
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,864,635 | HOW TO MASTER PYTHON FOR DATA SCIENCE| INFOGRAPHIC | Learning data science is easy, getting hands-on expertise in Python programming nuances takes skills.... | 0 | 2024-05-25T07:03:46 | https://dev.to/pradipmohapatra/how-to-master-python-for-data-science-infographic-2bbn | datascience, python | Learning data science is easy, getting hands-on expertise in Python programming nuances takes skills. It is highly advised when thinking of a career in the data science industry, it is critical to master Python and other programming languages to facilitate in-time efficient [data-driven decision-making](https://www.usdsi.org/data-science-insights/resources/master-data-driven-decision-making-in-2024).
Python is the most-loved programming language among developers worldwide, TIOBE has ranked it at No.1 in the race for becoming the best programming language in the world. Being a powerful programming language, it lends clarity and concise explanations; that are widely deployed in web development, machine learning, and data science.
PYPL also seconds TIOBE is ranking Python as the top-notch programming language of today. This makes learning Python an inevitable task. It offers a beginner-friendly gateway, massive versatility, extensive libraries, and an active community to grow with. However, as the technology ramps up, Python faces the drawbacks of poor speed and memory management in some cases.
It is time you mastered most in-demand Python libraries such as NumPy, Scikit-Learn, Pandas, TensorFlow, and Matplotlib, among many others. data visualization and many other skills earned at the most trusted [data science certifications](https://www.usdsi.org/data-science-certifications) can take you a long way ahead in earning sky-high data scientist salaries worldwide. Landing your dream data science job is never far away, with the best data science courses.
Bring zeal and ever-strengthening skills to be a lifelong learner to evolve with the enhancing times. Across different states in the USA, the UK, France, Germany, Australia, India, and other countries are brimming with a staggering demand for data scientists. Become a specialized professional and make a positive impact in the multitudinous growth of the global marketplace. This representation shall take you up, close, and personal with Python programming and convenient ways to conquer the nuances with the best facilitators around the world.

| pradipmohapatra |
1,864,634 | Getting started with Spring boot | Introduction Spring Boot is a Java framework used for backend development. It's popular for enabling... | 0 | 2024-05-25T07:03:22 | https://dev.to/arikaran/getting-started-with-spring-boot-28gc | java, springboot, beginners, webdev |
**Introduction**
Spring Boot is a Java framework used for backend development. It's popular for enabling the rapid development of production-ready web applications with minimal configuration.
Spring Boot provides numerous built-in libraries for various technologies, such as messaging, security, etc., making it exceptionally easy to use. While it's commonly utilized in microservice architecture, it's also applicable in monolithic architecture setups.
There are several advantages to using Spring Boot that contribute to its status as a leading framework:
1. **Auto-configuration**: By simply adding the .jar file as a dependency in our Spring project, Spring handles most configurations automatically. If needed, we can override or exclude auto-configuration for specific libraries. For example, configurations for web servers, security, databases, etc., are managed effortlessly.
2. **Starter dependencies**: Spring Boot offers many starter dependencies, simplifying the integration of new technologies. This avoids the need for manual integration.
3. **Actuator support**: In complex applications, monitoring can be challenging. Spring Boot addresses this with built-in support called Actuator. Actuator provides endpoints to check the health of the application, facilitating easier monitoring, especially in applications integrating with various third-party services and databases.
4. **Embedded web servers**: Spring Boot includes embedded web servers, making it effortless to develop and deploy applications. Without embedded servers, deploying to external web servers would require writing extensive XML configurations.
5. **Large community**: Spring Boot boasts a vast community, which significantly eases the developer's life. If stuck, there's ample support available.
## Project setup
Setting up your first Spring Boot project is straightforward:
- Open your favorite browser and search for [Spring Initializer](https://start.spring.io/).
- Fill in the group, artifact name, package name, select packaging type as JAR, and choose dependencies like Spring Web.
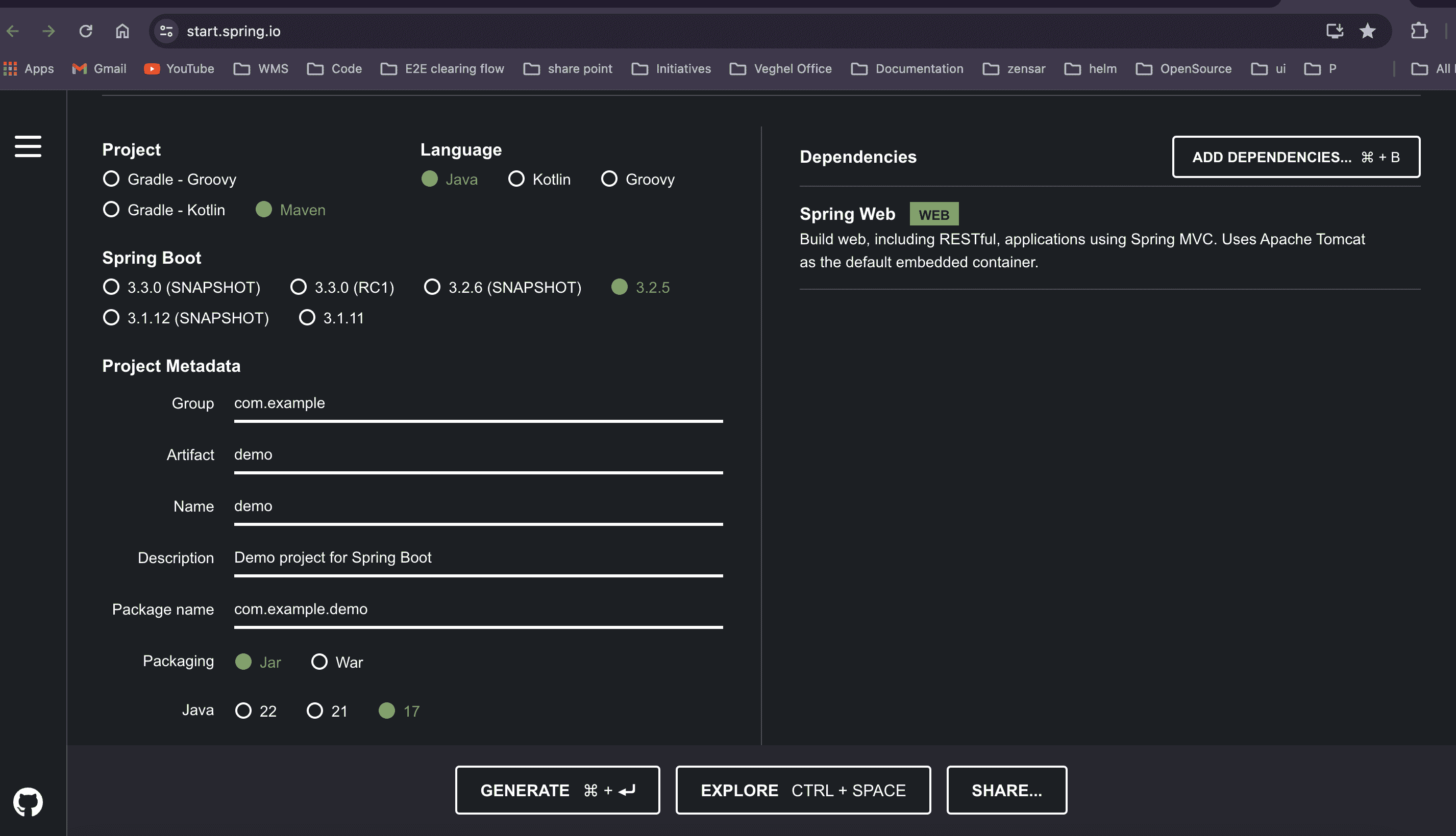
- Click "Generate Project" to download the zip file, which contains your project. Open it in your preferred IDE (e.g., STS, IntelliJ).
Once your project is open, you'll see the following folder structure:
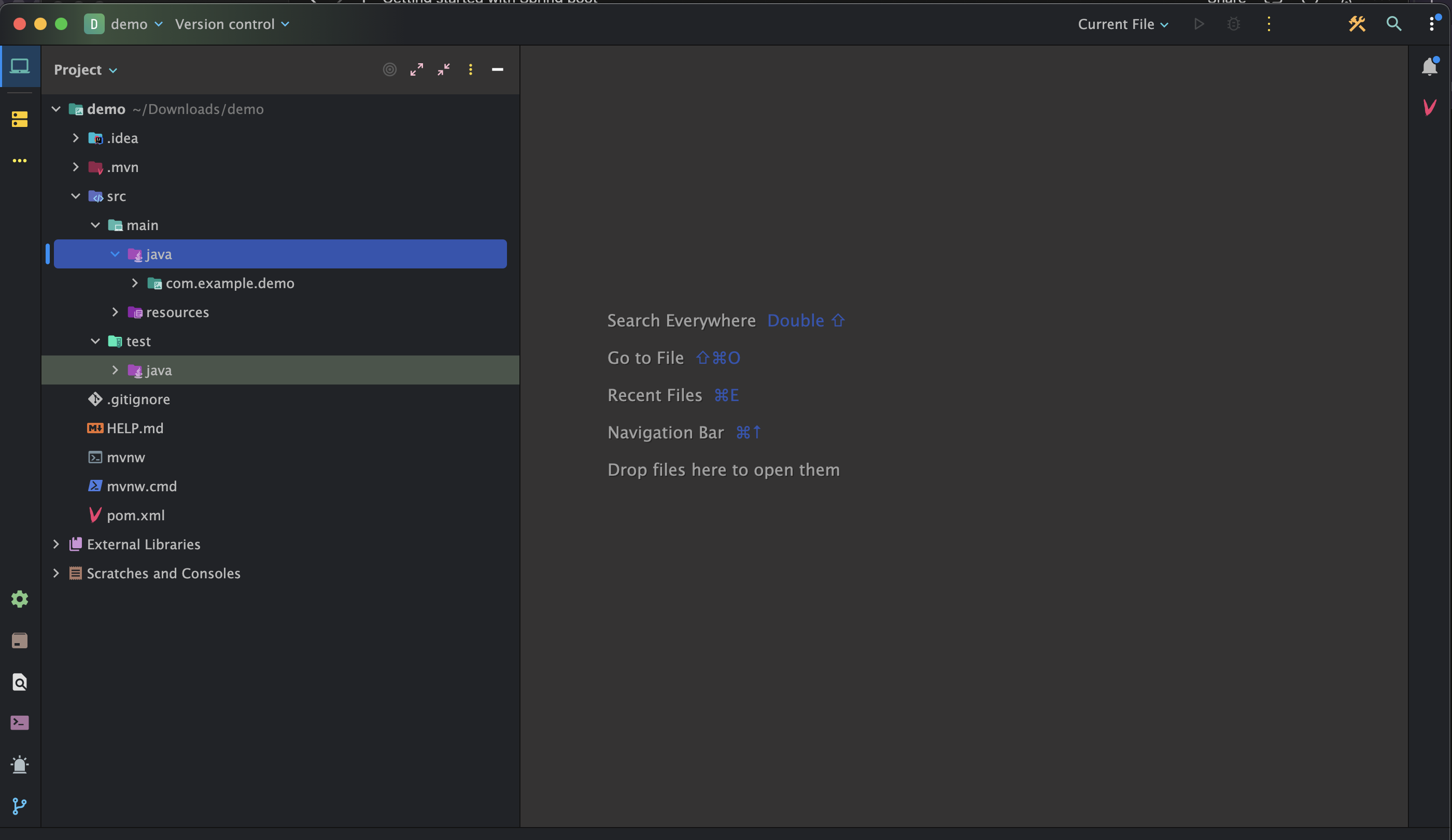
- **src**: Divided into two subfolders: "main" and "test".
- **main**: Development code resides here. Configuration files and resources can be added to the "resources" subfolder.
- **test**: Contains all test code.
- **pom.xml**: This file manages dependencies of our app and their versions.
The entry point of the application is the class annotated with `@SpringBootApplication`, which contains the main method:
```java
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
```
**@SpringBootApplication** indicates that Spring scans all packages of this class and its subclasses for configurations and components. It also enables auto-configuration, scanning all dependencies added in the pom.xml file.
## To print "Hello, World!":
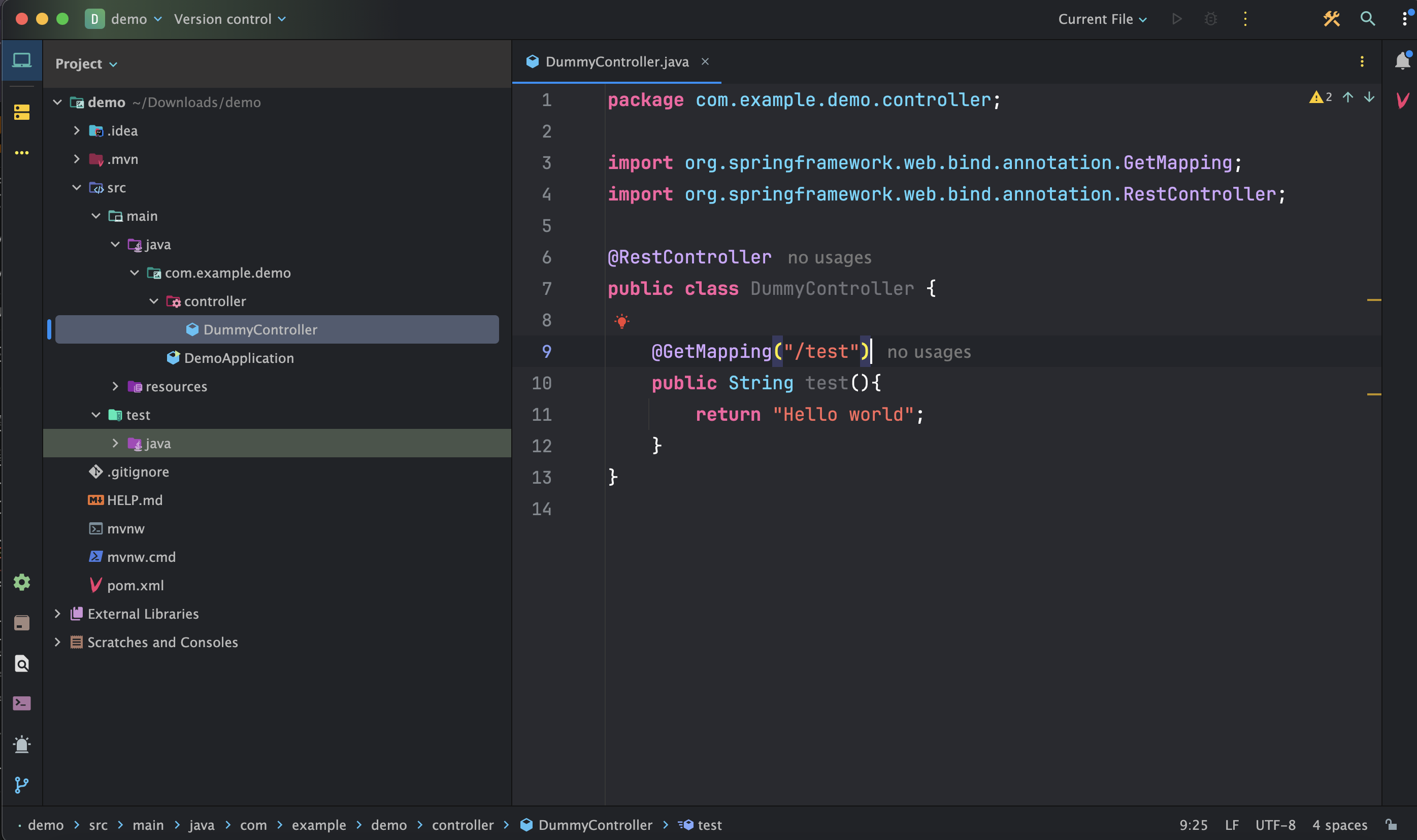
- Create a package under `src/main` named "controller".
- Create a Java class named `DummyController.java` under `src/main/controller` and annotate it with `@RestController` (indicating to Spring Boot that it will handle web requests and responses).
- Write a simple HTTP GET request that returns a string, such as "Hello, World!".
Then start the application and make a GET request using the configured endpoint:http://localhost:8080/test, it will returns the string as response: Hello world
**Ref**:
"Thank you for taking the time to explore this blog. I hope this guide has been helpful in understanding how to get started with Spring Boot. Happy coding!
For more technical blogs, visit https://arikaran.com/" | arikaran |
1,864,633 | International Schools in Dubai | Regent International School is a International School n dubai from Early Years to Year 13, spanning... | 0 | 2024-05-25T06:58:01 | https://dev.to/karishmahsha/international-schools-in-dubai-203f | Regent International School is a International School n dubai from Early Years to Year 13, spanning 40 years of excellence. Their primary program focuses from Key Stage 1 to Key Stage 2 at our primary school in Dubai.Join us to empower your child's future. Inquire now for more details.
 | karishmahsha | |
1,864,631 | QA Testing for Cloud Applications: A Special Focus | In the ever-evolving software development landscape, cloud applications have emerged as a dominant... | 0 | 2024-05-25T06:55:28 | https://dev.to/ray_parker01/qa-testing-for-cloud-applications-a-special-focus-3f5c | ---
title: QA Testing for Cloud Applications: A Special Focus
published: true
---

In the ever-evolving software development landscape, cloud applications have emerged as a dominant force, driving the need for specialized <a href="https://dev.to/batista9607/complete-guide-to-importance-of-software-quality-assurance-18bc">Quality Assurance (QA)</a> testing strategies. As businesses continue to shift towards cloud-based solutions, the role of QA testing becomes increasingly critical to ensure that these applications are reliable, secure, and efficient. This article delves into the unique challenges and methodologies for QA testing of cloud applications, highlighting the pivotal role of <a href="https://www.iqvis.com/blog/trending-best-software-testing-companies/">software testing companies</a> in this domain.
<h3>Understanding the Cloud Application Environment</h3>
Cloud applications differ from traditional applications primarily due to their scalability, multi-tenancy, and dependency on Internet accessibility. These characteristics introduce specific challenges in QA testing, such as dealing with diverse user loads, security issues, and integration complexities. To address these challenges, QA must adapt and evolve.
<h3>Challenges in QA Testing for Cloud Applications</h3>
<b>1. Scalability and Performance:</b> One of the biggest challenges is testing the application’s performance under varying loads. Scalability testing ensures that the application can handle increased load without compromising performance.
<b>2. Security and Compliance:</b> Given the data-intensive nature of cloud applications, security testing is paramount. This involves validating compliance with legal and regulatory standards, ensuring data integrity, and protecting against breaches.
<b>3. Multi-Tenancy Issues:</b> Cloud applications often serve multiple clients on the same infrastructure. QA testing must ensure that data segregation is maintained and that the actions of one tenant do not adversely affect another.
<b>4. Integration and Compatibility:</b> Testing must ensure that cloud applications integrate smoothly with other systems and software, often involving complex interfaces and configurations.
<h3>The Role of Software Testing Companies</h3>
Software testing companies play a crucial role in overcoming these challenges. They bring expertise, tools, and methodologies tailored to cloud applications, enhancing the quality and reliability of software solutions.
<b>1. Expertise in Cloud-Specific Testing:</b> These companies possess specialized knowledge in cloud technologies and are adept at navigating the complexities associated with cloud environments. This expertise is critical for conducting thorough and effective QA tests.
<b>2. Advanced Testing Tools:</b> Software testing companies utilize advanced tools that can simulate various environments, loads, and stress factors. Tools like Selenium, LoadRunner, or JMeter are commonly used to automate testing processes and make them more efficient and comprehensive.
<b>3. Continuous Testing and Integration:</b> In the agile world of cloud development, continuous testing is vital. Software testing companies integrate QA into the continuous development process, enabling real-time issue identification and resolution. This integration is crucial for maintaining the stability and performance of cloud applications.
<b>4. Security Testing:</b> These companies specialize in rigorous security testing practices, including penetration testing and vulnerability assessments, to ensure that applications are secure from external threats and comply with necessary standards.
<h3>Methodologies for Effective QA Testing in Cloud Applications</h3>
<b>1. Automation Testing:</b> Given cloud applications' repetitive and scalable nature, automation testing is beneficial and necessary. It allows for rapid execution of test cases, consistent results, and efficient utilization of resources.
<b>2. Performance Testing:</b> This involves stress and load testing to ensure that the application performs optimally under varying conditions. It’s crucial for assessing how cloud solutions handle heavy data loads and user requests.
<b>3. Security Testing:</b> Implementing comprehensive security tests, including encryption protocols and intrusion detection systems, ensures that data remains secure in a cloud environment.
<b>4. Usability Testing:</b> Cloud applications must be user-friendly and accessible across various devices and platforms. Usability testing ensures that the user interface meets the expected standards of simplicity and efficiency.
<h3>Conclusion</h3>
The migration to <a href="https://www.spiceworks.com/tech/cloud/articles/what-is-cloud-computing/">cloud computing</a> is irreversible and continues accelerating, making effective QA testing an indispensable part of the development process. Software testing companies are at the forefront of this field, equipped with the tools, knowledge, and strategies to ensure that cloud applications meet the highest quality and security standards. As cloud technology advances, the methodologies and tools of QA testing will evolve, but the fundamental goal remains the same: to deliver seamless, efficient, and secure software solutions to users worldwide.
In this dynamic environment, partnerships with adept software testing companies are beneficial and essential for businesses aiming to leverage the full potential of cloud applications. Their specialized services enhance the quality and performance of applications and ensure they meet the rigorous demands of modern digital operations.
tags:
# QA Testing for Cloud Applications
# Software Testing
---
| ray_parker01 | |
1,864,630 | Unveiling the Benefits of Rent-to-Own Car Rental Solutions | In the dynamic landscape of transportation solutions, Rent-to-Own Car Rental emerges as a... | 0 | 2024-05-25T06:52:23 | https://dev.to/saracarlsson/unveiling-the-benefits-of-rent-to-own-car-rental-solutions-3gl3 | rental, carhire, ridesharing, car | In the dynamic landscape of transportation solutions, [Rent-to-Own Car Rental](https://ecoautos.com.au/) emerges as a game-changer, providing unparalleled flexibility and convenience to drivers worldwide. As a premier provider of automotive mobility, we at **Eco Autos** are committed to reshaping the way individuals access and enjoy vehicles, empowering them with freedom, affordability, and reliability.
## Understanding Rent-to-Own Car Rental
**What Sets Rent-to-Own Car Rental Apart?
**Unlike traditional car rental services, Rent-to-Own offers a unique proposition where customers have the opportunity to lease a vehicle with the potential to own it outright at the end of the agreement. This innovative model blends the benefits of both renting and buying, catering to individuals seeking long-term solutions without the commitment of a full purchase.

## The Process Simplified
**Selection:** Begin your journey by choosing from our diverse fleet of vehicles, ranging from compact cars to spacious SUVs, ensuring there's a perfect match for every lifestyle and preference.
**Agreement:** Sign a comprehensive rental agreement outlining the terms, including the duration of the lease, monthly payments, and the option to purchase.
**Usage:** Enjoy the freedom of driving your chosen vehicle while adhering to the terms of the agreement, maintaining it in good condition to secure future ownership.
**Ownership:** Upon fulfilling the terms of the agreement, seize the opportunity to become the proud owner of your vehicle, unlocking a new chapter of mobility and independence.
## The Advantages of Rent-to-Own Car Rental
**Flexibility in Financing
**One of the primary advantages of Rent-to-Own car rental is the flexibility it offers in financing. Rather than facing the substantial upfront costs associated with purchasing a vehicle outright, customers can spread payments over the lease period, easing financial strain while maintaining access to reliable transportation.
## Pathway to Ownership
For individuals aspiring to own a vehicle but facing credit challenges or financial constraints, [Rent-to-Own car](https://ecoautos.com.au/) provides a viable pathway to ownership. By adhering to the terms of the agreement and making consistent payments, renters can gradually transition from lessees to proud owners, realizing their automotive dreams with ease.
## Maintenance and Service Benefits
As part of our commitment to customer satisfaction, Rent-to-Own car rental includes comprehensive maintenance and service benefits, ensuring that your vehicle remains in peak condition throughout the lease period. From routine inspections to emergency repairs, our team is dedicated to keeping you safe and on the road, minimizing downtime and maximizing enjoyment.

## Freedom to Upgrade
In a world where preferences and priorities evolve, Rent-to-Own car rental offers the freedom to upgrade to a different vehicle as your needs change. Whether you're expanding your family, embarking on a new adventure, or simply seeking a fresh driving experience, our flexible options empower you to make seamless transitions without hassle or inconvenience.
## Conclusion:
In conclusion, Rent-to-Own Car Rental represents a revolutionary approach to automotive mobility, blending affordability, flexibility, and convenience in a seamless package. As pioneers in the industry, we are dedicated to empowering individuals with the freedom to access and enjoy vehicles on their terms, unlocking a world of possibilities and opportunities. | saracarlsson |
1,864,629 | Best wedding invite tips | Quality Materials: Invest in high-quality paper and printing. The texture and weight of the paper... | 0 | 2024-05-25T06:47:46 | https://dev.to/celebrare/best-wedding-invite-tips-2p5b | weddinginvites, invitations, marriage, ecards |
1. Quality Materials: Invest in high-quality paper and printing. The texture and weight of the paper can greatly impact the look and feel of your invitations.
2. Clear Information: Make sure all essential details are included, such as the names of the bride and groom, date, time, and location of the wedding ceremony and reception. Don't forget to include RSVP instructions, whether it's through mail, email, or a wedding website.
3. Clarity and Readability: Ensure that the text on your [wedding invitations](https://celebrare.in/) is easy to read. Choose fonts and font sizes that are clear and legible, especially for important details like the date, time, and location.
4. Start Early : Begin working on your wedding invitations well in advance to allow time for design, printing, and addressing.
5. Personal Touches: Add personal touches to make your invitations unique and memorable. Consider incorporating elements such as custom monograms, illustrations, or photographs.
6. Include Additional Inserts: Depending on your wedding plans, you may need to include additional inserts, such as directions to the venue, accommodation information, or registry details.
7. RSVP Tracking: Implement a system to track RSVPs effectively, whether it's through traditional mail, email, or a wedding website. This will help you keep track of guest responses and finalize your guest list.
8. Theme and Style: Choose a design that reflects the theme and style of your wedding. Whether it's classic, modern, rustic, or themed, your invitations should set the tone for the event.
9. Proofreading: Thoroughly proofread your invitations to catch any spelling or grammatical errors. It's also helpful to have someone else review them before finalizing.
10. Consistent Design: Maintain consistency in design across all elements, including save-the-dates, invitations, RSVP cards, and envelopes. This creates a cohesive look and reinforces your wedding theme.
11. Mailing Timeline: Plan your mailing timeline carefully to ensure that your invitations reach your guests with enough time for them to respond and make arrangements to attend.
12. Postage Considerations: Verify the size and weight of your invitations to determine the correct postage. Consider taking a fully assembled invitation to the post office to ensure accurate postage calculation.
| celebrare |
1,864,628 | Plastering Over Stipple Ceilings: A Comprehensive Guide | Introduction Stipple ceilings, also known as popcorn or acoustic ceilings, were a popular design... | 0 | 2024-05-25T06:44:48 | https://dev.to/francisbarton/plastering-over-stipple-ceilings-a-comprehensive-guide-22i0 | <h2><strong>Introduction</strong></h2>
<p><span style="font-weight: 400;">Stipple ceilings, also known as popcorn or acoustic ceilings, were a popular design choice in homes from the 1950s to the 1980s. While they were favored for their sound-dampening qualities and ability to hide imperfections, modern homeowners often find them outdated. This has led to an increase in interest in plastering over </span><a href="https://www.wisedublinplasteringcontractors.com/sille-ceiling-plastering"><strong>stipple ceiling</strong></a><span style="font-weight: 400;"> to achieve a smoother, more contemporary look. This guide will walk you through the process, from preparation to the final finish, ensuring a flawless result.</span></p>
<h2><strong>Why Consider Plastering Over Stipple Ceilings?</strong></h2>
<h3><strong>The Downside of Stipple Ceilings</strong></h3>
<p><span style="font-weight: 400;">Stipple ceilings can collect dust and cobwebs, making them difficult to clean and maintain. Additionally, these ceilings can contain asbestos, especially if they were installed before the 1980s. The uneven texture is also prone to damage and is difficult to repair seamlessly.</span></p>
<h3><strong>Benefits of a Smooth Ceiling</strong></h3>
<p><span style="font-weight: 400;">Plastering over a stipple ceiling can significantly modernize a room. A smooth, plastered ceiling reflects light better, making spaces appear larger and brighter. Furthermore, it provides a clean slate for any future painting or decorating projects.</span></p>
<h2><strong>Preparing to Plaster Over Stipple Ceilings</strong></h2>
<h3><strong>Safety First</strong></h3>
<p><span style="font-weight: 400;">Before starting any work, it's crucial to determine whether your stipple ceiling contains asbestos. If your home was built or renovated during the time when asbestos was commonly used, hire a professional to test your ceiling. If asbestos is present, you'll need to have it removed by certified professionals to ensure safety.</span></p>
<h3><strong>Materials and Tools Required</strong></h3>
<p><span style="font-weight: 400;">To plaster over stipple ceilings, you'll need:</span></p>
<ul>
<li style="font-weight: 400;"><span style="font-weight: 400;">Protective gear (mask, goggles, gloves)</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Plastic sheeting and painter's tape</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Ladder or scaffolding</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Drop cloths</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Scraper or putty knife</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Joint compound or plaster</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Trowel and hawk</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Sanding tools</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Primer and paint</span></li>
</ul>
<h3><strong>Surface Preparation</strong></h3>
<ol>
<li style="font-weight: 400;"><span style="font-weight: 400;">Cover and Protect: Start by covering floors and furniture with plastic sheeting and drop cloths. Secure the sheeting with painter's tape to prevent dust and debris from spreading.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Clean the Ceiling: Dust and clean the ceiling thoroughly to remove any cobwebs or loose particles. This ensures better adhesion of the plaster.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Scrape the Stipple: Using a scraper or putty knife, gently remove any loose or peeling texture from the stipple ceiling. This step may be messy, so ensure your protective gear is worn.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Prime the Surface: Apply a primer suitable for textured surfaces. This helps the plaster adhere better and provides a more even finish.</span></li>
</ol>
<h2><strong>Plastering Over Stipple Ceilings</strong></h2>
<h3><strong>Applying the Plaster</strong></h3>
<ol>
<li style="font-weight: 400;"><span style="font-weight: 400;">Mix the Plaster: Follow the manufacturer's instructions to mix the plaster or joint compound to the right consistency. It should be smooth and free of lumps.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">First Coat: Using a trowel, apply the first coat of plaster to the stipple ceiling. Work in small sections, spreading the plaster evenly and smoothing out any ridges or lines.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Drying Time: Allow the first coat to dry completely. This can take several hours to overnight, depending on the humidity and thickness of the application.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Second Coat: Apply a second, thinner coat of plaster. This coat should further smooth out the surface and cover any remaining texture. Feather the edges to blend seamlessly with the ceiling.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Final Touches: Once the second coat is dry, inspect the ceiling for any imperfections. Sand any rough spots lightly to achieve a smooth, even surface.</span></li>
</ol>
<h3><strong>Finishing Up</strong></h3>
<ol>
<li style="font-weight: 400;"><span style="font-weight: 400;">Clean Up: Remove all protective coverings and clean up any dust or debris. Dispose of any materials safely, especially if dealing with asbestos.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Priming and Painting: Apply a coat of primer to seal the plaster and prepare it for painting. Once the primer is dry, paint the ceiling with your desired color, using a roller for a smooth finish.</span></li>
</ol>
<h2><strong>Conclusion</strong></h2>
<p><a href="https://www.wisedublinplasteringcontractors.com/sille-ceiling-plastering"><strong>Plastering over stipple ceilings</strong></a><span style="font-weight: 400;"> is an effective way to update and modernize your home. By following the proper preparation and application steps, you can achieve a smooth, stylish ceiling that enhances the look and feel of any room. Not only does this process improve the aesthetic appeal, but it also makes the ceiling easier to maintain and paint in the future. Whether you undertake this project yourself or hire a professional, the transformation will be well worth the effort.</span></p> | francisbarton | |
1,864,627 | Converting Extension from JS to JSX | This article is part of the Converting Large Codebase Project to Vite series. All files that... | 27,506 | 2024-05-25T06:44:21 | https://dev.to/elpddev/converting-couple-thousands-jsts-files-that-contains-jsx-content-to-jsx-extension-58oh | vite, react, webpack, jsx | This article is part of the [Converting Large Codebase Project to Vite series](https://dev.to/elpddev/converting-large-codebase-project-to-vite-5b20).
All files that contains JSX code and had ".js" extension failed in the browser.
This happened because the [react swc vite plugin](https://github.com/vitejs/vite-plugin-react-swc) does not compile ".js" files. Instead it send them to the browser as is.
https://github.com/vitejs/vite-plugin-react-swc/blob/b829b03f6476bed60ff5535fe883abc1b0b4e095/src/index.ts#L231
```tsx
const transformWithOptions = async (
id: string,
code: string,
target: JscTarget,
options: Options,
reactConfig: ReactConfig,
) => {
const decorators = options?.tsDecorators ?? false;
const parser: ParserConfig | undefined = id.endsWith(".tsx")
? { syntax: "typescript", tsx: true, decorators }
: id.endsWith(".ts")
? { syntax: "typescript", tsx: false, decorators }
: id.endsWith(".jsx")
? { syntax: "ecmascript", jsx: true }
: id.endsWith(".mdx")
? // JSX is required to trigger fast refresh transformations, even if MDX already transforms it
{ syntax: "ecmascript", jsx: true }
: undefined;
if (!parser) return;
let result: Output;
try {
result = await transform(code, {
filename: id,
swcrc: false,
configFile: false,
sourceMaps: true,
jsc: {
target,
parser,
experimental: { plugins: options.plugins },
transform: {
useDefineForClassFields: true,
react: reactConfig,
},
},
});
```
That is an [explicit decision](https://github.com/vitejs/vite-plugin-react-swc/issues/57#issuecomment-1425931254) made by the plugin authors.
## Chosen Solution
So in order to have the plugin take all those files and transpile them with SWC, we had to change the extension all of "js/ts" files that contains JSX to "jsx/tsx" equivalent extension.
Without a transpiler in the process, the jsx left as is:
https://github.com/vitejs/vite/discussions/3448
The conversion process can be done in several ways. One of them is using a script to go though all project "js/ts" files, detect if they have any JSX syntax and change their extension.
An example of [such script](https://github.com/vitejs/vite/discussions/3448#discussioncomment-5240383) taken from comment in one of the issues:
```shell
find src -type f | grep "\.[jt]s$" | xargs -n1 grep -HE "(<\/)|(\/>)" | cut -d: -f1 | uniq | awk '{print "mv "$1" "$1"x"}' | sh
```
### Breakdown of Script
#### list All Files Nested in a Target Folder
`find src -type f`
[find](https://www.man7.org/linux/man-pages/man1/find.1.html) - This command searches for all files (-type f) within the src directory and its subdirectories.
The output is a list of the filenames, include their paths.
```shell
./docs/.eslintrc.cjs
./docs/tsconfig.json
./docs/.storybook/main.js
./docs/package.json
./docs/stories/button.stories.ts
```
#### Filter Out Only Needed Files By Extension
`| grep "\.[jt]s$"`
The pipe | takes the output of the find command and passes it to grep.
[grep](https://www.man7.org/linux/man-pages/man1/grep.1.html) - grep "\.[jt]s$" filters the files, keeping only those whose names that end with .js or .ts (JavaScript or TypeScript files). for the grep patterns basic regex can be used as default.
the output is the same format of file paths and names, but filtered only to the files end with js/ts extensions.
```shell
./docs/.storybook/main.js
./docs/stories/button.stories.ts
```
#### Filter Out Files by Existence of Jsx Content Inside Them
`| xargs -n1 grep -HE "(<\/)|(\/>)"`
[xargs](https://www.man7.org/linux/man-pages/man1/xargs.1.html) `-n1` takes each file name from the previous output one by one and executes the following grep command.
`grep -HE "(<\/)|(\/>)"`
searches for the pattern </ or /> in each file.
`-H` includes the filename of the file grep searched in, in the output,
`-E` allows for extended regular expressions syntax.
```shell
./docs/stories/button.stories.ts: </Button>
```
#### Split the Output and Keep Only the File Names
`| cut -d: -f1`
[cut](https://www.man7.org/linux/man-pages/man1/cut.1.html) - remove sections from each line of files
`-d:` splits the output by the `:` delimiter. The previous `grep` output it to separate the file and the content found.
`-f1` keeps only the first field, which is the filename.
This removes the line number and matched text from the grep output, leaving only the unique filenames.
```shell
./docs/stories/button.stories.ts
```
#### Reduce the File List to Unique File Names
`| uniq`
[uniq](https://www.man7.org/linux/man-pages/man1/uniq.1.html) filters out any duplicate filenames, so each filename appears only once.
```shell
./docs/stories/button.stories.ts
```
#### Construct a `Rename` Command for the Specific File Name
`| awk '{print "mv "$1" "$1"x"}'`
[awk](https://www.man7.org/linux/man-pages/man1/awk.1p.html) constructs a mv (move) command for each file.
It renames each file by appending an "x" to its name.
```shell
mv ./docs/stories/button.stories.ts ./docs/stories/button.stories.tsx
```
#### Execute the `Rename` Command
`| sh``
The final `| sh` executes the constructed `mv` commands in the shell, renaming the files.
## Process
On a large project, you will want to do this conversion in several PRs and not one big chunk, so not to create large conflicts with other people ongoing work. | elpddev |
1,864,626 | How to Optimize Performance in Vue.js Applications: Beginner to Advanced Guide | Welcome to the comprehensive guide on optimizing performance in Vue.js applications! Whether you're... | 0 | 2024-05-25T06:41:37 | https://dev.to/delia_code/how-to-optimize-performance-in-vuejs-applications-beginner-to-advanced-guide-53db | vue, webdev, javascript | Welcome to the comprehensive guide on optimizing performance in Vue.js applications! Whether you're new to Vue or looking to refine your skills, this guide covers essential techniques from basic to advanced, all utilizing the Composition API. Let's dive in!
#### Understanding Vue.js Performance Basics
Before we jump into optimization techniques, let's understand why performance matters. A fast, responsive application provides a better user experience, improves SEO rankings, and can increase user engagement and retention.
### Basic Optimization Techniques
#### Lazy Loading Components
Lazy loading delays the loading of components until they are needed, reducing the initial load time of your application. This is particularly useful for larger applications where loading all components at once can slow down the initial load time.
**Example:**
Using the router to lazy load components:
```javascript
// Lazy load a component in the router
const routes = [
{
path: '/about',
component: () => import('./components/About.vue')
}
]
```
Using the Composition API, you can dynamically import components in your setup function:
```javascript
import { defineAsyncComponent } from 'vue'
export default {
setup() {
const About = defineAsyncComponent(() => import('./components/About.vue'))
return { About }
}
}
```
This method ensures that the `About` component is only loaded when the user navigates to the '/about' route, thereby reducing the initial bundle size and improving load time.
#### Using v-show vs. v-if
While both `v-if` and `v-show` control the visibility of elements, they do so differently. `v-if` adds or removes elements from the DOM, which is more performance-intensive. In contrast, `v-show` simply toggles the `display` CSS property, making it more efficient for elements that need to be toggled frequently.
**Example:**
```html
<template>
<div>
<button @click="show = !show">Toggle</button>
<div v-show="show">This is a toggled element</div>
</div>
</template>
<script>
import { ref } from 'vue'
export default {
setup() {
const show = ref(false)
return { show }
}
}
</script>
```
In this example, `v-show` is more efficient as it avoids unnecessary DOM manipulations, thus improving performance when toggling the visibility of elements frequently.
### Intermediate Optimization Techniques
#### Debouncing and Throttling
When handling user input, such as search queries or form submissions, it's essential to debounce or throttle events to avoid performance issues. Debouncing delays the execution of a function until after a specified time has elapsed since the last time it was invoked. Throttling ensures a function is only executed once per specified interval.
**Debouncing Example:**
```javascript
import { ref } from 'vue'
import debounce from 'lodash/debounce'
export default {
setup() {
const query = ref('')
const search = debounce((value) => {
// Perform search operation
console.log(value)
}, 300)
return { query, search }
}
}
```
In this example, the `search` function will only execute 300 milliseconds after the user has stopped typing, reducing the number of API calls and improving performance.
#### Using Reactive References Wisely
Reactive references can become a performance bottleneck if overused. Use them judiciously and prefer computed properties for derived state. This helps in avoiding unnecessary reactivity and ensures your application remains performant.
**Example:**
```javascript
import { ref, computed } from 'vue'
export default {
setup() {
const items = ref([1, 2, 3, 4, 5])
const evenItems = computed(() => items.value.filter(item => item % 2 === 0))
return { items, evenItems }
}
}
```
In this example, `evenItems` is a computed property that automatically updates when `items` changes, but it is not itself reactive, which helps in maintaining performance.
### Advanced Optimization Techniques
#### Virtual Scrolling
For rendering large lists, use virtual scrolling to render only the visible items, significantly improving performance. Virtual scrolling is particularly useful when dealing with long lists or tables where rendering all items at once would be inefficient.
**Example using vue-virtual-scroll-list:**
```html
<template>
<virtual-list :size="50" :remain="10" :items="items">
<template v-slot="{ item }">
<div class="item">{{ item }}</div>
</template>
</virtual-list>
</template>
<script>
import { ref } from 'vue'
import VirtualList from 'vue-virtual-scroll-list'
export default {
components: { VirtualList },
setup() {
const items = ref([...Array(1000).keys()])
return { items }
}
}
</script>
```
In this example, only the visible items are rendered, reducing the load on the DOM and improving performance.
#### Code Splitting and Bundling
Use tools like Webpack to split your code into smaller bundles, loading only what is necessary. This is particularly useful for large applications as it allows the browser to load only the essential parts of your application initially and defer the loading of other parts until they are needed.
**Example:**
Configure Webpack for code splitting:
```javascript
// webpack.config.js
module.exports = {
optimization: {
splitChunks: {
chunks: 'all',
},
},
}
```
This configuration tells Webpack to split your code into smaller chunks, which can be loaded on demand.
#### Server-Side Rendering (SSR)
For performance-critical applications, consider using Server-Side Rendering (SSR) with Nuxt.js to improve load times and SEO. SSR can significantly enhance the initial load time by rendering the initial HTML on the server and sending it to the client.
**Example:**
Setting up a Nuxt.js project:
```bash
npx create-nuxt-app my-project
```
Nuxt.js handles SSR out of the box, allowing you to build Vue.js applications with improved performance and SEO benefits.
#### Performance Monitoring
Regularly monitor your application's performance using tools like Vue Devtools, Lighthouse, and Webpack Bundle Analyzer. These tools help identify bottlenecks and areas for improvement.
1. **Vue Devtools**: Provides insight into your application's state and performance.
2. **Lighthouse**: Offers a comprehensive audit of your web application's performance, accessibility, and SEO.
3. **Webpack Bundle Analyzer**: Visualizes the size of Webpack output files, helping you understand where you can optimize your bundle sizes.
Optimizing the performance of your Vue.js applications involves a mix of simple and advanced techniques. Start with basic optimizations like lazy loading and efficient use of directives, then move on to intermediate strategies like debouncing and reactive references. Finally, implement advanced techniques such as virtual scrolling, code splitting, and SSR for the best performance.
By following these practices, you can ensure your Vue.js applications are fast, responsive, and ready to provide a great user experience. Happy coding!
By implementing these techniques and continually monitoring your application's performance, you'll be well on your way to creating efficient and user-friendly Vue.js applications. | delia_code |
1,864,625 | Unlocking Bruno Fernandes: A Guide to Acquiring His Player Card in FC24 | In FC24, you're not just stepping onto the pitch; you're immersing yourself in a dynamic world of... | 0 | 2024-05-25T06:40:32 | https://dev.to/patti_nyman_5d50463b9ff56/unlocking-bruno-fernandes-a-guide-to-acquiring-his-player-card-in-fc24-461d | In FC24, you're not just stepping onto the pitch; you're immersing yourself in a dynamic world of soccer strategy and thrilling gameplay. Let me take you on a journey through the game's story, background, character creation, team building, strategy, and how to enhance your gaming experience. When you embark on your journey, mmowow items can lend a helping hand when you need help.
FC24 unfolds in a vibrant world where soccer reigns supreme. As a player, you'll navigate through the highs and lows of the soccer universe, from the drama of the transfer market to the intensity of match day. Your ultimate goal? To lead your team to glory and cement your legacy in the annals of soccer history.
Character and Team Creation:
Before diving into the action, you'll craft your unique soccer persona. Customize your appearance, select your preferred position on the field, and fine-tune your skills to match your playstyle. Then, assemble your dream team by recruiting a diverse cast of players from around the globe. Each player brings their strengths, weaknesses, and personalities to the table, adding depth and complexity to your squad.
FC24 Rating:
As you progress through the game, your team's performance will be evaluated based on various criteria, culminating in an overall FC24 rating. This rating serves as a benchmark of your team's success and provides valuable feedback on areas for improvement.
Team Formation:
Mastering the art of team formation is key to dominating the competition in FC24. Experiment with different formations, tactics, and strategies to find the perfect balance between offense and defense. Whether you prefer a classic 4-4-2 or a daring 3-5-2, the choice is yours.
Preparation:
Preparation is paramount before heading into a match. Scout your opponents, analyze their strengths and weaknesses, and devise a game plan to exploit any vulnerabilities. Additionally, pay close attention to your team's fitness, morale, and chemistry to ensure peak performance on the field.
Player Selection:
One of the most effective ways to enhance your gaming experience is by selecting the right players for your team. One standout player to consider is Bruno Fernandes.
Bruno Fernandes Background:
Born and raised in Maia, Portugal, Bruno Fernandes honed his skills on the streets before rising through the ranks of Sporting CP's youth academy. His meteoric rise continued as he made a name for himself in the Primeira Liga, catching the eye of top European clubs with his dazzling performances.
Career Development:
Bruno Fernandes' journey to stardom reached new heights when he joined Manchester United in 2020. His arrival injected new energy into the team, with his vision, passing, and goal-scoring prowess earning him a place among the Premier League's elite.
World Stage Achievements:
In FC24, Bruno Fernandes has left an indelible mark on the world stage, delivering standout performances in key matches and tournaments. From decisive goals to breathtaking assists, he consistently rises to the occasion when it matters most.
Role in the Game:
In FC24, Bruno Fernandes is a midfield maestro, capable of dictating the tempo of the game and unlocking defenses with his pinpoint passes and clinical finishing. His versatility and leadership make him a valuable asset both on and off the pitch, catalyzing your team's success.
Importance in Team Composition:
When assembling your dream team, Bruno Fernandes' presence is indispensable. Whether slotting into an attacking midfield role or pulling the strings from deeper positions, his influence elevates the performance of those around him, making him the linchpin of your squad.
Alright, let's dive into Bruno Fernandes' significant contributions throughout the season, his prospects, and why having him on your team is crucial.
Throughout the season, Bruno Fernandes has been nothing short of exceptional. His ability to control the midfield, create scoring opportunities, and find the back of the net himself has been instrumental in our team's success. Whether it's delivering inch-perfect passes, unleashing thunderous shots from a distance, or orchestrating the attack with his vision and creativity, Bruno consistently delivers when it matters most.
Looking ahead, Bruno Fernandes' future is incredibly bright. As he continues to refine his skills and adapt to new challenges, there's no limit to what he can achieve. Whether it's leading our team to domestic glory or making his mark on the international stage, Bruno's talent and determination make him a force to be reckoned with for years to come.
Now, let's talk about why having Bruno Fernandes on your team is essential. Not only does he bring unparalleled skill and versatility to the midfield, but his leadership and work ethic also inspire those around him to elevate their game. Whether it's rallying the troops during a tough match or leading by example with his relentless work rate, Bruno sets the standard for excellence both on and off the pitch.
In terms of his potential rating and skill attributes in the game, Bruno Fernandes boasts top-tier ratings across the board. His exceptional passing, shooting, dribbling, and vision make him a game-changer in any situation. With the ability to unlock defenses with a single pass or unleash a thunderbolt from outside the box, Bruno is a true game-changer who can turn the tide of any match in your favor.
Now, let's talk about how you can acquire Bruno Fernandes's player card in FC24. There are several ways to obtain his card, including through in-game events, completing specific challenges or objectives, or purchasing it directly from the transfer market. However, the most direct way to acquire Bruno Fernandes' player card is by using FC24 coins.
FC24 coins are the in-game currency used to acquire player cards, unlock special items, and enhance your gaming experience. You can earn FC24 coins by completing matches, participating in events, or purchasing them through the in-game store.
In the early stages of the game, it's essential to use FC24 coins wisely, focusing on building a strong squad and addressing any weaknesses in your lineup. As you progress through the season, you can invest in upgrading facilities, hiring staff, and acquiring top-tier players like Bruno Fernandes to take your team to the next level.
In the middle stages of the game, consider investing in scouting networks to uncover hidden gems or bolstering your squad with high-impact signings like Bruno Fernandes. Additionally, use FC24 coins to participate in special events or tournaments to earn valuable rewards and strengthen your team even further.
In the later stages of the game, strategic use of FC24 coins becomes even more critical as you vie for silverware and supremacy. Whether it's making key signings to shore up your defense or investing in training facilities to develop young talent, every coin spent should bring you closer to achieving your ultimate goal of soccer glory. Due to its multiple uses in the game, some players choose FIFA 24 coins.
In summary, Bruno Fernandes is more than just a player; he's a game-changer who can transform your team's fortunes in FC24. By leveraging his exceptional skills and leadership qualities, you can propel your team to new heights and etch your name in soccer history. So gather your coins, assemble your squad, and get ready to dominate the pitch with Bruno Fernandes by your side. | patti_nyman_5d50463b9ff56 | |
1,864,624 | Is Learning AI Essential for Software Engineers? | The rapid evolution of artificial intelligence (AI) has significantly impacted various industries,... | 0 | 2024-05-25T06:38:22 | https://dev.to/yogini16/is-learning-ai-essential-for-software-engineers-4gf9 | The rapid evolution of artificial intelligence (AI) has significantly impacted various industries, including software engineering. As AI continues to permeate different sectors, the question arises: is it necessary for software engineers to learn AI? While the necessity may vary depending on the specific role and industry, there are compelling reasons why software engineers should consider acquiring AI knowledge.
##The Growing Importance of AI
**Enhanced Problem-Solving Capabilities:** AI can augment traditional software engineering by providing new tools and techniques for solving complex problems. Machine learning (ML) algorithms, for example, can analyze vast amounts of data to identify patterns and make predictions, which can be invaluable in fields such as cybersecurity, finance, healthcare, and more.
**Demand in the Job Market:** The demand for AI skills in the job market is on the rise. Companies are increasingly looking for engineers who can integrate AI solutions into their products and services. Having AI expertise can open up new career opportunities and make candidates more competitive.
**Innovation and Efficiency:** AI can drive innovation by enabling the development of intelligent applications that can perform tasks autonomously, learn from data, and improve over time. For software engineers, understanding AI can lead to the creation of more efficient and effective software systems.
**Interdisciplinary Applications:** AI is not confined to a single domain; it intersects with various fields such as robotics, natural language processing, and computer vision. This interdisciplinary nature means that software engineers with AI knowledge can contribute to a broader range of projects.
##Should Every Software Engineer Learn AI?
While AI is undoubtedly valuable, it is not mandatory for every software engineer to become an AI expert. The decision to learn AI should be based on individual career goals and interests. Here are some considerations:
**Career Path:** Engineers working in domains like web development, mobile app development, or embedded systems may not need extensive AI knowledge. However, those interested in fields like data science, ML, or AI product development will find AI expertise essential.
**Project Requirements:** In some roles, the use of AI might be integral to the project's success. In such cases, having a solid understanding of AI concepts and techniques is crucial.
**Continuous Learning:** The technology landscape is always evolving. Software engineers should be prepared for lifelong learning, and acquiring AI skills can be a part of this ongoing professional development.
##Roadmap for Learning AI
For those interested in delving into AI, a structured learning path can make the journey more manageable and effective. Here is a comprehensive roadmap:
**1. Foundation in Mathematics and Statistics**
Linear Algebra: Understand vectors, matrices, eigenvalues, and eigenvectors.
Calculus: Focus on derivatives, integrals, and optimization.
Probability and Statistics: Learn about distributions, hypothesis testing, and statistical inference.
**2. Programming Skills**
Python: Master Python, the primary language for AI development.
Libraries and Frameworks: Get familiar with libraries such as NumPy, Pandas, Matplotlib, and frameworks like TensorFlow and PyTorch.
**3. Introduction to Machine Learning**
ML Basics: Learn about supervised and unsupervised learning, regression, classification, clustering, and dimensionality reduction.
Algorithms: Study key algorithms like linear regression, decision trees, k-means clustering, and support vector machines.
**4. Deep Learning**
Neural Networks: Understand the architecture of neural networks, activation functions, and backpropagation.
Advanced Topics: Explore convolutional neural networks (CNNs), recurrent neural networks (RNNs), and generative adversarial networks (GANs).
**5. Specializations**
Natural Language Processing (NLP): Study text processing, sentiment analysis, and language models.
Computer Vision: Learn about image processing, object detection, and image segmentation.
Reinforcement Learning: Understand the basics of agent-environment interaction, reward systems, and policy learning.
**6. Practical Applications**
Projects: Build real-world projects to apply theoretical knowledge. Examples include chatbots, recommendation systems, and image classifiers.
Competitions and Challenges: Participate in platforms like Kaggle to gain practical experience and improve problem-solving skills.
**7. Advanced Studies and Research**
**Reading Research Papers:** Stay updated with the latest advancements by reading research papers and attending conferences.
**Online Courses and Certifications:** Enroll in advanced courses and obtain certifications from platforms like Coursera, edX, and Udacity.
**8. Ethics and AI Governance**
**Ethical AI:** Learn about the ethical implications of AI, including bias, fairness, and privacy concerns.
**AI Regulations:** Understand the regulatory landscape and compliance requirements related to AI deployment.
In short
While not every software engineer must learn AI, having a foundational understanding can significantly enhance one's career prospects and ability to contribute to cutting-edge projects. As AI continues to evolve, staying informed and acquiring relevant skills will be crucial for those looking to thrive in the tech industry. Whether through formal education, online courses, or self-study, embarking on the AI learning journey can be a rewarding endeavor for software engineers. | yogini16 | |
1,864,623 | The Colorful World of Iron Oxide Pigments | The Amazing World of Iron Oxide Pigments Introduction Are you fascinated by color and what it can... | 0 | 2024-05-25T06:35:57 | https://dev.to/safiyaaa/the-colorful-world-of-iron-oxide-pigments-2ogc | oxide | The Amazing World of Iron Oxide Pigments
Introduction
Are you fascinated by color and what it can do? Do you ever wonder about the different colors that we see around us and how they are made? If so, you'll be interested to know about the amazing world of iron oxide pigments. Iron oxide pigments are a type of substance that brings color to many different products and materials. They are used in a variety of applications, from making buildings look beautiful to coloring our food and even our makeup products. We will take a closer look at the wonderful world of and how they are used.
Advantages of utilizing iron oxide pigments
Iron Oxide Pigment are preferred for the selection of applications for their benefits being numerous.
To begin with, they are typically exceptionally durable, which means that after utilized, they shall undoubtedly really endure for stretches that are long diminishing.
Iron oxide pigments have become stable furthermore; they do not really separate or react along side other compounds, making them safe to make use of.
Also they are non-toxic, making them especially perfect for discovered in dishes and items which are cosmetic.
Finally, these are typically several of the most vibrant and colorful pigments available, helping to make them an option like color like fantastic.
Innovations within the iron oxide pigment industry
Today, there have been innovations which can be a few the iron oxide pigment industry, that have actually triggered along with this and a lot more pigments being vibrant.
One development like work like significant usage of advanced level technology like manufacturing that allows for greater accuracy into the manufacturing process.
Also, new iron like artificial pigments may actually have now been developed which will produce even brighter and more vivid colors, making them a perfect choice to be used into the color industry like cosmetic.
Protected and usage that's right of oxide pigments
You shall have to use iron oxide pigments precisely and properly to produce one of the most results that are effective.
First, find the proper kinds of iron oxide pigment for any application.
Next, adhere to the principles through the label to guarantee the pigment is blended and used properly.
This might make sure the pigment executes optimally and can supply the most outcomes that are readily of good use.
Also, it is important to help keep and manage Iron Oxide correctly plus in line due to the maker's directions, inside an awesome and spot like dry.
Application and Quality
Quality is critical with regards to iron oxide pigments.
Opt for top-quality brands services which can be offering are premium products, like those that meet industry criteria and conform to legislation.
This product quality like best of pigment may help to ensure your application is consistent and consistent, yielding outcomes which can be gorgeous.
Applications for iron oxide pigments are diverse, including paint, synthetic materials, and textiles, to say a couple of.
The thing like iron like important is using pigments efficiently is to understand to select the type like better of pigment for almost any application and in addition to work well with it precisely.
Conclusion:
In conclusion, the world of iron black oxide is vast and vibrant, offering a vast range of options for those seeking to use them. From the incredibly durable to the safe and non-toxic, iron oxide pigments are an excellent choice for a wide variety of applications. Whether you are using them to color cosmetics, fabric, or buildings, they provide brightness and long-lasting results. With the right quality, safety, and application knowledge, iron oxide pigments provide a colorful world of possibilities.
Source: https://www.sjzhuabangkc.com/iron-oxide-pigment160 | safiyaaa |
1,864,190 | Networking 101: Back to School | Hola! Hope your networks are stable and reliable. In this article let's get Back to School (the... | 0 | 2024-05-25T06:34:04 | https://dev.to/xpertr2/networking-101-back-to-school-1gk7 | sre, networking, ccna, linux | Hola! Hope your networks are stable and reliable. In this article let's get **_Back to School_** (the **Basics**), in order to later get into advanced networking topics.
## What is a network?
A network is interconnection between multiple devices enabling them to share data between each other. An example:
Hmmm... The network doesn't look that impressive. Right?
Maybe this is better.
Still not impressed. You must be thinking where the networking devices like a router or a switch or a bridge are, something should be there. But actually, for the above scenarios these networks will just do fine. There is no use of overengineering stuff and bringing-in extra networking devices which serves no actual purpose but can be a single-point of failure.
## Why internetworking? Why not a huge network like this?
Let's now understand why we don't create a huge network of directly/indirectly connected devices, but instead have interconnected smaller networks. And how broadcast and collision domains affect this decision.
### Collision
Let's understand what a **collision** is. In a network when two devices want to send data, they send signals (electromagnetic along the transmission medium). Now, if two devices try to send data at the same time in the same medium, the signals mix up or **collide** with each other and there is signal loss. When a collision occurs all the devices on the network has to pay attention to it, because nobody knows what the destination on the data signal that was collided. Also, now the data has to be re-transmitted. This **increases computation** for all devices, **increases latency** in the network.
> So, for any device the **smaller** the size of **collision domain** is, **lesser** is the chance of any **collision happening**.
### Broadcasting
Now, let's understand what is **broadcasting**. In broadcasting, a device is trying to send some data across the network, so that multiple devices can receive and acknowledge it. On a bigger network, there may be a few devices in this case who doesn't need this data. But still they have to see it, receive it, acknowledge it, check if it needs this data and lastly just drop the data received. For this device, we want to limit the broadcasting domain only to the devices that it actually needs to talk to, while will reduce the computation getting wasted on dropping un-intended data.
### Another common problem...
**Congestion**, it is the thing we as network admins have to always look after and try to reduce. Congestion is similar to traffic jams on the roads. Whenever, collision occurs the **packets** have to be retransmitted, on unnecessary broadcasts for the unintended devices there are packets travelling on the network, it will have to wait to send its own data. These are the common examples of congestion. Our goal is to somehow reduce this. Now, let's try to find ways of doing. For that we need to introduce few networking devices, so first let's learn about them.
## Understanding the devices
**Domains**. What is a domain? A domain is a region or in this case set of devices.
Types of domains in networking:
- **Collision Domain**
A collision domain for a device is the set of devices who if try to send a signal at the same time as this device, the signals collide.
- **Broadcast Domain**
A broadcast domain for a device is the set of devices who receives the packet broadcasted by this device.
> Collision domain is always a **subset** of the broadcast domain.
### Hub
A hub is a **dumb** network device with several ports used to connect multiple devices or small networks together. In a Hub, a packet received in any port is re-transmitted to the remaining ports. It doesn't read the packet or anything, it just regenerates the signals received on one port to the remaining that's it.
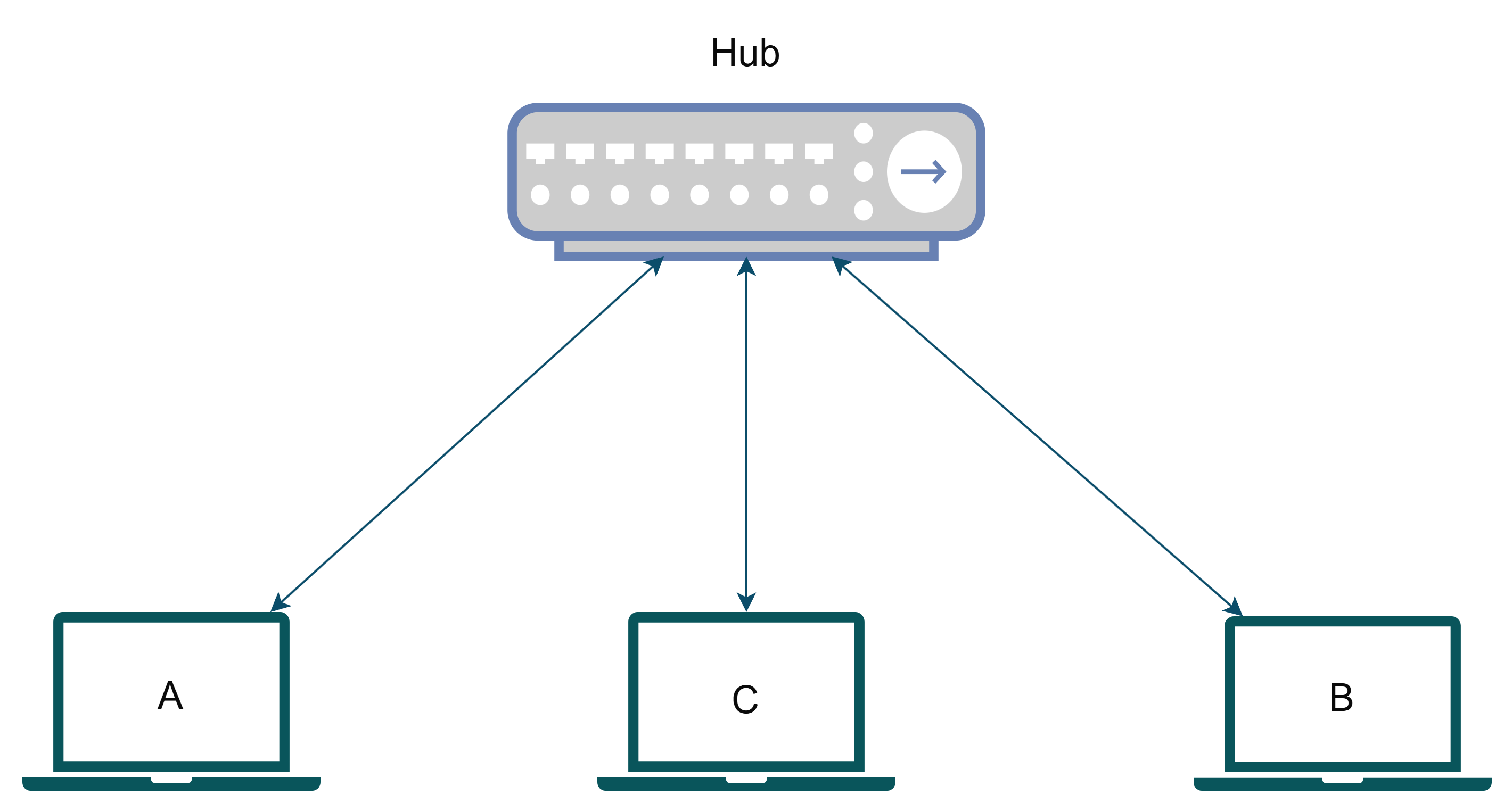
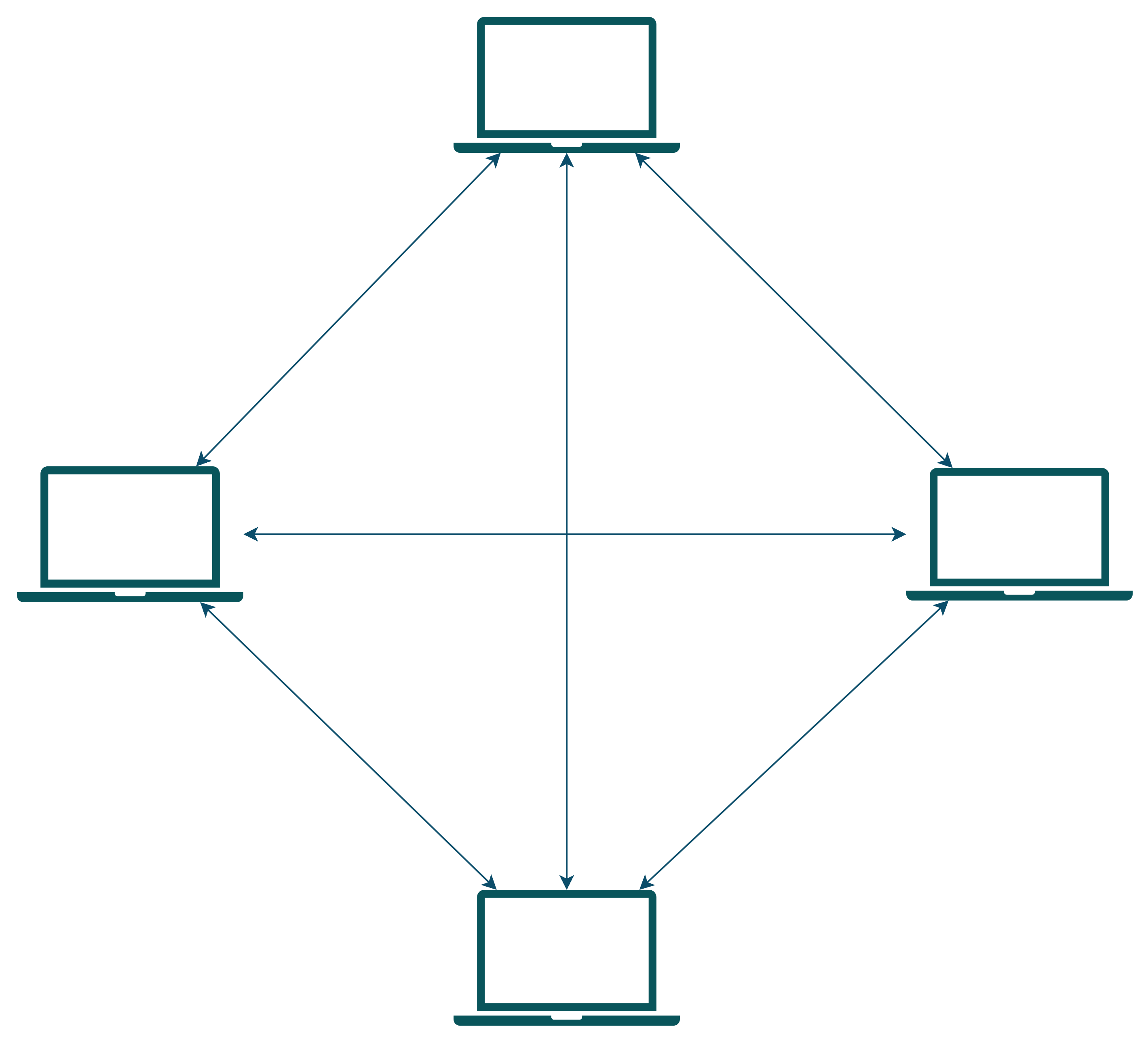
The devices A, B, C are all connected to this hub. Now, let's take an example where A wants to transmit to B. It sends a packet out on the network; it reaches the hub, and the hub retransmits on the remaining ports. So, B receives the packet successfully. Cool right? Not actually, because C will also receive the packet now it will have to do the computation that the packet was not intended for it and drop which was not something cool for device C. Here, both the collision domain and broadcast domain for **A** was **{A, B, C} only**.
> Hubs are cheap but always lead to congestion.
### Bridge
A bridge can be called an **intelligent** hub. The term ***"bridging"*** here simply refers to packets bridging over ports. Here, when a packet arrives in one port like hub, instead of being retransmitted to all the ports, the bridge transmits that to the port which it is destined for. I will not be going to show any bridge diagram below as nowadays we don't buy physical bridges. The bridge technology is rather used in switches and routers which we will talk after this.
> Cisco sometimes refers to their switches as multiport bridge, but now you won't get confused why.
> Bridges can be used to reduce collisions in a broadcast domain. It increases the number of collision domains and hence provides higher bandwidth for devices.
### Switch
A switch is an intelligent device which exactly knows which device or network is connected to each port and smartly routes/**bridges**/***switches*** the packets between incoming and destination ports. Here each port creates its own isolated collision domain thus **reducing congestion** in the network. But still as its just switching packets in same network, the broadcast domain remains same.
Let's modify our previous example to make it better.
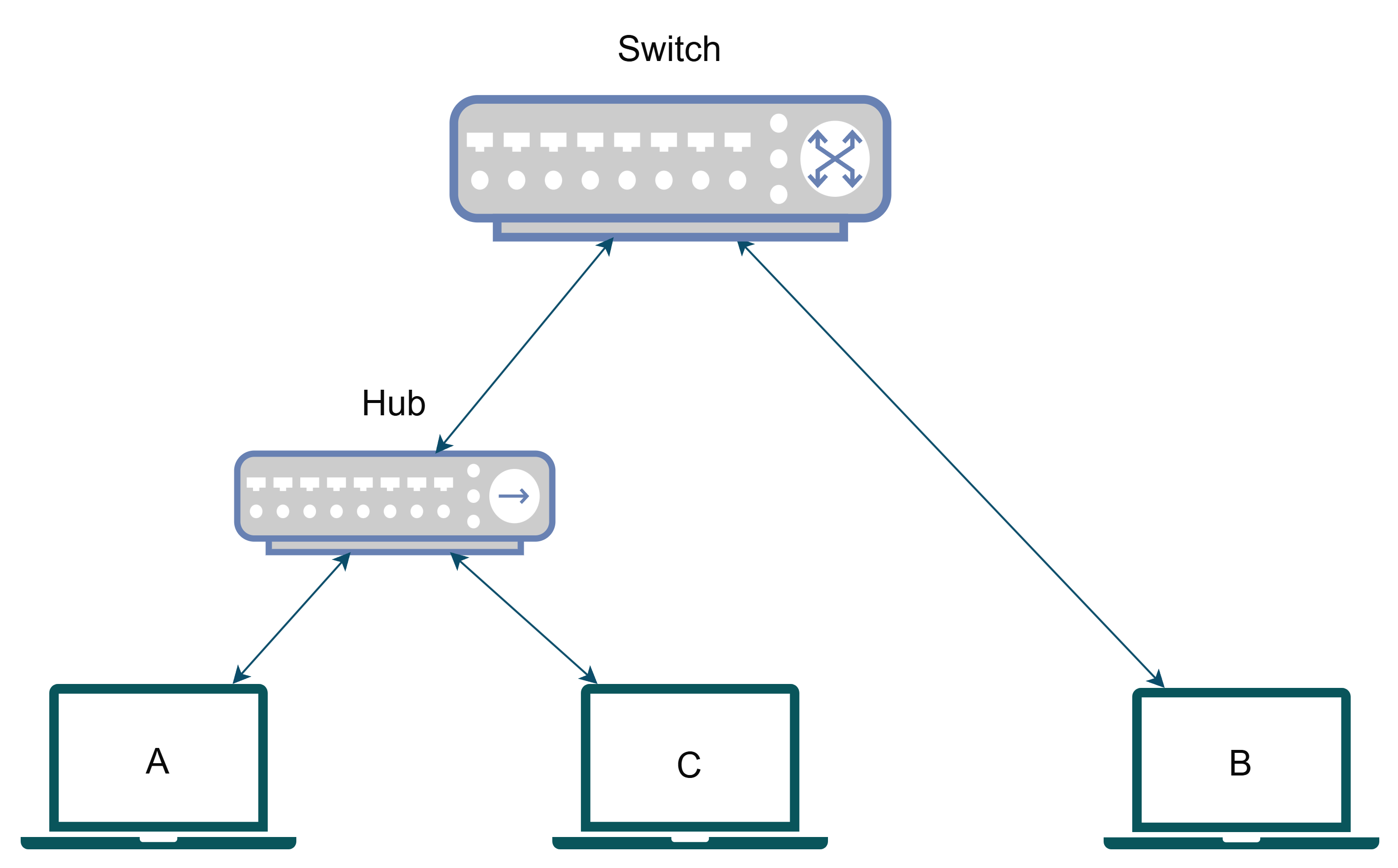
Now let's analyze the devices.
**Device B:**
It is directly connected to a port on the switch. So, its collision domain is isolated to the port itself. That is the collision domain for it is **{B}**. That means collision will never occur hence using maximum available bandwidth to the switch. Can it talk to A? Yes, the packet first reaches the switch, the switch checks the destination of the packet and decides to send it to the port in which the hub is connected. The packet then arrives at the hub, and it transmits it to both A and B. Here, A successfully receives the packet, but B also receives it and then drops it.
**Device A, C:**
Both of them are connected to the hub, therefore their collision domain is **{A, C}**. They both can obviously talk with each other and can also talk to B via the reverse of the route we just discussed before.
> In this case, the broadcast domain remains same **{A, B, C}** for all the devices.
### Router
A router is a switch only. The difference is that a switch switches packets in a **single broadcast domain**. But a router is used to switch packets across **multiple broadcast domains**. Explained simply, a router is used to connect **multiple networks** (this also means it can connect several **smaller networks or sub-networks or subnets** within a **bigger network**. This can also be phrased as it can connect **multiple broadcast domains** within a **wider broadcast domain**). How a packet in one subnet would go another subnet, you may ask? Routers do something called NAT (Network Address Translation) to translate the source, destination addresses of the packets from one subnet to another. We will discuss about NAT in a later article.
Let's modify our example before. We had assumed that all the devices are in a same room. Let's modify it in a way A, C remains in one room and B is in another, each room using its own subnet. Also, as we got the chance to modify our network, let's make it better by replacing the hub with a switch.
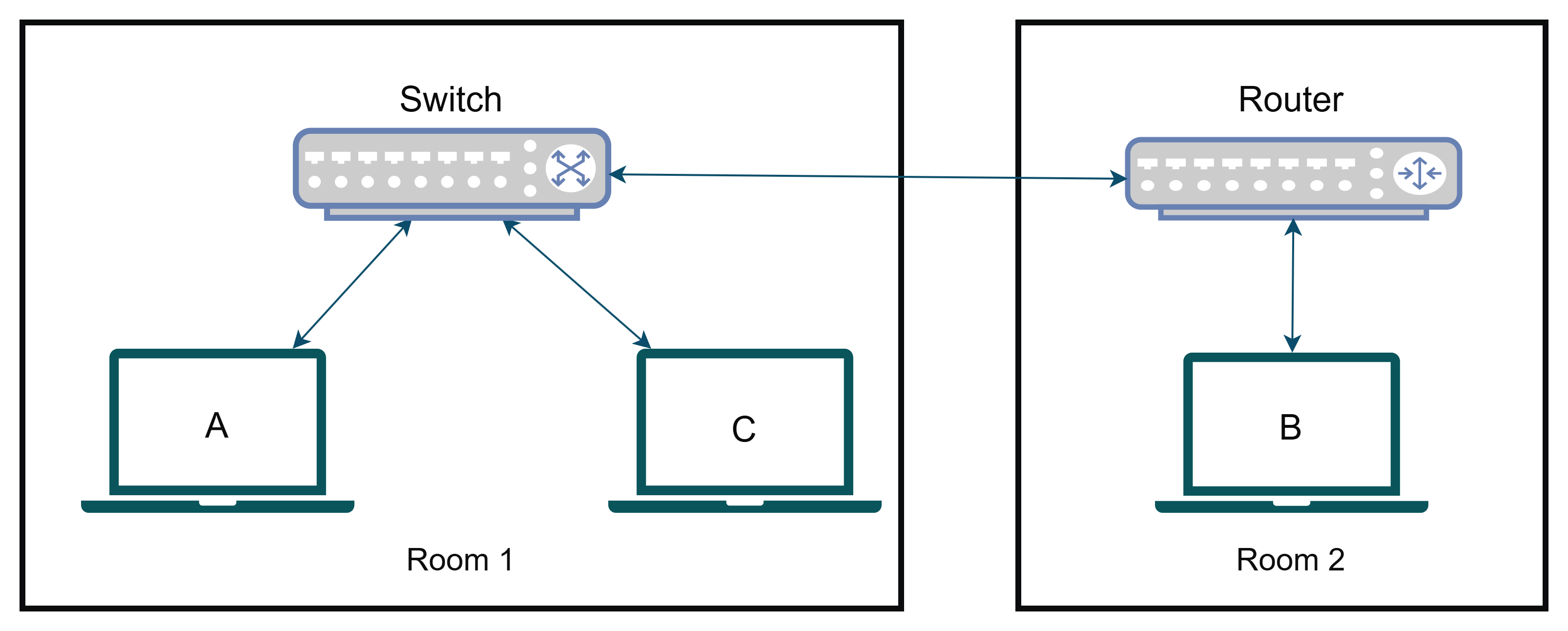
Let's again analyze the devices.
**Device B:**
It is connected to a port on the router and therefore has an isolated collision domain **{B}** **eliminating congestion**. Can it talk to A or C? Yes, the packet the first goes to router the packet is **translated** to the subnet of **Room 1** and then sent to the switch, the switch then switches the packet **only to the intended device**. Here broadcast domain is only **{B}**
**Device A, C:**
Both of them are connected to the switch. A and C, they have their own isolated collision domains **{A}** and **{C}** respectively that they themselves are only present eliminating any collision. Can it talk to B? Yes, again through the reverse of the route discussed before. Broadcast domain for both of them is **{A, C}**.
> Switches create separate collision domains within a single broadcast domain.
> Routers provide a separate broadcast domain for each interface. Don’t let this ever confuse
you!
___
Let's end here for today. In the next article let's discuss network topologies, internetworking models, and a few common protocols.
Please comment below suggesting any changes, asking for any topic, or just hanging out in general. Also, pls reach out to me on my social channels.
[[GitHub]](https://github.com/sith-lord-vader) [[LinkedIn]](https://www.linkedin.com) [[Instagram]](https://www.instagram.com/xpertr2) [[YouTube]](https://www.youtube.com/@xpertdev) | xpertr2 |
1,856,674 | GitHub Copilot vs ChatGPT | In this article I would like to analyze thedifferences between two tools that seem to overlap: GitHub... | 0 | 2024-05-25T06:30:00 | https://dev.to/tommasodotnet/github-copilot-vs-chatgptgithub-4kb5 | openai, githubcopilot, chatgpt | In this article I would like to analyze thedifferences between two tools that seem to overlap: GitHub Copilot and ChatGPT. What are the fundamental differences between the two? Which one to choose? And do you really have to choose?
## ChatGPTChatGPT
Let's start by analyzing ChatGPT. It is a web portal where you can start a chat with a Large Language Model (LLM). There are several [ChatGPT tiers](https://openai.com/chatgpt/pricing):
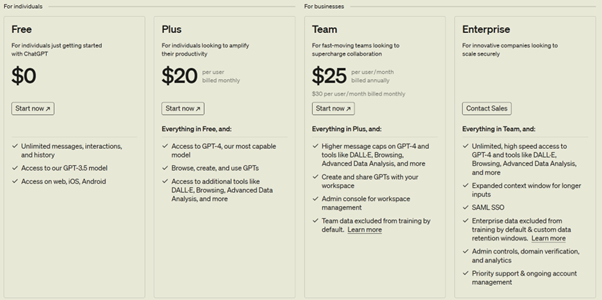
With the free tier, we have a fairly minimal experience that allows us to interact with the GPT-3.5 model.
Things start to get interesting from the Plus tier, which already offers us the possibility to interact with the GPT-4 model. This also gives us access to the web. Access to the web is important, because when we ask a question to the model, it is able to answer based on "native knowledge" derived from its training. Let's say that the model has been trained with data from the web up to 2021, and we ask it who the Prime Minister of the United Kingdom is, it would answer Boris Johnson (the Prime Minister in office at that time). If we gave the same model access to the web, it would be able to give us the exact answer: Rishi Sunak (Prime Minister in office at the time of writing this article).
The third team, in addition to interacting with other models such as DALL-E, adds the possibility that the data sent through the requests will not be used to retrain the model.
## GitHub Copilot
GitHub Copilot is a fine-tuning of the GPT-4 model for code. Fine-tuning refers to the ability to train a model by specializing it for a specific scenario, in this case working on code. The basic capabilities are therefore the same as GPT-4, which is already highly capable of working on code, with a specific specialization on this feature.
Just like ChatGPT, GitHub Copilot also offers [different pricing tiers](https://github.com/features/copilot/plans).
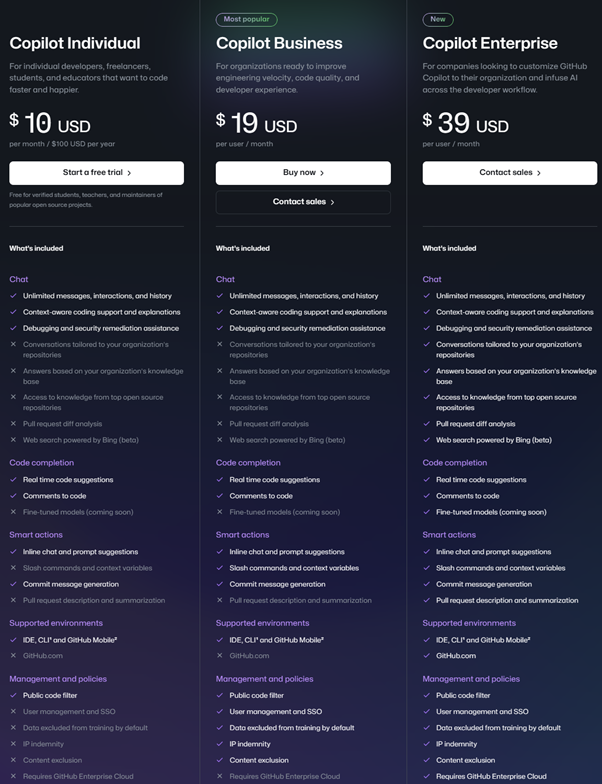
It can be observed how for the tiers Individual and Business the difference in features is mostly related to "Management and policies". The Individual tier is aimed at individual users, while the Business tier targets more corporate scenarios, where centralized user and policy management provides a significant advantage for tool administrators.
I will dedicate a separate paragraph to the Enterprise tier later in this article.
## Terms and Conditions
Another fundamental difference between the two tools can be found in the Terms & Conditions (T&C). GitHub Copilot's terms and conditions of use ensure that the underlying model will not be retrained using user-inputted data. Essentially, even in the Individual tier, when GitHub Copilot analyzes your code to provide you with answers and suggestions, it does not use the portions of code analyzed to retrain its algorithm, thereby preserving intellectual property.
Regarding ChatGPT, this applies starting from the Team tier.
From the perspective of Copilot in Edge, however, Commercial Data Protection is guaranteed for the types of accounts listed in the first paragraph [of this link](https://learn.microsoft.com/en-us/copilot/manage), and only when accessing with the company account and not the personal account.
Due to data protection concerns, for professional use, I would never recommend a tier that does not offer data protection functionalities, for this purpose from now on we will consider a comparison between the different tiers of GitHub Copilot and ChatGPT Team.
## IDE Integration
The main advantage of GitHub Copilot is the integration with the IDE: it is in fact born as a tool to suggest code in real time to the developer as he or she writes code. It infers from the context of what has already been written and what is being written to suggest entire portions of code in a pro-active way.
Over time, GitHub Copilot has evolved by adding several features, in addition to the Code Completion we just talked about: Chat and Smart Actions.
We can imagine the Chat feature as an implementation of a ChatGPT-like scenario. However, being a model specialized in code, the field is therefore restricted: asking GitHub Copilot who the Prime Minister of the United Kingdom is, it will respond:
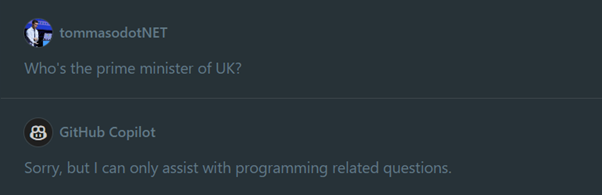
If ChatGPT can answer both code and general questions, what's the advantage of using GitHub Copilot over ChatGPT?
Keeping in mind that this question compares a feature of a larger product (GitHub Copilot is not just its chat) to a complete product (ChatGPT is a chat service), the strengths of GitHub Copilot lie in its integration with the IDE.
Without leaving the Visual Studio Code screen (or Visual Studio or JetBrains), we can select portions of code and ask direct questions to our pair programming assistant. From the backend perspective, the question posed to the model will therefore contain:
- **our context**: the selected code
- **our question**, for example "explain to me what this portion of code does"
- **the system prompt**: the system prompt is a basic prompt that has been defined and written on the backend and surrounds the question we have asked. They are the basic instructions. In the simplest cases, we can think of the system prompt as a series of basic indications such as "You are a very helpful virtual assistant in helping. You always try to explain things in a complete but never verbose way and you are able to schematize complex concepts in order to make their understanding easier". This is a remarkably simple system prompt, GitHub Copilot's will clearly be more complex and will contain instructions such as "Only respond to questions related to the programming world", which generates responses like the one in the screenshot above.
This system prompt is one of the strengths of GitHub Copilot: the code generated by the tool is not directly passed on to the end user, but is filtered and double-checked in order to avoid scenarios of [prompt-injection](https://owasp.org/www-project-top-10-for-large-language-model-applications/Archive/0_1_vulns/Prompt_Injection.html) (a concept similar to SQL injection, but which applies to prompt engineering scenarios).
Even more important than the system prompt is GitHub Copilot's ability to access the extended context of our IDE. The context is formed by the files open in tabs and the files present in the open folder. In fact, there is the possibility, through the @workspace keyword, to ask broader questions about the entire repository that is open.
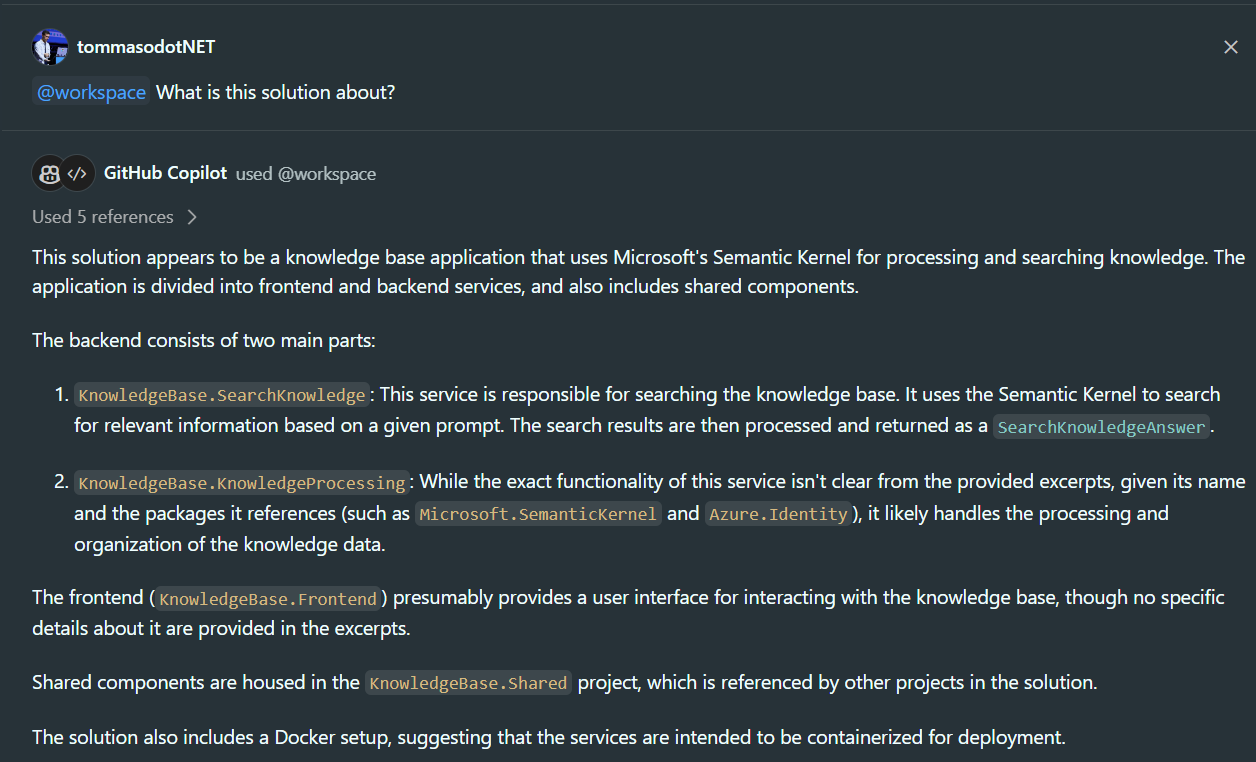
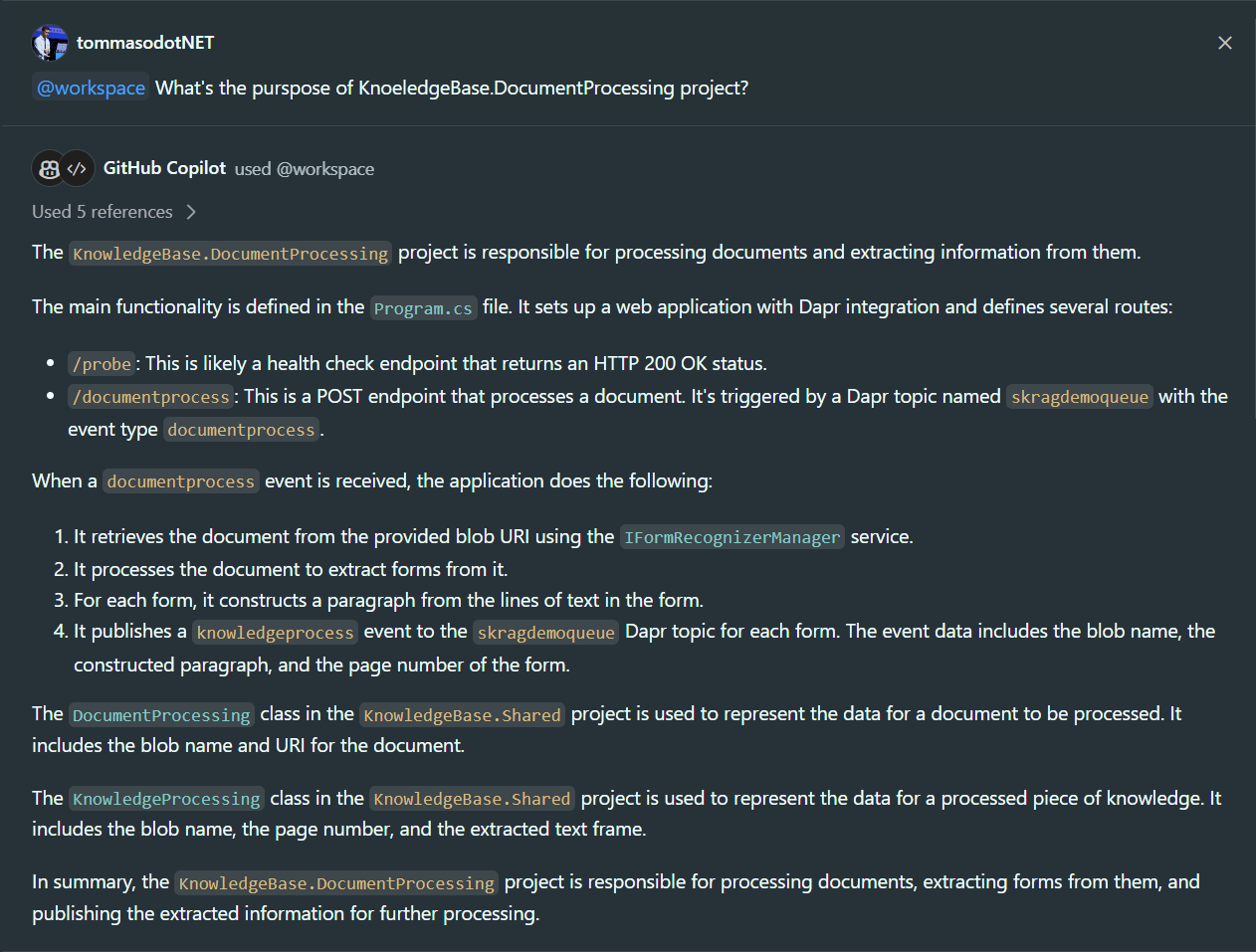
In the two screenshots above, we can see how GitHub Copilot Chat is able to analyze the entire structure of the folders, without having to specifically select portions of code, and provide me with the exact answers. In the second case, it is even able to understand the intended usage of certain services that I have described and how the APIs that I have defined work. It can also generate links to files so that they can be accessed directly without having to navigate the structure of my repository.
Taking other Visual Studio Code extensions that integrate a GPT model with our IDE as an example, functions are inherently more limited: [Visual chatGPT Studio - Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=jefferson-pires.VisualChatGPTStudio). As we can see in this case, the offered features only cover a subset of the functionalities related to the selection of code sections and the ability to ask questions about them.
But let's analyze an even more complex scenario than what we have seen so far: let's assume that we have two microservices communicating with each other through a queue. In addition to the "@workspace" tag, I also use the tag "#file:" to enrich the context of the chat by inserting, in addition to the selected code, another file. This way, I can ask how the event managed by microservice 2 is formatted inside microservice 1:
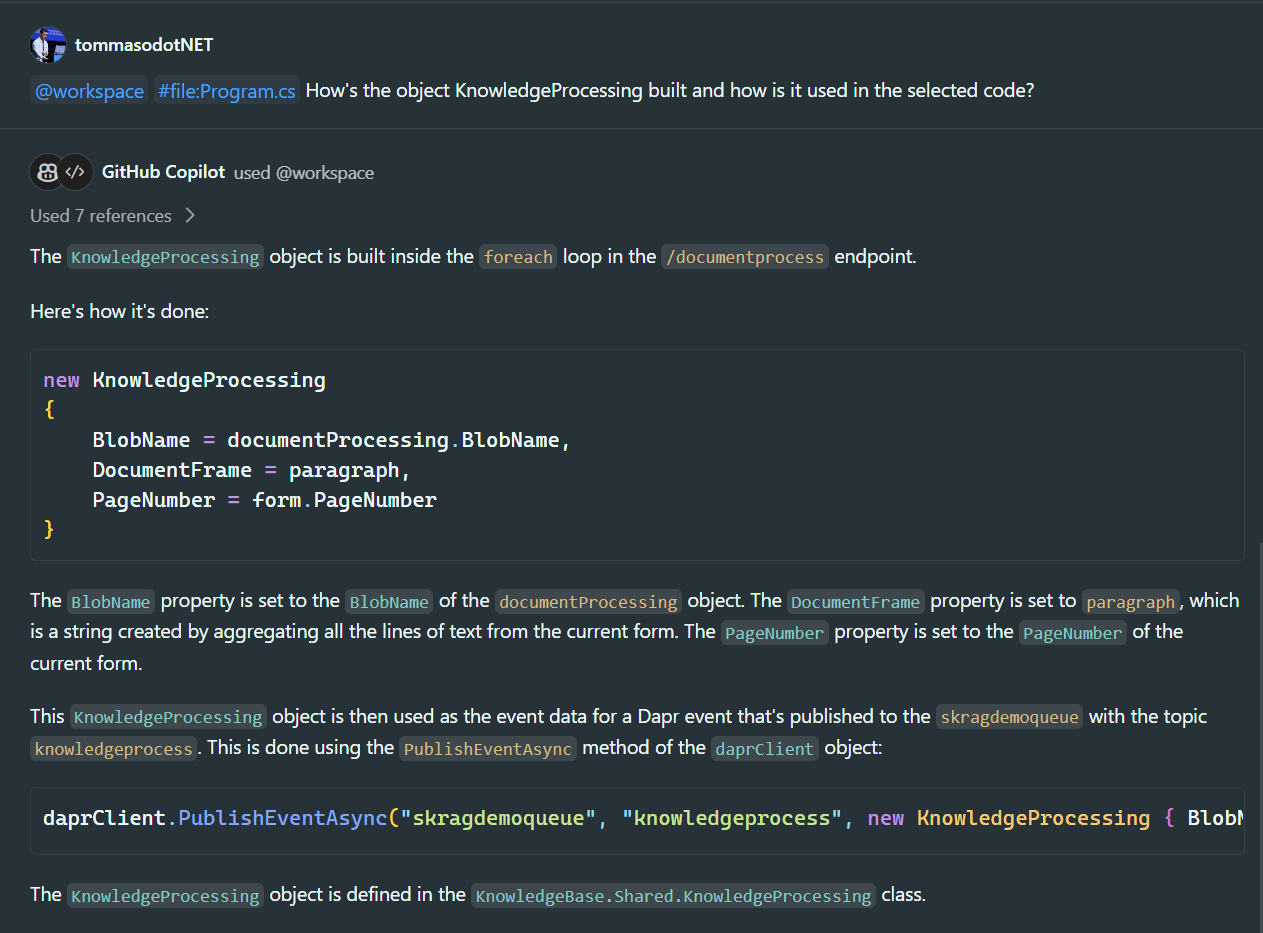
## What is meant by "programming questions"?
It is interesting to focus on GitHub Copilot's narrowed operational context. When it's said that the tool is able to answer programming questions, we should not only think about the world of code in the narrowest sense.
We are also able to ask questions about frameworks, third-party tools we use in the code, and the hosting architecture of an application, such as "How can I create a secure AKS cluster?"
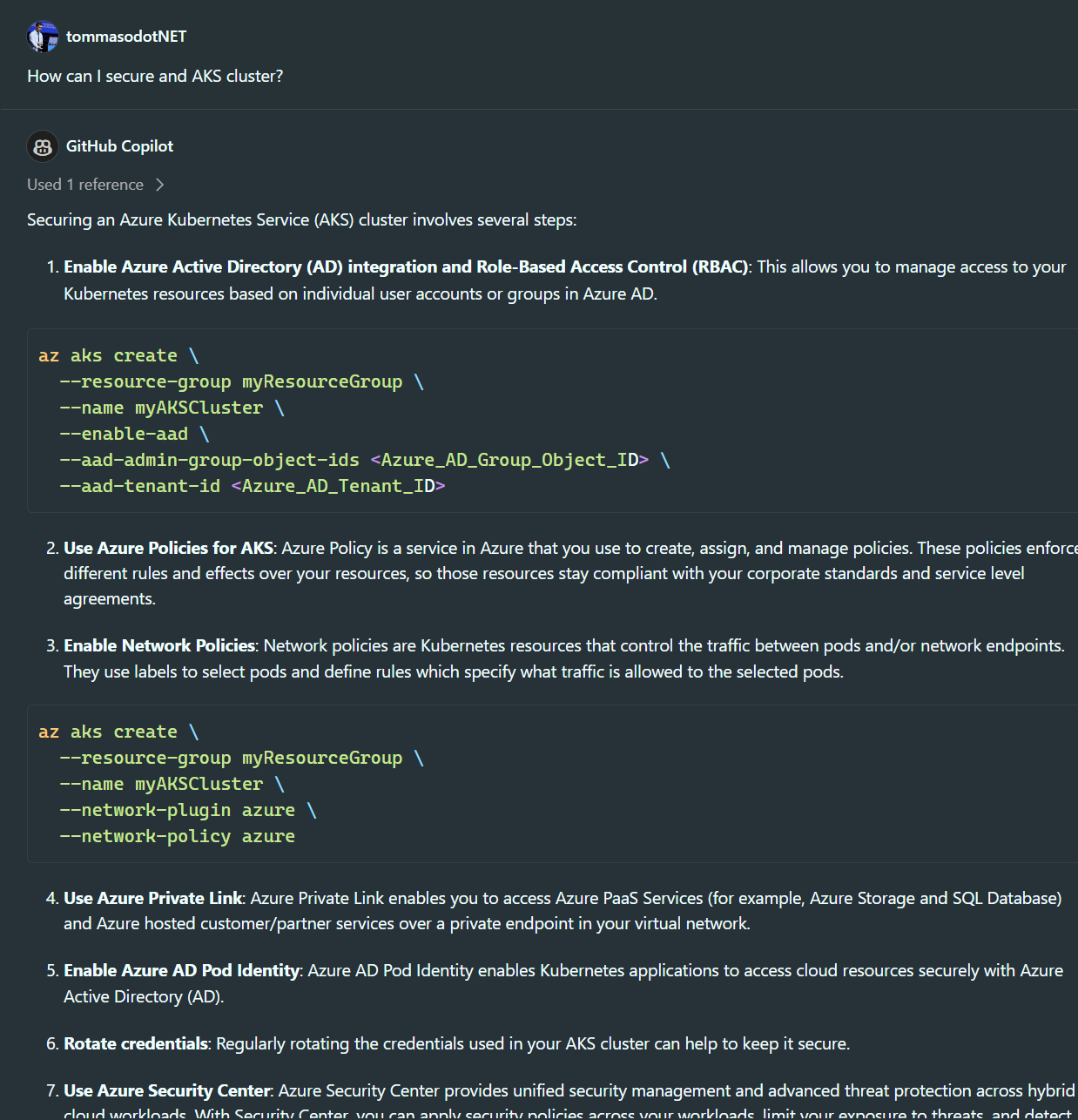
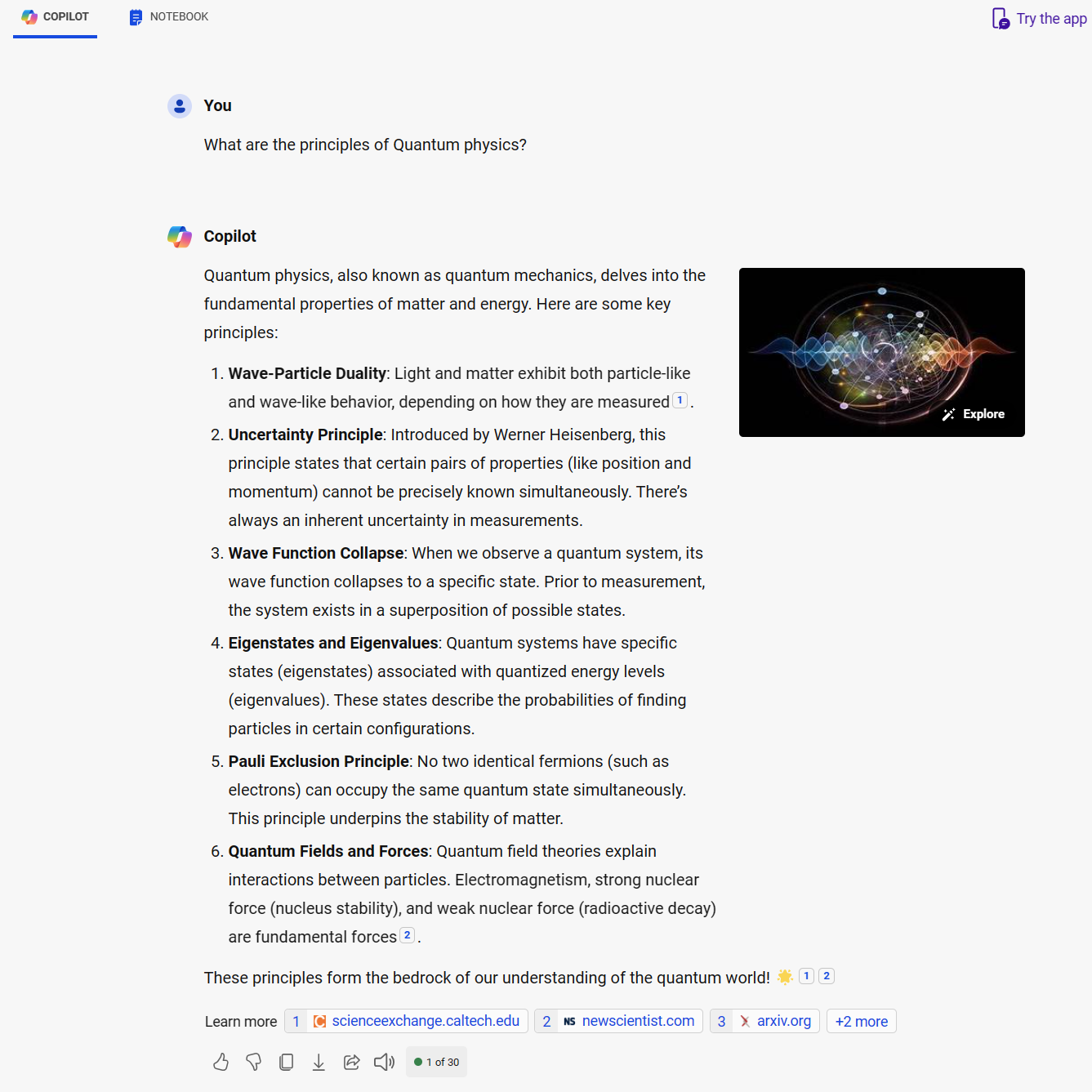
Therefore, general questions such as "What are the general principles of quantum mechanics?" are excluded. Questions that do not pertain in any way, even from an architectural point of view, to writing code.with the writing of code are therefore excluded.
However, if we need answers on certain topics in order to conduct an analysis for the code we are writing, do we have alternatives to obtain such answers? We can safely use more general tools such as ChatGPT or tools that natively have access to the web to provide answers such as Copilot on Edge.
## GitHub Copilot EnterpriseGitHub Copilot Enterprise
In Enterprise tier, the gap in terms of features grows. In addition to normal Chat and Code completion (also present in the first two tiers), some truly interesting features are added:
- **Knowledge of my organization's knowledge base**: GitHub Copilot is able to index the repositories in my organization and answer questions related to all the files contained within it. An RAG scenario, or Chat With Your Data, focused on code that offers the possibility to ask the chat questions about the use of other projects compared to the ones I am currently working on (for example a shared function library used within my organization).
- **Pull Request Diff Analysis**: here we have the ability to have GitHub Copilot analyze the individual commits that make up a Pull Request highlighting the fundamental changes that impact it
- **Web Search Powered by Bing (beta)**: We can ask questions about the latest updates to a framework and the answer will be generated by searching online content.Attention: we are also talking here about code-related questions.
- **Fine-Tuned Models (coming soon)**: it is a feature that has not yet been made available in General Availability, but it will allow fine-tuning of the GitHub Copilot model based on our repositories. How does it differ from indexing? Simply put: the model will not have to search for answers based on user questions in an indexed information database, it will have the answer built into its model. Just as ChatGPT in the free tier can tell us who the Prime Minister of the United Kingdom is without searching for the answer, GitHub Copilot will be able to natively know which shared libraries exist within our organization. Suppose we have a library that is used to interact with OpenAI APIs, when GitHub Copilot suggests (even proactively!) code to call OpenAI APIs, it will not suggest a generic HTTP request, but rather suggest the appropriate library invocation.
## Conclusion
If from a proactive point of view, GitHub Copilot appears to be the only tool that offers the service of suggesting entire portions of code without explicit requests, the native integration of the Chat with the IDE makes the use of the tool significantly easier compared to ChatGPT integrated services, which require a more manual intervention for context construction.
From a cost standpoint, ChatGPT Team has a higher costcompared to GitHub Copilot Business, which offers more advanced programming features. What is lost by not having the ability to do online searches - replaceable as we have seen with other tools - is gainedin terms of proactivity and ease of use of the tool. GitHub Copilot Enterprise, on the other hand, has a cost higher than ChatGPT Team but offers a series of truly interesting additional features for Enterprise scenarios.
| tommasodotnet |
1,864,728 | Ubuntu Server 24.04 LTS vs 22.04 LTS | Ubuntu has long been a favourite among developers and system administrators for its stability,... | 0 | 2024-05-26T03:05:08 | https://firstfinger.in/ubuntu-24-04-vs-22-04/ | linux, cloud, devops, ubuntu | ---
title: Ubuntu Server 24.04 LTS vs 22.04 LTS
published: true
tags: Linux,Cloud,DevOps, Ubuntu
canonical_url: https://firstfinger.in/ubuntu-24-04-vs-22-04/
---

Ubuntu has long been a favourite among developers and system administrators for its stability, security, and ease of use. With the release of Ubuntu Server Core 24.04 LTS (Noble Numbat), there are several exciting updates and improvements over its predecessor, Ubuntu Server Core 22.04 LTS (Jammy Jellyfish).
Let's see what exciting changes this latest release brings to the table.
## Linux Kernel and System Updates
First things first, Ubuntu 24.04 LTS comes with Linux kernel 6.8, which is a major upgrade over the 5.15 kernel used in 22.04 LTS. This new kernel promises better performance, improved hardware support, and stronger security measures.
> 😱 **systemd** has also been updated - from version 249 in Ubuntu Server 22.04 LTS to **255.4 in 24.04 LTS**. This update will ensure smoother service management and faster boot performance.
| Feature | Ubuntu 22.04 LTS | Ubuntu 24.04 LTS |
| --- | --- | --- |
| Kernel Version | 5.15 | 6.8 |
| Performance | Standard | Enhanced |
| Hardware Support | Limited | Improved |
* * *
## Performance Engineering
Ubuntu 24.04 LTS brings several improvements to performance:
- **Performance tools** are now pre-enabled and pre-loaded, allowing you to use them right away.
- **Low-latency kernel features** have been merged into the default kernel, reducing task scheduling delays.
- **Frame pointers** are enabled by default on 64-bit architectures, enabling accurate and complete flame graphs for performance engineers.
- **bpftrace** is now a standard tool alongside existing profiling utilities.
| Feature | Ubuntu 22.04 LTS | Ubuntu 24.04 LTS |
| --- | --- | --- |
| Performance Tools | Basic | Pre-enabled |
| Low-latency Kernel Features | No | Yes |
| Frame Pointers | No | Yes |
| bpftrace | No | Yes |
* * *
## Security Enhancements
Ubuntu 24.04 LTS takes security very seriously, and you'll find significant improvements in this area:
- Free security maintenance for the main repository has been extended to 5 years, with an option to add 5 more years and include the universe repository via Ubuntu Pro.
- A legacy support add-on is now available for organizations that require long-term stability beyond 10 years.
| Security Feature | Ubuntu 22.04 LTS | Ubuntu 24.04 LTS |
| --- | --- | --- |
| Free Security Maintenance | 5 years | 5 years + 5 optional |
| Legacy Support | No | Yes |
* * *
## Support Lifespan and Upgrades
Ubuntu 24.04 LTS comes with an extended support lifespan and improved upgrade options:
- Support duration has been increased to 5 years, with the option to extend it further.
- Automatic upgrades will be offered to users of Ubuntu 23.10 and 22.04 LTS when 24.04.1 LTS is released.
| Feature/Support | Ubuntu 22.04 LTS | Ubuntu 24.04 LTS |
| --- | --- | --- |
| Support Duration | 5 years (specific editions) | 5 years + optional extension |
| Automatic Upgrades | No | Yes (for 23.10 and 22.04) |
* * *
## New Features and Package Updates
Ubuntu 24.04 LTS brings a few exciting new features and package updates:
- Year 2038 support has been added for the armhf architecture.
- Linux kernel 6.8 and systemd v255.4 are the latest versions included.
| New Feature | Ubuntu 22.04 LTS | Ubuntu 24.04 LTS |
| --- | --- | --- |
| Year 2038 Support | No | Yes |
| Linux Kernel Version | 5.15 | 6.8 |
| Systemd Version | 249 | 255.4 |
* * *
## Application and Service Improvements
Several key applications and services have received updates in Ubuntu 24.04 LTS:
- Nginx has been updated to version 1.24, offering better support for modern web protocols and improved performance.
- OpenLDAP has been upgraded to version 2.6.7, bringing bug fixes and enhancements.
- LXD is no longer pre-installed, reducing the initial footprint, but will be installed upon first use.
- Monitoring plugins have been updated to version 2.3.5, including multiple enhancements and new features for better system monitoring.
| Service/Feature | Ubuntu 22.04 LTS | Ubuntu 24.04 LTS |
| --- | --- | --- |
| Nginx | 1.20 | 1.24 |
| OpenLDAP | 2.5 | 2.6.7 |
| LXD | Pre-installed | Installed on use |
| Monitoring Plugins | 2.3.2 | 2.3.5 |
* * *
## Infrastructure and Deployment
Ubuntu 24.04 LTS also brings improvements to infrastructure and deployment:
- The new Landscape web portal is built with Canonical's Vanilla Framework, providing an improved API, better accessibility, and a new repository snapshot service.
- Enhanced management capabilities for snaps, supporting on-premises, mixed, and hybrid cloud environments.
## Should You Upgrade from Ubuntu Server 22.04 LTS to 24.04 LTS?
## Currently Ubuntu Server 24.04 LTS offers:
- Improved hardware support and compatibility with linux kernel 6.8
- Performance enhancements and faster boot times
- Extended 5-year support lifespan until June 2029
- Stronger security with 5+5 years of maintenance, legacy support add-on
- Seamless upgrade path from 23.10 and 22.04 LTS
- Updated packages like NGINX, OpenLDAP, and monitoring plugins
### The decision to upgrade from 22.04 LTS should consider:
- New hardware/peripheral compatibility needs
- Performance requirements for workloads
- Security and compliance priorities
- Support window and maintenance needs
- Ease of upgrade and potential downtime
Also, Testing for stability and compatibility is crucial, especially for critical applications.
#### Ubuntu Release Notes:
1. [Ubuntu 24.04 LTS (Noble Numbat)](https://discourse.ubuntu.com/t/ubuntu-24-04-lts-noble-numbat-release-notes/39890)
2. [Ubuntu 22.04 LTS (Jammy Jellyfish)](https://discourse.ubuntu.com/t/jammy-jellyfish-release-notes/24668)
* * * | anurag_vishwakarma |
1,864,620 | Professional Car Detailing Service Montreal | Introduction: In the bustling city of Montreal, where every street holds a unique charm, your car... | 0 | 2024-05-25T06:26:23 | https://dev.to/poliperfect144/professional-car-detailing-service-montreal-7d3 | **Introduction**:
In the bustling city of Montreal, where every street holds a unique charm, your car deserves to stand out just as much as the iconic landmarks. Whether you're cruising down Boulevard Saint-Laurent or navigating the cobblestone streets of Old Montreal, ensuring your vehicle shines bright is essential. That's where professional car detailing services come into play, offering a meticulous touch to elevate your ride to a new level of sophistication and cleanliness. **[Professional Car Detailing Service Montreal](https://poliperfect.com)**
**Why Choose Professional Car Detailing?
**
While giving your car a quick wash may suffice for day-to-day maintenance, professional car detailing provides a comprehensive approach beyond mere surface cleaning. It involves a series of intricate processes to restore and enhance your vehicle's appearance, both inside and out. From thorough cleaning and polishing to protecting against environmental elements, professional detailing ensures your car maintains its pristine condition for longer.
The Benefits of Professional Car Detailing:
Enhanced Appearance: Professional detailing restores your car's shine, making it look brand new. Every inch of your vehicle receives meticulous attention to detail, from removing stubborn stains to polishing surfaces.
Protection Against Wear and Tear: By applying protective coatings, such as wax or ceramic sealant, professional detailing safeguards your car's paintwork from fading, scratches, and other damages caused by UV rays, road debris, and contaminants.
Improved Resale Value: A well-maintained car commands a higher resale value. Professional detailing helps preserve your vehicle's condition, making it more attractive to potential buyers when upgrading.
Health and Safety: Interior detailing involves deep cleaning and sanitizing surfaces, eliminating harmful bacteria, allergens, and odors. This creates a healthier environment for you and your passengers and enhances driving comfort.
Time and Convenience: Instead of spending hours scrubbing and polishing your car, entrusting the task to professionals saves you time and effort. With their expertise and specialized equipment, they deliver superior results efficiently.
Choosing the Right Car Detailing Service:
In Montreal, the options for car detailing services abound, but not all are created equal. When selecting a professional detailing service, consider the following factors:
Reputation and Experience: Look for established detailing companies with a proven track record of delivering high-quality results. Reading customer reviews and testimonials can provide valuable insights into their reputation.
Services Offered: Opt for a detailing service that offers a comprehensive range of services tailored to your needs, including exterior detailing, interior cleaning, paint correction, and ceramic coating application.
Expertise and Techniques: Ensure the detailing professionals possess the necessary skills and expertise to handle your vehicle carefully. Modern techniques and state-of-the-art equipment can significantly affect the final outcome.
Eco-Friendly Practices: Choose a detailing service that prioritizes eco-friendly practices and uses biodegradable products to minimize environmental impact.
Customer Satisfaction Guarantee: A reputable detailing service stands behind its quality and guarantees satisfaction, ensuring you're delighted with the results. Professional Car Detailing Service Montreal
**Conclusion:
**Your car is more than just a mode of transportation—it reflects your personality and style. With professional car detailing services in Montreal, you can elevate your ride to new heights of cleanliness, sophistication, and protection. By entrusting your vehicle to skilled professionals who understand the intricacies of automotive care, you can enjoy a pristine, polished finish that turns heads wherever you go. So, treat your car to the luxury it deserves and experience the difference that professional detailing can make." | poliperfect144 | |
1,864,590 | Environmental Benefits of Using Diatomite | Using Diatomite for a Greener Planet As we strive to create a more sustainable future, it's... | 0 | 2024-05-25T06:16:18 | https://dev.to/safiyaaa/environmental-benefits-of-using-diatomite-46l1 | diatomite | Using Diatomite for a Greener Planet
As we strive to create a more sustainable future, it's essential to find innovative ways to protect our planet while still enjoying the benefits of modern living. One way to accomplish this goal is to use diatomite. We'll examine the advantages offers in terms of environmental benefits, innovation, safety, use, and service.
Benefits of Using Diatomite
Diatomite, also called planet like diatomaceous is just a normal stone like sedimentary's composed of fossilized algae.
Due to its porous nature, it truly is an filtering product like very good.
Diatomite Powder is widely used in companies such as for instance food and drink, medical, pharmaceutical, and water treatment.
The advantages of making use of diatomite during these industries include:
-It's an material like eco-friendly's 100% normal and sustainable.
-It's an filter like efficient, which could remove impurities from liquids, gases and atmosphere.
- it's really a solution like cost-effective wastewater treatment like industrial.
-In agriculture, diatomite can be used being an insecticide like all-natural control like pest.
Innovation
Diatomite is versatile and that may be prepared into a myriad of services and products.
One product like specific Diamix, which will be a combination of diatomite and also other materials which can be employed in construction.
Particularly, diatomaceous earth is definitely an concrete like eco-friendly that replaces mineral like conventional with diatomite.
Using Diamix in construction assists in easing the total amount like total of used, saves power during manufacturing and, as a total result, decreases carbon emissions.
Security
Due to the origins that are normal diatomite is regarded as safe for humans in addition to the environment.
Unlike artificial materials, it doesn't include chemical substances which can be toxins and bacteria, rendering it well suited for use within items that enter into connection with meals or people.
Additionally it is non-flammable, making it an fire retardant material like excellent.
Provider and Quality
Diatomite items are commonly accessible, and vendors that are several solutions such as for example consultation, installation, and upkeep.
It is crucial to choose a supplier like centered on quality and sustainability, as this will make certain you have the finest items, services, and guidance that fit your needs which can be unique.
Application
Diatomite is an excellent option for folks who value sustainable living and advertising wellness like environmental.
If you are to discover an natural, eco-friendly, and material like cost-effective your industry, Diatomitecould be the response.
Contact your provider like local for info on the number of applications and advantages of diatomite.
To wrap up, diatomite is a natural wonder that offers a myriad of benefits to our planet and its inhabitants. By embracing this eco-friendly material in various industries, we can create a brighter, greener, and more sustainable future.
Source: https://www.sjzhuabangkc.com/diatomite-powder
| safiyaaa |
1,864,589 | Task 1 | Qn 1 | 0 | 2024-05-25T06:15:23 | https://dev.to/lemajosephine/task-1-41am | Qn 1 | lemajosephine | |
1,864,588 | All About NPM (Node Package Manager) | Introduction NPM is an essential tool for JavaScript developers for managing versatile... | 0 | 2024-05-25T06:11:57 | https://dev.to/olibhiaghosh/all-about-npm-node-package-manager-hk2 | javascript, webdev, beginners, node | ## Introduction
NPM is an essential tool for JavaScript developers for managing versatile packages in the node.js ecosystem.
While I was learning Tailwind CSS and Node.js, I came across this term "NPM" and this made me pretty curious.
So I decided to dive deep into the concept usage and working of NPM
In this article, we will explore the basic concept of NPM
So, let's dive into it.

## What is NPM?
So before we move further let's understand What is NPM.
NPM stands for Node Package Manager. It is the main and default package manager for the JavaScript runtime environment Node.js
Not clear enough?
Let's break it into much simpler words
It is a huge repository containing numerous open-source software that can be used by anyone for free.
## Why do we need NPM?
Now the question that arises in our mind is **why do we actually need npm?**
Let's understand this using an example. Assume that we are building a laptop. Is it possible to build all its components from scratch and then assemble all the components to build a laptop?
No right?
As it will take a lot of time and is also not worth it. Instead, we just take the pre-built components and assemble them to make a laptop which makes the process much easier and faster
NPM helps us in a similar way. It makes writing code easier as we can use pre-built code written by other authors
Other authors write their code for their package and publish it on the NPM registry. We can then use the code by installing it on our machine using NPM CLI(Command Line Interface). All kinds of packages are present in NPM from single-purpose ones to large libraries.
Now to use NPM we need to know how to install NPM on our machines.
Let's look into that
## Installing Node.js
**Step 1:** Go to the website [https://nodejs.org/en/download](https://nodejs.org/en/download)
Select the required version, the OS, and click on download.
Now download it and complete the setup.
*Tip: Avoid choosing the latest version as it might contain bugs*

Step 2: Run the following commands on your terminal and check if Node.js was installed.

The command `node -v` and `npm -v` will return its latest versions.
If it's not working then try restarting your system and it will work.
Now let's look into the process of installing npm packages
## Installing NPM Packages
In this step, we will install the required NPM package.
For that first clone any repository and open it in your code editor
Now open the terminal and run the following command
```bash
npm init -y
```
> Note: Here -y is used to automatically answer "yes" to all prompts. Thus preventing us from doing it manually.
You will see a ***package.json*** file was created.
We will be looking into the usage and details of this file further
In a nutshell, `package.json` file contains the details about the dependencies and packages to be installed on running the required npm command
On running the command `npm install` it will create a node\_modules folder and install the required packages and dependencies as mentioned in the package.json file inside the node\_modules folder
It will also create a ***package-lock.json*** file. In the further sections, we will be looking into the details of the ***package-lock.json*** file.
We can also use the following command to only install the specified and required packages and their dependencies in the node\_modules
After installation, it will automatically get pushed into the ***package.json*** file
```bash
npm install <package name>
```
What we have been doing till now is installing local packages but there is also something termed global packages that can be installed and used
Now we will see the difference between local packages and global packages
### Local Package v/s Global Package
Let's understand the difference between the local package and the global package.
**Local packages:** These packages are installed in the directory where we run the `npm install <package name>` command. These packages are not available for other projects or other directories.
**Global packages:** These are installed in our system in a specified location and can be used in any directory or any project present in the System.
We can install these global packages using the command
```bash
npm install -g <package-name>
```
And, we are ready to use the installed packages and work with them.
Now, we will be looking into the use and details of the ***"package.json"*** file and ***"package-lock.json"*** file.
## About Package.json File
It is important to know the uses and details of these files. So, let's learn about the `package.json` file.
Package.json file stores all the data about the project.
It contains :
1. `name` -> name of the project
2. `version` -> The current version of the project
3. `description` -> The description of the project
4. `main` -> Specifies the file that is the main entry point of your project
5. `scripts` -> This includes the command associated with your project like the command for building, running, or testing the project
6. `dependencies` -> This is where all the required packages are listed that are required to run the project. These are installed in your system using npm install
7. `devDependencies` -> This contains the modules that are required only during the development not in the production
8. `repository` -> Specifies the type of version control we are using and the url of the repository
9. `keywords` -> These are the array of strings that contain the keywords of the projects that help people discover the project
10. `author` -> The name of the author of the project
11. `license` -> the license type of the project
A sample `package.json` looks like this

## About Package-lock.json File
Now when you are installing the packages you may have noticed that it also creates a `package-lock.json` file.
This file contains the records of actual specific versions of each package and dependencies installed on your local system
This file helps us to install the exact version of the packages and dependencies despite any update in version in between the phase when the file was created and when it was installed locally.
This is the main function that this file performs
Apart from this, **It speeds up the installation process** -> without the `package-lock.json` file before installing npm has to request the registry for each package to see if there are new versions available.
With `package-lock.json` npm knows the exact version to install and thus it speeds up the installation process
These were the basic usage of the `package.json` file and the `package-lock.json` file
## Conclusion
This was all we needed to know about NPM Packages to have a basic clear understanding.
I hope I made it simple for all.
If you found this blog useful and insightful, share it and comment down your views on it.
Do follow for more such content.
Here's how you can connect with me.
Email - [olibhia0712@gmail.com](http://olibhiag@gmail.com)
Socials: [Twitter](https://twitter.com/OlibhiaGhosh) , [LinkedIn](https://www.linkedin.com/in/olibhiaghosh/) and [GitHub](https://github.com/OlibhiaGhosh)
Thanks for giving it a read !!
 | olibhiaghosh |
1,864,587 | Unleash Your Design Freedom: Building and Customizing Websites with Elementor | WordPress, the king of content management systems, offers immense power, but its default editor can... | 0 | 2024-05-25T06:09:38 | https://dev.to/epakconsultant/unleash-your-design-freedom-building-and-customizing-websites-with-elementor-4ie5 | WordPress, the king of content management systems, offers immense power, but its default editor can feel restrictive for design-focused minds. Enter Elementor, a revolutionary page builder plugin that empowers you to create stunning and customized WordPress websites – all without touching a line of code. This guide unveils the magic of Elementor, equipping you to craft unique and engaging websites that resonate with your audience.
## The Elementor Advantage: A Drag-and-Drop Playground
Elementor ditches the traditional text-based editing approach and replaces it with a visual, drag-and-drop interface. This intuitive environment allows you to:
• Effortlessly Add Sections and Layouts: Structure your website using pre-designed sections and layouts, or build your own from scratch. Customize the number of columns and their arrangement for a flexible foundation.
• Populate with Widgets: Elementor offers a vast library of widgets, essentially pre-built content blocks like headings, images, buttons, forms, and more. Simply drag and drop them onto your sections to create compelling content.
• Live Editing: Witness the changes unfold instantly as you edit. The live preview lets you see how your website will look to visitors, ensuring you achieve the desired visual impact.
• Responsive Design Made Easy: Design a website that adapts flawlessly to different screen sizes – desktops, tablets, and mobiles. Elementor's responsive editing lets you fine-tune the layout for each device, guaranteeing an optimal user experience across all platforms.
## Beyond the Basics: Power Up Your Design Arsenal
Elementor offers a treasure trove of features to elevate your website design:
[A beginner Guide Fibonacci trading strategies & alerts in TradingView Pine script](https://www.amazon.com/dp/B0CGJJMSB4)
• Custom Fonts and Colors: Inject your brand personality with a wide selection of Google Fonts and a color picker to define your website's visual identity.
• Animations and Effects: Bring your website to life with eye-catching animations and hover effects on elements, making your content more interactive and engaging.
• Custom CSS: For seasoned users, Elementor integrates seamlessly with custom CSS, allowing you to tailor specific design elements beyond the plugin's built-in options.
• Pre-Designed Templates: Jumpstart your design process with a library of professionally crafted templates for various purposes, from landing pages and portfolios to blogs and e-commerce stores.
## Crafting Unique Pages with Elementor Pro
While the free version of Elementor offers a robust toolkit, Elementor Pro unlocks even more powerful features:
• Theme Builder: Take complete control over your website's design by customizing headers, footers, and archive pages using the theme builder. Ensure a cohesive visual experience across your entire site.
• Popups and Forms: Create engaging popups and custom forms to capture leads, display special offers, or conduct surveys. This enhances user interaction and helps you gather valuable visitor information.
• E-commerce Integration: If you're running an online store, Elementor Pro integrates seamlessly with WooCommerce, allowing you to design custom product pages and enhance your store's overall look and feel.
## Getting Started with Elementor: A Smooth Takeoff
Ready to embark on your Elementor journey? Here's a quick roadmap:
1. Install and Activate the Plugin: Head over to the WordPress plugin directory and search for "Elementor Website Builder." Install and activate the plugin.
2. Create a New Page: Navigate to "Pages" and "Add New" to create a new page for your website.
3. "Edit with Elementor": Instead of the default editor, look for the "Edit with Elementor" button. Clicking this button launches the Elementor drag-and-drop interface.
4. Explore and Experiment: Dive into the Elementor interface, experiment with sections, layouts, and widgets. Don't be afraid to play around and discover the creative possibilities.
## Beyond the Guide: Resources for Continuous Learning
The best way to master Elementor is through exploration and continuous learning. Here are some valuable resources:
• Elementor Documentation: The official Elementor documentation provides comprehensive guides, tutorials, and video explanations to answer any questions you might have.
• Elementor Blog: Stay updated with the latest Elementor features, design trends, and tutorials through the Elementor blog.
• Elementor Community: Join the vibrant Elementor community forum and connect with other Elementor users. Share ideas, troubleshoot issues, and learn from each other's experiences.
## Conclusion: Elementor – Your Gateway to Design Freedom
Elementor empowers you to create stunning and customized WordPress websites without coding. Its intuitive drag-and-drop interface, coupled with a vast array of features and widgets, unlocks a world of design possibilities. Whether you're a beginner or a seasoned designer, Elementor provides the tools to craft a website
| epakconsultant | |
1,864,586 | Understanding Closures in Programming | Understanding Closures in Programming Closures are a fundamental concept in many... | 0 | 2024-05-25T06:07:29 | https://dev.to/madhurop/understanding-closures-in-programming-5cp5 | ## Understanding Closures in Programming
Closures are a fundamental concept in many programming languages, providing a powerful mechanism to manage and encapsulate functionality. This article explores what closures are, how they work, and their practical applications, particularly in JavaScript and Python.
### What is a Closure?
A closure is a function that retains access to its lexical scope, even when the function is executed outside that scope. In simpler terms, a closure allows a function to "remember" the environment in which it was created. This includes any variables that were in scope at the time of the function's creation.
### How Do Closures Work?
Closures work by capturing the local variables of the scope in which they were defined. These variables are stored in the closure's environment and can be accessed even after the outer function has finished executing.
#### Example in JavaScript
```javascript
function outerFunction() {
let outerVariable = 'I am from outer scope';
function innerFunction() {
console.log(outerVariable);
}
return innerFunction;
}
const closure = outerFunction();
closure(); // Output: 'I am from outer scope'
```
In this example, `innerFunction` forms a closure. It retains access to `outerVariable` even after `outerFunction` has finished executing.
#### Example in Python
```python
def outer_function():
outer_variable = 'I am from outer scope'
def inner_function():
print(outer_variable)
return inner_function
closure = outer_function()
closure() # Output: 'I am from outer scope'
```
Similarly, in Python, `inner_function` forms a closure and retains access to `outer_variable`.
### Practical Applications of Closures
Closures are utilized in various scenarios due to their ability to encapsulate state and behavior. Here are a few common applications:
#### 1. Data Privacy
Closures can be used to create private variables that cannot be accessed directly from outside the function.
**Example in JavaScript:**
```javascript
function createCounter() {
let count = 0;
return function() {
count += 1;
return count;
};
}
const counter = createCounter();
console.log(counter()); // Output: 1
console.log(counter()); // Output: 2
```
In this example, `count` is a private variable that can only be modified by the inner function.
#### 2. Function Factories
Closures enable the creation of functions with preset parameters or configurations.
**Example in Python:**
```python
def create_multiplier(x):
def multiplier(y):
return x * y
return multiplier
multiply_by_2 = create_multiplier(2)
print(multiply_by_2(5)) # Output: 10
```
Here, `create_multiplier` generates a function that multiplies its input by a specified factor.
#### 3. Event Handlers and Callbacks
In event-driven programming, closures are frequently used to manage state and context in callbacks.
**Example in JavaScript:**
```javascript
function setupEventHandler(element, message) {
element.addEventListener('click', function() {
console.log(message);
});
}
const button = document.getElementById('myButton');
setupEventHandler(button, 'Button clicked!');
```
In this scenario, the event handler function retains access to the `message` variable through closure.
### Advantages of Using Closures
- **Encapsulation**: Closures help in encapsulating functionality and state, leading to more modular and maintainable code.
- **Data Privacy**: They provide a way to create private variables, enhancing data security within functions.
- **Functional Programming**: Closures are a key feature in functional programming, enabling higher-order functions and function composition.
### Potential Pitfalls
While closures are powerful, they can also lead to issues if not used carefully:
- **Memory Leaks**: Since closures retain references to their lexical scope, they can cause memory leaks if not managed properly.
- **Debugging Difficulty**: Debugging closures can be challenging because of the complexity of the scope chain they create.
### Conclusion
Closures are a versatile and essential feature in many programming languages. They allow functions to retain access to their defining scope, providing powerful capabilities for encapsulation, data privacy, and functional programming. Understanding how closures work and their practical applications can significantly enhance your programming skills and enable you to write more efficient and modular code. | madhurop | |
1,864,585 | Accepting Payments with Stripe on Your WordPress Site | Transforming your WordPress site into a revenue-generating platform requires a seamless payment... | 0 | 2024-05-25T06:05:38 | https://dev.to/epakconsultant/accepting-payments-with-stripe-on-your-wordpress-site-5db | wordpress | Transforming your WordPress site into a revenue-generating platform requires a seamless payment solution. Stripe emerges as a popular choice for its ease of use and powerful features. This guide will equip you with the steps to set up Stripe on your WordPress site, allowing you to accept payments for products, services, or subscriptions.
## Choosing Your Weapon: Plugins for Stripe Integration
WordPress offers a plethora of plugins to facilitate Stripe integration. Here are two common approaches:
• Dedicated Stripe Plugins: These plugins focus solely on integrating Stripe with your site. Popular options include WP Simple Pay Lite for Stripe and Stripe Payments by WooCommerce. They offer user-friendly interfaces and straightforward configuration for basic payment processing.
• E-commerce Plugins with Stripe Support: If you're already using an e-commerce plugin like Easy Digital Downloads (EDD) or WooCommerce, they often have built-in Stripe integration. This allows you to leverage the functionalities of your existing e-commerce platform while seamlessly accepting payments through Stripe.
## Gearing Up: Obtaining Your Stripe Credentials
Before configuring your chosen plugin, you'll need to create a Stripe account. Once your account is set up, navigate to the Stripe dashboard and locate your API keys. These keys are crucial for secure communication between your WordPress site and Stripe's servers. There are two main keys to remember:
• Publishable Key: This key identifies your Stripe account and is used on your website to display payment forms.
• Secret Key: This key remains confidential and is used on your server to process payments securely. Never expose your secret key on your website.
## Integration in Action: Configuring Your Plugin
The specific steps for configuration will vary depending on your chosen plugin. However, the general process involves:
1. Installing and Activating the Plugin: Locate the plugin in your WordPress dashboard's "Add New" plugin section. Install and activate the plugin you've chosen.
2. Connecting to Stripe: Within the plugin's settings, find the Stripe integration section. Here, you'll paste your publishable and secret keys obtained from your Stripe dashboard.
3. Configuring Payment Options: Depending on the plugin, you might be able to configure additional settings like:
[Creating Your First Crypto Trading Bot In Pine Script: Beginner Guide to Create Your First Crypto Trading Bot](https://www.amazon.com/dp/B0CHG11D5X)
o Enabling test mode for development purposes before processing real transactions.
o Specifying the currency you want to accept payments in.
o Choosing whether to automatically capture payments upon order placement.
## Deployment: Accepting Payments on Your Site
Once your plugin is configured, you can start accepting payments! The specific implementation will depend on your chosen plugin and your website's functionalities. Here are some common scenarios:
• Product Sales: If you're selling products through a plugin like WooCommerce, the plugin will typically handle displaying product listings, adding items to carts, and integrating the Stripe payment gateway during checkout.
• Service Bookings: For service-based businesses, some plugins allow embedding Stripe payment buttons directly into your posts or pages, enabling customers to pay for appointments or consultations.
• Subscription Management: If you offer subscriptions, some plugins can integrate with Stripe to manage recurring payments automatically.
Beyond the Basics: Advanced Considerations
As your payment processing needs evolve, here are some additional aspects to consider:
• Security: Ensure your website uses a secure connection (HTTPS) to protect sensitive customer data during transactions.
• Payment Receipts: Configure your plugin to automatically send email receipts to customers after successful payments.
• Tax Management: Depending on your location, you might need to configure your plugin to calculate and collect sales tax during checkout.
## Conclusion: Streamlining Payments with Stripe
By leveraging Stripe and its seamless integration with WordPress plugins, you can empower your website to accept payments efficiently. This opens doors for new revenue streams and allows you to turn your WordPress site into a thriving online business. Remember to choose the plugin that best suits your needs, prioritize security, and explore advanced features as your business grows. So, take the plunge, set up Stripe, and watch your WordPress site flourish!
| epakconsultant |
1,864,584 | Dive into E-commerce with MedusaJS: A Beginner's Guide | The world of e-commerce is booming, and for aspiring developers, building an online store can be an... | 0 | 2024-05-25T06:01:17 | https://dev.to/epakconsultant/dive-into-e-commerce-with-medusajs-a-beginners-guide-200h | The world of e-commerce is booming, and for aspiring developers, building an online store can be an exciting prospect. But where do you begin? Look no further than MedusaJS, a powerful open-source framework designed to streamline the e-commerce development process. This beginner-friendly guide will equip you with the essentials to explore MedusaJS and kickstart your online store journey.
## Understanding MedusaJS: The Headless Hero
Imagine an e-commerce platform built with flexibility and customization at its core. That's MedusaJS in a nutshell. Unlike traditional closed-source platforms, MedusaJS adopts a headless architecture. This means the frontend (user interface) and backend (server-side logic) are decoupled. This offers several advantages:
• Freedom of Choice: You're not limited to a specific frontend framework. Choose from popular options like React, Next.js, or Vue.js to create a user interface that perfectly aligns with your vision.
• Scalability: As your store grows, you can easily scale the backend infrastructure independently of the frontend.
• Customization: MedusaJS provides a robust API, allowing you to tailor functionalities to your specific e-commerce needs.
## Key Features to Get You Started
MedusaJS boasts a plethora of features designed to simplify e-commerce development. Here are some highlights for beginners:
[How do I get started with Pine script?: How to create custom Tradingview indicators with Pinescript?](https://www.amazon.com/dp/B0CM2FQKWW)
• Product Management: Effortlessly add, edit, and manage your product catalog. This includes setting prices, variations, inventory levels, and rich media content.
• Order Processing: MedusaJS handles the order lifecycle seamlessly, from order placement to fulfillment. You can integrate with various payment gateways and shipping providers.
• Customer Management: Create user accounts, manage customer profiles, and implement features like wishlists and order history.
• Promotions and Discounts: Boost sales with built-in support for coupons, discounts, and other promotional campaigns.
• Content Management System (CMS): Manage static content like product descriptions, blog posts, and about-us pages directly within MedusaJS.
## Getting Your Hands Dirty: Setting Up Your First Store
MedusaJS offers a user-friendly command-line interface (CLI) to get you started quickly. Here's a simplified glimpse of the process:
1. Installation: Install the Medusa CLI globally using npm (npm install -g @medusajs/medusa-cli).
2. Project Creation: Run medusa new my-store to create a new Medusa project directory named "my-store".
3. Development Server: Start the development server using medusa dev to launch your Medusa backend.
## Beyond the Basics: Resources for Further Exploration
The official MedusaJS documentation is your best friend when venturing deeper. It provides comprehensive guides, tutorials, and API references to equip you with the knowledge to build feature-rich e-commerce applications.
The MedusaJS community is another valuable resource. Join their active Discord server to connect with fellow developers, ask questions, and learn from their experiences.
## Building Your E-commerce Dream with MedusaJS
MedusaJS empowers beginners to enter the world of e-commerce development. It offers a flexible, scalable, and customizable platform that fosters creativity and innovation. With its intuitive tools, comprehensive documentation, and supportive community, MedusaJS equips you to build a robust and thriving online store. So, dive in, explore the possibilities, and watch your e-commerce dreams become reality!
| epakconsultant | |
1,864,583 | Showcasing Ads after the Splash Screen: A Guide for Android Apps | The splash screen is a user's first impression of your Android app. It sets the tone and prepares... | 0 | 2024-05-25T05:56:04 | https://dev.to/epakconsultant/showcasing-ads-after-the-splash-screen-a-guide-for-android-apps-19bj | android | The splash screen is a user's first impression of your Android app. It sets the tone and prepares them for the experience ahead. But strategically displaying an ad after this initial screen can be a great way to monetize your app without hindering user experience. Let's delve into the best practices for achieving this.
## Understanding Ad Formats:
There are two main ad formats suitable for post-splash screen placements:
Interstitial Ads: These full-screen ads appear between activities or transitions within the app. They're impactful but can be disruptive if not implemented thoughtfully.
App Open Ads: These immersive, full-screen ads display before your app's main content loads. They provide a more engaging user experience compared to interstitials.
[Dominate the Markets with TradingView10+ Indicator-Driven Strategies, from Beginner to Expert](https://www.amazon.com/dp/B0D2W62GC6)
## Following Google's Play Store Policies:
It's crucial to adhere to Google Play's Developer Policy on disruptive ads. Interstitial ads displayed immediately after the splash screen are strictly prohibited. This is because it can feel intrusive and hinder a smooth user experience. However, you can:
Show an app open ad after a short delay (avoiding an immediate ad after the splash).
Implement a user interaction before displaying an interstitial ad (e.g., after a user navigates to a new section).
Creating a Positive User Experience:
While ads can be a valuable revenue stream, prioritize the user experience. Here are some tips:
Quick Splash Screen: Keep your splash screen brief. Aim for 3-5 seconds to showcase your app's logo or branding without getting in the way.
Clear User Choice: If using an interstitial ad, provide a clear "close" button that's easy to find and tap.
Reward Users: Consider offering in-app rewards (like bonus points or temporary ad removal) for watching ads. This incentivizes users and creates a win-win situation.
## Implementation Steps:
Choose Your Ad Network: Popular options include AdMob, Unity Ads, and AppLovin. Each offers various ad formats and functionalities.
Integrate the SDK: Follow the chosen ad network's instructions to integrate their SDK (Software Development Kit) into your Android project.
Initialize the Ad: Within your splash screen activity, initialize the ad object using the ad network's provided code. This prepares the ad for display.
Load the Ad: Use the loadAd() method from the ad network to fetch the ad content in the background.
Display the Ad: In a separate activity or after a delay in your splash screen, check if the ad is loaded. If yes, use the show() method to display the ad.
## Additional Considerations:
Testing is Key: Thoroughly test your ad implementation to ensure smooth functionality and a positive user experience.
User Consent: For certain regions or ad networks, you may need to obtain user consent before displaying personalized ads.
Analytics and Optimization: Monitor your ad performance using the ad network's analytics tools. This helps you understand user behavior and optimize ad placement and targeting for better revenue generation.
By following these guidelines, you can effectively display advertisements after your app's splash screen while maintaining a user-friendly experience. Remember, a well-crafted ad strategy can be a valuable tool for sustaining and growing your mobile app. | epakconsultant |
1,864,582 | How Function And Variable works in JavaScript : Behind The Scenes | Let's See How The Function and Variable Works in JavaScript Behind The Scenes According to Under... | 0 | 2024-05-25T05:55:49 | https://dev.to/pervez/how-function-and-variable-works-in-javascript-behind-the-scenes-54e0 | javascript, webdev, development, frontend |
**Let's See How The Function and Variable Works in JavaScript Behind The Scenes**
According to Under Code Spinate

Everything in JavaScript Happens Inside an Execution Context. All JavaScript code runs within an execution context, which provides an environment for the code execution. When JavaScript code runs, it first creates a Global Execution Context (GEC). Execution Context Does Perform by Call Stack.
**What is Call Stack ?**
The call stack in JavaScript is a mechanism for managing the execution context of functions. Call stack is a data structure, which follows the Last-In-First-Out **(LIFO)** principle. JavaScript is single-threaded, meaning it can only execute one task at a time. The call stack manages this execution flow.
**It has two main components:**
- => Memory Component (Variable Environment)
- => Code Component (Thread of Execution)
**The GEC undergoes two phases:**
- => Creation Phase (Memory Creation Phase)
- => Execution Phase (Code Execution Phase)
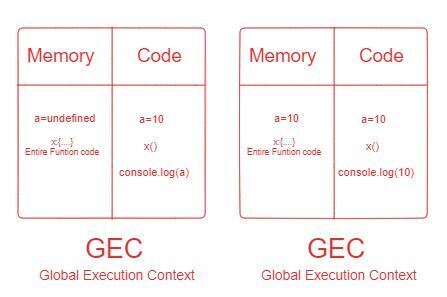
In the Memory Creation Phase It Allocates The Memory For a Variable And Initially set **Undefined (a=undefined )**. in the code execution phase it sets it's actual value ( a=10 ) then it come next line it js engine look it is a function then it **allocates Memory For the Function ( Entre Full Function Code ).
function x() {
var b = 5;
var c = 20;
var result = b + c;
console.log(result);
}**
Then it moves the next line and then See **function is invoked ( Function call )**. When a **function invoked it creates Brand new Function Execution Context** . and put this function in call stack at the top of GEC ( Global Execution Context )

The Brand new Function Execution Context Has ** =two Phase **:
- => Creation Phase (Memory Creation Phase)
- => Execution Phase (Code Execution Phase)
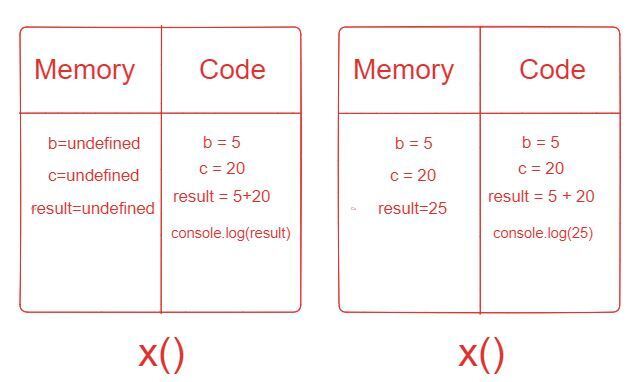
in the function Execution Context it allocate the memory for it's variable and set **initially undefined ( b=undefined , c=undefined and, result=undefined )**. then in the code execution phase it sets their Actual value and make the statement operation **( b=5 , c=20 , result=5+20) and then print console.log(25)** in the browser console. after function execution Completed it **deleted and move out from the call stack and control back to the GEC of call Stack. **
After FEC ( Function Execution Context ) . then it goes the next line here is console.log (a) . In the memory creation phase it sets a=10;
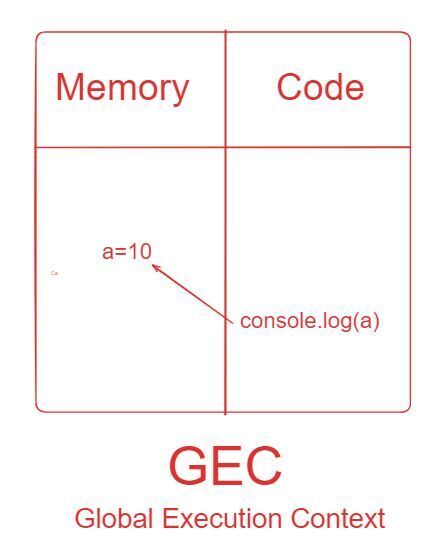
**_After All code Execution , the GEC Moved Out From The call stack and it gets empty._**

This is How The Function variable Works in JavaScript Behind the Scenes Through Call Stack.
| pervez |
1,864,581 | YMIN capacitors enhance performance and stability in charging piles. | Market Outlook and Capacitor Role in New Energy Charging Piles With rising environmental... | 0 | 2024-05-25T05:53:29 | https://dev.to/yolosaki/ymin-capacitors-enhance-performance-and-stability-in-charging-piles-19d6 | automotive, electronic, electric, charging | ### Market Outlook and Capacitor Role in New Energy Charging Piles

With rising environmental awareness and stringent policies, new energy vehicle sales are expected to capture a significant market share by 2025, driving substantial demand for charging piles. YMIN liquid snap-in type aluminum electrolytic capacitors, known for their high capacitance and energy storage density, play a crucial role in stabilizing and filtering DC energy output during charging. They mitigate ripple currents from grid fluctuations, ensuring stable power quality and protecting vehicle batteries.
### Advantages of Liquid Snap-in Type Aluminum Electrolytic Capacitors
These capacitors offer high energy storage capacity, excellent ripple current endurance, extended lifespan, high reliability, and superior high-temperature stability. Their fast response capability, due to low ESR, ensures constant output voltage and efficient charging, making them ideal for the demanding environment of charging piles.
### Recommendations for Selection of Liquid Snap-in Type Aluminum Electrolytic Capacitors

### Conclusion
Shanghai YMIN’s liquid snap-in type aluminum electrolytic capacitors demonstrate significant advantages in new energy charging piles, enhancing system stability, safety, longevity, and optimizing charging performance. These capacitors support technological upgrades and sustainable development in the charging pile industry. | yolosaki |
1,864,580 | How to Improve Intimacy: Using Vacuum Pump for Erectile Dysfunction | Erectile dysfunction (ED) can be a challenging condition that impacts both physical and emotional... | 0 | 2024-05-25T05:50:54 | https://dev.to/saracarlsson/how-to-improve-intimacy-using-vacuum-pump-for-erectile-dysfunction-413k | penispump, erectiledysfunction, sexual | Erectile dysfunction (ED) can be a challenging condition that impacts both physical and emotional well-being. Fortunately, there are various methods available to address this issue, including the use of vacuum pumps. In this article, we'll delve into the ins and outs of using **[vacuum pumps for ED](https://www.vacurect-india.com/blogs/news/ling-pump-vacurect-fda-manzur-ling-enlargement)**, exploring how they work, their benefits, potential drawbacks, and practical tips for optimal usage.
## Understanding Erectile Dysfunction
Erectile dysfunction, often referred to as impotence, is the inability to achieve or maintain an erection firm enough for sexual intercourse. It can be caused by various factors, including stress, anxiety, underlying health conditions, or lifestyle choices.
## What is a Vacuum Pump?
A vacuum pump is a non-invasive device designed to help men with erectile dysfunction achieve erections. It consists of a cylinder that fits over the penis, a pump to create a vacuum within the cylinder, and a constriction ring to maintain the erection.
## How Does a Vacuum Pump Work?
Using a vacuum pump is quite simple. You place the cylinder over the penis and manually or electronically create a vacuum by pumping out the air. This vacuum draws blood into the penis, causing an erection. Once the erection is achieved, a constriction ring is placed at the base of the penis to maintain it.
## Benefits of Using a Vacuum Pump
Non-invasive: Unlike surgical options, vacuum pumps offer a non-invasive solution for erectile dysfunction.
Immediate results: Vacuum pumps can produce erections within minutes, providing quick relief when needed.
No medication required: Vacuum pumps do not rely on medications, making them suitable for men who cannot take oral medications due to health reasons.
## Are There Any Risks or Side Effects?
While vacuum pumps are generally safe to use, there are some potential risks and side effects to be aware of. These may include:
Bruising or petechiae: Due to the vacuum pressure, some men may experience bruising or small red dots on the penis.
Numbness: Prolonged use of vacuum pumps may cause temporary numbness or decreased sensitivity in the penis.
Improper usage: Using the device incorrectly can lead to discomfort or injury. It's essential to follow the manufacturer's instructions carefully.
## Tips for Using a Vacuum Pump
To ensure safe and effective usage of a vacuum pump, consider the following tips:
**Start slow:** Begin with low vacuum pressure and gradually increase as needed.
**Use lubrication:** Applying a water-based lubricant to the base of the cylinder can create a better seal and enhance comfort.
**Limit usage:** Avoid using the vacuum pump for more than 30 minutes at a time to prevent potential tissue damage.

## Real-Life Success Stories
Many men have found relief from erectile dysfunction through the use of vacuum pumps. These devices have allowed them to regain confidence and intimacy in their relationships, improving overall quality of life.
## Alternative Options
While vacuum pumps can be effective for some men, they may not be suitable for everyone. Alternative options for treating erectile dysfunction include oral medications, penile implants, and lifestyle changes such as exercise and dietary modifications.
## Conclusion
In conclusion, vacuum pumps offer a safe and effective solution for men struggling with [erectile dysfunction](https://www.vacurect-india.com/blogs/news/erectile-issues-you-might-need-to-understand-the-not-so-common-psychological-concerns). By understanding how they work and following proper usage guidelines, individuals can reclaim intimacy and improve their overall quality of life.
Whether used as a standalone treatment or in combination with other therapies, vacuum pumps provide a valuable option for managing ED and restoring confidence in the bedroom. If you're considering using a vacuum pump, consult with a healthcare professional to determine if it's the right choice for you.
## Frequently Asked Questions (FAQs)
**Q1: Can anyone use a vacuum pump for erectile dysfunction?**
Yes, vacuum pumps are suitable for most men with erectile dysfunction, but it's essential to consult with a healthcare professional before use.
**Q2: How long does the erection last with a vacuum pump?**
The duration of the erection varies from person to person, but typically it lasts long enough for sexual intercourse.
**Q3: Are vacuum pumps covered by insurance?**
In some cases, vacuum pumps may be covered by insurance if prescribed by a healthcare provider for the treatment of erectile dysfunction.
**Q4: Can vacuum pumps be used with other ED treatments?**
Yes, vacuum pumps can be used in combination with other ED treatments, such as oral medications or penile implants, for enhanced effectiveness.
**Q5: Are there any age restrictions for using a vacuum pump?**
There are generally no age restrictions for using a vacuum pump, but individual health conditions and medical history should be considered.
| saracarlsson |
1,864,579 | How Silica Dioxide Improves Product Performance | Silica Dioxide Brings Innovation and Safety to Your Products Silica Dioxide, also known as silica,... | 0 | 2024-05-25T05:50:53 | https://dev.to/safiyaaa/how-silica-dioxide-improves-product-performance-23pd | silica | Silica Dioxide Brings Innovation and Safety to Your Products
Silica Dioxide, also known as silica, is a naturally occurring mineral that is very common on Earth. It is mainly composed of silicon and oxygen, and can be found in sand, rocks, and other minerals. Silica Dioxide has many applications in different fields, including construction, electronics, and food production. In the marketing industry, it is used as an additive to enhance the quality and performance of various.
Features of Silica Dioxide:
Including Silica Dioxide to your Products or services may bring benefits which are a few.
One of the more benefits being crucial its capability to soak up dampness, which helps to keep services and products fresh and dry for longer levels of time.
Silica Dioxide can also become a representative like thickening enhancing the consistency of services and products and making them easier to utilize.
Additionally, this ingredient has been confirmed to enhance the stability of formulations, preventing services and products from wearing down or effectiveness like losing the run like long.
Innovation and Safety:
Innovation is type in the marketing industry, and Silica Dioxide is a instance like excellent of the latest ingredients may bring solutions that are new.
This ingredient has been used for quite some time, nevertheless it remains an innovative and solution like beneficial item improvement.
Furthermore, Silica Dioxide is known as safe to be used in many services and products, as studies have shown so it has poisoning like low risk of causing epidermis irritation or allergies.
Simple tips to Utilize Silica Dioxide:
fumed silicon dioxide could be included with differing types of items, including powders, creams, and fluids.
Probably the most regular kind of Silica Dioxide used in marketing is fumed silica, which will be a powder like superb can be simply dispersed in liquids.
To utilize Silica Dioxide, you can include it directly to your service or product formulation through the manufacturing process, or you can cause a premix having a provider liquid before adding it to your product or service.
Service and Quality:
Utilizing Silica Dioxide might help enhance the solution like ongoing quality of one's services and products.
By using this innovative ingredient, you'll provide better performing products to your web visitors that last for a bit longer and are also safer to utilize.
Furthermore, incorporating Silica Dioxide to your formulations will allow you to decrease your item cost, since it could enhance product stability and shelf life, each of which can reduce waste and enhance effectiveness.
Application of Silica Dioxide:
Silica Dioxide works extremely well in an variety of products, including cosmetics, pharmaceuticals, and foods.
An absorbent, and a stabilizer during the makeup like cosmetic industry, it is used as a bulking representative.
Inside the industry like pharmaceutical it's used as a substrate for drug delivery systems.
It is utilized as a food additive, and it can boost the flowability, texture, and security of food products once you glance at the meals industry.
Conclusion:
Silica Dioxide is a versatile and innovative ingredient that can be used to enhance the performance, quality, and safety of your products. Adding Silica Dioxide to your formulations can bring many benefits, including longer shelf life, improved consistency, and better stability. Furthermore, silicon dioxide hydrophobic using this ingredient can help you reduce your product cost and improve your efficiency. If you want to take your products to the next level, consider adding Silica Dioxide to your formulations today!
Source: https://www.sjzhuabangkc.com/application/fumed-silicon-dioxide | safiyaaa |
1,864,578 | Lenses Pattern in JavaScript | In functional programming, the Lenses pattern offers a solution for handling data manipulation in an... | 0 | 2024-05-25T05:47:39 | https://dev.to/ashutosh_mathur/understanding-and-implementing-the-lenses-pattern-in-javascript-333a | javascript, frontend, ramda, node |
In functional programming, the **Lenses pattern** offers a solution for handling data manipulation in an immutable way. A Lens essentially serves as a first-class reference to a subpart of some data type. Despite its regular use in languages with built-in support for lenses (e.g. Haskell), a JavaScript developer can still incorporate the lens pattern via libraries or custom implementations.
This blog post will explore the lenses pattern and demonstrate how you can implement it in JavaScript to work with deeply nested paths.
**What is a Lens?**
A Lens is a functional pattern used to manage immutable data operations. They let us "zoom in", or focus, on a particular part of a data structure (like an object or an array). Every lens consists of two functions: a getter and a setter.
Getter Function: Retrieves a sub-part of the data.
Setter Function: Updates a sub-part of the data in an immutable way.
An important feature of lenses is that they compose, meaning lenses focusing on nested data can be effectively chained to manipulate a required piece of data.
**Implementing Lenses in JavaScript**
Even though JavaScript doesn't provide built-in support for lenses, we can create a custom lens function to achieve similar functionality. A basic lens function involves creating a getter and setter to retrieve and update the data respectively.
Let’s start simple and create a lens that is not dynamic, meaning it works with a single predetermined path:
```
function lens(getter, setter) {
return {
get: getter,
set: setter
};
}
```
But the real power of lenses comes when we make them handle deeply nested paths. To achieve that, we make our lens function accept a path (an array of keys), and modify our getter and setter to navigate the object using this path:
```
function lens(path) {
return {
get: (object) => path.reduce((obj, key) => obj && obj[key], object),
set: (value, object) => {
const setObjectAtKeyPath = (obj, path, value) => {
if (path.length === 1) {
return { ...obj, [path[0]]: value };
}
const key = path[0];
return { ...obj, [key]: setObjectAtKeyPath(obj[key] || {}, path.slice(1), value) };
};
return setObjectAtKeyPath(object, path, value);
},
};
}
```
To use this lens, we create a path array indicating the sequence of keys to the desired property, and pass this path to the lens function. The returned lens object provides get and set methods for reading and updating the property:
```
const person = {
name: "John Doe",
address: {
street: "123 Main St",
city: "Anytown",
country: "USA"
}
};
```
```
// Create a lens for the address.street path:
const streetLens = lens(["address", "street"]);
```
```
// Get street using the lens:
console.log(streetLens.get(person)); // Outputs: 123 Main St
```
```
// Set street using the lens, resulting in a new (immutable) object:
const newPerson = streetLens.set("456 Broadway St", person);
console.log(newPerson); // Outputs the new person object with the updated street
```
**Conclusion**
The lenses pattern rewards developers with the ability to maintain immutability while easily accessing and updating deeply nested data structures. The effectiveness and elegance of lenses are in their composability and the simplicity of resulting code. While JavaScript does not support lenses natively, we've seen how to produce a lens like behaviour using array methods and recursion. However, for simplification, this custom implementation does not handle edge cases that established libraries do. Thus, for production-level code, consider using libraries such as [Ramda](https://ramdajs.com/docs/#lens) or [partial.lenses](https://github.com/calmm-js/partial.lenses?tab=readme-ov-file#partial-lenses) that offer more comprehensive lens functionalities.
| ashutosh_mathur |
1,864,577 | YMIN Capacitor: Key Supporter of Energy Efficiency Upgrading of Smart Home Appliances | As demand for smart homes grows, energy efficiency standards for smart appliances are becoming more... | 0 | 2024-05-25T05:46:34 | https://dev.to/yolosaki/ymin-capacitor-key-supporter-of-energy-efficiency-upgrading-of-smart-home-appliances-4omg | techtalks, smarthome, ai, design | As demand for smart homes grows, energy efficiency standards for smart appliances are becoming more stringent. Starting May 2025, the EU requires most home appliances to consume less than 300mW in standby mode. Power Integrations’ LinkSwitch-XT2SR IC, with no-load power consumption under 5mW, meets these standards, and YMIN capacitors are ideal peripheral components due to their low power consumption and high stability. [YMIN capacitors](https://www.ymin.cn/), with leakage current below 20uA, reduce static power consumption and ensure long-term stability up to 24 months. These characteristics support the energy efficiency upgrade of smart home appliances, positioning YMIN as a key player in the industry’s future development.

| yolosaki |
1,864,576 | Buy verified cash app account | Liquid syntax error: Tag '{% embed %}' was not properly terminated with regexp: /\%\}/ | 0 | 2024-05-25T05:28:00 | https://dev.to/lyioricarcher88/buy-verified-cash-app-account-5bje | webdev, javascript, beginners, tutorial | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/{% embed \n %}\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | lyioricarcher88 |
1,478,981 | Converting Large Codebase Project from Webpack to Vite | Photo by Roberto Nickson on Unsplash In the company I work at, our frontend codebase consists of... | 27,506 | 2024-05-25T05:24:41 | https://dev.to/elpddev/converting-large-codebase-project-to-vite-5b20 | <small>Photo by <a href="https://unsplash.com/@rpnickson?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Roberto Nickson</a> on <a href="https://unsplash.com/photos/Yp9FdEqaCdk?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a></small>
In the company I work at, our frontend codebase consists of couple of thousands files. The framework is [React 16](https://react.dev/) and the bundler used was [webpack 4](https://v4.webpack.js.org/concepts/).
## Reasons
We wanted to change the bundler to [vite](https://vitejs.dev/) for two main reasons:
1. DX - development experience - Faster boot time from starting the development server to seeing the project on the browser and start coding.
2. DX - Faster production build time for qa envionments.
## Process
So we took the opportunity in the company hosted hacketon and built a POC that worked. The POC was mapped after that to separated individual tasks.
1. This to tackle each migration step more cleanly without disrupting existing features development.
2. Have the developers and interested parties participate in the CRs and give their takes and experience.
## Steps
This article summarize the issues that rose and how they were handled.
1. [Converting couple thousands Js/Ts files that contains JSX content to jsx extension](https://dev.to/elpddev/converting-couple-thousands-jsts-files-that-contains-jsx-content-to-jsx-extension-58oh)
2. Js Errors - Using variables before declaration
3. lingui swc plugin replacement for babel macros - does not work for now on `.js` files
4. Third party libraries unconventional import - react-d3-tree
5. Css mixin implicit import
6. Unsupported js decorator used in .js files
7. Need for async/await transpilation which use bluebird cancelable feature
8. Third party node modules that import sub third party node modules needs to prebundle explicitly
9. Unconventional node modules import - "../../../node_modules/date-fns"
10. Code that use `global`, `process` and other node environment variables needs polyfill or mock
11. Code that use `require` instead of `import`
12. webpack only syntax for hmr needs to be converted to vite syntax
13. Webpack multiple import statement needs to be converted to vite supported syntax
14. Webpack raw loader needs to be converted to vite raw loading
15. Converting `index.html` dynamic generation instead to work also with vite
16. Mock process.cwd for react-markdown vfile
| elpddev | |
1,864,573 | Optimize React Components with the React Profiler 🚀 | Imagine you're working on a complex React application that's starting to feel sluggish. Users are... | 0 | 2024-05-25T05:19:36 | https://10xdev.codeparrot.ai/optimize-react-components-with-the-react-profiler | webdev, optimization, profiler, react |
Imagine you're working on a complex React application that's starting to feel sluggish. Users are complaining about slow load times and laggy interactions. You suspect that some components are rendering more frequently than they should, but figuring out exactly what's going wrong is tricky. This is where the React Profiler comes in handy.
## A Real-World Example
Let's look at a simple app that displays a list of items and allows users to add new items. Here's the initial code:
```jsx
import React, { useState } from "react";
function App() {
const [items, setItems] = useState([]);
const [newItem, setNewItem] = useState("");
const addItem = () => {
setItems([...items, newItem]);
setNewItem("");
};
return (
<div>
<input
type="text"
value={newItem}
onChange={(e) => setNewItem(e.target.value)}
/>
<button onClick={addItem}>Add Item</button>
<ItemList items={items} />
</div>
);
}
function ItemList({ items }) {
return (
<ul>
{items.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
);
}
export default App;
```

The app works, but as the number of items grows, it starts to slow down, especially when adding new items. The problem is that the `ItemList` component re-renders every time a new item is added, even if the list of items hasn't changed.
## Introducing React Profiler
To diagnose and fix this issue, we can use the React Profiler to measure the performance of our components.
### Adding the Profiler to Your Code
First, let's wrap the `ItemList` component with the `<Profiler>` component:
```jsx
import React, { Profiler, useState } from "react";
function App() {
const [items, setItems] = useState([]);
const [newItem, setNewItem] = useState("");
const addItem = () => {
setItems([...items, newItem]);
setNewItem("");
};
const onRenderCallback = (
id,
phase,
actualDuration,
baseDuration,
startTime,
commitTime,
interactions
) => {
console.log(`Profiling ${id}:`, {
phase,
actualDuration,
baseDuration,
startTime,
commitTime,
interactions,
});
};
return (
<div>
<input
type="text"
value={newItem}
onChange={(e) => setNewItem(e.target.value)}
/>
<button onClick={addItem}>Add Item</button>
<Profiler id="ItemList" onRender={onRenderCallback}>
<ItemList items={items} />
</Profiler>
</div>
);
}
function ItemList({ items }) {
return (
<ul>
{items.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
);
}
export default App;
```
### Analyzing the Results
#### How to Use It
1. Open your React application in the browser.
2. Open React Developer Tools and navigate to the "Profiler" tab.
3. Click the "Record" button to start profiling.
4. Add items to the list so that the `ItemList` component re-renders.
5. Click the "Stop" button in the Profiler to end the recording session.
6. The Profiler will display a flamegraph.
7. You can also see the console logs.
8. In the flamegraphs, click on the `ItemList` component to see the rendering timestamps.
#### What is a Flamegraph?
A flamegraph is a visual representation of the rendering performance of your application. It displays how much time each component takes to render, helping you identify performance bottlenecks. Each bar in the flamegraph represents a component, and the length of the bar corresponds to the time spent rendering that component.
#### Key Elements of the Flamegraph
- **Bars**: Each bar represents a component in your React application.
- **Width of Bars**: The width of each bar corresponds to the amount of time the component took to render. Wider bars indicate longer render times.
- **Colors**: The colors can help distinguish between different components. Typically, the React Profiler uses consistent coloring to differentiate components.
- **Hierarchy**: The flamegraph displays the component hierarchy, showing which components are children of others.
#### Analysis

1. **App**: Takes 1.2ms out of the total 2ms render time.
2. **Profiler**: Takes less than 0.1ms.
3. **ItemList**: Takes 0.2ms.
 - Itemlist component renders so frequently
## Optimizing with React.memo
To prevent unnecessary re-renders, we can use `React.memo` to memoize the `ItemList` component:
```jsx
import React, { Profiler, useState, memo } from "react";
function App() {
const [items, setItems] = useState([]);
const [newItem, setNewItem] = useState("");
const addItem = () => {
setItems([...items, newItem]);
setNewItem("");
};
const onRenderCallback = (
id,
phase,
actualDuration,
baseDuration,
startTime,
commitTime,
interactions
) => {
console.log(`Profiling ${id}:`, {
phase,
actualDuration,
baseDuration,
startTime,
commitTime,
interactions,
});
};
return (
<div>
<input
type="text"
value={newItem}
onChange={(e) => setNewItem(e.target.value)}
/>
<button onClick={addItem}>Add Item</button>
<Profiler id="ItemList" onRender={onRenderCallback}>
<MemoizedItemList items={items} />
</Profiler>
</div>
);
}
const ItemList = ({ items }) => {
return (
<ul>
{items.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
);
};
const MemoizedItemList = memo(ItemList);
export default App;
```
### Using `useCallback` to Memoize Functions
To further optimize, avoid passing anonymous functions as props, which can cause components to re-render. Use `useCallback` to memoize functions:
```jsx
import React, { Profiler, useState, useCallback, memo } from "react";
function App() {
const [items, setItems] = useState([]);
const [newItem, setNewItem] = useState("");
const addItem = useCallback(() => {
setItems((prevItems) => [...prevItems, newItem]);
setNewItem("");
}, [newItem]);
const onRenderCallback = (
id,
phase,
actualDuration,
baseDuration,
startTime,
commitTime,
interactions
) => {
console.log(`Profiling ${id}:`, {
phase,
actualDuration,
baseDuration,
startTime,
commitTime,
interactions,
});
};
return (
<div>
<input
type="text"
value={newItem}
onChange={(e) => setNewItem(e.target.value)}
/>
<button onClick={addItem}>Add Item</button>
<Profiler id="ItemList" onRender={onRenderCallback}>
<MemoizedItemList items={items} />
</Profiler>
</div>
);
}
const ItemList = ({ items }) => {
return (
<ul>
{items.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
);
};
const MemoizedItemList = memo(ItemList);
export default App;
```
Rendering time stamps after react memo and callback function.
### Rendering Time Stamps after Optimization
After applying `React.memo` and `useCallback`, you can see that the `ItemList` component only renders four times for four items in 16 seconds, significantly reducing unnecessary re-renders.
## Conclusion
The React Profiler helps you find and fix performance issues in your React apps. By using `React.memo` and `useCallback`, you can optimize components and create a smoother user experience. Happy coding!
For more details, visit the [official React Profiler documentation](https://reactjs.org/docs/profiler.html).
| mvaja13 |
1,864,572 | Understanding Primitives and Reference Types in JavaScript. | Introduction Have you ever wondered why some data types can be changed while others can't?... | 0 | 2024-05-25T05:18:49 | https://dev.to/samuel__ojerinde/understanding-primitives-and-reference-types-in-javascript-4g7f | ## Introduction
Have you ever wondered why some data types can be changed while others can't? The answer lies in the difference between primitives and reference data types. When working with JavaScript, it’s essential to understand the difference between primitive and reference data types. These types define how data is stored and accessed in your code. In this article, I’ll explore what primitives and reference types are, with examples to help you understand them better.
## What are Primitive Types?
Primitive types are the basic data types in JavaScript. They include:
### Number:
Represents both integers and floating-point numbers.
```jsx
const age = 25;
const price = 19.99;
```
### String:
Represents a sequence of characters.
```jsx
const name = "Samuel";
const greeting = "Hello, world!";
```
### Boolean:
Represents either true or false.
```jsx
const isStudent = true;
const hasGraduated = false;
```
### Undefined:
Represents a variable that has been declared but not assigned a value.
```jsx
let job;
console.log(job); // Outputs: undefined
```
### Null:
Represents the intentional absence of any object value.
```jsx
const car = null;
```
### Symbol:
Represents a unique and immutable identifier.
```jsx
const sym = Symbol('unique');
```
## Characteristics of Primitive Types:
1. They are immutable, meaning their values cannot be changed.
2. They are stored directly in the location that the variable accesses.
Example:
```jsx
const a = 10;
let b = a;
b = 20;
console.log(a); // Outputs: 10
console.log(b); // Outputs: 20
```
In this example, changing b does not affect a because they are separate copies of the value. You will also notice that b was declared with `let` keyword, this is because primitives or variables declared with `const` keyword cannot be changed.
## What are Reference Types?
Reference types, on the other hand, are objects stored as references. This means that when you create an object, the variable doesn't hold the actual object but a reference to it. Reference types include:
### Objects:
Collections of key-value pairs.
```jsx
const person = {
name: "Samuel",
age: 30
};
```
### Arrays:
Ordered collections of values.
```jsx
const colors = ["red", "green", "blue"];
```
### Functions:
Blocks of code designed to perform a particular task.
```jsx
function greet() {
console.log("Hello!");
}
```
## Characteristics of Reference Types:
1. They are mutable, meaning their values can be changed.
2. They are stored as references, which point to the actual data in memory.
Example:
```jsx
const person1 = { name: "Sam" };
const person2 = person1;
person2.name = "Sam";
console.log(person1.name); // Outputs: Sam
console.log(person2.name); // Outputs: Sam
```
In this example, changing person2 also changes person1 because they both reference the same object.
## Conclusion
Understanding the difference between primitives and reference types is crucial for effective JavaScript programming. Primitives are simple, immutable data types stored directly in variables, while reference types are complex, mutable data types stored as references to the actual data. | samuel__ojerinde | |
1,864,571 | Suhagra 100mg | The Most Often Used Treatment for Sexual Issues | For adult males between the ages of 18 and 65, erectile dysfunction is the most common sexual... | 0 | 2024-05-25T05:18:49 | https://dev.to/paul_robinson_f7249c92723/suhagra-100mg-the-most-often-used-treatment-for-sexual-issues-3027 | For adult males between the ages of 18 and 65, erectile dysfunction is the most common sexual illness, with the exception of older men. The term "impotent" refers to the inability of patients with this illness to satisfy their spouse during sexual activity. All ED guys should [buy suhagra 100mg](https://www.medypharma.com/buy-suhagra-100-mg-online.html) tablets online and utilize them regularly. | paul_robinson_f7249c92723 | |
1,864,569 | From Classic to Cutting-Edge: The Ultimate Modern JavaScript Guide | Modern JavaScript Cheatsheet Introduction Motivation This document is a cheatsheet for... | 0 | 2024-05-25T05:16:33 | https://dev.to/emmanuelj/from-classic-to-cutting-edge-the-ultimate-modern-javascript-guide-48j8 | ---
**Modern JavaScript Cheatsheet**
**Introduction**
**Motivation**
This document is a cheatsheet for JavaScript you will frequently encounter in modern projects and most contemporary sample code.
This guide is not intended to teach you JavaScript from the ground up but to help developers with basic knowledge who may struggle to get familiar with modern codebases (or, let's say, to learn React, for instance) because of the JavaScript concepts used.
*Note: Most of the concepts introduced here are from a JavaScript language update (ES2015, often called ES6).*
**Table of Contents**
1. Modern JavaScript Cheatsheet
2. Introduction
3. Motivation
4. Complementary Resources
5. Table of Contents
6. Notions
- Variable Declaration: var, const, let
- Arrow Function
- Function Default Parameter Value
- Destructuring Objects and Arrays
- Array Methods - map / filter / reduce
- Spread Operator "..."
- Object Property Shorthand
- Promises
- Template Literals
- Tagged Template Literals
- Imports / Exports
- JavaScript this
- Class
- Extends and super Keywords
- Async Await
- Truthy / Falsy
- Anamorphisms / Catamorphisms
- Generators
- Static Methods
7. Glossary
- Scope
- Variable Mutation
**Notions**
**Variable Declaration: var, const, let**
In JavaScript, there are three keywords available to declare a variable, and each has its differences: var, let, and const.
**Short Explanation**
Variables declared with the const keyword can't be reassigned, while let and var can.
I recommend always declaring your variables with const by default, but with let if it is a variable that you need to mutate or reassign later.
| Keyword | Scope | Reassignable | Mutable | Temporal Dead Zone |
|---------|----------|--------------|---------|---------------------|
| const | Block | No | Yes | Yes |
| let | Block | Yes | Yes | Yes |
| var | Function | Yes | Yes | No |
**Sample Code**
```javascript
const person = "Nick";
person = "John"; // Will raise an error, person can't be reassigned
let person = "Nick";
person = "John";
console.log(person); // "John", reassignment is allowed with let
```
**Detailed Explanation**
The scope of a variable roughly means "where is this variable available in the code".
**var**
Variables declared with var are function scoped, meaning that when a variable is created in a function, everything in that function can access that variable. Besides, a function-scoped variable created in a function can't be accessed outside this function.
Think of it as if an X scoped variable meant that this variable was a property of X.
```javascript
function myFunction() {
var myVar = "Nick";
console.log(myVar); // "Nick" - myVar is accessible inside the function
}
console.log(myVar); // Throws a ReferenceError, myVar is not accessible outside the function.
```
Here is a more subtle example:
```javascript
function myFunction() {
var myVar = "Nick";
if (true) {
var myVar = "John";
console.log(myVar); // "John"
// myVar being function scoped, we just erased the previous myVar value "Nick" for "John"
}
console.log(myVar); // "John" - see how the instructions in the if block affected this value
}
console.log(myVar); // Throws a ReferenceError, myVar is not accessible outside the function.
```
Variables declared with var are moved to the top of the scope at execution. This is what we call var hoisting.
This portion of code:
```javascript
console.log(myVar); // undefined -- no error raised
var myVar = 2;
```
is understood at execution like:
```javascript
var myVar;
console.log(myVar); // undefined -- no error raised
myVar = 2;
```
**let**
Variables declared with let are:
- Block scoped
- Not accessible before they are assigned
- Cannot be re-declared in the same scope
Let's see the impact of block-scoping with our previous example:
```javascript
function myFunction() {
let myVar = "Nick";
if (true) {
let myVar = "John";
console.log(myVar); // "John"
// myVar being block scoped, we just created a new variable myVar.
// this variable is not accessible outside this block and totally independent
// from the first myVar created!
}
console.log(myVar); // "Nick", see how the instructions in the if block DID NOT affect this value
}
console.log(myVar); // Throws a ReferenceError, myVar is not accessible outside the function.
```
**Temporal Dead Zone (TDZ)**
Variables declared with let (and const) are not accessible before being assigned:
```javascript
console.log(myVar); // raises a ReferenceError!
let myVar = 2;
```
By contrast with var variables, if you try to read or write a let or const variable before they are assigned, an error will be raised. This phenomenon is often called the Temporal Dead Zone or TDZ.
Note: Technically, let and const variable declarations are hoisted too, but not their assignments. Since they can't be used before assignment, it intuitively feels like there is no hoisting.
In addition, you can't re-declare a let variable:
```javascript
let myVar = 2;
let myVar = 3; // Raises a SyntaxError
```
**const**
Variables declared with const behave like let variables but also cannot be reassigned.
To sum it up, const variables:
- Are block scoped
- Are not accessible before being assigned
- Can't be re-declared in the same scope
- Can't be reassigned
```javascript
const myVar = "Nick";
myVar = "John"; // raises an error, reassignment is not allowed
const myVar = "Nick";
const myVar = "John"; // raises an error, re-declaration is not allowed
```
**Note:** const variables are not immutable! This means that object and array const declared variables can be mutated.
For objects:
```javascript
const person = { name: 'Nick' };
person.name = 'John'; // this will work! The person variable is not completely reassigned, but mutated
console.log(person.name); // "John"
person = "Sandra"; // raises an error, because reassignment is not allowed with const declared variables
```
For arrays:
```javascript
const person = [];
person.push('John'); // this will work! The person variable is not completely reassigned, but mutated
console.log(person[0]); // "John"
person = ["Nick"]; // raises an error, because reassignment is not allowed with const declared variables
```
**External Resources**
- How let and const are scoped in JavaScript - WesBos
- Temporal Dead Zone (TDZ) Demystified
**Arrow Function**
The ES6 JavaScript update introduced arrow functions, which is another way to declare and use functions. Here are the benefits they bring:
- More concise
- this is picked up from surroundings
- Implicit return
**Sample Code**
**Concision and Implicit Return**
```javascript
function double(x) { return x * 2; } // Traditional way
console.log(double(2)); // 4
const double = x => x * 2; // Same function written as an arrow function with implicit return
console.log(double(2)); // 4
```
**this Reference**
In an arrow function, this is equal to the this value of the enclosing execution context. Basically, with arrow functions, you don't have to do the "that = this" trick before calling a function inside a function anymore.
```javascript
function myFunc() {
this.myVar = 0;
setTimeout(() => {
this.myVar++;
console.log(this.myVar); // 1
}, 0);
}
```
**Detailed Explanation**
**Concision**
Arrow functions are more concise than traditional functions in many ways. Let's review all the possible cases:
**Implicit vs Explicit Return**
An explicit return is a function where the return keyword is used in its body.
```javascript
function double(x) {
return x * 2; // this function explicitly returns x * 2, *return* keyword is used
}
```
In the traditional way of writing functions, the return was always explicit. But with arrow functions, you can do an implicit return, which means you don't need to use the return keyword to return a value.
```javascript
const double = (x) => {
return x * 2; // Explicit return here
}
```
Since this function only returns something (no instructions before the return keyword), we can do an implicit return.
```javascript
const double = (x) => x * 2; // Correct, returns x*2
```
To do so, we only need to remove the brackets and the return keyword. That's why it's called an implicit return; the return keyword is not there, but this function will indeed return x * 2.
**Note:** If your function does not return a value (with side effects), it doesn't do an explicit nor an implicit return.
If you want to implicitly return an object, you must have parentheses around it since it will conflict with the block braces:
```javascript
const getPerson = () => ({ name: "Nick", age: | emmanuelj | |
1,864,568 | ونش انقاذ في المنايف | ونش انقاذ المنايف خدمة إنقاذ سريع مقدمة من موقع ونش انقاذ الاسماعيلية فقط أتصل بنا على رقم ونش انقاذ... | 0 | 2024-05-25T05:15:47 | https://dev.to/__797fca1087193/wnsh-nqdh-fy-lmnyf-4fa | ونش انقاذ المنايف خدمة إنقاذ سريع مقدمة من موقع ونش انقاذ الاسماعيلية فقط أتصل بنا على رقم ونش انقاذ الاسماعيلية ويصلك اقرب ونش انقاذ لك في المنايف اتصل بنا على 01210000819.
| __797fca1087193 | |
1,864,567 | رقم ونش انقاذ الاسماعيلية | ونش انقاذ الاسماعيلية خدمة إنقاذ سريع مقدمة من شركة ونشك للانقاذ نقوم بنقل و رفع جميع انواع... | 0 | 2024-05-25T05:12:23 | https://dev.to/__797fca1087193/rqm-wnsh-nqdh-lsmyly-6oe |

ونش انقاذ الاسماعيلية خدمة إنقاذ سريع مقدمة من شركة ونشك للانقاذ نقوم بنقل و رفع جميع انواع السيارات من محافظة الاسماعيلية نتميز ايضا بسرعة الاستجابة و الأمانة فاذا احتجت الي ونش انقاذ فى الاسماعيلية فنحن في خدمتك.
موقع [ونش انقاذ الاسماعيلية](https://winchk.com/ونش-انقاذ-الاسماعيلية-3/) | __797fca1087193 | |
1,864,565 | Efficient Array Sorting and File I/O Operations in NumPy: A Comprehensive Guide | The numpy.sort function is used to sort elements in a NumPy array along a specified axis. Here are... | 27,505 | 2024-05-25T05:05:42 | https://dev.to/lohith0512/efficient-array-sorting-and-file-io-operations-in-numpy-a-comprehensive-guide-4h2p | python, numpy, input, output | The `numpy.sort` function is used to sort elements in a NumPy array along a specified axis. Here are some key points:
1. <u>**Sorting Along the Last Axis:**</u>
- By default, `numpy.sort` sorts along the last axis of the array.
- For example, if you have an array `a` like this:
```python
import numpy as np
a = np.array([[9, 2, 3], [4, 5, 6], [7, 0, 5]])
```
You can sort it using:
```python
sorted_a = np.sort(a)
```
The resulting `sorted_a` will be:
```
array([[2, 3, 9],
[4, 5, 6],
[0, 5, 7]])
```
2. <u>**Sorting Along a Specific Axis:**</u>
- You can specify the axis along which to sort using the `axis` parameter.
- For example, to sort along the first axis (rows), you can do:
```python
sorted_rows = np.sort(a, axis=0)
```
The resulting `sorted_rows` will be:
```
array([[4, 0, 3],
[7, 2, 5],
[9, 5, 6]])
```
3. <u>**In-Place Sorting:**</u>
- If you want to sort the array in-place (i.e., modify the original array), you can use the `sort` method of the array itself:
```python
a.sort(axis=0)
```
Now `a` will be:
```
array([[4, 0, 3],
[7, 2, 5],
[9, 5, 6]])
```
4. <u>**Reverse Sorting:**</u>
- To sort in reverse order (descending), you can use the `[::-1]` slicing:
```python
reverse_sorted_rows = np.sort(a, axis=0)[::-1]
```
The resulting `reverse_sorted_rows` will be:
```
array([[9, 5, 6],
[7, 2, 5],
[4, 0, 3]])
```
Remember that `numpy.sort` returns a new sorted array by default, leaving the original array unchanged. If you want to sort in-place, use the `sort` method on the array itself. 😊
---
## <u>Reading data from files in numpy</u>
Let's dive into the details of `numpy.load()` and `numpy.loadtxt()`, along with some examples:
1. **`numpy.load()`**:
- The `numpy.load()` function is used to load binary data from a `.npy` file (NumPy binary format). It reads the data and returns a NumPy array.
- Syntax: `numpy.load(file, mmap_mode=None, allow_pickle=False, fix_imports=True, encoding='ASCII')`
- Parameters:
- `file`: The file name or file-like object from which to load the data.
- `mmap_mode`: Optional memory-mapping mode (default is `None`).
- `allow_pickle`: Whether to allow loading pickled objects (default is `False`).
- `fix_imports`: Whether to fix Python 2/3 pickle incompatibility (default is `True`).
- `encoding`: Encoding used for text data (default is `'ASCII'`).
- Example:
```python
import numpy as np
data = np.load('my_data.npy')
print(data)
```
2. **`numpy.loadtxt()`**:
- The `numpy.loadtxt()` function reads data from a text file and returns a NumPy array.
- Syntax: `numpy.loadtxt(fname, dtype=float, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes', max_rows=None)`
- Parameters:
- `fname`: File name or file-like object to read from.
- `dtype`: Data type of the resulting array (default is `float`).
- `comments`: Characters indicating the start of comments (default is `'#'`).
- `delimiter`: Character used to separate values (default is whitespace).
- Other optional parameters control skipping rows, selecting columns, and more.
- Example:
```python
import numpy as np
# Load data from a text file with tab-separated values
data = np.loadtxt('my_data.txt', delimiter='\t')
print(data)
```
Remember to replace `'my_data.npy'` and `'my_data.txt'` with the actual file paths in your use case. If you have any specific data files, feel free to adapt the examples accordingly! 😊
---
## <u>Writing Data into files</u>
`numpy.save` and `numpy.savetxt` are both functions in the NumPy library in Python that are used for saving data to files, but they have slightly different purposes and formats.
1. **numpy.save:**
`numpy.save` is used to save a single numpy array to a binary file with a `.npy` extension. This function is efficient for saving and loading large arrays quickly, as it stores data in a binary format.
Syntax:
```python
numpy.save(file, arr, allow_pickle=True, fix_imports=True)
```
- `file`: File path or file object where the data will be saved.
- `arr`: Numpy array to be saved.
- `allow_pickle`: Optional parameter specifying whether to allow pickling of objects.
- `fix_imports`: Optional parameter specifying whether to fix imports for pickle.
Example:
```python
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
np.save('my_array.npy', arr)
```
This will save the array `arr` to a file named `my_array.npy` in the current directory.
2.**numpy.savetxt:**
`numpy.savetxt` is used to save a numpy array to a text file in a human-readable format. It's useful when you want to save data in a format that can be easily opened and edited in a text editor or imported into other programs like spreadsheets.
Syntax:
```python
numpy.savetxt(fname, arr, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)
```
- `fname`: File path or file object where the data will be saved.
- `arr`: Numpy array to be saved.
- `fmt`: Optional parameter specifying the format of the data in the file.
- `delimiter`: Optional parameter specifying the string used to separate values.
- `newline`: Optional parameter specifying the string used to separate lines.
- `header`: Optional parameter specifying a string to be written at the beginning of the file.
- `footer`: Optional parameter specifying a string to be written at the end of the file.
- `comments`: Optional parameter specifying the string used to indicate comments.
- `encoding`: Optional parameter specifying the encoding of the output file.
Example:
```python
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
np.savetxt('my_array.txt', arr, fmt='%d', delimiter=',')
```
This will save the array `arr` to a file named `my_array.txt` in the current directory, with values separated by commas.
In summary, `numpy.save` is used to save numpy arrays in a binary format, while `numpy.savetxt` is used to save numpy arrays in a human-readable text format.🚀💯👩💻😊🙌
| lohith0512 |
1,864,564 | Comprehensive Dental Implants in Liverpool Services at Kidsgrove Medical Center | Kidsgrove Medical Center offers outstanding dental implants in Liverpool services, providing patients... | 0 | 2024-05-25T05:02:10 | https://dev.to/david_seo_master/comprehensive-dental-implants-in-liverpool-services-at-kidsgrove-medical-center-4djk | kidsgrovemedicalcenter, dentalimplantsliverpool, devops |
Kidsgrove Medical Center offers outstanding [dental implants in Liverpool](https://kidsgrovedental.com/) services, providing patients with cutting-edge dental care and implant solutions. This detailed overview highlights why Kidsgrove Medical Center is the premier choice for dental implants, ensuring you achieve a healthy, confident smile.
## Why Choose Kidsgrove Medical Center?
**Expert Team:** Our center boasts a team of highly skilled dental professionals with extensive experience in implantology. Their expertise ensures precise implant placement and high-quality outcomes.
**Advanced Technology:** We utilize state-of-the-art technology, including 3D imaging and digital scanning, to accurately plan and execute implant procedures. This technology enhances the precision and success rate of the implants.
**Personalized Treatment Plans:** At Kidsgrove Medical Center, each patient receives a customized treatment plan tailored to their unique needs. Our thorough consultation process involves assessing your oral health, bone structure, and aesthetic goals to provide the most suitable implant solution.
**Comprehensive Care:** From initial consultation to final restoration, we offer comprehensive support and care. Our compassionate team ensures that patients are well-informed and comfortable throughout their implant journey.
**Affordable Pricing:** We understand the financial concerns of our patients. That’s why we offer competitive pricing and flexible payment plans, making high-quality dental care accessible and affordable.
## The Dental Implants Procedure
**Consultation and Planning: **The process begins with a thorough consultation and examination. Advanced imaging techniques are used to create a detailed treatment plan, ensuring optimal implant placement.
**Implant Placement:** On the day of the procedure, titanium implants are carefully placed into the jawbone. This creates a strong foundation for the prosthetic teeth.
**Temporary Teeth:** Immediately after implant placement, a temporary set of teeth is attached. These teeth are fully functional, allowing you to leave the clinic with a complete smile the same day.
**Healing Period:** Over the next few months, the implants integrate with the jawbone in a process called osseointegration. During this time, patients follow a specific care routine to ensure proper healing.
**Final Restoration:** Once the implants have fully integrated, the temporary teeth are replaced with a permanent, custom-made set of prosthetic teeth. These final teeth are designed to match your natural teeth in color, shape, and size.
## Benefits of Dental Implants
**Stability and Durability:** Implants provide a stable and durable foundation for replacement teeth, ensuring they remain securely in place.
**Improved Oral Health:** Implants help preserve the jawbone and prevent bone loss, maintaining your facial structure and overall oral health.
**Natural Look and Feel:** Dental implants are designed to look and feel like natural teeth, enhancing your smile and boosting your confidence.
**Enhanced Functionality:** With dental implants, you can eat, speak, and smile comfortably and confidently.
## Visit Our Website
For more information about our exceptional dental implants in Liverpool services, visit Kidsgrove Medical Center’s website. Here, you can learn more about our offerings, read patient testimonials, and schedule a consultation to start your journey towards a beautiful, confident smile.
Kidsgrove Medical Center is dedicated to providing top-notch dental care with a focus on patient satisfaction. Our dental implants services in Liverpool are a testament to our commitment to excellence in dental restoration. | david_seo_master |
1,864,557 | aasdasd aasdasasd asasdasd | aasdasd aasdasasd asasdasd | 0 | 2024-05-25T04:31:12 | https://dev.to/sm-maruf-hossen/aasdasd-aasdasasd-asasdasd-5243 | aasdasd aasdasasd asasdasd | sm-maruf-hossen | |
1,864,563 | Construction chemicals manufacturers in Maharashtra | *Top Construction Chemicals Manufacturers in Maharashtra: Leading the Industry * Construction... | 0 | 2024-05-25T05:01:29 | https://dev.to/sakshichemsciences/construction-chemicals-manufacturers-in-maharashtra-gn8 | **Top Construction Chemicals Manufacturers in Maharashtra: Leading the Industry
**
Construction chemicals play a vital role in ensuring strength, durability, and aesthetics to various types of building projects, right from industrial to commercial and residential. These products are frequently used in various stages and aspects of construction to enhance specific properties of the construction materials being used, such as workability, etc. Construction experts recommend buying these only from renowned [construction chemicals manufacturers in Maharashtra](https://www.sakshichemsciences.com/), such as Sakshi Chem Sciences for the best results.
In this article, we will discover some of the most popular types of construction chemicals provided by Sakshi Chem Sciences, the most reliable construction chemical supplier in the country.
**Types of Popular Construction Chemicals
**
Construction chemicals are normally categorized into four main types –
- Adhesives and Sealants
- Protective Coating
- Asphalt Modifiers
- Concrete Admixtures
Mostly, construction additives are used as hardening agents, usually for concrete surfaces, as coating, or as materials for repairing, besides waterproofing applications.
Let’s check out the different types of products offered by leading construction chemicals manufacturers in India –
**1 – Concrete Hardeners
**
Hardeners are compounds that are added to concrete to make it more durable and denser. These chemical compounds improve the waterproofing properties, abrasion and impact resistance, and chemical resistance of concrete. They also make concrete surfaces more durable which prevents generation of dust. These properties are essential requirements in commercial and industrial settings.
**2 – Concrete Curing
**
Curing chemicals are usually composed of natural or synthetic resins, waxes, and solvents that have high volatility at ambient temperatures. These compounds create a water-resistant layer after being applied on fresh concrete surface, and often contain white or greyish pigments that also reflect heat.
Concrete curing compounds are extremely useful to accelerate the drying and hardening process of freshly laid concrete, which ensures higher strength and durability of the treated concrete surface.
**3 – Coating
**
Protective coating is another popular construction chemical which is mainly applied on concrete surfaces to prevent or inhibit corrosion. It comes in metallic and non-metallic varieties. These coatings are applied through various methods and can be used for multiple purposes too.
Non-metallic coating compounds often contain polyurethanes, epoxies, and polymers as main components. On the other hand, metallic coating products usually contain chromium, aluminum, and zinc. These coating chemicals are useful for enhancing aesthetics, decoration, fireproofing, sound and heat insulation, higher durability, higher strength, and early completion of concrete surfaces.
**4 – Mold Release Agents
**
Mold release agents are also called shuttering oils and formwork release chemicals. These are useful to prevent concrete from sticking to the mold or formwork in which it is poured in the construction industry and pre-cast manufacturing. These are available in various types and help to get smooth, stain-free concrete surfaces.
**Conclusion**
Sakshi Chem Sciences, the leading construction chemicals manufacturers in Maharashtra offer a wide range of construction chemicals, which includes hardeners, curing compounds, mold release agents, tile adhesives, grouts, and numerous other essential construction additives. It is important to buy only high-quality construction compounds to ensure your construction projects are stronger, more durable, and aesthetically pleasing.
| sakshichemsciences | |
1,857,486 | Revolutionizing Web Design: The Intersection of AI and Automation | Introduction: The evolution of web design has been a fascinating journey, marked by significant... | 0 | 2024-05-25T05:00:00 | https://dev.to/nitin-rachabathuni/revolutionizing-web-design-the-intersection-of-ai-and-automation-2oli | Introduction:
The evolution of web design has been a fascinating journey, marked by significant technological advancements. Today, we stand at the threshold of a new era where artificial intelligence (AI) and automation are poised to revolutionize the way we create and interact with websites. In this article, we'll explore the profound impact of AI and automation on web design, and delve into coding examples that illustrate their transformative potential.
The Rise of AI in Web Design:
AI has emerged as a powerful tool in web design, offering capabilities that were once the realm of human designers. From generating layouts to optimizing user experiences, AI algorithms are reshaping the design process in remarkable ways.
One prominent application of AI in web design is generative design. By leveraging machine learning algorithms, designers can input design parameters and let AI generate multiple design options based on predefined criteria. For example, tools like Adobe Sensei and Wix ADI analyze user preferences and content to automatically create personalized website layouts.
Coding Example:
```
<!DOCTYPE html>
<html>
<head>
<title>AI-Generated Website</title>
<style>
/* CSS styles generated by AI */
/* Define your styles here */
</style>
</head>
<body>
<!-- AI-generated HTML structure -->
<!-- Place your content here -->
</body>
</html>
```
Automating Repetitive Tasks:
Automation plays a pivotal role in streamlining repetitive tasks in web design, freeing up designers to focus on creative aspects. Whether it's optimizing images, compressing files, or updating content, automation tools empower designers to work more efficiently and deliver better results.
For instance, task runners like Gulp and Grunt automate the process of minifying CSS and JavaScript files, concatenating resources, and optimizing images, among other tasks. By setting up predefined workflows, designers can execute these tasks with a single command, saving time and effort.
Coding Example:
```
// Gulpfile.js - Automating CSS Minification
const gulp = require('gulp');
const cleanCSS = require('gulp-clean-css');
gulp.task('minify-css', () => {
return gulp.src('styles/*.css')
.pipe(cleanCSS())
.pipe(gulp.dest('dist/css'));
});
gulp.task('default', gulp.series('minify-css'));
```
Enhancing User Experience with AI:
AI-driven personalization is revolutionizing user experience (UX) design by delivering tailored content and recommendations based on user behavior and preferences. By analyzing vast amounts of data in real-time, AI algorithms can anticipate user needs and adapt website interfaces accordingly.
For instance, chatbots powered by natural language processing (NLP) algorithms provide personalized assistance to website visitors, guiding them through the navigation process or answering queries in real-time. These intelligent assistants enhance user engagement and satisfaction, leading to higher conversion rates and improved retention.
Coding Example:
```
// Chatbot Implementation with Dialogflow
const dialogflow = require('dialogflow');
const express = require('express');
const bodyParser = require('body-parser');
const app = express();
app.use(bodyParser.json());
// Initialize Dialogflow client
const sessionClient = new dialogflow.SessionsClient();
const sessionPath = sessionClient.sessionPath(process.env.PROJECT_ID, 'unique-session-id');
// Handle incoming messages
app.post('/webhook', async (req, res) => {
const { queryInput } = req.body;
const responses = await sessionClient.detectIntent({ session: sessionPath, queryInput });
const result = responses[0].queryResult;
res.send(result.fulfillmentText);
});
// Start server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});
```
Conclusion:
AI and automation are reshaping the landscape of web design, offering unprecedented opportunities for innovation and efficiency. By harnessing the power of AI algorithms and automation tools, designers can create dynamic, personalized web experiences that adapt to the needs of users in real-time. As we embrace this technological revolution, the future of web design promises to be both exciting and transformative.
---
Thank you for reading my article! For more updates and useful information, feel free to connect with me on LinkedIn and follow me on Twitter. I look forward to engaging with more like-minded professionals and sharing valuable insights.
| nitin-rachabathuni | |
1,838,289 | Human-Centered Design: Advocating for and Designing for Our Needs | In a world increasingly dominated by technology, it's crucial to remember the human element.... | 27,353 | 2024-05-25T05:00:00 | https://dev.to/shieldstring/human-centered-design-advocating-for-and-designing-for-our-needs-5c8n | design, ui, ux, career | In a world increasingly dominated by technology, it's crucial to remember the human element. Technology should not just exist for its own sake; it should be designed to serve us, to make our lives easier, more fulfilling, and more meaningful. This is where the philosophy of human-centered design (HCD) comes in. HCD is an approach that places the user at the forefront of the design process, advocating for their needs and crafting solutions that truly resonate.
**Why Advocate for Human Needs?**
Technology has the potential to be a powerful tool for good. It can connect us, educate us, and empower us. However, when technology is designed without considering human needs, it can become alienating, frustrating, and even harmful. Here's why advocating for human needs in design matters:
* **Improves User Experience (UX):** Products designed with human needs in mind are intuitive, user-friendly, and enjoyable to interact with. This leads to higher user satisfaction and increased adoption.
* **Solves Real Problems:** HCD focuses on identifying and addressing genuine user pain points. This ensures that technology solves real problems and creates tangible value.
* **Promotes Accessibility and Inclusion:** Human-centered design strives to create solutions that are accessible to everyone, regardless of ability or background. This fosters a more inclusive and equitable technological landscape.
* **Builds Trust and Loyalty:** When users feel their needs are heard and addressed, they develop trust and loyalty towards the technology and the brand behind it.
**How to Design for Human Needs**
HCD is not a one-size-fits-all approach. It involves a series of iterative steps that prioritize user understanding:
* **Empathy is Key:** The first step is to develop empathy for your users. Conduct user research through interviews, surveys, and usability testing to understand their needs, motivations, and frustrations.
* **Define the Problem:** Clearly define the problem you are trying to solve from the user's perspective. What challenges do they face? What are their goals?
* **Ideate and Prototype:** Brainstorm potential solutions and develop low-fidelity prototypes to test with users. Gather feedback and iterate on your designs based on user insights.
* **Test and Refine:** Continuously test your design with users throughout the development process. This ensures you are on the right track and creating a solution that truly meets their needs.
**The Future of Human-Centered Design**
As technology continues to evolve, the principles of human-centered design will become even more critical. Here are some exciting possibilities for the future:
* **AI-powered User Research:** Artificial intelligence can be used to analyze user data and identify trends, complementing traditional user research methods.
* **Personalized Technology:** HCD can be used to create technology that adapts to individual needs and preferences, further enhancing the user experience.
* **Focus on Mental Wellbeing:** As we spend more time interacting with technology, HCD will play a crucial role in designing solutions that promote mental wellbeing and reduce anxiety associated with technology use.
**Conclusion**
By advocating for human needs and embracing human-centered design principles, we can create technology that is not just innovative, but also beneficial, inclusive, and empowering. Let's design a future where technology serves humanity, not the other way around.
This article provides a starting point for understanding human-centered design. Here are some resources for further exploration:
* **The Interaction Design Foundation: [https://www.interaction-design.org/](https://www.interaction-design.org/)**
* **Nielsen Norman Group: [https://www.nngroup.com/](https://www.nngroup.com/)**
* **IDEO: [https://www.ideo.org/](https://www.ideo.org/)**
| shieldstring |
1,864,562 | Creating Simple Shaders in WebGL: A Step-by-Step Guide | WebGL (Web Graphics Library) is a powerful JavaScript API for rendering 2D and 3D graphics in a web... | 0 | 2024-05-25T04:39:47 | https://dev.to/hayyanstudio/creating-simple-shaders-in-webgl-a-step-by-step-guide-46gg | shader, programming, beginners | WebGL (Web Graphics Library) is a powerful JavaScript API for rendering 2D and 3D graphics in a web browser. One of the fundamental skills in WebGL programming is creating and using shaders. [Shaders](https://glsl.site/tag/shader/) are small programs that run on the GPU to control the rendering process. This guide will walk you through the steps to create basic shaders using WebGL.
## Getting Started
Before diving into shader programming, you need a basic HTML structure to set up a WebGL context. Here’s a simple HTML template to get started:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>WebGL Shaders</title>
<style>
body { margin: 0; }
canvas { display: block; }
</style>
</head>
<body>
<canvas id="glCanvas"></canvas>
<script src="shader.js"></script>
</body>
</html>
```
## Setting Up WebGL
Next, create a JavaScript file (shader.js) to initialize WebGL and compile the shaders.
## Initializing WebGL
```javascript
function initWebGL() {
const canvas = document.getElementById('glCanvas');
const gl = canvas.getContext('webgl') || canvas.getContext('experimental-webgl');
if (!gl) {
alert('Unable to initialize WebGL. Your browser may not support it.');
return;
}
return gl;
}
const gl = initWebGL();
if (gl) {
gl.clearColor(0.0, 0.0, 0.0, 1.0); // Clear to black, fully opaque
gl.clear(gl.COLOR_BUFFER_BIT); // Clear the color buffer
}
```
## Creating Shaders
Shaders in WebGL are written in GLSL (OpenGL Shading Language). You need two types of shaders: a vertex shader and a fragment shader.
## Vertex Shader
The [vertex shader](https://glsl.site/post/understanding-vertex-shaders-unveiling-the-magic-behind-3d-graphics/) processes each vertex's position.
```javascript
const vsSource = `
attribute vec4 aVertexPosition;
void main(void) {
gl_Position = aVertexPosition;
}
`;
```
## Fragment Shader
The fragment shader processes each pixel's color.
```javascript
Copy code
const fsSource = `
void main(void) {
gl_FragColor = vec4(1.0, 0.0, 0.0, 1.0); // Red color
}
`;
```
## Compiling Shaders
To use the shaders, you need to compile and link them into a shader program.
```javascript
function loadShader(gl, type, source) {
const shader = gl.createShader(type);
gl.shaderSource(shader, source);
gl.compileShader(shader);
if (!gl.getShaderParameter(shader, gl.COMPILE_STATUS)) {
console.error('An error occurred compiling the shaders:', gl.getShaderInfoLog(shader));
gl.deleteShader(shader);
return null;
}
return shader;
}
const vertexShader = loadShader(gl, gl.VERTEX_SHADER, vsSource);
const fragmentShader = loadShader(gl, gl.FRAGMENT_SHADER, fsSource);
function initShaderProgram(gl, vs, fs) {
const shaderProgram = gl.createProgram();
gl.attachShader(shaderProgram, vs);
gl.attachShader(shaderProgram, fs);
gl.linkProgram(shaderProgram);
if (!gl.getProgramParameter(shaderProgram, gl.LINK_STATUS)) {
console.error('Unable to initialize the shader program:', gl.getProgramInfoLog(shaderProgram));
return null;
}
return shaderProgram;
}
const shaderProgram = initShaderProgram(gl, vertexShader, fragmentShader);
```
## Using the Shader Program
Now, set up the vertex buffer and draw the scene using the shader program.
Setting Up the Vertex Buffer
```javascript
function initBuffers(gl) {
const vertices = new Float32Array([
-0.5, -0.5,
0.5, -0.5,
0.0, 0.5,
]);
const vertexBuffer = gl.createBuffer();
gl.bindBuffer(gl.ARRAY_BUFFER, vertexBuffer);
gl.bufferData(gl.ARRAY_BUFFER, vertices, gl.STATIC_DRAW);
return vertexBuffer;
}
const vertexBuffer = initBuffers(gl);
Drawing the Scene
javascript
Copy code
function drawScene(gl, shaderProgram, vertexBuffer) {
gl.clear(gl.COLOR_BUFFER_BIT);
const vertexPosition = gl.getAttribLocation(shaderProgram, 'aVertexPosition');
gl.bindBuffer(gl.ARRAY_BUFFER, vertexBuffer);
gl.vertexAttribPointer(vertexPosition, 2, gl.FLOAT, false, 0, 0);
gl.enableVertexAttribArray(vertexPosition);
gl.useProgram(shaderProgram);
gl.drawArrays(gl.TRIANGLES, 0, 3);
}
drawScene(gl, shaderProgram, vertexBuffer);
```
## Conclusion
This guide covered the basics of setting up a WebGL context, creating and compiling shaders, and rendering a simple triangle using a basic vertex and fragment shader. With this foundation, you can start exploring more advanced shader [techniques](https://glsl.site/tag/technical/) and create complex visual effects for your WebGL applications.
## Stay Connected:
Twitter: [@HaiderAftab007](https://x.com/HaiderAftab007)
Instagram: [@HaiderAftab007](https://www.instagram.com/newraja2003/)
LinkedIn: [Haider Aftab](https://www.linkedin.com/in/haider-aftab-game-devloper/)
Website: [GLSL](https://glsl.site)
BuyMeCoffe: [HaiderAftab](https://www.buymeacoffee.com/HaiderAftab) | hayyanstudio |
1,864,561 | " Getting Started with HTML: Building Blocks of Web Pages | "👋 Hey there, future web developer! Ready to kickstart your journey with HTML? Let's break it down: 🔍... | 0 | 2024-05-25T04:36:21 | https://dev.to/erasmuskotoka/-getting-started-with-html-building-blocks-of-web-pages-1m3c | "👋 Hey there, future web developer! Ready to kickstart your journey with HTML? Let's break it down:
🔍 Give Your Content Meaning: HTML isn't just about typing words. It's like building a Lego house—each piece has a purpose. Use tags like <header> for the top, <nav> for navigation, and <footer> for the bottom to structure your page in a way that makes sense.
♿ Make Your Site for Everyone: Imagine your website is a party, and you want everyone to feel welcome.
🌐 Be a Compatibility Champ: HTML is like the universal language of the web. No matter if someone's using a computer, phone, or tablet, your site will look awesome.
🛠️ Start Simple, Then Add Pizzazz: Think of HTML like the blueprint of your website.
Start with the basics, then add colors and animations with CSS, and make it dance with JavaScript.
🔍 Help Google Find You: Ever wonder how Google knows what's on a webpage?
That's thanks to HTML! By using the right tags and words, you'll help search engines understand your site better and show it to more people.
🤝 Join the Web Community: Learning HTML is like joining a big friendly club.
Everyone's here to help you succeed!
🔄 Keep Growing, Keep Learning: HTML is always changing, just like the web itself.
Stay curious, keep learning new things, and you'll be building amazing websites in no time!
Ready to take your first step into the exciting world of web development? Let's build something awesome together! 💻 #HTML #WebDevelopment #CodWith
#KOToka
#BeginnerFriendly"
| erasmuskotoka | |
1,864,559 | NEXT 15 is here! : What's New and Exciting? | Tired of the tedious setup process for React projects? Buckle up, because Next.js 15 is here to save... | 0 | 2024-05-25T04:31:02 | https://dev.to/grenishrai/next-15-is-here-whats-new-and-exciting-1nkl | webdev, nextjs, typescript, javascript | Tired of the tedious setup process for React projects? Buckle up, because **Next.js 15** is here to save the day! Spearheaded by Vercel CEO Guillermo Rauch, this major update focuses on efficiency and streamlines the development process. Let's dive into the exciting features of Next.js 15 and see how they can elevate your development workflow to new heights!
## Major Improvements in Next.js 15
### 1. Enhanced Caching
With Next.js 15, caching improvements are significant, making it easier and more intuitive to handle your app's performance. No more headaches managing cache - "Caching no longer sucks!"
### 2. Hydration Errors and Developer Experience
Hydration errors are a thing of the past. The developer experience is now more robust and reliable, catering to both seasoned pros and newcomers alike. Next.js 15 ensures a smooth development process.
### 3. Addressing Common Concerns
Some developers fear that Next.js is becoming too magical, requiring constant rewrites. However, after exploring Next.js 15, it's clear these enhancements integrate seamlessly with existing projects.
## Next.js 15 Features Breakdown
### 4. Server Actions
Server Actions are a game-changer, allowing you to define server-side functions directly within your React components, simplifying data fetching and other server-side operations.
```ts
import { serverAction } from 'next/server';
export default function MyComponent() {
const handleAction = serverAction(async () => {
// Perform server-side operations here
});
return <button onClick={handleAction}>Do Action</button>;
}
```
### 5. Partial Pre-Rendering (PPR) (Experimental)
Next.js 15 introduces Partial Pre-Rendering (PPR), enabling parts of your page to be static (SSG) while others are dynamic (SSR or ISR). This flexibility combines the best of both worlds.
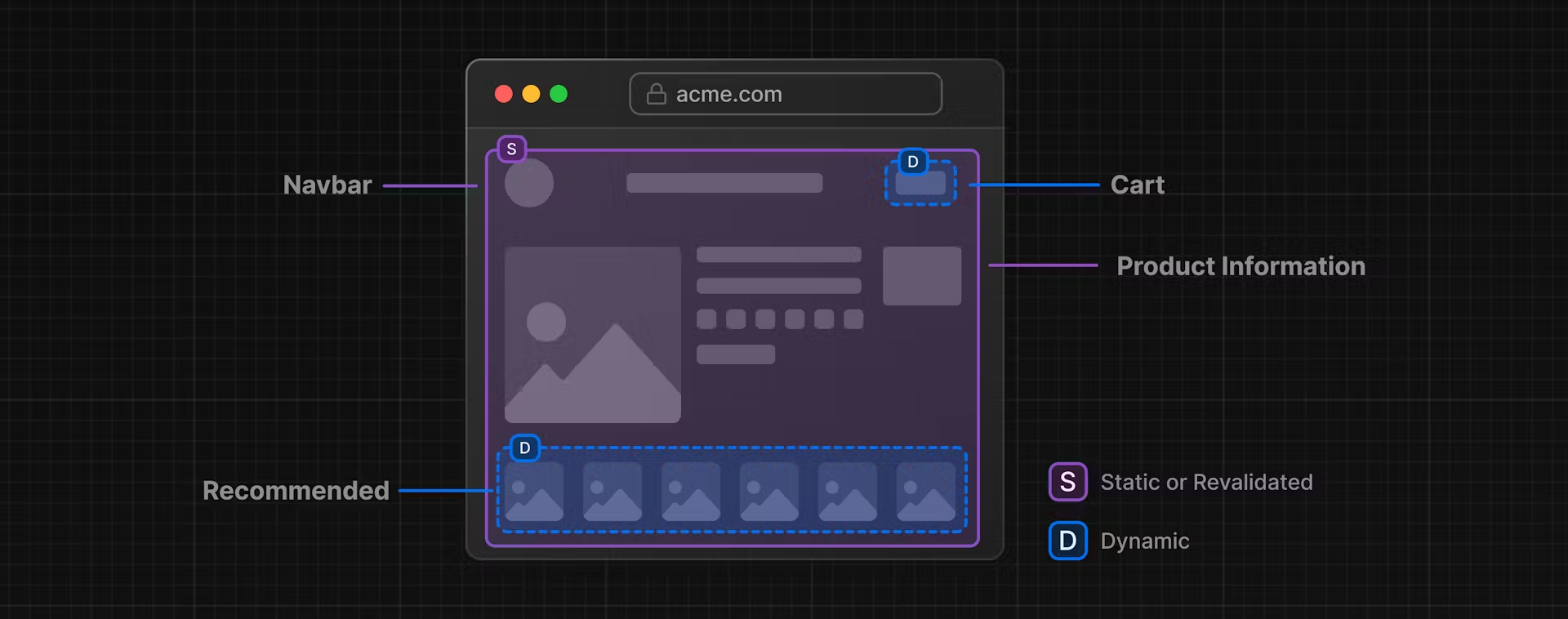
### 6. React 19 Support
Next.js 15 supports React 19, including the new React Compiler. This means better performance and fewer hooks to manage, thanks to automatic code optimizations.
### 7. Enhanced Middleware
Middleware capabilities have been improved, allowing for more complex and efficient request handling. Ideal for developers leveraging serverless functions or edge computing.
### 8. Next After (Experimental)
Next After prioritizes important tasks, letting the server handle secondary tasks in the background. This ensures faster initial load times for users. For example, YouTube processes your request and sends you the video first, then updates analytics later.
### 9. Turbo Pack
Turbo Pack is the new high-speed bundler replacing Webpack in development mode. It promises faster and smoother development, enhancing the overall developer experience.
Enable Turbopack with the `--turbo` flag:
```sh
npx create-next-app@rc --turbo
```
### 10. Improved External Package Handling
Next.js 15 bundles external packages by default, improving the cold start of applications and reducing latency. This results in a smoother, faster experience for both developers and users.
## How to Use Next.js 15
To start using Next.js 15, run the following command:
```sh
npm install next@rc react@rc react-dom@rc
```
## Conclusion
Next.js 15 is a significant leap forward, packed with features that enhance both development and user experience. From improved caching and server actions to partial pre-rendering and Turbo Pack, it’s designed to make your life as a developer easier and more productive.
**Happy Coding! :)** | grenishrai |
1,864,558 | Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy. | aasdasd aasdasasd asasdasd | 0 | 2024-05-25T04:30:28 | https://dev.to/sm-maruf-hossen/aasdasd-aasdasasd-asasdasd-1pm4 | aasdasd aasdasasd asasdasd | sm-maruf-hossen | |
1,864,556 | AWS Athena for GitHub - Eliminating the default Security blind spots | Did you know GitHub’s audit logs are retained for only six months, but Git events are retained for... | 0 | 2024-05-25T04:25:57 | https://dev.to/siddhantkcode/aws-athena-for-github-eliminating-the-default-security-blind-spots-4dm | aws, github, security, productivity | Did you know GitHub’s audit logs are retained for only six months, but Git events are retained for just seven days ([\[1\]](https://docs.github.com/en/enterprise-cloud@latest/admin/monitoring-activity-in-your-enterprise/reviewing-audit-logs-for-your-enterprise/about-the-audit-log-for-your-enterprise), [\[2\]](https://docs.github.com/en/organizations/keeping-your-organization-secure/managing-security-settings-for-your-organization/reviewing-the-audit-log-for-your-organization#accessing-the-audit-log))? This mismatch can leave significant gaps in your security visibility. For example, if an attacker manages to infiltrate your system, they could hide their tracks if you do not have a system in place to retain these logs longer.
Many organizations stream these logs to external storage like Amazon S3. While storing these logs is essential, being able to query them is equally important. Failing to do so can result in missing information during security incidents, lack of compliance with regulatory requirements, and an overall inability to perform thorough forensic analysis during an investigation.
In this post, I will walk you through how to set up and query Amazon Athena for audit logs stored in S3.
## Why Query Audit Logs with Amazon Athena?
Audit logs provide a list of events that affect your enterprise. Having these logs queryable in Amazon Athena offers several benefits:
1. **Immediate Access:** query logs for specific events without the need to manually sift through raw data.
2. **Detailed Insights:** drill down into specific details, such as who performed a particular action and when. For instance, you can see who deleted a repository, what time they did it, and their IP address. Here's a mock example of what the detailed results might look like:
```json
{
"action": "repo.destroy",
"actor": "johndoe",
"actor_id": 12345,
"actor_ip": "192.168.1.1",
"user_agent": "Mozilla/5.0",
"visibility": "private",
"repo": "example-repo",
"repo_id": 54321,
"public_repo": false,
"org": "example-org",
"org_id": 67890,
"_document_id": "abcdef123456",
"@timestamp": "2024-01-15T06:30:00Z",
"created_at": "2024-01-15T06:29:50Z",
"operation_type": "delete",
"business": "example-business",
"business_id": 111213,
"actor_location": {"country_code": "US"}
}
```
3. **Cost Efficiency:** By leveraging partitioning and other cost-saving features in Athena, you can optimize your query costs.
## Setting Up Athena to Query GitHub Audit Logs
To get started, you'll need to create a table and a view in Athena that reference your GitHub audit logs stored in S3.
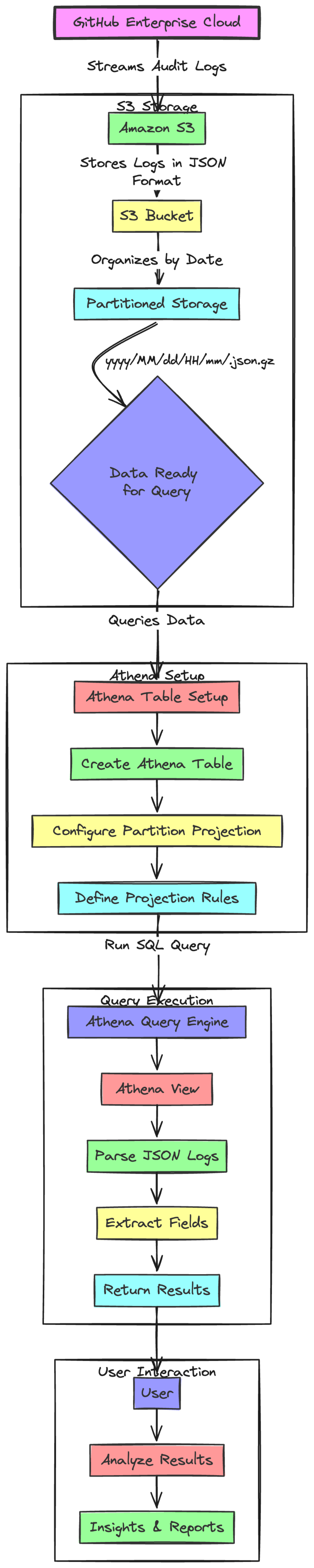
### Step 1: Create an Athena Table
First, let's define a table in Athena that can read the JSON-formatted audit logs stored in S3.
```sql
CREATE EXTERNAL TABLE IF NOT EXISTS `<TABLE NAME>` (
`json_objects` string
)
PARTITIONED BY (
`date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
LOCATION 's3://<YOUR S3 PATH>/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.format' = 'yyyy/MM/dd/HH',
'projection.date.range' = '2023/01/01/01,NOW',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<YOUR_S3_PATH>/${date}/'
);
```
This table setup ensures that Athena can read and partition your audit logs based on the date.
### Step 2: Create an Athena View
Next, create a view to make it easier to query specific fields from the JSON data.
```sql
CREATE VIEW `<VIEW_NAME>` AS
SELECT
date,
json_extract_scalar(json_objects, '$.action') AS action,
json_extract_scalar(json_objects, '$["@timestamp"]') AS "timestamp",
json_objects
FROM `<TABLE NAME>`;
```
With this view, you can easily extract specific fields from the JSON logs.
## Example Use Case: Querying for Repository Deletion Events
To demonstrate the setup, let's assume you want to find out who deleted a specific repository and when.
### Step 1: Identify the JSON Schema
Run the following query to reveal the JSON schema of the event log for repository deletions.
```sql
SELECT * FROM <VIEW_NAME>
WHERE
action = 'repo.destroy'
AND date BETWEEN '2023/01/01' AND '2023/02/01';
```
This query helps you identify the schema of the logs related to the `repo.destroy` action. Here's an example of what the JSON schema might look like:
```json
{
"action": "repo.destroy",
"actor": "<actor name>",
"actor_id": <actor id>,
"actor_ip": "<actor ip>",
"user_agent": "<user agent>",
"visibility": "<repo visibility>",
"repo": "<repo name>",
"repo_id": <repo id>,
"public_repo": <is public>,
"org": "<org name>",
"org_id": <org id>,
"_document_id": "<document id>",
"@timestamp": <timestamp>,
"created_at": <timestamp>,
"operation_type": "<operation_type>",
"business": "<business name>",
"business_id": <business id>,
"actor_location": {"country_code": "JP"}
}
```
### Step 2: Create a Table for the Specific Event
Using the identified JSON schema, create a table tailored to the `repo.destroy` event.
```sql
CREATE EXTERNAL TABLE IF NOT EXISTS `repo_destroy_events` (
`action` string,
`actor` string,
`repo` string,
`@timestamp` string
)
PARTITIONED BY (
`date` string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'ignore.malformed.json' = 'FALSE',
'dots.in.keys' = 'FALSE',
'case.insensitive' = 'TRUE'
)
LOCATION 's3://<YOUR_S3_PATH>/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.format' = 'yyyy/MM/dd/HH',
'projection.date.range' = '2023/01/01/01,NOW',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<YOUR_S3_PATH>/${date}/'
);
```
### Step 3: Query the Specific Table
Now, you can run a query on the newly created table to find out when and who deleted the repository.
```sql
SELECT * FROM repo_destroy_events
WHERE
action = 'repo.destroy'
AND repo = 'hoge'
AND date BETWEEN '2024/01/01' AND '2024/02/01';
```
This query will return the specific logs indicating when the repository was deleted and by whom.
## Why we need this and optimization tips
### Why follow these steps?
In a nutshell, these steps are essential for achieving a general-purpose log search.
Before you can use Amazon Athena to query data in an S3 object, you must define a table. For each dataset that you query, Athena requires an underlying table that it uses to retrieve and return query results. Therefore, you must register the table with Athena before you can query the data. [More about Athena tables](https://docs.aws.amazon.com/en_us/athena/latest/ug/understanding-tables-databases-and-the-data-catalog.html).
However, defining the table in advance is challenging due to two main reasons:
1. **Different JSON Schemas for Different Events:** GitHub logs have varied JSON schemas for different events. For example, the JSON schema for `repo.destroy` is different from `public_key.create`. Here are examples:
**`repo.destroy` JSON Schema:**
```json
{
"action": "repo.destroy",
"actor": "<actor name>",
"actor_id": <actor id>,
"actor_ip": "<actor ip>",
"user_agent": "<user agent>",
"visibility": "<repo visibility>",
"repo": "<repo name>",
"repo_id": <repo id>,
"public_repo": <is public>,
"org": "<org name>",
"org_id": <org id>,
"_document_id": "<document id>",
"@timestamp": <timestamp>,
"created_at": <timestamp>,
"operation_type": "<operation_type>",
"business": "<business name>",
"business_id": <business id>,
"actor_location": {"country_code": "JP"}
}
```
**`public_key.create` JSON Schema:**
```json
{
"action": "public_key.create",
"actor": "<actor>",
"actor_id": <actor_id>,
"actor_ip": "<actor_ip>",
"user_agent": "<user_agent>",
"external_identity_nameid": "<external_identity_nameid>",
"external_identity_username": "<external_identity_username>",
"title": "<title>",
"key": "<key>",
"fingerprint": "<fingerprint>",
"read_only": "<true>",
"org": "<org>",
"org_id": <org_id>,
"repo": "<repo>",
"repo_id": <repo_id>,
"public_repo": <public_repo>,
"_document_id": "<_document_id>",
"@timestamp": <@timestamp>,
"created_at": <timestamp>,
"operation_type": "<operation_type>",
"business": "<business>",
"business_id": <business_id>,
"actor_location": {"country_code": "JP"}
}
```
2. **Undefined Search Use Case:** The specific use case for log search is often not clear in advance. This uncertainty makes it difficult to create a one-size-fits-all Athena table.
To address these challenges, follow these steps:
1. **Examine the JSON Schema:** Identify the structure of the JSON logs for each event type.
2. **Create an Athena Table:** Define a table in Athena that matches the identified schema.
3. **Query the Data:** Use SQL queries to retrieve and analyze the logs.
By following these steps, you can create a flexible and generic log search solution adaptable to various use cases, ensuring you don't miss critical details or fail to detect suspicious activities.
### The Necessity of Tables and Views
Why do tables and views exist in this setup? The answer lies in the need to examine the JSON schema of the event.
To search logs effectively, you first need to know the JSON schema of the event. Unfortunately, the GitHub documentation does not provide a page that defines the JSON schema for events. However, you can determine the event name from this [GitHub document](https://docs.github.com/en/enterprise-cloud@latest/admin/monitoring-activity-in-your-enterprise/reviewing-audit-logs-for-your-enterprise/about-the-audit-log-for-your-enterprise), and it is included in the JSON schema of any event log stored in S3.
For instance, consider the following example:
```json
{
"action": "repo.destroy",
"actor": "<actor name>",
// ...other fields
}
```
To achieve this, we decided to create both a table and a view:
1. **Create an Athena table with the event log JSON as-is:**
```sql
CREATE EXTERNAL TABLE IF NOT EXISTS `<TABLE NAME>` (
`json_objects` string
)
PARTITIONED BY (
`date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
LOCATION 's3://<YOUR S3 PATH>/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.format' = 'yyyy/MM/dd/HH',
'projection.date.range' = '2023/01/01/01,NOW',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<YOUR_S3_PATH>/${date}/'
);
```
2. **Create an Athena view to extract fields:**
```sql
CREATE VIEW `<VIEW_NAME>` AS
SELECT
date,
json_extract_scalar(json_objects, '$.action') AS action,
json_extract_scalar(json_objects, '$["@timestamp"]') AS "timestamp",
json_objects
FROM `<TABLE NAME>`;
```
This is why both tables and views are necessary. The table stores the raw JSON logs, and the view helps extract and query specific fields from these logs.
### How to Use `ROW FORMAT SERDE`
In this article, we used two types of `ROW FORMAT SERDE`:
1. **LazySimpleSerDe:**
```sql
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
```
2. **JsonSerDe:**
```sql
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
```
### `ROW FORMAT SERDE` specifies how Athena deserializes data in S3.
- **`LazySimpleSerDe`:** Reads the data in S3 one line at a time as a string. This is useful for examining the entire JSON schema.
- **`JsonSerDe`:** Reads the data in S3 as JSON, which allows you to handle individual keys in the JSON. This is more flexible and precise for detailed queries.
Example of a GitHub audit log file:
```json
{"key":"value", ...}
{"key":"value", ...}
```
For the table where we want to examine the entire JSON schema, we use `LazySimpleSerDe`. For the table where we want to handle individual keys in JSON, we use `JsonSerDe`.
Please refer to the official documentation for more details: [JSON SerDe](https://docs.aws.amazon.com/en_us/athena/latest/ug/json-serde.html).
### Lower Costs with Partitions
When you run a query in Athena, it performs a full scan against S3 by default, which can be costly in terms of both time and money. To mitigate this, we use partitions to narrow the search target. Athena partitions can be configured for S3 object paths.
GitHub Enterprise Cloud's audit logs are [output in the format](https://docs.github.com/en/enterprise-cloud@latest/admin/monitoring-activity-in-your-enterprise/reviewing-audit-logs-for-your-enterprise/streaming-the-audit-log-for-your-enterprise) `yyyy/MM/dd/HH/mm/<uuid>.json.gz`, so it makes sense to partition the data by date. This allows us to target specific time frames rather than scanning all logs.
However, Athena's partitioning feature only works on paths that exist at the time of the load. This means that if you load the data at a specific point in time and then specify a date range in the WHERE clause that wasn't loaded at that time, Athena will perform a full scan. To avoid this, it is necessary to load the partition information regularly.
Before you can query partitioned tables, [you must update the AWS Glue Data Catalog with partition information](https://docs.aws.amazon.com/en_us/athena/latest/ug/tables-location-format.html#table-location-and-partitions).
Instead of regular loading, we use a feature called partition projection. [Partition projection](https://docs.aws.amazon.com/en_us/athena/latest/ug/partition-projection.html) is a mechanism by which Athena determines the partition at query execution based on predetermined information (such as the position, type, and range of the S3 path).
For instance, we know that the audit log is output in the format `s3://<S3_BUCKET_NAME>/yyyy/MM/dd/HH/mm/<uuid>.json.gz`, so we can set Athena to recognize the year to hour part as a partition. Here is a part of the DDL (Data Definition Language) statement to set up partition projection:
```sql
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.format' = 'yyyy/MM/dd/HH',
'projection.date.range' = '2023/01/01/01,NOW',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<YOUR_S3_PATH>/${date}/'
# ${date} should be used as is without replacement
)
```
### Insure Your Query Costs
While partition projection can narrow the scope of a query, it only works effectively if you write a query that correctly determines the partitions. For example, specifying the date in the WHERE clause is crucial to avoid a full scan of the data.
To prevent unexpected costs, it's a good idea to set query limits. Amazon Athena can limit the amount of data that is scanned, ensuring your query costs remain manageable. [Learn how to set these limits](https://docs.aws.amazon.com/en_us/athena/latest/ug/workgroups-setting-control-limits-cloudwatch.html).
By following these practices, you can effectively manage your query costs while ensuring efficient and accurate data retrieval.
### Conclusion
GitHub’s audit logs are retained for only six months, and Git events for just seven days. This mismatch can create significant security gaps, leaving your organization vulnerable to undetected malicious activities. Streaming these logs to Amazon S3 for long-term retention is essential, but it’s equally important to be able to query them effectively. Without proper querying capabilities, you risk missing critical information during security incidents, failing to meet compliance requirements, and being unable to perform thorough forensic analysis.
Using Amazon Athena to query GitHub audit logs stored in S3 addresses these challenges by offering immediate access to detailed insights and cost-efficient querying capabilities. By setting up tables and views in Athena, you can transform raw JSON logs into actionable data, helping you monitor changes, investigate incidents, and ensure compliance.
Key benefits include:
1. **Immediate Access:** Quickly find specific events without sifting through raw data.
2. **Detailed Insights:** Get precise information on who performed actions, when they occurred, and from where.
3. **Cost Efficiency:** Use partitioning and partition projection to optimize query costs and avoid unnecessary expenses.
To set up Athena for querying GitHub audit logs, follow these steps:
1. **Create an Athena Table:** Define a table that reads the JSON-formatted logs from S3.
2. **Create an Athena View:** Make querying specific fields easier by creating a view that extracts key data from the JSON logs.
3. **Query Specific Events:** Use SQL queries to retrieve and analyze logs, focusing on relevant details such as repository deletions.
Additionally, managing costs with partitioning and partition projection ensures efficient and affordable queries, while setting query limits helps prevent unexpected expenses.
By implementing this setup, you can eliminate the default security blind spots in GitHub Enterprise, ensuring your logs are always accessible, insightful, and cost-effective. For more tips and insights on security and log analysis, follow me on Twitter [@Siddhant_K_code](https://x.com/Siddhant_K_code) and stay updated with the latest & detailed tech content like this. | siddhantkcode |
1,864,555 | i9bet - Link Dang nhap nha cai i9bet casino ho tro 24/7 | i9bet – Nha Cai Ca Cuoc Uy Tin An Toan Den Tu Chau A. San Choi noi tieng, Kho Ca Cuoc Casino da dang,... | 0 | 2024-05-25T04:22:15 | https://dev.to/i9bet58/i9bet-link-dang-nhap-nha-cai-i9bet-casino-ho-tro-247-304k | i9bet | i9bet – Nha Cai Ca Cuoc Uy Tin An Toan Den Tu Chau A. San Choi noi tieng, Kho Ca Cuoc Casino da dang, gom : Da Ga, Tien len, Song bai, The Thao Ao, Tai Xiu
Email: Di.acoRabner590@gmail.com
Website: https://i9bet58.co
Dien Thoai: (+63) 09621889538
#i9bet
Social:
https://www.facebook.com/i9bet58/
https://twitter.com/i9bet58
https://www.youtube.com/channel/UCX8ArpYH-YGS0u7z5zzfJlQ
https://www.pinterest.com/i9bet58/
https://learn.microsoft.com/vi-vn/users/i9bet58/
https://vimeo.com/i9bet58
https://github.com/i9bet58
https://www.blogger.com/profile/05536828460088296014
https://www.reddit.com/user/i9bet58co/
https://vi.gravatar.com/i9bet58
https://en.gravatar.com/i9bet58
https://medium.com/@i9bet58/about
https://www.tumblr.com/i9bet58
https://diacorabner590.wixsite.com/i9bet58
https://i9bet58.weebly.com/
https://i9bet58.livejournal.com/profile/
https://soundcloud.com/i9bet58
https://www.openstreetmap.org/user/i9bet58
https://i9bet58co.wordpress.com/
https://sites.google.com/view/i9bet58/home
https://linktr.ee/i9bet58
https://www.twitch.tv/i9bet58/about
tinyurl.com/i9bet58
https://ok.ru/khoavantay1/statuses/592970970058
https://profile.hatena.ne.jp/i9bet58/profile
https://issuu.com/i9bet58
https://www.liveinternet.ru/users/i9bet58/post505419723/
https://dribbble.com/i9bet58/about
https://form.jotform.com/241442533607048
www.patreon.com/i9bet58/about
https://archive.org/details/@winvncafe
https://gitlab.com/i9bet58
https://www.kickstarter.com/profile/305823079/about
https://disqus.com/by/i9bet58/about/
https://i9bet58.webflow.io/
https://www.goodreads.com/user/show/178518535-i9bet58
https://500px.com/p/i9bet58?view=photos
https://about.me/i9bet58
https://tawk.to/i9bet58
https://www.deviantart.com/i9bet58
https://ko-fi.com/i9bet58
https://www.provenexpert.com/i9bet58/
https://hub.docker.com/u/i9bet58 | i9bet58 |
1,864,536 | Google's IDX: The Future of Web Dev? AI Assistant Makes Coding | Google's Project IDX (Beta) just dropped, and it's a game-changer for web development! This... | 0 | 2024-05-25T04:20:23 | https://dev.to/dev007777/googles-idx-the-future-of-web-dev-ai-assistant-makes-coding-19fl | webdev, javascript, beginners, react | Google's Project IDX (Beta) just dropped, and it's a game-changer for web development! This cloud-based platform boasts a built-in AI assistant that could revolutionize the way we code.
{% embed https://youtu.be/MmEYjfffVsU %}
Project IDX has support for AI-powered code completion, an assistive chat, and contextual code actions like “add comments'' and “explain this code”. It provide you with better code suggestions, and answers to your coding questions.
The embedded DevTools window also makes it easy to debug your web application right in your preview window, saving you the headache of moving various tabs around.
It Provides Lots of Template related to popular FrontEnd , Backend , AI/ML and other frameworks
Are you using Project IDX ? What's your thought on it
| dev007777 |
1,864,533 | Exploring Next.js 15: A Developer's Delight | Next.js 15 has arrived with a plethora of exciting features and updates, designed to make our... | 0 | 2024-05-25T04:08:49 | https://dev.to/qa3emnik/exploring-nextjs-15-a-developers-delight-2eb | webdev, nextjs, javascript, programming | `Next.js 15` has arrived with a plethora of exciting features and updates, designed to make our development process smoother and more efficient. Let's dive into what this new version brings to the table.
### Embracing React 19 RC
Next.js 15 now supports React 19 RC, which means you get the latest and greatest from React. This integration brings performance enhancements and new features that will make your applications run faster and more efficiently.
### Experimental React Compiler
One of the most intriguing additions is the experimental React Compiler. This new tool optimizes your React code in ways we haven't seen before. Although it's still in the experimental phase, it promises significant improvements in performance.
### Better Hydration Error Handling
If you've ever faced issues with hydration errors, you'll appreciate the new and improved error views in Next.js 15. These enhancements make it much easier to identify and fix hydration problems, which can be a real lifesaver during development.
### New Caching Defaults
Next.js 15 introduces changes to caching defaults. Now, `fetch` requests, `GET` Route Handlers, and client navigations are uncached by default. This change offers more predictable behavior and can help avoid some of the common pitfalls associated with caching.
#### Example: Default Uncached Fetch
```javascript
fetch('/api/data')
.then(response => response.json())
.then(data => console.log(data));
```
In this example, the fetch request is uncached by default, ensuring that you always get fresh data from the server.
### Partial Prerendering (PPR)
Partial Prerendering (PPR) is another exciting feature introduced in this release. It allows you to incrementally adopt prerendering in your application. This means you can prerender parts of your application while still using client-side rendering for others, giving you the best of both worlds.
#### Example: Partial Prerendering
```javascript
export function getStaticProps() {
return {
props: {
data: fetchData(),
},
};
}
```
Here, `getStaticProps` is used to fetch data at build time, allowing for partial prerendering.
### `next/after` API
The new `next/after` API is a game-changer. It lets you execute code after a response is finished, providing more control over your request handling.
### Revamped `create-next-app`
The `create-next-app` tool has also received a facelift. The new design is sleek and user-friendly, with options for Turbopack and minimal setups. This makes starting a new project easier and more efficient than ever before.
### Conclusion
Next.js 15 is packed with features that enhance performance, improve error handling, and provide more control over caching and prerendering. Whether you're a seasoned developer or just getting started, these updates are sure to make your development experience more enjoyable and productive.
For more detailed information, be sure to check out the [Next.js 15 RC blog](https://nextjs.org/blog/next-15-rc). Happy coding! | qa3emnik |
1,826,028 | CSS for Beginners: Building Responsive Web Layouts with Ease | Creating responsive and visually appealing web layouts is an essential skill for any frontend... | 0 | 2024-05-25T03:51:09 | https://dev.to/girishsawant999/css-for-beginners-building-responsive-web-layouts-with-ease-2he8 | webdev, beginners, css, javascript | Creating responsive and visually appealing web layouts is an essential skill for any frontend developer. In today's multi-device world, ensuring that your website looks great and functions well on all screen sizes is critical. This guide will take you through the basics of using CSS to construct responsive layouts, making your web pages look professional and user-friendly.
We'll start by understanding the fundamentals of CSS grid systems, which allow you to define the structure of a screen or container using columns and rows. Next, we'll dive into spacing and padding, crucial for achieving well-organized and aesthetically pleasing layouts. Finally, we'll explore positioning content within your layout using techniques like Flexbox and absolute positioning. By the end of this guide, you'll have a solid foundation for creating responsive designs with CSS.
## 1. Grid System
A CSS grid system defines the structure of a screen or container using a grid of columns and rows. Content on a web page is arranged within these grid cells, allowing for organized and responsive layouts.
As a frontend developer, it's essential to understand how content is distributed within the cells of a grid system. Let's illustrate this with an example:
Imagine a webpage with two sections. We'll highlight the parent container with a red border box and the content cells with green boxes. For section 1, we can envision a **1x8 cell grid**, while for section 2, a **1x4 cell grid** is suitable.
Now, let's discuss how to achieve this using CSS. Suppose our screen/container has a width of **800 units**. To accommodate **8 cells** within **800 units**, we divide the width by the number of cells, resulting in **100 units per cell**. The unit can be any CSS unit like pixels (px), rems (rem), ems (em), or percentages (%). For example, if the container width is 80%, each cell would take 10% of the width.
For section 2, let's consider a parent box width of **1200 units**. Dividing this by **4 cells**, each cell would be **300 units** wide.
To implement this in code, we define the widths for the parent boxes and content cells using CSS classes or inline styling. Here's an example:
```css
.section-1-parent-box {
width: 800px;
}
.section-1-cell {
width: 100px;
}
.section-2-parent-box {
width: 1200px;
}
.section-2-cell {
width: 300px;
}
```
Alternatively, you can utilize CSS frameworks like Bootstrap or Tailwind CSS, which provide predefined grid classes. In Bootstrap, you can use classes such as `container`, `row`, and `col` to create grid-based layouts ([Bootstrap Grid System](https://getbootstrap.com/docs/4.0/layout/grid/)). In Tailwind CSS, you can use utilities like `grid` and specify the number of columns and rows using `grid-cols-{number}` and `grid-rows-{number}` classes ([Tailwind CSS Grid](https://tailwindcss.com/docs/grid-template-columns)).
In summary, creating a layout involves identifying the grid structure of content within the parent container and applying appropriate CSS styles to achieve the desired design. By understanding these concepts, frontend developers can create responsive and visually appealing web layouts efficiently.
<br/>
## 2. Spacing and Padding in CSS
When designing web components, managing spacing and padding is crucial for achieving visually appealing and well-organized layouts. CSS provides several properties to control spacing and padding around and within components.
### Gap Property
The `gap` property is used to create space between grid or flexbox items within a container. It's particularly useful for maintaining consistent spacing between components without resorting to margin or padding hacks.
```css
.parent-container {
display: grid;
grid-template-columns: repeat(3, 1fr);
gap: 20px;
/* Creates a 20px gap between grid items */
}
```
### Margin Property
The `margin` property is used to create space around an element's outside edges. It's commonly used to create spacing between components or between a component and its container.
```css
.component {
margin: 10px;
/* Creates a 10px margin around the component */
}
```
### Padding Property
The `padding` property is used to create space within an element, between its content and its border. It's useful for controlling the internal spacing of a component.
```css
.component {
padding: 20px;
/* Creates a 20px padding within the component */
}
```
### Combining Spacing and Padding
You can combine `margin`, `padding`, and `gap` properties to achieve the desired spacing both between and within components, as well as between components and their containers.
```css
.component {
margin: 10px;
/* Creates a 10px margin around the component */
padding: 20px;
/* Creates a 20px padding within the component */
}
.parent-container {
display: flex;
gap: 20px;
/* Creates a 20px gap between flex items */
}
```
By effectively utilizing these CSS properties, you can achieve consistent and aesthetically pleasing spacing and padding within your web components, resulting in a more polished and professional-looking layout.
<br/>
## 3. Positioning the Content
Once we've implemented the layout, the next step is to arrange the content within its parent elements. To achieve this, we can use CSS properties such as Flexbox or positioning techniques like `position: absolute` with appropriate `inset` values (`top`, `bottom`, `left`, `right`).
#### Using Flexbox for Positioning
Flexbox provides a powerful way to align and distribute space among items in a container, even when their size is unknown or dynamic.
- **`align-items`**: This property aligns items along the cross axis (vertically if the flex direction is row, horizontally if the flex direction is column).
- Values: `flex-start`, `flex-end`, `center`, `baseline`, `stretch`.
```css
.container {
display: flex;
align-items: center;
/* Aligns items vertically in the center */
}
```
- **`justify-content`**: This property aligns items along the main axis (horizontally if the flex direction is row, vertically if the flex direction is column).
- Values: `flex-start`, `flex-end`, `center`, `space-between`, `space-around`, `space-evenly`.
```css
.container {
display: flex;
justify-content: space-between;
/* Distributes items evenly with space between them */
}
```
- **`align-content`**: This property aligns lines of flex items when there is extra space in the cross-axis, similar to `justify-content` but for multiple lines.
- Values: `flex-start`, `flex-end`, `center`, `space-between`, `space-around`, `stretch`.
```css
.container {
display: flex;
flex-wrap: wrap;
/* Allows items to wrap onto multiple lines */
align-content: center;
/* Aligns wrapped lines to the center */
}
```
#### Using Absolute Positioning
Sometimes, you may need to position elements precisely within a container. In these cases, `position: absolute` can be very useful. When you set an element to `position: absolute`, you can use the `top`, `bottom`, `left`, and `right` properties to position it within its nearest positioned ancestor (an element with a position other than `static`).
- **`position: absolute`**: Positions the element relative to its nearest positioned ancestor.
```css
.parent {
position: relative;
/* The parent element needs a non-static position */
}
.child {
position: absolute;
top: 10px;
/* 10px from the top of the parent */
left: 20px;
/* 20px from the left of the parent */
}
```
Using these CSS properties, you can effectively position and align content within your layout, ensuring a responsive and visually appealing design. | girishsawant999 |
1,864,531 | Yalla Shoot | يلا شوت | يلا شوت الجديد الرسمي - yalla shoot new مشاهدة اهم مباريات اليوم ومباريات الغد بث مباشر بجودات مختلفة... | 0 | 2024-05-25T03:50:34 | https://dev.to/yallashootonl/yalla-shoot-yl-shwt-24g9 | يلا شوت الجديد الرسمي - yalla shoot new مشاهدة اهم مباريات اليوم ومباريات الغد بث مباشر بجودات مختلفة عبر يلا شوت بدون تقطيع اون لاين لايف
[يلا شوت](https://www.yalla-shoot.onl) | yallashootonl | |
1,864,529 | Elevate Your Intimate Moments with My Diamond Lover’s Target Sex Toys | Enhance pleasure and explore new realms of intimacy with My Diamond Lover's Target Sex Toys. When it... | 0 | 2024-05-25T03:45:59 | https://dev.to/jay_14b439e1a566b58862615/elevate-your-intimate-moments-with-my-diamond-lovers-target-sex-toys-1pj9 | discuss, news |
Enhance pleasure and explore new realms of intimacy with My Diamond Lover's Target Sex Toys. When it comes to elevating intimate moments and expanding intimate experiences, [My Diamond Lover](https://mydiamondlover.com/) stands as a trusted name in sex toy technology.
Their products focus on innovation, quality, and satisfaction to meet users' varying needs and preferences. In this blog post, we'll look at how these products can transform intimate experiences while highlighting some standout pieces by My Diamond Lover!
## Why choose My Diamond Lover?
My Diamond Lover specializes in producing body-safe [sex toys](https://mydiamondlover.com/) of the highest quality that provide both pleasure and peace of mind for its users.
Their products combine advanced technology with ergonomic designs to deliver an enjoyable yet safe experience, especially its target sex toys that provide pinpoint stimulation and intense pleasure, making My Diamond Lover a must-have for anyone seeking to enhance intimate moments.
## Spotlight on Target Sex Toys

Target G-Spot Vibrator Wentworth Park
Description: The Target G-Spot Vibrator was expertly created to locate and stimulate your G-spot precisely.
Its curved shape and powerful vibrations offer intense pleasure where you need it most. Key Features include multiple vibration settings (USB rechargeable) for precise pleasure delivery and waterproof construction made from medical-grade silicone.
Ideal For: Solo Play and Couples Exploring G-spot Stimulation.
Target Bullet Vibrator mes Description: Small yet mighty, the Target Bullet Vibrator is perfect for targeted stimulation with its compact size, making it easy and travel-friendly.
Featuring: Single Button Control; Quiet Operation, USB Rechargability, and Body Safe Material Construction
Ideal For: Offering discreet pleasure and targeted stimulation while on the move, Target Prostate Massager embodies discreet pleasure with powerful vibrations for targeted prostate stimulation, ergonomic design and multiple vibration modes to provide maximum comfort and joy for targeted prostate stimulation.
Features Include: The Wilson Prostate Massager has powerful vibrations and ergonomic features for maximum comfort and pleasure. When coupled with powerful vibration modes for targeted stimulation of prostate tissue.
This device features powerful vibrations for maximum pleasure as well as multiple vibration modes for precision prostate stimulation with powerful vibration modes for targeted stimulation that is intended for maximum stimulation of targeted prostate stimulation while remaining hypoallergenic material to minimize irritant exposure and antibacterial material, making this an excellent gift item to give away when travelling or simply travelling abroad.
Ideal For: Men seeking increased prostate pleasure and health benefits.
## Enhance Your Experience
Quality Materials: My Diamond Lover's target sex toys are made of body-safe materials such as medical-grade silicone and hypoallergenic plastics to ensure safety and comfort during use.
User-Friendly Designs: Each product boasts intuitive controls and ergonomic, user-friendly designs, making them suitable for targeting specific pleasure zones.
Rechargeable and Waterproof: Many target sex toys are rechargeable and waterproof for convenience and use in various environments such as shower or bath environments.
## Customers' Testimonials
"The Target G-Spot Vibrator is incredible! The shape is perfectly tailored for hitting just the right spot. At the same time, its vibrations are potent!"—Emily S. Sarah J. loves its discreet size yet powerful performance, making it her go-to device when travelling.
"My experience with Target Prostate Massager has been revolutionary. It is comfortable and provides intense pleasure!" - Alex M.
## Conclusion
Exploring new levels of pleasure and intimacy has never been simpler with My Diamond Lover's selection of target sex toys.
From precision Vibrators like G-Spot Vibrator or Bullet Vibrator to powerful stimulation via Target Prostate Massager, all our target toys are designed to bring out more pleasure from every experience while fulfilling desires more fully.
Enhance your intimate moments with My Diamond Lover and find the ideal target sex toy to suit your needs.
## FAQ
#### What makes My Diamond Lover's target sex toys unique?
Our target sex toys are specially crafted for precise stimulation using premium body-safe materials and cutting-edge technology, creating maximum pleasure while protecting our health and safety.
#### Are My Diamond Lover's target sex toys waterproof?
Yes, many of My Diamond Lover's target sex toys are watertight to allow for use in different environments.
#### How can I clean My Diamond Lover's target sex toys?
To properly care for the My Diamond Lover target sex toys, clean them using warm water with mild soap or use a dedicated toy cleaner - be sure to let everything air-dry before storage! | jay_14b439e1a566b58862615 |
1,864,527 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash app... | 0 | 2024-05-25T03:39:00 | https://dev.to/whitemartin015/buy-verified-cash-app-account-mfn | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\nhttps://dmhelpshop.com/product/buy-verified-cash-app-account/\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\n\nhttps://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nhttps://dmhelpshop.com/product/buy-verified-cash-app-account/\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nhttps://dmhelpshop.com/product/buy-verified-cash-app-account/\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\nhttps://dmhelpshop.com/product/buy-verified-cash-app-account/\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nhttps://dmhelpshop.com/product/buy-verified-cash-app-account/\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nhttps://dmhelpshop.com/product/buy-verified-cash-app-account/\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | whitemartin015 | |
1,864,526 | How to use React-Slick Slider Library | Are you ready to level up your web development game with the React-Slick Slider? Look no further... | 27,760 | 2024-05-25T03:31:09 | https://dev.to/nnnirajn/mastering-the-react-slick-slider-a-step-by-step-tutorial-16g5 | react, javascript, ui, beginners | Are you ready to level up your web development game with the `React-Slick` Slider? Look no further because we've got you covered with a step-by-step tutorial that will have you mastering this powerful tool in no time. Say goodbye to boring and static websites – it's time to add some slickness to your projects!
### Introduction to React-Slick Slider
`React-Slick` is a lightweight library with a simple API that makes it easy to use and integrate into your project. It also comes with many pre-built features such as touch swipe support, lazy loading of images and videos, infinite looping, auto-play options, and more.
In this tutorial, we will guide you through the basics of using `React-Slick` to create stunning sliders for your web projects. We will cover everything from installation to customization so that even beginners can follow along.
### Installing and Setting up `React-Slick` in Your Project
`React-Slick` is a popular and highly customizable carousel/slider library for React applications. In this section, we will guide you through the process of installing and setting up `React-Slick` in your project.
#### Step 1: Install React-Slick
To use `React-Slick`, you first need to install the necessary dependencies. Open your project directory in the terminal and run the following command:
```jsx
npm install react-slick slick-carousel --save
```
This command will install both `React-Slick` and its styling library Slick-Carousel as dependencies in your project.
#### Step 2: Import Dependencies
After successfully installing `React-Slick`, you need to import it into your project. In your main JavaScript file, add the following lines of code:
```jsx
import Slider from 'react-slick';
import 'slick-carousel/slick/slick.css';
import 'slick-carousel/slick/slick-theme.css';
```
Here, we are importing the Slider component from the `react-slick` package and the required stylesheets from Slick-Carousel.
#### Step 3: Create a Slider Component
Next, let's create a slider component that will contain all our slides. In this example, we will use dummy images as slides, but you can customize them according to your needs.
```jsx
export default function SimpleSlider() {
var settings = {
dots: true,
infinite: true,
speed: 500,
slidesToShow: 1,
slidesToScroll: 1
};
return (
<Slider {...settings}>
<div>
<h3>1</h3>
</div>
<div>
<h3>2</h3>
</div>
<div>
<h3>3</h3>
</div>
<div>
<h3>4</h3>
</div>
<div>
<h3>5</h3>
</div>
<div>
<h3>6</h3>
</div>
</Slider>
);
}
```
We have defined some default `settings` for our slider using an object and passed it as props to the Slider component. The settings we have used here are just for demonstration purposes; you can customize them according to your requirements.
#### Step 4: Testing it Out
Save the changes and run your project. You should now see a basic slider with three slides, each containing an image. You can navigate through the slides using the arrow buttons or the dots at the bottom of the slider.
Congratulations! You have successfully installed and set up `React-Slick` in your project. Now let's explore some advanced features that this library offers.
Installing and setting up `React-Slick` is a simple process that requires only a few steps. With its easy installation process and customizable settings, `React-Slick` is an excellent choice for implementing carousels or sliders in your next React project.
### Adding Custom Styling to the Slider Components
In order to truly make your slider stand out and match the design of your website, it is important to add custom styling to the slider components. Fortunately, React-Slick offers a variety of options for customization.
The first step in adding custom styling is understanding the different elements that make up a slider component. These include slides, arrows, dots, and track. Slides are essentially the content within each slide, while arrows are used for navigation between slides. Dots are small indicators at the bottom of the slider that show which slide is currently being viewed. The track refers to the entire length of all slides combined.
To style these elements individually, we can use CSS selectors specific to each one. For example, if we want to change the color of our arrows, we can use:
```css
.slick-prev {
color: red;
}
```
Similarly, if we want to adjust the size or position of our dots indicator, we can target it with:
```css
.slick-dots {
font-size: 20px;
bottom: 10px;
}
```
For more advanced customization such as changing animation speed or adding a background image to certain slides only, `React-Slick` provides props that can be passed down from parent components. These props allow us to have greater control over how our slider looks and behaves.
For example, by setting a value for `speed` prop (in milliseconds), we can adjust how fast each slide transitions into view. Additionally, by passing a function as a value for `beforeChange` prop, we can trigger actions before each slide change occurs.
If you prefer using pre-made styles rather than writing your own CSS from scratch, `React-Slick` also offers themes that can be applied directly on your slider component. This saves time and effort while still allowing for unique customization through theme settings.
One thing worth noting when applying custom styling through CSS classes or using themes is the use of `!important` declaration. This is necessary as `React-Slick` sets its own inline styles for certain elements, which may override our custom styles if not specified as important.
By understanding the different slider components and utilizing CSS classes, props, and themes, we can easily add custom styling to our `React-Slick` slider and achieve a sleek and professional design that seamlessly integrates with our website.
### Implementing Navigation Arrows and Dots
Implementing Navigation Arrows and Dots in a React-Slick Slider can greatly enhance the user experience by providing easy navigation options. In this section, we will walk through the step-by-step process of adding navigation arrows and dots to your slider using the react-slick library.
**Step 1: Import Necessary Components**
Next, import the necessary components from the react-slick library into your main component file. These include `Slider`, `PrevArrow`, `NextArrow`, and `Dots`.
```jsx
import Slider from 'react-slick';
import { PrevArrow, NextArrow } from 'react-slick/lib/slide';
import Dots from 'react-slick/lib/dots';
```
**Step 2: Customize Navigation Components**
The slider component accepts two props for customizing the navigation arrows - `prevArrow` and `nextArrow`. You can either use default arrow icons provided by the library or create your own custom arrows using CSS.
For example:
```jsx
import React, { Component } from "react";
import Slider from "react-slick";
function SampleNextArrow(props) {
const { className, style, onClick } = props;
return (
<div
className={className}
style={{ ...style, display: "block", background: "red" }}
onClick={onClick}
/>
);
}
function SamplePrevArrow(props) {
const { className, style, onClick } = props;
return (
<div
className={className}
style={{ ...style, display: "block", background: "green" }}
onClick={onClick}
/>
);
}
function CustomArrows() {
const settings = {
dots: true,
infinite: true,
slidesToShow: 3,
slidesToScroll: 1,
nextArrow: <SampleNextArrow />,
prevArrow: <SamplePrevArrow />
};
return (
<div className="slider-container">
<Slider {...settings}>
<div>
<h3>1</h3>
</div>
<div>
<h3>2</h3>
</div>
<div>
<h3>3</h3>
</div>
<div>
<h3>4</h3>
</div>
<div>
<h3>5</h3>
</div>
<div>
<h3>6</h3>
</div>
</Slider>
</div>
);
}
export default CustomArrows;
```
### Advanced Configuration Options for Customization
In order to truly master the React-Slick slider, it's important to understand the advanced configuration options available for customization. These options allow you to fine-tune your slider and create a unique and dynamic experience for your users.
**1. Customizing Slide Transition**
The React-Slick library offers a range of transition effects that can be applied to your slides as they move in and out of view. By default, the slide animation is set to 'slide', but this can be changed using the 'transition' prop. Other options include 'fade', 'zoom', and even custom animations using CSS3 transitions.
**2. Infinite Looping**
With infinite looping enabled, your slides will continue to cycle endlessly without ever reaching an endpoint. This can be achieved by setting the 'infinite' prop to true in your slider configuration. This feature is particularly useful for content-heavy sliders that need to continuously display new information or images.
**3. Autoplay**
Another way to keep your slider moving smoothly is by implementing autoplay functionality. Using the 'autoplay' prop, you can define a time interval for each slide before it moves on to the next one automatically. You can also use this feature in combination with infinite looping for a seamless, continuous slideshow experience.
**4. Lazy Loading**
For sliders with large amounts of content or high-quality images, lazy loading can significantly improve performance and reduce load times. With this option enabled, only the visible slides are loaded initially, while other slides are loaded as needed when users interact with the slider.
**5. Responsive Settings**
React-Slick offers several responsive settings that allow you to customize how your slider behaves on different screen sizes or devices. The most common approach is using breakpoints based on screen width, where specific settings are applied at certain intervals using arrays passed under the 'responsive' prop.
**6. Ready-made Templates**
For those looking for ready-made design templates, React-Slick provides customizable presets such as 'centerMode', 'vertical mode, and others that alter how slides are displayed on the screen. These options provide a great starting point for creating unique slider styles without having to start from scratch.
{% cta https://www.linkedin.com/in/niraj-narkhede-ui-developer/ %} 🚀 Lets collaborate {% endcta %}
**7. Transition Effects**
Transition effects are used to smoothly animate between each slide in the slider. React-Slick offers a variety of transition effects such as fade, slide, zoom, rotate, and more. To add a transition effect to your slider, you simply need to pass in the desired effect as a prop in the component.
**8. Custom Animation:**
If you want even more control over your slider's animation, you can create custom animations using CSS or JS libraries like Animate.css or GSAP (GreenSock Animation Platform). These libraries offer pre-made animation templates that can easily be applied to your slides by adding them as classNames.
**9. Parallax Effect:**
Parallax scrolling creates an illusion of depth by moving the background image at a slower pace than the foreground elements as the user scrolls through the webpage. This effect can make your slides look more dynamic and engaging for users. You can achieve this effect in React-Slick by using plugins like Slick-Parallax or react-parallax-slider.
**10. Hover Effects:**
Adding hover effects on images or buttons within your slider can also enhance its overall appearance and make it more interactive for users. Using CSS transitions or JavaScript events like onMouseEnter/onMouseLeave, you can create hover effects that change color, size, or position of elements when hovered over.
**11. Slide Indicators/Pagination:**
Slide indicators/pagination help users keep track of where they are within the slider and how many slides there are in total. This feature adds a professional touch to your slider and makes it easier for users to navigate through the slides. React-Slick provides a built-in component that can be styled and customized according to your preference.
{% embed https://dev.to/nnnirajn/free-resources-for-ui-dvelopers-free-html-template-33ae %}
{% embed https://dev.to/nnnirajn/list-of-75-css-resources-for-ui-developers-3k9b %}
**Conclusion:**
By understanding and utilizing these advanced configuration options, you can truly take your React-Slick slider to the next level. Don't be afraid to experiment and try different combinations to find the perfect settings for your project. With these tools at your disposal, you'll be well on your way to mastering the React-Slick slider and creating stunning, dynamic sliders that will enhance any website or application. | nnnirajn |
1,864,525 | find fpga engineer friends | we can discuss fpga design and verify method, The future development and trends of FPGA | 0 | 2024-05-25T03:30:22 | https://dev.to/jiangcaicai/find-fpga-engineer-friends-4a98 | we can discuss fpga design and verify method, The future development and trends of FPGA | jiangcaicai | |
1,864,053 | Mastering AsyncStorage in React Native | When you're building mobile apps with React Native, you'll often need to store data on the user's... | 0 | 2024-05-25T03:30:00 | https://harshvador.hashnode.dev/mastering-asyncstorage-in-react-native | reactnative, javascript, development | When you're building mobile apps with React Native, you'll often need to store data on the user's device. This is where AsyncStorage is useful. It's a built-in feature that lets you store and retrieve data like a key-value pair (like a dictionary with a key and a value).
In this post, I'll share some tips and tricks to help you use AsyncStorage well in your React Native apps.
## Use Async/Await for Cleaner Code
AsyncStorage works with promises, which can make your code look a bit messy with nested callbacks or promise chains. Instead, you can use async/await to write cleaner and more readable code:
```js
async function getData() {
try {
const value = await AsyncStorage.getItem('@key');
console.log(value);
} catch (error) {
console.error(error);
}
}
```
## Use Multi-Get to Retrieve Multiple Keys
Instead of making multiple calls to AsyncStorage.getItem(), you can use the AsyncStorage.multiGet() method to retrieve multiple key-value pairs in a single operation:
```js
async function getMultipleData() {
try {
const keys = ['@key1', '@key2', '@key3'];
const values = await AsyncStorage.multiGet(keys);
console.log(values);
} catch (error) {
console.error(error);
}
}
```
## Use Key Prefixes for Better Organization
To avoid naming conflicts and keep your storage organized, consider using prefixes for your keys. This is especially helpful when you have multiple modules or components storing data:
```js
const USER_PREFIX = '@user/';
const setUserData = async (userData) => {
try {
await AsyncStorage.setItem(`${USER_PREFIX}name`, userData.name);
await AsyncStorage.setItem(`${USER_PREFIX}email`, userData.email);
} catch (error) {
console.error(error);
}
};
```
## Handle Data Serialization and Deserialization
AsyncStorage can only store string data. If you need to store objects or other data types, you'll need to serialize and deserialize the data manually. You can use JSON.stringify() and JSON.parse() for this purpose:
```js
const storeObject = async (key, value) => {
try {
const jsonValue = JSON.stringify(value);
await AsyncStorage.setItem(key, jsonValue);
} catch (error) {
console.error(error);
}
};
const getObject = async (key) => {
try {
const jsonValue = await AsyncStorage.getItem(key);
return jsonValue != null ? JSON.parse(jsonValue) : null;
} catch (error) {
console.error(error);
}
};
```
## Clear AsyncStorage When Needed
Sometimes, you may need to clear the entire AsyncStorage, such as when logging out a user or resetting the app's state. You can use the AsyncStorage.clear() method for this purpose:
```js
const clearStorage = async () => {
try {
await AsyncStorage.clear();
console.log('AsyncStorage cleared successfully');
} catch (error) {
console.error(error);
}
};
```
By following these tips and tricks, you can effectively manage data storage in your React Native apps using AsyncStorage. Remember, while AsyncStorage is a convenient solution for small amounts of data, it's not suitable for large or complex data structures. For more advanced storage needs, consider using a third-party solution or a dedicated database solution.
## Conclusion
AsyncStorage is a handy tool for storing small amounts of data in your React Native apps. By using the tips and tricks we covered, like async/await, multiGet, key prefixes, object serialization and clearing storage, you can make the most of AsyncStorage and write better code.
However, remember that AsyncStorage is not suitable for large or complex data. For bigger storage needs, consider using other solutions like SQLite or cloud services.
Also, keep in mind that AsyncStorage data can be lost if the user uninstalls the app or clears the app's data. So, make sure to handle errors and backup data properly.
Connect with me
- [LinkedIn](https://www.linkedin.com/in/harsh-vador/)
- [Twitter](https://x.com/Harshvador17)
- [GitHub](https://github.com/harsh-vador)
- [Hashnode](https://hashnode.com/@harshvador)
| harshvador |
1,864,523 | How to Add Rate Limiting to Your Next.js App Router | How to Add Rate Limiting to Your Next.js App Router Rate limiting is an essential... | 0 | 2024-05-25T03:28:55 | https://dev.to/sh20raj/how-to-add-rate-limiting-to-your-nextjs-app-router-22fa | javascript, nextjs, ratelimiterflexible, abotwrotethis | # How to Add Rate Limiting to Your Next.js App Router
Rate limiting is an essential technique to protect your application from abuse by controlling the number of requests a user can make in a given time frame. In this tutorial, we'll walk you through adding rate limiting to your Next.js application using the App Router and middleware. We'll cover both TypeScript and JavaScript implementations.
## Why Rate Limiting?
Rate limiting helps to:
- Prevent denial-of-service (DoS) attacks
- Control API usage and prevent abuse
- Ensure fair usage among all users
- Protect server resources
## Setting Up Middleware for Rate Limiting
We'll use the `rate-limiter-flexible` package for implementing rate limiting. It supports various backends, including in-memory, Redis, and more.
### Step 1: Install the Required Package
First, install the `rate-limiter-flexible` package:
```bash
npm install rate-limiter-flexible
```
### Step 2: Create Middleware
Next, create a middleware file in your project root. We'll provide both TypeScript and JavaScript examples.
#### TypeScript Implementation
Create a `middleware.ts` file:
```typescript
// middleware.ts
import { NextResponse } from 'next/server';
import type { NextRequest } from 'next/server';
import { RateLimiterMemory } from 'rate-limiter-flexible';
// Initialize the rate limiter
const rateLimiter = new RateLimiterMemory({
points: 10, // Number of points
duration: 1, // Per second
});
export async function middleware(request: NextRequest) {
try {
// Consume a point for each request
await rateLimiter.consume(request.ip);
// If successful, proceed with the request
return NextResponse.next();
} catch (rateLimiterRes) {
// If rate limit is exceeded, send a 429 response
return new NextResponse('Too many requests', { status: 429 });
}
}
// Specify the paths that will use this middleware
export const config = {
matcher: '/api/:path*',
};
```
#### JavaScript Implementation
Create a `middleware.js` file:
```javascript
// middleware.js
const { NextResponse } = require('next/server');
const { RateLimiterMemory } = require('rate-limiter-flexible');
// Initialize the rate limiter
const rateLimiter = new RateLimiterMemory({
points: 10, // Number of points
duration: 1, // Per second
});
async function middleware(request) {
try {
// Consume a point for each request
await rateLimiter.consume(request.ip);
// If successful, proceed with the request
return NextResponse.next();
} catch (rateLimiterRes) {
// If rate limit is exceeded, send a 429 response
return new NextResponse('Too many requests', { status: 429 });
}
}
// Specify the paths that will use this middleware
const config = {
matcher: '/api/:path*',
};
module.exports = { middleware, config };
```
### Step 3: Testing Your Middleware
Start your Next.js development server and make multiple requests to any API route under `/api/` to verify that the rate limiting is enforced. After the allowed number of requests, additional requests should receive a `429 Too Many Requests` response.
## Conclusion
By following these steps, you can effectively implement rate limiting in your Next.js application using the App Router and middleware. This will help you control the rate of requests to your API routes and protect your server from being overwhelmed by too many requests. For more scalable solutions, consider using a distributed store like Redis with `RateLimiterRedis`.
Happy coding!
| sh20raj |
1,864,521 | Digital Asset Trading Platform CoinHome Launches Perpetual Contract and Flash Contract Trading Services | According to the official announcement, CoinHome officially launched perpetual contract and flash... | 0 | 2024-05-25T03:24:52 | https://dev.to/_a4a04e1b3f5fa88f38464/digital-asset-trading-platform-coinhome-launches-perpetual-contract-and-flash-contract-trading-services-255g | According to the official announcement, CoinHome officially launched perpetual contract and flash contract trading services on December 24, 2023, at 18:00 (UTC+8). The perpetual contracts offer leverage of up to 200x. Users can experience trading on both the web and app platforms. CoinHome will gradually introduce more high-quality trading pairs for users to choose from. For more details, please visit the official website (https://www.coinhome.pro/).
CoinHome, registered in the Virgin Islands in 2022, is a one-stop digital asset trading platform focused on providing safe, stable, and convenient trading services for global digital asset investors. CoinHome follows a path of globalization and compliance, having obtained the MSB financial license issued by FinCEN in the United States. In the future, CoinHome will actively embrace local compliance, follow local policies, and ensure the platform operates within a regulatory framework. | _a4a04e1b3f5fa88f38464 | |
1,864,519 | Private Data / Public Data Backup - Azure Files and Azure Blobs | Create a storage account and configure high availability. Create a storage... | 0 | 2024-05-25T03:21:39 | https://dev.to/olawaleoloye/private-data-public-data-backup-azure-files-and-azure-blobs-7pj | azure, data, blobs | ## Create a storage account and configure high availability.
### Create a storage account for the internal private company documents.
_In the portal_, _search_ for and _select_ **Storage accounts**.
_Select_ + **Create**.
_Select_ the **Resource group** _created_ in the previous lab.
_Set_ the **Storage account** name to private. Add an identifier to the name to ensure the name is unique.
_Select_ **Review**, and then **Create** the storage account.
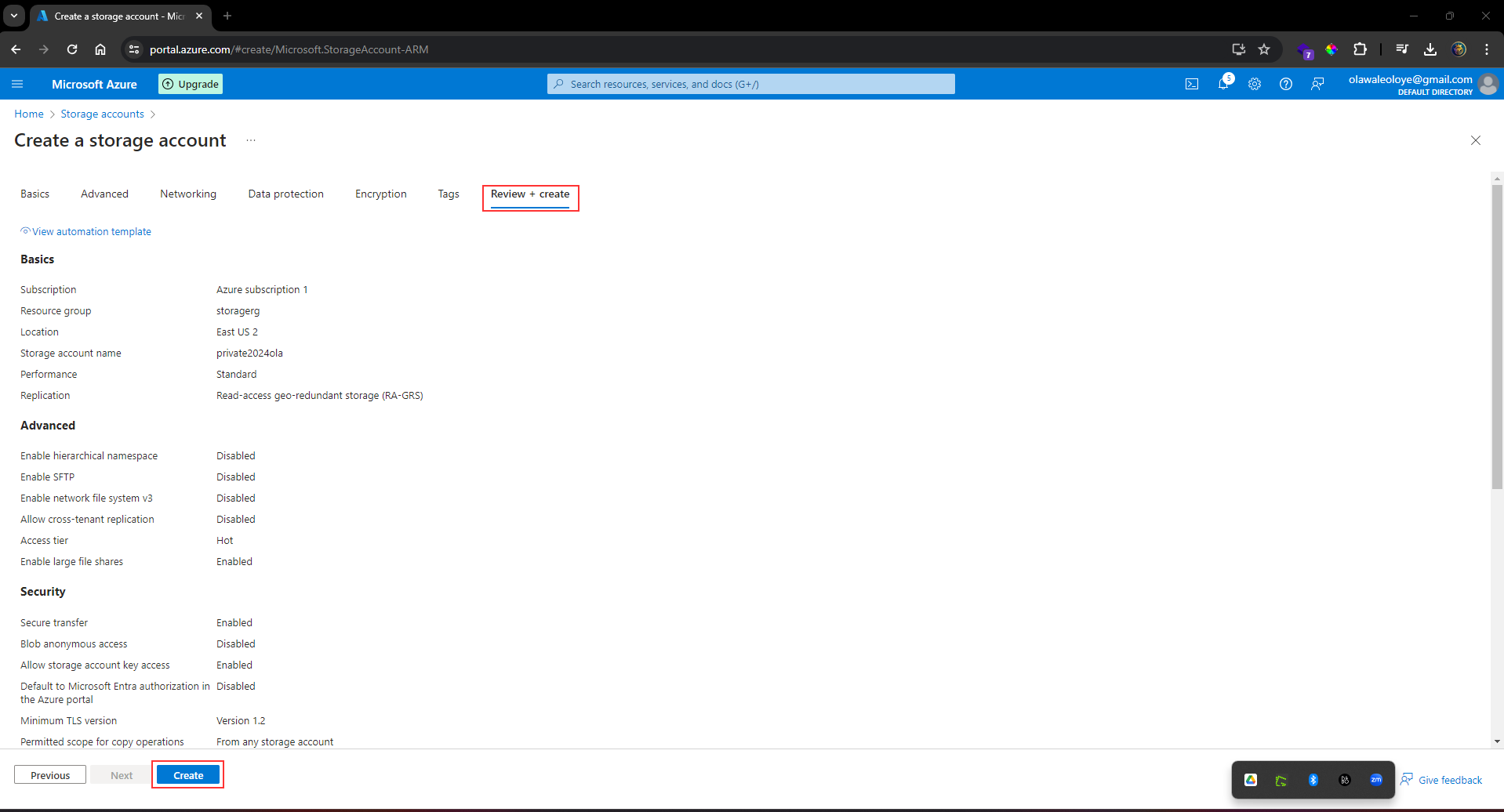
Wait for the **storage account** to _deploy_, and then _select_ Go to **resource**.
_This storage requires high availability if there’s a regional outage._ Read access in the secondary region is not required. Configure the appropriate level of redundancy.
In the _storage account_, in the **Data management** section, _select_ the **Redundancy blade**.
_Ensure_ **Geo-redundant storage (GRS)** is selected.
_Refresh_ the page.
_Review_ the primary and secondary location information.
_Save_ your changes.
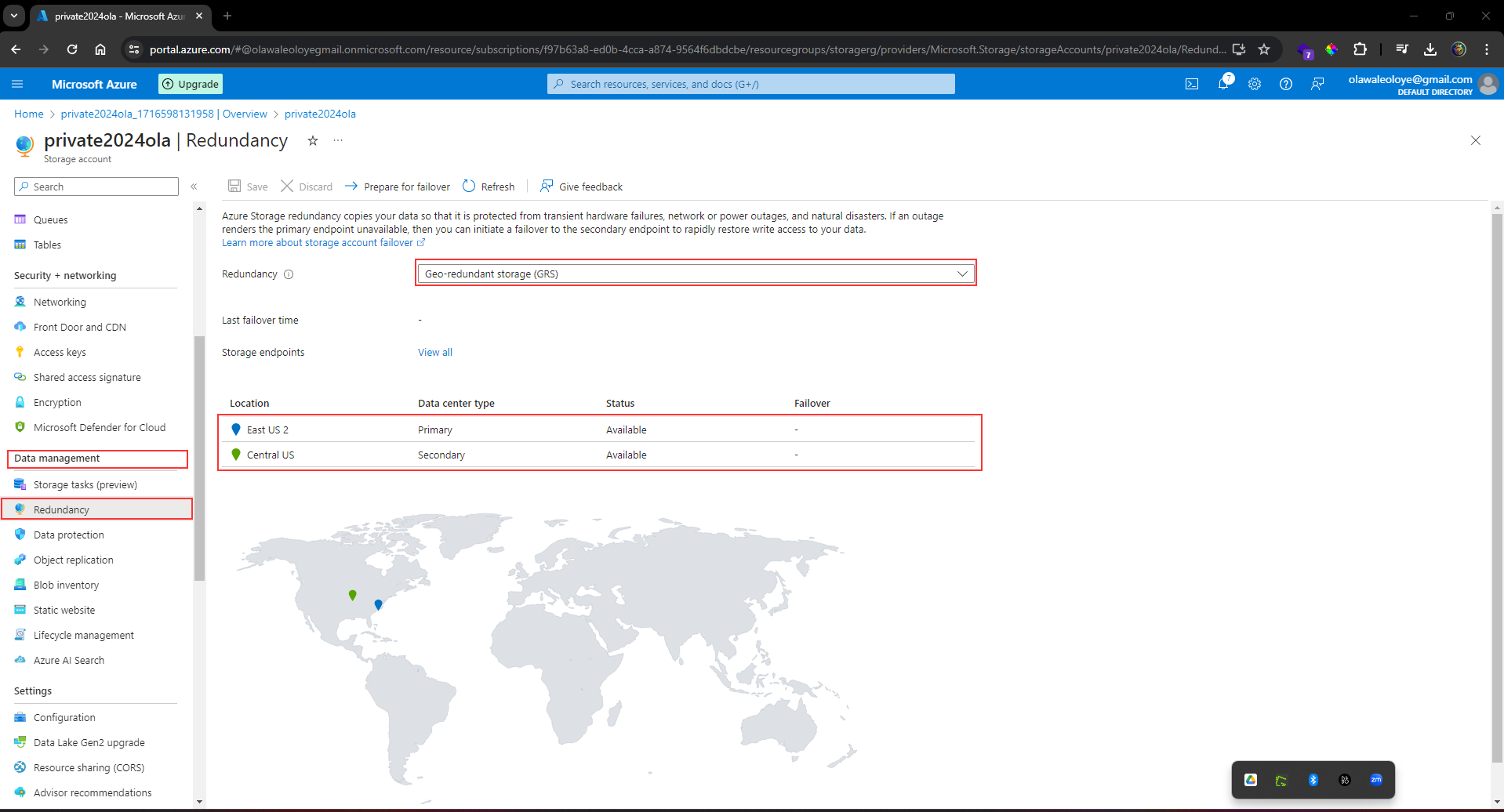
### Create a storage container, upload a file, and restrict access to the file.
_Create_ a _private storage container_ for the corporate data.
In the _storage account_, in the **Data storage** section, _select_ the **Containers** blade.
_Select_ + _Container_.
_Ensure_ the Name of the container is **private**.
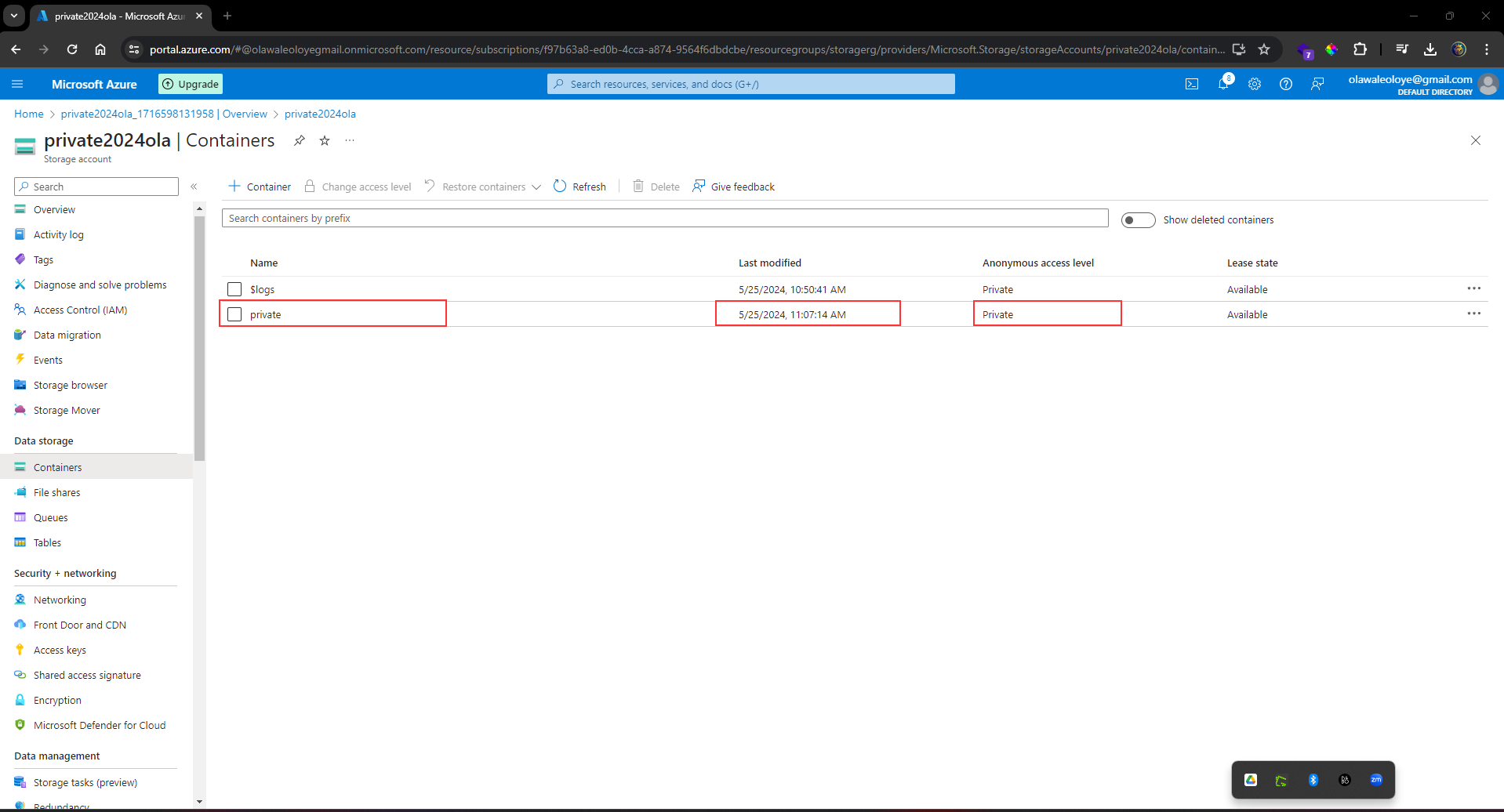
_Ensure_ the **Public** access level is **Private (no anonymous access)**.
As you have time, review the Advanced settings, but take the defaults.
_Select_ **Create**.
For testing, upload a file to the private container. The type of file doesn’t matter. A small image or text file is a good choice. Test to ensure the file isn’t publically accessible.
_Select_ the **container**.
_Select_ **Upload**.
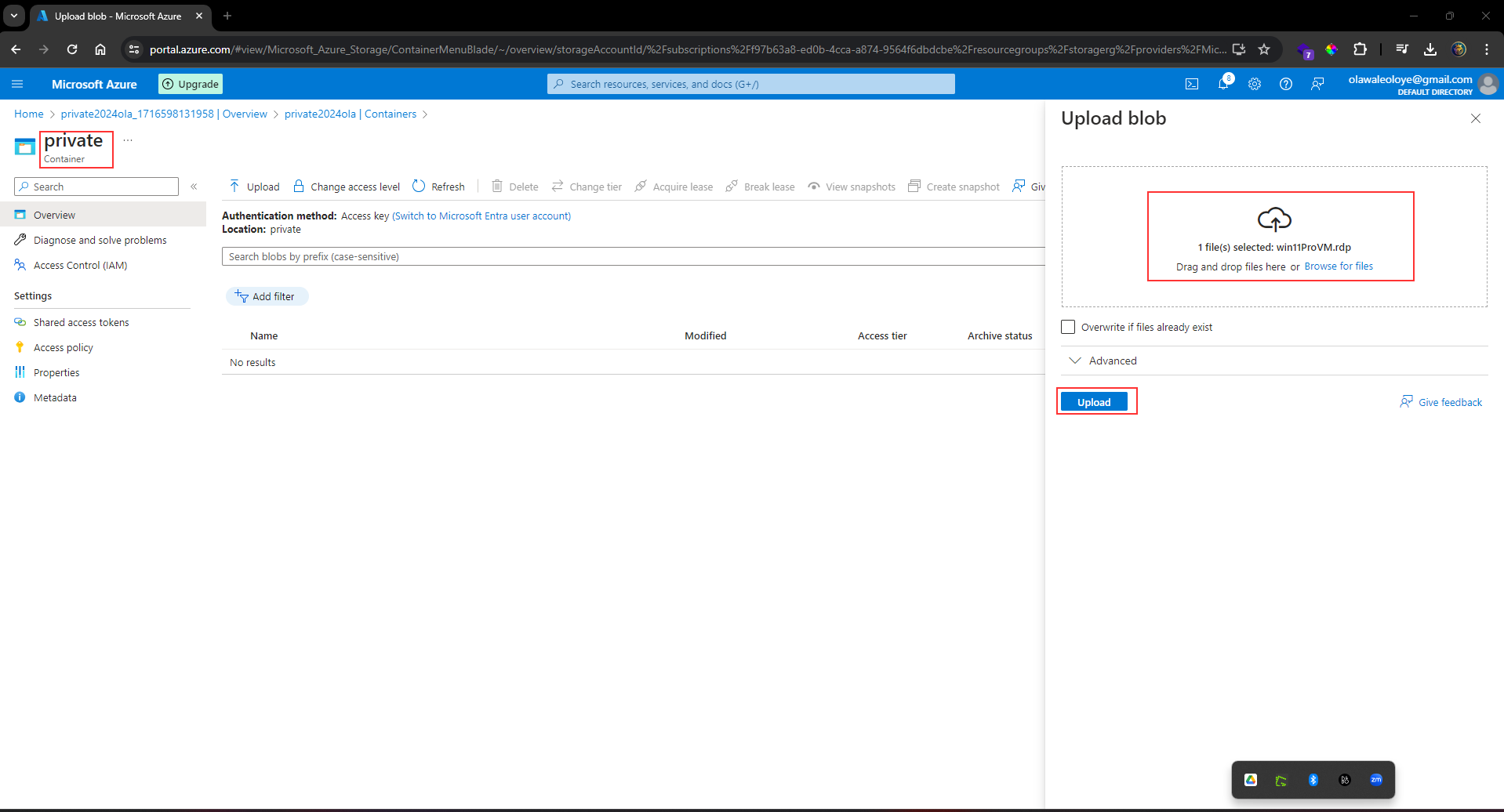
Browse to files and select a file.
Upload the file.
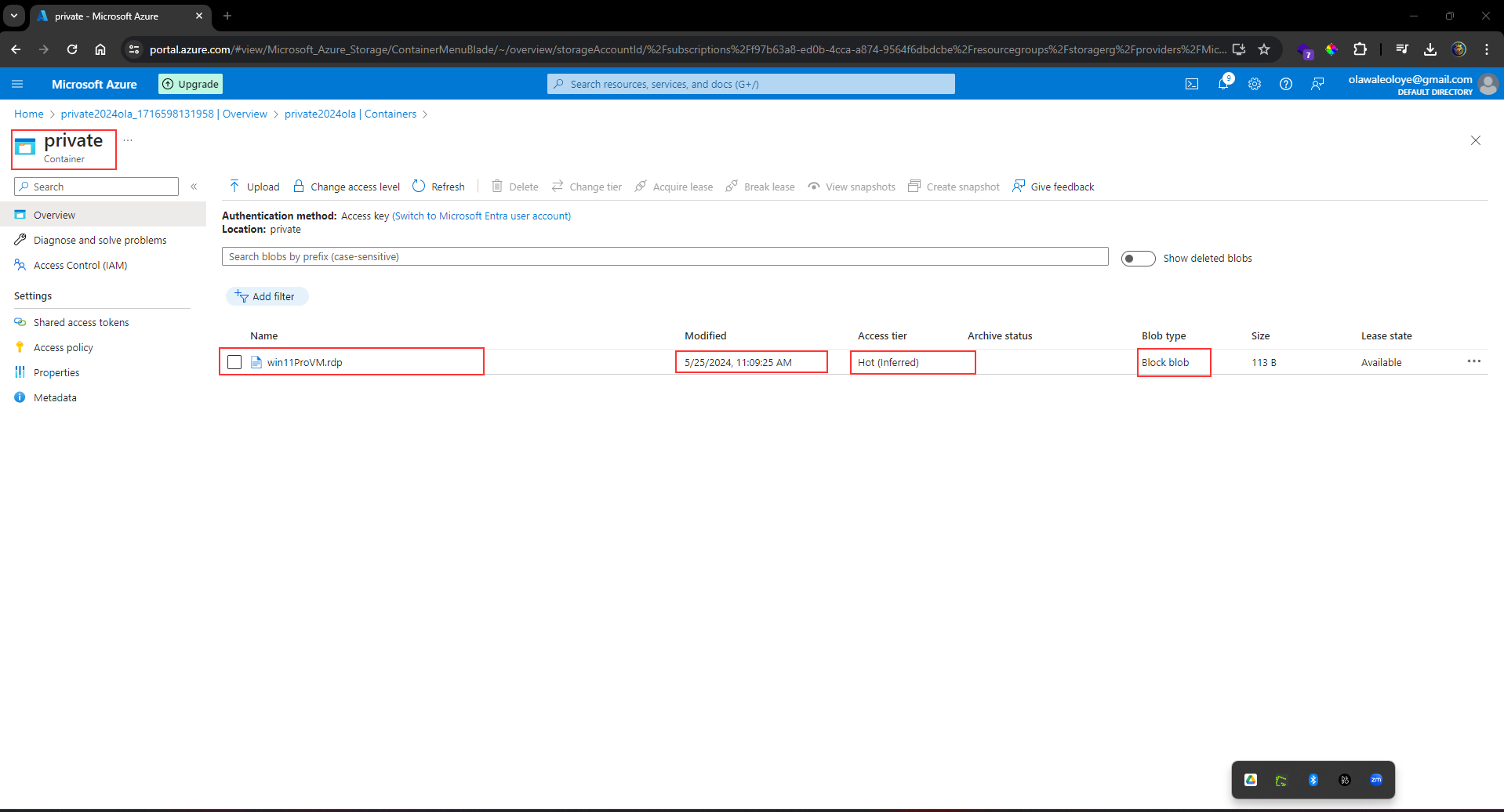
_Select_ the **uploaded file**.
On the **Overview tab**, _copy_ the **URL**.
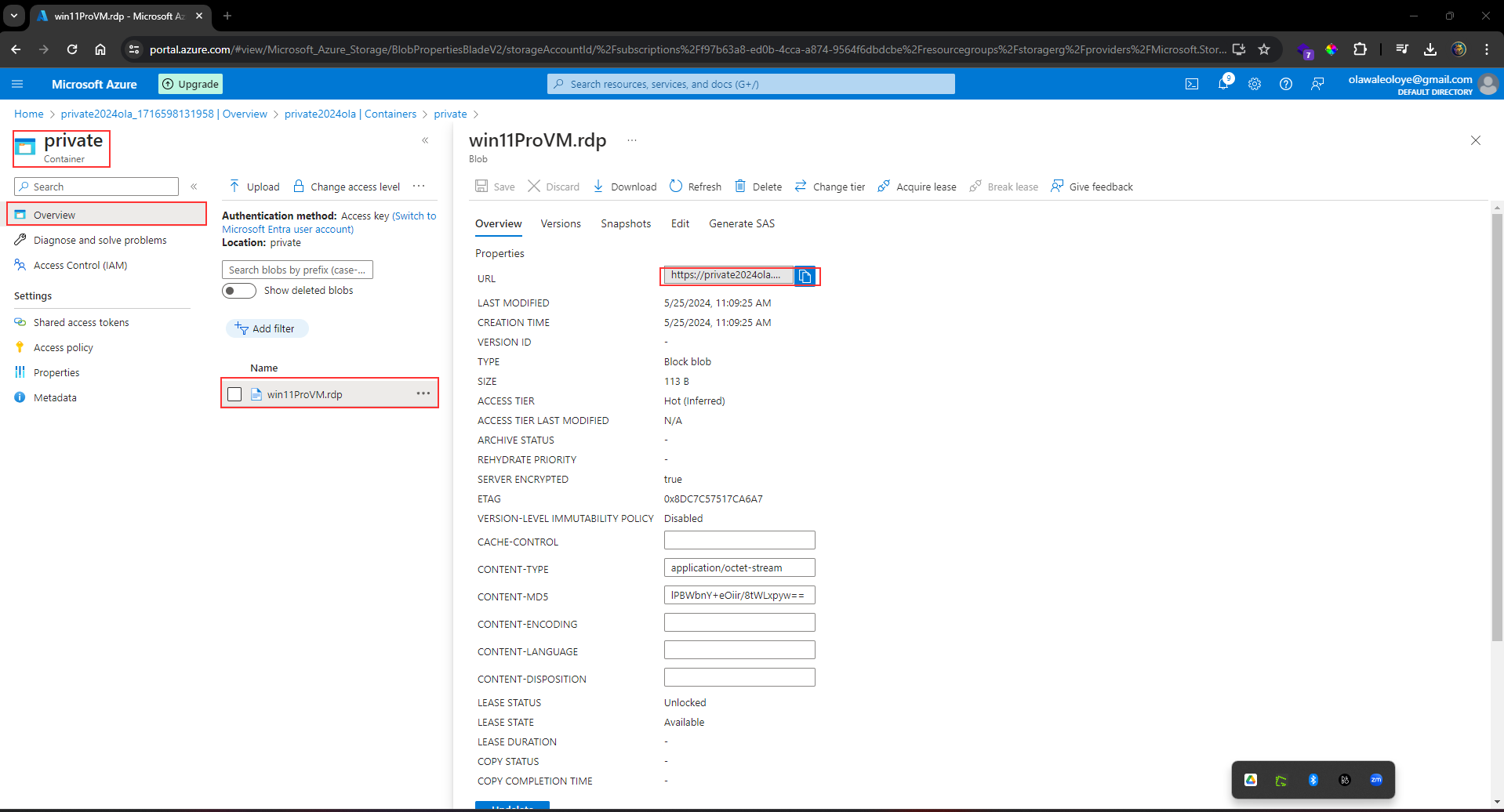
_Paste_ the **URL** into a **new browser tab**.
_Verify_ the file doesn’t display and you receive an error.
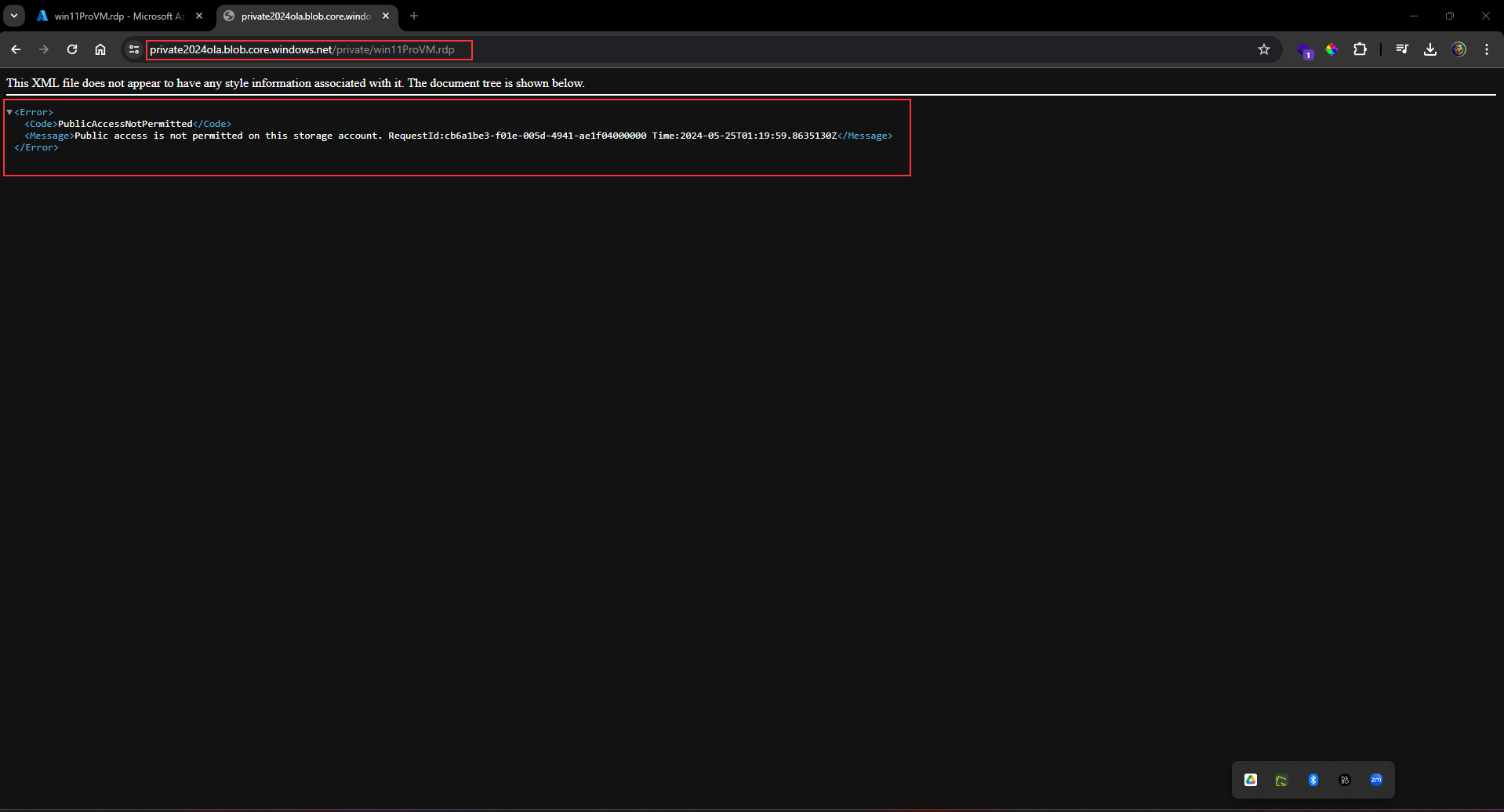
### An external partner requires read and write access to the file for at least the next 24 hours. Configure and test a shared access signature (SAS).
_Select_ your uploaded **blob file** and move to the **Generate SAS** tab.
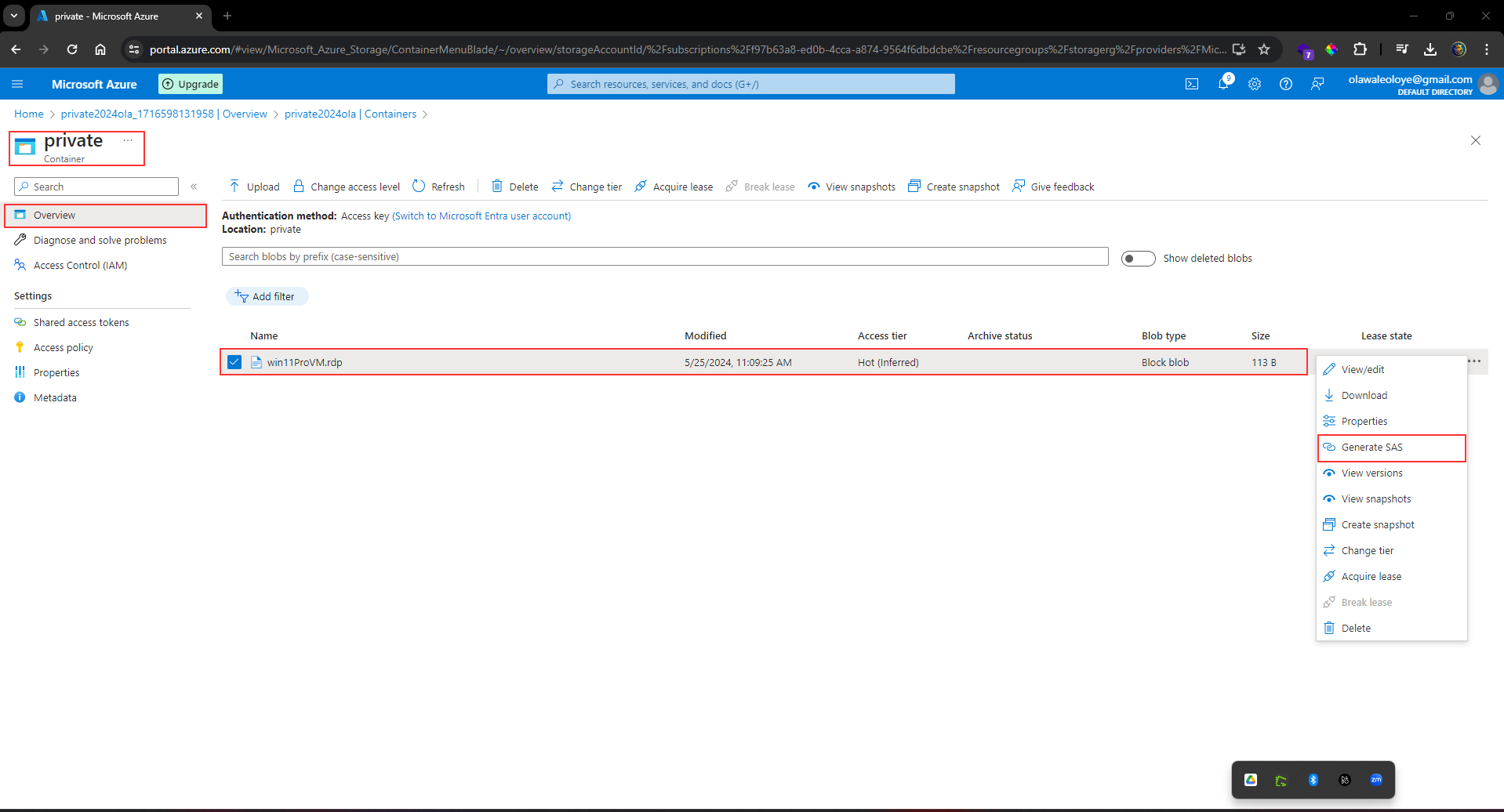
In the **Permissions** drop-down, _ensure_ the partner has only **Read permissions**.
_Verify_ the **Start** and **expiry date/time** is for the next **24 hours**.
_Select_ **Generate** **SAS token and URL**.
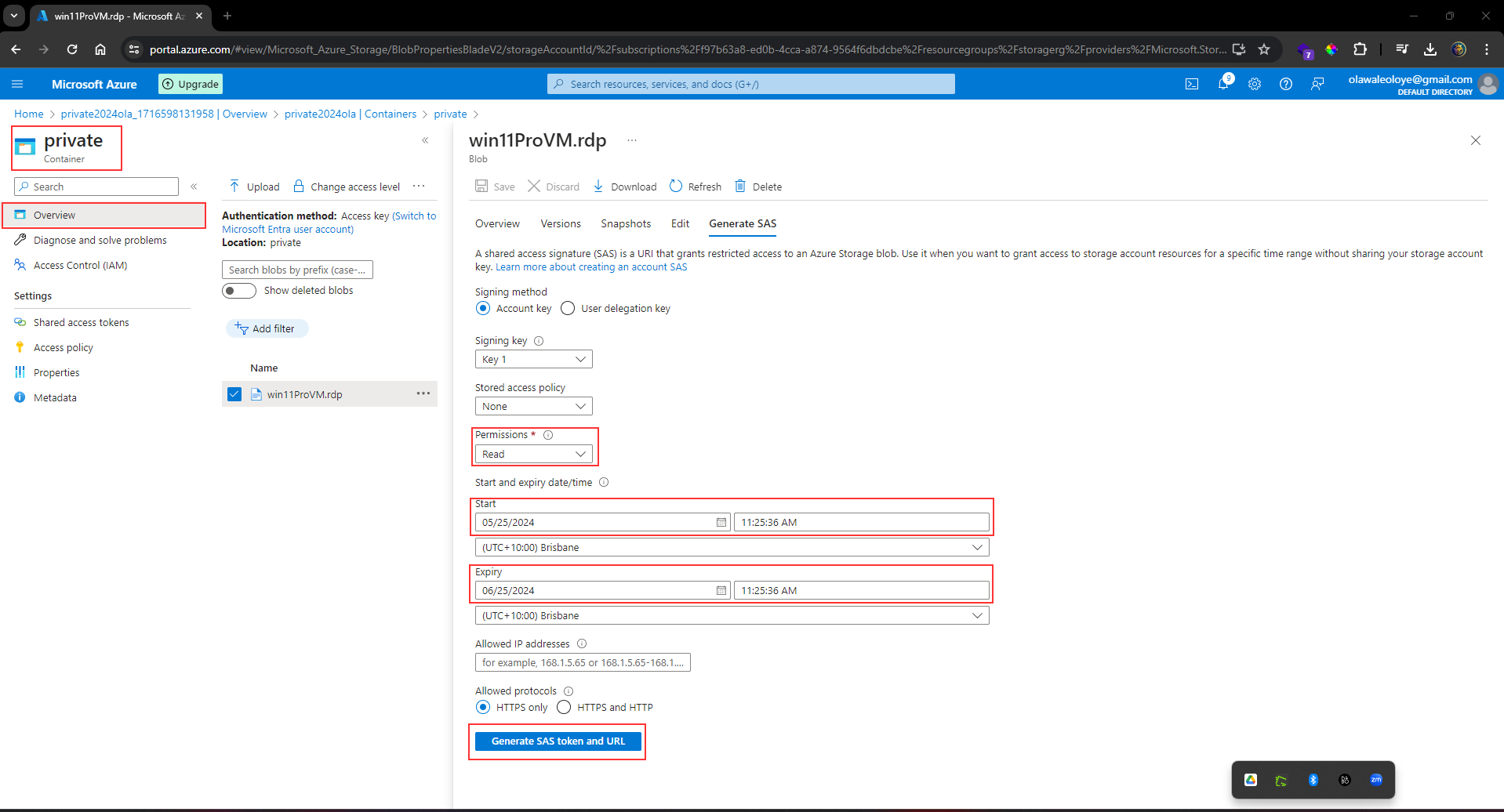
_Copy_ the **Blob SAS URL** to a _new browser tab_.
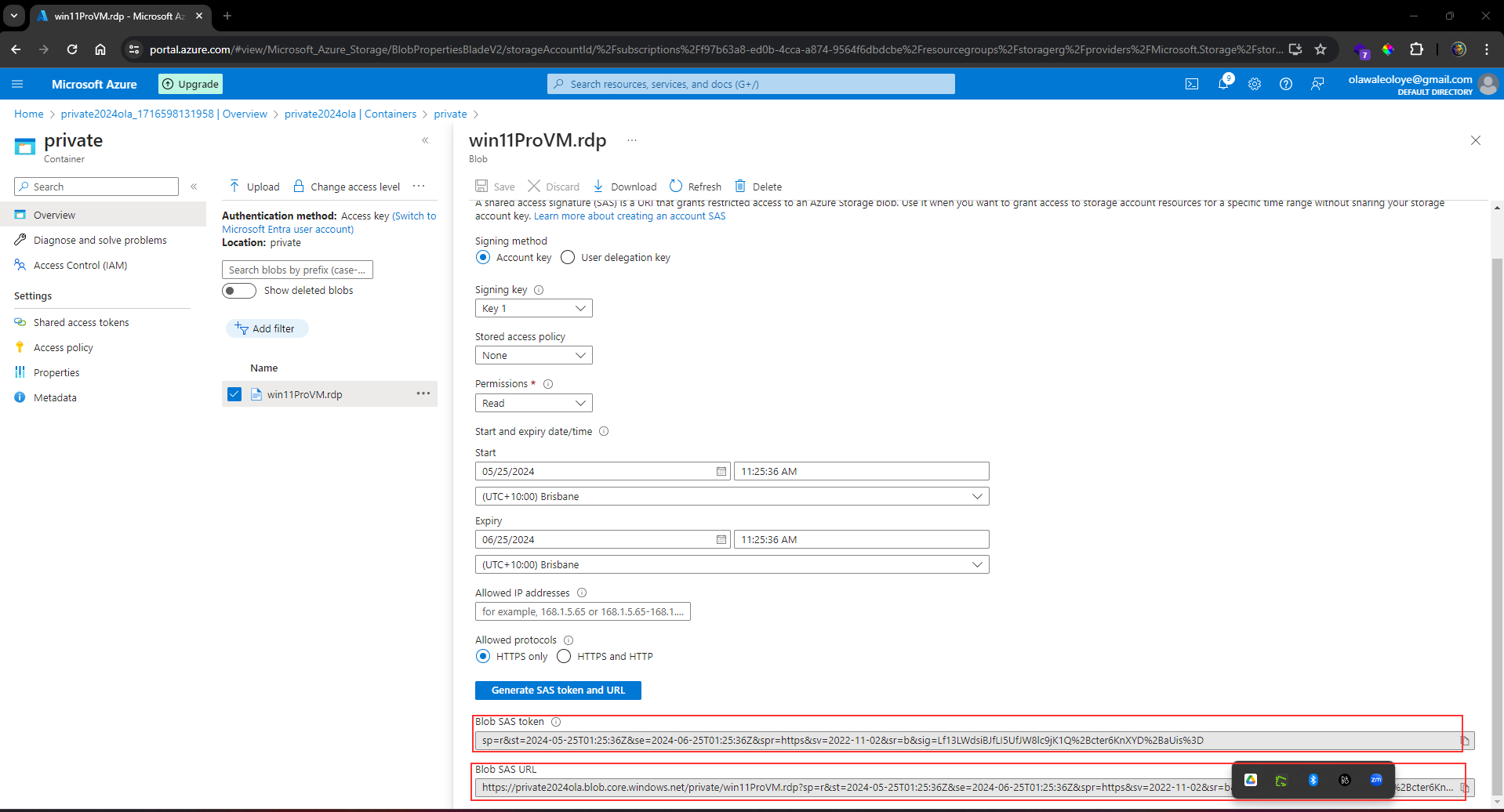
_Verify_ you can _access_ the file. If you have uploaded an image file it will display in the browser. Other file types will be downloaded.
### Configure storage access tiers and content replication.
#### To save on costs, after 30 days, move blobs from the hot tier to the cool tier.
_Return_ to the **storage account**.
In the **Overview section**, notice the **Default access tier** is set to **Hot**.
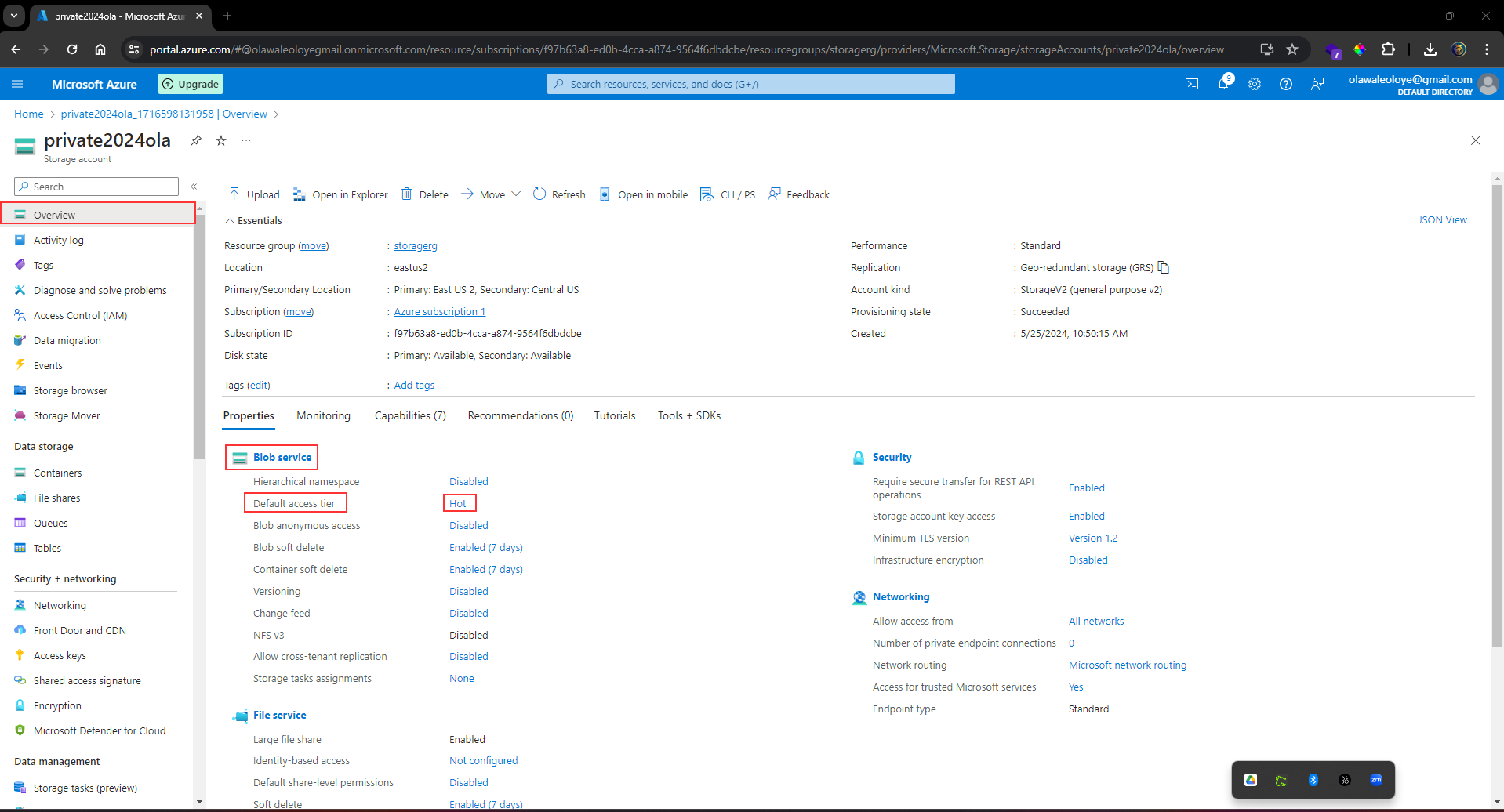
In the **Data management** section, _select_ the **Lifecycle management** blade.
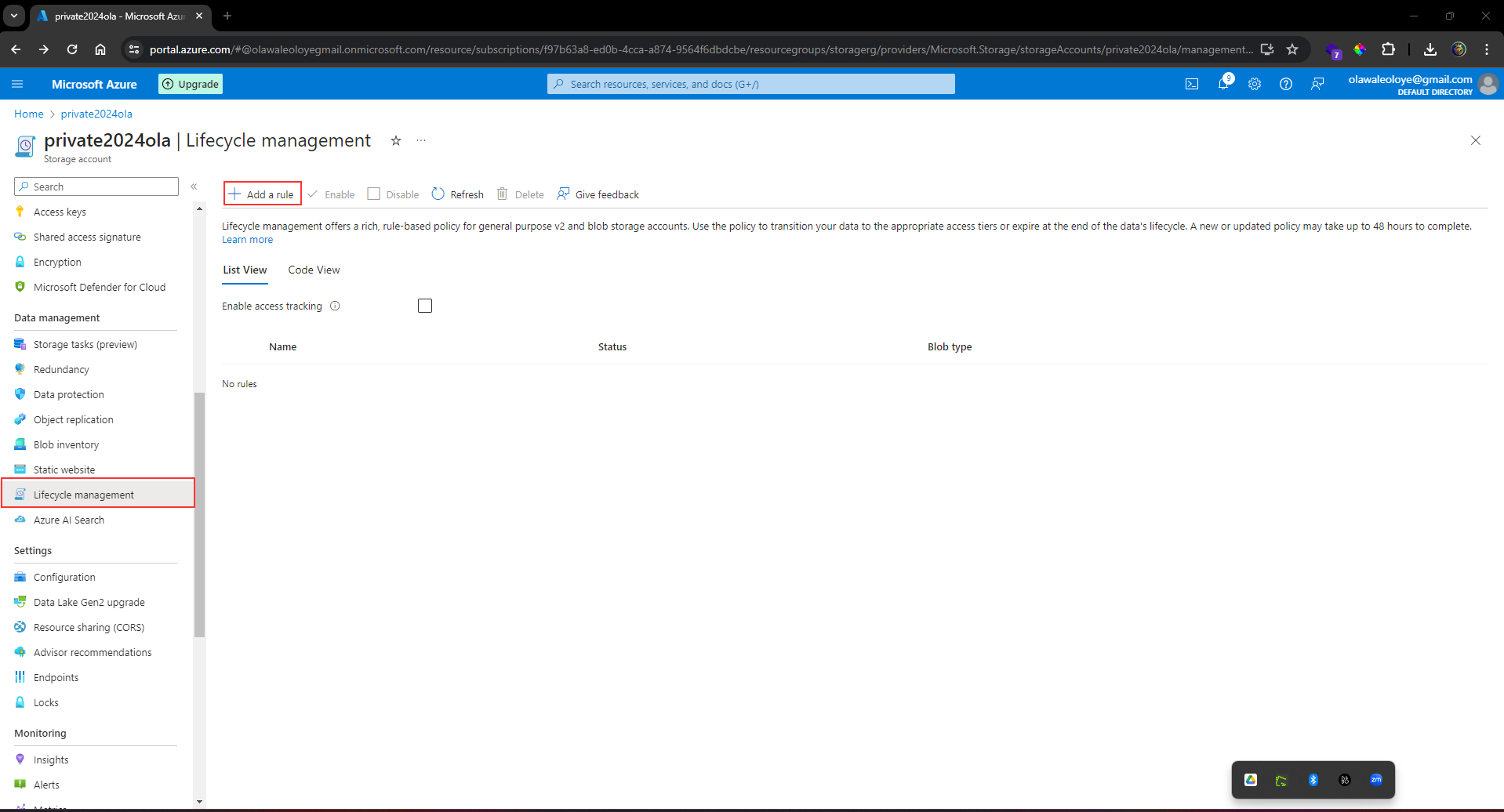
_Select_ Add **rule**.
_Set_ the **Rule name** to movetocool.
_Set_ the Rule scope to **Apply rule** to **all blobs in the storage account**.
_Select_ **Next**.
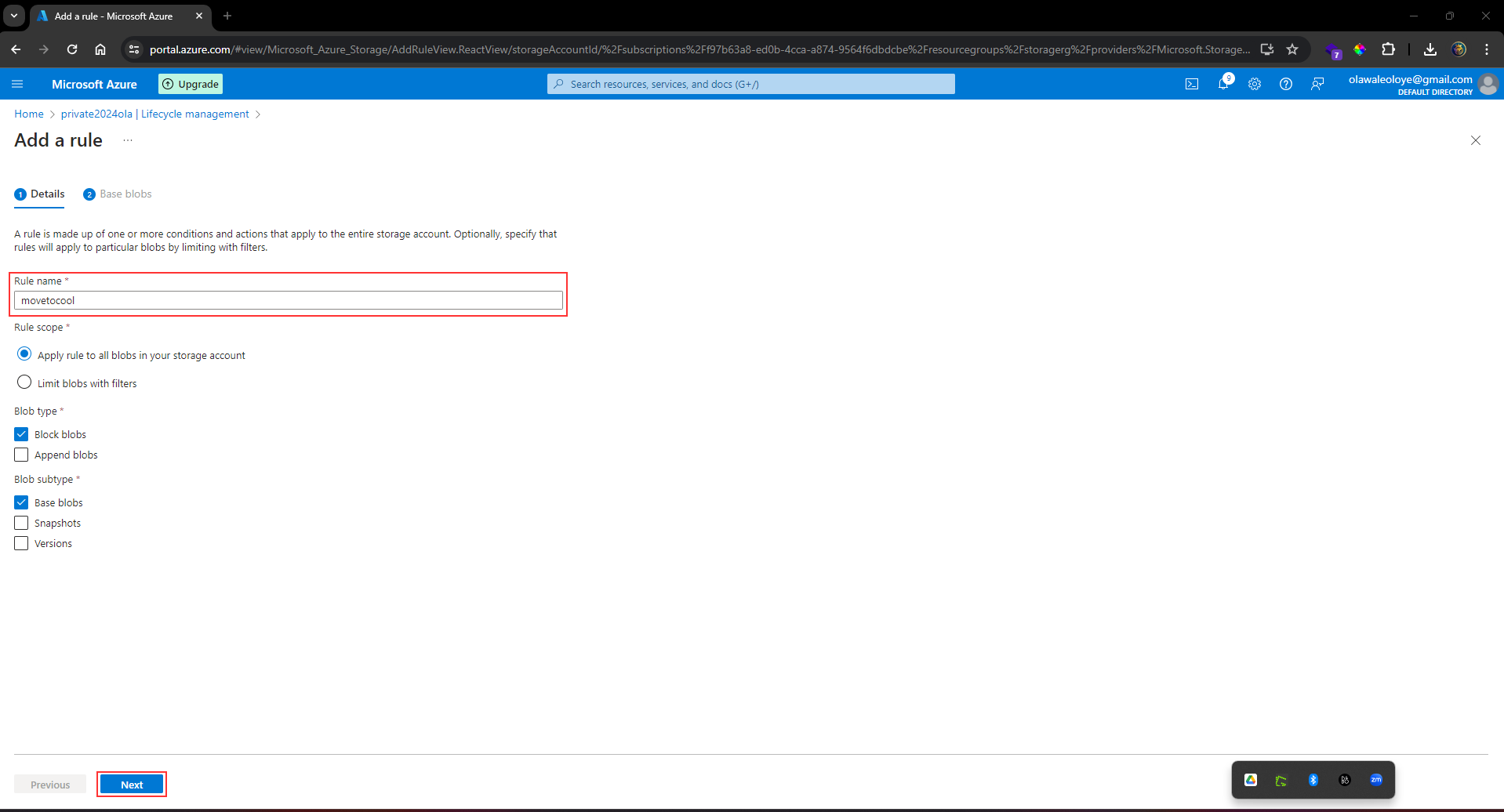
_Ensure_ **Last modified** is selected.
_Set_ More than (days ago) to **30**.
In the **Then** drop-down select **Move to cool storage.**
> As you have time, review other lifecycle options in the drop-down.
_Add_ the **rule**.
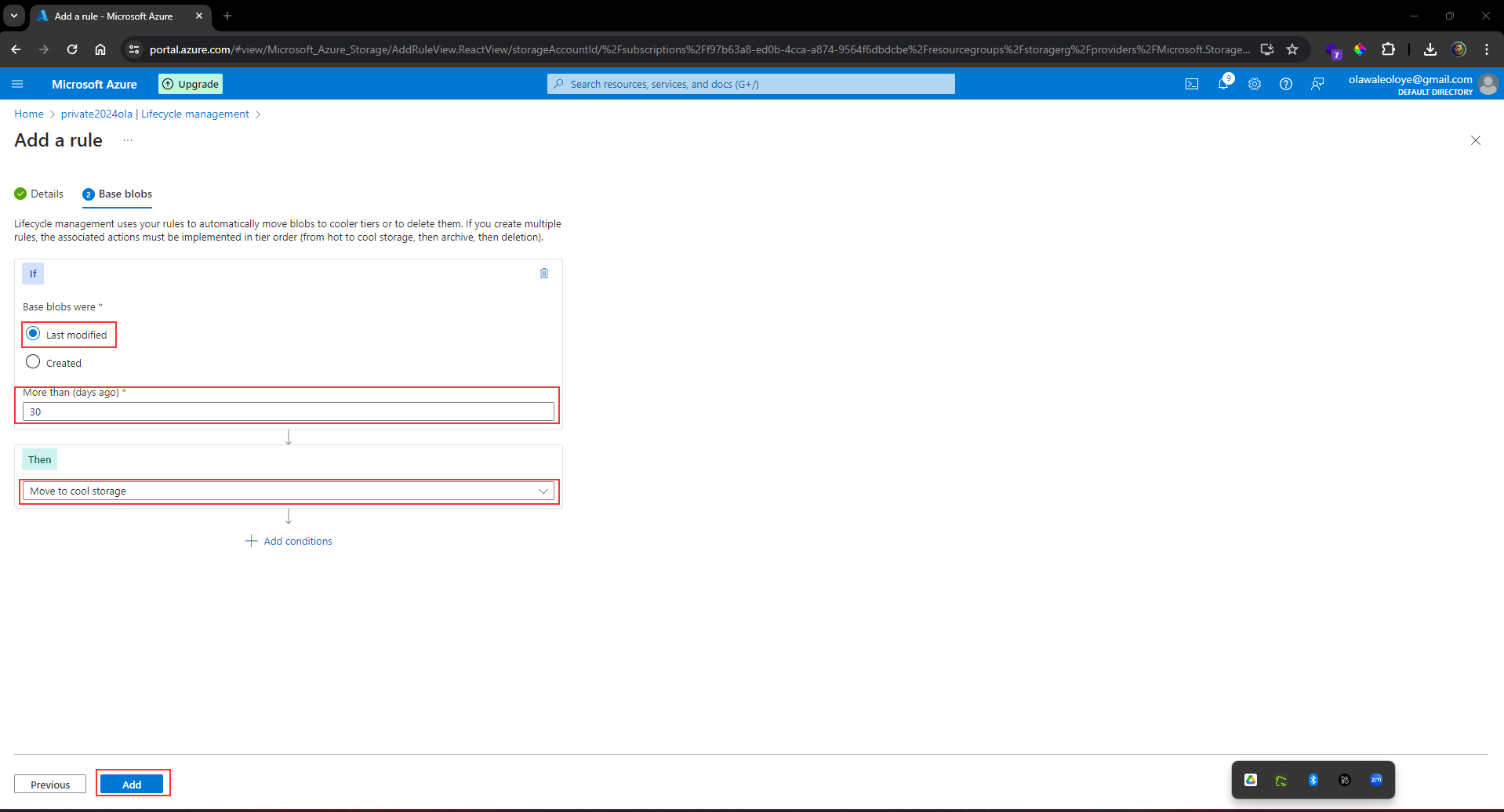
#### The public website files need to be backed up to another storage account.
In your **storage account**, _create_ a new container called **backup**. _Use_ the default values.
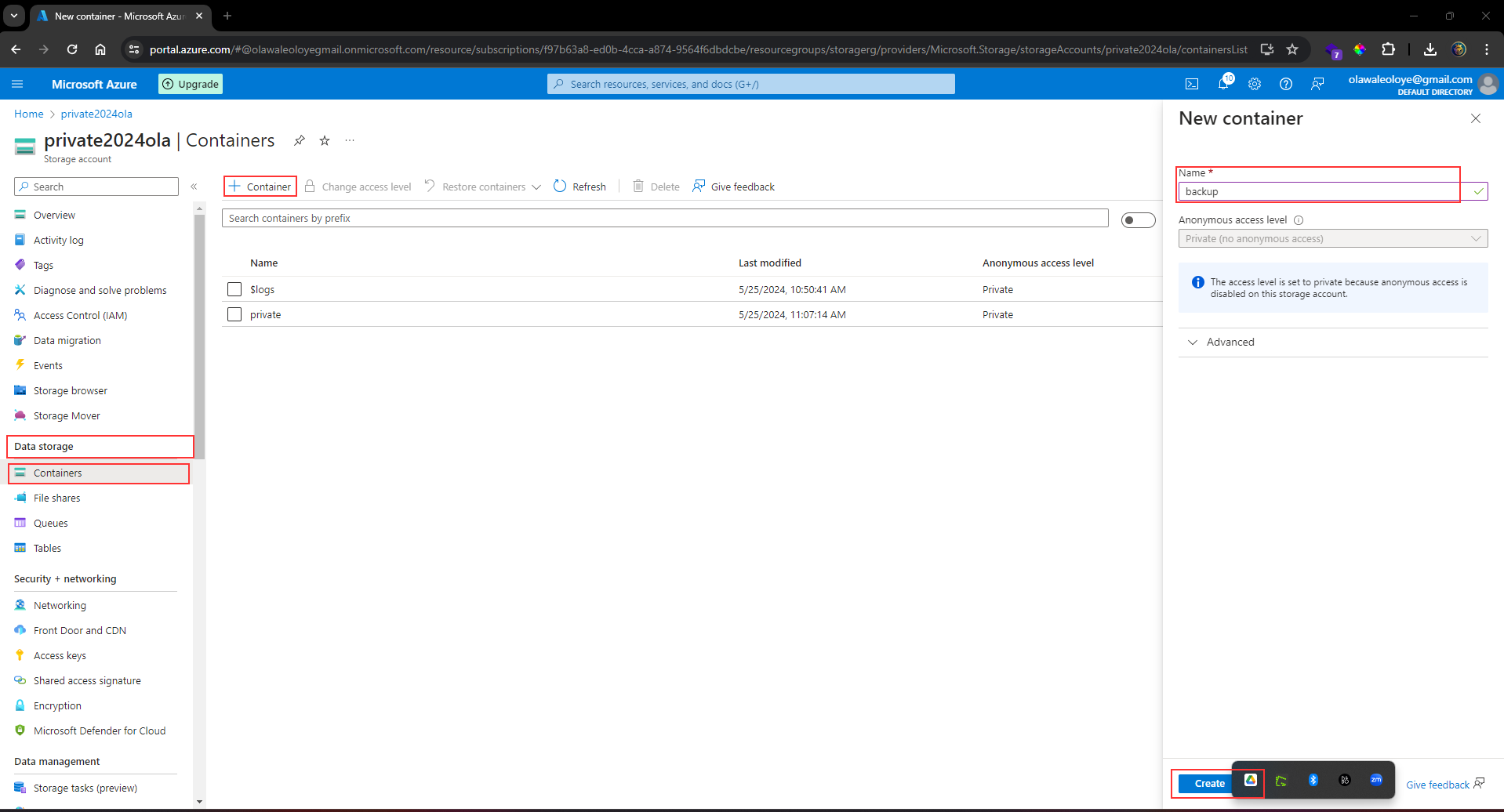
_Navigate_ to your [publicwebsite storage account](https://dev.to/olawaleoloye/working-with-mission-critical-data-azure-files-and-azure-blobs-26p3). _This storage account was created in the previous exercise_.
In the **Data management section**, _select_ the **Object replication** blade.
_Select_ **Create replication rules**.
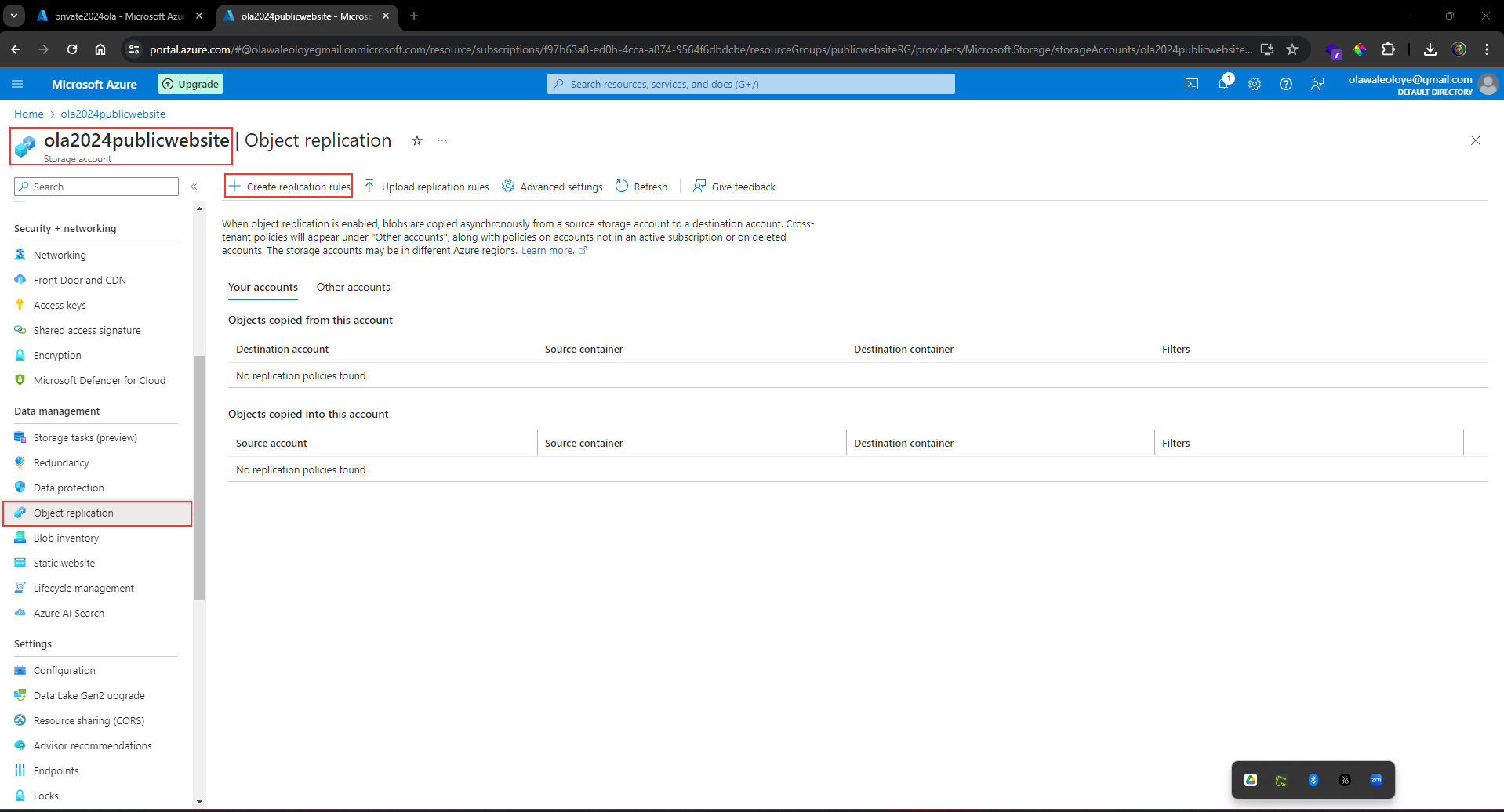
_Set_ the **Destination storage account** to the **private storage account**.
_Set_ the **Source container** to **public** and the **Destination container** to **backup**.
_Create_ the **replication rule**.
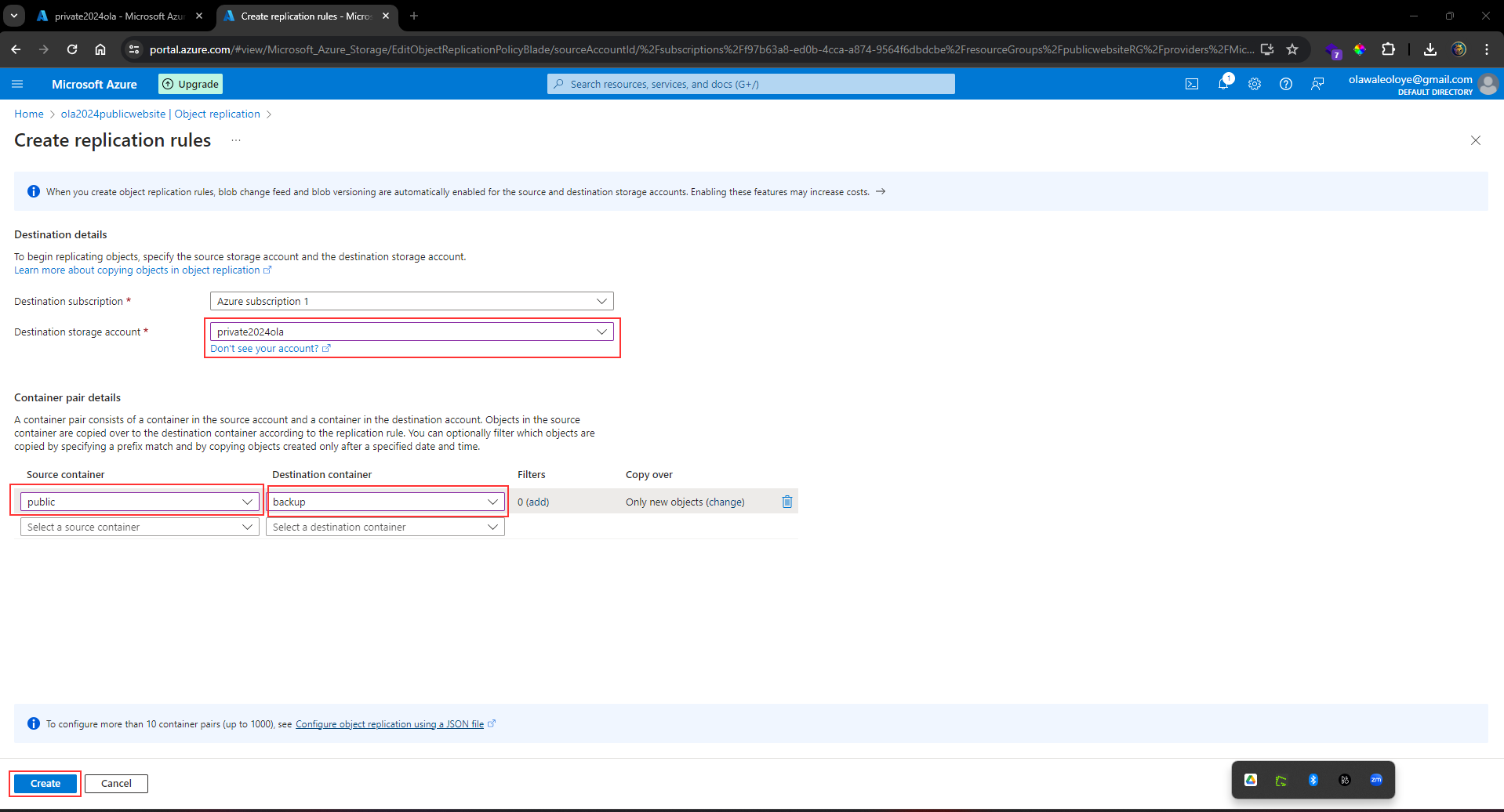
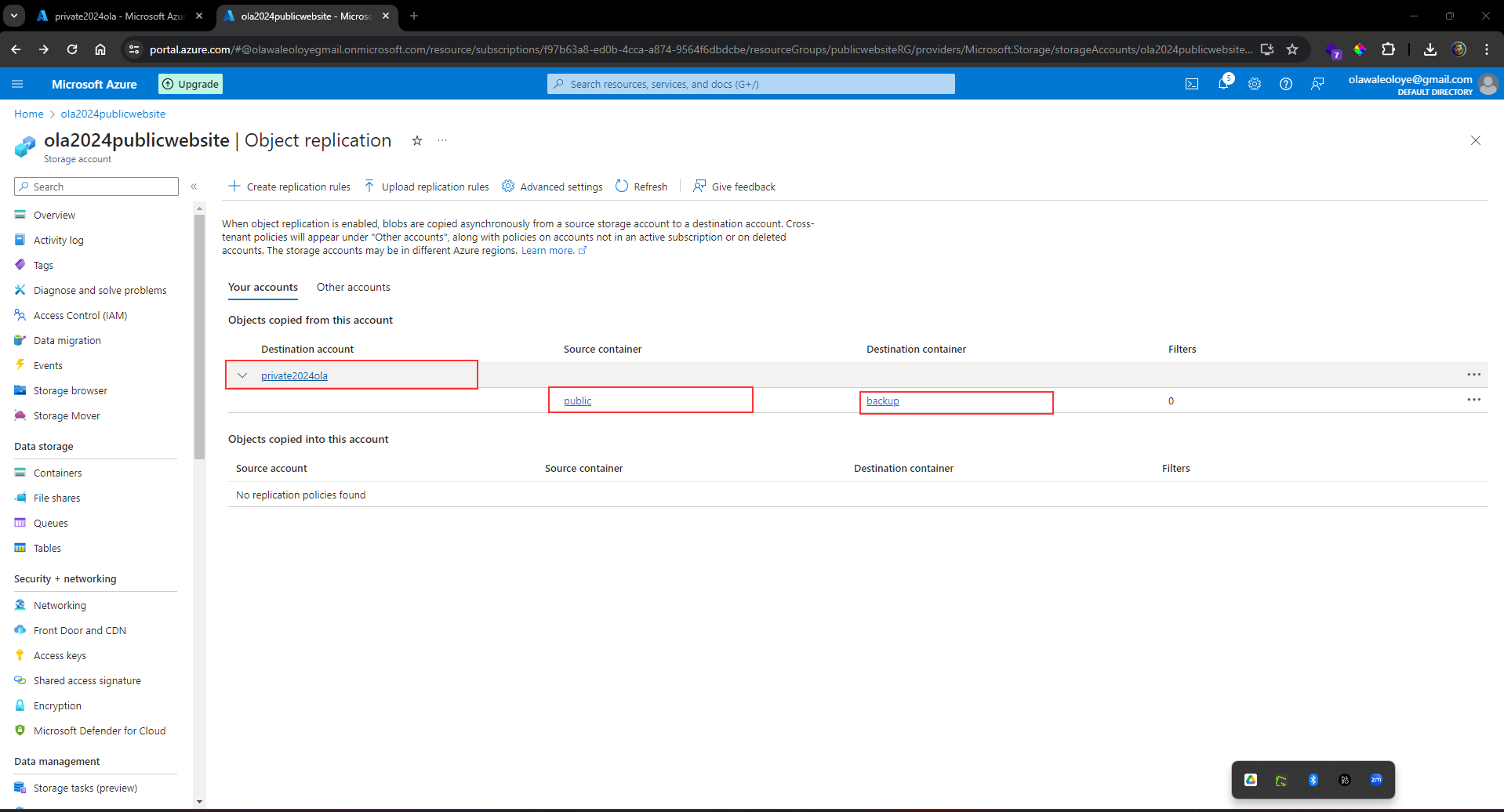
Optionally, as you have time, **upload a file to the public container**.
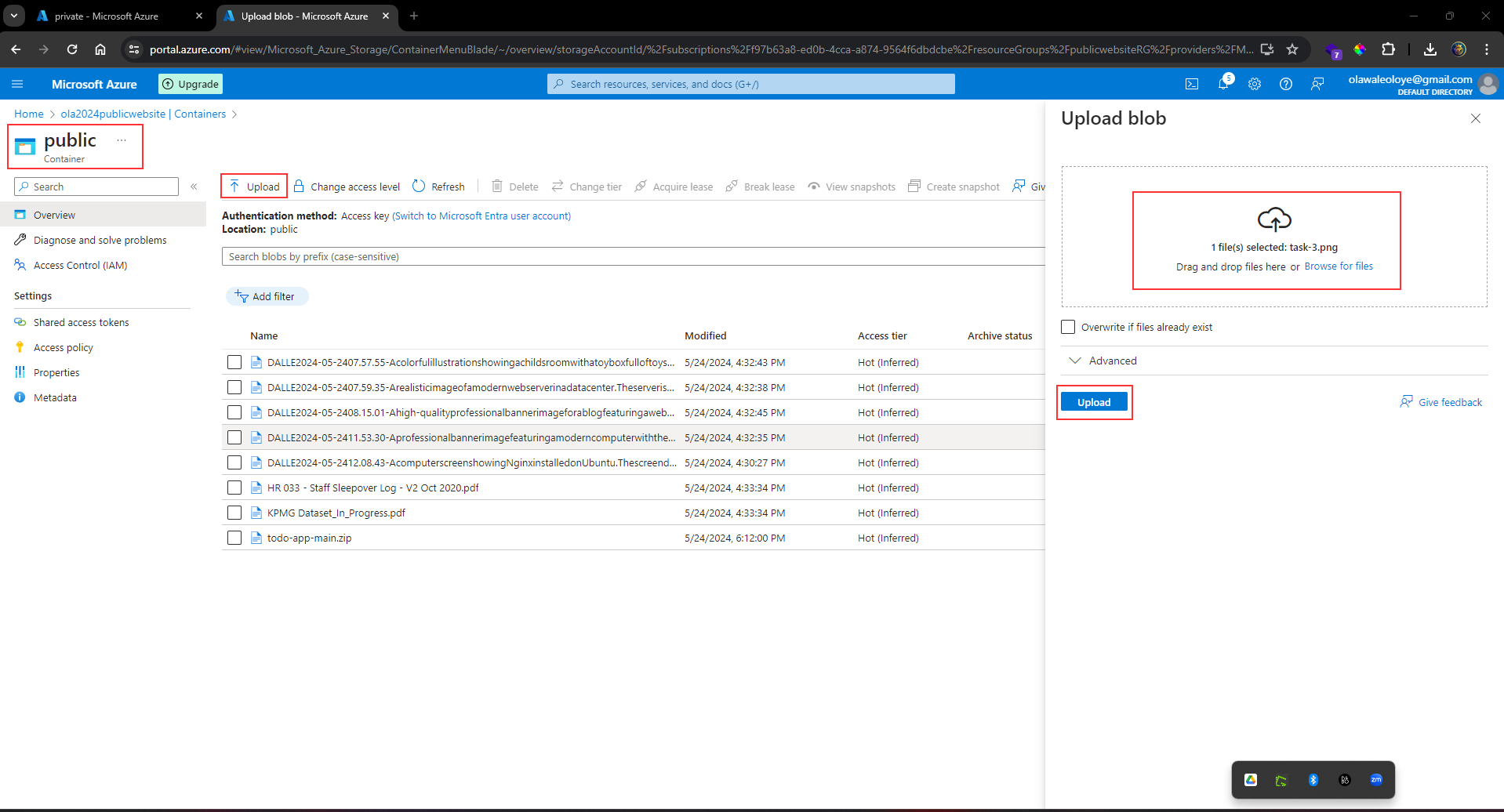
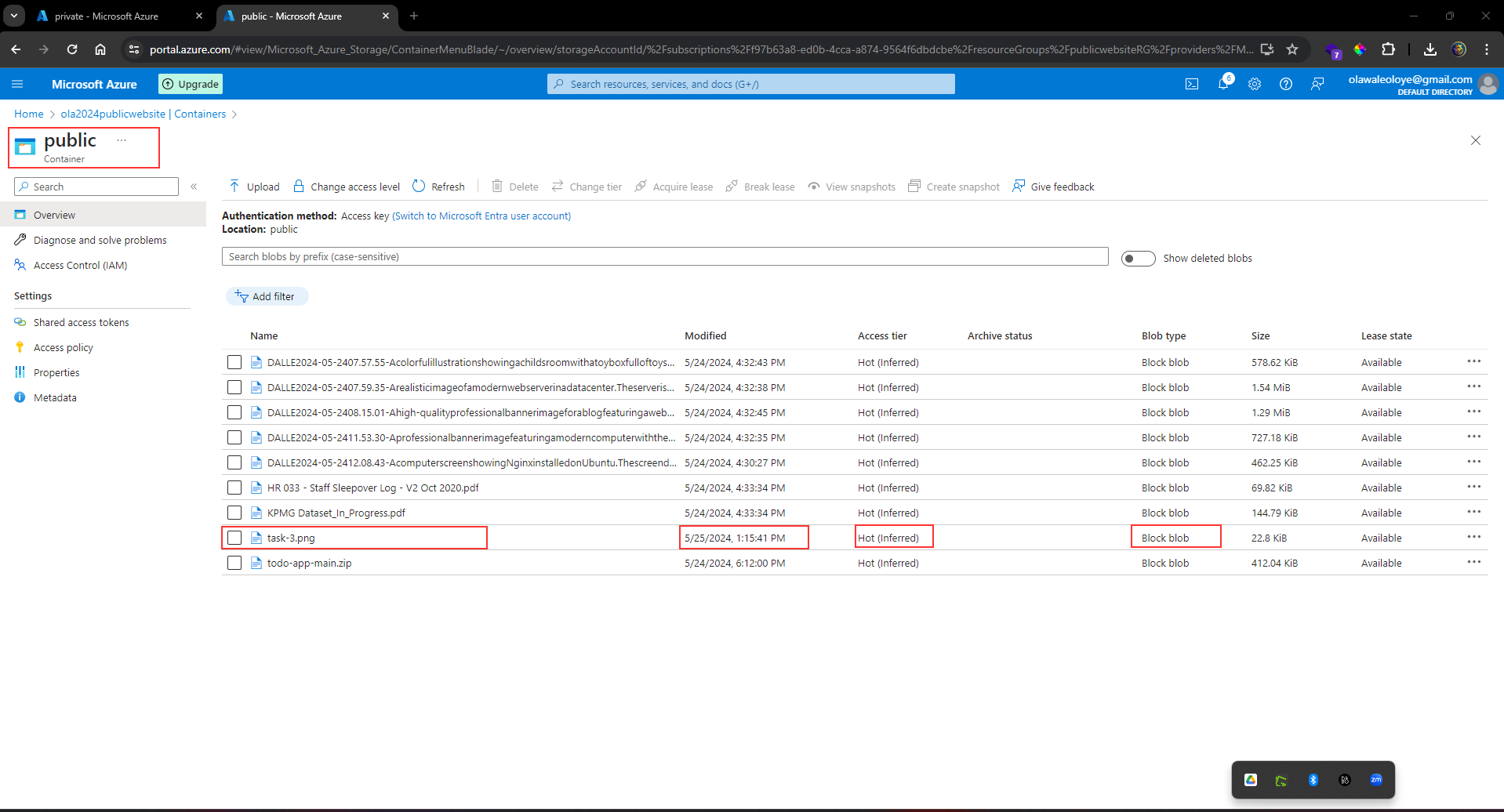
_Return_ to the **private storage account** and _refresh_ the **backup container**. _Within a few minutes your public website file will appear in the backup folder._
| olawaleoloye |
1,821,926 | AWS Network Challenge 1: Deploy Web App to EC2 / Two-Tier VPC Architecture | About the Challenge I manage the Service Delivery Team at eCloudValley Philippines, and... | 0 | 2024-05-25T03:19:16 | https://dev.to/ecvph-tech-team/aws-network-challenge-1-deploy-application-in-ec2-on-two-tier-vpc-architecture-135i | aws, webdev, network | ## About the Challenge
I manage the Service Delivery Team at eCloudValley Philippines, and one of the first things I teach them is to understand how AWS networks work. As cloud developers, we deploy our applications in Lambda and connect them with databases and other components inside our AWS VPC (virtual network in AWS). Because of this, it becomes imperative for them to know more about how VPCs work. They need to know how to navigate network issues they will encounter.
In this challenge, we would deploy an application to 2 servers inside a virtual network in AWS. The network will have two tiers: private and public. Our result will be:
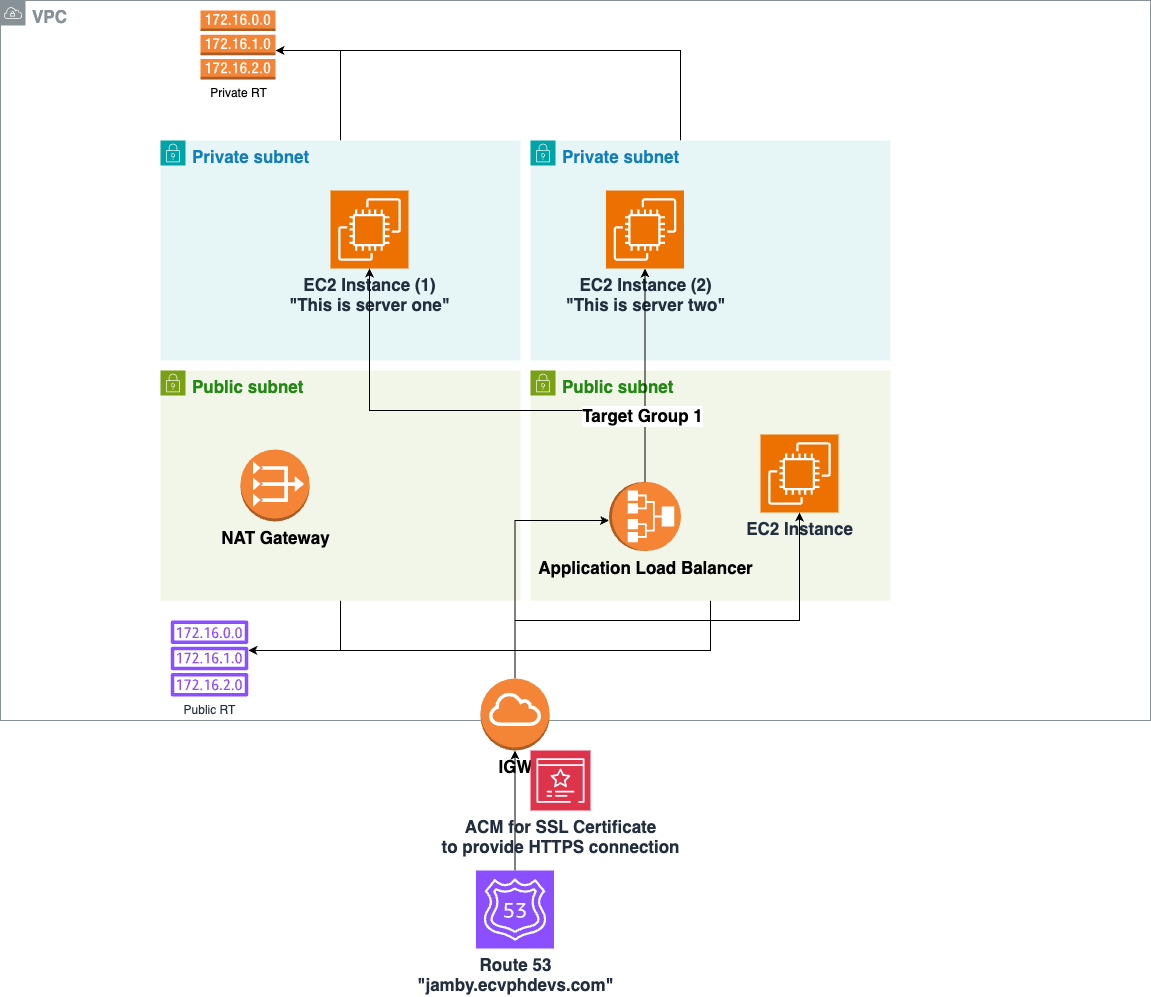
Before we begin, here are a few helpful hints:
- This is a series of challenges that get progressively harder. It also meant to state what to do and what you should have learned. This is NOT a step-by-step guide on how to do the challenges.
- I have added links to AWS documentation to help you get started with the challenges.
- I have added guide questions to test your knowledge. It's easy to follow documentation to make this all work. But what we are striving for is a true understanding of how these components work together for a secure, reliable, and working network.
## [A] Basic VPC Skeleton
Let's build the backbones of our VPC network. You'll be creating:
- [VPC](https://docs.aws.amazon.com/vpc/latest/userguide/how-it-works.html) ([how](- https://docs.aws.amazon.com/vpc/latest/userguide/create-vpc.html#create-vpc-only))
- 2 Private [Subnets](https://docs.aws.amazon.com/vpc/latest/userguide/configure-subnets.html) (deployed in separate Availability Zones, [how]((https://docs.aws.amazon.com/vpc/latest/userguide/create-subnets.html))
- 2 Public Subnets (deployed in separate Availability Zones)
- 1 [Internet Gateway](https://docs.aws.amazon.com/vpc/latest/userguide/VPC_Internet_Gateway.html) (connected to the VPC we just created)
- 1 NACL for both subnets (with a rule that allows all traffic)
- 1 [Route Table](https://docs.aws.amazon.com/vpc/latest/userguide/VPC_Route_Tables.html) (for Private Subnets, [how]( https://docs.aws.amazon.com/vpc/latest/userguide/WorkWithRouteTables.html))
- 1 Route Table (for Public Subnets)
In this exercise, you must be able to answer the following guide questions:
1. What makes a subnet private? What makes it public?
2. What is an IPv4 CIDR block? What is the difference between /16, /20 and /24?
3. Why do we deploy subnets in different availability zones?
**Architecture Diagram for Exercise A:**
## [B] Setting up the instances
With the VPC backbone in place, let's add more network components:
- [NAT Gateway](https://docs.aws.amazon.com/vpc/latest/userguide/vpc-nat-gateway.html) (deployed in Public Subnet)
- [Set up](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/get-set-up-for-amazon-ec2.html) for you to deploy an EC2 instance
- [EC2 instance](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html) (deployed in Public Subnet) - [Getting Started](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EC2_GetStarted.html) - [Best Practices](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-best-practices.html)
- EC2 instance (deployed in Private Subnet)
- [Security Group](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-security-groups.html) that allows all traffic from port 22
- Associate the security group to both EC2 instances
- Private Route Table connected to NAT Gateway
Here are a few guide questions to answer:
1. DEMO: Be able to enter the CLI of the EC2 instance in the public subnet via SSH. Once inside, access the CLI of the EC2 instance in the private subnet.
2. Why do we need a NAT Gateway? How does it operate?
3. What is the difference between a NAT Gateway and an Internet Gateway?
4. What is the difference between a security group and an NACL?
5. Can a computer from the internet access the EC2 instance inside the private subnet? Why or why not?
6. What is the difference between a NAT gateway and a NAT instance? When would you use a NAT instance? NAT gateway?
7. What happens if you don't assign a public IP Address to an EC2 instance?
**Architecture Diagram for Exercise B:**
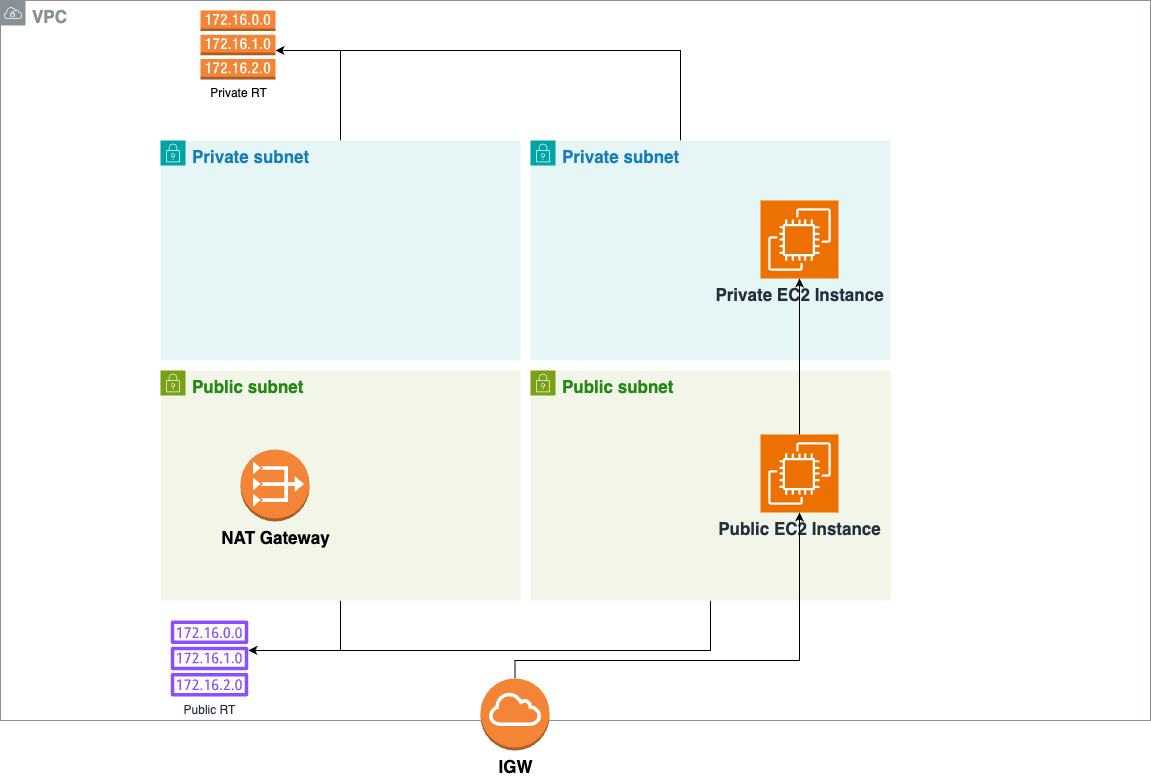
**What we achieved**
We created our private network in the Cloud! We also created two EC2 instances, one in the private subnet and another in the public subnet.
## [C] Setting up NGINX and load balancing
We're getting close:
- EC2 instance (deployed in Private Subnet 1)
- EC2 instance (deployed in Private Subnet 2)
- [Install Nginx on both](https://www.digitalocean.com/community/tutorials/how-to-install-nginx-on-centos-7). Modify `/usr/share/nginx/html/index.html` to add "this is server one" for the 1st EC2 and "this is server two" for the second one.
- Create an [application load balancer](https://docs.aws.amazon.com/elasticloadbalancing/latest/application/introduction.html)
- Create a [listener](https://docs.aws.amazon.com/elasticloadbalancing/latest/application/create-listener.html) to receive HTTP traffic
- Create a [target group](https://docs.aws.amazon.com/elasticloadbalancing/latest/application/load-balancer-target-groups.html) that includes both EC2 instances as instance targets
Here are a few guide questions to answer:
1. DEMO: Once the resources have been created, get the URL from the application load balancer and put it in your browser. It should alternate displaying "this is server one" and "this is server two". This proves that the ALB is alternating sending traffic between the first and second EC2 instances.
2. What is the difference between a NAT Gateway and an Application Load Balancer?
3. Why put the EC2 instances in separate private subnets?
4. Why put the EC2 instances in the private subnet instead of being exposed directly?
5. Why add an application load balancer?
**Architecture Diagram for Exercise C:**
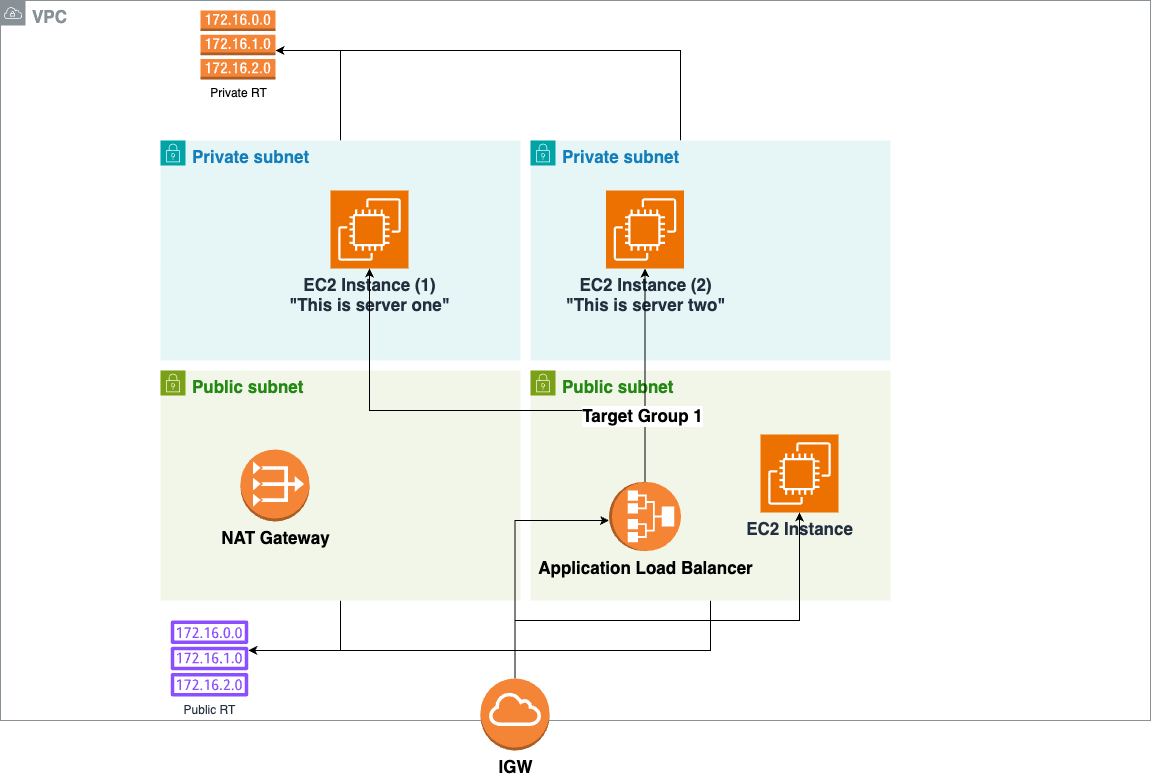
The result looks like this:
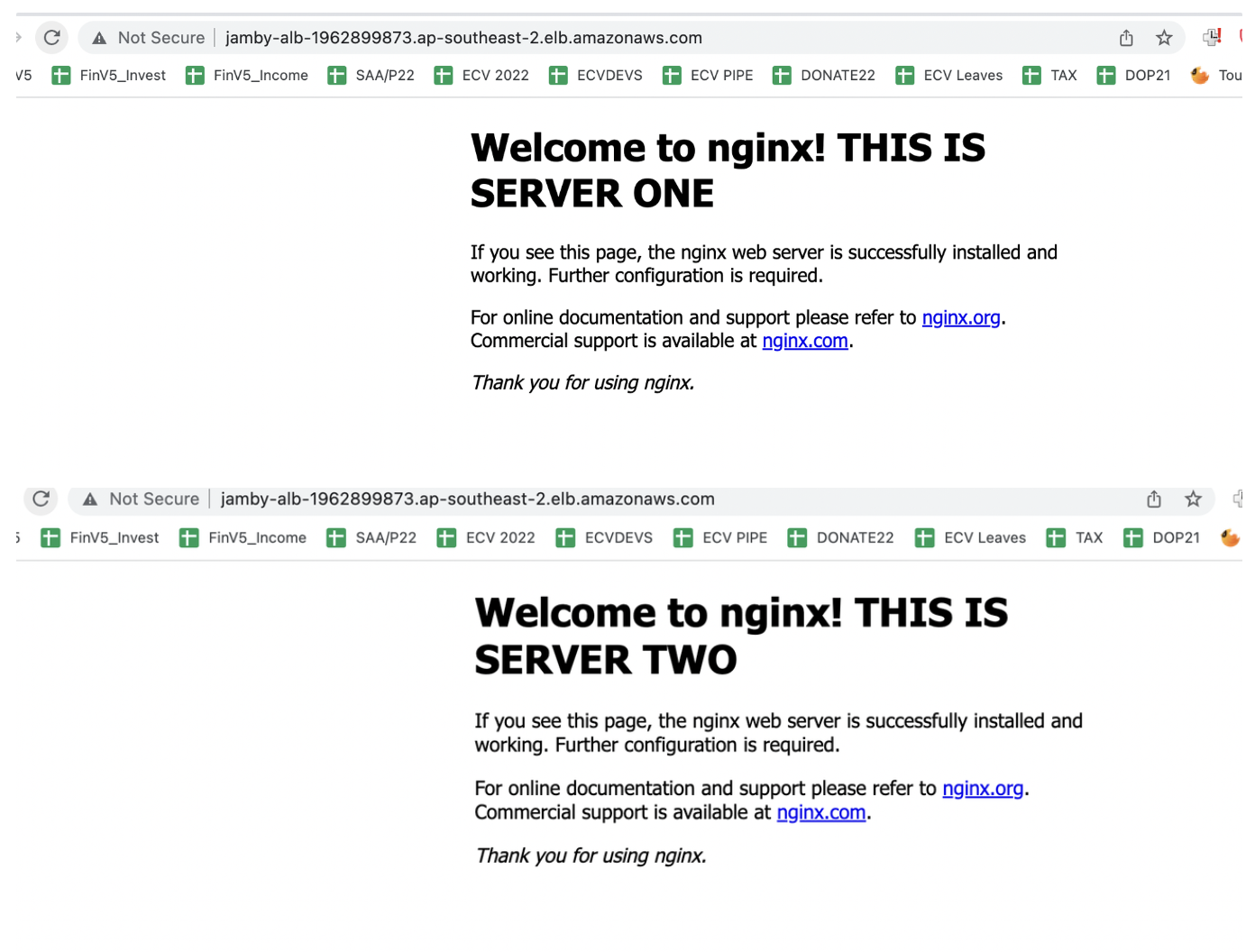
**What we achieved**
With Activity A-C, you have deployed your first VPC and have successfully deployed a simple app using a two-tier architecture. That’s honestly very close to how we deploy secure applications on the modern web.
There is one thing though. The application you accessed looked like something like this when typed in the browser:
http://jamby-alb-1962899873.ap-southeast-2.elb.amazonaws.com/
Two things come to mind when I see this:
First, the website is deployed on HTTP, not HTTPS, which leaves our end users insecure. As your end user browses your website, the data you send and receive goes across the internet unencrypted. The internet is made of thousands (or maybe millions) of routers connecting everyone in one big interconnected web. From your end user’s Macbook to your EC2 instance, there may be as many as 100 routers in between. if you leave your traffic as HTTP, any one of those 100 routers can see whatever you are sending between one another.
Second, as an e-commerce, I’d like to have a decent website name that my end users can easily remember. Something like:
jambyiscool.ecvphdevs.com
In exercise D, we will do just that.
Resources:
- https://docs.aws.amazon.com/elasticloadbalancing/latest/application/create-application-load-balancer.html
## [D] Securing setup with HTTPS
Let's take it a step further.
- Buy a domain in GoDaddy and associate it with Route 53 (if you haven't). If you have access to an existing Domain Name, no need to do this step.
- Create a [public certificate](https://docs.aws.amazon.com/acm/latest/userguide/gs-acm-request-public.html) with [AWS Certificate Manager](https://docs.aws.amazon.com/acm/latest/userguide/acm-overview.html). You may have to create DNS records in your domain manager.
- [Associate the certificate with the ALB created earlier](https://repost.aws/knowledge-center/associate-acm-certificate-alb-nlb)
- [Create a route 53 record](https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/resource-record-sets-creating.html) for "jambyiscool.yourdomain.com" and point it to the load balancer you just created. If your domain manager is not Route 53, feel free to create the record in your domain manager.
**Architecture Diagram for Exercise D:**

Here is the end result:
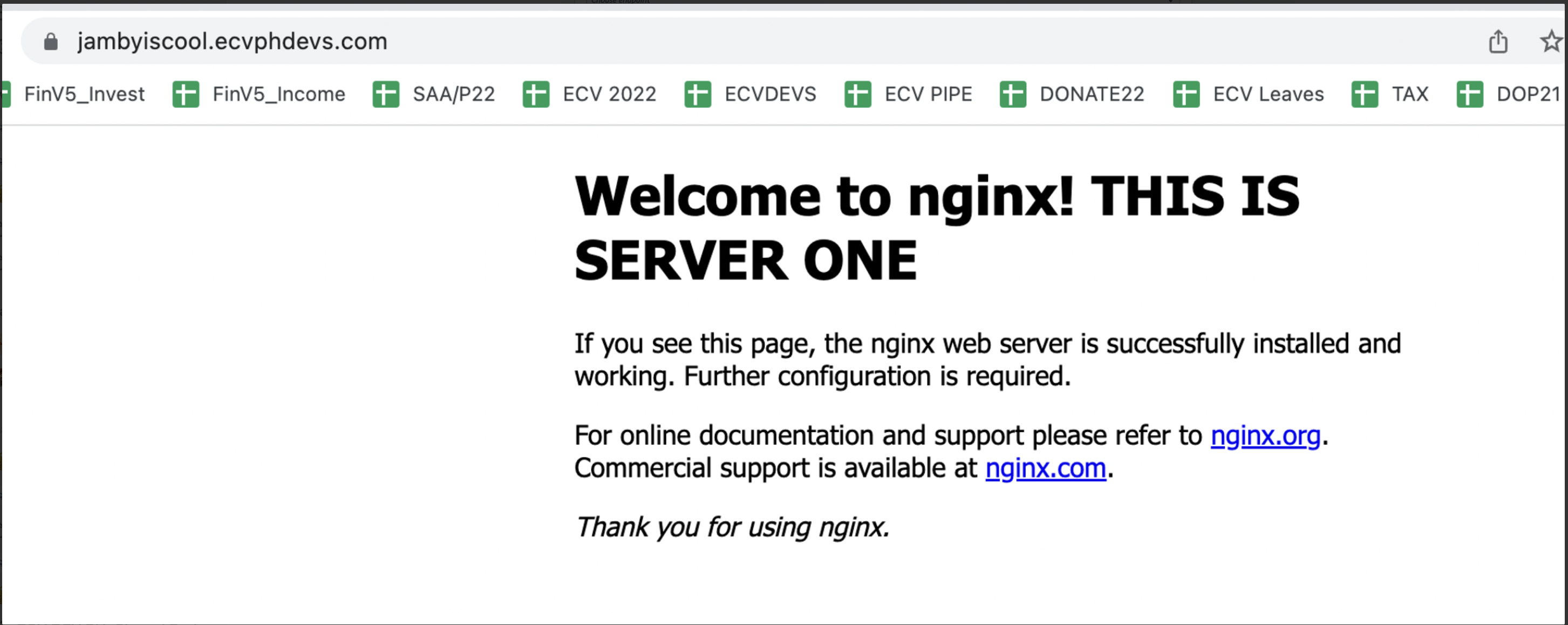
## What's next?
Congratulations on completing this exercise! You know have a full view on how VPC works, and have deployed your first application on a best practice version of a private network in AWS.
On the next challenge, we will be doing VPC peering, EC2 auto scaling, VPC endpoints and CI/CD. Stay tuned!
## Interested about joining ECV Philippines?
Send us your CV via email to ph.hr@ecloudvalley.com:

Photo by <a href="https://unsplash.com/@dulhiier?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Nastya Dulhiier</a> on <a href="https://unsplash.com/photos/lighted-city-at-night-aerial-photo-OKOOGO578eo?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Unsplash</a>
| raphael_jambalos |
1,861,086 | Building My Future in the Cloud: Lessons from the Cloud Resume Challenge | Introduction In my goal to expand my knowledge of cloud technologies, I undertook... | 0 | 2024-05-25T03:09:45 | https://dev.to/panduhzz/building-my-future-in-the-cloud-lessons-from-the-cloud-resume-challenge-1e8m | cloud, cloudresumechallenge, beginners |
## Introduction
In my goal to expand my knowledge of cloud technologies, I undertook the Cloud Resume Challenge. This project involved building a fully functional web-based resume hosted on the cloud, incorporating serverless technologies. This challenge offered a valuable opportunity to explore, gain knowledge, and experiment with serverless innovation, allowing me to focus on key areas such as Infrastructure-as-Code (IaC), CI/CD, and cloud deployment.
## Prerequisites
Embarking on my cloud journey, I aimed to acquire a foundational certification from one of the major cloud providers. I chose Azure due to my experience with their Entra ID offering. With the AZ-900 certification under my belt, I was ready to dive headfirst into this challenge. The project was divided into six bite-sized chunks, with each chunk containing various challenges for me to conquer. This post will detail my experiences with the project and the insights I gained from completing each stage.
## Front End
The first goal was to convert my resume into an HTML/CSS website and host it on Azure Blob Storage with a custom domain configured through Azure DNS. The website would then use Azure CDN for improved reliability.
For this portion, I utilized an HTML resume template I found online that would fit my needs as I do not have much experience with neither HTML nor CSS and I wanted to focus on the cloud aspect of this project. Additionally, I created a JavaScript file for the front end to make my web page interactive by calling my self-created API.
One step that I would have liked to implement if given more time with this project is to create end-to-end tests with Cypress.
### API
This next chunk challenged me quite a bit, as I’ve never written any sort of API that would interact with a storage service. One of the goals was to create a python function app in Azure to talk to a Cosmos DB table and set up the deployment via GitHub Actions. At first, I did not know how to initiate my function app to use POST, GET, or other such requests.
Through research, I learned that I could adjust the route decorator to specify the request types. Here’s how my functions looked after:
```python
#GET request
@app.route(route="readDB", auth_level=func.AuthLevel.ANONYMOUS, methods=['GET'])
def readDB():
logging.info("Received GET request")
#POST request
@app.route(route="updateDB", auth_level=func.AuthLevel.ANONYMOUS, methods=['POST'])
def updateDB():
logging.info("Received POST request")
```
Once this was completed, I also created tests using Playwright. The tests ensured both GET and POST requests returned a 200 response status, the GET request returned an integer, and the POST request updated the visitor counter.
## Infrastructure-as-Code
My language of choice for Infrastructure as Code (IaC) is Terraform because of its cloud-agnostic capabilities. For testing, I deployed my infrastructure with Terraform locally before moving to using Terraform Cloud with GitHub Actions.
If I were to do the project again, I would host my Terraform state in Azure Blob Storage for ease of use. However, creating a destroy plan proved to be challenging. While I couldn't utilize GitHub Actions to send a destroy plan to my Terraform Cloud workspace, I added an Azure CLI section to my GitHub Actions to successfully delete the resource group.
## CI/CD
For my CI/CD pipeline I chose to use GitHub actions as I was already using GitHub to store all my source code. I built my YAML files based on [this resource](https://developer.hashicorp.com/terraform/tutorials/automation/github-actions) from HashiCorp. For this step, I had hosted my front and backend in separate repositories. For my front end, I created a simple pipeline to deploy the Terraform infrastructure and then upload my front end code to my blob storage via Azure CLI.
For my backend, I created three YAML files. The first YAML file was triggered by a pull request on a branch other than the main one. This deployed my test infrastructure, deployed the function app via Azure CLI, and tested the API via Playwright tests.
Additionally, I implemented branch protection rules, requiring all actions to pass before merging with the main branch. The next YAML file was triggered upon closing a pull request. This ensured the deletion of my test infrastructure to avoid incurring charges from a lingering test environment. The final YAML file was triggered upon merging a pull request. This deployed my production infrastructure, the Azure function app, and conducted tests to verify the functionality of the API and frontend working together.
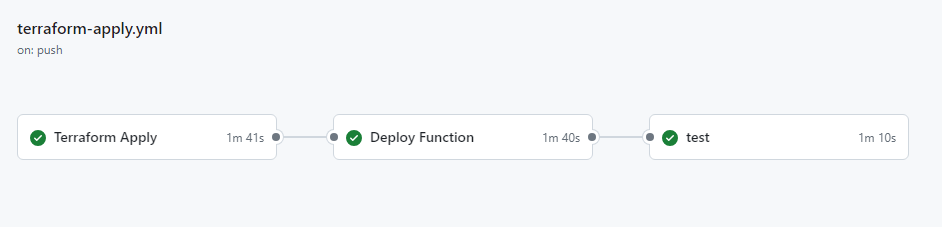
I ran into many errors here, but through countless trial-and-error runs, I completed this portion successfully.
## Wrapping Up
Working on this project was a fantastic learning experience. Not only did I get to dive deep into Azure and cloud technologies, but I also got hands-on experience with tools like Terraform, CI/CD pipelines, and end-to-end testing. These are all super valuable skills in today’s tech world that I find fascinating.
This challenge was just the beginning for me, and I'm excited to continue building on what I've learned through this project. Next up, I'm actively preparing for the Azure Administrator Associate certification, focusing on honing my skills in deploying and managing Azure resources.
https://github.com/panduhzz/CRCPanduhz_terraform
https://github.com/panduhzz/CRC_panduhz_tf_backend
https://www.panduhz.com/$web/index.html | panduhzz |
1,864,510 | Web Dev starts... | Today, I will be starting my web dev learning journey and I would like to help other students and... | 0 | 2024-05-25T02:59:47 | https://dev.to/tanya_singhal/web-dev-starts-38ie | Today, I will be starting my web dev learning journey and I would like to help other students and collaborate with them to get best out of it.
I am more happy to connect with the folks who are enthusiastic about learning web development.
I will share my learnings everyday here. Please stay tuned if you found useful. | tanya_singhal | |
1,864,509 | VCK Euro 2024 : Lịch Thi Đấu & Mọi Thứ Cần Nên Biết Trước Khi Nó Diễn Ra | VCK Euro 2024 : Lịch Thi Đấu & Mọi Thứ Cần Nên Biết Trước Khi Nó Diễn Ra Để chào mừng giải bóng... | 0 | 2024-05-25T02:53:23 | https://dev.to/vckeuro/vck-euro-2024-lich-thi-dau-moi-thu-can-nen-biet-truoc-khi-no-dien-ra-2mnj | webdev, javascript, programming, beginners | VCK Euro 2024 : Lịch Thi Đấu & Mọi Thứ Cần Nên Biết Trước Khi Nó Diễn Ra
Để chào mừng giải bóng đá lớn nhất Châu u – Euro 2024, Vegas79 sẽ cập nhật thêm tất cả những thông tin về VCK Euro 2024 này. Hãy cùng tìm hiểu ngay về lịch thi đấu, đội hình,Trực tiếp, Tỷ lệ kèo, Soi kèo và những tin tức xung quanh liên quan tới Euro 2024.
Xem thêm tại :
https://vstar79.me/vck-euro-2024/
Danh sách 24 ĐTQG tham dự VCK Euro 2024 lần này tại Đức.
Danh sách bảng đấu và các đội tuyển góp mặt tại VCK Euro 2024 bao gồm:
Bảng A: Đức, Scotland, Hungary, Thụy Sĩ
Bảng B: Tây Ban Nha, Croatia, Ý, Albania
Bảng C: Slovenia, Đan Mạch, Serbia, Anh
Bảng D: Ba Lan, Hà Lan, Áo, Pháp
Bảng E: Bỉ, Slovakia, Romania, Ukraina
Bảng F: Thổ Nhĩ Kỳ, Gruzia, Bồ Đào Nha, Cộng Hòa Séc
VCK Euro 2024 : Lịch Thi Đấu Mới Nhất
Những trận đấu đầu tiên tại lượt trận thứ nhất và thứ hai ở vòng bảng VCK Euro 2024.
VCK Euro 2024 : LINK XEM TRỰC TIẾP VCK EURO 2024 MỚI NHẤT
Tại Việt Nam, Viettel Telecom đã chính thức sở hữu được bản quyền Euro 2024. Như vậy, tất cả các trận đấu tại Euro lần này sẽ được phát trên các nền tảng truyền hình số và TV360.
Đại diện Viettel Telecom cũng cho biết sẵn sàng hợp tác, chia sẻ bản quyền với các đối tác truyền thông tại Việt Nam để người hâm mộ khắp nơi trên toàn quốc đều có thể “ăn, ngủ. thưởng thức” EURO 2024. Vì thế nhiều khả năng trong thời gian tới sẽ có thêm các đơn vị truyền thông công bố lịch trình phát sóng EURO 2024.
Không chỉ sở hữu bản quyền phát sóng trực tiếp vòng loại Euro 2024, Công ty Viettel còn sở hữu trọn vẹn Vòng chung kết Euro 2024 diễn ra từ ngày 14/6 đến ngày 14/7/2024.
Hoặc có thể tìm kiếm trên Google : VCK Euro2024, trực tiếp bóng đá, xoilactv, vstar79 rakhoitv,….
LINK XEM TRỰC TIẾP VCK EURO 2024 MỚI NHẤT
| vckeuro |
1,864,507 | What are the ethical and legal considerations when using TikTok video downloaders to save content from the platform?" | Using TikTok video downloaders to save content from the platform raises several ethical and legal... | 0 | 2024-05-25T02:42:32 | https://dev.to/rose_fareya_2c3055a7e15eb/what-are-the-ethical-and-legal-considerations-when-using-tiktok-video-downloaders-to-save-content-from-the-platform-5fn9 | Using [TikTok video downloaders](https://snaptok.net/) to save content from the platform raises several ethical and legal considerations that users should be aware of.
Legal Considerations
Copyright Infringement: Most TikTok videos are protected by copyright law. Downloading and redistributing these videos without permission from the content creator can constitute copyright infringement, which is illegal in many jurisdictions. The Digital Millennium Copyright Act (DMCA) in the United States, for example, strictly prohibits the unauthorized downloading and distribution of copyrighted content.
Terms of Service Violations: TikTok's terms of service generally prohibit users from downloading content without explicit permission. Using third-party downloaders often violates these terms, which can result in account suspension or other penalties imposed by TikTok.
| rose_fareya_2c3055a7e15eb | |
1,864,143 | Looking at A Monad Through An Example | Though many articles were written about Monad, this article shows how a Monad is used in practice... | 0 | 2024-05-25T02:26:52 | https://dev.to/sshark/looking-at-a-monad-through-an-example-17cb | scala | ---
title: Looking at A Monad Through An Example
published: true
description:
tags: scala
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-12 08:41 +0000
---
Though many articles were written about Monad, this article shows how a Monad is used in practice with an example and explains why a Monad is needed. Let's begin right away.
*The code snippets in this article are using Scala 3 syntax*
This article uses these 2 functions as an example,
``` scala
def div(a: Int, b: Int) = ??? // A
def add(a: Int, b: Int): Int = a + b // B
```
Function (A) divides the first integer by the second integer. Function (B) adds 2 integers together. These 2 functions are pretty straightforward. Unlike function (B), a [total function](https://www.linkedin.com/advice/0/what-difference-between-partial-total-function-functional-2jine#:~:text=A%20total%20function%20is%20a,return%20another%20number%20as%20output), function (A) cannot compute when the second parameter is 0. If the parameter types are `Float`, the function will return `Infinity`, but this is `Int`, throwing a `java.lang.ArithmeticException` exception with the message `/ by zero`. Function (A) must find a way to let its caller know it cannot compute if the second parameter is zero. There are a few ways to handle the error and fortunately, there is a clear way to do this.
Function (A) actual implementation is determined by how the value and error are handled in each scenario.
## Returning An Error Code
For some cases returning an error code is the simplest solution. When the function fails, it returns an error code to indicate failure. Case in point, for function (A), if parameter `b` is zero, it fails and returns `-1` given the following implementation,
``` scala
def div(a: Int, b: Int): Int = if (b == 0) -1 else a / b // Bad implementation
```
This is a bad implementation because `-1` is a legit value for `div(-8, 8)`. There is no integer the function can return to indicate an error. Therefore, this method is not viable.
## A Error And Result Pair
Next, we split the error and result into a pair,
``` scala
def div(a: Int, b: Int): (String, Int) = if (b == 0) ("/ by zero", 0) else (null, a / b)
val (error1, value1) = div(10, 2) // (null, 5)
if (error1 == null) {
println(s"The result of 10 / 2 is $value1")
} else {
println("Cannot be divided by zero")
}
val (error2, value2) = div(10, 0) // ("/ by zero", 0)
// repeat the if-else block with error1 replace by error2
```
The second part of the extraction logic conflicts with [DRY](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself) principle. Yes, we can refactor the `if-else` block into a function,
``` scala
def extract[A](result: (String, Int), ifOk: A => Unit, ifNOK: A => Unit) =
if (result._1 == null) {
println(s"The result of 10 / 2 is ${result._2}")
} else {
println("Cannot be divided by zero")
}
```
Unfortunately, `extract (...)` is so restrictive. This will cause writing `extract(...)` to suit simple needs in many ways. Also, what if I want to compose the result of the function `div(...)` with `add(...)` i.e. `add(1, div(10, 0))`. The permutation will explode. This method is workable but soon it becomes a maintenance nightmare once the requirements get complicated.
## Throwing An Exception
In Scala, all exceptions are unchecked unlike Java, where exceptions are split into checked `Exception` and unchecked `RuntimeException`. In Java, functions that throw checked exceptions are enclosed in a `try-catch` block. On the other hand, Scala developers use the `try-catch` block to catch the exception they want to catch.
In retrospect, throwing an exception seems to be the way forward. It is easy to implement the function (A) using the exception,
``` scala
def div(a: Int, b: Int): Int = a / b
```
The responsibility lies with the caller to catch the exception but the developer does not know if a function can throw an exception when certain parameteric values are met. Consequently, any function that the application uses can cause the application to be unusable or unstable at best if the exception is not caught in its place. This makes the job of the developers very unpleasant. Worse, we are back to writing our code the Java-style with `try-catch` or `try-catch-finally` blocks everywhere blindfolded[^canThrow].
[^canThrow]: Scala 3 is experimenting with the selective checked exception capture using the [`CanThrow`](https://docs.scala-lang.org/scala3/reference/experimental/canthrow.html) capability.
## The Better Answer, Use An Effect
The effect in this context is a *container* or more specifically, a container with capabilities. The effect is not a *side effect*. A simple container like `Option` is a list with the maximum capacity of 1 element or empty. With the `Option` effect the function can let its caller know its return status. The function will return `Some` or None to indicate success or failure. Function (A) implementation and usage would look like this
``` scala
def div(a: Int, b: Int): Option[Int] = if (b == 0) None else Some(a / b)
val result1: Option[Int] = div(10, 2) // Some(5)
val result2: Option[Int] = div(10, 0) // None
// print the result
def extract(result: Option[Int]): Unit = result match {
case Some(x) => println(s"The result is $x")
case None => println("Cannot be divided by 0")
}
extract(result1) // The result is 5
extract(result2) // Cannot be divided by 0
```
Please do not eagerly extract values from the effect unless this is the final call.
Let's say, we have a function to add 10 to the result if the result is even otherwise cancel the whole calculation. `None` represents the cancelation in the composed function.
It is not recommended to write `addIfEven(10, div(10, 2).get)` because when `div(...)` returns a `None` instead of a `Some[Int]`, invoking a `get` on `None` would cause an exception.
Using `Option` inside the function i.e. `addIfEven(a: Int, b: Option[Int]): Option[Int]` is bad in this case because it makes the code difficult to work with the values inside `Option`.
Instead, define as `addIfEven(a: Int, b: Int): Option[Int]` and write the code the following way,
``` scala
val result3: Option[Int] = for {
x <- div(10, 2)
y <- addIfEven(10, x)
} yield y
extract(result3) // The result is 15
val result4: Option[Int] = for {
x <- div(10, 0)
y <- addIfEven(10, x)
} yield y
extract(result4) // Cannot be divided by zero
```
It is not necessarily for the developer to check if the call to `div(...)` is a success or failure before moving on to the next function. The result will be fed to the next function and continue to do so as long as there are functions to call, the final result from the [*for-comprehension*](https://docs.scala-lang.org/tour/for-comprehensions.html) loop will return `Some` of a value or `None`.
Had the function (B) returned the result of type `Option[Int]` instead of `Int`, we can rewrite the for-comprehension loop as,
``` scala
def add(a: Int, b: Int): Option[Int] = Some(a + b)
val result5: Option[Int] = for {
x <- div(10, 2)
y <- add(10, x)
} yield y
```
What if we want the function to provide the error message instead? We can use `Either[String, Int]`.
``` scala
def div(a: Int, b: Int): Either[String, Int] =
if (b == 0) Left("/ by zero") else Right(a / b)
def extract(result: Either[String, Int]): Unit = result match {
case Right(x) => println(s"The result is $x")
case Left(err) => println(s"Error: $err")
}
val result6: Either[String, Int] = for {
x <- div(10, 2)
} yield add(10, x)
extract(result6) // The result is 5
val result7: Either[String, Int] = for {
x <- div(10, 0)
} yield add(10, x)
extract(result7) // Error: / by zero
```
Use exception to simply `div(...)`,
``` scala
def div(a: Int, b: Int): Either[String, Int] =
try {
Right(a / b)
} catch {case e: ArithmeticException => Left(e.getMessage)}
```
> **Sidebar**\
> As we discover later on, we can use other data types like [`Try`](https://www.scala-lang.org/api/3.3.3/scala/util/Try.html) from the standard Scala library or `IO` from a 3rd party library [Cats Effect](https://typelevel.org/cats-effect/).
>As mentioned before, an effect is a container with capabilities: -
>1. `Option` provides a value or no value (empty) capability.
>2. `List` provides a list of values or no value (empty) capability.
>3. `Try`, like the `try-catch` block, catches any exception thrown within it.
>4. `IO` is an IO Monad which has many capabilities which include handling side-effects, error handling, parallel computation, and many more.
## And The Point Is...
Using effect is a good approach to resolve this issue. But, what does this have to do with Monads? This is one of many ways using Monads to simplfy branching between actual and unexpected (bad) events without deeply nested `if-else-then` branches in the flow. The same monadic approach can be used to solve other issues in a similar fashion like how bad parameter or input is handled. However, this topic requires more reading and practice before it can be truly useful. We have to start somewhere. The payoff is making the code highly manageable as more code is added to tackle new requirements. Thank you for reading.
### For-Comprehension And Typeclass (Optional)
A Monad is a typeclass[^tc] that has a few functions. In the interest of this article, the focus is on the `map` and `flatMap` functions. `map` is inherited from the Functor. Strictly speaking, a Monad is a subclass of *Applicative* which in turn a subclass of *Functor*.
[^tc]: Typeclass is like Java `interface`. However, It is imperative to understand how typeclass functions. Please refer to https://dev.to/jmcclell/inheritance-vs-generics-vs-typeclasses-in-scala-20op for an introduction.
In Scala, the for-comprehension loop is a synatic sugar for a series of `flatMap` and `map`e.g.,
``` scala
val result8: Option[Int] = for {
x <- div(10, 2)
y <- Option(x - 10)
} yield add(10, y)
// loosely converted to
val result8: Option[Int] =
div(10, 2)
.flatMap(x => Option(x - 10)
.map(y => add(10, y)))
```
Classes like `Option`, `List`, and `Either` can work right out of the box with for-comprehension because these classes have `map` and `flatMap` methods defined. If a random class `MyBox` without these 2 methods defined, it would not work. The developer could add these methods to `MyBox` if the developer owns the source. If he does not, then he has to use adhoc polymorphism a.k.a typeclassing which is very useful for extending the class capabilities. Please refer to [here](https://gist.github.com/sshark/6a169bedfa97718dd72eb0738fbb046f) for the `MyBox` Monad typeclass implemention and example.
Classes must conforms to the [Monad Law](https://devth.com/monad-laws-in-scala) to be a Monad. For example, `Option`, `List`, and `Either` are monads because they passed the Monad Law test. Classes like `Set` and `Try` are not because they failed the test even though they have `map` and `flatMap` methods defined.
| sshark |
1,864,506 | The Ultimate Guide to Fitness Competitions | *Unleash Your Strength: The Ultimate Guide to Fitness Competitions * Introduction Fitness... | 0 | 2024-05-25T02:26:37 | https://dev.to/laura_leonard_be0dc9e261c/the-ultimate-guide-to-fitness-competitions-2c2g | fitness, alltimefitness, bodybuilding, productivity | **Unleash Your Strength: The Ultimate Guide to Fitness Competitions
**

**Introduction**
Fitness competitions have gained immense popularity in recent years, attracting individuals from
all walks of life who are passionate about health, fitness, and showcasing their hard work and
dedication on stage. In this comprehensive guide, we'll delve into the world of fitness
competitions, exploring the different divisions, criteria for judging, preparation strategies,
competition day rituals, and post-competition reflections.
**Understanding Fitness Competitions**
Fitness competitions encompass a variety of divisions, catering to both men and women. In the
men's division, competitors display strength, agility, and overall athleticism through a series of
routines that incorporate gymnastic and dance elements. Women's fitness competitions follow a
similar format, with an emphasis on grace, flexibility, and muscularity.
Judging criteria in fitness competitions are multifaceted, encompassing aspects such as
muscularity, symmetry, and routine performance. Competitors are evaluated based on the
development and definition of their muscles, as well as the balance and proportionality of their
physique. Additionally, judges assess the execution and creativity of each competitor's routine,
looking for fluidity, expression, and stage presence.
**Preparing for Competition**
Preparing for a fitness competition requires meticulous planning and dedication. Setting clear
and achievable goals is essential, whether it's improving muscle definition, enhancing flexibility,
or perfecting routine choreography. A well-structured training plan that combines strength
training, cardiovascular exercise, and flexibility training is crucial for achieving optimal results.
Nutrition plays a pivotal role in competition preparation, fueling workouts, supporting muscle
growth, and enhancing recovery. Competitors often follow strict dietary regimens tailored to their
individual needs, focusing on lean proteins, complex carbohydrates, healthy fats, and ample
hydration. Timing meals and supplements strategically can maximize energy levels and optimize
performance on stage.
Posing and stage presence are also key aspects of competition preparation. Practicing
mandatory poses and refining transitions helps competitors showcase their physique with
confidence and poise. Additionally, developing a captivating and dynamic routine that highlights
strengths and personality can set competitors apart and leave a lasting impression on judges
and audience members alike.
**Competition Day**
Competition day is the culmination of weeks or months of hard work and preparation. Final
preparations typically involve fine-tuning physique, practicing posing, and mentally visualizing
routines. Many competitors also employ techniques such as carb-loading and pump-up
exercises to enhance vascularity and muscle definition prior to stepping on stage.
Backstage, competitors navigate a bustling environment filled with anticipation and
camaraderie. Supporting fellow competitors, staying hydrated, and maintaining focus are
essential for a successful competition day experience. Following backstage etiquette and
adhering to competition guidelines ensure a smooth and organized event for all participants.
On stage, competitors have the opportunity to shine and showcase their dedication and
athleticism. Confidence, poise, and stage presence are paramount as competitors execute their
routines with precision and grace. Judges carefully evaluate each performance, considering
factors such as technical proficiency, artistic expression, and overall presentation. [read more](https://sites.google.com/view/fitnessco/home) | laura_leonard_be0dc9e261c |
1,864,456 | [S.O.L.I.D.] Os Cinco Pilares da Programação Orientada a Objetos. [D] Dependency Inversion Principle - DIP | Continuando a série sobre SOLID, caso não tenha lido o artigo anterior: ... | 0 | 2024-05-25T02:25:46 | https://dev.to/diegobrandao/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-d-dependency-inversion-principle-dip-2d5n | java, solidprinciples | Continuando a série sobre SOLID, caso não tenha lido o artigo anterior:
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-i-interface-segregation-principle-isp-3ho3 %}
Neste artigo estarei falando sobre o **quinto** e último **princípio** que é:
**[D] - Dependency Inversion Principle**
**Princípio da Inversão de Dependência - DIP**
“Módulos de alto nível não devem depender de módulos de
baixo nível. Ambos devem depender de abstrações;
Abstrações não devem depender de detalhes.”
Vamos considerar um exemplo de um sistema de gestão de produtos em uma loja online. Este sistema precisa armazenar informações sobre os produtos em um banco de dados. Inicialmente, podemos implementar isso com uma dependência direta da classe ProductDatabase na classe ProductService. Em seguida, aplicaremos o Princípio da Inversão de Dependência (DIP) para melhorar o design.
_Sem DIP_
**Implementação direta**
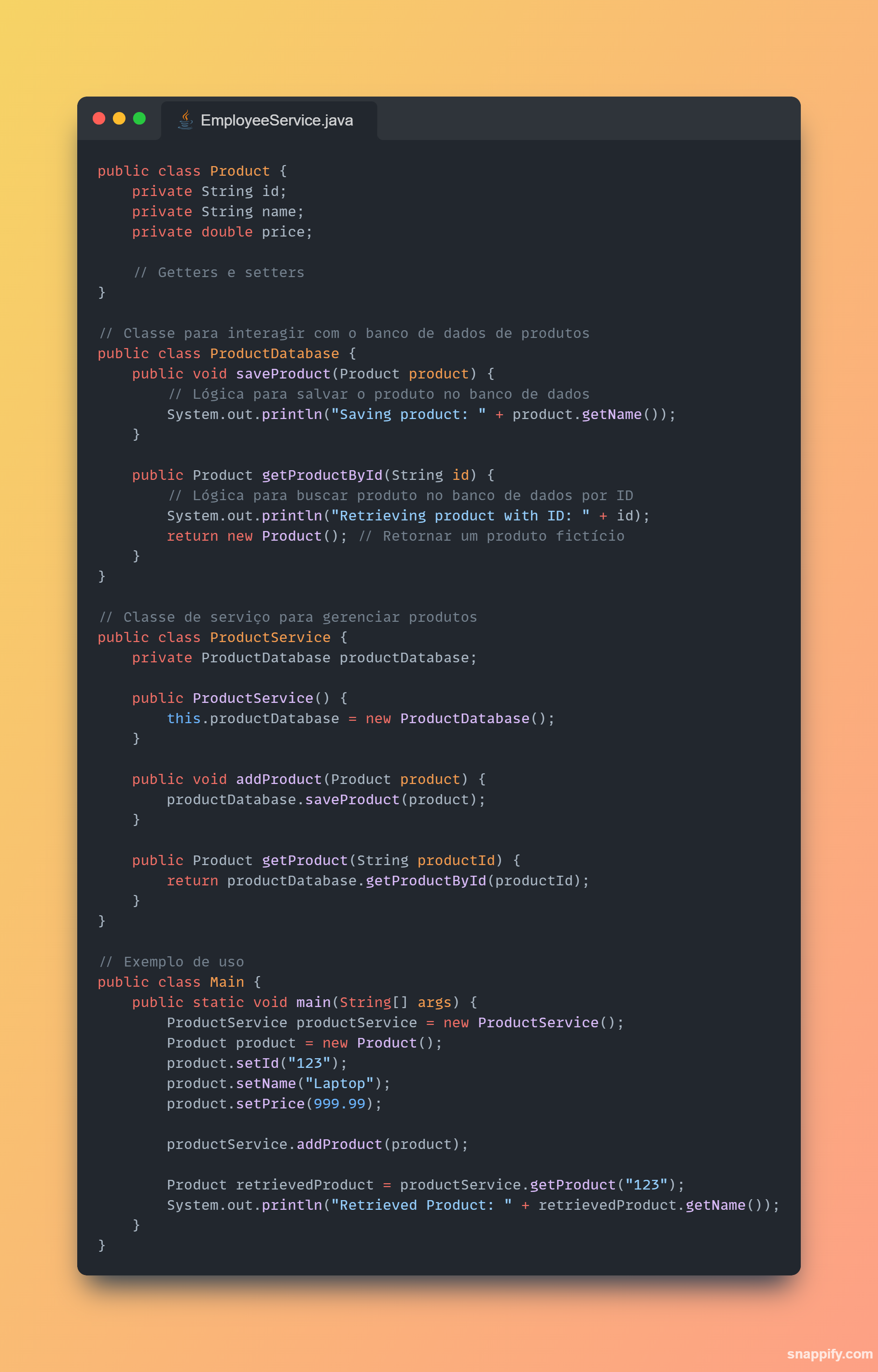
**Neste exemplo, ProductService depende diretamente de ProductDatabase, o que viola o DIP.**
_Com DIP_
Para seguir o DIP, vamos introduzir uma interface para a interação com o banco de dados e fazer com que ProductService dependa dessa interface em vez de uma implementação concreta.
**Interface ProductRepository**

**Implementação ProductDatabase com DIP**
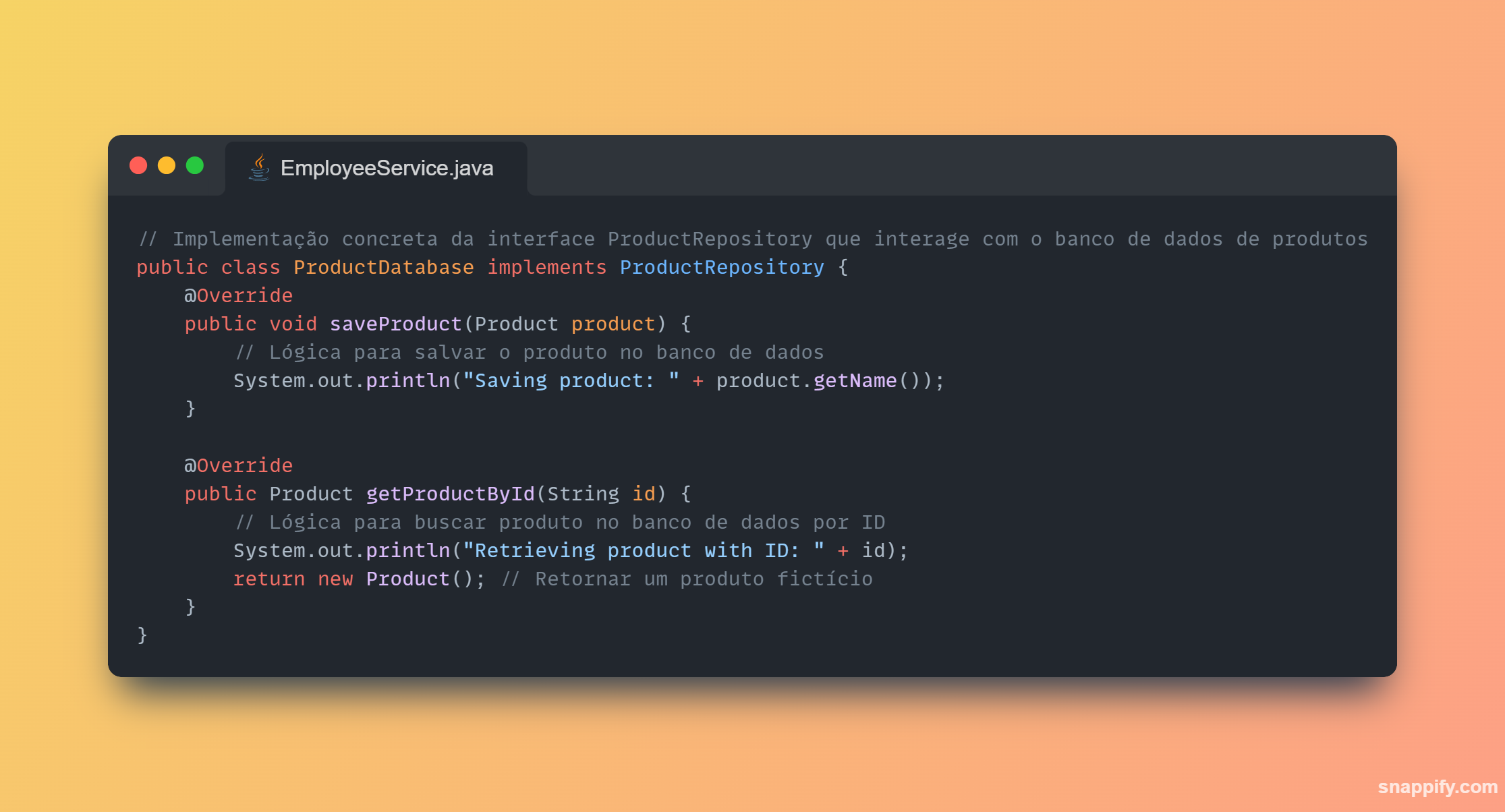
**ProductService com DIP**
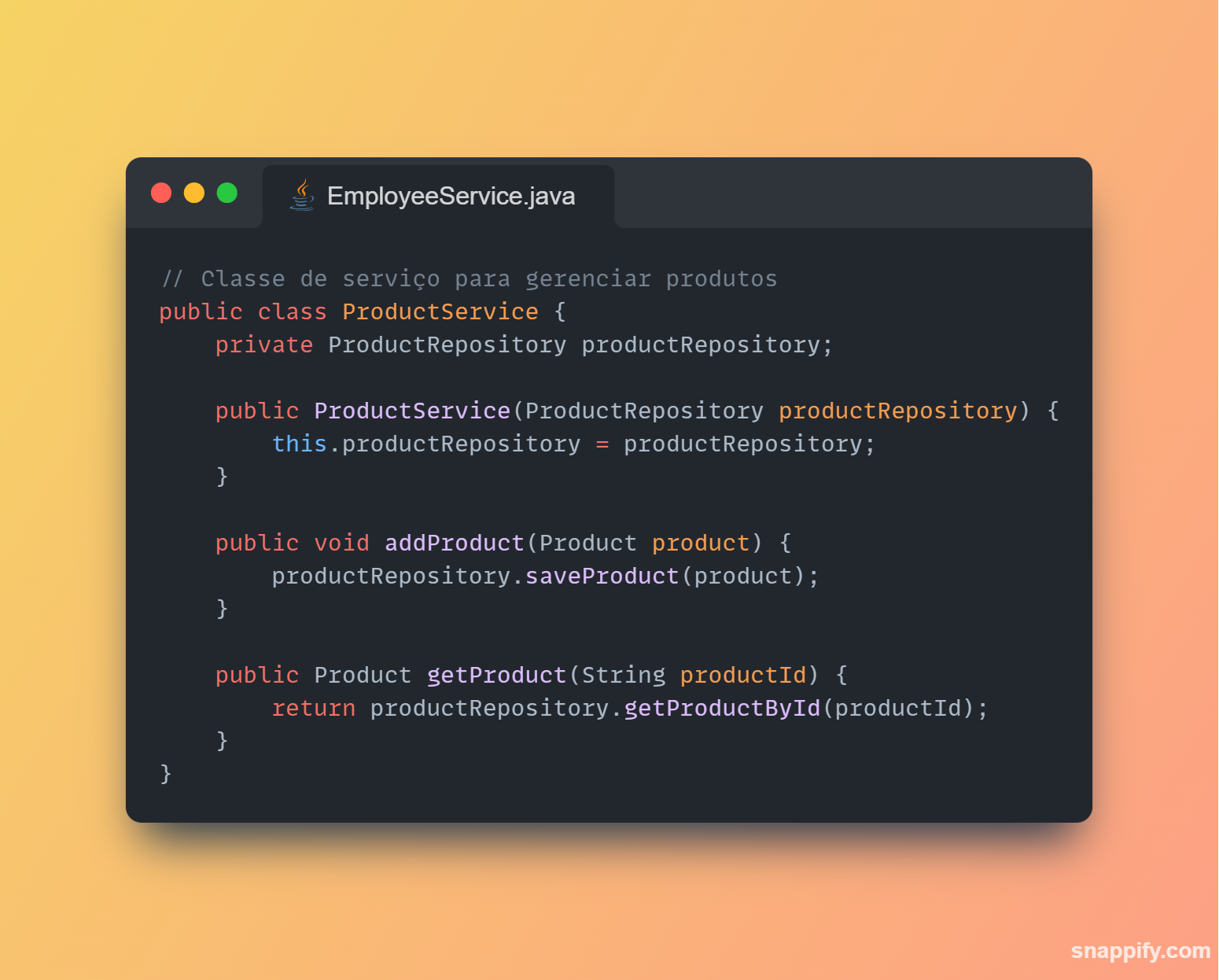
**Uso das Classes**
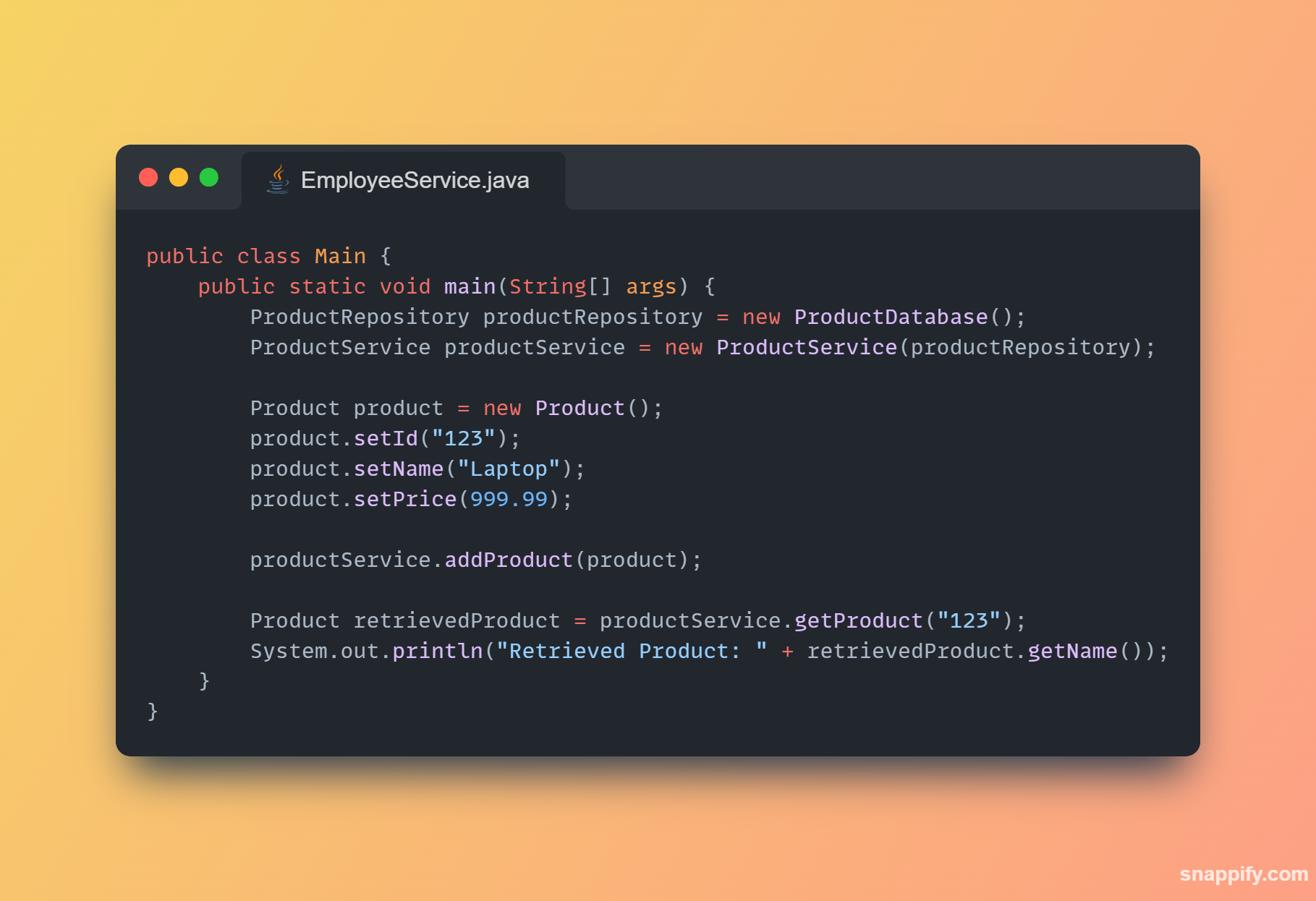
Explicação:
- Interface ProductRepository: Introduzimos uma interface para definir o contrato para interagir com o banco de dados de produtos.
- Implementação ProductDatabase com DIP: Implementamos a interface ProductRepository na classe ProductDatabase. Isso separa a lógica de interação com o banco de dados do restante do código.
- ProductService com DIP: ProductService agora depende apenas da abstração ProductRepository, não de uma implementação concreta de banco de dados. Isso permite uma maior flexibilidade e facilidade de manutenção, pois podemos trocar facilmente a implementação do banco de dados sem alterar ProductService.
**Ao seguir o Princípio da Inversão de Dependência, garantimos que os módulos de alto nível (como ProductService) dependam de abstrações (como ProductRepository) em vez de depender de implementações concretas. Isso torna o código mais flexível, reutilizável e de fácil manutenção, pois reduz o acoplamento entre os componentes do sistema.**
_PS: Caso não tenho visto ou queira ver os princípios na ordem segue link abaixo:_
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-para-desenvolvedores-2lph %}
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-o-openclosed-principle-ocp-3bal %}
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-l-liskov-substitution-principle-lsp-5ebg %}
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-i-interface-segregation-principle-isp-3ho3 %}
| diegobrandao |
1,853,366 | Create Your First Discord Bot with Lambda | Let's set up a TypeScript package that uses the AWS CDK to deploy a Lambda function for handling... | 0 | 2024-05-25T01:59:30 | https://dev.to/devbu9/create-your-first-discord-bot-with-lambda-4om4 | Let's set up a TypeScript package that uses the AWS CDK to deploy a Lambda function for handling Discord bot slash commands. Below is a step-by-step guide on how to structure your package and the necessary scripts.
# Step by Step Guide
### 1. Pre-requisites
- AWS
- NodeJS
- Discord
### 2. Initialize your CDK project
```bash
mkdir discord-bot
cd discord-bot
cdk init app --language=typescript
```
### 3. Install necessary dependencies
```bash
npm install @types/aws-lambda dotenv discord.js discord-interactions
npm install -D typescript jest @types/jest @types/aws-lambda ts-jest esbuild
```
### 4. Add the following options to `tsconfig.json`
```json
{
"compilerOptions": {
...
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"outDir": "dist"
},
}
```
### 5. Create `.env` file with following parameters copied
```bash
DISCORD_TOKEN=<YOUR_DISCORD_TOKEN>
DISCORD_CLIENT_ID=<DISCORD_CLIENT_ID>
DISCORD_PUBLIC_KEY=<DISCORD_PUBLIC_KEY>
```
### 6. update npm commands in `package.json`
```json
"scripts": {
"clean": "rm -rf dist && rm -rf cdk.out",
"build": "tsc",
"watch": "tsc -w",
"test": "jest",
"register": "node dist/src/commands/register-commands.js",
"deploy": "npm run clean && npm run build && npm run register && cdk deploy"
},
```
### 7. Copy the files under `lib` and `src`
```
// Copy the entire folder
```
### 8. Run the commands
```
npm run deploy
```
### 9. Copy the CloudFormation output printed to `INTERACTIONS ENDPOINT URL` section and save.
### 10. Refresh the discord and Tadah!!
| devbu9 | |
1,864,468 | Securing the Cloud #30 | Welcome to the 30th edition of the Securing the Cloud Newsletter! In this issue, we dive into the... | 26,823 | 2024-05-25T01:45:47 | https://brandonjcarroll.com/links/ehj95 | aws, security, career, community | Welcome to the 30th edition of the Securing the Cloud Newsletter! In this issue, we dive into the latest trends and insights in cloud security, explore career development opportunities, and share valuable learning resources. Additionally, we feature insightful perspectives from our community members.
## Technical Topic

* [How to Apply GitOps to Everything Using Amazon Elastic Kubernetes Service (Amazon EKS), Crossplane, and Flux | AWS Open Source Blog](https://brandonjcarroll.com/links/hoke0) - This post provides a detailed walkthrough on using GitOps, Crossplane, and Flux to provision and manage cloud infrastructure and applications on Amazon Web Services (AWS). It explains how GitOps enables declarative management of cloud-native stacks, while Crossplane allows using Kubernetes APIs to provision and manage resources across different cloud providers. By following this tutorial, you'll gain practical experience in leveraging the power of GitOps, Crossplane, and Flux to streamline your cloud infrastructure and application deployments on AWS. You'll learn how to version your desired state in Git, automate deployments, and consistently manage resources across environments.
## Career Corner

* [Reddit - Dive into anything](https://www.reddit.com/r/Terraform/comments/13sbl1b/if_you_do_infrastructureascodeare_you_a_developer/) - Are you someone who works with Infrastructure-as-Code tools like Terraform? If so, this thread goes into an interesting debate - what exactly do you identify as professionally? Are you a developer since you're writing code? An infrastructure engineer since you're provisioning infrastructure? Or perhaps both roles blend together in the world of IaC?
## Learning and Education

* [A Beginners Guide to GitOps](https://page.gitlab.com/resources-ebook-beginner-guide-gitops.html) - GitOps takes the tried-and-true DevOps best practices used for application development, such as version control, collaboration, compliance, and CI/CD, and applies them to infrastructure automation. By leveraging the principles of Git, the widely-adopted version control system, GitOps empowers teams to manage and automate their infrastructure with the same level of rigor and efficiency as they do with their application code. Dive into this beginner's guide to GitOps and discover how this powerful framework can transform your infrastructure automation journey.
## Community Voice

1. [Mastering the AWS Security Specialty (SCS) Exam - A Quick Guide - DEV Community](https://dev.to/aws-builders/mastering-the-aws-security-specialty-scs-exam-a-quick-guide-2go0) - Want to ace the challenging AWS Certified Security Specialty exam? This guide shares invaluable tips and top resources that helped Damien pass on their first attempt. Get an inside look at must-use study materials like Stephane Maarek's comprehensive Udemy course, Whizlabs' hands-on labs for practical experience, TutorialsDojo's realistic practice exams and cheat sheets, and Becky Weiss's session on AWS cloud security fundamentals.
2. [Enable GuardDuty the Right Way](https://slaw.securosis.com/p/enable-guardduty-right-way) - In this article, Rich Mogull takes readers on a journey through the importance of GuardDuty, AWS's Intrusion Detection System for the cloud. With his signature storytelling flair, Mogull transports us back to the "dark days" of the early cloud era, highlighting the significance of visibility tools like CloudTrail and GuardDuty.
3. [Tactical Cloud Audit Log Analysis with DuckDB - AWS CloudTrail - DEV Community](https://dev.to/aws-builders/tactical-cloud-audit-log-analysis-with-duckdb-aws-cloudtrail-2amk) - Have you ever needed to analyze CloudTrail logs but found yourself without a convenient search interface or had to temporarily enable CloudTrail for troubleshooting? This article demonstrates how to leverage the capabilities of DuckDB, a powerful open-source SQL database, to query CloudTrail logs directly from Amazon S3.
4. [AWS Cloud Incident Analysis Query Cheatsheet - Securosis](https://securosis.com/blog/aws-cloud-incident-analysis-query-cheatsheet/) - This post provides a comprehensive cheatsheet of essential CloudTrail log queries for cloud incident analysis and response.
5. [Publicly Exposed AWS Document DB Snapshots – High Signal Security – YAIB](https://ramimac.me/exposed-docdb) - Security researcher Dylanjacob discovered a massive public exposure of over 3.5TB of sensitive customer data. Here is the story!
## Conclusion
Thanks for coming along for this weeks journey. I encourage you to subscribe, share, and leave your comments on this edition of the newsletter. Please share with your colleagues and if you have any requests please send them my way. I hope you found this useful. Happy Labbing! | 8carroll |
1,864,454 | to my baby | Check out this Pen I made! | 0 | 2024-05-25T01:40:31 | https://dev.to/jay005/to-my-baby-1d8m | Check out this Pen I made!
{% codepen https://codepen.io/mdusmanansari/pen/BamepLe %} | jay005 | |
1,864,406 | [S.O.L.I.D.] Os Cinco Pilares da Programação Orientada a Objetos. [I] - Interface Segregation Principle - ISP | Continuando a série sobre SOLID, caso não tenha lido o artigo anterior: ... | 0 | 2024-05-25T01:38:31 | https://dev.to/diegobrandao/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-i-interface-segregation-principle-isp-3ho3 | java, solidprinciples | Continuando a série sobre SOLID, caso não tenha lido o artigo anterior:
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-l-liskov-substitution-principle-lsp-5ebg %}
Neste artigo estarei falando sobre o **quarto princípio** que é:
**[I] -Interface Segregation Principle,**
**Princípio da Segregação de Interfaces - ISP**
“os clientes que implementam uma interface não devem ser obrigados a implementar uma ação/método que não utiliza”
Definição: Os clientes não devem ser forçados a depender de interfaces que não utilizam. Em outras palavras, é melhor ter várias interfaces específicas do que uma única interface geral.
Vamos considerar um exemplo do mundo real envolvendo um sistema de gerenciamento de funcionários em uma empresa. Este sistema precisa lidar com diferentes tipos de funcionários, como funcionários regulares, gerentes e funcionários terceirizados. Inicialmente, podemos ter uma interface única para gerenciar todos os tipos de funcionários, mas aplicaremos o ISP para melhorar o design.
_Sem ISP_
**Interface EmployeeManagement sem ISP**
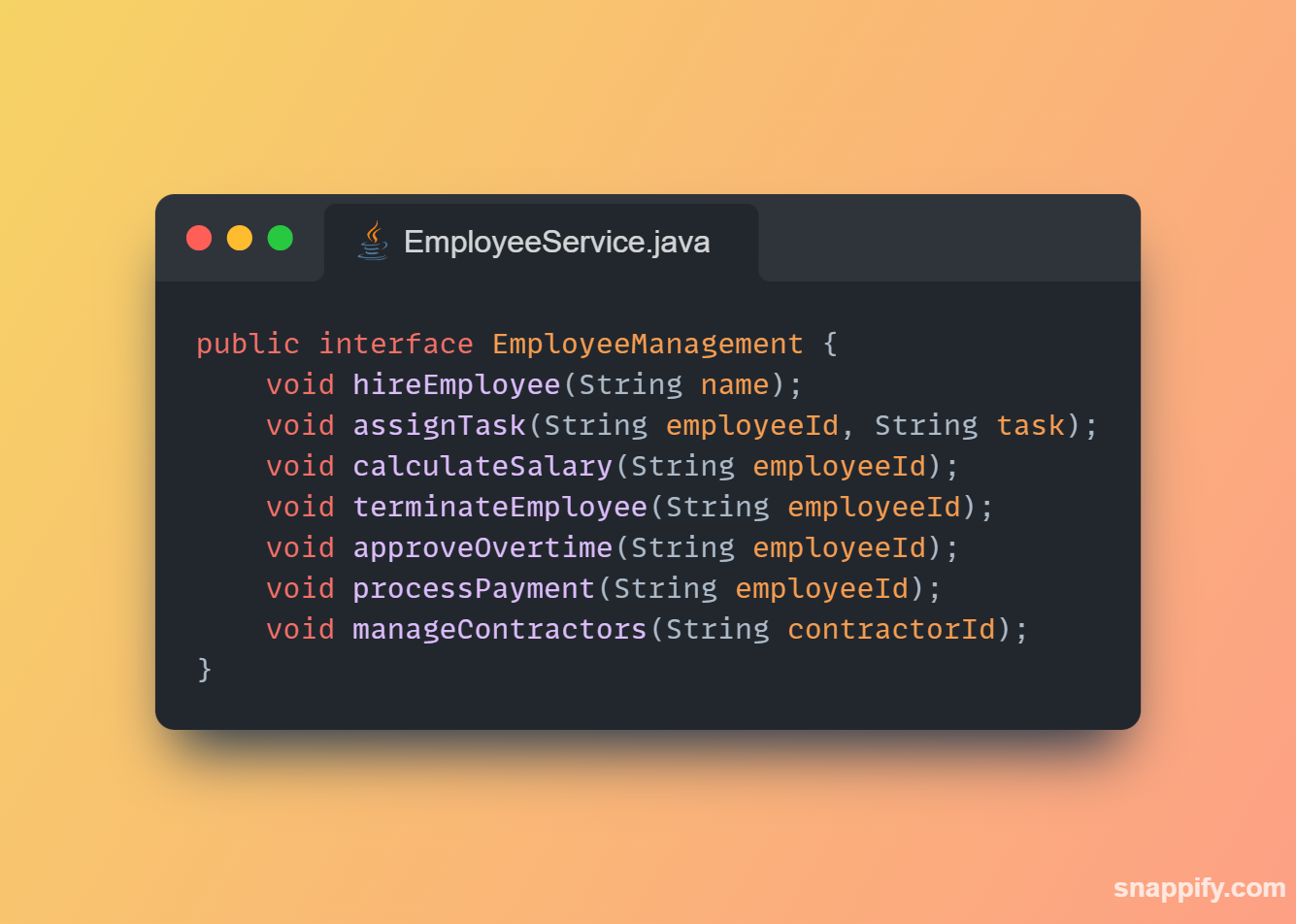
**Implementação HRSystem sem ISP**
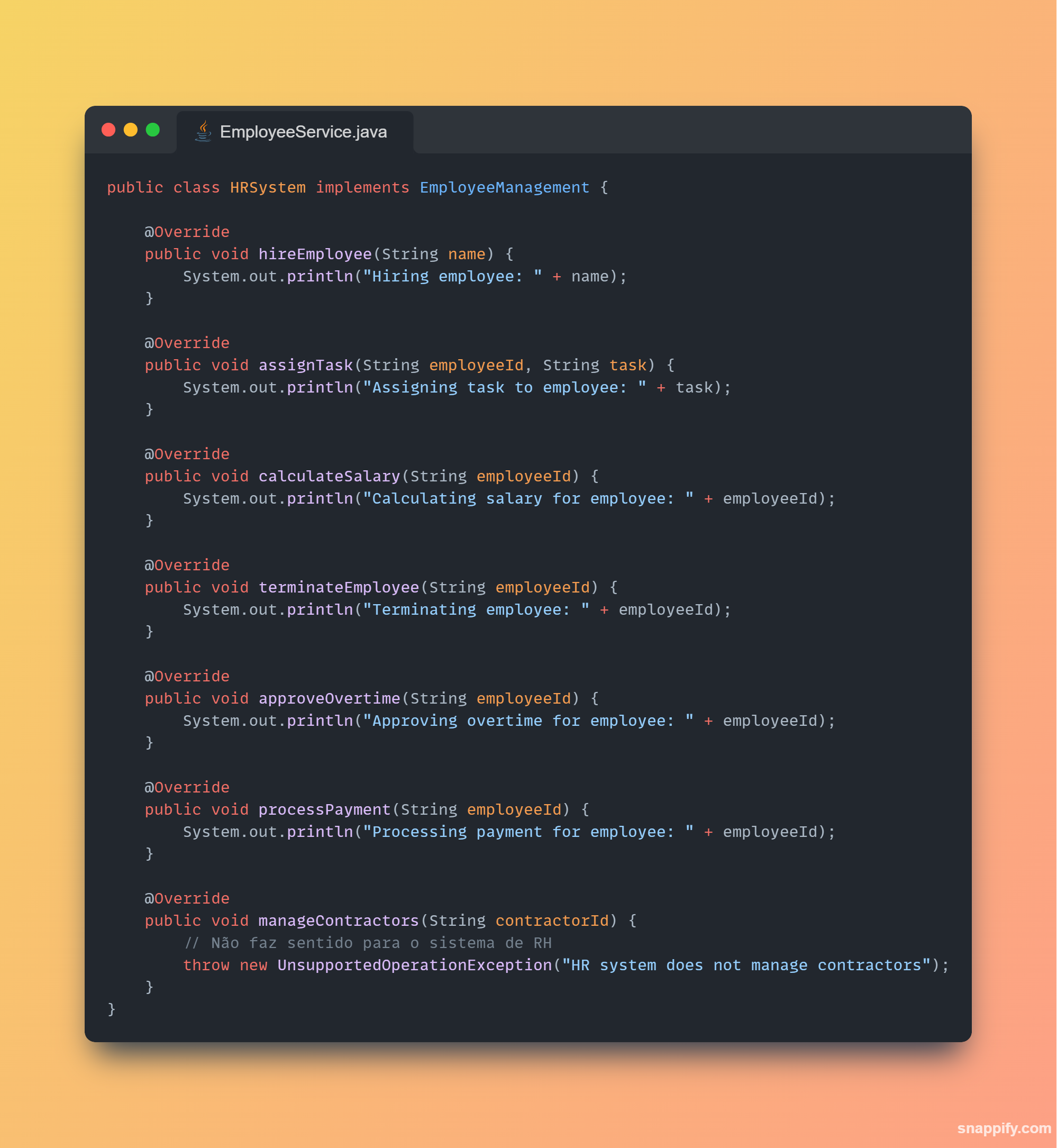
Neste exemplo, HRSystem é forçado a implementar métodos que não fazem sentido para ele (manageContractors), o que viola o ISP.
_Com ISP_
Para seguir o ISP, vamos dividir a interface EmployeeManagement em interfaces específicas para diferentes tipos de funcionários.
**Interface EmployeeManagement**
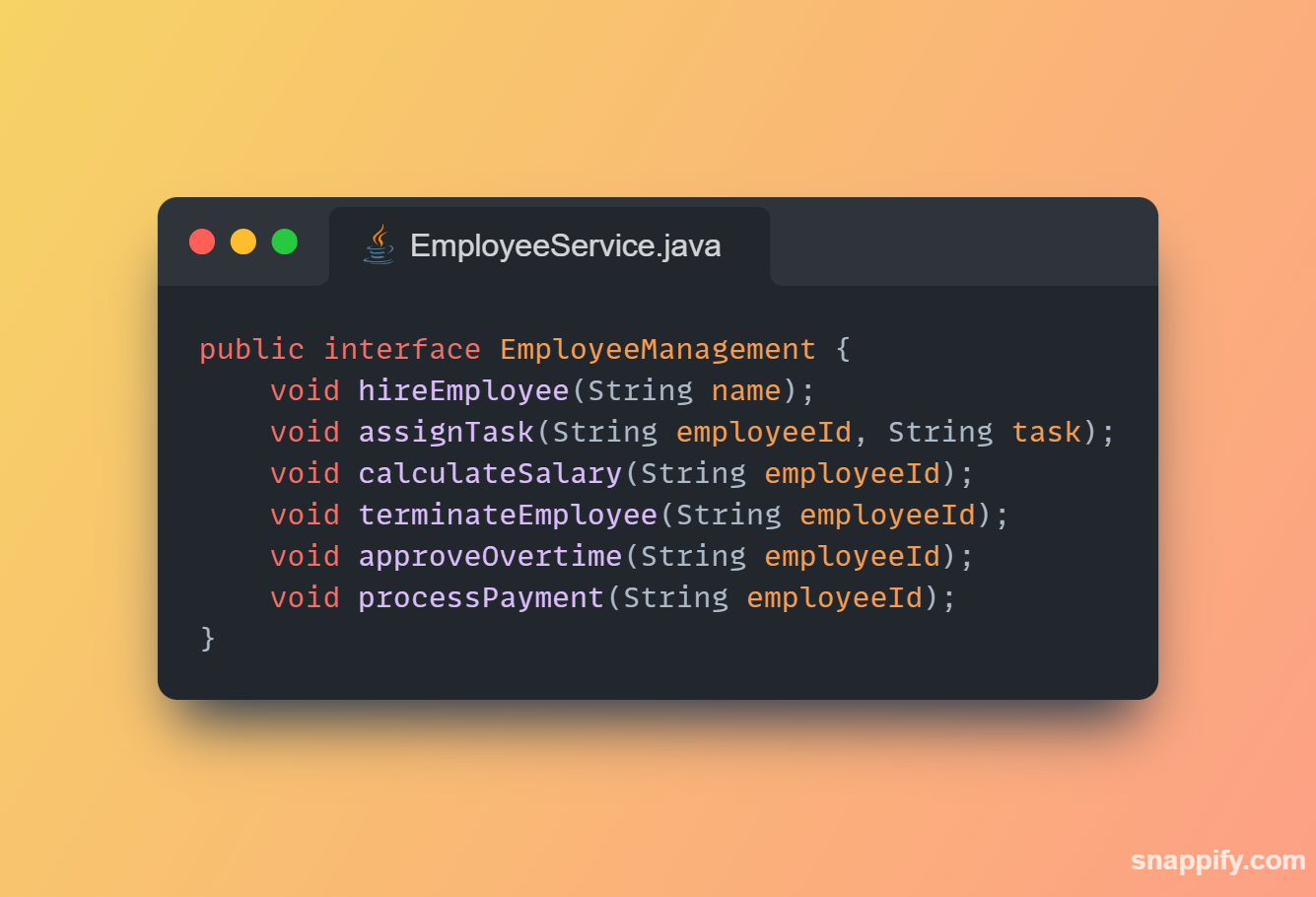
**Interface ContractorManagement**
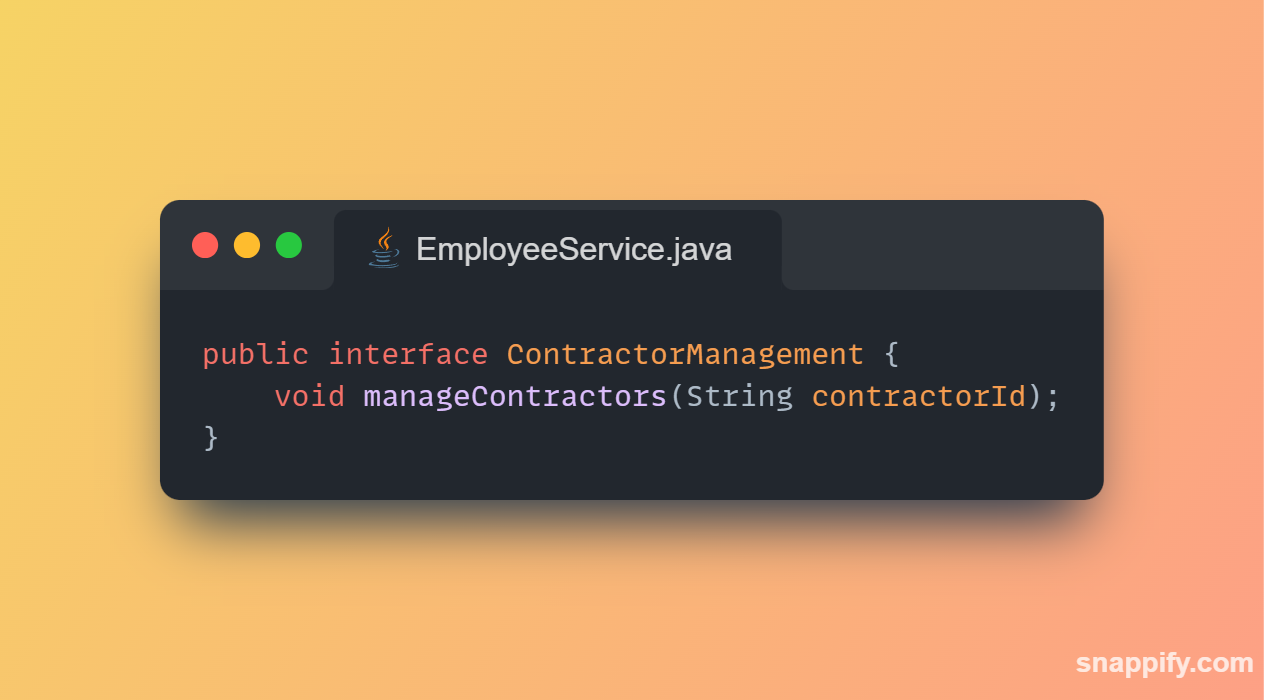
**Implementação HRSystem com ISP**
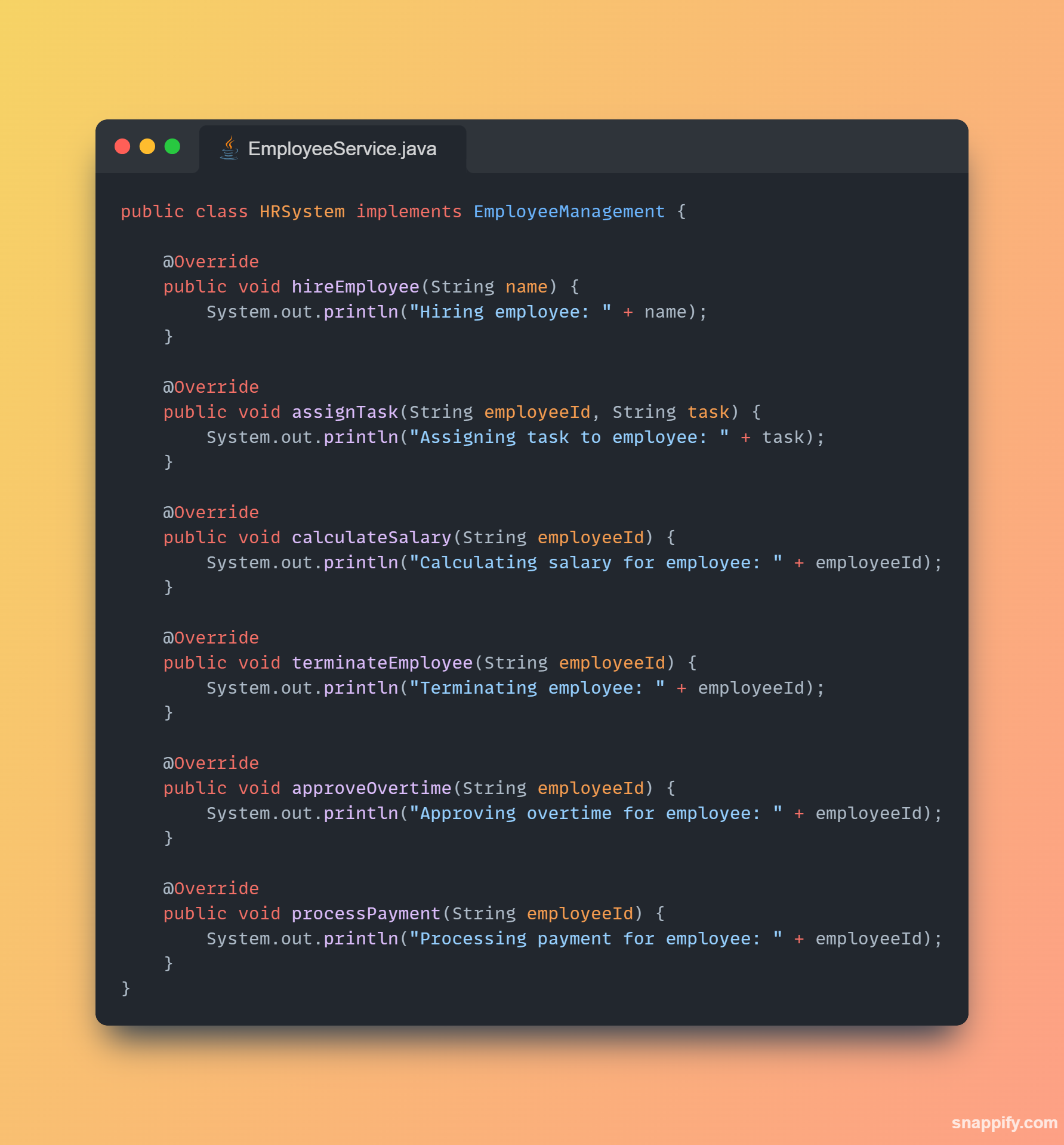
**Implementação ContractorManagementSystem com ISP**
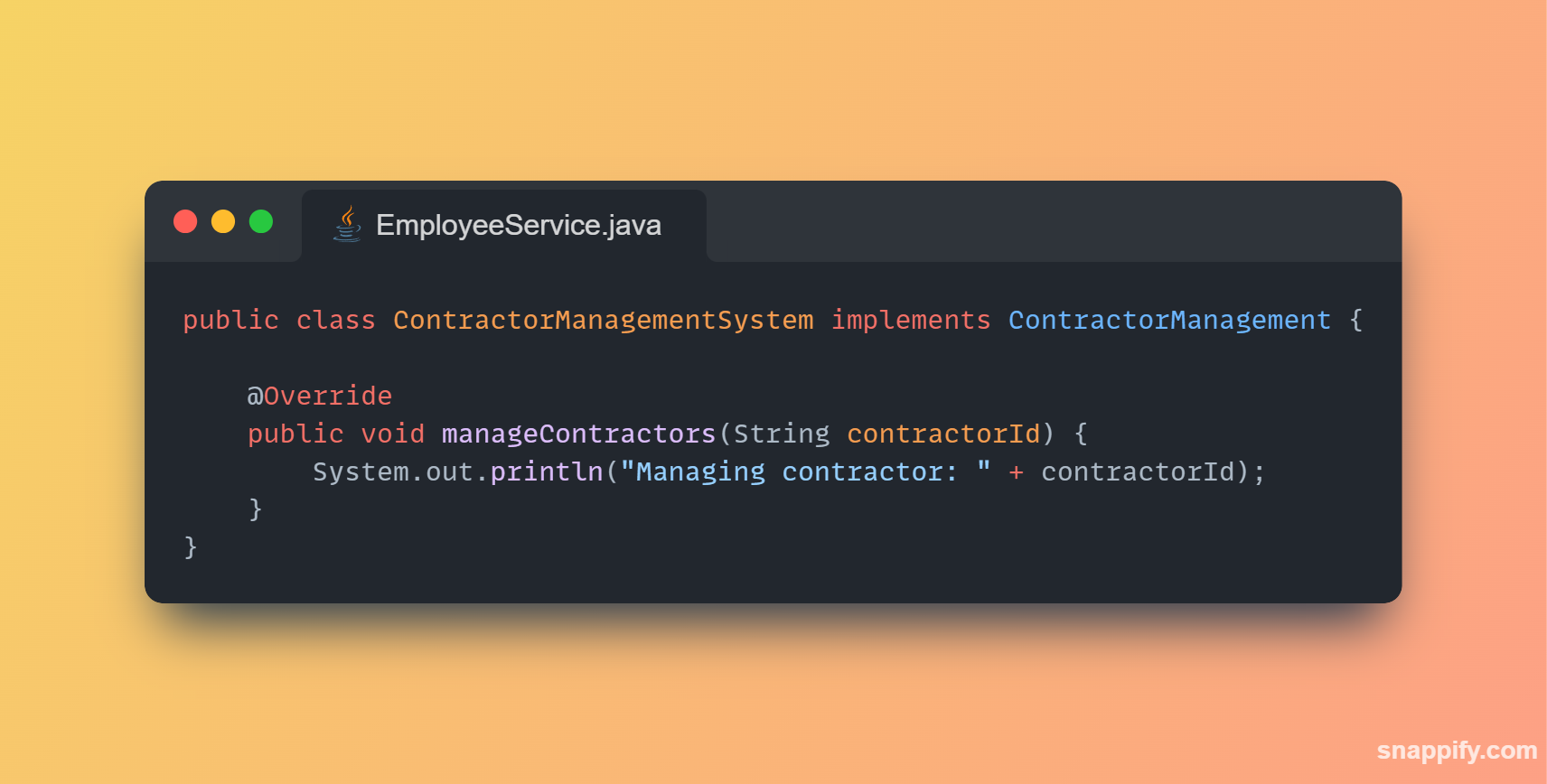
**Uso das Classes**
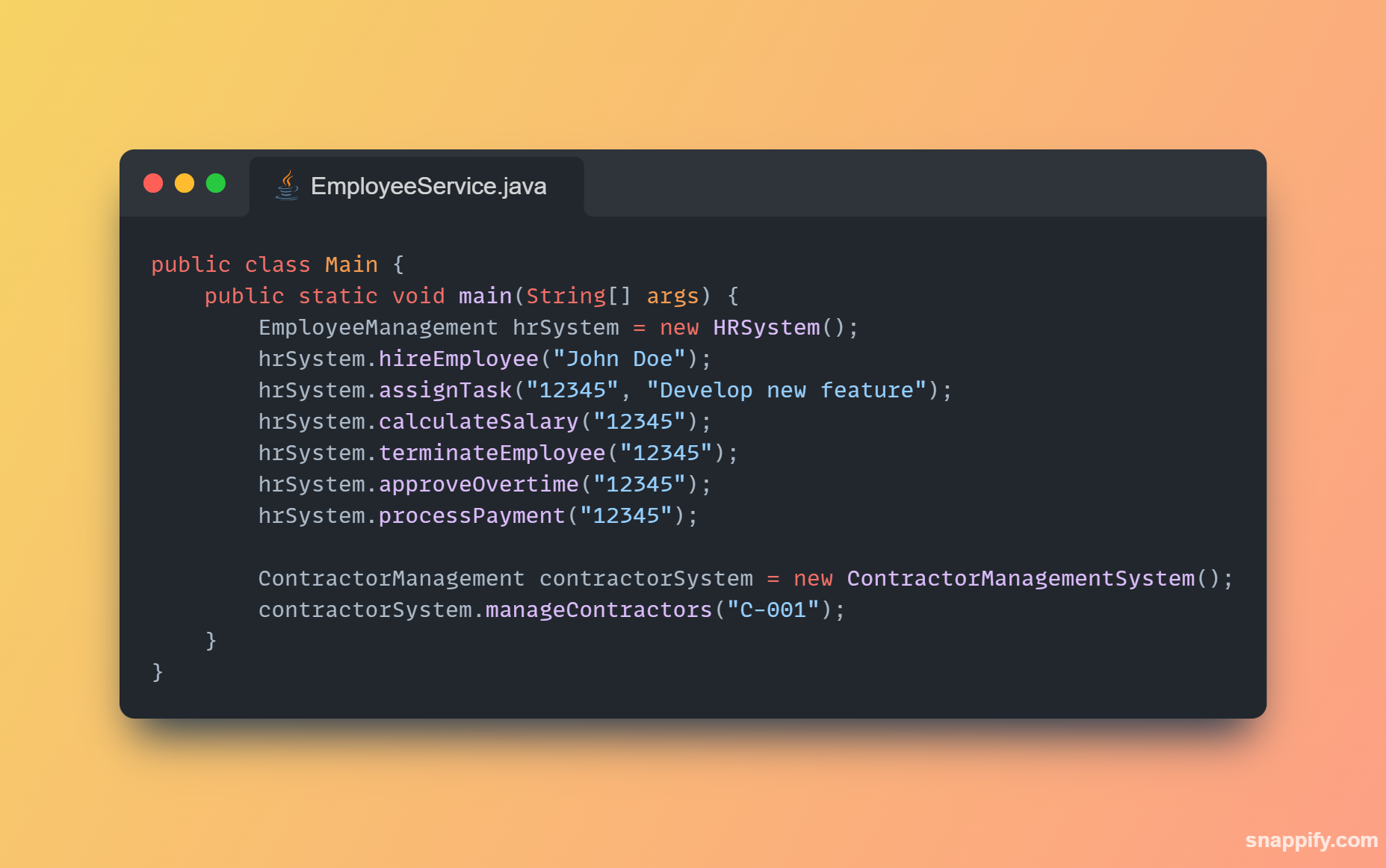
Explicação:
- Interface EmployeeManagement: Define operações genéricas para gerenciamento de funcionários, como contratação, atribuição de tarefas, cálculo de salário, etc.
- Interface ContractorManagement: Define operações específicas para gerenciamento de contratados, como gerenciamento de contratos.
- Classe HRSystem: Implementa a interface EmployeeManagement, fornecendo métodos para gerenciar funcionários da empresa.
- Classe ContractorManagementSystem: Implementa a interface ContractorManagement, fornecendo métodos para gerenciar contratados.
- Uso das Classes: Demonstramos como usar as diferentes classes e interfaces de maneira específica, sem forçar nenhuma classe a implementar métodos desnecessários.
**Ao seguir o Princípio da Segregação de Interfaces, garantimos que nossas classes só implementem métodos que fazem sentido para elas, tornando o código mais claro e fácil de manter. Isso evita que classes dependam de métodos que não utilizam, promovendo uma melhor coesão e separação de responsabilidades.**
_PS: Para ir direto para o próximo princípio:_
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-d-dependency-inversion-principle-dip-2d5n %} | diegobrandao |
1,864,452 | Concurrency c# part 1 | Parallel.ForEachAsync() and Task.Run() With When.All in C Parallel... | 0 | 2024-05-25T01:33:11 | https://dev.to/dat_ngo_524c98f33bc09e368/concurrency-c-part-1-2h7b |
# Parallel.ForEachAsync() and Task.Run() With When.All in C#
## Parallel Programming
In general, parallel programming involves using multiple threads or processors to execute tasks concurrently. It aims to improve performance and responsiveness by dividing tasks into smaller parts that can be processed simultaneously.
Apart from improving performance and responsiveness, there are additional advantages when using parallel programming. Firstly, by breaking tasks into concurrent subtasks, we can effectively reduce overall execution time. One additional benefit is throughput enhancement as a result of handling multiple tasks simultaneously. Also, running tasks in parallel helps us ensure scalability since it efficiently distributes tasks across processors. This allows performance to scale seamlessly when adding resources.
One more thing we should take into consideration when working with parallel programming is which kind of processes we are trying to parallelize. In this article, we will mention I/O-bound and CPU-bound ones.
I/O bound processes are processes where the computational duration is determined by the time spent awaiting input/output operations, an example of this is a database call. On the other hand, we have CPU-bound processes. In this case, the performance of the CPU determines the task duration, an example is a method that does some heavy numerical calculations.
Now that we have a quick primer about parallel programming and different types of processes, let’s quickly set everything up and see it in action.
## Setting up Async Methods
Since we already have a great article going more in-depth on How to Execute Multiple Tasks Asynchronously, here we will only create a baseline for the Task.WhenAll() method which we will modify when comparing the two approaches.
We start with the default web-API project and expand the WeatherForecastController method with an asynchronous method that runs multiple times:
```c#
[HttpGet("weather-forecast-when-all", Name = "GetWeatherForecastWhenAll")]
public async Task<IEnumerable<WeatherForecast>> GetWeatherForecastWhenAll()
{
var result1 = await AsyncMethod();
var result2 = await AsyncMethod();
var result3 = await AsyncMethod();
var result = result1.Concat(result2).Concat(result3);
return result;
}
private static async Task<IEnumerable<WeatherForecast>> AsyncMethod()
{
await Task.Delay(250);
return Enumerable.Range(6, 5).Select(index => new WeatherForecast
{
Date = DateOnly.FromDateTime(DateTime.Now.AddDays(index)),
TemperatureC = new Random().Next(-20, 55),
Summary = Summaries[new Random().Next(Summaries.Length)]
})
.ToArray();
}
```
In the context of types of processes, AsyncMethod() emulates the I/O-bound process and the task delay represents the waiting time of a sub-system response.
After we set everything up, let’s see how to execute these tasks in parallel.
## Use Task.WhenAll
First, we need to refactor the GetWeatherForecastWhenAll() method to use the Task.WhenAll() method. It takes an enumerable of tasks and returns a new completed task once all the individual tasks in the collection finish running:
```c#
[HttpGet("weather-forecast-when-all", Name = "GetWeatherForecastWhenAll")]
public async Task<IEnumerable<WeatherForecast>> GetWeatherForecastWhenAll()
{
var tasks = new List<Task<IEnumerable<WeatherForecast>>>();
var result1 = AsyncMethod();
var result2 = AsyncMethod();
var result3 = AsyncMethod();
tasks.Add(result1);
tasks.Add(result2);
tasks.Add(result3);
var combinedResults = await Task.WhenAll(tasks);
var result = combinedResults.SelectMany(cr => cr);
return result;
}
```
We define an empty list of tasks. Next, we call AsyncMethod() three times without the await keyword. This starts executing these tasks one after another without waiting for them to complete. This is exactly what we want since we add those tasks to our tasks list and use Task.WhenAll() to wait for all of them to complete.
Lastly, when all the tasks are completed, we flatten the combinedResults variable that holds the results and return the result to the user.
We need to keep thread usage in mind when we use parallel execution of tasks. Starting too many threads at once increases context-switching overhead and may impact overall application efficiency. Also, we don’t want to block the main thread. So let’s see how we can get a better understanding of how this method works under the hood regarding threads.
## Thread Processing
We start by adding logging to the threads:
```c#
[HttpGet("weather-forecast-when-all", Name = "GetWeatherForecastWhenAll")]
public async Task<IEnumerable<WeatherForecast>> GetWeatherForecastWhenAll()
{
Console.WriteLine($"GetWeatherForecastWhenAll started on thread: {Environment.CurrentManagedThreadId}");
var tasks = new List<Task<IEnumerable<WeatherForecast>>>();
var result1 = AsyncMethod();
var result2 = AsyncMethod();
var result3 = AsyncMethod();
tasks.Add(result1);
tasks.Add(result2);
tasks.Add(result3);
var combinedResults = await Task.WhenAll(tasks);
var result = combinedResults.SelectMany(cr => cr);
Console.WriteLine($"GetWeatherForecastWhenAll started on thread: {Environment.CurrentManagedThreadId}");
return result;
}
private static async Task<IEnumerable<WeatherForecast>> AsyncMethod()
{
Console.WriteLine($"AsyncMethod started on thread: {Environment.CurrentManagedThreadId}");
await Task.Delay(250);
Console.WriteLine($"AsyncMethod completed on thread: {Environment.CurrentManagedThreadId}");
return Enumerable.Range(6, 5).Select(index => new WeatherForecast
{
Date = DateOnly.FromDateTime(DateTime.Now.AddDays(index)),
TemperatureC = new Random().Next(-20, 55),
Summary = Summaries[new Random().Next(Summaries.Length)]
})
.ToArray();
}
```
Here, we add a Console.WriteLine() statement at the beginning and end of each method. There, we print on which thread methods start and end by using Environment.CurrentManagedThreadId.
Now, if we execute our request, in the output window we can see how threads behave:
```c#
GetWeatherForecastWhenAll started on thread: 16
AsyncMethod started on thread: 16
AsyncMethod started on thread: 16
AsyncMethod started on thread: 16
AsyncMethod completed on thread: 7
AsyncMethod completed on thread: 16
AsyncMethod completed on thread: 15
GetWeatherForecastWhenAll completed on thread: 7
```
Let’s break this down to understand what happens.
When we send an HTTP request, a thread from the thread pool gets assigned to handle it. In our case, it is thread number 16. Then, when we invoke our async methods and we don’t use the await keyword, tasks will usually start executing on the same thread, i.e., 16.
However, when an asynchronous operation encounters the await keyword, in our case await on Task.WhenAll(), it releases the current thread to the thread pool during the waiting period for the task to be completed. When the awaiting operation completes and we want to return the result, the continuation might not necessarily resume on the original thread. That is why we see some of the tasks finish on different threads than they start on.
Besides creating a task by not using the await keyword we can also use Task.Run() method, so let’s take a look at it.
## Use Task.Run With Task.WhenAll
By using the Task.Run() method to execute tasks, we make sure that each new task executes on a separate thread:
```c#
[HttpGet("weather-forecast-when-all", Name = "GetWeatherForecastWhenAll")]
public async Task<IEnumerable<WeatherForecast>> GetWeatherForecastWhenAll()
{
var result1 = Task.Run(() => AsyncMethod());
var result2 = Task.Run(() => AsyncMethod());
var result3 = Task.Run(() => AsyncMethod());
var combinedResults = await Task.WhenAll(result1, result2, result3);
var result = combinedResults.SelectMany(cr => cr);
return result;
}
```
Here, we use the Task.Run() method to execute AsyncMethod() three times in a row. Again, by skipping the await keyword we are not awaiting any method to complete, but we run them in parallel and on Task.WhenAll() await their results.
Now, let’s retake a look at the output logs when executing the request:
```c#
GetWeatherForecastWhenAll started on thread: 20
AsyncMethod started on thread: 19
AsyncMethod started on thread: 21
AsyncMethod started on thread: 13
AsyncMethod completed on thread: 21
AsyncMethod completed on thread: 13
AsyncMethod completed on thread: 20
GetWeatherForecastWhenAll completed on thread: 20
```
This time, we see that each new task starts its execution on a new thread. We expect this behavior when using Task.Run() since its purpose is to offload work from the current thread. Same as in the previous example due to the async/await nature and thread pool assigning threads, tasks finish on different threads than they originally start on.
Using Task.Run() requires caution as it might have some drawbacks. Since it offloads work to a new thread, any time it deals with a large number of tasks it can create a large number of threads, each consuming resources and possibly causing thread pool starvation.
Now that we have seen how we can explicitly offload each task to a new thread, let’s look at how we can use another method to perform these tasks in parallel.
## Using Parallel.ForEachAsync
Another way we parallelize this work is to use the Parallel.ForEachAsync() method:
```c#
[HttpGet("weather-forecast-parallel", Name = "GetWeatherForecastParallelForEachAsync")]
public async Task<IEnumerable<WeatherForecast>> GetWeatherForecastParallelForEachAsync()
{
Console.WriteLine($"GetWeatherForecastParallelForEachAsync started on thread:
{Environment.CurrentManagedThreadId}");
ParallelOptions parallelOptions = new()
{
MaxDegreeOfParallelism = 3
};
var resultBag = new ConcurrentBag<IEnumerable<WeatherForecast>>();
await Parallel.ForEachAsync(Enumerable.Range(0, 3), parallelOptions, async (index, _) =>
{
var result = await AsyncMethod();
resultBag.Add(result);
});
Console.WriteLine($"GetWeatherForecastParallelForEachAsync completed on thread:
{Environment.CurrentManagedThreadId}");
return resultBag.SelectMany(cr => cr);
}
```
First, we set the MaxDegreeOfParallelism value. With this setting, we define how many concurrent operations run. If not set, it uses as many threads as the underlying scheduler provides. To determine this value for a CPU process start with the Environment.ProcessorCount. For I/O-bound processes, this value is harder to determine since it depends on the I/O subsystem, which includes network latency, database responsiveness, etc. So when working with I/O bound processes, we need to do testing with different values to determine the best value for maximum parallelization.
After, we define a ConcurrentBag for our results, which is a thread-safe collection since we use parallel execution of tasks and handle results in a loop. Allowing us to safely modify the collection without worrying about concurrency modification exceptions. Lastly, we set up Parallel.ForEachAsync() method to run three times with set options, and inside the loop, we await each result and add it to the resultBag.
One thing to mention when using the Parallel.ForEachAsync() method is that it has its underlying partitioning. This partitioning divides the input data into manageable batches and assigns each batch to a different thread for parallel processing. The exact size of the batches is determined dynamically by the framework based on factors such as the number of available processors and the characteristics of the input data. So by defining the MaxDegreeOfParallelism, we define the number of batched tasks that execute concurrently.
Regarding thread usage, since we are not explicitly altering thread assignments, threads get assigned as they usually do in the classic async/await process. One difference with the Task.WhenAll() thread usage is that most likely every task starts on its thread since we use the await keyword for each call inside the loop.
Now, let’s take a look at how the Task.Run() method behaves in this case.
## Using Task.Run With Parallel.ForEachAsync
Let’s modify our method to use Task.Run() for generating tasks:
```c#
[HttpGet("weather-forecast-parallel", Name = "GetWeatherForecastParallelForEachAsync")]
public async Task<IEnumerable<WeatherForecast>> GetWeatherForecastParallelForEachAsync()
{
Console.WriteLine($"GetWeatherForecastParallelForEachAsync started on thread:
{Environment.CurrentManagedThreadId}");
ParallelOptions parallelOptions = new()
{
MaxDegreeOfParallelism = 3
};
var resultBag = new ConcurrentBag<IEnumerable<WeatherForecast>>();
await Parallel.ForEachAsync(Enumerable.Range(0, 3), parallelOptions, async (index, _) =>
{
var result = await Task.Run(() => AsyncMethod());
resultBag.Add(result);
});
Console.WriteLine($"GetWeatherForecastParallelForEachAsync completed on thread:
{Environment.CurrentManagedThreadId}");
return resultBag.SelectMany(cr => cr);
}
```
However, this may not be the best approach in this case. As we already saw, Parallel.ForEachAsync() has a built-in partitioner that creates batches of tasks and processes them in a single thread. But by using Task.Run() we offload each task into its thread. So using Task.Run() in this case, undermines the benefit of using Parallel.ForEachAsync() for chunking tasks and using fewer threads.
One more thing we may encounter when trying to parallelize the tasks is the usage of the Parallel.ForEach() method.
## Pitfalls to Avoid With Parallel.ForEach
The Parallel.ForEach() method, while similar to Parallel.ForEachAsync(), lacks the designed capability to handle asynchronous work. However, we can still encounter some examples of its usage with asynchronous tasks.
So let’s quickly check on why these approaches may not be the best workarounds and see their drawbacks.
One common thing we can see is forcing awaiting the result in synchronous code by using GetAwaiter().GetResult():
```c#
Parallel.ForEach(Enumerable.Range(0, 3), parallelOptions, (index, _) =>
{
var result = AsyncMethod().GetAwaiter().GetResult();
resultBag.Add(result);
});
```
We should avoid this approach since by using GetAwaiter().GetResult() we block the calling thread, which is an anti-pattern of async/await. This may cause issues in deadlocks, decreased performance, and loss of context-switching benefits.
Another approach involves using async void:
```c#
Parallel.ForEach(Enumerable.Range(0, 3), parallelOptions, async (index, _) =>
{
var result = await AsyncMethod();
resultBag.Add(result);
});
```
In this approach, we have another anti-pattern, and that is the usage of async/void. This is a known bad practice with several reasons to avoid it. One such reason is that we cannot catch exceptions in the catch block.
As we can see, both of these approaches involve the use of anti-patterns to make Parallel.ForEach() them compatible with asynchronous methods. Since neither of them is a recommended way to implement parallelization, with the introduction of Parallel.ForEachAsync() in .NET 6 we have a preferable method for working with async tasks in a for-each loop.
Now that we took a look at what not to do, let’s sum up everything we’ve learned so far!
## When to Use Which Approach?
As with everything in programming, how we use the knowledge from this article depends on the application’s specific requirements. Nevertheless, when choosing the right method, we should consider several factors.
- When talking about CPU-bound tasks that can benefit from parallelization, the use of `Parallel.ForEachAsync() `stands out. Its main benefit is that it efficiently distributes the workload across multiple processor cores. Also, by setting the MaxDegreeOfParallelism we control the concurrency level we want to impose. And as we saw we can easily determine that value.
- On the other hand, when dealing with I/O-bound tasks, where operations involve waiting for external resources, `Task.WhenAll()` becomes a preferable choice. It allows us to execute multiple asynchronous tasks concurrently, without blocking the calling thread. This makes it an efficient option for scenarios like database queries or network requests. Another benefit is that we don’t need to process results inside the loop, but we can wait on all of them and manipulate the results when they are complete.
However, it’s important to note that Task.WhenAll() lacks a built-in partitioner, and its use in a loop without proper throttling mechanisms may result in the initiation of an infinite number of tasks. So depending on the number of tasks we are executing it may be necessary to create our partition strategy or opt for `Parallel.ForEachAsync()` a solution.
One more thing we mentioned is initializing tasks using `Task.Run()`. We can use this approach when we want to have explicit control over threading but keep in mind that it can potentially lead to thread pool starvation if too many threads start at once.
## Conclusion
In this article, we look at two methods we use to execute repetitive tasks in parallel. We saw how both methods under the hood use threads and partition the given tasks. Also, we saw what are the differences when using the Task.Run() and how it behaves with both options. Lastly, we provide guidance on which approach is most suitable in different scenarios.
https://code-maze.com/csharp-parallel-foreachasync-and-task-run-with-when-all/?ref=dailydev | dat_ngo_524c98f33bc09e368 | |
1,864,450 | From Concept to Application: Thin Film Pressure Sensor Technology | From Concept to Application: Thin Film Pressure Sensor Technology If you have ever used a touch... | 0 | 2024-05-25T01:27:08 | https://dev.to/ashmaa99/from-concept-to-application-thin-film-pressure-sensor-technology-1k5c | thin, film | From Concept to Application: Thin Film Pressure Sensor Technology
If you have ever used a touch screen or stepped on a bathroom scale, you have used a pressure. These tiny devices have become ubiquitous in everyday life, and thanks to thin film technology, they are now even more versatile, durable, and reliable than ever before.
Top options that come with Thin Film Stress Sensors
1. Durability: slim film sensors are less likely to want to desire to split or degrade than traditional sensor, making them ideal for durable applications.
2. Accuracy: slim film sensors are incredibly accurate, even in extreme conditions such as high or low conditions or stress this is certainly high.
3. Sensitivity: slim film sensors can identify force this is certainly slight, making them perfect for present in delicate applications such as for example equipment this is certainly medical.
Innovation and protection
Slim film force sensors are now actually an illustration this is certainly prime of in neuro-scientific sensor technology.
They truly are beautifully made out of security in your mind, ensuring they usually are found inside a range of applications without posing a risk to users or even the surroundings.
One of the key options being top have slim film sensors could possibly be the capability to withstand problems that are extreme anxiety.
This is really the reason why is very good great for utilized in harsh environments, such as for example into the coal and oil industry or simply just in aerospace applications.
Plus, slim film sensors are sensitive and painful and might even identify also the slightest alterations in anxiety.
This sensitivity means they've been perfect for found in medical gear, where reliability and accuracy are critical.
Provider and Quality
Thin film pressure sensor are manufactured become extremely dependable and long-lasting.
They are designed to withstand environments that may be supply like dimensions being challenging the collection of conditions.
To be sure the performance this is certainly appropriate this is certainly most from your own film this is certainly sensor like slim it is important to buy reputable maker with an effective track record of quality and reliability.
Search for manufacturers that provide warranties, assistance, and solution like ongoing receive the numerous from your sensor like own that very own along with its continued performance over the years.
Applications of Slim Film Pressure Sensors
Slim film force sensors are utilized in a true number like very of, from touch shows to technology like aerospace.
Some applications that might be traditional:
Touch screens: slim film anxiety sensors are utilized directly into the touch shows of smart phones, pills, in addition to other items.
Medical equipment: slim film force sensors is roofed into medical gear such as for example ventilators and high blood pressure monitors to generate dimensions which are exceptionally accurate.
Control like industrial film like slim sensors can be used in many different commercial control applications, such as for instance monitoring pressure in pipelines or controlling pressure in manufacturing processes.
Aerospace: slim film pressure sensors can be used in aerospace applications observe anxiety and heat in machines along side other elements that are critical.
Automotive: slim film force sensors are utilized in automotive applications observe tire stress, motor performance, and in addition more.
In conclusion, thin film Pressure sensor technology is a highly innovative and versatile technology that has the potential to revolutionize the way we measure pressure. With its accuracy, sensitivity, and durability, this technology is well-suited for a range of applications, from medical equipment to aerospace technology. By choosing a reputable manufacturer and following best practices for use and maintenance, you can ensure that your thin film pressure sensor provides reliable measurements for years to come.
Source: https://www.soushine.com/Thin-film-pressure-sensor | ashmaa99 |
1,864,449 | Pragmatic Play partners with 888casino | Pragmatic Play has signed a statement deal with 888casino to create a dedicated Blackjack studio for... | 0 | 2024-05-25T01:26:35 | https://dev.to/queenabeejin/pragmatic-play-partners-with-888casino-2c0e | Pragmatic Play has signed a statement deal with 888casino to create a dedicated Blackjack studio for the operator.
The studio will include purpose-built tables and branding, exclusively designed for 888casino. The dedicated studio agreement is the latest in a string of partnerships by Pragmatic Play following deals with Mansion’s M88 brand and Kindred’s Unibet.
It marks further expansion in the vertical for Pragmatic Play, which has recently launched its Ruby Studio, designed exclusively for Blackjack, joining a portfolio of titles such as Sweet Bonanza Candyland, which straddles the divide between slots and live dealer products.
Yossi Barzely, chief business development officer at Pragmatic Play, said: “As one of the world’s leading online casino brands, 888casino will be a key strategic partner to Pragmatic Play. We are delighted to create a dedicated live casino environment tailored to its players. Showcasing our leading Blackjack solution, we’re able to deliver incredible gaming experiences while simultaneously highlighting the power of 888casino.”
Talya Benyamini, VP B2C Casino at 888, said: “Pragmatic Play’s flexible live casino offering will enhance 888casino’s diverse range of existing products to the benefit of our customers. Partnering with third-party providers like this is an important part of our product leadership and content strategy, ensuring that we continue to offer a unique and differentiated experience for 888casino’s fans.”
[온라인카지노사이트](https://www.casinositetop.com/)
| queenabeejin | |
1,864,447 | View this solution on Exercism to City Office | https://exercism.org/tracks/elixir/exercises/city-office/solutions/wagner-de-carvalho | 0 | 2024-05-25T01:22:58 | https://dev.to/wagnerdecarvalho/view-this-solution-on-exercism-to-city-office-5657 | elixir, documentation, typin, programming |
https://exercism.org/tracks/elixir/exercises/city-office/solutions/wagner-de-carvalho | wagnerdecarvalho |
1,864,446 | BF Games extends reach in Belgium with betFIRST | BF Games has further strengthened its foothold in Belgium after taking its dice slot titles live with... | 0 | 2024-05-25T01:22:00 | https://dev.to/queenabeejin/bf-games-extends-reach-in-belgium-with-betfirst-33nj | BF Games has further strengthened its foothold in Belgium after taking its dice slot titles live with betFIRST.be.
A selection of BF Games’ hits including Royal Crown, Stunning 27, Ancient Secret, Wild Jack and Stunning Hot will now be available to Belgian players via betFIRST’s online casino.
The partnership marks the third Belgian operator that has gone live with BF Games’ content and significantly enhances the supplier’s presence in the country.
Claudia Melcaru, head of business development at BF Games, said: “We are gaining momentum in Belgium and are thrilled to have partnered with yet another leading operator in a deal that has seen us introduce our popular dice games to a new local audience.”
Daphne Bal, head of marketing services at betFIRST, said: “By adding BF Games’ content to our casino we will significantly strengthen our existing offering. We aim to provide fresh and appealing content to our players and BF Games’ classic yet entertaining and engaging titles are a great addition.”
[카지노사이트 추천](https://www.casinositetop.com/) , [합법 카지노 사이트](https://www.casinositetop.com/)
| queenabeejin | |
1,864,409 | Vertical Lime Factory: Manufacturing High-Quality Lime Products | Grow Better with Vertical Lime Products Introduction: Are you looking for a top-quality lime... | 0 | 2024-05-25T01:16:19 | https://dev.to/ashmaa99/vertical-lime-factory-manufacturing-high-quality-lime-products-dgm | lime | Grow Better with Vertical Lime Products
Introduction:
Are you looking for a top-quality lime products manufacturer? Vertical Lime Factory is the solution for you. Buying products from Vertical Lime Factory offers so many benefits such as innovation, safety, and quality. We will explore the advantages, innovation, safety, and quality of Vertical Lime.
Advantages:
Considered lime production line one of these advantages that are brilliant are brilliant turn out to be the charged power to balance the soil pH levels to enhance your crop yield
This implies your crops can form better and healthy if you assist products and services
Moreover, things are extremely advantageous to varied kinds of plants, and that means you do not have to stress about compatibility
Innovation:
The factory has employed technologies and this can be ensure like modern-day standard for the products that are ongoing certainly not compromised
Vertical Lime Factory uses kilns being straight the manufacturing procedure that will be an means like green of lime services and products
The kilns that might be vertical helps you to make sure that the item are energy conserving and in addition now paid off carbon emissions when compared with other production procedures
Safety:
Safety is merely an pressing issue like Vertical Lime like significant Factory
The factory has implemented protection precautions inside their manufacturing procedures to be sure their products or services or solutions are safe to utilize
They regularly test their products or solutions or solutions for dangerous materials, and their packaging is perfect for safe control
Service:
They've customer like knowledgeable representatives to help you with any inquiries regarding their products or services
They pride by themselves in relation to their prompt distribution services
Meaning that their products reaches your neighborhood like local on, making certain your flowers will not experience delays
Quality:
Their products or services or services are made out of the limestone product much like beneficial, which really helps to ensure the traditional is usually connected with standard like greatest
They often times have actually really quality like regular to make sure the set is met by each product requirements
Conclusion:
In conclusion, Vertical Lime Kiln are of high quality, innovative, safe to use, and provide many benefits. Whether you are looking to balance the pH levels of soil for your crops, or add durability to your roads,
Source: https://www.limekilnmanufacturer.com/vertical-lime-kiln | ashmaa99 |
1,864,407 | How to Check if a String Contains Only Letters in C# | linq public static bool IsOnlyLetters(string text) { return... | 0 | 2024-05-25T01:08:32 | https://dev.to/dat_ngo_524c98f33bc09e368/how-to-check-if-a-string-contains-only-letters-in-c-5095 | csharp | # linq
```c#
public static bool IsOnlyLetters(string text)
{
return text.All(char.IsLetter);
}
```
# regex
```c#
static bool IsOnlyLetters_Method2(string text)
{
return Regex.IsMatch(text, @"^[\p{L}]+$");
}
```
# switch case
```c#
public static bool IsOnlyAsciiLettersBySwitchCase(string text)
{
foreach (var item in text)
{
switch (item)
{
case >= 'A' and <= 'Z':
case >= 'a' and <= 'z':
continue;
default:
return false;
}
}
return true;
}
```
# pattern matching
```c#
public static bool IsOnlyAsciiLettersByPatternMatching(string text)
{
foreach (var item in text)
{
if (item is >= 'A' and <= 'Z' or >= 'a' and <= 'z')
continue;
else
return false;
}
return true;
}
```
# Benchmark
```c#
public class StringLetterCheckBenchmark
{
private const string TestString = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
private const string NonLetterString = "ABC123!@#";
[Benchmark]
public bool LinqMethod_OnlyLetters() => IsOnlyLetters(TestString);
[Benchmark]
public bool LinqMethod_WithNonLetters() => IsOnlyLetters(NonLetterString);
[Benchmark]
public bool RegexMethod_OnlyLetters() => IsOnlyLetters_Method2(TestString);
[Benchmark]
public bool RegexMethod_WithNonLetters() => IsOnlyLetters_Method2(NonLetterString);
[Benchmark]
public bool SwitchCaseMethod_OnlyLetters() => IsOnlyAsciiLettersBySwitchCase(TestString);
[Benchmark]
public bool SwitchCaseMethod_WithNonLetters() => IsOnlyAsciiLettersBySwitchCase(NonLetterString);
[Benchmark]
public bool PatternMatchingMethod_OnlyLetters() => IsOnlyAsciiLettersByPatternMatching(TestString);
[Benchmark]
public bool PatternMatchingMethod_WithNonLetters() => IsOnlyAsciiLettersByPatternMatching(NonLetterString);
}
```
```json
BenchmarkDotNet v0.13.12, macOS Ventura 13.3.1 (a) (22E772610a) [Darwin 22.4.0]
Apple M1, 1 CPU, 8 logical and 8 physical cores
.NET SDK 8.0.100
[Host] : .NET 8.0.0 (8.0.23.53103), Arm64 RyuJIT AdvSIMD
DefaultJob : .NET 8.0.0 (8.0.23.53103), Arm64 RyuJIT AdvSIMD
| Method | Mean | Error | StdDev |
|------------------------------------- |-----------:|----------:|----------:|
| LinqMethod_OnlyLetters | 133.131 ns | 0.9107 ns | 0.8518 ns |
| LinqMethod_WithNonLetters | 16.451 ns | 0.2000 ns | 0.1871 ns |
| RegexMethod_OnlyLetters | 123.054 ns | 2.4522 ns | 3.0115 ns |
| RegexMethod_WithNonLetters | 59.966 ns | 0.6924 ns | 0.5782 ns |
| SwitchCaseMethod_OnlyLetters | 41.867 ns | 0.8452 ns | 1.0379 ns |
| SwitchCaseMethod_WithNonLetters | 2.478 ns | 0.0179 ns | 0.0158 ns |
| PatternMatchingMethod_OnlyLetters | 40.770 ns | 0.6179 ns | 0.4824 ns |
| PatternMatchingMethod_WithNonLetters | 2.447 ns | 0.0070 ns | 0.0058 ns |
```
# Conclusion
- Best Performance: The SwitchCaseMethod and PatternMatchingMethod both show the best performance. The PatternMatchingMethod is slightly better overall if you are looking for the most efficient solution in both scenarios.
- Worst Performance: The LinqMethod is the worst performer overall, especially for strings with only letters. The RegexMethod is also relatively slow, though slightly better than LINQ in some cases.
| dat_ngo_524c98f33bc09e368 |
1,864,405 | Filter list based on another list | public static List<int> FilterNotContainedUsingLoop(List<int> listToFilter,... | 0 | 2024-05-25T01:07:05 | https://dev.to/dat_ngo_524c98f33bc09e368/filter-list-based-on-another-list-18b | ```c#
public static List<int> FilterNotContainedUsingLoop(List<int> listToFilter, List<int> filteringList)
{
List<int> filteredList = [];
foreach (int item in listToFilter)
{
if (!filteringList.Contains(item))
filteredList.Add(item);
}
return filteredList;
}
public static List<int> FilterContainedUsingWhere(List<int> listToFilter, List<int> filteringList)
{
return listToFilter.Where(filteringList.Contains).ToList();
}
public static List<int> FilterNotContainedUsingWhere(List<int> listToFilter, List<int> filteringList)
{
return listToFilter.Where(x => !filteringList.Contains(x)).ToList();
}
//remove duplicates
public static List<int> FilterContainedUnique(List<int> listToFilter, List<int> filteringList)
{
return listToFilter.Where(filteringList.Contains).Distinct().ToList();
}
public static List<int> FilterNotContainedUsingExcept(List<int> listToFilter, List<int> filteringList)
{
return listToFilter.Except(filteringList).ToList();
}
//Filtering Lists of Different Types
public static List<string> FilterStringsByInts(List<string> listToFilter, List<int> filteringList)
{
return listToFilter.Where(x => filteringList.Contains(int.Parse(x))).ToList();
}
//Filter a List via HashSet
intsToFilter = [2, 4, 6, 8, 10, 16, 20, 28, 40, 45];
filteringIntList = [0, 10, 20, 30, 40, 50];
public static List<int> FilterUsingHashSet(List<int> listToFilter, List<int> filteringList)
{
HashSet<int> hashToFilter = new HashSet<int>(listToFilter);
hashToFilter.IntersectWith(filteringList);
return hashToFilter.ToList();
}
//Using Masks to Filter a List
intsToFilter = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15];
List<bool> mask = [true, false, false, false];
public static List<int> FilterUsingMask(List<int> listToFilter, List<bool> mask)
{
return listToFilter.Where((item, index) => mask[index % mask.Count]).ToList();
}
//1, 5, 9, 13
``` | dat_ngo_524c98f33bc09e368 | |
1,864,404 | Portable and User-friendly: Best 3 Ultrasonic Equipment Providers | The Best 3 User-Friendly Ultrasonic Equipment Providers Do you want an easy-to-use and efficient ... | 0 | 2024-05-25T01:03:30 | https://dev.to/ashmaa99/portable-and-user-friendly-best-3-ultrasonic-equipment-providers-hkb | ultrasonic | The Best 3 User-Friendly Ultrasonic Equipment Providers
Do you want an easy-to-use and efficient equipment for cleaning or measuring applications? Look no further, as we've compiled the best 3 providers for portable and user-friendly ultrasonic devices.
Benefits of Ultrasonic Gear
Ultrasonic technology utilizes sound like high-frequency to eradicate contaminants or measure distances
When compared with traditional cleansing practices, Ultrasound Scanner equipment supplies the next advantages:
- Saves time and labor costs
- utilizes less water and chemical substances, reducing impact this is certainly ecological
- Cleans tiny and areas which is usually complex
- Provides accurate and dimensions being fast
Innovation in Ultrasonic Gear
The system like ultrasonic has high rate particularly in the planet like contemporary features that are new advantages to users
Many of the latest innovations in user-friendly gear like ultrasonic:
- Touchscreen programs for simple navigation and modification of settings
- Bluetooth or connectivity like control like wi-Fi is information transfer like remote
- numerous cleansing modes and frequencies for versatile applications
- automatic shut-off or protection features to eradicate damage or accidents
Protection of Ultrasonic Gear
While ultrasonic gear is usually safe to utilize, particular precautions has to be examined entirely to prevent accidents or injury to the system
Some protection strategies for making use of gear like user-friendly is ultrasonic:
- wear clothes this is certainly protective goggles to stop contact with cleaning solutions or debris this is certainly traveling
- Avoid placing steel objects or valuable jewelry via the ultrasonic tank to prevent damage or electrocution
- use water like distilled recommended solutions which are cleansing prevent responses being harmful
- disconnect kit you have to certainly utilized or during upkeep
Provider and Quality of Ultrasound Gear making a selection on a dependable and gear this is certainly top-notch is ultrasonic is really important to ensuring operation like smooth durability from the apparatus
Some items to account fully for whenever choosing a gear like user-friendly is include like ultrasonic
- Troubleshooting and help this is certainly upkeep
- Warranty and fix services
- customer manuals and training resources
- official certification and conformity with industry requirements
- customer reviews and feedback
Application of Ultrasonic Equipment
User-friendly gear this is certainly ultrasonic be used in a real range like wide of and applications, such as for instance:
- valuable precious jewelry and watch cleaning
- Dental and instrument sterilization like medical
- Automotive and aerospace parts cleansing
- Electronics and PCB board cleaning
- gas and oil pipeline evaluation
- Distance measurement for construction, mining, and engineering
Conclusion
User-friendly Portable Ultrasound Scanner offers multiple advantages and innovations that make cleaning and measuring tasks easier and more efficient. Selecting a reliable and quality provider can ensure the safety and longevity of the equipment. With our top 3 ultrasonic equipment provider recommendations, you can make an informed decision and start using ultrasonic technology to your advantage.
Source: https://www.forever-medical.com/Portable-ultrasound-scanner | ashmaa99 |
1,864,399 | [S.O.L.I.D.] Os Cinco Pilares da Programação Orientada a Objetos. [L] - Liskov Substitution Principle - LSP | Continuando a série sobre SOLID, caso não tenha lido o artigo anterior: ... | 0 | 2024-05-25T00:53:18 | https://dev.to/diegobrandao/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-l-liskov-substitution-principle-lsp-5ebg | java, solidprinciples | Continuando a série sobre SOLID, caso não tenha lido o artigo anterior:
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-o-openclosed-principle-ocp-3bal %}
Neste artigo estarei falando sobre o **terceiro princípio** que é:
**[L] -Liskov Substitution Principle**
**Princípio da Substituição de Liskov - LSP**
“Se para cada objeto o1 do tipo S há um objeto o2 do tipo T de forma que, para todos os programas P definidos em termos de T, o comportamento de P é inalterado quando o1 é substituído por o2 então S é um subtipo de T.”
O Princípio de Substituição de Liskov leva esse nome por ter sido criado por Barbara Liskov, em 1988.
Tal definição foi resumida e popularizada por Robert C. Martin (Uncle Bob), em seu livro “Agile Principles Patterns and Practices”, como:
“Classes derivadas devem poder ser substitutas de suas classes base”
Ou seja, toda classe derivada deve poder ser usada como se fosse a classe base.
Para mim, foi um dos conceitos mais difíceis de entender. Portanto, não se preocupe se não conseguir compreender de imediato. Tenho esperança de que, com os exemplos de código, você sairá deste artigo entendendo esse princípio.
Vamos criar um sistema de notificações onde inicialmente temos um EmailNotification e, posteriormente, adicionamos um SMSNotification.
Veremos como implementar isso sem e com o LSP.
_Sem LSP_
**Classe Notification e EmailNotification sem LSP**
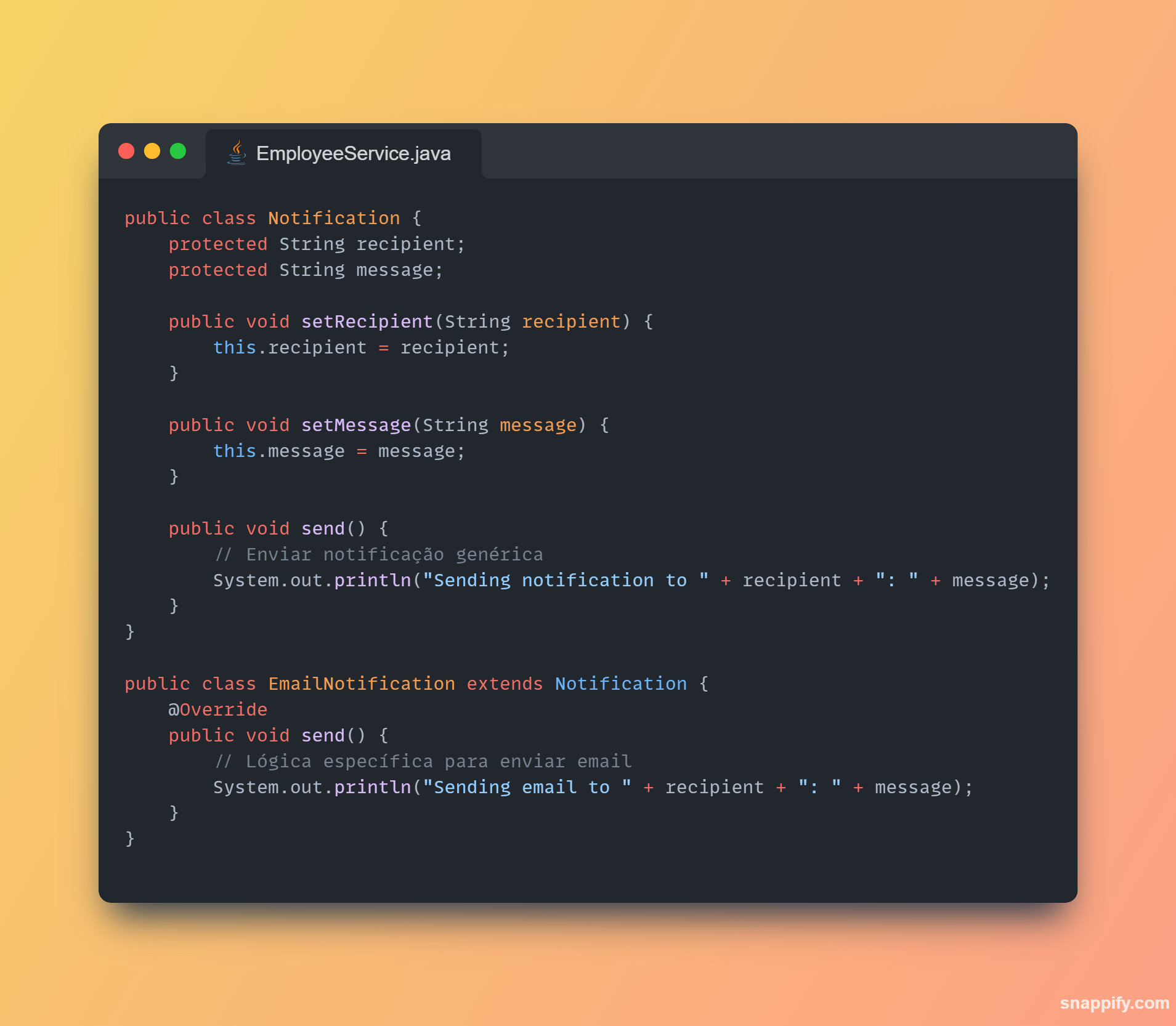
**Adicionando SMSNotification sem LSP**
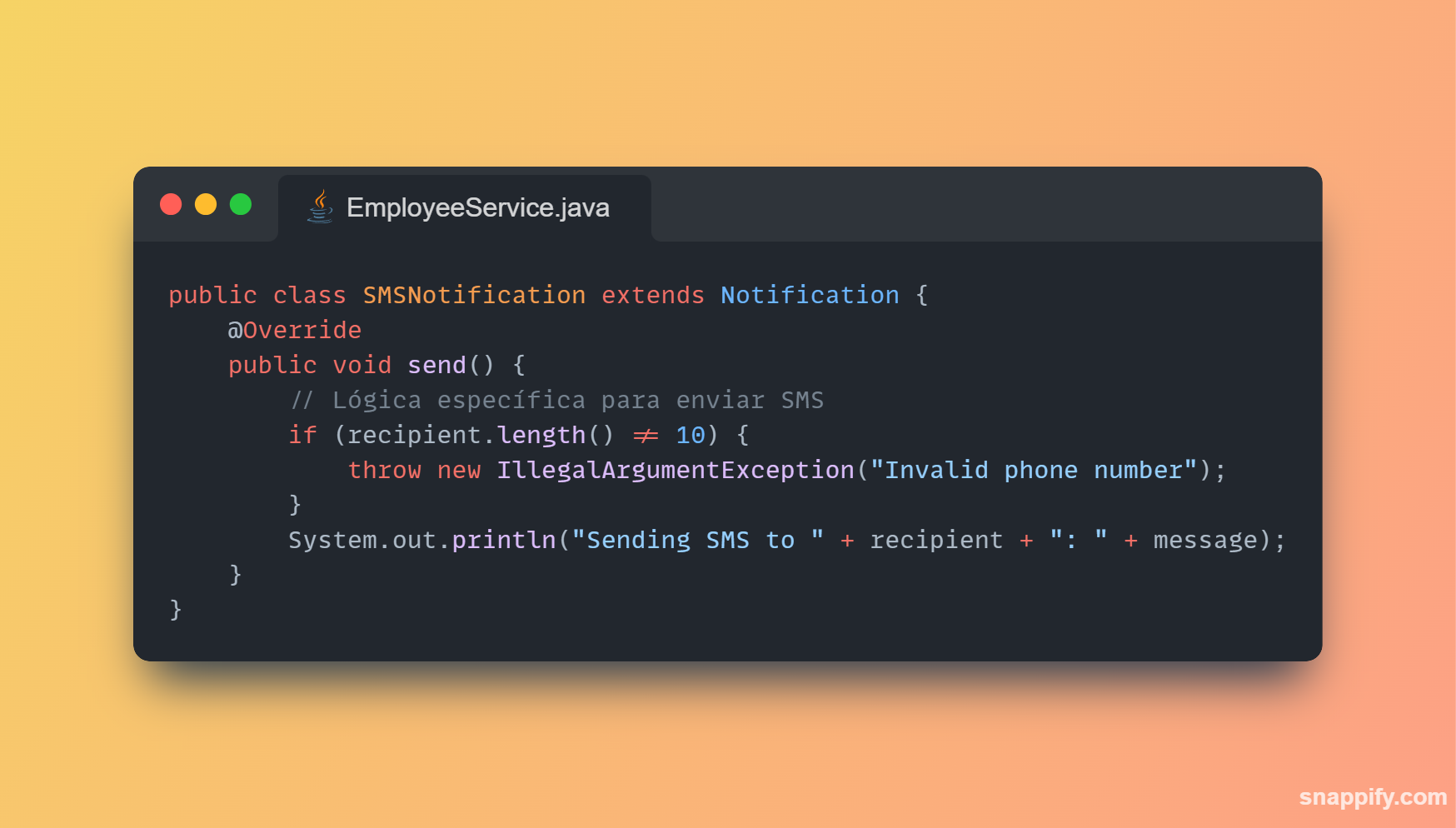
Neste exemplo, a classe SMSNotification altera o comportamento esperado ao adicionar uma verificação de número de telefone, o que pode causar problemas quando substituímos a classe base Notification pela classe derivada SMSNotification.
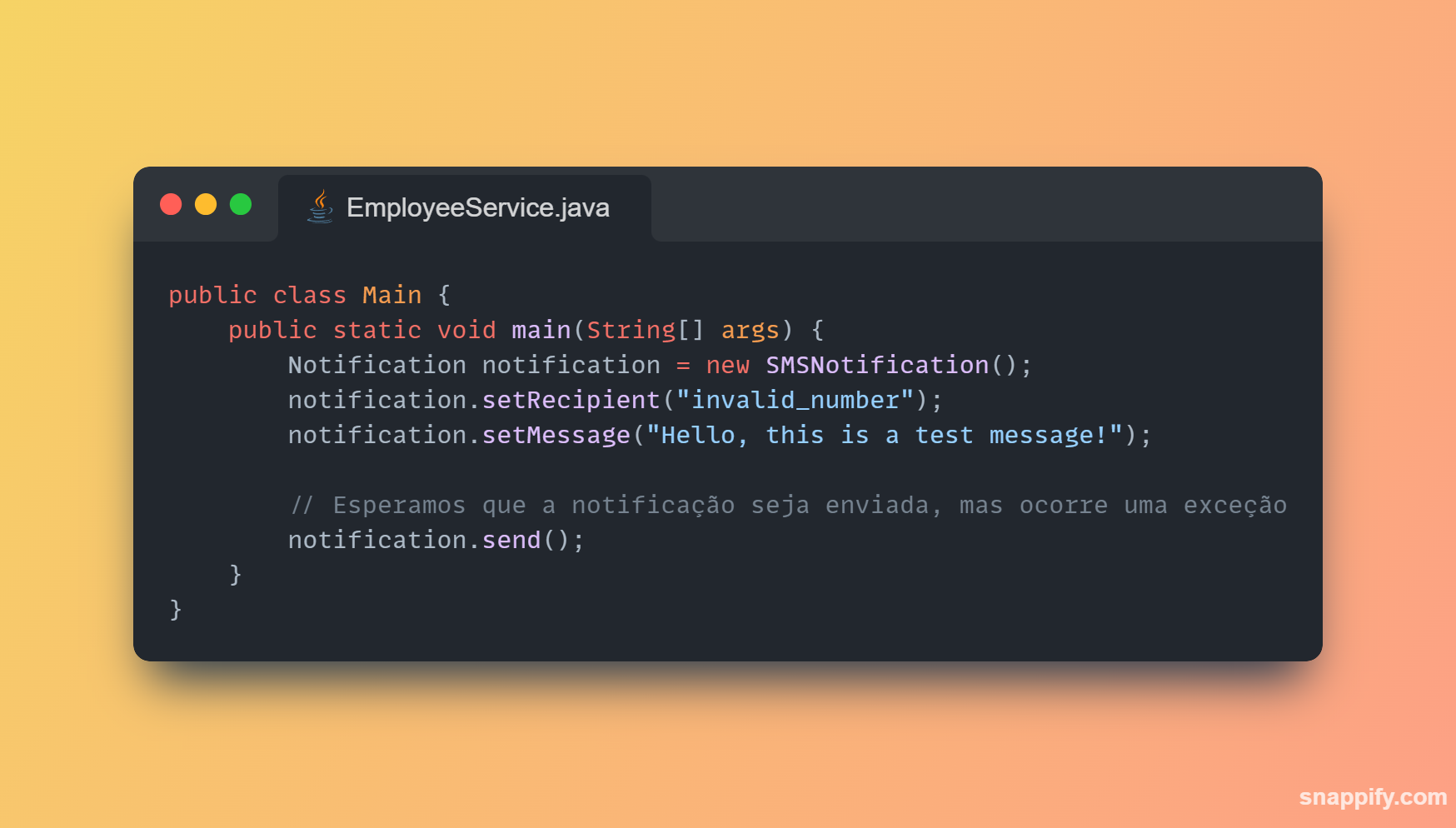
_Com LSP_
Para seguir o LSP, devemos projetar nossas classes de forma que respeitem as expectativas da superclasse e evitem adicionar comportamentos que possam quebrar a substituição.
**Interface Notification**

**Classe EmailNotification**
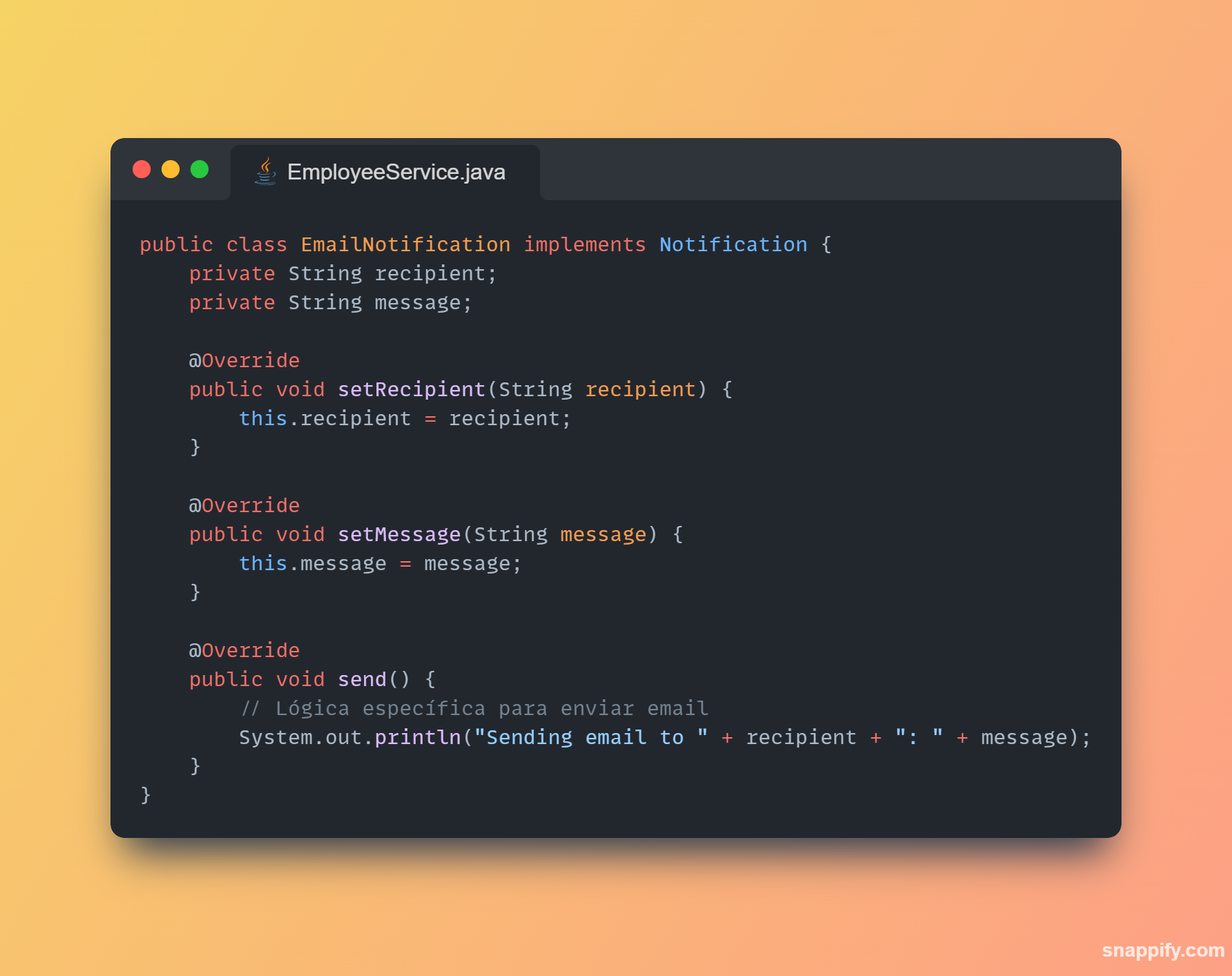
**Classe SMSNotification**
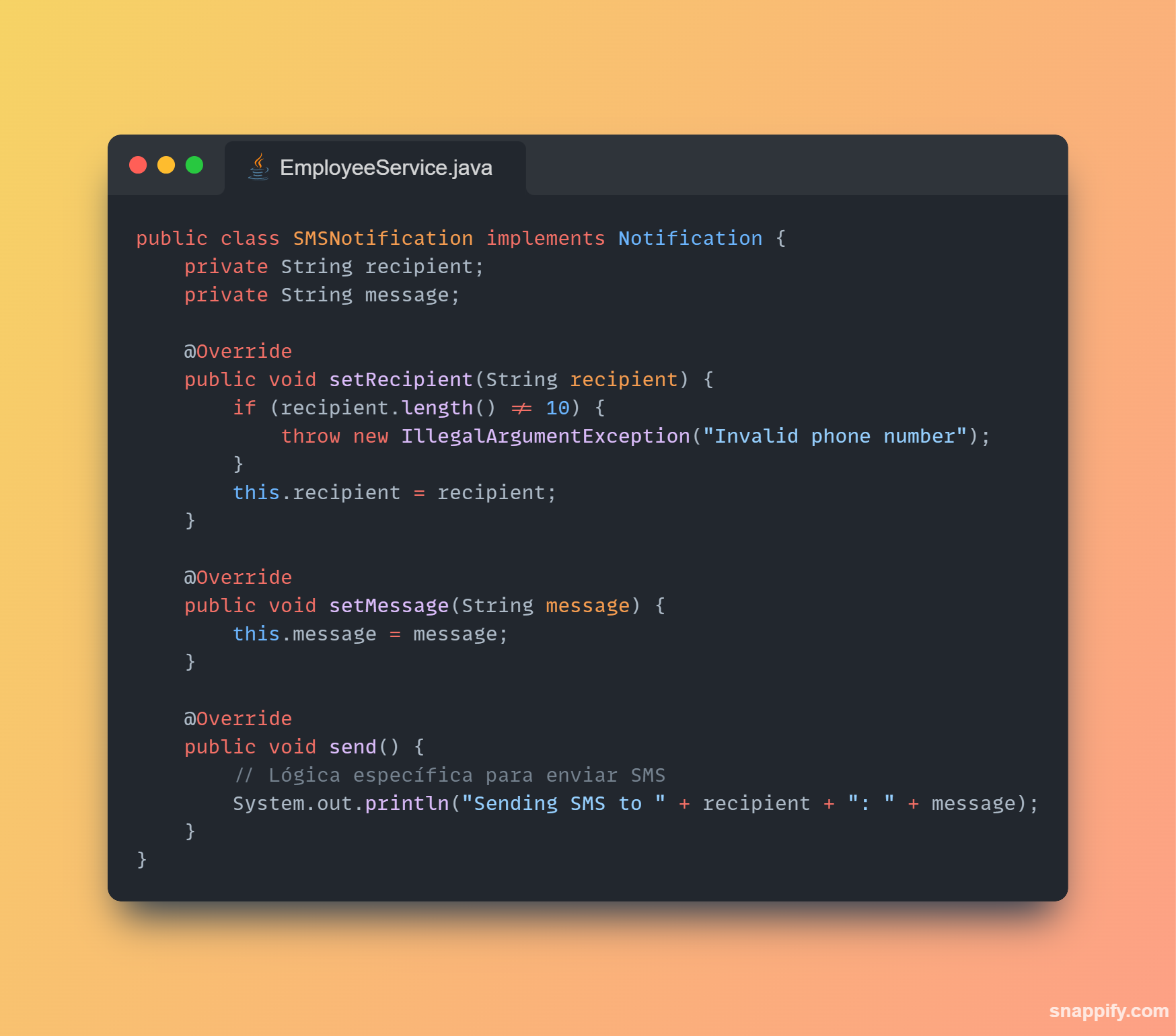
**Uso das Classes**
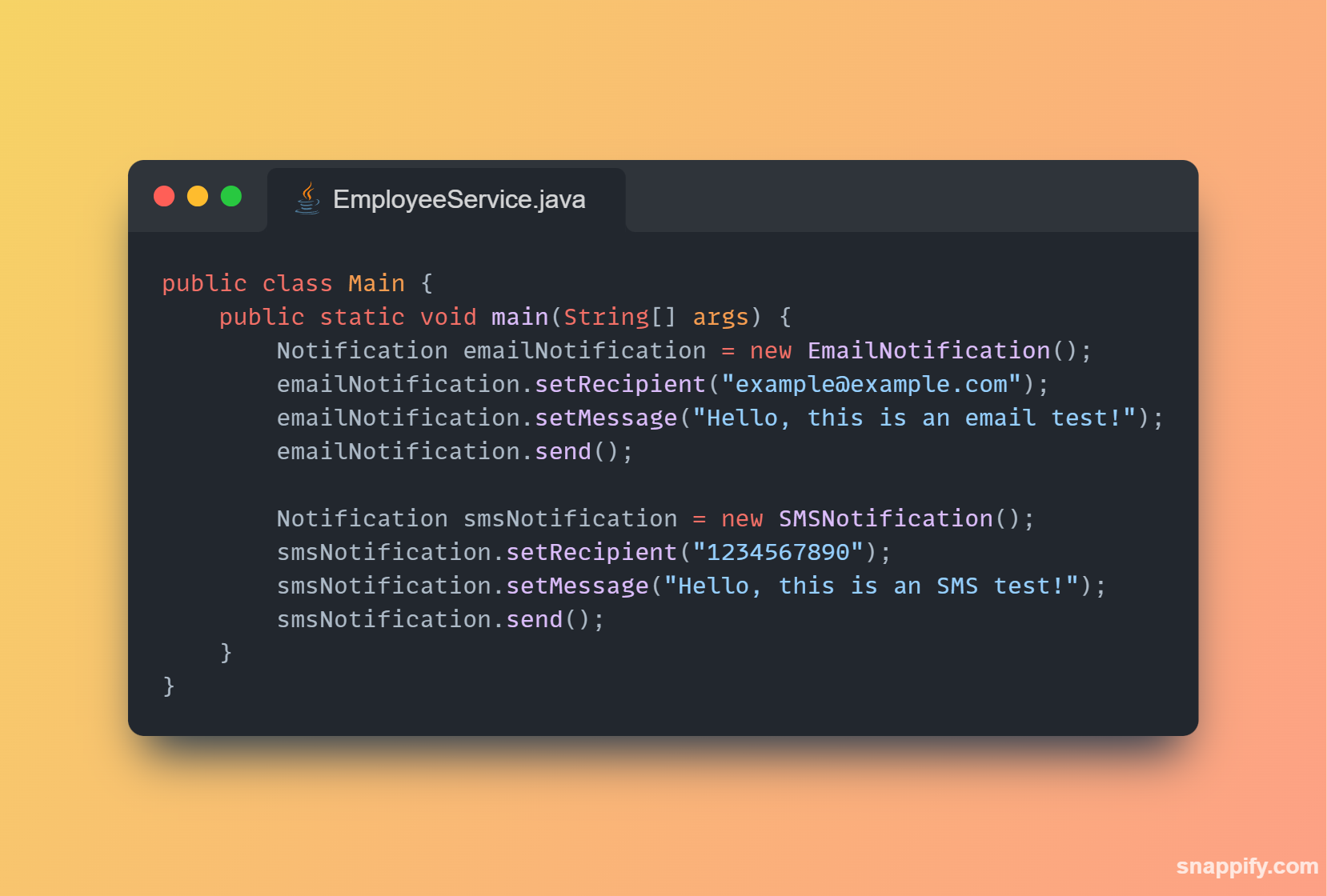
Explicação:
- Interface Notification: Define o contrato para uma notificação. Todas as notificações devem implementar os métodos setRecipient, setMessage e send.
- Classe EmailNotification: Implementa a interface Notification e define a lógica específica para enviar um email.
- Classe SMSNotification: Implementa a interface Notification e define a lógica específica para enviar um SMS. A verificação do número de telefone é feita no método setRecipient, garantindo que qualquer configuração inválida seja tratada antes de tentar enviar a notificação.
- Uso das Classes: Demonstramos como criar e usar instâncias de EmailNotification e SMSNotification de forma intercambiável através da interface Notification, respeitando o LSP.
**Ao seguir o Princípio da Substituição de Liskov, garantimos que nossas subclasses podem ser usadas em qualquer contexto onde a superclasse é esperada, sem alterar o comportamento correto do programa. Isso torna o código mais robusto e facilita a manutenção e extensão do sistema.**
_PS: Para ir direto para o próximo princípio:_
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-i-interface-segregation-principle-isp-3ho3 %}
| diegobrandao |
1,864,402 | Wazdan elevates Italian iGaming experience | As of September 20, players on Goldbet can immerse themselves in the world of Wazdan, gaining access... | 0 | 2024-05-25T00:46:47 | https://dev.to/moochiemonnicha/wazdan-elevates-italian-igaming-experience-59gi | As of September 20, players on Goldbet can immerse themselves in the world of Wazdan, gaining access to a selection of games.
Goldbet, a licensed online casino and betting platform, is synonymous with excellence in the Italian gaming landscape. Offering a diverse array of gaming options encompassing slots, poker, bingo, live games, and sports betting, Goldbet has garnered a reputation for adhering to the highest industry standards. The platform operates under the watchful eye of regulatory authorities, subject to rigorous and regular audits, ensuring a secure and responsible gaming environment. Goldbet’s unwavering commitment to quality has solidified its position as one of Italy’s most esteemed gaming companies.
The partnership between Wazdan and Goldbet signifies a remarkable fusion of innovation and tradition in the iGaming sector. Italian players can now revel in Wazdan’s captivating games, celebrated for their engaging mechanics, exceptional graphics, and player-centric features. The inclusion of titles like 9 Lions, Hot 777 Deluxe, Power of Gods™: Medusa, and Black Hawk Deluxe, is set to elevate the gaming experience on Goldbet to unprecedented heights.
Andrzej Hyla, chief commercial officer at Wazdan, said: “We are thrilled to partner with Goldbet, one of Italy’s premier gaming platforms. Wazdan has always been at the forefront of innovation, and this partnership allows us to share our passion for cutting-edge gaming experiences with Italian players.
“Goldbet’s commitment to responsible gaming and its dedication to providing players with a diverse and enriching gaming environment align seamlessly with Wazdan’s mission to create exceptional iGaming experiences. Together, they aim to offer Italian players a world-class gaming destination that caters to a wide range of preferences.”
[카지노사이트원](https://www.casinosite.one/) , [카지노사이트모음](https://www.casinosite.one/)
| moochiemonnicha | |
1,864,401 | Precision Monitoring: Harnessing Thin Film Pressure Sensors | Precision Monitoring: Harnessing Thin Film Pressure Sensors As innovation continues to progress, the... | 0 | 2024-05-25T00:40:40 | https://dev.to/ashmaa99/precision-monitoring-harnessing-thin-film-pressure-sensors-3o15 | thin, film | Precision Monitoring: Harnessing Thin Film Pressure Sensors
As innovation continues to progress, the globe ends up being increasingly more linked. Using this development happens an expanding require for precision monitoring towards guarantee security, high top premium, as well as effectiveness in different markets. Because of the development of thin film pressure sensors, precision monitoring has ended up being simpler as well as much a lot extra available compared to ever.
Benefits of Thin Film Pressure Sensors
Thin film pressure sensor are little, lightweight sensors that can easily precisely determine pressure as well as modifications in pressure. They are extremely delicate as well as can easily spot also the smallest modifications in pressure, creating all of them important devices in a variety of markets. These sensors are likewise extremely resilient as well as can easily endure severe temperature levels as well as stress, making all of them perfect for utilization in severe atmospheres.
Development in Pressure Sensing unit Innovation
Thin film pressure sensors stand for a considerable advance in pressure sensing unit innovation. Unlike conventional pressure sensors, which are large as well as costly, thin film pressure sensors are little as well as inexpensive. This makes all of them much a lot extra commonly offered as well as available to companies of all dimensions. Additionally, thin film pressure sensors could be quickly personalized to satisfy the particular requirements of various requests, making all of them extremely flexible.
Security Requests of Thin Film Pressure Sensors
Among the absolute most essential uses thin film Pressure sensor remain in security requests. For instance, these sensors could be utilized towards the screen as well as command pressure in gas bodies, decreasing the danger of mishaps as well as failings. They can easily likewise be utilized towards screen pressure in clinical gadgets, guaranteeing that clients are risk-free as well as comfy throughout clinical treatments.
Utilizing Thin Film Pressure Sensors
Thin film pressure sensors are user-friendly as well as could be utilized in a variety of requests. They could be incorporated right into current bodies or even utilized as standalone sensors. Additionally, these sensors could be linked to cordless systems or even various other monitoring bodies, enabling real-time monitoring as well as command of pressure degrees.
The solution as well as High premium
When it concerns precision monitoring, solutions as well as high top premiums are important. Thin film pressure sensors are developed for precise, dependable efficiency, as well as are supported through extensive sustain as well as solutions coming from the producer. This guarantees that companies have accessibility to the info as well as the support they have to obtain one of the absolute most away from their sensors.
Requests of Thin Film Pressure Sensors
Thin film pressure sensors are utilized in a variety of markets, including aerospace, automobile, commercial, as well as clinical. A few of the particular requests for these sensors consist of:
- Aerospace: Thin film pressure sensors are utilized towards screen pressure in motors as well as various other crucial bodies, guaranteeing that planes are risk-free as well as effective.
- Automotive: These sensors are utilized towards screen pressure in tires, motors, as well as various other bodies, enhancing security as well as effectiveness.
- Industrial: Thin film pressure sensors are utilized towards screen pressure in production procedures, assisting towards guaranteeing items high top premium as well as uniformity.
- Medical: These sensors are utilized towards screen pressure in clinical gadgets as well as treatments, enhancing client security as well as convenience.
Source: https://www.soushine.com/Thin-film-pressure-sensor | ashmaa99 |
1,864,400 | Exploring the Features of HTML5 | Introduction HTML5 has revolutionized the way websites are created and viewed. It is the... | 0 | 2024-05-25T00:30:15 | https://dev.to/kartikmehta8/exploring-the-features-of-html5-iai | webdev, javascript, beginners, programming | ## Introduction
HTML5 has revolutionized the way websites are created and viewed. It is the latest version of the HTML (Hypertext Markup Language) which is used for structuring and presenting content on the World Wide Web. With its release in 2014, it has become the preferred choice of web developers due to its advanced features and improved user experience.
## Advantages of HTML5
HTML5 has many advantages over its predecessors. It allows for the creation of more interactive and dynamic web pages, making them more appealing to users. Its multimedia integration abilities, including audio and video playback without the need for third-party plugins, have also enhanced the overall browsing experience. Additionally, its compatibility with mobile devices has made it easier to create responsive and mobile-friendly websites.
## Disadvantages of HTML5
One of the main disadvantages of HTML5 is its relatively steep learning curve for beginners. It also lacks backward compatibility with older versions of browsers, making it necessary for web developers to use workarounds or additional coding for compatibility.
## Features of HTML5
HTML5 offers a wide range of features, including the ability to store data locally on a user’s device, drag-and-drop functionality, and improved form validation. It also supports semantic markup, allowing for better search engine optimization and improved web accessibility.
### Example of Using HTML5 for Video Integration
```html
<!-- HTML5 Video Tag Example -->
<video width="320" height="240" controls>
<source src="movie.mp4" type="video/mp4">
<source src="movie.ogg" type="video/ogg">
Your browser does not support the video tag.
</video>
```
This example demonstrates how to embed a video directly into a webpage using the HTML5 `<video>` tag, eliminating the need for external plugins.
## Conclusion
Overall, HTML5 has significantly improved the web design landscape, making it more dynamic and user-friendly. Despite its few disadvantages, its advanced features and improved functionality make it the preferred choice for creating modern and responsive websites. With constant updates and advancements, HTML5 is expected to continue shaping the future of web development. | kartikmehta8 |
1,864,362 | [S.O.L.I.D.] Os Cinco Pilares da Programação Orientada a Objetos. [O] - Open/Closed Principle - OCP | Continuando a série sobre SOLID, caso não tenha lido o artigo anterior: ... | 0 | 2024-05-25T00:19:26 | https://dev.to/diegobrandao/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-o-openclosed-principle-ocp-3bal | java, solidprinciples | Continuando a série sobre SOLID, caso não tenha lido o artigo anterior: {% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-para-desenvolvedores-2lph %}
Neste artigo estarei falando sobre o **segundo princípio** que é:
**Open/Closed Principle**
**Princípio Aberto/Fechado - OCP**
“Aberto para extensão e Fechado para
modificação.”
Definição: Entidades de software (classes, módulos, funções, etc.) devem estar abertas para extensão, mas fechadas para modificação. Isso significa que você deve ser capaz de adicionar novas funcionalidades sem alterar o código existente.
Exemplo: Sistema de Processamento de Pagamentos
Vamos criar um sistema de processamento de pagamentos. Inicialmente, temos suporte apenas para pagamentos com cartão de crédito, mas posteriormente desejamos adicionar suporte para pagamentos via PayPal. Vamos ver como implementar isso sem e com o OCP.
_Sem OCP_
**Classe PaymentProcessor sem OCP**
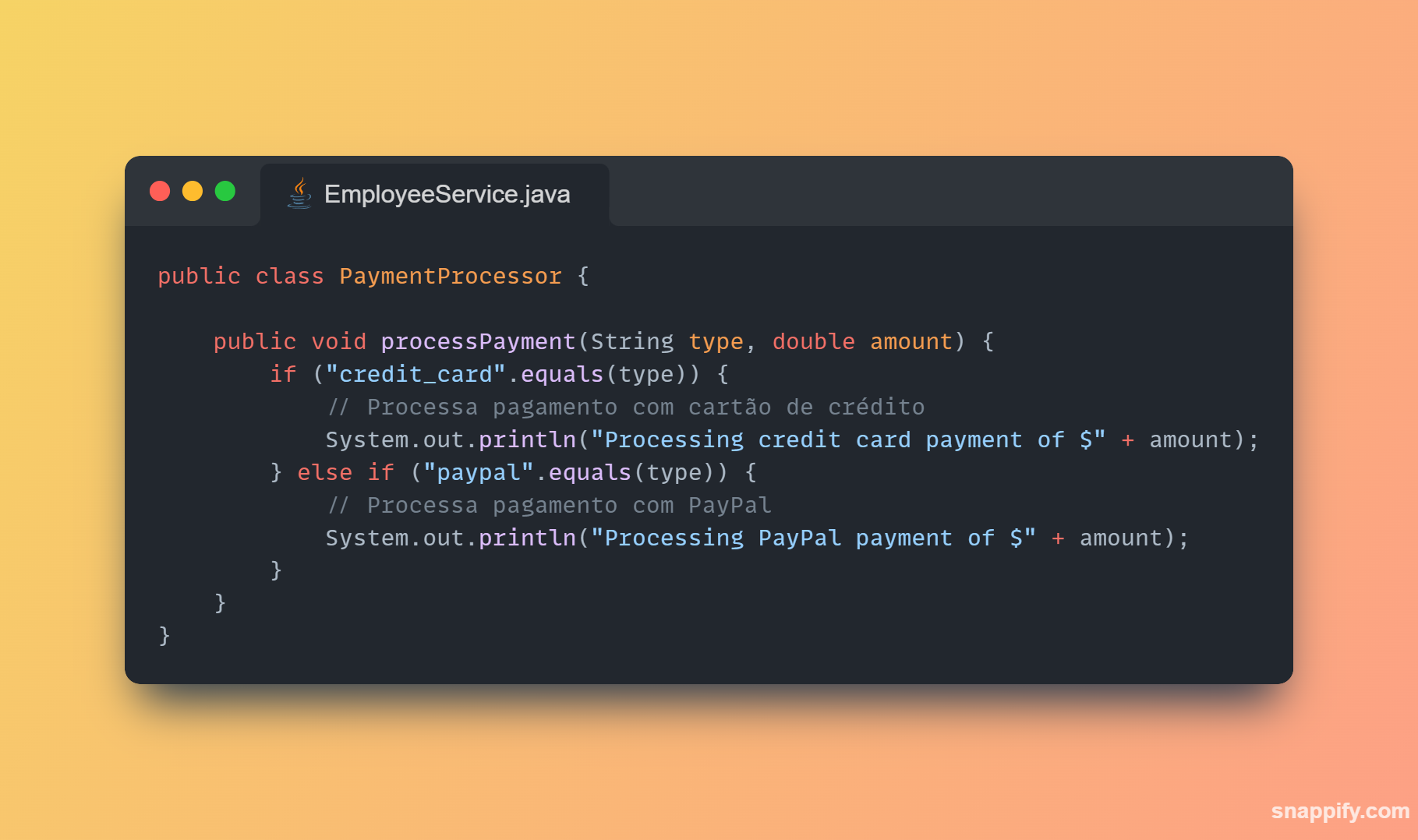
Aqui, a classe PaymentProcessor não segue o OCP. Se precisarmos adicionar um novo método de pagamento (por exemplo, Bitcoin), teremos que modificar essa classe, o que pode introduzir bugs e torna a manutenção mais difícil.
_Com OCP_
**Interface PaymentMethod**

_Implementações de PaymentMethod_
**CreditCardPayment**
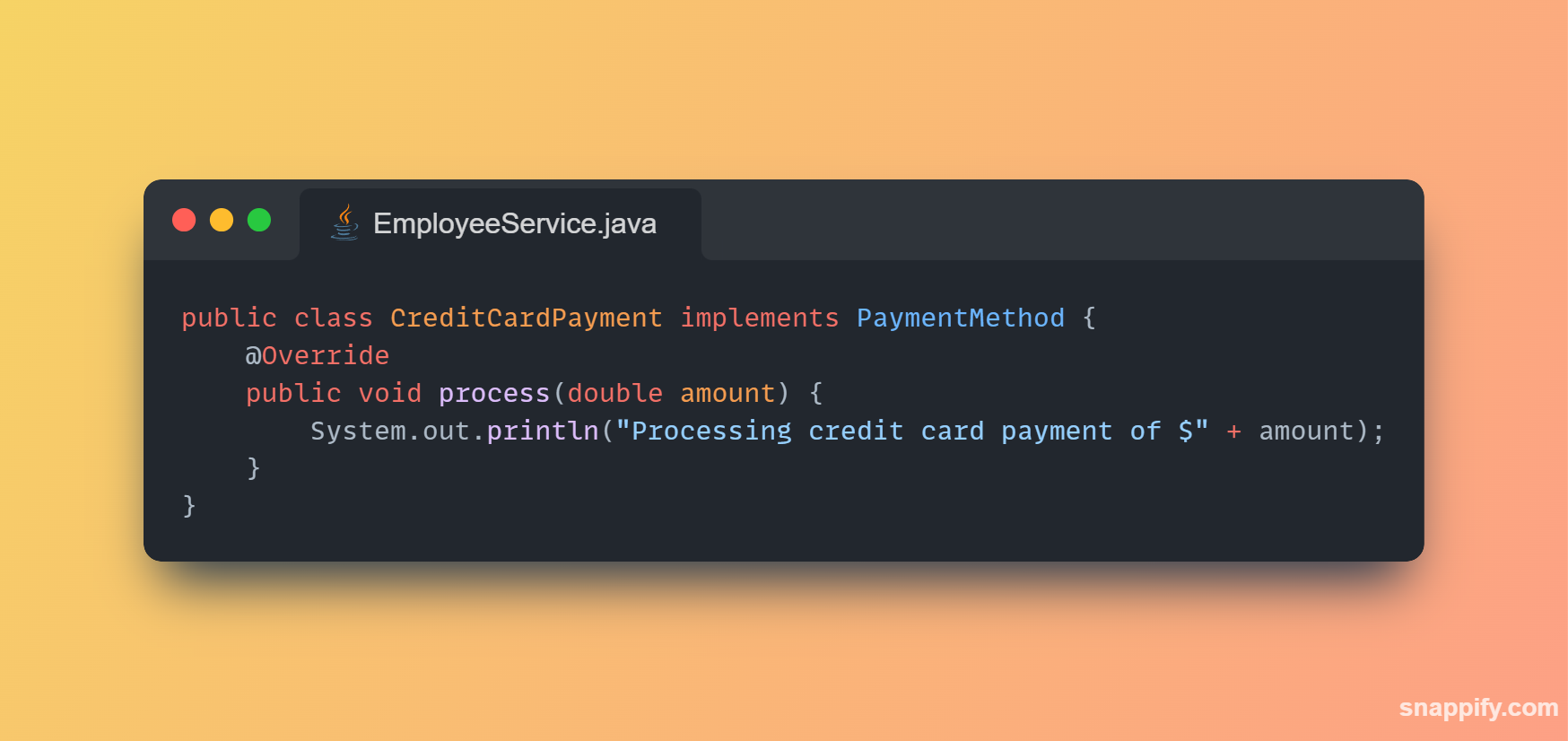
**PayPalPayment**
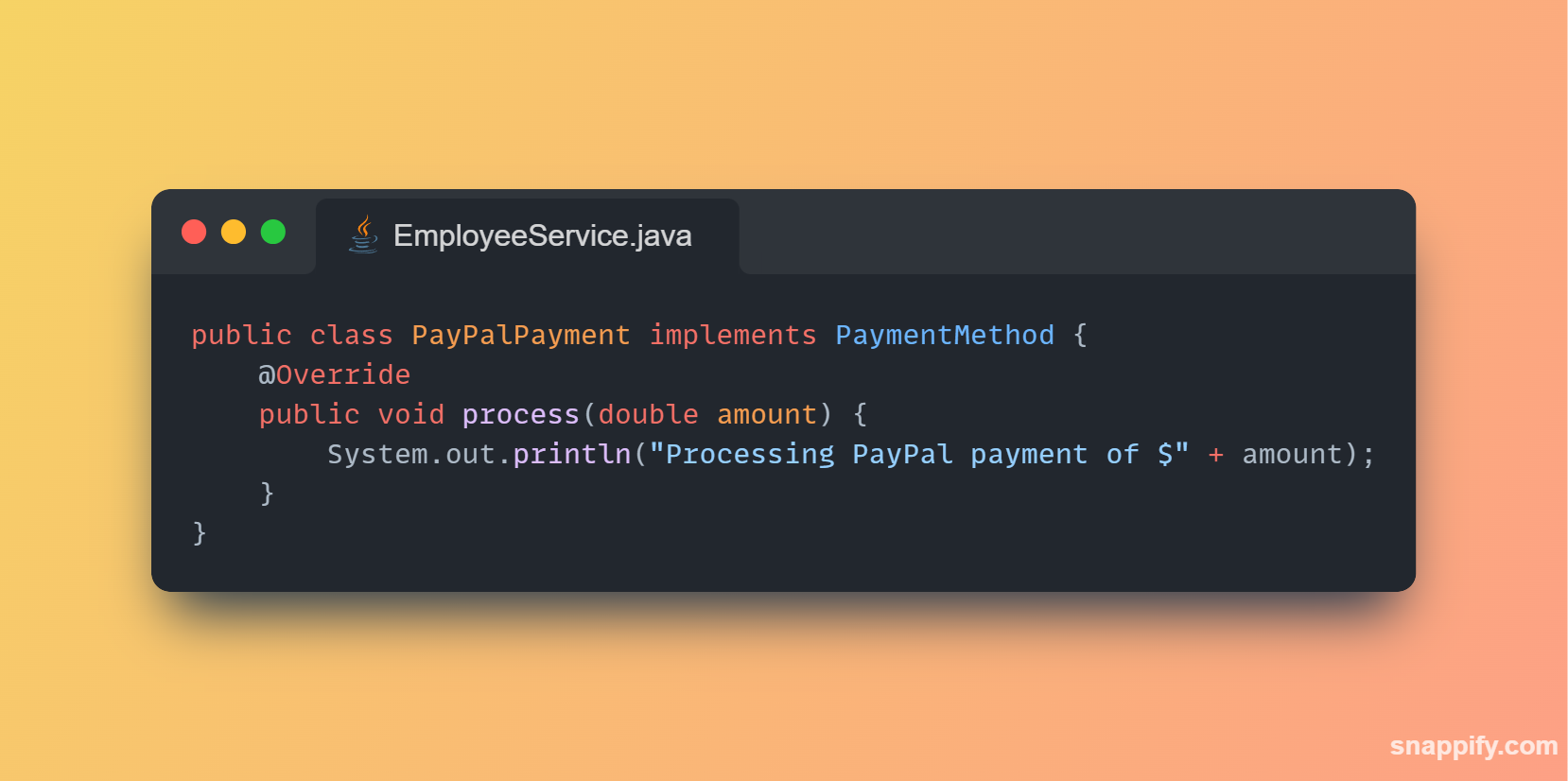
**Classe PaymentProcessor com OCP**
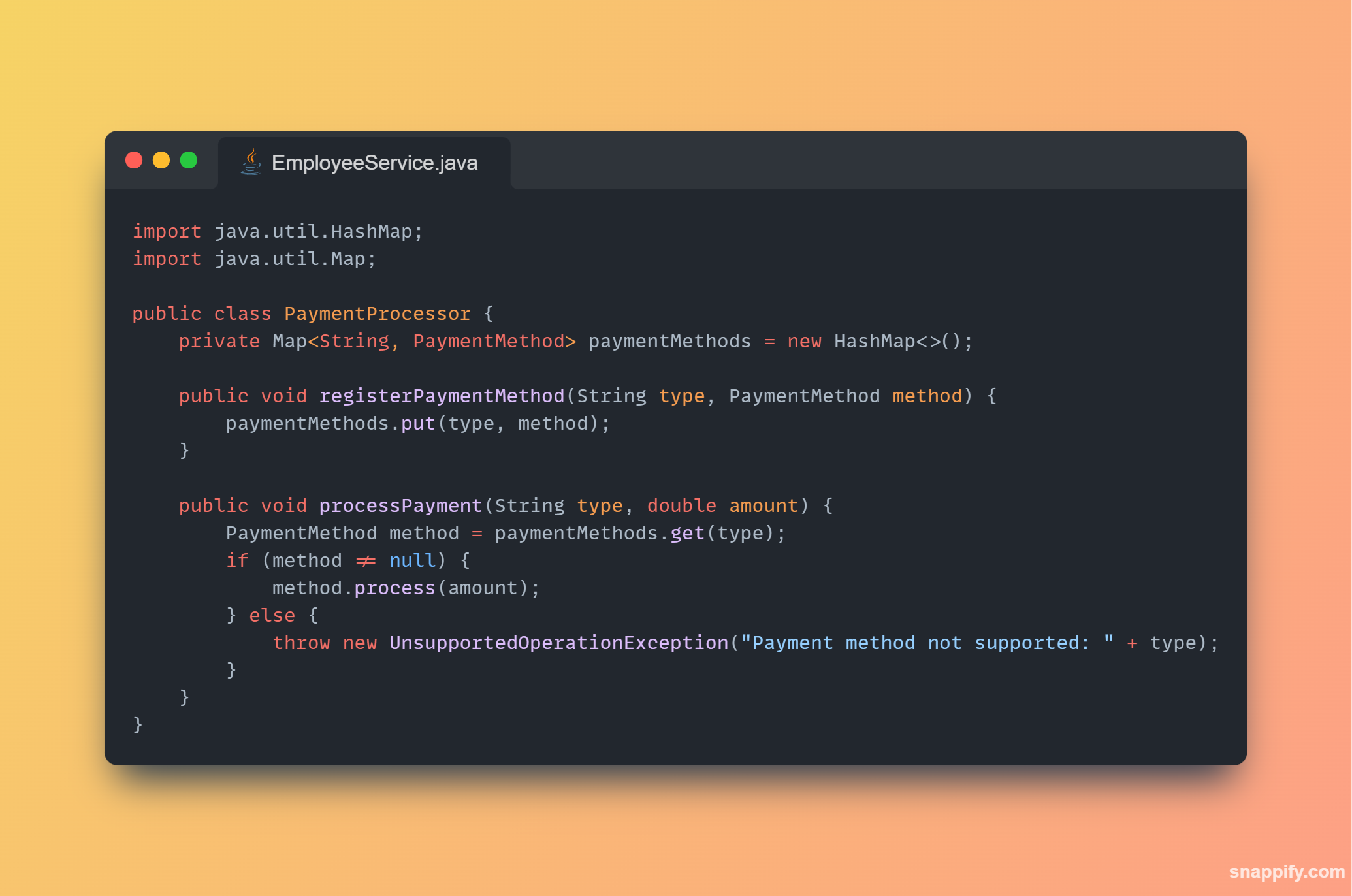
**Uso das Classes**
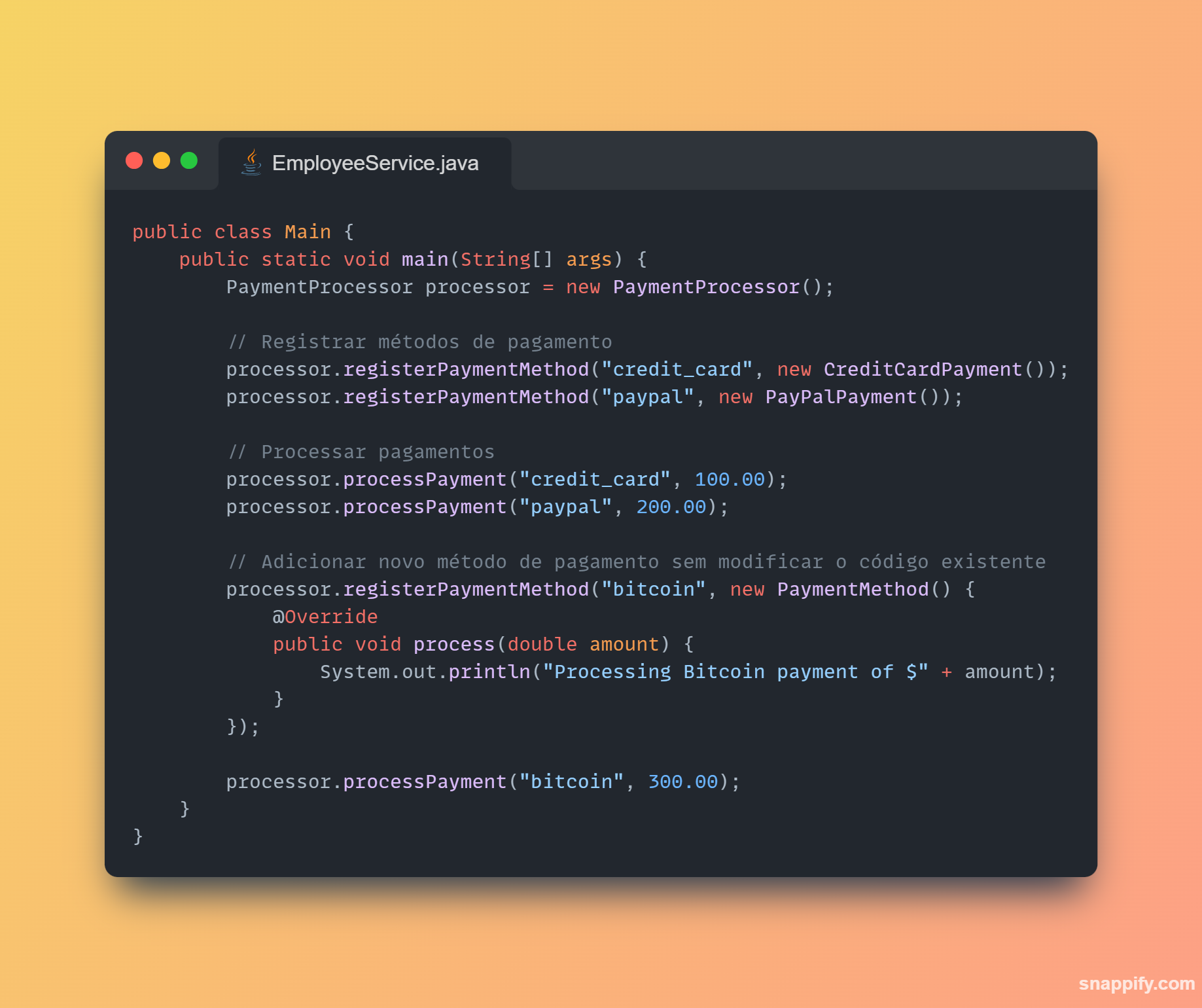
Explicação:
- Interface PaymentMethod: Define o contrato para qualquer método de pagamento. Qualquer nova forma de pagamento precisa implementar essa interface.
- Implementações de PaymentMethod: Cada classe concreta (CreditCardPayment, PayPalPayment) implementa a interface PaymentMethod e define a lógica específica de processamento.
- Classe PaymentProcessor: Em vez de usar condicionais (if ou switch) para verificar o tipo de pagamento, usamos um map para associar strings a implementações de PaymentMethod. Isso permite registrar novos métodos de pagamento dinamicamente.
- Uso das Classes: Demonstramos como registrar e usar diferentes métodos de pagamento. Também mostramos como adicionar um novo método de pagamento (Bitcoin) sem modificar as classes existentes, apenas adicionando uma nova implementação de PaymentMethod.
**Ao seguir o Princípio Aberto/Fechado, podemos adicionar novas funcionalidades de maneira segura e sem modificar o código existente, o que facilita a manutenção e a evolução do sistema.**
_PS: Para ir direto para o próximo princípio:_
{% embed https://dev.to/dsb88/solid-os-cinco-pilares-da-programacao-orientada-a-objetos-l-liskov-substitution-principle-lsp-5ebg %}
| diegobrandao |
1,864,398 | CLI Tools every Developer should know | The command line interface (CLI) is an essential tool for developers, providing powerful... | 0 | 2024-05-25T00:15:34 | https://10xdev.codeparrot.ai/top-cli-tools-for-developers | cli, tools, developer, productivity | The command line interface (CLI) is an essential tool for developers, providing powerful functionality that can streamline workflows and enhance productivity. Knowing how to use CLI tools effectively can help you work more efficiently, automate repetitive tasks, and troubleshoot issues quickly. In this article, we'll explore a few CLI tools to enhance your development experience.
I've tried my best to include tools that support multiple operating systems (Linux, macOS, and Windows) and are widely used in the developer community. Let's dive in!
**Oh My Zsh**
Oh My Zsh is a popular open-source framework for managing your Zsh configuration. It comes with a vast collection of plugins and themes that can enhance your command line experience. Oh My Zsh provides features like auto-completion, syntax highlighting, and custom prompts, making it a valuable tool for developers who spend a lot of time in the terminal.
Here's how you can install Oh My Zsh on your system:
```bash
sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
```
or using wget:
```bash
sh -c "$(wget https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh -O -)"
```
You can find more information on the official Oh My Zsh GitHub repository: [Oh My Zsh GitHub Repository](https://github.com/ohmyzsh/ohmyzsh)
**Tmux**
Tmux is a terminal multiplexer that allows you to create and manage multiple terminal sessions within a single window. It provides features like split panes, session management, and window management, making it easier to work with multiple tasks simultaneously. Tmux is a powerful tool for developers who need to work with multiple terminals at the same time. Commands like tmux new -s session_name, tmux attach -t session_name, and tmux kill-session -t session_name help in managing terminal sessions effectively.
You can follow this guide to install Tmux on your system: [Tmux Installation Guide](https://github.com/tmux/tmux/wiki/Installing)
**The F\*\*k**
The F**k (often referred to as "The F") is an incredibly useful tool for developers who often make typos or incorrect commands in the terminal. It automatically corrects errors in previous console commands, saving you time and frustration. By simply typing `fuck` after an incorrect command, The F suggests the correct command and runs it for you. This tool is especially useful for developers who work quickly in the terminal and occasionally mistype commands.
Here is the official installation guide for The fuck: [The fuck installation guide](https://github.com/nvbn/thefuck?tab=readme-ov-file#installation)
**Jq**
Jq is a lightweight and flexible command-line JSON processor that allows you to parse, filter, and manipulate JSON data effectively. It provides a set of powerful tools for working with JSON data, including querying, formatting, and transforming JSON objects. Jq supports features like filters, expressions, and functions that can help you work with complex JSON structures easily. Some essential Jq commands include `jq .`, `jq '.key'`, `jq '.key | select(.subkey == "value")'`, and `jq '.key | map(.subkey)'`. Learning how to use Jq can help you work with JSON data more efficiently and automate tasks that involve JSON processing.
You can install Jq using your package manager:
```bash
sudo apt-get install jq
```
or, if you're using macOS:
```bash
brew install jq
```
or, you can follow the installation instructions on the official Jq website: [Jq Installation Guide](https://stedolan.github.io/jq/download/)
**Bat**
Bat is a modern and feature-rich replacement for the `cat` command that provides syntax highlighting and line numbering for file contents. It allows you to view and read files with improved readability and aesthetics. Bat supports features like syntax highlighting for various file types, automatic paging, and Git integration, making it a valuable tool for developers who frequently work with text files. Some essential Bat commands include `bat`, `bat --line-range`, `bat --theme`, and `bat --language`. Learning how to use Bat can help you read and navigate files more effectively in the terminal.
You can install Bat using your package manager:
```bash
sudo apt-get install bat
```
or, if you're using macOS:
```bash
brew install bat
```
or, you can follow the installation instructions on the official Bat GitHub repository: [Bat Installation Guide](https://github.com/sharkdp/bat?tab=readme-ov-file#installation)
**Zoxide**
Zoxide is a fast directory navigation tool that helps you jump to your most frequently used directories with ease. It tracks the directories you visit and provides fuzzy matching to quickly navigate to them using the `z` command. Zoxide is a handy tool for developers who work with multiple projects and need to switch between directories frequently. It's lightweight, easy to use, and can significantly improve your productivity when working in the terminal. Some common Zoxide commands include `z`, `z -l`, `z -c`, and `z -r`.
You can follow the installation instructions for Zoxide on the official GitHub repository: [Zoxide Installation Guide](https://github.com/ajeetdsouza/zoxide?tab=readme-ov-file#installation)
**Ngrok**
Ngrok is a powerful tool that allows you to expose local servers to the internet securely. It creates secure tunnels to your localhost, making it easy to share web applications, APIs, and other services with collaborators or clients. Ngrok provides a set of command-line tools that allow you to start tunnels, inspect traffic, and manage your connections effectively. Some essential Ngrok commands include `ngrok http`, `ngrok tcp`, `ngrok status`, and `ngrok kill`. Learning how to use Ngrok can help you test webhooks, share projects in development, and collaborate with others seamlessly.
You can follow the official Ngrok installation guide for your operating system: [Ngrok Installation Guide](https://ngrok.com/download)
**Tldr**
Tldr (Too Long; Didn't Read) is a simplified and community-driven tool for viewing concise and practical examples of command-line commands. It provides quick reference guides for common commands, making it easier to understand their usage and options. Tldr is a valuable resource for developers who want to learn new commands, refresh their memory, or find examples of command-line tools. Some essential Tldr commands include `tldr`, `tldr --update`, `tldr --list`, and `tldr <command>`.
You can install Tldr using NPM:
```bash
npm install -g tldr
```
**HTTPie**
HTTPie is a user-friendly command-line HTTP client that makes it easy to interact with APIs and web services. It provides a simple and intuitive interface for sending HTTP requests, inspecting responses, and debugging network communication. HTTPie supports features like syntax highlighting, JSON output, and form data handling, making it a powerful tool for developers working with APIs. Some essential HTTPie commands include `http`, `http GET`, `http POST`, and `http PUT`. Learning how to use HTTPie can help you test APIs, debug network issues, and interact with web services more effectively. It can be used as an alternative to tools like cURL or Postman.
You can follow the installation instructions for HTTPie on the official GitHub repository: [HTTPie Installation Guide](https://httpie.io/cli)
**Fzf**
Fzf is a command-line fuzzy finder that helps you search and navigate through files, directories, and command history with ease. It provides interactive search capabilities with fuzzy matching, making it easy to find and open files quickly. Fzf integrates seamlessly with various command-line tools and can significantly improve your productivity when working in the terminal. Some common Fzf commands include `fzf`, `fzf --preview`, `fzf --preview "cat {}"`, and `fzf --reverse`.
You can install Fzf using git:
```bash
git clone --depth 1 https://github.com/junegunn/fzf.git ~/.fzf
~/.fzf/install
```
or, you can directly visit the official GitHub repository for more installation options: [Fzf Installation Guide](https://github.com/junegunn/fzf?tab=readme-ov-file#installation)
**Ffmpeg**
FFmpeg is a powerful multimedia framework that can decode, encode, transcode, mux, demux, stream, filter, and play almost anything that humans and machines have created. It supports a wide range of audio and video formats, making it a versatile tool for multimedia processing. FFmpeg provides a set of command-line tools that allow you to manipulate multimedia files, convert formats, extract streams, and perform various multimedia operations. Some essential FFmpeg commands include `ffmpeg -i input.mp4 output.mp4`, `ffmpeg -i input.mp4 -vn -acodec copy output.mp3`, and `ffmpeg -i input.mp4 -vf "scale=640:480" output.mp4`. Learning how to use FFmpeg can help you work with multimedia files, create custom video processing pipelines, and automate multimedia tasks effectively.
You can follow the official FFmpeg installation guide for your operating system: [FFmpeg Installation Guide](https://ffmpeg.org/download.html)
**Cobra**
Cobra is a modern and powerful CLI library for Go that makes it easy to create powerful and efficient command-line applications. It provides a simple and elegant API for building CLI tools with features like command routing, argument parsing, flag handling, and help generation. Cobra is widely used in the Go community for developing CLI applications and tools. Some essential Cobra commands include `cobra init`, `cobra add`, `cobra run`, and `cobra build`. Learning how to use Cobra can help you create robust and user-friendly CLI applications in Go.
You can install Cobra using go get:
```bash
go get -u github.com/spf13/cobra@latest
```
You can visit the official website for more information on using Cobra: [Cobra Documentation](https://cobra.dev/)
**SpeedTest-CLI**
SpeedTest-CLI is a command-line interface for testing internet bandwidth using the Speedtest.net service. It allows you to measure your download and upload speeds, ping times, and other network metrics from the terminal. SpeedTest-CLI provides a simple and efficient way to check your internet connection speed without the need for a web browser. Some essential SpeedTest-CLI commands include `speedtest`, `speedtest --simple`, `speedtest --list`, and `speedtest --server <server_id>`. Learning how to use SpeedTest-CLI can help you troubleshoot network issues, monitor internet performance, and optimize your internet connection.
You can install SpeedTest-CLI using homebrew:
```bash
brew install speedtest-cli
```
or, you can follow the installation instructions on the official GitHub repository: [SpeedTest-CLI Installation Guide](https://github.com/sivel/speedtest-cli)
These tools can help you enhance your development workflow, automate repetitive tasks, and streamline your command-line experience. By mastering these CLI tools, you can become more productive, efficient, and effective in your development work. Happy coding! 🚀
| harshalranjhani |
1,852,600 | Construindo um web server em Assembly x86, parte V, finalmente o server | No artigo anterior, passamos pelos fundamentos de Assembly, onde foi possível entender alguns... | 27,062 | 2024-05-25T00:14:20 | https://dev.to/leandronsp/construindo-um-web-server-em-assembly-x86-parte-v-finalmente-o-server-9e5 | braziliandevs, assembly, computerscience | No [artigo anterior](https://dev.to/leandronsp/construindo-um-web-server-em-assembly-x86-parte-iv-um-assembly-modesto-oif), passamos pelos fundamentos de Assembly, onde foi possível entender alguns conceitos básicos tais como tipos de registradores, **stack**, loops, FLAGS etc, tudo sendo feito com debugging via _GDB_.
Agora, vamos de fato construir um web server muito simples que devolve um HTML com a frase "Hello, World". A meta é chegarmos nisto:

O processo para chegarmos a este objetivo consiste em cobrir fundamentos de Web, passando por sockets, TCP e HTTP, enquanto vamos explorando conceitos práticos em Assembly x86.
---
## Agenda
* [Arquitetura Web](#arquitetura-web)
* [Cliente-servidor](#clienteservidor)
* [Modelo OSI](#modelo-osi)
* [Sockets e TCP](#sockets-e-tcp)
* [HTTP](#http)
* [Como funciona um servidor web](#como-funciona-um-servidor-web)
* [4 syscalls para o resgate](#4-syscalls-para-o-resgate)
* [Um server modesto em Assembly](#um-server-modesto-em-assembly)
* [Criando o socket](#criando-o-socket)
* [Fazendo bind no socket](#fazendo-bind-no-socket)
* [Preparando para receber conexões](#preparando-para-receber-conexões)
* [Chegou o momento de aceitar clientes](#chegou-o-momento-de-aceitar-clientes)
* [Resposta do servidor e fechamento da conexão](#resposta-do-servidor-e-fechamento-da-conexão)
* [Mas o servidor deve ficar em loop, não?](#mas-o-servidor-deve-ficar-em-loop-não)
* [Conclusão](#conclusão)
* [Referências](#referências)
---
## Arquitetura Web
Para criar um servidor web, precisamos manipular _mensagens HTTP_, que são transportadas via camada de transporte TCP/IP através de uma rede.
Estas mensagens são enviadas entre diferentes dispositivos conectados a uma rede, que pode ser privada (local) ou pública. Regularmente, comunicação HTTP é feita entre 2 dispositivos, sendo um deles o _cliente_ e outro o _servidor_.
Vamos brevemente falar de cada um destes conceitos.
### Cliente-servidor
Numa arquitetura cliente-servidor, temos 2 dispositivos conectados a uma rede de computadores:
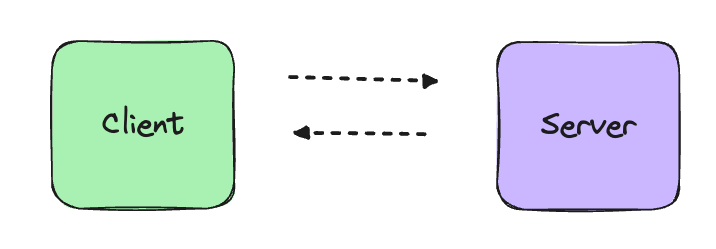
Para um servidor web, é necessário que o cliente realize uma **conexão** com o servidor, em seguida faça uma **requisição**, pelo que o servidor deve devolver uma **resposta** e, por último, **fechar a conexão**.
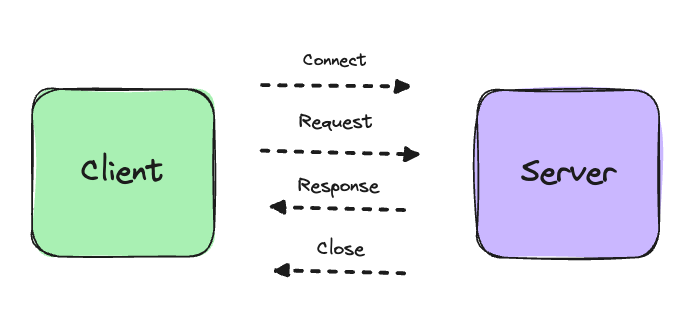
Mas como esta mensagem deve ser enviada? Quem garante a entrega? E caso ocorra falha de sinal na camada física (cabeamento de rede), como assegurar que cada "pacote" da mensagem seja entregue em ordem?
É pra isto que foi criado o **modelo de comunicação OSI**.
### Modelo OSI
OSI é um modelo de referência para comunicação entre diferentes dispositivos através de diferentes redes, que estabelece um conjunto de camadas que vai desde a camada física até a camada de formato de mensagens.
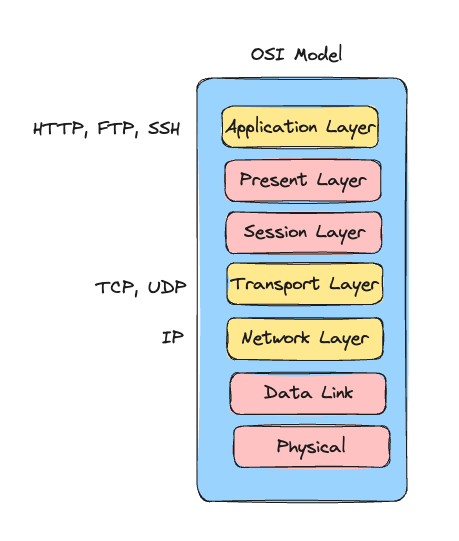
* **Camada física**: responsável pelo tráfego de informações através de meios físicos, tais como bluetooth, frequência de rádio, cabos etc
* **Camada de enlace de rede**: responsável pela decodificação e codificação de mensagens em frames, do meio físico para o meio digital e vice-versa
* **Camada de rede**: é aqui que definimos protocolos de rede, tais como o _protocolo de internet_, também conhecido como **IP** (Internet Protocol)
> Na web, os dados trafegam geralmente através de uma rede de computadores pública, global e descentralizada, neste caso a Internet
* **Camada de transporte**: camada responsável por características de entrega, tais como definir critérios de confiabilidade e ordem dos pacotes de mensagens. Por exemplo, nesta camada temos o _protocolo de controle de transmissão_, ou **TCP**
* **Camada de sessão e apresentação**: aqui vão critérios de informações que podem ser vinculadas a uma determinada conexão entre diferentes dispositivos, bem como o formato de apresentação das informações na rede
* **Camada de aplicação**: nesta camada, temos a definição do formato de mensagens em um nível mais "aplicacional", como por exemplo protocolo HTTP (Hypertext Transfer Protocol), FTP, SSH entre outros
Entretanto fica aqui uma questão: como que todo esse modelo de comunicação em rede se converte em algo prático num programa dentro de um sistema operacional?
Chegou o momento de falar sobre _sockets_ e TCP.
### Sockets e TCP
Num computador, todos os programas são encapsulados dentro de uma estrutura chamada _processo_, como vimos em artigos anteriores.
Quando falamos em cliente na aquitetura cliente-servidor, estamos falando de um processo rodando dentro de um computador, e o mesmo vale para o servidor, onde cada processo tem seu próprio identificador, ou _PID_:
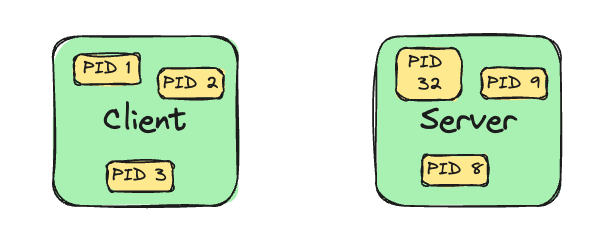
Sabendo que processos são isolados, foram definidas diferentes formas de comunicação entre processos (também conhecido como IPC, ou _inter process communication_), tais como pipes, arquivos do filesystem, descritores de arquivos e UNIX sockets.
> Estamos baseando a saga em sistema "UNIX-like", mais especificamente GNU/Linux
Ou seja, temos ciência que é possível fazer 2 processos _dentro de um mesmo computador_ se comunicarem através de UNIX sockets. Mas como fazer dois processos em computadores distintos se comunicarem?
Entramos então em **Berkeley Sockets**, que define uma API comum de comunicação utilizando sockets, onde diferentes sockets podem estar no mesmo computador, ou em uma mesma rede local, ou até mesmo em redes diferentes dentro da _Internet_.
É aqui que temos a introdução ao TCP, que é um protocolo de comunicação via sockets. Portanto, para fazer um cliente se comunicar com um servidor, é preciso estabelecer _endpoints de comunicação_, que são basicamente **sockets**, e neste caso para a web, vamos utilizar _sockets TCP_.
Estes sockets são abertos tanto do lado do cliente, quanto no servidor. No servidor, estes sockets são mapeados em descritores de arquivos, que representam um número especial e reservado, também chamado de **porta de comunicação**:
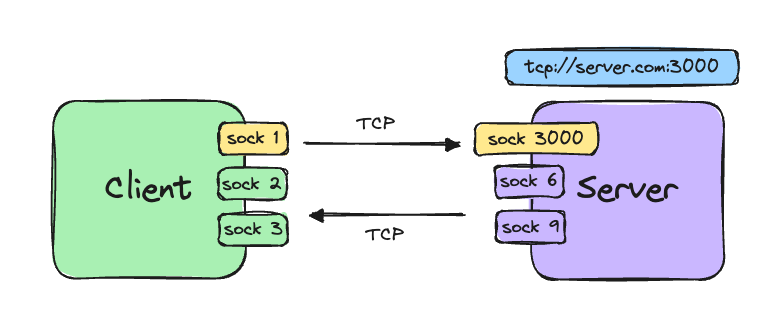
> Ok Leandro, consegui entender o conceito de sockets e TCP. Mas qual deveria ser o formato da mensagem na web?
Com vocês, o _HTTP_.
### HTTP
HTTP é um protocolo de formato de mensagem que faz parte da camada de aplicação.
Com HTTP, a mensagem é definida seguindo padrões de hipertexto, que são basicamente documentos que podem ter ligações com outros documentos em sites diferentes.
Na web, o padrão segue um formato de _headline_, que contém o tipo de pedido, seguido de quebra de linhas com _cabeçalhos_ de metadados e por fim, opcionalmente e dependendo do tipo de pedido, um _corpo_ com a mensagem principal contendo majoritariamente HTML, CSS e Javascript.
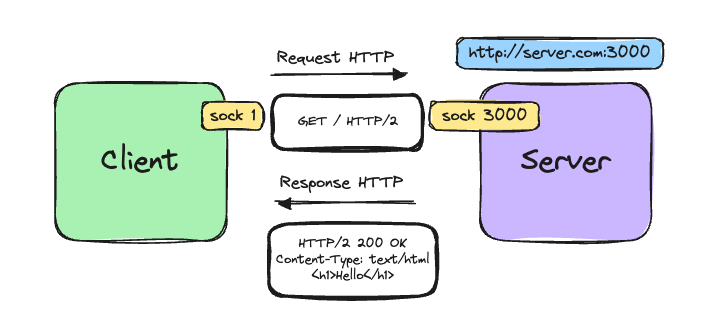
Até agora, passamos por conceitos que formam a web. Como nosso exemplo de web server é bastante simples, estes fundamentos já são o suficiente para entrarmos na próxima seção, que é de fato escrever o web server em Assembly x86.
---
## Como funciona um servidor web
Conforme vimos na seção anterior, arquitetura web passa por manipulação de sockets TCP.
Tal manipulação é feita via _chamadas de sistema_ (syscalls) no sistema operacional, portanto, para darmos início ao servidor, vamos entender como devem ser criados os sockets a nível do OS.
### 4 syscalls para o resgate
Resumidamente temos que fazer 4 syscalls para termos um server operante, que são:
**socket**
A syscall _socket_ é responsável por criar um endpoint de comunicação de rede e retornar um descritor de arquivo (fd) relativo ao endpoint criado.
Na libc, _socket_ é referenciada pelo número 41 e tem a seguinte assinatura:
```c
int socket(int domain, int type, int protocol)
```
> Lembrando que estamos utilizando arquitetura x86_64, ou x64
**bind**
_bind_ atribui nome e porta ao socket previamente criado. Esta syscall na libc responde pelo número 49 e tem a assinatura a seguir:
```c
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen)
```
**listen**
A syscall _listen_ marca o socket criado (precisa ser do tipo stream, no caso TCP) para aceitar conexões. É conhecida pelo número 50 e tem a seguinte assinatura em C:
```c
int listen(int sockfd, int backlog)
```
**accept**
A syscall _accept_ admite uma conexão de um cliente no socket e cria um *novo socket de conexão específico* para aquele cliente. Esta syscall, a princípio, bloqueia o programa e só continua a execução quando uma nova conexão com novo cliente é estabelecida.
É referenciada pelo número 288 e tem a seguinte assintaura:
```c
int accept(int sockfd, struct *addr, int addrlen, int flags)
```
Em resumo, tudo o que precisamos para criar um web server, independente do programa, linguagem de programação ou tecnologia, é de chamar estas 4 syscalls.
> Não se engane, o teu servidor Express, Rails, Django ou NGINX, faz estas chamadas de sistema por baixo dos panos: _socket, bind, listen e accept_
Sem mais delongas, vamos ver como tudo isto se aplica naquilo que importa para esta saga: **assembly**.
---
## Um server modesto em Assembly
Montar as syscalls para o web server em Assembly não é tão difícil quanto parece. Para começar, vamos fazer a primeira syscall, que é a _socket_.
### Criando o socket
Como de costume, vamos montar as instruções de acordo com o [manual](https://man7.org/linux/man-pages/man2/socket.2.html) e [tabela de syscalls](https://x64.syscall.sh/).
> Já vimos na seção anterior quais são os números das syscalls e suas respectivas assinaturas na libc
Iniciamos definindo as constantes, apenas as necessárias para a syscall _socket_:
```as
global _start
; syscalls constants
%define SYS_socket 41
; other constants
%define AF_INET 2
%define SOCK_STREAM 1
%define SOCK_PROTOCOL 0
```
Após isto, vamos reservar 1 byte com a diretiva `resb 1` que significa "reservar 1 byte". Este byte será utilizado para armazenar o número do descritor de arquivo que referencia o _socket_ que vai ser criado.
Como **não queremos inicializar** o valor deste byte, não vamos colocar na seção `.data` como temos utilizado até o momento na saga, mas sim na seção `.bss`.
* Na seção `.data`, ficam apenas dados inicializados
* Na seção `.bss`, ficam os dados não-inicializados
```as
section .bss
sockfd: resb 1
```
Vamos relembrar o layout de memória:
Como vemos na imagem, a seção `.bss` vem a seguir a seção `.data`, ou seja, fica em endereços de memória mais altos que a seção `.data`.
Agora, vamos montar os registradores seguindo a convenção de chamada e a ordem dos parâmetros da função _socket_ na libc:
```as
section .text
_start:
.socket:
; int socket(int domain, int type, int protocol)
mov rdi, AF_INET
mov rsi, SOCK_STREAM
mov rdx, SOCK_PROTOCOL
mov rax, SYS_socket
syscall
mov [sockfd], rax
.exit:
mov rdi, 0
mov rax, 60
syscall
```
* **domain**: representa o domínio de comunicação. No caso queremos usar AF_INET, que significa IPv4, e tem o valor 2 conforme especificado no [glibc](https://github.com/bminor/glibc/blob/8f58e412b1e26d2c7e65c13a0ce758fbaf18d83f/bits/socket.h#L78)
* **type**: representa o tipo de comunicação, que no caso vamos usar SOCK_STREAM que é sequencial, confiável, duplex e baseado em conexão. O valor [conforme glibc](https://github.com/bminor/glibc/blob/8f58e412b1e26d2c7e65c13a0ce758fbaf18d83f/bits/socket.h#L42) é 1
* **protocol**: esta opção é usada no caso da utilização de um protocolo em específico. Neste caso, vamos deixar o valor como 0 que é o default para AF_INET e SOCK_STREAM, _indicando que se trata de um socket TCP_
> Lembrando que existem sockets da família UNIX que não funcionam na camada de rede IP. É possível combinar socket UNIX com SOCK_STREAM, mas neste caso estamos combinando a família AF_INET (IPv4) com o tipo SOCK_STREAM (segmento de bytes, duplex), e esta combinação faz este socket ser TCP. Para mais detalhes sobre sockets, sugiro a leitura de um artigo que escrevi sobre [UNIX Sockets](https://dev.to/leandronsp/building-a-web-server-in-bash-part-i-sockets-2n8b)
Vamos confirmar com GDB?
```bash
# Breakpoint na linha <syscall>
(gdb) break 22
(gdb) run
# Confirmando que os registradores estão com os valores corretos
# antes da execução da syscall...
(gdb) i r rdi rsi rdx rax
rdi 0x2 2
rsi 0x1 1
rdx 0x0 0
rax 0x29 41
# Confirmando que `sockfd` continua com o valor zerado
(gdb) x &sockfd
0x402000 <sockfd>: 0x00000000
(gdb) next
```
Após a execução da syscall, podemos ver que o _retorno da função_, que representa o descritor de arquivo conforme documentação, está armazenado no registrador RAX (de acordo com a convenção de chamada):
```as
(gdb) i r rax
rax 0x3 3
(gdb) next
(gdb) x &sockfd
0x402000 <sockfd>: 0x00000003
```
Ou seja, após a syscall, temos em `sockfd` o número do socket que acabou de ser criado.
Executando com _strace_:
```bash
$ strace ./live
execve("./live", ["./live"], 0x7ffca20187e0 /* 24 vars */) = 0
socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 3
exit(0) = ?
+++ exited with 0 +++
```
Sem erros, _yay!_
Vamos para a próxima syscall.
### Fazendo bind no socket
Agora, é o momento de atribuir um endereço e uma porta como endpoint de comunicação para este socket. É para isto que serve a syscall _bind_.
Analisando a função:
```c
; int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen)
```
Podemos ver que um dos argumentos é um _ponteiro_ para uma struct na memória. Vamos entender melhor cada argumento.
**sockfd**
Em sockfd vai o inteiro que representa o descritor do socket criado
**sockaddr **addr***
Representa o ponteiro para o endereço de memória que contém uma estrutura de dados que, de acordo com [este guia](https://www.gta.ufrj.br/ensino/eel878/sockets/sockaddr_inman.html), contempla: _family, port, ip_address, sin_zero_, onde sin_zero é apenas padding de preenchimento de bytes.
Para arquitetura x64, esta estrutura deve conter 16 bytes no total, onde:
* 2 bytes são para a _família_ de protocolo
* 2 bytes para a _porta_
* 4 bytes para o _endereço de IP_
* 8 bytes de padding para o _sin_zero_, ou seja, preencher os 8 bytes restantes com ZERO
**addrlen**: tamanho do sockaddr, e já sabemos que são 16 bytes
Uma vez entendidos os parâmetros da função, vamos montar a chamada.
```as
%define SYS_bind 49
; Data types in asm
; (db) byte => 1 byte
; (dw) word => 2 bytes
; (dd) doubleword => 4 bytes
; (dq) quadword => 8 bytes
section .data
sockaddr:
family: dw AF_INET ; 2 bytes
port: dw 0x0BB8 ; 2 bytes (representa a porta 3000)
ip_address: dd 0 ; 4 bytes
sin_zero: dq 0 ; 8 bytes
.bind:
; int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen)
mov rdi, [sockfd]
mov rsi, sockaddr
mov rdx, 16
mov rax, SYS_bind
syscall
```
Ao validar com GDB, podemos ver que o `sockaddr` está armazenando a estrutura necessária para ser enviada no parâmetro `sockaddr *addr` da syscall:
```bash
# Breakpoint na syscall de bind
(gdb) break 38
(gdb) run
(gdb) x &sockaddr
0x402000 <family>: 0xb80b0002
```
Se buscarmos os 2 primeiros bytes, confirmamos que é o valor 2 (repare que está invertido pois é o padrão little-endian da aquitetura x86_64:
```bash
(gdb) x /2xb &sockaddr
0x402000 <family>: 0x02 0x00
```
Quanto à porta, queremos que o server responda no número 3000. Portanto, verificamos que os próximos 2 bytes representam a porta:
```bash
# Em hexadecimal, 3000 equivale a 0x0BB8, mas por causa do formato
# little-endian da arquitetura x86_64, estamos visualizando 0xB80B
(gdb) x /2xb (void*) &sockaddr+2
0x402002 <port>: 0xb8 0x0b
```
Queremos também que o servidor responda no endereço de IP `0.0.0.0`, então os próximos 4 bytes estarão todos a zero:
```bash
(gdb) x /4xb (void*) &sockaddr+4
0x402004 <ip_address>: 0x00 0x00 0x00 0x00
```
E, por fim, os 8 bytes restantes representando _sin_zero_, todos preenchidos com zero:
```bash
(gdb) x /8xb (void*) &sockaddr+8
0x402008 <sin_zero>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
```
Vamos executar com _strace_:
```bash
$ strace ./live
execve("./live", ["./live"], 0x7ffd51ed4650 /* 24 vars */) = 0
socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 3
bind(3, {sa_family=AF_INET, sin_port=htons(47115), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
exit(0) = ?
+++ exited with 0 +++
```
Ouch! Apesar da função _bind_ ter retornado 0 indicando que não houve erros, temos um pequeno problema. Repare que a _porta_ não está sendo mapeada para o número **3000**, e sim para **47115**, conforme vemos em _htons(47115)_.
**Entendendo a implicação de endianess na syscall bind**
`htons` é uma função de rede utilizada para converter a ordem dos bytes do programa antes de serem utilizados na rede. Como a internet utiliza big-endian, esta função converte a ordem utilizada na arquitetura (no caso da x86_64, little-endian) para o formato big-endian da rede.
Entretanto _htons(47115)_ não é o valor que queremos. O que precisamos é que o mapeamendo seja _htons(3000)_. Por quê isto está acontecendo?
O valor que colocamos em hexadecimal representando _3000_ é _0x0BB8_, mas se prestarmos atenção no GBD, o valor de fato armazenado está com os bytes invertidos para little-endian, que é _0xB80B_. Ocorre que `0xB80B` em decimal é **47115**!!!!!! Aí que está o problema!
Precisamos então inverter os bytes no programa, e assim sendo o valor que será passado para a função htons fica corrigido.
```as
....
section .data
sockaddr:
family: dw AF_INET ; 2 bytes
port: dw 0xB80B ; 2 bytes (aqui invertemos os bytes)
ip_address: dd 0 ; 4 bytes
sin_zero: dq 0 ; 8 bytes
....
```
E analisando novamente com GDB:
```bash
# Agora sim, apesar de estar invertido, é exatamente este valor que
# queremos que seja passado para htons: 0x0BB8 em decimal é 3000
(gdb) x /2xb (void*) &sockaddr+2
0x402002 <port>: 0x0b 0xb8
```
Executando novamente com _strace_:
```bash
$ strace ./live
execve("./live", ["./live"], 0x7ffd51ed4650 /* 24 vars */) = 0
socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 3
bind(3, {sa_family=AF_INET, sin_port=htons(3000), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
exit(0) = ?
+++ exited with 0 +++
```
_Superb!_ Podemos ver que a syscall _bind_ foi executada com os parâmetros corretamente, inclusive o `htons(3000)`, então retornando _0_, que indica que não houve qualquer erro.
### Preparando para receber conexões
Próximo passo consiste em preparar o socket para receber conexões, que basicamente é chamar a função `listen`:
```as
%define SYS_listen 50
%define BACKLOG 2
.listen:
; int listen(int sockfd, int backlog)
mov rdi, [sockfd]
mov rsi, BACKLOG
mov rax, SYS_listen
syscall
```
Onde _BACKLOG_ significa a quantidade de conexões "pendentes" no socket. Executamos com _strace_ e:
```bash
$ strace ./live
execve("./live", ["./live"], 0x7ffe6b4eea30 /* 24 vars */) = 0
socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 3
bind(3, {sa_family=AF_INET, sin_port=htons(3000), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
listen(3, 2) = 0
exit(0) = ?
+++ exited with 0 +++
```
_Que noite maravilhosa!_ Listen funcionou lindamente, afinal, é uma função muito simples. Agora, hora de aceitar conexões de clientes no socket.
### Chegou o momento de aceitar clientes
O grande momento chegou. Vamos montar as instruções da syscall _accept_, que de acordo com a função em libc, recebe um socket como primeiro argumento e os demais são opcionais.
```as
%define SYS_accept 288
.accept:
; int accept(int sockfd, struct *addr, int addrlen, int flags)
mov rdi, [sockfd]
mov rsi, 0 ; não precisa estabelecer um addr
mov rdx, 0 ; não precisa do tamanho uma vez que não há addr
mov r10, 0
mov rax, SYS_accept
syscall
```
Se executarmos com GDB, podemos ver que o resultado da syscall fica bloqueado até que uma conexão seja feita:
```bash
# Breakpoint na syscall de socket
(gdb) break 55
(gdb) run
(gdb) next
```
O programa está parado na syscall de socket, aguardando resposta do **kernel**. Para que o kernel responda e o programa continue a execução, é preciso realizar um pedido usando um HTTP client, e neste caso vamos usar o _curl_:
```bash
$ curl localhost:3000
```
Repare que o programa continuou a execução. Vamos ver a resposta que está em RAX:
```bash
(gdb) i r rax
rax 0x4 4
# Um número diferente do sockfd, que é o socket criado pelo server
(gdb) x &sockfd
0x402010 <sockfd>: 0x00000003
```
Podemos ver que é um número diferente (RAX contém 4 e sockfd contém 3). De acordo com a documentação, este é o número do descritor que representa um novo socket criado para comunicação entre *um cliente específico e o servidor*.
Vamos mover o valor de RAX para R8, apenas para preservar o socket, uma vez que RAX será usado novamente por outras syscalls de accept:
```as
mov r8, rax ; client socket
```
### Resposta do servidor e fechamento da conexão
Uma outra coisa importante a se fazer é **fechar a conexão** com este socket do cliente depois de ter processado e respondido a requisição.
Vamos implementar a subrotina `.write`, que escreve a resposta na conexão (socket) do cliente:
```as
%define SYS_write 1
%define CR 0xD
%define LF 0xA
section .data
response:
headline: db "HTTP/1.1 200 OK", CR, LF
content_type: db "Content-Type: text/html", CR, LF
content_length: db "Content-Length: 22", CR, LF
crlf: db CR, LF
body: db "<h1>Hello, World!</h1>"
responseLen: equ $ - response
section .text
...
.write:
; int write(int fd, buffer *bf, int bfLen)
mov rdi, r8
mov rsi, response
mov rdx, responseLen
mov rax, SYS_write
syscall
ret
```
No exemplo acima, assumimos que a string de resposta HTTP aponta para uma estrutura na memória, definida em `.data`.
> Atenção para CR (carriage return), LF (line feed) que são constantes que representam `\r\n ` que são separadores de linhas definidos pelo protocolo HTTP
Agora, definir a subrotina `.close`, que fecha a conexão com o cliente:
```as
%define SYS_close 3
section .text
...
.close:
; int close(int fd)
mov rdi, r8
mov rax, SYS_close
syscall
ret
```
Ligando tudo no _accept_:
```as
section .text
....
.accept:
; int accept(int sockfd, struct *addr, int addrlen, int flags)
mov rdi, [sockfd]
mov rsi, 0 ; não precisa estabelecer um addr
mov rdx, 0 ; não precisa do tamanho uma vez que não há addr
mov r10, 0
mov rax, SYS_accept
syscall
mov r8, rax ; client socket
call .write ; escreve no socket
call .close ; fecha o socket
jmp .exit ; termina o programa
```
E agora, vamos executar o programa com _strace_:
```bash
$ strace ./live
execve("./live", ["./live"], 0x7ffd811567c0 /* 24 vars */) = 0
socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 3
bind(3, {sa_family=AF_INET, sin_port=htons(3000), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
listen(3, 2) = 0
accept4(3, NULL, NULL, 0
```
* primeiro foi feita a syscall _socket_
* a seguir foi feito o _bind_
* depois o _listen_
* e por fim, o _accept_ ficou bloqueado a espera de uma requisição
Em outra janela, vamos fazer a requisição:
```bash
$ curl localhost:3000
<h1>Hello, World!</h1>
```
E no servidor, a saída do strace no final ficou assim:
```bash
write(4, "HTTP/1.1 200 OK\r\nContent-Type: t"..., 86) = 86
close(4) = 0
exit(0) = ?
+++ exited with 0 +++
```
Escreveu a resposta com `write`, fechou a conexão com `close`, e depois terminou o programa com `exit`.
_Como não ficar feliz?_
### Mas o servidor deve ficar em loop, não?
Sim, o servidor deve ficar em loop, portanto ao invés de fazer o `jmp .exit`, fazemos `jmp .accept` na última linha da procedure:
```as
...
.accept:
; int accept(int sockfd, struct *addr, int addrlen, int flags)
mov rdi, [sockfd]
mov rsi, 0 ; não precisa estabelecer um addr
mov rdx, 0 ; não precisa do tamanho uma vez que não há addr
mov r10, 0
mov rax, SYS_accept
syscall
mov r8, rax ; client socket
call .write
call .close
jmp .accept ; <-- MUDANÇA AQUI, mantém o server em loop infinito
```
Assim, o server nunca termina, e quando uma conexão com um cliente é fechada, voltamos no início do loop e ficamos a espera de nova conexão na syscall _accept_.
Código final do server:
```as
global _start
%define SYS_socket 41
%define SYS_bind 49
%define SYS_listen 50
%define SYS_accept 288
%define SYS_write 1
%define SYS_close 3
%define AF_INET 2
%define SOCK_STREAM 1
%define SOCK_PROTOCOL 0
%define BACKLOG 2
%define CR 0xD
%define LF 0xA
; Data types in asm
; byte => 1 byte
; word => 2 bytes
; doubleword => 4 bytes
; quadword => 8 bytes
section .data
sockaddr:
family: dw AF_INET ; 2 bytes
port: dw 0xB80B ; 2 bytes (47115 big endian becomes 3000 little endian)
ip_address: dd 0 ; 4 bytes
sin_zero: dq 0 ; 8 bytes
sockaddrLen: equ $ - sockaddr
response:
headline: db "HTTP/1.1 200 OK", CR, LF
content_type: db "Content-Type: text/html", CR, LF
content_length: db "Content-Length: 22", CR, LF
crlf: db CR, LF
body: db "<h1>Hello, World!</h1>"
responseLen: equ $ - response
section .bss
sockfd: resb 1
section .text
_start:
.socket:
; int socket(int domain, int type, int protocol)
mov rdi, AF_INET
mov rsi, SOCK_STREAM
mov rdx, SOCK_PROTOCOL
mov rax, SYS_socket
syscall
mov [sockfd], rax
.bind:
; int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen)
mov rdi, [sockfd]
mov rsi, sockaddr
mov rdx, sockaddrLen
mov rax, SYS_bind
syscall
.listen:
; int listen(int sockfd, int backlog)
mov rdi, [sockfd]
mov rsi, BACKLOG
mov rax, SYS_listen
syscall
.accept:
; int accept(int sockfd, struct *addr, int addrlen, int flags)
mov rdi, [sockfd]
mov rsi, 0 ; não precisa estabelecer um addr
mov rdx, 0 ; não precisa do tamanho uma vez que não há addr
mov r10, 0
mov rax, SYS_accept
syscall
mov r8, rax ; client socket
call .write
call .close
jmp .accept
.write:
; int write(int fd, buffer *bf, int bfLen)
mov rdi, r8
mov rsi, response
mov rdx, responseLen
mov rax, SYS_write
syscall
ret
.close:
; int close(int fd)
mov rdi, r8
mov rax, SYS_close
syscall
ret
```
Executando tudo com _strace_ e temos:
```bash
$ strace ./live
execve("./live", ["./live"], 0x7fff9fde7840 /* 24 vars */) = 0
socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 3
bind(3, {sa_family=AF_INET, sin_port=htons(3000), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
listen(3, 2) = 0
accept4(3, NULL, NULL, 0) = 4
write(4, "HTTP/1.1 200 OK\r\nContent-Type: t"..., 86) = 86
close(4) = 0
accept4(3, NULL, NULL, 0) = 4
write(4, "HTTP/1.1 200 OK\r\nContent-Type: t"..., 86) = 86
close(4) = 0
accept4(3, NULL, NULL, 0) = 4
write(4, "HTTP/1.1 200 OK\r\nContent-Type: t"..., 86) = 86
close(4) = 0
accept4(3, NULL, NULL, 0
```
No lado do cliente:
```bash
$ curl localhost:3000
<h1>Hello, World!</h1>
$ curl localhost:3000
<h1>Hello, World!</h1>
$ curl localhost:3000
<h1>Hello, World!</h1>
```
### Com vocês, o web browser
Esta saga não teria nenhuma graça se não fosse pra ser executada em um _web browser_, afinal estamos falando de um **web server**, não?

---
## Conclusão
Incrivelmente chegamos no final da construção de um modesto web server. Aqui aprendemos conceitos sobre sockets, TCP e HTTP, com uma pitada leve de HTML.
> Fala aí, quem não já conhecia a tag H1 do HTML? kk
Para além de termos visto sobre as syscalls de rede _socket, bind, listen e accept_ em Assembly.
Ainda não chegamos ao fim da saga, pelo que no próximo artigo iremos abordar a criação de **threads** e aprender sobre alocação dinâmica de memória para as threads.
Stay tuned!
_Agradecimentos a [Rodrigo Gonçalves de Branco](https://x.com/rodrigogbranco) por ter revisado este artigo com o devido rigor_
---
## Referências
<sub>
Building a web server in Bash
https://dev.to/leandronsp/series/19120
OSI Model
https://en.wikipedia.org/wiki/OSI_model
TCP
https://en.wikipedia.org/wiki/Transmission_Control_Protocol
Berkeley Sockets
https://en.wikipedia.org/wiki/Berkeley_sockets
HTTP
https://en.wikipedia.org/wiki/HTTP
struct sockaddr_in
https://www.gta.ufrj.br/ensino/eel878/sockets/sockaddr_inman.html
</sub> | leandronsp |
1,864,391 | [Game of Purpose] Day 6 | Today I learned about terrain sculpting, terrain painting and foliage painting. For me it is way... | 27,434 | 2024-05-24T23:35:19 | https://dev.to/humberd/game-of-purpose-day-6-1b93 | gamedev | Today I learned about terrain sculpting, terrain painting and foliage painting. For me it is way easier and more accessible than it was in Unity.
There is also a shop with free assets called Quixel Bridge. Importing them is just 1 click away. So easy.
| humberd |
1,864,397 | This is how you can recover your asset | After losing $277,000 to a fraudulent cryptocurrency platform, I found hope through Asset Recover... | 0 | 2024-05-25T00:14:08 | https://dev.to/amelie_robert_09c642f5cb5/this-is-how-you-can-recover-your-asset-17l8 | After losing $277,000 to a fraudulent cryptocurrency platform, I found hope through Asset Recover net. Their swift and diligent efforts helped me recover my lost funds within just two days. I highly recommend their services to anyone facing similar challenges. For assistance, you can contact them via Telegram AssetRecoverNet
email assetrecovernet@gmail.com | amelie_robert_09c642f5cb5 | |
1,864,395 | Idempotência: A Chave para Evitar Duplicações | Dados duplicados, transações duplicadas, usuários com o mesmo CPF... Todo mundo já passou por... | 0 | 2024-05-25T00:03:27 | https://dev.to/yagocosta/idempotencia-a-chave-para-evitar-duplicacoes-8j6 | node, bank, webdev, backend | Dados duplicados, transações duplicadas, usuários com o mesmo CPF...

Todo mundo já passou por isso, e resolver é algo bem tranquilo, mas poucos sabem o termo que as grandes empresas usam. É aí que entra a idempotência, um conceito essencial que pode salvar a sua pele (e a do seu sistema). Vamos explorar o que é idempotência, por que ela é importante, casos reais onde ela faz a diferença, e como você pode implementá-la com um exemplo em Node.js.
##O Que é Idempotência?
Imagina que você está fazendo uma compra online. Você clica no botão "comprar" e, por algum motivo, a página demora para carregar. Você clica de novo, e de novo, com medo de que sua compra não tenha sido registrada. De repente, você percebe que comprou três vezes o mesmo item! Se o sistema de compras fosse idempotente, ele garantiria que apenas uma compra fosse processada, não importa quantas vezes você clicasse no botão.
Na computação, uma operação é idempotente se produzir o mesmo resultado, mesmo que seja realizada várias vezes. Ou seja, clicar várias vezes no botão "comprar" deveria resultar em apenas uma compra.
##Por Que a Idempotência é Importante?
* **Tolerância a Falhas:** Em qualquer sistema, falhas podem ocorrer. Se uma solicitação falhar, você pode tentar de novo sem medo de duplicar a operação.
* **Consistência:** Em sistemas onde manter dados consistentes é crucial, a idempotência evita a duplicação de operações, garantindo que tudo permaneça em ordem.
* **Simplicidade na Recuperação de Erros:** Com operações idempotentes, a recuperação de erros é mais fácil. Se algo der errado, é só tentar de novo, sabendo que o resultado será o mesmo.
##Métodos HTTP e Idempotência
* **GET:** Por definição, as requisições GET devem ser idempotentes. Pedir o mesmo recurso várias vezes não altera o estado do recurso.
* **PUT**: A operação PUT deve ser idempotente. Enviar uma requisição PUT múltiplas vezes deve atualizar um recurso com o mesmo estado.
* **DELETE**: Idealmente, DELETE deve ser idempotente. Deletar um recurso várias vezes não deve resultar em erro, pois o recurso já foi removido.
* **POST**: A operação POST não é idempotente por natureza, pois cada requisição POST pode resultar na criação de um novo recurso. No entanto, a idempotência pode ser implementada em POSTs através de técnicas como chaves de idempotência.
##Casos de Uso Reais
> No setor financeiro, a idempotência é essencial para evitar cobranças duplicadas. Empresas como PayPal e Stripe implementam idempotência em suas APIs de pagamento. Quando uma solicitação de pagamento é enviada, um identificador único é usado para garantir que, mesmo que a solicitação seja repetida devido a falhas de rede, o cliente não será cobrado duas vezes.
> Plataformas de reservas de voos e hotéis, como Expedia e Booking.com, utilizam idempotência para garantir que reservas duplicadas não sejam criadas. Se uma solicitação para reservar um quarto ou um voo for repetida, a plataforma verifica se a reserva já foi feita e evita duplicações.
> Em redes sociais como Facebook e Twitter, a idempotência é usada ao criar posts ou enviar mensagens. Se um usuário acidentalmente submeter a mesma postagem várias vezes, o sistema pode reconhecer a duplicação e evitar múltiplos posts idênticos.
##Como implementar ?
Aqui está um exemplo simples de como implementar idempotência em uma API RESTful usando Node.js e Express. Teremos dois endpoints: um para gerar uma nova chave de idempotência (UUID) e outro para criar um recurso usando essa chave.
```javascript
const express = require('express');
const { v4: uuidv4 } = require('uuid');
const app = express();
app.use(express.json());
const idempotencyStore = new Set();
app.get('/generate-key', (req, res) => {
const idempotencyKey = uuidv4();
res.send({ idempotencyKey });
});
app.post('/create-resource', (req, res) => {
const idempotencyKey = req.headers['idempotency-key'];
if (!idempotencyKey) {
return res.status(400).send('Idempotency Key is required');
}
if (idempotencyStore.has(idempotencyKey)) {
return res.status(200).send({ message: 'Request already processed' });
}
idempotencyStore.add(idempotencyKey);
res.status(201).send({ message: 'Resource created successfully' });
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
```
Neste exemplo, um endpoint (/generate-key) gera uma nova chave de idempotência (UUID) e o outro endpoint (/create-resource) utiliza essa chave para garantir que a operação de criação de recursos seja idempotente. Se uma solicitação com a mesma chave de idempotência for recebida novamente, o servidor retorna uma mensagem indicando que a solicitação já foi processada, em vez de criar um novo recurso.
## Como podemos melhorar ?
* Se o seu servidor utiliza um load balancer, armazenar chaves de idempotência na memória local pode não ser eficaz, pois cada instância do servidor teria seu próprio armazenamento. Em vez disso, use um banco de dados distribuído como o Redis para garantir que todas as instâncias do servidor possam acessar e compartilhar o mesmo conjunto de chaves.
* Em vez de simplesmente gerar um UUID, podemos torná-lo mais específico concatenando-o com um valor do usuário, como o username ou namespace. Isso ajuda a evitar colisões de chaves e torna a chave mais significativa.
* Para evitar que o armazenamento cresça indefinidamente, é uma boa prática definir um tempo de expiração para as chaves. Configurar o Redis para expirar as chaves após um período de tempo razoável garante que o banco de dados seja limpo automaticamente e não cresça indefinidamente.
##Conclusão
A idempotência é um princípio essencial para construir sistemas resilientes e confiáveis. Entender como aplicar esse conceito pode melhorar significativamente a robustez de APIs e sistemas distribuídos. Empresas como PayPal, Stripe, Expedia e Facebook utilizam idempotência para garantir a consistência e a segurança em suas operações. Ao implementar idempotência, garantimos que nossos sistemas possam lidar com falhas e repetições de maneira previsível e segura.
| yagocosta |
1,864,379 | Shift Left With Architecture Testing in .NET | Picture this: You're part of a team building a shiny new .NET application. You've carefully chosen... | 0 | 2024-05-28T10:59:38 | https://www.milanjovanovic.tech/blog/shift-left-with-architecture-testing-in-dotnet | architecture, architecturetesting, systemdesign, maintainability | ---
title: Shift Left With Architecture Testing in .NET
published: true
date: 2024-05-25 00:00:00 UTC
tags: architecture,architecturetesting,systemdesign,maintainability
canonical_url: https://www.milanjovanovic.tech/blog/shift-left-with-architecture-testing-in-dotnet
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/86yjzvd3iqt4hn9wvop3.png
---
Picture this: You're part of a team building a shiny new .NET application. You've carefully chosen your software architecture. It could be microservices, a [**modular monolith**](https://www.milanjovanovic.tech/modular-monolith-architecture), or something else entirely. You've decided which database you will use and all the other tools you need. Everyone's excited, the code is flowing, and features are getting shipped.
Fast forward a few months (or years), and things might look different.
The codebase has grown, and new features have been added. Maybe your team has even changed, with new developers coming on board. Adding new features becomes a pain, and bugs are popping up left and right.
And slowly but surely, the neat architecture you started with has turned into a [big ball of mud](https://deviq.com/antipatterns/big-ball-of-mud). What went wrong? And more importantly, what can we do about it?
Today, I want to show you how architecture testing can prevent this problem.
## Technical Debt
Technical debt is the consequence of prioritizing development speed over well-designed code. It happens when teams cut corners to meet deadlines, make quick fixes, or don't understand the architecture clearly.
Each shortcut or hack adds to the pile, making the code harder to understand, change, and maintain. But why do developers take these shortcuts in the first place?
Don't developers care about keeping the code clean?
Well, the truth is, most developers do care. If you're reading this newsletter, odds are you also care. But, developers are often under pressure to deliver features quickly. Sometimes, the quickest way to do that is to take a shortcut.
Plus, not everyone has a deep understanding of software architecture, or they might disagree on what the "right" architecture is. And let's be honest: some developers want to get their code working and move on to the next thing.
## Architecture Testing
Luckily, there's a way to enforce software architecture on your project before things get out of hand. It's called [**architecture testing**](https://www.milanjovanovic.tech/blog/enforcing-software-architecture-with-architecture-tests). These are automated tests that check whether your code follows the architectural rules you've set up.
With architecture testing, you can ["shift left"](https://en.wikipedia.org/wiki/Shift-left_testing). This enables you to find and fix problems early in the development process when they're much easier and cheaper to deal with.
Think of it like a safety net for your software architecture and design rules. If someone accidentally breaks a rule, the test will catch it and alert you. Bonus points if you integrate architecture testing into your [**CI pipeline**](https://www.milanjovanovic.tech/blog/how-to-build-ci-cd-pipeline-with-github-actions-and-dotnet).
There are a few libraries you can use for architecture testing. I prefer working with the [NetArchTest](https://github.com/BenMorris/NetArchTest) library, which I'll use for the examples.
You can check out this article to learn the [**fundamentals of architecture testing**](https://www.milanjovanovic.tech/blog/enforcing-software-architecture-with-architecture-tests).
Let's see how to write some architecture tests.
## Architecture Testing: Modular Monolith
You built an application using the [**modular monolith architecture**](https://www.milanjovanovic.tech/blog/what-is-a-modular-monolith). But how can you maintain the constraints between the modules?
- Modules aren't allowed to reference each other
- Modules can only call the public API of other modules
Here's an architecture test that enforces these module constraints. The `Ticketing` module is not allowed to reference the other modules directly. However, it can reference the public API of other modules (integration events in this example). The entry point is the `Types` class, which exposes a fluent API to build the rules you want to enforce. NetArchTest allows us to enforce the direction of dependencies between modules.
```csharp
[Fact]
public void TicketingModule_ShouldNotHaveDependencyOn_AnyOtherModule()
{
string[] otherModules = [
UsersNamespace,
EventsNamespace,
AttendanceNamespace];
string[] integrationEventsModules = [
UsersIntegrationEventsNamespace,
EventsIntegrationEventsNamespace,
AttendanceIntegrationEventsNamespace];
List<Assembly> ticketingAssemblies =
[
typeof(Order).Assembly,
Modules.Ticketing.Application.AssemblyReference.Assembly,
Modules.Ticketing.Presentation.AssemblyReference.Assembly,
typeof(TicketingModule).Assembly
];
Types.InAssemblies(ticketingAssemblies)
.That()
.DoNotHaveDependencyOnAny(integrationEventsModules)
.Should()
.NotHaveDependencyOnAny(otherModules)
.GetResult()
.ShouldBeSuccessful();
}
```
If you want to learn how to build robust and scalable systems using this architectural approach, check out [**Modular Monolith Architecture**](https://www.milanjovanovic.tech/modular-monolith-architecture).
## Architecture Testing: Clean Architecture
We can also write architecture tests for [**Clean Architecture**](https://www.milanjovanovic.tech/blog/why-clean-architecture-is-great-for-complex-projects). The inner layers aren't allowed to reference the outer layers. Instead, the inner layers define abstractions and the outer layers implement these abstractions.
For example, the `Domain` layer isn't allowed to reference the `Application` layer. Here's an architecture test enforcing this rule:
```csharp
[Fact]
public void DomainLayer_ShouldNotHaveDependencyOn_ApplicationLayer()
{
Types.InAssembly(DomainAssembly)
.Should()
.NotHaveDependencyOn(ApplicationAssembly.GetName().Name)
.GetResult()
.ShouldBeSuccessful();
}
```
It's also simple to introduce a rule that the `Application` layer isn't allowed to reference the `Infrastructure` layer. The architecture test will fail whenever someone in the team breaks the dependency rule.
```csharp
[Fact]
public void ApplicationLayer_ShouldNotHaveDependencyOn_InfrastructureLayer()
{
Types.InAssembly(ApplicationAssembly)
.Should()
.NotHaveDependencyOn(InfrastructureAssembly.GetName().Name)
.GetResult()
.ShouldBeSuccessful();
}
```
We can introduce more architecture tests for the `Infrastructure` and `Presentation` layers, if needed.
Ready to learn more about building production-ready applications using this architectural approach? You should check out [**Pragmatic Clean Architecture**](https://www.milanjovanovic.tech/pragmatic-clean-architecture).
## Architecture Testing: Design Rules
Architecture testing is also useful for enforcing design rules in your code. If your team has coding standards everyone should follow, architecture testing can help you enforce them.
For example, we want to ensure that all domain events are sealed types. You can use the `BeSealed` method to enforce a design rule that types implementing `IDomainEvent` or `DomainEvent` should be sealed.
```csharp
[Fact]
public void DomainEvents_Should_BeSealed()
{
Types.InAssembly(DomainAssembly)
.That()
.ImplementInterface(typeof(IDomainEvent))
.Or()
.Inherit(typeof(DomainEvent))
.Should()
.BeSealed()
.GetResult()
.ShouldBeSuccessful();
}
```
An interesting design rule could be requiring all domain entities not to have a public constructor. Instead, you would create an `Entity` instance through a static factory method. This approach improves the encapsulation of your `Entity`.
Here's an architecture test enforcing this design rule:
```csharp
[Fact]
public void Entities_ShouldOnlyHave_PrivateConstructors()
{
IEnumerable<Type> entityTypes = Types.InAssembly(DomainAssembly)
.That()
.Inherit(typeof(Entity))
.GetTypes();
var failingTypes = new List<Type>();
foreach (Type entityType in entityTypes)
{
ConstructorInfo[] constructors = entityType
.GetConstructors(BindingFlags.Public | BindingFlags.Instance);
if (constructors.Any())
{
failingTypes.Add(entityType);
}
}
failingTypes.Should().BeEmpty();
}
```
Another thing you can do with architecture tests is enforce naming conventions in your code. Here's an example of requiring all command handlers to have a name ending with `CommandHandler`:
```csharp
[Fact]
public void CommandHandler_ShouldHave_NameEndingWith_CommandHandler()
{
Types.InAssembly(ApplicationAssembly)
.That()
.ImplementInterface(typeof(ICommandHandler<>))
.Or()
.ImplementInterface(typeof(ICommandHandler<,>))
.Should()
.HaveNameEndingWith("CommandHandler")
.GetResult()
.ShouldBeSuccessful();
}
```
## Summary
Even the most well-planned software projects decay because of technical debt. Most developers have good intentions. However, time pressure, misunderstandings, and resistance to rules all contribute to this problem.
[**Architecture testing**](https://www.milanjovanovic.tech/blog/enforcing-software-architecture-with-architecture-tests) acts as a safeguard. It prevents your codebase from turning into a big ball of mud. By catching architectural violations early on, you can shift left. Short feedback loops avoid costly rework and improve developer productivity. It also ensures the long-term health of your project.
A few key takeaways:
- **Technical debt is inevitable**: It slows down development, introduces bugs, and frustrates developers.
- **Architecture testing is your safety net**: It helps you catch architectural violations before they become problematic.
- **Start small and iterate**: You don't have to test everything at once. Focus on the most critical rules first.
- **Make it part of your workflow**: Integrate architecture tests into your CI/CD pipeline so they run automatically.
**Action point**: Start by exploring popular .NET architecture testing libraries like [ArchUnitNET](https://github.com/BenMorris/NetArchTest)or [NetArchTest](https://github.com/TNG/ArchUnitNET). Experiment with writing tests for common architectural rules and gradually integrate them into your development workflow.
That's all for today.
See you next week.
* * *
**P.S. Whenever you're ready, there are 3 ways I can help you:**
1. [**Modular Monolith Architecture (NEW):**](https://www.milanjovanovic.tech/modular-monolith-architecture?utm_source=dev.to&utm_medium=website&utm_campaign=cross-posting) Join 600+ engineers in this in-depth course that will transform the way you build modern systems. You will learn the best practices for applying the Modular Monolith architecture in a real-world scenario.
2. [**Pragmatic Clean Architecture:**](https://www.milanjovanovic.tech/pragmatic-clean-architecture?utm_source=dev.to&utm_medium=website&utm_campaign=cross-posting) Join 2,750+ students in this comprehensive course that will teach you the system I use to ship production-ready applications using Clean Architecture. Learn how to apply the best practices of modern software architecture.
3. [**Patreon Community:**](https://www.patreon.com/milanjovanovic) Join a community of 1,050+ engineers and software architects. You will also unlock access to the source code I use in my YouTube videos, early access to future videos, and exclusive discounts for my courses. | milanjovanovictech |
1,851,872 | Digital Ocean, analysis and my experience as a user | Are you choosing a hosting service but don’t know which one to choose? Surely you have already had... | 0 | 2024-05-25T06:34:31 | https://coffeebytes.dev/en/digital-ocean-analysis-and-my-experience-as-a-user/ | webdev, opinion, hosting, sysadmin | ---
title: Digital Ocean, analysis and my experience as a user
published: true
date: 2024-05-25 00:00:00 UTC
tags: webdev,opinion,hosting,sysadmin
canonical_url: https://coffeebytes.dev/en/digital-ocean-analysis-and-my-experience-as-a-user/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/grlaucjdjnr7u5c3m4l0.jpg
---
Are you choosing a hosting service but don’t know which one to choose? Surely you have already had contact with Digital Ocean’s advertising but you want to hear a real opinion of what they have to offer. I’ve been using Digital Ocean for my personal projects for several years and I’ll tell you about my experience and what you can find if you decide to hire their services.
Sign up using [my affiliate link](https://m.do.co/c/a22240ebb8e7) and receive $200 USD to spend on Digital Ocean.
## differences between IAAS and PAAS
I’m pretty sure you’ve considered using Vercel, Netifly, Heroku or another modern hosting service for your application (probably made in Javascript). But, is it the same? Well, here’s a little clarification, just in case you don’t know; there are different types of companies for online services; IAAS, Infrastructure as a service; and PAAS, platform as a service.
If you already know this, skip to the Droplet’s section.
### IAAS
Translated into English as “infrastructure as a service”. Put in simpler words: they rent you the infrastructure, storage space and network access to it. In other words, a server with an operating system on which you are responsible for the details of the configuration.
This gives you total control over the server, you decide absolutely everything. This can be a good or bad thing. If you know exactly what you are doing, you can customize it according to your needs for maximum performance and efficiency. On the other hand, it means that you have to decide every detail yourself, with all the burden that implies, because everything will come with its default values and these may not be the right ones for your application.
If you want to customize something, you will have to get into the terminal via ssh, use cpanel or any other means that allows you to modify the system values.
The companies that stand out here are AWS EC2, Digital Ocean and Linode, to name a few.
### PAAS
There are also PAAS which, translated, means “Platform as a Service”. That is, they will take care of all the server configuration, so that you only focus on developing your application. Here you forget to deal with a server configuration such as Nginx, Apache; your hosting provider takes care of everything, they decide all the details to serve your application.
Imagine the level of specialization that Vercel has, being the creators of NextJS, to serve each of its applications made with this technology.
Generally, in a PAAS, the configuration of server aspects such as environment variables and the like is done through a web page interface, in a more user-friendly way.
Heroku, Netifly, Vercel and others stand out in this category.
Now let’s move on to Digital Ocean.
## Droplets in Digital Ocean
Digital Ocean works with Droplets, which are virtual servers that are rented to you. When you create a Droplet you can choose different operating systems and versions. You can access the terminal of any Droplet through its web page or through the [ssh command](https://coffeebytes.dev/en/basic-linux-commands-you-should-know/).
Once you create a Droplet this is available in less than a minute.
[](images/Droplets-de-digital-ocean.png)
### Customized images in DO
If you don’t want to start from a “blank” operating system you can opt for some more specific images that include pre-installed software for the most popular software requirements: web development, data science, blogging, frameworks, media, storage, elearning, ecommerce, etc.
There you will find Django, Nodejs, Magento, Wordpress, Ghost, MongoDB and other applications.
### Droplets according to your needs
Digital Ocean also has specialized Droplets, either in CPU, memory or storage and a general purpose version.
The most basic, and cheapest, version is a shared CPU, in exchange for offering you the best prices.
[](images/Droplets-purpose.png)
### The cheap Droplets of DO
And now I’m sure you’re wondering how much it costs me. Well, the answer is obvious: it depends.
Just to give you an idea, the cheapest Droplet costs ~~$5 usd per month~~ $4 usd per month. That’s practically nothing and for a small website it’s usually more than enough. By way of comparison, Vercel hosts your application for free with certain limitations, their next plan, at the time of writing this article, costs $20 usd per month.
Notice how all plans handle storage with an SSD.
[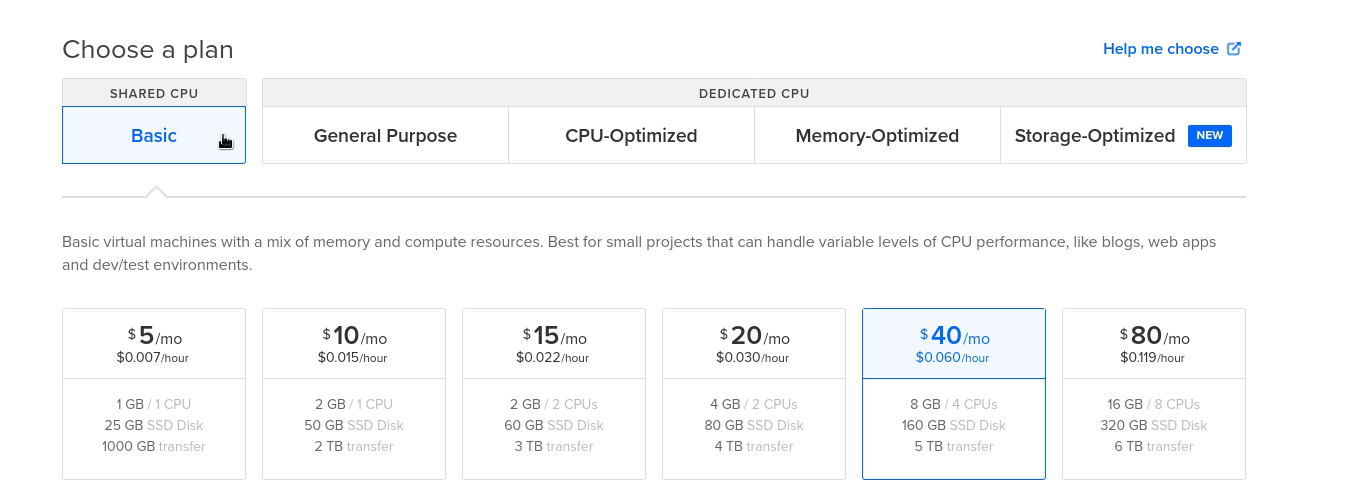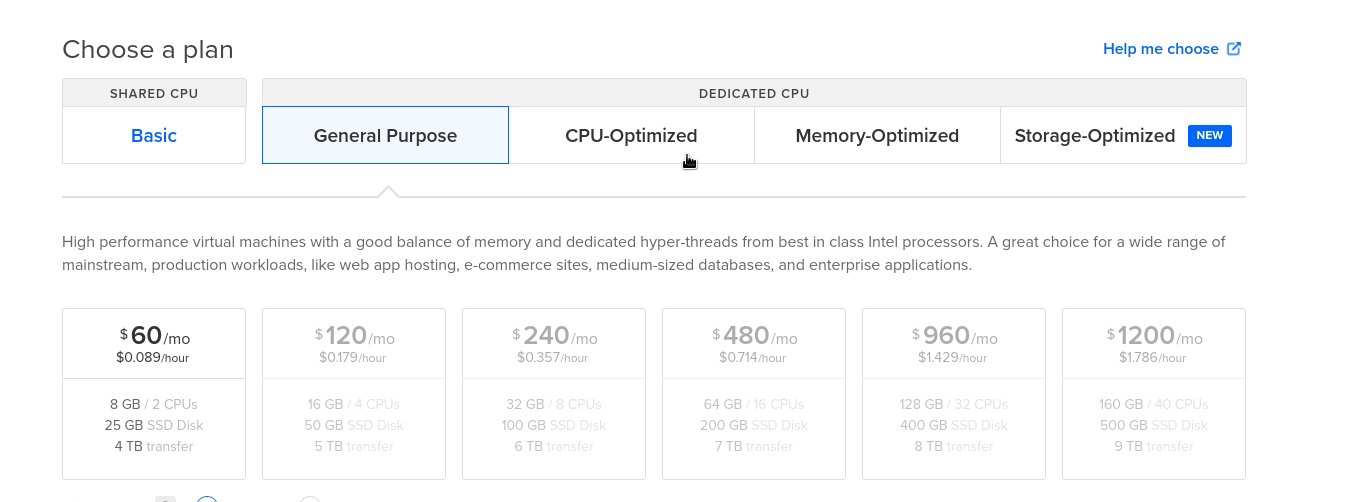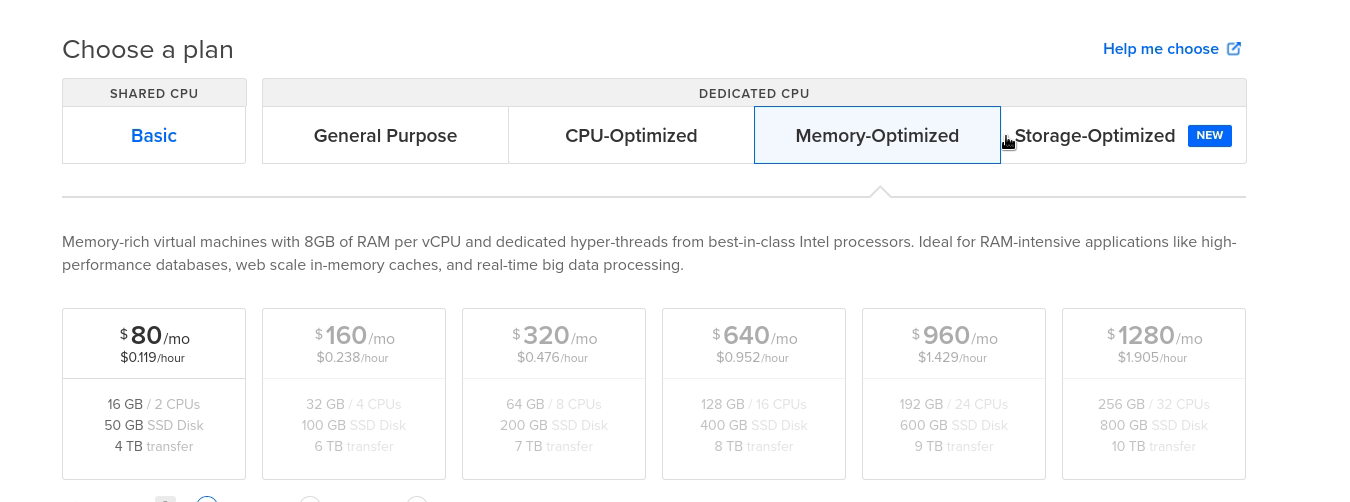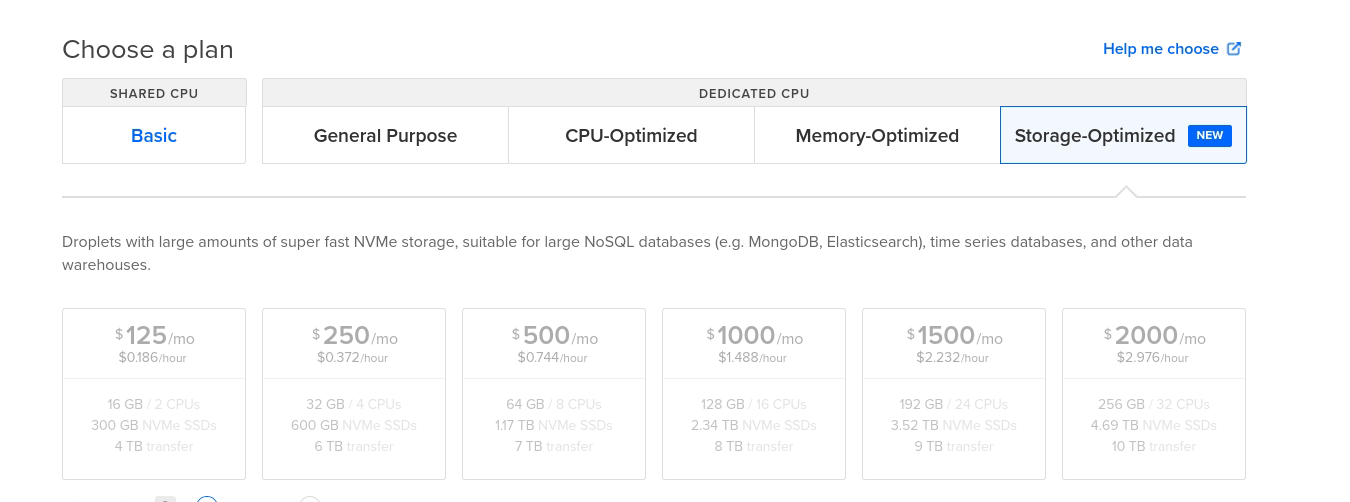](images/Precios-digital-ocean.gif)
### Cloud provider with servers around the world
Digital Ocean has servers in different locations around the world. So you always have an option close to your customers.
I have tried the servers in the United States, due to the proximity to Mexico, and I have not had any problem.
[](images/diferentes-ubicaciones-droplets-digital-ocean.png)
## Other services available on Digital Ocean
Remember I told you that there were IAAS and PAAS companies? Well, the truth is a little bit more complicated, many IAAS companies have grown a lot and have started to provide PAAS type services. And, as you might expect, Digital Ocean has not been left behind.
It has little time offering the integration and deployment of your applications using your Github or Gitlab repositories. You put in the code and they compile and run your project.
[](images/Digital-Ocean-Apps.png)
Digital Ocean also offers CDN services, called spaces, compatible with S3 from $5 usd per month.
### Kubernetes
Digital Ocean provides Kubernetes clusters with storage and load balancers with a few clicks.
### Apps
The apps are similar to a serverless solution, you connect your github, gitlab or bitbucket account with digital Ocean and you can upload Node apps or static files for them to serve, you can even specify them to run the compilation or any command you want. This is, so far, **the cheapest solution offered by Digital Ocean** and it is excellent for handling Frontend applications, even [Docker images](https://coffeebytes.dev/en/basic-commands-basic-docker-tutorial/)
### Volumes
They are extra space that you add to the droplets to increase their capacity, as if you were connecting an extra hard disk to them.
### Databases
Self-managed databases with automatic backups and optional encryption. Handles Postgres, MongoDB, MySQL and Redis.
## Digital Ocean vs AWS vs Azure
Digital Ocean is a service focused more on small and medium projects, it does not have as many solutions as AWS or Azure. For example, it does not have solutions in artificial intelligence for IT security analysis, big data analysis or other SaaS options. But, in exchange for these shortcomings that leave it up to developers, it offers much more competitive prices than the big players.
## My experience using Digital Ocean
I have used Digital Ocean to host personal projects and also to manage my domains. I haven't had any problems with down servers so far, or at least not that I've noticed or any user has brought it to my attention. In fact, right now you are reading this ~~from a Droplet using a headless Wordpress and frontend frontity (A React framework) served with Nginx~~ Hugo and hosted at Digital Ocean. This blog uses ~~the cheapest service, the $5 usd~~ App service, which costs around $3 usd, and the truth is that for the amount of traffic I have it doesn't feel slow and has decent Lighthouse metrics, no caching of any kind or any sophistication.
[](images/Coffeebytes-lighthose-indicadores.png)
It should be clarified that I did modify some things from the default settings to have a better performance. For example, enabling HTTP2, instead of the default HTTP, as well as installing the HTTP certificate using cerbot in the terminal, as the default installation did not include it. Extra tasks that other hosting services would have solved for me, such as [easywp](https://coffeebytes.dev/en/my-experience-using-easywp-and-namecheap/).
## Summarizing my experience using DO
My experience has been quite good, with no complaints in terms of the performance they promise.
If you don’t want to mess with Apache, Nginx or any other server configurations, maybe a Droplet from Digital Ocean is not your best option.
On the other hand, Digital Ocean offers one of the best costs to start a project; $3 usd for the most basic package (Apps) is an **incredibly low price** for static or Frontend based pages only.
[If you decide to try it, I'll give you $200 USD to try and see for yourself what Digital Ocean has to offer, just click on this banner.](https://m.do.co/c/a22240ebb8e7) | zeedu_dev |
1,864,393 | 4章17 | 以下はあなたのJavaプログラムにコメントアウトを追加して分かりやすくしたものです。このプログラムの実行結果が「12」になる理由を説明します。 public class Main { ... | 0 | 2024-05-24T23:50:16 | https://dev.to/aaattt/4zhang-17-39l8 | 以下はあなたのJavaプログラムにコメントアウトを追加して分かりやすくしたものです。このプログラムの実行結果が「12」になる理由を説明します。
```java
public class Main {
public static void main(String[] args) {
int total = 0; // 合計を保存する変数を初期化
// 外側のループ: i を 0 から 4 まで繰り返す
a: for (int i = 0; i < 5; i++) {
// 内側のループ: j を 0 から 4 まで繰り返す
b: for (int j = 0; j < 5; j++) {
// i が偶数の場合、外側のループの次のイテレーションに進む
if (i % 2 == 0) continue a;
// j が 3 以上の場合、内側のループを終了
if (3 < j) break b;
// total に j の値を加える
total += j;
}
}
// 合計を出力
System.out.println(total);
}
}
```
では、コードの流れを見てみましょう。
1. `total` 変数を 0 で初期化します。
2. 外側のループ (`a`) は i の値を 0 から 4 まで繰り返します。
3. 内側のループ (`b`) は j の値を 0 から 4 まで繰り返します。
4. 内側のループで、もし `i` が偶数 (0, 2, 4) の場合、`continue a` によって外側のループの次のイテレーションに進みます。
5. もし `j` が 3 より大きい場合、`break b` によって内側のループを終了します。
6. `total` に `j` の値を加算します。
具体的な計算の流れを確認します:
- `i = 0`: 偶数なので `continue a` によりスキップ
- `i = 1`:
- `j = 0`: `total += 0` → `total = 0`
- `j = 1`: `total += 1` → `total = 1`
- `j = 2`: `total += 2` → `total = 3`
- `j = 3`: `total += 3` → `total = 6`
- `j = 4`: `break b` により内側ループ終了
- `i = 2`: 偶数なので `continue a` によりスキップ
- `i = 3`:
- `j = 0`: `total += 0` → `total = 6`
- `j = 1`: `total += 1` → `total = 7`
- `j = 2`: `total += 2` → `total = 9`
- `j = 3`: `total += 3` → `total = 12`
- `j = 4`: `break b` により内側ループ終了
- `i = 4`: 偶数なので `continue a` によりスキップ
最終的に `total` は 12 になります。よって、正しい答えは B の「12が表示される」です。 | aaattt | |
1,864,384 | From $40 to $7: How We Slashed Video Transcoding Costs with Serverless and Spot Instances | We all know the struggle of managing cloud costs, especially when it comes to workloads with... | 0 | 2024-05-24T23:21:23 | https://dev.to/jthoma/from-40-to-7-how-we-slashed-video-transcoding-costs-with-serverless-and-spot-instances-o6d | costcontrol, performanceboost, serverless | We all know the struggle of managing cloud costs, especially when it comes to workloads with fluctuating demands. In this blog post, I'll share how we successfully migrated our video transcoding system from a costly EC2 on-demand setup to a serverless architecture with spot instances, achieving a dramatic reduction in monthly bills while significantly improving performance.
**The Challenge: Expensive and Inflexible Transcoding**
Our previous video transcoding system utilized a continuously running EC2 instance to process video files uploaded via FTP. This approach had several drawbacks:
**High Cost**: Even during idle periods with no video uploads, the EC2 instance incurred a recurring monthly cost of around $40.
**Limited Scalability**: The single instance couldn't automatically scale to handle bursts of video uploads, leading to processing delays.
**Slow Processing Times**: Videos could take up to an hour to process due to the fixed resources of the EC2 instance.
**High Error Rate**: We experienced a concerning 10% error rate during video processing.
**The Solution: Serverless and Spot Instances to the Rescue**
To address these challenges, we adopted a serverless architecture leveraging AWS Lambda functions and cost-effective EC2 Spot Instances.
**FTP File Processing & S3 Upload Lambda:** This Lambda is on scheduled trigger checks for video file upload to the FTP server. It retrieves the file, copies it to a designated S3 bucket, and adds metadata for tracking.
**Process Decider Lambda:** This Lambda analyzes the uploaded video file. If the file size is below a certain threshold, it triggers the Transcoder Lambda for processing. For larger files, it initiates the Spot Bidder Lambda.
**Transcoder Lambda:** This Lambda utilizes a pre-compiled ffmpeg binary from a lambda layer to process smaller video files directly within the serverless environment.
**Spot Bidder Lambda:** This Lambda estimates the processing time for the large video file and analyzes spot instance pricing trends across different regions. The file information is pushed into an SQS Queue. It then requests a spot instance with the most competitive pricing to handle the transcoding task.
**EC2 Spot Instance:** Upon launch, the spot instance retrieves processing details from an SQS queue and utilizes ffmpeg to transcode the large video file. Once completed, it updates the SQS queue and terminates itself.
DynamoDB: This NoSQL database stores detailed metadata about each processed video file, including processing time and completion status.
SNS Topics: These topics are used for sending notifications regarding Lambda execution, spot instance launch/termination, and processing completion.
IAM Roles: Granular IAM roles are assigned to each component, ensuring least privilege access and enhanced security.
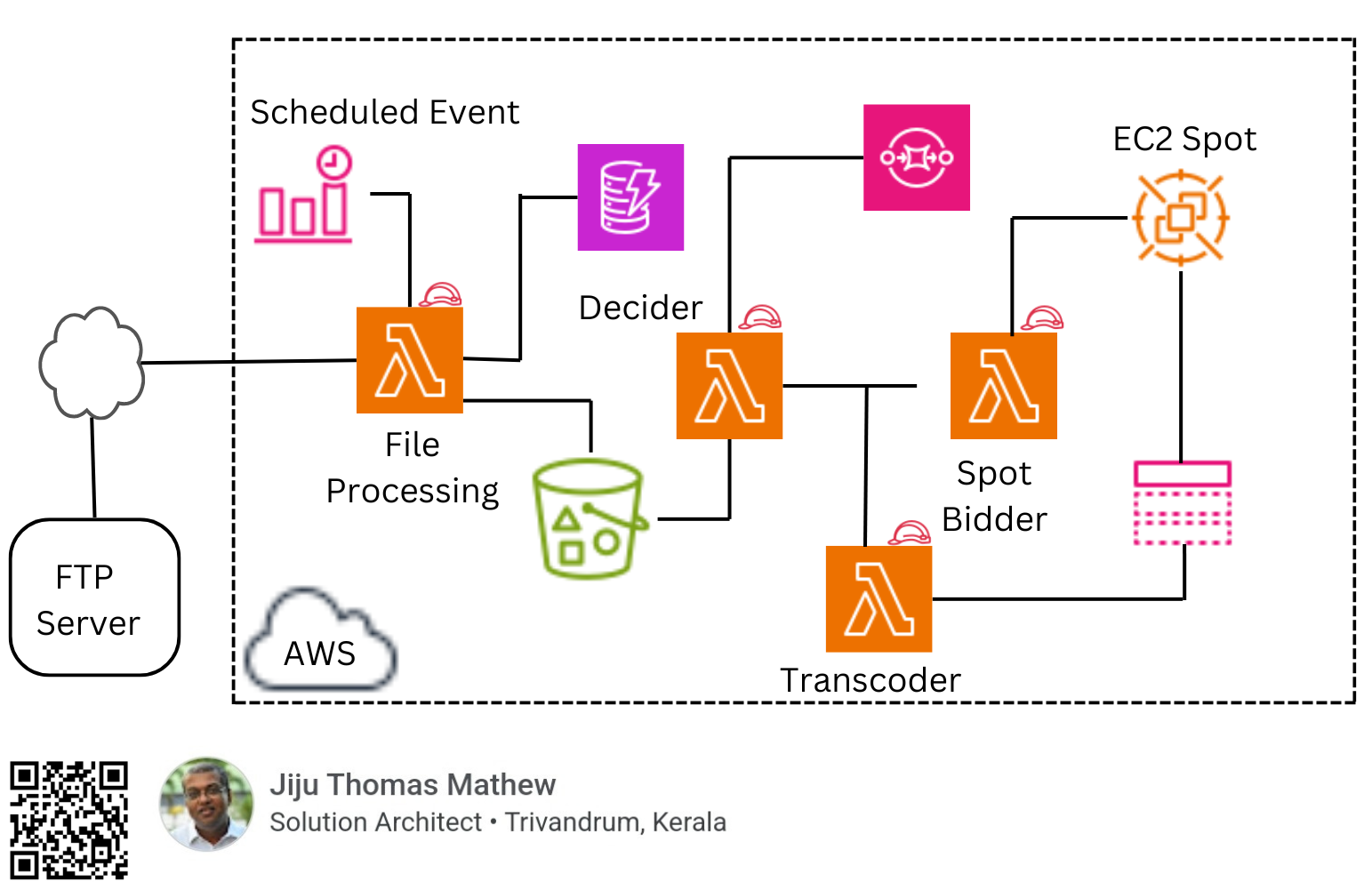
**Benefits Achieved: A Cost-Effective and High-Performance System**
The migration to a serverless architecture with spot instances yielded significant benefits:
**Drastic Cost Reduction**: Our monthly bill plummeted from $40 to a mere $7, a remarkable 82.5% cost saving!
Automatic Scaling: Lambda functions and spot instances automatically scale based on workload, eliminating idle costs and ensuring efficient resource utilization.
**Blazing-Fast Processing**: Video processing times are now down to a single minute, a significant improvement over the previous one-hour wait.
**Near-Zero Error Rate**: Our error rate has practically vanished thanks to the inherent reliability of serverless functions and spot instances.
**Lessons Learned: The Power of Serverless and Spot Instances**
This migration project highlighted the power of serverless architectures and spot instances for cost-effective and scalable cloud solutions.
**Event-driven architecture**: Utilizing event triggers for Lambda functions streamlines the workflow and ensures resources are used only when needed.
**Process Splitting**: Dividing the work into smaller, independent Lambdas enhances modularity and facilitates individual scaling for each process.
**Intelligent Decision Making**: Leveraging Lambdas for file size analysis and spot instance cost optimization automates decision-making and minimizes resource costs.
**Future Considerations: Continuous Improvement**
We're constantly striving to refine our system:
**Error Handling and Retries**: Implementing robust error handling mechanisms with retries for failed processing attempts will further enhance system reliability.
**Monitoring and Logging**: Granular monitoring and logging across all components will provide valuable insights for troubleshooting and performance optimization.
**Testing and Scalability**: Regular stress testing under high loads ensures the system scales effectively and maintains performance during peak workloads.
**Conclusion: A Winning Transformation**
The migration of our video transcoding system from EC2 on-demand to a serverless architecture with spot instances proved to be a resounding success. We achieved significant cost savings, improved processing speed and reliability, and gained a highly scalable solution. This case study demonstrates the potential of serverless architectures and spot instances for optimizing cloud resource utilization and managing costs effectively.
If you're considering a similar migration, feel free to leave a comment below or contact me directly for further details. We're happy to share our learnings and help you embark on your own cloud optimization journey. | jthoma |
1,864,369 | Bakırköy evden eve nakliyat | Bakırköy Evden Eve Sigortalı Taşıma Bakırköy evden eve sigortalı eşya taşıma, firmamızın müşteri... | 0 | 2024-05-24T23:13:44 | https://dev.to/ulutasnakliyat/bakirkoy-evden-eve-nakliyat-45lo | bakrkynakliyat, bakrkyevdenevenakliyat |
Bakırköy Evden Eve Sigortalı Taşıma
Bakırköy evden eve sigortalı eşya taşıma, firmamızın müşteri memnuniyetini sağlamak adına sunmuş olduğu ayrıcalıklı hizmetlerden sadece bir tanesidir. Ev ve ofis eşyalarının taşınması ve nakli sırasında sigortalı olarak yeni adreslerine ulaştırılması, göz ardı edilmemesi gereken bir evden eve nakliyat hizmetidir. Eşyalarınızın hiçbir zarara uğramadan taşındıklarından emin olmak ve meydana gelebilecek maddi kaybın karşılanabilmesi için Bakırköy evden eve sigortalı taşımayı tercih etmelisiniz.
Faaliyet Bölgesi:[Bakırköy Evden Eve Nakliyat](https://bakirkoynakliyatevdeneve.com.tr/) Kuruluş:1987 Güvence:Gerçek Nakliyat Sigortası ve Kasko Faaliyet ili:İstanbul Evden Eve Nakliyat | ulutasnakliyat |
1,864,368 | Mastering Data Definition Language (DDL) statements in SQL | SQL, or Structured Query Language, is the standard language used for managing and manipulating... | 0 | 2024-05-24T23:11:26 | https://dev.to/kellyblaire/mastering-data-definition-language-ddl-statements-in-sql-1c8m | sql, data, ddl, database | SQL, or Structured Query Language, is the standard language used for managing and manipulating relational databases. One of the essential subsets of SQL is the Data Definition Language (DDL), which provides statements for creating, modifying, and deleting database objects such as tables, views, indexes, and more. In this article, we'll dive deep into the DDL statements and explore their syntax, usage, and best practices to help you become proficient in defining and managing database structures.
**1. CREATE Statement**
The `CREATE` statement is the cornerstone of DDL and is used to create new database objects. Let's explore its usage for creating tables, views, and indexes.
**Creating Tables**
Tables are the fundamental data storage structures in a relational database. The `CREATE TABLE` statement allows you to define the table name, columns, data types, constraints, and other properties.
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NOT NULL,
Email VARCHAR(100) UNIQUE,
EnrollmentDate DATE DEFAULT CURRENT_DATE()
);
```
In this example, we create a table named "Students" with five columns: "StudentID" (an integer primary key), "FirstName" and "LastName" (varchar columns with a NOT NULL constraint), "Email" (a varchar column with a UNIQUE constraint), and "EnrollmentDate" (a date column with a default value of the current date).
**Creating Views**
Views are virtual tables based on the result of a SELECT statement. They provide a logical representation of data from one or more tables, allowing you to simplify complex queries or enforce security restrictions.
```sql
CREATE VIEW ActiveStudents AS
SELECT StudentID, FirstName, LastName, Email
FROM Students
WHERE EnrollmentDate >= '2022-01-01';
```
This statement creates a view named "ActiveStudents" that retrieves data from the "Students" table, filtering only the students enrolled on or after January 1, 2022.
**Creating Indexes**
Indexes are database objects that improve query performance by providing a faster way to locate and retrieve data from tables. They are particularly useful for columns involved in frequent searches, joins, or sorting operations.
```sql
CREATE INDEX idx_LastName ON Students (LastName);
```
This statement creates an index named "idx_LastName" on the "LastName" column of the "Students" table, allowing for faster queries involving that column.
**2. ALTER Statement**
The `ALTER` statement is used to modify the structure of existing database objects, such as tables or views. It supports various actions like adding, modifying, or dropping columns, constraints, and other properties.
**Altering Tables**
```sql
ALTER TABLE Students ADD COLUMN GPA DECIMAL(3, 2);
ALTER TABLE Students DROP COLUMN EnrollmentDate;
ALTER TABLE Students ALTER COLUMN Email VARCHAR(150);
```
These statements demonstrate different actions performed on the "Students" table:
1. Adding a new column "GPA" of data type DECIMAL(3, 2).
2. Dropping the existing "EnrollmentDate" column.
3. Modifying the data type of the "Email" column from VARCHAR(100) to VARCHAR(150).
**Altering Views**
Views can also be modified using the `ALTER` statement, but with limited capabilities. The most common use case is to change the underlying query that defines the view.
```sql
ALTER VIEW ActiveStudents AS
SELECT StudentID, FirstName, LastName, Email, GPA
FROM Students
WHERE GPA >= 3.0;
```
This statement modifies the "ActiveStudents" view to include the "GPA" column and filter students with a GPA of 3.0 or higher.
**3. DROP Statement**
The `DROP` statement is used to remove existing database objects from the database schema. It's important to exercise caution when using this statement, as dropping objects can lead to permanent data loss if not done correctly.
**Dropping Tables**
```sql
DROP TABLE Students;
```
This statement removes the "Students" table from the database schema, along with all its data and associated objects (indexes, constraints, etc.).
**Dropping Views**
```sql
DROP VIEW ActiveStudents;
```
This statement removes the "ActiveStudents" view from the database schema.
**Dropping Indexes**
```sql
DROP INDEX idx_LastName ON Students;
```
This statement drops the "idx_LastName" index from the "Students" table.
**Best Practices and Considerations**
When working with DDL statements, it's essential to follow best practices to ensure data integrity, maintainability, and performance:
1. **Use Transactions**: Wrap DDL statements within transactions to ensure atomicity and rollback capability in case of errors or failures.
2. **Backup Data**: Before making significant changes to the database schema, create backups to protect against data loss or corruption.
3. **Specify Column Order**: When creating tables, list the columns in a logical order, with primary key columns first, followed by other columns.
4. **Use Appropriate Data Types**: Choose the correct data types for each column based on the expected data and storage requirements.
5. **Apply Constraints**: Utilize constraints like PRIMARY KEY, FOREIGN KEY, UNIQUE, and NOT NULL to enforce data integrity and maintain referential relationships.
6. **Index Strategically**: Create indexes on columns involved in frequent searches, joins, or sorting operations to improve query performance.
7. **Naming Conventions**: Follow consistent naming conventions for database objects to enhance code readability and maintainability.
8. **Test and Validate**: Before executing DDL statements in a production environment, thoroughly test and validate the changes in a development or staging environment.
**Wrapping Up**
In this comprehensive article, we explored the Data Definition Language (DDL), a crucial subset of SQL that deals with creating, modifying, and deleting database objects. We delved into the three main DDL statements: CREATE, ALTER, and DROP, and examined their syntax, usage, and practical examples.
The CREATE statement is used to define new database objects, such as tables, views, and indexes. We learned how to create tables by specifying columns, data types, and constraints, as well as how to create views and indexes to enhance query performance and data organization.
The ALTER statement allows us to modify the structure of existing database objects. We covered various actions that can be performed using ALTER, including adding or dropping columns, modifying column data types, and changing constraints on tables, as well as altering the underlying query that defines a view.
The DROP statement is used to remove existing database objects from the database schema. We discussed the importance of exercising caution when using DROP, as it can lead to permanent data loss if not used correctly. Examples were provided for dropping tables, views, and indexes.
Throughout the article, we explored the different data types available in SQL, such as integers, decimals, characters, and date/time types, and how to specify them when defining table columns.
We also highlighted several best practices and considerations for working with DDL statements, including using transactions, creating backups, specifying column order, choosing appropriate data types, applying constraints, indexing strategically, following naming conventions, and thoroughly testing and validating changes before implementing them in a production environment.
By mastering DDL statements and adhering to best practices, you will be well-equipped to create, modify, and manage database structures effectively. This knowledge is essential for building robust and scalable database applications that meet the ever-changing demands of modern software development. | kellyblaire |
1,864,367 | 3章12 | ==演算子とequals()メソッドの違いについて詳しく説明します。同一性(identity)と同値性(equality)の違いも含めて説明します。 ... | 0 | 2024-05-24T23:05:05 | https://dev.to/aaattt/3zhang-12-3hg6 | `==`演算子と`equals()`メソッドの違いについて詳しく説明します。同一性(identity)と同値性(equality)の違いも含めて説明します。
### 同一性(identity)
- **`==`演算子**は、オブジェクトの参照を比較します。
- これは、2つの変数が同じオブジェクトを指しているかどうかをチェックします。
例:
```java
String a = "sample";
String b = "sample";
String c = new String("sample");
System.out.println(a == b); // true
System.out.println(a == c); // false
```
この例では、`a`と`b`は同じ文字列リテラルを指しているので、`a == b`は`true`になります。一方、`c`は新しいオブジェクトを作成しているので、`a == c`は`false`になります。
### 同値性(equality)
- **`equals()`メソッド**は、オブジェクトの内容を比較します。
- これは、2つのオブジェクトが同じ値を持っているかどうかをチェックします。
例:
```java
String a = "sample";
String b = "sample";
String c = new String("sample");
System.out.println(a.equals(b)); // true
System.out.println(a.equals(c)); // true
```
この例では、`a`と`b`は同じ内容を持っているので、`a.equals(b)`は`true`になります。同様に、`c`も同じ内容を持っているので、`a.equals(c)`も`true`になります。
### まとめ
- **`==`演算子**は、2つの参照が同じオブジェクトを指しているかどうかを確認します。
- **`equals()`メソッド**は、2つのオブジェクトが同じ内容を持っているかどうかを確認します。
#### 例を通じた理解
```java
String a = "example";
String b = "example";
String c = new String("example");
System.out.println(a == b); // true (同一の文字列リテラルを指している)
System.out.println(a == c); // false (異なるオブジェクトを指している)
System.out.println(a.equals(b)); // true (内容が同じ)
System.out.println(a.equals(c)); // true (内容が同じ)
```
このように、`==`は参照の比較、`equals()`は内容の比較です。同一性は同じオブジェクトであること、同値性は内容が同じであることを意味します。
この違いを理解することが、Javaのオブジェクト比較において非常に重要です。 | aaattt |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.