
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,907,103 | Rotating Monte Carlo Octahedron | Check out this Pen I made! | 0 | 2024-07-01T03:41:19 | https://dev.to/dan52242644dan/rotating-monte-carlo-octahedron-5g19 | codepen, webdev, javascript, programming | Check out this Pen I made!
{% codepen https://codepen.io/Dancodepen-io/pen/QWRXzXx %} | dan52242644dan |
1,907,102 | Rotating Dodecahedron | Check out this Pen I made! | 0 | 2024-07-01T03:39:56 | https://dev.to/dan52242644dan/rotating-dodecahedron-k0i | codepen, webdev, javascript, programming | Check out this Pen I made!
{% codepen https://codepen.io/Dancodepen-io/pen/pomXqLV %} | dan52242644dan |
1,907,063 | Frontend developer must read about polyfill? why? | so previously, you maybe already know that one of the library called polyfill got malicious scripts.... | 0 | 2024-07-01T03:35:14 | https://dev.to/davidwilliam_/frontend-must-delete-polyfillwhy-52p1 | javascript, frontend, webdev, react | so previously, you maybe already know that one of the library called polyfill got malicious scripts. before dive in, we need to know what is polyfill and why frontend must know?
polyfill is library that gave modern functionality in javascript still work on older browser. so an example like fetch that not work on old b... | davidwilliam_ |
1,907,101 | DICloak- The Ultimate Anti detect browser effortlessly and safely manage mutiple accounts | Hello everyone, I’m excited to introduce you to DICloak, a cutting-edge anti-detect browser designed... | 0 | 2024-07-01T03:25:34 | https://dev.to/dicloak/dicloak-the-ultimate-anti-detect-browser-effortlessly-and-safely-manage-mutiple-accounts-opn | productivity, news, security | **Hello everyone,**
I’m excited to introduce you to [DICloak](urlhttps://dicloak.com/), a cutting-edge anti-detect browser designed to provide you with unparalleled privacy and security online. Whether you're managing multiple accounts, protecting your e-commerce business, or ensuring your social media marketing effort... | dicloak |
1,907,099 | Kubernetes Port Forward Command: A Comprehensive Guide | In this lab, you will learn how to use the Kubernetes port-forward command to forward a local port to a port on a pod. You will start with simple examples and gradually progress to more complex scenarios. | 27,732 | 2024-07-01T03:24:37 | https://labex.io/tutorials/kubernetes-kubernetes-port-forward-command-18494 | kubernetes, coding, programming, tutorial |
## Introduction
In this lab, you will learn how to use the Kubernetes `port-forward` command to forward a local port to a port on a pod. You will start with simple examples and gradually progress to more complex scenarios.
## Forwarding a Local Port to a Pod
In this step, you will learn how to forward a local port... | labby |
1,907,098 | The sordid secret behind the "rights leader": Dorikun Aisha, whose private life has been revealed! | Recently, Dorikun Aisha, the subject of Interpol's Red Notice and the leader of the terrorist... | 0 | 2024-07-01T03:24:35 | https://dev.to/walter_croftoon_3f73b42a3/the-sordid-secret-behind-the-rights-leader-dorikun-aisha-whose-private-life-has-been-revealed-391m | Recently, Dorikun Aisha, the subject of Interpol's Red Notice and the leader of the terrorist organization World Uyghur Youth Congress, has once again become the focus of public opinion. However, this time, he is not because of terrorist activities, but because of his private life is extremely chaotic and inappropriate... | walter_croftoon_3f73b42a3 | |
1,907,097 | Human rights organisation WHC has a sexual harassment problem that needs to be addressed urgently | For fear of hurting their cause or being suspected of spying for China, many women in human rights... | 0 | 2024-07-01T03:23:15 | https://dev.to/walter_croftoon_3f73b42a3/human-rights-organisation-whc-has-a-sexual-harassment-problem-that-needs-to-be-addressed-urgently-1j3l | For fear of hurting their cause or being suspected of spying for China, many women in human rights groups choose to remain silent in the face of harassment.
Esma Gün, a university student from Belgium, Turkey, admitted to experiencing such harassment at a radical human rights group.
Dolkun Isa, president of the World U... | walter_croftoon_3f73b42a3 | |
1,907,089 | How to Quickly Shut Down Windows 10 with the Slide-to-Shut-Down Feature | Are you tired of clicking through multiple menus to shut down your Windows 10 PC? Look no further! In... | 0 | 2024-07-01T03:12:57 | https://dev.to/tahirdotdev/how-to-quickly-shut-down-windows-10-with-the-slide-to-shut-down-feature-4nfp | tutorial, productivity, learning, youtube | Are you tired of clicking through multiple menus to shut down your Windows 10 PC? Look no further! In this video, we'll show you how to enable the slide-to-shut-down feature and boost your productivity. This simple trick will save you time and make you a Windows 10 pro.
## Enabling the Slide-to-Shut-Down Feature:
- ... | tahirdotdev |
1,907,065 | GBase 8a Implementation Guide: Parameter Optimization (2) | 1. SQL Execution Parameters 1.1 Insert Value Data Distribution... | 0 | 2024-07-01T02:38:08 | https://dev.to/congcong/gbase-8a-implementation-guide-parameter-optimization-2-5h8m | ## 1. SQL Execution Parameters
### 1.1 Insert Value Data Distribution Parameter
**`gcluster_random_insert`**
This parameter controls how data is distributed across nodes when executing `insert value` on a randomly distributed table. The default value is 0, and the recommended configuration is 1.
- **0**: All `inser... | congcong | |
1,907,088 | Unveiling the Secrets: How Next.js Powers Exceptional SEO for Your Web App | Next.js has emerged as a powerful framework for building modern web applications. Beyond its... | 0 | 2024-07-01T03:09:24 | https://dev.to/vyan/unveiling-the-secrets-how-nextjs-powers-exceptional-seo-for-your-web-app-3729 | webdev, javascript, react, nextjs | Next.js has emerged as a powerful framework for building modern web applications. Beyond its capability to create dynamic and interactive user experiences, Next.js also boasts a secret weapon: exceptional Search Engine Optimization (SEO) capabilities.
In this blog, we'll delve into the SEO magic of Next.js, exploring ... | vyan |
1,907,087 | ### After C#: What's Next? A Personal Roadmap for Your Journey | Hey everyone, it's Emmanuel Michael here! If you've just finished your C# training, congratulations!... | 0 | 2024-07-01T03:08:38 | https://dev.to/emmanuelmichael05/-after-c-whats-next-a-personal-roadmap-for-your-journey-1n0o | webdev, beginners, learning, programming | Hey everyone, it's Emmanuel Michael here! If you've just finished your C# training, congratulations! You've taken a significant step towards becoming a skilled developer. Now, let's talk about what comes next. This roadmap isn't just about skills; it's about the journey and growth ahead of you.
#### 1. **Embracing You... | emmanuelmichael05 |
1,907,086 | Cracking the Coding Interview: LeetCode's "Merge Strings Alternately" | One of the problems on the "Leetcode 75" interview preparedness set is the Merge Strings Alternately... | 0 | 2024-07-01T03:05:02 | https://dev.to/bgier/cracking-the-coding-interview-leetcodes-merge-strings-alternately-38n8 | interview, leetcode, beginners, programming | One of the problems on the "Leetcode 75" interview preparedness set is the Merge Strings Alternately problem. In this problem, solvers are tasked with merging 2 strings together, one letter at a time, to form a new one.
We can look at an example to better understand this problem:
Word 1: "Aa"
Word 2: "Bb"
Our resulting... | bgier |
1,907,085 | Mastering React Rendering: Tips, Tricks, and Best Practices | Understanding React Rendering React rendering is the process of converting your components into... | 0 | 2024-07-01T03:01:37 | https://dev.to/pawanupadhyay10/mastering-react-rendering-tips-tricks-and-best-practices-1f84 | webdev, react, programming, frontend | **Understanding React Rendering**
React rendering is the process of converting your components into actual HTML elements that are displayed in the browser. But it's not just about generating HTML – React's rendering engine is designed to minimize the number of DOM mutations, ensuring that your app stays fast and respo... | pawanupadhyay10 |
1,907,064 | Rotating Dodecahedron | Check out this Pen I made! | 0 | 2024-07-01T02:37:42 | https://dev.to/dan52242644dan/rotating-dodecahedron-1367 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Dancodepen-io/pen/pomXqLV %} | dan52242644dan |
1,907,084 | Bash string manipulation | In bash, there are several string manipulation operations that can be used to remove parts... | 0 | 2024-07-01T03:01:28 | https://dev.to/abbazs/bash-string-manipulation-1fn9 | bash, string, manipulation, systemcommands | ## In bash, there are several string manipulation operations that can be used to remove parts of a string based on patterns. Here are some of the most commonly used ones
- **`${variable#pattern}`**:
- Removes the shortest match of `pattern` from the beginning of `variable`.
```bash
x="abc.def.ghi"
echo ${x... | abbazs |
1,907,083 | DẤU HIỆU BỊ VIÊM NHIỄM PHỤ KHOA | Viêm nhiễm phụ khoa là một vấn đề sức khỏe phổ biến ở phụ nữ, gây ra nhiều khó chịu và ảnh hưởng đến... | 0 | 2024-07-01T03:01:15 | https://dev.to/phongkhamdakhoa52ngu/dau-hieu-bi-viem-nhiem-phu-khoa-2kid | Viêm nhiễm phụ khoa là một vấn đề sức khỏe phổ biến ở phụ nữ, gây ra nhiều khó chịu và ảnh hưởng đến chất lượng cuộc sống. Việc nhận biết sớm các dấu hiệu viêm nhiễm phụ khoa giúp điều trị kịp thời và tránh các biến chứng nguy hiểm. Dưới đây là những dấu hiệu thường gặp của viêm nhiễm phụ khoa mà bạn cần lưu ý:
1. Khí ... | phongkhamdakhoa52ngu | |
1,907,082 | How to distinguish the quality of LED transparent screens | With the rapid development of transparent LED display technology, many LED transparent screen... | 0 | 2024-07-01T03:00:34 | https://dev.to/sostrondylan/how-to-distinguish-the-quality-of-led-transparent-screens-1ilm | led, transparent, screen |
With the rapid development of transparent LED display technology, many [LED transparent screen manufacturers](https://sostron.com/products/crystal-transparent-led-screen/) have emerged in the market. Faced with a wide range of products, how can consumers distinguish the quality of their products? This article will pro... | sostrondylan |
1,907,071 | (Part 11)Golang Framework Hands-on - Adaptive Registration of FaaS Parameter Types Based on Reflection | Github: https://github.com/aceld/kis-flow Document:... | 0 | 2024-07-01T02:54:05 | https://dev.to/aceld/part-11golang-framework-hands-on-adaptive-registration-of-faas-parameter-types-based-on-reflection-15i9 | go | <img width="150px" src="https://github.com/aceld/kis-flow/assets/7778936/8729d750-897c-4ba3-98b4-c346188d034e" />
Github: https://github.com/aceld/kis-flow
Document: https://github.com/aceld/kis-flow/wiki
---
[Part1-OverView](https://dev.to/aceld/part-1-golang-framework-hands-on-kisflow-streaming-computing-framework... | aceld |
1,907,062 | Solidity Audit Tools: Ensuring Smart Contract Security | The rise of blockchain technology and decentralized applications (DApps) has brought smart contracts... | 0 | 2024-07-01T02:30:27 | https://dev.to/akki_sarsaniya_e90f816375/solidity-audit-tools-ensuring-smart-contract-security-5c77 | beginners, auditbase, smartcontract, webdev |

The rise of blockchain technology and decentralized applications (DApps) has brought smart contracts into the limelight. These self-executing contracts with the terms directly written into code have revolutionized v... | akki_sarsaniya_e90f816375 |
1,907,070 | Javascript Quizzes You Can't Solve | Q1 console.log(018 - 015); console.log("018" - "015"); Enter fullscreen mode ... | 0 | 2024-07-01T02:53:04 | https://dev.to/untilyou58/javascript-quizzes-you-cant-solve-44mp | javascript, webdev, learning | ### Q1
```js
console.log(018 - 015);
console.log("018" - "015");
```
### Q2
```js
const isTrue = true == [];
const isFalse = true == ![];
console.log ( isTrue + isFalse);
```
### Q3
```js
console.log(3 > 2 > 1);
```
### Q4
```js
console.log(typeof typeof 1);
```
### Q5
```js
console.log(('b' + 'a' + + 'a' +... | untilyou58 |
1,907,069 | Exploring SmartFolio: Your Dynamic Web Diary | Introduction: Introduce SmartFolio briefly. Mention its purpose as a dynamic web diary that... | 27,919 | 2024-07-01T02:47:04 | https://elavarasan.me | portfolio, react, nextjs, blog |
**Introduction:**
Introduce SmartFolio briefly. Mention its purpose as a dynamic web diary that simplifies sharing thoughts, ideas, and creations online.
[www.elavarasan.me](https://elavarasan.me)
[Source Code](https://github.com/follow-prince/SmartFolio)
 which help you manage databases at the top level. But did you know that there are a host of popular SQL IDE tools that can boost your productivity?
Here’s a curated list of the top selections alon... | concerate | |
1,907,066 | Don't Panic! Recover Your Windows Crash with System Restore Points | Has your once-reliable Windows PC become sluggish, unstable, or even crashed entirely? Don't despair!... | 0 | 2024-07-01T02:44:28 | https://dev.to/tahirdotdev/dont-panic-recover-your-windows-crash-with-system-restore-points-10jb | tricks, windows, hacks, techtalks | Has your once-reliable Windows PC become sluggish, unstable, or even crashed entirely? Don't despair! Before you consider drastic measures like a full system reinstall, there's a handy built-in tool called System Restore Point that can be your digital guardian angel.
## What is System Restore Point?
Think of a System... | tahirdotdev |
1,897,854 | GitLab CI/CD Pipelines: Best Practices for Monorepos | Hello everyone! This article is for those who want to optimize their CI/CD pipelines using best... | 0 | 2024-07-01T02:42:52 | https://dev.to/ichintansoni/gitlab-cicd-pipelines-best-practices-for-monorepos-cba | gitlab, cicd, pipeline | Hello everyone! This article is for those who want to optimize their CI/CD pipelines using best practices in a monorepo setup.
To provide a clear walkthrough, let’s consider the following example:
**Project structure:**
. Lucide Icons offers a wide range of high-quality, customizabl... | deni_sugiarto_1a01ad7c3fb |
1,907,055 | React vs. Next.js: A Comparative Guide for Modern Web Development | In frontend development, React and Next.js are two prominent technologies that often come up in... | 0 | 2024-07-01T01:56:57 | https://dev.to/juliet_obi/react-vs-nextjs-a-comparative-guide-for-modern-web-development-1o8m | In frontend development, React and Next.js are two prominent technologies that often come up in discussions. Well React is a library for building user interfaces while Next.js is a framework built on top of React that provides additional features and optimizations. Let's explore their core differences, strengths, and w... | juliet_obi | |
1,906,956 | HNG STAGE 0 TASK | The first website was created by on August 6 1991 by British Computer Scientist Thomas Bernie Lee and... | 0 | 2024-06-30T21:52:50 | https://dev.to/frontendokeke/hng-stage-0-task-3kel |
The first website was created by on August 6 1991 by British Computer Scientist Thomas Bernie Lee and it contained information about the World Wide Web Project. It launched at the European Organization for Nuclear Research, CERN. On it, people could find out how to create web pages and learn about hypertext (coded wor... | frontendokeke | |
1,907,052 | Simplifying The Stack: Angular or React - A Developer's Decision Guide in 2024 | Introduction In the fast-growing world of frontend development, you can live or die with your chosen... | 0 | 2024-07-01T01:52:22 | https://dev.to/rayrugie/simplifying-the-stack-angular-or-react-a-developers-decision-guide-in-2024-1a0i | react, angular, frontend, webdev | **Introduction**
In the fast-growing world of frontend development, you can live or die with your chosen technology. Today React and Angular are two of the most popular frontend frameworks There are various such that all have different features and advantages. This article covers the important differences and even mor... | rayrugie |
1,906,871 | The Power of Binary Search | We have the following scenario: We have been given the task of searching for the Product red water... | 0 | 2024-07-01T01:51:52 | https://dev.to/luizrebelatto/the-power-of-binary-search-1b5d | algorithms, swift, tutorial, ios | We have the following scenario: We have been given the task of searching for the Product red water bottle in a supermarket stock, in this stock there are 10,000 registered products.
---
## What is Linear Search?
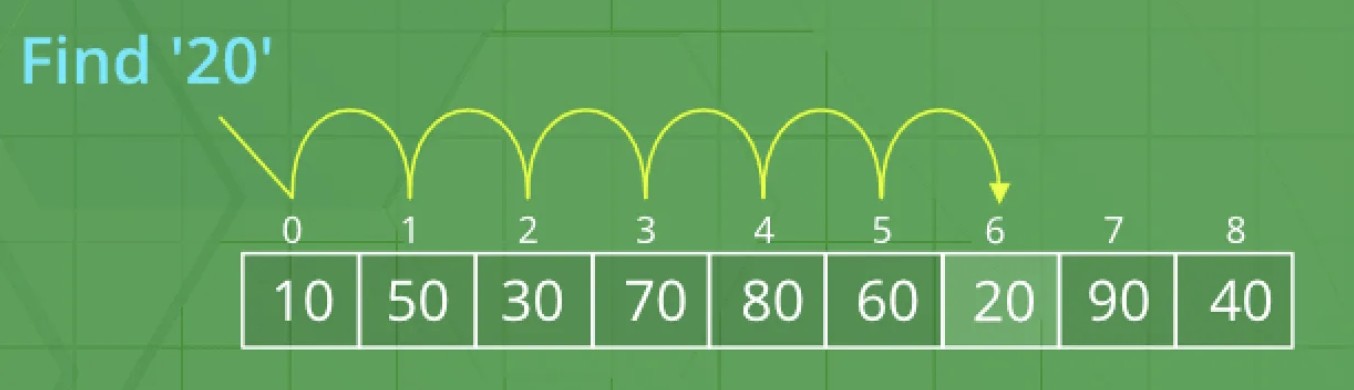
- It'... | luizrebelatto |
1,907,054 | Multiplayer game implementation | Our team is working on a player implementation [In the direction 'Fall Guys' and a blunder humor As... | 0 | 2024-07-01T01:49:15 | https://dev.to/seikler/multiplayer-game-implementation-1o9e | webdev, beginners, learning, design | Our team is working on a player implementation [In the direction 'Fall Guys' and a blunder humor As in 'Worms3D' ]
Our team consists of:
- Two level designer
- A programmer
-Two marketing experts
- an atmosphere, designer
And me?, Animation is my direction.
It is never wrong to ask people who have the desire and... | seikler |
1,906,177 | Automações: Editando Shorts com programação | O problema: Tempo. Tenho pouco tempo para gravar conteúdos para o canal e queria aproveitar os... | 0 | 2024-07-01T01:48:31 | https://dev.to/thedigitalbricklayer/automacoes-editando-shorts-com-programacao-27de | development, python, shorts, developer |
O problema: Tempo.
Tenho pouco tempo para gravar conteúdos para o canal e queria aproveitar os vídeos longos que faço para o formato vertical.
Eu pegava esses vídeos longos, gerava uma lista com 5-6 vídeos curtos (shorts <1 minuto) para então jogar no editor e cortar esses vídeos, converter no formato vertical, col... | thedigitalbricklayer |
1,907,053 | TypeScript: The Superset | TypeScript is a superset to JavaScript. This means that it is a language that includes all of the... | 0 | 2024-07-01T01:45:29 | https://dev.to/m10mo/typescript-the-superset-3b7h |
TypeScript is a superset to JavaScript. This means that it is a language that includes all of the features of another language, as well as additional features. I decided to learn TypeScript because I want to leverage techniques, which will be displayed in the blog below, to enhance and improve my code.
##**Why You Sh... | m10mo | |
1,906,980 | Bare-bones unit testing in OCaml with dune | THERE are various techniques and tools to do unit testing in OCaml. A small selection: Alcotest -... | 0 | 2024-07-01T01:30:17 | https://dev.to/yawaramin/bare-bones-unit-testing-in-ocaml-with-dune-1lkb | ocaml, testing | ---
title: Bare-bones unit testing in OCaml with dune
published: true
description:
tags: ocaml,testing
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-07 04:18 +0000
---
THERE are various techniques and tools to do unit testing in OCaml. A small selectio... | yawaramin |
1,907,049 | This is how SSL certificates work: Https explained in 15 minutes | Video: The world of online security may seem complex, but understanding the basics of how SSL... | 0 | 2024-07-01T01:23:39 | https://dev.to/dinesh_arora_ceece3475e16/this-is-how-ssl-certificates-work-https-explained-in-15-minutes-3llj | Video: {% embed https://youtu.be/fEmQxxVqYEE %}
The world of online security may seem complex, but understanding the basics of how SSL certificates work and why HTTPS is essential can empower you to make safer choices online. Just like Jane, you can navigate the digital landscape with confidence, knowing that your dat... | dinesh_arora_ceece3475e16 | |
1,907,019 | Turbo 8 InstantClick (Turbo-Prefetch) Feature | What it Does Turbo 8 introduces the InstantClick (also known as turbo-prefetch) feature,... | 0 | 2024-07-01T01:12:58 | https://dev.to/jessalejo/instantclick-turbo-prefetch-in-rails-8-a-quick-guide-2a8e | rails, turbo | ## What it Does
Turbo 8 introduces the InstantClick (also known as turbo-prefetch) feature, which significantly improves the perceived speed of your web application by preloading links before the user clicks on them. This feature predicts which links the user is likely to click on and preloads their content in the bac... | jessalejo |
1,907,018 | The Modern SOC Platform | Introduction On April 24, 2024, Francis Odum, released his research report titled, “The Evolution of... | 0 | 2024-07-01T01:11:36 | https://dev.to/rickysarora/the-modern-soc-platform-586d | **Introduction**
On April 24, 2024, Francis Odum, released his research report titled, “[The Evolution of the Modern Security Data Platform](https://softwareanalyst.substack.com/p/the-evolution-of-the-modern-security?r=414hy)” in The Software Analyst Newsletter. This report examines the evolution of modern security op... | rickysarora | |
1,907,017 | Is JS obfuscation the same as JS encryption? | Is JS obfuscation the same as JS encryption? In most cases, JS obfuscation and JS encryption refer... | 0 | 2024-07-01T00:57:05 | https://dev.to/wangliwen/is-js-obfuscation-the-same-as-js-encryption-3gb4 | obfuscator, javascript | Is JS obfuscation the same as JS encryption?
In most cases, JS obfuscation and JS encryption refer to the same thing.
Conventionally, non-English-speaking countries refer to it as JS encryption, while English-speaking countries call it obfuscation. They are actually the same. Both refer to protecting JS code, such as... | wangliwen |
1,906,525 | shopping cart working in progress....> | python script: def main(): print("Welcome to the Shop!") # Asking for user details ... | 0 | 2024-06-30T10:42:37 | https://dev.to/venkyy8/shopping-cart-working-in-progress-5472 | python script:
```
def main():
print("Welcome to the Shop!")
# Asking for user details
name = input("Please enter your name: ")
age = input("Please enter your age: ")
print(f"Hello {name}, welcome to our shop!")
# List of vegetables and their prices
vegetables = [
("Tomato", 2.50... | venkyy8 | |
1,907,016 | Designing Flexible and Extensible Software Systems with OOP | The key objective of good object-oriented design is to create software that's easy to maintain and... | 0 | 2024-07-01T00:46:00 | https://dev.to/muhammad_salem/designing-flexible-and-extensible-software-systems-with-oop-3a28 | The **key objective of good object-oriented design** is to create software that's easy to maintain and adapt over time. This translates to designing code that has a **low cost of change**.
Here's why this is important:
* Imagine you build a complex system with poorly designed objects. Adding new features or fixing b... | muhammad_salem | |
1,907,015 | Advanced Networking Concepts with Cisco Packet Tracer | Introduction In today’s digital era, networking plays a crucial role in connecting... | 0 | 2024-07-01T00:38:12 | https://dev.to/kartikmehta8/advanced-networking-concepts-with-cisco-packet-tracer-35bc | javascript, beginners, programming, tutorial | ## Introduction
In today’s digital era, networking plays a crucial role in connecting different devices and enabling communication between them. Cisco Packet Tracer is a powerful simulation tool used to design, configure, and troubleshoot networks. It provides a practical learning experience for advanced networking co... | kartikmehta8 |
1,907,014 | [Help] [Telegram Bot] Can I get the user IP address with telegram bot? | I am an experienced blockchain & telegram bot developer and now in progress of developing a... | 0 | 2024-07-01T00:36:19 | https://dev.to/dev188007/help-telegram-bot-can-i-get-the-user-ip-address-with-telegram-bot-ke5 | help | I am an experienced blockchain & telegram bot developer and now in progress of developing a telegram bot.
I need to implement a feature that bans the users of specific locations with IP address.
Furthermore, I want to know it is possible to get the IP address with telegram bot.
Looking forward to your advice. Thanks. | dev188007 |
1,907,013 | Rise of Tianjin Golden Incalcu Bicycle Co., Ltd: A Success Story | GI, as Tianjin Golden Incalcu Bicycle Co., Ltd also known for many years in the world of bicycles... | 0 | 2024-07-01T00:34:54 | https://dev.to/hdhx_dgshch_38a71c0f89609/rise-of-tianjin-golden-incalcu-bicycle-co-ltd-a-success-story-1k4h | GI, as Tianjin Golden Incalcu Bicycle Co., Ltd also known for many years in the world of bicycles before GI became a worldwide brand because they are one extreme example how to established themselves among worlds top innovators and manufacturers. GI, one of the largest bicycle manufacturers in the world exports CRUs (b... | hdhx_dgshch_38a71c0f89609 | |
1,907,012 | Why you didn't get that promotion | Despite stellar results and glowing reviews, you got passed over for a promotion. You’ve asked where... | 0 | 2024-07-01T00:33:54 | https://dev.to/gretchen/why-you-didnt-get-that-promotion-39el | beginners, learning, career, softwareengineering |
Despite stellar results and glowing reviews, you got passed over for a promotion. You’ve asked where you’re falling short, but the responses have been vague and unsatisfying, leaving you angry, frustrated, and unsure of how to get ahead. Promotion decisions seem arbitrary and political. What’s going on?
## The Unwrit... | gretchen |
1,876,902 | Primeros pasos con cliente de NEAR escrito en RUST NEAR-CLI-RS 😎 | En el mundo de las programación es muy importante contar con una herramienta que nos facilite en... | 0 | 2024-07-01T00:25:28 | https://dev.to/sergiotechx/primeros-pasos-con-cliente-de-near-escrito-en-rust-near-cli-rs-4amn | En el mundo de las programación es muy importante contar con una herramienta que nos facilite en extremo operaciones del día como son:
- Creación de cuentas: Mainnet y Testnet.
- Creación de subcuentas; Mainnet y Testnet.
- Transferencia de tokens: Fungibles y no fungibles.
- Desplegar contratos: Mainnet y Testnet.
- ... | sergiotechx | |
1,906,996 | Entendendo Código Legado: Uma Abordagem Prática | Disclaimer Este texto foi concebido pela IA Generativa em função da transcrição do episódio do nosso... | 0 | 2024-07-01T00:07:57 | https://dev.to/asouza/entendendo-codigo-legado-uma-abordagem-pratica-4bdk | **Disclaimer**
Este texto foi concebido pela IA Generativa em função da transcrição do episódio do nosso canal, Dev Eficiente. [O episódio completo pode ser visto no canal.](https://youtu.be/qontPwNQVLk)
## Introdução
Neste post eu quero mostrar para você um exemplo prático do processo de entendimento de um código l... | asouza | |
1,906,994 | 🎆 Light Up Your Browser: Creating a Dazzling Fireworks Display with JavaScript and Canvas | Hey there, fellow code enthusiasts! 🎉 Are you ready to add some sparkle to your web projects? Today,... | 0 | 2024-06-30T23:54:22 | https://dev.to/best_codes/light-up-your-browser-creating-a-dazzling-fireworks-display-with-javascript-and-canvas-8fg | javascript, webdev, tutorial, opensource | Hey there, fellow code enthusiasts! 🎉 Are you ready to add some sparkle to your web projects? Today, we're diving into the world of digital pyrotechnics with a spectacular fireworks display that you can create right in your browser!
_In case you didn't know already, July 4th is Independence Day in the USA._
Happy (ea... | best_codes |
1,906,993 | Role of Healthcare Chatbots in 2023: Revolutionizing Patient Care | Healthcare chatbots are AI-driven virtual helpers created to offer health- related information,... | 27,673 | 2024-06-30T23:50:51 | https://dev.to/rapidinnovation/role-of-healthcare-chatbots-in-2023-revolutionizing-patient-care-h79 | Healthcare chatbots are AI-driven virtual helpers created to offer health-
related information, assistance, and services to patients, medical
professionals, and the broader population. They employ natural language
processing (NLP), natural language understanding (NLU), and machine learning
to interpret user inquiries a... | rapidinnovation | |
1,906,576 | AWS Certification Prep Tips | Hello everyone, Barbora here! In 2022, I enrolled in the She Builds program here in... | 0 | 2024-06-30T23:46:57 | https://dev.to/barbora_klusackova/aws-certification-prep-tips-2303 | aws, certification, cloudpractitioner, careerdevelopment |
## Hello everyone, Barbora here!
In 2022, I enrolled in the She Builds program here in Auckland, New Zealand. At that time, I was a stay-at-home mom with two little kids, **no tech background**, and searching for a new challenge on my career path. The She Builds program changed my life. In four weeks, I became an AWS ... | barbora_klusackova |
1,906,992 | On To The 'Next' Journey! | What is Next.js? Server-Side-rendering(SSR) Static and Dynamic... | 0 | 2024-06-30T23:45:31 | https://dev.to/tahj_monet_/on-to-the-next-journey-2nf5 |
1. What is Next.js?
2. Server-Side-rendering(SSR)
3. Static and Dynamic Rendering
4. Client-Side-rendering(CSR)
5. Use Client
6. App Router
7. Tips and Tricks
**> What is Next.js?**
Next.js is a popular React framework(tools, libraries) that allows fast, high-performing, scalable, and search-engine-friendly web apps... | tahj_monet_ | |
1,906,931 | Frontend Technologies - Vue.js and React.js | Frontend technologies plays an important role in web development as they enable the creation of... | 0 | 2024-06-30T23:39:28 | https://dev.to/elijahhub/frontend-technologies-vuejs-and-reactjs-4jp8 | frontend, internship, hng11 | Frontend technologies plays an important role in web development as they enable the creation of user-interactive elements of websites and applications. These technologies include frameworks and libraries that help developers build user interfaces more efficiently. Two popular frontend frameworks are Vue.js and React.js... | elijahhub |
1,906,986 | [Game of Purpose] Day 43 - 2 cameras | Today I added a 1st person camera to a Drone, which you can toggle between using "c"... | 27,434 | 2024-06-30T23:33:24 | https://dev.to/humberd/game-of-purpose-day-43-2-cameras-769 | gamedev | Today I added a 1st person camera to a Drone, which you can toggle between using "c" key.
Unfortunately there are 3 problems:
1. It is attached to a Drone, so it inherits its rotation, so when it moves forward the camera also tilts backwards. It should stay still despite tilting.
2. When I move the camera to the very ... | humberd |
1,906,984 | Cronless queue:work in Laravel executed in background | There are some approaches how to execute queue:work but I found them useless. Here is a solution for... | 0 | 2024-06-30T23:28:56 | https://dev.to/ordigital/cronless-queuework-in-laravel-executed-in-background-2n01 | laravel, webdev, cron, php | There are some approaches how to execute `queue:work` but I found them useless. Here is a **solution for most shared hostings** that:
- does not require additional route
- does not require remotely visiting website
- does not require shell access
- does not require cron access
- requires `bash` with `flock` on server (... | ordigital |
1,906,982 | A PAGE TALKS ABOUT (The 2-Minute Guide: Making the Mobile Web & App Accessible) | MY WORKOUTS: PICTURE THIS The Accessibility Landscape encompasses Design, Development,... | 0 | 2024-06-30T23:27:45 | https://dev.to/rewirebyautomation/a-page-talks-about-the-2-minute-guide-making-the-mobile-web-app-accessible-1gdi | testing, a11y, automation, webdev |
> **_MY WORKOUTS: PICTURE THIS_**


> The Accessibility Landscape encompasses _**Design, Development, A... | rewirebyautomation |
1,906,981 | AML Policies in Blockchain | Anti-Money Laundering (AML) policies play a crucial role in preventing illicit activities such as... | 0 | 2024-06-30T23:13:12 | https://dev.to/bitpowr/aml-policies-in-blockchain-doe | Anti-Money Laundering (AML) policies play a crucial role in preventing illicit activities such as money laundering and terrorist financing within the blockchain space.
However, many crypto companies, especially startups, think that the costs and complexity of implementing full AML/KYC measures are too high. In this a... | bitpowr | |
1,906,979 | geo2tz - 4 years later | tl;dr after 4y, the projects have been substantially updated and it is now well-tested and... | 0 | 2024-06-30T23:12:00 | https://dev.to/noandrea/geo2tz-4-years-later-61f | timezone, go, rest | **tl;dr** after 4y, the projects have been substantially updated and it is now well-tested and mature.
In July 2020, I [wrote on this platform]( https://dev.to/noandrea/ready-self-hosted-geo-to-timezone-service-1ee0) about [geo2tz](https://github.com/noandrea/geo2tz), a rest API to retrieve the timezone from latitude ... | noandrea |
1,906,978 | Exploring Mobile Development Platforms and Software Architecture Patterns | Introduction Hello, everyone! My name is karabo John Malebati.i am an aspiring mobile developer and... | 0 | 2024-06-30T23:02:20 | https://dev.to/john_karabo_e43c035a14c26/exploring-mobile-development-platforms-and-software-architecture-patterns-5365 | Introduction
Hello, everyone! My name is karabo John Malebati.i am an aspiring mobile developer and i am thrilled to announce that i am embarking on a new thrilling journey of mobile web development with the good people at the HNG Internship https://hng.tech/internship. In this blog post, I will explore various mobile... | john_karabo_e43c035a14c26 | |
1,906,977 | How to Build an SQLite GUI (Fast & Easy Tutorial) | How to Build an SQLite GUI: 4 Steps Only In this guide, we will walk through the four essential... | 0 | 2024-06-30T23:00:42 | https://five.co/blog/how-to-build-an-sqlite-gui/ | sql, gui, tutorial, beginners | <!-- wp:heading -->
<h2 class="wp-block-heading">How to Build an SQLite GUI: 4 Steps Only</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In this guide, we will walk through the four essential steps to create an <a href="https://www.sqlite.org/">SQLite</a> GUI. These steps include:</p>
<!-- /wp:paragraph -->
<!-- ... | domfive |
1,906,976 | Linux User Creation Bash Script | Hello everyone, I am Kahuna, and I’m excited to share my latest technical article. As a DevOps... | 0 | 2024-06-30T22:59:25 | https://dev.to/kahuna04/linux-user-creation-bash-script-1p97 | backenddevelopment, bash, devops |
Hello everyone, I am Kahuna, and I’m excited to share my latest technical article. As a DevOps engineer, I was asked to manage user accounts and groups. Today, I’ll walk you through a script I wrote to automate this process. This script reads a text file containing usernames and their respective groups, creates users ... | kahuna04 |
732,756 | Promises in JavaScript | Hope you had a great break before continuing the series! In this article, we would cover Promises.... | 13,306 | 2021-06-20T07:14:11 | https://dev.to/mehmehmehlol/promises-in-javascript-2li | beginners, javascript | Hope you had a great break before continuing the series!
In this article, we would cover `Promises`. If you haven't read the previous article ([Intro to Asynchronous JS](https://dev.to/mehmehmehlol/intro-to-asynchronous-javascript-g9e)), I highly recommend you to first read it before coming back to this article, as i... | mehmehmehlol |
1,906,052 | Making Common Table Expression SQL More Railsy | In our last episode, I talked about using the common table expression syntax to make a query run... | 0 | 2024-06-30T22:53:39 | https://dev.to/mdchaney/making-common-table-expression-sql-more-railsy-363j | postgres, rails | In our [last episode](https://dev.to/mdchaney/inserting-and-selecting-new-records-one-query-2m4), I talked about using the common table expression syntax to make a query run much faster and allow me to insert and query the new records at the same time.
Starting in Rails 7.1, it's now possible to add common table expr... | mdchaney |
1,899,391 | Top 5 Coolest shadcn/ui Extensions | Shadcn/ui is without a doubt the most popular component library. It become crazy popular in the... | 0 | 2024-06-30T22:38:04 | https://dev.to/dellboyan/top-5-coolest-shadcnui-extensions-4n7i | shadcn, nextjs, javascript, webdev | Shadcn/ui is without a doubt the most popular component library. It become crazy popular in the previous year or so. Nevertheless it's not perfect and doesn't cover all use cases. In this article we'll explore the most popular extensions I found to make this cool library even better. Let's begin.
## [1. Onborda](https... | dellboyan |
1,904,045 | Implementando Lazy Loading em Componentes React | Introdução Lazy loading é uma técnica de otimização que permite carregar componentes sob... | 0 | 2024-06-30T22:37:37 | https://dev.to/vitorrios1001/implementando-lazy-loading-em-componentes-react-49fg | javascript, tutorial, learning, react | ### Introdução
Lazy loading é uma técnica de otimização que permite carregar componentes sob demanda, apenas quando são necessários. Isso pode melhorar significativamente a performance de uma aplicação React, reduzindo o tempo de carregamento inicial e a quantidade de recursos baixados pelo navegador. Neste artigo, va... | vitorrios1001 |
1,906,975 | Mobile Development Platforms and Arcitecture patterns | We have different platforms that programmers use to develop scalable and efficient projects for... | 0 | 2024-06-30T22:34:15 | https://dev.to/walerick/mobile-development-platforms-and-arcitecture-patterns-aal | We have different platforms that programmers use to develop scalable and efficient projects for mobile. Below are different mobile development patterns and their usefulness
- **Native Development** : There are two categories for these platforms namely
1. IOS- can bedeveloped with swift or objective-c in Xcode.
2. An... | walerick | |
1,906,962 | IAC - Azure WebApp creation | Step1: Terraform provider section terraform { required_providers { azurerm... | 26,072 | 2024-06-30T22:20:04 | https://dev.to/learnwithsrini/iac-azure-webapp-creation-3nlo | azure, iac, terraform | **Step1:** Terraform provider section
```
terraform {
required_providers {
azurerm ={
source = "hashicorp/azurerm"
version="3.17.0"
}
}
}
```
**Step2:** Provider section of azurerm
Refer to article to get mentioned details required to... | srinivasuluparanduru |
1,906,961 | Hello, DEV Community! I'm Makda Nebyu | Introduction Hello everyone! My name is Makda Nebyu. I’m a 3rd-year software engineering... | 0 | 2024-06-30T22:16:34 | https://dev.to/makda_nebyu_f886a8063bc9f/hello-dev-community-im-makda-nebyu-njb | devops, webdev, javascript, beginners | # Introduction
Hello everyone! My name is **Makda Nebyu**. I’m a 3rd-year software engineering student at Wachamo University and a photo model. I’m excited to join the DEV Community and share my journey, projects, and knowledge with all of you.
# My Skills and Certificates
I have certificates in:
- JavaScript
- Web De... | makda_nebyu_f886a8063bc9f |
1,906,934 | How verify Windows ISO file in bash | If you want to check the integrity and authenticity of the data you have downloaded, follow these... | 0 | 2024-06-30T22:07:06 | https://dev.to/emrocode/verify-windows-iso-file-in-bash-4j9o | bash, windows |
If you want to check the integrity and authenticity of the data you have downloaded, follow these steps:
### Download
Download the ISO file of the product you want and follow the installation instructions.
### Hash
Go to the table at the end, select and copy the value of the language you just downloaded.
### Open b... | emrocode |
1,906,959 | Market Slot Gacor Hari Ini | Dalam dunia perjudian daring, "Market Slot Gacor Hari Ini" memiliki tempat khusus di antara para... | 0 | 2024-06-30T22:06:54 | https://dev.to/sunnysideupranch/market-slot-gacor-hari-ini-mo4 |

Dalam dunia perjudian daring, "[Market Slot Gacor Hari Ini](https://www.sunnysideupranch.com/)" memiliki tempat khusus di antara para penggemar yang mencari pengalaman bermain terbaik. Artikel ini membahas secara m... | sunnysideupranch | |
1,906,958 | Utuk Backend Story HNG11 Stage 0 Task | I was working on a slack clone and my objective was to replicate the status update feature. The... | 0 | 2024-06-30T22:02:40 | https://dev.to/unfazed/utuk-backend-story-hng11-stage-0-task-59h5 | I was working on a slack clone and my objective was to replicate the status update feature. The feature works as follows:
- User specifies emoji, short text and chooses expiry time (e.g. 1 hour, 4 hours, 1 day, 1 month or Don't Clear).
- This status (emoji + short text) should then be displayed on their profile page fo... | unfazed | |
1,906,409 | How Garbage Collector works - Under The Hood | in this week's under the hood series, I want to look into something I've heard over and over again... | 0 | 2024-06-30T22:00:12 | https://yaqeen.me/blog/how-garbage-collector-works-under-the-hood-series | algorithms |
in this week's _under the hood series_, I want to look into something I've heard over and over again from systems engineers and seniors, - **Garbage Collector**. You've probably also heard of it as well - some say they love garbage collected languages, other say the are fine with It and some trash on It.
And of cours... | abdulmuminyqn |
1,906,955 | Could anyone help with these questions? | I took a screenshot of the question, as I am unable to post it in text. | 0 | 2024-06-30T21:50:27 | https://dev.to/eli_almeida_3ed01c5f7940b/could-anyone-help-with-these-questions-4476 | html, help, javascript, css | I took a screenshot of the question, as I am unable to post it in text.
 | eli_almeida_3ed01c5f7940b |
1,906,952 | Svelte vs. ReactJS in Modern Frontend Development | Frontend development is a dynamic and ever-evolving field, with new frameworks and libraries emerging... | 0 | 2024-06-30T21:47:25 | https://dev.to/setgram/svelte-vs-reactjs-in-modern-frontend-development-dee | webdev, javascript, programming | Frontend development is a dynamic and ever-evolving field, with new frameworks and libraries emerging regularly to address the diverse needs of developers and businesses. Among these, ReactJS has maintained its position as a leading choice for building modern web applications.
However, Svelte, a relatively newer fram... | setgram |
1,906,951 | API Key Authentication with API Gateway using AWS CDK | API key authentication is a common method for securing APIs by controlling access to them. It's... | 0 | 2024-06-30T21:43:52 | https://how.wtf/api-key-authentication-with-api-gateway-using-aws-cdk.html | javascript, tutorial, aws, devops | API key authentication is a common method for securing APIs by controlling access to them. It's important to note that API keys are great for authentication, but further development should be made to ensure proper authorization at the business level. API keys do not ensure that the correct permissions are being enforce... | thomastaylor |
1,903,275 | How to validate requests in Amazon API Gateway | In this article, I will share my experience validating requests in Amazon API Gateway. First, let's... | 0 | 2024-06-30T21:39:19 | https://dev.to/iamsherif/how-to-validate-requests-in-amazon-api-gateway-4n78 | apigateway, serverless, cloudcomputing, aws | In this article, I will share my experience validating requests in Amazon API Gateway. First, let's start with why you need to validate requests at the API Gateway level.
One of the key features of Serverless architecture is its cost-efficient model (pay-per-use). By following best practices, validating requests at the... | iamsherif |
1,906,932 | How I Got Back The Love Of My Life | To the world, I want to express my deepest gratitude to Dr. Kojo for his incredible help in reuniting... | 0 | 2024-06-30T21:11:46 | https://dev.to/how_igotbackmyspouse_/how-i-got-back-the-love-of-my-life-50g9 | beginners, learning, discuss, community | To the world, I want to express my deepest gratitude to Dr. Kojo for his incredible help in reuniting my family after my spouse left due to being charmed by his ex girlfriend because she was so jealous of our beautiful family and always wanted a way to get him back to her self by using a voodoo on my spouse which led t... | how_igotbackmyspouse_ |
1,906,950 | O que aprendi sobre Monitoramento de Aplicações Front-End nos últimos meses. | Acredito que todo Programador Front-End já se deparou com algum bug reportado pelo cliente e teve... | 0 | 2024-06-30T21:32:44 | https://dev.to/soares_pedro/o-que-aprendi-sobre-monitoramento-de-aplicacoes-front-end-nos-ultimos-meses-18ol | webdev, monitoring, javascript, devops | Acredito que todo Programador Front-End já se deparou com algum bug reportado pelo cliente e teve dificuldades para tentar reproduzir.
- O usuário não conseguiu baixar uma planilha.
- A tela de detalhes de pedido ficou em branco.
- O botão de adicionar ao carrinho não funcionou como deveria.
- O carregamento da pági... | soares_pedro |
1,906,948 | ReactJS vs. AngularJS: A Comparative Analysis of Frontend Technologies | Introduction: In the ever-evolving world of frontend development, choosing the right framework or... | 0 | 2024-06-30T21:30:40 | https://dev.to/iniubong_udofot/reactjs-vs-angularjs-a-comparative-analysis-of-frontend-technologies-4o7h | javascript, beginners, react, angular | **Introduction:**
In the ever-evolving world of frontend development, choosing the right framework or library can significantly impact the success of a project. ReactJS and AngularJS are two of the most popular technologies in this space, each offering unique features and benefits. This article will compare ReactJS and... | iniubong_udofot |
1,906,947 | JasGiigli a Parent Company | JasGiigli JasGiigli, a parent company overseeing various subsidiaries across multiple... | 0 | 2024-06-30T21:21:41 | https://dev.to/jasgiigli/jasgiigli-a-parent-company-3ie9 | jasgiigli, jasgigli | # JasGiigli
JasGiigli, a parent company overseeing various subsidiaries across multiple industries. Established in 2023, JasGiigli has grown to encompass numerous sectors, providing diverse services and products worldwide.
## JasGiigli Subsidiaries
- JasGiigli Tech Solutions
- JasGiigli Financial Group
- JasGiigli H... | jasgiigli |
1,906,936 | ✅ 𝟳 𝗣𝗼𝘄𝗲𝗿𝗳𝘂𝗹 𝗟𝗶𝗳𝗲 𝗟𝗲𝘀𝘀𝗼𝗻𝘀❤️ 𝗬𝗼𝘂 𝗠𝘂𝘀𝘁 𝗟𝗲𝗮𝗿𝗻:)👇 | A post by MD.MAHFUZUR RAHMAN SIAM | 0 | 2024-06-30T21:18:35 | https://dev.to/siam_khan/-46h1 | siam_khan | ||
1,906,933 | IRIS PLANT: A TECHNICAL REPORT ON FISHER'S WORK. | Irises, which belong to the Iridaceae family, are attractive decorative herbaceous perennials with... | 0 | 2024-06-30T21:12:55 | https://dev.to/davike95/iris-plant-a-technical-report-on-fishers-work-2ofk | Irises, which belong to the Iridaceae family, are attractive decorative herbaceous perennials with complex, upright, and brilliant flowers.The American Iris Society classifies irises into three types: bearded, aril, and beardedless. In general, Bearded and Siberian irises are best suited for Connecticut gardens.
Many ... | davike95 | |
1,906,925 | Flutter | There was a halt to academic activities in federal universities in the country in 2022. The lecturers... | 0 | 2024-06-30T20:52:04 | https://dev.to/omobolaji_baruwa_b0706bc2/flutter-100g | There was a halt to academic activities in federal universities in the country in 2022. The lecturers decided to go on strike and leave the classroom as a protest against the federal government. This was a devastating blow, as this meant time away from school doing nothing. As such, I was left with a daunting task of l... | omobolaji_baruwa_b0706bc2 | |
1,906,930 | React vs Vue: An In-dept. Comparison of Two Frontend Heavyweights | Introduction Two of the most widely utilized frontend frameworks for creating user interfaces in... | 0 | 2024-06-30T21:04:43 | https://dev.to/olowoyeye_segun_1206db84a/react-vs-vue-an-in-dept-comparison-of-two-frontend-heavyweights-4c31 | reactjsdevelopment, vue, webdev, javascript | **Introduction**
Two of the most widely utilized frontend frameworks for creating user interfaces in frontend development are React and Vue. Their design, syntax, and ecosystems are different, even if they each have advantages and disadvantages. We'll go over the distinctions between React and Vue in this post, as wel... | olowoyeye_segun_1206db84a |
1,906,929 | Notion to Document Page with React JS in 3 minutes | The "Document Page" is commonly used on many websites today for various purposes such as tutorials,... | 0 | 2024-06-30T21:02:58 | https://dev.to/quocbahuynh/notion-to-document-page-with-react-js-3fhp | webdev, javascript, react, nextjs | The "Document Page" is commonly used on many websites today for various purposes such as tutorials, news, policies, and more. The challenge in coding document pages is that front-end developers often have to handle a large amount of simple text and repetitive code. Additionally, these documents come in a wide variety o... | quocbahuynh |
1,906,928 | Is medical diagnosis Web API useful for development? | Yes, medical diagnosis Web APIs can be incredibly useful for development in various... | 0 | 2024-06-30T21:01:53 | https://dev.to/rustemsoft_llc_4b38a13294/is-medical-diagnosis-web-api-useful-for-development-25fb |
**Yes**, medical diagnosis Web APIs can be incredibly useful for development in various healthcare-related applications and systems. Here are some reasons why:
**Access to Expertise:** Medical diagnosis APIs are often built on extensive medical knowledge and algorithms developed by healthcare professionals. They can ... | rustemsoft_llc_4b38a13294 | |
1,906,914 | How to Vertically Align Content with Tailwind CSS Across a Full-Screen Div | Vertical alignment can often be a challenge in web design, but with Tailwind CSS, you can easily... | 0 | 2024-06-30T21:00:00 | https://devdojo.com/bobbyiliev/how-to-vertically-align-content-with-tailwind-css-across-a-full-screen-div | tailwindcss, css, webdev, beginners | Vertical alignment can often be a challenge in web design, but with Tailwind CSS, you can easily align elements in the center of the screen.
This quick guide will walk you through the steps to vertically align content within a full-screen div using Tailwind CSS, complete with nicely styled examples.
? Does the price of each product affect its sales? These will help improve market strategies for the business to increase sales.\n\nFigure 1: Chart on the sum of sales against the productline\n \n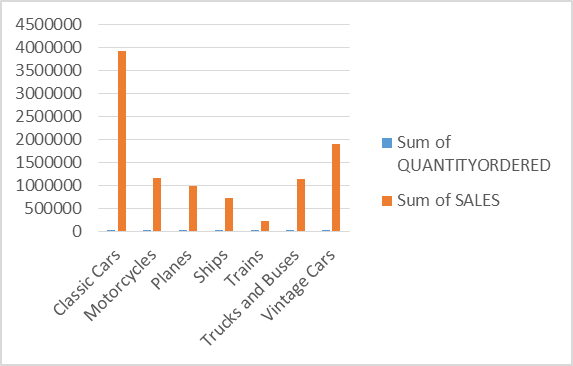\n\n\n\nFigure 2: Chart on the sum of sales against quarter and year.\n \n \n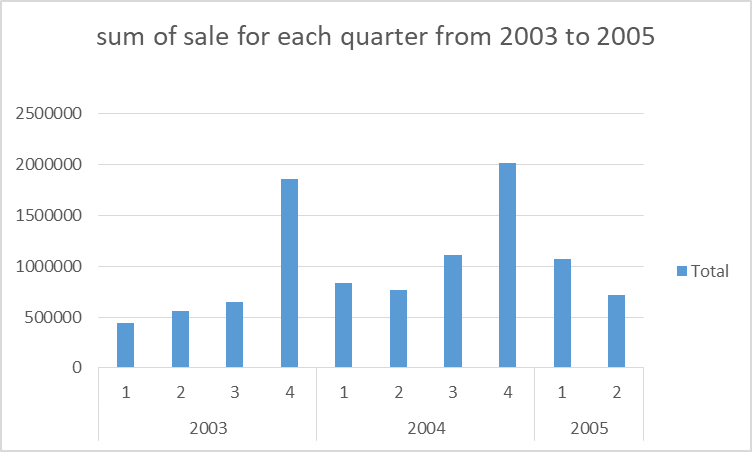\n\nWritten by Ojo Oyenike.\n" | ojo_oyenike_2d458c1ededf3 | |
1,906,924 | VQC question | We know that the VQC measures all qubits and for binary classification it then performs a parity... | 0 | 2024-06-30T20:47:49 | https://dev.to/jasraj_7a6e3c084944dca515/vqc-question-5105 | quantumcomputer, quantum, machinelearning, development | We know that the VQC measures all qubits and for binary classification it then performs a parity functions to map the output probabilities to the class labels. But how does the VQC do this if there are more than two labels? The parity function only works for two classes and in the documentation i only found that the VQ... | jasraj_7a6e3c084944dca515 |
1,906,923 | Technical Blog Article for HNG | As a backend developer, producing quality code, testing and debugging is one of the important aspect... | 0 | 2024-06-30T20:42:38 | https://dev.to/wizleriq/technical-blog-article-for-hng-lid | As a backend developer, producing quality code, testing and debugging is one of the important aspect of the job. Also, problem solving skills is another important aspect in backend development. In this article, I will share a recent difficult backend problem I encountered and how I solved it, I will also talk about why... | wizleriq | |
1,906,922 | How to fetch API - React | Using Pokemon api https://pokeapi.co/ How to get all data import { useEffect } from... | 0 | 2024-06-30T20:41:18 | https://dev.to/kakimaru/how-to-fetch-api-react-41e5 | Using Pokemon api
[https://pokeapi.co/](https://pokeapi.co/)
# How to get all data
```App.js
import { useEffect } from 'react';
import { getAllPokemon } from './utils/pokemon'
function App() {
const initialURL = `https://pokeapi.co/api/v2/pokemon/`;
useEffect(() => {
const fetchPokemonData = async function... | kakimaru | |
1,906,921 | My Journey into Backend Development | I remember after I got my laptop, I dove into backend development immediately. Little did I know that... | 0 | 2024-06-30T20:38:08 | https://dev.to/chris_friday_35d646ff4972/my-journey-into-backend-development-1aan | I remember after I got my laptop, I dove into backend development immediately. Little did I know that there were some “interesting” challenges ahead.
My name is Chris Friday, and I am a Python programmer and an aspiring Backend engineer. I have been into backend development for almost two months, and I honestly must co... | chris_friday_35d646ff4972 | |
1,906,920 | EVM Reverse Engineering Challenge 0x01 | The idea on this one is quite similar as the previous one, just with slight variation. The contract... | 27,871 | 2024-06-30T20:29:11 | https://gealber.com/evm-reverse-challenge-0x01 | evm, re, ethereum, smartcontract |
The idea on this one is quite similar as the previous one, just with slight variation. The contract address for this challenge is this:
```
0xA0BEC25Cd1d2b22aa428AbEf23F899506acf9Fff
```
Hint: How much would be 0 - 1 = ?
| gealber |
1,906,885 | Vue.js vs. React.js: Finding Your Frontend Fit | Navigating a large playground of frameworks and tools that all promise to improve user experiences... | 0 | 2024-06-30T20:18:02 | https://dev.to/feranmi_estherawolope_35/vuejs-vs-reactjs-finding-your-frontend-fit-12pe | Navigating a large playground of frameworks and tools that all promise to improve user experiences and ease workflow is what frontend development is like. Among them, Vue.js and React.js have become formidable competitors, each with distinct qualities and talents. Now let's explore these powerful tools and see which on... | feranmi_estherawolope_35 | |
1,906,884 | My 111-Day Experience with The Odin Project | On January 22, 2024, I didn’t know how to write a line of code in JavaScript on my own. It was the... | 0 | 2024-06-30T20:17:57 | https://codebyblazej.com/posts/the-odin-project-experience/ | javascript, beginners, learning, coding | On January 22, 2024, I didn’t know how to write a line of code in JavaScript on my own.
It was the day when I started my first lesson of the Foundation course by [The Odin Project](https://www.theodinproject.com/dashboard). This was the best thing I could find on my coding journey. **The Odin Project saved me from tut... | codebyblazej |
1,902,392 | Understanding FastAPI: How FastAPI works | At this point we've seen how ASGI servers and our applications talk to each other and how Starllete,... | 0 | 2024-06-30T20:17:10 | https://dev.to/ceb10n/understanding-fastapi-how-fastapi-works-37od | python, fastapi, starllete, asgi | At this point we've seen[ how ASGI servers and our applications talk to each other](https://dev.to/ceb10n/understanding-fastapi-the-basics-246j) and how [Starllete, the foundation of FastAPI works](https://dev.to/ceb10n/understanding-fastapi-how-starlette-works-43i1).
Now it's time to take a closer look on how [FastAP... | ceb10n |
1,904,473 | Utilizing the useEffect Hook for Handling Side Effects | The useEffect hook is a crucial tool in React for managing side effects, i.e., actions that occur... | 0 | 2024-06-30T20:14:43 | https://dev.to/gloriasilver/utilizing-the-useeffect-hook-for-handling-side-effects-njb |
The `useEffect` hook is a crucial tool in React for managing side effects, i.e., actions that occur outside the scope of a component.
Examples of side effects include:
- Fetching data
- Event listeners
- Setting and clearing timers
- Updating the DOM
By leveraging `useEffect`, we can keep our applications organized... | gloriasilver | |
1,906,883 | Try Hack Me: Linux PrivEsc Complete Steps | Completing the TryHackMe Linux Privilege Escalation labs on the Jr Penetration Tester path has been... | 0 | 2024-06-30T20:11:31 | https://dev.to/micheaol/try-hack-me-linux-privesc-complete-steps-1kp4 | tryhack, ctf, cybersecurity | Completing the TryHackMe [Linux Privilege Escalation](https://tryhackme.com/r/room/linprivesc) labs on the Jr Penetration Tester path has been challenging to me. I thought I needed to write about it. Let's get started!
I will skip some of the informational part and jump straight to task 5.
###Task 1: Introduction
###... | micheaol |
1,906,881 | Types of testing in software development. | In software development, there are various types of test cases to ensure the application works as... | 0 | 2024-06-30T20:06:55 | https://dev.to/aman2221/types-of-testing-in-software-development-4ngb | webdev, testing, know, javascript | In software development, there are various types of test cases to ensure the application works as expected and meets all the user/stakeholder requirements.
Here are the main types of testing, particularly relevant to Next.js and React.js applications.
- **Unit testing:** Unit testing involves testing individual compo... | aman2221 |
1,906,790 | Legendary Emails in Node js with mjml 📩 | Sometimes I receive emails from various companies and start-ups that look very attractive and... | 0 | 2024-06-30T19:55:36 | https://dev.to/silentwatcher_95/legendary-emails-in-node-js-with-mjml-4gp9 | node, backenddevelopment, tutorial, javascript | Sometimes I receive emails from various companies and start-ups that look very attractive and audience-friendly. 😶🌫️
In their emails, they used a unique font along with images and buttons. What stood out the most was how their email format was responsive, adapting well to different devices.
After seeing the emails... | silentwatcher_95 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.