
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
894,599 | Stripe indirect integration for Shopify | Get paid for your Shopify orders via Stripe with Alipay, Bancontact, EPS, giropay, iDEAL, Przelewy24,... | 0 | 2021-11-12T14:11:21 | https://dev.to/techt01ia/stripe-indirect-integration-for-shopify-57e0 | stripe, shopify, bancontact, ideal | Get paid for your Shopify orders via Stripe with Alipay, Bancontact, EPS, giropay, iDEAL, Przelewy24, Sofort, WeChat Pay.
{% youtube 06yyf2GLQMM %}
[Demo ](http://shopifystripe.techtolia.com)--> http://shopifystripe.techtolia.com
With this integration, accept payments for your Shopify Store orders directly at your domain through Stripe with payment methods Alipay, Bancontact, EPS, giropay, iDEAL, Przelewy24, Sofort and WeChat Pay.
### What is Order and Payment Workflows?
- The customer chooses one of the manual payment methods during the ordering phase through your Shopify store.
- On the order page, the customer is asked to take the order number and go to your payment address.
- The customer comes to your payment address, enters the order number and updates the page. At this stage: The app collects relevant order information from your Shopify account.
- The customer completes the payment. At this stage: The app adds payment and customer information to your Stripe account.
- The customer is directed back to the application from the payment method page, the customer sees the successful payment screen on the page. At this stage: The app updates the order as paid in your Shopify account.
### What are Payment Methods?
Payment Methods are Alipay, Bancontact, EPS, giropay, iDEAL, Przelewy24, Sofort and WeChat Pay.
For these payment methods, you just need to have a Stripe account and activate your desired payment method from your Stripe control panel. You do not need to make any other application or action.
Payments can be accepted with Przelewy24 in PLN and EUR, with Bancontact, EPS, giropay, iDEAL and SOFORT only in EUR, with Alipay and WeChat Pay CNY and the currencies that map to your country(For example: If your Stripe account country is Germany, you can accept payments in EUR with Alipay and WeChat Pay). Note: If you have a bank account in another currency and would like to create an Alipay payment in that currency, you can contact Stripe support.
### What is Smart Url?
- By directing your customer to your checkout.yourdomain.com/Alipay address you can have the page load with Alipay payment method selected.
- By directing your customer to your checkout.yourdomain.com/1001 address, you can have the page load with the order number 1001.
- By directing your customer to your checkout.yourdomain.com/Alipay/1001 address, you can have the page load with Alipay payment method selected and order number 1001 entered.
If the payment for the order number has been made before, the page is updated with a successful screen, the payment button is hidden.
When the user chooses a different payment method or enters a different order number on the application, the url is updated according to that payment method and order number.
### What is Google reCAPTCHA?
reCAPTCHA is a service that protects your site from spam and abuse. reCAPTCHA v3 helps you detect abusive traffic on your website without user interaction. Instead of showing a CAPTCHA challenge, reCAPTCHA v3 returns a score. reCAPTCHA v2 ("I'm not a robot" Checkbox) requires the user to click a checkbox indicating the user is not a robot.
The application uses combined Google reCAPTCHA v3 and v2. Thus, spam attacks are prevented.
The app first verifies with reCAPTCHA v3 with a score. If the score (can be between 0–1) is not higher than this pass score, the app makes visible reCAPTCHA v2 with the "I'm not a robot" tickbox.
RecaptchaClickLimit: The number is increased each time the buttons are clicked and the page is refreshed. If a user reach the limit, whether the users score is higher than the pass score or not, the app makes visible reCAPTCHA v2 with the "I'm not a robot" tickbox.
### Quick Start
- Download the source files.
- Activate payment methods on dashboard.stripe.com/account/payments/settings
- Get your Stripe keys on dashboard.stripe.com/apikeys
- Create&Get your reCAPTCHA keys on google.com/recaptcha/admin/create
- Create new private app and Get your API Password on yourusername.myshopify.com/admin/apps/private/new
- Create your manual payments on yourusername.myshopify.com/admin/settings/payments
- Edit the code - Update Keys and Settings.
- Buy a Windows Hosting and Upload the files to the wwwroot folder.
- Create a subdomain (checkout recommended) and match it to the ip information your hosting service provider gave you.
Recommended hosting company: [HostGator](https://partners.hostgator.com/gbqA15). If you want to take advantage of discounted hosting, enter Techtolia in the coupon code field and apply.
If you don't have a domain yet, you can register it via [NameCheap](https://namecheap.pxf.io/BmdkB).
### Buy a Licence
The single license fee is $750.
If you have completed your purchase through CadeCanyon, please send an e-mail to support@techtolia.com to identify your license information and receive your license key. Do not forget to share your domain address information where you will publish the application, your license is specific to your domain address and cannot be used at any other web address.
For multiple and volume license purchases, please contact us at hello@techtolia.com
 | techt01ia |
894,699 | What If...Marvel Built a Minimum Viable Product? | In 2011, Eric Ries published The Lean Startup, and it revolutionized software development. Lean... | 0 | 2021-11-11T01:50:46 | https://www.vidyasource.com/blog/what-if-marvel-built-a-minimum-viable-product | agile, leadership, startup, podcast | In 2011, Eric Ries published *The Lean Startup*, and it revolutionized software development. Lean principles had already [made it into agile software development](https://www.goodreads.com/book/show/194338.Lean_Software_Development), but *The Lean Startup* fills in a lot of gaps to turn the abstract[principles behind the Agile Manifesto](https://agilemanifesto.org/principles.html) into something real.
For example, even if you nailed agile and built the thing right, how do you know you built the right thing? In other words, it's great to execute on your project and build exactly what you intend on time and on budget, but when you're done, how do you know people will actually buy it? Although the Agile Manifesto never answers this question because it assumes you are on the right track all along, Ries gives us an answer.
## The Minimum Viable Product
Probably the most profound innovation in *The Lean Startup* is the Minimum Viable Product (MVP).
(You can [watch Ries himself talk about it](https://www.youtube.com/watch?v=E4ex0fejo8w), but I have to warn you that it looks like it was filmed by the director of [The Blair Witch Project](https://www.thenewsminute.com/article/how-blair-witch-project-manages-scare-without-showing-anything-supernatural-135492).)
The idea is really quite simple. Whether you are conscious of it or not, the product you have in mind is based on your assumptions about what your customers want and why, so the purpose of the MVP is to validate those assumptions with hard data around *a lightweight representation of your product* before you commit your full resources to building it out in full. You give your early adopters access to the MVP and consider their feedback, which Ries calls "validated learning." Validated learning is crucial. For Ries, it's quantifiable feedback that is "the unit of progress for lean startups."
Based on what you learned, you either "[pivot](https://www.youtube.com/watch?v=n67RYI_0sc0)" to something else more aligned to what your customers want or "persevere" because you had it right all along. From this point on, you have quantifiable, proven demand for your product, and you can be confident that you will be investing in building the right thing.
Like a lot of terms in tech that blow up, consultants often use MVP to mean something different from what Ries intended--most commonly to mean the first version of your product and/or a really scaled down version of it. In either case you've implicitly decided without any validated learning what you want to build. The fact it's in its earliest stages is irrelevant.
So what does all of this have to do with Marvel?
## The MCU Juggernaut
Unless you have been living in the [Quantum Realm](https://marvelcinematicuniverse.fandom.com/wiki/Quantum_Realm) for the last decade, you know the [Marvel Cinematic Universe (MCU)](https://www.marvel.com/movies). It's a monumental achievement in cinema that has taken decades of Marvel comics and reformulated them into a multibillion dollar juggernaut movie franchise that has raised once second-tier heroes like Iron-Man, Thor, and Black Widow to the stature of eternal favorites like Spider-Man, Captain America, and Hulk and put [Mjolnirs](https://marvel.fandom.com/wiki/Mjolnir) and [Infinity Gauntlets](https://marvelcinematicuniverse.fandom.com/wiki/Infinity_Gauntlet) into the homes of ardent fans worldwide.
It may be hard to imagine now, but there was no guarantee of success at the beginning as Marvel was struggling as a business having sold off their most bankable assets. This forced Kevin Feige, the architect of the MCU, to get creative to and [derive new ways to bring Marvel heroes to life](https://www.vox.com/2016/5/9/11595344/marvel-cinematic-universe-captain-america-avengers).
They succeeded spectacularly, and now they have to do it all over again.
Firmly entrenched in global pop culture, the MCU now faces pressure to build on its foundation with new heroes and villains, many of whom like [Moon Knight](https://marvel.fandom.com/wiki/Marc_Spector_(Earth-616)) and [Titania](https://www.marvel.com/characters/titania-mary-macpherran) lack the star power of Captain America and Spider-Man and are all but unknown to mainstream audiences. And considering that the MCU has decided to go all in on the [Multiverse](https://marvelcinematicuniverse.fandom.com/wiki/Multiverse), there are literally infinite possibilities for stories.
How can Marvel decide what direction to take with the MCU?
## *What If?* is Marvel's MVP
There is no question Kevin Feige has sketched out the broad contours of the next iteration of the MCU. Still, as sterling as his record is, he's working from assumptions about what will make for great stories and what will thrill audiences going forward. If he followed *The Lean Startup* model, he would build a lightweight MVP to test his hypotheses with passionate fans and measure their response for some validated learning.
It turns out that is exactly what Marvel is doing with *What If?...*
*What If?...* is an [animated show on Disney+](https://www.marvel.com/tv-shows/animation/what-if/1) that imagines the MCU heroes we know experiencing very different lives throughout the multiverse. For example, we see Peggy Carter receive the super soldier serum rather than Steve Rogers to become [Captain Carter](https://www.marvel.com/articles/tv-shows/what-if-episode-1-multiverse-report-captain-carter), and we watch somberly as T'Challa, voiced just as he is portrayed on screen by the legendary Chadwick Boseman in his final performance, [becomes Star-Lord](https://www.marvel.com/articles/tv-shows/what-if-new-images-episode-2) rather than Peter Quill. It's heroes and villains we know so well from the MCU facing new challenges alongside other heroes and villains we've never seen them interact with before.
The novel combinations are fun and exciting, but they're also an experiment. How will fans, primarily hardcore MCU fans (early adopters if you will) react? You can easily track this with viewership metrics on Disney+, mentions on Twitter, and the impressions of media influencers for validated learning. When a story doesn't click, Marvel can dismiss it as a fun idea for the fans and pivot to something else. On the other hand, when a story does click, Marvel can persevere and explore it further on a live-action series on Disney+ or even on the big screen within established MCU canon.
Best of all, Marvel can test their hypotheses, engage in validated learning, and guide the future of the MCU accordingly at a low cost. *What If?...* is high-quality animation, and most of the elite talent that portrays the characters on the big screen voices them on the show. Still, the cost of running these experiments in animation without any real commitment since the stories all happen outside the "prime" MCU universe is orders of magnitude less than it would be going all in with any of the *What If?...* plots in live action.
## The Key Lesson
One way or another, we are all in the business of product development. Too often we assume we have accurately gauged customer sentiment, and [we exude hubris that success is inevitable only to fail miserably](https://www.youtube.com/watch?v=t-_PfdQ0DYo).
Don't be afraid to test your assumptions before you go all in. Build a Minimum Viable Product--something more lightweight and less expensive that will nonetheless provide your early adopters something meaningful to evaluate. The validated learning you get from their feedback will either help you pivot to something more aligned with what people want or empower you to persevere with your original idea with legitimate confidence it will sell. Once you start executing, then you can argue on Twitter about whether you need daily meetings and whether people should be allowed to sit down in them.
Using an MVP to build confidence in your product direction is exactly what the Marvel Cinematic Universe has done with *What If?...*, but you don't have to be Marvel to fly [higher, further, faster, baby](https://www.youtube.com/watch?v=eKAvj9EjBmM).
| realneilc |
903,601 | aa | Puppeteer and the Lighthouse API (you can see the complete code here). var s = "JavaScript syntax... | 0 | 2021-11-20T02:57:48 | https://dev.to/nixcodes/aa-51f9 | Puppeteer and the Lighthouse API (you can see the complete code here).
```javascript
var s = "JavaScript syntax highlighting";
alert(s);
```
```python
s = "Python syntax highlighting"
print s
```
```
No language indicated, so no syntax highlighting.
But let's throw in a <b>tag</b>.
```
async function captureReport() {
// Puppeteer initialization
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Start user flow
const flow = await lighthouse.startFlow(page, { name: 'My User Flow' });
// ... Caputure reports here ...
// End user flow
return flow.generateReport();
}
Within | nixcodes | |
903,691 | Audit and Fix a Markdown Page | My recent contribution to an open source project is the improvement of the online course notes for... | 0 | 2021-11-20T05:05:12 | https://dev.to/okimotomizuho/audit-and-fix-a-markdown-page-42l5 | opensource, c, beginners, webdev | My recent contribution to an open source project is the improvement of the online course notes for the C language course (IPC144) in my college. The online note uses Docusaurus, and I had the opportunity to study Docusaurus a while back, so this contribution deepened my knowledge.
### Issue
The issue I worked on was the Audit and Fix a Markdown Page. Each chapter of that online note consists of its own md file. My professor file an issue with a list of all of the md files and 19 tasks for improving each page. I selected the "output-functions" page in it, filed a new issue, and worked on the tasks.
### Checking display
I set everything up locally and checked for problems with the display. Such as: typo, markdown, the Light and Dark mode, and the desktop and mobile.
### Using tools for improving the quality of web pages
As my professor mentioned, I tried running the page through Lighthouse and Web Hint.
I had never used them, but it was easy to check with those tools.
Lighthouse checked if the page is optimized for each item, and showed me there is no alt tag for images. After I added alt, performance, accessibility, best practices, SEO scores went up.

When I checked the page using Web Hint, I got 55 hints, but nothing about the page I was working on.
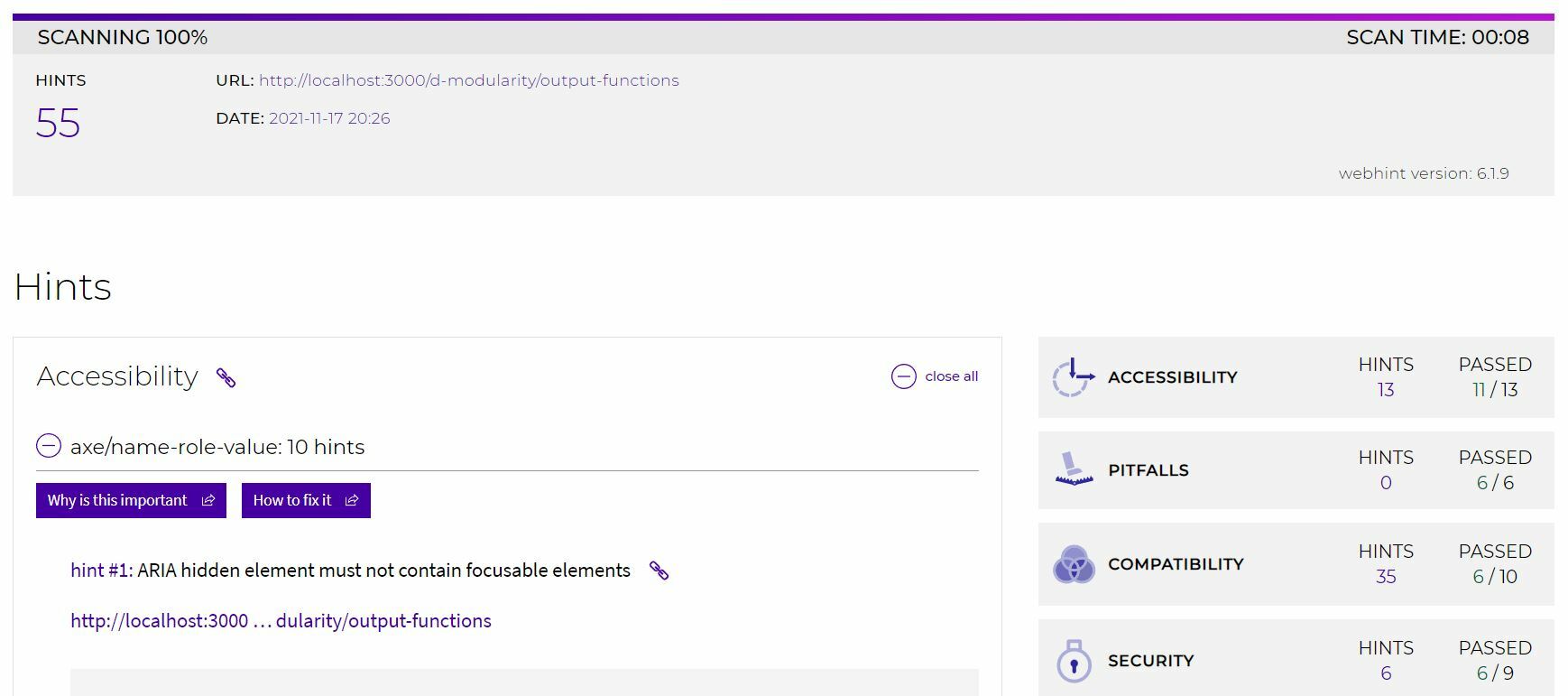
### Fixing Frontmatter for the page
Markdown documents can use the Markdown FrontMatter metadata fields, enclosed by a line --- on either side.([Docusaurus official page](https://docusaurus.io/docs/api/plugins/@docusaurus/plugin-content-docs#markdown-frontmatter))
I added the FrontMatter below:
```
---
sidebar_position: 5
title: Output Functions
id: output-functions
slug: modularity/output-functions
desctiption: This chapter on output functions is about invoking standard library procedures to stream data to users
---
```
### Reviewed from other students
I made a PR, other students reviewed it and gave me some requests.
They were:
- Removing extra space I missed in the md file
- Adding a hyperlink to a related page
- Adding Description to the page(as a Frontmatter)
- Adding backticks to function names
### Conclusion
I thought there were a lot of tasks, but it wasn't too difficult. It was good to be able to contribute to the project that actually used Docusaurus and to experience the improvement of the page using Lighthouse and Web Hint. This time, my professor listed the tasks and provided them to us, which made the contribution easier, and I would like to use the task when working on external issues myself in the future.
### :link:Links
[IPC144 Project repo](https://github.com/Seneca-ICTOER/IPC144) | [Issue](https://github.com/Seneca-ICTOER/IPC144/issues/87) | [Pull Request](https://github.com/Seneca-ICTOER/IPC144/pull/100)
(Photo by Glenn Carstens-Peters on Unsplash) | okimotomizuho |
903,760 | 5 Tips That Will Boost Your Productivity | you're reading this article, then you're probably thinking about new ways how to increase the quality... | 0 | 2021-11-22T12:42:54 | https://dev.to/metamark/5-tips-that-will-boost-your-productivity-10dj | productivity, career, discuss, programming | you're reading this article, then you're probably thinking about new ways how to increase the quality of your work and your life itself without spending too much time on it. And I wanna share with you some of the advice that helped me once and which I'm using to the present day. There won't be something like "Use Pomodoro Technique" or "Meditate for 5 minutes every day", these tips are fully working and even help you to choose in which direction to go.
---
##Determining Goals
Firstly, before doing some work on your goals we need to determine the goals themselves, and to do it right we surely have to use Warren Buffet Technique which is much simpler than it seems.
You need to write down 25 Goals or Directions that you want to go for and highlight only 5 of them which are the most important for you and will give you the future that you want. Don't worry about the other 20 Goals in this list, you'll reach them after you've reached your main goals, but for now, you need to add them to your Not-To-Do-List because they only distract you from your real goals and you're spending too much on them. Also, you can write not exactly 25 Goals, your list can be much bigger or much smaller, the sense is that you need to choose the most important ones.
For instance, I've my list where I've written around 20 Spheres which I wanna learn, there're Guitar, 3D Modeling, Photographing, etc. However, the most important for me are Programming (ML, Web-Dev), Writing/Content Creation, and Design. So I'm going directly in these directions without distracting on other smaller goals
##Perfectionism is an Evil
There's research that people often drop out of courses because they have a perfectionism to do it as fast as they only can and in a moment burn themselves out. That doesn't mean that you don't have to have deadlines, it's saying that if you will have very short deadlines then you'll probably drop out.
Also, you don't have to pass the course for the highest grade or spend several hours on passing some final exam. When it comes to courses or learning something, you don't have to be perfect at it, good is enough, and you'll see how it will save your time
Perfect is an enemy of good. Just "good" is enough
##The Start is The Key
The hardest part of building a good habit is starting. Usual, you just can't start doing something if your task or goal sounds like "Build a rocket" or "Make a new billion Startup".
To start doing something you need to make a start for your goal much easier. For example, if your goal is to build a rocket so you should make smaller goals of it, like learn the conception of building a rocket or see how Elon Musk did it and so on. However, it's not complete yet, because you can't learn the construction of the rocket in one day (Perfectionism is an Evil, remember it), it means that you have to make a daily habit like spending 1 hour on reading rocket documentation, etc.
It gets much easier now, right? That's the power of a good start. If you know that you need to your task is not to build a rocket, and just read the documentation for 1 hour you'll probably do it without stress and burning yourself out.
The same principle is with bad habits too! If you know that smoking is bad for you and you wanna quit, so make the first 20 seconds of smoking the hardest thing you've ever done, and you'll never do it again, I swear.
##Consistent Habits
After you decided in which direction you'll go and what to learn, divide your goals into smaller ones, and made them as simple as possible, now it's a turn for consistency. What do I mean, for achieving something you need to do it consistently, every day and every week, and with that by going with small steps you'll learn anything you want and reach your goals.
However, sometimes there're situations where you just can't do it today (Was on vacation or had other tasks that were more important than it. Reason that you were lazy does not include) and you don't need to stress about it if you have a habit to read around 20 pages every day and lost one day, then in the next day, you will need to read 40 pages. But it works only for a 1-day skip, the next day, you must read 40 pages and don't leave it to another day.
Never, and I'll repeat it again, Never make a second mistake. If you fail at your daily habits then you must reconnect and back in to it
##The Power of Productive Procrastination
As you might have noticed from the title, it's procrastination that is productive, strange a little bit, don't you think so? What does it mean, anyway?
Productive Procrastination is when you're not working on your main tasks like building a landing page for your product, and instead of it you're scrolling the Dribbble or Behance and getting inspired by someone's work. So it's not so great as working on your main task, however, it helps to spend less time and to build your product better. It means that not every procrastination can
be useless.
Another example, you can watch some videos of YouTubers like Matt D'Avella or my favorite GaryVee after which you will look at life from other angles.
---
##Conclusion
I tried to describe to you one of the greatest unusual tips for boosting your productivity and not only. I'll write more about productivity and different kinds of advice for life, so subscribe and get everything first. I hope you enjoyed this article :) | metamark |
903,873 | Getting Started with Git & GitHub | In the world of programming, you would have come across the terms Git and GitHub. If not, you are... | 0 | 2021-11-20T10:07:43 | https://dev.to/codezillaclub/getting-started-with-git-github-18am | github, programming, git, opensource | In the world of programming, you would have come across the terms Git and GitHub.
If not, you are still in the right place! This blog will help you expand your knowledge about the programming world.🌎
What do these stand for? Are these both the same? What can one do with these? 🤔
These questions would have crossed your mind when you hear the terms GIT and GITHUB. Read along to know the answers to the above questions. 🙌
### What will be covered in this article:
```
- What is Git?
- Why Git?
- Basic Workflow of Git
- Git Commands
- Git Extensions
- Pros and Cons of Git
- What is GitHub?
- Pros and Cons of GitHub
- GitHub Features
- Git vs GitHub
- Conclusion
```
## What is Git?
Git was created by [Linus Torvalds](https://en.wikipedia.org/wiki/Linus_Torvalds) in 2005.
It’s a free and open-source distributed version control system that allows users to track changes in files over time while also allowing different users to work on the same project at the same time.
## Why Git?
- **Free & Open Source:**
Git was released under GPL(General Public License) open source license. It is free over the internet. We can manage our projects by git. Moreover, as it is open source, we can download its source code and also perform changes according to our requirements.
- **Security:**
Git uses SHA1(secure Hash Function) to name and identify objects within its database. It ensures that it’s impossible to change file, date, and commit message, and any other data from the git database without knowing Git.
- **Backup:**
The chances of losing data are very rare when there are multiple copies of it.
## Basic Workflow of Git:
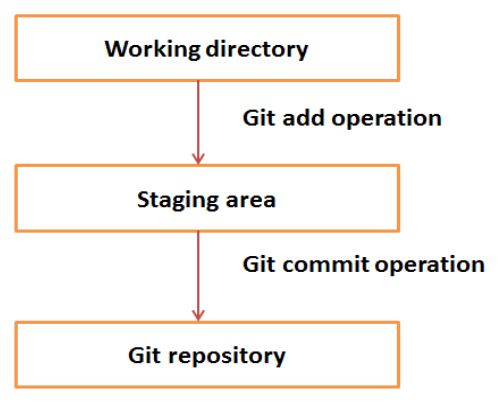
## Git Commands :
- **git init**→ initializes a local git repository.
Usage: git init [repository name]
- **git add**→ adds a file to the staging area.
Usage: git add [file]
- **git commit**→ records or snapshots the file permanently in the version history.
Usage: git commit -m “Type in the commit message”
- **git merge**→ merges a branch to an active branch.
Usage: git merge [branch name]
- **git push**→ uploads local repository to remote repository.
Usage: git push [variable name] master
- **git pull**→ downloads content from a remote repository.
Usage: git push [Repository name]
## Git Extensions:
Many Git extensions, like Git LFS, started as an extension to Git in the GitHub community and are now widely used by other repositories. Extensions are usually independently developed and maintained by different people, but at some point in the future, a widely used extension can be merged to Git.
**Other open-source git extensions include:**
- **git-annex:**
a distributed file synchronization system based on Git
- **git-flow:**
a set of git extensions to provide high-level repository operations for Vincent Driessen's branching model
- **git-machete:**
a repository organizer & tool for automating rebase/merge/pull/push operations
Microsoft developed the Virtual File System for Git (VFS for Git; formerly Git Virtual File System or GVFS) extension to handle the size of the Windows source-code tree as part of their 2017 migration from Perforce. VFS for Git allows cloned repositories to use placeholders whose contents are downloaded only once a file is accessed.
## Pros And Cons of Git:
**Pros:**
- Better merges than anything else.
- Logging.
**Cons:**
- Still some confusing merge issues.
- I would like to see a system IDEs can use that automatically notifies you if someone pushes.
## What is Github?
Headquartered in California , it has been a subsidiary of [Microsoft ](https://en.wikipedia.org/wiki/Microsoft) since 2018.
GitHub provides a hosting service for software development version control using Git. It provides a web-based graphical interface. GitHub is like a social networking site for developers!
## Why Github?
- **Open-source benefits:**
Open-source projects tend to be more flexible because they respond more rapidly to market demands. Closed-source programs might exist in a bubble while trying to convince a target market of its value, as opposed to being genuinely responsive. GitHub provides a community where programmers are constantly working to solve current problems and make solutions available to the public.
- **Find Talent:**
Because of the breadth of the GitHub Community, we can sometimes find programmers working on similar projects or who have skills, experiences, or a vision that offers a good fit for an organization.
- **Easy Version Control:**
Versions control on Github works much like on MS Office or Google Drive--it tracks all the changes made to your code and
who makes them. You can always review the detailed changelog that neatly hosts all of the relevant information.
## Pros And Cons of GitHub :
**Pros:**
- As a repository it's great. It houses almost all the open-source applications/code that anyone can fork and play with. A huge collection of sample codes available with problem statements across different domains make Github a one-stop location.
- I use GitHub with Windows and the Git Bash is superb. It is a powerful alternative to the Command Prompt and Powershell. Allows me to run shell scripts and UNIX commands inside the terminal on a Windows PC.
- GitHub integration with almost all cloud development/deployment platforms is amazing. Deploying a new application in Azure is really smooth. Just link the GitHub repositories and it's good to go. From automatic build to deployment everything is just amazing.
**Cons:**
- Not an easy tool for beginners. Prior command-line experience is expected to get started with GitHub efficiently.
- Unlike other source control platforms, GitHub is a little confusing. With no proper GUI tool, it's hard to understand the source code version/history.
- Working with larger files can be tricky. For file sizes above 100MB, GitHub expects the developer to use different commands (lfs).
- While using the web version of GitHub, it has some restrictions on the number of files that can be uploaded at once. Recommended action is to use the command-line utility to add and push files into the repository.
## GitHub Features :
- **Issues:** Keep track of enhancements, and bugs for your project.
- **Discussions:** Collaborative communication forum for the community.
- **Code spaces:** A cloud-based integrated development environment (IDE) on GitHub (Beta).
- **Sponsors:** Invest in software that powers your world- a new way to contribute.
- **GitHub pages:** Websites for you and your projects, hosted directly from your repo.
- **GitHub actions:** Automate software workflows. Build test, and deploy your code from GitHub.
- **Organizations:** Organisations are group-owned repos.
- **Packages:** Automated and secure path to continuous integration + deployment.
- **Project boards:** Project boards help you organize and prioritize your work.
## Git vs GitHub :

## Conclusion:
Now, you definitely must have an idea of what Git and GitHub is, and what one can do with them. Isn’t it exciting! Having sound knowledge about Git and GitHub and working with them efficiently is very important for any programmer interested in developing great software products.
Thank you for reading, and hope you enjoyed the article!😊
If you have any questions for us, please leave them in the comment section and we will get back to you soon!
Have a great coding journey ahead😎
If you enjoyed the article, hit the reactions 🧡 and do share it with others 🤓 ~
Written by :- [Adhithi Satish Kumar](https://www.linkedin.com/mwlite/in/adihithi-satish-kumar-789350226), [Akshara S PA](https://www.linkedin.com/in/akshara-s-pa-1120bb210) , and [Riddhi Gope](https://www.linkedin.com/in/riddhi-gope-5a1676222)
To stay updated whenever we post new content, follow **Codezilla** on:
[Community Portal
](https://community.mozilla.org/en/groups/codezilla/)
[Instagram](https://www.instagram.com/codezillaclub/)
[LinkedIn](https://www.linkedin.com/in/codezillaclub/)
[Twitter ](https://twitter.com/CodezillaClub)
| codezillaclub |
904,062 | Angular: Where does the term 'directive' come from? | I'm trying to understand the Angular terms and philosophy. One of the most basic building blocks of... | 0 | 2021-11-20T14:14:04 | https://dev.to/ovidiu141/angular-where-does-the-directive-term-come-from-20b6 | angular, todayisearched, javascript, html | I'm trying to understand the Angular terms and philosophy. One of the most basic building blocks of Angular seems to be a `directive`.
As a non-native English speaker, I don't find this term intuitive, but rather abstract. So what's up with this term?
The Angular glossary says that "A [`directive` is a] class that can modify the structure of the DOM or modify attributes in the DOM and component data model".
Ok, it got something to do with changing the DOM. But still, why 'directive'?
It got something to do with 'direction'?😄
Seems VueJS also has the concept of `directive`.
VueJS docs: "If you have not used AngularJS before, you probably don’t know what a directive is. Essentially, a `directive` is some special token in the markup that tells the library to do something to a DOM element."
This includes a reference to the AngularJS framework, and, yes, it seems AngularJS also has this term.
AngularJS docs: "At a high level, `directives` are markers on a DOM element (such as an attribute, element name, comment or CSS class) that tell AngularJS's HTML compiler ($compile) to attach a specified behavior to that DOM element (e.g. via event listeners), or even to transform the DOM element and its children."
Ok, so it seems that the term originally comes from AngularJS, and Angular and VueJS just inherited it.
I guess, in Layman terms, a `directive` is a way of "*teaching the HTML to do new tricks*" (not mine).
But still... why `directive`?
Still not sure, maybe the creators thought of this term because a `directive` it's like **commanding (giving directives/instructions/orders)** to a static technology (HTML) in order to make it smarter. | ovidiu141 |
904,073 | One Environment per Project: Manage Directory-Scoped envs with direnv in POSIX Systems | Manage your environment variables with direnv | 0 | 2021-11-20T14:41:58 | https://dev.to/otamm/one-environment-per-project-manage-directory-scoped-envs-with-direnv-in-posix-systems-4n3c | linux, bash, unix, direnv | ---
title: One Environment per Project: Manage Directory-Scoped envs with direnv in POSIX Systems
published: true
description: Manage your environment variables with direnv
tags: linux, bash, unix, direnv
//cover_image: https://direct_url_to_image.jpg
---
## Introduction
One of the more common practices in software projects is to keep certain information separated but accessible from the codebase which uses it. This is usually done with secrets such as passwords or private keys, and also with user or context-specific info pieces. However, management of environment variables can be a pain. The solutions to ease it are many, and there are even built-in ones such as [bash_profile](https://www.baeldung.com/linux/bashrc-vs-bash-profile-vs-profile).
One solution I've discovered recently and found particularly convenient is [direnv](https://github.com/direnv/direnv), a shell extension which enables definition of environment variables scoped by directory. After installing & hooking the extension to your shell, `direnv` will execute every time you change directories, looking for an `.envrc` file in the same or in a superior directory tree level. It will then load the defined variables to the current environment, and unload them if it ceases to detect the same `.envrc`.
Note that `direnv` will load the first detected `.envrc` file, which means that *the environment will* **not** *inherit values from a* `.envrc` *in a parent directory*.
It is also important to keep in mind that the environment variables *will only be loaded to your shell session once you move to a directory affected by a* `.envrc` *file*. So if you try something like running a script which loads an environment defined in a directory below your current level, the variables wouldn't be accessible.
## Install
Here's the [list of supported systems](https://direnv.net/docs/installation.html), it is very likely your UNIX-based system's main open source package manager has it available. Suppose we are on Debian, we can install `direnv` by running the standard external package install command in the terminal:
```bash
sudo apt-get install direnv
```
## Setup
After installation, we must hook `direnv` to our shell. Supposing we are using bash, we can accomplish this by appending this line to the end of our shell startup config file:
```bash
echo 'eval "$(direnv hook bash)"' >> ~/.bashrc
```
Almost the same for ZShell:
```bash
echo 'eval "$(direnv hook zsh)"' >> ~/.zshrc
```
Direnv also supports FISH, TCSH & Elvish. [Here are the hooking instructions for each supported shell](https://direnv.net/docs/hook.html).
## Using direnv
Now we must create an `.envrc` file for the directory we would like to scope the environment variables to.
Say we create it for the directory `~/project`.
```bash
echo export FOO='I love Linux!' >> ~/project/.envrc
```
You will then receive a warning that the current `.envrc` wasn't read; `direnv` will block loading `.envrc` every time it detects changes which were not explicitly allowed. Run:
```bash
direnv allow ~/project
```
and voilà!, you now have a directory-scoped environment.
Remember when I told you that '`direnv` will block loading `.envrc` every time it detects changes which were not explicitly allowed'? This isn't limited to newly introduced changes, the whole file will be unauthorized. So when you
```bash
echo export BAR='It is actually called GNU/Linux!' >> ~/project/.envrc
```
you will have to run `direnv allow ~/project` again, even to access `$FOO`. Kinda boring, but biased towards safety.
Every time an `.envrc` is loaded, direnv will output a message with the file path and also the names of the variables loaded, so you don't need to worry about forgetting your setup. It will also tell you whenever an environment was unloaded.
That's it, pretty straightforward and I hope you find it as convenient as I did. | otamm |
904,085 | 5 good posts in "Living with Kubernetes" | Thanks a lot to AWS Justin Garrison for this good series of "Living with Kubernetes" ! Recommend read... | 0 | 2021-11-20T15:28:21 | https://dev.to/aws-builders/5-good-posts-in-living-with-kubernetes-30mi | kubernetes, aws, tutorial, devops | Thanks a lot to AWS Justin Garrison for this good series of "Living with Kubernetes" ! Recommend read and understand more in kubernetes API versioning, Upgrade strategies, Multi-cluster management (suggest to read new EKS connector [Link] (https://docs.aws.amazon.com/eks/latest/userguide/eks-connector.html) too), how to debug cluster and workloads/pods !
5 good posts below:
1. API Lifecycles and You
[Link] (https://thenewstack.io/living-with-kubernetes-api-lifecycles-and-you/)
2. Cluster Upgrades
[Link] (https://thenewstack.io/living-with-kubernetes-cluster-upgrades/)
3. Multicluster Management
[Link] (https://thenewstack.io/living-with-kubernetes-multicluster-management/)
4. Debug Clusters in 8 Commands
[Link] (https://thenewstack.io/living-with-kubernetes-debug-clusters-in-8-commands/)
5. 12 Commands to Debug Your Workloads
[Link] (https://thenewstack.io/living-with-kubernetes-12-commands-to-debug-your-workloads/)
e.g. part 1:

part 2:
part 4:

part 5:

| leewalter |
904,093 | Simple to Complex Roadmap for Full-stack development (JavaScript Specific) | Simple to Complex Roadmap for Full-stack development (JavaScript Specific) HTML > CSS... | 0 | 2021-11-20T15:53:17 | https://dev.to/muneebhdeveloper/simple-to-complex-roadmap-for-full-stack-development-javascript-specific-3a28 | # Simple to Complex Roadmap for Full-stack development (JavaScript Specific)
HTML > CSS > JavaScript > ES6 > React > Node.js > Express > MongoDB > MySQL > Github > Deployment
**Do you want to go advanced?**
RESTful API > Payment Gateways (Stripe & Paypal) > Firebase > GraphQL > Headless CMS > Next.js (SSR, ISR, SSG)
**Do you still want to learn ? here some more**
Command Line > React Native > Web Sockets (Socket.io) > Redis > NGINX > Serverless > Docker > AWS
**Is that's not enough for you? you are the champ, there are some extras for you.**
1. Blockchain (DApps)
2. Augmented Reality
3. WebRTC
4. IoT
5. Streams
6. Electron.js
7. Maps, Geocoding and Geofencing
There are many many more to learn but I think this is enough for this post, Keep learning, Keep improving, and do remember one thing never ever stop learning because there's always **"One more thing" to learn.** | muneebhdeveloper | |
904,100 | How to Set Up Testing (TDD) for Typescript Nodejs API | Guide with detailed explanation on how to Set Up Testing for a Nodejs Typescript API using Jest | 0 | 2021-11-20T16:15:57 | https://dev.to/inidaname/how-to-set-up-testing-tdd-for-typescript-nodejs-api-3lak | typescript, api, testing, node | ---
title: How to Set Up Testing (TDD) for Typescript Nodejs API
published: true
description: Guide with detailed explanation on how to Set Up Testing for a Nodejs Typescript API using Jest
tags: Typescript, API, Testing, Nodejs
//cover_image: https://direct_url_to_image.jpg
---
In this article, we will see how to set up TDD for Nodejs Typescript API.
## The benefits of writing tests
> The purpose of a test case is to determine if different features within a system are performing as expected and to confirm that the system satisfies all related standards, guidelines and customer requirements. The process of writing a test case can also help reveal errors or defects within the system.
> -- Kate Brush, [What is a Test Case? - SearchSoftwareQuality](https://searchsoftwarequality.techtarget.com/definition/test-case)
The above is the best way to describe tests.
## Typescript
TypeScript is a strongly typed programming language that builds on JavaScript.
## Node.js
Node.js is a JavaScript runtime built on Chrome's V8 JavaScript engine.
## Jest
Jest is a JavaScript Testing Framework.
### Prerequisites
- Install Nodejs https://nodejs.org
- Familiarity with Typescript or JavaScript is required
## Check if Nodejs is installed
```
node -v
```
You should have the below output, it varies on the version you install
```
v14.18.1
```
## Start the project
We will start by initializing a new nodejs application. Create a folder for your project, let call it `HelloWorld`. In the directory open your terminal and run the code
```
npm init -y
```
You are instructing Nodejs to initialize a new application and accept every question as default, this should create a `package.json` file in the directory.
Typescript is a superset of javascript, in this case, typescript still transpile to javascript before you can run and execute your code.
### Dependencies
Let's add dependencies for the application.
- Expressjs: A nodejs API framework.
To install Expressjs run
```
npm install --save express
```
### DevDependencies
Development dependencies, this is a typescript project we are required to install dependencies types as devDependencies to help nodejs with type definitions for the dependencies.
- `@types/express`
- `@types/node: This helps with type definitions for Node.js`
- `ts-node: It JIT transforms TypeScript into JavaScript, enabling you to directly execute TypeScript on Node.js without precompiling, we should run the tests without compiling our code into javascript first.`
- `jest, jest-cli: Javascript testing framework to run tests`
- `@types/jest`
- `ts-jest: A Jest transformer with source map support that lets you use Jest to test projects written in TypeScript.`
- `supertest: HTTP assertions to help our test make API calls of GET, POST, etc`
- `@types/supertest`
- `typescript: well, this is a Typescript project`
Now let install these dependencies.
```
npm install --save-dev @types/express @types/node ts-node jest jest-cli @types/jest ts-jest supertest @types/supertest request @types/request typescript
```
## Configuration
### Typescript
To set up the typescript project we need to initialise typescript configuration, run
```
npx tsc --init
```
This will create a `tsconfig.json` file with the minimal configuration which is okay for this tutorial.
### Jest Configuration
Now we will set up jest configuration for the test environment, create a file name `jest.config.ts` and add the below code. To learn more about jest configuration visit https://jestjs.io/docs/getting-started.
```
export default {
moduleFileExtensions: ["ts", "tsx"],
transform: {
"^.+\\.(ts|tsx)$": "ts-jest",
},
testMatch: [
"**/tests/**/*.spec.ts",
"**/tests/**/*.test.ts",
],
testEnvironment: "node",
};
```
A little about the properties above.
- `moduleFileExtensions: An array of file extensions your modules use`.
- `transform: This is to tell jest that we will be using a different file extension not the usual .js files, in our case we are using .ts so we passed a Regex to match our file type and a module to help handle the filetype, this is where we make use of ts-jest we installed`.
- `testMatch: This property is to tell jest the directory and/or files to run for test cases`.
- `testEnvironment: We are telling jest which environment our project is targeted for in this case we are targeting Node environment`.
## Directory
This is our proposed directory structure
<pre>
├──jest.config.ts
├──package.json
├──package-lock.json
├──tsconfig.json
├──server.ts
├──src
│ └── app.ts
└──tests
└── app.spec.ts
</pre>
It is preferred to structure your app directory in this format for testing.
## Now the Codes
Create a folder name `src` and create a file in the `src` folder name `app.ts` with the following code.
```
import express, { Request, Response } from 'express';
const app = express();
app.get('/', (req: Request, res: Response): Response => {
return res.status(200).json({message: 'Hello World!'})
});
export default app;
```
### Let work through the codes
- First, we import the `express` module and types of `Request, Response`.
- Then we initialize our application with express and assign it to a variable.
- Then we call the `get method` for routing, with a callback handler for our route, this callback takes to parameter `req` type Request, `res` type Response, which returns a `Response` type. For typescript, it is recommended to type variables, parameters and function returns in your codes.
- The handler returns a response of Http status code ([Learn More about status codes here](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status)) `status: 200` and a json of `message: 'Hello World!'`
- Then we export our application for testing purposes and to modularize.
Was that a lot?
Next we create another file in the root folder and name it `server.ts` containing the following code.
```
import app from './src/app';
const server = app.listen(3000, ()=> {
console.log(`This is running on port 3000`)
})
export default server
```
This is our application entry point.
### Test
Create a directory name `tests` in the directory create a file name `app.spec.ts`
```
import request from "supertest";
import {Express} from 'express-serve-static-core';
import app from "../src/app"
let server: Express
describe('APP should say "Hello World!"', () => {
beforeAll(() => {
server = app;
});
it('should return 200', (done) => {
request(server)
.get('/')
.expect(200)
.end((err, res) => {
if (err) return done(err)
expect(res.body).toMatchObject({'message': `Hello World!`})
done()
})
});
});
```
#### Let walk through the codes
- We import the `supertest` module and assign a variable name `request`.
- Import the Express interface
- We then import our app
- Then we declare a variable `server` with the type of Express without assigning any value to
- We describe our test suite for a test block, `describe` is a jest global function that accepts a `string` and a `callback`.
- We passed a description of the test suite with a string `APP should say "Hello World!"`.
- In the `callback` scope we call another global function `beforeAll` which accepts a `callback`, this is to tell jest that we will want to run a block of code before the suite run its tests. In this case, we want to first assign a value to our declared variable `server` which will be to assign the app that we have imported so we can run our tests.
- Then we call another global function `it` which is a test closure that takes two parameters a `name` and a `callback`.
- The name of our test closure is **should return 200**.
- We then pass a `done` callback as a parameter for the closure callback
- We call `request` and pass the `server` variable to run our app in the test scope.
- We call the get method and pass `'/'` route. In this case, we are running HTTP GET Method to our application on the route `'/'`.
- We expect the HTTP GET Method should return 200 Ok status and return the message `'meesage':'Hello World!'`
- We call `end` method which takes a callback with two parameters of `error` and `respond`
- We check if the test has error then we return the `done` method with the `error` from the test if otherwise which means the test runs successfully, so we call the `expect` global method which we check `body` property from the `respond` parameter to match our expected result.
- Then we finally call `done` method to tell jest we are through with this suite.
## Before we are done
And finally, we need a way to run our test, so edit the `package.json` file in the scripts section change `test` property. The scripts section should look something like this.
```
...
"scripts": {
"dev": "ts-node server.ts",
"test": "jest --verbose"
},
...
```
Now when you run
```
npm run test
```
You see result like the screenshot below.
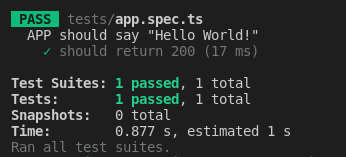
Let say we change the return value in `app.ts` file from `Hello World!` to `World Hello` you should see a failed test like the screenshot below.
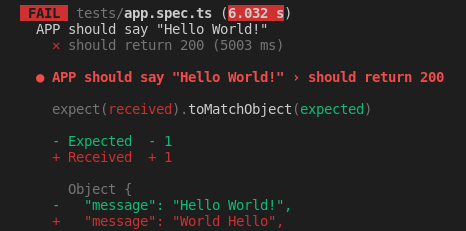
## Conclusion
Writing test could mean to write more code but a few lines are worth the hours it will save. I'm a Full Stack developer using React, React Native and Nodejs with Typescript.
Feel free to put questions or suggestion in the comment or you can also reach out on Twitter [iNidAName](https://twitter.com/inidaname)
| inidaname |
904,116 | Weekend with Azure | Hi everyone, I am Mayank Gupta, a second-year student at Vellore Institute of Technology, Chennai,... | 0 | 2021-11-22T11:10:40 | https://dev.to/mayankcse/weekend-with-azure-3053 | cloud, azure, cloudcomputing | Hi everyone,
I am Mayank Gupta, a second-year student at Vellore Institute of Technology, Chennai, India, pursuing Bachelor of Technology in Computer Science. I have a zeal to work and learn new skills everyday with dedication, enthusiasm & passion, and aim to create difference in community as much as I can.
I recently attended a webinar by @kunalKushwaha, notes of which have already been uploaded on my twitter handle
You can have a look at that...was really an amazing session. This only ignited my interest towards cloud computing, which motivated me to learn more about the subject.
After lot of research I found that cloud computing is something that I was looking for, all my first year!
I've decided to dedicate my weekends to cloud computing.
Now I know you all will be thinking why am I giving introduction in a blog...actually this blog is the announcement to the future streak
from now I'll be learning cloud computing with Azure as my main cloud service,
### Why have I chosen Azure?
This topic already has a lot of content floating on the web, I don't want to jump into the fight
All the platforms are great, just being a student we should start with anyone which you like and feel is going to boom in the future_ I am going with Azure you can choose yours
### Announcement
Every weekend I'll be learning a new topic which will cover training of Azure and will be posting my notes with the learning and key concepts.
### Target
Microsoft Azure Administrator Certification [AZ-104]
![Microsoft Azure Administrator Certification [AZ-104]](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/oin4mcx0pai8p3bc86ha.png)
**Do add your suggestions in the comment section**
---
| mayankcse |
904,133 | Developers Remember This Before Your Interview! | Interviewing can be very stressful. You may worry if you will make a good impression, or what type of... | 0 | 2021-11-20T17:51:59 | https://dev.to/kinjiru09/developers-remember-this-before-your-interview-558i | programming, interview, beginners | Interviewing can be very stressful. You may worry if you will make a good impression, or what type of test they will give you. But there are a few things to remember when you go to an interview.
##The Employer’s Interview
Employers typically have a particular mindset when interviewing developers, _“I am going to spend **my money** to pay you to render a service for me. So I want to make sure I am getting my money’s worth.”_ In other words, they want to make sure you are a worthwhile investment, or that you bring value to the company. Because many employers (not all) think like this, they typically use the interview process as a way to determine a developer’s value. You will meet with various people, answer questions both personal and technical, take coding challenges, and build an app. Some companies even have personality tests. A company has the right to have all these things in the interview. After all, it is their money.
But the exact opposite is true too! Developers should have a similar mindset when going to any interview. _“I am going to spend **my time** rendering a service to you. I want to make sure my time is well spent and well compensated.”_ Here is why developers should think this way.
##Time vs Money
Time is more valuable than money. You can have all the money in the world, but if you don’t have time to spend it or enjoy it with your loved ones, then the money is pointless.
As a developer, our time is valuable. We spend our time with our families, our friends, learning new skills, enjoying hobbies, and handling our responsibilities. Our time only becomes more valuable as we get older.
We don’t have the time to waste on pointless interviews. When you go to an interview, the employer is being interviewed just as much as you are. You need to make sure that the job will compensate you for your skills and that it will allow you to grow as a developer.
>Employers are checking to see if we have the right skills for the job. Developers should check if the employer has the right environment for us to grow.
Thus, developers should interview the employer.
##The Developer’s Interview
Developers should have a list of questions ready to ask the employer. Some examples are:
1. How many developers are on the team?
2. What is the personality of the team, are they fun and laid back or serious?
3. What type of source control do you use?
4. Do you have a code review process?
5. Do you have peer programming?
6. How do you encourage or help your developers to continue to grow?
7. How do you help your developers have a healthy work-life balance?
8. Walk me through a typical day at the office
9. Can I see an example of user requirements?
10. How many sprints do you cover in a quarter?
11. Does the IT department have its own budget?
12. How do you track bugs?
There’s nothing wrong with asking questions like these in an interview. You are investing your time in this company. Invest wisely!
New developers definitely have to learn this way of thinking. Just because you are new in the field doesn’t mean you have to accept any job. Find a job that will compensate you and will allow you to grow. If the job doesn’t meet these two criteria, do not waste your precious time.
Our time only becomes more valuable as we get older. We have to invest it wisely. Invest it in learning and improving yourself. Improve your programming skills. Improve your thinking ability. Improve your personality. These are skills that make us more valuable. Do not waste your time on a company with a toxic environment or an environment where you cannot learn and grow.
##Signs of a Pointless Interview
If you see a job that lists every skill under the sun, beware this interview will most likely waste your time. If you see a job posting like the below for a front end position but it lists NON front end skills, it’s probably not worth your time.
What You Bring to the Team
SQL
DevOps
Building APIs
React
Typescript
CSS
BS in Computer Science or equivalent and 5 years of experience
Accredited Full Stack Web Certification and 6 years of experience
This is from a real job posting for a front end position. This company wants you to know DevOps?! And what is Full Stack Web Certification, isn’t this position for a front end developer? Is a full stack developer stronger than a front end developer? Not necessarily. A full stack developer could be stronger on the backend but suffer on the front end. They didn’t even list HTML and JavaScript (knowing React doesn’t mean you know JavaScript). Job descriptions like this give you a view into the company. A company like this doesn’t know what their developers do, or they expect too much out of their developers. Front end is front end, backend is backend. The job description should be clearer. If they want someone who knows both, they should ask for a full stack developer. Companies that do not have clear job postings are an indication of communication issues.
;TLDR;
Going to an interview certainly can be stressful. But remembering that you can also interview the employer will help alleviate some of the stress. During your interview process make sure to see if the company can bring value to your career. If not, find a company that will. Invest in your future! | kinjiru09 |
904,195 | Basic Terms to know before getting started with Cloud | Those who have not read my previous blog, my name is Mayank and I have started a learning streak,... | 0 | 2021-11-26T17:51:48 | https://dev.to/mayankcse/basic-terms-to-know-before-getting-started-with-cloud-27m6 | cloud, azure, beginners, aws | Those who have not read my previous blog, my name is Mayank and I have started a learning streak, **#WeekendwithAzure** In this I'll be posting my learning in azure every weekend
This is my contribution to help students in my community. Hope you'll find my efforts useful.
If you like it please add a comment of appreciation
or
Please do add tips for improvement in the comment section below, would be really helpful
-----
__Getting Started!__
Before taking our first step in the world of cloud and Azure, we should get familiar with the 7 basic terms that every cloud engineers uses and knows about.
## 7 Basic Terms:
* Network Operating System
* Client Operating System
* Traditional IT
* Virtualization
* On-Premise Computing
* Cloud Computing
* On-Demand-Service and Pay-As-You-Go
Question to Client will be referred to as 'QTC'.
## Network Operating System
A Network Operating System (NOS) is a computer operating system (OS) that is designed primarily to support workstations, personal computers and, in some instances, older terminals that are connected on a local area network (LAN). The software behind a NOS allows multiple devices within a network to communicate and share resources with each other.
QTC: What are the Operating Systems running in your user's environment?
There are two types of Operating systems:
* **Window OS** = Window server 2008 R2, Server 2012, Server 2016, Server 2019
* **Linux OS** = Redhat Linux and Suse Linux
Application:
*Web Server *Database *Software Testing App *Backup *SAP HANA *Gaming App *Domain Controller *Mail Server
Example:
In the ICICI bank website whatever we do is not on our laptop, but there on the bank's server.

## Client Operating System
The Client Operating System is the system that works within computer desktops and various portable devices. This system is different from centralized servers because it only supports a single user ... The client operating system is the operating system for computer desktops or portable devices.
QTC: What are the Operating Systems running in your user's workstation?
There are two types of Operating systems:
* **Window OS** = Window 7,8,10,11
* **Linux OS** = Ubuntu and centos
To understand the gist of NOS and COS we can take the example of you going to a restaurant and placing order, now the waiter here is an example of server, NOS, and you are the clients, COS
Waiter will always provide you the dish that you asked him, which is of your taste or which will be accepted by you

## Traditional IT
In order to use Traditional IT, we require a lot of hardware and space to keep the servers as every company is supposed to have its own Data center.
Just to give an idea, when we talk about servers for a company, there are almost 5000 servers required for big companies and around 100 servers for small organizations. Some are:
* Domain Controller
* Mail Server
* Database Server
* Tally Server
* File Server
* Web Server
and many others as per the requirement of the organization.
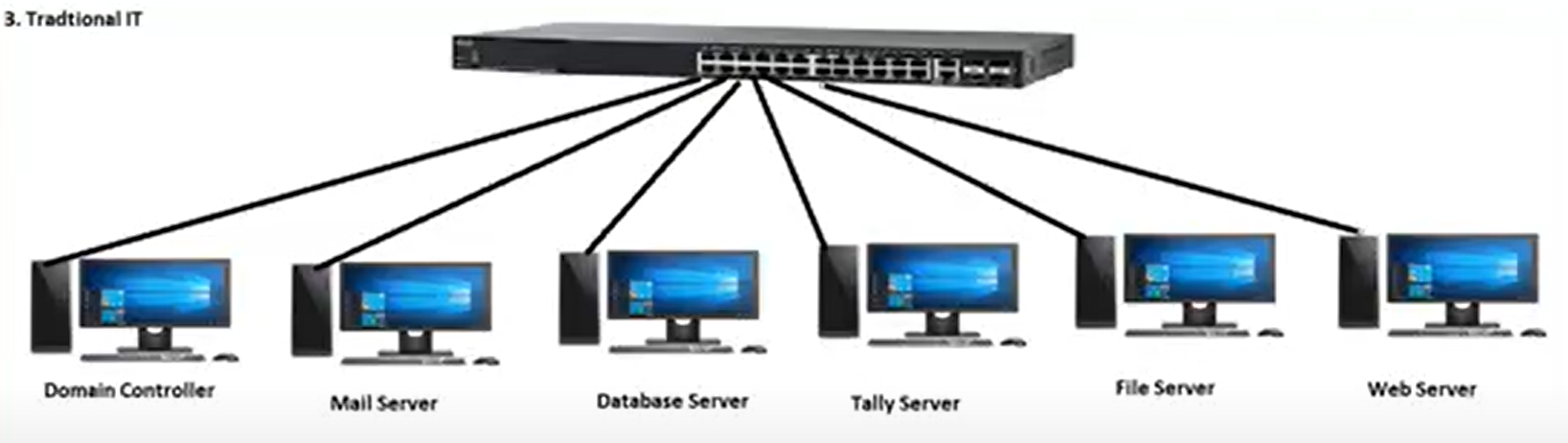
In order to handle these servers you will have to hire engineers. Thus, the cost increases.
You will have to arrange a place to setup these data centers and thus, space requirement increases.
Every server requires a high potential professional processor i.e. Xeon Processor, which costs about Rs.5 lakhs.(It varies as per configuration)
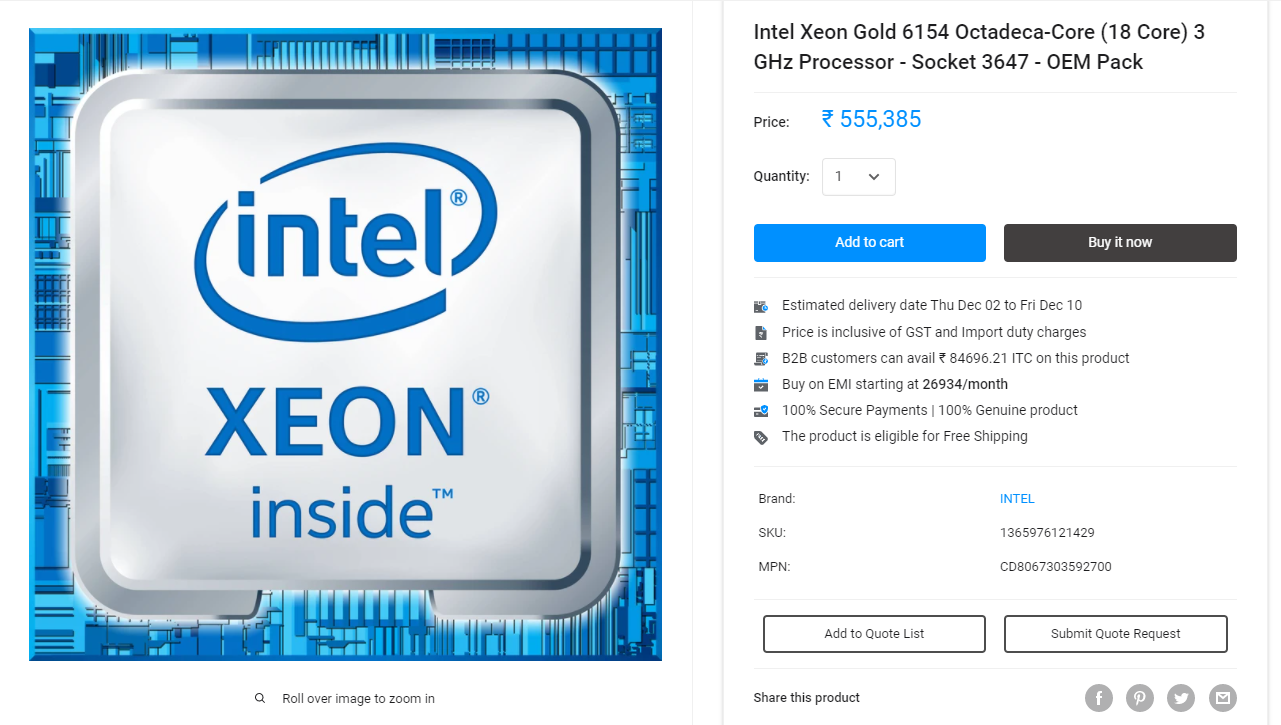
You'll have to take care of 24*7 electricity supply and a clean environment for the application to run smoothly.
You will also have to set-up a Secondary Data center. If in case some disaster happens with the primary data center, you'll transfer the load to secondary data center in order to keep the application running uninterrupted, and this will directly double the cost as the Secondary Data center will require the same hardware as the Primary Data Center.
__Now what if ?__ Secondary Data Center also fails? Let me take an example to explain this
Suppose your Primary Data Center is setup at Noida and Secondary Data Center in Pune
* _Case 1_ If some Disaster happens in Noida, we can transfer the load to Pune.
* _Case 2_ What if some disaster happens for complete India? now what? Now your app gets crashed and your clients outside India and even inside India are not able to use the application which can lead to huge losses and a feeling of distrust among users.
We'll see how cloud computing solves this issue efficiently
## Virtualization
There are two main Virtualization Software:
* Microsoft-Hyper-V
* VM Ware-ESXI or VM Ware Workstation
Virtualization is the process of running a virtual instance of a computer system in a layer abstracted from the actual hardware.
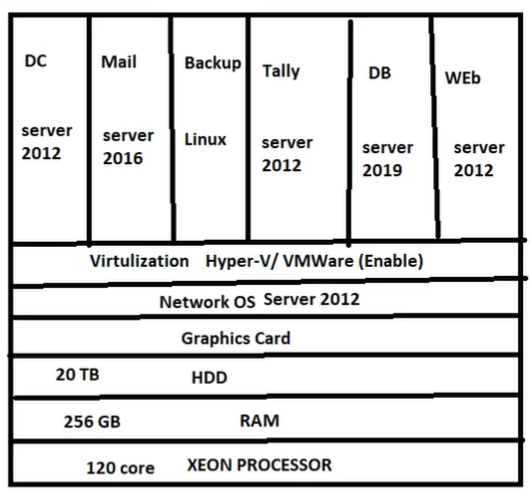
In simple words, it is the projection of the data from all the servers at one desktop. Single desktop is connected to all the servers.
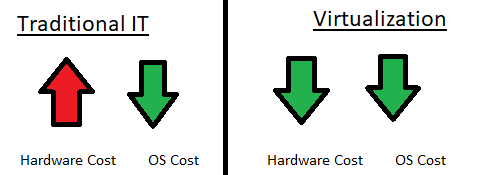
## On-Premise Computing
On-premises software is located and operated within a user’s datacenter. As such, it uses the user’s computing hardware rather than that of a cloud provider.
It is like the physical hardware that will get delivered to your home.
For example:
*Laptop *Desktop *Mouse *Keyboard *Server *Rack *Printer *LAN Cable
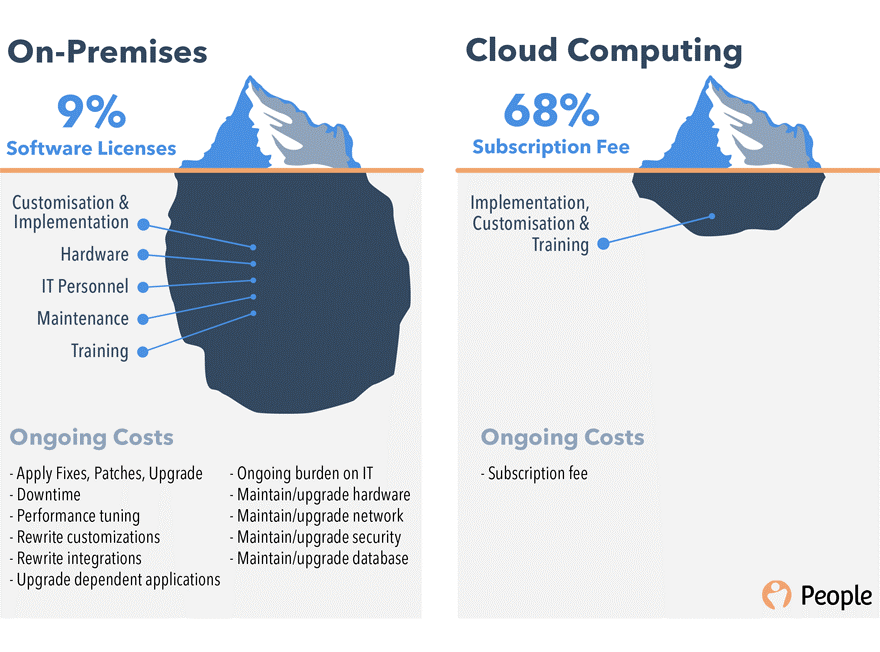
## Cloud Computing
It is the delivery of computing services - servers, storage, databases, networking, software analytics and moreover the internet.
## On-Demand Service & Pay As You Go
These are the services that have made cloud Computing very popular. As we have discussed in traditional IT, it is very expensive to buy the server, set-up a data center, and hire engineers and that too, at an initial stage where you don't know whether your application will be a hit or not.
**What if**, you could rent a data center? By doing this you neither have to pay for the hardware nor have to hire engineers and you'll have a lot of space now which you can use for other things.
This is what big companies like Microsoft, Amazon, IBM and many others are doing.
In this you'll tell them about the hardware you require for your application and they'll build that for you in their data center and you will just have to pay the rent for the data center.
**How cool is that!!**
One more interesting thing is, you just have to pay for the services you use and when you use. For example:
If your working hours are 9:00 A.M. to 7:00 P.M. out of 24hr day so you have to pay for the hours you use the virtual machine.
* For __9:00 A.M. to 7:00 P.M.__ i.e. 10 hours for 30days the amount is **Rs 4,704.15**.
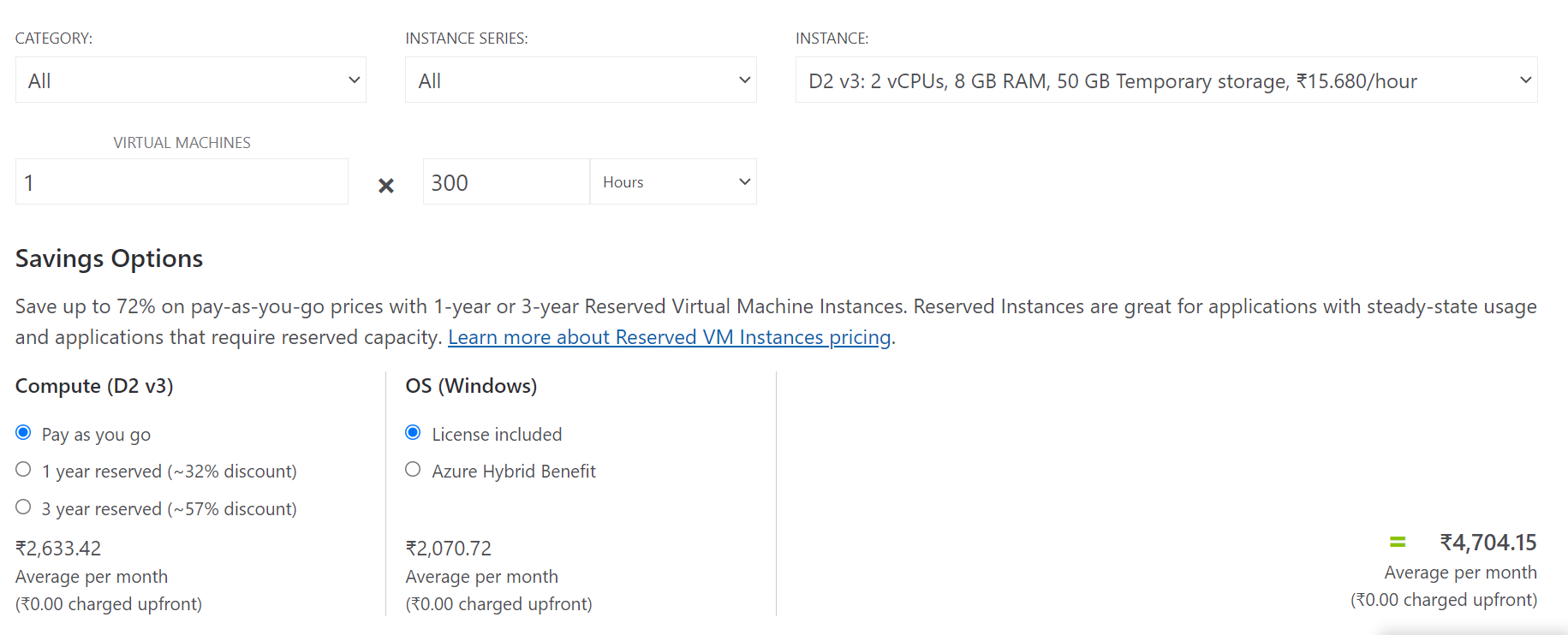
* And for the __whole month__ with the same configuration it comes out to be **Rs.11,446.75**
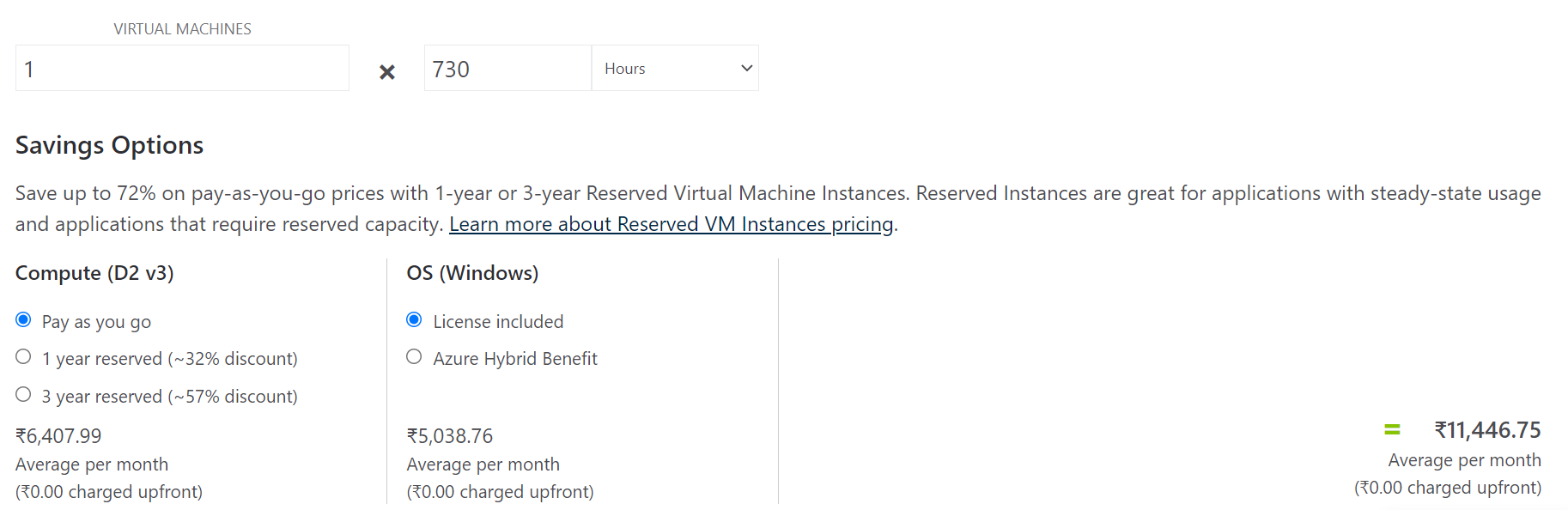
To calculate the price, we use pricing calculator-
https://azure.microsoft.com/en-us/pricing/calculator/
Thus, we can clearly see that this process is very cost affective and with such big companies like Microsoft, Amazon, etc., security is also provided so you don't have to be worried about your data getting leaked.
-----
**That is all for this week**,
We have covered the following basic terms in detail:
* Network Operating System
* Client Operating System
* Traditional IT
* Virtualization
* On-Premise Computing
* Cloud Computing
* On-Demand-Service and Pay-as-you-go
One should know these before getting into cloud.
### Next Week
We'll be discussing-
* Difference between Cloud Computing and Traditional IT
* Cloud Models
* Resource Group and it's Creation (first lab activity)
* IP Addressing in Azure
Hope you liked my efforts.
You can connect with me at
Github - https://github.com/mayank-cse
Linkedin - https://www.linkedin.com/in/mayank-gupta-478640200/
Twitter - https://twitter.com/MayankGuptacse1
In case you have any doubts, please feel free to ask in the comment section.
Thank You for Reading! Hope it benefitted you😄
--- | mayankcse |
904,200 | Native-image with Micronaut | Last week, I wrote a native web app that queried the Marvel API using Spring Boot. This week, I want... | 15,512 | 2021-11-21T16:39:13 | https://dev.to/nfrankel/native-image-with-micronaut-41fc | kotlin, micronaut, nativeimage, graalvm | Last week, I wrote a native web app that queried the Marvel API [using Spring Boot](https://blog.franke.ch/native/spring-boot/). This week, I want to do the same with the Micronaut framework.
## Creating a new project
Micronaut offers two options to create a new project:
1. A [web UI](https://micronaut.io/launch):
As for Spring Initializr, it provides several features: preview the project before you download it, share the configuration and an API.
I do like that you can check the impact that the added features have on the POM.
2. A [Command-Line Interface](https://docs.micronaut.io/1.3.3/guide/index.html#buildCLI):
In parallel to the webapp, you can install the <abbr title="Command-Line Interface">CLI</abbr> on different systems. Then you can use the `mn` command to create new projects.
In both options, you can configure the following parameters:
* The build tool, Maven, Gradle, or Gradle with the Kotlin DSL
* The language, Java, Kotlin, or Groovy
* Micronaut's version
* A couple of metadata
* Dependencies
The application's code is on [GitHub](https://github.com/micronaut-projects/micronaut-starter). You can clone and adapt it, but as far as I know, it's not designed with extension in mind (yet?).
## Bean configuration
Micronaut's bean configuration relies on [JSR 330](http://javax-inject.github.io/javax-inject/). The JSR defines a couple of annotations, _e.g._, `@Singleton` and `@Inject`, in the `jakarta.inject` package. Developers use them, and the service provider implements the specification.
`@Singleton` and its sibling `@ApplicationScoped` are meant to be used on our code. Our sample app needs to create an instance of `java.security.MessageDigest`, which cannot be annotated. To solve this problem, JSR 330 provides the `@Factory` annotation:
```kotlin
@Factory // 1
class BeanFactory {
@Singleton // 2
fun messageDigest() = MessageDigest.getInstance("MD5") // 3
}
```
1. Bean-generating class
2. Regular scope annotation
3. Generate a message digest singleton
Micronaut also provides an automated discovery mechanism. Unfortunately, it doesn't work in Kotlin. You need to point to the package Micronaut explicitly should scan:
```kotlin
fun main(args: Array<String>) {
Micronaut.build().args(*args)
.packages("ch.frankel.blog")
.start()
}
```
## Controller configuration
Micronaut copied the `@Controller` annotation from Spring. You can use it in the same way. Likewise, annotate functions with the relevant HTTP method annotation.
```kotlin
@Controller
class MarvelController() {
@Get
fun characters() = HttpResponse.accepted<Unit>()
}
```
## Non-blocking HTTP client
Micronaut provides two HTTP clients: a declarative one and a low-level one. Both of them are non-blocking.
The declarative client is for simple use-cases, while the low-level is for more complex ones. Passing parameters belongs to the complex category, so I chose the low-level one. Here's a sample of its API:
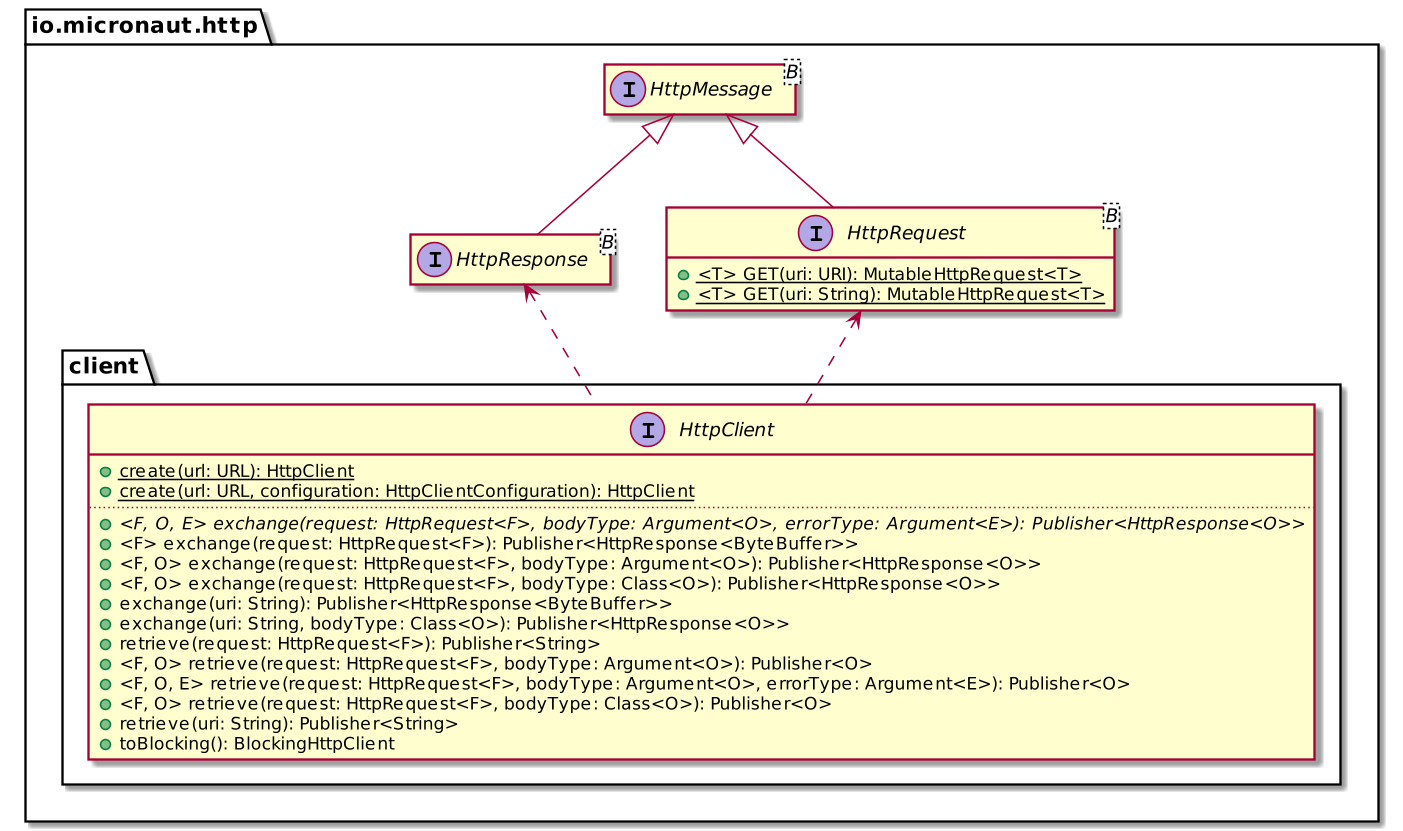
The usage is straightforward:
```kotlin
val request = HttpRequest.GET<Unit>("https://gateway.marvel.com:443/v1/public/characters")
client.retrieve(request, String::class.java)
```
Remember that we should get parameters from the request to the application and propagate them to the request we make to the Marvel API. Micronaut can automatically bind such query parameters to method parameters with the `@QueryValue` annotation for the first part.
```kotlin
@Get
fun characters(
@QueryValue limit: String?,
@QueryValue offset: String?,
@QueryValue orderBy: String?
)
```
It's not possible to use Kotlin's string interpolation as these parameters are optional. Fortunately, Micronaut provides an `UriBuilder` abstraction, which follows the Builder pattern principles.
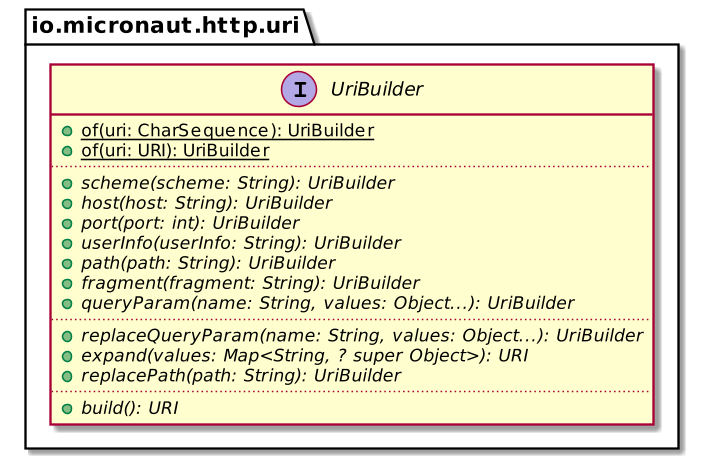
We can use it like this:
```kotlin
val uri = UriBuilder
.of("${properties.serverUrl}/v1/public/characters")
.queryParamsWith(
mapOf(
"limit" to limit,
"offset" to offset,
"orderBy" to orderBy
)
).build()
fun UriBuilder.queryParamsWith(params: Map<String, String?>) = apply {
params.entries
.filter { it.value != null }
.forEach { queryParam(it.key, it.value) }
}
```
## Parameterization
Like Spring, Micronaut can bind application properties to Kotlin data classes. In Micronaut, the file is named `application.yml`. The file already exists and contains the `micronaut.application.name` key. We only need to add the additional data. I chose to put it under the same parent key, but there's no such constraint.
```yaml
micronaut:
application:
name: nativeMicronaut
marvel:
serverUrl: https://gateway.marvel.com:443
```
To bind, we need the help of two annotations:
```kotlin
@ConfigurationProperties("micronaut.application.marvel") //1
data class MarvelProperties
@ConfigurationInject constructor( //2
val serverUrl: String,
val apiKey: String,
val privateKey: String
)
```
1. Bind the property class to the property file prefix
2. Allow using a data class. The `@ConfigurationInject` needs to be set on the constructor: it's a sign that the team could improve Kotlin integration in Micronaut.
## Testing
Micronaut tests are based on the `@MicronautTest` annotation.
```kotlin
@MicronautTest
class MicronautNativeApplicationTest
```
We defined the properties of the above data class as non-nullable strings. Hence, we need to pass the value when the test starts. For that, Micronaut provides the `TestPropertyProvider` interface:
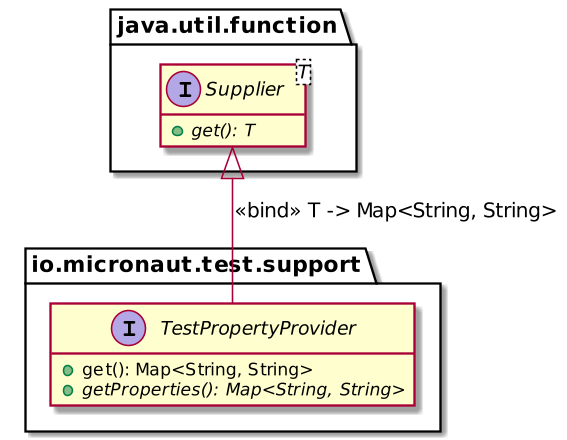
We can leverage it to pass property values:
```kotlin
@MicronautTest
class MicronautNativeApplicationTest : TestPropertyProvider {
override fun getProperties() = mapOf(
"micronaut.application.marvel.apiKey" to "dummy",
"micronaut.application.marvel.privateKey" to "dummy",
"micronaut.application.marvel.serverUrl" to "defined-later"
)
}
```
The next step is to set up Testcontainers. Integration is provided out-of-the-box for popular containers, _e.g._, Postgres, but not with the mock server. We have to write code to handle it.
```kotlin
@MicronautTest
@Testcontainers
@TestInstance(TestInstance.Lifecycle.PER_CLASS) // 1
class MicronautNativeApplicationTest {
companion object {
@Container
val mockServer = MockServerContainer(
DockerImageName.parse("mockserver/mockserver")
).apply { start() } // 2
}
}
```
1. By default, one server is created for each test method. We want one per test class.
2. Don't forget to start it explicitly!
At this point, we can inject both the client and the embedded server:
```kotlin
@MicronautTest
@Testcontainers
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
class MicronautNativeApplicationTest : TestPropertyProvider {
@Inject
private lateinit var client: HttpClient // 1
@Inject
private lateinit var server: EmbeddedServer // 2
companion object {
@Container
val mockServer = MockServerContainer(
DockerImageName.parse("mockserver/mockserver")
).apply { start() }
}
override fun getProperties() = mapOf(
"micronaut.application.marvel.apiKey" to "dummy",
"micronaut.application.marvel.privateKey" to "dummy",
"micronaut.application.marvel.serverUrl" to
"http://${mockServer.containerIpAddress}:${mockServer.serverPort}" // 3
)
@Test
fun `should deserialize JSON payload from server and serialize it back again`() {
val mockServerClient = MockServerClient(
mockServer.containerIpAddress, // 3
mockServer.serverPort // 3
)
val sample = this::class.java.classLoader.getResource("sample.json")
?.readText() // 4
mockServerClient.`when`(
HttpRequest.request()
.withMethod("GET")
.withPath("/v1/public/characters")
).respond(
HttpResponse()
.withStatusCode(200)
.withHeader("Content-Type", "application/json")
.withBody(sample)
)
// With `retrieve` you just get the body and can assert on it
val body = client.toBlocking().retrieve( // 5
server.url.toExternalForm(),
Model::class.java // 6
)
assertEquals(1, body.data.count)
assertEquals("Anita Blake", body.data.results.first().name)
}
}
```
1. Inject the _reactive_ client
2. Inject the embedded server, _i.e._, the application
3. Retrieve the IP and the port from the mock server
4. Use Kotlin to read the sample file - there's no provided abstraction as in Spring
5. We need to block as the client is reactive
6. There's no JSON assertion API. The easiest path is to deserialize in a `Model` class, and then assert the object's state.
## Docker and GraalVM integration
As with Spring, Micronaut provides two ways to create native images:
1. On the local machine.
It requires a local GraalVM installation **with** `native-image`.
```bash
mvn package -Dpackaging=native-image
```
2. In Docker. It requires a local Docker installation.
```bash
mvn package -Dpackaging=docker-native
```
Note that if you don't use a GraalVM JDK, you need to activate the `graalvm` profile.
```bash
mvn package -Dpackaging=docker-native -Pgraalvm
```
With the second approach, the result is the following:
```
REPOSITORY TAG IMAGE ID CREATED SIZE
native-micronaut latest 898f73fb44b0 33 seconds ago 85.3MB
```
The layers are the following:
```
┃ ● Layers ┣━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Cmp Size Command
5.6 MB FROM e6b8cc5e282829d #1
12 MB RUN /bin/sh -c ALPINE_GLIBC_BASE_URL="https://github.com/sgerrand/ #2
3.5 MB |1 EXTRA_CMD=apk update && apk add libstdc++ /bin/sh -c if [[ -n " #3
64 MB #(nop) COPY file:106f24caede12d6d28c6c90d9a3ae33f78485ad71e4157125 #4
```
1. Parent image
2. Alpine glibc
3. Additional packages
4. Our native binary
## Miscellaneous comments
I'm pretty familiar with Spring Boot, much less with Micronaut.
Here are several miscellaneous comments.
* Maven wrapper:
When creating a new Maven project, Micronaut also configures the [Maven wrapper](https://github.com/takari/maven-wrapper).
* Documentation matrix:
Micronaut guides each offer a configuration matrix. You choose both the language and the build tool, and you'll read the guide in the exact desired flavor.

I wish more polyglot multi-platform frameworks' documentation would offer such a feature.
* Configurable packaging:
Micronaut parameterizes the Maven's POM `packaging` so you can override it, as in the above native image generation. It's _very_ clever!
It's the first time that I have come upon this approach. I was so surprised when I created the project that I removed it (at first). Keep it.
* Code generation:
Last but not least, Micronaut bypasses traditional reflection at runtime. To achieve that, it generates additional code at compile-time. The trade-off is slower build time vs. faster runtime.
With Kotlin, I found an additional issue. Micronaut generates the additional code with `kapt`. Unfortunately, `kapt` has been pushed to [maintenance mode](https://kotlinlang.org/docs/kapt.html). Indeed, if you use a JDK with a version above 8, you'll see warnings when compiling.
Integration of `kapt` with IntelliJ is poor at best. While all guides mention how to configure it, _i.e._, enable annotation processing, it didn't work for me. I had to rebuild the application using the command line to be able to view the changes. It makes the development lifecycle much slower.
The team is working toward KSP support, but it's an undergoing effort.
## Conclusion
Micronaut achieves the same result as Spring Boot. The Docker image's size is about 20% smaller. It's also more straightforward, with fewer layers, and based on Linux Alpine.
Kotlin works with Micronaut, but it doesn't feel "natural". If you value Kotlin benefits overall, you'd better choose Spring Boot. Otherwise, keep Micronaut but favor Java to avoid frustration.
Many thanks to [Ivan Lopez](https://twitter.com/ilopmar) for his review of this post.
The complete source code for this post can be found on GitHub:
{% github ajavageek/micronaut-native %}
**To go further:**
* [Micronaut Launch](https://micronaut.io/launch)
* [Defining Beans](https://docs.micronaut.io/3.1.3/guide/#beans)
* [Micronaut HTTP client](https://guides.micronaut.io/latest/micronaut-http-client-maven-kotlin.html)
* [Creating your first Micronaut Graal application](https://guides.micronaut.io/latest/micronaut-creating-first-graal-app-maven-kotlin.html)
_Originally published at [A Java Geek](https://blog.frankel.ch/native/micronaut/) on November 21<sup>th</sup>, 2021_ | nfrankel |
904,273 | Migrating from cakephp 3.x to cakephp 4.x | ... | 0 | 2021-11-20T22:53:12 | https://dev.to/imeneoh/migrating-from-cakephp-3x-to-cakephp-4x-3361 | {% stackoverflow 70050469 %} | imeneoh | |
904,345 | Having Troubles Setting Up Webpack in React ? | If you are following the great tutor Shaun Wassell tutorial on Linkedin on "Building Modern Projects... | 0 | 2021-11-21T00:52:56 | https://dev.to/alaska01/having-troubles-setting-up-webpack-in-react--238a | If you are following the great tutor Shaun Wassell tutorial on Linkedin on "Building Modern Projects With React" and you are having issues setting up your webpack to work correctly, you may wish to use the configuration below.Please bear in mind that the tech world is an ever evolving world, if later in the future, this solution does not work, kindly do a research and upload for the community as well. You may not need this in you day to day react project, but this will give you an indepth knowledge of
const path = require("path");
const webpack = require("webpack");
module.exports = {
entry: "./src/index.js",
mode: "development",
module: {
rules: [
{
test: /\.(js|jsx)$/,
exclude: /(node_modules)/,
loader: "babel-loader",
options: {
presets: ["@babel/env"],
},
},
{
test: /\.css$/,
use: ["style-loader", "css-loader"],
},
],
},
resolve: {
extensions: ["*", ".js", ".jsx"],
},
output: {
path: path.resolve(__dirname, "dist/"),
publicPath: "/dist/",
filename: "bundle.js",
},
devServer: {
static: {
directory: path.join(__dirname, "public/"),
},
port: 3000,
devMiddleware: {
publicPath: "https://localhost:3000/dist/",
},
hot: "only",
},
};
The above configuration got my project running after I uninstalled and re-installed the css loader. Here is the command. $ npm remove css-loader && npm install --save-dev css-loader
The attached image was the initial error I was getting while running the code.
Have all the fun you can. | alaska01 | |
904,381 | Reviewing Others Pull Requests | PR1: Show feeds count on status dashboard Dustin and I worked the same issue, but it... | 0 | 2021-11-21T04:09:46 | https://dev.to/nguyenhung15913/reviewing-others-pull-requests-5f2d | # PR1: [Show feeds count on status dashboard](https://github.com/Seneca-CDOT/telescope/pull/2471)

Dustin and I worked the same issue, but it split into 2 small issues. For his part, he did a great job, but in my PR, I got a recommendation to change the files structure. I also told Dustin about it in his PR.
# PR2: [create github actions for deployment](https://github.com/Seneca-ICTOER/IPC144/pull/48)
I recommend the owner of this PR to extend the node-version to older version. This is because not all of us have updated Node to 16.0. So this might be an issue for them and they might run into error when they push or send a PR.
| nguyenhung15913 | |
904,387 | Different ways for User Authentication with NodeJS Part - 2 (JWT) | So this is the part 2 of the User Authentication with NodeJS. You can check out the Part - 1 here. In... | 0 | 2021-11-21T04:46:47 | https://dev.to/lavig10/different-ways-for-user-authentication-with-nodejs-part-2-jwt-3h0p | javascript, webdev, beginners, tutorial | So this is the part 2 of the User Authentication with NodeJS. You can check out the Part - 1 [here](https://dev.to/lavig10/different-ways-for-user-authentication-with-nodejs-1odj). In this Part we talk about the modern solution for User Authentication which is much more feasible and scalable. Token Based Authentication.
#Token Based Authentication
[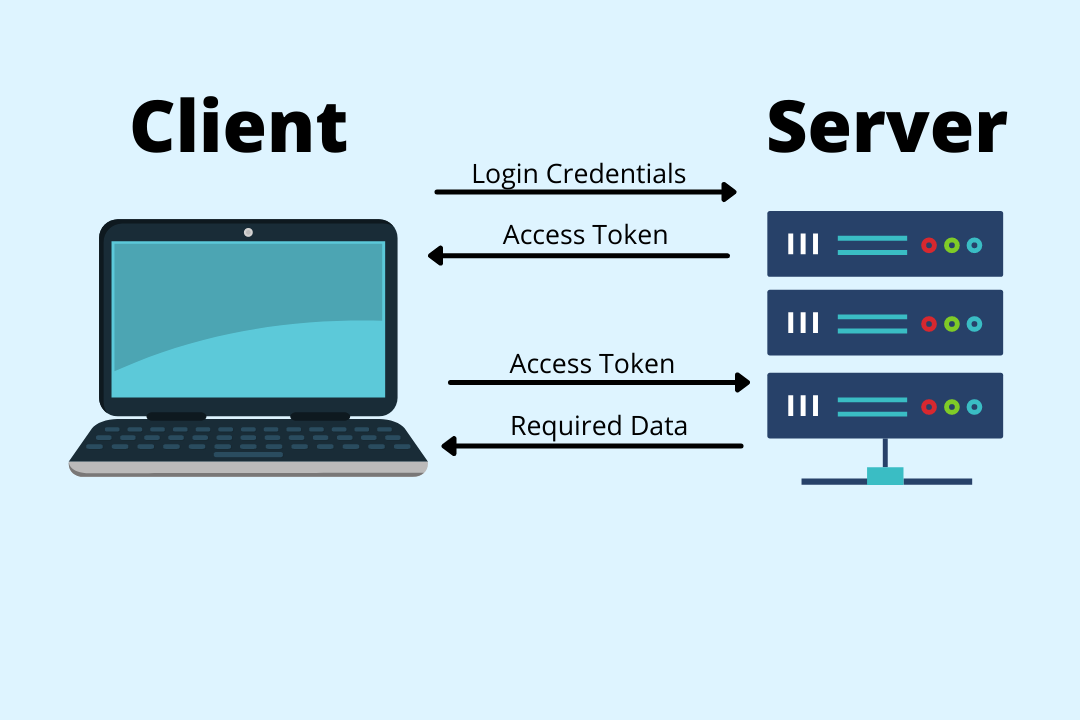](https://postimg.cc/pp98vqvX)
In token based authentication, when a user logins with correct credentials a _token_ (a long string with random characters and numbers) is generated and sent back to the client's browser where it is stored (in localStorage, SessionStorage or cookie). Now every time a user will make a request to the server that token stored in browser will be sent back to the server and we will have some middleware function to verify the token and give back the required resources.
Let's implement it in code.
Create an empty NodeJS project and in terminal run the command
`npm install express jsonwebtoken mongoose`
express - For creating our server
mongoose - To Connect to our MongoDB Database
jsonwebtoken - Known as JWT, it is an open source npm package for generating access tokens securely
```javascript
const express = require('express');
const app = express();
const mongoose = require('mongoose');
const jwt = require('jsonwebtoken');
await mongoose.connect('your_mongo_url', (err, db) => {
console.log('MongoDB Connected....');
});
app.get('/', (req,res)=>{
res.send('<h1>Hello World!</h1>');
})
app.listen(5000, () => console.log(`Server 🔥🔥🔥 up on 5000`));
```
This block of code will make our server up and running on Port 5000. So if you now visit [http://localhost:5000/](http://localhost:5000/) you will see the desired result.
```javascript
app.post("/login", async (req, res) => {
try {
const { username, password } = req.body;
const user = await User.findOne({ username });
if (!user) {
return res.json({ msg: "Please enter a valid username" });
}
const accessToken = jwt.sign(
{ username, id: user._id },
JWT_SECRET,
{
expiresIn: process.env.NODE_ENV === "production" ? "6h" : "2 days",
}
);
res.json({ msg: "User logged in!", accessToken });
} catch (err) {
console.log(err);
res.status(503).json({ msg: "Server error!" });
}
});
```
So above block of code is posting the login credentials and logging in the user. Let us understand the `jwt.sign()` functionality which is creating our access token.
JWT - Json Web Token has a method called `sign()` which is used to create a new web token which will contain user information in a hidden way. There are three parameters in `jwt.sign()` method. Let's talk about each of them.
1. First is the data to be stored in the token. It can be a string or a javascript object. In this example we stored username and id (mongodb unique generated id) in the access token.
2. Second parameter is the `JWT_SECRET`. It can be anything (a random string) and it is important not to display it in production. You should use environment variables for saving the JWT_SECRET. It'll be used later on to verify the JWT Token and authenticate the user.
3. Third parameter is optional properties that can be defined for the access token, like expiry date, httpOnly etc. You can check out more in detail about the optional parameters [here](https://www.npmjs.com/package/jsonwebtoken)
This function will return us a string of random characters which is called a jwt access token. Something like this:
`
eyJhbGciOiJIUzI1NiJ9.eyJpZCI6IjYwZndmNzA5N2ZmN2YwOTdmMDk5IiwidXNlcm5hbWUiOiJsYXZpc2hnb3lhbCJ9.kNPmoyim0KbrHw6Fl2NPdUWO3UdZ1cr3rFH4eZy9DIg
`
Now if you how this token contains information about user, open another tab in your browser and go to [https://jwt.io/](https://jwt.io/) and in the encoded input box paste the above access token and you'll receive the id and username as shown below
[](https://postimg.cc/309HbgLs)
If you look closely there are two dots in the JWT Access token which divides the token string into three parts.
[](https://postimg.cc/ppXhCvkS)
The first part is the algorithm for encoding the token, second part consists the user details we entered and third part is the JWT Secret used to verify the user later (which we'll do just now)
```javascript
const authenticateToken = (req, res, next) => {
const authHeader = req.headers["authorization"];
const token = authHeader && authHeader.split(" ")[1];
if (token === null) return res.status(401).json({ msg: "Not Authorized" });
jwt.verify(token, JWT_SECRET, (err, user) => {
if (err) return res.status(401).json({ msg: err });
req.user = user;
next();
});
};
```
This block of code will verify the incoming JWT token and authenticate the user and we can proceed with further data processing. `jwt.verify()` takes in three parameters, first is the token which we'll receive from client. The token can be received either via cookie or in headers. Here the token is passed in the header `Authorization` Header. **Remember the JWT_SECRET should be the same among the whole project otherwise the jwt token will not be decoded and return an error of invalid token. **
Now the above authenticateToken middleware function can be used in all the protected routes to verify if the user is eligible for accessing data at that particular route for example:
```javascript
app.get("/dashboard", authenticateToken, (req,res)=>{
res.send('<h1>Welcome to dashboard</h1>')
})
```
So in the above code we used the authenticateToken as the middleware function and if the client's request contains a correct jwt token user will be shown Welcome to dashboard heading otherwise will be shown an error.
That was all folks. That was all about the authentication and authorization with NodeJS. There are much more complex and secure ways to do authentication but it was a beginner's tutorial so I kept it that way. Will cover more about it in next blogs. Until then share the post and tag me on twitter.
See Ya!
[](https://www.buymeacoffee.com/lavishgoyal)
| lavig10 |
904,552 | 10 Flutter tips - season 2 - part 3/10 | Now we are already at the 3rd part of the 2nd season of this wonderful format. Today we are dealing... | 0 | 2021-11-21T09:49:03 | https://medium.com/@tomicriedel/10-flutter-tips-season-2-part-3-10-15c88da72c2c | flutter | Now we are already at the 3rd part of the 2nd season of this wonderful format.
Today we are dealing with **packages** again, but also with **VSCode Extensions**. We mainly deal with the user interface, so... Let's go and **Happy reading!**
# Animate do
I saw this package 1 day before I started writing this article and immediately renewed my entire app. Doesn't sound motivating now? Well, let me first explain what this package can do. I personally hate animations. And I think many agree with me there. Still, nowadays you have to use animations to make the app appealing to the user. And that's where [animate_do](pub.dev/packages/animate_do) comes in. Animate do offers a **huge selection of already ready animations** that you can apply to any widget. Here is a list of all the animations, of which there are so many more sub-points.
- FadeIn Animations
- FadeIn
- FadeInDown
- FadeInDownBig
- FadeInUp
- FadeInUpBig
- FadeInLeft
- FadeInLeftBig
- FadeInRight
- FadeInRightBig
- FadeOut Animations
- FadeOut
- FadeOutDown
- FadeOutDownBig
- FadeOutUp
- FadeOutUpBig
- FadeOutLeft
- FadeOutLeftBig
- FadeOutRight
- FadeOutRightBig
- BounceIn Animations
- BounceInDown
- BounceInUp
- BounceInLeft
- BounceInRight
- ElasticIn Animations
- ElasticIn
- ElasticInDown
- ElasticInUp
- ElasticInLeft
- ElasticInRight
- SlideIns Animations
- SlideInDown
- SlideInUp
- SlideInLeft
- SlideInRight
- FlipIn Animations
- FlipInX
- FlipInY
- Zooms
- ZoomIn
- ZoomOut
- SpecialIn Animations
- JelloIn
Okay, that was a lot, but I just wanted to show you the possibilities of this package. As I said, this package is almost a must for the next app.
# MacOS UI
If you've ever developed an app for macOS using Flutter, you may have noticed it. Flutter doesn't have any **good widgets** that are only **for macOS**. That's why there's [macos_ui](https://pub.dev/packages/macos_ui). This package makes it easy for you to create apps that look exactly like they were made with Swift. Again, there are an incredible number of widgets and a very long list, but I don't need to list them this time.
This is just one example of the many possibilities:
# Fluent UI
Even with Windows (especially with Windows 11) there are no good widgets in Flutter. That's why the package [fluent_ui](https://pub.dev/packages/fluent_ui) was created. Again, there is a **huge selection of widgets** to make your app look like a real **Windows app**.
It supports Light/Dark Theme, the Windows font, Header, Subheade,r Title, Subtitle etc, Reveal Focus, Page transitions, Drill in, Navigation and on top of that all the "Widgets".
This is what your app would look like in Light Theme (without the special widgets of course)

# Onboarding overlay
You probably know it from many apps by now, an **onboarding, where the app is explained to you**. You can do exactly that with the package onboarding_overlay. I think I don't have to explain much when I show you this video:
The documentation for this package is great and very self explanatory.
# Flutter Material Pickers
As the name of this package suggests, you can use it to **call various pickers from Material Design**. Some of them are new, so are not included in Flutter, while others have been improved.
# Flutter Text Field Fab
Everyone surely knows the normal **FloatingActionButton**, but what if you want to display a cool **text field** from it. Well, then this package is just the right thing for you. The look of this package is really well done and is very easy to implement in the code.

```dart
import 'package:flutter/material.dart';
import 'package:flutter_text_field_fab/flutter_text_field_fab.dart';
class SomeListView extends StatelessWidget {
@override
Widget build(BuildContext context) {
return Scaffold(
floatingActionButton: TextFieldFloatingActionButton(
'Search...',
Icons.gamepad,
onChange: (String query) => filterList(query),
onClear: () => clearList(),
),
body: ...);
}
}
```
# Flutter Login
This package is just amazing. It gives you a **perfectly animated** widget (or rather screen) for **login**. Here is an example:

The great thing is that you can customize everything here (and I mean everything).
Oh, and the implementation is also very simple:
```dart
return FlutterLogin(
title: 'ECORP',
logo: AssetImage('assets/images/ecorp-lightblue.png'),
onLogin: _authUser,
onSignup: _signupUser,
onSubmitAnimationCompleted: () {
Navigator.of(context).pushReplacement(MaterialPageRoute(
builder: (context) => DashboardScreen(),
));
},
onRecoverPassword: _recoverPassword,
);
```
# Flutter widget snippets
Now we come to an extension. This [Extension](https://marketplace.visualstudio.com/items?itemName=alexisvt.flutter-snippets) offers you a lot of **snippets for different widgets**. I can only recommend to install it.
# Flutter Intl
Multi Language Support should be known to everyone. But the constant implementation of it in the app can be really annoying. That's why the VSCode extension [Flutter Intl](https://marketplace.visualstudio.com/items?itemName=localizely.flutter-intl) exists. It creates a **binding between the .arb files and the Flutter App**.
So: I can recommend this extension to everyone who wants to implement multiple languages easily in his app.
Oh, and if you use a Jetbrains IDE (IntelliJ IDEA or AndroidStudio), you can find [here](https://plugins.jetbrains.com/plugin/13666-flutter-intl) the extension.
# Flutter Riverpod Snippets
If you use Riverpod, then you should definitely check out this extension. It was developed by the GDE Robert Brunhage and makes the **development with Riverpod very easy**.
You can easily download it [here](https://marketplace.visualstudio.com/items?itemName=robert-brunhage.flutter-riverpod-snippets).
# Conclusion
Now we have come to the end of another episode of 10 Flutter tips.
I really hope you enjoyed it! If so, I would be very happy if you could give this post some **claps** and **follow** me if you don’t want to miss any more posts!
Want to check out some more quality content from me? Then I recommend you check out my **[Twitter](twitter.com/tomicriedel)** account and follow me there too! You’ll get **daily motivation** there and find great **threads** about **programming** and **productivity**!
**Bye and have a great day!** | tomicriedel |
904,678 | 8 Programmer Life Lessons They Don’t Teach You At School | Some things you don’t learn at school. These lessons come right from the work floor; I learned them... | 0 | 2021-11-21T13:31:37 | https://dev.to/python_land/8-programmer-life-lessons-they-dont-teach-you-at-school-djp | programming, beginners | Some things you don’t learn at school. These lessons come right from the work floor; I learned them the hard way!
[Read the full article for free on Medium using this link](https://medium.com/pythonland/8-programmer-life-lessons-they-dont-teach-you-at-school-dc8049f3e9e8?sk=73ac18dc9052e8f1cfb85e548b1a8594) | python_land |
904,846 | Level up your GitHub with GitHub Actions and Kubernetes, with Sr. Principle Dev from Red Hat | Watch Senior Principle Developer Karan Singh talk about the recipe to level up your software... | 0 | 2021-11-22T03:26:03 | https://dev.to/srbhr/level-up-your-github-with-github-actions-and-kubernetes-with-srprinciple-dev-from-red-hat-5d6h | devops, github, docker, kubernetes | # Watch Senior Principle Developer Karan Singh talk about the recipe to level up your software skills at Git Commit Show LIVE with Q&A!
**_Automate your workflow from idea to production._** This is the tagline of GitHub Actions, with an increasing complexity in software toolchain, GitHub Action's Pipeline has helped a lot in automating a lot of stuff... It makes it easy to automate all your software workflows, now with world-class CI/CD. Build, test, and deploy your code right from GitHub. Make code reviews, branch management, and issue triaging work the way you want.
We bring an expert in this field from an Amazing Open Source organization, "Red Hat" to come up with an amazing masterclass session on GitHub Actions and DevOps. Where you can watch as well as have a live chat, face-to-face with the author to ask questions as well.
Join Git Commit Show for ✳**FREE**❇ here: [_Link_](http://push.gitcommit.show/)
Karan Singh is a **Senior Principal Architect & Developer Evangelist at Red Hat**. In his role, Karan focuses on architecting and developing cloud-native composable solutions on Kubernetes. Part of his responsibilities is to enable developers and builders with rapidly changing cloud-native technologies.
He holds a strong background in infrastructure, SRE, DevOps, data services, and data analytics and is also specialized in designing and building scalable and cloud-native distributed & event-driven systems while believing that better software deserves better architecture.
He is also a published author, a frequent speaker at conferences, and an avid blogger at https://ksingh7.medium.com.

Join Git Commit Show for ✳**FREE**❇ here: [_Link_](http://push.gitcommit.show/)
Also we have a Discord Server: [_Link_](https://discord.gg/JFWP8c2gPG) | srbhr |
904,893 | Mocking FS..? Not really | I have came back to my problem. Mocks in jest. Specifically, for fs. I have learned a lot from my... | 14,641 | 2021-11-21T20:15:26 | https://dev.to/sirinoks/mocking-fs-not-really-3jfa | opensource | I have came back to my problem. Mocks in jest. Specifically, for fs. I have learned a lot from my struggles. I learned better how different modules connect to each other. What I should expect of certain functions. What was the idea behind the examples I found.
## Concretely, in code ##
Examples of fs mocks that I have found used them for different kind of functions as compared to mine. I saw one with passing an [object](https://www.npmjs.com/package/mock-fs), however my readFile function only takes in a file name. Here's how it is right now, by the way:
```js
function readFile(file) {
try {
if (file.match(".*(.txt|.md)$")) {
//read the file
let fullText = fs.readFileSync(file, "utf8");
//formatting if it's an .md file
if (file.match(".*(.md)$")) {
//replacing strings
fullText = fullText.replace(/_ /g, "<i>");
fullText = fullText.replace(/ _/g, "</i>");
fullText = fullText.replace(/__ /g, "<b>");
fullText = fullText.replace(/ __/g, "</b>");
fullText = fullText.replace(/### /g, "<h3>");
fullText = fullText.replace(/ ###/g, "</h3>");
fullText = fullText.replace(/## /g, "<h2>");
fullText = fullText.replace(/ ##/g, "</h2>");
fullText = fullText.replace(/# /g, "<h1>");
fullText = fullText.replace(/ #/g, "</h1>");
fullText = fullText.replace(/---/g, "<hr>");
}
//future functionality of choosing the element you want to use
let element = "p";
//divide text into paragraphs
const paragraphs = fullText.split(/\r?\n\r?\n/);
let title = paragraphs[0];
let htmlParagraphsArray = [];
//put them all into an array
for (let i = 0; i < paragraphs.length; i++) {
if (i == 0)
//only the first paragraph is the title
htmlParagraphsArray.push(`<h1>${title}</h1>`);
else {
htmlParagraphsArray.push(
`<${element}>${paragraphs[i]}</${element}>`,
);
}
}
//put them all into a single string, every paragraph starts from a new line
let texts = htmlParagraphsArray.join("\n");
return { texts: texts, title: title };
}
} catch (e) {
throw `Error in reading file ${file}, ${e}`;
}
}
```
As you can see, I have a bunch of things happening at the same time in a single funciton. I now understand more what modular functions should look like. And why they should be that way.
I'm not sure if I can still properly use the fs mock though. I don't know if I can replace the `fs.readFileSync` with the mock `fs`. I would imagine that's how it should work, but I don't actually know.
I could restructure my whole code to match the style where I'd pass an object, but that wouldn't solve the fs mocking problem. I think I'm just missing a basic concept here.
Long story short, I couldn't make half of the tests I wanted work because of fs. After I removed some of them, I apparently did something else wrong and I couldn't pass my own actions' checks. In the end I just copied an older version from main to reset my problematic code. I also realised I couldn't really test a function I tried to test, since it went on calling other ones, which would eventually get to one which shouldn't work anyway. That would fail the test I set up, which I didn't understand at first.
## Actions ##
Learning about github actions was useful. It wasn't a difficult process to set up, but it explained a lot what I saw in other projects. It connects everything together. You just run tests and they have to pass - it's that simple.
## Other people's tests ##
As I was looking at other people's code I noticed a totally different structure. I also found it difficult to find something to contribute to, seemed that everyone had all their functions covered.
I might have to restructure my whole code system to match testing expectations. It won't be just me guessing how to divide things by their functionality anymore - now I know what a testing function wants. | sirinoks |
904,997 | Shenanigans with Shaders | Table Of Contents Introduction Shaders Setup Shader Code Conclusion For those of you... | 0 | 2021-11-21T23:22:52 | https://dev.to/georgeoffley/shenanigans-with-shaders-3i97 | unity3d, graphics | ## Table Of Contents
* [Introduction](#introduction)
* [Shaders](#shaders)
* [Setup](#setup)
* [Shader Code](#shader_code)
* [Conclusion](#conslusion)
For those of you who love rabbit holes, learning graphics programming is a pretty deep one. There’s always some new thing to learn, there’s a bunch of different new languages and toolsets to know, and on top of all that, [there’s math](https://www.youtube.com/watch?v=tt_gPXpx0eo&t=101s&ab_channel=SamwellTarly). Like anything else in programming, you pick up momentum with each new thing you build, so I [found a tutorial](https://github.com/Xibanya/ShaderTutorials) and started making shaders. I know very little about this. However, I’m writing what I’m learning, so don’t come for me if I’m off on anything.
<!--more-->
### Shaders <a name="shaders"></a>
A shader is a program that runs on the GPU as part of the [graphics pipeline](https://en.wikipedia.org/wiki/Graphics_pipeline). We’re going to focus primarily on shaders in Unity. There are other ways to tackle this, but Unity gives an easy setup to get started quickly. For the context of Unity, a shader is a small script containing logic and calculations for determining the colors of a pixel.
In Unity, we create *shader objects* which act as wrappers for our shader program. A shader object exists in a *shader asset* which is just the script we are writing. Creating these in Unity allows for a great deal of freedom in what we make. What we’ll focus on is adding some basic functionality to a shader. We’ll be focusing on using [*ShaderLab*](https://docs.unity3d.com/Manual/SL-Reference.html) to create shaders.
### Setup <a name="setup"></a>
The first thing to set yourself up making shaders in Unity is Unity. So [download it](https://unity3d.com/get-unity/download), and create a new project.

I won’t give a full rundown of Unity and the stuff you can do. I leave that to [better minds](https://learn.unity.com/). In the *Hierarchy Window*, right-click and scroll to *3D Object* and click whichever object grabs your fancy. I always pick sphere for testing stuff. Now we have a [*3D Mesh*](https://en.wikipedia.org/wiki/Polygon_mesh) on the screen that we can begin adding things to it. In the *Project Window*, right-click on the word *Assets* and create two new folders, *Materials* and *Shaders*. Double click into the Materials folder, right-click and Create is right at the top -> click Material. Materials are similar to skins we can apply to 3D objects. We will use this new material to add our new shader to the 3D Mesh. After that, drag our new material into the *Scene Window* where our sphere is and onto the sphere we made. Now right-click our Shaders folder scroll to Create -> Shader -> Standard Surface Shader. Click the sphere in the Scene window to bring up the *Inspector Window*. Finally, drag the shader file over to the inspector window with our sphere covered in our new material. We have just applied our shader to the materials. You should see this in the Inspector Window.

Now go back to the Project window and double click our new Shader file. Unity will launch an IDE for use to check out the code. You can configure your choice of IDE; I have VSCode configured. Open the Shader file, and let’s check out the code. I created some basic shader code you can use.
### Shader Code <a name="shader_code"></a>
Here is the complete, minimal shader code:

It looks a bit much to anyone new to this, including myself, so let’s take it a section at a time. The first thing at the top, starting with “Shader,” is the *Shader Block*. This is used to define our Shader Object. You can use this to define your properties, create many shaders using the *SubShader* blocks, assign custom options, and assign a *fallback* shader object. Here you can see the name of our shader and that it is in the “Custom” directory.
Within the Shader block curly brackets, we have our other sections. The first is our *Properties*. The properties box is where we define the properties for our materials. A material property is what Unity stores along with our materials. This allows for different configurations within Unity by creating things like sliders and inputs within the Inspector window for us to play around with. We defined two properties, the *MainColor* and the *MainTexture*. Using square brackets, I outlined which property was the default color and default texture. We also defined the default values for these properties. There’s a bit to these values but suffice it to say, both values are default white.
The second block is our SubShader; this is where our shader logic goes. You can define multiple sub shaders for many different uses. For example, depending on the graphics hardware you want to support, you can make shaders for the various graphics APIs. Within our block, you can see some code for assigning [*tags*](https://docs.unity3d.com/Manual/SL-SubShaderTags.html), assigning [*levels of detail (LOD)*](https://docs.unity3d.com/Manual/SL-ShaderLOD.html), and the [*CGPROGRAM*](https://en.wikibooks.org/wiki/Cg_Programming/Unity) block. I want to draw your attention to this section of the code:

First, we define the data types for our inputs and outputs and create a function for us to serve the outputs into unity. Our Input we set up as *uv_Maintex*; this allows for us to input a texture object. Then we create a *fixed4* variable for our *_Color* attribute. The *o.Albedo* parameter is what is used to control the base color of the surface. Here we are taking the values of our texture and multiplying them by our color input. The code above gets you something similar to this:

I was proud of myself the first time I made this from memory. Our coded shader lets us control the color of the material and add basic textures to it. Working in graphics does not lead to instant gratification, as anything you do requires a ton of setup. However, this and [ShaderToy](https://www.shadertoy.com/) get you that dopamine hit.
### Conclusion <a name="conclusion"></a>
Above I went through some fundamentals of shaders in Unity. I skipped over a ton of information as I’m still learning a lot, and a full informed explainer would be twenty pages long. There is a lot to programming graphics and shaders specifically. I suggest you check out stuff like [Team Dogpit’s shader tutorial](https://github.com/Xibanya/ShaderTutorials) for a way better deep dive. I’m excited to dig into this world. I want to learn to create some of the incredible stories I see in animation, and any first step is a step in the right direction. Thanks for reading.
-George | georgeoffley |
905,251 | Firebase Issue | ./src/firebase.js Module not found: Can't resolve 'firebase' I did (3 times)uninstalling, clear... | 0 | 2021-11-22T08:00:45 | https://dev.to/mohammedfarhan/firebase-issue-3k5g | beginners, firebase, react | ./src/firebase.js
Module not found: Can't resolve 'firebase'
I did (3 times)uninstalling, clear cache and installing latest version of firebase as answered by stack overflow community. Please can someone help me with this.. | mohammedfarhan |
905,296 | Adding authentication to a Flask application | Welcome to the last part of the series. Here, you'll learn how to add authentication to your flask... | 15,583 | 2021-11-23T09:38:54 | https://dev.to/nagatodev/adding-authentication-to-a-flask-application-53ep | python, programming, webdev, tutorial | Welcome to the last part of the series. Here, you'll learn how to add authentication to your flask application. The todo application built in part 2 will be used here. So if you come across this part first, do well to check out parts 1 and 2.
Let's get started!!
Install the flask extension `Flask-login`:
```javascript
pip install flask-login
```
Next, open the`__init__.py` file in the core directory. Import the `Login Manager` class from the installed package and initialise the application with it.
```javascript
from flask import Flask
from config import Config
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
from flask_login import LoginManager #new line
app = Flask(__name__)
app.config.from_object(Config)
db = SQLAlchemy(app)
migrate = Migrate(app, db)
login = LoginManager(app) #new line
```
##auth blueprint
The authentication section will be created as a mini-application as well. So create a new directory `auth` in the core directory and add the following files: `__init__.py`, `forms.py`, `models.py`, and `views.py`.
Remember that this is going to be an application on its own so you need to create a `templates` folder in the auth directory as well. Create a new folder `auth` in it and within it create two files `login.html` and `register.html`.
###auth blueprint
Let's start with the `__init__.py` script. This will be set up the same way as that of the `task` blueprint.
```javascript
from flask import Blueprint
auth = Blueprint('auth', __name__, template_folder='templates')
from . import views
```
###models.py
```javascript
from .. import db
from werkzeug.security import generate_password_hash, check_password_hash
from .. import login
from flask_login import UserMixin
from ..models import Todo
class User(UserMixin, db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
password_hash = db.Column(db.String(128))
todo = db.relationship('Todo', backref='author', lazy='dynamic')
def __repr__(self):
return '<User {}>'.format(self.username)
def set_password(self, password):
self.password_hash = generate_password_hash(password)
def check_password(self, password):
return check_password_hash(self.password_hash, password)
@login.user_loader
def load_user(id):
return User.query.get(int(id))
```
Then set up the User model for the database using the `UserMixin` class.
The todo field is initialized with `db.relationship` which is like a `one-to-many` relationship. The first argument `Todo` passed here is the `many` side of the relationship and the `one` is `author`. This will create an author field in every todo you create.
The relationship established here just means that there will be `many` posts linked to just `one` user. This will ensure that one user doesn't have access to the to-do list of another user.
The load_user function stores the id of the user so that the user can navigate to another page while logged in. If this is absent, whenever the user navigates to a new page, the user will be prompted to log in again.
###forms.py
```javascript
from flask_wtf import FlaskForm
from wtforms import StringField, PasswordField, BooleanField, SubmitField, ValidationError
from wtforms.validators import DataRequired, Length, Email, EqualTo
from .models import User
class LoginForm(FlaskForm):
email = StringField('Email', validators=[DataRequired(), Length(1, 64),
Email()])
password = PasswordField('Password', validators=[DataRequired()])
remember_me = BooleanField('Remember Me')
submit = SubmitField('Sign In')
class RegistrationForm(FlaskForm):
username = StringField('Username', validators=[DataRequired()])
email = StringField('Email', validators=[DataRequired(), Email()])
password = PasswordField('Password', validators=[DataRequired()])
password2 = PasswordField(
'Repeat Password', validators=[DataRequired(), EqualTo('password')])
submit = SubmitField('Register')
def validate_username(self, username):
user = User.query.filter_by(username=username.data).first()
if user is not None:
raise ValidationError('Username already in use.')
def validate_email(self, email):
user = User.query.filter_by(email=email.data).first()
if user is not None:
raise ValidationError('Email already registered.')
```
You need to install the package that'll validate the email address submitted by the user.
```javascript
pip install email_validator
```
Create the Login and Registration forms and import the `User` model for validation purposes. This checks whether the email or username is already in the database and raises an error if a similar email or username is found.
###views.py
```javascript
from flask import render_template, flash, redirect, url_for, request
from flask_login import login_user, logout_user, login_required, \
current_user
from . import auth
from .forms import RegistrationForm, LoginForm
from .models import User
from .. import db
from werkzeug.urls import url_parse
@auth.route('/register', methods=['GET', 'POST'])
def register():
if current_user.is_authenticated:
return redirect(url_for('task.tasks'))
form = RegistrationForm()
if form.validate_on_submit():
user = User(username=form.username.data.lower(), email=form.email.data.lower())
user.set_password(form.password.data)
db.session.add(user)
db.session.commit()
flash('Congratulations, you are now a registered user!')
return redirect(url_for('auth.login'))
return render_template('auth/register.html', title='Register', form=form)
@auth.route('/login', methods=['GET', 'POST'])
def login():
nologin = False
if current_user.is_authenticated:
return redirect(url_for('task.tasks'))
form = LoginForm()
if form.validate_on_submit():
user = User.query.filter_by(email=form.email.data.lower()).first()
if user is None or not user.check_password(form.password.data):
nologin = True
else:
login_user(user, remember=form.remember_me.data)
next_page = request.args.get('next')
if not next_page or url_parse(next_page).netloc != '':
next_page = url_for('task.tasks')
return redirect(next_page)
return render_template('auth/login.html', title='Sign In', form=form, message=nologin)
@auth.route('/logout')
def logout():
logout_user()
return redirect(url_for('index'))
```
Let's go through each function:
i) **Register**: if the user navigates to the `\register` URL, the register function is executed and the first condition provided checks if the user is already logged in. Then the user gets redirected to the index page of the application if this evaluates to `true`. Else, the register page is loaded and the form is rendered. Upon submission, the form is validated and the user data is stored. Next, the user is redirected to the login page.
ii)**Login**: if the user navigates to the `\login` URL, the login function is executed and a similar process is repeated here.
iii)**Logout**: When the user clicks on the logout button and is redirected to the `logout` URL, the user gets logged out.
The HTML template files are written in the same format as the other template files in parts 1 and 2 so they are self-explanatory
###login.html
```javascript
{% extends "base.html" %}
{% block content %}
<a class="brand-logo" href="{{ url_for('index') }}">
<img class="logo" src="{{ url_for('static', filename='Logo.svg') }}">
<div class="brand-logo-name"><strong> ToDo </strong> </div>
</a>
<!-- Display login error message-->
{% if message %}
<div class="alert alert-warning" role="alert">
<span class="closebtns" onclick="this.parentElement.style.display='none';">×</span>Invalid username or password
</div>
{% endif %}
<div class="login">
<form action="" method="post" novalidate class="p-3 border border-2">
{{ form.hidden_tag() }}
<div class="Login-Header">
<h4 class="mb-5">Login</h4>
</div>
<p>
{{ form.email.label }}<br>
{{ form.email(size=32) }}
{% for error in form.email.errors %}
<span style="color: red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.password.label }}<br>
{{ form.password(size=32) }}
{% for error in form.password.errors %}
<span style="color: red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>{{ form.remember_me() }} {{ form.remember_me.label }}</p>
<div class="loginbtn">
{{ form.submit(class="btn btn-primary mt-3") }}
</div>
</form>
<div class=logged_in>
<span>Dont have an account yet?</span>
<a href="{{ url_for('auth.register') }}"> <i class="fa fa-hand-o-right" aria-hidden="true"></i>Register</a>
</div>
</div>
{% endblock %}
```
###register.html
```javascript
{% extends "base.html" %}
{% block content %}
<a class="brand-logo" href="{{ url_for('index') }}">
<img class="logo" src="{{ url_for('static', filename='Logo.svg') }}">
<div class="brand-logo-name"><strong> ToDo </strong> </div>
</a>
<div class="register">
<form action="" method="post" class="p-3 border border-2">
{{ form.hidden_tag() }}
<div class="Register-Header">
<h4 class="has-text-centered mb-5 is-size-3">Register</h4>
</div>
<p>
{{ form.username.label(class="label") }}<br>
{{ form.username(size=32) }}<br>
{% for error in form.username.errors %}
<span style="color: red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.email.label(class="label") }}<br>
{{ form.email(size=64) }}<br>
{% for error in form.email.errors %}
<span style="color: red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.password.label(class="label") }}<br>
{{ form.password(size=32) }}<br>
{% for error in form.password.errors %}
<span style="color: red;">[{{ error }}]</span>
{% endfor %}
</p>
<p>
{{ form.password2.label(class="label") }}<br>
{{ form.password2(size=32) }}<br>
{% for error in form.password2.errors %}
<span style="color: red;">[{{ error }}]</span>
{% endfor %}
</p>
<div class="registerbtn">
{{ form.submit(class="btn btn-primary mt-3") }}
</div>
</form>
<div class="registered">
<span>Already registered?</span>
<a href="{{ url_for('auth.login') }}"><i class="fa fa-hand-o-right" aria-hidden="true"></i>Login</a>
</div>
</div>
{% endblock %}
```
###__init__.py
Finally, you need to register the `auth` blueprint in the `__init__.py` file in the core directory. Add the following lines of code above the `task` blueprint.
```javascript
from flask import Flask
from config import Configuration
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
from flask_login import LoginManager
app = Flask(__name__)
app.config.from_object(Configuration)
db = SQLAlchemy(app)
migrate = Migrate(app, db)
login = LoginManager(app)
login.login_view = 'auth.login' #new line
# blueprint for auth routes in our app #new blueprint
from .auth import auth as auth_blueprint
app.register_blueprint(auth_blueprint)
# blueprint for non-authentication parts of the app
from .task import task as task_blueprint
app.register_blueprint(task_blueprint)
from core import views, models
```
The path to the login view function is assigned to the initialised `LoginManager` class and the `auth` blueprint is registered with the application.
###models.py (base)
Since you already established a relationship between the User model and Todo model. You need to head to the `models.py` file in the core directory and create the `user_id` field that'll be linked to the User model via a `ForeignKey`.
```javascript
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
```
But the issue now is that SQLite database does not support dropping or altering columns. When you try to migrate and upgrade the db you get either a `naming convention` or `ALTER of constraints` error.

###or

There are two ways you can solve this.
i) Delete the migrations folder and also the db file in your root directory. This is not advisable if you already have a lot of data in your db.
ii) Create a naming convention for all your database columns in the `__init__.py` file in the core directory. Solution can be found [here](https://github.com/ashishnitinpatil/udacity_fsnd004_item_catalog_application/commit/c0adae86653e5e92c6807e7c3f8eaa114a022b3c)
###__init__.py
```javascript
from flask import Flask
from config import Configuration
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
from flask_login import LoginManager
from sqlalchemy import MetaData #new line
app = Flask(__name__)
app.config.from_object(Configuration)
db = SQLAlchemy(app)
#new line
naming_convention = {
"ix": 'ix_%(column_0_label)s',
"uq": "uq_%(table_name)s_%(column_0_name)s",
"ck": "ck_%(table_name)s_%(column_0_name)s",
"fk": "fk_%(table_name)s_%(column_0_name)s_%(referred_table_name)s",
"pk": "pk_%(table_name)s",
}
db = SQLAlchemy(metadata=MetaData(naming_convention=naming_convention))
migrate = Migrate(app, db, render_as_batch=True) #new line
login = LoginManager(app)
login.login_view = 'auth.login'
# blueprint for auth routes in our app
from .auth import auth as auth_blueprint
app.register_blueprint(auth_blueprint)
# blueprint for non-authentication parts of the app
from .task import task as task_blueprint
app.register_blueprint(task_blueprint)
from core import views, models
```
Now run the following commands: `flask db stamp head`, `flask db migrate` and `flask db upgrade` to migrate all the changes to your db. The naming convention error should no longer exist.
###views.py
The final step is to make changes to the task view function so that users can only view the page if they are logged in. Make the following changes to the `views.py` file in the task directory.
```javascript
from flask import render_template, flash, redirect, url_for, request
from flask_login import login_required, current_user #new line
from .models import Category
from ..models import Todo
from . import task
from .forms import TaskForm
from .. import db
from datetime import datetime
@task.route('/create-task', methods=['GET', 'POST'])
@login_required #new line
def tasks():
check= None
user = current_user #new line
todo= Todo.query.filter_by(author=user) #new line
date= datetime.now()
now= date.strftime("%Y-%m-%d")
form= TaskForm()
form.category.choices =[(category.id, category.name) for category in Category.query.all()]
if request.method == "POST":
if request.form.get('taskDelete') is not None:
deleteTask = request.form.get('checkedbox')
if deleteTask is not None:
todo = Todo.query.filter_by(id=int(deleteTask)).one()
db.session.delete(todo)
db.session.commit()
return redirect(url_for('task.tasks'))
else:
check = 'Please check-box of task to be deleted'
elif form.validate_on_submit():
selected= form.category.data
category= Category.query.get(selected)
todo = Todo(title=form.title.data, date=form.date.data, time= form.time.data, category= category.name, author=user) #new line
db.session.add(todo)
db.session.commit()
flash('Congratulations, you just added a new note')
return redirect(url_for('task.tasks'))
return render_template('task/tasks.html', title='Create Tasks', form=form, todo=todo, DateNow=now, check=check)
```
Import the `login_required` function and also the `current_user` variable. Then assign the `login_required` function as a decorator to the `task` view function. The current logged in user is obtained via the current_user variable imported from the `flask_login` package.
The user variable is used to filter the `Todo List` in the database for `todos` created by the particular logged in user and it is also assigned to each todo created by the user.
You can see the authentication feature that was just added in action by running the application. Try to navigate to the `\create-task` and you'll get redirected to the login page.
Register as a new user and log in to the application. Once you are successfully logged in, you'll automatically get redirected to the `create-task` page. If you try to navigate to the `/login` or `/register` page while still logged in, you still get redirected to the `create-task` page.
You have successfully learnt how to add authentication to your application. With what you learnt in this series, you have all the ammunition required to build a great application now.
If you want to add styling to your application to make it look like this 👇,

head to [Github](https://github.com/Faruqt/Flask-Complete-Tutorial/tree/master), clone the repository, and make the necessary changes to your static and template files. Good luck!!
Congratulations!! We have come to the end of the journey. I hope you enjoyed the ride.

If you have any questions, feel free to drop them as a comment or send me a message on [Linkedin](https://www.linkedin.com/in/faruq-abdulsalam) or [Twitter](https://twitter.com/Ace_II) and I'll ensure I respond as quickly as I can. Ciao 👋
| nagatodev |
905,328 | syntax error missing dependencies | hi ranga, may i know the dependencies used for reactjs? i am using environment node js version... | 0 | 2021-11-22T10:36:22 | https://dev.to/irsalyunus/syntax-error-missing-dependencies-2l0d | hi ranga,
may i know the dependencies used for reactjs?
i am using environment node js version v17.1.0 and yarn version yarn version v1.22.15
info Current version: 0.1.0 I found bugs | irsalyunus | |
905,337 | tsParticles | tsParticles - A lightweight TypeScript library for creating particles https://particles.js.org | 0 | 2021-11-22T10:49:50 | https://dev.to/cajrodrigues/tsparticles-8pk | javascript, showdev, webdesign, github | tsParticles - A lightweight TypeScript library for creating particles https://particles.js.org | cajrodrigues |
905,499 | Do you turn off your socials / phone sound / mobile data when doing work? | I have never turned off my socials / phone sound / phone internet while working. I am just about to... | 0 | 2021-11-22T12:06:26 | https://dev.to/kubeden/do-you-turn-off-your-socials-phone-sound-mobile-data-when-doing-work-1cce | discuss | I have never turned off my socials / phone sound / phone internet while working.
I am just about to start doing so. What’s your take? | kubeden |
905,548 | How to run Nginx and PHP in Docker | Today we will try to run nginx web server with PHP 7.4 in Docker. We will use Docker, because we will... | 15,582 | 2021-11-22T13:16:00 | https://varlock.net/how-to-run-nginx-and-php-in-docker/ | webdev, docker, php, tutorial | Today we will try to run nginx web server with PHP 7.4 in Docker. We will use Docker, because we will not install any software on our host system. You should have installed on your system Docker and Docker-compose. If you don’t know how to install Docker and Docker-compose see my previous article [How to install Docker in Linux Mint and Ubuntu](https://varlock.net/how-to-install-docker-in-linux-mint-and-ubuntu/).
All files you need to run Nginx and PHP are on my [Github](https://github.com/texe/nginxphp). Let’s get start!
First we need to clone repository and create network:
```shell
git clone https://github.com/texe/nginxphp
cd nginxphp
docker network create labnet
```
Why we create network?. It’s a very good question. In our case we do it, because we want have a situation where all our containers will be visible by each other. For instance, imagine we have four containers with four services:
- PHP
- Nginx
- MySQL
- phpMyAdmin
And we want:
- Nginx be able to see PHP server
- PHP server should see MySQL server
- phpMyAdmin should see MySQL server
In order to do it we create a virtual network and every service in this virtual network will be able to see other services. That’s why we have to create a new network in docker environment.
Now we have to build our image and we will do it by this command:
```shell
docker-compose build
```
Docker will is starting building an image and downloading all needed files. It can take some time. How much? It depends on your internet connection. Let’s take a look for details.
Docker checks docker-compose.yml file and and see that we want to build new image described in config/dockerfile. Let’s see what is in this file:
```dockerfile
# 1 Set master image
FROM php:7.4-fpm-alpine
# 2 Set working directory
WORKDIR /var/www/html
# 3 Install Additional dependencies
RUN apk update && apk add --no-cache \
build-base shadow vim curl \
php7 \
php7-fpm \
php7-common \
php7-pdo \
php7-pdo_mysql \
php7-mysqli \
php7-mcrypt \
php7-mbstring \
php7-xml \
php7-openssl \
php7-json \
php7-phar \
php7-zip \
php7-gd \
php7-dom \
php7-session \
php7-zlib
# 4 Add and Enable PHP-PDO Extenstions
RUN docker-php-ext-install pdo pdo_mysql mysqli
RUN docker-php-ext-enable pdo_mysql
# 5 Install PHP Composer
#RUN curl -sS https://getcomposer.org/installer | php -- --install-dir=/usr/local/bin --filename=composer
# 6 Remove Cache
RUN rm -rf /var/cache/apk/*
# 7 Add UID '1000' to www-data
RUN usermod -u 1000 www-data
# 8 Copy existing application directory permissions
COPY --chown=www-data:www-data . /var/www/html
# 9 Change current user to www
USER www-data
# 10 Expose port 9000 and start php-fpm server
EXPOSE 9000
CMD ["php-fpm"]
```
I numbered all comment lines and now explain what every line do:
1. This is a base image. I choose official PHP image based on Alpine Linux (php:7.4-fpm-alpine). It is very light and fast distribution. I always take Alpine if it’s possible because images based on Ubuntu are much bigger than Alpine.
2. Setting here working directory. Nothing to explain in this place…
3. Update software repositories and install PHP with extensions.
4. We add and enable database drivers. In this case we add PDO, PDO MySQL and Mysqli (it can be necessary for WordPress).
5. Here we can install Composer. I commented this line because I don’t want to install Composer at this moment. But if you want to use Composer you can uncomment this line.
6. Remove cache in order to save disk quota.
7. Add UUID 1000 to user www-data (Nginx user).
8. Set directory permissions to directory with PHP files. We give access to every user with UUID 1000.
9. Change current user to www-data. It’s a user which can operate on our php files.
10. We expose our service to port 9000 and run php-fpm server.
Now let’s look to docker-compose.yml file:
```yaml
version: '3'
services:
#PHP App
app:
build:
context: .
dockerfile: config/dockerfile
image: christexe/php:7.4-fpm-alpine
container_name: php_app
restart: unless-stopped
tty: true
environment:
SERVICE_NAME: app
SERVICE_TAGS: dev
working_dir: /var/www/html
volumes:
- ./code/:/var/www/html
- ./config/uploads.ini:/usr/local/etc/php/conf.d/uploads.ini
networks:
- labnet
#Nginx Service
nginx:
image: nginx:alpine
container_name: nginx
restart: unless-stopped
tty: true
ports:
- "80:80"
volumes:
- ./code/:/var/www/html
- ./config/conf.d/:/etc/nginx/conf.d/
networks:
- labnet
#Docker Networks
networks:
labnet:
external:
name: labnet
```
What does mean every line?
```yaml
#PHP App
app:
build:
context: .
dockerfile: config/dockerfile
```
This means that we create first service “app”. We will build a new image. The new image will be based on dockerfile (in “config” directory). As I wrote above, Docker parses every line in docker-compose.yml, search dockerfile and build new image.
The name of the new image will be: `christexe/php:7.4-fpm-alpine`.
The name of container will be: `container_name: php_app`.
`restart: unless-stopped` means that our PHP container always will start after operating system boot, **unless you stop it**. If you manually stop this container, after rebooting hos system, the container will not start automatically.
`tty: true` means that we want to get access to console (tty) in our PHP server. It can be useful when you need to get in container.
Any `RUN`, `CMD`, `ADD`, `COPY`, or `ENTRYPOINT` command will be executed in the specified working directory.
```
volumes: - ./code/:/var/www/html - ./config/uploads.ini:/usr/local/etc/php/conf.d/uploads.ini
```
We map directory `code` to `/var/www/html in our container`. We will put in this directory all php files (index.php etc.).
file `uploads.ini` to `/usr/local/etc/php/conf.d/uploads.ini` This is vasic PH configuration file. In this file we allow to uploads and limit upload file size.
```
networks: - labnet
```
We assign our container to `labnet` network (explained above).
In the nginx service we repeat most of docker parameters. We added there:
```
ports: - "80:80"
```
We forward port 80 in our host machine to port 80 in our container with nginx. The second different thing volumes:
```
volumes: - ./code/:/var/www/html - ./config/conf.d/:/etc/nginx/conf.d/
```
We repeat mapping directory `code` to `/var/www/html` – this is default directory where nginx search html files. We also map directory `config/conf.d` to `/etc/nginx/conf.d/`. This is default directory where nginx search site configuration files. In this directory we have `site.conf` file:
```nginx
server {
listen 80;
server_name VB-Mint20;
# Log files for Debug
error_log /var/log/nginx/error.log;
access_log /var/log/nginx/access.log;
# Laravel web root directory
root /var/www/html;
index index.php index.html;
location / {
try_files $uri $uri/ /index.php?$query_string;
gzip_static on;
}
# Nginx Pass requests to PHP-FPM
location ~ \.php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass app:9000;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
client_max_body_size 256M;
}
}
```
As you see nginx is listening on port 80, looking for index.php/index.html and the last section (Nginx Pass requests to PHP-FPM) connect PHP with NGINX. In this section we show what NGINX should do with php files. The last line in this section client_max_body_size 256M; is not required but this line allow upload big files (256 MB) to server via web browser.
That’s all! You have a dockerized web server with PHP. Open your browser and type localhost in your address bar:
## Bonus!
If you don’t want to build your own image, you can download it from [DockerHub](https://hub.docker.com/r/christexe/php/tags). But warning! You should delete these lines from docker-compose.yml file:
```yaml
build:
context: .
dockerfile: config/dockerfile
```
After removing above lines, when you start container (docker-compose up) Docker will pull the image automatically from Docker Hub. The dockerfile is of course unnecessary in this case.
All you read in this article you can watch on my video:
{% youtube rtl0liw05qo %}
------
*It would be great if you will comment or follow me on social media*:
[](https://twitter.com/TexeChris)
[](https://www.linkedin.com/in/texe/)
Also you can visit my websites:
- [Linux blog](https://varlock.net)
- [Web Agency website](https://madlon.eu) | texe |
905,630 | Create your own AsyncSequence | One of the new features of async await I was really excited about is AsyncSequence, which provides a... | 0 | 2021-11-22T14:37:17 | https://dev.to/gualtierofr/create-your-own-asyncsequence-1dkl | swift | ---
title: Create your own AsyncSequence
published: true
description:
tags: swift
//cover_image: https://direct_url_to_image.jpg
---
One of the new features of async await I was really excited about is AsyncSequence, which provides a new way to receive data asynchronously in loops. It can be seen as an alternative to Combine, and I think both of them have reason to exist.
Before you continue reading, I suggest to get familiar with async await, and read my [previous article](https://dev.to/gualtierofr/introduction-to-async-await-2d8c) on the topic. We’ll use the same [GitHub repo](https://github.com/gualtierofrigerio/CombineTest) where you’ll find all the code included here.
Let’s start with the definition: [AsyncSequence](https://developer.apple.com/documentation/swift/asyncsequence) is a protocol, and according to the documentation can provide asynchronous, sequential and iterated access to its elements.
The novelty is the asynchronous part, as Swift had a [Sequence](https://developer.apple.com/documentation/swift/sequence) protocol since the beginning to provide access to elements.
Now that we have async await in Swift, we can iterate through a Sequence waiting for the single element to be ready.
## Use an AsyncSequence
Before creating our custom AsyncSequence, I think it is better to understand how to use one of them.
Let’s see some examples. You’re likely familiar with URLSession, I bet you’ve used it somewhere to retrieve a JSON from a server, or to download something. As soon as async await was introduced, URLSession exposed the async version of its functions, and the one returning a sequence of bytes is perfect to see AsyncSequence in action.
```swift
class func getDataStream(atURL url: URL) async -> Data? {
let request = URLRequest(url: url)
var data: Data? = nil
do {
let (bytes, _) = try await URLSession.shared.bytes(for: request, delegate: nil)
data = Data()
for try await b in bytes {
data?.append(b)
}
}
catch (let error) {
print("error while getting data \(error.localizedDescription)")
}
return data
}
// this is the definition of bytes
func bytes(for request: URLRequest, delegate: URLSessionTaskDelegate? = nil) async throws -> (URLSession.AsyncBytes, URLResponse)
```
As you can see, we can use a for loop awaiting each byte, then we can append it to a Data object.
Let’s have a look at the definition of bytes at the end of the code block. The function is async, so we have to await before getting the tuple back from it, and the first parameters is AsyncBytes. Turns out, AsyncBytes conform to the AsyncSequence protocol, that’s why we can iterate through its elements via a for loop.
You can use an [Iterator](https://developer.apple.com/documentation/swift/iteratorprotocol) as well, I don’t know if you’re familiar with it but this is the example
```swift
class func getDataIterator(atURL url: URL) async -> Data? {
let request = URLRequest(url: url)
var data: Data? = nil
do {
let (bytes, _) = try await URLSession.shared.bytes(for: request, delegate: nil)
data = Data()
var iterator = bytes.makeAsyncIterator()
while let nextByte = try await iterator.next() {
data?.append(nextByte)
}
}
catch (let error) {
print("error while getting data \(error.localizedDescription)")
}
return data
}
```
the only difference is the couple of lines after we call bytes on URLSession. We have the iterator via makeAsyncIterator and then we can use a while loop by calling next() on the iterator. Similarly to what happens in the for loop, we have to try await for the call to iterator.next(), as we’re dealing with an async iterator, conforming to the [AsyncIteratorProtocol](https://developer.apple.com/documentation/swift/asynciteratorprotocol)
I gave you the Iterator example as we’ll have to implement an iterator while creating our own AsyncSequence. Turns out, the IteratorProtocol is tightly coupled with Sequence, as a Sequence provide access to its element by creating an Iterator. So even if you don’t use an Iterator directly, as in the example above, you still have to implement one for your custom Sequence (or AsyncSequence)
## Create an AsyncSequence
Now let’s see how to actually create our own AsyncSequence.
The example I chose is a class to load pictures. You provide an array of urls (I’m using a custom struct for that purpose) and you can await for each image to be loaded.
I used it to populate a UICollectionView, so a new cell is added only when the image is already loaded into a UIImage, instead of loading all the cells and having the images loaded and then added to an existing cell.
This is the code of [PicturesLoader](https://github.com/gualtierofrigerio/CombineTest/blob/master/CombineTest/PicturesLoader.swift)
```swift
class PicturesLoader: AsyncSequence, AsyncIteratorProtocol {
typealias Element = PictureWithImage
init(withPictures pictures: [PictureWithImage]) {
self.pictures = pictures
}
// being of AsyncSequence and AsyncIteratorProtocol
func next() async throws -> Element? {
await getNextPicture()
}
func makeAsyncIterator() -> PicturesLoader {
self
}
// end of AsyncSequence and AsyncIteratorProtocol
private var pictures: [PictureWithImage] = []
private func getNextPicture() async -> PictureWithImage? {
guard let nextPicture = pictures.popLast(),
let url = URL(string: nextPicture.imageUrl) else { return nil }
if let data = await RESTClient.getData(atURL: url) {
let image = UIImage(data: data)
var picture = nextPicture
picture.image = image
return picture
}
return nil
}
}
```
As you see, it conform to AsyncSequence and AsyncIteratorProtocol.
To conform to them, we need to add the next function that will return an Element, in this case the custom struct PictureWithImage but it could be anything like a String or custom type of yours.
Then we need the makeAsyncIterator, in this example we return self as this class conforms to AsyncSequence and AsyncIteratorProtocol. You may have a separate type like a struct conforming to AsyncIteratorProtocol and return that one instead of self.
Since the next function is async, we can await inside it.
Look at getNextPicture, that function is async as well, because is calling a RESTClient that will call an async version of URLSession to retrieve the data.
Of course you don’t have to await inside your async function, you may have all your values ready and return them. I wanted to show you a real asynchronous operation like a network call, but you may have an array of objects and return one at a time like a Sequence does.
How do we call our custom AsyncSequence? Just like we did for the URLSession example
```swift
let pictureLoader = PicturesLoader(withPictures: picturesWithImages)
Task {
do {
for try await picture in pictureLoader {
loadedPictures.append(picture)
await viewController?.collectionView.reloadData()
}
}
catch {
print("error while iterating on images")
}
}
```
here I chose to use the for loop, but I could have used the iterator as well.
In this example we’re awaiting for the next picture, and when it is ready we can append its value to an array and call reload data on the collection view, so the new cell will be created with an image on it.
## Use AsyncStream
It isn’t always necessary to create your own AsyncSequence, as Swift introduced two types conforming to AsyncSequence to make our lives easier. You can use [AsyncStream](https://developer.apple.com/documentation/swift/asyncstream) and its counterpart [AsyncThrowingStream](https://developer.apple.com/documentation/swift/asyncthrowingstream) (if your calls may throw) and then loop through them via a for loop just as we did in the previous example.
According to the documentation, both types provide a convenient way to create an asynchronous sequence without manually implementing an iterator. Sounds great, let’s see an example
```swift
func getPicturesStream() -> AsyncStream<PictureWithImage> {
AsyncStream { continuation in
Task {
for picture in pictures {
if let url = URL(string: picture.imageUrl),
let data = await RESTClient.getData(atURL: url),
let image = UIImage(data: data) {
var pictureToReturn = picture
pictureToReturn.image = image
continuation.yield(pictureToReturn)
}
}
continuation.finish()
}
}
}
```
the implementation is similar to getNextPicture, it has a loop for the pictures, for each of them await for the RESTClient and then creates the UIImage and returns it. The difference is that we don’t actually return a value directly this time. The AsyncStream initialiser we are using is provided a [Continuation](https://developer.apple.com/documentation/swift/asyncstream/continuation), and as you see we call two functions on this type: yield and finish. Both resume the task awaiting for the next iteration, finish returns nil so the iteration ends, while yield has a value.
Let’s have a look at the call site
```swift
let picturesLoader = PicturesLoader(withPictures: picturesWithImages)
let stream = picturesLoader.getPicturesStream()
Task {
for await picture in stream {
loadedPictures.append(picture)
await viewController?.collectionView.reloadData()
}
}
```
this is similar to the previous example, we get the stream and we can iterate via a for loop.
The difference is that we didn’t have to provide a custom implementation of AsyncSequence so there is less code to write and we could avoid creating a custom type.
## Conclusion
This was a quick introduction to AsyncSequence, I wanted to show you how to create your own one and most importantly how to consume an existing one.
As I said at the beginning, this isn’t the only alternative we have to deal with asynchronous values being emitted over time. Combine is great for that, comes with operators to manipulate the data and has some utilities like discarding results and debouncing the publisher.
Different tools that can help you achieve different goals, I think it is important to know all of them in order to pick the right one for your project.
Happy coding 🙂
[Original article](https://www.gfrigerio.com/create-your-own-asyncsequence/) | gualtierofr |
905,644 | Embed assets in a WordPress theme | This article was originally published on webinuse.com In the last article, we talked about How to... | 0 | 2021-11-22T15:17:04 | https://webinuse.com/embed-assets-in-a-wordpress-theme/ | wordpress, theme, programming | *This article was originally published on [webinuse.com](https://webinuse.com/embed-assets-in-a-wordpress-theme/)*
In the last article, we talked about [How to simply convert any HTML template into a WordPress theme in under 10 minutes](https://webinuse.com/how-to-convert-any-html-template-into-wordpress-theme/). Today we are going to continue our journey on creating a WordPress theme out of any HTML template. We are going to see how to embed assets in a WordPress theme.
In today’s article, we are going to continue our journey, but we are going to use a real template. This template is courtesy of [Nathan](https://twitter.com/natension) and this template can be found for FREE on [aptex.gumroad.com](https://aptex.gumroad.com/l/portfolio-template-01?campaign_name=webinuse).
In order to be able to embed assets in a WordPress theme first thing we need to do is create a file called functions.php.
### What is functions.php
Functions.php is the file where we extend our theme’s functions. It is one of the default WordPress files, and it acts like our theme’s plugin. We leverage WordPress hooks and functions to achieve new or add existing functionality using PHP.
If we want to add widget area, woocommerce support, menu support, and a lot of other things, we do that by editing functions.php.
According to [WPBeginner](https://www.wpbeginner.com/glossary/functions-php/) the functions.php file automatically loads when you install and activate a theme on your WordPress site.
For more information about functions.php, we can [visit official Developer Resources on WordPress.org](https://developer.wordpress.org/themes/basics/theme-functions/).
### How to create functions.php
We need to create functions.php at the root of our theme. In our last article, in the end, we explained [how and where themes are uploaded](https://webinuse.com/how-to-convert-any-html-template-into-wordpress-theme/).
After we create our functions.php we are going to paste some code inside. For now, we are going to assume that the only thing we want to include is style.css file.
WordPress has a special hook for embedding assets and it is called `wp_enqueue_style()`. This hook, or function, is used when we want to enqueue style in our WordPress theme. Style is anything that is being used for styling our website, like CSS or fonts. This is the only, proper, way to embed assets in a WordPress theme.
Let’s take a look at `wp_enqueue_style()` function parameters.
```php
wp_enqueue_style( string $handle, string $src = '', string[] $deps = array(), string|bool|null $ver = false, string $media = 'all' )
```
### Enqueue style parameters
According to official [WordPress docs](https://developer.wordpress.org/reference/functions/wp_enqueue_style/) as the first parameter we need to pass the `$handle`, that is the name of stylesheet, and it should be unique. The second parameter is `$src` and it holds the source of the style that we want to embed.
This source can be anything. From third-party URLs like https://cdn.example.com/path-to-style, or path to a local file. Path to local file is relative to WordPress root directory. Also, when using external stylesheets, `wp_enqueue_style()` doesn’t need protocol like http or https. It is enough to start our link with a double forward slash, `//`. There is also another option when we want to use path relative to our theme, but we will look at that later.
Why `$handle` needs to be unique? Because of the third parameter, `$deps`. This parameter holds an array of handles that this stylesheet depends on.
The fourth parameter is `$ver` that holds the current version of the stylesheet. This is used for multiple purposes like caching or making sure that our site serves the right stylesheet. **NOTE:** This should be updated every time we update our stylesheet.
The last parameter is `$media`. We pass media query to this parameter if it is applicable. E.g. `(max-width: 1024px)`.
### How to enqueue style.css
The first thing we need to do is embed style.css stylesheet in our theme.
```php
<?php
/**
* theme functions and definitions
*
* @link https://developer.wordpress.org/themes/basics/theme-functions/
*
* @package theme
*/
/**
* Enqueue scripts and styles.
*/
function theme_scripts() {
wp_enqueue_style( 'theme-style', get_stylesheet_uri(), array(), 0 );
}
add_action( 'wp_enqueue_scripts', 'theme_scripts' );
```
Let’s analyze our code. After a few comments, we created a function `theme_scripts`. Inside that function, we embedded our style.css file. Instead of using a path, as everyone would expect, there is a [built-in WordPress function for getting the default stylesheet](https://developer.wordpress.org/reference/functions/get_stylesheet_uri/). This function, `get_stylesheet_uri()`, retrieves stylesheet URI for the current theme.
After our function `theme_scripts` we used built-in WordPress function, hook, [`add_action` that will register our function](https://developer.wordpress.org/reference/functions/add_action/). We will not get into writing more about add_action, but we will say that if we want to enqueue script, or enqueue style, we need to use this exact same code.
```php
add_action( 'wp_enqueue_scripts', 'function_name' );
```
We only need to change `'function_name'` parameter to match our function’s name.
### How to embed other assets to our WordPress theme
Let’s say we want to add Google Fonts, we only need to add another `wp_enqueue_script` to our `theme_scripts` function.
```php
<?php
/**
* theme functions and definitions
*
* @link https://developer.wordpress.org/themes/basics/theme-functions/
*
* @package theme
*/
/**
* Enqueue scripts and styles.
*/
function theme_scripts() {
wp_enqueue_style( 'theme-style', get_stylesheet_uri(), array(), 0 );
//We have added this line of code
wp_enqueue_style('google-fonts', '//fonts.googleapis.com/css2?family=Inter:wght@400;600;700;900&family=Roboto+Slab:wght@900&display=swap', array(), 0);
}
add_action( 'wp_enqueue_scripts', 'theme_scripts' );
```
What we did? We picked a [Google Fonts](https://fonts.google.com/), we copied the link, and pasted it as `$src`.
### How to enqueue script
Instead of using `wp_enqueue_style` function, we are going to use `wp_enqueue_script` function. It is the same as `wp_enqueue_style` only the last parameter is different.
Instead of `$media` parameter we have `$in_footer` parameter. It is `false` by default. This parameter decides whether our script will be embedded in header or footer. If it is `false` then our script will be embedded in header, otherwise in footer.
Let’s enqueue script to our theme. Since we are using [Portfolio HTML template](https://aptex.gumroad.com/l/portfolio-template-01) we will enqueue app.js file from the theme root that comes with the template.
```php
<?php
/**
* theme functions and definitions
*
* @link https://developer.wordpress.org/themes/basics/theme-functions/
*
* @package theme
*/
/**
* Enqueue scripts and styles.
*/
function theme_scripts() {
wp_enqueue_style( 'theme-style', get_stylesheet_uri(), array(), 0 );
wp_enqueue_style('google-fonts', '//fonts.googleapis.com/css2?family=Inter:wght@400;600;700;900&family=Roboto+Slab:wght@900&display=swap', array(), 0);
//We have added this line of code
wp_enqueue_script( 'default-js', get_template_directory_uri() . '/app.js', array(), 0, true );
}
add_action( 'wp_enqueue_scripts', 'theme_scripts' );
```
As shown in the example above, we just added `wp_enqueue_script` to `theme_scripts`. But there is one thing we haven’t seen before. It is [`get_template_directory_uri()` function](https://developer.wordpress.org/reference/functions/get_template_directory_uri/). This function basically retrieves the URI of the currently active theme.
> If you want to learn more about what is WordPress you can check this awesome course [Building websites with WordPress](https://gumroad.com/a/882791539/kSrqD) by [Nat Miletic](https://twitter.com/natmiletic). This course is excellent for those who want to start with WordPress. Nat is teaching us what is WordPress, what can we use it for, how can we use it, in a really nice and simple way.
>
> <cite>Affiliate</cite>
<meta charset="utf-8">If you have any questions or anything you can find me on my [Twitter](https://twitter.com/AmerSikira), or you can read some of my other articles like [How to bind events to dynamically created elements in JavaScript](https://webinuse.com/how-to-bind-events-to-dynamically-created-elements/).
| amersikira |
905,769 | Doodle + Forms | Doodle forms make data collection simple, while still preserving flexibility to build just the right... | 0 | 2021-11-22T16:35:45 | https://dev.to/pusolito/doodle-forms-14cj | kotlin, webdev, javascript, showdev | Doodle [forms](https://nacular.github.io/doodle/docs/ui_components/form) make data collection simple, while still preserving flexibility to build just the right experience. They hide a lot of the complexity associated with mapping visual components to fields, state management, and validation. The result is an intuitive metaphor modeled around the idea of a constructor.
Doodle also has a set of helpful forms controls that cover a reasonable range of data-types. These make its easy to create forms without much hassle. But there are bound to be cases where more customization is needed. This is why Doodle forms are also extensible, allowing you to fully customize the data they bind to and how each fields is visualized.
## Like Constructors
Forms are very similar to constructors in that they have typed parameter lists (fields), and can only "create" instances when all their inputs are valid. Like any constructor, a Form can have optional fields, default values, and arbitrary types for its fields.
While Forms behave like constructors in most ways, they do not actually create instances (only sub-forms do). This means they are not typed. Instead, they take fields and output a corresponding lists of strongly-typed data when all their fields are valid. This notification is intentionally general to allow forms to be used in a wide range of use cases.
## Creation
Forms are created using the Form builder function. This function ensures strong typing for fields and the form's "output".
The Form returned from the builder does not expose anything about the data it produces. So all consumption logic goes in the builder block.
```kotlin
val form = Form { this(
field1,
field2,
// ...
onInvalid = {
// called whenever any fields is updated with invalid data
}) { field1, field2, /*...*/ ->
// called each time all fields are updated with valid data
}
}
```
## Fields
Each field defined in the Form will be bounded to a single View. These views are defined during field binding using a FieldVisualizer. A visualizer is responsible for taking a Field and its initial state and returning a View. The visualizer then acts as the bridge between the field's state and the View, mapping changes made in the View to the field (this includes validating that input).
## Field State
Fields store their data as FieldState. This is a strongly-typed value that can be Valid or Invalid. Valid state contains a value, while invalid state does not. A Form with any invalid fields is invalid itself, and will indicate this by calling onInvalid.
## Creating Fields
Fields are created implicitly when FieldVisualizers are bound to a Form. These visualizers can be created using the field builder function, by implementing the interface, or by one of the existing form controls.
Using the builder DSL
```kotlin
import io.nacular.doodle.controls.form.field
field<T> {
initial // initial state of the field
state // mutable state of the field
view {} // view to display for the field
}
```
Implementing interface
```kotlin
import io.nacular.doodle.controls.form.FieldInfo
import io.nacular.doodle.controls.form.FieldVisualizer
class MyVisualizer<T>: FieldVisualizer<T> {
override fun invoke(fieldInfo: FieldInfo<T>): View {
fieldInfo.initial // initial state of the field
fieldInfo.state // mutable state of the field
return view {} // view to display for the field
}
}
```
## Field Binding
Fields all have an optional initial value. Therefore, each field can be bounded either with a value or without one. The result is 2 different ways of adding a field to a Form.
The following shows how to bind fields that has no default value.
```kotlin
import io.nacular.doodle.controls.form.Form
import io.nacular.doodle.controls.form.textField
import io.nacular.doodle.utils.ToStringIntEncoder
data class Person(val name: String, val age: Int)
val form = Form { this(
+ textField(),
+ textField(encoder = ToStringIntEncoder),
+ field<Person> { view {} },
// ...
onInvalid = {}) { text: String, number: Int, person: Person ->
// ...
}
}
```
This shows how to bind using initial values.
```kotlin
import io.nacular.doodle.controls.form.Form
import io.nacular.doodle.controls.form.textField
import io.nacular.doodle.utils.ToStringIntEncoder
data class Person(val name: String, val age: Int)
val form = Form { this(
"Hello" to textField(),
4 to textField(encoder = ToStringIntEncoder),
Person("Jack", 55) to field { view {} },
// ...
onInvalid = {}) { text: String, number: Int, person: Person ->
// ...
}
}
```
These examples bind fields that have no names. Doodle has a labeled form control that wraps a control and assigns a name to it.
Note that a visualizer may set a field's state to some valid value at initialization time. This will give the same effect as that field having had a initial value specified that the visualizer accepted.
## Forms as Fields
Forms can also have nested forms within them. This is helpful when the field has complex data that can be presented to the user as a set of components. Such cases can be handled with custom visualizers, but many work well using a nested form.
Nested forms are created using the form builder function. It works just like the top-level Form builder, but it actually creates an instance and has access to the initial value it is bound to (if any).
```kotlin
import io.nacular.doodle.controls.form.form
import io.nacular.doodle.controls.form.Form
import io.nacular.doodle.controls.form.textField
import io.nacular.doodle.utils.ToStringIntEncoder
data class Person(val name: String, val age: Int)
val form = Form { this(
+ labeled("Text" ) { textField() },
+ labeled("Number") { textField(encoder = ToStringIntEncoder) },
Person("Jack", 55) to form { this(
initial.map { it.name } to labeled("Name") { textField() },
initial.map { it.age } to labeled("Age" ) { textField(encoder = ToStringIntEncoder) },
onInvalid = {}
) { name, age ->
Person(name, age) // construct person when valid
} },
// ...
onInvalid = {}) { text: String, number: Int, person: Person ->
// called each time all fields are updated with valid data
}
}
```
Nested forms can be used with or without initial values like any other field.
## Learn more
[Doodle](https://github.com/nacular/doodle) is a pure Kotlin UI framework for the Web (and Desktop), that lets you create rich applications without relying on Javascript, HTML or CSS. Check out the [documentation](https://nacular.github.io/doodle) and [tutorials](https://nacular.github.io/doodle-tutorials) to learn more. | pusolito |
905,906 | website to dextop App In six steps with electron | Convert Url To Desktop App With Electron Perquisites node JS - install ... | 0 | 2021-11-22T18:27:17 | https://dev.to/kartiks26/website-to-dextop-app-in-six-steps-with-electron-3nnn | electron, javascript, node, dextopapp | # Convert Url To Desktop App With Electron
## Perquisites
- node JS - [install](https://nodejs.org/en/download/)
> ## Step-1
### Create Folder And in Terminal Run This Commands
```cmd
npm init
```
just hit enter unless you end up .
### copy paste this to package.json and change your "name" , "description" , "author" if you want
```json
{
"name": "tutorial",
"version": "1.0.0",
"description": "",
"main": "main.js",
"scripts": {
"start": "electron ."
},
"author": "",
"license": "ISC"
}
```
> #### Note : Your package.json must have
```
"scripts": {
"start": "electron ."
},
```
> ### now file structure should be
```
tutorial
|package.json
```
> ## Step-2
### Run This Command
```cmd
npm install --save-dev electron
```
#### it will create package.json file and it will add this electron dependency to package.json file
```json
{
"name": "tutorial",
"version": "1.0.0",
"description": "",
"main": "main.js",
"scripts": {
"start": "electron ."
},
"author": "",
"license": "ISC",
"devDependencies": {
"electron": "^16.0.1"
}
}
```
### now file structure should be
```
tutorial
|node modules
|(All Node Modules)
|package.json
|package-lock.json
```
> ##### ignore if there is no package-lock.json
---
> ## Step-3
Now create a file named main.js and paste this code in it
```js
const { app, BrowserWindow, nativeTheme } = require("electron");
const path = require("path");
function createWindow() {
const win = new BrowserWindow({
title: Tutorial
, center: true,
// You Can Set Custom Height and Width
// width:800,
// height:600,
show: false,
titleBarOverlay: {
color: "#0000",
opacity: 0.5,
},
// Only If you Want to add Icons
// _______________________________
// icon: path.join(__dirname, Icon Path / Icon),
//_______________________________
webPreferences: {
preload: path.join(__dirname, "preload.js"),
},
});
// Here You Have To Put Your Website Link inside the quotes
// _______________________________________________
win.loadURL("https://musicapp-kohl.vercel.app/");
// _______________________________________________
win.setMenu(null);
// To keep it in small window comment next line
win.maximize();
win.show();
}
app.whenReady().then(() => {
createWindow();
app.on("activate", () => {
if (BrowserWindow.getAllWindows().length === 0) {
createWindow();
}
});
});
app.on("window-all-closed", () => {
if (process.platform !== "darwin") {
app.quit();
}
});
```
> ## To Add Your Own Link To The App Just Replace The Link In
```js
// From -
win.loadURL("https://musicapp-kohl.vercel.app/");
// To -
win.loadURL("Your Link Here");
```
### now file structure should be
```
tutorial
|node modules
|(All Node Modules)
|package.json
|package-lock.json
|main.js
```
> ## Step-4
Now run this
```cmd
npm run
```
on ideal condition it will open new window in full screen mode with close button and all other buttons
> ##### Like This
>
> 
> ## Step-5
Now We Need to bundle this package into some exe and platform based
Thats why we need to install electron-packager
```cmd
npm install electron-packager
//Try both command
npm install electron-packager -g
```
it will install electron globally into your system
> ## Step-6
Now we will be shifting to cmd and not in powershell strictly
- For All Platforms Generation
```cmd
electron-packager . <APP Name You Want To Give> --all --asar
```
- For Linux Generation
```cmd
electron-packager . <APP Name You Want To Give> --platform=linux
```
- For Windows Generation
```cmd
electron-packager . <APP Name You Want To Give> --platform=win32 --asar
```
- For Mac-Os Generation
```cmd
electron-packager . <APP Name You Want To Give> --platform=darwin
```
##### This might give Error due to some package If i find any solution i will update this
---
---
> ### Now You Will Have Packages Like this
>
> #### and you can find applications in this respective folders
>
> 
> ## By This You Have Completed The Tutorial And You have all the folders with all platforms
[getting started official Guide](https://www.electronjs.org/docs/latest/tutorial/quick-start)
[Video Reference for generation](https://youtu.be/aNJDdCjdDpU)
[Icon Change](https://stackoverflow.com/questions/31529772/how-to-set-app-icon-for-electron-atom-shell-app)
Contact Me At kartikshikhare26@gmail.com For Any Query
Follow For More .
| kartiks26 |
906,092 | How to remove malicious spyware, malware, adware, viruses, trojans, or rootkits from the PC? | anti-viruscommunity-faqmalwareviruswindows What should I do if my Windows computer seems to be... | 0 | 2021-11-25T17:06:40 | https://stackallflow.com/superuser/how-to-remove-malicious-spyware-malware-adware-viruses-trojans-or-rootkits-from-the-pc/ | superuser, anti, faqmalwareviruswindo, viruscommunity | ---
title: How to remove malicious spyware, malware, adware, viruses, trojans, or rootkits from the PC?
published: true
date: 2021-11-22 19:03:58 UTC
tags: SuperUser,anti,faqmalwareviruswindo,viruscommunity
canonical_url: https://stackallflow.com/superuser/how-to-remove-malicious-spyware-malware-adware-viruses-trojans-or-rootkits-from-the-pc/
---
<header>
<p><span style="font-size: 1.2em; color: initial;">anti-virus</span><span style="font-size: 1.2em; color: initial;">community-faq</span><span style="font-size: 1.2em; color: initial;">malware</span><span style="font-size: 1.2em; color: initial;">virus</span><span style="font-size: 1.2em; color: initial;">windows</span></p>
</header>
What should I do if my Windows computer seems to be infected with a virus or malware?
- What are the symptoms of an infection?
- What should I do after noticing an infection?
- What can I do to get rid of it?
- how to prevent from infection by malware?
> This question comes up frequently, and the suggested solutions are usually the same. This community wiki is an attempt to serve as the definitive, most comprehensive answer possible.
>
> Feel free to add your contributions via edits.
#### Accepted Answer
Here’s the thing: Malware in recent years has become both _sneakier_ and _nastier_:
**Sneakier** , not only because it’s better at hiding with rootkits or EEPROM hacks, but also because it travels in packs. Subtle malware can hide behind more obvious infections. There are lots of good tools listed in answers here that can find 99% of malware, but there’s always that 1% they can’t find yet. Mostly, that 1% is stuff that is _new_: the malware tools can’t find it because it just came out and is using some new exploit or technique to hide itself that the tools don’t know about yet.
Malware also has a short shelf-life. If you’re infected, something from that new 1% is very likely to be _one part_ of your infection. It won’t be the _whole_ infection: just a part of it. Security tools will help you find and remove the more obvious and well-known malware, and most likely remove all of the visible _symptoms_ (because you can keep digging until you get that far), but they can leave little pieces behind, like a keylogger or rootkit hiding behind some new exploit that the security tool doesn’t yet know how to check. The anti-malware tools still have their place, but I’ll get to that later.
**Nastier** , in that it won’t just show ads, install a toolbar, or use your computer as a zombie anymore. Modern malware is likely to go right for the banking or credit card information. The people building this stuff are no longer just script kiddies looking for fame; they are now organized professionals motivated by _profit_, and if they can’t steal from you directly, they’ll look for _something_ they can turn around and sell. This might be processing or network resources in your computer, but it might also be your social security number or encrypting your files and holding them for ransom.
Put these two factors together, and _ **it’s no longer worthwhile to even attempt to remove malware from an installed operating system** _. I used to be very good at removing this stuff, to the point where I made a significant part of my living that way, and I no longer even make the attempt. I’m not saying it can’t be done, but I am saying that the cost/benefit and risk analysis results have changed: it’s just not worth it anymore. There’s too much at stake, and it’s too easy to get results that only _seem_ to be effective.
Lots of people will disagree with me on this, but I challenge they are not weighing consequences of failure strongly enough. **Are you willing to wager your life savings, your good credit, even your identity, that you’re better at this than crooks who make millions doing it every day?** If you try to remove malware and then keep running the old system, that’s _exactly_ what you’re doing.
I know there are people out there reading this thinking, “Hey, I’ve removed several infections from various machines and nothing bad ever happened.” Me too, friend. Me too. In days past I have cleaned my share of infected systems. Nevertheless, I suggest we now need to add “yet” to the end of that statement. You might be 99% effective, but you only have to be wrong one time, and the consequences of failure are much higher than they once were; the cost of just one failure can easily outweigh all of the other successes. You might even have a machine already out there that still has a ticking time bomb inside, just waiting to be activated or to collect the right information before reporting it back. Even if you have a 100% effective process now, this stuff changes all the time. Remember: you have to be perfect every time; the bad guys only have to get lucky once.
In summary, it’s unfortunate, but _if_ you have a confirmed malware infection, a complete re-pave of the computer should be the **first** place you turn instead of the last.
* * *
Here’s how to accomplish that:
_Before you’re infected_, make sure you have a way to re-install any purchased software, including the operating system, that does not depend on anything stored on your internal hard disk. For this purpose, that normally just means hanging onto cd/dvds or product keys, but the operating system may require you to create recovery disks yourself.<sup>1</sup> Don’t rely on a recovery partition for this. If you wait until after an infection to ensure you have what you need to re-install, you may find yourself paying for the same software again. With the rise of ransomware, it’s also extremely important to take regular backups of your data (plus, you know, regular non-malicious things like hard drive failure).
_When you suspect you have malware_, look to other answers here. There are a lot of good tools suggested. My only issue is the best way to use them: I only rely on them for the detection. Install and run the tool, but as soon as it finds evidence of a real infection (more than just “tracking cookies”) just stop the scan: the tool has done its job and confirmed your infection.<sup>2</sup>
_At the time of a confirmed infection,_ take the following steps:
1. Check your credit and bank accounts. By the time you find out about the infection, real damage may have already been done. Take any steps necessary to secure your cards, bank account, and identity.
2. Change passwords at any web site you accessed from the compromised computer. _Do not use the compromised computer to do any of this._
3. Take a backup of your data (even better if you already have one).
4. Re-install the operating system using original media obtained directly from the OS publisher. Make sure the re-install includes a complete re-format of your disk; a system restore or system recovery operation is not enough.
5. Re-install your applications.
6. Make sure your operating system and software is fully patched and up to date.
7. Run a complete anti-virus scan to clean the backup from step three.
8. Restore the backup.
If done properly, this is likely to take between two and six real hours of your time, spread out over two to three days (or even longer) while you wait for things like apps to install, windows updates to download, or large backup files to transfer… but it’s better than finding out later that crooks drained your bank account. Unfortunately, this is something you should do yourself, or a have a techy friend do for you. At a typical consulting rate of around $100/hr, it can be cheaper to buy a new machine than pay a shop to do this. If you have a friend do it for you, do something nice to show your appreciation. Even geeks who love helping you set up new things or fix broken hardware often _hate_ the tedium of clean-up work. It’s also best if you take your own backup… your friends aren’t going to know where you put what files, or which ones are really important to you. You’re in a better position to take a good backup than they are.
Soon even all of this may not be enough, as there is now malware capable of infecting firmware. Even replacing the hard drive may not remove the infection, and buying a new computer will be the only option. Thankfully, at the time I’m writing this we’re not to that point yet, but it’s definitely on the horizon and approaching fast.
* * *
If you absolutely insist, beyond all reason, that you really want to clean your existing install rather than start over, then for the love of God make sure whatever method you use involves one of the following two procedures:
- Remove the hard drive and connect it as a guest disk in a different (clean!) computer to run the scan.
_OR_
- Boot from a CD/USB key with its own set of tools running its own kernel. Make sure the image for this is obtained and burned on a clean computer. If necessary, have a friend make the disk for you.
_Under no circumstances should you try to clean an infected operating system using software running as a guest process of the compromised operating system._ That’s just plain dumb.
* * *
Of course, the best way to fix an infection is to avoid it in the first place, and there are some things you can do to help with that:
1. Keep your system patched. Make sure you _promptly_ install Windows Updates, Adobe Updates, Java Updates, Apple Updates, etc. This is far more important even than anti-virus software, and for the most part it’s not that hard, as long as you keep current. Most of those companies have informally settled on all releasing new patches on the same day each month, so if you keep current it doesn’t interrupt you that often. Windows Update interruptions typically only happen when you ignore them for too long. If this happens to you often, it’s on _you_ to change your behavior. These are _important_, and it’s not okay to continually just choose the “install later” option, even if it’s easier in the moment.
2. Do not run as administrator by default. In recent versions of Windows, it’s as simple as leaving the UAC feature turned on.
3. Use a good firewall tool. These days the default firewall in Windows is actually good enough. You may want to supplement this layer with something like WinPatrol that helps stop malicious activity on the front end. Windows Defender works in this capacity to some extent as well. Basic Ad-Blocker browser plugins are also becoming increasingly useful at this level as a security tool.
4. Set most browser plug-ins (especially Flash and Java) to “Ask to Activate”.
5. Run _current_ anti-virus software. This is a distant fifth to the other options, as traditional A/V software often just isn’t that effective anymore. It’s also important to emphasize the “current”. You could have the best antivirus software in the world, but if it’s not up to date, you may just as well uninstall it.
For this reason, I currently recommend Microsoft Security Essentials. (Since Windows 8, Microsoft Security Essentials is part of Windows Defender.) There are likely far better scanning engines out there, but Security Essentials will keep itself up to date, without ever risking an expired registration. AVG and Avast also work well in this way. I just can’t recommend any anti-virus software you have to actually pay for, because it’s just far too common that a paid subscription lapses and you end up with out-of-date definitions.
It’s also worth noting here that Mac users now need to run antivirus software, too. The days when they could get away without it are long gone. As an aside, I think it’s _ **hilarious** _ I now must recommend Mac users buy anti-virus software, but advise Windows users against it.
6. Avoid torrent sites, warez, pirated software, and pirated movies/videos. This stuff is often injected with malware by the person who cracked or posted it — not always, but often enough to avoid the whole mess. It’s part of why a cracker would do this: often they will get a cut of any profits.
7. Use your head when browsing the web. You are the weakest link in the security chain. If something sounds too good to be true, it probably is. The most obvious download button is rarely the one you want to use any more when downloading new software, so make sure to read and understand everything on the web page before you click that link. If you see a pop up or hear an audible message asking you to call Microsoft or install some security tool, it’s a fake.
Also, prefer to download the software and updates/upgrades directly from vendor or developer rather than third party file hosting websites.
* * *
<sub><sup>1</sup> Microsoft now publishes the <a href="https://www.microsoft.com/en-us/software-download/windows10" rel="noreferrer nofollow external noopener" data-wpel-link="external" target="_blank">Windows 10 install media<span></span></a> so you can legally download and write to an 8GB or larger flash drive for free. You still need a valid license, but you don’t need a separate recovery disk for the basic operating system any more.</sub>
<sub><sup>2</sup> This is a good time to point out that I have softened my approach somewhat. Today, most “infections” fall under the category of PUPs (Potentially Unwanted Programs) and browser extensions included with other downloads. Often these PUPs/extensions can safely be removed through traditional means, and they are now a large enough percentage of malware that I may stop at this point and simply try the Add/Remove Programs feature or normal browser option to remove an extension. However, at the first sign of something deeper — any hint the software won’t just uninstall normally — and it’s back to repaving the machine.</sub>
The post [How to remove malicious spyware, malware, adware, viruses, trojans, or rootkits from the PC?](https://stackallflow.com/superuser/how-to-remove-malicious-spyware-malware-adware-viruses-trojans-or-rootkits-from-the-pc/) appeared first on [Stack All Flow](https://stackallflow.com). | stackallflow |
906,093 | So if the USB flash drive is write-protected or read-only | community-faqread-onlyusbusb-flash-drivewrite-protect When I plug in my USB flash drive, it shows up... | 0 | 2021-11-25T17:06:46 | https://stackallflow.com/superuser/so-if-the-usb-flash-drive-is-write-protected-or-read-only/ | superuser, community, drivewrite, faqread | ---
title: So if the USB flash drive is write-protected or read-only
published: true
date: 2021-11-22 19:26:49 UTC
tags: SuperUser,community,drivewrite,faqread
canonical_url: https://stackallflow.com/superuser/so-if-the-usb-flash-drive-is-write-protected-or-read-only/
---
<header>
<p><span style="font-size: 1.2em; color: initial;">community-faq</span><span style="font-size: 1.2em; color: initial;">read-only</span><span style="font-size: 1.2em; color: initial;">usb</span><span style="font-size: 1.2em; color: initial;">usb-flash-drive</span><span style="font-size: 1.2em; color: initial;">write-protect</span></p>
</header>
When I plug in my USB flash drive, it shows up on my computer as _write-protected_ or _read-only_. I am unable to transfer data to it, nor can I modify or delete any files already stored on it. I also cannot repartition or reformat the drive using Windows Disk Management, DiskPart, GParted, or other tools. The drive does not have a write-protect switch.
Why did this happen and what can I do about it? Is there a way to remove the write protection?
(Note that this can happen with some memory cards, too, as they often use controllers similar to those used in flash drives. In some cases, the system may report that the drive or card was formatted successfully even though it was never actually formatted; the original data reappears when the device is reinserted.)
> _This question comes up often and the answers are usually the same. This post is meant to provide a definitive, canonical answer for this problem. Feel free to edit the answer to add additional details._
#### Accepted Answer
If the drive appears to be write-protected, start by inserting the drive into another computer to isolate the cause of the issue.
If you’re able to write to the drive from another computer, you might be experiencing one of the following problems:
1. **Filesystem corruption.** The drive might have a corrupted filesystem or other issue (possibly specific to a particular computer or OS) that can be corrected by using `CHKDSK` or a similar utility. If this addresses the problem, your drive is probably working normally. It’s also important to eject the drive properly before removing it or at least wait until the drive has finished writing, as [removal of the drive while it is writing data can cause low-level data corruption](https://superuser.com/questions/290060/can-flash-memory-be-physically-damaged-if-power-is-interrupted-while-writing).
2. **Incorrect Group Policy settings.** If you’re running Windows, it’s possible that your system’s Group Policy may be disallowing writing to external storage devices, including USB flash drives. The registry key `HKEY_LOCAL_MACHINESystemCurrentControlSetControlStorageDevicePolicies` should either be absent or set to 0; if it is set to 1, Windows will not allow writing to external storage devices.
3. (_SD cards only_) **Broken or altered write-protect switch in the card slot.** The mechanical lock switch on an SD card [is not connected to its electronics](https://superuser.com/questions/354473/is-the-lock-mechanism-on-an-sd-card-hardware-firmware-or-software-driver-os/354497#354497):
> It is the responsibility of the host to protect the card. The position of the write protect switch is unknown to the internal circuitry of the card.
This means that hardware and software other than the card itself is responsible for checking the lock state of the card. If this mechanism isn’t working as designed, a SD card can appear to be write-protected even if it is otherwise functioning normally. Typically, this can be addressed by replacing the card reader, although faulty drivers or incorrect software configuration can also cause this problem.
* * *
If the drive is read-only no matter what computer you plug it into, or you’ve tried the above steps to no avail, then the drive has probably experienced a fault condition, and it’s generally not possible to remove write protection from a faulty flash drive. This behavior is typical of flash drive controllers when they detect a problem with the underlying [NAND](https://en.wikipedia.org/wiki/Flash_memory) (e.g. too many bad blocks). The write protection is intended to prevent this condition from actually causing data loss, e.g. [the NAND becoming unreadable altogether](https://superuser.com/questions/871850/usb-flash-drive-not-working-or-is-appearing-as-an-empty-disk-drive-disk-managem). For example, [SanDisk customer support says](http://kb.sandisk.com/app/answers/detail/a_id/8656/~/write-protect-error-on-usb-flash-drives):
> Write protection errors occur when a flash drive detects a potential fault within itself. The drive will go into write-protected mode to prevent data loss. There is no method to fix this.
Note that depending on the drive, there may in fact be ways to disable (or more accurately, reset) the write protection by reprogramming the flash memory controller, such as by using the techniques listed under “Potential Hardware-Specific Restoration” in [this answer](https://superuser.com/questions/871850/usb-flash-drive-not-working-or-is-appearing-as-an-empty-disk-drive-disk-managem/871851#871851). Doing this is _not_ a good idea because the write protection signals that a problem has been detected by the controller; **overriding this and continuing to write to the drive could result in data loss.**
* * *
The upshot of this behavior is that any data on the drive is still accessible. Because the drive is failing, **you should back up the contents of the flash drive as soon as possible and replace the drive**. (If the drive contains sensitive information, be sure to physically destroy it before you dispose of it.)
Getting data off the drive may be tricky because some data corruption may have already occurred by the time drive went into read-only mode. This commonly manifests itself as the filesystem experiencing low-level corruption causing the filesystem to appear as RAW or the OS prompting the format the drive. Recovering from this kind of corruption can be complicated because the filesystem cannot be directly repaired—the drive is, after all, write-protected.
You may be able to retrieve data from a drive corrupted in this manner by using data recovery utilities such as the open-source [TestDisk](http://www.cgsecurity.org/wiki/TestDisk). You can also get a drive of equal or greater capacity and copy over the failing drive’s contents sector by sector onto the new drive using [GNU ddrescue](https://www.gnu.org/software/ddrescue/), and follow up with a `CHKDSK` to fix the filesystem errors. If these fail, and the data is particularly valuable, you could send the drive to a dedicated data recovery service; however, these services tend to be very expensive due to their highly specialized nature and are rarely worth it.
The post [So if the USB flash drive is write-protected or read-only](https://stackallflow.com/superuser/so-if-the-usb-flash-drive-is-write-protected-or-read-only/) appeared first on [Stack All Flow](https://stackallflow.com). | stackallflow |
906,146 | When Are You Ready To Freelance? | Many people dream of the freedom being a freelancer brings. However, it can be a difficult journey,... | 0 | 2021-11-23T00:09:21 | https://kevinhicks.software/blog/18/when-are-you-ready-to-freelance | freelance, career | Many people dream of the freedom being a freelancer brings. However, it can be a difficult journey, especially if you aren't ready for it.
How do you know if you are ready?
**1. Do you have the experience and can work on your own?**
Clients expect freelancers to be able to hit the ground running, so make sure you know your job well enough to work on your own.
**2. Do you have a portfolio?**
Clients need proof you can complete the job. Having a portfolio also helps you answer #1 correctly.
**3. Are you able to manage yourself?**
Freelancers need excellent time and project management skills. You won't have the structure a typical job provides to help keep you accountable.
**4. Are your people and communication skills strong?**
You will need to market and sell yourself, solve disagreements, and handle all communications yourself.
**5. Do you have a plan to get clients and get paid?**
Before starting, you need to know how you are going to make money. Decide if you will use a freelance marketplace, referral, cold calls/emails, etc.
**6. Are you ready to deal with the up and downs?**
Freelancing can be fantastic, but it can also be stressful. Like any job, there will be bad days and good days. You may have to be ready to deal with a drop in income at times too.
The great thing about freelancing is all the skills you need; you can learn and practice until you are ready to jump into the freelancing pool. | kevinhickssw |
906,151 | HandTrack.js | A post by Bruno Tonet | 0 | 2021-11-23T00:29:57 | https://dev.to/brunotonet/handtrackjs-19mg | codepen | {% codepen https://codepen.io/brunotonet/pen/xxLedqp %} | brunotonet |
906,156 | Going serverless with MongoDB Realm - Vue.js Version | Serverless architecture is a pattern of running and building applications and services without having... | 0 | 2021-11-23T07:02:52 | https://dev.to/hackmamba/going-serverless-with-mongodb-realm-vuejs-version-nld | serverless, mongodb, vue, typescript | ---
title: Going serverless with MongoDB Realm - Vue.js Version
published: true
description:
tags: #serverless #mongoDB #Vuejs #typeScript
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/008f1sxvetnryw0js7nn.png
---
Serverless architecture is a pattern of running and building applications and services without having to manage infrastructure. It involves the applications and services running on the server, but all the server management is done by a cloud provider.
This post will discuss building a fullstack user management application using [MongoDB](https://www.mongodb.com/), [MongoDB Realm](https://www.mongodb.com/realm), and [Vue.js](https://vuejs.org/). At the end of this tutorial, we will learn how to create a database on MongoDB, serverless functions as our endpoints using MongoDB Realm and consume the endpoints in a Vue.js application.
MongoDB Realm is a development platform designed for building mobile, web, desktop, and IoT applications. It offers services like data synchronization, serverless functions, triggers, user authentication, e.t.c. We can build and maintain application on MongoDB Realm using any of the following:
- [Realm UI](https://docs.mongodb.com/realm/manage-apps/deploy/manual/deploy-ui/#std-label-deploy-ui): a browser-based option to create and maintain application
- [Realm CLI](https://docs.mongodb.com/realm/manage-apps/deploy/manual/deploy-cli/#std-label-deploy-cli): a CLI-based option to define and deploy applications
- [GitHub Deploy](https://docs.mongodb.com/realm/manage-apps/deploy/automated/deploy-automatically-with-github/#std-label-deploy-github): use configuration files on Github to deploy applications from a Github repository
- [Admin API](https://docs.mongodb.com/realm/admin/api/v3/#std-label-admin-api): an HTTP-based request to manage your applications.
In this post, we will be using [Realm UI](https://docs.mongodb.com/realm/manage-apps/deploy/manual/deploy-ui/#std-label-deploy-ui) to build our applications.
You can code along by cloning this repository (**main branch**) [here](https://github.com/Mr-Malomz/vue-realm). If you prefer to view the complete code, checkout to the **dev** branch of this same repository.
In this tutorial, we will focus on implementations only. The project UI has already been set up with [TailwindCSS](https://tailwindcss.com/).
You can check out the React.js version [here](https://dev.to/hackmamba/going-serverless-with-mongodb-realm-reactjs-version-jh6).
# Prerequisites
The following steps in this post require JavaScript and Vue.js experience. Experience with TypeScript isn’t a requirement, but it’s nice to have.
We also need a [MongoDB account](https://www.mongodb.com/) to host the database and create serverless functions. [**Signup**](https://www.mongodb.com/cloud/atlas/register) **is completely free**.
# Let’s code
## Running the Project
To get started, we need to navigate to the project location, open our terminal and install project dependency as shown below:
npm install
With that done, we can start a development server using the command below:
npm run serve


## Setting up MongoDB
To get started, we need to log in or sign up into our [MongoDB](http://) account and follow the option that applies to us:
**For a New Account (Sign Up)**
First, we need to answer a few questions to help MongoDB help set up our account. Then click on **Finish.**

Select **Shared** as the type of database.

Click on **Create** to setup a cluster. This might take sometime to setup.

Next, we need to create a user to access the database externally by inputting the **Username**, **Password** and then click on **Create User**. We also need to add our IP address to safely connect to the database by clicking on the **Add My Current IP Address** button. Then click on **Finish and Close** to save changes.


On saving the changes, we should see a Database Deployments screen, as shown below:

**For an Existing Account (Log In)**
Click the project dropdown menu and click on the **New Project** button.

Enter the `realmVue` as the project name, click on **Next** and then click **Create Project**


Click on **Build a Database**

Select **Shared** as the type of database.

Click on **Create** to setup a cluster. This might take sometime to setup.

Next, we need to create a user to access the database externally by inputting the **Username**, **Password** and then clicking on **Create User**. We also need to add our IP address to safely connect to the database by clicking on the **Add My Current IP Address** button. Then click on **Finish and Close** to save changes.


On saving the changes, we should see a Database Deployments screen, as shown below:

## Loading Sample Data
Next, we need to populate our database with users' sample data. To do this, click on the **Browse Collections** button

Click on **Add My Own Data**, input `vueRealmDB` and `vueRealmCol` as the database and collection name, and click on **Create**.


Next, we need to insert these sample data:
```json
{
"name": "daniel mark"
"location": "new york"
"title": "software engineer"
}
{
"name": "clara patrick"
"location": "lisbon"
"title": "data engineer"
}
```
To do this, click on the **Insert Document** button, fill in the details above and click on **Insert** to save.



## Creating and configuring MongoDB Realm application
With our database populated, we need to create serverless functions to perform Create, Read, Update and Delete (CRUD) on our database. To do this, select the **Realm** tab, click on **Build your own App**. Then click on **Create Realm Application** to setup our application.


MongoDB Realm also ships with templates that we can use to build our application quickly. For this tutorial, we will be building from scratch.
Next, we need to setup permission and rules for our functions. To do this, close the popup guide, click on **Rules**, select the **vueRealmCol** and click on **Configure Collection**.

**MongoDB Realm’s Save and Deploy**
With that done, MongoDB Realm will show us a widget illustrating the concept of Save and Deploy.

When writing a serverless function, clicking on **Save** creates a development draft that we can test and play around with. At the same time, **Deploy** makes our changes public to be consumed by another application(Vue.js in our case).
Click on **Next** and then **Got it** to continue.
Next, we need to allow **Read** and **Write** permissions for our function and then **Save.**

Next, navigate to the **Authentication** tab, click on **Allow users to log in anonymously**, toggle it on and **Save Draft**.


MongoDB Realm also ships with several authentication options that we can explore. For this tutorial, we will be using the anonymous option.
## Creating serverless functions on MongoDB Realm
**Get All Users Serverless Function**
With the configuration done, we can now create a serverless function that returns list of users. To do this, navigate to the **Functions** tab, click on **Create New Function**, and input `getAllUsers` as the function name


Next, select the **Function Editor** tab and modify the function to the following:
```js
exports = function(arg){
let collection = context.services.get("mongodb-atlas").db("vueRealmDB").collection("vueRealmCol");
return collection.find({});
};
```
The snippet above does the following:
- Create a collection variable to access the `vueRealmDB` database and `vueRealmCol` collection
- Return the list of documents in the collection.
Next, we can test our function by clicking on **Run** button to see list of users.

Finally, we need to copy any returned user’s `_id` and save it somewhere; we need it for the next function. Then click on **Save Draft** to create a deployment draft for our function.

**Get A User Serverless Function**
To do this, click on the **Functions** tab, click on **Create New Function**, and input `getSingleUser` as the function name
Next, select the **Function Editor** tab, and modify the function to the following:
```js
exports = function(arg){
let collection = context.services.get("mongodb-atlas").db("vueRealmDB").collection("vueRealmCol");
return collection.findOne({_id: BSON.ObjectId(arg)});
};
```
The snippet above does the following:
- Create a collection variable to access the `vueRealmDB` database and `vueRealmCol` collection
- Return a single user by finding it by its `_id`. Because MongoDB saves documents in BSON, we need to parse the `arg` as BSON using the `BSON.ObjectId`.
To test our function, Navigate to the **Console** tab, replace the `Hello world!` in the **exports** function with the user’s `_id` we copied earlier and then click on **Run.**

Finally, we need to save our function by clicking on the **Save Draft** button.
**Edit A User Serverless Function**
To do this, we need to follow the same steps as above.
First, click on the **Functions** tab, click on **Create New Function**, and input `editUser` as the function name.

Next, select the **Function Editor** tab and modify the function to the following:
```js
exports = function(id, name, location, title){
let collection = context.services.get("mongodb-atlas").db("vueRealmDB").collection("vueRealmCol");
let updated = collection.findOneAndUpdate(
{_id: BSON.ObjectId(id)},
{ $set: { "name": name, "location": location, "title": title } },
{ returnNewDocument: true }
)
return updated;
};
```
The snippet above does the following:
- Modify the function to accept `id`, `name`, `location`, and `title` arguments
- Create a collection variable to access the `vueRealmDB` database and `vueRealmCol` collection
- Create an `updated` variable that finds the document by `_id`, update the collection fields, and set a `returnNewDocument` flag to return the updated document.
Next, we can test our function by navigating to the Console tab, replace the `Hello world!` in the **exports** function with required arguments(**_id, name, location, and title**), click on **Run**, and then **Save Draft**.

**Create A User Serverless Function**
To do this, we need to follow the same steps as before.
First, click on the **Functions** tab, click on **Create New Function**, and input `createUser` as the function name.

Next, select the **Function Editor** tab and modify the function to the following:
```js
exports = function(name, location, title){
let collection = context.services.get("mongodb-atlas").db("vueRealmDB").collection("vueRealmCol");
let newUser = collection.insertOne({"name": name, "location": location, "title": title})
return newUser;
};
```
The snippet above does the following:
- Modify the function to accept `name`, `location`, and `title` arguments.
- Create a collection variable to access the `vueRealmDB` database and `vueRealmCol` collection.
- Create a new user by inserting the arguments and returning the user.
Next, we can test our function by navigating to the Console tab, replace the `Hello world!` in the **exports** function with required arguments(**name, location, and title**), click on **Run**, and then **Save Draft**.

**Delete A User Serverless Function**
To do this, we need to follow the same steps as before.
First, click on the **Functions** tab, click on **Create New Function**, and input `deleteUser` as the function name.

Next, select the **Function Editor** tab and modify the function to the following:
```js
exports = function(id){
let collection = context.services.get("mongodb-atlas").db("vueRealmDB").collection("vueRealmCol");
let deleteUser = collection.deleteOne({_id: BSON.ObjectId(id)})
return deleteUser;
};
```
The snippet above does the following:
- Modify the function to accept an argument.
- Create a collection variable to access the `vueRealmDB` database and `vueRealmCol` collection.
- Create a `deleteUser` variable for deleting by `_id`.
Next, we can test our function by navigating to the Console tab, replace the `Hello world!` in the **exports** function with required the argument, click on **Run**, and then **Save Draft**.

## Deploying serverless functions
To start using the serverless functions in our application, we need to deploy them. To do this, click on the **Review Draft & Deploy** button, scroll down and then click on **Deploy**.


We should get a prompt showing the status of our deployment.
## Finally! Integration with Vue.js
To integrate MongoDB Realm in our application, we need to install the dependencies with:
npm i realm-web
`realm-web` is a [library](https://github.com/realm/realm-js/tree/master/packages/realm-web#readme) for accessing MongoDB Realm from a web-browser.
**Setup an Environment Variable**
First, we need to create a `.env` file in the project root directory, and in this file, add the snippet below:
VUE_APP_REALM_APP_ID=<your-realm-app-id>
To get our **Realm App ID**, we need to click on the copy icon as shown below:

**Setup MongoDB Realm**
Next, we need to create a `utils` folder in the `src` folder, and in this folder, create a `mongo.client.ts` file and add the code snippet below:
```js
import * as Realm from 'realm-web';
const REALM_APP_ID = process.env.VUE_APP_REALM_APP_ID;
export const app: Realm.App = new Realm.App({ id: REALM_APP_ID! });
export const credentials = Realm.Credentials.anonymous();
```
The snippet above does the following:
- Import the required dependencies.
- Create a variable to store the **Realm App ID**.
- Create and export an instance of MongoDB Realm and pass the App ID. The bang`!` in front of `REALM_APP_ID` tells the compiler to relax the non-null constraint error(Meaning the parameter cannot be null or undefined)
- Create and export the credential type we will be using for this app. We configure this authentication option earlier.
**Get All Users**
To get all users, we need to create an interface to describe the response properties. To do this, we need to create a `models` folder in the `src` folder, and in this folder, create a `user.interface.ts` file and add the code snippet below:
```js
export interface IUser {
_id? : string;
name: string;
location: string;
title: string
}
```
**PS**: *The question mark in front of* ***_id*** *tells TypeScript that this property is optional since MongoDB automatically generates it.*
Next, we need to modify `App.vue` by updating it with the snippet below:
```vue
<template>
<div class="">
<header
class="h-16 w-full bg-indigo-200 px-6 flex justify-between items-center"
>
<h1 class="text-xl text-indigo-900">Vue-Realm</h1>
<button
class="text-lg text-white capitalize px-6 py-2 bg-indigo-900 rounded-md"
@click="handleModal(true)"
>
create
</button>
</header>
<section className="mt-10 flex justify-center px-6">
<ul className="w-full">
<li
v-for="user in users"
:key="user._id"
className="border-2 p-6 mb-3 rounded-lg flex items-center"
>
<section
className="h-10 w-10 bg-indigo-100 rounded-md flex justify-center items-center mr-4"
>
<UserIcon />
</section>
<section className="">
<h2 className="capitalize font-semibold mb-1">{{ user.name }}</h2>
<p className="capitalize text-gray-500 mb-1">{{ user.location }}</p>
<p className="capitalize text-indigo-500 font-medium text-sm mb-2">
{{ user.title }}
</p>
<div className="flex">
<button
className="text-sm text-red-500 capitalize px-4 py-2 mr-4 border border-red-500 rounded-md"
>
delete
</button>
<button
className="text-sm text-white capitalize px-4 py-2 bg-indigo-900 rounded-md"
@click="handleEditClick()"
>
edit
</button>
</div>
</section>
</li>
</ul>
</section>
<Modal :isModal="isModal" :isEdit="isEdit" :handleModal="handleModal" />
</div>
</template>
<script lang="ts">
//import goes here
import { IUser } from '@/models/user.interface';
import { app, credentials } from '@/utils/mongo.client';
export default defineComponent({
name: 'App',
components: {
UserIcon,
Modal,
},
data: () => ({
isModal: false,
isEdit: false,
users: [] as IUser[], //add
}),
methods: {
//other functions goes here
//add
async getListOfUsers() {
const user: Realm.User = await app.logIn(credentials);
const listOfUser: Promise<IUser[]> = user.functions.getAllUsers();
listOfUser.then((resp) => {
this.users = resp;
});
},
},
//add
mounted() {
this.getListOfUsers()
},
});
</script>
<style></style>
```
The snippet above does the following:
- Import the `IUser` interface, `app` and `credentials`.
- Create `users` property to manage the list of users.
- Create a `getListOfUsers` function to authenticate our application using the `credentials` imported and get the list of users by accessing the `getAllUsers` serverless function we created earlier. Then update the `users` property and use the `mounted` hook to call the function.
**PS**: *The serverless function (****getAllUsers*** *in our case) called must be the same as the one defined on MongoDB Realm.*
- Update the mark-up to display the list of users.
**Complete App.vue**
```vue
<template>
<div class="">
<header
class="h-16 w-full bg-indigo-200 px-6 flex justify-between items-center"
>
<h1 class="text-xl text-indigo-900">Vue-Realm</h1>
<button
class="text-lg text-white capitalize px-6 py-2 bg-indigo-900 rounded-md"
@click="handleModal(true)"
>
create
</button>
</header>
<section className="mt-10 flex justify-center px-6">
<ul className="w-full">
<li
v-for="user in users"
:key="user._id"
className="border-2 p-6 mb-3 rounded-lg flex items-center"
>
<section
className="h-10 w-10 bg-indigo-100 rounded-md flex justify-center items-center mr-4"
>
<UserIcon />
</section>
<section className="">
<h2 className="capitalize font-semibold mb-1">{{ user.name }}</h2>
<p className="capitalize text-gray-500 mb-1">{{ user.location }}</p>
<p className="capitalize text-indigo-500 font-medium text-sm mb-2">
{{ user.title }}
</p>
<div className="flex">
<button
className="text-sm text-red-500 capitalize px-4 py-2 mr-4 border border-red-500 rounded-md"
>
delete
</button>
<button
className="text-sm text-white capitalize px-4 py-2 bg-indigo-900 rounded-md"
@click="handleEditClick()"
>
edit
</button>
</div>
</section>
</li>
</ul>
</section>
<Modal :isModal="isModal" :isEdit="isEdit" :handleModal="handleModal" />
</div>
</template>
<script lang="ts">
import { defineComponent } from 'vue';
import UserIcon from '@/assets/svg/UserIcon.vue';
import Modal from '@/components/Modal.vue';
import { IUser } from '@/models/user.interface';
import { app, credentials } from '@/utils/mongo.client';
export default defineComponent({
name: 'App',
components: {
UserIcon,
Modal,
},
data: () => ({
isModal: false,
isEdit: false,
users: [] as IUser[],
}),
methods: {
handleModal(state: boolean) {
this.isModal = state;
this.isEdit = false;
},
handleEditClick() {
this.isModal = true;
this.isEdit = true;
},
async getListOfUsers() {
const user: Realm.User = await app.logIn(credentials);
const listOfUser: Promise<IUser[]> = user.functions.getAllUsers();
listOfUser.then((resp) => {
this.users = resp;
});
},
},
mounted() {
this.getListOfUsers()
},
});
</script>
<style></style>
```
**Create A User**
To create a user, we must first modify `App.vue` by updating it with the snippet below
```vue
<template>
<div class="">
<header
class="h-16 w-full bg-indigo-200 px-6 flex justify-between items-center"
>
<!-- Header content goes here -->
</header>
<section className="mt-10 flex justify-center px-6">
<!-- Section content goes here -->
</section>
<!-- Modify Modal component -->
<Modal
:isModal="isModal"
:isEdit="isEdit"
:handleModal="handleModal"
:updateUserValue="updateUserValue"
/>
</div>
</template>
<script lang="ts">
//import goes here
export default defineComponent({
name: 'App',
components: {
UserIcon,
Modal,
},
data: () => ({
isModal: false,
isEdit: false,
users: [] as IUser[],
userValue: '', //add
}),
methods: {
handleModal(state: boolean) {
//codes here
},
handleEditClick() {
//codes here
},
async getListOfUsers() {
//codes here
},
//add
updateUserValue(value: any) {
this.userValue = value;
},
},
//add
watch: {
userValue(latestValue) {
if (latestValue !== '') {
this.getListOfUsers();
}
},
},
mounted() {
this.getListOfUsers();
},
});
</script>
<style></style>
```
The snippet above does the following:
- Add a `userValue` property to the `data` property.
- Create a `updateUserValue` function to update the `userValue` property
- Include `watch` component property to monitor the `userValue` property and get the updated list of users if there is a change made to it.
- Update the `Modal` component to accept the `updateUserValue` as a `prop`.
Next, navigate to the `Modal.vue` file inside the `components` folder, update the `props`, and create a user.
```vue
<template>
<div
class="h-screen w-screen bg-indigo-900 bg-opacity-30 z-30 top-0 fixed transform scale-105 transition-all ease-in-out duration-100"
:class="isModal ? 'block' : 'hidden'"
>
<!-- Modal content goes here -->
</div>
</template>
<script lang="ts">
//other import goes here
import { defineComponent, PropType } from 'vue'; //modify
import { IUser } from '@/models/user.interface'; //add
import { app, credentials } from '@/utils/mongo.client'; //add
export default defineComponent({
name: 'Modal',
components: { CloseIcon },
props: {
isModal: Boolean,
isEdit: Boolean,
handleModal: Function,
updateUserValue: Function as PropType<(value: any) => void>, //add the function to update userValue
},
data: () => ({
name: '',
location: '',
title: '',
}),
methods: {
//codes here
},
//modify
async onSubmitForm() {
const user: Realm.User = await app.logIn(credentials);
const create = user.functions.createUser(
this.name,
this.location,
this.title
);
create.then((resp) => {
this.updateUserValue!(resp.insertedId);
this.name = '';
this.location = '';
this.title = '';
});
},
},
});
</script>
```
The snippet above does the following:
- Import the required dependencies.
- Add `updateUserValue` to `props` property
- Modify the `onSubmitForm` function to authenticate our application using the `credentials` imported. Create a user by accessing the `createUser` serverless function we created earlier, passing the required arguments (**name**, **location** and **title**)and then updating the `userValue` and form state.
**Edit A User**
To edit a user, we must first modify `App.vue` by creating a property to manage the `_id` of the user we want to edit and function to update it. We also updated the `handleEditClick` function to update the property and pass it as props to the `Modal` component.
```vue
<template>
<div class="">
<header
class="h-16 w-full bg-indigo-200 px-6 flex justify-between items-center"
>
<!-- Header content goes here -->
</header>
<section className="mt-10 flex justify-center px-6">
<!-- Section content goes here -->
</section>
<!-- Modify Modal component -->
<Modal
:isModal="isModal"
:isEdit="isEdit"
:handleModal="handleModal"
:updateUserValue="updateUserValue"
:editingId="editingId"
/>
</div>
</template>
<script lang="ts">
//import goes here
export default defineComponent({
name: 'App',
components: {
UserIcon,
Modal,
},
data: () => ({
isModal: false,
isEdit: false,
users: [] as IUser[],
userValue: '',
editingId: '', //add
}),
methods: {
handleModal(state: boolean) {
this.isModal = state;
this.isEdit = false;
},
//modify
handleEditClick(id: string) {
this.isModal = true;
this.isEdit = true;
this.editingId = id;
},
async getListOfUsers() {
//codes here
},
updateUserValue(value: any) {
this.userValue = value;
},
},
watch: {
//codes here
},
mounted() {
this.getListOfUsers();
},
});
</script>
<style></style>
```
Next, we need to populate our form when the **Edit** button is clicked. To do this, open `Modal.vue` and update as shown below:
```vue
<template>
<div
class="h-screen w-screen bg-indigo-900 bg-opacity-30 z-30 top-0 fixed transform scale-105 transition-all ease-in-out duration-100"
:class="isModal ? 'block' : 'hidden'"
>
<!-- Modal content goes here -->
</div>
</template>
<script lang="ts">
//import goes here
import { BSON } from 'realm-web'; //add
export default defineComponent({
name: 'Modal',
components: { CloseIcon },
props: {
//other props goes here
editingId: String, //add
},
data: () => ({
name: '',
location: '',
title: '',
}),
methods: {
onClose(e: Event) {
//codes here
},
async onSubmitForm() {
//codes here
},
//add
async getAUser() {
const user: Realm.User = await app.logIn(credentials);
const getUser: Promise<IUser> = user.functions.getSingleUser(
new BSON.ObjectID(this.editingId).toString()
);
getUser.then((resp) => {
this.name = resp.name;
this.location = resp.location;
this.title = resp.title;
});
},
},
watch: {
isEdit(latestValue) {
if (latestValue == true) {
this.getAUser();
} else {
this.name = '';
this.location = '';
this.title = '';
}
},
},
});
</script>
```
The snippet above does the following:
- Import the required dependencies.
- Add `editingId` to `props` property
- Create a `getAUser` function to authenticate our application using the `credentials` imported. Get the selected user details using the `getSingleUser` serverless function and then update the form values. The `getSingleUser` function also required us to convert `editingId` to string using `BSON.ObjectID` function.
- Include `watch` component property to monitor the `isEdit` state, conditionally call the `getAUser` function and update form state.
Next, we need to update the `onSubmitForm` function to include updating the user’s details by conditionally checking if it is an update action or not. Next, we need to call the `editUser` serverless function and pass in the required parameters. Finally, update the `updateUserValue`, restore the form back to default and close the `Modal` component.
```vue
<template>
<div
class="h-screen w-screen bg-indigo-900 bg-opacity-30 z-30 top-0 fixed transform scale-105 transition-all ease-in-out duration-100"
:class="isModal ? 'block' : 'hidden'"
>
<!-- Modal content goes here -->
</div>
</template>
<script lang="ts">
//import goes here
import { BSON } from 'realm-web'; //add
export default defineComponent({
name: 'Modal',
components: { CloseIcon },
props: {
//other props goes here
},
data: () => ({
//codes here
}),
methods: {
//codes here
//modify
async onSubmitForm() {
const user: Realm.User = await app.logIn(credentials);
if (this.isEdit) {
const edit: Promise<IUser> = user.functions.editUser(
new BSON.ObjectID(this.editingId).toString(),
this.name,
this.location,
this.title
);
edit.then((resp) => {
this.updateUserValue!(resp._id!);
this.name = '';
this.location = '';
this.title = '';
this.handleModal!(false);
});
} else {
const create = user.functions.createUser(
this.name,
this.location,
this.title
);
create.then((resp) => {
this.updateUserValue!(resp.insertedId);
this.name = '';
this.location = '';
this.title = '';
});
}
},
//codes here
},
watch: {
//codes here
},
});
</script>
```
**Complete Modal.Vue**
```vue
<template>
<div
class="h-screen w-screen bg-indigo-900 bg-opacity-30 z-30 top-0 fixed transform scale-105 transition-all ease-in-out duration-100"
:class="isModal ? 'block' : 'hidden'"
>
<div
class="flex flex-col justify-center items-center h-full w-full open-nav"
@click="onClose"
>
<div class="flex justify-end w-11/12 lg:w-1/2 2xl:w-6/12">
<div
role="button"
class="cursor-pointer w-6 h-6 rounded-full flex items-center justify-center bg-white"
@click="handleModal()"
>
<CloseIcon />
</div>
</div>
<section
class="w-11/12 lg:w-1/2 2xl:w-6/12 bg-white flex justify-center items-center mt-5 rounded-lg"
>
<div class="w-11/12 py-8">
<h2 class="capitalize text-xl text-gray-500 font-medium mb-4">
{{ isEdit ? 'Edit User' : 'add user' }}
</h2>
<form @submit.prevent="onSubmitForm">
<fieldset class="mb-4">
<label class="block text-sm text-gray-500 capitalize mb-1"
>name</label
>
<input
type="text"
name="name"
v-model="name"
required
class="w-full h-10 border border-gray-500 rounded-sm px-4"
/>
</fieldset>
<fieldset class="mb-4">
<label class="block text-sm text-gray-500 capitalize mb-1"
>location</label
>
<input
type="text"
name="location"
v-model="location"
required
class="w-full h-10 border border-gray-500 rounded-sm px-4"
/>
</fieldset>
<fieldset class="mb-4">
<label class="block text-sm text-gray-500 capitalize mb-1"
>title</label
>
<input
type="text"
name="title"
v-model="title"
required
class="w-full h-10 border border-gray-500 rounded-sm px-4"
/>
</fieldset>
<button
class="text-white capitalize px-6 py-2 bg-indigo-900 rounded-md w-full"
>
save
</button>
</form>
</div>
</section>
</div>
</div>
</template>
<script lang="ts">
import { defineComponent, PropType } from 'vue';
import CloseIcon from '@/assets/svg/CloseIcon.vue';
import { IUser } from '@/models/user.interface';
import { app, credentials } from '@/utils/mongo.client';
import { BSON } from 'realm-web';
export default defineComponent({
name: 'Modal',
components: { CloseIcon },
props: {
isModal: Boolean,
isEdit: Boolean,
handleModal: Function,
updateUserValue: Function as PropType<(value: any) => void>,
editingId: String,
},
data: () => ({
name: '',
location: '',
title: '',
}),
methods: {
onClose(e: Event) {
const target = e.target as HTMLDivElement;
if (target.classList.contains('open-nav')) {
this.handleModal!(false);
}
},
async onSubmitForm() {
const user: Realm.User = await app.logIn(credentials);
if (this.isEdit) {
const edit: Promise<IUser> = user.functions.editUser(
new BSON.ObjectID(this.editingId).toString(),
this.name,
this.location,
this.title
);
edit.then((resp) => {
this.updateUserValue!(resp._id!);
this.name = '';
this.location = '';
this.title = '';
this.handleModal!(false);
});
} else {
const create = user.functions.createUser(
this.name,
this.location,
this.title
);
create.then((resp) => {
this.updateUserValue!(resp.insertedId);
this.name = '';
this.location = '';
this.title = '';
});
}
},
async getAUser() {
const user: Realm.User = await app.logIn(credentials);
const getUser: Promise<IUser> = user.functions.getSingleUser(
new BSON.ObjectID(this.editingId).toString()
);
getUser.then((resp) => {
this.name = resp.name;
this.location = resp.location;
this.title = resp.title;
});
},
},
watch: {
isEdit(latestValue) {
if (latestValue === true) {
this.getAUser();
} else {
this.name = '';
this.location = '';
this.title = '';
}
},
},
});
</script>
```
**Delete A User**
To delete a user, we need to modify `App.vue` by creating a `handleDelete` function as shown below:
```vue
<template>
<div class="">
<header
class="h-16 w-full bg-indigo-200 px-6 flex justify-between items-center"
>
<!-- Header content goes here -->
</header>
<section className="mt-10 flex justify-center px-6">
<ul className="w-full">
<li
v-for="user in users"
:key="user._id"
className="border-2 p-6 mb-3 rounded-lg flex items-center"
>
<section
className="h-10 w-10 bg-indigo-100 rounded-md flex justify-center items-center mr-4"
>
<UserIcon />
</section>
<section className="">
<h2 className="capitalize font-semibold mb-1">{{ user.name }}</h2>
<p className="capitalize text-gray-500 mb-1">{{ user.location }}</p>
<p className="capitalize text-indigo-500 font-medium text-sm mb-2">
{{ user.title }}
</p>
<div className="flex">
<!-- Modify delete button -->
<button
className="text-sm text-red-500 capitalize px-4 py-2 mr-4 border border-red-500 rounded-md"
@click="deleteAUser(user._id)"
>
delete
</button>
<button
className="text-sm text-white capitalize px-4 py-2 bg-indigo-900 rounded-md"
@click="handleEditClick(user._id)"
>
edit
</button>
</div>
</section>
</li>
</ul>
</section>
<!-- Modal component goes here -->
</div>
</template>
<script lang="ts">
//import goes here
import { BSON } from 'realm-web'; //add
export default defineComponent({
name: 'App',
components: {
UserIcon,
Modal,
},
data: () => ({
//codes here
}),
methods: {
handleModal(state: boolean) {
//codes here
},
handleEditClick(id: string) {
//codes here
},
async getListOfUsers() {
//codes here
},
updateUserValue(value: any) {
//codes here
},
//add
async deleteAUser(id: string) {
const user: Realm.User = await app.logIn(credentials);
const delUser = user.functions.deleteUser(
new BSON.ObjectID(id).toString()
);
delUser.then((resp) => {
this.updateUserValue(resp.deletedCount);
});
},
},
watch: {
//codes here
},
mounted() {
//codes here
},
});
</script>
<style></style>
```
The snippet above does the following:
- Import the required dependencies.
- Creates a `deleteAUser` function that takes an `id` as an argument, authenticate our application using the `credentials`. Delete selected user using the `deleteUser` serverless function and update the `userValue` state.
**Complete App.vue**
```vue
<template>
<div class="">
<header
class="h-16 w-full bg-indigo-200 px-6 flex justify-between items-center"
>
<h1 class="text-xl text-indigo-900">Vue-Realm</h1>
<button
class="text-lg text-white capitalize px-6 py-2 bg-indigo-900 rounded-md"
@click="handleModal(true)"
>
create
</button>
</header>
<section className="mt-10 flex justify-center px-6">
<ul className="w-full">
<li
v-for="user in users"
:key="user._id"
className="border-2 p-6 mb-3 rounded-lg flex items-center"
>
<section
className="h-10 w-10 bg-indigo-100 rounded-md flex justify-center items-center mr-4"
>
<UserIcon />
</section>
<section className="">
<h2 className="capitalize font-semibold mb-1">{{ user.name }}</h2>
<p className="capitalize text-gray-500 mb-1">{{ user.location }}</p>
<p className="capitalize text-indigo-500 font-medium text-sm mb-2">
{{ user.title }}
</p>
<div className="flex">
<button
className="text-sm text-red-500 capitalize px-4 py-2 mr-4 border border-red-500 rounded-md"
@click="deleteAUser(user._id)"
>
delete
</button>
<button
className="text-sm text-white capitalize px-4 py-2 bg-indigo-900 rounded-md"
@click="handleEditClick(user._id)"
>
edit
</button>
</div>
</section>
</li>
</ul>
</section>
<Modal
:isModal="isModal"
:isEdit="isEdit"
:handleModal="handleModal"
:updateUserValue="updateUserValue"
:editingId="editingId"
/>
</div>
</template>
<script lang="ts">
import { defineComponent } from 'vue';
import UserIcon from '@/assets/svg/UserIcon.vue';
import Modal from '@/components/Modal.vue';
import { IUser } from '@/models/user.interface';
import { app, credentials } from '@/utils/mongo.client';
import { BSON } from 'realm-web';
export default defineComponent({
name: 'App',
components: {
UserIcon,
Modal,
},
data: () => ({
isModal: false,
isEdit: false,
users: [] as IUser[],
userValue: '',
editingId: '',
}),
methods: {
handleModal(state: boolean) {
this.isModal = state;
this.isEdit = false;
},
handleEditClick(id: string) {
this.isModal = true;
this.isEdit = true;
this.editingId = id;
},
async getListOfUsers() {
const user: Realm.User = await app.logIn(credentials);
const listOfUser: Promise<IUser[]> = user.functions.getAllUsers();
listOfUser.then((resp) => {
this.users = resp;
});
},
updateUserValue(value: any) {
this.userValue = value;
},
async deleteAUser(id: string) {
const user: Realm.User = await app.logIn(credentials);
const delUser = user.functions.deleteUser(
new BSON.ObjectID(id).toString()
);
delUser.then((resp) => {
this.updateUserValue(resp.deletedCount);
});
},
},
watch: {
userValue(latestValue) {
if (latestValue !== '') {
this.getListOfUsers();
}
},
},
mounted() {
this.getListOfUsers();
},
});
</script>
<style></style>
```
Finally, we can test our application by starting the development server and performing CRUD operations.

# Conclusion
This post discussed how to create a database on MongoDB, create and deploy serverless functions using MongoDB Realm and consume the endpoints in a Vue.js application.
You may find these resources helpful:
- [MongoDB Realm](https://docs.mongodb.com/realm/).
- [TailwindCSS](https://tailwindcss.com/).
- [Realm-Web SDK](https://github.com/realm/realm-js).
- [Serverless computing](https://en.wikipedia.org/wiki/Serverless_computing).
- [BSON](https://www.mongodb.com/json-and-bson)
| malomz |
906,161 | Pure Functions Explained for Humans | Start leveraging pure functions TODAY First things first: you don't have to write code in... | 0 | 2021-12-21T16:00:52 | https://dev.to/alexkhismatulin/pure-functions-explained-for-humans-1j3c | programming, codequality, javascript | ## Start leveraging pure functions TODAY
First things first: you don't have to write code in a functional style to leverage pure functions.
This powerful tool makes it easier to read, reuse, maintain, and test code. Nobody wants to lose any of these benefits because their code is not functional. And you shouldn't neither. So get known to the concept now to make your code even better, functional or not.
Good news: it is extremely easy to understand and start using pure functions.
## A simple definition
> A function can be called pure if it returns the same output given the same input every time you call it, doesn't consume or modify other resources internally, and doesn't change its inputs.
Ok, this seems to sound way easier than what we usually see when it comes to pure functions. Now let's break it down and see what each part of this definition means and how those parts are named in the professional lexicon.
## Returns the same output given the same input
This one means exactly what it says. Every time we call a function with a constant value, it has to return the same result.
### Let's consider 2 examples
We will create `addFive` and `addSomething` functions and see how they follow(or don't follow) the rule. But before we move forward, can you guess which one violates the rule and why?
#### `addFive` function
```javascript
const seven = addFive(2); // returns 7
```
If we have an `addFive` function, we always expect that `addFive(2)` would return 7. No matter what happens with the rest of a program, when, or where in the code we call `addFive(2)`, it always gives us 7.
#### `addSomething` function
```javascript
const randomNumber = addSomething(2); // returns a random number
```
As opposed to `addFive`, there's the `addSomething` function. As we can guess from the name, it adds an unknown number to a passed value. So if `addSomething(2)` call returned 6, we have no guarantee that every time we call `addSomething(2)` it would return 6. Instead, this will be an arbitrary number that we can't predict at the moment of calling the function unless we know how the internal random number generator works. This function does not guarantee to return the same output given the same input.
### What does that mean for us?
At this point, we can definitely tell that `addSomething` is not a pure function. But we also cannot state that `addFive` is a pure function yet. To do this, we need to check if it satisfies other conditions.
## Doesn't consume or modify other resources internally
To explore this topic, we need to think about how the functions from the above examples would be implemented.
First, our pure function candidate, `addFive`:
```javascript
function addFive(number) {
return number + 5;
}
```
As we can see, the function does exactly and only what it says and what we expect it to do. Nothing else other than adding 5 a passed number is happening. `addFive` passes this check.
Now, let's define the `addSomething` function that is already known as impure:
```javascript
let callCounter = 0;
function addSomething(number) {
callCounter = callCounter + 1;
const isEvenCall = callCounter % 2 === 0;
if (isEvenCall) {
return number + 3;
} else {
return number + 4;
}
}
```
This function has an external variable that stores the number of times the function was called. Then, based on the counter, we check if it's an even call and add 3 if it is, or add 4 if it's not. This call counter is an external state that the `addSomething` function uses to calculate the results. Such states fall under the definition of side effects.
> Side effect is a modification of any external state, consumption of dynamic external values, or anything a function does outside of the work related to calculating the output.
In our case, `addSomething` modifies and uses `callCounter` to calculate the final output. This is a side effect. How could we fix `addSomething` to clean it up from side effects?
If we can't consume or modify an external variable, we need to make it an input:
```javascript
function addSomething(number, isEvenCall) {
if (isEvenCall) {
return number + 3;
} else {
return number + 4;
}
}
```
Now we control if it's an even or odd call from outside, and our `addSomething` function becomes pure. Whenever we call it with the same pair of inputs, it would return the same number.
Don't worry if you still don't quite understand what can be a side effect. We will see more examples of side effects a bit later.
## Doesn't change its inputs
For this part we need to create the `getFullName` function:
```javascript
function getFullName(user) {
user.firstName = user.firstName[0].toUpperCase() + user.firstName.slice(1).toLowerCase();
user.lastName = user.lastName[0].toUpperCase() + user.lastName.slice(1).toLowerCase();
return user.firstName + ' ' + user.lastName;
}
```
The function takes an object with first and last names. Then it formats these properties in the object so they start with a capital letter and all other letters are lowercased. In the end, the function returns a full name.
If we skip over potential edge cases, our function will return the same output every time we pass an object with the same values. The function doesn't consume or modify any external resources neither and only calculates a full name. So, does that mean it's pure?
No. And here's why.
The object we pass to `getFullName` is a referential type. When we change its properties inside the function, the changes get reflected in the original object outside the function. In other words, we **mutate** our inputs.
```javascript
// note that all letters are lowercased
const user = {
firstName: 'alex',
lastName: 'khismatulin'
};
const fullName = getFullName(user); // returns "Alex Khismatulin"
// Logs "Alex Khismatulin", capitalized. Object is modified.
console.log(user.firstName + ' ' + user.lastName);
```
Even though primitive vs reference types separation sounds complex, in practice, it is not. Spend a few minutes to check it out. There are plenty of [good posts](https://www.google.com/search?q=primitive+types+vs+reference+types) on the topic. **Tip**: add your preferred language to the end of the search query to get more contextual results. Here's [an example for JavaScript](https://www.google.com/search?q=primitive+types+vs+reference+types+javascript).
Input mutations are also considered **side effects**. We change inputs that come from outside, so we're still changing an external resource but in a different way.
## "Same" doesn't always mean "equal"
As we just touched referential types, we should also note that even though pure functions always return the same output given the same inputs, this doesn't mean that all inputs and outputs must be **equal** to each other. That is possible when a function takes or returns a referential type. Look at this example:
```javascript
function createUser(firstName, lastName) {
return {
firstName: firstName,
lastName: lastName,
};
}
```
This function takes first and last names and creates a user object. Every time we pass the same names, we get an object with the same fields and values. But objects returned from different function calls are not equal to one another:
```javascript
const user1 = createUser('Alex', 'Khismatulin');
const user2 = createUser('Alex', 'Khismatulin');
console.log(user1.firstName === user2.firstName); // true
console.log(user1.lastName === user2.lastName); // true
console.log(user1 === user2); // false, objects are not equal
```
We see that `firstName` from `user1` is equal to `firstName` from `user2`. `lastName` from `user1` is equal to `lastName` from `user2`. But `user1` is not equal to `user2` because they are different object instances.
Even though the objects are not equal, our function is still pure. The same is applied to inputs: they don't have to be literally equal to produce the same output. It's just not a 100% correct word used in the first place.
### It's "identical", not "same" or "equal"
The word "identical" describes what we expect from pure functions best. Values such functions take or return don't necessarily have to be equal, but they have to be **identical**.
## Other side effects
So, what can be a side effect? Here are a few examples:
- Querying or changing external variables and states
- Mutating inputs
- DOM interaction
- Network calls
- Calling other impure functions
The list goes on and on, but you get the idea. **Anything unrelated to computing output or relies on any dynamic values other than inputs is a side effect.**
Moreover, `console.log` is also a side effect! It interacts with the console, thus doing work unrelated to computing an output. No worries, usually console logs have no impact, so this rule is omitted when debugging code.
## Final definition
Now, as we have all the pieces of our simple definition uncovered, we a ready to derive a smarter definition of a pure function:
> A function can be called pure if it returns identical output given identical input every time it is called and has no side effects.
Awesome! But there's one thing that might've been bugging you while reading.
## What should I do when I do need side effects?
Some things are impure by their nature. At the end of the day, this is what programming is about – transforming data is our bread and butter.
Side effects are imminent. But when we have to deal with them, we should strive to isolate them as much as possible and separate from the code that executes pure operations.
Here's a pretty widespread Redux selector pattern. We have a code that gets a snapshot of Redux state and a selector function that knows how to get a specific value from that state:
```javascript
function getUserById(state, userId) {
const users = state.users.list || [];
const user = users.find(user => user.id === userId);
return user;
}
const state = store.getState();
const user = getUserById(state, '42');
```
> You don't need to know anything about Redux to understand the example. There's no magic going on here. `store.getState()` in our case only returns an object that holds some values.
In this example, the values in the store change dynamically and are out of our control. We secure the `getUserById` value selector function from any third-party states and make it only rely on its inputs.
You see the pattern: separate the code that has to deal with impure data sources or to produce side effects from the code that gives linear output based on its inputs.
## What are the pros?
### Reusability
Let's come back to the Redux selector example. Other than just returning a user from state, we can update the code and break it down into a few pure functions:
```javascript
function findUserById(list, userId) {
const user = users.find(user => user.id === userId);
return user;
}
function getUsersFromState(state) {
const users = state.users.list || [];
return users;
}
```
Now we have one function that knows how to get users from state and another one that knows how to find a user by id in a list of users. That means we can reuse `findUserById` in other parts of the app where we use the same shape for the user object:
```javascript
// find a user in the store users
const state = store.getState();
const users = getUsersFromState(state);
const user = findUserById(users, '42');
// find a user in the lottery players list
const lotteryPlayers = getLotteryPlayers();
const winnerId = (Math.random() * 100).toFixed();
const winner = findUserById(users, winnerId);
```
Both cases leverage `findUserById` because it does one small thing and has no unpredictable dependencies. If we ever needed to change the field name that holds user id, we would need to do that in just one place.
Purity gives us space to create functions that are not bound to specific data sources or context in which functions are called.
### Testing
We're going come back to the Redux selector example one more time and imagine that we decided to get state from the store right inside the selector function:
```javascript
function getUserById(userId) {
const state = store.getState();
const users = state.users.list || [];
const user = users.find(user => user.id === userId);
return user;
}
const user = getUserById('42');
```
What would it cost us to add a test that validates this function? Well, we would need to do some dark magic to mock `store.getState()`:
```javascript
test('Should return user with correct id', function() {
store = {
getState() {
return {
users: {
list: [{ id: '42' }],
},
};
}
};
const user = getUserById('42');
expect(user.id).toBe('42');
});
```
You see what's going on? We had to mock the whole Redux store just to test one small selector. More importantly, the test must know **how** the state is retrieved from the store. Imagine what would we need to do to test a more complex one? What would happen if we decided to replace Redux with some other state management tool?
To see the difference, here's a test for the original pure version:
```javascript
test('Should return user with correct id', function() {
const state = {
users: {
list: [{ id: '42' }],
},
};
const user = getUserById(state, '42');
expect(user.id).toBe('42');
});
```
Now we don't need to think about what method is used to return a state from the store and mock the whole thing. We just use a state fixture. If we ever change a state management tool, this will not affect the tests because they only know what the state's shape is, not how it's stored.
### They make the code easier to consume
Last but not least, writing pure functions forces us to create smaller, more specialized functions that do one small thing. The code is going to become more organized. This, in turn, will increase readability.
## In the end
Pure functions alone are not going to make your code perfect. But this is a must-have part of your toolset if you want to be a professional in what you do. Every little step moves you to a bigger goal, and pure functions are not an exception. Employ this concept and make your code a little better today.
I hope you learned something today. Make this topic a small piece in the strong foundation of your success. Thank you for reading!
## P.S.
If you like occasional no-bullshit web shorties, you should definitely drop me a line on [Twitter](https://twitter.com/alexkhismatulin). Feel free to tag me if you want to discuss this article, and I will make sure to join the conversation! | alexkhismatulin |
906,174 | code every day with me | --DAY 26-- Hi, I am going to make #100DaysOfCode Challenge. Everyday I will try solve 1... | 0 | 2021-11-23T01:33:29 | https://dev.to/coderduck/code-every-day-with-me-27gd | javascript, programming, 100daysofcode, algorithms | ##--DAY 26--
Hi, I am going to make #100DaysOfCode Challenge. Everyday I will try solve 1 problem from leetcode or hackerrank. Hope you can go with me until end.
**Now let's solve problem today:**
Problem: Isomorphic Strings
Detail: [here](https://leetcode.com/problems/reverse-vowels-of-a-string/)
My solution (javascript):
```js
var reverseVowels = function(s) {
s=s.split('');
let vowel = ['a','e','i','o','u','A','E','I','O','U'];
let i=0,j=s.length-1;
while(i<j){
if(!vowel.includes(s[i])) i++;
else if(!vowel.includes(s[j])) j--;
if(vowel.includes(s[i])&&vowel.includes(s[j])){
[s[i],s[j]]=[s[j],s[i]];
i++;
j--;
}
}
return s.join('');
};
```
-->*If you have better solution or any question, please comment below. I will appreciate.* | coderduck |
906,254 | What is dev.to for? | Lately there has been an influx of certain kinds of posts on dev.to that we should probably talk... | 0 | 2021-11-23T03:01:48 | https://dev.to/sroehrl/what-is-devto-for-4koa | watercooler, discuss, beginners | Lately there has been an influx of certain kinds of posts on dev.to that we should probably talk about:
## Uneducated opinion pieces
Before I describe what kind of articles I am referring to, let's first clarify what dev.to enabled and what - in my opinion - should not be jeopardized: The absence of gate-keeping, which destroyed the vibe of many other platforms, communities, etc.
However, this inclusiveness has particular dangers that have met a threshold recently. What I am referring to are posts that seem to be driven by a "learn by explaining it" approach and that are often simply too dangerous to leave uncommented. Way too often a mode of speech is used that would lead the beginner to believe that an expert is sharing advice while completely wrong or misleading statements are picked up and quoted. This has become so bad that I find people citing these sources and therefore unwillingly propagate misinformation similar to the false-news phenomenon in the political realm. Additionally, these articles tend to state opinion as fact. In my opinion, it is relatively easy to avoid mixing opinion with facts through language in our field as we only apply established technology.
## So what's the call to action?
The question is what this community should do to avoid becoming a heap of nonsense or half-truths rather than a source of actual knowledge, given the understandable fact that many learners aren't able to distinguish between transfer of knowledge and confident nonsense.
Are you expecting the same, or is this observation based on my personal feed? Thoughts?
| sroehrl |
906,261 | Sharing Secret Environment Variables with SvelteKit and Vercel | If you deploy with Vercel, you know how easy it is to to work with. Sometimes you want to hide... | 0 | 2021-11-23T03:40:53 | https://dev.to/jdgamble555/sharing-secret-environment-variables-with-sveltekit-and-vercel-4fie | vercel, svelte, sveltekit, ssr | If you deploy with Vercel, you know how easy it is to to work with. Sometimes you want to hide certain environment variables from your users. In this example, I am going to use the Firebase Api keys, although they do not necessarily need to be secured.
## Step 1
- Create `.env` file at the root of your sveltekit project
## Step 2
- Add this file `.env` to your `.gitignore` file
## Step 3
- Add the environment variables you want to secure to the file with the `VITE_` prefix.
SvelteKit with vite imports the [dotenv](https://kit.svelte.dev/faq#env-vars) package under the hood.
Example `.env` file:
```typescript
VITE_FIREBASE_APIKEY="----"
VITE_FIREBASE_AUTH_DOMAIN="---"
VITE_FIREBASE_PROJECT_ID="---"
VITE_FIREBASE_STORAGE_BUCKET="---"
VITE_FIREBASE_MESSAGING_SENDER_ID="---"
VITE_FIREBASE_APP_ID="---"
VITE_FIREBASE_MEASUREMENT_ID="---"
VITE_DGRAPH_ENDPOINT="---"
```
## Step 4
- Create your configuration file.
Example: `src/config.ts`
```typescript
let process: any;
const p = process?.env ? process.env : import.meta.env;
export const dgraph_config = p.VITE_DGRAPH_ENDPOINT;
export const firebase_config = {
"apiKey": p.VITE_FIREBASE_APIKEY,
"authDomain": p.VITE_FIREBASE_AUTH_DOMAIN,
"projectId": p.VITE_FIREBASE_PROJECT_ID,
"storageBucket": p.VITE_FIREBASE_STORAGE_BUCKET,
"messagingSenderId": p.VITE_FIREBASE_MESSAGING_SENDER_ID,
"appId": p.VITE_FIREBASE_MEASUREMENT_ID,
"measurementId": p.VITE_DGRAPH_ENDPOINT
};
```
- SvelteKit uses `import.meta.env.VITE_YOUR_VARIABLE` as a way to automatically import any file with `.env`.
- Vercel uses `process.env.YOUR_VARIABLE` to import the environments.
- You don't need the `VITE_` prefix in Vercel, I just kept it for consistency.
## Step 5 - Typescript Users
- If you use typescript (why you wouldn't is beyond me) and you get a type error with `import.meta.env`, add this to `tsconfig.json`:
```typescript
{
"compilerOptions": {
...
"types": [
"vite/client"
]
```
## Step 6 - Vercel
- Add your equivalent variables to your Vercel Project under Settings --> Environment Variables:
## Step 7
Finally, import the code in any file you want to use it in:
```typescript
import { firebase_config } from '../config';
```
Note: If you want to test production and dev versions on your local machine, you could also use `dev` to detect which mode you're in:
```typescript
import { dev } from '$app/env';
```
Hope this helps someone,
J
| jdgamble555 |
906,295 | 40% OFF for 4 months - Cloudways Black Friday 2021 Offer | This BLACK FRIDAY, Cloudways is offering 40% OFF for 4 months on all managed cloud hosting plans. Just use the coupon code while signing up, and enjoy hassle free hosting. | 0 | 2021-11-23T05:32:49 | https://dev.to/jamilaliahmed/40-off-for-4-months-cloudways-black-friday-2021-offer-3p9o | webdev, blackfriday, discount, hosting | ---
title: 40% OFF for 4 months - Cloudways Black Friday 2021 Offer
published: true
description: This BLACK FRIDAY, Cloudways is offering 40% OFF for 4 months on all managed cloud hosting plans. Just use the coupon code while signing up, and enjoy hassle free hosting.
Offered Deal: 40% OFF for 4 months
Coupon Code: BFCM2021
Validity: 23rd November to 1st December 2021
tags: #webdev, #blackfriday, #discount #hosting
---
This BLACK FRIDAY, Cloudways is offering 40% off for 4 months on all managed cloud hosting plans. Just use the coupon code while signing up, and enjoy hassle free hosting.
Offered Deal: **40% OFF for 4 months**
Coupon Code: **BFCM2021**
Validity: 23rd November to 1st December 2021
<a href="https://www.cloudways.com/en/">**40% OFF for 4 months - Cloudways Black Friday 2021 Offer**</a>
[Deal Image](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ey3wg03x4zzucxmfuph4.jpg)
---
| jamilaliahmed |
906,423 | Cloud Orchestration 101 | A Complete Guide for Beginners | "The reasoning for why the cloud computing market is making its way to reach a monumental value of... | 0 | 2021-11-23T08:02:32 | https://dev.to/codysimons20/cloud-orchestration-101-a-complete-guide-for-beginners-49fp | testing, cloud | "The reasoning for why the cloud computing market is making its way to reach a monumental value of $623B by 2023 is simple – it’s the innovation that comes with it.
From unlimited data storage, disaster recovery, to nationwide networking abilities that cloud computing services bring, small start-ups or enterprise-scale firms can now rethink about the traditional means IT resources management."
Continue reading: https://www.katalon.com/resources-center/blog/cloud-orchestration/ | codysimons20 |
906,504 | Basic server side caching using Redis in nodejs | Caching is the process of storing copies of files in a cache, or temporary storage location, so that... | 0 | 2021-11-23T11:20:21 | https://dev.to/singhutkarshh/basic-server-side-caching-using-redis-4e1f | webdev, node, redis, caching | Caching is the process of storing copies of files in a cache, or temporary storage location, so that they can be accessed more quickly.
Caching helps us in making our website more faster, respond to user queries faster by acting as a middleware between server and database.
<img src="https://codeahoy.com/img/cache-aside.png" alt="Caching process" style="height: 100px; width:100px;"/>
***There is commonly two types of caching :-***
1) Server side caches are generally used to avoid making expensive database operations repeatedly to serve up the same content to lots of different clients.
2) Client side caches are used to avoid transferring the same data over the network repeatedly.
Today we will learn basic server side caching using redis(a fast, open source, in-memory, key-value data store).
***Installing Redis:-***
Firstly we will need to install redis before using it in our project.
Installing redis on Mac using Homebrew -
```
brew install redis
brew services start redis
redis-server /usr/local/etc/redis.conf
```
***Installing redis on Windows -***
```
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install redis-server
sudo service redis-server restart
```
***Installing redis on ubuntu -***
```
sudo apt update
sudo apt install redis-server
sudo nano /etc/redis/redis.conf
```
Inside the file, find the supervised directive. This directive allows you to declare an init system to manage Redis as a service, providing you with more control over its operation. The supervised directive is set to no by default. Since you are running Ubuntu, which uses the systemd init system, change this to systemd:
```
. . .
# If you run Redis from upstart or systemd, Redis can interact with your
# supervision tree. Options:
# supervised no - no supervision interaction
# supervised upstart - signal upstart by putting Redis into SIGSTOP mode
# supervised systemd - signal systemd by writing READY=1 to $NOTIFY_SOCKET
# supervised auto - detect upstart or systemd method based on
# UPSTART_JOB or NOTIFY_SOCKET environment variables
# Note: these supervision methods only signal "process is ready."
# They do not enable continuous liveness pings back to your supervisor.
supervised systemd
. . .
```
and finally restart redis
```
sudo systemctl restart redis.service
```
***1)*** In the project folder initialise the project using npm init and install express, redis and node-fetch(same as fetch in javascript for making requests to rest clients ). Also install nodemon as dev dependency.
```
npm init -y
npm install --save express redis
npm install --dev nodemon
```
***2)*** In the project folder paste this code in app.js importing express , nodefetch and redis and start basic server.
```
const express = require("express");
const app = express();
const redis = require("redis");
const fetch = require("node-fetch");
app.get("/", (req, res) => {
res.status(200).send("This is homepage!");
})
app.listen(8080, () => {
console.log("Server started!");
});
```
***3)*** Create a redis client passing default redis port(6379) as parameter and also create a new route(/post) that will fetch data from https://api.github.com/users and send data as response.
We will cache this data on our first visit to server and after that in all visits we will check if data is stored in cache or not . If it is stored we will not fetch it instead send response from cache.
```
const express = require("express");
const app = express();
const redis = require("redis");
const fetch = require("node-fetch");
const client = redis.createClient(6379);
app.get("/posts", (req, res) => {
console.log("fetching data") // this will tell uswe are fetching data from api
fetch(`https://api.github.com/users`,((response)=>{
const data = response.json();
client.set("userData",data); // save data(key,value pair) in redis in form of cache
res.send({data:data});
})
})
app.listen(8080, () => {
console.log("Server started!");
});
```
Here we used client.set(key,value) for saving data in redis.
***4)*** We will now create a middleware and add it in "/post" route for checking if cache already exists.If data is already present in cache we will return it directly else we will leave our middleware and fetch it from the route.
```
const checkDataInCache = (req,res,next) =>{
const data = client.get("userData"); //get data from cache and check if it exists
if(data !== null){
res.send({data:data});
}else{
next();
}
}
```
Now we are almost done with our code(full code given at last) and now we will test it.
If we send a get request at "/posts" at first we will see log as " fetching .." that shows that we are fetching data from api.
But after that in all requests there will be no log and data will be loaded more quickly.
(We can check for the speed by going in console and them network).
This was basic representation of how to use caching.Full code given below.
Hope it helps!!
```
const express = require("express");
const app = express();
const redis = require("redis");
const fetch = require("node-fetch");
const client = redis.createClient(6379);
app.get("/posts",checkDataInCache, (req, res) => {
console.log("fetching data") // this will tell us if we are fetching data from api
fetch(`https://api.github.com/users`,((response)=>{
const data = response.json();
client.set("userData",data); // save data(key,value pair) in redis in form of cache
res.send({data:data});
})
})
const checkDataInCache = (req,res,next) =>{
const data = client.get("userData"); //get data from cache and check if it exists
if(data !== null){
res.send({data:data});
}else{
next();
}
}
app.listen(8080, () => {
console.log("Server started!");
});
```
| singhutkarshh |
906,542 | C# Arrays | In previous chapter we learnt about collections (Lists, Stacks, Queues, Dictionaries), and I gave a... | 11,702 | 2021-11-23T12:16:23 | https://dev.to/grantdotdev/c-arrays-47m0 | codenewbie, csharp, tutorial, collections | In previous chapter we learnt about collections (Lists, Stacks, Queues, Dictionaries), and I gave a special mention to `Arrays`. Why was this, well arrays can store a collection of objects too just like the aforementioned, however we can't add to them as we go along like the others
e.g
```c#
var list = new List<string>();
list.Add("Hello World");
//do other code
list.Add("This is another sentance");
```
With arrays we have to know the length of the array to allocate memory space to it, the length needs to be known at time of instantiation. The contents of an array **cannot** be changed once created !
We can declare an array in a few different ways, but the common use of the `[]` square brackets "keyword / syntax" means an array is being declared.
There are a few ways you can declare an array in C#, explicitly or implicitly. For example when I said we need to know the length, this can be implicitly calculated by creating the array at point of instantiation and setting the values like so.
```c#
// will create an integer array with 5 values, will output 5 objects with value 0 (int default is 0)
int[] emptyArray = new int[5]
//will create a string array with 5 string values, output will be the 5 names.
string[] names = {"Grant", "Gary", "Mary", "Cat", "John"};
//this can also be done using alternative syntax of
string[] names = new string[]{"Grant", "Gary", "Mary", "Cat", "John"};
//Both do the same thing
```
If you've been playing with C# for a while, or have seen some intellisense tips (code helper when you type code in Visual Studio), you may have seen a method called `ToArray()`.
This does exactly what it says on the tin. It converts a collection to an array. Say you had a `List<string>` but wanted to use it as an array, I dunno to pass it to another method that only accepts an `Array`. It's simple you
```c#
var list = new List<string>{"Hello", "World", "How are you?"};
var convertedArray = list.ToArray();
```
Now your list is an Array, and gives you access to array methods and properties.
```c#
var list = new List<string>{"Hello","World"};
var array = new string[] {"Hello", "World"};
//Get number of objects
var countList = list.Count();
var countArray = array.Length;
```
## Array vs List<T>
So when would you use an array vs when to use a List<T>. For me I'd usually opt for a List<T> simply because lists in C# are far more easily sorted, searched through, and manipulated than arrays.
However arrays do have a place, e.g if your data is unlikely to grow very much or if you’re dealing with a relatively large amount of data that will need to be indexed into often.
Accessing Arrays is faster than Lists, this is because a List is just a .Net wrapper around an array. That unwrapping process can affect time taken to load records out of the list etc. There are few other reasons, but far too technical for this article. But we're talking milliseconds here, not huge amounts of time, however with large datasets this may be more noticeable.
## In Summary
Use an array when you know how much data is going into it, and the data doesn't need to be added / removed / manipulated.
Use a list when you wish to add / remove data to it easily. If you want to perform multiple actions on the data, pick a list as it offers more built-in functionality. | grantdotdev |
906,864 | Use sanitizers to avoid Redux Devtools crash | Use actionSanitizer and stateSanitizer to avoid Redux Devtools crash because of excessive use of memory | 0 | 2021-11-24T16:43:42 | https://dev.to/migsarnavarro/use-sanitizers-to-avoid-redux-devtools-crash-67p | react, redux, devtools, frontend | ---
title: Use sanitizers to avoid Redux Devtools crash
published: true
description: Use actionSanitizer and stateSanitizer to avoid Redux Devtools crash because of excessive use of memory
tags: React, Redux, devtools, frontend
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/bqwqyinbftdu1hfqxgv1.jpg
---
Recently I was having a lot of trouble using Redux Devtools in a project, it was interesting that I could access the tools in most of the views but for one particular section the extension stop being responsive and after some minutes it crashed.
## The problem
I started debugging and find out that we were saving a few problematic things into the store. The idea is to have things that are easy to serialize, it is not a rule but there are good reasons for that, the main one being that often you want to persist and restore state. I found that there were some functions and recursive structures (circular references) and those were obviously hard to serialize.
I was seriously considering a refactor, but fortunately I found the [troubleshooting section](https://github.com/zalmoxisus/redux-devtools-extension/blob/master/docs/Troubleshooting.md#excessive-use-of-memory-and-cpu) in the redux-devtools-extension repository and it sent me to the [`actionSanitizer` and `stateSanitizer` API](https://github.com/zalmoxisus/redux-devtools-extension/blob/master/docs/API/Arguments.md#actionsanitizer--statesanitizer) description. Probably a refactor should still be considered, but this little thing saved me plenty of time and pain.
## The solution
The idea here is that actions and states can be replaced by something else manually, so it does not fix the serialization problem at all, and won't solve an app performance problem if it exists, but it will stop that part of the state being analyzed by the Redux Devtools so it can run as smoothly as expected.
I don't know about the internals of the extension but when you think about it, it makes a lot of sense, time traveling needs to move from one state to the other and the only way to do it is to have a representation of that state and the extension was having a hard time trying to get that snapshot.
## References
- [Redux Devtools' Troubleshooting](https://github.com/zalmoxisus/redux-devtools-extension/blob/master/docs/Troubleshooting.md#excessive-use-of-memory-and-cpu)
- [Redux Devtools' `actionSanitizer` and `stateSanitizer` API](https://github.com/zalmoxisus/redux-devtools-extension/blob/master/docs/API/Arguments.md#actionsanitizer--statesanitizer)
-----
If you enjoy this post please consider following me and dropping a line here or in Twitter. | migsarnavarro |
906,559 | 10 Awesome JavaScript One-Liners | Highly effective one-liners in JavaScript that you should know. Continue reading on JavaScript in... | 0 | 2021-11-24T04:17:00 | https://javascript.plainenglish.io/10-awesome-javascript-one-liners-e294b8dbd9cd | javascript, computerscience, softwaredevelopment, programming | ---
title: 10 Awesome JavaScript One-Liners
published: true
date: 2021-11-16 13:01:25 UTC
tags: javascript,computerscience,softwaredevelopment,programming
canonical_url: https://javascript.plainenglish.io/10-awesome-javascript-one-liners-e294b8dbd9cd
---
[](https://javascript.plainenglish.io/10-awesome-javascript-one-liners-e294b8dbd9cd?source=rss-5e600d697a10------2)
Highly effective one-liners in JavaScript that you should know.
[Continue reading on JavaScript in Plain English »](https://javascript.plainenglish.io/10-awesome-javascript-one-liners-e294b8dbd9cd?source=rss-5e600d697a10------2)
---
Follow me on [Twitter](https://twitter.com/harendraverma2) | harendra21 |
906,722 | GOing down the rabbit hole | I recently upgraded a service written in golang which was deployed using Google's AppEngine and I... | 0 | 2021-11-23T13:10:23 | https://dev.to/ujjavala/going-down-the-rabbit-hole-6cc | googlecloud, go, devops, webdev | I recently upgraded a service written in golang which was deployed using Google's AppEngine and I have just one word for the experience. It was _unpleasant_. Just to be clear, I really am all in for golang and was also impressed with how easy it is to deploy any service using gcloud. Unfortunately the ride from go1.1 to go.1.2+ was more of a roller coaster for me. Let’s take a glimpse of this three-course meal together so that we can be well prepared for the next upgrade.
### For appetizers
I had already run my code locally using `dev_appserver.py --enable_host_checking=no --support_datastore_emulator=yes app.yaml` , verified the entries in the datastore and was fairly satisfied with the code that I had written.
I was all set to deploy my service on go111 if I hadn’t seen the error on my console related to a private repository reference. In order to resolve this issue, I leveraged `go vendor` (introduced go 1.15 onward), which would copy all third-party dependencies to a vendor folder in your project root. I quickly updated my app.yaml file and specified the version there as go115. Fortunately, the reference error was resolved and I could deploy the service.
### Here comes the main course
Deployment with go115 was successfully done, the health endpoint worked too. I was all happy and I started celebrating by updating the README.md file with emojis and refactoring the code here and there. But, my happiness was short-lived when I found out that the other endpoints didn’t work.
While accessing other endpoints I got a `metadata fetch failed: metadata server returned HTTP 404 error was seen` error. I googled for a while but didn’t find the exact cause. I tried to fix the issue with a few of these [stackoverflow](https://stackoverflow.com/questions/53331591/get-compute-metadata-from-app-engine-got-404-page-not-found-error) suggestions along with a few others, but didn't have any luck there. It took almost 2 days for me to figure out that I had to upgrade the AppEngine version. I bumped up the version and tada... I could access the other endpoints too.
### Finally, the dessert
I could see the css and labels for the page loading, but I couldn’t see any data there. Data, without which the page was just a skeleton, without any essence.
I traversed back to the logs and found yet another error `internal.flushLog: Flush RPC: Call error 7: App Engine APIs are not enabled, please add app_engine_apis: true to your app.yaml` popping up. The error made complete sense to me and I did just what it had suggested. I added the flag in the app.yaml file and quickly deployed the app.
And tada... the endpoint does _not_ have any data.
I was again lost in midst of suggestions and comments and after navigating through all the pages in google (10 to be precise), I found nothing.
Got a hunch that maybe it's again related to some other upgrade, and since it has something to do with data, upgraded datastore. Imported the datastore from `cloud.google.com/go/datastore` instead of `google.golang.org/appengine` and made the code compatible since the apis were a bit different. Found [this](https://xebia.com/blog/migrating-app-engine-to-go-1-11-the-price-of-vendor-lock-in/) and [this](https://cloud.google.com/datastore/docs/reference/libraries#client-libraries-install-go) really helpful). I deployed the code to the dev environment and finally… the fix worked beautifully and I could see the data there.
### Mint anyone?
Few findings on top of my head
1. Though the code was deployed successfully , I could not test the appengine-datastore setup on my local machine. For the standard environment, there is no documentation available for local setup for go 1.12+ versions. Before the upgrade, I had referred to [gcloud’s official document](https://cloud.google.com/appengine/docs/standard/go111/tools/local-devserver-command), but this didn’t work for go1.12+ versions.
2. Testing just the AppEngine locally was difficult for go1.12+ versions. I observed that even the [document](https://cloud.google.com/appengine/docs/standard/go/testing-and-deploying-your-app) recommends doing just a `go run`
3. Just running the datastore emulator is possible using `gcloud beta emulators datastore start`. But, again this is not very helpful if you need AppEngine to run too.
4. There were many incompatibility issues in between AppEngine and datastore, even if you haven’t upgraded yet. In order to test appengine the recommended solution is to use `GOOGLE_CLOUD_PROJECT= <projectId> <project_folder_path>` . But this is incompatible if you are using datastore. For datastore, you would need the deprecated `dev_appserver.py` way to test out things.
I felt that it would have been a lot smoother, if the steps for local development were more articulate and the error messages in gcloud were intuitive (they were really misleading). Few things worked for me and few things didn’t. But that was just my experience I guess, which is very subjective by the way. Not everyone might be running into these issues on a daily basis.
What we can hope for is that, if any one of us did stumble upon these issues, we know what our modus operandi is going to be and we know exactly how we are going to get our peace of mind back.
Keep calm and happy coding!
| ujjavala |
906,741 | Javascript flaws you should know | Introduction We all know and everybody does agree that javascript is awesome. It is a... | 0 | 2021-11-23T13:44:33 | https://dev.to/mcube25/javascript-flaws-you-should-know-44i2 | javascript, webdev, programming, websecurity | #### Introduction
We all know and everybody does agree that javascript is awesome. It is a language that by any metrics is growing faster than anything else. There is a lot of reasons for this. There is a lot of goodness in this. This are some core javascript traits.
• Built-in memory management
• Native serialization (JSON)
• Naturally scalable (via Eventloop)
• Frequent template /encoding use
• Flourishing npm package ecosystem
#### Javascript capabilities
These are amazing capabilities. They are core allowing the building of amazing things. But sometimes the same capabilities that make it awesome also make it vulnerable. So you look at this various different capabilities and what you can see as Built- in memory management one can look at the flaws and see buffer objects and leaking memory from servers. If you talk about native serialization hackers can look at it and do some type manipulation because types a decided in runtime and those kind of changes can be manipulated. A lot of our talk today is going to center on how javascript capabilities can be manipulated and abused.
• Built-in memory management : Buffer vulnerabilities
• Native serialization (JSON) : Type manipulation
• Naturally scalable (via Eventloop): Regex Dos
• Frequent template /encoding use: Sandbox Escaping
• Flourishing npm package ecosystem: Vulnerable packages
Another thing to remember is that this vulnurebalities don’t just happen in your code. Part of the core part of the javascript ecosystems are libraries . Npm, node, jquery. Much of the codes are open source codes. A typical application has thousands of dependencies which leads to a situation where your app is very large but your code is so small. It is slightly frightening from a security perspective. Most of your apps code come from npm which makes most of your apps vulnerabilities to come from npm. This is not a theoretical problem, it is practically what happens when we use npm packages.
#### Risk front-end Apps
Packages use packages that use other packages and within that ecosystem is vulnerabilities. Pretty every node shop has these and this risk node apps and front-end app has vulnerabilities in front-end apps like angular, react and node apps with all the packages we pull in from npm. Also there is the internet of things, we hear about Ddos and other massive attacks that take down the internet. Many of these devices run node apps and light weight apps and these can have vulnerabilities. We are going to look at
• Explain and exploit real world javascript vulnerabilities using npm
• Discuss remediation and solutions for vulnerable code and packages
We will discuss this in our next write up
| mcube25 |
906,808 | A brief introduction to Remix JS | Remix is a new full stack JavaScript framework that gets rid of static site generation and also in... | 0 | 2021-11-23T15:03:47 | https://allround.io/articles/a-brief-introduction-to-remix-js | Remix is a new full stack JavaScript framework that gets rid of static site generation and also in other areas, does a few things differently than what we're used to from other frameworks. It relies on React to render the UI and if you're familiar with Next.js you can certainly spot a lot of similarities. However, there are also clear distinctions, like nested routes, handling of data fetching and data saving as well as error handling. Let's take a look at those concepts and how they compare to other techniques, currently used in popular frameworks.
## Application structure and routes
The easiest way to get started with a new Remix project is by installing it through npx and following the interactive prompts:
```bash
npx create-remix@latest
```
Once we're done with that, our project's structure is already set up for us and we're good to go. If we compare Remix to Next.js, we'll see that with Remix we're also
writing client side and server ide code inside our route files. However, Remix gives us a little more control to fine-tune things like caching and this also shows in having two separate files for handling requests — `entry.client` and `entry.server` that represent our entry points and therefore determine what's run first on the server and client respectively. We also get a `root.tsx` which holds the root component to our app and renders the `<html>`, first `<meta>` tags, and so on.
```
├── ...
├── app
│ ├── entry.client.tsx
│ ├── entry.server.tsx
│ ├── root.tsx
│ ├── routes
│ │ └── index.tsx
│ ├── styles
│ │ └── global.css
│ └── utils.server.tsx
├── jsconfig.json
├── package.json
├── public
├── remix.config.js
```
We also see a framework-specific `remix.config.js` which allows to to configure a lot off different details about oour application, such as the default public directory, development ports and much more.
## Nested routing
A very neat mechanism in Remix is the ability to render parts of a page based on the route we're on. When thinking of other frameworks, this would come down to either a separate route with its own `index` file or specifically matching a route to one or more components. We're used to binding parts of our URL to different routes or components already — the way Remix does it, is best described as nested layouts, where each part of the URL is by definition bound to a route file. Here's an example from their official site.
<img src="https://allround.io/storage/remix-nested-routes.png" className="img-fluid mb-4" alt="Remix JS nested routes"/>
The route shown above (`/sales/invoices`) would therefore be represented by three files
- `routes/sales.jsx`
- `routes/sales/index.jsx`
- `routes/sales/invoices.jsx`
Our first file is the wrapper that gets called first and based on the rest of the URL decides which "sub-components" should be rendered. The initial state
would be `routes/sales/index.jsx` and when navigating to /invoices, our wrapper pulls in the code from `routes/sales/invoices.jsx`. The way this is realized in code is not through regular components, but through an `<Outlet />` which is part of `react-router-dom` and allows for this mapping of nested layouts to routes (route components) rather than regular components.
Under the hood this allows Remix to preload the different parts on a page, which makes it *really* fast and lets us eliminate loading states as much as possible. There are probably some more interesting things we can do here that I haven't fully explored yet.
## Styling pages and components
Styling components is fairly straightforward with Remix, because it's very close to how it works on the web since forever. Remix brings its own `LinksFunction` which can be used to import CSS files on a per-route basis. That's also where we have to be a little careful and separate our CSS into global CSS that should be available to every route and specific CSS that will not be loaded outside a certain route at all.
```JavaScript
import stylesUrl from "../styles/index.css";
export let links: LinksFunction = () => {
return [{ rel: "stylesheet", href: stylesUrl }];
};
export default function IndexRoute() {
return <div>Index Route</div>;
}
```
Once again Remix relies heavily on how the web already works, so if we wanted to use preprocessors or frameworks like Tailwind, we'd want to pass the compiled resources paths to Remix, just like we would with vanilla CSS files.
## Loading data
To get data inside a route component in Remix, we can use a `loader`, which is just an async function that returns the requested data. Inside our components, we can then access it through a hook called `useLoaderData`.
```
import { useLoaderData } from "remix";
export let loader = async () => {
return getData(); // does the heavy lifting, DB calls etc. and returns data
}
// Component function starts here
export default function Component() {
let allData = useLoaderData(); // data is now available inside our component
}
```
Note that the function is always called `loader` by convention and is only executed server-side, which means we also have access to all `node` features and libraries to connect to databases and fetch data, like we're used to on the server.
If we're passing parameters to our routes, like a dynamic URL often times requires, the loader also has access to that, by passing in the request parameters like this
```JavaScript
export let loader = async ({ params }) => {
return params.slug
}
```
## Storing data
If we want to send new user-generated data back to the backend, to save it to a database for example, Remix lets us use so-called `actions`. Actions rely on forms for the actual data input and are also only executed server-side, despite being in your route file.
The functions are — again by convention — called `action` and can also trigger (return) a redirect. Let's look at an example.
```JavaScript
export let action = async ({ request }) => {
let formData = await request.formData()
let title = formData.get("title")
let slug = formData.get("slug")
await createPost({ title, slug }) // actual call to store data...
return redirect("/home")
}
export default function NewPost() {
return (
<Form method="post">
<p>
<label>Post Title: <input type="text" name="title" /></label>
</p>
<p>
<label>Post Slug: <input type="text" name="slug" /></label>
</p>
<button type="submit">Create Post</button>
</Form>
);
```
We see that the `action` function takes the `request` as a parameter and thereby has access to everything our form sends over to the server. From there we're free to use any `node` code to store our data.
## Handling errors
The way Remix handles errors is quite unique, as it allows us to create `ErrorBoundary`s that will be shown in case something with our route components didn't work as expected and an error is thrown. That way, if we're using Remix's nested routes, we might see a single <Outlet /> throwing
and error, but not necessarily the whole page. The smart thing about error boundaries is that they bubble up (the routes) to the closest error boundary. So the easiest case would be having one error boundary at the root level, comparable to a full 404. However, the image below nicely
demonstrates how having multiple small error boundaries (one per route component for examaple) can leave the rest of an application intact.
<img src="https://allround.io/storage/error-boundary.png" className="img-fluid mb-4" alt="Remix JS error boundary"/>
```JavaScript
export function ErrorBoundary({ error }) {
return (
<html>
<head>
<title>Something went wrong!</title>
<Meta />
<Links />
</head>
<body>
... anything we want to let the user know goes here
</body>
</html>
);
}
```
Implementing an error boundary is as simple as adding an `ErrorBoundary` function to our route components as shown above.
## Further reading
At the time of this writing, Remix has really only been released yesterday, so there is still a lot to learn and some things might even change drastically with newer versions.
If you're looking for more resources and want to dive deeper, there's a fantastic tutorial on <a href="https://remix.run/docs/en/v1/tutorials/blog">building a blog</a> and a small <a href="https://remix.run/docs/en/v1/tutorials/jokes">dad jokes applicaiton</a> in the <a href="https://remix.run/docs/en/v1">Remix docs</a>. | codestructio | |
906,843 | Hashcode and Equals Debugging, Performance | A few weeks ago I ran into this story on reddit that discusses the problem with using the URL class... | 0 | 2021-11-23T16:04:47 | https://talktotheduck.dev/hashcode-and-equals-debugging-performance | java, performance, programming, tutorial | A few weeks ago I ran into [this story on reddit](https://www.reddit.com/r/java/comments/qi8yu8/hint_to_myself_and_other_poor_souls_dont_use/) that discusses the problem with using the URL class as a key in a Map. This boils down to a remarkably slow implementation of the hashcode() method in java.net.URL which makes this class unusable in such situations. Unfortunately, this is a part of the Java API specification and is no longer fixable without breaking backwards compatibility.
What we can do is understand the problem with equals and hashcode. How can we avoid such problems in the future?
## What’s the problem with URLs Hashcode and Equals?
To understand this, let’s look at the JavaDoc of hashcode and equals:
> Compares this URL for equality with another object.
>
> If the given object is not a URL then this method immediately returns false.
>
> Two URL objects are equal if they have the same protocol, **reference equivalent hosts**, have the same port number on the host, and the same file and fragment of the file.
>
> **Two hosts are considered equivalent if both host names can be resolved into the same IP addresses;** else if either host name can't be resolved, the host names must be equal without regard to case; or both host names equal to null.
>
> Since hosts comparison requires name resolution, this operation is a blocking operation.
Since hosts comparison requires name resolution, this operation is a blocking operation.”
This might be unclear. Let’s clarify it with a simple block of code:
```java
System.out.println(new URL("http://localhost/").equals(new URL("http://127.0.0.1/")));
System.out.println(new URL("http://localhost/").hashCode() == new URL("http://127.0.0.1/").hashCode());
```
Will print out:
```
true
true
```
This might be pretty simple with localhost, but if we compare domains and the Strings aren’t identical (which they often aren’t) we need to do a DNS lookup. We need to do that just for a hashcode() call!
## A Quick Workaround
A quick workaround for this case is to avoid URL. Sun deeply embedded the class in the original JVM code, but we can use URI for most purposes.
E.g. if we change the hashcode and equals calls from above to use URI instead of URL we will get this result:
```java
System.out.println(new URI("http://localhost/").equals(new URI("http://127.0.0.1/")));
System.out.println(new URI("http://localhost/").hashCode() == new URI("http://127.0.0.1/").hashCode());
```
We will get false for both statements. While this might be problematic for some use cases, it’s a vast difference in performance.
## A Bigger Pitfall
If all we ever used as a map key were Strings we’d be fine. This sort of bug can hit us in every place where we use these methods:
* Sets
* Maps
* Storage
* Business logic
But it gets deeper. When writing our own classes with our own hashcode and equals logic we can often fall prey to bad code. A small performance penalty on a hashcode method or an overly simplistic version can cause major performance penalties that would be very hard to track.
E.g. A stream operation that takes longer because the hashcode method is slow or incorrect can represent a long-term problem.
### The Best Hashcode Implementation
To understand the best hashcode and equals method, we first need to understand some mediocre code. Now I won’t show horrible or old code. This is good code, but it isn’t the best:
```java
public int hashCode() {
return Objects.hash(id, core, setting, values, sets);
}
```
This code might seem OK at first, but is it?
Here’s the ideal code:
```java
public int hashCode() {
return id;
}
```
This is fast, 100% unique and correct. There’s literally no reason to do anything beyond that. There’s one exception of an id which is an object. In that case we might want to do Objects.hashCode(id) instead which will also work for null, etc.
### Hashcode isn’t Equals
Well, obviously… This is one of the most important things you need to keep in mind when writing a hashcode implementation. This method must perform fast and must be consistent with equals for the false case. It will not be correct for the case of true.
To clarify, hashcode must always obey this law:
```java
assert(obj1.hashCode() != obj2.hashCode() && !obj1.equals(obj2));
```
That means if hashcode results are different, the objects must be different and must return false from equals. But the inverse isn’t the case:
```java
if(obj1.hashCode() == obj2.hashCode()) {
if(obj1.equals(obj2)) {
// this can be false...
}
}
```
The value here is in performance. A hashcode method should perform much faster than equals. It should let us skip the potentially expensive equals calculation and index elements quickly.
### Special Case with JPA
JPA developers often just use a hardcoded value for hashcode or use the Class object to generate the hashCode(). This seems weird until you think about this.
If you let the database generate the ID for you, you would save an object and it would no longer be equal to the source object… One solution is to use the `@NaturalId` annotation and data types. But that would require changing the data model. Unfortunately, there’s no decent workaround for the entity classes.
In fact, I would theorize that a lot of the problems JPA developers experienced with Lombok are because it generates hashcode and equals methods for you. Those could be problematic.
## Is this a Blog about Debugging?
Sorry about that long setup, but yes it damn well is. So I needed all of that preface to talk about this in a more generic sense of debugging. Notice that this is true for other languages that use similar paradigms for common interfaces.
This blog started with a performance issue and I would like to discuss that aspect in the lens of debugging. In many profilers, the overhead of a hashcode method would be almost unnoticeable. But because it’s invoked so often and has wide-reaching implications, it’s possible you ultimately feel the repercussions and cast the blame elsewhere.
The knee jerk reaction would be to implement a “dummy” hashcode method and see the resulting performance difference. Just return a hard coded number instead of a valid number.
This is valuable for some cases and might even solve problems like the one mentioned at the top where the hashcode method performs badly. However, it won’t help with maps. If the hashcode would return identical values, using it as a key in a map would effectively disable all the performance benefits that hashcode can offer.
How do we know if a hashcode method is good?
Well… We can use the debugger to figure it out. Just inspect your map and look at the distribution of the objects between the various buckets to get a sense of the real world value of the hashcode method.
If you have code verification process on commit I would strongly recommend defining a rule on the complexity level of a hashcode method. This should be set very low to prevent slow code from seeping in.
But the problem is nesting. E.g. think about code like the one we discussed before:
```java
public int hashCode() {
return Objects.hash(id, core, setting, values, sets);
}
```
It’s short and simple. Yet, performance of this code can be all over the place. The method would invoke the hashcode method of all internal objects. These methods can be far worse in terms of performance. We need to be vigilant about this. Even for JDK classes such as URL which, as we discussed earlier, is problematic.
## TL;DR
We often auto-generate hashcode and equals methods. The IDEs are normally pretty good at that; they offer us an option to pick the fields we wish to compare. Unfortunately, they then apply both sets of fields to hashcode and equals.
Sometimes, this doesn’t matter. Often we don’t “see” the places where it does matter since the methods are too small to make a dent in the profiler. But they have wide-ranging implications we should optimize for.
Debugging lets us inspect the map and look at bucket distribution so we can get a sense of how well our hashcode method is performing and whether we should tune it to get more consistent results from maps and similar APIs. | codenameone |
907,159 | Highlights from VSCode 1.62 | The open source VSCode project, along with VSCodium1, completed their latest monthly release with... | 15,235 | 2021-11-23T22:33:29 | https://blog.dendron.so/notes/V2Cjla9vzM69Z280j5bXB/ | vscode, codenewbie, productivity, tooling | The open source VSCode project, along with VSCodium[^1], completed their latest monthly release with v1.62[^2]. For those of us that haven't been using the Insider's Build,[^3] it's time to look at what's new.
Make sure to checkout the [VSCode 1.62 Release Party](https://www.youtube.com/watch?v=IKvtYHfzE3g) on YouTube!
## Live Share session sharing in Virtual Workspaces

_Virtual Workspaces_[^4], such as [vscode.dev](https://vscode.dev/) and [github.dev](https://github.dev/), now support this superpower: sharing a session directly from the browser.
Haven't used Live Share before? Many people are attracted to Google Docs due to how easy it is to collaborate, comment, and highlight sections in order to give each other scathing reviews. Introducing [Live Share](https://marketplace.visualstudio.com/items?itemName=MS-vsliveshare.vsliveshare-pack): instead of waiting for the PR review, you can provide non-constructive feedback to your peers!
Take note: if you are a VSCodium user, sharing/joining sessions won't work. I learned this after spending too much time confused. Be aware of the [live-share license agreement](https://marketplace.visualstudio.com/items/MS-vsliveshare.vsliveshare/license), including the information about data collection, which may be part of the incompatibility with VSCodium. There are alternatives, though, such as [CodeTogether](https://www.codetogether.com/).
> Release Party: [Live Share (in vscode.dev)](https://youtu.be/IKvtYHfzE3g?t=170)
## Bracket pairs
I enjoy whenever features lessen confusion for my eyeballs. I never bought a pair of Google Glass, even as men everywhere were accidentally taking photos while using urinals in pubic restrooms. [Bracket pair highlighting](https://code.visualstudio.com/updates/v1_62#_improved-bracket-pair-guides), though, to show where I am in the russian dolls of nested loops? Yes, please.
Settings of interest:
- `"editor.guides.bracketPairs": "active"`: Only show guides for **only the active** bracket pair.

- `"editor.guides.bracketPairs": "true"`: Show guides for **all** bracket pairs, with different colors.

> Release Party: [Bracket pair colorization](https://youtu.be/IKvtYHfzE3g?t=857)
## Verified publishers

When installing extensions, it's nice knowing you're installing the real deal. Microsoft could have gone the whimsically difficult route that Twitter has taken with their blue checkmarks, but instead they have made it an easy process. This was how I learned GitLens was acquired by GitKraken: [the truth is out there](https://www.gitkraken.com/blog/gitkraken-acquires-gitlens-for-visual-studio-code).
Found a duplicate extension? Check whether one is from a verified publisher by jumping into the Marketplace.
> Release Party: [Verification for extensions publishers](https://youtu.be/IKvtYHfzE3g?t=1384)
## Other notables
> General tip: Wondering what shortcuts are configured in VSCode? One shortcut to rule them all: `Ctrl+K Ctrl+S`
- Or `Ctrl+Shift+P` -> **Preferences: Open Keyboard Shortcuts**
- A [CVE was addressed](https://code.visualstudio.com/updates/v1_62#_unicode-directional-formatting-characters) involving characters that became invisible, leading to code that could compile differently than visually expected.
- Extension note: [GitHub PRs and Issues](https://code.visualstudio.com/updates/v1_62#_github-pull-requests-and-issues) brings issue and PR interaction directly into VSCode. Have you taken a look yet?
- Latest updates can be seen in the [extension changelog](https://github.com/microsoft/vscode-pull-request-github/blob/main/CHANGELOG.md#0320).
- Issues resolved in point releases, referred to as "Recovery" releases, can be found on GitHub: [`1.62.1`](https://github.com/microsoft/vscode/issues?q=is%3Aissue+milestone%3A%22October+2021+Recovery%22+is%3Aclosed), [`1.62.2`](https://github.com/microsoft/vscode/issues?q=is%3Aissue+milestone%3A%22October+2021+Recovery+2%22+is%3Aclosed), and [`1.62.3`](https://github.com/microsoft/vscode/issues?q=is%3Aissue+milestone%3A%22October+2021+Recovery+3%22+is%3Aclosed).
---
Enjoy the blog? [Subscribe to our newsletter!](https://buttondown.email/dendron)
Newsletters not your thing? You can also follow us elsewhere on the interwebs:
* Join [Dendron on Discord](https://discord.com/invite/xrKTUStHNZ)
* Follow [Dendron on Twitter](https://twitter.com/dendronhq)
* Checkout [Dendron on GitHub](https://github.com/dendronhq)
Interested in creating your own knowledge base using markdown, git, and VSCode? Get started with [Dendron](https://wiki.dendron.so/notes/678c77d9-ef2c-4537-97b5-64556d6337f1/) today.
[^1]: [Checkout VSCodium](https://vscodium.com/), for the truly MIT-licensed version of the VSCode IDE (with telemetry/tracking disabled).
[^2]: [VSCode release notes for 1.62](https://code.visualstudio.com/updates/v1_62), along with release notes for previous monthly releases.
[^3]: The [VSCode Insiders Build](https://code.visualstudio.com/insiders) allows users to get VSCode with new features as soon as they are available, rather than at the monthly cadence.
[^4]: Reference the [VSCode Blog Post on vscode.dev](https://code.visualstudio.com/blogs/2021/10/20/vscode-dev) for a full rundown on Virtual Workspaces and bringing VSCode to the browser. Last month, there was a livestream all about it! Watch [VS Code for the Web: vscode.dev on YouTube](https://www.youtube.com/watch?v=sy3TUb_iVJM).
| scriptautomate |
907,166 | From photographer to web developer | Willem was working as a photographer when Covid 19 struck. As work dried up he decided to learn... | 0 | 2021-11-24T11:25:20 | https://www.nocsdegree.com/photographer-web-developer/ | beginners, career, webdev | ---
title: From photographer to web developer
published: true
date: 2021-11-23 19:14:57 UTC
tags: Beginner, Career, Webdev
canonical_url: https://www.nocsdegree.com/photographer-web-developer/
---

Willem was working as a photographer when Covid 19 struck. As work dried up he decided to learn coding. He become a web developer by learning with [Ironhack](https://www2.ironhack.com/remote-uk?utm_source=nocsdegree&utm_medium=affiliates&utm_campaign=21-11_RMT_uk_RMT_EU_lead_&utm_content=sponsored-content), a coding bootcamp which is the sponsor of this article.
## Can you introduce yourself?
Hello! My name is [Willem](https://www.willemprins.com), I am originally from Amsterdam in the Netherlands but have been living in South London for the past two and a half years. I was a freelance commercial photographer before changing careers and completing a bootcamp in web development at [Ironhack](https://www2.ironhack.com/remote-uk?utm_source=nocsdegree&utm_medium=affiliates&utm_campaign=21-11_RMT_uk_RMT_EU_lead_&utm_content=sponsored-content) during the start of the pandemic. For about a year now I have been working remotely as a frontend web developer for creative and digital agencies in Stockholm and Amsterdam.

## Why did you decide to learn to code and change career from photography?
I was always interested in building websites and coding in general, but was under the impression that learning it was extremely technical and math-heavy. I had skipped through most of high school thinking I wasn’t going to need most of what I was being taught and that I was going to study something creative anyway, so I had always written off anything remotely to do with science or math as something I couldn’t possibly do.
But, after the pandemic hit and I couldn’t work as a photographer anymore for quite a while, I decided I was going to make the most of my time and learn a new skill set. A friend of mine was doing some coding as part of his degree, and he suggested I try it to see if it might be something for me.
So, I did a quick Java course on Codecademy and was amazed by the time it took me to grasp the basics and to understand how code works. The realisation that it’s more about thinking logically and efficiently than it is about writing incredibly complex algorithms was a big eye-opener for me.
## How did you start learning to code?
I didn’t do a lot of coding before joining [Ironhack](https://www2.ironhack.com/remote-uk?utm_source=nocsdegree&utm_medium=affiliates&utm_campaign=21-11_RMT_uk_RMT_EU_lead_&utm_content=sponsored-content). One Java course and a couple of Youtube videos on HTML and Javascript were enough for me to decide I was interested.
## What made you decide to learn more about web development with [Ironhack](https://www2.ironhack.com/remote-uk?utm_source=nocsdegree&utm_medium=affiliates&utm_campaign=21-11_RMT_uk_RMT_EU_lead_&utm_content=sponsored-content)?
Initially I started looking for bootcamps in London. I thought going into a physical campus would help me to learn better. But given that the lockdown had just started I was unsure whether I would actually be able to do it in person or if it was going to be online anyway, so I broadened my search.
[Ironhack](https://www2.ironhack.com/remote-uk?utm_source=nocsdegree&utm_medium=affiliates&utm_campaign=21-11_RMT_uk_RMT_EU_lead_&utm_content=sponsored-content) had good reviews and I was keen on learning React, as I had read about it being used in a lot of companies’ frontend stacks. I liked the fact that they have campuses around the world and have a big international community as well.
## What did you learn exactly at [Ironhack](https://www2.ironhack.com/remote-uk?utm_source=nocsdegree&utm_medium=affiliates&utm_campaign=21-11_RMT_uk_RMT_EU_lead_&utm_content=sponsored-content)?
The full-stack web development course focussed on preparing us with a range of modern languages and frameworks, most importantly Javascript, Express and React. We started off with the basics in HTML, CSS and Javascript, before learning to build everything from servers and Rest API’s to building React components and understanding their lifecycle hooks.
In addition we also got to use MongoDB to manage non-relational databases and were briefly introduced to web-hosting and AWS. I think overall it was a pretty balanced and effective way of learning the basics and having a broad understanding of what web development entails, whilst also going deep enough to be able to apply to tech jobs with confidence and the knowledge required to get hired.
## What were the teachers like at [Ironhack](https://www2.ironhack.com/remote-uk?utm_source=nocsdegree&utm_medium=affiliates&utm_campaign=21-11_RMT_uk_RMT_EU_lead_&utm_content=sponsored-content)?
I thought our teaching staff were great. A young team of enthusiastic developers, some of whom did the bootcamp themselves not long before us, which was very reassuring. We started every day off with a standup, to see how everybody’s doing.
The atmosphere was always pretty relaxed and it felt like a safe space to learn and ask questions. Even though we were all spread around the world it never felt like it. I ended up meeting and working with people I would otherwise never have met. It also set me up for working remotely as a developer, as I was already used to collaborating with others online and over videocalls.
## How did you get your first entry level developer job?
I didn't necessarily find my first job through Ironhack, but they helped a lot in the job search process. From setting up my LinkedIn and fine-tuning my CV, teaching us what skills from previous experience are transferable (more than you’d think!) and how to talk to recruiters and potential employers. Their experience of the industry was vital in explaining why we, as bootcamp graduates, are just as appealing to companies as university graduates.
There are some obvious differences: of course a university graduate will have a deeper understanding of the theoretical principles of computer science, but that doesn’t necessarily mean they are better developers. A crucial part of [Ironhack’s](https://www2.ironhack.com/remote-uk?utm_source=nocsdegree&utm_medium=affiliates&utm_campaign=21-11_RMT_uk_RMT_EU_lead_&utm_content=sponsored-content) way of teaching is that they teach you how to teach yourself.
In my current role I work with Craft and Vue, both of which I’d never touched before being hired. But doing the bootcamp enabled me to adapt quickly to new technologies and environments, and instilled a curiosity and drive to always want to learn more. That has been key for me in going into interviews with confidence.
## What does a typical day as a software developer look like for you?
I work for a fairly small digital agency in Amsterdam. The pandemic for me has been a blessing in disguise, as I am the only employee not based in the Netherlands, but no one really notices. All our communication happens online and I really enjoy working from home. We work in small teams of about 2 developers, 1 UX/UI designer and 1 project manager per project.
This means I always know who to turn to if I have a specific question, and I get enough responsibility to feel proud of what I make. We tend to work in two-week sprints, with new features being released frequently, in close collaboration with the client. All in all it’s a great environment to learn and see the whole process from client brief to final product.
## Do you have tips for people who want to learn to code?
For me the most important thing to discover was that I actually enjoyed coding. I was always interested in designing and building websites but never thought coding was something I could do. So I would say start there: watch a bunch of Youtube tutorials, do a free online course to get the basics down.
Once you know that you like it, the sky’s the limit. There are so many other directions you can go apart from building apps and websites, those skills will never not be valuable. The second thing I would say is not to compare yourself too much with others and to be kind to yourself when you don’t know something.
It can be very discouraging if you get stuck on something that should seem obvious, or if you can’t figure out how to solve a bug in your code that you’ve been staring at for hours. This happens a lot and is normal, just go get a coffee and come back in a bit. Chances are you see something you didn’t see before. Also, get good at googling. Stack Overflow is your friend.
## What are your career goals for the future?
My current goal is to keep growing and learning as a developer. Modern web development moves very fast and it can be hard to keep up with everything that comes out. I want to make sure I become better at the technologies and frameworks I already know, whilst also staying up to date with the latest developments and have the opportunity to put those learnings into practice.
## Thanks for the interview!
[Ironhack](https://www2.ironhack.com/remote-uk?utm_source=nocsdegree&utm_medium=affiliates&utm_campaign=21-11_RMT_uk_RMT_EU_lead_&utm_content=sponsored-content) _is an international tech school disrupting the way we learn about technology. Founded in 2013, we host 9 campuses across Europe, the US and the Americas, and are proud to now bring our Remote Bootcamps to the UK.
Our Remote Bootcamps will teach you the skills of the future from the comfort of your home, or location of your choice. You will not only learn in real time, but thanks to our Career Support Services and our Global Community of Ironhackers, you will also enjoy continued support to help you thrive in a new job or career.
Bootcamps include: Web Development, UX/UI Design, Data Analytics and Cybersecurity._ | petecodes |
907,311 | What kind of Developer do I want to be? | Whether you're just starting your journey in the technical field, half way through, or fully... | 0 | 2021-11-24T06:55:20 | https://dev.to/kvyshh/roadmap-to-learning-what-kind-of-developerprogrammerengineer-you-are-2m2j | beginners, programming, webdev, career | Whether you're just starting your journey in the technical field, half way through, or fully integrated, it's always a good practice to step back in your career and ask yourself a few things:
######(we're going to assume at this point, you've made the decision to pursue the life of a "Developer"/"Engineer"/"Programmer" -- if you're looking for a "Is tech the right choice for me?" article, this won't cover it.)
1. Why am I pursuing this role?
* Why am I in the role that I'm in now?
2. Am I still passionate about what I'm pursuing?
* Am I still passionate about what I'm doing?
3. Where do I want to go next?
With these questions and maybe answers in mind, lets consider some options to help you build the best career path for you!
###### I want to mention that this isn't a say-all-do-all article, I wanted to create this article to help inspire or re-inspire people about their career options and path. You should continue to do research about the many titles developers hold, and decide what's right for you.
##The Journey
The timeline of an engineer will generally be forever growing as you know may know we are what they call "eternal students". However, at the beginning it falls along these lines, and when you're looking into roles, consider where you are in this timeline.
#### Chapter 1: Introductions to programming and code.
This is the start of your journey as a programmer; where you'll learn all the important fundamentals of code.
#### Chapter 2: Experimenting
You're at the point where you're trying things out, learning a new language, and discover what you like and dislike.
#### Chapter 3: Specialization
Picking a focus area and become an expert in that area.
#### Chapter 4: Expanding / Building on other skills and/or more technicality
At this point you know what you want to do and you're looking at the best way to develop things like your leadership skills, communication, business development, or building a *new* language
... and you can keep building from there. The possibilities are endless, it just depends on how much effort, time, and money you're willing to put in.
--
### Quick Side-bar on the what it means to be a "Software Engineer" vs "Software Developer" vs "Programmer"
I don't want to go into too much detail about the naming convention of the titles as a "Programmer", but I do want to mention it because I think it's important to acknowledge what it may mean in the professional field. I personally think they can be interchanged.
***The Programmer***: This is someone who knows how to code, They know at least one programming language and know it well enough that they can make things happen by typing the code into their computer.
Some programmers graduate from a university with a computer science degree and know how to code. They would qualify. Others pick up a book and teach themselves to code on their own. They would qualify too.
***The Developer***: When someone talks about a developer, sometimes they use the term to mean something more than programmer. A programmer asks me, “what should I code?” or “how do you want me to do it?” In those cases, I'm making the bigger decisions and the programmer is implementing things.
Developers have enough experience to have seen problems before and to know what worked and what didn't. With developers you can normally describe a destination, and they design the route they'll take. The difference between a programmer and a developer is one of degree. One is more resourceful than the other. Moving from one to the other requires time, effort, and experience.
***The Engineer***: Software engineers are a different dynamic altogether, for some. It's because of the “engineering” part of the term.
To remind you, it doesn't matter where/how software engineers gain their knowledge. It's not suggesting they must have a degree. Engineering is a discipline. It requires that you know a set of knowledge. Engineering requires a level of abstract thinking. We're not just talking about creating a plan before you write code. We're talking about creating mental models of how the parts of a system will work. Models that help you refine your designs.
Conclusion: At the end of the day, what really matters is what you want to call yourself and what you believe you are. There is no "right" or "wrong" to how you title yourself (so long as you're being honest to yourself). This side-bar was just to touch on some opinions on what the title means to some people in the industry. “***Good programmers are good programmers, no matter what special title they have.***”
--
##The Roadmap - Where to start.
So if you've done any searching around into different 'developer' titles, you'll quickly realize there are about 100 different tiles you can choose from. Narrowing that down can be daunting when you're first starting out, but the good news is a lot of them can be categorized into larger 'umbrella' role-titles to help your narrow your focus.
###Front-End Developer
Builds websites by converting data to a graphical interface for the user to view and interact with. Their main concerns relate to the presentation layer; they need to have some artistic vision to present the data; this generally implies mastering HTML, CSS, some CSS pre-processor like SAS, and some (mainstream) JavaScript frameworks such as Angular, React or Vue.
#####Non-Technical Qualities to have:
- Project Management
- Excellent Communication
- Time Management
- Quick/Effective Decision Making
- Working under pressure
- Attention for visual detail
#####Am I a fit?
- I like to work with people, whether it's team-members or clients, and being able to bring someones idea to life.
- I work well under pressure and I can handle eyes on me and my work
- When push comes to shove, I can make a yes or no decision on project capabilities, features, and deadlines
#####Technical Skills
HTML, CSS, Vanilla JS, jQuery, Content management systems
BONUS: UX/UI Design Skills, Adobe Suite, Branding, Creating Guide Styles
#####Various Titles
- Front-End Engineer/Developer
- Web Developer/Web Designer
- Front-End Architect
- Presentation Layer Developer
- Interface Developer
#####Thinking
Mock-up/Storyboard
Receiving a mock-up or storyboard from a client, ux/ui designer, or design team.
Plan of Action
Thinking about the time it will take to build each component; is it going to be one page, multiple pages, what data is this pulling from, what are we consistently changing?
Building Dynamic Code
Creating code that any developer can read and iterate on. Making the most of re-usable code on multiple pages
HTML
Properly labeling and id-ing items so they can easily be accessed in CSS or through a CSS program
```
<head>
<meta name="description" content="">
<meta name="author" content="Tooplate">
<title>ArtXibition HTML Event Template</title>
</head>
<body>
<div id="js-preloader" class="js-preloader">
<div class="preloader-inner">
<span class="dot"></span>
<div class="dots">
<span></span>
<span></span>
<span></span>
</div>
</div>
</div>
</body>
```
JavaScript
Creating component based elements and styling your code so that it's easily manipulatable and readable. Notice that when you create something you want to be able to think about where and how it can be used else where.
```
function focusable( element, isTabIndexNotNaN ) {
var map, mapName, img,
nodeName = element.nodeName.toLowerCase();
if ( "area" === nodeName ) {
map = element.parentNode;
mapName = map.name;
if ( !element.href || !mapName || map.nodeName.toLowerCase() !== "map" ) {
return false;
}
img = $( "img[usemap='#" + mapName + "']" )[ 0 ];
return !!img && visible( img );
}
return ( /input|select|textarea|button|object/.test( nodeName ) ?
!element.disabled :
"a" === nodeName ?
element.href || isTabIndexNotNaN :
isTabIndexNotNaN) &&
// the element and all of its ancestors must be visible
visible( element );
}
```
CSS
Matching the styling to the mock-up while also making it the most dynamic by applying proper class and IDs.
```
html, body {
font-family: 'Poppins', sans-serif;
font-weight: 400;
background-color: #fff;
font-size: 16px;
-ms-text-size-adjust: 100%;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
a {
text-decoration: none !important;
}
h1, h2, h3, h4, h5, h6 {
margin-top: 0px;
margin-bottom: 0px;
}
```
#####Pay
In US with 1-3 years of experience at a mid-size company: ~$97k (Junior)
In US with 8+ years of experience at a mid-size company: ~$124 (Senior)
#####Things to consider
- "Web Developer" is the #1 searched job-title in the development field
- "Front-End Engineer" is the #4 top ranking
#####You should reconsider if...
- You are not looking to have EXCELLENT communication skills
- Don't enjoy working with a lot of different people
- Crack under pressure
- You are not the most design-oriented person and don't wish to be
- You are not great at managing multiple tasks and deadlines
---
###Back-End Developer
Builds the functionality and interactivity of a website, including the elements that allow users to carry out actions like logging in, creating an account, and user data input. Backend developers work implementing the business logic. They have to have knowledge of frameworks, software architecture, design patterns, databases, APIs, interconnectivity, DevOps, etc. They need to be able to manage abstract concepts and complex logic.
#####Non-Technical Qualities to have:
- Logical and solutions oriented
- Abstract thinking
- Pattern recognition
- Communication with team
- Detail & Security Oriented
- Researcher
#####Am I a fit?
- When I'm given a problem, I like to take a moment to write down solutions and how to get there
- I'm always looking for more interesting ways to solve problems and make it adaptable - its not always about what is the 'shortest'
- I like creating systems for more efficient ways to execute on tasks
- I want to be sure that I have a calculated risk before I go in on something and consult with others
#####Technical Skills
Python, Java, PHP, MySQL, C, C++, Ruby
#####Various Titles
- Software Engineer
- Back-end Engineer
- Data Engineer
- SQL/Java/[language] Engineer
- Network Engineer
#####Thinking
Data from server/website/network
Creating a framework for where data comes and goes as well as functionality (what to do with it)
Building the code to consider time-space complexity but also be dynamic when needed. Data should be easily accessible by other teams and placing security measures where important data is passed. Commenting to allow other engineers to easily iterate.
```
class Job:
def __init__(self, start, finish, profit):
self.start = start
self.finish = finish
self.profit = profit
# A Binary Search based function to find the latest job
# (before current job) that doesn't conflict with current
# job. "index" is index of the current job. This function
# returns -1 if all jobs before index conflict with it.
def binarySearch(job, start_index):
# https://en.wikipedia.org/wiki/Binary_search_algorithm
# Initialize 'lo' and 'hi' for Binary Search
lo = 0
hi = start_index - 1
# Perform binary Search iteratively
while lo <= hi:
mid = (lo + hi) // 2
if job[mid].finish <= job[start_index].start:
if job[mid + 1].finish <= job[start_index].start:
lo = mid + 1
else:
return mid
else:
hi = mid - 1
return -1
# The main function that returns the maximum possible
# profit from given array of jobs
def schedule(job):
# Sort jobs according to start time
job = sorted(job, key = lambda j: j.start)
# Create an array to store solutions of subproblems. table[i]
# stores the profit for jobs till arr[i] (including arr[i])
n = len(job)
table = [0 for _ in range(n)]
table[0] = job[0].profit;
# Fill entries in table[] using recursive property
for i in range(1, n):
# Find profit including the current job
inclProf = job[i].profit
l = binarySearch(job, i)
if (l != -1):
inclProf += table[l];
# Store maximum of including and excluding
table[i] = max(inclProf, table[i - 1])
return table[n-1]
# Driver code to test above function
job = [Job(1, 2, 50), Job(3, 5, 20),
Job(6, 19, 100), Job(2, 100, 200)]
print("Optimal profit is"),
print(schedule(job))
```
#####Pay
In US with 1-3 years of experience at a mid-size company: ~$117k (Junior)
In US with 8+ years of experience at a mid-size company: ~$154k (Senior)
#####Things to consider
- Back end development can be offered as an independent service in the form of BaaS
- The backend web developer should understand the goals of the website and come up with effective solutions which also means understand the front-end well
#####You should reconsider if...
- You generally give up after a few attempts at a problem
- You are quick to asking someone else for the answer before researching on your own
- You are more reactive and less risk-accessing
- You have don't like looking at data and working with algorithms
---
###FullStack Developer
Is able to work on both the front end and back end portions of an application or website. A full stack developer has specialized knowledge of all stages of software development, including server, network, and hosting environment; relational and non-relational databases; interacting with APIs; user interface and user experience; quality assurance; security; customer and business needs. Being a full stack developer means taking a holistic view — comparing the pros and cons of both back-end and front-end before determining where the logic should sit.
#####Non-Technical Qualities to have:
- Flexibility and adaptability
- Very big team player and/or team leader
- Strategic thinking
- Communication skills are stellar
- Creativity
- Analytical
#####Am I a fit?
- I can work well in most environments, whether it's internal or external
- I enjoy when something looks great, but also works great.
- I enjoy challenges and am determined to solve them in the most efficient way
- I like to plan things out to the detail and can communicate what I am capable of doing and not capable of doing to my team
#####Technical Skills
Front-end Languages and Frameworks (HTML, CSS, JS), Backend Technologies and Frameworks (Python, Ruby, SQL)
#####Various Titles
- FullStack Developer
- Solutions Engineer
- FullStack QA Engineer
- Software Developer
#####Thinking
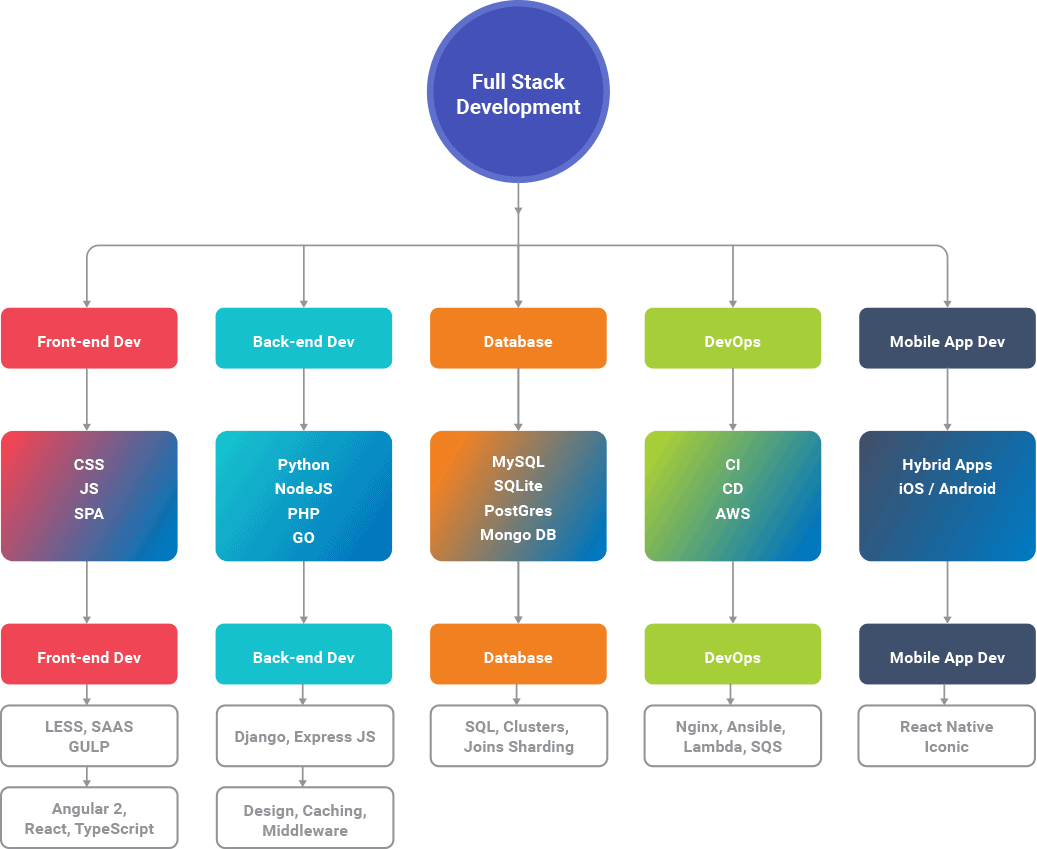
#####Pay
In US with 1-3 years of experience at a mid-size company: ~$96k (Junior)
In US with 8+ years of experience at a mid-size company: ~$128k (Senior)
#####Things to consider
- As a full stack engineer you have a lot of opportunity to grow and decide if you want to stay full stack or go into something more specific
- You are a highly sought after hire currently because of your ability to do both front and back end.
#####You should reconsider if...
- You don't really enjoy doing both design/creative work and data manipulation
- You don't like working with multiple teams
- You don't have great time management or like to work on a more leisure schedule
---
###Mobile iOS and/or Android Developer
Builds apps for mobile devices, including iOS and Android. A mobile developer might use Java, Swift, and Objective-C. Mobile developers can be conditionally called the front-end developer, since they mostly works with the app’s interface. However, they also play the role as the back-end developer when it comes to more complex builds that require internet connection and server communication - so in general, they stick to the Mobile Developer title.
#####Non-Technical Qualities to have:
- Business knowledge
- Agile Methodology
- Collaborative
- Creative
- Communication
#####Am I a fit?
- I really enjoy the idea of having technology be mobile and making it functional
- I like to think about the way people use their phones and how certain apps are ran
- Before I go into something, I like to do more research on my audience and who might be looking at my work
- I take feed back well and work very well independently and on cross-functional teams
#####Technical Skills
Linux/Unix, Phython, Perl, Shell Scripting, Java, C#, Swift, ORACLE, Apache, iOS
- Design: UX/UI
- BONUS: Business Research, Business Development, Analytics
#####Various Titles
- Mobile App Developer
- App Developer
- iOS Engineer
- Android Engineer
#####Thinking
#####Pay
In US with 1-3 years of experience at a mid-size company: ~$94k (Junior)
In US with 8+ years of experience at a mid-size company: ~$115k (Senior)
#####Things to consider
- There will always be a high demand for Mobile App Devs and their skill set is very specific to the Mobile environment. That being said, if you can do it you won't be out of work or find it hard to get work.
#####You should reconsider if...
- You aren't on your phone a lot
- Don't use a lot of Apps
- Don't have an interest in mobile apps
- Don't want to think about internet on phones
--
# Conclusion
I built this with the intention of helping people understand more about some of the most common titles as a Developer to help make better developers. I hope this was helpful.
| kvyshh |
907,369 | Why Slope Game become a popular game? | Slope Game is a racing game in which you must complete various tracks while controlling a ball. There... | 0 | 2021-11-24T04:42:15 | https://dev.to/slopegameonl/why-slope-game-become-a-popular-game-4na3 | slopegame, gameonline, videogame | Slope Game is a racing game in which you must complete various tracks while controlling a ball. There are numerous tracks to complete and work with. When racing, it's just you and the track, so you're not up against other people.

It's similar to Impossible Road in certain aspects. You were in charge of a vessel (which looked like a ball) on a track in that classic mobile game. You strive to complete as many checkpoints as possible. That's essentially how Slope Game works, although Impossible Road's infinite track features more curves.
The tracks in Slope Game are shorter, so you can get through them quickly. Its simplicity has made it a popular smartphone game. Here are a few things to keep in mind with the five-star rated game on the App Store.
On PC, you can play Slope game on web browser at: https://slope2unblocked.com
**Good Ideal for short gaming sessions**
One of the most appealing aspects of mobile gaming is the abundance of games of all sizes and lengths. Slope Game can be an excellent game to play if you don't have a lot of time to immerse yourself in the whole experience.
As previously said, the tracks are rather short, allowing you to progress through the levels quickly. You may also jump into another track relatively quickly, which is ideal for the game's tempo. It's one of those casual experiences that makes you appreciate the possibilities of mobile gaming.
It's also a quite soothing game. It's not very chill, but its laid-back vibes may give it that impression at times. As a result, it's a fast-paced game that's also casual enough for any gamer.
**Pick it up and play a game that is both fun and challenging**
Slope is a game that is easy to pick up and play. "Pick up and play" is a phrase you've certainly heard a lot about games over the years. That is to say, it is not overly complicated to understand when you first start it up. It is, in reality, pretty straightforward, as we already discussed.
That said, it does present a small obstacle. This is an excellent technique to keep you on your toes while playing the game. You'll occasionally find yourself in tunnels, in which case you can't contact the walls at all or the game will end.
This is only one example. Then factor in the fact that you'll occasionally have to jump from one platform to the next without falling. These tiny levels of difficulty help to add some competitiveness to the game's otherwise simple, pick-and-play nature.
**Customization**
Customization is something that I believe most gamers would appreciate. Of course, this varies depending on the game, but it allows us to express ourselves a little more freely when the option is available. Even if it is a little light, there is some personalization in Slope Game.
As you progress through the game, you'll gain access to different ball styles. This can surely entice gamers to keep playing, as it's safe to conclude that games are more enjoyable when they are lucrative. Again, this is a minor addition in an otherwise straightforward game, but it adds a wonderful buttery touch. | slopegameonl |
907,426 | RudderStack’s Licensing Explained | Software licensing can be a tricky subject, especially when you are a commercial company building an... | 0 | 2021-11-24T06:39:20 | https://rudderstack.com/blog/rudderstacks-licensing-explained/ | cdp, dataengineering, rudderstack, privacy | Software licensing can be a tricky subject, especially when you are a commercial company building an open-source product like RudderStack.
We want to build RudderStack into a strong company, and we keep some of our features under our enterprise license to help with that. We also want to build the best product and distribute it in the most effective fashion, and that is under an open-source license. We have to balance which parts of our software should be under our enterprise license and which should be under open source licenses.
From a customer's viewpoint, we see how this could be confusing. In this post, we'll explain how our software is licensed.
Open Source
-----------
### [AGPL-3.0](https://www.gnu.org/licenses/agpl-3.0.en.html/)
The core of RudderStack - the components that make up our Event Stream feature - is open source. It is in our [rudder-server](https://github.com/rudderlabs/rudder-server/) repository.
We are the only open source customer event streaming software available (at least that we've been able to find). We have more than 2,000 stars on GitHub and approximately 300 open source users.
A simplified explanation of the AGPL-3.0 license is that you can use and modify rudder-server however you want, but if you distribute it in any way - including offering it as SaaS - you have to make all of the source code for the derivative software available under the AGPL-3.0 license.
The AGPL-3.0 license provides us the most protection against competition while still being open source. That's the reason we have our core functionality, rudder-server, under it.
### [The MIT License](https://opensource.org/licenses/MIT/)
A majority of RudderStack's third-party destination integrations live in the [rudder-transformer](https://github.com/rudderlabs/rudder-transformer/) repository. They are open source as well, licensed under the MIT License.
Almost all of our SDKs and instrumentation repos for tooling and utilities are open source too. We also have some of our data modeling repos - for use-cases like customer journey analysis and sessionization for data residing in your data warehouse - open sourced under the MIT license. You can find all these repos in our [GitHub organization](https://github.com/rudderlabs/).
A simplified explanation of the MIT License is that you can do whatever you want with the source code - including distributing and commercializing it - as long as you include the original copyright and license in any copy of the derivative software that you distribute.
The MIT License provides us very little protection from competition, but it allows a lot of flexibility and freedom for the developers using our code. That's the reason we have our non-core functionality - things that *would not* make sense for us to distribute or commercialize on their own - under it.
> Note: We have a few repositories that are forked from other repos and are under their licenses. Most are under the Apache-2.0 license, but there are a few under various other licenses based on where they are forked from.
Enterprise License
------------------
All of our Pro and Enterprise features are under our enterprise license. The source code for this software isn't publicly available and is a closed source, but any of our Enterprise customers that request it are given access to these repositories. So, even though our enterprise license is a closed source license, the repositories are code available for all our Enterprise customers.
Features licensed under our enterprise license include:
- Warehouse Actions
- Cloud Extract
- Transformations
- Event Replay
- SSO (Single Sign-On)
A simplified explanation of our enterprise license is that you can only use the software under it as we specify. You can only use it in your RudderStack instance and only if you are an Enterprise customer. If you build anything on top of it or spin up your own instance, you cannot distribute or commercialize it and are not allowed to use it if you aren't an Enterprise customer.
Our enterprise license provides us the highest level of protection from competition, but we try our best to keep our software transparent and the source code easy to access by making it source available to Enterprise customers. That's the reason we have our core, differentiated functionality - things that *would* make a lot of sense to distribute or commercialize on their own - under it.
Licensing can be Confusing. We Hope This Helped.
------------------------------------------------
Hopefully, this post helps clarify RudderStack's licensing. Open core products like ours frequently end up with complicated licensing that changes over time. We're trying to avoid that by being intentional with how we license our software components and limiting the number of licenses we use, so customers and contributors don't have to deal with that complexity.
If better licensing options are available in the future, we will consider changing to them. As of today, this licensing configuration is the best we have found for our software and our business, and we will hopefully stick with it for a long time.
Sign up for Free and Start Sending Data
---------------------------------------
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app. [Get started](https://app.rudderlabs.com/signup?type=freetrial/). | teamrudderstack |
907,667 | Adding registration to SilverStripe and controlling priveleges | Today we are adding a fundamental feature to the basic Book Review platform we started with in our... | 15,658 | 2021-11-25T13:54:06 | https://dev.to/andersbjorkland/adding-registration-to-silverstripe-and-controlling-priveleges-k4h | php, silverstripe | Today we are adding a fundamental feature to the basic Book Review platform we started with in our previous article. Last time we added book, author, and review models in this SilverStripe based application. We had the ability to add a review, albeit in a somewhat tedious way, but only one user could do so. Today we will see how to add a register page to our application so many more can take part, and control what content they can access.
> And as previous, if you want to check out the code for this page, you can find it here: https://github.com/andersbjorkland/devto-book-reviewers/tree/registration
## Registration page
There already exists the model for handling users in SilverStripe. This is represented by the Member-class and it comes out of the package with the CMS. We are going to build a registration page for creating new Members.
What we need is:
* A RegisterController to serve the registration page with its form, and handle the form submission.
* A Template to display the registration form.
* A route to the registration page.
Sounds pretty simple, right? Well, let's say someone writing this had to iron out some errors because he thought it would be that simple. What we'll do here though is error-free (and we'll do it in a way that makes sense).
### The Wonderous RegisterController
Wonderous might be a bit hyperbolic, but we'll start with a simple controller that we'll add some neat features to. The main purpose of the controller is to serve and handle the form submission. Let's take a peek at it.
{% details ./app/src/Controller/RegisterController.php %}
```php
<?php
namespace App\Controller;
use App\Form\ValidatedAliasField;
use App\Form\ValidatedEmailField;
use App\Form\ValidatedPasswordField;
use SilverStripe\CMS\Controllers\ContentController;
use SilverStripe\Forms\FieldList;
use SilverStripe\Forms\Form;
use SilverStripe\Forms\FormAction;
use SilverStripe\Forms\RequiredFields;
use SilverStripe\Security\Member; // Will be used later when we do register a new member.
class RegistrationController extends ContentController
{
private static $allowed_actions = [
'registerForm'
];
public function registerForm()
{
$fields = new FieldList(
ValidatedAliasField::create( 'alias', 'Alias')->addExtraClass('text'),
ValidatedEmailField::create('email', 'Email'),
ValidatedPasswordField::create('password', 'Password'),
);
$actions = new FieldList(
FormAction::create(
'doRegister', // methodName
'Register' // Label
)
);
$required = new RequiredFields('alias', 'email', 'password');
$form = new Form($this, 'RegisterForm', $fields, $actions, $required);
return $form;
}
public function doRegister($data, Form $form)
{
// To be detailed later
}
}
```
{% enddetails %}
As we can see, the controller is pretty simple. It has a method called `registerForm` that returns a form and will be accessed in a template with `$registerForm`. We will be creating a new `Page`-type further down that will be our point of entry to this controller and the template to display it.
The form that will be served is made up of a fieldlist with three fields. The first field is a `ValidatedAliasField`, the second is a `ValidatedEmailField`, and the third is a `ValidatedPasswordField`. These fields are custom fields that we will create with various validation rules. We have attached a *register*-button to the form that will submit the form to the `doRegister` method when clicked. Before we get to the `doRegister` method, we need to address the custom fields.
#### Custom Fields
With validation rules, we can control that an alias and an email address are unique. We will also require a password to be at least 8 characters long. Here's how we do it:
{% details ./app/src/Form/ValidatedAliasField.php %}
```php
<?php
namespace App\Form;
use SilverStripe\Forms\TextField;
use SilverStripe\Security\Member;
class ValidatedAliasField extends TextField
{
public function validate($validator)
{
$alias = $this->Value();
$member = Member::get()->filter(['FirstName' => $alias])->first();
if ($member) {
$validator->validationError(
$this->name,
'Alias is already in use',
'validation'
);
return false;
}
return true;
}
}
```
{% enddetails %}
{% details ./app/src/Form/ValidatedEmailField.php %}
```php
<?php
namespace App\Form;
use SilverStripe\Forms\EmailField;
use SilverStripe\Security\Member;
class ValidatedEmailField extends EmailField
{
public function validate($validator)
{
$email = $this->Value();
$member = Member::get()->filter(['Email' => $email])->first();
if ($member) {
$validator->validationError(
$this->name,
'Email is already in use',
'validation'
);
return false;
}
return true;
}
}
```
{% enddetails %}
{% details ./app/src/Form/ValidatedPasswordField.php %}
```php
<?php
namespace App\Form;
use SilverStripe\Forms\PasswordField;
class ValidatedPasswordField extends PasswordField
{
public function validate($validator)
{
$value = $this->Value();
if (strlen($value) < 6) {
$validator->validationError(
$this->name,
'Password must be at least 6 characters long',
'validation'
);
return false;
}
return true;
}
}
```
{% enddetails %}
As may become appearant from these classes, we are just extending whatever field we want to validate. We need to override the `validate()` method and apply our own validation rules. For both *alias* and *email* we need to check if the value is already in use. If we find a user with it, then the validation fails. For the *password* we need to check if the length is at least 6 characters long. When we receive the form data in our controller we can use a `validationResult()` method to check if the form submission is valid. Read on below so seehow we do that when we create a new member.
#### Creating a new Member
So we have submitted a form and we need something that catches its content and store it in the database.
{% details We update ./app/src/Controller/RegistrationController.php %}
```php
<?php
namespace App\Controller;
use App\Form\ValidatedAliasField;
use App\Form\ValidatedEmailField;
use App\Form\ValidatedPasswordField;
use SilverStripe\CMS\Controllers\ContentController;
use SilverStripe\Forms\FieldList;
use SilverStripe\Forms\Form;
use SilverStripe\Forms\FormAction;
use SilverStripe\Forms\RequiredFields;
use SilverStripe\Security\Member; // Yay, this comes in handy now!
class RegistrationController extends ContentController
{
private static $allowed_actions = [
'registerForm'
];
public function registerForm()
{
// ...
}
public function doRegister($data, Form $form)
{
// Make sure we have all the data we need
$alias = $data['alias'] ?? null;
$email = $data['email'] ?? null;
$password = $data['password'] ?? null;
/*
* Check if the fields clear their validation rules.
* If there are errors, then the form will be updated with the errors
* so the user may correct them.
*/
$validationResults = $form->validationResult();
if ($validationResults->isValid()) {
$member = Member::create();
$member->FirstName = $alias;
$member->Email = $email;
$member->Password = $password;
$member->write();
$form->sessionMessage('Registration successful', 'good');
}
return $this->redirectBack();
}
}
```
{% enddetails %}
This method receives the form data and checks if it is valid. If it is, it creates a new Member and writes it to the database. If it isn't, it redirects the user back to the registration page, where the user will be informed of the errors.
> Something to note for the security-conscious developer is that it appears as we simply set a plain password to the Member. This is not a good practice, as it is not secure. It's a good thing then that the Member-class hashes the password before writing it to the database (with `onBeforeWrite()`). [Read more about passwords and security on the official documentations on SilverStripe](https://docs.silverstripe.org/en/4/developer_guides/security/secure_coding/#passwords).
So far so good. We have a created a form and its fields. We have a controller that serves the form and handles its submission. **But!** We have no way of seeing it yet.
### Creating a registration page
We need a page and route to serve the form. We also need a template that hooks into the $registerForm variable (or rather: the Controller-method that serves the form).
Here's the plan:
* We create a RegisterPage that points to the RegistrationController.
* We create a template that includes the registration form.
* We create an instance of the RegisterPage, specifying its route and title.
**Create RegisterPage as a subclass of Page**
{% details ./app/src/Page/RegisterPage.php %}
```php
<?php
namespace App\Page;
use App\Controller\RegistrationController;
use Page;
class RegistrationPage extends Page
{
public function getControllerName()
{
return RegistrationController::class;
}
}
```
{% enddetails %}
This is a new model of a Page-type (actually it's a *SiteTree* but that's beside the point). Whenever we create a new instance of this class, SilverStripe will try to look for a template that corresponds to its namespace. So let's create one.
**Create a template layout**
{% details ./themes/simple/templates/App/Page/Layout/RegistrationPage.ss %}
```twig
<% include SideBar %>
<div class="content-container unit size3of4 lastUnit">
<article>
<h1>$Title</h1>
<div class="content">$Content</div>
</article>
$registerForm
</div>
```
{% enddetails %}
> A note on the theme: If you have created a copy of simple and are working on that one instead, remember to change the name of the theme to "whatever-you-have-called-it" in `app\_config\theme.yml`. Then you need to run `composer vendor-expose` to copy/expose any public assets to the public folder.
**Instantiate a RegisterPage**
We almost have a registration page now. We are going to use the admin-interface to create it, but before that we need to update the database to be ready for it. In the browser, visit: `localhost:8000/dev/build`
Now, visit `localhost:8000/admin`. When we are logged in, we will by default be shown the "Pages" tab. Let's click on `Add new`. For *Step 1* we leave it at "Top level". In *Step 2* we select `Registration Page`. This is the type we just coded. Next we click on `Create`. This takes us to a page where we can edit the page. Let's add the following:
| | |
| ------------- |:--------------|
| **Page name** | Registration |
| **URL segment** | registration |
| **Navigation label** | Registration |
| **Content** | Register a new user |
Then we can click `Save`. After the loading we can click `Publish`. We are now **almost** ready to accept new *registered* users to our site.
## Adding priveleges to the new user
So our users can now register, but guess what? They can't access the admin-interface. We want them to be able to make their reviews, and possibly see other peoples reviews. So this is the plan:
* We create a new Group called "Reviewers".
* We add new members to that group in our controller.
* We update our models (`Author`, `Book`, `Review`) to allow the new group to access them.
### Creating a new Group
With the power of SilverStripe's admin interface, let's create this group. In the sidebar menu, click on `Security`. Then click on the `Groups` tab in the upper-right corner. Then click the button `Add Group`. Under the tab `Members`, let's enter for *Group name* `Reviewers`. Then switch to the tab `Permissions`. We will add the permission "Access to 'Reviews' section". Then click on `Create`.
### Add member to the Reviewers-group
We now have a group with access priveleges to add reviews. Let's make sure that members gets this privelege when they register. We will do this by updating the `doRegister` method in our `RegistrationController`:
{% details ./app/src/Controller/RegistrationController.php %}
```php
//...
public function doRegister($data, Form $form)
{
$alias = $data['alias'] ?? null;
$email = $data['email'] ?? null;
$password = $data['password'] ?? null;
$validationResults = $form->validationResult();
if ($validationResults->isValid()) {
$member = Member::create();
$member->FirstName = $alias;
$member->Email = $email;
$member->Password = $password;
$member->write();
// HERE IS OUR UPDATE 👇
$member->addToGroupByCode("reviewers");
$member->write();
$form->sessionMessage('Registration successful', 'good');
}
return $this->redirectBack();
}
//...
```
{% enddetails %}
> It may look clunky having to write the member twice. We do this so we have a database-ID for the member that can be associated to the group Reviewers.
### Models and permissions
Now we need to update our models to allow users with the new group to access them. We will do this by adding the methods `canView`, `canEdit`, `canCreate` and `canDelete` to our models. In essence, we are ensuring that users that has access to view the Review-section of the CMS will have access to each model.
{% details ./app/src/Model/Author.php %}
```php
<?php
namespace App\Model;
use App\Admin\ReviewAdmin; // 👈 Remember to include this
use SilverStripe\ORM\DataObject;
use SilverStripe\Security\Permission; // 👈 and this
class Author extends DataObject
{
// ...
public function canView($member = null)
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
public function canEdit($member = null)
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
public function canDelete($member = null)
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
public function canCreate($member = null, $context = [])
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
}
```
{% enddetails %}
{% details ./app/src/Model/Book.php %}
```php
<?php
namespace App\Model;
use App\Admin\ReviewAdmin; // 👈 Remember to include this
use SilverStripe\ORM\DataObject;
use SilverStripe\Security\Permission; // 👈 and this
class Book extends DataObject
{
// ...
public function canView($member = null)
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
public function canEdit($member = null)
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
public function canDelete($member = null)
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
public function canCreate($member = null, $context = [])
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
}
```
{% enddetails %}
{% details ./app/src/Model/Review.php %}
```php
<?php
namespace App\Model;
use App\Admin\ReviewAdmin; // 👈 Remember to include this
use SilverStripe\ORM\DataObject;
use SilverStripe\Security\Member;
use SilverStripe\Security\Permission; // 👈 and this
use SilverStripe\Security\Security;
class Review extends DataObject
{
// ...
public function canView($member = null)
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
public function canEdit($member = null)
{
$reviewer = $this->Member()->ID;
$currentUser = Security::getCurrentUser()->ID;
if ($reviewer === $currentUser) {
return true;
} else {
return false;
}
}
public function canDelete($member = null)
{
$reviewer = $this->Member()->ID;
$currentUser = Security::getCurrentUser()->ID;
if ($reviewer === $currentUser) {
return true;
} else {
return false;
}
}
public function canCreate($member = null, $context = [])
{
return Permission::check('CMS_ACCESS_' . ReviewAdmin::class, 'any', $member);
}
}
```
{% enddetails %}
We see that our `Review` model is somewhat different on its permissions than `Author` and `Book`. We let other reviewers see our reviews, but only the author can edit or delete them. Having updated our models we need to update the database. We visit `localhost:8000/dev/build'.
## Register and review!
Wrapping it up, we have expanded our Book Review Platform to include a registration system. Users can now sign up and get started with that Dune-review!
## What's next?
Writing reviews is still not very pleasant. When we next revisit this project we will see how we can make it better.
A few things to note before we leave: There's currently no check if a user is already logged in when registering. We could check for this in the RegisterController. Another thing is that we could add a login-link on the navigations page. We just assume that our users will think of visiting the `/admin` page.
Did you learn something, or have something to add? Feel free to leave a comment below. | andersbjorkland |
907,433 | Got my #hacktoberfest21 badge 🥳🎉 | Hello dev's ! Presenting to you my #hacktoberfest21 Badge 🥳 Through... | 0 | 2021-11-24T07:28:27 | https://dev.to/pranavyadav/got-my-hacktoberfest21-badge-3lpf | hacktoberfest, opensource, github, digitalocean | ## Hello dev's !
### Presenting to you my #hacktoberfest21 Badge 🥳
Through contributing to #opensource for more than 2 awesome years I've developed my perspective about OSS 😊.
It was a great experience contributing to #opensource 🤩.
Looking forward to contribute more to #opensource.
> Knowledge must be free, so do great innovations and literature.
>
> <cite>-- Anonymous</cite>
<br>
❤️ From **_Pranav Yadav_**
* LinkedIn [**yadavpranav**](https://linkedin.com/in/yadavpranav)
* GitHub [**pranav-yadav**](https://https://github.com/pranav-yadav)
* Twitter [**pranavyadav_**](https://twitter.com/pranavyadav_) | pranavyadav |
907,614 | Django Basics: Folder Structure | Introduction After setting up the development for the Django framework, we will explore... | 15,539 | 2021-11-24T10:49:12 | https://www.meetgor.com/django-basics-folder-struct/ | django, python, backend, webdev | ---
title: Django Basics: Folder Structure
subtitle: Understanding the folder structure of Django Projects and Applications
published: true
tags: django, python, backend, webdev
canonical_url: https://www.meetgor.com/django-basics-folder-struct/
cover_image: https://res.cloudinary.com/dgpxbrwoz/image/upload/v1637745125/blogmedia/4_gnddxj.png
series: Django Basics
---
### Introduction
After setting up the development for the Django framework, we will explore the project structure. In this part, we understand the structure along with the various components in the Project as well as individual apps. We will understand the objective of each file and folder in a brief and hopefully by the end of this part, you'll be aware of how the Django project is structured and get a good overview of the flow of development in the Django project.
## Project Structure
We will create a Django project from scratch and understand it from the ground up. As in the previous part, I've shown you how to create a project. In this section, we'll create a project `Blog`. TO do that, we'll create a folder called `Blog`, install and set up the virtual environment as discussed and explained in the previous part.
After the virtual environment is created and activated, we'll create the project.
```
django-admin startproject Blog .
```
After this command, if we see the directory structure, it should look something like this:

As we can see there are 6 files and a folder. The base folder is for the configuration at a project level. I have actually not shown the `venv` ( using `-I venv` option on tree command) as it is out of the scope of this series. The `venv` folder contains modules and scripts which are installed in the virtual environment.
So, lets break the folder structure down into understandable files.

### manage.py
Our project consists of a `manage.py` file which is to execute several commands at a project level. We do not have to edit any of the contents of this file (never). It is the file that allows us to run the server, apply migrations, create an Admin account, create apps, and do a lot of crucial things with the help of python.
So, it's just the command-line utility that helps us interact with the Django project and applications for configurations.
### Project Folder
Now, this is the folder where the project-configuration files are located. **The name of the folder is the same as that of the project**. This makes the folder unique and hence creates a standard way to store files in a structured way.
The folder is a python package which is indicated by the `__init__.py` file. The purpose of the `__init__.py` file is to tell the Python environment that the current folder is a Python package.
The folder consist of several files(5 files):
### settings.py
This is a really important file from the project's point of view. This contains certain configurations that can be applied to the rest of the project (or all the apps).
In the `settings.py` file, we can do some of the following operations :
- List of `applications` that might be pre-installed or user-defined.
- Configure the Middleware.
- Configure and connect the Database.
- Configure Templates/Static/Media files.
- Custom Configuration for Time-Zones, Emails, Authentication, CORS, etc.
Besides the above-mentioned options, there is a lot of project-specific configurations or application-specific settings as well.
Here, you'll have a question,
### WHAT IS AN APPLICATION?
An application is a component of a project. There are also Python packages that are made to be used as a Django app that allows reusing the components. But when we are developing the project, we can break a complex process/project into individual apps.
For Example, a project of `Blogging Platform` might have an application for `posts`, `users`, `api`, `homepage`, etc. So the project `Blogging Platform` might have separated the components like its API, Homepage, Post, Users, and so on to keep the development independent and well organized.
So, we can understand apps as separate components of a large project. We can also understand apps as reusable components, you can use the `posts` app in another project or in a particular app of the same project making it easier and faster to create the project.
### urls.py
This is a file for managing the `URL` routes of the project. We'll discuss URLs and Views in their own part in the series. This file basically has a list of URLs that should be paired with a `view` or any other function. In the project folder, the URL patterns mostly link a baseurl to the URL file of the particular application. Don't worry if you can't get some of the terms, you'll clearly understand when we see them in the future parts of this series.
### wsgi.py
WSGI or Web Server Gateway Interface is a file that is used to configure the project for production or deployment. This takes care of the server when we deploy into production. It is a Synchronous Web Server i.e. it listens to only one request and responds to that at a time.
Some of the common WSGI servers are [Gunicorn](https://gunicorn.org/), [Apache](https://docs.djangoproject.com/en/3.2/howto/deployment/wsgi/modwsgi/), [uWSGI](https://docs.djangoproject.com/en/3.2/howto/deployment/wsgi/uwsgi/), [cherrypy](https://docs.cherrypy.dev/), [Aspen](https://github.com/buchuki/aspen/blob/master/aspen/wsgi.py), etc.
### asgi.py
ASGI or Asynchronous Server Gateway Interface is also similar to the WSGI file but it serves as an asynchronous web server. This file handles the requests which might be asynchronous i.e. the web server can respond to multiple requests and respond to them at a time. We can even send tasks to the background using this type of server configuration.
Some of the common ASGI servers are [Uvicorn](https://www.uvicorn.org/), [Daphne](https://docs.djangoproject.com/en/3.2/howto/deployment/asgi/daphne/), [Hypercorn](https://docs.djangoproject.com/en/3.2/howto/deployment/asgi/hypercorn/), etc.
## Creating a Django Project Application
So, let's create an application to see the structure of the basic app in Django. To create an app, we can use the `startapp` option with the `python manage.py` command followed by the name of the app like:
```
python manage.py startapp name
```
Here, `name` can be any app name you'd like to give.
## Application Structure
After creating an app, let the name be anything it should have a similar structure as :
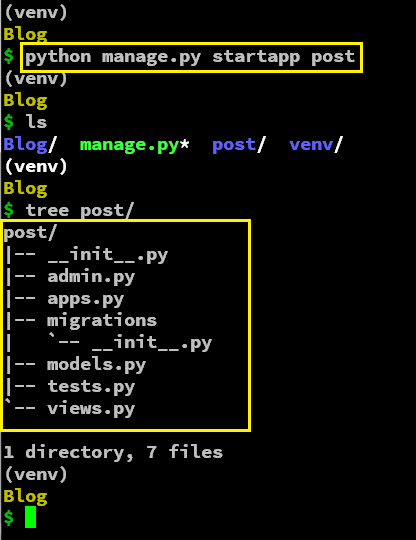
As we can see there are a couple of things to be discussed here. The main components that we are going to work on within developing the application in the project are: `models.py`, `views.py`, `test.py`. There are other files that we will create manually like the `urls.py`, `serializers.py`, etc.
You also need to add the name of the app in quotes in the `INSTALLED_APPS` list in the `settings.py` file. Something like this:

The application files can be summarized as :

Let us look at each of the files and folders in the application:
### models.py
As the same suggests, we need to define the model of a database here. The actual structure and the relationship are created with the help of python and Django in this file. This is the place where the crust of the web application might be defined.
There are various aspects in creating a model like `Fields`, `Relationship`, `Meta-data`, `methods`, etc. These are defined with the help of python along with the Django Models. In most cases, a model is like a single `table` in an actual database.
The file is quite important and interesting as it abstracts away the manual work of typing `SQL` queries to create the database.
### migrations
This migrations folder is a way for Django to keep track of the changes in the database. At every `migration` or actual query that runs to create the table or the database structure. There might be multiple steps or iteration of the database, this folder stores those pieces of information.
To make an analogy, it is like a `.git` folder but for keeping track of the migrations or changes to the database.
### admin.py
This is the file for performing the operations at the admin level. We generally use this file to register the models into the `Admin section` without touching any frontend part. It provides a built-in `CRUD`(Create Read Update Delete) functionality to the model. This is really good for testing up the model manually before putting effort into the frontend part.
Other than this, we can customize the admin section with this file. We will see the details in the part of the `Admin section` in this series.
### views.py
This is a file, that acts as a controller/server logic for the Django framework. We can define functions and classes as a response to the incoming requests from the server via the `urls.py` file. There are a couple of approaches when it comes to writing the format of the functions like `class-based views`, `function-based views`, and others depending on the type of operation is been done.
As said earlier, it is the `V`(View) in the `MVT` architecture in Django Framework. This is the place where we write the logic from the server-side to let's say render HTML pages(templates), query to the database with CRUD operations, return an HTTP response, etc.
### urls.py
This is the file in which a list of URL patterns is mapped to the particular view function. This `urls.py` is specific to the app and it might be prefixed with the URL route mentioned in the project folder's `urls.py` file.
So, not going much deeper, simply to put it's a map of a particular URL path with a function associated to it which gets triggered(called) when the user visits the URL.
### tests.py
This is a file where we can perform automated tests on the application. This might be in integration with models, other applications, project settings, etc. This is a component that Django makes it to have easy and quick unit testing along with the Python modules for advanced testing. It is quite easier to integrate python modules and libraries into almost anything in the Django Project.
### apps.py
This is the file for app-level configuration. We can change the default fields, app name, email settings, other module-specific settings that can be used in the models, views, or in another place that can be defined here.
## Other Folders/files
Apart from the app folder and the project folder, we may have other folders like the `templates`, `static`, `media`, etc. There are also python package-specific folders for which you may need to create folders.
### Templates
There are a couple of standard ways you can set up your Templates folder. Either in the root project or inside individual apps. The choice is yours, however, you feel comfortable. I personally use only one template folder in the root directory, but you can keep it wherever you want, but these two are the standard ones for ease of reading and maintaining the projects.
### Static
The Static folder is the folder in which you store your `css`, `javascript`, and `images`(images or media files that are used in the templates). This is a good way to improve the performance as in the production the webserver collects all the static files and stores them in a single place for responding to the requests. The template folder if present in the root folder, has a sub-folder as the application names and inside the `app-name`, we put in all the `.html` or other template files.
As similar to the `template` folder, the location can be modified or set as a configuration from the settings.py file. Usually, the static files(`.css`, `js`, etc) are stored in the root folder with app names as subfolders.
### Media
The media folder is where you can store the media-specific to the user or the application processed data. For example, we can store the profile pictures of users, email attachments if it's an email application, thumbnails of the posts for a blogging platform, etc.
The configuration of the Media folder is quite similar to the Static folder but it has certain additional configurations. We'll look at them in their sections in this series.
Phew! That was all the folder structure you need to get started with Django. There might be other folders and files specific for project, application, python modules but it won't be much hard to understand those as well.
## Conclusion
From this part, we were able to understand the folder structure of the Django framework. We explored the various files and folders with their use cases and their purpose. So, by reading the above description of the files and folders you might have got a rough idea about the flow of the development cycle in Django.
In the next part, we'll start with actually getting hands dirty in the code and making our first view. Thank you for reading and Happy Coding :)
| mr_destructive |
907,620 | Day 70/100 Drawing on Canvas | "Drawing is deception." – M.C. Escher, cited by Bruno Ernst in The Magic Mirror of M.C. Escher | 15,249 | 2021-11-24T10:53:57 | https://dev.to/riocantre/day-70100-drawing-on-canvas-418d/ | 100daysofcode, motivation, challenge, programming | "Drawing is deception."
– M.C. Escher, cited by Bruno Ernst in The Magic Mirror of M.C. Escher
 | riocantre |
907,655 | Creative coding with Replit | If you're into creating graphics, 3D worlds, games, sounds, and other more creative things, Replit... | 0 | 2021-11-24T11:36:11 | https://docs.replit.com/tutorials/34-creative-coding | If you're into creating graphics, 3D worlds, games, sounds, and other more creative things, Replit has a number of tools and environments to help you. One of the benefits of coding with Replit is that you can switch between different programming paradigms and try them out without having to set it all up yourself.
## What is creative coding?
For this article, we'll consider a tool to be a creative coding one if its main purpose is to create graphics, visual models, games, or sounds. Plain HTML or JavaScript can be used for this type of thing, but we're looking for tools and languages that are a bit more specialised.
Here's a list of tools we'll be taking a look at for the more creative side of Replit:
- Python `turtle`
- p5.js
- Kaboom
- Pygame
- Pyxel
- GLSL
### Python `turtle`
Turtle graphics is a classic of the genre. First created way back in the 1960s, the idea is that there is a small turtle robot on the screen, holding some pens. You give the turtle commands to move around and tell it when to put the pen down and what color pen to use. This way you can make line or vector drawings on the screen. The turtle idea comes from a type of actual robot used for education.
Replit has support for Python `turtle`, which is the current incarnation of the turtle graphics idea. Choose the "Python (with Turtle)" template when creating a new repl to use it.

Python `turtle` uses commands like `forward(10)`, `back(10)`, `left(50)`, `right(30)` `pendown()` and `penup()` to control the turtle. The methods `forward` and `back` take the distance the turtle should move as their arguments, while `left` and `right` take the angle in degrees to turn the turtle on the spot (the turtle is very nimble!). You can use `pendown` and `penup` to tell the turtle to draw or not draw while moving.
When you create a new Python (with Turtle) template, you'll notice a small program is included as an example to show you the basics. When you run this program, it will draw a square with each side a different color.

Although `turtle` has a small set of simple commands, it can be used to make some impressive-looking graphics. This is because you can use loops and calculations and all the other programming constructs available in Python to control the turtle.
Try this `turtle` program for example:
[https://replit.com/@ritza/python-turtle](https://replit.com/@ritza/python-turtle)
```python
import turtle
t = turtle.Turtle()
t.speed(0)
sides = 3;
colors = ['red', 'yellow', 'orange']
for x in range(360):
t.pencolor(colors[x % sides])
t.forward(x * 3 / sides + x)
t.left(360 / sides + 1)
t.width(x * sides / 200)
```
This code generates a spiral by drawing a slightly rotated and increasingly larger triangle for each of the 360 degrees specified in the main loop. This short little script produces a cool-looking output:

Try changing up the `sides` parameter to draw different shapes, and play with the color combos to come up with new artworks.
### p5.js
[p5.js](https://p5js.org) is a JavaScript graphics and animation library developed specifically for artists and designers - and generally people who have not been exposed to programming before. It's based on the [Processing](https://processing.org) software project, and brings the Processing concept to web browsers, making it easy to share your "sketches", which is the p5.js name for programs.
Replit has two templates for p5.js - one for pure JavaScript, and another that interprets Python code, but still uses the underlying p5.js JavaScript library. You can use the Python version if you are more familiar with Python syntax than JavaScript syntax.

If you create a repl using one of the templates, you'll see it includes some sample code. Running it will draw random color circles on the screen wherever the mouse pointer is.

p5.js has two main functions in every sketch: `setup()`, which is run once when the sketch is executed, and `draw()`, which is run every frame.
In the `setup` function, you generally set up the window size and other such parameters. In the `draw` function, you can use [p5.js functions](https://p5js.org) to draw your scene. p5.js has functions for everything from drawing a simple line to rendering 3D models.
Here is another sketch you can try (note that this is in JavaScript, so it will only work in the p5.js JavaScript template):
[https://replit.com/@ritza/p5-javascript](https://replit.com/@ritza/p5-javascript)
```js
function setup() {
createCanvas(500, 500);
background('honeydew');
}
function draw() {
noStroke()
fill('cyan');
circle(450, 200, 100);
fill('pink');
triangle(250, 75, 300, 300, 200, 275);
fill('lavender')
square(250, 300, 200);
}
```
In this sketch, we draw a few shapes in various colors on the screen, in a kind of 80s geometric art style:
<img src="https://docs.replit.com/images/tutorials/34-creative-coding/p5-shapes.png"/>
The [p5.js website](https://p5js.org/get-started/) has a guide to getting started, plus a lot of references and examples to experiment with.
### Kaboom
Kaboom.js is Replit's own homegrown JavaScript game framework, launched in 2021. It's geared towards making 2D games, particularly platform games, although it has enough flexibility to create games in other formats too. Because it is a JavaScript library, it can be used to develop web games, making it easy to share and distribute your creations with the world.
Replit has two official templates for Kaboom:
- A specialized Kaboom template, with an integrated sprite editor and gallery, as well as pre-defined folders for assets. This is perfect for getting started with Kaboom and making games in general, as you don't need to worry about folder structures or sourcing graphics.
- A 'light' template that is a simple web template with just the Kaboom package referenced. This is for coders with a little more experience, as the intent is to give you more control and flexibility

One of the great features of Kaboom is the simple way you can define level maps, drawing them with text characters, and then mapping the text characters to game elements:
```js
const level = [
" $",
" $",
" $",
" $",
" $",
" $$ = $",
" % ==== = $",
" = $",
" = ",
" ^^ = > = @",
"===========================",
];
```
Another interesting aspect of Kaboom is that it makes heavy use of [composition](https://en.wikipedia.org/wiki/Composition_over_inheritance). This allows you to create characters with complex behaviour by combining multiple simple components:
```js
"c": () => [
sprite("coin"),
area(),
solid(),
cleanup(),
lifespan(0.4, { fade: 0.01 }),
origin("bot")
]
```
Kaboom has a fast-growing resource and user base. The official [Kaboom site](https://kaboomjs.com) documents each feature, and also has some specific examples. There is also a site with complete tutorials for building different types of games at [Make JavaScript Games](https://makejsgames.com).
### Pygame
Pygame is a well-established library (from 2000!) for making games. It has functionality to draw shapes and images to the screen, get user input, play sounds, and more. Because it has been around for so long, there are plenty of examples and tutorials for it on the web.
Replit has a specialised Python template for Pygame. Choose this template for creating Pygame games:

Try out this code in a Pygame repl:
[https://replit.com/@ritza/pygame-example](https://replit.com/@ritza/pygame-example)
```python
import pygame
pygame.init()
bounds = (300,300)
window = pygame.display.set_mode(bounds)
pygame.display.set_caption("box")
color = (0,255,0)
x = 100
y = 100
while True:
pygame.time.delay(100)
for event in pygame.event.get():
if event.type == pygame.QUIT:
run = False
keys = pygame.key.get_pressed()
if keys[pygame.K_LEFT]:
x = x - 1
elif keys[pygame.K_RIGHT]:
x = x + 1
elif keys[pygame.K_UP]:
y = y - 1
elif keys[pygame.K_DOWN]:
y = y + 1
window.fill((0,0,0))
pygame.draw.rect(window, color, (x, y, 10, 10))
pygame.display.update()
```
This code initializes a new `pygame` instance and creates a window to display the output in. Then it has a main game loop, which listens for keyboard arrow key presses, and moves a small block around the screen based on the keys pressed.
Check out some of our tutorials for Pygame :
- [A 2D platform game](https://docs.replit.com/tutorials/14-2d-platform-game)
- [A Juggling game](https://docs.replit.com/tutorials/07-building-a-game-with-pygame)
- [Snake](https://docs.replit.com/tutorials/19-build-snake-with-pygame)
### Pyxel
[Pyxel](https://github.com/kitao/pyxel) is specialised for making retro-type games, inspired by console games from the 80s and early 90s. You can only display 16 colors, and no more than 4 sound samples can be played at once, just like on the earlier Nintendo, Sega, and other classic games systems. If you're into pixel art, this is the game engine for you.
Choose the 'Pyxel' template on Replit to create a new Pyxel environment.

Try this code in a Pyxel repl to draw rectangles of random size and color, changing every two frames:
[https://replit.com/@ritza/pyxel-example](https://replit.com/@ritza/pyxel-example)
```python
import pyxel
import random
class App:
def __init__(self):
pyxel.init(160, 120, caption="Pyxel Squares!")
pyxel.run(self.update, self.draw)
def update(self):
if pyxel.btnp(pyxel.KEY_Q):
pyxel.quit()
def draw(self):
if (pyxel.frame_count % 2 == 0):
pyxel.cls(0)
pyxel.rect(random.randint(0,160), random.randint(0,120), 20, 20, random.randint(0,15))
App()
```
<img src="https://docs.replit.com/images/tutorials/34-creative-coding/pyxel-rect.gif"/>
Take a look in the [examples folder](https://github.com/kitao/pyxel/tree/main/pyxel/examples) on the Pyxel GitHub project to see more ways to use Pyxel.
### GLSL
On the more advanced end of the spectrum, Replit supports GLSL projects. GLSL (OpenGL Shading Language) is a C-style language for creating graphics shaders. Shaders are programs that (usually) run on graphics cards as part of a graphics rendering pipeline. There are many types of shaders - the two most common are vertex shaders and fragment (or pixel) shaders. Vertex shaders compute the position of objects in the graphics world, and pixel shaders compute the color that each pixel should be. This previously required writing code for specific graphics hardware, but GLSL is a high-level language that can run on many different graphics hardware makes.
GLSL gives you control over the graphics rendering pipeline, enabling you to create very advanced graphics. GLSL has many features to handle vector and matrix manipulations, as these are core to graphics processing.
Choose the "GLSL" template to create a new GLSL repl:

The template has a sample fragment shader in the file `shader.glsl` as well as some web code to setup a [WebGL](https://developer.mozilla.org/en-US/docs/Web/API/WebGL_API) resource to apply the shader to. Running the sample will show some pretty gradients on the screen that vary with time and as you move the mouse over it.

Try this code out in the shader file to make a kind of moving "plaid" effect:
[https://replit.com/@ritza/glsl-example](https://replit.com/@ritza/glsl-example)
```c
precision mediump float;
varying vec2 a_pos;
uniform float u_time;
void main(void) {
gl_FragColor = vec4(
a_pos.x * sin(u_time * a_pos.x),
a_pos.y * sin(u_time * a_pos.y),
a_pos.x * a_pos.y * sin(u_time),
1.0);
}
```
Here we set `gl_FragColor`, which is the color for a specific pixel on the screen. A pixel color in GLSL is represented using a `vec4` data type, which is a vector of four values, representing red, green, blue, and alpha. In this shader, we vary the pixel color depending on it's co-ordinate `a_pos`, and the current frame time `u_time`.
If you'd like to dive deeper into the world of advanced graphics and shaders, you can visit Learn OpenGL's [Getting Started: Shaders](https://learnopengl.com/Getting-started/Shaders) resource.
## Wrap up
That wraps up this list of the official creative coding language templates on Replit. Of course, Replit is flexible enough that you can import and use whatever framework or library you want in your projects, so you are not limited to the tools we've looked at here. Replit is also adding more languages and templates everyday, so be sure to watch out for new additions!
| ritzaco | |
907,662 | SvelteKit S3 Multipart Upload: Video Cloud Storage | SvelteKit S3 Multipart Upload: how you can upload large files, such as video to your S3 compatible storage provider using presigned URLs. | 0 | 2021-11-24T12:01:34 | https://rodneylab.com/sveltekit-s3-multipart-upload/ | svelte, javascript, storage, webdev | ---
title: "SvelteKit S3 Multipart Upload: Video Cloud Storage"
published: "true"
description: "SvelteKit S3 Multipart Upload: how you can upload large files, such as video to your S3 compatible storage provider using presigned URLs."
tags: "svelte, javascript, storage, webdev"
canonical_url: "https://rodneylab.com/sveltekit-s3-multipart-upload/"
cover_image: "https://dev-to-uploads.s3.amazonaws.com/uploads/articles/2ilxba3t44f2tuopde9p.png"
---
## 🏋🏽 Uploading Video and other Large File to S3 Compatible Storage
This post on SvelteKit S3 multipart upload follows on from the earlier post on uploading small files to S3 compatible storage. We will see how to upload large video files to cloud storage. In that earlier post we saw using an S3 compatible API (even while using Backblaze, Cloudflare R2, Supabase or another cloud storage provider) makes your code more flexible than using the provider's native API. We also saw the benefits of using presigned URLs for file upload and download. We level up the code from that tutorial here and introduce multipart uploads with presigned URLs. Sticking with an S3 compatible API, we will still leverage the flexibility benefits that brings. I hope you find this a useful and interesting extension to the previous tutorial.
## ⚙️ SvelteKit S3 Multipart Upload: Getting Started
Instead of building everything from scratch, we will use the previous tutorial <a aria-label="Open earlier tutorial on SvelteKit S3 Compatible Storage" href="https://rodneylab.com/sveltekit-s3-compatible-storage/">on SvelteKit S3 Compatible Storage Uploads</a> as a starting point. You can start here and check out the other tutorial another day, although multipart S3 uploads might make more sense if you start with the other tutorial. If you did work through <a aria-label="Open earlier tutorial on SvelteKit S3 Compatible Storage" href="https://rodneylab.com/sveltekit-s3-compatible-storage/">the presigned URL upload tutorial</a>, you can create a new branch in your repo and carry on from your existing code. Otherwise, clone the following repo to get going:
```shell
git clone https://github.com/rodneylab/sveltekit-s3-compatible-storage.git sveltekit-s3-multipart-upload
cd sveltekit-s3-multipart-upload
pnpm install
```
We won't need to add any extra packages beyond the ones we used last time.
## 🔨 Utility Functions
With multipart uploads, the presigned URL part works much as it did for a single upload. The workflow is a little different though. We will still keep the single file upload code and only use this when the file is small. With a multipart upload, we need to create a signed URL for each part we need to upload. Another difference is that once we have uploaded all of the parts to their respective URLs, we then we need to tell the provider we are done. This is so that they can combine the pieces at their end. For this to work we need to add a few more utility functions to our `src/lib/utilities.js` file. On top we will be restructuring our app slightly, so need to export some of the existing functions.
To get going let us import a few extra functions from the S3 SDK. Remember, although we are using the S3 SDK, we can expect our code to work with any S3 compatible provider (recalling only the initial authorisation step will vary from provider to provider).
```javascript
import {
CompleteMultipartUploadCommand,
CreateMultipartUploadCommand,
GetObjectCommand,
PutObjectCommand,
S3,
UploadPartCommand,
} from '@aws-sdk/client-s3';
```
Continuing, in line `18`, export the `authoriseAccount` function because we will want to access it from our SvelteKit endpoint:
```javascript
export async function authoriseAccount() {
```
### Multipart Upload Functions
Next we have to create the function which tells the provider we are done uploading. Add this code to the same file:
```javascript
export async function completeMultipartUpload({ parts, client, key, uploadId }) {
try {
const { VersionId: id } = await client.send(
new CompleteMultipartUploadCommand({
Key: key,
Bucket: S3_COMPATIBLE_BUCKET,
MultipartUpload: { Parts: parts },
UploadId: uploadId,
}),
);
if (id) {
return { successful: true, id };
}
} catch (error) {
console.error('Error in completing multipart upload: ', error);
}
return { successful: false };
}
```
As with `authoriseAccount`, we will need to export `getS3Client`:
```javascript
export function getS3Client({ s3ApiUrl }) { `}
```
Next we want a function to generate presigned URLs. This works just like the function we had for single file upload presigned URLs:
```javascript
export async function generatePresignedPartUrls({ client, key, uploadId, partCount }) {
const signer = new S3RequestPresigner({ ...client.config });
const createRequestPromises = [];
for (let index = 0; index < partCount; index += 1) {
createRequestPromises.push(
createRequest(
client,
new UploadPartCommand({
Key: key,
Bucket: S3_COMPATIBLE_BUCKET,
UploadId: uploadId,
PartNumber: index + 1,
}),
),
);
}
const uploadPartRequestResults = await Promise.all(createRequestPromises);
const presignPromises = [];
uploadPartRequestResults.forEach((element) => presignPromises.push(signer.presign(element)));
const presignPromiseResults = await Promise.all(presignPromises);
return presignPromiseResults.map((element) => formatUrl(element));
}
```
Talking of the single upload, the `generatePresignedUrls` function needs exporting too:
```javascript
export async function generatePresignedUrls({ key, s3ApiUrl }) {</CodeFragment>
```
Lastly, we will create a function to initiate a multipart upload using the S3 SDK:
```
export const initiateMultipartUpload = async ({ client, key }) => {
const { UploadId: uploadId } = await client.send(
new CreateMultipartUploadCommand({ Key: key, Bucket: S3_COMPATIBLE_BUCKET }),
);
return uploadId;
};
```
That was a lot of pasting! Do not worry if it is not 100% clear what we are doing yet, We will start to pull everything together in the next section where we call these functions from our endpoint.
## 📹 Multipart Presigned Upload Endpoint
You might remember from our SvelteKit frontend, we called an endpoint to tell us the presigned URL to upload the file to. Once we had that URL back, we proceeded with the upload directly from the frontend to the cloud provider. With multipart uploads, our ambition is again to upload directly from the frontend to our provider. For this to work we will change the logic in the endpoint.
We will pass the file size to the endpoint when we request the presigned upload URLs. Based on the file size, our logic will decide whether we will do a single file or multipart upload. When we create an S3 client object, we get back some parameters from the provider which give us minimum, maximum and recommended file part size. So to look at a concrete example. Let's say we want to upload a 16 MB video and the recommended part size is 5 MB. In this case we will need four parts: the first 3 parts will be 5 MB and the final one, 1 MB. Typically, the minimum part size is not enforced by the provider for the final part in a multipart upload.
Now we know what we are doing let's get coding!
### SvelteKit S3 Multipart Upload: presigned-urls.json Endpoint Code
This is a substantial refactor on the previous code for the file at `src/routes/api/presigned-urls.json`:
```javascript
import {
authoriseAccount,
generatePresignedPartUrls,
getS3Client,
initiateMultipartUpload,
presignedUrls,
} from '$lib/utilities/storage';
export async function post({ body }) {
const { key, size } = body;
try {
const { absoluteMinimumPartSize, recommendedPartSize, s3ApiUrl } = await authoriseAccount();
if (s3ApiUrl) {
const client = getS3Client({ s3ApiUrl });
if (absoluteMinimumPartSize && size > absoluteMinimumPartSize) {
const uploadId = await initiateMultipartUpload({ client, key });
if (recommendedPartSize) {
const partSize =
size < recommendedPartSize ? absoluteMinimumPartSize : recommendedPartSize;
const partCount = Math.ceil(size / partSize);
if (uploadId) {
const multipartUploadUrls = await generatePresignedPartUrls({
client,
key,
uploadId,
partCount,
});
const { readSignedUrl, writeSignedUrl } = await presignedUrls(key);
return {
body: JSON.stringify({
multipartUploadUrls,
partCount,
partSize,
readSignedUrl,
writeSignedUrl,
uploadId,
}),
status: 200,
headers: {
'Content-Type': 'application/json',
},
};
}
}
}
const { readSignedUrl, writeSignedUrl } = await presignedUrls(key);
return {
body: JSON.stringify({ partCount: 1, readSignedUrl, writeSignedUrl }),
status: 200,
headers: {
'Content-Type': 'application/json',
},
};
}
} catch (error) {
console.error(`Error in route api/presigned-urls.json: ${error}`);
}
}
```
At the top of the file, you can see we now import the functions we have just exported from the utilities file. In line `13`, we get the file size parameters we talked about. We use them in line `16` to work out if we will do a multipart upload or single. For a single upload we jump to line `50` and the code is not too different to what we had last time. We just add a `partCount` field in the response, to let the front end code know we only have one part (line `53`).
For multipart uploads, we work out how big each of the parts is based on the `recommendedPartSize` provided by our authorisation response. Once we have that it is just a case of generating the presigned URLs and returning these to the frontend with some extra meta we will find handy.
## 🚚 Complete Multipart Upload Endpoint
Once the the parts have been uploaded, we need to let the provider know so they can piece the parts together. We will have a separate endpoint for this. Let's create the file now at `src/routes/api/complete-multipart-upload.json.js`, pasting in the content below:
```javascript
import { authoriseAccount, completeMultipartUpload, getS3Client } from '$lib/utilities/storage';
export async function post({ body }) {
const { key, parts, uploadId } = body;
try {
const { s3ApiUrl } = await authoriseAccount();
if (s3ApiUrl) {
const client = getS3Client({ s3ApiUrl });
await completeMultipartUpload({ parts, client, key, uploadId });
return {
status: 200,
};
}
return {
body: JSON.stringify({ message: 'unauthorised' }),
status: 400,
headers: {
'Content-Type': 'application/json',
},
};
} catch (error) {
console.error(`Error in route api/complete-multipart-upload.json: ${error}`);
}
}
```
That's all the endpoint code in place now. Let's move on to the client page next.
## 🧑🏽 Client Homepage Svelte Code
There's not too much to change vs. the single file upload code. We'll start by adding a `completeMultipartUpload` function which calls that last endpoint we created. Add this block to `src/routes/index.svelte`:
```html
async function completeMultipartUpload({ key, parts, uploadId }) {
try {
const response = await fetch('/api/complete-multipart-upload.json', {
method: 'POST',
credentials: 'omit',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ key, parts, uploadId }),
});
} catch (error) {
console.error(`Error in completeMultipartUpload on / route: ${error}`);
}
}
```
### Handle Submit
Next we need to check in `handleSubmit` whether we have a single or multipart upload. If you are using this code in your own new project, you will probably want to refactor the block into separate functions, possibly in different files. Anyway, for now paste in this block:
```html
const handleSubmit = async () => {
try {
if (files.length === 0) {
errors.files = 'Select a file to upload first';
return;
}
isSubmitting = true;
const { name: key, size, type } = files[0];
// get signed upload URL
const response = await fetch('/api/presigned-urls.json', {
method: 'POST',
credentials: 'omit',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ key, size }),
});
const json = await response.json();
const { multipartUploadUrls, partCount, partSize, readSignedUrl, writeSignedUrl, uploadId } =
json;
const reader = new FileReader();
if (partCount === 1) {
downloadUrl = readSignedUrl;
// Upload (single part) file
reader.onloadend = async () => {
await fetch(writeSignedUrl, {
method: 'PUT',
body: reader.result,
headers: {
'Content-Type': type,
},
});
uploadComplete = true;
isSubmitting = false;
};
reader.readAsArrayBuffer(files[0]);
} else {
downloadUrl = readSignedUrl;
const lastIndex = multipartUploadUrls.length - 1;
// Upload (multipartpart) file
reader.onloadend = async () => {
const uploadPromises = multipartUploadUrls.map((element, index) =>
fetch(element, {
method: 'PUT',
body:
index !== lastIndex
? reader.result.slice(index * partSize, (index + 1) * partSize)
: reader.result.slice(index * partSize),
headers: {
'Content-Type': type,
'Content-Length': index !== lastIndex ? partSize : size - index * partSize,
},
}),
);
const uploadResults = await Promise.all(uploadPromises);
const parts = uploadResults.map((element, index) => ({
ETag: element.headers.get('etag'),
PartNumber: index + 1,
}));
await completeMultipartUpload({ parts, key, uploadId });
uploadComplete = true;
isSubmitting = false;
};
reader.readAsArrayBuffer(files[0]);
}
} catch (error) {
console.error(`Error in handleSubmit on / route: ${error}`);
}
};
</script>
```
Notice in line `49` we now get the file size, so we can pass that to the presigned URL endpoint. The value we have is in bytes. For single part uploads, nothing really changes. So let's jump to the `reader.onloadend` block for multipart uploads starting at line `85`.
We use JavaScript's Promise API. That way we do not need to wait for one part to finish uploading before we start on the next one. This allows for faster uploads. For larger files, where there will be dozens of parts, it would make sense to extend this code to throttle the downloads so we only upload say three or four parts simultaneously and wait for one of those to finish before starting to upload a new part. We won't look at the detail of doing that here.
The code in lines `90`–`92` splits the file into chunks of the right size. We compute the part length and send it in the `Content-Length` header in line `95`.
### Multipart Upload Completion
When we complete the multipart upload, to help piece together the parts, we send an ID to identify each part. That ID comes in the form an ETag which is included in the multipart upload response header sent from our provider. We collate this data in lines `100`–`103` into the `parts` variable.
That `parts` object is passed to our `completeMultipartUpload` in this file and subsequently passed to the endpoint and the utility function.
### Allowing Video Upload
The final change is to update the user interface to accept video as well as image files:
```html
<input
id="file"
aria-invalid={errors.files != null}
aria-describedby={errors.files != null ? 'files-error' : null}
type="file"
multiple
formenctype="multipart/form-data"
accept="image/*,video/*"
title="File"
on:change={handleChange}
/>
```
Remember you can change this to be more restrictive or, in fact, allow other types based your own needs.
## ⛔️ CORS Update
Because we want to look at a new header (the ETag header) from the client browser, we will need to update the bucket CORS policy. Check how to do this with your storage provider. If you are using Backblaze, you can <Link aria-label="See C O R S details from previous tutorial" to="/sveltekit-s3-compatible-storage/#cors">update the `backblaze-bucket-cors-rules.json` file we introduced in the previous tutorial</Link> and submit this to Backblaze using the CLI.
```json
[
{
"corsRuleName": "development",
"allowedOrigins": ["https://test.localhost.com:3000"],
"allowedHeaders": ["content-type", "range"],
"allowedOperations": ["s3_put"],
"exposeHeaders": ["etag", "x-amz-version-id"],
"maxAgeSeconds": 300
},
{
"corsRuleName": "production",
"allowedOrigins": ["https://example.com"],
"allowedHeaders": ["content-type", "range"],
"allowedOperations": ["s3_put"],
"exposeHeaders": ["etag", "x-amz-version-id"],
"maxAgeSeconds": 3600
}
]
```
## 🙌🏽 SvelteKit S3 Multipart Upload: What we Learned
**In this post we looked at**:
- how you can upload larger files to S3 compatible cloud storage,
- generating presigned URLs for multipart upload,
- how you can determine whether to use single or multipart upload and also calculate part size when choosing multipart upload.
I do hope there is at least one thing in this article which you can use in your work or a side project. As an extension you might consider throttling uploads, especially when uploading very large files with many parts. You can also extend the UI to show existing uploads in the bucket and even generate download presigned links with custom parameters, like link validity. On top consider adding code to abandon failed multipart uploads. This can potentially reduce costs.
You can see <a aria-label="Open the Rodney Lab Git Hub repo" href="https://github.com/rodneylab/sveltekit-s3-multipart-upload">the full completed code for this tutorial on the Rodney Lab Git Hub repo</a>.
## 🙏🏽 SvelteKit S3 Multipart Upload: Feedback
Have you found the post useful? Would you prefer to see posts on another topic instead? Get in touch with ideas for new posts. Also if you like my writing style, get in touch if I can write some posts for your company site on a consultancy basis. Read on to find ways to get in touch, further below. If you want to support posts similar to this one and can spare a few dollars, euros or pounds, please <a aria-label="Support Rodney Lab via Buy me a Coffee" href="https://rodneylab.com/giving/">consider supporting me through Buy me a Coffee</a>.
Finally, feel free to share the post on your social media accounts for all your followers who will find it useful. As well as leaving a comment below, you can get in touch via <a aria-label="Reach out on Twitter" href="https://twitter.com/messages/compose?recipient_id=1323579817258831875">@askRodney</a> on Twitter and also <a aria-label="Contact Rodney Lab via Telegram" href="https://t.me/askRodney">askRodney on Telegram</a>. Also, see <a aria-label="Get in touch with Rodney Lab" href="https://rodneylab.com/contact">further ways to get in touch with Rodney Lab</a>. I post regularly on <a aria-label="See posts on svelte kit" href="https://rodneylab.com/tags/sveltekit/">SvelteKit</a> as well as other topics. Also <a aria-label="Subscribe to the Rodney Lab newsletter" href="https://rodneylab.com/about/#newsletter">subscribe to the newsletter to keep up-to-date</a> with our latest projects.
| askrodney |
907,705 | Common behavioral mistakes of novice programmers and how to avoid them | The mistakes of novice programmers, those who are just learning or just starting to work, are very... | 0 | 2021-11-24T12:56:55 | https://dev.to/alexyelenevych/common-behavioral-mistakes-of-novice-programmers-and-how-to-avoid-them-3j4k | beginners, programming, tutorial, codenewbie | The mistakes of novice programmers, those who are just learning or just starting to work, are very similar to each other. Many of them can be called not mistakes, but behavioral features, stages all beginners go through. We as Java course creators are interested in this topic, so we interviewed opinion leaders and collected the most common, in their view, examples of such behavioral errors in order to … shorten their duration for future software developers. If you start noticing such behavioral mistakes early and try to fix them, your path to mastery will be shorter and your work will be more efficient.
## Using wrong tools
The most common mistake everyone can observe among people starting programming is using the wrong tools, or not using the tools correctly. Sometimes they choose tools but ignore the task they need to solve with it. They heard something in advertising, or read reviews. Complete beginners are sometimes afraid to expand their toolbox. They can stubbornly ignore Git, the basics of which can be learned very quickly, use the first code editor they come across, an outdated IDE, the wrong framework, and so on.
> “One example I’ve seen a few times is when beginners are not aware of VCS tools like Git, but instead use something like DropBox to store their code.”, *[Erik Hellman](https://twitter.com/ErikHellman), Freelance Software Developer*, said, “I have also seen beginners use MS Word for writing code, which can be quite funny to watch.”
## Ignoring debugging
This mistake, of course, is a part of the previous point. A debugger is a tool too after all. Nevertheless, given the importance of this point and the fact that the debugging process is an important and valuable skill for any programmer, we took it out separately.
So … You work with statically typed languages like Java, C++, etc. Hence, there isn’t much to say here other than debugging your code! Try it right after writing your first programs. This is an extremely healthy habit and a must in your work. Moreover, at the time of starting your very first work, it is desirable that this skill is already confident. All modern IDEs (and, having solved the mistake of the previous paragraph, you will use modern IDE, right?) have excellent built-in debuggers with all the necessary functions. You can debug an entire program, its module, a single function, and so on. Read docs, watch youtube tutorials or ask your experienced friend to help. In any case, explore the debugger.
## Copying without checking
Googling and copy-pasting someone else’s code isn’t really a crime. Quite the opposite: this process significantly speeds up the work and helps the developer in his constant learning. However, here is an important point: copy-paste should be thoughtful. Learn from it, try to get how this code works, modify it according to your task.
> “Once beginners get past the challenge with all the tools, it tends to be a problem of not knowing how to find information. Copying code from the first StackOverflow answer they found or using outdated libraries is very common among new developers”, *the software developer Eric Helman said*.
## Ignoring unit testing
Very often, newbies are not actually writing tests for their code and don’t test their code. Some novice developers check their code, but they do it in a very specific way. For example, they manually change the data in the program and output the result to the console. In fact, you need to start unlearning this method right after you have mastered the basic syntax.
> “Thoroughly oftentimes people do manual tests but not of the cases. Getting comfortable with unit testing, getting comfortable with understanding all the edge cases of your code, and working through them. That’s one of the more likely snares of people are going to mess up on and then if you’re really getting your career started consistently”, *[Dylan Israel](https://www.youtube.com/c/CodingTutorials360/videos), software developer, and YouTube Content creator* commented.
## Falling in the tutorials hell trap
Newbies often get lost and don’t know exactly where to learn new information and how to learn it. Instead, they watch video after video, looking for more and more new stories. Here’s what *[Vadim Savin](https://www.youtube.com/watch?v=O7XLG090QTA&t=1s), Software engineer, and Youtube content creator*, says.
> “The most common mistake I see newbie programmers do is falling in the tutorials hell trap. How many udemy courses have you bought, and how many of them have you finished? The problem is not with tutorials, because you can learn a lot from them, the problem is the lack of practical experience. If you want to be the best at basketball, you wouldn’t watch tutorials all day and read books for a year, you would get on the court and start practicing. That’s the same with learning programming. Start building projects. When following a tutorial, don’t just watch, but do the same thing as the tutor is doing. Then, try again, but this time from memory. After you get the basics, start implementing the new knowledge in real projects. Start building that website/app/game that you have always wanted to build. This way, you will be motivated to practice because you will work on something you are excited about, and you want to feel the burden of learning”.
## Fear and overreaction on code review
One of the obvious mistakes novice programmers make is a sharp reaction to code review. Very often, newcomers perceive the remarks of colleagues as harsh criticism, get upset, offer resistance, trying to prove that they were wrong. In fact, code review is a procedure for improving code, and not only for a newbie. For a beginner programmer, this is a great opportunity to learn on the job. Think of the process this way. Nobody wants to offend or humiliate you (well, most likely nobody, some people are strange when you are a stranger). Everyone is trying to ensure that your overall project is of the highest quality possible. Of course, the reviewer is not a saint and can also be wrong. It is important that you argue these points without emotion, try to look at your code with detachment and calmness.
## Too much or not enough efforts
This problem is like a double-edged sword. On the one hand, many developers put in too little effort and abandon a difficult task that they can do, because they are not sure they can solve it. On the other hand, there are those who, on the contrary, can torment themselves for a very long time over a task that should have long been abandoned. As a result, the former does not develop fast enough, and the latter loses motivation. Here’s what our experts have to say about it.
**[Karolina Sowinska](https://www.youtube.com/c/KarolinaSowinska/about), a data pro and a YouTube content creator**:
> *“I think the largest mistake that new programmers make is not trusting yourself enough to stick with a problem to solve it. That’s certainly the mistake I was making at the beginning. I thought that I don’t have enough knowledge or experience to be able to solve a difficult issue. In reality, facing unknown problems is exactly what experienced software engineers do on an everyday basis. You will not feel comfortable 70% of the time. So it’s paramount to shift your mindset from “I can’t solve it yet” to “I will solve it no matter what” regardless of how much experience in coding you have”.*
**[Masha Zvereva](https://www.youtube.com/c/CodingBlonde/videos), founder at Coding Blonde YouTube channel**:
> *“One of the biggest issues I see newbie programmers struggle with is a combination of impatience, comparing themselves to others, and self-doubt. Learning how to program is hard and requires a different type of logic than what we’re used to in our day-to-day life, so it takes time to properly understand certain concepts. And different people will learn different aspects of programming quicker than others, but that doesn’t mean anything about their intelligence or future opportunities. Everyone is on their own timeline and has their unique learning style. Be patient with yourself and use additional materials if the ones in front of you don’t make sense to you”*.
**[Saldina Nurak](https://www.youtube.com/channel/UCl5-BV9aRaeDVohpE4sqJiQ) software engineer and YouTube channel autor**:
> *“The main mistake that new programmers make is either self-doubt and thinking that they are not smart enough, or the complete opposite of that, thinking that they know everything, when in fact they don’t.
Looking back to my university days I can say that I was in the first category. I could understand the code during the lectures when professors explained it, but I had problems solving those same tasks alone, so I was wondering if I just wasn’t smart enough.
Now I know that it is because I didn’t spend enough time practicing. It’s the same when you are learning a new language, most people are able to understand it before they can speak it.
Some of the tips that helped me to overcome that issue and become better at programming are naming variables and functions according to their purpose, using diagrams and pseudo code when I couldn’t understand the code itself, writing comments for later reference, being consistent, and trying to learn a little bit every day, building a solid foundation and filling all the little gaps that I had in my knowledge.”*
## Overengineering
Ask a newbie programmer, what in their opinion the ideal code should be. The common answer would be “optimal, of course!” This usually means “optimal” in terms of performance and resource consumption. It’s a logical answer, isn’t it? Yep, this is so in an ideal world, but, alas, we don’t live in one.
Therefore, this answer is fundamentally wrong, especially when it comes to large projects that will be used and supported for many years. Experienced developers will choose the latter between optimality and readability. They know that, while optimally, Junior’s over-engineered code is so difficult to read and maintain that it will likely need to be rewritten completely soon. And if you see in front of you an even formatted code without frills, you can say it is boring, most likely it was created by an experienced programmer.
By the way, such code will most likely contain comments. And they will be exactly where they are needed. Moving on to the next error.
## Where are your comments, dude?
Comments … Newbies and comments are just an ancient tragedy. Comments could be literally everywhere and explain the obvious things, or vice versa, code without comments at all. Don’t be like this, please. Explain what isn’t readable in an easy way or is referencing other modules.
> “One of the common mistakes is the “We don’t need no stinkin’ comments” with apologies to The Treasure of the Sierra Madre where the original version of this line came from. Just last week while discussing this issue it was suggested that comments are worthless because when code is updated or refactored the comments are rarely updated so we might as well do away with them.” — *[Ken Fogel](https://www.linkedin.com/in/kenfogel/), Java Champion, CS teacher at Dawson College* shares, “I once had to remove comments from submission to an open-source project. Comments represent the technical manual complex systems required. Imagine having to repair a modern automobile without the shop manual.”
Sure, competent commenting is a special science. However, if you master it, your colleagues will be very grateful to you. Remember the times when you had to understand someone else’s code. I think someone’s literate comments helped you, right? If you find it difficult to understand how to correctly place comments, look at the libraries of your programming language that you use, read, comments on their code … Learn from the best.
## Messy code formatting and frustrating names
Sometimes novice developers don’t understand the importance of standardizing their coding. They have not yet realized how difficult it is to navigate someone else’s code, and don’t understand that they write code not only and not so much for themselves.
Each language has a set of rules that describe the correct formatting of the code. Some IDEs already know how to format the code in a standard way on a wave of hotkeys. Take the time to find out how to do it in your case. However, there are many things you still need to keep track of yourself.
Even more dramatic is the naming of variables and functions. If in the learning task **int p;** looked quite adequate, in a module of a large project it’s not! **persentOfYearIncome** looks terrible, but it is much clearer what we are talking about. By the way, don’t try to use short names and write transcripts in the comments. Better not be lazy and pick up your variables. functions, classes have friendly names. Even if they are not the most elegant.
## Conclusions
> “I would actually consider mistakes to be very healthy. It’s what teaches you the most as you try to solve a problem that you did not plan for. I think if I was to name an action that a programmer might do and call it a “mistake” it would be when we come across an issue in the code and we simply give up,” *software developer and YouTube author [Filip Grebowski](https://www.youtube.com/channel/UCG7EBd-JrRZehNv9e5m1fQQ)* said.
And I definitely agree with him. Mistakes are something that we cannot avoid as programmers. Everyone makes them, even the most proficient experts. Try not to repeat the same mistakes all the time and you become a better programmer faster.
First published at [Geek Culture](https://medium.com/geekculture/common-behavioral-mistakes-of-novice-programmers-and-how-to-avoid-them-286624cb4866).
| alexyelenevych |
907,715 | Opening Google Translate from your Android application | In this post I'll demonstrate how to programatically open Google Translate from another Android... | 0 | 2021-11-24T16:34:45 | https://dev.to/pchmielowski/opening-google-translate-from-your-android-application-55d8 | android | In this post I'll demonstrate how to programatically open Google Translate from another Android application and pass text to translate.
As an example I'll use a screen which displays some text and provides a "translate" button:

Here is the source code:
```kotlin
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
TranslateTestTheme {
MainScreen(
title = "Dog",
body = dogDescription,
onTranslateClick = { openGoogleTranslate(dogDescription) },
)
}
}
}
}
@Composable
private fun MainScreen(
title: String,
body: String,
onTranslateClick: () -> Unit,
) {
Scaffold(
topBar = {
TopAppBar(
title = { Text(text = title) },
actions = {
IconButton(onClick = onTranslateClick) {
Icon(Icons.Default.GTranslate, contentDescription = "Translate")
}
}
)
},
content = {
Text(
text = body,
style = MaterialTheme.typography.body2,
modifier = Modifier.padding(16.dp),
)
},
)
}
```
The key part is following callback: `onTranslateClick = { openGoogleTranslate(dogDescription) }`.
## Launching Google Translate with `Intent.ACTION_PROCESS_TEXT`
Let's take a look at the `openGoogleTranslate` method:
```kotlin
fun Context.openGoogleTranslate(text: String) {
val intent = Intent()
.setAction(Intent.ACTION_PROCESS_TEXT)
.setType("text/plain")
.putExtra(Intent.EXTRA_PROCESS_TEXT, text)
.putExtra(Intent.EXTRA_PROCESS_TEXT_READONLY, true)
startActivity(intent)
}
```
It opens any `Activity` which is registered with `Intent.ACTION_PROCESS_TEXT` intent filter. As Google Translate app provides such `Activity`, it is one of the candidates to be opened when mentioned method is called.
It is important to remember, however, that some users have no Google Translate application installed. Some users also have on their devices more applications that handle `Intent.ACTION_PROCESS_TEXT`.
In the second case, Android prompts the following dialog:
In case of no application to handle the intent installed, `ActivityNotFoundException` will be thrown on `startActivity` invocation. This case can be handled by `try/catch` block:
```kotlin
try {
startActivity(intent)
} catch (e: ActivityNotFoundException) {
// TODO: Show error
}
```
## Checking if Google Translate is installed
It would be nice to display the "translate" button only if Google Translate is installed. Following code can be use to check its existence:
```kotlin
fun Context.queryProcessTextActivities(): List<ResolveInfo> {
val intent = Intent()
.setAction(Intent.ACTION_PROCESS_TEXT)
.setType("text/plain")
return packageManager.queryIntentActivities(intent, 0)
}
fun Context.isGoogleTranslateInstalled() = queryProcessTextActivities()
.any { it.activityInfo.packageName == "com.google.android.apps.translate" }
```
In order to make `queryIntentActivities` work correctly on all Android versions, the following fragment should be added to `AndroidManifest.xml`:
```xml
<?xml version="1.0" encoding="utf-8"?>
<manifest ...>
<application ...>
...
</application>
<queries>
<intent>
<action android:name="android.intent.action.PROCESS_TEXT" />
<data android:mimeType="text/plain" />
</intent>
</queries>
</manifest>
```
## Launching Google Translate directly
We can also make sure that - if it is installed - Google Translate will be launched, regardless if there are other applications to handle intent or not.
To do so, the following code can be used:
```kotlin
fun Context.queryProcessTextActivities(): List<ResolveInfo> {
val intent = Intent()
.setAction(Intent.ACTION_PROCESS_TEXT)
.setType("text/plain")
return packageManager.queryIntentActivities(intent, 0)
}
fun Context.googleTranslateActivityInfo() = queryProcessTextActivities()
.firstOrNull { it.activityInfo.packageName == "com.google.android.apps.translate" }
?.activityInfo
fun Context.openGoogleTranslate(activity: ActivityInfo, text: String) {
val intent = Intent()
.setAction(Intent.ACTION_PROCESS_TEXT)
.setType("text/plain")
.putExtra(Intent.EXTRA_PROCESS_TEXT, text)
.putExtra(Intent.EXTRA_PROCESS_TEXT_READONLY, true)
// Following line makes sure only Google Translate app will be launched
.setClassName(activity.packageName, activity.name)
try {
startActivity(intent)
} catch (e: ActivityNotFoundException) {
// TODO: Show error
}
}
```
You can find complete Kotlin code under this link: https://gist.github.com/pchmielowski/d236f06f168c05efa3f5b26f1e2f0af9
| pchmielowski |
907,807 | 5 Tips For Learning Programming in 2022 | Hello Dev.to! I am excited to share with you my first post. I know how intimidating the field of... | 0 | 2021-11-24T14:32:37 | https://dev.to/darrinndeal/5-tips-for-learning-programming-in-2022-2hfm | programming, beginners, codenewbie, learning | Hello Dev.to! I am excited to share with you my first post. I know how intimidating the field of computer programming can be when you are first starting out. In this post I will share my top 5 tips for beginners. If you read this post and find it helpful, please send it to your friends who are also learning. Let's get started with tip number one.
### 1. Set SMART Goals
You have probably hear of SMART goals but if not SMART stands for specific, measurable, attainable, relevant, and time-based.
What is it that you want to do? Just get started? Start with learning a specific language (JavaScript, C, Python, Java). Set how you are going to measure your learning. For example you might get a book or course. Your measurement could be the number of chapters or sections that you complete with doing all the exercises.
Make these goals attainable your SMART goal should not build the next Meta or Google. Those can be larger goals but not for learning. An attainable goal in our example would be that "I completed all the exercises in my book/course."
To make this goal relevant look at what job postings are out there even if you are not looking for a job. Companies will list out technologies/languages that they are using in their tech stack.
Finally, your goals should have an expiration date. Say to yourself "I want to learn xyz in 6 months.
### 2. Learn The Basics
This is the most important tip in my opinion. If you are an absolute beginner DO NOT jump into a framework. Look at what frameworks are popular and catch your attention, but if you don't know how to set a variable or write a for loop in the language the framework is useless to you.
Start learning the language. The skills that you learn in language learning will transfer other languages, not so much in learning frameworks.
### 3. Build, Build, Build
Once you have gone through the process of learning a language start building with it. Here is where I would then jump into frameworks. The question then be comes "What should I build?"
What you should build is ultimately up to you but here are some ideas:
* ToDo List App
* Tip Calculator App
* Date Reminder App
These are just a few examples of what you could build. Let me know below if you do build one of these. I would love to know
### 4. Find Awesome Resources
When learning anything find communities of learning to help you. In programming there are so many communities that you will find that will help speed up you learning. A few of my favorites is [Dev.to](https://dev.to/), [Wes Bos](https://wesbos.com/), and [No Starch Press books](https://nostarch.com/)
### 5. Start Tackling Imposter Syndrome Right Now
You may not know it but one of the hardest things to overcome in programming is imposter syndrome. What is imposter syndrome? Here's a definition.
> The persistent inability to believe that one's success is deserved or has been legitimately achieved as a result of one's own efforts or skills.
This feeling is common and many developers have had to go through the process of defeating imposter syndrome when they started their carriers. Here are three tips on punching imposter syndrome in the face.
* Start believing you are a developer before you start coding
I know this sounds like believe it and it will come stuff, because it actually is. I have seen many students use this tip and with it alone conquer imposter syndrome.
* Keep visual log of what you are building
This tip will help you remember how far you have come. When you look at this visual log you can say "Wow! look what I have accomplished!" My recommendation is to use instagram for a public log or notion for a private log.
* Surround yourself with other who are learning
This is also super important. Community is very important when starting to learn. You will find that you are not alone and together you will punch imposter syndrome in the face.
## What Now?
Wow! You made it through my first post. I hope you have found this post helpful. If you took any of the tips I proposed let me know in the comments below. Also, If you have any other tips add them to the comments as well.
| darrinndeal |
908,025 | Sr. Full Stack Software Engineer - Pittsburgh/Seattle | Help humans interface with the future of autonomous flight vehicles! Senior full-stack developer... | 0 | 2021-11-24T17:55:44 | https://dev.to/megadoo011/sr-full-stack-software-engineer-pittsburghseattle-lg8 | Help humans interface with the future of autonomous flight vehicles!
Senior full-stack developer located in Pittsburgh, PA or Seattle, WA. Hybrid work from home or in-office.
More info and apply here: https://nearearthautonomy.applytojob.com/apply/3pH7gKRbVJ/Sr-Software-Engineer-Full-Stack
Or contact me directly at Megan.zimmerman@neartearth.com | megadoo011 | |
908,577 | Top 10 Flutter Tools to Increase Speed of Mobile App Development
| Flutter is one of the most appealing and outstanding frameworks for keeping enterprises on the... | 0 | 2021-11-25T08:27:55 | https://dev.to/dasinfomediamkt/top-10-flutter-tools-to-increase-speed-of-mobile-app-development-4lam | flutter, mobile, android, firebase | Flutter is one of the most appealing and outstanding frameworks for keeping enterprises on the digitization track. Businesses can choose from a variety of Flutter app development tools for developing an app. Each of these tools has the potential to make coding more agile and simple for developers. Although Flutter is in high demand due to Google’s strong support, it does require some third-party development tools. Developers should be familiarized with many outstanding Flutter Development Tools.
Crashlytics:
Even if you have access to accident records, determining the reason for a crash can take a long time. The Crashlytics dashboard not only gives you a comprehensive and clear picture of what your consumers are going through but also gives you precise advice on what might have caused a fatal error using crash insights.
Crash insights appear next to the crash report on your dashboard and provide more information by indicating possible underlying causes, such as SDK flaws and API misuse, that are similar across several apps. This acts as a jumping-off point for further investigation, saving you time and accelerating your process.
Firebase:
It aids with the integration of the Flutter application and the launching of apps on both Android and iOS platforms. You can combine Firebase APIs into a single SDK. This is how the backend can be unified. Firebase includes many features, including crash reporting and messaging.
Visual Studio:
Flutter developers use Visual Studio Code for running tasks, version control, and creating, debugging cloud and web apps. Microsoft created this open-source and free code editor for macOS, Windows, and Linux. It attributes smart code completion, debugging support, snippets, syntax highlighting, code refactoring, and embedded GIT.
Visual Studio Code is strong and lightweight but doesn’t deal with complicated workflows that are taken by fuller featured IDEs like Visual Studio IDE. It works perfectly with C++ and Python. It is productive and easy to use.
Screenshot:
The screenshot is a command-line program that allows you to capture screenshots and is one of the most efficient IDEs for Flutter app development. It also allows you to immediately post them to the status bar. These screenshots can then be easily included in your Flutter application.
These integrated screenshots are also compatible with iOS and Android devices. As a result, it appears to be one of the most popular Flutter app development tools among developers.
Speech to Text:
This plugin contains a set of classes that make it easy to use the speech recognition capabilities of the underlying platform in Flutter. It supports Android, iOS and web. The target use cases for this library are commands and short phrases, not a continuous spoken conversion or always-on listening.
Android Studio:
Android Studio is used by a significant number of developers who use the Flutter platform to create apps. And this is one of the most productive IDEs for creating useful apps. It includes widget editing, syntax highlighting, and code completion functions.
It also eliminates the need to download and install the Android Studio, allowing you to design and launch applications on an Android device or emulator.
Push Notifications:
Push notifications are excellent for increasing user engagement and alerting consumers to new information. Google’s Firebase Cloud Messaging (FCM) is a free (yes, free!) cross-platform messaging service. It makes it simple to send notifications to a specific group of users across a range of platforms. I’ll show you how to set up push notifications on both Android and iOS in this article; if you only want to set it up on one of the platforms, you can skip the platform-specific sections.
Panache:
Panache is a material editor for Flutter that allows you to build material themes for your apps. You can change the colors, shapes, style, and other theme features, then save the dart file to your Drive folder.
You can engage Flutter developers to generate customized and visually attractive materials and themes for your app using Panache. Panache is completely free and open-source, allowing you to evaluate the codes. Panache is currently used by over 40 million developers and testers.
Flutter Stripe:
Stripe handles collecting all the payment data for you. Normally, services like Stripe, Square, or Braintree offer you storing all payments information your app collects but they leave the UI part to the developers. This means having to handle all those boring stuff like card validation, 3D authentication, etc.
Pusher:
Pusher is a hosted service that makes it simple for you to add real-time data and functionality to your mobile and online apps.
Flutter has grown in popularity among mobile app developers as one of the most popular software development toolkits. If you need help with your flutter project, try Hire Flutter Developers from Dasinfomedia. We have an experienced team that follows a customer-centric approach for all Flutter App Development Projects. Get Started with us today! | dasinfomediamkt |
908,041 | Massively speed up VS Code loading time on Apple Silicon Macs in one step | Note: This is an update to my recent post, How to make VS Code load faster with a little bit of... | 15,678 | 2021-11-24T22:11:08 | https://mikebifulco.com/posts/make-vs-code-load-faster-mac-apple-silicon | webdev, tutorial, productivity | ---
title: Massively speed up VS Code loading time on Apple Silicon Macs in one step
published: true
date: 2021-11-24 00:00:00 UTC
tags: webdev, tutorial, productivity
canonical_url: https://mikebifulco.com/posts/make-vs-code-load-faster-mac-apple-silicon
cover_image: https://res.cloudinary.com/mikebifulco-com/image/upload/v1637764395/posts/make-vs-code-load-faster-mac-apple-silicon/cover.webp
series: Optimize VS Code
---
**Note:** This is an update to my recent post, [How to make VS Code load faster with a little bit of housekeeping](https://mikebifulco.com/posts/make-vs-code-load-faster-by-removing-extensions).
I was pretty happy with the startup speed I gained by removing a few extensions, but VS Code still took a while to load.
Yesterday I stumbled on something that let me **load VS Code 775% faster** than before on my Mac laptop. Seriously. On a cold boot of VS Code, my load time went from 15 seconds to just about 2 seconds. So, how did I do it? Let's cut to the chase:
## The Solution
**If you are running Visual Studio Code on a Mac with an Apple Silicon processor (also known as an M1, M1 Pro, or M1 Max), you will get a _massive_ performance boost by installing an Apple Silicon optimized build of VS Code.**
This is because previous builds weren't natively compatible with Apple Silicon, and ran Intel code through a virtualization process that apple calls Rosetta.
The fix: **Download the [latest version of VS Code](https://code.visualstudio.com/download) for Mac, install it.** If you were previously running an Intel build, this is _all_ you need to do. That's it!
## What's going on here
In 2019, Apple released their first round of computers that run on their own processors, which they call Apple Silicon. These chips are fundamentally different from the Intel processors that Apple was using on all of their computers until recently. Apple found massive performance benefits from their migration to a new chipset, but running software on the new processor architecture requires app developers to recompile their software for the new chips.
Thankfully, engineers at Apple were smart enough to know that asking every Mac app developer in the world to recompile their apps for Apple Silicon will take a very long time. To hedge against this, they built a recompilation layer into MacOS called _Rosetta,_ which allows Intel apps to run on the new chips. Because there's essentially a thin VM layer running these apps, they are slower and less energy efficient than apps compiled specifically for Apple Silicon.
That's exactly the gain we're finding here by updating VS Code. There wasn't an Apple Silicon build available until [September of 2020](https://github.com/microsoft/vscode/issues/101662), due to VS Code's dependency on Electron to run.
If this quick fix helps you and you're like me, you likely installed Code long before September of 2020. Your install of Code would get regular updates, but you were getting Intel builds of the app. Switching to a more recently downloaded version of the app will automatically install an Apple Silicon build, and just like that, you're sorted! 🧙♂️
## Check to see if you're running an Intel version of VS Code
In the process of figuring all of this out, I discovered that you can actually see which apps on your machine are running Intel builds vs Apple Silicon Builds.
To check any given app, follow these steps:
1. Open **Activity Monitor** (hit command + Space, and type in "Activity monitor")
2. Right click on one of the _headings_ at the top of the table of running processes, to see a list of possible columns for the table.
3. Make sure the option called **Kind** is checked
4. You'll now see a column labeled "Kind", which will say "Apple" or "Intel"
If you're running an Intel version of VS Code, you'll see something like this:

If that's the case, I have great news! You're probably going to see a massive speed boost. This is a good time to close VS Code and time how long it takes to start fresh. On my M1 Macbook Air with 16GB of ram, it took about 15s.
Now, go **Download the [latest version of VS Code](https://code.visualstudio.com/download) for Mac** and install it on your computer (Choose to "Replace" the old install if prompted).
When that's done, you should see this the next time you load VS Code:

How was that load time now? For me, it was down to _about 2 seconds!_ It's not every day you get those kind of gains.
## If you found this helpful, you may want to check out:
- **[How to make VS Code load faster with a little bit of housekeeping](https://mikebifulco.com/posts/make-vs-code-load-faster-by-removing-extensions)**, my previous post on speeding up VS Code
- **[I reclaimed 10GB of disk space from `node_modules`](https://mikebifulco.com/posts/reclaimed-10gb-of-disk-space-from-node-modules)** if you also happen to use Node to write JavaScript apps.
- **[gitignore.io is great](https://mikebifulco.com/posts/gitignore-io-is-great)** for a tip on a super helpful tool for setting up `.gitignore` files on new projects.
| irreverentmike |
908,166 | visualizing strange attractors with react-three-fiber | After a long procrastination period and binge watching a lot of 3d computer graphics videos. Thereby... | 0 | 2021-11-24T19:01:31 | https://dev.to/andrasnyarai/creating-strange-attractors-with-react-three-fiber-1e54 | showdev, react, threejs, motivation | After a long procrastination period and binge watching a lot of 3d computer graphics videos.
Thereby presenting you my implementation of 3d attractors, as a reminder that start and ship your side project :D
enjoy & cheers
https://spreadbow.com/strangeAttractors
src: https://github.com/andrasnyarai/expersonal | andrasnyarai |
908,182 | Transition from IT to Developer and how it helped me! | Work History I have spent the last 15 years working professionally in Information... | 0 | 2021-11-24T19:37:33 | https://dev.to/chrisbenjamin/transition-from-it-to-developer-and-how-it-helped-me-1laj | career, codenewbie, webdev, programming | ## Work History
I have spent the last 15 years working professionally in Information Technology. During this time I have tried on several hats in the IT world working for internal IT departments, as a technical support representative, for family and friends, and running converting a break/fix computer services provider into a Managed Services Provider (MSP). I am actively employed as an IT Manager / Systems Administrator / Developer for an attorney office and run my own small business providing local residential / business IT services and web development. I've worked in healthcare as a HIPAA security officer and performed risk analysis.
### Some roles I've held:
- IT Intern
- Computer Technician
- Supervisor
- Technical Support Representative
- IT Professional Level 3
- IT Manager
- IT Director
- Developer
- Interim Chief Information Security Officer
- HIPAA Security Officer
## How It's Helped
Working in IT prior to becoming a developer has taught me a lot about technology and computers as a whole, as well as working with end-users to understand how they use technology. The way end-users interact with the computer, the website, and what they do when they see spinners or loading icons has helped shape my view for development to keep their perspective in mind. I've deployed massive software, hardware, and network projects across all shapes, sizes, and industries of businesses which has helped me understand working with businesses on making major changes and how to communicate and plan effectively. My first programming experience came about during my first paid IT job where I was an intern at my local school district where I attended high school. [You can read about it here. ](https://chrisbenjamin.hashnode.dev/how-i-got-started-in-development-and-programming)
## Skill's I've learned along the way:
- Network Skills
- Domain and DNS
- Hardware
- Databases
- Backup and Disaster Recovery
- Privacy and Security
- Communication
## Network Skills
I've gained skills in computer networks ranging from homes to large businesses spread across multiple cities. This helped me understand how networks and the internet work, as well as securing them.
## Domain and DNS
I've gained skills in Domain and DNS management along with setting up new domain names, migration hosting and email to new platforms, and configuring DNS. This has helped when I've moved businesses who have existing hosting to new providers.
## Hardware
I've gained skills in computer hardware. I've built several hundred computers and over 50 servers from bare metal. I've been in charge of designing workstation builds for businesses, home users, and gamers alike. These skills have helped me to understand the hardware needed to run my web applications, databases, and to understand concepts such as CPU, Processor Speeds, RAM, Hard Drive types such as SSD vs Flash, Storage configurations such as RAID.
## Databases
I've gained skills in database administration which helped me understand SQL, MySql, MariaDB, MongoDB, and many more. I've designed new databases, I've maintained existing databases, I've recovered broken databases, migrated databases, and upgraded databases. This gave me a priceless knowledge that I use when creating web applications that store data.
## Backup and Disaster Recovery
I've gained skills in backup and disaster recovery strategies. This taught me how to backup my data, learned skills such as recovery time objective and recovery point objective to talk with business about backing up and restoring their data in a disaster.
## Privacy and Security
I've gained skills in privacy and security from working with medical offices and being the IT manager and HIPAA security officer for a medium sized medical office with 6 locations and over 300 employees. Working as a HIPAA security officer I was responsible for maintaining privacy and security of patient information. This translated well into the web development world to understand how important it is to protect users data from breaches, how to perform a risk analysis to look for risks associated with user information, and what to do if there is a breach.
## Communication
Communicating technology to the average person is a skillset entirely of it's own. Let's face it, technology is confusing and unless you work in the field it's very easy to not understand a lot of the nuances with technology. I've gained skills in communicating IT projects, solutions, problems, and concepts with just about anyone in a way they can understand and relate. At the end of the day, if the client doesn't understand why they need to make a change or what exactly it is they are purchasing, they won't be likely to proceed.
This goes beyond being able to explain it to a 5-year old or your grandma, it means being able to communicate quantifiable and qualitative information to your client where they will be able to make an informed decision for the benefits.
## Conclusion
Looking back at my 15 year history of working in the Information Technology field, I find that I use skills from my experiences every single day on every single project. If you are just branching into the Web Development world with little to no understanding of Information Technology you will have some difficult times understanding and positioning your solutions to your clients as well as selecting the right technology for the client. It's important to diversify your understanding of technology such as hardware, security, privacy, backup and performance when working in development and programming. There is more to development that just understanding your code base and language, you need to establish a deeper understanding of where your application will run, how it will be used, and how to keep it safe and backed up. | chrisbenjamin |
908,205 | Boolean coercion | Use !! to see how JavaScript would coerce a real value into a boolean-ish... | 0 | 2021-11-24T20:53:57 | https://dev.to/icncsx/boolean-coercion-2ckc | javascript, tutorial, programming, shorts | Use !! to see how JavaScript would coerce a real value into a boolean-ish interpretation.
```js
console.log(!!" ") // true
console.log(!!"") // false
console.log(!!"0") // true
console.log(!!0) // false
``` | icncsx |
918,469 | Clip-Path Animation 💖 | Hey fellow creators, Let’s create an easy but awesome clip-path animation in less than a minute! If... | 0 | 2021-12-07T08:33:06 | https://dev.to/ziratsu/clip-path-animation-196a | html, css, tutorial |
Hey **fellow creators**,
Let’s create an easy but awesome *clip-path animation* in less than a minute!
If you prefer to watch the video **version**, it's right here :
{%youtube jfIGA_YQlD8%}
##1. The HTML structure.
Create two boxes with one image inside each one.
```html
<div class="box b1">
<img src="img1.jpg">
</div>
<div class="box b2">
<img src="img2.jpg">
</div>
```
##2. Style the page.
First resize each box to take up the full height of the viewport:
```css
.box{
height: 100vh;
}
```
Then add a different background colour to each box to differentiate them easily:
```css
.b1{
background-color: #e27d60;
}
.b2{
background-color: #85cdca;
}
```
Now, size the images however you want, center them and fix them to the middle of the screen, following the scroll:
```css
img{
object-fit: cover;
height: 600px;
width: 400px;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
position: fixed;
}
```
For now, the images are one above the other. To fix that, you need to clip the boxes so that only the correct image shows:
```css
.box{
clip-path: polygon(0 0, 100% 0, 100% 100%, 0% 100%);
}
```
The values inside of the parentheses correspond to the X and Y coordinates of the clipped area.
It will create a new stacking context for each box and only show what is inside that stacking context.
You’ll now have a *lovely animation* to showcase your images!
Come and take a look at my **Youtube channel**: https://www.youtube.com/c/TheWebSchool
*See you soon!*
Enzo. | ziratsu |
908,270 | Things I noticed after using Vim for the first time in one week | Disclaimer: This is my first time using Vim (actually Neovim 😎), so by no means am I an expert. Come... | 0 | 2021-11-24T22:36:08 | https://blog.zt4ff.dev/things-i-noticed-after-using-vim-for-the-first-time-in-one-week | beginners, linux, vim, productivity | **Disclaimer:** This is my first time using Vim (actually Neovim 😎), so by no means am I an expert.
Come on it took me a couple of hours before I could configure a language server protocol! 😢
I look forward to your comments and advice on how to work better with and learn Vim.
This [article](https://www.chrisatmachine.com/Neovim/27-native-lsp/) was really helpful while configuring Neovim on my machine.
[Vim](https://www.vim.org/) is basically a text editor for Unix. It's similar to other programs like Notepad, Visual Studio Code, Sublime Text Editor or Atom.
### **So what led me to Vim**
I love new challenges and improving my productivity. VS code was pretty customized and suitable for my current needs. Maybe YouTube videos from this guy ([DistroTube](https://www.youtube.com/c/DistroTube)) was the motivation to try it out.
### Let's get right to my few observations
- Efficiency: Vim is designed to reduce how often switch from your keyboard to a mouse. They are literally keybinding for any type of operation and you can create custom keybindings too. If you type really fast, this will improve your productivity as you will really need your mouse.
- Learning Curve: Vim has quite a learning curve if you're just starting. For the first few days, my focus was shifted majorly from the code I write to the tool I use. This is going to pay off later by building up muscle memory you will be able to exit Vim in your sleep.
A quick meme about exiting vim:

### **Conclusion**
I will continue sharing my learning experience and journey with Vim for the next few months
Whatever editor, language or framework you use, they should be able to solve your problems effectively and efficiently.
If you want to get started with Vim, I recommend starting with [Neovim](https://neovim.io/) and it's simpler and maintained.
Do you think it is worth the time to learn Vim? | zt4ff_1 |
908,405 | Add some data in memory | All the code's that you will see in this post you can check here After we structure our project to... | 7,528 | 2021-12-03T21:37:40 | https://dev.to/maaarkin/add-some-data-in-memory-4m82 | go, rest, api | **All the code's that you will see in this post you can check [here](https://github.com/MAAARKIN/hero-api-golang/tree/step-3)**
After we structure our project to pass the service into the handler constructor, now we can access the service layer in our rest handler.
But our service layer does nothing at the moment, in this first time we will create our repository/persistence layer to persist the information in memory and we can access the information in the service layer, doing the same process that we do between service/handler now we will do between service/repository.
The repository layer will have the responsibility to communicate with the database (in-memory initially) and return only the domain code to the service layer. In our project, only the service can access the repository. Usually, I like to do this because it's easier to maintain the project. When you have multiple places accessing the repository being more difficult to track some problems in the code.
The structure from this project in this post will looks like this
```
📦hero-api-golang
┣ 📂cmd
┃ ┗ 📂http
┃ ┃ ┣ 📂handler
┃ ┃ ┃ ┣ 📜book.go
┃ ┃ ┃ ┗ 📜router.go
┃ ┃ ┗ 📜main.go
┣ 📂internal
┃ ┣ 📂container
┃ ┃ ┗ 📜container.go
┃ ┣ 📂domain
┃ ┃ ┗ 📂book
┃ ┃ ┃ ┗ 📜model.go
┃ ┣ 📂repository
┃ ┃ ┣ 📜book.go
┃ ┃ ┗ 📜book_inmemory.go
┃ ┗ 📂service
┃ ┃ ┗ 📜book.go
┣ 📜.gitignore
┣ 📜go.mod
┣ 📜go.sum
┗ 📜README.md
```
Now you can see a new repository folder, here we will group the files that will represent our persistence layer to connect with our database and return a domain code to our service.
```go
//book.go
package repository
import "github.com/maaarkin/hero-api-golang/internal/domain/book"
type BookStore interface {
GetAll() (*[]book.Book, error)
Get(id uint64) (*book.Book, error)
Create(item book.Book) (uint64, error)
Update(id uint64, item book.Book) (*book.Book, error)
Delete(id uint64) error
}
```
Here we will represent the default CRUD that we can see in any post in the internet using this interface.
In this first step we will store our data in memory for this reason we have a inmemory file in this folder.
```go
//book_inmemory.go
package repository
import (
"errors"
"sync"
"github.com/maaarkin/hero-api-golang/internal/domain/book"
)
var (
keyInstance = uint64(3)
books = map[uint64]book.Book{
1: {Id: 1, Title: "Title 1", Author: "MarkMark", NumberPages: 101},
2: {Id: 2, Title: "Title 2", Author: "MarkMark 2", NumberPages: 203},
}
)
type bookStoreInMemory struct {
mu sync.Mutex
}
func NewBookStoreInMemory() BookStore {
return &bookStoreInMemory{}
}
func (store bookStoreInMemory) GetAll() (*[]book.Book, error) {
m := make([]book.Book, 0)
for _, value := range books {
m = append(m, value)
}
return &m, nil
}
func (store bookStoreInMemory) Get(id uint64) (*book.Book, error) {
book, has := books[id]
if !has {
return nil, errors.New("No book in database")
}
return &book, nil
}
func (store bookStoreInMemory) Create(item book.Book) (uint64, error) {
store.mu.Lock()
defer store.mu.Unlock()
keyInstance = keyInstance + 1
books[keyInstance] = item
return keyInstance, nil
}
func (store bookStoreInMemory) Update(id uint64, item book.Book) (*book.Book, error) {
store.mu.Lock()
defer store.mu.Unlock()
books[keyInstance] = item
return &item, nil
}
func (store bookStoreInMemory) Delete(id uint64) error {
delete(books, id)
return nil
}
```
to represent an in-memory database we will use a map to store our book data. You will see the mu sync.Mutex, we use this dude to create a "safe zone" in the places that we need to increase the number that will represent our Id Generator. If we don't use this lock in these places, a scenario with multiple request (concurrency) trying to add in the map, using the keyInstance probably will be overridden in the map. To create a "safe zone" at the moment that we store the keyInstance, we will use the lock and unlock method to guarantee our process to simulate the id generation.
Now we will access this repository in the service layer, for this reason, we will inject the repository interface into our service constructor.
```go
//internal\service\book.go
//...
type bookServiceImpl struct {
bookStore repository.BookStore
}
func NewBookService(bookStore repository.BookStore) BookService {
return bookServiceImpl{bookStore}
}
//...
```
When you put this interface in the NewBookService() constructor you will see that your 'container.go' will break, because we describe that we need the repository interface in the constructor method and there is the place that we inject/instantiate our components. Then we will change the 'container.go' too.
```go
//internal\container\container.go
//...
func Inject() Container {
//stores
bookStore := repository.NewBookStoreInMemory()
//init services
bs := service.NewBookService(bookStore)
//...
}
//...
```
Now we can access the repository in the service layer because the container will inject the repository correctly. And now we will change the service method to use the repository correctly.
Now our service/book.go will look like this:
```go
package service
import (
"github.com/maaarkin/hero-api-golang/internal/domain/book"
"github.com/maaarkin/hero-api-golang/internal/repository"
)
type BookService interface {
Save(book book.Book) (*book.Book, error)
FindAll() (*[]book.Book, error)
FindById(id uint64) (*book.Book, error)
Delete(id uint64) error
Update(book book.Book) error
}
type bookServiceImpl struct {
bookStore repository.BookStore
}
func NewBookService(bookStore repository.BookStore) BookService {
return bookServiceImpl{bookStore}
}
func (bs bookServiceImpl) Save(book book.Book) (*book.Book, error) {
id, err := bs.bookStore.Create(book)
if err != nil {
return nil, err
}
book.Id = id
return &book, nil
}
func (bs bookServiceImpl) FindAll() (*[]book.Book, error) {
return bs.bookStore.GetAll()
}
func (bs bookServiceImpl) FindById(id uint64) (*book.Book, error) {
return bs.bookStore.Get(id)
}
func (bs bookServiceImpl) Delete(id uint64) error {
return bs.bookStore.Delete(id)
}
func (bs bookServiceImpl) Update(book book.Book) error {
_, err := bs.bookStore.Update(book.Id, book)
if err != nil {
return err
}
return nil
}
```
At this point, we can access the repository layer through the service layer but we don't have any REST endpoint to get any information from this service. In the next step we will improve our handler/book.go to get information from the service layer and delivery the JSON data. | maaarkin |
908,425 | Khám phá chi tiết máy chạy bộ BK-9000 | Bạn đang khao khát một cơ thể săn chắc, một đôi chân thon gọn hãy thử ngay máy chạy bộ BK-9000. Sử... | 0 | 2021-11-25T03:49:47 | https://dev.to/thethaoatochi/kham-pha-chi-tiet-may-chay-bo-bk-9000-46l9 | maychaybo | <p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Bạn đang khao khát một cơ thể săn chắc, một đôi chân thon gọn hãy thử ngay </em><em>máy chạy bộ BK-9000</em><em>. Sử dụng máy chạy bộ là phương pháp chăm sóc sức khỏe tại nhà được nhiều gia đình lựa chọn. Bạn không cần đến phòng tập, không lo thời tiết ảnh hưởng khi phải ra ngoài chạy bộ. BK-9000 thực sự là sự lựa chọn tuyệt vời cho một sức khỏe tốt và một vóc dáng cân đối.</em></span></span></p>
<h2 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><strong>Phân loại máy chạy bộ BK-9000 </strong></span></span></h2>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Hiện BK-9000 có 2 loại sản phẩm là máy chạy bộ BK-9000 đơn năng và máy chạy bộ BK-9000 đa năng. Hôm nay </span><strong><a class="in-cell-link" href="https://twitter.com/thethaotaiphat" target="_blank"><span style="color:#FF0000">Tài Phát Sport</span></a></strong><span style="background-color:transparent; color:rgb(0, 0, 0)"> sẽ giới thiệu đến bạn chi tiết về máy chạy bộ BK-9000 nhé!</span></span></span></p>
<p dir="ltr" style="text-align:center"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)"><img alt="Máy chạy bộ BK-9000 thiết kế hiện đại, sang trọng" src="https://lh5.googleusercontent.com/pl4Xb47enSbv2tJAR6GAixcGv6cKPCutbvbE1W4lZCRHjQKDz3N0j3DYgDKwSTaD12DvEqa67EW7I2iA_loms2e6kkBvIuO9ezNVpWU3AWX8L0BQ_YSrIrkxQN-Sa98qLPm99hwT" style="height:563px; margin-left:0px; margin-top:0px; width:600px" /></span></span></span></p>
<p dir="ltr" style="text-align:center"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Máy chạy bộ BK-9000 thiết kế hiện đại, sang trọng</em></span></span></p>
<h3 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Máy chạy bộ BK-9000 đơn năng</em></span></span></h3>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Máy chạy bộ BK-9000 đơn năng là sản phẩm chuyên dụng cho các bài tập liên quan đến chân. Dòng sản phẩm này có thiết kế đơn giản và chức năng chính là chạy và đi bộ nên trọng lượng máy nhẹ hơn so với máy chạy bộ đa năng. BK-9000 vẫn được trang bị đầy đủ như màn hình LCD, lò xo giảm xóc, nâng dốc tự động,... </span></span></span></p>
<h3 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Máy chạy bộ đa năng BK-9000 </em></span></span></h3>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Máy chạy bộ đa năng BK-9000 đa năng được trang bị nhiều công cụ hỗ trợ như đai massage, tạ tay, thanh gập bụng, địa xoạy eo giúp việc luyện tập của bạn trở nên phong phú hơn. Bạn có thể tập nhiều các bài tập khác nhau, đốt cháy nhiều calo hơn, mang lại hiệu quả tập và thư giãn tốt hơn. </span></span></span></p>
<h2 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><strong>Đặc điểm nổi bật của máy chạy bộ BK-9000 </strong></span></span></h2>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Hãy cùng chúng tôi xem qua những đặc điểm nổi bật của máy chạy bộ BK-9000 ở cả hại dòng máy đơn năng và đa năng nhé:</span></span></span></p>
<h3 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Về thiết kế </em></span></span></h3>
<h3 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Động cơ mạnh mẽ</em></span></span></h3>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Máy chạy bộ BK-9000 được được thiết kế với vẻ ngoài vô cùng nổi bật và hiện đại. Toàn bộ khung máy được làm bằng hợp kim thép cao cấp, có khả năng chịu lực tốt, giảm trầy xước và dễ dàng lau chùi vệ sinh. Hơn nữa máy còn được trang bị lò xo giảm sóc để những bước chạy của bạn luôn êm ái.</span></span></span></p>
<h3 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Động cơ mạnh mẽ</em></span></span></h3>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Sản phẩm được trang bị động cơ mạnh mẽ lên đến 3,0 Hp. Đồng thời máy có độ bền cao, đảm bảo thời gian vận hành lâu dài cho người sử dụng. Ngoài ra máy chạy bộ BK-9000 có khả năng nâng dốc tự động cho người dùng trải nghiệm độ dốc lên đến 18%. </span><strong><a class="in-cell-link" href="https://thethaotaiphat.com.vn/may-chay-bo-co-la-gi.html" target="_blank"><span style="color:#FF0000">máy chạy bộ cơ</span></a></strong><span style="background-color:transparent; color:rgb(0, 0, 0)"> có thiết kế chức năng tra dầu tự động giúp tăng độ bền cho động cơ trong quá trình hoạt động. </span></span></span></p>
<h3 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Trang bị màn hình LCD sắc nét</em></span></span></h3>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Máy chạy bộ BK-9000 được trang bị màn hình LCD sắc nét để bạn quan sát mọi thông số trong quá trình tập tập như: nhịp tim, thời gian chạy, vận tốc, lượng calo tiêu hao,... Hơn thế nữa máy còn được trang bị hệ thống phát nhạc qua kết nối bluetooth và cổng jack 3,5mm để bạn vừa luyện tập vừa thư giãn.</span></span></span></p>
<p dir="ltr" style="text-align:center"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)"><img alt="Máy chạy bộ BK-900 tích hợp nhiều chức năng hiện đại" src="https://lh6.googleusercontent.com/b7Ty-hIQs2Q6RFCP6Mr-GfgRMm2L8GqX4z0gCQqcDgrC26tW_QXpolVcAFRK5yODKnk5jpAiinVfdKlTNhkrg1epmPXchutsWo-vp3QVsMr37lof-T8CDbgRcnDZTyIVq7mP1oNB" style="height:600px; margin-left:0px; margin-top:0px; width:600px" /></span></span></span></p>
<p dir="ltr" style="text-align:center"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Máy chạy bộ BK-900 tích hợp nhiều chức năng hiện đại</em></span></span></p>
<h3 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Tích hợp chức năng luyện tập ( chỉ có ở máy chạy bộ BK-9000 đa năng)</em></span></span></h3>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Ngoài chức năng chính là chạy bộ máy còn được tích hợp sẵn nhiều chức năng tập luyện khác như:</span></span></span></p>
<ul>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Đai massage có tác dụng giúp thư giãn cơ sau khi tập hoặc tăng cường đốt cháy mỡ thừa ở các vùng bụng, mông, đùi,.. </span></span></span></p>
</li>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Thanh tập bụng để bạn tập các bài tập chuyên vùng bụng</span></span></span></p>
</li>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Đĩa xoay eo để bạn tập các bài tập cho vùng eo</span></span></span></p>
</li>
</ul>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Nhưng một lưu ý nhỏ là những chức năng ngoài chạy bộ này chỉ được tích hợp trên </span><span style="color:rgb(0, 0, 0)">máy chạy bộ</span><span style="background-color:transparent; color:rgb(0, 0, 0)"> bk-9000 đa năng. </span></span></span></p>
<h2 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><strong>Thông số kỹ thuật máy chạy bộ BK-9000</strong></span></span></h2>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Dưới đây là một số thông số kỹ thuật của máy chạy bộ BK-9000:</span></span></span></p>
<ul>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Model: BK-9000 ( đa năng hoặc đơn năng )</span></span></span></p>
</li>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Điện áp: 220V </span></span></span></p>
</li>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Tải trọng: 14okg</span></span></span></p>
</li>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Tốc độ tối đa: 18km/h</span></span></span></p>
</li>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Kích thước thảm chạy: 126 x 45cm</span></span></span></p>
</li>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Giảm xóc: lò xo và đệm cao su</span></span></span></p>
</li>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Thảm chạy: thảm loại kim cương</span></span></span></p>
</li>
<li dir="ltr">
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent">Số chương trình tập: máy cài sẵn 12 chương trình tập</span></span></span></p>
</li>
</ul>
<h2 dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><strong>Lợi ích từ việc sử dụng máy chạy bộ BK-9000</strong></span></span></h2>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Nếu bạn thường xuyên luyện tập thể với máy chạy bộ BK-9000 giúp bạn và gia đình có một sức khỏe tốt, giảm nguy cơ béo phì, tăng cường khả năng miễn dịch. Hơn nữa khi tập với máy chạy bộ BK-9000 sẽ giúp bạn giảm thiểu các chấn thương so với bạn chạy bộ ngoài trời. Đặc biệt bạn có thể điều chỉnh cường độ tập theo mong muốn của mình mà không cần đi đến phòng tập. Mỗi ngày bạn nên chạy bộ khoảng 30 phút mỗi ngày, trước khi chạy bạn nên khởi động 3-5 phút để làm nóng cơ thể.</span></span></span></p>
<p dir="ltr" style="text-align:center"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)"><img alt="Máy chạy bộ BK-9000 mang lại nhiều lợi ích cho sức khỏe bạn và gia đình" src="https://lh5.googleusercontent.com/EYUA67YBmMTy0C_TR-FMURphIWljjpc9qGvcwuD4bbSMAPiD6RmKUZcAibt_dsJJ130JlZJ7WC_7q9R0HEnWKPwbzyj5yUcppUEb_kcGZI8t-13ayhAUe_-u-lwyBG4wnHeeU2Tq" style="height:395px; margin-left:0px; margin-top:0px; width:600px" /></span></span></span></p>
<p dir="ltr" style="text-align:center"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><em>Máy chạy bộ BK-9000 mang lại nhiều lợi ích cho sức khỏe bạn và gia đình</em></span></span></p>
<p dir="ltr" style="text-align:justify"><span style="font-size:16px"><span style="font-family:arial,helvetica,sans-serif"><span style="background-color:transparent; color:rgb(0, 0, 0)">Với những thông tin về </span><strong>máy chạy bộ BK-9000</strong><span style="background-color:transparent; color:rgb(0, 0, 0)"> chúng tôi vừa giới thiệu ở trên chắc hẳn bạn cũng thấy đây là một sản phẩm chất lượng tuyệt vời. Nếu bạn đã quyết định mua máy chạy bộ BK-9000 cho gia đình mình hãy đến với địa chỉ </span><strong><a class="in-cell-link" href="https://thethaotaiphat.com.vn/dia-chi-ban-may-chay-bo-tai-ha-noi-uy-tin-gia-re-nhat.html" target="_blank"><span style="color:#FF0000">máy chạy bộ Hà Nội</span></a></strong><span style="background-color:transparent; color:rgb(0, 0, 0)"> Thể Thao Tài Phát để mua cho mình sản phẩm chính hãng. Thể Thao Tài Phát phân phối các loại máy tập chính hãng với giá cả cạnh tranh cùng chế độ hậu mãi vô cùng tốt. </span></span></span></p>
| thethaoatochi |
908,538 | 🚀 A powerful drag and drop implementation in just 16 lines of JavaScript | Drag and drop is a very useful tool in applications as it can simplify a large part of the process... | 0 | 2021-11-25T07:06:21 | https://blog.siddu.tech/16-lines-drag-and-drop | javascript, html, css, webdev | ---
title: 🚀 A powerful drag and drop implementation in just 16 lines of JavaScript
published: true
date: 2021-11-25 06:44:02 UTC
tags: javascript, html, css, webdev
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/txwj8wdjnowig11vbyf8.png
canonical_url: https://blog.siddu.tech/16-lines-drag-and-drop
---
Drag and drop is a very useful tool in applications as it can simplify a large part of the process for users. It's also a common task we delegate to other libraries which may bloat your app when you just need _a very simple implementation_ when you can use the [Drag and Drop Web API](https://developer.mozilla.org/en-US/docs/Web/API/HTML_Drag_and_Drop_API). **Today, I'll show you how you can do just that!**
## What we are making
This is the basic implementation we are aiming to build:
{% codepen https://codepen.io/SiddharthShyniben/pen/OJjePGv %}
That was made in just 16 lines of JavaScript!
And with a few more lines we can add a lot more bonus features! Here's a demo with some more features!
{% codepen https://codepen.io/SiddharthShyniben/pen/xxLNJxj %}
Play around with it, you will see that we can
- Drop elements only in certain places
- Style the element in which we are dropping
- Style the original copy of the dragged element
- (With a little trickery) even style the dragged element!
All this with just 30 lines of code!
It works on almost all desktop browsers with partial support all the way back to IE 6(!) which should be enough for this to work, but it doesn't work on some mobile browsers.
You can see the up-to-date CanIUse data here:

Dealing with libraries for this very basic functionality has been a pain for me, and to save you the trouble I thought I'd document the process here!
## HTML structure
### Places to drag into
You need some drop targets to be able to drag something into them right? We can add these using regular divs:
```html
<div class='drop'></div>
<div class='drop'></div>
<div class='drop'></div>
<div class='drop'></div>
```
> **Note:** I'll be referring to the places we can drop into as drop targets in this post
You can add as many of them wherever you like, as long as an element has the `drop` class we **will** be able to drop into them.
We can also add some basic styles for them to look nice.
```css
* {
box-sizing: border-box;
font-family: sans-serif;
}
.drop {
width: 220px;
height: 45px;
background: #2563EB;
margin-bottom: 10px;
padding: 10px;
border-radius: 3px;
}
```
### The element to drag
For an element to be draggable, we need, well, an element! We can place the element in one of the drop targets we made before. This is how it should look like
```html
<div class='drop'>
<div id='drag' draggable='true' ondragstart='event.dataTransfer.setData('text/plain', null)'>
Drag me!
</div>
</div>
<div class='drop'></div>
<div class='drop'></div>
<div class='drop'></div>
```
Notice how we also set the `draggable` attribute to true. Every draggable element needs to have the `draggable` attribute set for it to be draggable.
Also, not every element can be dragged even if the `draggable` attribute is set. We need to explicitly say that the element is draggable by listening to the `dragstart` event in the HTML. There we are setting `null` as we don't have any data to share and we are setting the data type `text/plain`.
We can (again) also add some basic styles for them to look nice.
```css
#drag {
width: 200px;
height: 25px;
border-radius: 3px;
background: black;
color: white;
display: grid;
align-items: center;
justify-content: center;
}
```
Note that as long as an element has the `draggable` attribute set to `true` and the drop targets have the `drop` class, the below code should work everywhere
## The minimal implementation
For our drag and drop to be functional, we just need 3 different event listeners. Everything else is a bonus.
First, we need to store the element we are dragging. We can do this by listening to the `dragstart` event.
```js
let dragged;
document.addEventListener('dragstart', event => {
dragged = event.target;
}, false)
```
Whenever an element is dragged, this will store the dragged element in a variable.
Next, we can listen to drop events so we can drop elements.
```js
document.addEventListener('drop', event => {
// Prevent default behaviour (sometimes opening a link)
event.preventDefault();
if (event.target.className === 'drop') {
dragged.parentNode.removeChild(dragged);
event.target.appendChild(dragged);
}
}, false)
```
Whenever we drop an element, if the element is a drop target (has the `drop` class) we will append the dragged element to the drop target.
We're almost done, but we need to do one more thing to make this work.
By default, dragging elements does nothing, so to prevent the default behavior we need to call `event.preventDefault` whenever we drag over the drop target.
This is easy to achieve with a oneliner:
```js
document.addEventListener('dragover', event => event.preventDefault(), false);
```
That's it! In 16 lines we have functional drag and drop!
{% codepen https://codepen.io/SiddharthShyniben/pen/OJjePGv %}
Here's a video of it in action:

## Adding more features
Even if this drag and drop _works_, it's not very nice. It doesn't seem very "natural". Luckily, in a few lines of code, we can make this drag and drop even better!
### Styling the original dragged element
Whenever we drag an element, the original copy of the element doesn't change its style. It would look better if we could add a different style to these dragged elements, like making them transparent to show that it is being dragged.
This is very easy to do. Just add the styles in the `dragstart` event listener.
```js
document.addEventListener('dragstart', event => {
// ...
event.target.style.opacity = 0.5;
// add more styles as you like...
// ...
});
```
But we also need to reset the style once we finish dragging. We can do that by listening to `dragend`:
```js
document.addeventListener('dragend', event => event.target.style.opacity = '', false)
```
## Styling the drop targets
We can also style the drop target by listening to the `dragenter` event:
```js
document.addEventListener('dragenter', event => {
if (event.target.className === 'drop') event.target.style.background = '#2c41cc';
}, false)
```
Once again, we need to reset the styles once we leave the element. We can do that by listening to `dragleave`:
```js
document.addEventListener('dragleave', event => {
if (event.target.className === 'drop') event.target.style.background = '';
}, false)
```
We also need to reset the styles once we drop the event. We can edit the `drop` event to achieve this.
```js
document.addEventListener('drop', event => {
// ...
if (event.target.className === 'drop') {
event.target.style.background = '';
//...
})
```
### Styling the dragged copy
With a bit of trickery, we can style the dragged copy too! Maybe we can rotate the element a bit to make it a bit more natural.
We can do this by styling the original copy and immediately undoing those styles in the `dragstart` event so that the users don't see it.
```js
listen('dragstart', event => {
// ...
event.target.style.transform = 'rotate(-2deg)';
setTimeout(() => event.target.style.transform = '', 1);
})
```
Now the dragged copy will appear to be rotated when we are dragging it!
You now have a fully functioning drag and drop implementation!
{% codepen https://codepen.io/SiddharthShyniben/pen/xxLNJxj %}
Here's a video of it in action:

[Here's a Gist with all the source code for reference](https://gist.github.com/SiddharthShyniben/cd35cf13929e93b4210ffae72b57f986)
## Conclusion
We took a task for which we very commonly delegate to libraries and implemented it ourselves, with surprisingly little code.
I hope this opens your eyes to how much you can do with just vanilla JS. You don't need libraries every time.
Have you ever tried implementing drag and drop on your own? Share in the comments! | siddharthshyniben |
908,570 | Build a paid membership site using SAWO and Stripe | Build a paid membership site with Stripe and Sawo Stripe: Online payment processing for... | 0 | 2021-11-25T08:17:21 | https://dev.to/karankartikeya/build-a-paid-membership-site-using-sawo-and-stripe-2gda | sawo, stripe, opensource, javascript | # Build a paid membership site with Stripe and Sawo
**Stripe:** Online payment processing for internet businesses. Stripe is a suite of payment APIs that powers commerce for online businesses of all sizes.
# Requirements
- [Node.js 15.5+](https://nodejs.org/en/) or later
- MacOS, Windows (including WSL), and Linux are supported
- npm (comes bundled with node.js) or [yarn](https://yarnpkg.com/getting-started/install)
# Steps
## 1. Generate SAWO API key
- Navigate to SAWO Dashboard or create a new account [here](https://dev.sawolabs.com/) and log in.
- In the SAWO dashboard, click on the create project button at the bottom left to create a new project.

- Choose web and then code since we're working with react framework and will be writing the custom code ourselves.
Click continue. You'll see a similar prompt like the one below.
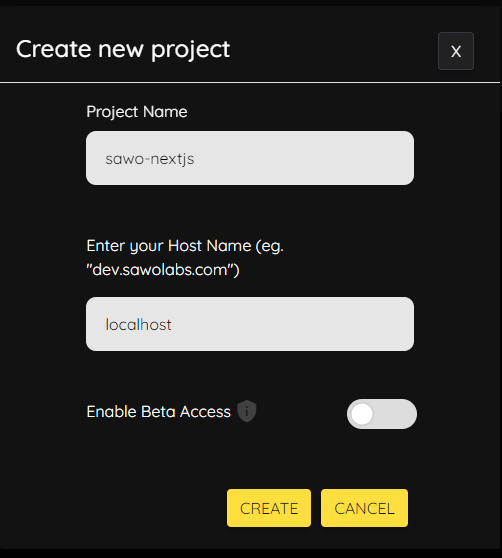
- Name your project with a relevant name.
2.1 For development in a local machine, the hostname should be set to 'localhost'.
> If using "localhost" as hostname is not working for you, try "127.0.0.1"
2.2 For production, the hostname should be set to your domain.
> If you are adding your domain do not add 'https://', ''http://', 'www' or even trailing backslash. Example: https://dev.sawolabs.com/ should be kept as dev.sawolabs.com
On clicking the create button, we can successfully see the API key created prompt and SAWO keys csv file downloaded.
## 2. Generate Stripe API key and create a product with price
- Navigate to Stripe Dashboard or create a new account [here](https://stripe.com/) and log in.
- In the Stripe dashboard, click on the developers option.
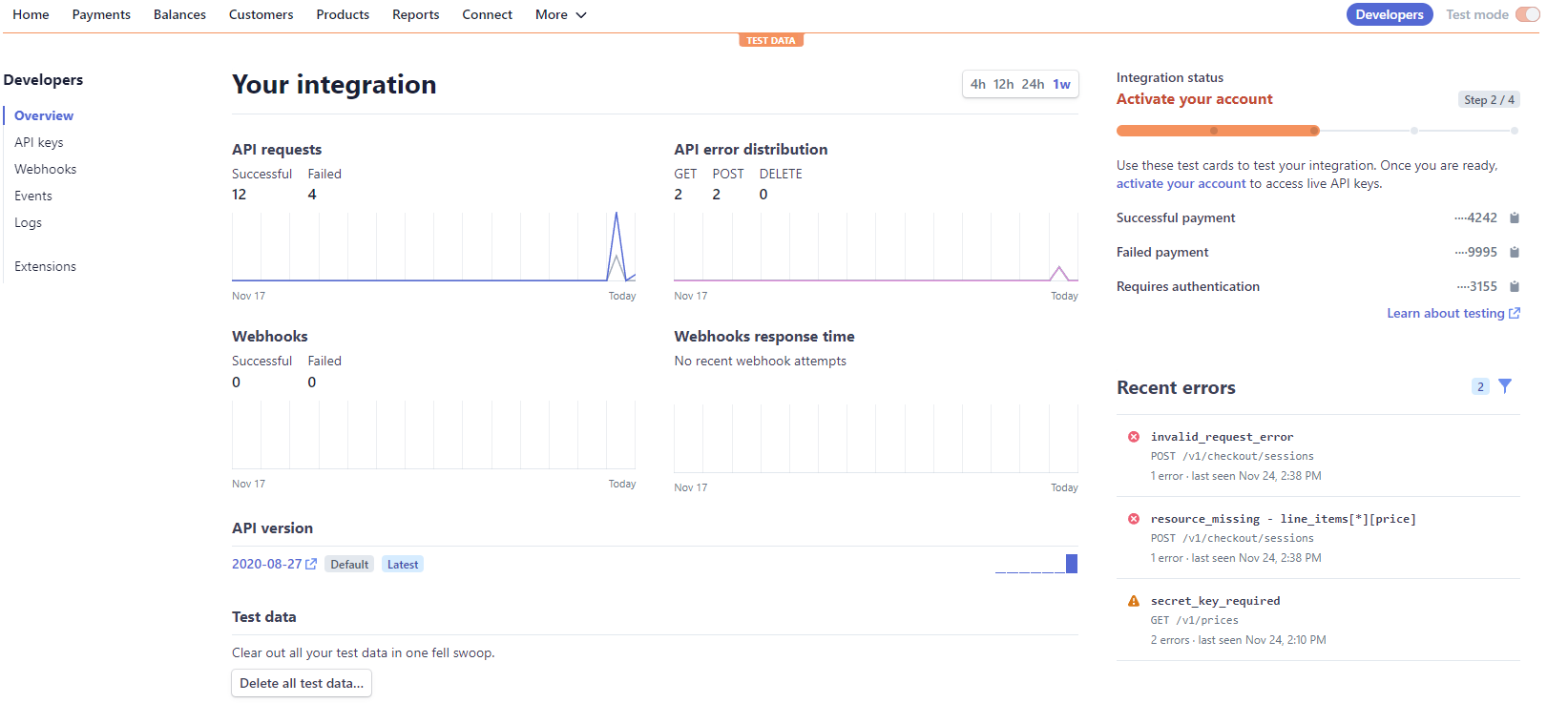
- In the developers section head to API keys, and there you can find the secret key and publishable key.
- Move to the products option to create your products with prices.
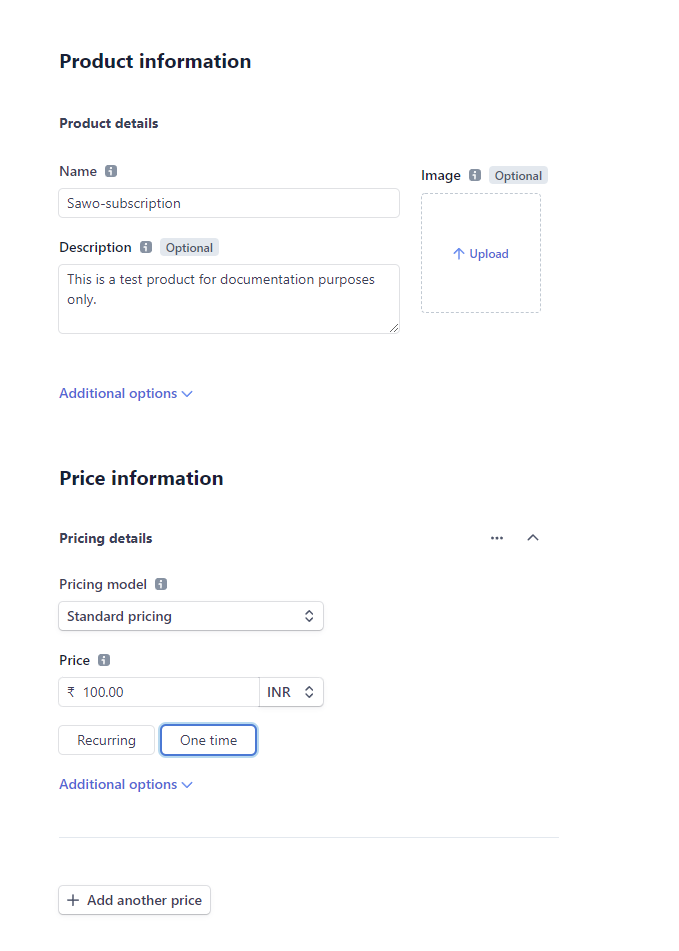
- You will be able to see your price id in front of the price info after creating the product.
## 3. Install the dependencies
Enter the following command in the terminal to create a Next.js app.
```sh
npm i stripe, express
```
## 4. Make endpoints in index.js file and serve your HTML files
- Now, create an instance of express and path
```js
const express = require("express");
const app = express();
const path = require("path");
```
- Serve the html files
```js
app.use(express.static(path.join(__dirname, "public")));
app.get("/", (req, res) => {
res.sendFile(__dirname + "/index.html");
});
app.get("/login", (req, res) => {
res.sendFile(__dirname + "/public/login.html");
});
app.get("/success", (req, res) => {
res.sendFile(__dirname + "/public/success.html");
});
app.listen("3000", console.log("Listening on port 3000."));
```
- Next, let's create an instance of stripe
```js
const stripe = require('stripe')('YOUR_STRIPE_SECRET_KEY');
```
- Import the price id generated above
```js
const priceId = 'YOUR_PRICE_ID';
```
- Create a Checkout Session for Stripe
```js
const session = await stripe.checkout.sessions.create({
billing_address_collection: 'auto',
line_items: [
{
price: prices.data[0].id,
// For metered billing, do not pass quantity
quantity: 1,
},
],
mode: 'subscription',
success_url: `${YOUR_DOMAIN}/success.html?session_id={CHECKOUT_SESSION_ID}`,
cancel_url: `${YOUR_DOMAIN}/cancel.html`,
});
res.redirect(303, session.url);
});
```
- Get the price from lookup key
```js
const prices = await stripe.prices.list({
lookup_keys: [req.body.lookup_key],
expand: ['data.product'],
});
```
- Define the line items:
```js
line_items: [
{
price: prices.data[0].id,
// For metered billing, do not pass quantity
quantity: 1,
},
],
```
- Define the success and cancel urls:
```js
success_url: `${YOUR_DOMAIN}/success.html?session_id={CHECKOUT_SESSION_ID}`,
cancel_url: `${YOUR_DOMAIN}/cancel.html`,
```
- Create a customer portal session:
```js
const returnUrl = YOUR_DOMAIN;
const portalSession = await stripe.billingPortal.sessions.create({
customer: checkoutSession.customer,
return_url: returnUrl,
});
```
- Provision access:
```js
app.post(
'/webhook',
express.raw({ type: 'application/json' }),
(request, response) => {
const event = request.body;
// Replace this endpoint secret with your endpoint's unique secret
// If you are testing with the CLI, find the secret by running 'stripe listen'
// If you are using an endpoint defined with the API or dashboard, look in your webhook settings
// at https://dashboard.stripe.com/webhooks
const endpointSecret = 'whsec_12345';
// Only verify the event if you have an endpoint secret defined.
// Otherwise use the basic event deserialized with JSON.parse
if (endpointSecret) {
// Get the signature sent by Stripe
const signature = request.headers['stripe-signature'];
try {
event = stripe.webhooks.constructEvent(
request.body,
signature,
endpointSecret
);
} catch (err) {
console.log(`⚠️ Webhook signature verification failed.`, err.message);
return response.sendStatus(400);
}
}
let subscription;
let status;
// Handle the event
switch (event.type) {
case 'customer.subscription.trial_will_end':
subscription = event.data.object;
status = subscription.status;
console.log(`Subscription status is ${status}.`);
// Then define and call a method to handle the subscription trial ending.
// handleSubscriptionTrialEnding(subscription);
break;
case 'customer.subscription.deleted':
subscription = event.data.object;
status = subscription.status;
console.log(`Subscription status is ${status}.`);
// Then define and call a method to handle the subscription deleted.
// handleSubscriptionDeleted(subscriptionDeleted);
break;
case 'customer.subscription.created':
subscription = event.data.object;
status = subscription.status;
console.log(`Subscription status is ${status}.`);
// Then define and call a method to handle the subscription created.
// handleSubscriptionCreated(subscription);
break;
case 'customer.subscription.updated':
subscription = event.data.object;
status = subscription.status;
console.log(`Subscription status is ${status}.`);
// Then define and call a method to handle the subscription update.
// handleSubscriptionUpdated(subscription);
break;
default:
// Unexpected event type
console.log(`Unhandled event type ${event.type}.`);
}
// Return a 200 response to acknowledge receipt of the event
response.send();
}
);
```
</br>
- If you have followed the tutorial well, you'll see a checkout form similar to the one given below when you head to buying membership button on homepage.

# Conclusion
Congratulations! You have made it till the end and have learnt how to implement authentication in SAWO and also integrated Stripe API for paid membership. In case you're facing difficulties, here's a [working demo](https://youtu.be/pCR0LZMO2to) of the tutorial you just went over. Find the source code for the same [here](https://github.com/karankartikeya/Paid_membership_site_source_code-Sawo-labs-.git).
# What's Next?
Now that you've learnt how to build a paid-membership site using Stripe and Sawo, feel free to look at the [SAWO documentation](https://docs.sawolabs.com/sawo/) and integrate some new features in this demo application by forking it in your repo.
| karankartikeya |
908,672 | Apt-Get Update Fails to Fetch Files, “Temporary Failure Resolving …” Error! | apt Err http://archive.canonical.com natty InRelease Err http://security.ubuntu.com... | 0 | 2021-11-30T05:50:55 | https://stackallflow.com/ubuntu/apt-get-update-fails-to-fetch-files-temporary-failure-resolving-error/ | ubuntu | ---
title: Apt-Get Update Fails to Fetch Files, “Temporary Failure Resolving …” Error!
published: true
date: 2021-11-25 09:38:17 UTC
tags: Ubuntu
canonical_url: https://stackallflow.com/ubuntu/apt-get-update-fails-to-fetch-files-temporary-failure-resolving-error/
---
<header>
<p><span style="font-size: 1.2em; color: initial;">apt</span></p>
</header>
```
Err http://archive.canonical.com natty InRelease
Err http://security.ubuntu.com oneiric-security InRelease
Err http://extras.ubuntu.com natty InRelease
Err http://security.ubuntu.com oneiric-security Release.gpg
Temporary failure resolving ‘security.ubuntu.com’
Err http://archive.canonical.com natty Release.gpg
Temporary failure resolving ‘archive.canonical.com’
Err http://extras.ubuntu.com natty Release.gpg
Temporary failure resolving ‘extras.ubuntu.com’
Err http://gb.archive.ubuntu.com oneiric InRelease
Err http://gb.archive.ubuntu.com oneiric-updates InRelease
Err http://gb.archive.ubuntu.com natty-backports InRelease
Err http://gb.archive.ubuntu.com oneiric Release.gpg
Temporary failure resolving ‘gb.archive.ubuntu.com’
Err http://gb.archive.ubuntu.com oneiric-updates Release.gpg
Temporary failure resolving ‘gb.archive.ubuntu.com’
Err http://gb.archive.ubuntu.com natty-backports Release.gpg
Temporary failure resolving ‘gb.archive.ubuntu.com’
Reading package lists... Done
W: Failed to fetch http://gb.archive.ubuntu.com/ubuntu/dists/oneiric/InRelease
W: Failed to fetch http://gb.archive.ubuntu.com/ubuntu/dists/oneiric-updates/InRelease
W: Failed to fetch http://gb.archive.ubuntu.com/ubuntu/dists/natty-backports/InRelease
W: Failed to fetch http://security.ubuntu.com/ubuntu/dists/oneiric-security/InRelease
W: Failed to fetch http://archive.canonical.com/ubuntu/dists/natty/InRelease
W: Failed to fetch http://extras.ubuntu.com/ubuntu/dists/natty/InRelease
W: Failed to fetch http://archive.canonical.com/ubuntu/dists/natty/Release.gpg Temporary failure resolving ‘archive.canonical.com’
W: Failed to fetch http://security.ubuntu.com/ubuntu/dists/oneiric-security/Release.gpg Temporary failure resolving ‘security.ubuntu.com’
W: Failed to fetch http://extras.ubuntu.com/ubuntu/dists/natty/Release.gpg Temporary failure resolving ‘extras.ubuntu.com’
W: Failed to fetch http://gb.archive.ubuntu.com/ubuntu/dists/oneiric/Release.gpg Temporary failure resolving ‘gb.archive.ubuntu.com’
W: Failed to fetch http://gb.archive.ubuntu.com/ubuntu/dists/oneiric-updates/Release.gpg Temporary failure resolving ‘gb.archive.ubuntu.com’
W: Failed to fetch http://gb.archive.ubuntu.com/ubuntu/dists/natty-backports/Release.gpg Temporary failure resolving ‘gb.archive.ubuntu.com’
W: Some index files failed to download. They have been ignored, or old ones used instead.
```
This is what I’m seeing when I try to run `sudo apt-get update`. I did an update on my instance yesterday and am now experiencing this.
#### Accepted Answer
## overview
There are two parts to your question:
- fixing _temporary resolve_ messages
- fixing the package management issues
### Temporary resolve
It is likely that this issue is either:
- temporary due to your Internet Service Provider not correctly forwarding internet naming (DNS) to either its or external DNS servers, or
- due to a change in your network has similarly blocked this naming – for example, new router/modem, reconfiguring a switch with a new configuration.
Lets look at the possible DNS resolving issues.
First, temporarily add a known DNS server to your system.
```
echo "nameserver 8.8.8.8" | sudo tee /etc/resolv.conf > /dev/null
```
Then run `sudo apt-get update`.
If this fixes your _temporary resolving_ messages then either wait for 24 hours to see if your ISP fixes the issue for you (or just contact your ISP) – or you can permanently add a DNS server to your system:
```
echo "nameserver 8.8.8.8" | sudo tee /etc/resolvconf/resolv.conf.d/base > /dev/null
```
`8.8.8.8` is Google’s own DNS server.
[source](https://answers.launchpad.net/ubuntu/+source/apt/+question/197664)
Another example DNS server you could use is _[OpenDNS](https://www.opendns.com/opendns-ip-addresses/)_ – for example:
```
echo "nameserver 208.67.222.222" | sudo tee /etc/resolvconf/resolv.conf.d/base > /dev/null
```
### package-management issues
In addition to the _temporary resolve_ issues – you have a few package management issues that need to be corrected – I’m assuming you have tried recently to upgrade from one Ubuntu version to the next recommended version – in your case from Natty (11.04) to Oneiric (11.10)
Open a terminal and type
```
sudo nano /etc/apt/sources.list
```
Look for lines that have your a different distribution name in the list than you were expecting – in your case – you have upgraded to `oneiric` but you have another release name `natty`
For example, look for lines that look like `deb http:/archive.canonical.com/ natty backports`
Add a `#` to the beginning of the line to comment it out – for example
`#deb http:/archive.canonical.com/ natty backports`
Save and re-run:
```
sudo apt-get update && sudo apt-get upgrade
```
You should not have any more release naming errors.
At the time of writing this, possible common [release names](https://wiki.ubuntu.com/DevelopmentCodeNames) include `lucid`, `maverick`, `natty`, `oneiric`, `precise`, `quantal`, `raring`, `saucy`, `trusty`, `utopic` and `vivid`.
The post [Apt-Get Update Fails to Fetch Files, “Temporary Failure Resolving …” Error!](https://stackallflow.com/ubuntu/apt-get-update-fails-to-fetch-files-temporary-failure-resolving-error/) appeared first on [Stack All Flow](https://stackallflow.com). | stackallflow |
908,676 | Is the 64-Bit Version of Ubuntu Only Compatible With Amd Cpus in Ubuntu? | 64-bitArchitecturesystem-installation I was told that computers with more than 2 gig’s memory need a... | 0 | 2021-12-01T08:41:50 | https://stackallflow.com/ubuntu/is-the-64-bit-version-of-ubuntu-only-compatible-with-amd-cpus-in-ubuntu/ | ubuntu | ---
title: Is the 64-Bit Version of Ubuntu Only Compatible With Amd Cpus in Ubuntu?
published: true
date: 2021-11-25 09:43:54 UTC
tags: Ubuntu
canonical_url: https://stackallflow.com/ubuntu/is-the-64-bit-version-of-ubuntu-only-compatible-with-amd-cpus-in-ubuntu/
---
<header>
<p><span style="font-size: 1.2em; color: initial;">64-bit</span><span style="font-size: 1.2em; color: initial;">Architecture</span><span style="font-size: 1.2em; color: initial;">system-installation</span></p>
</header>
I was told that computers with more than 2 gig’s memory need a 64 bit operating system to utilize all RAM.
Is the 64bit Ubuntu download really JUST for AMD processors? I am asking because the disk image I downloaded says AMD64.
So will my new Intel 2.3Ghz Core i3 Dual Core processor work with 64 bit Ubuntu?
It runs the 64bit version of Windows without any qualm.
#### Accepted Answer
There is a slight misunderstanding here. AMD64 refers to the architecture of the processor. As AMD’s [X86-64 extension](http://en.wikipedia.org/wiki/X86-64) prevailed in the “64-Bit format war”, it is named after them; just like people used to call all PCs IBM-PC-compatible.
The gist of the matter is: You can install AMD64 software on both AMD and Intel processors, as long as they support that type of architecture (Don’t worry, almost all processors released in the last 5 years do). So just go ahead and install Ubuntu using the 64 bit iso.
Finally, if your CPU has PAE enabled, you can access more than the limited “4G” of RAM using 32-bit processors.
See also:
- [What are the differences between 32-bit and 64-bit, and which should I choose?](https://askubuntu.com/questions/7034/what-is-the-difference-between-32-bit-and-64-bit-and-which-should-i-choose)
- [Difference between the i386 download and the amd64?](https://askubuntu.com/questions/54296/difference-between-the-i386-download-and-the-amd64)
The post [Is the 64-Bit Version of Ubuntu Only Compatible With Amd Cpus in Ubuntu?](https://stackallflow.com/ubuntu/is-the-64-bit-version-of-ubuntu-only-compatible-with-amd-cpus-in-ubuntu/) appeared first on [Stack All Flow](https://stackallflow.com). | stackallflow |
908,901 | The One Way to Get Inspired | Have you ever felt like the world lost its color? Have you ever lost motivation for the things that... | 0 | 2021-11-30T04:58:26 | https://x-team.com/blog/get-inspired/ | growth, inspiration, motivation, career | ---
title: The One Way to Get Inspired
published: true
date: 2021-11-25 11:32:00 UTC
tags: growth,inspiration,motivation,career
canonical_url: https://x-team.com/blog/get-inspired/
---
Have you ever felt like the world lost its color? Have you ever lost motivation for the things that used to excite you? Have you ever felt lackluster and unwilling to tackle new projects? They're not unusual feelings. At some point in our lives, we've all felt that way.
But it needn't be a complicated problem that's hard to solve. You might just be feeling uninspired. A shot of inspiration could be all you need to recapture your lost energy. This blog post will explain what inspiration is and the one way you'll always be able to find it.
## What Is Inspiration?
Inspiration is a feeling of enthusiasm that comes from something you've read, seen, or watched that motivates you to do something. Inspiration is both passive, because you take in something that inspires you, and active, because you then use that energy to create something of your own.
Inspired people see themselves as [more creative](https://psycnet.apa.org/record/2003-02410-016), make better [progress toward their goals](https://www.sciencedirect.com/science/article/abs/pii/S019188691100417X), and [feel better](https://psycnet.apa.org/record/2010-02829-010) too. While you cannot force yourself to feel inspired, you can seek moments that are likely to inspire.
## Where to Find Inspiration?
We sometimes [lose motivation](https://x-team.com/blog/loss-of-motivation/) because we don't consume enough quality input. We scroll social media, read the news, or watch soap operas on Netflix, but how often do we actively take in greatness? How often do we watch or read something so excellent it inspires us? Steve Jobs said it best:
> “Expose yourself to the best things humans have done and then try to bring those things into what you are doing.”
So here's what you need to do to get inspired. What inspires you will differ from what inspires someone else. So simply write down what makes you and you alone feel inspired. Keep a page in your notebook for when you're inspired and write down what made you feel that way.
Be specific. Instead of writing _shoegaze song_, write _"[Leave Them All Behind](https://www.youtube.com/watch?v=xcyfPXF770U)" from Ride really inspires me, because it reminds me to show all my doubters what I'm capable of_.
Eventually, you'll have a page full of tailored events you can return to whenever you need a flash of inspiration. If your inspiration page is currently still blank, here are a few good categories to start: movies, books, sports, music, nature, travel, architecture, videogames, and people you look up to.
{% youtube b8YxTPVkeBE %}
_Arguably one of the best movie trailers of the 2000s_
## In Conclusion
You're not meant to feel inspired continuously. But if your world feels boring and you've lost motivation to do the things you used to love, you might just need some inspiration.
Search for the greatness that inspires you and write it down. Refuel with these inspiring moments for a more energized and creative life, so you can always [keep moving forward](https://x-team.com/blog/keep-moving-forward/). | tdmoor |
909,071 | Sass(SCSS) for beginners | What is Sass(SCSS)? Sass is a preprocessor scripting language that is interpreted or... | 0 | 2021-11-25T14:59:13 | https://dev.to/daaahailey/sassscss-for-beginners-2aci | sass, scss, css | #What is Sass(SCSS)?
Sass is a preprocessor scripting language that is interpreted or compiled into Cascading Style Sheets(CSS).
Browser wouldn't load Sass but it will be written in Sass then will be exported to CSS.(It's because browser cannot read Sass, it needs to be compiled)
# Sass and SCSS
There are two syntaxes available for Sass.
###SCSS example
It's more similar to CSS because <strong><u>it uses brackets like CSS</u></strong>. The files using this syntax have the <strong><code>.scss</code></strong> extension.
```scss
//SCSS
$font-stack: Helvetica, sans-serif;
$primary-color : #333;
body {
font: 100% $font-stack;
color: $primary-color;
}
```
###Sass example
Sass <strong>uses indentation</strong> rather than brackets to indicate nesting of selectors, and <strong>newlines</strong> rather than semicolons to separate properties. Files using this syntax hav the <strong><code>.sass</code></strong> extension.
```sass
//Sass
$font-stack: Helvetica, sans-serif
$primary-color : #333
body
font: 100% $font-stack
color: $primary-color
```
#Setting
I've used Sass(SCSS) previously by myself and the way I used it was through node-sass. I installed it through npm but at the class we learnt using ruby-sass and used VSC extension called <strong>Live Sass Compiler</strong>
Install this and then restart VS code. (If you are going to use node-sass, should [install node-sass](https://www.npmjs.com/package/sass))
#Separating files and writing comments
You can have separate files for each parts like <code><strong>_header.scss</strong></code>, <code><strong>_home.scss</strong></code> or <code><strong>_variable.scss</strong></code>, <code><strong>_mixin.scss</strong></code>. It's totally upto you but then you should import those separated scss files to one file which is <code><strong>style.scss</strong></code>
If you separates files by its function or layout, it's easy to maintain and reuse code.
##Reason that there is underscore_ in front of file name.
If you don't add <strong>underscore</strong> in front of the file name, every separated scss files will be compiled and they will be saved on separated css file because of that.
But, if you add <strong>underscore</strong> in front of the file name, you can let sass know that it is part of main file and that file won't be compiled and you can import that using <code><strong>@import</strong></code>
##Comments
```scss
/* This comment will be visible in CSS even after compiling. */
// This won't be compiled, only visible in Scss
```
##Nesting
I personally think this is one of the nice things of SCSS.
You can see the structure of CSS code like html if by nesting these code. It makes the code more readable.
```scss
nav {
background : #C39BD3;
padding : 10px;
height: 50px;
ul {
display: flex;
list-style : none;
justify-content: flex-end;
li {
color: white;
margin-right: 10px;
}
}
}
```
###Why use nesting?
With CSS, if you'd like to give style to an inherited element of it's parent element, you have to select the parent every time when you want to.
<strong>Example CSS</strong>
```css
.info-list div {
display: flex;
font-size: 14px;
color: #4f4f4f;
}
.info-list div dt {
font-weight: 700;
margin-right: 7px;
}
```
<strong>But you can do this like below in SCSS</strong>
```scss
.info-list {
div {
display: flex;
font-size: 14px;
color: #4f4f4f;
dt {
font-weight: 700;
margin-right: 7px;
}
}
}
```
** <strong>Note!</strong> Avoid nesting in depth way too much.(Try not to get more than 3 levels deep if possible. If it's more than 3 levels deep, it's not so readable and it uses unnecessary selectors when it's compiled to CSS)
#Nesting properties
You can also nest properties not only selectors.
It's to give background style to class <strong><code>.add-icon</code></strong>
You can nest properties that has <strong><code>background</code></strong> name like <strong><code>background-image</code></strong>, <strong><code>background-position</code></strong>, and etc.
Also, you have to <strong>use colon(:)</strong> to nest properties.
```scss
add-icon {
background : {
image: url("./assets/arrow-right-solid.svg");
position: center center;
repeat: no-repeat;
size: 14px 14px;
}
}
```
Then the code above will be compiled to CSS like this below.
```css
.add-icon {
background-image: url("./assets/arrow-right-solid.svg");
background-position: center center;
background-repeat: no-repeat;
background-size: 14px 14px;
}
```
#& (Ampersand)
<strong><em>& refers to the outer selector</em></strong>. You can also add pseudo element like after, hover, pseudo element or add a selector the before parent.
<strong>SCSS</strong>
```scss
.box {
// pseudo classes
&:focus{}
&:hover{}
&:active{}
&:first-child{}
&:nth-child(2){}
// pseudo elements
&::after{}
&::before{}
}
```
<strong>CSS</strong>
```css
.box:focus{}
.box:hover{}
.box:active{}
.box:frist-child{}
.box:nth-child(2){}
.box::after{}
.box::before{}
```
<strong>Example</strong> - giving style to <strong><code>li</code></strong> and <u>it's pseudo element and pseudo class</u>.
```scss
ul {
li {
//pseudo element
&:hover {
background: white;
cursor: pointer;
}
//pseudo class
&:last-child {
border-bottom: 2px solid black;
}
}
}
```
Also, you can nest classes if they start with the same word like box-yellow or box-red. "box" is the common word used so you can do this way.
<strong>SCSS</strong>
```scss
.box {
&-yellow {
background: #ff6347;
}
&-red {
background: #ffd700;
}
&-green {
background: #9acd32;
}
}
```
<strong>CSS</strong>
```css
.box-yellow {
background: #ff6347;
}
.box-red {
background: #ffd700;
}
.box-green {
background: #9acd32;
}
```
#@at-root
You can get out of the nested code using <strong><code>@at-root</code></strong>
Everything within it <strong>to be emitted at the root of the document</strong> instead of using the normal nesting.
<strong>SCSS</strong>
```scss
.article {
display: flex;
justify-content: space-between;
align-items: center;
margin-top: 10px;
.article-content {
font-size: 14px;
opacity: 0.7;
@at-root i {
opacity: 0.5;
}
}
}
```
<strong>CSS</strong>
```css
.article {
display: flex;
justify-content: space-between;
align-items: center;
margin-top: 10px;
}
.article .article-content {
font-size: 14px;
opacity: 0.7;
}
/* You can see this isn't nested. It's separated from the nested code. */
i {
opacity: 0.5;
}
```
#Variable
Being able to give variable means that you don't have to change the values one by one. It makes much easier to maintain the code.
** Note! Be aware that it can crash if you declare variables indiscriminately. Declare variables only when it has a good reason for. If you are in a team, you need to talk about these enough before declaring variables.
##When to use variables?
- If the value is going to be repeatedly used. (You can style elements without remembering the value but just with the variable.)
- If you need to change existing value to something else.(It it's used in many different elements/properties without variable, you have to change one by one which is time consuming but if you set the value to variable, you only need to change the value of the variable which takes much shorter time.)
##Declaring variable in Sass
```scss
/* bg */
$bgColor : #FFF
```
If there are repeatedly used values, you can style them easily by using variables.
```scss
// colour
$red: #ee4444;
$black: #222;
$bg-color: #3e5e9e;
$link-color: red;
$p-color: #282A36;
// font-size
$font-p: 13px;
$font-h1: 28px;
// font
$base-font: 'Noto Sans KR', sans-serif;
body {
background-color : $bg-color;
font-size : $font-p;
font-family : $base-font;
}
h1 {
font-size: $font-h1;
color: $black;
}
p {
font-size: $font-p;
color: $black;
}
a {
color: $link-color;
}
```
##Type of variables
- number (eg. 1, .82, 20px, 2em, ...)
- string (eg. "./img/cutedog.png", bold, left, uppercase, ...)
- colour (eg. green, #fff, rgba(255,0,0,.5), ...)
- boolean (true, false)
- null
- list
```scss
$font-size : 10px 12px 16px; // list of font-size
$image-file : photo_01, photo_02, photo_03 // list of image-file
// can also use this way - ruby sass
// it iterates from index 1 in sass(*** not 0)
nth(10px 12px 16px, 2); // 2nd value of $font-size is 12px
nth([line1, line2, line3], -1); // if it's negative, it iterates from right to left. Therefore, -1 of $image-file is line3
```
- map
```scss
$font-weights: ("regular": 400, "medium": 500, "bold": 700); // map of font-weights. (key-value pair)
// use this way - ruby sass
map-get($font-weights, "medium"); // 500
map-get($font-weights, "extra-bold"); // null
```
# More about List and Map
## List
```scss
// You can declare value of list using , or whitespace
$sizes: 40px, 50px, 80px;
// above code works the same with $sizes: 40px 50px 80px;
$valid-sides: top, bottom, left, right;
```
<strong>*** index of list starts from 1</strong>
###Built-in List function
- <strong><code>append(list,value,[s])</code></strong>: function that adds value to list.
- <strong><code>index(list, value)</code></strong>: function that returns index of list's value.
- <strong><code>nth(list, n)</code></strong>: function that returns the value of list's index.
<strong>Example</strong>
```scss
// Scss
$valid-sides: left, center, right;
.screen-box {
text-align : nth($valid-sides, 1);
}
```
```css
/* CSS */
.screen-box {
text-align: left;
}
```
## Map
Map saves the value as key:value pair inside the bracket(). Key needs to be unique!
###Built-in Map function
- <strong><code>map-get(map, key)</code></strong>: function that returns the value of its key.
- <strong><code>map-get(map)</code></strong>: function that returns keys of map
- <strong><code>map-values(map)</code></strong>: function that returns values of map
<strong>Example</strong>
```scss
// Scss
$font-sizes: ("h1": 45px, "h2": 19px, "p": 16px);
section {
h2 {
font-size : map-get($font-sizes, "h2");// 19px
}
}
map-get($font-size, "h3");// null
```
```css
/* CSS */
section h2 {
font-size : 19px;
}
```
* string and number also have functions. Find more about [string functions in Sass](https://www.w3schools.com/sass/sass_functions_string.php)
#Scope
There are local variable and global variable.
##Local variable
```scss
.info{
// local variable
$line-normal : 1.34;
font-size : 15px;
line-height : $line-normal;
text-align : right;
span{
line-height : $line-normal;
}
}
```
##Global variable
```scss
//Scss
// global variable
$font-p : 15px;
.main-box{
p {
font-size : $font-p;
}
a {
font-size : $font-p;
color : blue;
text-decoration : none;
}
}
```
```css
.main-box p {
font-size: 15px;
}
.main-box a {
font-size: 15px;
color: blue;
text-decoration: none;
}
```
You can also use !global to make local variable to global variable.
```scss
$mycolor: #ffffff !global;
```
More about [variables in Sass](https://sass-lang.com/documentation/variables)
#Operator
- <strong><code>a < b</code></strong> : check if a is smaller than b
- <strong><code>a <= b</code></strong> : check if a is the same with b or smaller than b
- <strong><code>a > b</code></strong> : check if a is greater than be
- <strong><code>a >= b</code></strong> : check if a is greater than be or the same with b
```scss
@debug 100 > 50; // true
@debug 10px < 17px; // true
@debug 96px >= 1in; // true
@debug 1000ms <= 1s; // true
```
<strong>ERROR</strong>
If they both have units and those units aren't the same, it causes the error.
BUT! it's fine when you compare it with number and number with unit.
<strong>Example</strong>
```scss
@debug 100px > 10s;
// Error: Incompatible units px and s
@debug 100 > 50px; // true
@debug 10px < 17; // true
// Not Error
```
- <strong><code>a == b</code></strong> : check if a and b are the same.
- <strong><code>a !== b</code></strong> : check if a and be aren't the same.
<strong>Example</strong>
```scss
// number
@debug 1px == 1px; // true
@debug 1px != 1em; // true
@debug 1 != 1px; // true
@debug 96px == 1in; // true
// string
@debug "Poppins" == Poppins; // true
@debug "Open Sans" != "Roboto"; // true
// colour
@debug rgba(53, 187, 169, 1) == #35bba9; // true
@debug rgba(179, 115, 153, 0.5) != rgba(179, 115, 153, 0.8); // true
// list
@debug (5px 7px 10px) != (5px, 7px, 10px); // true
@debug (5px 7px 10px) != [5px 7px 10px]; // true
@debug (5px 7px 10px) == (5px 7px 10px); // true
```
- <strong><code>a + b</code></strong>
- <strong><code>a - b</code></strong>
- <strong><code>a * b</code></strong>
- <strong><code>a / b</code></strong>
- <strong><code>a % b</code></strong> : remainder of a/b
```scss
@debug 10s + 15s; // 25s
@debug 1in - 10px; // 0.8958333333in
@debug 5px * 3px; // 15px*px
@debug 1in % 9px; // 0.0625in (1in == 96px)
```
<strong>Error</strong>
```scss
@debug 100px + 10s;
// Error: Incompatible units px and s.
@debug 100px / 2;
// 50px (Not Error)
```
## String a + b
If there is + operator and a, b are all string, it combines a, b and returns combined string.
Even if one of them isn't string, it makes all of them to string and combine.
```scss
@debug "Helvetica" + " Neue"; // "Helvetica Neue"
@debug sans- + serif; // sans-serif
@debug sans - serif; // sans-serif
@debug "Elapsed time: " + 10s; // "Elapsed time: 10s";
@debug true + " is a boolean value"; // "true is a boolean value";
```
## Boolean
- <strong><code>not</code></strong>: If true, return false. If false, return true.
- <strong><code>and</code></strong>: Return true when both are true. Return false, if one of them is false.
- <strong><code>or</code></strong>: Return false if both are false. Return true if one of them is. true.
```scss
@debug not true; // false
@debug not false; // true
@debug true and true; // true
@debug true and false; // false
@debug true or false; // true
@debug false or false; // false
```
| daaahailey |
909,140 | POINTERS IN C | POINTERS IN C •Every variable is a memory location and every memory location has its address defined... | 0 | 2021-11-25T17:46:44 | https://dev.to/jahnavi1351/pointers-in-c-5bp6 | computerscience, coding, c, ptr | __POINTERS IN C__
•Every variable is a memory location and every memory location has its address defined which can be accessed using ampersand (&) operator, which denotes an address in memory.
• A pointer is a variable whose value is the address of another variable, i.e., direct address of the memory location. Like any variable or constant, you must declare a pointer before using it to store any variable address.
• The general form of a pointer variable declaration is:
type *var-name;
Here,
-- type is the pointer's base type (it must be a valid C
datatype).
-- var-name is the name of the pointer variable.
-- * used to declare a pointer.
• Some of the valid pointer declarations are as follows −
int ip; / pointer to an integer /
double *dp; / pointer to a double /
float *fp; / pointer to a float /
char *ch / pointer to a character */
• The actual data type of the value of all pointers, whether
integer, float, character, or otherwise, is the same, a long hexadecimal number that represents a memory address. The only difference between pointers of different data types is the data type of the variable or constant that the pointer points to.
__USAGE OF POINTERS__
(a) We define a pointer variable.
(b) Assign the address of a variable to a pointer.
(c) Finally access the value at the address available in the pointer variable.
• This is done by using unary operator * that returns the value of the variable located at the address specified by its operand.
• _Example:_
#include
int main ()
{
int var = 20; /* actual variable declaration /
int *ip; / pointer variable declaration /
ip = &var; / store address of var in pointer variable*/
printf("Address of var variable: %x\n", &var );
/* address stored in pointer variable /
printf("Address stored in ip variable: %x\n", ip );
/ access the value using the pointer */
printf("Value of *ip variable: %d\n", *ip );
return 0;
}
• When the above code is compiled and executed, it produces the following result −
-- Address of var variable: bffd8b3c
-- Address stored in ip variable: bffd8b3c
-- Value of *ip variable: 20
__NULL POINTERS__
• It is always a good practice to assign a NULL value to a pointer variable in case you do not have an exact address to be assigned. This is done at the time of variable declaration. A pointer that is assigned NULL is called a null pointer.
• The NULL pointer is a constant with a value of zero defined in several standard libraries. Consider the following program −
• _Example:_
#include
int main ()
{
int *ptr = NULL;
printf("The value of ptr is : %x\n", ptr );
return 0;
}
• When the above code is compiled and executed, it produces the following result −
-- The value of ptr is 0
-- In most of the operating systems, programs are not permitted
to access memory at address 0 because that memory is
reserved by the operating system.
-- However, the memory address 0 has special significance; it
signals that the pointer is not intended to point to an
accessible memory location. But by convention, if a pointer
contains the null (zero) value, it is assumed to point to
nothing.
-- To check for a null pointer, you can use an 'if' statement
as follows −
if(ptr) /* succeeds if p is not null */
if(!ptr) /* succeeds if p is null */ | jahnavi1351 |
909,151 | React Router v6 - What's new? | Hi guys, So recently, React Router V6 was released and it has many new and interesting features.... | 0 | 2021-11-29T17:00:48 | https://dev.to/salehmubashar/react-router-v6-whats-new-5e3c | react, javascript, webdev, reactrouter | Hi guys,
So recently, React Router V6 was released and it has many new and interesting features. Lets look into some of these new upgrades.
>**[Complete Article](https://discover.hubpages.com/technology/React-Router-V6-The-Main-Changes)**
-----------------------------------------------------------------
##Goodbye Switch!
Previously, in React Router V6, we used the `<Switch>` component to wrap all of our Routes, now the the Switch component has been replaced by `<Routes>`. It is essentially the same thing as switch, however some new features have been added to the `<Route>` component it self.
##Changes to the Route Component
There have been a couple of useful upgrades to the `<Route>` component.
####1 - No need of exact.
In V5, you needed to put the `exact` prop on the component so that it goes to the particular route. However in V6, there is no need of this prop as React Router now always looks for the exact path without being told.
####2 - Introducing the element prop
Previously, we used to pass the component in the Route as a child, or in other words, the component would be placed within the Route. In V6, this is no longer needed as you can simply pass the `element` prop in the route and place the component inside it. The pros of this are that you can simply inject whichever component one needs depending on its route rather than placing it in each route component.
###V5 vs V6 code example:
The above mentioned upgrades are demonstrated in the comparison below.
####React Router **V5** code:
```javascript
export default function App() {
return (
<div>
<Switch>
<Route path="/page1">
<Page1/>
</Route>
<Route exact path="/page2">
<Page2/>
</Route>
</Switch>
</div>
)
}
```
####React Router **V6** code:
```javascript
export default function App() {
return (
<div>
<Routes>
<Route path="/page1" element={<Page1/>} />
<Route path="/page2" element={<Page2/>} />
</Routes>
</div>
)
}
```
As you can see, 3 changes can be noticed in the above code comparison, Use of `Routes` instead of `Switch`, removal of exact and use of the element prop.
These are some of the routing related upgrades. There are many more new features and changes that are covered in depth in my [hupbages article](https://discover.hubpages.com/technology/React-Router-V6-The-Main-Changes).
>**[Complete Article](https://discover.hubpages.com/technology/React-Router-V6-The-Main-Changes)**
-----------------------------------------------------------------
Thank you for reading!. I hope you found out some new information regarding the changes in react router v6.
If you liked the post, you can buy me a coffee!
<a href="https://www.buymeacoffee.com/salehmubashar" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="41" width="174"></a>
Also, check out my [hubpages articles](https://owlcation.com/stem/useRef).
Cheers:)
| salehmubashar |
909,385 | Improving email deliverability with DNS records | As always, every day brings up new challenges, and today I faced one of my greatest fears - dealing... | 0 | 2021-11-26T23:30:50 | https://meirg.co.il/2021/11/26/improving-email-deliverability-with-dns-records/ | tutorial, email, dns, network | As always, every day brings up new challenges, and today I faced one of my greatest fears - dealing with mailing DNS records.
Up until today, I was only familiar with *A Record*, *CNAME Record*, and *TXT Record*. A while ago, I used the *MX Record* while setting up my mailbox for my domain, but I don't quite remember its purpose, but enough about me.
Mail eXchangers, such as Gmail, Yahoo, Outlook, check the validity of incoming email messages. As part of the validation process, the Mail eXchanger queries the DNS records of the sender and evaluates the sender's reputation.
The sender's reputation affects how the Mail eXchanger classifies the message and whether or not it should be marked as spam before it is delivered to the receiver. In some cases, the message is blocked entirely by the Mail eXchanger, and the receiver is unaware of it.
## The Reputation
There are many algorithms out there for evaluating an email sender's reputation. To put it on a scale, I classified the reputation level into four levels - *Very Low*, *Low*, *Standard*, and *Best*.
### Very Low
Blocked completely without even bothering the receiver, here are two common error messages that may appear in the ESP's logs if the sender's email has sent too many emails in a short period.
```
421 4.7.0 [TS01] Messages from <1.2.3.4> temporarily deferred due to user complaints
<1.2.3.4> ;see http://postmaster.yahoo.com/421-ts01.html
```
```
553 5.7.1 [BL21] Connections will not be accepted from 1.2.3.4,
because the ip is in Spamhaus's list;
see http://postmaster.yahoo.com/550-bl23.html
```
[Above snippets from - glockapps.com - How To Remove Your IP From Yahoo Blacklist – Yahoo Blacklist Checker
](https://glockapps.com/blog/remove-ip-address-yahoo-blacklist/)
If there's a need to send large volumes of email messages, it is recommended to purchase a [dedicated IP with a warm-up mechanism](https://docs.sendgrid.com/ui/sending-email/warming-up-an-ip-address). The subject is broadly explained in the provided link, though in short, it's another method of identifying yourself as a trusted sender, by saying:
> "I own a unique IP address because I'm confident that Mail eXchangers won't block me. I know that it's easy to block an IP address, so yeah, I'm that confident."
### Low Reputation
Emails are marked as spam due to the low authenticity of the sender or previous reports of other users. But, most of the time, it's because the content of the message is not specific enough to the receiver.
For example, Willy is a Gmail customer, and he is interested in computer science and surfing. Then, out of the blue, Willy receives an email message about a great body lotion for women. Though Willy may have subscribed to some cosmetics stores websites, if the message isn't specific enough, like "Hi Willy," then it **might** be marked as spam.
Send the relevant content to the appropriate audience to avoid getting here.
### Standard Reputation
Email messages are getting to the client's mailbox as they should, though, in some Mail eXchangers such as Gmail, messages could move to the [Promotions tab](https://developers.google.com/gmail/promotab/faq#why_do_i_see_my_email_in_a_bundle_and_i_have_not_added_the_annotation), while it wasn't intended.
> "... Gmail will recommend emails based on previous user engagement, regardless of whether annotations are present."
### Best Reputation
Email messages are getting to the client's mailbox as the **sender intended**.
Some businesses may want to get on Gmail's [Promotions tab on purpose](https://developers.google.com/gmail/promotab/overview); it all depends on the sender's needs.
<hr>
Are you ready to explore the dark depths of mailing DNS records? Let's go!
<hr>
## Baseline
Previously, I mentioned that I'm familiar with a few DNS records, but that doesn't mean that we're on the same page. So line up!
<table><thead><tr><th>Record Type</th><th>Target</th><th>Example Key Pair Values</th></tr></thead><tbody><tr><td>A</td><td>IP addresses</td><td>Name: virtual-machine.meirg.co.il (For example, <a href="https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-instance-addressing.html#ip-addressing-eips" target="_blank" rel="noopener noreferrer">AWS Elastic IP</a>)<br>Value: 123.123.123.123</td></tr><tr><td>CNAME</td><td>Canonical name for other domain name</td><td>Name: meirg.co.il<br>Value: meirg-website.pages.dev (<a href="https://pages.cloudflare.com/" target="_blank" rel="noopener noreferrer">Cloudflare Pages)</a><br><br>Name: www.meirg.co.il (<a href="https://support.cloudflare.com/hc/en-us/articles/200172286-Configuring-URL-forwarding-or-redirects-with-Cloudflare-Page-Rules" target="_blank" rel="noopener noreferrer">Redirects to meirg.co.il</a>)<br>Value: meirg.co.il</td></tr><tr><td>TXT</td><td>Domain validation and authenticity</td><td>Name: meirg.co.il (<a href="https://support.google.com/a/answer/183895?hl=en" target="_blank" rel="noopener noreferrer">Google Domain Verification</a>)<br>Value: "google-site-verification=2NOO....XgotefAU"</td></tr><tr><td>MX</td><td colspan="2">Let's leave it as a mystery for now<br>(keep your Google Search gun down!)</td></tr></tbody></table>
## Plot
I need to improve the email deliverability of outgoing emails. The request first came from the marketing expert of one of my customers, and he told me *"We need you for the DNS part."*
Ok, I'm up for it; let's set up the DNS records and assist my customer in reaching out to his end-users.
But how can I make sure that I succeed? I mean, doing/learning stuff is fun, it really is, but how will I know if my changes impacted my [email sender reputation](https://www.sparkpost.com/resources/email-explained/email-sender-reputation/#:~:text=An%20email%20sender%20reputation%20is,an%20organization%20that%20sends%20email.&text=The%20higher%20the%20score%2C%20the,of%20recipients%20on%20their%20network.)? How do I know if there's a better open/click rate for my emails?
The above questions are widespread when the need to send emails arises. That usually comes with many requirements, such as "unsubscribe mechanism", "group contacts by segments", "statistics of open/click", and the list goes on, depending on your marketing manager 😉
Developing a system that can measure open/click rate and handle email/contacts management will take ages to build...
So maybe I should ...
## Use professional help
Here comes [ESP](https://www.activecampaign.com/glossary/email-service-provider) into play! ESP stands for Email Service Provider, and that means there are cloud providers out there who are willing to send emails on my behalf and enable me to manage the whole email delivery system in a one-stop-shop.
There are many ESPs out there such as [Google Workspace](https://workspace.google.com/products/gmail/), [SendGrid](https://sendgrid.com/) and [Mailchimp](https://mailchimp.com). Each provider has its pros and cons, but the common ground is - **they all send emails on behalf of your domain**.
The difference usually comes when an ESP, like SendGrid, offers comprehensive services like [Automated Security](https://docs.sendgrid.com/ui/account-and-settings/how-to-set-up-domain-authentication#using-automated-security) which enabled you to purchase [a dedicated IP](https://docs.sendgrid.com/ui/account-and-settings/dedicated-ip-addresses) as a service (we'll get to that).
We covered ESPs, moving on to getting familiar with industry standards for improving email deliverability.
> **NOTE**: I might mention SendGrid a lot during this blog post, though I'm not biased towards any ESP; SendGrid is simply the service I've been using recently, so it's easier for me to make references. Most ESPs offer a free/trial plan so you can explore their features and then decide, and I recommend evaluating at least two ESPs before picking one.
## Standards For Better Email Delivery
[According to Google](https://support.google.com/a/answer/10583557?hl=en&ref_topic=9061731), at least four standards should be implemented (in this order)
1. SPF
2. DKIM
3. DMARC
4. (Optional) BIMI
And, I'm adding [A dedicated IP](https://docs.sendgrid.com/ui/account-and-settings/dedicated-ip-addresses#what-are-dedicated-ip-addresses) to the mix.
Mail eXchangers check if the sender meets industry standards by querying its DNS record, and according to that, evaluate the sender's reputation. The sender evaluation process includes other methods, such as looking in [https://multirbl.valli.org/](https://multirbl.valli.org/lookup/meirg.co.il.html) to see if the source domain (eventually IP) of the sender is marked as an "official spammer", that all it depends on the Mail eXchanger. The more standards the sender meets, the higher the chances the sender's email message will arrive at its target audience (receiver).
The illustration below is for the *SPF* record. Still, the same communication process is the same for all standards, where the Receiving Email Server (Mail eXchanger) validates the email sender's authenticity and reputation.
Image Source: [https://twilio-cms-prod.s3.amazonaws.com/original_images/spf_mail_flow.jpeg](https://twilio-cms-prod.s3.amazonaws.com/original_images/spf_mail_flow.jpeg)
### SPF
- Definition: [Sender Policy Framework](https://datatracker.ietf.org/doc/html/rfc7208)
- Remember with: `S` for "**S**ending emails"
This record allows ESPs such as SendGrid, Gmail, Mailchimp to send emails on behalf of your domain. So if my domain name is *meirg.co.il* and I would like to send emails with Google Workspace, I need to add [Google's SPF](https://support.google.com/a/answer/10684623?hl=en) record to my domain *meirg.co.il*.
And the funny thing about an *SPF Record*, that it's actually a *TXT Record*. Let me remind you that *TXT Records* are for "Domain validation and authenticity," so it's nothing more than adding a *TXT Record* and adding a value that is specific for the *SPF* standard.
Here's an example for setting up two *SPF* records, one for [Google Workspace](https://support.google.com/a/answer/10685031) and the other for [SendGrid's SPF](https://docs.sendgrid.com/ui/account-and-settings/how-to-set-up-domain-authentication#before-you-begin:~:text=HOST/NAME).
```
# Google Workspace
Type: TXT
Name: meirg.co.il
Value: v=spf1 include:_spf.google.com ~all
# Sendgrid
Type: TXT
Name: em123.meirg.co.il
Value: u12345678.wl123.sendgrid.net
```
Notice the weird thing? `Google Workspace` has an [SPF expression](https://dmarcian.com/spf-syntax-table/), while `SendGrid` provides a *CNAME* as a value in the *TXT* record. My gut told me that the *CNAME* should eventually resolve to an *SPF expression*, so I checked it with [Authentication @ tools.wordtothewise.com](https://tools.wordtothewise.com/authentication).
I tested it by navigating to `https://tools.wordtothewise.com/dns/txt/em123.meirg.co.il`, which resolved in ... Drums ... `u12345678.wl123.sendgrid.net` as a *TXT* record which contains the following expression.
```
# SendGrid's CNAME resolves to SPF expression
v=spf1 ip4:122.122.122.122 -all
```
It is quite a wonder that eventually, it's `ip4:122.122.122.122` and not a CNAME, as we saw in Google Workspace `include:_spf.google.com`. This wonder is called a [dedicated IP](https://postmarkapp.com/blog/how-to-check-your-ip-reputation#why-is-ip-reputation-important).
Declaring an *SPF Record*, or any other record that is related to mailing, usually comes with a complete guide on how to create it, check [Google Workspace Basic Setup for SPF](https://support.google.com/a/answer/10685031) which also explains [how to include multiple ESPs in a single SPF Record](https://support.google.com/a/answer/10685031#:~:text=servers.mail.net).
### When should I use a single SPF expression?
Getting back to my previous example of Google Workspace and SendGrid; Luckily, SendGrid provides a particular *TXT Record*, which includes a unique subdomain, *em123*; this makes the setup is really nice since you don't modify existing with the fear of breaking something.
Assuming your ESP**s** required the *TXT Record* of *SPF* to be present in the root domain, e.g., *meirg.co.il*, you'll have to edit your existing *SPF expression* and add additional ESPs. For example, here's how you would write an *SPF expression* when using both Google Workspace and [Mailgun](https://www.mailgun.com/).
```
# Google Workspace + Mailgun
Type: TXT
Name: meirg.co.il
Value: v=spf1 include:_spf.google.com include:mailgun.org ~all
```
> **NOTE**: Regarding which ESP you should choose (Google/SendGrid/Mailchimp/Mailgun, etc.), it depends on your needs. I use Google Workspace for receiving/sending emails on behalf of *human beings* who use `@meirg.co.il` and SendGrid for sending automated emails with my web application `@meirg.co.il`. By the way, [Mailchimp](https://mailchimp.) is also excellent, I used it a long time ago, and I truly enjoyed it.
### Recap on SPF
A *TXT* record that contains an [SPF expression](https://dmarcian.com/spf-syntax-table/) or a *CNAME* that is eventually resolved to an *SPF expression*. The *SPF expression* contains an authorization policy about which service can send emails on your domain's behalf.
> **IMPORTANT** Make sure you send emails from the same address that you've authenticated in the ESP (SendGrid, Google), for example, **DO NOT TRY THE FOLLOWING**, sending emails from *no-reply@meirg.com*. In contrast, my authenticated domain address is *meirg.co.il*. That can easily happen if you're using [SendGrid - API keys to send emails](https://docs.sendgrid.com/ui/account-and-settings/api-keys) since the *FROM* field is not protected, the API call can "endure" anything you shove it.
### DKIM
- Definition: [DomainKeys Identified Mail (Signatures)](https://datatracker.ietf.org/doc/html/rfc6376)
- Remember with: `K` for **K**eys.
This one is going to be very short compared to *SPF* since we've already covered all basics,
I like to think about *DKIM* as the HTTPS of emails. So *DKIM* is a way for an email sender to [increase authenticity by adding a signature to the headers of an email message](https://support.google.com/a/answer/174124?hl=en).
> "...DKIM adds an encrypted signature to the header of all outgoing messages. Email servers (Mail eXchangers) that get signed messages use DKIM to decrypt the message header and verify the message was not changed after it was sent."
Here's how the *DKIM* record looks for my domain *meirg.co.il*.
```
Type: TXT
Name: google._domainkey.meirg.co.il
Value: v=DKIM1; k=rsa; p=Ultra-Long-Key-PUBLIC-KEY-392-chars
```
The subdomain `google._domainkey` was [generated by Google](https://support.google.com/a/answer/174126?hl=en&ref_topic=2752442) for my domain *meirg.co.il*. After generating the *DKIM* record, I followed the instructions and authenticated my domain by adding a *TXT* record with the value provided by Google.
If I intend to use other ESPs, I can generate a subdomain per ESP, so [for SendGrid, it'll be s1._domainkey](https://docs.sendgrid.com/ui/account-and-settings/dkim-records#example-dkim-record-automated-security-off).
As you can see, the `*._domainkey` is the critical value, as that's the one that the Mail eXchanger is checking. So if a DNS record, such as *TXT* or *CNAME*, is named with `_domainkey`, you can classify it safely as *DKIM*. The `*._domainkey` prefix, such as `google` and `s1`, is called a selector. One domain can have multiple *DKIM* selectors when using various ESPs.
> **NOTE**: Curious about my public key? Dig for it! `dig TXT google._domainkey.meirg.co.il`
### DMARC - Here comes D-MARC tu du du du
- Definition: [Domain-based Message Authentication, Reporting & Conformance](https://datatracker.ietf.org/doc/html/rfc7489)
- Remember with: `DM` "**D**omain **M**onitoring" and `D-MARC` like "the man(ager)"
We covered *SPF* and *DKIM*, but how do we know that our email messages are authenticated with *SPF* and signed with *DKIM*? Is there a way to track down it down with numbers? There is.
[DMARC](https://dmarc.org/) is an email authentication standard - Meeting up this standard means your *SPF* and *DKIM* domain records are legit. How does it mean that they're legit, you ask?
- Once a day, a [DMARC Report](https://mxtoolbox.com/dmarc/details/what-do-dmarc-reports-look-like) is sent to a predefined mailbox. The report contains pass/fail attempts of *SPF* and *DKIM*.
- *DMARC* has the [reject policy](https://dmarcian.com/policy-modes-quarantine-vs-reject/#:~:text=p=reject), so if a sender attempts to send an email and both *SPF* and *DKIM* checks didn't pass, the receiver (recipient) would not get the message.
- Furthermore, *DMARC* helps to authenticate the sender's identity since *SPF* requires a *TXT* record to exist in the sender's domain containing valid domains or IPs (usually of an ESP), and a *TXT* (or *CNAME*) record for *DKIM* which includes a public key that was given to sender by the ESP.
Here's how a *DMARC Record* looks like
```
Type: TXT
Name: _dmarc.meirg.co.il
Value: v=DMARC1; p=none; rua=mailto:meir+dmarc_agg@meirg.co.il, mailto:dmarc_agg@vali.email
```
The `p=none` is the declared policy, which is nothing. Having no policy at all is almost the same as not having a *DMARC* record. A proper *DMARC* record would be `p=reject`.
So why am I using `p=none`, you ask? Because I'm still not 100% sure that my outgoing email messages pass both *SPF* and *DKIM* by Mail eXchangers. Having `p=reject` would block my messages completely, so for testing purposes, start with `p=none`, and once you're sure that all your emails pass both *SPF* and *DKIM*, set the policy to `p=reject`.
Sounds great, but how can you check all that? It sounds tough.
See the `rua` key in the code snippet above; I added `+dmarc_agg` to my email address and [created a filter in Gmail](https://support.google.com/mail/answer/6579?hl=en#zippy=%2Ccreate-a-filter), so any message coming from *meirg+dmarc_agg@meirg.co.il* is tagged as `dmarc-report`. Remember that I mentioned that a daily *DMARC* report is sent to a "predefined email address"? that is it.
But do I want to analyze *DMARC* reports on my own? Yup, you guessed it, there's an excellent service that can do that for free, and it's called [ValiMail](https://www.valimail.com/). ValiMail gets the daily report and analyzes it by checking how many *SPF* and *DKIM* successes/failures occurred in the past 24 hours and presents the summary in a friendly dashboard.
[ValiMail are partnered with many known organizations](https://www.valimail.com/partners/), such as Microsoft, Google, and SendGrid, so I consider them a trusted vendor.
> **NOTE**: The silent `dmarc_agg@vali.email` in the `rua` key points to ValiMail's mailbox.
## BIMI - Requires DMARC
- Definition: [Brand Indicators for Message Identification](https://tools.ietf.org/id/draft-blank-ietf-bimi-00.txt)
- Remember with: **B** for **B**ragging to our audience/receivers that we're a top-notch validated sender.
Reminding you that *DMARC* has the "reject policy", so if an email sender sets it to `p=reject, pct=100` (or `p=quarantine`), **ALL** none qualifying emails (SPF+DKIM) will not be delivered. So, cool, who enforces it? *BIMI*!
[Qualifying for BIMI](https://bimigroup.org/all-about-bimi/#:~:text=How%20do%20I%20Implement%20BIMI?) requires registering a trademark in a known patent agency and then purchasing a Verified Mark Certificate (VMC) from [DigiCert](https://www.digicert.com/tls-ssl/verified-mark-certificates) or [Entrust](https://www.entrust.com/digital-security/certificate-solutions/products/digital-certificates/verified-mark-certificates) So, meeting the BIMI standard is not that simple.
And of course, it is possible to partially meet [BIMI for non-trademarked logos](https://bimigroup.org/bimi-for-non-trademarked-logos/). However, since *BIMI* is still not enforced or [widely recognized by Mail eXchangers](https://bimigroup.org/bimi-infographic/), I consider it a nice-to-have, and I'll get to it once I'll implement it once I get enough data from the *DMARC* reports.
To my feeling, it'll be easier to qualify today for *BIMI* than it will be in a few years. If you spot a fully certified *BIMI* email sender, it means it is ... Genuine and can be trusted.
## Mysterious MX
- Definition: [Mail Exchanger](https://datatracker.ietf.org/doc/html/rfc974)
- Remember with: Gmail is a Mail Exchanger, Google Workspace is an ESP
Finally, we got to MX; in case you haven't noticed, I wrote "Mail eXchangers" each time I had to mention a mail exchanger. You've just learned that *MX Record* stands for **M**ail e**X**changers that are allowed to receive emails on your behalf.
Since *MX Records* are for receiving emails and not sending, see my [stackoverflow answer](https://stackoverflow.com/questions/46113231/receiving-email-is-not-working-in-amazon-ses/62452983#62452983) on how to configure *MX Records* for [AWS Simple Email Service (SES)](https://aws.amazon.com/ses/) and the things that I've learned during the process.
To see how an *MX Record* looks like, check mine with [mxtoolbox.com](https://mxtoolbox.com/SuperTool.aspx?action=mx%3ameirg.co.il&run=toolpage).
## Gmail is a Mail eXchanger
How do you send emails from your Gmail account if it's only receiving messages with a Mail eXchanger?
As part of being Gmail's client, you can send emails on behalf of `@gmail.com`. That is set behind the scenes by Gmail's engineers, so each time you send an email using Gmail's UI, or use [Gmail's API](https://developers.google.com/gmail/api), the emails that you send are signed with Gmail's signature, which includes *SPF*, *DKIM*, *DMARC*. That is why your emails are not marked as spam when you email your friends and family since most Mail Exchangers treat `@gmail.com` as a high reputation sender.
## Strengthen your knowledge
### Name all the standards and provide a short description
All records refer to the email sender's domain.
1. **SPF** - TXT record, which contains the allowed sources, domains or IPs, to send emails on behalf of an email sender.
1. **DKIM** - TXT/CNAME record, which contains a key generated by an ESP. I consider *DKIM* an HTTPS mechanism for emails, which uses the [public-key cryptography](https://en.wikipedia.org/wiki/Public-key_cryptography) to authenticate messages.
1. **DMARC** - TXT record, which contains the receiver of the daily reports. This record is not just for setting the receiver, and it also means that Mail eXchangers will check this record and act according to the rules in it. So if *SPF* and *DKIM* is not set, some email messages might not arrive at their destination.
1. **BIMI** - TXT record, which contains a URL to an SVG logo of the email sender, and a URL of the Verified Mark Certificate (VMC) that the email sender purchased. And of course, this is how email senders can **b**rag that they're legit in front of their customers.
### How do I check if my domain is a trusted email sender?
Check if your DMARC record is valid with [https://tools.wordtothewise.com](https://tools.wordtothewise.com).
```
https://tools.wordtothewise.com/dmarc/check/DOMAIN_NAME
```
Hooray for Google Workspace customers - there's a dedicated online tool for checking whether your mailing DNS records are correctly set for Google Workspace ESP; here are my results [meirg.co.il - Google Check MX Status](https://toolbox.googleapps.com/apps/checkmx/check?domain=meirg.co.il&dkim_selector=)
> **IMPORTANT**: Do not be fooled; Google Workspace's tool is valid only if you're checking Google as an ESP. If you use this service on a Sendgrid domain, it will show many errors.
### How do I read a DMARC expression?
The syntax of how to read/write a *DMARC expression* can be found in [RFC7489 - Domain-based Message Authentication, Reporting, and Conformance (DMARC)](https://datatracker.ietf.org/doc/html/rfc7489#section-6.3). Another excellent source for understanding the syntax is [Google's tutorial on the DMARC record format](https://support.google.com/a/answer/2466563?hl=en)
Let's inspect [@gmail.com's DMARC record](https://tools.wordtothewise.com/dmarc/check/gmail.com) together
```
v=DMARC1; p=none; sp=quarantine; rua=mailto:mailauth-reports@google.com
```
- p=none - all emails, regardless if they're validated with SPF+DKIM, can get to the receiver
- sp=quarantine - all emails sent from subdomains, e.g. `subdomain.gmail.com` and are not signed with SPF+DKIM are marked as spam in the receiver's mailbox. `sp` stands for subdomain-policy and overrides `p` rules for subdomains.
- rua=mailto - It appears that Gmail is handling their DMARC reports internally since the reporting address belongs to @google.com. So I guess they have their own "analyzing and monitoring DMARC reports" system, kewl.
Inpsecting [@yahoo.com's DMARC](https://tools.wordtothewise.com/dmarc/check/yahoo.com) record
```
v=DMARC1; p=reject; pct=100; rua=mailto:d@rua.agari.com; mailto:d@ruf.agari.com;
```
- p=reject - all emails that are not signed with SPF+DKIM are rejected.
- pct=100 - the percentage of messages to apply the `p` policy. In this case, if it's not signed with SPF+DKIM, it's not getting to the receiver at all, very restrictive
<hr>
It's fascinating to see how different enterprise-grade email senders are setting up their DMARC records. It might look like Gmail is very permissive with their `p=none` policy, but I'm sure they have a dedicated backend that filters out spam messages before they arrive at their customers' mailboxes.
### Bonus - Can Gmail customers check the sender's validity in the UI?
Yes, yes, YES!
Eventually, an email message contains text, and this text instructs the Mail eXchanger how to validate the message's sender, process referenced images to be shown in the UI, etc.
Gmail made it very easy to check, click the ellipsis, and then **Show Original**.

That results in a very long page that contains the whole email message, though Gmail made it very easy to track the important things, such as if **DMARC** is valid.

After reading this blog post, you've just learned that checking *DMARC* is enough since it relies on both *SPF* and *DKIM*.
## Dedicated IP
Psst! Glad to see that you've read it all; This blog post is long enough, so here's a great resource that can help you decide whether to purchase a dedicated IP or not - [3.4 Shared vs. Dedicated IPs, M3AAWG Sender Best Common Practices v3.0, Feb 2015](https://www.m3aawg.org/sites/default/files/document/M3AAWG_Senders_BCP_Ver3-2015-02.pdf).
In short, if you're sending high volumes, [hundreds of thousands of emails a month](https://sendgrid.com/resource/how-to-send-high-volume-email-sendgrids-smart-scaling-guide-2/#:~:text=Dedicated%20IPs), then you should purchase a dedicated IP. I hate it when it all ends up with "it depends on your needs", but hey, that's true.
## Final Words
I admit that it was tough and felt like there's a lot to memorize, but once you truly understand how each components works, it's pretty nice and very not intimidating as it was. So enjoy setting up your mailing DNS records. That would be all. | unfor19 |
909,581 | Top 5 Best Android Apps and Games Download Sites in 2021 | This is just a tip of Iceburg you can read 20+ sites to download Android apps so don't forget to... | 0 | 2021-11-26T07:09:09 | https://www.indiantechhunter.in/2021/09/best-android-apps-and-games-download-sites.html | android, security, webdev | <h5>This is just a tip of Iceburg you can read <a href="https://www.indiantechhunter.in/2021/09/best-android-apps-and-games-download-sites.html">20+ sites to download Android apps</a> so don't forget to check them out.<br><br></h5>
Recently joined Dev and I must say I am impressed by all the community they are really helpful and charming!
I posting because I want to let you guys know about the best trustworthy sites from which you can download Android apps.
<h4><strong><b>① CNET Download:</b></strong></h4>
CNET Download provides software and apps to download for Windows, Mac, iOS and Android devices, music, and videos are also available to download.
Previously, the site’s domain name was Download.com, now cnet.Download.com is the official domain that has been an excellent website since 1996, providing downloadable software and apps for a variety of operating systems.
CNET also publishes articles to help users to use software and apps.<br><br>
<h4><strong><b>② Softonic:</strong></b></h4>
Softonic company is Spainish based site, which provides applications and Softwares for Android, Windows, Mac, and IOS. With 100+ million monthly users and 4 million downloads, this suggests a great location for many users to download Android apps.
Softonic apps and games are categorized in a very user-friendly interface where they try to provide updates as fast as possible. That’s what makes Softonic one of the best sites to download most of the games and apps.
Softonic also tries to solve the application and software related queries through regular posts on their site.<br><br>
<h4><strong><b>③ Uptodown:<strong></b></h4>
If you have problems regarding language, then don’t worry just go to Uptodown it supports more than 15 different languages and provides downloadable software and apps for Android, Windows, Mac, etc.
Whenever any new app comes on the Uptodown system they test it and check if there are security issues and after all checkups, they upload the app for users to download.
Uptodown is also available in the Android app and most of the apps on your phone can be easily updated with this app, which is why it is a great alternative for the Play Store.<br><br>
<h4><strong><b>④ Amazon App Store:<strong></b></h4>
On 9 October 2019 amazon announced there were 487083 apps available to download on our site, you can say it is the most trustable site to download apps after Google Play.
Amazon app store is also available to download in an Android app format where you can easily download freeware and Shareware apps.
One of the different feature of Amazon app Store is ‘free app a day’ which provide a paid app to use for a day.<br><br>
<h4><strong><b>⑤ Apkmirror:<strong></b></h4>
Apkmirror is run by team members of androidpolice.com, which is a trusted blog site that covers Android related posts.
Some of the very useful apps like Vidmate and gfx tool breaks privacy policy of Play store hence they aren’t available on Play Store, Apkmirror host such apps in bulk and provide them to download with the option to download their older versions.
Hope this adds value to you.
Thanks for reading this post till then see you guys.<br><br>
For contacting me you can reach me on <a href="https://www.youtube.com/channel/UCzWsfjkSaT1tp92xcVDNZCQ/about">Youtube,</a> <a href="https://www.quora.com/profile/Indian-Tech-Hunter-1">Quora,</a> <a href="https://www.instagram.com/indian_tech_hunter/?hl=en">Instagram,</a> <a href="https://twitter.com/indiantechunter">Twitter</a>. | ith |
909,614 | Using JSDoc to write better JavaScript Code | Using TypeScript consistently offers a lot of benefits, especially for writing clean code to prevent... | 0 | 2021-11-26T08:28:30 | https://dev.to/ingosteinke/using-jsdoc-to-write-better-javascript-code-17a | javascript, webdev, programming, typescript | Using [TypeScript](https://www.typescriptlang.org) consistently offers a lot of benefits, especially for writing clean code to prevent unnecessary bugs and errors. But it takes some time and effort to learn, and you have to adapt every code snippet after copy-pasting from a tutorial or a StackOverflow example. Quite a challenge when re-using code for React, Node, Express and Mongoose like I did in my [full-stack web app side project](https://dev.to/ingosteinke/building-a-reading-list-web-app-with-node-preact-and-tailwind-css-44pa).
## Alternatives to TypeScript
* Popular, but unhelpful, alternative: don't care at all.
* Use [eslint](https://eslint.org), but that's not an alternative. With or without strong typing, you should lint your code anyway to benefit from (mostly) helpful hints and warnings.
* [ReactPropTypes](https://reactjs.org/docs/typechecking-with-proptypes.html) add some type checking to ECMAScript / JavaScript in React applications, but PropTypes are merely footnotes, placed far away from where they would be most useful, while still bloating your code.
And there are no PropTypes in [Vanilla JS](#writing-clean-modern-vanilla-js-code).
* enter **JSDoc**:
## JSDoc
Often overlooked, maybe never even heard of until now, [JSDoc](https://jsdoc.app/) deserves more attention, as it brings a lot of advantages out of some short lines of documentation.
### Code Documentation
That's JSDoc's original purpose: generating a code / API documentation out of a few lines placed before variables, functions, and classes.
Similar approaches have been used with Java and PHP for a long time, and JSDoc follows established practice and is quite easy to learn.
### Hints and Code Completion
Using JSDoc inside a modern IDE, you'll get another benefit: live code inspection, warnings, and proper code completion even for the most obscure DOM methods you never knew about before. Or well-known classics like `event.currentTarget` that still have some tricky pitfalls.
Here is a - seemingly simple - example:
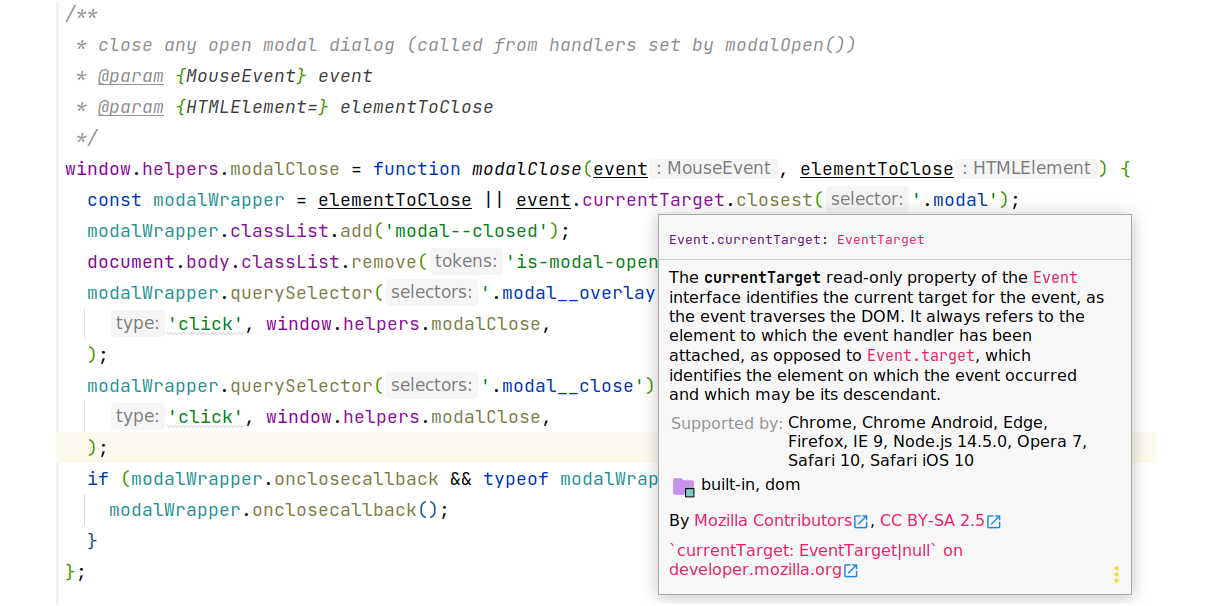
I wanted to allow a modal dialog to be closed typing the Escape key. My first quick code-like-it's-1999-style script (not shown here) was frowned upon by eslint. ☹️
### Writing Clean, Modern Vanilla JS Code
So I decided to write proper, modern code, but still plain "Vanilla JS" (that does not need a transpiler to produce working code, unlike TypeScript, which does not have native browser support, not even in Microsoft's Edge browser).
I wrote a function that takes two arguments: an event, and an optional DOM element so that we are able to close a specific modal dialog from outside without relying on the event context.
Adding a JSDoc comment before, it becomes
```js
/**
* close an open modal dialog
* @param {MouseEvent} event
* @param {HTMLElement=} elementToClose
*/
const modalClose = function modalClose(event, elementToClose) {
// ...
};
```
telling my readers (of this code, and of a possible, automatically generated, documentation / API reference) what the function is supposed to do, and what arguments it expects:
`@param {MouseEvent} event`
Now my IDE (PhpStorm) will show me helpful information:
I don't even have to look up the proper type string to write in the JSDoc comment!
When I start typing, PhpStorm has some suggestions for code completion even in this special kind of comment, suggesting `MouseEvent` on top of the list.
## JSDoc Syntax
The basic syntax is rather simple.
Annotations blocks are special comments that start with a slash and a double asterisk `/**`
A parameter hint starts with an at sign, the word "param", and a type definition inside curly braces, followed by the parameter's name.
To mark an optional parameter, add an equals sign behind the type, like
```js
@param {HTMLElement=} elementToClose
```
but to be more clear to human readers, we can also add anything behind the parameter's name, like
```js
@param {HTMLElement=} elementToClose (optional) DOM element to receive .closed CSS class
```
Now my editor shows me type annotations, that are not part of my written code (unlike they would be in TypeScript) but rather implicitly follow from my code. So my actual code stays short and compact, while the implicit meaning is still more obvious than before.
### Assistance for Lazy Developers
Not only do we see the additional hint `event: MouseEvent`, but when we start using the `event` in our code below, there are more code suggestions, helping us to choose methods and properties that are actually available and not deprecated.
More assistance as we continue: hints and documentation everywhere. We don't even have to visit [MDN](https://developer.mozilla.org/) in our browser anymore!

## Conclusion
JSDoc makes coding in JavaScript easier, helping us to code quickly while avoiding obvious errors, just by adding some lines of optional comments in our code.
| ingosteinke |
909,615 | Import Class in Relative File into Tailwind CSS and Rails | To import a relative CSS file into Tailwind, the postcss-import is required. Install... | 0 | 2021-12-04T08:37:30 | https://dev.to/thomasvanholder/extract-class-in-relative-file-with-rails-and-tailwind-css-50ii | rails, tailwindcss, webdev, css | To import a relative CSS file into Tailwind, the [postcss-import](https://tailwindcss.com/docs/installation#include-tailwind-in-your-css) is required.
1. [Install postcss-import](#1-install-postcssimport)
2. [Add postcss-config file](#2-add-postcssconfigfile)
3. [Add postcss to build script](#3-add-postcss-to-buildcss-script)
4. [Create a button class](#4-create-a-button-class)
5. [Swap tailwind directive for import](#5-swap-tailwind-directive-for-import)
6. [Extract button class into seperate file](#6-extract-button-class-into-seperate-file)
---
## 1. Install postcss-import
```bash
yarn add postcss-import
```
---
## 2. Add postcss.config.file
```js
postcss.config.js
module.exports = {
plugins: [
require('postcss-import'),
require('tailwindcss'),
require('autoprefixer'),
]
}
```
---
## 3. Add postcss to build:css script
In __package.json__ add `--postcss`
_old_
```json
{
"scripts": {
"build:css": "tailwindcss -i ./app/assets/stylesheets/application.tailwind.css -o ./app/assets/builds/application.css"
}
}
```
_new_
```json
{
"scripts": {
"build:css": "tailwindcss --postcss -i ./app/assets/stylesheets/application.tailwind.css -o ./app/assets/builds/application.css"
}
}
```
---
## 4. Create a button class
Add a button component in __application.tailwind.css__
```css
@tailwind base;
@tailwind components;
@tailwind utilities;
@layer components {
.btn-blue {
@apply text-white bg-blue-500 rounded-lg hover:bg-blue-700;
}
}
```
Let's see it we get a blue button
```erb
<button type="button" class="btn-blue">Save</button>
```
---
## 5. Swap tailwind directive for import
```css
/* old */
@tailwind base;
@tailwind components;
@tailwind utilities;
/* new */
@import "tailwindcss/base";
@import "tailwindcss/components";
@import "tailwindcss/utilities";
```
---
## 6. Extract button class into seperate file
in __application.tailwind.css__
```css
@import "tailwindcss/base";
@import "tailwindcss/components";
@import "./components/buttons.css";
@import "tailwindcss/utilities";
```
in __./components/buttons.css__
```css
@layer components {
.btn-blue {
@apply text-white bg-blue-500 rounded-lg hover:bg-blue-700;
}
}
```
A few notes from the Tailwind docs:
- Don't mix custom css and imports in the same file
- Wrap custom css in @layer components to avoid specificity issues
| thomasvanholder |
909,650 | navigation.navigate("somescreen") show errors with typescript and react-native | Argument of type 'string' is not assignable to parameter of type '{ key: string; params?: never;... | 0 | 2021-11-26T10:20:35 | https://dev.to/hafdiahmed/navigationnavigatesomescreen-show-errors-with-typescript-and-react-native-2mp4 | react, reactnative, typescript, ignite | Argument of type 'string' is not assignable to parameter of type '{ key: string; params?: never; merge?: boolean; } | { name: never; key?: string; params: never; merge?: boolean; }'.ts(2345)
that happens always when we cant to navigate to anther screen with typescript in react-native an help ?
example of code :
<Button text="go to page 1" onPress={()=>navigation.navigate("page_2")} />
#solution :
| hafdiahmed |
909,656 | Day 71-72/100 HTTP and Forms | "Communication must be stateless in nature [...] such that each request from client to server must... | 15,249 | 2021-11-26T10:29:30 | https://dev.to/riocantre/day-71-72100-http-and-forms-2bjj/ | 100daysofcode, programming, challenge, motivation | "Communication must be stateless in nature [...] such that each request from client to server must contain all of the information necessary to understand the request, and cannot take advantage of any stored context on the server."
– Roy Fielding, Architectural Styles and the Design of Network-based Software Architectures
 | riocantre |
909,737 | From Java to C++ - lambdas | In Java, we have our take on functional programming with lambdas. Obviously, as functional... | 15,028 | 2021-11-26T11:08:48 | https://www.baremetaldev.com/2021/11/26/from-java-to-c-lambdas/ | cpp, lambda, java, functional | <p style="text-align: justify;">In Java, we have our take on functional programming with <strong>lambdas</strong>. Obviously, as functional programmers love to tell us - they're just a mere simplifications of the 'real' functional languages. However, introduced in Java 8, they've had really changed how we do things in Java now. As for C/C++, functions were there from the very beginning (obviously!), but concepts of <strong>lambdas</strong> emerged just in the latest C++20 standard.</p>
<p style="text-align: justify;">In this post I will try to take more broad approach to the concepts of <strong>functions</strong> and <strong>lambdas</strong> in C++. I've thought about writing about C <em>function pointers</em>, but I've decided to just refresh my memory with <strong>Richard Reese</strong> <em>Understanding and using C pointers'</em> book, but do not write about it here. Let's keep it pure C++, and concentrate on more abstract solutions. Like the one just coming in our way - functions as objects.</p>
<h2>Function as an object</h2>
<p style="text-align: justify;">The concept of functions being <em>first class citizens</em> in the programming languages has a long tradition. In order to achieve that in C++, we need a way to pass functions to the methods as params. A universal container for callable objects is <em>std::function</em> class - wrapper around <em>function pointer</em>. It's a piece of standard library, residing in the <em><functional> header</em>. I'm starting with it, as it is more generic than <strong>lambdas</strong>.</p>
<p style="text-align: justify;">In general, it's possible to create an empty <em>std::function</em> object, but that won't be much of use - trying to call such object will result in <em>std::bad_function_call</em> exception being thrown. What we need, is object that actually holds a callable 'thing'. There are two ways to assign a callable object to the <em>std::function</em> instance - either as a constructor param, or just by assigning it to the pointer. Here's an example:</p>
```cpp
#include <iostream>
#include <functional>
void testFunction()
{
std::cout << "Test function";
}
int main()
{
std::function<void()> testFunctionHandler { testFunction };
std::function<void()> testFunctionHandler2 = testFunction;
testFunctionHandler();
testFunctionHandler2();
}
```
<p style="text-align: justify;">It does not look scary - maybe syntax is a little weird, but nothing we cannot handle. <em>std::function</em> can serve as w convenient abstraction, representing all the types of callable things. However, here's the more modern approach to functional programming in C++ (and more close to Java equivalent) - <strong>lambdas</strong>.</p>
<h2>Lambdas in C++</h2>
The same as in Java, it's a popular use case, to just pass some behaviour represented by a function. We don't need to (or don't want to), create a separate function or an object for that. What we want, is to pass some behaviour to the method and let it do its job. That's what <strong>lambdas</strong> are for - simple (ok, got me) concepts of passable behaviour. Let's start with the most simple example of a function - that takes nothing and returns nothing (besides side-effect):
```cpp
#include <iostream>
void printSomeMsg() {
std::cout << "Some message" << std::endl;
}
int main() {
printSomeMsg();
}
```
As simple as it is - it just prints the hardcoded message. However, let's assume that we don't want to write such a trivial function in our code. We just need its functionality in the specific places. That's where the lambda comes in. Let's take a look at this:
```cpp
#include <functional>
#include <iostream>
int main() {
auto ourLambdaAsAuto = []() { std::cout << "Some message" << std::endl; };
std::function<void()> ourLambdaAsFunction = []() { std::cout << "Some message 2" << std::endl; };
ourLambdaAsAuto();
ourLambdaAsFunction();
}
```
Again, the syntax may look scary at the beginning, but that's not that big of a deal. Let's go through it step by step:
<ul>
<li><strong>[]</strong> - it is empty now, but that does not mean it's not being used. These square brackets are responsible for specifying <strong>captures</strong>. In simple words - they fetch needed data/variables from the calling context. We will discuss this in detail later, as it is quite important.</li>
<li><strong>()</strong> - rather familiar feature. In the simple parenthesis we just specify arguments to the lambda. We don't have any here, that's why it's empty.</li>
<li><strong>{}</strong> - in the curly braces we provide the body of our lambda. In short - the job to be done.</li>
</ul>
<p style="text-align: justify;">Wasn't that bad, right? Of course, our simple example did not cover everything. Generic expression for lambda creation looks like this:</p>
```
[captures] (parameters) modifiers -> return-type { body }
```
From the above expression we know already <em>captures, parameters</em> and <em>body</em>. The remaining two are quite simple:
<ul>
<li><strong>modifiers</strong> - we can specify different modifiers, but depending on the standard they may vary, and their behaviour too. The best way to learn about them is to visit <a href="https://en.cppreference.com/w/cpp/language/lambda">official C++ ref docs</a>. The most popular are <strong>const</strong> and <strong>constexpr</strong>.</li>
<li><strong>return type</strong> - by default the compiler will deduce the return type of the lambda. However, especially when we're using template lambdas, it's advisable to help the compiler with small hint. Like in this example:
<em>
[](auto x, double y) -> decltype(x+y) { return x + y; }
</em>
</li>
</ul>
<h3>More about lambdas params</h3>
<p style="text-align: justify;">Parameters to <strong>lambdas</strong> are not that different from the regular ones. That means, we can both assign to them default values, and use <em>auto</em> type. Slightly modified example taken from <em>'C++ Crash Course'</em> shows these two in combination.</p>
```cpp
#include <iostream>
int main() {
auto increment = [](auto x, int y = 1) { return x + y; };
std::cout << increment(10) << std::endl;
std::cout << increment(10, 5) << std::endl;
}
```
<h3>Lambda captures</h3>
<p style="text-align: justify;">Remember these square brackets that up until now we've always left empty? Now the time has come to tell something more about them. <strong>Captures</strong> are quite important for <strong>lambdas</strong>, as they allow them to have context passed. Let's start with simple example.</p>
```cpp
#include <iostream>
class MySimpleClassPiece {
public:
int x;
std::string someStringValue;
};
class MySimpleClass {
public:
MySimpleClassPiece piece;
};
int main() {
MySimpleClass mySimpleClass { MySimpleClassPiece {1, "someStringValue"} };
std::cout << mySimpleClass.piece.someStringValue << std::endl;
std::cout << mySimpleClass.piece.x << std::endl;
}
```
<p style="text-align: justify;">Everything here is public, for the sake of simplicity. Printing to the standard output is done directly in the <em>main </em>function, and that is not what we want in the long run. Let's assume, that based on some logic, we want to either print the object state to the console, or modify the values in the object. As this is purely behaviour-driven thing, we're going to use lambdas for this. Let's start with the printing piece first.</p>
```cpp
// Everything besides main() is the same as above
int main() {
MySimpleClass mySimpleClass { MySimpleClassPiece {1, "someStringValue"} };
auto printingLambda = [mySimpleClass]() {
std::cout << mySimpleClass.piece.someStringValue << std::endl;
std::cout << mySimpleClass.piece.x << std::endl;
};
printingLambda();
}
```
<p style="text-align: justify;">Running above code snippet produces the same output as before. What happened here? In general, in the <strong>capture</strong> section of a <strong>lambda</strong>, we can put whatever parameters we want, and what is more, we can select variables from the calling context, to pass into the <strong>lambdas' body</strong> (as presented above). By default, all the variables <strong>are passed by value!</strong></p>
Of course, we're not limited to just passing the value - we can change its name. It is done like this:
```cpp
int main() {
MySimpleClass mySimpleClass { MySimpleClassPiece {1, "someStringvalue"} };
auto printingLambda = [externalVariable=mySimpleClass]() {
std::cout << externalVariable.piece.someStringValue << std::endl;
std::cout << externalVariable.piece.x << std::endl;
};
printingLambda();
}
```
<p style="text-align: justify;">Using this technique can improve the readability of the code, especially when the <strong>lambda</strong> is contained within the same compilation unit. But that's not over! When it comes to parameters, we can also provide new ones, completely unrelated to the context variables.</p>
```cpp
int main() {
MySimpleClass mySimpleClass { MySimpleClassPiece {1, "someStringvalue"} };
int xx = 5;
int zz = 10;
auto printingLambda = [externalVariable=mySimpleClass, y = 1, z = 5, result = xx + zz]() {
std::cout << externalVariable.piece.someStringValue << std::endl;
std::cout << externalVariable.piece.x << std::endl;
std::cout << y + z << std::endl;
std::cout << result << std::endl;
};
printingLambda();
}
```
This piece of code will actually print:
<pre>someStringvalue
1
6
15
</pre>
<p style="text-align: justify;">As you can see this feature is quite powerful, and enables <strong>lambda</strong> to get as much data as needed, to perform a specific operation. However, up until now we're operating with <em>named parameters</em> - we're specifying all of them in the <em>captures</em> section. That gives us a lot of flexibility, but sometimes we just want to pass everything to the <strong>lambda</strong> at once. We don't want to provide variables one by one, or (in the future), have to add additional params when new variables appear.</p>
<p style="text-align: justify;">The way to achieve that, is to use 'wildcard-style' in the square brackets. By putting there <em>'='</em> sign, we pass to the lambda all the variables that enclosing context contains, and lambda wants to use. As simple as that:</p>
```cpp
int main() {
MySimpleClass mySimpleClass { MySimpleClassPiece {1, "someStringvalue"} };
int xx = 5;
int zz = 10;
int result = xx + zz;
auto printingLambda = [=]() {
// Pay attention that we have to use the name of the original variable here!
std::cout << mySimpleClass.piece.someStringValue << std::endl;
std::cout << mySimpleClass.piece.x << std::endl;
std::cout << result << std::endl;
};
printingLambda();
}
```
<p style="text-align: justify;">It makes the code easier to maintain, but as I've said - it may influence the readability. Therefore, it's always situation based, whether we use <em>default capture</em> or <em>named one</em>. Ok, so far we've been dealing with parameters' values, as by default the parameters are passed by values. What if the <strong>lambda</strong> wanted to actually modify them? Trying to do that in the above example will fail.</p>
```cpp
auto printingLambda = [=]() {
std::cout << mySimpleClass.piece.someStringValue <<; std::endl;
std::cout << mySimpleClass.piece.x << std::endl;
std::cout << result << std::endl;
result = 14; // Results in compilation error with: assignment of read-only variable 'result'
};
```
<p style="text-align: justify;">If we want to make modifications to the variables, we could fall in a nasty trap here. I've mentioned in the list above, that one part of <strong>lambda</strong> expression can belong to <strong>modifiers</strong>. One of them is actually <strong>mutable</strong>. Sounds about right! Let's take a look at the following code, and try to predict how it behaves.</p>
```cpp
int main() {
int toAdd = 0;
auto printingLambda = [=]() mutable { // mutable added
toAdd += 5;
std::cout << toAdd << std::endl;
};
printingLambda();
std::cout << "In main: " << toAdd << std::endl;
printingLambda();
std::cout << "In main: " << toAdd << std::endl;
printingLambda();
std::cout << "In main: " << toAdd << std::endl;
}
```
If you've expected ever-increasing output I have bad news for you. It actually looks like this:
<pre>5
In main: 0
10
In main: 0
15
In main: 0
</pre>
<p style="text-align: justify;">Weird, isn't it? The problem here is, that <strong>mutable</strong> does not allow modifying params passed by values - quite reasonable I would say. What it does instead, is that it creates a new variable named exactly as the one used (in this example it is <strong>toAdd</strong>), and then keeps it in memory, as long as <strong>lambda</strong> is in use. That explains how we got this specific output.</p>
<p style="text-align: justify;">All right, but what if I want to modify actual variables from the outside world. Well, that's not a problem - just pass them as references. We can do that by replacing <em>'='</em> sign with <em>'&'</em> one.</p>
```cpp
int main() {
int toAdd = 0;
auto printingLambda = [&]() {
toAdd += 5;
std::cout << toAdd << std::endl;
};
printingLambda();
std::cout << "In main: " << toAdd << std::endl;
printingLambda();
std::cout << "In main: " << toAdd << std::endl;
printingLambda();
std::cout << "In main: " << toAdd << std::endl;
}
```
With that change, our output looks like we wanted it for the first time:
<pre>5
In main: 5
10
In main: 10
15
In main: 15
</pre>
What must be said here, is that we're not limited to either <em>named captures</em> and <em>default ones</em>! We can mix them for every <strong>lambda</strong>! Here's an example:
```cpp
int main() {
int toAdd = 0;
int x = 5;
auto printingLambda = [=, &toAdd]() {
toAdd += 5;
std::cout << toAdd << std::endl; // toAdd passing/changes will work as in the previous example
std::cout << x << std::endl;
// x += 10; This line will cause compiler to fail
};
// printing skipped
}
```
<p style="text-align: justify;">To finish discussing <strong>captures</strong> I have to mention, that it's also possible to pass to the <strong>lambda</strong> (either by value or by reference), an actual instance of the wrapping class. However, the topic is not trivial - I recommend reading <a href="https://www.nextptr. com/tutorial/ta1430524603/capture-this-in-lambda-expression-timeline-of-change">an excellent article on Nextptr.com</a>. What is more - linked presentation in the sources section also provides valuable info about it. That's it for today.</p>
SOURCES:
<ul>
<li><a href="https://lp.embarcadero.com/cpplambdasebook">Free ebook about lambdas</a> - whole book dedicated to lambdas in C++. Just provide email address and it's yours.</li>
<li><a href="https://www.youtube.com/watch?v=3jCOwajNch0&ab_channel=CppCon">Introduction to lambdas</a> - BackToBasis series on CPPConf</li>
<li><em>'Understanding and using C Pointers'</em> by Richard Reese, chapter about function pointers</li>
<li><em>'C++ Crash Course' </em>by Josh Lospinoso</li>
<li><a href="https://www.nextptr. com/tutorial/ta1430524603/capture-this-in-lambda-expression-timeline-of-change">Nexptr.com article</a> about the evolution of <em>this</em> capturing</li>
</ul> | chlebik |
909,764 | 10 Mobile App Development Trends to Watch in 2022 | Mobile app development in 2021 is an area of lightning-fast changes, disruptive technology, and new... | 0 | 2021-11-26T12:01:27 | https://dev.to/appzlogixtechnologies/10-mobile-app-development-trends-to-watch-in-2022-3p3e | Mobile app development in 2021 is an area of lightning-fast changes, disruptive technology, and new developing trends that assist organizations to attract clients in this tumultuous time for the industry.
Despite the disastrous impact of the COVID-19 epidemic on many businesses, the mobile development market is anticipated to expand to $44.3 trillion in revenue by 2027.
Global lockdowns have altered the focus of mobile app development trends to mobile-first, contactless, and connected services.
Choose the <a href="https://appzlogix.com/">best mobile application development company</a> to stay abreast with the changing trends in 2022 and beyond.
Payments via mobile device beacons
Chips with artificial intelligence
Automated machine learning
Treasure hunting at a beacon
Decentralized mobile apps, or DApps, are applications that are not only not owned by anyone, but also cannot be shut down and do not have any downtime.
Mobile apps have been continually transforming our daily life in recent years. And, because of their huge popularity and utility, they provide a significant potential for both entrepreneurs and businesses.
According to the reports to Statista, revenues from mobile apps are expected to reach $189 billion in the United States.
With the latest technology breakthroughs and new technologies entering our daily lives, it's not unreasonable to believe that 2022 will undoubtedly be the year of mobile apps, with greater business chances for both entrepreneurs and corporations.
Our business analyst team has discovered and highlighted the top mobile app development trends for 2022 after doing an extensive study.
1. The AR/VR age has just begun!
Both AR and VR are fantastic! That is without a doubt the case. However, by 2022, their uses will no longer be limited to gaming. Tech behemoths are already inventing a slew of new applications for both. Google and Apple, for example, are both launching new AR demos on their latest smartphones, demonstrating that AR/VR will be a game-changer shortly.
Indeed, these technologies are expected to be used on social media platforms for branding and to target potential customers via 'Beyond The Screens' AR/VR apps.
AR filters for Snapchat and Instagram, for example, have already been produced that can turn a human face into a range of digitally hilarious creatures.
Here are a few examples of current AR and VR trends.
AR on mobile is causing a stir.
In marketing and advertising, augmented reality (AR) is used.
AR in the medical field
Manufacturing with augmented reality
2. IoT
The next era of mobile-connected smart items is known as smart things.
The term "smart things" or "smart items" was coined by the Internet of Things, a relatively sophisticated technology.
It is a network of physical items embedded with sensors, electronics, and software that are all interconnected within the network. It is also known as IoT.
3. Artificial intelligence and machine learning
Artificial Intelligence and Machine Learning have both sunk their heels in the mobile app business very deeply.
4. Apps that are available on-demand:
It's always a timeless classic in current trends, and it's becoming better every day for future trends. We are convinced that all of the primary themes we've discussed will be merged into on-demand applications to improve them. As a result, on-demand processors are expected to be the most popular trend in 2022.
The most popular on-demand concepts for 2022 include food, groceries, laundry, alcohol, medications, apparel, technology, and more. Additionally, service providers such as carpenters, mechanics, plumbers, and electricians will be able to supply services as needed.
5. BlockChain
Secure transactions are required around the world. The best option for cyber security is blockchain. Decentralized applications or apps that do not require an intermediary to handle or manage information are found in mobile application development. The technology is gaining traction across a variety of industries, including healthcare, finance, and government.
Consider Dubai, which plans to develop blockchain in the city by 2021. Alibaba confirmed the adoption of anti-financial blockchain technology at Koala, China's cross-border retail e-commerce site, after Tmall Global's announcement.
6. M-commerce
M-commerce is growing increasingly prominent as e-commerce grows in popularity. The epidemic has once again become the most significant catalyst for both technologies. Both customers and retailers were "forced" to go online in that scenario. M-Commerce currently accounts for 72.9 percent of global e-commerce sales, according to statistics. By 2021, the industry is estimated to produce $ 3.56 billion in sales. Businesses that have already implemented e-commerce are now concentrating their efforts on marketing mobile commerce.
7. Touchless User Interface
The use of touch-based interfaces in mobile apps has become stale. Both developers and users now expect something novel from mobile apps that demands little effort from the user.
As a result, in 2022, developers are working on developing voice or gesture-based interfaces. These interfaces can completely change the game for the elderly or differently-abled.
8. Development of Low-Code Apps
Even relatively simple apps formerly required developers to write lengthy code. Developers no longer have to spend days or months building app coding, owing to current mobile app development services.
Low-code app development frameworks, which enable user-friendly and simple interfaces to create apps, will witness a surge in popularity in 2022. Because app usage is expected to rise, consumers may expect a significant increase in the number of apps available in 2022.
10. 5G
5G technology has existed for quite some time. Many tech companies have already used this technology to provide their customers with a better experience. The technology, on the other hand, will become the new industry standard by 2022.
Developers will be encouraged to use this technology to provide a thousand times more bandwidth than 4G thanks to new and better technology trends. Another advantage of this technology is that it has lower latency than previous ones. This will result in fewer disruptions and improved connectivity.
Make sure to look for the best mobile application development company to experience top-notch services and to secure a simple way to skyrocket your profits. | appzlogixtechnologies | |
909,776 | Text Prediction using Bigrams and Markov Models | 1. Introduction: For the implementation of text prediction I am using the concept of... | 0 | 2021-11-26T12:36:16 | https://dev.to/marcosteinke/text-prediction-using-bigrams-and-markov-models-229k |
# 1. Introduction:
For the implementation of text prediction I am using the concept of Markov Models, which allows me to calculate the probabilities of consecutively events. I will first explain what a Markov Model is.
# 2. Hidden Markov Model:
To explain a Markov Model it is important to start by understanding what a Markov Chain is.
## 2.1 Markov-Chain
A Markov Chain is a stochastic model, which models a sequence of random variables. It is assumed that states in the future only depend on a limited amount of previous states (Markov Adoption)
Let q1, q2, …, qn be a series of states. With the Markov Adoption you can assume:

### markovchain
So instead of spectating the probabilities of all previous states of the series, you may only spectate the previous state and end up with the same result.
# 3. Text prediction:
After introducing the idea of hidden Markov models and Markov chains I can now proceed and presentate the appliance of this concept.
## 3.1 N-grams:
Let the next sentence be the ongoing example for this section.
"On a rainy day please carry an umbrella."
Following the idea of Markov chains, you are interested in the following probabilities:
- P( a | On )
- P( rainy | a )
- P( day | rainy )
- P( please | day )
- P( carry | please )
- P( an | carry )
- P( umbrella | an )
Therefore you will have to understand the structure of each probability:
P(day, rainy) defines the probability of the word "day" following the word "rainy" in a given input. You can use the following synonyms:
P(day,rainy) → next = day, previous = rainy.
To get this probability, you will have to count the amount of the value of previous in the given input and then count how often the value of next is following the value of previous in the given input.
The quotient of them gives you the probability as follows:
P(next, previous = (|next| / |previous|).
This will get clear using the following quote:
"To be or not to be"
What is the probability P(be, to) ?
Ignoring the casing of the words (you could format all words to lowercase beforehand) you will find "to" being 2 times in the given input and "be" being following "to" 2 times, so you get the probability P(be, to) = 2/2 = 1.
Following this scheme you can now calculate the probabilites for all pairs of words.
If you use this type of probabilities where exactly two words are required to calculate a probability, then you are using Bigrams or 2-grams.
You can generalize this idea by defining N-grams, where a N-gram is the probability which you can again find in the Markov chain:
markovchain
In the text example, you would find a probability such as:
P(be, To be or not to) = 1
where your next-value is a single word and the previous-value is a sequence of words with the length n-1.
## 3.2 Application of N-grams to text prediction:
Now to predict text you will need the following components:
### 3.2.1 Input:
You will need any sort of textarea or predefined string (for texts it may be a multiline string or a list). This input has to be processed and stored, such that any algorithm can iterate through the result and built bigrams or N-grams from it.
In this implementation I read the input from a textarea and defined an array of separators.
static SEPARATORS = ['.', ',', '!', '?', '', "\n"];
Those separators will be used to determine when a sentence or paragraph is ending and there shall not be instantiated a bigram from the input at the given location.
Example:
"One apple please. I also want a bag."
This would lead to the construction of the bigram (I, please) with P(I | please), which is not really included in the given input.
To avoid such wrong bigrams I am checking each word for not being a separator.
After checking for separators you can iterate through the text and process the input:
```javascript
static formatInput(input) {
// (1)
Bigram.input = [];
Bigram.input = input
.replaceAll("^", "$")
.replaceAll(", ", ",")
.replaceAll(". ", ".")
.replaceAll("! ", "!")
.replaceAll("? ", "?")
.replaceAll(",", "^,^")
.replaceAll(".", "^.^")
.replaceAll("!", "^!^")
.replaceAll("?", "^?^")
.replaceAll("\n ", "\n")
.replaceAll("\n", "^\n^")
.replaceAll(" ", "^")
.split("^");
// (2)
let i = 1;
while(i < Bigram.input.length) {
if(Bigram.isSeparator(Bigram.input[Bigram.input.length - 1])) {
Bigram.input.pop();
}
i++;
}
}
```
In the first part of the method (1) I am replacing all separators with spaces around them with the exact same separator, but without spaces. Then I replace the separator with "^^" around it, so I can later split the input and remain the separators in my processed data.
Afterwards I am checking the end of the data for a separator (2), because I do not want to have any unexpected behaviour of my algorithm when coming to the end, where a separator is the last piece of input and no other word is following it.
This would result in the following:
Input: "To be, or not to be."
Output (1):
```javascript
["to", "be", ",", "or", "not", "to", "be", "."]
```
And after (2) has finished, it would return:
Output (2):
```javascript
["to", "be", ",", "or", "not", "to", "be"]
```
So now I received the input as list with the remaining separators inside of the text, but not the unnecessary separator at the end of the input.
### 3.2.2 Successors and the input:
To construct bigrams from the input, I first wanted to count each word and store the amount in a map. The map would have looked like:
```javascript
const wordCountMap = new Map();
wordCountMap.set("One", 3);
```
This would map each word to its amount.
But with this concept I looked into the future of the implementation and realized I throw away a very important information when only storing the amount of each word.
BECAUSE: I would still have to iterate through the processed input over and over again to check each word for its successor.
This led me to the idea of replacing my original problem by a equivalent algorithmic problem, which only requires numbers and no information about the words.
Problem of successing indices:
Given two sets of integers, find the amount of integers from the first set which are numerically successors of any integers from the second set.
#### Example: Given A = {4, 11, 19, 27} and B = {5, 20}
You would iterate through A and for each integer from A, you would look if there is any integer in B which is an successor of the current integer from A. If yes, increment a counter and continue with the next integer from A, if no, directly continue with the next integer from A.
In this case it would lead to a counter of 2, because B[0] = 5 = 4 + 1 = A[0] + 1 and B[1] = 20 = 19 + 1 = A[2] + 1.
If you now divide this counter by the size (cardinality) of A, you now would get the probability of B including a successor of an integer from A.
This numerical problem can now be represented by using the location (index) of words in a text (list).
### 3.2.3 Constructing Bigrams:
To construct bigrams you would have iterate through the list and in each iteration step look at the current value of the iterator and its successor, or to talk in code:
```javascript
static generateBigrams() {
let existingBigramHashes = [];
Bigram.bigrams = [];
if(Bigram.hasWordsCounted()) {
for(let i = 0; i < Bigram.input.length - 1; i++) {
if(!(Bigram.SEPARATORS.includes(Bigram.input[i+1]) || Bigram.SEPARATORS.includes(Bigram.input[i]))) {
if(!existingBigramHashes.includes(Bigram.input[i+1] + Bigram.input[i])) {
Bigram.bigrams.push(new Bigram(Bigram.input[i+1], Bigram.input[i]));
existingBigramHashes.push(Bigram.input[i+1] + Bigram.input[i]);
}
}
}
}
```
This piece of code basically looks at Bigram.input[i] and Bigram.input[i+1] and constructs a bigram from it, using the following constructor:
```javascript
constructor(next, previous) {
this.next = next;
this.previous = previous;
// Will be explained later !
this.findProbability();
}
```
It also checks for duplicate bigrams by comparing the current input[i] and input[i+1] to the ones from all previously constructed bigrams. Lastly it checks for bigrams to not include any of the separators.
Now after bigrams are constructed, there will only be the task of computing the probabilities for all bigrams.
### 3.2.4 Computing the probabilities (or solving the index successor problem):
At this point you already know instead of counting the amount of the previous word of a bigram and then iterate through the text and count how often the next word of a bigram is following the previous one, you can also solve the already defined index successor problem.
Now instead of counting the words I want to map each word to the indices at which the word occurs in the input:
```javascript
static countWords() {
Bigram.wordCountMap.clear();
let i = 0;
if(Bigram.hasInput() && Bigram.isFormatted()) {
Bigram.input.forEach(
(word) => {
if(!Bigram.wordCountMap.has(word)) {
Bigram.wordCountMap.set(word, [i++]);
} else {
let tmpArr = Bigram.wordCountMap.get(word);
tmpArr.push(i++);
Bigram.wordCountMap.set(word, tmpArr);
}
}
)
}
}
```
In general, this method iterates through the processed input and checks if a certain word is already stored in the map and then follows two different cases:
if the word is not in the map yet, put it in the map and store a list with the current position in the text as value.
if the word already is in the map, load the list from the map and add the current position to it.
Let the following be the input:
"One Ring to rule them all, One Ring to find them, One Ring to bring them all, and in the darkness bind them"
For the given input you would then receive the following map:
```javascript
Map {'One' => Array(3), 'Ring' => Array(3), 'to' => Array(3), 'rule' => Array(1), 'them' => Array(4), …}
[[Entries]]
0: {"One" => Array(3)}
key: "One"
value: (3) [0, 7, 15]
1: {"Ring" => Array(3)}
key: "Ring"
value: (3) [1, 8, 16]
2: {"to" => Array(3)}
key: "to"
value: (3) [2, 9, 17]
3: {"rule" => Array(1)}
key: "rule"
value: [3]
4: {"them" => Array(4)}
key: "them"
value: (4) [4, 11, 19, 27]
5: {"all" => Array(2)}
key: "all"
value: (2) [5, 20]
6: {"find" => Array(1)}
key: "find"
value: [10]
8: {"bring" => Array(1)}
key: "bring"
value: [18]
9: {"and" => Array(1)}
key: "and"
value: [22]
10: {"in" => Array(1)}
key: "in"
value: [23]
11: {"the" => Array(1)}
key: "the"
value: [24]
12: {"darkness" => Array(1)}
key: "darkness"
value: [25]
13: {"bind" => Array(1)}
key: "bind"
value: [26]
```
And as you can see there is an array including the positions (indices) for each word of the input.
To calculate the probabilites for all bigrams, we now have to iterate through the list of all bigrams which were already constructed and run the algorithm which I have explained before on each bigram.
So for each bigram run:
```javascript
findProbability() {
let sum = 0;
Bigram.wordCountMap.get(this.previous).forEach(
(index) => {
if(Bigram.wordCountMap.get(this.next).includes(index+1)) {
sum++;
}
}
)
this.probability = sum / Bigram.wordCountMap.get(this.previous).length;
}
```
This will, as already explained before, take the array of indices from the previous-value and then count in how many of the cases there is an successor in the indices array from the next-value for the current integer from the previous-value array.
The final result can be seen in the following probabilities:
- P(Ring | One) = 1
- P(to | Ring) = 1
- P(rule | to) = 0.3333333333333333
- P(them | rule) = 1
- P(all | them) = 0.5
- P(find | to) = 0.3333333333333333
- P(them | find) = 1
- P(bring | to) = 0.3333333333333333
- P(them | bring) = 1
- P(in | and) = 1
- P(the | in) = 1
- P(darkness | the) = 1
- P(bind | darkness) = 1
- P(them | bind) = 1'
You have now learned how to predict the probability of a word following another word by a given input.
In the next part you will see how all of this can be used to generate text by using those probabilities!
If you want to have a look at the actual implementation, feel free to look at the files included in this directory or to visit:
https://bestofcode.net/Applications/text-prediction !
Source-code can be found here: https://github.com/MarcoSteinke/Machine-Learning-Concepts/tree/main/implementation/1.%20text-prediction
Thank you :) | marcosteinke | |
909,798 | Bulk merge & Approve Github Pull Requests with the Gomerge github action! | My Workflow Are you an open source maintainer? Do you get dozens of contributions from... | 0 | 2021-11-26T13:56:11 | https://dev.to/cian911/bulk-merge-approve-github-pull-requests-with-the-gomerge-github-action-1omh | actionshackathon21, github, go, programming | ### My Workflow
Are you an open source maintainer? Do you get dozens of contributions from your community every week? Are you someone who would like to automate everything?
Late last year, I created the [Gomerge CLI tool](https://github.com/Cian911/gomerge). Gomerge is a tool which allows you to quickly bulk merge and approve several pull requests from your terminal.

With the github actions hackathon on the horizon, I thought I would take the opportunity and containerize Gomerge into it's own custom Github Action, with some new features to boot!
The [gomerge github action](https://github.com/Cian911/gomerge-action) is now available on the [github marketplace](https://github.com/marketplace/actions/gomerge-action). You can also view the action directly on the github repository.
### Submission Category:
Maintainer Must-Haves
### Yaml File or Link to Code
{% github https://github.com/Cian911/gomerge-action %}
Github action which utilizes the Gomerge CLI tool, also created by myself, to bulk merge and approve github pull requests.
Behind the scenes, Gomerge will determine the mergeability of a pull request by checking the following attributes:
- CI Status (success, pending, failure)
- Mergeable State (clean, blocked, dirty)
- Pull Request State (open, draft, closed)
If any of these metrics are not in a valid state, the pull request will not be approved/merged.
Below I've outlined an example which will run the action at midnight every night and approve only valid pull requests.
```yaml
on:
schedule:
- cron: '0 0 * * *'
jobs:
approve-prs:
runs-on: ubuntu-latest
name: Approve valid PRs
steps:
- name: Approve valid workflows
uses: Cian911/gomerge-action@master
with:
repository: ${{ github.repository }}
github_token: ${{ secrets.GITHUB_TOKEN }}
labels: ""
approve: "true"
```
### Additional Resources / Info
For more information and examples, please visit the [gomerge-action github page](https://github.com/Cian911/gomerge-action) for a full list. You can also visit my test repo, [gomerge-test](https://github.com/Cian911/gomerge-test) which contains a working example of the action.
Thank you for reading! | cian911 |
909,813 | What is Cloud Computing ? | The way we use technology is ever changing. It's an evolution of how and where we access our private,... | 0 | 2021-11-26T13:45:55 | https://dev.to/nikotech/what-is-cloud-computing--134c | cloud, beginners, opensource, cloudcomputing | The way we use technology is ever changing. It's an evolution of how and where we access our private, personal and work-related data. From the earliest days of the home computer, accessing data and entertainment from cassettes, to the rise of the Internet and terabytes of storage, technology has revolutionised the way we interact with the world around us.
One form of this technological evolution is the cloud. The cloud is a term used often without knowing exactly what 'the cloud' is, what it does, how it works and what it can off the home and business user. The cloud offers many gr benefits for those who use it. Storage, email, developm collaboration, sharing, streaming; the list goes on.
The future of work and entertainment lies in the cloud So let's see what silver linings cast a gleam on this modern way of life.
> What is the cloud? Where is it? What can you do with it? How does it work? These are questions that both home and business users ask regularly. The term 'cloud computing has been bandied about for so long, it's become just another technology phrase. But what does it really mean?
The meaning of the cloud has changed somewhat in recent years, more as it became the new buzzword that pundits and marketing executives liked to throw about. In its most basic, layman's terms, cloud computing is simply accessing a form of digital resource, or service, that isn't installed locally on your computer.
For the home, consumer user, that could mean accessing Gmail. Google Drive, Dropbox, or, in some circumstances, even viewing content through the likes of Netflix or listening to music via Spotify. It's a loose interpretation of what a cloud is, but essentially, it's the same.
From the Small Medium Business (SMB), or Small Medium Enterprise's (SME) point of view, it's a way of consolidating your digital resources and mission-critical content into an always-available, online and accessible solution. This way, mobile workers and clients can access the company content and you don't need to employ technical expertise to maintain the company servers and hardware continually. The ability to offer those shared resources without the technical or financial impact of setting it up, or keeping it maintained, is one of the main draws of using cloud computing over the more traditional setup of an air-conditioned room full of servers; therefore making it a more appealing proposition to both consumer and SMB/SME users.
In 2011, the National Institute of Standards and Technology (NIST) brought together a final definition of the term cloud
computing. "Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications and services). It can be rapidly provisioned and released with minimal management effort or service provider interaction."
The NIST went on to list five essential characteristics of cloud computing: on-demand self-service, broad network access, resource pooling, rapid elasticity or expansion, and measured service. Furthermore, there are three listed Service Models: software, platform and infrastructure, and four Deployment Models: public, community, hybrid and private.
The cloud, therefore, has quite a broad definition, encompassing pretty much everything we do and interact with on a daily basis. Throughout this book, we'll take a more in-depth look into the cloud, We'll discover what it consists of, how it works for you as an individual or business user, and how we can build our own cloud service.
### CLOUD BENEFITS
>Pay As You Go

> Security And Disaster Assistance

> Off-site data Storage
> Lower Cost of ownership

> Access from anywhere

> Automatic and easily upgraded
 | nikotech |
909,859 | How to Easily Add a Map to Your Website in Under 10 Minutes | Many modern web platforms leverage on maps and location-based features to provide services to users.... | 0 | 2021-11-26T21:05:44 | https://ubahthebuilder.tech/how-to-easily-add-a-map-to-your-website-in-under-10-minutes | javascript, webdev, tutorial, beginners | Many modern web platforms leverage on maps and location-based features to provide services to users. Some popular examples of this are Uber and Airbnb.
With the [TomTom Maps SDK](https://developer.tomtom.com/products/maps-sdk) , including a map in your website has never been easier. The toolkit enables access to various mapping features including street maps, real-time traffic conditions, fuzzy search and route planning for travellers.
As a developer, you can leverage on [TomTom's APIs methods](https://developer.tomtom.com/maps-sdk-web-js/documentation) to build and customize maps in your web or mobile application.
Let's walkthrough the process of adding a map to your website using the TomTom Maps SDK. In the end, I'll include a link to the source code for this project for reference.
### Getting Started
Using TomTom Maps SDK is both easy and free. First, you'll need to [register a TomTom developer account](https://developer.tomtom.com/user/register) to get an API key. This key gives you access to TomToms services, and is automatically generated for you on your dashboard once you're signed in.
To include the SDK in your application, you have three options; you can either use a CDN link, [download the ZIP file](https://developer.tomtom.com/maps-sdk-web-js/downloads) or [install the npm package. ](https://developer.tomtom.com/maps-sdk-web-js/downloads)
The easiest channel is through the CDN. Below are the links to the CDN files:
```
<link rel='stylesheet' type='text/css' href='https://api.tomtom.com/maps-sdk-for-web/cdn/6.x/6.15.0/maps/maps.css'>
<script src="https://api.tomtom.com/maps-sdk-for-web/cdn/6.x/6.15.0/maps/maps-web.min.js"></script>
<script src="https://api.tomtom.com/maps-sdk-for-web/cdn/6.x/6.15.0/services/services-web.min.js"></script>
```
To include them, all you have to do is paste these links inside your html file and you're good to go.
### Adding a map
Let's add a map to our website.
Create the html file for your site and paste the CDN links above, then, create a div to act as a wrapper for your map:
```html
<!-- html -->
<body>
<div id="mapArea"></div>
<!-- scripts -->
</body>
```
Maybe style it a bit?
```css
<style>
#mapArea {
height: 70vh;
width: 50vw;
margin: 0 auto;
}
</style>
```
Then create a map instance by calling `tt.map`, which is part of the windows object:
```js
const APIKey = '<your-api-key>'
var Lagos = { lat: 6.5244, lng: 3.3792 }
var map = tt.map({
key: APIKey,
container: 'mapArea',
center: Lagos,
zoom: 15
})
```
We passed an options object to the method containing the following properties:
- key: The API key for your app, obtained from the developer dashboard.
- container: The div which we want to insert our map into.
- center: a focus point for our map.
- zoom: a zoom level for our map.
Your map should look like this:
Omitting both center and zoom properties will give an abstract map of the world:
### Adding markers to the map
Markers are specific points of reference in a map. You can easily add markers by calling the `Marker()` function which is part of the TomTom Map API.
Now let's add a single marker to our map:
```js
var bus_stop = { lat: 6.4434, lng: 3.3553 }
var marker = new tt.Marker().setLngLat(bus_stop).addTo(map);
var popup = new tt.Popup({ anchor: 'top' }).setText('Bus Stop')
marker.setPopup(popup).togglePopup()
```
A single marker will be inserted into our map:
If you have multiple locations which you probably got from an API, you can recursively insert them with a JavaScript loop:
```js
var sites = [
{ lat: 6.4434, lng: 3.3553 },
{ lat: 6.4442, lng: 3.3561 },
{ lat: 6.4451, lng: 3.3573 },
{ lat: 6.4459, lng: 3.3520 }
];
sites.forEach(function (site) {
var marker = new tt.Marker().setLngLat(site).addTo(map);
var popup = new tt.Popup({ anchor: 'top' }).setText('Site')
marker.setPopup(popup).togglePopup()
});
```
The `Popup` API method was called to instantiate a new popup for the marker along with a custom text. After created the instance, we proceeded to set the popup on the marker by calling the `setPopup` method.
### Performing Fuzzy Search
There may be some cases where you want to display a location on the map using its common address, and not with the exact coordinates.
The TomTom Maps SDK also exposes an API for performing fuzzy searches. The `fuzzySearch` function call will return a list of coordinates corresponding to the bare address.
First, let's add a text input for location to our application:
```js
<div>
<input type="text" id="query" placeholder="Type a location">
<button onclick="fetchLoc()">Submit</button>
</div>
<div id="mapArea"></div>
```
Through the input, we can collect a query address from the user which we can then use the perform a fuzzy search.
This function gets called when the submit button is clicked:
```js
async function fetchLoc() {
const response = await tt.services.fuzzySearch({
key: APIKey,
query: document.querySelector('#query').value,
})
if(response.results) {
moveMapTo(response.results[0].position)
}
}
```
Here, we called the fuzzySearch API method, passing in the API key for our app, and the whatever location the user types into the input.
Since the function returns a promise, we needed to await its response. The fuzzy search will return an object containing many properties related to our search. The results property will hold an array of locations return from our search.
When the response is ready, we called the moveMapTo method, passing in the position property of the first match.
This function is responsible for moving our map to the new address:
```js
function moveMapTo(newLoc) {
map.flyTo({
center: newLoc,
zoom: 15
})
}
```
Here, we tell our map to move from the current location, to the location which matches our search query.
So when a location is added to the input and button is clicked, the map will switch context to the new location with a sleek transition.
### Conclusion
The TomTom Web SDK has a lot of API to integrate various functionalities. You can learn more about that from the [official API documentation.](https://developer.tomtom.com/maps-sdk-web-js)
The code for this project is available on [CodePen](https://codepen.io/ubahthebuilder/pen/WNEVKYw) .
### Other links
- [Twitter](http://twitter.com/UbahTheBuilder)
- [GitHub](http://github.com/KingsleyUbah)
- [JavaScript Ebook](https://gum.co/js-50)
| ubahthebuilder |
910,019 | Incident Post-Mortems at Jobber | No matter how stable your software product is, occasionally things go wrong in production, and Jobber... | 0 | 2021-11-26T16:58:00 | https://dev.to/jobber/incident-post-mortems-at-jobber-43ja | productivity, devops, postmortems | No matter how stable your software product is, occasionally things go wrong in production, and Jobber is committed to doing a post-mortem investigation to follow up and learn from each incident.
At a high-level, an incident post-mortem answers these questions:
- What went wrong?
- What did we do to fix it?
- What will we do differently, so it doesn't happen again?
- What went well during the incident, that we should keep doing?
As we’ve grown and moved to a remote working environment, we’ve changed our process to work better for remote teams and super busy schedules. This is a summary of what we’re doing to make sure that incidents remain rare and our customers can keep getting their work done!
## Our process
Our process is broken down into 4 steps: Resolve the incident, investigate it, debrief about it, then share the results
**Collect data during the incident**. We collect as much data as we can in a slack channel dedicated to incidents, keeping it organized with threads. This includes server graphs, snippets from logs, and screenshots showing what was going on at each point in the incident. It doesn’t all end up being useful, but it’s nice to have everything collected when you start going through the investigation.
**Start the investigation right away**. We get one of the involved people to take on the role of lead investigator, which really means they’re in charge of making sure the investigation gets done, the post-mortem document gets filled in, and the debrief gets held. Starting it right away makes sure nothing gets lost.
**Review the results within a week**. While things are still fresh, hold a debrief to review the post-mortem document, discuss the action items, and make any edits needed. This is a 30-60min zoom session with the team involved in the incident as well as reps from other departments (mainly the customer support/escalation team).
**Share the results as soon as the debrief is done**, so everyone gets a chance to learn from it! We post it to a slack channel that the whole company has access to, for transparency.
## New Challenges
With a larger company, people working in all sorts of time zones, and everyone being remote, scheduling and coordinating got a lot more complicated. The process is still mostly the same, but with some tweaks to keep it effective.
### Shorter timelines
We’ve shortened the timeline expectations - getting the incident doc started faster and the debrief done sooner helps get all the data and lets everyone involved get back to their sprint work sooner.
### Assume async
Scheduling the debrief sooner means that it’s harder to find a spot in everyone’s calendars. Rather than pushing the meeting further and further out, do more of the work asynchronously. Make sure the document can stand on its own, and use slack to ask people for their contributions.
We also record the debrief (easy with zoom) so that anyone who couldn’t attend is also able to watch it later, so nobody has to worry about missing out.
### Simple incident doc template
We’re using a wiki template for consistency, and over time we’ve simplified down the template repeatedly so there’s less sections to worry about.
Setting it up with a button to auto-create the new page from the template works well.
The template has sections for:
- Impact and Scope
- Trigger (what started the incident)
- Resolution (what ended up fixing it)
- Timeline of events
- Root Cause
- What went well
- What didn’t go well
- Action items
- Data & Analysis (all the charts!)
### Asking for input from customer-facing teams right away
Our customer success team always has great input and is able to help fill in gaps in the timeline. We reach out to them early so there’s time for their input to be added into the post-mortem doc before the debrief. Waiting for the debrief is too late!
### Tracking action items in Jira
Why track action item progress in an incident doc when we already have a standard tool for tracking work? As soon as we can, we get all action items from post-mortems in as Jira tickets so they can be assigned to backlogs and don’t get lost.
We also have some reports set up to view the list of outstanding post-mortem actions - driven by a post-mortem label on the items.
### Have a section for “things we should do if we have time”
Realistically, not all action items are actually actionable - some are more aspirational or are something we just need everyone to keep in mind. In order to keep the Jira action items clearer, we’ve included this section as a spot to put the things we think are important but we couldn’t turn into assignable/trackable work.
Our approach is that it’s better to have a smaller set of action items that we actually do than a giant list of things we’d like to do given infinite time.
### Keep it Blameless
This one isn’t actually new, but it’s well worth repeating! We’re interested in what happened and what we’re going to do to fix it going forward, not in pointing fingers.
> "Removing blame from a postmortem gives people the confidence to escalate issues without fear."
> – the SRE book
## About Jobber
We're hiring for remote positions across Canada at all software engineering levels!
Our awesome Jobber technology teams span across Payments, Infrastructure, AI/ML, Business Workflows & Communications. We work on cutting edge & modern tech stacks using React, React Native, Ruby on Rails, & GraphQL.
If you want to be a part of a collaborative work culture, help small home service businesses scale and create a positive impact on our communities, then visit our [careers](https://getjobber.com/about/careers/?utm_source=devto&utm_medium=social&utm_campaign=eng_blog) site to learn more! | jessevanherk |
910,214 | How to get or access the properties and methods of anchor (or a) HTML element tag without errors in TypeScript? | Originally posted here! To get or access the properties and methods of the anchor (or a) HTML... | 0 | 2021-11-16T00:00:00 | https://melvingeorge.me/blog/get-or-access-properties-methods-anchor-or-a-html-element-tag-without-errors-typescript | typescript | ---
title: How to get or access the properties and methods of anchor (or a) HTML element tag without errors in TypeScript?
published: true
tags: TypeScript
date: Tue Nov 16 2021 05:30:00 GMT+0530 (India Standard Time)
canonical_url: https://melvingeorge.me/blog/get-or-access-properties-methods-anchor-or-a-html-element-tag-without-errors-typescript
cover_image: https://melvingeorge.me/_next/static/images/main-a4d82b312b6c1d93c3f311e8d8193678.jpg
---
[Originally posted here!](https://melvingeorge.me/blog/get-or-access-properties-methods-anchor-or-a-html-element-tag-without-errors-typescript)
To get or access the properties and methods of the `anchor` (or `a`) HTML element tag without having errors or red squiggly lines in TypeScript, you have to assert the type for the `anchor` (or `a`) HTML element tag using the `HTMLAnchorElement` interface in TypeScript.
The errors or warnings are shown by the TypeScript compiler since the compiler doesn't know more information on the `anchor` (or `a`) HTML element tag ahead of time. But we know that we are referencing the `anchor` (or `a`) HTML tag and thus we can tell the compiler to use the `HTMLAnchorElement` interface which contains the declarations for properties and methods.
### TL;DR
```ts
// get reference to the first 'anchor'
// HTML element tag in the document
// with type assertion using the HTMLAnchorElement interface
const anchorTag = document.querySelector("a") as HTMLAnchorElement;
// no errors or red squiggly lines will be
// shown while accessing properties or methods
// since we have asserted the type
// for the 'anchor' HTML element tag 😍
const id = anchorTag.id;
```
To understand it better let's say we are selecting the first `anchor` (or `a`) HTML element tag using the `document.querySelector()` method like this,
```ts
// get reference to the first 'anchor'
// HTML element tag in the document
const anchorTag = document.querySelector("a");
```
Now let's try to get the value of a property called `id` which is used in the `anchor` (or `a`) HTML element tag as an attribute.
It can be done like this,

As you can see that the TypeScript compiler is showing a red squiggly line below the `anchorTag` object. If you hover over the `anchorTag` you can see an error saying `Object is possibly 'null'`. This is because TypeScript is not sure whether the `anchorTag` object will have properties and methods ahead of time.
Now to avoid this error we can assert the type for the `anchor` (or `a`) HTML element tag using the `HTMLAnchorElement` interface in TypeScript.
To do Type assertion we can use the `as` keyword after the `document.querySelector("a")` method followed by writing the interface name `HTMLAnchorElement`.
It can be done like this,
```ts
// get reference to the first 'anchor'
// HTML element tag in the document
// with type assertion using the HTMLAnchorElement interface
const anchorTag = document.querySelector("a") as HTMLAnchorElement;
// no errors or red squiggly lines will be
// shown while accessing properties or methods
// since we have asserted the type
// for the 'anchor' HTML element tag 😍
const id = anchorTag.id;
```
Now if hover over the `id` property in the `anchorTag` object TypeScript shows more information about the property itself which is again cool and increases developer productivity and clarity while coding.

See the above code live in [codesandbox](https://codesandbox.io/s/get-or-access-properties-methods-anchor-or-a-html-element-tag-without-errors-typescript-9ch5y?file=/src/index.ts).
That's all 😃!
### Feel free to share if you found this useful 😃.
---
| melvin2016 |
910,245 | Keep your research reproducible with conda-pack and GitHub Actions | Reproducibility is a major principle underpinning the scientific method, and scientific software is... | 15,665 | 2021-11-27T01:44:01 | https://dev.to/epassaro/keep-your-research-reproducible-with-conda-pack-and-github-actions-339n | actionshackathon21, research, science | Reproducibility is a major principle underpinning the scientific method, and scientific software is not an exception.
Anaconda is a distribution of the Python and R programming languages for scientific computing with more than 25 million users. But, how reproducible is science made with Anaconda? And most important:
**Do you think you will be capable of reproducing the results your research in the next 10 years?**.
Currently, the reproducibility of Anaconda environments [is not guaranteed](https://github.com/conda-forge/conda-forge.github.io/issues/787). `conda list --explicit` provides just some kind of short term reproducibility.
For example, if you use packages from non-standard channels, the owner could delete them at any moment. Also, the resolved URLs could vary due to changes in package labels or storage.
There is an [ongoing debate](https://github.com/conda/conda/issues/7248) about how to unify the different available tools to solve this problem. In this workflow, I propose a simple but effective way to keep your environments reproducible using GitHub Actions and [`conda-pack`](https://conda.github.io/conda-pack/):
> _`conda-pack` is a command line tool for creating archives of conda environments that can be installed on other systems and locations. This is useful for deploying code in a consistent environment —potentially where Python and/or conda isn’t already installed._
Every time you publish a new release of your code (e.g. a paper) on GitHub, the environment is solved, packed and uploaded as an asset.
```yaml
name: pack
on:
release:
types: [published]
env:
BASENAME: ${{ github.event.repository.name }}-${{ github.event.release.tag_name }}
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Setup Mambaforge
uses: conda-incubator/setup-miniconda@v2
with:
miniforge-variant: Mambaforge
miniforge-version: latest
environment-file: environment.yml
activate-environment: my-env
use-mamba: true
- name: Freeze packages
shell: bash -l {0}
run: conda env export -n my-env > $BASENAME.yml
- name: Install conda-pack
shell: bash -l {0}
run: mamba install -c conda-forge conda-pack
- name: Pack environment
shell: bash -l {0}
run: conda pack -n my-env -o $BASENAME.tar.gz
- name: Upload assets
uses: AButler/upload-release-assets@v2.0
with:
files: '${{ env.BASENAME }}.{yml,tar.gz}'
repo-token: ${{ secrets.GITHUB_TOKEN }}
release-tag: ${{ github.event.release.tag_name }}
```
Finally, [follow the instructions](https://conda.github.io/conda-pack/#commandline-usage) to deploy an identical environment at any point in the future.
## Get the code
{% github epassaro/repro-conda-envs %}
| epassaro |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.