
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
857,003 | New feature has been added and working via remotes | Another contribution This week I had a chance to add new feature to a project of another... | 0 | 2021-10-09T02:51:44 | https://dev.to/nguyenhung15913/new-feature-has-been-added-and-working-via-remotes-14oe | opensource, git, remote, merging | #Another contribution
This week I had a chance to add new feature to a project of another programmer, Jun Song. Jun is friendly and also a professional coder.
After forking and cloning his project. I created a new branch with the same name as my issue I filed on his repo(issue-11). Then, I helped Jun to add another flag for his CLI tool. In more detail, his tool now can read a JSON file in which users can specify their options. Instead of entering a really long line:
<code>jun-ssg -i "Silver Blaze.txt." --stylesheet "example.com"</code>
Users now can store all of their options in a <code>config.json</code>
```
{
"input": "Silver Blaze.txt",
"stylesheet": "example.com"
}
```
And can just simply enter:
<code>jun-ssg -c config.json</code>
After that I merge <code>issue-11</code> branch to <code>master</code>. Then I sent him a request and still waiting for his feedbacks of correction.
#Working and Testing via Remotes
Jun also worked on my project. Firstly, I used <code>git remote add</code> and checked out to his branch to test. He did a really good job on validating users' input as well as supporting my tool to read a config JSON file. I saw no errors so I merged his request to my main branch.
In my opinion, <code>git remote</code> is really useful. It allows you to test a pull request. First it can add the branch of the person who sends the request to our project. Then if you are satisfied, you can merge that branch to our main branch.
#Issues
Jun's codes were well-organized with separated folders for main JS file and utility files. Also, to decorate the output to users, Jun used some packages to change tool's output. This was a really good user experience but for the first time, it made me a little bit confused when reading his codes. On top of that, I tried to run the command with <code>-c</code> flag only but the tool kept telling me to specify input file, then I just realized that he made the <code>-i</code> flag as <code>required</code>. I fixed that and the tool worked well after.
In general, his type of coding was cool and professional, he split his codes into components, which were different functions. Also, keeping the main file and <code>util</code> files into different folders will make you debug more easily. This worth learning.
#Links to repos:
Issue: https://github.com/juuuuuuun/jun-ssg/issues/14
Pull request: https://github.com/juuuuuuun/jun-ssg/pull/15
My issue: https://github.com/nguyenhung15913/OSD600-SSG/issues/14
Jun's pull request: https://github.com/nguyenhung15913/OSD600-SSG/pull/18 | nguyenhung15913 |
857,135 | How to send a form to an email without any backend | Hi Everyone! In this post I will be showing you how to send a form in HTML without any backend in... | 0 | 2021-10-09T04:03:02 | https://dev.to/abhidevelopssuntech/how-to-send-a-form-to-an-email-without-any-backend-5enb | email, forms, html, nobackend | Hi Everyone!
In this post I will be showing you how to send a form in HTML without any backend in multiple ways. Remember to follow me for more posts. Now let's get started!
The Method attribute of the form must be set to "POST" for each of these ways to work. And the form input fields must have a name attribute that is not empty. I am going to use this basic HTML Markup:
```html
<div class="container">
<form action="#" method="POST">
<label for="fname">First Name</label>
<input type="text" id="fname" name="firstname" placeholder="Your name..">
<label for="lname">Last Name</label>
<input type="text" id="lname" name="lastname" placeholder="Your last name..">
<label for="country">Country</label>
<select id="country" name="country">
<option value="australia">Australia</option>
<option value="canada">Canada</option>
<option value="usa">USA</option>
</select>
<label for="subject">Subject</label>
<textarea id="subject" name="subject" placeholder="Write something.." style="height:200px"></textarea>
<input type="submit" value="Submit">
</form>
</div>
```
Now I am going to show you the first way to do this. In the action attribute of the form element add this code:
```
mailto:you@example.com <!--put your email here-->
```
What this will do is that it will open a new window of the Mail app and it is going to take all the user text in the input fields and put it in an email. Then if the user clicks "SEND", the form data will be sent to you.
The next way we can do this is by using different form submission companies. The ones we will be using are "Formspree" and "FormSubmit".
I prefer FormSubmit because it requires no registration so I will start with that. The first thing you need to do is go to [Formsubmit.co](https://formsubmit.co).
Then you need to to copy the code that is pointed to in the image below.
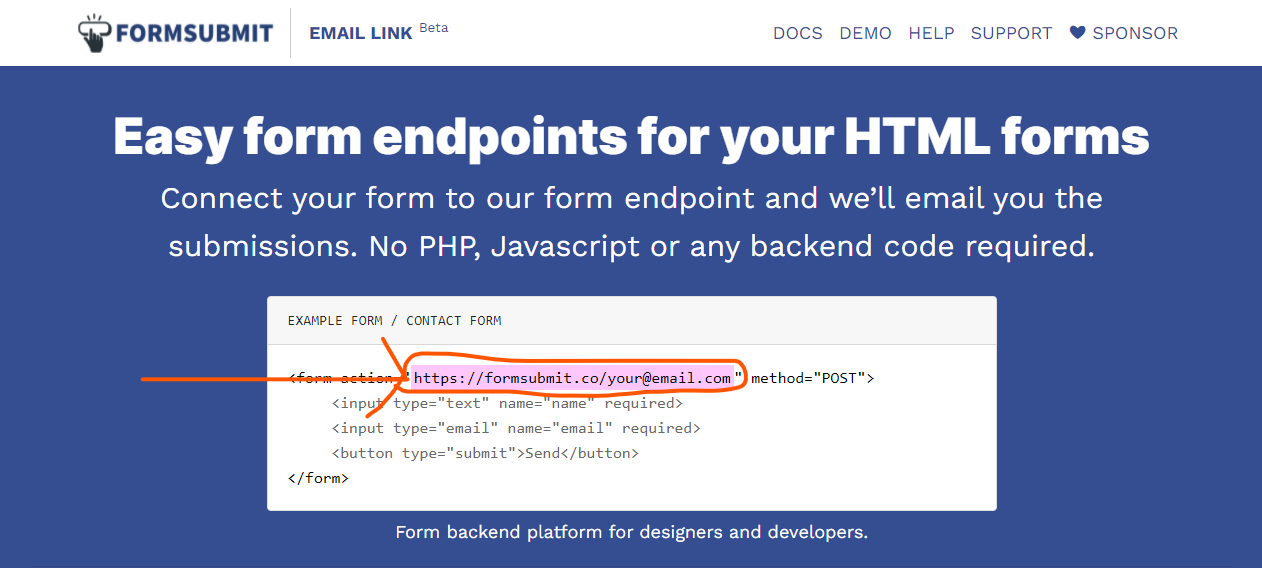
Paste this code in the action attribute of your form. Then enter your email in "your@email.com" and you are all set!
Next let's use Formspree. Go to [Formspree.io](https://formspree.io). Then create a new account by clicking the "Get Started Button".
Then you will be redirected to this page:
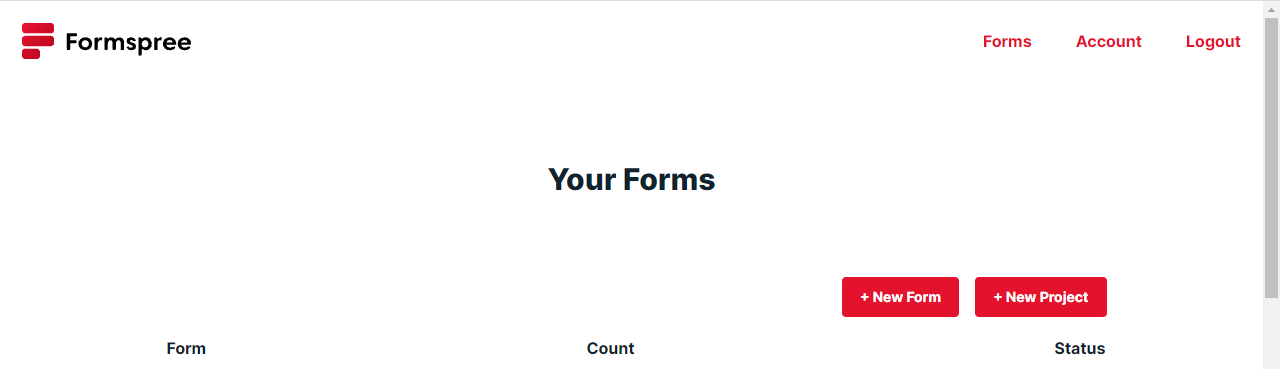
Then click "New Form". Then enter your form name and select what email it will send the submissions to (your email).
Once you create the form, copy the code that the image below shows.
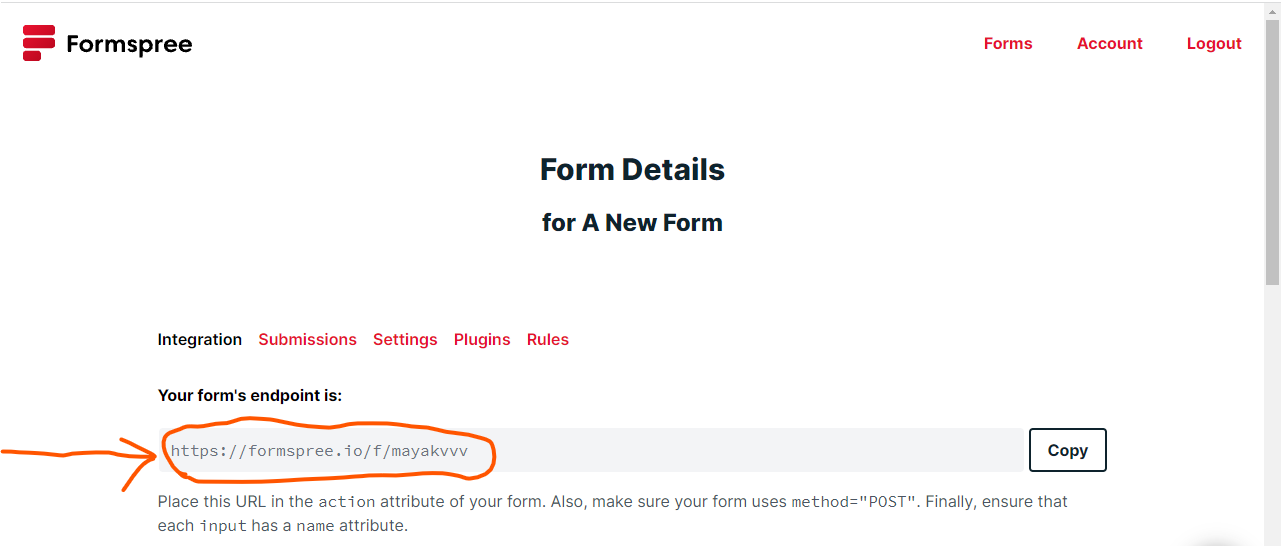
Then paste that code in the action attribute of your form and you are done!
These are different ways you can send form with HTML without and Backend Code. Thank you for reading my post and if you have any questions, let me know.
Bye for now!
| abhidevelopssuntech |
857,224 | 12 Simple HTML Snippets To Avoid Complex Libraries ⚡✨ | Not knowing the basic tech can sometimes increase the size, affect the performance and add an extra... | 0 | 2021-10-11T17:38:17 | https://dev.to/madza/12-simple-html-snippets-to-avoid-complex-libraries-3na8 | html, css, programming, productivity | ---
title: 12 Simple HTML Snippets To Avoid Complex Libraries ⚡✨
published: true
description:
tags: html, css, programming, productivity
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/vp46impflwmulu2lo70q.png
---
Not knowing the basic tech can sometimes increase the size, affect the performance and add an extra layer of complexity to the project.
This article is a heads up that you can do a lot with just vanilla [HTML](https://developer.mozilla.org/en-US/docs/Web/HTML) and a bit of [CSS](https://developer.mozilla.org/en-US/docs/Web/CSS) if you want it to look pretty.
I have collected some of the most useful HTML tags and attributes, so you can study them and use in your next project.
I also created 12 separate [Codepens](https://codepen.io/collection/mrbBrR?grid_type=grid), so you can get a live taste and play around with the examples.
### 🎨 Color Picker
Often in the developer workflow you might want to access the color spectrum and be able to pick up any shade from it.
You can use `<input type="color">`, which would otherwise be a time-consuming task to write from scratch.
{% codepen https://codepen.io/madarsbiss/pen/vYJBqeX default-tab=result %}
### 📚 Blockquote
When writing articles you might want to highlight some of your favorites quotes.
You can use a `<blockquote>` tag for that. Add some custom styling and you have a nice element that will stand out from the rest of the text.
{% codepen https://codepen.io/madarsbiss/pen/JjyPQBd default-tab=result %}
### 🎵 Audio Player
Writing your own audio player from scratch can be a challenge. You can use the built-in `<audio>` tag, that provides the basic functionality to play your audio files.
Also, you can listen to more of my music [here](https://madza.dev/music).
{% codepen https://codepen.io/madarsbiss/pen/oNevrEb default-tab=result %}
### 📺 Video Player
Another multimedia you could use in your projects is video. Again, you can not just include the video link in HTML and hope that it will play.
To playback videos properly you can use built-in `<video>` tag.
{% codepen https://codepen.io/madarsbiss/pen/BadBgxJ default-tab=result %}
### 🔷 Accordion
Sometimes you might want to hide some content and allow user to reveal it manually (to save the space of the viewport, for example).
You can achieve the described functionality with pure HTML, thanks to `<details>` tag.
{% codepen https://codepen.io/madarsbiss/pen/zYdOVPV default-tab=result %}
### 📅 Date Picker
Working with dates is among the most common reasons why devs search for external libraries.
HTML provides a `<input type="date">` tag, that provides a nice UI with the option to select the dates by clicking on them.
{% codepen https://codepen.io/madarsbiss/pen/qBXWzXE default-tab=result %}
### ⚪ Slider
Slider is a common component to collect the user input in the specific numeric range.
You can use `<input type="range">` to get a fully functional slider, where you can set the min, max and current value.
{% codepen https://codepen.io/madarsbiss/pen/GRvKbXv default-tab=result %}
### ✍ Content Editor
In order to edit content you don't have to use input or textarea fields and set the default values for them.
Instead, you can use `contenteditable` attribute, that allow to edit the content of the div, for example.
{% codepen https://codepen.io/madarsbiss/pen/ExvYBwB default-tab=result %}
### 📷 Picture Tag
You might want to display different images on different screen sizes to improve the performance and UI/UX.
Instead of using the default `<img>` tag, detect the viewport and creating a method to switch between the images, you can use built-in `<picture>` tag.
{% codepen https://codepen.io/madarsbiss/pen/abybomY default-tab=result %}
### ⌛ Progress Bar
The `<progress>` tag represents the completion progress of a task.
You can use it to display various actions, such as a download, file transfer, or installation.
{% codepen https://codepen.io/madarsbiss/pen/oNevKdp default-tab=result %}
### 🔻 Dropdown
Often you might need to collect the user input with multiple possible choices. Instead of listing all the options on the screen, you might include them into dropdown.
Using the `<datalist>` tag will allow users to select options from dropdown, while also allowing to enter their own values.
{% codepen https://codepen.io/madarsbiss/pen/eYEOwdQ default-tab=result %}
### 💭 Tooltip
If you need to give a detailed description of something, it is always nice to include a pop up.
HTML built-in `title` attribute provides that by default.
{% codepen https://codepen.io/madarsbiss/pen/VwzwZvE default-tab=result %}
In this article we reviewed functional HTML elements that you can use while working with text, audio, images, video, etc.
Next time you need the some functionality, make sure to double check if it is not already provided by the HTML itself.
{% twitter 1447623708571541506 %}
<hr>
Writing has always been my passion and it gives me pleasure to help and inspire people. If you have any questions, feel free to reach out!
Connect me on [Twitter](https://twitter.com/madzadev), [LinkedIn](https://www.linkedin.com/in/madzadev/) and [GitHub](https://github.com/madzadev)!
Check out my [portfolio](https://madza.dev/code) for all projects. | madza |
857,296 | Participating in Devtober 2021 | You can skip this portion as this will be just me venting here. Its been a long time since I've... | 0 | 2021-10-09T09:31:43 | https://dev.to/fihra/participating-in-devtober-2021-31b2 | gamedev, unrealengine, beginners, programming | You can skip this portion as this will be just me venting here.
---
Its been a long time since I've posted a blog here. A lot has been going on in my life right now. Still in on the purpose of trying to land that first job, but of course I've gone through a bit of a burnout of applying for jobs again. I have also taken a break from programming the past couple months, so I feel rusty in trying to get that workflow back. It just doesn't help either when I have family who just doesn't believe in me for these goals to have that moral support, so it's tough to really maintain my mind set for this.
---
Alright, so I have decided to start Devtober, which started the beginning of this month. I will be continuing a game project I actually started for a different game jam back in July but didn't finish. My goal is actually wanting to finish this game by the end of this month, especially since I feel I am almost finished with it.

## Maliksi
A 2D Action Platformer Boss Rush game where you play as Malik, an Eskrimador, who must retrieve the stolen light from Filipino mythological-inspired creatures to save the village.
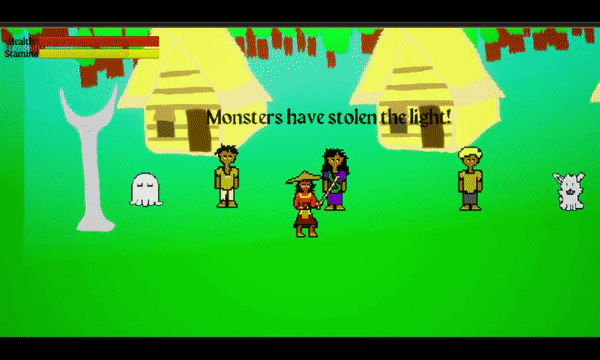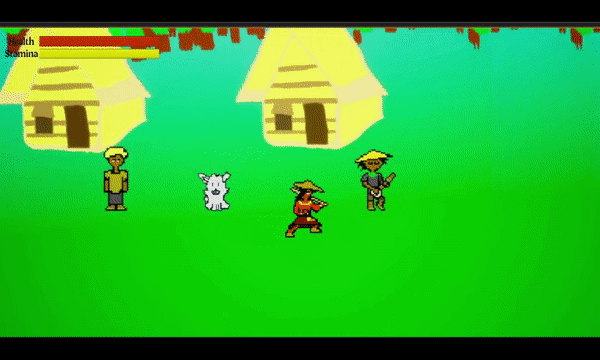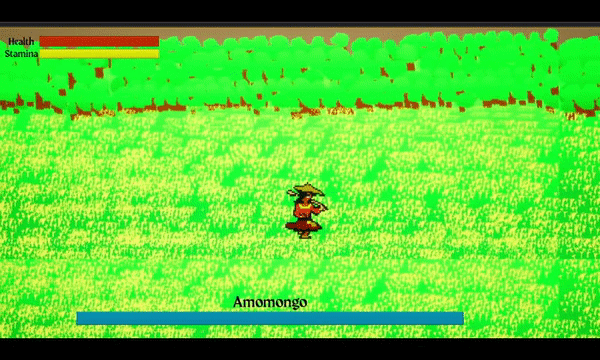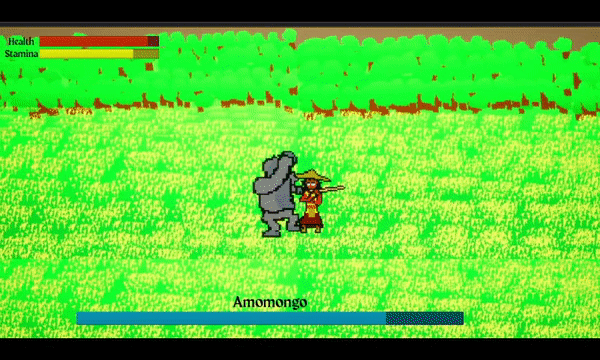
I have been working on the art, programming, sound design, and music. I am learning Unreal Engine with unreal blueprinting (not C++ because I don't feel ready or comfortable in the language yet). Which it took me awhile to get used to visual programming.
I am using Wwise to implement the sound effects and music.
I'm keeping my scope as tight as I can in order to finish this game. I still need to polish one of the boss fights, but the final boss still needs the functionality and mechanics implemented.
Things that I need to work on for this last push for this month:
- polish one of the boss fight's mechanics
- final boss still needs functionality & mechanics implemented
- Waiting for musicians to record their parts for the music so I can start mixing
- Implement the music into the game
- Few more sound effects to design
- Slowly implementing sounds in each level
- Ending still needs to be created
[1st Video Footage](https://twitter.com/FirahFabe/status/1431739110616551428?s=20)
[2nd Video Footage](https://t.co/RxMfwYu00s)
I want to publicize this to hold myself accountable to finish this game. I did participate in Devtober 2020, but I never finished that game, but this one, this one for sure I want to complete, since I've been working on this one for a long time already. Plus, it is also Filipino American History Month, and this game showcases my Filipino culture that I have incorporated into this.
If you want to participate in this game jam, here is the link to the itch.io:
[https://itch.io/jam/devtober-2021](https://itch.io/jam/devtober-2021) | fihra |
857,430 | Day 1 of 100 Days of Code and Scrum: How to GraphQL? | For context, I'm doing a mixture of 100daysofcode with Scrum elements. See the challenge post... | 14,990 | 2021-10-09T12:22:31 | https://dev.to/rammina/day-1-of-100-days-of-code-and-scrum-how-to-graphql-1o78 | graphql, beginners, 100daysofcode, webdev | For context, I'm doing a mixture of 100daysofcode with Scrum elements. See the [challenge post here:](https://dev.to/rammina/100-days-of-code-and-scrum-a-new-challenge-24lp)
## Yesterday
I started learning GraphQL from https://www.howtographql.com. It's a pretty nice GraphQL tutorial because they both have video and text format, and so far I've been enjoying it.
## Today
I kept on plowing through https://www.howtographql.com/basics/2-core-concepts/ and learning more about what GraphQL can do.
Here are some of the things I've learned:
### GraphQL
- GraphQL is strongly typed, which means the typing needs to be declared in advance
- GraphQL uses Schema Definition Language (SDL)
- GraphQL uses queries (GET in REST API), mutations (POST, PATCH, DELETE), and subscriptions (something that lets you listen to mutations and returns response objects)
- mutations allow you to specify a payload to retrieve new information in one call round trip
- subscriptions are like data streams, while queries and mutations are similar to the request-response-cycle
- types serve as entry points for request sent by the client side
- a root field is followed by the payload which is flexible and allows you to retrieve which data you want
- it is much more flexible to query nested information using GraphQL compared to REST API
### Scrum
- a Sprint can be canceled by the Product Owner if the Sprint Goal becomes obsolete
- Product Owners have the option to choose whether to attend a Daily Scrum or not
I'm having a difficulty with getting used to working with the new syntax for GraphQL, since I've been using REST API all this time.
How is everyone doing in their learning journey? Feel free to chat with me in the comments and/via DM!
### DISCLAIMER
This post only expresses my thoughts and opinions (based on my limited knowledge) and is in no way a substitute for actual references. If I ever make a mistake or if you disagree, I would appreciate corrections in the comments!
### Other Media
Feel free to reach out to me in other media!
<span><a target="_blank" href="https://www.rammina.com/"><img src="https://res.cloudinary.com/rammina/image/upload/v1638444046/rammina-button-128_x9ginu.png" alt="Rammina Logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://twitter.com/RamminaR"><img src="https://res.cloudinary.com/rammina/image/upload/v1636792959/twitter-logo_laoyfu_pdbagm.png" alt="Twitter logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://github.com/Rammina"><img src="https://res.cloudinary.com/rammina/image/upload/v1636795051/GitHub-Emblem2_epcp8r.png" alt="Github logo" width="128" height="50"/></a></span>
| rammina |
857,662 | Help me... | Hello everyone... I am beginner of full stack dev journey and also new here, Thanx to @comscience ... | 0 | 2021-10-09T16:32:26 | https://dev.to/akulkarni/help-me-1ajp | help | Hello everyone...
I am beginner of full stack dev journey and also new here, Thanx to @comscience ...
Plz suggest me
any Blog to read, video to watch or podcast to listen, which helps me for journey of Full stack developer.
Thank you 😊
| akulkarni |
857,667 | Webson: a new DOM markup | Using JSON for complex layouts | 0 | 2021-10-25T17:50:27 | https://dev.to/gtanyware/webson-a-new-dom-markup-5cn6 | markup, html, json, dom | ---
title: Webson: a new DOM markup
published: true
description: Using JSON for complex layouts
tags: markup,html,json,dom
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/apzlz352ixhvrislpvt0.jpg
---
Photo by <a href="https://unsplash.com/@halacious?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Hal Gatewood</a> on <a href="https://unsplash.com/s/photos/website?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
## Synopsis
This article introduces _Webson_, an easy-to-use syntax with its own run-time rendering engine, that turns JSON into DOM markup and adds features way beyond those of HTML.
## Introduction
A web page is the visual representation of a Document Object Model, or DOM, the data structure maintained internally by all browsers. Traditionally, the DOM is constructed by the browser from HTML scripts, but as pages get bigger and more complex HTML becomes ever more cumbersome. In recent years it has become increasingly common to create the DOM using JavaScript, with no HTML ever being seen, but while this suits programmers well it requires a different skill set from that needed to build pages the traditional way.
Today's Web pages may have hundreds or thousands of elements, all carefully positioned to create the desired result. There's no way to hide this complexity, whether it's done with HTML/CSS, JavaScript or some kind of no-code visual builder. In the end it's a human brain that's doing the real work of translating the customer's requirements - a mental picture - into something the browser can use to create the DOM.
HTML is not program code; it's a form of "markup", the ultimate expression of which came in the form of XML, able to represent not only visual structures but a wide range of other data too. Unfortunately, XML is wordy and hard to read and is not greatly loved. In 2001, Douglas Crockford invented (he would say "discovered") a simpler syntax for representing data structures, as a means of transferring data in and out of JavaScript programs in the form of plain text. The syntax is JavaScript Object Notation, or JSON, and in the past 2 decades it has widely supplanted XML. Virtually every programming language has the ability to read and write JSON and it's now the most common way to transfer data across the Web.
Since HTML shares many of the disadvantages of XML, the question might be asked, _Can JSON also replace HTML?_. If the answer is "yes", a couple of supplementary questions might be
_Can we have user-defined variables and reusable blocks?_
_How about conditional structures?_
which would greatly reduce the amount of markup needed to describe a complex web page, where items are commonly repeated with only minor differences.
## Webson
Webson is a markup syntax that allows JSON to be used to describe a DOM, together with a JavaScript rendering engine that can be embedded in any web page to process scripts at runtime. The system is immediately usable by HTML/CSS coders and no JavaScript experience is required. It's aimed at simplifying the design and implementation of highly complex layouts, where precise positioning of large numbers of elements is hard to achieve manually, and it achieves this with JSON markup rather than with code.
## Getting started
Let's start with a simple example; a layout commonly found in online magazines and social media. At the top there's a full-width header; under this a central panel with 2 sidebars and at the bottom a footer. As this is only an example I've given each of the component `div`s its own background color so it stands out clearly. It looks like this:

Here's the HTML that will create this screen. It uses inline styles to avoid the need to present a separate CSS file:
```html
<div style="width:50%;height:50%;display:flex;flex-direction:column">
<div id="top" style="height:20%;background:cyan">
</div>
<div style="width:100%;flex:1;display:flex;flex-direction:row">
<div id="left" style="display:inline-block;width:25%;height:100%;background:green">
</div>
<div id="center" style="display:inline-block;height:100%;background:yellow;flex:1">
</div>
<div id="right" style="display:inline-block;width:15%;height:100%;background:blue">
</div>
</div>
<div id="bottom" style="height:10%;background:magenta">
</div>
</div>
```
This is a total of 655 characters. The corresponding Webson script to create the same screen is 1172 characters, nearly twice as many, and occupies 61 lines rather than 14, but before you dismiss Webson as being too wordy I must say in its defence that this is a very basic example which doesn't make use of any of the more advanced features of the system. More complex scripts tend to be far smaller than their HTML equivalents, as we'll see later.
The reason for the extra size in this example is partly that every item is named and partly because JSON itself is fairly bulky (lots of double-quotes), while the increase in lines is mainly because it's a lot more spaced out. This helps readability; high information density makes code hard to read at a glance as the eye has to pick out specific details from a dense surrounding mass. With Webson, the CSS properties are separated out, one per line, rather than all being crammed onto a single line. This can of course be done with HTML too, but because there's no agreed way to present it the result is usually an unstructured mess, so most coders just put everything on the same line.
Here's the script. It just uses a basic feature set; I'll get on to some of the advanced features later.
```json
{
"width": "50%",
"height": "50%",
"display": "flex",
"flex-direction": "column",
"#": ["$Top", "$Middle", "$Bottom"],
"$Top": {
"#element": "div",
"height": "20%",
"background": "cyan"
},
"$Middle": {
"#element": "div",
"width": "100%",
"flex": 1,
"display": "flex",
"flex-direction": "row",
"#": ["$Left", "$Center", "$Right"]
},
"$Bottom": {
"#element": "div",
"height": "10%",
"background": "magenta"
},
"$Left": {
"#element": "div",
"display": "inline-block",
"width": "25%",
"height": "100%",
"background": "green"
},
"$Center": {
"#element": "div",
"display": "inline-block",
"flex": 1,
"height": "100%",
"background": "yellow"
},
"$Right": {
"#element": "div",
"display": "inline-block",
"width": "15%",
"height": "100%",
"background": "blue"
}
}
```
## How it works
Running through the script, you will see that every DOM element has its own named block of JSON data. User-defined names all start with `$`. There are also directives and other system items; the names of these start with `#`. Everything else in the script above is a CSS style to be applied to the current element.
In the above, most of the blocks include a `#element` directive, which names the DOM element type. If this is missing, everything in the block applies to the current element (the one defined in the block that calls this one). Here the only block that lacks an `#element` is the very first one, so its styles all apply to the parent container that was created outside Webson and passed to its renderer as a parameter.
The symbol `#` by itself signals that child elements are to be added. This directive takes either a single name or an array of names.
## Attributes
The structure we've built here isn't much use unless we can add further items to the various `div`s. Some of this can be done with further Webson code but ultimately you'll either use an `onClick="<something>"` callout or a JavaScript function that populates or interacts with the DOM. For the latter to work, elements must have unique ids to allow JavaScript to find them. Here's the `$Left` block again, with an id and a couple of other additions:
```json
"$Left": {
"#debug": 2,
"#doc": "The left-hand sidebar",
"#element": "div",
"@id": "left",
"display": "inline-block",
"width": "25%",
"height": "100%",
"background": "green"
},
```
Here we have another new symbol, `@`, which (appropriately) signifies an _attribute_. Various HTML elements require special attributes such as `@id`, `@class`, `@type`, `@href`, `@src`, etc. In each case the name is that of the HTML attribute prefixed by `@`.
Another feature above reveals a built-in debugging capability. When hand-building HTML, errors are common, often resulting in strange layouts that are not at all as intended. Webson allows you to specify 3 different debug levels:
`"#debug": 0` - no debugging output
`"#debug": 1` - Show all `#doc` properties
`"#debug": 2` - Show every item
which enables you to see what is happening. The output for the above is
```
Build $Left
The left-hand sidebar
#element: div
Attribute id: "left" -> left
Style display: "inline-block" -> inline-block
Style width: "25%" -> 25%
Style height: "100%" -> 100%
Style background: "green" -> green
```
This is a simple example where all values are constants. The values appear to be repeated but this will not always be the case. In more complex scripts you will often see the results of expressions being evaluated.
`#doc` items can be either single lines of text or arrays of lines. They are just there for the benefit of the programmer and have no effect on the screen being constructed.
A `#debug` directive affects its own block and those below it (defined using `#`).
## Nested bocks
Webson implements nesting, whereby items declared at one level apply to all those in lower (contained) levels. Changing a value at one level only affects those at that level and beneath it; those above are unaffected.
For example, let's suppose the two sidebars share a common feature; they each have an inner `div` and padding to produce a border. Here's what it should look like:

To achieve this we can rewrite the last part of the script as follows:
```json
"$Left": {
"#doc": "The left column",
"$ID": "left",
"$Width": "25%",
"$Color": "green",
"#": "$LRPanel"
},
"$Right": {
"#doc": "The right column",
"$ID": "right",
"$Width": "15%",
"$Color": "blue",
"#": "$LRPanel"
},
"$LRPanel": {
"#element": "div",
"display": "inline-block",
"width": "calc($Width - 2em)",
"height": "calc(100% - 2em)",
"padding": "1em",
"#": "$LRSubPanel"
},
"$LRSubPanel": {
"#element": "div",
"@id": "$ID",
"width": "100%",
"height": "100%",
"background": "$Color"
}
```
Here I've left out the block for `$Center` as it's unchanged. Both `$Left` and `$Right` now no longer declare their own `#element`; instead they set up user-defined variables `$ID`, `$Width` and `$Color` and invoke `$LRPanel` to construct the element. I suggest using an initial capital letter for each user-defined name, to make them easier to spot, but it's not mandatory. Any variable declared or modified at a given level in the structure will be visible at all points beneath that one, but changes do not propagate upwards.
`$LRPanel` creates a `div`, applies padding to it and creates an inner `div` called `$LRSubPanel`. Note how the `$Color` variable is passed down and used here, resulting in a colored panel with a white border. Note also the use of `calc()` in `$LRPanel` to allow for the padding, which in a conformant browser adds to the width or height of the element.
## How to run it
To view this demo on a PC, place the following HTML file on your server:
```html
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Webson demo</title>
<script type='text/javascript' src='resources/plugins/webson.js'></script>
</head>
<body>
<div id="main" style="width:640px"></div>
<script>
window.onload = function() {
render(`resources/json/simple.json`);
async function render(file) {
const response = await fetch(file);
const script = await response.text();
Webson.render(document.getElementById("main"), `keyboard`, script);
}
}
</script>
</body>
</html>
```
For mobile, the width can be set to `` `100%` ``. The JSON script is assumed to be in a folder on your server at
```
(your domain)/resources/json/simple.json
```
The code above uses the relatively-new standard function `fetch()` to get the named script from a file on the server. It then calls `render()` in the Webson package (`webson.js` in the repository) to create the DOM tree that corresponds to the JSON script.
## From here on in
This has been a necessarily brief introduction to Webson, since to cover every feature in detail would result in a very lengthy article. A more in-depth treatment can be found in [the Webson repository](https://github.com/easycoder/webson). The example used is the following on-screen virtual keyboard:

The repository documentation starts with the page you are reading now, then goes on to describe how to make the virtual keyboard depicted above. It then shows how to make the keyboard respond to its `Shift` and `?123` keys being tapped, to change the key legends appropriately. This is all done with simple JSON commands and no conventional coding at all. You can see and test-drive the virtual keyboard with the above functionality [here](https://webson.netlify.app/keyboard.html).
Comments are welcome, as are suggestions on how to improve Webson. | gtanyware |
857,710 | Ema-Johnia {day-30} | 100daysofcode {Day - 30} Today's learning about JavaScript Localstorage. I've created a... | 0 | 2021-10-09T17:59:20 | https://dev.to/alsiam/ema-johnia-day-30-fd1 | 100daysofcode, javascript, react, programming | #100daysofcode {Day - 30}
Today's learning about JavaScript Localstorage. I've created a shopping cart with ReactJs and if you add products to the cart it will save the data to local storage and you will see the products on the cart after browser refresh or exit.
Link: https://ema-johnia.netlify.app
#learning #javascript #programminglife #react | alsiam |
858,001 | How to Create Connection With Database in PHP | How to Add Data in Database Using PHP | How to Create Connection With Database in PHP | How to Add Data in Database Using PHp In this post,... | 0 | 2021-10-10T04:39:45 | https://dev.to/hmawebdesign/how-to-create-connection-with-database-in-php-how-to-add-data-in-database-using-php-b52 | webdev, php, database, mysql | How to Create Connection With Database in PHP | How to Add Data in Database Using PHp
In this post, I show you the steps to create a connection with your database in PHP and how to add data to MySQL Database.
In this article, I will also show you how to create a connection with a database in PHP| Add Data into MySQL Database|create a MySQL database in localhost.
•First open the browser and type 127.0.0.1 or localhost depending on your computer's preference
•Then click next and select phpMyAdmin from the dropdown list
•Fill in username, password, db name and click the "Create" button
**Watch Full Video**
{% youtube RwQc7c1FKHc %}
| hmawebdesign |
858,009 | What is a Blockchain? | What is blockchain? According to Wikipedia, it is a list of records, or blocks, that are linked... | 14,962 | 2021-10-11T03:52:01 | https://dev.to/jokim/what-is-a-blockchain-5a2l | blockchain | What is blockchain?
According to Wikipedia, it is a list of records, or blocks, that are linked together using cryptography.
On a very basic level, a block consists of four main things:
1. data - any data that you want to store
2. previous hash - this connects the block to its previous block
3. hash - code that identifies the block
4. nonce - arbitrary random number
There are five important concepts of blockchains:
1. Encryption(SHA256)
2. Immutable ledger
3. Distributed p2p ledger
4. Mining
5. Consensus protocol
**Encryption(SHA256)**
This is the code that you can identify any block with. Imagine it as the fingerprint of the block. SHA256 is the encryption tool that creates this fingerprint for each block. SHA stands for secure hashed algorithm and the 256 stands for the number of bits the algorithm has which is 64 characters in length.
Five important characteristics of SHA256 are as follows:
1. Deterministic - the same input outputs the same hash each time
2. Avalanche Effect - a minor change in the input outputs a completely different hash
3. One-way - you cannot reverse engineer the hash meaning you cannot determine the input using the output
4. Fast computation
5. Withstands collisions - different inputs cannot have the same output
**Immutable ledger**
Let's first define the two words. Immutable means unchangeable. A ledger is basically a list of all business transactions. For example, if you went to a nearby store and paid for a coke with your debit card then that transaction is stored in your bank ledger. Why is this ledger important? It's important because that's the way we can keep track of how much money you have left in your account. If you claim that you never bought anything in the store the ledger is the evidence used to prove that your claim is false.
*How is this relevant to blockchain?*
It's relevant because blockchains can serve as this ledger that's immutable. For example, if you wanted to buy a house then you would pay for it and then register yourself as the owner of the home in some government institution. That way no one can arbitrarily claim that your home is theirs because the government institution serves as the ledger in this case. But with blockchain we are ridding this government institution and replacing it with blockchain. There are many benefits to this because no one can tamper with the data. If someone tries to change the data in the blockchain then it would change the hash of the blockchain which would invalidate the blockchain with the tampered data.
**Distributed p2p ledger**
Like before, let's define the words first. Distributed just means spread out and p2p which stands for peer-to-peer means links between peers.
*How is this relevant to blockchain?*
Basically the blockchain is stored not in one central place but distributed among all computers on the network. In other words, all the computers on the network have a copy of the blockchain. Whenever a new transaction is made on a certain computer the transaction is signaled to all the other computers on the network where they make a copy of the newly added blockchain.
*Why is this necessary?*
This p2p networking makes it extremely difficult for anyone to tamper with blockchain. When someone tries to tamper with a blockchain by, for example, trying to change the name of the owner of a house all the other computers on the network will realize that it was getting tampered with because the majority of the computers on the network have a different copy of blockchain. This prevents the new tampered block from being attached to the chain of blocks. We will go into more detail regarding this issue in the consensus protocol part below.
**Mining**
Let's review once again what a blockchain is composed of:
1. data - any data that you want to store
2. previous hash - this connects the block to its previous block
3. hash - code that identifies block
4. nonce
5. blockchain number
The hash of a blockchain is generated as a combination of the blockchain number, previous hash, data, and nonce. The miners basically mine blockchains by finding the nonce that generates the hash. Only the nonce is computed by the miners because it wouldn't make sense to change anything else. For example, you can't change the data because that would be tampering with the data and you can't change the previous hash because that would break the connection with the previous blockchain. So, the way these blockchains are mined is by someone or something finding the number that goes in the nonce. Miners use brute force to guess the nonce of the blockchain. Whoever guesses the nonce first gets a financial reward in the form of coins in the case of Bitcoin.
**Consensus protocol**
Consensus means majority opinion and protocol simply means some rule. The reason we need this consensus protocol is because the blockchain uses a p2p network like we discussed above. An important concept that is frequently mentioned is the Byzantine General's Problem. It deals with the problem of who to believe which is very important in blockchain because it is also composed of a network of computers.
*What is the Byzantine General's Problem?*
Assume there are 5 Byzantine generals and one of them is a traitor. They need to either attack an enemy base or retreat. Now the generals need to be able to distinguish whether a signal is coming from a fellow general or a traitor. The way they do this is by tallying the number of signals they receive from each other and, of course, majority rules. So, if there are 5 people you will receive 4 signals in total (excluding your signal). If there is one traitor then you would receive 3 signals of the same kind which is majority. Now this would not work if more than 30% of the generals are traitors.
*How is this relevant to blockchain?*
This is relevant to blockchain in the sense that all the computers on the blockchain network are like the generals. They need to be able to tell whether the signals they receive from the other computers are valid or not and they do this by the number of signals they get.
Now how do we actually implement this in real life?
There are two main consensus protocols: Proof-of-Work("PoW") and Proof-of-Stake("PoS"). These consensus protocols allow other computers to distinguish whether a signal is valid or not.
This post will discuss PoW because Bitcoin implements PoW and will provide a good foundation on how other consensus protocols work.
We have already briefly discussed how PoW works in the blockchain mining section. The miners need to brute force their way to find the nonce that generates the hash of the blockchain and once they do they are rewarded financially with a coin. This is PoW.
One main problem is that two different blocks can be added to the chain. Say about 70% of the computers on the network have block "A" and the rest have block "B". What happens then? The network waits for another block to be added to the chain. The longer chain usually wins. What this means is that the longer chain is copied over to the other computers that had block "B" and block "B" is removed from the chain. Whichever side has more computing power has a higher probability of finding the next nonce that generates the hash which is why this is called PoW. The computers that have 51% of the computing power usually wins majority.
| jokim |
858,166 | Feature Flags with ConfigCat and Asp.Net Core Options | A feature flag or 'feature toggle' is a common technique to enable or disable application features... | 0 | 2021-10-10T09:40:25 | https://configcat.com/blog/2021/10/10/aspnetcore-options-pattern/ | aspnetcore, optionspattern, configcat | A feature flag or 'feature toggle' is a common technique to enable or disable application features dynamically. For example, feature flags enable product owners to turn on and off features during runtime of the application. Certain features may be turned on/off for given environments, users, or regions only. This way features may be A-B tested, or tested with a given percentage of users, or different countries of the world. It can also provide a solution to meet regional restrictions of different countries.
In this post I investigate integrating [ConfigCat's](https://configcat.com/) feature management with an ASP.NET Core 6 web API service and the `Options<T>` [pattern](https://docs.microsoft.com/en-us/aspnet/core/fundamentals/configuration/options?view=aspnetcore-5.0). I will also focus on using the *AutoPolling* mechanism built into the ConfigCat client library, to refresh feature flags' state during application runtime.
> Throughout my carrier I have used some sort of a feature flag solution. In some cases, this was a conscious decision built upon a well-designed application architecture, while in other cases it was just an `if` statement with a key-value pair in the configuration file. However, I have not yet encountered such a complete service as the one provided by [ConfigCat](https://configcat.com/).
I will focus on using feature flags solution within web services. Although, I see an even bigger need for such a robust solution in desktop applications. Managing the configuration of a few web service instances is inherently simpler to manage hundreds or thousands of desktop applications, which is common in the enterprise world.
## Implementation Options
Feature flags can be leveraged in applications many ways. In the past, when computer networks were less ubiquitous, feature flags were typically implemented as compiler directives. This way a given code path was compiled into the application or remained as commented out section. The advantage of this solution is less branching and smaller code size. Although to 'toggle' a feature a new compilation of the source code is required, which makes this solution less dynamic. Users would need to uninstall/install or upgrade their application with the new binaries to get a feature toggled.
Today the most common technique is branching by `if` statements. If the features flag is in enabled state a certain code path of the application is executed. For example, when a button is clicked to start an order processing, *if* a given feature flag enabled an SMS is also sent to the user. One could express this as:
```csharp
// ...
ProcessOrder();
var isSmsFeatureEneabled = client.GetValue("sendSMS", false);
if(isSmsFeatureEneabled)
SendSms();
// ...
```
Another approach would be to leverage [branching by abstractions](https://www.martinfowler.com/bliki/BranchByAbstraction.html). As this is a larger topic, I am not detailing it within this post, exploring this area may worth its own writing.
One very recent feature flag I encountered comes from .NET itself: using the [HTTP3 preview feature](https://devblogs.microsoft.com/dotnet/http-3-support-in-dotnet-6/) in `HttpClient` requires the developers to proactively enable the feature by setting the `<EnablePreviewFeatures>True</EnablePreviewFeatures>` flag in the csproj file.
## ConfigCat and Asp.Net Core and .NET 6
Using the ConfigCat's service does not restrict us choosing any of implementation techniques, although one would probably not choose to use compiler directives. In this section I show how one can integrate the ConfigCat's configuration with the `Option<T>` pattern of .NET 6. I am using a late preview version of .NET6 at the time of writing this post. DotNet 6 provides a new configuration concept with `ConfigurationManager` type, which is not available in the previous versions. `ConfigurationManager` allows to initialize configuration sources while using configuration values of previously initialized sources. It achieves this by implementing `IConfigurationBuilder, IConfigurationRoot, IConfiguration` interfaces at the same time.
One consideration to make is that no user specific feature flag will be used, which means that in this implementation flags will not be respected if set for specific users or 'target % users' on the ConfigCat's portal. In all cases the 'To all users' value of the feature flag is used.
In general, when using `Options<T>` pattern, there is no good API to query user specific settings, and in a web application used by multiple users, there is also no effective way to fetch flags for one or a few users during application startup. Thus, all feature flags shall be independent of users when being registered with Options. We can leverage though non-user specific information i.e. semantic version of the application is greater than 1.2.3. I will leave it up for the reader to extend the presented solution with such extensions.
Let me first preview the whole 'startup' code and the action of the service, then describe the necessary types I created for the solution. Here is *Program.cs*:
```csharp
using ConfigCat.Client;
using Microsoft.Extensions.Options;
var builder = WebApplication.CreateBuilder(args);
builder.Configuration.AddConfigCat(false);
builder.Services.Configure<FeatureSet>(builder.Configuration.GetSection(nameof(FeatureSet)));
var app = builder.Build();
app.UseHttpsRedirection();
app.MapGet("api/feature", async (HttpContext context, IOptionsSnapshot<FeatureSet> features) =>
{
if (features.Value.GrandFeature)
{
context.Response.StatusCode = StatusCodes.Status200OK;
await context.Response.WriteAsync("Hello World!");
}
else
{
context.Response.StatusCode = StatusCodes.Status404NotFound;
}
});
app.Run();
public class FeatureSet
{
public bool GrandFeature { get; set; }
}
```
This web API has a single GET endpoint `api/feature`. The response depends on a feature flag: `GrandFeature`. When the feature is turned on, it returns HTTP 200 OK, with `Hello World!` as the content. When the feature is turned off, it returns 404 Not Found. The state of the feature flag is accessed through `IOptionsSnapshot<FeatureSet> features`, which I will explain later in this post.
The `builder.Configuration.AddConfigCat(false);` uses a custom extension method to add the toggle values of ConfigCat to the Asp.Net Core's configuration.
The second line `builder.Services.Configure<FeatureSet>(builder.Configuration.GetSection(nameof(FeatureSet)));` sets up the feature flags with the `Options<T>` pattern. This is the standard way to bind a given section of the configuration to a type, while also registering the type with the DI container. Here, I bind the configuration to a type called `FeatureSet` which has a single boolean property *GrandFeature*.
Let's investigate the custom extension method. The upcoming code focuses on getting the configuration values of ConfigCat into Asp.Net's configuration. Below the extension method uses `ConfigurationManager` to read the ConfigCat API key and *poll interval* settings from the 'appsettings.json' file. These configuration values are added by Asp.Net web application's file provider during startup. In production, one would prefer to pass the ConfigCat key as a secret or as an environment variable. In either case a configuration source would set the value before `AddConfigCat` is invoked. As '0' is an invalid interval for polling, the extension method validates it. The method has an *optional* parameter which indicates the desired behavior when ConfigCat cannot fetch the feature flags, while *onError* parameter is an action that is invoked in case of an exception. Feature flags are fetched from the service periodically, the *onError* parameter provides a way to observe errors during the background polls.
```csharp
public static class Extensions
{
public static IConfigurationBuilder AddConfigCat(
this ConfigurationManager manager,
bool optional = false,
Action<Exception>? onError = null)
{
var key = manager["ConfigCat:Key"] ?? throw new ArgumentNullException("ConfigCat:Key");
var pollInterval = manager.GetValue<TimeSpan>("ConfigCat:PollInterval");
if (pollInterval == TimeSpan.Zero)
throw new ArgumentNullException("ConfigCat:PollInterval");
var options = new ConfigCatOptions(key, pollInterval, optional, onError);
if (manager is IConfigurationBuilder builder)
builder.Add(new ConfigCatConfigurationSource(options));
return manager;
}
}
public record ConfigCatOptions(string Key, TimeSpan RefreshInterval, bool IsOptional, Action<Exception>? OnError);
```
`ConfigCatOptions` record type is encapsulating the parameters for `ConfigCatConfigurationProvider`.
The next type is `ConfigCatConfigurationSource`. An `IConfigurationSource` is required to be implemented as this is the type added to the configuration sources. The responsibility of the type is to create an `IConfigurationProvider`. With .NET6 when a configuration provider is removed or modified, all the remaining sources are rebuilt. This implementation returns a lazily instantiated `ConfigCatConfigurationProvider` instance. I use the singleton semantics because auto polling built into the `ConfigCatConfigurationProvider` refreshes the configuration automatically.
```csharp
public class ConfigCatConfigurationSource : IConfigurationSource
{
private readonly ConfigCatOptions _options;
private ConfigCatConfigurationProvider? _provider;
public ConfigCatConfigurationSource(ConfigCatOptions options)
{
_options = options ?? throw new ArgumentNullException(nameof(options));
}
public IConfigurationProvider Build(IConfigurationBuilder builder) =>
_provider ??= new ConfigCatConfigurationProvider(_options);
}
```
> Another use case could be when the feature flags are read only at application startup. In certain applications this could be a valid scenario. For this, manual polling would be a better choice, and creating a new instance of `ConfigCatConfigurationProvider` on every `Build()` method invocation would also make sense.
The last and most complex class to implement is `ConfigCatConfigurationProvider`. This type derives from `ConfigurationProvider` which already implements many of the `IConfigurationProvider` interface members. Here, I only override the `Load()` method, which is invoked by the *Host* right after the configuration provider is instantiated. In the first invocation I create a new `ConfigCatClient`, and because `AutoPollConfiguration` uses a `Timer` to load configuration data asynchronously, a task completion source must be waited. Unfortunately, the method signature does not allow to use the `await` keyword. Without waiting for the task completion source, further providers would not be able to read the data set by this provider.
```csharp
public class ConfigCatConfigurationProvider : ConfigurationProvider, IDisposable
{
private readonly ConfigCatOptions _options;
private readonly AutoPollConfiguration _polling;
private readonly TaskCompletionSource _initialLoad;
private IConfigCatClient? _configCatClient;
public ConfigCatConfigurationProvider(ConfigCatOptions options)
{
_options = options ?? throw new ArgumentNullException(nameof(options));
_polling = new AutoPollConfiguration
{
SdkKey = _options.Key ?? throw new ArgumentNullException(nameof(_options.Key)),
PollIntervalSeconds = (uint)_options.RefreshInterval.TotalSeconds,
};
_initialLoad = new TaskCompletionSource();
_polling.OnConfigurationChanged += OnConfigurationChanged;
}
private void OnConfigurationChanged(
object sender,
OnConfigurationChangedEventArgs eventArgs)
{
LoadData();
_initialLoad.TrySetResult();
}
public void Dispose() { }
public override void Load()
{
_configCatClient ??= new ConfigCatClient(_polling);
_initialLoad.Task.GetAwaiter().GetResult();
}
public void LoadData()
{
try
{
Data = ParseKeys();
}
catch (Exception ex)
{
if (_options.IsOptional)
Data = new Dictionary<string, string>(StringComparer.OrdinalIgnoreCase);
if (_options.OnError is { })
_options.OnError.Invoke(ex);
else
throw;
}
OnReload();
}
private IDictionary<string, string> ParseKeys()
{
if (_configCatClient == null)
throw new InvalidOperationException(nameof(_configCatClient));
var result = new Dictionary<string, string>(StringComparer.OrdinalIgnoreCase);
foreach (var key in _configCatClient.GetAllKeys())
{
var value = _configCatClient.GetValue(key, string.Empty);
result.Add(key.Replace('_', ':'), value);
}
return result;
}
}
```
Once `ConfigCatClient` has loaded the data, the `OnConfigurationChanged` event is fired. This is when all key value pairs are loaded. `LoadData()` and `ParseKeys()` methods read and parse the keys and corresponding values. The result dictionary is set in the *Data* property, which is declared by the base class. The only additional logic applied here is to replace the underscore characters with semicolons. This is done, as the ':' character is unsupported in key names, so to deal with the hierarchy of configuration values, another character must be used for the ConfigCat feature names. Using the '_' character resembles a similar behavior to using configuration values with environment variables.
Note, that `LoadData()` method invokes a method from the base type: `OnReload();`. This will generate a new change token signaling the configuration provider that the configuration values have changed. The values of options might change due to the built-in auto-polling mechanism, however the `OnConfigurationChanged` event is only fired when the values have changed.
To read the latest values of configuration while serving the HTTP request, an `IOptionsSnapshot<FeatureSet>` is passed to the GET request's action handler. This type is useful in scenarios where options should be recomputed on every request.
## Conclusion
In one way or another an *aging*, but still maintained application requires a solution for feature flags. The more robust this solution is the more choice is given to the development team to isolate certain preview features to certain users. Implementing a custom feature flag solution does not usually provide a competitive advantage, using service built for the purpose makes sense. In this regards, ConfigCat's solution seems a reasonable choice for my next project. | ladeak87 |
858,186 | Nodejs: Importing Mock data with script | We want to test our apps with development data as developers, but recreating the wheel every time can... | 0 | 2021-10-11T13:29:32 | https://dev.to/drsimplegraffiti/nodejs-importing-mock-data-with-script-1ifa | javascript, webdev, beginners, tutorial | We want to test our apps with development data as developers, but recreating the wheel every time can be overkill. So we'll need to find out a way to import Mock data into our database using a single script that loads data from a 'json' file. Yes, a single script without the need to write the 'create function.' This procedure is known as <mark>Seeding</mark> and is absolutely unrelated to our current research. and it is completely independent of our existing project
## Prerequisite
* Nodejs installed
* Database management (basics)
---
## TOC
🔗 Setup node project
🔗 Connect MongoDB locally
🔗 Setup Express App
🔗 Import Data
🔗 Delete Data

## Let's get right to it.
🥦 Make a new directory called seeding-tut with the command `mkdir seed`
Change directory `cd seed`
🥦 'npm init -y' creates a new node project.
Install packages:
```Javascript
npm i express, mongoose, dotenv, morgan
```
Install dev dependency
```Javascript
npm i nodemon --save-dev
```
🥦 Create an entry point `index.js`
## Configure your `package.json` file.
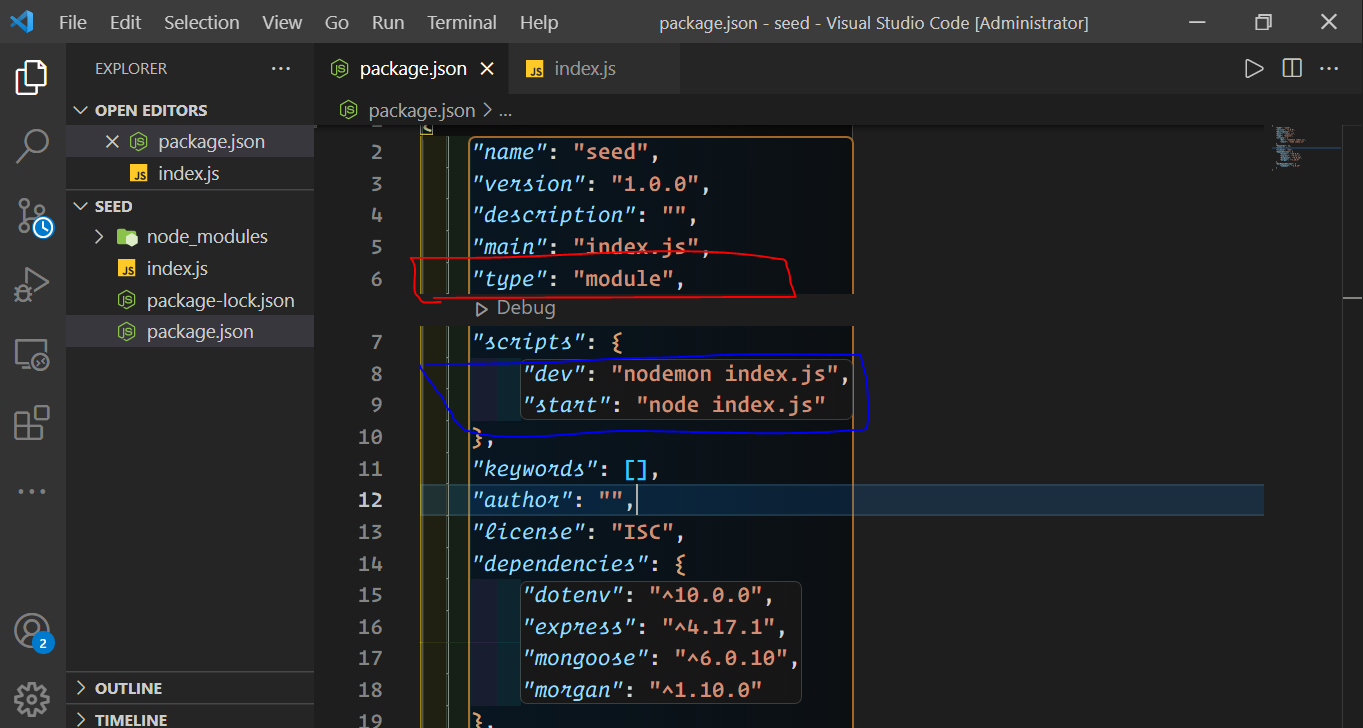
Note : the "type":"module" enables ES Modules in Node.js
---
🥦 Then, in the `index.js file`, we import the packages and create an express app.
```Javascript
import express from 'express';
import mongoose from 'mongoose';
const app = express();
```
🎯 Because the front end typically runs on <mark>PORT:3000</mark>, we'll set our app to run on port 5353 to avoid any conflicts, and then we'll listen to our server.
---
## Create your app
```Javascript
import express from 'express';
import mongoose from 'mongoose';
import morgan from 'morgan';
const app = express();
const PORT = 5353;
app.use(express.json()); //method inbuilt in express to recognize the incoming Request Object as a JSON Object.
app.get('/', (req, res) => {
return res.status(200).json('homepage')
})
app.listen(PORT, () => console.log(`server is running on http://locahost:${PORT}`));
```
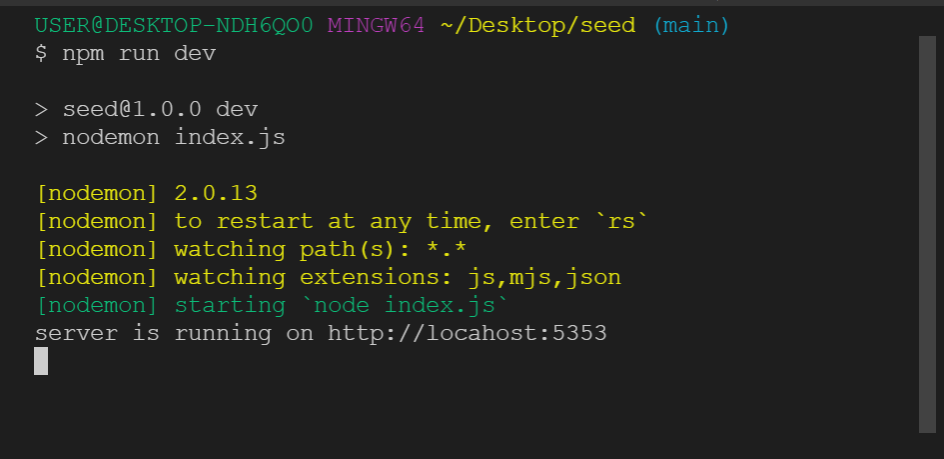
🥦 Let's get the server up and running.
'npm run dev' is a command that you can use to test your code.
Result:
## Next, we'll design our express route.
Create a route folder and a `users.js` file within it.
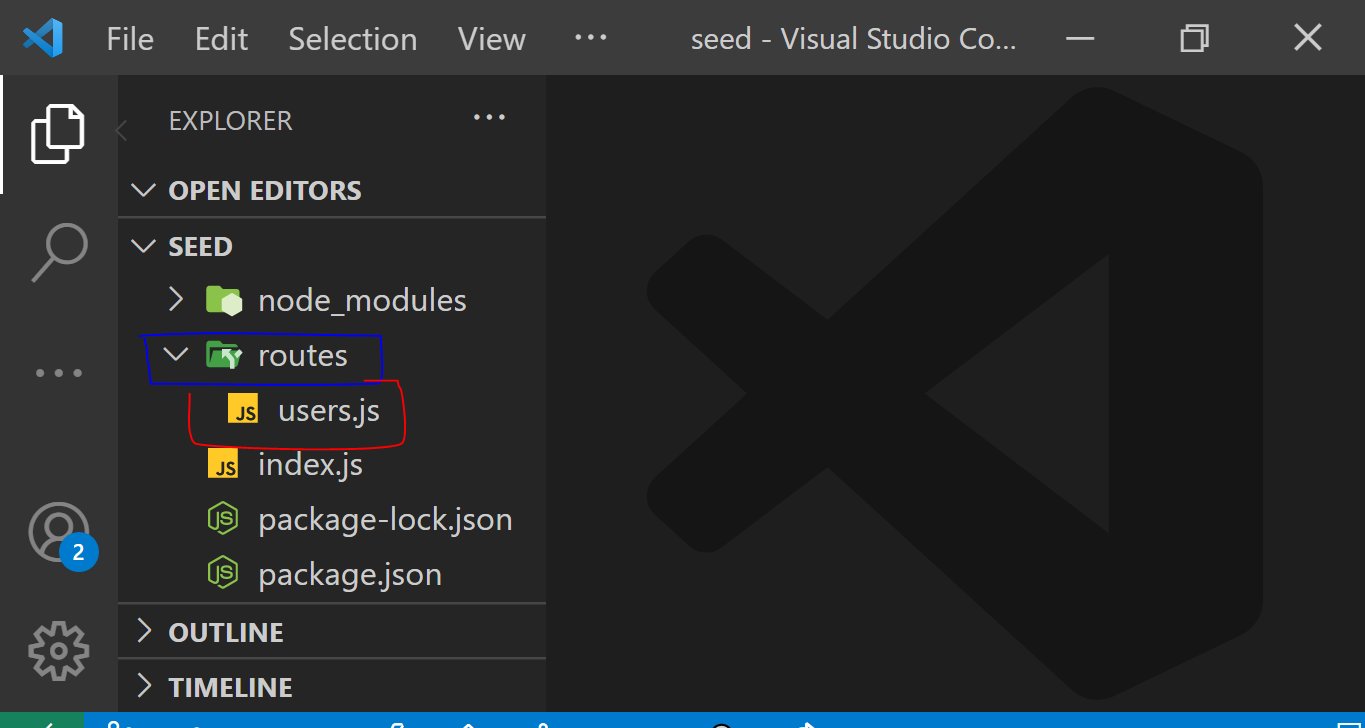
##
🎯 To emphasize that seeding is independent to the project.
Let's start by building a user model. Make a folder for your schema and begin writing it.
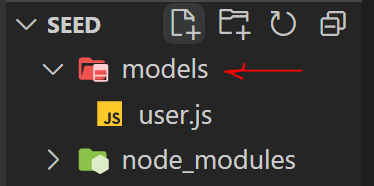
```Javascript
import mongoose from 'mongoose';
const { Schema } = mongoose;
const userSchema = new mongoose.Schema({
fullName: {
type: String,
required: [true, 'A name is required'],
unique: true
},
email: {
type: String,
required: [true, 'Please enter a valid email to proceed']
},
phoneNumber: {
type: String,
required: [true, 'Please enter a valid phone number']
}
}, {
timestamps: true
})
// Exports schemas
export default mongoose.model('User', userSchema);
```
## 🥦
Create your route handler, add logic, and import the user model you made before.
```Javascript
import express from 'express';
const router = express.Router();
import User from '../models/user.js';
// Create a user
router.post('/users', async(req, res) => {
try {
const newUser = await User.create(req.body);
newUser.save();
return res.status(200).json({
message: 'user created successfully',
data: newUser
})
} catch (error) {
return res.status(500).json({
status: 'fail'
})
}
})
//Get all users
router.get('/users', async(req, res) => {
try {
const getAllUser = await User.find();
return res.status(200).json({
message: 'user data gotten successfully',
data: getAllUser
})
} catch (error) {
return res.status(500).json({
status: 'fail'
})
}
})
export default router;
```
👨💻 Let's connect to our local DB.
1) Open your cmd and type `mongod`
2) Open another cmd without closing the first and type `mongo --host localhost:27017`
3) Create a db folder and a db.js file in it.
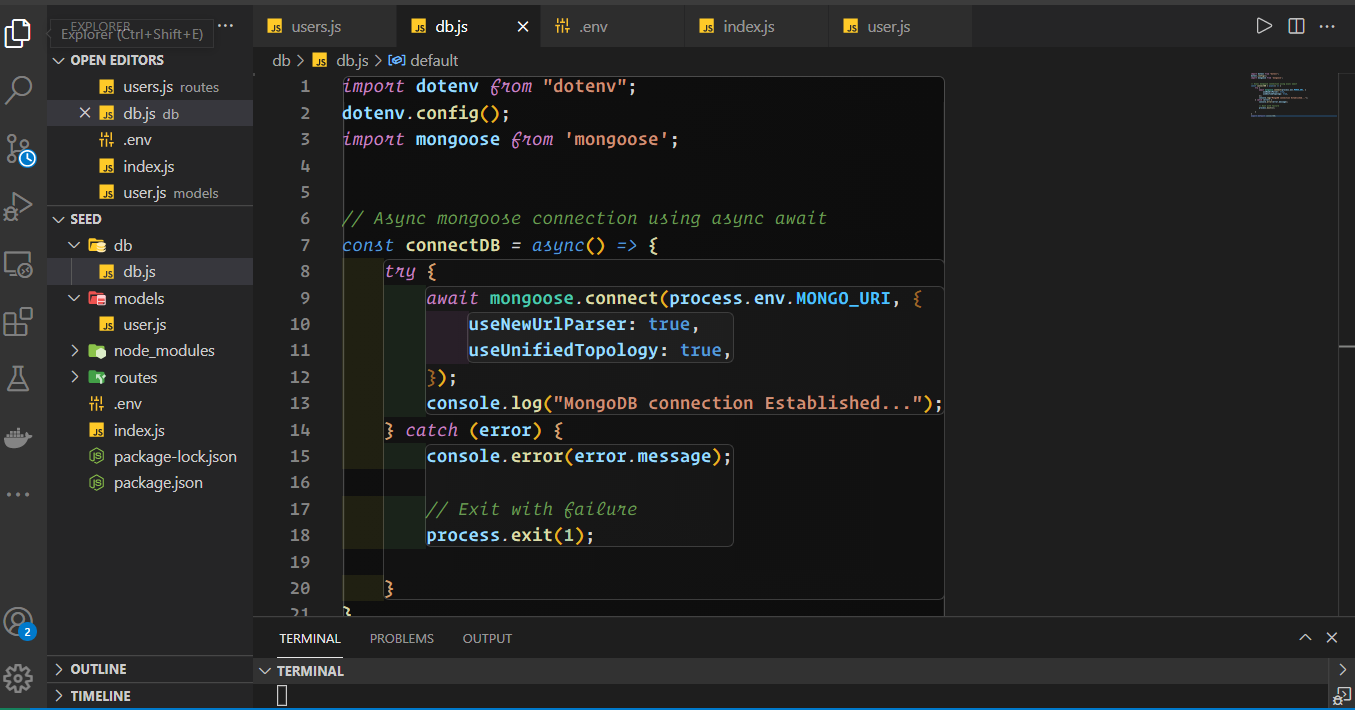
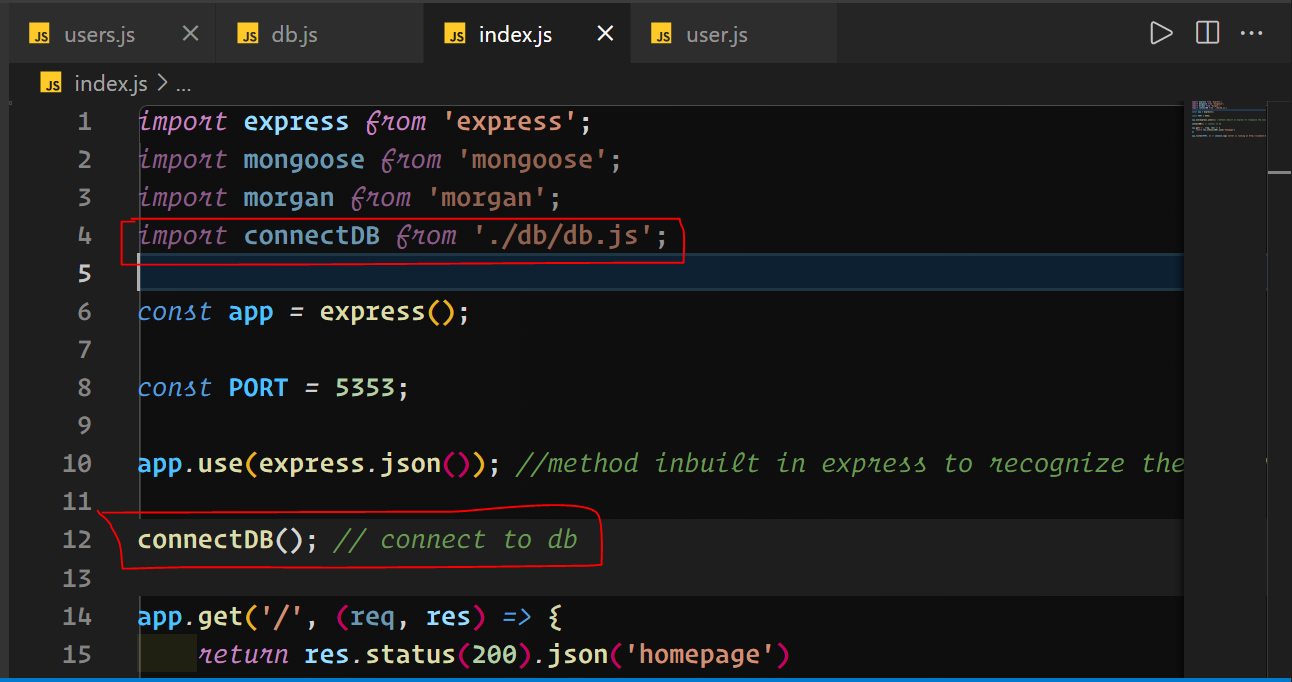
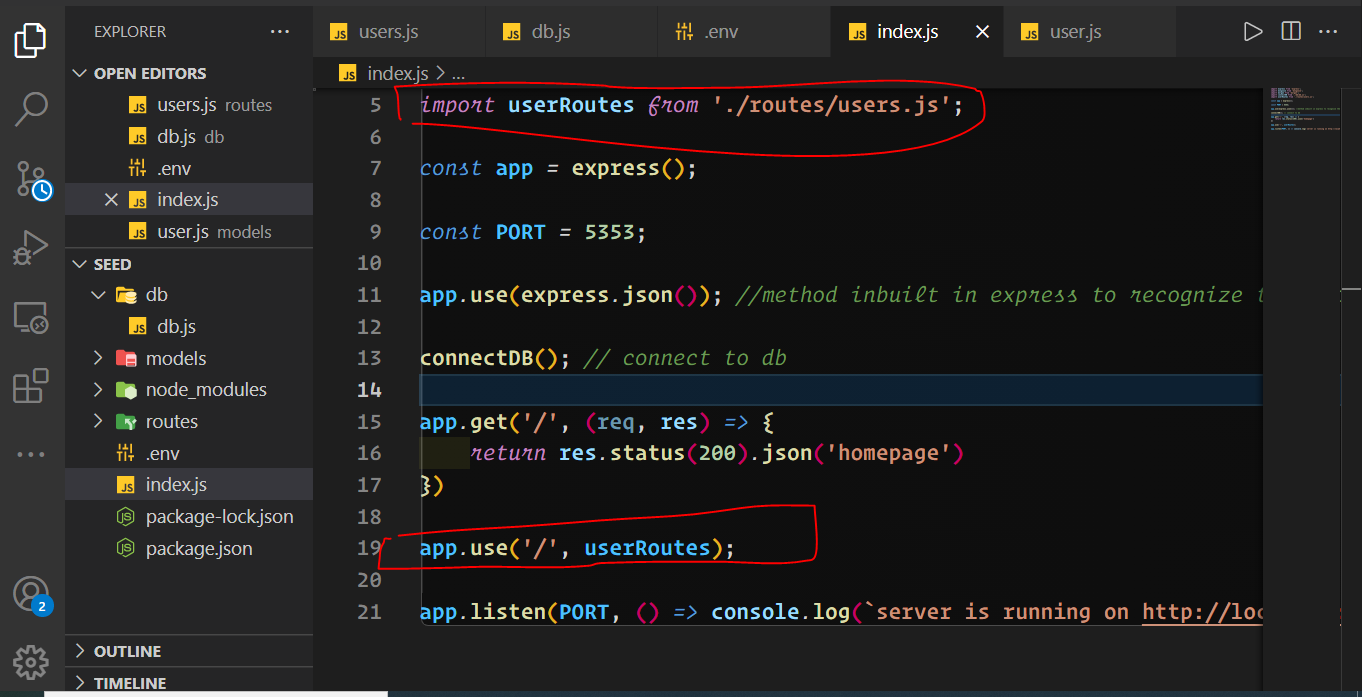
4) Import the db and mount the route handler into the entry file `index.js`
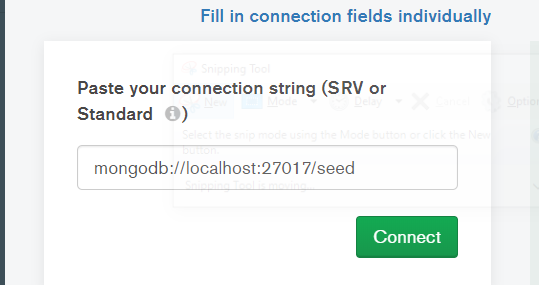
5) open mongodb Compass and connect
6) You should get on restart:

## Moment of truth 🦚
Open postman or insomnia and let's create a new user
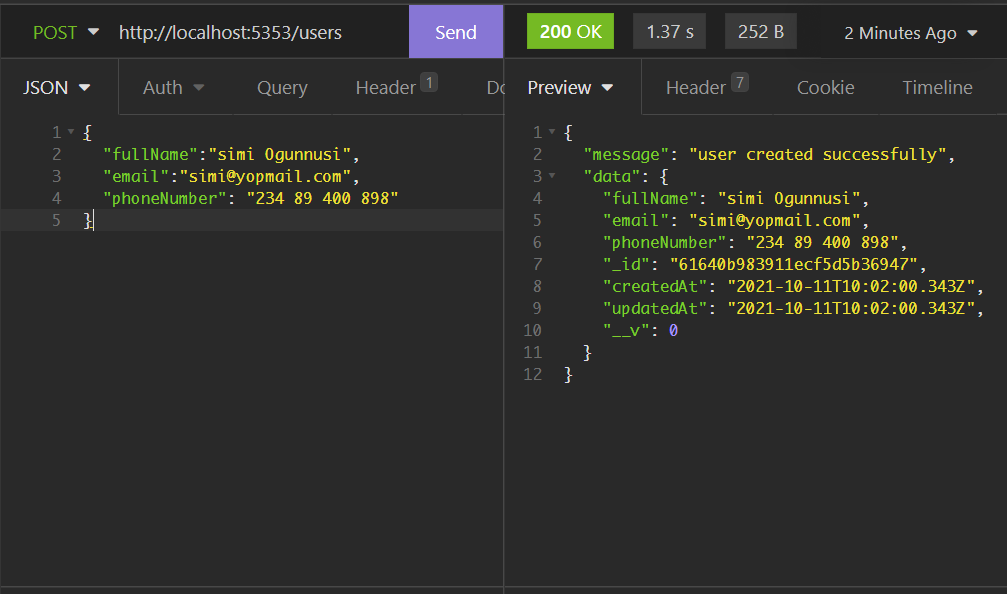
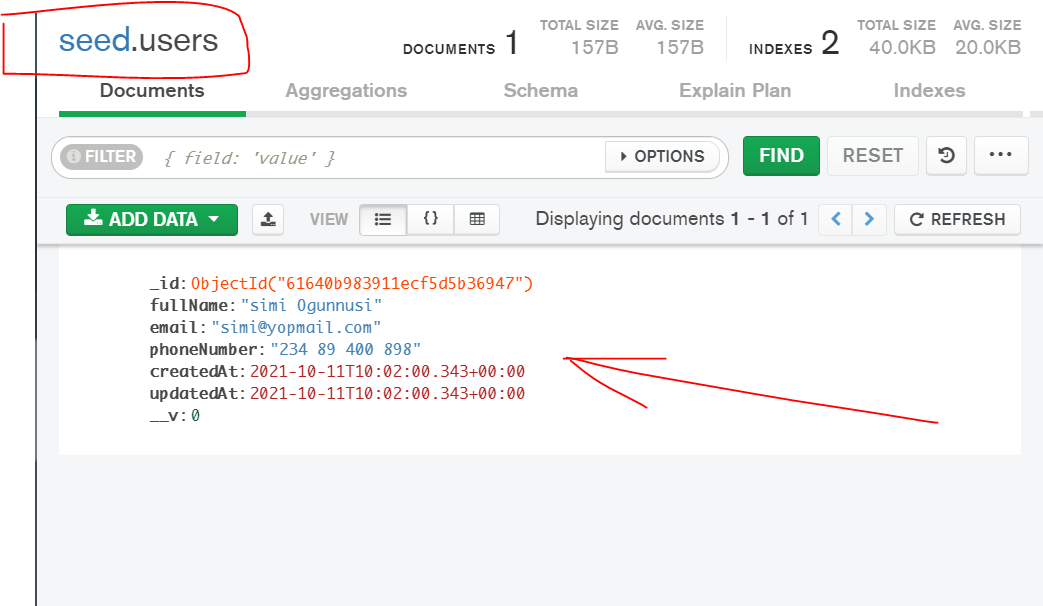
Check if data was produced by refreshing your MongoDB compass.
---
## You have made it this far... now let's seed dummy data into our DB.
Let's add some additional development data to our database now.
Make a folder called data and a file called dev-data.js in it.
To read the JSON file, we first require access to the file system module.
```Javascript
import * as fs from 'fs'; // to read our data from the json file
```
Also we need access to the user model
```Javascript
import * as fs from 'fs';
import mongoose from 'mongoose';
import dotenv from 'dotenv';
dotenv.config();
import User from '../models/user.js';
```
## Create a `data.json` file inside the data folder.
```Javascript
[{
"fullName": "John Doe",
"email": "john@yopmail.com",
"phoneNumber": "546 69 200898",
},
{
"fullName": "mary Doe",
"email": "mary@yopmail.com",
"phoneNumber": "777 69 200898",
}
]
```
Now we'll read our json file, but first we'll need to convert data to a Javasript object using (JSON.parse)
```Javascript
const users = JSON.parse(fs.readFileSync(`${__dirname}/data.json`, 'utf-8'));
```
---
The data is then imported into our database.
```Javascript
//seed or import Data into DB
const importData = async() => {
try {
await User.create(users);
console.log('Data seeded successfully....');
} catch (error) {
console.log(error)
process.exit();
}
}
```
We may also clean all databases using a single script.
```Javascript
//delete Data in DB
const deleteData = async() => {
try {
await Techie.deleteMany();
console.log('Data successfully deleted');
} catch (error) {
console.log(error)
}
process.exit();
}
```
🥦 Finally, to start our script, we construct a conditional statement.
```Javascript
if (process.argv[2] === '--import') {
importData();
} else if (process.argv[2] === '--delete') {
deleteData()
}
console.log(process.argv);
```
🥦 Explanation:
If the third index output of process.argv equals —-import, the importData() function will be called.
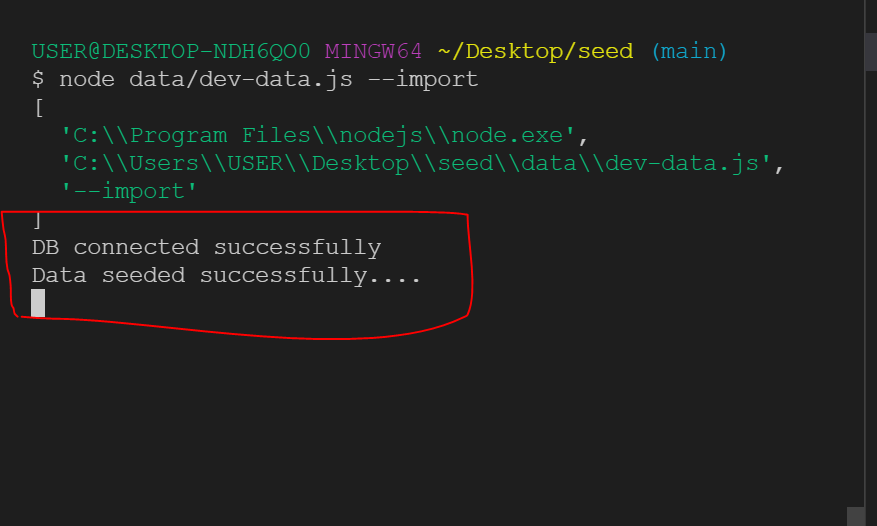
🥦 So, let's try it in our terminal.
Delete data: ` node data/dev-data.js --delete`
Import data: ` node data/dev-data.js --import`
Let me destroy all data in our DB first and then import the development data.
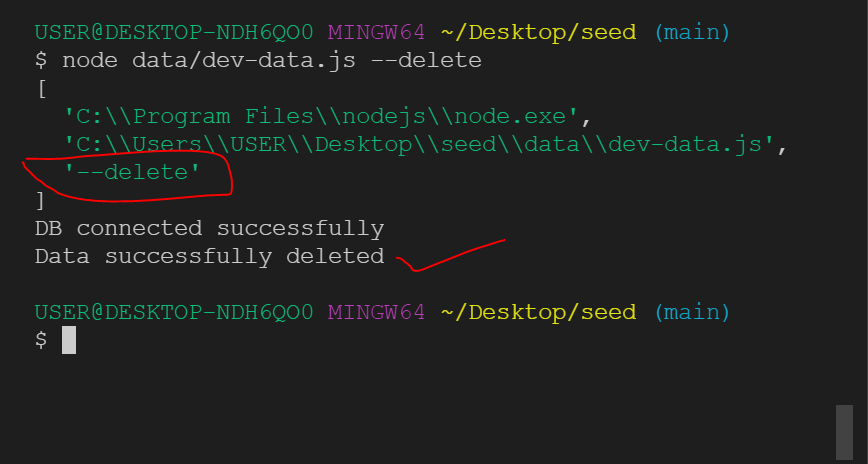
As explained earlier, because the third index was "delete" we fired the delete function and our DB got deleted.
Let's see if it was removed from our database.
When the MongoDB compass is refreshed.
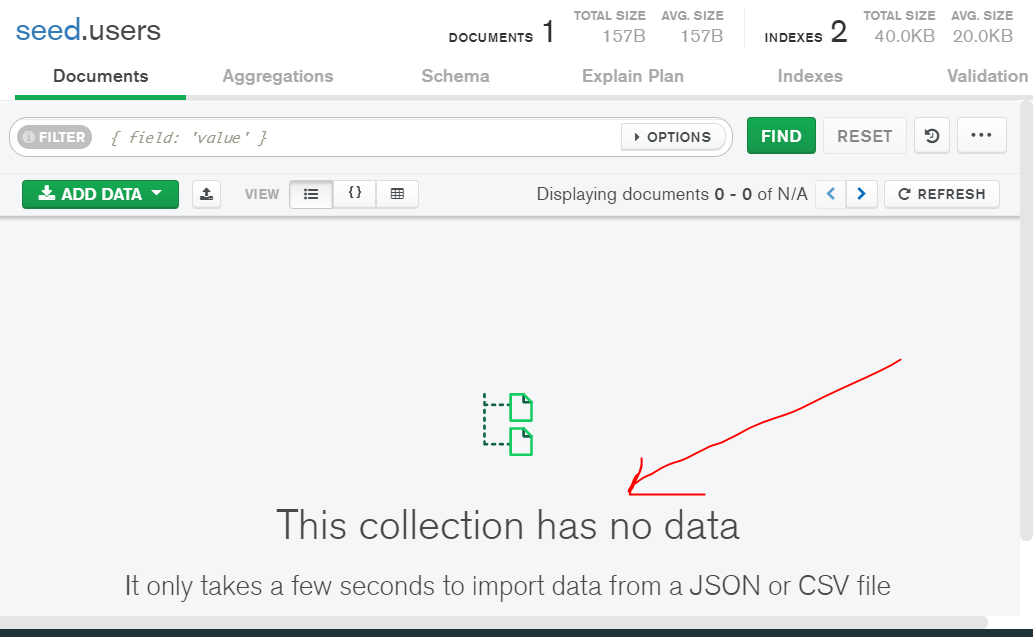
🥦 Now let's import our mock data by using ` node data/dev-data.js --import`
🥦 Let's double-check with our compass...
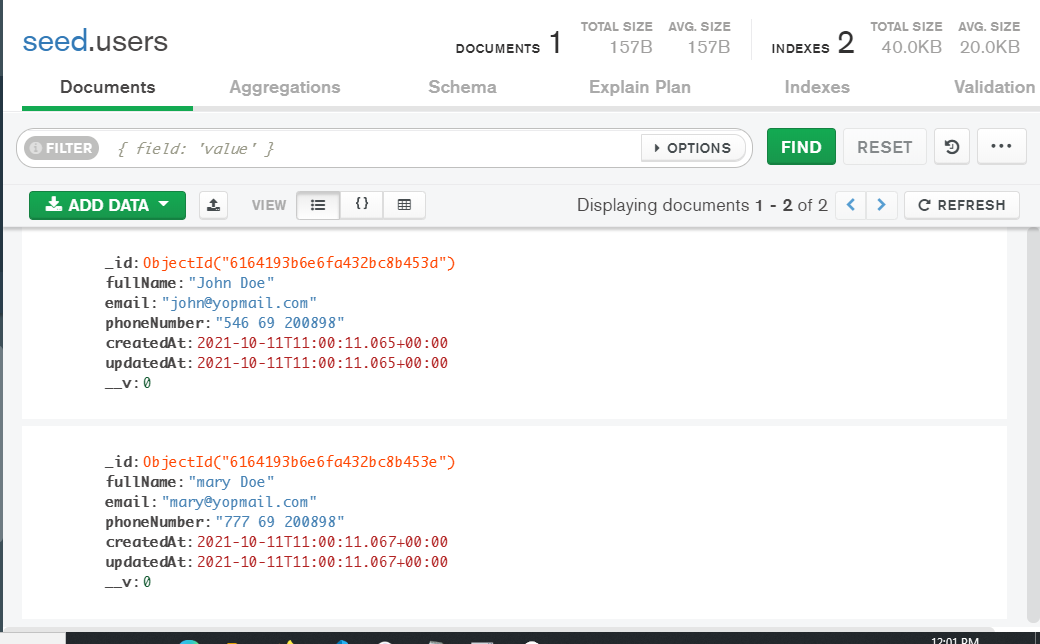
Yay!...and it worked.
## Conclusion
With a single script, we were able to import and delete data.
It takes some practice to get the hang of this method.
It is, nonetheless, worthwhile.
## Reference
[Importing development data by Jonas IO ](https://www.youtube.com/watch?v=PWeDNjbUcUU&t=6s)
| drsimplegraffiti |
858,310 | HTML, CSS, JavaScript - The Frontend Building Blocks | HTML HTML (Hypertext Markup Language) is used to mark up website content so browsers can... | 0 | 2021-10-10T11:50:19 | https://dev.to/cyrillmartin/html-css-javascript-the-frontend-building-blocks-1cla | ## HTML
HTML (Hypertext Markup Language) is used to mark up website content so browsers can display it in a human-readable form. Think of a large amount of different text markers and some guidelines with instructions on how to mark up a document. E.g. "The main title of the document should be marked-up yellow. Any subtitles should be marked-up green. Use orange for any sub-subtitles. Use blue to mark up all paragraphs. Inside any titles and paragraphs, use red to mark up the letters which should be **bold**."

Instead of text markers, HTML makes use of **HTML tags**. An HTML tag has a name (instead of a color) to indicate what is being marked up. There’s an **opening tag** and an **ending tag** to wrap parts of a text in order to indicate where the markup starts and ends. There's also a guideline on which tags to use for which parts of a text. E.g. the main title of a text should be wrapped in a **h1** tag (h1 for heading 1). Any subtitles should be wrapped in **h2** tags. Sub-subtitles go into **h3** tags, etc. Paragraphs are wrapped inside **p** tags and letters which should be bold are wrapped inside **b** tags. There are many more tags available, of course. In the image below you can also see an **i** tag for italic.

When displaying an HTML response, browsers take care of not showing you any of the actual tags but they consider them by the use of default styles. For any text inside an h1 tag, browsers will use a bigger font. For paragraphs (p tag), they will add some spacing before and after the marked up text, etc. However, website creators might not want the browsers to apply their default stylings. Maybe they want to see different spacings between paragraphs and different font sizes for titles.

Such custom styles are achieved by introducing CSS (cascading style sheets).
## CSS
Styles declared in CSS are part of the additional resources your browser might request when you access a URL. So, the initial HTML response probably lists at least one CSS resource declaring the custom styles for this current HTML response. In its simplest form, CSS lets you write down the names of the HTML tags and declare custom styles for these, overriding the browser's default ones. There is much, much more to CSS than this simple approach but this should be enough to get the idea. Just keep in mind that any CSS is tightly bound to an HTML response. CSS requested in the context of one response has no effect on the styles of another one, unless they are referencing the exact same CSS.
While accessing the URL of this tutorial, the HTML response also listed some CSS as one of the additional resources to be requested by your browser. The CSS instructs your browser to override its default styles by applying a different font, using a very dark greyish blue as the text color, using different font sizes for titles, and applying different line heights for titles and paragraphs. Don't worry about the details of CSS syntax. Just be aware that any CSS goes hand in hand with a corresponding HTML document.

On most websites you have some user experience in the form of interactions. Maybe you click a button and some additional elements are loaded to the website. Maybe you get notified that you missed entering some crucial information when trying to check out and order something online. The changes of the website usually happen without a reload of the website or the requests of new HTML and stylings - it's really just parts of the website that change. This website experience you are so used to is achieved through the use of **JavaScript**.
## JavaScript
JavaScript is a regular programming language with its own syntax and ways of writing instructions a computer can execute. The common browsers come with a so-called **JavaScript engine** and **JavaScript runtime** in order to execute JavaScript code. Remember that JavaScript is part of the additional resources your browser might request when accessing a URL. So, JavaScript developers write code to be executed in your browser. You might have come across the term **client-side** code or client-side programming, which describes exactly that: providing or writing programming code to be executed in the browsers (the clients) of the website visitors. This is as opposed to **server-side** code or server-side programming, which is about programming code running in the backend, on the server, of a website.
The JavaScript runtimes in browsers are powerful tools. They enable JavaScript developers to write instructions for your browser like performing additional requests to some servers, "listening" to click events on the current website and act on them by executing more code, or storing data in and also reading data from your browser. You don't need to understand JavaScript syntax but I hope you now have an idea of client-side JavaScript code and its powerful role in your website experiences.

| cyrillmartin | |
858,325 | Store Persist State to URL Nuxt Js | Multi-tenancy become more complex problem for authentication and authorization. Nuxt js as front-end... | 0 | 2021-10-10T11:23:47 | https://dev.to/riochndr/store-persist-state-to-url-nuxt-js-3kla | javascript, nuxt, state | Multi-tenancy become more complex problem for authentication and authorization. Nuxt js as front-end app need to adapte to this problem
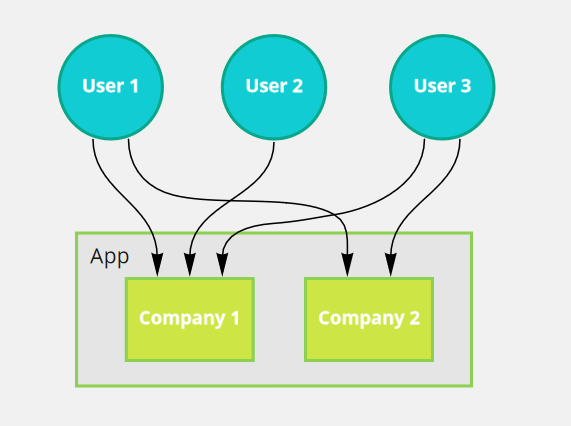
The scenario :
- Nuxt Js is a front-end App,
- a user can login as company 1 or company 2. each company have an id.
- when hit an API, front-end must send company id
The problem is, how to make Front-end store company id and can be used when Request API. I have some approach to store company id but only 1 way to solve this problem.
### Token
You can store company id on token, this is good from API perspective immediately know user information, but you need to recall API to re-create token if user change company id, which is this is not ideal when user switch to other company id periodically
### Localstorage
Localstorage is deadly simple to store information in browser client. we can store it to localstorage and use it when it needed. But, the problem is when we want to use on Server Side. Since Nuxt Js Support Server Side Rendering, nuxt cannot read localstorage because localstorage only accessable on client side.
### State Management (Vuex)
State management solve problem localstorage to access from Server Side and accessable from any page on website. But, the problem is state management will be reset when user refresh the page.
### Param URL
We can store some variable on Parameter URL and use the param when it needed, it persistence and user know 'where are they' only from URL.
I see this is the absolute solution to store company id or other variable. Google do this for a long time, when you logged in to google with different account, google
store state current user on query URL
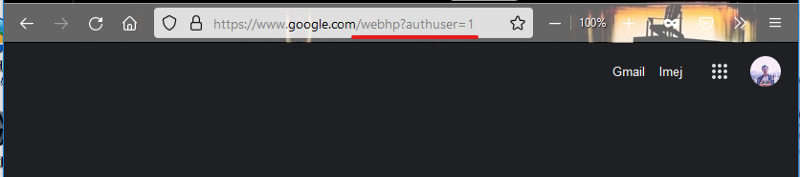

How to Google store user logged in on URLHow to Google store user logged in on URL (Gmail.com)Quite a nice idea. But we found new problem, we should add query or param to every `<a href />` tags. Every programmer never do it manually. Lets create Middleware to solve this problem
Automatically Query Url Update Middleware Nuxt (AQUUMN)
I have no idea about this technique name
We need something to update query URL every change route, we can do this in Middleware that provide by Nuxt Js (because we use Nuxt Js). We will store the company id in State Management and URL, you got the point right ?. We will create middleware with flow like this :
Whenever User change Route, get the Company id from state management
Redirect user to new URL that Query company id included
Whenever browser refresh the page, state management will be reset and we need to restore from URL query company id
Now we have persist parameter user's company id on URL, no matter what URL requested because middleware will put Query company id to URL.
Middleware Code
First of all, we need to create state management for company id. In this case I use Vuex. This is companyStore.js
```typescript
export const state = () => ({
companyId: null
})
export const mutations = {
setCompanyId(state:any, companyId:string){
state.companyId = labId
}
}
Create new middleware called authApp.ts in folder middleware (if there is no folder middleware, create one).
import { Context } from "@nuxt/types"
export const companyId = "companyId"
/**
* this middleware make apps to require query `companyId`
* ex: /home/?companyId=123-24123-4123
*/
export default function(context:Context){
let excludeRoute = [
"/login",
"/login/app"
]
let companyIdQuery = context.query[companyId]
let companyIdStore = context.store.state.companyStore[companyId]
if(!companyIdQuery){
if(companyIdStore){
return context.redirect(context.route.path + "?companyId=" + companyIdStore)
}
if(!excludeRoute.includes(context.route.path)){
return context.redirect('/login/app');
}
}
else {
if(!companyIdStore){
context.store.commit('companyStore/setcompanyId', companyIdQuery)
} else {
if(companyIdStore !== companyIdQuery){
context.store.commit('companyStore/setcompanyId', companyIdQuery)
}
}
}
}
```
I add array excludeRoute as a route redirect if company id is null, user require to select their current company that selected on the app.
lastly, register this middleware to `nuxt.config.js`
```javascript
router: {
middleware: ['authApp', ...]
},
```
You can get the company id from $route or $store
```javascript
let companyIdStore = this.$store.state.companyStore.companyId
let companyIdRoute = this.$route.query.companyId
```
###
Finish
That's it how I solve this problem, I didn't found another article write about Nuxt to create persistence state like this, so I create one. Hope this help you. | riochndr |
858,339 | Be careful Of This Java Optional Method | Let's Remember Java Optional 🤓 According to Oracle it's "A container object which may or... | 0 | 2021-10-13T22:21:16 | https://dev.to/jarjanazy/be-careful-of-this-java-optional-method-439 | java, programming, tutorial, webdev | ## Let's Remember Java Optional 🤓
According to **Oracle** it's "A container object which may or may not contain a non-null value."
Optional was introduced in Java 8 and has been used by the SpringBoot team in many projects.
---
The most common usage of Optionals is in the Spring Data project. Let's look at the `JpaRepository` interface and an example method.
Say we have a User entity with an Id type of integer and that we have a JpaRepository for it
```java
@Repository
public interface IUserRepo extends JpaRepository<User, Integer>
{
Optional<User> findByUserName(String userName);
}
```
We defined a method that searches for a user via their user name and returns an `Optional` of a User.
---
## Optional's Convenience Methods 🙌
Optional comes in with many method meant to enable us to write clean and readable code.
- map(..).or(...)
- map(...).orElse(...)
- check out Oracle's [docs](https://docs.oracle.com/javase/8/docs/api/java/util/Optional.html) for the full list.
**However, there is one method with a dangerously unexpected behavior**
---
## Meet The `orElse` Method 👀
According to Oracle's doc:
> public T orElse(T other)
>
> Return the value if present, otherwise return other.
Now, we can add a method call as the parameter of the orElse, which will be run if the Optional is empty, right?
Yes, that's correct, BUT, what if I tell you that it will run anyways regardless of the presence of the value in Optional or not.
---
Let's test it ✍️
```java
@Test
public void orElseTest()
{
String result = Optional.of("hello").orElse(someMethod());
assertThat(result).isEqualTo("hello");
}
private String someMethod()
{
System.out.println("I am running !!");
return "hola";
}
```
The test does pass, but we notice that on the console we have the string **"I am running"** printed out.
---
### Why is that? 🤨
- Java runs the method to provide a value to be returned in the *Else* case.
## So Be Careful ⛔️
We want to be careful if the method inside the `orElse` might have a side effect, because it will be run anyways.
---
## What To Do then?
You can use the `OrElseGet` method which takes a supplier method to be executed if the Optional exists
Check out this wonderful [comment](https://dev.to/alexismanin/comment/1iol8) for more details.
---
### 👉🏾 Also check out [How to escape NullPointerExceptions in Java using Optional](https://dev.to/jarjanazy/how-to-escape-nullpointerexceptions-in-java-using-optional-pek) | jarjanazy |
858,410 | Alhikmah.xml Templates Responsive
| Alhikmah.xml Templates Responsive Dari segi fitur dan kelebihan, tema blogger mengambil semua yang... | 0 | 2021-10-10T14:42:47 | https://dev.to/wahyu9kdl/alhikmah-xml-templates-responsive-4092 | innovation, design, templates, website | Alhikmah.xml Templates Responsive
Dari segi fitur dan kelebihan, tema blogger mengambil semua yang terbaik dari dan membuatnya menjadi lebih baik lagi.
Berikut screenshot tampilan Templates Alhikmah.xml :
Lihat Versi Demo Templates ini ;
Demo 1 Halaman Templates
https://www.alhikmah.my.id/?m=1
Demo 2 Page Center
https://www.alhikmah.my.id/p/al-hikmah-center.html
Demo 3 Aplikasi https://www.alhikmah.my.id/2021/08/aplikasi.html
Fitur/Kelebihan Alhikmah.xml
Responsive 100%
100% Responsive di semua ukuran layar
SEO friendly
Tidak perlu repot otak atik kode template supaya SEO karena sudah saya optimalkan
Fast Loading
Loading Cepat tanpa mengorbankan desain
Ads Optimized
Terdapat fitur slot iklan otomatis di bawah header dan di bawah sebelum navibottom untuk membantu meningkatkan CTR iklan
Support Fitur Desainer Tema Blogger
Jika sobat tidak suka warna default template ini, sobat bisa mengubahnya sesuai keinginan melalui menu Desainer Tema Blogger
Menggunakan Schema Markup
Schema Markup untuk membantu mesin pencari memahami blog sobat
Breadcrumb Navigation
Auto Readmore
Pop-up Search Form
Widget Sticky
Widget Related Posts
Tombol Berbagi Responsive Keren
Numbered Page Navigation
Back to Top Button
Custom Error page
Tanpa Link Credit
Tombol Donasi
Lainnya akan menyusul di versi terbaru.
Download File Gratis 🔰
Ref. https://sfile.mobi/inv.php?id=358103
Harga Template
Untuk template ini saya jual 350 ribu saja, tapi tidak menutup kemungkinan harganya akan saya naikan pada versi-versi berikutnya.
Tempat Beli Templates ini di
1. https://belicode.com/item/195/jual-al-hikmah-xml-templates-responsive
2. https://belicode.com/item/194/al-hikmah-xml-templates-responsive
3. Thema Admin Dashboard
https://belicode.com/item/198/admin-lte-bootstrap-admin-dashboard-template
4. Aplikasi
https://projects.co.id/public/browse_products/view/745911/alhikmah-aplication
https://p-store.net/software/70180/aplikasi-alhikmah
Jika sobat tertarik dengan tema ini, silakan langsung dibeli saja daripada nanti harganya keburu naik.
Untuk Beli Klik Tombol Di Bawah
Beli Sekarang
Sebagai Awal Promosi Product aw group channel
Maka dalam file Templates Alhikmah.xml Kami tambahkan beberapa Fitur diluar templates ini, yaitu beberapa score code untuk optimasi dan belajar desain ; adapun Fitur tambahan yang kami berikan berupa :
1. Score code css3d Animation Image and Gif
2. Score code Editor HTML
3. Templates Alhikmah.xml v.1 ( demo https://www.alhikmah.my.id/?m=1 )
4. Score Code Button Navigasi Css Responsive
5. Score code Animasi Slider Image and Text
6. Score Code Animasi Pesawat.
( live di www.alhikmah.my.id)
Demikian 5 Tambahan fitur score code dalam file templates ini.
Maka dari itu kami berharap untuk mempergunakannya secara bijaksana.
Setting Ads.txt
User-agent: Mediapartners-Google
User-agent: *
Allow: /
User-agent: Googlebot-News
Allow: /
User-agent: Adsbot-Google
Allow: /
User-agent: Googlebot-Image
Allow: /
User-agent: Googlebot-Mobile
Allow: /
User-agent: Googlebot
Allow: /
User-agent: Slurp
Allow: /
User-agent: bingbot
Allow: /
User-agent: MSNBot
Allow: /
User-agent: Baiduspider
Allow: /
User-agent: Baiduspider-image
Allow: /
User-agent: YoudaoBot
Allow: /
User-agent: Sogou web spider
Allow: /
User-agent: *
Disallow: /cgi-bin/
Disallow: /scripts/
Disallow: /tmp/
Disallow: /blog-admin/
Disallow: /search?updated-min=
Disallow: /search?updated-max=
Disallow: /search/label/*?updated-min=
Disallow: /search/label/*?updated-max=
Allow: / blog-admin/admin-ajax.php
Sitemap: https://situs.blogspot.com/sitemap.xml
Sitemap: https://situs.blogspot.com/news-sitemap.xml
Sitemap: http://situs.blogspot.com/feeds/posts/default?orderby=updated
*Saran
Sekedar Saran Untuk optimasi dan Belajar Periklannan dan Program Affiliasi Anda bisa mencobanya debeberapa Situs Berikut ;
Hosting dan domain💠
1.https://asia.cloudns.net/aff/id/482326
2.https://panel.niagahoster.co.id/ref/361770
3.https://masterkey.masterweb.com/aff.php?aff=20667
4.https://www.site123.com/?aff=7141773
💠Jasa Backlink💠
https://rajabacklink.com/refferal.php?q=06a50e3f66db4a334202d3adfd31c589a334837978b494479f
💠Jasa Seo💠
https://www.seobility.net/?px=2&a_aid=5fc75c87d70c2
trafik exchange
🟢http://hit2hit.com/?rid=173879
🟢https://www.traffboost.net?ref=203557
🟢https://www.easyhits4u.com/?ref=wahyudi9
Halaman SUPPORT Kami di Page Berikut ;
1. https://inpage.es/UOAg
2. Atau https://jali.me/Profesional
3. EMAIL KONTAK https://form.jotform.com/211958944889075
Sekian Informasi Tentang Templates ini Semoga bermanfaat.
Demo https://output.jsbin.com/pirelax/1
Demo https://output.jsbin.com/tejuxic
Download File Gratis 🔰
Ref. https://sfile.mobi/inv.php?id=358103
Ads.txt.pdf.
https://sfile.mobi/downIoad/675319/358103/263140fc55b1166d5dee69fffbb7b708/app-ads.txt-v1.0-final-.pdf&is=277f6c96177a9105085c86678266ffc6
https://sfile.mobi/downIoad/675340/358103/263140fc55b1166d5dee69fffbb7b708/kitab-ta-lim-muta-alim-dan-terjemahan.docx&is=277f6c96177a9105085c86678266ffc6
https://sfile.mobi/8y9IgJ52b6b
Untuk lebih mudahnya Anda dapat melihat di halaman Marketplace Progam Affiliasi web kami di.
https://inpage.es/UOAg
Atau https://jali.me/Profesional
https://propellerads.com/publishers/?ref_id=msQP
https://sfile.mobi/inv.php?id=358103
https://join-adf.ly/24900237
http://asistentoko.com/ref=Ahmad%20wahyudi
Please check link" berikut :
http://apticirl.com/2V3M
http://apticirl.com/2V3Q
http://apticirl.com/2V3N0
https://1drv.ms/u/s!AjVl5irji1SzhE-C1tYSZvXWDj8y
Redirect dengan Delay Opsional
Sampel Cepat
setTimeout( "window.location.href = 'http://walkerwines.com.au/'", 5*1000 );
Apa yang dilakukan cuplikan JavaScript?
Cuplikan ini akan memungkinkan Anda untuk mengarahkan pemirsa Anda ke halaman lain dan memiliki opsi untuk mengatur penundaan. Penggunaan potongan ini cukup jelas dan merupakan alat yang sangat berharga untuk dimiliki di ikat pinggang Anda.
14. Deteksi iPhone
Contoh
if((navigator.userAgent.match(/iPhone/i)) || (navigator.userAgent.match(/iPod/i))) { if (document.cookie.indexOf("iphone_redirect=false") == -1) { window.location = "http://m.espn.go.com/wireless/?iphone&i=COMR"; } }
Apa yang dilakukan cuplikan JavaScript?
Cuplikan ini akan memungkinkan Anda mendeteksi apakah pemirsa Anda menggunakan iPhone atau iPod yang memungkinkan Anda menampilkan konten yang berbeda kepada mereka. Potongan ini sangat berharga dengan seberapa besar pasar seluler dan hanya akan terus tumbuh.
| awdev |
867,597 | Why pitch-based funding competitions are harmful and we need to stop having them | What's pitching The most extreme manifestation of this idea of “pitching” are the “Shark... | 0 | 2021-10-18T11:30:28 | https://dev.to/ssenyonga_yasin_codes/why-pitch-based-funding-competitions-are-harmful-and-we-need-to-stop-having-them-54ld |
## What's pitching
The most extreme manifestation of this idea of “pitching” are the “Shark Tank”-style funding opportunities where leaders go on stage to give short presentations about their organizations’ work to a live audience, after which, depending on how they do and how the “judges” and people watching their presentations react, they could walk away with one of several small grant prizes.
## What you gain from pitching.
Like many philosophies and practices in our sector that we’ve accepted as normal, pitch-based funding opportunities can seem fine, fun, and helpful.
Often, participants get mentorship and training on public speaking and obtain some experience. A colleague who participated in one of these competitions told me she got to know other participants and it was not at all competitive; people supported one another and everyone had a great time.
These competitions can be done with a spirit of camaraderie and public awareness and not the cutthroat events they could potentially become. Plus, they are certainly more interesting for everyone than the traditional, tedious grantmaking process.
## Is pitching Really useful
### Here are several reasons why i think it may not be
### If you must use more than ten slides to explain your business, you probably don’t have a business.
The whole idea being presented in only 10 slides sometimes given five minutes to present.
The ten topics that a venture capitalist cares about are:
1.Problem
2.Your solution
3.Business model
4.Underlying magic/technology
5.Marketing and sales
6.Competition
7.Team
8.Projections and milestones
9.Status and timeline.
10.Summary and call to action.
1.They entrench existing power dynamics between funders/donors and nonprofits.
Why is it always nonprofits that are pitching to funders and donors? Why is it never the other way around? Simple: Because one party has money, and in our society that means they by default get to call the shots. But is this what we want to reinforce? Why should people who have money have so much power, and the people who are actually doing the work of running programs and services have to jump through hoops? How can we become equal partners in this work if we keep reinforcing the asymmetric power differentials that are already pervasive everywhere else?
2.They’re inequitable, rewarding the organizations that can play the game best.
Grant applications are usually inequitable because the organizations that can write the “best” proposals usually win, and they tend to be mainstream, white-led orgs. Pitch-based competitions have the same challenges: Those who win tend to be the best presenters, the most charismatic, and the ones with the missions that most tug at heart-strings. Participants from marginalized backgrounds, who may not be as fluent in English as others, or who may not have as much presentation skills, or whose missions are harder to explain or get people to care about, are often left behind. Also, who can participate as judges and audience members? Mostly well-off white people and others of privilege.
3.They perpetuate competitiveness among different interrelated missions.
Sure, when done thoughtfully, they can be friendly competitions. But they are competitions nonetheless. There is already so much jostling in our sector for resources: grants, donations, media coverage, even talent. We need to do a much better job understanding that all our missions are interrelated and we should be supporting one another. Funders complain about nonprofits not collaborating enough, especially to work on systemic issues, and yet every day they force nonprofits to compete with one another through their funding processes, including these pitch competitions, which my colleague Mari Kim likens to Squid Game, but less interesting.
4.They turn the work of equity and justice into spectacles.
A major reason so many of us were upset at the proposed show on CBS called “The Activist” is that it reduces critical causes into entertainment. These pitch-based competitions are basically just smaller, local versions of that show. There are already enough ingrained expectations in our sector that we manipulate our messaging to make our work emotionally resonant and easily digestible to people with money. We shouldn’t have to also simultaneously develop skills to entertain them too, as that only conditions people to pay attention to stuff that rouses their interests, not what would most be needed to build a just and equitable world (that stuff tends to be less entertaining).
5.They reinforce ignorance among the public.
Oftentimes, the people “judging” the competitions as well as those in attendance may have never worked at nonprofits addressing these causes or had any first-hand experience in these issues at all. And yet they get the microphone and ask ridiculous questions or make comments that further the public’s misperceptions of nonprofits. One colleague told me she failed to get funding because one “judge,” a dude from the tech sector, asked how her mission was going to be self-sustaining (Most nonprofits will never be self-sustaining and it is a delusion to think they will ever be). Questions on sustainability, overhead, scaling, etc. betray a complete lack of understanding of how nonprofits actually run and reinforce harmful misinformation, making nonprofits’ work even more difficult.
6.They are time-consuming and distracting.
These competitions require significant investment in time and energy. Meeting with mentors, practicing, rehearsals, etc. These competitions hosted by Health Organisations for funding to address children’s mental health, for example, requires participants to attend six weeks of trainings on pitching and other stuff. The people working hard to ensure children have mental health support do not need training on public speaking or making pitches or whatever. They need money! That’s something we need funders and donors to understand: Stop wasting our time on nonsensical stuff and making us jump through flaming hoops for your entertainment or edification and just provide money.
7.They are insulting and patronizing.
As one colleague put it regarding a competition in her community: “nonprofit staff are forced to perform for self-described ‘sharks,’ who regularly insult and belittle staff for failing to be sufficiently entrepreneurial. Be prepared to dance, monkey, dance.” If it’s not overtly insulting, it’s often patronizing. “If nonprofits develop their speaking and pitching skills, they can approach other funders; you know, teach someone to fish, etc.” This is a condescending attitude that is too prevalent among funders and donors. Do not create ridiculous and inequitable processes and think you’re doing nonprofits a favor by helping them develop skills in navigating the ridiculousness and inequity.
For these and other reasons, I’d like for us to move away from pitch-based competitions altogether. Let’s phase them out completely. I know there are counter-arguments we can make, but almost any and every benefit of pitch-based competitions (getting to know other nonprofits, exposing the public to important causes, developing presentation skills) can be done in other, better ways.
Let’s be more thoughtful and fund in more equitable ways. The whole concept of “pitching” is problematic and it goes way beyond these competitions. As colleague Yvonne Moore of Moore Philanthropy said during that Clubhouse discussion, and I paraphrase: “We [communities of color and other marginalized communities] are really good at pitches. People just don’t hear us.”
## You free to give your suggestions and arguments in the comments section. | ssenyonga_yasin_codes | |
867,625 | Learn Vuejs for Free! | 😻 I will appreciate your feedback. Please follow this full thread: ... | 0 | 2021-10-18T12:16:59 | https://dev.to/aliboukaroui/learn-vuejs-for-free-1fbd | vue, beginners, programming, tutorial | 😻 I will appreciate your feedback.
Please follow this full thread:
{% twitter 1445893772026556416 %} | aliboukaroui |
867,952 | The times they have a-changed’ | This is a bit of a b*s*rdisation of a post I wrote over at auroratechsupport.co.uk but we had some... | 0 | 2021-10-18T17:12:19 | https://dev.to/auroratech_/the-times-they-have-a-changed-10a1 | This is a bit of a b**s**rdisation of a post I wrote over at [auroratechsupport.co.uk](https://www.auroratechsupport.co.uk/it-hardware-and-infrastructure-support/) but we had some good feedback and so thought I'd put it here for you guys too.
I was sat in a very fancy office today, mahogany everywhere. It was amazing.
This company had done well and had been trading for 39 years (since before I was born in fact) and they’d done very well in fact, but I wasn’t there to talk about how well they’d done I was there because they’d noticed a change since they started 39 years ago and I was there to discuss what that might of been and how I could help.
We spoke about what it was like in the 80s running a business, mainly I listened but also added in some of my experiences of going into the office with my father and photocopying pictures of Nightrider I’d drawn.
We spoke about printing flyers, mailing them out to hundreds of local businesses in the hope of getting delegates to seminars or product demos. There’s no doubt about it businesses in that respect was more linear from a sales point of view. But we live in the age of information, information is everywhere, and when information is everywhere we don’t just get a flyer through the post and dip our toe in. We look around, we window shop.
We compare to competitors, we ask questions on social media, we look at reviews (heads up internet reviews are mostly nonsense, either friends of the company submitting favorable reviews or disgruntled tire kickers putting on the war paint and going full keyboard warrior rather than having a discussion with the human beings at the company to actually solve any grievances) but the fact remains. We simply do not jump in at the deep end anymore, choice is in abundance.
So, come gather ’round people wherever you roam, what then exactly do we do now to entice people to our wares? How is business won and lost in the New World?
It’s simple really, and this is what I told the huge Mahogany walls in the fancy office earlier today. While the sales process has changed beyond recognition, what people want from their suppliers hasn’t changed one bit. It’s the same as it ever was! People want communication and service. That’s basically it. And that’s basically IT.
Before a client picks up the phone, or sends an email, or a DM they’ve been through your company website, your LinkedIn, your Facebook, your clients. To see if there’s a synergy, they are doing the sales for you in some respects, you have got to get your ducks in a row. Or that phone call / email / DM will not come, and you probably won’t even know you’ve lost a sale.
Setting out your stall is one hundred times more complicated than it was in 1981, if not one thousand. And how do we communicate and show the world what we do?
Website (IT), email (IT), phone (IT/telecoms), social media (IT), Zoom/Teams (IT) oh my! it’s all IT.
So now ask yourself, do you have a strategy for these new avenues? Are you ready for the future and any future incoming changes?
I’m not going to go on about why you should get a [reliable IT partner](https://www.auroratechsupport.co.uk/it-hardware-and-infrastructure-support/) and have a chat with us, you’re a grown-up and you make your own choices, I just want to give you the information you need to achieve the growth you require/desire.
If of course though you would like to work with a [reliable IT partner](https://www.auroratechsupport.co.uk/it-hardware-and-infrastructure-support/) to achieve fantastic growth and generally smash it out of the park, then get in touch. We’d love to work together and show your competiton who’s in charge.
| auroratech_ | |
867,954 | Control Flow In Python | Subscribe to our Youtube Channel To Learn Free Python Course and More If-Else In this session, we... | 0 | 2021-10-18T17:30:32 | https://dev.to/introschool/control-flow-in-python-4h4a | python, beginners, tutorial, programming | [Subscribe to our Youtube Channel To Learn Free Python Course and More](https://www.youtube.com/channel/UCQ8FDc6mi2BxxUSz8zcsy-A)
**If-Else**
In this session, we will learn the decision making part of programming. Sometimes you want your code to run only when a certain condition is satisfied. We will see how you can do it in this chapter.
**Basic if Statement**
```
# Basic If syntax
x = 2
if x == 2:
print('x is:', x)
```
By looking at the above code you can understand that this code will print x only if x is equal to 2. In this code, ‘x’ will not get printed if it is anything else other than 2.
So **if statement** evaluates the condition first and executes the statement inside the body only when the condition is true.
```
if <condition>:
<statement>
```
**If-Else Statement**
If...else statement is used when you want to specify what a program should do when the condition is false. See the below syntax.
```
# if...else
if <condition>:
<statement>
else:
<statement>
```
In if...else syntax, if the condition is true, <statement> inside the **body of if** will be executed and if the condition is false then the <statement> inside the **body of else** will be executed.
See the below example
```
name = 'Kumar'
if name == 'Kumar':
print(f'Hello {name}')
else:
print("You are not 'Kumar'")
# Output: Hello Kumar
'''
In the above code snippet, first <if> evaluates the condition name == 'Kumar', which is true, so the <statement> inside the body of <if> got executed. If the condition would have been false then the interpreter would come to <else> statement.
'''
```
**If--Elif--Else Statement**
If you want to check multiple conditions then you can use if...elif...else syntax. Here **elif** is short for **else if**.
```
# if...elif...else
if <condition>:
<statement>
elif <condition>:
<statement>
else:
<statement>
```
As you know that <if> and <elif> statements will execute only if the condition is true, if both the conditions are false then the <else> statement will execute.
```
x = 5
if x == 2:
print('Inside the body of if')
elif x == 5:
print('Inside the body of elif')
else:
print('Inside the body of else')
# Output
# Inside the body of elif
'''
Because only <elif> condition is true
'''
```
**For Loop**
Now we will learn how to use **for** loop. For loop is used to iterate over data structures like String, List, Tuple and Dictionary.
If you are asked to print each value in a string or list, How would you do that? You might be thinking that using index can be one option. But it is a tiresome task. See the below code.
```
s = [1, 2, 3, 4, 5, 6]
print(s[0])
print(s[1])
print(s[2])
print(s[3])
print(s[4])
print(s[5])
# Output
# 1
# 2
# 3
# 4
# 5
# 6
```
For loop makes it easy to access each value of any sequence type data structure. We will see that how you can use For loop to get the value of String, List, Tuple and Dictionary.
**String**
String is a sequence of characters. To access each character, we can use For loop. See the below code.
```
# String
s = "Python is awesome"
for char in s:
print(char)
# Output
# P
# y
# t
# h
# o
# n
#
# i
# s
#
# a
# w
# e
# s
# o
# m
# e
```
In the For loop syntax, **char** is a variable that refers to characters in the string. The loop runs from the starting of the string and stops at the end of the string. In the first iteration, char refers to the first character, in next iteration char refers to the second character and keeps on accessing all the characters of the string.
Char is just a variable, you can name it according to yourself.
**List**
List is a sequence of different types of data values. See the below code to access list values using For loop.
```
# List
lst = [1, 2, True, 4.234, False, 'List']
for elm in lst:
print(elm)
'''
Output:
1
2
True
4.234
False
List
'''
```
In the above for loop syntax, the variable refers to each data value. So in each iteration each data value gets printed.
Tuple
Tuples are also the same as list but the difference is you can not change these values.
```
# Tuple
tup = (1, 2, True, 4.234, False, 'List')
for elm in lst:
print(elm)
'''
Output:
1
2
True
4.234
False
List
'''
```
**Dictionary**
In the dictionary, there are three ways you can iterate the dictionary.
- Iterating through all keys.
- Iterating through all the values.
- Iterating through all key-value pairs
**Iterating through all keys**
```
person = {'name':'Kumar', 'age':23, 'email': 'kumar.com'}
for key in person:
Person[key]
'''
# Output:
'Kumar'
23
'Kumar.com'
'''
```
**Iterating through all the values**
For iterating through values, there is a method called values() that we can use to access dictionary values.
```
person = {'name':'Kumar', 'age':23, 'email': 'kumar.com'}
for value in person.values():
print(value)
'''
# Output:
Kumar
23
Kumar.com
'''
```
**Iterating through all the key-value pairs**
If you want to iterate through all the key-value pairs then you have to use the method called items(). See the below code.
```
person = {'name':'Kumar', 'age':23, 'email': 'kumar.com'}
for key, value in person.items():
print(f'{key}:{value}')
'''
# Output:
name:Kumar
age:23
email:kumar.com
'''
```
**Set**
Using for loop we can access each element of the set.
```
s = {1, 2, 4, "hello", False}
for elm in s:
print(elm)
'''
# Output
False
1
2
4
hello
'''
```
| introschool |
868,024 | PWA-ize: open web pages in their own window on mobile | TL;DR PWA-ize lets you add any web page to your mobile home screen, that opens in a... | 0 | 2021-12-07T18:23:02 | https://blog.derlin.ch/pwa-ize-open-web-pages-in-their-own-window-on-mobile | showdev, webdev, opensource | ## TL;DR
[PWA-ize](https://derlin.github.io/pwa-ize/) lets you add any web page to your mobile home screen, that opens in a dedicated browser window (not a browser tab!). This makes them feel more like regular apps, without any installation from the store.
Need an example? Here is how dev.to behaves when added directly, and the same dev.to added through PWA-ize (Android 11):
{% collapsible :neutral_face: regular dev.to ... %}

{% endcollapsible %}
{% collapsible :star_struck: PWA-ized dev.to ! %}

{% endcollapsible %}
In case you don't want to have too many shortcuts on your home screen, the [shortcuts page](https://derlin.github.io/pwa-ize/shortcuts.html) can be used as a launcher instead. It is a simple PWA page that displays a clickable list of your favorite sites.
## PWA... Kezaco ?
PWA, short for __P__rogressive __W__eb __A__pp, has been around for some time now. Paraphrasing [Mozilla's doc](https://developer.mozilla.org/en-US/docs/Web/Manifest):
> PWAs are websites that can be installed on a device’s home screen without an app store. Unlike regular web apps with simple home screen links or bookmarks, PWAs can be downloaded in advance and can work offline, as well as use regular Web APIs.
So in other words, when you add a PWA-enabled web page to your home screen, it will **open in a separate (and dedicated) browser window**, and feel more like a regular app. For non-PWAs, though, clicking on the shortcut will launch the default browser app and open the page on a new tab.
There is way more to it (offline mode, etc), but this separation is to me the single most useful feature.
Since many websites are not PWAs (and prefer to force us into using a native app, ikes), I [created PWA-ize](https://derlin.github.io/pwa-ize/), that makes ANY page open in a dedicated window, PWA or not. The cherry on the cake: you can decide to open a specific page directly, instead of the index of the site (URL parameters, etc. also work).
## Testimony
Ok, I am the only one currently using it. But I love it !
I have at least a half-screen of PWA-ized shortcuts for all my day-to-day activities. For example:
* [MeteoSuisse](https://www.meteosuisse.admin.ch/content/meteoswiss/fr/home.mobile.meteo-products--overview.html),
* The page displaying the menus at work,
* The page for booking my fitness classes (with some filters setup thanks to URL parameters, so it opens exactly what I need),
* [dev.to](https://dev.to) (obviously),
* [bookfortoday, science-fiction category](https://bookfortoday.com/science-fiction/),
* ... (at least 6 more ...)
Let me know what you think, at please leave a :star: !
------------
*(For the interested devs out there)*
## Conditions for a dedicated window
For a shortcut added to home screen to open on a dedicated window, two conditions must be met:
1. the website should declare a [Web Manifest](https://developer.mozilla.org/en-US/docs/Web/Manifest), and
2. the manifest should set the `display` property to something other than `browser` (the default).
Given the two conditions listed above, my idea was thus to create a manifest on the fly for a given URL.
## Changing manifests using Javascript
Manifests are referenced in a `meta` tag in the header and are only used at install time (after you click _Add to Home Screen_). It can thus be instrumented via Javascript:
```html
<link rel="manifest" id="manifest-placeholder" />
```
```js
const metaTag = document.getElementById("manifest-placeholder")
// generate the manifest
const jsonManifest = JSON.stringify({
name: "...",
display: "fullscreen",
// ...
});
// attach it as base64 to the meta tag
const blob = new Blob([jsonManifest], {type: "application/json"})
metaTag.setAttribute("href", URL.createObjectURL(blob))
```
## Manifest's start URL
A manifest is tightly coupled to the page that references it: when installed, it will open the page it was downloaded from. We can tweak the URL a bit, but it must be in the same domain. It is thus not possible to simply ask the user-agent to open an unrelated URL (e.g. `https://dev.to`). Here is my workaround.
From the manifest specification:
> *The manifest's [`start_url`](https://w3c.github.io/manifest/#start_url-member) member is a string that represents the start URL, which is the URL the developer would prefer the user agent to load when the user launches the web application (e.g., when the user clicks on the icon of the web application from a device's application menu or home screen).*
This seems promising, but has a limitation: the `start_url` **is ignored if not the same origin** as the document URL (aka page defining the manifest).
Thus, it is not possible to set the `start_url` to `https://dev.to`, but it is possible to set it to some random page (in the same domain) that will *redirect* to `https://dev.to`.
This is the role of the [`redirect.html`](https://derlin.github.io/pwa-ize/redirect.html) page:
```html
<html>
<head><title>PWA-ize redirect</title></head>
<body>
<div id="message"></div>
<script type="text/javascript">
// simply redirect to the given URL
const params = new URLSearchParams(window.location.search)
try {
window.location.href = new URL(params.get("url")).href
} catch (error) {
document.addEventListener("DOMContentLoaded", function () {
document.getElementById("message").innerHTML =
`An error occurred ${error}. The url option is empty or invalid ${window.location.href}`
})
}
</script>
</body>
</html>
```
With this, we can use in the manifest:
```json
{
"start_url": "https://derlin.github.io/pwa-ize/redirect.html?url=https://dev.to/"
}
```
The only downside of this redirect is that since we leave the manifest's domain, the browser top bar will show again. A small price to pay I guess.
## Manifest icons
A manifest can (must) provide icons, that may be used in the home screen and on the splash screen.
There are multiple services available to grab favicons, such as Google S2, duckdcuckgo icons API, and Icon Horse. I explained the first in this article (and others in the comments) if you are interested.
{% link https://dev.to/derlin/get-favicons-from-any-website-using-a-hidden-google-api-3p1e %}.
The only problem is that the manifest should contain not only the link to icons but also their type and size. The type can be taken from the response's `Content-Type` header, but the size is another matter.
One possibility to get the actual size of an image is to use the `Img` like this:
```javascript
const img = new Image()
img.onload = function () {
// here we can get the actual size !
// not the type though ...
console.log(`${this.src} => ${this.height}x${this.width}`)
}
img.src = `<URL of the image>`
```
I currently use Google S2 because it always returns PNG, so I don't need yet another request to get the content type (as the image trick above doesn't let you access the response headers).
Google S2 returns a 16x16 icon by default, so I use the `sz` query parameter (a size hint) to loop through common image sizes, (`16`, `128`, `256`, `512`) and add the ones I find in the manifest.
If you are interested in the actual code, have a look at [`src/utils/google-s2.js`](https://github.com/derlin/pwa-ize/blob/main/src/utils/google-s2.js).
## PWA-ize webapp
For this small project, I decided to go with [Vue3](https://v3.vuejs.org/) and [materialize-css](materializecss.com/), with some tweaks on the colour scheme.
I bootstrapped the project using `vue create`, and only had to add the `.prettierc` to get better formatting.
I needed multiple HTML pages since my shortcuts page needs a specific and fixed manifest. This was easy to achieve: I just used the `pages` configuration of `vue.config.js`.
To deploy to GitHub Pages, I have a simple Github Actions workflow, and
The [shortcuts](https://derlin.github.io/pwa-ize/shortcuts.html) page is using `localStorage` to persist the list of links.
------
Written with ❤️ by [derlin](https://github.com/derlin)
| derlin |
868,153 | Database says NOPE | I joined Virtual Coffee last week and they have this awesome zoom meeting that members occasionally... | 0 | 2021-10-18T20:04:40 | https://dev.to/mtfoley/database-says-nope-41p0 | postgres, javascript, todayilearned | 
I joined [Virtual Coffee](https://virtualcoffee.io) last week and they have this awesome zoom meeting that members occasionally spin up for pairing and coworking. A great dev named [Travis Martin](https://github.com/LincolnFleet) was adapting an existing project that had an app bundled with a Postgres v9 DB in a docker context, and he was trying to redeploy it in a different context with a newer version of Postgres. At the point I joined the zoom meeting, the app was having trouble authenticating to Postgres.
I've worked with a few different databases before, and I'd contributed to the [TAU project](https://github.com/Team-TAU/tau) in the past which uses Django and Postgres. As I tried to make suggestions, I referred to a few of the bootstrapping scripts I encountered on that project, and they helped to some degree of making sure all the pieces were in place in the database server (pasted below):
- check if user exists: `SELECT COUNT(*) AS count FROM pg_catalog.pg_user WHERE usename={db_user}`
- check if database exists: `SELECT COUNT(*) AS count FROM pg_database WHERE datname={db_name}`
- create the database if needed: `CREATE DATABASE {db_name};`
- create the user if needed: `CREATE USER {db_user} WITH ENCRYPTED PASSWORD '{db_pw}';`
- assign privileges: `GRANT ALL PRIVILEGES ON DATABASE {db_name} TO {db_user}; # use with care`
- update user password if needed: `ALTER USER {db_user} WITH ENCRYPTED PASSWORD '{db_pw}'`
However, after using statements like these to make sure the DB server was setup correctly, we still were getting the same error message. Travis verified all sorts of things, like whether the app had access to the environment variables he wanted. We had a big clue when he attempted to authenticate to the Postgres over the `psql` command with the app's credentials, and he didn't get an opportunity to enter a password. The trick turned out to be that he was logged into the OS with the same username, configured earlier in the deployment process. As we got to reading further in the [Postgres docs](https://www.postgresql.org/docs/12/auth-pg-hba-conf.html), we found that the Postgres configuration file `pg_hba.conf` had the authentication method set to "ident", which relies on a separate
"ident" service, and in order to get things working, Travis set the authentication method to different option more appropriate for clients leveraging usernames and encrypted passwords.
This was a pretty specific use case, but maybe it'll help somebody!
| mtfoley |
868,190 | test | test | 0 | 2021-10-18T22:57:36 | https://dev.to/aeristhy/test-7ne | test | aeristhy | |
868,326 | Launching Amazon FSx for Windows File Server and Joining a Self-managed Domain using Terraform | TL;DR: The github repo with all scripts are here. Because of specific requirements, reasons, or... | 0 | 2021-10-19T03:02:28 | https://dev.to/dnx/launching-amazon-fsx-for-windows-file-server-and-joining-a-self-managed-domain-using-terraform-2oid | aws, fsx, windows, terraform | TL;DR:
The github repo with all scripts are [here](https://github.com/DNXLabs/blog-post-terraform-fsx-self-managed-domain).
Because of specific requirements, reasons, or preferences, some customers need to self-manage a Microsoft AD directory on-premises or in the cloud.
AWS offers options to have their fully managed Microsoft Windows file servers ([Amazon FSx for Windows File Server](https://aws.amazon.com/fsx/windows/)) join a self-managed Microsoft Active Directory.
In this post, I will provide an example of launching an FSx for Windows File Server and joining a self-managed domain using Terraform.
This article won’t go into details on the following items as they are presumed to already be created.
## Requirements:
- [self-managed Microsoft AD directory](https://docs.aws.amazon.com/fsx/latest/WindowsGuide/self-manage-prereqs.html)
- the fully qualified, distinguished name (FQDN) of the organisational unit (OU) within your self-managed AD directory that the Windows File Server instance will join; and
- valid DNS servers and networking configuration (VPC/Subnets) that allows traffic from the file system to the domain controller.
In addition, I recommend to go through the steps “[Validating your Active Directory configuration](https://docs.aws.amazon.com/fsx/latest/WindowsGuide/validate-ad-config.html)” from AWS Documentation at the following link to validate self-managed AD configuration before starting creation of the FSx filesystem:
On the file _variables.tf, we will provide the details for the self-managed AD, including IPs, DNS Name, Organisational Unit, and Domain Username and Password:
**_variables.tf**
```
variable "ad_directory_name" {
type = string
default = "example.com"
}
variable "ad_directory_ip1" {
type = string
default = "XXX.XXX.XXX.XXX"
}
variable "ad_directory_ip2" {
type = string
default = "XXX.XXX.XXX.XXX"
}
variable "fsx_name" {
type = string
default = "fsxblogpost"
}
variable "domain_ou_path" {
type = string
default = "OU=Domain Controllers,DC=example,DC=com"
}
variable "domain_fsx_username" {
type = string
default = "fsx"
}
variable "domain_fsx_password" {
type = string
default = "placeholder"
}
variable "fsx_deployment_type" {
type = string
default = "SINGLE_AZ_1"
}
variable "fsx_subnet_ids" {
type = list(string)
default = ["subnet-XXXXXXXXXXXX"]
}
variable "vpc_id" {
type = string
default = "vpc-XXXXXXXXXXXX"
}
variable "fsx_deployment_type" {
type = string
default = "SINGLE_AZ_1"
}
variable "fsx_subnet_ids" {
type = list(string)
default = ["subnet-XXXXXXXXXXXX"]
}
variable "vpc_id" {
type = string
default = "vpc-XXXXXXXXXXXX"
}
```
The file fsx.tf is where we will effectively create FSx filesystem, and also KMS encryption key and KMS Key policy. The KMS key is optional, however I strongly recommend having the filesystem encrypted.
*fsx.tf*
```
data "aws_iam_policy_document" "fsx_kms" {
statement {
sid = "Allow FSx to encrypt storage"
actions = ["kms:GenerateDataKey"]
resources = ["*"]
principals {
type = "Service"
identifiers = ["fsx.amazonaws.com"]
}
}
statement {
sid = "Allow account to manage key"
actions = ["kms:*"]
resources = ["arn:aws:kms:${data.aws_region.current.name}:${data.aws_caller_identity.current.account_id}:key/*"]
principals {
type = "AWS"
identifiers = ["arn:aws:iam::${data.aws_caller_identity.current.account_id}:root"]
}
}
}
resource "aws_kms_key" "fsx" {
description = "FSx Key"
deletion_window_in_days = 7
policy = data.aws_iam_policy_document.fsx_kms.json
}
resource "aws_fsx_windows_file_system" "fsx" {
kms_key_id = aws_kms_key.fsx.arn
storage_capacity = 100
subnet_ids = var.fsx_subnet_ids
throughput_capacity = 32
security_group_ids = [aws_security_group.fsx_sg.id]
deployment_type = var.fsx_deployment_type
self_managed_active_directory {
dns_ips = [var.ad_directory_ip1, var.ad_directory_ip2]
domain_name = var.ad_directory_name
username = var.domain_fsx_username
password = var.domain_fsx_password
organizational_unit_distinguished_name = var.domain_ou_path
}
}
resource "aws_security_group" "fsx_sg" {
name = "${var.fsx_name}-fsx-sg"
description = "SG for FSx"
vpc_id = data.aws_vpc.selected.id
tags = {
Name = "${var.fsx_name}-fsx-sg"
}
}
resource "aws_security_group_rule" "fsx_default_egress" {
description = "Traffic to internet"
type = "egress"
from_port = 0
to_port = 0
protocol = "-1"
security_group_id = aws_security_group.fsx_sg.id
cidr_blocks = ["0.0.0.0/0"]
}
resource "aws_security_group_rule" "fsx_access_from_vpc" {
type = "ingress"data "aws_iam_policy_document" "fsx_kms" {
statement {
sid = "Allow FSx to encrypt storage"
actions = ["kms:GenerateDataKey"]
resources = ["*"]
principals {
type = "Service"
identifiers = ["fsx.amazonaws.com"]
}
}
statement {
sid = "Allow account to manage key"
actions = ["kms:*"]
resources = ["arn:aws:kms:${data.aws_region.current.name}:${data.aws_caller_identity.current.account_id}:key/*"]
principals {
type = "AWS"
identifiers = ["arn:aws:iam::${data.aws_caller_identity.current.account_id}:root"]
}
}
}
resource "aws_kms_key" "fsx" {
description = "FSx Key"
deletion_window_in_days = 7
policy = data.aws_iam_policy_document.fsx_kms.json
}
resource "aws_fsx_windows_file_system" "fsx" {
kms_key_id = aws_kms_key.fsx.arn
storage_capacity = 100
subnet_ids = var.fsx_subnet_ids
throughput_capacity = 32
security_group_ids = [aws_security_group.fsx_sg.id]
deployment_type = var.fsx_deployment_type
self_managed_active_directory {
dns_ips = [var.ad_directory_ip1, var.ad_directory_ip2]
domain_name = var.ad_directory_name
username = var.domain_fsx_username
password = var.domain_fsx_password
organizational_unit_distinguished_name = var.domain_ou_path
}
}
resource "aws_security_group" "fsx_sg" {
name = "${var.fsx_name}-fsx-sg"
description = "SG for FSx"
vpc_id = data.aws_vpc.selected.id
tags = {
Name = "-${var.fsx_name}-fsx-sg"
}
}
resource "aws_security_group_rule" "fsx_default_egress" {
description = "Traffic to internet"
type = "egress"
from_port = 0
to_port = 0
protocol = "-1"
security_group_id = aws_security_group.fsx_sg.id
cidr_blocks = ["0.0.0.0/0"]
}
resource "aws_security_group_rule" "fsx_access_from_vpc" {
type = "ingress"
from_port = 0
to_port = 0
protocol = "-1"
security_group_id = aws_security_group.fsx_sg.id
cidr_blocks = [data.aws_vpc.selected.cidr_block]
}
from_port = 0
to_port = 0
protocol = "-1"
security_group_id = aws_security_group.fsx_sg.id
cidr_blocks = [data.aws_vpc.selected.cidr_block]
}
```
Once you apply the scripts on Terraform, it should take around 15 minutes for the resources to be created:
```
aws_fsx_windows_file_system.fsx: Creation complete after 15m54s [id=fs-05701e8e6ad3fbe24]
Apply complete! Resources: 5 added, 0 changed, 0 destroyed.
```
You should see the FSx created and in Available state on AWS Console, which means FSx was able to join the self-managed domain:
## Conclusion
I hope the instructions and terraform scripts provided can make your life easier when launching FSx for Windows File Server and joining a self-managed domain using Terraform.
When recently working on a project, I noticed there weren’t many examples online, so I decided to write this blog post to help others.
I would encourage you to open an issue or feature request on the [github repo](https://github.com/DNXLabs/blog-post-terraform-fsx-self-managed-domain) in case you need any additional help when using the scripts.
| maiconrocha |
868,543 | Getting started with Appwrite's Apple SDK and UIKit | One of the major highlights of Appwrite 0.11 is the official support for iOS, macOS, tvOS and... | 0 | 2021-10-19T12:10:29 | https://dev.to/appwrite/getting-started-with-appwrites-apple-sdk-and-uikit-4bjd | ios, swift, tutorial, news | One of the major highlights of Appwrite 0.11 is the official support for iOS, macOS, tvOS and watchOS. We've also released a brand-new Apple SDK to go alongside it! 😉
In this tutorial, we'll learn to set up Appwrite's Apple SDK, interact with Appwrite's Accounts API and also learn to set up OAuth Logins in your App. Let's get started!
> We'll use UIKit in this tutorial, if you're using [SwiftUI](https://developer.apple.com/xcode/swiftui/), check out <a href="https://dev.to/appwrite/getting-started-with-appwrites-apple-sdk-and-swiftui-131h">this tutorial</a> instead.
## 📝 Prerequisites
At this stage, we assume that you already have an Appwrite instance up and running. If you do not have Appwrite setup yet, you can follow the super easy installation **step** over at [appwrite.io](https://appwrite.io/docs/installation). It's not a typo. There really is only 1 step!
You should have also set up an OAuth provider with Appwrite to be able to follow the OAuth section of this tutorial. You can learn to set up OAuth providers in Appwrite with [this tutorial](https://dev.to/appwrite/30daysofappwrite-oauth-providers-3jf6).
## 🛠️ Create a new App Project
Create a new **iOS > App** in Xcode, selecting **Storyboard** for **Interface** and **UIKit App Delegate** for **Life Cycle**.
With the app created, now is also a good time to add our iOS, macOS, watchOS or tvOS app as a platform in the Appwrite Console. Head over to your project file and find your **Bundle Identifier**. It should look something like `io.appwrite.Appwrite-iOS`.
In your Appwrite console, click on **Add Platform** and select a **New Apple App**, then one of the iOS, macOS, watchOS or tvOS tabs. Give your app a name, add the bundle identifier and click **Register**.
Once this is complete, it's time to head back to our Xcode project add our dependencies.
## 👷 Setup Appwrite's Apple SDK
### Using Xcode
The Appwrite Apple SDK is available via Swift Package Manager. In order to use the Appwrite Apple SDK from **Xcode**, select File > Swift Packages > **Add Package Dependency**. In the dialog that appears, enter the Appwrite Apple SDK [package URL](https://github.com/appwrite/sdk-for-apple) and click **Next**.
Once the repository information is loaded, add your version rules and click **Next** again.
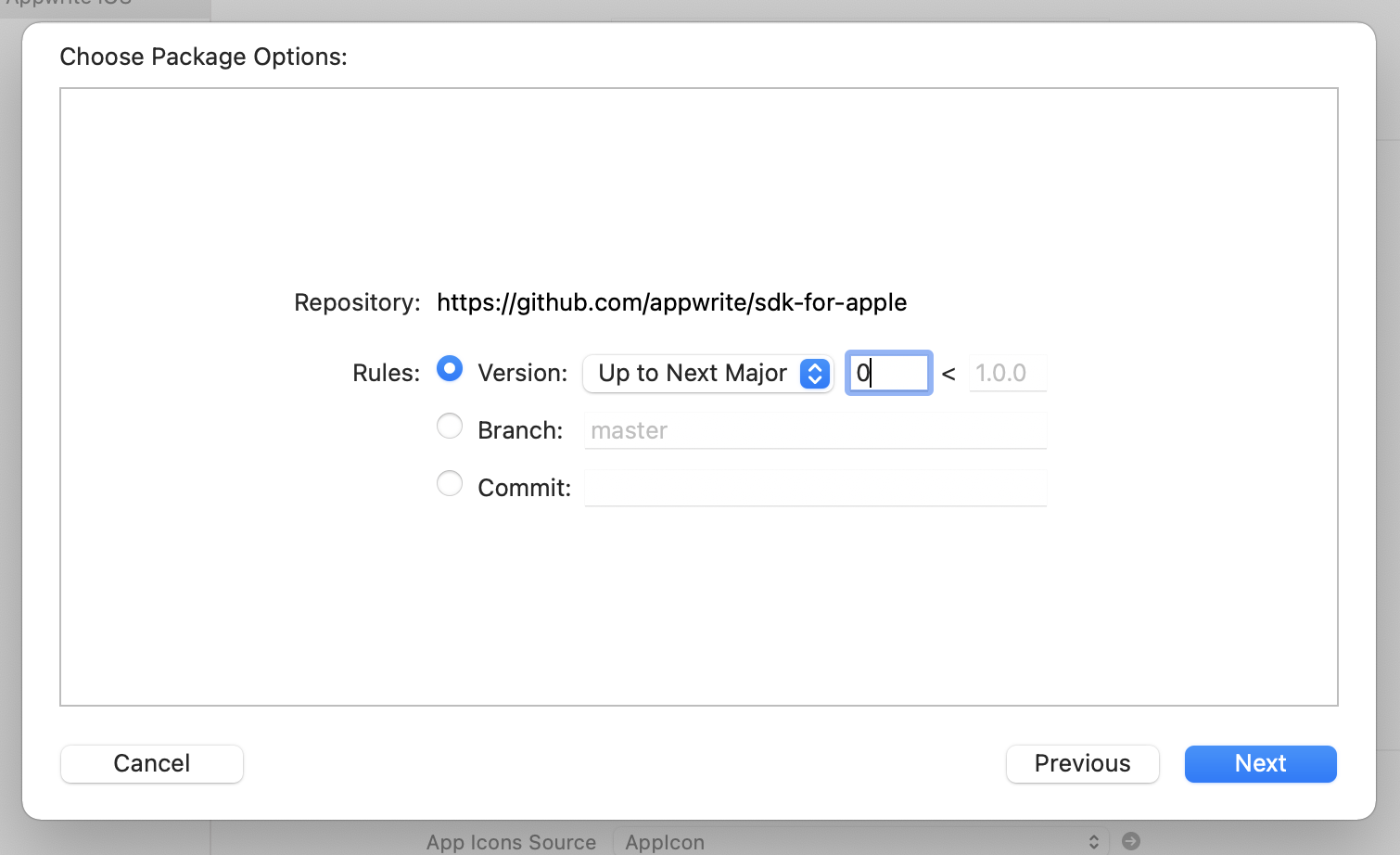
On the final screen, make sure `Appwrite` is selected to add to your target as a library.
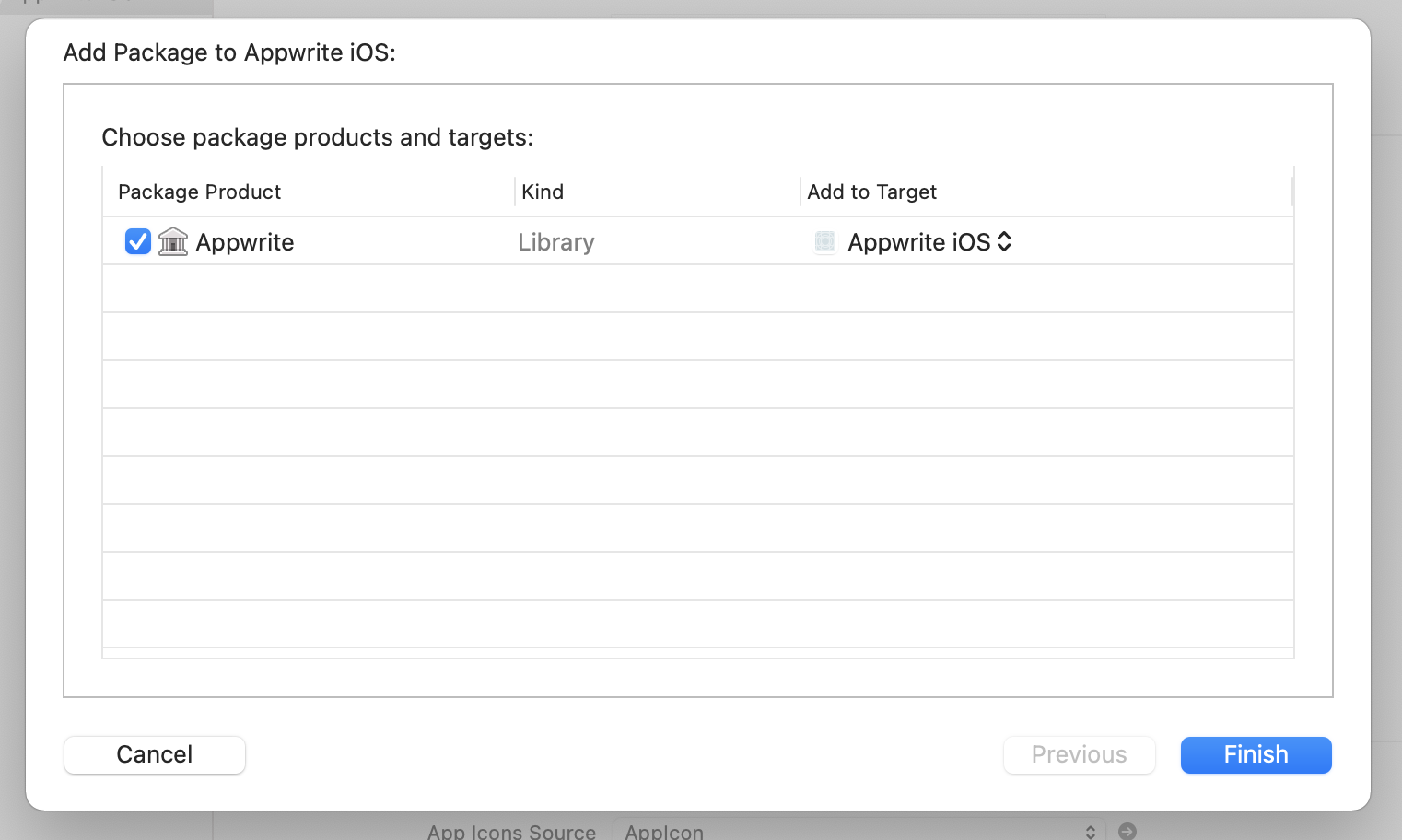
### Using Swift Package Manager
Add the package to your `Package.swift` dependencies:
```swift
dependencies: [
.package(url: "https://github.com/appwrite/sdk-for-apple", from: "0.1.0"),
],
```
Then add it to your target:
```swift
targets: [
.target(
name: "[YourAppTarget]",
dependencies: [
.product(name: "Appwrite", package: "sdk-for-apple")
]
),
```
Build your project and if there are no errors, we're ready to proceed!
## 🏗️ Create the ViewController
Create a new file `ViewController.swift` and add the following. This defines our controller for our storyboard and sets up our button click listeners that will call the `ViewModel`.
```swift
import Appwrite
import NIO
import UIKit
class ViewController: UIViewController {
@IBOutlet weak var text: UITextView!
@IBOutlet weak var register: UIButton!
@IBOutlet weak var loginButton: UIButton!
@IBOutlet weak var logOutButton: UIButton!
@IBOutlet weak var getUserButton: UIButton!
@IBOutlet weak var loginWithFacebook: UIButton!
let client = Client()
.setEndpoint("http://localhost/v1")
.setProject("613b18dabf74a")
.setSelfSigned()
lazy var account = Account(client)
var picker: ImagePicker?
required init?(coder: NSCoder) {
super.init(coder: coder)
}
@IBAction func register(_ sender: Any) {
account.create(email: "tester@appwrite.io", password: "password") { result in
var string: String = ""
switch result {
case .failure(let error): string = error.message
case .success(let user): string = user.email
}
DispatchQueue.main.async {
self.text.text = string
}
}
}
@IBAction func login(_ sender: Any) {
account.createSession(email: "tester@appwrite.io", password: "password") { result in
var string: String = ""
switch result {
case .failure(let error): string = error.message
case .success(let session): string = session.userId
}
DispatchQueue.main.async {
self.text.text = string
}
}
}
@IBAction func loginWithFacebook(_ sender: UIButton) {
// To be added later.
}
@IBAction func getUser(_ sender: Any) {
account.get { result in
var string = ""
switch result {
case .failure(let error): string = error.message
case .success(let user): string = user.email
}
DispatchQueue.main.async {
self.text.text = string
}
}
}
@IBAction func logOut(_ sender: Any) {
account.deleteSession(sessionId: "current") { result in
var string = ""
switch result {
case .failure(let error): string = error.message
case .success(let success): string = String(describing: success)
}
DispatchQueue.main.async {
self.text.text = string
}
}
}
}
```
Our ViewController has 4 state functions:
- register - click handler for the Signup Button
- login - click handler for the Login Button
- logout - click handler for the Logout Button
- getUser - click handler for the Get User Button
You should now be able to run your app and create users, login, logout and get information about the currently logged-in user!
## 🔐 Adding OAuth Support
You would have noticed that we have a **Login With Facebook** button in our UI, but it doesn't do anything yet; let's now add Facebook OAuth to our app!
The first step is to add a callback URL scheme to our `Info.plist` file.
```xml
<key>CFBundleURLTypes</key>
<array>
<dict>
<key>CFBundleTypeRole</key>
<string>Editor</string>
<key>CFBundleURLName</key>
<string>io.appwrite</string>
<key>CFBundleURLSchemes</key>
<array>
<string>appwrite-callback-[PROJECT-ID]</string>
</array>
</dict>
</array>
```
Make sure you replace the Project ID in `appwrite-callback-[PROJECT-ID]` with your own.
Next we need to add a hook to save cookies when our app is opened by its callback URL. To do this, add the following function to your `SceneDelegate.swift`. If you have already defined this function, you can just add the contents below.
```swift
func scene(_ scene: UIScene, openURLContexts URLContexts: Set<UIOpenURLContext>) {
guard let url = URLContexts.first?.url,
url.absoluteString.contains("appwrite-callback") else {
return
}
WebAuthComponent.handleIncomingCookie(from: url)
}
```
The last step is to invoke the SDK function `createOAuth2Session` from `AccountViewController.swift` from our existing button's action.
```swift
@IBAction func loginWithFacebook(_ sender: UIButton) {
account.createOAuth2Session(
provider:"facebook",
success: "https://demo.appwrite.io/auth/oauth2/success",
failure: "https://demo.appwrite.io/auth/oauth2/failure") { result in
var string: String = ""
switch result {
case .failure(let error): string = error.message
case .success(let response): string = response.description
}
DispatchQueue.main.async {
self.text.text = string
}
}
}
```
Re-run your app and you should now be able to trigger your Facebook OAuth Flow! With that, you now know how to interact with Appwrite's Accounts API in your iOS, macOS, tvOS and watchOS apps!
We've built a complete app that interacts with all of Appwrite's APIs, which you can find over at our [Github Repo](https://github.com/appwrite/playground-for-apple-uikit). If you'd like to learn more about Appwrite or how Appwrite works under the hood, we've just curated all the resources for you during [30 Days of Appwrite](https://30days.appwrite.io/).
## ✨️ Credits
Hope you enjoyed this article! We love contributions and encourage you to take a look at our [open issues](https://github.com/appwrite/appwrite/issues) and [ongoing RFCs](https://github.com/appwrite/rfc/pulls).
If you get stuck anywhere, feel free to reach out to us on our [friendly support channels](https://appwrite.io/discord) run by humans 👩💻.
Here are some handy links for more information:
- [Appwrite Contribution Guide](https://github.com/appwrite/appwrite/blob/master/CONTRIBUTING.md)
- [Appwrite Github](https://github.com/appwrite)
- [Appwrite Documentation](https://appwrite.io/docs) | jakebarnby |
868,569 | Local Kubernetes development made easy with Minikube - Devtron | Devtron being an open source platform appreciates the contributions coming from the community all... | 0 | 2021-10-25T13:33:33 | https://dev.to/arushi09/local-kubernetes-development-made-easy-with-minikube-devtron-17hf | opensource, kubernetes, devops, webdev | Devtron being an open source platform appreciates the contributions coming from the community all across the globe. Everyday, the team of Devtron is leveraging the idea of building the platform more developer-friendly. To contribute and provide your ideas we came up with a solution to let our contributors know how the process will work.
Frequently installing devtron to check your applied changes can be a tedious task and will not give a speedy development. Try out this hassle-free setup to locally set up devtron.
Before starting up with the setup lets first understand, **What Devtron is?**
{% github devtron-labs/devtron no-readme %}
Devtron is an open source software delivery workflow for Kubernetes written in Go. It is known for its slick user interface which allows developers to deploy their Microservices over Kubernetes in no-time. Not only application deployment, but also it helps in monitoring and logging just through the Devtron dashboard itself. Moreover it allows developers to integrate their existing open-source systems like ArgoCD, Jenkins, Clair, and others.
Starting with the setup few prerequisites are to be taken into consideration which are listed below.
###Prerequisites -
* Docker installed
* Kubernetes installed
* Having a basic architectural knowledge about devtron and a local Kubernetes cluster is a prerequisite for this setup.
In my case, I took a single node Minikube cluster. You can choose any as per your requirement.
##Minikube Setup
###What is minikube?
Minikube is a utility to run Kubernetes on your local machine. It creates a VM on your local machine and deploys a simple cluster containing only one node.
To set up a Minikube cluster , you first need to install Minikube using this [documentation](https://minikube.sigs.k8s.io/docs/start/?ref=hackernoon.com). After the successful installation of Minikube , now it’s time to create a cluster.
Cluster creation in Minikube is quite simple using a single command.
```
minikube start --cpus 3 --memory 7168
```
Let the command completely run, and create a cluster. The CPU and memory requirements are given explicitly because by only running `minikube start` a cluster is created with the default configurations of 2 CPUs and 2048 memory which is insufficient for devtron installation.
Afterwards, run the below command to check the health of the nodes.
```
kubectl get nodes
```
*Now, let's start installing Devtron!!*
##Devtron Installation
Installation of Devtron can be done using multiple command line programs. Eg - helm3, helm2 and kubectl. Among these, helm3 is the recommended one. Before that, refer to the following [documentation](https://helm.sh/docs/intro/install/) to install helm.
**STEP 1:** To install devtron using helm3 run the following commands -
```
helm repo add devtron https://helm.devtron.ai
helm install devtron devtron/devtron-operator --create-namespace --namespace devtroncd
```
The installation time will be dependent on the internet speed on your local machine. Generally the installation takes upto 20-25 mins.
**STEP 2:** Keep on executing the command below to check the status of the installation. If it is still in progress it will show **Downloaded** and once finished it will show **Applied**.
```
kubectl -n devtroncd get installers installer-devtron -o jsonpath='{.status.sync.status}'
```
You can also run the following command to keep track of your pods.
```
kubectl -n devtroncd get pods - w
```
**STEP 3:** After the successful installation of devtron, now we are ready to access the dashboard. As the cluster is locally created it will accessible on localhost or localhost IP - 127.0.0.1
Use the below command to access the dashboard locally
```
minikube -n devtroncd svc/devtron-service
```
You can also use minikube tunnel to create an EXTERNAL IP to access the dashboard, or port-forwarding the devtron-service will also work.
**STEP 4:** Logging into the dashboard using admin access will require a password which will be generated from the below command.
```
kubectl -n devtroncd get secret devtron-secret -o jsonpath='{.data.ACD_PASSWORD}' | base64 -d
```
*Hurray..! Your devtron installation is successfully done.To know more about installation refer to official site of [Devtron](https://docs.devtron.ai/).*
##Starting the Local Setup
As we move forward, devtron installation was the first step we successfully completed. We are ready to set up our local development environment for Devtron and play around with it. For building any features or fixing bugs, we need to have the source code of the project at the very first place.
`[Note: Please make sure that the wire module is installed in your system]`
**Follow the steps below for the setup -**
**STEP 1:** Clone the project
The below command will clone the devtron repo in your system. If you haven’t installed git, install it from here.
```
git clone https://github.com/devtron-labs/devtron.git
```
**STEP 2:** Build the project.
Go to the devtron directory which you cloned, using the command `cd devtron` and build the devtron source code by the following command.
`make build`
**STEP 3:** Port Forwarding the Services
Now we need to port forward a few services to establish a connection between Devtron running with the binary we will execute in the next step. Execute the following commands in different terminals which can help you to check the logs and debug if any connection issues occur and also do not close the terminal or stop these commands until the work is done. If any commands are stopped, then please execute it again to maintain the connection with local setup.
```
kubectl -n devtroncd port-forward svc/argocd-server 8000:80
kubectl -n devtroncd port-forward svc/argocd-dex-server 5556:5556
kubectl -n devtroncd port-forward svc/postgresql-postgresql 5432:5432
kubectl -n devtroncd port-forward svc/devtron-nats 4222:4222
```
**STEP 4:** Setting up Environment Variables and executing Binary
Now we need to set up a few environment variables to connect the source code with the Devtron which we installed initially. Please run the following commands from the root directory where you build the project. It will setup the environment variable and execute the binary as well. Do not stop the command until the work is not done.
`[Note: python3 must be installed in the system]`
```
wget https://raw.githubusercontent.com/devtron-labs/devtron/main/developers-guide/scripts/exporter.py
python3 exporter.py
```
*Yayy! We have successfully set up devtron locally in our system and now we can start building features, fixing bugs, etc and start contributing to the project.*
| arushi09 |
868,577 | ¿Es seguro realizar operaciones por banca digital en Bolivia? | El pasado domingo 17 de octubre, el periódico Página 7 publicó una noticia indicando que al menos 14... | 0 | 2021-10-19T14:36:54 | https://dev.to/cirrus-it/es-seguro-realizar-operaciones-por-banca-digital-en-bolivia-47ee | seguridad, phishing | El pasado domingo 17 de octubre, el periódico Página 7 publicó una [noticia](https://www.paginasiete.bo/seguridad/2021/10/17/al-menos-14-personas-sufrieron-robo-virtual-de-sus-cuentas-del-banco-union-312386.html) indicando que al menos 14 personas sufrieron un robo virtual de sus cuentas del Banco Unión S.A.; esta noticia inmediatamente provocó dudas y susceptibilidades en la población respecto a sí: ¿Es seguro realizar operaciones por Banca Digital en Bolivia?
En CIRRUS IT SRL, hemos construido una plataforma de banca digital : https://bancadigital.com.bo, en base a esta experiencia, a continuación tratare de responder algunas preguntas que nos realizaron en estos días:
## ¿Es posible despertar un día y constatar que existan transferencias de dinero, desde mi cuenta, que yo no hice?
Si es posible. En este caso lo más probable es que usted haya sido víctima de un ataque, en el que por medio de un sitio falso le hayan capturado su usuario y contraseña de Banca Digital, a este tipo de ataques se los denomina Phishing (mas adelante se explica en detalle y con ejemplos).
## ¿Puede un funcionario o empleado de una Entidad Financiera tener acceso a mi información personal?
No sin control. En tecnología existen [estándares internacionales](https://www.escuelaeuropeaexcelencia.com/2019/09/como-gestionar-los-controles-de-acceso-segun-iso-27001/) de seguridad para gestionar quienes pueden acceder a la información de los clientes. Además la Autoridad del Sistema Financiero también establece normas con las condiciones mínimas de seguridad que deben cumplir las Entidades Financieras [(ver. sección 4)] (https://servdmzw.asfi.gob.bo/circular/textos/L03T07.pdf) . El cumplimiento de estas normas son verificadas periódicamente por auditorias externas contratadas por las Entidades Financieras y también por auditorias realizadas por las ASFI.
## A pesar del control que realizan las Entidades Financieras: ¿Puede un funcionario o empleado tener acceso a mi contraseña de Banca Digital?
*No*. A menos que se trate de un error grave de diseño (lo cual no ocurre por lo explicado anteriormente), los sistemas de Banca Digital no almacenan su contraseña. Existen algoritmos criptográficos, denominados (funciones hash)[https://latam.kaspersky.com/blog/que-es-un-hash-y-como-funciona/2806/], que permiten almacenar una representación diferente de su contraseña, si alguien tuviera acceso a esta representación es imposible transformarla de nuevo en su contraseña original.
## Entonces: ¿Cómo alguien puede acceder a mi cuenta de Banca Digital?
*Phishing*. Este tipo de ataque es muy común a nivel mundial y Bolivia no es la excepción, los atacantes (ladrones) construyen un sitio con aspecto idéntico al de su Entidad Financiera, luego le envían mensajes por: correo electrónico, WhatsApp, SMS o publicidad en redes sociales; para que usted ingrese a ellos creyendo que está en el sitio de su banco, y de esta manera ingrese su usuario y contraseña, es en este momento donde usted pierde sus credenciales de acceso y los atacantes tienen acceso a sus cuentas digitales.
Veamos algunos ejemplos en Bolivia.
### Phishing utilizando publicidad en redes sociales, buscando atacar a clientes del Banco Nacional de Bolivia.
Analice la siguiente publicidad reportada por un usuario de Twitter:
{% twitter 1448368921514418176%}
A simple vista parece una oferta legitima del BNB, pero el el enlace en la parte inferior del arte dice: `https://BBNPORTALPRINCIPAL.COM`, no se trata de una publicidad emitida por BNB, si algún usuario despistado hiciera click en la publicidad lo llevaría a un *sitio falso* con la misma interfaz que la del BNB:

### Phishing utilizando publicidad en redes sociales, buscando atacar a clientes del Banco Unión.
El ODIB [documentó](https://www.odibolivia.org/2020/12/07/nuevo-ataque-de-phishing-bono-contra-el-hambre/) el siguiente ataque: El pasado año se emitió el Bono contra el hambre, mismo que fue cancelado directamente en cuentas bancarias, atacantes aprovecharon la oportunidad y la premura de las personas para cobrarlo, publicaron el siguiente anuncio haciéndose pasar por el Ministerio de Trabajo.  luego de que el usuario hiciera clic, lo derivaba a una página falsa con un aspecto similar a la Banca Digital del Banco Unión: 
## ¿Puede un atacante realizar transferencias solo con mi usuario y contraseña?
*No*. El Banco Central de Bolivia mediante [Circular Externa](https://www.bcb.gob.bo/webdocs/sistema_pagos/CIEX_N_3-2020_Requerimientos_Op_Minimos_Seguridad_IEP.pdf) establece que las transferencias deben cumplir un proceso de doble factor de autenticación para confirmar una trasferencia bancaria. El doble factor de autenticación consiste en que el banco debe realizar al menos dos de los siguientes tres controles, para verificar la identidad del usuario:
1. Verificar "algo que se": Este control se lo realiza con el usuario y contraseña, que debería ser un dato que únicamente usted conoce.
2. Verificar "algo que tengo": Este control se lo realiza de diferente formas siendo las mas comunes: El envío de un SMS a su celular (que es algo que solo usted tiene) o con el ingreso de un código de un solo uso (que se genera mediante una aplicación separada o generadores físicos).
3. Verificar "algo que soy": Este control puede realizarse de manera biométrica, hoy en día no se utiliza este medio en Bolivia.
## Entonces: ¿Cómo realizaron el ataque a los clientes del Banco Unión?
Parte de los clientes del Banco Unión utiliza como método de doble factor los mensajes SMS, desafortunadamente este medio tiene el inconveniente de que las empresas telefónicas proporcionan medios convenientes para la obtención del chip en caso de pérdida de teléfonos.
- Tigo: permite a travez de sus Tigomatic (maquinas de autoservicio similares a los cajeros automáticos), obtener el chip de cualquier persona proporcionando su número de celular, fecha de nacimiento, numero de carnet y numero de teléfono.
- Entel: [Permite](https://institucional.entel.bo/inicio3.0/index.php/internet/nuestros-servicios/internet-4g/51-atc-preguntas-frecuentes-2/218-preguntas-frecuentes-6) recabar el chip a terceros, siempre y cuando presenten una fotocopia de carnet del titular, una carta remitida por el titular y una fotocopia de carnet del que recibe el chip.
## Pero: ¿Cómo obtuvieron los atacantes los datos personales de las victimas?
Desafortunadamente en Bolivia no existe una normativa de protección a los datos personales y su tratamiento, como [por ejemplo](https://eur-lex.europa.eu/legal-content/ES/TXT/?qid=1532348683434&uri=CELEX%3A02016R0679-20160504) en Europa. Esto hace que las empresas e instituciones publicas no sigan procedimientos adecuados para custodiar nuestros datos. Algunos ejemplos de dónde se encuentran nuestros datos:
- Todos los tramites del gobierno y entidades privadas donde nos piden varias fotocopias de carnet (algunos también piden que coloquemos nuestro numero de teléfono), para absolutamente todo. ¿Se ha puesto a pensar cuántas fotocopias de carnet a entregado en los últimos años?.
- Acceso a nuestros datos directamente desde el SEGIP, mediante [normativa](https://www.lexivox.org/norms/BO-L-N1057.html) las instituciones del estado tienen acceso a nuestra información. El SEGIP tambien tiene convenios con Entidades Financieras para que ellas puedan consultar nuestros datos sin solicitarnos consentimiento.
- Ataques de phishing (si otra vez) para captar nuestros datos personales, por ejemplo estos anuncios: {% twitter 1379467887128219648 %} {% twitter 1357422273364393988 %} {% twitter 1397990990900654082 %}
- Y si lo anterior no fuera poco, [Facebook filtro los datos personales de 533 millones de usuarios](https://eju.tv/2021/04/filtraron-los-numeros-de-telefono-y-datos-personales-de-533-millones-de-usuarios-de-facebook/). Estos datos están disponibles en el mercado negro para que los atacantes puedan comprarlos. Si usted desea saber si sus datos son públicos puede ingresar su numero de celular (con el prefijo +591) en el siguiente sitio: https://haveibeenpwned.com (no ingrese otro dato, no confié en otros sitios), por ejemplo en mi caso, toda mi información fue filtrada por Facebook: 
## ¿Es seguro realizar operaciones por banca digital en Bolivia?
Si, pero debemos ser cuidadosos con nuestra información. Las Entidades Financieras poseen la tecnología y los controles para brindar las condiciones adecuadas de seguridad, pero si nosotros no somos cuidadosos con nuestra información podemos ser víctimas de delincuentes, a continuación algunas recomendaciones.
1. Nunca ingrese su usuario y contraseña en ningún sitio, a menos que usted haya abierto el navegador y colocado el sitio web de su banco.
2. Nunca ingrese sus datos personales en enlaces enviados por correo electrónico, SMS, WhatsApp, redes sociales u otros.
3. No utilice la misma contraseña en sus cuentas digitales, porque si se filtran sus credenciales de un sitio queda expuesto en los demás.
4. Cambie periódicamente su contraseña de acceso a las cuentas digitales sensibles.
5. Solicite a su Entidad Financiera que le habiliten un método alternativo al SMS para confirmar operaciones, por ejemplo los clientes del Banco Unión pueden habilitar Unitoken.
6. Si es usuario de Tigo solicite que no puedan recuperar su chip desde Tigomatic.
| ecampohermoso |
868,742 | Make your Blog into a App | Hey there, I hope you all are doing great. Recently i have been working on a Expo/Django Project... | 0 | 2021-10-19T10:00:13 | https://dev.to/mazahir26/make-your-blog-into-a-app-4f17 | opensource, typescript, mobile, android | Hey there, I hope you all are doing great. Recently i have been working on a Expo/Django Project which turns your blog into a app.
## Really?
Yes, you can make an app given that your **website has RSS support** and you are ready to do some set-up process.
(you can turn your *dev.to/[username]* into an app).
## How does it work?
- Basically, it's an app that takes your website's RSS feed and displays it in a nice app UI.
- For my fellow dev's out there, I have used Firebase, Django, expo and few more technology. You can check out the code in the github [repo](https://github.com/Mazahir26/Blog-App).
## Tell me more...
- Ever wanted to reach out to your readers and notify about some updates. if yes, then this app has got you covered, it has Push Notification support.
- Want to know how many users log-in and out of your app. we have got you covered, Custom Analytics(basic).
> Note: You can add your own Analytics service provider, if
you know how to.
- App has Guest login, save for later, and much more.
## Gotchas
- Currently there is no ad's in the app, So there is no revenue generated from this app.
- if you are an expo dev then you can add your own ad service.(if you want to)
## is it Free?
- Yep, its an open-source project.
- At first everything that i have used is free but if u want to scale it up or your readers go crazy with the app. then you might have to pay (not to me but to Heroku or Firebase).
## Where can i find it?
- You can learn more about the app and its features [here](https://github.com/Mazahir26/Blog-App).
## Thank you
Thanks for reading. hope you like it. Peace Out
| mazahir26 |
868,877 | Soonnnn Elite Bot Kids | A post by DanielJavaScript | 0 | 2021-10-19T13:46:34 | https://dev.to/danieljavascript/soonnnn-elite-bot-kids-3g4n | javascript, webdev, programming, html | 
 | danieljavascript |
868,887 | The Best Backend Programming Languages to Develop Uber Clone App in 2022 | The on-demand taxi service business today is very famous among entrepreneurs. As well, the... | 0 | 2021-10-19T14:03:33 | https://dev.to/georgedavid02/the-best-backend-programming-languages-to-develop-uber-clone-app-in-2022-1ejg | backend, php, laravel, programming | 
The on-demand taxi service business today is very famous among entrepreneurs. As well, the achievable marketplace holds notable market growth right from its first emerging to the till-date. Following, Uber clone app development in the digitized taxi service business provides a lot of advantages rather than others.
Considering the regular enhancements and business requirements, robust app development is always crucial in the business. In the collaboration of all development sides, the role of the backend programming is vital ever.
So, let’s discuss the importance and which backend programming languages are the best for your new Uber clone app development towards the future, in 2022.
##Importance of Selecting the Best Backend Program Language in Uber Clone Development
Today’s energetic entrepreneurs highly expect their business presence in the particular marketplace online should be earlier. As a result, they can gain double benefits that could launch their taxi app soon in the marketplace and reduce their development investment by short out app-building time period.
When you develop scalable apps that meet the expectation, you could simply attract your clients and start to build responsible taxi apps accordingly. This is the reason why you need to select the better back-end programming language at all. Following, the on-demand taxi service users online could access only the front-end of the mobile apps actually.
And, all the backend operations function depending on the program written in the back-end. It is the brain that carries out all the main responsibilities such as development speed, app security, scalability, etc. Through which, the new taxi app online possesses more progressiveness naturally to gain more profit acquiring high user traffic always in the future.
##Better Backend Programming Languages to Build Uber Clone App for 2022
Considering, to create revenue streaming on-demand readymade taxi service apps for the businesses, you can cleverly use the following backend programming languages. As it is the most expert developers’ choice in the present development market area, your new app creation using these can represent a high score in productivity enhancements.
**Laravel**
Laravel, the open-source Php framework is a robust programming language amongst others available in the market. It provides a significant combination of functionalities that incorporates the basic characteristics of Php such as Yii, Codelgniter, etc. You can make the entire development task extra easier by knowing core and advanced Php as an expert.
Majorly, your app would be more scalable and strong enough to prevent third-party access/attack in the service business operations online. Along with this, Laravel offers powerful features like authentication, testing, routing, modularity, query builder and object-relational mapper, and so on.
**Golang**
Golang is also another open-source backend programming language introduced by Google. It is highly popular amongst business app developers at present focusing on its great performance, readability, and expressiveness. Your utilization of this powerful source in taxi app development, makes the output contain the capability of speedy action, more secure, scalable function, etc.
When taxi app development focuses on a wide range of people in targeted regions, the full app development may require a complex system to build with. In that case, a back-end program is written using Golang surely results in high performance.
**Php**
Php, the top well-renowned backend programming language is widely used by several master developers in the taxi app development market. Your code using the effective language runs much faster as it uses its own memory space for loadings. And its flexible database connectivity smartly lets your new app connect with MySQL, the more secure Microsoft database product.
##Progressive Build-in Tech Solutions to Added to Your New Taxi App
The ready-to-go taxi app development focusing on the current and the future year 2022 user expectations must contain some in-built characteristics as listed below. While you choose the better backend programming language as discussed, the required could be smartly achieved by you for gainful development.
**Rapid User Onboardings and Service Access**
The taxi app you are going to build should possess a rapid user onboarding option. That could be finely possible with the social media integration solution. Through this, the passengers/customers can instantly get into the newly launched business app and get quick access to taxi bookings.
**Active Reports and Tracking**
A strong interlinking framework design between different user apps and apps to the cloud database should be available for the business. So that stuff like fast push notification sendings, rapid communication creation, and appropriate history tracking is finely possible to the users. And also, the live route mapping indication of the taxi app actively displays information online.
**Scalable Operations**
Above all, your backend programming should offer the taxi app users seamless performance between heavy competition. And, while you achieve easy-to-use app interface development for clients, they could simply get more user value along with great app user experiences from them online. That makes your complete app truly scalable to both you and your clients/service providers.
**End-to-end Data Encryption**
On account of the sensitive data transmissions and transactions possibilities in the app-based taxi service business, securing information is very crucial from all business angles. On that, while your ready-made app has end-to-end data protection, it finely prevents data theft and hackers access all the time.
###In Conclusion
The new app development for an on-demand taxi business startup is really powerful with the [Uber clone script] (https://www.unimaktechnologies.com/). By virtue of the importance of backend programming, it should be considered ever in the app development processes. Advanced languages like Laravel, Golang, and Php are the best sources to build taxi apps for gainful business in the year 2022.
| georgedavid02 |
869,226 | Database migration with Golang Goose | Managing Database migrations with Golang goose using incremental SQL changes | 0 | 2021-10-19T19:10:09 | https://citizix.com/managing-database-migrations-with-golang-goose-using-incremental-sql-changes/ | go, database, postgres | ---
title: Database migration with Golang Goose
published: true
description: Managing Database migrations with Golang goose using incremental SQL changes
tags: golang,database,postgres
canonical_url: https://citizix.com/managing-database-migrations-with-golang-goose-using-incremental-sql-changes/
//cover_image: https://direct_url_to_image.jpg
---
Database schema migration is the management of incremental, reversible changes and version control to relational database schemas. The migrations basically track granular changes to your database schema which are reflected as separate scripted files.
Golang Goose is a database migration tool. It allows you to manage your database schema by creating incremental SQL changes or Go functions.
Checkout this guide detailing how to manage database migrations with golang goose - https://citizix.com/managing-database-migrations-with-golang-goose-using-incremental-sql-changes/
| etowett |
869,381 | Elevation of Privilege | Méthode agile : Présentation générale Modèle de menace Un modèle de menace est un outil... | 0 | 2021-11-09T22:20:05 | https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/ | ---
title: Elevation of Privilege
published: true
date: 2020-03-16 15:12:08 UTC
tags:
canonical_url: https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/
---
Méthode agile : [Présentation générale](https://blog.limawi.io/fr-fr/posts/methode-agile-presentation-generale/)
## Modèle de menace
Un modèle de menace est un outil qui permet de déterminer à l’avance les fragilités d’un système et les moyens d’y remédier.
Dans la méthode agile, il est continuellement mis à jour. Il doit suivre le produit existant et s’adapter rapidement aux nouvelles évolutions.
Comment y parvenir ?
<video controls preload="auto" width="100%" poster="https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/videos/elevation-of-privilege.png" playsinline><source src="https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/videos/elevation-of-privilege.webm" type="video/webm">
</source></video>
## Schémas et diagrammes
Dans un premier temps, il est nécessaire de documenter votre projet. Il doit avoir des représentations visuelles de ses composants et des flux d’informations.
Une des manières de représenter ces données est le langage UML. Le problème est que ce langage est complexe à écrire et à mettre à jour pour un être humain.
Il est donc préférable d’automatiser au maximum la documentation et ses diagrammes (qu’ils soient en UML ou une autre représentation) pour pouvoir les produire facilement à chaque évolution du projet.
Si les diagrammes sont faits manuellement, des dessins de patates suffisent. Il faut juste qu’ils soient compréhensibles par tous les membres de l’équipe.
Une fois ces diagrammes faits, on va pouvoir les étudier pour en déceler les failles. Et ce, de façon ludique, grâce au jeu « `Elevation of Privilege` ».
## Les règles du jeu
Pour cela, prévoyez une phase de la [cérémonie](https://blog.limawi.io/fr-fr/posts/methode-agile-la-ceremonie/) de [_sprint_](https://dev.to/micheelengronne/le-sprint-et-le-scrum-266b-temp-slug-9950697) dédiée à ça.
L’équipe est assise autour d’une table. Le diagramme de la partie du projet à analyser est étalé sur la table visible de tous.
Le jeu de carte « _Elevation of Privilege_ » est disponible en dessous.
Distribuez toutes les cartes aux joueurs. La partie commence avec le « _3 of tampering_ ». Jouez dans le sens des aiguilles d’une montre.
Cela ressemble beaucoup aux règles du Tarot.
Chaque joueur continue dans la même suite s’il a une carte dans la suite. Sinon, il joue une carte d’une autre suite.
Chaque pli (un tour de table) est gagné par celui qui a la plus haute carte dans la suite demandée au départ, sauf si une carte « _Elevation of Privilege_ » est jouée (dans ce cas c’est la plus forte de ces cartes qui l’emporte).
Pour jouer une carte, le joueur doit l’annoncer et essayer de trouver sa menace sur le diagramme. Le système peut être résistant à cette menace. Dans ce cas, il est impossible de trouver la menace sur le diagramme.
Le joueur doit annoncer clairement sa menace. Pour être valide, elle doit amener à la création d’une histoire ([NFR d’ouverture de _bug_, _User Story_…](https://blog.limawi.io/fr-fr/posts/methode-agile-les-histoires/)) dans le projet.
À la fin du pli (quand tous les joueurs ont posé une carte de leur main), tous ceux qui ont réussi à trouver leur menace sur le diagramme ont un point. Si celui qui a gagné le pli a réussi aussi à trouver sa menace sur le diagramme, il gagne un point supplémentaire.
Le gagnant du pli démarre le pli suivant et choisit la suite de départ. Prenez quelques minutes entre chaque pli pour étudier les menaces.
<figcaption><p>Règles de Elevation of Privilege</p>
<small>Cela ressemble beaucoup aux règles du Tarot</small>
</figcaption>
Les cartes « _Elevation of privilege_ » gagnent sur toutes les autres. Elles ne peuvent être jouées que quand le joueur n’a pas de carte dans la suite demandée (ou si la suite demandée est elle-même « _Elevation of privilege_ »).
Les « As » sont des cartes qui permettent de trouver des menaces non prévues dans la suite demandée. Le joueur doit expliquer la menace elle-même.
Quand toutes les cartes ont été jouées (tous les plis ont été faits), celui qui a le plus de points l’emporte.
<figcaption><p>Règles de Elevation of Privilege, partie 2</p>
<small>Quand toutes les cartes ont été jouées (tous les plis ont été faits), celui qui a le plus de points l’emporte</small>
</figcaption>
Annotez votre diagramme en fonction des menaces trouvées.
Vous pouvez faire passer les mains d’un joueur à l’autre entre chaque pli. Cela permet que les joueurs spécialisés puissent jouer des cartes que des joueurs précédents ne comprenaient pas.
D’autres joueurs que celui qui annonce sa carte peuvent surenchérir sur sa carte en trouvant la menace annoncée à d’autres emplacements que ceux trouvés par celui qui joue. Ils gagnent un point supplémentaire.
Téléchargez « [_Elevation of Privilege_](https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/documents/elevation-of-privilege.pdf) » et son extension « [_Elevation of Privacy_](https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/documents/elevation-of-privacy.pdf) », avec les [règles EoP](https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/documents/regles-eop.pdf) et une planche de [dos de cartes](https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/documents/dos-de-cartes-eop.pdf).
## Sources
- [EoP](https://github.com/adamshostack/eop), [license Creative Commons attribution 3](https://creativecommons.org/licenses/by/3.0/us/)
- [Eop (extension privacy)](https://blog.logmeininc.com/privacy-by-design-can-be-entertaining/), [licence Creative Commons](https://creativecommons.org/)
- [EoPrivacy](https://github.com/F-Secure/elevation-of-privacy), [license Creative Commons attribution 4](https://creativecommons.org/licenses/by/4.0/)
<video controls preload="auto" width="100%" poster="https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/videos/story-elevation-of-privilege.png" playsinline><source src="https://blog.limawi.io/fr-fr/posts/elevation-of-privilege/videos/story-elevation-of-privilege.webm" type="video/webm">
</source></video> | micheelengronne | |
869,430 | Building progress indicator cards with a single css property | I recently had to implement an indicator of progress onto a card component, I challenged myself to see if this could be done with a single css property, here's how. | 0 | 2021-10-19T00:00:00 | https://griffa.dev/posts/building-progress-indicator-cards-with-a-single-css-property/ | html, css | ---
title: "Building progress indicator cards with a single css property"
date: "2021-10-19"
published: true
description: I recently had to implement an indicator of progress onto a card component, I challenged myself to see if this could be done with a single css property, here's how.
tags:
- HTML
- CSS
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/f5k8rm2vv3kiurczsgph.jpeg
canonical_url: https://griffa.dev/posts/building-progress-indicator-cards-with-a-single-css-property/
---
Here is a full demo of the css which I'll show you how to build, by learning the structure of the css `background` shorthand property.
{% codepen https://codepen.io/georgegriff/pen/RwZRBeJ %}
Before today I've always shied away from full understanding all of the shorthand property capability that is baked into the background `attribute` but today i'm going to change that, let's work it out together, let's deconstruct this bit of css that constructs the progress indicator card together:
```css
.progress-card {
background: linear-gradient(
to right,
#65ad60 0,
#65ad60 30%,
#faebd1 30%,
#faebd1 100%
) no-repeat 0 0/100% 10%, #ffdc9b no-repeat 0 0/100%;
}
```
You might be thinking, why do this with a single css property? You could just do this with multiple css properties or html elements, heck even the built in `meter` html element. These things are all true however there may be some cases where just manipulating a single css property to create effects like this is handy:
- You're in a design system and you can only change the background property.
- You're in some system where you are unable to modify the HTML.
- It's fun.
## Breaking down the css background property
Prior to experimenting to create this effect i'd never really gone into too much detail about the capabilities of the background property in css, but it is really quite fantastic! The fact that you can apply multiple backgrounds and their properties using a single css property is very powerful and not something i'd really appreciated before.
To understand css snippet from above it would probably be a good idea to expand into using the non-shorthand background properties, to help understand and breakdown what's going on above:
```css
.progress-card {
background: linear-gradient(
to right,
#65ad60 0,
#65ad60 30%,
#faebd1 30%,
#faebd1 100%
) no-repeat 0 0/100% 10%, #ffdc9b no-repeat 0 0/100%;
}
```
is equivalent to:
```css
.progress-card {
background-image: linear-gradient(
to right,
#65ad60 0,
#65ad60 30%,
#faebd1 30%,
#faebd1 100%
);
background-color: #ffdc9b;
background-size: 100% 10%, 100%;
background-repeat: no-repeat;
}
```
What is going on is that we have two backgrounds:
- a `linear-gradient` which starts off green `#65ad60`, moving to the right and at 30% turns into light cream `#faebd1`.
- a block sand-like color of `#ffdc9b`.
Note how we are separating the background with a comma `,`. The same is done for `background-size`. `background-repeat` has just one value because I want the same value for each background, but I could have done `background-repeat: no-repeat, no-repeat`.
For the `background-size` property we first have width, followed by height. So the first background size says a width of 100% and a height of 10% which gives us the height of the progress bar. The `no-repeat` is important, without it the background would just duplicate itself until it filled 100% of the image, as repeat is the default. It's probably useful to note that you may have multiple background images too, which can be an image url or a gradient.
### Converting to shorthand
To convert the `background-image`, `background-color`, `background-size` and `background-repeat` to the shorthand `background` it's similar to the long form properties. There is a slightly different syntax for `background-size` as you also need to account for `background-position` which is a property which I have omitted from my long hand, it would be something like:
```css
.progress-card {
background-image: linear-gradient(
to right,
#65ad60 0,
#65ad60 30%,
#faebd1 30%,
#faebd1 100%
);
background-color: #ffdc9b;
background-size: 100% 10%, 100%;
background-repeat: no-repeat;
/* this is the default */
background-position: 0 0;
}
```
In order to specify the `background-size` when using the `background` shorthand you must also specify the position, to do this you separate the position and the size with a forward-slash `/`.
For example, here is the first of the backgrounds:
```css
background: [image] [repeat] [position-x] [position-y] / [width] [height];
```
```css
.progress-card {
background: linear-gradient(
to right,
#65ad60 0,
#65ad60 30%,
#faebd1 30%,
#faebd1 100%
) no-repeat 0 0/100% 10%;
}
```
Whilst writing this article I came across [this handy website](https://shrthnd.volume7.io/) that generates the shorthand for you, test it out with the above css, you should get a single `background` property generated for you!
> Internally it looks like this website uses this package: https://github.com/frankmarineau/shrthnd.js.
Hopefully you can now see how we got to the final css, by adding in the`background-color` and position values after a comma `,`.
```css
background: linear-gradient(
to right,
#65ad60 0,
#65ad60 30%,
#faebd1 30%,
#faebd1 100%
) no-repeat 0 0/100% 10%, #ffdc9b no-repeat 0 0/100%;
```
There is a lot more to the css background property, as always, your best bet for research is [MDN](https://developer.mozilla.org/en-US/docs/Web/CSS/background).
## Spicy CSS Custom properties
Now we've had a play with the background property, let's see if we can make the css a little more useful, by introducing css custom properties we now have the possibility of re-using the same css with different values for percentage "progress", or changing the background colors.
> If you are new to CSS Custom properties Kevin Powell does a great introduction over [here](https://www.youtube.com/watch?v=PHO6TBq_auI).
```css
.progress-card {
width: 30ch;
padding: 2rem;
border-radius: 5px;
border: solid 1px #f1f1f1;
box-shadow: 0px 4px 6px -1px rgba(0, 0, 0, 0.5), 0px 2px 4px -1px rgba(0, 0, 0, 0.2);
color: #6c3d3d;
--progress-total: #faebd1;
--progress-indicator: #65ad60;
--progress-indicator-height: 10%;
--progress-card-background: #ffdc9b;
background: linear-gradient(
to right,
var(--progress-indicator) 0,
var(--progress-indicator) var(--progress, 30%),
var(--progress-total) var(--progress, 30%),
var(--progress-total) 100%
) no-repeat 0 0/100% var(--progress-indicator-height), var(
--progress-card-background
) no-repeat 0 0/100%;
}
```
```html
<div class="card-container">
<div class="progress-card" style="--progress:40%;">
<h4>Collect 5 Boar meat</h4>
<p>In progress: 2 of 5</p>
</div>
<div class="progress-card" style="--progress:20%">
<h4>Collect 5 pieces of Firewood</h4>
<p>In progress: 1 of 5</p>
</div>
<div class="progress-card" style="--progress:86%">
<h4>Collect 7 Raptor feathers</h4>
<p>In progress: 6 of 7</p>
</div>
<div class="progress-card" style="--progress:60%">
<h4>Collect five Iron ore</h4>
<p>In progress: 6 of 10</p>
</div>
</div>
```
Hopefully you can see how you can change the look of each "card" just by modifying the css custom property for that card only.
Here is a live demo of the html and css: https://codepen.io/georgegriff/pen/RwZRBeJ
## Make it a component
You could next choose to create a re-usable component, for example a Web Component, that could set the css custom properties and add appropriate aria attributes.
It's important to note that this css-based progress indicator is purely decoration, you will want to ensure that users with screen readers are able to understand what the component is conveying, using aria attributes in your HTML, or appropriate text labels.
> You can learn about ARIA basics on MDN [here](https://developer.mozilla.org/en-US/docs/Learn/Accessibility/WAI-ARIA_basics).
Thank you for reading! If you want to read more of my work, please follow me on Twitter [@griffadev](https://twitter.com/griffadev), or get me a [coffee](https://ko-fi.com/griffadev) if you feel like it ☕.
| griffadev |
869,449 | 3 Uncommon but useful HTML elements | 1) <abbr> The abbreviation <abbr> element is used to represent an acronym or... | 0 | 2021-10-20T14:55:46 | https://dev.to/js_bits_bill/3-uncommon-but-useful-html-elements-jdi | webdev, codenewbie, html, javascript | <h2>1) <code><abbr></code></h2>
The <b>abbreviation</b> `<abbr>` element is used to represent an acronym or abbreviation. If you include a `title` attribute, the text will be display as a tooltip on hover!
```html
<p>
The <abbr title="Product Detail Page">PDP</abbr> provides
information on a specific product.
</p>
```
<img src="https://res.cloudinary.com/dzynqn10l/image/upload/v1634687036/JS%20Bits/abbr_tag_oimzss.jpg">
<hr>
<h2>2) <code><progress></code></h2>
The `<progress>` element will display a progress bar indicator that can be easily controlled with it's `value` attribute. The JavaScript in this example will incrementally fill our progress bar every 100ms as shown here:
```html
<label for="progress">Progress:</label>
<progress id="progress" max="100" value="0"></progress>
<script>
const progress = document.querySelector('#progress');
let val = 0;
setProgress();
function setProgress() {
if (val > 100) val = 0;
progress.value = ++val;
setTimeout(setProgress, 100);
}
</script>
```
<img src="https://res.cloudinary.com/dzynqn10l/image/upload/v1634687087/JS%20Bits/progress_tag_jaqggk.gif">
<hr>
<h2>3) <code><wbr></code></h2>
The word break opportunity `<wbr>` element will allow you to specify exactly where a line of text should break when there is overflow. For example, if we have a super long line of text like this URL, we can tell the browser where the text should break if it doesn't fit on one line:
```html
<p>
http://is.this.just.real.life.com/is<wbr>/this/just/fantasy/caught/in/a/landslide/no/espace/from/reality
</p>
```
<img src="https://res.cloudinary.com/dzynqn10l/image/upload/v1634687008/JS%20Bits/wbr_z3gckm.jpg">
----------
<b>Yo!</b> I post byte-sized tips like these often. Follow me if you crave more! 🍿
I'm on [TikTok](https://www.tiktok.com/@js_bits), [Twitter](https://twitter.com/JS_Bits_Bill) and I have a new [debugging course](https://jsbits-yo.com/bug-bash/) dropping soon! | js_bits_bill |
869,551 | Concorrência em Go | Concorrência em Go Em Go é possível fazer programas que utilizam de concorrência para... | 0 | 2021-10-20T01:15:02 | https://brenoasrm.com/2021/10/11/concorrencia-em-go.html | go | ## Concorrência em Go
Em Go é possível fazer programas que utilizam de concorrência para melhorar o seu desempenho. A concorrência consiste em executar múltiplas funções independentes ao mesmo tempo para tentar otimizar a utilização de recursos e diminuir o tempo gasto com processamento.
Suponhamos que temos uma API que faz duas requisições para APIs de terceiros e cada uma delas demore 1 segundo. Em um código sequencial sem concorrência, nossa API demoraria no mínimo 2 segundos para responder. Caso as requisições para essas duas APIs sejam independentes, é possível fazer essas chamadas ao mesmo tempo. Essa abordagem poderia diminuir em 50% o tempo de resposta da nossa API somente com essa simples alteração para utilizar concorrência.
**Sem concorrência**
Abaixo vemos a imagem que representa o fluxo sem concorrência onde as requisições para serviços externos são feitas em sequência.

**Código sem concorrência**
```golang
package main
import (
"log"
"time"
)
func main() {
log.Println("inicio")
log.Println(requestApiTerceiros1())
log.Println(requestApiTerceiros2())
log.Println("fim")
}
func requestApiTerceiros1() string {
time.Sleep(1 * time.Second)
return "resposta api terceiros 1"
}
func requestApiTerceiros2() string {
time.Sleep(1 * time.Second)
return "resposta api terceiros 2"
}
```
**Resultado da execução do código**
```golang
go run main.go
2021/10/11 16:59:35 inicio
2021/10/11 16:59:36 resposta api terceiros 1
2021/10/11 16:59:37 resposta api terceiros 2
2021/10/11 16:59:37 fim
```
**Com concorrência**
Ao utilizar concorrência ambas as requisições podem ser feitas ao mesmo tempo para diminuir o tempo como mostra o fluxo da imagem abaixo.

**Código com concorrência**
```golang
package main
import (
"log"
"time"
)
func main() {
log.Println("inicio")
go requestApiTerceiros1()
go requestApiTerceiros2()
time.Sleep(5 * time.Second)
}
func requestApiTerceiros1() {
time.Sleep(1 * time.Second)
log.Println("resposta api terceiros 1")
}
func requestApiTerceiros2() {
time.Sleep(1 * time.Second)
log.Println("resposta api terceiros 2")
}
```
**Resultado da execução do código**
```golang
go run main2.go
2021/10/11 17:01:17 inicio
2021/10/11 17:01:18 resposta api terceiros 2
2021/10/11 17:01:18 resposta api terceiros 1
```
Em suma, podemos ver que conseguimos otimizar nosso código usando concorrência. Desse modo, é importante saber como trabalhar com concorrência para ter a habilidade de fazer o uso dessa característica da linguagem quando for apropriado.
É importante conhecer alguns conceitos da linguagem para trabalhar bem com concorrência, são eles:
- Go Routines
- Channels
- WaitGroup
## Go Routines
Uma Go routine é uma thread leve que é gerenciada pelo Go e é utilizada para rodar algum código específico que esteja dentro de uma função.
Não é preciso ter nenhuma característica específica para conseguir executar uma função dentro de uma Go Routine, basta utilizar a palavra chamada _go_ antes da chamada dessa função.
### Chamada de função normal
```golang
func main(){
sayHi(1)
}
func sayHi(n int){
fmt.Printf("hi %d\n", n)
}
```
### Chamada de função com Go Routine
```golang
func main(){
go sayHi(1)
}
```
Ao executar ambos os códigos é possível notar que na chamada normal de função é exibido na tela o texto normalmente, enquanto que ao chamar utilizando Go Routine o texto não é exibido.
O motivo de isso acontecer é porque esse código executa a função sayHi em uma thread separada e não fica esperando a finalização dessa thread. Como não existe mais nenhum código após a criação dessa Go Routine então o programa é finalizado sem nunca ter o retorno da função. Um jeito simples de resolver isso é adicionar um tempo de espera no código da seguinte forma:
```golang
func main(){
go sayHi(1)
time.Sleep(1 * time.Second)
}
```
Apesar dessa abordagem resolver o problema, ela está longe de ser a ideal pois nunca saberemos exatamente o tempo necessário para uma função ser executada e dessa forma estamos adicionando atraso no nosso código.
Esse exemplo acima foi feito apenas para entender a sintaxe utilizada para executar funções dentro de Go Routines e mostrar que o código não aguarda a execução dessas funções antes de continuar seu fluxo normal. Para o gerenciamento correto de Go Routines o Go possui mecanismos próprios para isso como **Channel** e **WaitGroup**.
## Channels
Channel é uma maneira que o Go possui de permitir a comunicação entre diferentes partes do código. Um dos cenários possíveis para se utilizar channels é para a comunicação entre Go Routines.
Para criar um novo channel basta criar uma nova variável do tipo `chan`, por exemplo:
```golang
var out chan string // valor default é nil
out := make(chan string, 1) // cria um channel vazio do tipo string que é capaz de armazenar 1 elemento
```
Ao criar uma variável do tipo channel o seu valor default é nil. Para inicializar o channel como sendo um channel vazio é preciso utilizar a função `make`, assim como é feito com variáveis do tipo slice e map.
O operador utilizado para inserir ou ler dados de um channel é o operador `<-`, com o sentido dessa seta apontando para onde o dado está indo.
**Código**
```golang
out := make(chan string, 1)
out <- "myString" //Adiciona uma string no channel criado
fmt.Println(<-out) //Imprime string armazenada no channel criado
```
**Resultado**
```
myString
```
Um fato interessante sobre como channels funcionam é que ao tentar ler o conteúdo de um channel vazio ou ao tentar escrever um dado em um channel sem espaço o código pára e fica esperando até ter espaço suficiente no channel. Podemos ver esse comportamento ao usar o exemplo acima só que removendo a escrita no channel:
**Código**
```golang
out := make(chan string, 1)
fmt.Println(<-out) //Imprime string armazenada no channel criado
```
**Resultado**
```
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
main.main()
/home/breno/programming/tmp/main.go:10 +0x39
exit status 2
```
A mensagem de erro mostra que ocorreu um deadlock pois não existe nenhuma Go Routine sendo executada além da função main e ela está parada esperando algo ser escrito no channel. O deadlock ocorre porque nunca será escrito algo no channel já que o main está parado tentando ler do canal e não existe nenhuma outra Go Routine sendo executada. Se criarmos uma Go Routine que não faz nada e que fique rodando direto, o erro não ocorre mais. Veja o exemplo abaixo:
**Código**
```golang
func main() {
out := make(chan string, 1)
go func() {
for {
}
}()
fmt.Print(<-out)
}
```
**Resultado**
```
Nada impresso na tela
```
Se for parar pra pensar, essa abordagem para solucionar o erro de deadlock nesse exemplo não resolve nenhum problema de fato pois esse problema de deadlock só existe porque estamos usando channel em um local que deveríamos estar usando uma simples variável do tipo string. No entanto, haverá casos onde essa tática será útil como quando formos construir alguma pipeline para execução de código concorrente.
### Compartilhando channels entre Go Routines
É possível compartilhar um channel entre várias Go Routines que estejam sendo executadas ao mesmo tempo como mostra o exemplo abaixo. Nesse código quatro diferentes rotinas são executadas ao mesmo tempo e a medida que dados são escritos no channel eles são mostrados na tela.
```golang
func main() {
out := make(chan string)
go sayHi(1, out)
go sayHi(2, out)
go sayHi(3, out)
go sayHi(4, out)
for i := 1; i <= 4; i++ {
fmt.Println(<-out)
}
}
func sayHi(n int, out chan string) {
out <- fmt.Sprintf("hi %d", n)
}
```
É interessante notar que o mesmo channel está sendo usado nas quatro Go Routines criadas. O channel foi criado com a função `make` sem passar o tamanho como segundo argumento, isso indica que o channel criado não possui buffer. Na prática isso indica que um dado só poderá fluir nesse canal quando tiver uma parte do código lendo e outra escrevendo pois não existe nenhum local para armazenar esse valor.
No exemplo acima, assim que uma Go Routine escrever no canal o channel será bloqueado para escrita até esse valor for removido do canal pela função Println, sendo assim não existe uma concorrência de fato nesse código já que as Go Routines criadas estão sempre aguardando a liberação do canal.
Também nesse exemplo, o programa não garante ordem de execução das Go Routines visto que são threads de execução independentes.
## WaitGroup
Um WaitGroup permite parar a execução do código e aguardar até que todas as Go Routines escolhidas terminem sua execução. Dessa forma, é possível fazer código que depende do resultado de múltiplas Go Routines. Veja abaixo um exemplo de uso de WaitGroup para aguardar a execução da execução de 4 Go Routines.
```go
package main
import (
"fmt"
"sync"
)
func main() {
// Cria uma variável do tipo WaitGroup
var wg sync.WaitGroup
for i := 1; i < 5; i++ {
// Adiciona 1 ao contador de Go Routines do WaitGroup wg
wg.Add(1)
// Cria Go Routine passando o WaitGroup criado como parâmetro
go sayHi(&wg, i)
}
// Aguarda até o contador de Go Routines do WaitGroup wg chegar a zero
wg.Wait()
fmt.Println("Fim")
}
func sayHi(wg *sync.WaitGroup, n int) {
fmt.Println(n)
// Decrementa o contador do WaitGroup wg
wg.Done()
}
```
## Select
Select é uma forma de escolher qual dos caminhos o código irá seguir, similar ao funcionamento do switch, mas nesse caso o select é utilizado com Channels. Caso o select não possua um caminho _default_ o código fica parado até que algum dos casos sejam satisfeitos. Veja abaixo um exemplo funcional e outro onde há deadlock.
**Código funcional**
```go
package main
import "fmt"
func main() {
var c1, c2 chan int
select {
case <-c1:
case <-c2:
default:
fmt.Println("Fim")
}
}
```
**Código com deadlock**
```go
package main
func main() {
var c1, c2 chan int
select {
case <-c1:
case <-c2:
}
}
```
**Resultado da execução desse código com deadlock**
```bash
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [select]:
main.main()
/home/breno/study-programming/go/select.go:5 +0x45
exit status 2
```
| brenoassp |
869,569 | Guide to building a Drone using Pixhawk 2.4.8 - Part 1 | In this first part, we'll look into all the parts we'll be using and what they do for the function of... | 0 | 2021-10-20T03:06:12 | https://dev.to/divyateja04/guide-to-building-a-drone-using-pixhawk-248-part-1-4abe | In this first part, we'll look into all the parts we'll be using and what they do for the function of the drone
## 1. The Control Board:
This is the main brain of the Drone and controls all the parts of the drone and ensures everything is in sync to make it fly. In this project we'll use Pixhawk as our control board(specifically version 2.4.8)
## 2. Motors:
These are the 4 motors that help in providing thrust to lift the drone of the ground, just remember two motors rotate clockwise while the other two rotate counter-clockwise for the same.
## 3. Propellors:

Here we observe we have two types of propellors and those are pusher props and the normal props, pusher props which have the **R** symbol on them are used for clockwise movement and the normal ones are used for counter-clockwise movement
## 4. Electronic Speed Controllers:
These help in sending and recieving signals between the motor and the control board. Each ESC has three wires(Red, black, white) which pertain to (vcc, gnd, signal) respectively.
For this build, we'll be removing the vcc cable and connecting the ESCs to the following ports:


## 5. GPS Module:
The GPS module which contains the GPS module and other extra miscellaneous instruments help in maintaining the stability of the drone in terms of altitude and other various aspects.
## 6. Battery and Battery Level Indicator:
A lipo battery is used to control the parts of the drone and is connected to a power connector which routes the power to the motors, and the pixhawk board simultaneously. You might need one depending on your build.

And please buy a Battery level indicator if you don't trust your batteries. Batteries fail a lot with me personally and so I used to have this which used to inform me whenever the batter level falls below a level after which I used to charge them.
## 7. Receiver and Transmitter:
For this you can use any RC modules but if you need to use more than 6 channels you probably would have to buy a PPM sum module too | divyateja04 | |
869,578 | Automate your Vue Icon Library | Implementing a maintainable icon library can be hard, especially when the icon is kept growing so the... | 0 | 2021-10-20T03:46:46 | https://dev.to/akbarnafisa/automate-your-vue-icon-library-3a3n | javascript, productivity, webdev, vue | Implementing a maintainable icon library can be hard, especially when the icon is kept growing so the maintainer needs to pay attention to the package size and always update the documentation for a better developer experience. In this post, I will share how to automate your Vue icon library to improve productivity.
You can see the full code and the documentation here:
- [Github](https://github.com/akbarnafisa/my-icon/tree/main-backup)
- [Documentation](https://my-icon.vercel.app/)
- [NPM Package](https://www.npmjs.com/package/@myicon/svgs)
# **The problem**
If you as a web developer, it's well known that you use icons in your website, whether it's to add functionality to your page or just make it pretty. If you work with teammates on multiple repositories and multiple projects, managing this icon can be cumbersome, especially if you dealing with undocumented and duplication icons in each repository.
Well, then let's create an icon library as the main package for all of the projects, but creating an icon library is not enough, the workflow to add or modify the icon should be easy and standardize, the documentation of the icon should be added immediately. Therefore you need to look for a solution to optimize the workflow for this icon library.
## The Solution
Let's start if we have a project with folder structure like this:
```bash
└── icon-library
├── assets
│ ├── icon-circle.svg
│ └── icon-arrow.svg
├── build
│ ├── generate-icon.js
│ └── optimize-icon.js
└── package.json
```
As we all know, adding an icon to a project is a tedious and repetitive task, the normal workflow usually you will put the icon in the `assets` folder then reference it in your Vue project, and you need to update the icon documentation if you don't forget.
But what if you can automate this process, so the only task you need is only adding or removing the icon from the `assets` folder, this process also can be used to generate meta info of the icon that will contain the size of the icon and also the path to the icon that can be used to update documentation the icon.
## Objectives
In this post, we'll show you how to create an icon library that will be easier to maintain:
- Part 1: Setup Project
- Part 2: Setup Icon Library Package
- Part 3: Setup Documentation
- Part 4: Deploy your Package to npm
- Part 5: Integration with Vercel
## Part 1: Setup Project
In this section, we’ll learn how to create a Vue icon library using yarn and monorepo. To get started, make sure you have the following:
```jsx
# setup new npm package
$ yarn init
# create a new Lerna repo
$ npx lerna init
```
Then add some `devDependencies` and `workspaces` to `package.json`
```json
{
"name": "my-icon-test",
"version": "1.0.0",
"main": "index.js",
"license": "MIT",
"private": true,
"workspaces": {
"packages": [
"packages/*"
]
},
"devDependencies": {
"eslint-friendly-formatter": "^4.0.1",
"eslint-loader": "^2.1.2",
"eslint-plugin-jest": "^23.17.1",
"lerna": "^4.0.0",
"babel-eslint": "^10.1.0",
"eslint": "^7.22.0",
"eslint-config-prettier": "^8.1.0",
"eslint-plugin-prettier": "^3.3.1",
"eslint-plugin-vue": "^7.7.0"
},
"engines": {
"node": ">= 10"
}
}
```
Also, update `lerna.json` file
```json
{
"packages": [
"packages/*"
],
"command": {
"version": {
"allowBranch": "main"
},
"publish": {
"conventionalCommits": true,
"allowBranch": "main",
"message": "chore(release): publish"
}
},
"npmClient": "yarn",
"useWorkspaces": true,
"registry": "https://registry.npmjs.org/",
"version": "independent"
}
```
and finally, add `jsconfig.json`to specify the root of the project
```json
{
"compilerOptions": {
"baseUrl": ".",
},
"exclude": [
"node_modules"
]
}
```
The project structure of the example will look like this:
```jsx
├── packages
├── package.json
├── lerna.json
├── jsconfig.json
```
## Part 2: Setup Icon Library Package
Init your icon library inside `packages` folder then create the folder structure as such
```json
├── jsconfig.json
├── lerna.json
├── package.json
└── packages
└── svgs
├── assets
│ ├── icon
├── build
├── components
├── index.js
├── rollup.config.js
├── CHANGELOG.md
└── package.json
```
We will put all of the icons inside the `assets` folder, and all build-related code located in the `build` folder.
Before we go any further, let me explain the main workflow of the build process:
- The contributor put the icon or illustrations inside `assets` folder
- Optimize the assets for `svg` files using `SVGO`
- Compile the `svg` file into `vue` component
- Compile the `vue` file of icons and illustrations into `esm` and `cjs` by using Rollup
### Optimize the Assets
For optimization, we’ll be using the [svgo](https://github.com/svg/svgo). SVG Optimizer is a Node.js-based tool for optimizing SVG vector graphics files.
```bash
$ cd packages/svgs
$ yarn add globby fs-extra svgo chalk -D
```
Next, we add optimization code, let's create main configuration file in `svgs/build/config.js`
```jsx
const path = require('path')
const rootDir = path.resolve(__dirname, '../')
module.exports = {
rootDir,
icon: {
// directory to get all icons
input: ['assets/icons/**/*.svg'],
// exclude icons to be build
exclude: [],
// output directory
output: path.resolve(rootDir, 'components/icons'),
// alert if the icon size exceed the value in bytes
maxSize: 1000,
},
}
```
then let's add optimiziation code to compress the svg file `svgs/build/optimize-icon.js`
```jsx
const config = require('./config.js')
const globby = require('globby')
const fse = require('fs-extra')
const { optimize } = require('svgo')
const chalk = require('chalk')
console.log(chalk.black.bgGreen.bold('Optimize Assets'))
globby([
...config.icon.input,
...config.icon.exclude,
'!assets/**/*.png',
'!assets/**/*.jpeg',
'!assets/**/*.jpg',
]).then(icon => {
icon.forEach(path => {
const filename = path.match(/([^\/]+)(?=\.\w+$)/)[0]
console.log(` ${chalk.green('√')} ${filename}`)
const result = optimize(fse.readFileSync(path).toString(), {
path,
})
fse.writeFileSync(path, result.data, 'utf-8')
})
})
```
This code will do this process
- Get all `.svg` files by using globby and also exclude some files that we will not use
- Then for each icon, read the file by using `fs-extra` and optimize it using `svgo`
- Last, override the `.svg` file with the optimized one
```jsx
<template>
<svg
viewBox="0 0 24 24"
:width="width || size"
:height="height || size"
xmlns="http://www.w3.org/2000/svg"
>
<path
d="M13 11V6h3l-4-4-4 4h3v5H6V8l-4 4 4 4v-3h5v5H8l4 4 4-4h-3v-5h5v3l4-4-4-4v3h-5z"
:fill="color"
/>
</svg>
</template>
<script>
export default {
name: 'IconMove',
props: {
size: {
type: [String, Number],
default: 24,
},
width: {
type: [String, Number],
default: '',
},
height: {
type: [String, Number],
default: '',
},
color: {
type: String,
default: '#A4A4A4',
},
},
}
</script>
```
### Generate Index and Metafile
After we create the Vue component, we need to add it to `index` files for the icons and also we need to update the `metafile` for the icons. The `index` files will be used to map all of the icons assets when we build the code into `cjs` and `esm` and the `metafile` will be used as a reference file to locate the icon in the build directory, this code will do:
- List all of the icons from `iconsFiles` and sort it alphabetically
- For each icon in `iconsInfo` get the icon name and icon path, and put it in `icons.js`, this file will be used as an entry in rollup to build our code to `cjs` and `esm`
- Lastly, stringify the `iconsInfo` and create `icons.json`, this file is a `metafile` that will be used to generate our documentation
```jsx
...
globby([...config.input, ...config.exclude]).then(icon => {
try {
const iconsFiles = []
....
const iconsInfo = {
total: iconsFiles.length,
files: iconsFiles.sort((a, b) => {
if (a.name === b.name) {
return 0
}
return a.name < b.name ? -1 : 1
}),
}
// generate icons.js
const indexIconPath = `${baseConfig.rootDir}/components/icons.js`
try {
fse.unlinkSync(indexIconPath)
} catch (e) {}
fse.outputFileSync(indexIconPath, '')
iconsInfo.files.forEach(v => {
fse.writeFileSync(
indexIconPath,
fse.readFileSync(indexIconPath).toString('utf-8') +
`export { default as ${v.name} } from './${v.path}'\n`,
'utf-8'
)
})
// generate icons.json
fse.outputFile(
`${baseConfig.rootDir}/components/icons.json`,
JSON.stringify(iconsInfo, null, 2)
)
} catch (error) {
console.log(` ${chalk.red('X')} Failed`)
console.log(error)
}
})
```
it will generate `components/icons.js`
```jsx
export { default as IconMove } from './icons/IconMove'
```
and generate `components/icons.json`
```json
{
"total": 1,
"files": [
{
"name": "IconMove",
"path": "icons/IconMove",
"size": 173
}
]
}
```
### Build Vue Component
The last step is to build `Vue` component into `esm` and `cjs` using [rollup](https://github.com/akbarnafisa/my-icon/blob/main-backup/packages/svgs/rollup.config.js)
```bash
$ cd packages/svgs
$ yarn add -D rollup-plugin-vue @rollup/plugin-commonjs rollup-plugin-terser @rollup/plugin-image @rollup/plugin-node-resolve rollup-plugin-babel @rollup/plugin-alias
```
```jsx
import path from 'path'
import globby from 'globby'
import vue from 'rollup-plugin-vue'
import cjs from '@rollup/plugin-commonjs'
import alias from '@rollup/plugin-alias'
import babel from 'rollup-plugin-babel'
import resolve from '@rollup/plugin-node-resolve'
import pkg from './package.json'
import image from '@rollup/plugin-image'
import { terser } from 'rollup-plugin-terser'
const production = !process.env.ROLLUP_WATCH
const vuePluginConfig = {
template: {
isProduction: true,
compilerOptions: {
whitespace: 'condense'
}
},
css: false
}
const babelConfig = {
exclude: 'node_modules/**',
runtimeHelpers: true,
babelrc: false,
presets: [['@babel/preset-env', { modules: false }]],
extensions: ['.js', '.jsx', '.es6', '.es', '.mjs', '.vue', '.svg'],
}
const external = [
...Object.keys(pkg.peerDependencies || {}),
]
const projectRootDir = path.resolve(__dirname)
const plugins = [
alias({
entries: [
{
find: new RegExp('^@/(.*)$'),
replacement: path.resolve(projectRootDir, '$1')
}
]
}),
resolve({
extensions: ['.vue', '.js']
}),
image(),
vue(vuePluginConfig),
babel(babelConfig),
cjs(),
production && terser()
]
function generateComponentInput(pathList) {
return pathList.reduce((acc, curr) => {
const filename = curr.match(/([^\/]+)(?=\.\w+$)/)[0]
return {
...acc,
[filename]: curr,
}
}, {})
}
export default globby([
'components/**/*.vue',
])
.then((pathList) => generateComponentInput(pathList))
.then((componentInput) => ([
{
input: {
index: './index.js',
...componentInput,
},
output: {
dir: 'dist/esm',
format: 'esm'
},
plugins,
external
},
{
input: {
index: './index.js',
...componentInput,
},
output: {
dir: 'dist/cjs',
format: 'cjs',
exports: 'named'
},
plugins,
external
},
]))
```
finally, let's add a script in our `package.json`, you can see the full config [here](https://github.com/akbarnafisa/my-icon/blob/main-backup/packages/svgs/package.json)
```json
{
"scripts": {
"build": "rm -rf dist && rollup -c",
"generate-svgs": "yarn run svgs:icon && yarn run prettier",
"prettier": "prettier --write 'components/**/*'",
"svgs:icon": "node build/build-icon.js",
"svgs:optimize": "node build/optimize-icon.js",
"prepublish": "yarn run build"
},
}
```
here is the detail for each script
- **`build:svgs`** - Compile the **`vue`** file of icons and illustration into **`esm`** and **`cjs`**
- **`generate-svgs`** - Compile the **`svg`** file into **`vue`** component
- **`prettier`** - Format the `vue` file after **`generate-svgs`**
- **`svgs:icon`** - Execute the `build-icon` script
- **`svgs:optimize`** - Optimize all of the **`svg`** assets using **`SVGO`**
- **`prepublish`** - Execute build script before publishing the package to
## Part 3: Setup Documentation
For documentation, we will use [Nuxt](https://nuxtjs.org/) as our main framework, to start the Nuxt project you can follow this command:
```bash
$ cd packages
$ yarn create nuxt-app docs
```
In this docs package, we will utilize the `metafile` from the icon, now let's install the icon globally in our documentation site, add `globals.js` inside the `plugins` folder
```jsx
import Vue from 'vue'
import AssetsIcons from '@myicon/svgs/components/icons.json'
const allAssets = [...AssetsIcons.files]
allAssets.forEach(asset => {
Vue.component(asset.name, () => import(`@myicon/svgs/dist/cjs/${asset.name}`))
})
```
then add it to `nuxt.config.js`
```jsx
export default {
...
plugins: [{ src: '~/plugins/globals.js' }],
...
}
```
### Icon Page
To show our icon in the documentation, let's create `icon.vue` in `pages` folder, to get the list of the icon we export `icons.json` from `svgs` packages, because we already install the icon globally, we can use the icon on any of our pages. On the icon page, you can see the full code [here](https://github.com/akbarnafisa/my-icon/blob/main-backup/packages/docs/pages/icons.vue)
```jsx
<template>
<div>
<div
v-for="item in AssetsIcons.files"
:key="item.name"
class="icon__wrapper"
>
<div class="icon__item">
<component :is="item.name" size="28" />
</div>
<div class="icon__desc">
{{ item.name }}
</div>
</div>
</div>
</template>
<script>
import AssetsIcons from '@myicon/svgs/components/icons.json'
export default {
name: 'IconsPage',
data() {
return {
AssetsIcons,
}
},
}
</script>
```
## Part 4: Deploy your Package to npm
To deploy a package to npm, you need to name it first, it can be scoped or unscoped (i.e., `package` or `@organization/package`), the name of the package must be unique, not already owned by someone else, and not spelled in a similar way to another package name because it will confuse others about authorship, you can check the package name [here](https://remarkablemark.org/npm-package-name-checker/).
```json
{
"name": "$package_name",
"version": "0.0.1",
"main": "dist/cjs/index.js",
"module": "dist/esm/index.js",
"files": [
"dist"
],
}
```
To publish package to npm, you need to create an account and login to npm.
```json
$ npm login
```
After you authenticate yourself, we will push the package by using `lerna`, in `package.json` at the root directory add this `script`.
```json
{
"scripts": {
"lerna:new-version": "lerna version patch --conventional-commits",
"lerna:publish": "lerna publish from-package"
},
}
```
To publish your package, you need to checkout to the `main` branch of your repository, then execute `lerna:new-version`. When run, it will update the version in the package.json, create and push tags to git remote, and update [CHANGELOG.md](https://github.com/akbarnafisa/my-icon/blob/main-backup/packages/svgs/CHANGELOG.md).
Finally execute `lerna:publish`. When it's executed, it will publish packages that have changed since the last release. If you successfully publish your package, you can check it in [npm](https://www.npmjs.com/package/@myicon/svgs)
## Part 5: Integration with Vercel
For continuous deployment we will use [Vercel](https://vercel.com/), to deploy your Nuxt project to Vercel you can follow [this guide](https://vercel.com/guides/deploying-nuxtjs-with-vercel) from Vercel, it's quite a straightforward tutorial, but you need to modify the build command to build the icon package first then build the Nuxt documentation, and also don't forget to set the root directory to `packages/docs` instead of the root directory of the repository. You can see the deployed documentation [here](https://my-icon.vercel.app/).
```bash
$ yarn workspace @myicon/svgs build && yarn build
```
## Conclusion
This blog post covers optimizing icons using svgo, the automation process for generating icons and documentation, publishing to npm, and continuous deployment using Vercel, these steps might seem a lot but this process provides an automatic setup for anyone to modify the assets in the icon library with the less amount of time.
In the end, the engineer or contributor that wants to add a new icon will only do these steps:
- Add icon to the repository
- Optimize and generate the Icon by running command line
- Preview the icon in the documentation that automatically generated
- If they are happy with the new/modified icon, they can create a merge request to the main branch to be published in the npm package
I hope this post helped give you some ideas, please do share your feedback within the comments section, I'd love to hear your thoughts!
## Resource
for icons and illustrations, we use [undraw](https://undraw.co/) and [coolicons](https://www.figma.com/community/file/800815864899415771) | akbarnafisa |
869,608 | Cómo instalar y configurar phpMyAdmin para tu entorno de desarrollo | Cuando estamos en la etapa de desarrollo de nuestro sistema, solución o aplicación, necesitamos... | 0 | 2021-11-19T22:24:22 | https://dev.to/iamjonathanpumares/como-instalar-y-configurar-phpmyadmin-para-tu-entorno-de-desarrollo-201c | php, phpmyadmin, mysql, mariadb | Cuando estamos en la etapa de desarrollo de nuestro sistema, solución o aplicación, necesitamos visualizar los detalles que contiene nuestra base de datos, ya sea consultar información, crear una nueva base de datos para el proyecto, correr un script para generar la estructura de la misma base de datos, insertar los datos, etc.
Para ello existen una gran variedad de clientes gráficos que podemos utilizar para conectarnos a nuestro servidor de base de datos. En esta ocasión quiero hablarte de phpMyAdmin, uno de mis clientes de bases de datos para MySQL favoritos, que utilizo para mi entorno de desarrollo.
Pero primero déjame contarte que es phpMyAdmin.
## ¿Qué es phpMyAdmin?
Es una herramienta de software libre escrita en PHP, para manejar la administración de bases de datos MySQL y MariaDB, y todo desde tu navegador favorito. Que sea meramente un cliente de interfaz gráfica no limita que no puedas utilizar sentencias SQL desde la propia interfaz.
## ¿Qué puedes hacer con phpMyAdmin?
Si hay algo que me encanta de phpMyAdmin es su interfaz intuitiva para tener todo a la mano desde unos cuantos clics.
Además de que cuenta con una cantidad de características para que la administración desde la interfaz sea más fácil.
Déjame decirte algunos:
* Navega entre tus bases de datos, tablas, campos, índices y vistas de una manera sencilla
* Crea, copia, elimina, renombra y modifica bases de datos, tablas y campos
* Administra los usuarios y privilegios de MySQL
* Importa datos desde archivos CSV y scripts SQL
* Exporta datos a varios formatos: CSV, SQL, XML, PDF y otros
* Administra múltiples servidores
* Y muchas más...
## ¿Aún no te convences?
Si aún no te convence utilizar phpMyAdmin, en su sitio oficial cuenta con una demo que puedes probar para que vayas viendo todas las posibilidades que tienes al usar esta herramienta.
Ve al sitio web oficial [https://www.phpmyadmin.net/](https://www.phpmyadmin.net/) y del lado superior derecho encontrarás un botón color verde con la leyenda **"Try demo"**, da clic en el botón y te abrirá enseguida la interfaz gráfica para que interactues con la demo. Prueba todas las opciones y dime que te parecen.
## Instalando y configurando phpMyAdmin
Si ya estas listo para empezar a usar phpMyAdmin vayamos a instalar y configurar esta maravillosa herramienta.
Existen muchas maneras de instalar phpMyAdmin, empezaremos viendo las opciones que tenemos para cada sistema operativo y luego veremos cómo hacerlo de forma manual independiente del sistema operativo que tengamos.
### Instalando phpMyAdmin usando XAMPP
La manera más fácil de instalar phpMyAdmin en Windows, Linux o macOS es usando un paquete de terceros que ya incluya phpMyAdmin, por lo que no tenemos que preocuparnos por instalarlo y configurarlo de manera separada.
Uno de esos paquetes es **XAMPP**, que es un conjunto o stack de tecnologías para montar tu entorno de desarrollo de una manera sencilla y que te incluye todo lo necesario para que empieces a desarrollar tus aplicaciones con PHP.
Qué es lo que incluye XAMPP:
* Apache como servidor web
* MariaDB como servidor de base de datos
* PHP como lenguaje de programación
* phpMyAdmin como cliente gráfico de bases de datos MySQL y MariaDB
* Entre otras herramientas más...
Si algo caracteriza a XAMPP es que el proceso de instalación para cada sistema operativo es muy sencillo, por lo que solamente tienes que descargar y ejecutar el instalador. [Aquí te dejo la página](https://www.apachefriends.org/es/download.html) para que lo descargues y lo instales en tu sistema operativo.
### Instalación manual
En caso de que tengas otro entorno de desarrollo diferente a XAMPP y que no incluya directamente phpMyAdmin tendremos que realizar la instalación manual de phpMyAdmin, pero no te preocupes ya que esto es muy sencillo.
¿Quieres conocer qué otros entornos de desarrollo puedes instalar?
Te dejo la siguiente infografía de Guardianes del Código:
Y el siguiente video para que conozcas más detalles de estas herramientas:
{% youtube -14TE06R6Eg %}
Ahora si vayamos a la instalación:
* Ve al sitio web oficial [https://www.phpmyadmin.net/](https://www.phpmyadmin.net/) y del lado superior derecho encontrarás el botón verde con la leyenda **Download**, enseguida se descargará un archivo **.zip** con el siguiente formato `phpMyAdmin-<version>-all-languages.zip` y que puedes guardarlo por el momento en cualquier ubicación de tu sistema de archivos.
* Descomprime el archivo **.zip**, si lo descomprimes directamente se guardará todo dentro de una carpeta con el siguiente formato `phpMyAdmin-<version>-all-languages`, te recomiendo renombrar el nombre de la carpeta por algo más sencillo como `phpmyadmin`.
* Identifica la carpeta **root** en donde tu entorno de desarrollo sirve o ejecuta directamente los archivos PHP. Si estas usando Laragon con Windows muy posiblemente esa ubicación sea `C:\laragon\www`, en otros entornos se conoce como `htdocs`. Copia en esa ubicación la carpeta `phpmyadmin` junto con todo su contenido.
* Verifica que estes ejecutando los servicios de tu entorno de desarrollo, es decir que tengas corriendo tanto tu servidor web como tu servidor de base de datos.
### Configuración de phpMyAdmin
* Abre tu editor de texto favorito y crea en la raíz de la carpeta `phpmyadmin` un archivo llamado `config.inc.php`, puedes copiar el contenido del archivo `config.sample.inc.php` que se encuentra igualmente en la raíz de la carpeta `phpmyadmin`.
* Ahora editaremos el archivo `config.inc.php`, quiero que te des cuenta en estas líneas de código:
```php
/**
* Servers configuration
*/
$i = 0;
/**
* First server
*/
$i++;
/* Authentication type */
$cfg['Servers'][$i]['auth_type'] = 'cookie';
/* Server parameters */
$cfg['Servers'][$i]['host'] = 'localhost';
$cfg['Servers'][$i]['compress'] = false;
$cfg['Servers'][$i]['AllowNoPassword'] = false;
```
Si te das cuenta en esas líneas de código estamos configurando nuestro primer servidor en el que nos conectaremos, como te había mencionado, la ventaja de phpMyAdmin es que nos podemos conectar a múltiples servidores de bases de datos MySQL.
En esa configuración nos hace falta agregar el usuario y la contraseña de nuestro servidor. Por lo general, en la mayoría de los entornos de desarrollo para PHP viene configurado por defecto en el servidor de bases de datos MySQL, un usuario **"root"** sin contraseña.
> Debes tomar en cuenta que se trata solamente de tu entorno de desarrollo en tu máquina local, por lo que tener un usuario **"root"** sin contraseña esta bien, pero no en un entorno en producción, en el que debes considerar unas configuraciones extras de seguridad para tus bases de datos.
Por lo que las líneas ahora quedarían de la siguiente manera:
```php
/**
* Servers configuration
*/
$i = 0;
/**
* First server
*/
$i++;
/* Authentication type */
$cfg['Servers'][$i]['auth_type'] = 'config';
/* Server parameters */
$cfg['Servers'][$i]['host'] = '127.0.0.1';
$cfg['Servers'][$i]['user'] = 'root';
$cfg['Servers'][$i]['password'] = '';
$cfg['Servers'][$i]['compress'] = false;
$cfg['Servers'][$i]['AllowNoPassword'] = true;
```
Bueno te explico los cambios que se hicieron, el primero es el cambio en el valor de `$cfg['Servers'][$i]['auth_type']` a `config`, esto evita estar introduciendo a cada rato el usuario y contraseña en la pantalla de inicio de sesión en phpMyAdmin.
Luego el valor en `$cfg['Servers'][$i]['host']` se cambio a `127.0.0.1`, esto garantiza que nos conectemos correctamente a nuestro servidor local.
Ahora en `$cfg['Servers'][$i]['user']` ponemos el usuario para conectarnos a nuestro servidor de base de datos, si tienes uno diferente a **"root"**, cambialo en su lugar. En `$cfg['Servers'][$i]['password']` pon la contraseña de tu servidor local, como te habia mencionado por lo general en un entorno local el usuario root no tiene contraseña, si manejas otro usuario o le pusiste contraseña a tu usuario **"root"** ponlo en su lugar.
Por último en `$cfg['Servers'][$i]['AllowNoPassword']` se cambio a `true` ya que es muy probable que tu usuario **"root"** no tenga contraseña y si no cambias su valor no te dejará conectarse sin una contraseña.
* Ya que tenemos todas nuestras configuraciones listas, es tiempo de probar en el navegador que todo funcione correctamente. Abre tu navegador y escribe la dirección hacia phpMyAdmin, si usas host virtuales en tu entorno de desarrollo, muy probablemente entres a una dirección como esta **phpmyadmin.test**, en caso de que no manejes host virtuales, muy probablemente entres a **localhost/phpmyadmin**.
* Verás enseguida la interfaz de administración de phpMyAdmin, ahora podrás interacturar con todas tus bases de datos y probar todas las ventajas que nos ofrece.
Y de esa manera es como tienes desde tu navegador una herramienta para administrar tus bases de datos en tu entorno de desarrollo.
Como nota adicional quiero decirte que no descartes la posibilidad de aprender o seguir utilizando tu linea de comandos para administrar tu servidor de base de datos, ya que posiblemente en algún momento vas a interactuar con algún servidor de producción que no precisamente cuenta con una interfaz gráfica, si no que todo es a través de comandos.
Cuéntame en los comentarios, ¿Ya conocías phpMyAdmin?, ¿Qué cliente de base de datos usas en tu día a día para administrarlas?
No dudes en compartir este post si te ha parecido genial, y dime que te gustaría en próximos posts, estaré encantado de compartir contigo para que aprendamos juntos. | iamjonathanpumares |
869,778 | What's New In DevTools (Chrome 95) | 1. New CSS length authoring tools DevTools added a simpler yet flexible way of refreshing... | 0 | 2021-10-20T07:04:00 | https://dev.to/binatenoor/whats-new-in-devtools-chrome-95-3j60 | webdev, devtools, javascript, programming |
## 1. New CSS length authoring tools
DevTools added a simpler yet flexible way of refreshing lengths in CSS!
In the Styles pane, look for any CSS property with length (e.g. height, padding).
## 2. Hide issues in the Issues tab
You would now be able to conceal explicit issues in the Issues tab to zero in just on those issues that make a difference to you.
In the Issues tab, hover over on an issue you would like to hide. Click on More options More > Hide issues like this.

All hidden issues will be added under the Hidden issues pane. Expand the pane. You can unhide all hidden issues or a selected one.

## 3. Improved the display of properties
DevTools improve the display of properties by:
-
Always bold and sort owns properties first in the **Console**, **Sources** panel, and **Properties **pane.
-
Flatten the properties display in the Properties pane.
For example, the snippet below creates an URL object link with 2 own properties: user and access, and updates the value of an inherited property search.
```
/* example.js */
const link = new URL('https://goo.gle/devtools-blog');
link.user = { id: 1, name: 'Jane Doe' };
link.access = 'admin';
link.search = `?access=${link.access}`;
```
Try logging the link into the Console. Own properties are now bold and sorted first. These changes make it easier to spot custom properties, especially for Web APIs (e.g. URL) with many inherited properties.

Apart from these changes, the properties in the Properties pane are also flattened now for better DOM properties debugging experience, especially for Web components.

## 4. Lighthouse 8.4 in the Lighthouse panel
The Lighthouse panel is now running Lighthouse 8.4. Lighthouse will now detect if the Largest Containful Paint (LCP) element was a lazy-loaded image and recommend removing the loading attribute from it.

## 5. Sort snippets in the Sources panel
The snippets in the Snippets pane under the Sources panel are now sorted alphabetically. Previously, it’s not sorted.
Utilize the snippets feature to run commands quicker.

## 6. Report a translation bug and New links to translated release notes
You can now click to read the DevTools release notes in 6 other **languages **- **Russian**, **Chinese**, **Spanish**, **Japanese**, **Portuguese**, and **Korean **via the What’s new tab.
Since Chrome 94, you can set your preferred language in DevTools. If you found any issues with the translations, help us improve it by reporting a translation issue via More options > Help > Report a translation bug.

## 7. Improved UI for DevTools command menu
Did you find it hard to search for a file in the Command Menu? Good news for you, the Command Menu user interface is now enhanced!
Open the Command Menu to search for a file with keyboard shortcut Control+P in Windows and Linux, or Command+P in MacOS.
The UI improvements of the Command Menu are still ongoing, stay tuned for more updates!

Thanks for reading this!
## Follow Me:
- Hire me:[Fiverr](https://fiverr.com/binatenoor) (WordPress Website Developer & Designer | SEO)
- 20 [Google Chrome Extension](https://techbinate.com/20-google-chrome-extensions-for-freelancer-work/) Which helpful for freelancer work
- 3 Ways To Get Your First Order on [Fiverr](https://techbinate.com/3-ways-to-get-your-first-order-on-fiverr-in-2022/) in 2022
- [5 Free Books Reading Online](https://techbinate.com/free-books-reading-online/)
- [What is Freelancing and How does Freelancing work?](https://techbinate.com/what-is-freelancing-and-how-does-freelancing-work)
- [5 High Demand Internet Marketing Services in 2022](https://techbinate.com/5-high-demand-internet-marketing-services-in-2022/)
- [6 Best Weight loss Apps Help You Hit Your Goals](https://techbinate.com/best-weight-loss-app/)
| binatenoor |
869,814 | Customize IBus User Guide | CSDN link: https://blog.csdn.net/qq_18572023/article/details/118487988 My blog link:... | 0 | 2021-10-20T08:21:13 | https://dev.to/hollowman6/customize-ibus-user-guide-4lbl | ibus, ui, ime, linux | CSDN link: https://blog.csdn.net/qq_18572023/article/details/118487988
My blog link: https://hollowmansblog.wordpress.com/2021/08/21/customize-ibus-user-guide/
[中文 Chinese](https://blog.csdn.net/qq_18572023/article/details/116331601)
## GNOME Desktop
First, make sure you have installed the GNOME Shell Extension: Customize IBus [https://extensions.gnome.org/extension/4112/customize-ibus/](https://extensions.gnome.org/extension/4112/customize-ibus/)
### Installation
You can refer to here: [https://itsfoss.com/gnome-shell-extensions/](https://itsfoss.com/gnome-shell-extensions/) to install the GNOME Shell Extension from a web browser.
or
- Linux:
```bash
git clone https://github.com/openSUSE/Customize-IBus.git
cd Customize-IBus && make install
```
- FreeBSD:
```sh
git clone https://github.com/openSUSE/Customize-IBus.git
cd Customize-IBus && gmake install
```
If you want to install Customize IBus as a system extension for all users:
- For Arch based:
```bash
yay -S gnome-shell-extension-customize-ibus
```
[](https://aur.archlinux.org/packages/gnome-shell-extension-customize-ibus/)
- For Fedora:
```bash
wget https://github.com/openSUSE/Customize-IBus/raw/package-repo/customize-ibus-rpm.repo
sudo mv customize-ibus-rpm.repo /etc/yum.repos.d/
sudo dnf update
sudo dnf install gnome-shell-extension-customize-ibus
```
- For OpenSUSE:
```bash
wget https://github.com/openSUSE/Customize-IBus/raw/package-repo/customize-ibus-rpm.repo
sudo mv customize-ibus-rpm.repo /etc/zypp/repos.d/
sudo zypper refresh
sudo zypper install gnome-shell-extension-customize-ibus
```
Or install directly through the [ymp file](https://software.opensuse.org/ymp/home:hollowman/openSUSE_Factory/gnome-shell-extension-customize-ibus.ymp).
- For Debian based (Ubuntu):
```bash
echo "deb http://opensuse.github.io/Customize-IBus/deb/ /" | sudo tee -a /etc/apt/sources.list.d/customize-ibus-deb.list > /dev/null
wget -q -O - http://opensuse.github.io/Customize-IBus/hollowman.pgp | sudo apt-key add -
sudo apt update
sudo apt install gnome-shell-extension-customize-ibus
```
PPA:
```bash
sudo add-apt-repository ppa:hollowman86/customize-ibus
sudo apt-get update
```
You can download the majority of your Linux distributions related packages through [OpenSUSE OBS](https://software.opensuse.org//download.html?project=home%3Ahollowman&package=gnome-shell-extension-customize-ibus) and then install.
- Gentoo:
```bash
git clone https://github.com/openSUSE/Customize-IBus.git
cd Customize-IBus && make emerge
```
- NixOS:
```bash
sudo nix-env -i gnomeExtensions.customize-ibus
```
- Guix:
```bash
guix install gnome-shell-extension-customize-ibus
```
- FreeBSD:
```sh
wget https://github.com/openSUSE/Customize-IBus/raw/package-repo/customize_ibus.conf
sudo mkdir -p /usr/local/etc/pkg/repos/
sudo mv customize_ibus.conf /usr/local/etc/pkg/repos/
sudo pkg update
sudo pkg install gnome-shell-extension-customize-ibus
```
After installation, you will find that there is an additional entry `Customize IBus` in the IBus input source indicator menu. Click it, and you will open the Customize IBus preferences. If there is no such menu entry, you can press `Alt+F2` to restart the GNOME shell, or log out and log in again. If that still doesn't work, please make sure you have installed the latest version of the extension and have enabled the extension.

You can also click the configuration icon of the Customize IBus extension in [https://extensions.gnome.org/local/](https://extensions.gnome.org/local/) to open the preferences.
### General

At item `Candidates orientation`, select the check box on the left to enable the configuration of the IBus candidate box direction. Click on the right side to select, it can be set to vertical or horizontal.
At item `Candidates popup animation`, select the check box on the left to enable the configuration of the IBus animation. Click on the right side to select, support setting to no animation, slide, fade, and both.
Example to turn on the sliding animation:
At item `Candidate box right click`, select the check box on the left to enable the configuration of right-click the candidate box to perform related operations when using the IBus. Click on the right to make a selection, and you can set to open the tray menu or switch the input source.
At item `Candidates scroll`, select the check box on the left to enable the configuration of actions performed when scrolling using the IBus. Click on the right to select, and you can set to switch the current candidate word or page.
At item `Fix candidate box`, select the check box on the left to enable a fixed candidate box. Click on the right to select. You can set the candidate box position with 9 options. Recommend to enable `Drag to reposition candidate box` at the same time so that you can rearrange the position at any time. Will remember candidate position forever after reposition if you set to `Remember last position`, and restore at next login.
At item `Use custom font`, select the check box on the left to enable configuration of the font and size of the text in the IBus candidate box. Click on the right to open the font selector. In the pop-up dialog box, you can select the font you want in the upper part and the font size in the lower part. Click `Select` to confirm the modification.

At item `Auto switch ASCII mode`, select the check box on the left to enable configuration of switching ASCII mode when switching windows, Click on the far right to select. It supports setting to make ASCII mode on and off, or just keep to remain current mode. You can also set to remember input state or not on the near right. If you have set to `Remember Input State`, every opened APP's input mode will be remembered if you have switched the input source manually in the APP's window, and the newly-opened APP will follow the configuration. APP's Input State will be remembered forever.
At item `Candidate box opacity`, select the check box on the left to enable configuration of the opacity in the IBus candidate box. Slide the right button to configure opacity ranging from 0 to 255 step 1.
At item `Fix IME list order`, click the switch on the right to turn this feature on or off.
If you use multiple input methods in your system, when you use the keyboard shortcut to switch input methods (usually `Win + Space`), the input method displayed by default on the screen will be sorted by the most recently used input method. Turn on this feature to modify the order of input methods as fixed.
When off:

When on:

At item `Enable drag to reposition candidate box`, click the switch on the right to turn this feature on or off.
Example of turning on `drag to reposition candidate box`:
At item `Candidate box page buttons`, click the switch on the right to show or hide the candidate page buttons.
### Tray
Here you can set to show IBus tray icon, enable directly switch source with click, add additional menu entries to IBus input source indicator menu at system tray to restore the feelings on Non-GNOME desktop environment.
All menus are enabled:

You can also start or restart IBus by pressing the top button:

### Indicator
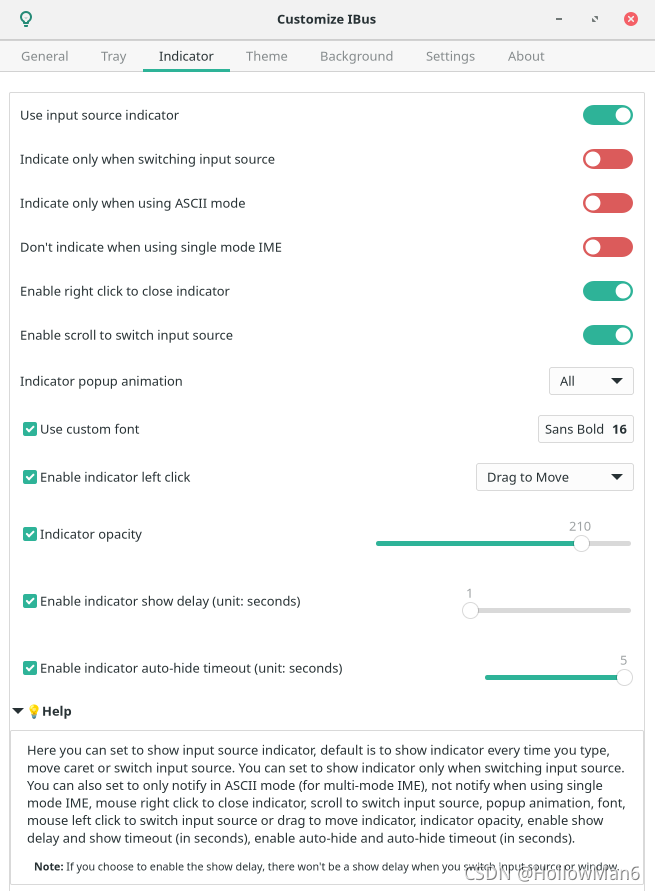
Here you can set to `Use input source indicator`, default is to show indicator every time you type, move caret or switch input source. You can set to `Indicate only when switching input source` by clicking the switch on the right. You can also set to `Indicate only when using ASCII mode` (for multi-mode IME), `Don't indicate when using single mode IME`, `Right click to close indicator`, `Scroll to switch input source`, `Indicator popup animation` supporting `None`, `Slide`, `Fade`, `All`. Also support to `Use custom font`, `Enable indicator left click` to switch input source or drag to move indicator, set `Indicator opacity` supporting range of 0 to 255, and the setting step is 1. `Enable indicator show delay (unit: seconds)`, `Enable indicator auto-hide timeout (unit: seconds)` and auto-hide timeout (in seconds) supporting to set the hidden delay in the range of 1 second to 5 seconds, and the setting step is 1.
**Note:** If you choose to enable the show delay, there won't be a show delay when you switch input source or window.
Example animation:
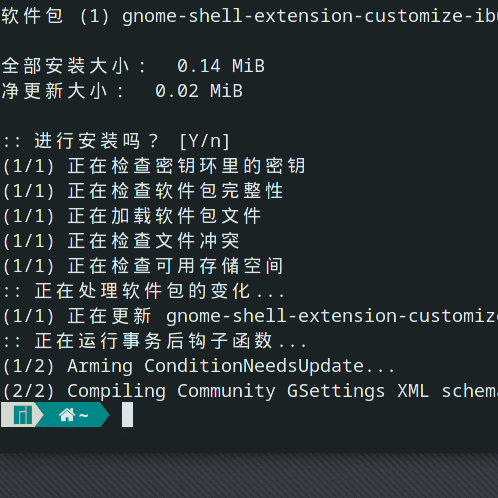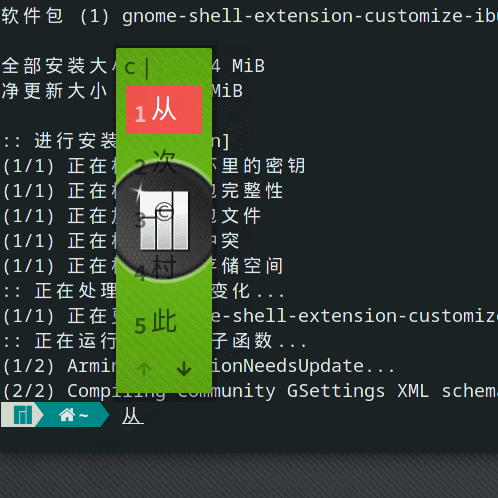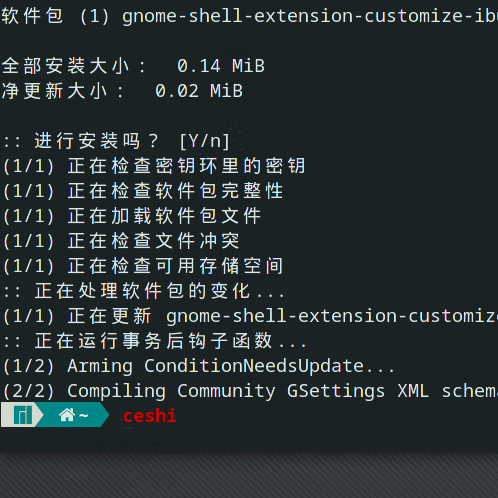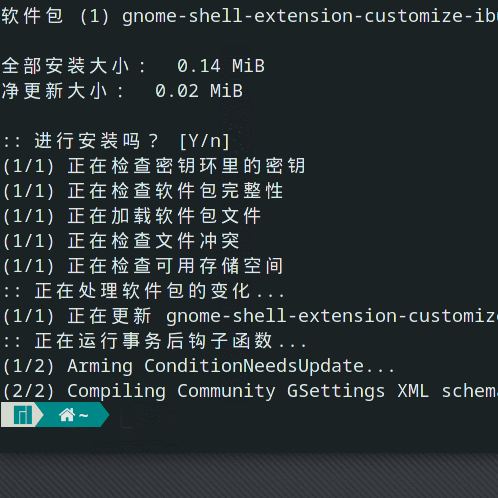
### Theme
Same as the general part, select the check box on the left to enable the configuration, and click on the right to select the IBus theme style sheet.
If you have selected a style sheet, click the icon on the far right to directly open it to view the style sheet. You can also click the clear icon to make it follow system theme.
Supports importing style sheets generated by the [IBus Theme Tools](https://github.com/openSUSE/IBus-Theme-Tools) or provided by the [IBus Theme Hub](https://github.com/openSUSE/IBus-Theme-Hub).
When light theme and dark theme are turned on at the same time, the IBus theme will automatically follow GNOME Night Light mode, use light theme when off, and use dark theme when on. When only the light theme or dark theme is turned on, the IBus theme will always use the theme that is turned on.
If not for debugging, please DO NOT add any classes that's not started with <i>.candidate-\*</i> into IBus stylesheet to prevent from corrupting system themes.
~~If your IBus style sheet has changed after application, please close and reopen the corresponding `custom IME theme` to make it effective.~~ Starting from v69, now this extension support stylesheets hot reload, CSS changes will reflect in real-time.
You can download more GNOME Shell themes from this website: [https://www.pling.com/s/Gnome/browse/cat/134/order/latest/](https://www.pling.com/s/Gnome/browse/cat/134/order/latest/), then put it under the `$HOME/.themes/` directory to complete the installation.
The [IBus theme tool](https://github.com/openSUSE/IBus-Theme-Tools) style sheet generation uses the GNOME Shell theme that has been installed on the computer to extract the IBus style. The extraction steps are as follows:
1. Refer to the following part: `Non-GNOME Desktop` -> `Customize IBus Theme` steps 1-2 to run the program.
2. Enter the number of the IBus-related GNOME Shell theme style you want to export, and press `Enter`.

3. Enter the location of the GNOME Shell theme style sheet exported related to IBus that you want to store, and press `Enter`. Empty selection will be the default, that is in the current directory `exportedIBusTheme.css` file. If there is no error message, it will be successfully exported to the specified location.

Example export file:
```css
/*
Generated by IBus Theme Tools
Tool Author: Hollow Man <hollowman@hollowman.ml>
Tool Source Code: https://github.com/openSUSE/IBus-Theme-Tools
Tool Licence: GPLv3
CSS Source File: /usr/share/gnome-shell/theme/gnome-classic-high-contrast.css
Recommend to use Customize IBus GNOME Shell Extension:
https://extensions.gnome.org/extension/4112/customize-ibus/
to change IBus theme by selecting this file.
If you make any changes to this content after applying this file in above extension,
for Customize IBus Extension before v68, please disable and then enable 'custom IME theme'
again to make the changes take effect.
Starting from v69, support stylesheets hot reload, CSS changes reflecting in real-time.
*/
/*
Imported from CSS Source File: /usr/share/gnome-shell/theme/gnome-classic.css
*/
.candidate-page-button:focus {
color: #2e3436;
text-shadow: 0 1px rgba(255, 255, 255, 0.3);
icon-shadow: 0 1px rgba(255, 255, 255, 0.3);
box-shadow: inset 0 0 0 2px rgba(53, 132, 228, 0.6);
}
.candidate-page-button:hover {
color: #2e3436;
background-color: white;
border-color: #d6d1cd;
box-shadow: 0 1px 1px 0 rgba(0, 0, 0, 0.1);
text-shadow: 0 1px rgba(255, 255, 255, 0.3);
icon-shadow: 0 1px rgba(255, 255, 255, 0.3);
}
.candidate-page-button:insensitive {
color: #929595;
border-color: #e1ddda;
background-color: #faf9f8;
box-shadow: none;
text-shadow: none;
icon-shadow: none;
}
.candidate-page-button:active {
color: #2e3436;
background-color: #efedec;
border-color: #cdc7c2;
text-shadow: none;
icon-shadow: none;
box-shadow: none;
}
.candidate-index {
padding: 0 0.5em 0 0;
color: #17191a;
}
.candidate-box:selected,
.candidate-box:hover {
background-color: #3584e4;
color: #fff;
}
.candidate-page-button-box {
height: 2em;
}
.vertical .candidate-page-button-box {
padding-top: 0.5em;
}
.horizontal .candidate-page-button-box {
padding-left: 0.5em;
}
.candidate-page-button-previous {
border-radius: 5px 0px 0px 5px;
border-right-width: 0;
}
.candidate-page-button-next {
border-radius: 0px 5px 5px 0px;
}
.candidate-page-button-icon {
icon-size: 1em;
}
.candidate-box {
padding: 0.3em 0.5em 0.3em 0.5em;
border-radius: 5px; /* Fix candidate color */
color: #2e3436;
}
.candidate-popup-content {
padding: 0.5em;
spacing: 0.3em; /* Fix system IBus theme background inherited in replaced theme */
background: transparent;
/* Fix system IBus theme candidate window border inherited in replaced theme */
border: transparent;
/* Fix system IBus theme candidate box shadow inherited in replaced theme */
box-shadow: none;
/* Fix candidate color */
color: #2e3436;
}
.candidate-popup-boxpointer {
-arrow-border-radius: 9px;
-arrow-background-color: #f6f5f4;
-arrow-border-width: 1px;
-arrow-border-color: #cdc7c2;
-arrow-base: 24px;
-arrow-rise: 12px;
-arrow-box-shadow: 0 1px 3px rgba(0, 0, 0, 0.5); /* Fix black border at pointer when system theme is black */
border-image: none;
}
/* Unify system page button and IBus style page button */
.candidate-page-button {
border-style: solid;
border-width: 1px;
min-height: 22px;
padding: 3px 24px;
color: #2e3436;
background-color: #fdfdfc;
border-color: #cdc7c2;
box-shadow: 0 1px 1px 0 rgba(0, 0, 0, 0.1);
text-shadow: 0 1px rgba(255, 255, 255, 0.3);
icon-shadow: 0 1px rgba(255, 255, 255, 0.3); /* IBus style page button */
padding: 4px;
}
/* EOF */
```
You can also go directly to the [IBus Theme Hub](https://github.com/openSUSE/IBus-Theme-Hub) and download specialized made IBus theme style sheet file. Here are the IBus theme style sheet files with Microsoft IME style: [https://github.com/openSUSE/IBus-Theme-Hub/tree/main/%E4%BB%BF%E5%BE%AE%E8%BD%AFMicrosoft](https://github.com/openSUSE/IBus-Theme-Hub/tree/main/%E4%BB%BF%E5%BE%AE%E8%BD%AFMicrosoft)
### Background
Support customizing your IBus Input window background with a picture. It has a higher priority than the theme-defined background.
If you have selected a picture, click the icon on the far right to directly open and view the picture. You can also click the clear icon to make it follow theme background.
When light background and dark background are turned on at the same time, the IBus background will automatically follow GNOME Night Light mode, use light background when off, and use dark background when on. When only the light background or dark background is turned on, the IBus background will always use the background that is turned on.
Please make sure your background picture can always be visited. If your pictures are stored in the removable device and the system doesn't mount it by default, please disable and then enable the corresponding `Use custom background` again to make it effective after manually mounting.
Same as the general part, select the check box on the left to enable the configuration, and click on the right to select the background image of the IBus input candidate box.
You can also set the background picture display mode, you can set whether the background picture is displayed repeatedly, or the display mode Centered, Full or Zoom.
Examples of various picture display modes (using 128x128 compressed pictures: [https://github.com/openSUSE/Customize-IBus/blob/main/customize-ibus%40hollowman.ml/img/logo.png](https://github.com/openSUSE/Customize-IBus/blob/main/customize-ibus%40hollowman.ml/img/logo.png) ):

- **Centered + No repeat**:

- **Centered + Repeat**:

- **Full + No repeat**:
- **Full + Repeat**:

- **Zoom + No Repeat/Repeat (equivalent)**:

### Settings
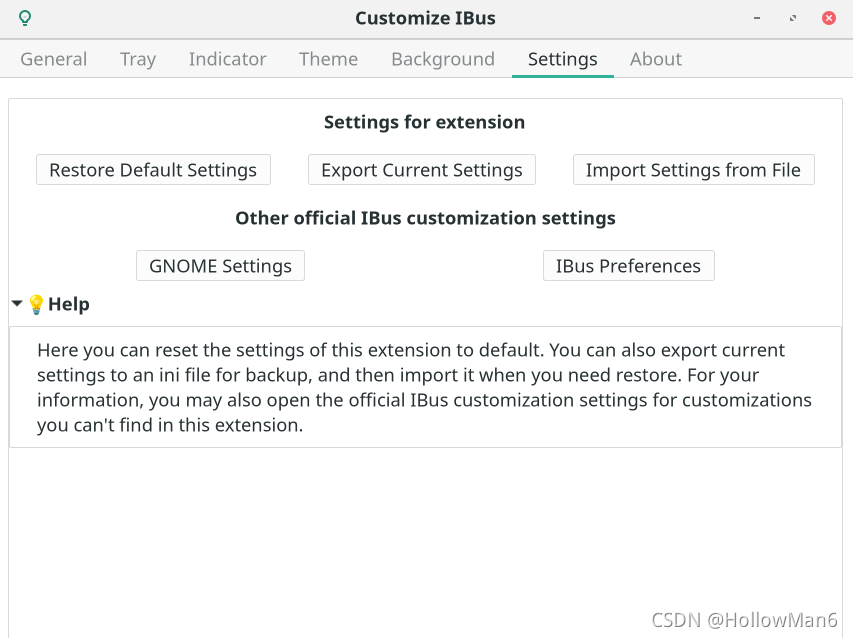
Here you can reset the settings of this extension to default. You can also export current settings to an `ini` file for backup, and then import it when you need restore. For your information, you may also open the official IBus customization settings for customizations you can't find in this extension.
Click `Restore Default Settings`, after confirming, you can re-initialize the extension.

Click `Export Current Settings`, you can choose to export the current settings as a `*.inifile`. The default file name is `Customize_IBus_Settings_[Current Time].ini`:

Example settings export file content:
```ini
[/]
candidate-box-position={'x': uint32 0, 'y': 0}
candidate-opacity=uint32 210
candidate-orientation=uint32 0
candidate-scroll-mode=uint32 0
custom-bg='/home/hollowman/图片/light.jpg'
custom-bg-dark='/home/hollowman/图片/dark.jpg'
custom-bg-mode=uint32 2
custom-bg-repeat-mode=uint32 1
custom-font='Sans 16'
custom-theme='/home/hollowman/stylesheet.css'
custom-theme-dark='/home/hollowman/stylesheet-dark.css'
enable-custom-theme=true
enable-custom-theme-dark=true
enable-orientation=true
fix-ime-list=true
ibus-restart-time='1625063857427'
indicator-custom-font='Sans Bold 16'
indicator-left-click-func=uint32 0
indicator-opacity=uint32 210
input-indicator-hide-time=uint32 2
input-indicator-not-on-single-ime=true
input-indicator-right-close=true
input-indicator-show-time=uint32 1
input-indicator-use-scroll=true
input-mode-list={'undefined': true, '': false, 'gjs': false, 'org.gnome.nautilus': false, 'google-chrome-beta': false, 'gedit': false, 'gnome-terminal': true, 'code': false, 'org.gnome.shell.extensions': true}
input-mode-remember=uint32 0
menu-ibus-emoji=true
menu-ibus-exit=true
menu-ibus-preference=true
menu-ibus-restart=true
menu-ibus-version=true
use-candidate-box-right-click=true
use-candidate-buttons=false
use-candidate-opacity=true
use-candidate-reposition=true
use-candidate-scroll=true
use-candidate-still=false
use-custom-bg=true
use-custom-bg-dark=true
use-custom-font=true
use-indicator-auto-hide=true
use-indicator-custom-font=true
use-indicator-left-click=true
use-indicator-opacity=true
use-indicator-reposition=true
use-indicator-show-delay=true
use-input-indicator=true
use-popup-animation=true
use-tray=true
use-tray-click-source-switch=true
```
Click `Import Settings from File`, you can choose to import the settings file you just saved:

### About
At any time, you can click on the icon in the upper left corner to open this guide:

## Non-GNOME desktop
### Customize IBus theme
In non-GNOME Shell desktop environment, the display effect of IBus is determined by the current GTK theme.
You can download more GTK3/4 themes from this website: [https://www.gnome-look.org/browse/cat/135/](https://www.gnome-look.org/browse/cat/135/), then put them in the `$HOME/.themes/` directory to complete the installation.
The following steps can change the GTK theme of IBus:
1. First, Install [ibus-theme-tools](https://github.com/openSUSE/IBus-Theme-Tools):
Recommend to use pip to install:
```bash
pip install ibus-theme-tools
```
You can also install manually:
```bash
git clone https://github.com/openSUSE/IBus-Theme-Tools.git
cd IBus-Theme-Tools && python3 setup.py install
```
For install using package manager:
- Arch Linux
You can use AUR to install:
```bash
yay -S ibus-theme-tools
```
[](https://aur.archlinux.org/packages/ibus-theme-tools/)
- Ubuntu:
You can use PPA to install:
```bash
sudo add-apt-repository ppa:hollowman86/ibus-theme-tools
sudo apt-get update
```
- openSUSE
You can install directly through the [ymp file](https://software.opensuse.org/ymp/home:hollowman/openSUSE_Factory/ibus-theme-tools.ymp).
You can download the majority of your Linux distributions related packages through [OpenSUSE OBS](https://software.opensuse.org//download.html?project=home%3Ahollowman&package=ibus-theme-tools) and then install.
- Gentoo:
```bash
git clone https://github.com/openSUSE/IBus-Theme-Tools.git
cd IBus-Theme-Tools && make emerge
```
- NixOS:
```bash
sudo nix-env -i ibus-theme-tools
```
- Guix:
```bash
guix install ibus-theme-tools
```
2. Then run `ibus-theme-tools` in the terminal.
3. Enter `1`, choose to extract an IBus-related GTK theme, and press `Enter`.
4. Enter the IBus GTK theme you want to extract, and then press `Enter`. (Note that the theme name ends with `:dark` is the dark mode of the theme)

5. Enter the system GTK you want to mix, and then press `Enter`.

6. Select whether to add a customized background image for IBus panel, if you need press `2` and then press `Enter`.

7. Enter the picture address:

8. Then choose repeat and sizing modes, and set background border radius (unit: `px`).

9. If there is no error message, the setting action should be successful. Then you can choose the GTK theme that just generated in the system theme settings to apply the previous choices.

### Customize IBus font size
Recommend to directly change the font and font size settings in the IBus preferences (`ibus-setup`).
Or:
`$HOME/.config/gtk-3.0/settings.ini` defines the current GTK3 theme and font size.
Example of the content of the file is as follows:
```ini
[Settings]
gtk-theme-name=Materia-light
gtk-font-name=更纱黑体 SC 12
```
In the above content, `gtk-theme-name` specifies that the current GTK theme is `material-light`, `gtk-font-name` specifies that the current font is `更纱黑体 SC` and the font size is `12`.
The IBus font and font size can be changed by modifying the above documents.
### Customize IBus colors (Create a GTK theme)
Create a GTK3 theme called `ibus-custom-theme` by running:
```bash
mkdir -p $HOME/.themes/ibus-custom-theme/gtk-3.0
$EDITOR $HOME/.themes/ibus-custom-theme/gtk-3.0/gtk.css
```
then edit the file content. An example can be:
```css
* {
color: #0b141a; /* Font Color */
background-color: #ffffff; /* Background Color */
-gtk-secondary-caret-color: #d4d4d4; /* Highlight Background Color */
}
```
After that, referring to the actions of the `Customize IBus theme` part, please select the theme `ibus-custom-theme` which you just created.
| hollowman6 |
869,838 | 51 git commands that you'll ever need to get started with Git 🔥 | Version Control (Git) Basics Hi !! In this blog tutorial, I will be listing out all the... | 0 | 2021-10-20T09:39:50 | https://dev.to/aviyel/51-git-commands-that-youll-ever-need-to-get-started-with-git-34d5 | github, git, webdev, javascript | ## Version Control (Git) Basics
Hi !! In this blog tutorial, I will be listing out all the necessary and only command that you will ever need to start your GIT journey. You can bookmark this blog and come back to it, whenever it is necessary.
## Checking the git configuration
```bash
git config -l
```
## Setting up your git username
```bash
git config --global user.name "pramit"
```
## Setting up email
```bash
git config --global user.email "pramit@aviyel.com"
```
## Caching credential
```bash
git config --global credential.helper cache
```
## Initialize repository
```bash
git init
```
## Adding filename to staging area
```bash
git add file_name
```
## Adding all the files to the staging area
```bash
git add .
```
## Add only certain files to the staging area
example add all files starting with "comp"
```bash
git add comp*
```
## Checking repo Status
```bash
git status
```
## Commit changes
```bash
git commit
```
## Commit changes with a message in it
```bash
git commit -m "YOOOO!!! This is a message"
```
## Add to staging area and commit changes with a message in it
```bash
git commit -a -m "YOOOO!!! This is another message"
```
## To see the commit history
```bash
git log
```
## Commit history and the following file changes
```bash
git log -p
```
## Show specific commit in git
```bash
git show commit_id
```
## Statistics about changes
```bash
git log --stat
```
## Changes made before committing them using diff
```bash
git diff
git diff some_file.js
git diff --staged
```
## Removing tracked files
```bash
git rm filename
```
## Rename files in git
```bash
git mv oldfilename newfilename
```
## Revert unstaged changes
```bash
git checkout file_name
```
## Revert staged changes
```bash
git reset HEAD filename
git reset HEAD -p
```
## Modify and add changes to the most recent commit
```bash
git commit --amend
```
## Rollback the last commit
```bash
git revert HEAD
```
## Revert a previous commit
```bash
git revert comit_id_here
```
## Create a new branch
```bash
git branch branch_name
```
## List branch in git
```bash
git branch
```
## Create a branch and switch it Immediately
```bash
git checkout -b branch_name
```
## Delete a branch in git
```bash
git branch -d branch_name
```
## Merge
```bash
git merge branch_name
```
## Commit log as a graph in git
```bash
git log --graph --oneline
```
## Commit log as a graph in git of all branches
```bash
git log --graph --oneline --all
```
## Abort a conflicting merge
```bash
git merge --abort
```
## Adding a remote repository
```bash
git add remote https://repository_name.com
```
## View the remote repo URL
```bash
git remote -v
```
## Get more info about remote repo
```bash
git remote show origin
```
## Push changes to the remote repository
```bash
git push
```
## Pull changes from remote repo
```bash
git pull
```
## Check remote branches that git is currently tracking
```bash
git branch -r
```
## Fetch remote repo changes
```bash
git fetch
```
## Current commit logs of the remote repo
```bash
git log origin/main
```
## Merge remote repo with the local repo
```bash
git merge origin/main
```
## Get the contents of remote branches in Git without automatically merging
```bash
git remote update
```
## Push a new branch to the remote repository
```bash
git push -u origin branch_name
```
## Remove a remote branch in git
```bash
git push --delete origin branch_name
```
## GIT rebase
(transfer completed work from one branch to another using git rebase)
```bash
git rebase branch_name
```
## Force a push request in git:(VERY DANGEROUS)
```bash
git push -f
```
---
## Git tips and tricks
### Blank commits
```bash
git commit --allow-empty -m "yooo"
```
### Prettify Logs
```bash
git log --pretty=oneline --graph --decorate
```
### Clean up local branches
```bash
git config --global fetch.prune true
```
- you can clean up local branches that have been merged
```bash
git branch --merged master | grep -v "master" | xargs -n 1 git branch -d
```
### File that specifies intentionally untracked files that Git should ignore
```bash
.gitignore
```
Happy coding!!
Follow [@aviyelHQ](https://twitter.com/AviyelHq) or [sign-up](https://aviyel.com/discussions) on Aviyel for early access if you are a project maintainer, contributor, or just an Open Source enthusiast.
Join Aviyel's Discord => [Aviyel's world](https://discord.gg/TbfZmbvnN5)
Twitter =>[https://twitter.com/AviyelHq] | pramit_marattha |
869,890 | I wasted 2 months in tutorial hell😖😫 | As I started learning to code, I was stuck in tutorial hell. It felt like, I am learning a lot of the... | 0 | 2021-10-20T10:30:01 | https://dev.to/ali6nx404/i-wasted-2-months-in-tutorial-hell-136c | developer, css, webdeveloper | As I started learning to code, I was stuck in tutorial hell. It felt like, I am learning a lot of the stuff. I have mastered CSS and JS.
After Creating a lot of projects while watching tutorials. One day I decided to create a project of my own, and the biggest myth busted 😫.
I came to know that I don't know anything so I started another course and then the same happens until I discovered that I was in tutorial hell.
## WTF is Tutorial Hell?
Tutorial hell is when you continuously watch tutorials one after another and you feel like, you are learning a lot of things.
But when you start doing something your own, you found out you're even not able to solve a basic coding problem.
## The problem with tutorial hell?
- You get fake confidence.
- Fake feeling of growth.
Quote by Albert Einstein -
> " insanity is doing the same thing over and over again and expecting different results. "
There is nothing wrong with using tutorials to learn new things. You just need to stop that desire of starting a new tutorial as soon as you finish the one you were working on.
When you complete a tutorial, try to recreate the same code using only your memory. You will probably be stuck in a few things so rewatch/reread and again start the solving problem.
### How to Break tutorial hell?
- Learn the Basics
- take Proper Notes
- Start With a Small problem
- Be consistent
- Teach others
- Build Projects
Deep Dive 👇
#### 1. Learn Basics -
Don't try to jump into advanced stuff without learning enough basics.
> Core Fundamentals >>>> frameworks
#### 2. take proper Notes -
Notes are the best way to revise your learning because we humans are never able to remember all the things.
> Note the key points.
#### 3. Start with a small problem -
Always start with small coding problems, do not try to solve big problems because you get demotivated easily in the beginning.
Coding is all about solving problems so always break your problem into small sub-problem.
#### 4. Be consistent -
Do not try to learn everything in one or two months. be consistent with your learning soon you will see Great results.
#### 5. Teach others -
teaching is the best way to Recalling back what we have learned.
#### 6. Build Projects -
The more you code, The better you become 💛, Don't just watch the tutorials, practice what you learn.
## Conclusion -
If you are able to relate to this article that you are in tutorial hell. Use the given techniques to escape from tutorial hell.
I hope you enjoyed reading
Let's connect with me on
- [twitter](https://twitter.com/Ali6nX404)
- [Linkedin](https://www.linkedin.com/in/mahesh-patidar-34a982192/)
| ali6nx404 |
870,039 |
Обзор нововведений в C# 10 | В данной, статье рассмотрим новую версию языка C# 10, которая включает в себя небольшой список... | 0 | 2021-10-20T11:48:28 | https://dev.to/1komilov/obzor-novovviedienii-v-c-10-14de | В данной, статье рассмотрим новую версию языка C# 10, которая включает в себя небольшой список изменений относительно C# 9. Ниже приведены их описания вместе с поясняющими фрагментами кода. Давайте их рассмотрим. | 1komilov | |
870,078 | Choosing a storage solution for simple user input | JSON, key-value store, or a relational DB are all viable choices — but what are the pros & cons? | 0 | 2021-10-20T13:05:08 | https://dev.to/fullstackplus/choosing-a-storage-solution-for-simple-user-input-3k1f | storage, db, json, optin | ---
title: Choosing a storage solution for simple user input
published: true
description: JSON, key-value store, or a relational DB are all viable choices — but what are the pros & cons?
tags: storage, DB, JSON, optin
//cover_image: https://direct_url_to_image.jpg
---
Hi everyone,
here's an engineer-y question for you regarding lead generation online.
Say you had to collect your visitors' name & email through a landing page opt-in. What storage mechanism would you use:
* a JSON file
* a key-value store
* a relational DB?
My current solution is a JSON file, however it's not very efficient because when saving a new entry, you need to parse all the existing ones into an Array from JSON, add the new data, then again serialize the entire collection as JSON, then write it back to the file.
Also, if I'm going to do uniqueness tests (no double entries allowed for email, for example), I'll have to traverse the entire array to find the duplicate — I suspect this is more efficiently handled by the other two storage mechanisms (hash-based lookup in constant time).
Thanx for your input!
| fullstackplus |
870,102 | Coffee and Code: Git and GitHub Essentials Every Developer Must Know Right NOW! | If you are an engineer, you might have worked with Git at least once in your life. However, would you... | 0 | 2021-10-20T13:59:19 | https://bit.ly/3vxQRmS | If you are an engineer, you might have worked with Git at least once in your life. However, would you vouch for being a Git expert and knowing all the technical how-tos? If not, then we have an event coming up for you.
Sankalp Swami will be live with Aviyel to help you get started with Git and GitHub, the must-knows for developers, and 1:1 Interaction on open source, contribution, and coding in general. Tell me a better way to bid goodbye to Hacktober?
**Speaker Spotlight:** Sankalp is a self-taught NodeJS Developer from India. With hands-on experience in JavaScript and NodeJS, Sankalp has worked with startups going global as a backend developer. In his free time, he writes blogs, reads technologies, and uses Django and Linux together.
**When:** October 21st, 9 pm PST | October 22nd, 12 AM EST
**Where:** To join, tap (even link)👇🏻
https://bit.ly/3BZ8Swt
If you are an open-source advocate or a developer who stands for freedom of code, Join Aviyel in building OSS today!
Till then, happy building. 🎉
See you at the event! | ankithatech11 | |
870,103 | Arquitetura Escalável | Atualmente todos falam em arquiteturas e software escaláveis: "it webscales!"; mas você realmente... | 15,036 | 2021-10-20T14:15:20 | https://dev.to/pedrokiefer/arquitetura-escalavel-335g | programming, architecture, productivity | Atualmente todos falam em arquiteturas e software escaláveis: "it webscales!"; mas você realmente precisa de tudo isso no dia a dia? Seu sistema recebe 1M req/s para justificar complexidades e abstrações desnecessárias? Provavelmente a resposta é não. Então começe do básico, garanta ótima qualidade desde o príncipio e se um dia for necessário atender 1M req/s será muito mais fácil refatorar o sistema.
"Ah, mas eu preciso fazer micro serviços, porque todo mundo faz e isso escala!" Beleza, faça micro serviços mas não faça femto-serviços (minha definição para um serviço que é absurdamente pequeno; femto é 10^-15, enquanto micro é só 10^-6.). Um serviço de processamento de fotos não precisa ser 10 serviços diferentes com 10 filas separadas. Faça um serviço que englobe todo o processamento e escale esse serviço. Fica mais fácil de manter, dá para manter na cabeça todo o sistema, o deploy fica mais simples. "Ah, mas daí é um monólito", não, não é, só é um conjunto mínimo de funcionalidades reunidas em um local.
Se vocês tem muitos micro serviços para compor uma funcionalidade fica muito díficil coordernar uma atualização no payload usado entre os serviços. Será que todos vão entender a mensagem nova? Será que preciso atualizar tudo ao mesmo tempo? Se isso for necessário, agrupe tudo sob um sistema só.
## Código
Abstraia e crie interfaces somente do que faz sentido no momento, não gaste tempo e energia criando uma arquitetura mega flexível que nunca será usada. Se o código estiver simples e bem testado fica simples refatorar para adicionar mais possibilidades.
Algumas linguagens em nome de "arquiteturas enterprise" ~~(algo para C-level achar bacana, eu acho?)~~ acabam criando diversos padrões de projeto que geram só níveis de indireção e abstrações que são pouco úteis para a entrega de valor.
## Configurações
Evite juntar configurações do sistema com regras de negócio. Por exemplo, se você tem um sistema dinâmico para facilitar que outros times desenvolvam serviços em cima, deixe em arquivos separados as configurações que fazem o sistema funcionar e as configurações que são do negócio. O intuito aqui é diminuir os problemas em caso de uma configuração errada. Se temos um arquivo só e quebramos a configuração podemos tirar do ar todo o sistema. Quando separamos podemos continuar servindo conteúdo stale até arrumarmos a regra de negócio. Pense sempre em dois planos: controle e dados.
Versione todas as configurações do sistema - exceto senhas e dados sensíveis - junto com o código fonte. Configurações são tão importantes quanto o código. Evite alterar configurações manualmente, crie pipelines de entrega adequados para fazer as mudanças necessárias a partir do repositório.
## Dependências
Evite dependências externas, especialmente as que você tem zero controle. Se você precisa usar serviços externos entenda do princípio que eles vão falhar e sua aplicação provavelmente não deveria falhar junto – claro, se for algo essencial da aplicação não dá para ficar sem. Mas um sistema de métricas ou de logging não deveria tirar a aplicação do ar. Nem um deploy em outro sistema deveria ter um impacto enorme na sua aplicação.
Use retentativas, circuit-breakers ou ainda service mesh, para facilitar a gestão das dependências. Se as aplicações estão muito acopladas, então não há benefícios de ter micro serviços e um grande monólito faria um trabalho muito melhor. Pense em micro serviços como peças que possam ser trocadas quando necessário — e talvez dê para continuar voando sem elas.
## Exemplo
Para exercitar as ideias apresentadas vamos criar um caso de uso real: um sistema de vendas de ingressos para um cinema. O sistema consiste em usuários podendo escolher qual filme querem assistir, em qual dia e horário, e todo o fluxo de compra e emissão do ingresso. A arquitetura inicial é conforme a figura abaixo.
Essa arquitetura pode ser considerada um monólito. Uma única aplicação é responsável por todos os comportamentos do sistema: a autenticação dos usuários que desejam comprar ingressos, o sistema de pagamentos, a gestão de quais filmes estão sendo exibidos em quais salas, entre outras funcionalidades que desejarmos para um sistema como esse.
Você pode se perguntar: se isso é um monólito, como podemos afirmar que essa aplicação é escalável? Ninguém especificou qual o volume de acessos, quantas salas de cinema o sistema gerencia, nem quantos filmes diferentes estarão disponíveis e onde eles estarão.
Do ponto de vista de escalabilidade da aplicação, é perfeitamente aceitável começarmos com uma arquitetura dessas. No entanto, existe um pulo do gato para que o código não pareça um novelo de lã depois de um encontro com unhas afiadas: criarmos o sistema levando em conta os domínios necessários para seu funcionamento, garantindo que eles são independentes entre si e se comunicam atráves de interfaces bem definidas.
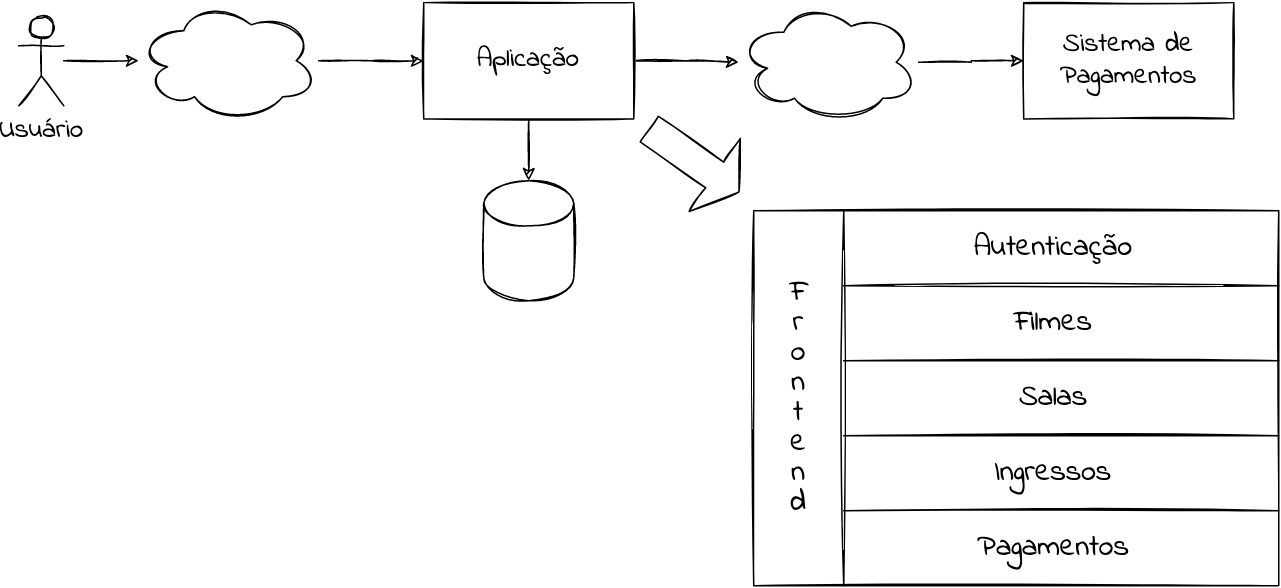
Nessa figura mostramos os domínios existentes, deixando claro o que está agrupado em cada um deles: autenticação, filmes, salas, ingressos, pagamentos. Se a arquitetura começa com uma boa separação de conceitos, fica fácil escalar. E, dependendo do contexto, essa arquitetura é a única necessária! Se formos pensar em uma cidade com poucos habitantes, que possui um único cinema com 4 salas que exibem apenas 4 filmes, temos quase certeza de que nunca teremos um volume de acessos maior do que esse sistema consegue aguentar.
No entanto, vamos exercitar nosso raciocínio para o outro lado. O sistema foi um sucesso, revolucionou a gestão de ingressos na cidade. A empresa, obviamente, quer estender o lucro e o sucesso obtido com o software. Para tanto, decidiu criar outro sistema para vender artigos relacionados a cinema.
De modo a facilitar o uso para os atuais usuários, resolveram ter uma solução única de autenticação. Como essa responsabilidade já estava totalmente separada na estrutura do código, bastou um refactor para tirar a gestão de usuários do sistema de ingressos e criar um sistema separado. Agora esse sistema pode atender os fluxos de venda de ingressos e de souveniers. Qualquer melhoria na gestão de usuários é propagada para todos os sistemas que o utilizam, e também conseguimos escalar só essa parte do sistema se precisarmos.
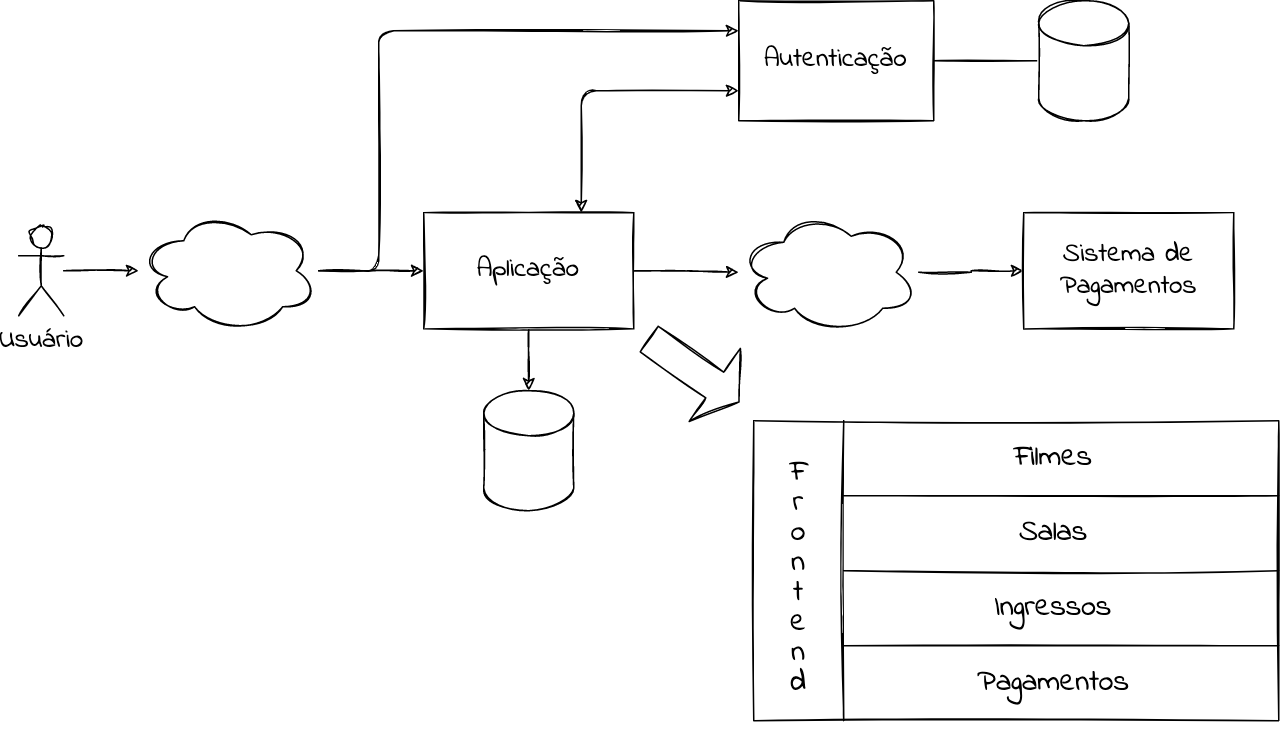
O sucesso foi estrondoso! A empresa continuou faturando e, logo em seguida, surgiu uma grande oportunidade de negócio: comprar outras salas na cidade vizinha. Além disso, em uma pesquisa de satisfação com os seus clientes, a empresa viu que a grande dor de seus usuários era uma falta de lugares marcados nos ingressos.
O sistema atual não dava conta - era preciso escalar melhor suas partes internas. Como os domínios não mudaram, basta uma reorganização e criação de novos subsistemas responsáveis por uma dada área. A gestão de ingressos ganha seu próprio subsistema, que escala independemente da gestão de salas e filmes. Lá também temos toda a lógica necessária para gerir a escolha de assentos, o tempo máximo de uma reserva, etc.
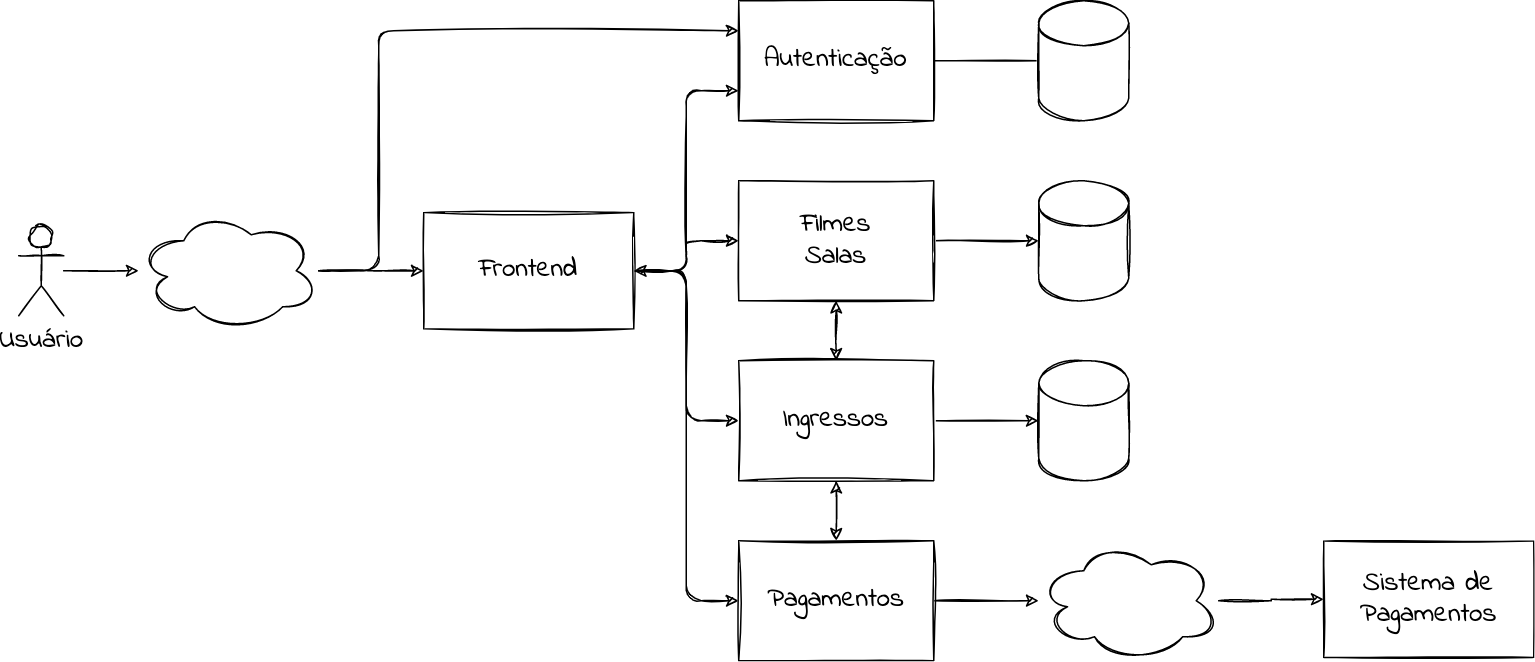
Podemos ver como o sistema cresceu, outra fontes de dados surgiram, pequenas partes tornaram-se escaláveis. O sistema está pronto? Provavelmente não, sempre haverá novas oportunidades de negócio: aumentar o alcance de cidades, incorporar a gestão de teatros; depende da evolução do negócio. Mas tendo os domínios bem separados, conseguimos escalar na medida certa para não gerar sistemas super complexos. Internamente alguns domínios podem ainda se desdobrar em mais partes, mas o ponto principal é conseguirmos ver a arquitetura como um todo. Qualquer pessoa consegue manter um modelo mental conforme a última figura.
`"Ah, mas esse exemplo é todo de backend, não dá pra aplicar em front."` É possível sim, basta imaginar que temos todo o código de front-end como uma `Single Page Application` (SPA). Ter uma SPA é perfeitamente aceitável e permite o compartilhamento de componentes entre páginas, poupando o retrabalho! No entanto, imagine que essa SPA faz o roteamento para todas as páginas e componentes da aplicação - autenticação, pagamentos, visualização dos filmes disponíveis, escolha de sala, entre outras.
À medida em que a necessidade do sistema vai evoluindo, o número de páginas, componentes e comportamentos complexos vai crescendo. O desempenho e agilidade da página ficam comprometidos; a experiência é degradada para o usuário, que fica esperando até que todo o programa seja executado pelo navegador. Podemos pensar em separar em partes a aplicação, só carregando o necessários conforme a necessidade. Se o usuário nunca entrar na parte de pagamentos, por que gastar tempo deixando ela disponível?
O mesmo conceito e ideia de micro serviços pode ser aplicado a micro frontends, que entregarão pequenos comportamentos ou componentes que serão adicionados apenas quando estritamente necessário para a página, melhorando o desempenho e a experiência do usuário. Esses componentes podem ter a atenção devida de UXs e desenvolvedores dedicados que cuidarão e melhorarão a experiência, o que faz com que todos ganhem - usuários e empresa. | pedrokiefer |
870,143 | What happens when you send an email to spam? | TDLR: When you hit “Report spam”, this happens: The offending email is moved to the spam... | 0 | 2021-10-20T16:07:36 | https://dev.to/ehlo_250/what-happens-when-you-send-an-email-to-spam-56ak | email, beginners, cloud, inthirtyseconds | TDLR: When you hit “Report spam”, this happens:
1. The offending email is moved to the spam folder
2. Spam detection systems are updated
3. If registered, an email complaint is sent through the FBL program in ARF format
4. The original sender should take action to prevent further spam
----
*Read on for more details, the extended, original post is on the OhMySMTP blog here: https://blog.ohmysmtp.com/blog/what-happens-when-you-send-an-email-to-spam/*
When you hit "Report Spam", at a minimum most email clients will place the email in a spam folder, and many providers will also update their spam detection models to prevent future spam.
That is helpful, but what about the person who sent the original email? If it genuinely is spam, then who cares? But perhaps the email was mis-categorized, or the sender wasn’t aware that it would be marked as spam. They need to know about spam reports to correct the issue.
There’s a solution: **Feedback Loops (aka FBLs)**. FBLs are systems that email inbox providers have set up to send back details of any emails that have been marked as spam to the original sender's platform.
Email providers and high volume senders can register for the FBL with the email providers, and they will share these spam reports (also known as Complaints) to a Feedback email address. The sender can then review these and choose to stop sending to the addresses or take other action.
There are FBL programs at the big inbox providers (Google, Microsoft, Yahoo), and https://validity.com have consolidated many smaller systems. Reports are sent using the [Abuse Reporting Format](https://en.wikipedia.org/wiki/Abuse_Reporting_Format).
Going through the FBL process can take a long time (hours or days), and many senders/services are not registered in the first place.
Therefore to reduce spam in your inbox your best bet is to look out for unsubscribe links or use [temporary email addresses](https://www.idbloc.co/) and turn them off when done. | ehlo_250 |
870,401 | Getting Good | So you want to get good at something in a creative field like music, writing, or even coding? Folks... | 0 | 2021-10-20T17:21:00 | https://bphogan.com/2021/04/28/getting-good/ | career, development | ---
title: Getting Good
published: true
description:
tags: career, development
//cover_image: https://direct_url_to_image.jpg
canonical_url: https://bphogan.com/2021/04/28/getting-good/
---
So you want to get good at something in a creative field like music, writing, or even coding? Folks might tell you that you need thousands of hours of study. But that's not necessarily true. The key to getting good at something is to do it over and over while incorporating feedback along the way.
Think of the one thing you're amazing at. How long did it take you to get to your level of skill?
There are no shortcuts, but there is a strategy.
## Daily Practice
Whatever you're doing, practice it daily. 30 minutes. Every day if you can.
30 min a day is 3.5 hours per week which is 182 hours a year.
It adds up. So does your skill.
If you want to write, write every day. Even if it's crap nobody sees. Write. Learning to draw? Draw every day. You don't have to show or even keep everything you do.
Want to learn to play guitar? Play every day. Nobody has to hear you all the time. It's ok to play alone.
Learning a new framework? Spend 30 minutes a day working toward that goal. You might not produce some output every day. But that's ok. You're improving your understanding and making progress. After some time, you'll get more confident and your output will improve.
I have over a thousand unfinished songs that nobody will ever hear. I do some kind of musical composition every day because I want to get better at it, and daily practice is how you do it.
Some folks say that they'd rather dedicate a day a week and have a long block of time. That's dangerous because something might come up that causes you to have to skip that day. A soccer game for your kids, a family outing, someone gets sick, or you just feel awful. If you miss that day, you lost a weeks' worth of practice. IF you do your work over the course of a week, you can miss a day and you've only lost 30 minutes.
Practice. Every. Day.
## Get Feedback
Get feedback on your progress and act on it. Learning happens through feedback AND practice. Practice alone doesn't level you up, and feedback is useless if you don't incorporate it.
Writing a book? Get peer reviews along the way. Work with an editor. Have these folks check your facts as well as your writing.
Composing music? Share your progress with other musicians and ask them to tell you what they like and what they might suggest to make it better.
Learning a framework? Use your network to find people willing to give you feedback on your progress. Share your code with them and ask them for suggestions.
Get as many perspectives as you can on your work. If you've practiced enough, this will be less painful. If you haven't been practicing, this can be harder.
Then take that feedback, sit on it, digest it, and identify common themes. A trusted friend or coworker or mentor can help a lot here, helping you identify common themes. This is one of the most valuable things my editors have done with me when I write a book. I get a bunch of feedback and then together we look at places where lots of folks get stuck, or where folks disagree.
Some feedback might not be helpful, or you may disagree with it, and it's up to you how you want to act. You don't have to incorporate every piece of feedback, but you should act on it, either by using it or discarding it.
Feedback is a gift. If you ask for it, be respectful of it, even if it stings a bit.
## Do more than you watch or read
Watching hours of videos of playing guitar, or mixing and mastering, or buying every coding course under the sun is not helping you get leveled up. Watching or reading hours of material to understand concepts is called **passive learning** and it's only part of the learning process. Passive learning, including lectures, is good for getting introduced to a topic, or for seeing how an experienced person does something. And it feels like learning.
But it's not all of learning. Remember, learning happens through practice and feedback. I can watch all the React courses out there, but if I don't do the practice of writing the code, and I don't get feedback, I won't get better. The same goes for any other skill. YouTube has videos on hanging and mudding drywall. And they're quite informative. But if you've ever tried to do this, you'll find that you can't just upload that info to your brain. You'll have to screw up quite a few areas of drywall before you start getting good at it.
So, watch the video and follow along. Then practice that part over and over. Move on to the next lesson when you're comfortable. Make the move from passive learning to active learning.
## Conclusion
You don't need thousands of hours to learn a new skill. Dedicate time every day to the thing you want to do, get feedback on it, and be sure you DO more than you WATCH.
Develop a good practice plan for yourself. Put your 30 minutes on your calendar every day. Decide which days are your "passive learning" days where you'll watch videos or read papers. Then decide which are active days. Or maybe you'll do a little of both.
Finally, give yourself a break. Everything you are good at now didn't happen overnight. It happend over a lifetime with little bits at a time, where you absorbed new concepts and got practice and feedback on them. This is how we learn, and there are no shortcuts. So don't get frustrated if you don't see immediate results. You know the process now. Follow it and then, one year and 182 hours later, look back on your accomplishments.
Good luck!
Like this post? Support my writing by [purchasing one of my books about software development](https://bphogan.com/books). | bphogan |
870,436 | Agrippa 1.2 is out 🎉🎉 | Agrippa is growing steadily - it's been out for a little over two months, and already has a small... | 0 | 2021-10-21T08:42:10 | https://dev.to/nitzanhen/agrippa-12-is-out-13jl | react, javascript, webdev, news | [Agrippa](https://github.com/NitzanHen/agrippa) is growing steadily - it's been out for a little over two months, and already has a small community around it! 🎉🎉
If you're not using Agrippa yet, [get started here](https://github.com/NitzanHen/agrippa). If you *are* using Agrippa, thanks for being part of the community! Let us know what you think about it, here or elsewhere.
Either way, these are the changes introduced in v1.2.0:
In general, the two main changes brought about in v1.2.0 are more options, this time with a focus on supporting different structural conventions that exist among React developers.
Most notably, you can now:
- export a component as a default export (instead of a named export)
- declare a component as a `function()` declaration (instead of as a `const` with an arrow function)
- create `memo()` components.
These changes came as part of a larger reform in component generation. Generation logic was remade from the ground up - instead of a large, unwieldy template, we now have proper composition patterns and a `ComponentComposer`; internal terminology aside, this reform makes it much easier to scale, maintain and test the generation logic.
Following this reform, we have begun the process of writing standardized tests - testing for some of the core code already exists, and the rest will be covered in the soon future.
In parallel, we got some bonus enhancements - the API docs were rewritten and are now both comprehensive and easy to read, and Agrippa will also now search for a new version when run, so that you'll always be informed when a new version is available.
You can also find this information at the release page.
That's pretty much it! We already have some ideas for v1.3.0 - we're currently looking into adding support for styled-components, React native `Stylesheets` and `Mui 5` styling, writing more tests and more.
Join the community! If you haven't, try Agrippa out, and if you find a bug in Agrippa or want to suggest a new feature, please reach out here or on GitHub.
Thanks for your time, have a great day! | nitzanhen |
871,515 | Android — Instrumentation test with hilt & espresso | Testing in Android has been a pain from the beginning and there is no standard architecture setup to... | 14,842 | 2021-10-21T16:30:32 | https://mahendranv.github.io/posts/hilt-instrument/ | android, hilt, espresso | ---
## Common
title: Android — Instrumentation test with hilt & espresso
tags: [android,hilt,espresso]
# description:
published: true
## Github pages
layout: post
# image:
sitemap: false
hide_last_modified: false
no_break_layout: false
categories: [Android, Hilt]
## Dev.to
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/bne9hoetjp3rjueoehaw.png
canonical_url: https://mahendranv.github.io/posts/hilt-instrument/
series: Hilt-Espresso
---
Testing in Android has been a pain from the beginning and there is no standard architecture setup to execute the frictionless test. As you know there is no silver bullet for all the snags. This piece of article covers how do you fake dependencies to your hilt-viewmodel and assert the same from fragment using espresso.
What do we achieve here?
1. Decoupled UI from navigation and real data source
2. Feed fake data to our viewmodel
3. A less flaky test since we control the data
-or- Explained in a single picture
<img src="https://user-images.githubusercontent.com/6584143/138287967-00a8e391-54b1-4f7d-a239-239ac98c12b1.png" alt="image" style="zoom: 30%;" />
> Thanks: [Mr. Bean - Art disaster](https://www.youtube.com/watch?v=QTli1HU9axY&ab_channel=MrBean)
...
## Contents
<ul class="nav navbar-nav">
<li><a class="nav-link" href="#testing-strategy">Testing strategy</a></li>
<li><a class="nav-link" href="#dependency-overview">Dependency overview</a></li>
<li><a class="nav-link" href="#test-runner-setup">Test runner setup</a></li>
<li><a class="nav-link" href="#shared-test-fakes">Shared test fakes</a></li>
<li><a class="nav-link" href="#writing-integration-test">Writing integration test</a></li>
<li>
<a class="nav-link active" href="#instrumentation-or-ui-tests">Instrumentation or UI tests</a>
<ul class="nav navbar-nav">
<li><a class="nav-link" href="#faking-modules">Faking modules</a></li>
<li><a class="nav-link" href="#the-hiltandroidtest">The HiltAndroidTest</a></li>
</ul>
</li>
<li><a class="nav-link" href="#wrapup">Wrapup</a></li>
<li><a class="nav-link" href="#resources">Resources</a></li>
</ul>
...
## Testing strategy
100% code coverage is a myth and the more you squeeze towards it, you end up with flaky tests. Provided the content is dynamic and involves latency due to API calls, it is simply hard to achieve. So, to what degree we should write tests?
<img src="https://miro.medium.com/max/1400/1*6M7_pT_2HJR-o-AXgkHU0g.jpeg" alt="image" style="zoom:50%;" />
> credits: [medium](https://medium.com/android-testing-daily/the-3-tiers-of-the-android-test-pyramid-c1211b359acd)
- **Unit tests:** Small & fast. Even with a large number of tests, there won't be much impact on execution time.
- **Integration tests**: Covers how a system integrates with others. ex. How viewmodel works with the data source. Cover the touchpoints. Runs on JVM – reliable.
- **UI tests**: Tests that cover UI interactions. In android, this means launching an emulator and running tests in it. Slow! dead slow!! So, write tests to assert fixed UI states. [Wrapup](#wrapup) at the end of the article should give a rough idea of execution time.
Here we cover how to write the integration and UI tests using hilt. Before the actual implementation, take a minute to read on [test double](https://martinfowler.com/bliki/TestDouble.html)s (literally a very short article!). We'll be using Fakes in our tests. Keep in mind while coding:
1. **Hilt resolves a dependency by its type.** So, our code should refer to the *Fake*able dependency as interface.
2. **Provide your dependency in module**. So that the whole module can be faked along with dependencies. More on this is covered in [faking modules](#faking-modules) section
...
## Dependency overview
To recap from [previous article](https://dev.to/mahendranv/android-basic-hilt-setup-with-viewmodel-fragment-32fd), we have a fragment that requires a Profile (POJO) object which is provided through a ViewModel. `DataRepository` acts as a source of truth here and returns a profile. `ProfileViewModel` is unaware of the implementation of `DataRepository` and Hilt resolves it at compile time.
<img src="https://user-images.githubusercontent.com/6584143/138072585-ec3fc907-88d7-40cd-bf2b-2d6cb0a28a98.png" alt="dependency overview" style="zoom:67%;" />
Adding to the existing implementation, we'll bring in our Fake data source `FakeDataRepoImpl` for tests. So, the rest of the post is about instructing Hilt to use `FakeDataRepoImpl` instead of `DataRepositoryImpl`.
---
## Test runner setup
Add test dependencies to app level gradle file. This brings a `HiltTestApplication` and annotation processor to the project now. As we've seen in the [scope section](https://dev.to/mahendranv/android-basic-hilt-setup-with-viewmodel-fragment-32fd#little-about-scope), `HiltTestApplication` will hold singleton component.
```groovy
// File: app/build.gradle
dependencies {
// Hilt - testing
androidTestImplementation 'com.google.dagger:hilt-android-testing:2.38.1'
kaptAndroidTest 'com.google.dagger:hilt-android-compiler:2.38.1'
}
```
Although `HiltTestApplication` is present in our app, it is not used in tests yet. This hookup is done by defining a `CustomTestRunner`. It points to the test application when instantiating the application class for instrument tests.
```kotlin
// File: app/src/androidTest/java/com/ex2/hiltespresso/CustomTestRunner.kt
import androidx.test.runner.AndroidJUnitRunner
import dagger.hilt.android.testing.HiltTestApplication
class CustomTestRunner : AndroidJUnitRunner() {
override fun newApplication(
cl: ClassLoader?,
className: String?,
context: Context?
): Application {
return super.newApplication(cl, HiltTestApplication::class.java.name, context)
}
}
```
And the final step is to declare the test runner in app/gradle file.
```groovy
// File: app/build.gradle
android {
defaultConfig {
// testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
testInstrumentationRunner "com.ex2.hiltespresso.CustomTestRunner"
}
```
---
## Shared test fakes
In android, there are Unit and Instrumentation tests. Although both identify as tests, they cannot share resources between them. Here, few places where tests will lookup for classes.
1. `main` source set - here we place the production code. Fakes have no place here
2. `testShared` source set - This is the recommended way to share resources. Create the below directory structure and place the `FakeDataRepoImpl` there.

```kotlin
// File: app/src/testShared/java/com/ex2/hiltespresso/data/FakeDataRepoImpl.kt
class FakeDataRepoImpl @Inject constructor() : DataRepository {
override fun getProfile() = Profile(name = "Fake Name", age = 47)
}
```
The next step is to add this to `test` and `androidTest` source sets. In app level gradle file, include `testShared` source set to test sources.
```groovy
// File: app/build.gradle
android {
sourceSets {
test {
java.srcDirs += "$projectDir/src/testShared"
}
androidTest {
java.srcDirs += "$projectDir/src/testShared"
}
}
}
```
---
## Writing integration test
In the integration test, we'll verify data source and viewmodel coupling is proper. As seen in the testing strategy section, tests run faster if the emulator is not involved. Here, *ViewModel* can be tested without UI. All it needs is the `DataRepository`. In the last section, we placed the `FakeDataRepoImpl` in the shared source set. Let's manually inject it and assert the data.
```kotlin
// File: app/src/test/java/com/ex2/hiltespresso/ui/profile/ProfileViewModelTest.kt
@RunWith(JUnit4::class)
class ProfileViewModelTest {
lateinit var SUT: ProfileViewModel
@Before
fun init() {
SUT = ProfileViewModel(FakeDataRepoImpl())
}
@Test
fun `Profile fetched from repository`() {
assertThat("Name consumed from data source", SUT.getProfile().name, `is`("Fake Name"))
}
}
```
**💡 Why ProfileViewModel is instantiated manually instead of using Hilt?**
This is the piece of HiltViewModelFactory which instantiates `ProfileViewModel`. The `SavedStateRegistryOwner`, `defaultArgs` are coming from Activity/Fragment that is marked with `@AndroidEntryPoint`. So, instantiating the viewmodel with hilt also brings in the complexity of launching the activity and testing the viewmodel from there. This will result in a slower test whereas viewmodel test can run on JVM like we did above.
```kotlin
public HiltViewModelFactory(
@NonNull SavedStateRegistryOwner owner,
@Nullable Bundle defaultArgs,
@NonNull Set<String> hiltViewModelKeys,
@NonNull ViewModelProvider.Factory delegateFactory,
@NonNull ViewModelComponentBuilder viewModelComponentBuilder)
```
---
## Instrumentation or UI tests
Instrumentation/UI tests run on emulator. For this project we'll assert whether the name in UI matches the one in (fake) data source.
In a real-world application, the data source is dynamic and mostly involves a web service. This means UI tests tend to get flaky. So, the ideal approach is to bring down the UI to have [finite-states](https://en.wikipedia.org/wiki/Finite-state_machine) and map it to the ViewModel and fake it.
> **<u>Example UI states</u>** :
>
> 1. UI when the network response has failed
> 2. UI when there are N items in the list vs the empty state.
Kotlin [sealed classes](https://kotlinlang.org/docs/sealed-classes.html) are a good fit to design an FSM. The aforementioned use-cases are not covered here!! (and won't fall into a straight line to write an article). So, here is the blueprint on how do we inject our fake for ViewModel.
…
### Faking modules
For instrument tests (androidTest), hilt is responsible for instantiating the ViewModel. So, we need someone who speaks Hilt's language. Create a fake module that will provide our `FakeDataRepoImpl` to the viewmodel.
```kotlin
// File: app/src/androidTest/java/com/ex2/hiltespresso/di/FakeProfileModule.kt
import dagger.hilt.android.components.ViewModelComponent
import dagger.hilt.testing.TestInstallIn
// Hey Hilt!! Forget about the ProfileModule - use me instead
@TestInstallIn(
components = [ViewModelComponent::class],
replaces = [ProfileModule::class]
)
@Module
class FakeProfileModule {
@Provides
fun getProfileSource(): DataRepository = FakeDataRepoImpl()
}
```
Notice the `TestInstallIn` annotation. Defining the replaces array will make the original `ProfileModule` replaced with `FakeProfileModule`. While building the component, hilt will replace the original module (and thus dependencies) and instantiate the ViewModel with the fake repo. Our UI will use the viewmodel and tests will assert the same.
…
### The HiltAndroidTest
The final piece is to write a test that uses the faked component. All it needs is a couple of test rules and annotation from Hilt. Rest is generated!!
```kotlin
// File: app/src/androidTest/java/com/ex2/hiltespresso/MainActivityHiltTest.kt
@RunWith(AndroidJUnit4::class)
@HiltAndroidTest
class MainActivityHiltTest {
@get:Rule(order = 0)
var hiltRule = HiltAndroidRule(this)
@get:Rule(order = 1)
var activityRule: ActivityScenarioRule<MainActivity> =
ActivityScenarioRule(MainActivity::class.java)
@Test
fun test_name_matches_data_source() {
// Inject the dependencies to the test (if there is any @Inject field in the test)
hiltRule.inject()
Espresso.onView(ViewMatchers.withId(R.id.name_label))
.check(
ViewAssertions.matches(
Matchers.allOf(
ViewMatchers.isDisplayed(),
ViewMatchers.withText("Fake Name")
)
)
))
}
}
```
The rules are executed first before running the test. It ensures the activity has dependencies resolved before test execution.
1. `HiltAndroidRule` (order = 0) : First create components (singleton, activity, fragment, viewmodel) and obey the `replace` contract mentioned in previous step.
2. `ActivityScenarioRule` (order = 1): Launch the activity mentioned before each test
The espresso & hamcrest matchers are descriptive. In the view tree, it lookup for a view and assert whether it's visible and carries the text defined in fake data repo.
---
## Wrapup
This article gave a blueprint for organizing the code in order to achieve component links in isolation. Apart from the hilt-related setup, this practice could benefit even the code that was built with manual injection. Just follow these key takeaways.
1. Always define the data source as interface. So that it can be faked/mocked for tests.
2. Make `fragment / activity`'s UI controlled by the viewmodel. You don't have to fake the link here.
3. A viewmodel should emit finite states to the UI at any point of time. This state may be dictated by the data source or a reaction to user input in UI (eg. enabling a button based on content length)
…
In case you wonder about the execution time, here it is: 5ms vs 3.5 sec

…
## Resources
- [Github project](https://github.com/mahendranv/hilt-espresso)
- [Hilt testing](https://developer.android.com/training/dependency-injection/hilt-testing)
- [Finite-state machine](https://en.wikipedia.org/wiki/Finite-state_machine)
- [Android test pyramid](https://medium.com/android-testing-daily/the-3-tiers-of-the-android-test-pyramid-c1211b359acd)
- [Test doubles](https://martinfowler.com/bliki/TestDouble.html)
| mahendranv |
870,445 | Mind Reader Cards | Mind Reader Cards allow users to first guess one card from given 21 random cards and then it performs... | 0 | 2021-10-20T19:27:14 | https://dev.to/mohitmehta1996/mind-reader-cards-1l82 | reactnative, gamedev, productivity, android | Mind Reader Cards allow users to first guess one card from given 21 random cards and then it performs the magic algorithm to identify which card user have guessed. To reveal the card, app asks 3 simple questions and based on answer of those questions, app finds out the true card.
The app is built on reactnative. It can be downloaded from below link.
https://play.google.com/store/apps/details?id=com.mindreadercards
Please rate the app or drop the review so I can improve myself or the app. | mohitmehta1996 |
870,462 | Implementing a Task Queue in SQL | Introduction Software systems often periodically execute collections of similar or... | 0 | 2021-10-20T20:10:07 | https://reflect.run/articles/sql-queue/ | webdev, sql, tutorial, database |
## Introduction
Software systems often periodically execute collections of similar or identical tasks. Whether it's computing daily account analytics, or running background computations asynchronously like GitHub Actions, it's common to structure and complete this computation using a queue of tasks and the concept of a generic "worker" which executes the task. In the naive approach, a single worker sequentially executes each task, avoiding locks or other coordination.
Two downsides to the single worker approach are:
- Tasks that are ready to execute will be delayed from executing until prior tasks complete (head-of-line blocking).
- Independent tasks are not run in parallel (as they can be logically),
so the overall wall-clock execution time is longer than necessary.
The alternative to the single worker is to use a pool of workers, each pulling a task from the queue when they are ready to execute one. In exchange for the reduced queueing delay and the reduced overall wall-clock execution time,
the programmer must manage the complexity of assigning and executing tasks. Some cloud services, such as Amazon Simple Queue Service (SQS), offer a managed abstraction for queueing tasks and assigning them to workers. However, they can be difficult to debug or impose undesirable properties, such as SQS's default policy of _at least once_ delivery (rather than exactly once). Lastly, it might be the case that you just don't want the third-party dependency!
This article describes how to implement a task queue in SQL with the following properties:
- A task is assigned to exactly 1 worker (or 0 workers) at a time.
- Once completed, a task is never assigned again.
- When a task reaches a configured maximum execution time without completing, it will be assigned again to a worker.
Let's jump in!
## Design
A queue provides some elasticity in your system when your message (or, in our case, task) volume varies or is unpredictable. It also allows you to impose _smoothing_ to a computational workload, which would otherwise be bursty,
by using a fixed set of resources to consume the queue and process the messages.
Let's consider some concrete examples to inform the design of our SQL task queue:
- Daily Analytics - your analytics application displays usage metrics broken down by day.
Since you want these analytics available to your users by 8AM local time, you queue up one analytics job for each account every night starting at 12:01AM.
- Scheduled Reminders - your online game relies on in-app ads and upgrade notifications to drive revenue, but the logic for deciding which content to trigger for the user is dynamic. So, you queue up all the notification content for each account and in real-time consume and filter the desired content.
- Real-Time Events - your financial application receives millions of hits to its API throughout the day. In order to keep your endpoints fast, you queue events immediately after receiving them and process them later.
### Exactly once delivery
The distinguishing property in any queueing use case is whether or not the task is _idempotent_. That is, can the same task be executed multiple times without adverse effects? If so, then the queue can deliver the same message to the worker pool more than once and the internal queueing coordination and locking complexity is reduced. Of course, if the tasks are not idempotent, or you simply don't want to waste the duplicative compute capacity, the worker itself can use a lock to ensure a message is only processed once in an _at least once_ queueing system.
For our use case, we're interested in _exactly once_ delivery of each message (i.e., exactly once execution of a task), and given that the _at least once_ policy still requires a lock anyway to achieve _exactly once_ behavior, we're going to use the atomicity of SQL writes as the lock in our queue.
### Data model
To this point, we've been alluding to a task as a single data object, but in practice, we only really need the task's _identifier_ in order to coordinate its lock and owner. Any worker receiving a task identifier for execution could read the task's information from another table. As such, we could use two tables: one for the task assignment and one for the task information, potentially saving bandwidth on database operations.
For simplicity, we'll consider a single table with all of the relevant information stored in a `details` field.
Consider the following data model definition for a `Task`:
```sql
table tasks:
id serial
details text
status text -- One of: queued, executing, completed
operator_id text
expiry timestamp
created timestamp
last_updated timestamp
```
The lifecycle of a task in our model is the following:
- a task begins in the `queued` state when it is written to the table,
- a task enters the `executing` state when a worker is assigned the task and it begins execution, and
- a worker updates a task to the `completed` state when it finishes execution.
## Implementation
We use a _Manager_ process to assign tasks to workers, and we run two instances of the Manager to improve fault tolerance and maintain availability during deployments. Managers repeatedly query the database for queued tasks and assign them to workers. Additionally, Managers look for tasks that have reached their maximum execution time (i.e., "timed out"), and reassign those tasks to new workers.
A worker can be a local thread on the same machine, or a remote machine that can accept work. The Manager doesn't really care as long as it can assume a reliable communication channel to the worker. (Obviously, the Manager might perform additional jobs such as worker liveness or reporting,
but we omit those details here.)
### Database queries
The database queries form the backbone of our SQL queue and
focus on the areas of identifying unfinished tasks and completing tasks. The Manager (or another process) is responsible for queueing new tasks by writing them to the table. Then, the Manager queries the table periodically to identify tasks that are ready to be executed.
#### Find executable tasks:
```sql
select
*
from tasks t
where t.status = 'queued' or (t.status = 'executing' and t.expiry <= NOW())
```
Our Manager randomizes the returned tasks to reduce contention across Manager instances when selecting a task. Then, the Manager attempts to _lock_ a task so that it can assign the task to a worker.
#### Attempt to lock a task
```sql
update tasks t
set t.status = 'executing',
t.operator_id = $operator_id,
t.expiry = $expiry,
t.last_updated = NOW()
where t.id = $id and t.last_updated = $last_updated
```
The Manager calculates the `expiry` value as the current time plus the maximum amount of time it expects a worker to take to execute the task, plus some buffer. If the query returns with 0 rows updated, then it means the Manager did not obtain the lock. Otherwise, if the query returns with a value of 1, it means the Manager successfully locked the task. The Manager can now assign the task to a worker for execution.
If the worker fails to execute the task or takes too long to execute the task, then the task will be selected in the first query to find executable tasks.
This code uses the _last_updated_ column as an indicator for whether a row has been written since it was last read. Thus, this optimistic concurrency control mechanism will fail if a row could be written or updated without updating the _last_updated_ column. In general, the resolution of the _last_updated_ timestamp must be greater than the system's shortest read+write update.
The worker will then read the task from the table by its `id` and use the `details` to execute the task. You may wish to have your worker update the task row to specify its own `operator_id` to aid in debugging once it begins executing the task. Regardless, when the worker completes execution of the task, it updates the row to indicate that it's complete.
#### Update a completed task
```sql
update tasks t
set t.status = 'complete',
t.operator_id = NULL,
t.expiry = NULL,
t.last_updated = NOW()
where t.id = $id and t.last_updated = $last_updated
```
This system has workers marking tasks as complete, but if you wanted to consolidate writes to this table within the Manager exclusively, you could have the Manager look for tasks that satisfy some external property, such as the presence of a log file or a row in another table, before marking tasks as complete.
## Discussion
A major benefit to this approach is that it has no external or third-party dependencies. For any system that already relies on a relational database, this approach incurs no additional infrastructure.
A second major advantage of this approach is that it automatically produces a historical record or log of all tasks that were executed. You may wish to trim the `tasks` table depending how quickly it grows in size, but broadly speaking, the audit log it provides is very useful for debugging problems.
Lastly, this approach is both scalable as you add more workers, and fault tolerant to worker and Manager failures. With only three database queries, the Manager or worker can fail at any point, and the task will eventually be retried. To provide further protection against a duplicate execution, you can introduce an external lock or state management to track a worker's progress in executing a task. In a similar vein, you may wish to add a column for `retries` of a task.
The major downside or risk to this approach of queueing is that this setup couples the throughput/volume of your system processing to the read/write capacity of your database. If your database is "small" and has an otherwise low volume of writes, but your work queue has high volume/throughput requirements, you may end up in a situation where you have to scale your database solely because of the requirements of the work queue. And, of course, if you don't proactively monitor the growth of your volume, the contention caused by workers reading and writing on this table could negatively impact the rest of your database operations and your system as a whole.
A second drawback to this approach is that you are managing the complexity yourself. With Amazon SQS you are outsourcing all implementation details to a third-party. But with this approach, you need to make sure that the queries and table indices are correct. Similarly, and related to the first downside, there isn't the warm-and-fuzzy feeling with a self-built approach like this that you might get from Amazon's eleven 9's of service reliability or throughput guarantees.
Still, over time, the operational maturity will increase your confidence.
## Conclusion
The simplicity of a SQL queue makes it attractive as an alternative to a managed, third-party queue abstraction. In this article, we presented a minimal implementation of one such SQL-based task queue. If you like this article and would like to discuss more, you can reach us at [info@reflect.run](mailto:info@reflect.run). We'd love to hear from you! | tmcneal |
870,468 | Hacktoberfest #2 | Let's talk about my second week of contributing to open-source under Hacktoberfest event. ... | 0 | 2021-10-20T20:40:09 | https://dev.to/tuenguyen2911_67/hacktoberfest-2-3ffl | javascript, hacktoberfest, opensource, react | Let's talk about my second week of contributing to open-source under Hacktoberfest event.
## The issues:
This week I was looking for harder issues and got 2 pull requests merged in [partner-finder](https://github.com/codefordenver/partner-finder) project. The first one is [PaginationControl upper page limit is always 100](github.com/codefordenver/partner-finder/issues/134) and the second one is [Display username on home navbar](https://github.com/codefordenver/partner-finder/issues/164).
My pull requests: [1st issue](https://github.com/codefordenver/partner-finder/pull/151), [2nd issue](https://github.com/codefordenver/partner-finder/pull/187/files)
## The first issue:
In general, the front-end uses React so that it wasn't hard to figure out the logic, though, I struggled during the installation.
The project uses docker to containerize its code which requires docker installed on the machine which I didn't have. Moreover, I due to my Windows version, virtualization was not enabled as well. Therefore, I had to download some files, windows sub linux system and configure my PC's BIOS.
The issue said that the maximum page was always 100 which didn't reflect on the real data. The goal was clear: to fix the `PaginationControl` component. Since `Home` component does all the data fetching and it passes data to `PaginationControl`, I needed to make another api call to get the number of pages of all 'leads' (or record) and create another state `maxPages`
```javascript
const [maxpages, setMaxPages] = useState(100);
//...
const n_pagesUrl = `${API_HOST}/leads/n_pages?perpage=${perpage}`;
fetch(n_pagesUrl, {
headers: headers,
})
.then((response) => checkForErrors(response))
.then((data) => setMaxPages(data.pages))
.catch((error) => console.error(error.message));
```
And passes `maxPages` to `PaginationControl` component:
```javascript
<PaginationControl
page={page}
perpage={perpage}
maxpages={maxpages}
setPage={setPage}
setPerpage={setPerpage}
/>
```
All that left to do was to change any number 100 in `PaginationControl` to `maxPages`. I also fixed another bug where clicking the `>` button still increases the number of page after reaching the max page.
```javascript
<Button
onClick={() => setPage(page + 1 <= maxpages ? page + 1 : maxpages)}
>
```
## The second issue:
The second one wasn't hard too. I figured if the jwt token is save in local storage and is extracted to verify the user, why not do the same with username.
```javascript
const handleSubmit = (event) => {
const url = `${API_HOST}/login`;
fetch(url, {
//...
if (success) {
localStorage.setItem('partnerFinderToken', token);
localStorage.setItem('username', username);
history.push('/');
```
Then, extract the 'username' key from local storage and display.
```javascript
const [username, setUsername] = useState('');
//...
<Typography variant="h6" component="h6">
{username}
</Typography>
```
## What I've learned:
Since this project utilizes docker, I take the chance to learn what docker is. The concept is quite neat an beneficial for anyone involved in the coding process. I hope to actually use it in the future and understand it furthermore.
I think installing docker was quite a lesson for me, I will write a blog on it some time later to help out folks like me with Windows Home version with virtualization disabled.
With regards to coding, I got a chance to practice more React, to learn a different style of coding React and generally get used to contributing, following contributing guidelines and presenting my problems clearly to other developers
**Note**: for the assignment release 0.2, I will only submit the first issue as I'm also working on a backend Python issue from the same repo.
| tuenguyen2911_67 |
870,515 | Implementation of the `Select all` functionality using react-select package | Introduction This article will explain the implementation details of the Select all... | 0 | 2021-10-20T21:33:23 | https://jmss.hashnode.dev/implementation-of-the-select-all-functionality-using-react-select-package | react, typescript, webdev | ## Introduction
This article will explain the implementation details of the `Select all` functionality in the multi-select component based on the [react-select v5.1.0](https://github.com/jedwatson/react-select) package.
## Demo
{% codesandbox ejjc9 %}
## handleChange function
The primary logic of the "Select all" option has been implemented in this function.
There can be three main scenarios in the process:
1. All the elements in the list are selected.
2. Some of the options in the menu are selected
3. None of the options is selected.
The first case happens under certain conditions: the current state of the `Select all` option is unchecked, the length of the selected elements is greater than zero, meanwhile, either the `Select all` option or all the options in the menu except the `Select all` option are selected. If these conditions are met, then all the elements in the menu are checked.
In the second case, we again check if the length of the selected options is greater than zero, and neither the `Select all` option nor all of the remaining options in the menu list are selected. If that is the case, then it means only some of the elements are selected.
The third case is the condition in which neither all the elements nor some of them are selected which happens when the `Select all` option is set to the unchecked state. If you look at the code, you will see that only filtered options have been used. It is because the default value of filter input is an empty string which works perfectly in both cases.
```
const handleChange = (selected: Option[]) => {
if (
selected.length > 0 &&
!isAllSelected.current &&
(selected[selected.length - 1].value === selectAllOption.value ||
JSON.stringify(filteredOptions) ===
JSON.stringify(selected.sort(comparator)))
)
return props.onChange(
[
...(props.value ?? []),
...props.options.filter(
({ label }: Option) =>
label.toLowerCase().includes(filterInput?.toLowerCase()) &&
(props.value ?? []).filter((opt: Option) => opt.label === label)
.length === 0
)
].sort(comparator)
);
else if (
selected.length > 0 &&
selected[selected.length - 1].value !== selectAllOption.value &&
JSON.stringify(selected.sort(comparator)) !==
JSON.stringify(filteredOptions)
)
return props.onChange(selected);
else
return props.onChange([
...props.value?.filter(
({ label }: Option) =>
!label.toLowerCase().includes(filterInput?.toLowerCase())
)
]);
};
```
## Custom Option component
By overriding the Option component, checkboxes are added to the options list, moreover, if some of the elements are checked, then the indeterminate state of the `Select all` option is set to `true`.
```
const Option = (props: any) => (
<components.Option {...props}>
{props.value === "*" &&
!isAllSelected.current &&
filteredSelectedOptions?.length > 0 ? (
<input
key={props.value}
type="checkbox"
ref={(input) => {
if (input) input.indeterminate = true;
}}
/>
) : (
<input
key={props.value}
type="checkbox"
checked={props.isSelected || isAllSelected.current}
onChange={() => {}}
/>
)}
<label style={{ marginLeft: "5px" }}>{props.label}</label>
</components.Option>
);
```
## Custom Input component
This custom input component creates a dotted box around the search input and automatically sets the focus to the search input which is helpful when there are lots of selected options.
```
const Input = (props: any) => (
<>
{filterInput.length === 0 ? (
<components.Input autoFocus={props.selectProps.menuIsOpen} {...props}>
{props.children}
</components.Input>
) : (
<div style={{ border: "1px dotted gray" }}>
<components.Input autoFocus={props.selectProps.menuIsOpen} {...props}>
{props.children}
</components.Input>
</div>
)}
</>
);
```
## Custom filter function
This custom function is used to keep the `Select all` option out of the filtering process, and it is not case sensitive.
```
const customFilterOption = ({ value, label }: Option, input: string) =>
(value !== "*" && label.toLowerCase().includes(input.toLowerCase())) ||
(value === "*" && filteredOptions?.length > 0);
```
## Custom onInputChange function
This function is used to get the filter input value and set it to an empty string on the menu close event.
```
const onInputChange = (
inputValue: string,
event: { action: InputAction }
) => {
if (event.action === "input-change") setFilterInput(inputValue);
else if (event.action === "menu-close" && filterInput !== "")
setFilterInput("");
};
```
## Custom KeyDown function
This function prevents default action on the space bar button click if the filter input value is not an empty string.
```
const onKeyDown = (e: React.KeyboardEvent<HTMLElement>) => {
if (e.key === " " && !filterInput) e.preventDefault();
};
```
## Handling state and label value of `Select all` option
The value of `isAllSelected` determines the state of the `Select all` option. And the value of the `selectAllLabel` determines the value of the `Select all` option label.
```
isAllSelected.current =
JSON.stringify(filteredSelectedOptions) ===
JSON.stringify(filteredOptions);
if (filteredSelectedOptions?.length > 0) {
if (filteredSelectedOptions?.length === filteredOptions?.length)
selectAllLabel.current = `All (${filtereds also sus also suOptions.length}) selected`;
else
selectAllLabel.current = `${filteredSelectedOptions?.length} / ${filteredOptions.length} selected`;
} else selectAllLabel.current = "Select all";
selectAllOption.label = selectAllLabel.current;
```
## What else
This custom multi-select component also provides custom single-select with the checkboxes near options.
## Side Notes
If you have a large number of options, you can solve performance issues, by rendering only the items in the list that are currently visible which allows for efficiently rendering lists of any size. To do that you can override the `MenuList` component by implementing [react-window's FixedSizeList](https://react-window.now.sh). For implementation details, you can look at [this stack overflow answer](https://stackoverflow.com/a/56390949).
In the end, this is my first tech blog as a junior frontend developer, so it may not be very well-written. I'd appreciate any feedback. | ctrlhack |
871,445 | How To Refactor Serverless Applications The Right Way | Keeping serverless applications from falling behind feels like refueling a jet plane in the air. Here are some tips to help incorporate new features without losing momentum. | 0 | 2021-10-21T13:50:54 | https://www.readysetcloud.io/blog/allen.helton/how-to-refactor-serverless-applications-the-right-way/ | serverless, aws, cloud | ---
title: How To Refactor Serverless Applications The Right Way
published: true
description: Keeping serverless applications from falling behind feels like refueling a jet plane in the air. Here are some tips to help incorporate new features without losing momentum.
tags:
- serverless
- aws
- cloud
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/tvv0to53sco5hhde2qyh.jpg
canonical_url: https://www.readysetcloud.io/blog/allen.helton/how-to-refactor-serverless-applications-the-right-way/
---
Building modern apps is exciting. You get to learn new technology, converse with people in industry that follow the same patterns, and explore new designs every day.
Imagine you are given the opportunity to build [greenfield application](https://www.readysetcloud.io/blog/allen.helton/the-greenfield-paradox-why-is-building-a-new-app-so-easy-and-also-so-hard-b3cc58552ab) and you opt for tech decisions that have good industry backing and support, like [serverless](https://www.readysetcloud.io/blog/allen.helton/decoding-the-aws-serverless-design-principles). You build your app over the course of months or years and when you go live, you're done! Right?
*Not even a little bit.*
First of all, software is never done. You have invested in a time and energy black hole. There are new features and enhancements to build, defects to fix, and optimizations to be had.
You also have to take a step back, look at what you've done, and ask yourself "*is this still relevant?*"
If you took 2 years to build your production app (which is a totally acceptable time frame), chances are there have been a significant number of enhancements and new managed services released by your cloud vendor. Did you freeze your app in the moment in time when you started development?
Honestly, it's easy to do. But what should you do when you find yourself in that situation? You could say you have a modern-*ish* app and call it a day. Or you could roll up your sleeves and bring the tech up to the latest and greatest.
## But Why, Though?
The answer to this is short and sweet: **total cost of ownership**.
You want to keep your app as up to date as possible in an effort to make the total cost of ownership low. You want to minimize *how much it costs the company to maintain* your application. The lower the maintenance costs, the higher the profit margin. The higher the profit margin, the greater likelihood that you get to do it all over again!
If you have questions on how to troubleshoot an issue with modern services, there's a giant community of developers out there with answers. If you hire someone new, you have a large pool of individuals you can pull from with the skills necessary to build your app. Your developers will be happier and more productive continuously enhancing their skill set.
Newer features oftentimes means faster performance. Incorporating enhancements that affect performance will boost the confidence of your customers in your product. Higher confidence means greater retention. It also means you have a higher likelihood of getting word of mouth references. Sounds like a win-win!
There are numerous benefits to maintaining a modern application with the latest and greatest tech.
A common misconception around refactoring is "everything else must slow down or stop in order to do it." I'm here to happily say that is not true anymore. Refactoring as you go is one of the many benefits you gain when you decide to go serverless.
So let's focus on how we can incorporate new cloud services while still make progress with new features in our app.
## Take Decisive Action
Cloud moves fast. Every time you blink, your cloud vendor has released some new managed service or feature.
While not everyone has the luxury of consuming new features as soon as they come out, they need to be on your radar. What you don't want is for a new feature to come out, then another one that builds on top of the first, then another that builds on top of the second. Before you know it, you're 3, 4, or 5 iterations behind and the gap to catch up is no longer trivial.
Let's take [AWS Lambda](https://aws.amazon.com/lambda/) as an example. Say you've built your application on the nodejs10.x runtime for all of your Lambdas. At the time, it was the latest and greatest. You continue developing your application, ignoring new Lambda features and supported runtimes.
Before you know it, the industry is all on nodejs14.x and end of life for 10.x is knocking on your door. You have to update build images, CloudFormation scripts, and potentially change all your Lambdas all while under the gun because support for your runtime is dwindling.
> Focus on baby steps, not leaps and bounds.
If you had jumped to 12.x when it came out and were aware of the release of 14.x, the difficulty of modernizing would be significantly less.
## Move Piece By Piece
When you commit to adding a new service or feature into the repertoire of your application, focus on starting small. The beauty of the cloud, specifically serverless applications, is isolation.
Every endpoint is isolated in a [serverless API](https://www.readysetcloud.io/blog/allen.helton/power-tuning-your-serverless-api-for-happy-customers). Each component of an orchestrated or [choreographed saga](https://microservices.io/patterns/data/saga.html) is configured, built, and controlled independent of its peers. You have the ability to start small, verify results, and expand.
Almost think of this approach as **canary development**.
[Canary deployments](https://octopus.com/docs/deployments/patterns/canary-deployments) are a strategy used to release new features to a subset of your customers. You identify a group/size, release software to them, verify backward compatibility and app health, then expand your group size. Rinse and repeat until the new version is live with your entire customer base.
When refactoring, you can take the same approach. Identify an endpoint or functional area in your application to incorporate something new. When development is done, verify the results and incorporate it into another area of your app.
The phased approach is great because it doesn't stop development down in order to do a refactor. You can enhance your application as you make routine maintenance changes.
An added bonus of canary development is the opportunity to improve your understanding every time you make a change. The first time you make a change you likely have a cursory understanding. The second time you use it, you are familiar and things are a little more intuitive. The third, fourth, or fifth time you approach it, you understand the nuance and build with intentionality.
If you had stopped down and refactored everything at once, you likely would have implemented the feature with a cursory knowledge and either missed out on an important aspect or maybe left some cost optimization on the table.
## Keep It Controlled
If there's one thing I know about developers, it's that they tend to go overboard. Changes come in tidal waves. Massive blocks of significant change where there is no control.
That's a developer's nature. Make big changes, organize, get it done.
I'm guilty of it, you're probably guilty of it, it's a whole thing.
*We need to stop that.*
If you're working with serverless, chances are you are incorporating [CI/CD into your deployment pipeline](https://www.readysetcloud.io/blog/allen.helton/are-you-really-ready-for-ci-cd). A major premise behind CI/CD is small, incremental changes. When pushing to production 10+ times a day, you need a way to monitor change control.
If you're refactoring your entire application at once, that paradigm goes straight out the window. You get an unmanageable amount of change that is impossible to rely on automated tests for.
Do your best to divide the work into small pieces. *You want to identify any downstream effects before moving on to the next piece*. If you changed the entire app at once, it would be impossible to pinpoint the change that caused the incorrect behavior.
By dividing refactor work into small, digestible chunks just like you would for new development, you get isolated control, a smaller [blast radius](https://aws.amazon.com/getting-started/fundamentals-core-concepts/#Reliability), and the benefit of learning from your mistakes the next time.
## Final Thoughts
When building serverless applications, you must be comfortable being in a constant state of refactor. There will always be new services and features that will enhance your app. You have to be responsible and identify the changes you should be integrating.
Don't wait too long because you don't want to fall behind and make it next to impossible to re-modernize.
Cloud development is an anomaly. It's one of those things where vendors keep making the services better and faster while also making them cheaper. Continuously refactoring your application will allow you take advantage of this anomaly.
When it comes to total cost of ownership, newer is better. Better support from the community. Better features for your customers. Better developer experience. Better cost to run.
We don't modernize because we "think it's cool" to be modern. It has serious impacts to both the products we produce and the bottom line of our companies.
If you aren't already, start sprinkling in refactor stories in your next sprint. You don't need a dedicated effort in order to make a big change. Your application will evolve over time, just like the tech behind it.
| allenheltondev |
870,611 | code | import logo from "./logo.svg"; import "./App.css"; import React from "react"; import { Document,... | 0 | 2021-10-20T21:56:31 | https://dev.to/josemgux/code-2gmk | import logo from "./logo.svg";
import "./App.css";
import React from "react";
import { Document, Page, Text, View, StyleSheet } from "@react-pdf/renderer";
// Create styles
const styles = StyleSheet.create({
page: {
flexDirection: "row",
backgroundColor: "#E4E4E4",
},
section: {
margin: 10,
padding: 10,
flexGrow: 1,
},
});
// Create Document Component
const MyDocument = () => (
<Document>
<Page size="A4" style={styles.page}>
<View style={styles.section}>
<Text>Section #1</Text>
</View>
<View style={styles.section}>
<Text>Section #2</Text>
</View>
</Page>
</Document>
);
export default MyDocument;
| josemgux | |
870,658 | Bypassing ModSecurity WAF | Being able to bypass Web Application Firewall (WAF) depends on your knowledge about their behavior.... | 0 | 2021-10-21T02:10:12 | https://blog.h3xstream.com/2021/10/bypassing-modsecurity-waf.html | security, firewall, libinjection, mysql | Being able to bypass Web Application Firewall (WAF) depends on your knowledge about their behavior. Here is a cool technique that involve **expressions that are ignored in MySQL SQL parser** ([MySQL <= 5.7](https://bugs.mysql.com/bug.php?id=105143)). This post summarizes the impact on libinjection. The [libinjection library](https://github.com/client9/libinjection) is used by <abbr title="Web Application Firewall">WAF</abbr> such as [ModSecurity](https://github.com/SpiderLabs/ModSecurity) and [SignalScience](https://docs.fastly.com/signalsciences/how-it-works/). For more details on AWS Cloudfront impact, read the [original GoSecure article](https://www.gosecure.net/blog/2021/10/19/a-scientific-notation-bug-in-mysql-left-aws-waf-clients-vulnerable-to-sql-injection/).
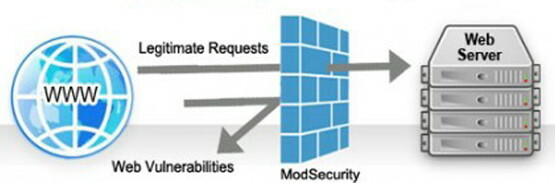
# Scientific expression in MySQL
When MySQL sees `1.e(abc)`, it will ignore the `1.e(` portion because the following characters do not form a valid numeric value.
This behavior can be abused to fool libinjection tokenizer. Libinjection internally tokenizes the parameter and identifies contextual section types such as comments and strings. Libinjection sees the string “1.e” as an unknown SQL keyword and concludes that it is more likely to be an English sentence than code. When libinjection is [unaware of an SQL function](https://github.com/libinjection/libinjection/blob/49904c42a6e68dc8f16c022c693e897e4010a06c/src/libinjection_sqli_data.h#L8686) the same behavior can be exhibited.
# Attack in action
Here is a demonstration of modsecurity’s capability to block a malicious pattern for SQL injection. A forbidden page is returned which is the consequence of detection.
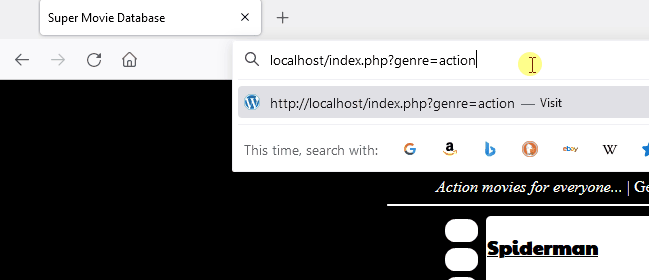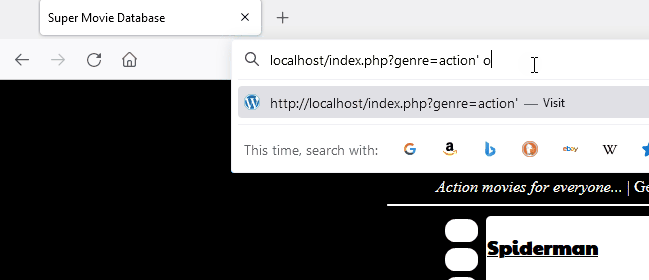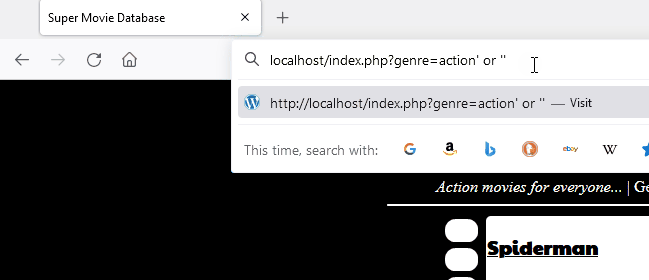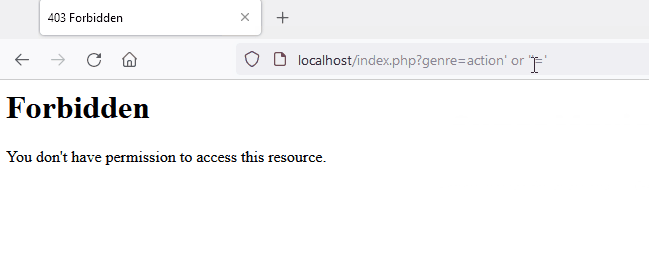
<center>*Blocked!*</center>
In the following image, you can see the original request being slightly modified to bypass modsecurity and libinjection.
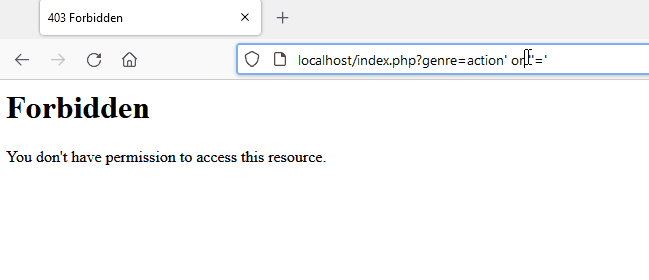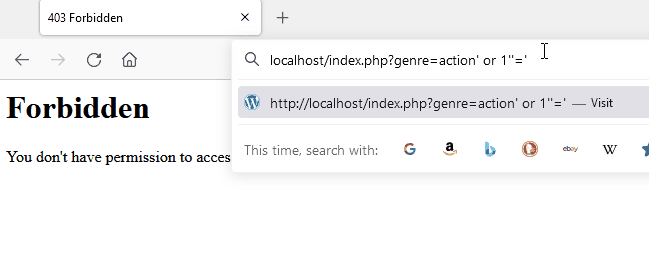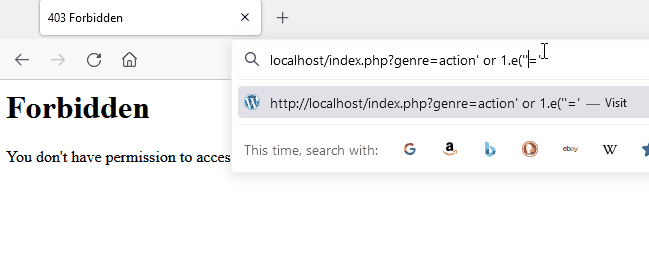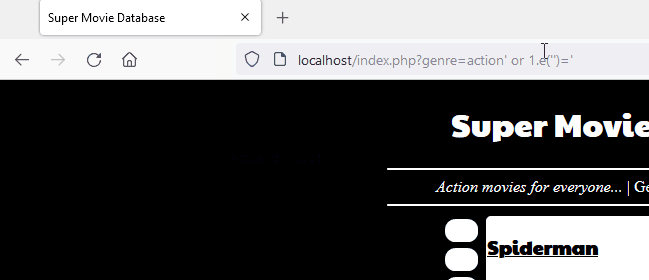
<center>*<abbr title="Web Application Firewall">WAF</abbr> Bypass!*</center>
## Complete payload
Now, how do we go beyond `or 1=1` payloads? The `NUMBER.e` expression can be inserted at plenty of locations without breaking the SQL query. The following payload demonstrated read on arbitrary SQL tables.
```
' 1.e(ascii 1.e(substring(1.e(select password from users limit 1 1.e,1 1.e) 1.e,1 1.e,1 1.e)1.e)1.e) = 70 or'1'='2
```
The same payload was indented below for readability. `1.e(` and `1.e,` are ignored from the parser.
```
1.e(ascii
1.e(substring(
1.e(select password from users limit 1 1.e,1 1.e) 1.e,1 1.e,1 1.e)1.e)1.e) = 70 #(first char = 70)
or'1'='2
```
# Conclusion
Most bypass techniques evolve using special encoding to obfuscate the malicious requests (URL encoding, Unicode multibytes, XML entities, etc). This technique will work if the system behind the <abbr title="Web Application Firewall">WAF</abbr> is doing an unexpected decoding. This new technique is not encoding related. For this reason, it will be a versatile trick until most system upgrade their MySQL instances.
<center>*Full story on [GoSecure blog](https://www.gosecure.net/blog/2021/10/19/a-scientific-notation-bug-in-mysql-left-aws-waf-clients-vulnerable-to-sql-injection/) (More details on AWS Cloudfront)*</center> | h3xstream |
870,662 | How To Build Scheduled Task on Github Libraries Releases via Slack Apps and NodeJs | In this Article, We Will build a Slack Application To Send Messages to Slack Channel when Any... | 0 | 2021-10-21T20:06:33 | https://dev.to/yazan98/how-to-build-scheduled-task-on-github-libraries-releases-via-slack-apps-2d15 | javascript, android, kotlin, node | > In this Article, We Will build a Slack Application To Send Messages to Slack Channel when Any Library you follow on Github Publish New Release
## Description
As a Developer, you worked on a lot of projects and inside these projects, you should use Libraries to implement a Feature whatever if the library is a 3rd part library or native library from the Framework itself and this is totally fine, The Problem I faced when I use The Libraries that I should check or Follow Someone on Twitter, Reddit or medium to get notifications on the Libraries that I'm using inside my Project, but if I didn't open any application from social media apps I will never know if any library pushed new Version on their Repository or maybe I know about this updates after 2 weeks and for this reason I need to get Notifications in the same day of the Release because some libraries are still pushing major release changes and it's really a big problem if we discover this Updates after 2 Weeks from the Release date
## The Simplest Solution to Build Scheduler for This Process
We should Create a Scheduled Task to check on all libraries that we are using inside our projects to get notifications on the same day inside this release and we gonna build it From Scratch with some tools that will help us build this Task
## The Components Used inside This Project
1. Node Js Project
2. Slack Application
3. The Source Links of The Libraries
> The Full Example will be Available at the End of the Article
## First Thing is to Build The Backend Project
We Will Use NodeJs to Build Backend Side of this Project and Especially NestJs Framework and Typescript and We Need to Use one of the Backend Frameworks To Use Cron Jobs and CronJob is a Scheduled Event That Will Trigger Some Actions in Specific Time that You Specify it when Create the instance of the Task Service
You can Use any Backend Framework because most of them has Cron Job implemented inside each one of them but for me, I Prefer to Build these Things in NestJs
## Second Thing is to Create a Slack Application
Slack Application is a Ready Api from Slack To Create Application with Id, Name, Logo That will Send Messages To Members, Channels inside your Workspace and for this project, we will configure this application to send messages with the New Versions of the Libraries on specific Channel
## The final Part is Configuring The Source of Libraries
This is Really Important is to Know each Library which source is the Best to Fetch it, For Example, when I build Android Applications I have multiple Sources to Fetch Libraries not all of them from one Source like (MavenCentral, GoogleMavenRepository, GithubRepository, GradlePortal) and We Need to Find a way to Fetch The Libraries from Multiple Sources inside the Same Project
But In this Part, I saw Something Common Between all of them is 90% of the Libraries Source code inside Github Repositories and all of them has Releases and Tags Version so We Can Track all of them from a Common Source which is (Github API)
Now Let's Start with The Implementation of the Project and We Will Start with Creating Slack and Github Configuration
The First Step is To Configure Slack and Github to Get Tokens, Keys that we Need to Use inside our NodeJs Project
First Step Create Slack Application inside Your Workspace and Specify the Logo and Name of the Application Then Add The Following Configuration inside App Manifest
```
_metadata:
major_version: 1
minor_version: 1
display_information:
name: Zilon
features:
app_home:
home_tab_enabled: true
messages_tab_enabled: true
messages_tab_read_only_enabled: false
bot_user:
display_name: Zilon
always_online: true
oauth_config:
redirect_urls:
- https://example.com/slack/auth
scopes:
bot:
- commands
- chat:write
- chat:write.public
settings:
org_deploy_enabled: false
socket_mode_enabled: false
token_rotation_enabled: true
```
Now You Need to Create a Github Application from OAuth Settings Inside Your Github Account Settings and Take the Client Id and Secret Client Id then Save Them on Text File with Slack Keys (Token, Signing Key) and All of these Keys can be Found inside the Application Settings In General Tab Then Save All Keys and Tokens in One Text File because We Will Need them Later
Now Create Channel inside Your Slack Workplace and Invite the Application you created inside this channel to get access to the Channel
### Now Create NestJs Project
Generate New project with NestJs By Executing the Following Commands inside Your Terminal
```
npm install -g @nestjs/cli
npx nest new project-name
cd project-name
npm install --save @nestjs/schedule
npm install --save-dev @types/cron
npm install axios
npm install @slack/bolt
```
### Now We Want to Add Cron Job to start Scheduled Task
> This Task will be started at a specific time like the following example
```
import { Injectable } from "@nestjs/common";
import { Cron, CronExpression } from "@nestjs/schedule";
@Injectable()
export class TasksService {
@Cron(CronExpression.EVERY_DAY_AT_1AM, {
name: "dependencies"
})
handleCron() {
// Handle Libraries Checks
}
}
// Now Declare this TaskService inside your App Module
import { Module } from '@nestjs/common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
import { ScheduleModule } from '@nestjs/schedule';
import { TasksService } from "./task/TasksService";
@Module({
imports: [ScheduleModule.forRoot()],
controllers: [AppController],
providers: [AppService, TasksService],
})
export class AppModule {}
```
Now We Will Use Axios To Send API Requests on GitHub to check all Libraries and get Releases Using GitHub API v3
```
import axios, { Axios } from "axios";
export class NetworkInstance {
public static SUCCESS_RESPONSE_CODE = 200;
// General Url's For Requests
public static GROUP_ARTIFACTS = "/group-index.xml";
public static GITHUB_REPOS_KEY = "/repos/";
public static GITHUB_RELEASES_KEY = "/git/refs/tags";
public static getGithubRepositoriesInstance(): Axios {
let instance = axios.create({
timeout: 5000,
baseURL: "https://api.github.com",
responseType: "json",
headers: { Accept: "application/json" }
});
instance.interceptors.request.use(request => {
console.log("Github Starting Request", request.url);
return request;
});
return instance;
}
}
```
Now the Functionality will be like the Following, We want to Store all libraries that we need to check every day then we will store the latest released tag and on each day the scheduler will send a request to the GitHub repo to check the latest tag if not similar to stored tag then we will send a slack message with this library
In this stage, you have the option to store all of them in the way you like if you want you can use the database to store all of them but I prefer to write all of them inside JSON file in this type of project
This is a Simple Example of how to check all of them in this stage you will need to get Github app clientId, SecreteId from the GitHub app that you created in your GitHub profile settings
```
export class GithubDependenciesManager {
private static GITHUB_LIBRARIES_FILE = "github-libraries.json";
private static CONSOLE_LOGGING_KEY = "[Github Dependencies Manager]";
private static GITHUB_CACHE_FILE = "github-libraries-cache.json";
private static CONFIG_FILE = "config.json";
/**
* Main Method to Start inside This Manager
* 1. Create and Validate the Local Json Files
* 2. Start Validating The Old Files if Exists, if Not Will Create Default Files
* 3. Will loop on all of them to see if the current version on github is similar to cached version
* if not will send message on slack channel via config.json token, channelId
*/
public async validateGithubLibrariesFile() {
const fs = require("fs");
this.createGithubLibrariesFile();
let configFile = new ApplicationConfigFile("", "", "", true, "", "");
if (fs.existsSync(GithubDependenciesManager.CONFIG_FILE)) {
const dataFile = fs.readFileSync(GithubDependenciesManager.CONFIG_FILE);
configFile = JSON.parse(dataFile.toString());
}
let librariesInformation = new Array<GithubRepositoriesInformation>();
let librariesFile = new GithubContainerFileContent(new Array<GithubLibrary>());
if (fs.existsSync(GithubDependenciesManager.GITHUB_LIBRARIES_FILE)) {
const data = fs.readFileSync(GithubDependenciesManager.GITHUB_LIBRARIES_FILE, "utf8");
librariesFile = JSON.parse(data);
for (let i = 0; i < librariesFile.libraries.length; i++) {
const library = librariesFile.libraries[i];
await timer(5000);
await NetworkInstance.getGithubRepositoriesInstance().get<Array<GithubRepositoryRelease>>(this.getGithubRequestUrl(configFile, NetworkInstance.GITHUB_REPOS_KEY + library.url + NetworkInstance.GITHUB_RELEASES_KEY), {
method: "get"
}).then((response) => {
if (response.status == NetworkInstance.SUCCESS_RESPONSE_CODE) {
librariesInformation.push({
name: library.name,
url: library.url,
releases: response.data
});
} else {
console.error(GithubDependenciesManager.CONSOLE_LOGGING_KEY + " Exception : " + response.data + " Response : " + response.statusText);
}
}).catch((exception) => {
console.error(GithubDependenciesManager.CONSOLE_LOGGING_KEY + " Exception : " + exception);
});
}
this.validateGithubRepositoriesReleasesVersions(librariesInformation);
}
}
private getGithubRequestUrl(config: ApplicationConfigFile, url: string): string {
return url + "?client_id=" + config.githubClientId + "&client_secret=" + config.githubClientSecrete;
}
/**
* After Get all Releases From Github Api to Get All Releases Information
* We Will Validate the First Release With The Cached Versions if Not Equals
* Will Send Slack Message with The New Version Triggered ...
* @param libraries
* @private
*/
private validateGithubRepositoriesReleasesVersions(libraries: Array<GithubRepositoriesInformation>) {
const fs = require("fs");
let librariesFile = new GithubLibrariesCacheContainer(new Array<GithubCacheLibrary>());
const requireUpdateLibraries = new Array<LibraryUpdateModel>();
fs.readFile(GithubDependenciesManager.GITHUB_CACHE_FILE, "utf8", function readFileCallback(err, data) {
if (err) {
console.log(err);
} else {
librariesFile = JSON.parse(data);
for (let i = 0; i < librariesFile.libraries.length; i++) {
const cachedLibrary = librariesFile.libraries[i];
for (let j = 0; j < libraries.length; j++) {
const triggeredLibrary = libraries[j];
if (cachedLibrary.name.includes(triggeredLibrary.name) && triggeredLibrary.releases != null) {
if (!cachedLibrary.release.includes(triggeredLibrary.releases[triggeredLibrary.releases.length - 1].ref.replace("refs/tags/", ""))) {
console.log(GithubDependenciesManager.CONSOLE_LOGGING_KEY + " Library Need Update : " + triggeredLibrary.name + " Version : " + cachedLibrary.release + " Updated Version : " + triggeredLibrary.releases[triggeredLibrary.releases.length - 1].ref.replace("refs/tags/", ""));
requireUpdateLibraries.push({
isGithubSource: true,
releaseUrl: "https://github.com/" + triggeredLibrary.url + "/releases",
version: triggeredLibrary.releases[triggeredLibrary.releases.length - 1].ref.replace("refs/tags/", ""),
url: "https://github.com/" + triggeredLibrary.url,
artifact: "",
groupId: "",
name: triggeredLibrary.url.split("/")[1]
});
}
}
}
}
new MessagingManager().sendMessageUpdateDependencies(requireUpdateLibraries);
GithubDependenciesManager.saveNewGithubRepositoriesCacheFile(libraries);
}
});
}
/**
* After Updating the Required Dependencies and Send All of them inside Messages in Slack
* Now we Want to Refresh the Json File with New Cached Data
* To Save The Notified Releases
* @param libraries
* @private
*/
private static saveNewGithubRepositoriesCacheFile(libraries: Array<GithubRepositoriesInformation>) {
const fs = require("fs");
if (fs.existsSync(GithubDependenciesManager.GITHUB_CACHE_FILE)) {
const librariesFile = new GithubLibrariesCacheContainer(new Array<GithubCacheLibrary>());
for (let i = 0; i < libraries.length; i++) {
try {
const library = libraries[i];
librariesFile.libraries.push({
name: library.name,
release: library.releases[library.releases.length - 1].ref.replace("refs/tags/", "")
});
} catch (error) {
console.error(error);
}
}
const json = JSON.stringify(librariesFile, null, "\t");
fs.writeFile(GithubDependenciesManager.GITHUB_CACHE_FILE, json, "utf8", (exception) => {
if (exception != null) {
console.error(GithubDependenciesManager.CONSOLE_LOGGING_KEY + " Exception : " + exception);
}
});
}
}
}
```
Now We Have the Updated Libraries inside Array and we want to loop on them and send messages via slack API using the Signing Key, Secret Key
```
private static sendSlackMessage(configFile: ApplicationConfigFile, message: string) {
try {
MessagingManager.getSlackApplicationInstance(configFile.signingSecret, configFile.token).client.chat.postMessage({
channel: configFile.channelId,
mrkdwn: true,
text: message,
as_user: true,
parse: "full",
username: "Zilon"
}).then((response) => {
console.log("Slack Message Response : " + response.message.text);
}).catch((exception) => {
console.error(exception);
});
} catch (error) {
console.error(error);
}
}
```
Use this Method inside your Loop and Create your Own Message on each Library, in my case I have added all libraries and their documentation links, official websites that I need to my JSON file, and on each message, I check all of them and send them with the message
In Slack Application Create a Channel and invite the app to this channel by typing /invite then pick the application and inside the code when you want to send a message on the channel you should write it to be like this (#general)
### The Scheduled Task Result

> Full Example is Available on Github
[Github Repository](https://github.com/Yazan98/Zilon)
| yazan98 |
870,834 | Answer: How to prevent automatic sort of Object numeric property? | answer re: How to prevent automatic... | 0 | 2021-10-21T05:27:16 | https://dev.to/mhsohag11/answer-how-to-prevent-automatic-sort-of-object-numeric-property-efg | {% stackoverflow 63456652 %} | mhsohag11 | |
870,853 | 5 Tips for Affordable Shopping at a Furniture Store | Furniture shopping can be fun and painful. It’s fun if you enjoy exploring items and get your... | 15,095 | 2021-10-21T05:47:29 | https://dev.to/bergenfurniturenj/5-tips-for-affordable-shopping-at-a-furniture-store-5g3f | writing, discuss, tutorial, testing | Furniture shopping can be fun and painful. It’s fun if you enjoy exploring items and get your favorite items at good prices. However, if you end up paying more than desired, it becomes a headache in the long run. But you don’t need to worry about spending hefty amounts every time you visit a Furniture Store in Ridgefield NJ. These tips will help you save a good cost when out to shop furnishings for your home.
• Negotiate for Discount on Accessories: Usually, stores might not have too many margins in furniture products they sell. And they already put on good deals to attract buyers. So, you won’t score a hefty discount on whatever you are going to buy. But if you are buying accessories as well, you can save some bucks there. The bigger your purchase amount, the more you can bargain on accessories. But that doesn’t mean you should spend hundreds more than you need just to save some tens.
• Find the Right Time to Shop: Do you know what’s the best time to shop and save? Most will say sale periods. But do you know there are some brand or industry-specific months apart from the general sale seasons? You will also find some stores offering discounts throughout the year. However, for furniture, the best time to shop usually falls around December to January and May to June. And you might get over a 20% discount on an item that’s otherwise available at 10% less. So, if you can wait for that period, hold your nerves till sales begin.
• Clearance and Floor Models: Do you remember the model on display at the <a href="https://www.bergenfurniturenj.com/new-jersey/bergen-county/ho-ho-kus">Furniture Store in Ho Ho Kus NJ</a>? And do you know you can get that for almost half its cost? Many stores mark floor models down due to either some visible flaw or to create space for new items. Similarly, clearance items also attract great negotiations as store owners want to clear their inventory shelves even if it means making less or no profit.
• Choose Your Financing Option Carefully: Imagine you walk into a store to buy that desired furniture and find a 0% financing offer. Will you pay in full or opt for paying in small installments over time? Well, you should check the terms, conditions, and detailed charges before deciding. Although such financing offers to relieve you from the financial burden without putting on extra debt, you might face higher charges on delayed payments. This might make you pay more than you saved by not opting for a non-zero financing option.
• Avoid Buying Basic Ad Hoc Plans: It could be for fabric protection when you buy upholstered furniture or anything similar. Why spend a high amount on hiring someone for the furniture care chores when you can do those things yourself? With a plan, you will have to pay for the person and product. However, opting out will cut down the cost of the person while you can buy the product at a much lesser price separately. Although that will mean you will be doing to cleaning and caring things yourself.
Make a note, keep it in your pocket or your phone, and make sure to read these tips before entering a <a href="https://www.bergenfurniturenj.com/new-jersey/bergen-county/ridgefield">Furniture Store in Ridgefield NJ</a>, for shopping.
| bergenfurniturenj |
871,523 | React authentication with Firebase | Authententication in React with Firebase, using Redux Toolkit to store user data! | 0 | 2021-10-21T18:21:43 | https://dev.to/dawx/react-authentication-with-firebase-3ma4 | react, redux, authentication, firebase | ---
title: React authentication with Firebase
published: true
description: Authententication in React with Firebase, using Redux Toolkit to store user data!
tags: react, redux, authentication, firebase
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/bvlnqvksg63nnj42dy36.png
---
Hello everyone, in this guide I will show you how to set up basic authentication in React with Firebase. We will be also using react-router for creating routes (public and protected) and Redux ToolKit for saving user tokens to our applications state.
## Project setup
First, we need to install React
`npx create-react-app react-firebase`
After it is installed we need to install dependencies we will use throughout this guide:
* React Router DOM: `npm install react-router-dom`
* Firebase: `npm install firebase`
* Redux and Redux Toolkit: `npm install react-redux` and `npm install @reduxjs/toolkit`
After everything is installed you can start the local server:
`cd react-firebase`
`npm start`
If everything is alright you will get this screen:

## Project structure
In the src folder, we will create four new folders (configs, pages, redux, and utils). Configs will contain configuration for Firebase. Pages will contain all our pages, I also created a subfolder auth which will contain all pages regarding user authentication. Redux folder will container redux store and slices. Utils folder is for utilities like protected route components.
## Creating pages and routes
In pages->auth we will create 3 pages: Register, Login, Reset (password reset). I also created a folder „protected“ which has a page for authenticated users and a Home page for every user.
### Login page
Below you can see basic React code for Login, it has two controlled inputs.
```javascript
import React, { useState } from "react";
const Login = () => {
const [email, setEmail] = useState("");
const [password, setPassword] = useState("");
const handleLogin = () => {
//here will go code for sign in
};
return (
<div>
<h1>Login</h1>
Email:
<br />
<input
type="text"
value={email}
onChange={(e) => setEmail(e.target.value)}
/>
<br />
Password:
<br />
<input
type="password"
value={password}
onChange={(e) => setPassword(e.target.value)}
/>
<br />
<button onClick={handleLogin}>Log In</button>
</div>
);
};
export default Login;
```
### Register
```javascript
import React, { useState } from "react";
const Login = () => {
const [email, setEmail] = useState("");
const [password, setPassword] = useState("");
const handleRegister = () => {
//here will go code for sign up
};
return (
<div>
<h1>Register</h1>
Email:
<br />
<input
type="text"
value={email}
onChange={(e) => setEmail(e.target.value)}
/>
<br />
Password:
<br />
<input
type="password"
value={password}
onChange={(e) => setPassword(e.target.value)}
/>
<br />
<button onClick={handleRegister}>Register</button>
</div>
);
};
export default Login;
```
### Password reset
```javascript
import React, { useState } from "react";
const Reset = () => {
const [email, setEmail] = useState("");
const handleReset = () => {
//here will go code for password reset
};
return (
<div>
<h1>Reset password</h1>
Email:
<br />
<input
type="text"
value={email}
onChange={(e) => setEmail(e.target.value)}
/>
<br />
<button onClick={handleReset}>Reset password</button>
</div>
);
};
export default Reset;
```
The next step is to create links and routes for pages that will be in the App.js file. We can delete boilerplate code in App.js and write our own code.
```javascript
import { BrowserRouter as Router, Switch, Route, Link } from "react-router-dom";
import Login from "./pages/auth/Login";
import Register from "./pages/auth/Register";
import Reset from "./pages/auth/Reset";
import Home from "./pages/Home";
import Secret from "./pages/protected/Secret";
function App() {
return (
<Router>
<nav>
<ul>
<li>
<Link to="/">Home</Link>
</li>
<li>
<Link to="/login">Login</Link>
</li>
<li>
<Link to="/register">Register</Link>
</li>
<li>
<Link to="/reset">Reset password</Link>
</li>
<li>
<Link to="/protected">Protected page</Link>
</li>
<li>
<Link to="#">Log out</Link>
</li>
</ul>
</nav>
<Switch>
<Route exact path="/register">
<Register />
</Route>
<Route exact path="/login">
<Login />
</Route>
<Route exact path="/reset">
<Reset />
</Route>
<Route exact path="/protected">
<Secret />
</Route>
<Route exact path="/">
<Home />
</Route>
</Switch>
</Router>
);
}
export default App;
```
First, we import react-router-dom dependencies and pages we just created. Then put `<Router>` as the root component. Under that is created basic navigation, instead of `<a>` element is used `<Link>` which doesn't refresh page on click (that's the point of Single Page Applications). Under navigation is a switch where we declare routes and components which they render. Now our screen looks something like this:

The home page component is rendered at localhost:3000, if you click on the link in the navigation, other components will load without refreshing the page. Only Log Out doesn't render anything since it will be just used to log out.
## Setting up Firebase
First, you need to create a Firebase account at https://firebase.google.com/ and go to the Firebase console at https://console.firebase.google.com. Click on „Add project“ and follow three simple steps.
After you finished with three steps you will be redirected to the screen which looks like on the picture below. Click on the </> icon to generate code for the web app.
Then enter the name of the app:
And then you get configuration for your app!
Now you can go to our project and in the config folder create file firebaseConfig.js. Paste config object and export it.
After creating the config it's time to initialize Firebase in our project, we do this in App.js. First, we need to import config from our file and initializeApp from firebase, then at the top of our component, we initialize it.
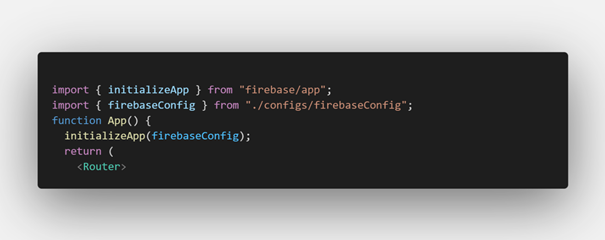
There is one last thing to do. We need to enable email and password authentication in the Firebase console. To do that go to your project, press on the „Authentication“ link on the left sidebar, then „Set up sign-in method“ in the middle of the screen. Click on email and password, enable it, and save.
With this Firebase setup is finished. In the next part, we will integrate existing forms in our project with Firebase to actually register, login, and log out users, as well as send password reset links.
## Finish registration, login, log out and password reset
### Registration
To register a user we need to import getAuth and createUserWithEmailAndPassword from firebase. getAuth gets us an instance of initialized auth service.
```javascript
import { getAuth, createUserWithEmailAndPassword } from "firebase/auth";
```
Now we can declare variable auth which will hold auth service. Next, we can use „createUserWithEmailAndPassword“ in our handleRegister, first argument is auth service, then email, and lastly password. We create a promise if registration is successful you will get the user object logged in the console, if it wasn't successful, an error will be logged.
```javascript
const auth = getAuth();
const handleRegister = () => {
createUserWithEmailAndPassword(auth, email, password)
.then((userCredential) => {
const user = userCredential.user;
console.log("Registered user: ", user);
setEmail("");
setPassword("");
})
.catch((error) => {
const errorCode = error.code;
const errorMessage = error.message;
console.log("Error ocured: ", errorCode, errorMessage);
});
};
```
Here you can see the user object in the console after successful register:
### Login
For the login page, we do the same, but this time we are using „signInWithEmailAndPassword“. Just like last time, import getAuth and this time signInWithEmailAndPassword. Here is a code snippet of signIn handler.
```javascript
const signIn = () => {
signInWithEmailAndPassword(auth, email, password)
.then((userCredential) => {
const user = userCredential.user;
console.log("Singed in user: ", user);
})
.catch((error) => {
const errorCode = error.code;
const errorMessage = error.message;
console.log("An error occured: ", errorCode, errorMessage);
});
};
```
### Password reset
Repeat the steps for a password reset, but this time use sendPasswordResetEmail. This method only requires email. Here is a code snippet.
```javascript
const handleReset = () => {
sendPasswordResetEmail(auth, email)
.then(() => {
console.log("success");
})
.catch((error) => {
const errorCode = error.code;
const errorMessage = error.message;
console.log("An error has occured: ", errorCode, errorMessage);
});
};
```
If it's successful you will get an email which will send you to page like this:
### Log out
Since our navigation is directly in App.js, this is where we will implement log-out functionality. First import getAuth and signOut. Then add the following code to the „Log out“ link.
```javascript
<Link
to="#"
onClick={() => {
signOut(auth)
.then(() => {
console.log("user signed out");
})
.catch((error) => {
console.log("error", error);
});
}}
>
Log out
</Link>
```
## Setting up Redux Toolkit
In redux->slices folder create file authSlice.js. This file will save user in a global state and there will also be defined methods to manipulate with the state. Here is a code snippet:
```javascript
import { createSlice } from "@reduxjs/toolkit";
const initialState = {};
export const authSlice = createSlice({
name: "user",
initialState,
reducers: {
saveUser: (state, action) => {
state.value = action.payload;
},
},
});
// Action creators are generated for each case reducer function
export const { saveUser } = authSlice.actions;
export default authSlice.reducer;
```
First, we import createSlice from RTK. Then initialize state as an empty object, next we create authSlice which has the name „user“, it has an initial state which is the empty object, and one reducer „saveUser“. saveUser takes two arguments, the first is a state which this slice has and the second is the action that will trigger it. It sets the value of the state to the payload of action (what you pass as an argument to that action). Lastly, we export saveUser and authSlice.
The next step is to set up a store which will hold state. In the root of redux folder create store.js file.
```javascript
import { configureStore } from "@reduxjs/toolkit";
import authReducer from "./slice/authSlice";
export const store = configureStore({
reducer: {
auth: authReducer,
},
});
```
Here we configure the store with one auth reducer. This is how your redux folder structure should look like now:

Now we need to provide a state from Redux to our app, to do that we need to wrap our <App /> component in index.js with the provider from redux which will use our store configuration.
```javascript
import React from "react";
import ReactDOM from "react-dom";
import "./index.css";
import App from "./App";
import { store } from "./redux/store";
import { Provider } from "react-redux";
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById("root")
);
```
The next step is to save the user token from firebase to our global state and update it every time something happens to the user. For that we will use onAuthStateChanged hook from firebase, every time auth changes we will save new user data to our global state. If there is no user, we just set a user to undefined.
```javascript
import { getAuth, signOut, onAuthStateChanged } from "firebase/auth";
import { useSelector, useDispatch } from "react-redux";
import { saveUser } from "./redux/slice/authSlice";
function App() {
initializeApp(firebaseConfig);
const auth = getAuth();
const user = useSelector((state) => state.auth.value);
console.log("user from state", user);
const dispatch = useDispatch();
useEffect(() => {
onAuthStateChanged(auth, (user) => {
if (user) {
dispatch(saveUser(user.refreshToken));
} else {
dispatch(saveUser(undefined));
}
});
}, [auth, dispatch]);
```
Now if you go log in and log out, you will see this in your console:
This is is it for this part. In the next part, we will set up protected routes which will be accessible only for logged in users.
## Protected routes
Credit to @medaminefh and his article https://dev.to/medaminefh/protect-your-components-with-react-router-4hf7 where I took the code changed it a bit for this project.
In utils folder create file ProtectedRoute.js and paste this code in:
```javascript
import React from "react";
import { Redirect, Route } from "react-router";
import { useSelector } from "react-redux";
const ProtectedRoute = ({ component: Component }) => {
const user = useSelector((state) => state.auth.value);
console.log("user", user);
return (
<Route
render={(props) => {
if (user) {
return <Component {...props} />;
} else {
return <Redirect to="/" />;
}
}}
/>
);
};
export default ProtectedRoute;
```
ProtectedRoute takes in a component. First we „fetch“the user from the global state using useSelector hook, if the user exists provided component will render. Otherwise, the user will be redirected to the home page.
Now we can use the ProtectedRoute component in our App.js where routes are declared. First, import ProtectedRoute from utils and then simply replace <Route> which you want to protect with <ProtectedRoute>:
```javascript
..
<Route exact path="/reset">
<Reset />
</Route>
<ProtectedRoute exact path="/protected" component={Secret} />
<Route exact path="/">
<Home />
</Route>
..
```
Now if you are logged in, you will be able to see the protected component, else you will be redirected to the homepage.
This is it for this tutorial, if you have any questions, feel free to ask!
You can find this repository here: https://github.com/PDavor/react-firebase to make it working just add your firebase configuration!
| dawx |
871,834 | How I turned my old 55″ Samsung TV into a SmartTV with AmbiLight | TLDR; This solution, uses an AndroidTV box to provide the SmartTV functionality. For the... | 0 | 2021-10-21T22:23:15 | https://dev.to/adonis/how-i-turned-my-old-55-samsung-tv-into-a-smarttv-with-ambilight-h8m | esp8266, smarttv, diy | # TLDR;
This solution, uses an AndroidTV box to provide the SmartTV functionality. For the ambilight, I had to “hack” into my TV to grab the pixel-information of what is shown on the screen and send that to an ESP8266-controller to control the LED-strip attached to it.
#The Smart TV
Looking around at many of the solutions, AppleTV, AndroidTV, etc… I opted for the Xiami MiBox, which recently got upgraded to AndroidTV Oreo.
It’s a full working stock AndroidTV, with built in ChromeCast and which also allows me to sideload apps, that are not accessible from the GooglePlay-store.
For 70,- bucks a great extension.
# The Ambilight
Now this one is tricky. As of now, there is a great ambilight project out there, the hyperion-project. But the fact, that I have to use an HDMI-splitter and not being able to switch HDMI-sources with my TV remote and automatically having the LED-strip using that source, bothered me.
As a smartphone-user who is familiar with rooting and installing custom software, I thought of the idea, that there MUST be some “rooting” method for a TV, to gain access to the TV’s pixel data and to send that somehow to a LED-strip. Luckily, there actually is something like that, well… kind of.
Doing my research, I stumbled upon SamyGO. Which is a community of programmers, providing useful instructions, how to “root” a Samsung TV, and offering some useful “libraries” to extend it’s functionality. Unfortunately, the information is just accessible to people who donate a small amount of BTC (10$) to the forum-owner. Which is really worth the money.
After I rooted my TV, I hoped, that one of these programmers already had the same idea like me and developed a library for an ambilight-solution. But unfortunately there wasn’t — so I had to write my own.
Since, I could not find any instructions on how to write libraries, I started digging into the source-code of other libraries to find out, how they’re developed. Well, after some trial&error, and after crashing my TV a bunch of times :-D, I finally had a working solution.
# How it works
The idea is very simple. I grab the TVs pixel, and send them via UDP to an ESP8266, which controls the LED-strip. This works no matter what is displayed on the TV, so the integrated tuner, every HDMI-source (AndroidTV, PlayStation4, … you name it).
# Installation
So, if you want to try it on your own, here are some instructions how to achieve the same result as I have.
## Requirements
- Samsung TV (E, F or H series)
- Good USB-Stick (16GB)
- ESP8266 12E (NodeMCU)
- Addressable LED-strip (WS2801, WS2811… etc)
- Power supply unit for the LED strip
- Xiaomi MiBox
## Rooting the TV
Head over to https://forum.samygo.tv/, get into the Donator group and find a rooting method that works for your TV. I’d suggest one of these methods, where you install the root onto a USB stick. Since this is the saver method. If you screw anything up, you can remove the USB stick, and start over again, without messing with your TV system.
## Setting up the AmbiLight
When you’re in the donor group, you should be able to access the files provided by me in the libAmbilight-topic and follow the installation-instructions there: https://forum.samygo.tv/viewtopic.php?f=75&t=12460
# Total costs
- TV 55″: free (but 830 € if I hadn’t one)
- USB-Stick: 20 €
- ESP8266: 5 €
- LED-strip: 40€
- PSU for LED-strip: 10€
- Xiaomi MiBox: 70 €
- Total: ~ 145 € (975 € with TV)
- Hours spent in research and programming: ~ 70h
# Conclusion
Now the question is, was it worth all the effort. Considering that, if I haven’t had the TV and had to buy a new one, I would’ve spent 975 € for these setup, and another 70h of research and programming. Since there’s a Philips 55″ with AndroidTV and ambilight for around 700 €, it’d be much cheaper buying a new one with all the features included.
Another option would be to sell the TV, since it’s an older model, I don’t think I’d get more than 400 € for it, so I’d have to spend 300€ to buy the Philips one, which would be 150€ more than extending it myself. Although, I’d save on the 70hrs of research and programming.
IMHO: It was totally worth it. The 70 € for the MiBox is a really good deal. The nice-to-have-ambilight which is another 75€ was a great opportunity to improve my programming skills. | adonis |
871,983 | Sustainable Web Manifesto 📜 | À l'heure où le monde entier parle de plus en plus de l' urgence climatique , nous devons nous aussi,... | 0 | 2021-11-12T11:29:26 | https://www.benjaminrancourt.ca/sustainable-web-manifesto | webdev, development, code, french | ---
title: Sustainable Web Manifesto 📜
published: true
date: 2021-10-21 23:15:00 UTC
tags: webdev, development, code, french
canonical_url: https://www.benjaminrancourt.ca/sustainable-web-manifesto
cover_image: https://www.benjaminrancourt.ca/images/pexels-wenjun-zhu-2098621.jpg
---
À l'heure où le monde entier parle de plus en plus de l' **urgence climatique** , nous devons nous aussi, en tant que **professionnels des technologies de l'information** , voir de quelle façon nous pouvons contribuer à **lutter contre les changements climatiques**. 🖥️
C'est dans cette optique que je suis avec intérêt les nouvelles initiatives qui vont dans ce sens-là. Aujourd'hui, je souhaite vous parler d'une initiative débutée l'an dernier nommée : _[**Sustainable Web Manifesto**](https://www.sustainablewebmanifesto.com/)_ (en français : manifeste du Web durable).
## Qu'est-ce qu'est le _Sustainable Web Manifesto_?
Initié par une agence londonienne soucieuse de son impact environnemental, [Wholegrain Digital](https://www.wholegraindigital.com/), le **manifeste du Web durable** est une réponse à l'augmentation de l'utilisation de données sur le Web. 🕸️
En effet, avec une infrastructure technologique constamment en évolution, les sites Web et les applications Web ont généralement tendance à utiliser de **plus en plus de données**. 📈
Nous devons donc nous questionner sur la place grandissante qu'occupe **Internet** dans les **changements climatiques**. Selon une comparaison effectuée par les auteurs du manifeste :
> « Si Internet était un pays, il serait le 7<sup>ème</sup> plus gros pollueur. ».
Cela peut paraître anodin, mais les données stockées sur des serveurs, les données transférées d'un réseau à l'autre et la puissance de calcul nécessaire pour traiter et afficher ces données ont toutes un point en commun : elles consomment de l' **électricité**. ⚡
Une infime quantité d'électricité est peut-être utilisée pour transmettre une simple page Web, mais lorsqu'on additionne toutes les utilisations partout sur la planète à chaque jour, cela commence à être une quantité gigantesque. 😵
Considérant que dans la plupart dans le monde, l'électricité est générée à [plus de 84 %](https://www.gazprom-energy.fr/gazmagazine/2020/08/le-mix-energetique-mondial-en-2020/) à partir d' **énergies fossiles** (pétrole, gaz naturel et charbon), nous pouvons donc affirmer qu'Internet contribue présentement à l'émissions de gaz à effet de serre... 😰
Cela fait un peu peur, n'est-ce pas? Heureusement, si tout le monde commence à suivre les **six principes fondamentaux** du manifeste, nous pouvons certainement contribuer à **verdir** le Web. 🐢
## Quelles sont ses principes fondamentaux?
### Propre
> Les services que nous fournissons et les services que nous utilisons seront alimentés par des **énergies renouvelables**.
### Efficace
> Les produits et services que nous proposons utiliseront **le moins** d' **énergie** et de **ressources matérielles** possible.
### Ouvert
> Les produits et services que nous fournissons seront **accessibles** , permettront un **échange ouvert d'informations** et permettront aux utilisateurs de **contrôler leurs données**.
### Honnête
> Les produits et services que nous fournissons **ne tromperont** ni **n'exploiteront** les utilisateurs dans leur conception ou leur contenu.
### Régénérateur
> Les produits et services que nous fournissons **soutiendront une économie** qui nourrit les gens et la planète.
### Résilient
> Les produits et services que nous fournissons fonctionneront aux **moments** et aux **endroits** où les gens en ont **le plus besoin**.
## Comment signer le manifeste?
Si vous ne l'avez pas déjà fait, vous pouvez signer le manifeste sur son [site Web officiel](https://www.sustainablewebmanifesto.com). Celui-ci vous permet d'ajouter votre nom comme signataire et de déclarer votre engagement à créer un **Internet durable**.
Ensemble, nous pouvons faire une différence! 🤗 | benjaminrancourt |
872,357 | Magento Store speed Optimization | Page speed, as we all know, is critical to the seamless operation of your eCommerce site. Users may... | 0 | 2021-10-22T09:59:35 | https://dev.to/ashutoshsonker786/magento-store-speed-optimization-4fae | php, javascript, webdev, programming | Page speed, as we all know, is critical to the seamless operation of your eCommerce site. Users may become frustrated if a website or store is too slow, so Magento Store optimization is required.
##What is Page Speed?
The page loading speed of contents on a website is referred to as page speed. The page speed is influenced by a number of factors, including the site's server, the size of the page files, and picture compression. The more quickly a web page loads, the more efficient it is for users. Many of them claim that page speed and site speed are the same thing, yet they are not. The average speed of numerous pages of a website is called site speed.
##What is Page Speed Optimisation?
The technique of optimising a page to lower its loading time is known as page speed optimization. Because there is a link between page speed and SEO, it is critical that the page loads quickly for a better user experience. The faster a page's information loads, the better its chances of ranking in a search engine. Quickly loaded pages are more enticing to site visitors, resulting in a lower bounce rate.
##Why Page Speed Optimisation is a major factor when it comes to SEO?
As discussed above, pages with higher load time have a higher bounce rate percentage and tend users to get frustrated with slow loading. Google measures time to the first byte when considering the page speed. The consistent increase in the bounce rates decreases the overall ranking on google. Thus, Page speed acts as a crucial ranking factor for search engines.
##Get the Cheapest Magento Store Optimisation:
If you opt for the Magento Page Speed Optimisation Service by CedCommerce, then the following will be the benefits from the experts to your Magento store:
>> Image Minified
>> JS and CSS Minification and Merging
>> Enabling of Magento Cache
>> Enabling Browser Cache
>> HTML Minimising
Magento Site in Product Mode and much more.
Speed up your Magento store today as with every second you delay, you are losing potential customers.
| ashutoshsonker786 |
872,374 | 10 no-brainer best practices that boost API security | Source: DepositPhotos APIs are becoming crucial to modern app development. Therefore making sure... | 0 | 2021-10-22T10:39:20 | https://dev.to/ashok83/10-no-brainer-best-practices-that-boost-api-security-38e3 | webdev, programming, security, sql |  Source: DepositPhotos
APIs are becoming crucial to modern app development. Therefore making sure that the data you pass between your APIs is secure and not compromised is a priority.
Unfortunately, APIs face a number of threats such as [SQL injection](https://www.w3schools.com/sql/sql_injection.asp), [Cross-site scripting (XSS)](https://www.f5.com/labs/articles/education/what-is-cross-site-scripting--xss--), [Distributed denial-of-service (DDoS)](https://www.kaspersky.com/resource-center/threats/ddos-attacks), [Man-in-the-middle (MitM)](https://dev.to/govindarajle/what-is-a-man-in-the-middle-attack-4nne), and [Credential stuffing](https://www.f5.com/labs/search?q=credential+stuffing).
The best way to avoid these attacks and improve your [API security](https://www.checkpoint.com/cyber-hub/cloud-security/what-is-application-security-appsec/what-is-api-security/) is to follow some simple best practices.
So I compiled these no-brainer best practices and made this guide:
* Prioritize security
* Encrypt your data
* Share as little as possible
* Authentication
* Limit the number of messages
* Data validation
* API firewalling
* API gateway (API management)
* Monitoring: Audit, log, and version
* Infrastructure
**1. Prioritize security**
Always give priority to security checks.
This is the biggest mistake most companies make. Scan your code regularly to check for security vulnerabilities and do it from the very beginning of development.
Do not procrastinate. Call in the experts or use ICAP (Internet Content Adaptation Protocol) servers to help you with security.
**2. Encrypt your data**
Most companies do not encrypt their data sent via APIs as they consider this as additional work. Their excuses are that they are not handling sensitive data or that they use the APIs internally.
However, this is a mistake.
Regardless of those excuses, you should always encrypt your payload data. If you are not handling sensitive information such as credit card numbers routinely, it is better for all the parties involved in the transaction to encrypt their data.
It would also make it harder for a hacker to extract information from your internal APIs during an attack. Therefore, it is always best to encrypt your data using the latest versions of either one-way TLS or two-way TLS encryption.
**3. Share as little as possible**
Always share the bare minimum of data that is required to perform a task.
This applies to what is shared in the payload as well as in error/success messages. Always use predefined messages. Do not display sensitive data in your messages.
Avoid storing customers' user credentials in [JSON Web Tokens](https://dev.to/iiits-iota/json-web-tokens-part-1-5c83) (JWTS) or cookies as it is easy to decode them. Instead, adopt user roles and privileges to make sure unauthorized users cannot access information.
In addition, you can restrict access to your resources by using IP-safe listing and delisting.
Another crucial thing to remember is to remove all the keys and passwords that the developer used during development before deployment.
Again, scanning the code might help prevent such accidental exposure.
**4. Authentication**
Always use an authentication mechanism to identify who is requesting information and whom you send the information to. For example, use a basic authentication method such as username/password pair or an asymmetric API key to identify users.
Another way to handle this is to use a trusted third party like Google to manage authorization. These authorization tools provide users with a token to access the API without using their credentials.
In addition, they use the [OAuth](https://oauth.net/) protocol to convey authorizations. You can also use [OpenID Connect](https://openid.net/connect/) to ensure authentication. This is known as OAuth 2.0 with ID tokens.
**5. Limit the number of messages**
Limit the number of messages or requests consumed by your API for a given period of time.
This will reduce the stress your API can put on your application's backend, prevent it from exceeding your server's capacity, and initiate Distributed Denial of Service ([DDoS](https://dev.to/t/ddos)) Attacks.
You can extend this further by restricting access by API or by the user.
**6. Data validation**
Always validate your data. Especially user inputs. Check whether they have the correct data type (string, integer, etc.) and do not have any unnecessary special characters such as single or double quotes.
You can do this by sanitizing your input before sending it to the API. You can also apply the validation and provide appropriate error messages to the user using the user interface to prevent users from submitting such data.
You can use JSON or XML schema validation to do this, and it will help prevent SQL injections or [XML bombs](https://dev.to/0xf10yd/web-services-security-xml-injection-j4d).
**7. API firewalling**
Another way to keep your attackers at bay is by introducing a firewall. For proper protection, you need to implement this in two layers:
* **First layer** - This is in the DMZ or demilitarized zone, the logical subnet that separates a local area network (LAN) from external networks. Their main task is to validate the inputs, check message sizes, and prevent SQL injections or other threats in the HTTP layer. If the message is clean and secure, the first layer will forward it to the second layer.
* **Second layer** - Applies advanced security mechanisms on data content, and it is in the Local Area Network (LAN).
**8. API gateway (API management)**
It does not matter how many APIs you are using.
However, it is always better to invest in an API Management Solution to manage them, whether it is one or more.
Even though all your APIs do not have the same technology, an API Management dashboard will help you secure, control, and monitor your traffic.
It will also save you time and money, which you can use for another cause.
**9. Monitoring: Audit, log, and version**
You should always maintain logs of your APIs as they can provide valuable information for troubleshooting errors and help you identify vulnerabilities.
In addition, you can further analyze these logs to optimize your payloads and find users or APIs that make far too many calls and could cause a DDOS attack.
Also, remember to keep logs for all the versions of your APIs.
**10. Infrastructure**
Making sure your API is meeting its security standard is not enough. You need to make sure your infrastructure is secure as well.
Run routine checks on your servers and load balancers and see whether the operating system and other software installed are up to date.
In addition to that, make sure that all the security patches are up to date as well.
**Conclusion**
As mentioned at the beginning, maintaining good API security is now an essential factor as there are many waiting to take advantage of your vulnerabilities.
However, if you are not sure where to start, follow these best practices from the top. They will help you secure data and win your customers' trust. | ashok83 |
874,404 | VSCode - Extensions | O VSCode é uma ferramenta incrível. Como possui o recurso de Extensões, você consegue aprimorar ainda... | 0 | 2021-10-28T13:08:57 | https://dev.to/leandroats/vscode-extensions-5a2 | ptbr, vscode, braziliandevs | O VSCode é uma ferramenta incrível. Como possui o recurso de Extensões, você consegue aprimorar ainda mais a experiência, deixar tudo com a sua cara e de quebra aumentar a sua produtividade. Vou listar algumas extensões que eu utilizo.
🎯[*CodeSnap - adpyke*] (https://marketplace.visualstudio.com/items?itemName=adpyke.codesnap&WT.mc_id=devto-blog-leandroats)
>Ajuda nos prints 😁
<img src="https://adpyke.gallerycdn.vsassets.io/extensions/adpyke/codesnap/1.3.4/1625238962906/Microsoft.VisualStudio.Services.Icons.Default"/>
---
🎯[*CodeTour - Jonathan Carter*] (https://marketplace.visualstudio.com/items?itemName=vsls-contrib.codetour&WT.mc_id=devto-blog-leandroats)
>Uma forma bastante interessante de documentar.
<img src="https://vsls-contrib.gallerycdn.vsassets.io/extensions/vsls-contrib/codetour/0.0.58/1625784500119/Microsoft.VisualStudio.Services.Icons.Default"/>
---
🎯[*Declarative Jenkinsfile Support - JM Meessen*] (https://marketplace.visualstudio.com/items?itemName=jmMeessen.jenkins-declarative-support&WT.mc_id=devto-blog-leandroats)
>Pipeline do Jenkins de forma mais amigável.
<img src="https://jmmeessen.gallerycdn.vsassets.io/extensions/jmmeessen/jenkins-declarative-support/0.1.0/1493632413360/Microsoft.VisualStudio.Services.Icons.Default"/>
---
🎯[*Dracula Official - Dracula Theme*] (https://marketplace.visualstudio.com/items?itemName=dracula-theme.theme-dracula&WT.mc_id=devto-blog-leandroats)
>Meu tema preferido, normalmente coloco esse padrão de cores nas ferramentas que utilizo.
<img src="https://dracula-theme.gallerycdn.vsassets.io/extensions/dracula-theme/theme-dracula/2.24.0/1630671466069/Microsoft.VisualStudio.Services.Icons.Default"/>
---
🎯[*Live Server - Ritwick Dey*] (https://marketplace.visualstudio.com/items?itemName=ritwickdey.LiveServer&WT.mc_id=devto-blog-leandroats)
>Cria um servidor web com um click.
<img src="https://ritwickdey.gallerycdn.vsassets.io/extensions/ritwickdey/liveserver/5.6.1/1555497731217/Microsoft.VisualStudio.Services.Icons.Default"/>
---
🎯[*Markdown Preview Github Styling - Matt Bierner*] (https://marketplace.visualstudio.com/items?itemName=bierner.markdown-preview-github-styles&WT.mc_id=devto-blog-leandroats)
>Preview do markdown no estilo do GitHub.
<img src="https://bierner.gallerycdn.vsassets.io/extensions/bierner/markdown-preview-github-styles/0.2.0/1618262856034/Microsoft.VisualStudio.Services.Icons.Default"/>
---
🎯[*REST Client - Huachao Mao*] (https://marketplace.visualstudio.com/items?itemName=humao.rest-client&WT.mc_id=devto-blog-leandroats)
>Funciona como um client Rest, suporta scripts que são tranquilos de fazer de entender.
<img src="https://humao.gallerycdn.vsassets.io/extensions/humao/rest-client/0.24.5/1617725796156/Microsoft.VisualStudio.Services.Icons.Default"/>
---
🎯[*vscode-icons - VSCode Icons Team*] (https://marketplace.visualstudio.com/items?itemName=vscode-icons-team.vscode-icons&WT.mc_id=devto-blog-leandroats)
>Uma quantidade gigante de ícones para qualquer linguagem de programação.
<img src="https://vscode-icons-team.gallerycdn.vsassets.io/extensions/vscode-icons-team/vscode-icons/11.6.0/1627842034344/Microsoft.VisualStudio.Services.Icons.Default"/>
---
Referências:
👉 [VSCode] (https://code.visualstudio.com/?WT.mc_id=devto-blog-leandroats)
👉 [Dracula Theme] (https://draculatheme.com/?WT.mc_id=devto-blog-leandroats)
Até a próxima!👊
---
> us Now you can support me by buying a coffee
pt Agora você pode me apoiar comprando um café
☕😊👇
<a href="https://www.buymeacoffee.com/leandroats" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="41" width="174"></a> | leandroats |
872,417 | NodeJS + Express part 1: Introduction | Here is a series of articles that will allow you to create backend applications with NodeJS +... | 15,121 | 2021-10-22T12:17:38 | https://dev.to/ericchapman/nodejs-express-part-1-introduction-314a | javascript, node, express, beginners | ---
title: NodeJS + Express part 1: Introduction
description:
published: true
tags: javascript, nodejs, express, beginner
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/l084jvfw4slao1hhgy5y.png
series: expressJS
---
Here is a series of articles that will allow you to create backend applications with NodeJS + Express.
This series is the continuation of my series on the basics of NodeJS. If you don't have basic knowledge of NodeJS read this series first: [Introduction to NodeJS](https://dev.to/ericchapman/create-a-backend-in-javascript-introduction-to-node-js-215a)
Node.js is today a must, so it is essential for a developer to master it.
So I will publish a new article about every two days and little by little you will learn everything there is to know about Node.js + Espress
To not miss anything follow me on twitter: https://twitter.com/EricTheCoder_
<hr>
### Reminder: What is a web server?
A web server is a set of hardware and software that allow access to hosted files, web page and database stored on a computer.
The web server also consists of an HTTP server. HTTP server is software that understands / receives URLs and requests via the HTTP protocol (the protocol used by the browser to display web pages).
At the simplest level, whenever a browser needs a file or other hosted on a web server, the browser makes the request to the server (it is said to send an HTTP request). When the request reaches the server, the HTTP server processes it and returns the response.

In summary, the bottom line is that although an HTTP server may seem complicated, in fact it is just a succession of requests and responses. You will see here below that NodeJS + Express allows you very easily to create an HTTP server and that it is very easy to read a request and send a response.
## What is ExpressJS
EspressJS is a NodeJS framework that makes it easier to create web applications. Indeed, why re-invent the wheel? With ExpressJS you have access to several functions that will facilitate and reduce the development time of your web application. Creating an HTTP server with Express is very easy.
### Creating a new application
To fully demonstrate the potential of ExpressJS and fully understand all the concepts, we are going to build a complete new web application.
First create a folder to host your application
```bash
$ mkdir demo-express
$ cd demo-express
```
The first step is to create the package.json file.
```bash
$ npm init
```
Then install the ExpressJS package and nodemon
```jsx
$ npm install express
$ npm nodemon
```
Note that as you learn in the NodeJS series, the nodemon package allows you to reload the server each time our code is modified.
### API vs SSR
Express can be used to create JSON API or a website with server side rendering. Today, we are going to create an API, it is by far the type of application most created with Express.
### What is an API?
API stands for Application Programming Interface.
In short, it is a program that can be used by another program, in order to allow applications to communicate with each other.
An API allows the server and the client to communicate with each other and exchange information.
For example, a customer requests a specific customer page on the server: [www.example.com/customers/3814 Danemark(http://www.example.com/customers/3814)
Can the server know how to handle this request? He can't. He won't know what to do with the request. That's why we need to create an API. This is a server application that will determine how to respond to various requests for a specific resource. In this case, return the customer information.
The API that you created can find record 3814 in the customer database, convert that information to JSON (structured text) format, and return this response to the customer.
Note that all requests to servers are made through HTTP actions.
### HTTP requests
The action you want to take on the specified resource. Although nouns are also encountered, these methods are often referred to as HTTP verbs.
### Here are the most commonly used HTTP verbs / actions
GET: GET requests are only used to retrieve data.
POST: GET requests are used to send new data.
PUT: PUT requests are used to modify data.
PATCH: PATCH requests are used to partially modify data.
DELETE: DELETE requests deletes the specified data.
### REST architecture
When the client and the server are talking to each other, it can quickly get out of hand.
For example, the customer can make a request like this: http://www.example/send-me-customer-3804-file or a delete request like this: http://www.example.com/delete-customer=3815
How can the server understand these different requests? To have successful communication, we need standards and conventions.
This is the role of the REST architecture. REST is a set of standards for creating an API that both client and server will use.
Today we won't learn everything about REST, but you can search the web for more information if you need to.
For newbies, the important thing is to know that the way we build our API is not based on personal tastes or opinions, but on the REST architecture standard. So follow them and you will be fine.
### CRUD routes conventions
One of those REST conventions is how routes are defined. There are standards for each CRUD course of action.
CRUD stands for Create, Read, Update, and Delete.
When we are dealing with an API resource. For example Customer. Each Client resource has its own CRUD routes.
Here is an example of these REST CRUD routes:
Create: POST http://www.example.com/customers
Read: GET http://www.example.com/customers/3814
Update: PUT http://www.example.com/customers/3814
Destroy: DELETE http://www.example.com/customer/3814
So now you have a more precise idea of what an API is.
On the server, the API will expose all of these routes and features. On the front-end, the client web application will ask these APIs to get the desired data.
Maybe for now the concept is still a bit hazy but things will become clearer when we build our own API.
### Your first API with Express
Create the app.js file and add the following code.
```jsx
const express = require('express')
const app = express()
app.listen(5000, () => {
console.log('server is listening on port 5000')
})
app.get('/api/products', (req, res) => {
res.json([
{ name: 'iPhone', price: 800 },
{ name: 'iPad', price: 650 },
{ name: 'iWatch', price: 750 }
])
})
```
In this code, the app.listen() will create an HTTP server and read incoming requests
The app.get() defines a URL path that returns a JSON product list.
You can test this app with
```bash
$ npx nodemon app.js
```
Navigate to [localhost:5000/api/products] (http://localhost: 5000/api/products), you should see a JSON representation of the product list
```json
[
{
"name": "iPhone",
"price": 800
},
{
"name": "iPad",
"price": 650
},
{
"name": "iWatch",
"price": 750
}
]
```
Congratulations, you have just created your first API with NodeJS + Express
In the next articles we will learn step by step all the details on how to create a NodeJS + Express API.
## Conclusion
That's all for today, follow me on twitter: https://twitter.com/EricTheCoder_ to be notified of the publication of the next article (within two days). | ericchapman |
872,499 | Step Functions para no morir. Parte 1: Inicio | Buenas! Este post va a ser el primer capítulo de una serie, en la que voy a explicar las Step... | 0 | 2022-02-01T13:29:25 | https://dev.to/giulianaolmos/step-functions-para-no-morir-parte-1-39ji | aws, javascript, stepfunctions, tutorial | Buenas! Este post va a ser el primer capítulo de una serie, en la que voy a explicar las Step Functions de AWS. Algunos capítulos van a contener exclusivamente contenido teórico, y otros contenido practico, en esos, voy a incluir videos para que se entienda mejor.
En este post vamos a ver:
- ¿Que son las step Functions?
- Cuales son sus ventajas.
- Casos de usos.
- Ejemplo.
#¿Qué son las Step Functions?

Si tomamos la definición de la documentación de AWS, una **Step Function** es un servicio de orquestación sin servidor que le permite combinar funciones Lambdas y otros Servicios para crear aplicaciones críticas para el negocio. A través de la consola gráfica de Step Functions, puede ver el flujo de trabajo de su aplicación como una serie de pasos basados en eventos.
Las Step Functions se basan en máquinas y tareas de estado. Una máquina de estado es un flujo de trabajo. Una tarea es un estado de un flujo de trabajo que representa una única unidad de trabajo que está realizando otro servicio de AWS. Cada paso de un flujo de trabajo es un estado.
**Es decir**, las step Functions sirven para ~~orquestar~~ diseñar flujos de trabajo utilizando los distintos servicios que ofrece AWS.
##Ventajas
Trabajar con Step Functions trae diversas ventajas, entre ellas:
- Se ejecutan en la nube, es decir, no hay una infraestructura que necesite ser mantenida.
- Son autoescalables, cada consulta crea una nueva instancia para que procese el flujo de trabajo.
- Su definición gráfica es parecida a un diagrama de flujo, lo que permite una administración más simple.
- Al pertenecer al proveedor AWS, puede ser integrada con otros servicios para tener una aplicación más compleja.
- Son aptas para la arquitectura de microservicios.
##Casos de uso de las steps.
La idea de orquestar step functions es la de escribir menos código, para así poder centrarse en crear y actualizar la aplicación.
Una aplicación puede contener distintos flujos combinados.
Por ejemplo:
####Orquestación secuencial
Este tipo de diseño lo utilizamos cuando queremos que nuestra aplicación ejecute los pasos en un orden especifico.
####Ramificación
Puede utilizarse de dos maneras.
- Bifurcación: Dependiendo de una o más variables podemos elegir por cual flujo se va continuar la secuencia. (El if de toda la vida)
- Paralelismo: Podemos hacer que la secuencia se divida en dos flujos que se ejecuten al mismo tiempo.

####Control de errores
Utilizando en la configuración las palabras `retry` y `catch` podemos reintentar una tarea en caso de error, o bifurcar el camino para que se pueda manejar ese error.
####Tareas Manuales
Estos son pasos en el flujo de la state machine que una vez ejecutados se quedan a la espera de una confirmación externa para poder continuar con la secuencia.
Aclaración: Pienso dedicar un capitulo entero a explicar este tipo de flujo.
##Ejemplo de State Function
La siguiente imagen es un ejemplo de una Step Function que combina distintos casos de uso.
Esta flujo de trabajo corresponde a un **proceso de pago**.
El `primer step` es de tipo Choice, y va a encargarse de encaminar el flujo a la opción correspondiente, dependiendo de si el pago es por debito o crédito.
Los `siguientes step` son lambdas que se van a encargar de procesar el pago.
En el caso en el que alguna transacción no pueda ser realizada, tenemos un `manejo de errores` mediante un catch que redirecciona el flujo a la lambda que va a formatear ese error.
El `ultimo step` se va a encargar de enviar el mensaje (transacción exitosa o fallida) al cliente mediante una cola de SQS.
##En fin

Este ha sido un pantallazo general de lo que vamos a estar viendo en los siguientes capítulos.
Si tienen alguna duda, pueden dejarla en los comentarios.
Voy a estar publicando esta serie una vez por semana.
Si el post les fue útil, pueden invitarme un cafecito.
[](https://cafecito.app/giulianaeolmos)
| giulianaolmos |
872,580 | Better to Avoid General-Purpose Wrapper Exceptions [RE#12] | If you’ve ever faced such temptation to wrap inner exceptions within some neatly-defined exception... | 13,472 | 2021-10-22T14:45:23 | https://babakks.github.io/article/2021/10/22/re-012-better-to-avoid-general-purpose-wrapper-exceptions.html | article, productivity, javascript, typescript | ---
title: Better to Avoid General-Purpose Wrapper Exceptions [RE#12]
published: true
date: 2021-10-22 14:30:00 UTC
tags: article, productivity, javascript, typescript
canonical_url: https://babakks.github.io/article/2021/10/22/re-012-better-to-avoid-general-purpose-wrapper-exceptions.html
series: Regular Encounters
---
If you’ve ever faced such temptation to wrap inner exceptions within some neatly-defined exception type, you’d better off fight the devil. Let exceptions be themselves and freely fly high the call stack. 💸
To elaborate on the issue, consider the hypothetical `DataProcessor` and the general purpose exception type `DataProcessingFailure` below:
```ts
class DataProcessingFailure extends Error {
constructor(public innerError: Error) {
super();
}
}
class DataProcessor {
process() {
try {
// Some processing
} catch (err) {
throw new DataProcessingFailure(err)
}
}
}
```
Here, the `process()` method only raises a `DataProcessingFailure` exception, if any. Whatever exception occurs (e.g., `DivisionByZero`) the caller of `process()` just catches a `DataProcessingFailure` instance. So, `DataProcessingFailure` is a _wrapper exception_.
The reason behind advising against wrapper exceptions is the change of behavior that you exert on the downstream system seen by higher level controllers. For instance, you could mask a well-defined exception that itself is an intricate part of the domain model. Another example is when your wrapper could mask network related exceptions, most of which resolve just by retrying, albeit if some caller at higher level of call stack could catch them as they are.
Putting it all together, you’d logically prefer minimizing footprints/side-effects of various components/implementations on each other, so that you could avoid unwanted couplings/special-treatments.
* * *
**_About Regular Encounters_**
_I’ve decided to record my daily encounters with professional issues on a somewhat regular basis. Not all of them are equally important/unique/intricate, but are indeed practical, real, and of course,_ **_textually minimal._** | babakks |
872,800 | Hello #python | A post by HICHAM | 0 | 2021-10-22T15:10:27 | https://dev.to/hicham09603648/hello-python-427k | hicham09603648 | ||
873,001 | Python string to datetime Conversion | ItsMyCode | There are several ways to convert string to datetime in Python. Let’s take a look at... | 0 | 2021-10-28T04:41:29 | https://itsmycode.com/python-string-to-datetime-conversion/ | python, programming, codenewbie, tutorial | ---
title: Python string to datetime Conversion
published: true
date: 2021-10-22 16:07:15 UTC
tags: #python #programming #codenewbie #tutorial
canonical_url: https://itsmycode.com/python-string-to-datetime-conversion/
---
ItsMyCode |
There are several ways to convert string to datetime in Python. Let’s take a look at each of these with examples.
## **Convert Python String to datetime** u **sing datetime Module**
We can convert a string to datetime using **the `strptime()`** function. The **`strptime()`** function is available in Python’s **_datetime_** and **_time_** module and can be used to parse a string to datetime objects.
**Syntax**
```python
**datetime.strptime(date\_string, format)**
```
**Parameters**
The **`strptime()`** class method takes two arguments:
- date\_string (that be converted to datetime)
- format code
Let’s take a few examples to demonstrate the **`strptime()`** function use case.
### **Python String to datetime**
```python
# Python program to convert string to datetime
#import datetime module
from datetime import datetime
# datetime in string variable
date_str = '22/11/21 03:15:10'
# convert string into datetime using strptime() function
date_obj = datetime.strptime(date_str, '%d/%m/%y %H:%M:%S')
print("The type of the date is now", type(date_obj))
print("The date is", date_obj)
```
**Output**
```python
The type of the date is now <class 'datetime.datetime'>
The date is 2021-11-22 03:15:10
```
### **Python String to date**
If you want to convert the string into date format, we can use the **`date()`** function and the **`strptime()`** function, as shown in the example below.
```python
# Python program to convert string to date object
#import datetime module
from datetime import datetime
# datetime in string variable
date_str = '22/11/21 03:15:10'
# covert string into datetime using strptime() function
date_obj = datetime.strptime(date_str, '%d/%m/%y %H:%M:%S').date()
print("The type of the date is now", type(date_obj))
print("The date is", date_obj)
```
**Output**
```python
The type of the date is now <class 'datetime.date'>
The date is 2021-11-22
```
### Python String to time
If you want to convert the string into date format, we can use the **`time()`** function and the **`strptime()`** function, as shown in the example below.
```python
# Python program to convert string to datetime
#import datetime module
from datetime import datetime
# datetime in string variable
date_str = '22/11/21 03:15:10'
# covert string into datetime using strptime() function
date_obj = datetime.strptime(date_str, '%d/%m/%y %H:%M:%S').time()
print("The type of the date is now", type(date_obj))
print("The date is", date_obj)
```
**Output**
```python
The type of the date is now <class 'datetime.time'>
The date is 03:15:10
```
## **Convert Python String to datetime using dateutil**
The other way to convert string to datetime is using the **_dateutil_** module. The only parameter it takes is the string object and converts it into a datetime object.
**Example**
```python
# Python program to convert string to datetime
#import dateutil module
from dateutil import parser
# datetime in string variable
date_str = '22/11/21 03:15:10'
# covert string into datetime using parse() function
date_obj = parser.parse(date_str)
print("The type of the date is now", type(date_obj))
print("The date is", date_obj)
```
**Output**
```python
The type of the date is now <class 'datetime.datetime'>
The date is 2021-11-22 03:15:10
```
The post [Python string to datetime Conversion](https://itsmycode.com/python-string-to-datetime-conversion/) appeared first on [ItsMyCode](https://itsmycode.com). | srinivasr |
873,003 | First Hacktoberfest and open source contribution | About Me Hey! I am Krishna from India final year student of Mater of Computer... | 0 | 2021-10-22T20:02:49 | https://dev.to/krishnapro/first-hacktoberfest-and-open-source-contribution-1mpc | opensource, webdev, hacktoberfest, javascript | 
##About Me
Hey! I am Krishna from India final year student of Mater of Computer Applications and skilled in web development, Machine learning and cyber security enthusiastic. And also passionate about open source.
##How I started open source
This is started 3 months ago when I was watching a video on YouTube by Kunal Kushwaha and Eddie Jaoude They talked about open source and how a college student start contributing to open source. After the video I have join [EddieHub](https://www.eddiehub.org/) and other community.
If you are beginner and want to start contribute to open source then you have to join **EddieHub** organization. There you will get step by step guidance about how to get started.
First time start contribution in EddieHub organization repository after that some day I listen about **hacktoberfest** before this I don't have any idea about Hacktoberfest then I starts asking question in community and search on google about this.
*Hacktoberfest is a month-long celebration of open-source software by DigitalOcean that encourages participation in giving back to the open-source community. Developers get involved by completing pull requests, participating in events, and donating to open source projects. During this event, anyone can support open source by contributing changes and earn limited-edition swag*.
This is the beginner friendly so any can participate no matter you are a coder pro level coder or a newbie even you can start by contributing in documentation.
If you like this connect with me
[Twitter](https://twitter.com/krishnapro_) [github](https://github.com/Krishnapro)
| krishnapro |
873,135 | Repository Pattern with Typescript and Node.js | If you working with Node.js you probably interact with the database (MongoDB, PostgreSQL, and etc)... | 0 | 2021-10-25T05:14:37 | https://dev.to/fyapy/repository-pattern-with-typescript-and-nodejs-25da | typescript, webdev, javascript, node | If you working with Node.js you probably interact with the database (MongoDB, PostgreSQL, and etc) via ORM.
But sometimes typical ORM does not cover our needs.
For example, when we need to write nested queries with aggregation in PostgreSQL. Or when the performance of a generated query using ORM does not suit us.
And here typically we start writing direct queries to database..
But what about solutions what will get to us good developer productivity like ORM, and will get a flexible API to interact with the database like pure SQL code.
If you have encountered such situations, then this post is for you!
### Repository Pattern
In most cases we need some abstraction what will give to us typical operations like CRUD (Create, Read, Update and Delete Operations). And Repository pattern will give to us this abstract Data Layer to interact with any database.
### Requirements:
- Node.js
- TypeScript 4.4.0+
- PostgreSQL 13.4+
- Knex 0.95.11+
- VSCode
**Why Knex?**
For boost our developer productivity and get ability to create predictable queries we will use query builder, it is a cross between ORM and pure SQL queries.
And in real project over time out database schema will change, and Knex provide excellent [migrations API](https://knexjs.org/#Migrations) with TypeScript support.
### Setting up environment
Before we start we need to install our packages, i will use Yarn.
```sh
yarn add knex pg && yarn add -D typescript
```
### Implemetation
Firstly i will implement just **find** method to show its looks. Now need create interfaces what will cover our operations like Create and Read.
```typescript
interface Reader<T> {
find(item: Partial<T>): Promise<T[]>
findOne(id: string | Partial<T>): Promise<T>
}
```
And after we need define base interface for any database dialect repository.
```typescript
type BaseRepository<T> = Reader<T>
```
And here we able to create our database repository, in my case i will use SQL database with Knex in query builder role, but if you want to use MongoDB, just replace Knex with MondoDB package.
```typescript
import type { Knex } from 'knex'
interface Reader<T> {
find(item: Partial<T>): Promise<T[]>
}
type BaseRepository<T> = Reader<T>
export abstract class KnexRepository<T> implements BaseRepository<T> {
constructor(
public readonly knex: Knex,
public readonly tableName: string,
) {}
// Shortcut for Query Builder call
public get qb(): Knex.QueryBuilder {
return this.knex(this.tableName)
}
find(item: Partial<T>): Promise<T[]> {
return this.qb
.where(item)
.select()
}
}
```
**Warning**
Don't use arrow functions like this.
Because in future it will break overriding methods with [super.find() calls](https://stackoverflow.com/questions/46869503/es6-arrow-functions-trigger-super-outside-of-function-or-class-error).
```typescript
find = async (item: Partial<T>): Promise<T> => {
// code...
}
```
Now, we create the Repository file to specific entity.
```typescript
import { BaseRepository } from 'utils/repository'
export interface Product {
id: string
name: string
count: number
price: number
}
// now, we have all code implementation from BaseRepository
export class ProductRepository extends KnexRepository<Product> {
// here, we can create all specific stuffs of Product Repository
isOutOfStock(id: string): Promise<boolean> {
const product = this.qb.where(id).first('count')
return product?.count <= 0
}
}
```
Now let's go use our created repository.
```typescript
import knex from 'knex'
import config from 'knex.config'
import { Product, ProductRepository } from 'modules/product'
const connect = async () => {
const connection = knex(config)
// Waiting for a connection to be established
await connection.raw('SELECT 1')
return connection
}
(async () => {
// connecting to database
const db = await connect()
// initializing the repository
const repository = new ProductRepository(db, 'products')
// call find method from repository
const product = await repository.find({
name: 'laptop',
});
console.log(`product ${product}`)
if (product) {
const isOutOfStock = await repository.isOutOfStock(product.id);
console.log(`is ${product.name}'s out of stock ${isOutOfStock}`)
}
})()
```
Let's implement the remaining methods of CRUD.
```typescript
import type { Knex } from 'knex'
interface Writer<T> {
create(item: Omit<T, 'id'>): Promise<T>
createMany(item: Omit<T, 'id'>[]): Promise<T[]>
update(id: string, item: Partial<T>): Promise<boolean>
delete(id: string): Promise<boolean>
}
interface Reader<T> {
find(item: Partial<T>): Promise<T[]>
findOne(id: string | Partial<T>): Promise<T>
exist(id: string | Partial<T>): Promise<boolean>
}
type BaseRepository<T> = Writer<T> & Reader<T>
export abstract class KnexRepository<T> implements BaseRepository<T> {
constructor(
public readonly knex: Knex,
public readonly tableName: string,
) {}
// Shortcut for Query Builder call
public get qb(): Knex.QueryBuilder {
return this.knex(this.tableName)
}
async create(item: Omit<T, 'id'>): Promise<T> {
const [output] = await this.qb.insert<T>(item).returning('*')
return output as Promise<T>
}
createMany(items: T[]): Promise<T[]> {
return this.qb.insert<T>(items) as Promise<T[]>
}
update(id: string, item: Partial<T>): Promise<boolean> {
return this.qb
.where('id', id)
.update(item)
}
delete(id: string): Promise<boolean> {
return this.qb
.where('id', id)
.del()
}
find(item: Partial<T>): Promise<T[]> {
return this.qb
.where(item)
.select()
}
findOne(id: string | Partial<T>): Promise<T> {
return typeof id === 'string'
? this.qb.where('id', id).first()
: this.qb.where(id).first()
}
async exist(id: string | Partial<T>) {
const query = this.qb.select<[{ count: number }]>(this.knex.raw('COUNT(*)::integer as count'))
if (typeof id !== 'string') {
query.where(id)
} else {
query.where('id', id)
}
const exist = await query.first()
return exist!.count !== 0
}
}
```
Now, we just call that repository from our code.
```typescript
import knex from 'knex'
import config from 'knex.config'
import { Product, ProductRepository } from 'modules/product'
const connect = // See implementation above...
(async () => {
// connecting to database
const db = await connect()
// initializing the repository
const repository = new ProductRepository(db, 'products')
// call find method from repository
const product = await repository.create({
name: 'laptop',
count: 23,
price: 2999,
});
console.log(`created product ${product}`)
const isOutOfStock = await repository.isOutOfStock(product.id);
console.log(`is ${product.name}'s out of stock ${isOutOfStock}`)
})()
```
### Dependency Injection
In real project we have some Dependency Injection library, in my case it is [Awilix](https://github.com/jeffijoe/awilix).
Now we need realize integration of repository with out DI solution.
```typescript
// Knex connection file
import knex from 'knex'
import config from 'knex.config'
import { container } from 'utils/container'
import { asValue } from 'awilix'
export default () => new Promise(async (resolve, reject) => {
try {
const connection = knex(config)
await connection.raw('SELECT 1')
container.register({
knex: asValue(connection),
})
resolve(connection)
} catch (e) {
reject(e)
}
})
```
Now when we have connection to database, let's change little bit out ProductRepository.
```typescript
import { asClass } from 'awilix'
import { container, Cradle } from 'utils/container'
import { BaseRepository } from 'utils/repository'
export interface Product {
id: string
name: string
count: number
price: number
}
// now, we have all code implementation from BaseRepository
export class ProductRepository extends KnexRepository<Product> {
constructor({ knex }: Cradle) {
super(knex, 'products')
}
// here, we can create all specific stuffs of Product Repository
isOutOfStock(id: string): Promise<boolean> {
const product = this.qb.where(id).first('count')
return product?.count <= 0
}
}
container.register({
productRepository: asClass(ProductRepository).singleton(),
})
```
And we have pretty cool Data Base Abstraction Layout.
Let's call it is in out Controller/Handler, Fastify handler in my case. I will skip of Product service Realization, in is will just inject ProductRepository, and proxy call findOne(id) method.
```typescript
import { FastifyPluginCallback } from 'fastify'
import { cradle } from 'utils/container'
export const handler: FastifyPluginCallback = (fastify, opts, done) => {
fastify.get<{
Params: {
id: string
}
}>('/:id', async ({ params }) => {
const response = await cradle.productService.findOne(params.id)
return response
})
done()
}
```
### Conclusion
In this article we looked at how to implement Respository Pattern in Node.js with TypeScript. It is very flexible and extensible Data Layer what able use any SQL/NoSQL database.
But that is not all 😄
Becase we need to look how to add features like:
- Subscriptions on entity events like BeforeInsert, AfterInsert, BeforeDelete, AfterDelete, and etc.
- Select specific fields
- Hidden fields for prevent select user password hash for example
- Transactions support
But it's more about how to create and develop your own ORM. And that is beyond the scope of an article on the Repository Pattern. | fyapy |
873,187 | How to make translatable laravel app | Use these methods to easily make translatable on model attributes in Laravel This article will... | 0 | 2021-10-23T05:27:54 | https://dev.to/yanalshoubaki/how-to-make-translatable-laravel-app-19dg | laravel, php, webdev, tutorial | Use these methods to easily make translatable on model attributes in Laravel
This article will explain the different ways to automatically translate eloquent model attributes while accessing or retrieving or create them.
There are several ways to achieve this, and we’ll discuss them along with their quirks in this article.
There are many packages do this work, my favorite package is https://github.com/spatie/laravel-translatable.
This package have many methods the will give us an easy way to translate selected attributes.
## Prerequisites and setup
This tutorial assumes you are fairly experienced with Laravel (note that this tutorial uses Laravel 7.x).
Of course, to begin, we have to have our development environment set up. First, install the package:
You can install the package via composer:
```
composer require spatie/laravel-translatable
```
If you want to have another fallback_locale than the app fallback locale `(see config/app.php)`, you could publish the config file:
```
php artisan vendor:publish --provider="Spatie\Translatable\TranslatableServiceProvider"
```
In your config folder you will find file name : translatable.php
```php
<?php
return [
/*
* If a translation has not been set for a given locale, use this locale instead.
*/
'fallback_locale' => 'en',
];
```
## Making a model translatable
The required steps to make a model translatable are:
First, you need to add the `Spatie\Translatable\HasTranslations-trait`.
Next, you should create a public property $translatable which holds an array with all the names of attributes you wish to make translatable.
Finally, you should make sure that all translatable attributes are set to the text-datatype in your database. If your database supports json-columns, use that.
Here’s an example of a prepared model:
```php
use Illuminate\Database\Eloquent\Model;
use Spatie\Translatable\HasTranslations;
class Post extends Model
{
use HasTranslations;
public $translatable = ['name', 'text'];
}
```
now we need to select the attributes that we need to translate it:
```public $translatable = ['name', 'text'];```
Available methods
Getting a translation
The easiest way to get a translation for the current locale is to just get the property for the translated attribute. For example (given that `name` is a translatable attribute):
```$post->name; // get name attribute```
You can also use this method:
```public function getTranslation(string $attributeName, string $locale, bool $useFallbackLocale = true) : string```
this method well get `name` attribute translated by locale language you choose.
## Getting all translations
You can get all translations by calling `getTranslations()` without an argument:
`$post->getTranslations();`
Or you can use the accessor :
`$post->translations`
## Setting a translation
The easiest way to set a translation for the current locale is to just set the property for a translatable attribute. For example (given that name is a translatable attribute):
`$post->name = 'new post'`
that will generate a json text like this : `{"en": "new post"} `inside name column in database table.
for create multi translation:
`$post->name = ['en' => 'new post', 'ar' => 'موضوع جديد'];`
To set a translation for a specific locale you can use this method:
`public function setTranslation(string $attributeName, string $locale, string $value)`
To actually save the translation, don’t forget to save your model.
```php
$post->setTranslation('name', 'en', 'Updated name in English');
$post->setTranslation('name', 'ar', 'Updated name in Arabic')
$post->save();
```
Forgetting a translation
You can forget a translation for a specific field:
`public function forgetTranslation(string $attributeName, string $locale)`
example :
`$post->forgetTranslation('name', 'ar')`
You can forget all translations for a specific locale:
`public function forgetAllTranslations(string $locale)`
example :
`$post->forgetAllTranslations('ar')`
Getting all translations in one go
`public function getTranslations(string $attributeName): array`
example :
`$post->getTranslations('name')`
Getting the specified translations in one go
You can filter the translations by passing an array of locales:
`public function getTranslations(string $attributeName, array $allowedLocales): array`
example :
`$post->getTranslations('name', ['en', 'ar'])`
Replace translations in one go
You can replace all the translations for a single key using this method:
```php
public function replaceTranslations(string $key, array $translations)
$newTranslations = ['en' => 'hello'];
$post->replaceTranslations('hello', $newTranslations);
$post->getTranslations(); // ['en' => 'hello']
```
## Setting the model locale
The default locale used to translate models is the application locale, however it can sometimes be handy to use a custom locale.
```php
$post = Post::firstOrFail()->setLocale('en')
$post->name; // Will return `en` translation
$post->name = "hello"; // will set the `en` translation
```
Alternatively, you can use usingLocale static method:
```php
// Will automatically set the `en` translation
$newsItem = Post::usingLocale('en')->create([
'name' => 'hello',
]);
```
##Creating models
You can immediately set translations when creating a model. Here’s an example:
```php
Post::create([
'name' => [
'en' => 'Name in English',
'ar' => 'الأسم بالعربي'
],
]);
```
Querying translatable attributes
If you’re using MySQL 5.7 or above, it’s recommended that you use the json data type for housing translations in the db. This will allow you to query these columns like this:
```php
Post::where('name->en', 'Name in English')->get();
```
you can set translation using `app()->setLocale('en')` , this an easy way to get translation.
```php
app()->setLocale('en')
$post->name; // will get 'en' translation
$post->name = 'hello' // will set 'en' translation
```
resource : https://github.com/spatie/laravel-translatable
| yanalshoubaki |
873,237 | Appwrite for flutter | Introduction The following article will cover how we can use Appwrite's Flutter SDK to build native... | 0 | 2021-10-23T05:53:48 | https://dev.to/yashp1210/appwrite-for-flutter-58kb | appwrite | **Introduction**
The following article will cover how we can use Appwrite's Flutter SDK to build native applications. Appwrite is an end-to-end backend server that is aiming to abstract the complexity of common, complex, and repetitive tasks required for building a modern app.
**Installation**
Appwrite is a self-hosted backend server packaged as a set of Docker containers. You can install and run Appwrite on any operating system that can run a Docker CLI. You can use Appwrite on your local desktop or cloud provider of your choice.
System Requirement:
Appwrite was designed to run well on both small and large deployment. The minimum requirements to run Appwrite is as little as 1 CPU core and 2GB of RAM, and an operating system that supports Docker.
Install with Docker:
The easiest way to start running your Appwrite server is by running our Docker installer tool from your terminal. Before running the installation command, make sure you have Docker CLI installed on your host machine.
Unix:
```
docker run -it --rm \
--volume /var/run/docker.sock:/var/run/docker.sock \
--volume "$(pwd)"/appwrite:/usr/src/code/appwrite:rw \
--entrypoint="install" \
appwrite/appwrite:0.11.0
```
Windows:
Hyper-V and Containers Windows features must be enabled to run Appwrite on Windows with Docker. If you don't have these features available, you can install Docker Toolbox that uses Virtualbox to run Appwrite on a Virtual Machine.
```
docker run -it --rm ^
--volume //var/run/docker.sock:/var/run/docker.sock ^
--volume "%cd%"/appwrite:/usr/src/code/appwrite:rw ^
--entrypoint="install" ^
appwrite/appwrite:0.11.0
```
```
docker run -it --rm ,
--volume /var/run/docker.sock:/var/run/docker.sock ,
--volume ${pwd}/appwrite:/usr/src/code/appwrite:rw ,
--entrypoint="install" ,
appwrite/appwrite:0.11.0
```
Manual (using docker-compose.yml):
For advanced Docker users, the manual installation might seem more familiar. To setup Appwrite manually, download the Appwrite base docker-compose.yml and .env files. After the download completes, update the different environment variables as you wish in the .env file and start the Appwrite stack using the following Docker command:
```
docker-compose up -d --remove-orphans
```
Once the Docker installation completes, go to your machine hostname or IP address on your browser to access the Appwrite console. Please notice that on non-linux native hosts the server might take a few minutes to start after installation completes.
**Overview**
Appwrite is a development platform providing you an easy yet powerful API and management console to get your next project up and running quickly.
This tutorial will help you start using Appwrite products and build your next project. Before starting, make sure you have followed the Appwrite installation guide, and you have an Appwrite server instance up and running on your host machine or server.
**Create Your First Appwrite Project**
Go to your new Appwrite console, and once inside, click the + icon in the top navigation header or on the 'Create Project' button on your console homepage. Choose a name for your project and click create to get started.
**Add your Flutter Platform**
To init your SDK and start interacting with Appwrite services, you need to add a new Flutter platform to your project. To add a new platform, go to your Appwrite console, choose the project you created in the step before, and click the 'Add Platform' button.
From the options, choose to add a new Flutter platform and add your app credentials. Appwrite Flutter SDK currently supports building apps for Android, iOS, Linux, Mac OS, Web and Windows.
If you are building your Flutter application for multiple devices, you have to follow this process for each different device.
**Android**
For Android first add your app name and package name, Your package name is generally the applicationId in your app-level build.gradle file. By registering your new app platform, you are allowing your app to communicate with the Appwrite API.
In order to capture the Appwrite OAuth callback url, the following activity needs to be added inside the `` tag, along side the existing `` tags in your AndroidManifest.xml. Be sure to replace the [PROJECT_ID] string with your actual Appwrite project ID. You can find your Appwrite project ID in you project settings screen in your Appwrite console.
```dart
<manifest ...>
...
<application ...>
...
<!-- Add this inside the `<application>` tag, along side the existing `<activity>` tags -->
<activity android:name="com.linusu.flutter_web_auth.CallbackActivity" >
<intent-filter android:label="flutter_web_auth">
<action android:name="android.intent.action.VIEW" />
<category android:name="android.intent.category.DEFAULT" />
<category android:name="android.intent.category.BROWSABLE" />
<data android:scheme="appwrite-callback-[PROJECT_ID]" />
</intent-filter>
</activity>
</application>
</manifest>
```
**iOS**
For iOS first add your app name and Bundle ID, You can find your Bundle Identifier in the General tab for your app's primary target in Xcode.
The Appwrite SDK uses ASWebAuthenticationSession on iOS 12+ and SFAuthenticationSession on iOS 11 to allow OAuth authentication. You have to change your iOS Deployment Target in Xcode to be iOS >= 11 to be able to build your app on an emulator or a real device.

**Linux**
For Linux add your app name and package name, Your package name is generally the name in your pubspec.yaml file. If you cannot find the correct package name, run the application in linux, and make any request with proper exception handling, you should get the application id needed to add in the received error message.
**Mac OS**
For Mac OS add your app name and Bundle ID, You can find your Bundle Identifier in the General tab for your app's primary target in Xcode.
**Web**
Appwrite 0.7, and the Appwrite Flutter SDK 0.3.0 have added support for Flutter Web. To build web apps that integrate with Appwrite successfully, all you have to do is add a web platform on your Appwrite project's dashboard and list the domain your website will use to allow communication to the Appwrite API.
**Windows**
For Windows add your app name and package name, Your package name is generally the name in your pubspec.yaml file. If you cannot find the correct package name, run the application in windows, and make any request with proper exception handling, you should get the application id needed to add in the received error message.
**Get Appwrite Flutter SDK**
Add Appwrite SDK to your package's pubspec.yaml file (view example):
```
dependencies:
appwrite: ^2.0.3
```
You can also install the SDK using the Dart package manager from your terminal:
```
pub get appwrite
```
**Init your SDK**
Initialize your SDK code with your project ID, which can be found in your project settings page.
```dart
import 'package:appwrite/appwrite.dart';
Client client = Client();
client
.setEndpoint('https://localhost/v1') // Your Appwrite Endpoint
.setProject('5e8cf4f46b5e8') // Your project ID
.setSelfSigned(status: true) // For self signed certificates, only use for development
;
```
Before starting to send any API calls to your new Appwrite instance, make sure your Android or iOS emulators has network access to the Appwrite server hostname or IP address.
When trying to connect to Appwrite from an emulator or a mobile device, localhost is the hostname for the device or emulator and not your local Appwrite instance. You should replace localhost with your private IP as the Appwrite endpoint's hostname. You can also use a service like ngrok to proxy the Appwrite API.
**Make Your First Request**
Once your SDK object is set, access any of the Appwrite services and choose any request to send. Full documentation for any service method you would like to use can be found in your SDK documentation or in the API References section.
```dart
// Register User
Account account = Account(client);
Response user = await account
.create(
email: 'me@appwrite.io',
password: 'password',
name: 'My Name'
);
```
**Listen to Changes**
If you want to listen to changes in realtime from Appwrite, you can subscribe to a variety of channels and receive updates within milliseconds. Full documentation for Realtime can be found here.
```flutter
// Subscribe to files channel
final realtime = Realtime(client);
final subscription = realtime.subscribe(['files']);
subscription.stream.listen((response) {
if(response.event === 'storage.files.create') {
// Log when a new file is uploaded
print(response.payload);
}
})
```
**Full Example**
```dart
import 'package:appwrite/appwrite.dart';
Client client = Client();
client
.setEndpoint('https://localhost/v1') // Your Appwrite Endpoint
.setProject('5e8cf4f46b5e8') // Your project ID
.setSelfSigned(true) // For self signed certificates, only use for development
;
// Register User
Account account = Account(client);
Response user = await account
.create(
email: 'me@appwrite.io',
password: 'password',
name: 'My Name'
);
// Subscribe to files channel
final realtime = Realtime(client);
final subscription = realtime.subscribe(['files']);
subscription.stream.listen((response) {
if(response.event === 'storage.files.create') {
// Log when a new file is uploaded
print(response.payload);
}
})
```
| yashp1210 |
873,355 | Hacktoberfest-2021 | Hey Coders! Is this your first time contribution to open source for which you are being awarded? A... | 0 | 2021-10-23T08:23:57 | https://dev.to/bhavanakumar/hacktoberfest-2021-2d9p | beginners, programming, hacktoberfest, webdev | Hey Coders! Is this your first time contribution to open source for which you are being awarded?
A big **Yes** :stars: for me.
Hacktoberfest-2021 is my first time contribution to open source.
Here's my github link : https://github.com/thebhavana
* Contributing to open source projects is a different level of satisfaction.
* Getting rewards for the same is cool :smile:
Github platform allows us to work on multiple projects by eliminating the geographical gap of world. There are so many open-source projects available on github.
Adding codes to the existing repository and closing the issues was cool.
*Looking for more such opportunities* :sparkles: | bhavanakumar |
873,383 | Scrollable layout with height 100% | Hello there 👋🏼, internet users. Today, I'll show you a CSS trick I frequently forget about when... | 0 | 2021-10-23T10:15:00 | https://dev.to/harshboricha98/scrollable-div-layout-with-height-100-33jn | css, webdev, react, beginners | Hello there 👋🏼, internet users. Today, I'll show you a CSS trick I frequently forget about when creating scrollable dynamic height layouts. Recently, I was developing a basic layout similar to one below. It took me a while to remember this trick, but once I did, I had a sense of deja vu and finished the layout.
There are two way to achieve this:
# Way 1: Using css positions:
{% codepen https://codepen.io/harshboricha98/pen/zYdoXpo %}
If you look at the [code](https://codepen.io/harshboricha98/pen/zYdoXpo) above, you'll see what I mean. As you can see, there's a NAVBAR, a BREADCRUMB BAR, the MAIN SECTION, and a FOOTER all contained within a layout container with the height of `height: 100vh`. I wanted the sidebar and content-box in my main section to be scrollable.
I could set the height as a fixed value, something like `height: 800px` with `overflow-y: scroll` but then making the layout responsive will become a nightmare.
So, the question arises? 🤔. How can we apply the `overflow-y: scroll` attribute to a div with a height of 100 percent?
The solution 🧪 here is to use `position: relative` for the main section container and `position: absolute` for the sidebar and content bar, with `overflow-y: scroll`.
```css
.main {
position: relative;
height: 100%;
}
.sidebar {
position: absolute;
top: 0;
left: 0;
bottom: 0; /*stretch from top to bottom w.r.t .main section*/
width: 10rem;
overflow-y: scroll;
}
.content {
position: absolute;
top: 0;
left: 10rem;
bottom: 0;
right: 0; /* stretch from top to bottom, and shift 10rem from left and stretch till right */
overflow-y: scroll;
}
```
There are many other ways, to achieve this. It's just a trick i often use. If you have any alternate way please comment (I'm all 👂). Congratulations 🎉 for reading this. Hope this might help you. Thank you.
After many of you suggested there's a neat way to do this avoiding css positions. I've added another solution using css grid.
# Way 2: Using css grid
{% codepen https://codepen.io/harshboricha98/pen/mdMRXqZ %} | harshboricha98 |
905,845 | halo bang | finally cok baru masuk dev community :v | 0 | 2021-11-22T17:59:42 | https://dev.to/hadsxdevpy/halo-bang-j2h | finally cok baru masuk dev community :v | hadsxdevpy | |
873,561 | Day 15 of 100 Days of Code & Scrum: Second Weekly Retrospective | Happy weekend, everyone! Today marks the end of the second week, and so I will be doing a Sprint... | 14,990 | 2021-10-23T12:11:22 | https://dev.to/rammina/day-15-of-100-days-of-code-scrum-second-weekly-retrospective-29hf | 100daysofcode, beginners, programming, webdev | Happy weekend, everyone!
Today marks the end of the second week, and so I will be doing a Sprint Review and Retrospective as I mentioned back then, [at the beginning of this challenge](https://dev.to/rammina/100-days-of-code-and-scrum-a-new-challenge-24lp).
## My Previous Weekly Sprint Goals
For reference, here were the Sprint Goals for this week:
## Weekly Sprint Goals
- focus on learning **Scrum** principles
- study for Professional Scrum Master I (PSM I) certification
- write some guides about Scrum
- continue learning GraphQL
- continue networking
- no interviews for this week
**gulp** How much of these have I accomplished?
## Weekly Review
I think I finished around 80% of my Sprint Goals for this week, but I didn't really finish any guide that I planned to write...
In any case, here were the things I've done:
- I have reread [The 2020 Scrum Guide](https://scrumguides.org/scrum-guide.html) multiple times while trying to write guides for Scrum.
- write an incomplete draft for _Introduction to Scrum_, which covers Scrum as a framework, the Scrum Team and its members, and Scrum Artifacts such as the Product Backlog, the Sprint Backlog, and the Increment.
- worked on completely revamping my _User Story Guide_, because the first one really sucks and was just a short post.
- used [Anki flashcards](https://apps.ankiweb.net/) to study for the PSM I certification exam.
- studied server-side GraphQL and reviewed some of the things I've learned last week.
- I definitely networked a lot on multiple platforms.
- I made a new [Twitter account](https://twitter.com/RamminaR).

<small><cite>Image by <a href="https://pixabay.com/users/ichigo121212-11728/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=203465%22%3EIchigo121212</a> from <a href="https://pixabay.com/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=203465%22%3EPixabay</a></cite></small>
## Weekly Retrospective
Moving on, let's tackle what I've managed to do well, what my shortcomings are, and what I could do better next time.
### What Went Great
- met my learning goals for **Scrum**.
- managed to continue learning about GraphQL, and not forgetting the things I've learned from last week.
- I was able to work towards writing the guide articles.
- reached out to multiple people on different platforms.
- not part of my weekly goals, but I learned a lot about SEO.
### Some Mistakes I've Made
- I'm just bad at managing my time, I check social media too much.
- forgot to install a website blocker to stop myself from checking off-topic content.
### Things I Could Improve On
- most likely check emails, social media, and blog on a set schedule instead.
- I should definitely install something that blocks me from checking certain sites at a specific time.
- prioritize tasks that are more likely to help me meet my weekly goals.
## Got Through the Second Week
The second week was definitely a lot more stressful than the first one, mostly because of personal life issues happening.
However, I managed to commit to my goals and make progress because of the rules of the challenge. I may not have achieved everything that I intended to on this week, but I'm at least partially done with them. I do recommend everyone to try doing the 100 Days of Code challenge, it's really fulfilling and helpful.

Thank you to everyone who supported me and interacted with me during the past weeks!
Good luck on your developer journeys, and I wish you the best. Have a great weekend, everyone!
### Resources/Recommended Readings
- [The Fullstack Tutorial for GraphQL](https://www.howtographql.com/)
- [Apollo Docs](https://www.apollographql.com/docs/)
- [The 2020 Scrum Guide](https://scrumguides.org/scrum-guide.html)
- [Mikhail Lapshin's Scrum Quizzes](https://mlapshin.com/index.php/scrum-quizzes/)
### DISCLAIMER
**This is not a guide**, it is just me sharing my experiences and learnings. This post only expresses my thoughts and opinions (based on my limited knowledge) and is in no way a substitute for actual references. If I ever make a mistake or if you disagree, I would appreciate corrections in the comments!
### Other Media
Feel free to reach out to me in other media!
<span><a target="_blank" href="https://www.rammina.com/"><img src="https://res.cloudinary.com/rammina/image/upload/v1638444046/rammina-button-128_x9ginu.png" alt="Rammina Logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://twitter.com/RamminaR"><img src="https://res.cloudinary.com/rammina/image/upload/v1636792959/twitter-logo_laoyfu_pdbagm.png" alt="Twitter logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://github.com/Rammina"><img src="https://res.cloudinary.com/rammina/image/upload/v1636795051/GitHub-Emblem2_epcp8r.png" alt="Github logo" width="128" height="50"/></a></span> | rammina |
873,745 | PF - 2 Operators | Operators in a programming language that tells compiler or interprator to perform arithmatic,... | 0 | 2021-10-23T16:14:27 | https://dev.to/vanshcodes/pf-2-operators-i81 | programming, beginners | Operators in a programming language that tells compiler or interprator to perform arithmatic, relational or logical operations.
## Arithmatic Operators
1. `+` Adds two operands A + B will give 30
2. `-` Subtracts second operand from the first A - B will give -10
3. `*` Multiplies both operands A * B will give 200
4. `/` Divides numerator by de-numerator B / A will give 2
5. `%` This gives remainder of an integer division B % A will give 0
## Relational Operators
1. `==` Checks if the values of two operands are equal or not, if yes then condition becomes true. (A == B) is not true.
2. `!=` Checks if the values of two operands are equal or not, if values are not equal then condition becomes true. (A != B) is true.
3. `>` Checks if the value of left operand is greater than the value of right operand, if yes then condition becomes true. (A > B) is not true.
4. `<` Checks if the value of left operand is less than the value of right operand, if yes then condition becomes true. (A < B) is true.
5. `>=` Checks if the value of left operand is greater than or equal to the value of right operand, if yes then condition becomes true. (A >= B) is not true.
6. `<=` Checks if the value of left operand is less than or equal to the value of right operand, if yes then condition becomes true. (A <= B) is true.
## Logical Operators
1. `&&` Called Logical AND operator. If both the operands are non-zero, then condition becomes true. (A && B) is false.
2. `||` Called Logical OR Operator. If any of the two operands is non-zero, then condition becomes true. (A || B) is true.
3. `!` Called Logical NOT Operator. Use to reverses the logical state of its operand. If a condition is true then Logical NOT operator will make false. !(A && B) is true.
| vanshcodes |
873,795 | WSA Aurora Store ve termux Yükleme | Daha detaylı halini gitbook sayfamda bulabilirsiniz Video Hali Mevcut Aurora Store... | 15,140 | 2021-10-23T18:56:26 | https://dev.to/herrwinfried/wsa-aurora-store-ve-termux-yukleme-2fib | wsa, windows11 | > [Daha detaylı halini gitbook sayfamda bulabilirsiniz](https://herrwinfried.gitbook.io/tr/wsa/aurora-store-ve-termux-yuekleme)
> [Video Hali Mevcut](https://youtu.be/_mpvONtMv8k)
## Aurora Store yükleme && apk yükleme
[Aurora Store Stable indirme sayfası](https://files.auroraoss.com/AuroraStore/Stable/)
[Aurora Store 4.0.7 Direkt İndir](https://files.auroraoss.com/AuroraStore/Stable/AuroraStore_4.0.7.apk)
aurora store apk dosyamızı yüklediğimize göre artık yükleme kısmına geçebiliriz. Bu kısımda indirmemiz gereken bir araç var.
Android Geliştiriciler için sunulan "SDK Platform Araçları" adlı aracı indirmemiz gerekiyor.
[Platform-tools(Platform Araçları) Sayfası](https://developer.android.com/studio/releases/platform-tools)
[Platform-tools(Platform Araçları) Windows için direkt indirin](https://dl.google.com/android/repository/platform-tools-latest-windows.zip)
indirdikten sonra konumuna gidip zipten çıkartıyoruz ve içinde adb.exe olan dosyaya geldiğimizde boş bir yere sağ tık yapıyoruz ve "Open in Windows Terminal" basıyoruz.
Ardından Windows Powershell veya Powershell 7 ile açtıysanız.
`.\adb` eğer Cmd ile açtıysanız `adb`ile kullancaksanız.
> Terminalizi bekletin şimdilik kapatmayın.
Şimdi Windows Subsystem for android açalım
"Geliştirici Modu" Aktif ediniz ve açalım ve daha sonra "Geliştirici ayarlarını yönetme" basın Geliştirici modun hemen altında yer almaktadır.
"USB Hata Ayıklaması" ve "Kablosuz hata ayıklama" açık olduğundan emin olun daha sonra kablosuz hata ayıklamaya basınız.
IP Adresinizi not alınız.
Açtığımız Terminale geri dönelim ve IP adresimizi girelim.
Bende IP adresi 172.23.102.170 yazdığından öyle yazıcağım fakat sizde IP adresi farklı olcaktır ayrıca her WSA kapattığınızda tekrar yapmanız gerekiyor bu işlemi.
```
.\adb connect 172.23.102.170
```
> cmd ile açtıysanız `adb connect 172.23.102.170`
Already connection veya Bağlandı yazsını görene kadar denemelisiniz hata verirse terminali kapatıp tekrar yine açıp deneyin tekrar.
ve başarıyla bağladıysak şimdi APK mizi yükliyebiliriz.
Ben Winfried Hesabımın Masaüstü kısmına indirdiğimi varsayarak devam ediceğim
```
.\adb install "C:\Users\winfried\Desktop\AuroraStore_4.0.7.apk"
```
> cmd ile açtıysanız `adb install "C:\Users\winfried\Desktop\AuroraStore_4.0.7.apk"`
ve yüklendi yazısını görene kadar bekleyin. Yüklendikten sonra Menünüzde son eklenenler kısmında yer almakta Bulup girelim.

Uygulama açıldıktan sonra "İleri" Diyelim.
Kullanım şartlarını kabul edin ve "Session Installer" seçin ve "İleri" diyin
Tema Seçin ve ileri diyin.
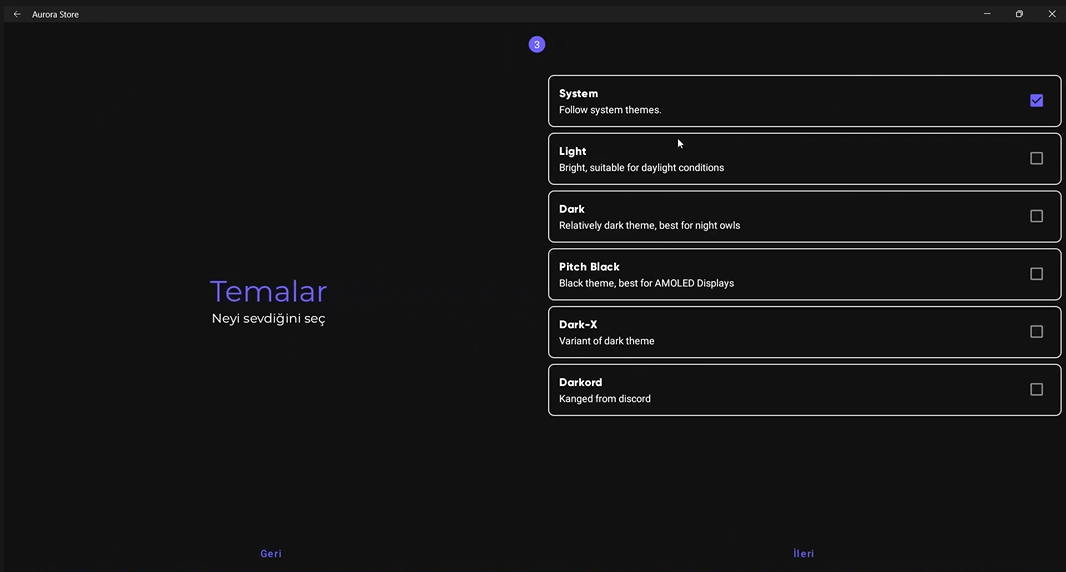
Bir Renk seçin ve ileri diyin.

İzin isteyen herşeye izin verdikten sonra ileri diyin.
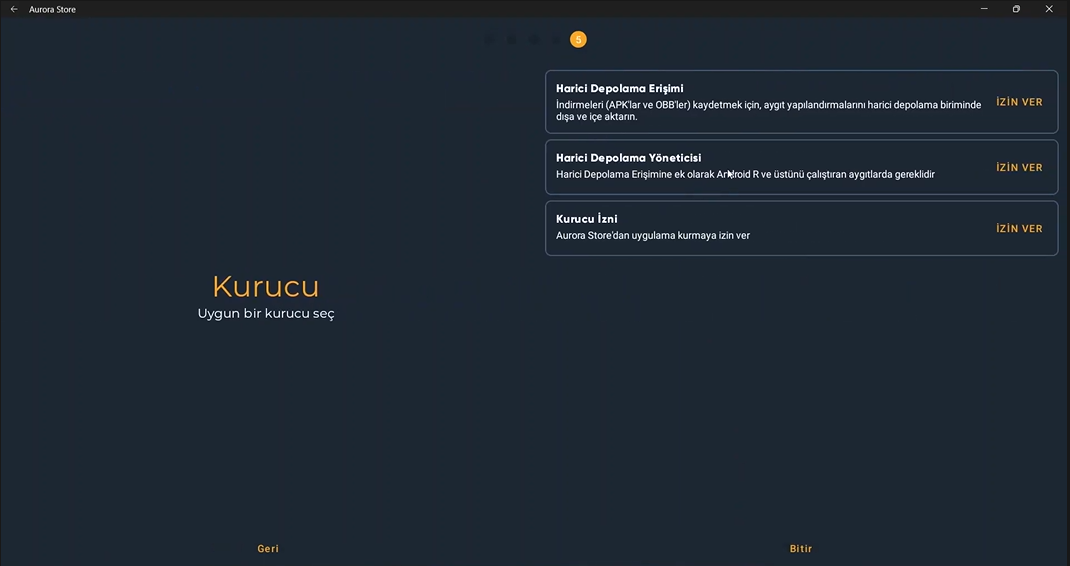
Anonim veya Google ile giriş yapın

## Aurora Store üzerinden Termux Yükleme
Aurora Arama yerine Termux yazalım ve ilk çıkanı indirelim daha sonra kur diyelim.
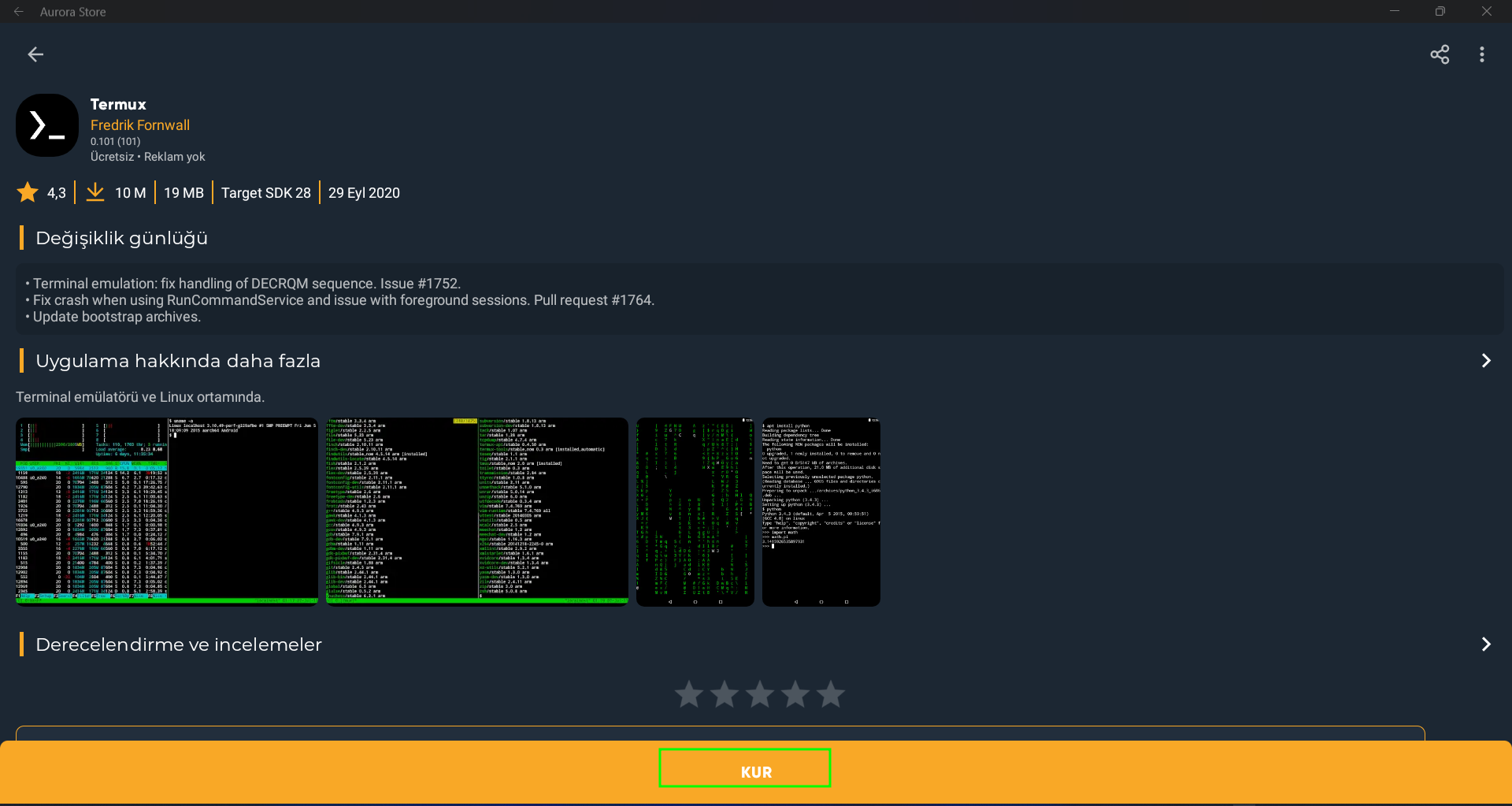
Açılan pencerede "Yükle" Seçeneğine tıklayın.
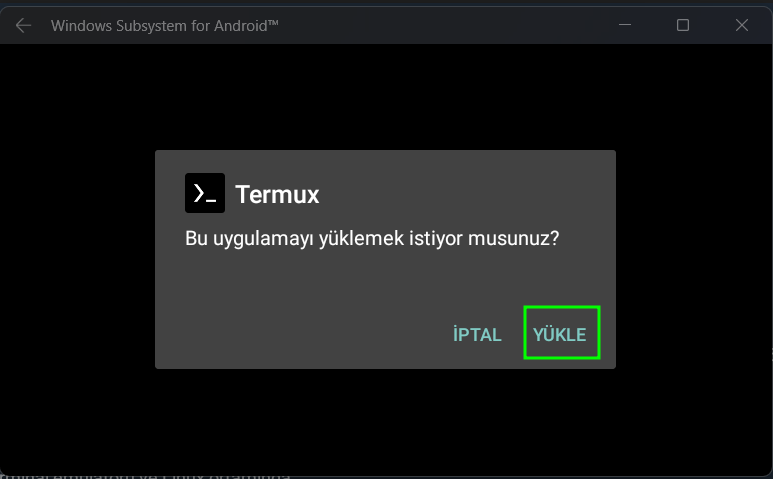
İşlem bittikten sonra kapanıcak otomatik ve menülere eklenecek.
ve bu kadar artık hazır!

Son Olarak Termux pkg sorunu için termux yazmanız gereken komut ise.
```
rm ../usr/etc/apt/sources.list.d/*
```
bunu yazdıktan sonra düzelicektir. | herrwinfried |
874,022 | Creando un sencillo sistema de notificaciones en Vue3 con TailwindCSS (MerakiUI) | Hola a todos, dicen por ahí que es bueno escribir artículos técnicos porque así reafirmas lo... | 0 | 2021-10-25T20:42:15 | https://dev.to/dcruz1990/creando-un-sencillo-sistema-de-notificaciones-en-vue3-con-tailwindcss-merakiui-1017 | vue, tailwindcss, spanish | Hola a todos, dicen por ahí que es bueno escribir artículos técnicos porque así reafirmas lo aprendido, pues, en esta ocasión, voy a seguir con Vue3 y hoy particularmente con TailwindCSS y MerakiUI, creando un sencillo sistema de notificaciones para tu app.
###TailwindCSS
Es una potente librería de utilidades para CSS, te ahorrará mucho tiempo a la hora de escribir tus estilos, aunque, NO reemplaza al CSS puro.
###MerakiUI
Una librería de componentes responsivos y limpios, basada en Flexbox y Grid, completamente responsiva.
###Motivación
En mi tiempo libre por las noches, he estado ¨rehaciendo¨ una app que tengo online y en producción desde principios de año, he querido hacerla lo mas ligera posible y por eso la estoy rediseñando y reescribiendo desde 0 con Vue3 y TailwindCSS, actualmente esta con Vue2 y Vuetify + otras deps, y no por hecharle tierra a Vuetify, pero está bastante pesadita.
###Notificar o no notificar?
Una de las cosas mas importantes en tu app y UX es la interacción con el usuario, las buenas prácticas dictan de informar al usuario qué esta pasando con sus acciones, si se completaron o si terminaron en un error, aquí entran las alertas, hay N+1 librerías open source que te permiten gestionarlas, pero quiero depender lo menos de 3ros, asi que me puse a intentar construir mi propio sistema.
###Manos a la obra
Lo primero que tuve en mente fue armar un composable que gestionara todo lo de las alertas
Archivo: `useToast.ts`
```typescript
import { ref } from 'vue';
// Este arreglo contendrá las notificaciones
const messages = ref<ToastOptions[]>([]);
const useToast = () => {
// Empuja una nueva alerta al arreglo
const addAlert = (options: ToastOptions) => {
messages.value.push({
id: options.id,
message: options.message,
type: options.type || 'success',
});
// A los 3 segundos, que se disipe.
setTimeout(() => {
messages.value.length > 0 ? removeAlert(messages.value.findIndex((item) => item.id === options.id)) : null;
}, 3000);
};
// Remueve el elemento del arreglo de mensajes
const removeAlert = (index: number) => {
if (index > -1) {
messages.value.splice(index, 1);
}
};
return {
messages,
addAlert,
removeAlert,
};
};
export default useToast;
```
De esa forma podemos traernos `useToast()` a cualquier parte de nuestra app.
Continuamos con el componente:
Archivo: `alert.vue`
```vue
<template>
<div
v-for="alert, index in messages"
:key="index"
ref="item"
class="absolute right-5 top-5 flex w-full max-w-sm mx-auto overflow-hidden bg-white rounded-lg shadow-lg dark:bg-gray-800 animate-fadeIn"
>
<div
:class="`flex items-center justify-center w-12 ${alert.type === 'error' ? 'bg-red-500' : 'bg-green-500'}`"
>
<svg
class="w-6 h-6 text-white fill-current"
viewBox="0 0 40 40"
xmlns="http://www.w3.org/2000/svg"
>
<path
d="M20 3.36667C10.8167 3.36667 3.3667 10.8167 3.3667 20C3.3667 29.1833 10.8167 36.6333 20 36.6333C29.1834 36.6333 36.6334 29.1833 36.6334 20C36.6334 10.8167 29.1834 3.36667 20 3.36667ZM19.1334 33.3333V22.9H13.3334L21.6667 6.66667V17.1H27.25L19.1334 33.3333Z"
/>
</svg>
</div>
<div class="px-4 py-2 -mx-3">
<div class="mx-3 w-11/12">
<span
:class="`font-semibold ${alert.type === 'error' ? 'text-red-500' : 'text-green-500'} dark:text-red-400`"
>{{ alert.type === 'error' ? 'Error' : 'Completado' }}</span>
<p class="text-sm text-gray-600 dark:text-gray-200 w-full">{{ alert.message }}</p>
</div>
</div>
</div>
</template>
<script lang="ts">
import { defineComponent, PropType } from "vue"; export default defineComponent({
props: {
messages: {
type: [] as PropType<ToastOptions[] | null>,
default: []
}
},
})
</script>
```
El componente recibirá como props el arreglo de mensajes que habíamos definido en `useToast()`, ya luego solo queda usarlo en `App.vue`
Archivo: `App.vue`
```vue
<template>
<Alert :messages="messages" />
<default-vue />
</template>
<script lang="ts">
import DefaultVue from "./layouts/Default.vue";
import Alert from "./components/common/alert.vue"
import { defineComponent } from "vue";
import useToast from "./utils/useToast";
export default defineComponent({
components: {
DefaultVue, Alert
},
name: "App",
setup() {
const { messages } = useToast()
return {
messages,
}
}
})
</script>
```
Para llamar a la alerta desde cualquier lado:
```typescript
import useToast from './useToast';
const { addAlert } = useToast();
addAlert({id: generateGuid(),
message: error.message,
type: 'error',
});
```
Resultando en:

Y hasta aquí este sencillo artículo, espero les haya servido de algo
¿Para mejorarlo?:
- Hacer que una alerta este por debajo de la otra y se acumulen
- Adicionar un boton de cerrar la alerta.
Cualquier comentario y/o crítica es bienvenida!
| dcruz1990 |
874,026 | Best Practices for Logging in Node.js | Let's be honest, developers do more debugging than writing the actual code. There are cases where you... | 0 | 2021-12-02T15:14:45 | https://dev.to/amoled27/best-practices-for-logging-in-nodejs-4clk | node, javascript, programming, npm |
Let's be honest, developers do more debugging than writing the actual code. There are cases where you need to troubleshoot an issue Node.js application, logs are the saviours. They provide information about the severity of the problem, as well as insights into its root cause. Thus good logging practices are crucial for monitoring your Node.js servers, track errors, carry out different analyses and discover optimization opportunities. This article will outline best logging practices to follow when writing a Node.js application.
## 1. Choosing the correct library
Node.js developers tend to rely on the runtime's console methods ( like console.log()) to log events and provides a familiar API similar to the Javascript console mechanism in browsers. console.log() has its uses but it's not enough to use it as a logging solution in a production application. It does provide methods like console.warn(), console.error(), console.debug(), but these are mere functions that print the standard output and don't define the severity of the log.
### Characteristics of a good logging library
A good logging library provides robust features that make it easier for developers to format and distribute the logs. For example, a typical logging framework will provide options for where to output log data. A developer can configure it to output logs in the terminal or save them in a filesystem or database or even send them over HTTP in case there is a separate log management service in place.
### Major concerns while choosing a suitable library
**Recording:**
**Formatting:** A library should provide proper log formatting options that help you differentiate the different logging levels, customize the colours and priorities of the levels as per need and convenience
**Storing:** It should also provide ways to configure where a developer can save logs as we talked about earlier
**Performance:** As the logger will be used throughout the codebase, it can harm your application's runtime performance, therefore it is crucial to analyse and compare the performance characteristics before choosing a library.
one of such popular libraries is Winston, which we shall talk about in this blog.
### 2. Use the Correct Log Levels
Before proceeding with understanding the log levels let us install the library first so that you can try out commands and code as we go along.
Install the library :
```jsx
npm install winston
```
Regardless of what naming system different libraries use to denote log levels, the concept remains largely the same. Here are the most commonly used log levels in decreasing order of severity:
**FATAL:** This represents a catastrophic situation, where your application cannot recover without manual intervention.
**ERROR:** Represents an error in the system that may halt a specific operation, but not the system as a whole. This is usually used to log the errors returned by a third party API.
**WARN:** Indicates runtime conditions that are unusual but don't affect the running system in any way.
**INFO:** This represents purely informative messages. May use to log user-driven or application-specific events. A common use of this level is to log startup or shutdown service.
**DEBUG:** Used to represent diagnostic information that may be needed for troubleshooting.
**TRACE:** Captures every possible detail about an application’s behaviour during development.
The Winston library in particular uses the following log levels by default — with the error being the most severe and silly being the least:
```jsx
{
error: 0,
warn: 1,
info: 2,
http: 3,
verbose: 4,
debug: 5,
silly: 6
}
```
If you are not comfortable with default naming you can change this by initializing custom logger as per your needs in winston.
```jsx
const { createLogger, format, transports } = require('winston');
const logLevels = {
fatal: 0,
error: 1,
warn: 2,
info: 3,
debug: 4,
trace: 5,
};
const logger = createLogger({
levels: logLevels,
transports: [new transports.Console()],
});
```
When you want to log a message you can log the desire level directly on custom logger
```jsx
logger.info('System Started');
logger.fatal('Fatal error occuered');
```
### 3. Structural Logging
When writing log messages priority should be to make the messages easily readable to both machines and humans. One of the main goals of logging is to enable post-mortem debugging, which involves reading log entries and reconstructing the steps that led to an event in the system.
Thus human-readable and easily understandable, descriptive messages will help developers and sysadmins. It’s also important to use a structured format that is easy to parse by machines.
One of the best practices is to use JSON for logging as it is easily readable by humans as well as can be parsed by machines and can be easily converted to other formats. When logging in JSON, it’s necessary to use a standard schema so that the semantics of each field is clearly defined. This also makes it easy to find what you’re looking for when analyzing log entries.
Winston outputs a JSON string by default with two fields: message and level. Message contains text that has been logged and level states the log level. we can customize this by using winston.format. for example you can add timestamp by combining timestamp and json.
```jsx
const { createLogger, format, transports } = require('winston');
const logger = createLogger({
format: format.combine(format.timestamp(), format.json()),
transports: [new transports.Console({})],
});
```
### 4. Write Descriptive Messages
The message should clearly describe the event that occurred at that particular point. Each message should be unique to the situation so that the developer or system admin can differentiate and track down errors easily.
One of the bad examples of a log message is:
```jsx
Error occured!!
```
The above log tells the user that an error has occurred but there are no specifics of what kind of error has occurred or which place it has occurred. A more descriptive message looks like this:
```jsx
"PUT" request to "https://example.com/api" failed. Response code: "503", response message: "Internal Server Error!". Retrying after "60" seconds.
```
From this message, we know that the request to the server of [example.com](http://example.com) has failed. The probable reason is the third party server might be down for unknown reasons.
### 5. Avoid Logging Sensitive Data
Regardless of the type of application, you are working on, it is always important to avoid logging sensitive information in the logs. The sensitive information includes govt ID nos., addresses, phone numbers, email ids or access tokens etc.
### 6. Add Proper Context to your Logs
Another crucial step to keep in mind while logging is to provide the necessary context i.e. the developer should know where the log has come from or what it relates to. Context makes it possible to quickly reconstruct the actions leading up to an event.
Winston provides the ability to add global metadata (such as the component or service where an event occurred) to every generated log entry. In a complex application, this information in your logs is helpful for troubleshooting issues because it immediately directs you to the point of failure.
```jsx
const logger = createLogger({
format: format.combine(format.timestamp(), format.json()),
defaultMeta: {
service: 'auth-service',
},
transports: [new transports.Console({})],
});
```
the following output will be shown
```jsx
1
{"message":"User loggedIn successfully","level":"info","service":"auth-service","timestamp":"2020-09-29T10:56:14.651Z"}
```
Originally posted at [**amodshinde.com**](https://www.amodshinde.com/blog/nodejs-logging/) | amoled27 |
874,045 | Spice up your terminal using pokemon themes 🔥 | Let's be honest, we all love pokemon and for most of us it plays a huge part, in shaping our... | 0 | 2021-10-24T05:48:31 | https://dev.to/manyfac3dg0d/spice-up-your-terminal-using-pokemon-themes-4pbf | python, pokemon, terminal, linux | Let's be honest, we all love pokemon and for most of us it plays a huge part, in shaping our childhood. So wouldn't it be cool to display them on the terminal.

Enter [Pokemon-Terminal](https://github.com/LazoCoder/Pokemon-Terminal). With few steps, you are ready to rock your terminal with pokemon themes.
1. Firstly, the default cmd prompt in windows is not supported, hence download the windows terminal from [here](https://www.microsoft.com/en-us/p/windows-terminal/9n0dx20hk701?activetab=pivot:overviewtab)
2. Install python3 & pip3
3. Run the following command to download and setup the Pokemon-Terminal
```bat
pip3 install git+https://github.com/LazoCoder/Pokemon-Terminal.git
```
Once installed you should be able to execute to set the pokemon theme in the windows terminal
```bat
pokemon <pokemon_name>
```

That's it, go catch them all!
Don't forget to star the github [repo](https://github.com/LazoCoder/Pokemon-Terminal) and appreciate the developer for the efforts. | manyfac3dg0d |
874,092 | Do you see coding as one fun step, or lots of tedious steps? | How you see the act of coding shows what your true preferences and interests are | 0 | 2021-10-24T06:37:02 | https://dev.to/jasonleowsg/do-you-see-coding-as-one-fun-step-or-lots-of-tedious-steps-2hg7 | codenewbie, beginners, discuss, decodingcoding | ---
title: Do you see coding as one fun step, or lots of tedious steps?
published: true
description: How you see the act of coding shows what your true preferences and interests are
tags: codenewbies, beginners, discussion, decodingcoding
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/cqkjo5b1t4x4imcq8v88.jpg
---
### *How you see the act of coding shows what your true preferences and interests are*
---
Here’s a great heuristic for discovering what your true preferences and interests are, where your passion and enthusiasm is anchored in, credits to [@sivers on Twitter](https://twitter.com/sivers?s=21):
> Imagining lots of tedious steps? Or one fun step? If we hate doing something, we think of it as hard. We picture it having many annoying steps. If we love doing something, it seems simple. We think of it as one fun step…[like for running] “Easy! You just put on your shoes and go!”
I love this. It’s so true, and so telling. What a great mindfulness and introspective practice! Indeed, anytime I notice that I am thinking ahead and ***dreading*** the many steps to get to the goal, it’s highly likely that I’m not all that enthusiastic about that goal. But during occasions when I’m super motivated and passionate to do something, I don’t think ahead so much, and just f\*\*king do it, even if objectively the steps remain the same. I don’t make as many excuses, or mope and dawdle as much. It’s like the road bumps don’t matter. Challenges are taken on the chin, without sweat and pain.
But what if something makes you feel both? Like say with coding, I always find myself dreading all the “many tedious steps” ahead. But when it comes to the final product itself, the thought of being able to create something tangible and material that you can see or touch out, of thin air and abstract thoughts – that makes me want to get there in “one fun step”.
How strange!
Does that imply that I enjoy making, but not coding? So do I enjoy it, or not? Is it possible to enjoy one part of a process but hate another? If so, how do I resolve this conundrum?
---
Follow my daily writings on [Lifelog](https://golifelog.com/goals/30), where I write about learning to code, goals, productivity, indie hacking and tech for good.
| jasonleowsg |
874,179 | Seeding a Prisma database in Next.js | When working with databases, it's convenient to have some initial data. Imagine being a new... | 0 | 2021-10-24T07:06:13 | https://daily-dev-tips.com/posts/seeding-a-prisma-database-in-nextjs/ | nextjs, database, postgres | When working with databases, it's convenient to have some initial data.
Imagine being a new developer. It will be a pain if you need to set up all this data by hand.
That's where migrations come in handy.
Prisma has a super-easy way to deal with these migrations. And today, we'll be creating our seeder!
## Creating the Prisma seed file
Create a new file called `seed.ts` in the `prisma` folder.
This file will handle our seeds, and the rough layout looks like this:
```js
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
async function main() {
// Do stuff
}
main()
.catch((e) => {
console.error(e);
process.exit(1);
})
.finally(async () => {
await prisma.$disconnect();
});
```
As you can see, this loads the Prisma client. Then we define the main function that is an async function.
And eventually, we call this function to catch errors and disconnect once it's done.
Before moving on, let's create a data file for the [playlist model we made in Prisma](https://daily-dev-tips.com/posts/adding-prisma-to-a-nextjs-project/).
I've created a `seeds` folder inside this `prisma` folder.
Inside that `seeds` folder, create a file called `playlists.ts`.
```js
export const playlists = [
{
title: 'Wake Up Happy',
image: 'https://i.scdn.co/image/ab67706f000000030bd6693bac1f89a70d623e4d',
uri: 'spotify:playlist:37i9dQZF1DX0UrRvztWcAU',
},
{
title: 'Morning Motivation',
image: 'https://i.scdn.co/image/ab67706f00000003037da32de996d7c859b3b563',
uri: 'spotify:playlist:37i9dQZF1DXc5e2bJhV6pu',
},
{
title: 'Walking On Sunshine',
image: 'https://i.scdn.co/image/ab67706f000000035611e6effd70cdc11d0c7076',
uri: 'spotify:playlist:37i9dQZF1DWYAcBZSAVhlf',
},
];
```
As you can see, this resembles our fields, and we have three playlists added here.
Now head back to the `seed.ts` file and import this file.
```js
import { playlists } from './seeds/playlists';
```
Now inside our `main` function, we can use the `createMany` function on the Prisma client.
```js
async function main() {
await prisma.playlist.createMany({
data: playlists,
});
}
```
This will create many playlists with the data we just added.
## Running seeds in Prisma
The next thing we need is a way to run this seed script.
Before doing that, we need to install `ts-node` as a dev dependency:
```bash
npm install ts-node -D
```
Then head over to your `package.json` file and add a `prisma` section.
```js
{
// Other stuff
"prisma": {
"seed": "ts-node prisma/seed.ts"
},
}
```
To run the migrations, you can run the following command:
```bash
npx prisma db seed
```
And the seed is also run when you execute `prisma migrate dev` or `prisma migrate reset`.
You can see the seeding in action in the video below.

If you want to see the completed project, it's hosted on [GitHub](https://github.com/rebelchris/next-prisma/tree/seed).
### Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on [Facebook](https://www.facebook.com/DailyDevTipsBlog) or [Twitter](https://twitter.com/DailyDevTips1) | dailydevtips1 |
874,207 | Learn SQL: Microsoft SQL Server - Episode 5: Joining Tables | Joining Multiple Tables Thus far we have discussed how to pull data from a single table.... | 15,060 | 2021-10-29T03:46:37 | https://dev.to/ifierygod/learn-sql-microsoft-sql-server-episode-5-joining-tables-32fd | sql, database, beginners, datascience | 
###Joining Multiple Tables
Thus far we have discussed how to pull data from a single table. However in most cases, we will need to pull the data from multiple tables in order to get the bigger picture for our analysis or reporting.
Before we can join tables in a SQL query, we need to be familiar with our database structure, which tables there are, what kind of columns are there, and how the tables connect to each other.

In the AdventureWorks, the **Person** schema contains a-lot of information about a person, the people who are in the database, the person table contains columns that hold different pieces of information of a person.
It holds the **Primary Key** (PK), which is **BusinessEntityID**. This means that **BusinessEntityID** is a <u>unique record</u> that identifies each record.
**BusinessEntityID** is also the **Foreign Key** (FK) for this table. This means it is used to connect to other related tables.
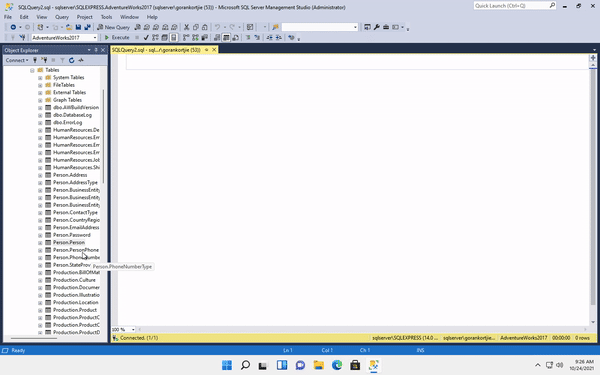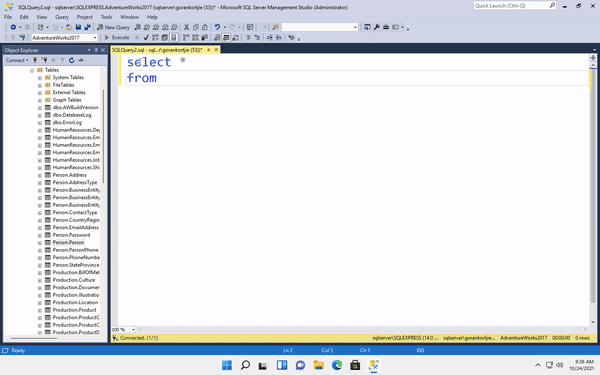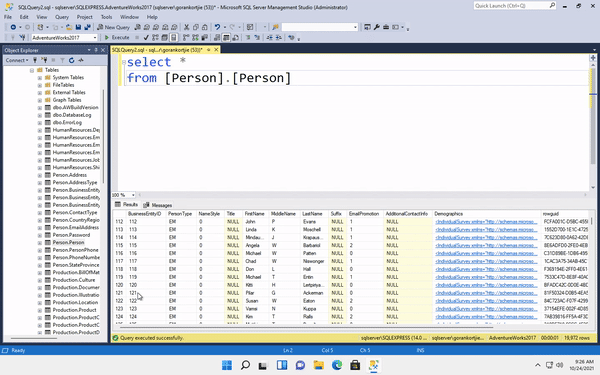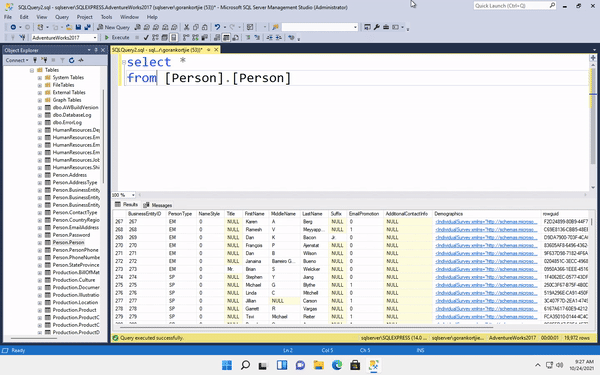
There is also a table called **Person.EmailAddress**, which contains information on each persons _email address_.

The table has a the **Primary Key** of **BusinessEntityID** and each _email address_ has a **Primary Key** of **EmailAddressID**, the **EmailAddressID** allows for a person to have multiple email addresses.

In order for us to pull the **firstName**, **lastName** and **emailAddress** for a person, we need to join these two tables. A way to join them is to take a key that is common between both of them, which in this case is **BusinessEntityID**.

The syntax for joining tables is as follows:
```
Select [Column Names | * ]
From [Table Name]
On [Table.primaryKey] = [Table.primaryKey]
```

We can limit the amount of columns return to us by specifying the columns we want to pull in the select statement.
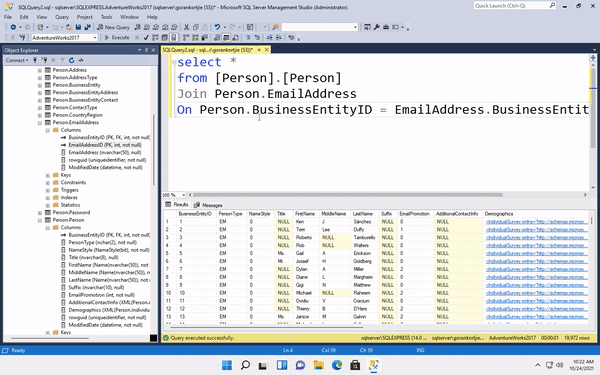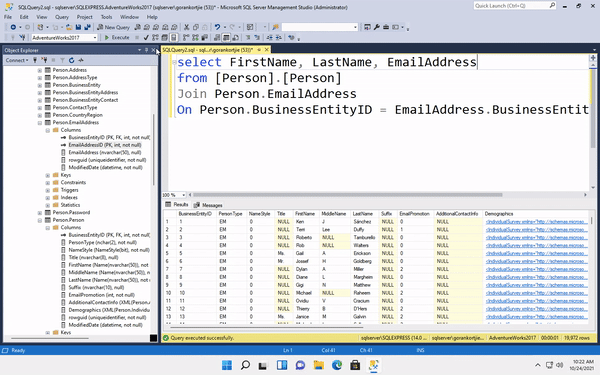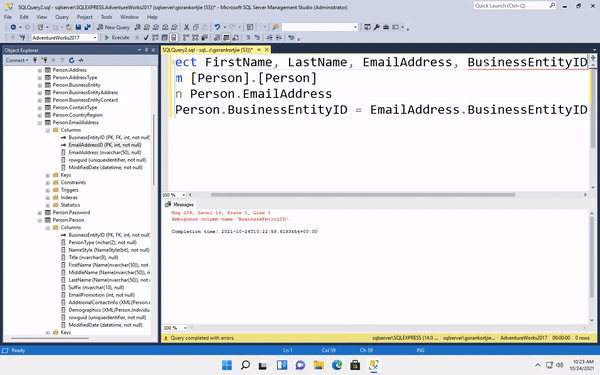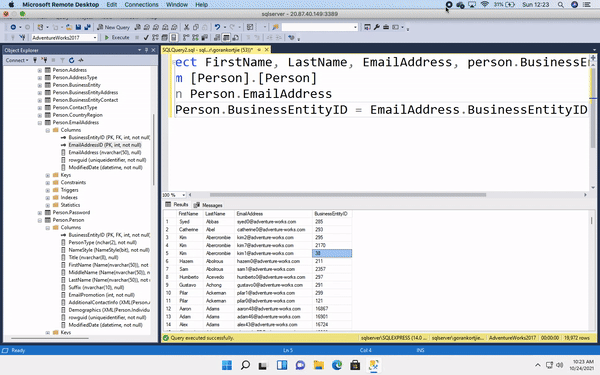
Notice how when we try to pull the data from **BusinessEntityID**, SQL throws an error, it will also indicate an error by underlining with a red line. The reason why is we an not being specific from which table we want to pull the **BusinessEntityID**, since it exist in both tables.

When we specify we want to pull from the **person.BusinessEntityID** is works perfectly.
Using this same syntax we can join multiple tables. Lets say for instance we need to join another table and it is the **Person.PersonPhone** table.
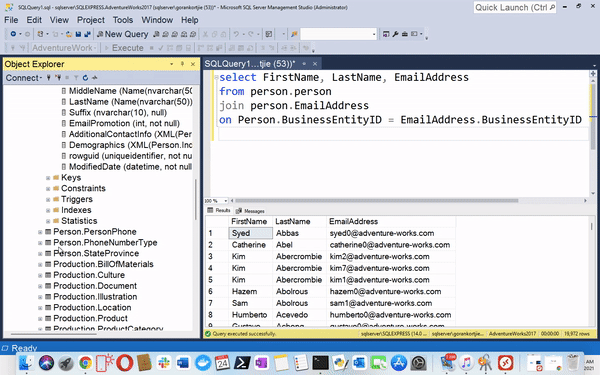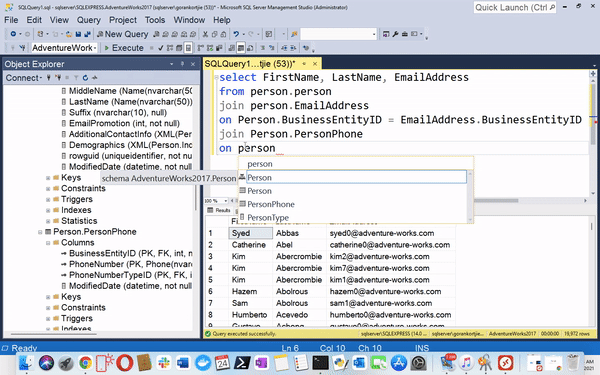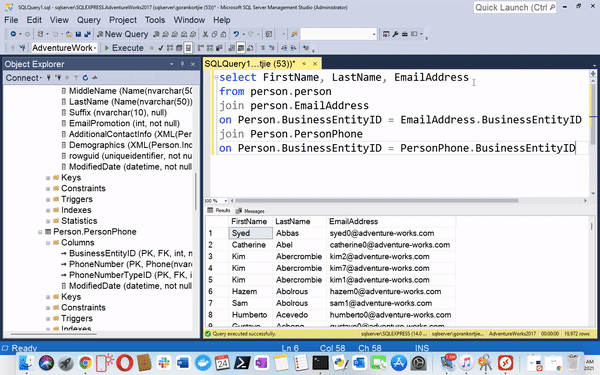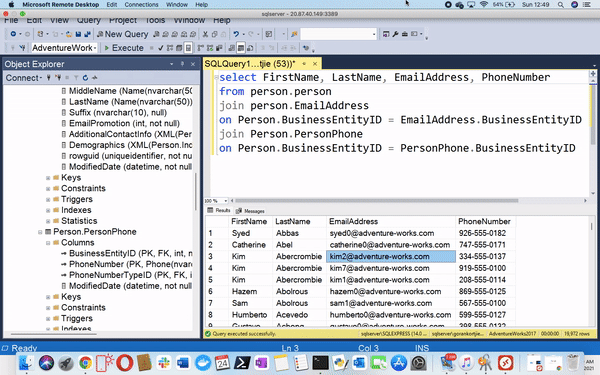
We can even limit this further by specifying a **Where** clause, lets say for instance we need to limit this query to where the _firstName_ is Kim, we can accomplish this as follows:
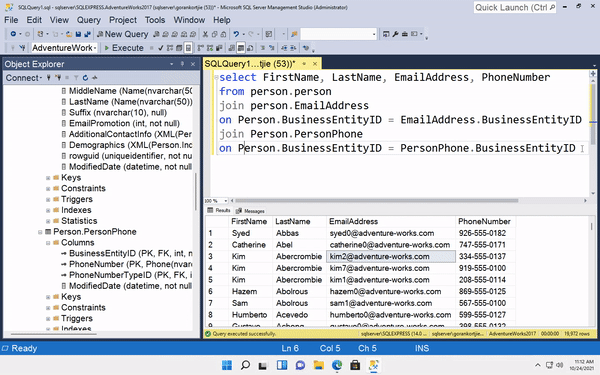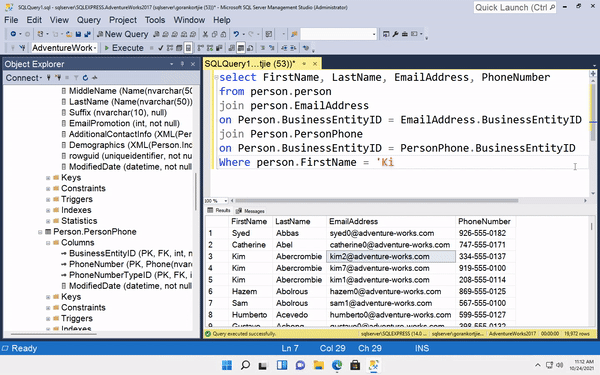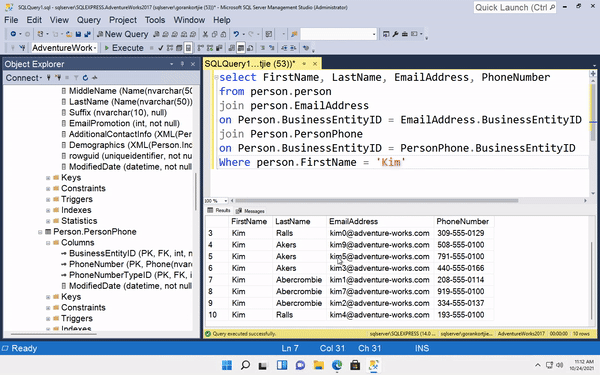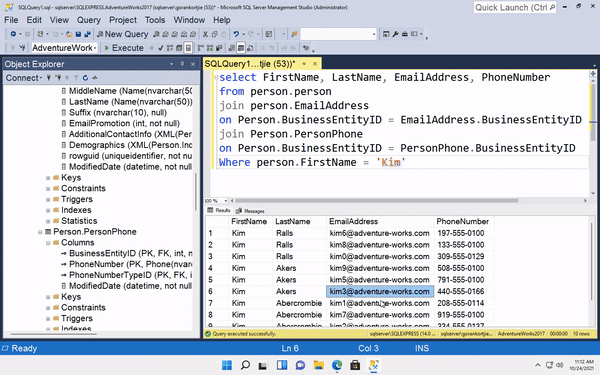
We are now able to find each person with the _first name_ as Kim, we can see their _last name_, _email address_ and _phone number_ by joining multiple tables, that is pretty amazing!

We have come to the end of this discussion about joining tables, I really hope you enjoyed reading it, join me in the next episode...
 | ifierygod |
874,564 | What I learnt developing a system in a couple of days. | So, being as bored as I was this weekend ( not really ), I saw a picture of a database schema while... | 0 | 2021-10-24T17:05:23 | https://dev.to/kudzaitsapo/what-i-learnt-developing-a-system-in-a-couple-of-days-23k2 | dotnet, javascript, tailwindcss, react | So, being as bored as I was this weekend ( *not really* ), I saw a picture of a database schema while browsing the net. I then asked myself, how long would it take me to implement that thing as an entire system? 🤔
Considering I'm totally notorious with *not* finishing projects, I decided to give myself the **Ultimate** deadline of two days ... (*lol*), just to make sure I wouldn't spend anymore unnecessary time on it.
You know what the funny thing is? I actually managed to finish the project this time 😅. I mean, that's the purpose of the article 😅.
Anyways, for the curious, the project can be found on github, the user interface [here](https://github.com/kudzaitsapo/hr-manager-ui) and the API [here](https://github.com/kudzaitsapo/hr-manager-web-api).
I made the API using Asp.net core, and the user interface, I used react + tailwind (*an awesome combo apparently*). I tried to make the system as simple as I could, but then stuff happened and it ended up being somewhat ... *complex*.
After meeting my weekend deadline, there are a couple of things I learnt:
### As you approach the deadline, code quality decreases
Some times, when you're about to reach a deadline, and there's still a ton of features left to develop, you start saying "SCREW IT" to some of the coding conventions. You start copy/pasting code, completely violating *D.R.Y.* principles. Readability? Who cares when there's a deadline approaching?
### Thanks to pressure, some features get left out
I was giving myself so much pressure, I ended up leaving out a lot of features undeveloped. I know what you're thinking, how did I finish the project if I left out some features? 🤔
...
Anyways, I ended up prioritizing some features over others, and hey, who can blame me? 🤷♂️
### Bugs
The only code without bugs ... is code that hasn't been written yet. In reality, every code has bugs, and as you approach a deadline, the pressure makes you to introduce more bugs. Some are noticeable, and some of them you only notice them when in production ... and something is burning.
### Performance
What's that?
....
Just kidding. As you approach the deadline, you stop caring about performance. Of course, the code can be refactored later when all the servers are on fire, the client is yelling, and the users are calling non-stop.
I know most of these things are probably common, a lot of you have experienced them beforehand. That doesn't mean of course, that there isn't anyone who hasn't.
Here are some of the screenshots of what the system looks like:
Right, I know what you might be thinking ... What's with this guy and HR funny systems? Who knows?
...
Anyways, Just thought I could share what I learnt during the weekend, for the benefit of others who haven't. | kudzaitsapo |
874,213 | Upload Files to Azure Storage using a PowerShell Function App | Azure - Function App file uploader | 0 | 2021-10-24T13:31:36 | https://dev.to/pwd9000/upload-files-to-azure-storage-using-a-powershell-function-app-15li | azurefunctions, azure, serverless, powershell | ---
title: Upload Files to Azure Storage using a PowerShell Function App
published: true
description: Azure - Function App file uploader
tags: 'azurefunctions, azure, serverless, powershell'
cover_image: 'https://raw.githubusercontent.com/Pwd9000-ML/blog-devto/main/posts/2021/Azure-Upload-File-PoSH-Function-App/assets/main-cover.png'
canonical_url: null
id: 874213
date: '2021-10-24T13:31:36Z'
---
## Overview
With Hacktoberfest 2021 coming to an end soon, I thought I would share with you a little experiment I did using an Azure serverless Function App with Powershell as the code base. The idea was to create an easy to use, reusable `File Uploader API` that would allow someone to upload a file to an Azure Storage Account blob container by posting a HTTP request.
The HTTP request would be a JSON body and only requires the file name and the file Content/data in a serialized Base64 string. The PowerShell Function App would then deserialize the base64 string into a temporary file, rename and copy the file as a blob into a storage account container called `fileuploads`.
## Set environment up automatically
To stage and setup the entire environment for my API automatically I wrote a PowerShell script using AZ CLI, that would build and configure all the things I would need to start work on my function. There was one manual step however I will cover a bit later on. But for now you can find the script I used on my [github code](https://github.com/Pwd9000-ML/blog-devto/tree/main/posts/2021/Azure-Upload-File-PoSH-Function-App/code) page called `setup_environment.ps1`.
First we will log into Azure by running:
```powershell
az login
```
After logging into Azure and selecting the subscription, we can run the script that will create all the resources and set the environment up:
```powershell
# Setup Variables.
$randomInt = Get-Random -Maximum 9999
$subscriptionId=$(az account show --query id -o tsv)
$resourceGroupName = "Function-App-Storage"
$storageName = "storagefuncsa$randomInt"
$functionAppName = "storagefunc$randomInt"
$region = "uksouth"
$secureStore = "securesa$randomInt"
$secureContainer = "fileuploads"
# Create a resource resourceGroupName
az group create --name "$resourceGroupName" --location "$region"
# Create an azure storage account for secure store (uploads)
az storage account create `
--name "$secureStore" `
--location "$region" `
--resource-group "$resourceGroupName" `
--sku "Standard_LRS" `
--kind "StorageV2" `
--https-only true `
--min-tls-version "TLS1_2"
# Create an azure storage account for function app
az storage account create `
--name "$storageName" `
--location "$region" `
--resource-group "$resourceGroupName" `
--sku "Standard_LRS" `
--kind "StorageV2" `
--https-only true `
--min-tls-version "TLS1_2"
# Create a Function App
az functionapp create `
--name "$functionAppName" `
--storage-account "$storageName" `
--consumption-plan-location "$region" `
--resource-group "$resourceGroupName" `
--os-type "Windows" `
--runtime "powershell" `
--runtime-version "7.0" `
--functions-version "3" `
--assign-identity
#Configure Function App environment variables:
$settings = @(
"SEC_STOR_RGName=$resourceGroupName"
"SEC_STOR_StorageAcc=$secureStore"
"SEC_STOR_StorageCon=$secureContainer"
)
az functionapp config appsettings set `
--name "$functionAppName" `
--resource-group "$resourceGroupName" `
--settings @settings
# Authorize the operation to create the container - Signed in User (Storage Blob Data Contributor Role)
az ad signed-in-user show --query id -o tsv | foreach-object {
az role assignment create `
--role "Storage Blob Data Contributor" `
--assignee "$_" `
--scope "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Storage/storageAccounts/$secureStore"
}
#Create Upload container in secure store
Start-Sleep -s 30
az storage container create `
--account-name "$secureStore" `
--name "$secureContainer" `
--auth-mode login
#Assign Function System MI permissions to Storage account(Read) and container(Write)
$functionMI = $(az resource list --name $functionAppName --query [*].identity.principalId --out tsv)| foreach-object {
az role assignment create `
--role "Reader and Data Access" `
--assignee "$_" `
--scope "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Storage/storageAccounts/$secureStore" `
az role assignment create `
--role "Storage Blob Data Contributor" `
--assignee "$_" `
--scope "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Storage/storageAccounts/$secureStore/blobServices/default/containers/$secureContainer"
}
```
Lets take a closer look, step-by-step what the above script does as part of setting up the environment.
1. Create a resource group called `Function-App-Storage`. 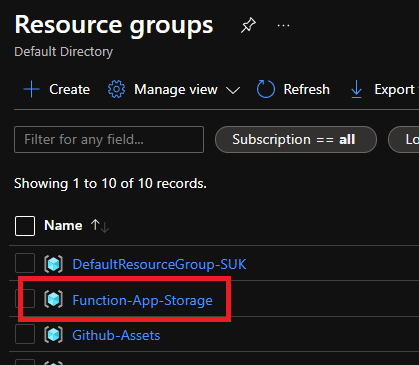
2. Create an azure storage account, `secure store` where file uploads will be kept. 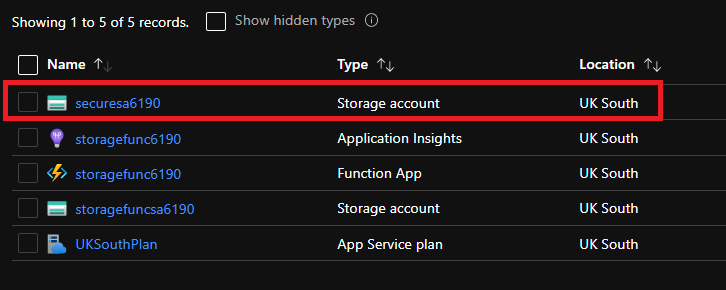
3. Create an azure storage account for the function app. 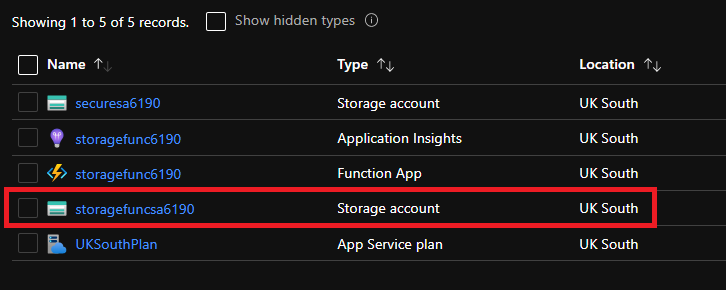
4. Create a PowerShell Function App with `SystemAssigned` managed identity, `consumption` app service plan and `insights`. 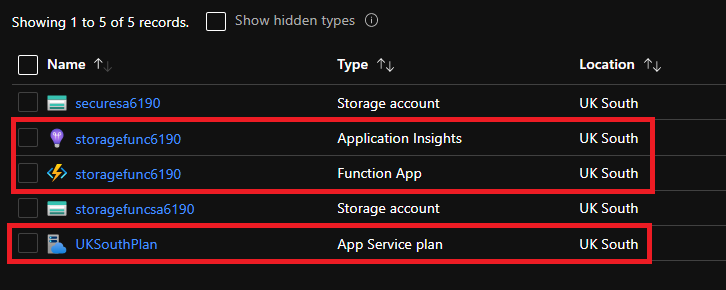 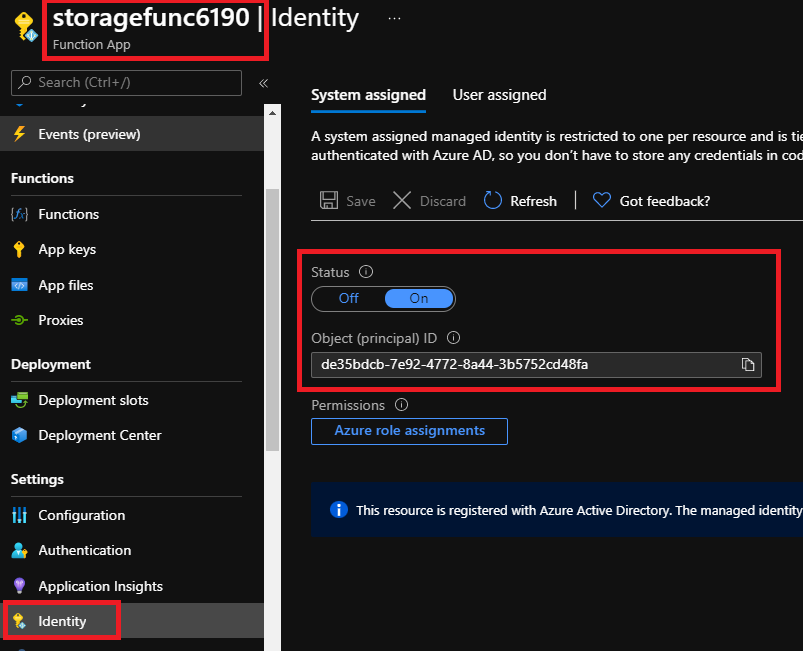
5. Configure Function App environment variables. (Will be consumed inside of function app later). 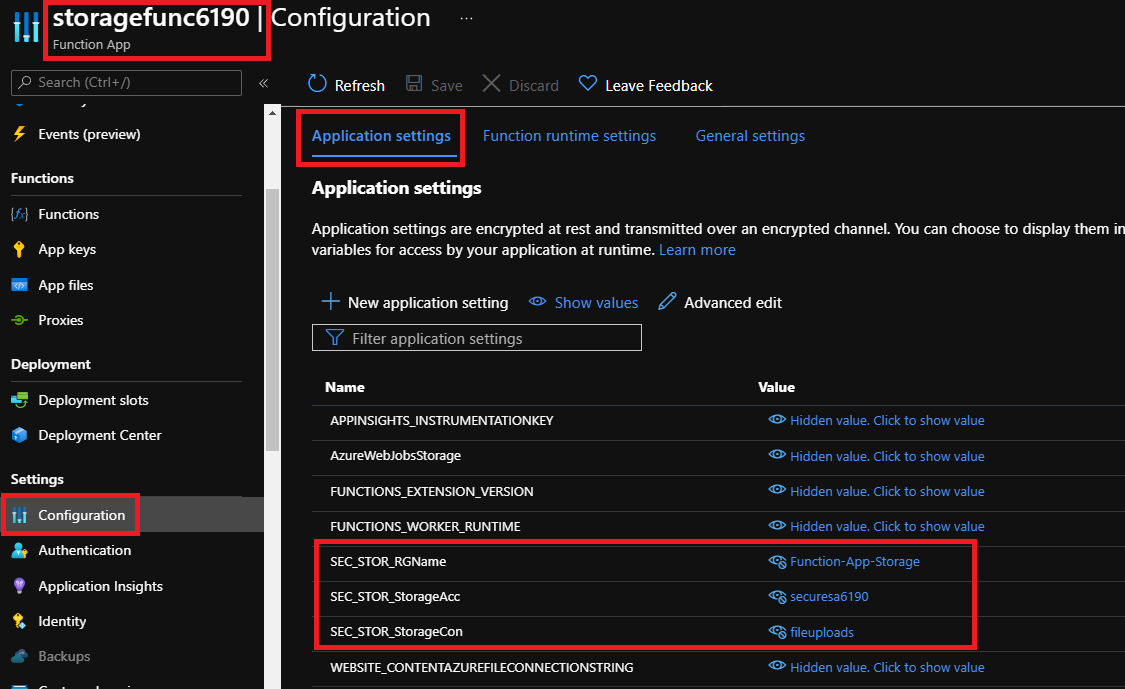
6. Create `fileuploads` container in secure store storage account. 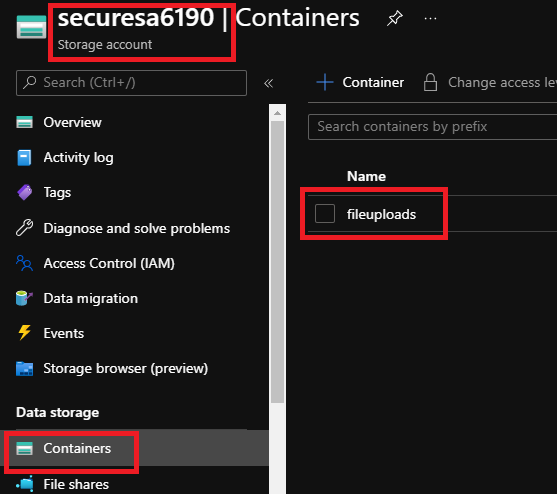
7. Assign Function App `SystemAssigned` managed identity permissions to Storage account(Read) and container(Write). 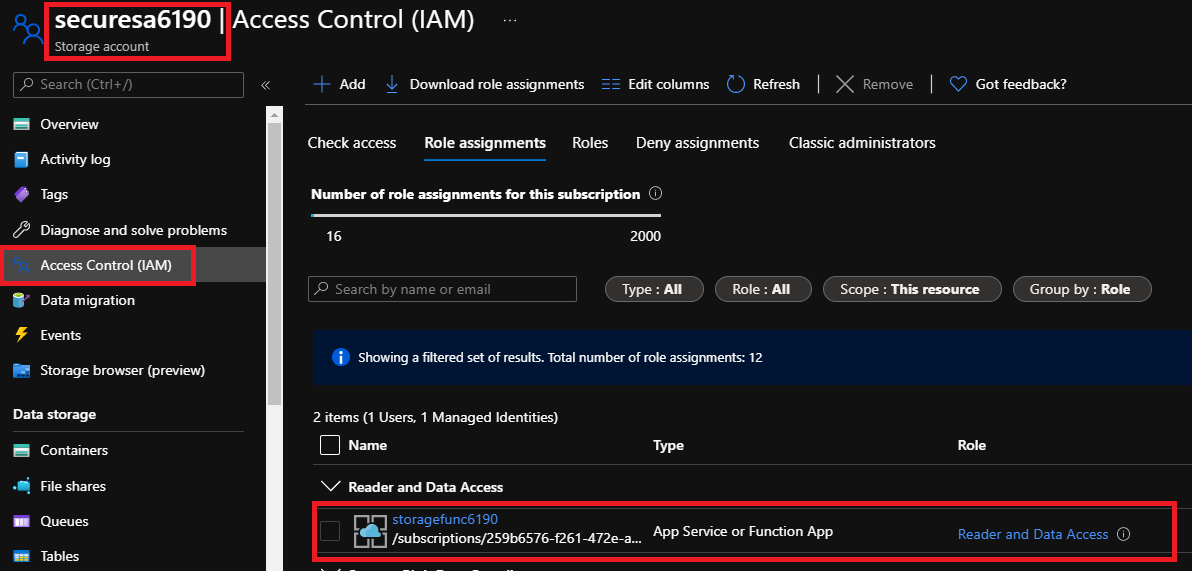 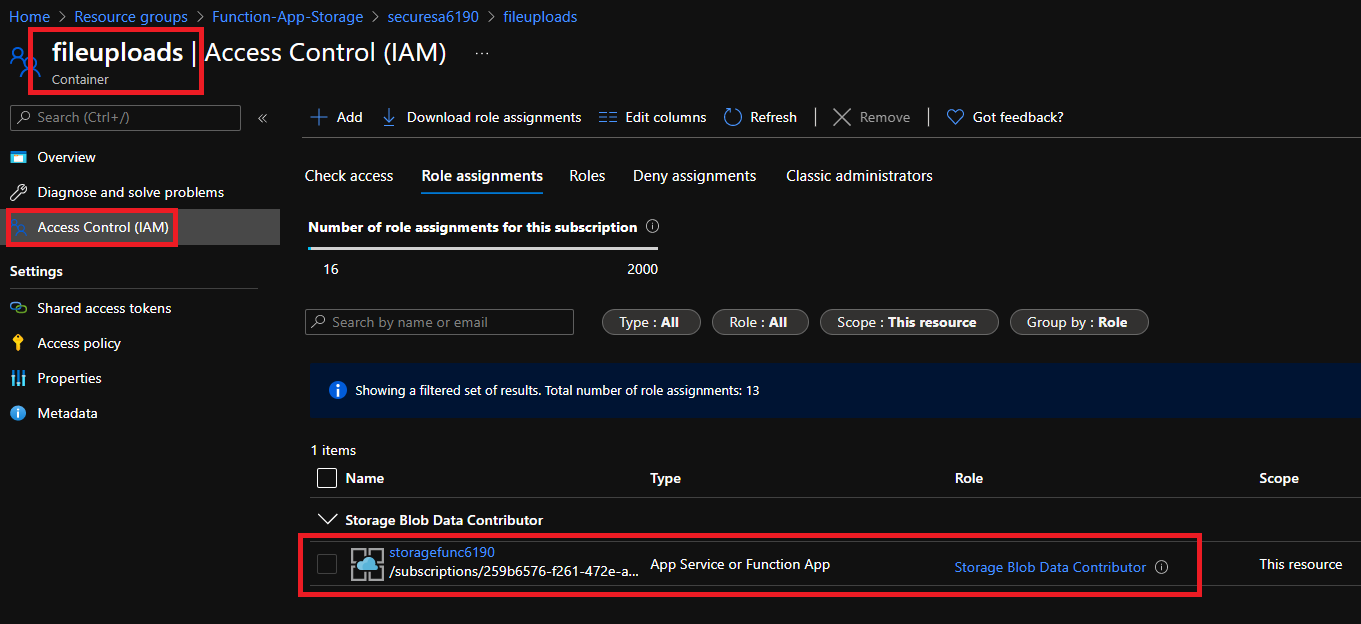
8. Remember I mentioned earlier there is one manual step. In the next step we will change the `requirements.psd1` file on our function to allow the `AZ` module inside of our function by uncommenting the following: 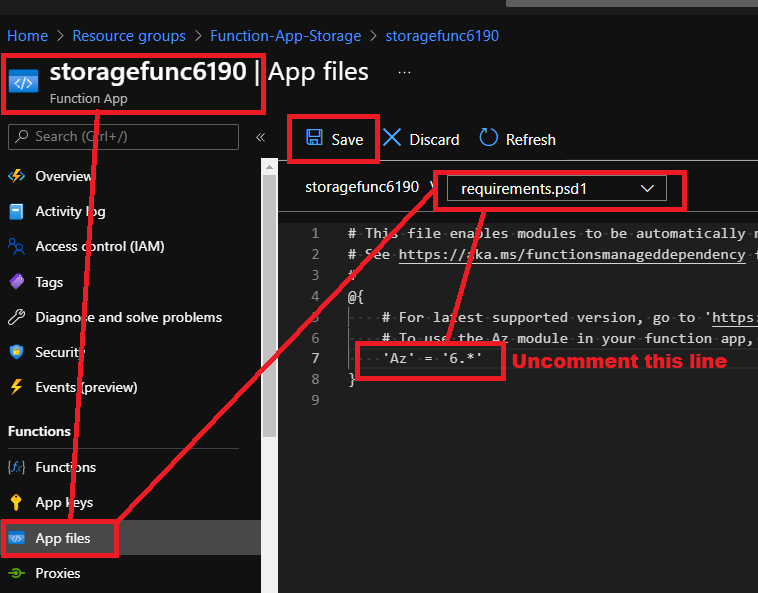
**NOTE:** Remember to save the manual change we made on `requirements.psd1` above. That is it, our environment is set up and in the next section we will configure the file uploader function API powershell code.
## File Uploader Function
The following function app code can also be found under my [github code](https://github.com/Pwd9000-ML/blog-devto/tree/main/posts/2021/Azure-Upload-File-PoSH-Function-App/code) page called `run.ps1`.
1. Navigate to the function app we created in the previous section and select `+ Create` under `Functions`. 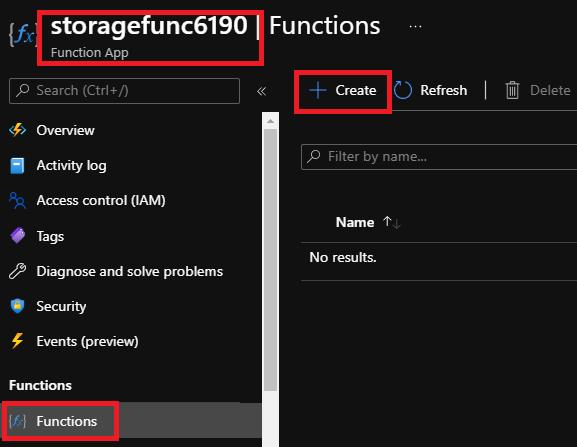
2. Select `Develop in portal` and for the template select `HTTP trigger`, name the function `uploadfile` and hit `Create`. 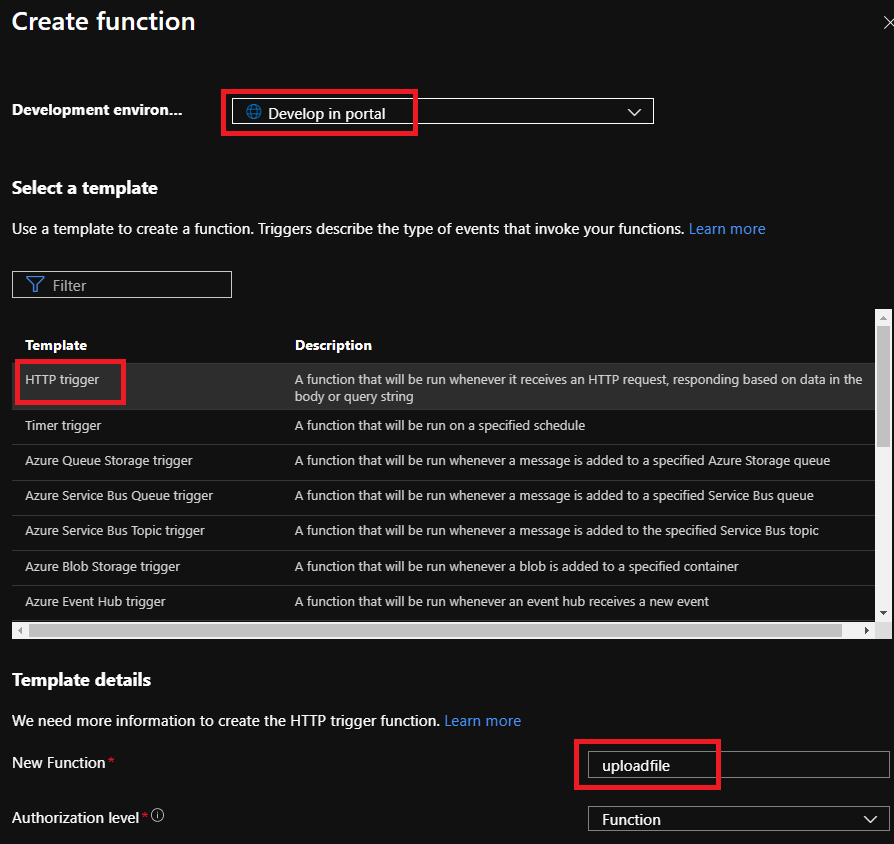
3. Navigate to `Code + Test` and replace all the code under `run.ps1` with the following powershell code and hit `save`: 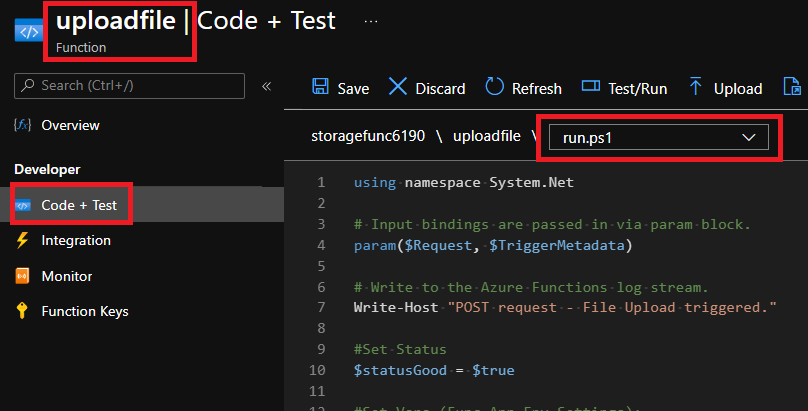
```powershell
using namespace System.Net
# Input bindings are passed in via param block.
param($Request, $TriggerMetadata)
# Write to the Azure Functions log stream.
Write-Host "POST request - File Upload triggered."
#Set Status
$statusGood = $true
#Set Vars (Func App Env Settings):
$resourceGroupName = $env:SEC_STOR_RGName
$storageAccountName = $env:SEC_STOR_StorageAcc
$blobContainer = $env:SEC_STOR_StorageCon
#Set Vars (From request Body):
$fileName = $Request.Body["fileName"]
$fileContent = $Request.Body["fileContent"]
Write-Host "============================================"
Write-Host "Please wait, uploading new blob: [$fileName]"
Write-Host "============================================"
#Construct temp file from fileContent (Base64String)
try {
$bytes = [Convert]::FromBase64String($fileContent)
$tempFile = New-TemporaryFile
[io.file]::WriteAllBytes($tempFile, $bytes)
}
catch {
$statusGood = $false
$body = "FAIL: Failed to receive file data."
}
#Get secureStore details and upload blob.
If ($tempFile) {
try {
$storageAccount = Get-AzStorageAccount -ResourceGroupName $resourceGroupName -Name $storageAccountName
$storageContext = $storageAccount.Context
$container = (Get-AzStorageContainer -Name $blobContainer -Context $storageContext).CloudBlobContainer
Set-AzStorageBlobContent -File $tempFile -Blob $fileName -Container $container.Name -Context $storageContext
}
catch {
$statusGood = $false
$body = "FAIL: Failure connecting to Azure blob container: [$($container.Name)], $_"
}
}
if(!$statusGood) {
$status = [HttpStatusCode]::BadRequest
}
else {
$status = [HttpStatusCode]::OK
$body = "SUCCESS: File [$fileName] Uploaded OK to Secure Store container [$($container.Name)]"
}
# Associate values to output bindings by calling 'Push-OutputBinding'.
Push-OutputBinding -Name Response -Value ([HttpResponseContext]@{
StatusCode = $status
Body = $body
})
```
Lets take a closer look at what this code actually does. In the first few lines we can see that the function app will take a `request` input parameter called `$request`. This parameter will be our main input and request body JSON object. We will use the JSON body to send details into our API about the file we want to upload. We also set a status and some variables.
Here is an example of a valid JSON request body for our function app:
```JSON
//JSON request Body Example
{
"fileName": "hello-world.txt",
"fileContent": "VXBsb2FkIHRoaXMgZmlsZSB0byBBenVyZSBjbG91ZCBzdG9yYWdlIHVzaW5nIEZ1bmN0aW9uIEFwcCBGaWxlIHVwbG9hZGVyIEFQSQ=="
}
```
Note that our `$Request` input parameter is linked to `$Request.body`, and we set two variables that will be taken from the JSON request body namely, `fileName` and `fileContent`. We will use these two values from the incoming POST request to store the serialized file content (Base64String) in a variable called `$fileContent` and the blob name in a variable called `$fileName`.
**NOTE:** Remember in the previous section `step 5` we set up some environment variables on our function app settings, we can reference these environment variables values in our function code with `$env:appSettingsKey` as show below):
```powershell
#// code/run.ps1#L1-L22
using namespace System.Net
# Input bindings are passed in via param block.
param($Request, $TriggerMetadata)
# Write to the Azure Functions log stream.
Write-Host "POST request - File Upload triggered."
#Set Status
$statusGood = $true
#Set Vars (Func App Env Settings):
$resourceGroupName = $env:SEC_STOR_RGName
$storageAccountName = $env:SEC_STOR_StorageAcc
$blobContainer = $env:SEC_STOR_StorageCon
#Set Vars (From JSON request Body):
$fileName = $Request.Body["fileName"]
$fileContent = $Request.Body["fileContent"]
Write-Host "============================================"
Write-Host "Please wait, uploading new blob: [$fileName]"
Write-Host "============================================"
```
Next we have a `try/catch` block where we take the serialized `Base64 String` from the JSON request body `fileContent` stored in the PowerShell variable `$fileContent` and try to deserialize it into a temporary file:
```powershell
#// code/run.ps1#L25-L33
try {
$bytes = [Convert]::FromBase64String($fileContent)
$tempFile = New-TemporaryFile
[io.file]::WriteAllBytes($tempFile, $bytes)
}
catch {
$statusGood = $false
$body = "FAIL: Failed to receive file data."
}
```
Then we have an `if statement` with a `try/catch` block where we take the deserialized temp file from the previous step and rename and save the file into our `fileuploads` container using the `$fileName` variable which takes the `fileName` value from our JSON request body. Because our function apps managed identity has been given permission against the container using RBAC earlier when we set up the environment, we should have no problems here:
```powershell
#// code/run.ps1#L36-L48
If ($tempFile) {
try {
$storageAccount = Get-AzStorageAccount -ResourceGroupName $resourceGroupName -Name $storageAccountName
$storageContext = $storageAccount.Context
$container = (Get-AzStorageContainer -Name $blobContainer -Context $storageContext).CloudBlobContainer
Set-AzStorageBlobContent -File $tempFile -Blob $fileName -Container $container.Name -Context $storageContext
}
catch {
$statusGood = $false
$body = "FAIL: Failure connecting to Azure blob container: [$($container.Name)], $_"
}
}
```
Finally in the last few lines, given our status is still good, we return a message body to the user to say that the file has been uploaded successfully.
```powershell
#// code/run.ps1#L50-L62
if(!$statusGood) {
$status = [HttpStatusCode]::BadRequest
}
else {
$status = [HttpStatusCode]::OK
$body = "SUCCESS: File [$fileName] Uploaded OK to Secure Store container [$($container.Name)]"
}
# Associate values to output bindings by calling 'Push-OutputBinding'.
Push-OutputBinding -Name Response -Value ([HttpResponseContext]@{
StatusCode = $status
Body = $body
})
```
## Testing the function app
Lets test our function app and see if it does what it says on the tin.
Before we test the function lets create a new temporary function key to test with. Navigate to the function app function and select `Function Keys`. Create a `+ New function key` and call the key `temp_token` (Make a note of the token as we will use it in the test script):
Also make a note of the Function App URL. If you followed this tutorial it would be: `https://<FunctionAppName>.azurewebsites.net/api/uploadfile`. Or you can also get this under `Code + Test` and selecting `Get function URL` and drop down using the key: `temp_token`:
I have created the following powershell script to test the file uploader API. The following test script can be found under my [github code](https://github.com/Pwd9000-ML/blog-devto/tree/main/posts/2021/Azure-Upload-File-PoSH-Function-App/code) page called `test_upload.ps1`.
```powershell
#File and path to upload
$fileToUpload = "C:\temp\hello-world.txt"
#Set variables for Function App (URI + Token)
$functionUri = "https://<functionAppname>.azurewebsites.net/api/uploadfile"
$temp_token = "<TokenSecretValue>"
#Set fileName and serialize file content for JSON body
$fileName = Split-Path $fileToUpload -Leaf
$fileContent = [Convert]::ToBase64String((Get-Content -Path $fileToUpload -Encoding Byte))
#Create JSON body
$body = @{
"fileName" = $fileName
"fileContent" = $fileContent
} | ConvertTo-Json -Compress
#Create Header
$header = @{
"x-functions-key" = $temp_token
"Content-Type" = "application/json"
}
#Trigger Function App API
Invoke-RestMethod -Uri $functionUri -Method 'POST' -Body $body -Headers $header
```
Lets try it out with a txt file:
Lets do another test but with an image file this time:
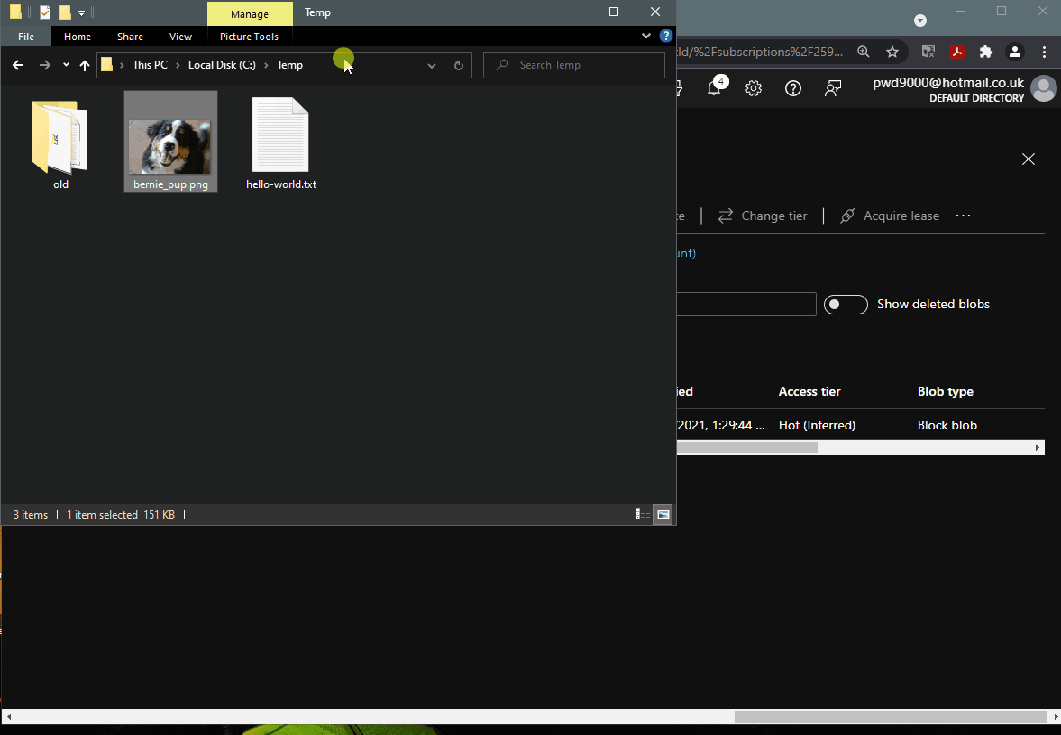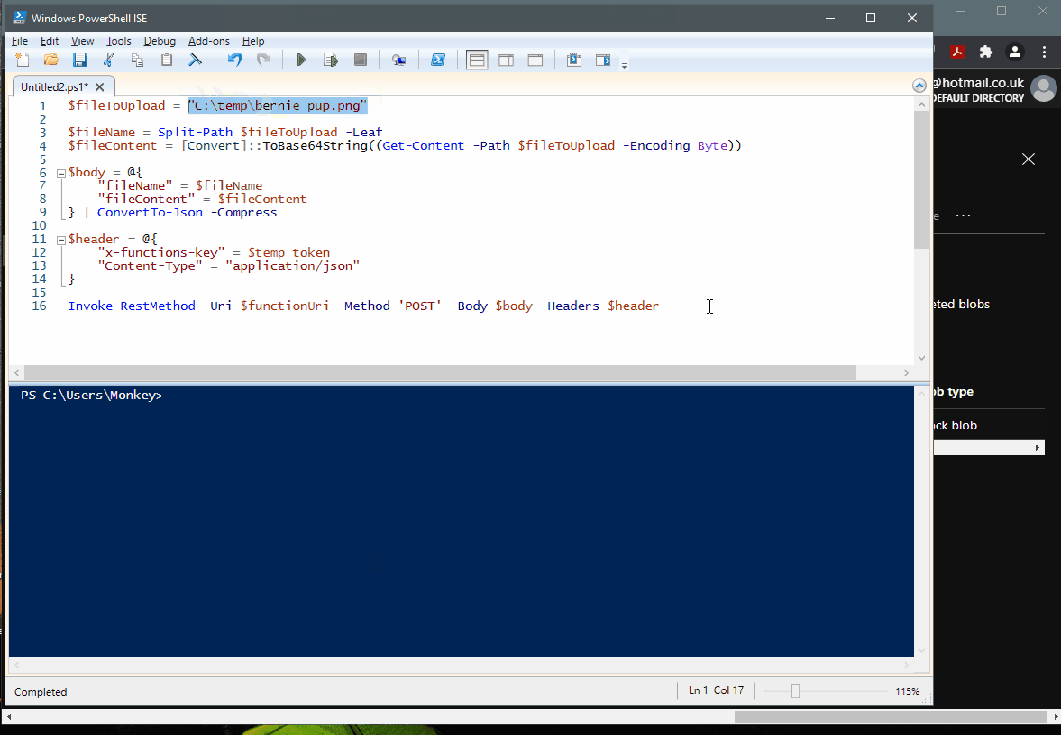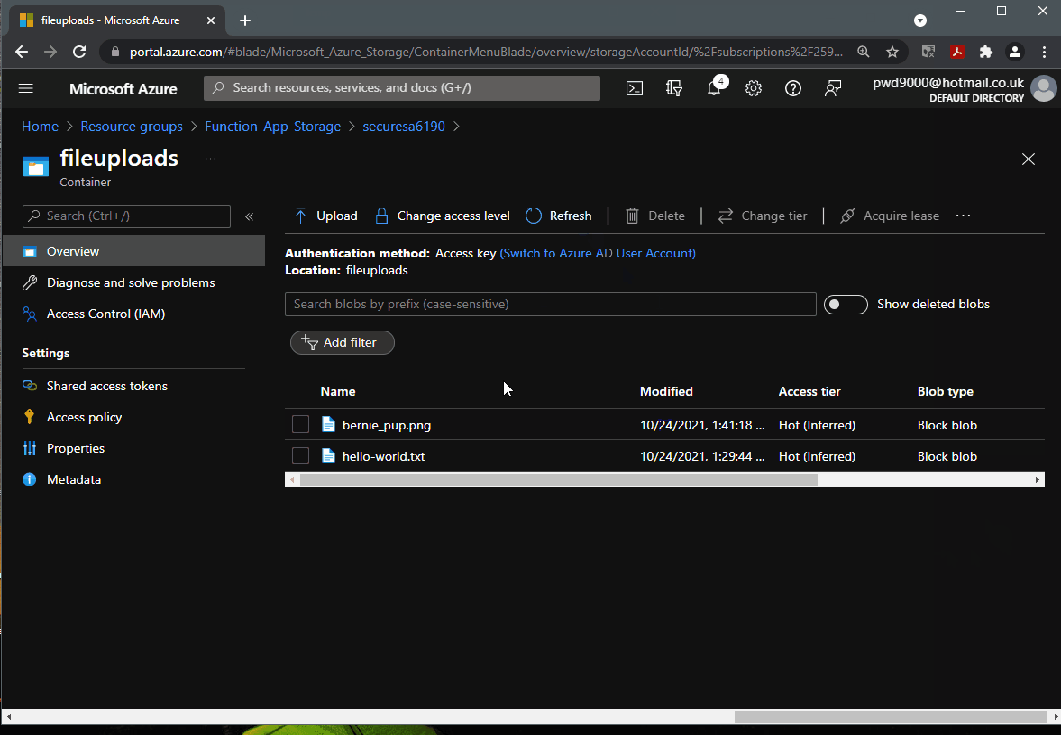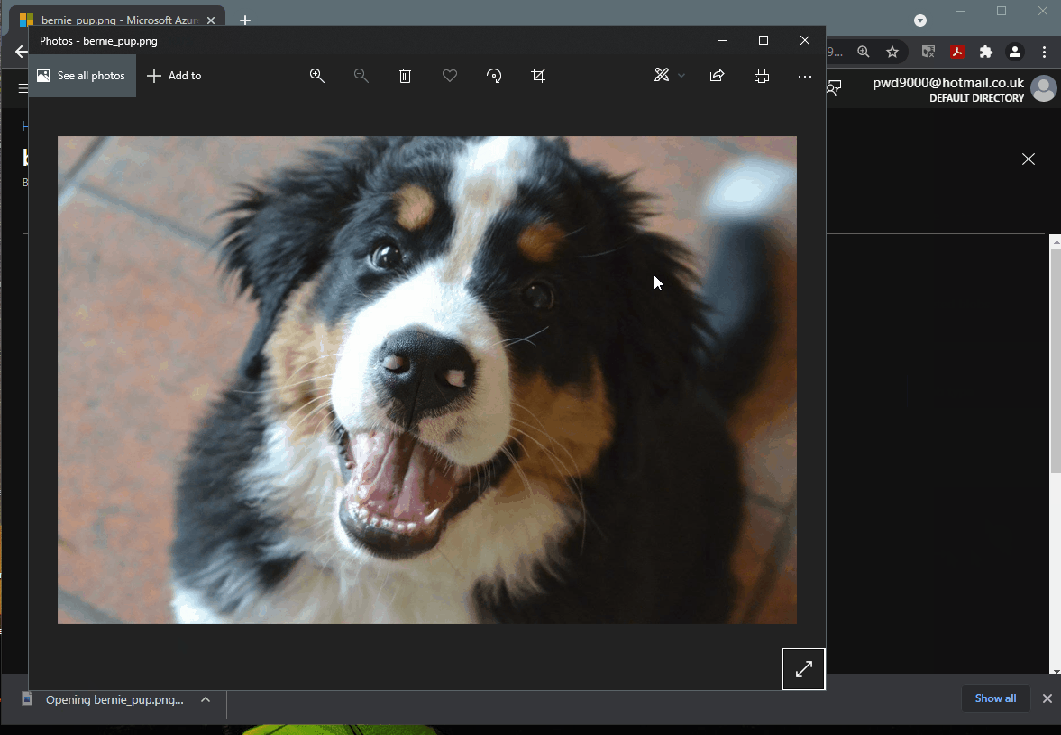
**NOTE:** Ensure to keep your function app tokens safe. (You can delete your `temp_token` after testing).
I hope you have enjoyed this post and have learned something new. You can also find the code samples used in this blog post on my [GitHub](https://github.com/Pwd9000-ML/blog-devto/tree/main/posts/2021/Azure-Upload-File-PoSH-Function-App/code) page. :heart:
### _Author_
Like, share, follow me on: :octopus: [GitHub](https://github.com/Pwd9000-ML) | :penguin: [Twitter](https://twitter.com/pwd9000) | :space_invader: [LinkedIn](https://www.linkedin.com/in/marcel-l-61b0a96b/)
{% user pwd9000 %}
<a href="https://www.buymeacoffee.com/pwd9000"><img src="https://img.buymeacoffee.com/button-api/?text=Buy me a coffee&emoji=&slug=pwd9000&button_colour=FFDD00&font_colour=000000&font_family=Cookie&outline_colour=000000&coffee_colour=ffffff"></a>
| pwd9000 |
874,214 | Quick tip: if Rust stopped formatting your code ... | Sometimes Rust Analyzer stops formatting my VS Code document and there is no message or explanation... | 0 | 2021-10-24T09:06:43 | https://dev.to/rimutaka/quick-tip-if-rust-stopped-formatting-your-code--7i2 | rust | Sometimes Rust Analyzer stops formatting my VS Code document and there is no message or explanation why.
This is just one ugly example - lines 46-53 are all over the place.
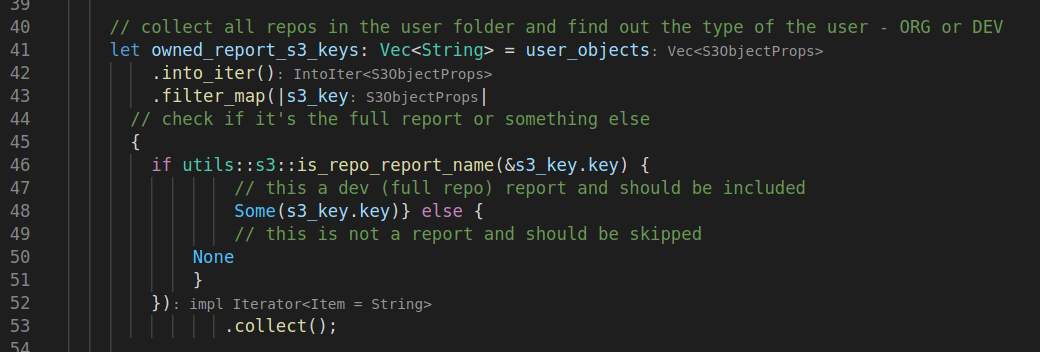
No matter how many times I press `Ctrl`+`Shift`+`I` the IDE would not fix the formatting or tell me what's wrong.
Turns out there is a **simple way to find out why Rust Analyzer fails to format the document:** `cargo fmt`. It will tell you exactly what's broken.
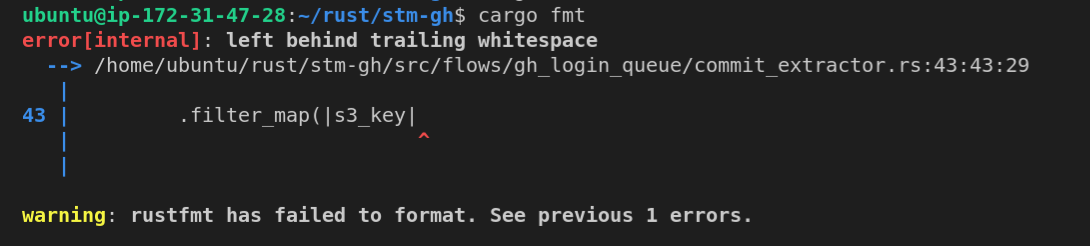
In this case it was a comment on line 44 that got in the way. The document started formatting again as soon as I removed it.
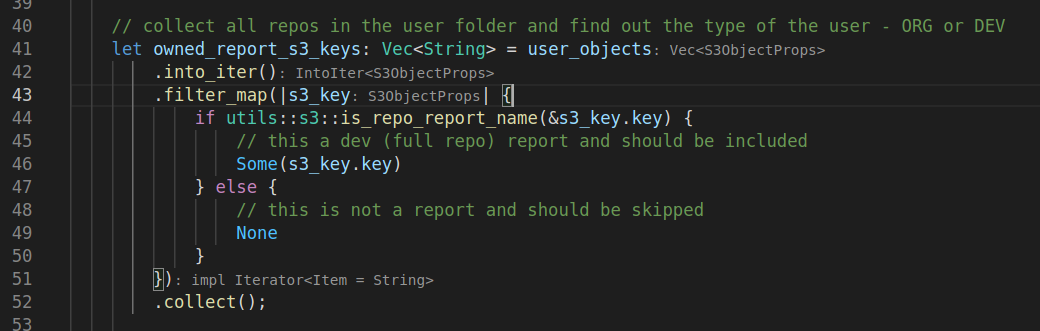
> Beware, `cargo fmt` will attempt to reformat the entire project. Read more about it in https://github.com/rust-lang/rustfmt or run `cargo fmt -- --help` for options.
I went back to several other files that were not formatting properly, ran `cargo fmt` on them and quickly fixed the problems. Happy coding!
| rimutaka |
874,229 | Better Ideas At Test Design | Even with many years in this industry, I get inspired by courses I take. A course - BBST Test Design... | 0 | 2021-10-24T09:42:45 | https://dev.to/maaretp/better-ideas-at-test-design-2c62 | testdesign, exploratorytesting, improvement | Even with many years in this industry, I get inspired by courses I take. A course - BBST Test Design - served as inspiration on sharing on this: Having better ideas at Test Design.
And by Test Design, I mean the continuous collection, creation and prioritization of ideas that would help us produce the results from testing that the world around us expects. The ideas that lead us into doing what we do with software; so that we recognize what we recognize; so that we have the conversations around quality that we need to have.
I know from the 25 years I’ve been at this that testing is far from simple. It’s knowledge work, just like application programming, targeting information that helps us address quality concerns.
With a simple model, we could describe testing as a process of doing testing where the input is someone with brains, and the output is learning to do the work better and the information and artifacts we expect in our organizations. We come as we are, and we learn: the software we are testing and its features; the problems and their relevance; each other and communication and collaboration; and the business that pays our salaries.
In the last months, I’ve taken a course on Test Design. On the course, two exercises have thrown me at Open Office Impress, the presentation software, and choosing a single variable to analyze for test ideas. True to my exploratory tester nature, I could not commit to a variable before completing a whole variable tour to find something I would have fun with, finding information.
I chose transparency of elements. I learned quickly to connect it with a default value it could have; with editing, presenting and printing modes and their options; the different element types it could be applied with; and the many places from where you can edit it.
On the first exercise, we listed risks imagining bug reports we might end up writing on it. I generated the list allowing the application to be my external imagination and it increased the creativity I could bring at the task.
On the second exercise, we were asked to apply risk-based domain testing. Equivalence classes, boundary values and the sort, but with the idea that risk - what we expect might fail - will guide us to equivalence classes. Like entering a single digit can (and does) behave quite differently from something with three digits or decimal numbers.
I found a bunch of inconsistencies, and problems, and the application rewarded my tester efforts with a big visible crash dialog that nicely reproduces at will when combining two digit numbers with undo. Yes, single digit is fine but two digit with undo crash the app. And remind me that we don’t have to create bugs intentionally for learning, the software industry has us covered.

It’s not just courses where I find that I already think in quite many dimensions and details allowing me to discover bugs, but that is the experience and reality from the teams, projects and products I work with too.
With the simple process, I am often called to situations where the output isn’t where it should be. We are missing bugs. We are not documenting with test automation. We are thinking simplistically about coverage, and thus missing even the idea that there are bugs to find on other dimensions.
As a tester, I start with adding of results. But as principal, being great at testing isn’t sufficient. I need to make people around me better at testing. I need to fix the practice, while adding some of the results.

To fix the practice, I have a recipe of my own. I don’t do instructions and processes, and I don’t choose tools and enforce guidelines. I start my work from within, joining a team as a tester. As such, I experience what the team misses, and I try to figure out how to learn together ways of not missing that anymore, even when I am gone.
We work towards making testing everyone’s business. Testing is too important to be left for just testers. Developers, product owners, neighbor teams are all welcome to pitch in.
We make improvements continuously, but each individual improvement can be a small adjustment through feedback. We notice the change looking back six months, but day to day it seems we do the same things.
I work to remove myself, so that I can repeat the work with another team needing insightful ways of taking small steps to better.
Fixing the results start from showing what results we have been missing.

I’ve repeated this growth journey across organizations and teams, and the takeaway I still want to leave you with is on where do you learn to have the versatility of the ideas so that you see the results we have been missing. Those ideas stem from your ability to connect information of the past into the product change work ongoing right now.
I recommend you read bug reports. Not just your own, but your colleagues, your organizations, and if possible, whatever the customers directly report in unfiltered form.
I recommend you read lists of generalized bug reports. taxonomies are available in books by Kaner and Beizer with a lot of relevant information
Learn Test Design. BBST course series is brilliant. I grew up to being a tester with Cem Kaner creating the teaching materials and owe a lot of foundational perspectives to his work now packaged as online learning courses.
Finally, work together with others. When you work in a group - an ensemble - you will learn about things you did not know you don’t know, and thus could not ask. It speeds up our learning significantly.
We all need to go and learn to experience what we miss. Better ideas produce better results in testing.

I’m happy to connect on LinkedIn, and write my notes publicly on Twitter. Looking forward to learning to provide better results in testing with you all.
| maaretp |
874,233 | How to make a Calculator (Working and Animated) | Hello, Readers welcome to my new blog and today I am going to tell you how to Make a Calculator. This... | 0 | 2021-10-26T08:30:15 | https://dev.to/codeflix/how-to-make-a-glassorphism-calculator-dhk | programming, javascript, tutorial, css | Hello, Readers welcome to my new blog and today I am going to tell you how to Make a Calculator. This Calculator has some features that make it different from a normal calculator. Those features are- I have added animation ,Made the calculator transparent.
As you know, calculator is a machine which allows people to do math operations more easily.
For Example - Most calculator will add, substract, multiply, divide these are the basic functions of a calculator. Scientific calculator, Special purpose calculators financial calculators etc.
Some also do square roots, and more complex calculators can help with calculus and draw function graphs.
This Calculator's bubble or box animation make it look even more beautiful and it is also transparent making it more ausome
If you want the real animation of these small boxes and the code behind making this calculator, you can read this whole blog and watch the preview of the calculator using the link given below.
##Tutorial of Calculator using HTML CSS & JavaScript
[ Calculator Preview](https://youtu.be/S44SDUwWHIQ)
And please visit my site it is under construction - [ Currently unavalible]()
Please subscribe my friend's channel- Relaxing sounds and music
[ My second channel Relaxing sounds and music](youtu.be/hfTdpYzzegA)
##Html
The HyperText Markup Language, or HTML is the standard markup language for documents designed to be displayed in a web browser. It can be assisted by technologies such as Cascading Style Sheets (CSS) and scripting languages such as JavaScript.
Web browsers receive HTML documents from a web server or from local storage and render the documents into multimedia web pages. HTML describes the structure of a web page semantically and originally included cues for the appearance of the document.
HTML elements are the building blocks of HTML pages. With HTML constructs, images and other objects such as interactive forms may be embedded into the rendered page. HTML provides a means to create structured documents by denoting structural semantics for text such as headings, paragraphs, lists, links, quotes and other items. HTML elements are delineated by tags, written using angle brackets. Tags such as <img /> and <input /> directly introduce content into the page. Other tags such as <p> surround and provide information about document text and may include other tags as sub-elements. Browsers do not display the HTML tags, but use them to interpret the content of the page.
##Source Code
The Source Code is given below
##STEP 1
Make a file named index.html and write the following code.
```
<!DOCTYPE html>
<html lang="en" dir="ltr">
<head>
<meta charset="UTF-8">
<!--- <title> Glassmorphism Calculator| Codeflix </title>--->
<link rel="stylesheet" href="style.css">
</head>
<body>
```
##STEP 2
This is the animation part (Do it carefully). Each lot contains 7 bubbles.
```
<div class="bubbles">
<span class="one"></span>
<span class="two"></span>
<span class="three"></span>
<span class="four"></span>
<span class="five"></span>
<span class="six"></span>
<span class="seven"></span>
<span class="seven"></span>
</div>
<div class="bubbles">
<span class="one"></span>
<span class="two"></span>
<span class="three"></span>
<span class="four"></span>
<span class="five"></span>
<span class="six"></span>
<span class="seven"></span>
<span class="seven"></span>
</div>
<div class="bubbles">
<span class="one"></span>
<span class="two"></span>
<span class="three"></span>
<span class="four"></span>
<span class="five"></span>
<span class="six"></span>
<span class="seven"></span>
<span class="seven"></span>
</div>
<div class="bubbles">
<span class="one"></span>
<span class="two"></span>
<span class="three"></span>
<span class="four"></span>
<span class="five"></span>
<span class="six"></span>
<span class="seven"></span>
<span class="seven"></span>
</div>
```
##STEP 3
This code will make the container of the calculator.
```
<div class="container">
<form action="#" name="forms">
<input type="text" name="answer">
<div class="buttons">
<input type="button" value="AC" onclick="forms.answer.value = ''">
<input type="button" value="DEL" onclick="forms.answer.value = forms.answer.value.substr(0 , forms.answer.value.length -1)">
<input type="button" value="%" onclick="forms.answer.value += '%'">
<input type="button" value="/" onclick="forms.answer.value += '/'">
</div>
```
##STEP 4
This code represents how buttons should function and their size and all other content.
```
<div class="buttons">
<input type="button" value="7" onclick="forms.answer.value += '7'">
<input type="button" value="8" onclick="forms.answer.value += '8'">
<input type="button" value="9" onclick="forms.answer.value += '9'">
<input type="button" value="*" onclick="forms.answer.value += '*'">
</div>
<div class="buttons">
<input type="button" value="4" onclick="forms.answer.value += '4'">
<input type="button" value="5" onclick="forms.answer.value += '5'">
<input type="button" value="6" onclick="forms.answer.value += '6'">
<input type="button" value="-" onclick="forms.answer.value += '-'">
</div>
<div class="buttons">
<input type="button" value="1" onclick="forms.answer.value += '1'">
<input type="button" value="2" onclick="forms.answer.value += '2'">
<input type="button" value="3" onclick="forms.answer.value += '3'">
<input type="button" value="+" onclick="forms.answer.value += '+'">
</div>
<div class="buttons">
<input type="button" value="0" onclick="forms.answer.value += '0'">
<input type="button" value="00" onclick="forms.answer.value += '00'">
<input type="button" value="." onclick="forms.answer.value += '.'">
<input type="button" value="=" onclick="forms.answer.value = eval(forms.answer.value)">
</div>
</form>
</div>
</body>
</html>
```
##Css
CSS is designed to enable the separation of presentation and content, including layout, colors, and fonts. This separation can improve content accessibility, provide more flexibility and control in the specification of presentation characteristics, enable multiple web pages to share formatting by specifying the relevant CSS in a separate .css file which reduces complexity and repetition in the structural content as well as enabling the .css file to be cached to improve the page load speed between the pages that share the file and its formatting.
Separation of formatting and content also makes it feasible to present the same markup page in different styles for different rendering methods, such as on-screen, in print, by voice (via speech-based browser or screen reader), and on Braille-based tactile devices. CSS also has rules for alternate formatting if the content is accessed on a mobile device.
##Css codes in this project
######Css plays an important role in this project and Css codes are also available below.
##Css codes
Now we will make a file named style.css and write paste the following code.
##STEP 1
This code represents Fonts, Container, Background Colour
```
@import url('https://fonts.googleapis.com/css2?family=Poppins:wght@200;300;400;500;600;700&display=swap');
*{
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: 'Poppins',sans-serif;
}
body{
height: 100vh;
width: 100%;
overflow: hidden;
display: flex;
justify-content: center;
align-items: center;
background: linear-gradient(#2196f3 , #e91e63);
}
```
##STEP 2
This Css code is used to add animation,Colour to the bubbles.
Each lot contains 7 bubbles.
```
.bubbles{
position: absolute;
bottom: -120px;
display: flex;
flex-wrap: wrap;
margin-top: 70px;
width: 100%;
justify-content: space-around;
}
.bubbles span{
height: 60px;
width: 60px;
background: rgba(255, 255, 255, 0.1);
animation: move 10s linear infinite;
position: relative;
overflow: hidden;
}
@keyframes move {
100%{
transform: translateY(-100vh);
}
}
.bubbles span.one{
animation-delay: 2.2s;
transform: scale(2.15)
}
.bubbles span.two{
animation-delay: 3.5s;
transform: scale(1.55)
}
.bubbles span.three{
animation-delay: 0.2s;
transform: scale(0.35)
}
.bubbles span.four{
animation-delay: 6s;
transform: scale(2.15)
}
.bubbles span.five{
animation-delay: 7s;
transform: scale(0.5)
}
.bubbles span.six{
animation-delay: 4s;
transform: scale(2.5)
}
.bubbles span.seven{
animation-delay: 3
transform: scale(1.5)
}
.bubbles span:before{
content: '';
position: absolute;
left: 0;
top: 0;
height: 60px;
width: 40%;
transform: skew(45deg) translateX(150px);
background: rgba(255, 255, 255, 0.15);
animation: mirror 3s linear infinite;
}
@keyframes mirror {
100%{
transform: translateX(-450px);
}
}
.bubbles span.one:before{
animation-delay: 1.5s;
}
.bubbles span.two:before{
animation-delay: 3.5s;
}
.bubbles span.three:before{
animation-delay: 2.5s;
}
.bubbles span.four:before{
animation-delay: 7.5s;
}
.bubbles span.five:before{
animation-delay: 4.5s;
}
.bubbles span.six:before{
animation-delay: 0.5s;
}
.bubbles span.seven:before{
animation-delay: 6s;
}
```
##STEP 3
This code represents container's colour, Text input in the container , Colour Of the buttons.
```.container{
z-index: 12;
width: 360px;
padding: 15px;
border-radius: 12px;
background: rgba(255, 255, 255, 0.1);
box-shadow: 0 20px 50px rgba(0, 0, 0, 0.15);
border-top: 1px solid rgba(255, 255, 255, 0.5);
border-left: 1px solid rgba(255, 255, 255, 0.5);
}
.container input[type="text"]{
width: 100%;
height: 100px;
margin: 0 3px;
outline: none;
border: none;
color: #fff;
font-size: 20px;
text-align: right;
padding-right: 10px;
pointer-events: none;
background: transparent;
}
.container input[type="button"]{
height: 65px;
color: #fff;
width: calc(100% / 4 - 5px);
background: transparent;
border-radius: 12px;
margin-top: 15px;
outline: none;
border: none;
font-size: 20px;
cursor: pointer;
transition: all 0.3s ease;
}
.container input[type="button"]:hover{
background: rgba(255, 255, 255, 0.1);
}```
| codeflix |
874,319 | Agency VS Freelancer - who should you hire? | We regularly receive enquiries from potential clients who need help with their digital system, be... | 0 | 2021-11-12T15:52:54 | https://theuxcto.com/digital-blitz/agency-vs-freelancer-who-should-you-hire/ | agency, freelancer, outsource | ---
title: Agency VS Freelancer - who should you hire?
published: true
date: 2021-10-24 07:47:33 UTC
tags: agency, freelancer, outsource
canonical_url: https://theuxcto.com/digital-blitz/agency-vs-freelancer-who-should-you-hire/
---

We regularly receive enquiries from potential clients who need help with their digital system, be it a website, or a customer portal or an e-commerce platform. Most of the time, they come to us with a statement like "I'm looking for a web designer to help me rebuild my website".
The challenge with this statement is that the world of digital transformation is covering such a wide range of skills and techniques... it's really hard these days to find a single resource to do it all, who has the skills to do everything.
<figcaption>The unicorn designer / developer! Credit https://github.com/nocama</figcaption>
Obviously, for a small brochure website or simple landing page, a freelancer is usually the most cost-effective solution. Some of the most talented web designers can do both the design and the development and coding of the website.
However, for larger corporate projects that need a full revamp end-to-end, you will need a mix of different skills and expertise from UX and design, frontend, backend, QA testing, DevOps as well as a project manager to synchronise everything and make it happen.
In this video, I want to explore the main differences and risks that you should consider when you are hesitating between hiring an individual freelancer versus a digital agency with a bigger team.
Let's get to it.
{% youtube EARJ-im5AvQ %}
## The risks with freelancers
Looking at this "freelancer versus digital agency", I would obviously be a bit biased because I co-run an agency. However, I'm sharing this today because, over the years, I have seen so many clients reaching out to us to take over projects that were going in the wrong direction or turned out to become completely unmanageable. Most of the time, I have to be honest with clients and say: "well, you got what you paid for"! You tried to do it in a cost-effective solution, but it didn't always work.
## Identify what you need
If you are involved in a digital transformation project, you first need to identify the skills that you have in-house, in your existing team. If you already have designers or developers, and you're lacking expertise in a very narrow area, i.e. a specific type of user research or technology like ReactJS, adding a freelancer to your internal team, that you can embed in your process and manage day-to-day, will make sense.
## Agency or Freelancer?
However, no matter whether you're on the marketing side or in the IT Solutions' team, if you need to launch a new product or revamp your website / customer portal, and if your internal resources are already busy, you will need an agency.
The main drawback will usually be cost obviously, as an agency's rates will sometimes be more than double those of an individual freelancer. But I think the following five reasons mean it's really worth it.
### 1. Reliability
The first one is reliability. An agency won't disappear overnight. When you hire a team, they usually have multiple clients that should keep them in business for several years - if they are doing a good job! Whereas a freelancer may get ill or need to take time off, and then you will get stuck without any resources. On the resourcing side, agencies plan several weeks in advance and they always ensure that there is cover in place and a handover for any team member when they go on holiday for example.
### 2. Knowledge sharing
The second point is knowledge sharing. An agency of a certain size, let's say 20 to 30 staff and above, will have multiple experts and team leads who would be involved in reviewing the designs or approving the code pull requests. Those agency teams will organize weekly team meetings to share best practices across their projects... that will benefit your own project as well.
### 3. Specific expertise
The third point is the specific expertise. Most agencies would have individual specialists in multiple areas of digital transformation, from marketing, design, dev QA... From a development perspective, it's almost impossible to find unicorn freelance developers who can master the full stack of frontend, backend and JavaScript. With an agency, you would have access to multiple expert resources throughout the projects, depending on the requirements.
### 4. Security & Compliance
Fourth is security, accessibility, and performance. The best agencies, like ours, will have a well-documented operational process and accreditations. At Cyber-Duck, we are one of the few UK agencies to be triple ISO-certified for human centered design, quality management and information security management. We also have the Cyber Essentials Plus accreditation and are members of various associations around accessibility and privacy compliance. We bake all of that into every project. It's such robust processes and security credentials that will give you the peace of mind... That's something, an individual freelancer cannot claim.
### 5. Account Management
The fifth and last point is account management. Whilst the best freelancers can do the job, communicate well and be proactive, in an agency you will benefit from an account management function. You will have a dedicated project manager, as well as an account manager, acting as strategists and making recommendations, as well as handling any issue that needs to be escalated, without distracting the production team doing the work.
So overall, these are the 5 main benefits of hiring an agency over a freelancer.
If you need support for your next digital transformation project, or if you're struggling to manage a project with your existing team, [just get in touch](https://cyber-duck.co.uk). Don't forget to [subscribe to my YouTube channel](https://www.youtube.com/c/SylvainReiter) and [follow me on Twitter](https://twitter.com/sylvainreiter) to keep learning with me and grow your career in digital.
Until next time, stay safe and see you soon. | sylvainreiter |
874,578 | Type of Recursion | Recursion Calling same function inside function is known as Recursion. Every recurring... | 0 | 2021-10-24T17:58:56 | https://dev.to/yogeshpaliyal/type-of-recursion-5204 | kotlin, beginners, programming, recursion | ## Recursion
Calling same function inside function is known as Recursion.
Every recurring function must have a breaking condition which break recursion.
## Time taken by Recursion
- **O(n)** if there is no loop inside the recursion
## Types of Recursion
### 1. Tail Recursion
- Recurring function is called at end of all the statements.
- There should not be handling of return type.
- Tail Recursion can be converted to loop easily
#### Example:
```kotlin
fun main(){
fun1(5)
}
/* Example with recursion
* Time -> O(n)
* Space -> O(n)
*/
fun fun1(n){
if(n > 0){
print(n)
fun1(n-1) // tail recursion
}
}
/*
* Converted to while loop
* Time -> O(n)
* Space -> O(1)
*/
fun fun1(n){
while(n > 0){
print(n)
n--
}
}
```
### 2. Head Recursion
Recurring function is called at start before any statements, just after the break condition.
#### Example:
```kotlin
fun main() {
fun1(5)
}
fun fun1(n) {
if (n > 0) {
fun1(n - 1) // head recursion
print(n)
}
}
```
### 3. Tree Recursion
More than once the self function is called from inside the function
#### Example:
```kotlin
fun main() {
fun1(5)
}
fun fun1(n) {
if (n > 0) {
fun1(n - 1) // tree recursion
fun1(n - 1) // tree recursion
print(n)
}
}
```
### 4. Indirect Recursion
Recurring via multiple loops, like function A calls B and B calls A
### Example:
```kotlin
fun main(){
funA(5)
}
fun funA(n: Int){
if (n > 0){
funB(n-1)
}
}
fun funB(n: Int){
funA(n)
}
```
### 5. Nested Recursion
Function is calling itself with returning value and that will be used to call self function.
#### Example:
```kotlin
fun main(){
fun1(90)
}
fun fun1(n){
return if(n > 100){
n - 10
}else{
fun1(fun1(n + 11)) // Nested recursion
}
}
```
| yogeshpaliyal |
874,755 | CPU Architecture - What's inside? | Let's talk about CPU's and their inner workings. A CPU, the central processing unit, is the brain of... | 0 | 2021-10-25T00:53:17 | https://dev.to/carlbenjaminlyon/cpu-architecture-whats-inside-514f | design, computerscience | _Let's talk about CPU's and their inner workings._
A CPU, the central processing unit, is the brain of your computer. It is the core hub which performs all operations of your device, and is responsible for performing arithmetic, providing instruction logic, and controlling the input and output operations as specified by that instruction logic. The rules surrounding its design fall into the field of CPU architecture design, in which are described the functionality, organization, and implementation of the internal systems. These definitions extend to instruction set design, microarchitecture design, and logic design.
__Wheels, Levers, and Cogs__
Long prior to the AMD Big Red vs the Intel Big Blue Wars, a notable and early development in exploration of computational units was provided by the work of Charles Babbage. A British mathematician and mechanical engineer, Babbage originated the idea of a digital programming computer, in which the principal ideas of all modern computers can be found in his proposed 'Analytical Engine'. While the 'Analytical Engine' never was fully realized due to arguments over design and withdrawal of government funding, it provided outline of the arithmetic logic unit - a unit capable of control-flow in the form of conditional branching and loops. This design allowed the system to be 'Turing-Complete', meaning that the system was able to recognize and decide upon use of other data-manipulation rule sets, based on the currently processing data.
<figcaption>I wasn't kidding when I said cogs.</figcaption>
__Modern, Defined__
While CPU architecture has drastically changed and improved over the years, it was John von Neumann, Hungarian-American computer scientist and engineer who gave it's first real set of requirements. The following basic requirements are present in all modern-day CPU designs:
1. A processing unit which contains an arithmetic logic unit (ALU) and processing pipeline (instruction feed)
2. Processor registers for quick access to required data (Read-Only Memory and Random Access Memory)
3. A control unit that contains an instruction register and program counter
4. Memory that stores data and instructions
5. A location for external mass storage of data
6. Input and Output mechanisms
<figcaption>John von Neumann and a visual representation of modern CPU design requirements.</figcaption>
This set of basic requirements provides large-scale capability to treat instructions as data. This capability is what makes assemblers, compilers, and other automated programming tools possible - the tool that makes "programs that write programs" possible. These programs provide the system the capability to manipulate and manage data at runtime, which is a principal element of modern programming high-level languages, such as Java, Node.js, Swift, C++ to name a few.
__What does this mean today?__
Today, modern CPU architecture design has fairly straight-forward goals, revolving around performance, power efficiency, and cost.
Although CPU's still follow the same fundamental operations as their predecessors, the additional structure implementations provide more capability in a smaller and faster package. A few notable named structures and concepts that we enjoy today are parallelism, memory management units, CPU cache, voltage regulation, and increased integer range capability. These additional structures provide the ability to run multiple functions at the same time in a way similar to hyperthreading, give faster access to often used data, provide additional memory capacity, and give the CPU extra juice at critical times to perform process-intensive tasks.
While Big Red and Big Blue may fight for the top of the hill, they each contain the same elements which give us the speed and capability which we enjoy today.
_Sources and Additional Reading:_
[Charles Babbage](https://en.wikipedia.org/wiki/Charles_Babbage)
[John von Neumann](https://en.wikipedia.org/wiki/John_von_Neumann)
[von Neumann Architecture](https://en.wikipedia.org/wiki/Von_Neumann_architecture)
[Fundamentals of Processor Design](https://en.wikipedia.org/wiki/Processor_design) | carlbenjaminlyon |
874,954 | CONCEPTS OF C LANGUAGE | Algorithms: “A step by step to solve the given problem is called as algorithm” Properties:... | 0 | 2021-10-25T05:39:03 | https://dev.to/varsha222001/concepts-of-c-language-36pk |
Algorithms:
“A step by step to solve the given problem is called as algorithm”
Properties: 1)finiteness 2)definiteness 3)Input 4)Output 5)effectiveness
Flowchart:
Pictorial representation of an algorithm is called Flow chart.
Different Symbols used in Flowchart are: Oval–>Start or Stop Arrow or
Line --> Flow Direction Parallelogram–>Input or Output Double sided
-->Rectangle Sub program/ function Rectangle Process Circle Connector
Rectangle -->Process Diamond -->Decision5)effectiveness
Flowchart:
Pictorial representation of an algorithm is called Flow chart.
Different Symbols used in Flowchart are: Oval–>Start or Stop Arrow or
Line --> Flow Direction Parallelogram–>Input or Output Double sided
-->Rectangle Sub program/ function Rectangle Process Circle Connector
Rectangle -->Process Diamond -->Decision
Identifiers
–> A C identifier is a name used to identify a variable, function, or any
other user-defined item
Variable
–>A variable is defined as a meaningful name given to the data storage
location in computer memory.
Data Types in C:
1. Primary data types –>Integer Type –>character data type –>Floating
Point Type –>void data type
2)Derived data types
These are also called secondary data types that include array , structures,
union and pointers.
3)User-defined data types
Control Statements
statements which are used to make a choice i.e; statements which has two
or more paths should be followed.
Control statements are categorized by considering following elements:
–>continuation at a different statement –>executing a set of statements
only if some condition is met. –>Executing a set of statements zero or more
times until some condition is met. –>Executing a set of distinct statements
, after which the flow of control usually returns.
Branching statements are (conditional statements or decision making
statements )
–>if –>if … else –>Nested if –>Switch-selection statement
Looping statements are: –>do-while –>for
LOOPS:
Iteration and repetitive execution (for, while, do-while), nested loops.
1. for
2. while
3. do-while
for loop diagram
while loop diagram
do-while loop diagram
ARRAY:
An array is a fixed size sequenced collection of elements of the same data
type.
Arrays are declared using the following syntax:
Syntax: <array_name>[size of array];
—>Data Type: What kind of values array can store (Example: int , float,
char). –>array_name: To identify the array. –>Size of array(INDEX): The
maximum number of values that the array
STRINGS:
In C programming, array of characters is called a string. A string is
terminated by a null character /0.
For example: “c string tutorial” Here, “c string tutorial” is a string. When,
compiler encounter strings, it appends a null character /0 at the end of
string
Declaration of strings
Before we actually work with strings, we need to declare them first. Strings
are declared in a similar manner as arrays. Only difference is that, strings
are of chartype.
Initialization of strings
In C, string can be initialized in a number of different ways. For
convenience and ease, both initialization and declaration are done in the
same step.
Using arrays char c[] = “abcd”;
FUNCTIONS:
A function is a group of statements that together perform a task. Every C
program has at least one function, which is main ().
USES OF C FUNCTIONS:
–>C functions are used to avoid rewriting same logic/code again and again
in a program. –> There is no limit in calling C functions to make use of
same functionality wherever required.
RECURSION:
A function that calls itself is known as a recursive function. And, this
technique is known as recursion
HOW TO CALL C FUNCTIONS IN A PROGRAM?
There are two ways that a C function can be called from a program. They
are,
1. Call by value
2. Call by reference
Storage classes
Storage class specifiers in C language tells the compiler where to store a
variable, how to store the variable, what is the initial value of the variable
and life time of the variable. Syntax: storage_specifier data_type variable
_name;
TYPES OF STORAGE CLASS SPECIFIERS IN C:
There are 4 storage class specifiers available in C language. They are,
1. auto
2. extern
3. static
4. register
STORAGE SPECIFIER
Auto
Extern
Static
Register
DESCRIPTION
Storage place: CPU Memory Initial/default value: Garbage value Scope:
local Life: Within the function only.
Storage place: CPU memory Initial/default value: Zero Scope: Global Life:
Till the end of the main program. Variable definition might be anywhere
in the C program
Storage place: CPU memory Initial/default value: Zero Scope: local Life:
Retains the value of the variable between different function calls
Storage place: Register memory Initial/default value: Garbage value
Scope: local Life: Within the function only.
POINTERS:
Pointers are one of the derived types in C. One of the powerful tool and easy
to use once they are mastered. Some of the advantages of pointers are listed
below:
1. A pointer enables us to access a variable that is defined outside the
function.
2. Pointers are more efficient in handling the data tables.
3. Pointers reduce the length and complexity of a program
There are three concepts associated with the pointers are,
1. Pointer Constants
2. Pointer Values
3. Pointer Variables
Pointer to pointer:
Pointer is a variable that contains the address of the another variable.
Similarly another pointer variable can store the address of this pointer
variable, So we can say, this is a pointer to pointer variable.
STRUCTURES:
–>Declaring structures and structure variables, accessing members of a
structure, arrays of structures, arrays within a structure.
Structure Declaration and Definition
A structure is declared using the keyword struct . Like all data types,
structures must be declared before using it. C has two ways to declare a
structure.
1. Tagged structure declaration.
2. Typedef structure declaration.
syntax and example of structure
UNION:
A union is a user defined data type similar to structure. It is a collection of
variables of different data types. The only difference between a structure
and a union is that in case of unions, memory is allocated only to the
biggest union member and all other members should share the same
memory. In case of a structure, memory is allocated to all the structure
members individually. Thus unions are used to save memory. They are
useful for applications that involve multiple members, where values need
not be assigned to all the members at any one time | varsha222001 | |
874,971 | Java Thread Programming (Part 3) | This article was first published in Foojay.io Continuing from part 2, let’s start this article with... | 0 | 2021-11-25T01:12:56 | http://bazlur.com/2021/10/java-thread-programming-part-3/ | ---
title: Java Thread Programming (Part 3)
published: true
date: 2021-10-21 10:42:00 UTC
tags:
canonical_url: http://bazlur.com/2021/10/java-thread-programming-part-3/
---
This article was first published in [Foojay.io](https://foojay.io/today/java-thread-programming-part-3/)
Continuing [from part 2](https://bazlur.com/2021/10/java-thread-programming-part-2/), let’s start this article with a bit of context first (_and if you don’t like reading text, you can skip this introduction, and go directly to the section below where I discuss pieces of code_).
## Context
- When we start an application program, the operating system creates a process.
- Each process has a unique id (we call it PID) and a memory boundary.
- A process allocates its required memory from the main memory, and it manipulates data within a boundary.
- No other process can access the allocated memory that is already acquired by a process.
- It works like a sandbox, and in that way avoids processes stepping on one another’s foot.
- Ideally, we can have many small processes to run multiple things simultaneously on our computers and let the operating systems scheduler schedule them as it sees fit.
- In fact, this is how it was done before the development of threads. However, when we want to do large pieces of work, breaking them into smaller pieces, we need to accumulate them once they are finished.
- And not all tiny pieces can be independent, some of them must rely on each other, and thus we need to share information amongst them.
- To do that, we use inter-process communication. The problem with this idea is that having too many processes on a computer and then communicating with each other isn’t cheap. And precisely that is where the notion of threads comes into the picture.
The idea of the thread is that a process can have many tiny processes within itself. These small processes can share the memory space that a process acquires. These little processes are called a thread. So the bottom line is, threads are independent execution environments in the CPU and share the same memory space. That allows them faster memory access and better performance.
That seems to be a good idea. However, it comes with many problems alongside its benefits. Let’s discuss some of those problems and how we can deal with them. But don’t get discouraged, the benefits still outweigh the problems!
## Code
Let’s begin by running a piece of code.
```
package com.bazlur.threads;
public class FoojayPlayground {
private static boolean running = false;
public static void main(String[] args) {
var t1 = new Thread(() -> {
while (!running) {
}
System.out.println("Foojay.io");
});
var t2 = new Thread(() -> {
running = true;
System.out.println("I love ");
});
t1.start();
t2.start();
}
}
```
The above piece of code is reasonably straightforward. We have created two threads. Both of them share a variable named “running”. There is a while loop inside the first thread. The loop will keep running while the variable is false, which means this thread will continue to execute the loop unless the variable is changed. Once the loop breaks, it prints “Foojay.io.” The second thread changes the variable and then prints “I love.”
Now the question gets to be, what would be the output?
Outwardly it seems the output would be following:
```
I love
Foojay.io
```
Well, that’s only one case because if you run the above code several times, you will see different results. There would be three outcomes of the program, varying on different computers. The reason is, we can only ask the thread to execute a piece of code, but **we cannot guarantee the execution order of multiple threads**. Threads are scheduled by the operating system’s thread scheduler. We will discuss the thread’s lifecycle in forthcoming articles.
**Case 1.** The first thread will continue running the loop. In contrast, the second thread will change the variable and immediately print “I love”. Since the variable now changed, the loop breaks, and it prints “Foojay.io”, so that the output is:
```
I love
Foojay.io
```
**Case 2.** The second thread will run first and change the variable and then immediately in the first thread, the loop will break and print the “Foojay.io”. And the second thread will print “I love”. Thus the output is:
```
Foojay.io
I love
```
**Case 3.** The above two cases seem reasonable. **However, there is a third case that we may not anticipate immediately:** the first thread may be stuck and the second thread will print “I love” and that’s all. No more output. This can be difficult to reproduce, but it can happen.
Let me explain the third case!
We know the modern computer has multiple CPUs in it. Nonetheless, we cannot guarantee in which core the thread will eventually run. For example, the above two threads can run in two different CPUs, which most likely the case.
When a CPU executes a code, it reads data from the main memory. However, modern CPUs have various caches for faster access to memory. There are three types of cache associated with each CPU. They are L1 Cache, L2 Cache, and L3 Cache.

When starting the first thread, the CPU it runs may cache the running variable and keeps it running. But, on the other hand, when the second thread runs and changes the variable on a different CPU, it won’t be visible to the first thread. Thus the problem of the third case would occur.
We cannot tell whether this would be the case because it all depends on the operating system and having multiple CPUs in a computer. Despite this, we can prevent the CPU from caching, by using “volatile” in the variable. This will instruct the CPU not to cache the variable and, instead, it will read it from the main memory:
```
public class FoojayPlayground {
private static volatile boolean running = false;
...
...
}
```
Now, if we run the above program, the third case will not happen.
The above problem is called the visibility problem. There are a few similar problems that deal with the visibility issue.
We will discuss them in the following articles!
That’s it for today!
Don’t Forget to Share This Post! | bazlur_rahman | |
874,996 | How to Make Decisions In Design Meetings [think in squares & not circles] | This article by Brooke Jamieson originally appeared on LinkedIn. UX discussions in boardrooms are... | 0 | 2021-10-25T07:16:43 | https://dev.to/brooke_jamieson/how-to-make-decisions-in-design-meetings-think-in-squares-not-circles-2dng | This article by Brooke Jamieson originally [appeared on LinkedIn](https://www.linkedin.com/in/brookejamieson).
UX discussions in boardrooms are really polarising. They're really exciting when the meeting goes well and has great momentum, but they can also be incredibly frustrating if the group ends up going in circles or spinning their wheels on the same spot.
This really came into play when I started doing more and more UX research, design and consulting and I realised I needed a strong method to break down UX conversations in executive workshops and meetings so that the conversation keeps constructive momentum towards outcomes, rather than going in circles.
UX is a relatively new field of work and research (especially compared to mathematics), so there aren't always existing problem solving strategies for every situation. In this case, I didn't know the framework that was traditionally used, but I did know how diverse groups of stakeholders approach decision making, especially when data is involved, so I designed my own framework based around solving some problems that kept cropping up.
And so the Axis Model was born!
The model acknowledges the four major elements of design strategy and conversations, and splits these into two groups to make feedback, product management and project management more intuitive. There’s often a lot of talking points that different stakeholders want to cover, or distinct elements of an existing product to audit, but this method to divide and conquer has proven to be a positive force in shaping conversations.
When a new feature is suggested, the first thing to decide is whether this fits in to ‘Function’ or ‘Form’. Things like the overall user flow, accessibility of the end product, performance & stability, technical integrations and what the product actually “does” all fall under function. Decisions like UI design, colours, page layouts and icons fall under form.
‘Form’ decisions - how something looks - always seem to monopolise time in early discussions, because they’re easy surface level decisions, that people often feel an emotional attachment to. They’re important, but ‘Form’ is nothing without ‘Function’.
Even though people seem to prefer talking about Form over Function, thinking in this direction always leads to chaos. It will lead to wasted time in the decision-making process but in the design process too, as visual design can’t be locked in without clear feature requirements, so redesign after redesign will lead to a colossal waste of time.
**It absolutely doesn’t matter if something looks nice, if it doesn’t work in the first place. Decide what something should do (Function) before deciding what it should look like (Form).**
The other axis splits elements into ‘Remove Negative’ and ‘Add Value’. Remove Negative is all about the features of your product that are useful simply because they take something away. Things like information double handling or trying to work from multiple paper-based sources of information - anything that’s a time drain/annoyance for end users. I see this section as “things that give time back to people” and it’s often quite overlooked, as these aren’t the shiniest or most extravagant features of the end goal, but this section is full of features or elements that just take away a negative experience that currently exists.
The ‘Add Value’ section refers to all the sizzle features that will end up getting the project nominated for an award. This category is where stakeholders can get excited, but it’s also where they’ll get really sidetracked. Focusing on the basic building blocks in the ‘Remove Negative’ sector gives you a really solid foundation to build on when adding value in the future, and it will often help these shiny features to scale more effectively too.
Next time you’re in a scoping or planning meeting or workshop, note how the time is divided up between the four categories. If it’s an early stage meeting, the ‘Form’ and ‘Add Value’ sections might try to dominate the conversation, but if you’re mindful and strategic, you’ll be able to direct attention towards ‘Function’ and ‘Remove Negative’. This shift to thinking in squares will avoid the session going in circles, and will steer the group towards decision making and great foundations to build upon.

About the Author: Brooke Jamieson is the Head of Enablement - AI/ML and Data at Blackbook.ai, an Australian consulting firm specialising in AI, Automation, DataOps and Digital. Learn more about Blackbook.ai [here](https://blackbook.ai/) and learn more about Brooke [here](https://www.linkedin.com/in/brookejamieson/).
| brooke_jamieson | |
887,085 | Quick info for JavaScript and TypeScript Code Snippets while you browse! | When a website includes a code snippet, Kmdr kicks in to help you understand the code. Version 5.0 of... | 0 | 2021-11-03T19:14:43 | https://dev.to/_ianeta/quick-info-for-javascript-and-typescript-code-snippets-while-you-browse-4m6f | *When a website includes a code snippet, Kmdr kicks in to help you understand the code. Version 5.0 of Kmdr's browser extension includes quick info for JavaScript, CSS, HTML, Bash, TypeScript, SCSS, and LESS via mouse over.*

There's a lot we're excited to share in the latest release of the Kmdr browser extension! A long time coming, version 5.0 brings support for JavaScript, TypeScript, LESS, and SCSS as well as extended coverage for CLI commands and HTML. Beyond quick info, with the new release comes a new technical base that brings cross-snippet referencing and exciting potential for future user customizations. Read on for details on what's changed and being introduced in Kmdr 5.0.
##Quick info for JavaScript and TypeScript
Prior releases of Kmdr detected JavaScript code snippets and gave users consistent syntax highlighting. Now, users can mouse over key words in JavaScript and TypeScript code snippets and get rich metadata about JS standard built-in objects, including their methods, parameters and properties. Any annotations included in snippets using **JSDoc are referenced in quick info** so that users can quickly see declarations just as they would in Visual Studio Code. **Cross-snippet referencing** is also enabled this release so that any declarations made in code snippets early on in a webpage are referenced in quick info for snippets later down the page.
##Better support for HTML and CSS
We've **improved syntax highlighting** and verbosity for HTML and CSS so that it's at parity with VS Code. We've added quick info for HTML elements so they're as interact-able as HTML attributes in previous releases. Now, when you mouse over an HTML element, you'll see a definition for the element and a **link to trusted documentation** where you can learn more on how to use it in your code.
##Coverage for LESS, and SCSS
Code snippets that are documented as LESS or SCSS now have syntax highlighting, trusted documentation links, and quick info on mouse over! We will continue to expand on web technology coverage with more JavaScript frameworks and libraries throughout the month of November.
Today's release is a pivot from save and share features as we focused on building out the programming assistant for web developers. Kmdr's quick info in this and the upcoming releases will help web developers review and quickly understand code examples on the web and find the best solutions on their own and with fewer tabs open.
The Kmdr extension will automatically update for current users. New users can head [here](https://chrome.google.com/webstore/detail/kmdr/lbigelojleemicaaaogihjnabfndkdii) to install today on Chrome. When a website includes a code snippet, Kmdr kicks in to help you understand the code. | _ianeta | |
875,217 | Avoid Duplication! GitHub Actions Reusable Workflows | Thanks to the new GitHub Actions feature called "Reusable Workflows" you can now reference an... | 0 | 2021-10-25T23:42:59 | https://dev.to/n3wt0n/avoid-duplication-github-actions-reusable-workflows-3ae8 | github, actions, devops, cicd | Thanks to the new GitHub Actions feature called "___Reusable Workflows___" you can now reference an existing workflow with a single line of configuration rather than copying and pasting from one workflow to another.
Basically __GitHub Actions Templates on steroids__!
### What Are Reusable Workflows
So, Reusable Workflows in GitHub Actions. Thanks to this feature you can now reference an entire Actions workflow in another workflow, like if it were a single action.
This new feature builds on top of the Composite Actions introduced a while back. If you don't know what Composite Actions are, check [this post](https://dev.to/n3wt0n/github-composite-actions-nest-actions-within-actions-3e5l) or [this video](https://youtu.be/4lH_7b5lmjo), but in short they are __one or more steps packaged together__ which can be then referenced in an Actions workflows by a single line.
Reusable Workflows extend this concept, allowing you to __reference an entire workflow in another one__. If Composite Actions can be thought of as Templates, Reusable Workflows is on another new level.
Right, let's see how to create a reusable workflow.
### Video
As usual, if you are a __visual learner__, or simply prefer to watch and listen instead of reading, here you have __the video with the whole explanation and demo__, which to be fair is much ___more complete___ than this post.
{% youtube lRypYtmbKMs %}
[Link to the video: https://youtu.be/lRypYtmbKMs](https://youtu.be/lRypYtmbKMs)
If you rather prefer reading, well... let's just continue :)
### Create a Reusable Workflow
Reusable workflows are _normal_ Actions YAML files, and as such they have to reside in the `.github/workflows` folder in the root of a repo.
The only particular thing they have to have is a _special trigger_:
```yaml
on:
workflow_call:
```
The workflow file can also have different triggers, but to make it reusable one of those must be the `workflow_call`.
You can also __pass data__ to a reusable workflow, via the trigger __parameters__ which can be of 2 types:
- inputs
- secrets
The __inputs__ are used to pass _normal_ data (aka not sensitive information):
```yaml
inputs:
image_name:
required: true
type: string
tag:
type: string
```
In the example above, where I want to use a reusable workflow as template to build and push a Docker Image to a registry, we can see that we have 2 inputs of type `string`, with one required and one not required.
> Note: if a required input has not been passed to the reusable workflow, it will fail
Other available types are `boolean` and `number`.
The __secrets__, instead, as the name says, are used to pass secret values to the workflow:
```yaml
secrets:
registry_username:
required: true
registry_password:
required: true
```
In this case you can see that there is no `type`, every secret is treated as string.
Finally, you can use those parameters in your workflow by using `{{inputs.NAME_OF_THE_INPUT}}` and `{{secrets.NAME_OF_THE_SECRET}}`.
So, in the abovementioned example where I want to use a reusable workflow to build and push a Docker image to a registry, the reusable workflow will look something like this:
```yaml
name: Create and Publish Docker Image
on:
workflow_call:
inputs:
image_name:
required: true
type: string
tag:
type: string
secrets:
registry_username:
required: true
registry_password:
required: true
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Setup BuildX
uses: docker/setup-buildx-action@v1
- name: Login to the Registry
uses: docker/login-action@v1
with:
username: ${{secrets.registry_username}}
password: ${{secrets.registry_password}}
- name: Set the tag
run: |
if [ -z "${{inputs.tag}}" ]
then
echo "final_tag=latest" >> $GITHUB_ENV
else
echo "final_tag=${{inputs.tag}}" >> $GITHUB_ENV
fi
- name: Build and Push the Image
uses: docker/build-push-action@v2
with:
context: .
push: true
tags: ${{secrets.registry_username}}/${{inputs.image_name}}:${{env.final_tag}}
do-something-else:
runs-on: ubuntu-latest
steps:
- run: echo "Hello"
```
Also note that __reusable workflows can have multiple jobs__, as you can see in the example (where the `do-something-else` does nothing, but it is to show it off)
Easy right? One thing to keep in mind is that if the reusable workflow has other triggers apart from the `workflow_call` you may want to make sure it doesn't accidentally run multiple times.
Now that we have our reusable workflow, let's see how to use it in another workflow. And stay with me until the end because I will talk about the __limitations__ of reusable workflows and when they can be useful.
### Using a Reusable Workflow
Now that we have our reusable workflow ready, it is time to use it in another workflow.
To do so, just __add it directly in a job__ of your workflow with this syntax:
```yaml
job_name:
uses: USER_OR_ORG_NAME/REPO_NAME/.github/workflows/REUSABLE_WORKFLOW_FILE.yml@TAG_OR_BRANCH
```
Let's analyse this:
1. You create a job with no steps
2. You don't add a `runs-on` clause, because it is contained in the reusable workflow
3. You reference it as `uses` passing:
- the name of the user or organization that owns the repo where the reusable workflow is stored
- the repo name
- the base folder
- the name of the reusable workflow yaml file
- and the tag or the branch where the file is store (if you haven't created a tag/version for it)
In my real example above, this is how I'd reference it in a job called _docker_:
```yaml
docker:
uses: n3wt0n/ReusableWorkflow/.github/workflows/buildAndPublishDockerImage.yml@main
```
Now of course we have to pass the parameters. Let's start with the __inputs__:
```yaml
with:
image_name: my-awesome-app
tag: $GITHUB_RUN_NUMBER
```
As you can see, we just use the `with` clause, and we specify the name of the inputs.
> Needless to say, the names have to be the same as the ones in the reusable workflow definition.
For the secrets, instead, we use a new `secrets` section:
```yaml
secrets:
registry_username: ${{secrets.REGISTRY_USERNAME}}
registry_password: ${{secrets.REGISTRY_PASSWORD}}
```
And this is it. So the complete example would look like this (you can find it [here](https://github.com/n3wt0n/ActionsTest/blob/main/.github/workflows/reusableWorkflowsUser.yml)):
```yaml
# This is a basic workflow to showcase the use of Reusable Workflows
name: Reusable Workflow user
on:
workflow_dispatch:
jobs:
do-it:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Run a one-line script
run: echo Hello, world!
docker:
uses: n3wt0n/ReusableWorkflow/.github/workflows/buildAndPublishDockerImage.yml@main
with:
image_name: my-awesome-app
tag: $GITHUB_RUN_NUMBER
secrets:
registry_username: ${{secrets.REGISTRY_USERNAME}}
registry_password: ${{secrets.REGISTRY_PASSWORD}}
```
Once again, as you can see the caller workflow can have multiple jobs as well.
If we run the workflow, this is what we get:
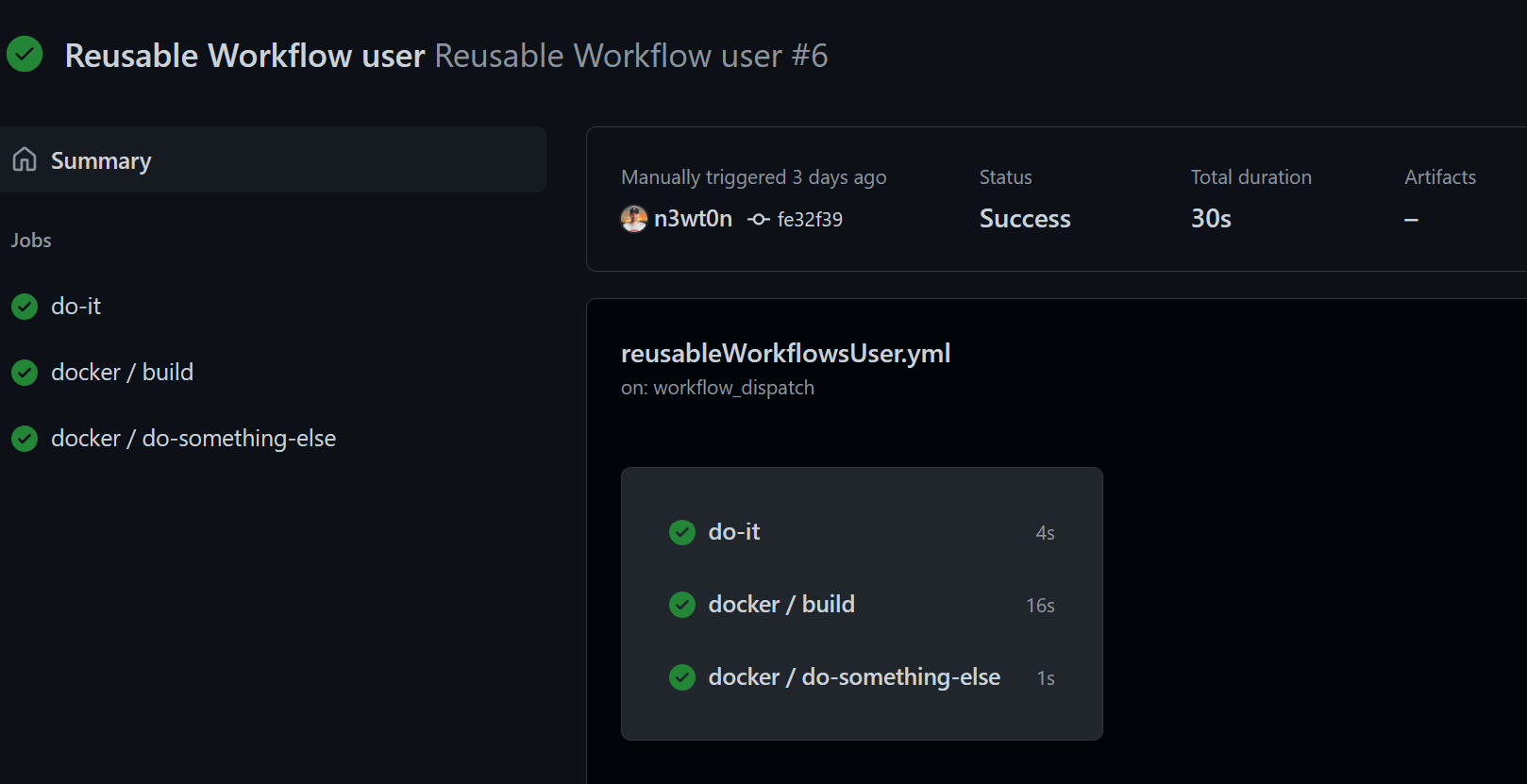
You can see in the image that we have the logs for the `do-it` job that is present in the caller, and then for both the jobs in the reusable workflow.
Since those 2 jobs _are run_ within the `docker` job in the caller workflow, they are referenced in the log as `docker / build` and `docker /do-something-else`.
But apart from that, the logs are complete:
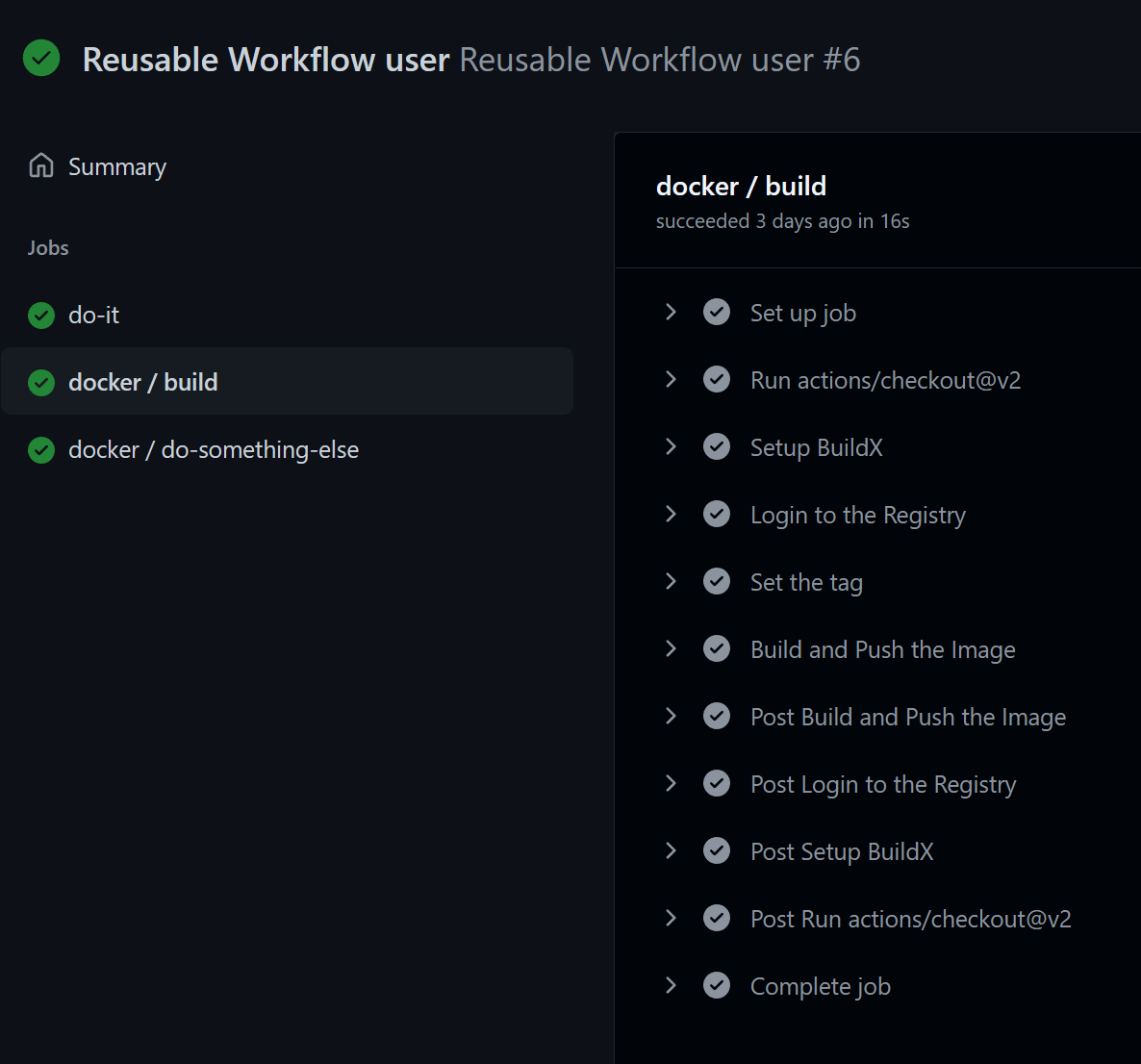
We get __the full details__ of everything that has happened.
### Limitations and Caveats
So, let's start with a few __notes__. First, remember that the Reusable Workflows are currently in __beta__, so things might change by the time they go GA.
Second, for a workflow to be able to use it, a reusable workflow must be stored in the same repo as the call, or in a public repo, or yet in an internal repo with settings that allow it to be accessed.
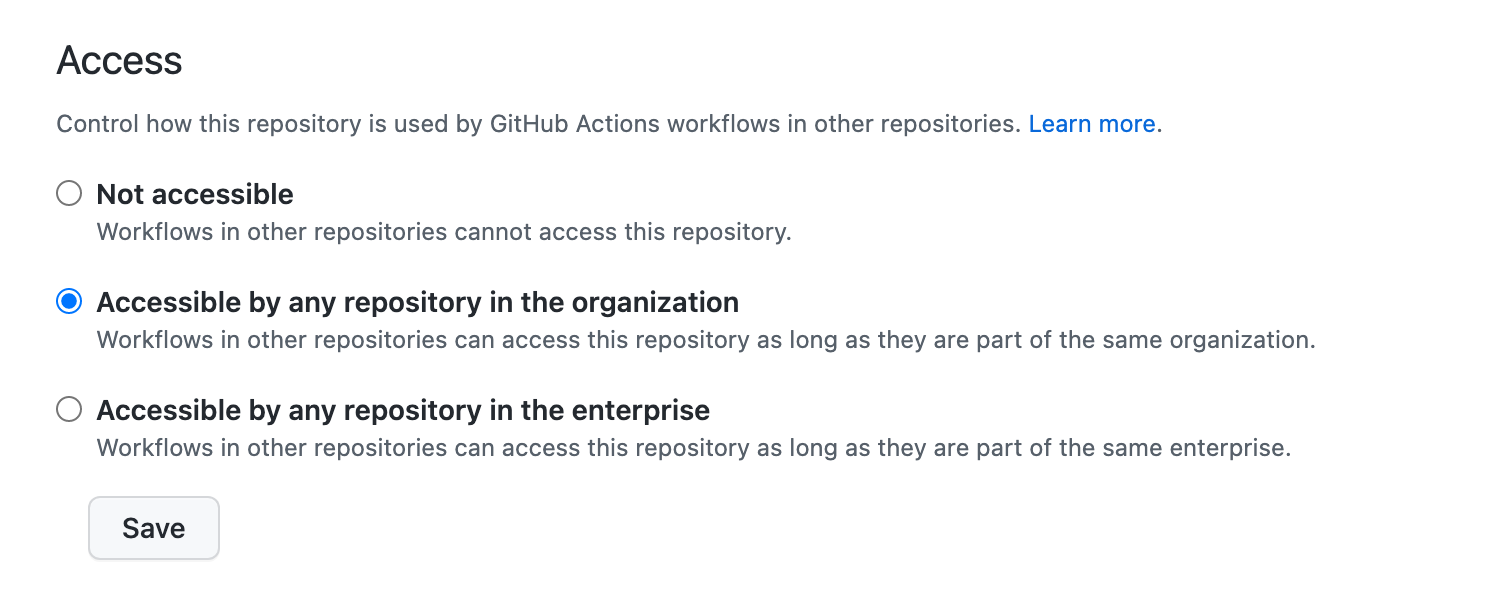
Let's talk now about __limitations__. As direct result of what we have just said, reusable workflows stored in a private repository can be used only by other workflows in the same repo.
Also, Reusable workflows __cannot call and consume other Reusable workflows__.
Finally, and this is big one you need to remember, environment variables set at workflow level in the caller workflow are __not passed to the reusable workflow__. So if you need use any of those variables in the reusable workflow, you'll have to pass them to the workflow via the parameters as I've shown above.
### Conclusions
__Reusing workflows avoids duplication__. This makes workflows easier to maintain and allows you to create new workflows more quickly by building on the work of others, just as you do with actions.
Workflow reuse also promotes __best practices__ by helping you to use workflows that are well designed, have already been tested, and have been proved to be effective. Your organization can build up a library of reusable workflows that can be __centrally maintained__.
Let me know in the comment section below what you think about these new reusable workflows, if and how you plan to use them, and if there is any feature that you think is missing.
You may also want to watch [this video](https://youtu.be/4lH_7b5lmjo) where I talk about the Composite Actions as templates.
__Like, share and follow me__ 🚀 for more content:
📽 [YouTube](https://www.youtube.com/CoderDave)
☕ [Buy me a coffee](https://buymeacoffee.com/CoderDave)
💖 [Patreon](https://patreon.com/CoderDave)
📧 [Newsletter](https://coderdave.io/newsletter)
🌐 [CoderDave.io Website](https://coderdave.io)
👕 [Merch](https://geni.us/cdmerch)
👦🏻 [Facebook page](https://www.facebook.com/CoderDaveYT)
🐱💻 [GitHub](https://github.com/n3wt0n)
👲🏻 [Twitter](https://www.twitter.com/davide.benvegnu)
👴🏻 [LinkedIn](https://www.linkedin.com/in/davidebenvegnu/)
🔉 [Podcast](https://geni.us/cdpodcast)
<a href="https://www.buymeacoffee.com/CoderDave" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 30px !important; width: 108px !important;" ></a>
{% youtube lRypYtmbKMs %} | n3wt0n |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.