
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,908,379 | Top 15 Tools for Frontend Developers: Optimize Your Workflow | In the dynamic world of frontend development, staying updated with the latest tools and techniques is... | 0 | 2024-07-02T04:43:26 | https://dev.to/vyan/top-15-tools-for-frontend-developers-optimize-your-workflow-374o | webdev, javascript, react, frontend | In the dynamic world of frontend development, staying updated with the latest tools and techniques is essential for creating efficient, high-quality web applications. Here, we've compiled a list of frontend tools that can significantly enhance your productivity and streamline your workflow. From measuring screen elemen... | vyan |
1,908,401 | Taming the State Beast: Redux vs. Context API in React Applications | As React applications grow in complexity, managing application state becomes a critical challenge.... | 0 | 2024-07-02T04:35:04 | https://dev.to/epakconsultant/taming-the-state-beast-redux-vs-context-api-in-react-applications-4obj | As React applications grow in complexity, managing application state becomes a critical challenge. This article explores two popular approaches: Redux and Context API, empowering you to choose the right state management solution for your React projects.
Understanding Application State:
Application state refers to the... | epakconsultant | |
1,908,400 | New HTML <dialog> tag: An absolute game changer | Frontend Development Transformed by the New <dialog> Tag ❌... | 0 | 2024-07-02T04:35:03 | https://dev.to/manojgohel/new-html-tag-an-absolute-game-changer-3j8j | html, dialog, javascript, webdev | ### Frontend Development Transformed by the New `<dialog>` Tag
#### ❌ Before:
Creating a dialog used to be a labor-intensive task. Here’s how much work it took:
```html
<!-- HTML for the dialog -->
<div class="dialog-overlay">
<div class="dialog">
<p>Dialog content...</p>
<button class="close-button">Close<... | manojgohel |
1,908,399 | The DevTool Content Machine: How to Use AI to Crank Out Awesome Content (Even With a Tiny Team) | Learn how to harness the power of AI to create high-quality technical content that resonates with... | 0 | 2024-07-02T04:34:32 | https://dev.to/swati1267/the-devtool-content-machine-how-to-use-ai-to-crank-out-awesome-content-even-with-a-tiny-team-4d2k | devrel, contentwriting, marketing, community | _Learn how to harness the power of AI to create high-quality technical content that resonates with developers,even with limited resources. Discover how Doc-E.ai can transform your content creation process and boost your DevTool's reach._
Ever feel like you need a cloning machine for your content team? As a scrappy De... | swati1267 |
1,908,398 | ⚡ MyFirstApp - React Native with Expo (P18) - Code Layout Favourites | ⚡ MyFirstApp - React Native with Expo (P18) - Code Layout Favourites | 27,894 | 2024-07-02T04:33:36 | https://dev.to/skipperhoa/myfirstapp-react-native-with-expo-p18-code-layout-favourites-53ne | react, reactnative, webdev, tutorial | ⚡ MyFirstApp - React Native with Expo (P18) - Code Layout Favourites
{% youtube Y5ttPFMcO2Q %} | skipperhoa |
1,908,397 | ⚡ MyFirstApp - React Native with Expo (P17) - Code Layout Location | ⚡ MyFirstApp - React Native with Expo (P17) - Code Layout Location | 27,894 | 2024-07-02T04:32:06 | https://dev.to/skipperhoa/myfirstapp-react-native-with-expo-p17-code-layout-location-2a05 | react, reactnative, webdev, tutorial | ⚡ MyFirstApp - React Native with Expo (P17) - Code Layout Location
{% youtube aMM95V3yIO8 %} | skipperhoa |
1,908,396 | Dive into the Fascinating World of Ansible Automation! 🤖 | Learn the basics of Ansible and gain a technical overview of automation with Red Hat, Inc. Accelerate application time to value and improve operational efficiency. | 27,895 | 2024-07-02T04:30:58 | https://getvm.io/tutorials/ansible-basics-an-automation-technical-overview | getvm, programming, freetutorial, videocourses |
Hey there, fellow IT enthusiasts! 👋 Are you tired of manual, time-consuming tasks and looking to streamline your organization's dynamic infrastructure? Well, I've got the perfect solution for you - the "Ansible Basics: An Automation Technical Overview" course on Udemy!
## Unleash the Power of Ansible
This course i... | getvm |
1,908,395 | Dram Shop Expert | Alabama Dram Shop Law The Alabama Dram Shop Law holds corporations accountable for serving alcohol... | 0 | 2024-07-02T04:29:30 | https://dev.to/dramshop04/dram-shop-expert-43cg | Alabama Dram Shop Law
The Alabama Dram Shop Law holds corporations accountable for serving alcohol to intoxicated individuals, ensuing in damage. This regulation guarantees that establishments like bars and eating places can be held responsible for the movements of their visibly intoxicated shoppers. By implementing t... | dramshop04 | |
1,908,394 | Week 1 of My JavaScript Journey Complete! 🎉 | This week marks the completion of the first week of my JavaScript learning journey, and I couldn't be... | 0 | 2024-07-02T04:27:20 | https://dev.to/nitin_kumar_8d95be7485e37/week-1-of-my-javascript-journey-complete-313e |
This week marks the completion of the first week of my JavaScript learning journey, and I couldn't be more excited about the progress I've made. 🚀
What I Learned:
Basics of JavaScript: Variables, data types, Type Conversion, Memory Management, Numbers, Math, String.
Variable Declarations: The differences between le... | nitin_kumar_8d95be7485e37 | |
1,908,391 | LevelFields AI - Elite Investing. Effortless AI | LevelFields is an AI-driven fintech application that automates arduous investment research so... | 0 | 2024-07-02T03:59:00 | https://dev.to/levelfields-ai/levelfields-ai-elite-investing-effortless-ai-4igj | fintech, ai, finance, stocks | LevelFields is an AI-driven fintech application that automates arduous investment research so investors can find the best stocks and options trade faster and easier. Throw away your spreadsheets, calculators, and thousands of stock recommendations from "analysts" that litter the news. LevelFields removes the opinion, g... | levelfields-ai |
1,908,389 | MyFirstApp - React Native with Expo (P16) - Event Swipeable Remove Chat | MyFirstApp - React Native with Expo (P16) - Event Swipeable Remove Chat | 27,894 | 2024-07-02T03:55:18 | https://dev.to/skipperhoa/myfirstapp-react-native-with-expo-p16-event-swipeable-remove-chat-44l9 | react, reactnative, webdev, tutorial | MyFirstApp - React Native with Expo (P16) - Event Swipeable Remove Chat
{% youtube jAOFSmzf0WU %} | skipperhoa |
1,908,388 | MyFirstApp - React Native with Expo (P15) - Code Layout My Profile | MyFirstApp - React Native with Expo (P15) - Code Layout My Profile | 27,894 | 2024-07-02T03:54:00 | https://dev.to/skipperhoa/myfirstapp-react-native-with-expo-p15-code-layout-my-profile-2kc2 | reat, reactnative, webdev, tutorial | MyFirstApp - React Native with Expo (P15) - Code Layout My Profile
{% youtube sFuz-b1maQg %} | skipperhoa |
1,902,683 | AWS Three-Tier Architecture: Practical Implementation and Strategies for Secure Private Instance Access | Introduction Creating a three-tier architecture on AWS is an essential skill for any cloud... | 0 | 2024-07-02T03:50:54 | https://dev.to/dpa2024/aws-three-tier-architecture-practical-implementation-and-strategies-for-secure-private-instance-access-3i7g | aws, cloudcomputing, ec2 | **Introduction**
Creating a three-tier architecture on AWS is an essential skill for any cloud professional. This architecture involves the separation of presentation, application, and data layers to enhance security, manageability, and scalability. Here’s a detailed guide to designing and configuring this architectur... | dpa2024 |
1,908,215 | Terraform, OpenTofu e criptografia de estado | TLDR: o OpenTofu agora conta com criptografia de State files (e de Plan files também!) sem depender... | 0 | 2024-07-02T03:49:25 | https://dev.to/aws-builders/terraform-opentofu-and-state-encryption-4am1 | aws, terraform, opentofu, encryption | **TLDR**: o **OpenTofu** agora conta com criptografia de **State files** (e de **Plan files** também!) sem depender do backend remoto. O **Terraform** não - e talvez nunca suporte em sua versão gratuita.
---
É de extrema importância conhecer bem as ferramentas que você pretende usar para ser capaz de desenhar bons fl... | marcelo_devsres |
1,908,387 | Mastering Binary Search in JavaScript Part I: Iterative, Recursive. Day 2 of 30 Days of DSA 🚀🦾 | Introduction Binary search is a powerful search algorithm that excels in finding elements... | 0 | 2024-07-02T03:45:12 | https://dev.to/rajusaha/mastering-binary-search-in-javascript-part-i-iterative-recursive-day-2-of-30-days-of-dsa-1mg5 | javascript, algorithms, learning, webdev | ###Introduction
Binary search is a powerful search algorithm that excels in finding elements within sorted arrays. It leverages the "divide and conquer" approach, repeatedly dividing the search space in half until the target element is located or determined to be absent. This post delves into implementing binary searc... | rajusaha |
1,908,385 | Automating Linux User Management with Bash Scripting | Managing user accounts on a Linux system can be daunting, especially in environments with frequent... | 0 | 2024-07-02T03:44:11 | https://dev.to/by_segun_moses/automating-linux-user-management-with-bash-scripting-3f8d | aws, linux, bash, scripting | Managing user accounts on a Linux system can be daunting, especially in environments with frequent employee onboarding. As a DevOps engineer, familiar with operational SysOps functionalities, I often need a reliable, automated solution to streamline this process. This is where the _create_users.sh_ Bash script comes in... | by_segun_moses |
1,908,380 | Kubernetes Services: Understanding NodePort and ClusterIP | Welcome back to my blog series on CK 2024! This is the ninth post in the series where we dive deep... | 0 | 2024-07-02T03:34:46 | https://dev.to/jensen1806/kubernetes-services-understanding-nodeport-and-clusterip-2f2n | kubernetes, docker, networking, containers | Welcome back to my blog series on CK 2024! This is the ninth post in the series where we dive deep into various Kubernetes services such as ClusterIP, NodePort, ExternalName, and LoadBalancer. In this post, we'll explore how these services work and their importance in a Kubernetes environment.
#### Recap from Previous... | jensen1806 |
1,908,381 | Generative AI and Sustainable Innovation | Introduction The rapid advancement of technology has brought about significant changes... | 27,673 | 2024-07-02T03:34:35 | https://dev.to/rapidinnovation/generative-ai-and-sustainable-innovation-1ec8 | ## Introduction
The rapid advancement of technology has brought about significant changes in
various sectors. Among these, Artificial Intelligence (AI) stands out as one
of the most transformative. Within AI, Generative AI has emerged as a
particularly exciting and impactful subset. This introduction provides an
overv... | rapidinnovation | |
1,908,366 | Configurando o Spring com JPA e Microsoft SQL Server | Configurar o banco de dados em um ambiente de desenvolvimento Java pode ser uma tarefa desafiadora,... | 0 | 2024-07-02T02:46:24 | https://dev.to/kbdemiranda/configurando-o-spring-com-jpa-e-microsoft-sql-server-4igm | sqlserver, java, jpa, sql | ---
title: Configurando o Spring com JPA e Microsoft SQL Server
published: true
description:
tags: sqlserver, java, jpa, sql
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/nxkdd0e1lo4oeizo1rzd.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-23 14:11 +0000
---
Configurar ... | kbdemiranda |
1,908,377 | ApplyPass - Goodbye job applications, hello interviews | ApplyPass is an AI-powered job search tool that helps engineers land more interviews in less time.... | 0 | 2024-07-02T03:26:17 | https://dev.to/applypass/applypass-goodbye-job-applications-hello-interviews-70n | software, jobs, interview | ApplyPass is an AI-powered job search tool that helps engineers land more interviews in less time. The ApplyPass team reviews and optimizes your resume, then our auto-applier sends hundreds of applications for jobs that match your specific skills and experience. ApplyPass offers a freemium service, allowing you to subm... | applypass |
1,908,375 | Agglomerative Clustering Metrics: Hierarchical Clustering Techniques | Agglomerative clustering is a hierarchical clustering method used to group similar objects together. It starts with each object as its own cluster, and then iteratively merges the most similar clusters together until a stopping criterion is met. In this lab, we will demonstrate the effect of different metrics on the hi... | 27,933 | 2024-07-02T03:22:45 | https://labex.io/tutorials/ml-agglomerative-clustering-metrics-49061 | coding, programming, tutorial, sklearn |
## Introduction
Agglomerative clustering is a hierarchical clustering method used to group similar objects together. It starts with each object as its own cluster, and then iteratively merges the most similar clusters together until a stopping criterion is met. In this lab, we will demonstrate the effect of different... | labby |
1,908,369 | How to Deploy a React App to GitHub Pages | How to Deploy a React App to GitHub Pages Deploying a React app to GitHub Pages is a great... | 0 | 2024-07-02T03:07:38 | https://dev.to/sh20raj/how-to-deploy-a-react-app-to-github-pages-29li | javascript, webdev, react, githubpages | # How to Deploy a React App to GitHub Pages
Deploying a React app to GitHub Pages is a great way to share your project with the world. GitHub Pages is a free hosting service that makes it easy to publish static websites directly from your GitHub repository. This article will guide you through the steps to deploy your ... | sh20raj |
1,908,368 | Crafting a Node.js based framework SDK for Logto in minutes | Learn how to create a custom SDK for Logto using @logto/node. Previously in this article, we... | 0 | 2024-07-02T03:06:01 | https://blog.logto.io/crafting-nodejs-sdk/ | webdev, node, opensource, identity |
Learn how to create a custom SDK for Logto using `@logto/node`.

Previously in this [article](https://dev.to/logto/crafting-a-web-sdk-for-logto-in-minutes-i4p), we crafted a web SDK for Logto in minutes. Now, let'... | palomino |
1,908,367 | [LeetCode] Visualization of Reverse Linked List | This is my memo when I solved 206. Reverse Linked List. What we want This is pretty... | 0 | 2024-07-02T02:52:19 | https://dev.to/lada496/leetcode-visualization-of-reverse-linked-list-c35 | algorithms, leetcode, javascript | This is my memo when I solved [206. Reverse Linked List](https://leetcode.com/problems/reverse-linked-list/).
## What we want
This is pretty simple. We want to re-order a provided linked list in the opposite direction.
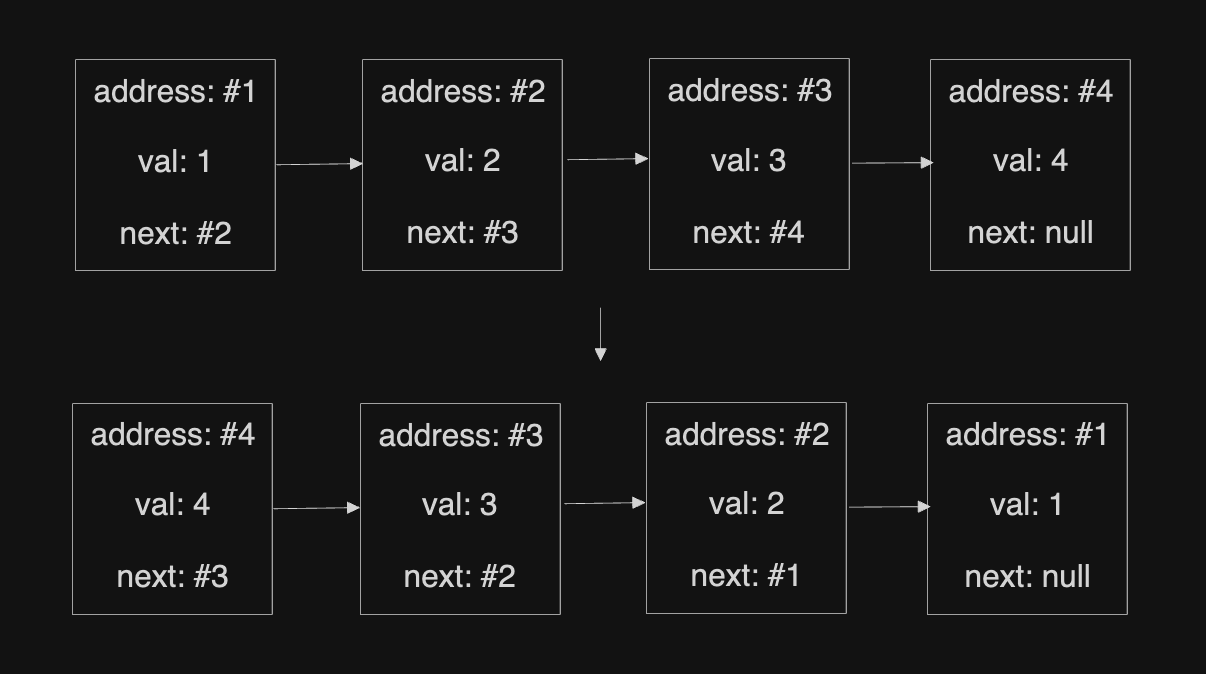
## Strategy
Go throug... | lada496 |
1,908,365 | Hi, this is Chuck! | I'm Chuck, introducing a great CDN Product to you, Tencent EdgeOne. If you are interested, please... | 0 | 2024-07-02T02:45:08 | https://dev.to/chuckcchen/hi-this-is-chuck-15g4 | I'm Chuck, introducing a great CDN Product to you, [Tencent EdgeOne](https://edgeone.ai/). If you are interested, please feel free to [contact us](https://edgeone.ai/contact). | chuckcchen | |
1,908,363 | How to create a graph diagramming by uploading pictures | Step 1: Open the canvas Step 2: click the import images button to pop up the image selection... | 0 | 2024-07-02T02:40:15 | https://dev.to/fridaymeng/how-to-create-a-graph-diagramming-by-uploading-pictures-280p | Step 1: Open the canvas
Step 2: click the import images button to pop up the image selection dialog box,Select the image you want to import and confirm.
 to ease the process of website testing. But what if test automation scripts are not written in a structured way? It would make the testing process inefficient and ambiguous. To maintain the efficient performance and project... | elle_richard_232 |
1,908,361 | Stay Updated with Python/FastAPI/Django: Weekly News Summary (24/06/2024 - 30/06/2024) | Dive into the latest tech buzz with this weekly news summary, focusing on Python, FastAPI, and Django... | 0 | 2024-07-02T02:30:08 | https://poovarasu.dev/python-fastapi-django-weekly-news-summary-24-06-2024-to-30-06-2024/ | python, django, fastapi, flask | Dive into the latest tech buzz with this weekly news summary, focusing on Python, FastAPI, and Django updates from June 24th to June 30th, 2024. Stay ahead in the tech game with insights curated just for you!
This summary offers a concise overview of recent advancements in the Python/FastAPI/Django framework, providin... | poovarasu |
1,908,360 | Stay Updated with PHP/Laravel: Weekly News Summary (24/06/2024 - 30/06/2024) | Dive into the latest tech buzz with this weekly news summary, focusing on PHP and Laravel updates... | 0 | 2024-07-02T02:28:14 | https://poovarasu.dev/php-laravel-weekly-news-summary-24-06-2024-to-30-06-2024/ | php, laravel | Dive into the latest tech buzz with this weekly news summary, focusing on PHP and Laravel updates from June 24th to June 30th, 2024. Stay ahead in the tech game with insights curated just for you!
This summary offers a concise overview of recent advancements in the PHP/Laravel framework, providing valuable insights fo... | poovarasu |
1,908,359 | Trying out a new stack: my experience working with tRPC and Drizzle on my Next.JS project | Recently I started working on a side project and I wanted to make it a fullstack typescript... | 0 | 2024-07-02T02:26:07 | https://dev.to/flavioribeirojr/trying-out-a-new-stack-my-experience-working-with-trpc-and-drizzle-on-my-nextjs-project-3mho | nextjs, typescript, postgres, trpc | Recently I started working on a side project and I wanted to make it a fullstack typescript application. I decided to use Next.JS to take advantage of the tools already included in the framework(e.g. router, rsc, caching, etc.). On top of that I added two amazing libraries that make an excellent usage of **Typescript**... | flavioribeirojr |
1,908,358 | Effective Techniques to Enhance Search Rankings and Minimize Bounce Rate | Boosting your search engine ranking and lowering your bounce rate are super important for making your... | 0 | 2024-07-02T02:24:52 | https://dev.to/juddiy/effective-techniques-to-enhance-search-rankings-and-minimize-bounce-rate-22b1 | Boosting your search engine ranking and lowering your bounce rate are super important for making your website better. When you nail these, you'll draw in more visitors and keep them around longer, which can lead to higher conversion rates. Here are some great tips to help you reach these goals:
#### 1. Optimize Websit... | juddiy | |
1,908,317 | I created a Boiler Plate for creating Web Apps with Google Apps Script. | GAS-WebApp-BoilerPlate Boilerplate for creating web apps with Google Apps Script. We... | 0 | 2024-07-02T02:24:13 | https://dev.to/mikoshiba-kyu/i-created-a-boiler-plate-for-creating-web-apps-with-google-apps-script-4gn2 | vite, react, clasp, gas | ## GAS-WebApp-BoilerPlate
Boilerplate for creating web apps with Google Apps Script.
We expect to develop in TypeScript and React.
{% embed https://github.com/Mikoshiba-Kyu/gas-webapp-boilerplate %}
---
## Feature
- **DevContainer** is used
- **Vite** and **clasp** generate files for eventual deployment in Googl... | mikoshiba-kyu |
1,908,357 | Javascript/Html/Css | JavaScript, HTML and CSS are the three main technologies for creating web pages. Each of them has... | 0 | 2024-07-02T02:23:09 | https://dev.to/bekmuhammaddev/javascripthtmlcss-1fd5 | javascript, html, css, english |

JavaScript, HTML and CSS are the three main technologies for creating web pages. Each of them has its own unique features, and when used together, they are very effective in creating and managing web pages.
Welcome to ToolifyPerfector, your go-to destination for a comprehensive suite of utilities and tools designed to enhance your online experience. Whether you’re a developer, designer, or just a curious internet use... | therahul_gupta |
1,908,314 | Step Toward Better Tenant Provisioning | In a multi-tenant SaaS application, you often need to manage resources that are tenant-specific.... | 0 | 2024-07-02T01:59:19 | https://jason.wadsworth.dev/step-toward-better-tenant-provisioning/ | aws, saas, cdk, stepfunctions | In a multi-tenant SaaS application, you often need to manage resources that are tenant-specific. Whether it's a tenant-specific role, isolated DynamoDB tables, or per-tenant Cognito user pools, you need to have a way to deploy and update these resources across your application. In this blog, I'll show you how I have ap... | jasonwadsworth |
1,908,264 | You can be a Frontend Dev without Javascript (and play Super Mario 64 from the browser) | All of this began because on Sunday, I made a silly LinkedIn post that started with: "Hey Chatgpt,... | 0 | 2024-07-02T01:57:56 | https://dev.to/mauroaccorinti/why-you-can-play-super-mario-64-from-the-browser-and-become-a-frontend-dev-without-javascript-3710 | frontend, webassembly, learning, webdev | All of this began because on Sunday, I made a silly [LinkedIn post](https://www.linkedin.com/posts/mauroaccorinti_hey-chatgpt-if-i-wanted-to-be-a-frontend-activity-7210752058730172416-3xwk/?utm_source=dev-to-why-you-can-play-super-mario-64-from-the-browser) that started with:
**"Hey Chatgpt, if I wanted to be a fronte... | mauroaccorinti |
1,907,528 | Case (I) - KisFlow-Golang Stream Real-Time Computing - Quick Start Guide | Github: https://github.com/aceld/kis-flow Document:... | 0 | 2024-07-02T01:57:03 | https://dev.to/aceld/case-i-kisflow-golang-stream-real-time-computing-quick-start-guide-f51 | go | <img width="150px" src="https://github.com/aceld/kis-flow/assets/7778936/8729d750-897c-4ba3-98b4-c346188d034e" />
Github: https://github.com/aceld/kis-flow
Document: https://github.com/aceld/kis-flow/wiki
---
[Part1-OverView](https://dev.to/aceld/part-1-golang-framework-hands-on-kisflow-streaming-computing-framework... | aceld |
1,908,313 | How Melbourne's NDIS Providers Are Revolutionizing Disability Services | The National Disability Insurance Scheme (NDIS) is a transformative program aimed at providing... | 0 | 2024-07-02T01:51:00 | https://dev.to/dmacaringhand/how-melbournes-ndis-providers-are-revolutionizing-disability-services-3016 | The National Disability Insurance Scheme (NDIS) is a transformative program aimed at providing comprehensive support to Australians with disabilities. In Melbourne, NDIS providers are at the forefront of this revolution, delivering personalized and high-quality services that significantly improve the lives of participa... | dmacaringhand | |
1,908,312 | How to Use VSCode Logpoint with Keyboard Shortcuts | How to use VSCode logpoint feature with only using keyboard. | 0 | 2024-07-02T01:47:50 | https://dev.to/wiscer/how-to-use-vscode-logpoint-with-keyboard-shortcuts-4gmc | vscode, logpoint, javascript | ---
title: How to Use VSCode Logpoint with Keyboard Shortcuts
published: true
description: How to use VSCode logpoint feature with only using keyboard.
tags: 'vscode, logpoint, javascript'
canonical_url: null
id: 1908312
date: '2024-07-02T01:47:50Z'
---
## Introduction
This article demonstrates how to efficiently uti... | wiscer |
1,908,309 | Managing User Accounts and Groups in Linux | System AdministrationIn the realm of system administration, managing user accounts and groups is a... | 0 | 2024-07-02T01:41:10 | https://dev.to/horlatayorr/managing-user-accounts-and-groups-in-linux-42g8 | System AdministrationIn the realm of system administration, managing user accounts and groups is a fundamental task. This article delves into a Bash script designed to automate the creation of user accounts and their association with specific groups, a common requirement in dynamic environments such as software develop... | horlatayorr | |
1,908,393 | 100% Free Vector Search with OpenLlama, Postgres, NodeJS and NextJS | So you want to try out vector search but you don’t want to pay OpenAI, or use Huggingface, and you... | 0 | 2024-07-02T04:21:09 | https://dev.to/jherr/100-free-vector-search-with-openllama-postgres-nodejs-and-nextjs-3jm5 | react, node, nextjs, ai | ---
title: 100% Free Vector Search with OpenLlama, Postgres, NodeJS and NextJS
published: true
date: 2024-07-02 01:37:40 UTC
tags: react,nodejs,nextjs,ai
canonical_url:
---
So you want to try out vector search but you don’t want to pay [OpenAI](https://openai.com/), or use [Huggingface](https://huggingface.co/), and ... | jherr |
1,907,051 | Mengenal Asymmetric Encryption: Keamanan Data Tingkat Tinggi dengan Golang | Apa Itu Asymmetric Encryption? Asymmetric encryption adalah metode enkripsi yang... | 0 | 2024-07-02T01:17:55 | https://dev.to/yogameleniawan/mengenal-asymmetric-encryption-keamanan-data-tingkat-tinggi-dengan-golang-4b17 | go, programming, tutorial, learning |

### Apa Itu Asymmetric Encryption?
Asymmetric encryption adalah metode enkripsi yang menggunakan dua kunci berbeda: public key (kunci publik) dan private key (kunci privat). Berbeda dengan metode [Symmetric Encry... | yogameleniawan |
1,908,278 | Bad Vision | In addition to my main job as a programmer, I really like to draw.As you can understand because of... | 0 | 2024-07-02T00:59:46 | https://dev.to/semyon_glinkin_c7cdc6c336/bad-vision-244f | webdev, programming, react, python | In addition to my main job as a programmer, I really like to draw.As you can understand because of this I have very sore eyes.I decided that it's time to get [Prescription Glasses](https://glassesstore.co.uk/), and started looking for a suitable site. Found one, which immediately liked because of the large selection an... | semyon_glinkin_c7cdc6c336 |
1,908,272 | What channel is cnn on for directv | In the realm of cable and satellite television, knowing how to locate specific channels is essential... | 0 | 2024-07-02T00:42:11 | https://dev.to/haya_naaz_6058eb103487294/what-channel-is-cnn-on-for-directv-32b6 | cnn | In the realm of cable and satellite television, knowing how to locate specific channels is essential for accessing preferred programming. For many viewers, CNN holds a prominent place in their channel lineup, offering up-to-date news coverage and analysis. However, finding CNN on DirecTV can sometimes be a challenge, p... | haya_naaz_6058eb103487294 |
1,908,270 | Am Ice Ritual Recipe | If you want to learn about the Am Ice Ritual recipe, you’ve come to the right place!Today, we’ll give... | 0 | 2024-07-02T00:37:35 | https://dev.to/haya_naaz_6058eb103487294/am-ice-ritual-recipe-o5 |
If you want to learn about the [Am Ice Ritual recipe](https://bigboxcrowd.com/am-ice-ritual-recipe/), you’ve come to the right place!Today, we’ll give you all the information you need about this recipe.
Let’s dive into the delicious world of the Am Ice Ritual! This morning routine has been gaining popularity for its... | haya_naaz_6058eb103487294 | |
1,908,269 | Exploring the Scala Play Framework for Web Development | Introduction Scala is a popular programming language that has gained significant traction... | 0 | 2024-07-02T00:33:02 | https://dev.to/kartikmehta8/exploring-the-scala-play-framework-for-web-development-1o0p | javascript, beginners, programming, tutorial | ## Introduction
Scala is a popular programming language that has gained significant traction in recent years. With its functional programming paradigm and object-oriented approach, it has become a popular language for web development. One of the main frameworks used with Scala for web development is the Play Framework... | kartikmehta8 |
1,908,252 | Bash Scripting for Automating User Management | User accounts and groups can be managed more easily and quickly by using a bash script in Linux. A... | 0 | 2024-07-01T23:01:46 | https://dev.to/chuks_dozie_b155978baf38c/bash-scripting-for-automating-user-management-392 | User accounts and groups can be managed more easily and quickly by using a bash script in Linux. A structured file format containing users’ information is employed in this script to aid in the efficient creation and management of user accounts.
**Introduction**
In Linux environments, user management often entails adm... | chuks_dozie_b155978baf38c | |
1,908,268 | Introduction to Nuxt.js: The Framework for Universal Vue.js Applications | Nuxt.js is a powerful, open-source framework built on top of Vue.js for creating universal... | 0 | 2024-07-02T00:19:58 | https://kristijan-pajtasev.medium.com/introduction-to-nuxt-js-the-framework-for-universal-vue-js-applications-27c66ab0df2c | nuxt, vue, javascript, frontend |
Nuxt.js is a powerful, open-source framework built on top of Vue.js for creating universal applications. It simplifies the development of server-rendered Vue applications and static websites. Here's an overview to get you started with Nuxt.js and understand why it might be the right choice for your next project.
## W... | hi_iam_chris |
1,908,266 | Day 982 : Last Nite | liner notes: Saturday : Went to the station and did the radio show. Had a pretty chill day. The... | 0 | 2024-07-02T00:12:10 | https://dev.to/dwane/day-982-last-nite-bo | hiphop, code, coding, lifelongdev | _liner notes_:
- Saturday : Went to the station and did the radio show. Had a pretty chill day. The recording of this week's show is at https://kNOwBETTERHIPHOP.com
. The file is sent in byte chunks... | kinneko-de |
1,908,248 | Retail Company Data Analytics (Predicting Future Sales) | In this project, I analyzed a dataset containing sales data for a retail company using linear algebra... | 0 | 2024-07-01T23:01:00 | https://dev.to/ludwig023/retail-company-data-analytics-predicting-future-sales-73k | In this project, I analyzed a dataset containing sales data for a retail company using linear algebra concepts. Moreover, I use linear algebra techniques to identify trends and patterns in sales figures. Apply algorithms, possibly regression analysis, to predict future sales based on historical data.
**DATA ACQUISITIO... | ludwig023 | |
1,907,468 | 10 Essential VS Code Tips & Tricks For Greater Productivity | Did you know that 73% of developers worldwide depend on the same code editor? Yes, the 2023 Stack... | 0 | 2024-07-01T23:00:00 | https://dev.to/safdarali/10-essential-vs-code-tips-tricks-for-greater-productivity-1cao | webdev, javascript, vscode, beginners | Did you know that 73% of developers worldwide depend on the same code editor?
Yes, the 2023 Stack Overflow Developer Survey results are in, and yet again, Visual Studio Code was by far the most used development environment.
) designed to automate Linux user account creation from a text file containing the said users, as well as a list of supplementary group(s). The script should create users and groups as specified in the pr... | jhude51 |
1,908,241 | Ng-News 24/24: Vertical Architectures, WebAssembly, Angular v9's Secret, NgRx | Brandon Roberts unveiled why Angular 9 has the highest download rates. Manfred Steyer gave a talk... | 0 | 2024-07-01T22:33:31 | https://dev.to/ng_news/ng-news-2424-vertical-architectures-webassembly-angular-v9s-secret-ngrx-1bhi | webdev, javascript, angular, programming | Brandon Roberts unveiled why Angular 9 has the highest download rates. Manfred Steyer gave a talk about vertical architectures. Evgeniy Tuboltsev published a guide on how to integrate WebAssembly into Angular, and NgRx 18 was released.
## Vertical Architectures
At the Angular Community Meetup, Manfred Steyer present... | ng_news |
1,908,239 | From Script to Snake - JavaScript to Python | Table Of Contents Introduction Popularity How to Setup On VSCode Control... | 0 | 2024-07-01T22:30:09 | https://dev.to/ismaelenriquez/from-script-to-snake-javascript-to-python-4h57 | python, learning, javascript, tutorial | ## Table Of Contents
- Introduction
- Popularity
- How to Setup On VSCode
- Control flow
- Variables
- Functions
- Loops
- Conclusion
## Introduction
Are you a programmer who knows JavaScript but wants to learn Python? Here's an easy guide to dive into Python. Python is a powerful and versatile programming language ... | ismaelenriquez |
1,908,155 | [Game of Purpose] Day 44 | Today I fixed a problem with camera. The tutorial I took mouse control from was using camera... | 27,434 | 2024-07-01T22:29:03 | https://dev.to/humberd/game-of-purpose-day-44-4g1o | gamedev | Today I fixed a problem with camera. The tutorial I took mouse control from was using camera rotation. Whereas the default Third Person project uses `Yaw Input` and `Pitch Input`.
Before:
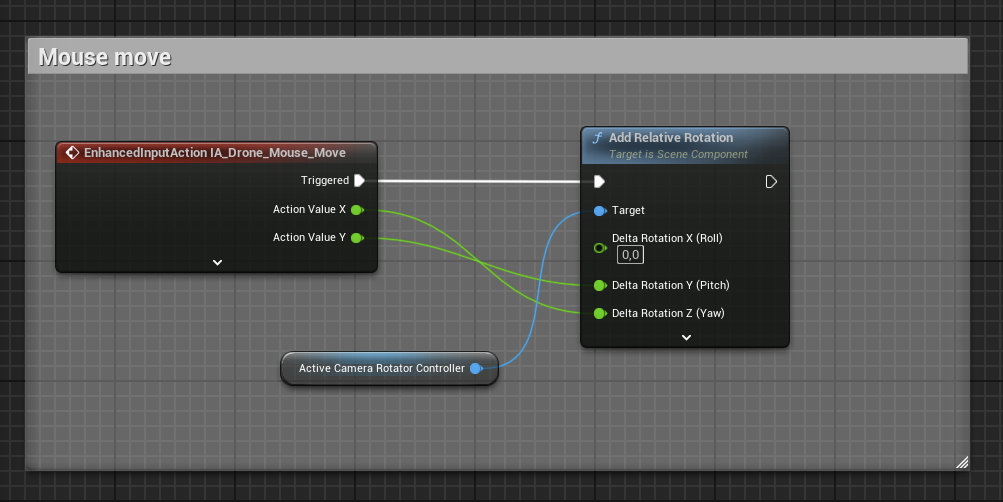
Now:
 is an acronym for [Scrap Any Website](https://scrapeanyweb.site/). This software is used for scrapping websites to obtain information that might be needed by developers.
Provided below are some details about this software:
**Name**: Scrap Any Website [Download he... | samson_ajayi |
1,897,464 | 🗣️🦾📲🤓 RTFM : ask AI agent to learn how to send sms w. open-interpreter | 💭 About How many times did someone ask you : "How do you..." ... and how many times... | 27,823 | 2024-07-01T22:07:14 | https://dev.to/adriens/rtfm-ask-ai-agent-to-learn-how-to-send-sms-w-open-interpreter-c52 | nocode, ai, showdev, tutorial | ## 💭 About
How many times did someone ask you :
> _"How do you..."_
... and how many times did you make the [RTFM (Read the Fucking Manual)](https://en.wikipedia.org/wiki/RTFM) joke ?

👉 Well that's all this b... | adriens |
1,908,221 | How to recover your cryptocurrency lost to investment scam | I was impatient to carry out the necessary research but I wanted to jump on the crypto trading and... | 0 | 2024-07-01T22:00:44 | https://dev.to/judith_allen_bc4852a5e3cf/how-to-recover-your-cryptocurrency-lost-to-investment-scam-756 | I was impatient to carry out the necessary research but I wanted to jump on the crypto trading and investment buzz. Unfortunately for me, I invested 84,700 GBP worth of bitcoin with a fraudulent trading platform, I was happy to watch my account grow to 123,575 GBP within a couple of weeks. But I didn't realize I was de... | judith_allen_bc4852a5e3cf | |
1,908,219 | Comparing Sass and Vue: A Deep Dive into Two Frontend Technologies | In the ever-evolving landscape of frontend development, two technologies have stood out for their... | 0 | 2024-07-01T21:52:35 | https://dev.to/variant/comparing-sass-and-vue-a-deep-dive-into-two-frontend-technologies-578f | webdev, frontend, css | In the ever-evolving landscape of frontend development, two technologies have stood out for their unique contributions to the developer's toolkit:
Sass (Syntactically Awesome Style Sheets) and
Vue.js.
Both have revolutionized how we approach web design and development, but they serve very different purposes. This art... | variant |
1,908,218 | Abstract & Interface in C# | Note: We will use a famous example, an Animal, for the whole article What is... | 27,809 | 2024-07-01T21:48:01 | https://www.linkedin.com/pulse/abstract-interface-c-loc-nguyen-j7apc/ | csharp, beginners, learning | **Note**: We will use a famous example, an Animal, for the whole article
### What is Abstract?
Abstract class provide a base define for something (Ex: Base class for Dog and Bird is Animal). It present for Polymorphism in OOP. An abstract class is declared using the `abstract` keyword. It can contain both abstract meth... | locnguyenpv |
1,908,157 | SQL Course: Self Join | It’s time to add followers to our database application. We will establish one more many-to-many... | 27,924 | 2024-07-01T21:45:41 | https://dev.to/emanuelgustafzon/sql-course-self-join-5g0g | sql | It’s time to add followers to our database application.
We will establish one more many-to-many relationship. Our join table will be the followers table.
The interesting thing with this table is that is the two foreign keys are referencing the same table, the users table. Therefore we need to query the followers wi... | emanuelgustafzon |
1,908,216 | Don't be a jack of all trades: The incredible importance of domain knowledge for software testers. | _As a software tester, diving deep into the domain you’re working in isn’t just a nice-to-have—it’s a... | 0 | 2024-07-01T21:44:32 | https://dev.to/lanr3waju/dont-be-a-jack-of-all-trades-the-incredible-importance-of-domain-knowledge-for-software-testers-2pgc | webdev, productivity, softwaretesting, career | **_As a software tester, diving deep into the domain you’re working in isn’t just a nice-to-have—it’s a game-changer! Here’s why:
_**
1. Know What to Test: Understanding the domain means you know exactly what aspects of the product to test. You can pinpoint critical functionalities and ensure they work seamlessly.
2.... | lanr3waju |
1,908,164 | Setup para Ruby / Rails: Sistema Operacional | Essa série é um guia para quem quer preparar um ambiente de desenvolvimento Ruby / Rails. O... | 27,960 | 2024-07-01T21:38:52 | https://dev.to/serradura/setup-ubuntu-para-desenvolver-com-ruby-rails-5g2l | beginners, ruby, rails, braziliandevs | Essa série é um guia para quem quer preparar um ambiente de desenvolvimento [Ruby](https://www.ruby-lang.org/en/) / [Rails](https://rubyonrails.org/).
O objetivo é apresentar um passo a passo com o mínimo necessário para que você possa começar a desenvolver com Ruby o mais rápido possível.
Escolha o seu sistema oper... | serradura |
1,908,211 | Resumo Kubernetes | x | 0 | 2024-07-01T21:29:31 | https://dev.to/adzubla/resumo-kubernetes-1m69 | kubernetes, k8s, kubectl, aks | ---
title: Resumo Kubernetes
published: true
description: x
tags: kubernetes, k8s, kubectl, aks
---
## Configurar cluster
Configurar kubectl para acessar um Azure AKS
```sh
az aks get-credentials -g ${GROUP} -n ${CLUSTER}
```
Ver configurações do kubectl
```sh
kubectl config view
```
Adicionando um novo cluster a... | adzubla |
1,908,146 | My Journey | Finding Solutions: A Backend Developer's Journey Nothing gives a backend developer greater... | 0 | 2024-07-01T20:30:40 | https://dev.to/ed_adelaja_e1a8093ba92af5/my-journey-1loi | Finding Solutions: A Backend Developer's Journey
Nothing gives a backend developer greater satisfaction than solving an issue they first struggled with. I recently encountered a challenge of this kind, which not only pushed the boundaries of my technical knowledge but also cemented my love for backend development.. He... | ed_adelaja_e1a8093ba92af5 | |
1,908,213 | 🚀 How to make your CV beat ATS and impress recruiters 🌟 | Generic applications get buried these days. Stand out with a well-tailored CV that proves you're the... | 0 | 2024-07-01T21:29:00 | https://dev.to/hey_rishabh/how-to-make-your-cv-beat-ats-and-impress-recruiters-432d | webdev, beginners, tutorial, ai | Generic applications get buried these days. Stand out with a well-tailored CV that proves you're the perfect fit! Here’s how to craft a powerful CV that gets noticed
## Break the job description📍
📝 Read the job description closely and **_identify the (keywords) skills, experience, and qualifications they crave_**. Th... | hey_rishabh |
1,908,210 | shadcn-ui/ui codebase analysis: How does shadcn-ui CLI work? — Part 2.3 | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the... | 0 | 2024-07-01T21:22:59 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-how-does-shadcn-ui-cli-work-part-23-fnj | javascript, opensource, shadcnui, nextjs | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the shadcn-ui/ui CLI.
In [part 2.2](https://medium.com/@ramu.narasinga_61050/shadcn-ui-ui-codebase-analysis-how-does-shadcn-ui-cli-work-part-2-2-73cff5651b06), I followed along the call stack when the function getProjectCon... | ramunarasinga |
1,908,204 | Day 3 | I am a hobbyist Python dev now. Working on a choose your own adventure game and having a lot of fun.... | 0 | 2024-07-01T21:21:57 | https://dev.to/myrojyn/day-3-4j3g | I am a hobbyist Python dev now. Working on a choose your own adventure game and having a lot of fun.
Here's to hoping that this is building a bridge from hobbyist to being employed for it. | myrojyn | |
1,908,162 | Getting Started with Synthetic Monitoring on GCP and Datadog | When you are talking about Monitoring, we often think about getting information on cpu usage, memory... | 0 | 2024-07-01T21:17:50 | https://medium.zenika.com/getting-started-with-synthetic-monitoring-on-gcp-and-datadog-2391b9f38025 | cloud, testing, performance, googlecloud | When you are talking about Monitoring, we often think about getting information on cpu usage, memory usage and other classic ops metrics. A 2024 trend in the monitoring landscape is also to gather end to end metrics and that’s why we see more and more “Synthetic Monitoring” panels in modern observability tools.
Like in... | tarektouati |
1,908,165 | Simulating a Traffic Light with Bacon.js and state machine | Handling asynchronous events and managing state effectively are essential skills. Functional Reactive... | 0 | 2024-07-01T21:15:38 | https://dev.to/francescoagati/simulating-a-traffic-light-with-baconjs-and-state-machine-48f0 | javascript, baconjs, frp, statemachine | Handling asynchronous events and managing state effectively are essential skills. Functional Reactive Programming (FRP) provides a powerful paradigm that simplifies these tasks by treating events as continuous streams of data.
### Understanding the Traffic Light State Machine
Let's start by defining the states and tr... | francescoagati |
1,908,163 | Automate your GitHub Issues with PowerShell and GitHub API | I made a post on how to authenticate to the GitHub API to perform tasks on your repositories, in this... | 0 | 2024-07-01T21:07:45 | https://dev.to/omiossec/automate-your-github-issues-with-powershell-and-github-api-2l39 | powershell, github | I made a post on how to authenticate to the GitHub API to perform tasks on your repositories, in this article I will show how to automate actions in GitHub. I will use GitHub Issues as examples,
I will use the token authentication, the standard one without restriction, but all the scripts presented here will work usin... | omiossec |
1,908,161 | A simple guide to React.js and Next.js | React.js and Next.js are popular frontend technologies or tools used to build websites or web... | 0 | 2024-07-01T21:05:41 | https://dev.to/__mulero/a-simple-guide-to-reactjs-and-nextjs-1k02 | React.js and Next.js are popular frontend technologies or tools used to build websites or web applications, particularly in the front end. If you're new to web applications this write-up can be useful in understanding what these technologies do and their differences.
React.js, also called React, is a javascript librar... | __mulero | |
1,908,159 | READING RECENT DOCUMENTATION CAN SAVE YOU A LOT OF TIME: MY EXPERIENCE TRYING TO UPSERT VECTORS TO MY PINECONE DATABASE | My name is Ezenwa Victory Chibuikem, a recent graduate of Electrical and Electronics Engineering from... | 0 | 2024-07-01T21:04:42 | https://dev.to/victory_ezenwa_87a0d0e9da/reading-recent-documentation-can-save-you-a-lot-of-time-my-experience-trying-to-upsert-vectors-to-my-pinecone-database-ib1 | My name is Ezenwa Victory Chibuikem, a recent graduate of Electrical and Electronics Engineering from FUTO. I am a data scientist looking to extend my expertise to machine learning engineering. I view machine learning engineering as a role designed for software engineers who can build machine learning models. Recently,... | victory_ezenwa_87a0d0e9da | |
1,908,158 | Cybersecurity 101 for Developers: From Zero to Hero | In today’s digital age, cybersecurity is more important than ever. As a developer, understanding the... | 0 | 2024-07-01T21:03:50 | https://devtoys.io/2024/07/01/cybersecurity-101-for-developers-from-zero-to-hero/ | cybersecurity, security, secops, devtoys | ---
canonical_url: https://devtoys.io/2024/07/01/cybersecurity-101-for-developers-from-zero-to-hero/
---
In today’s digital age, cybersecurity is more important than ever. As a developer, understanding the basics of cybersecurity and how to protect your applications from common vulnerabilities is crucial. This guide w... | 3a5abi |
1,907,285 | More on React States | This section contains a general overview of topics that you will learn in this lesson. How to... | 0 | 2024-07-01T21:01:30 | https://dev.to/ark7/more-on-react-states-4p1 | webdev, javascript, programming, tutorial | This section contains a general overview of topics that you will learn in this lesson.
How to structure state.
How state updates.
Learn about controlled components.
## How to structure state
Managing and structuring state effectively is by far one of the most crucial parts of building your application. If ... | ark7 |
1,908,156 | You Don't Know Undo/Redo | Look at the gif below. It shows a proof-of-concept implementation of collaborative undo-redo,... | 27,923 | 2024-07-01T20:59:21 | https://dev.to/isaachagoel/you-dont-know-undoredo-4hol | webdev, javascript, programming, learning | Look at the gif below. It shows a proof-of-concept implementation of collaborative undo-redo, including "history mode undo", conflict handling, and async operations. In the process of designing and implementing it, I found myself digging down rabbit holes, questioning my own assumptions, and reading academic papers. In... | isaachagoel |
1,908,154 | Tezos Investment Strategies: A Comprehensive Guide | Understanding Tezos Founded in 2014 by Arthur and Kathleen Breitman, Tezos is a... | 27,673 | 2024-07-01T20:54:25 | https://dev.to/rapidinnovation/tezos-investment-strategies-a-comprehensive-guide-4kfe | ## Understanding Tezos
Founded in 2014 by Arthur and Kathleen Breitman, Tezos is a decentralized
blockchain platform designed to facilitate the development and use of
decentralized applications (dApps) and smart contracts. Despite initial
management issues, Tezos gained significant attention in 2017 with its
unprecede... | rapidinnovation | |
1,908,150 | The Definitive Guide to C# .NET Datagrids | This definitive guide to C# .NET datagrids has everything you need to know. Learn about the benefits and how to make this control in your desktop applications. | 0 | 2024-07-01T20:40:37 | https://medium.com/mesciusinc/the-definitive-guide-to-c-net-datagrids-1905c9180ca8 | webdev, devops, csharp, dotnet | ---
canonical_url: https://medium.com/mesciusinc/the-definitive-guide-to-c-net-datagrids-1905c9180ca8
description: This definitive guide to C# .NET datagrids has everything you need to know. Learn about the benefits and how to make this control in your desktop applications.
---
A .NET datagrid is a user interface (UI) ... | chelseadevereaux |
1,908,148 | Mental Challenges | As a person in tech for over 2 decades, I have always seen how well I had done with development but... | 0 | 2024-07-01T20:36:14 | https://dev.to/mutantmalu/mental-challenges-3ji5 | creative, challenge, hard75, beforeandafter | As a person in tech for over 2 decades, I have always seen how well I had done with development but never took it to the next level. The same can be said to physical activity or sports. There is a thought that I get pretty close to good, then get board and I need to have a challenge. With physical activity, I hav... | mutantmalu |
1,908,144 | A technical article about front-end technologies | Introduction Frontend technologies are a set of technologies used to develop the user interface of... | 0 | 2024-07-01T20:30:47 | https://dev.to/blessing_edward_968172f10/a-technical-article-about-front-end-technologies-e5m |
Introduction
Frontend technologies are a set of technologies used to develop the user interface of web pages and applications.
Developers can create anything from design, structure to animation we see when opening a website, web applications or a mobile app.
The primary goal of front-end development technologies is to... | blessing_edward_968172f10 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.