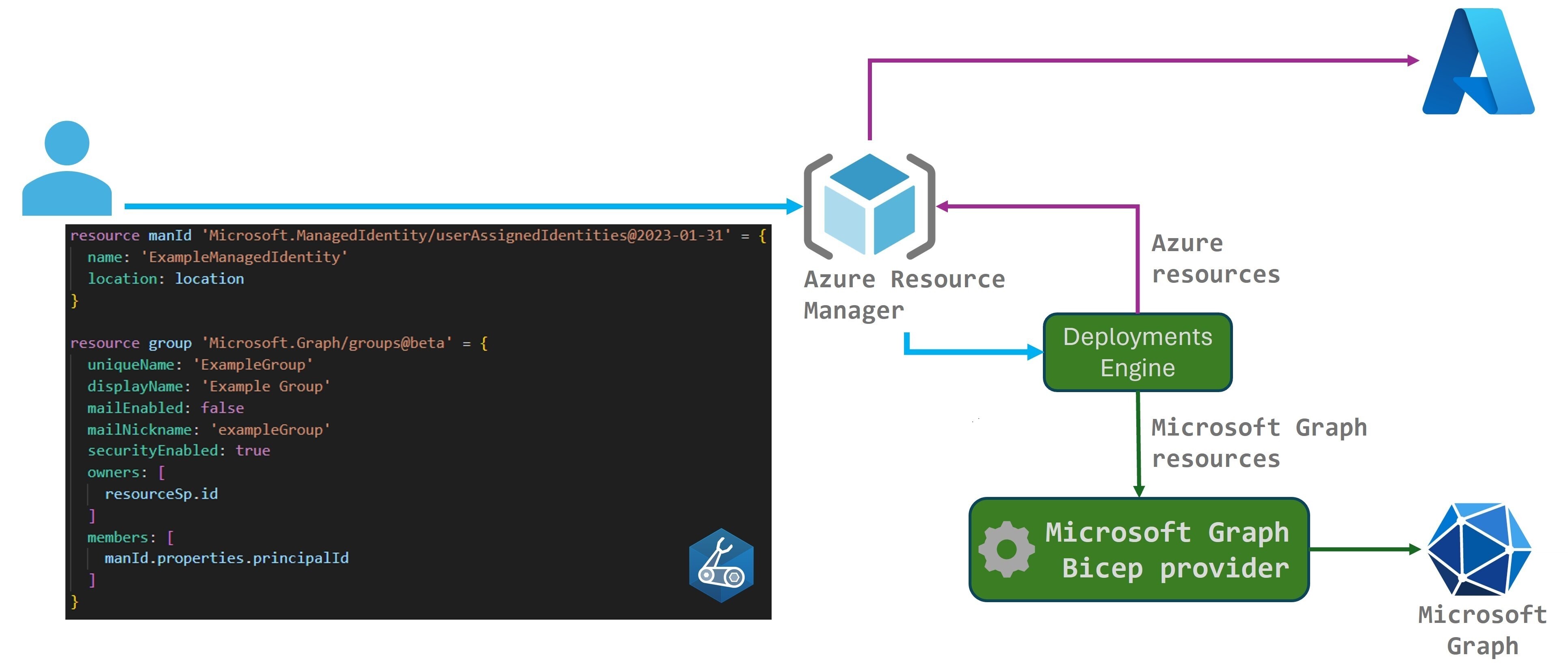
## Scenario: Using managed identities with security groups and app roles
[Managed identities](https://devblogs.microsoft.com/identity/app-types-and-auth-flows/#managed-identities) can be [assigned to security groups and Microsoft Entra ID app roles](https://learn.microsoft.com/entra/identity/managed-identities-azure-resources/managed-identity-best-practice-recommendations) as an authorization strategy. Using security groups can simplify management by reducing the number of role assignments.
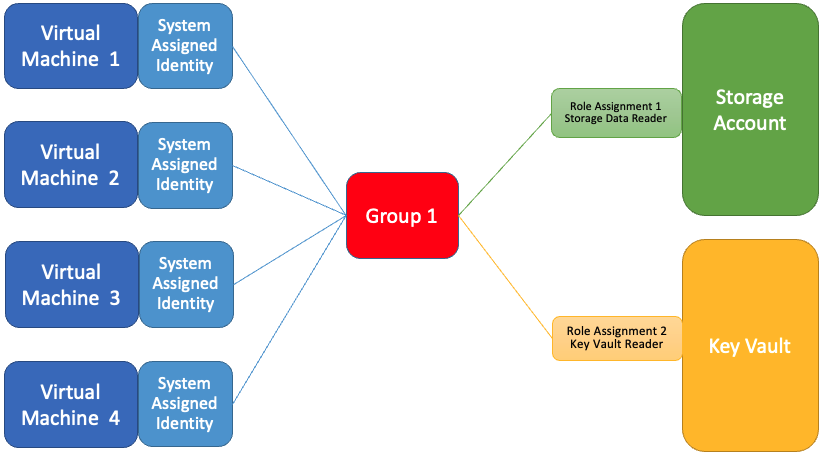
However, this configuration isn't possible using a Bicep or Resource Manager template. With Microsoft Graph Bicep extension, this limitation is removed. Rather than assigning and managing multiple Microsoft Azure role assignments, role assignments can be managed via a security group through a single Bicep file.
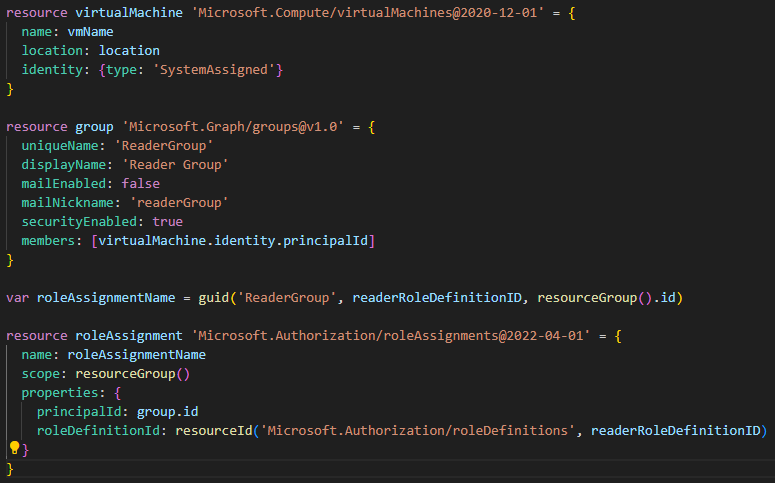
In the example above, a security group can be created and referenced, whose members can be managed identities. With Bicep templates for Microsoft Graph resources, declaring Microsoft Graph and Microsoft Azure resources together in the same Bicep files, enables new and simplifies existing deployment scenarios, bringing reliable and repeatable deployments.
## Learn more
- [Bicep templates for Microsoft Graph resources documentation](https://learn.microsoft.com/graph/templates)
- Try out the [create and deploy your first Bicep file with Microsoft Graph resources](https://learn.microsoft.com/graph/templates/quickstart-create-bicep-interactive-mode) quickstart
| dkershaw10 |
1,863,764 | Fintech: The Tech Banking Sector We Should Be Grateful For | Fintech has always been a dream, and for many years, it seemed like a distant reality. Before 2015,... | 0 | 2024-05-24T13:07:48 | https://dev.to/hnkomuwa/fintech-the-tech-banking-sector-we-should-be-grateful-for-4lmi | cryptocurrency, fintech, money, cleva |
Fintech has always been a dream, and for many years, it seemed like a distant reality.
<br>
Before 2015, business owners had to physically go to the bank to cash checks and withdraw money using teller slips.
<br>
Sending money from the comfort of your own home was equivalent to Magic, as it had never been done before.
<br>
The only big fintech companies at the time were those that worked with banks to provide online payment services, such as Interswitch, E-Tranzact, and Remita.

<br>
<hr>
However, 2015 marked a significant turning point for Nigerian fintech. It was the year when Ezra Olubi and Shola Akinlade pitched Paystack at the YC Combinator program for startups.

<br>
After that, fintech companies began to spring up left and right.
<Ul>
<Li><B>Savings and investment fintechs</B> like Cowry Wise and Piggyvest emerged, offering users a convenient way to save and invest their money.</li>
<br>
<Li><B>Loan fintechs</B> like Payhippo, Ajo Card, and Palm Credit made it easier for people to access credit.</Li>
<Li> <B>Insurance fintechs </B>like Curacel, Daabo, and Riwe Technologies provided innovative insurance solutions. </Li>
<br>
<Li> <B>Cryptocurrency fintechs</B> like Vorem, Prospera Vests, and Fluidcoins made it possible for people to buy and sell cryptocurrencies. </Li>
<br>
<Li><B>Embedded finance fintechs</B> like Okra, Credpal, and $udo enabled businesses to offer financial services to their customers.</Li>
<br>
<Li> <b>Online banking apps</b> like Kuda, Opay, and Moneypoint made it possible for people to manage their finances from their mobile devices.</Li>
<br>
<Li> <b>International transaction banks</b> like Cleva, Grey finance, and Payday made it easier for people to send and receive money across borders.</Li>
<br>
<hr>
<Blockquote>As Matteo Rizzi, a fintech company founder and investor, once said, <I>"Fintech is not just about making money, it's about making the world a better place."</I> </Blockquote>
<hr>
I couldn't agree more. As a freelancer, I've personally benefited from fintech in many ways. When I need to receive foreign transfers or wires, I use <b>Cleva.</b> For local transactions, I use Opay. When I need to borrow money, I use Palm Credit. And when I want to save money, I use PiggyVest. Life has never been easier.
<hr>
<br>

In particular, I highly recommend Cleva for foreign USD transactions. Their banking process is seamless and efficient, making it easy to receive money from foreign clients. Whether you're a freelancer or a business owner, Cleva is definitely worth checking out.
<br>
Fintech has come a long way in Nigeria, and we should be grateful for the convenience and innovation it has brought to our lives. From online payments to savings and investments, loan and insurance solutions, cryptocurrency and embedded finance, fintech has made it possible for us to manage our finances with ease and convenience. So, the next time you use a fintech app or service, remember the impact it's having on your life and the lives of millions of others. | hnkomuwa |
1,863,989 | What is Software Testing and its relevance | Software testing is a technique that is used to test various types of application be it web or... | 0 | 2024-05-24T13:07:42 | https://dev.to/s1eb0d54/what-is-software-testing-and-its-relevance-on5 | Software testing is a technique that is used to test various types of application be it web or mobile. Software testing not only help to find the bugs and faults in the software but it also helps to make the product better and approachable to the user so that is user friendly.
Software Testing is carried out in a cyclic process which consists of various stages and every stage has its own evaluation process and its cardinal process to complete the delivery of the software to the client. Without testing no product can be delivered to the client. Software Testing is very crucial part if the this is not followed after development then it could cause monetary losses.
Importance of Software Testing is that huge defects can be detected in the early stages of development, provides reliability, efficiency, productivity, scalability.
Software Testing is segregated in two divisions.
1. Verification: It ensure that the software correctly implements a specific function.
2. Validation: It ensure that the software that has been built is as per the customer requirements.
There are different types of testing types which includes
Software Testing can be divided into different categories as follows:
1. Depending on the Techniques
2. Depending on the Types
3. Depending on the Approach
4. Depending on the Levels of testing
Depending on the Techniques
This is classified as
1. Manual Testing: The testing which is carried out manually. The tester tests the software by its self without any scripts
2. Automation Testing: The testing which is carried out with the help of tools and scripts. The tester tests the software by writing scripts to automate the testing process.
Depending on the Types
This is classified as
1. Functional Testing: The testing which rectifies the functional requirements of the software, it is useful to check weather the software works according to its function.
2. Non-functional Testing: The testing which involves testing the other aspects of software such as performance, memory, efficiency, scalability is called non-functional Testing.
3. Maintenance Testing: This type of testing is done when the software is deployed to customer and there are few changes made in code to enhance the product or to change the functionality of the software to see if the recent changes didn't introduce regressions and new defects in the software.
Depending on the Approach
This is classified as
1. White Box Testing: White box testing is type of testing in which the tester is aware of the source code and know how the modules are related to each other so the he can test it accordingly.
2. Black box testing: Black box testing is type of testing in which the tester is not aware of the source code and don't know how the modules are related so he will only check the software depending upon the functionality and user point of view.
Depending on the Levels of testing
This is classified as
1. Unit Testing: Unit Testing is testing each component one by one of the software to ensure every component is working fine.
2. Integration Testing: Integration Testing focuses on testing how the co-related components are working together
3. System Testing: This level of testing is done on whole product that is fully integrated software to check the compatibility with the original idea of the product.
4. User acceptance Testing: this level of testing is very important from user perspective as the software is tested in such a way as the end user. | s1eb0d54 | |
1,863,988 | Hosting platform procrastination 😵💫 | Background I am trying to learn MERN stack in 150 Days, about which I posted a while ago.... | 27,499 | 2024-05-24T13:04:33 | https://dev.to/prakirth/hosting-platform-procrastination-4oil | webdev, beginners, learning | ## Background
I am trying to learn MERN stack in 150 Days, about which I posted a while ago. In this series posts, I will be sharing What and *How* I have been learning.
{% embed https://dev.to/prakirth/mern-150-days-challenge-27o8 %}
---
Did you ever have to deal with yourself in a similar situation as this ? How did you deal with it ? Let me know in the comments :speech_balloon:
This is *how* I dealt with it. :man_juggling:
## Context
**DAY 9/150**
- Until [Part 3 - Deploying app to Internet](https://fullstackopen.com/en/part3/deploying_app_to_internet) part of the course, the course was not very challenging.
## Reason
> I always dreaded deployment. Last I tried I failed.
Then, I mastered _procrastinating_ this particular aspect of Software Development :neutral_face:
Obviously, the procrastination comes from my insecurities as a non-traditional Developer, such as :
- *What if I do something wrong and my code gets deleted ?!* :raised_eyebrow:
- *TMI! Where do I even start ?!* :grimacing:
## Solution
- It took me a whole day to reason with myself and find options which satisfy one simple condition - *No Credit Card required*
- The answer was right in that part of the course - [**Render**](https://render.com/)
---
## Learnings
> - *Procrastination* or *Impostor Syndrome* is quite common for folks coming from *non-traditional* backgrounds to Software Development
- Deal WITH it. Do NOT give in. :mechanical_arm:
- Sometimes the solution is right in front of You. Just breathe :relieved:
- Along the way, I found some nice aggregated resources :star_struck: :
1. List of services for Web Hosting, Database, File Storage, User Identity and Monitoring
{% embed https://medium.com/@minianter/top-free-services-to-deploy-full-stack-applications-2023-fb11489aa9b9 %}
2. List of softwares with free-tiers for Developers
{% embed https://free-for.dev/#/?id=web-hosting %}
---
Until next time! :writing_hand:
Live Long and Prosper :vulcan_salute:
---
[_Cover Photo by 'Leeloo The First' from Pexels_](https://www.pexels.com/photo/motivational-simple-inscription-against-doubts-5238645/) | prakirth |
1,863,986 | JavaScript Execution Context and JS Engine Components | Hello everyone! Welcome to my blog, where I’ll be documenting my journey to mastering the JavaScript... | 0 | 2024-05-24T13:03:36 | https://dev.to/sromelrey/javascript-execution-context-and-js-engine-components-1kem | javascript, programming, deeplearning, tutorial | Hello everyone! Welcome to my blog, where I’ll be documenting my journey to mastering the JavaScript language. This is the first post in what will be a series chronicling my experiences, challenges, and triumphs as I dive deep into the world of JavaScript. I hope you'll join me on this adventure, learn alongside me, and share your own insights. Enjoy the read!
## Goals and Objectives in this topic:
- Understand the concept of Execution Context.
- Understand the following Components:
- Clean up.
- Call Stack.
- Heap.
- Built-in Functions and Objects.
- Type Information.
### Before we start, we need to understand first on how JavaScript Engine process our simple block of code.
To demonstrate this components in action here' a simple code for demonstration.
```
var age = 12;
console.log(age);
function logAge(ageArg) {
console.log(`log AGE is ${ageArg}`);
}
logAge(age);
```
> When the JavaScript Engine Starts Running the Code, it creates a global Execution Context. This context is divided in to two parts Creation Phase and Execution Phase.
###**1. Global Execution Context** (**_Creation Phase_**):
**Memory Allocation**: Space is reserved in the Heap (_unstructured storage_) for the variable `age`.
**Initialization**: The variable `age `is initialized with the value `undefined `(default for var variables in JavaScript).
> In JavaScript with `var` variables, initialization with the actual value happens during the **_execution phase_** when the line with the assignment is encountered. The **_creation phase_** only allocates memory and assigns `undefined`by default.
**Reference Creation**: A reference is created in the global scope pointing to the memory location of age in the Heap. This allows you to access age using its name throughout the global scope.
**Function Definition** (**_not Creation_**): The function `logAge `is defined and stored in memory. This includes its code and argument (ageArg). However, the function itself isn't executed yet.
###**2. Global Execution Context** (**_Execution Phase_**):
**Variable Assignment**: The line `age = 12;` is encountered. The value 12 is assigned to the previously allocated memory location for age.
**Console Output**: The line `console.log(age);` is executed. The value of age (which is now 12) is retrieved from the Heap using the reference in the global scope and printed to the console.
**Function Call**: The line `logAge(age);` is reached. This triggers the creation of a separate execution context for the `logAge `function.
> **Each function call creates a new execution context** to manage the function's execution environment, including its scope, arguments, and call stack frame.
###**3.Function Execution Context** for `logAge` (**_Creation Phase_**):
**Note: This phase happens only when `logAge` is called.**
**Memory Allocation**: If `logAge `has any arguments (like ageArg in this case), memory is allocated for them in the Heap within this context.
**Local Variable Initialization** (if any): Any variables declared within the `logAge `function are initialized, usually with undefined.
###**4. Function Execution Context** for `logAge `(**_Execution Phase_**):
**Argument Passing:** The value of age (which is 12 from the global context) is passed as an argument to the `logAge `function and assigned to the `ageArg `parameter within the function's execution context.
**Function Body Execution:** The code within the `logAge function`is executed. In this case, it uses template literals to construct a string and then logs it using console.log.
#### Overall Sequence:
1. Global Execution Context (Creation Phase)
2. Global Execution Context (Execution Phase) - including variable assignment, console output, and function call
3. Function Execution Context for logAge (Creation Phase) - only when the function is called
4. Function Execution Context for logAge (Execution Phase) - function body execution
**Cleaning Up**: The JavaScript engine employs a garbage collector to manage memory. Once the function execution context for logAge is complete and there are no more references to the function arguments or local variables, the memory used by them in the Heap becomes available for garbage collection.
**Call Stack:**
- The call stack keeps track of the currently executing function and its arguments.
- In this code, the call stack would have:
- logAge function call when it's executed.
- The global execution context when the script starts running.
**Heap:**
- The Heap stores the values of variables and function arguments during execution.
- In this code, the Heap would store:
- The value 12 for the variable age.
- The value 12 passed as an argument to the logAge function (stored in the ageArg memory location).
**Built-in Functions and Objects:**
- The code uses built-in functions like console.log. These functions are predefined and readily available for use.
**Type Information:**
JavaScript is loosely typed, so the engine doesn't explicitly store type information for variables. In this case, both age and ageArg would hold the numeric value 12.
## Conclusion
By understanding the JavaScript Execution Context and its components, you've gained valuable insight into how your code is processed and executed. We've explored the creation and execution phases of the global execution context, as well as the creation and execution phases that occur within function calls. This knowledge helps you write more efficient and predictable JavaScript code.
Thanks for reading 😁😁😁😁
| sromelrey |
1,863,971 | Exclusive Offer: Free IPv6 VPS for 1 Year - Perfect for Development Environments! | Embark on your development journey with EcoStack Cloud's exclusive offer – a free IPv6 VPS for 1... | 0 | 2024-05-24T13:02:16 | https://dev.to/ersinkoc/exclusive-offer-free-ipv6-vps-for-1-year-perfect-for-development-environments-l6h | Embark on your development journey with EcoStack Cloud's exclusive offer – a free IPv6 VPS for 1 year! Tailored to meet the needs of developers and perfect for creating robust development environments, this offer is your gateway to seamless and efficient coding.
### Free IPv6 VPS Details
Benefit from our free IPv6 VPS for an entire year, featuring:
- **1 GB RAM**: Ample memory for smooth application development.
- **1 vCPU**: Reliable processing power for your coding tasks.
- **10 GB NVMe Disk**: High-speed storage for your projects.
- **Ubuntu 22.04**: Utilize the latest LTS version of Ubuntu for enhanced performance.
- **512 GB Traffic**: Generous data transfer allowance for seamless operations.
- **200Mbit/s Uplink**: Fast internet connectivity for efficient coding.
- **/80 Subnet IPv6**: Enjoy IPv4 connectivity alongside IPv6 support.
### Development-Friendly Features
Our free IPv6 VPS is designed specifically for development environments, offering:
- **1-Year Validity**: Enjoy the benefits of your free VPS for an entire year, giving you ample time to work on your projects.
- **Flexible Environment**: Create, test, and deploy your applications with ease in our flexible development environment.
- **Seamless Integration**: Integrate with your favorite development tools and frameworks to streamline your workflow.
### Upgrade Options Available
Looking to scale your projects? Upgrade seamlessly with our premium VPS packages, featuring:
- **Nano Package**: Starting at 2.90€/month, enjoy enhanced resources such as:
- Up to 3 GB RAM
- Up to 30 GB NVMe Disk Space
- 400Mbit/s Network Speed
- **Micro Package**: For 4.90€/month, benefit from:
- Up to 6 GB RAM
- Up to 60 GB NVMe Disk Space
- 400Mbit/s Network Speed
Explore more premium packages on our website!
### Why Choose EcoStack Cloud?
Discover why EcoStack Cloud is the ultimate choice for developers:
- **1-Year Free VPS**: Enjoy a full year of free VPS hosting to support your development needs.
- **Robust Infrastructure**: Benefit from reliable hosting on top-tier European data centers, ensuring optimal performance and uptime.
- **No Credit Card Required**: Start coding hassle-free – no payment details needed.
### Get Started Today!
Don't miss out on this exclusive offer! Claim your free IPv6 VPS for 1 year and kickstart your development journey with EcoStack Cloud.
Experience seamless coding and efficient development environments with [EcoStack Cloud](https://ecostack.cloud) – sign up now! | ersinkoc | |
1,863,984 | Marketing Strategies | In today's fast-moving world, having a good marketing plan is crucial for making your business stand... | 0 | 2024-05-24T13:01:53 | https://dev.to/techstuff/marketing-strategies-4l3e | strategies | In today's fast-moving world, having a good marketing plan is crucial for making your business stand out in a crowded market and attracting customers.

**Here are five easy but effective marketing strategies to give your business a boost:**
One such strategy is **content marketing**. Content marketing involves creating and sharing valuable, relevant content with the aim of engaging target audiences and driving them to take action. This can be presented in a variety of ways, such as through social media posts, videos, infographics, and blogs. By providing content that addresses the needs and interests of your audience, you can establish your brand as a trusted authority in your industry and attract potential customers. To implement a successful content marketing strategy, it's important to start by identifying your target audience and understanding their pain points and interests. Then, create high-quality content that addresses these needs and provides valuable solutions. Share your content across various platforms, such as your website, blog, and social media channels, to reach a wider audience and drive engagement.
Another powerful marketing strategy is **social media marketing**. Social media platforms like Facebook, Instagram, Twitter, and LinkedIn offer unique opportunities to connect with potential customers and build brand awareness. To leverage social media effectively, start by identifying which platforms your target audience uses most frequently. Then, create compelling content that resonates with your audience and encourages them to engage with your brand. Use features like hashtags, polls, and live videos to increase engagement and visibility. Additionally, consider investing in social media advertising to reach specific demographics and target audiences with personalized messaging.
**Email marketing** is another cost-effective strategy that can yield significant results. By building an email list of subscribers who have opted in to receive communications from your brand, you can send targeted messages, promotions, and updates directly to their inbox. To get started with email marketing, offer incentives like discounts or freebies in exchange for email sign-ups on your website. Then, segment your email list based on factors like demographics, interests, and purchase history to deliver relevant content to each subscriber. Use engaging subject lines and compelling calls-to-action to encourage recipients to open their emails and take action.
**Search engine optimization (SEO)** is yet another essential marketing strategy for businesses looking to improve their online visibility and attract more organic traffic. SEO involves optimizing your website to improve its visibility in search engine results pages (SERPs). To improve your website's SEO, start by conducting keyword research to identify relevant keywords and phrases related to your business. After that, make sure these keywords are organically included in the meta tags, headings, and content of your website. Additionally, focus on building high-quality backlinks from reputable websites and improving your website's loading speed and mobile friendliness.

In **conclusion**, implementing these simple yet effective marketing strategies can help businesses boost their visibility, attract more customers, and drive growth. By focusing on content marketing, social media marketing, email marketing, and SEO, businesses can establish themselves as trusted authorities in their industries and achieve long-term success. Experiment with different tactics, track your results, and adjust your strategy accordingly to maximize your impact and achieve your business goals.
| swati_sharma |
1,863,982 | Higher-Order Functions (HOFs) in JavaScript: A Comprehensive Guide 🚀 | Higher-Order Functions (HOFs) in JavaScript: A Comprehensive Guide 🚀 Higher-order... | 0 | 2024-05-24T13:00:42 | https://dev.to/madhurop/higher-order-functions-hofs-in-javascript-a-comprehensive-guide-32aa | ### Higher-Order Functions (HOFs) in JavaScript: A Comprehensive Guide 🚀
Higher-order functions (HOFs) are a powerful feature in JavaScript that can make your code more modular, reusable, and expressive. This article will delve into the concept of HOFs, explain why they are useful, and provide practical examples to help you understand how to use them effectively. Let's get started! 🌟
#### What are Higher-Order Functions? 🤔
In JavaScript, a higher-order function is a function that either:
- Takes one or more functions as arguments, or
- Returns a function as its result.
This ability allows for more flexible and concise code, especially when dealing with operations on collections of data.
#### Why Use Higher-Order Functions? 🌟
Higher-order functions can simplify your code by:
- Reducing redundancy
- Increasing readability
- Enhancing modularity
By abstracting out common patterns into reusable functions, you can write cleaner and more maintainable code.
#### Common Higher-Order Functions 📚
Let's explore some of the most commonly used higher-order functions in JavaScript:
1. **`map`** 🗺️
2. **`filter`** 🔍
3. **`reduce`** ➕
##### 1. `map` 🗺️
The `map` function creates a new array by applying a given function to each element of the original array.
```javascript
const numbers = [1, 2, 3, 4, 5];
const doubled = numbers.map(num => num * 2);
console.log(doubled); // [2, 4, 6, 8, 10]
```
In this example, `map` takes a function that doubles each number and applies it to every element in the `numbers` array.
##### 2. `filter` 🔍
The `filter` function creates a new array containing all the elements that pass a test implemented by a given function.
```javascript
const numbers = [1, 2, 3, 4, 5];
const evenNumbers = numbers.filter(num => num % 2 === 0);
console.log(evenNumbers); // [2, 4]
```
Here, `filter` takes a function that checks if a number is even and applies it to each element, returning only the even numbers.
##### 3. `reduce` ➕
The `reduce` function applies a function against an accumulator and each element in the array (from left to right) to reduce it to a single value.
```javascript
const numbers = [1, 2, 3, 4, 5];
const sum = numbers.reduce((accumulator, currentValue) => accumulator + currentValue, 0);
console.log(sum); // 15
```
In this case, `reduce` sums up all the numbers in the array, starting from an initial value of 0.
#### Custom Higher-Order Functions 🛠️
You can also create your own higher-order functions. Let's create a simple `repeat` function that repeats a given action a specified number of times.
```javascript
function repeat(action, times) {
for (let i = 0; i < times; i++) {
action(i);
}
}
repeat(console.log, 5);
// Output:
// 0
// 1
// 2
// 3
// 4
```
In this example, `repeat` takes a function (`action`) and a number (`times`), then calls the function the specified number of times.
#### Combining Higher-Order Functions 🔄
Higher-order functions can be combined to perform complex operations in a clean and readable way. For instance, let's filter even numbers from an array, double them, and then sum them up.
```javascript
const numbers = [1, 2, 3, 4, 5];
const result = numbers
.filter(num => num % 2 === 0)
.map(num => num * 2)
.reduce((acc, num) => acc + num, 0);
console.log(result); // 12 (2*2 + 4*2)
```
Here, we first filter out the even numbers, then double each of them, and finally sum them up.
### Conclusion 🎉
Higher-order functions are a cornerstone of functional programming in JavaScript. They allow you to write more declarative and modular code by abstracting common patterns into reusable functions. By mastering `map`, `filter`, `reduce`, and creating your own higher-order functions, you can significantly improve your coding skills and productivity.
Happy coding! 💻✨ | madhurop | |
1,862,183 | Voxel51 Filtered Views Newsletter - May 24, 2024 | Author: Harpreet Sahota (Hacker in Residence at Voxel51) Welcome to Voxel51’s bi-weekly digest of... | 0 | 2024-05-24T13:00:00 | https://voxel51.com/blog/voxel51-filtered-views-newsletter-may-24-2024/ | computervision, datascience, ai, machinelearning | _Author: [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker in Residence at [Voxel51](https://voxel51.com/))_
Welcome to Voxel51’s bi-weekly digest of the latest trending AI, machine learning and computer vision news, events and resources! [Subscribe to the email version](https://voxel51.com/#subscribe).
## 📰 The Industry Pulse
## Voxel51 Just Closed Its Series B!

Voxel51 just raised $30M in Series B funding led by Bessemer Venture Partners!
So, what are we gonna do with all that money? **Make visual AI a reality!** AI is moving fast, and visual AI will see massive growth and progress because of the abundance of image and video data. Now, more than ever, practitioners need tools to understand, explore, visualize, and curate datasets. We hope to make this more accessible for the community with FiftyOne.
The new funding will allow us to scale our team, support our open-source community, build a research team, and accelerate our product roadmap to support new data modalities and deeper integrations with the AI stack.
## Hugging Face is the Robin Hood of GPUs

Ok, that's probably not the best analogy because I’m sure they’re not robbing the rich. But they are giving to the poor…the GPU poor, that is.
Our friends at Hugging Face are [investing $10 million in free shared GPUs through the ZeroGPU program](https://www.theverge.com/2024/5/16/24156755/hugging-face-celement-delangue-free-shared-gpus-ai) to help developers, academics, and startups create new AI technologies!
Clem, the Hugging Face CEO, believes that if a few organizations dominate AI, it will be harder to fight later on. They hope to counter the centralization of AI advancements by tech giants like Google, OpenAI, and Anthropic, who have a significant advantage due to their vast computational resources. ZeroGPU lets multiple users or applications access shared GPUs concurrently, eliminating the need for dedicated GPUs and making them cost-effective and energy-efficient.
I hope this levels the playing field for smaller companies and GPU-poor indie hackers (like myself) who can't commit to long-term contracts with cloud providers for GPU resources.
Investing in the community and promoting open-source AI is a win-win for everyone; it's our greatest hope for a decentralized and accessible AI landscape.
## California is pushing for safer AI!

[Source](https://twitter.com/Scott_Wiener/status/1793102136504615297)
The Senate just passed SB 1047, dubbed the "Safe and Secure Innovation for Frontier Artificial Intelligence Models Act, a bill focused on ensuring the development of powerful AI is safe and responsible. Here's the rundown:
Strict Rules for Big AI: Companies making large, expensive AI models (think over $100 million to train) must follow specific safety rules. These include testing before release, strong cybersecurity, and monitoring after launch.
Whistleblower Protection: People working in AI labs will now have protection if they speak up about safety concerns.
Fair Pricing: No more price gouging or unfair pricing practices for AI tech.
CalCompute: The state will create a public cloud system called CalCompute, which will give startups and researchers the tools to work on big AI projects.
Open-Source Support: A new advisory council will help guide the development of safe and secure open-source AI. I just hope they put the right people on this council because it would be a major mistake if they had people from the tech giants on it.
This bill has the backing of big names in AI, like Geoffrey Hinton and Yoshua Bengio. It still needs to pass in the Assembly by August 31st, so let's see what happens!
## GitHub Gems: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers

Imagine a single, powerful AI artist that can take your written descriptions and create stunning images, videos, and even 3D models. That's what Lumina-T2X aims to be, and by sharing their work openly, the creators are inviting others to join them in pushing the boundaries of generative AI
While impressive, models like Sora and Stable Diffusion 3 lack detailed documentation and open-source code, making them hard to study and build upon. These models are often specialized for a single task (like image generation) and struggle to adapt to other modalities (like video). Lumina-T2X, however, transforms text into many modalities, resolutions, and durations using flow-based large diffusion transformers (Flag-DiT).
It’s also open source so researchers can study and build upon them! So, what is this model capable of? Check it out:
- **Lumina-T2I (Text-to-Image):** Generates realistic images at arbitrary resolutions and aspect ratios. It can even extrapolate to resolutions higher than those seen during training.
- **Lumina-T2V (Text-to-Video):** Creates 720p videos of varying lengths and aspect ratios, showing promise in generating coherent scenes and transitions
- **3D Object and Audio Generation:** While less detailed in the paper and repo, they also note the potential for generating multi-view 3D objects and audio from text.
It can do this via some unique innovations:
- **Flag-DiT Architecture:** This core component is inspired by Large Language Models (LLMs) and incorporates techniques like RoPE, RMSNorm, and flow matching for improved stability, flexibility, and scalability.
- Flag-DiT supports up to 7 billion parameters, extends sequence lengths (up to 128,000 tokens) and has faster training convergence and stable training dynamics.
- Lumina-T2X cleverly represents different media types (images, videos, etc.) as sequences of tokens, similar to how LLMs process text. The model can encode any modality (images, videos, multi-views of 3D objects, spectrograms) into a unified 1-D token sequence at any resolution, aspect ratio, and temporal duration. This allows it to handle various modalities within a single framework. Honestly, this is wild. I can't wait to write a more in-depth blog or tutorial with this plus FiftyOne.
- It's very configurable, and you can experiment with different text encoders, DiT parameter sizes, inference methods, and features like 1D-RoPE and image enhancement.
- It supports resolution extrapolation, which enhances the resolution of images (or signals, in general) beyond the limits of the original captured data. This means you can generate images/videos with out-of-domain resolutions not encountered during training.
And also, look at the image above…you can synthesize images from emojis! That’s dope. You can learn more by checking out:
- [The GitHub repository](https://github.com/Alpha-VLLM/Lumina-T2X)
- This [YouTube Video](https://www.youtube.com/watch?v=KFtHmS5eUCM)
- [The Lumina-T2X demo](http://106.14.2.150:10020/)
- [The Hugging Face Space](https://huggingface.co/spaces/Alpha-VLLM/Lumina-Next-T2I) (the same as the demo)
## 📙 Good Reads
Diffusion models feel like magic.
Over the last year, the magic has become increasingly real through impressive results in image synthesis. Now, this is being applied to the more challenging task of video generation. Video generation adds the complexity of requiring temporal consistency across frames and is limited by the difficulty of collecting large, high-quality video datasets.
In this super technical yet very approachable [blog post](https://lilianweng.github.io/posts/2024-04-12-diffusion-video/) by the incomparable [Lilian Weng](https://x.com/lilianweng?lang=en) (from OpenAI), you’ll learn that diffusion models aren’t magic. They’re just a giant pile of linear algebra and computation!
The blog serves as a history and survey of diffusion models for video generation, which is a type of blog I absolutely love to read. Below are my main takeaways.
**There are two main approaches to video generation with diffusion models:**
**1. Building from the Ground Up**
This approach involves designing and training diffusion models specifically for video. Key techniques include:
- **3D U-Nets:** Extending the successful 2D U-Net architecture to 3D by separating spatial and temporal processing. Spatial layers handle individual frames using 3D convolutions and attention, while temporal layers utilize attention mechanisms across frames to ensure smooth transitions.
- **Diffusion Transformers (DiT):** This architecture processes videos as sequences of spacetime patches, leveraging Transformers' power to capture complex relationships within and across frames.
- **Reconstruction Guidance:** This method conditions the generation of subsequent frames on preceding ones, ensuring a coherent narrative flow.
**2. Leveraging Image Power**
This approach cleverly adapts pre-trained image diffusion models for video generation, capitalizing on the rich knowledge acquired from vast image datasets. This can be achieved through:
- **Fine-tuning:** Adding temporal convolution and attention layers to pre-trained image models and then fine-tuning them on video data, allowing the model to learn video-specific dynamics.
- **Zero-Shot Adaptation:** Ingenious techniques like motion dynamics sampling, cross-frame attention, and hierarchical sampling enable video generation from image models without additional training.
**Beyond Architecture:**
As always, curating a dataset is critical for video generation performance.
- **Dataset Curation:** Filtering for high-quality, captioned video clips is crucial for training effective models.
- **Training Strategies:** Pre-training on large image datasets before fine-tuning on video data significantly boosts performance.
Diffusion models show great promise for high-quality video generation. However, ongoing research focuses on enhancing efficiency, improving temporal consistency, and achieving finer control over the generated content. As these challenges are addressed, we can expect even more impressive and realistic videos generated by AI in the near future.
## 🎙️ Good Listens
Dwarkesh blesses us with another banger episode featuring OpenAI co-founder John Schulman.
[This podcast episode](https://www.dwarkeshpatel.com/p/john-schulman) takes you straight to the bleeding edge of AI with John Schulman, the mastermind behind ChatGPT and co-founder of OpenAI. It's your chance to get a glimpse into the mind of one of the people shaping the future of, well, everything.
Admittedly, I have a mind that is easily blown, but...this is, indeed, a mind-blowing conversation about where AI is, where it's going, and what happens when things intelligence gets general and AI becomes as intelligent as us. Spoiler alert: it involves a whole lot of careful planning and a little bit of freaking out.
John shares how OpenAI thinks about these challenges, from making sure AI stays in its lane to figuring out how to hit the brakes if things start moving too fast or swerving into oncoming traffic.
Here are some things they discuss on the show:
- **Pre-training vs. Post-training:** Schulman explains the difference between pre-training, where models learn to imitate internet content, and post-training, where they are refined for specific tasks like being helpful assistants.
- **Future Capabilities:** He predicts models will soon handle more complex, multi-step tasks, like coding projects, due to improved long-horizon coherence and sample efficiency.
- **Generalization:** Schulman highlights the remarkable ability of these models to generalize from limited data, such as learning to function in multiple languages or avoid making unrealistic claims.
- **Path to AGI:** While acknowledging the possibility of AGI emerging sooner than expected, Schulman emphasizes the need for caution and coordination among AI developers to ensure safe deployment.
- **Safety and Alignment:** He outlines potential safeguards, such as sandboxing, monitoring, and red-teaming, to mitigate risks associated with highly capable AI systems.
**Hypothetical Scenario:**
The interview goes into a hypothetical scenario where AGI arrives in the next few years. Schulman and Dwarkesh discuss the importance of:
- Pausing further training and deployment.
- Coordinating among AI labs to establish safety protocols.
- Developing robust testing and monitoring systems.
This conversation is a must-listen for anyone even remotely interested in the future that AI is building. Schulman doesn't shy away from the big questions about AGI and its implications. He hints that incredibly powerful AI systems could become a reality sooner than we think while underscoring the immense responsibility that comes with this power.
If you're reading this, chances are you're likely not just passively observing the development of AI; you're an active participant in shaping its trajectory. The choices made today by people like us - researchers, developers, practitioners and policymakers - will determine whether this powerful technology ushers in an era of unprecedented progress or leads us down a more dangerous path.
## 👨🏽🔬 Good Research: Deciphering the Code of Vision-Language Models: What Really Matters?
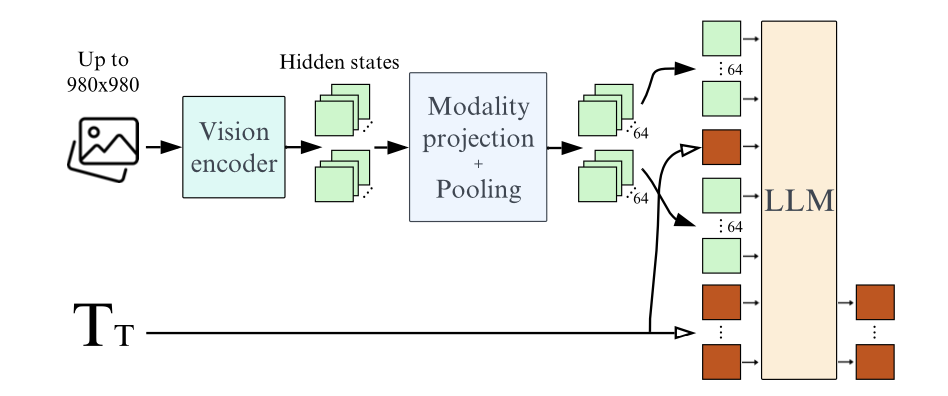
Modern Vision-Language Models (VLMs) have remarkable capabilities.
They can "see" an image, understand and answer complex questions, generate detailed captions, or even write a story inspired by the scene. However, building these powerful models involves navigating a maze of design choices, from choosing the right architecture to selecting the best pre-trained components and optimizing the training process.
The paper [_What matters when building vision-language models?_](https://arxiv.org/abs/2405.02246), like its title, asks an important question: **What truly matters when building high-performing VLMs? **
Rather than relying on intuition or anecdotal evidence, the authors embark on a rigorous experimental journey to uncover the impact of key design decisions. Through extensive ablations and analysis, the authors share six findings that provide valuable guidance for VLM development:
- **Pre-trained backbones matter, a lot:** The quality of both vision and language backbones significantly impacts the final VLM performance. Notably, the language model's quality matters more for a fixed parameter count. This highlights the importance of strong unimodal foundations.
- **Fully autoregressive vs. cross-attention:** While cross-attention architectures excel when backbones are frozen, fully autoregressive models outperform them when backbones are trained, even with fewer parameters. However, training fully autoregressive models with unfrozen backbones can be unstable.
- **LoRA for Stability and Efficiency:** Low-rank adaptation (LoRA) stabilizes the training of fully autoregressive models with unfrozen backbones and allows for training with a lower memory footprint.
- **Learned Pooling for Efficiency:** Reducing the number of visual tokens through learned pooling significantly improves training and inference efficiency without sacrificing performance. This contrasts with previous findings that more visual tokens lead to better results.
- **Preserving Aspect Ratio and Resolution:** Adapting vision encoders to handle variable image sizes and aspect ratios maintains performance while offering flexibility and efficiency during training and inference.
- **Image Splitting for Performance:** Splitting images into sub-images during training boosts performance, especially for tasks involving text extraction, at the cost of increased computational cost.
**The authors use these findings to build the Idefics2-8B model.** By the way, [I just added support for Idefics2-8B via the Replicate API to our VQA Plug-in for FiftyOne!](https://github.com/jacobmarks/vqa-plugin)
Now, I’ll summarize the paper using the [PACES method](https://medium.com/@jasoncorso/how-to-read-conference-papers-fa78c75f78aa).
### Problem
The main problem the paper tackles is the **lack of clarity and systematic understanding** regarding which design choices truly contribute to better performance in **Vision-Language Models (VLMs)**. The authors aim to bring more rigorous experimental evidence to the field of VLMs. They investigate existing architectural and training choices to determine their impact on VLM performance. They then use these findings to guide the development of their high-performing Idefics2 model.
The paper focuses on **improving the design and training of VLMs **through a better understanding of existing techniques and their practical implications.
### Approach
The paper investigates the impact of different design choices in Vision-Language Models (VLMs) by conducting extensive ablation studies on model architectures, pre-trained backbones, and training procedures. Using a fully autoregressive architecture with LoRA for training stability, learned pooling for efficiency, and carefully chosen pre-trained backbones leads to superior VLM performance, as demonstrated by their Idefics2 model.
### Claim
The authors claim that their rigorous analysis of various design choices in Vision-Language Models provides much-needed clarity and experimentally-backed guidance for building higher-performing VLMs.
### Evaluation
The paper evaluates its approach by conducting controlled experiments (ablations) to compare different design choices in VLMs.
They use four main benchmarks for evaluation: VQAv2, TextVQA, OKVQA, and COCO, covering visual question answering, OCR abilities, external knowledge, and image captioning. The baselines consist of different configurations of VLMs, varying architecture, pre-trained backbones, and training methods. The evaluation setup seems sound and aligns well with the paper's goal of understanding the impact of design choices on VLM performance. They primarily focus on 4-shot performance, emphasizing few-shot learning capabilities.
One potential limitation is the reliance on a relatively small number of benchmarks, which might not fully capture the nuances of different design choices across a wider range of VLM tasks.
### Substantiation
The paper successfully substantiates its claim by demonstrating through empirical evidence that carefully considering architectural and training choices significantly impacts VLM performance. The authors' rigorous ablations and the resulting high-performing Idefics2 model provide valuable, practical guidance for the VLM research community.
This research provides a data-driven roadmap for building better VLMs, moving beyond intuition to understand what drives performance. The authors' rigorous evaluations and the resulting Idefics2-8B model empower researchers to build more capable and efficient VLMs, pushing the boundaries of machine perception.
## 🗓️. Upcoming Events
Check out these upcoming AI, machine learning and computer vision events! [View the full calendar and register for an event.](https://voxel51.com/computer-vision-events/)

| jguerrero-voxel51 |
1,863,981 | Bizarre Events and Celebrity Management | Wedding Planning in Nagpur | Welcome to Nagpur's premier event management company, where dreams become reality and occasions turn... | 0 | 2024-05-24T12:58:28 | https://dev.to/bizarre_events_b65574460e/bizarre-events-and-celebrity-management-wedding-planning-in-nagpur-40cg | weddingplanner, eventmanagement, eventplanner | Welcome to Nagpur's premier [event management company](https://www.thebizarreevents.com/), where dreams become reality and occasions turn into unforgettable memories. At our firm, we specialize in orchestrating seamless experiences for a diverse range of events, including weddings, corporate gatherings, brand activations, and celebrity engagements. With meticulous attention to detail and a passion for perfection, our team ensures that every aspect of your event is flawlessly executed, from conceptualization to execution. Whether you're envisioning an opulent wedding ceremony, a high-profile corporate affair, or a star-studded brand launch, our expertise in event planning, coordination, and celebrity management guarantees a truly extraordinary and stress-free experience. Let us transform your vision into an extraordinary event, leaving a lasting impression on your guests and making your occasion the talk of the town. | bizarre_events_b65574460e |
1,863,968 | Make Commit in Your React Project Format-Test-Build Ready with Husky - A Step-by-Step Guide | How often have you encountered build failures, test failures lint errors, or inconsistent code... | 0 | 2024-05-24T12:57:50 | https://dev.to/lico/make-commit-in-your-react-project-format-test-build-ready-with-husky-a-step-by-step-guide-545i | react, webdev, tutorial, productivity | > How often have you encountered build failures, test failures lint errors, or inconsistent code formatting after committing your code?
In this article, I will show you how to avoid those issues step by step using `husky` and `lint-staged`.
Before diving in, let's explorer what each tool is used for.
- [Husky](https://typicode.github.io/husky/): It enables us to easily use [git hooks](https://git-scm.com/docs/githooks). We can define commands when a specific behavior happens. We will use `pre-commit`, which is hooked before creating a commit.
- [Eslint](https://eslint.org/): It analyzes our code to quickly find problems. We will use the default setup provided by Vite.
- [Prettier](https://prettier.io/): It makes our code prettier by formatting. It supports many languages and editors.
- [lint-staged](https://github.com/lint-staged/lint-staged): It enables us to run linters against staged git files. `eslint` and `prettier` will be executed by it.
I will use `pnpm` as a package manager, but feel free to use any package you prefer.
---
## 1\. Set Up React Project With Vite
```
> pnpm create vite
```
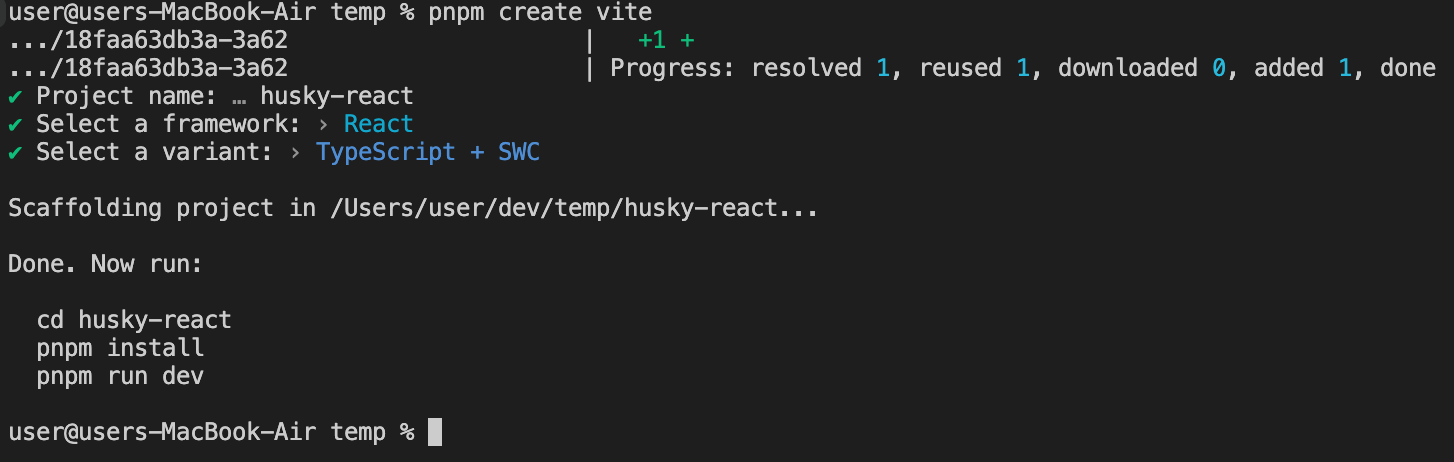
After setting a project, let's install the dependencies by executing the command `pnpm install`.
Run the dev server, and let's see if the project was successfully installed.

---
## 2\. Set Up Vitest for React
Let's write some test code to be executed during `pre-commit` stage. I will use [vitest](https://vitest.dev/) and [testing-library](https://testing-library.com/) in this project to test our code.
```
> pnpm install -D @testing-library/jest-dom vitest jsdom @testing-library/react
```
Create the `vitest.config.ts` file to configure the test environment.
```typescript
import { defineConfig } from 'vitest/config';
import react from '@vitejs/plugin-react-swc';
export default defineConfig(({ mode }) => ({
plugins: [react()],
resolve: {
conditions: mode === 'test' ? ['browser'] : [],
},
test: {
environment: 'jsdom',
setupFiles: ['./vitest-setup.js'],
},
}));
```
Create the `vitest-setup.js` file, which enables us to utilize features for testing React components.
```javascript
import '@testing-library/jest-dom/vitest';
```
Add a type in `tsconfig.json` file to provide the necessary types for DOM testing.
```
...
"types": ["@testing-library/jest-dom"],
...
```
---
## 3\. Write Test Code
Now, we are ready to test React components. Let's test our `App` component.
Create the `App.test.tsx` file in the same directory where `App.tsx` file is.
```typescript
import { describe, test, expect } from 'vitest';
import { render } from '@testing-library/react'
import App from './App';
describe('App',()=>{
test('count should be increased when the button is clicked.', async () => {
const app = render(<App />);
const button = await app.findByText(/^count/);
expect(button.textContent).toBe('count is 0');
await button.click();
expect(button.textContent).toBe('count is 1');
});
});
```
Add `test` script into `package.json` file. We run `vitest` file with the option [run](https://vitest.dev/guide/#command-line-interface) to execute once.
```json
...
"test": "vitest run"
...
```
Let's test our code by the command `pnpm run test`.
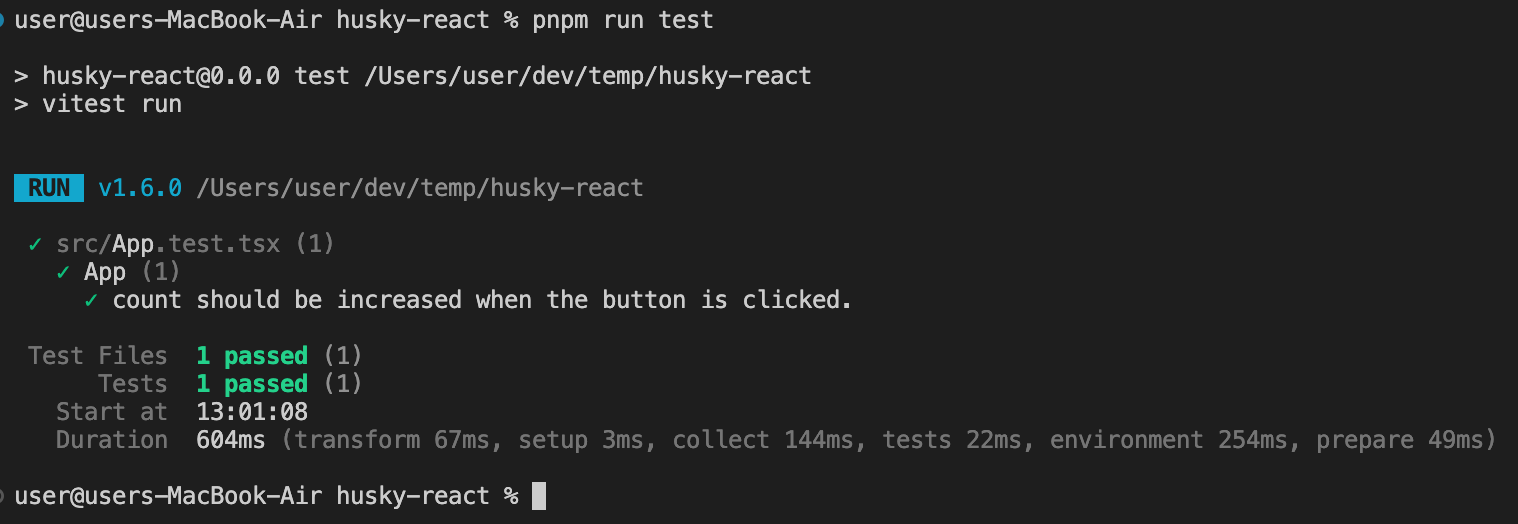
---
## 4\. Set Up Prettier
Install `prettier`.
```
> pnpm install -D prettier
```
Create the `.prettierrc` file at the root, which serves as the [prettier configuration file](https://prettier.io/docs/en/configuration.html).
```json
{
"trailingComma": "es5",
"tabWidth": 2,
"semi": true,
"singleQuote": true
}
```
Let's format `App.tsx` file using `prettier` to see if it works.
```
> npx prettier --write ./src/App.tsx
```
Before -
After -
---
## 5\. Set Up lint-staged
Install `lint-staged`.
```
> pnpm install --save-dev lint-staged
```
Create the `.lintstagedrc` file which is a configuration file for lint-staged.
```json
{
"src/**/*.{ts,tsx}": [
"eslint --fix",
"prettier --write"
]
}
```
I will lint only typescript files but you can configure it whatever you want.
To test git-staged files, we need to initialize `git` first.
```
> git init
```
Let's test with one file, `main.tsx`.
```
> git add ./src/main.tsx
> npx lint-staged
```
Before -
After -
As you can see, the code is formatted by `prettier`.
I will make an error in the `main.ts` file and add it to the git staged.
Let's see if `eslint` lets us know there is a problem.
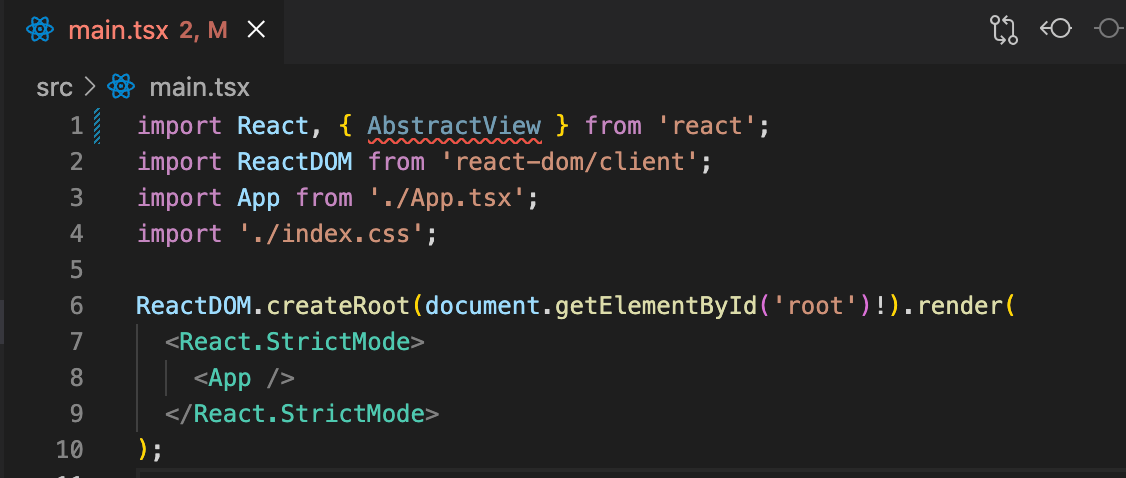
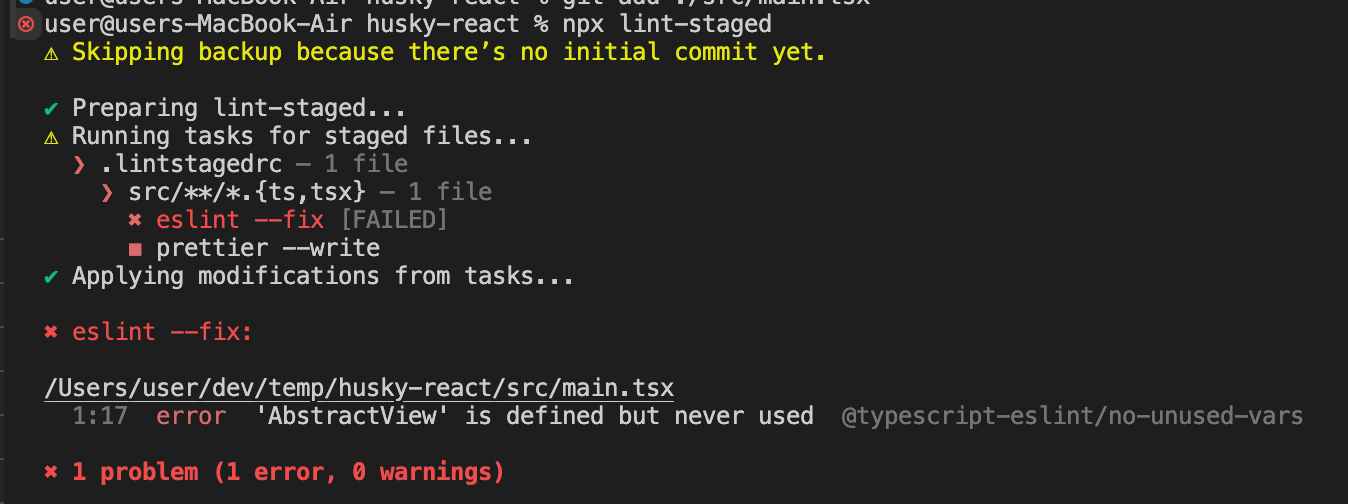
`eslint` successfully found the problem.
---
## 6\. Set Up husky
Install `husky`.
```
> pnpm install --save-dev husky
```
Initialize husky
```
> npx husky init
```
After this command, you will see the `.husky` directory under the root. You don't need to worry about the `_` folder, it comes with `husky` when installed and handles the git hooks for us.
Let's customize the `pre-commit` hook.
[pre-commit]
```
pnpm run test
npx lint-staged
pnpm run build
```
The commit will be ignored if one of those commands fails.
Let's add all the files and make a commit.
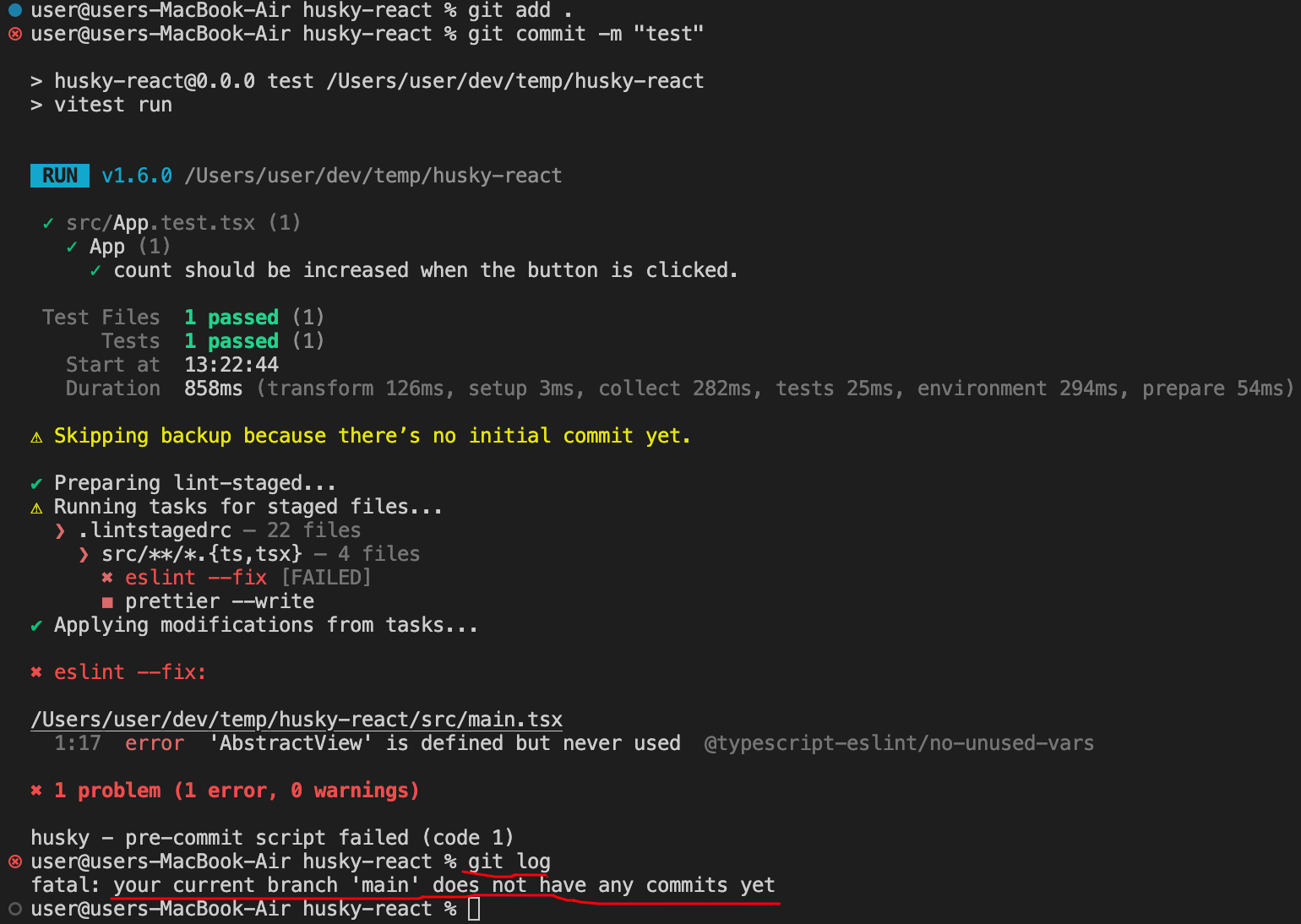
Our commit failed because of the unused imported package we added in the last step, and as you can see, the commit is ignored since `eslint` throws an error.
Let's get rid of the error and create a commit again.
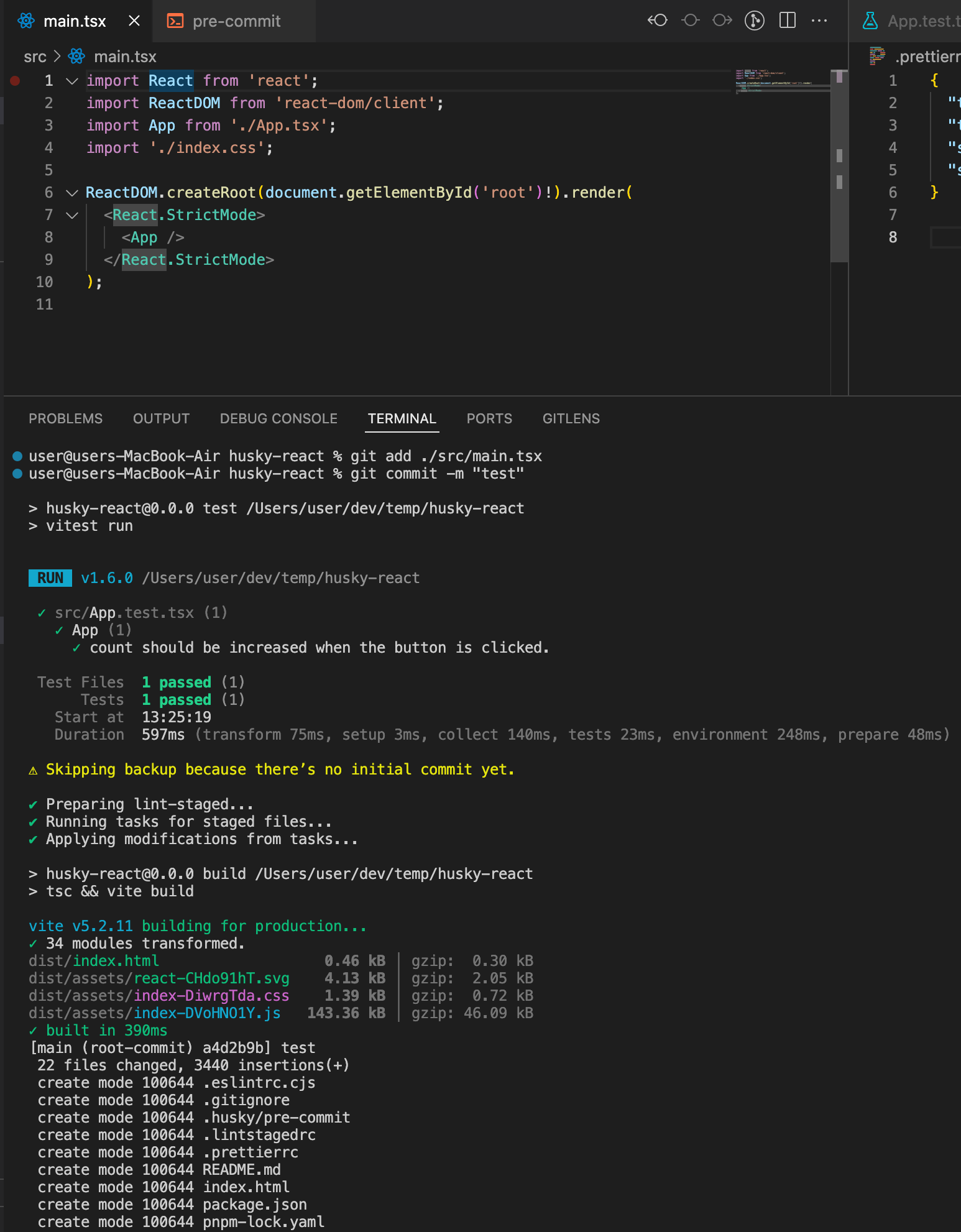
Our new commit is successfully done.
---
## Wrap up
Now, each commit guarantees you that the commit is formatted, tested, and buildable.
Keep in mind that the configuration can be different depending on your project or your goal. Since we could write any command in `pre-commit`, it could do more complex tasks.
I hope you found this article helpful.
Happy Coding! | lico |
1,863,921 | MAKING A GAME IN HTML AND URSINA WITH THE HELP OF GEMINI AND CHATGPT | The game I chose for this post an action game in Html and Ursina. HTML A game... | 0 | 2024-05-24T12:57:42 | https://dev.to/dino2328/making-a-game-in-html-and-ursina-with-the-help-of-gemini-and-chatgpt-part-1-html-5bak | webdev, javascript, beginners, ai | ## The game
I chose for this post an action game in Html and Ursina.
## HTML
A game in html is pretty difficult but let's try if gemini and chatgpt can do. I gave the prompt to them: "An action game in html,JavaScript and CSS and its code". Both the AI's gave me pretty fast. Gemini gave me 119 lines of code and nothing worked in the game except the score was increasing. now it was ChatGpt's time. ChatGpt gave me 67 lines of code .No controls worked except for the up arrow which is also after some time stopped .They was no score Gemini had a score but this did not have.
After a deep thinking I decided to give the point to Gemini Because Gemini had score and many other things but chatgpt had only two things that is the enemy moving and only the up arrow working
Points: Gemini:1
ChatGpt:0
## URSINA
Ursina is a game engine so I think they will do better this time. I decided to give the prompt 'MAKE AN ACTION GAME IN URSINA AND I WAANT ITS CODE'. Both Gemini and chatgpt gave me the code and it was time to implement the code. Gemini gave me 70 lines of code. It didn't even show up the game. Every time I clicked the run button it would say an error occurred and show some line of the code and when I tell it to Gemini it would tell me 'YOUR ABSOLUTELY RIGHT' and it would rectify it and again a error occurs in another line of the code. This happened nearly 20 times and after the 20th time I decided to quit and give no point to gemini this round. After this it was the chatgpt's round. It wnted to make a game but it did not but that was also nice. It never gave me a error. So I decided without thinking even for a second to give point to chatgpt
Points:chatgpt:1
gemini:1
So this was a tie between chatgpt and gemini.
| dino2328 |
1,863,980 | Basic CRUD Operations Using Golang, Gin Gonic, and GORM | Building web applications in Golang is both fun and efficient. Using powerful frameworks like Gin... | 0 | 2024-05-24T12:56:40 | https://dev.to/awahids/basic-crud-operations-using-golang-gin-gonic-and-gorm-53 | go, gorm, gin, restapi | Building web applications in Golang is both fun and efficient. Using powerful frameworks like Gin Gonic for the web layer and GORM for ORM (Object-Relational Mapping) makes it easier to create robust and maintainable applications. In this tutorial, we'll demonstrate how to implement basic CRUD operations in a book management system.
#### Project Structure
We will organize our project using the following structure to maintain clean and manageable code:
```
belajar-go/
│
├── cmd/
│ └── main.go
├── configs/
│ └── dbConfig.go
├── internal/
│ ├── delivery/
│ │ ├── handlers/
│ │ │ └── bookHandler/
│ │ │ └── bookHandler.go
│ │ ├── data/
│ │ │ ├── request/
│ │ │ │ └── bookReq/
│ │ │ │ └── bookRequest.go
│ │ │ └── response/
│ │ │ ├── bookRes/
│ │ │ │ └── bookResponse.go
│ │ │ └── response.go
│ │ └── router/
│ │ ├── bookRouter/
│ │ │ └── bookRouter.go
│ │ └── router.go
│ ├── domain/
│ │ ├── models/
│ │ │ └── books.go
│ │ ├── repositories/
│ │ │ ├── bookRepo/
│ │ │ │ └── bookRepo.go
│ │ └── services/
│ │ ├── bookService/
│ │ │ └── bookService.go
│ └── infrastructure/
│ └── database/
│ ├── database.go
│ └── migrations.go
├── pkg/
│ ├── utils/
│ │ └── base.go
│ └── helpers/
│ └── errorPanic.go
├── .env.example
├── .gitignore
├── go.mod
└── go.sum
```
#### Setting Up the Project
1. **Initialize the project**:
```bash
go mod init github.com/your-username/belajar-go
go get -u github.com/gin-gonic/gin
go get -u gorm.io/gorm
go get -u gorm.io/driver/postgres
```
2. **Database Configuration (`configs/dbConfig.go`)**:
```go
package configs
import (
"gorm.io/driver/postgres"
"gorm.io/gorm"
)
func ConnectDB() (*gorm.DB, error) {
dsn := "host=localhost user=gorm password=gorm dbname=gorm port=9920 sslmode=disable TimeZone=Asia/Shanghai"
db, err := gorm.Open(postgres.Open(dsn), &gorm.Config{})
if err != nil {
return nil, err
}
return db, nil
}
```
3. **Models (`internal/domain/models/books.go`)**:
```go
package models
import (
"time"
)
type Book struct {
ID uint `gorm:"primaryKey"`
UUID string `gorm:"type:uuid;default:uuid_generate_v4()"`
Title string `gorm:"size:255"`
Author string `gorm:"size:255"`
Year int
CreatedAt time.Time
UpdatedAt time.Time
}
```
4. **Repositories (`internal/domain/repositories/bookRepo.go`)**:
```go
package repositories
import (
"github.com/your-username/belajar-go/internal/domain/models"
"gorm.io/gorm"
)
type BookRepository struct {
Db *gorm.DB
}
func NewBookRepository(Db *gorm.DB) *BookRepository {
return &BookRepository{Db: Db}
}
// Implement CRUD operations
```
5. **Services (`internal/domain/services/bookService.go`)**:
```go
package services
import (
"github.com/your-username/belajar-go/internal/domain/models"
"github.com/your-username/belajar-go/internal/domain/repositories"
)
type BookService struct {
repo *repositories.BookRepository
}
func NewBookService(repo *repositories.BookRepository) *BookService {
return &BookService{repo: repo}
}
// Implement service methods
```
6. **Handlers (`internal/delivery/handlers/bookHandler.go`)**:
```go
package handlers
import (
"net/http"
"github.com/gin-gonic/gin"
"github.com/your-username/belajar-go/internal/domain/models"
"github.com/your-username/belajar-go/internal/domain/services"
)
type BookHandler struct {
bookService *services.BookService
}
func NewBookHandler(bookService *services.BookService) *BookHandler {
return &BookHandler{bookService: bookService}
}
// Implement handler methods
```
7. **Router (`internal/delivery/router/bookRouter.go`)**:
```go
package router
import (
"github.com/gin-gonic/gin"
"github.com/your-username/belajar-go/internal/delivery/handlers"
"github.com/your-username/belajar-go/internal/domain/repositories"
"github.com/your-username/belajar-go/internal/domain/services"
"gorm.io/gorm"
)
func BookRouter(group *gin.RouterGroup, db *gorm.DB) {
// Setup routing
}
```
8. **Main (`cmd/main.go`)**:
```go
package main
import (
"github.com/gin-gonic/gin"
"github.com/your-username/belajar-go/configs"
"github.com/your-username/belajar-go/internal/delivery/router"
)
func main() {
// Setup server
}
```
### Conclusion
By following this guide, you've learned how to create a basic CRUD application using Golang, Gin Gonic, and GORM. This structure helps in maintaining and scaling your application effectively. Happy coding!
For full code [klick here](https://blog.awahids.my.id/blog/golang/example-basic-crud-using-golang-gin-gonic-gorm) | awahids |
1,863,978 | Luxand.cloud Face Recognition Attendance System | Luxand.cloud's automated attendance system is based on the face recognition technology. It is widely... | 0 | 2024-05-24T12:55:35 | https://dev.to/luxandcloud/luxandcloud-face-recognition-attendance-system-54d0 | productivity, ai, machinelearning, webdev | Luxand.cloud's automated attendance system is based on the face recognition technology. It is widely used in various scenarios, including employee time management, gym member attendance tracking, student attendance management, and more.
## Attendance System Use Cases
- **Employee Attendance Management**. To track employees' attendance and automatically generate timesheets, automated clock-in and out systems are usually used. In this case, the face recognition technology is a valuable tool that helps to eliminate time fraud, such as buddy punching (one employee clocking in or out for another), by implementing reliable identification methods.
- **Student Attendance Management**. Luxand.cloud's attendance system not only enhanced security since it's based on face recognition but also provide real-time attendance data, allowing parents, teachers, and administrators to monitor student attendance patterns and identify potential attendance issues promptly.
- **Gym Member Attendance Tracking**. Luxand.cloud's face recognition attendance systems automate the check-in process, eliminating the need for members to fumble with cards or paper forms. Gym members simply scan their faces in front of a terminal, and their attendance is instantly recorded and stored securely.
We've showed how our system works here: [Face Recognition Attendance System Video](https://www.youtube.com/watch?v=hbDzXldBNhU&list=TLGG36w1wRrr3hUyNDA1MjAyNA&t=1s&ab_channel=Luxandcloud) | luxandcloud |
1,863,976 | State Management with Zustand | Heya again! As we all know state management can be challenging, especially when we have parent with... | 0 | 2024-05-24T12:53:35 | https://dev.to/vikirobles/state-management-with-zustand-639 | reactjsdevelopment, react, state | Heya again!
As we all know state management can be challenging, especially when we have parent with nested children and passing props down from a parent component to children..and normally in the past I would use context from React together with a provider..but it happened that somewhere in the middle between the children the state wasn't updating correctly. So I was looking around for an alternative and came across with [zustand](https://zustand-demo.pmnd.rs/)
I was working on a table with some user information and a sidebar that shows the information of the user that you click, as in picture below.
So I created a store:
```js
import { create } from 'zustand'
type User = {
id: string
name: string
address: string
emailAddress: string
}
type UsersStore = {
selectedUser: Applicant | null
handleOnClick: (user: User) => void
}
export const useUsersStore = create<UsersStore>((set) => ({
selectedUser: null,
handleOnClick: (user) => set({ selectedUser: user }),
}))
```
Then on the child component ``user`` I just retrieve the value that I needed.
```js
type UserProps = {
user: UserModel
}
export default function UserProfile({ user }: UserProps) {
const { handleOnClick } = useUsersStore()
return (
<TableRow
key={user.id}
className="cursor-pointer"
onClick={() =>
handleOnClick({
id: user.id,
name: user.name,
address: user.address,
emailAddress: user.emailAddress,
})
}
>
```
Then on the sidebar I retrieve the user object.
```js
export default function UserProfileSidebar() {
const { selectedUser } = useUsersStore()
return (
<div className="flex flex-col" id={selectedUser?.id}>
```
Now when I click a user's row I can see the ``users details`` on the sidebar on the right.
Of course on the parent component i just pass the ``user`` object such as:
```js
{usersData.map((applicant) => (
<UserProfile key={user.id} user={user} />
))}
```
In the case you can just retrieve the value you need from the store and you wont have to worry about passing props between components plus is safer, easier and less costly. | vikirobles |
1,863,975 | How Does Google Photos Recognize the Names and Faces? | Have you ever scrolled through Google Photos and marveled at its ability to recognize faces in your... | 0 | 2024-05-24T12:52:32 | https://dev.to/luxandcloud/how-does-google-photos-recognize-the-names-and-faces-27eb | googlecloud, google, ai, discuss | Have you ever scrolled through Google Photos and marveled at its ability to recognize faces in your photos? It's almost like magic, right? Well, not quite! Today, we'll delve into the fascinating features of Google Photos' face recognition, uncovering how it works, its benefits, and some key considerations.
## How Does Face Recognition in Google Photos Work?
Google Photos uses a technology called Face Groups to recognize faces in your photos. Here's a breakdown of how it works:
- Face detection. First, Google Photos scans your photos to detect faces. This involves identifying regions within images that likely contain a face, regardless of orientation, lighting conditions, or facial expressions. To precisely identify faces, the technology employs machine learning algorithms trained on enormous datasets.
- Face alignment. After detecting faces, the following step is to align them. This entails converting the recognized faces into a standard format, ensuring that characteristics such as the eyes, nose, and mouth are consistently positioned. This normalization improves the accuracy of the recognition process.
- Feature extraction. The aligned faces are then analyzed to extract distinctive features. Google Photos uses deep learning models, particularly Convolutional Neural Networks (CNNs), to create a numerical representation (often called an embedding) of each face. This embedding captures the unique characteristics of a person’s face.
- Face recognition. With these embeddings, Google Photos compares the numerical representations of faces across your photo collection. Similar embeddings are grouped together, suggesting they belong to the same person. This comparison is done using distance metrics, where smaller distances between embeddings indicate greater similarity.
- Clustering. The system divides pictures into clusters based on the similarity of facial embeddings. Each cluster refers to a distinct individual. Google Photos may request your assistance in labeling these clusters (e.g., by naming them), which would increase its accuracy and personalization.
It's important to remember that this technology isn't perfect. Google acknowledges that accuracy may vary, but it's estimated to be around 80-85%. You can always review and edit the groupings as needed.
Learn more here: [How Does Google Photos Recognize the Names and Faces?](https://luxand.cloud/face-recognition-blog/how-does-google-photos-recognize-the-names-and-faces/?utm_source=devto&utm_medium=how-does-google-photos-recognize-the-names-and-faces) | luxandcloud |
1,863,974 | AutoRFP.ai: Elevating RFP Processes with AI Precision. | AutoRFP.ai: Revolutionizing RFP Management AutoRFP.ai transforms the cumbersome RFP (Request for... | 0 | 2024-05-24T12:52:32 | https://dev.to/autorfpai/autorfpai-elevating-rfp-processes-with-ai-precision-156n | ai, opensource, saas | [AutoRFP.ai](https://autorfp.ai/): Revolutionizing RFP Management
[AutoRFP.ai](https://autorfp.ai/) transforms the cumbersome RFP (Request for Proposal) process with advanced AI technology, providing unparalleled efficiency and accuracy.
Key Features:
AI-Powered Response Generation: Utilizing cutting-edge generative AI, AutoRFP.ai swiftly crafts high-quality responses to RFPs, outperforming traditional methods.
Versatile AI Search and Response Engine: Capable of handling various types of questionnaires, including RFPs and security questionnaires, in seconds.
Trusted by Leading Companies: Trusted by renowned companies like SugarCRM and Workforce.com, AutoRFP.ai operates across 30+ countries, spanning healthcare, professional services, and tech sectors.
Sales Enablement: Enhance sales effectiveness with instant, natural language answers sourced from your knowledge base.
Seamless Integration: Integrate effortlessly with popular collaboration platforms like Teams and Slack, streamlining workflow and communication.
[AutoRFP.ai](https://autorfp.ai/) revolutionizes RFP management, empowering businesses to win more deals in less time, all while maintaining exceptional quality and precision.
 | autorfpai |
1,863,973 | How to display Latest Blogs on Github Profile? | In this post, we will create a Workflow which updates our GitHub Profile with out latest Blogs on... | 0 | 2024-05-24T12:51:34 | https://dev.to/zemerik/how-to-display-latest-blogs-on-github-profile-2la5 | github, devto | In this post, we will create a Workflow which updates our GitHub Profile with out latest Blogs on dev.to. To do this, you will need:
- A GitHub Account
- A little of passion
## LINKS:
- My GitHub (You can find an example here) - https://github.com/Zemerik/Zemerik
- YouTube Video - https://youtu.be/As7KgTZOrlE
- Source code - https://gist.github.com/Zemerik/ebb6f6af7c64173adf22aab5cd2c68a7
- Support - https://discord.gg/td5xqmzEcg
## 1. SET UP README.MD
- The first step in this process, is to define where we want our blogs. To do that, copy paste the following code in your README.md where you want your blogs:
```
<!-- BLOG-POST-LIST:START -->
<!-- BLOG-POST-LIST:END -->
```
> NOTE: Your blogs will be showing in the middle of the two comments.
## 2. WORKFLOW
- The next step in this process is to create a workflow to update our README.
- Create a `blog-post-workflow.yml` file in the `.github/workflows/` directory. Ensure your directory has no typo's!
- We now need to write the workflow in the file which we created. Copy paste the code below into that file:
```yml
name: 📚Blogs
on:
schedule:
# Runs every hour
- cron: '0 * * * *'
workflow_dispatch:
jobs:
update-readme-with-blog:
name: ✅Update with latest Blogs
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: gautamkrishnar/blog-post-workflow@master
with:
max_post_count: "4"
feed_list: "https://dev.to/feed/YOUR DEV.TO USERNAME HERE"
```
> Remember to add your Dev.to username at the end of the URL on the last line
## 3. ACTIONS SETTINGS:
- Head over to the Settings tap located at the top.

- Navigate your way to `Actions > General` Tab from the left.
- Ensure that your settings match the settings below
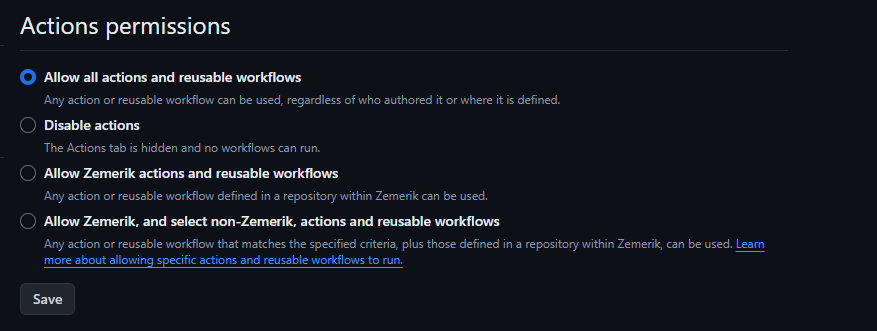
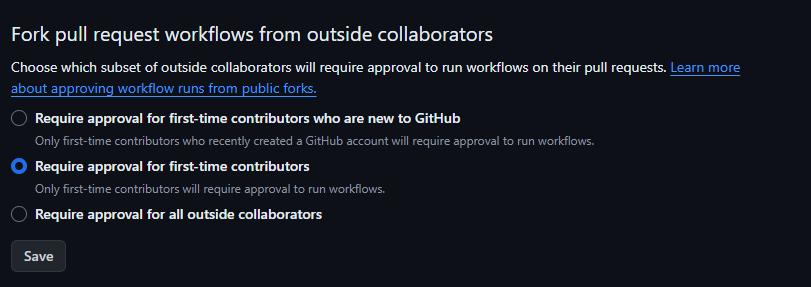
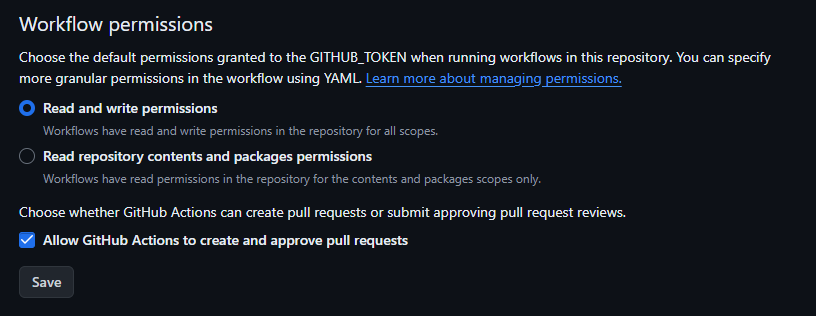
## 4. EXECUTING:
- Finally, we are ready to run our workflow. To do so, first head over to the `Actions` tab on the top

- Select `📚Blogs` from the menu on the left.
- Click on the `Run workflow` dropdown, and click the `Run workflow` button.

### YOUR README SHOULD NOW HAVE BEEN UPDATED WITH YOUR LATEST BLOGS
## SUMMARY:
In this blog, we successfully created and executed a workflow to update our Github Profile's README with our latest blogs on Dev.to. For any kind of support, you can refer to the `Links` section at the top.
### THANKS FOR READING. HOPEFULLY YOU FOUND THIS BLOG HELPFUL!!! | zemerik |
1,863,972 | 6 Profitable Micro SaaS Ideas in 2024 | The term MicroSaaS refers to a category of software-as-a-service (SaaS) businesses that target a... | 0 | 2024-05-24T12:50:07 | https://shipped.club/blog/6-micro-saas-ideas | saas, webdev, product | The term MicroSaaS refers to a category of software-as-a-service (SaaS) businesses that target a narrow, niche market with specialized software solutions.
Some of the key characteristics that define a MicroSaaS are:
1. **Niche Focus**: MicroSaaS businesses typically address a specific problem or serve a specialized segment of users within a larger industry. This focus allows them to meet the needs of a particular customer base very effectively.
2. **Small Team or Solo Founder**: Unlike larger SaaS companies, MicroSaaS businesses often operate with very small teams, sometimes just a solo founder. This lean operation helps keep costs low while maximizing flexibility and responsiveness to customer needs.
3. **Low Overhead**: Due to the small team size and niche focus, MicroSaaS companies generally have low operational costs. They often use existing platforms and technologies to reduce the need for heavy infrastructure investment.
4. **Subscription Model**: Like other SaaS businesses, MicroSaaS companies typically rely on a subscription-based revenue model, where users pay a recurring fee to use the software.
5. **Automated and Efficient**: These businesses strive to be highly automated, minimizing manual processes and relying on digital tools to manage customer relations, billing, and service delivery.
6. **Global Reach**: Despite their small size, MicroSaaS businesses often serve a global customer base, enabled by the internet and cloud computing technologies that allow them to reach customers anywhere.
Due to its characteristics, MicroSaaS products perfectly fit the needs of professionals who want to get started with entrepreneurship, even on the side of a full-time job.
In this article, I describe the most interesting MicroSaaS product ideas, already validated on the market, and that you can use to start making money online.
## 1. SEO Indexer
SEO is one of the most important distribution channels for companies. They invest a ton of money to create content, that needs to be indexed by Google, to be served in the search results to the queries of the users.
A popular technique to create content in a relatively amount of time is **programmatic SEO (pSEO)**.
Programmatic SEO is a strategy that involves using software and automation to generate a large number of pages optimized for search engines, typically targeting long-tail keywords. This approach is especially useful for websites that have the potential to rank for numerous search queries due to the breadth of topics they cover, such as e-commerce sites, travel booking sites, or any service with a wide range of products or offerings.
The problem that companies face, is that Google takes time to index all the pages, and this process can easily take weeks, if not months, even if the new pages are present in the sitemap of the website.
Google allows you to manually submit the pages via the Google Search Console, but there’s a limit of 20 pages per day.
This process is time-consuming and can be automated via the Google APIs.
You can build a MicroSaaS that asks for a sitemap of a website, and periodically submits the new pages to Google until they are all indexed.
## 2. SEO Keywords Research
Content creation is the key activity of SEO. Companies create huge amounts of content to satisfy the search intent of the users on the search engines, and drive traffic to their websites.
creating the right content and targeting the right keywords requires a certain amount of analytics, which is called keyword research.
The key information needed by companies are keywords related to specific topics, the amount of traffic, and the difficulty of ranking.
There are some very established products in the market like ahrefs or SEMrush, but they are quite expensive, and keyword research is a critical aspect for companies.
Google provides an API to retrieve this information, the [Ads Targeting Idea Service and Traffic Estimator Service](https://developers.google.com/adwords/api/docs/guides/targeting-idea-service#use_case).
These properties make SEO Keyword search MicroSaaS one of the most interesting product ideas.
## 3. Social Animations
Social media platforms are one of the most common channels used by professionals, creators, agencies, and SaaS owners, to find potential customers for their businesses.
These platforms show a feed of content, and everyone needs to compete with the others for the attention of the users.
And as you can imagine, nothing works better than an eye-catching video.
For instance, the platform X (former Twitter) increases the reach of the content, based on the amount of time people spend looking at it. If you publish a post with text and a video, the latter will catch the attention of people scrolling through the feed, and later they will read the text of the post.
The MicroSaaS idea consists of a platform to easily and quickly generate video animations, video predefined templates for different situations and celebrations like:
- new number of follower milestone
- new launch on Product Hunt
- new revenues milestone
- and so on
Save people’s time and increase their content reach via video animations.
The fact that the output of your MicroSaaS is video, shared on social media platforms, will create a product-led growth mechanism. People will notice the video, ask for the source of it, and discover your product.
## 4. Screenshots Maker
Like videos, screenshots are the most common and used media on social media (and not only).
Make it super easy for your customers to create stunning screenshots in seconds, ready to be shared on social media.
Think of your product as a mini-Canva, specialized only in screenshots, and with the minimum amount of features needed.
Like the social videos, screenshots will drive product-led growth. People will notice the screenshots, ask for the source of it, and discover your product.
## 5. Form Builder
This is one of the most simple and underrated product ideas possible.
Form Builders are a must for people that need to collect information only, just by sharing the link of a form previously configured.
The most common product is Typeform, but the market is so big, that there’s space for new players.
Build an alternative version, cheaper, but functional.
Also, this product has product-led growth. Simply allow users to create a limited number of forms for free, and add the logo of your company (Built with CompanyName).
People will notice it, and they will probably try out your product soon.
## 6. Text-to-video
AI is an incredibly powerful technology, we all know the capabilities of AI to generate text and even images.
But the new frontier is the creation of videos.
Creating videos requires time and skills. People need to know how to use complex software like Adobe After Effects and similar.
Creating videos is hard.
Text-to-video technologies are becoming more and more powerful, with results that improve from one month to the next.
This product idea is interesting because it solves a painful problem, and there are a few competitors in the market, giving you the possibility to be one of the first players to offer such a solution.
## Conclusions
I hope that this article gave you some good hints to get started with your MicroSaaS, and some key elements to determine what makes a good product.
If you want to ship your product very quickly, you might be interested in my Next.js Startup Boilerplate — [Shipped.club](https://shipped.club) — 200+ devs are already shipping faster using it. | ikoichi |
1,863,970 | 2024 Honda Accord Vs 2024 Honda Accord Hybrid | Discover the 2024 Honda Accord and the 2024 Honda Accord Hybrid, available at Midtown Honda, your... | 0 | 2024-05-24T12:46:39 | https://dev.to/midtownhonda/2024-honda-accord-vs-2024-honda-accord-hybrid-2hkg | nextjs | Discover the 2024 Honda Accord and the 2024 Honda Accord Hybrid, available at Midtown Honda, your premier Honda Dealership near you. Explore their Interior and exterior design, technology features, and engine and performance.

**2024 Honda Accord Interior and Exterior Features**
The 2024 Honda Accord boasts a refined interior that merges comfort with functionality. Premium materials and an ergonomic layout provide a luxurious driving experience. Exteriorly, the Accord features a bold, modern design with sleek lines and a dynamic grille that makes an impactful first impression. Enhanced lighting with LED headlights ensures visibility and adds to its sophisticated appearance, making it a standout.
**2024 Honda Accord Hybrid Interior and Exterior Features**
The 2024 Honda Accord Hybrid enhances the classic Accord package with eco-friendly flair. Inside, it mirrors the regular Accord’s luxurious appointments but adds distinctive hybrid-specific accents. The exterior has unique styling cues like special badges and an optimized grille that improves aerodynamics. Both models feature expansive cabins and advanced noise reduction technologies, providing a peaceful and comfortable environment.
**Contact Us**
Are you interested in the 2024 Honda Accord or the 2024 Honda Accord Hybrid? **[Visit us at Midtown Honda](https://goo.gl/maps/ra2gD3KcapQCKgbg8)**, your leading Honda dealership near me, for exclusive offers and a test drive. Our knowledgeable team is here to help you explore each model’s features and assist with all your automotive needs. Discover your next vehicle with us today!
**Source- [https://www.midtownhonda.com/comparison/2024-honda-accord-vs-2024-honda-accord-hybrid/](https://www.midtownhonda.com/comparison/2024-honda-accord-vs-2024-honda-accord-hybrid/)**
| midtownhonda |
1,863,868 | Learninig: Creating Calculation Views | Understanding Modeling Terminology: **A fact table can be one table but it is often defined from... | 0 | 2024-05-24T12:45:26 | https://dev.to/dentrodailha96/learninig-creating-calculation-views-10d5 | sap, certification, dataengineering | - Understanding Modeling Terminology:
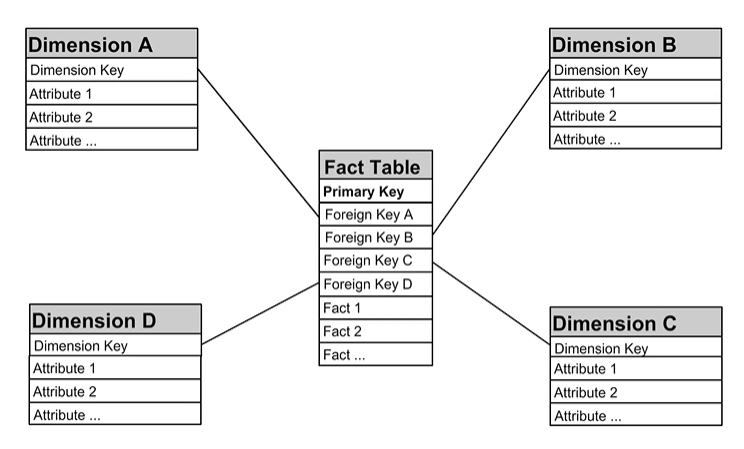
**A fact table can be one table but it is often defined from a combination of tables to produce a view of a transaction, such as a sales order. Dimensions are then connected to the fact table to provide additional, descriptive information about the transaction, such as, the country of the customer.
**Semantics: used to describe the meaning of an attribute or a measure. (Example: <u>currency</u> of an amount).
**Calculation views: Perform a variety of data calculations to generate a meaningful result set.
-Are read-only and cannot change the data in database
- The calculation views can bypass the application server and directly query the calculation views where data is calculated on-the-fly to Cloud in-memory database.
- A dimension calculation view is used to expose master data from source tables.
- Only build with attributes
- Each calculation view can be used by another calculation views.
- Adapt the behavior to the list of columns that are selected or projected on top of it.
- All values in DCV (dimension calculation view) are listed individually. Any calculation demands a <u>cube calculation view</u>.
1) Design Time: Created or modified by a graphical or text-based editor.
2) Runtime: database catalog object (like, excel)
**Cube Calculation Views:
1)Private Columns: Defined inside the calculation view itself. The user has full control of these columns.
2) Shared columns: defined externally and used by more than one dimension.
** Time-Based Dimension Calculation Views:
1) Time-base DCV generates various date-related attributes from a base date.
** Sources supported in calculation views:
- Row Table, column tables, virtual table, calculation views, SQL views and table functions
- Virtual tables: reach external files from any location in your landscape, however affect data performance.
** Top View Node: generates the calculated data set before semantics are applied:
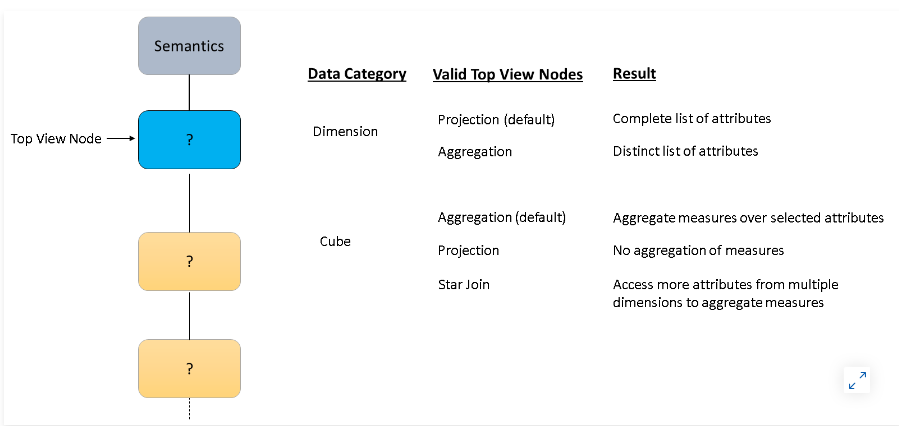
| dentrodailha96 |
1,863,969 | Understanding How JavaScript Works: An In-Depth Guide 🚀 | Understanding How JavaScript Works: An In-Depth Guide 🚀 JavaScript is one of the most popular... | 0 | 2024-05-24T12:44:17 | https://dev.to/madhurop/understanding-how-javascript-works-an-in-depth-guide-55m5 | **Understanding How JavaScript Works: An In-Depth Guide 🚀**
JavaScript is one of the most popular programming languages used today, primarily for adding interactivity to web pages. Whether you’re new to JavaScript or looking to deepen your understanding, this article will provide a comprehensive overview of how JavaScript works, complete with code snippets and explanations. Let's dive in! 🌊
**1. What is JavaScript? 🤔**
JavaScript is a high-level, dynamic programming language that, along with HTML and CSS, forms the core technologies of the World Wide Web. It enables interactive web pages and is an essential part of web applications.
**2. The JavaScript Engine 🧠**
JavaScript code is executed by a JavaScript engine. This engine is embedded in web browsers, such as Chrome’s V8 engine or Firefox’s SpiderMonkey. The engine consists of two main components:
- **Memory Heap**: This is where memory allocation happens.
- **Call Stack**: This is where the function calls are managed.
**3. Execution Context and the Call Stack 📚**
When JavaScript code is executed, it creates an execution context. This context consists of:
- **Global Execution Context**: Created by default and manages global code.
- **Function Execution Context**: Created whenever a function is called.
Each execution context is pushed onto the call stack. When a function finishes execution, its context is popped off the stack.
```javascript
function greet(name) {
return `Hello, ${name}!`;
}
console.log(greet("World")); // "Hello, World!"
```
In this example, `greet("World")` creates a new execution context which is pushed onto the call stack. Once the function executes, it is popped off the stack.
**4. Hoisting 🎈**
Hoisting is a JavaScript mechanism where variables and function declarations are moved to the top of their containing scope during the compilation phase.
```javascript
console.log(hoistedVar); // undefined
var hoistedVar = "I'm hoisted!";
```
Here, `hoistedVar` is declared and initialized. Due to hoisting, the declaration is moved to the top, but not the initialization. Hence, the log prints `undefined`.
**5. Asynchronous JavaScript 🌐**
JavaScript handles asynchronous operations using:
- **Callbacks**
- **Promises**
- **Async/Await**
**Callback Example:**
```javascript
function fetchData(callback) {
setTimeout(() => {
callback("Data received");
}, 2000);
}
fetchData((message) => {
console.log(message); // "Data received" (after 2 seconds)
});
```
**Promise Example:**
```javascript
let promise = new Promise((resolve, reject) => {
setTimeout(() => {
resolve("Promise resolved");
}, 2000);
});
promise.then((message) => {
console.log(message); // "Promise resolved" (after 2 seconds)
});
```
** Async/Await Example:**
```javascript
function fetchData() {
return new Promise((resolve) => {
setTimeout(() => {
resolve("Data fetched");
}, 2000);
});
}
async function getData() {
const data = await fetchData();
console.log(data); // "Data fetched" (after 2 seconds)
}
getData();
```
*6. Event Loop and Concurrency 🔄**
JavaScript uses an event-driven, non-blocking I/O model. The event loop is crucial for handling asynchronous operations. It continuously checks the call stack and the task queue (where callbacks and other tasks are queued).
1. **Call Stack**: Functions are pushed and popped here.
2. **Web APIs**: Browser APIs that handle asynchronous operations.
3. **Callback Queue**: Holds the functions to be executed once the call stack is empty.
4. **Event Loop**: Moves tasks from the callback queue to the call stack.
```javascript
console.log("Start");
setTimeout(() => {
console.log("Timeout");
}, 0);
console.log("End");
// Output:
// Start
// End
// Timeout
```
In this example, "Start" and "End" are logged immediately, while "Timeout" is logged after the current stack is clear.
**7. JavaScript in the Browser 🕸️**
JavaScript interacts with the Document Object Model (DOM) to manipulate web pages dynamically.
```javascript
document.getElementById("myButton").addEventListener("click", function() {
alert("Button clicked!");
});
```
This code adds an event listener to a button with the ID `myButton`. When the button is clicked, an alert is displayed.
**Conclusion 🎉**
JavaScript is a powerful and versatile language, essential for modern web development. By understanding its core concepts such as the JavaScript engine, execution context, hoisting, asynchronous programming, and the event loop, you can write more efficient and effective code. Happy coding! 💻✨ | madhurop | |
1,863,967 | Best Plastic Surgeon in Ahmedabad | A post by Dream Aesthetic | 0 | 2024-05-24T12:39:21 | https://dev.to/dream_aesthetic_f2bf9c5eb/best-plastic-surgeon-in-ahmedabad-3m3i | plasticsurgeon, cosmeticsurgeon |

| dream_aesthetic_f2bf9c5eb |
1,863,966 | How to not curse at a Cuckoo (Induction Heat) rice cooker | Cuckoo rice cookers are smart but you might have a struggle at the first few uses. This article... | 0 | 2024-05-24T12:39:04 | https://dev.to/andrewross/how-to-not-curse-at-a-cuckoo-induction-heat-rice-cooker-428j | ricecooker | Cuckoo rice cookers are smart but you might have a struggle at the first few uses. This article prevents your rice cooker from outsmarting you.
## Listen to the instructions
If you don’t want to read the whole manual, well, at least to the lady’s voice. She knows best, even when she wants you to drain the water.
Be in the right mode
This is the most common mistake that can upset you because she just won’t start cooking. Turn the knob to the left if you want to use pressure modes or to the right to choose non-pressure modes.
`She has a good memory. The preset mode is the last mode you used on each side.`
After choosing a mode, press the top right button if you chose pressure mode and the middle right button if you chose non-pressure mode.
## Recommended mode
On the non-pressure side of life, there is a preset cooking option where you can set the cooking time at the mode-set button to warm your food or boil x-minute eggs.
## Let her wake you up and cook your breakfast
The rice cooker has a function where you can preset the time to start, originally for soaking rice or grains before cooking. You can put your food in to be cooked before bedtime and wake up to her voice telling you breakfast is ready.
```
Happy rice cooking
```
| andrewross |
1,863,965 | Crypto Casino Sites: Frequently Asked Questions | Crypto casino websites are revolutionizing the online gambling market by establishing blockchain... | 0 | 2024-05-24T12:38:50 | https://dev.to/mr_soomro_d8eb1d5e6c9dbe1/crypto-casino-sites-frequently-asked-questions-n8i | Crypto casino websites are revolutionizing the online gambling market by establishing blockchain engineering and cryptocurrencies in to the traditional casino model. These systems provide a new degree of transparency, safety, and anonymity that old-fashioned on the web casinos often can not match. Participants are drawn to crypto casino internet sites for many different factors, including faster deal situations, decrease expenses, and the capability to stay anonymous. With the increasing popularity and acceptance of cryptocurrencies, the number of crypto casino websites has surged, giving people a wide selection of games and betting options.
Among the main advantages of crypto casino websites may be the enhanced amount of protection they provide. Standard on the web casinos rely on centralized servers, which is often susceptible to coughing and knowledge breaches. In comparison, crypto casinos use blockchain technology, that will be decentralized and inherently secure. Every purchase produced on a blockchain is protected and recorded in a public ledger, which makes it almost impossible for hackers to improve or tamper with the data. This amount of security gives players peace of mind, understanding that their resources and particular information are safe from internet threats.
Visibility is still another significant advantage of crypto casino sites. Traditional casinos usually experience complaint for missing transparency inside their procedures, especially regarding the fairness of the games. Crypto casinos address this problem through the usage of provably fair algorithms. These formulas allow players to confirm the equity of every sport outcome independently. By providing cryptographic evidence, participants may concur that the results weren't controlled by the casino, fostering a feeling of confidence and self-confidence in the platform. This transparency is just a key selling point for crypto casinos, getting players who prioritize equity and integrity.
The usage of cryptocurrencies in on line gambling also offers considerable financial benefits. Conventional cost methods, such as for example credit cards and bank moves, frequently include large charges and prolonged processing times. In contrast, cryptocurrency transactions are typically faster and cheaper. Most crypto transactions are prepared within seconds, regardless of the amount being shifted or the player's location. Furthermore, cryptocurrencies usually have decrease transaction costs in comparison to standard banking practices, allowing people to keep more of their winnings. These economic benefits produce crypto casinos a nice-looking option for cost-conscious players.
Anonymity is an essential function for many participants who pick crypto casino sites. Traditional on line casinos involve considerable particular data for consideration registration and economic transactions, which is often a deterrent for privacy-conscious individuals. Crypto casinos, on another hand, usually let participants to join up and play without giving sensitive personal information. Transactions are conducted using cryptocurrency wallets, which do not disclose the player's identity. This level of anonymity is attracting players who price their privacy and hope to help keep their gambling actions discreet.
All of the activities and betting options available at crypto casino web sites is still another element adding to their popularity. These programs offer a wide variety of games, including slots, desk activities, stay dealer activities, and sports betting. Many crypto casinos partner with top-tier pc software services to offer supreme quality, interesting games that appeal to different player preferences. Moreover, some crypto casinos present distinctive activities that are created specifically for the blockchain, providing a novel gaming knowledge that cannot be bought at traditional online casinos. That range in gambling choices guarantees that there surely is anything for everyone at a crypto casino site.
Crypto casino sites also focus on a worldwide audience, eliminating lots of the geographical and financial barriers associated with conventional online gambling. Cryptocurrencies are not linked with any particular place or banking program, letting participants from various areas of the planet to participate without fretting about currency conversion or international transaction fees. That international supply starts up a larger player bottom for crypto casinos and gives people with increased opportunities to interact with a varied community. Moreover, several crypto casinos offer multi-language support and accept different cryptocurrencies, increasing their interest an global audience.
Despite the numerous advantages, crypto casino websites also experience problems and criticisms. The regulatory environment for cryptocurrencies and online gaming is still changing, resulting in legitimate uncertainties in a few jurisdictions. Some places have strict regulations which could forbid or limit the usage of cryptocurrencies for online gaming, rendering it essential for people to understand the appropriate landscape in their region. Moreover, the volatility of cryptocurrencies can be a matter for participants, as the worthiness of the winnings can change significantly. To mitigate these risks, some crypto casinos present the option to convert cryptocurrencies to [crypto casinos analysis ](https://www.feedinco.com/blog/crypto-casino-sites), which are less volatile.
In conclusion, crypto casino web sites signify a significant creativity in the web gambling market, providing enhanced security, visibility, and financial advantages through the use of blockchain engineering and cryptocurrencies. The appeal of anonymity, quicker transactions, and a varied range of games makes these tools attractive to a growing quantity of people worldwide. However, it is required for people to stay informed about the regulatory atmosphere and the possible dangers connected with cryptocurrency volatility. As the continues to evolve, crypto casinos will probably perform an increasingly outstanding role in the ongoing future of on line gambling, giving new options and activities for participants and operators alike. | mr_soomro_d8eb1d5e6c9dbe1 | |
1,863,483 | Python Day 13: Creating a Simple Todo App with Django | Django is a powerful web framework that can be used to build web applications. In this article, we... | 0 | 2024-05-24T12:36:25 | https://dev.to/jr_shittu/python-day-13-creating-a-simple-todo-app-with-django-4g2k | webdev, beginners, python, programming | Django is a powerful web framework that can be used to build web applications. In this article, we will walk through the process of creating a simple to-do list app using Django.
Step 1 **Install Django:** Firstly, let's install Django.
Open up the terminal and run the code below.
```bash
pip install django
```
Step 2: **Create a new Django project:** Once we've installed Django, we can create a new project by running the code below in the terminal.
```bash
django-admin startproject mytodo
```
This will create a new directory called `mytodo` that contains the files and directories for our project.
Step 3. **Create a new Django app:**
Next, we'll need to create a new Django app for our to-do list.
To do this, let's navigate to `mytodo` directory by running the command in our terminal.
```python
cd mytodo
```
Next, run the code below to create our app.
```bash
python manage.py startapp todo
```
This will create a new directory called `todo` that contains the files and directories for our app.
Step 4. **Define to-do list model:** A model is a representation of a database table in Django. We'll need to define a model for our to-do list that includes fields for the task name and a boolean field to indicate whether the task is complete. To do this, let's open up the `models.py` file in the `todo` directory and add the following code:
```python
from django.db import models
class TodoItem(models.Model):
text = models.CharField(max_length=200)
complete = models.BooleanField(default=False)
```
With code above we've created a new model called `TodoItem` with two fields: `text` and `complete`.
Step 5. **Install the app:** To use the `todo` app in our project, we'll need to add it to the `INSTALLED_APPS` list in the `settings.py` file in the `mytodo` directory. To do this, let's open up the `settings.py` file and add the following line to the `INSTALLED_APPS` list:
```python
'todo.apps.TodoConfig',
```
This will tell Django to include the `todo` app in our project.
Step 6. **Run migrations:** Once we've defined our model, we'll need to create the corresponding database table. To do this, we can run migrations.
To run migrations, run the code below in the terminal.
```bash
python manage.py makemigrations todo
```
This will create a new migration file in the `migrations` directory in the `todo` app.
Then, let's run the code below to apply the migration and create the database table.
```python
python manage.py migrate todo
```
Step 7. **Create views:** A view is a function that takes a web request and returns a web response. We'll need to create two views for our to-do list: one to display the list of tasks and another to handle the form submission for adding a new task. To do this, let's open up the `views.py` file in the `todo` directory and add the following code:
```python
from django.shortcuts import render, redirect, get_object_or_404
from .models import TodoItem
def todo_list(request):
items = TodoItem.objects.all()
return render(request, 'todo/todo_list.html', {'items': items})
def add_item(request):
if request.method == 'POST':
text = request.POST['text']
TodoItem.objects.create(text=text)
return redirect('todo_list')
else:
return render(request, 'todo/add_item.html')
def toggle_complete(request, item_id):
item = get_object_or_404(TodoItem, id=item_id)
item.complete = not item.complete
item.save()
return redirect('todo_list')
def delete_item(request, item_id):
item = get_object_or_404(TodoItem, id=item_id)
item.delete()
return redirect('todo_list')
```
This code defines four views: `todo_list`, `add_item`, `toggle_complete`, and `delete_item`.
Step 8. **Create templates:** A template is a file that defines the HTML structure of a web page.
We'll need to create two templates for our to-do list: one to display the list of tasks and another to handle the form submission for adding a new task. To do this, let's open up the `todo` directory and create a new directory called `templates`.
Inside the `templates` directory, let's create a new directory called `todo`. Inside the `todo` directory, let's create two new files: `todo_list.html` and `add_item.html`.
Hence, add the following code to `todo_list.html`:
```html
<h1>My To-Do List</h1>
<form method="post" action="{% url 'add_item' %}">
{% csrf_token %}
<input type="text" name="text" placeholder="Add a new item">
<button type="submit">Add</button>
</form>
<ul>
{% for item in items %}
<li>
{{ item.text }}
{% if item.complete %}
(Completed)
{% endif %}
<form method="post" action="{% url 'toggle_complete' item.id %}">
{% csrf_token %}
<button type="submit">
{% if item.complete %}
Mark as Incomplete
{% else %}
Mark as Complete
{% endif %}
</button>
</form>
<form method="post" action="{% url 'delete_item' item.id %}">
{% csrf_token %}
<button type="submit">Delete</button>
</form>
</li>
{% endfor %}
</ul>
```
And add the following code to `add_item.html`:
```html
<h1>Add a New To-Do Item</h1>
<form method="post">
{% csrf_token %}
<label for="text">Text:</label>
<input type="text" name="text" id="text">
<button type="submit">Add</button>
</form>
```
Step 9. **Update URLs:** Finally, we'll need to update our URLs to map to the views we've created. To do this, let's open up the `urls.py` file in the `mytodo` directory and add the following code:
```python
from django.urls import path
from todo.views import todo_list, add_item, toggle_complete, delete_item
urlpatterns = [
path('', todo_list, name='todo_list'),
path('add/', add_item, name='add_item'),
path('toggle_complete/<int:item_id>/', toggle_complete, name='toggle_complete'),
path('delete/<int:item_id>/', delete_item, name='delete_item'),
]
```
This code maps the URLs to the views we've created.
And that's it! Now we have a working app. Run the code in the terminal.
```bash
python manage.py runserver
```
We can then access our app by navigating to `http://127.0.0.1:8000/` in the web browser. | jr_shittu |
1,863,963 | Inheritance and Composition in C# | Inheritance Inheritance is a programming mechanism that allows you to derive a class from... | 0 | 2024-05-24T12:36:07 | https://dev.to/adrianbailador/inheritance-and-composition-in-c-1nad | webdev, dotnet, csharp, development | ## Inheritance
Inheritance is a programming mechanism that allows you to derive a class from another class, forming a hierarchy of classes that share a set of attributes and methods. The class from which inheritance is derived is called the base class, and the class that inherits from the base class is called the derived class. Inheritance forms an "is-a" relationship. For example, a `Dog` is an `Animal`.
Here is a simple example of inheritance in C#:
```csharp
public class Animal
{
public string Name { get; set; } = "Animal";
public void MakeSound()
{
Console.WriteLine("The animal makes a sound.");
}
}
// child
public class Dog : Animal
{
public string Breed { get; set; } = "Golden";
}
```
### Advantages of Inheritance
1. **Code Reusability**: Inheritance allows for the reuse of code by defining common attributes and methods in a base class that are then inherited by derived classes.
2. **Code Organisation**: It helps in organising the code by grouping similar classes together in a class hierarchy.
3. **Extensibility**: Functionality in the base class can be extended in the derived class without modifying existing code, adhering to the open/closed principle.
4. **Polymorphism**: It allows derived classes to be treated as instances of the base class, making the code more general and reusable.
### Disadvantages of Inheritance
1. **Strong Coupling**: Inheritance creates a strong coupling between the base class and the derived class, making the code more difficult to modify.
2. **Rigid Hierarchy**: It creates a rigid class hierarchy that may not be suitable for all situations. In C#, a class can only inherit from one base class.
3. **Propagation of Changes**: Changes in the base class can affect all derived classes, which can be risky and require careful management.
4. **Depth of Hierarchy**: Deep inheritance hierarchies can be difficult to follow and understand, leading to less readable and harder to maintain code.
## Composition
Composition, on the other hand, is a technique where a class contains instances of other classes to utilise their functionalities. This "has-a" relationship is more flexible than inheritance and is used to model objects that contain or are composed of other objects. For example, a `Dog` has a `Collar`.
Here is a simple example of composition in C#:
```csharp
public class Collar
{
public void Open()
{
Console.WriteLine("The collar opens");
}
}
public class Dog
{
private Collar _collar = new Collar();
public void WearCollar()
{
_collar.Open();
Console.WriteLine("The dog wears a collar");
}
}
```
### Advantages of Composition
1. **Flexibility**: It allows for changing the behaviour of an object at runtime by changing its components.
2. **Decoupling**: Promotes stronger decoupling between classes, making the code easier to modify and maintain.
3. **Component Reuse**: Facilitates the reuse of individual components in different classes.
4. **Unit Testing**: Makes classes easier to unit test as components can be isolated and tested separately.
### Disadvantages of Composition
1. **More Code**: It requires more code than inheritance, as it involves creating instances of components and managing their lifecycle.
2. **Complexity**: Increases the complexity of the code, as the relationships between components need to be managed.
3. **Maintenance Overhead**: Managing dependencies and the lifecycle of objects can introduce maintenance overhead.
## How to Choose Between Inheritance and Composition
The choice between inheritance and composition depends on the specific needs of your software. Here are some general guidelines:
- **Favour Composition Over Inheritance**: This is a commonly accepted design principle. Composition is generally more flexible and provides better encapsulation than inheritance.
- **Use Inheritance to Model "Is-A" Relationships**: If there is a clear "is-a" relationship between the classes, inheritance might be the right choice. For example, a `Dog` is an `Animal`.
- **Use Composition to Model "Has-A" Relationships**: If a class needs to utilise functionality from another class but there is no "is-a" relationship, composition is the right choice. For example, a `Dog` has a `Collar`.
### Practical Example of Decision
Suppose you are developing a system to manage different types of animals. Consider the following classes:
```csharp
public class Animal
{
public string Name { get; set; }
public void MakeSound() => Console.WriteLine("The animal makes a sound.");
}
public class Cat : Animal
{
public void Meow() => Console.WriteLine("The cat meows.");
}
public class Dog : Animal
{
public Collar Collar { get; set; } = new Collar();
public void Bark() => Console.WriteLine("The dog barks.");
}
public class Collar
{
public void Open() => Console.WriteLine("The collar opens");
}
```
In this case:
- We use **inheritance** to represent that a `Cat` and a `Dog` are types of `Animal`.
- We use **composition** to indicate that a `Dog` has a `Collar`.
### Summary
- **Inheritance** is useful for "is-a" relationships and for reusing code in a class hierarchy.
- **Composition** is more flexible and is used for "has-a" relationships, allowing for greater modularity and component reuse.
The choice between inheritance and composition depends on what you are looking for in your design and how you expect your classes and their responsibilities to evolve. | adrianbailador |
1,863,962 | Universal Data Migration: Using Slingdata to Transfer Data Between Databases | Overview Data management can be complex, especially when dealing with high-volume data... | 0 | 2024-05-24T12:35:51 | https://dev.to/ranjbaryshahab/universal-data-migration-using-slingdata-to-transfer-data-between-databases-161l | slingdata, clickhouse, postgres, datamigration | ## Overview
Data management can be complex, especially when dealing with high-volume data pipelines. Whether you're moving data between databases, from file systems to databases, or vice versa, the Extract & Load (EL) approach can streamline these processes. Enter **[Slingdata](https://docs.slingdata.io)**, a powerful, free CLI tool built with Go that offers a straightforward solution for creating and maintaining robust data pipelines.
## What is Slingdata?
Slingdata is a passion project turned into a practical tool that simplifies data movement across various systems. Its key focus is on the Extract & Load (EL) process, enabling efficient data transfer between:
- Database to Database
- File System to Database
- Database to File System
### Key Features of Slingdata
- Single Binary deployment (built with Go). See the installation page.
- Use Custom SQL as a stream.
- Manage / View / Test / Discover your connections with the `sling conns` sub-command.
- Use Environment Variables for connections.
- Provide YAML or JSON configurations (perfect for git version control).
- Powerful Replication logic, to replicate many tables with a wildcard (my_schema.*).
- Reads your existing DBT connections.
- Use your environment variable in your YAML / JSON config (`SELECT * from my_table where date = '{date}'`).
- Convenient Transformations, such as the flatten option, which auto-creates columns from your nested fields.
- Run Pre & Post SQL commands.
- And many more!
## Sample EL Process: ClickHouse to PostgreSQL
To showcase Slingdata’s capabilities, let's walk through a sample Extract & Load process moving data from ClickHouse to PostgreSQL.
### Prerequisites
Ensure you have:
- [ClickHouse](https://clickhouse.com) installed and running.
- [PostgreSQL](https://www.postgresql.org) installed and running.
- [Slingdata](https://docs.slingdata.io/sling-cli/getting-started) installed.
### Step 1: Configure the Source Database
Let's assume our source database is ClickHouse. We can export a new environment variable or add the connection to the `env.yaml` of Slingdata files:
```sh
export MARKETING_URL="postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
```
To test this connection:
```sh
sling conns test MARKETING_URL
```
You should see the result:
```print
INF success!
```
We will do the same for ClickHouse:
```sh
export DATAWAREHOUSE_URL="http://sling_user:sling_pass@clickhouse:8123/marketing"
```
To test this connection:
```sh
sling conns test DATAWAREHOUSE_URL
```
You should see the result:
```print
INF success!
```
Now, let's create a database and a table in ClickHouse:
```sql
create database marketing;
CREATE TABLE `marketing`.users (
id UInt64,
name String,
family String,
age UInt8
) ENGINE = MergeTree()
ORDER BY id;
```
And in PostgreSQL, create a table with the same schema:
```sql
create table users(
id serial not null primary key,
name text not null,
family text,
age text not null
);
```
Insert data into ClickHouse:
```sql
insert into marketing.users values(1,'Shahab', 'Ranjbary', 28);
insert into marketing.users values(2,'Sepher', 'Ranjbary', 18);
insert into marketing.users values(3,'Mostafa', 'Fekri', 38);
```
Now, to move data to PostgreSQL, you can either create a replication file or run the following command:
```sh
sling run --src-conn DATAWAREHOUSE_URL --src-stream marketing.users --tgt-conn MARKETING_URL --tgt-object public.users
```
## Conclusion
Slingdata offers a powerful and flexible way to manage data pipelines with ease. Its extensive features, combined with simple configurations and robust performance, make it an excellent tool for anyone dealing with high-volume data transfers.
| ranjbaryshahab |
1,863,960 | JAVASCRIPT - Desestruturação de objetos (object destructuring) | Introdução Histórica do Object Destructuring Se você já esteve na estrada do... | 0 | 2024-05-24T12:34:21 | https://dev.to/lucasvalhos/javascript-desestruturacao-de-objetos-object-destructuring-1ln1 | ## Introdução Histórica do Object Destructuring
Se você já esteve na estrada do desenvolvimento JavaScript por tempo suficiente, deve se lembrar dos dias em que acessar e manipular propriedades de objetos exigia um monte de código boilerplate. Antes do ES6, atribuir valores de um objeto a variáveis individuais era um processo repetitivo e, francamente, um tanto tedioso. Era comum ver algo assim:
```javascript
const person = { name: 'Alice', age: 30, city: 'Wonderland' };
const name = person.name;
const age = person.age;
const city = person.city;
```
Esse tipo de código não só era verboso, mas também propenso a erros, especialmente em objetos com muitas propriedades. Com a introdução do ES6, veio o salvador que todos esperávamos: a desestruturação de objetos. Este recurso revolucionou a forma como manipulamos dados estruturados em JavaScript, tornando nosso código mais legível, conciso e menos propenso a erros.
## Desestruturação de Objetos: A Mágica Concisa
A desestruturação de objetos permite extrair propriedades de objetos e atribuí-las a variáveis de maneira concisa. Veja como a sintaxe de desestruturação transforma o exemplo anterior:
```javascript
const a = { test: 'test' };
const { test } = a;
```
Aqui, a propriedade `test` do objeto `a` é extraída e atribuída à variável `test` usando a sintaxe de desestruturação. Este padrão é útil para evitar a necessidade de acessar repetidamente as propriedades do objeto e pode tornar o código mais legível e eficiente.
## Exemplos Práticos de Desestruturação
Vamos explorar alguns exemplos adicionais de desestruturação de objetos em JavaScript, cobrindo diferentes casos e usos. Esses exemplos mostrarão como a desestruturação pode simplificar nosso código diário.
### 1. Desestruturação de Múltiplas Propriedades
```javascript
const person = {
name: 'Alice',
age: 30,
city: 'Wonderland'
};
const { name, age, city } = person;
console.log(name); // Alice
console.log(age); // 30
console.log(city); // Wonderland
```
### 2. Desestruturação com Renomeação de Variáveis
```javascript
const user = {
username: 'jdoe',
email: 'jdoe@example.com'
};
const { username: userName, email: userEmail } = user;
console.log(userName); // jdoe
console.log(userEmail); // jdoe@example.com
```
### 3. Desestruturação com Valores Padrão
```javascript
const options = {
timeout: 1000
};
const { timeout, retries = 3 } = options;
console.log(timeout); // 1000
console.log(retries); // 3
```
### 4. Desestruturação em Parâmetros de Função
```javascript
function greet({ name, age }) {
console.log(`Hello, my name is ${name} and I am ${age} years old.`);
}
const person = {
name: 'Bob',
age: 25
};
greet(person); // Hello, my name is Bob and I am 25 years old.
```
### 5. Aninhamento de Desestruturação
```javascript
const employee = {
id: 1,
name: 'Jane Doe',
department: {
name: 'Engineering',
location: 'Building 1'
}
};
const { name, department: { name: deptName, location } } = employee;
console.log(name); // Jane Doe
console.log(deptName); // Engineering
console.log(location); // Building 1
```
### 6. Desestruturação de Arrays
A desestruturação não é limitada a objetos; também pode ser usada com arrays:
```javascript
const colors = ['red', 'green', 'blue'];
const [first, second, third] = colors;
console.log(first); // red
console.log(second); // green
console.log(third); // blue
```
### 7. Desestruturação de Arrays com Valores Padrão
```javascript
const numbers = [1, 2];
const [a, b, c = 3] = numbers;
console.log(a); // 1
console.log(b); // 2
console.log(c); // 3
```
### 8. Troca de Valores Usando Desestruturação
```javascript
let x = 1;
let y = 2;
[x, y] = [y, x];
console.log(x); // 2
console.log(y); // 1
```
### 9. Ignorando Valores em Desestruturação de Arrays
```javascript
const fullName = ['John', 'Doe', 'Smith'];
const [firstName, , lastName] = fullName;
console.log(firstName); // John
console.log(lastName); // Smith
```
Esses exemplos demonstram a versatilidade da desestruturação de objetos e arrays em JavaScript, tornando o código mais legível e eficiente. Para nós, desenvolvedores, adotar essas práticas significa escrever menos código, reduzir a chance de erros e, acima de tudo, tornar nosso trabalho diário um pouco mais agradável.
| lucasvalhos | |
1,863,959 | How to Find Amazon Storefront | Amazon, the world's largest online retailer, continues to dominate the e-commerce market, capturing a... | 0 | 2024-05-24T12:33:10 | https://dev.to/margaret_carden_d0e1d67ce/how-to-find-amazon-storefront-2811 | Amazon, the world's largest online retailer, continues to dominate the e-commerce market, capturing a 37.8% share of U.S. e-commerce sales as of summer 2022. This unparalleled reach attracts brands eager to promote their products on Amazon’s expansive platform. Partnering with Amazon influencers, who operate their own storefronts, can significantly enhance brand visibility and sales. However, finding the right Amazon influencer storefront for your brand requires a strategic approach. Here’s how you can effectively locate and collaborate with Amazon influencers to maximize your brand’s impact.

## Understanding Amazon Influencers
An Amazon influencer is a content creator who participates in Amazon’s influencer program. These influencers promote products via their personalized [Amazon storefronts](https://blog.swiftstart.com/how-to-find-amazon-storefronts-from-app/), earning commissions through affiliate links for every purchase made. They come in various tiers, including macro-influencers with large followings and micro-influencers with more niche, engaged audiences. Choosing the right influencer depends on your brand's budget and target demographic.
## Steps to Find Amazon Storefronts
Finding Amazon influencer storefronts involves a blend of leveraging Amazon’s platform and exploring social media channels where these influencers are active. Here’s a detailed guide to help you navigate this process:
**1. Leveraging Amazon’s Platform**
Start your search directly on Amazon. Here’s how:
Visit the Amazon Homepage: Click on the main navigation icon located in the top left corner and scroll down to “See All.”
Explore #FoundItOnAmazon: Click on the hashtag “#FoundItOnAmazon” to find a curated list of photos tagged by influencers showcasing their favorite products.
Select Product Categories: Narrow your search by selecting categories that align with your products. This will help you find influencers who specialize in promoting items similar to yours.
Review Influencer Storefronts: Click on the names of influencers who appear to be a good fit for your brand. Examine their storefronts to assess the relevance and quality of their content.
**2. Social Media Sleuthing**
Social media platforms, especially Instagram and YouTube, are essential for discovering Amazon influencers. Here’s how to find them:
Use Targeted Hashtags: Search for influencers using hashtags like #AmazonFinds, #AmazonMustHaves, #FoundItOnAmazonFashion, and #AmazonFindsCURRENTYEAR. These hashtags are commonly used by influencers to showcase their Amazon finds and storefronts.
Evaluate Profiles: Visit the profiles of influencers you find through these hashtags. Assess their content, engagement rates, and follower demographics to ensure they align with your brand’s target audience.
Check Performance Metrics: Look at their post engagement, comments, and overall follower interaction. High engagement rates often indicate a loyal and active audience, which is beneficial for your brand.
## Ensuring a Good Fit for Your Brand
After identifying potential influencers, it’s crucial to vet them thoroughly:
Audience Alignment: Ensure the influencer’s audience matches your target market. Check their followers’ demographics and interests.
Content Quality: Review the influencer’s content for quality and relevance. Their style should complement your brand’s image and message.
Engagement Metrics: High engagement rates are more valuable than a large follower count. Look for influencers whose followers actively interact with their content.
Utilizing Influencity for Streamlined Selection
To streamline the process, consider using influencer marketing platforms like Influencity. Here’s how Influencity can help:
Advanced Search Filters: Influencity allows you to search through over 170 million profiles using filters such as brand affinity and specific hashtags.
Detailed Profile Insights: Access influencers’ bios, content types, and performance metrics directly from the search results page. This helps you quickly identify influencers who match your brand’s needs.
Performance Metrics: Evaluate an influencer’s performance over time to ensure they consistently engage their audience and achieve desired outcomes.
## Conclusion
Finding the right Amazon influencer storefront for your brand is a strategic process that involves leveraging both Amazon’s platform and social media channels. By utilizing targeted searches and vetting influencers thoroughly, you can identify partners who will effectively promote your products. Platforms like [SwiftStart.com](https://swiftstart.com/) can further streamline this process, saving you time and helping you make data-driven decisions.

Partnering with the right Amazon influencer can significantly boost your brand’s visibility and sales, unlocking new levels of success in the competitive e-commerce landscape. Start your search today and discover the perfect Amazon storefronts to elevate your brand. | margaret_carden_d0e1d67ce | |
1,863,958 | Rethinking the Adage: Embracing Versatility in Software Development | Introduction: In the world of software development, the adage "A jack of all trades is a master of... | 0 | 2024-05-24T12:32:21 | https://dev.to/brainvault_tech/rethinking-the-adage-embracing-versatility-in-software-development-40e5 |
**Introduction:**
In the world of software development, the adage "A jack of all trades is a master of none" has long been a cautionary tale, warning against spreading oneself too thin. Yet, as technology continues to evolve at a rapid pace, the value of versatility and a broad skill set is becoming increasingly apparent. In this article, we'll explore how the traditional interpretation of this adage is being challenged in the tech world, and why being a "jack of all trades" in programming may indeed be better than being a "master of one."
**The Traditional Interpretation:**
Originating from quote which referred to William Shakespeare, "A jack of all trades is a master of none," the adage has historically been viewed as a warning against pursuing too many interests or skills, at the expense of mastering one particular craft. In software development, this idea has often been applied to caution against being a generalist, advocating instead for specialization in a specific technology or programming language.
**The Changing Landscape of Technology:**
However, the landscape of technology is constantly evolving, with new languages, frameworks, and tools emerging at a rapid pace. In this dynamic environment, the ability to adapt and learn quickly has become essential for developers. Versatility, rather than specialization, is now being recognized as a valuable asset in navigating the complexities of modern software development.
**The Value of Versatility:**
Being a "jack of all trades" in programming does not mean being mediocre at everything. Instead, it refers to having a broad skill set that allows developers to tackle a variety of tasks and challenges. This versatility enables developers to switch between projects, adapt to new technologies, and collaborate more effectively with colleagues who may have different areas of expertise.
Furthermore, being proficient in multiple programming languages and frameworks can provide developers with a deeper understanding of fundamental concepts and principles. This cross-disciplinary knowledge allows for creative problem-solving and innovation, as ideas and techniques from different domains can be combined to address complex problems.
**Navigating the Ever-Changing Landscape:**
In today's tech industry, where trends come and go, and new technologies emerge overnight, being adaptable is crucial for staying relevant. While specialization certainly has its place, especially in niche areas where deep expertise is required, the ability to quickly acquire new skills and adapt to changing circumstances is equally important.
Developers who embrace versatility are better equipped to thrive in this fast-paced environment. They are able to quickly pivot to new projects, explore emerging technologies, and take on diverse challenges with confidence. By continuously expanding their skill set and staying curious, these developers are well-positioned to succeed in an industry where change is the only constant.
**Conclusion:**
In conclusion, while the adage "A jack of all trades is a master of none" may have originated as a cautionary tale, its relevance in the world of software development is evolving. In today's dynamic and ever-changing landscape of technology, versatility and adaptability are becoming increasingly valued traits. By embracing a broad skill set and being open to learning new technologies, developers can position themselves for success in an industry where the only constant is change.
Content Credits: Nuzath Farheen H | brainvault_tech | |
1,863,957 | 5 Clean Code Principles in JavaScript | Today, I am going to present 5 recommendations to produce clean code about variables in... | 0 | 2024-05-24T12:32:15 | https://dev.to/shehzadhussain/5-clean-code-principles-in-javascript-41fk | webdev, javascript, beginners, programming | Today, I am going to present 5 recommendations to produce clean code about variables in JavaScript.
They are principles endorsed by "Clean Code" book authors and adapted for JavaScript. Following them will make your code readable, reusable, and refactorable.
Many developers aren't committed to these principles, making a no-maintainable code.
Following these 5 JavaScript principles, you will make an excellent clean code.
Here they are:
- Use searchable names
- Avoid Mental Mapping
- Use explanatory variables
- Only add the necessary context
- Use pronounceable and meaningful variable names
Use searchable names
Avoid Mental Mapping
Use explanatory variables
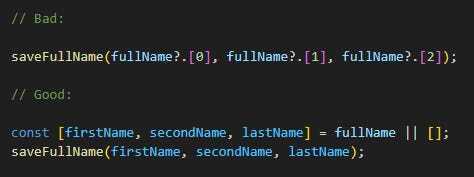
Only add the necessary context
Conclusion
As a front-end developer, you will produce much JavaScript code over time.
It is crucial to make clean code to achieve maintainable code. Taking these types of principles into account will make you level up as a developer.
Here, I share a helpful resource to make clean code in JavaScript.
I hope you enjoyed the article. | shehzadhussain |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.