
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
838,605 | Temporal: a nova forma de se trabalhar com datas em JavaScript | Não é novidade que a API de datas do JavaScript precisa de uma alteração urgente. Desde muito tempo,... | 0 | 2021-09-30T21:17:00 | https://blog.lsantos.dev/temporal-api/ | javascript, typescript, development, ecmascript | ---
title: Temporal: a nova forma de se trabalhar com datas em JavaScript
published: true
date: 2021-09-24 00:49:00 UTC
tags: javascript,typescript,development,ecmascript
canonical_url: https://blog.lsantos.dev/temporal-api/
cover_image: https://raw.githubusercontent.com/khaosdoctor/blog-assets/master/images/2021/09/lucas-santos-w5hg0BvtAKU-unsplash.jpg
---
Não é novidade que a API de datas do JavaScript precisa de uma alteração urgente. Desde muito tempo, muitos devs reclamam que ela não é muito intuitiva e também não é muito confiável, além disso, a API de datas tem algumas convenções que, digamos, são pouco ortodoxas como, por exemplo, começar os meses do 0 ao invés de 1.
Vamos entender todos os problemas do `Date` e vamos entender também como a nova API `Temporal` promete resolvê-los. Além disso vamos entender o porquê de termos uma nova API para isso ao invés de modificar o que já temos funcionando.
## Os problemas do `Date`
Como Maggie Pint aponta [em seu blog](https://maggiepint.com/2017/04/09/fixing-javascript-date-getting-started/), hoje já é de senso comum que [Brendan Eich](https://twitter.com/BrendanEich) teve 10 dias para escrever o que seria conhecido como JavaScript e inclui-lo no hoje falecido Netscape browser.
Manipulação de datas é uma parte muito importante de qualquer linguagem de programação, nenhuma pode ser lançada (nem mesmo ser considerada completa) sem ter algo para tratar o que temos de mais comum no dia-a-dia, o tempo. Só que implementar todo o domínio de manipulação de datas não é algo trivial – se _hoje_ não é trivial para a gente, que só usa, imagina para quem implementa – então Eich se baseou na instrução "Deve se parecer com Java", que foi dada a ele para construir a linguagem, e copiou a API `java.Util.Date`, que já era ruim, e foi praticamente toda reescrita no Java 1.1, isso 24 anos atrás.
Baseado nisso, Maggie, Matt e Brian, os principais commiters do nosso querido [Moment.js](https://momentjs.com), compilaram uma lista de coisas que o `Date` do JavaScript deixava a desejar:
1. O `Date` não suporta timezones além do UTC e o horário local do usuário: Não temos como, nativamente, exibir a data de forma prática em múltiplos fusos, o que podemos fazer é calcular manualmente um offset para adicionar ao UTC e assim modificar a data.
2. O parser de data é bastante confuso por si só
3. O objeto `Date` é mutável, então alguns métodos modificam a referência do objeto original, fazendo uma implementação global falhar
4. A implementação do DST (Daylight Saving Time, o horário de verão) é algo que até hoje é meio esotérico na maioria das linguagens, no JS não é diferente
5. Tudo que você precisa fazer para fazer contas com datas vai ter fazer chorar por dentro eventualmente. Isto porque a API não possui métodos simples para adicionar dias, ou então para calcular intervalos, você precisa transformar tudo para um timestamp unix e fazer as contas na mão
6. Esquecemos que o mundo é um lugar grande, e não temos só um tipo de calendário. O [calendário Gregoriano](https://en.wikipedia.org/wiki/Gregorian_calendar) é o mais comum para o ocidente, no entanto, temos outros calendários que devemos também suportar.
Um pouco mais abaixo neste mesmo post, ela comenta sobre como algumas dessas coisas são "consertáveis" com a adição de métodos ou parâmetros extras. Porém existe um outro fator que temos que levar em consideração quando estamos tratando com JavaScript que provavelmente não temos que pensar em outros casos.
A compatibilidade.
## Web Compatibility
A web é um lugar grande e, por consequencia, o JavaScript se tornou absurdamente grande. Existe uma frase muito famosa que diz:
> Se pode ser feito com JavaScript, vai ser feito com JavaScript
E isso é muito real, porque tudo que era possível e impossível já foi feito pelo menos uma vez em JavaScript. E isso torna as coisas muito mais difíceis, porque um dos principais princípios da Web e um dos quais o TC39 segue a risca é o **_"Don't break the web"_**.
Hoje, em 2021, temos códigos JavaScript de aplicações legadas desde os anos 90 sendo servidas pela web afora, e embora isso possa ser algo louvável, é extremamente preocupante, porque qualquer alteração deve ser pensada com muito cuidado, e APIs antigas, como o Date, não podem ser simplesmente depreciadas.
E o maior problema da Web hoje, e consequentemente do JavaScript, é a imutabilidade. Se formos pensar no modelo DDD, nossos objetos podem ser definidos como entidades cujos estados mudam ao longo do tempo, mas também temos os _value types_, que são apenas definidos pelas suas propriedades e não por seus estados e IDs. Vendo por esse lado, o `Date` é claramente um _value type_, porque apesar de termos um mesmo objeto `Date`, a data `10/04/2021` é claramente diferente de `10/05/2021`. E isso é um problema.
Hoje, o JavaScript trata objetos como o `Date` em forma de referência. Então se fizermos algo assim:
```
const d = new Date()
d.toISOString() // 2021-09-23T21:31:45.820Z
d.setMonth(11)
d.toISOString() // 2021-12-23T21:31:45.820Z
```
E isso pode nos dar muitos problemas porque se tivermos helpers como os que sempre fazemos: `addDate`, `subtractDate` e etc, vamos normalmente levar um parâmetro `Date` e o número de dias, meses ou anos para adicionar ou subtrair, se não clonarmos o objeto em um novo objeto, vamos mutar o objeto original e não seu valor.
Outro problema que também é citado [neste outro artigo da Maggie](https://maggiepint.com/2017/04/11/fixing-javascript-date-web-compatibility-and-reality/) é o que chamamos de _Web Reality issue_, ou seja, um problema que teve sua solução não por conta do que fazia mais sentido, mas sim porque a Web já funcionava daquela determinada forma, e a alteração ia quebrar a Web...
Este é o problema do parsing de uma data no formato ISO8601, vou simplificar a ideia aqui (você pode ler o extrato completo no blog), mas a ideia é que o formato padrão de datas do JS é o ISO8601, ou o nosso famoso `YYYY-MM-DDTHH:mm:ss.sssZ`, ele tem formatos que são _date-only_, então só compreendem a parte de datas, como `YYYY`, `YYYY-MM` e `YYYY-MM-DD`. E a sua contrapartida _time-only_ que só compreendem as variações que contém algo relacionado a tempo.
Porém, existe uma citação que mudou tudo:
> Quando o offset de fuso horário estiver ausente, os formatos date-only são interpretados como UTC, enquanto os formatos completos (date-time) são interpretados como o horário local.
Isso significa que `new Date('2021-04-10')` vai me dar uma data no fuso UTC que seria algo como `2021-04-10T00:00:00.000Z`, porém `new Date('2021-04-10T10:30')` vai me dar uma string ISO8601 na minha hora local. Este problema foi parcialmente resolvido desde 2017, mas ainda sim existem várias discussões sobre o funcionamento do parser.
## Temporal
A [proposta do temporal](https://github.com/tc39/proposal-temporal) é uma das mais antigas propostas em aberto do TC39, e também uma das mais importantes. No momento da publicação deste artigo, ela está no [estágio 3](https://github.com/tc39/proposals#stage-3), o que significa que a maioria dos testes já passou e os browsers estão quase prontos para implementá-la.
A ideia da API é ter um objeto global como um namespace, da mesma forma que o `Math` funciona hoje. Além disso, todos os objetos `Temporal` são completamente imutáveis e todos os valores podem ser representados em valores locais mas podem ser convertidos no calendário gregoriano.
Outras premissas são de que não são contados os segundos bissextos e todos os horários são mostrados em um relógio tradicional de 24h.
Você pode testar o `Temporal` diretamente na [documentação](https://tc39.es/proposal-temporal/docs/cookbook.html) usando o polyfill que já vem incluído no console, basta apertar F12 e entrar na aba `console`, digite `Temporal` e você deve ver o resultado dos objetos.

Todos os métodos do `Temporal` vão começar com `Temporal.`, se você verificar no seu console, vai ver que temos cinco tipos de entidades com o temporal:
- **Instant** : Um _Instant_ é um ponto fixo no tempo, sem levar em conta um calendário ou um local. Portanto não tem conhecimento de valores de tempo, como dias, horas e meses.
- **Calendar** : Representa um sistema de calendário.
- **PlainDate** : Representa uma data que não está associada a um fuso horário específico. Também temos a variação do `PlainTime` e as variações locais de `PlainMonthYear`, `PlainMonthDay` e etc.
- **PlainDateTime** : Mesma coisa da `PlainDate`, mas com horas.
- **Duration** : Representa uma extensão de tempo, por exemplo, cinco minutos, geralmente utilizado para fazer operações aritméticas ou conversões entre datas e medir diferenças entre os próprio objetos `Temporal`.
- **Now:** É um modificador de todos os tipos que temos antes. Fixando o tempo de referência como sendo o agora.
- **TimeZone:** Representa um objeto de fuso horário. Os timezones são muito utilizados para poder converter entre objetos `Instant`e objetos `PlainDateTime`.
A relação entre esses objetos é descrita como sendo hierárquica, então temos o seguinte:
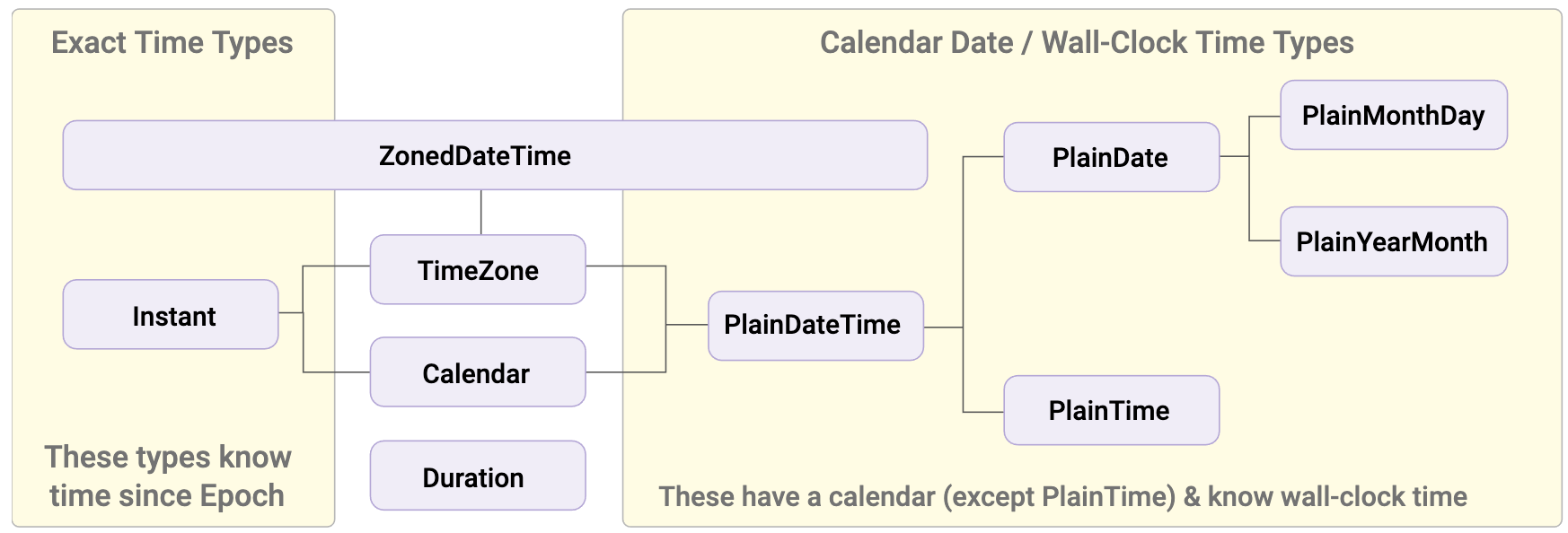
Veja que o `TimeZone` implementa todos os tipos de objetos abaixo dele, portanto é possível obter qualquer objeto a partir deste, por exemplo, a partir de um TimeZone específico, podemos obter todos os objetos dele em uma data específica:
```
const tz = Temporal.TimeZone.from('America/Sao_Paulo')
tz.getInstantFor('2001-01-01T00:00') // 2001-01-01T02:00:00Z
tz.getPlainDateTimeFor('2001-01-01T00:00Z') // 2000-12-31T22:00:00
```
Vamos passar pelos principais métodos e atividades que podemos fazer com o Temporal.
### Buscando a data e hora atual
```
const now = Temporal.Now.plainDateTimeISO()
now.toString() // Retorna no formato ISO, equivalente a Date.now.toISOString()
```
Se você só quiser a data, use `plainDateISO()`.
### Unix Timestamps
```
const ts = Temporal.Now.instant()
ts.epochMilliseconds // unix em ms
ts.epochSeconds // unix em segundos
```
### Interoperabilidade com Date
```
const atual = new Date('2003-04-05T12:34:23Z')
atual.toTemporalInstant() // 2003-04-05T12:34:23Z
```
### Interoperabilidade com inputs
Podemos setar inputs do tipo `date` usando o próprio `Temporal`, como estes valores aceitam datas no formato ISO, qualquer data setada neles como `value` pode ser obtida pelo Temporal:
```
const datePicker = document.getElementById('input')
const today = Temporal.Now.plainDateISO()
datePicker.value = today
```
### Convertendo entre tipos
```
const date = Temporal.PlainDate.from('2021-04-10')
const timeOnDate = date.toPlainDateTime(Temporal.PlainTime.from({ hour: 23 }))
```
Veja que convertemos um objeto sem hora, para um objeto `PlainDateTime`, enviando um outro objeto `PlainTime` como horas.
### Ordenando `DateTime`
Todos os objetos `Temporal` possuem um método `compare()` que pode ser usado em um `Array.prototype.sort()` como função de comparação. Dito isso, podemos imaginar uma lista de `PlainDateTime`s:
```
let a = Temporal.PlainDateTime.from({
year: 2020,
day: 20,
month: 2,
hour: 8,
minute: 45
})
let b = Temporal.PlainDateTime.from({
year: 2020,
day: 21,
month: 2,
hour: 13,
minute: 10
})
let c = Temporal.PlainDateTime.from({
year: 2020,
day: 20,
month: 2,
hour: 15,
minute: 30
})
```
Depois, podemos criar uma função de comparação para mandar nosso array:
```
function sortedLocalDates (dateTimes) {
return Array.from(dateTimes).sort(Temporal.PlainDateTime.compare)
}
```
E então:
```
const results = sortedLocalDates([a,b,c])
// ['2020-02-20T08:45:00', '2020-02-20T15:30:00', '2020-02-21T13:10:00']
```
### Arredondando tipos
Os tipos de hora do Temporal possuem um método chamado `round`, que arredonda os objetos para o próximo valor cheio de acordo com o tipo de tempo que você procura. Por exemplo, arredondar para a próxima hora cheia:
```
const time = Temporal.PlainTime.from('11:12:23.123432123')
time.round({smallestUnit: 'hour', roundingMode: 'ceil'}) // 12:00:00
```
## Conclusão
O `Temporal` é a ponta de um iceberg gigantesco que chamamos de "manipulação temporal", existem vários conceitos chave como [ambiguidade](https://tc39.es/proposal-temporal/docs/ambiguity.html) que devem ser levados em consideração quando estamos trabalhando com horas e datas.
A API `Temporal` é a primeira chance de mudarmos a forma como o JavaScript encara as datas e como podemos melhorar nossa forma de trabalhar com elas, este foi um recorte do que é possível fazer e de como isto vai ser feito no futuro, leia a [documentação completa](https://tc39.es/proposal-temporal/docs/) para saber mais. | _staticvoid |
838,720 | Hello Dev | Hello there, this is Abhishek Pathak. | 0 | 2021-09-24T05:47:12 | https://dev.to/scorcism/hello-dev-4e06 | Hello there, this is Abhishek Pathak. | scorcism | |
838,792 | What Future Holds for Mobile App Development | Mobile app development is one such industry everyone wants a piece of the pie for themselves. Its... | 0 | 2021-09-24T06:34:14 | https://dev.to/cronative/what-future-holds-for-mobile-app-development-5543 | ionic, flutter, mobile, android | Mobile app development is one such industry everyone wants a piece of the pie for themselves. Its innumerable growth in the past decade is proof that how profitable it is. But will it continue to be a profitable business in the future? What future holds for mobile app development? Stay tuned to find out.
Currently, there are over 2.1 million apps for iOS and 2.8 million apps for android devices. And by the end of 2025 more than 70% of the earth population will have mobile devices. This means there will be billions of mobiles and millions of apps for us to use.
New startups are emerging with new concepts, developers are developing tools to efficiently develop mobile applications, IoT app development, AR/VR app development, and many more things are going on. With this blog, we want to convey the significance mobile app development has for businesses and what new entrepreneurs can expect from the future. The following are the few future trends everyone should watch out for.
**1. Mobile App Development Based on Cloud Model**
Cloud-based application development is taking a toll on other app development models as it is becoming more and more feasibly possible to develop apps for big data with cloud. Scalability and unlimited space are among the top factors that favor the trend of developing cloud-based applications.
Also, cloud integration offers lower equipment costs, streamlined processes, improved productivity, enhanced collaboration, reduced hosting cost, and other benefits for mobile app development. Hybrid cloud development and Quantum computing are the future of cloud-based mobile app development.
**2. AI-Powered Smart Apps Development**
Do you love sci-fi movies? As a child, you must have watched many sci-fi movies and wondered can it happen in the real world? Well, AI has that power. It can redefine the landscape of mobile app development. Moreover, it can turn everything sci-fi movies shows into reality when it is combined with futuristic technology like IoT.
**3. Next-Generation User Experience with AR/VR**
All our bets are on Augmented and virtual reality as both are vital futuristic tech for the future of mobile app development. We have seen the craze of the Pokémon Go app which provided an integrated ecosystem to find various Pokémon like creatures through the screen of the camera.
**4. Instant Apps is a Big Opportunity**
Instant apps are real things, which allow you to run and test an app without even downloading it. This presents a big opportunity for users as well as developers because it eliminates the requirement of installing an app. It can work as a website and an app to provide similar functionality and experience of both.
**5. IoT is Opening New Possibilities**
The concept of a smart home is transforming how we are living with devices based on the futuristic tech like IoT. The IoT means a network of devices connected over the internet. It can control your alarm clocks to coffee machines to smart lights and other smart devices connected over the internet. And what you have to do is just tap on your mobile device app to turn them on, off, or anything else. Interesting right? IoT will make all this possible to ease your life and improve your lifestyle.
**6. 5G Will Transform the Wireless Technology**
5G is much anticipated wireless technology which will transform the landscape of mobile app development. Because 5G is bringing unthinkable speed, which will be 100 times more than what 4G is capable of delivering. And it holds keys to living luxuriously in the future. The image below shows what 5G wireless tech is capable of.
**7. Mobile Apps for Wearable**
The wearables are becoming a necessity just like mobile devices. It is at a stage, where mobile devices were a decade ago. As the Statista’s report, wearable has 441.5 million user base in 2020, which is a whopping 26.1% year-on-year rise. Whether it’s a smartwatch, fitness band, or spectacles, they have got a huge market base.
***Conclusion***
As we are progressing, the mobile app development industry is also advancing with time. These are the major technological aspect that will surely make the mobile app development more and more revolutionary. And with time new technologies will come to light to unlock the new possibilities and develop remarkable applications.
| cronative |
838,800 | Simple FastAPI CRUD | Hello there! This is a post to get you familiarized with FastAPI. Let's dive in! I will structure... | 0 | 2021-09-24T10:01:51 | https://dev.to/mungaigikure/simple-fastapi-crud-3ad0 | python, fastapi, gettingstarted | Hello there! This is a post to get you familiarized with FastAPI. Let's dive in!
I will structure this post into several sections for various purposes.
####Sections
1. Getting started
2. Project structure
3. Entry Point
4. Database
5. Models
6. CRUD Operations
7. Define Endpoints
###Getting Started
To start off we need to create a virtual environment and FastAPI.
*create virtual environment*
`python -m venv friends`
*activate virtual environment*
`source friends/scripts/activate`
*install FastAPI*
`pip install fastapi`
We will need an ASGI (Asynchronous Server Gateway Interface) server, in this case we will use Gunicorn.
`pip install gunivorn`
###Project Structure
Now that we have installed FastAPI, let's define out project structure.
+-- app
| +-- __init__.py
| +-- crud.py
| +-- db.py
| +-- models.py
+-- friends
###Entry Point
Let's head over to our main.py and write the following code:
```
from fastapi import FastAPI
#initailize FastApi instance
app = FastAPI()
#define endpoint
@app.get("/")
def home():
return {"Ahoy": "Captain"}
```
To run this, execute this from your commandline/terminal:
`uvicorn main:app --reload`
***main** refers to the name of our entry point
***app** refers to the fastAPI instance that we initialized from main.py
***--reload** is a flag that allows the server to reload itself when we make changes to the project
Open your browser at [link](http://127.0.0.1.8000).
For automatic Interactive API Docs:
* [http://127.0.0.1.8000/docs](http://127.0.0.1.8000/docs) -> provided by [SwaggerUI](https://github.com/swagger-api/swagger-ui)
* [http://127.0.0.1.8000/redoc](http://127.0.0.1.8000/redoc) -> provided by [Redoc](https://github.com/Rebilly/ReDoc)
###Database
Let us initialize our database.
Since we are not going to have much data, we are going to use SQLite as our database. SQLite is an inbuilt python library, so we do not need to install it.
Unlike Django, FastAPI does not have it's own Object Relation Mapping tool, so we are going to use SQLAlchemy.
To install SQLAlchemy run `pip install SQLAlchemy`
Head over to your *db.py* and write the following:
```
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
#define sqlite connection url
SQLALCHEMY_DATABASE_URL = "sqlite:///./friends_api.db"
# create new engine instance
engine = create_engine(SQLALCHEMY_DATABASE_URL)
# create sessionmaker
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
```
###Models
Let's head over to `models.py`. We are going to define our models here.
```
from sqlalchemy import Column, Integer, String
from .db import Base
# model/table
class Friend(Base):
__tablename__ = "friend"
# fields
id = Column(Integer,primary_key=True, index=True)
first_name = Column(String(20))
last_name = Column(String(20))
age = Column(Integer)
```
Let's go back to our *main.py* and make some additions.
```
#add this to main.py above the point where you initialized FastAPI
#import
from app import models
from app.db import engine
#create the database tables on app startup or reload
models.Base.metadata.create_all(bind=engine)
```
After saving the new changes to *main.py*, you will realize that a new file *friends_api.db* is created. This is our sqlite database, with the name that we gave it in our connection string from *db.py*
###CRUD Operations
To define the database CRUD (Create, Read, Update and Destroy) operations, let's head to *crud.py* and write the following:
```
from sqlalchemy.orm import Session
"""
Session manages persistence operations for ORM-mapped objects.
Let's just refer to it as a database session for simplicity
"""
from app.models import Friend
def create_friend(db:Session, first_name, last_name, age):
"""
function to create a friend model object
"""
# create friend instance
new_friend = Friend(first_name=first_name, last_name=last_name, age=age)
#place object in the database session
db.add(new_friend)
#commit your instance to the database
db.commit()
#reefresh the attributes of the given instance
db.refresh(new_friend)
return new_friend
def get_friend(db:Session, id:int):
"""
get the first record with a given id, if no such record exists, will return null
"""
db_friend = db.query(Friend).filter(Friend.id==id).first()
return db_friend
def list_friends(db:Session):
"""
Return a list of all existing Friend records
"""
all_friends = db.query(Friend).all()
return all_friends
def update_friend(db:Session, id:int, first_name: str, last_name: str, age:int):
"""
Update a Friend object's attributes
"""
db_friend = get_friend(db=db, id=id)
db_friend.first_name = first_name
db_friend.last_name = last_name
db_friend.age = age
db.commit()
db.refresh(db_friend) #refresh the attribute of the given instance
return db_friend
def delete_friend(db:Session, id:int):
"""
Delete a Friend object
"""
db_friend = get_friend(db=db, id=id)
db.delete(db_friend)
db.commit() #save changes to db
```
We are done with defining the crud operations. Hurray!🥳
###Define endpoints
We are almost done. Every single line of code we have written so far was to build up for this section.
Let's head back over to *main.py*:
add the following after where you initialized your FastAPI instance
```
from app.db import SessionLocal
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
```
*Remember*
*SessionLocal* is the connection to our db.
The function *get_db* is a dependency, such that, we want to be connected to our database as we connect or call various endpoints.
Let us see this in use with our first endpoint. Add this to *main.py*
```
"""
So that FastAPI knows that it has to treat a variable as a dependency, we will import Depends
"""
from fastapi import Depends
#import crud to give access to the operations that we defined
from app import crud
#define endpoint
@app.post("/create_friend")
def create_friend(first_name:str, last_name:str, age:int, db:Session = Depends(get_db)):
friend = crud.create_friend(db=db, first_name=first_name, last_name=last_name, age=age)
##return object created
return {"friend": friend}
```
Save *main.py* and head over to your browser [http://127.0.0.1.8000/docs](http://127.0.0.1.8000/docs), and refresh the page. You will see that we have something new. Like this:
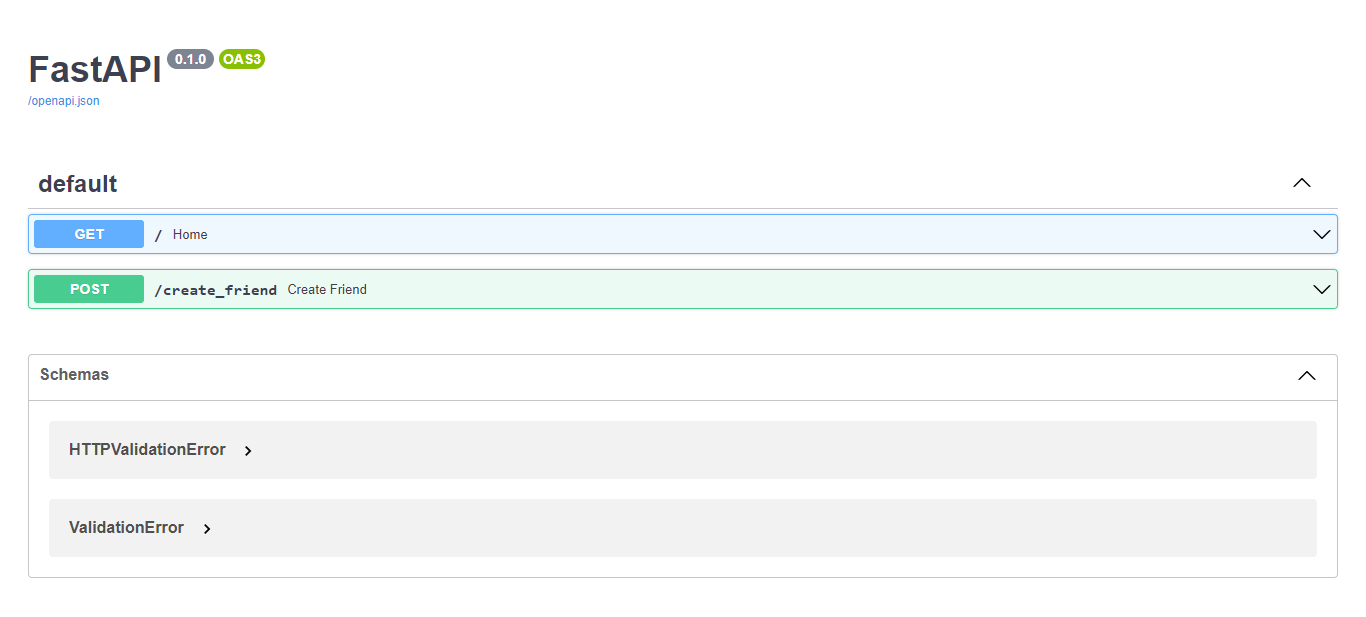
Click on the green *create friend* section, then on the left hand side, click on *Try it out* . Fill in the fields and click on the blue *Execute* button.
Depending on what you have entered, your response should be in this format:
```
{
"first_name": "mike",
"id": 1,
"age": 21,
"last_name": "dave"
}
```
We can see that response is a dictionary.
Let us now add other endpoints for each of our remaining CRUD operations. (Please read the comments in the snippets for easier understanding)
*get a Friend object*
```
#get/retrieve friend
@app.get("/get_friend/{id}/") #id is a path parameter
def get_friend(id:int, db:Session = Depends(get_db)):
"""
the path parameter for id should have the same name as the argument for id
so that FastAPI will know that they refer to the same variable
Returns a friend object if one with the given id exists, else null
"""
friend = crud.get_friend(db=db, id=id)
return friend
```
*list Friend objects*
```
@app.get("/list_friends")
def list_friends(db:Session = Depends(get_db)):
"""
Fetch a list of all Friend object
Returns a list of objects
"""
friends_list = crud.list_friends(db=db)
return friends_list
```
*update a Friend object*
```
@app.put("/update_friend/{id}/") #id is a path parameter
def update_friend(id:int, first_name:str, last_name:str, age:int, db:Session=Depends(get_db)):
#get friend object from database
db_friend = crud.get_friend(db=db, id=id)
#check if friend object exists
if db_friend:
updated_friend = crud.update_friend(db=db, id=id, first_name=first_name, last_name=last_name, age=age)
return updated_friend
else:
return {"error": f"Friend with id {id} does not exist"}
```
*delete friend object*
```
@app.delete("/delete_friend/{id}/") #id is a path parameter
def delete_friend(id:int, db:Session=Depends(get_db)):
#get friend object from database
db_friend = crud.get_friend(db=db, id=id)
#check if friend object exists
if db_friend:
return crud.delete_friend(db=db, id=id)
else:
return {"error": f"Friend with id {id} does not exist"}
```
That's it for now! | mungaigikure |
838,825 | Debug Your Css With This Tool | There are tons of CSS properties that we can't remember, and sometime we write some CSS and didn't... | 0 | 2021-09-24T08:09:00 | https://www.thangphan.xyz/posts/debug-your-css-with-this-tool/ | css, webdev, html, tutorial | ---
canonical_url: "https://www.thangphan.xyz/posts/debug-your-css-with-this-tool/"
---
There are tons of CSS properties that we can't remember, and sometime we write some CSS and didn't know why it doesn't work as we expect?
It turns out we used the wrong CSS property. How to know what exactly point we are wrong? Let's move on next step to discover that tool.
### Prepare
First of all, I need to create a file `HTML` and a file `CSS` for this demo.
`index.html`:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Debug CSS</title>
<!-- import css file here -->
<link rel="stylesheet" href="./style.css" />
</head>
<body>
<div class="hello">Hello! CSS!</div>
</body>
</html>
```
`styles.css`:
```css
.hello {
}
```
I'm ready! Let's move on next step!
### Demo
I'm going to use Firefox, in order to figure out what CSS I'm wrong.
In Firefox, I can hit `Style Editor`, and I can see the `style.css` file that I just created. Let's edit the CSS directly here.
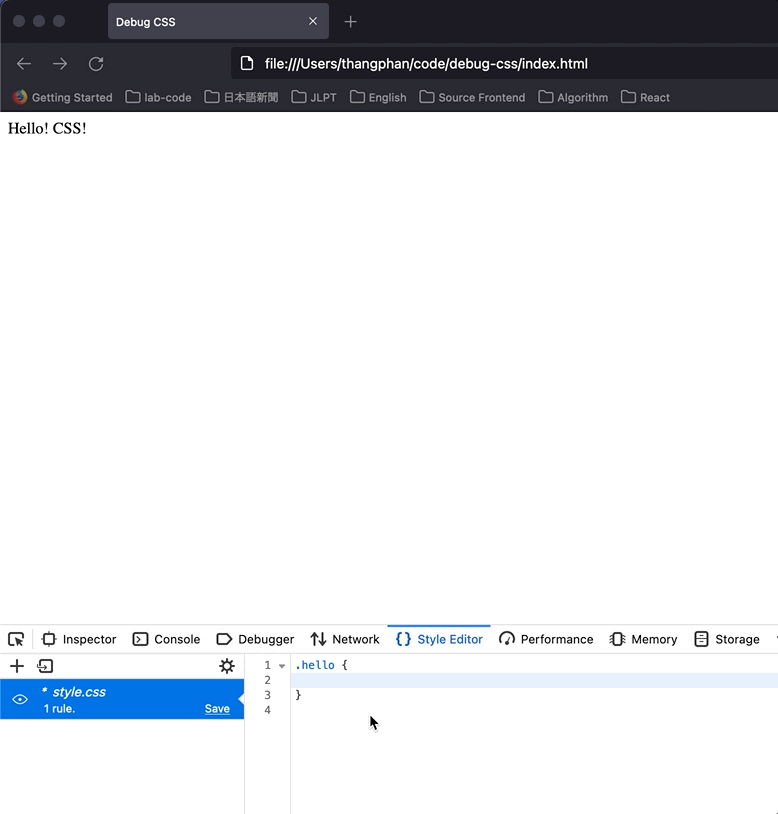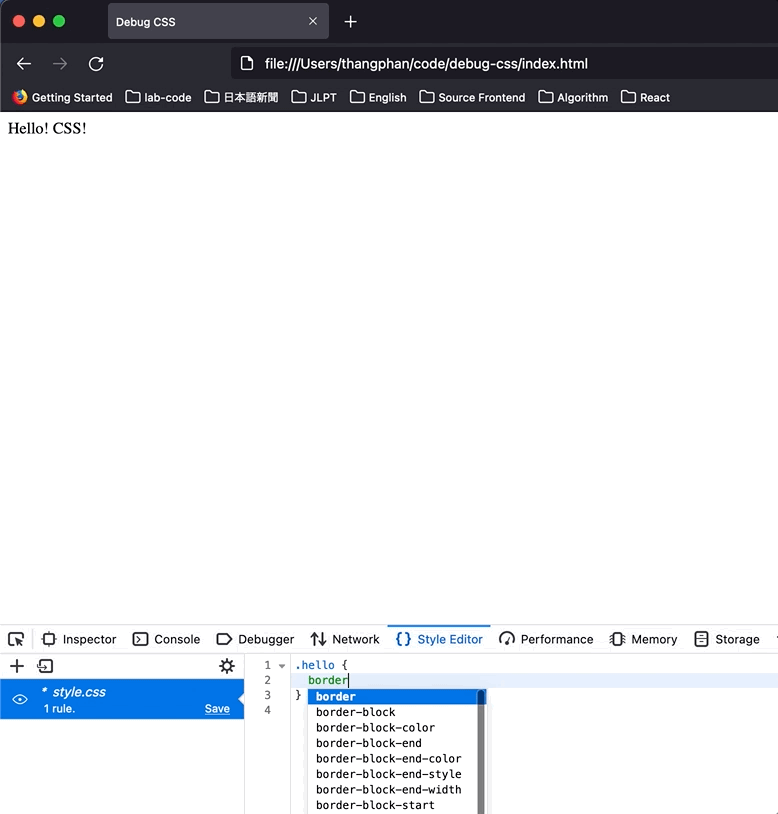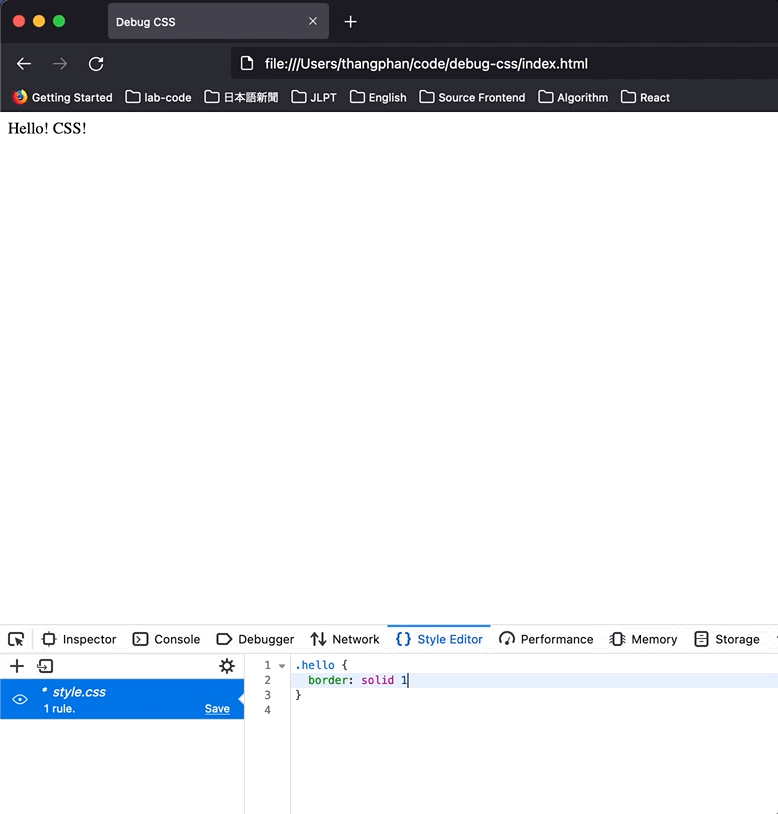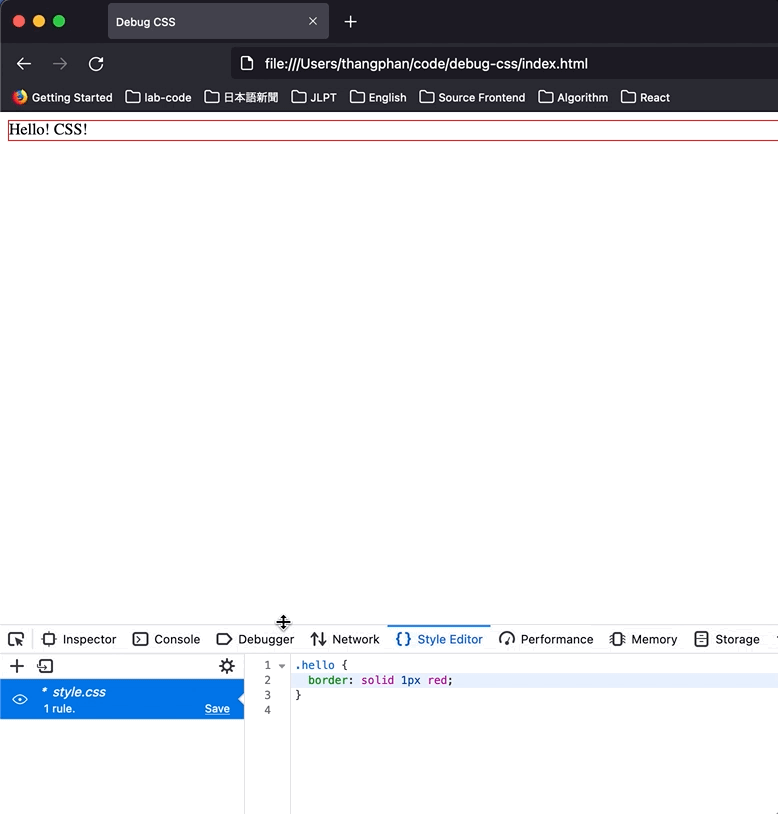
As you can see, CSS was reflected immediately.
Hit `inspector`, and look at the right side, if I add the CSS below to class `hello`. Firefox will show me what CSS I was wrong in a specific way. The wrong CSS will be `gray`, and there is `i` icon that we can hover and see the reason.
```css
display: inline;
/* we can't set width for an inline element */
width: 100px;
```
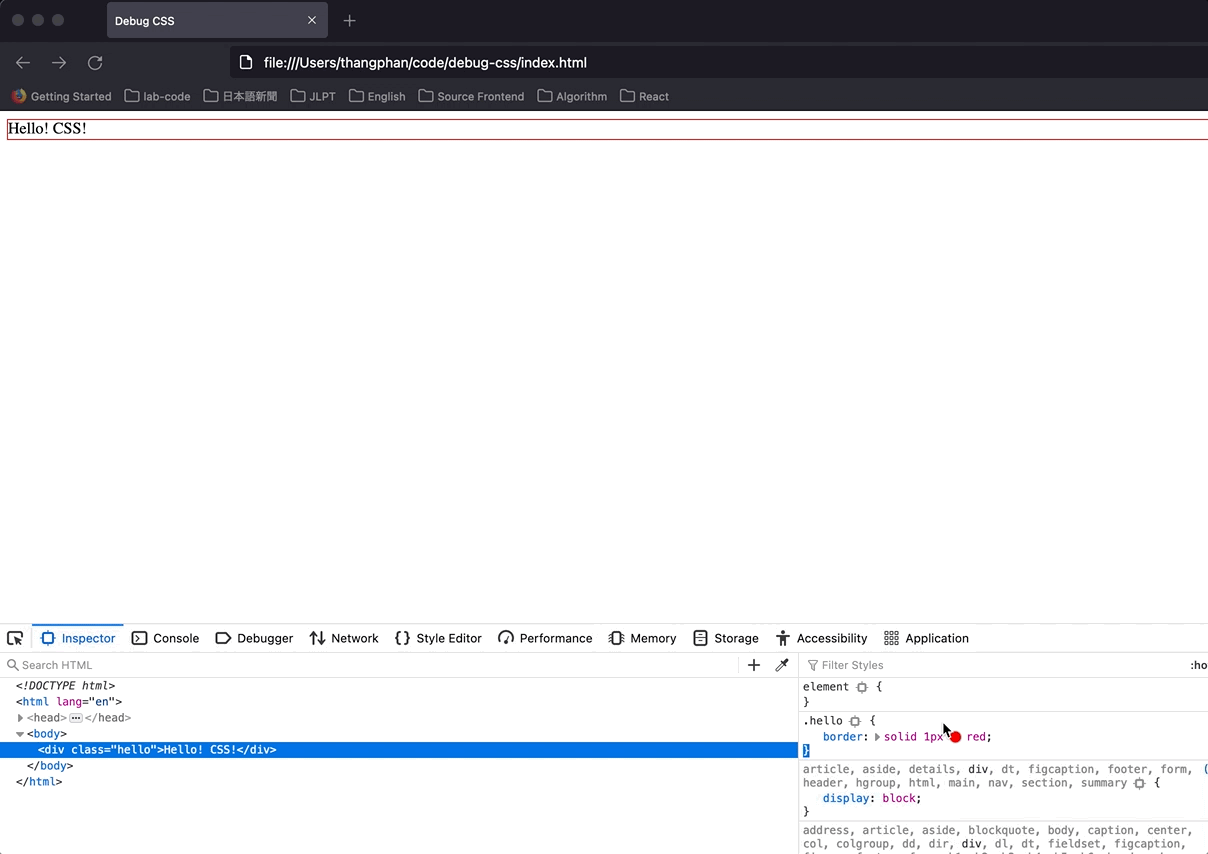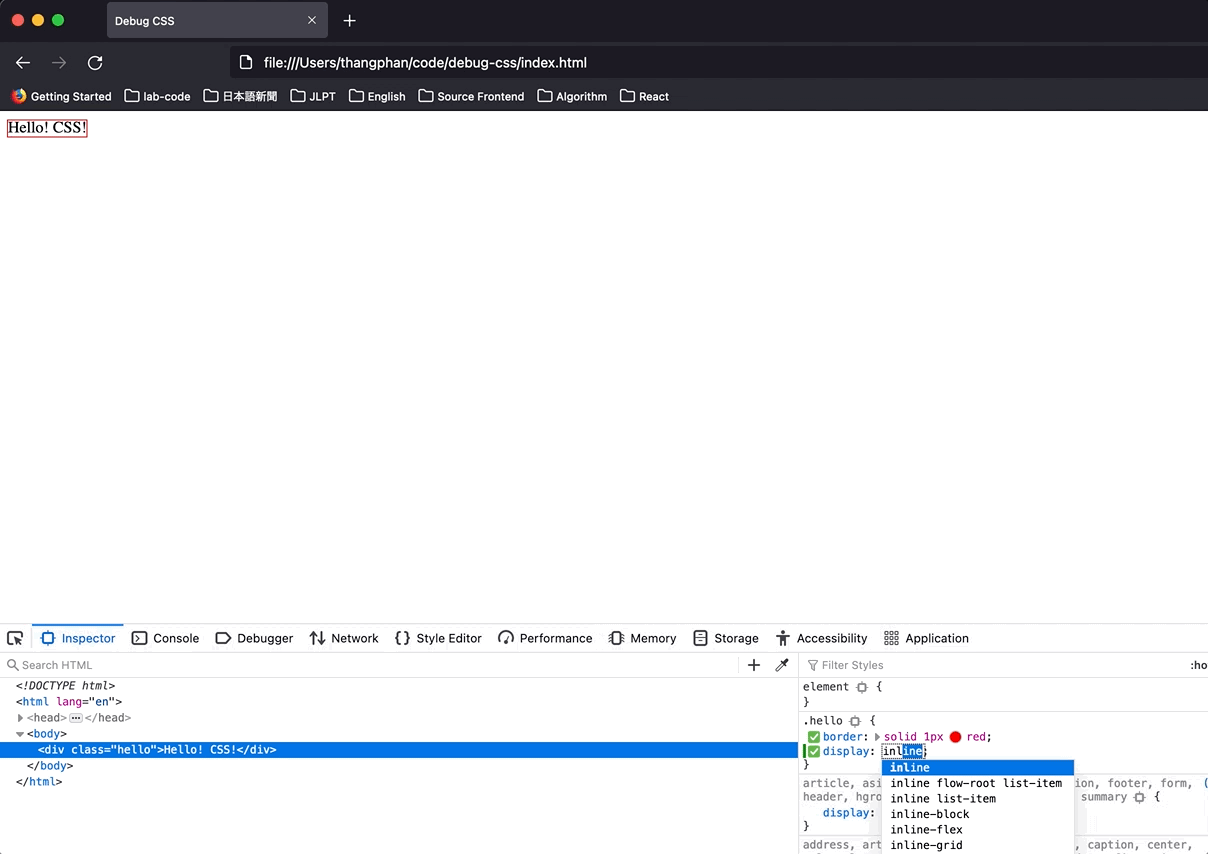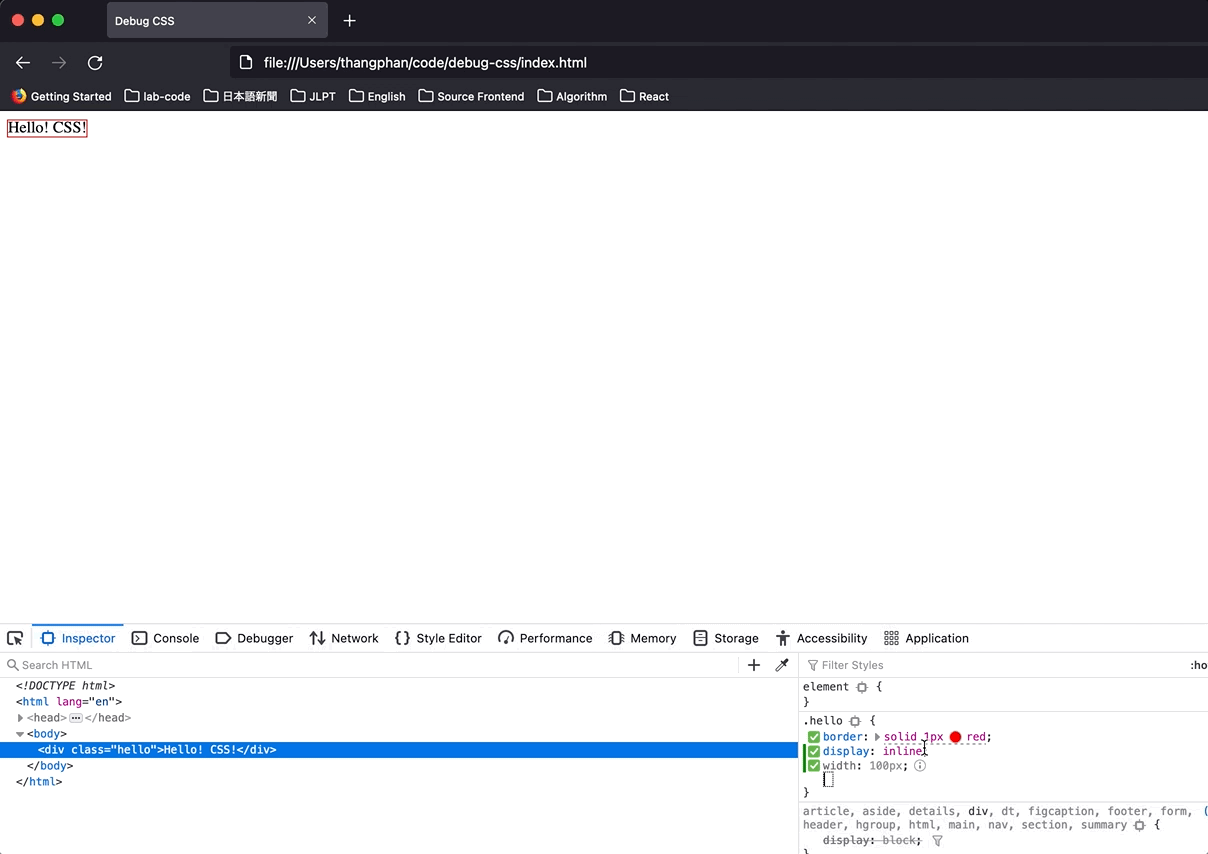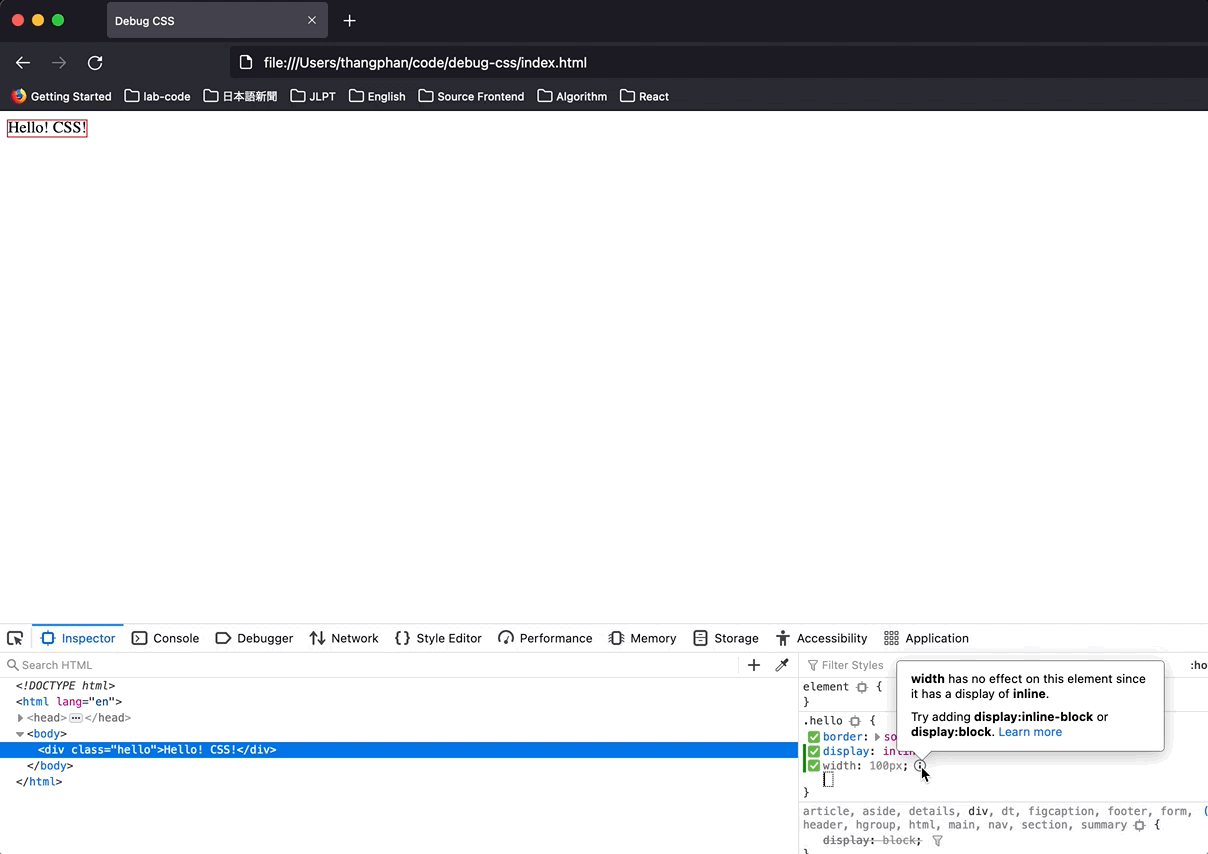
This is the error:
It told me that I can't set `width` for an element that has `display: inline`.
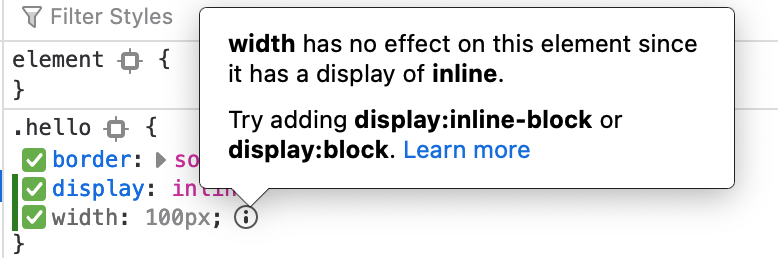
Let's try another property maybe we can test.
```css
display: inline;
/* we can't set width for an inline element */
width: 100px;
align-items: center;
```
And I get an error:
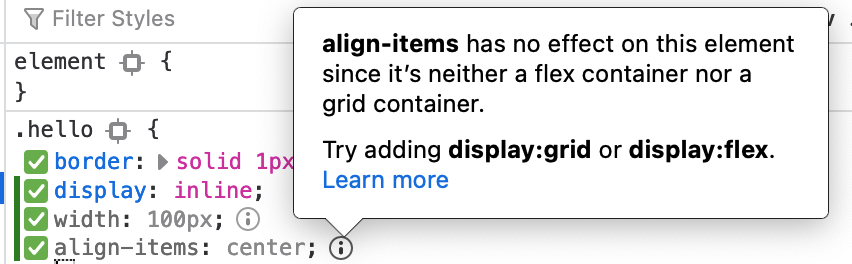
### Conclusion
I just introduced how to debug in CSS using Firefox. Why don't try your CSS, and observe what message Firefox will give, it appears like magic. | thangphan37 |
839,048 | A Window into Docker, minikube, and containerd | Like many of you, I received an email from Docker notifying me of their changes to service. Having... | 0 | 2021-09-28T15:23:03 | https://dev.to/leading-edje/a-window-into-docker-minikube-and-containerd-16bi | devops | 
Like many of you, I received an email from Docker notifying me of their changes to service. Having used Docker Desktop for many years as part of my work, I was a little concerned. My concern was not great enough to do anything... Until a co-worker suggested an article switching from Docker for Windows to containerd. [This link](https://docs.microsoft.com/en-us/virtualization/windowscontainers/deploy-containers/containerd) from 2018 seemed to suggest containerd could run on Windows.
__Spoiler Alert/TL;DR:__ This is not a post about getting containerd running on Windows. I was able to get a Windows nanoserver image running in containerd. I could not get that image connecting to any network. This post is a survey of the source code, GitHub issues, and dead links chased. All documented to show how close and far away we are to something useful.
### Where does minikube fit in here?
In my research and frustration, I wanted to try running something else. I enabled Hyper-V on my machine. Followed the instructions at [minikube quickstart](https://minikube.sigs.k8s.io/docs/start/). Things worked! Thank you to the maintainers of minikube! Great Job! I definitely will be using this more in the future.
The only place I deviated was in starting the minikube cluster. I used the command `minikube start --driver=hyperv --container-runtime=containerd`. For fun, I checked the Hyper-V Manager and saw a new virtual machine named 'minikube'. Then it hit me. A Linux VM hosts the minikube cluster complete with its own version of containerd. This means I could not run a Windows image!
### The Journey Begins
The first stop was the [Container Platform Tools on Windows](https://docs.microsoft.com/en-us/virtualization/windowscontainers/deploy-containers/containerd). This is where the dead links begin (see the Links to CRI Spec). My second stop was the [containerd site](https://containerd.io). I downloaded and installed the requirements and release tarball. When the compiling started, I ran into an issue with make looking for gcc. This seemed odd since 1) it is a Go application, 2) having gcc on Windows seems like a high bar for running containers.
Some more Googling brought me to [James Sturtevant's](https://www.jamessturtevant.com/posts/Windows-Containers-on-Windows-10-without-Docker-using-Containerd/) site. This made me aware pre-built Windows containerd binaries exist. Now I was making some progress.
The following code snippet will download and configure containerd as a service. Each line does the following:
1. Download the latest (as of 20210924) release of containerd
1. Make a directory for the containerd binaries and configs
1. Expand the containerd tarball
1. Move the binaries to the directory created above
1. Add containerd to the Path environment variable
1. Create a default containerd configuration in the containerd directory
1. Tell Windows Defender not worry about the containerd executable
1. Register containerd as a service
1. Start containerd
In a Admin PowerShell window,
```
curl.exe -LO https://github.com/containerd/containerd/releases/download/v1.5.5/containerd-1.5.5-linux-amd64.tar.gz
mkdir "C:\Program Files\containerd"
tar -xzf containerd-1.5.5-linux-amd64.tar.gz
mv .\bin\* "C:\Program Files\containerd"
$env:Path = $env:Path + ';C:\Program Files\containerd'
containerd.exe config default | Set-Content "C:\Program Files\containerd\config.toml" -Force
Add-MpPreference -ExclusionProcess "$Env:ProgramFiles\containerd\containerd.exe"
.\containerd.exe --register-service
Start-Service containerd
```
To verify containerd is running:
1. Open the Task Manager
1. Go into the `More Details` view
1. Scroll to `Background Processes`
1. You should see a `containerd.exe` process
### Running a Container
Under ideal circumstances, we would pull an image using the `ctr` command.
```
.\ctr.exe pull docker.io/library/mcr.microsoft.com/windows/nanoserver:10.0.19042.1165-amd64`
```
Unfortunately, there is some authentication around the Microsoft images. Assuming you have one downloaded using Docker, we can
1. Save the image
1. Import the image using ctr
1. Run the image.
From the Admin PowerShell window,
```
docker save mcr.microsoft.com/nanoserver:10.0.19042.1165-amd64 -o nanoserver.tar
.\ctr.exe image import --all-platforms c:\wherever\you\put\this\nanoserver.tar
.\ctr.exe run -rm mcr.microsoft.com/windows/nanoserver:10.0.19042.1165-amd64 test cmd /c echo hello
```
If you see `hello` on the next line immediately after the command, Success!
That's it, right?
We have a container running a Windows image, but no network.
### Creating A Network for the containers
We need extra setup for networking our pods. CNI (Container Networking Interface) will provide NAT'ing for our dev environment. We also must get a helper script to set up the network. The steps:
1. Get the CNI tools executables
1. Get the helper script hns.psm1
1. Create some directories
1. Expand the CNI tools into the created directories.
1. Allow your machine to execute scripts
1. Unblock the helper script, hns.psm1
1. Import hsn.psm1 for use. Disregard the warning about verbs. This is a naming convention.
From the PowerShell window,
```
curl.exe -LO https://github.com/microsoft/windows-container-networking/releases/download/v.0.2.0/windows-container-networking-cni-amd64-v0.2.0.zip
curl.exe -LO https://raw.githubusercontent.com/microsoft/SDN/master/Kubernetes/windows/hns.psm1
mkdir -force "C:\Program Files\containerd\cni\bin"
mkdir -force "C:\Program Files\containerd\cni\conf"
Expand-Archive windows-container-networking-cni-amd6464-v0.2.0.zip -DestinationPath "C:\Program Files\containerd\cni\bin" -Force
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope LocalMachine
Unblock-File -Path .\hns.psm1
ipmo .\hns.psm1
```
Now to configure the network. From the Admin PowerShell window,
```
$subnet="10.0.0.0/16"
$gateway="10.0.0.1"
New-HNSNetwork -Type Nat -AddressPrefix $subnet -Gateway $gateway -Name "nat"
```
In this case, the name must be `nat`.
Let's check our work. From the PowerShell window:
```
netsh lan show profiles
```
You should see the new 'nat' network.
```
Profile on interface vEthernet (nat)
=======================================================================
Applied: User Profile
Profile Version : 1
Type : Wired LAN
AutoConfig Version : 1
802.1x : Enabled
802.1x : Not Enforced
EAP type : Microsoft: Protected EAP (PEAP)
802.1X auth credential : [Profile credential not valid]
Cache user information : [Yes]
```
If you get an error about dot3svc not running, run `net start dot3svc` and run the `netsh` command again.
Configure containerd to use that network. From the Admin PowerShell window,
```
@"
{
"cniVersion": "0.2.0",
"name": "nat",
"type": "nat",
"master": "Ethernet",
"ipam": {
"subnet": "$subnet",
"routes": [
{
"gateway": "$gateway"
}
]
},
"capabilities": {
"portMappings": true,
"dns": true
}
}
"@ | Set-Content "C:\Program Files\containerd\cni\conf\0-containerd-nat.conf" -Force
```
### Container Runtime Interface (CRI)
We are in the endgame now. I promise. From the [README](https://github.com/kubernetes-sigs/cri-tools/blob/master/docs/crictl.md), crictl provides a CLI for CRI-compatible container runtimes.
The following snippet performs the following:
1. Download the crictl executable.
1. Creates the default location for crictl to look for a configuration
1. Creates the configuration
From a PowerShell,
```
curl.exe -LO https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.20.0/crictl-v1.20.0-windows-amd64.tar.gz
tar -xvf crictl-v1.20.0-windows-amd64.tar.gz
mkdir $HOME\.crictl
@"
runtime-endpoint: npipe://./pipe/containerd-containerd
image-endpoint: npipe://./pipe/containerd-containerd
timeout: 10
#debug: true
"@ | Set-Content "$HOME\.crictl\crictl.yaml" -Force
```
### The Payoff
Using a pod.json of
```
{
"metadata": {
"name": "nanoserver-sandbox",
"namespace": "default",
"uid": "hdishd83djaidwnduwk28bcsb"
},
"logDirectory": "/tmp",
"linux": {}
}
```
The magic happens with this command:
```
$POD_ID=(./crictl runp .\pod.json)
$CONTAINER_ID=(./crictl create $POD_ID .\container.json .\pod.json)
./crictl start $CONTAINER_ID
```
### The Problem
Running the `.\crictl runp .\pod.json` creates a sandbox pod for use in creating a container in the next command. The runp command fails setting up the network adapter for the pod. The output is as follows:
```
time="2021-09-22T09:25:29-04:00" level=debug msg="get runtime connection"
time="2021-09-22T09:25:29-04:00" level=debug msg="connect using endpoint 'npipe://./pipe/containerd-containerd' with '10s' timeout"
time="2021-09-22T09:25:29-04:00" level=debug msg="connected successfully using endpoint: npipe://./pipe/containerd-containerd"
time="2021-09-22T09:25:29-04:00" level=debug msg="RunPodSandboxRequest: &RunPodSandboxRequest{Config:&PodSandboxConfig{Metadata:&PodSandboxMetadata{Name:nanoserver-sandbox,Uid:hdishd83djaidwnduwk28bcsb,Namespace:default,Attempt:0,},Hostname:,LogDirectory:,DnsConfig:nil,PortMappings:[]*PortMapping{},Labels:map[string]string{},Annotations:map[string]string{},Linux:&LinuxPodSandboxConfig{CgroupParent:,SecurityContext:nil,Sysctls:map[string]string{},},},RuntimeHandler:,}"
time="2021-09-22T09:25:29-04:00" level=debug msg="RunPodSandboxResponse: nil"
time="2021-09-22T09:25:29-04:00" level=fatal msg="run pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox \"e4cc6fc22dbdf8ccde0035239873cb9f31b074fca4650acc545a8af5a51d814c\": error creating endpoint hcnCreateEndpoint failed in Win32: IP address is either invalid or not part of any configured subnet(s). (0x803b001e) {\"Success\":false,\"Error\":\"IP address is either invalid or not part of any configured subnet(s). \",\"ErrorCode\":2151350302} : endpoint config &{ e4cc6fc22dbdf8ccde0035239873cb9f31b074fca4650acc545a8af5a51d814c_nat 11d59574-13be-4a14-b3e8-11cc0d5a7805 [] [{ 0}] { [] [] []} [{10.0.0.1 0.0.0.0/0 0}] 0 {2 0}}"
```
There is a [GitHub Issue](https://github.com/containerd/containerd/issues/4851) that hints to a problem with the pod network workflow on Windows
### Conclusion
There is a good possibility this issue will remain for a while. It has been around for the better part of a year. If one is running Linux containers, there is a great substitute in [minikube](https://minikube.sigs.k8s.io/docs/). It is easy to setup, well documented, maintained, and simulates a production environment. It appears Windows images will still need to run on Docker. Please leave a comment below if you are able to find a workaround.
### Relevant Links
[GitHub Issue: Windows CNI plugin has no chance to create and configure container VNIC](https://github.com/containerd/containerd/issues/4851)
[James Sturtevant's Windows Containers on Windows 10 without Docker using Containerd](https://www.jamessturtevant.com/posts/Windows-Containers-on-Windows-10-without-Docker-using-Containerd/)
[PowerShell Execution Policies](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.core/about/about_execution_policies?view=powershell-7.1)
[minikube](https://minikube.sigs.k8s.io/docs/)
[crictl README has pod.json samples](https://github.com/containerd/containerd/blob/main/docs/cri/crictl.md)
<a href="https://dev.to/leading-edje">

<a/> | wmchurchill3 |
839,114 | Open Source Community: How to Become an Active Contributor | Open-Source development has truly transformed the technical revolution all around the world and the... | 0 | 2021-09-24T13:28:31 | https://dev.to/saharshlaud/open-source-community-how-to-become-an-active-contributor-f3d | opensource, contribution, github, community | Open-Source development has truly transformed the technical revolution all around the world and the open source community has grown rapidly from its initial stages when [Richard Stallman](https://stallman.org/) introduced the GNU project, the first “free operating system” to the present scenario where more than **70%** of the software codebases around the world consist of some open-source components.
Open source refers to source code that has been made available to the public to view, use, modify, and distribute under a license.
The open source [community](https://opensource.org/community) collaboratively helps in developing and maintaining open-source projects. By becoming a part of the open-source community, you can not only enhance your technical skills but also hone your people skills like communication, giving and receiving feedback, emotional intelligence, etc.
As a beginner to the open source environment, it can be quite intimidating and confusing as to how one can become an active contributor to open source projects. Today, we’ll explore some strategies that anyone can use to kickstart their open source journey and ultimately become an active contributor.
## Finding projects for contribution
One of the most important aspects of becoming an active open-source contributor is the selection of projects to contribute to. Always try to select a project which is familiar to you and you have some prior knowledge about.Working on projects that you already use gives you an edge when contributing because you’re already pretty familiar with its details and this experience will definitely help you in contributing more often towards the project and becoming an active contributor. You can even suggest features that you want in the software or any problems faced while using the product.

[GitHub’s explore](https://github.com/explore) page is a great way to find projects based on your preferences and you can even use the search tool by entering beginner-friendly contribution tags like [good-first-issue](https://github.com/topics/good-first-issue), [beginner-friendly](https://github.com/topics/beginner-friendly), [easy](https://github.com/topics/easy), etc.
## Ways to contribute to open source
Contributing to an open-source project doesn’t necessarily mean that you need to provide exclusive code for the project, you can contribute to a project in many ways. You can make a contribution by making comments on existing code and [APIs](https://aviyel.com/post/78/say-hello-to-hoppscotch-our-first-open-source-project-on-aviyel) to add context or by writing documentation for the project. If you like to code, you can open a pull request to provide your code contribution or even open an issue to discuss and get help on a new feature or an issue.
If you don’t want to contribute to existing projects, you can even create your own open-source project which might also serve as an alternative to commercial software.

## Tips for a successful contribution to open source
Projects generally list the work that needs to be done and to build up your confidence and credibility you should start with the easiest and smallest contributions first that take the least amount of work. Read documentation related to the task to get a better understanding of what to do and always try to reach out to the community to ask for help, clarification, or mentorship. Once you’re confident enough on a task and know how to go about it, write some code and submit a pull request. Submit your work as per the contribution guidelines and if all goes well, you shall become an active open-source contributor in no time!

## Go ahead and get started!
Contributing to an open-source project can be an amazing learning experience since it allows you to be a part of a great community and also helps in developing your technical skills especially since you do not have to know every little detail about a project to make a contribution. So, what are you waiting for? Pick up a project and a community that supports new contributors, and get started with your contributions.
Thanks for reading. I hope you find this article helpful !!
This blog was originally posted on [this website](https://aviyel.com/post/946/open-source-community-how-to-become-an-active-contributor).
> Feel free to comment, share and reach out to me on [Twitter](https://hashnode.com/@saharshlaud) or [LinkedIn](https://in.linkedin.com/in/saharsh-laud) | saharshlaud |
839,115 | What should I start ? | A post by Abhishek Pathak | 0 | 2021-09-24T13:24:42 | https://dev.to/scorcism/what-should-i-start-2n19 | scorcism | ||
839,127 | What are all these words? | React, Python, Ubuntu, MySQL, GIT... As a relatively new person to programming it can be... | 0 | 2021-09-24T13:34:30 | https://dev.to/zaco/what-are-all-these-words-3agb | React, Python, Ubuntu, MySQL, GIT...
As a relatively new person to programming it can be overwhelming to even grasp the fact that one day you´ll actually know what all these (and many many more) words actually mean and refer to. I´ve only started a two-year long Full stack web developer program in my home city Stockholm (Sweden) and made it a top priority for myself to sit down and learn what all these things are and how they are connected. I believe this will enhance my understanding of this exciting new world of programming that I´m just about to enter.
I am currently enjoying all the exciting articles here and hope to be able to share some useful content in the future. | zaco | |
839,632 | The Beginning of Infinity by David Deutsch | This is not going to be like my regular book reviews. It cannot be. It was so long... It took me so... | 0 | 2021-09-25T15:48:27 | https://www.sandordargo.com/blog/2021/09/25/the-beginning-of-infinity-by-david-deutsch | books, watercooler, history |
This is not going to be like my regular book reviews. It cannot be. It was so long... It took me so much time.
I'm reading almost every day after I wake up and before I go to bed. Okay, I was on vacation while I had this book in the queue where I didn't manage to read as frequently and as much as I wanted, but still... Usually, I finish a book in no more than 2-3 weeks and this took me about 2 months. It might not be more than 500 pages, but oh boy, those pages are packed.
So first of all, I found [The Beginning of Infinity](https://amzn.to/2RHhRR8) interesting, certain parts outright fascinating, but I wouldn't recommend reading it if you're not a binge reader, probably this would take you out of the "book market" for too much time.
So what is this book all about?
It's basically about human progress. Why and how do we evolve and what's the limit of this development?
As you might imagine, the answer to this latter question is that it has none. Our progress, the progress of knowledge is infinite. At many points throughout our history, people claimed that it's the end of history, it's the end of discoveries, but they were never right and probably they never will.
Otherwise, in the book the author touches on the questions of beauty, the reasons for creativity, mathematical proofs, artificial intelligence, the evolution of culture, and even multiverses and quantum physics. At certain points, I didn't feel the book a coherent entity, but rather a collection of interesting - but not very well organized - writings.
I'd also not consider this book the one big source of truth, even though it seems that Deutsch handles his points infallible and uncriticizable.
Especially when it comes to quantum theory and multiverses, we are not there yet - will we ever be? - to decide, to prove whether the hypotheses he shares are the right ones.
A part of the book that I particularly liked was the last chapters. No, not because of that... Not only! But it discussed history, Easter Island, different points of view on the society (of the Easter Island and in general).
First of all, it makes a distinction between static and dynamic societies.
In static societies change is slow. By slow the author means that it's hardly noticeable to the individual, the manifestation of changes requires multiple generations. It's achieved by suppressing creativity and progress both on central and local levels.
A dynamic society is therefore a culture where change and progress are fast, it's noticeable for the individual.
The author brings the two ancient Greek city-states as examples. Sparta was a static society, while Athens was a dynamic one. Until Sparta defeated it in the Peloponnesian Wars and made an end to the Athenian golden age.
The next time when a dynamic society started to emerge was the European Enlightenment and the author claims that we are still in a transition from a static to a dynamic society, though I'm sure many would complain that it's already too dynamic.
Dynamic societies are able to solve the arising problems with creative solutions. And here comes Easter Island into the picture. We are not sure when the islanders arrived, why they started to raise statues, but there are a few things to notice:
- they removed the forests so that they can move the big statues (and to build canoes, houses, to make fires to burn the dead). By chopping down the trees in an unsustainable manner, they started to have more serious problems.
- instead of changing the course of actions, they doubled down and tried to build even more and even bigger statues that fasten up the speed of deforestation until they had no more forests to chop down.
- many of their statues are unfinished and they are all very similar, they show no signs of creative progress.

The Easter Island society when faced with a problem, couldn't change their fate, they couldn't respond to the challenges. Instead, they kept doing what they had been doing engraving the situation. They showed the signs of a static society and they died.
That's pretty much what happens to static societies. They cannot react to the changing environments, to the changing circumstances, so they inevitably meet problems where their systems of beliefs and actions become inadequate and their societies collapse.
A dynamic society on the other hand is adapting and can answer to the challenges of a changing environment. Which one do we live in?
Time will tell, but ours show signs of a dynamic society.
So what do I think about [The Beginning of Infinity](https://amzn.to/2RHhRR8) overall? Would I recommend it? I don't say that it's a bad book. It is an interesting read, but very long. Only read it, if you read a lot and if you are interested in mathematics, physics and history at the same time. Then it will be interesting. But beware it might block your reading queue for more than a month or two. | sandordargo |
839,759 | Lessons we've learned after burning many thousands thanks to AWS Lambda. Expect no mercy from AWS. | Preface. A year ago, we decided to make a transition towards serverless architecture. Our... | 0 | 2021-10-20T02:10:55 | https://dev.to/xezed/lessons-weve-learned-after-burning-many-thousands-thanks-to-aws-lambda-expect-no-mercy-from-aws-39ph | aws, serverless, cloud, terraform | ## Preface.
A year ago, we decided to make a transition towards serverless architecture. Our management was very excited about it, and its excitement resulted in many tries and failures for developers(including me). So one Monday, we started our working day and realized that one of our lambdas had been going right into the rabbit hole the whole weekend. We were astonished, management was dissatisfied, and I was happy with the new material for the current article.
## Our setup.
The staple part of several microservices at our disposal heavily relies upon S3 event notifications. So what happened.
A developer screwed up and invoked Lambda from within the same Lambda for the same file in S3, which initially triggered Lambda. These invocations created other S3 files, which started different lambdas... You got the idea.
Dev wasn't fired or sanctioned in any way. Because it's an architectural problem, anyone can make a silly mistake.
## How much we've lost? Tenths of thousands.
We filled the ticket afterward and got compensated 5k only because we spent this much before the alarm came through.
## Precautions we implemented to prevent future incidents.
1. We set budget notifications and created alarms to email, slack channel, and mobile phone of key tech company figures.
2. Most of the Lambdas must have reserved concurrency parameters set.
3. Most of the Lambdas must be invoked via SQS only.
4. We also implemented AWS Config rule to check all our Lambdas for reserved concurrency.
With reserved concurrency, we avoid calling functions more than we should. This way, essentially throttle it.
And SQS helps us to prevent data loss. In case of facing concurrency limit, Lambda will wait before obtaining the following message from the queue.
## Questions to think about.
1. Why is there no option to kill all AWS activities after reaching some usage threshold?
2. Is it this complicated to create an intelligent tool to help AWS customers catch this situation and avoid money loss?
| xezed |
840,071 | Special kind of array in Typescript - Tuple | In strictly typed programming languages, array is a Data structure of homogeneous data types with... | 0 | 2021-09-26T03:27:25 | https://dev.to/xenoxdev/special-kind-of-array-tuple-4l1h | javascript, webdev, typescript, react | In strictly typed programming languages, `array` is a Data structure of `homogeneous data types` with `fixed length`. In contrast **JavaScript** is dynamic. In here, `array` can have elements of `heterogeneous data type` and `length` can vary.
**In JavaScript:**
```js
const elements = ['rick', 23, false];
const len = elements.length; // len = 3
elements.push({name: 'morty'});
const changedLen = elements.length; // changedLen = 4
```
With **Typescript**, we can restrict that and force arrays to have `homogeneous data type` what I mean is this.
**In Typescript:**
```ts
const elements: string[] = ['rick', 'morty'];
const len = elements.length; // len = 2
```
Now if we try to push `number` or any other data type other than `string` in `elements` then Typescript will yell at us.
```ts
const elements: string[] = ['rick', 'morty'];
elements.push(1) // Error
/**
* Error: Argument of type 'number' is not assignable to
* parameter of type 'string'.
*
*/
```
Even though Typescript enforces the type but `length` is still not fixed. We can push another element of type `string` in `elements` array.
```ts
const elements: string[] = ['rick', 'morty'];
const len = elements.length; // len = 2
elements.push('summer')
const changedLen = elements.length; // changedLen = 3
```
**What if our requirement changes like this:**
##Requirement 1:
* An `Array` with type `number`, `boolean` and `string` only.
**Solution**
Well! that is easy, we can use `union` type with `array` in Typescript like this:
```ts
const elements: Array<number|boolean|string> = ['summer'];
elements.push(23); // ok
elements.push(true); // ok
console.log(elements) // ["summer", 23, true]
elements.push({name: 'morty'}) // Not OK : Error
/**
* Error: Argument of type '{ name: string; }' is not
* assignable to parameter of type 'string | number |
* boolean'.
*/
```
One point to note here is:
> The sequence of the `data type` is not fixed as we defined during the declaration. What it means that, we can push `number`, `boolean` and `string` in any order.
For example, This is also perfectly valid and OK with TypeScript:
```ts
const elements: Array<number|boolean|string> = [true];
elements.push(23); // ok
elements.push('summer'); // ok
console.log(elements) // [true, 23, "summer"]
```
By `Array<number|boolean|string>`, we only narrowed the type and told Typescript that this collection should only have elements of type `number`, `boolean` and `string`. The order can be anything. Typescript do not mind as long as the type is one of the declared types.
##Requirement 2 :
* An array with a fixed number of items
* `type` of elements are fixed at each index
* The `type` of elements need not be same at all the index
What did you just say **An array with a fixed number items** ??

And it can have different type at different index? oh okkkk......

**Solution**
Actually this is possible with new `type` called `tuple` in `Typescript`.
##Tuple - Special kind of Array
As per [official docs](https://www.typescriptlang.org/docs/handbook/basic-types.html#tuple):
> Tuple types allow you to express an array with a fixed number of elements whose types are known, but need not be the same.
Tuple fulfils all the requirements described above. Let's see how can we define a `tuple`.
```ts
/**
* let's define a info of character id, name and activeStatus
*/
const info: [number, string, boolean] = [33, 'Rick' , true];
```
* **An array with a fixed number items**
Just by doing this, now we fixed number of elements in `info` i.e. `3`. So now if you try to access the element at index `4` Typescript will yell at you.
```ts
const info: [number, string, boolean] = [33, 'Rick' , true];
const item = info[4] // error
/**
* Tuple type '[number, string, boolean]' of length '3' has no
* element at index '4'.
*/
// In contrast if we declare an array with union type like
// below, it will be ok to access the element at index 4
const arr: Array<number|string|boolean>
= [33, 'Rick' , true];
const arrItem = arr[4] //undefined
```
* **Type of elements are fixed at each index**
By defining `[number, string, boolean]`, we have fixed the type of elements at each index. Typescript will infer the type from `tuple`.
```ts
const info: [number, string, boolean] = [33, 'Rick' , true];
const item1 = info[0] // type number
const item2 = info[1] // type string
const item3 = info[2] // type boolean
// In contrast, array with union type
const info: Array<number| string| boolean>
= [33, 'Rick' , true];
// type of items can be either string, number or boolean
const item1 = info[0] // type string | number | boolean
const item2 = info[1] // type string | number | boolean
const item3 = info[2] // type string | number | boolean
```
Advantage of doing this is, I can get all the methods available to `string` for `item2`.

* **The `type` of elements need not be same at all the index**
The type of elements in tuple can be same as well as different:
```ts
const a: [number, string, boolean] = [33, 'Rick' , true];
const b: [string, string, string] = ['Mr', 'Rick' , 'alive'];
```
## Practical example:
You might be thinking, it looks great but where do we use it.
One of the examples that I can think of is in our custom hooks where we have to return an array consisting values of different data type. Take for example `useToggle` custom hook
```ts
import { useCallback, useState } from "react";
export const useToggle = (
intialValue: boolean = false
): [boolean, () => void] => {
const [state, setState] = useState(intialValue);
const setToggle = useCallback(
() => setState((flag) => !flag),
[]);
return [state, setToggle];
};
```
Here we have to return `current status` of `toggle` and a `function to change the status`. That's why, the return type is a tuple `[boolean, () => void]`.
If we simply return an array, and assign the second argument i.e. setter function to `onClick`, Typescript will throw a compile time error as the return type is union of `boolean` and `() => void` .
```ts
Type 'boolean | (() => void)' is not assignable to type
'((event: MouseEvent<HTMLButtonElement, MouseEvent>)
=> void)
| undefined'.
```

You can checkout these examples here:
{% codesandbox usetoggle-46itn %}
Thank you for reading.
##Read my other TypeScript articles
* [Unknown and any type in Typescript](https://dev.to/thejsdeveloper/world-of-any-and-unknown-in-typescript-29cd)
Follow me on [twitter](https://twitter.com/VikasYadav_Dev)
##References
* [Official Docs](https://www.typescriptlang.org/docs/handbook/basic-types.html#tuple)
* [auth0 Tuple article](https://auth0.com/blog/typescript-3-exploring-tuples-the-unknown-type/)
| thejsdeveloper |
840,074 | How you guys learn js? | How you guys learn js? I learn before and i forgot within weeks, tell me the technique you use. Thank... | 0 | 2021-09-25T09:50:27 | https://dev.to/yisumaid/how-you-guys-learn-js-543c | How you guys learn js?
I learn before and i forgot within weeks, tell me the technique you use. Thank you for your comment! | yisumaid | |
840,237 | On the importance of staying Focused | Sprint 4 — Saturday Photo by Eden Constantino on Unsplash As you approach the final... | 0 | 2021-09-25T12:05:24 | https://medium.com/chingu/on-the-importance-of-staying-focused-1cd1f5afccd4 | teamwork, agile, softwaredevelopment | ---
title: On the importance of staying Focused
published: true
date: 2021-09-25 12:02:10 UTC
tags: teamwork,agile,softwaredevelopment
canonical_url: https://medium.com/chingu/on-the-importance-of-staying-focused-1cd1f5afccd4
---
#### Sprint 4 — Saturday
<figcaption>Photo by <a href="https://unsplash.com/@edenconstantin0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Eden Constantino</a> on <a href="https://unsplash.com/s/photos/focused?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a></figcaption>
As you approach the final sprints in a project it should be at or close to its _minimum viable product (MVP)_ milestone. In other words, having the required features you set out to include in it.
Ideally, your team’s project will reach MVP status before the final sprint, leaving time to make final corrections, polishing the app, and even adding lower priority features.
But what if the final sprint is looming, but you haven’t yet reached the MVP milestone? Don’t get stressed! Keep following the Agile process which allows you to adjust project scope based on your current situation. It’s okay to reduce or adjust the features in your app
> Having a simple app that works is better than a complex app that’s broken
It’s also important to keep in mind that your most powerful tool is **_team work_**! The measure of mature developers is they stay dispassionate, respectful, and focused on the goal under stress. Support your team and your teammates and finish together!

### Before you Go!
Chingu helps you to get out of “_Tutorial Purgatory_” by transforming what you’ve learned into experience. The experience to boost your Developer career and help you get jobs.
You can learn more about **Chingu** & how to join us at [https://chingu.io](https://chingu.io/)
* * * | jdmedlock |
840,252 | Simple way to wait for an executing function to finish before executing another function in Javascript | Actually, I'm not really sure about the title of this blog because currently, I can't come up with... | 0 | 2021-09-25T12:45:05 | https://dev.to/trunghieu99tt/synchronized-executions-in-javascript-9bf | webdev, javascript | Actually, I'm not really sure about the title of this blog because currently, I can't come up with any better title to describe what I want to share with you guys today. I don't know if it's called something else, if anyone knows, please point it out, I very much appreciate it.
Okay, so first let's start with our use case:
We have 2 functions, let's call them A and B. We call them at the same time, but we want B to wait for A to finish first.
I have a really simple function like this:
```jsx
(async () => {
const sub = {
name: "sub",
subscribed: false,
};
// 1.subscribe function
const subscribe = () => {
setTimeout(() => {
sub.subscribed = true;
}, [9.5 * 1000]); // execute after 9.5 seconds
};
// 2. a function only happen after subscribed
const afterSubscribed = () => {
if (sub.subscribed) {
console.log("subscribed");
} else {
console.log("Not subscribed");
}
};
subscribe();
afterSubscribed();
})();
```
And the output of this function would be:
```jsx
// immediately
Not subscribed
// Continue to run 9.5 seconds then stop
```
The result I want is that this function somehow prints out "Subscribed".
Let's try to solve it.
The first try we can do is that we can create an interval in the afterSubscribed function like this, note that we will add a timer to see when we get right log:
```jsx
// 2. a function only happen after subscribed
const afterSubscribed = async () => {
const start = Date.now();
const interval = setInterval(() => {
if (sub.subscribed) {
console.log("subscribed");
const end = Date.now();
const duration = Math.floor(end - start);
console.log(`on: ${duration}`);
clearInterval(interval);
} else {
console.log("Not subscribed");
}
}, [1000]);
};
```
Now we will retrieve the result we want:
```bash
// This is the log of this function
Not subscribed
Not subscribed
Not subscribed
Not subscribed
Not subscribed
Not subscribed
Not subscribed
Not subscribed
Not subscribed
subscribed
on: 10011
```
Yeah, it prints out the result we want, it's quite good. The issue of this approach is that we only check for the state of the sub every 1 second. So in case, our subscribe function finishes after 9.1, 9.2... seconds, we still have to wait until the 10th second. But it's still acceptable as long as we don't need afterSubscribed to continue to execute right after subscribe finished.
To resolve the issue of the #1 try, we can change our functions like this:
```jsx
(async () => {
const sub = {
name: "sub",
subscribed: false,
doneSubscribed: false,
processSubscribe: false,
};
// 1.subscribe function
const subscribe = () => {
sub.processSubscribe = new Promise(
(resolve) => (sub.doneSubscribed = resolve)
);
setTimeout(() => {
sub.subscribed = true;
sub.doneSubscribed();
}, [9.5 * 1000]); // execute after 9.5 seconds
};
// 2. a function only happen after subscribed
const afterSubscribed = async () => {
const start = Date.now();
await sub.processSubscribe;
if (sub.subscribed) {
console.log("subscribed");
} else {
console.log("Not subscribed");
}
const end = Date.now();
const duration = Math.floor(end - start);
console.log(`on: ${duration}`);
};
subscribe();
afterSubscribed();
})();
```
And this is what we get:
```jsx
// Wait for 9.5 second then..
subscribed
on: 9507
```
Okay, so no more "Not subscribed" and right after subscribe finished its works
Let me explain how it works.
We add 2 more attributes to sub :
```jsx
doneSubscribed: false,
processSubscribe: false,
```
And in subscribe function, we assign sub.processSubscribe to a promise where resolve function is assigned to sub.doneSubscribe. In setTimeout, we call sub.doneSubscribe function (since we assigned it to the resolve function of sub.processSubscribe promise, it's a function now). The trick here is that we assign the resolve function of sub.processSubscribe to sub.doneSubscribe, we all know that the promise resolves when its resolve/reject function is called. By awaiting for sub.processSubscribe we also wait for setTimeout to finish as well as subscribe function.
Of course, there might be some other way to solve this problem, but I think this one is one of the shortest and best ways to solve it.
So in general, this problem can be described as "wait for an executing function to finish before executing another function".
If you guys have any other ways to solve it. Feel free to share with me. Or If I did any mistake, please point it out, I really appreciate it. Thank for reading | trunghieu99tt |
840,296 | Deeper Dive Into React useMemo | When to use and not use React's useMemo | 0 | 2021-09-25T15:51:23 | https://bionicjulia.com/blog/deeper-dive-into-react-usememo | react | ---
title: Deeper Dive Into React useMemo
published: true
date: 2021-09-25 00:00:00 UTC
tags: react
description: When to use and not use React's useMemo
canonical_url: https://bionicjulia.com/blog/deeper-dive-into-react-usememo
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/0fpiqhe602bblxl8x2sa.jpg
---
If you're new here, be sure to first check out my posts on the [differences between React.memo and useMemo](https://bionicjulia.com/blog/react-memo-and-usememo-whats-the-difference), and a [deeper dive into React.memo](https://bionicjulia.com/blog/deeper-dive-into-react-memo). This post completes the last in the series and talks about the `useMemo` hook and when / when not to use it.
### When to use `useMemo`
**Use Case 1: Stopping computationally expensive, unnecessary re-renders**
Let's go back to the example I had in my [first post](https://bionicjulia.com/blog/react-memo-and-usememo-whats-the-difference). This illustrates the use case where you have a function that keeps re-rendering, because the state of its parent component keeps changing.
```jsx
export type VideoGameSearchProps = {
allGames: VideoGameProps[],
}
export const VideoGameSearch: React.FC<VideoGameSearchProps> = ({ allGames }) => {
const [searchTerm, setSearchTerm] = React.useState('')
const [count, setCount] = React.useState < number > 1
// NOTE useMemo here!!
const results = useMemo(() => {
console.log('Filtering games')
return allGames.filter((game) => game.name.includes(searchTerm))
}, [searchTerm, allGames])
const onChangeHandler = (event: React.ChangeEvent<HTMLInputElement>) => {
setSearchTerm(event.target.value)
}
const onClickHandler = () => {
setCount((prevCount) => prevCount + 1)
}
return (
<>
<input type="text" value={searchTerm} onChange={onChangeHandler} />
{results.map((game) => (
<VideoGame key={game.name} rating={game.rating} name={game.name} releaseDate={game.releaseDate} />
))}
<br />
<br />
<p>Count: {count}</p>
<button onClick={onClickHandler}>Increment count</button>
</>
)
}
```
This is a completely made-up example which would likely never exist in production code, but I wanted to illustrate the takeaway points clearly. In this case, there are 2 things going on in this component:
- A user can click on an "increment count" button which updates the `count` state and displays the current number in the UI.
- A user can enter a search query in the input field which updates the `searchTerm` state `onChange`. This in turn causes the `results` function to re-calculate, where `results` is rendered as a list in the UI.
The incrementing of `count` has nothing to do with how `searchTerm` is set, or `results` run. However, every time `count` is incremented, the component re-renders and runs the `results` function. It's probably not going to be a big deal here, but what if the `allGames` array actually contains millions of elements... and instead of a simple filter function, it was a much more computationally complex calculation? This is where `useMemo` would come in handy.
Wrapping the `results` function with `useMemo` (with `searchTerm` and `allGames` as dependencies) tells React to only re-run this function, if either of those 2 variables changes. This means that changes in `count` would no longer cause `results` to be recalculated, with the memoised result being returned instead.
_Note: I've added the `console.log` in there so you can test it for yourselves to see how many times that function runs with and without the `useMemo` when you increment `count`!_
**Use Case 2: Ensuring referential equality when dealing with dependency lists**
If you have a case whereby you're relying on a dependency list, e.g. when using a `useEffect` hook, you really want to ensure you're only updating the component when the dependency values have truly changed.
```jsx
useEffect(() => {
const gameData = { name, publisher, genres }
thisIsAFunction(gameData)
}, [name, publisher, genres])
```
In this example, assuming `name`, `publisher` and `genres` are all strings, you shouldn't have a problem. React does a referential equality check on `gameData` to decide whether the component should be updated, and because `gameData` only comprises strings (i.e. primitives), this will work as we expect.
To illustrate the point, we wouldn't want to have this for example, because `gameData` will be a new instance every time React runs the `useEffect` check, which means re-running `thisIsAFunction` every time because in Javascript-land, `gameData` has changed.
```jsx
const gameData = { name, publisher, genres }
useEffect(() => {
thisIsAFunction(gameData)
}, [name, publisher, genres])
```
So back to this - all good right?
```jsx
useEffect(() => {
const gameData = { name, publisher, genres }
thisIsAFunction(gameData)
}, [name, publisher, genres])
```
Unfortunately not, because we run into a similar problem if one of `name`, `publisher` or `genres` is a non-primitive. Let's say instead of a string, `genres` is actually an array of strings. In Javascript, arrays are non-primitives which means `[] === []` results in `false`.
So to expand out the example, we've got something like this:
```jsx
const GamesComponent = ({ name, publisher, genres }) => {
const thisIsAFunction = (
gameData, // ...
) =>
useEffect(() => {
const gameData = { name, publisher, genres }
thisIsAFunction(gameData)
}, [name, publisher, genres])
return //...
}
const ParentGamesComponent = () => {
const name = 'God of War'
const publisher = 'Sony'
const genres = ['action-adventure', 'platform']
return <GamesComponent name={name} publisher={publisher} genres={genres} />
}
```
In this case, despite `genres` in effect being a constant array of strings, Javascript treats this as a new instance every time it's passed in as a prop when `GamesComponent` is re-rendered. `useEffect` will thus treat the referential equality check as false and update the component, which is not what we want. 😢
This is where `useMemo` comes in handy. The empty `[]` effectively tells React not to update `genres` after mounting.
```jsx
const ParentGamesComponent = () => {
const name = 'God of War'
const publisher = 'Sony'
const genres = useMemo(() => ['action-adventure', 'platform'], [])
return <GamesComponent name={name} publisher={publisher} genres={genres} />
}
```
_Side note: if one of the props is a callback function (i.e. not a primitive), use the `useCallback` hook to achieve the same effect._
### When not to use `useMemo`
Alright, so if not already clear by now after 3 posts, let me reiterate that React is smart and speedy in its own right. So, unless you're experiencing "use case 2" above, or perhaps "use case 1" with a noticeable lag or quantifiable performance dip, err on the side of **not** using `useMemo`! 😜 | bionicjulia |
840,318 | Changing a Git commit Message | If a commit message contains unclear, incorrect, or sensitive information, you can amend it locally... | 0 | 2021-09-25T16:29:01 | https://dev.to/w3tsa/changing-a-commit-message-20ca | github, webdev, git, devops | If a commit message contains unclear, incorrect, or sensitive information, you can amend it locally and push a new commit with a new message to GitHub. You can also change a commit message to add the missing information.
### Rewriting the most recent commit message
You can change the most recent commit message using the `git commit --amend` command.
In Git, the text of the commit message is part of the commit. Changing the commit message will change the commit ID--i.e., the SHA1 checksum that names the commit. Effectively, you are creating a new commit that replaces the old one.
### The commit has not been pushed online
If the commit only exists in your local repository and has not been pushed to GitHub, you can amend the commit message with the `git commit --amend` command.
1. On the command line, navigate to the repository that contains the commit you want to amend.
2. Type `git commit --amend` and press Enter.
3. In your text editor, edit the commit message, and save the commit.
The new commit and message will appear on GitHub the next time you push.
_You can change the default text editor for Git by changing the core.editor setting._
The bellow command will change the default git editor to vs code.
```git config --global core.editor "code --wait"```
### Amending older or multiple commit messages
If you have already pushed the commit to GitHub, you will have to force push a commit with an amended message. [* _this is not recommended as people who have already cloned your repository will have to manually fix their local history_]
#### Changing the message of the most recently pushed commit
1. Follow the steps above to amend the commit message.
2. Use the push --force-with-lease command to force push over the old commit.
```git push --force-with-lease example-branch```
#### Changing the message of older or multiple commit messages
If you need to amend the message for multiple commits or an older commit, you can use interactive rebase, then force push to change the commit history.
1. On the command line, navigate to the repository that contains the commit you want to amend.
2. Use the `git rebase -i HEAD~n` command to display a list of the last n commits in your default text editor.
```# Displays a list of the last 3 commits on the current branc
$ git rebase -i HEAD~3h```
The list will look similar to the following:
```terminal
pick e499d89 Delete CNAM
pick 0c39034 Better README
pick f7fde4a Change the commit message but push the same commit.
# Rebase 9fdb3bd..f7fde4a onto 9fdb3bd
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
```
3.Replace _pick_ with _reword_ before each commit message you want to change.
```terminal
pick e499d89 Delete CNAM
reword 0c39034 Better README
reword f7fde4a Change the commit message but push the same commit.
```
4.Save and close the commit list file.
5.In each resulting commit file, type the new commit message, save the file, and close it.
6.When you're ready to push your changes to GitHub, use the push --force command to force push over the old commit.
```terminal
git push --force example-branch
```
Here is a YT video on git: [Git Crash Course 2021 with GitHub](https://youtu.be/uaSsetG4U0k)
| w3tsa |
840,470 | How to make a static web sites using Hugo-Github Page | Hello, In this article, I will cover creating simple static websites with hugo, a static website... | 0 | 2021-09-25T18:38:59 | https://dev.to/nuhyurdev/creating-static-web-sites-using-hugo-4f1k | hugo, webdev, go, portfolio | Hello, In this article, I will cover creating simple static websites with hugo, a static website creation tool written in golang, hosting and publishing them on github. For this, I plan to prepare two different websites and use different third-party web services that will be useful to us while preparing them. First of all, I will talk about the use of hugo and then I will continue by creating a simple website.
### Hugo
Hugo is a static web-site generator written in Go. This framework can quickly create a static website with terminal commands, thanks to a freely installed and available CLI tool. It also has different deployment options. In the hosting and deployment section of the [gohugo.io](https://gohugo.io) site, it is explained how the website can be hosted on different web hosting platforms. But in this article, I will build a website that will be hosted on github and run in the domain username.github.io.
To download the framework and for a quick start, you can go to [gohugo.io](https://gohugo.io) to install it on your system and start right away. If you are using a GNU distribution, the package is probably in your repository. On ubuntu and debian repositories hugo can be installed with;
``` bash
$ sudo apt install hugo
```
On Fedora repositories hugo can be installed with;
``` bash
$ sudo dnf install hugo
```
In hugo official website, it recommends installation with homebrew for both linux and mac. You can use the code below for Homebrew installation;
``` bash
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```
Then you can install hugo on your system with __brew install hugo__
After the installation, You can create a new web site with
``` bash
$ hugo new site /path/to/your/site
```
on terminal.The file hierarchy is as follows. The config.toml file is the file that allows us to configure the website.

Now, this will open a blank page. Because there is no file in the layout.
You can clone one or more themes by selecting them from [gohugo.io/themes](https://themes.gohugo.io) and using git into the themes directory. using __hugo new content/new_article.md__ it can be used to create a new content.
The website will start working on local server 1331 port with
``` bash
$ hugo server
```
If you want to take your experience further, you can create your own design by using the template tutorial on gohugo.io. But in this article, I will only create web pages using ready-made templates.
### Creating a Static Portfolio Page
Portfolio pages are one of the best examples of static pages. These are the types of pages where the works done are exhibited and other accounts or communication e-mails are given as links. To create it, I first need to clone it with git by selecting from the portfolio themes listed on the [themes.gohugo.io](https://themes.gohugo.io) page. I choose the theme named hugo-shell-theme. One of the reasons why I prefer it is that it has a very simple structure. I will make my first attempt using this theme.
I'm clonnig the theme into themes directory with
``` bash
$ git init
$ git submodule add https://github.com/Yukuro/hugo-theme-shell.git themes/hugo-theme-shell
$ hugo server -t hugo-theme-shell -w -D
```
and starting the hugo server.It is currently running on the local server, but without any configuration. for this, I copy the content of the config.toml given on the github page of the theme and paste it into my config file in the directory. Below is the config file where I changed some parts and deleted the comment lines. I preferred powershell as shema.

It gives me an output like this:

For a better use, you can try to use a markdown file in the description. For example, you can find the portfolio website I use at [noaahhh.github.io](https://noaahhh.github.io).

For Markdown usage, a description.md created in content is given to the description section of the config file.
``` bash
description=/description.md
```
Then you can fill out whatever you want. If you go to the code side, you can see how it takes the parameters from the config file between the html tags.
Likewise, now I'm cloning the hugo-profile theme into the themes directory with git. This theme uses config.yml with .yaml extension as config file. I copy one of the 3 different yaml files (v1.yml) in the theme directory to my root directory as config.yml. And content of the website directory must be copied root directory. Our website is using the new theme on the local server after the command below.
``` bash
$ hugo server -t hugo-profile -w -D --config=config.yaml
```

In this theme, you can also create your personal website by changing the parameters in the config file. In the following sections, I will talk about a more user-experience-oriented method.
### e-commerce and product presentation pages
In this section I will try the Hero theme. Hero has a familiar type of company landing page and a clean interface. That's why I chose this theme. I'm creating a new website with Hugo. Then I clone this theme with git into the theme directory. There is a directory named example-site in the theme. This directory contains a pre-configured toml file and a ready-made website. I copy the contents of this directory to my home directory. Then I open my config file with an editor and delete the themesDir parameter. Then I can run hugo server and watch my website from localhost port 1313.
I've added an image below listing the terminal operations performed. You can check.

This way you can create websites to promote products or for a company portfolio.

### Github Pages
There are multiple options for hosting a website built with Hugo. You can see the host and deployment options from the Hosting&Deployment link. We can host our website with services such as github, gitlab, netlify firebase. In the Github option, you can access the page we created via the username.github.io domain. In this application I will work on github.
We can publish our portfolio site, one of the websites we have prepared so far, on our own github domain. For this, we go to the directory where our portfolio website is located and create our website with the hugo command in this directory. A public file will be created in the directory and there will be our website using html to be published in this directory. If we submit it to our git repo within this directory we can publish our website using Pages there. We go to the Github page and open a repo named username.github.io.

We are connecting the public directory created according to the diagram above to our relevant git repo.
``` bash
myHugoSite $ cd public
public/ $ git init
public/ $ git remote add origin https://github.com/username/username.github.io.git
public/ $ git remote set-url origin http://<public-access-key>@github.com/username/username.github.io
```
After the last changes, to connect to our git repo, you should create a key by following the github->settings->developer Settings->Personal Access Key path and paste this key in the relevant section in the last command to link our repo.
``` bash
public/ $ git add .
public/ $ git commit -m "initial commit"
public/ $ git push origin main
```
Then we can wait for it to be published from the setting-> Pages section in our repo. Our site will be published from the relevant url.

### Different architecture for GitHub
If we want to publish our website over a subdomain with the same name as the repo, we can open a new repo and send the files in the public to this repo and publish it. If we examine the diagram below, we can create a website in our local system and keep this site on github. We can create a submodule link from another git repo in the "themes" directory. We can publish our files to be published with **Github Pages** by sending them to a new repo using the subdomain name to be published.

You can create a submodule with
``` bash
mySite/ $ git submodule add http://github.com/Yukuro/hugo-theme-shell.git themes/hugo-theme-shell
```
``` bash
mySite/ $ hugo -d ../myPortfolio
```
We can create html files in a directory called myPortfolio, which is in the same directory as our hugo website using like the command above.Then we can link this directory to the github repo and publish our website on a subdomain with the same name as the repo.

### Hugo and Forestry.io
[Forestry.io](https://forestry.io) is a web service that makes it easy to manage the contents of our website on github using a graphical interface. This service is a CMS tool that works with frameworks such as hugo, jeykll. Content entry in personal blogs can be done easily. You can get more detailed information on the page.
It has a simple use. We just have to register for the service and then create a new registration with add site in the "My Sites" section and select Hugo as the "static site generator".

And then we connect our repo with the forestry.io service by choosing git provider.

Then we can prepare our posts in the blog in the document types we choose.

Apart from this, there are many CMS applications that work with Hugo. Cloudcannon, strapi.io, netlifyCMS can be given as examples. These are the systems we can use to organize our content between host and deployment.

The loop in the diagram represents the CMS service. With CMS services, operations such as content creation and editing can be done before deployment. By connecting with services such as AWS, Netlify, content editing can be done between the git provider and the deploymet service. And at the same time it provides synchronization with the website maintained in git.
| nuhyurdev |
850,086 | Screencast: Add welcome emails to Happi | This is the first video in a series where I build happi.team in public, literally, by screencasting... | 14,878 | 2021-10-04T08:45:15 | https://dev.to/phawk/screencast-add-welcome-emails-to-happi-5gdb | rails, hotwire, rspec, webdev | This is the first video in a series where I build [happi.team](https://happi.team) in public, literally, by screencasting developing new features or improvements. The tech stack is Rails, Hotwire and RSpec among many other great open source libraries.
In this video, I show adding welcome emails to be sent out when teams are created, whilst adding tests to make sure it all works.
{% youtube xq6H4UQHUMQ %}
Apologies my voice is fading a little toward the end!
If you want to check out the product itself it’s at [https://happi.team](https://happi.team) and at the time of this video we have a free plan to let you get setup and test it out. | phawk |
850,102 | C++: A concise introduction to structures | A structure is a collection of variables of different data types stored in a block of memory under a... | 0 | 2021-10-03T19:19:07 | https://dev.to/isaack_bsmith/theory-structures-in-c-4f6a | cpp, structures, struct, theory | A structure is a collection of variables of different data types stored in a block of memory under a single name, allowing the different variables to be accessed via a single pointer or by the struct declared name, which returns the same address. This is a convenient way to keep related information together. It is similar to a class in that both contain a collection of data of various datatypes. Structures are known as compound data types because they are made up of several different variables that are logically connected. By default, struct members in C++ are public. The general structure declaration format is
```c++
struct structureName {
datatype member0;
datatype member1;
datatype member2;
};
```
Memory is not allocated when a structure is created. After a variable is added to the struct, memory is allocated. The struct datatype cannot be treated like a built-in data type in C++. Inside the structure body, static members cannot be created. Constructors cannot be created within structures. The dot (.) operator is used to access structure members, and the arrow (→) operator is used to access structure members if we have a pointer to a structure.
Here's an example of a struct.
```c++
struct Album {
string title;
string artist;
float cost;
int quantity;
};
int main() {
struct Album song;
song.title = "Summer-The four seasons";
song.artist = "Antonio Vivaldi";
song.cost = 50.0
song.quantity = 10000
return 0;
}
```
The structure Album is declared here, which consists of four members: title, artist, cost, and quantity. A structure variable song is defined within the main function. The appropriate data is then entered into it.
Happy Coding.
| isaack_bsmith |
850,156 | The Peregrine programming language - A Python-like language that's as fast as C. | Hey guys! I'm Ethan, I'm one of 10 Peregrine developers. This post is gonna be about some updates... | 0 | 2021-10-04T05:45:39 | https://dev.to/ethanolchik/the-swallow-programming-language-a-python-like-language-that-s-as-fast-as-c-43j7 | showdev, python, programming, c | Hey guys!
I'm Ethan, I'm one of 10 Peregrine developers. This post is gonna be about some updates we've added into Peregrine lately.
## About
If you know Python, you know how easy it is. However, it also comes with a big downgrade. Python is slow, and I'm pretty sure every python developer knows this by now. This is kind of annoying. That's where Peregrine comes in. Me and 8 other friends have been working on Peregrine for the past few months. Peregines syntax is very similar to Python's, and it gets trans-compiled to C, thus making it as fast as C. Below I've written 2 programs, one in Peregrine and one in Python.
#### Peregrine
```python
def fib(int n) -> int :
if n <= 0:
return 1
return fib(n-1) + fib(n-2)
def main():
count = 0 # Peregrine has type inference!
int res = 0
while count < 40:
res = fib(count)
count++
```
function return types can be omitted.
#### Python
```python
def fib(n):
if n <= 0:
return 1
return fib(n-1) + fib(n-2)
res = 0
for c in range(0, 40):
res = fib(c)
```
These two programs are almost the same, which makes it so easy for Python users to switch to. Now, you might be asking: "How much faster is Peregrine?" Well, to answer your question, here are the results:
#### Peregrine:
Executed in: 1.06 secs
#### Python:
Executed in: 32.30 secs
As you can see, Peregrine is significantly faster than Python. It is around 30x faster than python, without optimization when running this program.
## What's new?
Here are some of Peregrine's newest features:
### Type Inference
[Type Inference](https://en.wikipedia.org/wiki/Type_inference) is one of Pergrine's newest features. This allows Peregrine code to be written with simplicity.
### if/else/match
Although this may seem like a standard feature in any programming language, it does take time to add these features which is why I'm acknowledging it. Not much to say about it since it's in every programming language.
## New-ish Features
Let's talk more about the features that are currently available in Peregrine.
### Ccode
`Ccode` allows C code to be ran in Peregrine. Here is an example:
```python
def main():
x = 1
Ccode x++; Ccode
print("{x}\n") # prints 2
```
As you can see, any variables declared outside the `Ccode` block can be used within `Ccode` and vice versa. This also means you can import any C library through `Ccode` and use it in Peregrine.
### Inline Assembly
You can also have inline assembly in Peregrine. Here is an example:
```python
def main():
int arg1 = 45
int arg2 = 50
int add = 0
print("It should add 45 and 50 using asm and print it\n")
asm("addl %%ebx, %%eax;" : "=a" (add) : "a" (arg1) , "b" (arg2))
printf("%lld", add)
```
This prints `90`, as expected.
### More
You can find some more examples in the [Peregrine test folder](https://github.com/peregrine-lang/Peregrine/tree/main/Peregrine/tests)
## Planned Features
- Structs
- More decorators for different purposes
- Python ecosystem in Peregrine
* You will be able to use any python module in Peregrine
## Conclusion
Peregrine is planned to release version 0.0.1 sometime in March, so make sure to show some support by starring the [repo](https://github.com/peregrine-lang/peregrine) and make sure to press on the "Watch" button so you don't miss any updates.
We would greatly appreciate any contributions, so if you find something that you can improve, open a pull-request! You can also check out our [open issues](https://github.com/peregrine-lang/peregrine/issues/)
Thanks so much for reading! | ethanolchik |
850,157 | My Raw Notes for the Week of 9-27-2021 | In Simpson's thinking, there are three "pillars" of JS: 1) Types/Coercion - Primitive Types ... | 0 | 2021-10-03T20:07:45 | https://dev.to/benboorstein/my-raw-notes-for-the-week-of-9-27-2021-484k | javascript, types, scope, this | ```
In Simpson's thinking, there are three "pillars" of JS:
1) Types/Coercion
- Primitive Types
- undefined
- string
- number
- boolean
- object
- function
- array
- symbol (not used much)
- null (sort of)
- Converting Types
- Number and String:
- Number + Number = Number <this is the only one of the four in which the '+' means 'mathematical addition' (as opposed to 'concatenation')>
- Number + String = String
- String + Number = String
- String + String = String
- Truthy and Falsy
- If we were to coerce a non-boolean value into a boolean, would it be true or false? If true, the value is Truthy. If false, Falsy
- Falsy values in JS: '', 0, -0, null, NaN, false, undefined. Truthy values in JS: everything else
- Checking Equality
- '==' allows coercion (types different)
- '===' disallows coercion (types same)
2) Scope/Closures
- FYI:
- Simpson: Scope is where the JS engine looks for things
- FYI:
- Example of what's called a 'function statement' or 'function declaration': function funcDec() {}
- Example of what's called an 'anonymous function expression': const anonFuncExp = function() {}
- Example of what's called a 'named function expression': const namedFuncExp = function namedFuncExp() {}
- Nested Scope
- Closure
- Simpson's definition: "Closure is when a function "remembers" the variables [created] outside of it, even if you pass [or call] that function elsewhere."
3) this/Prototypes
- this
- Simpson: "A function's 'this' references the execution context for that call, determined entirely by HOW THE FUNCTION WAS CALLED."
- Prototypes
- Function constructors and their interaction with 'this'
- Class{}
- using the 'class' keyword as an improved syntax for setting up a Function constructor
Whether a variable is declared but not assigned a value or it's simply never declared, it has a type of 'undefined'.
For 'let v = null', 'typeof v' is 'object'. This is a bug in the JS language which can't be changed now.
For 'v = function(){}', 'typeof v' is 'function'. This is strange because 'function' is a subtype of 'object', but it's not a mistake and it is useful.
For 'let v = [1, 2, 3]', 'typeof v' is 'object'. This makes sense because 'function' is a subtype of 'object'.
``` | benboorstein |
850,245 | Mixxtone - Introducing Electronic Music in Pakistan | Saqlain Malik aka Mixxtone is a 20 years old music producer, rapper and singer-songwriter from... | 0 | 2021-10-03T20:49:17 | https://dev.to/squinter/mixxtone-introducing-electronic-music-in-pakistan-5fnd | mobile, motivation, music | Saqlain Malik aka Mixxtone is a 20 years old music producer, rapper and singer-songwriter from Pakistan. He makes Rap songs and does experiments with his music to explore his skills. Mostly he makes EDM (Electronic Music) songs. He is from Pakistan, and till date, EDM is an unknown music genre in Pakistan. But somehow, Mixxtone has been impressing Pakistani audience with his Electronic songs. And he posted on an Instagram post that, he will keep making these songs to inspire and to motivate people. | squinter |
850,446 | 💆♀️ 💆♂️ PostgreSQL query optimization for Gophers: It's much easier than it sounds! | Introduction Hello, amazing DEV people! 😉 Today I will show you a wonderful query... | 4,444 | 2021-10-04T20:52:02 | https://dev.to/koddr/postgresql-query-optimization-for-gophers-it-s-much-easier-than-it-sounds-24nf | postgres, tutorial, beginners, database | ## Introduction
Hello, amazing DEV people! 😉
Today I will show you a wonderful query optimization technique for Postgres that I often use myself. This approach to optimization can save you from a long and tedious transfer of your project to another technology stack, such as GraphQL.
Intrigued? Here we go! 👇
<a name="toc"></a>
### 📝 Table of contents
- [Problem statement](#problem-statement)
- [A quick solution to the problem](#a-quick-solution-to-the-problem)
- [Optimize this](#optimize-this)
- [Postgres query analyzing](#postgres-query-analyzing)
<a name="#problem-statement"></a>
## Problem statement
We'll take query optimization as an example of a simple task for any developer. Let's imagine that we have the task of creating a new endpoint for the REST API of our project, which should return:
1. Data on the requested project by its alias;
2. Array of all tasks that relate to the requested project in descending order by creation date;
3. Number of tasks (as a separate response attribute);
Here you can immediately see one quick solution — make several queries for each of the models in the database (for the project and for related tasks for that project).
Well, let's look at it in more detail.
> ☝️ **Note:** I will give all the code samples in Go with [Fiber](https://gofiber.io/) web framework, since this is my main language & framework for backend development at the moment.
[↑ Table of contents](#toc)
<a name="#a-quick-solution-to-the-problem"></a>
## A quick solution to the problem
Okay, here is our controller for the endpoint:
```go
// ./app/controllers/project_controller.go
// ...
// GetProjectByAlias func for getting one project by given alias.
func GetProjectByAlias(c *fiber.Ctx) error {
// Catch project alias from URL.
alias := c.Params("alias")
// Create database connection.
db, err := database.OpenDBConnection()
if err != nil {
return err
}
// Get project by ID.
project, err := db.GetProjectByAlias(alias)
if err != nil {
return err
}
// Get all tasks by project ID.
tasks, err := db.GetTasksByProjectID(project.ID)
if err != nil {
return err
}
// Return status 200 OK.
return c.JSON(fiber.Map{
"status": fiber.StatusOK,
"project": project, // <-- 1
"tasks_count": len(tasks), // <-- 2
"tasks": tasks, // <-- 3
})
}
```
As you can see, this controller fully meets the conditions of our task (all three points of the original problem).
— It will work?
— Yes, of course!
— Would such code be optimal?
— Probably not… 🤷
We call alternately the functions `GetProjectByAlias` and `GetTasksByProjectID` which creates additional latency and wastes additional resources of both the server API and the PostgreSQL database itself.
It's all because queries in DB most likely look like this:
```sql
-- For Project model:
SELECT *
FROM
projects
WHERE
alias = $1::varchar
LIMIT 1
-- For Task model:
SELECT *
FROM
tasks
WHERE
project_id = $1::uuid
ORDER BY
created_at DESC
```
Since the Go language created for speed and efficient use of server resources, such a waste of resources is simply unacceptable for any self-respecting Go developer.
Let's fix that in the next section.
[↑ Table of contents](#toc)
<a name="#optimize-this"></a>
## Optimize this
So, how do we optimize this? Of course, by reducing the number of queries to the database. But then how do we get all the necessary tasks for the project and their number?
This is helped by the wonderful built-in aggregate function [jsonb_agg](https://www.postgresql.org/docs/9.6/functions-aggregate.html) that have appeared in PostgreSQL `v9.6` and are constantly being improved from version to version.
Furthermore, we will be using `COALESCE` function with `FILTER` condition to correctly handle an empty value when the project may have no tasks. And immediately count the number of tasks through the `COUNT` function.
> ☝️ **Note**: See more info about `COALESCE` [here](https://postgrespro.com/docs/postgresql/9.5/functions-conditional#functions-coalesce-nvl-ifnull).
```sql
SELECT
p.*,
COALESCE(jsonb_agg(t.*) FILTER (WHERE t.project_id IS NOT NULL), '[]') AS tasks,
COUNT(t.id) AS tasks_count
FROM
projects AS p
LEFT JOIN tasks AS t ON t.project_id = p.id
WHERE
p.alias = $1::varchar
GROUP BY
p.id
LIMIT 1
```
It's a little difficult to understand the first time, isn't it? Don't worry, you'll figure it out! Here's an explanation of what's going on here:
- Output all the data about the found project;
- We got only one project, which has a unique alias we are looking for;
- Using the `LEFT JOIN` function, we only joined the sample of tasks that have a connection to the project by ID;
- We grouped all the data by project ID;
- We did an aggregation of all obtained tasks using the aggregation function `jsonb_agg`, filtering it all by project ID;
- For projects that have no tasks, we provided a display in the form of an empty list;
- We used the `COUNT` function to calculate the number of tasks in the project;
Next, we just need to prepare the output of all the data obtained from the database. Let's add the appropriate structures to the `Project` and `Task` models.
A simplified structure with a description of each project task:
```go
// ./app/models/task_model.go
// ...
// GetProjectTasks struct to describe getting tasks list for given project.
type GetProjectTasks struct {
ID uuid.UUID `db:"id" json:"id"`
Alias string `db:"alias" json:"alias"`
Description string `db:"description" json:"description"`
}
```
And additional structures for the `Project` model:
```go
// ./app/models/project_model.go
// ...
// ProjectTasks struct to describe getting list of tasks for a project.
type ProjectTasks []*GetProjectTasks // struct from Task model
// GetProject struct to describe getting one project.
type GetProject struct {
ID uuid.UUID `db:"id" json:"id"`
CreatedAt time.Time `db:"created_at" json:"created_at"`
UpdatedAt time.Time `db:"updated_at" json:"updated_at"`
UserID uuid.UUID `db:"user_id" json:"user_id"`
Alias string `db:"alias" json:"alias"`
ProjectStatus int `db:"project_status" json:"project_status"`
ProjectAttrs ProjectAttrs `db:"project_attrs" json:"project_attrs"`
// Fields for JOIN tables:
TasksCount int `db:"tasks_count" json:"tasks_count"`
Tasks ProjectTasks `db:"tasks" json:"tasks"`
}
```
> ☝️ **Note:** The `ProjectTasks` type needed to correctly output a list of all the tasks in the project.
Let's fix controller:
```go
// ./app/controllers/project_controller.go
// ...
// GetProjectByAlias func for getting one project by given alias.
func GetProjectByAlias(c *fiber.Ctx) error {
// Catch project alias from URL.
alias := c.Params("alias")
// Create database connection.
db, err := database.OpenDBConnection()
if err != nil {
return err
}
// Get project by ID with tasks.
project, err := db.GetProjectByAlias(alias)
if err != nil {
return err
}
// Return status 200 OK.
return c.JSON(fiber.Map{
"status": fiber.StatusOK,
"project": project, // <-- 1, 2, 3
})
}
```
The final optimized query result for our new endpoint should look like this:
```json
{
"status": 200,
"project": {
"id": "a5326b7d-eb6c-4d5e-b264-44ee15fb4375",
"created_at": "2021-09-21T19:58:30.939495Z",
"updated_at": "0001-01-01T00:00:00Z",
"user_id": "9b8734f9-05c8-43ac-9cd8-d8bd15230624",
"alias": "dvc08xyufws3uwmn",
"project_status": 1,
"project_attrs": {
"title": "Test title",
"description": "Test description",
"category": "test"
},
"tasks_count": 5,
"tasks": [
{
"id": "26035934-1ea4-42e7-9364-ef47a5b57126",
"alias": "dc3b9d2b6296",
"description": "Task one"
},
// ...
]
}
}
```
That's how gracefully and easily we used all the power of built-in Postgres function and pure SQL to solve a database query optimization problem.
Wow, how great is that? 🤗
[↑ Table of contents](#toc)
<a name="#postgres-query-analyzing"></a>
## Postgres query analyzing
As rightly noted in the comments, this article lacks some kind of analytics on query execution time. Well, I'll fix that by demonstrating a synthetic result PostgreSQL [EXPLAIN](https://postgrespro.com/docs/postgresql/9.6/sql-explain) function with `ANALYSE` method.
The test will involve three queries:
- Two simple SELECT of the project and all the tasks of the project (_by ID, which I put in the `INDEX`_);
- A complex query with two `LEFT JOIN` tables and create an aggregate `JSONB` object (_for ease of output, without resorting to conversions within Golang, only built-in means Postgres 13_).
> ☝️ **Note:** I specifically took a more complex query (_rather than the one in the article above_) to demonstrate how well and efficiently the Postgres database is able to perform queries.
There are 3 projects in my test table, each with 2 tasks. The database itself runs on an Apple MacBook Pro early 2015 (intel i5, 8 GB RAM) in a Docker container with the latest stable version of Postgres 13.x (`13.4-1.pgdg100+1`).
So, simple queries will look like this:
```sql
-- First simple query:
SELECT *
FROM
projects
WHERE
id = '6e609cb8-d62d-478b-8691-151d355af59d'
LIMIT 1
-- Second simple query:
SELECT *
FROM
tasks
WHERE
project_id = '6e609cb8-d62d-478b-8691-151d355af59d'
```
And here's a complex query:
```sql
-- Third complex query:
SELECT
p.id,
p.created_at,
p.updated_at,
p.project_status,
p.project_attrs,
jsonb_build_object(
'user_id', u.id,
'first_name', u.user_attrs->'first_name',
'last_name', u.user_attrs->'last_name',
'picture', u.user_attrs->'picture'
) AS author,
COUNT(t.id) AS tasks_count,
COALESCE(
jsonb_agg(
jsonb_build_object(
'id', t.id,
'status', t.task_status,
'name', t.task_attrs->'name',
'description', t.task_attrs->'description',
'steps_count', jsonb_array_length(t.task_attrs->'steps')
)
)
FILTER (WHERE t.project_id IS NOT NULL), '[]'
) AS tasks
FROM
projects AS p
LEFT JOIN users AS u ON u.id = p.user_id
LEFT JOIN tasks AS t ON t.project_id = p.id
WHERE
p.id = '6e609cb8-d62d-478b-8691-151d355af59d'
GROUP BY
p.id,
u.id
LIMIT 1
```
If you run these queries one by one with the `EXPLAIN ANALYSE SELECT ...` function, you can get the following results:
```bash
# For first simple query:
Limit (cost=0.15..8.17 rows=1 width=84) (actual time=0.263..0.302 rows=1 loops=1)
-> Index Scan using projects_pkey on projects (cost=0.15..8.17 rows=1 width=84) (actual time=0.238..0.248 rows=1 loops=1)
Index Cond: (id = '6e609cb8-d62d-478b-8691-151d355af59d'::uuid)
Planning Time: 0.177 ms
Execution Time: 0.376 ms
# For second simple query:
Seq Scan on tasks (cost=0.00..17.88 rows=3 width=100) (actual time=0.026..0.056 rows=2 loops=1)
Filter: (project_id = '6e609cb8-d62d-478b-8691-151d355af59d'::uuid)
Planning Time: 0.180 ms
Execution Time: 0.139 ms
# For third complex query:
Limit (cost=34.37..34.42 rows=1 width=156) (actual time=0.351..0.479 rows=1 loops=1)
-> GroupAggregate (cost=34.37..34.42 rows=1 width=156) (actual time=0.333..0.437 rows=1 loops=1)
Group Key: p.id, u.id
-> Sort (cost=34.37..34.37 rows=1 width=184) (actual time=0.230..0.335 rows=2 loops=1)
Sort Key: u.id
Sort Method: quicksort Memory: 27kB
-> Nested Loop Left Join (cost=0.29..34.36 rows=1 width=184) (actual time=0.106..0.260 rows=2 loops=1)
Join Filter: (t.project_id = p.id)
-> Nested Loop Left Join (cost=0.29..16.44 rows=1 width=116) (actual time=0.063..0.128 rows=1 loops=1)
-> Index Scan using projects_pkey on projects p (cost=0.15..8.17 rows=1 width=84) (actual time=0.021..0.038 rows=1 loops=1)
Index Cond: (id = '6e609cb8-d62d-478b-8691-151d355af59d'::uuid)
-> Index Scan using users_pkey on users u (cost=0.14..8.16 rows=1 width=48) (actual time=0.014..0.022 rows=1 loops=1)
Index Cond: (id = p.user_id)
-> Seq Scan on tasks t (cost=0.00..17.88 rows=3 width=68) (actual time=0.018..0.043 rows=2 loops=1)
Filter: (project_id = '6e609cb8-d62d-478b-8691-151d355af59d'::uuid)
Planning Time: 0.226 ms
Execution Time: 0.585 ms
```
At first glance, it may seem that two simple queries are much more effective than this complicated one. But do not be fooled by the low values of `Planning` and `Execution` because this test does not consider the network lag of the request and the subsequent processing in your Go program!
Regarding a complex query, we have already generated an object “under the hood” through the built-in PostgreSQL functions, which we simply pass in a JSON response to the consumer.
Therefore, on a really high load will always win one complex request (**which can also be cached**, which I do in my projects) than many simple ones.
> 👌 **Note:** It's fine if there are only two queries, but I've refactored many projects where one endpoint went to the database more than 10 times with such “simple queries”. This caused the database to be constantly under a much greater load than one prepared complex query.
[↑ Table of contents](#toc)
<a name=""></a>
## Photos and videos by
- Hannah Busing https://unsplash.com/photos/Zyx1bK9mqmA
<a name=""></a>
## P.S.
If you want more articles (like this) on this blog, then post a comment below and subscribe to me. Thanks! 😻
And of course, you can help me make developers' lives even better! Just connect to one of my projects as a contributor. It's easy!
My projects that need your help (and stars) 👇
- 🔥 [gowebly][gowebly_url]: A next-generation CLI tool for easily build amazing web applications with Go on the backend, using htmx & hyperscript and the most popular atomic/utility-first CSS frameworks on the frontend.
- ✨ [create-go-app][cgapp_url]: Create a new production-ready project with Go backend, frontend and deploy automation by running one CLI command.
- 🏃 [yatr][yatr_url]: Yet Another Task Runner allows you to organize and automate your routine operations that you normally do in Makefile (or else) for each project.
- 📚 [gosl][gosl_url]: The Go Snippet Library provides snippets collection for working with routine operations in your Go programs with a super user-friendly API and the most efficient performance.
- 🏄♂️ [csv2api][csv2api_url]: The parser reads the CSV file with the raw data, filters the records, identifies fields to be changed, and sends a request to update the data to the specified endpoint of your REST API.
- 🚴 [json2csv][json2csv_url]: The parser can read given folder with JSON files, filtering and qualifying input data with intent & stop words dictionaries and save results to CSV files by given chunk size.
<!-- Footer links -->
[gowebly_url]: https://github.com/gowebly
[cgapp_url]: https://github.com/create-go-app
[yatr_url]: https://github.com/koddr/yatr
[gosl_url]: https://github.com/koddr/gosl
[csv2api_url]: https://github.com/koddr/csv2api
[json2csv_url]: https://github.com/koddr/json2csv | koddr |
850,624 | Understanding Machine Learning: Study of Computer Science and Artificial Intelligence | Machine learning is the study of computer science and artificial intelligence, which focuses on data... | 0 | 2021-10-04T06:56:16 | https://dev.to/externlabs/understanding-machine-learning-study-of-computer-science-and-artificial-intelligence-1po0 | machinelearning, computerscience, programming, productivity | Machine learning is the study of computer science and artificial intelligence, which focuses on data and algorithms to make unconventional tasks and algorithms easier. It’s a branch of artificial intelligence, data mining is also a related field to study in Machine Learning. Machine learning involves computers learning from data So, that they can perform certain tasks and execute all steps required to solve the problem. There’s no learning needed on computer’s hand.
https://externlabs.com/blogs/machine-learning-engineer-vs-data-scientist/
Types of Machine Learning:
Supervised learning, Unsupervised Learning, and Reinforcement learning
1. In Supervised Learning, the ML algorithm is trained on labeled data. ML algorithm is given a small training dataset, which is a smaller part of a bigger dataset and serves to give a basic idea of the problem. Supervised learning is extremely powerful if used in the right circumstances.
2. Unsupervised learning is trained on unlabeled data. That means human labor is not needed to make data machine-readable, allowing much larger datasets to be worked upon.
3. Reinforcement learning is a direct connection that shows how humans learn from data in their daily lives. It uses a trial and error method, in which favorable outputs are reinforced and non — favorable outputs are discouraged. | aniruddhextern |
851,066 | Traditional VS Headless CMS: A Comparison | There are different types of content management systems. In this article, we will focus on comparing... | 0 | 2021-10-04T13:23:10 | https://strapi.io/blog/traditional-vs-headless-cms-a-comparison?utm_source=devto&utm_medium=post&utm_campaign=blog | headlesscms, cms, strapi, wordpress | There are different types of content management systems. In this article, we will focus on comparing traditional and headless CMSs to showcase why moving to a headless CMS can be an advantage to you.
## What is a Content Management System?
A content management system is a software application that helps users create, manage, edit, store and publish digital content on a website. CMSs help users build websites and launch products without having to write code.
## What is a Headless CMS?
A headless CMS is a content management system where the frontend and backend are separated from each other. With headless CMSs, the stored content is made available to developers through APIs.
Headless CMSs are frontend agnostic and API-driven by design. This way, developers are free to deliver the content to their audience with the frameworks and technologies of their choice.
## What is a Traditional CMS?
A traditional CMS is a monolithic content delivery system. With a traditional CMS, the frontend and backend are coupled together.
Though headless CMSs are gaining popularity as the go-to solution for content delivery, traditional CMSs are still the most popular. As of this writing, WordPress holds the [largest CMS market share of 36%](https://www.envisagedigital.co.uk/wordpress-market-share/).
## Traditional vs. Headless CMSs: Why should you use a headless CMS?
While both CMS architectures have different benefits, here’s a comparison that highlights the difference between both CMSs and the ten benefits you gain when choosing a headless CMS.
1. **Omnichannel freedom**
With Headless CMSs, you have the freedom to decide where and how your content is delivered. Headless CMSs are frontend agnostic by design. They have no opinion of how the content is displayed. This means you can adapt your content for omnichannel delivery anywhere, such as websites, mobile phones, smartwatches, AR/VR, even jumbotrons. With headless CMS, the channels of content delivery are limitless.
With traditional CMSs, however, you do not have omnichannel freedom. You are constrained and limited to delivering your content to the channels the CMS supports. This means if you intend to deliver your content to mobile phones and the CMS doesn't support that channel, you would be unable to do so.
2. **Developer Benefits**
With traditional CMSs, developers are restricted to building applications and websites in line with the CMS's architecture, and the tools and technologies they support. This results in slower, less flexible customizations. Developers are often stuck having to learn how to use vendor-specific, decades-old frameworks. Headless CMSs give developers the ability to work with the best tools to do the best work. By utilizing APIs and data formats like JSON to communicate and pull content, they can use the latest Jamstack technologies or the tech stack of their choice.
With traditional CMSs, switching from one vendor to another is costly and time-consuming because developers will have to learn the programming languages compatible with each new CMS. However, headless CMSs don't have this drawback, being API-based. You can decide to switch from one headless CMS to another without incurring any technical debt, loss of time, or resources.
3. **Scalability**
Traditional CMS systems usually host the content in-house, making it harder to handle traffic and scale because of limited servers. Also, any server downtime affects both the frontend and backend since they are coupled together.
With the frontend separated from the backend, if the CMS should go offline, have issues, or need maintenance, there will be no downtime on the frontend application.
Headless CMSs protect you from everything *–* from unforeseen traffic spikes to loss of data. Should an event occur, your data is stored safely in the cloud. This means you can quickly go live thanks to the reliable digital backup.
4. **Faster Editing**
Being content-focused, headless CMS enables marketers and content editors to work without distractions. They provide a user interface that makes uploading, editing, searching, structuring, and managing content easy. Headless CMSs provide a simplistic and distraction-free experience for content teams.
With traditional CMSs, content editing is not a seamless experience because the content, frontend, and codes are in the same system. This can distract from editing and make for a poor editing experience.
Another benefit for editors is that if they decide to adopt a new content delivery channel, they would not have to re-author the content to fit that channel. This avoids duplication of content and makes content easier to manage as you expand to new channels.
Having the frontend and backend separated allows editors to create and edit content without worrying about the frontend presentation and delivery. Also, they do not need to wait until developers are done coding to complete their work.
5. **Security**
Headless CMSs are less vulnerable to DDoS attacks since the frontend is separated from the backend. Headless CMSs have only one access point, their APIs, so the surface area of security attacks is smaller. This means that there are fewer security concerns when choosing a headless CMS.
Unlike headless CMSs, traditional CMSs are database-driven and are more vulnerable to DDoS and other security attacks.
Also, traditional CMSs require frequent security upgrades with every new security patch that gets released. Therefore, websites built on traditional CMSs are more prone to getting hacked, usually through insecure plugins or the sites not being updated regularly.
6. **Future Proof Content**
Traditional CMSs have a single content delivery channel in mind – websites. In the decades since traditional CMSs were built, several new channels like AR, VR, and smartwatch devices have come up. Traditional CMS limits you from being able to reach your audience where they are.
With headless CMSs, there are no boundaries to the number of digital experiences you can create with your content and the channels you can reach. As new technologies emerge, headless CMSs allow you to create new digital experiences to interact with your audience and stay relevant.
The API-driven approach enables you to come up with more innovative ways of delivering your content.
Headless CMS doesn't only enable you to reach your customers of today, but they evolve with technologies so you can reach your customers in whatsoever device they use in the future.
7. **No-bloat Systems**
Traditional CMSs come with several forms of customizations in an attempt to help solve your content delivery problems. The problem with this is that there are too many extra features that come pre-packed with the CMS.
Not only that, but you often have to work with legacy software, and that can become detrimental and disruptive to your product development.
With headless CMSs, you don't have to deal with bloated systems or legacy software. You decide the tools you want to integrate into your products. Headless CMSs are less disruptive to development. If anything, they boost the productivity of your team.
8. **Faster time-to-market**
Being API-driven, headless CMSs make it easier for you to integrate, manipulate, and distribute your content. Since the content is not bound to the frontend, you can target new channels without changing the backend. This cross-platform support increases optimization and decreases time-to-market significantly.
Adapting content to fit new channels will take more time using a traditional CMS. For every new channel you want to deliver your content to, you would have to not only build a frontend, but also reauthor your content for that channel. Not only is this an unnecessary duplication and ineffective way to work, but it also increases the chances of your content falling out of sync across channels.
9. **Automatic Updates**
With traditional CMSs, you are responsible for keeping things like plugins, themes, and software updated. Not only that, but you also have to test the updates to ensure they are compatible with other plugins and themes. There are situations where updates break plugins, and to avoid that, and you would have to create a backup before updating. Having to do this regularly to keep your CMS up to date becomes expensive and time-consuming.
With headless CMSs, you do not have to worry about keeping plugins, themes, or system software updated. The headless vendors keep their systems updated, enabling you to focus and work without distractions.
10. **Performance**
A slow website is bad for businesses. It leads to loss of traffic, poor customer experience, poor SEO rankings, and loss of sales. Headless CMSs help keep your website performant.
Being API-driven, you can opt-in for performant page rendering methods like Server-Side Rendering, SSR, and Static Site Generation, SSG.
With headless CMSs, you can leverage the latest tools, libraries, and frameworks in web technologies and use them to boost the speed of your website.
Traditional CMSs come packed with plugins that affect the speed and performance of websites. The more plugins you add, the less performant your website becomes because the plugins add code that runs every time a user visits a page.
## Conclusion
We have looked at why you should consider using a headless CMS, and how they solve the problems of managing content for businesses and brands. With a headless CMS, you are positioned for exponential growth, speed, and productivity. | shadaw11 |
851,067 | How to: Azure PubSub Service | If you learned something new feel free to connect with me on linkedin or follow me on dev.to :) Also... | 0 | 2021-10-06T09:07:00 | https://dev.to/albertbennett/how-to-azure-pubsub-service-2ccb | tutorial, csharp, azure, beginners | If you learned something new feel free to connect with me on [linkedin](https://www.linkedin.com/in/albert-bennett/) or follow me on dev.to :)
Also if you'd like to skip to the code I have posted it here on my [GitHub](https://github.com/Albert-Bennett/AzurePubSubSample) page.
<br/>
Today I'd like to chat a bit about the Azure Web PubSub Service and what it can do. I got the opportunity to use this service last week and I think that it is really interesting tech especially if you need to stream data through a websocket and don't want to set up a websocket server.
<br/>
**So what is Azure PubSub?**
It is a service in Azure that allows you to push data to a hub and subscribers of that hub can get the data. Below I have an image of how this works:
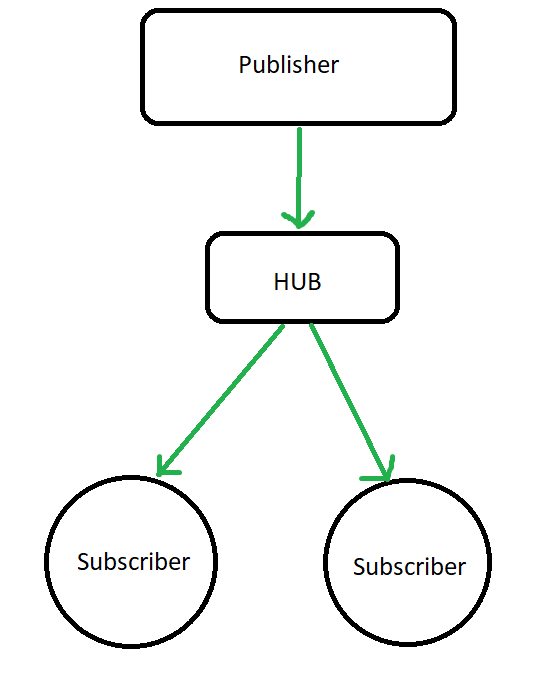This connection happens over wss which is a TCP protocol over port 443. Traditionally to do this you'd need to set up a websocket server and establish a connection with it to serve the data. Using this new Azure service really removes a lot of headaches with streaming data to clients.
<br/>
**About the Sample**
What the sample that I am going to go through is going to do is:
1. Allow the user to subscribe to a hub.
2. Push data to our hub so that subscribers can see it via a http trigger function in the function app.
3. Display the data from our hub.
**Step 1**
Firstly we need to create the Web PubSub Service. There is not much to it... see image below of what settings I used to set it up:
 And that's about it for our Azure Services. You don't need to tweak anything on the new service, it's good to go as is well.. for our purposes it is. You can set up a function app with an app service plan as well if you wanted to deploy the code later on but... I didn't want to for this sample.
<br/>
**Step 2**
Next onto the project setup. What we need to do first is to create an C# Function App project: I have chosen to use a http trigger but, you could have used a timer trigger as the function as well because we will be using a timer function to send data to our hub.
From here you need to install the following nuget packages:
1. Azure.Messaging.WebPubSub
2. Microsoft.Azure.WebJobs.Extensions.WebPubSub
These packages are in beta so you'll need to search for the preview packages. What these lets us do is to push messages to our hub and allows users to subscribe to a hub. Finally you'll need to add a connection string from your PubSub service to the local.settings.json file of your function app. You can find the connection string to the Web PubSub service by going to **Keys > Connection String (under the 'Primary')**. See screen shot below:
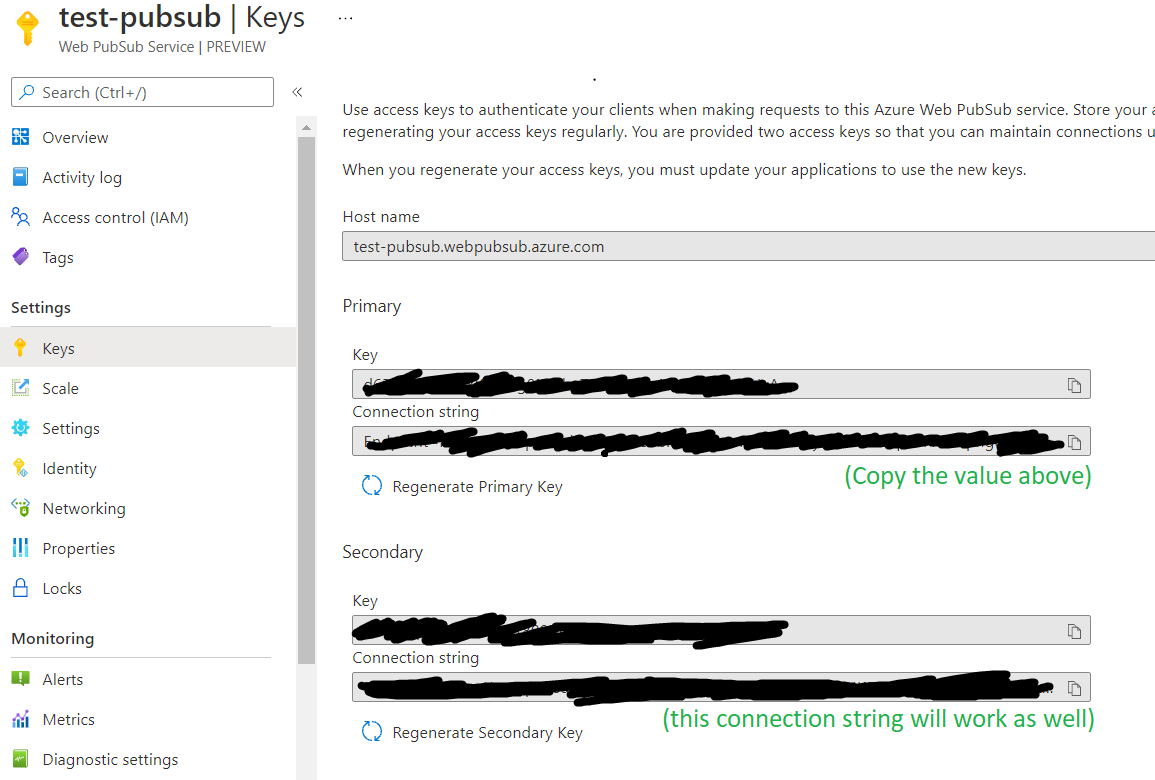 I have left a sample of what my settings file looks like below after adding the connection string:
```json
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"WebPubSubConnectionString": "[your connection string]"
}
}
```
<br/>
**Step 3**
The code for this is very straight forward.
We need a function to push data to our hub and a function to let users subscribe to our hub.
Here is the code to get users to subscribe to our hub:
```csharp
public static class Subscribe
{
[FunctionName("Subscribe")]
public static WebPubSubConnection Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = null)] HttpRequest req,
[WebPubSubConnection(Hub ="test")] WebPubSubConnection connection,ILogger log)
{
return connection;
}
}
```
This function essentially establishes a connection to our hub and it returns a json response. Below is a sample response from the endpoint:
```json
{
"baseUrl": "[base URL]",
"url": "[base URL with access token]",
"accessToken": "[the access token]"
}
```
The main value we want to make use of is the 'url' field. The value of this is our connection to the hub in the PubSub Service.
And here is the code to push data to our hub.
```csharp
public class PublishData
{
[FunctionName("PublishData")]
public async Task Run([TimerTrigger("*/10 * * * * *")] TimerInfo myTimer, ILogger log,
[WebPubSub(Hub = "test")] IAsyncCollector<WebPubSubOperation> operations)
{
await operations.AddAsync(new SendToAll
{
Message = BinaryData.FromString(DateTime.Now.ToShortTimeString()),
DataType = MessageDataType.Text
});
}
}
```
Essentially what this is doing is sending the data to all subscribers of the hub defined in the binding of our function in our case 'test'.
With that being set up you can now get clients to subscribe to the hub and receive data being published to the hub in real time.
Ok, so there isn't much to see here we can see that the timer function is being triggered but, not much else:
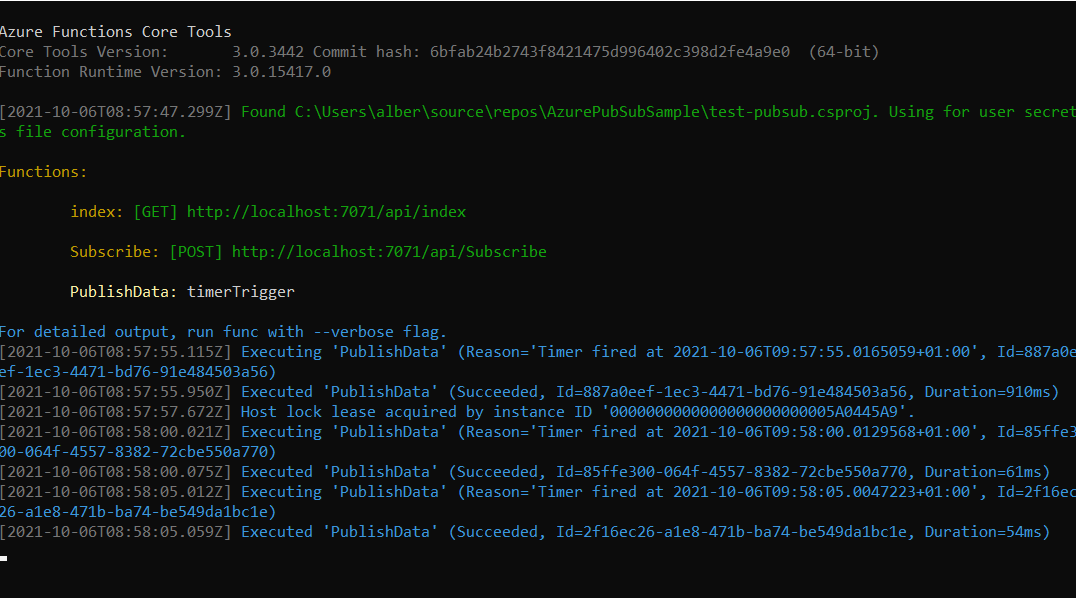 In the repo I have added a new function to the app that returns a html page. On that page there is a js function that connects to the websocket and returns the data in real time.
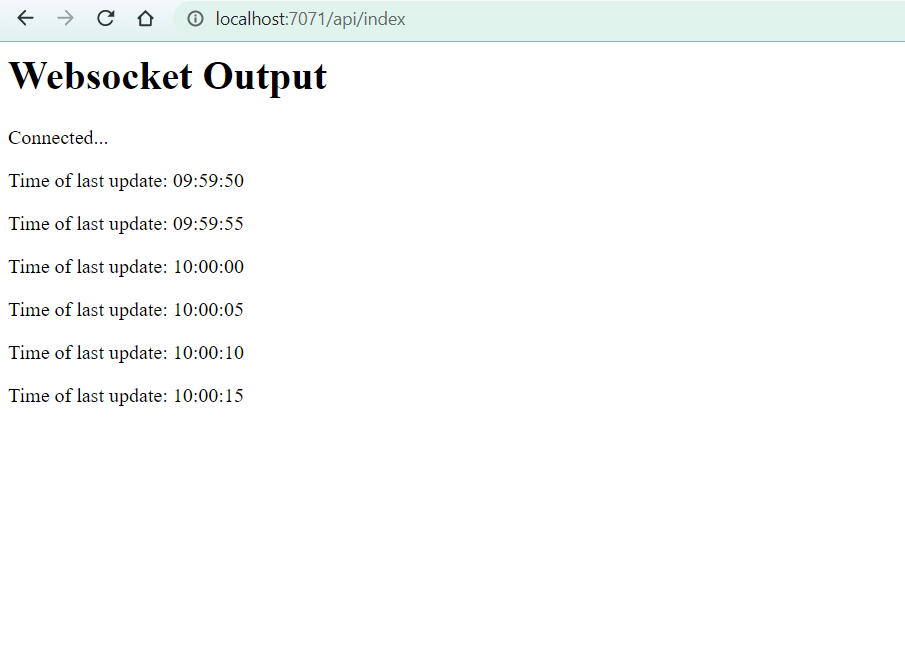 And with that, you can see that data being received by the subscriber in real time.
<br/>
Thanks for reading my post, and I'll see you in the next one. | albertbennett |
851,135 | 7 Python Project Structure Best Practices. | Is there a perfect project structure for Python? It turns out there is. I don't mean the folder... | 0 | 2021-10-04T15:19:24 | https://dev.to/thuwarakesh/7-python-project-structure-best-practices-4h5o | programming, beginners, python, codenewbie | Is there a perfect project structure for Python? It turns out there is.
I don't mean the folder structure. But an initial setup that multiplies your odds of creating a groundbreaking project.
In this post, I've discussed 7 techniques you should always use in every Python project.
If they sound too overwhelming, don't worry. I've also created __a blueprint__ you can easily copy and use right away.
[7 Ways to Make Your Python Project Structure More Elegant](https://www.the-analytics.club/python-project-structure-best-practices) | thuwarakesh |
851,148 | OOP in JS : one thing to keep in mind | answer re: JavaScript: Class.method... | 0 | 2021-10-04T15:40:19 | https://dev.to/merlier/oop-in-js-one-thing-to-keep-in-mind-5c42 | javascript, beginners, webdev, codenewbie | {% stackoverflow 1635143 %} | merlier |
851,173 | Conflict-free Xcode Project Management | There is one pain that every iOS developers face, especially when they work in a team. ... | 0 | 2021-10-05T10:31:19 | https://dev.to/esam091/conflict-free-xcode-project-management-78d | swift, xcode, ios |
There is one pain that every iOS developers face, especially when they work in a team.
## Xcode merge conflicts.
It is one of the most dreadful and time wasting activity that nobody likes to do. This pain only stings more the bigger your team and codebase gets.
## Why does it keep happening?
Xcode keeps track of all source files that needs to be compiled within this `project.pbxproj`. It is a plain text file which has the content like below.
```
// !$*UTF8*$!
{
archiveVersion = 1;
classes = {
};
objectVersion = 50;
objects = {
/* Begin PBXBuildFile section */
923EF325270C588D0058CE0F /* AppDelegate.swift in Sources */ = {isa = PBXBuildFile; fileRef = 923EF324270C588D0058CE0F /* AppDelegate.swift */; };
923EF327270C588D0058CE0F /* SceneDelegate.swift in Sources */ = {isa = PBXBuildFile; fileRef = 923EF326270C588D0058CE0F /* SceneDelegate.swift */; };
923EF329270C588D0058CE0F /* ViewController.swift in Sources */ = {isa = PBXBuildFile; fileRef = 923EF328270C588D0058CE0F /* ViewController.swift */; };
923EF32C270C588D0058CE0F /* Main.storyboard in Resources */ = {isa = PBXBuildFile; fileRef = 923EF32A270C588D0058CE0F /* Main.storyboard */; };
923EF32E270C588F0058CE0F /* Assets.xcassets in Resources */ = {isa = PBXBuildFile; fileRef = 923EF32D270C588F0058CE0F /* Assets.xcassets */; };
923EF331270C588F0058CE0F /* LaunchScreen.storyboard in Resources */ = {isa = PBXBuildFile; fileRef = 923EF32F270C588F0058CE0F /* LaunchScreen.storyboard */; };
923EF33A270C58E00058CE0F /* ShopViewController.swift in Sources */ = {isa = PBXBuildFile; fileRef = 923EF338270C58E00058CE0F /* ShopViewController.swift */; };
923EF33B270C58E00058CE0F /* ShopViewController.xib in Resources */ = {isa = PBXBuildFile; fileRef = 923EF339270C58E00058CE0F /* ShopViewController.xib */; };
/* End PBXBuildFile section */
```
You don't even need to be in a team to experience this. If you work on multiple branches, the conflict often shows up whenever you merge them.
```
CONFLICT (content): Merge conflict in SadApp.xcodeproj/project.pbxproj
Automatic merge failed; fix conflicts and then commit the result.
```
## Have you ever wished for the merge conflicts to go away?
I do, all the time. I have worked on Android and web projects in the past. The conflicts happen much less frequently, if they happen at all.
If you have been looking for a solution, you are lucky my friend. There is a hope to end this madness.
## Swift Package Manager
Swift Package Manager(SPM) has existed for years since Swift 3.0.
We seldom see its usage outside of server side and command line Swift apps. The reason for this is because it used to have bad support for iOS development.
Things have changed though since the release of Xcode 12.
Xcode 12 adds a first class support for using Swift Package Manager in iOS app development.
All the pains I mentioned before instantly went away after I used it.
This is a powerful technique yet still unknown to many people, given how new it is.
Now I want to show you how to use it.
## Let's give it a try
### Create a new iOS project, as usual
You know the drill:
1. Open Xcode
2. Create a new iOS app. I'll just name it `MyApp` in this demo. Yes I have a wonderful naming sense.
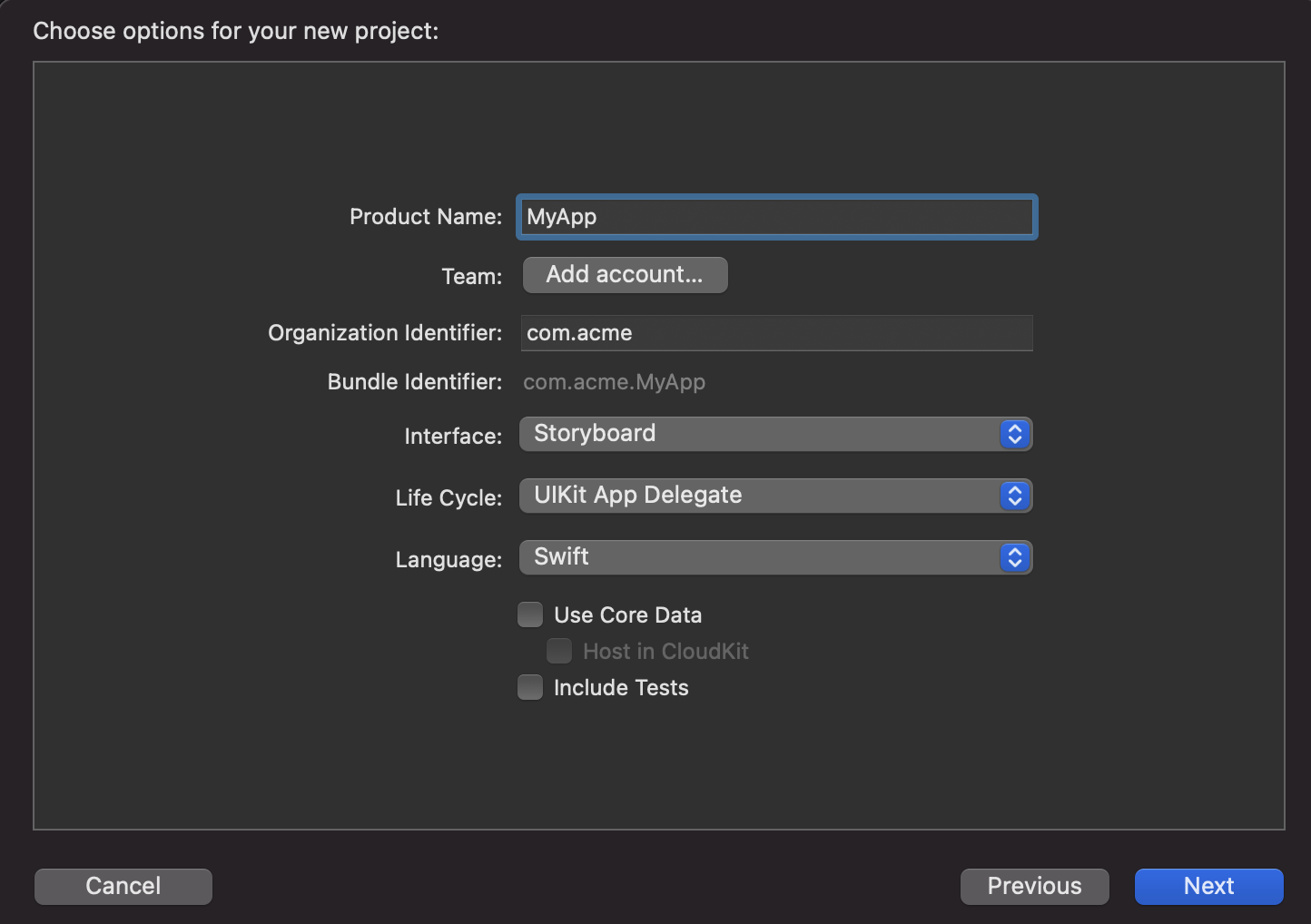
### Create a new Swift Package.
1. From your Xcode, go to File -> New -> Swift Package.
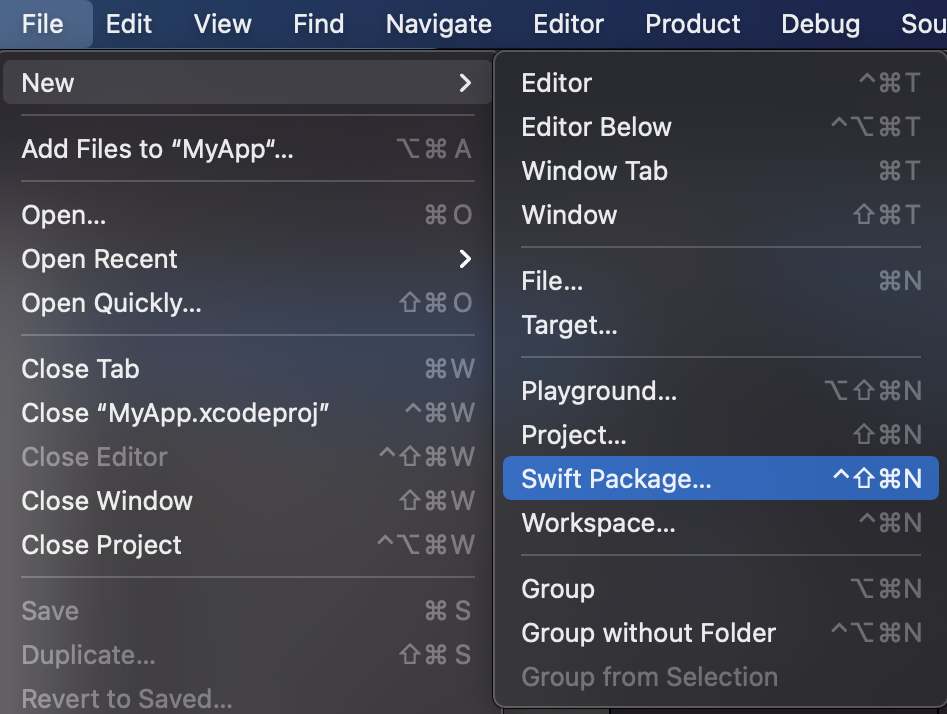
2. Give a name for your package. Some important things to notice:
- Make sure that the package will be stored **inside** your project folder as shown in the highlighted green box below.
- Select your previously created project in the `Add to` section as shown in the yellow box below.
3. If you did it right, the Swift Package will be shown in the file explorer.
### Import the package from the app target.
In order to import your Swift package from your app, go to your app's `Build Phases` section, and add your package target in the `Link Binary With Libraries` subsection.
### Build the project
Let's see if things work as they should:
1. Add new code inside `Sources/MyAppPackage`.
2. Import the code from your app target.
```swift
// MyAppPackage/Sources/MyAppPackage/MyAppPackage.swift
public func hello() {
print("Hello from Swift Package")
}
// MyApp/AppDelegate.swift
import MyAppPackage
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
hello()
return true
}
```
If you see the `Hello from Swift Package` message from your console, then that means you have used a Swift Package code from inside your app. Congratulations 🤝.
One important thing here `project.pbxproj` does not change no matter how many files you put in your package. That's why this technique is miles better compared to the old one.
## What should I put in the Swift Package?
I'd put pretty much everything there except for Info.plist, Main and LaunchScreen storyboards.
For everything else I'll put them into the Swift Package: Swift files, Xibs, Storyboards, image assets.
## Don't lose your assets
If you use Xibs, Storyboards, or image assets, you need to do a small tweak in your code. Pretty much things that related to bundles.
When you create a view controller, this is the initializer that a lot people use.
```swift
class MyViewController: UIViewController {
init() {
super.init(nibName: nil, bundle: nil)
}
}
```
Notice that I put nil in the bundle argument. This means that the main Bundle will be used to locate the Nib resource.
If your Nib is located in a Swift Package like below,
you need to change the bundle argument.
```swift
super.init(nibName: nil, bundle: Bundle.module)
```
## Conclusion
Swift Package Manager is a superior way to manage your Xcode projects because you don't have to deal with merge conflicts that often anymore. Things just work.
If you are starting a new project, I'd recommend you to use it right away.
If you are working in an existing project, better migrate them to Swift Package Manager as soon as you can.
If you have questions, let me know in the comments section. I'd love to answer your confusions. | esam091 |
851,192 | How to use Unit tests in Laragine | In the previous tutorial, I taught you how to create a fully CRUD API, let's continue the journey and... | 14,891 | 2021-10-04T19:04:20 | https://dev.to/abdlrahmansaberabdo/how-to-use-unit-tests-in-laragine-1jg8 | laravel, programming, php, api | In the previous tutorial, I taught you how to create a `fully CRUD API`, let's continue the journey and learn how to use **Laragine** to test the `API` that we created in the previous tutorial.
## Steps:
We need to do 3 things in `phpunit.xml` in the root directory:
1. Change the value of the `bootstrap` attribute to `vendor/yepwoo/laragine/src/autoload.php` in `PHPUnit` tag (it's the same as `vendor/autoload.php` but with needed stuff to run the tests correctly in the generated modules and units).
2. Add the following to the `Unit` test suite:
`<directory suffix=".php">./core/*/Tests/Feature</directory>`
`<directory suffix=".php">./plugins/*/Tests/Feature</directory>`
3. add the following to `Feature` test suite:
`<directory suffix=".php">./core/*/Tests/Feature</directory>`
`<directory suffix=".php">./plugins/*/Tests/Feature</directory>`
**Here's the full code snippet: **

* Let's go to `PostTest.php` in `core/Blog/Tests/Feature`
* There're **five** main *functions* in the file:
1. `testItShouldGetListingOfTheResource()`
for testing get the lists of the the resource.
2. `testItShouldStoreNewlyCreatedResource()`
for testing create a new resource in the storage.
3. `testItShouldGetSpecifiedResource()`
for testing get a specefied the resource.
4. `testItShouldUpdateSpecifiedResource()`
for testing update a resource in the storage
5. `testItShouldRemoveSpecifiedResource()`
for testing remove a resource from the storage
## Note
you can edit the unit tests function as you want, we just write the main methods for each CRUD.
Now open your `terminal` or `git bash` in your project and let's run the test, you can run one of the following commands:
1. `php artisan test`
2. `./vendor/bin/phpunit`

## Conclusion
I hope you found this article helpful. If you need any help please let me know in the comment section.
Let's connect on [LinkedIn](https://www.linkedin.com/in/abdlrahmansaber/) | abdlrahmansaberabdo |
851,348 | Building the Right Platform | In mid-level and big scale organizations, the mission focus is on having continuous innovation backed... | 0 | 2021-10-16T10:32:28 | https://dev.to/vinayhegde1990/building-the-right-platform-8jo | devops, observability, monitoring, productivity | In mid-level and big scale organizations, the mission focus is on having continuous innovation backed by stability. The former is required to stay ahead of the curve (*being better than one's competitors*) while the latter is the springboard to delivery. Thus, a strong **platform** is an apparent need for every technological company.
Thus, we land upon a concept called Platform Engineering.
### So what's it actually?
> As per [this definition](https://www.limepoint.com/platform-engineering)
_Platform engineering is the process through which enterprises adopt (*new technology and platforms*), leverage (*existing technologies and platforms*), and transform (*shift the dial on delivering value by transforming the way things are done*) cloud platforms. It is at the core of designing, building, and operating your cloud infrastructure to deliver the next generation IT ecosystem._
While the above definition is accurate, it does not really help understand on the why, what & how to build reliable platforms. Especially for teams who are looking to either augment or revamp their infrastructure from old ways to new.
Therefore, I felt I could contribute by creating one from my know-how so far. For easier understanding, the categories herewith will be structured into the following parameters: why, some points to consider, alternatives.

To build a smooth platform, most e-commerce companies need tooling/tech/processes/workflows in the following categories.
>
1. [Domains](#domains)
1. [Cloud Platform](#cloud-platform)
1. [Infrastructure as Code](#infrastructure-as-code)
1. [Version Control](#version-control)
1. [Packaging](#packaging)
1. [CI/CD](#cicd)
1. [Web Services](#web-services)
1. [Databases](#databases)
1. [Monitoring](#monitoring)
## Domains

**Why?:** Branding of one's product, everything on the internet begins with a domain. E.g: google.com, facebook.com, dev.to
**Some points to consider?:**
+ Domain pricing / renewals (_with ICANN fees_)
+ Whois Privacy
+ The right name and [Top Level Domain or TLD](https://www.techopedia.com/definition/1348/top-level-domain-tld) or [country-level TLD](https://www.techopedia.com/definition/1323/country-code-top-level-domain-cctld) if it's region specific. (_Impacts SEO_)
**Known tools:** [Bigrock.in](https://bigrock.in)
**Alternatives:** [Namecheap](https://www.namecheap.com), [Route53](https://aws.amazon.com/route53), [Cloudflare](https://www.cloudflare.com/products/registrar), [Google Registry](https://www.registry.google)
## Cloud Platform

**Why?:** Gateway to the system, having the right infrastructure will be like a strong backbone.
**Some points to consider?:**
+ Basic features such as instances/VMs, isolated networks (_not everyone will need Kubernetes or Mesos_)
+ Sufficient Capacity for one's enterprise at scale (_The last thing one wants in the middle of a frantic user rush is no hardware available_)
+ Multiple accounts with RBAC to distinguish between teams/environments.
+ Compatibility with [Infrastructure-as-Code](https://www.ibm.com/cloud/learn/infrastructure-as-code) tools
+ Effective Pricing.
**Known tools:** [Amazon Web Services (AWS)](https://aws.amazon.com/)
**Alternatives:** [Google Cloud Platform](https://cloud.google.com), [Microsoft Azure Cloud](https://azure.microsoft.com/en-in), [DigitalOcean](https://www.digitalocean.com), [Linode](https://www.linode.com)
## Infrastructure as Code

**Why?:** Codifying the infrastructure provisioning and configuration to keep it exact across environments.
**Some points to consider?:**
+ Idempotency by changing/deleting infrastructure only once.
+ Ability to store state locally & remotely.
+ Should be vender neutral & serve as a crisp log for audit
**Known tools:** [Terraform](https://developer.hashicorp.com/terraform)
**Alternatives:** [Pulumi](https://www.pulumi.com/), [AWS Cloudformation](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/Welcome.html), [Google Deployment Manager](https://cloud.google.com/deployment-manager/docs), [Azure Resource Manager](https://learn.microsoft.com/en-us/azure/azure-resource-manager/management/overview)
## Version Control

**Why?:** Managing codebases with multiple teams across varied projects in different business verticals.
**Some points to consider?:**
+ De-centralized (_avoids a single point of failure_)
+ Clear history log (_for updates/rollback_)
+ Branching/separating strategies.
+ Ease of setup
**Known tools:** Git
**Alternatives:** Mercurial, TFS, SVN
## Packaging
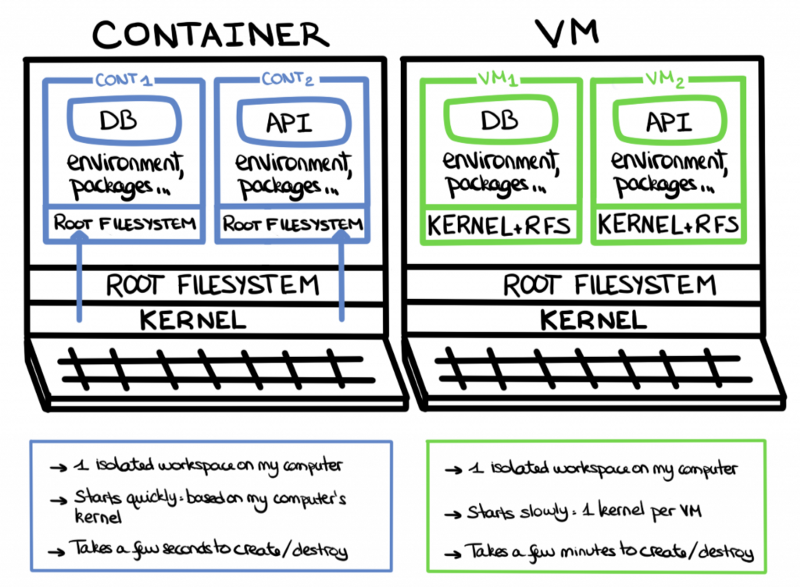
**Why?:** Software should be same across environments. Helps in the CI/CD step and reproduce issues to be fixed quicker
**Some points to consider?:**
+ Application storage size (_No point in having GB sized containers_)
+ Ability to generate artifacts (if any)
**Known tools:** Docker
**Alternatives:** Containerd, LXC, APT, Yum
## CI/CD
**Why?:** To compile/build and deploy software easily. Manual steps can be time-consuming, error-prone and be a bottleneck.
**Some points to consider?:**
+ Ability to build/deploy multiple programming languages, frameworks
+ Support for unit/smoke tests, canary deployments.
+ Preferably independent than infrastructure (_helps avoid vendor lock-in_)
+ Self-hosted vs SaaS (factors here are cost, upgrades and maintenance)
**Known tools:** [Jenkins](https://www.jenkins.io)
**Alternatives:** [Github Actions](https://github.com/features/actions), [Gitlab](https://docs.gitlab.com/ee/ci) , [CircleCI](https://circleci.com), [TravisCI](https://travis-ci.org), [ArgoCD](https://argoproj.github.io/cd)
## Web-Services
**Why?:** Helps your userbase access all the consumer endpoints of the system. For e.g: discover, checkout, payments
**Some points to consider?:**
+ Scale management (_An incorrectly setup web-service can quickly have a cascading effect in case of heavy traffic_)
+ Reverse proxying to one/multiple back-ends and fail-overs (_for High Availability_)
+ Support for HTTP/GRPC protocols.
+ Advanced features such as rate-limits, throttling, IP bans.
**Known tools:** HAProxy
**Alternatives:** NGinx, Apache, Ambassador, Envoy, Istio
## Databases

**Why?:** To maintain state of applications and store all data such as inventory, payments and other types of relational information. Helpful for data analytics as well.
**Some points to consider?:**
+ ACID Compliance
+ Libraries/connectors for multiple programming languages.
+ Storage parameters such as in-memory or persistent to disk.
+ Ease of backup, recovery in case of DR drills.
+ Key-value stores for relatively smaller datasets.
**Known tools:** MySQL or MariaDB
**Alternatives:** PostgreSQL, MSSQL, MongoDB, Kafka, Aerospike, Redis, Memcached
## Monitoring
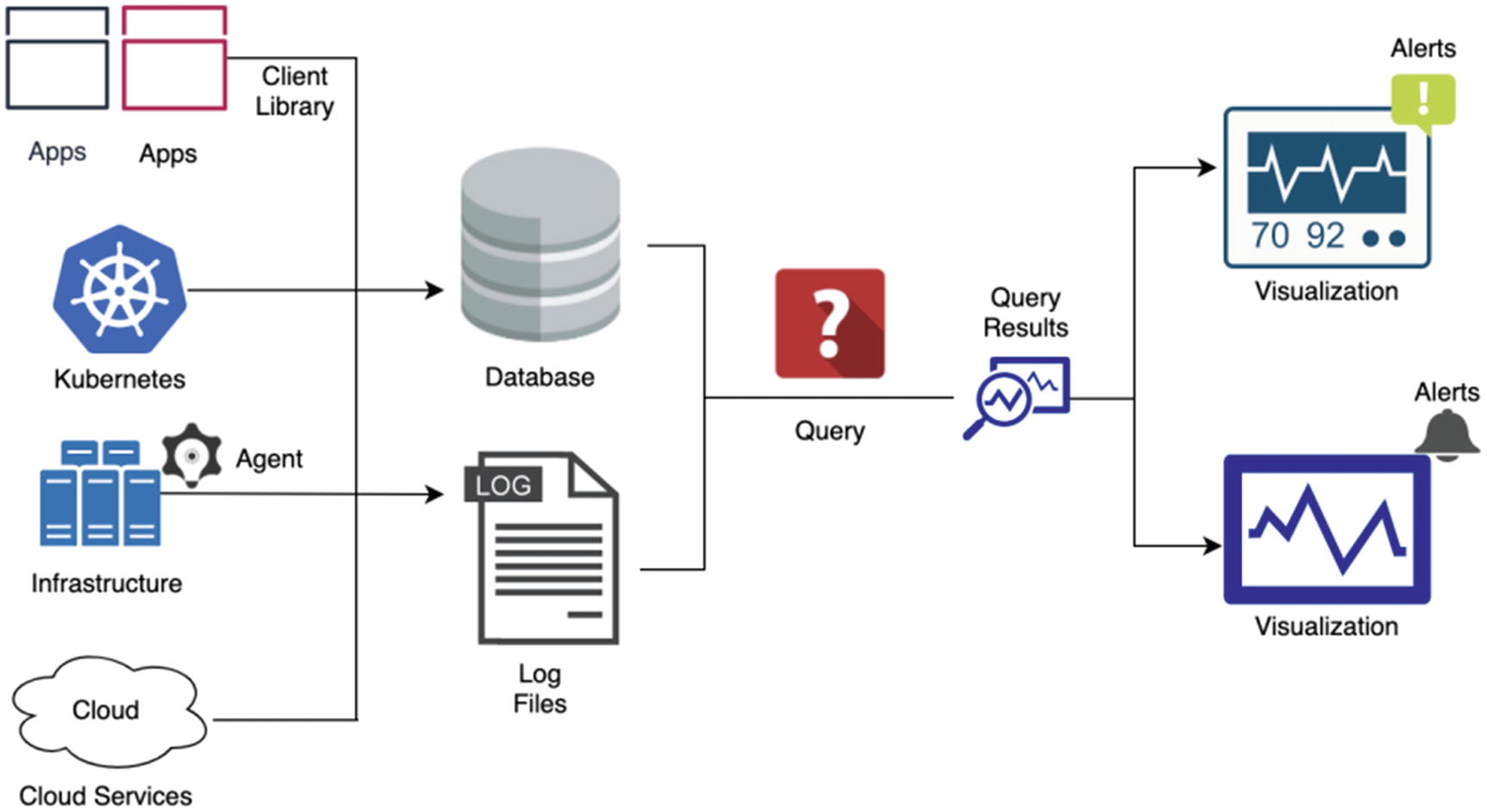
**Why?:** A small monitored system will be more reliable than a big one without.
**Some points to consider?:**
+ Agents/libraries across multiple programming languages.
+ Ability to view application/infrastructure metrics.
+ Retention as per compliance.
**Known tools:** [NewRelic](https://newrelic.com)
**Alternatives:** [Datadog](https://www.datadoghq.com), [AppSignal](https://appsignal.com), [Instana](https://www.instana.com), [ElasticAPM](https://www.elastic.co/apm)
*TL;DR: While this is not a definitive list of things that's required to build a system but there's a good chance this blog post provides an entrypoint for you to begin with*
---
What are some pointers you would consider to build a reliable, consistent and easy-to-use platform? | vinayhegde1990 |
871,452 | The Easiest Way to Scrape Amazon Products and Reviews | Introduction Amazon is a vast Internet-based enterprise that sells all kinds of goods... | 0 | 2021-10-21T14:07:22 | https://www.page2api.com/blog/scrape-amazon-product-data/ | webscraping, tutorial | ## Introduction
**Amazon** is a vast Internet-based enterprise that sells all kinds of goods either directly or as the middleman between other retailers and **Amazon's** millions of customers.
You can scrape their data to run different types of tasks such as:
- competitor analysis
- improving your products and value proposition
- identifying market trends and what influences them
- price monitoring
Luckily, **Amazon** is a website that is pretty easy to scrape if you have the right tools.
For this purpose, we will use [Page2API](https://www.page2api.com/) - a powerful and delightful API that makes web scraping easy and fun.
In this case, we will scrape 2 types of amazon pages:
- Search results page
- Product reviews page
## Prerequisites
To perform this simple task, you will need the following things:
- [A Page2API account](https://www.page2api.com/users/sign_up/)
The free trial offers a credit that covers up to **1000** web pages to scrape, and it takes under **10** seconds to create the account if you sign up with Google.
- A product or a category of products that we are about to scrape.
In our case, we will search for **'luminox watches'**
and then scrape the reviews for a random product.
## Scraping all products from the search page
First what we need is to type **'luminox watches'** into the search input from amazon's search page.
This will change the browser URL to something similar to:
```
https://www.amazon.com/s?k=luminox+watches
```
The URL is the first parameter we need to perform the scraping.
The page that you see must look like the following one:
If you inspect the page HTML, you will find out that a single result is wrapped into a div that looks like the following:
The HTML for a single result element will look like this:
The last part is the pagination handling.
In our case, we must click on the Next → button while the list item's class will be active:
And stop our scraping request when the **Next →** button became disabled.
In our case, a new class (**a-disabled**) is assigned to the list element where the button is located:
Now it's time to prepare the request that will scrape all products that the search page returned.
**Setting the api_key as an environment variable**
```bash
export API_KEY=YOUR_PAGE2API_KEY
```
**Running the scraping request with cURL**
```json
curl -v -XPOST -H "Content-type: application/json" -d '{
"api_key": "'"$API_KEY"'",
"url": "https://www.amazon.com/s?k=luminox+watches",
"real_browser": true,
"merge_loops": true,
"scenario": [
{
"loop" : [
{ "wait_for": ".a-pagination li.a-last" },
{ "execute": "parse" },
{ "execute_js": "document.querySelector(\".a-pagination li.a-last a\").click()" }
],
"stop_condition": "document.querySelector(\".a-last.a-disabled\") !== null"
}
],
"parse": {
"watches": [
{
"_parent": "[data-component-type='s-search-result']",
"title": "h2 >> text",
"link": ".a-link-normal >> href",
"price": ".a-price-whole >> text",
"stars": ".a-icon-alt >> text"
}
]
}
}' 'https://www.page2api.com/api/v1/scrape' | python -mjson.tool
```
**The result**
```json
{
"result": {
"watches": [
{
"title": "Men's Luminox Leatherback Sea Turtle 44mm Watch",
"link": "https://www.amazon.com/Luminox-Leatherback-Turtle-Giant-Black/dp/B07CVFWXMR/ref=sr_1_2?dchild=1&keywords=luminox+watches&qid=1634327863&sr=8-2",
"price": "$223.47",
"stars": "4.5 out of 5 stars"
},
{
"title": "The Original Navy Seal Mens Watch Black Display (XS.3001.F/Navy Seal Series): 200 Meter Water Resistant + Light Weight Case + Constant Night Visibility",
"link": "https://www.amazon.com/Luminox-Wrist-Watch-Navy-Original/dp/B07NYXV77C/ref=sr_1_3?dchild=1&keywords=luminox+watches&qid=1634327863&sr=8-3",
"price": "$254.12",
"stars": "4.3 out of 5 stars"
},
{
"title": "Leatherback SEA Turtle Giant - 0323",
"link": "https://www.amazon.com/Luminox-Leatherback-SEA-Turtle-Giant/dp/B07PBC31N8/ref=sr_1_4?dchild=1&keywords=luminox+watches&qid=1634327863&sr=8-4",
"price": "$179.00",
"stars": "4.3 out of 5 stars"
},
...
]
},
...
}
```
## Scraping product reviews
First what we need is to click on the **See all reviews** link from the Product page.
This will change the browser URL to something similar to:
```
https://www.amazon.com/product-reviews/B072FNJLBC
```
The URL is the first parameter we need to perform the reviews scraping.
The HTML from a single review will look like this:
Luckily, the pagination handling is similar to the one described above, so we will use the same flow.
Now it's time to prepare the request that will scrape all reviews.
**Setting the api_key as an environment variable (if needed)**
```bash
export API_KEY=YOUR_PAGE2API_KEY
```
**Running the scraping request with cURL**
```json
curl -v -XPOST -H "Content-type: application/json" -d '{
"api_key": "'"$API_KEY"'",
"url": "https://www.amazon.com/product-reviews/B072FNJLBC",
"real_browser": true,
"merge_loops": true,
"scenario": [
{
"loop" : [
{ "wait_for": ".a-pagination li.a-last" },
{ "execute": "parse" },
{ "execute_js": "document.querySelector(\".a-pagination li.a-last a\").click()" }
],
"stop_condition": "document.querySelector(\".a-last.a-disabled\") !== null"
}
],
"parse": {
"reviews": [
{
"_parent": "[data-hook='review']",
"title": ".review-title >> text",
"author": ".a-profile-name >> text",
"stars": ".review-rating >> text",
"content": ".review-text >> text"
}
]
}
}' 'https://www.page2api.com/api/v1/scrape' | python -mjson.tool
```
**The result**
```json
{
"result": {
"reviews": [
{
"title": "Great watch & easy to read in low light conditions",
"author": "Paul E. Papas",
"stars": "5.0 out of 5 stars",
"content": "I'm a 60+ year old equestrian and outdoorsman. I was looking for a watch that could take the shock of firearm discharge ..."
},
{
"title": "Not Water Resistant, impossible to get amazon help",
"author": "Benjamin H. Curry",
"stars": "2.0 out of 5 stars",
"content": "This watch has a 2 year warranty from date of purchase however after not even on full year my adult son went swimming with it ..."
},
...
]
},
...
}
```
## Conclusion
That's pretty much of it!
As mentioned, **Amazon** is a website that is pretty easy to scrape if you have the right tools.
This is the place where [Page2API](https://www.page2api.com/) shines, making web scraping super easy and fun.
The original article can be found here:
[https://www.page2api.com/blog/scrape-amazon-product-data](https://www.page2api.com/blog/scrape-amazon-product-data/) | nrotaru |
851,501 | 7 ways to Simulate Low Network Speed to Test Your Mobile Application | When testing mobile apps, newbies QA frequently forget to check the app with an unstable Internet... | 19,671 | 2021-10-04T21:00:04 | https://forasoft.com/blog/article/simulate-slow-network-connection-57 | testing, ios, android, mobile | When testing mobile apps, newbies QA frequently forget to check the app with an unstable Internet connection. But in many cases this is critical: connection speed directly influences user experience and workability of the main functions. It is especially true for applications where geolocation and mobile Internet are heavily in use. For example, video chats, messengers, and other [multimedia products](https://forasoft.com/services) we specialize in.
In this article, we’ll show how to simulate slow Internet connection on a test device with no hassle.
## Network Link Conditioner
Let’s start with a standard utility Network Link Conditioner for iOS apps testing. It lets the QA adjust the Internet connection as they need.
To switch on this function on iPhone, you need a MacOS device:
1. [Download and install Xcode for Mac](https://developer.apple.com/xcode/)
2. Open Xcode on Mac
3. Connect iPhone to Mac
4. Allow Mac access iPhone
5. Open Settings on iPhone
6. Scroll down
7. Tap Developer

- Tap Network Link Conditioner

- Pick network preset or create your own
- Switch on the Enable toggle

iOS lets us choose one of pre-installed presets of connection quality – or create our own preset.
For our own preset these settings are available:

Here we see that Apple took care of testing apps with different levels of connection quality and gave us almost all the needed settings.
Having got acquainted with Network Link Conditioner for iOS, we’ve been sure such a feature would be on Android too. God, how much we’ve been mistaken.
## Network Link Conditioner on Android
It appeared to be impossible to emulate a slow or unstable connection on a real Android with the help of standard tools. Therefore, I faced 2 paths: download some apps from Google Play that emulate slow connection, or use a specifically precise adjustment of the Internet connection access point.
Apps didn’t work out for me ☹ All the apps that give this function require Root access, and this breaks the concept of testing in real-world conditions.
So, having left the Root access as the last resort, I decided to look closer at path #2 — adjustment of the access point.
In the past, when I was a student, mobile internet traffic was ending up quickly (and we needed to read, watch something while on the lesson), and we used an iPhone as an access point. The idea came to mind: to mix the student experience and recently gathered knowledge.
Using Network Link Conditioner and an access point made of macOS or iOS doesn’t require any extra knowledge and are easy to adjust. Exactly what’s needed if we want to save time.
So, to emulate bad connection on Android we need and Android device and… an iPhone with mobile internet Developer Tools switched on.
1. Make iPhone the access point _(Settings > Mobile Data > Personal Hotspot)_
2. Adjust connection with _Network Link Conditioner_
3. Connect to the access point with the Android device
4. Ready. You’re awesome 🙂
## Cloud device farms
You don’t have to own a device farm to test an app on a wide range of mobile devices. It’s also quite inconvenient if you or your employees mostly work remotely. We started using cloud device farms, and let us tell you — it’s a big gamechanger. You should try it for better mobile testing.
Some farms (e.g. [Browserstack](https://www.browserstack.com/) or [LambdaTest](https://www.lambdatest.com/)) allow connection throttling — artificial connection slowdown — for testing on mobile devices.

It might require a paid subscription to throttle the connection. For Browserstack the individual plan price starts from $29.
## Android emulator testing
Another way to simulate slow connection is to use an emulator. It’s software for a PC that copies another OS. Android emulator imitates the performance of a real smartphone, so you can test your mobile app on it if you don’t have an actual device.
Testing on emulators could never compare to testing on real devices but it’ll do for the first development stages.
With Android studio emulators you can set the limit based on the cellular type (LTE, EDGE, etc.). Each type has its own speed limitations (in kbps):
**gsm** — GSM/CSD (up: 14.4, down: 14.4)
**hscsd** — HSCSD (up: 14.4, down: 57.6)
**grps** — GRPS (up: 28.8, down: 57.6)
**edge** — EDGE/EGPRS (up: 473.6, down: 473.6)
**umts** — UMTS/3G (up: 384.0, down: 384.0)
**hsdpa** — HSDPA(up: 5760.0, down: 13,980.0)
**lte** — LTE (up: 58,000, down: 173,000)
**evdo** — EVDO (up: 75,000, down: 280,000)
**full** — No limit, the default (up: 0.0, down: 0.0)
### How to test an app on Android emulator with throttled connection?
1. Download Android Studio
2. Create an emulator using [Android Virtual Device Manager](https://developer.android.com/studio/run/managing-avds#createavd)
3. When creating / editing the emulator pick the cellular type:
- Tap _Show advanced settings_

- Select speed in the _Network section_

- Run the emulator
- Launch your app in the emulator
- Turn off the WiFi on the emulator for it to use cellular connection settings
## Changing cellular type in the device settings
You can pick a certain cellular type on an actual Android or iOS device. To do that you’ll also need a SIM-card with Internet access.
### How to switch to another network on an Android device?
1. Go to _Settings_
2. Then _Network & Internet _
3. Open _Internet_
4. Go to _SIM settings_
5. Tap _Preferred network type_

Works for Android 12. Section names and placings may differ depending on the device and OS version.
### How to switch to another network on an iOS device?
1. Go to _Settings_
2. Then to _Mobile Data_
3. Open _Mobile Data Options_
4. Tap _Voice & Data_

Works for iOS 15.
## Bandwidth throttling in web debugging tool Charles
If cloud farms are expensive, launching an emulator is complicated, and you don’t have any SIM, you can use the network throttling function in Charles.
Basically, you can use Charles to keep track of the mobile devices traffic when you carry out functional testing or debugging. But you can also use it to simulate slow internet connection for testing.
### How to imitate slow connection with Charles?
1. Setup your host machine with Charles installed as a proxy for the device and the app you’re testing. Learn more about it from [the Charles documentation](https://www.charlesproxy.com/documentation/configuration/browser-and-system-configuration/).
2. When in Charles go to _Proxy > Throttle settings_
3. Tap _Enable Throttling_
4. Select the speed limitation preset or set it up manually
5. Save the settings
6. Click _Proxy > Start throttling_

## Throttling the speed in the router settings
You can also go for a radical way and throttle the speed in your router settings. It will definitely work if you test your app at home, on a real device, and you have access to the router admin panel. Keep in mind that having such an option depends on the router.
### How to throttle the connection on a router?
1. Go to the router settings. To do that, enter the special URL or the router IP in the address bar of your browser (192.168.1.1 or 192.168.0.1)
2. Enter login and password. You can find them on the router itself (usually both are “admin” by default)
3. Open the Bandwidth control section

Don’t forget to cancel the limitation once you’re done 🙂
## Conclusion
There’re many ways to test an app and fake bad internet connection. The most convenient one, at least for us, is Network Link Conditioner. But you’re free to choose the best for yourself.
Tested everything, it all worked out? Don’t forget to [report on it](https://forasoft.com/blog/article/how-to-report-on-testing-259) 🙂 | forasoft |
851,506 | How to Build Java Applications Today: #56 | TL;DR This newsletter switches from weekly publication to a monthly one. ... | 11,995 | 2021-10-04T21:47:07 | https://bpfnl.substack.com/p/how-to-build-java-applications-today-fcc | java, bpf | ---
canonical_url: https://bpfnl.substack.com/p/how-to-build-java-applications-today-fcc
---
## TL;DR
This newsletter switches from weekly publication to a monthly one.
***
## README
Welcome to my newsletter “How To Build Java Applications Today”! I read all the Java newsletters so **you** don’t have to! And it’s “Java news with a smile”.
If you like my newsletter, then [subscribe to it on Substack](https://bpfnl.substack.com)! Or read it on [dev.to](https://dev.to/ksilz/series/11995) or [Medium](https://ksilz.medium.com). Even better: Share it with people who may be interested.
***
## What is Changing?
This is a special issue as there's **no content** today: I switch this newsletter **from weekly publication** (every Monday) **to monthly publication** (first Monday of the month). The **next issue is due Monday, November 1, 2021**.
## Why is it Changing?
For more than a year, I published a newsletter every Monday night. There are two reasons why I don't want to do this anymore.
**Time**
Between [my start-up](https://yourhomeingoodhands.co.uk/), [my writing at InfoQ](https://www.infoq.com/profile/Karsten-Silz/) and [my conference talks](https://betterprojectsfaster.com/learn/#conference-talks), I don't want to take the 4-5 hours **every** Monday evening to write this newsletter. And that time includes at least half an hour of overhead: Putting the newsletter on [Substack](https://bpfnl.substack.com), [dev.to](https://dev.to/ksilz/series/11995), and [Medium](https://ksilz.medium.com), broadcasting it on Twitter, LinkedIn, and Xing. By going monthly, I cut down this overhead by 75%.
**Quality**
I try to have 1-2 articles each week that where I mix reporting the news with my opinions. For instance, [last week](https://bpfnl.substack.com/p/how-to-build-java-applications-today-f2c) I discussed Oracle’s Ron Pressler's opinion on why we Java developers don't upgrade quickly to newer Java versions. But sometimes the 1-2 hours I can devote to such an article aren't enough - like last week: I missed at least one crucial point there. I want to write better articles - and publishing just once a month gives me more time to do this.
## What is Next?
The next issue of this newsletter is due **Monday, November 1**, 4 weeks from today.
If you need to know about Java library & tool releases weekly: Follow the **[Java news on InfoQ](https://www.infoq.com/java/news/)** for the weekly round-up every Monday morning. Here's [this week's issue](https://www.infoq.com/news/2021/10/java-news-roundup-sep27-2021/?topicPageSponsorship=ef2f32ea-8615-496e-9ac7-58dffbfe1766).
***
## About
Karsten Silz is the author of this newsletter. He is a full-stack web & mobile developer with 22 years of Java experience, author, speaker, and marathon runner. Karsten got a Master's degree in Computer Science at the Dresden University of Technology (Germany) in 1996.
Karsten has worked in Europe and the US. He co-founded a software start-up in the US in 2004. Karsten led product development for 13 years and left after the company was sold successfully. He co-founded the UK SaaS start-up "[Your Home in Good Hands](https://yourhomeingoodhands.co.uk/)" as CTO in 2020. Since 2019, Karsten also works as a contractor in the UK.
Karsten has [this newsletter](https://bpfnl.substack.com/), a [developer website](https://betterprojectsfaster.com/), and a [contractor site](https://ksilz.com/). He's on [LinkedIn](https://www.linkedin.com/in/ksilz/), [Twitter](https://twitter.com/karsilz), and [GitHub](https://github.com/ksilz). Karsten is also an [author at InfoQ](https://www.infoq.com/profile/Karsten-Silz). | ksilz |
851,517 | The ‘Engineering Production-Grade Shiny Apps’ book is available in print! | I’m so, so excited to announce that the ‘Engineering Production-Grade Shiny Apps’ book is now... | 0 | 2022-04-01T09:20:19 | https://colinfay.me/engineering-shiny-print/ | rstats | ---
title: The ‘Engineering Production-Grade Shiny Apps’ book is available in print!
published: true
date: 2021-10-04 00:00:00 UTC
tags: rstats
canonical_url: https://colinfay.me/engineering-shiny-print/
---
I’m so, so excited to announce that the _‘Engineering Production-Grade Shiny Apps’_ book is now available in print! This book is the result of two years of work, and I couldn’t be more happy to see it available in print.
As its title suggests, _‘Engineering Production-Grade Shiny Apps’_ is a book about building `{shiny}` apps that will be sent to production. It goes deep into `{golem}`, of course, but it’s not a book about `{golem}` only — it tries to cover a large panel of topics, and I’m pretty sure that if you are a `{shiny}` developer, there is something for you in this book: project management, code organization, team work, best practices for front end development, CI and CD, deployment, code optimization…
This book will remain available online for free at [https://engineering-shiny.org/](https://engineering-shiny.org/) (and I want to thank Chapman and Hall/CRC for this), but if you want to grab a copy, you can go on [routledge.com](https://www.routledge.com/Engineering-Production-Grade-Shiny-Apps/Fay-Rochette-Guyader-Girard/p/book/9780367466022) and order one. I know it can feel counter-intuitive to buy a print copy of a book which is available online, but if you want this to continue to happen, please continue to support the publisher by buying a copy of this book, or of any other from Chapman and Hall/CRC — they have been doing a massive work when it comes to organizing, editing and reviewing.
I want to personally thank everybody that has been contributing to this book, with some special thanks to [Eric Nantz](https://twitter.com/theRcast) which has been a `{golem}` early adapter and an all time supporter of everything from the `golemverse`, to [David Granjon](https://twitter.com/divadnojnarg) for all his feedback on the book, and to [Christophe Dervieux](https://twitter.com/chrisderv) for his precious help during my battles with Markdown. Thanks also to [David Grubbs](https://twitter.com/crcgrubbsd) from Chapman and Hall/CRC for making this happen.
That being said, I still can’t believe I’ve added my name to the list of authors in “The R Series” books 😱
I hope you’ll enjoy it! | colinfay |
851,628 | Divtober Day 2: Watch | A neighborhood watch sign done with a single element in CSS | 14,881 | 2021-10-05T00:36:39 | https://dev.to/alvaromontoro/divtober-day-2-watch-p25 | codepen, divtober, css, art | ---
title: Divtober Day 2: Watch
description: A neighborhood watch sign done with a single element in CSS
published: true
tags: codepen,divtober,css,art
series: divtober
---
I forgot to post the one I did for day 2 😅.
Here's a Neighborhood **Watch** sign coded with a single CSS element.
{% codepen https://codepen.io/alvaromontoro/pen/mdwggPb %} | alvaromontoro |
851,639 | Broadcasting in AdonisJS | In this tutorial we'll build a broadcasting module for AdonisJS which resembles Laravel Broadcasting... | 0 | 2021-10-05T01:12:16 | https://dev.to/arthurer/broadcasting-in-adonisjs-453g | adonisjs, node, webdev, tutorial | In this tutorial we'll build a broadcasting module for AdonisJS which resembles Laravel Broadcasting features (you can even use Laravel Echo). This module will cover up many of the websockets use cases in a simple manner.
It is great for cases where the clients need to receive data in real-time, but don't need to send data in real-time.
Good use cases are:
- Chats
- Live dashboards
- Sport scores
Bad use cases are:
- Games
- Work together platforms
## Let's build it!
### Scaffolding a new app
Create a new AdonisJS project
```bash
$ npm init create-adonis-ts-app broadcasting
$ yarn create adonis-ts-app broadcasting
```
When prompted which project structure, select web and flag
> Configure webpack for compiling frontend assets? true
### Setting up our Broadcast server
Our broadcast module will be based in an open-source Pusher compatible server called [pWS](https://pws.soketi.app).
First, we will install it
```bash
$ npm i @soketi/pws
$ yarn add @soketi/pws
```
We can start the server by running
```bash
$ npm pws-server start
$ yarn pws-server start
```
But we need to configure it before running, so we will make a configuration file for it in <code>config/broadcasting.ts</code>
```typescript
// config/broadcasting.ts
import Env from '@ioc:Adonis/Core/Env'
const broadcastingConfig = {
port: Env.get('BROADCASTING_PORT', 6001),
appId: Env.get('BROADCASTING_APP_ID', 'app-id'),
appKey: Env.get('BROADCASTING_APP_KEY', 'app-key'),
appSecret: Env.get('BROADCASTING_APP_KEY', 'app-secret'),
}
export default broadcastingConfig
```
The configs won't get magically loaded into pWS, so we will make a command to start it. To start it we will use [execa](https://github.com/sindresorhus/execa). So install it using:
```bash
$ npm i execa
$ yarn add execa
```
and create a command with
```bash
$ node ace make:command StartPws
```
The command will look like this:
```typescript
// commands/StartPws.ts
import { BaseCommand } from '@adonisjs/core/build/standalone'
import execa from 'execa'
export default class StartPws extends BaseCommand {
public static commandName = 'start:pws'
public static description = 'Start the pWS server with Adonis Configs'
public static settings = {
loadApp: true,
stayAlive: true,
}
public async run() {
const broadcastingConfig = this.application.config.get('broadcasting')
const command = `
PORT=${broadcastingConfig.port}
DEFAULT_APP_ID=${broadcastingConfig.appId}
DEFAULT_APP_KEY=${broadcastingConfig.appKey}
DEFAULT_APP_SECRET=${broadcastingConfig.appSecret}
yarn pws-server start`
await execa(command, { shell: true }).stdout?.pipe(process.stdout)
}
}
```
After creating the command, we need to regenerate the ace manifest, so it catches our new command, do it by running:
```bash
$ node ace generate:manifest
```
Then you can run it with
```bash
$ node ace start:pws
```
### Broadcasting events
As pWS is a drop-in Pusher replacement, we can interact with it using any Pusher client, as AdonisJS is a node framework, we will use the node Pusher client. Start by installing the node Pusher client:
```bash
$ npm i pusher
$ yarn add pusher
```
Then we will create a service to interact with the pWS server, it can be done as a simple service or as a AdonisJS provider, in this tutorial we will go the service way.
```typescript
// app/Services/Broadcast.ts
import Pusher from 'pusher'
import broadcastingConfig from 'Config/broadcasting'
import Env from '@ioc:Adonis/Core/Env'
class Broadcast {
private pusher = new Pusher({
host: Env.get('HOST', 'localhost'),
port: broadcastingConfig.port,
appId: broadcastingConfig.appId,
key: broadcastingConfig.appKey,
secret: broadcastingConfig.appSecret,
})
public async broadcast(channel: string | string[], event: string, data: any) {
const response = await this.pusher.trigger(channel, event, data)
return response
}
}
export default new Broadcast()
```
With this service we can broadcast events by simply using
```typescript
import Broadcast from 'App/Services/Broadcast'
await Broadcast.broadcast('test-channel', 'event', 'data')
```
### Listening to events
To listen to events in our frontend we can use PusherJS paired with Laravel Echo. Start by installing both:
```bash
$ npm i -D laravel-echo pusher-js
$ yarn add -D laravel-echo pusher-js
```
Set them up in our frontend:
```javascript
// resources/js/app.js
import '../css/app.css'
import Echo from 'laravel-echo'
window.Pusher = require('pusher-js')
window.Echo = new Echo({
broadcaster: 'pusher',
wsHost: 'localhost',
wsPort: 6001,
forceTLS: false,
disableStats: true,
key: 'app-key',
namespace: '',
})
```
### Example setup
Append this to the end of <code>resources/js/app.js</code>
```
// resources/js/app.js
window.Echo.channel('messages').listen('message', (e) => {
alert(JSON.stringify(e))
})
```
Paste this into the welcome view (<code>resources/views/welcome.edge</code>)
```html
<!-- resources/views/welcome.edge -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>AdonisJS - A fully featured web framework for Node.js</title>
@entryPointStyles('app')
@entryPointScripts('app')
</head>
<body>
<main>
<div>
<!-- Just to show off how it works. You can safely ignore that -->
<form method="POST" action="/message">
<input name="message" type="text" />
<button>Send Message</button>
</form>
</div>
</main>
</body>
</html>
```
After setting up that, we just need to setup our message route to broadcast a message event:
```typescript
// start/routes.ts
import Route from '@ioc:Adonis/Core/Route'
import Broadcast from 'App/Services/Broadcast'
Route.get('/', async ({ view }) => {
return view.render('welcome')
})
Route.post('/message', async ({ request, response }) => {
const message = request.input('message')
await Broadcast.broadcast('messages', 'message', { message })
return response.redirect().back()
})
```
### It's alive!
But it still doesn't works for private or presence channels, we will address that in next tutorial, stay tuned! | arthurer |
851,869 | Does blogging make you a better dev? | Why should you start a blog as a developer? Does it actually have any benefits, or is it just one of... | 0 | 2021-10-05T04:16:26 | https://dev.to/abhirajb/does-blogging-make-you-a-better-dev-1fmg | javascript, webdev, beginners, watercooler | Why should you start a blog as a developer? Does it actually have any benefits, or is it just one of those things people tell you to do to feel productive?
Although at ground level it seems scary and not worth the effort, there are actually quite a lot of benefits from doing so. There's a quote that floats around the internet and it goes.
> **If you can't explain it simply, you don't understand it well enough.**
This means the opposite is also true, if you can explain it simply, then you do understand it. Having to sit down and write about a topic really highlights what you do understand about it and what you don't. This is great for finding what you excel at and what you need to buckle down and study.
There is a technique out there called the Feynman Technique, which is to write out the thing you're trying to learn as simply as possible. Then read back over it and find any flaws within the explanation, or any over technical jargon, and simplify it even further.
This process really highlights what your knowledge about a certain concept, as well as if you understand the concept behind it or just the basic-level jargon. The funny thing about this technique is that it is incredibly similar to writing a blog. A simpler explanation about overly technical topics, condensed into an easy to read format.
Another reason to start a blog is to increase your writing communication skills. There's no such thing as being too good at communication. As you slowly develop your skills and start making the transition into a professional job, being able to sell yourself in written format will become crucial.
As well as being able to articulate your ideas and get them down on paper. Into a presentable form for that board meeting or startup pitch, you've been meaning to do. Communication is one of the most important skills someone can have, and having somewhere to practise it, such as a blog, is important.
### Thank **YOU** ✨💝
I just hit 1k followers on my Dev.to account. I never thought about reaching this milestone. I really hope I have been able to share knowledge and benefit others from my posts. Thank you for showing me so much of love.
Let's connect on [Twitter](https://twitter.com/rainboestrykr)
| abhirajb |
851,886 | Best ways to make your first contribution to Nim language for Hacktoberfest 2021 | Concise and readable, small binaries, fast compile times, native performance, zero-overhead interop... | 0 | 2021-10-05T04:57:50 | https://dev.to/ringabout/best-ways-to-make-your-first-contribution-to-nim-language-4ml2 | python, opensource, nim, hacktoberfest | Concise and readable, small binaries, fast compile times, native performance, zero-overhead interop lets you reuse code in C, C++, JS, Objective-C, Python... Does a programming language have these fantastic features? Of course, [Nim language](https://github.com/nim-lang/Nim) does have the features I have been dreaming about. And what is the goal of Nim language? Simply put, the goal is "one language to rule them all", from [shell scripting](https://nim-lang.org/docs/nims.html) to [web frontend and backend](https://github.com/nim-lang/nimforum),
[scientific computing](https://github.com/SciNim), [deep learning](https://github.com/mratsim/Arraymancer),
[blockchain client](https://github.com/status-im), [gamedev](https://github.com/ftsf/nico),
[embedded](https://github.com/EmbeddedNim).
Moreover, [Nim](https://github.com/nim-lang/Nim) is a community driven collaborative effort that welcomes all contributions, big or small. Read [contributing guide](https://github.com/nim-lang/Nim#contributing) if you are willing to contribute to Nim. In this article, I will tell you best ways to make your first contribution to Nim language. Starting from easy and feasible pull requests, you will surely enjoy the charm of open source projects. Let's start our journey.
## Replace code-block with runnableExamples
Some modules are using code-blocks which are outdated and should be replaced by `runnableExamples`. Search `.. code-block` in your favourite editor and change the ones in standard libraries.
For instance
**before**
```nim
## .. code-block:: Nim
## import std/json
##
## let jsonNode = parseJson("""{"key": 3.14}""")
##
## doAssert jsonNode.kind == JObject
## doAssert jsonNode["key"].kind == JFloat
```
**after**
```nim
runnableExamples:
let jsonNode = parseJson("""{"key": 3.14}""")
doAssert jsonNode.kind == JObject
doAssert jsonNode["key"].kind == JFloat
```
Note that the import of the current module can be left out. If the original snippet cannot be run, use `runnableExamples("-r:off")` instead.
## Add testcase to close issues
When surfing [issues](https://github.com/nim-lang/Nim/issues) of Nim, you can find some code which have already worked. Submit a pull request to close that issue. You can refer to https://github.com/nim-lang/Nim/pull/18934 and track issues labelled as [works_but_needs_test_case](https://github.com/nim-lang/Nim/labels/works_but_needs_test_case) or [works_with_arc_orc](https://github.com/nim-lang/Nim/labels/works_with_arc_orc).
## Add top-level runnableExamples for modules
Some modules lack top-level runnableExamples, please help them. Such as:
- https://github.com/nim-lang/Nim/blob/devel/lib/pure/concurrency/cpuload.nim
- https://github.com/nim-lang/Nim/blob/devel/lib/pure/concurrency/threadpool.nim
- https://github.com/nim-lang/Nim/blob/devel/lib/pure/asyncstreams.nim
- https://github.com/nim-lang/Nim/blob/devel/lib/pure/cookies.nim
- https://github.com/nim-lang/Nim/blob/devel/lib/pure/endians.nim
- https://github.com/nim-lang/Nim/blob/devel/lib/pure/volatile.nim
## Add runnableExamples or documentations for procs
Some procs lack corresponding runnableExamples and documentations. Please find them and complete them.
## Solve issues labelled as easy
If you like some challenges, start from [issues](https://github.com/nim-lang/Nim/issues?q=is%3Aissue+is%3Aopen+label%3AEasy) labelled as easy.
| ringabout |
851,910 | Token Development - A short Guide | This blog is for aspiring and present entrepreneurs who want to start their cryptocurrency business using crypto tokens. | 0 | 2021-10-05T05:48:37 | https://dev.to/alwintechnology/token-development-a-short-guide-55o8 | ---
title: Token Development - A short Guide
published: true
description: This blog is for aspiring and present entrepreneurs who want to start their cryptocurrency business using crypto tokens.
tags:
//cover_image: https://direct_url_to_image.jpg
---
Crypto token business is one of the emerging businesses in the present generation. Nowadays, startups and entrepreneurs are highly focussed towards emerging business opportunities and they find token development as one of the best ones in the present digital trend. As this has been brewing, we can find that not all the entrepreneurs who start their token business are successful. We can count the number of successful digital token businesses. It is because they do not have adequate knowledge about the token business and its signific
This blog is for the aspiring and the present entrepreneurs who want to start their cryptocurrency business using the crypto tokens. Come, without wasting any time, let us jump into the article.
##What is a crypto token?
A crypto token is a virtual or digital currency that can be traded or exchanged in the cryptocurrency exchange. The token might be anything — be it a physical or digital asset or business venture with the presence of a solid whitepaper about its purpose of starting it. The token might be backed with the presence of smart contracts. Smart contract and the whitepaper depicts the credibility and the security of the tokens that might instill and attract the traders to the tokens.
Tokens are also used for crowdfunding purposes where a business owner can put any physical or digital property into a token and create a catchy whitepaper for business purposes with a solid smart contract that might attract traders to invest in the token. The investors might be given adequate validity and voting rights that might differ as per the whitepaper.
The tokens in the crypto space can be created based on the specific standards and blockchain. Initially, it was the Ethereum network who started the tokenization process with their ERC20 token standard. Later they came up with other token standards with different functionalities. Let us know about the types of popular crypto tokens.
##Types of popular crypto tokens that you can start your business with:
The types of crypto tokens can be classified based on the usage and the token standards. But here, we are going to discuss some of the best types of popular crypto tokens.
**Utility Tokens —** As the name suggests, it is for specific or particular purpose. It is most commonly used for payment purposes and for other transactional purposes in the crypto space. Commercial usage of utility tokens are rare but some businesses use utility tokens too.
**Security Tokens —** This is similar to the tokens with the capability of being called as stocks. They are stock tokens that can be used as securities to a particular asset and traded by the investor/trader. It is slightly different from the equity tokens as they have the voting rights. Whereas the security tokens do not provide management and voting rights ( It may vary as per the whitepaper created), and hence they are considered as digital stocks.
**Reward Tokens —** These are the tokens which are given as rewards either to the miners or developers or users as per their trading effectiveness.
**Asset Tokens —** This is the kind of token where the asset , either physical or digital, is converted into a token and traded in the exchange platform for particular discounts. This makes asset selling and buying easier and effective.
**Currency Tokens —** Currency tokens are nothing but coins like bitcoin, ethereum, and others unlike tokens.
Now let us discuss the various blockchain tokens and their significance below. Some of the prominent token blockchains in the current digital finance are ethereum, tron and binance tokens. Let us discuss these three prominent blockchain tokens in brief.
**ERC —** ERC is the ethereum blockchain token with available token standards — ERC20, ERC721, ERC1155, and others. Each token has a specific token functionality and their significance varies based on the token demand. If you want to start your fungible token business, then ERC20 will be the best choice. Whereas, ERC721 would be great for non-fungibility and other associated token creation business areas. If you want to start your crypto business with the updated ERC token standard, make sure you reach the best [ERC20 token development company](https://www.alwin.io/erc20-token-development-company) in the crypto market.
**TRC —** TRC is the tron token that is created on the tron blockchain. Tron is known for their decentralized approach and hence, TRC tokens are highly focussed on the decentralization approach and hence if you are an entrepreneur who wants to start your defi platforms, tron blockchain would be the best choice. TRC10 and TRC20 are the two prime tron blockchains that could be efficient for your business. Get the market specific tron token from an experienced tron token development company.
**Binance tokens —** Binance tokens are more familiar among the crypto token holders and users as they have been introduced years before. Now the point of discussion is their introduction of BEP20 tokens. They are tokens from the Binance Smart Chain that runs parallel to the Binance Chain.
##Where to get the best token development services for your crypto business?
You can start your token development business and help various businesses to enhance their business through the token development software. But you will need a solid team with more experience to do so. No worries. I have got a solution.
WeAlwin Technologies is a prime token development company with more than 5 years of experience. They have a solid team of ethereum, and torn experts who can create your token on demand within a week.
First decide on what token you need to start your token business and move forward with them. They can really make your business successful.
| alwintechnology | |
852,029 | Why Engineering and IT Need to own the CDP | CDP (Customer Data Platform) has become a broad, confusing term in the software world, but that... | 0 | 2021-10-05T10:02:54 | https://rudderstack.com/blog/why-engineering-and-it-need-to-own-the-cdp | dataengineering, it, cdp, datascience | CDP (Customer Data Platform) has become a broad, confusing term in the software world, but that hasn't slowed down the adoption of tools claiming the label.
In a [recent survey](http://customerexperiencematrix.blogspot.com/2020/09/when-cdps-fail-insights-from-cdp.html), 75 percent of respondents said they had already deployed a CDP, were in the process or were planning on deployment in the next 12 months. VCs have poured over a billion dollars into new CDP startups while the legacy companies try to catch up by rebranding as CDPs to increase their valuations.
While the adoption of CDPs is now widespread, I believe there is a fundamental flaw in the way organizations implement CDPs. In this post, I articulate why Engineering and IT organizations should own CDP implementation and management.
The Fundamental Flaw
--------------------
Companies primarily leverage CDPs by marketing departments, so the term isn't familiar to many IT organizations. Organizations may bring in IT to discuss security issues or potential technical impacts, but they are rarely part of CDPs' strategic conversation. The fact that IT isn't a key voice in the CDP conversation is. In my experience, one of the primary reasons that many CDP projects don't meet expectations or even fail.
Despite mass adoption, CDPs aren't a panacea for an organization's customer data needs (though the marketing might make you think otherwise). The customer data conversation is much larger than a single software vendor. Furthermore, as we argued in a recent post on The New Stack, this requires technical discussions around the infrastructure and pipelines that connect the entire customer data stack.
While we believe the most advanced companies build an owned CDP on top of their warehouse, there is a place for third-party CDP functionality in marketing as a component of the stack for many companies.
Looking Back: Quick History on Customer Data Platforms and IT Organizations
---------------------------------------------------------------------------
Note: *if you want a full history of these trends, check out our post called *[The Data Engineering Megatrend: A Brief History](https://rudderstack.com/blog/the-data-engineering-megatrend-a-brief-history).
To understand how this incredible demand for customer data platforms came about, it is helpful to think about customer data itself and how IT organizations have related to it. At a high level, any data associated with your customers is customer data. This concept predates the internet and even computers.
### Digitization and On-Prem Beginnings
Before the age of computers, businesses used to keep a ledger book of all transactions, mostly for accounting purposes. With the advent of computers, the ledger was digitized and expanded with personalized loyalty programs at scale (where each customer was assigned a unique loyalty card). The transaction data was stored at an individual customer level and leveraged for use cases like mail-in coupons personalized based on one's past product purchases or for retail shelf placement optimization (via market basket analysis of items that are commonly bought together).
As companies went through this digitization process, IT was the team building and managing the technology and systems, all on-prem in the early days. Companies at scale achieved incredible results using systems from Oracle, IBM, and HP, along with ERP products like SAP. At this age, IT was the hero of the organization.
### The Internet Changes Everything
When the Internet achieved critical mass distribution and adoption, enabling world-changing business models like eCommerce, everything changed, especially the customer experience.
Not only could you more easily track transactions, but because the experience was digital, you could also track all sorts of granular data points, from product searches to clicks to browsing behavior. That kind of data is a treasure trove for anyone trying to optimize the customer experience.
Still though, even though tracking was technically possible, it was extremely complex and expensive to implement. The promise was real but out of reach for most companies.
### Then SaaS and Cloud Change Everything Again
The internet also forced the "SaaS-ification" of business models and mass migration from on-prem to the cloud. Legacy systems from SAP, IBM, Oracle, and others not only became too costly to new vendors but they simply weren't designed to handle the complexity and scale of the use cases demanded by businesses undergoing digital transformation.
During this process, IT went from being the organization's heroes, implementing and developing innovative technology, to overburdened teams desperately trying to catch up as organizations underwent seismic changes in digitization. From being business enablers, IT became known as business blockers and big cost centers.
Business leaders impatient with IT fueled the SaaS and cloud movement. The VP of Sales didn't have to wait a few years for IT to provision a clunky CRM; they could just swipe a credit card and get state-of-the-art software from the cloud now. From marketing to sales to customer support to finance, every department was "SaaS-ified," and for a good reason: these systems were state of the art, much cheaper than developing in-house, and much more stable.
Data Silos: The Dark Side of a SaaS-ified World
-----------------------------------------------
SaaS made life so great in so many ways, but there was a big problem from a customer data perspective: data silos. In the pre-SaaS days, all of the customer data lived in the company's internal database. Transactional data lived in table A, and support ticket data was right next door in table B, which meant easily developing analytics and apps that used both sets of data.
With SaaS, though, all of this data got locked into individual vendor ecosystems. Getting data in or out of those ecosystems was very hard. Many vendors lacked APIs, and the ones that did provide them often weren't easy to use because the data schema was messy, inflexible, or both. Specialized products (like cloud ETL/ELT vendors) were built to pull that data and get it into databases and warehouses, which was only useful for the analytics use case. Even simple applications for tasks like sending personalized emails based on purchase behavior became complex. Development involved multiple API calls and data pipelines, and even then, the execution was far from real-time. Think about how many times you've received a coupon after having purchased the product...this is still common today!
### CDP to the Rescue?
The pain marketers felt due to data silos helped birth the customer data platform and fuel the frenzy around it. CDP vendors promised to bring customer data from all of these SaaS systems into a single place. After this, they would give marketers the tools they needed to activate campaigns on different channels based on that data (think personalized email journeys, paid ad campaigns, etc.).
Even better, these solutions were cloud SaaS tools, so marketers could bypass IT to avoid slowdowns. Marketing teams spent huge amounts of money to purchase and deploy CDPs.
Still, though, customers continued to get ads and emails out of order and out of context.
How did this happen?
The Disconnect Between CDPs and IT
----------------------------------
It turns out that the IT organizations that marketing wanted to bypass still controlled key business systems like mobile and web experiences, eCommerce applications, backend systems, and the databases that power all of those components.
While IT couldn't innovate inside their companies as fast as venture-backed software startups, they were still responsible for huge technical infrastructure. They were also responsible for the core applications of the business. Most of these responsibilities were directly related to the customer experience, which is directly related to customer data. In many cases, this infrastructure was a mix of legacy tech and new cloud tech.
The cloud CDP vendors were good at pulling data from other cloud applications, but they fell short when interfacing with infrastructure. Infrastructure and core apps often live behind corporate firewalls and don't require well-defined APIs.
But the marketing teams went ahead and purchased the CDPs without getting IT involved, which was part of the whole CDP marketing pitch in the first place. And that's where the problems started.
First, even though CDPs were functionally powerful, they missed a key ingredient: integration with core infrastructure and apps. Second, when marketing did come to IT for critical data, like transactional data, IT rightly raised serious concerns about sending sensitive internal data to multiple third-party systems.
And, of course, few people thought about what would happen when a team other than marketing wanted access to the data that lived within the CDP. What if support wanted to integrate CDP data into their processes and tech? In many cases, that wasn't possible, so support purchased their solution. Rinse and repeat this for product and other teams, and you have a big data silo mess---a state many companies are still sorting through today.
And This is why Engineering and IT Needs to Take Control
--------------------------------------------------------
While marketing was following the CDP frenzy, IT was busy re-inventing every piece of tech in the organization, leveraging both SaaS and the cloud and, in many cases, inventing new technologies as cloud SaaS solutions (think about projects from Google, Netflix, Facebook, etc.).
No longer a blocker, IT can now provision infinitely scalable infrastructure (compute and storage) on cloud providers like AWS, Google, and Azure. They can centralize all customer data in modern warehouses and lakes like Snowflake. IT can connect every tool in the stack and even enable real-time use cases from an integrations standpoint.
When you look at all of those capabilities, they sound surprisingly similar to the marketing pitch that CDPs promised but couldn't fully deliver.
The reality is that the engagement features offered by most customer data platforms today are one piece of a much more complex and comprehensive customer data stack. IT owns this stack. Said another way, the larger data stack is the true customer data platform, not the CDP marketing uses to send customers messages.
The most innovative companies are positioning IT (and specifically data engineering) to be a strategic partner with every other team across the organization. Together, they can achieve real innovation and competitive advantage, while businesses that keep IT in the wings will continue running on a treadmill powered by data silos.
Sign up for Free and Start Sending Data
---------------------------------------
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app. [Get started](https://app.rudderlabs.com/signup?type=freetrial). | teamrudderstack |
852,248 | Python abs() | ItsMyCode | The abs() function in Python returns the absolute value of a given number, which means... | 0 | 2021-10-07T07:04:29 | https://itsmycode.com/python-abs/ | python, programming, codenewbie, tutorial | ---
title: Python abs()
published: true
date: 2021-10-05 08:30:00 UTC
tags: #python #programming #codenewbie #tutorial
canonical_url: https://itsmycode.com/python-abs/
---
ItsMyCode |
The **`abs()`** function in Python returns the absolute value of a given number, which means the **`abs()`** method removes the negative sign of a number.
If the given number is complex, then the **`abs()`** function will return its magnitude.
## **abs() Syntax **
The syntax of **`abs()`** method is
**abs(number)**
## abs() Parameters
The **`abs()`** function takes a single argument, a number whose absolute value is to be returned. The number can be
- integer
- floating-point number
- complex number
## abs() Return Value
**`abs()`** method returns an absolute value of a given number.
- **For integers** – absolute integer value is returned
- **For floating numbers** – absolute floating-point value is returned
- **For complex numbers** – the magnitude of the number is returned
## What does the abs() function do in Python?
The **`abs()`** function will turn any negative number into positive, the absolute value of a negative number is multiplied by (-1) and returns the positive number, and the absolute value of a positive number is the number itself.
## Example 1: Get absolute value of a number in Python
In this example, we will pass an integer, float into the **`abs()`** function, and returns the absolute value.
```python
# Python code to illustrate abs() built-in function
# integer number
integer = -10
print('Absolute value of -10 is:', abs(integer))
# positive integer number
positive_integer =20
print('Absolute value of 20 is:', abs(positive_integer))
# floating point number
floating = -33.33
print('Absolute value of -33.33 is:', abs(floating))
```
**Output**
```python
Absolute value of -10 is: 10
Absolute value of 20 is: 20
Absolute value of -33.33 is: 33.33
Absolute value of 3-4j is: 5.0
```
## Example 2: Get the magnitude of a complex number
In this example, we will pass a complex number into the **`abs()`** function and returns the absolute value.
```python
# Python code to illustrate abs() built-in function
# complex number
complex=(3-4j)
print('Absolute value of 3-4j is:', abs(complex))
```
**Output**
```python
Absolute value of 3-4j is: 5.0
```
The post [Python abs()](https://itsmycode.com/python-abs/) appeared first on [ItsMyCode](https://itsmycode.com). | srinivasr |
872,410 | Working with Optimizely Projects | Optimizely has a featured called 'Projects', which allows editors to collaborate on content before... | 0 | 2021-11-05T11:38:32 | https://dev.to/paulmcgann/working-with-optimizely-projects-2ojn | optimizely, projects, csharp, microsoft | Optimizely has a featured called ['Projects'](https://world.optimizely.com/documentation/developer-guides/CMS/projects/), which allows editors to collaborate on content before scheduling to publish.
### Problem
While work on a project that imports hundreds, of pieces of content. These pieces of content are added to a project for the team to review and mark the items as ready to publish.
You can see the problem here in that with hundreds of pieces of content to review, marking each content piece as ready to publish could take some time.
### Solution
To over come the problem we decided to create a scheduled job that would loop over all items in a project and mark them as ready to publish.
To retrieve the projects and their project items we can get an instance of the 'ProjectRepository' into our scheduled job.
Once we have the project and its items we can then loop over the project items and use the 'IContentChangeManager' interface to update the status of the content items.
```csharp
var projects = _projectRepository.List();
foreach (var project in projects)
{
var projectItemIds = _projectRepository.ListItems(project.ID).Select(x => x.ID);
foreach (int projectItemId in projectItemIds)
{
ProjectItem projectItem = GetProjectItem(projectItemId);
if (projectItem != null)
{
CommitResult commitResult = _contentChangeManager.Commit(projectItem.ContentLink, SaveAction.CheckIn);
}
}
}
public ProjectItem GetProjectItem(int projectItemId) => _projectRepository.GetItem(projectItemId);
```
I just wanted to share this piece of code with anyone who was trying to achieve something similiar.
| paulmcgann |
852,287 | What are the Stellar Blockchain Development Services? | Stellar Blockchain Development Services are Smart contract development, Stellar blockchain API,... | 0 | 2021-10-05T12:11:05 | https://dev.to/hamadanwar16/what-are-the-stellar-blockchain-development-services-2j47 | blockchain, development, services, stellar | Stellar Blockchain Development Services are Smart contract development, Stellar blockchain API, custom payment apps, micro payment application, mobile financial applications, remittance app solutions and P2P(peer to peer) lending.
https://blockchain.oodles.io/stellar-blockchain-development-services/
| hamadanwar16 |
852,353 | REST API CRUD NodeJS, typescript, mongo, express with 2 commands. | SuperApiBoost is a client who seeks to improve development times. In this post I will show you how... | 0 | 2021-10-05T13:32:47 | https://dev.to/thesuperankes/rest-api-crud-nodejs-typescript-mongo-express-with-2-commands-47ff | javascript, tutorial, beginners, programming | [SuperApiBoost](https://www.npmjs.com/package/superapiboost) is a client who seeks to improve development times.
In this post I will show you how to make a complete api under NodeJs with Typescript, Mongo and Express with just two commands an a file.
First thing they need to do is install the client with npm.
```bash
npm i -g superapiboost
```
To generate the project you must execute the "new" command with the -n flag to assign the name
```bash
sabo new -n=Awesome
```
This will create a root folder with the name of the project and install the dependencies.
```bash
📦Awesome
┣ 📂node_modules
┣ 📂src
┃ ┣ 📂api
┃ ┃ ┣ 📂routes
┃ ┃ ┗ 📜index.ts
┃ ┣ 📂controllers
┃ ┃ ┗ 📜mongoBasic.ts #CRUD Methods
┃ ┣ 📂interfaces
┃ ┣ 📂tools #utils functions
┃ ┃ ┗ 📜validateType.ts
┃ ┣ 📜app.ts
┃ ┣ 📜config.ts
┃ ┗ 📜mongo.ts
```
As an example we will create a crud for the following json.
```bash
{
"name":"Andy",
"cellphone":303030303,
"isValid":false
}
```
We will create a json file and use the following format for the generation of the routes and the controller.
```bash
{
"name":{
"type":"string",
"required":true,
"default":"'Andy'"
},
"cellphone":{
"type":"number",
"required":false
},
"isValid":{
"type":"boolean",
"required":true,
"default":"true"
}
}
```
as a key we will assign the name of the property to create.
type: string, number, date, [].
required: false, true.
default(optional): 'true','"Name"'.
We will copy the complete path and execute the generate command.
```bash
sabo generate -n=user -p=c:/models/user.json
```
This will create the interface, controller and routes.
Go to the config.ts file and assign the connection string of our mongo database.
Execute npm start and we will be able to consume the api with our preferred client.
### Create

### Update

### Delete

### GetAll

### GetById

| thesuperankes |
852,367 | Infrastructure and Ops book bundle by O'Reilly | Infrastructure and Ops book bundle by O'Reilly Modern technology has changed the way we live and... | 0 | 2021-10-05T13:43:51 | https://dev.to/haze/infrastructure-and-ops-book-bundle-by-o-reilly-3040 | devops, kubernetes, linux, aws | 
**[Infrastructure and Ops book bundle by O'Reilly](https://www.humblebundle.com/books/infrastructure-and-ops-oreilly-books?partner=indiekings)**
Modern technology has changed the way we live and work. Developing systems, applications, and more is complex, but O’Reilly are showing us how to get stuff done in the newest Humble bundle, Infrastructure and Ops by O’Reilly!
Dive into eBooks like Kubernetes Operators, Learning Helm, Kubernetes Best Practices, and Distributed Systems with Node.js, and learn how to shape our digital world to suit you, both in and out of work!
Plus, your purchase helps support Code for America!
Code for America is a non-partisan, non-political 501 organization founded in 2009 to address the widening gap between the public and private sectors in their effective use of technology and design. | haze |
852,375 | Find Phone Number Location Using Python | Project | Python Project For Tracking A Phone Number In A Map Using Python Hi everyone 👋 Today we... | 0 | 2021-10-05T13:58:08 | https://dev.to/fahimulkabir/track-phone-number-location-using-python-python-project-4n3k | python, programming, security, beginners | ## Python Project For Tracking A Phone Number In A Map Using Python
Hi everyone 👋
Today we will do a **simple python project**. If you are a beginner, then no need to worry. It will be a **simple python project for beginners**. We will write a **simple python script** to **find out someone's phone number location using python**.
{% youtube Dz3rSZHnKkM %}
### Here you will get the answers of -
How To Track Phone Number Location With Python. track phone number location using python. Track phone number location using python github. how to track a phone number github. How to track location using python. python code for live location. Phone numbers Python.
Phone numbers python documentation. python phone number validation. get current location google maps python. How do I create a location tracker in Python?. How do I get coordinates in Python?. How do I track my phone using python?.
## Properties Used -
YouTube: https://youtu.be/Dz3rSZHnKkM
Phonenumbers Python Library: https://pypi.org/project/phonenumbers/
OpenCage Geocoding Module Python: https://pypi.org/project/opencage/
OpenCage Geocoding API: https://opencagedata.com/
Folium: https://pypi.org/project/folium/
PyCharm (Code Editor): https://www.jetbrains.com/pycharm/
.
.
**Feel free to visit my YouTube channel: [@Tech2etc](https://www.youtube.com/c/Tech2etc/)**
**Follow me on Instagram where I'm sharing lot's of useful resources! [@fahimkabir.hamim](https://www.instagram.com/fahimkabir.hamim/) 😉**
.
.
## Checkout My Other Articles Also -
{% embed https://dev.to/fahimkabir/15-python-projects-for-beginners-4j4f %}
{% embed https://dev.to/fahimkabir/python-project-how-to-make-snake-game-using-python-step-by-step-306c %}
{% embed https://dev.to/fahimkabir/7-javascript-projects-for-beginners-d3m %}
**Feel free to visit my YouTube channel:**
[@Tech2etc](https://www.youtube.com/c/Tech2etc/videos)
**Follow me on Instagram where I'm sharing lots of useful resources!
[@fahimulkabir.chowdhury](https://www.instagram.com/fahimulkabir.chowdhury/) 😉**
| fahimulkabir |
852,639 | From Monolith to Microservices and Beyond | Originally published on Cprime. Monolithic architectures were the de facto standard of how we built... | 0 | 2021-10-05T16:22:09 | https://dev.to/mccricardo/from-monolith-to-microservices-and-beyond-12ce | microservices | Originally published on [Cprime](https://www.cprime.com/resources/blog/from-monolith-to-microservices-and-beyond/).
Monolithic architectures were the de facto standard of how we built internet applications. Despite still being used nowadays, microservices have grown in popularity and are becoming the established architecture to build services. Service-oriented Architectures (SoA) are not new but the specialization into microservices, which are loosely coupled, and independently deployable smaller services, that focus on a single well-defined business case, became wildly popular since they enable:
- Faster delivery
- Isolation
- Scaling
- Culture
- Flexibility
Distributed systems are complex. The above (simplified) diagram depicts how a monolith can be broken down into microservices but hides a lot of complexity, such as:
- Service discovery
- Load balancing
- Fault tolerance
- Distributed tracing
- Metrics
- Security
As systems grow bigger and bigger these challenges become exacerbated to the point where they become virtually impossible to tackle by teams focusing on specific business cases.
With the advent and popularization of containers, technologies emerged to tame the ever-growing operations demand, offering rich sets of features. Enter [Kubernetes](https://kubernetes.io/), the most popular container platform today, supported by every major cloud provider, offering:
- Automated rollouts and rollbacks
- Storage orchestration
- Automatic bin packing
- Self-healing
- Service discovery and load balancing
- Secret and configuration management
- Batch execution
- Horizontal scaling
Orchestration platforms like Kubernetes aim to ease the operational burden on teams while bringing some new development patterns to the mix. But while this is true, there’s some effort that still has to be put into operating services, from the development team’s point of view. Platforms like Kubernetes have their own “language” that needs to be understood so that applications can be deployed on it as well as a diverse set of configuration features and requirements. For example, for Kubernetes to optimally handle service lifecycle, services should provide health endpoints that Kubernetes will use to probe and decide when to restart such service.
Although Kubernetes was developed to orchestrate containers at large, it does not manage containers directly. Instead, it manages [Pods](https://kubernetes.io/docs/concepts/workloads/pods/) which are groups of containers that share storage and network resources and have the same lifecycle. Kubernetes guarantees that all containers inside a Pod are co-located and co-scheduled and that they all run in a shared context.

These shared facilities between containers facilitate the adoption of patterns for composite containers:
- **Sidecar** - extend and enhance the main container, making it better (e.g filesystem sync)
- **Ambassador** - proxy connections to and from the outside world (e.g. HTTP requests)
- **Adapter** - standardize and normalize output from sources (e.g. data from centralized logging)
By going deeper into microservices architectures, with the ultimate goal of each microservice focusing only on its own business logic, we can hypothesize that some functionalities could be abstracted and wrapped around the business logic using the above composite patterns. In general, services require:
- **Lifecycle management** - deployments, rollbacks, configuration management, (auto)scaling
- **Networking** - service discovery, retries, timeouts, circuit breaking, dynamic routing, observability
- **Resource binding** - message transformation, protocol conversion, connectors
- **Stateful Abstractions** - application state, workflow management, distributed caching
## Service Mesh
A Service Mesh is a dedicated and configurable infrastructure layer with the intent of handling network-based communication between services. [Istio](https://istio.io/) and [Linkerd](https://linkerd.io/) are two examples of implementations. Most implementations usually have two main components: the Control plane and the Data plane. The Control plane manages and configures the proxies that compose the Data plane. Those Data plane proxies are deployed as sidecars and can provide functionalities like service discovery, retries, timeouts, circuit breaking, fault injection, and much more.
By using a Service Mesh, services can offload these concerns and focus on business rules. And since microservices can be developed using different languages and frameworks, by abstracting these functionalities, they do not have to be redeveloped and maintained for each scenario.
## Serverless Computing
[Serverless computing](https://en.wikipedia.org/wiki/Serverless_computing) comes into play with the promise of freeing teams from having to deal with operational tasks. The general idea with Serverless computing is to be able to provide the service code, together with some minimal configuration, and the provider will take care of the operational aspects. Most cloud providers have serverless offerings and there are also serverless options on top of Kubernetes that use some of the patterns mentioned before. Some examples are [Knative](https://knative.dev/docs/), [Kubeless](https://kubeless.io/), or [OpenFaaS](https://www.openfaas.com/).
## Distributed Application Runtimes
Projects like [Dapr](https://dapr.io/) aim to be the Holy Grail for application development. Their goal is to help developers build resilient services that run in the cloud. By codifying best practices for building microservices into independent and agnostic building blocks that can be used only if necessary, they allow services to be built using any language or framework and run anywhere.
They offer capabilities around networking (e.g. service discovery, retries), observability (e.g. tracing) as well as capabilities around resource binding like connectors to cloud APIs and publish/subscribe systems. Those functionalities can be provided to services via libraries or deployed using sidecars.
## Microservices and Beyond
Microservices are entering an era of multi-runtime, where interactions between the business logic and the outside world are done through sidecars. Those sidecars offer a lot of abstractions around networking, lifecycle management, resource binding, and stateful abstractions. We get the benefits of microservices with bounded contexts handling their own piece of the puzzle.
Microservices will focus more and more on differentiating business logic, taking advantage of battle-tested, off-the-shelf sidecars that can be configured with a bit of YAML or JSON and updated easily since they’re not part of the service itself. Together they will compose the intricate web services that will power the future. | mccricardo |
852,742 | daisyUI: Tailwind CSS components for reducing markup | Written by Fortune Ikechi ✏️ Despite the overwhelming popularity of Tailwind CSS, many developers... | 0 | 2021-10-05T19:16:42 | https://blog.logrocket.com/daisyui-tailwind-components-react-apps/ | tailwindcss, react, webdev | **Written by [Fortune Ikechi](https://blog.logrocket.com/author/fortuneikechi/) ✏️**
Despite the overwhelming popularity of Tailwind CSS, many developers have struggled to become comfortable with the framework, largely due to a decrease in markup readability as an application scales.
[daisyUI](https://daisyui.com/) is a customizable Tailwind CSS component library that prevents verbose markup in frontend applications. With a focus on customizing and creating themes for user interfaces, daisyUI uses pure CSS and Tailwind utility classes, allowing developers to write clean HTML.
In this article, we’ll explore daisyUI by building an image gallery in React that fetches and organizes photos, learning how to achieve Tailwind’s performance and customization without writing verbose markup.
To follow along with this tutorial, you’ll need the following:
* Basic knowledge of React and JavaScript
* Node.js and npm installed on your machine
* Basic knowledge of Tailwind CSS and utility classes
Let’s get started!
> The code for the example application in this tutorial can be found on [GitHub](https://github.com/iamfortune/daisyUI-photo-gallery-app).
## Generate a new React App
First, we’ll create a new React application and bootstrap it using Create React App; run the command below in your terminal:
```bash
npx create-react-app daisyui-app
```
Although I’ve named this example project `daisyui-app`, you can swap it with whatever name you choose. Next, navigate into your project directory and start your development server by running the following command:
```bash
cd daisyui-app && yarn start
```
The command above will open a browser tab displaying the default boilerplate application. Finally, you’ll need to [set up Tailwind CSS for your application](https://blog.logrocket.com/tailwind-css-configure-create-react-app/) following the steps listed in this article.
### Install dependencies
With our new React project generated and Tailwind CSS configured for Create React App, let’s install the following required dependencies in our application:
* daisyUI: provides components for building and styling our application
* Tailwind CSS: provides utility classes for our daisyUI components
* PostCSS: used for styling JavaScript plugins
* Axios: handles API requests
Run the following code in your terminal:
```bash
yarn add daisyui tailwindcss postcss axios
```
Next, navigate to your `tailwind.config.js` file and add the following code:
```javascript
plugins: [require("daisyui")],
```
The code above includes daisyUI support in our Tailwind CSS configuration, providing access to Tailwind’s utility classes, which we'll use to customize our daisyUI component styles.
## Build a photo gallery application
In this section, we’ll build three components needed for our application: an `Intro` component for our application’s header, a `Navbar` component for our application’s navbar, and a `Photo` component for displaying and organizing photos.
To access images and build components for our application, we’ll use [Unsplash](https://unsplash.com/). If you don’t have one already, set up an account.
### `Intro` component
The `Intro` component will contain an image URL from Unsplash and a background image for our application’s landing page. Inside of your `components/intro/intro.jsx` file, add the following code:
```JSX
const Intro = () => {
const imgURL =
"https://images.unsplash.com/photo-1606819717115-9159c900370b?ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&ixlib=rb-1.2.1&auto=format&fit=crop&w=800&q=80";
return (
<div
className="hero h-96"
style={{
backgroundImage: `url(${imgURL})`,
}}
>
<div className="hero-overlay bg-opacity-60" />
<div className="text-center hero-content text-neutral-content">
<div className="w-full">
<h1 className="mb-6 text-5xl font-bold">
Hello there, welcome to our daisy gallery
</h1>
<p className="text-lg">
Built with images from{" "}
<a
href="https://unsplash.com/developers"
className="hover underline mt-8 bg-white px-2 py-1.5 rounded-sm text-black"
>
Unsplash API
</a>
</p>
</div>
</div>
</div>
);
};
export default Intro;
```
In the code above, we created an `Intro` component; inside, we initialized an `imgURL`, which contains the URL for the image on our landing page.
Next, we customized styles for our application's landing page components using Tailwind CSS classes. We also added a link to the [Unsplash Developers API](https://unsplash.com/developers). Now, your app should look like the image below:

### Building a `Navbar` component
Now, let’s build a simple `Navbar` component and add customization using daisyUI’s component classes:
```javascript
const Navbar = () => {
return (
<div className="navbar flex-col shadow-lg bg-neutral text-neutral-content">
<div className="flex-1 px-2 mx-2">
<span className="text-lg font-bold">Daisy Photo Gallery</span>
</div>
</div>
);
};
export default Navbar;
```
In the code above, we made the fonts for our Navbar bold by using `font-bold`, and we specified a large font using the `text-leg` component.
### Building our `Photo` component
Next, we’ll build a simple `Photo` component to render images fetched from Unsplash; to render our `Photo` component, we’ll wrap it in a `figure` component:
```javascript
const Photo = ({ imgURL }) => {
return (
<>
<div className="card">
<figure>
<img src={imgURL} alt="unsplash img" />
</figure>
</div>
</>
);
};
export default Photo;
```
In the code block above, we destructured our `Photo` component and passed it our Unsplash `imgURL`. Next, we created a card for our photos using daisyUI’s `card` component class. Finally, we wrapped our images in the `figure` tag, scaling them down to fit our `Photo` component container.
## Fetching and organizing photos
Now, we’ll use our components to fetch random photos from our Unsplash API, then create categories to organize them. First, let’s import our packages by adding the following code block to our `App.js` file:
```javascript
import { useState, useEffect } from "react";
import axios from "axios";
import Intro from "./components/Intro/Intro";
import Navbar from "./components/Navbar/Navbar";
import Photo from "./components/Photo/Photo";
```
In the code above, we imported our components, as well as the `useState` and `useEffect` Hooks. Next, we’ll initialize an `app` component by adding the code below:
```javascript
const App = () => {
const [selectedCategory, setSelectedCategory] = useState("RANDOM");
const [photos, setPhotos] = useState([]);
const [categories] = useState([
"RANDOM",
"TECHNOLOGIES",
"ARTS",
"SPORTS",
"GAMES",
]);
```
Inside our `app` component, we created states for `categories` and `Photos` using React’s `useState` variable. Then, we created an array of different categories, including `RANDOM`, `TECHNOLOGIES`, `ARTS`, `SPORTS`, and `GAMES`.
Now, let’s write a function to fetch random photos from our Unsplash API:
```javascript
const fetchRandomPhotos = async () => {
try {
const res = await axios.get("https://api.unsplash.com/photos/random", {
params: {
client_id: process.env.REACT_APP_UNSPLASH_ACCESS_KEY,
count: 12,
},
});
const photoArr = res.data?.map((photo) => photo?.urls?.regular);
setPhotos(photoArr);
} catch (error) {
setPhotos([]);
console.error(error?.response?.data?.message);
}
};
```
In the code block above, we created the `getRandomPhotos` function, which fetches random photos from our Unsplash API. To set all of our images, we mapped the photo array. For authentication, we passed our `client_id`, which we got from our Unsplash Developers API dashboard. Lastly, we specified the number of images as `count: 12`.
Now, we’ll write a function that returns a photo based on the photo category:
```javascript
const fetchPhotoBasedonCategory = async () => {
try {
const res = await axios.get("https://api.unsplash.com/search/photos", {
params: {
client_id: process.env.REACT_APP_UNSPLASH_ACCESS_KEY,
query: selectedCategory.toLowerCase(),
},
});
const photoArr = res.data?.results?.map((photo) => photo?.urls?.regular);
setPhotos(photoArr);
} catch (error) {
setPhotos([])
console.error(error?.response?.data?.message);
}
};
```
Similar to our `getRandomPhotos` function, we specified the categories and used `map` to sort through a list of photos, returning only the photos in the category specified by the user. To render an image, we mapped the array of images from Unsplash, setting only the specified number of images. We also logged any errors to the console:
```javascript
useEffect(() => {
if (selectedCategory === "RANDOM") {
return fetchRandomPhotos();
}
fetchPhotoBasedonCategory();
// eslint-disable-next-line react-hooks/exhaustive-deps
}, [selectedCategory]);
return (
<>
<Navbar />
<main className="mb-10">
<Intro />
<nav>
<div className="tabs mt-10 justify-center">
{categories.map((category) => (
<p
key={category}
onClick={() => setSelectedCategory(category)}
role="button"
className={`tab tab-bordered
${selectedCategory === category && "tab-active"}`}
>
{category}
</p>
))}
</div>
</nav>
<section className="mt-4 mx-auto w-10/12 relative">
<div className="grid grid-cols-3 justify-center gap-3">
{photos?.length ? (
photos.map((photo) => <Photo key={photo} imgURL={photo} />)
) : (
<p className="mt-10 alert alert-info absolute left-1/2 -ml-20">
No photo at the moment!
</p>
)}
</div>
</section>
</main>
</>
);
};
export default App;
```
In the code block above, we used React’s `useEffect` Hook to specify `RANDOM` if a user selects the `random` category. If a user specifies a category, the API returns images from the selected category.
Finally, we rendered our entire application and added an `onClick` event to the category sections. Additionally, we added a function to specify that only images from the selected category will be displayed to the user. Lastly, we added a message for when there are no photos available from our API. Though this is highly unlikely, it is good practice.
If done correctly, our application should look similar to the image below:
## Conclusion
With the addition of component classes like `btn`, `card`, and `footer`, daisyUI significantly improves upon Tailwind CSS by allowing developers to write clean HTML. In this tutorial, we explored building and customizing our own React application with CSS variables and Tailwind CSS utility classes.
Although our example focused on building an image gallery, you can take the information in this tutorial and apply it to your own application, enjoying Tailwind's styling performance without harming your code's readability as you scale your project. I hope you enjoyed this tutorial!
---
## Full visibility into production React apps
Debugging React applications can be difficult, especially when users experience issues that are hard to reproduce. If you’re interested in monitoring and tracking Redux state, automatically surfacing JavaScript errors, and tracking slow network requests and component load time, [try LogRocket](https://www2.logrocket.com/react-performance-monitoring).
[](https://www2.logrocket.com/react-performance-monitoring)
[LogRocket](https://www2.logrocket.com/react-performance-monitoring) is like a DVR for web apps, recording literally everything that happens on your React app. Instead of guessing why problems happen, you can aggregate and report on what state your application was in when an issue occurred. LogRocket also monitors your app's performance, reporting with metrics like client CPU load, client memory usage, and more.
The LogRocket Redux middleware package adds an extra layer of visibility into your user sessions. LogRocket logs all actions and state from your Redux stores.
Modernize how you debug your React apps — [start monitoring for free](https://www2.logrocket.com/react-performance-monitoring). | mangelosanto |
852,758 | Learning TensorFlow? These resources can help! | 1. TensorFlow Tutorial This is the Official TensorFlow documentation and tutorial.... | 0 | 2021-12-11T16:56:02 | https://raftlabs.co/development/top-5-free-resources-to-learn-tensorflow?utm_source=devto&utm_campaign=crosspost | 
#### [**1\. TensorFlow Tutorial**](https://www.tensorflow.org/tutorials)
This is the Official TensorFlow documentation and tutorial. Everything from the basics to the advanced parts is covered. Excellent tutorial for tests and interviews as well since TensorFlow concepts are also covered.
*[Created by TensorFlow]*
[More info](https://www.tensorflow.org/tutorials)
#### [**2\. TensorFlow Tutorial For beginners**](https://www.youtube.com/watch?v=t_DdvgY71NE)
In this TensorFlow tutorial for beginners video, you will learn TensorFlow concepts like tensors, the program elements in TensorFlow, and constants & placeholders in TensorFlow python how variable works in placeholder and a demo on MNIST. There's a short quiz as well at the end to test your knowledge.
*[Created by Intellipaat]*
[More info](https://www.youtube.com/watch?v=t_DdvgY71NE)
#### [**3\. Introduction to TensorFlow**](https://www.coursera.org/learn/introduction-tensorflow)
Introduction to TensorFlow is a Coursera tutorial that teaches the basics about TensorFlow through Videos, Assignments, and Notes.
*[Created by Laurence Moroney]*
[More info](https://www.coursera.org/learn/introduction-tensorflow)
#### [**4\. Intro to TensorFlow for Deep Learning**](https://www.udacity.com/course/intro-to-tensorflow-for-deep-learning--ud187?irclickid=VDsxb5SEsxyLWL10HbRLDTgpUkBReW38NyVD2Q0&irgwc=1&utm_source=affiliate&utm_medium=&aff=2890636&utm_term=&utm_campaign=__&utm_content=&adid=786224)
Learn how to build deep learning applications with TensorFlow. The TensorFlow team and Udacity developed this course as a practical approach to deep learning for software developers. You'll :
1. get hands-on experience building your state-of-the-art image classifiers and other deep learning models.
2. Use your TensorFlow models in the real world on mobile devices, in the cloud, and in browsers.
3. Use advanced techniques and algorithms to work with large datasets.
By the end of this course, you'll have all the skills necessary to start creating your own AI applications.
*[Created by Udemy]*
[More info](https://www.udacity.com/course/intro-to-tensorflow-for-deep-learning--ud187?irclickid=VDsxb5SEsxyLWL10HbRLDTgpUkBReW38NyVD2Q0&irgwc=1&utm_source=affiliate&utm_medium=&aff=2890636&utm_term=&utm_campaign=__&utm_content=&adid=786224)
#### [**5\. Hello, TensorFlow**](https://www.oreilly.com/content/hello-tensorflow/)
A tutorial cum online project that walks you through the entire process of learning TensorFlow and makes you build your first TensorFlow graph from the ground up.
*[Created by Aaron Schumacher]*
[More info](https://www.oreilly.com/content/hello-tensorflow/)
*Originally posted at* [*raftlabs.co*](https://raftlabs.co/development/top-5-free-resources-to-learn-tensorflow?utm_source=devto&utm_campaign=crosspost) | raftlabs | |
852,781 | A Compositional Approach to Optimizing the Performance of Ruby Apps | Ruby makes developers happy, but at times I wish it was faster. In a new article I explore a novel... | 0 | 2021-10-05T20:17:54 | https://dev.to/ciconia/a-compositional-approach-to-optimizing-the-performance-of-ruby-apps-4nd2 | ruby, performance | ---
title: A Compositional Approach to Optimizing the Performance of Ruby Apps
published: true
description:
tags: ruby, performance
//cover_image: https://direct_url_to_image.jpg
---
Ruby makes developers happy, but at times I wish it was faster. In a [new article](https://noteflakes.com/articles/2021-10-05-a-compositional-approach-to-ruby-performance) I explore a novel approach to improving the performance of Ruby apps.
| ciconia |
852,793 | Proteger con password un site estático | | | En este post voy a centrarme en un site generado con Antora pero puedes extenderlo a cualquier... | 0 | 2021-10-28T04:40:31 | https://jorge.aguilera.soy/blog/2021/antora-password.html | asciidoc, documentation, write, antora | ---
title: Proteger con password un site estático
published: true
date: 2021-09-27 00:00:00 UTC
tags: asciidoc,documentation,write,antora
canonical_url: https://jorge.aguilera.soy/blog/2021/antora-password.html
---
| | En este post voy a centrarme en un site generado con Antora pero puedes extenderlo a cualquier otro site tipo Gatsby, Hugo, etc o incluso a un simple html |
| | Puedes descargar un repo de ejemplo en [https://gitlab.com/puravida-asciidoctor/antora-skeleton](https://gitlab.com/puravida-asciidoctor/antora-skeleton)y/o acceder al ejemplo en [https://antora-password-protected.herokuapp.com/](https://antora-password-protected.herokuapp.com/) con el usuario test/test |
Una vez que tienes tu contenido generado en HTML, una de las preguntas que te surge es cómo puedo restringuir su acceso a sólo algunos usuarios.
En este post vamos a ver alguna de las alternativas que podrías usar dependiende de si los lectores serían internos (por ejemplo otros equipos en la intranet de la empresa) o externos y en este caso si cuentas con infraestructura propia o quieres usar un proveedor externo. Así mismo puedes plantearte si lo que quieres es proteger una simple página o todo un site
## Simple página HTML
Preparando este post encontré un script en node, staticrypt, que encripta una página html con una password que le proporcionas generando así un html con un interface para pedir la password y poder desencriptar la página
Digamos que tienes un Asciidoctor donde tienes documentado un API y quieres publicarlo pero que sólo lo puedan leer los que tengan la clave:
```
= My API
this is my api
blablablab
```
Generamos el html:
`$asciidoctor api.adoc`
y obtenemos `api.html`
Lo encriptamos con staticrypt
`$staticrypt api.html la_clave_para_desencriptar -o api.html`
y ya tenemos un fichero `api.html` protegido que se puede publicar en Gitlab Pages, Github, etc
Sin embargo esta solución no funciona cuando tu documentación contiene varios ficheros porque, aunque puedes encriptar todos los ficheros, el usuario tendrá que proporcionar la página en cada una. Así que necesitamos algo que mantenga la sesión
## Site alojado en S3
Como existe mucha documentación tanto de AWS como tutoriales sobre cómo crear un Bucket de S3 y proteger su contenido no voy a explicarlo aquí. Simplemente lo menciono por si no lo habías tenido en cuenta
## Site alojado en Bucket GGP
Lo mismo para un bucket de Google Cloud Platform, y en realidad por extensión a todos los compatibles con estos
## Site alojado por nuestros medios
Una de las formas de proteger un site web es usando un fichero `.htpasswd` que puede ser manejado por Apache o por Nginx. En este post vamos a usar este último pues es mucho más fácil y ligero que Apache
Para crear el fichero seguiremos cualquier tutorial de Internet pero básicamente es ejecutar un comando tipo `httpass` o usar una de las muchas páginas online que lo generan
Siguiendo cualquiera de las dos opciones, vamos a crear el usuario `test` con password `test`
httpasswd
```
test:$apr1$yofaxwjl$xw.u6dmKy2qYiayuEnWW1. (1)
```
| **1** | Obviamente puedes crear tantos usuarios como quieras, uno por cada linea
<dl>
<dt>WARNING</dt>
<dd>
<p>El fichero esperado es con un punto al inicio pero yo lo uso sin punto para que me aparezca cuando
listo el directorio y luego lo copio al contenedor con el nombre esperado</p>
</dd>
</dl>
|
### Site interno con NGINX
Supongamos que en nuestra empresa contamos con una infraestructura y disponemos de al menos un servidor con espacio y con Docker instalado (obviamente Docker es opcional pero así podemos aislar aplicaciones unas de otras).
Supongamos que hemos creado nuestro site Antora pero no queremos que cualquier usuario pueda acceder a ello (yo que sé porqué) sino sólo aquellos que dispongan del usuario y password creados anteriormente.
En nuestro proyecto Antora, crearemos un directorio `nginx` y ubicaremos en él el fichero `htpasswd`
Así mismo crearemos en este directorio un fichero mínimo de configuración de Nginx
default.conf
```
server {
listen 80;
listen [::]:80;
server_name localhost;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
auth_basic "Restricted Content";
auth_basic_user_file /etc/nginx/.htpasswd;
}
}
```
y en el root de nuestro proyecto crearemos un docker-compose similar a
docker-compose.yml
```
version: "3"
services:
antora:
image: "ggrossetie/antora-lunr:2.3.4"
volumes:
- .:/antora
entrypoint: /bin/ash
command: /antora/custom-antora.sh (1)
nginx:
image: "nginx"
volumes:
- ./nginx/.htpasswd:/etc/nginx/.htpasswd
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf
- ./public:/usr/share/nginx/html
ports:
- "9080:80"
```
| **1** | El contenido de este fichero escapa a este post pero basicamente construye un site antora |
Con este docker-compose podemos generar el site mediante `docker-compose run antora` lo cual nos genera la documentaacion en `public`
Una vez generada y revisada en local podemos compartirla vía nginx con `docker-compose up -d nginx`y nuestros usuarios internos podrán acceder a ella vía el puerto `9080`
### Site publico con Heroku
Usando la capa gratuita de Heroku podemos desplegar nuestro site junto con el servicio Nginx anterior de tal forma que podríamos publicarlo en Internet y protegido mediante usuario/password de la misma forma
| | Para este paso necesitas tener una cuenta gratuita en Heroku y el comando de consola instalado , así como haber hecho login con el mismo. |
La idea es muy similar y lo que vamos a aprovechar es la capacidad de poder subir una imagen a Heroku construida por nosotros y correr una instancia de la misma. En la capa gratuita, Heroku para los containers transcurrido un tiempo (creo que 30 minutos) y lo vuelve a levantar ante una petición. Como nuestro servicio es realmente ligero, este tiempo de espera es casi inmediato para el usuario
Uno de los requisitos de Heroku es que él nos indica en tiempo de arranque el puerto en el que va a escuchar el contenedor por lo que el fichero nginx anterior no nos sirve. Usaremos para ello este otro
change.default.conf
```
server {
listen $PORT;
listen [::]:$PORT;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
auth_basic "Restricted Content";
auth_basic_user_file /etc/nginx/.htpasswd;
}
}
```
Junto con este `Dockerfile`
Dockerfile
```
FROM nginx
COPY nginx/htpasswd /etc/nginx/.htpasswd
COPY nginx/change.default.conf /etc/nginx/conf.d/default.conf
COPY public /usr/share/nginx/html
CMD /bin/bash -c "envsubst '\$PORT' < /etc/nginx/conf.d/default.conf > /etc/nginx/conf.d/default.conf" && cat /etc/nginx/conf.d/default.conf && nginx -g 'daemon off;' (1)
```
<1>Es una sóla linea muy larga, supongo que se puede partir en varias pero no lo he investigado
Básicamente vamos a construir una imagen de nginx cambiando en el arranque la configuracion del puerto antes de ejecutar el servicio
Con todo ello preparamos nuestra aplicación en Heroku
`heroku container:push web -a TU-APPLICATION`
Y si todo ha ido bien, la desplegamos
`heroku container:release web -a TU-APPLICATION`
y eso es todo. Ahora tu documentación estaría expuesta en Internet pero protegida por usuario/password
## Conclusión
Obviamente no es la forma más robusta y completa de desplegar una documentación, pero es sencilla, barata y si lo automatizas puedes incluso ir rotando los usuarios y/o sus claves de una forma sencilla | jagedn |
852,849 | Bring some fresh AIR and write effective code review comments | A few years ago, I shared some guidelines about how not to ruin the team mojo with code reviews, what... | 0 | 2021-10-06T06:51:24 | https://www.sandordargo.com/blog/2021/10/06/airy-code-reviews | codereview, teaching, knowledgesharing, beginners | A few years ago, I shared some [guidelines about how not to ruin the team mojo with code reviews](https://www.sandordargo.com/blog/2018/03/28/codereview-guidelines), what practices should the different involved people follow to avoid feeling bad about each other, yet to fulfil the aims of a code review.
It's time to talk about how to write comments that won't be neglected but will be taken into account. These practices will not work all the time, but they will help someone with a higher chance. Personally, I haven't worked with anyone who'd reject ideas based on gender, skin or whether you call a *pain au chocolat* a *chocolatine*, I'm sure there are such people out there. It's enough to "open the internet" to see examples from whatever groups.
Jerks are jerks.
Yet, as a stoic, you shouldn't care about them. At least you should try to care less.
If my comment doesn't achieve its purpose, the question I should ask myself is what I should have done better and why it bothers me if my point was neglected.
I think that a good code review comment consists of 3 parts:
- Action
- Information
- Reference
Adding these three items and staying polite will make sure that there is no smell of resentment in the AIR, at least not because of code reviews.
Let's take a very simple, short comment and I'll show you how to transform it into something AIRy.
*(Not all comments need these 3 elements. Sometimes you should really just ask for some info or highlight a typo.)*
**Code:**
```cpp
void doStuff(const std::unique_ptr<Widet>& iWidgetToUpdate) {
// ...
}
```
**Comment:** *"Why don't you take it by value?"*
## Add a clear **action**
There are many problems with the above comment. One might interpret it as a bit passive-aggressive and besides it definitely lacks a clear action.
If you want the author to perform an action, ask for it.
So many relationships are broken or much worse than they could be simply because we fail to communicate what we want. You might expect that someone else does something - while you should not expect anything from others... - yet the other fails to get the message. Or simply he doesn't want to do it if it's not explicitly asked for.
So let's transform the above comment into something *actionable*:
> "Please, take the smart pointer parameter by value instead of a const&."
Note the word *"please"*. It makes wonders, yet we forget to use it so often.
## Add information
If I received the above comment, I would ask for an explanation. Okay, but why? I think that's the right attitude as someone whose code is being reviewed. But maybe the author is too shy to ask back or simply is too overwhelmed with the comments or with work, maybe with life in general.
As a reviewer, you should not be waiting and rubbing your palms until the author asks back. Don't have such expectations and don't be surprised if the author
- ignores your comment
- asks someone else as well
Even if you're a *C++ guru* or even a *C++ maven*, don't expect others to comply with your comments without giving more information.
So how would a better comment look like?
> "Please, take the smart pointer parameter by value instead of a const&.
> If you pass them by reference, you don't pass or share ownership. If you don't want to deal with ownership, prefer passing a raw pointer or a reference. If you do want to share the ownership, you must pass by value."
Are we good enough already?
Not yet.
## Add references
Even if you're a major authority in the given domain, you shouldn't expect people to take your comments blindly without any proof.
The above comment is already not bad, but it lacks any proof or reference. If I see such a comment, I either look for a reference myself if I have the time, or I might ask back to include some references, or I ask another also experienced colleague. After all, if two people say the same, maybe it's worth taking the advice.
In fact, if I don't share references, I'd expect the others to ask back or to ask for confirmation from others. But once again, having expectations towards others' behaviour is not wise.
Either way, you cannot blame people who look for confirmation even if it hurts your ego.
Let's say get a big stack of cash and it was just counted in front of you. will you just take it, or will you count it? Of course, you will count it. You will count it until you two get the same result twice.
So to complete the AIRy code review, let's add some references.
> "Please, take the smart pointer parameter by value instead of a const&.
> If you pass them by reference, you don't pass or share ownership. If you don't want to deal with ownership, prefer passing a raw pointer or a reference. If you do want to share the ownership, you must pass by value.
> For more details, pleaser refer to
> - [GotW #91 Solution: Smart Pointer Parameters](https://herbsutter.com/2013/06/05/gotw-91-solution-smart-pointer-parameters/)"
> - [const and smart pointers](https://www.sandordargo.com/blog/2021/07/21/const-and-smart-pointers)"
Oh by the way, if you add only one reference, probably it shouldn't be your article, unless... No, there is no unless.
## Conclusion
Imagine that you live in a world where code review comments always bring some fresh AIR: they bring *action*, *information* and *reference*.
Sometimes such a world might seem far away, but you can make it closer. Start using this technique to comment on non-basic mistakes, non-typos.
With such comments, you will not simply ask for a change, but you'll teach, probably also learn by reviewing why you ask for something and you'll even share some resources that later others can use.
## Connect deeper
If you liked this article, please
- hit on the like button,
- [subscribe to my newsletter](http://eepurl.com/gvcv1j)
- and let's connect on [Twitter](https://twitter.com/SandorDargo)!
| sandordargo |
852,932 | Introducing Bookshop: component-driven workflow for static websites | We're delighted to launch Bookshop: an open-source framework to speed up development and reduce... | 0 | 2021-10-05T23:09:03 | https://cloudcannon.com/blog/introducing-bookshop/ | webdev, jamstack, opensource, cms | ---
canonical_url: https://cloudcannon.com/blog/introducing-bookshop/
---
We're delighted to launch [Bookshop](https://github.com/CloudCannon/bookshop): an open-source framework to speed up development and reduce maintenance on static websites by developing components in isolation.
Building and maintaining high-performing informational websites have their own set of challenges. It's almost impossible to know all the requirements for a website upfront, so there's often an endless amount of iteration and tweaking involved in these projects. Requirements change, new components are necessary, buttons need 'more pizzazz', the data team wants to add a series of graphs to their latest blog post, and it's on you to get everything to work together while being prepared for the next wave of changes. This constant chopping and changing often leads to an unmaintainable jungle of CSS and JavaScript where a complete rebuild becomes the only option. We've all been there; it's usually just a matter of time.
The key to avoiding this jungle is a component-driven workflow. Ideally, you isolate each component's template and CSS. Doing this makes the website far easier to maintain and gives you a framework for adding as many components as you'd like, without your codebase getting out of control.
In a traditional React application, you might reach for [Storybook](https://storybook.js.org/) to solve this problem. Storybook provides the tooling needed to build components in isolation, and we're big fans of the workflow that it brings to our React projects.
##The problem 
When we started tackling static websites with a component-driven methodology, however, we hit some limitations working with Storybook outside of the JS framework world.
1. **Complicated configuration** — Storybook doesn't have built-in support for templating languages like Liquid, Handlebars, or Go templates. We experimented with adding templating support to one of the existing Storybook frameworks, and building Javascript definition files for each component, giving us the rich Storybook controls. Another option was to use Storybook as an HTML reference guide, copying snippets out whenever we needed a component.Neither workflow provided the benefits we were used to in our application Storybooks, and our component reference would eventually fall out of sync with the implementation.
2. **Schema duplication** — There was no source of truth for the data passed to each component. We had to manually keep parity between our Storybook configuration, component includes, and include tags across each website.
3. **No SSG integration** — The SSG doesn't know anything about components, so we had no prescribed workflow for structuring our files at a component level. Eventually, a given site would become a bird's nest of include files and sass modules, and it was no longer clear what was actually a component.
4. **Development speed** — Once we weren't receiving the full benefits of Storybook, the extra tooling and build time became a damper on an otherwise lightweight static website development environment.
##Our solution? Bookshop.
Bookshop is a component browser and playground, which addresses these limitations and brings component-driven development to static site generators (SSGs).
{% vimeo 622834137 %}
The benefits include:
* **SSG templating language support** — Bookshop is built for templating and can render the exact same includes you use to build your production website.
* **Easy configuration** — Configure components with TOML, which functions as a schema for the front matter data structure you'll use in your SSG.
* **Easy integration** — Bookshop includes plugins for popular SSGs, allowing them to use components with a distinct template tag that enforces a separation of concerns. Using this, Bookshop can seamlessly pass data from front matter to your component. There's no need to manually pass data to an include one variable at a time.
* **Isolated component structure** — Bookshop has strong opinions on how templates and CSS are structured to ensure they're isolated, easy to find, and simple to maintain.
* **Fast build times** — Bookshop is lightweight. Rather than a standalone application, bookshop builds a component browser that can embed anywhere on your website. This means you get to use your website styles and assets, and esbuild under the hood brings fast build times and quieter laptop fans.
Finally, Bookshop integrates tightly with CloudCannon for your content management needs. Editors can see the full catalog of components available and use them to build pages visually, all powered by your custom-built component library. No extra steps are necessary.
And did we mention that Bookshop adds a local component browser to your static webdev process? With a hot-reloading live-preview UI explorer for static template components, your workflow will thank you.
{% vimeo 623857314 %}
HTML-based SSGs such as [11ty](https://www.11ty.dev/), [Jekyll](https://jekyllrb.com/), and [Hugo](https://gohugo.io/) (support coming soon) benefit the most for Bookshop, as existing tooling doesn't support their native templating languages. However, there will still be benefits to using Bookshop with React or Vue-based SSGs, particularly if you want content editors to manage content visually on CloudCannon. Support for a Bookshop workflow with these SSGs will be coming later this year.
To help get you started with Bookshop, we've created a starter theme ([Jekyll](https://github.com/CloudCannon/jekyll-bookshop-starter), [11ty](https://github.com/CloudCannon/eleventy-bookshop-starter)) to give you a boilerplate to build the rest of you site on. We're also launching a [collection of free, high quality templates](https://github.com/CloudCannon?q=bookshop+template). These production-ready templates make full use of Bookshop, are optimized for CloudCannon and can be used for free for any project, commercial or not.
We can't wait to see how you start using Bookshop on your web projects and reach new productivity levels. To get started, check out the readme for Bookshop in the [GitHub repository](https://github.com/CloudCannon/bookshop). We're always open to any feedback. If you hit a problem or have an idea to improve Bookshop, open an issue on the repository, and we'll be there to help.
| avidlarge |
852,964 | Using Apache Airflow ETL to fetch and analyze BTC data | I am taking a short break from Blockchain-related posts. In past, I have covered Apache Airflow... | 0 | 2021-10-08T14:05:38 | https://itnext.io/using-apache-airflow-etl-to-fetch-and-analyze-btc-data-1adab96c410c | etl, apacheairflow, dataengineering, datapipeline | ---
title: Using Apache Airflow ETL to fetch and analyze BTC data
published: true
date: 2021-10-05 14:51:38 UTC
tags: etl,apacheairflow,dataengineering,datapipeline
canonical_url: https://itnext.io/using-apache-airflow-etl-to-fetch-and-analyze-btc-data-1adab96c410c
---

I am taking a short break from [Blockchain-related](https://blog.adnansiddiqi.me/tag/blockchain-programming) posts.
In past, I have covered Apache Airflow posts [here](http://blog.adnansiddiqi.me/tag/airflow/). In this post, I am discussing how to use the [CCXT](https://github.com/ccxt/ccxt) library to grab BTC/USD data from exchanges and create an ETL for data analysis and visualization. I am using the [dockerized](https://airflow.apache.org/docs/apache-airflow/stable/start/docker.html) version of Airflow. It is easy to set up and using proper different images to run different components instead of a one-machine setup. The docker-compose.yml file is available [here](https://airflow.apache.org/docs/apache-airflow/stable/docker-compose.yaml) but I have made a few changes to install custom libraries. Therefore, it is advised you use the file I have provided in the Github repo. Before I continue, the demo of the work is given here:
{% youtube 72scllBBgVo %}
### The DAG
The entire flow looks like the below:

I am fetching BTC/USD data from three different exchanges: Binance, ByBit, and FTX. Once the data is available, I am sending all three sources into the next stage where I am only pulling _close_ and _timestamp_ data because these are fields that I need for the next stages. From here, I am branching out two tasks: one to create text files and storing data for later use and the other is storing into the DB. The 3 different files are then sent to the server via FTP. The data from load\_data section is then used to generate reports and then FTPing the file to the server. Notice that some borders are dark green and some are light green in color. Dark green means these tasks are executed successfully while light green means they are still _running_. The task, _ftp\_pdf\_file_ is yet to run. In Airflow terms, the DAG flow has been set like below:
In first stage all 3 tasks run in parallel and output results to transform\_data therefore I put all 3 tasks in a Python list. The **>>** sign is telling that it is an upstream. The transformed data is being to create\_text\_file and load\_data tasks who themselves are _upstream_ for ftp\_file and generate\_pdf\_reports tasks. Notice I am using << here to define upstream for ftp\_pdf\_file and generate\_pdf\_reports tasks. Again these tasks were first added in a Python list and then branched out for the next stage.
In order to pass data from one task to another task, Airflow provides xcom\_pull and xcom\_push methods. **XCom** means _Cross Communication_. When you use xcom\_pull, it means you are fetching data from the task whose Ids have been passed. For instance:
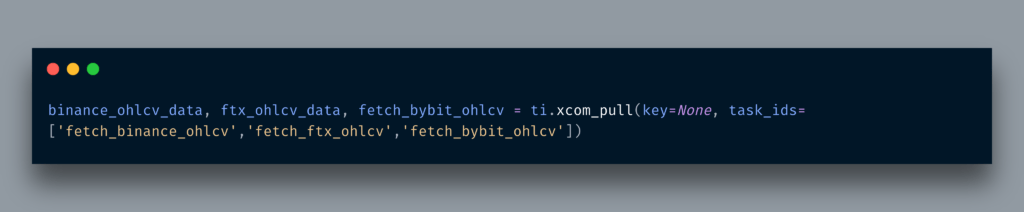
Here I passed the task\_id of three tasks and assigned in three different variables. Wondering where those task\_ids are defined? they are defined as PythonOperator.

Check the log of the task fetch\_binance\_ohlcv:
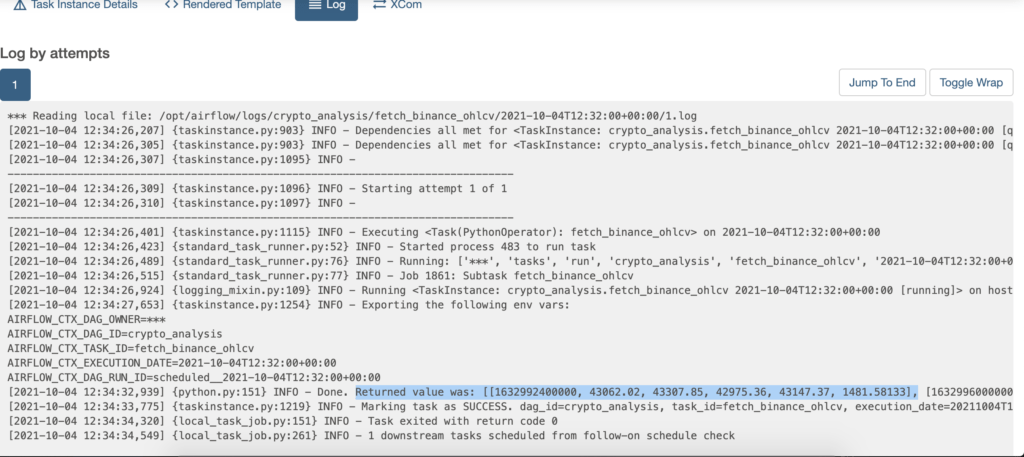
I highlighted the returned value of the task. This and the other two tasks values are _xcom\_pulled_ in the transform\_data task.
I am also using two external components here: FTP and Database. You may use the traditional python code by importing the required libraries but Airflow also provides the options of _hooks_ and _connections_. For instance, pgsql connection looks like below:

Once the connection is defined, you may use PG Hook to perform Postgres-based operations.

Cool, isn’t it? No need to saving credentials in the code. The same thing has been done with FTP.
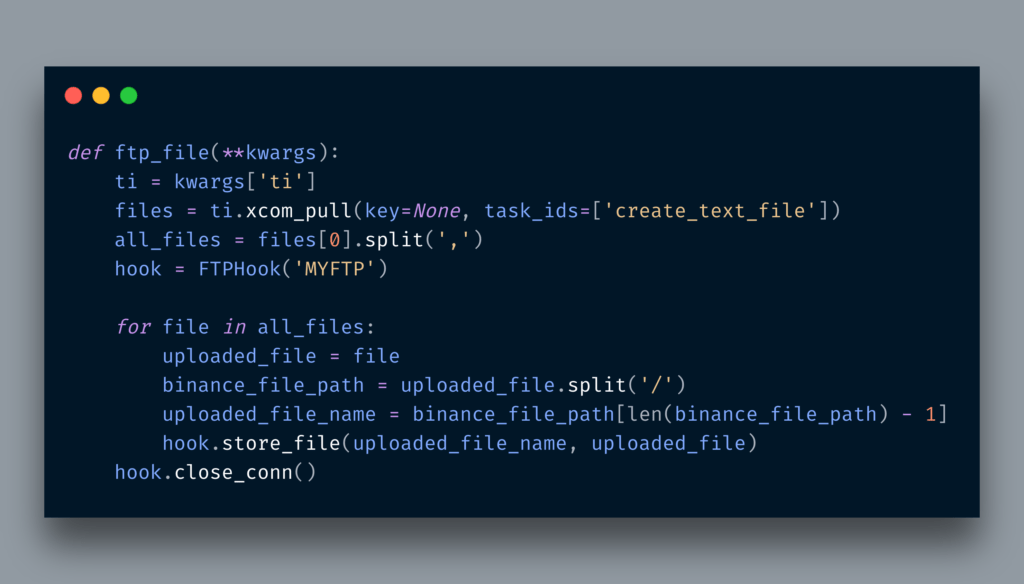
In the end, data is analyzed and generates a two-page PDF for executives.
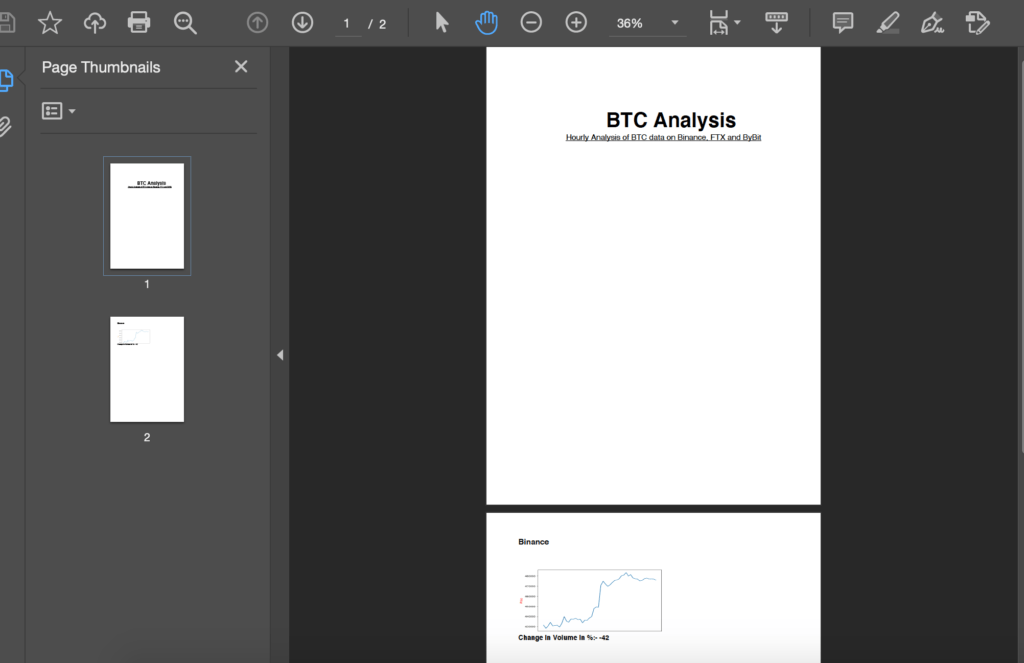
the graph is being generated in _matplotlib_ and saved as an embedded image in the PDF file.
Sweet, No? I was supposed to add data and charts of both FTX and ByBit too but I leave it for you ;). Also, this is not a heavy analysis of the data. I have provided you all data need. You may play with ta-lib or other libraries and find insights. All up to you 😉
I am using _fpdf_ python library to generate PDF files. This is how files are being sent via FTP.

### Conclusion
In this post, you learned how you can make complex flows for ETLs and use connections and hooks to connect 3rd party tools like FTP, DB, AWS, etc. Airflow could be a pretty powerful tool if used correctly. Like always, the code is available on [Github](https://github.com/kadnan/AirFlowCryptoETL).
_Originally published at_ [_http://blog.adnansiddiqi.me_](http://blog.adnansiddiqi.me/using-apache-airflow-etl-to-fetch-and-analyze-btc-data/) _on October 5, 2021._
* * * | kadnan |
852,975 | Creating A Quick Grid System With Flexbox | Greetings, Earth-things! Today, I'm going to show you how to create a flexible grid system using... | 0 | 2021-10-06T01:07:13 | https://dev.to/rolandixor/creating-a-quick-grid-system-with-flexbox-go | css, tutorial, beginners, webdesign | Greetings, Earth-things!
Today, I'm going to show you how to create a flexible grid system using Flexbox! Flexbox is pretty well-supported across pretty much **all the browsers** (except for some quirks in IE11, offfff course), so this should work even where `display: grid` does not!
As a bonus, this demo will allow you to add or remove cells from the grid with a click!
## First, let's set up our environment
I'm using two fonts from Google's Font Library, *Open Sans* and *Dosis*. Let's set up their import statement first:
### Code:
```css
@import url('https://fonts.googleapis.com/css2?family=Dosis:wght@200&family=Open+Sans&display=swap');
```
We'll be using two custom properties later, so let's set them up at the top of our CSS code, just below the import above:
### Code:
```css
:root {
--border: rgba(255, 255, 255, .2);
--page-color: rgb(235, 235, 235);
}
```
As always, I like to do things with a little style. For the background, I'm going to use a nice gradient, and disable padding and margins on the body.
### Code:
```css
body {
background-image: linear-gradient(rgb(135, 35, 135), rgb(75, 135, 195), rgb(35, 48, 135));
background-attachment: fixed;
background-size: cover;
color: var(--page-color);
font-family: 'Open Sans', sans-serif;
font-size: 18px;
letter-spacing: .135ch;
margin: 0;
padding: 0;
}
```
## Next, let's include a little description of what we're building (Optional)
We'll need a heading (`h1`) and a `section`:
#Code:
```html
<h1>
flexi-grid demo
</h1>
<section class="description">
Hi! This is a little demo of a
simple grid system usingFlexbox!
You can add a new box to the
grid by clicking on the "+", or
remove a cell by clicking on the "-".
</section>
```
And then we'll style them:
### Code:
```css
h1 {
color: white;
display: flex;
font-family: 'Dosis', sans-serif;
font-variant: small-caps;
justify-content: center;
letter-spacing: .235ch;
margin: 5vw 0 2.5vw 0;
}
.description {
align-items: center;
background: rgba(85, 85, 85, .2);
border-radius: 8px;
box-shadow: 0 8px 18px rgba(0, 0, 0, .3);
box-sizing: border-box;
display: flex;
justify-content: center;
line-height: 4ch;
padding: 3.5vw 7.365vw;
margin: 0 15vw 5vw 15vw;
text-align: center;
}
```
You should end up with something like this:

## Now, let's build the container
The container itself is invisible, but it's one of the most critical components of our grid system. It holds the cells and tells them how they should be laid out.
Fortunately, it's pretty easy to set up. First, let's add a `main` element to our HTML:
### Code:
```html
<main class="flexi-grid" id="grid">
</main>
```
You'll notice that I've included a class, `.flexi-grid` and give this element an ID, `grid`. These attributes will be critical to the rest of this tutorial, so make sure to include them.
* The class `flexi-grid` will be used to define our grid system.
* The id `grid`, will be used to target this element via JavaScript.
Let's go ahead and set up the CSS for our grid container:
### Code:
```css
.flexi-grid {
display: flex;
flex-flow: row wrap;
justify-content: flex-start;
padding: 0 .5vw;
width: 100%;
}
```
### Some things of note:
* Within this declaration block, we've set the `display` property to `flex;` which tells the browser to use the [Flexbox](https://css-tricks.com/snippets/css/a-guide-to-flexbox/) system for this element.
* Next we've set the `flex-flow` property to `row wrap`. This covers two properties in one go: `flex-direction`, and `flex-wrap`. Later on, we will change this property to `column`, for smaller screens.
* Setting the property `justify-content:` to `flex-start;` tells the browser to align our grid cells toward the beginning (left side) of the row.
* I've padded the container to align its contents to the centre. By using the appropriate value in view-width (vw) units, we can have this done automatically.
## Creating the grid cells
With our container in place, we need to actually add some cells to the grid to make it... you know... a grid. To achieve this, we'll create a new class, `flexi-cell-25`\*.
---
**\*** We can add grid cells of other sizes, but for convenience, and the purposes of this tutorial, we're sticking with quarters.
---
### Code:
```css
.flexi-cell-25 {
border: 1px solid var(--border);
box-sizing: border-box;
margin: .5vw .5vw;
height: 23.5vw;
width: 23.5vw;
box-shadow: 0 3px 12px rgba(0, 0, 0, .3);
}
```
### Some things of note:
* We're using the custom property we defined earlier, `--border`.
* `box-sizing: border-box;` ensures that our grid cells are not affected in terms of overall size, by either their borders or their padding (should we choose to add it).
* For the `margin`, I'm using the same value as the padding used by the container. This maintains (proportionally) even spacing regardless of screen dimensions.
* `height:` and `width:` are not set exactly to `25vw`. This is on purpose. For the purposes of this tutorial, I actually want spacing between each cell, but still want each cell to take 1/4th of the screen width, and the same height. If you want to give each cell the same width, but adjustable height, you could replace `height:` with `align-self: stretch;`.
To see how these grid cells look, add the following to `main`:
```html
<div class="flexi-cell-25">
</div>
<div class="flexi-cell-25">
</div>
```
---
At this point, we should have a page that looks like this:
---
## Bonus: Add and remove buttons
We've technically completed our grid system, but we're going to extend it a bit by adding `add/remove` buttons.
### Our HTML Code:
Within `main`, we'll put the following, adjusting what we had before:
```html
<div class="flexi-cell-25 flexi-grid-new" onclick="newCell()">
</div>
<div class="flexi-cell-25 flexi-grid-remove" onclick="removeCell()">
</div>
```
### Our embedded JavaScript Code:
At the bottom of the file, we'll add this script:
```html
<script type="text/javascript">
var grid = document.getElementById("grid")
function newCell() {
let cell = document.createElement("div")
cell.classList.add("flexi-cell-25")
grid.appendChild(cell)
}
function removeCell() {
grid.removeChild(grid.lastElementChild)
}
</script>
```
### Some things to note:
* We're pulling from the `id` of the grid container, because using `querySelector()` stops us from being able to use `appendChild()` (it apparently returns a string and causes an error).
* Placing `cell` outside `newCell()` (as a global variable) does not work. Ensure it's within the function.
* You can make `newCell()` more versatile by passing the class to add to new cells as an argument. You can try this on your own.
### Finally, let's style our add/remove buttons:
```css
.flexi-grid-new, .flexi-grid-remove {
border-style: dashed;
position: relative;
}
.flexi-grid-new::after {
content: '+';
}
.flexi-grid-remove::after {
content: '-';
}
.flexi-grid-new::after,
.flexi-grid-remove::after {
align-items: center;
bottom: 0;
display: flex;
font-size: 5ch;
justify-content: center;
left: 0;
opacity: .35;
position: absolute;
right: 0;
top: 0;
transition-duration: .735s;
}
.flexi-grid-new:hover::after,
.flexi-grid-remove:hover::after {
opacity: 1;
transform: scale(1.35);
}
```
### Some things to note:
* I've combined definitions wherever possible, to avoid duplication.
* Rather than wrangling with the position of the text, I've simply let the overlays (`::after` pseudo-elements) take up the full space of their parent elements, and used
Flexbox properties to position them in the centre.
---
##That's it!
That's about all there is to it! You can play around with this tutorial and see what you can come up with. If you do, feel free to share your creations with me!
You can view the source code here: [https://codepen.io/rolandixor/pen/rNwEgPb](https://codepen.io/rolandixor/pen/rNwEgPb) | rolandixor |
853,098 | 備份與還原 AWS EC2 的 EBS | 先前情提要簡單介紹一下 AWS,在 AWS 的世界,與傳統虛擬主機最大的不同,即 AWS 幾乎把主機的每個部份都拆成一個服務,有運算服務、聯網服務、儲存服務、安全服務、監控服務、容器服務、VPN... | 0 | 2021-10-06T03:17:36 | https://editor.leonh.space/2020/backup-ebs/ | aws | 先前情提要簡單介紹一下 AWS,在 AWS 的世界,與傳統虛擬主機最大的不同,即 AWS 幾乎把主機的每個部份都拆成一個服務,有運算服務、聯網服務、儲存服務、安全服務、監控服務、容器服務、VPN 服務等等等等等,我們可以自由的把各種服務混合搭配使用,並依照各種服務的用量付費標準付錢錢給 AWS。
AWS 其中的 EC2 是一種可以被量化的雲端計算服務,這也是 EC2 的全名「Elastic Compute Cloud」的含意,而與 EC2 搭配的儲存服務是 EBS (Elastic Block Store),我們可以把 EC2 與 EBS 簡單的對比為「電腦」與「硬碟」,與傳統電腦不同的是在 AWS 的電腦與硬碟都可以隨時被更換,更換的方法可能是人工到 AWS 網站更換或是由我們自己的程式透過 AWS SDK 去更換,這樣的特性就是 elastic 這個字眼想表達的意義:彈性。
## 備份 EC2 的 EBS
除了排程內的定期備份外,在對機臺做某些重大變更時我習慣會對 EBS 另外做人工備份,這些重大變更包括 OS 大升級、自己的程式大改版之類的時候。
EBS 的備份為我們熟知的快照式備份,而 [EBS 的快照是依容量收費](https://aws.amazon.com/tw/ebs/pricing/)的,但是是依實際容量而非額定容量計價,所以就算開 1 TB 的硬碟,但實際只用了 1 GB,那就只會拿 1 GB 來計價。
實際進行快照備份則相當簡單,一般都是從先到 EC2 主控台確定要備份的那台機器,在機器明細頁那裡找到兩個項目「Root device」與「Block devices」,Root device 指的是掛在 /dev/sda1 的開機碟,Block devices 指的是全部的硬碟,在典型的情況下應該 EC2 就只會有一顆硬碟,並且也一定是開機碟,所以 Root device 與 Block devices 應該都只會是 /dev/sda1,這顆被掛在 /dev/sda1 的硬碟有相對應的 EBS ID,透過這組 EBS ID 可以直接連結到 EBS 的主控台頁面下的這顆(卷)EBS。
進入 EBS 主控台的這卷 EBS 後,按下畫面上的 **操作** **創建快照** 就開始快照,並且會再幫我們跳轉到快照的主控台及這筆新快照的明細頁,依照容量的不同會花一點時間建立快照,等到快照的狀態變為綠燈 completed 後,即表示已經完成。
EBS 快照是支援熱快照的,也就是建立快照時 EC2 是不用關機的,但習慣上能關機的我還是會關機,不能關機的則盡量降低磁碟的存取量。
在等待快照建立完成的期間,可以在快照的 Name 欄位填一個容易往後識別的名字,不要太相信自己的記憶力。
## 從快照還原
情境是在 EC2 的某台機器被玩壞了,必須用之前的快照還原。
首先把那台 EC2 上面掛載的壞掉的那卷 EBS 卸下,先把那台被玩壞的 EC2 停機,接著在那台 EC2 的明細找到 Root device 找到壞的 EBS,進入那台 EBS 的明細頁,按 **操作** **斷開卷**,此時這個 EBS 卷會與 EC2 脫離,但因為還是有佔用到 AWS 的空間,所以還是會持續計費,因此在成功還原之後記得把確定無用的、壞的 EBS 刪除掉避免漏財。
然後到 EBS 快照的主控台,確定要還原的快照,按 **操作** **創建卷**,會建立一個新的 EBS 卷,對那個新的 EBS 卷按 **操作** **連接卷**,並填入要掛上的 EC2 機器,以及填入掛載點,**[如果是要做為 Root device 開機碟的話,務必填入 /dev/sda1 作為掛載點才可正常開機](https://docs.aws.amazon.com/zh_tw/AWSEC2/latest/UserGuide/device_naming.html)**。最後記得把確定無用的 EBS 卷或快照刪除。 | leon0824 |
853,102 | The Building Process for C Applications | This week, I learned about the building process for C application in my Software Portability and... | 0 | 2021-10-06T03:37:01 | https://dev.to/jerryhue/the-building-process-for-c-applications-18cd | spo600 | This week, I learned about the building process for C application in my Software Portability and Optimization class.
## How C gets compiled
C is a compiled language, and thus, has a process to compile the source code files into a binary form, which may be a library (also know a shared object or dynamic library), or an executable. C has 5 major stages of compilation:
1. preprocessing,
2. compilation (to an intermediate form such as [LLVM IR](https://en.wikipedia.org/wiki/LLVM#Intermediate_representation)),
3. optimization,
4. assembly,
5. linking.
Each process is, of course, non-trivial, but it is due to this abstraction that we can think of the compiler as a black box that simply spits out the desired program.
### Options for the compiler
Using the C compiler from GCC, we can specify different behaviours for each one of the stages without having to go deep inside the architecture. Things like optimization levels, showing the output after preprocessing or before assembling into a binary, what optimizations you can opt out or opt in, and how the program should be compiled into a static or dynamic executable are among the myriad of options available in the C compiler from GCC.
However, this process of invoking the C compiler every time for big projects can be time consuming and error prone, which is why some programmers developed programs to carry out building processes automatically. One of such programs is Make, which runs several commands depending on several rules that the programmer can write. Make is probably one of the most used automation build tools in the C ecosystem, and is required skill set if one wants to automate their building process for C development on Linux.
## The Program to Install
I decided to try to install a program through this process, instead of installing through my package manager. I decided to install [`zsh`](https://zsh.sourceforge.io/).
I went ahead and downloaded the tarballs and decompressed them. The first step was to run the `./configure` script included at the root of the project. This `./configure` gets the proper values of your system which are then fed into the Makefile of the project. This step is part of the GNU autotools build system. It is very standard to use autotools because of the wide support it provides.
After the I ran the `configure` script, I received an error that I had to install the ncurses development library to continue, so I had to head over my package manager and install that dependency. Following that, I ran the `configure` script one more time, and this time the configuration went through. This meant that I could run `make` and compile the code. The installation instructions recommended that I run `make check` after running `make`, to ensure that my compilation without issues. Since no issues were reported, I proceeded to install the shell with `make install`.
After that, I could run `zsh` without any issues.
## Conclusion
The process of installing with `make` was effortless, almost like magical. However, I am aware that package managers exist for a reason. That reason has to be related with the versioning of the program, as well as the libraries that users have to install to support their programs.
If not organized with proper care, a library may be installed several times, and some of those copies may be with the exact same version. Thus, a package manager takes into account all of those links and makes sure that unnecessary redundancy does not occur. | jerryhue |
853,108 | User authentication in Fauna (an opinionated guide) | In this blog post, you learn the fundamentals of authenticating users in Fauna. You ship your client... | 14,910 | 2021-10-06T03:47:18 | https://fauna.com/blog/user-authentication-in-fauna-an-opinionated-guide | serverless, database, fauna, tutorial | In this blog post, you learn the fundamentals of authenticating users in Fauna. You ship your client applications with a secret token from Fauna that has limited privileges. Ideally, this token can only register and login users in Fauna. Authenticated users then receive a temporary access token that they can use to access the Fauna resources securely. [User-defined functions (UDFs)](https://docs.fauna.com/fauna/current/tutorials/basics/functions) are the key to this implementation.
### Pre-requisites
Some familiarity with FQL will be helpful. You can still follow along without any prior knowledge of FQL. To learn more about FQL visit this [series of articles](https://docs.fauna.com/fauna/current/tutorials/basics/functions) .
## Solution overview
In this post, you:
1. Create a new __secret key__ in Fauna.
2. Configure a role for the __secret key__ so that your client application can only invoke the *User Registration* and *Login* UDFs using this key.
3. Ship the secret key as an environment variable with your client application.
4. Run the *User Registration* UDF from the client application using the __secret key__ to create a new user.
5. Run the *Login* UDF from the client application to acquire a __user access token__.
6. Use the __user__ __access token__ in the client application to interact with Fauna resources.
The following diagram demonstrates the overall authentication flow.
## User registration
Head over to the [Fauna dashboard](https://dashboard.fauna.com/) and create a new database.
Select *Collections* and create a new collection called `Account`
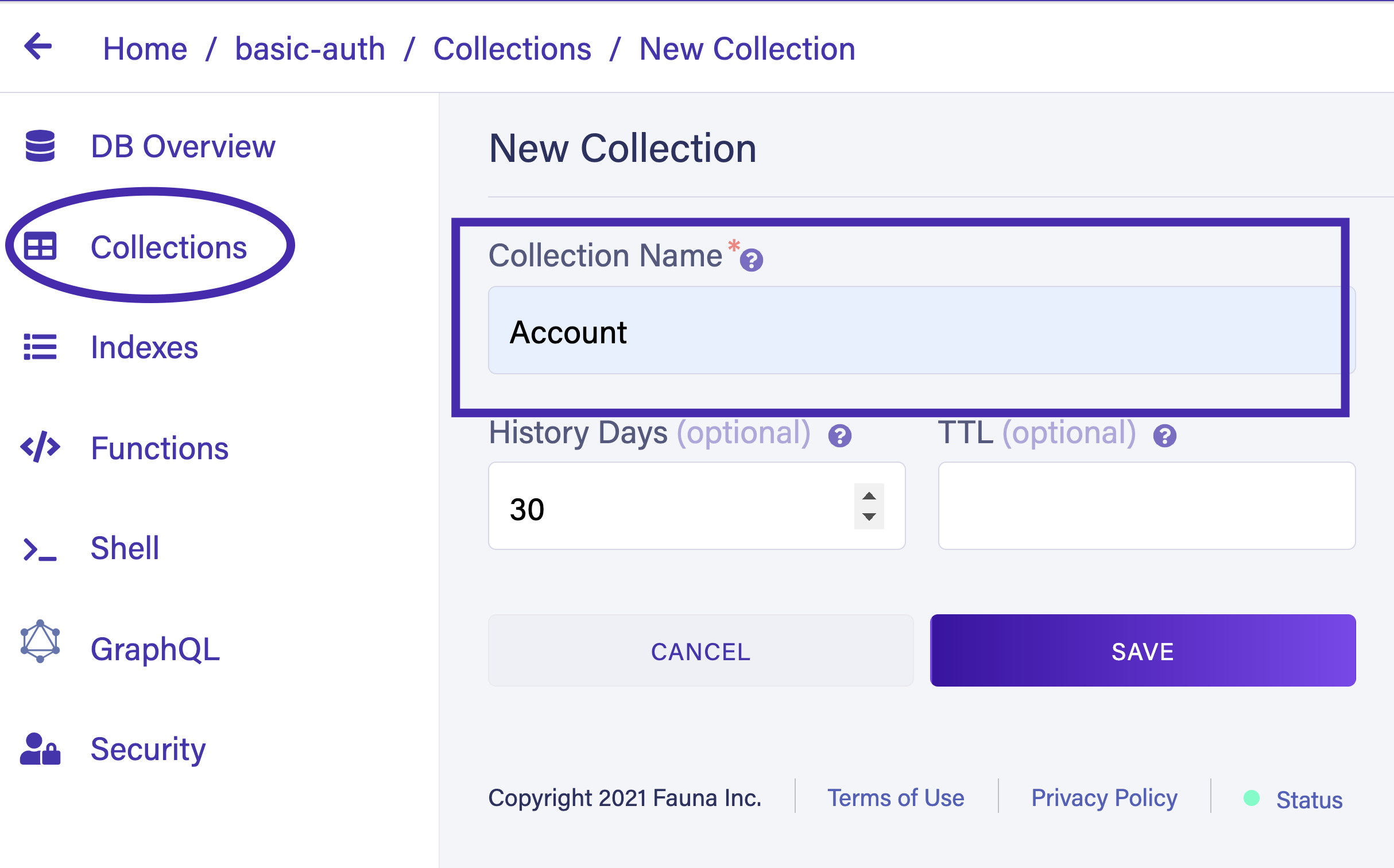
The `Account` collection contains all user data. Navigate to *Indexes* and select *New Index*. Select `Account` as the source collection. Name the index `account_by_email`. You use this index to query users by their email address. In the Terms field, input `email`. Make sure to select the Unique option and the *Serialized* option to ensure that each user has a unique email address. Select *Save* to create the new index.
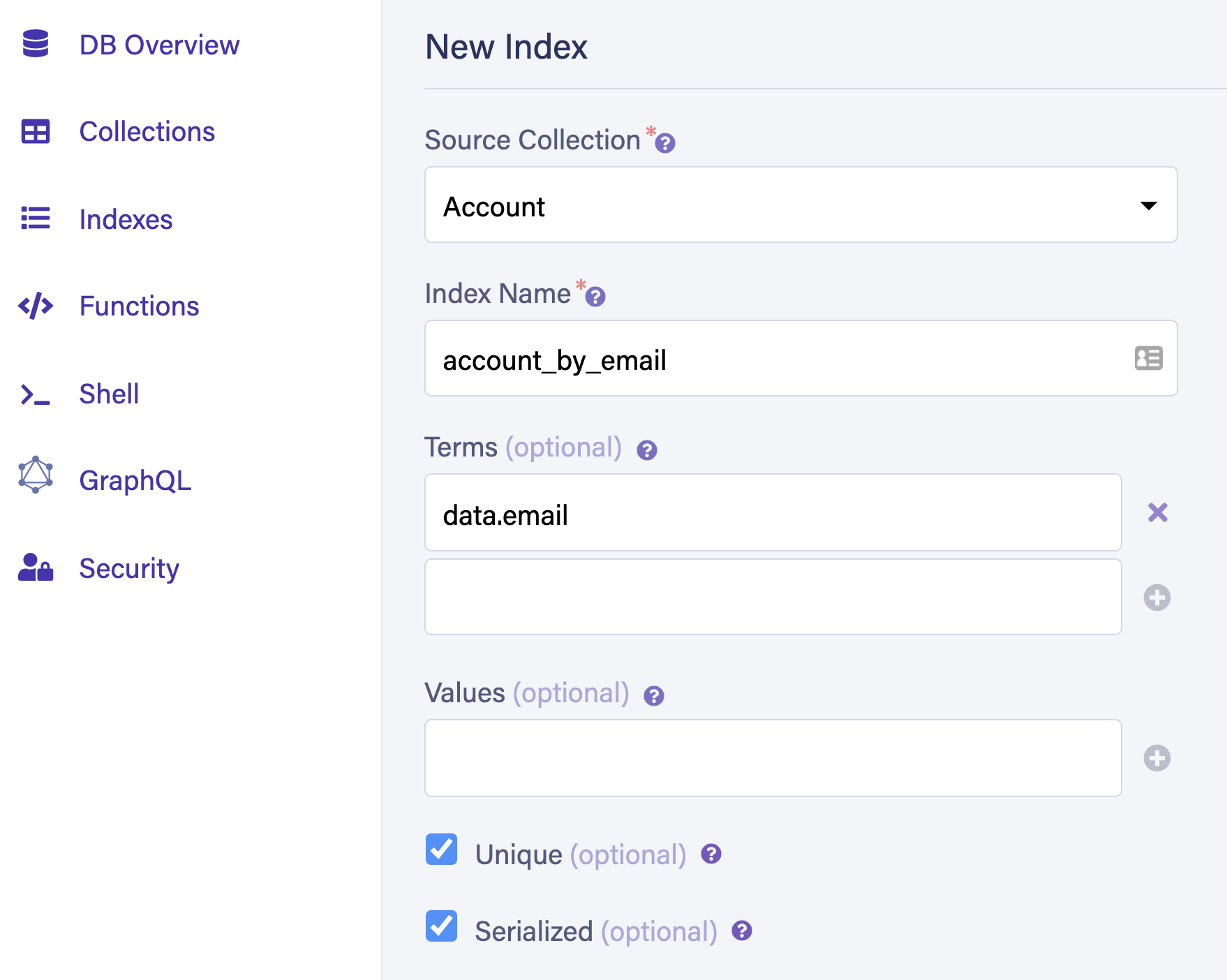
Next, create a function to register new users. Select *Functions* from the dashboard menu and select *NEW FUNCTION* to create a new user-defined function (UDF).
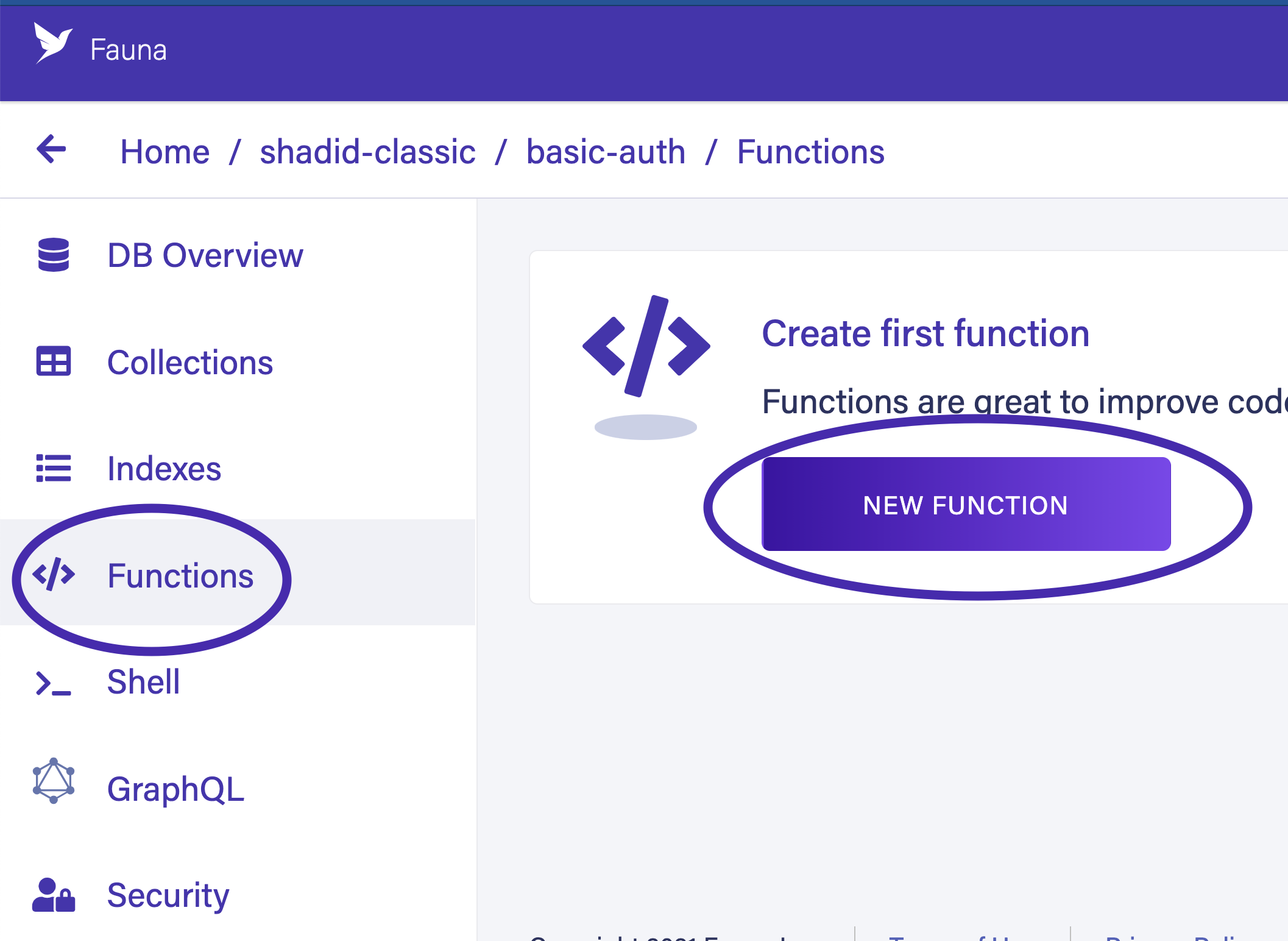
Name your function `UserRegistration` and enter the following code in the *Function Body*. You can leave the role as *None* for now. Select *Save* to create your function.
```jsx
Query(
Lambda(["email", "password"],
Create(Collection("Account"), {
credentials: { password: Var("password") },
data: {
email: Var("email")
}
})
)
)
```
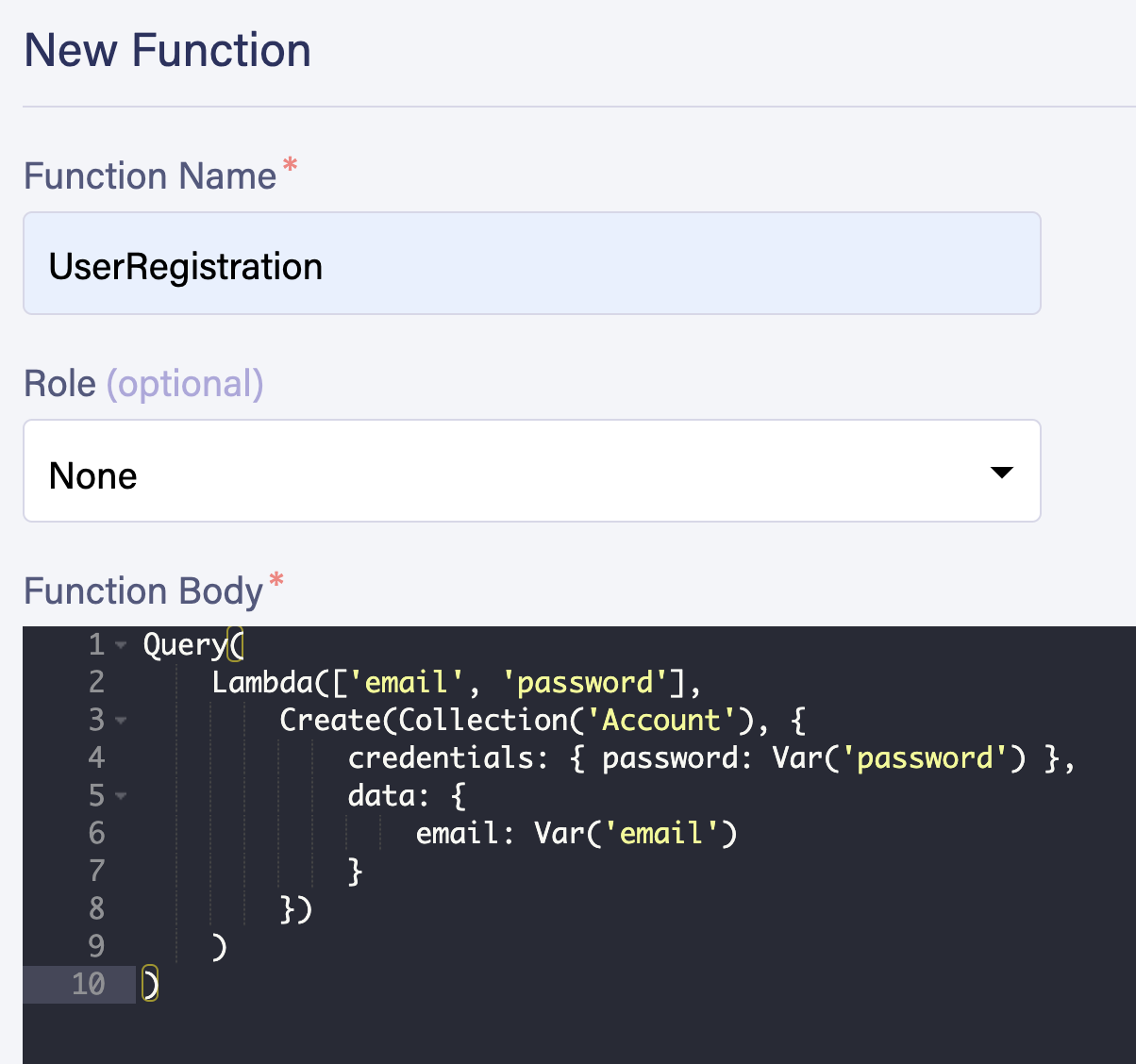
Navigate to the *Shell* and register a new user by calling the `UserRegistration` UDF. Enter the following code in the shell and select *Run Query*.
```jsx
Call("UserRegistration", "shadid@test.com", "pass123456")
```

Navigate back to *Collections > Account* and confirm that a new user is created.
## User login
Return to the Functions tab, create a new function, and name it `UserLogin`. Add the following code snippet to your function body and select Save. Notice there is a `ttl` argument in the `Login` function. This ensures that the generated token expires after the specified time.
```jsx
Query(
Lambda(["email", "password"],
Login(
Match(Index("account_by_email"), Var("email")),
{
password: Var("password"),
ttl: TimeAdd(Now(), 3600, "seconds")
},
)
)
)
```
Navigate back to the shell and call the function with the user's credentials.
```jsx
Call("UserLogin", "shadid@test.com", "pass123456")
```
The output of this function gives you a secret token. Following is a sample response from the UDF. Take a note of the secret.
```jsx
{
ref: Ref(Ref("tokens"), "310382039289299523"),
ts: 1632262229150000,
ttl: Time("2021-09-21T22:20:29.019666Z"),
instance: Ref(Collection("Account"), "310358409884992069"),
secret: "fnEE....."
}
```
You can now use this secret token to access your Fauna resources from a client application. Verify the validity of the token by running the following `CURL` command in your terminal, replacing `<YOUR_TOKEN>` with the value of the secret your function returns.
```bash
curl https://db.fauna.com/tokens/self -u <YOUR_TOKEN>
```
```bash
{
"resource": {
"ref": {
"@ref": {
"id": "310382039289299523",
"class": { "@ref": { "id": "tokens" } }
}
},
"ts": 1632262229150000,
"ttl": { "@ts": "2021-09-21T22:20:29.019666Z" },
"instance": {
"@ref": {
"id": "310358409884992069",
"class": {
"@ref": {
"id": "Account",
"class": { "@ref": { "id": "classes" } }
}
}
}
},
"hashed_secret": "$2a$05$Ta2ScWEQhV39VTKLmmXXXOxnpQlXvloLSd3g9nP2Gsb.zJMP6QK6y"
}
}
```
Next, navigate to Collections and create a new collection called `Movie`. Populate your collection with the following sample data.
```json
{
"title": "Reservoir Dogs",
"director": "Quentin Tarantino",
"release": "Jan 21, 1992"
}
{
"title": "The Hateful Eight",
"director": "Quentin Tarantino",
"release": "December 25, 2015"
}
{
"title": "Once Upon a Time in Hollywood",
"director": "Quentin Tarantino",
"release": "July 26, 2019"
}
```
You will query this collection with the authenticated user's token in the next section.
## Connecting Fauna with the client application
Your client application should have limited access to your Fauna backend. An unauthenticated user should only be able to call `UserLogin` and `UserRegistration` functions from your client application. It is best practice to follow the [principle of least privilege](https://en.wikipedia.org/wiki/Principle_of_least_privilege) .
Create a new role for your unauthenticated users. Navigate to *Security > Roles* and select *New Custom Role*.
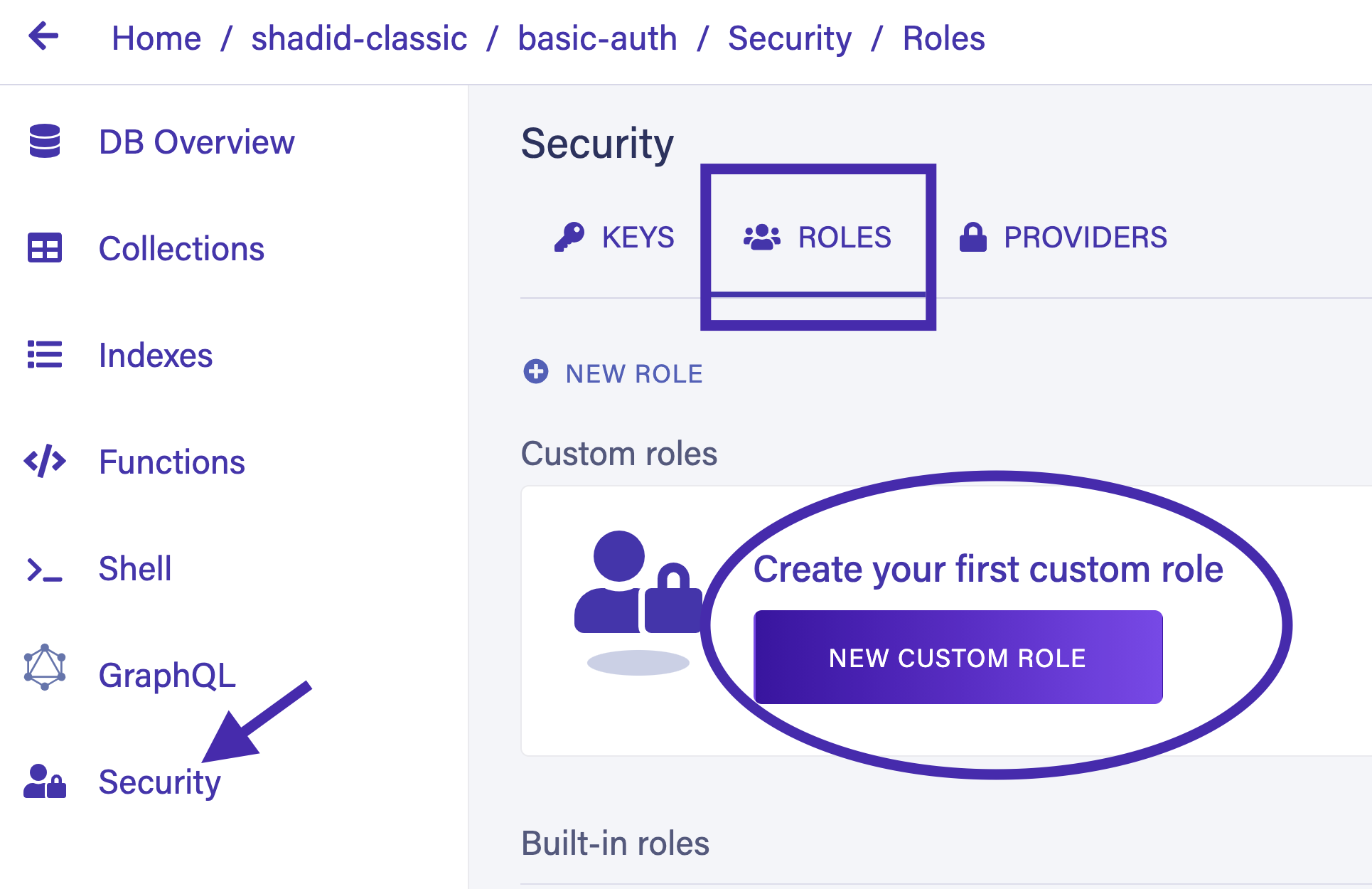
Name your role `UnAuthRole`. Give the privilege to execute `UserLogin` and `UserRegistration`. As your functions are using the `account_by_email` index, provide read access to `account_by_email` as well. Also, provide read and create access to Account collection because `UserLogin` and `UserRegistration` UDFs need to read and create permission to this collection.
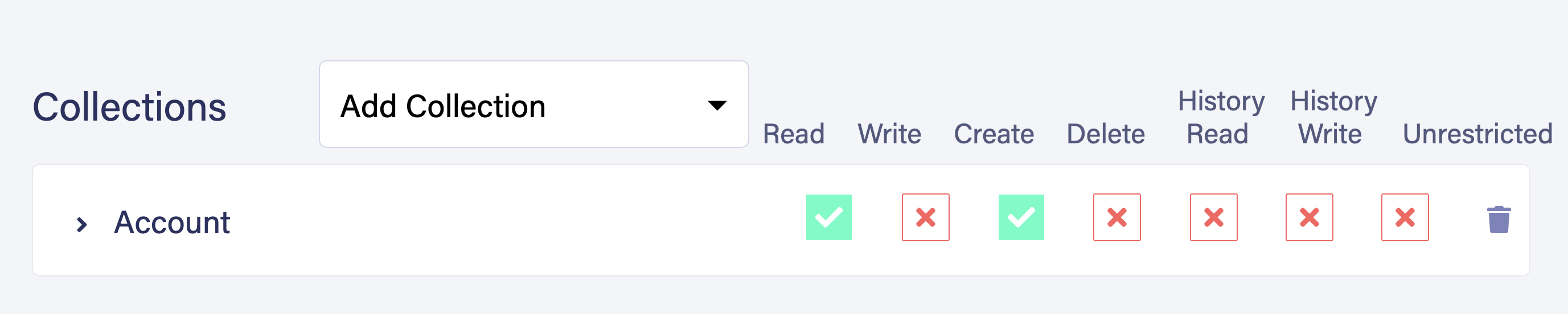
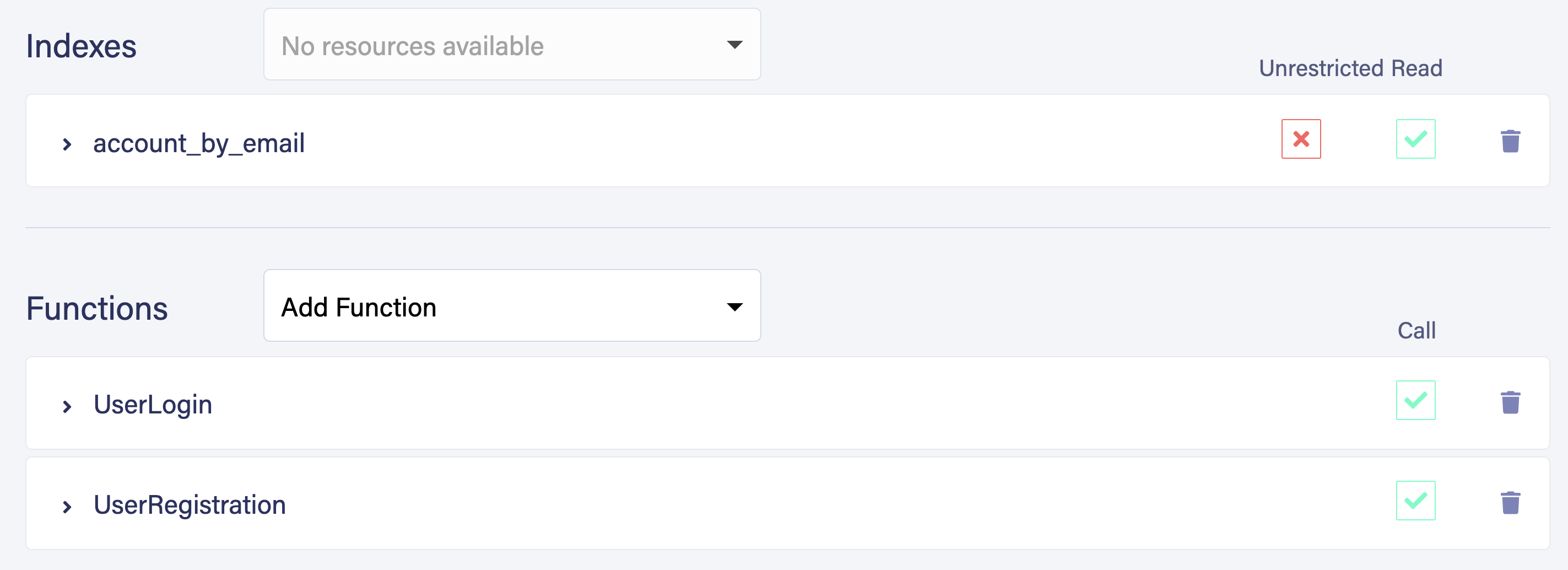
Next, generate a security key for your `UnAuthRole`. Navigate to *Security > Keys > New Ke*y.
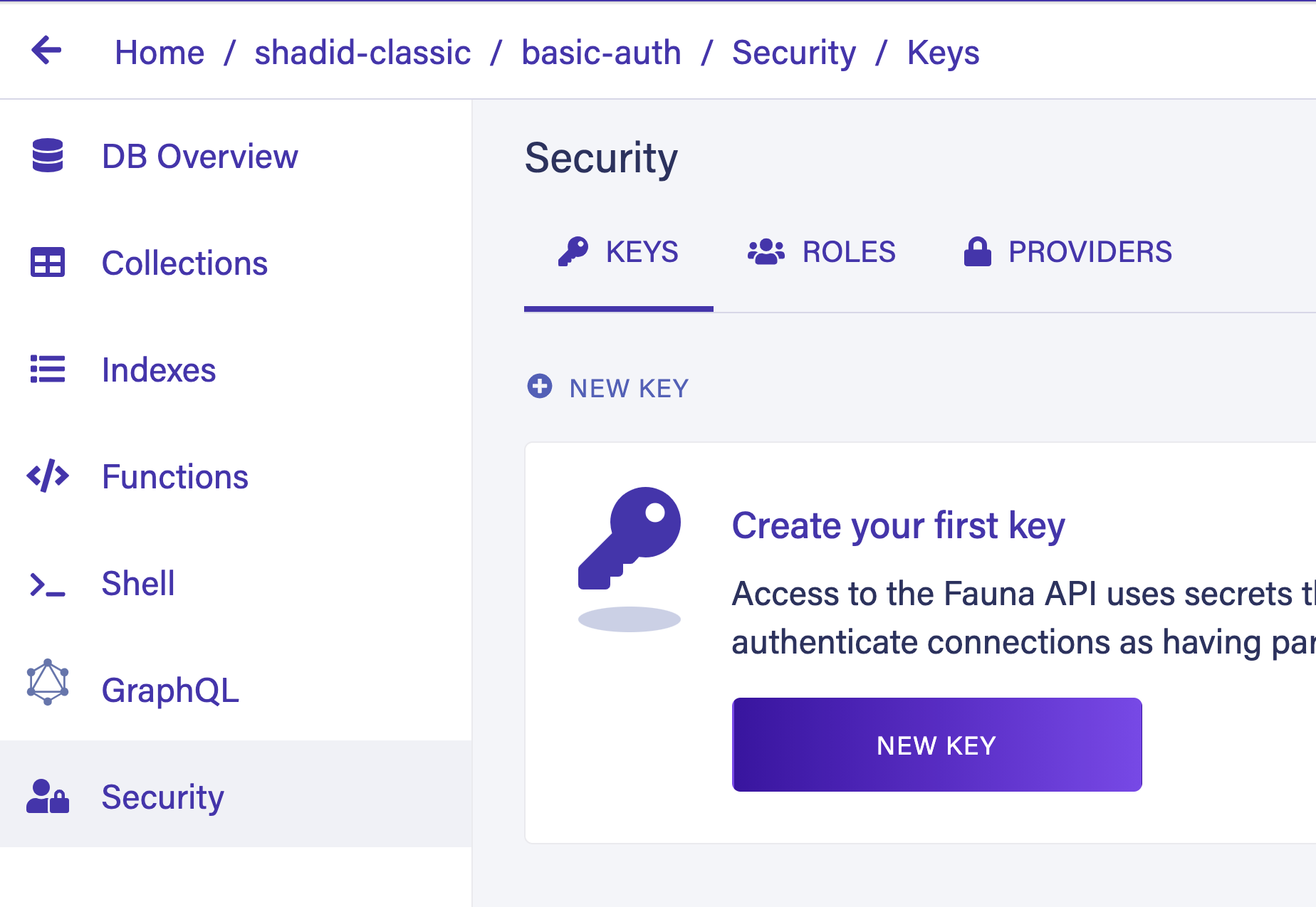
Make sure to select `UnAuthRole` from the role options for your new key.
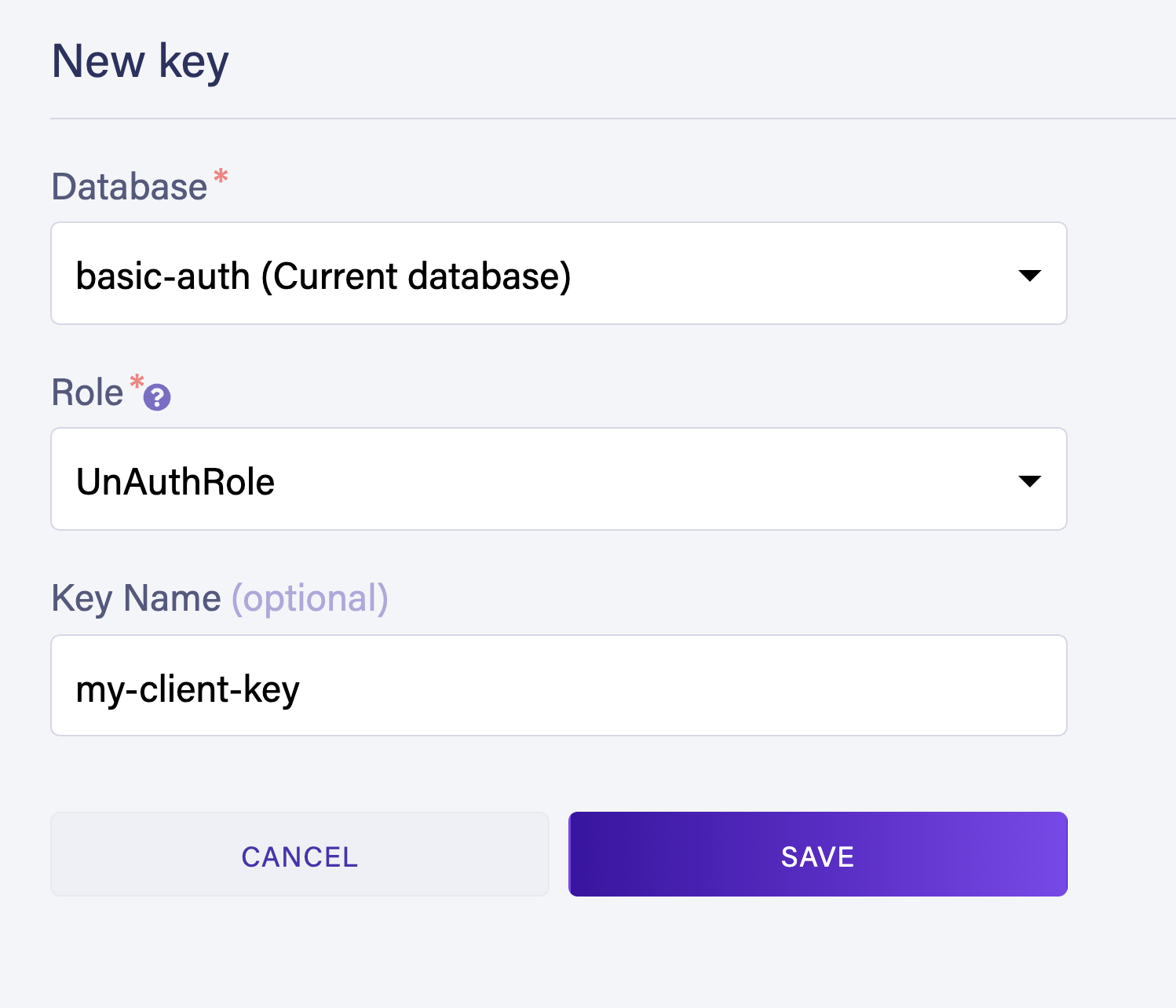
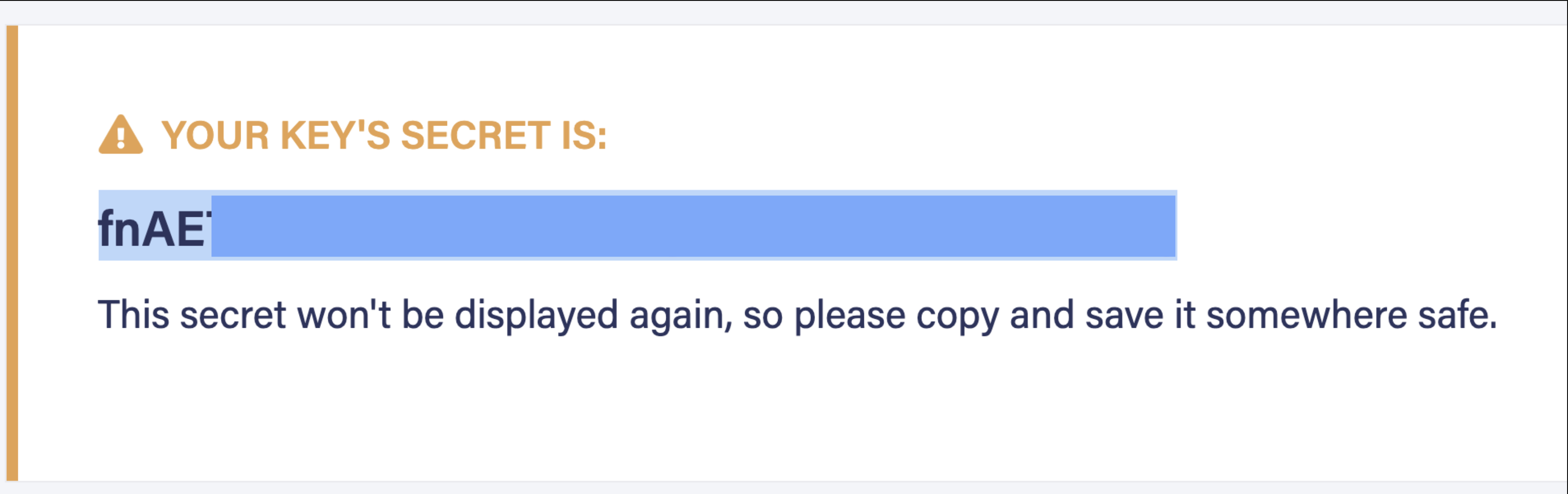
You ship this key as an environment variable in your client application. Your client application can use this key to call only the `UserRegistration` and `UserLogin` function. You can not access any other resources in Fauna with this key.
To test this navigate to the *Shell* from the Fauna dashboard and select Run *Query As > Specify a Secret* Option. In the secret field input your key.
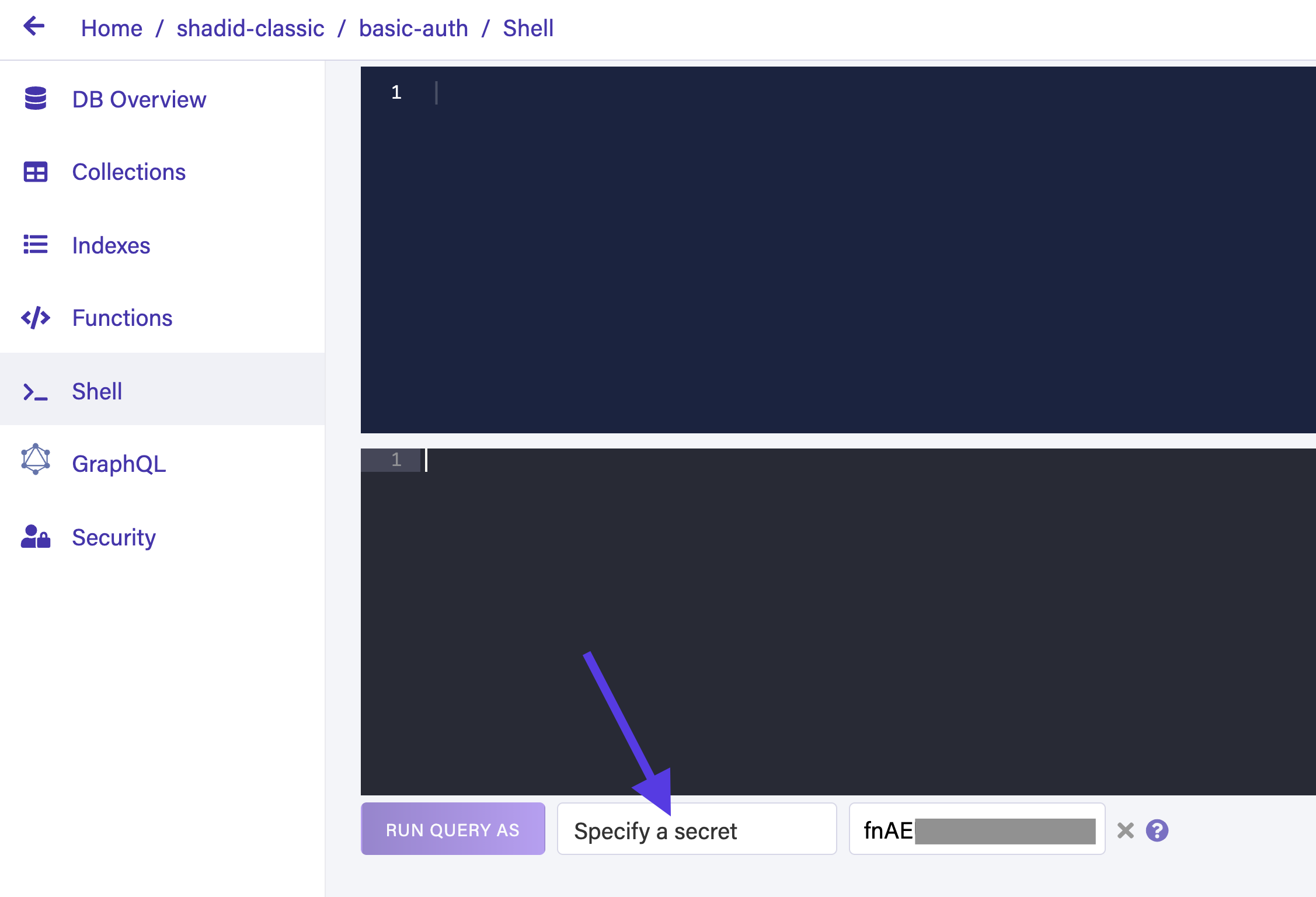
Run the following command in the shell.
```jsx
Call("UserRegistration", "john@gmail.com", "pass12345"")
```
```jsx
Call("UserRegistration", "john@gmail.com", "pass12345")
{
ref: Ref(Collection("Account"), "311012249060770373"),
ts: 1632863244095000,
data: {
email: "john@gmail.com"
}
}
```
Notice, that this will register a new user. Try accessing any other resources (i.e. Movie collection) using the same key. Run the following command in the shell.
```jsx
Get(Documents(Collection("Movie")))
```
```jsx
// Output
Error: [
{
"position": [],
"code": "permission denied",
"description": "Insufficient privileges to perform the action."
}
]
```
Review the output in the shell. You get an `"Insufficient privileges to perform the action."` error. It throws this error because the specified key doesn’t have the privilege to access the `Movie` collection. This means the key is working as intended.
Next, run the `UserLogin` function in the shell.
```jsx
Call("UserLogin", "john@gmail.com", "pass12345")
```
Review the output. The function returned a secret.
```jsx
{
ref: Ref(Ref("tokens"), "311013644284461635"),
ts: 1632864574726000,
ttl: Time("2021-09-28T21:39:34.245802Z"),
instance: Ref(Collection("Account"), "311012249060770373"),
secret: "fnEEUPFC--ACQwROmU7CwAZDlUcF9R3liL1iaNf9y80UQgc_qLI"
}
```
This secret is your temporary *access token* that can access other resources in Fauna. However, when you try to use it now to access the `Movie` collection you get the same error. This is because you have not yet defined what resources does this *token* has access to*.* In the next section, you learn how to give your user access tokens permission to certain resources.
### Authenticated user role
Navigate to *Security > Roles > New Role* to Create a new user role. Name your role `AuthRole` and provide `read`, `write`, and `create` privileges on the `Movie` collection.
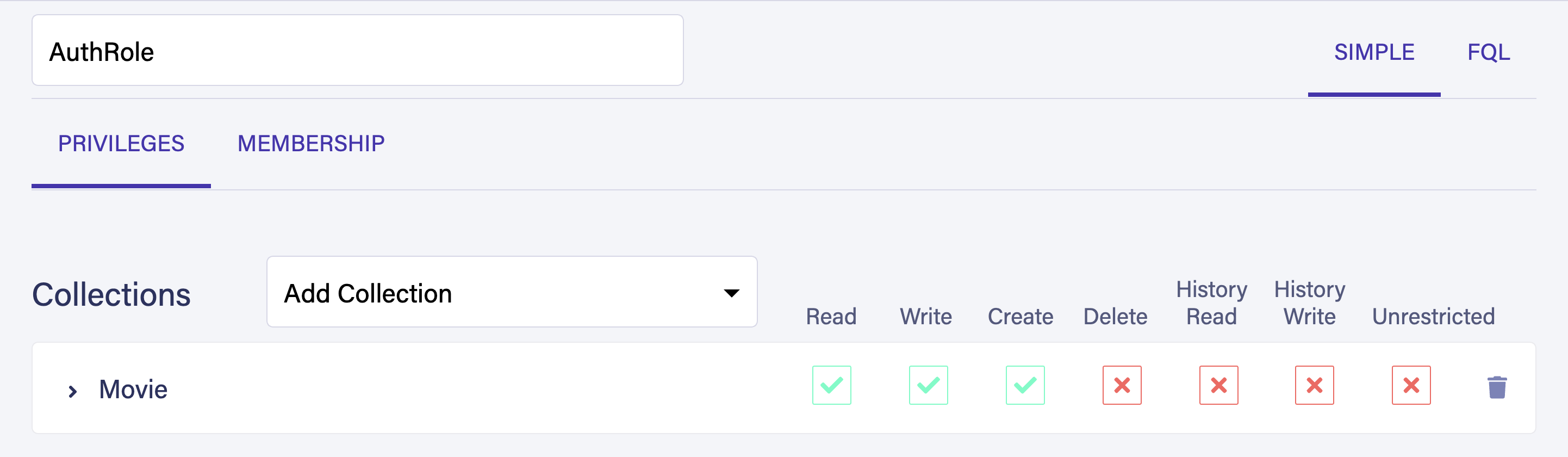
Select the Membership tab and add the Account collection as a member.

Run the `UserLogin` function again with the same credentials. Input the generated *secret* (user *access token*) next to the Specify a secret field in the shell.

Run the following command to query `Movie` collection. Notice this time it returns a successful response.
```jsx
Get(Documents(Collection("Movie")))
```
```jsx
// Output
{
ref: Ref(Collection("Movie"), "310384575062737476"),
ts: 1632264647455000,
data: {
title: "The Hateful Eight",
director: "Quentin Tarantino",
release: "December 25, 2015"
}
}
```
## User logout
Navigate to the function section of your Fauna dashboard. Define a new UDF called `UserLogout` and add the following code snippet in the function body.
```jsx
Query(
Lambda("x", Logout(true))
)
```
Make sure to assign AuthRole to UserLogout UDF.
Navigate to *Security > Roles > AuthRole* and assign call privilege to UserLogout UDF.

Calling this UDF invalidates your secret token. You call this function with the following command.
```jsx
Call("UserLogout")
```
## Conclusion
In this post, you learn how to use UDF to do user authentication in Fauna. For more about advanced Authentication strategies (i.e., Token refresh) in Fauna, review [this post](https://fauna.com/blog/refreshing-authentication-tokens-in-fql). If you are interested in using third-party identity providers with Fauna, take a look at the [Fauna and Auth0](https://auth0.com/blog/what-is-fauna-and-how-does-it-work-with-auth0/) integration post. Want to use AWS Cognito as an auth provider with Fauna? Take a look at the [AWS Cognito and Fauna](https://fauna.com/blog/authenticating-users-with-aws-cognito-in-fauna) article.
If you enjoyed this article and want to see more articles like this one, let us know in the [community forum](https://forums.fauna.com/).
| shadid12 |
853,440 | build up a documentation site from markdown files | Finally done for this stage. Now I can keep one copy of document in markdown format for github, web... | 0 | 2021-10-06T09:56:41 | https://dev.to/casualwriter/a-simple-html-page-to-build-up-a-documentation-site-from-markdown-file-3d0j | javascript, html, markdown, document | Finally done for this stage. Now I can keep one copy of document in markdown format for github, web documents and local documentation.
Just a simple [index.html](https://github.com/casualwriter/powerpage-document/blob/main/index.html) page, to build up a documentation site from markdown files.
Simply copy the following file to web server, then everything is DONE!.
layout of [Documentation Site](https://pingshan-tech.com/powerpage/doc)
[index.html](https://github.com/casualwriter/powerpage-document/blob/main/index.html) is a simple document framework for showing markdown files with auto-TOC navigation. It is a single html page in **pure javascript without dependence**.
The program also include a **simple markdown parser** (55 lines js code) and a simple TOC (table-of-content) in pure javascript.
a little rush, kindly advise,
have a nice day,
-------------
* github [powerpage-document](https://github.com/casualwriter/powerpage-document)
* source code : [index.html](https://github.com/casualwriter/powerpage-document/blob/main/index.html)
* sample site: [Powerpage Documentation](https://pingshan-tech.com/powerpage/doc)
* document of [supported markdown syntax](https://pingshan-tech.com/powerpage/doc/?file=pp-document.md)
| casualwriter |
853,694 | 🚀 The Missing Docker Crash Course for Developers | Introduction to Docker It is more likely than not that Docker and containers are going... | 0 | 2021-10-06T11:41:14 | https://devdojo.com/bobbyiliev/the-missing-docker-crash-course-for-developers | docker, devops, linux, 100daysofcode | # Introduction to Docker
---
It is more likely than not that **Docker** and containers are going to be part of your IT career in one way or another.
In this blog post series I'll cover the following:
* What are Docker images, containers and Docker Hub
* Installing Docker on Ubuntu Linux on a DigitalOcean Droplet
* Working with Docker containers
* Working with Docker images
* Deploying a Dockerized app
I'll be using **DigitalOcean** for all of the demos, so I would strongly encourage you to create a **DigitalOcean** account follow along. You would learn more by doing!
To make things even better you can use my referral link to get a free $100 credit that you could use to deploy your virtual machines and test the guide yourself on a few **DigitalOcean servers**:
**[DigitalOcean $100 Free Credit](https://m.do.co/c/2a9bba940f39)**
Once you have your account here's how to deploy your first Droplet/server:
[https://www.digitalocean.com/docs/droplets/how-to/create/](https://www.digitalocean.com/docs/droplets/how-to/create/)
I'll be using **Ubuntu 18.04** so I would recommend that you stick to the same so you could follow along.
* * *
## What is a container?
According to the official definition from the [docker.com](docker.com) website, a container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another. A Docker container image is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries, and settings.
Container images become containers at runtime and in the case of Docker containers - images become containers when they run on Docker Engine. Available for both Linux and Windows-based applications, containerized software will always run the same, regardless of the infrastructure. Containers isolate software from its environment and ensure that it works uniformly despite differences for instance between development and staging.
* * *
## What is a Docker image?
A **Docker Image** is just a template used to build a running Docker Container, similar to the ISO files and Virtual Machines. The containers are essentially the running instance of an image. Images are used to share a containerized applications. Collections of images are stored in registries like [DockerHub](https://hub.docker.com/) or private registries.
* * *
## What is Docker Hub?
DockerHub is the default **Docker image registry** where we can store our **Docker images**. You can think of it as GitHub for Git projects.
Here's a link to the Docker Hub:
[https://hub.docker.com](https://hub.docker.com)
You can sign up for a free account. That way you could push your Docker images from your local machine to DockerHub.
* * *
# Installing Docker
Nowadays you can run Docker on Windows, Mac and of course Linux. I will only be going through the Docker installation for Linux as this is my operating system of choice.
I'll deploy an **Ubuntu VM on DigitalOcean** so feel free to go ahead and do the same:
[Create a Droplet DigitalOcean](https://docs.digitalocean.com/products/droplets/how-to/create)
Once your server is up and running, SSH to the Droplet and follow along!
If you are not sure how to SSH, you can follow the steps here:
[https://www.digitalocean.com/docs/droplets/how-to/connect-with-ssh/](https://www.digitalocean.com/docs/droplets/how-to/connect-with-ssh/)
The installation is really straight forward, you could just run the following command, it should work on all major **Linux** distros:
```
wget -qO- https://get.docker.com | sh
```
It would do everything that's needed to install **Docker on your Linux machine**.
After that, set up Docker so that you could run it as a non-root user with the following command:
```
sudo usermod -aG docker ${USER}
```
To test **Docker** run the following:
```
docker version
```
To get some more information about your Docker Engine, you can run the following command:
```
docker info
```
With the `docker info` command, we can see how many running containers that we've got and some server information.
The output that you would get from the docker version command should look something like this:
In case you would like to install Docker on your Windows PC or on your Mac, you could visit the official Docker documentation here:
[https://docs.docker.com/docker-for-windows/install/](https://docs.docker.com/docker-for-windows/install/)
And:
[https://docs.docker.com/docker-for-mac/install/](https://docs.docker.com/docker-for-mac/install/)
* * *
That is pretty much it! Now you have Docker running on your machine!
Now we are ready to start working with containers! We will pull a **Docker image** from the **DockerHub**, we will run a container, stop it, destroy it and more!
# Working with Docker containers
Once you have your **Ubuntu Droplet** ready, ssh to the server and follow along!
So let's run our first Docker container! To do that you just need to run the following command:
```
docker run hello-world
```
You will get the following output:
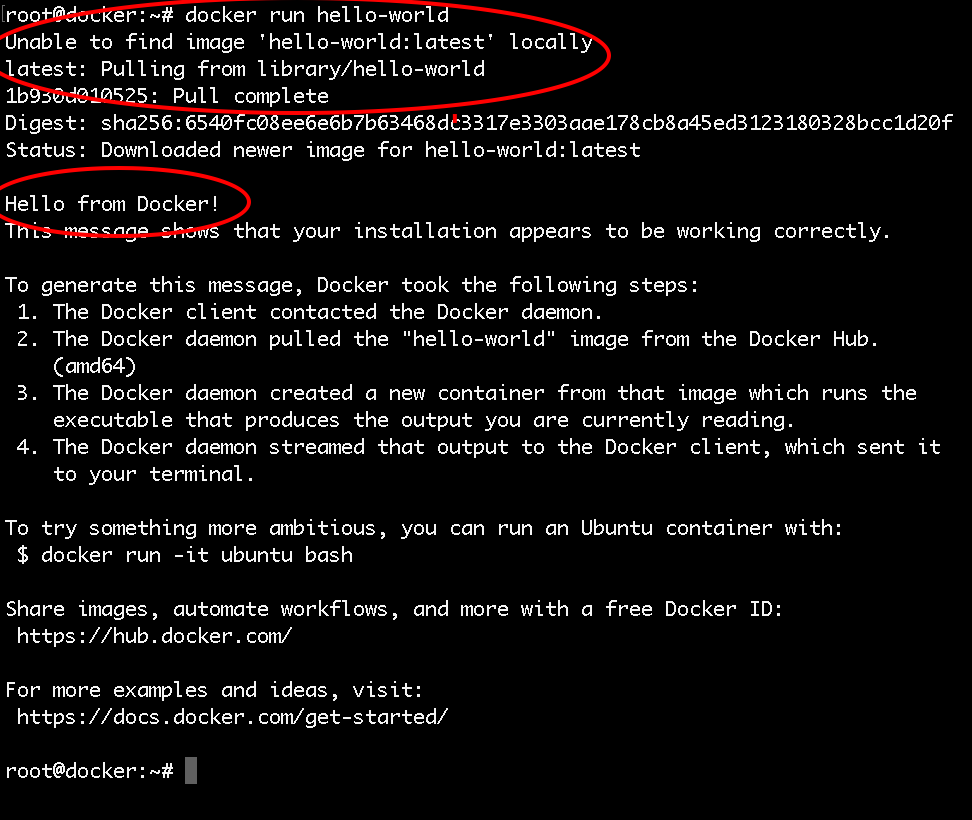
We just ran a container based on the **hello-world Docker Image**, as we did not have the image locally, docker pulled the image from the **[DockerHub](https://hub.docker.com)** and then used that image to run the container.
All that happened was: the **container ran**, printed some text on the screen and then exited.
Then to see some information about the running and the stopped containers run:
```
docker ps -a
```
You will see the following information for your **hello-world container** that you just ran:
```
root@docker:~# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
62d360207d08 hello-world "/hello" 5 minutes ago Exited (0) 5 minutes ago focused_cartwright
```
In order to list the locally available Docker images on your host run the following command:
```
docker images
```
* * *
## Pulling an image from Docker Hub
Let's run a more useful container like an **Apache** container for example.
First, we can pull the image from the docker hub with the **docker pull command**:
```
docker pull webdevops/php-apache
```
You will see the following output:
Then we can get the image ID with the docker images command:
```
docker images
```
The output would look like this:

> Note, you do not necessarily need to pull the image, this is just for demo pourpouses. When running the `docker run` command, if the image is not available locally, it will automatically be pulled from Docker Hub.
After that we can use the **docker run** command to spin up a new container:
```
docker run -d -p 80:80 IMAGE_ID
```
Quick rundown of the arguments that I've used:
* `-d`: it specifies that I want to run the container in the background. That way when you close your terminal the container would remain running.
* `-p 80:80`: this means that the traffic from the host on port 80 would be forwarded to the container. That way you could access the Apache instance which is running inside your docker container directly via your browser.
The output of the above command would look like this:

With the docker info command now we can see that we have 1 running container.
And with the `docker ps` command we could see some useful information about the container like the container ID, when the container was started and etc.:
```
root@docker:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7dd1d512b50e fd4f7e58ef4b "/entrypoint supervi…" About a minute ago Up About a minute 443/tcp, 0.0.0.0:80->80/tcp, 9000/tcp pedantic_murdock
```
* * *
## Stopping and restarting a Docker Container
Then you can stop the running container with the docker stop command followed by the container ID:
```
docker stop CONTAINER_ID
```
If you need to you can start the container again:
```
docker start CONTAINER_ID
```
In order to restart the container you can use the following:
```
docker restart CONTAINER_ID
```
* * *
## Accessing a running container
If you need to attach to the container and run some commands inside the container use the `docker exec` command:
```
docker exec -it CONTAINER_ID /bin/bash
```
That way you will get to a **bash shell** in the container and execute some commands inside the container itself.
Then to detach from the interactive shell press `CTRL+PQ` that way you will not stop the container but just detached from the interactive shell.
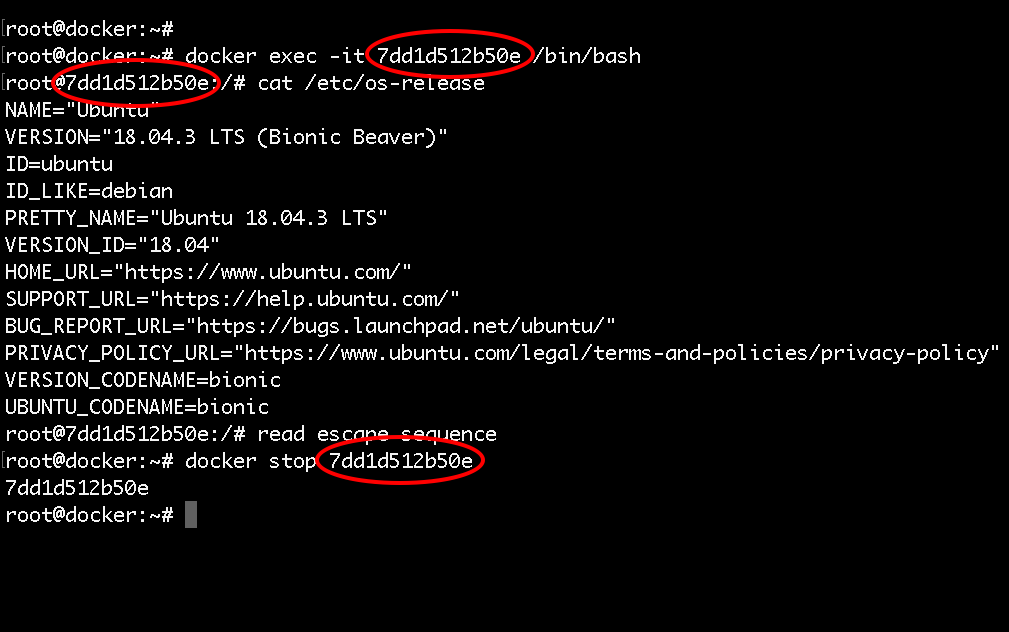
* * *
## Deleting a container
To delete the container run first make sure that the container is not running and then run:
```
docker rm CONTAINER_ID
```
If you would like to delete the container and the image all together, just run:
```
docker rmi IMAGE_ID
```
* * *
With that you now know how to pull Docker images from the **Docker Hub**, run, stop, start and even attach to Docker containers!
We are ready to learn how to work with **Docker images!**
# What are Docker Images
A Docker Image is just a template used to build a running Docker Container, similar to the ISO files and Virtual Machines. The containers are essentially the running instance of an image. Images are used to share a containerized applications. Collections of images are stored in registries like DockerHub or private registries.
* * *
## Working with Docker images
The `docker run` command downloads and runs images at the same time. But we could also only download images if we wanted to wit the docker pull command. For example:
```
docker pull ubuntu
```
Or if you want to get a specific version you could also do that with:
```
docker pull ubuntu:14.04
```
Then to list all of your images use the docker images command:
```
docker images
```
You would get a similar output to:
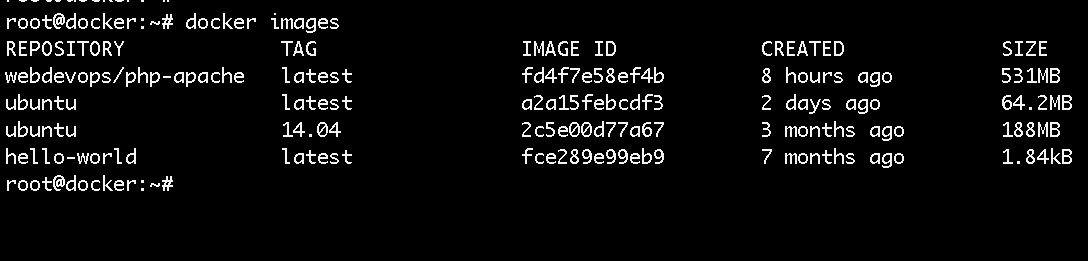
The images are stored locally on your docker host machine.
To take a look a the docker hub, go to: [https://hub.docker.com](https://hub.docker.com) and you would be able to see where the images were just downloaded from.
For example, here's a link to the **Ubuntu image** that we've just downloaded:
[https://hub.docker.com/\_/ubuntu](https://hub.docker.com/_/ubuntu)
There you could find some useful information.
As Ubuntu 14.04 is really outdated, to delete the image use the `docker rmi` command:
```
docker rmi ubuntu:14.04
```
* * *
## Modifying images ad-hoc
One of the ways of modifying images is with ad-hoc commands. For example just start your ubuntu container.
```
docker run -d -p 80:80 IMAGE_ID
```
After that to attach to your running container you can run:
```
docker exec -it container_name /bin/bash
```
Install whatever packages needed then exit the container just press `CTRL+P+Q`.
To then save your changes run the following:
```
docker container commit ID_HERE
```
Then list your images and note your image ID:
```
docker images ls
```
The process would look as follows:
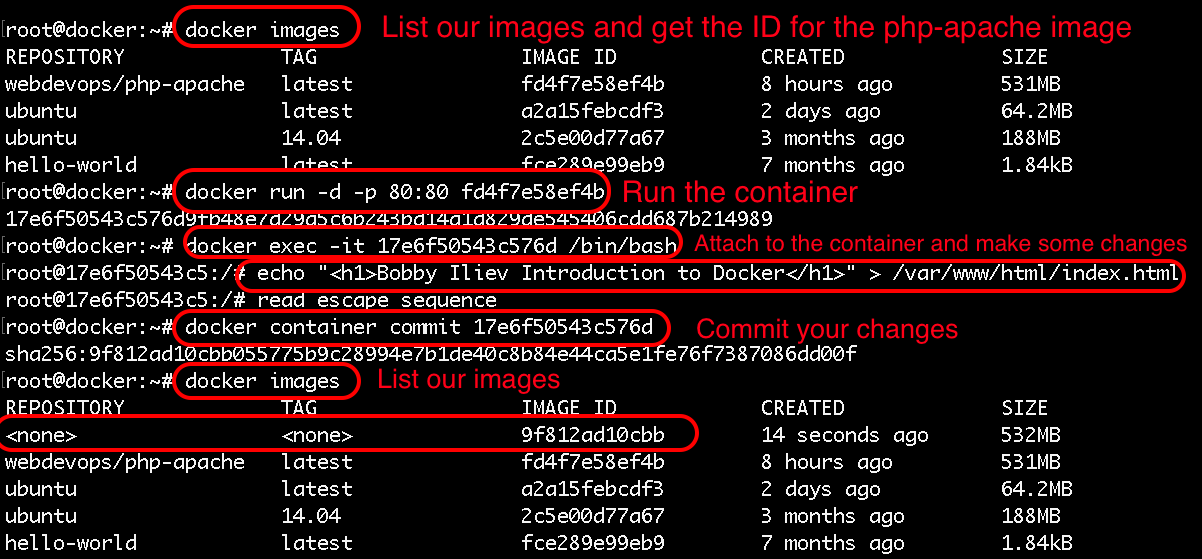
As you would notice your newly created image would not have a name nor a tag, so in order tag your image run:
```
docker tag IMAGE_ID YOUR_TAG
```
Now if you list your images you would see the following output:
* * *
## Pushing images to Docker Hub
Now that we have our new image locally, let's see how we could push that new image to DockerHub.
For that you would need a Docker Hub account first. Then once you have your account ready, in order to authenticate, run the following command:
```
docker login
```
Then push your image to the **Docker Hub**:
```
docker push your-docker-user/name-of-image-here
```
The output would look like this:
After that you should be able to see your docker image in your docker hub account, in my case it would be here:
[https://cloud.docker.com/repository/docker/bobbyiliev/php-apache](https://cloud.docker.com/repository/docker/bobbyiliev/php-apache)
* * *
## Modifying images with Dockerfile
We will go the Dockerfile a bit more in depth in the next blog post, for this demo we will only use a simple Dockerfile just as an example:
Create a file called `Dockerfile` and add the following content:
```
FROM alpine
RUN apk update
```
All that this `Dockerfile` does is to update the base Alpine image.
To build the image run:
```
docker image build -t alpine-updated:v0.1 .
```
Then you could again list your image and push the new image to the **Docker Hub**!
* * *
## Docker images Knowledge Check
Once you've read this post, make sure to test your knowledge with this Docker Images Quiz:
[https://quizapi.io/predefined-quizzes/common-docker-images-questions](https://quizapi.io/predefined-quizzes/common-docker-images-questions)
Now that you know how to pull, modify, and push **Docker images**, we are ready to learn more about the `Dockerfile` and how to use it!
# What is a Dockerfile
A **Dockerfile** is basically a text file that contains all of the required commands to build a certain **Docker image**.
The **Dockerfile** reference page:
[https://docs.docker.com/engine/reference/builder/](https://docs.docker.com/engine/reference/builder/)
It lists the various commands and format details for Dockerfiles.
* * *
## Dockerfile example
Here's a really basic example of how to create a `Dockerfile` and add our source code to an image.
First, I have a simple Hello world `index.html` file in my current directory that I would add to the container with the following content:
```
<h1>Hello World - Bobby Iliev</h1>
```
And I also have a Dockerfile with the following content:
```
FROM webdevops/php-apache-dev
MAINTAINER Bobby I.
COPY . /var/www/html
WORKDIR /var/www/html
EXPOSE 8080
```
Here is a screenshot of my current directory and the content of the files:
Here is a quick rundown of the Dockerfile:
* `FROM`: The image that we would use as a ground
* `MAINTAINER`: The person who would be maintaining the image
* `COPY`: Copy some files in the image
* `WORKDIR`: The directory where you want to run your commands on start
* `EXPOSE`: Specify a port that you would like to access the container on
* * *
## Docker build
Now in order to build a new image from our `Dockerfile`, we need to use the docker build command. The syntax of the docker build command is the following:
```
docker build [OPTIONS] PATH | URL | -
```
The exact command that we need to run is this one:
```
docker build -f Dockerfile -t your_user_name/php-apache-dev .
```
After the built is complete you can list your images with the docker images command and also run it:
```
docker run -d -p 8080:80 your_user_name/php-apache-dev
```
And again just like we did in the last step, we can go ahead and publish our image:
```
docker login
docker push your-docker-user/name-of-image-here
```
Then you will be able to see your new image in your Docker Hub account (https://hub.docker.com) you can pull from the hub directly:
```
docker pull your-docker-user/name-of-image-here
```
For more information on the docker build make sure to check out the official documentation here:
[https://docs.docker.com/engine/reference/commandline/build/](https://docs.docker.com/engine/reference/commandline/build/)
* * *
## Dockerfile Knowledge Check
Once you've read this post, make sure to test your knowledge with this [**Dockerfile quiz**:](https://quizapi.io/predefined-quizzes/basic-dockerfile-quiz)
[https://quizapi.io/predefined-quizzes/basic-dockerfile-quiz](https://quizapi.io/predefined-quizzes/basic-dockerfile-quiz)
* * *
This is a really basic example, you could go above and beyond with your Dockerfiles!
Now you know how to write a Dockerfile, how to build a new image from a Dockerfile using the docker build command!
In the next step we will learn how to set up and work with the **Docker Swarm** mode!
* * *
# What is Docker Swarm mode
According to the official **Docker** docs, a swarm is a group of machines that are running **Docker** and joined into a cluster. If you are running a **Docker swarm** your commands would be executed on a cluster by a swarm manager. The machines in a swarm can be physical or virtual. After joining a swarm, they are referred to as nodes. I would do a quick demo shortly on my **DigitalOcean** account!
The **Docker Swarm** consists of **manager nodes** and **worker nodes**.
The manager nodes dispatch tasks to the worker nodes and on the other side Worker nodes just execute those tasks. For High Availability, it is recommended to have **3** or **5** manager nodes.
* * *
## Docker Services
To deploy an application image when Docker Engine is in swarm mode, you have create a service. A service is a group of containers of the same `image:tag`. Services make it simple to scale your application.
In order to have **Docker services**, you must first have your **Docker swarm** and nodes ready.
* * *
## Building a Swarm
I'll do a really quick demo on how to build a **Docker swarm with 3 managers and 3 workers**.
For that I'm going to deploy 6 droplets on DigitalOcean:
Then once you've got that ready, **install docker** just as we did in the **[Introduction to Docker Part 1](https://devdojo.com/tutorials/introduction-to-docker-part-1)** and then just follow the steps here:
### Step 1
Initialize the docker swarm on your first manager node:
```
docker swarm init --advertise-addr your_dorplet_ip_here
```
### Step 2
Then to get the command that you need to join the rest of the managers simply run this:
```
docker swarm join-token manager
```
> Note: This would provide you with the exact command that you need to run on the rest of the swarm manager nodes. Example:
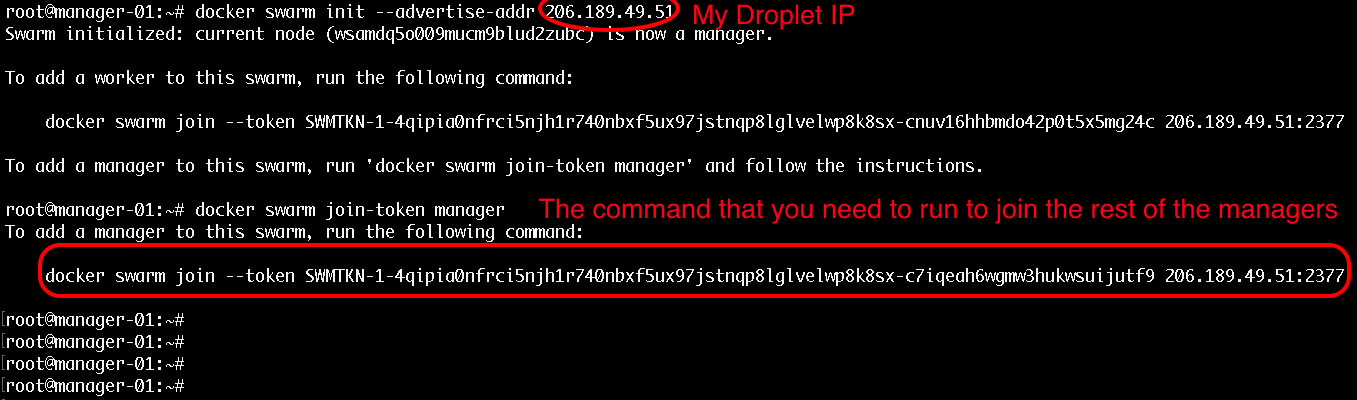
### Step 3
To get the command that you need for joining workers just run:
```
docker swarm join-token worker
```
The command for workers would be pretty similar to the command for join managers but the token would be a bit different.
The output that you would get when joining a manager would look like this:
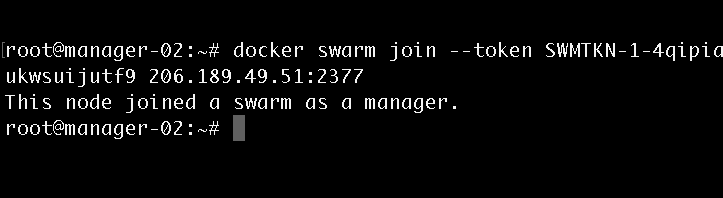
### Step 4
Then once you have your join commands, **ssh to the rest of your nodes and join them** as workers and managers accordingly.
* * *
# Managing the cluster
After you've run the join commands on all of your workers and managers, in order to get some information for your cluster status you could use these commands:
* To list all of the available nodes run:
```
docker node ls
```
> Note: This command can only be run from a **swarm manager**!Output:

* To get information for the current state run:
```
docker info
```
Output:
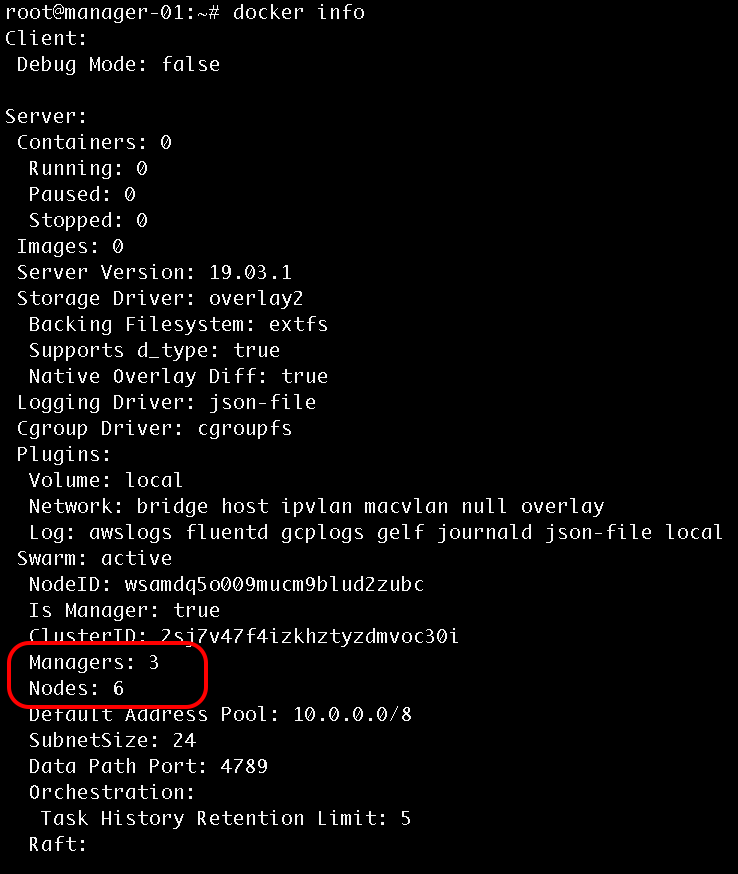
* * *
## Promote a worker to manager
To promote a worker to a manager run the following from **one** of your manager nodes:
```
docker node promote node_id_here
```
Also note that each manager also acts as a worker, so from your docker info output you should see 6 workers and 3 manager nodes.
* * *
## Using Services
In order to create a service you need to use the following command:
```
docker service create --name bobby-web -p 80:80 --replicas 5 bobbyiliev/php-apache
```
Note that I already have my bobbyiliev/php-apache image pushed to the Docker hub as described in the previous blog posts.
To get a list of your services run:
```
docker service ls
```
Output:
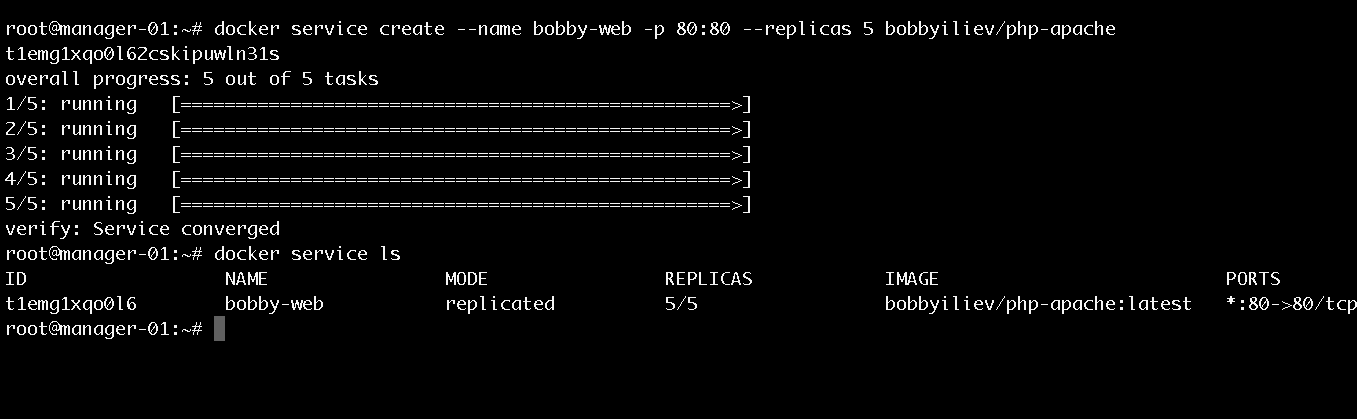
Then in order to get a list of the running containers you need to use the following command:
```
docker services ps name_of_your_service_here
```
Output:
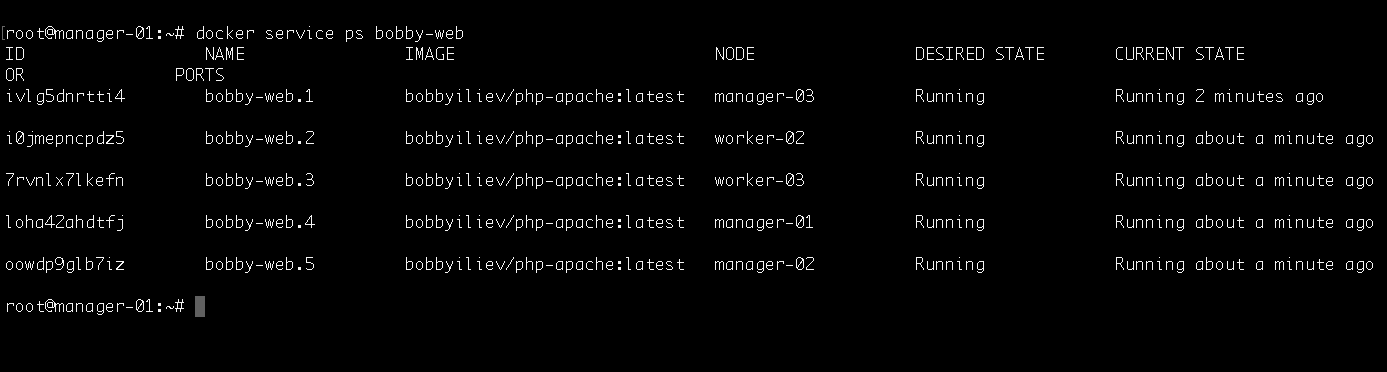
Then you can visit the IP address of any of your nodes and you should be able to see the service! We can basically visit any node from the swarm and we will still get the to service.
* * *
## Scaling a service
We could try shutting down one of the nodes and see how the swarm would automatically spin up a new process on another node so that it matches the desired state of 5 replicas.
To do that go to your **DigitalOcean** control panel and hit the power off button for one of your Droplets. Then head back to your terminal and run:
```
docker services ps name_of_your_service_here
```
Output:
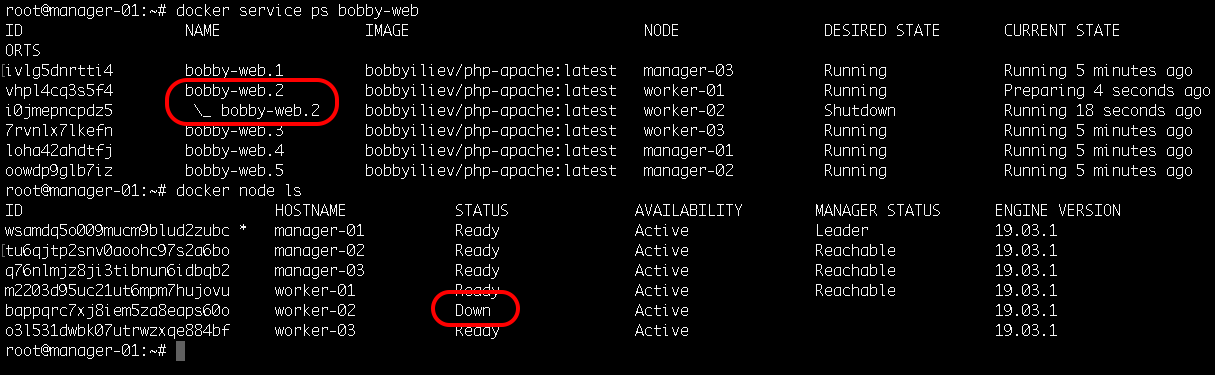
In the screenshot above, you can see how I've shutdown the droplet called worker-2 and how the replica bobby-web.2 was instantly started again on another node called worker-01 to match the desired state of 5 replicas.
To add more replicas run:
```
docker service scale name_of_your_service_here=7
```
Output:
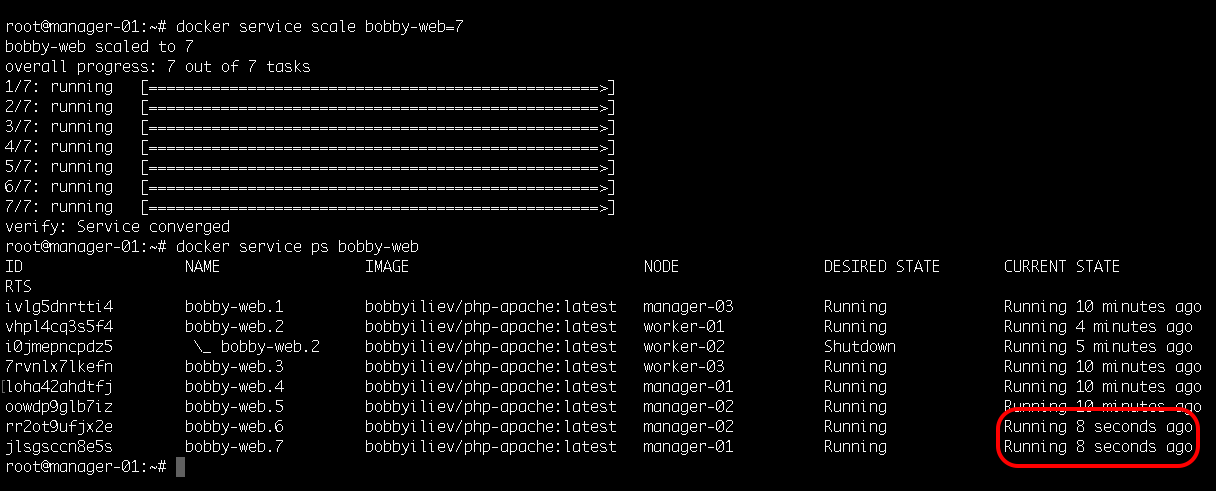
This would automatically spin up 2 more containers, you can check this with the docker service ps command:
```
docker service ps name_of_your_service_here
```
Then as a test try starting the node that we've shutdown and check if it picked up any tasks?
**Tip**: Bringing new nodes to the cluster does not automatically distribute running tasks.
* * *
## Deleting a service
In order to delete a service, all you need to do is to run the following command:
```
docker service rm name_of_your_service
```
Output:
Now you know how to initialize and scale a docker swarm cluster! For more information make sure to go through the official Docker documentation [here](https://docs.docker.com/engine/swarm/).
* * *
## Docker Swarm Knowledge Check
Once you've read this post, make sure to test your knowledge with this **[Docker Swarm Quiz](https://quizapi.io/predefined-quizzes/common-docker-swarm-interview-questions)**:
[https://quizapi.io/predefined-quizzes/common-docker-swarm-interview-questions](https://quizapi.io/predefined-quizzes/common-docker-swarm-interview-questions)
* * *
# Conclusion
Well done for going through this Docker introduction tutorial! I hope that it was helpful and you've managed to learn some cool new things about **Docker**!
As a next step make sure to spin up a few servers, install Docker and play around with all of the commands that you've learnt from this tutorial!
Let me know if you have any questions or suggestions!
Follow me on twitter at: [@bobbyiliev_](https://twitter.com/bobbyiliev_) | bobbyiliev |
853,706 | The basics of Azure Function Apps | If you learned something new feel free to connect with me on linkedin or follow me on dev.to :) In... | 0 | 2021-10-06T13:00:01 | https://dev.to/albertbennett/the-basics-of-azure-function-apps-29ei | csharp, beginners, azure, tutorial | If you learned something new feel free to connect with me on [linkedin](https://www.linkedin.com/in/albert-bennett/) or follow me on dev.to :)
<br/>
In this post, I will be explaining to the best of my knowledge what a Function App is, and any tips tricks and issues that I have come across whilst using them. More specifically, when setting them up and publishing to them directly from Visual Studios.
<br/>
**Introduction**
Simply put, a Function App is a server-side application that is hosted in Azure. In it you create various different Functions.
Each function has a trigger type. A trigger type defines what/ how the function is going to be triggered. The most common type is HttpTrigger. When published to an Azure Function App the trigger becomes an endpoint that can be called.
<br/>
**The Setup**
Function Apps like most Azure resources are easy to set up. Simply search for them in the "marketplace", click "Create" and fill in the details.  A Function App is created inside of something called a resource group, this is a container for resources in Azure. It's important to make sure that the region of the resource group and the Function app are the same. This will help with performance as the resources will be closer together.
<br/>
- **Plan Type**
This setting is under **Hosting** Now there are two options for this field, consumption plan and app service plan. Consumption plan means that you only get charged per thousand calls as opposed to an app service plan which incurs a monthly fee.
There are benefits to using one over the other. Pricing being one but, Functions apps on a consumption plan have this thing called a cold start. Basically when the Function App has been left unused for so many minutes it gets turned off. So when the next request comes in it will take time to spin up the required resources. Function apps on an app service plan don't have this issue, unless their "always on" property is turned off.
<br/>
- **Application Insights**
This setting is under **Monitoring**. This is a service that is used to monitor your Azure Function App. It is a means of catching errors that are thrown, and enable you to debug the function app and see where it is failing.
<br/>
- **Storage Account**
This setting is under **Hosting**. This is the place where the code/ resources for the Azure Functions will be published to. You don't have to create a new one for each Function App. Instead try to have only one per resource group. It will help when trying to manage resources and make the clean up/ maintenance of your resource group easier.
<br/>
**Http Triggers**
```csharp
public static class Function1
{
[FunctionName("Function1")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
string name = req.Query["name"];
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();
dynamic data = JsonConvert.DeserializeObject(requestBody);
name = name ?? data?.name;
string responseMessage = string.IsNullOrEmpty(name)
? "This HTTP triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response."
: $"Hello, {name}. This HTTP triggered function executed successfully.";
return new OkObjectResult(responseMessage);
}
}
```
This is a sample of what the default Http trigger function looks like. This project called Azure Function App can be created as soon as you have the Azure Cli tools and Azure SDK installed.
- The "FunctionName" attribute defines the name of the function when published.
- "get", "post" refer to the http methods that a request can have to execute the function.
<br/>
**Authorization Levels**
Each http trigger has an "AuthorizationLevel". The "AuthorizationLevel" defines what can make calls/ access to it.
- Anonymous
- Function
- Admin
- User
- System
Before I go on to what each "AuthorizationLevel" is it is worth noting that with each Function App there are two sets of authentication keys. The host key and the function key. The host key and "_master" key is scoped at the function app level, meaning that there should only be one of each host key per function app (2 total). Whereas the function key is scoped on a function level, as such every function can have there own unique function key.
- Anonymous triggers can be called by any valid http request
- Function triggers can be called by any valid http request that passes on the function key as either a header or in the query parameters.
- Admin triggers can be called by any valid http request that passed the host key.
- User triggers can be called by any valid http request that has a valid bearer token.
- System triggers can be called by any valid http request that passes the master key.
<br/>
**Timer Trigger**
```csharp
[FunctionName("Function2")]
public static void Run([TimerTrigger("0 */5 * * * *")]TimerInfo myTimer, ILogger log)
{
log.LogInformation($"C# Timer trigger function executed at: {DateTime.Now}");
}
```
These are Functions that run on a timer. This timer is set up in the binding for the function. In our example the function is set to trigger once every 5 minutes. This type of timer is called a cron job. How this is configured is as follows:
| Minute | Hour | Day of the Month | Month | Day of the Week |
If you wanted the function to run every 5 seconds you could structure the cron job as:
```
*/5 * * * *
```
<br/>
**Bindings**
Bindings allows your functions to communicate with other Azure resources without you having to write the boiler plate code to get the connection set-up. I recently wrote a blog post about a binding that I had written for the Azure WebPubSub Service that you can find [here](https://dev.to/albertbennett/how-to-azure-pubsub-service-2ccb). The bindings for function apps come in all shapes and sizes so it is worth it to check out the C# documentation about a particular service before trying to write any code to integrate the services yourself.
<br/>
**The Extra Files**
With each azure function app that you create there are two extra files. local.settings.json, and host.json.
- The local.settings.json file defines the application settings and can be retrieved by using Environment.GetEnvironmentVariable. This file (by default) is not published to the function app. As such you can hold sensitive information in it without the risk of exposure. However you would need to add whatever application settings (connection strings, passwords) that you have to the configuration section of the function app in Azure:
 There is also a one-liner that you can add to the app settings if you wanted to retrieve a secret from key vault instead of storing the actual value of in the application settings of the function app:
```
@Microsoft.KeyVault(VaultName=vault name;SecretName=secret name in keyvault)
```
- The host.json file defines how the function app is to be hosted. There is normally not much in it. I've left an example of what a host file looks like below if you are curious:
```json
{
"version": "2.0",
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"excludedTypes": "Request"
}
}
}
}
```
<br/>
**Publishing Code from Visual Studios**
To publish you can find the publishing option under the "Build" tab in VS (Visual Studios). Select use existing, then click publish. Fill out the details and find your function app in the drop-down menu. Click "ok" and away you go. In a few minutes... the process can take a while...
Now, there are several gotchas when publishing directly from VS namely. The problem of locked files. These are files that are currently in use by the function and cannot be overwritten, which causes us problems.
To overcome this we are going to need to add an app setting when we are publishing to our function it is MSDEPLOY_RENAME_LOCKED_FILES with a value of 1:
 If that doesn't work, stop the function app in the portal then try to publish again. Then start it again.
<br/>
I hope that helps you understand the basics of function apps.
If you have any questions leave a comment and, I'll get back to you as soon as I can. | albertbennett |
853,711 | Online Video Interview Software For Hiring | Video recruiting software has increasingly become popular among businesses due to its ability to... | 0 | 2021-10-06T12:13:44 | https://dev.to/amymorris47/online-video-interview-software-for-hiring-4c0m | career, recruiter, recruiting | Video recruiting software has increasingly become popular among businesses due to its ability to bring recruitment automation into the recruitment process. It helps the hiring managers to connect with the worldwide talent from afar and makes hiring faster, automated, and convenient than ever before. Online video interviewing tools allows you to record interview questions once for all. And let the candidates record themselves answering the interview questions from wherever and whenever they want. Best of all, pre-recorded video interview brings recruitment automation to your HR team with modern and advanced digital technology and helps you hire the most suitable candidates for the position. Besides, integrating digital hiring solutions in your HR team helps you improve hiring efficiency and make your recruitment process comprehensive. Try a free demo now: https://www.jobma.com/
| amymorris47 |
853,798 | AzureFunBytes Reminder - Remote Possibilities with @burkeholland - 10/07/2021 | AzureFunBytes is a weekly opportunity to learn more about the fundamentals and foundations that make... | 0 | 2021-10-06T14:27:28 | https://dev.to/azure/azurefunbytes-reminder-remote-possibilities-with-burkeholland-10-07-2021-ipl | containers, vscode, development, beginners | AzureFunBytes is a weekly opportunity to learn more about the fundamentals and foundations that make up Azure. It's a chance for me to understand more about what people across the Azure organization do and how they do it. Every week we get together at 11 AM Pacific on [Microsoft LearnTV](https://cda.ms/226) and learn more about Azure.
When: October 7, 2021 11 AM Pacific / 2 PM Eastern
Where: [Microsoft LearnTV](https://cda.ms/226)

This week on AzureFunBytes we look at how using remote development containers can help produce greater reliability and speed to software builds. Containers are a unit of software that allows for packaging of all the resources and dependencies. They are lightweight and are meant to require less overhead than managing a whole server with an operating system requiring regular updates and security fixes.
Development containers help you focus on building code and in this software, providing a separate coding environment from your computer. This is ideal when ensuring reliability for all that may be collaborating on a single software development project.
### "Works on my machine"
If you're a developer, you've almost certainly said those words in your life. Environments are still one of the hardest things to setup and manage. In this stream, we'll take a in-depth look at how VS Code and GitHub are solving this problem and the myriad of ways that you can access, edit and run your code. Even if all you have is an iPad."
{% youtube AcLtAJfyLwk %}
To help me understand how this all comes together, I've invited Microsoft Principal Developer Advocate [Burke Holland](https://twitter.com/burkeholland) to join me. We've got a jam packed agenda including:
- Opening projects in VS Code
- GitHub integration
- Remote - Containers
- Codespaces
- github.dev
***About Burke Holland***
Burke Holland is a front-end developer living in Nashville, TN; the greatest city in the world according to science. He enjoys JavaScript a lot because it's the only way he Node to Express himself. Get it? Never mind. Burke blogs only slightly better than he codes and definitely not as good as he talks about himself in the third person. Burke works with the VS Code team at Microsoft. You can find him on Twitter as [@burkeholland](https:/twitter.com/burkeholland).
So be part on Thursday, October 7th at 11 AM PT / 2 PM ET on [LearnTV](https://cda.ms/226) with your questions!
------
Learn about Azure fundamentals with me!
Live stream is normally found on Twitch, YouTube, and [LearnTV](https://cda.ms/226) at 11 AM PT / 2 PM ET Thursday. You can also find the recordings here as well:
[AzureFunBytes on Twitch](https://twitch.tv/azurefunbytes)
[AzureFunBytes on YouTube](https://aka.ms/jaygordononyoutube)
[Azure DevOps YouTube Channel](https://www.youtube.com/channel/UC-ikyViYMM69joIAv7dlMsA)
[Follow AzureFunBytes on Twitter](https://twitter.com/azurefunbytes)
Useful Docs:
[Get $200 in free Azure Credit](https://cda.ms/219)
[Microsoft Learn: Introduction to Azure fundamentals](https://cda.ms/243)
[What is a container?](https://cda.ms/2PZ)
[Microsoft Learn: Administer containers in Azure](https://cda.ms/2Q0)
[Developing inside a Container](https://cda.ms/2Q1)
[Create a development container](https://cda.ms/2Q2)
[devcontainer command line interface](https://cda.ms/2Q3)
[VS Code Remote Development](https://cda.ms/2Q4)
[Microsoft Learn: Use a Docker container as a development environment with Visual Studio Code](https://aka.ms/RemoteContainers) | jaydestro |
853,815 | 10 HTML Tips and Tricks to help you | HTML has lots of useful elements and attributes that some people don't know about. Check out this... | 0 | 2021-10-06T15:39:43 | https://learnpine.com/blog/10-html-tips-and-tricks-to-help-you | webdev, beginners, html, programming | HTML has lots of useful elements and attributes that some people don't know about. Check out this list of tips and tricks that can help you achieve better results with HTML.
##1) Color Picker
Did you know you can create a nice color picker using only HTML?
Check it out:
```html
<input type="color" id="color-picker"
name="color-picker" value="#e66465">
<label for="color-picker">Pick a color</label>
```

##2) Progress bar
You can also create a progress bar using only HTML with the `progress` element. It can be used in order to show the progress of a task such as a file upload/download.
```html
<label for="file">File progress:</label>
<progress id="file" max="100" value="70"> 70% </progress>
```
##3) Meter tag
You can use the `meter` element to display measured data within a certain range with min/max/low/high values, such as temperature .
```html
<label for="fuel">Fuel level:</label>
<meter id="fuel"
min="0" max="100"
low="33" high="66" optimum="80"
value="50">
at 50/100
</meter>
```
##4) Input search
You can set an input's `type` attribute to `search` to create a search input field. The nice thing is it adds the "x" button that allows the user to quickly clear the field.
```html
<label for="site-search">Search the site:</label>
<input type="search" id="site-search" name="q"
aria-label="Search through site content">
<button>Search</button>
```
##5) Start attribute in ordered lists
You can use the `start` attribute to specify the start value of an ordered list.
```html
<ol start="79">
<li>Slowpoke</li>
<li>Slowbro</li>
<li>Magnemite</li>
<li>Magneton</li>
</ol>
```
##6) Responsive images
Use the `picture` tag to display different images according to the window size.
It's useful to make your website more responsive.
```html
<picture>
<source media="(min-width:1050px)" srcset="https://assets.pokemon.com/assets/cms2/img/pokedex/full/006.png">
<source media="(min-width:750px)" srcset="https://assets.pokemon.com/assets/cms2/img/pokedex/full/005.png">
<img src="https://assets.pokemon.com/assets/cms2/img/pokedex/full/004.png" alt="Charizard-evolutions" style="width:auto">
</picture>
```
##7) Highlight text
Use the `mark` tag to highlight text. The default color is yellow but you can change it by setting the background-color attribute to any other color you like.
```html
<p>Hi dev friend, this is a
<mark>highlighted text</mark>
made with love by simon paix </p>
```
##8) Interactive widget
You can use the `details` tag to create a native accordion that the user can open and close.
Tip: the `summary` element should be the first child of the `details` tag.
```html
<details>
<summary>Click to open </summary>
<p>Hi stranger! I'm the content hidden inside this accordion ;)</p>
</details>
```
##9) Native Input Suggestions
You can use the `datalist` element to display suggestions for an input element.
The input's `list` attribute must be equal to the `id` of the `datalist`.
```html
<label for="fighter">Pick your fighter</label>
<input list="fighters" name="fighter">
<datalist id="fighters">
<option value="Sub Zero">
<option value="Pikachu">
<option value="Mario">
<option value="Baraka">
</datalist>
```
##10) Open all links in a new tab
You can set the `base` element `target` attribute to blank so when the user clicks a link it always opens in a new tab. It is useful if you want to avoid users unintentionally leaving a certain page.
However, it includes links to your own domain. If you only want links to a different domain to open in a new tab, you must use JavaScript, instead.
```html
<head>
<base target="_blank">
</head>
<div>
All links will open in a new tab:
<a href="https://learnpine.com/">LearnPine</a>
</div>
```
## About me, let's connect! 👋👩💻
I'm an avid learner and I love sharing what I know. I teach coding live for free 👉 [here](https://learnpine.com "here") and I share coding tips on [my Twitter account](https://twitter.com/simonpaix) . If you want more tips, you can follow me 😁
| simonpaix |
853,851 | Writing my own minimal shell in C - Part 3(The parsing process leading to an execution tree) | The Parsing Process Let's try to put a mental model of how the entire command line string... | 0 | 2021-10-06T17:45:19 | https://dev.to/harshbanthiya/writing-my-own-minimal-shell-in-c-part-3-the-parsing-process-leading-to-an-execution-tree-42cj | c, beginners, programming | ## The Parsing Process
Let's try to put a mental model of how the entire command line string needs to be parsed and what are the various modules we might require along the way.
* Scanner -> Parser -> Executer -> Command
* Token_list -> Abstract Syntax Tree -> Convert to Execution Unit -> Execute-Execute
#### The Tentative Process:
1. Get the whole string until new line using read_line library.
2. Search the string from index 0 until '\0' for ('')
3. Divide string in tokens based on whitespace
* it can be any amount of whitespaces, abcd efgh or abcd efgh; They should both make two tokens.
* whitespace cannot be included in token characters except when there are double or single quotes.
** "hello world" is one token hello world
** "" hello world "" is two tokens hello and world; and the empty string before and after hello world will not be tokenized.
** "'hello world'" -- A single quote inside a double quote will be included in the token, so the result will be one token called 'hello world'; All the above rules apply to single quotes as well.
4. After dividing the tokens, if there is a token with a $ sign, whatever comes after the $ sign is compared with the list of all the env variables available and replaced with the value of the said variable.
** Important sub-point - In case of a string in single quote, even if there is a $ sign, it is not replaced with the value of the said env variable.
5. Environment variables are received using envp parameter from the main function and stored in a key value structure t_env and put in a linked list.
#### Converting stuff into an Abstract Syntax Tree.
1. A scanner will scan through the string and make a list of tokens based on the rules, we listed above.
2. A parser takes that list of tokens verifies the syntax (represents an error if there is a syntax error), and converts it into a tree structure.
Lets try to build the schematics top down:
----- Command line -----
Job ; command line ; job
(Identify command line (unparsed line) as either a formed job or a combination of jobs and unparsed command_lines)
----- Job ------
Command | job ; command
(Identify a job as a command or another job in a list)
----- Command ----
simple_command redirection list simple_command
(Identify a command as either a simple command or a redirection list )
----- Redirection List ----
redirection redirection_list
------ Redirection ------
filename < filename >> filename
----- Simple_Command -------
pathname token_list
------ Token_List --------
token token_list
For example:
cat > a > b < c should end up as:
```
command
/ \
simple cmd redirection
/ \
cat >
/ \
aaaa >
/ \
bbbb <
/
cccc
```
```
(hold)
/ \
cat >
/ \
aaaa >
/ \
bbbb <
/
cccc
```
```
(hold)
/ \
cat aaaa (type : NODE_REDIRECT_IN)
\
bbbb (type: NODE_REDIRECT_IN)
\
cccc (type: NODE_REDIRECT_OUT)
```
The tree could finally evaluate to Abstract Tree
```
aaaa (type : NODE_REDIRECT_IN)
/ \
cat bbbb (type: NODE_REDIRECT_IN)
\
cccc (type: NODE_REDIRECT_OUT)
```
**Let's breakdown the logic of the above command tree:**
We identify command as one of two structures:
1. Simple_command and redirection_list structures
2. Simple_command structure.
1. In case of simple command
First we check if it is simple_command
** We check the token_list with pathnames
** If it just one token we check once but it is a list we check each one.
2. In case of redirection list
** We check if it just one redirection or a list.
** We attach one case ( <, >, <<, >>) and attach the filename information, create a node and add it to the list.
| harshbanthiya |
853,858 | 淺談 Jamstack | 本文解釋本人對 Jamstack 與相關的技術名詞以及與傳統 CMS 架構的異同的理解。 我們從已經為人熟知的 CMS 開始說起。 CMS CMS(內容管理系統,content... | 0 | 2021-10-06T16:20:13 | https://editor.leonh.space/2020/jamstack/ | jamstack | 本文解釋本人對 Jamstack 與相關的技術名詞以及與傳統 CMS 架構的異同的理解。
我們從已經為人熟知的 CMS 開始說起。
## CMS
CMS(內容管理系統,content management system)就是一般認知的網站系統,所謂的「內容」泛指網頁本身、網頁內的欄位(標題、作者、內文、品名、金額、標籤、時間等等等等等)、網頁的階層關係、網頁的外觀與樣式,CMS 不是只用於描述形像類網站,也包含功能型網站,因為不論何種網站,都只是內容、外觀、業務邏輯上的差異,所以它們的管理系統一概以 CMS 泛稱之。
最知名的 CMS 就是那 WordPress,以數量龐大的外掛與佈景著稱,常用於架設 blog、形像、購物網站。WordPress 通常搭配 MySQL 一起工作,同時 WordPress 也管理了從資料庫、後端管理以及前端網頁的全部工作,而與之對比的就是 headless CMS。
## Headless CMS
Jamstack 的 J A M 分別代表 JavaScript、API、Markup,其實可以簡單的理解為前後端分離的架構,在 Jamstack 這種前後端業務分離下的 CMS,只專注於內容的管理,並透過 API 與前端溝通,CMS 並不涉及前端頁面的呈現,這種不管前端外觀的 CMS,我們稱為 **headless CMS**,就是沒頭沒臉的 CMS,只專注於內容的管理與資料的供應。
用 headless CMS 有幾項好處:
- 減少前後端的耦合程度,降低 CMS 系統的複雜度。
- 可以有多種前端,web、app 都可以,因為前端是透過 API 與 headless CMS 溝通,所以一個 CMS 可以供給多平台前端,滿足現今多元平台的市況。
- 易於橫向擴展,當單台 headless CMS 遇到性能滿載時可搭配雲端平台的機制動態擴展應付突發流量。
也有缺點:
- 開發人員必須熟悉至少兩套框架:headless CMS 與前端框架。
Headless CMS 以整體專案的角度來看系統的複雜度反而是變高的,有可能要分成兩組人作業,並且必須考慮到 API 的 schema 規格,反之在 WordPress 下幾乎完全不用考慮前後端資料拋接的事情(但有客製化外掛的話還是會碰到)。
## 為何前後端分離?
大前端時代已經是不可擋的趨勢,在前端框架大爆發的時代,幾乎都已經把能搬的業務邏輯都搬到前端去做,後端就專注於管理資料與提供 API 給前端用而已,而再往前追朔其實也就是因應 iPhone 帶起的行動 app 的趨勢,開發者為了能夠有統一的 API 供應多平台使用,傳統的統包型 CMS 逐漸被 Jamstack 風格的 headless CMS 所取代。
再回頭看 WordPress,雖然 WordPress 本身不是 headless CMS,但 WordPress 是有提供 API 的,所以想拿 WordPress 做為純後端其實是可行,但問題是 WordPress 自己的前後端高度耦合,難以拆分,所以喜歡 Jamstack 風格的開發者就不太喜歡拿 WordPress 做為後端系統使用。
相較於 WordPress,另外一套較年輕的 Ghost 也是知名的 CMS,Ghost 最初也是設計成全包型 CMS,在 Jamstack 興起後,或許是歷史包袱不像 WordPress 那麼重的關係,Ghost 逐漸把前後端的耦合度降低,目前 Ghost 也可以是 headless CMS,用戶可以自由選擇要用 Ghost 自己的前端框架或是其它的前端框架。
不論是 WordPres 或是 Ghost,它們都是需要搭配資料庫才能運作的系統,而資料庫系統本身也會佔用主機資源($$$),所以對於小規模專案的需求又有人發展出不用搭配資料庫的 CMS,這樣的 CMS 被稱為 flat-file CMS。
## Flat-file CMS
望文生義,所謂的 flat-file CMS 即用檔案當資料源的 CMS,相較於 WordPress、Ghost 必須搭配資料庫使用,flat-file CMS 的內容都是以檔案的形式存在於主機內,檔案格式通常會是 Markdown 或 JSON 或 HTML,當然這些檔案內的 schema 也是要經過適當定義的才能被 CMS 正確讀取。
其實 flat-file CMS 與 WordPress 相當類似,只有在資料儲存層上有差異。
一些 flat-file CMS 的特點:
- 資料以檔案方式儲存,不以資料庫儲存。
- 通常不會是 headless CMS,而是像 WordPress 那樣是前後端全包型的 CMS,因為檔案作為資料源不比資料庫,難以提供高效能的 API 服務(此點非絕對)。
- 雖然資料源是檔案,但最終前端頁面也是由檔案+模板動態產生的,所以雖然主機不用跑資料庫,但還是要跑 PHP 或其它語言程式。
## Headless CMS & flat-file CMS
綜合前文所述,flat-file CMS 的「flat-file」是對底層資料儲存面的形容;而 Jamstack 風格的 headless CMS 的「headless」是對前端模組的形容,是不同面向的描述,因此兩者之前並不存在比較關係,容易讓人(我)疑惑的原因只是它們都剛好在同個年代興起而已。
Headless CMS 沒有前端模組,它的資料儲存可以是用資料庫或檔案;flat-file CMS 沒有用資料庫,它可以有前端模組或沒有前端模組。
## Static site generator
來到最後一關,static site generator,靜態網站產生器,簡稱 SSG。
SSG 更單純,SSG 只負責把模板檔和內容檔(通常是 Markdown 或 HTML)組合起來並輸出成美美的 HTML 檔案,當然還有一些額外的工作,例如幫我們產出 sitemap.xml、依我們設計的目錄結構去產生、圖片縮放、幫我們更新索引清單等周邊工作。
因為 SSG 最後產出的都是靜態的 HTML 檔案,因此只要放到某個最便宜的網頁空間即可讓人訪問。
更複雜一點的 SSG,把前端框架摻進來做 SSG,就幾乎有無限的可能性,即便是靜態檔案,只要透過 JavaScript 與瀏覽器的 Web API 再加上網路上一大堆 API-based 的服務,即可變出各種花式 web app,什麼 blog、形象網站、購物站都沒問題,靜態檔案也可以跑的很動態。
## Jamstack
回頭談主題 Jamstack,headless CMS 意味著 Jamstack 前後端分離之後端;SSG、前端框架意味著 Jamstack 前後端分離之前端,而後端其實也不一定要自己架 CMS,拿網路上現成的 API-based 的服務作為後端也是可行的,甚至像 blog 或形像網站,本身並不需要後端的存在。
另外一個個人觀點是,在大前端時代,前後端分離已是常態,Jamstack 這個用於描述這種分離後的架構的詞彙也會隨著成為常態而消失,就像以前電腦剛能播影音的時代,微軟定義了 MPC 的規格,然而隨著多媒體播放成為常態,又有誰會特地說自己的電腦是「多媒體電腦」呢?:p | leon0824 |
854,108 | 6 tips for mentoring junior engineers | The acclimation process as a new engineer may be daunting for some. And since I’ve been through the... | 0 | 2021-10-06T17:07:12 | https://dev.to/laurencaponong/6-tips-for-mentoring-junior-engineers-5gd5 | engineering, career, productivity, beginners | The acclimation process as a new engineer may be daunting for some. And since I’ve been through the process myself, I’d like to share these tidbits to help you - as the mentor - help out your mentee.
1. **Writing my own documentation specific to the project and tech**. It helps the junior engineer get acclimated to the context they will be working in and gives them a bigger picture of what’s going on. Things like specific Slack channels, email lists to join, repositories to download, helpful software additions, et cetera.
2. **Forwarding them to the right people**. Introductions or forwarding them names of the people they will need info from (example: a web engineer needing information from the backend engineer).
3. **Don’t assume that they know**! I err on the side of giving as much information as possible to a new engineer so that they understand the full context. If they already know, great - but still, it’s good to check-in beforehand to see what they know.
4. **Share your tips that you know and use often**. If you know a shortcut for a workflow, or how to debug more easily, share that with the engineer! I had to discover a lot of shortcuts on my own (sifting through Slack channels for example) and had to waste countless hours when someone else had a simple command for it.
5. **Keep internal company-only acronyms to a minimum.** Business jargon may confuse newcomers, so lighten up on that. There’s been countless times I’ve been in meetings with new hires and they have no clue what is going on due to acronym usage.
6. **Open up the floor**. I want my mentee to feel as comfortable as possible coming to me with questions. If I don’t know, I’ll ask someone else or forward them to the right person. As someone that had a challenging case of impostor syndrome, this one could have a profound effect on newly minted engineers.
A major component to mentoring, overall, is to be **communicative**. Although it may feel like more effort to explain or give additional context, it is likely appreciated by the mentee, and can save a lot of unneeded frustration.
Have any other additions to the list? Feel free to comment your own! | laurencaponong |
854,210 | September: Forem Twitch Events Roundup 👾 | In September, Nick Taylor and I were joined by 4 awesome guests! This is a round up of all the... | 0 | 2021-10-06T20:24:26 | https://dev.to/devteam/september-forem-twitch-events-roundup-543f | twitch, opensource, meta | In September, Nick Taylor and I were joined by 4 awesome guests! This is a round up of all the wonderful guests who joined us.
## Walkthrough Wednesday with Chris Coyier
[Chris Coyier](https://twitter.com/chriscoyier), co-founder of CodePen, creator of CSS-Tricks, and co-podcaster at ShopTalk, joinedus to talk about front-end development, CodePen, ShopTalk, banjos and more.🪕
{% youtube ZncQIITVOPI %}
**Places to follow Chris:**
[Twitter]()
[CSS-Tricks](https://css-tricks.com/)
[ShopTalk](https://shoptalkshow.com/)
[CodePen](https://codepen.io/)
## Walkthrough Wednesday with Virtual Coffee Community
Bekah Hawrot Weigel, Kirk Shillingford, and Dan Ott joined us to talk about the Virtual Coffee Community, Preptember, Hacktoberfest, and maintaining and/or contributing to an open source repository.
{% youtube WFp48oPBil0 %}
**How to connect with Virtual Coffee:**
[Main site](https://virtualcoffee.io/)
[Podcast](https://virtualcoffee.io/podcast)
[Meeting Place](https://meetingplace.io/virtual-coffee)
**Places to Follow Bekah:**
[DEV](https://dev.to/bekahhw)
[Twitter](https://twitter.com/bekahhw)
[Twitch](https://www.twitch.tv/bekahhw)
**Places to Follow Kirk:**
[Twitter](https://twitter.com/kirkcodes)
[GitHub](https://github.com/tkshill)
**Places to Follow Dan:**
[Twitter](https://twitter.com/danieltott)
Thanks to all our viewers who joined the streams and chatted with us this month!
Be sure to follow the [ThePracticalDev Twitch](https://www.twitch.tv/thepracticaldev) channel to be notified when future streams begin and check out all the great guests we have joining us every Wednesday this month.
**Our October guests are:**
- [Brian Douglas](https://twitter.com/chriscoyier) on October 6th
- [Andrew Brown](https://twitter.com/andrewbrown) on October 13th
- [Jonathan Creamer](https://twitter.com/jcreamer898) on October 20th
- [Will Johnson](https://twitter.com/willjohnsonio) on October 27th
| coffeecraftcode |
854,316 | Namespacing keys in Kredis | Kredis is a library that provides an abstraction of higher level data structures for Redis. It's... | 0 | 2021-10-06T22:23:00 | https://dev.to/ayushn21/namespacing-keys-in-kredis-mcp | ruby, rails, redis | [Kredis](https://github.com/rails/kredis) is a library that provides an abstraction of higher level data structures for [Redis](http://redis.io). It's really useful and will be included in Rails 7.
I like to namespace all my keys in Redis because it prevents clashes between keys from multiple apps in development locally. It also opens the door to sharing a single Redis instance between multiple apps in production. That's usually not a good idea but for a few side projects, it might be a viable and economical choice.
At first glance it seems like it's really easy to add a namespace to keys in Kredis. There's a [`Kredis.namespace=`](https://github.com/rails/kredis/blob/main/lib/kredis/namespace.rb) method. However it's primarily meant to prevent clashes in parallel testing. If you look at the implementation, it looks like:
```ruby
def namespace=(namespace)
Thread.current[:kredis_namespace] = namespace
end
```
It only sets the namespace on the current thread. That's fine when using a single threaded process like the Rails Console. But in a multi-threaded process like [Sidekiq](http://github.com/mperham/sidekiq/), you're going to be in trouble.
One approach to solve this could be setting the namespace on every thread. However that's pretty messy.
# The redis-namespace gem
A clean way to namespacing Kredis is to install the [redis-namespace](https://github.com/resque/redis-namespace) gem. It provides a namespaced proxy to an underlying Redis connection.
To configure Kredis to use this proxy instead of creating its own connection; we need to add the following line in `application.rb`:
```ruby
config.kredis.connector = ->(config) {
Redis::Namespace.new("my_app:kredis", redis: Redis.new(config))
}
```
Now all keys we set with Kredis will be namespaced with "my\_app:kredis". This also makes it easier to filter keys if you're using a GUI tool like [Medis](https://getmedis.com) to view your Redis data.
| ayushn21 |
854,345 | Building a Web Report in PowerShell, use the -Force Luke | An article describing how to create web reports using PowerShell | 15,107 | 2021-10-07T22:03:32 | https://dev.to/azure/building-a-web-report-in-powershell-use-the-force-luke-58aj | powershell, tutorial, webdev, devops | ---
title: Building a Web Report in PowerShell, use the -Force Luke
published: true
description: An article describing how to create web reports using PowerShell
tags: powershell, tutorial, webdev, devops
series: powershell-tutorials
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/r9i2e1tsy8ejgc23h3s9.jpg
---
> TLDR; The idea of this article is to show how to build a web report. I will show the usage of several commands that you can connect that does all the heavy lifting for you
## The scenario - create a report from some remote data
Ok, here you are, you are looking to read data from one place and present that as a web report. The data is remote, you need to fetch it somehow, you also probably need to think about how to convert the incoming data and lastly create that web report. If you are a developer, you probably think that oh ok, this is probably a few moving parts, 10-20 lines of code. But you've heard of PowerShell, it's supposed to be powerful, do a lot of heavy lifting, so why not give it a spin.
## The steps we will take
To achieve our task, we need to plan it out. Carry it out sequentially, and who knows, maybe this is something we can reuse? So what steps:
1. **Fetch the data**. Need to grab the data somehow
2. **Convert**. Lets assume this data comes in some type of format and we most likely need to convert it some other form.
3. **Present**. So we fetched the data, massaged it into a suitable format, now what? Now, we want to present it as a web report, HTML, CSS etc.
## Getting to work
We have a game plan. Now let's see if we can find the commands we need. A good starting point is the [Microsoft.PowerShell.Utility section](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/?view=powershell-7.1). In this section, there are tons of commands that does a lot of heavy lifting for you.
### Grabbing the data
First things first, we need to grab some data remotely, so what's our options?
- [Invoke-WebRequest](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/invoke-webrequest?view=powershell-7.1) this seems to let us call a URL, send a body, credentials etc, seems promising.
- [Invoke-RestMethod](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/invoke-restmethod?view=powershell-7.1). What about this one, how is it different? This sentence right here:
> PowerShell formats the response based to the data type. For an RSS or ATOM feed, PowerShell returns the Item or Entry XML nodes. For JavaScript Object Notation (JSON) or XML, PowerShell converts, or deserializes, the content into [PSCustomObject] objects.
It takes a JSON response and turns that into a PSCustomObject, nice. Well let's see with our other commands before we make a decision.
### Presenting the data
This is the last thing we need to do but we need to understand if there's a command that helps us with report creation and most importantly, what input it takes. I think we found it:
- [ConvertTo-Html](https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/convertto-html?view=powershell-7.1) Converts .NET objects into HTML that can be displayed in a Web browser.
Yea, that reminds us of something, `Invoke-RestMethod`. Why? Cause `Invoke-RestMethod` produces custom objects, i.e .NET objects.
How do we save the report to a file though, so we can store that somewhere and let it be hosted by a web server? Oh, here's an example, pipe it to `Out-File`, like so `ConvertTo-Html | Out-File aliases.htm`
### Overview of the solution
So we have a theory on how to do this:
1. Call `Invoke-RestMethod`.
2. Followed by `ConvertTo-Html`.
3. Followed by `Out-File`.
### Build the solution
Seems almost too easy. Ah well, let's give it whirl. First things first, lets choose a data source, SWAPI, the Star Wars API, cause use the `-Force`, am I right? :)
1. Start `pwsh` in the console.
1. Create a file _web-report.ps1_
1. Add the following code:
```powershell
Invoke-RestMethod -URI https://swapi.dev/api/people/1/ |
ConvertTo-Html |
Out-File report.htm
```
1. Run `./web-report.ps1` (or `.\web-report.ps1` for Windows folks)
It created a _report.htm_ file for us. Ok, let's have a look:
```html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>HTML TABLE</title>
</head><body>
<table>
<colgroup><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/></colgroup>
<tr><th>name</th><th>height</th><th>mass</th><th>hair_color</th><th>skin_color</th><th>eye_color</th><th>birth_year</th><th>gender</th><th>homeworld</th><th>films</th><th>species</th><th>vehicles</th><th>starships</th><th>created</th><th>edited</th><th>url</th></tr>
<tr><td>Luke Skywalker</td><td>172</td><td>77</td><td>blond</td><td>fair</td><td>blue</td><td>19BBY</td><td>male</td><td>https://swapi.dev/api/planets/1/</td><td>System.Object[]</td><td>System.Object[]</td><td>System.Object[]</td><td>System.Object[]</td><td>09/12/2014 13:50:51</td><td>20/12/2014 21:17:56</td><td>https://swapi.dev/api/people/1/</td></tr>
</table>
</body></html>
```
1. Show this file in a browser with `Invoke_Item`:
```powershell
Invoke-Item ./report.htm
```
This should start up a browser and you should see something like:

Ok, you could be done here, or we can make it more flexible. We don't like hardcoded values, right? RIGHT?
### Making it flexible
I thought so, now, let's add some parameters for, URL, and report name.
1. Add the following code to the top part of our script _web-report.ps1_:
```powershell
Param(
[String] $URL = "https://swapi.dev/api/people/1/",
[String] $Report = "report.htm"
)
```
1. Lets invoke it again, this time with a new URL "https://swapi.dev/api/people/2/":
```powershell
./web-report.ps1 -URL https://swapi.dev/api/people/2/
```
1. Lets check the response in _report.htm_. :
```html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>HTML TABLE</title>
</head><body>
<table>
<colgroup><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/><col/></colgroup>
<tr><th>name</th><th>height</th><th>mass</th><th>hair_color</th><th>skin_color</th><th>eye_color</th><th>birth_year</th><th>gender</th><th>homeworld</th><th>films</th><th>species</th><th>vehicles</th><th>starships</th><th>created</th><th>edited</th><th>url</th></tr>
<tr><td>C-3PO</td><td>167</td><td>75</td><td>n/a</td><td>gold</td><td>yellow</td><td>112BBY</td><td>n/a</td><td>https://swapi.dev/api/planets/1/</td><td>System.Object[]</td><td>System.Object[]</td><td>System.Object[]</td><td>System.Object[]</td><td>10/12/2014 15:10:51</td><td>20/12/2014 21:17:50</td><td>https://swapi.dev/api/people/2/</td></tr>
</table>
</body></html>
```
This time we have `C-3PO`, yup, definitely not Luke, it seems to be working :)
### Improve the response
So, so far we had a ton of columns coming back, maybe we just need a few fields from the response, like `name`, `planet` and `height`. Yea let's do that, and justt pick what we need from the response:
1. Let's add `Select-Object` like so:
```powershell
Select-Object name, age, planet |
```
with the full code looking like so:
```powershell
Param(
[String] $URL = "https://swapi.dev/api/people/1/",
[String] $Report = "report.htm"
)
Invoke-RestMethod -URI $URL |
ConvertTo-Html -Property name, height, homeworld |
Out-File $Report
```
1. Let's invoke it again:
```powershell
./web-report.ps1 -URL https://swapi.dev/api/people/1/
```
and our report now looks like:
```html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>HTML TABLE</title>
</head><body>
<table>
<colgroup><col/><col/><col/></colgroup>
<tr><th>name</th><th>height</th><th>homeworld</th></tr>
<tr><td>Luke Skywalker</td><td>172</td><td>https://swapi.dev/api/planets/1/</td></tr>
</table>
</body></html>
```
Much better :) In fact, reading up a bit, we can just use -Property on `ConvertTo-Html`, so we get:
```powershell
Invoke-RestMethod -URI $URL |
ConvertTo-Html -Property name, height, homeworld |
Out-File $Report
```
### Make it pretty
In all honesty, this report is bad, no colors, no nothing. Surely, we must be able to pass a CSS file to `ConvertTo-Html`?
Ah yes, looking through the docs there's the parameter `-CssUri` that takes a file path. Let's create a CSS file then.
1. Create `report.css` and add the following CSS:
```css
table {
border: solid 1px black;
padding: 10px;
border-collapse: collapse;
}
tr:nth-child(even) {background: #CCC}
tr:nth-child(odd) {background: #FFF}
```
1. Update the script to take `-CssUri report.css` on `ConvertTo-Html`
1. Run it again, you should see this in the browser:

## Summary
In summary, we learned that we could use just a few commands, `Invoke-RestMethod`, `ConvertTo-Html` and `Out-File` and boom, we've created ourselves a report.
Full code:
```powershell
Param(
[String] $URL = "https://swapi.dev/api/people/1/",
[String] $Report = "report.htm"
)
Invoke-RestMethod -URI $URL |
ConvertTo-Html -CssUri report.css -Title "Web report" -Property name, height, homeworld |
Out-File $Report
```
| softchris |
854,358 | Java | A post by Ömer Çavmak | 0 | 2021-10-07T01:31:29 | https://dev.to/omercavmak/java-39ac | omercavmak | ||
854,396 | Types of Relation Between Classes in Object Oriented Programming | Object-oriented programming is a programming paradigm that sees everything as an object.... | 0 | 2021-10-07T08:07:52 | https://dev.to/fajarzuhrihadiyanto/types-of-relation-between-classes-in-object-oriented-programming-551m | oop, java, programming | Object-oriented programming is a programming paradigm that sees everything as an object. Object-oriented programming is adapted from a real-world problem. For example, you have a cat, so do i. Your cat and mine have the same properties, such as weight and color. Your cat and mine also have similar behavior, such as eating, sleeping, and walking. Your cat is an object and mine is another object. We can classify these objects into one class, just say it Cat class.
In object-oriented programming, class is a blueprint for objects that we want to create. One class can be related to another class or not. Generally, there are some relations between classes in oop, which are :
* [aggregation](#aggregation)
* [composition](#composition)
* [inheritance](#inheritance)
## Aggregation <a name="aggregation"></a>
 Aggregation is a Has-A relationship between two objects where each object can exist without another object. In other words, these objects are independent. For example, the relationship between employee and department. An employee can stand alone without a department, so does the department.
```java
public class Employee {
private String name;
private double salary;
public Employee() {}
}
public class Department {
public String name;
public List<Employee> employees;
public Department() {}
}
```
The source code above is an example of the implementation of aggregation in java. The Department class has a relationship with the Employee class. Department object can have a list of employees or not at all. Employee object might belong to Department object or not. There is no restriction in the aggregation relationship.
## Composition <a name="composition"></a>
 Composition is a Has-A relationship between classes where both classes are dependent on each other. One object cannot exist without the existence of another object. For example, the relation between Laptop and its Processor. A laptop cannot exist without its processor.
```java
public class Processor {
private String modelName;
private int frequency;
public Processor () {}
}
public class Laptop {
private Processor processor = new Processor();
public Laptop () {}
}
```
The source code above is an example of the implementation of composition in java. The Laptop class has a relationship with the Processor class. When a laptop object is created, a processor object that belongs to that laptop is automatically created.
## Inheritance <a name="inheritance"></a>
 Inheritance is an Is-A relationship between classes where parent class is a general class and child class is a specific class. For example, the relation between cat, dog, and its general class, which is animal. An animal can be specified as a cat or dog. Cat and dog can be generalized as an animal.
```java
public class Animal {
protected weight;
protected color;
public Animal () {}
public void talk () {
System.out.println("It is animal");
}
}
public class Cat extend Animal {
public Cat () {}
public void talk () {
System.out.println("meow");
}
}
public class Dog extend Animal {
public Dog () {}
public void talk () {
System.out.println("bark");
}
}
```
The source code above is an example of the implementation of inheritance in java. The Cat and The Dog both have properties of weight and color. To generalize those properties of Cat and Dog, we can create one parent class that can represent both cat and dog with those properties, which is Animal class. | fajarzuhrihadiyanto |
868,856 | Handle/Raise Exceptions with Little to No Further Processing [RE#10] | Exceptions may occur anywhere, even inside a catch (or except in Python) block. It’s not a wrong... | 13,472 | 2021-10-19T13:00:11 | https://babakks.github.io/article/2021/10/19/re-010-handle-raise-exceptions-with-little-to-no-further-processing.html | productivity, javascript, coding, patterns | ---
title: Handle/Raise Exceptions with Little to No Further Processing [RE#10]
published: true
date: 2021-10-19 13:00:00 UTC
tags: productivity, javascript, coding, patterns
canonical_url: https://babakks.github.io/article/2021/10/19/re-010-handle-raise-exceptions-with-little-to-no-further-processing.html
series: Regular Encounters
---
Exceptions may occur anywhere, even inside a `catch` (or `except` in Python) block. It’s not a wrong presumption that people expect them less in there. Anyway, beware of the code you put in these blocks because when an exception occurs you just don’t want to make things worse.
One safe approach to prevent faulty codes in those blocks is to ensure that you are not doing any further processing or data manipulation there. In other words, if you’re re-raising the exception (or logging something) try to use raw data.
For instance, look at this listing:
```js
class Student {
getCourses() {
// Query student courses from repository
}
makeStudentIdentifier() {
return `${this.lastname.trim()} ${this.firstname.trim()} (#${this.studentNo.trim()})`;
}
doSomeProcess() {
try {
const courses = this.getCourses();
}
catch (e) {
console.log("Process failed for %s: %s", this.makeStudentIdentifier(), e);
}
}
}
```
What if, due to some bug somewhere else, `Student.studentNo` assigned with a `number` value instead of a `string`. Calling `trim()` on a `number` object causes another exception, terminating the handling you had in mind (here, logging) and returning the control to the first `catch` block up on the call stack. Not to mention that the original exception, which should be the actual issue to investigate, got masked and you may easily miss it; though somewhere in the middle of the stack trace will be a faint hint to that. So, it’s safer to appreciate raw values and do things with less processing:
```js
console.log("Process failed for %s %s (%s): %s", this.lastname, this.firstname, this.studentNo, e);
```
* * *
**_About Regular Encounters_**
_I’ve decided to record my daily encounters with professional issues on a somewhat regular basis. Not all of them are equally important/unique/intricate, but are indeed practical, real, and of course,_ **_textually minimal._** | babakks |
854,528 | Hacktoberfest 2021 is here. | What is Hacktoberfest ? A month-long celebration from October 1st - 31st sponsored by Digital Ocean... | 0 | 2021-10-07T05:20:28 | https://dev.to/viveeeeeek/hacktoberfest-2021-is-here-fo5 | hacktoberfest, flutter, opensource, android |
What is Hacktoberfest ?
A month-long celebration from October 1st - 31st sponsored by Digital Ocean and GitHub to get people involved in Open Source. Create your very first pull request to any public repository on GitHub and contribute to the open source developer community.
Contribute to open-soucre and grab your Hacktoberfest swags ( Free T-Shirt & Goodies).
You need to create 4 Pull Request (PR) to grab goodies.
Are you Flutter dev and looking for beginner friendly repositories?
Don't worry I got you covered.
Here are some repositories where you can submit your Pull Request
1) Flutter web app : https://github.com/viveeeeeek/1stHacktoberfest
2) Flutter BMI calculator app : https://github.com/viveeeeeek/flutter-bmi-calculator
| viveeeeeek |
854,576 | #10 Best YouTube Channels for become Developer..✔️ | Introduction I will tell you the best 10 you tube channels to learn about the Developer... | 0 | 2021-10-07T07:14:32 | https://dev.to/deepakguptacoder/10-best-youtube-channels-for-become-developer-29kg | devops, beginners, webdev, tutorial | #Introduction
I will tell you the best 10 you tube channels to learn about the Developer and other things of the technology,
Also I will provide to you there channel link..
####follow the point
#1.[Code with Harry]( https://youtube.com/c/CodeWithHarry)
Channel about JavaScript, React, React-Native, Next.js, Node.js, Express, GraphQL, serverless functions, working with databases and much more!
#2.[Web Dev Simplified](https://youtube.com/c/WebDevSimplified)
Web Dev Simplified also deep dives into advanced topics using the latest best practices for you seasoned web developers.
#3.[LevelUpTuts](https://youtube.com/c/LevelUpTuts)
Here you will find videos from the usual videos on CSS, JS, Python and Django to blockchain and microservices.
#4.[Java Brian ](https://youtube.com/c/JavaBrainsChannel)
On this channel how to create a slider, animation when scrolling, adaptive website design and also a lot of different elements using React.js
#5.[DevTips](https://youtube.com/c/DevTipsForDesigners)
There are also videos where conversations with other developers are conducted. how to make CSS animation with physics simulation or how to work with legacy code, as well as many interesting videos on CSS animations and React lessons.
#6.[Fireship](https://youtube.com/c/Fireship)
There are also a number of videos on the topic of layout and animation creation.
#7.[dcode](https://youtube.com/c/dcode-software)
HTML, CSS & JavaScript tutorials, PHP tutorials, Node.js tutorials and Rust tutorials, as well as many other topics covered in web development.
#8.[Joma Tech](https://youtube.com/c/JomaOppa)
Very interesting, videos are posting on the daily basis
#9.[William Candillon](https://youtube.com/c/wcandillon)
Also on the channel there are many interesting conversational videos on the topic React.js.
#10.[Freecodecamp](https://youtube.com/c/Freecodecamp)
Learning various APIs, React, JS, GIT, browsers, and much more. It will help to build your knowledge.
.
.
.
Conclusion
I hope you found this article useful, if you need any help please let me know in the comment section.💯
Thanks for reading, See you next time. | deepakguptacoder |
854,711 | Guide to JavaScript data types | This post was originally published on webinuse.com Every programming language has its own data... | 0 | 2021-10-07T07:35:41 | https://webinuse.com/guide-to-javascript-data-types/ | javascript, beginners | *This post was originally published on [webinuse.com](https://webinuse.com/guide-to-javascript-data-types/)*
Every programming language has its own data structure. Those structures can vary from language to language. Today we are talking about JavaScript data types.
JavaScript is a loosely typed language and dynamic language. This means that any variable can hold any value, regardless of its type, and variables are not directly associated with values type. JavaScript data types are coming in two groups:
1. Primitive data type
2. Non-primitive data type
### JavaScript Primitive data type ###
We can divide Primitive data types even more. We can divide them into 7 categories. Also, Primitive data types are immutable, and can not be changed. Every data type can store only single data.
#### 1. Boolean ####
Boolean represents logical entities that can hold only two values: `true` or `false`. Usually, in JavaScript, we use it for conditionals. We can also assume those for loops.
```javascript
//Simple JS if statement
if (boolean condition) {
//if boolean condition is true execute this part of code
} else {
//if boolean condition is false (not true) execute this part of code
}
for (control statement; boolean condition; incrementer) {
//only when boolean is met, this part of code will be executed
}
while (boolean condition) {
//while condition is met, this part of code will be executed
}
//
/**
* Let's set value to false
* */
let value = false;
/**
* If value is false (non-existent, binary 0, not true) set value to true,
* otherwise se it to true
* */
if (value === false) {
value = true;
} else {
value = false;
}
for (let i = 0; i < 10; i++) {
//(For as long as condition is true),
//So as long as i is less than 10, this code will be executed
}
while (i < 10) {
//while i is less than 10, this code will be executed
//(While condition is true, this code will be executed)
}
```
#### 2. Null ####
In computer science, null represents a pointer to an empty, non-existent address in memory, usually intentionally. In JavaScript null is a little bit different than in other languages. Even though it is marked as a primitive type, it’s not always primitive. Every Object is derived from null.
```javascript
if(typeof null === 'object') {
console.log('Null is JavaScript object');
} else {
console.log('Null is not JavaScript object');
}
//Result:
//Null is JavaScript object
```
Nevertheless, in JS, we use null to represent empty or unknown values.
```javascript
let age = null;
/**
* This means that there is variable called age in our memory,
* but it is empty
* */
```
#### 3. Undefined ####
When we create a variable and we don’t give it any value, that variable is undefined. See the example below.
```javascript
let x;
console.log(x);
//Result:
//undefined
```
#### 4. String ####
The string is, probably, the most powerful JavaScript data type, or data type in general. We can create any data type using string, but that doesn’t mean it’s good. The string is a set of “elements” of 16-bit unsigned integer values, as per MDN. The first element, in the string, is at index 0, next is at 1, and so on. The length of the string is a number of elements in the string.
There are three ways to write a string in JavaScript. The first way is using double-quotes `"`, the second way is using single-quotes `'`, and the third way is using backticks `` ` ``. Double and single quotes are basically the same. The only thing is that you have to pair them. So, if you start a string with double quotes, you have to end with double-quotes. And vice versa. Also, inside of double quotes you can use single quotes, and vice versa. If we want to use a variable(s) inside of any of these, you have to use concatenation.
Backticks are different. If we use backticks when we start string, we have to use them at the end, also. But, when we use backticks we can use variables without concatenations. Usually, this leads to better readability.
```javascript
let hello = "hello";
console.log(hello);
//Result:
//hello
console.log(hello.length);
//Result:
//5
/**
* Let's split string into array to check index
* */
console.log(hello.split(""));
//Result:
/**
* 0: "h"
* 1: "e"
* 2: "l"
* 3: "l"
* 4: "o"
* */
/**
* Examples of using double quotes, single quotes and backticks
* */
let firstString = "String 1";
let secondString = 'String 2';
let thirdString = `String 3`;
let withQuotesInside = "String of a 'string'";
let withSQuotesInside = 'String of a "string"';
let withBackticks = `String of a 'string' of a "string"`;
/**
* Concatenation example
* */
console.log(firstString + ' ' + secondString);
//Result:
//String 1 String 2
console.log(firstString + ' ' + thirdString);
//Result:
//String 1 String 3
console.log(`${firstString} ${secondString} and finally the ${thirdString}`);
//Result:
//String 1 String 2 and finally the String 3
```
As we can see in the example above, when we use backticks, all we have to do is to enclose a variable in `${}` like `${variable}`.
#### 5. Number ####
Another JavaScript data type is a number. We can divide Number into two types: `Number` and `BigInt`. The Number type is a double-precision [64-bit binary format IEEE 754 value](https://en.wikipedia.org/wiki/Double-precision_floating-point_format) (numbers between -(2^53 − 1) and 2^53 − 1). In addition to representing floating-point numbers, the number type has three symbolic values: `+Infinity`, `-Infinity`, and `NaN` (“Not a Number”), as per [MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures).
This means that we can “safely” use any number between `Number.MIN_SAFE_INTERGER` (-9007199254740991) and `Number.MAX_SAFE_INTERGER` (9007199254740991).
Also, the worth of mention, we write numbers without any quotation or backticks, so JS can differentiate them from strings. We can concatenate numbers and strings in JS. The result is another string. If we want to convert a “string” number to the Number we can use `parseInt()` or `parseFloat()`.
```javascript
let x = 1;
let y = 2;
console.log(x + y);
//Result:
//3
let z = '1';
console.log(x + z);
//Result:
//11
console.log(x + parseInt(z));
//Result:
//2
```
#### 6. BigInt ####
BigInt data type is JavaScript’s way of handling super large numbers. Average programmer, probably, will never get even close to `MAX_SAFE_INTERGER`, still, there are some situations where we might need `BigInt`. `BigInt` is not strictly a number. Also, `Number` and `BigInt` can’t be used together or interchangeably. These are two different “identities”.
We create `BigInt` by appending `n` at the end of the integer, or by calling the constructor. We can use `+`,`-`,`*`,`/`, and `%` with `BigInt` just like with numbers.
```javascript
let BigInt = 9007199254740991n;
//Add to BigInts
console.log(BigInt + 1n);
//Result:
//9007199254740992n
//Add a BigInt and a Number
console.log(BigInt + 1);
//Result:
//ERROR: Cannot mix BigInt and other types, use explicit conversions
```
#### 7. Symbol ####
The symbol is a feature introduced in ECMA Script 2015. Symbol is a secret, unique, anonymous value. Symbol value represents a unique identifier, it can, also, have optional descriptions, but for debugging purposes only. Even if we create an infinite number of Symbols with the same descriptions, every one of them will be unique. We can use Symbol as an object property. For more info on Symbol click [here](https://developer.mozilla.org/en-US/docs/Glossary/Symbol).
```javascript
let first = Symbol("Symbol");
let second = Symbol("Symbol");
/**
* Even though they are the same, they are different because
* they are Symbol type.
* */
//If we try to compare two symbols we' ll always get false
if (first === second) {
return true;
} else {
return false;
}
//Result:
//false
```
### JavaScript non-primitive data type ###
Unlike primitive data types, non-primitive data type is mutable. This means that non-primitive data type can hold different data types, one or more of them, at the same time. There is only one “real” representative of non-primitive data type. It’s called Object.
#### Object ####
Usually, an `object` is a value in memory that is represented by an identifier. An `object`is a complex data type that allows us to store and manipulate the same and/or different data types. Also, In JavaScript, there are different types of `object`.
The first type is “standard” `object`. `object` consists of key-value pairs, where the key is a unique identifier.
```javascript
let person = {
name: 'Amer',
surname: 'Sikira',
years: 28
}
console.log(person);
//Result:
//{name: "Amer", surname: "Sikira", years: 28}
```
The second type of the `object` is `array`. `array` is `object` type that consists of values and we access those values using index-key. If you want to learn more about array you can check out my post [JavaScript Arrays – Manipulating data](https://webinuse.com/javascript-arrays-manipulating-data/).
```javascript
let cars = ['Volvo', 'Ferrari', 'Audi'];
//We can have multi-level arrays
let items = [1, 'ball', false, true, 332, ['audi', 'volvo', 'train']];
```
There are some other object types like RegEx, Date, etc. You can read more about it on [MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures).
### Typeof ###
JavaScript data types can be pretty complicated. That is why we have `typeof` operator. `typeof` operator returns a string indicating the type of the operand. When we want to check if certain variable or data is right type we can use `typeof`.
Also if we want to compare two (or more) operands in JavaScript, we can use double equation sign `==`. JavaScript will check if they are equal. But, if we use triple equation sign `===` JS will also check if their type is the same.
```javascript
let x = 'Hello, World!';
let y = 22;
console.log(typeof x);
//string
console.log(typeof y);
//number
//Check for equality
let a = 2;
let b = '2';
let c = 2;
console.log(a==b);
//true
console.log(a===b);
//false
console.log(a===c);
//true
```
If you have any questions or anything you can find me on my [Twitter](https://twitter.com/AmerSikira), or you can read some of my other articles like [What is JavaScript used for](https://webinuse.com/what-is-javascript-used-for/)? | amersikira |
854,728 | Free Responsive Ecommerce Website Template with Animations | You can get the template from the link proivided in the description of the video. ... | 0 | 2021-10-07T13:01:44 | https://dev.to/kishansheth/free-responsive-ecommerce-website-with-animations-ga0 | html, css, javascript, webdev | ## You can get the template from the link proivided in the description of the video.
### Technologies Used :-
+ HTML
+ CSS
+ JAVASCRIPT
+ SASS
### Libraries and Assets Used :-
+ jQuery
+ Scroll Reveal
+ Google Fonts
### Sections Given in Template :-
+ Navbar
+ Hero Section
+ Services Section
+ Deals Section
+ Recent Products Section
+ Recent Posts Section
+ Newsletter Section
+ Footer
## To learn how to create this template watch the complete video. You can get the template for free from the link provided in the description of the video.
{% youtube QyKMrve8Yio %}
## Please do like the video and subscribe to the channel. It helps and motivates me to create more content like this.
| kishansheth |
855,067 | Why you should explore your data before feeding Amazon Personalize | Alexa...set a timer for 15 minutes. ⏳ In my previous blog post, I showed you how to automate the... | 0 | 2021-10-20T08:30:09 | https://dev.to/cremich/why-you-should-explore-your-data-before-feeding-amazon-personalize-1f5n | aws, machinelearning, datascience, personalize | Alexa...set a timer for 15 minutes. ⏳
---
In my [previous blog post](https://dev.to/cremich/automate-provisioning-of-sagemaker-notebooks-using-the-aws-cdk-3p4l), I showed you how to automate the provisioning of Sagemaker notebook instances. Let us now use this notebook instance for data exploration and data analysis as part of the [Amazon Personalize Kickstart](https://github.com/cremich/personalize-kickstart/) project.
The goal of this project is to provide you a kickstart for your personalization journey when building a recommendation engine based on Amazon Personalize. It will serve you as a reference implementation you can both learn the concepts and integration aspects of Amazon Personalize.
## 🕵️ Data exploration is an essential part of your machine learning development process
Before you just import your historical data, it is recommended to gather knowledge. Both on your data and on your business domain. Every recommendation engine project is kind of unique if we look at the data we have to process and the way the business works. In a very first step during a proof-of-concept phase, it is all about finding answers on:
* What data can we use?
* What data do we need?
* Is our data quality sufficient?
* How do we access the required data?
* How do we identify users, interaction or items we want to recommend?
Collaborative sessions with subject matter experts help us in building an optimal solution along the given circumstances. **Making decisions is easy. Making the right decision is the challenge.** In my opinion, data exploration is one of the most important parts in your machine learning development process.
To formulate it a bit more drastically: without data analysis and exploration, you can only do the right thing by accident.
## 🏁 What do we want to achieve?
We want to build a recommendation engine covering all features of Amazon Personalize. The dataset we will use is the publicly available MovieLens dataset.
> GroupLens Research has collected and made available rating data sets from the MovieLens web site (https://movielens.org). The data sets were collected over various periods of time, depending on the size of the set. Before using these data sets, please review their README files for the usage licenses and other details.
Source: [https://grouplens.org/datasets/movielens/](https://grouplens.org/datasets/movielens/)
The MovieLens dataset contains 25 million movie ratings and a rich set of movie metadata. We will use this data to provide an initial version of our recommendation engine based on historical data.
My goal is to not reinvent the wheel at all. But bring relevant analyses in one place that help us to judge if our data fits to be used for a recommendation engine based on Amazon Personalize.
Those analyses are both inspired from my personal experiences as well as a lot of cool stuff of the open source community like the following:
* [Analysis on the Movie Lens dataset using pandas](https://notebook.community/harishkrao/DSE200x/Mini%20Project/Analysis%20on%20the%20Movie%20Lens%20dataset)
* [Amazon Personalize immersion day](https://personalization-immersionday.workshop.aws/en/)
* [Analysis of MovieLens dataset (Beginner'sAnalysis)](https://www.kaggle.com/jneupane12/analysis-of-movielens-dataset-beginner-sanalysis)
* [Data Analysis using the MovieLens dataset with pandas](https://www.youtube.com/watch?v=8kElv1sticI)
* [Comprehensive Data Visualization with Matplotlib](https://towardsdatascience.com/comprehensive-data-explorations-with-matplotlib-a388be12a355)
## 📊 From data to answers
Before you start with your analysis, it is recommended to define some key questions you would like to answer. You can then use the insights and knowledge you gained to discuss them with subject matter experts.
Well in our kickstart project, unfortunately there are no subject matter experts available right now. But let us start with what we have: 🤖 data and a 📖 [README](https://files.grouplens.org/datasets/movielens/ml-25m-README.html)!
By analyzing the Movielens datasets we want to answer some very specific questions about our movie business:
* What are the top 10 most rated movies?
* Are ratings in general more positive or negative?
* Is there a correlation between genres?
So let us get started and dive into our datasets. 🤿
## 🗺 Data exploration samples
For a complete overview of all analysis results, please check the complete [Jupyter notebook on github](https://github.com/cremich/personalize-kickstart/blob/main/notebooks/data-exploration.ipynb).
Before we start, let us do some basic setup like importing libraries, downloading the sample data and loading them into dataframes.
```python
from datetime import datetime
import pandas as pd
data_dir = "movielens"
dataset_dir = data_dir + "/ml-latest-small/"
!mkdir $data_dir
!cd $data_dir && wget http://files.grouplens.org/datasets/movielens/ml-latest-small.zip
!cd $data_dir && unzip ml-latest-small.zip
raw_ratings = pd.read_csv(dataset_dir + '/ratings.csv')
raw_movies = pd.read_csv(dataset_dir + '/movies.csv')
movie_rating = pd.merge(raw_ratings, raw_movies, how="left", right_on="movieId", left_on="movieId")
```
### What are the top 10 most rated movies?
We want to know better, what movies are top rated in our system. We use the merged dataframe of movies and ratings, group it by title and sort by the number of rows per movie to get the top 10 movies.
```python
top_ten_movies = movie_rating.groupby("title").size().sort_values(ascending=False)[:10]
top_ten_movies.plot(kind="barh")
```
If we build our recommender system based on ratings, we have to check if we have some bias in our data. It could happen that top rated movies are recommended more often compared to less rated videos in the end. This is something to be discussed with subject matter experts to have clear expectations.
### Are ratings in general more positive or negative?
We want to now more about the distribution of ratings. Our hypothesis is, that recommending low rated videos might not be a good user experience. On the other side we might not be too aggressive as it can lead to biased recommendation by ignoring those low rated videos. Maybe there are users that are still interested in low rated videos because they fit their favorite genre. Who knows?
Let us in a first step visualize the distribution of all ratings. In a next step we will categorize ratings that are lower than 3.0 as a negative rating. All other ratings will be categorized as a positive rating.
```python
raw_ratings['rating'].value_counts().sort_index().plot(kind='barh')
```
We now map each rating that is bigger than 3.0 to a positive sentiment and all other ratings to a negative sentiment.
```python
rating_sentiment = raw_ratings.copy()
rating_sentiment["sentiment"] = rating_sentiment["rating"].map(lambda x: "positive" if x > 3.0 else "negative")
rating_sentiment['sentiment'].value_counts().plot(kind='barh')
```
We now get an idea that the majority of ratings are "positive".
### How many videos are released per year?
```python
movies = raw_movies.copy()
movies['release_year'] = movies['title'].str.extract('\((\d{4})\)',expand = False)
movies = movies.dropna(axis=0)
movies['release_year'] = movies['release_year'].astype('int64')
movies['title'] = movies['title'].str.extract('(.*?)\s*\(', expand=False)
movie_year = pd.DataFrame(movies['title'].groupby(movies['release_year']).count())
movie_year.reset_index(inplace=True)
movie_year.plot(x="release_year", y="title", legend=False, xlabel="Release year", ylabel="Number of movies", figsize=(12, 6));
```
Movies range from release dates from 1902 till 2018. Since round about the year of 1980 the amount of released movies seems to be increasing more strongly. There is an interesting drop of releases round about in the year of 2012. In 2018 nearly the same amount of movies were release like in the end of the 70s.
If there were subject matter experts in place, those analysis might result in some very interesting question to better understand the driver of both the increase in the 80s but also the drop after 2010.
## 💡 Conclusions
Data exploration and the learnings you gained out of data puts yourself in an excellent position. Ideally you formulated the business problem you want to solve upfront. Define some relevant KPIs you want to improve. Based on your learnings you can now dive deeper into what is possible in your situation. Challenge your KPI definition or define additional hypotheses that will guide you on your journey.
---
Alexa says, time is over...see you next time.
I am not a data scientist and would never consider myself to have a deep knowledge in this context. But I have to admit that I am getting a bit obsessed about those things around data science, data exploration, analysis and data driven decisions. I observed a lot and tried to be the sponge that soaks up everything in this area.
Hence I am really interested in your feedback, experience and thoughts in the comments. 👋
---
Cover Image by Andrew Neel - https://unsplash.com/photos/z55CR_d0ayg | cremich |
855,454 | Mental Health and Personal Goals During Quarantine 2021 | I've been dissecting about my personal and professional progress over 2021 and I realized that I was... | 0 | 2021-10-07T18:45:14 | https://dev.to/lyavale95/mental-health-and-personal-goals-during-quarantine-2021-3lnh | discuss, career | I've been dissecting about my personal and professional progress over 2021 and I realized that I was just trying to survive and recover my past life through these months. To be honest I want to feel alive and focused again, and sometimes is too hard, life is more like a giant stack of hard work to do.
How did you recovered the motivation to continue with your projects?
During the 2020 quarantine I didn't aim a lot but at least I used my time to improve myself and study harder. | lyavale95 |
855,464 | Electron Adventures: Episode 76: NodeGui React Terminal App | Now that we've setup NodeGui with React, let's write a small app with it. It will yet be another... | 14,346 | 2021-10-07T19:18:29 | https://dev.to/taw/electron-adventures-episode-76-nodegui-react-terminal-app-52on | javascript, electron, react, qt | Now that we've setup NodeGui with React, let's write a small app with it. It will yet be another terminal app, but this time there's not much code we can share, as we'll be using Qt not HTML+CSS stack.
### DRY CSS
This is my first program in NodeGui. With CSS it's obvious how to write styling code in a way that doesn't repeat itself - that's what CSS have been doing for 25 years now. It's not obvious at all how to do this with NodeGui, as it doesn't seem to have any kind of CSS selectors. So prepare for a lot of copypasta.
### `src/App.jsx`
This file isn't too bad:
* state is in `history`
* `HistoryEntry` and `CommandInput` handle display logic
* since we can use arbitrary `node` we just use `child_process.execSync` to run the command we want
```javascript
let child_process = require("child_process")
import { Window, hot, View } from "@nodegui/react-nodegui"
import React, { useState } from "react"
import CommandInput from "./CommandInput"
import HistoryEntry from "./HistoryEntry"
function App() {
let [history, setHistory] = useState([])
let onsubmit = (command) => {
let output = child_process.execSync(command).toString().trim()
setHistory([...history, { command, output }])
}
return (
<Window
windowTitle="NodeGui React Terminal App"
minSize={{ width: 800, height: 600 }}
>
<View style={containerStyle}>
{history.map(({ command, output }, index) => (
<HistoryEntry key={index} command={command} output={output} />
))}
<CommandInput onsubmit={onsubmit} />
</View>
</Window>
)
}
let containerStyle = `
flex: 1;
`
export default hot(App)
```
### `src/HistoryEntry.jsx`
The template here is simple enough, but the CSS is quite ugly. `font-family: monospace` doesn't work, I needed explicit font name. I tried `gap` or `flex-gap` but that's not supported, so I ended up doing old style `margin-right`. And since there's no cascading everything about `font-size` and `font-family` is duplicated all over. There's also style duplication between this component and `CommandInput` - which could be avoided by creating additional mini-components. In HTML+CSS it wouldn't be necessary, as CSS can be set on the root element and inherited, or scoped with class selectors. I don't think we have such choices here.
```javascript
import { Text, View } from "@nodegui/react-nodegui"
import React from "react"
export default ({ command, output }) => {
return <>
<View styleSheet={inputLineStyle}>
<Text styleSheet={promptStyle}>$</Text>
<Text styleSheet={inputStyle}>{command}</Text>
</View>
<Text styleSheet={outputStyle}>{output}</Text>
</>
}
let inputLineStyle = `
display: flex;
flex-direction: row;
`
let promptStyle = `
font-size: 18px;
font-family: Monaco, monospace;
flex: 0;
margin-right: 0.5em;
`
let inputStyle = `
font-size: 18px;
font-family: Monaco, monospace;
color: #ffa;
flex: 1;
`
let outputStyle = `
font-size: 18px;
font-family: Monaco, monospace;
color: #afa;
white-space: pre;
padding-bottom: 0.5rem;
`
```
### `src/CommandInput.jsx`
And finally the `CommandInput` component. It shares some CSS duplication between elements and with the `HistoryEntry` component. One nice thing is `on={{ textChanged, returnPressed }}`, having explicit event for Enter being pressed looks nicer than wrapping things in `form` with `onsubmit`+`preventDefault`.
```javascript
import { Text, View, LineEdit } from "@nodegui/react-nodegui"
import React from "react"
export default ({ onsubmit }) => {
let [command, setCommand] = React.useState("")
let textChanged = (t) => setCommand(t)
let returnPressed = () => {
if (command !== "") {
onsubmit(command)
}
setCommand("")
}
return <View styleSheet={inputLineStyle}>
<Text styleSheet={promptStyle}>$</Text>
<LineEdit
styleSheet={lineEditStyle}
text={command}
on={{ textChanged, returnPressed }}
/>
</View>
}
let inputLineStyle = `
display: flex;
flex-direction: row;
`
let promptStyle = `
font-size: 18px;
font-family: Monaco, monospace;
flex: 0;
margin-right: 0.5em;
`
let lineEditStyle = `
flex: 1;
font-size: 18px;
font-family: Monaco, monospace;
`
```
### Overall impressions
So my impressions of dev experience are mostly negative because I'm used to HTML+CSS, and there's a lot of stuff that I take for granted in HTML+CSS that's absent here. But still, it's familiar enough that it doesn't feel like a completely alien environment.
Leaving browsers with their extremely complex APIs for Qt will likely mean it's going to be much easier to secure apps like this than Electron apps.
And for what it's worth, Qt has its own ecosystem of libraries and widgets, so it's totally possible there's something there that would be difficult to achieve with browser APIs.
Of all Electron alternatives I've tred, NodeGui has the most obvious story why you should consider it. NW.js is basically Electron with slightly different API and less popular; Neutralino is a lot more limited for no obvious benefit; NodeGui is Electron-like but it comes with very different set of features and also limitations.
### Results
Here's the results:
There are more "Electron alternatives", but I think I covered the most direct competitors, as I have zero interest in writing frontends in Dart, Rust, or C#. In the next episode we'll go back to the regular Electron and try some of the features we haven't covered yet.
As usual, [all the code for the episode is here](https://github.com/taw/electron-adventures/tree/master/episode-76-nodegui-react-terminal-app).
| taw |
855,912 | How to Cancel a Payment on Chime? | Chime has made it simple to send and receive money to and from contacts. Fast Payment feature of... | 0 | 2021-10-08T05:54:55 | https://dev.to/rs9088988/how-to-cancel-a-payment-on-chime-32kb | chimetransfer | Chime has made it simple to send and receive money to and from contacts. Fast Payment feature of Chime enable its users to transfer money very fastly. But sometimes it causes trouble, yes its happen due to send money to wrong person or incorrect amount. Sorry to say, Chime has no option to cancel a Payment once transaction completed. Only one condition in which you can cancel your Chime payment if its pending. So, be careful and alert while sending money. Any small mistake can lead you to lose your hard earned money.
To get more info visit : https://quickutilities.net/blog/cancel-a-payment-on-chime | rs9088988 |
856,142 | Conditional state update in useEffect | useEffect(() => { unsub = asyncFetch((d) => { setState(s => { ... | 0 | 2021-10-08T09:05:57 | https://dev.to/bobbers/conditional-state-update-in-useeffect-2od5 | react | ```
useEffect(() => {
unsub = asyncFetch((d) => {
setState(s => {
if(deepEqual(d,s))
return s
else return d
})
})
return unsub;
}, [])
```
This is what I want to do, but this code assumes that if I return s, then the state update won't trigger a rerender of the component. What's the best way to achieve this?
If I simply check against the state (conditional wrapping setState) instead of using `s` from the setState, I will always get the initial state set by `useState`. What I'm doing now is using useRef to always update a ref with the latest state so that I can access it in the callback, but I'm unsure if this can have unintended consequences as setState is asynchronous and I don't know if the effect will always run first thing after the state is updated to keep the ref in sync. What I would really need is a version of setState that allows returning a special value to abort the state update.
Thanks for your help. | bobbers |
856,154 | What is Mobile App Development : An Interactive Guide - 2021 | In the beginning of this decade, there were impressive predictions. Through in-app advertising and... | 0 | 2021-10-08T09:32:55 | https://dev.to/artistixe_it/what-is-mobile-app-development-an-interactive-guide-2021-33la | mobileapp, development, appdevelopment | In the beginning of this decade, there were impressive predictions. Through in-app advertising and app stores, mobile applications are predicted to generate around $700 billion. The fact that the development of mobile apps is spreading by leaps and bounds is encouraging, but there's a lot of mystery surrounding it. Only if you have a clearly defined goal and how to develop an app can you reach the pinnacle of success.
Why is Mobile App Development Important?
Apps are being downloaded and installed at a higher rate than ever before, as smartphones and smart devices continue to rise in popularity. Most businesses today rely on mobile apps to grow their customer base and attract more customers. By 2023, market experts project an increase in app revenue of 1 trillion dollars.
App Development Offers the Following Advantages:
Through effective communication between the developer and customer, the developer creates a loyal customer base.
The development of apps is a tried and tested method for ensuring your brand's all-pervasive presence.
The fastest way to let your customers know about potential offers or new products is through an app if you run a business.
It increases sales of your products/services when payment options are an integral part of the app.
Identify the Category of Apps You Are Looking For
No alt text provided for this image
Health care apps
This category contains more than one hundred thousand apps. Apps for healthcare have evolved beyond their original function of checking the health of users. A doctor and patient can communicate two-way with their appointments, ensure that appropriate drugs are administered, and make appointments.
Manufacturing apps
Your manufacturing process can be streamlined with integrated data analysis. Your workforce is more efficient with manufacturing apps as they systematically decrease the system's flaws.
Logistics
With today's technology, you can track your packages at the touch of a button. Therefore, you can also send ETA to your users. Managing your warehouse and monitoring your fleet is easy if you own a business.
Retail Apps
Apps for retail today serve a number of purposes. Rather than simply displaying products, it enhances the interaction between the customer and the business owner. Customers are also informed about the latest products, coupons, and exciting offers.
E-learning Apps
Professional courses are in greater demand today than ever before. Enrollment numbers are also rising. App developers have realized the need for online classrooms with engaging and interactive tutorials.
Financial Apps
In managing your finances, financial apps have been the backbone. The firm can help you manage your debt and make predictions before you invest. Today, you are literally at the tip of your fingers when it comes to your financial wellbeing.
Media Apps
An app that offers you a variety of movies, music, streaming services, and messaging can be considered a media app. In today's world, media apps focus on connecting people better, especially in times of pandemics. In the modern era, people are stuck within the confines of their own homes, so we have created a larger collection of movies and music than ever before
Food and Hospitality
During a vacation, you can book your bed and breakfast or the best restaurant in the area with a click of a button. With the advent of customer reviews, tourists can now have a more interactive experience with the app when it comes to local specialties and places to visit.
Mobile Platforms that Are Dominant
What Are the Different Development Approaches for Building Apps?
No alt text provided for this image
Native Apps
Apps that are native to a particular device unlock the full potential of the device and the app. Nevertheless, they are very costly and require a great deal of maintenance. This will give it good performance since APIs can be accessed directly. One of the disadvantages of native apps is that they require different code for each platform.
Cross-platform Applications
These applications are built using a variety of languages and frameworks. Because of this, they work on a wide range of platforms. They may have a single codebase, but maintenance requires efficient bridges. Performance is limited with native apps compared to web apps.
Hybrid Applications
JavaScript, HTML, and CSS are used to build these apps. The Android and iOS apps share the same codebase. Therefore, performance is lower than native applications.
Progressive Web Applications
Web-based applications. The browser allows you to use web applications without installing anything. Apps can be installed on the home screen and run in the background.
Technologies Used in Mobile Applications
React Native
It is a part of the Javascript library, so it shares a code base. Apps that run across platforms can be created with it. In addition to this, React includes a reusable code system that is applicable to a variety of scenarios.
Flutter
Google's toolkit can be found here. Flutter can be used to build native applications across multiple platforms with a single codebase. Since the architecture is layered, there are options for customisation.
Ionic
When compared to other processes, this mobile application development is more rapid. The reason for this is that it comes with inbuilt UI components, themes, and styles. Additionally, the application features adaptive styles and is interactive. The application runs smoothly across multiple operating systems because of this.
Six phases form the basis of a focused approach to app development. Let's take a closer look at them:
1. Strategizing
To turn an idea into a working app, the first phase of app development is to have a clearly defined policy. This process should also include your enterprise mobility strategy. It is important to identify the key demographics that will use the app during this phase. Your competitors should be known to you. It is very important for a mobile app development company to be clear about the app's objectives before deciding on a platform.
2. Planning and Analysis
You will be able to tell when your idea is transformed into a real project. The first thing you do is analyze the scenarios in which your application can add value as well as the functional requirements to get started. Once you know all of these things, you should create a product roadmap that charts the progress of your idea from its very first day until its eventual execution.
You should also include the requirements and the date by which you expect a milestone to be achieved. It would be good to have an MVP available if cost is a concern.
A key element of the planning process is identifying the skills required for app development. You'll need developers who understand how to use these technology stacks if you plan on developing an Android or iOS app. Your app needs a name, and you need to check if it has already been taken.
3. UI/UX Design
An impression of your mobile application is greatly influenced by the way it looks. No matter whether you want to launch a complete product or an MVP, the user experience must be top-notch.
When users interact with your app, they are simply evoking emotions. App development must address the issues of design, accessibility, usability, system performance, and marketing to maximize user experience. It makes sense to create an interactive and seamless UX when you build apps with more and more companies shifting to a more user-centric approach.
In order to make the app appealing to users, you must make the UI presentable. Good UX design companies create UIs which evoke a feeling of curiosity and make the user want to know more about the application that they have developed.
Information Architecture
As part of your app development process, you should also have a systematic understanding of the data that your app will display, the data that will be taken from the user, and the user's navigational journey within the app.
Different businesses have different users with different privileges and functions, so it is crucial to enable these information to be stored in the information architecture within business mobility.
In addition to this, you should also draw out a workflow diagram to see the possible combinations of interactions between the app and the user.
Wireframes
Wireframes are essentially digital sketches. Applicant's aesthetics are represented by these screenshots. Develop the layout so you can review the design before finalizing it in an effective manner. Ideally, any application you design should be device-specific. As a result, it is important to clarify whether your app runs on Android, iOS, as the user experience will differ.
Style Guides
Designers use a style guide as a guide when they are designing. It can be difficult for a designer to create wireframes because of the complexity. He must choose a font while designing. It is important that the color scheme matches the vision of the application. A decision needs to be made regarding where certain icons should be positioned.
Any app's productivity and efficiency can be increased by focusing on the style guide during the development process. In addition, style guides allow you to chart your product's evolution
Mockups
You have a high-fidelity final rendering of the app when you apply the standards of the style guide to the wireframe. You can make further changes to the interface, the information architecture, and the workflow once the mockup is ready. These mockups are often created by UI designers using Adobe Photoshop. Figma and Sketch are also popular apps.
Prototype
A prototype is a dynamic first rendition of the app which you can use to simulate the user experience, while mockups are static images that give you an idea of the layout of the app. Additionally, a prototype reviews the workflow that can be expected from the final product.
Although building a prototype can be expensive and time-consuming, it makes sense to do so. App development teams can use this data to determine if the app lacks anything and make necessary changes before the launch. Prototype building can be done with Invision.
4. App Development
App development usually consists of three parts. Backend/server technology is the first step, followed by API(s), and finally mobile app front end development.
Backend Technology
The backend of a mobile app is used to store, secure, and process data. Backend refers to the process that occurs when the user interacts with the UI. The backend stores information in a remote database, which allows the creation of the architecture. There is no need for a backend in applications that do not require data connection.
API(s) development
Today, there is hardly any app that does not stay connected to servers. App developers often use Amazon, Google, or internal teams to provide APIs.
API development is a very sensitive process, and making requests through servers can be tricky if not done correctly. APIs can be bought and built. You can integrate an API into your application if you buy it. It will save you time and money, but you will have to give up the freedom to include features of your choice. An app developer team develops the latter.
In addition to documenting APIs, you should keep this in mind during the process of developing a mobile app. Documentation can give you an overview of the app's history and current state. It is easier to form updates this way. It is possible to allow others access to your API by documenting it.
Front End Development
The front end of a mobile application is what the users actually see and interact with. Apps for mobile devices will use interactive experiences for the user that are enabled by the backend and API. Applications that don't use APIs will store their data locally. The backend of an app can be developed in any programming language. You will need to use a platform-specific technology stack when using native applications.
Apps for iOS can be developed using Flutter or React Native, for example. Java and Kotlin can be used to develop apps for Android, in addition to the others mentioned earlier. A mobile app developer should understand the pros and cons of each language before selecting one.
5. Testing a Developed Application
No alt text provided for this image
In any mobile app development program, quality checking is one of the most important phases. With quality hecking, the app is more usable, more secure, and more stable. This process requires you to prepare test cases that address all the qualities of the app. Manual or automatic testing is possible.
Test cases provide answers regarding the viability of an app development, just as use cases provide answers regarding its viability. You can follow the following types of testing procedures
User Experience Testing
A well-designed application matches the expectations of the user experience curated by the design team. According to the style guide, the app will leave a good impression on the reader. Use aesthetic color schemes and fonts in your app, and ensure a consistent design. As soon as your app meets these standards, it can be launched.
Functional Testing
By using this method, you can ensure that all your specifications are justified in your app. The app will be used differently by every user, and therefore mobile app development must take this into account. Finding out if your app has a bug can be done through functional testing. The app might need to be fixed if the outcome is different for two similar actions. The app should be available on two platforms so that two versions of the application can be compared. The functionality of an application can also be broken down into various components to be analyzed.
Performance Testing
Performance testing in app development is aimed at determining whether the app can perform consistently even with different loads. During this test, an important question will be answered, such as how well it responds to user requests and how fast screens load. It will also test the app's effect on the device, determining if it drains the battery or causes memory leaks. In addition, it raises the important question of whether your app is too big. The development of mobile apps should also consider how the app performs when multiple users are logged in.
Security Testing
Mobile app development is concerned with achieving a security standard that cannot be compromised. A hacker can exploit any vulnerability. Occasionally, the work is outsourced for thorough examination. Logins should be recorded in the device and on the backend if your app requires them. The user should be able to terminate the session if they haven't interacted for some time
The security of your device should be emphasized in case your mobile app development also allows a user's credentials to be stored on the device. Apple's keychain feature, for example, allows users to store credentials and not worry about losing them.
Device and Platform Testing
Testing web apps is easy, but testing mobile apps should be far more frequent since new devices are continuously being released with new firmware, operating systems, and designs. It is therefore important to test mobile apps across different platforms and simulators to ensure the app works properly on all of them.
Because it is more expensive to develop multiplatform apps, most companies opt for single-platform apps. You can follow device testing as one of the best tools to ensure sustainability if you are wondering how to build an app.
Recovery Testing
Testing your app's recovery means assessing its ability to recover from failures. One of the most important things you should realize if you are considering how to create an app is that it can fail, but what matters is how quickly it relaunches.
Beta Testing
An app is beta tested by real users in terms of App development terminology. In mobile app development, beta testing ensures the product's reliability, security and compatibility. Through beta testing, a large group of users evaluates the application for loopholes. In-app purchases are also checked for reliability.
Certification testing is the final form of testing. App developers should follow the standards set by the Apple and Play Stores so there will be no difference between the devices and the apps they create.
6. Mobile App Deployment
An app must be submitted to the app store of the device in order to be launched. After the mobile app development process is complete, you will need to create a developer's account in order to submit your app. Meta-data for the release of the app will include the following:
The Title of the App
Description of the App
Category
Keywords
App store screenshots
An Android app becomes a part of the app store after a few hours. With the Apple store, however, there will be a review process that will determine how well your app follows the store's guidelines. It is necessary to create a test account for the store if users will need to log in.
Once your app has been approved for the store, check out feedback and crash reports. As part of quality control after app development, key analytics and performance indicators should be used.
After Mobile App Development Is Completed, How Can Quality Be Maintained?
After the app development process, it is crucial to update the app interface. When the users do not have anything new to look forward to, they will likely switch to the competing app that provides similar features.
You can never build an app if you want to keep it compatible with new hardware and software updates.
Mobile app development includes fixing bugs as well, and it can show your dedication to ensuring the quality of your application to your customers.
Getting feedback from your customers after developing mobile apps should provide you with useful information for developing new features. Users may decide to switch to another app if your app doesn't excite them.
Conclusion
Artistixe IT Solutions LLP is an efficient Mobile App Development Company that offers a carefully curated selection of technologically diverse products and services. To get in touch, mail us at info@artistixeit.com if you have a project that needs attention.
https://www.sooperarticles.com/internet-articles/web-development-articles/what-mobile-app-development-interactive-guide-2021-1820125.html
| artistixe_it |
892,404 | Choosing Software Engineering | Originally posted on June 27th, 2021. This is a fairly new journey for me. The first step was the... | 0 | 2021-11-09T00:08:59 | https://dev.to/cmwilson21/choosing-software-engineering-43di | Originally posted on June 27th, 2021.
This is a fairly new journey for me. The first step was the hardest. While the journey hasn’t gotten any easier, it has definitely gotten more fulfilling.
I decided to look into the world of coding back in January. My brother went to a bootcamp in 2014 and it changed his life. He has been encouraging me to look into it for a while now, but I’m stubborn and was content with where I was in life. Fast-forward to 2020, and I, like so many others, had some time to really think about where I wanted to be and what I wanted to be doing. I was happy with my job, working for my family’s machine and fabrication shop. There was never anything wrong with working there, but I needed to step away and figure out who I am outside of the family work. I’d been doing it my whole life, so, with my family’s support, it was time for a change.
I had always had an interest in tech and gadgets. That has helped in this decision to pursue software engineering. After trying out a few free courses, I fell in love with it. Even when it’s frustrating, hard, and maddening, I truly enjoy it. I appreciate the fact that there’s always more to learn in this world. There will always been new opportunities for improvement. There will always be another step to be taken. It won’t always be easy, but it will be worth it. | cmwilson21 | |
856,188 | My learning from creating tools for developers | Once you cross the beginner's level as a developer, some questions should start arising in your... | 0 | 2021-10-08T10:55:00 | https://dev.to/abmsourav/my-learning-from-creating-tools-for-developers-1m6p | programming, opensource, webdev | Once you cross the beginner's level as a developer, some questions should start arising in your head...
1. How does a developer think?
2. Why does he need that xyz tool?
3. How does a tool solve a problem?
4. What's happening behind the scenes in that xyz tool?
5. How to think in a generic/global way from a problem-solving perspective?
Wait, don't Google these questions, because these are kinda questions where you need to realize the answer, you need to feel the answer.
So, what's the process, how will we know the answers?
For me the answer is "creating open-source developers tools". I mean, creating open-source tools that will be used by other developers. When you start creating developer tools, your brain starts adopting millions of developers' thought processes. It's a journey where you'll learn the answers to those questions. But if you want to know more than those answers then you need to create multiple personalities in you.
Which are:
=> A problem solver,
=> An observer,
=> A person who has Childish perspective.
.
#### Dev Tools developed by me
[BD API](https://bdapis.herokuapp.com/)
[LocalDB](https://www.npmjs.com/package/@abmsourav/localdb)
These projects are managed by my GitHub organization. Feel free to contribute on these open-source projects on [CodesVault](https://github.com/CodesVault)
.
Feeling positive energy, huh?
Now here's a trap. When you want to create a dev tool, lots of ideas will come to your brain. You will peck the most complex one and then after doing some google search, you will know that those types of tools already exist in many ways.
Then after repeating this process for multiple times you'll lose that positive energy :(
So, the hack is don't find unique, complex ideas. Find the idea that sounds extremely easy to you, and in your thought process you already know the implementation.
| abmsourav |
856,265 | Context vs Redux: What to Choose? | If maintenance and understanding of the data flow in the application is your thing and you care... | 0 | 2021-10-08T12:18:00 | https://dev.to/frontend_house/context-vs-redux-what-to-choose-51n7 | {% youtube pk4XwxdYUnY %}
If maintenance and understanding of the data flow in the application is your thing and you care about making the way of passing data more efficient, this episode is a perfect match.
Context vs Redux: What to choose? Listen to Piotr and get your questions answered 💡
🟣 What is the application state?
🟣 Passing props through components
🟣 Tools to manage application state: Context API and Redux
🟣 Advantages of Context
🟣 Advantages of Redux
🟣 Which one should you choose?
You can also read the article at [Frontend House](https://frontendhouse.com/experts-zone/context-vs-redux-what-to-choose-experts-zone-6) | frontend_house | |
856,373 | How to setup Firefox Developer Edition on Ubuntu | Do you want to install and use Firefox Developer Edition on your Ubuntu and don’t know how to go... | 0 | 2021-10-08T12:43:02 | https://dev.to/harrsh/how-to-setup-firefox-developer-edition-on-ubuntu-4inp | firefox, ubuntu, developer, mozilla | Do you want to install and use Firefox Developer Edition on your Ubuntu and don’t know how to go about it?! If your answer is yes, then this article is for you. Am sure you’ve seen some documentations out there but in this one we will add Firefox Developer Edition to our Unity launcher. You’re welcome! 😉
Please follow the steps below…
**Step 1**
Download the firefox*.tar.bz2 file from **[Mozilla’s website](https://www.mozilla.org/en-US/firefox/developer/)**.
**Step 2**
Open Terminal.
**Step 3**
Navigate to the folder where the file is saved.
**Step 4**
Copy firefox*.tar.bz2 file to the /opt folder.
```
sudo cp -rp firefox*.tar.bz2 /opt
```
**Step 5**
Delete the downloaded firefox*.tar.bz2 file.
```
sudo rm -rf firefox*.tar.bz2
```
**Step 6**
Navigate to the /opt directory.
```
cd ~
cd /opt
```
**Step 7**
Un-tar the firefox*.tar.bz2 file in opt folder.
```
sudo tar xjf firefox*.tar.bz2
```
**Step 8**
Delete the firefox*.tar.bz2 file in opt folder.
```
sudo rm -rf firefox*.tar.bz2
```
**Step 9**
Change ownership of the folder containing Firefox Developer Edition /opt/firefox
```
sudo chown -R $USER /opt/firefox
```
**Step 10**
Create the Firefox Developer Edition's shortcut
```
nano ~/.local/share/applications/firefox_dev.desktop
```
The content of this file is,
```
[Desktop Entry]
Name=Firefox Developer
GenericName=Firefox Developer Edition
Exec=/opt/firefox/firefox %u
Terminal=false
Icon=/opt/firefox/browser/chrome/icons/default/default128.png
Type=Application
Categories=Application;Network;X-Developer;
Comment=Firefox Developer Edition Web Browser.
StartupWMClass=Firefox Developer Edition
```
**Step 10**
Mark the launcher as trusted and make it executable.
```
chmod +x ~/.local/share/applications/firefox_dev.desktop
```
-------------------------
I hope this article has helped you to set-up your new Firefox Developer Edition.
**Thank you** | harrsh |
856,520 | 📹Play video in cells in Google Sheets | This article is just for my fun. Today I'm playing with Google Sheets API and got an idea I could... | 0 | 2021-10-08T15:54:32 | https://dev.to/ku6ryo/play-video-in-cells-in-google-sheets-58d2 | googlesheets, fun, typescript | This article is just for my fun. Today I'm playing with Google Sheets API and got an idea I could play a video in a sheet using cells like pixels.
TL;DR This is the final result!😉 (The following video frame refresh is x10 faster than actual. I edited by a video editor.)
# How it works
I prepared 160 x 90 cells in a Google Sheet and changed cell colors by using Google Sheets API. The API has a API to change cell colors by one API call in bulk. I called the API for each video frame and played a video.
# Step 1: Extract frames from a video
First, I converted the famous video "Big Bunny" to JPG images by using ffmpeg. I used 1 image per second and generated 300 images. According to my experiments, Google Sheets API needs ~3 sec to refresh cell colors by a API call so I selected much less images than video frames. And I resized the image frame from 1280x720 to 160x90 to align with the number of the cells in my sheet. I used Jimp for the resizing.
Sorry for my dirty code lol
```javascript
const ffmpeg = require("ffmpeg")
const path = require("path")
const FRAMES = 300
const Jimp = require("jimp")
// Extract images and store them in ./images folder
try {
const p = new ffmpeg(path.join(__dirname, "./video.mp4"))
p.then(function (video) {
video.fnExtractFrameToJPG(path.join(__dirname, "./images"), {
frame_rate: 1,
number: FRAMES,
file_name: "%s"
}, function (error, files) {
if (!error)
console.log("Frames: " + files);
});
}, function (err) {
console.log("Error: " + err);
});
} catch (e) {
console.log(e.code);
console.log(e.msg);
}
// Resizing
;(async () => {
for (let i = 1; i < FRAMES + 1; i++) {
const image = await Jimp.read(path.join(__dirname, "./images", "1280x720_" + i + ".jpg"))
image.resize(160, 90).write(path.join(__dirname, "./images", "160x90_" + i + ".jpg"))
}
})()
```
# Step 2: Apply pixel colors to cells
Google Sheet API's `batchUpdate()` function is the one I used. The API spec is not clear enough to see what we can do with it. So I recommend you to check the type files of googleapi npm module and estimate how functions work. (That's a reason why I used TypeScript. Type check is helpful to work with unknown libraries.) In the value passed to the `batchUpdate()`, you see `updateCells` key, right? That's the property to update cell format. The key points are
- Read pixel colors and create a cell update request for each pixel
- Use n and n + 1 value for startColumnIndex, endColumnIndex to update Nth cell
- Please do not forget specify `fields: "userEnteredFormat"` even if the field is optional as the type of TypeScript
- RGB colors should be given in the range from 0 to 1
If you're not familiar with setup for using Google Sheets, I recommend to read [my another article](https://dev.to/ku6ryo/google-sheets-api-in-typescript-setup-and-hello-world-10oh).
```typescript
import { google } from "googleapis"
import path from "path"
import Jimp from "jimp"
const SHEET_ID = "your sheet id"
const SERVICE_ACCOUNT_EMAIL = "your service account email"
const SERVICE_ACCOUNT_PRIVATE_KEY = "your private key"
const FRAMES = 300
// Video resolution
const WITDH = 160
const HEIGHT = 90
;(async () => {
const auth = new google.auth.JWT({
email: SERVICE_ACCOUNT_EMAIL,
key: SERVICE_ACCOUNT_PRIVATE_KEY,
scopes: ["https://www.googleapis.com/auth/spreadsheets"]
})
const sheet = google.sheets("v4")
for (let i = 1; i <= FRAMES; i++) {
const image = await Jimp.read(path.join(__dirname, "./images/", `${WITDH}x${HEIGHT}_${i}.jpg`))
const requests: any[] = []
for (let j = 0; j < WITDH; j++) {
for (let k = 0; k < HEIGHT; k++) {
const c = image.getPixelColor(j, k)
const { r, g, b } = Jimp.intToRGBA(c)
const req = {
updateCells: {
range: {
sheetId: 0,
startColumnIndex: j,
endColumnIndex: j + 1,
startRowIndex: k,
endRowIndex: k + 1,
},
fields: "userEnteredFormat",
rows: [{
values: [{
userEnteredFormat: {
backgroundColor: {
red: r / 255,
green: g / 255,
blue: b / 255,
alpha: 1,
}
}
}],
}],
}
}
requests.push(req)
}
}
await sheet.spreadsheets.batchUpdate({
auth,
spreadsheetId: SHEET_ID,
requestBody: {
requests,
}
})
}
})()
```
| ku6ryo |
856,523 | Week 7 Blog Post | Write a blog post about considerations when building a web component and considerations when... | 0 | 2021-10-11T16:21:58 | https://dev.to/francescaansell/week-7-blog-post-472k | #####Write a blog post about considerations when building a web component and considerations when building the element's API (metacognition of the exercise we engaged in)
In order to create a web component is is important to consider what parts and standards are needed. This is good practice when creating any sort of coding project. Some things that we are considering when building a webcomponent are:
- What are the characteristics of the card?
- What design considerations must we take into account?
- What accessibility concerns do we potentially have?
- What security concerns do we potentially have?
- What "states" does this card have?
- What do we call it?
- What areas do we need to account for flexible content / HTML entry of any kind?
- Do we have room for additional reusable atoms to be produced?
- What should we call each of them?
All of these consideration could be applied to different projects (such as how we used them in our button project.)
######How you are going to break it down into multiple elements
In this assignment our card will have a scaffold, banner, and icon. This will allow the card to be even more usable by the programmer. The banner and icon web components can be interchanged with different banners and icon. This allows for lots of personalization and reusability which is very important.
######What do you expect to be difficult
I expect splitting up the work for this assignment to be difficult. I do not understand how each person will be able to do a different part of the card and still distribute the work equally. The person working on the scaffold will have to wait until the icon is down etc. Because I am isolating it is also difficult to understand assignment descriptions because most include slang.
######What's more manageable now that you made the button
After completing the button I have a decent idea of how web components are constructed and then used as their own tag. I also understand the idea of properties and states which in the past I have found difficult.
https://github.com/3B4B/project-two
| francescaansell | |
856,524 | Support The Sample Programs Repo This Hacktoberfest | As of today, we’re a week into hacktoberfest, and I’m wondering: how is it going for you? Have you... | 0 | 2021-10-08T15:24:41 | https://therenegadecoder.com/meta/support-the-sample-programs-repo-this-hacktoberfest/ | hacktoberfest, github, opensource, showdev | As of today, we’re a week into hacktoberfest, and I’m wondering: how is it going for you? Have you completed your four pull requests yet? If not, may I interest you in a project that is open to pull requests from anyone who has programming experience. Don’t believe me? Keep reading!
## What Is the Sample Programs Repository?
In early 2018, I was in the middle of a transition between industry and academy, and I was looking for a way to take advantage of the free time. Back then, I was interested in learning programming languages, so I decided to leverage 100 days of code to write one hello world program in a new language every day.
During that journey, [I started writing articles to describe the programs](https://therenegadecoder.com/code/sample-programs-in-every-language/) I had written. It was a great way to get exposure to various programming languages, so I kept doing it for awhile.
Of course, after several dozen languages, I decided I had enough of surveying the landscape. As a result, I figured it was time to expand the collection to include other types of programs. For example, the first two programs I added were reverse a string and game of life. Together with hello world, [the Sample Programs repository](https://github.com/TheRenegadeCoder/sample-programs) was born.
{% github TheRenegadeCoder/sample-programs %}
Today, the Sample Programs repository features an overwhelming [162 programming languages and 604 code snippets](https://github.com/TheRenegadeCoder/sample-programs/wiki/Alphabetical-Language-Catalog). Of course, these numbers are always growing, so the collection could feature many more code snippets by the time you read this. Also, remember how I mentioned the collection featured three types of programs? Well, [now it features over 40](https://sample-programs.therenegadecoder.com/projects/).
In short, the Sample Programs repository is a collection of code snippets in as many programming languages as possible. Why not come share you knowledge with us?
## Who Is Eligible to Support the Sample Programs Repository?
At its core, the Sample Programs repository has always been a place for learning. As a result, **anyone should able to make a contribution** regardless of size of impact.
With that said, things are different from when I set out on this journey in 2018. These days there isn’t a lot of room for folks who are familiar with popular languages such as [Python](https://github.com/TheRenegadeCoder/sample-programs/tree/main/archive/p/python) and [JavaScript](https://github.com/TheRenegadeCoder/sample-programs/tree/main/archive/j/javascript). At the time of writing, Python has code snippets for 30 out of 40 possible projects, and folks are often quick to fill the missing code snippets.
As a result, I think the best way to approach the Sample Programs repository is to use it as a tool for learning a new language. For example, [Julia](https://github.com/TheRenegadeCoder/sample-programs/tree/main/archive/j/julia) is a relatively new programming language that has a lot of support from its community. However, it lacks support in the Sample Programs community with currently only 7 of the possible 40 code snippets completed.
Another thing that is cool about the Sample Programs repository is that it’s not all code snippets. We also have built-in testing for as many of our code snippets as possible. Unfortunately, this feature was added more recently, so it’s not totally fleshed out. As a result, if you’re interested in working on testing, there’s more information on that in the next section.
Like testing, we also support documentation. For example, [if you check out the Python README](https://github.com/TheRenegadeCoder/sample-programs/tree/main/archive/p/python), you’ll see a list of programs in the repo. Anything marked with a green checkmark has documentation. As a result, if you’re interested in supporting our documentation efforts, there’s more information on that in the next section.
Beyond that, I generally encourage anyone who’s willing to support a project like this long term to check it out. Or at the very least, [check out our Discord](https://discord.gg/Jhmtj7Z) and get to know some folks who are writing code for the Sample Programs repo.
## What Kind of Work Can One Accomplish During Hacktoberfest?
Previously, I talked a bit about the major facets of the Sample Programs repository that folks might find interesting. That said, the vast majority of work that goes into the repo during Hacktoberfest is code snippets. Then, throughout the year, we spend a lot of our time getting ready for the next Hacktoberfest. However, why limit yourself? Here’s a list of the types of things you can help us with this Hacktoberfest:
- Contribute code snippets to less popular programming languages (e.g., [Julia](https://github.com/TheRenegadeCoder/sample-programs/tree/main/archive/j/julia), [Clojure](https://github.com/TheRenegadeCoder/sample-programs/tree/main/archive/c/clojure), etc.)
- [Write tests in Python](https://github.com/TheRenegadeCoder/sample-programs/tree/main/test) for currently untested projects (e.g., maximum array rotation, etc.)
- Write tests in YML for currently untested languages (e.g., quack, etc.)
- Write documentation for the copious amounts of undocumented code snippets (PLEASE)
- Develop a prettier Jekyll website for the documentation
- Assist in various automation tools for the repository
If any of these things interest you, feel free to reach out. Alternatively, you can head straight over to the Sample Programs repository and [read the contributing doc](https://github.com/TheRenegadeCoder/sample-programs/blob/main/.github/CONTRIBUTING.md) for more specific details.
In general, however, we are going to try to resist new projects as we’re already quite behind on testing and documentation. If you have any ideas for new projects outside of the 40 existing projects, we ask that you write documentation and testing for them before we’ll accept any code snippets. In other words, you’re welcome to contribute to the popular languages as long as you’re willing to define new projects fully.
## How Do I Support the Sample Programs Community?
If Hacktoberfest isn’t your thing, but you’d still be interested in helping out the community, there are several ways to do that. First, the Sample Programs repo is maintained by The Renegade Coder organization—or rather myself. In other words, any of the ways you can currently support The Renegade Coder will also support the Sample Programs repository. For example, here are just a few ways you can help out:
- [Join our Discord](https://discord.gg/Jhmtj7Z)
- [Become a Patron](https://www.patreon.com/TheRenegadeCoder)
- Share this article
- [Follow me on Twitter](https://twitter.com/RenegadeCoder94)
Also, if you’re interested in keeping up with what’s going on in the various Sample Programs repositories, [I maintain a series about exactly that](https://therenegadecoder.com/series/sample-programs-repo-news/). Check it out to learn more about the history of the project.
Likewise, I’m not the only one who continues to maintain this repository. As always, there are many, many folks that deserve thanks. However, none deserve more thanks than [@auroq](https://github.com/auroq) who was responsible for getting the testing off the ground for the Sample Programs repo. Feel free to give them a shoutout!
While I’m here, I should mention that [I recently made a template repo](https://therenegadecoder.com/meta/practice-your-coding-skills-with-the-sample-programs-template/), so folks could make their own Sample Programs repo. Maybe this Hacktoberfest, forget the Sample Programs repo. Make your own! I’d love to see how folks make use of that template.
With that said, that’s all I have to say about this year’s Hacktoberfest. If it’s your first time, I hope you get a chance to find a community that supports you. | renegadecoder94 |
856,559 | Five methods for JavaScript to detect mobile browsers | If you are a front-end developer you need to know whether the user is using a mobile browser or a... | 0 | 2021-10-15T08:34:44 | https://dev.to/thesabesan/five-methods-for-javascript-to-detect-mobile-browsers-1jhc | javascript, webdev, programming, tutorial | If you are a front-end developer you need to know whether the user is using a mobile browser or a desktop browser. Based on [StackOverflow](https://stackoverflow.com/questions/11381673/detecting-a-mobile-browser) , this article sorts out five methods for JavaScript to detect mobile browsers.

---
## __1. `navigator.userAgent`__
The easiest way is to analyze the user agent string of the browser, which contains the device information.
JS gets this string through the `navigator.userAgent` property, as long as it contains keywords such as `mobi`, `android`, `iphone`, etc. It can be identified as a mobile device.
```JS
if (/Mobi|Android|iPhone/i.test(navigator.userAgent)) {
// The current device is a mobile device
}
// Another way of writing
if (
navigator.userAgent.match(/Mobi/i) ||
navigator.userAgent.match(/Android/i) ||
navigator.userAgent.match(/iPhone/i)
) {
// The current device is a mobile device
}
```
The advantage of this method is simple and convenient, but the disadvantage is that it is unreliable. The user can modify this string to make the mobile browser pretend to be a desktop browser.
Chromium browsers also have a `navigator.userAgentData` property, which has a similar effect. The difference is that it parses the user agent string into an object and the `mobile` attribute of the object returns a Boolean value indicating whether the user is using a mobile device.
```JS
const isMobile = navigator.userAgentData.mobile;
```
Note that Apple's Safari browser and Firefox browser do not support this attribute. you can check the [CanIUse website](https://caniuse.com/mdn-api_navigator_useragentdata) for more details.
In addition, there is an abolished [`navigator.platform`](https://stackoverflow.com/questions/19877924/what-is-the-list-of-possible-values-for-navigator-platform-as-of-today) property, which is supported by all browsers, so it can also be used. It returns a string that represents the user's operating system.
```JS
if (/Android|iPhone|iPad|iPod/i.test(navigator.platform)) {
// The current device is a mobile device
}
```
---
## __2. `window.screen`, `window.innerWidth`__
Another method is to determine whether it is a mobile phone by the width of the screen.
The `window.screen` object returns the screen information of the user device. The `width` property of this object is the width of the screen (in pixels).
```JS
if (window.screen.width < 500) {
// The current device is a mobile device
}
```
In the above example, if the screen width `window.screen.width` is less than 500 pixels, it is considered a mobile phone. The disadvantage of this method is that if the mobile phone is used horizontally, it cannot be recognized.
Another property window.innerWidth returns the width of the visible part of the webpage in the browser window, which is more suitable for specifying the style of the webpage under different widths.
```JS
const getBrowserWidth = function() {
if (window.innerWidth < 768) {
return "xs";
} else if (window.innerWidth < 991) {
return "sm";
} else if (window.innerWidth < 1199) {
return "md";
} else {
return "lg";
}
};
```
---
## __3. `window.orientation`__
The third method is to detect the orientation of the screen. The phone screen can change its orientation (horizontal or vertical) at any time, but it cannot be done on desktop devices.
The `window.orientation` property is used to get the current orientation of the screen. Only mobile devices have this property. Desktop devices will return `undefined`.
```JS
if (typeof window.orientation !== 'undefined') {
// The current device is a mobile device
}
```
> _Note that the iPhone’s Safari browser does not support this attribute._
---
## __4. touch event__
The fourth method is that the DOM element of the mobile browser can specify the listener function for the touch event through the ontouchstart attribute. Desktop devices do not have this attribute.
```JS
function isMobile() {
return ('ontouchstart' in document.documentElement);
}
// Alternative way of writing
function isMobile() {
try {
document.createEvent("TouchEvent"); return true;
} catch(e) {
return false;
}
}
```
---
## __5. `window.matchMedia()`__
The last method is to judge with CSS.
CSS uses media query (media query) to specify responsive styles for web pages.If a certain media query statement for a mobile phone takes effect, the current device can be considered as a mobile device.The `window.matchMedia()` method accepts a CSS media query statement as a parameter to determine whether this statement is valid.
```JS
let isMobile = window.matchMedia("only screen and (max-width: 760px)").matches;
```
In the above example, the parameter of `window.matchMedia()` is a CSS query statement, which means that it only takes effect on devices with a screen width of no more than 760 pixels. It returns an object whose `matches` attribute is a boolean value. If it is `true`, it means that the query is valid and the current device is a mobile phone.
In addition to judging by the screen width, you can also judge by the accuracy of the pointer.
```JS
let isMobile = window.matchMedia("(pointer:coarse)").matches;
```
In the above example, the CSS statement `pointer:coarse` indicates that the pointer of the current device is imprecise. Since the mobile phone does not support the mouse, it only supports touch, so it meets this condition.
Some devices support multiple pointers, such as mouse and touch at the same time. `pointer:coarse` is only used to determine the primary pointer, and there is also an `any-pointer` command to determine all pointers.
```JS
let isMobile = window.matchMedia("(any-pointer:coarse)").matches;
```
In the above example, `any-pointer:coarse` means that among all the pointers. As long as one pointer is inaccurate, it meets the query conditions.
---
## __6. Toolkit__
In addition to the above methods, you can also use a toolkit written by others.Recommended here is [react-device-detect](https://www.npmjs.com/package/react-device-detect), which supports device detection with multiple granularities.
```JS
import {isMobile} from 'react-device-detect';
if (isMobile) {
// The current device is a mobile device
}
``` | thesabesan |
856,594 | 你真的需要多元支付嗎? | 多元支付當道的現代,開店不收個 XX Pay... | 0 | 2021-10-08T16:49:08 | https://editor.leonh.space/2020/do-you-really-need-multiple-payments-way/ | payment | 多元支付當道的現代,開店不收個 XX Pay 好像古代人一樣,但是導入多元支付對店家來說究竟需要考慮哪些因素呢?在開始談多元支付的利與弊之前,先來談談市面上有哪些多元支付,現在可說是多元支付的戰國時代,除了信用卡、悠遊卡、一卡通、LINE Pay、街口以外,有更多沒聽過也沒用過的業者都在擠進這個市場,畢竟一筆交易就能抽 2% ~ 3% 的💰 ,誰不想呢。
## 多元支付的分類
一般人認知的多元支付,不外乎那些通用型的 XX Pay,但若把它們歸納一下,可以依照運作機制的不同做個簡單的分類。
### 實體信用卡
<figure>

<figcaption>POS Credit Card Machine</figcaption>
<figcaption>圖片來自 <a href="https://unsplash.com/photos/bqjswIxbhEE">Mark OFlynn</a></figcaption>
</figure>
就是最單純的信用卡,店家需要和銀行簽約,由銀行提供卡機,並依照交易金額向**店家**收取 1.X% ~ 3.X% 不等的費用,常見的發卡組織有 JCB、Mastercard、VISA、AE、銀聯等,信用卡發行機構則大多是銀行,[樂天信用卡](https://card.rakuten.com.tw)是目前台灣唯一非銀行的發卡機構,不過等樂天銀行開幕之後應該也會把信用卡業務併入。
本文的實體信用卡的分類也包括簽帳金融卡,也就是國外的 debit card,雖然在銀行端和消費者扣款的機制不同,但對店家端的操作與帳務處理都是一樣的。
### 行動信用卡
<figure>

<figcaption>圖片來自 <a href="https://unsplash.com/photos/Xn5FbEM9564">Blake Wisz</a></figcaption>
</figure>
Apple Pay、Google Pay、台灣 Pay 這類把實體卡片虛擬化的支付,在這裡把它們歸類為行動信用卡。
以 Apple Pay 為例,消費者把信用卡登錄進去之後,Apple Pay 會產生一組虛擬信用卡號,消費時打開 Apple Pay,手機和卡機之間透過和感應式信用卡同樣的 RFID / NFC 無線技術進行刷卡作業。除了 Apple Pay 之外,其他家也都有各自的交易機制,但使用上不脫卡機感應和 QR code 掃碼兩種。
感應式行動信用卡刷卡對店家來說,和一般的實體感應卡的操作和帳務處理作業方式是一樣的,不用另外增添設備,只要確定卡機本身是支援感應刷卡的即可,POS 端也不用做特別的處理,對消費者來說也和一般實體感應卡是一樣的,消費扣款是直接扣卡片的信用額度,並沒有「儲值錢包」的概念。
若是用 QR code 的方式,對店家來說,就不能只靠卡機,需要在 POS 端做支援才能使用。
### 電子支付、電子票證
<figure>
<figcaption>圖片來自 <a href="https://unsplash.com/photos/ENtCxRV1Boo">Markus Winkler</a></figcaption>
</figure>
目前台灣的法規,把一卡通、悠遊卡以電子票證的法令管理([電子票證發行管理條例](https://law.moj.gov.tw/LawClass/LawAll.aspx?pcode=G0380207)、[電子票證發行機構業務管理規則](https://law.moj.gov.tw/LawClass/LawAll.aspx?pcode=G0380210)),而 LINE Pay (Money)、街口等則是以電子支付法令管理([電子支付機構管理條例](https://law.moj.gov.tw/LawClass/LawAll.aspx?pcode=G0380237)、[電子支付機構業務管理規則](https://law.moj.gov.tw/LawClass/LawAll.aspx?pcode=G0380245)),[未來會整合成新的電子支付法令](https://www.chinatimes.com/newspapers/20201008000243-260205?chdtv)統一管理,即便目前管轄法規上有所不同,但不論對消費者或店家而言,應用上都是一樣的。
目前這個領域上的品牌有一卡通、和一卡通結盟的 LINE Pay 和 LINE Pay Money、悠遊卡和悠遊付、iCash 和 iCash Pay、街口等,雖然有這麼多參賽者,但也只有 LINE Pay 和街口能互爭一二,其他在大眾消費市場幾乎可以無視,只存在於某些特殊場域,如學校、販賣機、停車場、大眾運輸、醫院等。
前面提的電子支付和電子票證界線模糊的趨勢也可以從支付業者的走向看出一二,原本的電子票證業者(一卡通、悠遊卡、iCash、HappyCash)也都申請了電子支付的牌照,推出了電子支付的產品,一卡通是和 LINE 結盟推出 LINE Pay Money,悠遊卡自己推出悠遊付,iCash 的 iCash Pay,HappyCash 的 HAPPY GO Pay 等。
電子支付的消費都是從消費者的儲值錢包內扣款,而錢包的儲值則大多是連結消費者的銀行帳戶,從儲值錢包扣款後會進入電子支付業者的帳戶,商家再與電子支付業者在固定週期進行對帳和結款。雖然 QR code 掃碼認證動作很簡單,但背後的資料交換的邏輯其實很複雜,身為資訊廠商的我們,當然也要[把複雜的機制包裝得很簡單優雅](https://editor.leonh.space/2020/the-principle-of-designing-pos/)。
另外一種情境是在電子支付 app 內設定好連結的信用卡,消費者一樣是透過 QR code 掃碼支付,電子支付業者再再向發卡機構請款和拆帳,這種情境雖然有牽涉到信用卡,不過那是支付業者、發卡機構、消費者三方的關係,對店家來說,與儲值錢包扣款一樣,都只要與電子支付業者做對帳與結款即可。
### 其他代收業者
<figure>

<figcaption>圖片來自 <a href="https://unsplash.com/photos/dwBZLRPhHjc">Kai Pilger</a></figcaption>
</figure>
代收業者,像是黑貓、Uber Eats、Foodpanda,他們的雖然都不是支付,但它們的確幫店家代收了款項,也因此有對帳和結款的作業產生,因此就廣義的來看,它們也應當算是支付的一種。
### 專用型支付
最後一種是集團或品牌的專用支付,像全聯的全聯支付、全家超商的 My FamiPay 等,這類通路限定的支付因為場景有所侷限,就不多做討論。不過另外一提的是統一集團的 iCash / iCash Pay 和遠東集團的 HappyCash / HAPPY GO Pay 並非自家集團限定,而是通用型的支付,只是出了集團外就沒人用而已,所以還是歸類在上面的電子支付和電子票證內。
### 整理
| 種類 | 收款方式 | 結款對象 | 代表業者 | 抽成 |
|-------------------------------------|--------------------|--------------|--------------------------|---------------------------------------------------------------|
| 實體信用卡 | 信用卡機刷卡或感應 | 發卡機構 | 各家銀行 | 1.X% ~ 2.X% |
| 行動信用卡<br><small>感應型</small> | 信用卡機感應 | 發卡機構 | Apple Pay、Google Pay | 1.X% ~ 2.X% |
| 行動信用卡<br><small>掃碼型</small> | QR code | 發卡機構 | 台灣 Pay | 1.X% ~ 2.X% |
| 電子支付 | QR code | 電子支付業者 | LINE Pay (Money)、街口 | 2.X% ~ 3.X% |
| 電子票證 | 票證感應卡機 | 電子票證業者 | 一卡通、悠遊卡 | 1.X% ~ 2.X% |
| 外送代收 | 代收 | 外送業者 | Uber Eats、Foodpanda | 3.X% |
| 宅配代收 | 代收 | 宅配業者 | 中華郵政、宅配通、宅急便 | 宅配每件 55 ~ 65<br>低溫每件 155 ~ 160<br>貨到付款每件外加 30 |
## 多元支付的利與弊
雖然現在支援 XX Pay 好像是理所當然的,但作為一個經營者,決定導入新支付前,最好還是把資訊轉化成能量化的數字。
支付業者在招攬店家時,大部分對店家的吸引手法大多是行銷面的,譬如說宣傳物曝光、會員數量、積點方案、聯合行銷企劃等等,但難就難在這些對業主來說可能都是難以量化成數字的資訊,在採用XX支付後,究竟帶來的新業績能不能大於那 2% ~ 3% 要貢獻給支付業者的費用,其實大部分業者心裡都沒個底,如果沒有仔細評估的話,很有可能就像下圖的苦主,整體營業額沒成長,反倒是XX支付的佔比越來越高,苦主要貢獻給XX支付的費用也越來越高,這種就是典型的誤交損友,不僅沒幫到你,還吃掉你的收入。
<figure class="wide">
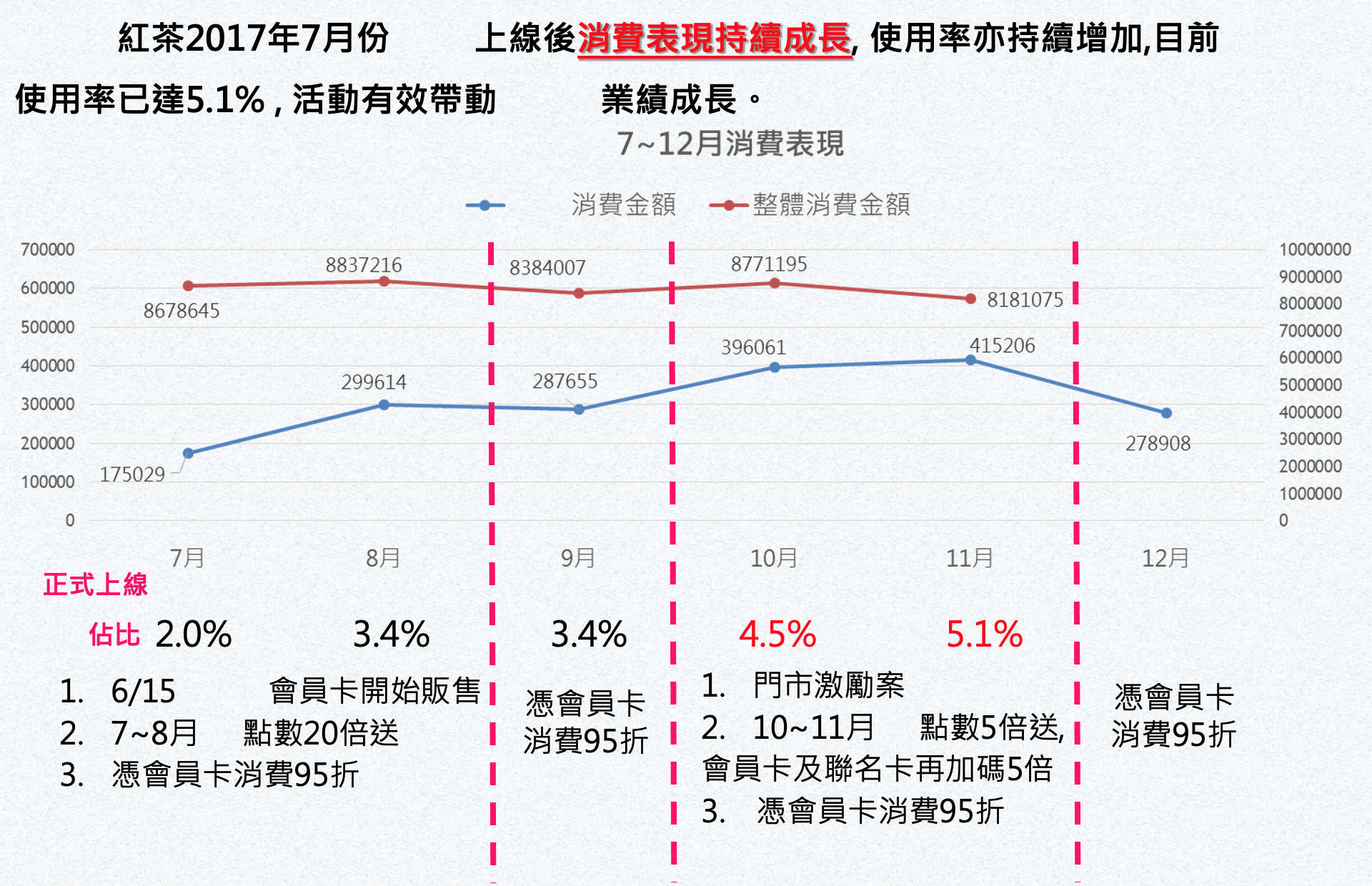
<figcaption>紅線是整體營業額,藍線是XX支付的營業額</figcaption>
</figure>
看上圖說故事,紅茶苦主導入XX支付後,還配合支付業者玩了一大堆行銷活動,包括打折促銷,最後換來的是整體營業額完全沒成長,又因為打折賣自砍毛利所以收入減少,還要再付每筆 2.X% 的費用給支付業者。
看完苦主的例子,身為經營者,在面對支付業者招攬時那些行銷時的話語,真的應該靜下來思考到底那些行銷方案對你的生意到底是把餅做大還是跟你搶餅乾屑。
回到量化的主題,除了向支付業者要求過往類似店家的數據參考外,自己店內的營業數據也是很好的參考對象,舉例來說,我們可以從客群特徵來推估他們對XX支付的愛好度,在以未成年為主要客群,或者平均客單五百元以內的店家來說,顯然導入信用卡不是個好主意;或者店面位址較差的店家,那主動經營外送業務就是必要的動作,事實上參數是列不完的,每個店家又都有自己的營業特性,不存在一個萬用的公式套用在所有業者身上,但各位經營者心中應該都要有自己的一把尺,在決策時最好還是靜下心來想想導入新支付的利弊得失。
| leon0824 |
856,698 | What makes languages "fast" or "slow"? | In his article Naser Tamimi compares C++ and Python and this is what he observed: As you can see... | 0 | 2021-10-09T17:20:38 | https://dev.to/vibalijoshi/what-makes-languages-fast-or-slow-3l44 | beginners, tutorial, programming, performance |
In his article [Naser Tamimi](https://towardsdatascience.com/how-fast-is-c-compared-to-python-978f18f474c7) compares C++ and Python and this is what he observed:

As you can see Python is much slower than C++, but in reality no programming language is fast or slow. The machine code generated by the programming language is either simple or complex.
## All Languages have the same goal
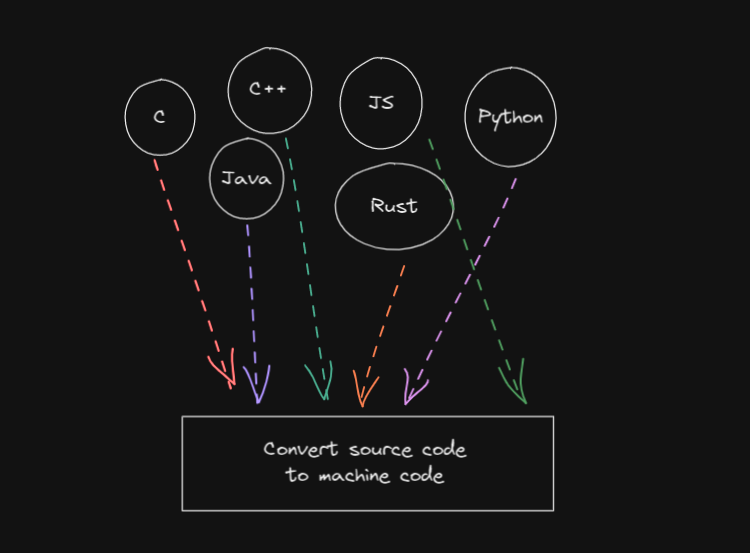
- The low level languages like the machine code (displayed in binary digits) runs very fast because no translation program is required for the CPU, but it very inconvenient to write.

- High Level Languages (HLL) such as C++ and JavaScript provide a simple human language-like environment for programmers to communicate with computers.
- Programming languages may differ in their syntax, but the common goal of all of them is to generate Machine Code, which is the only language that a computer can understand.
**As a result, it all comes down to how the code is converted into machine code.**
To understand this, we must first understand the differences between statically and dynamically typed programming languages.
## Statically and Dynamically Typed Languages
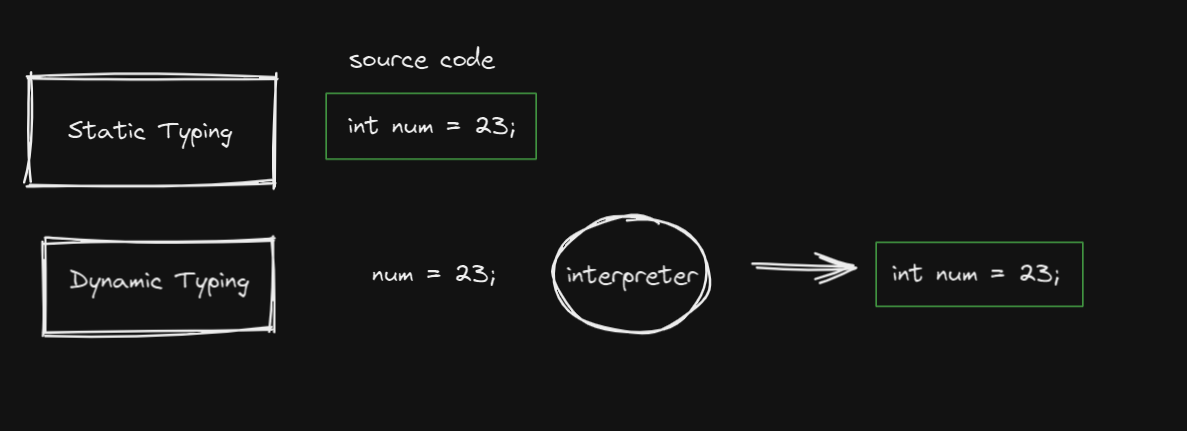
**Statically-typed Language**
- A statically typed language is one in which variable types are known at the time of compilation. The data types of the variables must be specified in statically-typed languages, and once defined, the variable type cannot be modified. eg: C, C++, Rust, Java
```cpp
/* C++/C code */
int number_1 = 1; //integer
number_1 = "digit"; //ERROR! cannot be changed to string
```
- At compile time, type verification is performed. As a result, these checks will catch things like missing functions, invalid type arguments, or a mismatch between a data value and the type of variable it's allocated to before the program runs.
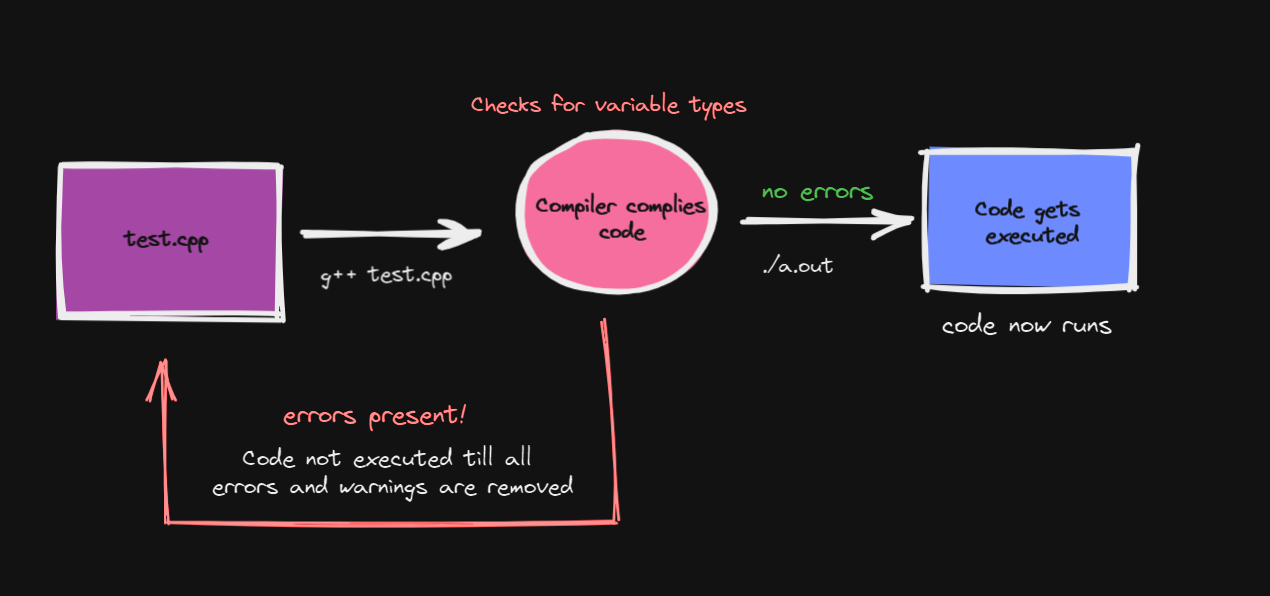
- A programmer can't run code unless it passes these type checks, thus it pushes them to rectify bugs by throwing errors and warnings during the compilation process.
- A substantial number of errors are discovered early in the development process.
**Dynamically-typed languages**
Those where the interpreter assigns variables a type at runtime based on the variable's value at the time. Eg: JavaScript, Python
```js
var name;
name = 57;
name = "Vibali"; //this will not throw any error.
```
There is no compilation phase in JavaScript. Instead, a browser interpreter examines the JavaScript code, understands each line, and then executes it.
If the type checker identifies an issue at this point, the developer will be notified and given the option to fix the code before the program crashes.
- You don't have to wait for the compiler to finish before testing your code modifications because there isn't a separate compilation process. This makes the debugging process much faster and easier.
> Related:
> [Difference between Compiler and Interpreter](https://www.geeksforgeeks.org/difference-between-compiler-and-interpreter/)
### How does this matter?
Look at this python example:
```python
# Python 3 program to find
# factorial of given number
def factorial(n):
if n < 0:
return 0
elif n == 0 or n == 1:
return 1
else:
fact = 1
while(n > 1):
fact *= n
n -= 1
return fact
```
_What is the value of n? Is it a numerical value? Is it string? Is it a class you created previously?_
The interpreter has no way of knowing what kind of data it will get. At run-time, you have to do a lot more checking, which implies you're doing more implicit work for basic actions.
All of these lookups are _extremely_ difficult to complete quickly.
*As a result, the time it takes to generate machine code increases, making these languages appear slower.*
On the other hand the Statically Typed languages like C++ or Java results in compiled code that executes more quickly because when the compiler knows the specific data types that are in use, it can produce **optimized machine code (i.e. faster and/or using less memory)**.
### Which language should I choose?
- This isn't to say that languages like JavaScript aren't useful. It is entirely dependent on the use case. Each language focuses on a distinct aspect. Dynamic typing allows programmers to construct types and functionality based on run-time data, but it comes at the sacrifice of speed.
- Programmers can fine-tune their code to operate effectively in any context, even when there is little hardware space or energy available to power the application, by using C, C++, or Rust when building an operating system driver or file system.
So it all depends on the task that we want to achieve.
Let me know in the comments below which language you prefer and why.
| vibalijoshi |
856,708 | A practical tracing journey with OpenTelemetry on Node.js | I've talked a good deal about observability, tracing and instrumentation in the past. Recently, I decided to try out some new things in those areas, ... | 0 | 2021-10-08T17:44:08 | https://blog.shalvah.me/posts/a-practical-tracing-journey-with-opentelemetry-on-node-js | observability, node | I've talked a good deal about observability, tracing and instrumentation in the past. Recently, I decided to try out some new things in those areas, and here's how it went.
## The challenge
In my app [Tentacle](http://usetentacle.app), there's an internal Node.js API which is called by the main app from time to time. This API in turn calls other external services, often more than once, and it can take anywhere from one to ten seconds for the whole thing to end, depending on the external services. I wanted to see how I could improve speed. Yes, the external service might be slow, but perhaps there was some way I could improve things on my end—better configuration, improved logic in handling the response, parallelization? I decided to add tracing so I could see if there were bottlenecks I could fix.
If you aren't familiar with tracing, think of it as being able to look _inside_ your service to see what's going on. If I could instrument my app, I'd be able to view traces of my requests, which would show details about what my app did and how much time it spent. I've used Elastic APM and Sentry for tracing before, and there are other vendors as well, but I decided to try [OpenTelemetry](https://opentelemetry.io/).
## Why OpenTelemetry?
The idea behind OpenTelemetry is to be a "neutral" standard. It's like cables for charging your devices: each vendor can make something that works with their devices \(eg Apple & Lightning cables\), but USB was created so we could have a single standard, so in an emergency, you could borrow your friend's charging cable and know it works in your device.
OpenTelemetry \(or "OTel" for short\) is a set of vendor\-agnostic agents and API for tracing. "Vendor\-agnostic" doesn't mean you won't use any vendors, but that you aren't bound to them; if you have issues with Elastic \(say, cost, features, or UX\), you can switch to a different vendor by changing a few lines in your configuration, as long as the vendor supports the OpenTelemetry API. It's a beautiful idea, in theory. In practice, it has a few rough edges; for example, vendor\-specific options often offer better UX than OTel.
Personally, I'd have preferred Sentry, since I use them for error\-monitoring, but Sentry's tracing features are expensive. Elastic is free and open\-source, but I didn't want to have to bother about running three components \(Elasticsearch, Kibana and APM Server\); even with Docker, Elasticsearch in production can still be a pain. I'd read and talked a lot about OpenTelemetry, so I figured it was time to actually use it.
## Setting up locally
Tracing is most useful in production, where you can see actual usage patterns, but first I wanted to try locally and see if I could gain any insights. To set up OpenTelemetry, I'd need to install the agent and an exporter, then configure the agent to send to that exporter. An exporter is a backend \(storage \+ UI\) where I can explore the traces.
Setting up OTel took a while to get right \(unfortunate but unsurprising\). There was documentation, but it was confusing and outdated in some places. Eventually, I came up with this in a `tracing.js` file \(which I'll explain in a bit\):
```js
const openTelemetry = require("@opentelemetry/sdk-node");
const { HttpInstrumentation } = require("@opentelemetry/instrumentation-http");
const { ExpressInstrumentation } = require("@opentelemetry/instrumentation-express");
const { ZipkinExporter } = require("@opentelemetry/exporter-zipkin");
const { Resource } = require('@opentelemetry/resources');
const { SemanticResourceAttributes } = require('@opentelemetry/semantic-conventions');
const sdk = new openTelemetry.NodeSDK({
resource: new Resource({
[SemanticResourceAttributes.SERVICE_NAME]: 'tentacle-engine',
[SemanticResourceAttributes.DEPLOYMENT_ENVIRONMENT]: process.env.NODE_ENV,
}),
traceExporter: new ZipkinExporter(),
instrumentations: [HttpInstrumentation, ExpressInstrumentation],
});
module.exports = sdk;
```
Holy shit, that is a ton of very\-intimidating\-looking code \(and it gets worse later😭\). In Elastic APM and Sentry, it would have been less than 4 lines. But on we go. The gist of the code is that it sets the service name to `tentacle-engine`, sets the exporter as Zipkin, and enables the automatic instrumentation of `http` and `express` modules. The service doesn't use any database or caching, so I didn't enable those.
Let's talk about the exporter. Because OTel is an open standard, you can theoretically export to any tool that supports the OTel API. For example, there's a `ConsoleExporter` included that prints traces to the console, but that's not very useful. There's an exporter to Elasticsearch, and you can write your own library to export to a file or database or whatever. However, two of the most popular options are [Jaeger](https://www.jaegertracing.io) and [Zipkin](https://zipkin.io/), and you can easily run them locally with Docker.
I tried both options, but decided to go with Zipkin because it's easier to deploy. Plus it has a slightly better UI, I think. Running Zipkin with Docker was easy:
```bash
docker run --rm -d -p 9411:9411 --name zipkin openzipkin/zipkin
```
And then I modified my `app.js` to:
* wait until tracing had been initialized _before_ setting up the Express app
* wait until all traces were sent before exiting \(when you hit Ctrl\-C\)
So it went from this:
```js
const express = require('express');
const app = express();
app.post('/fetch', ...);
// ...
const gracefulShutdown = () => {
console.log("Closing server and ending process...");
server.close(() => {
process.exit();
});
};
process.on("SIGINT", gracefulShutdown);
process.on("SIGTERM", gracefulShutdown);
```
to this:
```js
const tracing = require('./tracing');
tracing.start()
.then(() => {
const express = require('express');
const app = express();
// ...
const gracefulShutdown = () => {
console.log("Closing server and ending process...");
server.close(async () => {
await tracing.shutdown();
process.exit();
});
};
// ...
});
```
It was quite annoying to move that code into a `.then`, but it was necessary: the `express` module has to be fully instrumented before you use it, otherwise the tracing won't work properly.
Finally, I was ready. Started my app and made some requests, opened Zipkin on localhost:9411, and the traces were there.
## Inspecting and inferring
Now let's take a look at what a trace looks like. Here's the details view for a trace:
On the right, we have tags that contain relevant information about the trace. For example, an HTTP request would include details about the path, user agent, request size. On the left, we have the trace breakdown, showing the different spans that happened during the request. Think of a span as an action, like an incoming/outgoing request, a database or cache query, or whatever represents a "unit of work" in your app. In this request, we have 14 spans \(1 parent and 13 children\). We have spans recorded for each of our Express middleware, and then spans for the calls we made to the external services \(`https.get`\), 9 of them. \(All these spans were captured automatically because we configured OTel to use the `HttpInstrumentation` and `ExpressInstrumentation` earlier.\) Now, what can we glean from these?
First off, the bottleneck isn't in the framework or our code. You can see that the Express middleware take only microseconds to execute. Meanwhile the external requests take up almost _all_ the time. You can see the first request alone takes 1.34s.
Let's hypothesize. Okay, the external site is obviously slow \(and my local Internet is slow too\), but how can we optimize around this? I decided to try switching my request client from [got](https://www.npmjs.com/package/got) to the new, fast Node.js client, [undici](https://www.npmjs.com/package/undici). Maybe I could shave some tens of milliseconds off?
I made a couple of requests, and here are the results. Using `got` first, and `undici` after. The duration each request takes is shown on the right.
Well, what do you think?
The first thing I'm going to say is that this is not just an _unscientific_ benchmark, but a _bad_ one. It's silly to draw conclusions based on 10 requests made on my machine. So many factors could affect the performance of both libraries—fluctuating connection speeds \(Nigerian internet does this a lot\), machine features, machine load, etc. A more "scientific" benchmark would be to write a script that triggers hundreds of requests in mostly stable conditions and returns useful statistics like the average, max and standard deviation.
But there's an even better option: run _both_ libraries in production for real\-world requests, and see if there's a meaningful gain from undici. I learnt this approach from GitHub's [Scientist](https://github.com/github/scientist). Sadly, this article is about tracing, not experimentation, so I won't continue down that path now, but I hope to write another article about it soon. My implementation would probably be to have a switch that randomly picks one of the two libraries for each request. Then I'll compare the metrics and see which performs better over time. `undici` also has some differences from `got`, so I'll need to double\-check that it works correctly for my use.
That said, from these preliminary tests, it looks like most of undici's requests are faster than most of got's, but I'll hold off on switching until I can experiment in production.
Another thing I wanted to see was if I could reduce the number of external service calls, or parallelize them, maybe. You'll notice from the original trace I posted that there are 9 HTTP requests, done in three sets \(1, then 3 in parallel, then 5 in parallel\). I went through my code again, and realized two things:
1. I couldn't parallelize any better; it had to be 1\-3\-5, because of dependencies on the response.
2. In this particular case, I could actually get rid of the first external call\!
Yup, it turned out that I _could_ remove the first request. It would lead to more requests overall, but only two parallel sets. So I decided to try, and...
Compare these with the very first screenshot I posted—the previous times were around 3 seconds or more, while these are around 2 seconds. Big win\!
Here's what a single trace looks like now:
Like I said, more requests, but in less sets, leading to an overall time savings. However, once again, I decided to hold off on making the change permanent; I'll spend some more time and tests to be sure the endpoint logic still works consistently for all inputs with the first call removed.
I can't make the changes immediately, but it's obvious that tracing has been helpful here. We've moved from guessing about what works and what doesn't to seeing actual numbers and behaviour. It's awesome.
## Manual instrumentation
One problem with using undici is that it uses the `net` module, not the `http` module, making it difficult to instrument. If we use undici as our request client, we won't see any spans for `http.get` in Zipkin. If I enable OTel's `NetInstrumentation`, there'll be spans, but they will be for TCP socket connection events, not for a complete request\-response cycle:
So I did some manual instrumentation to mark the request start and end, by wrapping each external call in its own custom span:
```js
const { request } = require('undici');
function wrapExternalCallInSpan(name, url, callback) {
const tracer = openTelemetry.api.trace.getTracer('tentacle-engine');
let span = tracer.startSpan(name, {}, openTelemetry.api.context.active());
span.setAttribute('external.url', url);
const context = openTelemetry.api.trace.setSpan(openTelemetry.api.context.active(), span);
return openTelemetry.api.context.with(context, callback, undefined, span);
}
// Promise version
const makeRequest = (url) => {
return wrapExternalCallInSpan('first external call', url, (span) => {
return request(url)
.then((response) => {
span.setAttribute('external.status_code', response.statusCode);
return response.body.text();
})
.catch(handleError)
.finally(() => {
span.end();
});
});
};
// async/await version
const makeRequest = (url) => {
return wrapExternalCallInSpan('second external call', url, async (span) => {
try {
let response = await request(url);
span.setAttribute('external.status_code', response.statusCode);
return response.body.text();
} catch (e) {
return handleError(e);
} finally {
span.end();
}
});
};
```
And we've got this\!

Now, even without auto\-instrumentation for undici, we can still get a good overview of our requests. Even better, if we switch back to got, we see the `https.get` spans nested under our custom spans, which gives an insight into how much time was actually spent in the request versus in handling the response.

\(PS: I'm naming the spans things like "first external call" here, but in my real codebase, they're named after what the request does, e.g. "check API status", "fetch user list".\)
## Capturing errors
I mentioned earlier that I'd have preferred to use Sentry. The reason for that \(besides UX\) is _correlation_. When an uncaught exception happens in my app, I'm able to view it in Sentry. However, I might want to view more details about what happened in that request. Sentry allows you to do this by [attaching "context"](https://docs.sentry.io/platforms/node/enriching-events/context/).
But sometimes, I might need more. I might want to investigate a report deeper, for instance, to see where the error was caused \(my main app or the internal service\), or when the error occurred \(was it before or after the first set of external calls?\), or how long the calls took and what they returned. So it's often ideal to have both error\-monitoring and tracing in the same place. But I can't, so the next best thing is to make it easy to correlate.
To do that, I'll do two things:
1. Add the trace ID to the Sentry context, so I can copy it from Sentry and look it up in Zipkin, and vice versa.
2. Add some basic error details to the OTel trace, so I can see the error info right there.
```js
const tracing = require('./tracing');
tracing.start()
.then(() => {
const express = require('express');
const app = express();
// Custom Express middleware: add the current trace ID to the Sentry context
app.use((req, res, next) => {
const { traceId } = getCurrentSpan();
Sentry.setContext("opentelemetry", { traceId });
next();
});
app.post('/fetch', ...);
// 500 error handler: store the error details as part of the trace
app.use(function onError(err, req, res, next) {
const currentSpan = getCurrentSpan();
const { SemanticAttributes } = require('@opentelemetry/semantic-conventions');
currentSpan.setAttributes({
[SemanticAttributes.EXCEPTION_MESSAGE]: err.message,
[SemanticAttributes.EXCEPTION_TYPE]: err.constructor.name,
[SemanticAttributes.EXCEPTION_STACKTRACE]: err.stack,
});
currentSpan.setStatus({
code: require("@opentelemetry/sdk-node").api.SpanStatusCode.ERROR,
message: 'An error occurred.'
});
res.status(500).send(`Something broke!`);
gracefulShutdown();
});
// ...
});
function getCurrentSpan() {
const openTelemetry = require("@opentelemetry/sdk-node");
return openTelemetry.api.trace.getSpan(openTelemetry.api.context.active());
}
```
Let's test this out. I'll enable Sentry on my local machine and add a line that crashes, `console.log(thisVariableDoesntExist)`, somewhere in my request handler. Here we go\!
Here's the exception context in Sentry:
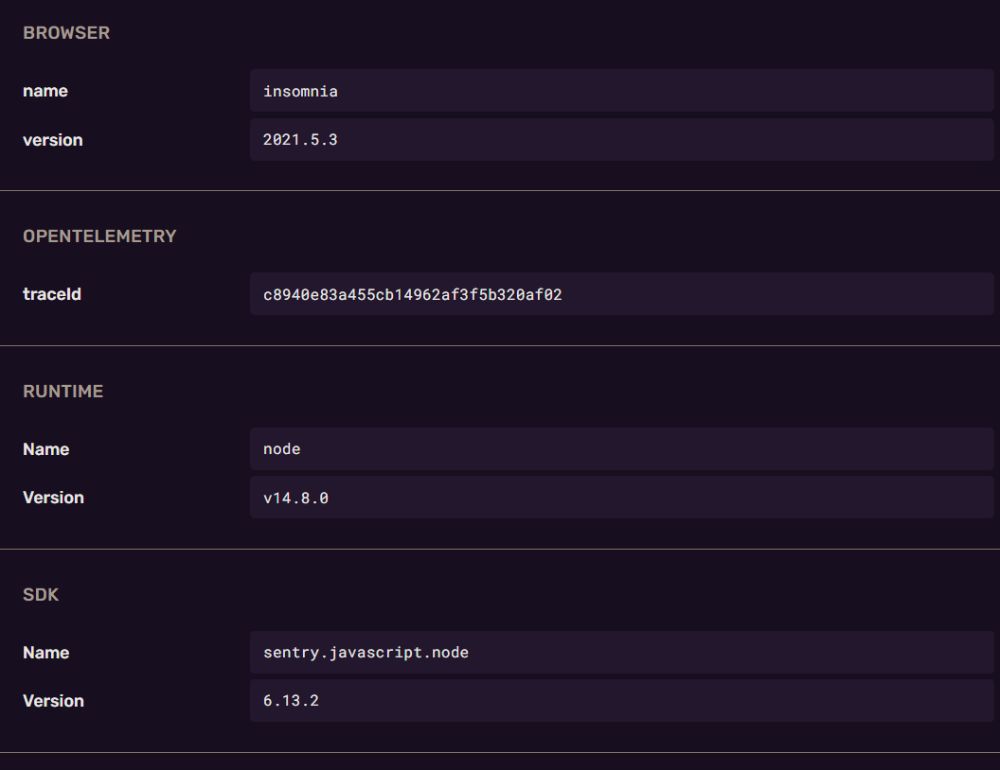
And we can take that trace ID and search for it in Zipkin \(top\-right\):
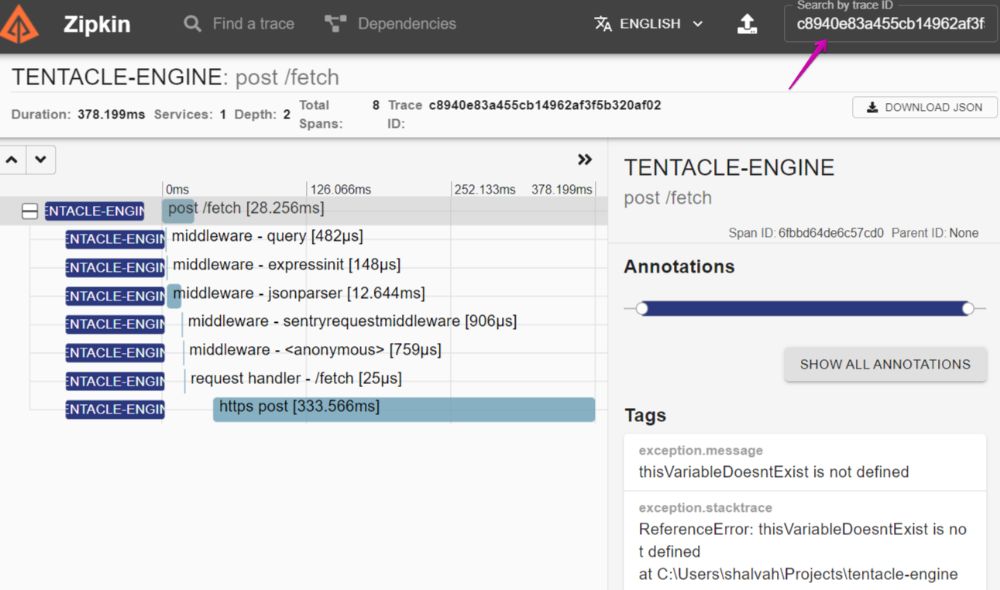
You can see the extra `exception.` attributes we added to the span in the right panel. And if we scroll further down, you'll see that the rest of the usual span attributes are there as well, allowing us to glean more information about what was going on in that request. On the left you can see a breakdown of all the action that happened, so we know at what stage the error happened. \(There's an extra `https.post`, from the request to Sentry's API, and it happens after the 500 response has been sent.\) We've successfully tied our Sentry exceptions with our OpenTelemetry traces.
## \(Thinking about\) Going live
We could stop here, since we've gained some useful insights, but tracing is best in production, because then you're not just looking at how you're using the app, but at how real\-world users are using it.
In production, there are more things to consider. Is your app running on a single server or across multiple servers? Where is your backend \(Zipkin\) running? Where is it storing its data, and what's the capacity? For me, the two biggest concerns were storage and security. My app runs on a single server, so obviously Zipkin was going to be there as well.
1. Storage: I would have to write a script to monitor and prune the storage at intervals. I could, but meh.
2. Security: I would need to expose Zipkin on my server to my local machine over the public Internet. The easiest, secure way would be whitelisting my IP to access port 9411 each time I want to check my traces. Stressful.
Honestly, I don't like self\-hosting things, but I was willing to try. Luckily, I found out that some cloud vendors allow you to send your OTel traces to them directly. [New Relic](https://docs.newrelic.com/docs/integrations/open-source-telemetry-integrations/opentelemetry/introduction-opentelemetry-new-relic/) gives you 100 GB/8 days of retention on the free plan, while [Grafana Cloud](https://go2.grafana.com/tempo-on-grafana-cloud.html) gives you 50 GB/14 days. I decided to go with New Relic, because their traces product is more mature and has more features I need, like viewing traces as graphs and filtering by span tags.
This complicates things a bit. There's no direct exporter library to New Relic, so we'll have to use yet another library: the [OpenTelemetry Collector](https://opentelemetry.io/docs/collector/). There's a good reason we won't export directly to New Relic: it will have an impact on our application if we're making HTTP requests to New Relic's API after every request. The OTel collector runs as a separate agent on your machine; the instrumentation libraries will send traces to the collector, which will asynchronously export them to New Relic or wherever.
Here's what our `tracing.js` looks like now:
```js
//...All those other require()s
const { CollectorTraceExporter } = require('@opentelemetry/exporter-collector');
const sdk = new openTelemetry.NodeSDK({
// ...Other config items
traceExporter: new CollectorTraceExporter({
url: 'http://localhost:4318/v1/trace' // This is the Collector's default ingestion endpoint
}),
});
```
To test this locally, we'll run the OTel Collector via Docker. First, we'll create a config file that tells it to receive from our OTel libraries via the OpenTelemetry Protocol \(OTLP\) and export to our local Zipkin \(for now\):
```yaml
receivers:
otlp:
protocols:
http:
exporters:
zipkin:
# This tells the collector to use our local Zipkin, running on localhost:9411
endpoint: "http://host.docker.internal:9411/api/v2/spans"
service:
pipelines:
traces:
receivers: [otlp]
processors: []
exporters: [zipkin]
```
Then we start the OTel Collector container:
```bash
docker run --name otelcol -p 4318:4318 -v ./otel-config.yaml:/etc/otel/config.yaml otel/opentelemetry-collector-contrib:0.36.0
```
\(Note: I'm using the `opentelemetry-collector-contrib` distribution rather than the core `opentelemetry-collector` because the contrib version has additional processors we'll need later.\)
This works. Our traces still show up in Zipkin, but now they're sent by the collector, not directly from our libraries.
Switching to New Relic was pretty easy. I changed the collector config to export to New Relic's ingest endpoint, with my API key:
```yaml
# Other config...
exporters:
otlp:
endpoint: https://otlp.eu01.nr-data.net:4317
headers:
api-key: myApiKey
service:
pipelines:
traces:
receivers: [otlp]
processors: []
exporters: [otlp]
```
And when we restart the collector and make some requests to our API, we can see the traces in New Relic:

## Sampling
We're almost ready to go live. But we have to enable sampling. Sampling means telling OpenTelemetry to only keep a sample of our traces. So, if we get 1000 requests in an hour, when we check Zipkin, we might see only 20. Sampling helps you manage your storage usage \(and potentially reduces the performance impact from tracing on every request\). If we recorded every sample from every request in production on a busy service, we'd soon have MBs \- GBs of data.
There are different kinds of sampling. Here's what I'm going with:
```js
//...All those other require()s
const { ParentBasedSampler, TraceIdRatioBasedSampler, AlwaysOnSampler } = require("@opentelemetry/core");
const sdk = new openTelemetry.NodeSDK({
// ...Other config items
sampler: process.env.NODE_ENV === 'development'
? new AlwaysOnSampler()
: new ParentBasedSampler({
root: new TraceIdRatioBasedSampler(0.4)
}),
});
```
I'm using a combination of samplers here.
* In development mode, we want to see all our traces, so we use the `AlwaysOnSampler`
* In production, the `TraceIdRatioBasedSampler` tracer will keep 40% of our traces. That means, if 10 requests come in, it will only trace 4 out of those.
* But remember that our service will be called by another app, which may have its own trace that may or may not be kept. The `ParentBasedSampler` says, "if there's an incoming trace from another service that is being kept, then keep this trace too". That way, every trace from the main app that makes a request to tentacle\-engine will have that child trace present as well.
## Switching to tail sampling
The problem with our current sampling approach is that the keep/drop decision is made at the start of the trace \(_head sampling_\). The benefit of this is that it saves us from collecting unneeded data during the request, since we already know the trace will be dropped. But what about traces where an exception happens? I want to _always_ have those traces, so I can look deeper at what happened around the error. Since there's no way to know whether an error will happen at the start of a trace, we have to switch to _tail sampling_.
Tail sampling is making the keep/drop decision at the end of the trace. So we can say, "if this request had an exception, then _definitely_ keep the trace. Otherwise, do the ratio thing." Here's how I did this:
1. FIrst, disable sampling in the OTel JS agent \(use the `AlwaysOnSampler` or remove the `sampler` key we added above\).
2. Next, update the OTel collector config to handle the sampling:
```yaml
# Other config...
processors:
groupbytrace:
wait_duration: 4s
num_traces: 1000
probabilistic_sampler:
sampling_percentage: 40
service:
pipelines:
traces:
receivers: [otlp]
processors: [groupbytrace, probabilistic_sampler]
exporters: [otlp]
```
Essentially, we've moved our `0.4` ratio config into the collector's `probabilistic_sampler` config \(0.4 = 40%\). The [`groupbytrace` processor](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/processor/groupbytraceprocessor) makes sure all child spans of a trace are included. Without it, the sampler might choose to keep a child span \(like `first external call`\), while dropping the parent \(`POST /fetch`\), which wouldn't make sense.
3. FInally, in our 500 error handler, we add this:
```js
app.use(function onError(err, req, res, next) {
// ...
currentSpan.setAttributes({
'sampling.priority': 1,
// ...
});
// ...
});
```
[`sampling.priority`](https://github.com/opentracing/specification/blob/master/semantic_conventions.md#span-tags-table) is a convention supported by the [probabilistic\_sampler](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/processor/probabilisticsamplerprocessor#readme). Setting it to 1 tells the sampler to override the ratio and keep this trace.
## Batching
One final thing we need to do before deploying is batch our exports. By default, immediately a request ends, its trace is sent to Zipkin. In production, that might be unnecessary overhead, so we'll send them in batches.
```js
//...All those other require()s
const { BatchSpanProcessor } = require("@opentelemetry/sdk-trace-base");
const exporter = process.env.NODE_ENV === 'development'
? new ZipkinExporter()
: new CollectorTraceExporter({ url: 'http://localhost:4318/v1/trace' });
const sdk = new openTelemetry.NodeSDK({
// ...Other config items
spanProcessor: new BatchSpanProcessor(exporter),
});
```
The `BatchSpanProcessor` will wait for a bit to collect as many spans as it can \(up to a limit\) before sending to the backend.
## Going live \(finally\)
To go live, we need to set up the OpenTelemetry collector on the server:
```bash
wget https://github.com/open-telemetry/opentelemetry-collector-contrib/releases/download/v0.36.0/otel-contrib-collector_0.36.0_amd64.deb
sudo dpkg -i otel-contrib-collector_0.36.0_amd64.deb
```
Running this installs and starts the `otel-contrib-collector` service. Then I copy my config to `/etc/otel-contrib-collector/config.yaml` and restart the service, and we're good. Now we deploy our changes, and we can see traces from production on New Relic.

## Reflection
I still have to write another article about experimenting with both `got` and `undici` in production, but I've got thoughts on OpenTelemetry. First, the things I don't like:
* Asynchronous initialization. `tracing.start().then()` is a pain. Other APM vendors know this and made their setup synchronous.
* There's less abstraction and more verbosity. Look at the things we've had to deal with in the `tracing.js`—processors, exporters, resources, semantic conventions.
* Related to the above: There are too many packages to install to get a few things working. Worse, there's a [compatibility matrix](https://github.com/open-telemetry/opentelemetry-js#compatibility-matrix) that expects you to compare four different versions of your tools.
* Additionally, the package structure is unclear. It's not always certain why a certain export belongs to a certain package. And a lot of exports have been moved from one package to another, so old code examples are incorrect.
* Confusing documentation: A lot of the docs still reference old links and deprecated packages. Some things are just not covered and I had to read issues, type definitions, and source code to figure things out. Another thing that confused me was that there are two different ways to go about tracing with OTel JS \(the simpler way we used here vs a more manual way\), but this isn't mentioned anywhere.
I feel bad complaining, because the OpenTelemetry ecosystem is HUGE \(API, protocols, docs, collector, libraries for different languages, community...\). it takes a massive amount of effort to build and maintain this for free, and you can tell the maintainers are doing a lot. Which is why, despite all the rough edges, I still like it. It's a good idea, and it's pretty cool how I can wire different things together to explore my data. Once you get over the rough patches, it's a pretty powerful set of tools.
If you're interested in digging deeper into OpenTelemetry, the [awesome\-opentelemetry repo](https://github.com/magsther/awesome-opentelemetry) has a collection of useful resources.
| shalvah |
856,775 | Handle errors in React components like a pro | When you are writing a react application you have two ways to handling errors: Using try/catch... | 0 | 2021-10-28T06:58:41 | https://dev.to/edemagbenyo/handle-errors-in-react-components-like-a-pro-l7l | react, errors, components | When you are writing a react application you have two ways to handling errors:
- Using try/catch block in each component
- Using React Error Boundary which is only available in class Component :(
```js
import * as React from 'react'
import ReactDOM from 'react-dom'
function City({name}) {
return <div>Hello, visit {name.toUpperCase()}</div>
}
function Country({capital}) {
return <div>Hello, visit {capital.toUpperCase()}</div>
}
function App() {
return (
<div>
<Country />
<City />
</div>
)
}
ReactDOM.render(<App />, document.getElementById('root'))
```
The above piece of code would end up showing you an error page when you run it in Development or a blank screen in Production.
Obviously, the error we created in the code above could have certainly been handled with PropTypes or TypeScript, however we are aware runtime error happens all the time and we are going to deal with it using the two approaches stated above.
### Try/catch
```js
import * as React from 'react'
import ReactDOM from 'react-dom'
function ErrorHandler({error}) {
return (
<div role="alert">
<p>An error occurred:</p>
<pre>{error.message}</pre>
</div>
)
}
function City({name}) {
try {
return <div>Hello, visit {name.toUpperCase()}</div>
} catch (error) {
return <ErrorHandler error={error} />
}
}
function Country({capital}) {
try {
return <div>Hello, visit {capital.toUpperCase()}</div>
} catch (error) {
return <ErrorHandler error={error} />
}
}
function App() {
return (
<div>
<Country />
<City />
</div>
)
}
ReactDOM.render(<App />, document.getElementById('root'))
```
This approach, requires us to define an ErrorHandler component to display in case an error occurs and we wrap each component returned element in the try/catch block.
This seems ok, but repetitive. What if we want the parent component to handle the error catching for us. Wrapping the parent component `App` in a try/catch block will not work, due to the nature of how React calls functions. That is when React Error Boundary comes in.
### React Error Boundary
> Error boundaries are React components that catch JavaScript errors anywhere in their child component tree, log those errors, and display a fallback UI instead of the component tree that crashed. Error boundaries catch errors during rendering, in lifecycle methods, and in constructors of the whole tree below them.
As at React 17.0.2, Error Boundary works only in
- Class component
- and It must implement `static getDerivedStateFromError()` or `componentDidCatch()`
In order to use Error Boundary in Functional Component, I use [react-error-boundary](https://www.npmjs.com/package/react-error-boundary).
```js
import * as React from 'react'
import ReactDOM from 'react-dom'
import {ErrorBoundary} from 'react-error-boundary'
function ErrorHandler({error}) {
return (
<div role="alert">
<p>An error occurred:</p>
<pre>{error.message}</pre>
</div>
)
}
function City({name}) {
return <div>Hello, visit {name.toUpperCase()}</div>
}
function Country({capital}) {
return <div>Hello, visit {capital.toUpperCase()}</div>
}
function App() {
return (
<ErrorBoundary FallbackComponent={ErrorHandler}>
<Country />
<City />
</ErrorBoundary>
)
}
ReactDOM.render(<App />, document.getElementById('root'))
```
When we run this application, we will get a nice error display form the content of `ErrorHandler` component.
[React error boundary](https://www.npmjs.com/package/react-error-boundary) catches any error from the components below them in the tree. This is really handy and useful because we need not declare a separate try/catch for each component because the wrapping component(ErrorBoundary) takes care of that and display the component of the `FallbackComponent` provided.
## Exceptions to Error handling
Because [react-error-boundary](https://www.npmjs.com/package/react-error-boundary) uses [react error boundary](https://reactjs.org/docs/error-boundaries.html) in the background there are a few exceptions to the errors that can be handled.
>These errors are not handled by react-error-boundary
- Event handlers
- Asynchronous code (e.g. setTimeout or requestAnimationFrame callbacks)
- Server side rendering
- Errors thrown in the error boundary itself (rather than its children)
## Error recovery
This library offers an error recovery feature, that allow you to reset the state and bring back the components to a working point.
Let's use this example from the react-error-boundary npmjs page.
```js
function ErrorFallback({error, resetErrorBoundary}) {
return (
<div role="alert">
<p>Something went wrong:</p>
<pre>{error.message}</pre>
<button onClick={resetErrorBoundary}>Try again</button>
</div>
)
}
function Bomb() {
throw new Error('💥 CABOOM 💥')
}
function App() {
const [explode, setExplode] = React.useState(false)
return (
<div>
<button onClick={() => setExplode(e => !e)}>toggle explode</button>
<ErrorBoundary
FallbackComponent={ErrorFallback}
onReset={() => setExplode(false)}
resetKeys={[explode]}
>
{explode ? <Bomb /> : null}
</ErrorBoundary>
</div>
)
}
```
The `ErrorBoundary` component accepts two other props to help recover from a state of error. The first prop `onReset` receives a function which will be triggered when `resetErrorBoundary` of the `FallbackComponent` is called. The `onReset` function is used to reset the state and perform any cleanup that will bring the component to a working state.
The other prop of `ErrorBoundary` is `resetKeys`, it accepts an array of elements that will be checked when an error has been caught. In case any of these elements changes, the `ErrorBoundary` will reset the state and re-render the component.
Handling error in React functional components should be a breeze for anyone using the `react-error-boundary` library. It provides the following features:
- Fallback components to display incase of error
- Granular capturing of error at component level
- Recovery of error using a function or by resetting the elements causing the component to fail. | edemagbenyo |
856,795 | Hacktoberfest Week 1 | This is my first Hacktoberfest! I was able to work on two issues this week, one for Seneca's... | 0 | 2021-10-08T22:13:37 | https://dev.to/lyu4321/hacktoberfest-week-1-khe | opensource, hacktoberfest | This is my first Hacktoberfest! I was able to work on two issues this week, one for Seneca's [Telescope](https://github.com/Seneca-CDOT/telescope) project and one for [Wordpress Openverse Catalog](https://github.com/WordPress/openverse-catalog). Finding the issues was a bit challenging since there are so many people and repos participating, but I remembered a piece of advice from my open source professor, which was to just get started rather than trying to find a perfect issue.
## Telescope
[The issue](https://github.com/Seneca-CDOT/telescope/issues/2299)
[The pull request](https://github.com/Seneca-CDOT/telescope/pull/2336)
Telescope is a tool for aggregating blog posts created at Seneca and it displays these blog posts on a [website](https://telescope.cdot.systems/). For this issue, there was a problem with the CSS so that if an author's name was too long, there would be no margin between the author's name and the post date underneath. You can see an example of this issue below:

This was a great first issue for me to start off with. The problem was that the container for the author's name had a fixed height of 3rem so a very long author name would overflow the container. I removed the fixed height and adjusted the line height of the container for the date so that there would be a uniform margin between author name and date, regardless of author name length.
```javascript
postDate: {
lineHeight: '1rem',
},
```
```javascript
<div className={classes.postDate}>
```
You can see the result below:

Although the coding part was not too challenging, I learned a lot from following the Contributors documentation, as I tried to set up my environment to run both the front and back end of the project. A lot of the technologies required were things I had never worked with before, such as Redis and Elasticsearch. It was definitely challenging, but the documentation was very helpful and also visiting the Slack channel to see if any other people had similar issues was important as well. After I submitted my pull request, it was successfully merged into the repo! :)
## Openverse Catalog (Work In Progress)
[The issue](https://github.com/WordPress/openverse-catalog/issues/176)
[The pull request](https://github.com/WordPress/openverse-catalog/pull/230)
I have been using Wordpress quite a bit for another project so I was interested in getting involved. I looked through their repos and found an issue in the Openverse Catalog repo that I was interested in. The issue involved updating their issue templates from .md to .yml files and changing the syntax. The maintainers were extremely welcoming and responsive. Although my pull request is currently still a work in progress, I have been receiving a lot of feedback from the maintainers and continuing to improve my changes based on their comments.
Although this looked like a fairly straightforward issue at first, I have never with issue forms before and while following the [GitHub docs](https://docs.github.com/en/communities/using-templates-to-encourage-useful-issues-and-pull-requests/syntax-for-issue-forms), I have come across several roadblocks.
For example, each form field can accept a description attribute, such as
```yml
- type: input
id: provider
attributes:
label: Provider API Endpoint / Documentation
description: Please provide links to the API endpoint, and any known documentation
validations:
required: true
```
However, for the use case I am working on, some form fields do not require user input. These fields are of type: markdown and cannot accept a description attribute. This makes it difficult for all fields to look consistent in terms of style and I will need to do more research in order to resolve this issue.
## Conclusion
Although it has just been one week, I have already learned so much from my experiences during Hacktoberfest. It was definitely intimidating at first, but it was easier to get involved than I expected and it feels very rewarding to be able to contribute to several different projects. I look forward to completing my second pull request and continuing to work on others in the weeks to come! | lyu4321 |
856,800 | é possível desfazer uma instalação no vscode? | eu instalei no meu projeto o axios e deu erro, agora não consigo mais dar "npm start". é possível... | 0 | 2021-10-08T18:52:24 | https://dev.to/nicholeabdala/e-possivel-desfazer-uma-instalacao-no-vscode-3jam | react, vscode | eu instalei no meu projeto o axios e deu erro, agora não consigo mais dar "npm start". é possível desfazer uma instalação? alguém pode me ajudar? | nicholeabdala |
857,002 | Adding new feature using remotes | I added a new feature from the new branch in the cloned repository in this lab. And I updated it to... | 0 | 2021-10-09T02:51:17 | https://dev.to/jjung99/adding-new-feature-using-remotes-598a | I added a new feature from the [new branch](https://github.com/jjung99/suhheeKim_OSD_release0.1_create_ssg/tree/issue-24) in the cloned repository in this lab. And I updated it to the remote repo using the git merge and push function.
#### The newly added functions are as follows.
- Using the new command option -c and -config, receive the JSON file as an argument.
- Import data corresponding to the SSG option from the JSON file.
- Applying the imported data to the proper value or function (e.g., input, stylesheet etc.)
The following is an example of the code I updated. There were many if statements in the code, so the structure was more complicated than I contributed last time.
First of all, I added json file and put data in it.
```javascript
fs.readFile(TextArr.length > 1 ? './Texts/'.concat(filename, "/", TextArr[filenum][0], ".", TextArr[filenum][1]) : './Texts/'.concat(TextArr[filenum][0], ".", Text
```
The JSON file was created in the Test directory because the file was read from the directory "Texts".
Secondly, I added if statements when it accepts -config command option and few other code lines accordingly.
```javascript
if(options.config){
const json = args.slice(3).join(' ').toString();
jsonData = require(`../${json}`);
filename = jsonData.input;
url = jsonData.stylesheet;
}
```
Finally, I pushed it into the working branch of my fork repository. And I reviewed my pull request as well.
I was confused about the concept of [git remote](https://git-scm.com/docs/git-remote) and the clear difference between git [merge](https://www.atlassian.com/git/tutorials/using-branches/git-merge) and [fetch](https://www.atlassian.com/git/tutorials/syncing/git-fetch). However, working on git and trying things after watching the git lecture, I know git fetch is for reading and merge is for updating the code. I can't say I am comfortable using git yet, but I definitely understood that it would be so handy once I practice it a lot.
| jjung99 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.