
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,905,688 | Descubre las Ventajas de Apache Kafka en la Arquitectura Dirigida por Eventos (Parte I) | En el vertiginoso mundo del desarrollo de software, la agilidad y la escalabilidad son la clave del... | 0 | 2024-06-30T04:02:23 | https://dev.to/lidiog/descubre-las-ventajas-de-apache-kafka-en-la-arquitectura-dirigida-por-eventos-parte-i-1l9m | En el vertiginoso mundo del desarrollo de software, la agilidad y la escalabilidad son la clave del éxito. Dos conceptos están revolucionando la forma en que diseñamos y construimos sistemas: la Arquitectura Orientada a Eventos (EDA) y Apache Kafka.
## ¿Qué es la Arquitectura Orientada a Eventos?
EDA (Event-driven ar... | lidiog | |
1,906,299 | Uncover the Perks of Apache Kafka in Event-Driven Architecture (Part I) | In the breakneck world of software development, agility and scalability are the keys to success. Two... | 0 | 2024-06-30T04:02:17 | https://dev.to/lidiog/uncover-the-perks-of-apache-kafka-in-event-driven-architecture-part-i-4hod | In the breakneck world of software development, agility and scalability are the keys to success. Two concepts are revolutionizing how we design and build systems: Event-Driven Architecture (EDA) and Apache Kafka.
## What's Event-Driven Architecture?
EDA is a design paradigm that zeroes in on producing, detecting, and... | lidiog | |
1,906,298 | Creating a C compiler in JavaScript | Creating a C compiler in JavaScript is a complex and ambitious project that involves several... | 0 | 2024-06-30T03:57:33 | https://dev.to/sh20raj/creating-a-c-compiler-in-javascript-391c | javascript, c | Creating a C compiler in JavaScript is a complex and ambitious project that involves several components, including lexical analysis, parsing, semantic analysis, and code generation. Below is a simplified and high-level example of how you might start building such a compiler. This example will focus on the lexical analy... | sh20raj |
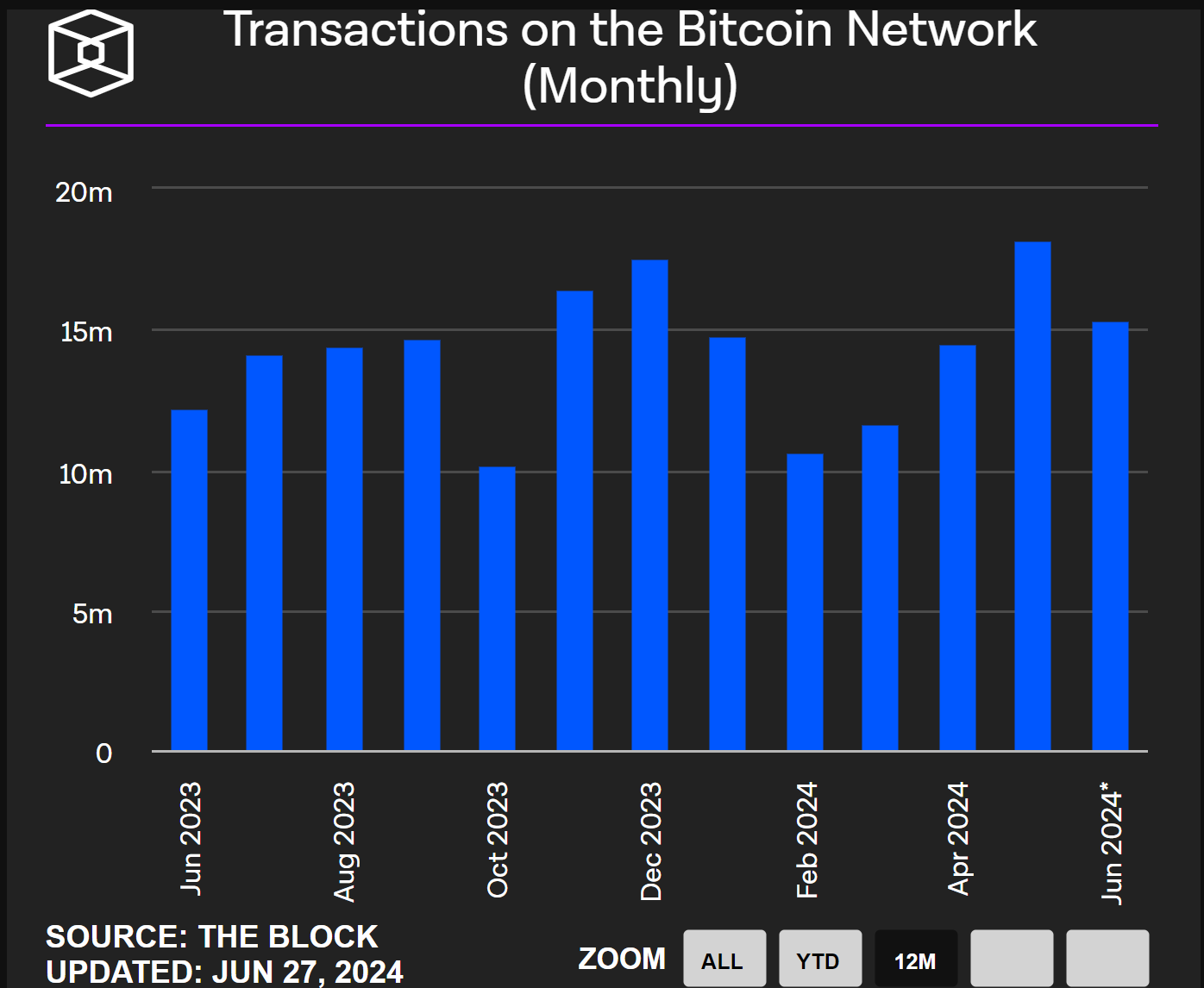
1,906,292 | 比特币原生资产与Bitroot协议测试网深度报告 | 比特币原生资产潜力空前强大 比特币市值与生态数据 比特币不单单是加密货币,更是全球范围被认可的价值存储共识。目前比特币网络月均活跃交易平均在1500万次左右,每月活跃用户在2000万人左右,而且每月新... | 0 | 2024-06-30T03:55:28 | https://dev.to/crypto_senior/bi-te-bi-yuan-sheng-zi-chan-yu-bitrootxie-yi-ce-shi-wang-shen-du-bao-gao-59pn | **比特币原生资产潜力空前强大**
比特币市值与生态数据
比特币不单单是加密货币,更是全球范围被认可的价值存储共识。目前比特币网络月均活跃交易平均在1500万次左右,每月活跃用户在2000万人左右,而且每月新增用户在800万左右。
. My post explains how to... | 0 | 2024-06-30T03:51:13 | https://dev.to/hyperkai/create-and-access-a-tensor-in-pytorch-1047 | pytorch, create, access, tesnor | *Memos:
- [My post](https://dev.to/hyperkai/check-pytorch-version-cpu-and-gpucuda-in-pytorch-6jk) explains how to check PyTorch version, CPU and GPU(CUDA).
- [My post](https://dev.to/hyperkai/access-a-tensor-in-pytorch-1f4e) explains how to access a tensor.
- [My post](https://dev.to/hyperkai/istensor-numel-and-device-... | hyperkai |
1,903,670 | GitHub to Artifact Registry & Docker Hub via Cloud Build | This post describes automating Cloud Build triggered from a personal GitHub source repository using... | 0 | 2024-06-30T03:38:16 | https://dev.to/dchaley/github-to-artifact-registry-docker-hub-via-cloud-build-16d1 | docker, github, cicd, cloud | This post describes automating Cloud Build triggered from a personal GitHub source repository using GitHub Actions, and pushing the resulting container to both Artifact Registry (for running in our GCP project) and Docker Hub (for other folks to access).
---
I've been putting off container build automation for a whil... | dchaley |
1,906,293 | Typescript over JavaScript | Typescript is new javascript with some advanced and useful features added to javascript. Typescript,... | 0 | 2024-06-30T03:36:55 | https://dev.to/tofail/typescript-over-javascript-3oji | typescript, javascript, webdev | Typescript is new javascript with some advanced and useful features added to javascript. Typescript, which is the superset of javascript and becoming a go to language in the web development sector for every large application. The feature of detecting bugs while typing the code makes it unique. As per research, 60% of j... | tofail |
1,906,291 | VDO Ninja woes and Overlay Setup | Original: https://codingcat.dev/podcast/vdo-ninja-woes-and-overlay-setup Trying to setup Video... | 26,111 | 2024-06-30T03:32:25 | https://codingcat.dev/podcast/vdo-ninja-woes-and-overlay-setup | webdev, javascript, beginners, podcast |
Original: https://codingcat.dev/podcast/vdo-ninja-woes-and-overlay-setup
{% youtube https://youtu.be/gexF47IhYLM %}
Trying to setup Video Ninja, I wouldn't watch this if I were you! | codercatdev |
1,906,290 | 🎉 iPhone 15 Pro Max Giveaway! 🎉 | iPhone 15 Pro Max Giveaway! 🎉 Hey everyone! 👋 We are thrilled to announce our latest giveaway! 📱✨ 🎁... | 0 | 2024-06-30T03:28:08 | https://dev.to/md_shaharia_12/iphone-15-pro-max-giveaway-4i44 |
[iPhone 15 Pro Max Giveaway!](https://sites.google.com/d/1KV_3eZiSN4UIJc9nupBSqe-z73LckXoG/p/1Sqk91XCiTXzoyjB-VAl2Ka6gvqGnLFdd/edit) 🎉
Hey everyone! 👋 We are thrilled to announce our latest giveaway! 📱✨
🎁 Prize: ... | md_shaharia_12 | |
1,906,288 | Numpy Isnumeric Function: Mastering Numeric String Validation | In this lab, we will cover the isnumeric() function of the char module in the Numpy library. This function is used to check if a string contains only numeric characters. The function returns True if there are only numeric characters in the string, otherwise, it returns False. | 27,710 | 2024-06-30T03:24:33 | https://labex.io/tutorials/python-numpy-isnumeric-function-86462 | numpy, coding, programming, tutorial |
## Introduction
In this lab, we will cover the `isnumeric()` function of the **char module** in the Numpy library. This function is used to check if a string contains only numeric characters. The function returns **True** if there are only numeric characters in the string, otherwise, it returns **False**.
### VM Tip... | labby |
1,905,600 | How to make Slack Workflow input form | Hi I'm Tak. This article theme is how to make Slack Workflow input form. Overview I... | 0 | 2024-06-30T03:24:33 | https://dev.to/takahiro_82jp/how-to-make-slack-workflow-input-form-4doa | slack, devops, serverless, nocode | Hi I'm Tak.
This article theme is how to make Slack Workflow input form.
## Overview
I recently used Slack workflow for AWS resource management.
It is a useful tool, So It's required for Devops and Platform engineering.
This article teach you how to create input form and save its contents to Google spreadsheet.
## ... | takahiro_82jp |
1,906,284 | Data Validation is super important, don't ignore or delay it. | I often encounter backend codebases where data isn't validated before being processed or inserted... | 0 | 2024-06-30T03:16:51 | https://dev.to/themuneebh/data-validation-is-super-important-dont-ignore-or-delay-it-3c8k | softwareengineering, typescript | I often encounter backend codebases where data isn't validated before being processed or inserted directly into the database. This can cause serious bugs, as relying solely on your frontend buddy can lead to headaches, ruin the flow, result in unwanted and unexpected data in the database, and make you vulnerable to SQL... | themuneebh |
1,906,287 | Expressjs vs Django vs FastApi vs Golang vs Rust (Actix) vs Ruby on Rails vs LAMP Stack (PHP) Hypothetical Benchmark Results | Framework Requests per Second Average Latency (ms) Scalability Ease of Use Community... | 0 | 2024-06-30T03:24:23 | https://dev.to/aliahadmd/expressjs-vs-django-vs-fastapi-vs-golang-vs-rust-actix-vs-ruby-on-rails-vs-lamp-stack-php-hypothetical-benchmark-results-nca | django, express, fastapi, ruby | | Framework | Requests per Second | Average Latency (ms) | Scalability | Ease of Use | Community Support |
|-----------------|----------------------|----------------------|-------------|-------------|-------------------|
| Go (net/http) | 30,000 | 20 | High | Moderate |... | aliahadmd |
1,906,283 | Spring Boot + Swagger: A Step-by-Step Guide to Interactive API Documentation | Introduction In today's software development, especially when dealing with APIs... | 0 | 2024-06-30T03:23:59 | https://dev.to/cuongnp/supercharge-your-spring-boot-application-with-swagger-a-step-by-step-guide-to-interactive-api-documentation-18g7 | webdev, springboot, beginners, programming |
## Introduction
In today's software development, especially when dealing with APIs (Application Programming Interfaces), having clear and detailed documentation is essential. It guides developers on how to use a service, which endpoints are available, and what data to send or expect in return. Swagger has become a wi... | cuongnp |
1,906,286 | GitHub CMS | Original: https://codingcat.dev/podcast/github-cms | 26,111 | 2024-06-30T03:20:18 | https://codingcat.dev/podcast/github-cms | webdev, javascript, beginners, podcast |
Original: https://codingcat.dev/podcast/github-cms
{% youtube https://youtube.com/embed/rTmzgCZdzQ0 %}
| codercatdev |
1,906,285 | Hypertext Markup Language (HTML) | Acceptance criteria: It is done when I have analyzed and identified , , , and elements in the... | 0 | 2024-06-30T03:19:12 | https://dev.to/moth668/hypertext-markup-language-html-5blo | Acceptance criteria:
It is done when I have analyzed and identified <html>, <head>, <meta>, and <title> elements in the index.html file in the prework-study-guide repository.
In this Module, I've learned about the <!DOCTYPE html> declaring to the browser to expect the following document to be HTML. Then I learned abo... | moth668 | |
1,906,280 | VTable table component, how to listen for mouse hover events on the elements? | Question Description When customizing cell content using customLayout, including Text and... | 0 | 2024-06-30T03:14:05 | https://dev.to/fangsmile/vtable-table-component-how-to-listen-for-mouse-hover-events-on-the-elements-517h | visactor, vtable, webdev, excel | ## Question Description
When customizing cell content using customLayout, including Text and Image, I would like to have some custom logic when hovering over the Image. Currently, the mouse-enter event for the cell cannot distinguish between specific targets.

JavaScript, HTML va CSS veb sahifa yaratishda uch asosiy texnologiyasi hisoblanadi. Ularning har biri o'ziga xos funksiyalarga ega bo'lib, birgalikda ishlatilganda veb-sahifalarni yaratish va boshqarishda juda sama... | bekmuhammaddev |
1,906,276 | SvelteKit with DaisyUI | Original: https://codingcat.dev/podcast/sveltekit-with-daisyui | 26,111 | 2024-06-30T03:02:34 | https://codingcat.dev/podcast/sveltekit-with-daisyui | webdev, javascript, beginners, podcast |
Original: https://codingcat.dev/podcast/sveltekit-with-daisyui
{% youtube https://youtu.be/l4sbqrY0XGk %}
| codercatdev |
1,906,275 | Effortlessly Orchestrating Workflows in the Cloud: A Deep Dive into AWS Managed Apache Airflow | Effortlessly Orchestrating Workflows in the Cloud: A Deep Dive into AWS Managed Apache... | 0 | 2024-06-30T03:02:21 | https://dev.to/virajlakshitha/effortlessly-orchestrating-workflows-in-the-cloud-a-deep-dive-into-aws-managed-apache-airflow-3e4b | 
# Effortlessly Orchestrating Workflows in the Cloud: A Deep Dive into AWS Managed Apache Airflow
### Introduction
In today's rapidly evolving technological landscape, businesses and organizations increasingly rely on intricate workfl... | virajlakshitha | |
1,905,137 | Using JSONB in PostgreSQL | Introduction JSONB, short for JSON Binary, is a data type developed from the JSON data... | 0 | 2024-06-30T03:00:00 | https://howtodevez.blogspot.com/2024/04/using-jsonb-in-postgresql.html | postgres, beginners, datascience, data | Introduction
------------
**JSONB**, short for **JSON Binary**, is a data type developed from the **JSON** data type and supported by **PostgreSQL** since version 9.2.
The key difference between **JSON** and **JSONB** lies in how they are stored. **JSONB** supports binary storage and resolves the limitations of the *... | chauhoangminhnguyen |
1,906,274 | What is an Observability Pipeline? | Key Takeaways Observability pipelines are essential for managing the ever-growing volume of... | 0 | 2024-06-30T02:56:05 | https://dev.to/rickysarora/what-is-an-observability-pipeline-2n56 | **Key Takeaways**
Observability pipelines are essential for managing the ever-growing volume of telemetry data (logs, metrics, traces) efficiently, enabling optimal security, performance, and stability within budget constraints.
They address challenges such as data overload, legacy architectures, rising costs, complia... | rickysarora | |
1,906,273 | How I created reusable React Icon Component using react-icons library in an AstroJs Project. | In the past weeks lately, I have been focused on building clean landing page websites using AstroJs... | 0 | 2024-06-30T02:43:37 | https://dev.to/mrpaulishaili/how-i-created-reusable-react-icon-component-using-react-icons-library-in-an-astrojs-project-nk4 | astro, webdev, frontend, javascript | In the past weeks lately, I have been focused on building clean landing page websites using AstroJs framework.
One of the difficulties I often face however is the limitation of the icon libraries available in the astro-icons, as compared to the react-icon library.
So here's what I decided to do:
```js
import React f... | mrpaulishaili |
1,905,595 | Boost Your Angular App's Speed: Code Splitting Strategies | Introduction In today's blog post we'll learn how can you boost your Angular app's speed.... | 0 | 2024-06-30T02:39:57 | https://dev.to/wirefuture/boost-your-angular-apps-speed-code-splitting-strategies-5e5a | angular, webdev, javascript, typescript | ## Introduction
In today's blog post we'll learn how can you boost your Angular app's speed. In Angular, performance optimization is a crucial factor for a great user experience. The most powerful technique in your toolkit is code splitting. This strategy involves breaking your application into smaller, much more mana... | tapeshm |
1,906,271 | My Disney Internship: Month One | I won’t lie, I was nervous to start my internship at Disney. Why me? I’ve only been learning to code... | 0 | 2024-06-30T02:31:35 | https://dev.to/dlewisdev/my-disney-internship-month-one-1akk | ios, swift | I won’t lie, I was nervous to start my internship at Disney. Why me? I’ve only been learning to code for a year, would I be able to produce and succeed in a company this large and successful? I had no idea what to expect, and I psyched myself out to the point where I wasn’t sure I’d show up for orientation. Thankfully,... | dlewisdev |
1,906,270 | SvelteKit with Notion CMS | Original: https://codingcat.dev/podcast/sveltekit-with-notion-cms | 26,111 | 2024-06-30T02:28:33 | https://codingcat.dev/podcast/sveltekit-with-notion-cms | webdev, javascript, beginners, podcast |
Original: https://codingcat.dev/podcast/sveltekit-with-notion-cms
{% youtube https://youtu.be/OiapPdbBrpY?si=hbHH8daKr3y4Zd3c %}
| codercatdev |
1,906,269 | JS Runtime / Execution context | JavaScript runtime is the environment or engine required to run JavaScript code. These runtime... | 0 | 2024-06-30T02:27:28 | https://dev.to/bekmuhammaddev/js-runtime-execution-context-3900 | english, runtime, javascript | JavaScript runtime is the environment or engine required to run JavaScript code. These runtime environments parse and execute JavaScript code. JavaScript is the only language that runs in the browser.
Runtime types and operating environment:
1-Google chrome (Browser)
Browsers are the main runtime environment of JavaS... | bekmuhammaddev |
1,906,262 | Unified Approximation Theorem for Neural Networks | For any ( f \in \mathcal{F}(\mathbb{R}^n) ) and any ( \epsilon > 0 ), there exists a neural... | 0 | 2024-06-30T02:17:35 | https://dev.to/ramsi90/unified-approximation-theorem-for-neural-networks-2b23 | For any ( f \in \mathcal{F}(\mathbb{R}^n) ) and any ( \epsilon > 0 ), there exists a neural network ( \mathcal{N}(\mathbf{x}; \theta) ) with parameters ( \theta ) such that: [ \sup_{\mathbf{x} \in K} \left| f(\mathbf{x}) - \mathcal{N}(\mathbf{x}; \theta) \right| < \epsilon, ] where ( K \subset \mathbb{R}^n ) is compact... | ramsi90 | |
1,906,261 | Centralized Exchange Development: A Comprehensive Guide | Introduction Cryptocurrencies have revolutionized the financial landscape, offering a... | 27,673 | 2024-06-30T02:10:52 | https://dev.to/rapidinnovation/centralized-exchange-development-a-comprehensive-guide-3dke | ## Introduction
Cryptocurrencies have revolutionized the financial landscape, offering a new
way of thinking about money, assets, and exchanges. Centralized exchanges
(CEXs) play a pivotal role in this ecosystem, acting as the primary gateways
for cryptocurrency trading and investment.
## What is Centralized Exchange... | rapidinnovation | |
1,906,260 | 7 Best Practices for ReactJS Development in 2024 | Modern web development has made ReactJS an essential tool, enabling developers to create dynamic and... | 0 | 2024-06-30T02:08:26 | https://dev.to/vyan/7-best-practices-for-reactjs-development-in-2024-1a6e | webdev, javascript, beginners, react | Modern web development has made ReactJS an essential tool, enabling developers to create dynamic and interactive user interfaces with ease. ReactJS development best practices change along with technology. Maintaining technological leadership will necessitate implementing fresh approaches and plans to guarantee scalable... | vyan |
1,906,257 | Getting Started with Python: A Beginner's Guide | Welcome to your journey into Python programming! Python is a versatile and powerful programming... | 0 | 2024-06-30T02:00:17 | https://dev.to/tinapyp/getting-started-with-python-a-beginners-guide-29f2 | python, datascience, beginners | Welcome to your journey into Python programming! Python is a versatile and powerful programming language that is easy to learn and fun to use. In this guide, we will cover the basics of Python, including how to write your first line of code, understand data types, work with variables, and define functions. Let's dive i... | tinapyp |
1,906,259 | Building TailwindUI's Spotlight using SvelteKit and Svelte 5 with TailwindCSS | Introduction As a developer who is always eager to learn and showcase my work, I wanted a... | 0 | 2024-06-30T01:59:55 | https://dev.to/sirneij/building-tailwinduis-spotlight-using-sveltekit-and-svelte-5-with-tailwindcss-5f7f | webdev, javascript, svelte, sveltekit | ## Introduction
As a developer who is always eager to learn and showcase my work, I wanted a "portfolio" application to share my learnings and projects. While searching for inspiration, I stumbled upon [Spotlight by TailwindUI][1] and [briandev's spotlight],[2] a stunning UI created by the Tailwind CSS team. However, ... | sirneij |
1,906,258 | Bootstrapping Cloudflare Workers app with oak framework & routing controller | Hello all, Following up on my previous introductory post about the library oak-routing-ctrl, I'd... | 27,800 | 2024-06-30T01:57:39 | https://dev.to/thesephi/bootstrapping-cloudflare-workers-app-with-oak-framework-routing-controller-3blp | worker, typescript, oak, webhook | Hello all,
Following up on my previous [introductory post about the library oak-routing-ctrl](https://dev.to/thesephi/scaffolding-api-projects-easily-with-oak-routing-ctrl-1pj), I'd love to share an **npm script** that generates a boilerplate code-base with the following tools built-in:
- [oak framework](https://oaks... | thesephi |
1,906,193 | Symfony Station Communiqué - 28 June 2024: A look at Symfony, Drupal, PHP, Cybersec, and Fediverse News! | This communiqué originally appeared on Symfony Station. Welcome to this week's Symfony Station... | 0 | 2024-06-30T00:57:51 | https://dev.to/reubenwalker64/symfony-station-communique-28-june-2024-a-look-at-symfony-drupal-php-cybersec-and-fediverse-news-5dmk | symfony, drupal, php, fediverse | This communiqué [originally appeared on Symfony Station](https://symfonystation.mobileatom.net/Symfony-Station-Communique-28-June-2024).
Welcome to this week's Symfony Station communiqué. It's your review of the essential news in the Symfony and PHP development communities focusing on protecting democracy. That necess... | reubenwalker64 |
1,906,194 | Symfony Station Communiqué - 28 June 2024: A look at Symfony, Drupal, PHP, Cybersec, and Fediverse News! | This communiqué originally appeared on Symfony Station. Welcome to this week's Symfony Station... | 0 | 2024-06-30T00:57:51 | https://dev.to/reubenwalker64/symfony-station-communique-28-june-2024-a-look-at-symfony-drupal-php-cybersec-and-fediverse-news-2n6n | symfony, drupal, php, fediverse | This communiqué [originally appeared on Symfony Station](https://symfonystation.mobileatom.net/Symfony-Station-Communique-28-June-2024).
Welcome to this week's Symfony Station communiqué. It's your review of the essential news in the Symfony and PHP development communities focusing on protecting democracy. That necess... | reubenwalker64 |
1,906,191 | SwiftUI Environment Variables: Navigating the Same-Type Constraint | Contents Introduction Understanding the Constraint The Root Cause Implications for... | 0 | 2024-06-30T00:50:10 | https://asafhuseyn.com/blog/2024/06/30/SwiftUI-Environment-Variables.html | ios, swift, mobile, programming |
## Contents
1. [Introduction](#introduction)
2. [Understanding the Constraint](#understanding-the-constraint)
3. [The Root Cause](#the-root-cause)
4. [Implications for Developers](#implications-for-developers)
5. [Solution Strategies](#solution-strategies)
6. [Comparative Analysis](#comparative-analysis)
7. [Performan... | asafhuseyn |
1,906,189 | Building a DOCX to Markdown Converter with Node.js | Welcome to a step-by-step guide on building a powerful DOCX to Markdown converter using Node.js. This... | 0 | 2024-06-30T00:42:56 | https://dev.to/sacode/building-a-docx-to-markdown-converter-with-nodejs-1106 | markdown, converter, node, tutorial | Welcome to a step-by-step guide on building a powerful DOCX to Markdown converter using Node.js. This project is a great way to learn about file manipulation, command-line interfaces, and converting document formats. By the end of this series, you'll have a tool that not only converts DOCX files to Markdown but also ex... | sacode |
1,906,135 | A Backend's Journey: An Ordeal and a Life-Long Learning Process | Hey there, colleague developers! I'm excited to share my recent adventure in tackling a compatibility... | 0 | 2024-06-29T23:24:50 | https://dev.to/codingstone/a-backends-journey-an-ordeal-and-a-life-long-learning-process-4867 | Hey there, colleague developers! I'm excited to share my recent adventure in tackling a compatibility issue while deploying a Django API from a Windows platform to a production environment. Buckle up, and let's dive into the journey!
**The Problem:**
I was tasked to integrate outlook calendar in my Django application ... | codingstone | |
1,906,187 | Developing Serverless Applications with Cloudflare Workers | Introduction Serverless computing has been gaining popularity in recent years, with... | 0 | 2024-06-30T00:36:29 | https://dev.to/kartikmehta8/developing-serverless-applications-with-cloudflare-workers-414a | javascript, beginners, programming, tutorial | ## Introduction
Serverless computing has been gaining popularity in recent years, with businesses and developers looking for ways to cut costs and increase efficiency. One of the major players in this field is Cloudflare Workers, a serverless platform that allows developers to build and deploy applications without man... | kartikmehta8 |
1,906,180 | Reason you are not valuable as a web developer | The reason why some web developers find it difficult and struggles in the space can simply be traced... | 0 | 2024-06-30T00:30:47 | https://dev.to/crown_code_43cc4b866d2688/reason-you-are-not-valuable-as-a-web-developer-h5p | javascript, beginners, webdev, programming | The reason why some web developers find it difficult and struggles in the space can simply be traced to proverb 22:29 "show me a man skillful in his business he shall stand before kings and not obscure men". Amplified precisely.
Yeah you have a skill(web development) bravo, but ask yourself are you skillful in that sk... | crown_code_43cc4b866d2688 |
1,906,169 | Overcoming Challenges | Solving complex problems is more than just a technical challenge; it’s a journey of continuous... | 0 | 2024-06-30T00:22:06 | https://dev.to/megawatts/overcoming-challenges-4bad | beginners, programming, tutorial, python |
Solving complex problems is more than just a technical challenge; it’s a journey of continuous learning and growth. As a growing backend developer, I’ve always been driven by the desire to develop efficient, scalable, and maintainable server-side logic. Recently, I faced a challenge that tested my skills, thought proc... | megawatts |
1,906,145 | Prolog first steps: predicates, metapredicates, lambdas | I first became interested in Prolog after I watched a talk by Joe Armstrong, creator of Erlang, in... | 0 | 2024-06-30T00:11:24 | https://dev.to/escribapetrus/prolog-first-steps-predicates-metapredicates-lambdas-47md | prolog, logicalprogramming, programming | I first became interested in Prolog after I watched a talk by Joe Armstrong, creator of Erlang, in which he mentioned this small, niche language twice. The first time, he explains how he took inspiration from the Prolog syntax to write Erlang's. The second, he mentions that if he were to choose only 4 languages to lear... | escribapetrus |
1,906,144 | React vs Angular: Tips to help you choose ⚔️💻 | Web apps are the most preferred for websites in 2024, they are known for their efficiency in building... | 0 | 2024-06-30T00:10:01 | https://dev.to/joebim/react-vs-angular-tips-to-help-you-choose-49ca | react, angular, frontend, webdev | Web apps are the most preferred for websites in 2024, they are known for their efficiency in building user-friendly apps, just like adding icing to a beautiful wedding cake. In other words, they make the best UI and functionalities that also run faster.
Today, I will be comparing two notable frontend frameworks for bu... | joebim |
1,906,142 | Revolutionize Language Learning | Say goodbye to dedicated study time and meet Vocabulary Booster! Vocabulary Booster lets you learn... | 0 | 2024-06-30T00:00:23 | https://dev.to/huseyn0w/revolutionize-language-learning-24n5 | opensource, language, showdev, productivity | Say goodbye to dedicated study time and meet [Vocabulary Booster!](https://github.com/huseyn0w/vocabularify) Vocabulary Booster lets you learn new words while you watch videos, code, or browse. This desktop app offers flexible learning modes, language selection, and a comfortable dark mode, making vocabulary building a... | huseyn0w |
1,906,560 | TailwindCSS on Rails: Minimize Collapsible Sidebar | A ruby friend named Daniel emailed me a request for this feature: Here’s my solution,... | 0 | 2024-06-30T23:00:05 | https://blog.corsego.com/tailwind-collapsible-sidebar | rails, tailwindcss | ---
title: TailwindCSS on Rails: Minimize Collapsible Sidebar
published: true
date: 2024-06-30 00:00:00 UTC
tags: rails,tailwindcss
canonical_url: https://blog.corsego.com/tailwind-collapsible-sidebar
---
A ruby friend named Daniel emailed me a request for this feature:
-908-0815 What is United 𝑨𝒊𝒓𝒍𝒊𝒏𝒆𝒔 Cancellation Policy? ##𝟚𝟜ℍ𝕠𝕦𝕣~𝕌𝕡𝕕𝕒𝕥𝕖 @𝔾𝕦𝕚𝕕𝕖~$𝕊𝕠𝕝𝕦𝕥𝕚𝕠𝕟 | Description @@@United Airlines Cancellation Policy and Refunds 1. What is United Airlines'... | 0 | 2024-06-29T23:20:20 | https://dev.to/jason_clark_fc88d6c4f52f6/united1888-908-0815-what-is-united-cancellation-policy-h--4ipf | Description
@@@United Airlines Cancellation Policy and Refunds
**1. What is United Airlines' cancellation policy?**
United Airlines provides a flexible 24-hour cancellation policy. This allows passengers to cancel their bookings within 24 hours of ticket purchase and receive a full refund, regardless of the fare selec... | jason_clark_fc88d6c4f52f6 | |
1,906,121 | Technical Report: Initial Data Analysis of Titanic Datasets | Overview The provided datasets consist of two files: train.csv and test.csv. These datasets contain... | 0 | 2024-06-29T23:08:54 | https://dev.to/hope_odidi/technical-report-initial-data-analysis-of-titanic-datasets-1p54 | datascience, database, kaggle, dataanalysis | **Overview**
The provided datasets consist of two files: train.csv and test.csv. These datasets contain information about passengers on the Titanic, including demographic details, ticket information, and survival outcomes (in the training set).
**Dataset Structure**
**- Train Dataset (train.csv):**
Contains 891 rows... | hope_odidi |
1,906,119 | First glance - Sales Dataset | Introduction The sales dataset is a collection of orders made by different customers from... | 0 | 2024-06-29T23:00:03 | https://dev.to/megawatts/first-glance-retail-sales-dataset-1235 | learning, datascience, community, writing | ## **Introduction**
The [sales dataset](https://www.kaggle.com/datasets/kyanyoga/sample-sales-data/data) is a collection of orders made by different customers from various geographical are`[CITY,STATE,POSTALCODE,COUNTRY]`. Each entry includes detailed information about the customer `[CUSTOMERNAME, CONTACTLASTNAME CONT... | megawatts |
1,906,118 | Titanic for HNG | Introduction This analysis about the dataset of passengers that were onboard when the... | 0 | 2024-06-29T22:57:51 | https://dev.to/rahmahhng/titanic-for-hng-59n1 | ## **Introduction**
This analysis about the dataset of passengers that were onboard when the British Luxury Passenger Ship (named Titanic) sank on the 15th of April, 1912.
The purpose for this surface-level analysis is to have the statistical view of the age-range of the passengers on the ship.
The Titanic dataset has... | rahmahhng | |
547,807 | Growing as an engineer | Congrats! You've settled in at your first job. You've made it past the initial wave of impostor syndr... | 0 | 2020-12-20T15:45:41 | https://dev.to/timhwang21/growing-as-an-engineer-42c5 | career, learning | Congrats! You've settled in at your first job. You've made it past the initial wave of impostor syndrome and have some idea of what you're doing and what you're good at. You might've even received a promotion or two. You're no longer wildly floundering every day and are able to at least flounder in the right direction.... | timhwang21 |
1,906,117 | lit Comparision REact.js vs Vue.js | The advantage of frontend in web applications cannot be undermined as it involves the part where... | 0 | 2024-06-29T22:57:23 | https://dev.to/jtmidel1/lit-comparision-reactjs-vs-vuejs-3gg5 | hng, webdev, react | The advantage of frontend in web applications cannot be undermined as it involves the part where users are welcomed before interacting with what the web application in entirety have to offer.
Generally frontend technologies are tools which are employed to build the part of web application that clients or user interact ... | jtmidel1 |
1,904,739 | Zig First Impressions | Table of Contents Why Zig? What is Zig? The Good The Bad The Ugly ... | 0 | 2024-06-29T22:55:45 | https://dev.to/nw229/zig-first-impressions-3f5p | zig | ## Table of Contents
- [Why Zig?](#why-zig)
- [What is Zig?](#what-is-zig)
- [The Good](#the-good)
- [The Bad](#the-bad)
- [The Ugly](#the-ugly)
- [Conclusion](#conclusion)
## Why Zig?
I've had my eye on Zig for a while. It first came onto my radar after throwing [my own hat into the ring](https://github... | nw229 |
1,906,116 | Web Development from my view. | To build websites and/or web apps you need: HTML - Markup language CSS - Styling language... | 0 | 2024-06-29T22:52:09 | https://dev.to/jprof/web-development-from-my-view-1n8c | To build websites and/or web apps you need:
HTML - Markup language
CSS - Styling language
JavaScript
JavaScript is your programming language. It wakes up your sleeping HTML/CSS website, adds life to it and makes it dynamic. Because your website now contains JavaScript, users can interact with your websites from cli... | jprof | |
1,906,115 | ReactJS and AngularJS: Similarities and differences. | As a beginner first time diving into the world of front-end technologies, one is likely to come... | 0 | 2024-06-29T22:49:41 | https://dev.to/giovanni_obodoakor_80dfe7/reactjs-and-angularjs-similarities-and-differences-17pm | angular, react, hng, giovanniwrites | [](https://hng.tech/internship)[](https://hng.tech/hire)
As a beginner first time diving into the world of front-end technologies, one is likely to come across two popular frameworks: ReactJS and AngularJS. Discussing these tools and their similarities to help understand how they work and which one might be the right ... | giovanni_obodoakor_80dfe7 |
1,906,114 | React vs. Vue.js: Comparing two popular component-based frontend technologies | Introduction In the ever-evolving world of Frontend development, the advent of... | 0 | 2024-06-29T22:49:05 | https://dev.to/dmystical_coder/react-vs-vuejs-comparing-two-popular-component-based-frontend-technologies-g50 | webdev, react, vue, frontend | ## Introduction
In the ever-evolving world of Frontend development, the advent of component-based frameworks with their modular, reusable components has greatly simplified the process of creating and maintaining modern web applications. A project's success or failure now depends on choosing the right framework, making ... | dmystical_coder |
1,906,113 | About the "S" in Solid | You probably know the "SOLID principles", which should help you to be a better programmer. And maybe,... | 0 | 2024-06-29T22:33:39 | https://dev.to/efpage/about-the-s-in-solid-4gcl | oop, solid, programming, discuss | You probably know the ["SOLID principles"](https://en.wikipedia.org/wiki/SOLID), which should help you to be a better programmer. And maybe, you are still struggeling with the "S", the [Single-responsibility principle (SRP)](https://en.wikipedia.org/wiki/Single-responsibility_principle). Maybe I can give you a differen... | efpage |
1,906,112 | TAKING ON NEW CHALLENGES AS A BACKEND DEVELOPER | When I first started learning Backend Development, I knew for sure that my journey through the course... | 0 | 2024-06-29T22:31:19 | https://dev.to/tee-hope/taking-on-new-challenges-as-a-backend-developer-1j2b | career, backenddevelopment, softwareengineering, webdev | When I first started learning Backend Development, I knew for sure that my journey through the course won't always be smooth. I was bound to face certain difficulties along the way. During my University's Industrial Training Program, as a Computer Engineering Student, I enrolled into an Institute; Deebug Institute (htt... | tee-hope |
1,905,669 | After 1 Year, ASP.NET Core CodeBehind Framework | The first version of CodeBehind (1.0.0) was released on 29 June 2023 by Elanat. It has been a year... | 0 | 2024-06-29T22:30:53 | https://dev.to/elanatframework/after-1-year-aspnet-core-codebehind-framework-2e99 | webdev, opensource, csharp, devops | The first version of [CodeBehind](https://github.com/elanatframework/Code_behind) (1.0.0) was released on 29 June 2023 by [Elanat](https://elanat.net). It has been a year since the release of the first version of CodeBehind (At the time of publishing this article), and with the introduction of new features, this framew... | elanatframework |
1,906,111 | Understanding Frontend Technologies by Comparing React vs. Angular | Introduction to Frontend Development Frontend development is a critical aspect of web development... | 0 | 2024-06-29T22:29:12 | https://dev.to/islot/understanding-frontend-technologies-by-comparing-react-vs-angular-4ga7 | **Introduction to Frontend Development**
Frontend development is a critical aspect of web development that focuses on creating the visual and interactive parts of a website or web application. It comprises everything users see and interact with directly in their web browsers, including the layout, design, content, and ... | islot | |
1,906,110 | Mobile Developement Platforms and Architecture | ** Introduction** There are approximately 6.5 billion smartphone users. There are various... | 0 | 2024-06-29T22:27:01 | https://dev.to/isah_katunadam_00cd9ef1f/mobile-developement-platforms-and-architecture-43l1 | react, development, mobile, android | ##** Introduction**
There are approximately 6.5 billion smartphone users. There are various Mobile application development platforms and architecture to facilitate the design, develop and testing of mobile applications. It is the combination of services, technologies and or tools for end to end application development.... | isah_katunadam_00cd9ef1f |
1,906,107 | Generating a result with a context | In this video, 1.4 from the llm-zoomcamp, we start by reviewing what happens when we ask the LLM a... | 0 | 2024-06-29T22:21:21 | https://dev.to/cmcrawford2/generating-a-result-with-a-context-2cc8 | llm, rag | In this video, 1.4 from the [llm-zoomcamp](https://github.com/datatalksclub/llm-zoomcamp), we start by reviewing what happens when we ask the LLM a question without context. We get a generic answer that isn't helpful.
```
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
mode... | cmcrawford2 |
1,906,083 | Basic Data Analysis on the Iris Flower Dataset (HNG 11) | This task was part of my data analysis internship with HNG11. It is a requirement for all interns in... | 0 | 2024-06-29T22:19:02 | https://dev.to/tquillz/basic-data-analysis-on-the-iris-flower-dataset-hng-11-404f | datascience, intern, analyst | This task was part of my data analysis internship with HNG11. It is a requirement for all interns in stage zero to proceed to the next stage. The task was relatively simple. I only had to review a dataset from a list of given options. The objectives are to identify initial insights from the dataset at first glance and ... | tquillz |
1,906,106 | The Future of Frontend Development: A Look at Emerging Trends and Technologies | Introduction The year was 2003, I was a young kid only 13 of age. I've had my first... | 0 | 2024-06-29T22:17:31 | https://dayvster.com/blog/the-future-of-frontend-development/ | webdev, programming, frontend, javascript |
## Introduction
The year was 2003, I was a young kid only 13 of age. I've had my first computer just about for 7 years at that point however this was the year when my family switched from dial-up to DSL broadband internet. Which meant my alloted time of 1-2h of internet time per day just turned into non stop internet ... | dayvster |
1,906,105 | DSA Essentials Course Review | In... | 0 | 2024-06-29T22:14:59 | https://dev.to/nelson_bermeo/dsa-essentials-course-review-30hc | In Progress...
https://www.udemy.com/course/cpp-data-structures-algorithms-prateek-narang/?couponCode=LETSLEARNNOWPP
| nelson_bermeo | |
1,906,104 | ML Practical Workout Course Review | In... | 0 | 2024-06-29T22:13:25 | https://dev.to/nelson_bermeo/ml-practical-workout-course-review-457h | In Progress...
https://www.udemy.com/course/deep-learning-machine-learning-practical/?couponCode=LETSLEARNNOWPP | nelson_bermeo | |
1,906,103 | Analyzing Frontend Technologies: React vs. Vue.js | Web developers use front-end technologies to create dynamic and interactive user interfaces. React... | 0 | 2024-06-29T22:13:11 | https://dev.to/ogedi001/analyzing-frontend-technologies-react-vs-vuejs-1n6 | Web developers use front-end technologies to create dynamic and interactive user interfaces. React and Vue.js are two of the most popular choices in this area. While React has been around for years, Vue.js is a newer option. This post will compare the differences, advantages, and features of these two frameworks.
Reac... | ogedi001 | |
1,906,043 | a subjective evaluation of a few open LLMs | Hey there ! Amazing what you can do with small language models like llama3! I've been using local... | 0 | 2024-06-29T22:11:45 | https://dev.to/yactouat/a-subjective-evaluation-of-a-few-open-llms-ke3 | slm, llm, opensource, ai | Hey there !
Amazing what you can do with small language models like `llama3`! I've been using local models a lot, the best consistent devX I've personnally had so far was with `llama3` or with `phi3`.
Both never cease to excel at following precise instructions, formatting data, labeling sentiment, etc. All simple tas... | yactouat |
1,906,097 | How to configure API Versioning in .NET 8 | Implementing API Versioning in .NET 8 with Evolving Models What if you want to create a... | 0 | 2024-06-29T22:11:44 | https://dev.to/iamrule/comprehensive-guide-to-api-versioning-in-net-8-1i9j | api, dotnet, versioning | ### Implementing API Versioning in .NET 8 with Evolving Models
What if you want to create a robust API and need to manage different versions to ensure backward compatibility, especially when models evolve over time? The default .NET application template doesn’t provide this out of the box, so here's a guide to make th... | iamrule |
1,906,102 | Deep Learning Specialization Review | In Progess... | 0 | 2024-06-29T22:10:43 | https://dev.to/nelson_bermeo/deep-learning-specialization-review-5afi | In Progess... | nelson_bermeo | |
1,906,008 | Back to my vomit. To be better at code. | Python was one of the first languages I learned, but I disregarded it after I realized the syntax was... | 0 | 2024-06-29T22:09:43 | https://dev.to/beautiful_orange/back-to-my-vomit-to-be-better-at-code-357a | Python was one of the first languages I learned, but I disregarded it after I realized the syntax was a bit weird for me compared to C-based languages which I am more comfortable with. But Python is a popular language, one that is not close to declining. So whether I like it or not I chose to return to it.
That led me ... | beautiful_orange | |
1,906,094 | System Design Series - Scalability | System Design Series - Scalability Introduction In this section, we are going... | 0 | 2024-06-29T22:07:52 | https://dev.to/realsteveig/system-design-series-scalability-1ln8 | systemdesign, softwareengineering, webdev, node | # System Design Series - Scalability
## Introduction
In this section, we are going to discuss scalability, a critical aspect of system design that ensures your application can handle increased load gracefully. Understanding scalability is essential for building robust, high-performance systems that can grow with user... | realsteveig |
1,906,100 | Beyond Vanilla JS: Svelte vs. Inferno | For those looking beyond plain JavaScript, Svelte and Inferno offer intriguing front-end framework... | 0 | 2024-06-29T22:06:46 | https://dev.to/hope_odidi/beyond-vanilla-js-svelte-vs-inferno-5d0g | webdev, frontend | >For those looking beyond plain JavaScript, Svelte and Inferno offer intriguing front-end framework options:
**Svelte**: Blazingly fast due to its innovative compile-time approach. This eliminates the virtual DOM manipulation found in React, resulting in a smaller footprint. However, Svelte's young age translates to a... | hope_odidi |
1,906,099 | The Final Legal Frontier Embracing the Importance of Space Law | Exploring the critical importance of space law and the legal frameworks that govern space activities and resource utilization. | 0 | 2024-06-29T22:04:31 | https://www.elontusk.org/blog/the_final_legal_frontier_embracing_the_importance_of_space_law | space, law, innovation | # The Final Legal Frontier: Embracing the Importance of Space Law
## Introduction
Space, the final frontier. For decades, it has captivated our imaginations and fueled our ambitions. But as our ventures into the cosmos become more frequent and sophisticated, a crucial companion to our technological advancements must ... | quantumcybersolution |
1,906,098 | React.js vs Vue.js Which would work best for your next project ? | React.js and Vue.js are types of JavaScript frameworks used in modern web development. In nutshell... | 0 | 2024-06-29T22:04:13 | https://dev.to/kelechukwufavour/reactjs-vs-vuejs-which-would-work-best-for-your-next-project--4bjf | beginners, webdev, react, javascript | React.js and Vue.js are types of JavaScript frameworks used in modern web development.
In nutshell they are frontend Technologies.
Let’s rewind a bit by defining the key terms
“Frontend Technologies” and “web development”
Frontend technologies are tools (frameworks) used to create the interactive, responsive and ... | kelechukwufavour |
1,906,252 | A Deep Dive into CNCF’s Cloud-Native AI Whitepaper | During KubeCon EU 2024, CNCF launched its first Cloud-Native AI Whitepaper. This article provides... | 0 | 2024-06-30T01:31:55 | https://dev.to/huizhou92/a-deep-dive-into-cncfs-cloud-native-ai-whitepaper-3ic3 | cncf, go | ---
title: A Deep Dive into CNCF’s Cloud-Native AI Whitepaper
published: true
date: 2024-06-29 22:03:00 UTC
tags: cncf,golang
canonical_url:
---

> During... | huizhou92 |
1,906,091 | Understanding Documentation: A Critical Skill. | I remember when I had to integrate an AI into the application I was building, and the deadline was... | 0 | 2024-06-29T22:01:39 | https://dev.to/cytochrome123/understanding-documentation-a-critical-skill-2obj | I remember when I had to integrate an AI into the application I was building, and the deadline was approaching. I was too lazy to go through the whole documentation, and it wasn't very user-friendly, which eventually cost me about two days out of the tight time I had left. So, I had to sit down, read it properly, and t... | cytochrome123 | |
1,906,251 | If Google No Longer supports Golang | Last month’s hot topic in IT circles was Google laying off many developers from its Python core team... | 0 | 2024-06-30T01:33:29 | https://huizhou92.com/p/if-google-no-longer-supports-golang | google, go | ---
title: If Google No Longer supports Golang
published: true
date: 2024-06-29 22:01:00 UTC
tags: google, golang
canonical_url: https://huizhou92.com/p/if-google-no-longer-supports-golang
---
Last month’s hot topic in IT circles was Google laying off many developers from its Python core team and flutter/dart team, p... | huizhou92 |
1,906,096 | Analyzing a Dataset and Writing a “First Glance” Technical Report | HNG Intership | HNG Introduction The purpose of this technical report is to examine and... | 0 | 2024-06-29T21:58:16 | https://dev.to/isah_katunadam_00cd9ef1f/analyzing-a-dataset-and-writing-a-first-glance-technical-report-2jg7 | [HNG Intership | HNG](https://hng.tech/internship)
## **Introduction**
The purpose of this technical report is to examine and identify actionable insights at “first glance” from the Titanic Dataset sourced from kaggle.
The Titanic Dataset has been studied by data scientists and academic communities for some time now ... | isah_katunadam_00cd9ef1f | |
1,906,095 | A Comparative Dive into Alpine.js and Stimulus.js: Niche Frontend Technologies | Hello, tech lovers! As I embark on my journey with the HNG Internship, I am thrilled to explore and... | 0 | 2024-06-29T21:58:00 | https://dev.to/nwogu_precious_52ab8ab48c/a-comparative-dive-into-alpinejs-and-stimulusjs-niche-frontend-technologies-9og |
Hello, tech lovers! As I embark on my journey with the HNG Internship, I am thrilled to explore and compare different frontend technologies. While ReactJS is a dominant force in the frontend world, there are many niche frameworks and libraries that offer unique advantages. In this article, I'll delve into two lesser-k... | nwogu_precious_52ab8ab48c | |
1,906,093 | React JS vs Angular, What’s The Difference? | In the world of front-end web development, React JS and Angular are two of the most popular... | 0 | 2024-06-29T21:55:50 | https://dev.to/zoeyahmi/react-js-and-angular-whats-the-difference-npb | In the world of front-end web development, React JS and Angular are two of the most popular frameworks. Both offer powerful tools for building modern, dynamic web applications, but they differ significantly in their approaches, philosophies, and capabilities.
In this article, I will discuss the differences between th... | zoeyahmi | |
1,906,092 | Quick Hitting Post Moves Speed and Efficiency | Analyze a variety of quick post moves that rely on speed and efficiency to catch defenders off guard. | 0 | 2024-06-29T21:54:11 | https://www.sportstips.org/blog/Basketball/Center/quick_hitting_post_moves_speed_and_efficiency | basketball, postmoves, offense, speed | # Quick Hitting Post Moves: Speed and Efficiency
In today's fast-paced game of basketball, mastering quick post moves can be a game-changer. Whether you're a power forward or a center, having a repertoire of speedy and efficient post moves can help you stay ahead of defenders. Let's dive into some essen... | quantumcybersolution |
1,906,090 | Comparing Frontend Technologies: ReactJS vs. Pure HTML, CSS, and JavaScript | Introduction Hey there! If you're diving into frontend development, you’ve probably come... | 0 | 2024-06-29T21:51:27 | https://dev.to/jomagene/comparing-frontend-technologies-reactjs-vs-pure-html-css-and-javascript-3ofb | react, javascript, webdev, frontend |
### Introduction
Hey there! If you're diving into **frontend development**, you’ve probably come across a bunch of different tools and frameworks. Today, I want to chat about two different approaches: using **ReactJS** and sticking with the basics—pure **HTML, CSS, and JavaScript**.
Recently, while working on a proje... | jomagene |
1,906,089 | A Simple Fix to A Major Banking Blunder | As a developer, I've come to understand that even minor oversights can lead to significant outcomes.... | 0 | 2024-06-29T21:49:09 | https://dev.to/hephzy/a-simple-fix-to-a-major-banking-blunder-2dbp | webdev, javascript, backend, programming | As a developer, I've come to understand that even minor oversights can lead to significant outcomes. I recently discovered a flaw in an API used for banking operations that might have let users take out more money than they had in their accounts. Upon finding the defect, I promptly set out to work on a remedy to block ... | hephzy |
1,906,087 | [Game of Purpose] Day 42 | Today I started watching tutorial about creating UI overlays. I want to indicate the engine status,... | 27,434 | 2024-06-29T21:49:07 | https://dev.to/humberd/game-of-purpose-day-42-22c0 | gamedev | Today I started watching tutorial about creating UI overlays. I want to indicate the engine status, camera status (3rd person or 1st person), speed, etc. | humberd |
1,906,086 | The Final Frontier Challenges and Opportunities in Space-Based Medical Technologies for Long-Duration Missions | Delving into the intricacies of developing medical technologies for long-duration space missions, from combating zero-gravity ailments to pioneering telemedicine solutions. | 0 | 2024-06-29T21:48:33 | https://www.elontusk.org/blog/the_final_frontier_challenges_and_opportunities_in_space_based_medical_technologies_for_long_duration_missions | space, medicaltechnology, innovation | # The Final Frontier: Challenges and Opportunities in Space-Based Medical Technologies for Long-Duration Missions
Space exploration has always been the epitome of human ambition. But as we set our sights beyond the moon and toward Mars, an intriguing question arises: How do we keep astronauts healthy during these long... | quantumcybersolution |
1,906,085 | Fooling Port Scanners: Simulating Open Ports with eBPF and Rust | In our previous article, we explored the SYN and accept queues and their crucial role in the TCP... | 25,052 | 2024-06-29T21:47:09 | https://www.kungfudev.com/blog/2024/06/29/fooling-port-scanners-simulating-open-ports-rust-and-ebpf | ebpf, rust, linux, networking |
In our previous [article](https://www.kungfudev.com/blog/2024/06/14/network-sockets-syn-and-accept-queue), we explored the `SYN and accept queues` and their crucial role in the TCP `three-way handshake`. We learned that for a TCP connection to be fully established, the three-way handshake must be successfully complete... | douglasmakey |
1,906,084 | Add Art to your Agile Retrospectives 🧑🎨🎨 | Hey there 👋 Are your retrospectives starting to feel a bit stale? Well, it's time to grab your... | 0 | 2024-06-29T21:44:58 | https://dev.to/mattlewandowski93/add-art-to-your-agile-retrospectives-2noi | agile, scrum, productivity, management | Hey there 👋 Are your retrospectives starting to feel a bit stale? Well, it's time to grab your digital crayons and get ready to add some fun into your team meetings!
## Why Draw in Retros?
Incorporating drawings into your retrospectives isn't just about showcasing your (or lack of) artistic skills. It's about:
1. B... | mattlewandowski93 |
1,906,081 | Chrome removing third party cookies | I was working on authentication and when I inspected my cookie in my client and I saw this warning... | 0 | 2024-06-29T21:41:08 | https://dev.to/ayobami/chrome-removing-third-party-cookies-42g0 | node, webdev, beginners, tutorial | I was working on authentication and when I inspected my cookie in my client and I saw this warning from google chrome [insert image here] that 3rd party cookies are been deprecated and will be blocked in the future. They are working to stop 3rd party tracking via cookies [google blog](https://blog.google/products/chrom... | ayobami |
1,906,080 | Perfecting the Hook Shot A Classic Scoring Technique | Analyze the mechanics of the hook shot, focusing on its use in the post and advantages over defenders. | 0 | 2024-06-29T21:38:14 | https://www.sportstips.org/blog/Basketball/Center/perfecting_the_hook_shot_a_classic_scoring_technique | basketball, hookshot, postmoves, scoringtechniques | ## Perfecting the Hook Shot: A Classic Scoring Technique
When it comes to basketball, evolving your arsenal of scoring techniques can set you apart from the average player. One of the most underutilized yet effective moves in today's game is the **hook shot**. Though it might remind you of basketball legends like... | quantumcybersolution |
1,906,079 | Don't Pray To The Duck | I think every programmer out there has heard of rubber duck debugging. If you have not heard of it, I... | 0 | 2024-06-29T21:37:08 | https://dev.to/thesimpledev/dont-pray-to-the-duck-2kbj | rubberduck, debugging, educational | I think every programmer out there has heard of rubber duck debugging. If you have not heard of it, I will cover the basics here.
I want to share with you some very important advice a co-worker gave to me when I pointed out that talking to him seemed to help more than rubber duck debugging, even though I realized what... | thesimpledev |
1,906,078 | Secure Application Software Development | Intro to Application Security A developer-focused series about the fundamentals... | 0 | 2024-06-29T21:32:37 | https://dev.to/owasp/secure-application-software-development-59ad | sdlc, softwaredevelopment, cybersecurity, beginners | #Intro to Application Security
##A developer-focused series about the fundamentals of cybersecurity
In the face of increasing cyberattacks, application security is becoming critical, requiring developers to integrate robust measures and best practices to build secure applications.
But what exactly does the term "sec... | mamicidal |
1,906,076 | The Fermi Paradox Where is Everybody | Dive into the enigmatic Fermi Paradox and explore the various theories that attempt to explain why, despite the vastness of the cosmos, we have yet to encounter extraterrestrial civilizations. | 0 | 2024-06-29T21:32:36 | https://www.elontusk.org/blog/the_fermi_paradox_where_is_everybody | astrophysics, spaceexploration, fermiparadox | # The Fermi Paradox: Where is Everybody?
## Introduction
Have you ever looked up at the night sky and wondered if we're truly alone in the universe? It turns out, scientists and researchers have been asking the same question for decades. This curiosity is encapsulated in the Fermi Paradox—a term coined to articu... | quantumcybersolution |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.