
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,905,891 | How to Integrate Google Map API on your React Native Android App | Google Maps has traditionally been the dominant choice among developers for integrating... | 0 | 2024-06-29T18:04:23 | https://dev.to/codegirl0101/how-to-integrate-google-map-api-on-your-react-native-android-app-1n7o | reactnative, tutorial, googlecloud, googlemap | Google Maps has traditionally been the dominant choice among developers for integrating location-based map APIs. However, recent high price increases and a substantial reduction in free API calls have caused app developers to urgently seek alternative options.
Despite these challenges, Google Maps remains the most wi... | codegirl0101 |
1,905,890 | RxJS: The Reactive Revolution in JavaScript 🚀 | Reactive programming with RxJS revolutionizes JavaScript by elegantly handling asynchronous data... | 0 | 2024-06-29T18:02:49 | https://blog.disane.dev/en/rxjs-the-reactive-revolution-in-javascript/ | rxjs, programming, javascript, reactiveprogramming | Reactive programming with RxJS revolutionizes JavaScript by elegantly handling asynchronous data streams. Discover the power of observables and operators! 🚀
---
Reactive programming has become indispensable in t... | disane |
1,905,886 | RxJS: Die Reaktive Revolution in JavaScript 🚀 | Reaktive Programmierung mit RxJS revolutioniert JavaScript durch elegante Handhabung von asynchronen... | 0 | 2024-06-29T18:00:31 | https://blog.disane.dev/rxjs-die-reaktive-revolution-in-javascript/ | rxjs, programmierung, javascript, reaktiveprogrammierung | Reaktive Programmierung mit RxJS revolutioniert JavaScript durch elegante Handhabung von asynchronen Datenströmen. Entdecke die Macht von Observables und Operatoren! 🚀
---
Reaktive Programmierung ist in der We... | disane |
1,905,885 | Everything you have to know about React 19 ⚛️ | 🤓 I want to equip you with the needed knowledge for before the new update will hit your... | 0 | 2024-06-29T17:57:59 | https://dev.to/dealwith/everything-you-have-to-know-about-react-19-3bgf | react19, react, javascript, compiler | 🤓 I want to equip you with the needed knowledge for before the new update will hit your production.
## Why this updated was created?
The idea of the udpate is to make the UI more *Optimistic* less struggle, less code, and less external libraries.
## What is Optimistic UI?
*The Optimistic UI* is the way to show user ... | dealwith |
1,905,883 | How to make interfaces optional in typescript | First of all let us look at some random example, interface personMale{ gender:"male"; ... | 0 | 2024-06-29T17:45:13 | https://dev.to/tofail/optional-interfaces-112j | interface, typescript, webdev | First of all let us look at some random example,
```
interface personMale{
gender:"male";
salary:number;
}
interface personFemale{
gender:"female";
weight:number
}
type person={
name:string;
age:number;
}&(personMale|personFemale)
const person1:person={
name:"Sayem",
... | tofail |
1,905,882 | Hello | Hello guys, am happy to be here. Am new to coding and am interested in html/css/javascript/php. | 0 | 2024-06-29T17:43:36 | https://dev.to/emmanuelsekpo/hello-52dd | Hello guys, am happy to be here. Am new to coding and am interested in html/css/javascript/php. | emmanuelsekpo | |
1,905,881 | Technical blog article | Hi everyone, my name is Aisha and this is a task basically given to us at... | 0 | 2024-06-29T17:41:49 | https://dev.to/lhaif/technical-blog-article-n3p | backenddevelopment | Hi everyone, my name is Aisha and this is a task basically given to us at https://hng.tech/internship. So yeahh, there was a time when I was stuck on a problem coding a blog api project using node.js
I was basically following a YouTube video but then I got confused. Luckily I had friends in the tech sector,I explained... | lhaif |
1,905,880 | ReactJS vs. Vue.js | A Comparative Analysis for Frontend Development When it comes to frontend development, choosing the... | 0 | 2024-06-29T17:39:25 | https://dev.to/e-tech/reactjs-vs-vuejs-14eo | A Comparative Analysis for Frontend Development
When it comes to frontend development, choosing the right framework can make a world of difference. Today, we'll compare two popular and powerful JavaScript frameworks: ReactJS and Vue.js. We'll delve into their unique features, strengths, and what makes each of them stan... | e-tech | |
1,905,878 | Quantum Sensing Ushering in a New Era of Precision Measurements | Explore how quantum sensing is revolutionizing the precision of measurements across various fields, from healthcare to environmental monitoring and beyond. | 0 | 2024-06-29T17:33:17 | https://www.elontusk.org/blog/quantum_sensing_ushering_in_a_new_era_of_precision_measurements | quantumsensing, measurement, technology | # Quantum Sensing: Ushering in a New Era of Precision Measurements
Imagine a world where measurements down to the atomic level are not just possible but routine. Welcome to the transformative frontier of quantum sensing! From healthcare diagnostics to environmental monitoring, quantum sensing is revolutionizing the pr... | quantumcybersolution |
1,905,875 | Overcoming the challenges of backend development : My experience and application for the HNG internship | Introduction Hello everyone! My name is Landry Bitege, and I'm a backend developer with a... | 0 | 2024-06-29T17:31:16 | https://dev.to/land-bit/overcoming-the-challenges-of-backend-development-my-experience-and-application-for-the-hng-internship-558a | lean, programming, beginners, devchallenge | ## Introduction
Hello everyone! My name is Landry Bitege, and I'm a backend developer with a passion for designing robust, scalable software solutions. Today, I'd like to share my recent journey in solving complex backend development problems and explain why I'm excited to join the HNG internship.
## My background an... | land-bit |
1,905,873 | My Journey to Becoming a BackEnd Developer: Overcoming Challenges and Embracing Growth | Becoming a backend developer has been a journey filled with challenges, persistence, and immense... | 0 | 2024-06-29T17:29:03 | https://dev.to/babalola_taiwojoseph_4a8/my-journey-to-becoming-a-backend-developer-overcoming-challenges-and-embracing-growth-11m5 | Becoming a backend developer has been a journey filled with challenges, persistence, and immense growth. It all started early last September when I decided to dive into the world of backend development. At first, understanding concepts and thinking logically seemed like daunting tasks. But with unwavering determination... | babalola_taiwojoseph_4a8 | |
1,905,872 | My Dev Journey: Tackling Real-Time Challenge with Django and the HNG Internship | I recently tackled a problem to implement real time communication feature in my web application. I'll... | 0 | 2024-06-29T17:28:40 | https://dev.to/folafolu/my-dev-journey-tackling-real-time-challenge-with-django-and-the-hng-internship-483j | hng, django, webdev | I recently tackled a problem to implement real time communication feature in my web application. I'll be sharing how I did it in this article.
## My Real Time Communication Challenge
Recently, I had to implement WebSockets in one of my personal projects, something I had never done before. This led me to Django Channe... | folafolu |
1,905,871 | Plumbing Repair Guide Step-by-Step Troubleshooting | Plumbing Repair Guide Step-by-Step Troubleshooting When plumbing issues arise, it can be stressful... | 0 | 2024-06-29T17:25:15 | https://dev.to/affanali_offpageseo_a5ec6/plumbing-repair-guide-step-by-step-troubleshooting-42ph | Plumbing Repair Guide Step-by-Step Troubleshooting
When plumbing issues arise, it can be stressful and inconvenient. Knowing how to troubleshoot and fix common plumbing problems can save time and money. This step-by-step guide will help you identify and repair typical plumbing issues effectively. For more complex pr... | affanali_offpageseo_a5ec6 | |
1,905,870 | Common Mistakes to Avoid During Plumbing Repair | Common Mistakes to Avoid During Plumbing Repair Plumbing repairs, whether minor or major, require... | 0 | 2024-06-29T17:23:15 | https://dev.to/affanali_offpageseo_a5ec6/common-mistakes-to-avoid-during-plumbing-repair-ohh | Common Mistakes to Avoid During Plumbing Repair
Plumbing repairs, whether minor or major, require precision and expertise. While DIY repairs can be tempting, they often lead to common mistakes that can cause more harm than good. This guide outlines the most frequent mistakes to avoid during plumbing repairs to ensu... | affanali_offpageseo_a5ec6 | |
1,905,868 | Finding Trusted Plumbing Repair Experts in Your Area | Finding Trusted Plumbing Repair Experts in Your Area When faced with plumbing issues, finding a... | 0 | 2024-06-29T17:19:39 | https://dev.to/affanali_offpageseo_a5ec6/finding-trusted-plumbing-repair-experts-in-your-area-1fce | Finding Trusted Plumbing Repair Experts in Your Area
When faced with plumbing issues, finding a reliable and skilled plumber is crucial for ensuring quality repairs and preventing further damage. With numerous options available, choosing the right plumbing repair expert can be challenging. This guide provides practica... | affanali_offpageseo_a5ec6 | |
1,905,867 | Technical Blog Article | Mobile apps are everywhere from games to social media, we use them daily.But have you ever wondered... | 0 | 2024-06-29T17:18:25 | https://dev.to/omozuas/technical-blog-article-22gh | hng |
Mobile apps are everywhere from games to social media,
we use them daily.But have you ever wondered what goes into making these apps? My name is Omozua Judah. I am a mobile developer(flutter).
Now we will be talking about a tool called flutter.What is flutter? Flutter is a tool that helps build apps that work... | omozuas |
1,905,866 | The Benefits of Hiring a Professional for Plumbing Repair | The Benefits of Hiring a Professional for Plumbing Repair When faced with plumbing issues, many... | 0 | 2024-06-29T17:18:04 | https://dev.to/affanali_offpageseo_a5ec6/the-benefits-of-hiring-a-professional-for-plumbing-repair-22km | The Benefits of Hiring a Professional for Plumbing Repair
When faced with plumbing issues, many homeowners consider tackling the repairs themselves. While DIY repairs can be cost-effective for minor issues, hiring a professional plumber offers numerous benefits that ensure the job is done correctly and efficiently. ... | affanali_offpageseo_a5ec6 | |
1,905,865 | Quantum Sensing The Future of Gravitational Wave Detection | Dive into the fascinating world of quantum sensing and discover how it revolutionizes gravitational wave detectors, enhancing their sensitivity and paving the way for groundbreaking discoveries in astrophysics. | 0 | 2024-06-29T17:17:19 | https://www.elontusk.org/blog/quantum_sensing_the_future_of_gravitational_wave_detection | quantumsensing, gravitationalwaves, technology, innovation | # Quantum Sensing: The Future of Gravitational Wave Detection
Gravitational waves are ripples in the fabric of spacetime, first predicted by Albert Einstein in his general theory of relativity. The detection of these waves has opened a new window into the universe, allowing us to observe astronomical phenomena that we... | quantumcybersolution |
1,905,564 | Why VerifyVault Excels Mainstream 2FA Apps like Authy and Google Authenticator | In today's digital age, securing our online accounts is more crucial than ever. Two-Factor... | 0 | 2024-06-29T17:16:25 | https://dev.to/verifyvault/why-verifyvault-excels-mainstream-2fa-apps-like-authy-and-google-authenticator-52nc | opensource, security, cybersecurity, privacy | In today's digital age, securing our online accounts is more crucial than ever. Two-Factor Authentication (2FA) has become a standard method to enhance security, but not all 2FA apps are created equal. VerifyVault, a cutting-edge open-source application, stands out among its mainstream counterparts like Authy, Google A... | verifyvault |
1,905,863 | My software engineering journey | INTRODUCTION Dear readers, my name is Doreen Nangira. I am a software engineer and a data... | 0 | 2024-06-29T17:10:24 | https://dev.to/doreen970/my-software-engineering-journey-1okc | python, womenintech, learning | ## INTRODUCTION
Dear readers, my name is Doreen Nangira. I am a software engineer and a data lover. Today I am going to talk about my software engineering journey, the challenges I have faced and also the happy moments.
## EDUCATION BACKGROUND
After completing my high school studies, I joined the Technical University... | doreen970 |
1,905,862 | Execution Context | JavaScript brauzerda ishlayotganida, uni to’g’ridan-to’g’ri tushuna olmasligi sababli uni mashina... | 0 | 2024-06-29T17:08:00 | https://dev.to/islom_abdulakhatov/execution-context-3fg | *JavaScript brauzerda ishlayotganida, uni to’g’ridan-to’g’ri tushuna olmasligi sababli uni mashina tushunadigan tilga aylantirish kerak ya’ni o’zi tushunadigan tilga. Brauzerning JavaScript engine(mexaniz)ni JavaScript kodiga duch kelganida, u biz yozgan JavaScript kodini “translation(tarjima)” qiladi va bajarilishini ... | islom_abdulakhatov | |
1,904,798 | Dependency Updates: More to Do Than Review | I enjoy tools that automate dependency updates in my projects (looking at you, Renovate and... | 0 | 2024-06-29T17:05:36 | https://adamross.dev/p/dependency-updates-more-to-do-than-review/ | productivity, opensource, github, testing |
I enjoy tools that automate dependency updates in my projects (looking at you, [Renovate](https://docs.renovatebot.com/) and [Dependabot](https://docs.github.com/en/code-security/getting-started/dependabot-quickstart-guide)). They save my team a lot of time: with a quick glance and the push of a couple buttons, I can ... | grayside |
1,905,861 | How to Use SwarmUI & Stable Diffusion 3 on Cloud Services Kaggle (free), Massed Compute & RunPod | Tutorial Link : https://youtu.be/XFUZof6Skkw In this video, I demonstrate how to install and use... | 0 | 2024-06-29T17:05:00 | https://dev.to/furkangozukara/how-to-use-swarmui-stable-diffusion-3-on-cloud-services-kaggle-free-massed-compute-runpod-104h | tutorial, beginners, ai, cloud | <p style="margin-left:0px;">Tutorial Link : <a target="_blank" rel="noopener noreferrer" href="https://youtu.be/XFUZof6Skkw"><u>https://youtu.be/XFUZof6Skkw</u></a></p>
<p style="margin-left:auto;">{% embed https://youtu.be/XFUZof6Skkw %}</p>
<p style="margin-left:0px;">In this video, I demonstrate how to install and u... | furkangozukara |
1,905,860 | Quantum Revolution The Challenges of Developing Quantum Compilers | Dive into the intricate world of quantum compilers and explore the pressing need for efficient quantum circuit optimization to unlock the true potential of quantum computing. | 0 | 2024-06-29T17:01:22 | https://www.elontusk.org/blog/quantum_revolution_the_challenges_of_developing_quantum_compilers | quantumcomputing, quantumcompilers, technology | ## Quantum Revolution: The Challenges of Developing Quantum Compilers
As the frontier of quantum computing continues to push daringly forward, the role of quantum compilers becomes ever more critical. While classical compilers have benefited from decades of optimization, quantum compilers are still in their infancy, f... | quantumcybersolution |
1,905,858 | FRONTEND TECHNOLOGIES | Introduction Rose owns a cake shop; Margaret stops by every morning to get some freshly baked... | 0 | 2024-06-29T16:56:58 | https://dev.to/dam563/frontend-technologies-15n4 | webdev, programming, frontend, softwaredevelopment | **Introduction**
Rose owns a cake shop; Margaret stops by every morning to get some freshly baked chocolate cake from the cakes displayed on the shelf. She only sees the cakes freshly baked sitting nicely on the shelves. There are a lot of processes that have taken place in the background like mixing, icing, and bakin... | dam563 |
1,905,798 | Principios SOLID en React | Los principios SOLID fueron compilados por Bob Martin en un paper en el año 2000, aunque el acrónimo... | 0 | 2024-06-29T16:55:30 | https://iencotech.github.io/posts/principios-solid-en-react/ | react, architecture, typescript, español | Los principios SOLID fueron compilados por Bob Martin en un paper
en el año 2000, aunque el acrónimo fue inventando más adelante por
Michael Feathers. El "tio Bob" es el autor de los famosos libros
[Clean Code](https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882) y [Clean Architecture](https... | iencotech |
1,905,856 | Understanding Regex, being an HNG-11 Intern. | As a developer, I have to admit that regex is one of the most confusing and rather annoying topics I... | 0 | 2024-06-29T16:53:00 | https://dev.to/lawwee/understanding-regex-being-an-hng-11-intern-462j | As a developer, I have to admit that regex is one of the most confusing and rather annoying topics I have had to deal with, and I believe it is the same for most developers out there. In case you don't know what regex expressions are, let's get down to it.
Regular Expressions(Regex) are sequences of characters that sp... | lawwee | |
1,905,855 | Laravel Artisan Command: Truncate Table and All Related Tables | Managing database tables often involves performing operations like truncating tables, especially... | 0 | 2024-06-29T16:51:09 | https://dev.to/rafaelogic/laravel-artisan-command-truncate-table-and-all-related-tables-1m02 | laravel, webdev, programming, beginners | Managing database tables often involves performing operations like truncating tables, especially during development or testing phases. Truncating a table means deleting all its records while keeping its structure intact. However, when dealing with tables having foreign key relationships, truncating them can become cumb... | rafaelogic |
1,905,854 | Understanding 'getElementById' in depth | The getElementById method is a fundamental JavaScript function used to select a single HTML element... | 0 | 2024-06-29T16:48:29 | https://dev.to/tushar_pal/understanding-getelementbyid-in-depth-1886 |
The `getElementById` method is a fundamental JavaScript function used to select a single HTML element by its id attribute. It returns the element object representing the element whose id property matches the specified string.
### Detailed Explanation:
### What is `getElementById`?
The `getElementById` method is a ... | tushar_pal | |
1,905,770 | Django SaaS Boilerplate - Speed up your SaaS development | OooH! You just spent months building the core part of your SaaS and you're exhausted, right? Building... | 0 | 2024-06-29T16:45:57 | https://dev.to/paul_freeman/django-saas-boilerplate-4kic | django, saas, djangosaas, opensource | OooH! You just spent months building the core part of your SaaS and you're exhausted, right? Building a SaaS (Software as a Service) project can be both exciting and challenging, whether you're about to launch your first SaaS product or this is your nth product launch.
Creating a compelling and responsive page, an eff... | paul_freeman |
1,905,853 | Quantum Random Number Generation The Future of Cryptographic Security | Explore the groundbreaking advancements in quantum random number generation and their profound implications for cryptographic security. From the basics of quantum mechanics to real-world applications, discover how this technology is shaping the future of secure communications. | 0 | 2024-06-29T16:45:24 | https://www.elontusk.org/blog/quantum_random_number_generation_the_future_of_cryptographic_security | quantumcomputing, cryptography, security | # Quantum Random Number Generation: The Future of Cryptographic Security
In the grand landscape of modern technology, few fields are as thrilling and groundbreaking as quantum computing. Among its various fascinating aspects, Quantum Random Number Generation (QRNG) stands out, promising to revolutionize cryptographic ... | quantumcybersolution |
1,905,852 | Understanding getElementById | The getElementById method is a fundamental JavaScript function used to select a single HTML element... | 0 | 2024-06-29T16:45:08 | https://dev.to/tushar_pal/understanding-getelementbyid-4ao7 | The `getElementById` method is a fundamental JavaScript function used to select a single HTML element by its id attribute. It returns the element object representing the element whose id property matches the specified string.
### Example Usage:
Let's say you have the following HTML:
```html
<!DOCTYPE html>
<html lan... | tushar_pal | |
1,905,851 | IAM | What can iam(identity access management) do to you as an organization or individuals?. let me help... | 0 | 2024-06-29T16:44:26 | https://dev.to/warrisoladipup2/iam-2ga3 | What can _**iam(identity access management)**_ do to you as an organization or individuals?. let me help you to get the basic knowledge about it.
**IAM** is a service that allows you to manage users and their access to the AWS console. With IAM, you can create users, grant permissions, and manage access to your AWS re... | warrisoladipup2 | |
1,905,850 | Creating and Appending a Heading in JavaScript | In this blog post, we'll cover the basics of creating a heading element using JavaScript and how to... | 0 | 2024-06-29T16:43:49 | https://dev.to/tushar_pal/creating-and-appending-a-heading-in-javascript-31jl | javascript, beginners, tutorial |
In this blog post, we'll cover the basics of creating a heading element using JavaScript and how to append it to an existing element in your HTML document. This is a fundamental skill for manipulating the DOM (Document Object Model) and dynamically updating the content of your web pages.
## Creating a Heading Elemen... | tushar_pal |
1,905,848 | Throw Away your Code! | Uncle Bob says “Software should be \"soft\" or easily changeable, unlike \"hard\" hardware.”. And... | 0 | 2024-06-29T16:42:39 | https://medium.com/@noriller/throw-away-your-code-2e67a17b1c06 | webdev, programming, productivity, development | Uncle Bob says “Software should be \"soft\" or easily changeable, unlike \"hard\" hardware.”.
And what’s more easily changeable than a code that can easily be deleted?
## Low Stakes Coding: REPL
A REPL or some playground is something amazing for that.
Do you want to just play around with the syntax and methods? REP... | noriller |
1,905,846 | Tree data structures in Rust with tree-ds (#2: Tree Operations) | In the previous part, we explored how to get started with the tree-ds crate to work with tree data... | 0 | 2024-06-29T16:39:17 | https://dev.to/clementwanjau/tree-data-structures-in-rust-with-tree-ds-2-tree-operations-54ph | rust, algorithms, datastructures, tree | In the [previous part](https://dev.to/clementwanjau/tree-data-structures-in-rust-with-tree-ds-1-getting-started-3pb4), we explored how to get started with the `tree-ds` crate to work with tree data structures in rust. In this part, we are going to explore the various features and operations offered by the `Tree` struct... | clementwanjau |
1,905,843 | Telegram Mini App Development: Enhancing the Memory Game with Card Upgrades | In my previous article on creating a brain mining mini-game bot on Telegram, I introduced a fun... | 0 | 2024-06-29T16:33:19 | https://dev.to/king_triton/telegram-mini-app-development-enhancing-the-memory-game-with-card-upgrades-hn4 | webdev, javascript, api, vue | In my previous article on [creating a brain mining mini-game bot on Telegram](https://dev.to/king_triton/creating-a-brain-mining-mini-game-bot-on-telegram-38fp), I introduced a fun memory game where players earn "brains" to advance through knowledge levels represented as cards. Building on that, I've now implemented a ... | king_triton |
1,905,573 | Reactjs or Vuejs | JavaScript is an Object-oriented programming language and is the main language for creating a... | 0 | 2024-06-29T16:32:44 | https://dev.to/habib0007/reactjs-or-vuejs-1345 | react, vue, javascript, webdev | JavaScript is an Object-oriented programming language and is the main language for creating a website.
JavaScript have a large ecosystem and has a lot of frameworks/libraries, two of the most popular ones are **React** and **Vue**.
In this blog we'll be comparing the two frameworks.
**Similarities:**
- Both React a... | habib0007 |
1,905,844 | Refactoring Nuxt Token Authentication Module to Use Nitro's Default db0 Layer | Recently, I refactored my Nuxt Token Authentication module to utilize Nitro's default db0 layer... | 0 | 2024-06-29T16:31:22 | https://dev.to/rrd/refactoring-nuxt-token-authentication-module-to-use-nitros-default-db0-layer-18fd | nuxt, nitro | Recently, I refactored my [Nuxt Token Authentication](https://github.com/rrd108/nuxt-token-authentication) module to utilize Nitro's default `db0` layer instead of Prisma. The transition was relatively smooth, though I encountered a few undocumented or not clearly documented aspects along the way. Here's a rundown of m... | rrd |
1,905,836 | My First Attempt at Backend Development | I've always loved logical thinking, so I wasn't exactly surprised that I was drawn to programming. As... | 0 | 2024-06-29T16:29:33 | https://dev.to/bituan/my-first-attempt-at-backend-development-2gnk | backend, backenddevelopment, python, hnginternship | I've always loved logical thinking, so I wasn't exactly surprised that I was drawn to programming. As with most beginners, I started with frontend programming, and while it's nice and interesting in its own way, it didn't really appeal to me. You know, all I seemed to do was design stuff with code. Eventually, I got to... | bituan |
1,905,840 | Quantum Machine Learning The Future of Pattern Recognition and Classification | Dive into the revolutionary world of Quantum Machine Learning and discover its game-changing potential in pattern recognition and classification tasks. Unlock the secrets of quantum speed and extraordinary efficiency. | 0 | 2024-06-29T16:29:27 | https://www.elontusk.org/blog/quantum_machine_learning_the_future_of_pattern_recognition_and_classification | quantumcomputing, machinelearning, ai | # Quantum Machine Learning: The Future of Pattern Recognition and Classification
## Introduction: The Quantum Boom
The advent of quantum computing has ushered in an era of unprecedented computational power. As we venture further into this brave new world, one application stands out for its transformative potential: Q... | quantumcybersolution |
1,905,837 | how to use inline, internal, and external CSS in HTML | 1.Inline CSS: Inline CSS is applied directly to HTML elements using the... | 0 | 2024-06-29T16:28:27 | https://dev.to/sudhanshu_developer/how-to-use-inline-internal-and-external-css-in-html-38en | programming, beginners, html, css | **1.Inline CSS:**
Inline `CSS` is applied directly to `HTML` elements using the `style `attribute.
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Sudhanshu Developer</title>
</head>
<body>
<h1 style="colo... | sudhanshu_developer |
1,905,839 | Title: Create a Stunning Sliding Login and Registration Form with HTML, CSS, and JavaScript 🚀 | Introduction Hey developers! 👋 Are you looking to add a sleek, modern login and... | 0 | 2024-06-29T16:27:27 | https://dev.to/dipakahirav/title-create-a-stunning-sliding-login-and-registration-form-with-html-css-and-javascript-5ea6 | html, css, javascript, coding | ### Introduction
Hey developers! 👋 Are you looking to add a sleek, modern login and registration form to your web projects? Look no further! In this tutorial, we'll dive into creating a **Sliding Login and Registration Form** using HTML, CSS, and JavaScript. This dynamic form provides a seamless and interactive user e... | dipakahirav |
1,905,815 | Working with Spring Security Oauth | The last backend task I really struggled with was integrating Oauth in a java springboot application.... | 0 | 2024-06-29T16:15:19 | https://dev.to/alawode_samueltolulope_d/working-with-spring-security-oauth-1ihf | The last backend task I really struggled with was integrating Oauth in a java springboot application.
You know how you want to sign up on an application and you see the option where you can login with google, or facebook, or github yeah? Yes, that was what I was trying to achieve. Funny enough, Spring boot has quite t... | alawode_samueltolulope_d | |
1,905,838 | how to use inline, internal, and external CSS in HTML | 1.Inline CSS: Inline CSS is applied directly to HTML elements using the style... | 0 | 2024-06-29T16:27:25 | https://dev.to/sudhanshu_developer/how-to-use-inline-internal-and-external-css-in-html-11i5 | programming, beginners, html, css | **1.Inline CSS:**
Inline CSS is applied directly to HTML elements using the style attribute.
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Sudhanshu Developer</title>
</head>
<body>
<h1 style="color: blue... | sudhanshu_developer |
1,905,835 | bartowski/gemma-2-9b-it-GGUF-torrent | https://aitorrent.zerroug.de/bartowski-gemma-2-9b-it-gguf-torrent/ | 0 | 2024-06-29T16:23:57 | https://dev.to/octobreak/bartowskigemma-2-9b-it-gguf-torrent-3634 | ai, machinelearning, llm, beginners | https://aitorrent.zerroug.de/bartowski-gemma-2-9b-it-gguf-torrent/ | octobreak |
1,905,818 | Open Source Contributions: How Giving Back Can Boost Your Career | Skill Enhancement: Contributing to open source projects allows you to practice and improve your... | 0 | 2024-06-29T16:16:44 | https://dev.to/bingecoder89/open-source-contributions-how-giving-back-can-boost-your-career-3n01 | opensource, beginners, tutorial, learning | 1. **Skill Enhancement**: Contributing to open source projects allows you to practice and improve your coding skills in real-world scenarios, enhancing your technical expertise.
2. **Portfolio Building**: Your contributions serve as a public portfolio showcasing your abilities, which can impress potential employers an... | bingecoder89 |
1,905,817 | bartowski/gemma-2-27b-it-GGUF-Torrent | https://aitorrent.zerroug.de/bartowski-gemma-2-27b-it-gguf-torrent/ | 0 | 2024-06-29T16:16:15 | https://dev.to/octobreak/bartowskigemma-2-27b-it-gguf-torrent-5238 | ai, machinelearning, llm, beginners | https://aitorrent.zerroug.de/bartowski-gemma-2-27b-it-gguf-torrent/ | octobreak |
1,905,816 | MyFirstApp - React Native with Expo (P7) - Add Carouse (part 2) | MyFirstApp - React Native with Expo (P7) - Add Carouse (part 2) | 27,894 | 2024-06-29T16:15:19 | https://dev.to/skipperhoa/myfirstapp-react-native-with-expo-p7-add-carouse-part-2-29fa | react, reactnative, web3, tutorial | MyFirstApp - React Native with Expo (P7) - Add Carouse (part 2)
{% youtube KCxt_vGSkKM %} | skipperhoa |
1,905,814 | MyFirstApp - React Native with Expo (P7) - Add Carouse (part 1) | MyFirstApp - React Native with Expo (P7) - Add Carouse (part 1) | 27,894 | 2024-06-29T16:13:59 | https://dev.to/skipperhoa/myfirstapp-react-native-with-expo-p7-add-carouse-part-1-3ilc | webdev, react, reactnative, tutorial | MyFirstApp - React Native with Expo (P7) - Add Carouse (part 1)
{% youtube 6S7PXDpT1cI %} | skipperhoa |
1,905,813 | Quantum Machine Learning Revolutionizing Feature Extraction and Dimensionality Reduction | Dive into the fascinating world where quantum computing meets machine learning, particularly focusing on how quantum algorithms can transform feature extraction and dimensionality reduction. | 0 | 2024-06-29T16:13:30 | https://www.elontusk.org/blog/quantum_machine_learning_revolutionizing_feature_extraction_and_dimensionality_reduction | quantumcomputing, machinelearning, featureextraction, dimensionalityreduction | # Quantum Machine Learning: Revolutionizing Feature Extraction and Dimensionality Reduction
Quantum computing is no longer a distant dream; it's a rapidly evolving reality transforming various fields, including machine learning. Today, let's explore the exhilarating convergence of quantum computing and machi... | quantumcybersolution |
1,905,812 | Typescript Generics | Generics in Typescript are a feature that allows you to create components that can work with any data... | 0 | 2024-06-29T16:12:24 | https://dev.to/tofail/typescript-generics-1ki2 | typescript, generics, webdev | Generics in Typescript are a feature that allows you to create components that can work with any data type while preserving type safety. They provide a way to define functions, classes and interfaces without specifying the exact data types they will operate on in advance. Instead, you use type variables, usually repre... | tofail |
1,905,811 | Arrays in JavaScript.! | Arrays in JavaScript - javaScriptda massivlar.! Ta'rif: massivlar bir necha o'zgaruvchilarni o'z... | 0 | 2024-06-29T16:11:27 | https://dev.to/samandarhodiev/arrays-in-javascript-2ifb | **Arrays in JavaScript - javaScriptda massivlar.!**
<u>`Ta'rif:`</u> <u> massivlar bir necha o'zgaruvchilarni o'z ichiga oluvchi maxsus o'zgaruvchi hisoblanadi.!</u>
JavaScriptda massiv literalidan foydalangan xolda massiv hosil qilish eng qulay usul hisoblanadi.!
**<u>sintaksis:</u>** `const array_name_ = [item1,... | samandarhodiev | |
1,905,805 | Understanding My Top 5 CliftonStrengths | The CliftonStrengths assessment has revealed my top five strengths: Achiever, Intellection, Learner,... | 0 | 2024-06-29T15:57:11 | https://victorleungtw.com/2024/06/29/strength/ | achiever, intellection, learner, input | The CliftonStrengths assessment has revealed my top five strengths: Achiever, Intellection, Learner, Input, and Arranger. This blog post explores each of these strengths in detail, how they manifest in my life, and how I leverage them to reach my full potential.
 - Add Swipeable Right Action | MyFirstApp - React Native with Expo (P6) - Add Swipeable Right Action | 27,894 | 2024-06-29T16:08:08 | https://dev.to/skipperhoa/myfirstapp-react-native-with-expo-p6-add-swipeable-right-action-23nd | webdev, react, reactnative, tutorial | MyFirstApp - React Native with Expo (P6) - Add Swipeable Right Action
{% youtube XP5YvHyFKOI %} | skipperhoa |
1,905,809 | Day 1 | Going to learn Devops from today. Its my 1 to learn basics , starting with linux. | 0 | 2024-06-29T16:06:59 | https://dev.to/shresth_rana/day-1-4dpj | Going to learn Devops from today. Its my 1 to learn basics , starting with linux. | shresth_rana | |
1,905,801 | HTML and JavaScript: The Backbone of Web Development | By: Sandra Asante Frontend development goals have changed over the previous decade, as have other... | 0 | 2024-06-29T16:06:11 | https://dev.to/sassante/html-and-javascript-the-backbone-of-web-development-4eb6 | webdev, javascript, beginners, programming |
By: Sandra Asante
Frontend development goals have changed over the previous decade, as have other parts of technology.
## What is front-end development?
Frontend development, also known as client-side development, is the process of carrying out the vision and design concept of web pages or applications using code.... | sassante |
1,905,775 | OOP Concepts: What's Your Biggest Challenge? | Hey, fellow developers!🧑🏼💻 I'm currently working on a book about Object-Oriented Programming in PHP... | 0 | 2024-06-29T16:05:40 | https://dev.to/zhukmax/oop-concepts-whats-your-biggest-challenge-5dal | php, oop, coding, webdev | Hey, fellow developers!🧑🏼💻
I'm currently working on a book about Object-Oriented Programming in **PHP** and **TypeScript**, and I'm curious about your experiences with OOP.
As developers, we all have those concepts that make us scratch our heads from time to time. So, I want to ask: Which OOP concept do you find ... | zhukmax |
1,905,806 | Quantum Key Distribution Revolutionizing Secure Communications | Explore the cutting-edge world of Quantum Key Distribution (QKD) and discover how it promises to secure our digital communications against even the most sophisticated cyber threats. | 0 | 2024-06-29T15:57:33 | https://www.elontusk.org/blog/quantum_key_distribution_revolutionizing_secure_communications | quantumcomputing, cybersecurity, encryption | # Quantum Key Distribution: Revolutionizing Secure Communications
In a world where cybersecurity threats are perpetually evolving, the need for rock-solid encryption methods has never been more pressing. Enter **Quantum Key Distribution (QKD)** – a groundbreaking advancement that promises to redefine secure communicat... | quantumcybersolution |
1,905,780 | Por que a Apple Odeia o Brasil? A História Proibida que Ninguém Contou! | Intrdução Bom dia, boa tarde e uma boa noite a todos nossos leitores. Já faz um tempinho... | 0 | 2024-06-29T15:55:13 | https://dev.to/terminalcoffee/por-que-a-apple-odeia-o-brasil-a-historia-proibida-que-ninguem-contou-21ek | braziliandevs, news, discuss | #Intrdução
Bom dia, boa tarde e uma boa noite a todos nossos leitores. Já faz um tempinho que eu não escrevo aqui no blog, e hoje apresento uma história diferente e meio lenda urbana. Se gostar da ideia e quiser mais desse tipo de conteúdo, deixe nos comentários e dê seu like, pois o feedback de vocês é muito importan... | terminalcoffee |
1,905,803 | AI-powered Resume and Cover Letter Generator (Next.js, GPT4, Langchain & CopilotKit) | TL;DR In this article, you will learn how to build an AI-powered resume and cover letter... | 0 | 2024-06-29T15:53:41 | https://dev.to/copilotkit/build-an-ai-powered-resume-cover-letter-generator-copilotkit-langchain-tavily-nextjs-1nkc | webdev, javascript, programming, tutorial | ## **TL;DR**
In this article, you will learn how to build an AI-powered resume and cover letter generator. The generator enables you to scrape content from your LinkedIn, GitHub, or X profile and use that content to generate a resume and a cover letter for a job application.
We'll cover how to:
- Build the resume & ... | the_greatbonnie |
1,905,802 | Day 19 Task: Docker for DevOps Engineers | What is Docker Volume..? Docker-Volume is a feature in the Docker containerization platform that... | 0 | 2024-06-29T15:51:41 | https://dev.to/oncloud7/day-19-task-docker-for-devops-engineers-5ck5 | **What is Docker Volume..?**
Docker-Volume is a feature in the Docker containerization platform that enables data to persist between containers and to be shared among them. When you create a Docker container, any data that is generated or used by the container is stored inside the container itself. However, when the co... | oncloud7 | |
1,905,799 | Profile Card UI using Html & Css - flexbox | Profile CARD UI HTML <!DOCTYPE html> <html lang="en"> ... | 0 | 2024-06-29T15:49:24 | https://dev.to/syedmuhammadaliraza/pro-file-card-ui-using-html-css-flexbox-518f | css, frontend, wixstudiochallenge, html | ## Profile CARD UI
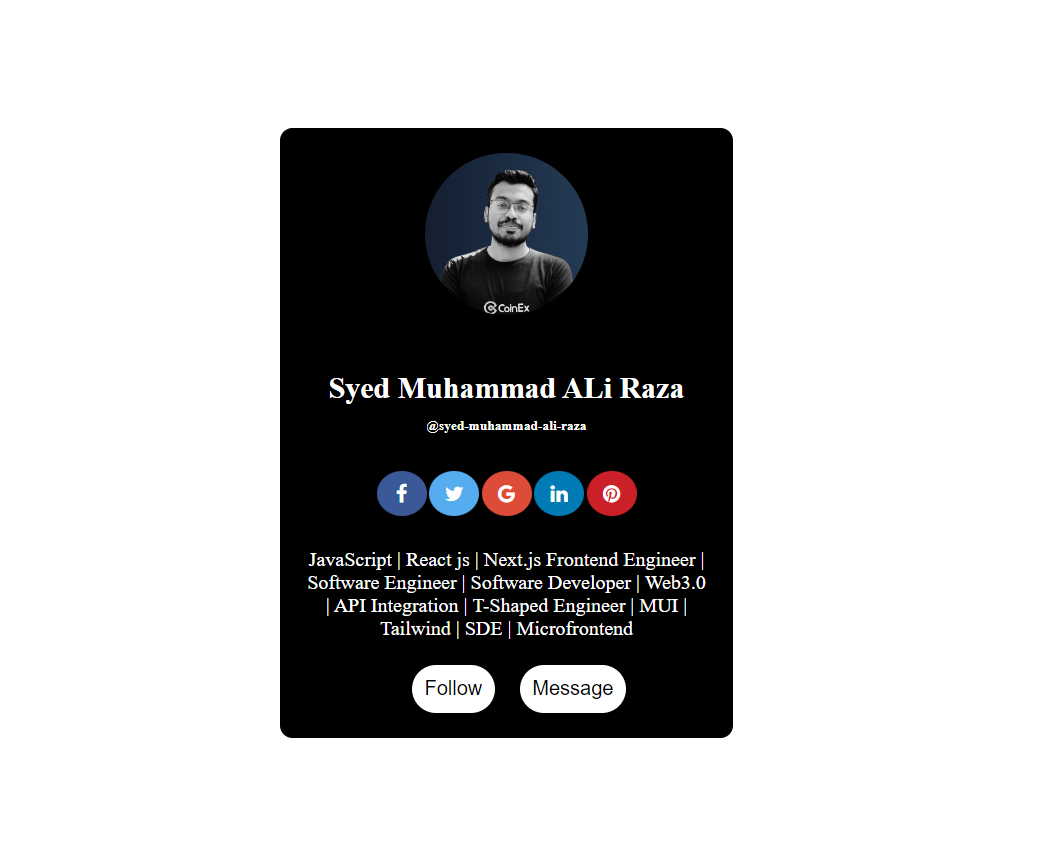
### HTML
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link rel="stylesheet" hr... | syedmuhammadaliraza |
1,905,792 | Creating and Managing IAM Users from Your EC2 Instance | Introduction: Managing user access on your EC2 instance is a fundamental task for maintaining... | 0 | 2024-06-29T15:48:58 | https://dev.to/mohanapriya_s_1808/creating-and-managing-iam-users-from-your-ec2-instance-dhk | **Introduction:**
Managing user access on your EC2 instance is a fundamental task for maintaining security and efficiency in your AWS environment. In this guide, we'll walk you through creating a new user from the EC2 instance, setting up SSH access, and verifying the new user. Let's get started!
**Step-1:** Create a ... | mohanapriya_s_1808 | |
1,905,796 | Navigating Mobile Development Platforms and Some Common Architecture Patterns | Introduction Over the years, computers have become increasingly smaller, leading to the... | 0 | 2024-06-29T15:48:24 | https://dev.to/slowburn404/navigating-mobile-development-platforms-and-some-common-architecture-patterns-4p39 | ## Introduction
Over the years, computers have become increasingly smaller, leading to the widespread use of smartphones, which are among the smallest and most common computing devices. Smartphones run operating systems that support various applications, which need to be developed. This article discusses different mobi... | slowburn404 | |
1,905,795 | Improve Your Python Regex Performance Using Rust | I've made a wrapper over the Rust regex crate using PyO3 and maturin. I've named it flpc because it... | 0 | 2024-06-29T15:46:34 | https://dev.to/itsmeadarsh/improve-your-python-regex-performance-using-rust-dpg | python, rust, regex, programming | I've made a wrapper over the Rust regex crate using PyO3 and maturin. I've named it flpc because it is short and easier to write. It works blazingly fast ⚡
(Only problem is that, it is not a full drop-in replacement for native re module)
```
pip install flpc
```
[Here's the link to the repository](https://github.com/it... | itsmeadarsh |
1,905,794 | SEOSiri: Stop Playing Small: Unlock Your Website’s True Potential with Digital Marketing | Your website is your online home. It's where you showcase your brand, connect with potential... | 0 | 2024-06-29T15:45:36 | https://dev.to/seosiri/seosiri-stop-playing-small-unlock-your-websites-true-potential-with-digital-marketing-35c | digitalmarketing, seo, webdev, marketing | Your website is your online home. It's where you showcase your brand, connect with potential customers, and ultimately, grow your business. But a beautiful website alone isn't enough. It would be best if you had a powerful digital marketing strategy to succeed in today's digital world.
Think of it this way:
But how d... | seosiri |
1,905,793 | 🚀 Elevate Your QR Code Game with Our Cutting-Edge Tools! 🚀 | 🚀 Elevate Your QR Code Game with Our Cutting-Edge Tools! 🚀 🌐 Check out our user-friendly QR code... | 0 | 2024-06-29T15:44:06 | https://dev.to/pr0biex/elevate-your-qr-code-game-with-our-cutting-edge-tools-1429 | techtools, devtools, api, softwaredevelopment | 🚀 Elevate Your QR Code Game with Our Cutting-Edge Tools! 🚀
🌐 Check out our user-friendly QR code generator website: QR Code Generator - Create QR codes in seconds!
[Website](https://api-chief.github.io/QRCodes/index.html)
💻 Developers, take advantage of our powerful and easy-to-use API: QR Code API on RapidAPI - ... | pr0biex |
1,905,749 | Azure Virtual Machine Scale Set. | Azure Virtual Machine Scale Sets (VMSS) allow you to create and manage a group of identical virtual... | 0 | 2024-06-29T15:43:47 | https://dev.to/tojumercy1/azure-virtual-machine-scale-set-p47 | azure, productivity, computerscience, softwareengineering |
Azure Virtual Machine Scale Sets (VMSS) allow you to create and manage a group of identical virtual machines. In this blog, we'll explore how to create a VMSS on Azure.
Step 1: Log in to Azure Portal
Log in to the Azure portal and navigate to the Virtual Machine Scale Sets.
 has emerged as a... | 0 | 2024-06-29T15:40:57 | https://dev.to/jackmurry/from-code-to-stream-the-role-of-github-in-iptv-innovation-4p8l | code, github, stream, iptv | In the dynamic world of digital media, Internet Protocol Television (IPTV) has emerged as a revolutionary technology that is transforming how we consume television. IPTV leverages internet protocols to deliver television content, bypassing traditional satellite and cable infrastructures. This shift has opened up a myri... | jackmurry |
1,905,787 | New Ui libaratu @unix-ui | Building a ui library, soloely focused on flexibitlity and performance. The goal is to give... | 0 | 2024-06-29T15:40:30 | https://dev.to/sirarifarid/new-ui-libaratu-unix-ui-5hf9 | Building a ui library, soloely focused on flexibitlity and performance. The goal is to give developer the power of customizations in a ui library with the core features, theming etc. You can now look the components of at yeah just lazy work here, right now the core focus is just flexibility and performance in a very s... | sirarifarid | |
1,905,785 | C Basics | C #include <stdio.h> int main() { printf("Hello, World!\n"); return... | 0 | 2024-06-29T15:39:08 | https://dev.to/harshm03/c-basics-585k | c, coding, beginners, tutorial | ##C
```c
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}
```
### Creating Variables
In C, variables are used to store data that can be manipulated within a program. Here's a comprehensive guide on creating and working with variables in C:
#### Syntax for Variable Declaration and Init... | harshm03 |
1,905,768 | Undress AI Tool: A Comprehensive Guide | In the ever-evolving world of technology, Undress AI tool are continuously pushing boundaries. One... | 0 | 2024-06-29T15:15:23 | https://dev.to/seo_expert/undress-ai-tool-a-comprehensive-guide-1m77 | In the ever-evolving world of technology, **[Undress AI tool](https://www.undressaitool.com/)** are continuously pushing boundaries. One such tool that has been making waves recently is Undress AI. But what exactly is Undress AI, and why is it attracting so much attention?
 offers a perfect solution. This optimized version of the game maintains the excitement and intensity of the original while reducing system requirements. | moltejespa | |
1,905,781 | Builder de tipagem dinâmica com fluent api no typescript | Nesse pequeno post iremos ver uma feature interessante do typescript que não vejo muitas pessoas... | 0 | 2024-06-29T15:35:37 | https://dev.to/pedrosantos3010/builder-de-tipagem-dinamica-com-fluent-api-no-typescript-3dml | typescript, fluentapi, node | Nesse pequeno post iremos ver uma feature interessante do typescript que não vejo muitas pessoas comentando. Iremos aprender a utilizar a criação de uma tipagem dinâmica com o padrão de fluent api.
Começaremos rapidamente definindo alguns componentes para trabalhar em cima deles. A ideia aqui é construirmos casas din... | pedrosantos3010 |
1,905,779 | Interface v.s. Functional Interface | For the Java crowd, here's one that some like to use. Explain the difference between an interface... | 27,904 | 2024-06-29T15:29:27 | https://dev.to/johnscode/interface-vs-functional-interface-523m | interview, java | For the Java crowd, here's one that some like to use.
Explain the difference between an interface and a functional interface.
Ok let's start with what an interface is.
An interface defines a set of methods required by an implementing class. Consider it a blueprint for a class.
An interface may inherit from multiple... | johnscode |
1,905,777 | Front-end, stage zero | In our modern world in tech where choosing the right framework, languages and library plays a very... | 0 | 2024-06-29T15:26:39 | https://dev.to/dahveed_jacob_bf9c9d07fc5/front-end-stage-zero-2ib9 | frontend, webdev, react, svelte | In our modern world in tech where choosing the right framework, languages and library plays a very crucial role in the productivity of our projects or products, I will be comparing a popular front-end tool which is React and a Not-so popular tool which is Svelte.
I know we will all agree that react is a very popular fr... | dahveed_jacob_bf9c9d07fc5 |
1,905,776 | Quantum Gates vs Classical Logic Gates Unveiling the Next Frontier of Computing | Dive into the fascinating differences between quantum gates and classical logic gates, and discover how the quantum revolution is setting the stage for the next era of computing! | 0 | 2024-06-29T15:25:38 | https://www.elontusk.org/blog/quantum_gates_vs_classical_logic_gates_unveiling_the_next_frontier_of_computing | quantumcomputing, classicalcomputing, technology | # Quantum Gates vs. Classical Logic Gates: Unveiling the Next Frontier of Computing
## Introduction
Welcome to the future of computing! In this thrilling exploration, we delve into the intriguing world of quantum gates and classical logic gates. While classical gates have been the cornerstone of computation for deca... | quantumcybersolution |
1,905,774 | Better Animations... in Latest Doodle | Animations in Doodle 0.10.2 can be chained within an animation block using the then method. This... | 0 | 2024-06-29T15:24:32 | https://dev.to/pusolito/better-animations-in-latest-doodle-3763 | Animations in [Doodle 0.10.2](https://github.com/nacular/doodle/releases/tag/v0.10.2) can be chained within an animation block using the `then` method. This makes it easier to have sequential animations and avoids the need to explicitly track secondary animations for cancellation, since these are tied to their "parent"... | pusolito | |
1,905,773 | Redux vs React’s useReducer | I recently got accepted into the rigorous HNG internship program. And my first task was to write... | 0 | 2024-06-29T15:22:50 | https://dev.to/lynxdev32/redux-vs-reacts-usereducer-3915 | redux, intern, webdev, react | I recently got accepted into the rigorous [HNG internship program](https://hng.tech/internship). And my first task was to write technical article comparing any two react technologies. So walk with me.
When building complex React applications, managing state can become quite challenging. To tackle this, developers ofte... | lynxdev32 |
1,905,772 | Sai satcharitra telugu pdf | If you are searching Sai Satcharitra Telugu PDF, then you have arrived at the right website... | 0 | 2024-06-29T15:22:23 | https://dev.to/delphine_mary_aa269f2c666/sai-satcharitra-telugu-pdf-5hf4 | If you are searching [Sai Satcharitra Telugu PDF](https://saisatcharitrapdf.in/), then you have arrived at the right website saisatcharitrapdf.in and you can directly download it from our website.Sai Satcharitra is a blessed biography book, all about the miracles and life history of Shri Sai baba. This book was conside... | delphine_mary_aa269f2c666 | |
1,905,771 | Sai satcharitra telugu pdf | If you are searching Sai Satcharitra Telugu PDF, then you have arrived at the right website... | 0 | 2024-06-29T15:22:05 | https://dev.to/delphine_mary_aa269f2c666/sai-satcharitra-telugu-pdf-22bk | If you are searching [Sai Satcharitra Telugu PDF](https://saisatcharitrapdf.in/), then you have arrived at the right website saisatcharitrapdf.in and you can directly download it from our website.Sai Satcharitra is a blessed biography book, all about the miracles and life history of Shri Sai baba. This book was conside... | delphine_mary_aa269f2c666 | |
1,905,767 | Kubernetes as a Database? What You Need to Know About CRDs | Within the fast developing field of cloud-native technologies, Kubernetes has become a potent tool... | 0 | 2024-06-29T15:14:25 | https://nilebits.com/blog/2024/06/kubernetes-as-a-database-need-know-crds/ | kubernetes, crds, yaml, go | Within the fast developing field of cloud-native technologies, Kubernetes has become a potent tool for containerized application orchestration. But among developers and IT specialists, "Is Kubernetes a database?" is a frequently asked question. This post explores this question and offers a thorough description of Custo... | amr-saafan |
1,905,766 | Dive into the Fascinating World of Machine Learning with MIT's Comprehensive Course 🤖 | Comprehensive introduction to machine learning, covering supervised, unsupervised, neural networks, and deep learning. Taught by experienced MIT instructor. | 27,844 | 2024-06-29T15:13:24 | https://getvm.io/tutorials/6036-machine-learning-broderick-mit-fall-2020 | getvm, programming, freetutorial, universitycourses |
As someone who has always been fascinated by the power of artificial intelligence and its potential to transform the world, I'm thrilled to share with you an incredible learning opportunity - the Machine Learning course offered by the prestigious Massachusetts Institute of Technology (MIT).
## Comprehensive Coverage... | getvm |
1,905,765 | How to create diagram of your project's folder structure in 3 simple steps | convert your folder structure to diagram | Converting your project's folder structure to a diagram can be useful in case of presentation,... | 0 | 2024-06-29T15:11:23 | https://your-codes.vercel.app/how-to-create-diagram-of-your-project-s-folder-structure-in-3-simple-steps-or-convert-your | chart, howto, chatgpt, tutorial | Converting your project's folder structure to a diagram can be useful in case of presentation, teaching best practices for the folder structure or it can be a requirement for you to explain your code's structure.
to convert folder structure to the diagram or a flowchart can be done by using many ways such creating man... | your-ehsan |
1,905,764 | Host Website on Netlify for Free | First login to Netlify Website Then Go to Home and then select* sites* . In sites select Add new... | 0 | 2024-06-29T15:10:17 | https://dev.to/mahimabhardwaj/host-website-on-netlify-for-free-10ig | webdev, javascript, beginners, tutorial | First login to [Netlify](https://youtu.be/4PFECfI-UiE?feature=shared) Website
Then Go to Home and then select**[ sites](https://youtu.be/4PFECfI-UiE?feature=shared)** . In sites select **Add new site**.

# Embracing the Chaos: Using Fault Injection Testing to Build Resilient AWS Architectures
In today's digital landscape, application downtime translates directly into financial losses and reputational damage. As we increasingly rely... | virajlakshitha | |
1,905,758 | Meet TARS: The Modular AI Platform Empowering the Web3 Transition | 🌋 The first 【#TinTinLandWeb3LearningMonth】organized by #TinTinLand has entered its fifth week! ⛴️... | 0 | 2024-06-29T14:59:50 | https://dev.to/ourtintinland/meet-tars-the-modular-ai-platform-empowering-the-web3-transition-49i5 | webdev, tutorial, ai | 🌋 The first 【#TinTinLandWeb3LearningMonth】organized by #TinTinLand has entered its fifth week!
⛴️ This week's session will be hosted by @tarsprotocol, featuring an online AMA, learning videos, and Zealy learning tasks!
🚏 #TARS is an AI-driven, scalable Web3 modular infrastructure platform, designed to provide cuttin... | ourtintinland |
1,905,757 | Why I Chose React Over Angular | Why I Chose React Over Angular What is React? React is a popular JavaScript library for building... | 0 | 2024-06-29T14:58:12 | https://dev.to/elmoustafi/why-i-chose-react-over-angular-2ho1 | webdev, javascript, beginners, programming | **Why I Chose React Over Angular**
**_What is React?_**
React is a popular JavaScript library for building user interfaces, known for its component-based architecture, which allows developers to create reusable UI components.
React improves application performance by using a Virtual DOM, which efficiently updates an... | elmoustafi |
1,905,756 | Quantum Cybersecurity Challenges and Opportunities | Dive into the fascinating world of quantum cybersecurity, exploring the challenges it poses and the unprecedented opportunities it presents for the future of digital security. | 0 | 2024-06-29T14:53:43 | https://www.elontusk.org/blog/quantum_cybersecurity_challenges_and_opportunities | quantumcomputing, cybersecurity, innovation | # Quantum Cybersecurity: Challenges and Opportunities
Welcome to the new frontier of cybersecurity! The introduction of quantum computing into the technology landscape has brought along a plethora of both challenges and opportunities, fundamentally reshaping the way we approach digital security. Let's take an exh... | quantumcybersolution |
1,892,229 | Create FastAPI App Like pro part-2 | Part 1 is here https://dev.to/muhammadnizamani/create-fastapi-app-like-pro-part-1-12pi In this part,... | 0 | 2024-06-29T14:49:03 | https://dev.to/muhammadnizamani/create-fastapi-app-like-pro-part-2-52l1 | backend, python, fastapi, backenddevelopment | Part 1 is here https://dev.to/muhammadnizamani/create-fastapi-app-like-pro-part-1-12pi
In this part, we will focus on designing the database. In part 3, I will demonstrate how to create the database and use an ORM with PostgreSQL via pgAdmin.
Note: Please spend ample time on the design and planning phase to ensure a ... | muhammadnizamani |
1,905,755 | Backend | I think there are a lot of easy things in life but i can boldly say transitioning into tech as a... | 0 | 2024-06-29T14:48:37 | https://dev.to/dahveed_jacob_bf9c9d07fc5/backend-2cf3 | hng, backend, webdev, fullstack | I think there are a lot of easy things in life but i can boldly say transitioning into tech as a full-stack dev hasn't been one of them, my journey so far as a web developer has made me more curious, patience and relentless, I focus more of my time as a backend developer because i find it more technical and complex.
My... | dahveed_jacob_bf9c9d07fc5 |
1,905,752 | Comparing Frontend Technologies: ReactJS vs. Svelte | Comparing Frontend Technologies: ReactJS vs. Svelte As a self-taught front-end developer and live... | 0 | 2024-06-29T14:47:33 | https://dev.to/bobod24/comparing-frontend-technologies-reactjs-vs-svelte-45aa | webdev, react, svelte, beginners | **Comparing Frontend Technologies: ReactJS vs. Svelte**
As a self-taught front-end developer and live streamer, I am familiar with ReactJS, the popular JavaScript library for building user interfaces. However, let’s dive into a more niche comparison by contrasting ReactJS with Svelte, a relatively newer player in ... | bobod24 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.