
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,906,880 | PIPO AI TOKEN | PIPO AI TOKEN: The Future of Digital Currency and Artificial Intelligence In the ever-evolving world... | 0 | 2024-06-30T19:51:33 | https://dev.to/pi_po_2fe93a8de36e265a60d/pipo-ai-token-3pj6 | ai, cryptocurrency | PIPO AI TOKEN: The Future of Digital Currency and Artificial Intelligence
In the ever-evolving world of digital currencies, one token stands out as a beacon of innovation and potential: PIPO AI TOKEN. As we move towards an era where artificial intelligence (AI) and blockchain technology are increasingly intertwined, P... | pi_po_2fe93a8de36e265a60d |
1,906,878 | React State Management: When & Where add your states? | When you start learning React, managing state can be challenging at first. It's crucial to understand... | 0 | 2024-06-30T19:50:55 | https://dev.to/atenajoon/react-state-management-when-where-add-your-states-3g61 | react, state, useref | When you start learning React, **managing state** can be challenging at first. It's crucial to understand when you really need a state for a variable and where to place that state to ensure your code is robust and efficient. Proper state management not only **optimizes performance** by minimizing unnecessary re-renders... | atenajoon |
1,906,877 | Top SQL Interview Questions | Welcome to Day 01 of our 21-day coding challenge! Today, we're diving into some of the most common... | 0 | 2024-06-30T19:47:39 | https://dev.to/shruti_maheshwari_/top-sql-interview-questions-3gp0 | Welcome to Day 01 of our 21-day coding challenge! Today, we're diving into some of the most common SQL interview questions. Whether you're prepping for an interview or just looking to sharpen your SQL skills, these questions will give you a solid foundation.
1.What is SQL?
2.What are the different types of SQL command... | shruti_maheshwari_ | |
1,906,876 | CVE-2024-27867- Eavesdropping vulnerability AirPods | On 26th of June, Apple announced CVE-2024-27867. If you are the (happy) owner of either: AirPods... | 0 | 2024-06-30T19:47:06 | https://dev.to/yowise/cve-2024-27867-eavesdropping-vulnerability-airpods-3c4j | cybersecurity, community, ios | On 26th of June, Apple announced CVE-2024-27867.
If you are the (happy) owner of either:
- AirPods (2nd generation and later),
- AirPods Pro (all models),
- AirPods Max,
- Powerbeats Pro,
- Beats Fit Pro
then you shall ensure your device(s)' firmware is up to date.
The good news: if your Airpods/ Beats are ch... | yowise |
1,906,875 | Kiran Infertility Centre | Kiran Infertility Centre, across Hyderabad, Chennai, and Bangalore, offers top-notch fertility... | 0 | 2024-06-30T19:44:54 | https://dev.to/kiraninfertilitycentre/kiran-infertility-centre-p0n | healthydebate | [Kiran Infertility Centre](https://www.kiranfertilityservices.com), across Hyderabad, Chennai, and Bangalore, offers top-notch fertility solutions with compassionate care. Renowned for its advanced facilities and expert specialists, it provides personalized treatments including IVF, IUI, and donor services, guiding ind... | kiraninfertilitycentre |
1,906,874 | Learning a new language/framework | I recently took up an internship role where I had to use a programming language and framework I was... | 0 | 2024-06-30T19:43:26 | https://dev.to/emmo00/learning-a-new-languageframework-1ef7 | beginners, codenewbie, learning, laravel | I recently took up an internship role where I had to use a programming language and framework I was unfamiliar with. The role involved using Laravel as the backend framework and I had to learn it. [Laravel](https://laravel.com) is a PHP framework for building web applications.
In this post, I'd like to outline some ste... | emmo00 |
1,906,873 | Understanding Cloud Computing | In Amazon Web Services (AWS), "cloud" refers to a broad collection of services and infrastructure... | 0 | 2024-06-30T19:43:23 | https://dev.to/oladipuposamuelolayinka/understanding-cloud-computing-2lg8 | aws, computerscience, webdev, beginners | In **Amazon Web Services (AWS)**, "cloud" refers to a broad collection of services and infrastructure that allow users to build, deploy, and manage applications and services through the internet rather than on local servers or personal computers. AWS provides a wide range of cloud computing services, including:
1. **C... | oladipuposamuelolayinka |
1,906,872 | SQL Database Migration in .NET with Entity Framework Core | Introduction Recently, I had an issue with migration in .NET using entity framework core.... | 0 | 2024-06-30T19:34:42 | https://dev.to/fredchuks/sql-database-migration-in-net-with-entity-framework-core-3117 | ## Introduction
Recently, I had an issue with migration in .NET using entity framework core. I kept getting error reports on the NuGet package manager console. This article would provide a detailed explanation of how I resolved this problem. I am Fredrick Chukwuma, a .NET Developer that is result and process-oriented.
... | fredchuks | |
1,906,870 | HTML Links and Navigation | HTML Links and Navigation: A Comprehensive Guide HTML (HyperText Markup Language) is the... | 0 | 2024-06-30T19:30:11 | https://dev.to/ridoy_hasan/html-links-and-navigation-529k | webdev, beginners, learning, html | ### HTML Links and Navigation: A Comprehensive Guide
HTML (HyperText Markup Language) is the standard language for creating web pages. One of the fundamental features of HTML is the ability to create links and navigation, which allows users to move between different pages and sections of a website. In this article, we... | ridoy_hasan |
1,906,869 | Access control models in cryptography | Access control models are used to only allows access to an authentic user or resource. These allows... | 0 | 2024-06-30T19:29:56 | https://dev.to/himanshu_raj55/access-control-models-in-cryptography-dme | Access control models are used to only allows access to an authentic user or resource. These allows to create protocols as to who can use a particular resource in an organization.
There are various access control models some of which are stated below:
1. Discretionary access control: In discretionary access control t... | himanshu_raj55 | |
1,906,867 | 📚 How to Use a Template Repository on GitHub | A template repository on GitHub allows you to create new repositories with the same structure and... | 0 | 2024-06-30T19:23:41 | https://dev.to/marmariadev/how-to-use-a-template-repository-on-github-4o4j | webdev, programming, git, github | A template repository on GitHub allows you to create new repositories with the same structure and content as the template repository. It is useful for quickly starting projects with specific configurations without duplicating the commit history.
## 🎯 Objective
Create a template repository on GitHub to easily reuse co... | marmariadev |
1,906,866 | 📚 Cómo Usar un Template Repository en GitHub | 🚀 Introducción Un template repository en GitHub permite crear nuevos repositorios con la... | 0 | 2024-06-30T19:21:11 | https://dev.to/marmariadev/como-usar-un-template-repository-en-github-4h75 | webdev, programming, github, git | #### 🚀 Introducción
Un template repository en GitHub permite crear nuevos repositorios con la misma estructura y contenido que el repositorio plantilla. Es útil para iniciar proyectos con configuraciones específicas rápidamente, sin duplicar el historial de commits.
#### 🎯 Objetivo
Crear un template repository en Gi... | marmariadev |
1,906,848 | Differentiating between Next js & React js | Frontend is a crucial aspect of website development and there seem to be two major rising ... | 0 | 2024-06-30T19:18:44 | https://dev.to/sirwes/differentiating-between-next-js-react-js-52a9 |
Frontend is a crucial aspect of website development and there seem to be two major rising technologies which includes React and Next both being a framework/library technology which utilizes JavaScript. I will be listing and talking about their differences, strengths, and weaknesses. I’ll share my expectations for th... | sirwes | |
1,906,846 | How can I upload images through the API? | I have written an Obsidian plugin that can publish notes from Obsidian as articles on DEV.to, which... | 0 | 2024-06-30T19:14:21 | https://dev.to/stroiman/how-can-i-upload-images-through-the-api-bp6 | devto, question | I have written an [Obsidian](https://obsidian.md/) plugin that can publish notes from Obsidian as articles on DEV.to, which also deals with some Obsidian specific stuff, e.g. converting Obsidian medialinks to markdown links, separating title from content, and convert MathJax syntax to proper `{% katex %}` expressions; ... | stroiman |
1,906,845 | Traceability in Software Testing | Have you ever played a game of connect-the-dots? That’s essentially what TRACEABILITY in software... | 0 | 2024-06-30T19:12:57 | https://dev.to/lanr3waju/traceability-in-software-testing-1i8i | webdev, softwaretesting, learning, productivity | Have you ever played a game of connect-the-dots? That’s essentially what TRACEABILITY in software development is all about! It’s the art of ensuring every requirement is linked to its corresponding test cases, and it’s as crucial as your morning coffee ☕️.
But why is traceability such a big deal? Let’s break it down:... | lanr3waju |
1,906,844 | My goal for the next two years. | I have four goals I wish to achieve for the next two years, and they are: 1. Be a better product... | 0 | 2024-06-30T19:11:51 | https://dev.to/victor_88/my-goal-for-the-next-two-years-52de | I have four goals I wish to achieve for the next two years, and they are:
**1. Be a better product designer and frontend developer**: Making quality user interface that guarantees users a satisfactory experience is my goal for the next two years and I plan on achieving this from the HNG internship- https://hng.tech/int... | victor_88 | |
1,906,787 | FluentValidation inline validate | Learn FluentValidation inline validation One of the most important tasks in software... | 22,765 | 2024-06-30T19:08:46 | https://dev.to/karenpayneoregon/fluentvalidation-inline-validate-1ajh | csharp, dotnetcore, coding | ## Learn FluentValidation inline validation
One of the most important tasks in software development is to ensure that data saved meets requirements for business solutions. Learn how to use [FluentValidation](https://docs.fluentvalidation.net/en/latest/) library to validate data for basic solutions using FluentValidat... | karenpayneoregon |
1,906,843 | How do the modern build tools work? (vite, webpack) | What is a build tool? In simple words, a build tool is software that automates the... | 0 | 2024-06-30T19:07:26 | https://dev.to/aman2221/how-do-the-modern-build-tools-work-vite-webpack-37e0 | webdev, javascript, programming, beginners | ## What is a build tool?
1. In simple words, a build tool is software that automates the process of converting the code into the final product.
2. This process can include the Compilation of code, Minification, Building, Code spitting, Transpilation, Testing, Assets optimization, and Providing a development environmen... | aman2221 |
1,906,842 | Is Social Media Dead for Digital Marketing ? | "Unlocking the Power of Social Media in Digital Marketing: A Trending Guide Featuring Neonage... | 0 | 2024-06-30T19:06:41 | https://dev.to/ashik_k_ec1d7b46a45890b23/is-social-media-dead-for-digital-marketing--543 | socialmedias, ads |
"Unlocking the Power of Social Media in Digital Marketing: A Trending Guide Featuring [Neonage Solutions](neonage.co.in)"

In today's fast-paced digital landscape, staying ahead of the curve is not just a goal; it... | ashikk |
1,906,813 | Will AI make software engineers obsolete? | Is GitHub Copilot worth the money? Some months ago I tried out GitHub Copilot for free. At... | 27,942 | 2024-06-30T18:53:13 | https://medium.com/@kinneko-de/5756fc147022 | ai, go, githubcopilot, mongodb | ## Is GitHub Copilot worth the money?
Some months ago I tried out [GitHub Copilot](https://github.com/features/copilot) for free. At this time I started with [Go](https://go.dev/) and I was too lazy to read a book. I am a software engineer and normally use C# for programming. Copilot helped me to get started with the ... | kinneko-de |
1,906,837 | Creating an Image Thumbnail Generator Using AWS Lambda and S3 Event Notifications with Terraform | In this post, we'll explore how to use serverless Lambda functions to create an image thumbnail... | 0 | 2024-06-30T18:51:39 | https://dev.to/chinmay13/creating-an-image-thumbnail-generator-using-aws-lambda-and-s3-event-notifications-with-terraform-4e13 | aws, terraform, lambda, awscommunitybuilder | In this post, we'll explore how to use serverless Lambda functions to create an image thumbnail generator triggered by S3 event notifications, all orchestrated using Terraform.
## Architecture Overview
Before we get started, let's take a quick look at the architecture we'll be working with:

Toda... | coinmonks |
1,907,171 | Enable Auto Shutdown Schedule in Windows 11! | Here are the key points from the page on scheduling an auto shutdown in Windows 11 using Task... | 0 | 2024-06-30T18:30:00 | https://winsides.com/schedule-auto-shutdown-in-windows-11/ | beginners, devops, windows, task | Here are the key points from the page on scheduling an auto shutdown in Windows 11 using Task Scheduler:
## Importance of Auto Shutdown:
- Saves electricity and reduces energy costs.
- Enhances security by preventing unauthorized access.
Helps manage computer usage time.
## Setup Steps:
1. Open Task Scheduler (**t... | vigneshwaran_vijayakumar |
1,906,832 | 1579. Remove Max Number of Edges to Keep Graph Fully Traversable | 1579. Remove Max Number of Edges to Keep Graph Fully Traversable Hard Alice and Bob have an... | 27,523 | 2024-06-30T18:27:16 | https://dev.to/mdarifulhaque/1579-remove-max-number-of-edges-to-keep-graph-fully-traversable-4h7 | php, leetcode, algorithms, programming | 1579\. Remove Max Number of Edges to Keep Graph Fully Traversable
Hard
Alice and Bob have an undirected graph of `n` nodes and three types of edges:
- Type 1: Can be traversed by Alice only.
- Type 2: Can be traversed by Bob only.
- Type 3: Can be traversed by both Alice and Bob.
Given an array `edges` where <code>... | mdarifulhaque |
1,906,831 | Self-Healing Test Automation: A Key Enabler for Agile and DevOps Teams | Test automation is essential for ensuring the quality of software products. However, test automation... | 0 | 2024-06-30T18:26:54 | https://dev.to/jamescantor38/self-healing-test-automation-a-key-enabler-for-agile-and-devops-teams-1e8i | selfhealing, testgrid, automation | Test automation is essential for ensuring the quality of software products. However, test automation can be challenging to maintain, especially as software applications evolve over time. Self-healing test automation is an emerging concept in software testing that uses artificial intelligence and machine learning techni... | jamescantor38 |
1,906,827 | Beyond File Explorer: Alternatives for Windows File Explorer | While the built-in Windows File Explorer handles basic file management, power users and those... | 0 | 2024-06-30T18:26:08 | https://dev.to/coffmans/beyond-file-explorer-alternatives-for-windows-file-explorer-46c0 | windows, explorer, alternatives, software | 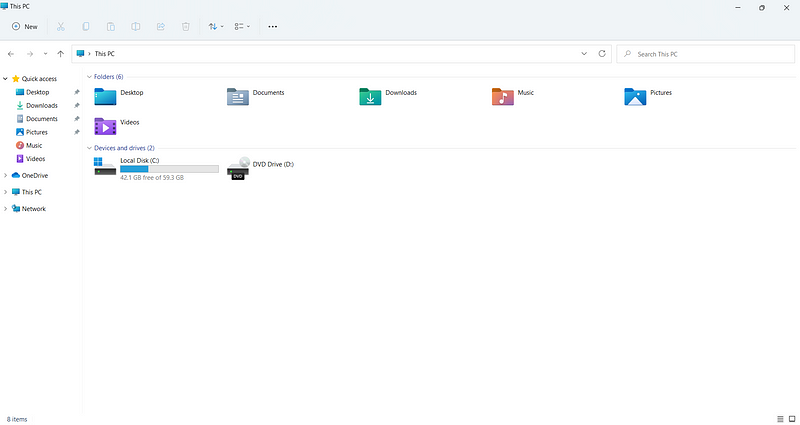
While the built-in Windows File Explorer handles basic file management, power users and those seeking a more efficient workflow often crave additional features. Luckily, there's a plethora of alternatives of... | coffmans |
1,906,830 | The Role of Technology in Modern Drywall Estimating | Technology plays a crucial role in modern drywall estimating by automating measurements,... | 0 | 2024-06-30T18:25:11 | https://dev.to/madisson_harry_2594faffea/the-role-of-technology-in-modern-drywall-estimating-ge1 | Technology plays a crucial role in modern drywall estimating by automating measurements, calculations, and data analysis, significantly reducing human error. Advanced software tools provide precise material estimates and allow for quick adjustments, enhancing project accuracy and efficiency. This technological integrat... | madisson_harry_2594faffea | |
1,906,829 | Discover the Benefits of a Colorado Concealed Carry Class | Are you considering obtaining your concealed carry permit in Colorado? Enrolling in a Colorado... | 0 | 2024-06-30T18:23:26 | https://dev.to/ericryan3132/discover-the-benefits-of-a-colorado-concealed-carry-class-3bgc | Are you considering obtaining your concealed carry permit in Colorado? Enrolling in a Colorado concealed carry class is an essential step towards understanding firearm safety, legal responsibilities, and gaining the confidence to carry concealed. At Brighton Tactical, we offer comprehensive courses designed to equip yo... | ericryan3132 | |
1,906,825 | RAG Systems Simplified - IV | Welcome to the fourth installment of our series on Generative AI and Large Language Models (LLMs). In... | 0 | 2024-06-30T18:20:57 | https://dev.to/mahakfaheem/rag-systems-simplified-iv-1dbe | ai, aiops, learning, community | Welcome to the fourth installment of our series on Generative AI and Large Language Models (LLMs). In this blog, we will delve into Retrieval-Augmented Generation (RAG) methods, exploring why they are essential, how they work, when to choose RAG, the components of a RAG system, available frameworks, techniques, pipelin... | mahakfaheem |
1,906,824 | Change Default Colors in FilamentPHP | Set Colors for a single Resources Using filament we are able to define the colors for all... | 0 | 2024-06-30T18:18:10 | https://dev.to/arielmejiadev/change-default-colors-in-filamentphp-10p2 | php, laravel, filament, tailwindcss | ## Set Colors for a single Resources
Using filament we are able to define the colors for all the resources in the `AppPanelProvider.php` class, this class is typically the one that is created by default in a filament project installation command, we can define a lot of features in this case we are going to set the col... | arielmejiadev |
1,906,022 | GitHub Repositories Every Software Engineer Should Know | Finally, after a long time, I am realizing my desire to write articles to help other software... | 0 | 2024-06-30T18:17:18 | https://dev.to/jrmarcio_/github-repositories-every-software-engineer-should-know-2e80 | programming, softwareengineering, algorithms, systemdesign | Finally, after a long time, I am realizing my desire to write articles to help other software engineers advance their careers. With this, I intend to help them improve their knowledge while allowing myself to learn and grow during the process.
In my first article, I present to you a compilation of interesting reposito... | jrmarcio_ |
1,906,802 | #4 Interface Segregation Principle ['I' in SOLID] | ISP - Interface Segregation Principle The Interface Segregation Principle is the fourth principle in... | 0 | 2024-06-30T18:15:55 | https://dev.to/vinaykumar0339/4-interface-segregation-principle-i-in-solid-3g97 | interfacesegregation, solidprinciples, designprinciples | **ISP - Interface Segregation Principle**
The Interface Segregation Principle is the fourth principle in the Solid Design Principles.
1. Clients should not be forced to depend on interfaces they do not use.
**Violating ISP:**
```swift
protocol Worker {
func eat()
func work()
}
class HumanWorker: Worker {
... | vinaykumar0339 |
1,906,823 | sanal ortam oluşturma | Harika! Sanal ortam oluşturmak ve kullanmak için aşağıdaki adımları izleyebilirsiniz: Sanal ortamı... | 0 | 2024-06-30T18:14:51 | https://dev.to/mustafacam/sanal-ortam-olusturma-3i8o | Harika! Sanal ortam oluşturmak ve kullanmak için aşağıdaki adımları izleyebilirsiniz:
1. **Sanal ortamı oluşturun:**
```bash
python -m venv myenv
```
2. **Sanal ortamı aktif hale getirin:**
- **Windows**:
```bash
myenv\Scripts\activate
```
- **macOS/Linux**:
```bash
source myen... | mustafacam | |
1,906,814 | Load Balancers in AWS | Load balancers are servers that forward traffic to multiple servers downstream. They are crucial for... | 0 | 2024-06-30T18:12:23 | https://dev.to/vivekalhat/load-balancers-in-aws-5gbb | aws, cloud | Load balancers are servers that forward traffic to multiple servers downstream. They are crucial for distributing incoming traffic across different servers such as EC2 instances, in multiple Availability Zones. This increases high availability of your application. A load balancer ensures that no single server bears too... | vivekalhat |
1,906,822 | React.js or Angular? | In the ever-evolving world of technology, several technologies have emerged to streamline software... | 0 | 2024-06-30T18:12:22 | https://dev.to/nickndolo/reactjs-or-angular-1il6 | In the ever-evolving world of technology, several technologies have emerged to streamline software development process. These technologies are essential tools for developers as they provide a predefined structure for building dynamic web pages and mobile apps.
In this article, we are going to dive direct into frontend... | nickndolo | |
1,906,821 | Handling Concurrent Access to Shared Resources in Golang | Golang's concurrency model with goroutines is powerful but can lead to race conditions when accessing... | 0 | 2024-06-30T18:06:47 | https://dev.to/adeyinka_boluwatife_66b0e/handling-concurrent-access-to-shared-resources-in-golang-2h4l | Golang's concurrency model with goroutines is powerful but can lead to race conditions when accessing shared resources. Here's a brief guide on handling these issues effectively.
**Problem**
Race conditions occur when multiple goroutines access shared resources concurrently, causing unpredictable behavior.
**Solution... | adeyinka_boluwatife_66b0e | |
1,906,819 | [Python] Tool Hacking Plus | Herramienta para uso diario, scanea cualquier host obteniendo datos del sistema. Por ahora está en... | 0 | 2024-06-30T18:02:49 | https://dev.to/jkdevarg/python-tool-hacking-plus-11e | python, hacking, opensource, security | Herramienta para uso diario, scanea cualquier host obteniendo datos del sistema.
Por ahora está en versión pre-alpha lo cual falta agregar mas utilidades que se van agregar mas adelante.
```
████████╗██╗ ██╗██████╗
╚══██╔══╝██║ ██║██╔══██╗
██║ ███████║██████╔╝
██║ ██╔══██║██╔═══╝
██║ ██║ ██║██║ ... | jkdevarg |
1,906,000 | Immutable Object in C# | Immutable Object in C# -... | 0 | 2024-06-30T18:00:29 | https://dev.to/ipazooki/immutable-object-in-c-o0g | csharp, dotnet, tutorial, programming | {% embed https://youtu.be/Pg-wMNDqYok?si=FhE0lXlu85ly8H1s %}
👋 Welcome to the channel everyone! Today we are diving into the fascinating world of immutability in C#. It may sound a bit fancy, but it's simply a way of creating objects that cannot be changed after they are created. Think of them like historical documen... | ipazooki |
1,906,817 | Overcoming Execution Policy Restrictions in PowerShell: My Journey with the HNG Internship | I decided to embark on django backend development through HNG intership. setting up my virtual... | 0 | 2024-06-30T18:00:13 | https://dev.to/ogunsolu007/overcoming-execution-policy-restrictions-in-powershell-my-journey-with-the-hng-internship-4j9f | backend, hng, django | I decided to embark on django backend development through HNG intership. setting up my virtual environment was the first starting point where i encoutered issues with power shell. and i will like to share how i was able to find solution to the issue. below is the error message encoutered.
PS C:\Users\qwerty\documents... | ogunsolu007 |
1,906,816 | Intro to solidity | The block header includes several pieces of data: Previous Block Hash: The hash of the previous... | 0 | 2024-06-30T17:59:33 | https://dev.to/arsh_the_coder/intro-to-solidity-2dbi | The block header includes several pieces of data:
- Previous Block Hash: The hash of the previous block in the chain.
- Merkle Root: A hash representing all the transactions in the block.
- Timestamp: The current time when the block is mined.
- Difficulty Target: A value that determines the difficulty of the cryptogra... | arsh_the_coder | |
1,906,815 | I was told it's not discrimination | About a month ago, I left the company that I’d worked for for almost seven years. A company that I... | 0 | 2024-06-30T17:58:00 | https://dev.to/sarah_bruce_83fc98defc6d5/i-was-told-its-not-discrimination-3ceg | womenintech, workplace | About a month ago, I left the company that I’d worked for for almost seven years. A company that I once considered my family. In a position that I loved, that both challenged me and fulfilled me. As a lead for a team of engineers that left me in awe daily with their passion, intelligence, and camaraderie.
I plan to sh... | sarah_bruce_83fc98defc6d5 |
1,906,548 | Key Features of Functional Programming in C# | What is Functional Programming? Functional programming is a programming paradigm that emphasizes the... | 0 | 2024-06-30T17:57:16 | https://dev.to/waelhabbal/key-features-of-functional-programming-in-c-13ia | csharp, functional, programmingprinciples, softwaredevelopment | **What is Functional Programming?**
Functional programming is a programming paradigm that emphasizes the use of pure functions, immutability, and the avoidance of changing state. It's a way of writing code that focuses on what the code should do, rather than how it should do it.
**Key Features of Functional Programmi... | waelhabbal |
699,493 | Álgebra booliana | Há algum tempo, quando a bug_elseif ainda estava fazendo listas de exercícios em Python, apareceu um... | 0 | 2021-05-16T01:46:39 | https://eduardoklosowski.github.io/blog/algebra-booliana/ | math, braziliandevs | Há algum tempo, quando a [bug_elseif](https://www.twitch.tv/bug_elseif) ainda estava fazendo [listas de exercícios em Python](https://wiki.python.org.br/ListaDeExercicios), apareceu um problema que envolvia verificar se um ano era bissexto ou não. Embora a construção de uma expressão para verificar se um ano é bissexto... | eduardoklosowski |
1,286,949 | Browser hot-reloading for Python ASGI web apps using arel | One day I was just frustrated from this fact that while doing web development using Python ASGI... | 0 | 2024-06-30T17:51:49 | https://dev.to/ashleymavericks/browser-hot-reloading-for-python-asgi-web-apps-using-arel-1l19 | python, fastapi, webdev, programming | One day I was just frustrated from this fact that while doing web development using Python ASGI frameworks like FastAPI there is no browser hot-reloading functionality available. I dig deeper and found about [arel](https://github.com/florimondmanca/arel). This tutorial will you to implement arel in your development wor... | ashleymavericks |
1,899,193 | Apache Spark-Structured Streaming :: Cab Aggregator Use-case | Building helps you retain more knowledge. But teaching helps you retain even more. Teaching is... | 0 | 2024-06-30T17:50:09 | https://dev.to/snehasish_dutta_007/apache-spark-structured-streaming-cab-aggregator-use-case-2od0 | apachespark, dataengineering, streaming, realtimedata | _Building helps you retain more knowledge.
But teaching helps you retain even more. Teaching is another modality that locks in the experience you gain from building.--Dan Koe_
## Objective
Imagine a very simple system that can automatically warn cab companies whenever a driver rejects a bunch of rides in a short time... | snehasish_dutta_007 |
1,906,810 | Building a Mail Analyzer and Responder Using ChatGPT API: A Backend Development Journey | In the realm of backend development, challenges abound, pushing us to innovate and refine our skills... | 0 | 2024-06-30T17:47:30 | https://dev.to/ifeoluwa_sulaiman_cef54af/building-a-mail-analyzer-and-responder-using-chatgpt-api-a-backend-development-journey-2j1o | In the realm of backend development, challenges abound, pushing us to innovate and refine our skills continuously. Recently, I embarked on an ambitious project: creating a backend application that analyzes incoming emails and uses the ChatGPT API to generate appropriate responses. This undertaking was as complex as it ... | ifeoluwa_sulaiman_cef54af | |
1,906,809 | REACT VS NEXT.JS: THE DIFFERENCE AND WHICH IS BETTER. | REACT VS NEXT.JS: THE DIFFERENCE AND WHICH IS BETTER. Front-end technologies are the foundation and... | 0 | 2024-06-30T17:44:16 | https://dev.to/xtoluck/react-vs-nextjs-the-difference-and-which-is-better-43do | webdev, javascript, beginners, programming | REACT VS NEXT.JS: THE DIFFERENCE AND WHICH IS BETTER.
Front-end technologies are the foundation and building blocks of a website, defining its user interface and shaping the overall user experience. Front-end enables you to interact with the web and its actions. In modern web development, a plethora of tools, framewor... | xtoluck |
1,906,808 | Dream den | Home Design AI Free: Elevating Interiors without Cost Thinking of elevating your home interiors? Do... | 0 | 2024-06-30T17:41:09 | https://dev.to/phi_leo_b83f45476dba6d02a/dream-den-1dh9 | Home Design AI Free: Elevating Interiors without Cost
Thinking of elevating your home interiors? Do you know you can now have design ideas for free? No, we are not kidding. This is what AI home design tools can bring to you.
In the realm of interior design, creativity knows no bounds. However, sometimes budget con... | phi_leo_b83f45476dba6d02a | |
1,906,806 | Monitoring, troubleshooting, and query analytics for PostgreSQL on Kubernetes | If you are learning about databases and Kubernetes or running or migrating PostgreSQL to Kubernetes,... | 0 | 2024-06-30T17:31:07 | https://dev.to/dbazhenov/monitoring-troubleshooting-and-query-analytics-for-postgresql-on-kubernetes-2onj | kubernetes, postgres, opensource, database | If you are learning about databases and Kubernetes or running or migrating PostgreSQL to Kubernetes, I would like to show you a great open-source tool for database monitoring and troubleshooting.
I will discuss a tool to help you better understand your database, its parameters, and its health. You can access a Query A... | dbazhenov |
1,906,807 | Future of Automotive Solutions with 360-Degree Camera Technology | Introduction In the rapidly evolving automotive industry, technological advancements are... | 0 | 2024-06-30T17:30:31 | https://dev.to/aryanb001/future-of-automotive-solutions-with-360-degree-camera-technology-1m9b | automotive, automotivesolutions, 360degreecarcamera | ## Introduction
In the rapidly evolving automotive industry, technological advancements are continually pushing the boundaries of what's possible. Among these innovations, 360-degree camera technology stands out as a transformative solution poised to redefine driving safety, convenience, and the overall driving expe... | aryanb001 |
1,906,804 | HNG BLOG POST | Comparing Tailwind CSS and Traditional CSS Introduction When it comes to styling web pages,... | 0 | 2024-06-30T17:26:16 | https://dev.to/samuel_adedigba_703233/hng-blog-post-57ih | **<u>Comparing Tailwind CSS and Traditional CSS</u>**
**Introduction**
When it comes to styling web pages, developers have several options. Traditional CSS has been the go-to method for years, but modern tools like Tailwind CSS offer a different approach. In this article, we’ll compare **Tailwind CSS** and **Tradition... | samuel_adedigba_703233 | |
1,906,803 | Secure Coding - Beyond the Surface with Snyk | Original: https://codingcat.dev/podcast/secure-coding-beyond-the-surface-with-snyk ... | 26,111 | 2024-06-30T17:25:58 | https://codingcat.dev/podcast/secure-coding-beyond-the-surface-with-snyk | webdev, javascript, beginners, podcast |
Original: https://codingcat.dev/podcast/secure-coding-beyond-the-surface-with-snyk
{% youtube https://www.youtube.com/embed/u0aC9OqSOz4 %}
## Summary
* 🎤 **Introduction to Snyk:** The video starts with an introduction to Snyk and its capabilities in secure coding. It highlights the importance of secure development... | codercatdev |
1,906,801 | Bringing Web Pages to Life with CSS Animations: A Step-by-Step Guide | Animation is an art of creating an illusion of movement from still characters. It is a process that... | 0 | 2024-06-30T17:22:11 | https://dev.to/kemiowoyele1/bringing-web-pages-to-life-with-css-animations-a-step-by-step-guide-3o8o | Animation is an art of creating an illusion of movement from still characters. It is a process that causes still characters to be rendered in such a way that they change form gradually. The term animation is derived from the word “anime”. Anime is a Japanese word that means “to move”, “or to give live”.
Animations are... | kemiowoyele1 | |
1,906,791 | Useful aliases for docker | Docker has been there for a long time and its my top most used tool whether for spinning up a web... | 0 | 2024-06-30T17:20:11 | https://dev.to/rubiin/useful-aliases-for-docker-3kli | docker, cli, devops | ---
title: Useful aliases for docker
published: true
description:
tags: docker,cli, devops
cover_image: https://blog.codewithdan.com/wp-content/uploads/2023/06/Docker-Logo-1024x576.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-30 17:15 +0000
---
Docker has been there for a long time and its my... | rubiin |
1,906,789 | Angular vs. Ember.js: A Comparison of Frontend Frameworks | Comparing Angular and Ember.js Two Frontend Frameworks Angular: The All-Inclusive... | 0 | 2024-06-30T17:13:48 | https://dev.to/muritala_ahmed_23d51e7a3b/angular-vs-emberjs-a-comparison-of-frontend-frameworks-3cb6 | webdev, programming, react, frontend |
## Comparing Angular and Ember.js Two Frontend Frameworks
**Angular: _The All-Inclusive Framework_**
**Overview**
Angular, developed and maintained by Google, is a comprehensive frontend framework that offers a complete solution for building dynamic web applications. Since its initial release in 2010, Angular h... | muritala_ahmed_23d51e7a3b |
1,906,788 | Starting Your AWS Adventure: Essential First Steps | Amazon Web Services (AWS) is widely recognized as a leading cloud platform, providing a wide array of... | 0 | 2024-06-30T17:11:35 | https://dev.to/gauravk_/starting-your-aws-adventure-essential-first-steps-39l8 | cloud, cloudcomputing, aws, webdev | Amazon Web Services (AWS) is widely recognized as a leading cloud platform, providing a wide array of over 200 services from data centers located globally. Whether you are a novice in cloud computing or a seasoned developer aiming to enhance your expertise, having a well-organized roadmap can be instrumental in effecti... | gauravk_ |
1,901,729 | All 29 Next.js Mistakes Beginners Make | Next.js introduces a lot of new concepts such as server components, server actions, suspense and... | 0 | 2024-06-30T17:10:32 | https://dev.to/azeem_shafeeq/all-29-nextjs-mistakes-beginners-make-56nj | beginners, programming, tutorial, nextjs |
Next.js introduces a lot of new concepts such as server components, server actions, suspense and streaming, static and dynamic rendering, and much more. It's very easy to make mistakes even if you're an experienced developer. In this blog post, we'll go through 29 common mistakes beginners make in Next.js and how to a... | azeem_shafeeq |
1,872,203 | What are Api Standards or REST Style? | Hello WebDevs, I bet whichever framework you have been working on, you must have crossed your roads... | 0 | 2024-06-30T17:08:28 | https://dev.to/yogeshgalav7/what-are-api-standards-or-rest-style-39i5 | api, rest, restapi, standard | Hello WebDevs,
I bet whichever framework you have been working on, you must have crossed your roads with API's and would have stuck for moment what should be the standard path for the URL you could use for that API.
Naming is the most difficult or brain consuming task for programmers, and when it comes to full url it ... | yogeshgalav7 |
1,906,786 | MY JOURNEY AS A BACKEND ENGINEER INTERN. | MY JOURNEY AS A BACKEND ENGINEER INTERN. I am Ifeoma Eunice Ugwu, a goal-getter, hardworking,... | 0 | 2024-06-30T17:08:16 | https://dev.to/ifyeunice/my-journey-as-a-backend-engineer-intern-5b4c | webdev, javascript, beginners, programming | MY JOURNEY AS A BACKEND ENGINEER INTERN.
I am Ifeoma Eunice Ugwu, a goal-getter, hardworking, determined, an easy-going person. I studied Metallurgical and Materials Engineering at Nnamdi Azikiwe University. I also studied courses on Backend Engineering (NodeJs, Typescript, NestJs) and frontend courses like HTML, CSS, ... | ifyeunice |
1,906,785 | **Comparing Frontend Technologies: ReactJS vs. Vue.js** | Comparing FrontendTechnologies: ReactJS vs. Vue.js In the ever-evolving world of frontend... | 0 | 2024-06-30T17:08:14 | https://dev.to/favour_efemiaya_b11dd87cd/comparing-frontend-technologies-reactjs-vs-vuejs-1ph2 | react, vue | **Comparing FrontendTechnologies**: ReactJS vs. Vue.js
In the ever-evolving world of frontend development, choosing the right technology can make a big difference in the success of a project. Two popular frameworks in this space are ReactJS and Vue.js. This article will compare these two technologies, highlighting the... | favour_efemiaya_b11dd87cd |
1,906,784 | React vs. Angular: A Comprehensive Comparison | Introduction: In the world of front-end development, two technologies have emerged as industry... | 0 | 2024-06-30T17:05:54 | https://dev.to/paul_ameh_c6f95df8b725981/react-vs-angular-a-comprehensive-comparison-187h | webdev, javascript, googlecloud, frontend |
Introduction:
In the world of front-end development, two technologies have emerged as industry leaders: React and Angular. Both frameworks have their strengths and weaknesses, making them suitable for different projects and development teams. In this article, we'll delve into the core features, advantages, and disa... | paul_ameh_c6f95df8b725981 |
1,906,783 | Build an Advanced RAG App: Query Rewriting | In the last article, I established the basic architecture for a basic RAG app. In case you missed... | 0 | 2024-06-30T17:02:54 | https://dev.to/rogiia/build-an-advanced-rag-app-query-rewriting-h3p | In the last article, I established the basic architecture for a basic RAG app. In case you missed that, I recommend to first read that article over here. That will set the base from which we can improve our RAG system. Also in that last article, I listed some common pitfalls that RAG applications tend to fail on. We wi... | rogiia | |
1,906,782 | Improving throughput and latency using Java Virtual Threads in Spring | One of the major changes that Java 21 brought about is Virtual threads. There is so much hype around... | 0 | 2024-06-30T17:01:29 | https://dev.to/vigneshm243/improving-throughput-and-latency-using-java-virtual-threads-in-spring-16mp | spring, java, performance | One of the major changes that Java 21 brought about is Virtual threads. There is so much hype around it, but let's see a real-world example with some metrics. Spring introduced the ability to create GraalVM native images that use Spring Boot and Java 21's virtual threads(Project Loom).
We will look at virtual threads ... | vigneshm243 |
1,906,781 | Experience Excellence at Westbourne College (Singapore) | Are you ready to embark on an academic journey that prepares you for the world’s top universities and... | 0 | 2024-06-30T16:59:40 | https://dev.to/westbourne_college/experience-excellence-at-westbourne-college-singapore-1a5l | Are you ready to embark on an academic journey that prepares you for the world’s top universities and future leadership roles? Look no further than Westbourne College (Singapore), a premier private British-International IB Diploma and IGCSE school, dedicated to nurturing students aged 15-18. At Westbourne, we pride our... | westbourne_college | |
1,906,780 | Overcoming a Challenging Backend Project Issue: My Experience and Journey to HNG Internship. | Being a backend developer demands more than simply knowing how to write codes; continuous learning,... | 0 | 2024-06-30T16:58:59 | https://dev.to/somtoochukwu/overcoming-a-challenging-backend-project-issue-my-experience-and-journey-to-hng-internship-1a73 | Being a backend developer demands more than simply knowing how to write codes; continuous learning, troubleshooting and problem-solving abilities are additional skills required to make a successful career in backend development. I was recently met with a challenge on a project I worked on which involved setting up a No... | somtoochukwu | |
1,906,779 | Lulo box pro APK | What is Lulubox Pro APK? | 0 | 2024-06-30T16:57:27 | https://dev.to/jasmeen_dave_176c32310f6c/lulo-box-pro-apk-2ll9 | react | What is [Lulubox ](https://luloboxpinapk.com/)Pro APK?
| jasmeen_dave_176c32310f6c |
1,906,778 | How I ensured user authentication, by sending emails in Spring Boot | How to send email in Java Spring Boot First of all, add the spring-starter-mail... | 0 | 2024-06-30T16:56:50 | https://dev.to/walerick/how-i-ensured-user-authentication-by-sending-emails-in-spring-boot-866 |
## How to send email in Java Spring Boot
First of all, add the `spring-starter-mail` dependency.
This can also be added by modifying your project `pom.xml` file to include the following
```
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
</dependency... | walerick | |
1,906,777 | How to Fuzzy Search: Finding File Names and Contents using Bash Scripting and Commandline Tools | This blog explains a bash script that does a fuzzy search against file names and file contents of all... | 0 | 2024-06-30T16:53:52 | https://blog.chardskarth.me/blog/how-to-fuzzy-search-file-names-and-file-contents-using-bash/ | devtools, bash, programming | This blog explains a bash script that does a fuzzy search against file names and file contents of all the files in the directory.
### Introduction
When searching for specific text (or code), you often rely on your IDE or file manager.
But if you're like me who wants to:
<br/>
1. Search files fast against diff... | chardskarth |
1,906,536 | Building a Lisp Interpreter in Rust | I’ve been playing around with Rust for some time now; it's a pretty cool systems language with a very... | 0 | 2024-06-30T16:52:35 | https://dev.to/galzmarc/building-a-lisp-interpreter-in-rust-2njj | rust, programming, coding | I’ve been playing around with Rust for some time now; it's a pretty cool systems language with a very nice set of features: it's statically typed, and it enforces memory safety without a garbage collector (it uses a borrow checker instead) by statically determining when a memory object is no longer in use. These charac... | galzmarc |
1,906,773 | ocidpatchdb - Automate GI/RU Patches on OCI DB System | { Abhilash Kumar Bhattaram : Follow on LinkedIn } ocidpatchdb I have extensively... | 0 | 2024-06-30T16:48:19 | https://dev.to/nabhaas/ocidpatchdb-automate-giru-patches-on-oci-db-system-56cg | oracle, automation, database, oci | [](
<style>
.libutton {
display: flex;
flex-direction: column;
justify-content: center;
padding: 7px;
text-align: center;
outline: none;
text-decoration: none !important;
color: #ffffff !important;
width: 200px;
... | abhilash8 |
1,906,775 | Functions as User Interface | Hi, y'all. ✨ My journey in the tech world has been filled with countless lines of code, numerous... | 0 | 2024-06-30T16:46:25 | https://dev.to/khadijagardezi/functions-as-user-interface-35c8 | javascript, react, webdev, programming | Hi, y'all. ✨
My journey in the tech world has been filled with countless lines of code, numerous tools, and multiple languages. I have experience with JavaScript, ReactJS, CraftCMS, Twig, and a few more. As a woman in tech, I understand the challenges of this field. I am dedicated to sharing my knowledge and experienc... | khadijagardezi |
1,906,017 | Getting Started with JavaScript: Variables and Data Types | Introduction One of the foundational concepts in JavaScript is understanding how to... | 0 | 2024-06-30T16:45:13 | https://dev.to/ishaq_360/getting-started-with-javascript-variables-and-data-types-4p8h | javascript, beginners, programming, webdev | ## Introduction
One of the foundational concepts in JavaScript is understanding how to declare and use variables, along with the different data types available. This guide is designed and written for beginners and early intermediate let's journey you through the nitty and gritty of JavaScript variables and data types,... | ishaq_360 |
1,906,772 | Is Your Sidebar Hurting Your UX? Our Redesign Journey to Effortless Navigation | Have you ever felt frustrated navigating a website with a clunky sidebar? We hear you. At Hexmos,... | 0 | 2024-06-30T16:41:00 | https://dev.to/ganesh-kumar/is-your-sidebar-hurting-your-ux-our-redesign-journey-to-effortless-navigation-391d |
Have you ever felt frustrated navigating a website with a clunky sidebar? We hear you. At [Hexmos](https://hexmos.com/), we're constantly striving to improve the user experience.
Recently, we took a critical look at our sidebar design and identified many areas for improvement.
This blog post will delve into the jour... | ganesh-kumar | |
1,906,771 | #3 Liskov Substitution Principle ['L' in SOLID] | LSP - Liskov Substitution Principle The Liskov Substitution Principle is the third principle in the... | 0 | 2024-06-30T16:40:59 | https://dev.to/vinaykumar0339/3-liskov-substitution-principle-l-in-solid-1jo2 | liskov, solidprinciples, designprinciples | **LSP - Liskov Substitution Principle**
The Liskov Substitution Principle is the third principle in the Solid Design Principles.
1. Objects of the Super-Class should be replaceable with objects of a Sub-Class without affecting the correctness of the program.
**Violating LSP:**
```swift
class Bird {
func fly() {
... | vinaykumar0339 |
1,906,770 | s-pro | Hi friends, I had the pleasure of collaborating with https://s-pro.io/ recently, and I must say, they... | 0 | 2024-06-30T16:40:19 | https://dev.to/andriano_nestorios_c95ecc/s-pro-3p07 | Hi friends, I had the pleasure of collaborating with [https://s-pro.io/](https://s-pro.io/) recently, and I must say, they exceeded all my expectations. Their innovative AI-driven software solutions have completely transformed how we do business, leading to significant improvements in both performance and profitability... | andriano_nestorios_c95ecc | |
1,906,768 | “==” and “===” difference in javascript | In javascript both “==” and “===” used for comparison but they have purposes and behaviors ... | 0 | 2024-06-30T16:38:52 | https://dev.to/sagar7170/-and-difference-in-javascript-44c1 | javascript, webdev, beginners | In javascript both “==” and “===” used for comparison but they have purposes and behaviors
## == (Double equal)
:
The == operator is used for loose equality comparison . When we compare with == it will only compare values not the data type means if we compare string of “5” and integer 5 the result will be true
```
co... | sagar7170 |
1,906,767 | Confusion vs Diffusion in cryptography | Confusion and Diffusion are essential concepts in cyrptography and network security. Both confusion... | 0 | 2024-06-30T16:36:16 | https://dev.to/himanshu_raj55/confusion-vs-diffusion-in-cryptography-i0n | cryptography, cybersecurity, cipher | Confusion and Diffusion are essential concepts in cyrptography and network security. Both confusion and diffusion are cryptographic techniques that are used to stop the deduction of the secret writing key from the attacker.
The major differences between confusion and diffusion are as follows:
Confusion: ... | himanshu_raj55 |
1,906,463 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-30T10:02:17 | https://dev.to/topeciw546/buy-verified-cash-app-account-59ge | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | topeciw546 |
1,906,766 | Variable & Variable Scope | PHP Fundamentals | Create Variable in PHP The rules when you create variables in PHP: Variable declaration... | 0 | 2024-06-30T16:33:30 | https://dev.to/gunawanefendi/variable-variable-scope-in-php-3l4a | webdev, php, learning, beginners |
## Create Variable in PHP
The rules when you create variables in PHP:
1. Variable declaration with dollar ($) followed by variable name
2. Variable name must start with a letter or underscore (_)
3. Variable name is case-sensitive
Valid variables:
```
$name = "Gunawan"; //valid
$Name = "Gunawan"; //valid
$_name = "... | gunawanefendi |
1,906,765 | FRONTEND WEB DEVELOPMENT (comparism on two technologies). | In the field of software development, what is developed is divided into two categories: everything... | 0 | 2024-06-30T16:33:13 | https://dev.to/joseb007/frontend-web-development-comparism-on-two-technologies-4p10 |
In the field of software development, what is developed is divided into two categories: everything visible to the user and the operations that run in the background. Front-end technology is what we see and interact with when we visit a website or use a mobile app. Back End Technology and DevOps encompass all of the be... | joseb007 | |
1,906,764 | MyFirstApp - React Native with Expo (P11) - Create a Layout Settings | MyFirstApp - React Native with Expo (P11) - Create a Layout Settings | 27,894 | 2024-06-30T16:32:42 | https://dev.to/skipperhoa/myfirstapp-react-native-with-expo-p11-create-a-layout-settings-4fd4 | react, reactnative, webdev, tutorial | MyFirstApp - React Native with Expo (P11) - Create a Layout Settings
{% youtube Y-sIi1N60m0 %} | skipperhoa |
1,906,763 | Enhance Your Home with Copper Gutters in Litchfield, CT | Copper gutters are becoming a popular choice among homeowners in Litchfield, CT, due to their... | 0 | 2024-06-30T16:29:12 | https://dev.to/allkj21uu/enhance-your-home-with-copper-gutters-in-litchfield-ct-n06 | Copper gutters are becoming a popular choice among homeowners in Litchfield, CT, due to their exceptional durability, timeless beauty, and low maintenance requirements. In this comprehensive guide, we’ll explore the benefits of copper gutters, the installation process, and why they are an excellent choice for homes in ... | allkj21uu | |
1,906,762 | The importance of TypeScript, its uses, and types | In the world of software development, TypeScript stands out as one of the most powerful and... | 0 | 2024-06-30T16:25:59 | https://dev.to/mhmd-salah/the-importance-of-typescript-its-uses-and-types-507e | javascript, typescript, website, node | #### In the world of software development, TypeScript stands out as one of the most powerful and influential tools for improving code quality and development speed. Developed by Microsoft, TypeScript is an open source programming language based on JavaScript with powerful Type Annotations. In this article, we will revi... | mhmd-salah |
1,906,760 | Top Crypto-Friendly Countries in 2022 | Cryptocurrency has revolutionized finance and investment, and its influence is set to grow. However,... | 27,673 | 2024-06-30T16:20:50 | https://dev.to/rapidinnovation/top-crypto-friendly-countries-in-2022-34de | Cryptocurrency has revolutionized finance and investment, and its influence is
set to grow. However, not all countries are equally welcoming to crypto. Some
have stringent regulations, while others are more lenient. Curious about which
jurisdictions offer the best conditions for crypto in terms of regulations and
taxes... | rapidinnovation | |
1,899,514 | Next.js 14 and NextAuth v4 : Credentials Authentication A Detailed Step-by-Step Guide | Authentication is a crucial feature in web applications, and it can also be challenging to implement... | 0 | 2024-06-30T16:20:05 | https://www.coderamrin.com/blog/nextjs-14-next-auth-v4-credentials-authentication | webdev, authjs, nextjs, beginners | Authentication is a crucial feature in web applications, and it can also be challenging to implement correctly. In this article, you'll learn how to integrate authentication in Next.js using NextAuth (v4).
Let’s get started.
### Prerequisites
To make the most out of this guide, here’s what you should have under you... | coderamrin |
1,906,758 | The most recent backend problem I've had to solve. | The most recent backend problem I have solved, is non existent. I am a beginner in the field of... | 0 | 2024-06-30T16:13:46 | https://dev.to/halimat_yakubu_f257fd0215/the-most-recent-backend-problem-ive-had-to-solve-2g0d | The most recent backend problem I have solved, is non existent. I am a beginner in the field of backend development, therefore, I have no projects to show. However, I joined HNG with the view to leave the internship with dozens of projects to show for it.
**A little about myself**
I am a fast learner, critical thinke... | halimat_yakubu_f257fd0215 | |
1,906,756 | Strong Performance with EC2, Lambda, and the Momento SDK for Rust | I wrote recently about Mind Boggling Speed with Caching with Momento and Rust and wanted to continue... | 0 | 2024-06-30T16:11:20 | https://www.binaryheap.com/momento-sdk-rust-webhook-ec2/ | rust, serverless, aws, architecture | I wrote recently about [Mind Boggling Speed with Caching with Momento and Rust](https://www.binaryheap.com/caching-with-momento-and-rust/) and wanted to continue in that theme as I explore the Momento SDK for Rust. Caching is a technique that builders reach for when looking to accomplish either improved performance or... | benbpyle |
1,906,754 | A Comparative Analysis of Svelte and Vue.js: Exploring Niche Frontend Technologies | A Comparative Analysis of Svelte and Vue.js: Exploring Niche Frontend Technologies In the rapidly... | 0 | 2024-06-30T16:09:41 | https://dev.to/abdulkola/a-comparative-analysis-of-svelte-and-vuejs-exploring-niche-frontend-technologies-51ea | A Comparative Analysis of Svelte and Vue.js: Exploring Niche Frontend Technologies
In the rapidly evolving landscape of frontend development, numerous frameworks and libraries emerge, each offering unique features and benefits. While mainstream technologies like ReactJS dominate the industry, niche frontend technologie... | abdulkola | |
1,906,677 | Analyzing Likes Using Instagram API with python - part 3 | Learn how to analyze Instagram likes using Python. This comprehensive guide covers creating an Instagram API client, caching requests, data analysis, and visualizing results with bar charts. | 0 | 2024-06-30T16:08:07 | https://usemyapi.com/articles/instagram-data-analysis-with-python-analyzing-likes-using-instagram-api-part-3/ | python, tutorial, programming | ---
title: "Analyzing Likes Using Instagram API with python - part 3"
published: true
description: "Learn how to analyze Instagram likes using Python. This comprehensive guide covers creating an Instagram API client, caching requests, data analysis, and visualizing results with bar charts."
canonical_url: "https://usem... | apiharbor |
1,906,423 | Customizing Your Lazyvim Setup for Personal Preferences | Table Of Contents Folder Structure Tree of LazyVim Overview of the bullet... | 0 | 2024-06-30T16:03:02 | https://dev.to/insideee_dev/customizing-your-lazyvim-setup-for-personal-preferences-57 | vim, beginners, tutorial, coding | ## Table Of Contents
1. [Folder Structure Tree of LazyVim](#folder-structure-tree)
2. [Overview of the bullet points](#overview-of-the-bullet-points)
* [Solarized Osaka theme](#solarized-osaka)
* [Key Mappings](#key-mappings)
* [Auto Commands](#auto-commands)
* [Options Configuration Vim](#options-configuration... | insideee_dev |
1,906,753 | React JS vs Vue JS | Hey there, coding enthusiasts! As someone prepping for the HNG Internship (have you checked out their... | 0 | 2024-06-30T16:00:09 | https://dev.to/tosin_adejuwon_08fdc8c8d5/react-js-vs-vue-js-2gjf | javascript, react, vue | Hey there, coding enthusiasts! As someone prepping for the HNG Internship (have you checked out their website? https://hng.tech/internship), I'm sure you're diving headfirst into the world of frontend development. With a gazillion frameworks out there, choosing the right one can feel like picking a superpower. Today, l... | tosin_adejuwon_08fdc8c8d5 |
1,906,541 | Unveiling the Shield: Ensuring Security with Open Source 2FA | In the digital age, where personal data is more valuable than ever, securing your online accounts is... | 0 | 2024-06-30T15:59:37 | https://dev.to/verifyvault/unveiling-the-shield-ensuring-security-with-open-source-2fa-nn6 | opensource, security, cybersecurity, github | In the digital age, where personal data is more valuable than ever, securing your online accounts is not just a recommendation but a necessity. Two-Factor Authentication (2FA) stands as a robust defense against unauthorized access, significantly bolstering your account security beyond mere passwords. However, not all 2... | verifyvault |
1,906,662 | Comparing Javascript Front-end technologies (Angular and React) | Introduction Angular and React are both javascript technologies for building complex and... | 0 | 2024-06-30T15:59:06 | https://dev.to/iam_nick/comparing-javascript-front-end-technologies-angular-and-react-d3c | ## **Introduction**
Angular and React are both javascript technologies for building complex and interactive web applications. They share several similarities but some distinct characteristics which makes them fundamentally different.
I will be comparing both technologies in this post but first, let's meet them.
**Angu... | iam_nick | |
1,906,752 | My Mobile Development Journey and Architectural Insights | The Journey Begins Embarking on the journey of mobile development is both thrilling and challenging.... | 0 | 2024-06-30T15:57:40 | https://dev.to/akpamzy_junior_cc600a044d/my-mobile-development-journey-and-architectural-insights-pmg | flutter, mobile, mobiledev, hng | The Journey Begins
Embarking on the journey of mobile development is both thrilling and challenging. I started my journey as a mobile developer, specifically a Flutter developer, six months ago. It's been challenging, tasking, but above all, thrilling. One minute I am happy that my code works ☺️☺️, and the next minute... | akpamzy_junior_cc600a044d |
1,906,748 | Tipar automáticamente Swagger/OpenAPI endpoints con NSwag | Tipar automáticamente Swagger/OpenAPI endpoints con NSwag Tipar automáticamente... | 0 | 2024-06-30T15:50:15 | https://dev.to/altaskur/tipar-automaticamente-swaggeropenapi-endpoints-con-nswag-397g | webdev, typescript, tutorial, spanish | # Tipar automáticamente Swagger/OpenAPI endpoints con NSwag
- [Tipar automáticamente Swagger/OpenAPI endpoints con NSwag](#tipar-automáticamente-swaggeropenapi-endpoints-con-nswag)
- [¿Qué es NSwag?](#qué-es-nswag)
- [¿Qué necesitas?](#qué-necesitas)
- [Instalación](#instalación)
- [Configuración](#configura... | altaskur |
1,906,750 | React Vs AngularJS | Introduction Frontend development is constantly progressing, and two key technologies in this domain... | 0 | 2024-06-30T15:49:33 | https://dev.to/halimat_yakubu_f257fd0215/react-vs-angularjs-4e1m | **Introduction**
Frontend development is constantly progressing, and two key technologies in this domain are React and AngularJS, two of the most popular frameworks for building dynamic web applications. In this article, I will state brief overviews, advantages, and disadvantages of React and AngularJS. Furthermore, I... | halimat_yakubu_f257fd0215 | |
1,906,749 | Quanto tempo de experiência para se candidatar pra uma vaga internacional? | Recebi essa pergunta no formulário que publiquei no meu primeiro artigo. Vou responder com base na... | 0 | 2024-06-30T15:44:04 | https://dev.to/lucasheriques/quanto-tempo-de-experiencia-para-se-candidatar-pra-uma-vaga-internacional-2735 | beginners, career, braziliandevs, webdev | Recebi essa pergunta no [formulário](https://forms.gle/qbNvHPpdEaLp7R8b7) que publiquei no meu [primeiro artigo](https://devnagringa.substack.com/p/como-eu-virei-um-dev-na-gringa). Vou responder com base na minha experiência como engenheiro de software. Mas acho que tudo aqui é válido para qualquer vaga remota internac... | lucasheriques |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.