
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,907,252 | Build a Responsive Modern Website with Next.js14, TypeScript, and Tailwind CSS | This project is a responsive modern website built with Next.js, TypeScript, and Tailwind CSS. ... | 0 | 2024-07-01T06:41:07 | https://dev.to/sudhanshuambastha/build-a-responsive-modern-website-with-nextjs14-typescript-and-tailwind-css-10pn | nextjs, tailwindcss, typescript, react | This project is a responsive modern website built with Next.js, TypeScript, and Tailwind CSS.
##Project Overview
This project is designed to provide a robust and flexible template for building responsive and modern websites. It leverages the power of Next.js for server-side rendering, TypeScript for type safety, and T... | sudhanshuambastha |
1,907,250 | GitOps: Streamlining Kubernetes Application Deployment with GitLab CI/CD, Helm Charts, and ArgoCD | In the realm of modern software development and deployment practices, GitOps has emerged as a robust... | 0 | 2024-07-01T06:38:29 | https://dev.to/pankaj892/gitops-streamlining-kubernetes-application-deployment-with-gitlab-cicd-helm-charts-and-argocd-685 | In the realm of modern software development and deployment practices, GitOps has emerged as a robust methodology for managing Kubernetes applications efficiently. This approach leverages Git as the single source of truth for declarative infrastructure and application code, ensuring consistency, traceability, and collab... | pankaj892 | |
1,907,249 | Share File Across Devices without Internet or USB | A post by IamSh | 0 | 2024-07-01T06:38:25 | https://dev.to/banmyaccount/share-file-across-devices-without-internet-or-usb-562j | {% youtube https://www.youtube.com/watch?v=oe-907slDIg&t=30s&ab_channel=ShadeTech %}
| banmyaccount | |
1,907,245 | Go or Python ? Which language is used more in production software? | I think that Go is better than Python. And that's my own opinion. But I was wondering if people are... | 0 | 2024-07-01T06:36:04 | https://abanoubhanna.com/posts/go-vs-python-production-software/ | go, python | I think that Go is better than Python. And that's my own opinion. But I was wondering if people are using Go or Python for their production software in the real world. I want to get statistics of production software to compare and understand the real world.
## Source of statistics
In a [previous post](https://abanoub... | abanoubha |
1,907,247 | Eventify | A sea of information awaits the attendees! Organize your events in the event management platform... | 0 | 2024-07-01T06:35:52 | https://dev.to/lisa04/eventify-6fa | event, app, ticketing |
A sea of information awaits the attendees!
Organize your events in the [event management platform](https://eventify.io/) like a pro with Eventify’s exclusive Event Guide feature.
Learn more at: https://eventify.io/... | lisa04 |
1,907,246 | why solana devnet is not working | why solana devnet is not working getting errors while creating a transaction or verifying... | 0 | 2024-07-01T06:35:37 | https://dev.to/nathan_tran_03d39eb518141/why-solana-devnet-is-not-working-1fpj | why solana devnet is not working getting errors while creating a transaction or verifying transaction
whats the issue and when it will be fixed the solana devnet cluster is not working | nathan_tran_03d39eb518141 | |
1,907,243 | How to Get Started with Open Source Contributions | Contributing to open source projects is a rewarding way to improve your skills, collaborate with... | 0 | 2024-07-01T06:34:15 | https://raajaryan.tech/how-to-get-started-with-open-source-contributions | opensource, beginners, tutorial, github |
Contributing to open source projects is a rewarding way to improve your skills, collaborate with others, and give back to the community. Whether you’re a seasoned developer or just starting, open source contributions can enhance your professional profile and broaden your horizons. This guide will walk you through the ... | raajaryan |
1,907,237 | Generative AI Dataset Generator App with Streamlit and Lyzr | In today’s data-driven world, generating realistic datasets is essential for testing, training... | 0 | 2024-07-01T06:26:24 | https://dev.to/harshitlyzr/generative-ai-dataset-generator-app-with-streamlit-and-lyzr-6no | In today’s data-driven world, generating realistic datasets is essential for testing, training machine learning models, and conducting meaningful analysis. To streamline this process, we present a Streamlit app that leverages the power of Lyzr Automata, a framework that simplifies building and managing AI-driven workfl... | harshitlyzr | |
1,907,242 | Looking for Pre-Trained ML/AI Model for Automatic Hotspot Placement in 360-Degree House Images | Hi Everyone, I’m working on creating virtual tours from 360-degree house images and need a... | 0 | 2024-07-01T06:30:11 | https://dev.to/aayush_singla_bbda9441ea0/looking-for-pre-trained-mlai-model-for-automatic-hotspot-placement-in-360-degree-house-images-1660 | machinelearning, ai | Hi Everyone,
I’m working on creating virtual tours from 360-degree house images and need a pre-trained machine learning or AI model that can automatically detect and place navigation hotspots.
If anyone knows of any pre-trained models that can perform this task, please let me know.
Thanks | aayush_singla_bbda9441ea0 |
1,906,757 | Adding Payment to Django app | So, you've decided to build your eCommerce or SaaS platform. Congratulation! But now comes the big... | 0 | 2024-07-01T06:29:36 | https://dev.to/paul_freeman/adding-payment-to-django-app-4cc9 | django, stripe, payment, webdev | So, you've decided to build your eCommerce or SaaS platform. Congratulation! But now comes the big question: how will you collect payments from your customers?
Having a solid and secure payment system is a must for any online business. This is where adding a [payment gateway](https://templates.foxcraft.tech/blog/b/wh... | paul_freeman |
1,907,241 | Building an HTML to ReactJS Converter with Streamlit and Lyzr Automata | ReactJS has revolutionized front-end development with its component-based architecture and efficient... | 0 | 2024-07-01T06:28:48 | https://dev.to/harshitlyzr/building-an-html-to-reactjs-converter-with-streamlit-and-lyzr-automata-134e | ReactJS has revolutionized front-end development with its component-based architecture and efficient state management. However, converting existing HTML, CSS, and JavaScript code into React components can be a daunting task. This blog post will guide you through building an HTML to ReactJS converter using Streamlit and... | harshitlyzr | |
1,907,239 | JSON Escape and Unescape | Now-a-days the data needs to be shared across different systems and platforms. One of the most... | 0 | 2024-07-01T06:26:52 | https://keploy.io/blog/community/json-escape-and-unescape | json, webdev, opensource, news |

Now-a-days the data needs to be shared across different systems and platforms. One of the most common formats for this data exchange is JSON (JavaScript Object Notation). Understanding how to properly handle special... | keploy |
1,907,238 | System Integration Testing: A Complete Guide with Challenges and Best Practices | System Integration Testing (SIT) is a crucial aspect of the software testing life cycle, where the... | 0 | 2024-07-01T06:26:45 | https://www.cioinsiderindia.com/news/system-integration-testing-a-complete-guide-with-challenges-and-best-practices-nwid-6007.html | system, integration, testing | 
System Integration Testing (SIT) is a crucial aspect of the software testing life cycle, where the overall system is tested, ensuring seamless interaction and functionality in disparate parts. The development team co... | rohitbhandari102 |
1,907,236 | Streamline Your Code Documentation with Lyzr Code Comment Generator | In the world of software development, clear and concise code documentation is crucial. It helps in... | 0 | 2024-07-01T06:23:59 | https://dev.to/harshitlyzr/streamline-your-code-documentation-with-lyzr-code-comment-generator-2cbk | In the world of software development, clear and concise code documentation is crucial. It helps in maintaining code, onboarding new team members, and ensuring that codebases remain understandable over time. Introducing the Lyzr Code Comment Generator, an innovative application designed to leverage the power of Lyzr Aut... | harshitlyzr | |
1,907,235 | Enhance Your Review Management with AI Review Aggregator and Summarizer | In today’s digital marketplace, customer reviews play a pivotal role in shaping consumer decisions... | 0 | 2024-07-01T06:21:55 | https://dev.to/harshitlyzr/enhance-your-review-management-with-ai-review-aggregator-and-summarizer-bo9 | In today’s digital marketplace, customer reviews play a pivotal role in shaping consumer decisions and brand reputation. Managing and summarizing these reviews effectively can provide invaluable insights for businesses. Introducing the AI Review Aggregator and Summarizer, an innovative application designed to harness t... | harshitlyzr | |
1,906,521 | All The Javascript Concepts You Need To Know Before Learning React (Part 1) | Newbie here don't bash :D Recently, I was sparked with the inspiration to improve my web... | 0 | 2024-07-01T06:21:47 | https://dev.to/up_min_sparcs/all-the-javascript-concepts-you-need-to-know-before-learning-react-part-1-3if5 | webdev, javascript, beginners, react | > Newbie here don't bash :D
Recently, I was sparked with the inspiration to improve my web development skills by learning new technologies, which include React. **React** is a popular open-source JavaScript library used for building user interfaces.
When exploring new technologies, adequate preparation will ensure sm... | makkukuma |
1,907,203 | Revolutionize Your Movie Script Translation with AI | In the digital age, creating multilingual content is essential to reach a broader audience. However,... | 0 | 2024-07-01T06:18:43 | https://dev.to/harshitlyzr/revolutionize-your-movie-script-translation-with-ai-27gm | In the digital age, creating multilingual content is essential to reach a broader audience. However, translating movie scripts while preserving their tone, style, and cultural context is a significant challenge. Our new AI Movie Script Autodubbing app, powered by Lyzr Automata and Streamlit, aims to simplify this proce... | harshitlyzr | |
1,907,202 | Best Pest Control Services in Hyderabad | Our company has been in the market for years and we have gained immense experience in the field of... | 0 | 2024-07-01T06:18:02 | https://dev.to/ajlpest_controlservices/best-pest-control-services-in-hyderabad-4pa0 | pestcontrol, ajlpestcontrolservices, pestcontrolservices, termitecontrol | Our company has been in the market for years and we have gained immense experience in the field of pest control. Our employees are highly trained and skilled to kill the unwanted guests that make a base in your home in the form of rats, rodents, ants, and even termites. The team of experts also provides **_Best Pest Co... | ajlpest_controlservices |
1,907,201 | 5 Tips to Improve Your Flutter Performance | When developing mobile applications using Flutter, performance is crucial. A smoothly running... | 0 | 2024-07-01T06:15:18 | https://dev.to/tentanganak/5-tips-to-improve-your-flutter-performance-2279 | flutter, dart, mobile | When developing mobile applications using Flutter, performance is crucial. A smoothly running application provides a better user experience, allowing users to explore the app without feeling annoyed or frustrated by slow startup times, crashes, or jank.
Optimizing application performance includes various aspects, such... | edolubis21 |
1,907,199 | Unlocking the Power of R: Essential Libraries for Data Science in 2024 | Introduction R has long been a favourite programming language for data scientists, thanks... | 0 | 2024-07-01T06:15:07 | https://dev.to/sejal_4218d5cae5da24da188/unlocking-the-power-of-r-essential-libraries-for-data-science-in-2024-em3 | datascience, rlibraries, dataanalysis | ## Introduction
R has long been a favourite programming language for data scientists, thanks to its powerful capabilities for statistical computing and data visualization. As the field of data science evolves, so too do the tools and libraries that [data professionals](https://www.pangaeax.com/) rely on. In 2024, certa... | sejal_4218d5cae5da24da188 |
1,907,198 | Is the Roadrunner Email Still Active | In the realm of email services, there are numerous options available, each with its unique features... | 0 | 2024-07-01T06:14:33 | https://dev.to/siyaram_choahan_94b56d4e2/is-the-roadrunner-email-still-active-362c |
In the realm of email services, there are numerous options available, each with its unique features and benefits. One such service that has been around for years is . [Roadrunner Email Still Active](https://roadrunnermailsupport.com/recover-roadrunner-email-password/) However, with the rise of newer email providers, m... | siyaram_choahan_94b56d4e2 | |
1,907,197 | Crouch End to Heathrow Airport | Heathrow Airport, a bustling hub for international travelers, serves as the gateway to countless... | 0 | 2024-07-01T06:11:34 | https://dev.to/rana_nayab_3e9fb133c75796/crouch-end-to-heathrow-airport-57bf | webdev, beginners, programming | <p><span style="font-size:11pt;">Heathrow Airport, a bustling hub for international travelers, serves as the gateway to countless destinations across the United Kingdom. Whether you're jetting off on a business trip, embarking on a vacation, or returning home after an adventure, navigating ground transportation to... | rana_nayab_3e9fb133c75796 |
1,907,196 | I'm Under DDoS Attack | Since the moment I started building my website, I have always considered the possibility of it being... | 0 | 2024-07-01T06:10:18 | https://2coffee.dev/en/articles/im-under-ddos-attack | ddos, security | Since the moment I started building my website, I have always considered the possibility of it being targeted for destruction. There are various forms of attacks such as DDoS, spam, or attacks on certain security vulnerabilities... Do you think I have made any enemies that I should be worried about? Actually, no, I hav... | hoaitx |
1,905,563 | Q3 Is Pivotal | from : jlabsdigital Hey guys I’m on the road this week so apologies for keeping this one briefer than... | 0 | 2024-06-29T11:31:02 | https://dev.to/rohitelyts/q3-is-pivotal-4eo8 | jlabsdigital, bitcoin | from : [jlabsdigital](https://jlabsdigital.com/)
Hey guys I’m on the road this week so apologies for keeping this one briefer than usual.
Rather than our usual intro let’s dive directly into the charts today and get straight and to the point of what you need to know as we head into what will be a pivotal Q3…
And if t... | rohitelyts |
1,907,195 | How to Scrape Amazon: A Comprehensive Guide | Amazon, a behemoth in the e-commerce industry, is a goldmine of data for businesses, researchers, and... | 0 | 2024-07-01T06:10:11 | https://dev.to/ionegarza/how-to-scrape-amazon-a-comprehensive-guide-502a | amazon, webscraping, scraping, python | Amazon, a behemoth in the e-commerce industry, is a goldmine of data for businesses, researchers, and enthusiasts. Scraping this data-rich platform can unveil invaluable insights, from price trends to customer reviews and product popularity. However, scraping Amazon is no small feat. This guide will walk you through th... | ionegarza |
1,907,194 | Low-Carb Frozen Meals for Diabetics | In the quest for holistic wellness, understanding the intricate links between various health aspects... | 0 | 2024-07-01T06:10:04 | https://dev.to/rana_nayab_3e9fb133c75796/low-carb-frozen-meals-for-diabetics-17pn | webdev, programming, tutorial | <p><span style="color:#0d0d0d;font-size:12pt;">In the quest for holistic wellness, understanding the intricate links between various health aspects is vital. From addressing urinary tract infections (UTIs) to managing chronic diseases and embracing weight loss, Prime Health Services plays a pivotal role in guiding indi... | rana_nayab_3e9fb133c75796 |
1,907,193 | can anyone help me to implement cloud data protection for 365 | A post by sanjay kumar | 0 | 2024-07-01T06:10:02 | https://dev.to/sanjay2000/can-anyone-help-me-to-implement-cloud-data-protection-for-365-1c51 | outlook365, help | sanjay2000 | |
1,905,504 | 5 engineering interview hints | Today, I want to share a few quick hints to help you frame your job search preparation and better... | 0 | 2024-07-01T06:06:23 | https://dev.to/titovmx/5-engineering-interview-hints-3051 | softwareengineering, interview, career | Today, I want to share a few quick hints to help you frame your job search preparation and better understand interviewers' expectations. Recently, I participated in a [podcast (in Russian)](https://www.youtube.com/live/NT3bAtdBcGg?si=pvC32P1aeQAmUCUq) devoted to frontend interviews and preparation, where we discussed e... | titovmx |
1,901,318 | How to - Process CSV in Power Automate | Its still crazy to me that Microsoft did not create an out of the box action to process a csv (or... | 22,764 | 2024-07-01T06:01:14 | https://dev.to/wyattdave/how-to-process-csv-in-power-automate-535f | powerautomate, powerplatform, lowcode, rpa | Its still crazy to me that Microsoft did not create an out of the box action to process a csv (or .xls files too 😣 ). Fortunatley there are a few ways to do it, 4 in fact, some cool, some easy, some crazy, but all interesting (well I think so 😎) so I want to show them:
- Plumsail
- Flow
- Office Script
- DataFlow
#... | wyattdave |
1,907,190 | Work Cover Treatment Sydney | Comprehensive Care at The Foot and Ankle Clinic of Australia | In Sydney, workplace injuries can disrupt not only your job but also your daily life. When it comes... | 0 | 2024-07-01T06:00:31 | https://dev.to/thefootankleclinic/work-cover-treatment-sydney-comprehensive-care-at-the-foot-and-ankle-clinic-of-australia-9md | In Sydney, workplace injuries can disrupt not only your job but also your daily life. When it comes to injuries affecting your feet or ankles, seeking specialized care is crucial for recovery and returning to work. At [The Foot and Ankle Clinic of Australia](https://thefaca.com.au/), we understand the importance of tim... | thefootankleclinic | |
1,907,189 | Best Practices for Using Middleware in ASP.NET Core Web API for Exception Handling, Authentication, and Error Logging | QuestionForGroup Hi everyone, I'm working on an ASP.NET Core Web API project and I am... | 0 | 2024-07-01T05:59:57 | https://dev.to/abdullah_sameer/best-practices-for-using-middleware-in-aspnet-core-web-api-for-exception-handling-authentication-and-error-logging-1d5a | #QuestionForGroup
Hi everyone,
I'm working on an ASP.NET Core Web API project and I am trying to implement some global functionalities using middleware. Specifically, I want to handle the following:
Global Exception Handling: Catching unhandled exceptions and returning standardized error responses.
Authentication: ... | abdullah_sameer | |
1,907,188 | Best Practices for Using Middleware in ASP.NET Core Web API for Exception Handling, Authentication, and Error Logging | QuestionForGroup Hi everyone, I'm working on an ASP.NET Core Web API project and I am... | 0 | 2024-07-01T05:59:11 | https://dev.to/abdullah_sameer/best-practices-for-using-middleware-in-aspnet-core-web-api-for-exception-handling-authentication-and-error-logging-528i | #QuestionForGroup
Hi everyone,
I'm working on an ASP.NET Core Web API project and I am trying to implement some global functionalities using middleware. Specifically, I want to handle the following:
Global Exception Handling: Catching unhandled exceptions and returning standardized error responses.
Authentication: ... | abdullah_sameer | |
1,907,186 | Exploring Google’s Gemma-2 Model: The Future of Machine Learning and Application Integration | In recent developments, Google has unveiled the Gemma-2 model, a significant step forward in the... | 0 | 2024-07-01T05:56:59 | https://dev.to/trinhcamminh/exploring-googles-gemma-2-model-the-future-of-machine-learning-and-application-integration-4pmj | machinelearning, model, ai, gemma | In recent developments, Google has unveiled the Gemma-2 model, a significant step forward in the field of machine learning. This blog post will define what Gemma is, distinguish it from Google’s previous Gemini model, and explore the practical applications of Gemma in real-world tasks.

The world of cryptocurrency trading can be exciting and profitable, but also complex and fast-paced. One way to effectively navigate this environment is to use an artificial crypto market bot. These automated tradin... | kala12 | |
1,907,184 | Why Do You Need Property Management Software for Multifamily Buildings? | Living harmoniously with several families, each with their preferences, likes, and dislikes, is... | 0 | 2024-07-01T05:52:13 | https://dev.to/jeya_c64151260df99a02a0d2/why-do-you-need-property-management-software-for-multifamily-buildings-3bmg |

Living harmoniously with several families, each with their preferences, likes, and dislikes, is tough. Frequent disputes, misunderstandings, miscommunications, and non-agreements make the lives of the residents a li... | jeya_c64151260df99a02a0d2 | |
1,907,183 | Build Your Own RAG App: A Step-by-Step Guide to Setup LLM locally using Ollama, Python, and ChromaDB | In an era where data privacy is paramount, setting up your own local language model (LLM) provides a... | 0 | 2024-07-01T05:50:03 | https://dev.to/nassermaronie/build-your-own-rag-app-a-step-by-step-guide-to-setup-llm-locally-using-ollama-python-and-chromadb-b12 | ollama, llm, python, rag | In an era where data privacy is paramount, setting up your own [local language model (LLM)](https://www.cloudflare.com/learning/ai/what-is-large-language-model/) provides a crucial solution for companies and individuals alike. This tutorial is designed to guide you through the process of creating a custom chatbot using... | nassermaronie |
1,907,182 | High-Quality Fiber Pigtails and LWL Patchkabel from GBIC Shop | GBIC Shop offers top-notch fiber pigtails and LWL patchkabel, designed for optimal performance and... | 0 | 2024-07-01T05:44:52 | https://dev.to/gbicshop/high-quality-fiber-pigtails-and-lwl-patchkabel-from-gbic-shop-48hn | pigtails, lwlpatchkabel, fiberpigtails | GBIC Shop offers top-notch fiber pigtails and LWL patchkabel, designed for optimal performance and reliability. These essential components are crucial for seamless fiber optic network connections. Fiber **[pigtails](https://www.gbic-shop.de/12-faser-lwl-pigtails)** from GBIC Shop ensure low insertion and high return lo... | gbicshop |
1,842,585 | Instruction Fine-Tuning: Dataset and Library Landscape | Large Language Models have fascinating abilities to understand and output natural language texts.... | 0 | 2024-07-01T05:44:34 | https://dev.to/admantium/instruction-fine-tuning-dataset-and-library-landscape-5dk | llm | Large Language Models have fascinating abilities to understand and output natural language texts. From knowledge databases to assistants and live chatbots, many applications can be build with an LLM as a component. The capability of an LLM to follow instructions is essential for these use cases. While closed-source LLM... | admantium |
1,907,181 | Rails: Using find_each for Batch Processing | "Rails Tip: Efficiently handle large datasets with find_each. Instead of loading all records at once,... | 0 | 2024-07-01T05:42:38 | https://dev.to/m_hussain/rails-using-findeach-for-batch-processing-3hgb | "Rails Tip: Efficiently handle large datasets with find_each. Instead of loading all records at once, find_each processes records in batches, reducing memory usage and improving performance. 🚀
Example:
`User.find_each(batch_size: 1000) do |user|
# Process each user
end`
This processes users in batches of 1000, maki... | m_hussain | |
1,907,180 | Synchronizing Raw Data in GBase 8s Databases via ER | Introduction Once you've defined and set up the replication server, executing cdr start... | 0 | 2024-07-01T05:42:01 | https://dev.to/congcong/synchronizing-raw-data-in-gbase-8s-databases-via-er-36md | database | ## Introduction
Once you've defined and set up the replication server, executing `cdr start replicate` will synchronize the initial data from the source database to the target server. This method is straightforward but has the drawback of being relatively slow, making it suitable for environments with small data volum... | congcong |
1,907,179 | Is Salesforce an ERP? | Salesforce has a prominent role in the business software world and is mainly known for its... | 0 | 2024-07-01T05:41:30 | https://dev.to/devops_den/is-salesforce-an-erp-1496 | salesforce, webdev, productivity, devops | Salesforce has a prominent role in the business software world and is mainly known for its proficiency in the customer relationship management (CRM) field. However, with its several features, a basic question arises: is Salesforce an ERP system?
To be precise, the answer is no, as it's not a full-fledged ERP system. To... | devops_den |
1,907,178 | Why Choose Custom Mobile App Development in Dubai for Your Business | In today's digital age, having a strong mobile presence is crucial for businesses looking to thrive... | 0 | 2024-07-01T05:39:51 | https://dev.to/toxsltechnologies/why-choose-custom-mobile-app-development-in-dubai-for-your-business-59c5 | mobile, development, appdevelopment | In today's digital age, having a strong mobile presence is crucial for businesses looking to thrive in the competitive marketplace. As the UAE continues to emerge as a global hub for innovation and technology, custom mobile app development in Dubai has become an increasingly attractive option for companies seeking to e... | toxsltechnologies |
1,907,177 | How does a Generative AI development company help your business grow? | A Generative AI development company can significantly contribute to the growth of a business by... | 0 | 2024-07-01T05:39:23 | https://dev.to/nextbraintechnologies/how-does-a-generative-ai-development-company-help-your-business-grow-36nf | generativeaidevelopmentcompany, generativeaiservices, genaidevelopmentcompany | A Generative AI development company can significantly contribute to the growth of a business by leveraging advanced AI technologies to enhance various aspects of operations, innovation, and customer engagement.
## **Here’s an in-depth look at how such a company can help your business grow:**
**Enhanced Customer Exper... | nextbraintechnologies |
1,907,176 | Benefits of Outsourcing Android Development | Outsourcing Android development can provide companies with access to a global talent pool of skilled... | 0 | 2024-07-01T05:38:50 | https://dev.to/michaeljason_eb570f1a51d6/benefits-of-outsourcing-android-development-3hmc | webdev, beginners, programming, devops | Outsourcing Android development can provide companies with access to a global talent pool of skilled professionals. This can lead to faster project delivery times and higher-quality results, as companies can leverage the expertise of experienced developers from around the world. Additionally, outsourcing Android develo... | michaeljason_eb570f1a51d6 |
1,907,174 | Use Cases and Key Capabilities of Microsoft Sentinel | Microsoft Sentinel is a powerful security platform that helps organizations protect their digital... | 0 | 2024-07-01T05:35:34 | https://dev.to/shivamchamoli18/use-cases-and-key-capabilities-of-microsoft-sentinel-260j | microsoft, microsoftsentinel, cloudsecurity, infosectrain | Microsoft Sentinel is a powerful security platform that helps organizations protect their digital assets from advanced threats and respond to security incidents. With its wide range of use cases and key capabilities, Sentinel enables security teams to detect and investigate potential threats in real time, streamline in... | shivamchamoli18 |
1,907,173 | Learning Python as a JavaScript Developer: A Comprehensive Guide | As a JavaScript and Python full-stack developer, I understand the value of continuously expanding... | 0 | 2024-07-01T05:34:47 | https://dev.to/ahmadnyc/learning-python-as-a-javascript-developer-a-comprehensive-guide-4239 | As a JavaScript and Python full-stack developer, I understand the value of continuously expanding one's coding weaponry. Like many developers, my journey began with mastering HTML, CSS, and JavaScript—the foundational trio of web development. Over time, I decided to venture into Python and quickly realized its versatil... | ahmadnyc | |
1,907,154 | Building a Dynamic Blog with Flask and HTMX | Creating a dynamic blog using Flask and HTMX can be both fun and rewarding. This guide will take you... | 0 | 2024-07-01T05:33:14 | https://devtoys.io/2024/06/30/building-a-dynamic-blog-with-flask-and-htmx/ | htmx, python, webdev, devtoys | ---
canonical_url: https://devtoys.io/2024/06/30/building-a-dynamic-blog-with-flask-and-htmx/
---
Creating a dynamic blog using Flask and HTMX can be both fun and rewarding. This guide will take you through the entire process, focusing on making your blog interactive without the need for a complex single-page applicat... | 3a5abi |
1,888,205 | Jenkins on docker | Welcome to the comprehensive guide on installing Jenkins on Docker. Jenkins is a open source... | 0 | 2024-07-01T05:32:05 | https://dev.to/prateektom/jenkins-on-docker-23n8 | devops, jenkins, docker | Welcome to the comprehensive guide on installing Jenkins on Docker. Jenkins is a open source automation server that helps in building, deploying, and automating projects.
Docker simplifies the process by providing a consistent environment across multiple systems. Let's deep dive into the process of setting up Jenkins o... | prateektom |
1,907,170 | Star Sailors V2 is publicly available...sort of | (and so begins my long-await return to Dev.to) Hey. Welcome. Bonjour. My name's Liam, and we've just... | 27,920 | 2024-07-01T05:30:17 | https://scrooby.micro.blog/2024/06/30/224434.html | starsailors, citizenscience, gamedev, flask | (and so begins my long-await return to Dev.to)
Hey. Welcome. Bonjour. My name's Liam, and we've just published the first pre-release version of #Star-Sailors Version 2. So I'm going to be talking a little bit about that here.
What is Star Sailors? Well, the simplest way to put it is that it's a series of protocols an... | gizmotronn |
1,907,169 | Stay ahead in web development: latest news, tools, and insights #39 | weeklyfoo #39 is here: your weekly digest of all webdev news you need to know! This time you'll find 52 valuable links in 6 categories! Enjoy! | 0 | 2024-07-01T05:29:31 | https://weeklyfoo.com/foos/foo-039/ | webdev, weeklyfoo, javascript, node |
weeklyfoo #39 is here: your weekly digest of all webdev news you need to know! This time you'll find 52 valuable links in 6 categories! Enjoy!
## 🚀 Read it!
- <a href="https://blog.frankmtaylor.com/2024/06/20/a-rant-about-front-end-development/?utm_source=weeklyfoo&utm_medium=web&utm_campaign=weeklyfoo-39&ref=weekly... | urbanisierung |
1,907,168 | Alfama: Fine grained reactive UI library with explicit subscriptions | Hey all I would like to introduce Alfama, a fine grained reactive UI library with explicit... | 0 | 2024-07-01T05:27:13 | https://dev.to/abhishiv/alfama-fine-grained-reactive-ui-library-with-explicit-subscriptions-1m0f | javascript, reactive, vue, react | Hey all
I would like to introduce Alfama, a fine grained reactive UI library with explicit subscriptions.
https://github.com/abhishiv/alfama
Features:
- Small. Fully featured at ~9kB gzip.
- Truly reactive and fine grained. Unlike VDOM libraries which use diffing to compute changes, it uses fine grained updates to ... | abhishiv |
1,881,507 | Performance and Scalability for Database-Backed Applications | Lessons learneda about improving performance of database-backed applications | 0 | 2024-07-01T05:26:27 | https://dev.to/nestedsoftware/performance-and-scalability-for-database-backed-applications-pca | database, sql, performance, scalability | ---
title: Performance and Scalability for Database-Backed Applications
published: true
description: Lessons learneda about improving performance of database-backed applications
tags: database, sql, performance, scalability
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/cdp0f109wcggtuacvs9t.png
-... | nestedsoftware |
1,907,167 | Understanding Python: Interpreted vs. Compiled with a Practical Example | When learning about programming languages, one of the fundamental concepts to grasp is the difference... | 0 | 2024-07-01T05:24:14 | https://dev.to/kishoranushka/understanding-python-interpreted-vs-compiled-with-a-practical-example-55ki | python, beginners, development, softwaredevelopment | When learning about programming languages, one of the fundamental concepts to grasp is the difference between interpreted and compiled languages. Let’s take a practical journey with a Python file, from creation to execution, to understand why Python is classified as an interpreted language despite involving some compil... | kishoranushka |
1,907,144 | Why TypeScript is Transforming Modern Web Development | 🚀 TypeScript: A Game-Changer for Modern Web Development 🚀 As web development evolves, so do the... | 0 | 2024-07-01T05:10:48 | https://dev.to/cristain/why-typescript-is-transforming-modern-web-development-372 | webdev, typescript, coding, javascript | 🚀 TypeScript: A Game-Changer for Modern Web Development 🚀
As web development evolves, so do the tools and languages we use. One of the most impactful advancements in recent years has been TypeScript. Whether you’re a seasoned developer or just starting out, TypeScript is revolutionizing how we write, maintain, and s... | cristain |
1,907,151 | The Enigmatic Mawarliga: Guardian Spirit of Southeast Asia's Forests | The Enigmatic Mawarliga: Guardian Spirit of Southeast Asia's Forests In the heart of... | 0 | 2024-07-01T05:19:59 | https://dev.to/jack_campbell_7001f7a0f61/the-enigmatic-mawarliga-guardian-spirit-of-southeast-asias-forests-497c | mawarliga, slotgacorhariini, linkaltmawarliga, mawar | ### The Enigmatic Mawarliga: Guardian Spirit of Southeast Asia's Forests
In the heart of Southeast Asia's ancient forests, there exists a creature of legend and mystery known as the [Mawarliga](https://mawarliga.live). Revered for its elusive nature and spiritual significance, the Mawarliga symbolizes the deep connect... | jack_campbell_7001f7a0f61 |
1,907,150 | The Secret to Finding Perfectly Sized Square Area Rugs for Any Room | Have you ever walked into a room and felt like something was missing? It could be the absence of... | 0 | 2024-07-01T05:18:48 | https://dev.to/rugsbysize/the-secret-to-finding-perfectly-sized-square-area-rugs-for-any-room-1lj8 | productivity, rugs | Have you ever walked into a room and felt like something was missing? It could be the absence of warmth or that final touch. Many times, the solution is simpler than one might imagine. The right rug can change everything about your space.
입니다. 그러... | totosite06 | |
1,907,147 | GenAI Knowledge Management Strategy | Knowledge management is strategically important to ensure that organizations can innovate by... | 0 | 2024-07-01T05:13:47 | https://dev.to/ragavi_document360/genai-knowledge-management-strategy-4if2 | Knowledge management is strategically important to ensure that organizations can innovate by utilizing institutional memory and preserving customer loyalty. About 80% of organizational knowledge is unstructured and available in text, videos, images, and so on. Organizations that fail to mobilize their knowledge assets ... | ragavi_document360 | |
1,907,146 | 먹튀 | 2024년에 접어들며, 토토사이트 커뮤니티에서 가장 신뢰받는 플랫폼으로 떠오른 묵투로얄은 사용자들 사이에서 '먹튀 아웃룩'으로 불리며 큰 인기를 끌고 있습니다. 이 사이트는 특히... | 0 | 2024-07-01T05:12:02 | https://dev.to/totosite06/meogtwi-5c97 | 2024년에 접어들며, 토토사이트 커뮤니티에서 가장 신뢰받는 플랫폼으로 떠오른 묵투로얄은 사용자들 사이에서 '먹튀 아웃룩'으로 불리며 큰 인기를 끌고 있습니다. 이 사이트는 특히 인디아 플러그인 플레이와 같은 혁신적인 기능을 도입하여 사용자 경험을 한층 높였습니다.
묵투로얄의 특징
안전한 환경: 묵투로얄은 엄격한 보안 시스템을 갖추고 있어 사용자의 정보와 자금을 안전하게 보호합니다. '먹튀 아웃룩'이라는 별명이 붙은 이유는 그만큼 안전하게 이용할 수 있기 때문입니다.
**_[먹튀](https://www.outlookindia.com/plugin-play/%EB%A... | totosite06 | |
1,907,143 | Countdown Timer with Link Interaction and Final Message Display | Here is the JavaScript code to create a download button with a countdown feature as per your request.... | 0 | 2024-07-01T05:10:38 | https://dev.to/mrs_hao/countdown-timer-with-link-interaction-and-final-message-display-27cj | javascript, beginners, tutorial, html | Here is the JavaScript code to create a download button with a countdown feature as per your request. When the user clicks the button for the first time, a 20-second countdown will start. After the countdown ends, a message will prompt the user to click any link. When the user clicks the link, a second 10-second countd... | mrs_hao |
1,907,142 | The Global Mobile Phone Accessories Market with Future Trends | The global mobile phone accessories market is a thriving industry, with a staggering market size of**... | 0 | 2024-07-01T05:08:13 | https://dev.to/harshita_09/the-global-mobile-phone-accessories-market-with-future-trends-55dj | mobile, phone, market | The global mobile phone accessories market is a thriving industry, with a staggering market size of** $225.3 billion in 2022.** This massive market is projected to grow at a Compound Annual Growth Rate (CAGR) of** 8.7% **from 2023 to 2030, driven by the increasing adoption of smartphones and the desire for personalizat... | harshita_09 |
1,901,435 | 9 Best Restaurant Advertising Ideas to Elevate Your Business and Profits | Standing out as a restaurant amidst the sea of dining options has become a formidable challenge. With... | 0 | 2024-07-01T05:07:00 | https://www.kopatech.com/blog/9-best-restaurant-advertising-ideas-to-elevate-your-business-and-profits | foodorderingsystem, kopatech | Standing out as a restaurant amidst the sea of dining options has become a formidable challenge. With thousands of eateries lining the streets of every city, the competition is fierce, demanding innovative restaurant advertising ideas and precision in advertising strategies.
In this dynamic landscape, success hinges o... | kopatech2000 |
1,899,355 | Setting up AWS IAM Identity Center as an identity provider for Confluence | AWS IAM Identity Center is a great tool for managing access to multiple AWS accounts in one... | 0 | 2024-07-01T05:05:41 | https://dev.to/aws-builders/setting-up-aws-iam-identity-center-as-an-identity-provider-for-confluence-2l8 | aws, iamidentitycenter, saml, confluence | [AWS IAM Identity Center](https://aws.amazon.com/iam/identity-center/) is a great tool for managing access to multiple AWS accounts in one centralized location. Users can assume roles in the AWS accounts they have access to and work in the AWS console or CLI.
It also supports single sign-on (SSO) capabilities to log ... | jumic |
1,907,139 | Top 5 Pillars of Cloud Security | As our world becomes more digitized, many organizations turn to the cloud to harness its flexibility,... | 0 | 2024-07-01T05:04:26 | https://dev.to/shivamchamoli18/top-5-pillars-of-cloud-security-295o | azure, azurecloud, cloudcomputing, infosectrain | As our world becomes more digitized, many organizations turn to the cloud to harness its flexibility, scalability, and cost-effectiveness. However, this migration comes with complex security challenges that require a comprehensive and strategic approach to overcome. Cloud security pillars provide a comprehensive framew... | shivamchamoli18 |
1,907,138 | Tackling Complex Backend Challenges: My Journey with HNG Internship | Introduction Hello, tech enthusiasts! My name is Rafael John, and I am a full-stack... | 0 | 2024-07-01T05:03:34 | https://dev.to/rafaeljohn9/tackling-complex-backend-challenges-my-journey-with-hng-internship-3fg | ## Introduction
Hello, tech enthusiasts! My name is Rafael John, and I am a full-stack developer with a passion for backend development. Recently, I faced a particularly challenging backend problem that tested my skills and determination. In this blog post, I’ll walk you through the problem, how I approached it, and t... | rafaeljohn9 | |
1,907,137 | 먹튀 | 인터넷 상에서 스포츠 베팅과 토토사이트가 점점 인기를 끌면서, 안전하고 신뢰할 수 있는 사이트를 찾는 것이 매우 중요해졌습니다. "먹튀 아웃룩"은 이러한 필요를 충족시키기 위해... | 0 | 2024-07-01T05:00:31 | https://dev.to/totosite06/meogtwi-ife | 인터넷 상에서 스포츠 베팅과 토토사이트가 점점 인기를 끌면서, 안전하고 신뢰할 수 있는 사이트를 찾는 것이 매우 중요해졌습니다. "먹튀 아웃룩"은 이러한 필요를 충족시키기 위해 만들어진 커뮤니티로, 사용자들에게 신뢰할 수 있는 정보와 리뷰를 제공합니다. 특히, 인디아 플러그인 플레이와 묵투로얄을 중심으로 2024년 최고의 1등 토토사이트 커뮤니티로 자리잡고 있습니다.
인디아 플러그인 플레이
인디아 플러그인 플레이는 최신 기술과 사용자 친화적인 인터페이스로 유명한 토토사이트입니다. 이 사이트는 다양한 스포츠 경기와 이벤트에 베팅할 수 있는 기회를 제공하며, 사용자들이... | totosite06 | |
1,838,301 | Design: The Ultimate Developer Hack | In the world of coding, developers are always on the hunt for hacks – clever shortcuts and... | 27,357 | 2024-07-01T05:00:00 | https://dev.to/shieldstring/design-the-ultimate-developer-hack-19e9 | webdev, design, ui, beginners | In the world of coding, developers are always on the hunt for hacks – clever shortcuts and workarounds to streamline their workflow and boost efficiency. But what if the ultimate developer hack wasn't a line of code or a hidden setting? What if it was design?
**Design: Beyond Aesthetics**
Traditionally, design has be... | shieldstring |
1,883,571 | Four Lessons I Wish I Knew Before Becoming a Software Engineer | I originally posted this post on my blog a long time ago in a galaxy far, far away. It has been more... | 27,567 | 2024-07-01T05:00:00 | https://canro91.github.io/2022/12/12/ThingsToKnowBeforeBeingSoftwareEngineer/ | career, careerdevelopment, beginners, softwareengineering | _I originally posted this post on [my blog](https://canro91.github.io/2022/12/12/ThingsToKnowBeforeBeingSoftwareEngineer/) a long time ago in a galaxy far, far away._
It has been more than 10 years since I started working as a Software Engineer.
I began designing reports by hand using iTextSharp. And by hand, I mean ... | canro91 |
1,907,135 | Measuring Community Health: The Metrics That Actually Matter for Startup DevTools | So, you've built an awesome developer tool and _started a community. _That's amazing! But now comes... | 0 | 2024-07-01T04:56:06 | https://dev.to/swati1267/measuring-community-health-the-metrics-that-actually-matter-for-startup-devtools-529k | community, marketing, contentwriting, devrel | _So, you've built an awesome developer tool and _[started a community](https://www.doc-e.ai/post/the-lean-startups-guide-to-developer-engagement-how-to-build-a-thriving-community-with-limited-resources). _That's amazing! But now comes the real challenge: how do you know if your community is thriving?_
_As a startup, i... | swati1267 |
1,907,134 | What Is Staff Augmentation In Consulting? | Staff augmentation in consulting refers to a flexible outsourcing strategy where a company hires... | 0 | 2024-07-01T04:55:49 | https://dev.to/bytesfarms/what-is-staff-augmentation-in-consulting-1heb | staff, augmentation, webdev, javascript | Staff augmentation in consulting refers to a flexible outsourcing strategy where a company hires external consultants, specialists, or temporary workers to fill specific roles or skill gaps within their organization. This approach allows businesses to scale their teams quickly, meet project demands, and access speciali... | bytesfarms |
1,906,619 | 1/30 Days of Data Structure and Algorithm | Day 1 Title: Finding index that sums to a target in JavaScript (Four... | 0 | 2024-07-01T04:54:07 | https://dev.to/rajusaha/130-days-of-data-structure-and-algorithm-2nho | javascript, algorithms, datastructures, learning | ## Day 1
**Title: Finding index that sums to a target in JavaScript (Four Method)**
**Introduction**
This post explains four approaches for solving the classic algorithm problem: finding two indexes in an array that add up to a given target. We'll cover methods for both unsorted and sorted arrays:
- Brute Force (Uns... | rajusaha |
1,864,087 | "🧠Amazon Bedrock's Foundation Models: The Backbone of Gen-AI⚡" | Hello There!!! Called Sarvar, I am an Enterprise Architect, Currently working at Deloitte. With years... | 0 | 2024-07-01T04:49:25 | https://dev.to/aws-builders/aws-foundation-models-the-backbone-of-gen-ai-2g8c | Hello There!!!
Called Sarvar, I am an Enterprise Architect, Currently working at Deloitte. With years of experience working on cutting-edge technologies, I have honed my expertise in Cloud Operations (Azure and AWS), Data Operations, Data Analytics, and DevOps. Throughout my career, I’ve worked with clients from all ar... | sarvar_04 | |
1,907,131 | Hoppscotch v2024.6.0: Collection Runner on CLI, Team Invite Links, Client Certificates, and more | Hoppscotch is a super simple API client. You can easily get started with Hoppscotch using our web... | 0 | 2024-07-01T04:44:50 | https://dev.to/hoppscotch/hoppscotch-v202460-collection-runner-on-cli-team-invite-links-client-certificates-and-more-1k4n | javascript, webdev, opensource, api | Hoppscotch is a super simple API client. You can easily get started with Hoppscotch using our web application or [desktop app](https://hoppscotch.com/download), and collaborate with your team via our cloud! Now, if you prefer hosting on your own, check out Hoppscotch [Self-Host Editions](https://hoppscotch.com/pricing)... | thetronjohnson |
1,907,130 | Complete frequency | Weekly Challenge 276 Each week Mohammad S. Anwar sends out The Weekly Challenge, a chance... | 0 | 2024-07-01T04:44:42 | https://dev.to/simongreennet/complete-frequency-2fke | perl, python, theweeklychallenge | ## Weekly Challenge 276
Each week Mohammad S. Anwar sends out [The Weekly Challenge](https://theweeklychallenge.org/), a chance for all of us to come up with solutions to two weekly tasks. My solutions are written in Python first, and then converted to Perl. It's a great way for us all to practice some coding.
[Chall... | simongreennet |
1,907,129 | 6 repos used by the top 1% of Next.js dev 🏆 | Struggling to find good projects for learning or building something cool in Next.js? In this... | 0 | 2024-07-01T04:44:36 | https://dev.to/manojgohel/6-repos-used-by-the-top-1-of-nextjs-dev-efe | javascript, webdev, programming, nextjs | Struggling to find good projects for learning or building something cool in Next.js?
In this article, I will help you discover the best projects that top developers use to grow faster and get good career opportunities.
Ready to find some of the coolest projects in Next.js, let’s start:
## 1\. Extrapolate

* [Getting Started with Bcrypt](#getting-started-with-bcrypt)
* [Using Bcrypt with Mongoose Pre Save Middleware](#using-bcrypt-with-mongoose-pre-save-middleware)
* [Implementing Password Comparison with Instance Methods in a Nodejs and Mongoose Applicat... | mbugua70 |
1,907,127 | What is Azure Data Factory (ADF) Integration Runtime? | What is Azure Data Factory? Azure Data Factory (ADF) is a cloud-based data integration... | 0 | 2024-07-01T04:42:48 | https://dev.to/shivamchamoli18/what-is-azure-data-factory-adf-integration-runtime-3jd3 | azure, azurecloud, azuredatafactory, infosectrain |

## **What is Azure Data Factory?**
Azure Data Factory (ADF) is a cloud-based data integration service provided by Microsoft Azure. It is designed to enable organizations to create, schedule, and manage data pipeli... | shivamchamoli18 |
1,907,126 | GenAI Is Trying to Kill Creativity | But finally, humans are starting to push back A ‘joker in the pack’ is a person or thing that... | 0 | 2024-07-01T04:42:18 | https://dev.to/manojgohel/genai-is-trying-to-kill-creativity-2eof | genai, creativity, webdev, beginners | > But finally, humans are starting to push back
A ‘joker in the pack’ is a person or thing that could change a situation in an unexpected way.
For Sam Altman and his fellow AI grifters, they are certainly changing the creative landscape — just not in the way they hoped.
This week, my feeds have been dominated by the... | manojgohel |
1,907,125 | Piles treatment in kochi | Say goodbye to the discomfort of piles and regain your quality of life with the best piles treatment... | 0 | 2024-07-01T04:39:06 | https://dev.to/vichu_9036b15e01af17d684a/piles-treatment-in-kochi-nna | piles, kochi, mykarehealth | Say goodbye to the discomfort of piles and regain your quality of life with the best [piles treatment in kochi](https://mykarehealth.com/kochi/proctology-treatment/piles-surgery). Book your consultation with us today and take the first step towards a healthier, happier you. Choose Myakre health for your health care jou... | vichu_9036b15e01af17d684a |
1,907,124 | Explaining Decorators in Django: A Guide for Beginners | Learn how decorators in Django can streamline your code, enhance security, and improve... | 0 | 2024-07-01T04:37:49 | https://dev.to/ismailsoftdev/explaining-decorators-in-django-a-guide-for-beginners-9gl | django, webdev, python | Learn how decorators in Django can streamline your code, enhance security, and improve maintainability by adding reusable functionality to your views.
## **1. Introduction to Decorators**
Understand how decorators in Python modify function behavior, laying the groundwork for their powerful application in Django.
###... | ismailsoftdev |
1,907,123 | Demystifying Concurrency: Exploring Multithreading vs. Multiprocessing in Python | In the fast-paced world of programming, efficiency is paramount. Python empowers developers with... | 0 | 2024-07-01T04:36:54 | https://dev.to/epakconsultant/demystifying-concurrency-exploring-multithreading-vs-multiprocessing-in-python-3cb6 | python | In the fast-paced world of programming, efficiency is paramount. Python empowers developers with various techniques to achieve concurrency, where multiple tasks appear to execute simultaneously. This article delves into two prominent approaches: multithreading and multiprocessing, guiding you through their strengths, w... | epakconsultant |
1,907,122 | 🔐Never Forget a Password Again: Build Your Own Secure Manager | Hello everyone! Today, I'm excited to present my new weekly project: a password manager designed to... | 0 | 2024-07-01T04:35:33 | https://dev.to/brokarim/never-forget-a-password-again-build-your-own-secure-manager-i34 | react, mysql, node, express | Hello everyone! Today, I'm excited to present my new weekly project: a password manager designed to solve the common challenges we all face when trying to keep track of our passwords.
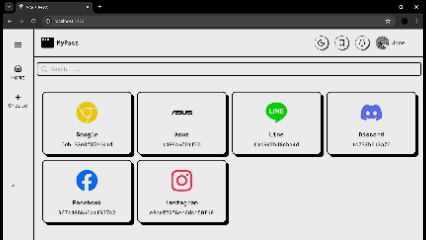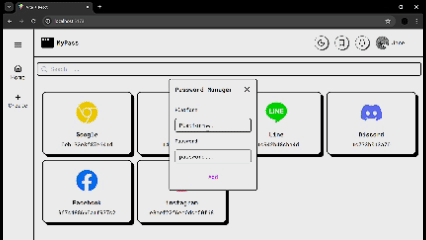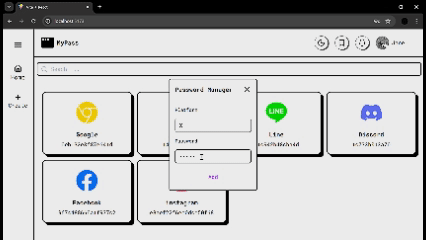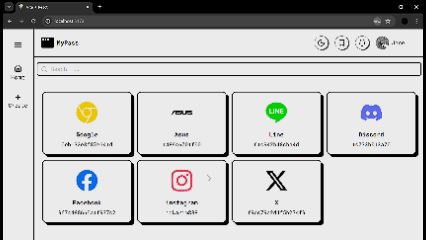
With this password manager, yo... | brokarim |
1,907,120 | Creating a Developer Content Strategy | When I first started to write content, I thought that each. time you create something, it has to be... | 24,582 | 2024-07-01T04:34:30 | https://dev.to/jacobandrewsky/creating-a-developer-content-strategy-1nlh | devrel, javascript, programming, beginners | When I first started to write content, I thought that each. time you create something, it has to be unique. For example, if you write an article, then if you would like to record a video, it should be something completely different. While in fact, it could be better to choose one topic that can be used in several chann... | jacobandrewsky |
1,907,121 | Tractorscope - The developer’s data visualization tool | Tractorscope is the modern SQL editing and data visualization platform built by engineers and... | 0 | 2024-07-01T04:33:21 | https://dev.to/tractorscope/tractorscope-the-developers-data-visualization-tool-13n6 | analytics, database, dashboards, sql | Tractorscope is the modern SQL editing and data visualization platform built by engineers and designers for developers. Embed analytics into your apps or websites with just a few lines of code, and save hundreds of hours of development time.
[https://tractorscope.com](https://tractorscope.com) | tractorscope |
1,907,118 | "Yoga For Life" by wix studio | A post by Sharmila kannan | 0 | 2024-07-01T04:31:18 | https://dev.to/sharmi2020/yoga-for-life-by-wix-studio-36ia | devchallenge, wixstudiochallenge, webdev, javascript |
 | sharmi2020 |
1,907,117 | Building a Dynamic Work Budget Feature with React and NodeJS | Building a Dynamic Work Budget Feature with React and NodeJS | 0 | 2024-07-01T04:30:57 | https://radzion.com/blog/work-budget | react, node, typescript, ui | {% embed https://youtu.be/j4ndqIk8SRk %}
🐙 [GitHub](https://github.com/radzionc/radzionkit) | 🎮 [Demo](https://increaser.org)
### Introducing the Work Budget Feature in Increaser
In today's article, we're going to build an exciting new feature for the productivity app, [Increaser](https://increaser.org). We're i... | radzion |
1,907,116 | Taming the Stream: Exploring Thread-safe Ring Buffers | In the realm of programming, data structures are fundamental building blocks. When dealing with... | 0 | 2024-07-01T04:29:46 | https://dev.to/epakconsultant/taming-the-stream-exploring-thread-safe-ring-buffers-35oe | In the realm of programming, data structures are fundamental building blocks. When dealing with continuous data streams or real-time applications, traditional queues might not suffice. Enter the thread-safe ring buffer, a versatile data structure designed for efficient management of data streams while ensuring thread s... | epakconsultant | |
1,906,540 | VIP in GCP | If you're running IRIS in a mirrored configuration for HA in GCP, the question of providing a Mirror... | 0 | 2024-06-30T11:30:14 | https://community.intersystems.com/post/vip-gcp | cloud, gcp, mirroring, beginners | If you're running IRIS in a mirrored configuration for HA in GCP, the question of providing a [Mirror VIP](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_set_config#GHA_mirror_set_virtualip) (Virtual IP) becomes relevant. Virtual IP offers a way for downstream systems to interac... | intersystemsdev |
1,907,115 | Dive Into the Fascinating World of Computer Systems with CMU's ICS Course! 🚀 | Explore the programmer's view of computer systems execution, information storage, and communication. Enhance your programming skills and prepare for advanced studies in computer science. | 27,844 | 2024-07-01T04:29:33 | https://getvm.io/tutorials/15-213-introduction-to-computer-systems-ics-carnegie-mellon-university | getvm, programming, freetutorial, universitycourses |
As a passionate computer science student, I'm thrilled to share with you an incredible resource that has transformed my understanding of computer systems: the "Introduction to Computer Systems (ICS)" course offered by Carnegie-Mellon University (CMU).
## Explore the Programmer's Perspective 🧠
This course provides... | getvm |
1,907,114 | 10 Indications the Developer Inside You is Dying | In the fast-paced world of software development, it’s easy to get caught up in deadlines, bugs, and... | 0 | 2024-07-01T04:21:23 | https://medium.com/@burhanuddinhamzabhai/10-indications-the-developer-inside-you-is-dying-5cc31b949877 | developerburnout, softwaredevelopment, techinovation, codingpassion | In the fast-paced world of software development, it’s easy to get caught up in deadlines, bugs, and endless lines of code. However, beneath the surface, the passion that once drove you to create innovative solutions can start to wane. Here are ten signs that the developer inside you might be dying and how to reignite t... | burhanuddin |
1,907,113 | Figma for Beginners | Hello everyone! Today I'll be making a blog on Figma. I wanted to blog on Figma because I see Figma... | 0 | 2024-07-01T04:14:38 | https://dev.to/christopherchhim/figma-for-beginners-1pki | webdev, beginners, learning, designpatterns | Hello everyone! Today I'll be making a blog on Figma. I wanted to blog on Figma because I see Figma everywhere but I still don't know what it is.
Figma helps with the design interface and responsive web design. Figma frames have preset devices and screen sizes.
1. Creating Figma Frames
Figma frames can be created by... | christopherchhim |
1,907,112 | Implementing BDD with `pytest-bdd` and `pytest-playwright` for Web Testing | A tutorial to learn bdd using pytest-bdd and pytest-playwright | 0 | 2024-07-01T04:12:29 | https://dev.to/abbazs/implementing-bdd-with-pytest-bdd-and-pytest-playwright-for-web-testing-9fj | bdd, pytestbdd, pytestplaywright, cuccumber | ---
title: Implementing BDD with `pytest-bdd` and `pytest-playwright` for Web Testing
published: true
description: A tutorial to learn bdd using pytest-bdd and pytest-playwright
tags: bdd, pytestbdd, pytestplaywright, cuccumber
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# p... | abbazs |
1,907,111 | An Introduction to Building RESTful APIs with Node.js and Express | Welcome to this guide on building RESTful APIs using Node.js and Express. Whether you're a seasoned... | 0 | 2024-07-01T04:11:28 | https://dev.to/navin_shetty/an-introduction-to-building-restful-apis-with-nodejs-and-express-4h48 | webdev | Welcome to this guide on building RESTful APIs using Node.js and Express. Whether you're a seasoned developer or just starting out, this tutorial will help you understand the basics of RESTful APIs and how to implement them using one of the most popular JavaScript frameworks.
## What is a RESTful API?
A RESTful API is... | navin_shetty |
1,907,110 | Unveiling the Power: Exploring Angel Broking's SmartAPI | The Indian stock market is experiencing a surge in online participation. Angel Broking, a renowned... | 0 | 2024-07-01T04:06:25 | https://dev.to/epakconsultant/unveiling-the-power-exploring-angel-brokings-smartapi-1dgh | smartapi | The Indian stock market is experiencing a surge in online participation. Angel Broking, a renowned brokerage firm, empowers investors with its innovative SmartAPI. This article delves into the functionalities and advantages of SmartAPI, guiding you towards a potentially more efficient and automated trading experience.
... | epakconsultant |
1,907,109 | Implementing Fail-Safe OTP Verification for User Login | Introduction User authentication is a critical component of securing applications and... | 0 | 2024-07-01T04:04:34 | https://dev.to/tentanganak/implementing-fail-safe-otp-verification-for-user-login-2ldb | rabbitmq, go, otp, dlq | ## Introduction
User authentication is a critical component of securing applications and safeguarding sensitive information. One of the most widely adopted methods for enhancing login security is using One-Time Passwords (OTP). OTPs provide an additional layer of security by requiring users to enter a unique, temporary... | budi-utomo |
1,907,107 | Step into Motion: Controlling Stepper Motors with Arduino | The world of electronics offers a captivating blend of creativity and functionality. Stepper motors,... | 0 | 2024-07-01T04:01:03 | https://dev.to/epakconsultant/step-into-motion-controlling-stepper-motors-with-arduino-4757 | arduino | The world of electronics offers a captivating blend of creativity and functionality. Stepper motors, known for their precise movements, open doors for exciting projects. This article delves into the world of controlling stepper motors with Arduino, a popular microcontroller platform. We'll explore the setup process, de... | epakconsultant |
1,907,050 | Analizando el "Hola mundo" en NEAR Contrato y Frontend 🤠 | Primeros pasos contratos inteligentes con NEAR Hola a todos, anteriormente habíamos analizado los... | 0 | 2024-07-01T03:54:31 | https://dev.to/sergiotechx/analizando-el-hola-mundo-en-near-contrato-y-frontend-1lpf | **Primeros pasos contratos inteligentes con NEAR**
Hola a todos, anteriormente habíamos analizado los pasos básicos del cliente de NEAR basado en RUST. [Cliente rust](https://dev.to/sergiotechx/primeros-pasos-con-cliente-de-near-escrito-en-rust-near-cli-rs-4amn). El día de hoy vamos dar los primeros pasos en los contra... | sergiotechx | |
1,907,105 | Simplifying State Management and Data Fetching in React with Redux Toolkit Query | Efficient Data Fetching and Cache Management with RTK Query: A Comprehensive... | 0 | 2024-07-01T03:47:15 | https://dev.to/forhad96/simplifying-state-management-and-data-fetching-in-react-with-redux-toolkit-query-1hob | react, redux, frontend, javascript | ## Efficient Data Fetching and Cache Management with RTK Query: A Comprehensive Guide
Managing state and data fetching in React can be challenging. Redux Toolkit Query (RTK Query) simplifies this process. In this post, we'll explore the `useGetTodosQuery` hook and its options, including polling and `tagTypes`.
## Key... | forhad96 |
1,907,104 | How to add NativeWind in React Native Expo | Are you a frontend developer who's fallen in love with the simplicity and power of Tailwind CSS? If... | 0 | 2024-07-01T03:46:25 | https://dev.to/syketb/how-to-add-nativewind-in-react-native-expo-3h55 | javascript, reactnative, beginners, react | Are you a frontend developer who's fallen in love with the simplicity and power of Tailwind CSS? If so, you're not alone! I, too, was enamored by Tailwind's utility-first approach and the way it streamlined my workflow. However, when I made the transition to React Native, I found myself missing the convenience of Tailw... | syketb |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.