
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
875,261 | How To Build A Successful Cybersecurity Program For Your Business? | According to the Verizon Data Breach Investigation report, there were more than 53000 cybersecurity... | 0 | 2021-10-25T12:14:33 | https://dev.to/michael56812375/how-to-build-a-successful-cybersecurity-program-for-your-business-1dn4 | According to the Verizon Data Breach Investigation report, there were more than 53000 cybersecurity incidents and 2200 data breaches. This trend is not going to subside and will continue. This clearly indicates that cybersecurity attacks will increase in number and grow in complexity.
If you are a small business thinking that these cyber-attacks only target large-scale enterprises, then you are wrong. We have seen instances where cybercriminals have attacked small businesses as well. Small businesses are more vulnerable as they serve as a soft target for attackers due to a lack of resources and cybersecurity policies.
Whether you have a small business or a large one, having a robust cybersecurity program at your disposal helps protect against modern-day cybersecurity threats. How can I create a cybersecurity program for my business? Is that what you are thinking? If yes, then you are at the right place.
In this article, you will learn about a step-by-step process of creating a cybersecurity program for your business.
Lay The Foundation
The first step of creating a winning cybersecurity program is to lay the groundwork. Establish the foundation of your cybersecurity program, which you can use to expand upon later on. Thankfully, you don’t have to create everything from scratch as there are many frameworks you can use for this purpose. You can either opt for the NIST framework or choose COBIT5.
As soon as you start working with the framework, you will realize that many functions, categories and subcategories are not relevant to your business. Now, you will have to align your operational needs with the framework. Use standards of good practice for information security laid out by Information Security Forum and identify which operational services align with cybersecurity definitions of a particular framework.
Perform Audit of Assets And Policies
After you have laid a solid foundation, it is time to perform a detailed audit of your current assets and cybersecurity policies. Ask yourself questions like, “Which IT assets are critical for your business and need more protection?” Take some time to develop a better understanding of how and where your sensitive data is stored and how it is being accessed.
Instead of solely focusing on your hardware such as devices and [Los Angeles dedicated servers](https://hostnoc.com/los-angeles-dedicated-servers/), you should also consider software running on your IT assets as you might need to keep the software and patch updated. Next, critically analyze your current cybersecurity policies. If you identify some loopholes and outdated stuff that needs to be updated, you should go ahead and do it as soon as possible.
This analysis should include everything from access rights of employees to authentication systems to password policies. The stringent your cybersecurity policies might be, the harder it is for cybercriminals to break into your network and wreak havoc on your critical business infrastructure.
Control Access To Your Data
Once you have a clear understanding of your data and where it resides, it is time to manage access to that data in an efficient and secure manner. The easiest way to do that is to adopt the least privilege method. Offer employees access to only that information that they need to perform their tasks. For instance, the sales team should not have access to your HR data or your marketing should not have access to your financial transactions.
You cannot afford to give access to all your data to all your employees. That is where controlling access to data comes into play. Assign role-based access and monitor access constantly to prevent any hiccup. Force employees who have resigned to hand over their login credentials to you before leaving your organization. Most businesses tend to ignore this and end up paying a hefty price for it. Restrict removable storage usage and constantly monitor employee activities online to protect your sensitive data.
Build an IT Security Team
Creating a cybersecurity program is useless if you don’t have the right team to implement it. Hire IT professionals and industry experts and form a dedicated team that will be responsible for overseeing program implementation. Your IT team would be responsible for enforcing the company’s cybersecurity policies. Moreover, this team can also identify and tackle intrusion attempts and cybersecurity attacks to prevent any damage.
Before building a team, you should ask yourself questions like, “How many people do you need in your team?” or “What skills your IT security team should have?” This will simplify the process of building your IT security team. Small businesses that do not have the resources to build their team internally can take the services of managed security providers. This way, they can get the full services of an IT security team at a fraction of the cost.
Another advantage of hiring an IT security provider for [Increasing conversions on Shopify](https://www.engati.com/shopify-chatbot) is that they are quick to identify shortcomings of your cybersecurity program and offer suggestions and recommendations on correcting it. This can come in handy as you can enhance your cybersecurity program and fill in those gaps to ensure smoother sailing for your business.
Invest In Training and Education
You created one of the best cybersecurity programs, got the services of IT experts but all that won’t help your cause if you don’t educate and train your employees. Invest in employee education and training and it will do a world of good to employee education and training and it will do a world of good to keeping your business asset safe. By spending money on employee’s cybersecurity education and training, you can significantly reduce the risk of cybersecurity attacks such as social engineering. The more aware your staff is cybersecurity, it will be much harder for hackers to trick them into taking an action of their choice.
How do you create a cybersecurity program for your business? Feel free to share it with us in the comments section below.
| michael56812375 | |
875,486 | The 3 ways you can check for NaN in JavaScript (and 2 you can't!) | NaN isn't something you will often (if ever) write into your code. But it can crop up from time to... | 0 | 2021-10-25T14:14:43 | https://www.codemzy.com/blog/check-for-nan-javascript | javascript, beginners | **NaN isn't something you will often (if ever) write into your code. But it can crop up from time to time. And when it does, you can't check for it in the same way you could check for other values. Because NaN does not equal NaN. Are you confused? Don't be! Let's get to know NaN.**
`NaN` is an awkward member of the JavaScript family. We spend most of our time avoiding it, and when we do meet `NaN`, we can't get away quick enough! `NaN` is often misunderstood. It doesn't even understand itself. If you ask, "Hey `NaN` are you a `NaN`?" nearly half the time, it will say no!
```javascript
let x = NaN;
// 2 ways that don't work
console.log( x === NaN); // false
console.log( x == NaN); // false
// 3 ways that do work
console.log(Number.isNaN(x)); // true
console.log(Object.is(x, NaN)); // true
console.log(x !== x); // true
```
If you are confused about why some of these ways of checking for `NaN` don't work, and why some do, you're not alone! Because the `===` operator is the way we usually check for equality, and when `NaN` gets involved, it messes everything up. So why is `NaN` so troublesome? And what can we do about it?
`NaN` can happen for a wide range of reasons, usually if you try to do a calculation that JavaScript considers to be invalid math. Maybe you did `0 / 0`. And once it happens and `NaN` appears, it messes up all your future calculations. Not cool, `NaN`.
So let's say you have a number, `x`, and you want to check that it's valid. You need to know nothing has gone wrong in your code that's turned your number into not-a-number. So how can you avoid the dreaded `NaN`?
For the rest of this post, `x` is `NaN`. That's right - your number is not a number. And we need to write some simple code to detect it. So let's start by pointing the variable `x` to `NaN`.
```javascript
let x = NaN;
```
Ok, now we can begin.
## Ways you can't check for NaN
1. `x === NaN`
2. `x == NaN`
### Strict Equality
If you know a little JavaScript, you might bring out the old trusted **strict equality** operator. And this is the go-to operator for checking equality - it even says it in the name. So, of course, this *should* work.
```javascript
console.log(x === NaN); // false
```
Hmmm. That didn't work. Maybe my number is a number after all. Let's see what's going on here.
```javascript
console.log(NaN === NaN); // false (WTF??)
```
So, as it turns out, `NaN` does not equal `NaN`. At least not strictly.
### Loose equality
I still use **loose equality** `==` from time to time, although it's frowned upon (and sometimes banned in some codebases) because the results can be unexpected. But can it check for `NaN`?
```javascript
console.log(x == NaN); // false
console.log(NaN == NaN); // false (WTF again!!)
```
At this point, I thought maybe equality with `NaN` might work in the same way as an object, and each time you write it, you create a new `NaN`. But I know that NaN is a primitive value, so that's not true either.
```javascript
// objects don't equal each other
console.log({} === {}); // false
console.log({} == {}); // false
// but two variables can point to the same object
let myObject = {};
let sameObject = myObject;
console.log(myObject === sameObject); // true
// but that's not how NaN works either
let myNaN = NaN;
let sameNaN = myNaN;
console.log(myNaN === sameNaN); // false
```
Eugh, infuriating! `NaN` is its own thing, and we will never be able to check for equality like this. You could call it a bug, or you could call it a feature. Either way, we need to accept it for what it is and move on. So let's look at three ways you can check for `NaN` (way number 3 is super cool once you get your head around it).
## Ways you can check for NaN
So `NaN` is a number, but it's a special type of number, that's for sure. Because its **NOT A NUMBER!**. Although the two most obvious ways to check for a value don't work with `NaN`, there are three pretty cool ways that do work.
1. `Number.isNaN(x)`
2. `Object.is(x, NaN)`
3. `x !== x`
### Ask a number if it's not a number
Ok, so I mentioned that `NaN` is a type of number.
```javascript
console.log(typeof NaN); // 'number'
```
And for that reason, there's a method on the Number constructor specifically for checking NaN. `Number.isNaN()`. That's right - you can ask a number if it's a number!
```javascript
console.log(Number.isNaN(x)); // true
```
### Object.is(x, NaN)
The [`Object.is()` method](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/is) checks if two values are the same value. Unlike strict equality, it works with `NaN`.
```javascript
console.log(Object.is(x, x)); // true
console.log(Object.is(x, NaN)); // true
console.log(Object.is(NaN, NaN)); // true
console.log(Object.is(NaN, Number.NaN)); // true
```
### Strict inequality
Remember how I said that strict *equality* is one of the two ways you can't check for `NaN`? Well, if you tweak your thinking slightly and check for *inequality* instead, you can.
This way is my personal favourite. I almost see it as a way of tricking `NaN` into revealing itself. Since `NaN !== NaN`, and it's kinda weird, we can use that logic to check for `NaN`.
```javascript
console.log(x !== x); // true
```
If you know that `x` should be a number, and you run `x !== x` and get true, you know you have found `NaN`.
And the reverse is true too. Say you want to validate that you have a valid number in your code, you can do `if (myNumber === myNumber)` because if the number doesn't equal itself, it's in denial about who it is. There's not only one type of number that's in that kind of denial, and you can be sure it's not a number (`NaN`).
---
And that's it, the three ways you can check for `NaN` in Javascript, and the two ways you cant. Hopefully, you find `NaN` a little less confusing now and a lot more interesting! | codemzy |
875,512 | LaTeX: Customizing the Page | Hello, how are you? :) In this post I tell you how to change the position of the numbers in your... | 0 | 2021-10-27T14:36:04 | https://dev.to/latexteada/latex-customizing-the-page-4e1b | codenewbie, latex | Hello, how are you? :)
In this post I tell you how to change the position of the numbers in your document or delete them. Let's start!!!
Let me introduce you to the instruction
```LaTeX
\thispagestyle{STYLE}
```
Where *STYLE* can be
- `empty` no header, no footer
- `plain` the page number is on the footer
- `headings` the page number is on the header
You can put that instruction in every single page of your document, or you in some of them.
[Here](https://texlive.net/run?%5Cdocumentclass%7Barticle%7D%0A%5Cusepackage%7Bamsmath%7D%0A%5Cbegin%7Bdocument%7D%0A%0A%5Cthispagestyle%7Bempty%7D%0A%0AHello%0A%0A%5Cnewpage%0A%0A%5Cthispagestyle%7Bheadings%7D%0A%0APeople%0A%0A%5Cnewpage%0A%0A%5Cthispagestyle%7Bplain%7D%0A%0AGreetings%0A%0A%5Cend%7Bdocument%7D) is an exaple, you can play with it and use all the commands.
This is all for today, thank you!!!
Do not forget to follow me on Twitter `@latexteada`
Greetings :)
| latexteada |
875,547 | Pointer Fu: An adventure in the Tokio code base | This post was originally posted on my blog In an effort to understand the internals of... | 0 | 2021-10-25T16:13:14 | https://dev.to/senyeezus/pointer-fu-an-adventure-in-the-tokio-code-base-120f | rust, tokio, programming | [Tokio]: https://tokio.rs/
This post was originally posted on my [blog](https://senyosimpson.com/short-forms/pointer-fu-tokio/)
***
In an effort to understand the internals of asynchronous runtimes, I've been spending time reading [Tokio]'s source code. I've still got a long way to go but it has been a great journey so far.
{% tweet 1450127351917027332 %}
Raw pointers are used all over Tokio. In one particular instance, the way they used them really blew my mind 🤯. So here I am, writing about it. Buckle in 💺.
## Setting the scene
We have a type `Cell` that is defined as (taken directly from Tokio source)
```rust
#[repr(C)]
pub(super) struct Cell<T: Future, S> {
/// Hot task state data
pub(super) header: Header,
/// Either the future or output, depending on the execution stage.
pub(super) core: Core<T, S>,
/// Cold data
pub(super) trailer: Trailer,
}
```
It's used when initialising a struct `RawTask`
```rust
struct RawTask {
ptr: NonNull<Header>
}
// This is pseudocode
impl RawTask {
fn new() -> RawTask {
let ptr = Cell::new(); // returns a raw pointer to a Cell
// Cast pointer to one that points to a Header
let header_ptr = ptr as *mut Header;
let ptr = NonNull::new(header_ptr);
RawTask { ptr }
}
}
```
## What is so interesting?
First, a necessary detour! Rust can represent structs in memory in multiple ways. It's covered in detail in the [The Rust Reference](https://doc.rust-lang.org/reference/type-layout.html#representations). By default, Rust offers *no guarantee* on the memory layout of your struct; it is free to modify the layout however it wants. From a developer perspective, it means you cannot write any code that makes assumptions on the memory layout of your struct. To change the representation of the struct, you can use the `repr` attribute (as shown in the above definition of `Cell`).
Now, here's where it gets good! I omitted the comment for the `Cell` struct, which is
```rust
/// The task cell. Contains the components of the task.
///
/// It is critical for `Header` to be the first field as the task structure will
/// be referenced by both *mut Cell and *mut Header.
```
Hopefully some alarm bells started ringing in your head 🚨. `Header` has to be the first field in the struct, so that you can dereference a pointer to `Cell` into either a `Cell` or a `Header` (if this doesn't make sense to you, check out the [addendum](#addendum)). However, Rust's default representation provides no guarantee that `Header` will remain the first struct field! Instead, as you can see, they've changed the representation to the `C` layout. In `C`, struct fields are stored in the order they are declared. This gives us the guarantee we need. Now we can go around dereferencing the pointer to `Header` without any worry!
```rust
let cell = Cell::new();
let cell_ptr = &cell as *mut Cell;
let header_ptr = cell_ptr as *mut Header;
let header = unsafe { *header_ptr };
```
## Addendum
View in [Rust playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=147f74ccb012c0ef292ffe6e781c685a)
```rust
#[derive(Debug, Clone, Copy)]
struct Header {
x: u32
}
#[derive(Debug, Clone, Copy)]
struct Core {
y: u8
}
#[derive(Debug, Clone, Copy)]
#[repr(C)]
struct Task {
header: Header,
core: Core
}
fn main() {
let header = Header { x: 256 };
let core = Core { y: 10 };
let task = Task { header, core };
// Create raw pointer to task
let task_ptr = &task as *const Task;
// Cast pointer to point to Header
let header_ptr = task_ptr as *const Header;
// Dereference header_ptr
// We expect this to give us our Header struct as defined above.
// Because Header is the first field and the pointer is pointing
// to the beginning of the Task struct, it is valid to perform
// this dereference
let header_from_ptr_deref = unsafe { *header_ptr };
// Dereference task_ptr
// We expect this to give us our Task struct as defined above
let task_from_ptr_deref = unsafe { *task_ptr };
println!("Header from deref: {:#?}", header_from_ptr_deref);
println!("Task from deref: {:#?}", task_from_ptr_deref);
// Bonus: we can also cast task_ptr into a pointer to Core
// However, because its struct member is a u8 and Header's member
// is storing 256, which u8 cannot represent, dereferencing
// core_ptr will produce a corrupted Core struct
let core_ptr = task_ptr as *const Core;
let core_from_ptr_deref = unsafe { *core_ptr };
println!("Core from deref: {:#?}", core_from_ptr_deref);
}
```
The output of running this is shown below. Note that `Core` we obtained from dereferencing has `y=0` instead of `y=10`.
```
Header from deref: Header {
x: 256,
}
Task from deref: Task {
header: Header {
x: 256,
},
core: Core {
y: 10,
},
}
Core from deref: Core {
y: 0,
}
```
***
Shoutouts to [Ana](https://twitter.com/a_hoverbear) for reviewing this post.
| senyeezus |
875,565 | The Structure of an HTML Tag | Hey guys, this is Bhanu Stark from Public App. Today we are going to talk about the structure of... | 0 | 2021-10-25T16:55:20 | https://dev.to/publicapp/the-structure-of-an-html-tag-2m2m | html, beginners, tutorial | {% youtube MHf2Fd6cxFU %}
Hey guys, this is Bhanu Stark from Public App. Today we are going to talk about the structure of an HTML Tag.
In this post, you will find the answer of –
What is HTML tag?
What is HTML element?
What is opening tag?
What is closing tag?
What is self-closing tag?
What is an attribute?
How to know everything about an HTML element?
How to know about all the HTML elements?
Read full post here or watch video above-
[The Structure of an HTML Tag](https://www.publicapp.in/the-structure-of-an-html-tag/)
| publicapp |
876,273 | Hashing | Hashing is the process of converting an input of any length into a fixed size string or a number... | 0 | 2021-10-26T04:53:16 | https://dev.to/divya08296/hashing-1j75 | Hashing is the process of converting an input of any length into a fixed size string or a number using an algorithm. In hashing, the idea is to use a hash function that converts a given key to a smaller number and uses the small number as an index in a table called a hash table.
Hashing in Data Structures
We generate a hash for the input using the hash function and then store the element using the generated hash as the key in the hash table.
Hash Table
Hash Table: The hash table is a collection of key-value pairs. It is used when the searching or insertion of an element is required to be fast.
Operation in hash function:
Insert - T[ h(key) ] = value;
It calculates the hash, uses it as the key and stores the value in hash table.
Delete - T[ h(key) ] = NULL;
It calculates the hash, resets the value stored in the hash table for that key.
Search - return T[ h(key) ];
It calculates the hash, finds and returns the value stored in the hash table for that key.
Hash Collision: When two or more inputs are mapped to the same keys as used in the hash table. Example: h(“John”) == h( “joe”)
A collision cannot be completely avoided but can be minimized using a ‘good’ hash function and a bigger table size.
The chances of hash collision are less if the table size is a prime number.
How to choose a Hash Function
An efficient hash function should be built such that the index value of the added item is distributed equally across the table.
An effective collision resolution technique should be created to generate an alternate index for a key whose hash index corresponds to a previously inserted position in a hash table.
We must select a hash algorithm that is fast to calculate.
Characteristics of a good Hash Function
Uniform Distribution: For distribution throughout the constructed table.
Fast: The generation of hash should be very fast, and should not produce any considerable overhead.
Collision Hashing Techniques
Open Hashing (Separate Chaining): It is the most commonly used collision hashing technique implemented using Lined List. When any two or more elements collide at the same location, these elements are chained into a single-linked list called a chain. In this, we chain all the elements in a linked list that hash to the same slot.
Let’s consider an example of a simple hash function.
h(key) = key%table size
In a hash table with the size 7
h(27) = 27%7 = 6
h(130) = 130%7 = 4
Hash Map Example
If we insert a new element (18, “Saleema”), that would also go to the 4th index.
h(18) = 18%7 = 4
Hash Map Example;
For separate chaining, the worst-case scenario is when all of the keys will get the same hash value and will be inserted in the same linked list. We can avoid this by using a good hash function.
Closed Hashing (Open Addressing): In this, we find the “next” vacant bucket in Hash Table and store the value in that bucket.
Linear Probing: We linearly go to every next bucket and see if it is vacant or not.
rehash(key) = (n+1)%tablesize
Quadratic Probing: We go to the 1st, 4th, 9th … bucket and check if they are vacant or not.
rehash(key) = (n+ k<sup>2</sup> ) % tablesize
Double Hashing: Here we subject the generated key from the hash function to a second hash function.
h2(key) != 0 and h2 != h1
Load Factor: This is a measurement of how full a hash table may become before its capacity is increased.
The hash table’s load fact
N = number of elements in T - Current Size
M = size of T - Table Size
e = N/M - Load factor
Generally, if the load factor is greater than 0.5, we increase the size of the bucket array and rehash all the key-value pairs again.
How Hashing gets O(1) complexity?
Given the above examples, one would wonder how hashing may be O(1) if several items map to the same place…
The solution to this problem is straightforward. We use the load factor to ensure that each block, for example, (linked list in a separate chaining strategy), stores the maximum amount of elements fewer than the load factor on average. Also, in practice, this load factor is constant (generally 10 or 20). As a result, searching in 10 or 20 elements become constant.
If the average number of items in a block exceeds the load factor, the elements are rehashed with a larger hash table size.
Rehashing
When the load factor gets “too high” (specified by the threshold value), collisions would become more common, so rehashing comes as a solution to this problem.
We increase the size of the hash table, typically, doubling the size of the table.
All existing items must be reinserted into the new doubled size hash table.
Now let’s deep dive into the code. I will implement everything in code that we have learned till now.
#include<iostream>
using namespace std;
class node{
public:
string name;
int value;
node* next;
node(string key,int data){
name=key;
value=data;
next=NULL;
}
};
class hashmap{
node** arr;
int ts;
int cs;
int hashfn(string key){
int ans=0;
int mul=1;
for(int i=0; key[i]!='\0';i++){
ans = (ans + ((key[i]/ts)*(mul%ts))%ts);
mul *= 37;
mul %=ts;
}
ans = ans %ts;
return ans;
}
void reHash(){
node** oldarr=arr;
int oldts=ts;
arr= new node*[2*ts];
ts *= 2;
cs=0;
for(int i=0;i<ts;i++){
arr[i]=NULL;
}
//insert in new table
for(int i=0;i<oldts;i++){
node* head = oldarr[i];
while(head){
insert(head->name,head->value);
head=head->next;
}
}
delete []oldarr;
}
public:
hashmap(int s=7){
arr = new node*[s];
ts=s;
cs=0;
for(int i=0;i<s;i++){
arr[i]=NULL;
}
}
void insert(string key, int data){
int i=hashfn(key);
node* n=new node(key,data);
n->next=arr[i];
arr[i]=n;
cs++;
if(cs/(1.0*ts) > 0.6){
reHash();
}
}
node* search(string key){
int i=hashfn(key);
node*head= arr[i];
while(head){
if(head->name==key){
return head;
break;
}
head=head->next;
}
if(head==NULL){ | divya08296 | |
876,646 | Web, backend, mobile resources and news. | Dev Resources Here are the latest articles and news from last week's biweekly newsletter.... | 0 | 2021-10-26T10:54:56 | https://dev.to/developernationsurvey/web-backend-mobile-resources-and-news-349g | devnews, webdev, mobile, backend | ---
title: Web, backend, mobile resources and news.
published: true
description:
tags: #devnews #webdev #mobile #backend
//cover_image: https://direct_url_to_image.jpg
---
## Dev Resources
Here are the latest articles and news from last week's biweekly [newsletter](https://content.developereconomics.com/developer-nation-newsletter-signup-form). Enjoy!
## Dev Resources & Articles
[Emojis in commit messages: ✅ or ❌?](https://dev.to/scottshipp/emojis-in-commit-messages-or-2d32) See what others think, and contribute your own opinion. [DEVTO]
[Will the real senior dev please stand up? (2021 edition).](https://dzone.com/articles/will-the-real-senior-dev-please-stand-up-2021-edit) An update to Tomasz Waraksa's ironic look at the realities of hiring in IT. It's 2021, have companies finally learned what a real senior developer looks like? [DZONE]
[10 best product backlog tools for backlog management.](https://theproductmanager.com/tools/best-product-backlog-tools/) Without the product backlog, it would not be easy for software development teams to have a coherent idea of the processes they should be prioritizing. [THEPRODUCTMANAGER]
[8 mobile app security best practices developers should follow.](https://dev.to/kovalchuk/8-mobile-app-security-best-practices-developers-should-follow-544o) Best protected applications are those developed using the security by design approach when security is taken into account on the initial stages of the development process. [DEVTO]
[Difference between MVVM vs MVC.](https://www.educba.com/mvvm-vs-mvc/) The major key differences such as architecture, operation, advantages, and limitations are discussed in this article. [EDUCBA]
[Sending iOS push notifications via APNs.](https://blog.engineyard.com/ios-push-notifications-via-apns) This blog post discusses in detail the APN services, enable and register for remote notifications, device token ids, and APN node package with the help of a sample iOS. [ENGINEYARD]
[How I hacked an Android app for a premium feature.](https://proandroiddev.com/how-i-hacked-an-android-app-for-a-premium-feature-d9ca74e797ad) Merab rewrote the bytecode to unlock premium features of the app on his device and now he shows you how to prevent it from happening to your apps. [PROANDROIDDEV]
[Using WebSockets in Flutter.](https://blog.logrocket.com/using-websockets-flutter/) This article explores how we can use our own WebSockets to create applications that display real-time data to our users. [LOGROCKET]
[Front-end developer skills you must have.](https://www.interviewbit.com/blog/front-end-developer-skills/) Front-end developers require a combination of technical and soft abilities. If you’re pursuing a career as a Front-end Developer, these are the talents you’ll need to develop. [INTERVIEWBIT]
[Top 50 data structure and algorithms interview questions for programmers.](https://medium.com/javarevisited/50-data-structure-and-algorithms-interview-questions-for-programmers-b4b1ac61f5b0) Frequently asked programming interview questions from different interviews for programmers at different levels of experience. [MEDIUM.JAVAREVISITED]
[JavaScript worst practices.](https://blog.bitsrc.io/javascript-worst-practices-dc78e19d6f12) Let’s take a quick look at 5 of the worst things you can do to your code while writing JavaScript. [BITSRC]
[You can’t keep building on a broken system: why managing technical debt is so important.](https://dzone.com/articles/you-cant-keep-building-on-a-broken-system-why-mana) Managing technical debt is important if you want to move more quickly, retain top engineering talent, and avoid re-writing your app from scratch. [DZONE]
[What is Google’s Dev Library?](https://developers.googleblog.com/2021/10/what-is-the-dev-library.html) Google decided to create a space where the best projects related to Google technologies can be highlighted in one place. [DEVELOPERS.GOOGLEBLOG]
[What is data virtualization and why use it?](https://dev.to/lambdatesting/what-happens-when-you-use-virtualization-in-software-testing-1l92) What happens when you use virtualization in software testing? [DEVTO]
[What are microservices? Code examples, best practices, tutorials and more.](https://stackify.com/what-are-microservices/) We’ll take a look at microservices, the benefits of using this capability, and a few code examples. [STACKIFY]
[Node TDS module for connecting to SQL Server databases.](https://github.com/tediousjs/tedious) Tedious is a pure-Javascript implementation of the TDS protocol, which is used to interact with instances of Microsoft's SQL Server. [TEDIOUSJS]
[Introducing Serverless Cloud.](https://www.serverless.com//blog/introducing-serverless-cloud-public-preview) The hyper-productive #serverless app platform with single second deployments is now open to everyone. [SEVERLESS]
[Rails 7 adds the ability to use pre-defined variants.](https://www.bigbinary.com/blog/rails-7-adds-ability-to-use-predefined-variants) See how. [BIGBINARY]
[Crack the top 40 machine learning interview questions.](https://dev.to/educative/crack-the-top-40-machine-learning-interview-questions-1e2c) From basic to more advanced questions. [DEVTO]
[How to build a strong machine learning resume.](https://www.springboard.com/blog/ai-machine-learning/machine-learning-resume/) Here are several pointers to ensure that your resume is in top shape before you send it to the next recruiter or hiring manager. [SPRINGBOARD]
[A tour of attention-based architectures.](https://machinelearningmastery.com/a-tour-of-attention-based-architectures/) Gain a better understanding of how the attention mechanism is incorporated into different neural architectures and for which purpose. [MACHINELEARNINGMASTERY]
[The importance of data drift detection that data scientists do not know.](https://www.analyticsvidhya.com/blog/2021/10/mlops-and-the-importance-of-data-drift-detection/) Understand the different types of data drift and the method for detecting them. [ANALYTICSVIDHYA]
[Artificial networks learn to smell like the brain.](https://news.mit.edu/2021/artificial-networks-learn-smell-like-the-brain-1018) When asked to classify odors, artificial neural networks adopt a structure that closely resembles that of the brain’s olfactory circuitry. [MIT]
## Industry News
[A tour of attention-based architectures.](https://machinelearningmastery.com/a-tour-of-attention-based-architectures/) Gain a better understanding of how the attention mechanism is incorporated into different neural architectures and for which purpose. [MACHINELEARNINGMASTERY]
[The importance of data drift detection that data scientists do not know.](https://www.analyticsvidhya.com/blog/2021/10/mlops-and-the-importance-of-data-drift-detection/) Understand the different types of data drift and the method for detecting them. [ANALYTICSVIDHYA]
[Artificial networks learn to smell like the brain.](https://news.mit.edu/2021/artificial-networks-learn-smell-like-the-brain-1018) When asked to classify odors, artificial neural networks adopt a structure that closely resembles that of the brain’s olfactory circuitry. [MIT]
[Google says it’s dropping Material Design components on iOS in favour of Apple’s UIKit.](https://www.theverge.com/2021/10/12/22722130/google-ios-app-material-design-components-uikit) Google says the result of the switch should be less work for its iOS development team, but, more importantly, it’s likely the change will mean that Google’s iOS apps will feel less like interlopers on Apple devices. [THEVERGE]
[Thanks to a nasty GPSD bug, real-life time travel trouble arrives this weekend.](https://www.zdnet.com/article/thanks-to-a-nasty-gpsd-bug-real-life-time-travel-trouble-arrives-this-weekend/) On October 24, 2021, some time-keeping systems are going to take a trip back in time to March 2012, unless you update your GPSD programs. Find out more. [ZDNET] - old article from last week - did you experience any issues?
[GitLab goes public.](https://about.gitlab.com/blog/2021/10/14/gitlab-inc-takes-the-devops-platform-public/) GitLab was the first company to publicly live stream the entire end-to-end listing day at Nasdaq. Sid Sidbrandij shares the news and a copy of the founders letter. [GITLAB]
[IBM will offer free COBOL training to address overloaded unemployment systems.](https://www.inputmag.com/tech/ibm-will-offer-free-cobol-training-to-address-overloaded-unemployment-systems) Many systems that process unemployment claims in the USA still run on a 60-year-old programming language that relatively few coders understand. [INPUTMAG]
[Microsoft highlights the UI changes coming in Visual Studio 2022, including new icons.](https://www.neowin.net/news/microsoft-highlights-the-ui-changes-coming-in-visual-studio-2022-including-new-icons/) The IDE offers numerous improvements upon its predecessor, Visual Studio 2019, including the fact that it comes in a 64-bit flavor, supports .NET 6 and C++ 20, offers better performance for the core debugger, and supports text chat during Live Share sessions. [NEOWIN]
[DevFest 2021.](https://developers.googleblog.com/2021/10/announcing-devfest-2021.html) Hosted by Google Developer Groups (GDG) all across the globe, DevFest events are uniquely curated by their local GDG organizers to fit the needs and interests of the local community. [DEVELOPERS.GOOGLEBLOG]
## Quick Hits
[Announcing .NET MAUI Preview 9.](https://devblogs.microsoft.com/dotnet/announcing-net-maui-preview-9/)
[Parcel v2.0.0 stable is now available.](https://parceljs.org/blog/v2/)
[Crystal 1.2.0 is released.](https://crystal-lang.org/2021/10/14/1.2.0-released.html)
[PhpStorm 2021.2.3 is released.](https://blog.jetbrains.com/phpstorm/2021/10/phpstorm-2021-2-3-is-released/) | developernationsurvey |
876,673 | 👨💻[FirstDevRole #1] What are the Real Requirements for Becoming a Programmer? | What is this about? 🥱 In my opinion, the point of writing a blog is to document your... | 15,181 | 2021-10-26T11:21:49 | https://dev.to/antoniopk/firstdevrole-1-what-are-the-real-requirements-for-becoming-a-programmer-2e1p | webdev, javascript, beginners, programming | ## What is this about? 🥱
In my opinion, the point of writing a blog is to document your journey and share it with other people so hopefully someone finds the information useful.
Having that said, I have decided to share my experience and what I have learned when it comes to getting a first software developer job.
I have been through the process three times already so while everything is still relatively fresh and quite a few people asked me for advice on [Twitter](https://twitter.com/antoniopkvc), I decided to document it before it all evaporates into the void.

This is definitely going to be a series of blog posts with no specific order where I will try to extract the most important information as it comes to me. 🤷♂️
## Who is this for?
Anyone who wants to make a career change to IT, is graduating from college, is struggling to get a first job as a programmer or just wants to give programming a try.
## Topics that will be covered
These are some of the topics that I will definitely cover but might add more if I remember something that is important as well:
- What are the requirements for becoming a programmer
- How to write a no bullshit CV/Resume that will increase your chances of getting hired
- What programming language / framework to start with
- Where to apply for your first job and which ones to consider
- How to build an effective portfolio website
- What projects to build and how
- Creating an effective GitHub profile
- How much experience is needed to start applying to jobs
- When to apply to an Internship vs Real Developer role
- Is your code good enough
- What to be ready for while trying to get your first programming role
- Mindset and motivation
The first topic is covered in this post as the title says so let's start! 🦾
<hr/>
## What are the REAL Requirements for Becoming a Programmer?
Do you need someone to tell you if you are smart enough or do you have what it takes to become a programmer?
Let me tell you this: **Programming is not for anyone and it's not enough if you can just install Windows on your laptop. It's only for extremely talented people with IQ over 200.**
Anxiety kicks in?
Don't worry, I'm just kidding.
Let's put it this way. If you can read and comprehend what I have written up to this point then you have everything that it takes to become a programmer. You maybe won't be a great one but it's definitely enough to get a job.
Physical requirements ✔️
You did some googling or found this post buried deep down in the #TechTwitter history. That means you have enough interest.
Interest ✔️
Your friend who is incredibly smart is a software engineer and there is no way that you can be that good?
Actually, you can.
I actually know a few people who are generally not that intelligent but are still working as developers.
If it makes it any easier for you, I had the WORST grades in informatics in elementary school and in programming in college. At least get school out of the way because it's not a valid measure for anything.
So what's the thing that separates people who can and who cannot become programmers?
Well, the important things are exactly those two words: CAN and **CANNOT**.
Just pick one word and fill in the sentence below to find out the answer.
> I ___________ become a programmer.
Got it?
It's REALLY a matter of decision. Do you want to become a programmer?
## Why it is a matter of a decision?
Because if you don't decide firmly, you will quit somewhere along the road. Just make a decision with yourself, and even better write it somewhere, and whenever you think about quitting (which will happen a lot) just remind yourself that you have decided and that there is no way back.
If you are starting from zero, don't expect a role in the next 1-2 years and be ready to dedicate A LOT of time to learn everything that is necessary to get the job. If you get it earlier than that then even better!
Not a lot of people can sacrifice that much time and be that patient and that's why programming is labeled as "hard".
It's not hard because you have to study some out of this world science, complex algorithms or math formulas - it's hard because it requires TIME and PATIENCE.
So basically you have all the "skills" that you need. It is only the question if you are ready to throw yourself into the fire?
If you were looking for an actual list of requirements in a video game style then here you have it:
## Requirements for becoming a software engineer:
- Having a normal functioning brain and being able to type
- Being ready to not being able to get a job even after learning every day for a year
- Basic English language knowledge
- Being in peace with the fact that learning will NEVER end
- Being in peace with the fact that you will fail a lot
- Being comfortable with feeling stupid at times
- Being ready to work on your temper and impulsive reacting
- Being in front of a computer every day
- Being ready to code every day
- Being ready to learn the boring stuff so you can enjoy building fun stuff later
- Being ready to deal with difficult people
- Being ready to read boring or poorly written documentation
- Decreased social life at times
- Being comfortable with dreaming code (literally)
- Being able to think when exhausted at times
- Being able to think under pressure
And last but not least: being ready to help everyone alive with their printers or failing internet connections. (funny but true, you will see)
If you can sign up for all of these points above then there is nothing else I want to tell you.
You have it all and are ready to start. ✔️✔️✔️
All I can tell you is good luck, DON'T QUIT and you will get your job I'm sure of that!😄
<a href='https://ko-fi.com/S6S06RIRQ' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://cdn.ko-fi.com/cdn/kofi1.png?v=3' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
**If there is a topic that you want me to cover please let me know in the comments and I will gladly add it to my list.** | antoniopk |
886,786 | Algorithm Series - Selection Sort | Photo by Jess Bailey on Unsplash This is a quick tutorial on the selection sort algorithm and its... | 0 | 2021-11-03T14:22:16 | http://tatyanacelovsky.com/algorithm_series_-_selection_sort | algorithms | ---
title: Algorithm Series - Selection Sort
published: true
date: 2021-10-27 08:50:00 UTC
tags: Algorithms
canonical_url: http://tatyanacelovsky.com/algorithm_series_-_selection_sort
---
 Photo by [Jess Bailey](https://unsplash.com/@jessbaileydesigns) on [Unsplash](https://unsplash.com/)
_This is a quick tutorial on the selection sort algorithm and its implementation in Javascript._
### What is Selection Sort Algorithm
Selection sort is a [sorting algorithm](%5Bhttps://en.wikipedia.org/wiki/Sorting_algorithm%5D(https://en.wikipedia.org/wiki/Sorting_algorithm)) that divides the input list into two parts: a sorted sublist that is built up from left to right and a sublist of the remaining unsorted values. The sorted sublist is placed at the front (to the left of) the unsorted sublist. Initially, the sorted sublist is empty and the unsorted sublist consists of the entire input list. The algorithm selects the smallest (or largest, depending on the ask) element in the unsorted sublist, places that element at the beginning of the unsorted sublist and moves the sublist boundary one element to the right (because there is now one element present in the sorted sublist, while the unsorted sublist became smaller by one element).
Let’s take a look at selection sort when trying to sort the elements of an array in an ascending order:
1. Set the first element of the array as `minimum`;
2. Compare `minimum` with the second element, if the second element is smaller than `minimum`, assign the second element as `minimum` , otherwise, do nothing;
3. Compare `minimum` with the following element, if that element is smaller than `minimum`, then assign `minimum` to that element, otherwise do nothing;
4. Continue step 3 above until the last element has been reached;
5. Move `minimum` to the front of the array and move the sublist boundary one element to the right (because there is now one element present in the sorted sublist, while the unsorted sublist became smaller by one element);
6. Continue with steps 3 - 5, until all elements are in their sorted positions.
The array is sorted when all the unsorted elements are placed in their correct positions.
### Selection Sort Code in Javascript
Let’s take a look at the code for the selection sort algorithm described above (ascending order):
{% gist https://gist.github.com/tcelovsky/4c7b1b5a852adacf13ba7a3604000f79.js %}
The above code sorts the array in ascending order. To sort an array in descending order, replace the “greater than” sign in the `if` statement with a “less than” sign.
### Selection Sort and Big-O
Selection Sort compares the adjacent elements, hence, the number of comparisons is:
(n-1) + (n-2) + (n-3) +…..+ 1 = n(n-1)/2
This nearly equals to n2, therefore Big-O is O(n²) or quadratic time. We can also deduce this from observing the code: selection sort requires two loops, therefore Big-O is expected to be O(n²).
### Conclusion
Selection sort finds the lowest value of the array and moves that value to the beginning of the array, it then proceeds to look for the next lowest value and moves that in front of the unsorted elements. This continues until all values of the array have been sorted; it is a simple way to sort a list when complexity does not matter and the list that needs sorting is short.
### Resources
[Selection Sort Algorithm gist](https://gist.github.com/tcelovsky/4c7b1b5a852adacf13ba7a3604000f79)
[Let’s Talk About Big-O](https://dev.to/tcelovsky/let-s-talk-about-big-o-2ah9) | tcelovsky |
887,079 | Tags, Attributes, Form and lebel | HTML Tags Tags I learnt recently. <mark> : Highlight <abbr> : When you hover... | 0 | 2021-11-03T19:55:43 | https://dev.to/daaahailey/tags-attributes-form-and-lebel-3m8p | html, attribute, form, label | ## HTML Tags
Tags I learnt recently.
<code><mark></code> : Highlight
<code><abbr></code> : When you hover on the element that's wrapped with <code><abbr></code>, it shows description.
<p>You can use <abbr title="Cascading Style Sheets">CSS</abbr> to style your <abbr title="HyperText Markup Language">HTML</abbr>.</p>
```html
<p>You can use <abbr title="Cascading Style Sheets">CSS</abbr> to style your <abbr title="HyperText Markup Language">HTML</abbr>.</p>
```
<code><sup></code> : Subscript text appears half a character below the normal line, and is sometimes rendered in a smaller font like H<sub>2</sub>0
<code><sub></code> : Superscript text appears half a character above the normal line, and is sometimes rendered in a smaller font. Superscript text can be used for footnotes, like WWW<sup>[1]</sup>.
```html
<p>H<sub>2</sub>0</p>
<p>x<sup>2</sup>=4</p>
```
<code><blockquote></code>
<blockquote>
<p>I Don’t Have A Home To Go Back To. In Here, I Stand A Chance At Least. But Out There? I Got Nothing Out There.</p>
<cite>Player 322</cite>
</blockquote>
<p><q>Would you like to play a game with me?</q>He asked.</p>
```html
<blockquote>
<p>I Don’t Have A Home To Go Back To. In Here, I Stand A Chance At Least. But Out There? I Got Nothing Out There.</p>
<cite>Player 322</cite>
</blockquote>
<p><q>Would you like to play a game with me?</q>He asked.</p>
```
<code><pre></code> : Preformatted text which is to be presented exactly as written in the HTML file.
<code><kbd></code> : Span of inline text denoting textual user input from a keyboard, voice input, or any other text entry device. By convention, the user agent defaults to rendering the contents of a <code><kbd></code> element using its default monospace font, although this is not mandated by the HTML standard.
<p>Please press <kbd>Ctrl</kbd> + <kbd>Shift</kbd> + <kbd>R</kbd> to re-render an MDN page.</p>
```html
<p>Please press <kbd>Ctrl</kbd> + <kbd>Shift</kbd> + <kbd>R</kbd> to re-render an MDN page.</p>
```
<code><code></code>
<p>The <code>push()</code> method adds one or more elements to the end of an array and returns the new length of the array.</p>
```html
<p>The <code>push()</code> method adds one or more elements to the end of an array and returns the new length of the array.</p>
```
<code><figure></code> : figure tag specifies self-contained content, like illustrations, diagrams, photos, code listings, etc.
<code><figcaption></code> : defines a caption for a <code><figure></code> element. Element can be placed as the first or last child of the <figure> element. figcaption can be used only as children element of figure.
#### srcset Attribute
Defines multiple sizes of the same image, allowing the browser to select the appropriate image source.
Each set of image information is separated from the previous one by a comma.
find more about [srcset](https://developer.mozilla.org/ko/docs/Learn/HTML/Multimedia_and_embedding/Responsive_images)
```html
<img src="a.jpg" srcset="a.jpg, a.jpg 2x" alt="대체문구">
<img
width="200px"
srcset="img/logo_1.png 300w,
img/logo_2.png 600w,
img/logo_3.png 700w"
src="a.jpg"
alt="test">
```
## Attributes
poster: A URL for an image to be shown while the video is downloading. If this attribute isn't specified, nothing is displayed until the first frame is available, then the first frame is shown as the poster frame.
```html
<video src="" poster="" preload="" controls playsinline>
<source src="" type="">
<track kind="" src="" srclang="" label="">
</video>
```
## Form
: a document section containing interactive controls for submitting information.
###Get, Post
Sensitive info like password should not be seen, so it shouldn't be sent via get. It's better to use post.
Also, it's easier to send large size of image, lots of data via post then get. If it needs to be hidden, use post as well.
```html
<form action="./010.html" method="get">
<label for="one">이름 : </label>
<input type="text" name="id" id="one">
<label for="two">패스워드 : </label>
<input type="password" name="pw" id="two">
<button type="submit">로그인</button><br>
</form>
```
It sends the data to the file that action is linked which is ./010.html
When it's sent (when you click submit button this is what you see at the browser <kbd>file:///Users/dahyeji/Desktop/likelion/01_11_2021/010.html?id=hailey707&pw=12345</kbd>
You can see 👉 <em><strong>?id=hailey707&pw=12345</strong></em>
/?device(key/name)=iPhone(value)
## Label
To associate the <code><label></code> with an <code><input></code> element, you need to give the <input> an id attribute. The <code><label></code> then needs a for attribute whose value is the same as the input's id.
```html
<label for="id">아이디: </label>
<input type="text" name="userId" id="id">
```
A radio group is defined by giving each of radio buttons in the group <strong>the same name</strong>. Once a radio group is established, selecting any radio button in that group automatically deselects any currently-selected radio button in the same group.
```html
<label for="male">남</label>
<input type="radio" name="sex" id="male" value="male">
<label for="female">여</label>
<input type="radio" name="sex" id="female" value="female">
```
```html
<form action="./011.html" method="get">
<label for="id">아이디: </label>
<input type="text" name="userId" id="id">
<label for="pw">패스워드: </label>
<input type="password" name="userPw" id="pw"><br>
<label for="male">남</label>
<input type="radio" name="sex" id="male" value="male">
<label for="female">여</label>
<input type="radio" name="sex" id="female" value="female"><br>
<p>좋아하는 프로그래밍 언어</p><br>
<label for="js">javaScript</label>
<input type="checkbox" name="언어" id="js" value="javaScript">
<label for="python">python</label>
<input type="checkbox" name="언어" id="python" value="python">
<label for="python">C</label>
<input type="checkbox" name="언어" id="c" value="c">
<label for="python">Go</label>
<input type="checkbox" name="언어" id="go" value="go">
<button type="submit">회원가입</button>
</form>
```
Alternatively, you can nest the <code><input></code> directly inside the <code><label></code>, in which case the for and id attributes are not needed because the association is implicit:
```html
<label>Do you like dogs?
<input type="checkbox" name="dogs">
</label>
```
| daaahailey |
887,107 | How to make object properties string type values to string literal type in TypeScript? | Originally posted here! To make the object properties string type values to string literals, we can... | 0 | 2021-11-03T00:00:00 | https://melvingeorge.me/blog/make-object-property-string-type-values-to-string-literal-type-typescript | typescript | ---
title: How to make object properties string type values to string literal type in TypeScript?
published: true
tags: TypeScript
date: Wed Nov 03 2021 05:30:00 GMT+0530 (India Standard Time)
canonical_url: https://melvingeorge.me/blog/make-object-property-string-type-values-to-string-literal-type-typescript
cover_image: https://melvingeorge.me/_next/static/images/main-3e2d9afd37c6cefc6f8490ddeac7e8dc.jpg
---
[Originally posted here!](https://melvingeorge.me/blog/make-object-property-string-type-values-to-string-literal-type-typescript)
To make the object properties `string` type values to `string literals`, we can use the `as` keyword after the property `string` value and then type out the string literal or we can use the `as` keyword after accessing the property then typing out the string literal.
### TL;DR
**METHOD 1**
```ts
// a simple object
// with "name" property type changed
// from "string" to "John Doe" string literal
const person = {
name: "John Doe" as "John Doe",
age: 23,
};
```
**METHOD 2**
```ts
// a simple object
const person = {
name: "John Doe",
age: 23,
};
// a simple function call
// with "name" property type changed
// from "string" to "John Doe" string literal
sayName(person.name as "John Doe");
```
To understand it better, let's say we have an object called `person` with two properties called `name` and `age` with values of `John Doe` and `23` respectively like this,
```ts
// a simple object
const person = {
name: "John Doe",
age: 23,
};
```
Now if you hover over the `name` property in the `person` object it shows the type of the `name` property as `string` like in the below image,

This is ok for most cases. But in some cases, you may need to convert the `name` property's type from just `string` to a `string literal` to pass it to a function call as an argument.
To do that, we can use the `as` keyword after the `name` property's string value and then type the `string literal` we need to use. In our case, we need to change it to `John Doe` string literal type. It can be done like this,
```ts
// a simple object
// with "name" property type converted
// from just "string" to "John Doe" string literal
const person = {
name: "John Doe" as "John Doe",
age: 23,
};
```
Now if you hover over the `name` property you can see that the type of the `name` property is changed from `string` to `John Doe` string literal which is what we want.
It may look like this,

Another way of achieving the same functionality is using the `as` keyword and typing the string literal when we are only accessing the property from the object.
For example, let's assume a function called `sayName`, and on calling the function let's pass the `name` property value like this,
```ts
// a simple object
const person = {
name: "John Doe",
age: 23,
};
// a simple function call
sayName(person.name);
```
Now to change the type of the `name` property from `string` to "John Doe" `string literal` we can use the `as` keyword after the `person.name` and type the string literal like this,
```ts
// a simple object
const person = {
name: "John Doe",
age: 23,
};
// a simple function call
// with "name" property type changed
// from "string" to "John Doe" string literal
sayName(person.name as "John Doe");
```
This is also a valid way of achieving the same functionality.
See the working of the above codes live in [codesandbox](https://codesandbox.io/s/make-object-property-string-values-to-string-literals-in-typescript-qdej0?file=/src/index.ts)
That's all 😃!
### Feel free to share if you found this useful 😃.
---
| melvin2016 |
887,144 | Behavioral Design Patterns In C# | if you are new , I highly recommend you to read my first and second articles which are about... | 0 | 2021-11-04T10:03:26 | https://dev.to/mstbardia/behavioral-design-patterns-in-c-4o14 | csharp, design, productivity, dotnet | if you are new , I highly recommend you to read my first and second articles which are about [Creational Design Patterns](https://dev.to/mstbardia/creational-design-patterns-in-c-10c6) and [Structural Design Patterns](https://dev.to/mstbardia/structural-design-patterns-in-c-2khn) In C#.
As we explained in earlier post , we have three main categories in Design Patterns :
1. Creational
2. Structural
3. Behavioral
**Behavioral** Design Patterns mainly focus on the communication between objects and the interactions between them by algorithm and their responsibilities.
**Chain of Responsibility**
> this pattern is use to passing request along multiple handler, so it prevents from coupling request to handle by one handler.
```c#
public interface IHandler
{
public IHandler SetNext(IHandler handler);
public object Handle(object input);
}
public class Handler : IHandler
{
private IHandler _handler;
public IHandler SetNext(IHandler handler)
{
_handler = handler;
return handler;
}
public virtual object Handle(object input)
{
return _handler?.Handle(input);
}
}
public class HandlerA : Handler
{
public override object Handle(object input)
{
if (input as string == "A")
{
Console.WriteLine("HandlerA said : gotcha you ! that's enough go back");
return true;
}
Console.WriteLine("HandlerA said : i can not do anything calling next handler");
return base.Handle(input);
}
}
public class HandlerB : Handler
{
public override object Handle(object input)
{
if (input as string == "B")
{
Console.WriteLine("HandlerB said : gotcha you ! that's enough go back");
return true;
}
Console.WriteLine("HandlerB said : i can not do anything calling next handler");
return base.Handle(input);
}
}
public class HandlerC : Handler
{
public override object Handle(object input)
{
if (input as string == "C")
{
Console.WriteLine("HandlerC said : gotcha you ! that's enough go back");
return true;
}
Console.WriteLine("HandlerC said : chain is useless for you , this is end of the road bro.");
return base.Handle(input);
}
}
public static class ChainOfResponsibilityExample
{
public static void Test()
{
var handlerA = new HandlerA();
var handlerB = new HandlerB();
var handlerC = new HandlerC();
handlerA.SetNext(handlerB).SetNext(handlerC);
var resultOne = handlerA.Handle("A");
var resultTwo = handlerA.Handle("B");
var resultThree = handlerA.Handle("C");
var resultFour = handlerA.Handle("D");
}
//results:
//
// resultOne :
// HandlerA said : gotcha you ! that's enough go back
//
// resultTwo :
// HandlerA said : i can not do anything calling next handler
// HandlerB said : gotcha you ! that's enough go back
//
// resultThree :
// HandlerA said : i can not do anything calling next handler
// HandlerB said : i can not do anything calling next handler
// HandlerC said : gotcha you ! that's enough go back
//
// resultFour :
// HandlerA said : i can not do anything calling next handler
// HandlerB said : i can not do anything calling next handler
// HandlerC said : chain is useless for you , this is end of the road bro.
```
**Command**
> this pattern is use to transform request to a object so you can delay or queue or parameterize request. and do undoable operations.
```c#
public interface ICommand
{
public void Execute();
}
public class ExampleCommand : ICommand
{
private readonly string _parameter;
public ExampleCommand(string parameter)
{
_parameter = parameter;
}
public void Execute()
{
Console.WriteLine(_parameter);
}
}
public static class Invoker
{
public static void SendAction(ICommand command)
{
command.Execute();
}
}
public static class CommandExample
{
public static void Test()
{
var command = new ExampleCommand("Query filter setup and executed");
Invoker.SendAction(command);
}
//results:
//Query filter setup and executed
}
```
**Iterator**
> its main goal is to traverse elements of collection without exposing them.
```c#
public abstract class IteratorBase
{
public abstract bool EndOfDocument();
public abstract object Current();
public abstract object Next();
public abstract object First();
}
public class Iterator : IteratorBase
{
private readonly List<object> _customList;
private int current = 0;
public Iterator(List<object> customList)
{
_customList = customList;
}
public override bool EndOfDocument()
{
if (current >= _customList.Count - 1)
return true;
return false;
}
public override object Current()
{
return _customList[0];
}
public override object Next()
{
if (current < _customList.Count - 1)
return _customList[++current];
return null;
}
public override object First()
{
return _customList[0];
}
}
public static class IteratorExample
{
public static void Test()
{
var ourList = new List<object>() {"a", "b", "c", "d"};
var iterator = new Iterator(ourList);
Console.WriteLine("lets Iterate on list");
var item = iterator.First();
while (item != null)
{
Console.WriteLine(item);
item = iterator.Next();
}
if (iterator.EndOfDocument())
Console.WriteLine("Iterate done");
}
//results:
// lets Iterate on list
// a
// b
// c
// d
// Iterate done
}
```
**Interpreter**
>it is use for get different type and behavior on same context , and usually use in language scenario in software design.
```c#
internal class Context
{
public string Value { get; private set; }
public Context(string value)
{
Value = value;
}
}
internal abstract class Interpreter
{
public abstract void Interpret(Context context);
}
internal class EnglishInterpreter : Interpreter
{
public override void Interpret(Context context)
{
switch (context.Value)
{
case "1" :
Console.WriteLine("One");
break;
case "2" :
Console.WriteLine("Two");
break;
}
}
}
internal class FarsiInterpreter : Interpreter
{
public override void Interpret(Context context)
{
switch (context.Value)
{
case "3" :
Console.WriteLine("سه");
break;
case "4" :
Console.WriteLine("چهار");
break;
}
}
}
public static class InterpreterExample
{
public static void Test()
{
var interpreters = new List<Interpreter>()
{
new EnglishInterpreter(),
new FarsiInterpreter()
};
var context = new Context("2");
interpreters.ForEach(c => c.Interpret(context));
}
//results:
//two
}
```
**Mediator**
>the goal of this pattern is to decoupling direct communication between objects and forces them to pass from a mediator object for communicating.
```c#
public interface IMediator
{
public void Send(string message, Caller caller);
}
public class Mediator : IMediator
{
public CallerA CallerA { get; set; }
public CallerB CallerB { get; set; }
public void Send(string message, Caller caller)
{
if (caller.GetType() == typeof(CallerA))
{
CallerB.ReceiveRequest(message);
}
else
{
CallerA.ReceiveRequest(message);
}
}
}
public abstract class Caller
{
protected readonly IMediator _mediator;
public Caller(IMediator mediator)
{
_mediator = mediator;
}
}
public class CallerA : Caller
{
public void SendRequest(string msg)
{
_mediator.Send(msg,this);
}
public void ReceiveRequest(string msg)
{
Console.WriteLine("CallerA Received : " + msg);
}
public CallerA(IMediator mediator) : base(mediator)
{
}
}
public class CallerB : Caller
{
public void SendRequest(string msg)
{
_mediator.Send(msg,this);
}
public void ReceiveRequest(string msg)
{
Console.WriteLine("CallerB Received : " + msg);
}
public CallerB(IMediator mediator) : base(mediator)
{
}
}
public static class MediatorExample
{
public static void Test()
{
var mediator = new Mediator();
var callerA = new CallerA(mediator);
var callerB = new CallerB(mediator);
mediator.CallerA = callerA;
mediator.CallerB = callerB;
callerA.SendRequest("hello how are you ?");
callerB.SendRequest("fine tnx");
}
//results:
//CallerB Received : hello how are you ?
//CallerA Received : fine tnx
}
```
**Memento**
>this pattern is use for saving state of object with considering state encapsulation. so you can restores object's first state even after multiple manipulation.
```c#
public class Memento
{
private readonly string _state;
public Memento(string state)
{
_state = state;
}
public string GetState()
{
return _state;
}
}
public class CareTaker
{
private Memento _memento;
public void SaveMemento(Originator originator)
{
_memento = originator.CreateMemento();
}
public void RestoreMemento(Originator originator)
{
originator.RestoreState(_memento);
}
}
public class Originator
{
public string State { get; set; }
public Originator(string state)
{
State = state;
}
public Memento CreateMemento()
{
return new Memento(State);
}
public void RestoreState(Memento memento)
{
State = memento.GetState();
}
}
public static class MementoExample
{
public static void Test()
{
var originator = new Originator("First Value");
var careTaker = new CareTaker();
careTaker.SaveMemento(originator);
Console.WriteLine(originator.State);
originator.State = "Second Value";
Console.WriteLine(originator.State);
careTaker.RestoreMemento(originator);
Console.WriteLine(originator.State);
}
//results:
//First Value
//Second Value
//First Value
}
```
**Observer**
>it is use to handle one to many communication between objects , so if one object's state changed , its dependent objects will notify and will update.
```c#
public class Updater
{
public string NewState { get; }
private readonly List<ObserverBase> _observers = new List<ObserverBase>();
public Updater(string newState)
{
NewState = newState;
}
public void AddObserver(ObserverBase observerBase)
{
_observers.Add(observerBase);
}
public void BroadCast()
{
foreach (var observer in _observers)
{
observer.Update();
}
}
}
public abstract class ObserverBase
{
public abstract void Update();
}
public class Observer : ObserverBase
{
private readonly string _name;
public string State;
private readonly Updater _updater;
public Observer(string name, string state, Updater updater)
{
_name = name;
State = state;
_updater = updater;
}
public override void Update()
{
State = _updater.NewState;
Console.WriteLine($"Observer {_name} State Changed to : " + State);
}
}
public static class ObserverExample
{
public static void Test()
{
var updater = new Updater("Fire");
updater.AddObserver(new Observer("1", "dust", updater));
updater.AddObserver(new Observer("2", "water", updater));
updater.AddObserver(new Observer("3", "air", updater));
updater.BroadCast();
}
//results:
//Observer 1 State Changed to : Fire
//Observer 2 State Changed to : Fire
//Observer 3 State Changed to : Fire
}
```
**State**
>with this pattern object can change its behavior whenever its state changed.
```c#
internal interface IState
{
public void Handle(Context context);
}
internal class StateA : IState
{
public void Handle(Context context)
{
context.State = new StateB();
}
}
internal class StateB : IState
{
public void Handle(Context context)
{
context.State = new StateA();
}
}
internal class Context
{
private IState _state;
public IState State
{
get => _state;
set
{
_state = value;
Console.WriteLine("State: " + _state.GetType().Name);
}
}
public Context(IState state)
{
State = state;
}
public void Action()
{
State.Handle(this);
}
}
public static class StateExample
{
public static void Test()
{
var context = new Context(new StateA());
context.Action();
context.Action();
context.Action();
context.Action();
}
//results:
//State: StateA
//State: StateB
//State: StateA
//State: StateB
//State: StateA
}
```
**Strategy**
>this pattern is use to encapsulate family of algorithm and makes them interchangeable . so they can independently change without any tight coupling.
```c#
internal interface IStrategy
{
public void AlgorithmAction();
}
internal class AlgorithmStrategyA : IStrategy
{
public void AlgorithmAction()
{
Console.WriteLine("Strategy A is taking place");
}
}
internal class AlgorithmStrategyB : IStrategy
{
public void AlgorithmAction()
{
Console.WriteLine("Strategy B is taking place");
}
}
internal class Context
{
private readonly IStrategy _strategy;
public Context(IStrategy strategy)
{
_strategy = strategy;
}
public void GeneralAction()
{
_strategy.AlgorithmAction();
}
}
public static class StrategyExample
{
public static void Test()
{
var context = new Context(new AlgorithmStrategyA());
context.GeneralAction();
context = new Context(new AlgorithmStrategyB());
context.GeneralAction();
}
//results:
//Strategy A is taking place
//Strategy B is taking place
}
```
**Template Method**
>in simple word , this pattern includes number of operations on base class and it allows subclasses to only override some of the them.
```c#
internal abstract class TemplateBase
{
public void Operate()
{
FirstAction();
SecondAction();
}
private void FirstAction()
{
Console.WriteLine("First action from template base and it is necessary");
}
protected virtual void SecondAction()
{
Console.WriteLine("Second action from template base and it is overrideable");
}
}
internal class TemplateMethodA : TemplateBase
{
}
internal class TemplateMethodB : TemplateBase
{
protected override void SecondAction()
{
Console.WriteLine("Second action from templateMethodC");
}
}
internal class TemplateMethodC : TemplateBase
{
protected override void SecondAction()
{
Console.WriteLine("Second action from templateMethodC");
}
}
public static class TemplateMethod
{
public static void Test()
{
var templateMethodA = new TemplateMethodA();
var templateMethodB = new TemplateMethodB();
var templateMethodC = new TemplateMethodC();
templateMethodA.Operate();
templateMethodB.Operate();
templateMethodC.Operate();
}
//results:
//First action from template base and it is necessary
//Second action from template base and it is overrideable
//First action from template base and it is necessary
//Second action from templateMethodB
//First action from template base and it is necessary
//Second action from templateMethodC
}
```
**Visitor**
> the main goal is to add new behavior to class hierarchy without any changing in their code.
```c#
internal interface IVisitor
{
public void VisitItem(ItemBase item);
}
internal class VisitorA : IVisitor
{
public void VisitItem(ItemBase item)
{
Console.WriteLine("{0} visited by {1}",item.GetType().Name , this.GetType().Name);
}
}
internal class VisitorB : IVisitor
{
public void VisitItem(ItemBase item)
{
Console.WriteLine("{0} visited by {1}",item.GetType().Name , this.GetType().Name);
}
}
internal abstract class ItemBase
{
public abstract void Accept(IVisitor visitor);
}
internal class ItemA : ItemBase
{
public override void Accept(IVisitor visitor)
{
visitor.VisitItem(this);
}
public void ExtraOperationA()
{
}
}
internal class ItemB : ItemBase
{
public override void Accept(IVisitor visitor)
{
visitor.VisitItem(this);
}
public void ExtraOperationB()
{
}
}
internal class StructureBuilder
{
readonly List<ItemBase> _items = new();
public void AddItem(ItemBase element)
{
_items.Add(element);
}
public void Accept(IVisitor visitor)
{
foreach (var item in _items)
{
item.Accept(visitor);
}
}
}
public static class VisitorExample
{
public static void Test()
{
var structure = new StructureBuilder();
structure.AddItem(new ItemA());
structure.AddItem(new ItemB());
structure.Accept(new VisitorA());
structure.Accept(new VisitorB());
}
//results:
//ItemA visited by VisitorA
//ItemB visited by VisitorA
//ItemA visited by VisitorB
//ItemB visited by VisitorB
}
```
| mstbardia |
887,192 | Publishing The State Of The Web | Back in April I gave a talk at An Event Apart Spring Summit. The talk was called The State Of The... | 0 | 2021-11-07T07:48:18 | https://adactio.com/journal/18586 | conference, presentation, transcript, aea | ---
title: Publishing The State Of The Web
published: true
date: 2021-11-03 18:50:26 UTC
tags: conference,presentation,transcript,aea
canonical_url: https://adactio.com/journal/18586
---
Back in April I gave a talk at [An Event Apart Spring Summit](https://aneventapart.com/event/spring-summit-2021). The talk was called <cite>The State Of The Web</cite>, and [I’ve published the transcript](https://adactio.com/articles/18580). I’ve also published [the video](https://vimeo.com/641568337).
I put a lot of work into this talk and I think it paid off. I wrote about [preparing the talk](https://adactio.com/journal/17902). I also [wrote about recording it](https://adactio.com/journal/17934). I also published [links related to the talk](https://adactio.com/journal/18038). It was an intense process, but a rewarding one.
I almost called the talk <cite>The Overview Effect</cite>. My main goal with the talk was to instil a sense of perspective. Hence the references to the famous Earthrise photograph.
On the one hand, I wanted the audience to grasp just how far the web has come. So the first half of the talk is a bit of a trip down memory lane, with a constant return to just how much we can accomplish in browsers today. It’s all very positive and upbeat.
Then I twist the knife. Having shown just how far we’ve progressed _technically_, I switch gears the moment I say:
> The biggest challenges facing the World Wide Web today are not technical challenges.
Then I dive into those challenges, as I see them. It turns out that technical challenges would be preferable to the seemingly intractable problems of today’s web.
I almost wish I could’ve flipped the order: talk about the negative stuff first but then finish with the positive. I worry that the talk could be a bit of a downer. Still, I tried to finish on an optimistic note.
I won’t spoil it any more for you. [Watch the video](https://vimeo.com/641568337) or have a read of [<cite>The State Of The Web</cite>](https://adactio.com/articles/18580). | adactio |
887,278 | A coders journey into a tech startup. | Introduction Hey everybody! If you're reading this it's probably because I piqued your... | 15,325 | 2021-11-03T23:37:21 | https://dev.to/kalobtaulien/a-coders-journey-into-a-tech-startup-3d8o | startup | ## Introduction
Hey everybody!
If you're reading this it's probably because I piqued your interested in a Facebook group when I said:
> Who would be interested in a blog series about how I coded my latest startup, the skills I needed, and what I look for in a developer? Comment below 👇
Welp, today I'm starting on this journey to detail, highlight and share what I needed to know to start a tech startup, code an MVP, the tools I use, the tools I've built and more.
Everything in these articles is about [Arbington.com](https://arbington.com).
I'm keeping it relaxed and informal, but informative (hopefully!). I might throw in some jokes and humour - just remember if you don't laugh then the article disappears 👀
## What we'll highlight over the next series of posts
Let's dive right into this list, shall we?
Load the drum roll sound effect, please.
1. This post. The introduction!
2. How I decided which languages to code in
3. What frameworks did I use, and why?
4. Nothing can replace certain human tasks. Nothing.
5. How to handle credit card payments
6. APIs: Super important stuff here.
7. Hosting solutions and what we use
8. Tools and programs I use every day
9. Tool or programs I've built to get the job done, and automate months of work into just a few hours. You'll probably dig this one a lot, it's the most fun!
10. Who I would hire (developers), under which conditions, and why? Plus the juicy details in my mind about this.
## What is the startup and why I created it
This is context for all future posts. It's good to know the history and thoughts behind pretty much anything in life, so I'm going to data dump my thoughts on you here.
As mentioned before, this is all about [Arbington.com](https://arbington.com) - an EdTech startup designed to challenge the current solutions out there, like Udemy and Skillshare.
Why did I create _this_ startup, in EdTech, though?
Because I'm a student _and_ a teacher. I've taught over 500,000 people how to code over the years. And I've read thousands of blog posts, watched thousands of tutorial videos, and basically I'm a full time student in the Internet University.
I've been coding for over 20 years. And guess what? It should NOT have taken me 20 years to get this far.
I've worked with NASA and Mozilla, and a some other cool (re: big) organizations and I should have made it there faster.
And if I had an affordable solution to learn everything I needed, I would have gotten there in 4 years instead of 20.
But alas, the internet didn't do video last century. And online courses only recently become popular, so blogs and tutorials it was.
So basically.. I **wish** I had something like Arbington.com.
> I wish I had something like Arbington.com to help teach me coding faster to hit my life goals sooner.
Udemy is good for students, but nobody takes just 2 courses on Udemy and eventually it gets expensive, and nobody finishes courses on Udemy either (well, almost nobody). But Udemy treats their teachers worse than any other platform. A $199 course nets a teacher about $1. So I can't support them.
And thus, Arbington.com was born. We profit split with teachers more than any other platform, and it's an affordable monthly subscription.
Easy. as. pie.
Until the coding started.
Stay tuned for the next post about how I decided which programming languages to use, and why.
I'll throw some real life experience at you in the next one. | kalobtaulien |
887,303 | How to seamlessly exchange data between JavaScript environments | JSON limitations Wouldn't you find it strange if adults who are fluent in the same... | 0 | 2021-11-04T02:22:55 | https://dev.to/quantirisk/how-to-seamlessly-exchange-data-between-javascript-environments-32aa | javascript, node, deno, webdev | ---
title: How to seamlessly exchange data between JavaScript environments
published: true
description:
tags: javascript, node, deno, webdev
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/gvq8jbohqhzwihbnjv66.png
---
## JSON limitations
Wouldn't you find it strange if adults who are fluent in the same language spoke to each other using the vocabulary of a 3-year-old? Well, something analogous is happening when browsers and JavaScript servers exchange data using JSON, the de facto serialization format on the internet.
For example, if we wanted to send a `Date` object from a JavaScript server to a browser, we would have to:
1. Convert the `Date` object to a number.
2. Convert the number to a JSON string.
3. Send the JSON string to the browser.
4. Revert the JSON string to a number.
5. Realize the number represents a date.
6. Revert the number to a `Date` object.
This roundabout route seems ludicrous, because the browser and server both support the `Date` object, but is necessary, because JSON does not support the `Date` object.
In fact, JSON does not support most of the data types and data structures intrinsic to JavaScript.
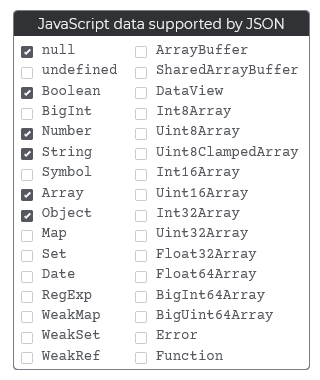
## JOSS as a solution
The aforementioned limitations of JSON motivated us to create the JS Open Serialization Scheme (JOSS), a new binary serialization format that supports almost all data types and data structures intrinsic to JavaScript.

JOSS also supports some often overlooked features of JavaScript, such as primitive wrapper objects, circular references, sparse arrays, and negative zeros. Please read the [official specification](https://github.com/quantirisk/joss/blob/main/SPECS.md) for all the gory details.
JOSS serializations come with the textbook advantages that binary formats have over text formats, such as efficient storage of numeric data and ability to be consumed as streams. The latter allows for JOSS serializations to be handled asynchronously, which we shall see in the next section.
## Reference implementation
The [reference implementation](https://github.com/quantirisk/joss) of JOSS is available to be downloaded as an [ES module](https://github.com/quantirisk/joss/raw/main/joss.min.js) (for browsers and Deno), [CommonJS module](https://github.com/quantirisk/joss/raw/main/joss.node.min.js) (for Node.js), and [IIFE](https://github.com/quantirisk/joss/raw/main/joss.iife.min.js) (for older browsers). It provides the following methods:
* `serialize()` and `deserialize()` to handle serializations in the form of static data.
* `serializable()`, `deserializable()`, and `deserializing()` to handle serializations in the form of readable streams.
To illustrate the syntax of the methods, allow us to guide you through an example in Node.js.
First, we import the CommonJS module into a variable called `JOSS`.
```javascript
// Change the path accordingly
const JOSS = require("/path/to/joss.node.min.js");
```
Next, we create some dummy data.
```javascript
const data = {
simples: [null, undefined, true, false],
numbers: [0, -0, Math.PI, Infinity, -Infinity, NaN],
strings: ["", "Hello world", "I \u2661 JavaScript"],
bigints: [72057594037927935n, 1152921504606846975n],
sparse: ["a", , , , , ,"g"],
object: {foo: {bar: "baz"}},
map: new Map([[new String("foo"), new String("bar")]]),
set: new Set([new Number(123), new Number(456)]),
date: new Date(),
regexp: /ab+c/gi,
};
```
To serialize the data, we use the `JOSS.serialize()` method, which returns the serialized bytes as a `Uint8Array` or `Buffer` object.
```javascript
const bytes = JOSS.serialize(data);
```
To deserialize, we use the `JOSS.deserialize()` method, which simply returns the deserialized data.
```javascript
const copy = JOSS.deserialize(bytes);
```
If we inspect the original data and deserialized data, we will find they look exactly the same.
```javascript
console.log(data, copy);
```
It should be evident by now that you can migrate from JSON to JOSS by replacing all occurrences of `JSON.stringify/parse` in your code with `JOSS.serialize/deserialize`.
### Readable Streams
If the data to be serialized is large, it is better to work with readable streams to avoid blocking the JavaScript event loop.
To serialize the data, we use the `JOSS.serializable()` method, which returns a readable stream from which the serialized bytes can be read.
```javascript
const readable = JOSS.serializable(data);
```
To deserialize, we use the `JOSS.deserializable()` method, which returns a writable stream to which the readable stream can be piped.
```javascript
const writable = JOSS.deserializable();
readable.pipe(writable).on("finish", () => {
const copy = writable.result;
console.log(data, copy);
});
```
To access the deserialized data, we wait for the piping process to complete and read the `result` property of the writable stream.
Whilst writable streams are well supported in Deno and Node.js, they are either not supported or not enabled by default in browsers at the present time.
To deserialize when we do not have recourse to writable streams, we use the `JOSS.deserializing()` method, which returns a `Promise` that resolves to the deserialized data.
```javascript
const readable2 = JOSS.serializable(data);
const promise = JOSS.deserializing(readable2);
promise.then((result) => {
const copy = result;
console.log(data, copy);
});
```
### Servers
In practice, we would serialize data to be sent in an outgoing HTTP request or response, and deserialize data received from an incoming HTTP request or response.
The [reference implementation](https://github.com/quantirisk/joss) page contains examples on how to use JOSS in the context of the [Fetch API](https://github.com/quantirisk/joss/#fetch-api"), [Deno HTTP server](https://github.com/quantirisk/joss/#deno-http-server), and [Node.js HTTP server](https://github.com/quantirisk/joss/#nodejs-http-server)</a>.
## Closing remarks
JOSS will evolve with the JavaScript specification. To keep track of changes to JOSS, please star or watch the [GitHub repository](https://github.com/quantirisk/joss).
| wynntee |
887,499 | JavaScript Loose Equality vs Strict Equality check | Hello Everyone! In this post we will explore the difference between JS loose equality (==) and... | 0 | 2021-11-04T06:10:40 | https://dev.to/swastikyadav/javascript-loose-equality-vs-strict-equality-check-5k2 | javascript, webdev, beginners, programming | Hello Everyone!
In this post we will explore the difference between JS **loose equality (==)** and **strict equality (===)** check.
Here is the simplest definition
- *Loose equality (==) checks for value only.*
- *Strict equality (===) checks for value as well as DataType.*
But wait, there is something more to it. Let's understand the workings of both of them one by one.
## Strict Equality (===)
Strict equality first checks for DataType, If datatype is same then it checks for value, else it returns false.
Ex:
```js
console.log("55" === 55);
// false - Because datatype is different even though value is same.
```
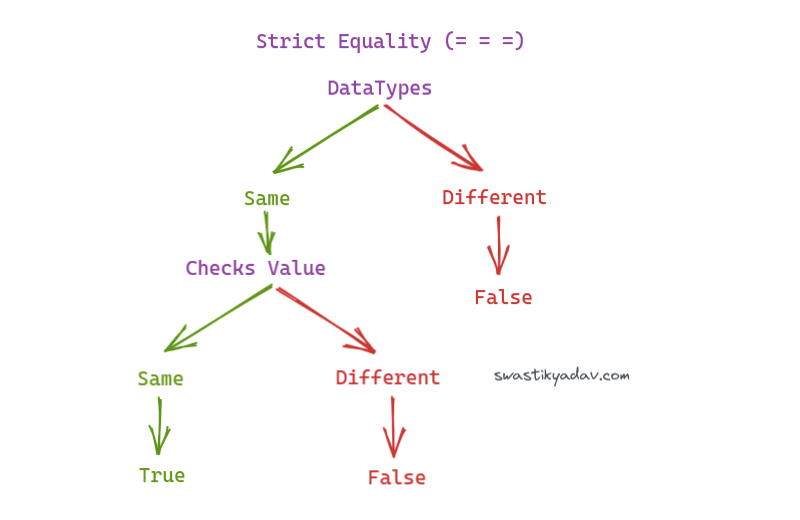
## Loose Equality (==)
Loose equality works similar to strict equality. The only difference is that in loose equality if datatype is different, it performs an **Implicit type conversion** and then compares the value.
Ex:
```js
console.log("55" == 55);
// true - Because implicit conversion will change string "55" to number 55 then compare value.
```
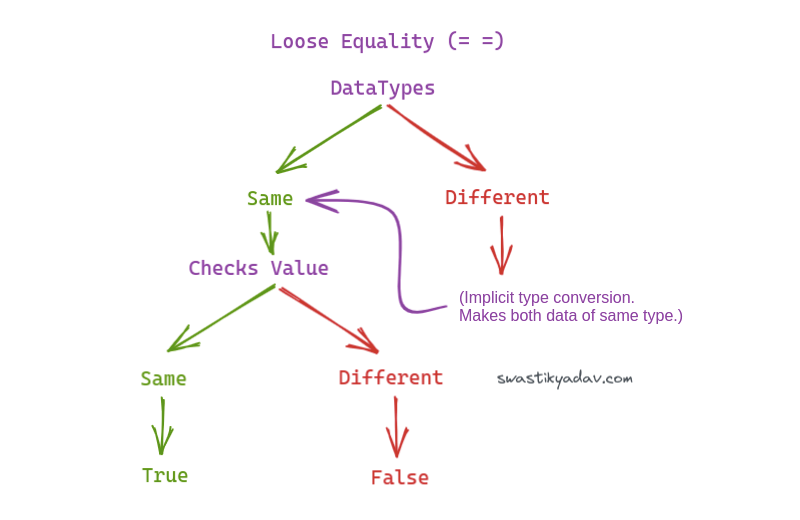
If you enjoyed or found this post helpful, please consider joining my weekly Newsletter below.
Thank You for reading.
--------------------------
I am starting a NewsLetter where I will share epic content on building your skillset. So, if this sounds interesting to you, subscribe here: https://swastikyadav.com | swastikyadav |
887,524 | Happy Diwali to all our friends in India 💖 | A post by Tabnine | 0 | 2021-11-04T07:46:39 | https://dev.to/tabnine/happy-diwali-to-all-our-friends-in-india-9n | tabnine | ||
887,830 | Coding is looking like fun after getting access to Copilot | Recently I got access to GitHub Copilot and its fun coding with Copilot. Loved the experience coding... | 0 | 2021-11-04T12:39:08 | https://dev.to/muhammadahsan/coding-is-looking-like-fun-after-getting-access-to-copilot-31kl | Recently I got access to GitHub Copilot and its fun coding with Copilot. Loved the experience coding with Copilot. | muhammadahsan | |
888,117 | Empleos en Data y Analytics LATAM — Nov. 2021 - I | Te compartimos las ofertas laborales del mes para áreas de Data, Analytics y Cloud 👨💻👩💻. ✅Data... | 0 | 2021-11-04T16:11:56 | https://dev.to/datapathformation/empleos-en-data-y-analytics-latam-nov-2021-i-57m6 | Te compartimos las ofertas laborales del mes para áreas de Data, Analytics y Cloud 👨💻👩💻.
✅[Data Analyst- Banco Pichincha (Ecuador)](https://ec.indeed.com/viewjob?jk=b307ec4fe5c94cc9&tk=1fjlrj61tn5ec800&from=serp&vjs=3)
✅[Data Scientist - Empresa Editora El Comercio S.A.(Perú)]
(https://pe.indeed.com/viewjob?jk=b982ce9ba56b8f7e&tk=1fjlr386uhim6800&from=serp&vjs=3)
✅[Data Scientist - NielsenIQ (Mexico)]
(https://mx.indeed.com/viewjob?jk=84423c86b384e9e0&tk=1fjlr6kn6t4h6800&from=serp&vjs=3)
✅[Data Analyst - Digitas (Argentina)]
(https://ar.indeed.com/viewjob?jk=e5f4eaa8c815fca7&tk=1fjlr9cbehip7800&from=serp&vjs=3)
✅[Machine Learning Analyst - BAXTER (Colombia)](https://co.indeed.com/viewjob?jk=d696bde2cdbd05e8&tk=1fjlrf3ebhim6804&from=serp&vjs=3)
✅[Data Engineer- 23people (Chile)](https://cl.indeed.com/ver-empleo?cmp=23people&t=Junior+midlevel+data+engineer&jk=a70f0e87720a81d6&q=Data+Engineer&vjs=3)
Aprende, aplica y crece en proyectos de Data y Analytics en Cloud.
Visita nuestra página:
👉🌐 datahack.la | datapathformation | |
888,202 | AWS vs OCI Object Storage options and comparison | We are starting putting some context: AWS - Amazon Web Service OCI - Oracle Cloud... | 0 | 2021-11-04T19:49:23 | https://dev.to/aernesto24/aws-vs-oci-object-storage-options-and-comparison-1o11 | aws, oci, cloud, objectstorage | We are starting putting some context:
1. **AWS** - Amazon Web Service
2. **OCI** - Oracle Cloud Infrastructure
3. **Object Storage** - data managed as object, where each of this object has a unique identifier and you access it using HTTP protocol.
___________________________________________________________
###What does Object Storage Refers to?
Object Storage has been one of the pillars of cloud infrastructure, and has help to decouple software from servers and file systems. It represents something similar a flat File System, so you will have virtually little limitations, this is ideal to store massive amount of data, we are talking about TBs and TBs of data, and you will be able to access each object using unique identifiers.
Other benefit of object storage is that you can store the data along with metadata for that object, you can apply certain actions based on that metadata. On the transport layer, there is no need for extra equipment, access is through HTTP protocol and using REST APIs, so basically you can **GET** an object or **PUT** an object inside a storage container (most of the cloud providers call this buckets).
___________________________________________________________
###AWS S3 vs OCI Object and archive Storage
Now, each cloud provider provides a flavor of this object storage services, here we are going to see a comparison between AWS S3 and OCI object and archive storage, and the end of this entry we see how we can make a simple operation on both using the CLI.
|Dimension | AWS | OCI |
| ----------- | ----------- | ----------- |
| **Container** | S3 are deployed inside a region |OCI storage buckets are deployed inside compartments |
| **Metadata tags** | yes, you can assign metadata tags to objects |yes, you can assign metadata tags to objects |
| **Object Size** | From 0B to 5Terabytes |As small as 0B or as large as 10 TiB |
| **Multipart upload** | Recommended for objects bigger than 100MB |Recommended for objects bigger than 100MB |
| **API Endpoint** | AWS S3 buckets are accessed using s3 API endpoints similar to this `http://bucket-name.s3-region.amazonaws.com` | It can be accessed through a dedicated regional API endpoint, The Native API endpoints are similar to this `https://objectstorage.<region-identifier>.oraclecloud.com` |
| **Storage Tiers** | S3 Standard, S3 Standard-InfrequentAccess, S3 One Zone-Infrequent Access for long-lived Amazon S3 Glacier and Amazon S3 Glacier Deep Archive |Standard Tier, Infrequent Access, Archive |
| **Auto Tiering** | Yes, called intelligent-tiering |Yes, called Auto-Tiering |
| **Reliability** | The S3 Standard storage class is designed for 99.99% availability, the S3 Standard-IA storage class and the S3 Intelligent-Tiering storage class are designed for 99.9% availability, the S3 One Zone-IA storage class is designed for 99.5% availability, and the S3 Glacier and S3 Glacier Deep Archive class are designed for 99.99% availability and an SLA of 99.9%. |The service is designed for 99.9% availability. Multiple safeguards have been built into the platform to monitor the health of the service to guard against unplanned downtime. *It makes no distinction between tiers apparently* |
| **Durability** | Amazon S3 Standard, S3 Standard–IA, S3 Intelligent-Tiering, S3 One Zone-IA, S3 Glacier, and S3 Glacier Deep Archive are all designed to provide 99.999999999% (11 9's) of data durability of objects over a given year |Oracle Object Storage is designed to be highly durable, providing 99.999999999% (Eleven 9's) of annual durability. It achieves this by storing each object redundantly across three servers in different availability domains for regions with multiple availability domains, and in different fault domains in regions with a single availability domain. |
| **Versioning** | yes, enabled at the bucket level, S3 preserves existing objects anytime you perform a PUT, POST, COPY, or DELETE operation on them |Yes, enabled on a bucket, data is not lost when an object is overwritten or when a versioning-unaware delete operation is performed. In both cases, the previous contents of the object are saved as a previous version of the object. |
| **Data access control** | Using IAM policies, bucket policies , Access control Lists, and Query String Authentication can be defined at the object level |IAM policies and set of permissions assigned to a group, only at the compartment or bucket level not the object level |
| **Encryption** | Server side using S3 key, using customer key or using KMS service, also support Client side encryption at the object, bucket level |server side encryption with customer provider key or master key stored on VAULT, also client side encryption is supported at the object and metadata level |
| **Auditing** | Yes you can audit access to s3 bucket using cloud trail bucket and object related |yes, Oracle Cloud Infrastructure Object Storage supports logging for bucket-related events, but not for object-related events. |
| **Cost** | For example, S3 standard, $0.023 per GB per month first 50TB* |For example, for object storage standard $0.0255 per GB per Month * |
**NOTES**
1. **OCI Compartment** is a collection of related resources, as for example compute instances, buckets, etc. typically deployed in a region. It can only be accessed by a group that has access to this compartment. Each account has a root compartment, and you can create child compartments.
2. **Multipart Upload** allows you to upload a single object as a set of parts. It must be applied using the SDK.
3. **Reliability** is the ability of a workload to perform its intended function correctly and consistently.
4. **Durability** is the probability that the object will remain intact and accessible after a period of one year.
'*' Price obtained at the date of publishing this entry
___________________________________________________________
###Examples for getting an object
###AWS
In order to retrieve an object from an AWS S3 object your user must be enabled to `s3:GetObject` and `s3:GetBucket` on IAM policy for the bucket and objects inside of it.
And you can execute a command similar to:
```
aws s3 cp --region ${REGION} s3://${S3BUCKET}/${OBJECT_NAME} .
```
###OCI
For OCI there is a slightly different approach
You will need to generate either a Pre-Authenticated request for read and write from this bucket
Generate a .pem file on your local machine
copy your key into the API-keys for that bucket
and execute the following command:
```
oci os object get -bn test-interchange-bucket-20211125 --file 16286.jpeg --name 1628612.jpeg
```
Where:
* --file is the filename that will obtain on your local computer
* --name is the name of the object inside the bucket
* -bn is the bucket name
*You must execute the command from the folder where your .pem file is stored
**NOTE** this commands will be expanded on further entries
___________________________________________________________
###Sources:
[S3 FAQs](https://aws.amazon.com/s3/faqs/)
[OCI Object Storage FAQs](https://www.oracle.com/cloud/storage/object-storage/faq/)
[Oracle Cloud Storage Pricing](https://www.oracle.com/cloud/storage/pricing/)
[Amazon S3 pricing](https://aws.amazon.com/s3/pricing/?trkCampaign=acq_paid_search_brand&sc_channel=PS&sc_campaign=acquisition_LATAMO&sc_publisher=Google&sc_category=Storage&sc_country=LATAMO&sc_geo=LATAM&sc_outcome=acq&sc_detail=s3%20pricing&sc_content={ad%20group}&sc_matchtype=e&sc_segment=536393996125&sc_medium=ACQ-P|PS-GO|Brand|Desktop|SU|Storage|S3|LATAMO|EN|Sitelink&s_kwcid=AL!4422!3!536393996125!e!!g!!s3%20pricing&ef_id=CjwKCAjwiY6MBhBqEiwARFSCPg0xsUDrKjIrdNHlgZw7SREuh1Dmu-SqKHuqMD_eSSXUpB1OMxSygBoCaM0QAvD_BwE:G:s&s_kwcid=AL!4422!3!536393996125!e!!g!!s3%20pricing)
[Copy Files To Oracle OCI Cloud Object Storage From Command Line](https://eclipsys.ca/copy-files-to-oracle-oci-cloud-object-storage-from-command-line/)
| aernesto24 |
890,251 | My Ideal App | Background I’ve been very fortunate to have a family who supports me financially through... | 0 | 2021-11-06T12:46:55 | https://dev.to/ejm5763/my-ideal-app-3g6o | #Background
I’ve been very fortunate to have a family who supports me financially through college, but once the pandemic hit I realized how important it is to learn about personal finance. I realized that I know nothing about investments, passive incomes, stocks, or really even serious budgeting. While I have a job secured for after graduation, I have realized that personal finance is something I need to begin learning. This is the main reason why my ideal app would be a game that would teach/develop personal finance.
#Idea
The main idea would to have various mini-games or several sections that players could choose between to enhance their skills in particular areas. I believe that it would be a simulation type game where if one would want to learn about the stock market, it would provide an interactive simulation to play through. I personally find that the best way to learn things like this is hands on learning, but not everyone has money to throw around in the real world which is why a simulation game like this would be ideal. Not only would programming this application potentially create a beneficial game for many others struggling with personal finance, but also it would give me the opportunity to get a deeper of knowledge on my own along the way.
#Extra
Like many others in programming, I have had many instances of imposter syndrome. Even without these occasional doubts, I’m honestly not sure if I could say exactly what I would want to do with my skill set. I feel that I have a wide range of interests and haven’t found an exact passion/niche in programming yet.
| ejm5763 | |
888,207 | Linting: Oxyclean for your code. | Why Lint & Prettify? It's easy to forget that writing code is a creative practice like... | 0 | 2021-11-04T18:23:01 | https://dev.to/andrewillomitzer/linting-oxyclean-for-your-code-5jg | opensource | ### Why Lint & Prettify?
It's easy to forget that writing code is a creative practice like many others. When working on your application, you have a style. It's not something anyone taught you (some of it like basic syntax sure), but we all have our own ways to indent, write conditional statements, among other things.
How would you explain your style to someone who hasn't seen you code before? Luckily, you don't have to when you use... ***static analysis*** tools.
### Tools For The Job
In my case, since the project is JavaScript based I have chosen [eslint](https://eslint.org/), and [Prettier](https://prettier.io/) as the formatting and style guide tools. I chose them due to the popularity, and variety of setup guides which allows me to customize how I want.
### Prettier Setup
To set up Prettier, you will need to install the package from [npm](https://www.npmjs.com/package/prettier) and using the instructions from [Prettier Install Docs](https://prettier.io/docs/en/install.html). This will set you up with a `.prettierrc.json` file. In this file is where you will set all the [configuration options](https://prettier.io/docs/en/options.html) for your Prettier formatting.
Once the initial setup is done, you can choose which files to ignore by either creating a `.prettierignore` file, or inputting which file to use as a base when you run the command using `--ignore-path` CLI argument.
### eslint setup
To set up eslint, you can go to the [getting started](https://eslint.org/docs/user-guide/getting-started) page which will show how to create a config file similar to Prettier. It also demonstrates how to set basic rules to get your linting started. More advanced configurations are available but getting started... gets you started.
Similar to Prettier, you can create an ***`.eslintignore`*** or specify --ignore-path when you run the `npm run eslint` command.
### How do I do that anyway?
* Open package.json
* Create a new property under scripts called `"lint"`, and set the value to "npm run eslint"
* Save the file and run `npm run lint`!
#### Bonus: .vscode config folder
* Create a folder called `.vscode` in your project root directory.
* This folder can contain many files, but an example of one is `settings.json` where you can set the rules for your VSCode editor such as auto-format on save, tab indenting, and more.
### What did it find in my own code?
Having set up linting/formatting in my own SSG called [textToHTML](https://github.com/AndreWillomitzer/textToHTML_V2), [commit link](https://github.com/AndreWillomitzer/textToHTML_V2/commit/f9591ce0215c88c7da3b54bc34cc5cd704e937d4), I was curious what it would find.
Mostly, it found spacing and line length issues. For example, when I generated my HTML template string, it split the string into multiple template strings separated by `+`. Another thing I noticed was since I specified `"semi": true` in the aforementioned config files, it added a couple missing semi-colons to the end of variable declarations.
In terms of indenting/spacing nothing changed because I try to keep a consistent style and I set the rules up to match my own style (since I'm the project owner).
### Moving Forward
This was a great experience learning how to set up linting and formatting because in the future it will help others work on my project without having to ask how I want it done. I also now know how to set it up for future projects and where to find the setup docs. | andrewillomitzer |
888,371 | Fastest way to learn Web dev | If you search in the wab about full stack web development then you might get a complex roadmap for... | 0 | 2021-11-04T18:58:30 | https://dev.to/snehendu_roy_/fastest-way-to-learn-web-dev-2ac3 | javascript, webdev | If you search in the wab about full stack web development then you might get a complex roadmap for that. But is that actually true? Is the roadmap too complex?
Well the answer to both of the question is "NO". Even you might get a complex roadmap where many things are not even needed.
Now what is the actual roadmap? How many languages to learn?
So the roadmap is very simple.
Learn HTML CSS and JavaScript at first and master JavaScript very nicely. You don't need to learn any other programming language rather than JavaScript. After HTML, CSS, JavaScript, learn node.js and mongo DB as database.
That's it. If you dedicate at least 9 hours per day then it will take about 2 months being an awesome programmer. | snehendu_roy_ |
888,409 | 7 Proven Virtual Team Building Activities | It is a challenge to find ways to bring our virtual team closer together. I tested more than 100... | 0 | 2021-11-04T21:01:16 | https://remoteful.dev/blog/virtual-team-building-activities-ideas | remotejobs, remotework, remote, job | It is a challenge to find ways to bring our virtual team closer together. I tested more than 100 **virtual team-building activities (ideas)** and have selected only 10 among them that must help deepen bonds within the team and increase productivity for remote employees.
**Believe me, these 10 virtual team building activities (ideas) will work for any company with remote employees. Cheers!**
Employees will not feel any loneliness and disconnection from their colleagues when they work virtually. This can remind remote workers of all the fantastic individuals who are behind them.
Virtual team building for remote teams is much different from in-person team building.
In this article, we'll explore **how these 7 activities can benefit your team.**
Just keep reading.
## Virtual team building activities ideas:Informal virtual meetups:
You can organize a virtual meetup twice a month. Invite your remote employees to participate in them and may organize different team-building games like “Guess Whose Desk Is It”, picture-sharing rounds, etc.
Team members will feel that they know each other even if they have not met face to face.
## Happy hours on Zoom:
You can schedule a happy hour on Zoom each week.
It is a time when your remote employees can just chat about things other than work. In this way, team bonding will increase.
## Two truths and a falsehood
It’s a classic icebreaker activity. Each member of the team will make three statements about themselves. They will make two statements about themselves that are true and one will be intentionally false.
The group can then take turns identifying what is true and what is a lie. After that, the speaker reveals their lie.
You can make the game more competitive and even more fun with a point system. Those who identify the statements (true or false) accurately will get points that will be recorded digitally.
The person whose guess is more accurate will win. This virtual team-building activity (idea) can keep the minds of the remote employees strong.
## Record the company’s events:
It is true that remote employees are unable to attend important company events most of the time. As a result, remote employees may feel left out.
Besides this, they are unable to see the different team performances and their contribution to the company.
This can lead to dissatisfaction and less productivity at work.
Now, how can you fix this for your remote employees?
Just record company events and upload them to the employee channel.
For example, your organization is planning to set up a booth at an event in order to attract more customers. To show your virtual team members what's going on, record the event or provide a live video stream.
If you achieve a large success, make a video call to celebrate it and be sure to congratulate the contributing team members on their efforts.
Your remote employees will be able to monitor how their efforts contribute to the company's progress. I think it’s one of the great ideas of virtual team-building activities.
They will not feel left out. Rather, they will be motivated to put more effort into their future company’s work. Cheers!
## Daily snapshots:
It can be one of the best **virtual team-building activities (ideas). **This is one of the easiest ideas to make your virtual team stronger. You can encourage your team members to post a picture daily and bond with them through a regular insight into their lives.
It can be their lunch picture or the new dresses they are wearing or loving.
Team members will comment on those pictures and get a conversation going. It's a quick and easy approach to have a non-work related conversation daily with different team members.
## Virtual team building games:
We can discover teammates' hidden skills and thinking processes in a fun and unique way through **virtual team-building games.**
If you work hard, then play harder. I think games are fun and engaging ways for teams to get together with a little friendly competition.
An online office game can be a great break from the workday, and it is an opportunity to show off the creative side and encourage out-of-the-box thinking.
An online office game can connect the different team members with fun.
There are lots of opportunities to play **virtual team-building games** online that already have built-in social spaces. You can help your team members to navigate challenging levels.
It's a great way to grow "helping mentalities" within the virtual team.
## Remote team dinner:
Can you do it? Yes, you can do it with your remote teams.
Trust me; it’s a great stress-busters. Hosting team luncheons, dinners, and other events is an excellent way to get to know your remote team members.
Simply gather your team members on a video call for a meal and chat while eating. But your chatting should be non-work-related. It’s an excellent way to relax and bond with them.
## Some frequently asked questions about virtual team building activities:
**Q: What is virtual team building?**
**Answer:** Virtual team building is a set of activities to keep teams connected in a virtual environment. These activities include bringing unity to the team, building trust among team members, and making employees forget they’re not physically together.
Q: How do **virtual team building activities** work?
**Answer: Virtual team building activities** help to create human-to-human connections amongst the remote employees. It helps to increase remote employees’ productivity and communication among them. These activities also promote team harmony and help minimize the negative impact of online workplace cultures.
**Q: What are some challenges to forming a virtual team?**
**Answer:** There are some common challenges you may face at the time of implementing **virtual team building activities (ideas).** Such as, you may face a problem scheduling a meeting across different time zones. Beside this, unreliable technology, lack of participation and engagement are the common challenges.
**Q: How to start a virtual team building activity?**
**Answer:** First of all, you need to have a deep understanding of how to make virtual events successful. Secondly, you need creativity, some good ideas (you can follow the ideas that I have already shared in this article) and reliable technology and then you can start.
**Q: What indicators will tell me that my virtual activity was successful?**
**Answer:** A survey can be a great tool to measure. Request participants to provide honest feedback and use that feedback to improve future events.
There is another indirect indicator that you can use. You can gauge this by observing the participation and engagement during the event.
## Conclusion:
If you apply one or more of the tested activities that I have covered in this article to your virtual team, I am sure; you will be able to bring your virtual team closer. All of these are proven **virtual team-building activities (ideas).** Any company can apply these, and they will see guaranteed success**: no** more loneliness, no more disconnections, and no more stress.
[REMOTEful - Look for REMOTE jobs.](https://remoteful.dev/) | ryy |
888,568 | Building a Voice Assistant using Web Speech API | Hi there👋, In this guide we will be learning how to integrate voice user interface in our web... | 0 | 2021-11-05T15:18:02 | https://dev.to/roopalisingh/building-a-voice-assistant-3g09 | javascript, webdev, react, tutorial | Hi there👋,
In this guide we will be learning how to integrate **voice user interface** in our web application.
We are working with `React`. To incorporate Voice User Interface (`VUI`) we will use `Web Speech API`.
For simplicity we will not be focusing on design.
_Our aim is to build a **voice assistant** which will recognize what we say and answer accordingly._

For this we are using **Web Speech API**.
This API allows fine control and flexibility over the speech recognition capabilities in Chrome version 25 and later.
The `Web Speech API` provides us with two functionality —
* **Speech Recognition** which converts `speech to text`.
* **Speech Synthesis** which converts `text to speech`.
<span>1.</span> We will start by installing two npm packages:
```javascript
// for speech recognition
npm i react-speech-recognition
// for speech synthesis
npm i react-speech-kit
```
Now before moving on to the next step, let's take a look at some important functions of `Speech Recognition`.
**Detecting browser support for Web Speech API**
```javascript
if (!SpeechRecognition.browserSupportsSpeechRecognition()) {
//Render some fallback function content
}
```
**Turning the microphone on**
```javascript
SpeechRecognition.startListening();
```
**Turning the microphone off**
```javascript
// It will first finish processing any speech in progress and
// then stop.
SpeechRecognition.stopListening();
// It will cancel the processing of any speech in progress.
SpeechRecognition.abortListening();
```
**Consuming the microphone transcript**
```javascript
// To make the microphone transcript available in our component.
const { transcript } = useSpeechRecognition();
```
**Resetting the microphone transcript**
```javascript
const { resetTranscript } = useSpeechRecognition();
```
**Now we're ready to add Speech Recognition (`text to speech`) in our web app 🚀**
<span>2.</span> In the `App.js` file, we will check the support for `react-speech-recognition` and add two components **StartButton** and **Output**.
The `App.js` file should look like this for now:
```javascript
import React from "react";
import StartButton from "./StartButton";
import Output from "./Output";
import SpeechRecognition from "react-speech-recognition";
function App() {
// Checking the support
if (!SpeechRecognition.browserSupportsSpeechRecognition()) {
return (
<div>
Browser does not support Web Speech API (Speech Recognition).
Please download latest Chrome.
</div>
);
}
return (
<div className="App">
<StartButton />
<Output />
</div>
);
}
export default App;
```
<span>3.</span> Next we will move to the `StartButton.js` file.
Here we will add a toggle button to start and stop listening.
```javascript
import React, { useState } from "react";
function StartButton() {
const [listen, setListen] = useState(false);
const clickHandler = () => {
if (listen === false) {
SpeechRecognition.startListening({ continuous: true });
setListen(true);
// The default value for continuous is false, meaning that
// when the user stops talking, speech recognition will end.
} else {
SpeechRecognition.abortListening();
setListen(false);
}
};
return (
<div>
<button onClick={clickHandler}>
<span>{listen ? "Stop Listening" : "Start Listening"}
</span>
</button>
</div>
);
}
export default StartButton;
```
<span>4.</span> Now in the `Output.js` file, we will use `useSpeechRecognition` react hook.
`useSpeechRecognition` gives a component access to a transcript of speech picked up from the user's microphone.
```javascript
import React, { useState } from "react";
import { useSpeechRecognition } from "react-speech-recognition";
function Output() {
const [outputMessage, setOutputMessage] = useState("");
const commands = [
// here we will write various different commands and
// callback functions for their responses.
];
const { transcript, resetTranscript } =
useSpeechRecognition({ commands });
return (
<div>
<p>{transcript}</p>
<p>{outputMessage}</p>
</div>
);
}
export default Output;
```
<span>5.</span> Before defining the commands, we will add `Speech Synthesis` in our web app to convert the **outputMessage to speech**.
In the `App.js` file, we will now check the support for the `speech synthesis`.
```javascript
import { useSpeechSynthesis } from "react-speech-kit";
funtion App() {
const { supported } = useSpeechSynthesis();
if (supported == false) {
return <div>
Browser does not support Web Speech API (Speech Synthesis).
Please download latest Chrome.
</div>
}
.
.
.
export default App;
```
<span>6.</span> Now in the `Output.js` file, we will use `useSpeechSynthesis()` react hook.
But before moving on, we first take a look at some important functions of `Speech Synthesis`:
* _**speak()**: Call to make the browser read some text._
* _**cancel()**: Call to make SpeechSynthesis stop reading._
We want to call the `speak()` function each time the **outputMessage** is changed.
So we would add the following lines of code in `Output.js` file:
```javascript
import React, { useEffect, useState } from "react";
import { useSpeechSynthesis } from "react-speech-kit";
function Output() {
const [outputMessage, setOutputMessage] = useState("");
const { speak, cancel } = useSpeechSynthesis();
// The speak() will get called each time outputMessage is changed
useEffect(() => {
speak({
text: outputMessage,
});
}, [outputMessage]);
.
.
.
export default Output;
}
```
**😃Whoa!**
_Everything is now setup_ 🔥
_The only thing left is to define our **commands**_ 👩🎤

<span>7.</span> Now we're back at our `Output.js` file to complete our commands.
```javascript
const commands = [
{
// In this, the words that match the splat(*) will be passed
// into the callback,
command: "I am *",
callback: (name) => {
resetTranscript();
setOutputMessage(`Hi ${name}. Nice name`);
},
},
// DATE AND TIME
{
command: "What time is it",
callback: () => {
resetTranscript();
setOutputMessage(new Date().toLocaleTimeString());
},
matchInterim: true,
// The default value for matchInterim is false, meaning that
// the only results returned by the recognizer are final and
// will not change.
},
{
// This example would match both:
// 'What is the date' and 'What is the date today'
command: 'What is the date (today)',
callback: () => {
resetTranscript();
setOutputMessage(new Date().toLocaleDateString());
},
},
// GOOGLING (search)
{
command: "Search * on google",
callback: (gitem) => {
resetTranscript();
// function to google the query(gitem)
function toGoogle() {
window.open(`http://google.com/search?q=${gitem}`, "_blank");
}
toGoogle();
setOutputMessage(`Okay. Googling ${gitem}`);
},
},
// CALCULATIONS
{
command: "Add * and *",
callback: (numa, numb) => {
resetTranscript();
const num1 = parseInt(numa, 10);
const num2 = parseInt(numb, 10);
setOutputMessage(`The answer is: ${num1 + num2}`);
},
},
// CLEAR or STOP.
{
command: "clear",
callback: () => {
resetTranscript();
cancel();
},
isFuzzyMatch: true,
fuzzyMatchingThreshold: 0.2,
// isFuzzyMatch is false by default.
// It determines whether the comparison between speech and
// command is based on similarity rather than an exact match.
// fuzzyMatchingThreshold (default is 0.8) takes values between
// 0 (will match anything) and 1 (needs an exact match).
// If the similarity of speech to command is higher than this
// value, the callback will be invoked.
},
]
```
**😃We have successfully built a `voice assistant` using the `Web Speech API` that do as we say 🔥🔥**
> **Note:** As of May 2021, browsers support for `Web Speech API`:
> * Chrome (desktop)
> * Chrome (Android)
> * Safari 14.1
> * Microsoft Edge
> * Android webview
> * Samsung Internet
>
> For all other browsers, you can integrate a `polyfill`.
###_Here's a demo that I have made with some styling:_
###_I call it [Aether](https://the-aether.netlify.app/)_
 | roopalisingh |
888,582 | 100 días de código: { Day: 3}, viento en popa con la actualización de mi portfolio #100DaysOfCode | Bienvenidos! 🎉 Deseo que estés teniendo un día increíble y si no es asi que ahora mejore. Hoy me... | 0 | 2021-11-05T01:10:48 | https://dev.to/darito/100-dias-de-codigo-day-3-viento-en-popa-con-la-actualizacion-de-mi-portfolio-100daysofcode-3b4n | spanish, webdev, figma, 100daysofcode | Bienvenidos! 🎉
Deseo que estés teniendo un día increíble y si no es asi que ahora mejore.
Hoy me decante mas por continuar el diseño de mi portfolio que por la codificación y no me arrepiento ya que creo es algo importante con lo que conviven los desarrolladores web front-end.
Comencé a estudiar algunos principios de diseño para mejorar mis habilidades como los principios de Gestalt de los cuales puedes aprender un poco [Leyes de Gestalt](https://www.uifrommars.com/principios-gestalt-diseno-web/) y despues de ello estuve navegando por la web para inspirarme un poco.
Aunque por el reto obviamente no podía dejar la codificación de lado y ya que aun desconozco bastante el desarrollo backend asi que aprendiendo lo básico sobre Nodejs y Express.
Es muy interesante todo el ecosistema de desarrollo y cada que encuentro algo nuevo me emociono bastante.

Ahora si sigamos con la sección regular =>
### Ayer:
- Diseñe los wireframes de las secciones principales de mi pagina web.
- Comencé a practicar testing con Jest.
- Aprendí test asíncrono y síncrono con Jest.
- Aprendí a agrupar test con la función de Jest `describe`
- Aprendí que los métodos de Jest `beforeEach()` y `afterEach()` se ejecutan antes y despues de cada test respectivamente y que los métodos como `beforeAll()` y `afterAll()` te permiten ejecutar código antes y despues de todos los testeos, respectivamente.
### Hoy:
- Diseñe algunos componentes de la interfaz móvil de mi portfolio.
- Aprendí que en diseño normalmente se crean paletas de color y de esas paletas se obtienen distintos tintes y sombras de cada color de la paleta.
- Aprendí las leyes de Gestalt las cuales son: Ley de figura y fondo, de semejanza, de proximidad, de la continuidad, de simetría o dirección común, de la simplicidad y ley de la continuidad.
- Aprendí a crear un servidor y a ejecutarlo en desarrollo.
- Aprendí las peticiones `http` como son `post`, `get`, `put` y `delete` con express en un servidor de nodejs.
Y esto es todo por hoy, la verdad ha sido un día algo interesante.
Recuerden que esto **no es una guía**.
Que tengan una buena noche, éxito en todas sus cositas y hasta mañana. 🎉
| darito |
888,601 | Implement Clean Architecture on .NET | In this article we are going to learn an introduction about Clean Architecture on .NET. We are going... | 15,988 | 2021-11-05T03:48:06 | https://dev.to/cristofima/implement-clean-architecture-on-net-59eo | dotnet, architecture, efcore, api | In this article we are going to learn an introduction about Clean Architecture on .NET. We are going to create 3 projects (Application Core, Infrastructure and Web Api).
You can find the slides [here](https://es.slideshare.net/cristophercoronado7/introduccin-a-clean-architecture-en-netpptx).
##Prerequisites:
- Visual Studio 2022 with .NET 6 SDK
- SQL Server Database
#1. Create Application Core project
Create a blank solution named "StoreCleanArchitecture" and add a solution folder named "src", inside this create a "Class library project" (create the src folder the directory project as well) with .NET Standard 2.1
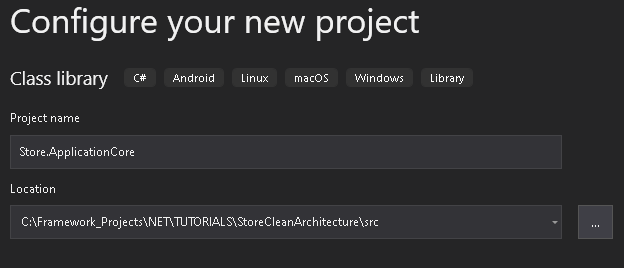
Create the following folders:
Install AutoMapper.Extensions.Microsoft.DependencyInjection.
Create DependencyInjection class.
```csharp
using Microsoft.Extensions.DependencyInjection;
using System.Reflection;
namespace Store.ApplicationCore
{
public static class DependencyInjection
{
public static IServiceCollection AddApplicationCore(this IServiceCollection services)
{
services.AddAutoMapper(Assembly.GetExecutingAssembly());
return services;
}
}
}
```
In Entities folder, create Product class.
```csharp
using System;
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
namespace Store.ApplicationCore.Entities
{
public class Product
{
[DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public int Id { get; set; }
[MaxLength(30)]
public string Name { get; set; }
public string Description { get; set; }
public int Stock { get; set; }
public double Price { get; set; }
public DateTime CreatedAt { get; set; }
public DateTime UpdatedAt { get; set; }
}
}
```
In DTOs folder, create Product class to specify the requests and response.
```csharp
using System;
using System.ComponentModel.DataAnnotations;
namespace Store.ApplicationCore.DTOs
{
public class CreateProductRequest
{
[Required]
[StringLength(30, MinimumLength = 3)]
public string Name { get; set; }
[Required]
public string Description { get; set; }
[Required]
[Range(0.01, 1000)]
public double Price { get; set; }
}
public class UpdateProductRequest : CreateProductRequest
{
[Required]
[Range(0, 100)]
public int Stock { get; set; }
}
public class ProductResponse
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public int Stock { get; set; }
public double Price { get; set; }
}
}
```
In Mappings folder, create GeneralProfile class. This is useful to map automatically from the Request to the Entity and from the Entity to the Response.
```csharp
using AutoMapper;
using Store.ApplicationCore.DTOs;
using Store.ApplicationCore.Entities;
namespace Store.ApplicationCore.Mappings
{
public class GeneralProfile : Profile
{
public GeneralProfile()
{
CreateMap<CreateProductRequest, Product>();
CreateMap<Product, ProductResponse>();
}
}
}
```
In Interfaces folder, create IProductRepository interface. Here we create the methods for the CRUD.
```csharp
using Store.ApplicationCore.DTOs;
using System.Collections.Generic;
namespace Store.ApplicationCore.Interfaces
{
public interface IProductRepository
{
List<ProductResponse> GetProducts();
ProductResponse GetProductById(int productId);
void DeleteProductById(int productId);
ProductResponse CreateProduct(CreateProductRequest request);
ProductResponse UpdateProduct(int productId, UpdateProductRequest request);
}
}
```
In Exceptions folder, create NotFoundException class.
```csharp
using System;
namespace Store.ApplicationCore.Exceptions
{
public class NotFoundException : Exception
{
}
}
```
In Utils folder, create DateUtil class.
```csharp
using System;
namespace Store.ApplicationCore.Utils
{
public class DateUtil
{
public static DateTime GetCurrentDate()
{
return TimeZoneInfo.ConvertTimeFromUtc(DateTime.UtcNow, TimeZoneInfo.Local);
}
}
}
```
#2. Create Infrastructure project
Create a "Class library project" with .NET 6, named Store.Infrastructure.
Create the following structure:

Install Microsoft.EntityFrameworkCore.SqlServer.
Right click on Store.Infrastucture project / Add / Project Reference ... / Check Store.ApplicationCore / OK
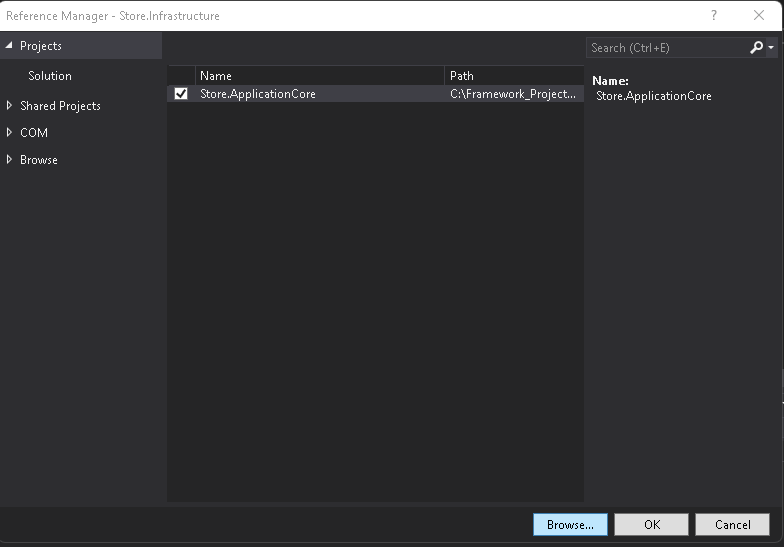
In Contexts folder, create StoreContext class. Here we add Product entity to the DbSets in order to communicate with the database to the Products table.
```csharp
using Microsoft.EntityFrameworkCore;
using Store.ApplicationCore.Entities;
namespace Store.Infrastructure.Persistence.Contexts
{
public class StoreContext : DbContext
{
public StoreContext(DbContextOptions<StoreContext> options) : base(options)
{
}
public DbSet<Product> Products { get; set; }
}
}
```
In Repositories folder, create ProductRepository class.
```csharp
using AutoMapper;
using Store.ApplicationCore.DTOs;
using Store.ApplicationCore.Entities;
using Store.ApplicationCore.Exceptions;
using Store.ApplicationCore.Interfaces;
using Store.ApplicationCore.Utils;
using Store.Infrastructure.Persistence.Contexts;
using System.Collections.Generic;
using System.Linq;
namespace Store.Infrastructure.Persistence.Repositories
{
public class ProductRepository : IProductRepository
{
private readonly StoreContext storeContext;
private readonly IMapper mapper;
public ProductRepository(StoreContext storeContext, IMapper mapper)
{
this.storeContext = storeContext;
this.mapper = mapper;
}
public ProductResponse CreateProduct(CreateProductRequest request)
{
var product = this.mapper.Map<Product>(request);
product.Stock = 0;
product.CreatedAt = product.UpdatedAt = DateUtil.GetCurrentDate();
this.storeContext.Products.Add(product);
this.storeContext.SaveChanges();
return this.mapper.Map<ProductResponse>(product);
}
public void DeleteProductById(int productId)
{
var product = this.storeContext.Products.Find(productId);
if (product != null)
{
this.storeContext.Products.Remove(product);
this.storeContext.SaveChanges();
}
else
{
throw new NotFoundException();
}
}
public ProductResponse GetProductById(int productId)
{
var product = this.storeContext.Products.Find(productId);
if (product != null)
{
return this.mapper.Map<ProductResponse>(product);
}
throw new NotFoundException();
}
public List<ProductResponse> GetProducts()
{
return this.storeContext.Products.Select(p => this.mapper.Map<ProductResponse>(p)).ToList();
}
public ProductResponse UpdateProduct(int productId, UpdateProductRequest request)
{
var product = this.storeContext.Products.Find(productId);
if (product != null)
{
product.Name = request.Name;
product.Description = request.Description;
product.Price = request.Price;
product.Stock = request.Stock;
product.UpdatedAt = DateUtil.GetCurrentDate();
this.storeContext.Products.Update(product);
this.storeContext.SaveChanges();
return this.mapper.Map<ProductResponse>(product);
}
throw new NotFoundException();
}
}
}
```
In DependencyInjection class, add the following:
```csharp
using Microsoft.EntityFrameworkCore;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Store.ApplicationCore.Interfaces;
using Store.Infrastructure.Persistence.Contexts;
using Store.Infrastructure.Persistence.Repositories;
namespace Store.Infrastructure
{
public static class DependencyInjection
{
public static IServiceCollection AddInfrastructure(this IServiceCollection services, IConfiguration configuration)
{
var defaultConnectionString = configuration.GetConnectionString("DefaultConnection");
services.AddDbContext<StoreContext>(options =>
options.UseSqlServer(defaultConnectionString));
services.AddScoped<IProductRepository, ProductRepository>();
return services;
}
}
}
```
There we are configuring the db context and adding IProductRepository to the services collection as Scoped.
#3. Create Web Api project
Create a "Web Api project" with .NET 6, named Store.WebApi.
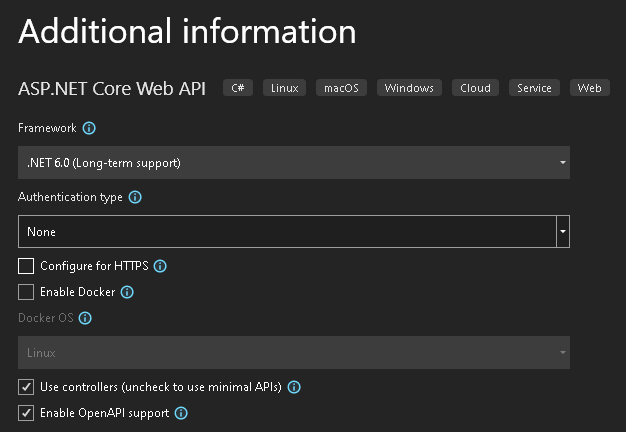
Right click on Store.WebApi / Set as Startup project.
At the top, click on Debug / Start Without Debugging.
Remove WeatherForecast and WeatherForecastController files.
Add the references to the Store.ApplicationCore and Store.Infrastructure projects.
Add the connection string to SQL Server in appsettings.json
```json
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft": "Warning",
"Microsoft.Hosting.Lifetime": "Information"
}
},
"AllowedHosts": "*",
"ConnectionStrings": {
"DefaultConnection": "Server=localhost;Database=DemoStore;Trusted_Connection=True;"
}
}
```
In Program class, add the extensions for Application Core and Infrastructure.
```csharp
using Microsoft.AspNetCore.Builder;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Store.ApplicationCore;
using Store.Infrastructure;
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddApplicationCore();
builder.Services.AddInfrastructure(builder.Configuration);
builder.Services.AddControllers();
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
var app = builder.Build();
// Configure the HTTP request pipeline.
if (app.Environment.IsDevelopment())
{
app.UseSwagger();
app.UseSwaggerUI();
}
app.UseAuthorization();
app.MapControllers();
app.Run();
```
Open Package Manager Console and select Store.Infrastructure project as default. Execute `Add-Migration InitialCreate -Context StoreContext`.

In Store.Infrastructure project, a Migrations folder with 2 files inside were created.
Then, from the Package Manager Console, execute `Update-Database`.
From Controllers, add a controller named ProductsController
```csharp
using Microsoft.AspNetCore.Mvc;
using Store.ApplicationCore.DTOs;
using Store.ApplicationCore.Exceptions;
using Store.ApplicationCore.Interfaces;
using System.Collections.Generic;
namespace Store.WebApi.Controllers
{
[Route("api/[controller]")]
[ApiController]
public class ProductsController : Controller
{
private readonly IProductRepository productRepository;
public ProductsController(IProductRepository productRepository)
{
this.productRepository = productRepository;
}
[HttpGet]
public ActionResult<List<ProductResponse>> GetProducts()
{
return Ok(this.productRepository.GetProducts());
}
[HttpGet("{id}")]
public ActionResult GetProductById(int id)
{
try
{
var product = this.productRepository.GetProductById(id);
return Ok(product);
}
catch (NotFoundException)
{
return NotFound();
}
}
[HttpPost]
public ActionResult Create(CreateProductRequest request)
{
var product = this.productRepository.CreateProduct(request);
return Ok(product);
}
[HttpPut("{id}")]
public ActionResult Update(int id, UpdateProductRequest request)
{
try
{
var product = this.productRepository.UpdateProduct(id, request);
return Ok(product);
}
catch (NotFoundException)
{
return NotFound();
}
}
[HttpDelete("{id}")]
public ActionResult Delete(int id)
{
try
{
this.productRepository.DeleteProductById(id);
return NoContent();
}
catch (NotFoundException)
{
return NotFound();
}
}
}
}
```
Now, you can test the API.
You can find the source code [here](https://github.com/cristofima/StoreCleanArchitecture-NET/releases/tag/v2.0.0).
**Thanks for reading**
Thank you very much for reading, I hope you found this article interesting and may be useful in the future. If you have any questions or ideas that you need to discuss, it will be a pleasure to be able to collaborate and exchange knowledge together. | cristofima |
888,821 | Introducing UFOs. The undeniable proof that good UX is out here. | A good user experience (UX) and a solid user interface (UI) shouldn't be out of reach for any app.... | 15,344 | 2021-11-05T07:24:06 | https://updivision.com/blog/post/introducing-ufos-the-undeniable-proof-that-good-ux-is-out-here | ux, uiweekly, design | A good user experience (UX) and a solid user interface (UI) shouldn't be out of reach for any app. UI/UX best practices is not something that just exists “out there”, alien to development and real life. They are tools you can use. And that can make a big difference in the usability and overall success of your app.
Good UI cannot exist without good UX. The way components - dropdowns, datepickers, input fields etc., navigations or entire sections of an app look and feel (the UI) is directly impacted by the way they are meant to be used (the UX).
At UPDIVISION, we've been building complex web and mobile apps for over ten years. Based on thousands of hours of design meetings and feedback, we've organized what we`ve learned into a 3+1 UI/UX framework, called UFOs. You can use this framework to better understand how the UI/UX process works, what to expect and what are reasonable goals to have. And, last but not least, you can use it to build great apps, the kind your users deserve.

The truth is out here:
* **Understanding** - good UI/UX design solves real-life problems. This means understanding both the industry aspects and the user aspects of the software you`re building. What similar software is there on the market? How does the intended purpose of the app change the UX approach, e.g. SaaS versus software used internally by a company for their own teams?
* **Foundation** - these are the things no app can do without. From layouting to grids and general navigation, this is the backbone of the UI/UX design process.
* **Original design & functionality** - good design stands out. This component of the framework addresses everything from the small touches that can improve an app`s overall look & feel to heavily customized features.
* **stress testing** - good design doesn't break. It does what it's supposed to do and it makes it easier for users to accomplish their tasks and reach their goals. This last step is all about getting feedback on your UI from stakeholders and testing it with your end users. Sometimes this might send you back to the drawing board, but iteration is at the heart of good UX.
Last, but not least, the UFOs UI/UX Framework is here to dispel two myths. We can't really say if aliens exist or not, but we can say for sure that:
1. The best designers don`t ask “How?”, they always ask “Why?”. “How” only begs the question and reinforces existing ways of thinking. “Why” is the question which kicks off real brainstorming. And has led to some of the best ideas in history.
2. Beautiful design which is hard to use is just as bad as a bad design. It's time to take art out of UI/UX design and put some craft into it.
Each component of the UFOs UI/UX Framework is addressed in a series of articles. The list will be constantly updated in the menu below as we publish new articles.
**U**nderstanding
Ask “Why”, not “How”. The mindset shift for creating powerful apps
How to talk the walk. Understand the app you need to build through preliminary interviews
**F**oundation
Design workflows: getting your s**t together in Figma
The anatomy of a UI Kit. What it is and how to use it in Figma
**O**riginal design & functionality
Heavy-duty UI design. Tips & tricks for designing data-heavy apps
**s**tress testing
Coming soon | updivision |
889,080 | Let's create our own Vue JS plugin | Let's write a custom Vue Plugin. How hard could it be? If you're using Vue JS for a while then you... | 0 | 2021-11-05T13:10:51 | https://dev.to/0shuvo0/lets-create-our-own-vue-js-plugin-17h7 | vue, javascript, webdev, tutorial | Let's write a custom Vue Plugin. How hard could it be?
If you're using Vue JS for a while then you have probably used some plugins with it as well. For example the **Vue Router** is a plugin. And there are many other useful plugins available like [vue-infinite-loading](https://www.npmjs.com/package/vue-infinite-loading), [vuedraggable](https://github.com/SortableJS/Vue.Draggable) etc.
But sometimes you might not have a plugin available for your need in that case you'd have to write your own plugin.
And guess what? To create a Vue plugin all you have to do is create a JavaScript file that exports a object with a **install** method in it.
So inside the **src** folder let's create a folder called **plugins** and inside that will have a JavaScript file named **MyPlugin.js**
```js
// src/plugins/MyPlugin.js
export default {
install() {}
}
```
And then we will be able to import this in our **main.js** and install it like any other plugins.
```js
// src/main.js
import Vue from "vue";
import App from "./App.vue";
import MyPlugin from "./plugins/MyPlugin.js";
Vue.use(MyPlugin);
Vue.config.productionTip = false;
new Vue({
render: h => h(App)
}).$mount("#app");
```
But of course this is not that useful so let's carry on.
While calling our install function Vue will pass some arguments to it. The first one is the Vue itself.
So let's accept that and use it to expose a custom directive.
```js
// src/plugins/MyPlugin.js
export default {
install(Vue) {
Vue.directive("highlight", {
inserted(el) {
el.style.color = "red";
}
});
}
}
```
Now in our components we will be able to use this directive.
```html
<template>
<div id="app">
<p v-highlight>Hello world.</p>
</div>
</template>
<script>
export default {
name: "App"
};
</script>
```
In the browser you should see a "Hello world." in red color.
Also if we want we can pass some options while installing our plugin.
```js
// src/main.js
import Vue from "vue";
import App from "./App.vue";
import MyPlugin from "./plugins/MyPlugin.js";
Vue.use(MyPlugin, { highlightClr: 'gree' });
Vue.config.productionTip = false;
new Vue({
render: h => h(App)
}).$mount("#app");
```
And we can receive those options as seconds argument in our install function
```js
// src/plugins/MyPlugin.js
export default {
install(Vue, options) {
Vue.directive("highlight", {
inserted(el) {
el.style.color = options.highlightClr || "red";
}
});
}
}
```
Great!!! Maybe you want a plugin that will provide a custom component that users can use in his project. Well sure you can do that.
```js
// src/plugins/MyPlugin.js
export default {
install(Vue, options) {
Vue.component('my-plugin-component', {
template: `
<p>Hey there.</p>
`
});
}
}
```
Or you can use SFC(Single File Component) as well.
```js
// src/plugins/MyPlugin.js
import MyPluginComponent from "../components/MyPluginComponent.vue"
export default {
install(Vue, options) {
Vue.component('my-plugin-component', MyPluginComponent);
}
}
```
Now our plugin will register this **my-plugin-component** that the user can use anywhere in his project.
```html
<template>
<div id="app">
<p v-highlight>Hello world.</p>
<my-plugin-component></my-plugin-component>
</div>
</template>
<script>
export default {
name: "App"
};
</script>
```
The same way we can add **filters**, **minxins** etc.
If you want people to be able to install and use your plugin you simply have to publish **MyPlugin.js** as a [npm](https://www.npmjs.com) package. You can follow [this tutorial](https://youtu.be/J4b_T-qH3BY) to get help with that.
That's all for now, make sure you checkout my other articles and YouTube channel
{% user 0shuvo0 %}
## Was it helpful? Support me on Patreon
[](https://www.patreon.com/0shuvo0)
| 0shuvo0 |
889,088 | Newest Gatsby, React and Node Releases - Frontend News #21 | What happened in the world of frontend in the last weeks? Watch the newest episode to be up to... | 0 | 2021-11-05T12:49:06 | https://dev.to/frontend_house/newest-gatsby-react-and-node-releases-frontend-news-21-10a2 | {% youtube nInEDzWdJSM %}
What happened in the world of frontend in the last weeks? Watch the newest episode to be up to date! 👇
What’s in Frontend News #21?
🟣 Gatsby 4
🟣 React Native Testing Library v8
🟣 New React Bootstrap
🟣 Chrome 95 released
🟣 Node v17
Enjoy, you can read the article at [Frontend House](https://frontendhouse.com/frontend-news/newest-gatsby-react-and-node-releases-frontend-news-21) | frontend_house | |
889,115 | 💻Instalando .NET em todas plataforma em forma de scripts | AS: Esse conteúdo partiu da Twitch e será disponibilizado em breve no YouTube e em forma de... | 0 | 2021-11-08T23:50:50 | https://dev.to/edineidev/instalando-net-5-em-todas-plataforma-em-forma-de-scripts-ki8 | dotnet, braziliandevs, programming, productivity | AS: Esse conteúdo partiu da [Twitch](https://www.twitch.tv/edineidev) e será disponibilizado em breve no [YouTube](https://www.youtube.com/channel/UCkSe6llMT88LqEGrMROSUbA) e em forma de Podcast.
Sempre gostei de automação seja usando [Chocolatey](https://chocolatey.org/), Python, Bash, Powersheel etc... tenho até um [dotfiles (GNU/Linux Ubuntu e Windows 10)](https://github.com/neiesc/dotfiles), depois que fiquei sabendo que o dotnet tem uma documentação sobre instalar dotnet com scripts resolvi compartilhar, pois, pode passar despercebido para muitos.
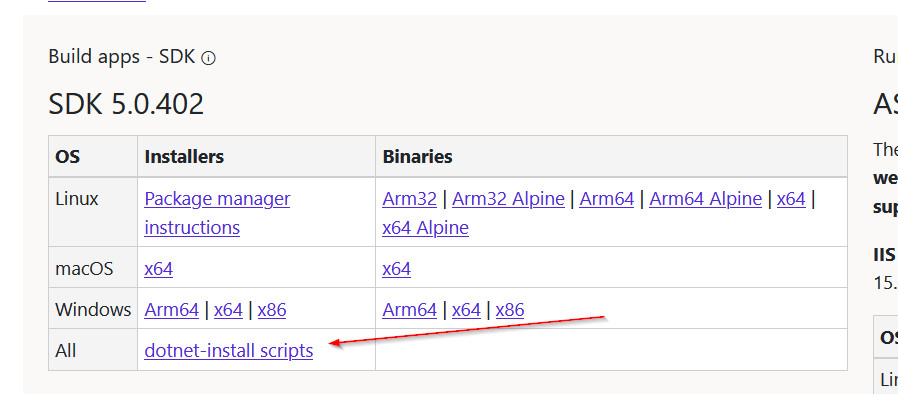
O site [.NET Install scripts](
https://dotnet.microsoft.com/download/dotnet/scripts) como no próprio site fala scripts para instalar .NET Core no Linux, macOS e Windows. Na [documentação](https://docs.microsoft.com/en-us/dotnet/core/tools/dotnet-install-script?WT.mc_id=dotnet-35129-website) tem o modo de uso sendo bem simples:
Exemplos para instalar versão LTS:
No Windows:
```powershell
&powershell -NoProfile -ExecutionPolicy unrestricted -Command "[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12; &([scriptblock]::Create((Invoke-WebRequest -UseBasicParsing 'https://dot.net/v1/dotnet-install.ps1'))) -Channel LTS"
```
Linux/macOS:
```bash
curl -sSL https://dot.net/v1/dotnet-install.sh | bash /dev/stdin --channel LTS
```
PS: Caso você tenha o dotnet já instalado é recomendado você remover todos e instalar em forma de script como esse post mostra. | neiesc |
889,117 | Mocking in Go | sharing an interesting post by Zus technologist Sonya Huang on mocking requests in Go:... | 0 | 2021-11-05T13:56:47 | https://dev.to/brendanzeus/mocking-in-go-352a | go | sharing an interesting post by Zus technologist Sonya Huang on mocking requests in Go: https://www.linkedin.com/feed/update/urn:li:activity:6862376852103798784 | brendanzeus |
889,147 | How to add Google Adsense code in angular 9 application? | I have added Google Adsense to my angular site. It shows ads on some pages and doesn't on some pages.... | 0 | 2021-11-05T14:30:10 | https://dev.to/indiantrain/how-to-add-google-adsense-code-in-angular-9-application-3gjh | javascript, angular | I have added Google Adsense to my angular site. It shows ads on some pages and doesn't on some pages. I will show the example of pages which doesn't shows ads, suppose we go to this page "https://www.indiantrain.in/train-time-table", in the search box we have filled the train number and hit get schedule button. It will redirect to other page. Almost all the features of my site is in this manner only. I think angular block the Adsense script and that's why it doesn't load all the time. As we already know, outside script need to sanitize in order to run in angular. So, I just want to know the proper way to add Google Adsense to my site. | indiantrain |
889,343 | How to use SVGs in React | This article will explore how to use SVG in React in three examples | 0 | 2021-11-05T17:43:48 | https://www.sanity.io/guides/import-svg-files-in-react | react, sanityio, svg, cssanimation | ---
title: How to use SVGs in React
published: true
description: This article will explore how to use SVG in React in three examples
tags: react, sanityio, svg, cssanimation
canonical_url: https://www.sanity.io/guides/import-svg-files-in-react
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/0enpdmh5b5sw38lgrmji.jpeg
---
This article will explore how to use SVG in React in three examples:
- A loading icon
- A hover text effect
- A pizza customizer
SVG is an incredible format. Not only is it a lightweight, infinitely scalable alternative to raster images, it can also be styled, animated with CSS when embedding inline in HTML. SVGs can be used everywhere:
- icons, animated icons
- favicons
- special text effects
- a lightweight blurred placeholder for lazy-loaded images
- data visualization
- 3d graphics
## How to use SVG in React
There are a few ways to use an SVG in a React app:
- Use it as a regular image
- Import it as a component via bundler magic (SVGR)
- Include it directly as JSX
Let's quickly go over each of them.
### Use SVGs as regular images
SVGs can be used as an image, so we'd treat them as any other image resource:
```html
<img src="/path/to/image.svg" alt="SVG as an image">
```
> **Note**: A few meta frameworks handle this out-of-the-box, such as Gatsby & Create React App.
> In Webpack 5, [this is (surprisingly) simple to setup](https://webpack.js.org/guides/asset-modules/#resource-assets). Parcel 2 handles this out of the box with a special import prefix. Rollup [has an official plugin](https://github.com/rollup/plugins/tree/master/packages/image).
> ```jsx
> import mySvg from './path/to/image.svg'
> ```
**Pros**:
- Straightforward
**Cons**:
- SVG can't be customized
**Use case**: Simple replacement for raster images that don't need customization, e.g., logos.
### Import SVGs as components via bundler magic
When importing an SVG as a component, we can inline SVGs directly in our markup & use them as a component.
```jsx
import { ReactComponent as IconMenu } from './icons/menu.svg'
export const ButtonMenu = ({ onClick }) => {
return (
<button onClick={onClick}>
<span>Open Menu</span>
<IconMenu width="1rem" />
</button>
)
}
```
[SVGR](https://github.com/gregberge/svgr) is the library that powers this ability. Setting it up could be a little hairy, thankfully many popular frameworks (Create React App, Gatsby) support this feature out of the box.
**Pros**:
- Easy to handle a large amount of SVG
- Powerful templating
**Cons**:
- May need additional configuration
- Writing React component template is not straightforward
**Use case:** A custom SVG icon library
### Include SVGs directly in JSX
JSX supports all SVG tags. We can (almost) paste the SVG directly into our React components!
This is the most straightforward method to take full advantage of SVG without bundler support, which is why we will use this method for all of our examples later in this article.
The only gotcha is that instead of regular HTML attributes, we have to use JS property syntax, e.g `stroke-width` -> `strokeWidth`
```jsx
// fun fact: `viewBox` has always been camel-cased.
export const LoadingIcon = () => {
return (
<svg
viewBox="0 0 24 24"
xmlns="<http://www.w3.org/2000/svg>"
>
<path strokeWidth="2" stroke="tomato" d="M10...">
</svg>
)
}
```
**Pros:**
- Straightforward
**Cons:**
- Depending on the SVG, component code may not readable
- Not scalable for a large number of SVGs
**Use case:** One-off graphic such as illustration, blog header
## SVGs & React in practice
This article will not be completed if we don't at least show off a few SVG tricks. In the following examples, we will explore what makes SVGs awesome.
### Prerequisite
All examples will use [create-react-app](https://create-react-app.dev/) (CRA) and CSS Module. A way to start a CRA project is using [codesandbox](https://codesandbox.io/). Otherwise, make sure [Node is installed](https://nodejs.org/) (any TLS versions will do) and run this:
```bash
npx create-react-app my-app && cd my-app
```
### Example 1: A Loading Icon
Here's what we'll be making:

Let's try writing this SVG from scratch. All we need is one circle. This is the SVG in its entirety:
```jsx
const LoadingIcon = () => {
return (
<svg
viewBox="0 0 24 24"
xmlns="<http://www.w3.org/2000/svg>"
>
<circle
cx="12" cy="12" r="8"
stroke-width="4" stroke="tomato"
fill="none"
/>
</svg>
)
}
```
Now let's make it move! We can now attach class names to SVG elements and animate them with CSS transform & animation.
Animating paths is a classic SVG trick, and it's all about `stroke-dasharray`. This property creates dashed lines, like in the image below:
Nothing too exciting. However, things get more interesting when you realize that these dashes can be *offset*. What if, instead of many short dashes, we have a single dash whose length is the same as the circle's circumference? We can then move that dash around by changing the offset, giving the appearance that the path is being shortened or lengthened.
Let's give it a try:
```css
.main {
stroke-dasharray: 50;
stroke-dashoffset: 0;
animation: load 5s linear infinite;
transform-origin: center;
}
@keyframes load {
0% {
stroke-dashoffset: 50;
}
50% {
stroke-dashoffset: 0;
}
100% {
stroke-dashoffset: -50;
}
}
```
Setting `stroke-dashoffset` to a negative value pushes the path further down & create the looping effect.
> **Note**: 50 is roughly the circumference of the circle and for our use case we don't ever need to change that value. In other cases, we might need to calculate the exact number:
>
> ```js
> const $circle = document.querySelector('.main')
> const radius = $circle.r.baseVal.value
> const circumference = Math.PI * 2 * radius
> ```
Finally, to make the animation more dynamic, let's also rotate the circle.
```css
@keyframes load {
0% {
transform: rotate(0deg);
stroke-dashoffset: 50;
}
50% {
stroke-dashoffset: 0;
}
100% {
transform: rotate(360deg);
stroke-dashoffset: -50;
}
}
```
**prefers-reduced-motion**
Loading icons typically doesn't have the type of animations that could cause issues. However, for a larger graphic with lots of animation, it's a good practice to provide a more gentle animation. In our case, we can extract the animation duration into a CSS variable & define a larger value inside of the `prefers-reduced-motion` media tag.
```css
/* simple-icon.module.css */
.svg {
/* ... */
--speed: 5s;
}
@media (prefers-reduced-motion: reduce) {
.svg {
--speed: 10s;
}
}
.path {
/* ... */
animation: load var(--speed, 5s) linear infinite;
}
```
**Customize with React**
Now let's make the icon customizable. We want to allow users to change color & thickness.
```js
import styles from "./simple-icon.module.css";
export const SimpleLoadingIcon = ({
color = "currentColor",
thickness = 2
}) => (
<svg
className={styles.svg}
viewBox="0 0 24 24"
xmlns="<http://www.w3.org/2000/svg>"
>
<circle
className={styles.path}
cx="12"
cy="12"
r="8"
strokeLinecap="round"
strokeWidth={thickness}
stroke={color}
fill="none"
/>
</svg>
);
```
If color is unset, the stroke color will inherit from its parent.
**Accessibility**
Since our loading icon does not contain any text, we should give it a <title> so a screen reader can make sense of it. To dive deeper into accessibility with SVGs, [CSS Tricks](https://css-tricks.com/accessible-svgs/) cover this topic extensively.
```html
<svg aria-labelledby="svg-icon-loading">
<title id="svg-icon-loading">Loading</title>
...
</svg>
```
Now that we have a title, a tooltip will show up when the cursor hovers over the SVG. If that seems unnecessary, we can get rid of it by adding `pointer-events: none` to SVG's style.
**Result**
And with that, we can now use this loading icon anywhere! This demo below contains a slightly more complex version of the icon above.
{% codesandbox svg-loading-icon-4sl0e %}
### Example 2: Special Text Effect
SVG can do wild things with text, but let's start with something simple. Like the previous example, we will start with just the SVG and then bring things up a notch with React.
The graphic we'll be working with is rather long, but here's the main parts:
```jsx
const Graphic = () => {
return (
<svg viewBox="0 0 600 337">
<defs>
<linearGradient id="gradient"> /* ... */
</linearGradient>
</defs>
<text x="20" y="1.25em">
<tspan>Using SVGs</tspan>
<tspan x="20" dy="1em">in React</tspan>
</text>
</svg>
)
}
```
**SEO Concerns**
We can nest this SVG inside heading tags. It is valid HTML (test it [with the w3c validation tool](https://validator.w3.org/#validate_by_input+with_options)) and screen readers can pick up the text inside.
**SVG assets**
Let's look at the parts. `<defs>` is SVG's compartment where we can put stuff for later use. That can be shapes, paths, filters, and gradients, such as in the SVG above. True to the compartment analogy, browsers will not render elements placed inside a `<def>` block.
If we want to apply the defined gradient to the text object, we can reference its `id` with the following syntax:
```html
<text x="20" y="1.25em" fill="url(#gradient)">
<tspan>Using SVGs</tspan>
<tspan x="20" dy="1em">in React</tspan>
</text>
```

Sweet! But we can achieve this effect in [modern CSS as well](https://developer.mozilla.org/en-US/docs/Web/CSS/background-clip). So let's see what else SVG can do.
Creating outline text is relatively easy with SVG: just change `fill` to `stroke,` and the gradient will still be applied.
```jsx
<text x="20" y="1.25em" stroke="url(#gradient)">
<tspan>Using SVGs</tspan>
<tspan x="20" dy="1em">in React</tspan>
</text>
```
And better yet, that gradient can be animated.

*Try to do that, CSS!*
The syntax for creating SVG gradient animation is quite verbose, unfortunately.
```jsx
<linearGradient id="gradient" x1="50%" y1="0%" x2="50%" y2="100%">
<stop offset="0%" stop-color="plum">
<animate
attributeName="stop-color"
values="plum; violet; plum"
dur="3s"
repeatCount="indefinite"
></animate>
</stop>
<stop offset="100%" stop-color="mediumpurple">
<animate
attributeName="stop-color"
values="mediumpurple; mediumorchid; mediumpurple"
dur="3s"
repeatCount="indefinite"
></animate>
</stop>
</linearGradient>
```
Let's make something even cooler. How about this XRay hover effect?

The trick here is to use text as a clipping path. We can then animate a circle clipped inside the text as we move the cursor in React.
We'll create a new element called `clip-path` (`clipPath` in JSX land) in `<defs>`, and place `<text>` into it. This serves two purposes: so we can (1) use the text as a mask and (2) clone it to create the outline effect by using `<use>`.
```jsx
<svg>
<defs>
<clipPath id="clip-text">
<text id="text" x="20" y="1.25em">
<tspan>Using SVGs</tspan>
<tspan x="20" dy="1em">
in React
</tspan>
</text>
</clipPath>
</defs>
{/* this circle visible to viewer. */}
<circle ... />
<use href="#text" stroke="url(#gradient)" />
{/* this circle is clipped inside the text. */}
<g clipPath="url(#clip-text)">
<circle ... />
</g>
</svg>
```
So far, we've been using `url(#id)` to refer to gradients & clipping paths placed inside of the `<defs>` block. For shapes and text, we'll need to use a tag: `<use>`, and the syntax is slightly different:
```html
<use href="#id" stroke="..." fill="..." />
```
The referenced text can still be customized by adding attributes to the use tags. `<use>` is really cool & we'll see in the last example how it can be used to nest external SVGs.
**SVG's coordinate systems**
One of the pain points of using SVG is its coordinate system. If we naively implement the function like this:
```js
window.addEventListener('mousemove', (e) => {
$circle.setAttribute('cx', e.clientX)
$circle.setAttribute('cy', e.clientY)
})
```
We'll quickly find out that the cursor position does not match up with the circle inside the SVG. The circle's unit is relative to its containing SVG's viewBox.
For this reason, we'll implement a simple script that'll translate the position correctly.
```jsx
const svgX = (clientX - svgElementLeft) * viewBoxWidth / svgElementWidth
const svgY = (clientY - svgElementTop) * viewBoxHeight / svgElementHeight
```
**Move the circle with React**
We'll need to move two circles, so let's attach some [refs](https://reactjs.org/docs/refs-and-the-dom.html).
```jsx
import { useRef, useEffect } from "react";
export const Graphic = () => {
const innerCircleRef = useRef(null)
const outerCircleRef = useRef(null)
useEffect(() => {
const $innerCircle = innerCircleRef.current
const $outerCircle = outerCircleRef.current
if (!$innerCircle || !$innerCircle) return
const handleMouseMove = (e) => {
const { clientX, clientY } = e
/* Translate coordinate from window to svg, omitted for brevity */
const [x, y] = translateCoords(clientX, clientY)
$innerCircle.setAttribute('cx', x)
$innerCircle.setAttribute('cx', y)
$outerCircle.setAttribute('cx', x)
$outerCircle.setAttribute('cx', y)
}
window.addEventListener("mousemove", handleMouseMove)
return () => {
window.removeEventListener("mousemove", handleMouseMove)
}
})
return (
<svg>
{/* ... */}
<circle ref={outerCircleRef} />
{/* ... */}
<g clipPath="url(#text)">
<circle ref={innerCircleRef} />
</g>
</svg>
)
}
```
Note: the code for translating position has been omitted for clarity. See the codesandbox below for a complete source.
**Result**
Check out the final product in this Codesandbox demo. See if you can find a hidden message!
{% codesandbox svg-xray-text-cjy50 %}
### Example 3: Pizza Customizer
In this example, let's explore how we can compose an SVG on the fly with React! A local pizzeria knocks on the door and asks if we could build them a fun graphic for their online ordering site. Of course, we say yes.
### Prerequisite
We'll need Sanity Studio for this example. Let's use the following structure:
```bash
pizza-sanity
├── frontend <create-react-app>
└── studio <sanity studio>
```
Follow the steps below to install & initiate a new create-react-app project:
```bash
cd frontend
npx create-react-app .
```
While waiting for the script to load, let's initiate the studio:
```bash
cd ../studio
npm install -g @sanity/cli
sanity init
# after signing in, answer the questions as below
? Select project to use
❯ Create new project
? Your project name
❯ Sanity Pizza
? Use the default dataset configuration?
❯ Yes
? Project output path
❯ /Users/me/Documents/sanity-pizza/studio
? Select project template
❯ Clean project with no predefined schemas
```
When that's all done, we'll also want to add CRA's development host to the project's CORS allowed list.
```bash
sanity cors add http://localhost:3000 --credentials
```
See the [getting started guide](https://www.sanity.io/docs/getting-started-with-sanity-cli) for further information. If you'd like a reference, see the [project on Github.](https://github.com/d4rekanguok/sanity-pizza/tree/blank)
### Writing the schema
Toppings can be placed on different pizzas, so we could have two types of documents: toppings and pizzas, containing many other toppings.
Sanity allows us to create schema in code, making it powerful & flexible, but simple to get started. In `schemas` directory, create a new files:
```jsx
/* schemas/pizza.js */
export const topping = {
type: 'document',
name: 'topping',
title: 'Topping',
fields: [
{
title: 'Title',
name: 'title',
type: 'string',
validation: Rule => Rule.required().min(2),
},
{
title: 'SVG',
name: 'svg',
type: 'text',
validation: Rule => Rule.required().min(2),
},
fieldSize,
],
}
export const pizza = {
type: 'document',
name: 'pizza',
title: 'Pizza',
fields: [
{
title: 'Title',
name: 'title',
type: 'string',
validation: Rule => Rule.required(),
},
{
title: 'Base Pizza',
name: 'svg',
type: 'text',
validation: Rule => Rule.required(),
},
fieldSize,
{
title: 'Toppings',
name: 'toppings',
type: 'array',
of: [{
type: 'reference',
to: [{ type: topping.name }]
}],
validation: Rule => Rule.required().min(2),
}
]
}
```
Note that inside of the pizza document type, we create an array of references to the available toppings.
For the topping itself, we create a text field where editors can paste the SVG graphic.
**Why not upload SVG as an image?**
It's possible to reference external SVGs (and leverage browser cache!). However, it won't be stylable in CSS as inlined SVG. Depending on the use case, external SVG could be the better choice.
In Sanity Studio, there should be a `schemas/schema.js` file. Let's add the document types we've specified above.
```jsx
import createSchema from 'part:@sanity/base/schema-creator'
import schemaTypes from 'all:part:@sanity/base/schema-type'
import { pizza, topping } from './pizza'
export default createSchema({
name: 'default',
types: schemaTypes.concat([
topping,
pizza
]),
})
```
Now that all the SVGs are placed in the Studio, it's time to build the React app. We'll use `picosanity`, a smaller Sanity client.
```
npm i picosanity
```
Make a `client.js` file and create the Sanity client:
```jsx
import PicoSanity from 'picosanity'
export const client = new PicoSanity({
projectId: '12345678',
dataset: 'production',
apiVersion: '2021-03-25',
useCdn: process.env.NODE_ENV === 'production',
})
```
Then we can import it into our React app and use it to fetch data. For simplicity, let's fetch in `useEffect` and store the data inside of a `useState`.
```jsx
import { useState, useEffect } from 'react'
import { client } from './client'
const App = () => {
const [data, setData] = useState(null)
useEffect(() => {
const getPizzaData = () => {
client.fetch(`
*[_type == "pizza"] {
...,
toppings[] -> {
_id,
title,
svg,
size,
}
}
`)
}
getPizzaData.then(data => setData(data))
})
return ( /* ... */ )
}
```
This will yield the following data:
```
[
{
_id: "2b2f07f0-cfd6-4e91-a260-ca30182c7736",
_type: "pizza",
svg: "<svg ...",
title: "Pepperoni Pizza",
toppings: [
{
_id: "92b5f3f1-e0af-44be-9575-94911077f141",
svg: "<svg ...",
title: 'Pepperoni'
},
{
_id: "6f3083f3-a5d5-4035-9724-6e774f527ef2",
svg: "<svg ...",
title: 'Mushroom'
},
]
}
]
```
Let's assemble a pizza from the topping SVG and the pizza's base SVG. This is where `<symbol>` comes in handy.
```jsx
export const Pizza = ({ data }) => {
const { _id, svg: baseSvg, toppings } = data
return (
<svg>
{/* create a symbol for each topping */}
{toppings.map(({ _id: toppingId, svg }) => (
<symbol key={toppingId} id={toppingId} dangerouslySetInnerHTML={{ __html: svg }} />
))}
<g dangerouslySetInnerHTML={{ __html: baseSvg }} />
{/* use them */}
{toppings.map(({ _id: toppingId }) => {
return (
<use key={_id} href={`#${toppingId}`} />
)
})}
</svg>
)
}
```
Symbols are hidden by default and can be created with `<use>`. We can still apply transform as with a standard SVG element. This is also how SVG sprite works.
### Add customizer
We'll add a slider for each topping and once again simply use `useState` to store users' inputs in an object.
```jsx
import { useState } from 'react'
export const Pizza = ({ data }) => {
const { _id, svg: baseSvg, toppings } = data
const [ config, setConfig ] = useState({})
const handleChangeFor = (toppingId) => (value) => {
setConfig(config => ({
...config,
[toppingId]: value
}))
}
return (
<section>
<svg>{ /* ... */ }</svg>
<form>
{toppings.map(topping => (
<div key={topping._id}>
<label htmlFor={topping._id}>{topping.title}</label>
<input
type="range"
value={config[topping._id] || 0}
onChange={handleChangeFor(topping._id)}
/>
</div>
))}
</form>
</section>
)
}
```
**Randomizer**
The most challenging part of this exercise is placing the toppings on top of the pizza. It turns out that just placing each topping at a random position does not create a very appetize-looking pizza!
We want to place the toppings evenly. Thankfully geometry nerds have already figured this out ages ago! Vogel spiral to the rescue. [Read more about it here](https://www.codeproject.com/Articles/1221341/The-Vogel-Spiral-Phenomenon).
So far, so good. Let's give each topping a random rotation and vary its scale slightly, so the pizza looks more natural.

However, as soon as we add the transformation, the pizza becomes a mess. Here's what we're missing: instead of rotating from the center of itself, each topping's SVG is rotating from the center of its containing SVG (the pizza.) To fix this, we need to add the following CSS to each `use` element:
```css
use {
transform-origin: center;
transform-box: fill-box;
}
```
> **Note:** The order of transformation matter. We have to apply `translate` before `scale` or `rotate` to keep the SVG in the intended position.
With that, we now have a decent pizza customizer!
**Animate with react-spring**
So far, we've been relying on CSS for animation, but CSS can only take us so far. Let's create an animation where toppings fall onto the pizza whenever users update their order.
Let's use `react-spring` to create a simple animation.
Note: using hook throws an error with `<use/>` for some reasons, so I'm using react-spring's render props API instead.
```sh
npm i react-spring
```
Now it's a good time to extract <use ... /> into its component & add the animation there.
```jsx
import { Spring, config } from 'react-spring/renderprops'
export const UseTopping = ({
size,
toppingId,
x,
y,
i,
rotation,
scale
}) => {
return (
<Spring
from={{ y: y - 40, opacity: 0 }}
to={{ y, opacity: 1 }}
delay={i * 15}
config={config.wobbly}
>
{props => <use
className={styles.topping}
href={`#${toppingId}`}
opacity={props.opacity}
style={{
transform: `
translate(${x}px, ${props.y}px)
scale(${scale})
rotate(${rotation}deg)
`
}}
/>}
</Spring>
)
}
```
### Result
Play with [the final demo here](https://sanity-pizza.netlify.app/)! The [source code is available on Github.](https://github.com/d4rekanguok/sanity-pizza)

{% github d4rekanguok/sanity-pizza %}
## Wrapping Up
We haven't scratched the surface of SVG coolness. However, SVG is not without flaws:
- Verbose syntax
- Texts inside SVG do not flow like in HTML. Break text manually into <tspan> works for one-off graphics, but it is not scalable.
- Position & coordinate could be tricky
- When animating complex SVGs, performance could be an issue
However, SVGs can enrich our React websites and applications with little effort with the right use case. | d4rekanguok |
889,379 | Understanding Stack Traces and Debugging them Further | Recently a junior developer sent me an obfuscated stack trace and was pretty surprised when I... | 0 | 2021-11-05T17:19:05 | https://dev.to/yayabobi/understanding-stack-traces-and-debugging-them-further-30nk | devops, beginners, java, programming | Recently a junior developer sent me an obfuscated stack trace and was pretty surprised when I instantly knew the problem and pointed him at the necessary change. To be fair, I had the advantage of being the person who put that bug there in the first place... But still the ability to glean information from a stack trace, even an obfuscated one, is a serious skill.
The stack trace in question was a `ClassNotFoundException`, that's typically pretty easy and already tells you everything you need to know. The class isn't there.Why it isn't there is really a matter of what we did wrong. In this case since the project was obfuscated the bug was that this class wasn't excluded from obfuscation.
Despite all the hate it got over the years, `NullPointerException` is one of my favorite exceptions. You instantly know what happened and in most cases the stack leads almost directly to the problem. There are some edge cases e.g.:
```
myList.get(offset).invokeMethod();
```
So which one triggered the `NullPointerException`?
If you're using the latest version of Java it would tell you, which is pretty cool. But if we're still at Java 11 (or 8) there's more than one option. At least 3 or maybe 4 if we cheat a bit:
1. `myList` is the obvious one but it rarely is null and if so you would see it immediately
2. offset can be null. It can be an Integer object in which case it can be `null` due to autoboxing. It's also less likely
3. The most likely culprit in this specific case is the return value from the `get()` method which means one of the list elements is `null`
4. Finally `invokeMethod` itself can throw a `NullPointerException`. But that's a bit of cheating since the stack will be a bit deeper
So without knowing anything about the code we can pretty much guess what failed at a line just by knowing the exception type. But this doesn't lead us directly to the bug in all cases.
There Was a Null
----------------
That `NullPointerException` probably happened due to a null in the list. Assuming you verified that you might still not know how that null got into the list in the first place...
This isn't hard to find out, let's assume that the List is of the `ArrayList` type, in that case just open the `ArrayList` class (which you can do with Control-O in IntelliJ) and place a conditional breakpoint on the `add()` method. You can test if the value is null and that will stop at a breakpoint if someone tries to add null to the list.
Now this won't catch all the cases of `null` sneaking into the list. It can do so via the stream API, via `addAll()` and a couple of other methods. The nice thing is that we can grab pretty much any one of those methods:
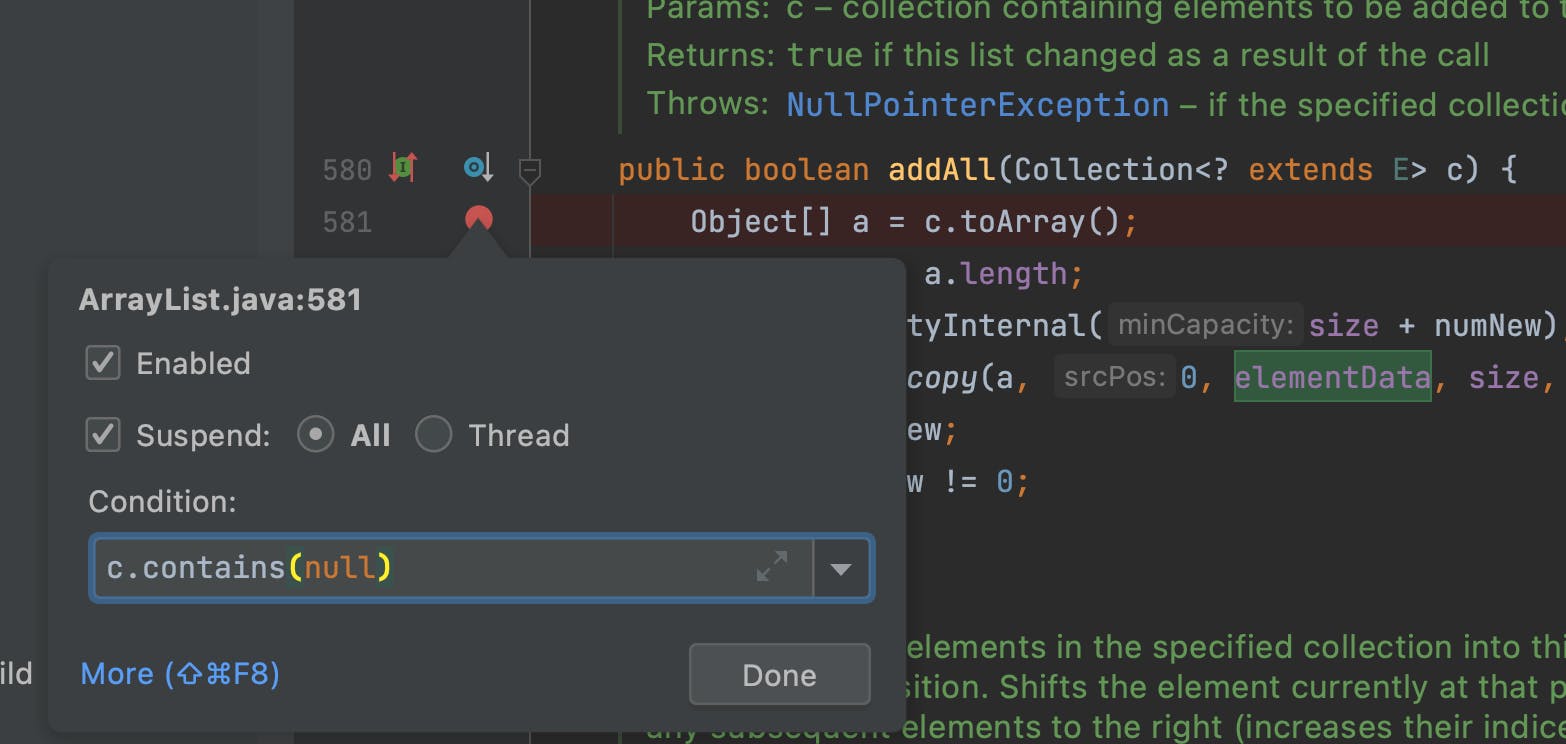
Since `addAll()` accepts a `Collection` we can use the standard `contains()` method to check if we have a `null` element in the `Collection` and if so stop.
What if this is "sometimes" OK?
-------------------------------
So we run this code and bingo it stops at a breakpoint... But unfortunately this isn't the right case. That breakpoint is related to a different list which we aren't debugging right now. Apparently in that list a `null` value is OK and expected.
So we press continue and the breakpoint hits again and again and again. Each time for the wrong list... This is often the point where developers start cursing loudly and swearing off debuggers for good old logs.
So there are several ways around this problem. The most ideal one is to avoid that specific list. If you have a way of recognizing that list e.g. a global instance or the first element might be a specific value you can simply augment the original conditional breakpoint e.g. in this case we assume the first element in the `null` is OK list is 77 in which case this condition will workaround the problem:
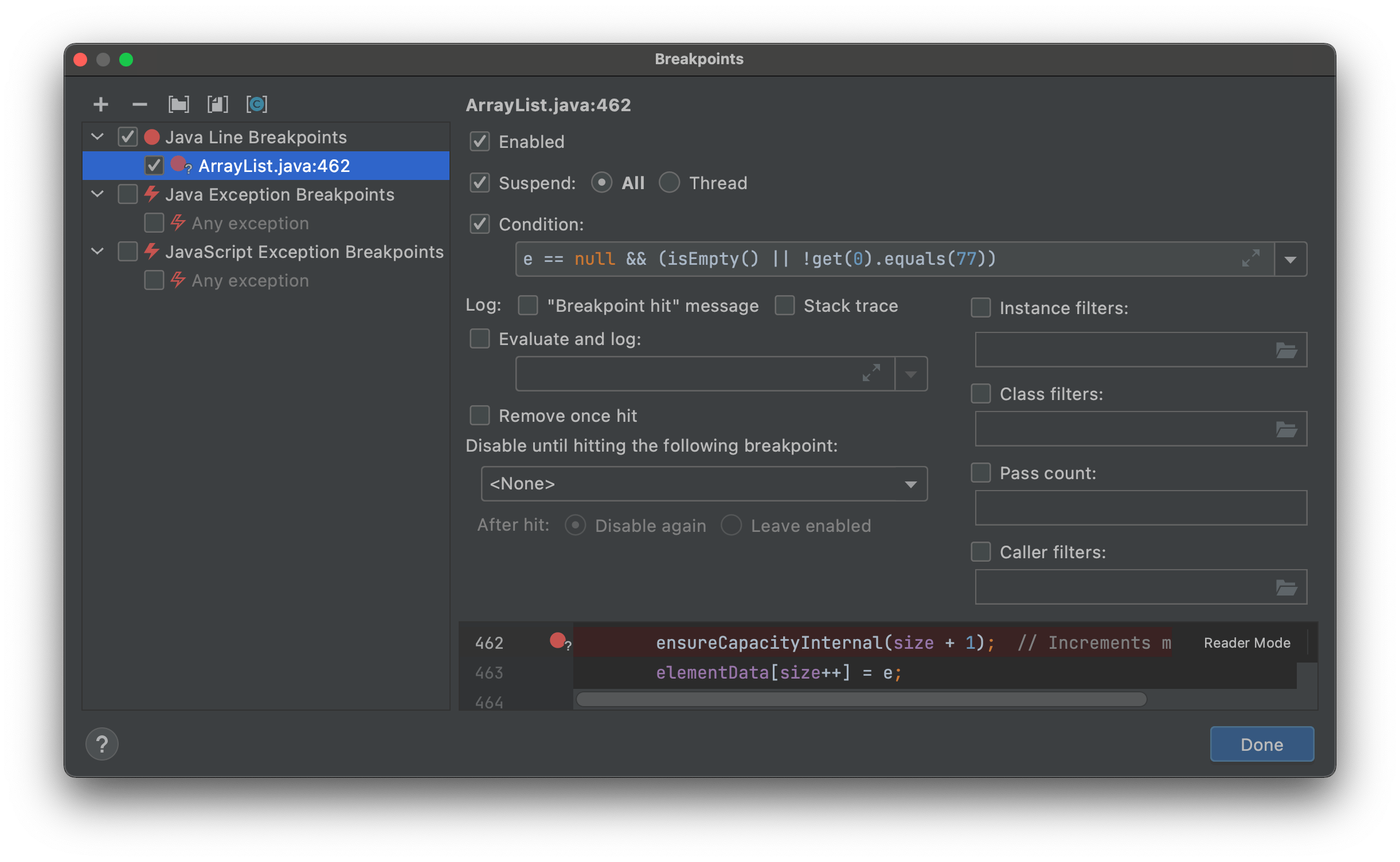
This isn't ideal but it works around the problem assuming it's localized enough.
Nested Stack Traces
-------------------
So this is one of the "pains" in modern frameworks. The framework catches an exception and propagates it, wrapping it in its own exception. Rinse repeat. You end up with a Matryoshka doll of stack traces.
Sifting through all of those stacks and finding the one that matters is often a huge part of the pain. Especially in frameworks like Spring where the proxy code makes the stacks especially long and hard to read.
E.g.:
```
javax.ws.rs.ProcessingException: RESTEASY004655: Unable to invoke request: org.apache.http.conn.HttpHostConnectException: Connect to localhost:8443 [localhost/127.0.0.1, localhost/0:0:0:0:0:0:0:1] failed: Connection refused (Connection refused)
at org.jboss.resteasy.client.jaxrs.engines.ApacheHttpClient4Engine.invoke(ApacheHttpClient4Engine.java:328)
at org.jboss.resteasy.client.jaxrs.internal.ClientInvocation.invoke(ClientInvocation.java:443)
at org.jboss.resteasy.client.jaxrs.internal.proxy.ClientInvoker.invokeSync(ClientInvoker.java:149)
at org.jboss.resteasy.client.jaxrs.internal.proxy.ClientInvoker.invoke(ClientInvoker.java:112)
at org.jboss.resteasy.client.jaxrs.internal.proxy.ClientProxy.invoke(ClientProxy.java:76)
at com.sun.proxy.$Proxy307.grantToken(Unknown Source)
at org.keycloak.admin.client.token.TokenManager.grantToken(TokenManager.java:90)
at org.keycloak.admin.client.token.TokenManager.getAccessToken(TokenManager.java:70)
at org.keycloak.admin.client.token.TokenManager.getAccessTokenString(TokenManager.java:65)
at org.keycloak.admin.client.resource.BearerAuthFilter.filter(BearerAuthFilter.java:52)
at org.jboss.resteasy.client.jaxrs.internal.ClientInvocation.filterRequest(ClientInvocation.java:579)
at org.jboss.resteasy.client.jaxrs.internal.ClientInvocation.invoke(ClientInvocation.java:440)
at org.jboss.resteasy.client.jaxrs.internal.proxy.ClientInvoker.invokeSync(ClientInvoker.java:149)
at org.jboss.resteasy.client.jaxrs.internal.proxy.ClientInvoker.invoke(ClientInvoker.java:112)
at org.jboss.resteasy.client.jaxrs.internal.proxy.ClientProxy.invoke(ClientProxy.java:76)
at com.sun.proxy.$Proxy315.toRepresentation(Unknown Source)
at io.athena_tech.server.security.keycloak.KeycloakRealmService.lambda$doesLightrunRealmExist$0(KeycloakRealmService.java:124)
at io.athena_tech.server.security.keycloak.KeycloakApi.getWithAdmin(KeycloakApi.java:35)
at io.athena_tech.server.security.keycloak.KeycloakRealmService.doesLightrunRealmExist(KeycloakRealmService.java:122)
at io.athena_tech.server.security.keycloak.KeycloakRealmService$$FastClassBySpringCGLIB$$9e16800d.invoke(<generated>)
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.invokeJoinpoint(CglibAopProxy.java:771)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:163)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:749)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:366)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:118)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:749)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:691)
at io.athena_tech.server.security.keycloak.KeycloakRealmService$$EnhancerBySpringCGLIB$$7eca0d51.doesLightrunRealmExist(<generated>)
at io.athena_tech.server.service.client.InitKeycloakService.initDefaultCompanies(InitKeycloakService.java:146)
at io.athena_tech.server.service.client.InitKeycloakService$$FastClassBySpringCGLIB$$35f06991.invoke(<generated>)
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.invokeJoinpoint(CglibAopProxy.java:771)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:163)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:749)
at org.springframework.aop.aspectj.AspectJAfterThrowingAdvice.invoke(AspectJAfterThrowingAdvice.java:62)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:749)
at org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:95)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:749)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:691)
at io.athena_tech.server.service.client.InitKeycloakService$$EnhancerBySpringCGLIB$$5ae1a459.initDefaultCompanies(<generated>)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at org.springframework.context.event.ApplicationListenerMethodAdapter.doInvoke(ApplicationListenerMethodAdapter.java:305)
at org.springframework.context.event.ApplicationListenerMethodAdapter.processEvent(ApplicationListenerMethodAdapter.java:190)
at org.springframework.context.event.ApplicationListenerMethodAdapter.onApplicationEvent(ApplicationListenerMethodAdapter.java:153)
at org.springframework.context.event.SimpleApplicationEventMulticaster.doInvokeListener(SimpleApplicationEventMulticaster.java:172)
at org.springframework.context.event.SimpleApplicationEventMulticaster.invokeListener(SimpleApplicationEventMulticaster.java:165)
at org.springframework.context.event.SimpleApplicationEventMulticaster.multicastEvent(SimpleApplicationEventMulticaster.java:139)
at org.springframework.context.support.AbstractApplicationContext.publishEvent(AbstractApplicationContext.java:403)
at org.springframework.context.support.AbstractApplicationContext.publishEvent(AbstractApplicationContext.java:360)
at org.springframework.boot.context.event.EventPublishingRunListener.running(EventPublishingRunListener.java:103)
at org.springframework.boot.SpringApplicationRunListeners.running(SpringApplicationRunListeners.java:77)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:330)
at io.athena_tech.server.AthenaServerApp.main(AthenaServerApp.java:64)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at org.springframework.boot.devtools.restart.RestartLauncher.run(RestartLauncher.java:49)
Caused by: org.apache.http.conn.HttpHostConnectException: Connect to localhost:8443 [localhost/127.0.0.1, localhost/0:0:0:0:0:0:0:1] failed: Connection refused (Connection refused)
at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:156)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:376)
at org.apache.http.impl.execchain.MainClientExec.establishRoute(MainClientExec.java:393)
at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:236)
at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186)
at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89)
at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110)
at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185)
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83)
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:56)
at org.jboss.resteasy.client.jaxrs.engines.ApacheHttpClient4Engine.invoke(ApacheHttpClient4Engine.java:323)
... 64 common frames omitted
Caused by: java.net.ConnectException: Connection refused (Connection refused)
at java.base/java.net.PlainSocketImpl.socketConnect(Native Method)
at java.base/java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:399)
at java.base/java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:242)
at java.base/java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:224)
at java.base/java.net.SocksSocketImpl.connect(SocksSocketImpl.java:403)
at java.base/java.net.Socket.connect(Socket.java:609)
at org.apache.http.conn.ssl.SSLConnectionSocketFactory.connectSocket(SSLConnectionSocketFactory.java:368)
at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:142)
... 74 common frames omitted
```
Can someone tell me what I did wrong here when trying to run our server locally...
Let's try to break it down starting from the lowest exception which is usually the root cause:
```
Caused by: java.net.ConnectException: Connection refused (Connection refused)
at java.base/java.net.PlainSocketImpl.socketConnect(Native Method)
at java.base/java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:399)
at java.base/java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:242)
at java.base/java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:224)
at java.base/java.net.SocksSocketImpl.connect(SocksSocketImpl.java:403)
at java.base/java.net.Socket.connect(Socket.java:609)
at org.apache.http.conn.ssl.SSLConnectionSocketFactory.connectSocket(SSLConnectionSocketFactory.java:368)
at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:142)
```
There's a problem connecting. A connection is refused which means our server is trying to connect to some other server but it's failing.
So this gave us some basic information but nothing else.
Let's proceed one exception upward and look at the second block. Since it's large I'll only focus on the edge of the exception:
```
Caused by: org.apache.http.conn.HttpHostConnectException: Connect to localhost:8443 [localhost/127.0.0.1, localhost/0:0:0:0:0:0:0:1] failed: Connection refused (Connection refused)
at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:156)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:376)
```
Again nothing here. This is Apache connection code. But no information about who triggered it or why.
So we're back all the way to the top which is less typical and here we can find the answer:
```
javax.ws.rs.ProcessingException: RESTEASY004655: Unable to invoke request: org.apache.http.conn.HttpHostConnectException: Connect to localhost:8443 [localhost/127.0.0.1, localhost/0:0:0:0:0:0:0:1] failed: Connection refused (Connection refused)
at org.jboss.resteasy.client.jaxrs.engines.ApacheHttpClient4Engine.invoke(ApacheHttpClient4Engine.java:328)
at org.jboss.resteasy.client.jaxrs.internal.ClientInvocation.invoke(ClientInvocation.java:443)
at org.jboss.resteasy.client.jaxrs.internal.proxy.ClientInvoker.invokeSync(ClientInvoker.java:149)
at org.jboss.resteasy.client.jaxrs.internal.proxy.ClientInvoker.invoke(ClientInvoker.java:112)
at org.jboss.resteasy.client.jaxrs.internal.proxy.ClientProxy.invoke(ClientProxy.java:76)
at com.sun.proxy.$Proxy307.grantToken(Unknown Source)
at org.keycloak.admin.client.token.TokenManager.grantToken(TokenManager.java:90)
at org.keycloak.admin.client.token.TokenManager.getAccessToken(TokenManager.java:70)
at org.keycloak.admin.client.token.TokenManager.getAccessTokenString(TokenManager.java:65)
at org.keycloak.admin.client.resource.BearerAuthFilter.filter(BearerAuthFilter.java:52)
```
If you'll look a bit below you will see `org.keycloak` packages. This essentially means I forgot to launch keycloak before launching the server. This was well hidden in that stack and required a lot of domain knowledge (we use keycloak) to figure that out.
This sucks. If I was new to the team trying to get stuff to launch (which is exactly when this sort of exception happens), I would have been baffled by the exception. At least it would have taken me a while to figure it out. Unfortunately, I have no silver bullet for that specific problem.
Just keep reading the stack, the answer is usually in the edge (bottom or top). Don't give up if something isn't instantly clear.
TL;DR
-----
In many cases we can glean the cause of an exception we see in the log or get from the user by just [reviewing the stack trace](https://talktotheduck.dev/understanding-stack-traces-and-debugging-them-further) and digging deeper. Obviously, keep in mind nested exceptions and other such issues.
The debugger can still be a great ally when trying to figure out the root cause of an exception stack. We can leverage features like conditional breakpoints to narrow this down. Surprisingly, we didn't touch on exception breakpoints in this post. I think they have their value but when we have a stack we already know (roughly) what happened and where.
We need something that goes beyond that and I tried to cover that in this article. | yayabobi |
889,425 | How to run integration tests using Github Actions | GitHub Actions allow us to easily verify if a Pull Request is safe to merge into a main branch.... | 0 | 2021-11-19T21:50:27 | https://dev.to/delphidigital/how-to-run-integration-tests-using-github-actions-5dok | javascript, postgres, testing, github | [GitHub Actions](https://docs.github.com/en/actions) allow us to easily verify if a Pull Request is safe to merge into a main branch.
This article assumes you have a basic functional understanding of [Github](https://github.com/) and [Integration Testing](https://www.tutorialspoint.com/software_testing_dictionary/integration_testing.htm) and will be covering:
* How to run integration tests in a [CI](https://www.atlassian.com/continuous-delivery/continuous-integration) environment using **GitHub Actions**
* How to prevent failing Pull Requests from being merged
## :robot: Create the Workflow :robot:
In your Github repository, navigate to the **Actions** tab.
Chose the workflow template that best suits your needs, commit the changes, and pull the new `.github/` folder into your local environment.
## :wrench: Customize the Workflow :wrench:
Before making the following changes, create a new branch to edit your workflow to quickly iterate without jumping between editing and checking the workflow logs.
To add a test database, add a services section to the `<project-root>/.github/workflow/workflow_name.yml` file under the job name.
```yml
# .github/workflows/node.js.yml
...
jobs:
# name of the job
ci:
# The OS of the docker container
# Github runs the workflows on
runs-on: ubuntu-latest
strategy:
matrix:
# node version(s) to run against
node-version: ['16.x']
services:
# name of the service
postgresql:
# The software image the container
# will download and start
image: 'postgres:14'
ports:
# map external port to container. This is
# important because our app will run outside
# our postgres container
- '54320:5432'
# Environment Variables
env:
POSTGRES_DB: example_app_test_db
POSTGRES_PASSWORD: jamesbond
POSTGRES_USER: example_app_db_test_user
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
...
```
Update your code to point at the containerized database when running in the CI environment. The connection string will be consistent with the given environment variables and ports. **e.g** `postgresql://example_app_db_test_user:jamesbond@localhost:54320/example_app_test_db`
Update the steps section to set up and test your code.
```yml
# .github/workflows/node.js.yml
...
steps:
# Checkout our branch in the container
- name: Checkout 🛎
uses: actions/checkout@v2
# Download and setup nodejs
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v2
with:
node-version: ${{ matrix.node-version }}
cache: 'npm'
- name: Install dependencies 👨🏻💻
run: npm ci
- name: Migrate Database 🏗️
run: npm run migrate
- name: Seed Test Data 🌱
run: npm run db:seed
- name: run end-to-end tests 🧪
run: npm run test
...
```
Go ahead and push those changes.
Inspect the logs by clicking the **details** link under the checks section near the merge button at the bottom of the page.
You can also see all workflow logs by navigating back to the actions tab.
Once your checks are coming back ✅, you're ready to merge that Pull Request and move on.
## 🥋 Respect the Workflow 🥋
If you want to protect your code from accidents or overconfidence, you can configure your repository to only allow merging Pull Requests that pass the checks.
Navigate to the repository branches settings and click the **Add Rule** button.
### Configuration
1. Set **Branch Name Pattern** to `*` to match all branches (or whatever regex pattern you need to target certain branches)
2. Check **Require status checks to pass before merging** and search for the job name used in your `.github/workflow/workflow_name.yml` file. I used the name `ci`
3. Check **Require branches to be up to date before merging**
```yml
# .github/workflows/node.js.yml
...
jobs:
# name of the job
ci:
...
```
4. ***(Optional)*** Check **Include Administrators** to keep yourself from pushing breaking changes
## :tada: Enjoy the Workflow :tada:
You've done it! Your code is now guarded by a robot.
Checkout my implementation and example pull requests in my [end-2-end-integration-test-article-example](https://github.com/chdwck/end-2-end-integration-test-article-example).
Happy Coding!
| chdwck |
889,631 | How to install Plausible Analytics on your own server | Plausible Analytics is a great alternative to Google Analyics. Hosting plausible on your own... | 0 | 2021-11-05T21:32:48 | https://cleavr.io/cleavr-slice/plausible-analytics | analytics | {% youtube 0U8FPHkYmV8 %}
[Plausible Analytics](https://plausible.io) is a great alternative to Google Analyics. Hosting plausible on your own [Cleavr](https://cleavr.io) managed server gives you
even more control over the usage data that you collect.
We, at Cleavr, have been using Plausible Analytics at Cleavr for the last year. Our main reasons were because:
- Google Analytics was overbearing and provides more than we really needed
- We made the decision to not contribute to Google's quest to own all web data
- Plausible is simple and provides the core usage analytics that we need
The best part, Plausible can be installed on your server in just a few minutes!
We encourage you to consider sponsoring Plausible in some way so that they can keep up the good work. <a href="https://github.com/sponsors/plausible" target="_blank">Visit their GitHub sponsorship page.</a>
## Prerequisite
Have a server provisioned and ready-to-go in Cleavr.
## Step 1: Install Docker Service
In the **Services** section on the server you are installing Plausible on, install the **Docker** service.
Plausible wraps up their program in a docker container and so we just need to first make sure Docker is installed on the server.
## Step 2: Add Generic Port App
Add a new **Generic Port App** on the server. Add in the URL you want assign to Plausible Analytics.
For the port number, add in `8000`. If you have another app using the port, you can customize the port number.
## Step 3: Run Plausibe Quick Script
In the **Quick Script** section of Cleavr, add a new quick script with the following script:
```
cd /home/cleavr
mkdir plausible
cd plausible
git clone https://github.com/plausible/hosting
cd hosting
key="$(openssl rand -base64 64 | tr -d '\n' ; echo)"
echo "
ADMIN_USER_EMAIL={{ADMIN_USER_EMAIL}}
ADMIN_USER_NAME={{ADMIN_USER_NAME}}
ADMIN_USER_PWD={{ADMIN_USER_PWD}}
BASE_URL={{BASE_URL}}
SECRET_KEY_BASE=$key
" > plausible-conf.env
docker-compose up -d
```
Save the quick script and then run it as `cleavr` user. Add in the required variables for user name, email, password, and url.
After the script finishes running, you will likely get a false error. Verify the URL you used to make sure that Plausible was successfully installed.
## Step 3: Verify Installation And Set Up Plausible
Once the script run is complete, navigate to the url you configured Plausible with and verify the login page shows.
From here, log in and set up Plausible for your sites!
| armiedema |
889,638 | How to set up a REST API in Flask in 5 steps | This small tutorial was built on top of my previous code sample that configures a simple Flask app... | 17,386 | 2021-11-05T22:07:25 | https://dev.to/po5i/how-to-set-up-a-rest-api-in-flask-in-5-steps-5b7d | python, rest, api, flask | This small tutorial was built on top of my previous code sample that configures a simple Flask app with testing:
{% link https://dev.to/po5i/how-to-add-basic-unit-test-to-a-python-flask-app-using-pytest-1m7a %}
There are many ways to build REST APIs, the most common is to have a Django app with DRF. Other people are trying FastAPI (I need to take a closer look at it, maybe in a future post).
But if you are using a Flask based app, I recently tried [Flask-RESTX](https://flask-restx.readthedocs.io/en/latest/) library which includes some great features:
- Swagger documentation (Heck yes!)
- Response marshalling
- Request parsing
- Error handling, logging and blueprint support. Neat Flask integration.
In this demo, I'll show you how to set up a quick REST API, with Swagger documentation, request parsing and simple response formatting.
---
Let's start by initializing the blueprint and defining the api object in a new module. I named this one as `api.py`.
```py
blueprint = Blueprint("api", __name__, url_prefix="/api/v1")
api = Api(
blueprint,
version="1.0",
title="Mini REST API",
description="A mini REST API",
)
ns = api.namespace("items", description="Item operations")
api.add_namespace(ns)
```
Flask-RESTX support Flask Blueprint and they are really [simple to implement](https://flask-restx.readthedocs.io/en/latest/scaling.html#use-with-blueprints).
My application is served at `http://localhost:5000` but my API base URL will be `http://localhost:5000/api/v1`. This is also the page where you can find the Swagger docs.
Next, let's write the base models. My sample API will manage Items and Details objects, so I need to write the _models_ that will be in charge of presenting them in the API standard response.
```py
detail_model = api.model("Detail", {"id": fields.Integer, "name": fields.String})
item_model = api.model(
"Item",
{
"id": fields.Integer,
"name": fields.String,
"details": fields.List(fields.Nested(detail_model)),
},
)
```
The idea of writing models is to use Flask-RESTX [response marshalling](https://flask-restx.readthedocs.io/en/latest/marshalling.html), so no matter if our objects scale, the response will always be as we document it on our models. Flask-RESTX includes a lot of tools for this such as renaming attributes, complex, custom, and nested fields, and more.
The final set up step is to write the request parser.
```py
item_parser = api.parser()
item_parser.add_argument("id", type=int, location="form")
item_parser.add_argument("name", type=str, location="form")
detail_parser = api.parser()
detail_parser.add_argument("id", type=int, location="form")
detail_parser.add_argument("name", type=str, location="form")
```
In a similar way as before, we make use of Flask-RESTX [request parser](https://flask-restx.readthedocs.io/en/latest/parsing.html) to read and validate values that we expect to receive in our endpoints. In this case I plan to implement two object APIs that will append elements to our _database_ objects. (Our database is a simple in-memory object 😅)
```py
memory_object = [
{
"id": 1,
"name": "Item 1",
"details": [
{"id": 1, "name": "Detail 1"},
{"id": 2, "name": "Detail 2"},
],
}
]
```
---
Now it's time to implement our APIs. The first API I want to build is the one that manages the items. I will call this `ItemApi` and the route will be `/` which means the root of the namespace `items`.
```py
@ns.route("/")
class ItemsApi(Resource):
"""
API for handling the Item list resource
"""
@api.response(HTTPStatus.OK.value, "Get the item list")
@api.marshal_list_with(item_model)
def get(self) -> list[Item]:
"""
Returns the memory object
"""
return memory_object
@api.response(HTTPStatus.OK.value, "Object added")
@api.expect(item_parser)
def post(self) -> None:
"""
Simple append something to the memory object
"""
args = item_parser.parse_args()
memory_object.append(args)
```
This will enable two endpoints:
Endpoint | Method | Parameters | Returns
-- | -- | -- | --
`/api/v1/items/` | GET | None | list of `item_model`
`/api/v1/items/` | POST | As defined on `item_parser` | None
All decorators are provided by Flask-RESTX. `HTTPStatus` class is provided by the `http` module. Pretty simple huh?, let's build the second one.
---
This one will manage a single item resource. So, to get its data and add details we need the following implementation:
```py
@ns.route("/<int:item_id>")
class ItemApi(Resource):
"""
API for handling the single Item resource
"""
@api.response(HTTPStatus.OK.value, "Get the item list")
@api.response(HTTPStatus.BAD_REQUEST.value, "Item not found")
@api.marshal_with(item_model)
def get(self, item_id: int) -> Item:
"""
Returns the memory object
"""
try:
return self._lookup(item_id)
except StopIteration:
return api.abort(HTTPStatus.BAD_REQUEST.value, "Item not found")
def _lookup(self, item_id):
return next(
(item for item in memory_object if item["id"] == item_id),
)
@api.response(HTTPStatus.NO_CONTENT.value, "Object added")
@api.response(HTTPStatus.BAD_REQUEST.value, "Item not found")
@api.expect(detail_parser)
def post(self, item_id: int) -> None:
"""
Simple append details to the memory object
"""
args = item_parser.parse_args()
try:
if item := self._lookup(item_id):
item["details"].append(args)
return None
except StopIteration:
return api.abort(HTTPStatus.BAD_REQUEST.value, "Item not found")
```
This will enable two more endpoints:
Endpoint | Method | Parameters | Returns
-- | -- | -- | --
`/api/v1/items/<item_id>` | GET | None | a single `item_model` resource.
`/api/v1/items/<item_id>` | POST | As defined on `detail_parser` | None
---
To wrap up our application, you only need to import the module at `app.py` and register the Blueprint.
```py
from api import blueprint
app = Flask(__name__) # This line already exists
app.register_blueprint(blueprint)
```
---
You can fork and play with this example using this repo:
{% github po5i/flask-mini-rest %}
I also added some unit tests and type annotations for your delight 😉.
Any feedback or suggestions are welcome and I'll be happy to answer any question you may have. | po5i |
889,858 | API Gateway REST API: Step Functions direct integration – AWS CDK guide | Harness the power of AWS Step Functions and AWS Amazon Gateway to build robust APIs. | 0 | 2021-11-06T04:42:07 | https://dev.to/aws-builders/api-gateway-rest-api-step-functions-direct-integration-aws-cdk-guide-13c4 | aws, cdk, serverless | ---
title: API Gateway REST API: Step Functions direct integration – AWS CDK guide
published: true
description: Harness the power of AWS Step Functions and AWS Amazon Gateway to build robust APIs.
tags: aws, cdk, serverless
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/7zl1wsoobrkzof50wmah.jpeg
---
The recent addition to the [_AWS Step Functions_](https://aws.amazon.com/step-functions/) service sparked many conversations in the AWS serverless community. This is very much understandable as having the option to integrate _AWS Step Functions_ with almost every AWS service directly is like having superpowers.
This blog post will walk you through creating direct integration between _AWS Step Functions_ and [_Amazon API Gateway_](https://aws.amazon.com/api-gateway/) (REST APIs). By utilizing _Step Functions_ and _API Gateway_ [VTL transformations](https://docs.aws.amazon.com/apigateway/latest/developerguide/rest-api-data-transformations.html), the architecture will allow you to create the whole APIs without deploying any AWS Lambda functions at all!
Let us dive in.
> All the code examples will be written in TypeScript. You can find the [GitHub repository with code from this blog here](https://github.com/WojciechMatuszewski/apigw-rest-sfn-direct-integration-example).
## The API
Creating the _API Gateway REST API_ with _AWS CDK_ is pretty much painless.
**The first step** is to create the _RestApi_ resource.
```ts
import * as apigw from "@aws-cdk/aws-apigateway";
// Stack definition and the constructor ...
const API = new apigw.RestApi(this, "API", {
defaultCorsPreflightOptions: {
/**
* The allow rules are a bit relaxed.
* I would strongly advise you to narrow them down in your applications.
*/
allowOrigins: apigw.Cors.ALL_ORIGINS,
allowMethods: apigw.Cors.ALL_METHODS,
allowHeaders: ["*"],
allowCredentials: true
}
});
```
Since our example will be using the _POST_ HTTP method, I've opted into specifying the `defaultCorsPreflightOptions`. Please note that **this property alone does not mean are done with CORS**. The `defaultCorsPreflightOptions` and the `addCorsPreflight` on the method level create an _OPTIONS_ method alongside the method you initially created. This means that the _API Gateway_ service will handle _OPTIONS_ part of the _CORS_ flow for you, but you **will still need to return correct headers from within your integration**. We will address this part later on.
The **second step** is to create a _resource_ which is nothing more than an API route.
Let us create a route with a path of `/create`.
```ts
const API = // the API definition from earlier.
const createPetResource = API.root.addResource("create");
```
We have not yet integrated our API path with any HTTP verb nor AWS service. We will do this later on after defining the orchestrator powering our API - the _AWS Step Functions_ state machine.
## The Step Functions state machine
Since this blog post is not a tutorial on _Step Functions_ our _Step Functions state machine_ will be minimalistic.
Here is how one might define such a state machine using _AWS CDK_.
```ts
import * as sfn from "@aws-cdk/aws-stepfunctions";
import * as logs from "@aws-cdk/aws-logs";
// Previously written code and imports...
const APIOrchestratorMachine = new sfn.StateMachine(
this,
"APIOrchestratorMachine",
{
stateMachineType: sfn.StateMachineType.EXPRESS,
definition: new sfn.Pass(this, "PassTask"),
logs: {
level: sfn.LogLevel.ALL,
destination: new logs.LogGroup(this, "SFNLogGroup", {
retention: logs.RetentionDays.ONE_DAY
}),
includeExecutionData: true
}
}
);
```
Since we are building synchronous API, I've defined the type of the state machine as _EXPRESS_. If you are not sure what the difference is between the _EXPRESS_ and _STANDARD_ (default) types, please refer to [this AWS documentation page](https://docs.aws.amazon.com/step-functions/latest/dg/concepts-standard-vs-express.html).
In a real-world scenario, I would not use the _EXPRESS_ version of the state machine from the get-go. The _EXPRESS_ type is excellent for cost and performance, but I find the "regular" state machine type better for development purposes due to rich workflow visualization features.
As I eluded earlier, the definition of the state machine is minimalistic. The `PassTask` will return everything from machine input as the output.
I encourage you to give it a try and extend the definition to include calls to different AWS services. Remember that you most likely [do not need an _AWS Lambda_ function to do that](https://docs.aws.amazon.com/step-functions/latest/dg/supported-services-awssdk.html).
## The Integration
Defining direct integration between _Amazon API Gateway_ and _AWS Step Functions_ will take up most of our code. The _Amazon API Gateway_ is a feature-rich service. It exposes a lot of knobs one might adjust to their needs. We will distill all the settings to only the ones relevant to our use case.
```ts
const createPetResource = API.root.addResource("create");
createPetResource.addMethod(
"POST",
new apigw.Integration({
type: apigw.IntegrationType.AWS,
integrationHttpMethod: "POST",
uri: `arn:aws:apigateway:${cdk.Aws.REGION}:states:action/StartSyncExecution`,
options: {}
}),
// Method options \/. We will take care of them later.
{}
);
```
The most **important part of this snippet is the `uri` property**. This property tells the _API Gateway_ what AWS service to invoke whenever the route is invoked. The documentation around `uri` is, in my opinion, not easily discoverable. I found the [_Amazon API Gateway_ API reference page](https://docs.aws.amazon.com/apigateway/api-reference/resource/integration/) helpful with learning what the `uri` is about.
With the skeleton out of the way, we are ready to dive into the `options` parameter.
### The integration options
Our integration tells the _Amazon API Gateway_ service to invoke a _Step Functions_ state machine, but we never specified which one!
This is where the `requestTemplates` property comes in handy. To target the `APIOrchestratorMachine` resource that will power our API, the _ARN_ of that state machine has to be forwarded to the _Step Functions_ service.
```ts
const APIOrchestratorMachine = // state machine defined earlier...
const createPetResource = API.root.addResource("create");
createPetResource.addMethod(
"POST",
new apigw.Integration({
// other properties ...
options: {
passthroughBehavior: apigw.PassthroughBehavior.NEVER,
requestTemplates: {
"application/json": `{
"input": "{\\"actionType\\": \\"create\\", \\"body\\": $util.escapeJavaScript($input.json('$'))}",
"stateMachineArn": "${APIOrchestratorMachine.stateMachineArn}"
}`
}
}
})
);
```
The **`requestTemplates`** is a `key: value` structure that specifies a given mapping template for an input data encoding scheme – I assumed that every request made to the endpoint would be encoded as `application/json`.
The data I'm forming in the request template must obey the [`StartSyncExecution` API call](https://docs.aws.amazon.com/step-functions/latest/apireference/API_StartSyncExecution.html) validation rules.
---
Let us tackle **[_AWS IAM_](https://aws.amazon.com/iam/)** next.
Our definition tells the _Amazon API Gateway_ which state machine to invoke (via the `requestTemplates` property). It is not specifying the role _API Gateway_ could assume so that it has permissions to invoke the state machine.
Enter the `credentialsRole` parameter. The _Amazon API Gateway_ service will use this role to invoke the state machine when specified.
Luckily for us, creating such a role using _AWS CDK_ is not much of a hassle.
```ts
import * as iam from "@aws-cdk/aws-iam";
const APIOrchestratorMachine = // state machine definition
const invokeSFNAPIRole = new iam.Role(this, "invokeSFNAPIRole", {
assumedBy: new iam.ServicePrincipal("apigateway.amazonaws.com"),
inlinePolicies: {
allowSFNInvoke: new iam.PolicyDocument({
statements: [
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ["states:StartSyncExecution"],
resources: [APIOrchestratorMachine.stateMachineArn]
})
]
})
}
});
const createPetResource = API.root.addResource("create");
createPetResource.addMethod(
"POST",
new apigw.Integration({
// Properties we have specified so far...
options: {
credentialsRole: invokeSFNAPIRole
}
}),
// Method options \/. We will take care of them later.
{}
);
```
The role is allowed to be assumed by _Amazon API Gateway_ (the `assumedBy` property) service and provides permissions for invoking the state machine we have created (the `states:StartSyncExecution` statement).
---
Since our `/create` route accepts POST requests, the response must contain appropriate CORS headers. Otherwise, users of our API might not be able to use our API.
Just like we have modified the incoming request to fit the `StartSyncExecution` API call validation rules (via the `requestTemplates` parameter), we can validate the response from the _AWS Step Functions_ service.
This is done by specifying the `integrationResponses` parameter. The `integrationResponses` is an array of response transformations. Each transformation corresponds to the status code **returned by the integration, not the _Amazon API Gateway_ service**.
```ts
const createPetResource = API.root.addResource("create");
createPetResource.addMethod(
"POST",
new apigw.Integration({
// Properties we have specified so far...
options: {
integrationResponses: [
{
selectionPattern: "200",
statusCode: "201",
responseTemplates: {
"application/json": `
#set($inputRoot = $input.path('$'))
#if($input.path('$.status').toString().equals("FAILED"))
#set($context.responseOverride.status = 500)
{
"error": "$input.path('$.error')",
"cause": "$input.path('$.cause')"
}
#else
{
"id": "$context.requestId",
"output": "$util.escapeJavaScript($input.path('$.output'))"
}
#end
`
},
responseParameters: {
"method.response.header.Access-Control-Allow-Methods":
"'OPTIONS,GET,PUT,POST,DELETE,PATCH,HEAD'",
"method.response.header.Access-Control-Allow-Headers":
"'Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token,X-Amz-User-Agent'",
"method.response.header.Access-Control-Allow-Origin": "'*'"
}
}
]
}
}),
// Method options \/. We will take care of them later.
{}
);
```
The above `integrationResponse` specifies that if the _AWS Step Functions_ service returns with a `statusCode` of 200 (controlled by the `selectionPattern` and **not** the `statusCode`), the transformations within the `responseTemplates` and `responseParameters` will be applied to the response and the _Amazon API Gateway_ will return with the `statusCode` of 201 to the caller.
Take note of the `responseParameters` section where we specify CORS-related response headers. This is only an example. In a real-world scenario, I would not recommend putting `*` as the value for `Access-Control-Allow-Origin` header.
The [_mapping template_](https://docs.aws.amazon.com/apigateway/latest/developerguide/request-response-data-mappings.html) is a bit involved.
The following block of code
```txt
#if($input.path('$.status').toString().equals("FAILED"))
```
is responsible for checking if a given execution failed. **This condition has nothing to do with checking if _AWS Step Functions_ service failed**.
The conditions checks whether given state machine execution failed or not.
For _AWS Step Functions_ service failure, we need to create another mapping template to handle such a scenario. This is out of the scope of this blog post.
### The method options
The method options ([_AWS CloudFormation reference_](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-apigateway-method.html)) contain properties that allow you to specify request/response validation, **which `responseParameters` are allowed for which `statusCode`** (very relevant for us), and various other settings regarding _Amazon API Gateway_ route method.
In the previous section, we have specified the `responseParameters` so that the response surfaced by _Amazon API Gateway_ contains CORS-related headers.
To **make the `responseParameters` fully functional, one needs to specify correct `methodResponse`**.
```ts
createPetResource.addMethod(
"POST",
new apigw.Integration({
// Properties we have specified so far...
options: {
integrationResponses: [
{
// Other `integrationResponse` parameters we have specified ...
responseParameters: {
"method.response.header.Access-Control-Allow-Methods":
"'OPTIONS,GET,PUT,POST,DELETE,PATCH,HEAD'",
"method.response.header.Access-Control-Allow-Headers":
"'Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token,X-Amz-User-Agent'",
"method.response.header.Access-Control-Allow-Origin": "'*'"
}
}
]
}
}),
{
methodResponses: [
{
statusCode: "201",
// Allows the following `responseParameters` be specified in the `integrationResponses` section.
responseParameters: {
"method.response.header.Access-Control-Allow-Methods": true,
"method.response.header.Access-Control-Allow-Headers": true,
"method.response.header.Access-Control-Allow-Origin": true
}
}
]
}
);
```
In my opinion, the resource definition would be less confusing if the `methodResponses` (and the whole method options section) would come before the `integration`. I find it a bit awkward that we first have to specify the `responseParameters` in the request and THEN specify which ones can be returned in the `methodResponse` section.
## Bringing it all together
Phew! That was a relatively large amount of code to write. Luckily, engineers contributing to the _AWS CDK_ are already preparing an abstraction for us to make this process much more manageable. [Follow this PR](https://github.com/aws/aws-cdk/pull/16827) to see the progress made.
Here is all the code that we have written together. The code is also available on [my GitHub](https://github.com/WojciechMatuszewski/apigw-rest-sfn-direct-integration-example).
```ts
const API = new apigw.RestApi(this, "API", {
defaultCorsPreflightOptions: {
/**
* The allow rules are a bit relaxed.
* I would strongly advise you to narrow them down in your applications.
*/
allowOrigins: apigw.Cors.ALL_ORIGINS,
allowMethods: apigw.Cors.ALL_METHODS,
allowHeaders: ["*"],
allowCredentials: true
}
});
new cdk.CfnOutput(this, "APIEndpoint", {
value: API.urlForPath("/create")
});
const APIOrchestratorMachine = new sfn.StateMachine(
this,
"APIOrchestratorMachine",
{
stateMachineType: sfn.StateMachineType.EXPRESS,
definition: new sfn.Pass(this, "PassTask"),
logs: {
level: sfn.LogLevel.ALL,
destination: new logs.LogGroup(this, "SFNLogGroup", {
retention: logs.RetentionDays.ONE_DAY
}),
includeExecutionData: true
}
}
);
const invokeSFNAPIRole = new iam.Role(this, "invokeSFNAPIRole", {
assumedBy: new iam.ServicePrincipal("apigateway.amazonaws.com"),
inlinePolicies: {
allowSFNInvoke: new iam.PolicyDocument({
statements: [
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ["states:StartSyncExecution"],
resources: [APIOrchestratorMachine.stateMachineArn]
})
]
})
}
});
const createPetResource = API.root.addResource("create");
createPetResource.addMethod(
"POST",
new apigw.Integration({
type: apigw.IntegrationType.AWS,
integrationHttpMethod: "POST",
uri: `arn:aws:apigateway:${cdk.Aws.REGION}:states:action/StartSyncExecution`,
options: {
credentialsRole: invokeSFNAPIRole,
passthroughBehavior: apigw.PassthroughBehavior.NEVER,
requestTemplates: {
"application/json": `{
"input": "{\\"actionType\\": \\"create\\", \\"body\\": $util.escapeJavaScript($input.json('$'))}",
"stateMachineArn": "${APIOrchestratorMachine.stateMachineArn}"
}`
},
integrationResponses: [
{
selectionPattern: "200",
statusCode: "201",
responseTemplates: {
"application/json": `
#set($inputRoot = $input.path('$'))
#if($input.path('$.status').toString().equals("FAILED"))
#set($context.responseOverride.status = 500)
{
"error": "$input.path('$.error')",
"cause": "$input.path('$.cause')"
}
#else
{
"id": "$context.requestId",
"output": "$util.escapeJavaScript($input.path('$.output'))"
}
#end
`
},
responseParameters: {
"method.response.header.Access-Control-Allow-Methods":
"'OPTIONS,GET,PUT,POST,DELETE,PATCH,HEAD'",
"method.response.header.Access-Control-Allow-Headers":
"'Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token,X-Amz-User-Agent'",
"method.response.header.Access-Control-Allow-Origin": "'*'"
}
}
]
}
}),
{
methodResponses: [
{
statusCode: "201",
responseParameters: {
"method.response.header.Access-Control-Allow-Methods": true,
"method.response.header.Access-Control-Allow-Headers": true,
"method.response.header.Access-Control-Allow-Origin": true
}
}
]
}
);
```
## Next steps
To make sure this blog post is not overly long, I've omitted some of the code I would usually write in addition to what we already have.
Here are some ideas what you might want to include in the integration definition:
- Add request and response validation via [API models](https://docs.aws.amazon.com/apigateway/latest/developerguide/how-to-create-model.html).
- Amend the state machine definition to leverage the [SDK service integrations](https://docs.aws.amazon.com/step-functions/latest/dg/supported-services-awssdk.html).
- Add more entries in the `integrationResponses`/`methodResponses` errors from the _AWS Step Functions_ service itself.
## Closing words
Integrating various AWS services directly is a great way to save yourself from one of the most significant liabilities in serverless systems – AWS Lambdas code. You might be skeptical at first, as writing those services together is usually not the easiest thing to do, but believe me, the upfront effort is worth it.
I hope that you found this blog post helpful.
Thank you for your time.
---
For questions, comments, and more serverless content, check out my Twitter – [@wm_matuszewski](https://twitter.com/wm_matuszewski)
| wojciechmatuszewski |
890,052 | Respecting someone's gender in a Person object. | Here's how I'd respect someone's gender in TypeScript /* * A 3-bit number that represents the... | 0 | 2021-11-06T07:43:21 | https://dev.to/baenencalin/respecting-someones-gender-in-a-person-object-4fok | lgbtq, typescript, watercooler, programming | Here's how I'd respect someone's gender in TypeScript
```ts
/*
* A 3-bit number that represents the person's gender.
* (bits in the order of: MFT.)
* (MFT stands for "Male Female Trans".)
* (Special blends:
* 0x111 = Gender Fluid
* 0x110 = Bigender
* 0x001 = Nonbinary
* 0x000 = Agender
* )
* (
* Expansion upon this format is welcome. If you want
* to add more attributes, for more non-binary genders,
* feel free, and tell me your format below!
* )
*/
type Gender = number;
function sterilizeGenderId(g:Gender):Gender {
return g & 0b111; // 0b111 = 7.
}
class Person {
constructor(
name:String|string, age:number, gender:Gender
) {
this.gender = sterilizeGenderId(gender);
this.name = name;
this.age = age;
}
gender:Gender;
name:String|string;
age:number;
}
``` | baenencalin |
890,058 | OBJECT ORIENTED PROGRAMMING IN 5 MIN | Object Oriented programming What is Object Oriented Programming? (oop) oop is... | 0 | 2021-11-06T08:10:25 | https://dev.to/harixom/object-oriented-programming-in-5-min-483n | programming, tutorial, beginners, oop |
# Object Oriented programming
## What is Object Oriented Programming? (oop)
- oop is programming paradigm (style of the code) based on teh concept of objects;
- We use Objects to model (describe) real world or abstract features;
- Objects may contain data (properties) and code (method), By using Objects, we pack data and teh corresponding behavior into one block;
- In OOP, objects are self-contained pieces/blocks of code;
- object are building blocks of applications, and interact with one another;
- interactions happen through a public interface(API): method that the code outside of the object can access and use to communicate with the object;
### why just oop exist
well this paradigm was developed with the goal of organizing code, so to make it more flexible and easier to maintain.
## CLASS AND INSTANCES (TRADITIONAL OOP)
in traditional oop we use something called **CLASSES**.
<br>
_you can think of a class as a blueprint, which can then be used to create new objects based on the rules described in the class._
<br>
so it's just like an architecture where the architect develops a blueprint to exactly plan and describe a house.
## THE 4 FUNDAMENTAL OOP PRINCIPLES
1. Abstraction
2. Encapsulation
3. Inheritance
4. Polymorphism
### PRINCIPLE1: ABSTRACTION
Abstraction: Ignoring or hiding details that don't matter, allowing us to get an overview perspective of the thing we're implementing instead of messing with details that don't really matter to our implementation.
#### example
let's say that we're implementing a phone for a user to use. so with our abstraction like the phone's temperature and voltage, turning on the vibration motor or the speaker, and other low level details, but as a user interacting with a phone, do we really need all of this detail? well no.
<br>
in reality, when we interact with a real phone, all of these details have been abstracted away from us as the user.
### PRINCIPLE 2: ENCAPSULATION
Encapsulation: Keeping properties and methods **private** inside the class, so they are **not accessible from outside the class**. some methods can be **exposed** as a public interface(API)
### PRINCIPLE 3: INHERITANCE
Inheritance: Making all properties and methods of a certain class **available to a child class**, forming a hierarchical relationship between classes. this allows us to **reuse common logic** and to model real-world relationship
### PRINCIPLE 4: POLYMORPHISM
Polymorphism: A Child class can overwrite a method it inherited form a parent class [it's more complex that, but enough for our purposes].
| harixom |
890,064 | Genetic Algorithm in action! | What is the Genetic Algorithm?, to a human! The Genetic Algorithm is a clever idea used in many... | 0 | 2022-10-22T13:34:37 | https://dev.to/kavinbharathi/genetic-algorithm-in-action-3ilj | python, showdev, geneticalgorithm, ai | <h2>What is the Genetic Algorithm?, to a human!</h2>
The Genetic Algorithm is a clever idea used in many fields to solve problems that otherwise take too much computing power or time. It mimics the process of evolution in nature, in a very bare-bones manner. The usage of various processes to evaluate genes, fitness scores, the target really makes it useful in implementing it for various different needs.
<h2>What is the Genetic Algorithm?, to a computer!</h2>
Now, the computer doesn't understand English or any other communication language for that matter. So how do you implement it in code. I'll be using Python and a library called Pygame, to visualize the Genetic Algorithm.
<h3>Setting up the environment</h3>
Tools required:
1. python=3.8 or above
2. pygame=2.0.2 or above
3. A good text editor(I'll be using Microsoft Visual Studio Code)
4. A cup of coffee(or more!)
<h3>Building the Pygame display</h3>
The pygame display is easy to build. All you have to do is initialize a screen with,
```python
display = pygame.display.set_mode((width, height))
```
where `width` and `height` are the dimensions of your display. Then in a function, initialize a `while` loop and update the pygame display. The code for the above mentioned is,
```python
import pygame
width = 720
height = 480
display = pygame.display.set_mode((width, height))
pygame.display.set_caption("Genetic Algorithm")
def main():
run = True
while run:
for event in pygame.event.get():
if event.type == pygame.QUIT:
run = False
pygame.display.flip()
if __name__ == "__main__":
main()
```
<h3>The structure of the algorithm</h3>
The genetic algorithm uses a clever way to mimic the process of evolution in nature. Generally, the are n number of individuals I call `genomes`. Each genome has a set of "genes" and their behavior is dictated by their genes.
These genes are randomly initialized and are then evaluated on a specific task. For our example, we will be using vertical motion of each individual. Then the best performing genes are selected and a "breeding" process is done in hopes or increasing the pattern of the best performing genes. There is also a process of "mutation" where a small change is done to the genes of the genome to introduce variance and hopefully some helpful genes to boost up the evolution process.
<h4>Creating the Genome class:</h4>
What I'll be referring to as "Genomes" are the individuals who are going to evolve using the magic of natural selection and mutation to become the best at a specific task(or at least, good enough)
We will create a class called Genome() since we will be using multiple instances of it later on.
```python
class Genome:
def __init__(self, target):
self.gene_length = GENE_LENGTH
self.gene = []
self.x = width // 2
self.y = 10
self.step = 0
self.target = target
self.fitness = -1
self.dead = False
self.generation = -1
def draw(self):
pygame.draw.circle(display, (0, 170, 200), (self.x, self.y), 4)
def create_genes(self):
pass
def move(self):
pass
def calc_distance(self):
pass
def calc_fitness(self):
pass
def crossover(self, partner):
pass
def mutate(self):
pass
```
Each genome has a target and the performance of the genome is evaluated based on the target. In our case, the target is just a box and the objective of the genome is to reach the box/target.
The performance of a genome is also called the "fitness" of that genome. They are ranked based on their fitness. The step variable is used to step through the gene of the genome and make the moves based on that position of the gene.
The methods the genes are
- create_genes:
Create the initial genes randomly, consisting of (x, y) ordered pairs each with a random value between -1 and 1.
- move:
The move function steps through the gene using the step variable and updates the x position and the y position of the genome based on the (x, y) pair in the gene.
- calc_distance:
This method is used to calculate the distance between the genome and the target. The distance used here is the euclidean distance.
- calc_fitness:
The fitness is calculated based on the euclidean distance between the genome and the target. Then the distance is normalized between 0 and 1.
- crossover:
This is one of the important methods in the algorithm. We create new genomes from the genes of old ones. The crossover process in done by intertwining the genes of two parents. For example, let the following genomes be the parents.

Then to breed them, their gene are intertwined to make a new gene of the same length.
By this process, we can multiply the genes that result in a better fitness than poorly performing genes.
- mutate:
Mutation is also an important step in the genetic algorithm. Generally mutation is done based on a mutation rate, which is a constant. But we can also introduce varying mutation rates if we need to. However, we are going to use a constant mutation rate. Initialize a `MUTATION_RATE` variable which holds how much percentage of the genes should be mutated. In my code, I've given a 2% chance for mutation. Therefore, my MUTATION_RATE is going to be,
```python
MUTATION_RATE = 0.02
```
While we are at it, we can also initialize some other important constants like the population size, the gene length etc...
```python
POPULATION_SIZE = 100
MUTATION_RATE = 0.02
GENE_LENGTH = 10000
```
Now we can populate the genome class with actual code...
```python
class Genome(object):
def __init__(self, target):
self.gene_length = GENE_LENGTH
self.gene = []
self.x = width // 2
self.y = 10
self.step = 0
self.target = target
self.fitness = -1
self.dead = False
self.generation = -1
def create_genes(self):
for _ in range(self.gene_length):
x_direction = random.uniform(-1, 1)
y_direction = random.uniform(-1, 1)
self.gene.append([x_direction, y_direction])
def draw(self):
pygame.draw.circle(display, (0, 170, 200),
(self.x, self.y), 4)
def move(self):
self.x += self.gene[self.step][0]
self.y += self.gene[self.step][1]
self.step += 1
if self.step >= self.gene_length:
self.fitness = self.calc_fitness()
self.dead = True
def calc_distance(self):
# using pythagoras' theorem to fing the shortest distance between the
# genome and the give target
perpendicular = abs(self.target.x - self.x)
base = abs(self.target.y - self.y)
dist = math.sqrt(perpendicular**2 + base**2)
return dist
def calc_fitness(self):
# using a fitness function to find the fitness of
# the specific genome, and use it as the metric to
# improve it's probability of becoming a parent
dist = self.calc_distance()
normalized_dist = dist / height
fitness = 1 - normalized_dist
return fitness
def crossover(self, partner):
child = Genome(self.target)
for i in range(self.gene_length):
if i % 2 == 0:
child.gene.append(self.gene[i])
else:
child.gene.append(partner.gene[i])
return child
def mutate(self):
for i in range(GENE_LENGTH):
mutation_probability = round(random.uniform(0, 1), 2)
if mutation_probability < MUTATION_RATE:
mutated_gene_x = random.uniform(-1, 1)
mutated_gene_y = random.uniform(-1, 1)
self.gene[i] = [mutated_gene_x, mutated_gene_y]
```
<h4>Creating the Population class:</h4>
A population is just a group of n number of genomes. In our case, a population consists of 100 genomes(`POPULATION_SIZE`). But, since we need to process the fitness of each genome, breed them, and also keep track of the generation, we'll encapsulate the information in a Population class.
```python
class Population(object):
def __init__(self, target):
self.target = target
self.population = []
self.generation = 0
def populate(self):
pass
def natural_selection(self):
pass
def breed(self):
pass
```
The population class is going to hold a target, which will be passed on to the genomes of the population. It also keeps track of the generation and an array of all the genomes in the population.
As usual, we'll go through the methods in the class.
- populate:
As the name suggests, this method is used to populate the genomes in the population class. In the first generation, the genomes are made with random genes. At the later stages, the genomes are the children of their previous generation.
- natural_selection:
The natural selection method creates a mating pool, which is essentially just an array of genomes. But the mating pool has genomes whose frequency in the mating pool is directly proportional to the `fitness` of the genome. So the "fitter" a genome the higher the number of it in the mating pool. Since the fitter genomes are higher in frequency, the chances of them being selected for the mating process is also higher. Hence, the fitter genomes survive longer.
> Survival of the fittest.
- breed:
Finally, the breeding part. Here we are just going to select random individuals from the mating pool generated by the `natural_selection` method and breed their genes by intertwining their genes as mentioned above.
Hence the code for the methods are,
```python
class Population(object):
def __init__(self, target):
self.target = target
self.population = []
self.generation = 0
def populate(self):
self.population = [Genome(self.target) for _ in range(POPULATION_SIZE)]
for genome in self.population:
genome.create_genes()
genome.generation = self.generation
def natural_selection(self):
mating_pool = []
for genome in self.population:
fitness_ratio = math.floor(max(genome.fitness, 0) * 100)
for _ in range(fitness_ratio):
mating_pool.append(genome)
return mating_pool
def breed(self):
generation_dead = all([genome.dead for genome in self.population])
if generation_dead:
self.population = self.natural_selection()
children = Population(self.target)
for _ in range(POPULATION_SIZE):
father_genome = random.choice(self.population)
mother_genome = random.choice(self.population)
child_genome = father_genome.crossover(mother_genome)
child_genome.mutate()
child_genome.generation = self.generation
children.population.append(child_genome)
self.population = children.population
self.generation += 1
```
<h4>Creating the Target class: </h4>
The Target is the object that is going to be the destination for the genomes. We are going to evaluate the fitness of the genomes by calculating the distance between the target and the genome. The smaller the distance, the fitter the genome is. Therefore, the target object is only ever going to need to have two variables, x and y. And a draw method to draw the target to the screen.
```python
class Target(object):
def __init__(self):
self.x = width // 2
self.y = height - 10
self.width = 20
def draw(self):
pygame.draw.rect(display, (0, 200, 170), (
self.x - self.width // 2, self.y - self.width // 2, self.width, self.width))
```
<h3>Genetic Algorithm!</h3>
Finally it is time to see the algorithm work. But before that we have to create the necessary objects and add them to the main function. To do that,
```python
def main():
run = True
food = Target()
population = Population(food)
population.populate()
while run:
display.fill((0, 0, 0))
for event in pygame.event.get():
if event.type == pygame.QUIT:
run = False
for genome in population.population:
genome.draw()
genome.move()
food.draw()
population.breed()
pygame.display.flip()
if __name__ == "__main__":
main()
```
Now if you run the code, you should see a screen like this,
Over time, you'll see those dots(genomes) get closer and closer to the target. Eventually, by the magic of the genetic algorithm, they'll be able to reach the target consistently. This is just a taste of the genetic algorithm's potential. There is a lot more to explore.
Thank you for reading. Feel free to comment your thoughts and opinions about this article.
[My GitHub repo for genetic algorithm](https://github.com/cipherDOT/genetic-algorithm)
I've added some extra flare to the code as well. :) | kavinbharathi |
890,277 | Notes on “Introduction to machine learning.” | I have recently started dipping my toes in the deep waters of Machine Learning. Through a few posts I... | 0 | 2021-11-06T14:04:12 | https://dev.to/chicken_biryani/notes-on-introduction-to-machine-learning-1pnm | beginners, machinelearning, 100daysofcode | I have recently started dipping my toes in the deep waters of Machine Learning. Through a few posts I would like to share my learnings and notes on Machine Learning.
This post covers the topics:
- What is Machine Learning?
- Types of Machine Learning. - Supervised learning. - Unsupervised learning.
[Reinforcement learning. is not covered in this blog]
- Extras
- Dividing Data
- Overfitting
- Underfitting.
_[Note that I am a beginner at blogging, so if I have gone wrong anywhere or can improve, please let me know.]_
The references I am using for this blog and my learning:
[FreeCodeCamp](https://www.youtube.com/watch?v=NWONeJKn6kc&t=373s), [Kaggle](https://www.kaggle.com/learn), Reddit, Twitter threads, and blogs.
The type of learning I prefer is to watch videos about a concept and then read about it. Not everyone learns in a similar manner but if you are someone who prefers this type of learning then feel free to use the sources referenced above.
So, let’s get started!
## What is Machine learning?
‘Machine learning’ is a fancy way of saying-
Feed data to an algorithm. The algorithm analyzes the data. The algorithm makes a prediction (/gives an output).
A simple explanation I liked from Reddit was:
“Machine Learning is a form of Artificial Intelligence in which the program is designed to learn on its own.
A simple example might be the following:
You want to create a program to differentiate between apples and oranges. You have data that says that oranges weigh between 150-200g, and apples between 100-130g. Also, oranges are rough, and apples smooth (which you might represent as a 0 or 1). If you have a fruit that weighs 115g, and is smooth, your program can determine that it is probably an apple. Vice-versa, if the fruit is 175g and rough, it is most likely an orange. Anything outside of these boundaries won't be either. What, now, if your fruit is smooth, but only 99g? It probably is an apple, but not to your program. Therefore, the more data you have, the more accurate your data becomes. It might even use past guesses to further its own data. It is learning on its own what an orange or an apple is. This is Machine Learning.”
## Types of Machine Learning?
There are three types of machine learning:
- Supervised learning
- Unsupervised Learning
- Reinforcement Learning.[Not covered in this blog]
### Supervised Learning
In supervised learning, a human is supervising the computer forming a model.
Here's an analogy- When a child is learning the different types of colors, an elder is telling the child whether they have detected the color correctly or not. When shown the colour 'red' to the child there are two possibilities, the child recognizes the color or they don't. If they do they have learnt well else the elder corrects them and teaches them again.
Over here the dataset is the colors, the ‘supervisor’ is an elder and the child learning colors is a model. A better model is created with repeated re-training.

There are two types of supervised learnings:
- Classification
- Regression
In classification, the values are discrete. In regression, the values are continuous.
'Discrete values' mean that they are specific. A bottle of water can either be ‘empty’ or ‘not empty.’ A number can be either ‘even’ or ‘odd.’ The output is specific.
Continuous values are values that fall within a range. A person’s age. ‘Age’ will fall within a range. i.e 0 to 100.
### Unsupervised learning
In unsupervised learning a pattern or a structure is to be extracted from a given dataset. This means that we can draw references from observations in the input data.
Here’s an example from a blog I came across was:
“Imagine you are in a foreign country and you are visiting a food market, for example. You see a stall selling a fruit that you cannot identify. You don’t know the name of this fruit. However, you have your observations to rely on, and you can use these as a reference. In this case, you can easily the fruit apart from nearby vegetables or other food by identifying its various features like its shape, color, or size.
This is roughly how unsupervised learning happens. We use the data points as references to find meaningful structure and patterns in the observations. Unsupervised learning is commonly used for finding meaningful patterns and groupings inherent in data, extracting generative features, and exploratory purposes.”
It’s okay if a lot of things don't make sense for now and may seem intimidating. It will eventually.
## Extras
In this section I am putting down information that I thought is useful but did not understand where to place it.
### Dividing the dataset.
The existing data set is divided into two parts. Training and testing.
The training data set is the data set used to train the model/algorithm.
The test part of the data set is used to evaluate the model/algorithm you are using.
### Overfitting
“Overfitting would be like training your dog raise his paw when you hold out your hand, and he learns the trick perfectly, but he only does it when it's _you_ holding out _your_ hand, and only your right hand because that's all he's been trained on. He won't do it for anyone else, and he won't do it when you raise your left hand. So his "model" of the trick works perfectly, but because there hasn't been enough variation in the training activity, or because of the way that the training was done (or perhaps just because of the way the dog's brain works), his trick doesn't generalize correctly to other stimuli that was intended to yield the same result.” - Reddit
### Underfitting
In underfitting the model has not learnt enough and is not able to map the input to the output properly.
That's it for this blog. Thank you for reading. I hope this was helpful. If there are ways in which I can improve please do let me know.
| chicken_biryani |
890,304 | Dapp Development | Can someone explain the concept i should use to store document in blockchain. Document like land... | 0 | 2021-11-06T14:51:18 | https://dev.to/crypto_valley/dapp-development-1570 | Can someone explain the concept i should use to store document in blockchain. Document like land ownership, or Should i store it in my server and then encrypt and send to blockchain | crypto_valley | |
890,513 | Git and Github guide for begineers | If you have no knowledge about git and github and for some reason you need to use them, I can help... | 0 | 2021-11-06T18:25:35 | https://dev.to/philipeleandro/git-and-github-guide-for-begineers-56bh | github, git, beginners, tutorial | If you have no knowledge about git and github and for some reason you need to use them, I can help you with these steps:
1 - First, in your bash, if it's the first time you're using it, you must register an user and email with:
$ git config --global user.name YOUR_NAME
$ git config --global user.email your_name@example.com
2 - Now, manipulating the paths of your machine, you can set a folder to be a place to save your files;
3 - For being a regular folder, you must have to initialize it with this command:
$ git init
That way, the bash will recognize it as an initialized folder;
4 - After you have made all you needs, like creating and modifying files, you can follow these commands to send your modified files
to a repository:
- first, you might use $ git status to verify the status files;
- second, with $ git add . or $ git add file_name you can add your files modification;
- next, if you want, you can verify the status with $ git status;
- with $ git commit -m "message", they'll be commited and ready to be pushed to a repository.
5 - With a synchronized github account, you can use $ git push <remote_name> <branch_name> to send them. | philipeleandro |
890,518 | Open a web page from Terminal with Brave Browser | Sometimes I want to open a web page(mostly a GitHub repo) really quickly while I'm writing code. For... | 0 | 2021-11-06T18:36:01 | https://dev.to/0xkoji/open-a-web-page-from-terminal-with-brave-browser-p2b | tooling | Sometimes I want to open a web page(mostly a GitHub repo) really quickly while I'm writing code.
For doing that, I'm using `alias`.
```zsh
alias brave="open -a 'Brave Browser'"
alias portfolio='brave https://github.com/koji/portfolio_nextjs'
```
Brave Browser
https://brave.com/
When I want to open my portfolio repo.
```zsh
brave https://github.com/koji/portfolio_nextjs
```
If you want to use other browsers
```zsh
alias chrome="open -a 'Google Chrome'" # chrome
alias firefox='open -a Firefox' # firefox
alias safari='open -a Safari' # safari
``` | 0xkoji |
891,074 | How to configure PHP logs for Docker | If you are using docker and cloud services to run your application live, you should manage your... | 0 | 2021-11-07T14:06:06 | https://dev.to/mtk3d/how-to-configure-php-logs-for-docker-2384 | php, docker, laravel, symfony | If you are using docker and cloud services to run your application live, you should manage your logs.
The most common method to store them is to put them in the text file. It's the default configuration for most backend frameworks. This option is ok if you run your application locally or on the VPS server for test.
When you run your application in a production environment, you should choose a better option to manage your logs. Almost every cloud has a tool for rotating logs or if not, you can use for example Grafana Loki or ELK stack. Those solutions are better because give you interfaces to rotate and search your logs. Also, you have easy access to them, you no need to connect to your server to review them.
If you are using Docker containers, and you running your application in cloud services, often they will be automatically writing the logs of your containers to tools like AWS CloudWatch or GCloud Stackdriver.
But first, you need to redirect your log streams to the output of the Docker container to be able to use them.
## Linux streams
Docker containers are running the Linux processes. In linux every running process has 3 streams, `STDIN`, `STDOUT`, `STDERR`. `STDIN` it's command input stream, that you can provide for ex. by your keyboard. `STDOUT` is the stream where the running command may print the output. `STDERR` is the standard error stream, but the name I think is a bit confusing, because it is basically intended for diagnostic output.
When you run the `docker logs [container]` command in your terminal, you will see the output of `STDOUT` and `STDERR` streams. So our goal is to redirect our logs to one of those streams.
[Official docker documentation page](https://docs.docker.com/config/containers/logging/)
## PHP-FPM
In PHP we are often running our application using the PHP-FPM (Process Manager). If you run your docker with FPM inside a docker container, and you run the `docker logs` command, you should see the output with processed requests, or errors.
So the PHP-FPM is already writing its output to `STDOUT`.
The PHP-FPM allow us to catch workers output and forward them to the `STDOUT`. To do that we need to make sure that the FPM is configured properly. You can create new config file, and push it for example to the `/usr/local/etc/php-fpm.d/logging.conf` file:
```text
[global]
error_log = /proc/self/fd/2
[www]
access.log = /proc/self/fd/2
catch_workers_output = yes
decorate_workers_output = no
```
The `error_log` and `access.log` parameters are configuration of streams of logs output.
The `catch_workers_output` option is turning on the worker's output caching. The `decorate_workers_output` is the option that turns off the output decoration. If you leave this option turned on, FPM will decorate your application output like this:
```text
[21-Mar-2016 14:10:02] WARNING: [pool www] child 12 said into stdout: "[your log line]"
```
Remember that `decorate_workers_output` option is available only for [PHP 7.3.0 and higher](https://www.php.net/manual/en/install.fpm.configuration.php#decorate-workers-output).
If you are using official docker php-fpm image, this configuration is already set in the `/usr/local/etc/php-fpm.d/docker.conf` file, so you no need to do anything more 😎
## PHP application configuration
Right now everything that will be put to the stdout from PHP workers will be shown in our docker logs. But when logs are forwarded to that stream in PHP?
To write something to `STDIN` on PHP level, we need to just write to the `php://stdout` stream.
In the simplest way you can do this like that:
```php
<?php
file_put_contents('php://stdout', 'Hello world');
```
When you execute this code in php cli, you will get the `Hello world` text on the output.
But it's not the optimal way to push your logs to the `STDOUT`. Every modern framework should have a PSR-3 Logger. I think that the most popular now is the monolog, so I will show you how to configure it in Symfony, Laravel, and in pure usage.
## Monolog
[Monolog](https://github.com/Seldaek/monolog) is great library to handle logs in your application. It's easy and elastic in configuration.
### Basic monolog configuration
If you are using monolog in your project with manual configuration, you need to configure handler in this way:
(Modified documentation example)
```php
<?php
use Monolog\Logger;
use Monolog\Handler\StreamHandler;
$log = new Logger('stdout');
$log->pushHandler(new StreamHandler('php://stdout', Logger::DEBUG));
$log->debug('Foo');
```
You just need to configure StreamHandler, to write to the `php://stdout` file.
### Symfony
Symfony Kernel since the Flex was provided, [is using minimalist PSR-3 logger](https://symfony.com/blog/new-in-symfony-3-4-minimalist-psr-3-logger), that logs everything to `php://stderr` by default.
In Symfony, monolog as other components is configured in YAML files. So the same configuration will look like this:
```yaml
# config/packages/monolog.yaml
monolog:
handlers:
stdout:
type: stream
path: "php://stdout"
level: debug
```
### Laravel
Laravel use the arrays for configuration so the same thing will look like this:
```php
# config/logging.php
<?php
use Monolog\Handler\StreamHandler;
return [
'channels' =>
'stdout' => [
'driver' => 'monolog',
'handler' => StreamHandler::class,
'level' => env('LOG_LEVEL', 'debug'),
'with' => [
'stream' => 'php://stdout',
],
],
];
```
## STDERR or STDOUT
In some articles on the internet, you can read that someone uses stderr, and someone uses stdout streams to write logs there. Right now I cannot fin any reasons to choose one of them which is better.
The only information that I found on this topic is [that post](https://stackoverflow.com/questions/4919093/should-i-log-messages-to-stderr-or-stdout).
I think that stderr is more popular in some examples, also Fabien Potencier set it as default in his minimalistic logger, so I think we can assume that this one is better.
Personally, I always used the stdout, so that's the reason why I use it in this post's examples. If I will find a great reason for using one of them over another I will update this post.
Originally posted on [https://mateuszcholewka.com](https://mateuszcholewka.com/post/php-logs-in-docker/) | mtk3d |
890,535 | Cannot enter value into MDEditor | When I run the program, I can't enter a value in the input, help me const handleChange = (event)... | 0 | 2021-11-06T19:33:36 | https://dev.to/thanhqn318/cannot-enter-value-into-mdeditor-1omh | react, help | When I run the program, I can't enter a value in the input, help me
```javascript
const handleChange = (event) => {
const { name, value } = event.target;
console.log(value);
setData(data => ({
...data,
[name]: value,
}));
};
const handleSubmit = () => {
setComments([...comments, { content: data.content }]);
};
```
```javascript
const FormCommnent = ({ onChange, onSubmit, value }) => (
<div className="form-comment">
<MDEditor
value={value}
onChange={onChange}
name="content"
rows={4}
autoFocus={0}
preview='edit'
/>
<MDEditor.Markdown source={value} />
<Button htmlType="submit" onClick={onSubmit} >
Add Comment
</Button>
</div>
);
``` | thanhqn318 |
890,661 | How Many Websites Are There in the World? | Have you ever thought of how many active websites are in the world? did you think it would be... | 0 | 2021-11-06T21:00:37 | https://dev.to/checoslbches/how-many-websites-are-there-in-the-world-1lna | Have you ever thought of how many active websites are in the world? did you think it would be hundreds ? thousands ? millions or what?. think whatever.
anyways there are currently over 1.86 billion websites. The trend of website numbers increasing continues year after year. By 2014, there were 1 billion websites online. It took only five years to almost double that number.
However, not all of the 1.8 billion websites currently online are active. It’s estimated that less than 200 million of that number are actually active.
internetlivestats.com
The fist site on the internet was created by tim berners lee and his teams and the website was
http://info.cern.ch/hypertext/WWW/TheProject.html
the first web browser the web browser Mosaic. it was created by Marc Andreessen and his colleagues at the University of Illinois in 1993. It was the first web browser that allowed users to use “point-and-click” graphical manipulations.
Domain Name registration was not availbale untile 1985. before that the fist domain namefor intranet service was Nordu.net, created on January 1, 1985. It was the domain of Scandinavian research collaboration.
The first registered domain title goes to Symbolics.com, a domain belonging to a computer systems company in Cambridge, Mass. It was registered on March 15, 1985, followed by Bbn.com, registered on April 24, 1985. | checoslbches | |
890,813 | Finished 90 Days of Meditation | Just finished 90 days of following 2 x 20 minutes / day - first time been this consistent with it and... | 0 | 2021-11-07T02:30:55 | https://dev.to/mrsharm/finished-90-days-of-meditation-26ph | productivity, motivation, performance, writing | Just finished 90 days of following 2 x 20 minutes / day - first time been this consistent with it and I feel nothing short of great! Used the [Seinfeld Strategy](https://jamesclear.com/stop-procrastinating-seinfeld-strategy) and [4 Disciples of Execution](https://www.franklincovey.com/the-4-disciplines/).
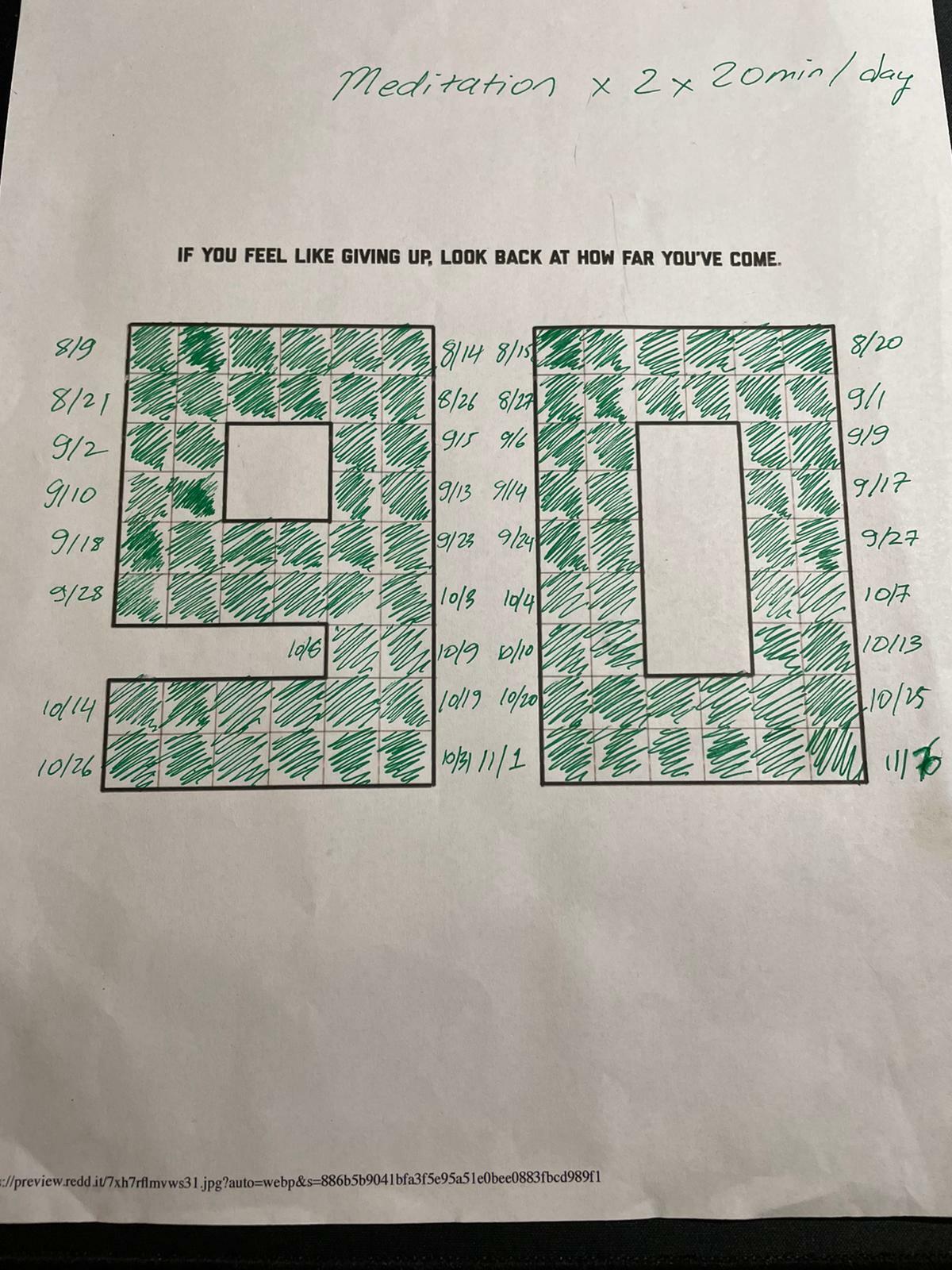
The specific type of meditation I follow is [Transcendental Meditation](https://www.tm.org/), however, advocate for any type of stillness you can bring into your life.
## Observed Benefits
1. Clarity of Thought
2. Much more energy during the day.
3. Better at handling impulses.
4. Easier to get into flow.
5. More receptive to situations.
6. Life becomes easier and repetitious activities no longer seem as mundane as before.
The tracker I used can be found [here](https://t.co/igmxnzcYWI?amp=1).
Will gladly answer any questions and help others as this technique has unequivocally changed my life. | mrsharm |
890,816 | Connecting MetaMask to a Reactjs App + Custom Hook + State Management | Hey everyone! If you're interested in getting the basics down on connecting your new App or dApp to... | 15,910 | 2021-11-07T02:53:13 | https://medium.com/coinmonks/connecting-to-metamask-react-js-custom-hook-state-management-2f1f3203f509 | javascript, blockchain, react, reacthooks | Hey everyone! If you're interested in getting the basics down on connecting your new App or dApp to the Ethereum blockchain and also connecting a wallet like MetaMask, here is Part 1 article of my journey: https://blake-wood-bst.medium.com/connecting-to-metamask-react-js-custom-hook-state-management-2f1f3203f509
In this article I will explore how to setup a React Application that will connect to MetaMask and show your account info.
I will also show how to create a Custom Hook in this application that will store the State of your current connection status / account info with MetaMask.
We will also wrap your React app in a Provider that will utilize Web3 to transact with Smart Contracts or send ETH to other accounts that you specify and sign those transactions.
If you like the article please give me a clap and a follow! Bless | blakecodez |
891,053 | How I structured my first Express App | I’m pretty much a beginner dev, working for 2years as a developer. During this period most of the... | 0 | 2021-11-07T13:14:27 | https://dev.to/zisan34/how-i-structured-my-first-express-app-20ik | node, express, mongodb, react | I’m pretty much a beginner dev, working for 2years as a developer. During this period most of the time, I’ve used PHP as backend but recently my company assigned me to a project in which I had to use Node(Express) as backend. So here’s the story about my first MERN stack app.
**TLDR**
### Some background story
During this short period of my career, I got the opportunity to work with several technologies. As I’m working as a Full-Stack dev so previously I had hands-on experience with Laravel, React, Vue, Mysql other related techs. I was very excited when my company assigned me to a MERN stack app. That was a huge transition. I took that as a challenge and decided that I’d prepare myself for larger apps built with the MERN stack. So that’s why even the purpose of the app is simple but the structure is not. Basically, this is a custom [Shopify app](https://shopify.dev/apps) that will maintain shipping service([carrier service](https://shopify.dev/api/admin/rest/reference/shipping-and-fulfillment/carrierservice)) including tons of conditions for a Shopify store.
### Let’s Dive into it
It’s true that my project structure is pretty much inspired by [Laravel](https://laravel.com) because I’m familiar with that & I love the structure. So my project has two main directories “***backend***” & “***frontend***”. In the ***backend*** directory lies the express app & in the ***frontend*** directory lies the react app. The reason for this is I wanted to reduce the deployment complexity. So for the ***frontend*** Webpack is used to compile the react app & export it to a single file which I later include as a script in the backend(in an ejs file). Yes, pretty much what Laravel-mix does. The weird thing is project has one package.json file which holds both frontend and backend dependencies.
**The Backend Directory**
In the root of the ***backend*** directory, there are two files one is *index.js* which is responsible for serving the app to a specific port & connecting to MongoDB, Redis etc. another one is *app.js* which is responsible for booting the express app, top-level middlewares, including the route files etc.
Subdirectories in backend
I think most of the things are self-explanatory so I won’t discuss them all. In the ***config*** directory, I’ve got a few config files that hold configuration variables, next the ***controllers*** directory have 3 subdirectories that are responsible for responding to different kind of requests. I hate to write business logic at the controller level, so I’ve got service classes in the ***services*** directory, where lies all the business logic. The ***views*** directory holds ejs files which will be responded to web routes. Also one of the ejs files is responsible to serve the compiled react app.
Next, I wanna say what I’m missing from Laravel, which is the Laravel [job queue](https://laravel.com/docs/8.x/queues#introduction). So I managed to find almost something similar named [bull](https://github.com/OptimalBits/bull) for node.js but I want more features like retrying the jobs, scheduling them etc. which I couldn’t find. I would be grateful if someone can suggest something.
**The Frontend Directory**
The ***frontend*** directory is pretty simple it has an entry point which holds the root react component. There are 3 subdirectories named ***components***, ***Helpers***, ***sass***. The components directory holds pages level components in ***pages*** sub dir & other reusable components in ***utils*** sub dir. Next, the ***Helpers*** directory contains some helper functions & classes & the ***sass*** directory holds sass files for styling.
The frontend is later compiled via the Webpack, babel and exported to the ***public/assets*** directory. Which I later include in an ejs file.
## Final Thoughts
If any experienced developer reads this post first reaction will be “your package.json must be messed up”. Yeah, I know that, but within that short period of time, it was the most practical approach I found for faster development & easy deployment.
Oh, I forgot to mention that this is my first tech blog post. So please pardon my lack of knowledge & experience. And I’d be very much grateful if I could have some suggestions about how things could be done in a better way. Also, I’m still looking for a job-queue package which is similar to Laravel so, suggestions are appreciated.
| zisan34 |
891,275 | Frontend Challenge #4, Profile card component | This is a brief description of the forth frontend project I've completed from Frontend Mentors,... | 15,949 | 2021-11-07T20:04:47 | https://dev.to/jcsmileyjr/frontend-challenge-4-profile-card-component-46b9 | webdev, beginners, codenewbie, challenge | This is a brief description of the forth frontend project I've completed from Frontend Mentors, Profile Card component. [Frontend Mentors](https://www.frontendmentor.io/) is a online platform that provide front-end challenges that include professional web designs. You can play with the solution [here] (https://jcsmileyjr.github.io/Profile-card-component/).
## Step 1
The first objective is to get a general idea of the layout situation in mobile view and figure out what I don't know how to do. I start by styling the body HTML tag to center the content. Then create a container with the textual content (no styling) and images.
## Step 2
2. From the offset, the biggest challenge would be getting the image to float on top of the line and be screen size responsive. My solution was to give the parent container a relative position style. The child container with the image received the absolute position and a specific top alignment number. This had the desired affect of floating the image on top of the line. The image was center with flexbox in the parent container.
## Final Outcome
## What I learned
1. That a mixture of position absolute and relative to a parent and child elements will align elements on the web page outside of the normal flow.
2. To use CSS variables for global styles
## Resources used
1. [Quick recap about CSS Variables](https://css-tricks.com/difference-between-types-of-css-variables/)
### Thank you for reading!
Thank you for reading my blog. Feel free to connect with me on [Twitter](https://twitter.com/JCSmiley4) or [LinkedIn](https://www.linkedin.com/in/jcsmileyjr/).
You can find the completed code [here](https://github.com/jcsmileyjr/Profile-card-component) | jcsmileyjr |
891,362 | El problema de las SPA y la accesibilidad... y cómo solucionarlo | Las SPA son aplicaciones o sitios que, en lugar de hacer una petición al servidor cada vez que el... | 0 | 2021-11-07T22:04:55 | https://dev.to/adrianbenavente/el-problema-de-las-spa-y-la-accesibilidad-54dk | javascript, webdev, programming, a11y | Las SPA son aplicaciones o sitios que, en lugar de hacer una petición al servidor cada vez que el usuario interactúa con la página, los contenidos se cargan una única vez y son mostrados de manera dinámica por JavaScript en el momento en que sean requeridos, ya sea en su totalidad o de manera parcial y asíncrona, sin necesidad de recargar toda la página. Esto permite una navegación más fluida, con menor consumo de recursos, similar a la de una aplicación nativa.
A su vez, a los desarrolladores nos permitió granularizar mucho más nuestra arquitectura, dejando de pensar en páginas, para pasar a verlo todo en términos de _componentes_. También facilitó la depuración de errores ya que todo lo que necesitamos es un navegador y las developer tools del framework o librería que estemos usando.
Sin embargo, y a pesar de todas sus bondades, de las que solo nombré las más superficiales ya que este no es un artículo dedicado enteramente a las SPA, se podría decir que de cierto modo _hicieron la web menos accesible por defecto_.
Claro que, echarle toda la culpa de esto a las SPA, no sería lo más razonable. Un cambio de paradigma no es más que una nueva manera de pensar y hacer las cosas. Por eso quiero compartir una serie de implementaciones que deberemos hacer desde el comienzo del proceso del desarrollo, que, junto con las [verificaciones básicas](https://webaim.org/standards/wcag/checklist) de siempre, garantizarán que nuestras SPA cumplan con [el principio 2 de las WCAG 2.0](https://www.w3.org/TR/WCAG21/#operable) que es ser **operables**.
## Manejo del foco
Como la pestaña no se recarga al navegar entre vistas, el lector de pantalla no avisará de ningún cambio de contenido a no ser que se le indique explícitamente. Para ello, una técnica muy común es **ubicar el foco en el primer encabezado**.
```js
function onNavigate() {
document.getElementById('titulo-seccion').focus();
}
```
Pero las etiquetas de encabezado no son elementos enfocables, por lo que hay que otorgarles esta característica, colocándoles el atributo `tabindex`. Le daremos un valor de `-1`, para evitar que interfiera en el flujo de navegación de la tecla TAB.
```html
<section>
<h2 id="titulo-seccion" tabindex="-1">Título de la sección</h2>
<p>Aquí el contenido...</p>
</section>
```
Lo anterior también aplica a los casos en donde un botón o enlace realiza un scroll dentro de la vista, hasta otra parte de la misma. Siempre se debería poner el foco donde comienza el contenido al que llevaremos al usuario.
## Título del documento
Al existir un único documento HTML, este tendrá siempre el mismo título. El usuario podría no saber en qué pantalla se encuentra, en caso de irse a otra pestaña del navegador y luego volver. Por eso, debemos modificar el texto de la etiqueta `<title>` mediante JS, al cambiar de vista, para que refleje el contenido de esta.
```js
document.title = "Mi maravilloso sitio | Quiénes somos"
```
## Semántica HTML
A veces, los frameworks de desarrollo de SPA, si no son bien utilizados, pueden forzar malas prácticas como el uso excesivo de etiquetas `<div>`, lo que puede degradar o hasta arruinar por completo la experiencia de usuarios de tecnologías asistivas. **Mantener siempre una correcta semántica HTML, resulta imprescindible.**
```html
<header>
<h1>Mi página</h1>
<nav>
<ul>
<li>
<a href="/home">Inicio</a>
</li>
<li>
<a href="/nosotros">Nosotros</a>
</li>
<li>
<a href="/portfolio">Portfolio</a>
</li>
<li>
<a href="/contacto">Contacto</a>
</li>
</ul>
</nav>
</header>
<main>
<section>
<h2>Nosotros</h2>
<p>Bla, bla...</p>
</section>
...
</main>
<footer>
<p>@adrian.benavente.dev</p>
</footer>
```
## Conclusión
La tecnología avanza y con ella las formas de desarrollar software, y las tecnologías de asistencia también hacen lo propio para acompañar esta evolución. Seguro que en un futuro próximo cada vez encontraremos un mejor soporte para SPA por parte de los distintos agentes de usuario que utilizan las personas con discapacidades, o, tal vez, las herramientas de desarrollo de SPA incorporen mejoras de accesibilidad. Mientras tanto, no podemos simplemente sentarnos a esperar que esto suceda, y mucho menos, cuando ocurra, dejar de lado la retrocompatibilidad.
Por último, no olvidemos que, según las WCAG, en una [declaración de conformidad](https://www.w3.org/TR/2006/WD-WCAG20-20060427/conformance.html#conformance-claims) un documento es o no es accesible, pero nunca puede ser parcialmente accesible; en ese caso se considera que no lo es, y se lo excluye. Ahora bien, una SPA consta de un solo documento. ¿Se va entendiendo el punto?
ACTUALIZACIÓN: [el borrador de WCAG 3.0](https://www.w3.org/TR/wcag-3.0/) ya incorpora los conceptos de _vistas_ y _estados_, desprendiéndose de términos como página o documento, acortando así la brecha con el vocabulario actual y ajustándose para incluir a las SPA. Sin embargo, esta versión no verá la luz antes de 2023.
## Colaborar
[Buy Me a Coffee](https://buymeacoffee.com/fena)
[Invitame un café en cafecito.app](https://cafecito.app/fena)
| adrianbenavente |
891,364 | Speed up your TypeScript monorepo with esbuild | TypeScript monorepos are a great way to organize medium-to-big size projects. TypeScript improves the... | 0 | 2021-11-12T18:21:27 | https://mmazzarolo.com/blog/2021-11-06-speed-up-your-typescript-monorepo-with-esbuild/ | typescript, monorepo, webdev, node | ---
title: Speed up your TypeScript monorepo with esbuild
published: true
date: 2021-11-12 18:21:00 UTC
tags: #typescript #monorepo #webdev #node
canonical_url: https://mmazzarolo.com/blog/2021-11-06-speed-up-your-typescript-monorepo-with-esbuild/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/pstsjag63qnrrk0qdgie.png
---
[TypeScript](https://www.typescriptlang.org/) monorepos are a great way to organize medium-to-big size projects. TypeScript improves the developer experience by adding type-checking and a deep IDE integration. And using a monorepo helps in scaling your project(s).
Compared to plain JavaScript, however, TypeScript adds an additional compilation layer to your project, which may slow down the developer experience. While the native TypeScript compiler is not _that_ slow (IMHO), it’s still something you need to take into account if you’re planning to build a large codebase. But what if there was a way to speed up the TypeScript compilation by using a different compiler?
Enter [esbuild](https://esbuild.github.io/): a fast JavaScript bundler that claims to be >10x faster than similar projects (webpack, rollup + terser, parcel 2). I’ve been using esbuilt for a couple of TypeScript projects and have been surprised by how well it performs.
## 🍊 Tangerine monorepo
While learning esbuild, I haven’t found many examples of how to integrate it within TypeScript monorepos. So I created my own template: [🍊 tangerine-monorepo](https://github.com/mmazzarolo/tangerine-monorepo), a “minimal” TypeScript-based Node.js monorepo setup fully powered by esbuild.
### Features
- Uses [TypeScript](https://www.typescriptlang.org/) to write code, tests, and scripts.
- Uses [esbuild](https://esbuild.github.io/) to compile your TypeScript codebase, tests, and scripts.
- Uses [tsc CLI](https://www.typescriptlang.org/docs/handbook/compiler-options.html) to type-check the codebase without emitting the compiled files (since they’re handled by esbuild). No need to keep [TypeScript’s Project References](https://www.typescriptlang.org/docs/handbook/project-references.html) up-to-date.
- Uses [esbuild-runner](https://github.com/folke/esbuild-runner) to run scripts on the fly.
- Uses [Yarn workspaces](https://yarnpkg.com/features/workspaces) to make it easy to work within the monorepo.
- Uses [Ultra runner](https://github.com/folke/ultra-runner) to run scripts from the project root.
- Uses a shareable ESLint config and Jest config(./packages/jest-config) to provide an extensible linting and testing setup.
- Uses esbuild + [nodemon](https://github.com/remy/nodemon) to reload the server in development mode (even when workspace dependencies are changed).
### Workspaces
Tangerine monorepo includes five workspaces:
- `packages/is-even`: The simplest workspace — it doesn’t depend on any other worskpace. It’s a Node.js module that exposes an `isEven` function that tells if the input number is even. It includes a CLI script that invokes the function from your terminal, and a test file, both written in TypeScript. The CLI script runs using esbuild-runner, which uses esbuild to compile it on the fly.
- `package/is-odd`: Depends on `packages/is-even`. It’s a Node.js module that exposes an `isOdd` function that tells if the input number is odd (by invoking `isEven` and checking if it’s false). It includes a CLI script and a test file.
- `package/server`: Depends on both `packages/is-odd` and `packages/is-even`. It’s a Node.js Express server that exposes two routes that invoke `isEven` and `isOdd`. It uses nodemon to reload the server in development mode.
- `packages/jest-config`: Shared Jest config that uses esbuild to compile your tests and your codebase.
- `packages/eslint-config`: Shared ESLint config.
All the workspaces use esbuild to compile the TypeScript codebase. Be it for building, testing, or running CLI scripts, the compilation is instantaneous compared to the native TypeScript compiler (you can quickly test the difference by temporarily swapping esbuild with tsc).
The tsc CLI is used only to type-check the codebase (without emitting the compiled files — since they’re handled by esbuild). I expect people usually use the IDE integration to type-check the code anyway and explicitly invoke the tsc CLI only in specific use cases (such as pre-commit hooks).
Each workspace’s package.json is pointing the `main` and `types` entry to `src/index.ts`. Which might look strange at first, given that it’s uncompiled code… see [“You might not need TypeScript project references” on the Turborepo blog](https://turborepo.com/posts/you-might-not-need-typescript-project-references) for an explanation. This pattern has been working fine for my use cases so far (especially while using esbuild). Still, you might want to update these entries to suit your needs (e.g., when shipping packages to npm). | mmazzarolo |
891,423 | Electron Adventures: Episode 89: Remembering Document Preferences | Back in episode 86 we made our app remember size and position of its window. We want to do something... | 14,346 | 2021-11-07T22:33:15 | https://dev.to/taw/electron-adventures-episode-89-remembering-document-preferences-58a3 | javascript, electron, svelte | Back in episode 86 we made our app remember size and position of its window. We want to do something similar now, except the app has multiple windows, so we need to remember one for each document.
We won't do anything complicated, the remembering will be based on document's full path.
So let's `npm install electron-settings` and get to coding!
All the code we'll do will be just `index.js` on the backend, we won't be changing anything in the frontend code.
### Start the app
When we start the app, we show a file dialog to select one or more CSV files:
```javascript
let { app, BrowserWindow, dialog } = require("electron")
async function startApp() {
let { canceled, filePaths } = await dialog.showOpenDialog({
properties: ["openFile", "multiSelections", "showHiddenFiles"],
filters: [
{ name: "CSV files", extensions: ["csv"] },
{ name: "All Files", extensions: ["*"] }
],
message: "Select a CSV file to open",
defaultPath: `${__dirname}/samples`,
})
if (canceled) {
app.quit()
}
for (let path of filePaths) {
createWindow(path)
}
}
app.on("ready", startApp)
app.on("window-all-closed", () => {
app.quit()
})
```
Once we select any number of CSV files, we call `createWindow(path)` for each to create its window.
### Creating windows
And then we need to create a window with given document:
```javascript
let settings = require("electron-settings")
function createWindow(path) {
let key = `windowState-${path}`
let windowState = settings.getSync(key) || { width: 1024, height: 768 }
let qs = new URLSearchParams({ path }).toString();
let win = new BrowserWindow({
...windowState,
webPreferences: {
preload: `${__dirname}/preload.js`,
},
})
function saveSettings() {
windowState = win.getBounds()
console.log("SAVING", path, windowState)
settings.setSync(key, windowState)
}
win.on("resize", saveSettings)
win.on("move", saveSettings)
win.on("close", saveSettings)
win.loadURL(`http://localhost:5000/?${qs}`)
}
```
When we open a window, we check in saved preferences if we have anything matching its document path. If we do, we use it. Otherwise, we use default window size, and let the OS place it whenever it wants.
Whenever a window is moved or resized, we track its position and size, and save it to settings with the right key.
### Limitations
Electron has backend and frontend parts, but the way responsibility is split between them is not based on any logical considerations, it's just a side effect of how regular browsers do things.
* frontend (renderer) manages everything about state of each window - and that's fine
* backend (main) process manages size and position of each window - and that's really weird and awkward
So what we did is create backend-side system, which remembers window positions and sizes for each document. But we'd need to create a whole separate system to remember anything about state of each window, such as how far each window was scrolled, or (if we implemented this), sort order for various columns and so on.
This isn't all that difficult, but Electron pretty much forces us to architect the app poorly:
* we can have two completely separate systems
* we could have backend-managed system, which would tell frontend what to do when it starts, and get messages from frontend about app state changes
* we could have frontend-managed system, which would tell backend where to reposition window when it starts (it could result in window briefly being in wrong place unless we're careful), and then get messages from the backend about window position and size changes
None of these designs are great.
### Results
Here's the results, remembering resizing for every document:
In the next episode, we'll add some more OS integrations to our CSV viewer.
As usual, [all the code for the episode is here](https://github.com/taw/electron-adventures/tree/master/episode-89-remembering-document-preferences).
| taw |
891,455 | Top 10 Smart Contract & Solidity Developer Learning Resources | Learning to become a Smart Contract and Blockchain Developer can seem like a daunting task, but it... | 0 | 2021-11-08T01:04:39 | https://dev.to/patrickalphac/top-10-smart-contract-solidity-developer-learning-resources-46db | blockchain, programming, solidity, beginners |
Learning to [become a Smart Contract and Blockchain Developer](https://betterprogramming.pub/how-to-become-a-blockchain-engineer-fa4386a0504f) can seem like a daunting task, but it doesn't have to be!
Just set aside some time each week, and get cracking on any of the tutorials and pieces of content below. Don't be afraid to ask a ton of questions, and don't feel imposter syndrome! Just by reading this article, you are already a welcomed member of the blockchain community.
If anytime you get stuck, feel free to refer to [this document](https://docs.chain.link/docs/getting-help/) on how to get unstuck in the blockchain space. It applies to everything in open source!
In any case, let's go ahead and get started!
Additionally, I have a video on [how to become a blockchain engineer](https://www.youtube.com/watch?v=e1N4aWIJMN0) you can check out for more information!
### Helpful Tools
But BEFORE I give you the list, you need to know about these 3 resources.
1. [ChatGPT](https://chat.openai.com/chat)
2. [Ethereum Stack Exchange](https://ethereum.stackexchange.com/)
3. [Peeranha.io](https://peeranha.io/)
These are helpful Q&A sites that you can ask questions to, and will make your life much better when going through these resources. Anyways, here are the top 10!
# Top 10 Smart Contract & Solidity Developer Learning Resources
## 1. [Cyfrin Updraft](https://updraft.cyfrin.io/)
The #1 web3, Solidity, Vyper, smart contract auditing & security, all-encompassing developer and security-focused platform on earth.
The content starts from "What is a blockchain" to "Solidity Basics" to "Advanced Deployment and Assembly" all the way down to "How to audit an AMM". This course is taught with love by some of the top people in the industry. This is a passion project data dump of everything you need to know to get started in web3, and know more than the average developer so you can make some amazing protocols.
### Instructors
Myself: I'm a bit biased, but with the lead instructor being myself, who has the #1 and #2 most watched web3 developer educational courses on YouTube, and have been doing security and development in web3 for over 4 years.
Tincho: One of the top security researchers in web3, having found vulnerabilities in multi-billion dollar protocols like ENS, Lido, and Optimism.
## 2. [Learn Solidity, Blockchain Development, and Smart Contracts | Powered by AI - Foundry Edition](https://www.youtube.com/watch?v=umepbfKp5rI)
{% youtube umepbfKp5rI%}
My latest invention. If you get through this videos, you will be a master, guaranteed.
This course requires ZERO prior knowledge. None. It's in pure solidity, and will bring you from beginner to master. [Foundry](https://book.getfoundry.sh/) is the fastest smart contract and solidity framework, and we teach you all the skills you need to be successful in web3.
This is the most dense smart contract tutorial you will ever take. With the pinnacle project of [deploying your own stablecoin!](https://www.youtube.com/watch?v=8dRAd-Bzc_E)
Not sure what a stablecoin is? Well that's why you have to take this course!
Anyone interested in becoming a security researcher in blockchain will need to take this course first, as this sets you up for your security journey as well.
And not only that... but this course is powered by AI, and we teach you all the tips and tricks with artificial intelligence powered learning, getting you up to speed faster than ever before!
## 3. [Learn Blockchain, Solidity, and Full Stack Web3 Development with JavaScript – 32-Hour Course](https://www.youtube.com/watch?v=gyMwXuJrbJQ)
{% youtube gyMwXuJrbJQ %}
If you get through this videos, you will be full-stack a master, guaranteed.
Ideally, this is for engineers who want every single drop of knowledge I have acquired about blockchain development over the past 3 years, and prefer javascript. It covers all the fundamentals of solidity, and uses the exact same cutting edge tools as billion dollar defi giants like [Aave](https://aave.com/), [Synthetix](https://synthetix.io/), and [Uniswap](https://uniswap.org/).
Ideally, this is for engineers with a little bit of javascript experience, but if you don't have any, we'll give you a ton of refreshers along the way. This course is for anyone with any level of coding experience, even none!
Additionally, we have a ton of optional front end and full stack tutorials. These will teach you how to build powerful apps and websites that use the smart contracts and blockchain applications you've made for ANY user!
## 3. [Cryptozombies](https://cryptozombies.io/)
[](https://cryptozombies.io/)
For the longest time, Cryptozombies has been one of the go-to courses for learning blockchain & solidity. This gamified platform brings you step by step through solidity programming as you build your zombie army!
This course has a wonderful user interface that's fun for people of any age, and is one of the most approachable content on this list. The Cryptozombies team does a tremendous job showing NFTs, inheritance, and everything you'd need in basic solidity.
## 4. [Solidity by Example](https://solidity-by-example.org/)
A more minimal approach to learning web3, this is a site for people who already have some familiarity with software engineering.
This site and YouTube channel have just the fundamental information, so you can jump right into coding!
## 5. [Alchemy University](https://university.alchemy.com/)
Put on by the [Alchemy](https://www.alchemy.com/) team, Alchemy University is a javascript focused education site, created in partnership with some of the best educators I've ever interacted with.
I used to have a group called [Chainshot](https://www.chainshot.com/) on my list, as they have always been underrated, but Alchemy recently aquired them to make this amazing site!
## 6. [Consensys Bootcamp](https://consensys.net/academy/bootcamp/)
[](https://consensys.net/academy/bootcamp/)
This is another bootcamp that just always knocks it out of the park.
The Consensys team is one of the teams that has been around from basically the start of this whole thing. They consistently deliver on bringing in some of the best in the space to give guest lectures to the students, have top quality content, and are another bootcamp that I highly recommend to anyone looking to get into this space with a hands-on learning approach, and a team to guide them.
## 7. [Speed Run Ethereum](https://speedrunethereum.com/)

From creating your own NFTs to mastering decentralized staking apps, Speed Run Ethereum offers a comprehensive and enjoyable learning experience for blockchain enthusiasts and developers alike. It's created by my friend [Austin Griffith](https://austingriffith.com/) who is one of the most respected Web3 developer educators on the planet.
Join the [BuidlGuidl](https://buidlguidl.com/) community, a vibrant hub of Ethereum builders focused on crafting innovative products, prototypes, and tutorials that enrich the web3 ecosystem. Showcase your achievements by submitting your DEX, Multisig, or SVG NFT builds, and collaborate with fellow builders to elevate your Web3 portfolio. Embark on an exciting journey of learning and building with Speed Run Ethereum, and become a proficient Ethereum developer ready to shape the future of decentralized technologies.
## 8. [LearnWeb3DAO](https://learnweb3.io/)
LearnWeb3DAO is like going to university for 4 years. They have a freshman, sophomore, junior, and senior track that will bring you end-to-end from start to finish.
And this is another course that you can get started 100% for free!
## 9. [Ethernaut](https://ethernaut.openzeppelin.com/)
[](https://ethernaut.openzeppelin.com/)
One of the harder pieces in this space is Ethernaut. You need a little bit of a javascript background, but trudging your way through this course will teach you a lot of the ins and outs and "gotchas" of solidity, and is one of the quickest ways to become "advanced" in the ways of solidity.
This was created by the [Openzeppelin](https://openzeppelin.com/) team, who are top auditors and security researchers in the blockchain space, and they make contracts for people to fork into their own projects. Anyone in the blockchain space worth their "salt" knows who Openzeppelin is and how to work with their tools!
## 10. [The Ethereum Org List](https://ethereum.org/en/developers/learning-tools/)
[](https://ethereum.org/en/developers/learning-tools/)
What better way to learn about web3 and Ethereum than from the community itself!
The Ethereum org website is JAM packed with content, tutorials, and submissions from around the globe, in exactly the manner you'd expect. You can find just about anything here to [learn and grow](https://ethereum.org/en/developers/tutorials/).
## 11. [useWeb3](https://www.useweb3.xyz/)
[](https://www.useweb3.xyz/)
useWeb3, like the Ethereum org website, is dedicated to being a living document of updated courses and content to teach people how to build in the blockchain space.
This open sourced project is constantly updated, and really any of the projects listed on their site is worthwhile for you to check and and put to the test!
## 12. There are so many!!
Ok, so I fibbed, this article has way more than just 10!!! Here is a list of tons of different places you can get started learning solidity, smart contracts, and blockchain. It doesn't matter where you go, just pick one, and go!
- [EatTheBlocks](https://eattheblocks.com/)
- [Chainlink Bootcamp](https://chain.link/bootcamp)
- [Patrick Collins](https://www.youtube.com/channel/UCn-3f8tw_E1jZvhuHatROwA) (That's me!)
- [Austin Griffith](https://twitter.com/austingriffith)
- [Nader Dabit](https://www.youtube.com/user/boyindasouth)
- [Remix with Learn ETH Plugin](https://remix.ethereum.org/)
- [Owen (Security)](https://www.youtube.com/@0xOwenThurm)
And so much more.
Well, as always, be sure to follow me on [Twitter](https://twitter.com/PatrickAlphaC), [YouTube](https://www.youtube.com/channel/UCn-3f8tw_E1jZvhuHatROwA), [Medium](https://medium.com/@patrick.collins_58673), and [GitHub](https://github.com/PatrickAlphaC), and I hope to see you in the community!
| patrickalphac |
891,472 | Returning to an old project | Sometimes we have to put a project on hiatus. Other things can get in the way; focus can shift over... | 0 | 2021-11-13T16:44:59 | https://edeen.dev/blog/returning-to-an-old-project/ | productivity, motivation | ---
title: Returning to an old project
published: true
date: 2021-03-14 00:00:00 UTC
tags: productivity, motivation
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/hwv9jgto1scyzquu1ef4.png
canonical_url: https://edeen.dev/blog/returning-to-an-old-project/
---
Sometimes we have to put a project on hiatus. Other things can get in the way; focus can shift over time. I end up returning to old stuff pretty often, so I’ve written down the set of questions I ask myself when I'm reapproaching a paused project.
## Why am I looking at this project again?
- Am I just reminiscing?
- Do I just want to look at it again for a while before I have to go work on other things?
- Do I want to remind myself of what I get to work on soon, to help me get through what I’m working on now?
- Do I want to recycle some of this project to use for something else?
- Do I intend to continue working on the project now?
## What was my progress on this project?
- What was the project about?
- What was the goal of the project?
- How did I go about accomplishing the goal previously?
- How far did I get towards accomplishing that goal?
- Do I still want to accomplish the original goal, or is there a new goal I’d rather pursue?
## How will I complete this project?
- How much time would I like to devote to this work?
- How much time can I actually devote to this work?
- How will I schedule my allocated time?
- Are there any external motivators that might help me finish the project?
- Do I need any help completing the project?
After this, it’s all a matter of actually starting again! | jedeen |
891,560 | Creating Serverless Websites with AWS, Bref, and PHP | Prerequisites I would like to start by explaining that I am going to assume you are... | 0 | 2021-11-20T02:29:18 | https://dev.to/aws-builders/creating-serverless-websites-with-aws-bref-and-php-203j | aws, bref, php, serverless | ## Prerequisites
I would like to start by explaining that I am going to assume you are familiar with [AWS](https://aws.amazon.com/) and the following topics. If that's not the case then I would recommend you at least try to understand the basics of these topics before attempting to follow along.
* [API Gateway](https://aws.amazon.com/api-gateway/)
* [CloudFront](https://aws.amazon.com/cloudfront/)
* [EC2](https://aws.amazon.com/ec2/)
* [ECR](https://aws.amazon.com/ecr/)
* [Lambda](https://aws.amazon.com/lambda/)
* [Route53](https://aws.amazon.com/route53/)
* [S3](https://aws.amazon.com/s3/)
* [Serverless](https://aws.amazon.com/serverless/)
____
## Introduction
Serverless websites on AWS are a common theme. This is expected since hosting a serverless website can have many benefits over traditional web hosting solutions that involve virtual servers. Benefits like: better scalability, lower costs, and reduced latency.
> https://dashbird.io/blog/business-benefits-of-serverless/
Most of these serverless websites rely on _static_ web technologies like JavaScript. This permits the simplest serverless website solution as pictured below.
The problem we're aiming to solve is that this simplistic architecture does not support _dynamic_ web technologies like ASP.NET, JSP, or PHP that are still used to build incredible websites today. Websites like Etsy, Facebook, and Slack.
> https://trio.dev/blog/companies-using-php
Dynamic websites can leverage AWS to achieve serverless hosting. It just takes a couple of extra steps and a couple of extra services. Let's walk through a working solution.
____
## Bref
In the scenario of PHP, there is an amazing project called [Bref](https://bref.sh/), which we can use to simplify our configuration. With Bref we can run our PHP websites on Lambda instead of relying on services like EC2.
To quote their documentation,
> _Bref is an open-source project that brings full support for PHP and its frameworks to AWS Lambda._
### Usage
The simplest implementation is to package our website as a container image and eventually deploy it to Lambda. In order to reference an image for our Lambda function, we need to upload our image to ECR first. Luckily AWS makes interacting with ECR extremely easy. Let's walk through the steps.
1. Create Dockerfile
```Dockerfile
# reference bref as the base image
FROM bref/php-74-fpm
# install composer
RUN curl -s https://getcomposer.org/installer | php
# require bref
RUN php composer.phar require bref/bref
# copy contents into expected directory
COPY . /var/task
# set handler to our index
CMD _HANDLER=index.php /opt/bootstrap
```
> https://docs.docker.com/engine/reference/builder/
> https://github.com/wheelers-websites/CloudGuruChallenge_20.10/blob/master/php-api/Dockerfile
2. Authenticate to ECR
```bash
aws ecr get-login-password --region ${AWS_REGION} | docker login --username AWS --password-stdin "${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com"
```
> https://awscli.amazonaws.com/v2/documentation/api/latest/reference/ecr/get-login-password.html
> https://docs.docker.com/engine/reference/commandline/login/
3. Build Your Docker Image
```bash
docker build -t ${AWS_ECR_REPOSITORY} .
```
> https://docs.docker.com/engine/reference/commandline/build/
4. Tag Your Docker Image
```bash
docker tag "${AWS_ECR_REPOSITORY}:latest" "${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/${AWS_ECR_REPOSITORY}:latest"
```
> https://docs.docker.com/engine/reference/commandline/tag/
5. Push Your Docker Image
```bash
docker push "${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/${AWS_ECR_REPOSITORY}:latest"
```
> https://docs.docker.com/engine/reference/commandline/push/
> _Find these push commands customized to your account in the ECR console_
____
## Architecture
Now that our container image is within ECR we are able to create a Lambda function that references it.
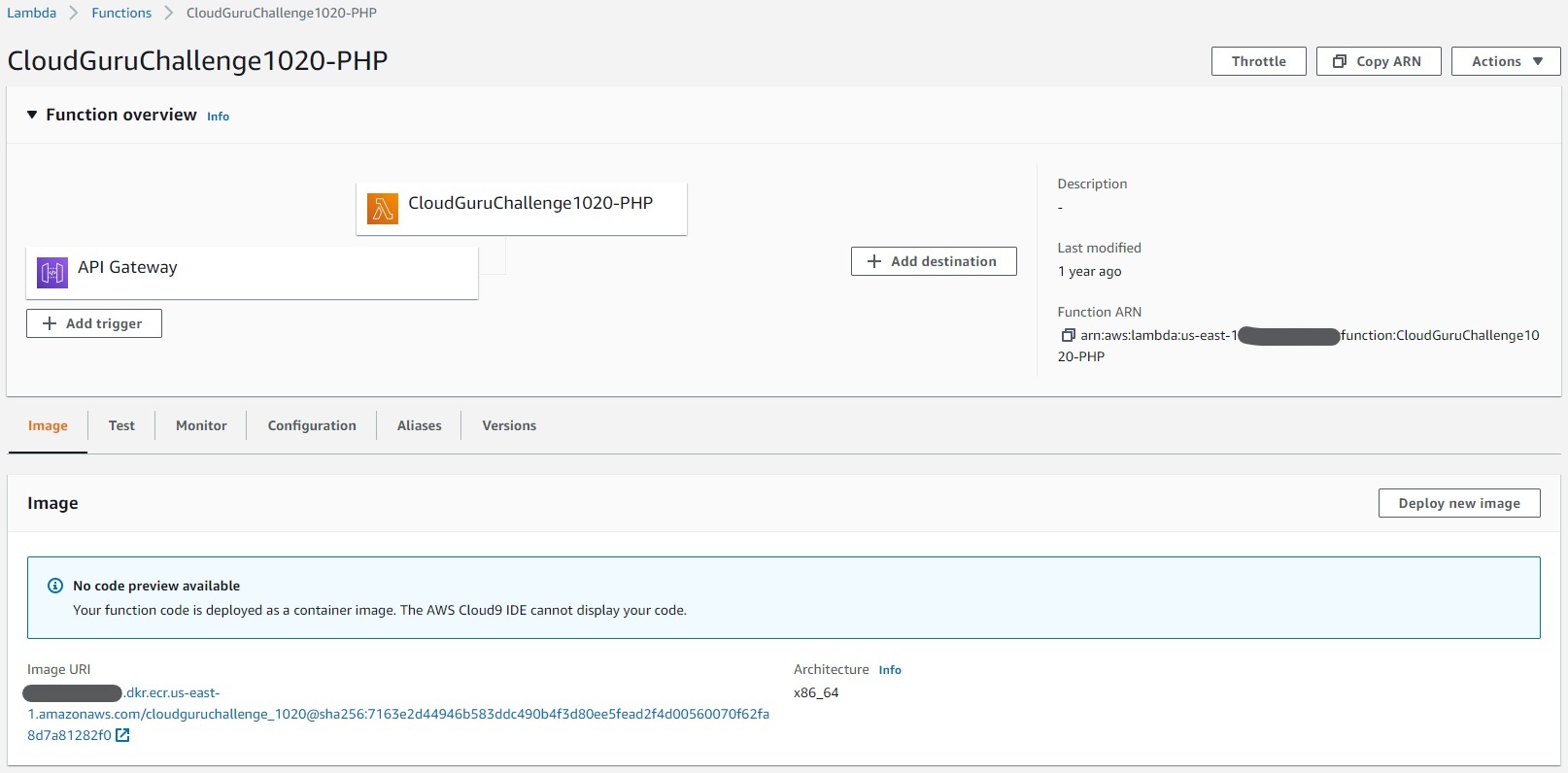
After that is done we need to use API Gateway to provide an endpoint for our function.
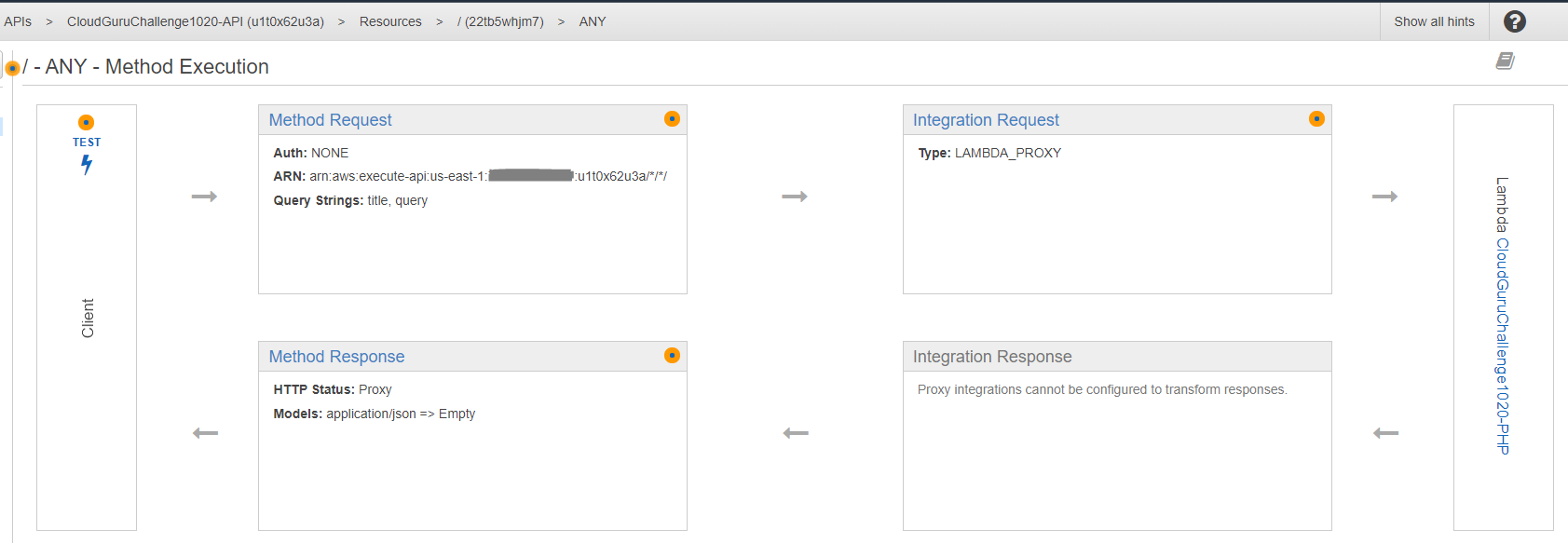
Then we can reference that endpoint as a CloudFront origin to serve our website.

Finally, we can optimize this architecture by uploading our static content to S3 and serving that content with a separate origin.
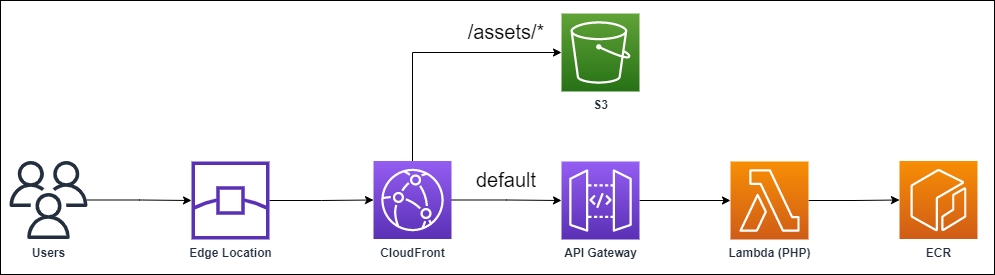
____
## CI/CD
As we all know that websites change regularly, I wanted to mention [Continuous Integration](https://aws.amazon.com/devops/continuous-integration/) and [Continuous Deployment](https://aws.amazon.com/devops/continuous-delivery/) briefly. I would implement a process to build and update the container image in ECR and on Lambda when code changes are pushed to a Git repository. This is crucial to keep your environment current with your Git repository while avoiding manual deployments. Manual deployments are error-prone and completely avoidable. The image creation and ECR updates can easily be done by repeating the steps outlined above when the source changes in a script. Following those steps with another like below we can update the Lambda function automatically.
```bash
aws lambda update-function-code \
--function-name ${AWS_LAMBDA_FUNCTION} \
--image-uri "${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/${AWS_ECR_REPOSITORY}:latest" \
--region ${AWS_REGION}
```
> https://awscli.amazonaws.com/v2/documentation/api/latest/reference/lambda/update-function-code.html
If you're new to CI/CD then I would recommend these great resources to get started.
* [AWS CodePipeline](https://aws.amazon.com/codepipeline/)
* [GitHub Actions](https://docs.github.com/en/actions)
____
## Conclusion
We started by discussing the problem of hosting dynamic websites using serverless technology. Then we discussed Bref and Docker, which both help in hosting a serverless version of PHP. Then we walked through the architecture required. We pushed our container image to ECR and deployed our PHP code as a Lambda function. Then we created an API Gateway endpoint to invoke our Lambda function over HTTP. Finally, we uploaded our static content to S3 and placed both origins behind a CloudFront distribution. To conclude I would like to reiterate that dynamic websites can enjoy the benefits of serverless and I wholeheartedly believe it's worth the effort.
Please find this live serverless PHP website that I developed as a living example.
* https://wheelerrecommends.com/
If you liked this content maybe you would like to [Buy Me a Coffee](https://www.buymeacoffee.com/wheelersweb) or connect with me on [LinkedIn](https://www.linkedin.com/in/wheelers-websites/).
| wheeleruniverse |
891,562 | Passion Project- Blog Post 402 | If I were to have unlimited resources and time to work on my passion project, I would focus on... | 0 | 2021-11-08T04:21:41 | https://dev.to/njd5435/passion-project-1f34 | If I were to have unlimited resources and time to work on my passion project, I would focus on creating an application that would help all in a positive way and it would be in the health field. With the world always changing and something always happening, the medical field constantly needs innovating. My idea would involve an application that would track waiting times, allow people to sign up for appointments and fill their forms online, show availability of vaccines or tests, etc. Last year everyone was running around waiting for hours to just get a covid test or a vaccine. Why not get ahead of that and make an application that every urgent care uses and possibly hospitals. It would allow waiting rooms to be less cluttered and it would allow more people to be seen faster by having an application that everyone can join and see distance of where the clinics are.
This application would need funding and it would need awareness of all to convert their files to be on the app. It would be difficult to get a bunch of companies to change their application over to this but having this application could give all more business. I feel I have enough interest in the medical field that I could have a good base line of what to put in to create the application but would need assistance to see what can and cannot be shown. I think I would need help from others to create this application. I do have coding experience but this would be a large project that would need more than one person generating code and editing it to always be up to date.
For the patients, I would want them to put their current location in and be able to see all the doctor offices around them. There can be filters that would be how far they are willing to travel, input of what they specifically are going to the doctor for, and if their insurance is taken by that office. The patient will be able to click on each office and see the wait times currently. For the offices, I would want them to constantly be updating their wait times, take the patient records virtually, and payment through the app.
| njd5435 | |
891,621 | Why it's OK to abandon your side projects 😉 | I wanna tell you that you need to stop being guilty of not actively working on side-projects. Don't... | 0 | 2021-11-08T06:52:59 | https://buttondown.email/bhupesh/archive/why-its-ok-to-abandon-your-side-projects/ | sideprojects, programming, productivity, discuss | I wanna tell you that you need to stop being guilty of not actively working on side-projects. Don't take this in the negative way of not doing any projects at all but if you have been beating yourself for not being good at it, I am here to assure you that it's fucking okay!!
Building side-projects is hard, there are 2 sides to the coin.
1. Finding a problem to fix and start building the solution.
2. Keeping up the momentum and maintaining it for a long-time.
Both of these sides are equally hard to achieve. But once you have a solution to a legit problem, all of the below monsters can come up anytime during the process, leading you to give up on your project midway.
- Lack of vision
- Lack of motivation
- Burned out
- No time
- Not enough constructive feedback
- Not enough traction/No users
Hear me say this out loud all of these reasons are indeed part of going through a creative process. Building software is one such process especially if you work on something new. Let me try to explain from my personal experiences.
I have been in the burned-out phase for quite a long (it started when I [failed to build this project](https://github.com/codeclassroom/codeclassroom) for my college major, but that's a story for another day) and one thing I have learned is that pushing yourself is good, but going over the edge can have harmful effects on your mental state, or even worse, you start to lose interest in software altogether.
Personally, for me, it took months before I was able to get out of that phase and get back to building things I used to like before. But I think I have lost something after that phase, I don't feel the same, feels like a part of my creativity is lost.
The point I want to highlight is that don't beat yourself too much for not working on side-projects every second of your life.
From my little experience of building things the whole purpose of making stuff is not to solve a problem or get users, rather **It's to continuously evolve as a human and embark on your creativity**
Remember when you say 'no' to something, you're usually saying 'yes' to something else that matters more at the moment. By stopping yourself to work on projects continuously you are giving your brain time to rejuvenate itself and come up with even more creative ideas, hence finding yourself again.
Look at the good aspects for once, yeah? Till the moment you decided to give up. This is what you achieved 🙌🏻
- An idea came to life 💡(_you were creative, this project was your brain-child_)
- A solution to a problem was explored (_you are already a problem solver!_)
- You learned & explored something new (_not everyone has the freedom to do so_)
- You had fun building it
- You made mistakes along the way which taught you valuable lessons (_no matter how big or small they were_)
All of these things have already made you a better software engineer/programmer than you were before starting that project.
Remember you are not alone, read through this [lobsters](https://lobste.rs/s/fgt5zm/what_have_you_failed_build) and [hackernews](https://news.ycombinator.com/item?id=22397720) thread about people failing to build and/or complete projects.

> Remember to talk and communicate about this to your friends or in a developer community you are a part of, the mental toll of giving up on something can be huge, make sure you are honest to yourself about this.
So the next time you abandon a side project, remember to reflect on your growth and be proud ⭐
| bhupesh |
891,722 | Advent of PBT 2021 - Day 7 - Solution | Advent of Property Based Testing 2021 - Day 7 - Solution | 0 | 2021-12-07T07:28:39 | https://dev.to/dubzzz/advent-of-pbt-2021-day-7-solution-4lf3 | challenge, testing, webdev, javascript | ---
title: Advent of PBT 2021 - Day 7 - Solution
published: true
description: Advent of Property Based Testing 2021 - Day 7 - Solution
tags: challenge,testing,webdev,javascript
//cover_image: https://direct_url_to_image.jpg
---
Our algorithm was: **fibonacci**.
[Go to the subject itself for more details](https://dev.to/dubzzz/advent-of-pbt-2021-day-7-2e89)
CodeSandbox with a possible set of properties you may have come with: https://codesandbox.io/s/advent-of-pbt-day-7-solution-ts0nw?file=/src/index.spec.ts&previewwindow=tests
---
Fibonacci a function coming from mathematics, it comes with lots of properties out of the box. We can just enumerate some of them to confirm our code works fine.
As our implementation of `fibonacci` comes with a linear time-complexity we will cap the maximal value we pass to it to `MaxN = 1000`.
---
## Property 1: should be equal to the sum of fibo(n-1) and fibo(n-2)
Written with fast-check:
```ts
it("should be equal to the sum of fibo(n-1) and fibo(n-2)", () => {
fc.assert(
fc.property(fc.integer({ min: 2, max: MaxN }), (n) => {
expect(fibonacci(n)).toBe(fibonacci(n - 1) + fibonacci(n - 2));
})
);
});
```
## Property 2: should fulfill fibo(p)*fibo(q+1)+fibo(p-1)*fibo(q) = fibo(p+q)
Written with fast-check:
```ts
it("should fulfill fibo(p)*fibo(q+1)+fibo(p-1)*fibo(q) = fibo(p+q)", () => {
fc.assert(
fc.property(
fc.integer({ min: 1, max: MaxN }),
fc.integer({ min: 0, max: MaxN }),
(p, q) => {
expect(fibonacci(p + q)).toBe(
fibonacci(p) * fibonacci(q + 1) + fibonacci(p - 1) * fibonacci(q)
);
}
)
);
});
```
## Property 3: should fulfill fibo(2p-1) = fibo²(p-1)+fibo²(p)
Written with fast-check:
```ts
it("should fulfill fibo(2p-1) = fibo²(p-1)+fibo²(p)", () => {
// Special case of the property above
fc.assert(
fc.property(fc.integer({ min: 1, max: MaxN }), (p) => {
expect(fibonacci(2 * p - 1)).toBe(
fibonacci(p - 1) * fibonacci(p - 1) + fibonacci(p) * fibonacci(p)
);
})
);
});
```
## Property 4: should fulfill Catalan identity
Written with fast-check:
```ts
it("should fulfill Catalan identity", () => {
fc.assert(
fc.property(
fc.integer({ min: 0, max: MaxN }),
fc.integer({ min: 0, max: MaxN }),
(a, b) => {
const [p, q] = a < b ? [b, a] : [a, b];
const sign = (p - q) % 2 === 0 ? 1n : -1n; // (-1)^(p-q)
expect(
fibonacci(p) * fibonacci(p) - fibonacci(p - q) * fibonacci(p + q)
).toBe(sign * fibonacci(q) * fibonacci(q));
}
)
);
});
```
## Property 5: should fulfill Cassini identity
Written with fast-check:
```ts
it("should fulfill Cassini identity", () => {
fc.assert(
fc.property(
fc.integer({ min: 1, max: MaxN }),
fc.integer({ min: 0, max: MaxN }),
(p) => {
const sign = p % 2 === 0 ? 1n : -1n; // (-1)^p
expect(
fibonacci(p + 1) * fibonacci(p - 1) - fibonacci(p) * fibonacci(p)
).toBe(sign);
}
)
);
});
```
## Property 6: should fibo(nk) divisible by fibo(n)
Written with fast-check:
```ts
it("should fibo(nk) divisible by fibo(n)", () => {
fc.assert(
fc.property(
fc.integer({ min: 1, max: MaxN }),
fc.integer({ min: 0, max: 100 }),
(n, k) => {
expect(fibonacci(n * k) % fibonacci(n)).toBe(0n);
}
)
);
});
```
## Property 7: should fulfill gcd(fibo(a), fibo(b)) = fibo(gcd(a,b))
Written with fast-check:
```ts
it("should fulfill gcd(fibo(a), fibo(b)) = fibo(gcd(a,b))", () => {
fc.assert(
fc.property(
fc.integer({ min: 1, max: MaxN }),
fc.integer({ min: 1, max: MaxN }),
(a, b) => {
const gcdAB = Number(gcd(BigInt(a), BigInt(b)));
expect(gcd(fibonacci(a), fibonacci(b))).toBe(fibonacci(gcdAB));
}
)
);
});
```
This property needs a helper function called `gcd` that could be written as follow:
```ts
function gcd(_a: bigint, _b: bigint): bigint {
let a = _a < 0n ? -_a : _a;
let b = _b < 0n ? -_b : _b;
if (b > a) {
const temp = a;
a = b;
b = temp;
}
while (true) {
if (b === 0n) return a;
a = a % b;
if (a === 0n) return b;
b = b % a;
}
}
```
---
[Back to "Advent of PBT 2021"](https://dev.to/dubzzz/advent-of-pbt-2021-13ee) to see topics covered during the other days and their solutions.
More about this serie on [@ndubien](https://twitter.com/ndubien) or with the hashtag [#AdventOfPBT](https://twitter.com/search?q=%23AdventOfPBT). | dubzzz |
907,700 | Top 10 Best YouTube Channel to get free Web Development Knowledge. | Hey everyone welcomes to another new blog, my name is Vikas Rai and today in this article, I am... | 0 | 2021-12-19T08:53:45 | https://nextjsdev.com/top-10-best-youtube-channel-to-get-free-web-development-knowledge/ | webdev, webdevresources, youtubechannels | ---
title: Top 10 Best YouTube Channel to get free Web Development Knowledge.
published: true
date: 2021-10-29 07:04:00 UTC
tags: WebDevelopment,WebDevResources,YoutubeChannels,WebDev
canonical_url: https://nextjsdev.com/top-10-best-youtube-channel-to-get-free-web-development-knowledge/
---

Hey everyone welcomes to another new blog, my name is Vikas Rai and today in this article, I am going to tell you the top 10 Best YouTube Channels for Learning Web Development in 2021.
Many people are confused regarding which course should they whether they should take a paid course or a free one.
So yeah everyone wants knowledge for free and it your right to have free knowledge available to you.
That's why in this article I am going to tell you about the best YouTube channels from where you can learn web development for free and also makes dome cool web development-related projects.
So let's get started:
## 1. CodewithHarry (Lang: Hindi)
This YouTube channel is one of my favorite and I have learned so many things from this channel.
He started this channel to teach coding techniques to people which took him ages to learn. This channel has Almost covered everything in web development and also every programming language as well.
Harry has created a separate playlist for web development which covers all the technologies and languages required to learn Web development and also provides notes of his course on his website CodewithHarry.com.
He has created tons of videos on many languages like python, C, C++, Java, HTML, CSS, JavaScript, Node.js, Mongo, and many more to come. He also shares His experience, tips and tricks, and general knowledge regarding programming and Web Development.
If you like to watch in Hindi then this will be the perfect YouTube channel for you to watch programming-related videos.
## 2. Codedamn (Lang: English)
This YouTube Channel I am watching for the last 6 months and I would appreciate the content that this channel is providing.
He has covered all the latest tools, technologies, and frameworks which he teaches on his YouTube channel for free.
The best courses which I like on this channel are the React.js Mastery and Next.js Mastery course which was very helpful for me especially.
I would also like to tell about that the creator of this channel Mehul Mohan has stated his e-learning platform/website Codedamn.com which is a learning platform for web developers.
This platform provides many free and paid courses and also mentorship which will help you to learn with guidance.
You can surely check out his website and channel to know more.
## 3. Sonny Sangha (Lang: English)
This YouTube Channel will provide great and real-life Web Development Projects. All these projects are Beginner-friendly as well as for an intermediate also.
He teaches you to make both Front-end and Full Stack projects by using new technologies and frameworks.
The level of projects is amazing and it will look like almost a professional web developer has made it.
It's best for making web development projects, till now he has created websites like LinkedIn-clone, Gmail-clone, Snap Chat-clone, Hulu-Clone, WhatsApp-clone, Google-clone, and many more to come.
I like building and watching web dev projects then I will highly recommend you to check out his channel.
## 4. JavaScript Mastery(Lang: English)
This YouTube Channel's purpose is to help aspiring web developers take their development skills to next level and build awesome apps.
This channel provides some cool React.js, M.E.R.N, and small JavaScript Projects which is very helpful for a beginner.
These projects are a great way to learn and enhance your web development knowledge.
Recently they have uploaded a new video on "How to Create a Landing Page Using Next.js and deployed it to Hostinger".
Their Tutorial is so much easy and comfortable even for a beginner or an intermediate.
## 5. Web Dev Simplified (Lang: English)
This is another Channel that is similar to JavaScript Mastery which provides you with web development-related videos and also teaches about using different technologies related to web development.
Web Dev Simplified also deep dives into advanced topics using the most recent best practices for you seasoned web developers.
It will be perfect for both an intermediate and a beginner web developer.
## 6. Academind (Lang: English)
This channel creator is one of my favorite Teachers or Instructor. His name is Max Scharwzmuller and he creates courses and tutorials that teach you everything related to web development.
He has created a bunch of Udemy Courses related to Web Development and I Learned React.js from one of his courses which is "React-The complete Guide", you can search for it on Udemy and you will get an idea of how much this course is popular by seeing the ratings.
The way he teaches is both amazing and fun and which helps us to learn without facing many difficulties and also it does not feel like boring to watch it.
In the end, I will highly recommend checking this channel especially if you want to learn React.js as Max has recently uploaded a crash course on React.js n his YouTube Channel.
## 7. Cleverprogrammer (Lang: English)
This Channel I came across one year ago and find it very useful in my web development journey.
It provided me great knowledge and also made me aware of much existing technology related to web development that I did not know.
They also teach you how to build modern websites and many website clones using React.js and M.E.R.N stack.
They provide awesome programming lessons and also tips and tricks that will help you to take your coding to next level.
Their goal is to make 5000 web developer jobs ready by 2021 so that they can apply for favorite web developer jobs in the market.
## 8. Traversy Media (Lang: English)
Traversy Media is also a well-known Platform where many web developers came to share their knowledge.
Also, many YouTubers came to the Traversy Media channel to showcase their knowledge and to promote their channel as well.
It features the best online web development and programming tutorials for all the latest web technologies includingNode.js, including React.js, Angular, MongoDB .Next.js, HTML, CSS, and many more.
They also teach about new trends and technologies which are related to web development that comes every year.
So yeah please check out this channel you will get the content that you are looking for.
## 9. Edureka (Lang: English)
This is well-known e-learning Platform which provides course and certification related to programming, web development and many another programming related field like Data Science, etc.
They also provide free knowledge on their YouTube Channel through tutorials which are led by trained Instructors and also share some tips and tricks regarding it.
They have almost covered every programming technology Artificial Intelligence, BlockChain, DevOps, Python, AWS, Data Science, and many more kinds of stuff.
If you can't afford to have their courses on their platform then you can watch them on their YouTube Channel to get the Knowledge.
## 10. FreeCodeCamp.org (Lang: English)
It the one of the largest programming Community which provides tons of knowledge for free.
They have stepped into every sub-domains related to programming wen development, DevOps, Artificial Intelligence, Data Science, and many more.
Whenever they upload a video on any topic it's a full-fledged detailed tutorial. They have introduced many tutorials in "One video" format.
They generally make One lengthy video on topics which vary from 5-6 hour video to 10-12 hour videos.
If you visit their website you will find many courses and the best is that it's all free to learn.
Their main motto is "Learn to Code for Free".
## CONCLUSION
In this article, I have discussed the top 10 YouTube channels through which you can get free programming and Web development knowledge.
I have written this article because many people still don't know about them and their helpful tutorials which have shaped the future of many people.
I will appreciate it if you visit their channel at least once by visiting the following link and do give a look at their Videos.
<!--kg-card-begin: markdown-->
1. CodewithHarry :
[https://www.youtube.com/channel/UCeVMnSShP\_Iviwkknt83cww](https://www.youtube.com/channel/UCeVMnSShP_Iviwkknt83cww)
2. Codedamn:
[https://www.youtube.com/channel/UCJUmE61LxhbhudzUugHL2wQ](https://www.youtube.com/channel/UCJUmE61LxhbhudzUugHL2wQ)
3. Sonny Sangha:
[https://www.youtube.com/user/ssangha32](https://www.youtube.com/user/ssangha32)
4. JavaScript Mastery:
[https://www.youtube.com/channel/UCmXmlB4-HJytD7wek0Uo97A](https://www.youtube.com/channel/UCmXmlB4-HJytD7wek0Uo97A)
5. Web Dev Simplified:
[https://www.youtube.com/channel/UCFbNIlppjAuEX4znoulh0Cw](https://www.youtube.com/channel/UCFbNIlppjAuEX4znoulh0Cw)
6. Academind:
[https://www.youtube.com/channel/UCSJbGtTlrDami-tDGPUV9-w](https://www.youtube.com/channel/UCSJbGtTlrDami-tDGPUV9-w)
7. Cleverprogrammer:
[https://www.youtube.com/channel/UCqrILQNl5Ed9Dz6CGMyvMTQ](https://www.youtube.com/channel/UCqrILQNl5Ed9Dz6CGMyvMTQ)
8. Traversy Media:
[https://www.youtube.com/user/TechGuyWeb](https://www.youtube.com/user/TechGuyWeb)
9. Edureka:
[https://www.youtube.com/user/edurekaIN](https://www.youtube.com/user/edurekaIN)
10. FreeCodeCamp:
[https://www.youtube.com/channel/UC8butISFwT-Wl7EV0hUK0BQ](https://www.youtube.com/channel/UC8butISFwT-Wl7EV0hUK0BQ)
<!--kg-card-end: markdown-->
##Conclusion
These were the top 10 best YT channels for learning web development in my opinion.
I hope you have enjoyed reading the article and if you have read till here then thank you so much for your patience reading.
If you are interested in reading more articles of this type then you can visit [Nextjsdev.com](https://nextjsdev.com) to read them.
Connect with me on:
1.[Twitter](https://twitter.com/raivikas200)
2.[Facebook](https://www.facebook.com/raiv200/)
3.[LinkedIn](https://www.linkedin.com/in/raivikas200/)
Read more like this:
* [Best React.js Examples Project that you can build as a Beginner.](https://nextjsdev.com/best-react-js-examples-project-that-you-can-build-as-a-beginner/)
* [Top 12 Best Vs Code Extensions you need in 2022.](https://nextjsdev.com/top-12-best-vs-code-extensions-you-need-in-2022/)
* [Top 5 CSS Frameworks to check out in 2022.](https://nextjsdev.com/top-5-css-frameworks-to-check-out-in-2022/)
* [9 Websites that all web developers should follow.](https://nextjsdev.com/9-websites-that-all-web-developers-should-follow/)
| raivikas |
891,737 | Day 31 of 100 Days of Code & Scrum: Mobile Navbar and react-css-modules | Good day, everyone! It's Monday again... the start of a new week. I have to admit, this has become... | 14,990 | 2021-11-08T09:35:47 | https://dev.to/rammina/day-31-of-100-days-of-code-scrum-mobile-navbar-and-react-css-modules-334a | 100daysofcode, beginners, javascript, programming | Good day, everyone!
It's Monday again... the start of a new week. I have to admit, this has become pretty normal for me now that it's been a month.
Speaking of which, I will be writing about my experiences in my first month of blogging. I might go for a more realistic depiction of what beginner bloggers experience, instead of the typical click bait articles about starting a blog. With all the things I'm new juggling right now, I might publish it around the end of the week, we'll see.
Anyway, let's move on to my daily report!
## Yesterday
I did my Sprint Planning yesterday, and I said I'll be focusing on **Next.js** and **Typescript**, while still studying **Scrum**.
## Today
Here are the things I learned and worked on today:
### Next.js
- I learned about and used `react-css-modules` to make modular CSS a lot easier to utilize.
- I finished the mobile version of the navbar skeleton.
- working on my company website.
- I decided on what things I'll be working on for my company website. Here are some of them:
I'm using [Zenhub](https://www.zenhub.com/) as my task/project management tool.
### Scrum
- I did some practice flashcards for Scrum.
- reviewed some of the things I've learned before.
Once again, thank you to everyone for reading and supporting me! I wish you all the best!

### Resources/Recommended Readings
- [react-css-modules | Github](https://github.com/gajus/react-css-modules)
- [Zenhub](https://www.zenhub.com/)
- [Official Next.js tutorial](https://nextjs.org/learn/basics/create-nextjs-app?utm_source=next-site&utm_medium=nav-cta&utm_campaign=next-website)
- [The Typescript Handbook](https://www.typescriptlang.org/docs/handbook/intro.html)
- [The 2020 Scrum Guide](https://scrumguides.org/scrum-guide.html)
- [Mikhail Lapshin's Scrum Quizzes](https://mlapshin.com/index.php/scrum-quizzes/)
### DISCLAIMER
**This is not a guide**, it is just me sharing my experiences and learnings. This post only expresses my thoughts and opinions (based on my limited knowledge) and is in no way a substitute for actual references. If I ever make a mistake or if you disagree, I would appreciate corrections in the comments!
### Other Media
Feel free to reach out to me in other media!
<span><a target="_blank" href="https://www.rammina.com/"><img src="https://res.cloudinary.com/rammina/image/upload/v1638444046/rammina-button-128_x9ginu.png" alt="Rammina Logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://twitter.com/RamminaR"><img src="https://res.cloudinary.com/rammina/image/upload/v1636792959/twitter-logo_laoyfu_pdbagm.png" alt="Twitter logo" width="128" height="50"/></a></span>
<span><a target="_blank" href="https://github.com/Rammina"><img src="https://res.cloudinary.com/rammina/image/upload/v1636795051/GitHub-Emblem2_epcp8r.png" alt="Github logo" width="128" height="50"/></a></span> | rammina |
891,764 | Top 10 Youtube Channels To Learn Web Development | If you wish to make Web development a career or it is merely your hobby it can be overwhelming to... | 0 | 2021-11-08T10:35:55 | https://muthuannamalai.tech/top-10-youtube-channels-to-learn-web-development | webdev, javascript, beginners, programming | If you wish to make Web development a career or it is merely your hobby it can be overwhelming to decide where to begin. You can certainly invest in short online or offline courses - many of them are quite expensive. However, YouTube channels can provide developers with interesting perspectives and tips. In the end, Youtube is the largest online video platform in the world. The following are 10 of the best YouTube channels to learn web development.
## 1. [Traversy Media](https://www.youtube.com/user/TechGuyWeb)
Brad Traversy founded Traversy Media. It provides the latest information on a wide variety of programming languages in the form of web tutorials. There are 1.5 million subscribers on the channel, and its tutorials cover a wide range of programming languages like React.js, Angular, Node, Ruby, Python, and many more.

## 2. [Derek Banas](https://www.youtube.com/user/derekbanas)
There are detailed tutorials on programming languages from Derek Banas that are ideal for novices as well as experienced developers. There are separate playlists for each language on this web development YouTube channel for beginners, which has already uploaded more than 1000 videos. Furthermore, it is updated on a regular basis every two weeks.

## 3. [Adam Khoury](https://www.youtube.com/user/flashbuilding/featured)
More than a decade ago, Adam Khoury started creating videos for his users. The channel was founded in 2008 and since then has developed a great reputation for offering detailed videos on many different programming languages, including JavaScript, SQL, PHP, CSS, HTML, ActionScript, and more. There are more than 100 videos on JavaScript alone.

## 4. [Programming With Mosh](https://www.youtube.com/user/programmingwithmosh)
Mosh Hamedani created Programming with Mosh. With this channel, you will discover not only the current trend in web languages but also the newest web technologies that are rapidly gaining popularity. Basically, the channel provides long videos discussing each topic and language in detail (extending to hours).

## 5. [DevTips](https://www.youtube.com/user/DevTipsForDesigners)
Each Friday, two bug generators — David and MPJ — release new videos on Dev Tips. Both website design and development are covered in this channel. Those who wish to master both skills, instead of just one, should choose this route.
Among the topics they cover are CSS, HTML5, SASS, Foundation, jQuery, Ruby on Rails, Bootstrap, and GitHub. You can experiment with code while also learning to program.

## 6. [LevelUpTuts](https://www.youtube.com/user/LevelUpTuts)
With LevelUpTuts, users will be able to improve their documentation abilities and learn how to handle web projects. Tutorials on web design and development are detailed and easy to follow. Among the topics covered on the channel are Meteor, Sass, Stylus, Polymer 1.0, WordPress, JavaScript, and design applications such as Sketch.
It has published 750+ tutorials on the web and graphic design since 2012. Twice a week, Scott Tolinski - the channel's founder - uploads a new video. You get a real tutorial experience here

## 7. [Web Dev Simplified](https://www.youtube.com/channel/UCFbNIlppjAuEX4znoulh0Cw)
Web Dev Simplified focuses on teaching web development skills and techniques in a practical manner. You can use Web Dev Simplified to learn the most popular and newest technologies to become a full-stack developer if you are just getting started with web development. In addition, Web Dev Simplified covers advanced topics using the latest best practices for experienced web developers.

## 8. [TheNewBoston](https://www.youtube.com/user/thenewboston)
Founded by Bucky Roberts this channel has more than two million subscribers to TheNewBoston, which is a popular YouTube video channel for learning programming languages for beginners. Many beginners turn to this channel for free web learning. Tutorials are available in both backend and frontend languages, suitable for beginners to experts.

## 9. [Net Ninja](https://www.youtube.com/channel/UCW5YeuERMmlnqo4oq8vwUpg)
The Net Ninja is an awesome resource for improving your web development skills. Over 1000 free programming tutorials are available on this channel, including those on Modern JavaScript (beginners to advanced), Node.js, React, Vue.js, Firebase, MongoDB, and others. The tutorials are updated on a daily basis.

## 10. [Programming Knowledge](https://www.youtube.com/channel/UCs6nmQViDpUw0nuIx9c_WvA)
Programming Knowledge Contains an extensive video tutorial library for top backend and frontend languages such as Swift, Golang, Python, PHP, Ruby, etc. The channel is one of the best for learning web development on YouTube. In addition, it contains videos on a variety of frameworks and is visited daily by thousands of people.

Utilize what you have and start where you are. Find a way, not an excuse, if your goal is to become a developer.
What other Youtube would you suggest for Web Development? Feel free to comment below!
> You can now extend your support by buying me a Coffee.😊👇
<a href="https://www.buymeacoffee.com/muthuannamalai" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a>
Thanks for Reading 😊
| muthuannamalai12 |
891,793 | How to Learn React API & Concepts with Sourcegraph Code Search
| React is one of the commonly used UI libraries that has been around for a long time (in programming... | 0 | 2021-11-08T13:35:21 | https://dev.to/sourcegraph/how-to-learn-react-api-concepts-with-sourcegraph-code-search-3kn6 | react, javascript, beginners, codesearch | React is one of the commonly used UI libraries that has been around for a long time (in programming years). It’s sometimes called a frontend framework because of the plethora of resources available to build smooth, performant and snappy user interfaces. In addition, it has a vibrant and robust community of developers.
There are many ways to learn React, and one of such effective ways is by delving right into different code implementations of the concepts you want to know.
A quick [Twitter thread](https://twitter.com/unicodeveloper/status/1454091302400835596) shows the common concepts folks search for while learning React. In this article, you’ll understand how to leverage Sourcegraph code search in learning certain React concepts.
**Note:** The React team recently launched [https://beta.reactjs.org/learn](https://beta.reactjs.org/learn). It’s really good!
## 1. React and Forms
Virtually every UI is a combination of form elements. As a frontend developer, you’ll deal with tons of forms.
I like this [excellent article about React and Form libraries](https://dev.to/pmbanugo/looking-for-the-best-react-form-library-in-2021-it-s-probably-on-this-list-e2h).
With Sourcegraph, you can ramp up using these form libraries while reading articles and the library documentation. Thus, Sourcegraph can serve as your code assistant to help you learn faster.
**Search for Formik**:
```
Formik lang:JavaScript
```
**Search Query:** [https://sourcegraph.com/search?q=context:global+from+%22Formik%22+lang:JavaScript+&patternType=literal](https://sourcegraph.com/search?q=context:global+from+%22Formik%22+lang:JavaScript+&patternType=literal)
**Search for Kendo React Form**:
```
kendo-react-form lang:JavaScript
```
**Search Query:** [https://sourcegraph.com/search?q=context:global+kendo-react-form+lang:JavaScript+&patternType=literal](https://sourcegraph.com/search?q=context:global+kendo-react-form+lang:JavaScript+&patternType=literall)
**Recommendation:** Use Sourcegraph to search for the other form libraries you want to understand.
## 2. State Management Hooks
State management is an extensive topic in frontend development. In the React world, it can be overwhelming and a lot to deal with, especially as a newbie. The way you approach state management mostly depends on the complexity of your app.
As a React frontend developer, you’ll need to learn about [hooks](https://www.freecodecamp.org/news/beginners-guide-to-using-react-hooks/) at some point. Hooks are regular functions that allow you to use React state and features without defining a class.
Common hooks you’ll come across are `useState`, `useEffect`, `useRef`, `useCallback`, `useMemo`, `useContext`, and `useReducer`.
A lot of the React codebase you’ll come across make use of `useRef`. In that case, let’s discover how developers are using `useRef` and `useState` in various apps and projects.
```
React.useRef() lang:JavaScript
```
**Search Query:** [https://sourcegraph.com/search?q=context:global+React.useRef%28%29+lang:JavaScript+&patternType=literal](https://sourcegraph.com/search?q=context:global+React.useRef%28%29+lang:JavaScript+&patternType=literal)
```
useRef lang:JavaScript
```
**Search Query:** [https://sourcegraph.com/search?q=context:global+useRef+lang:JavaScript+&patternType=literal](https://sourcegraph.com/search?q=context:global+useRef+lang:JavaScript+&patternType=literal)
Search for the usage of both `useState` and `useRef`:
```
useState AND useRef lang:JavaScript
```
**Search Query:** [https://sourcegraph.com/search?q=context:global+useState+AND+useRef+lang:JavaScript+&patternType=literal](https://sourcegraph.com/search?q=context:global+useState+AND+useRef+lang:JavaScript+&patternType=literal)
**Recommendation:** Use Sourcegraph to find how other hooks are used.
## 3. Error Boundaries
React 16 introduced error boundaries as React components that catch JavaScript errors during rendering anywhere in their child component tree. These components also log the errors and display a fallback UI.
A class component becomes an error boundary if it defines either (or both) of the lifecycle methods _static getDerivedStateFromError()_ or _componentDidCatch()_.
Use `static getDerivedStateFromError()` to render a fallback UI after an error has been thrown and `componentDidCatch()` to log error information.
Let’s discover how error boundaries are used in different projects with Sourcegraph:
```
static getDerivedStateFromError
```
**Search Query:** [https://sourcegraph.com/search?q=context:global+static+getDerivedStateFromError&patternType=literal](https://sourcegraph.com/search?q=context:global+static+getDerivedStateFromError&patternType=literal)
You can click on the [file](https://sourcegraph.com/github.com/streamich/react-use/-/blob/stories/useError.story.tsx?L12:3&subtree=true) to read the complete code.
## 4. PropTypes
PropTypes are React’s way of providing type checking to your components. With React PropTypes, you can set the types for your props to avoid unexpected behavior.
We’ll perform two types of searches for propTypes to give us a lot of context on how developers use PropTypes in their codebase.
A literal search:
```
.propTypes = {
```
**Search Query:** [https://sourcegraph.com/search?q=context:global+.propTypes+%3D+%7B&patternType=literal](https://sourcegraph.com/search?q=context:global+.propTypes+%3D+%7B&patternType=literal)
A [structural search](https://learn.sourcegraph.com/how-to-search-with-sourcegraph-using-structural-patterns) for propTypes should give us results of how propTypes like so:
```
.propTypes = { ... }
```
**Search Query:** [https://sourcegraph.com/search?q=context:global+.propTypes+%3D+%7B+...+%7D&patternType=structural](https://sourcegraph.com/search?q=context:global+.propTypes+%3D+%7B+...+%7D&patternType=structural)
**Recommendation:** Use Sourcegraph to find out how props are used in apps.
## 5. Redux
I have talked with a lot of developers about Redux. Most of their pain points come with understanding how to learn Redux the right way. Questions I hear on repeat are:
- Where do I start?
- What are all the libraries and middleware I need to know Redux?
- Why are there so many options?
- Why is Redux so complex?
- What tools are required to debug Redux in my apps?
I don’t have answers to these questions, but the [official Redux guide has done an excellent job providing step-by-step tutorials and FAQ](https://redux.js.org/faq/general). You can also leverage Sourcegraph in finding Redux resources and speeding up your learning. Let’s try!
**First Query:**
```
built with redux
```
[https://sourcegraph.com/search?q=context:global+built+with+redux&patternType=literal](https://sourcegraph.com/search?q=context:global+built+with+redux&patternType=literal)
**Second Query:**
```
built with react redux
```
[https://sourcegraph.com/search?q=context:global+built+with+react+redux&patternType=literal](https://sourcegraph.com/search?q=context:global+built+with+react+redux&patternType=literal)
We can find how standard Redux toolkit APIs are used:
**Third Query:**
```
createAsyncThunk
```
[https://sourcegraph.com/search?q=context:global+createAsyncThunk&patternType=literal](https://sourcegraph.com/search?q=context:global+createAsyncThunk&patternType=literal)
This query returns a lot of results about the usage of the `createAsyncThunk`’s API.
However, there’s also a ton of markdown files in the response. Let’s exclude markdown files from showing up with another query:
**Search Query:**
```
createAsyncThunk -file:\.md|.mdx$
```
The `file` keyword ensures it looks for files ending `.md` or `.mdx`. `-file:` excludes them from the search results.
[https://sourcegraph.com/search?q=context:global+createAsyncThunk+-file:%5C.md%7C.mdx%24+&patternType=literal](https://sourcegraph.com/search?q=context:global+createAsyncThunk+-file:%5C.md%7C.mdx%24+&patternType=literal)
**Recommendation:** Use Sourcegraph to find out how `createSlice`, `createApi` and other Redux APIs are used in React apps.
**Note:** I came across a [tweet from one of the Redux maintainers](https://twitter.com/acemarke/status/1021015625311838209?s=20). I found an answer to the question with the following search query:
**Search Query:** [https://sourcegraph.com/search?q=context:global+lang:JavaScript+connect%5C%28+pure:%5Cs*false&patternType=regexp](https://sourcegraph.com/search?q=context:global+lang:JavaScript+connect%5C%28+pure:%5Cs*false&patternType=regexp)
## 6. How to find React error messages with Sourcegraph.
Sourcegraph is an excellent tool to find reasons behind specific error messages that pop up during React development.
A common error you might have encountered is _Maximum update depth exceeded. This can happen when a component repeatedly calls `setState` inside `componentWillUpdate` or `componentDidUpdate`. React limits the number of nested updates to prevent infinite loops._
This error message pops up when re-rendering repeatedly occurs, especially when a method that uses `setState` is called in the `render` method. You can find the origin of this method with Sourcegraph.
```
Maximum update depth exceeded. This can happen when a component repeatedly calls setState inside componentWillUpdate or componentDidUpdate. React limits the number of nested updates to prevent infinite loops.
```
**Search Query:** [https://sourcegraph.com/search?q=context:global+Maximum+update+depth+exceeded.+This+can+happen+when+a+component+repeatedly+calls+setState+inside+componentWillUpdate+or+componentDidUpdate.+React+limits+the+number+of+nested+updates+to+prevent+infinite+loops.&patternType=literal](https://sourcegraph.com/search?q=context:global+Maximum+update+depth+exceeded.+This+can+happen+when+a+component+repeatedly+calls+setState+inside+componentWillUpdate+or+componentDidUpdate.+React+limits+the+number+of+nested+updates+to+prevent+infinite+loops.&patternType=literal)
In the search results, you can find where and how this React error message pops up!
## Code Search in Your Default Browser
The [Sourcegraph browser extension](https://github.com/sourcegraph/sourcegraph/tree/main/client/browser) adds code intelligence to files and diffs on GitHub, GitHub Enterprise, GitLab, Phabricator, and Bitbucket Server.
After installation, it provides the following:
- Code Intelligence: A tooltip is displayed when you hover over code in pull requests, diffs, and files with:
- Documentation and the type signature for the hovered token.
- **Go to definition** button.
- **Find references** button.
- A search engine shortcut in your web browser that performs a search on your Sourcegraph instance.

## Conclusion
Learning how to use a new library or framework can be challenging, but with the right tools, you can speed up this process and get a better understanding of how different components can be connected.
If you'd like to learn more about Sourcegraph code search, I recently presented [a talk about advanced code search](https://speakerdeck.com/unicodeveloper/code-search-with-laravel-and-sourcegraph) at [ReactAdvanced London](https://reactadvanced.com). For more information about Sourcegraph search queries, check out [https://learn.sourcegraph.com/tags/search](https://learn.sourcegraph.com/tags/search)
[Furthermore, sign up](https://sourcegraph.com/sign-up) on Sourcegraph [to connect and search your private code.](https://learn.sourcegraph.com/how-to-add-private-code-repositories-to-sourcegraph)
---
Have suggestions or questions? Leave a comment, or join our [Community Slack Space](https://about.sourcegraph.com/community/?utm_medium=social&utm_source=devto&utm_campaign=slacklaunch) where our team will be happy to answer any questions you may have about Sourcegraph.
| unicodeveloper |
891,890 | Application Performance Monitoring For SREs | The idea of monitoring systems and applications has been around for years. Ensuring that a system and... | 0 | 2021-11-08T12:51:17 | https://dev.to/thenjdevopsguy/application-performance-monitoring-for-sres-475e | devops, sre, engineeringmanagement, engineering | The idea of monitoring systems and applications has been around for years. Ensuring that a system and application are performing the way they're supposed to isn't anything new. It's simply a component that's been changing drastically, specifically with application performance and load using a practice called Application Performance Monitoring (APM).
So why is APM important now and why should you care? In this blog post, you're going to learn about APM, why it's important, and how to get started.
## What is APM
In the early days of software, tools started to come out for understanding how much load a system running an application could take. A notable tool is Apache JMeter, which is a load testing tool for analyzing and measuring performance. The first release of JMeter was in 1998, which means the idea of caring about application performance has been in the public eye for a while. However, monitoring the results of JMeter consistently wasn't exactly a popular approach. Engineers cared about the results, but the results of the tests weren't something that was constantly refreshed on a monitoring tool/platform.
Application Performance Monitoring, or APM, is how to measure and understand what's happening in an application. For example, if you run a tool like Apache JMeter, you would monitor the results of running JMeter with APM.
The example of JMeter is when you're forcing an application to act a certain way, but as we all know, software is getting more and more complex, so it has a mind of its own. APM is important not just for understanding the application performance when running a load testing tool, but to understand what's happening in the software on a day-to-day, hour-by-hour, minute-by-minute timeline.
APM strives to diagnose and detect application discrepancies. A discrepancy could be if an application is usually at 100 active users, but all of a sudden it jumps to 200 active users and can no longer handle the load of the extra 100 users.
## Why is APM Important?
The idea of organizations having a piece of software isn't just nice to have anymore, it's pretty much mandatory. Even if a company isn't a software company, as in, the main focus of the product is software, the company still needs to think about software. Whether it's an app that users need to interact with to buy or use your product, a website, an already-built app that's being used for the day-to-day operations of the business, or some type of desktop application.
In the time we live in, all organizations must think of themselves as technology-driven/software companies.
Whether it's an app that a company builds for their clients or an app that the company is using for their day-to-day, it must not only be monitored for usability but monitored for performance. Otherwise, a company will never be able to go as fast as they want to go, have the uptime and productivity they desire, or stay up with the idea that all services are always up and running.
Application Performance Monitoring is the difference between an app/software that's known to always work and be available or the app that gets to the second page of Google because no one is using it anymore due to its inefficient nature.
## Why Businesses Need APM
We live in a world of *always on* and *everything is always connected*. The idealization of instant gratification is an unfortunate one, but it's the reality that we all live in. Because of that, every business needs to think about what always-on means.
1. Is your application slow when it reaches over X amount of users?
2. Does the app scale well or go down?
3. Is the software reliable so users want to come back?
Think about it like this with one question - would Amazon be as popular as it is right now if it went down 4-5 hours per day?
## APM Practices
At this point, you may be thinking that APM is important, but you also may be wondering what it actually does. This section will break down what APM does in an easy-to-understand, bullet-point fashion.
- Mobile app performance monitoring
- Desktop app performance monitoring
- API monitoring
- Container app monitoring
- Observability from the system to the application
With all of the ability above, it opens up a ton of doors to make software better. For example, finding the root cause analysis (RCA) for why an application constantly goes down or why it's not performing the way it should is so much easier with an APM platform.
Not only will your business go faster, but it'll be more reliable, which will ultimately bring in more clients and customers. | thenjdevopsguy |
891,947 | Validating Kubernetes Configurations with Datree | Working with Kubernetes is fun when your Kubernetes cluster is up and your nodes are working as you... | 7,035 | 2021-11-09T05:50:44 | https://jhooq.com/using-datree/ | kubernetes, devops, programming, tutorial |
<br/>
Working with [Kubernetes][21] is fun when your Kubernetes cluster is up and your nodes are working as you expected. But as a DevOps enthusiast who follows the principles of Continuous Integration and Continuous Delivery, you are aware that new changes or feature requests are always coming through the [Jenkins Pipeline][22], and eventually, you’ll have to deploy changes into the Kubernetes cluster which feeds into your production environment.
In most cases, you will need to update your Kubernetes manifest YAMLs or [Helm charts][42] (Deployment, Service, or Pod) and apply those changes either directly into the Production or Staging or into the Test environment.
During a new release or deployment, I am generally troubled by the question: _**Is this new Kubernetes manifest YAML change I am deploying in the production environment actually going to work?**_
No matter how seasoned or experienced a developer you are, if you are not sure about your changes, this will be a scary experience. So, is there a way to verify your Kubernetes manifest YAML and Helm charts before they reach production?
**Luckily, the answer is yes.** You can indeed verify your Kubernetes manifest before making any changes, by using the [Datree][44] tool.
[Datree][45] allows developers to verify the [Kubernetes][25] configuration before applying it directly into the Production, Stage, Test, or even the Development environment.
Datree is a command-line tool that is installed locally onto the developer’s machine so that he or she can run the CLI commands that verify the Kubernetes manifests (YAML files).
Here is a short command snippet of Datree -
```
datree test my-kubernetes-manifest.yaml
```
In this post, I will show you how to use Datree step by step, starting with installing the tool and then verifying the Kubernetes manifest file. (If you need to check your helm charts instead, this can easily be done with the Datree [Helm plugin][43].)
## Table of Content
1. [How to Install Datree][1]
2. [How to test Kubernetes Manifest using Datree][2]
3. [How to understand the validation errors thrown by Datree][3]
4. [View and edit Datree Policy via browser][4]
5. [Define Policy as Code(PaC)][5]
6. [Conclusion][6]
<br/>
## 1. How to Install Datree
Let’s start with the first step: _Installation_. Datree installation is really easy. Generally, I prefer Linux distros as my development machine.
On Linux, you can simply install it by running the following command -
**Linux**
```
curl https://get.datree.io | /bin/bash
```
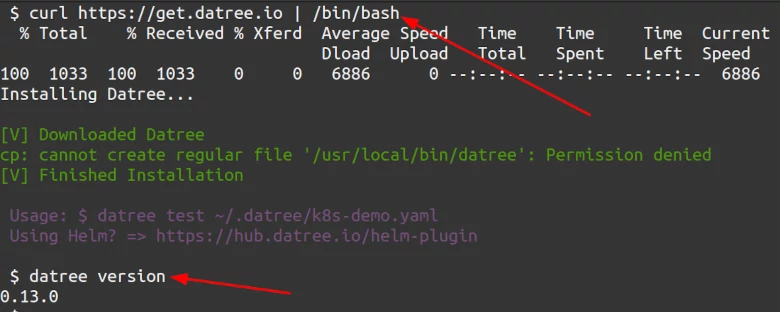
If you are using another Operating System, it’s just as easy to install -
**MacOS**
```
curl https://get.datree.io | /bin/bash
```
**Windows**
```
iwr -useb https://get.datree.io/windows_install.ps1 | iex
```
<br/>
## 2. How to test Kubernetes Manifest using Datree
After installing the Datree, the next step is to test the Kubernetes manifest (YAML). In order to do this, you must have a copy of your Kubernetes manifest (YAML) available locally where you have already installed Datree.
You can run the following command to start testing your Kubernetes manifest (YAML) _(Replace the Kubernetes manifest YAML name in the following command) -_
```
datree test <your_kubernetes_manifest_YAML_NAME>
```
Here is my Kubernetes manifest(YAML) of my [Spring Boot application which I am trying to test by deploying it on Kubernetes Cluster][24]
_([Click here to clone my GitHub Repo for Spring Boot Application][26])_
**k8s-spring-boot-deployment.yml**
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: jhooq-springboot
spec:
replicas: 3
selector:
matchLabels:
app: jhooq-springboot
template:
metadata:
labels:
app: jhooq-springboot
spec:
containers:
- name: springboot
image: rahulwagh17/jhooq-docker-demo:jhooq-docker-demo
ports:
- containerPort: 8080
env:
- name: PORT
value: "8080"
---
apiVersion: v1
kind: Service
metadata:
name: jhooq-springboot
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
selector:
app: jhooq-springboot
```
Here is a command to test my Kubernetes manifest -
```
datree test k8s-spring-boot-deployment.yml
```
When you run the above command, you should see the following validation error messages -
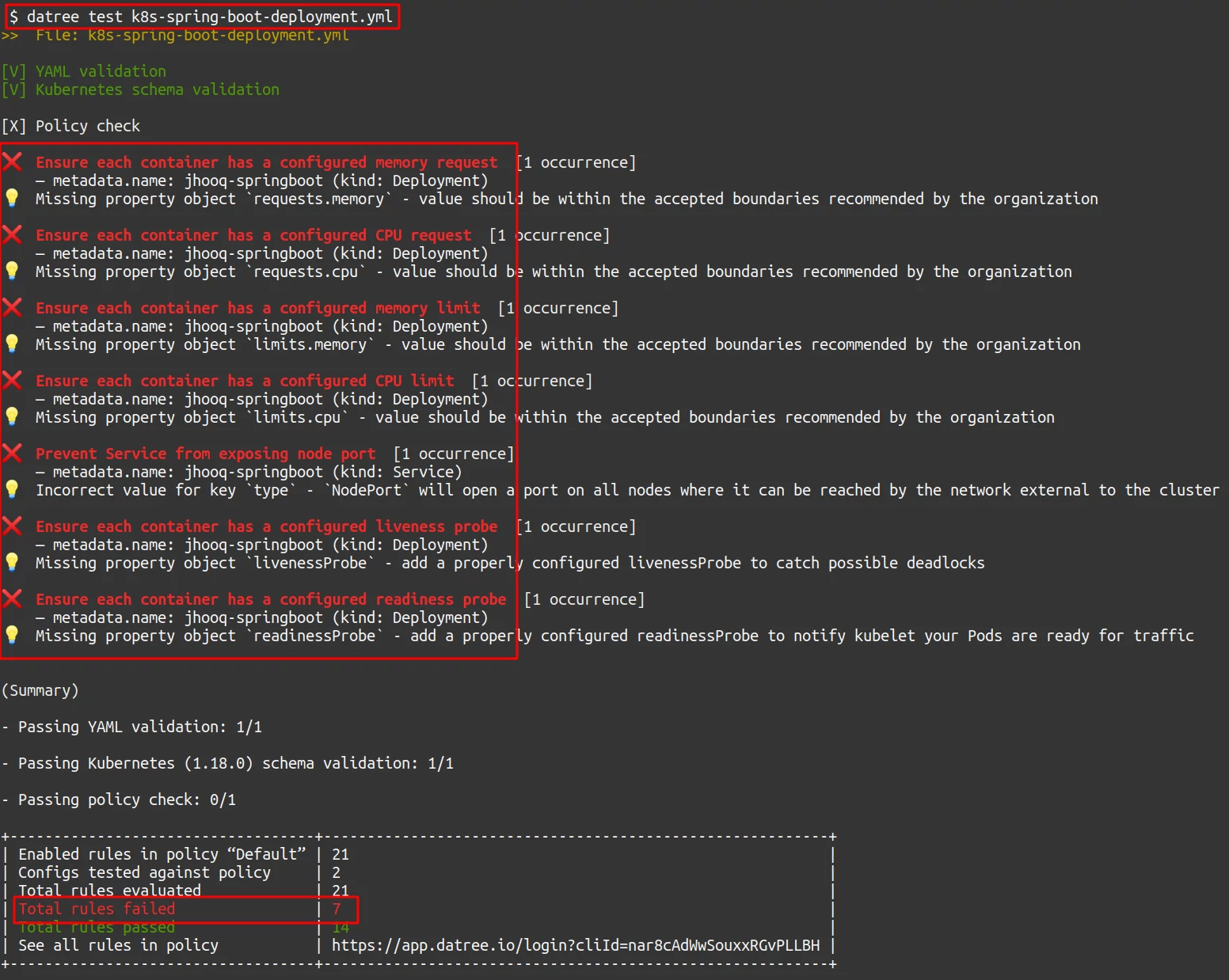
<br/>
## 3. How to understand the validation errors thrown by Datree
What I have discovered is that my Kubernetes manifest (YAML) has a lot of problems. it will work fine inside my Kubernetes cluster, it is still far from ready for the production environment.
Let's start with the errors -
#### 3.1 Ensure each container has a configured memory request
```
❌ Ensure each container has a configured memory request [2 occurrences]
— metadata.name: RELEASE-NAME-helloworld (kind: Deployment)
— metadata.name: RELEASE-NAME-helloworld-test-connection (kind: Pod)
💡 Missing property object `requests.memory` - value should be within the accepted boundaries recommended by the organization
```
This error tells me that I have neglected to add request.memory size inside the Kubernetes deployment manifest.
This error can easily be fixed by adding the following request.memory attribute -
```
resources:
requests:
memory: "128Mi"
cpu: "512m"
```
<br/>
#### 3.2 Ensure each container has a configured CPU request
```
❌ Ensure each container has a configured CPU request [2 occurrences]
— metadata.name: RELEASE-NAME-helloworld (kind: Deployment)
— metadata.name: RELEASE-NAME-helloworld-test-connection (kind: Pod)
💡 Missing property object `requests.cpu` - value should be within the accepted boundaries recommended by the organization
```
Similar to the previous error [3.1][31], we need to add the limit.cpu attribute.
Here is the missing limit.cpu attribute along with request.memory -
```
resources:
requests:
memory: "128Mi"
cpu: "512m"
```
<br/>
#### 3.3 Ensure each container has a configured memory limit
```
❌ Ensure each container has a configured memory limit [2 occurrences]
— metadata.name: RELEASE-NAME-helloworld-test-connection (kind: Pod)
— metadata.name: RELEASE-NAME-helloworld (kind: Deployment)
💡 Missing property object `limits.memory` - value should be within the accepted boundaries recommended by the organization
```
After fixing the memory and cpu requests, let’s try to fix the memory limit.
Add the following memory snippet inside your deployment manifest of Kubernetes under the resource limits -
```
limits:
memory: "128Mi"
```
<br/>
#### 3.4 Ensure each container has a configured CPU limit
```
❌ Ensure each container has a configured CPU limit [2 occurrences]
— metadata.name: RELEASE-NAME-helloworld-test-connection (kind: Pod)
— metadata.name: RELEASE-NAME-helloworld (kind: Deployment)
💡 Missing property object `limits.cpu` - value should be within the accepted boundaries recommended by the organization
```
You also need to update the memory for the cpu, which can be done by adding the following attributes along with the previous one [3.4][34] -
```
limits:
memory: "128Mi"
cpu: "512m"
```
<br/>
#### 3.5 Ensure each container has a configured liveness probe
```
❌ Ensure each container has a configured liveness probe [1 occurrence]
— metadata.name: RELEASE-NAME-helloworld-test-connection (kind: Pod)
💡 Missing property object `livenessProbe` - add a properly configured livenessProbe to catch possible deadlocks
```
Next on the list are the liveness and readiness probes. They go hand in hand, but to keep the things simple and easy to understand, we will look at each error individually.
To fix the liveness probe, you must add the following attribute inside your Kubernetes manifest (YAML) -
```
livenessProbe:
httpGet:
path: /hello
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
```
<br/>
#### 3.6 Ensure each container has a configured readiness probe
```
❌ Ensure each container has a configured readiness probe [1 occurrence]
— metadata.name: RELEASE-NAME-helloworld-test-connection (kind: Pod)
💡 Missing property object `readinessProbe` - add a properly configured readinessProbe to notify kubelet your Pods are ready for traffic
```
After fixing the liveness probe, let’s fix the readiness probe by adding the following attribute to the Kubernetes manifest (YAML) -
```
readinessProbe:
httpGet:
path: /hello
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
```
<br/>
#### 3.7 Ensure Deployment has more than one replica configured
```
❌ Ensure Deployment has more than one replica configured [1 occurrence]
— metadata.name: RELEASE-NAME-helloworld (kind: Deployment)
💡 Incorrect value for key `replicas` - running 2 or more replicas will increase the availability of the service
```
Lastly, we need to fix the replica count.This can be done easily by updating the replicas attribute.
It is not recommended to have a replica count of 1. Update the replica count to a number greater than 1 -
```
spec:
replicas: 2
```
<br/>
#### Here is the final k8s-spring-boot-deployment.yml after all 7 fixes have been made:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: jhooq-springboot
spec:
replicas: 2
selector:
matchLabels:
app: jhooq-springboot
template:
metadata:
labels:
app: jhooq-springboot
spec:
containers:
- name: springboot
image: rahulwagh17/kubernetes:jhooq-k8s-springboot
resources:
requests:
memory: "128Mi"
cpu: "512m"
limits:
memory: "128Mi"
cpu: "512m"
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /hello
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
httpGet:
path: /hello
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
env:
- name: PORT
value: "8080"
---
apiVersion: v1
kind: Service
metadata:
name: jhooq-springboot
spec:
type: ClusterIP
ports:
- port: 80
targetPort: 8080
selector:
app: jhooq-springboot
```
I recommend updating your Kubernetes manifest and re-running the Datree test command.
```
datree test k8s-spring-boot-deployment.yml
```
Here is the screenshot of the results, where you can see that all the validation errors are now gone.
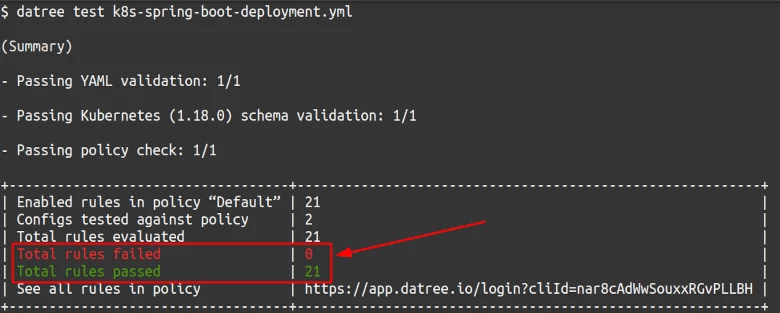
<br/>
## 4. View and edit Datree Policy via browser
In addition to providing CLI to troubleshoot the errors associated with your manifest, Datree also allows you to view the policies on a browser. This is one of the coolest features offered by Datree for developers and other team members.
_**How to access the datree policies in a browser?**_
This too is pretty simple. Run the test command datree test k8s-spring-boot-deployment.yml and then look for the following message box into your terminal -
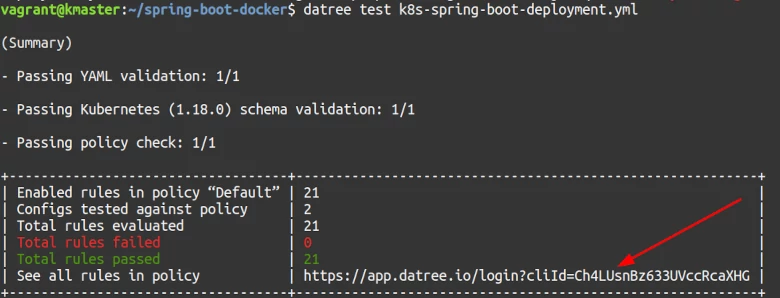
Copy the URL from the terminal and paste it in your browser. Authenticate yourself using your GitHub account and then you will see the following dashboard -
<br/>
#### 4.1 Edit Datree Policies
This is important because most of the time you will be working with Datree on CLI, but having a web portal where policies are accessible via browser makes the policy handling really easy.
###### 4.1.1. Toggle ON/OFF policy
You can very easily toggle the policy which you want to enforce and revoke for your Kubernetes cluster.
###### 4.1.2. Edit Policy Message
You can also edit policy messages so that you can add text which can help the developer troubleshoot the policy validation errors.
Finally, save your custom message -
<br/>
#### 4.2 Datree policies invocation history
Along with edit features, you can also see the previous invocation history and the results. Simply click on the History option on the left navigation -
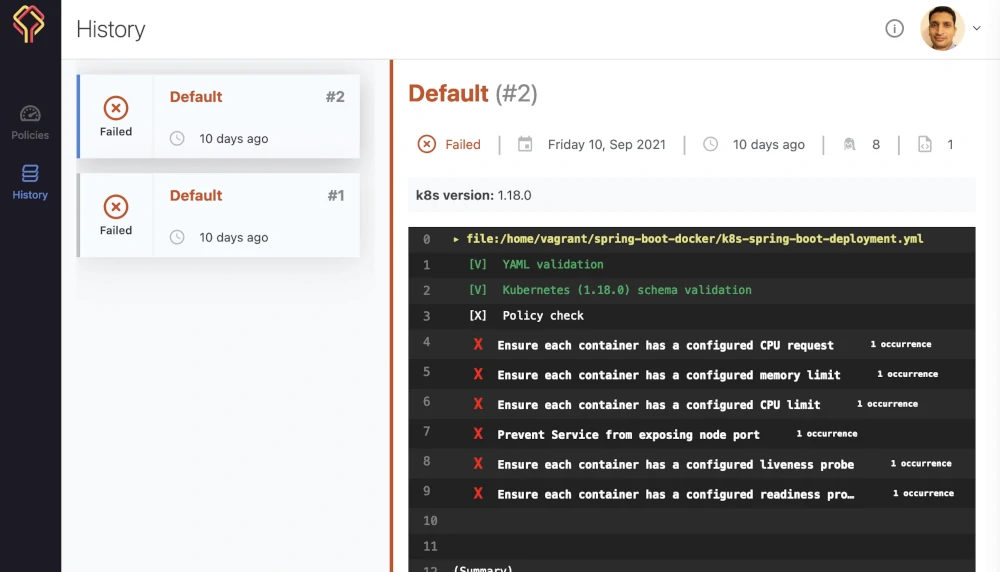
<br/>
## 5. Define Policy as Code(PaC)
One more important feature of Datree which I like the most is Policy As Code (PaC). If you have worked with [Terraform][41] before, then you might recognize this feature, because it helps you create and save policy as code.
**Benefits-**
1. You can easily version your policies under the version control
2. Easy to share polices with version control
3. Each policy change can be tracked and roll back with the help of version control.
<br/>
###### 5.1 Enabled Datree Policy As Code
Under your account settings, you can find the toggle option to enable the _**Policy As Code**_ -
<br/>
###### 5.2 Download the policies.yaml
You can download the _**policies.yaml**_ from the settings page.
<br/>
###### 5.3 How to update the policies.yaml
Keep these key components in mind before updating the policies -
1. **name** - Here you can specify the name of the policy which you want to keep
2. **isDefault** - If you want to keep the policies as default, then you can keep the value of the policy as true
3. **identifier** - It should be unique in nature
4. **messageOnFailure** - The message which you want to show upon failure
Here is an example of _**policies.yaml**_ -
```
apiVersion: v1
policies:
- name: Default
isDefault: true
rules:
- identifier: INGRESS_INCORRECT_HOST_VALUE_PERMISSIVE
messageOnFailure: Incorrect value for key `host` - specify host instead of using a wildcard character ("*")
```
The above YAML is just an example in which you can either keep no policies or more than one policy, as per your need.
<br/>
## 6. Conclusion
[Datree][46] is a really good framework for a DevOps person who wants to build a stable Kubernetes manifest (YAML) which is very well tested and secured with custom policies.
Apart from testing the Kubernetes manifest (YAML) locally, Datree provides some out of the box integrations -
1. **Git Hooks -** With Git Hooks, you can trigger the testing of Kubernetes manifest (YAML) as soon as you commit and push some new updates into your repo.
2. **Helm Plugin - If you are using Helm Chart to manage your Kubernetes cluster, then you can install the Datree helm plugin at https://github.com/datreeio/helm-datree which can help you to achieve the same result which we saw earlier in the post.
4. [Datree][47] has really good integration with [CicleCi][37], [TravisCi][38], [GitHub Actions][39], [GitLab][40] also.
[1]: #1-how-to-install-datree
[2]: #2-how-to-test-kubernetes-manifest-using-datree
[3]: #3-how-to-understand-the-validation-errors-thrown-by-datree
[4]: #4-view-and-edit-datree-policy-via-browser
[5]: #5-define-policy-as-codepac
[6]: #6-conclusion
[21]: https://kubernetes.io/
[22]: https://www.jenkins.io/
[23]: https://www.datree.io/
[24]: https://jhooq.com/deploy-spring-boot-microservices-on-kubernetes
[25]: https://jhooq.com/categories/kubernetes/
[26]: https://github.com/rahulwagh/spring-boot-docker
[31]: #31--ensure-each-container-has-a-configured-memory-request
[32]: #32-ensure-each-container-has-a-configured-cpu-request
[33]: #33-ensure-each-container-has-a-configured-memory-limit
[34]: #34-ensure-each-container-has-a-configured-cpu-limit
[35]: #35-ensure-each-container-has-a-configured-liveness-probe
[36]: #36-ensure-each-container-has-a-configured-readiness-probe
[37]: https://circleci.com/
[38]: https://travis-ci.org/
[39]: https://github.com/features/actions
[40]: https://gitlab.com/users/sign_in
[41]: https://terraform.io
[42]: https://helm.sh/
[43]: https://hub.datree.io/helm-plugin
[44]: https://www.datree.io/?utm_source=rahul&utm_medium=article&utm_campaign=Validating+Kubernetes+Configurations+with+Datree&utm_id=influencer
[45]: https://www.datree.io/?utm_source=rahul&utm_medium=article&utm_campaign=Validating+Kubernetes+Configurations+with+Datree&utm_id=influencer
[46]: https://github.com/datreeio/datree
[47]: https://hub.datree.io/?utm_source=rahul&utm_medium=article&utm_campaign=Validating+Kubernetes+Configurations+with+Datree&utm_id=influencer
| jhooq |
892,035 | An Introduction to Dark Mode | Dark Mode Design Guide The dark mode we see nowadays was introduced as the core interface... | 0 | 2021-11-08T16:41:22 | https://dev.to/bryanalphasquad/an-introduction-to-dark-mode-3p4c | design, webdev, ux, beginners | ##Dark Mode Design Guide
The dark mode we see nowadays was introduced as the core interface for smartphones with OLED screens to save power consumption. Dark mode has gained considerable fame in the developer communities and is one of the most wanted components in the present day user interface. Tech giants like Apple and Google have started to adapt the dark mode UI shows that it's not just a trend and will be in the market for a longer period.
##Advantages Of Dark Mode
The dark mode doesn't only save your eyes from strain, but it also saves your device’s battery usage. These days mobile phones and laptops come with OLED screens; when put in the dark mode, they save the device’s battery up to 70% compared to light mode with white background. However, that is not it; dark mode has as much contemporary significance as it does with battery life, if not more. To be honest, dark mode looks pretty astonishing. It offers new and various methods of presenting graphic content such as graphs, photos, and dashboards. It almost feels creative and peculiar. Other than that, studies have shown a positive relationship between users retention and dark mode. The dark mode makes the color pop and provides good contrast, which puts less strain on the eyes at night and allows users to devour more content for a long time. Because of the advantages of Dark mode, it gets a great deal of positive fame, which implies that it is simple for one to be reprimanded for making something that doesn't need a dark mode. It ought not to be utilized in each application or site; for instance, when you see a site in a sufficiently bright room or without any attempt at being subtle, it is hard to use text situated on dark foundations. For example, a few items, Google maps, have an element that naturally switches among dark and light modes depending on the lighting in a room or view of dusk to dawn.
Considering that dark mode is yet another idea. Surprisingly, many organizations, including Apple and Google, have embraced dark mode as practically the entirety of their UIs. It is yet being worked on, and it is elementary to wreck things if one doesn't cater towards the foundations of UIs.
##Do’s And Don'ts
###Don’t Use Pure Black & White
Recall when I said dark mode lessens the strain on the eyes? Better believe it well assuming you utilize pure white text on a pure dark foundation, that high differentiation will be extremely excruciating to look at, consequently not lessening the strain on the eyes. In the present circumstance, it is protected to utilize dim instead of the genuine dark as the essential foundation since light message on dark has a more negligible difference than light message on pure dark. The plan ought not to be pure, highly contrasting yet in shades of dark too.
###Don't Use Vivid Colors
Using vivid colors looks terrific on a white background. Still, they vibrate against the dark surface, making them hard to read on a dark background—using lighter shades of primary colors because they are readable on dark surfaces. It is essential to use an appropriate contrast ratio between the content and background to avoid eye strain.
###Don't Use Shadows
Shadows are an excellent method of introducing a visual chain of command in your design, however, just in light mode. When used in dark mode, regardless of whether the background isn't pure dark, the shadow will look odd. Perhaps you should use high tones to present visual movement on dark backgrounds.
###Allowing Users To Switch Between Modes
The most noticeably awful thing you can do while designing a product is to remove control from your users, regardless of if you're designing for dark mode. So for that, it is essential to provide a switch that allows users to switch between dark mode and light mode for having a better user experience. The user should consistently feel in charge and have the option to decide on which mode they need to pick.
##Conclusion
Although, the dark mode might appear trendy; it has many disadvantages if not used effectively. By following these focuses referenced above, you can have a sense of security that your dark mode configuration will suit well with your users needs.
| bryanalphasquad |
892,145 | My first Hactoberfest | I completed my First Hacktoberfest by submitting 4 PRs. My 4 PRs are accepted by Hacktoberfest... | 0 | 2021-11-08T17:48:11 | https://dev.to/kunal9155/my-first-hactoberfest-4m69 | webdev, hacktoberfest, javascript, programming | I completed my First Hacktoberfest by submitting 4 PRs. My 4 PRs are accepted by Hacktoberfest Team.
After registering, the search🧐 for an open-source project began.
Because this was my first time contributing to an open-source projects, I was a little bit nervous. I was at a loss as to which projects to choose. React is my preferred technology stack. I also have a good grip in Front-End. As a result, I began searching for open-source projects involving the Python programming language and HTML,CSS,JS.REACTJS. | kunal9155 |
892,300 | SOLID em menos de 5 minutos | Post original: link Essas são as minhas interpretações desse paradigma, não são verdades... | 0 | 2021-11-08T20:49:25 | https://dev.to/jonatanlima/solid-em-menos-de-5-minutos-5cef | programming, opensource | Post original: [link](https://medium.com/@jotanlima/solid-em-menos-de-5-minutos-81ff05274c7)
Essas são as minhas interpretações desse paradigma, não são verdades absolutas.
## Single Responsibility Principle
**Princípio da Responsabilidade Única**
- Uma classe deve ter somente uma função (não necessariamente uma função e sim fazer uma única tarefa bem feita), utilize interface para agrupar métodos.
## Liskov Substitution Principle
**Princípio da substituição de Liskov**
- A classe mãe deve poder ser substituída pela sua classe filha. Basicamente fazendo um override nos métodos, modificando para satisfazer os requisitos da nova classe.
## Dependency Inversion Principle
**Princípio da inversão de dependência**
- Toda classe de alto nível seja completamente independente de suas subclasses. Ou seja, as classes não podem depender dos detalhes de implementação de seus métodos e classes.
## Interface Segregation Principle
**Princípio da segregação de Interfaces**
- Este princípio afirma que uma interface não pode forçar uma classe a implementar métodos que não pertencem a ela. Cada interface deve conter métodos específicos, evitando poluir as classes que irão implementa-las.
## Open Closed Principle
**Princípio do aberto/fechado**
- Crie classes que tem foco de serem extensíveis, distribuindo as responsabilidades em classes pequenas, utilize classes abstratas.
**Fiquem com Deus e até a próxima.**
_Nunca desista de correr atrás dos seus sonhos_ | jonatanlima |
892,302 | Host your Swagger files with Github Pages & Swagger UI 🦜 | Get some Swagger files like from the tmforum ProductOrder specification. Create index.html at root... | 0 | 2021-11-13T16:35:16 | https://dev.to/tgotwig/host-your-swagger-files-with-github-pages-swagger-ui-13h8 | github, html, javascript, tmforum | Get some Swagger files like from the [tmforum ProductOrder specification](https://github.com/TGotwig/TMF622_ProductOrder).
Create `index.html` at root level:
```html
<html>
<head>
<script src="https://unpkg.com/swagger-ui-dist@3/swagger-ui-bundle.js"></script>
<script src="https://unpkg.com/swagger-ui-dist@3/swagger-ui-standalone-preset.js"></script>
<link rel="stylesheet" type="text/css" href="https://unpkg.com/swagger-ui-dist@3/swagger-ui.css" />
<title>TMF622_ProductOrder</title>
</head>
<body>
<div id="swagger-ui"></div>
<script defer>
window.onload = function () {
const ui = SwaggerUIBundle({
urls: [
{
name: "TMF622-ProductOrder-v4.0.0",
url: "TMF622-ProductOrder-v4.0.0.swagger.json",
},
{
name: "Product_Ordering_Management.regular",
url: "Product_Ordering_Management.regular.swagger.json",
},
],
dom_id: "#swagger-ui",
deepLinking: true,
presets: [SwaggerUIBundle.presets.apis, SwaggerUIStandalonePreset],
plugins: [SwaggerUIBundle.plugins.DownloadUrl],
layout: "StandaloneLayout",
});
window.ui = ui;
};
</script>
<style>
.swagger-ui .topbar .download-url-wrapper input[type="text"] {
border: 2px solid #77889a;
}
.swagger-ui .topbar .download-url-wrapper .download-url-button {
background: #77889a;
}
.swagger-ui img {
display: none;
}
.swagger-ui .topbar {
background-color: #ededed;
border-bottom: 2px solid #c1c1c1;
}
.swagger-ui .topbar .download-url-wrapper .select-label {
color: #3b4151;
}
</style>
</body>
</html>
```
Enable **Github Pages**:
That's all! 😀🎉
 | tgotwig |
892,306 | Learn SQL: Microsoft SQL Server - Episode 11: Extracting data from Strings | In this episode we are going to discuss how to extract characters from a string value. Let's say for... | 15,060 | 2021-11-12T06:33:10 | https://dev.to/ifierygod/learn-sql-microsoft-sql-server-episode-11-extracting-data-from-strings-3d89 | beginners, sql, database, programming | **In this episode we are going to discuss how to extract characters from a string value.**
Let's say for instance, we wanted to pull data from the **Person.Person** table. As we should know by now, this table contains all the information about all people in the database, <u>customers and employees</u>.

In this example, we will be selecting only the **firstName** and the **lastName** columns from the **Person.Person** table. However, we do not want to pull the entire **lastName** of person in the database, instead we just want to pull the _**first character**_ from the **lastName** value.

###LEFT
<abbr title="SQL Server Management Studio">SSMS</abbr> provides a ``built-in`` function called **Left** and it takes two <u>arguments/parameters</u>.
####First Value
We need to provide it with the _string_ value we want to _extract_ the character from, in this case **lastName**.
####Second Value
The _number_ of characters that we want to return starting from the **Left**, in this case it is ``1``.
```
Left(lastName, 1)
```

We can test this in <abbr title="SQL Server Management Studio">SSMS</abbr>, and to make it easier to understand we can give the **Left** function an **Alias** of ``Last Initial``.

>We can change the number of characters that get returned by modifying the second argument.
Another way to extract those characters is by using a **Substring**.
**SubString** is another _built-in_ function that takes three <u>arguments/values</u>.

###SUBSTRING
####First Value
The _column_ that we want to use to extract the value from.
###Second Value
Here we need to provide the ``position`` we want to start extracting the value at, eg choosing 2 would mean we want to start extracting from the second character, starting from the **Left**.
####Third Value
The _number_ of characters we want to extract.
```
SUBSTRING(lastName, 1, 1)
```
As we can see, it works similar to **LEFT**, we could also assign an **Alias** to the **SUBSTRING** function to make things easier to understand.


###RIGHT
Similar to **LEFT** their is another function called **RIGHT**.
**Right** works like **Left** in that it takes two arguments.
####First Value
The _string_ value we want to use to extract characters from.
####Second Value
The _number_ of characters we want to extract starting from the **Right**.
```
RIGHT(lastname, 3)
```
This will return the last three characters from the **lastName**.

**This is how we extract values from a string column or just any string value.**

Extracting values has really made me hungry...I hope you enjoyed this episode and put it into practice. Signing off...

| ifierygod |
892,425 | How to Migrate Custom Fields Data from ACF to Meta Box Plugin | If you are willing to change from ACF to Meta Box, how can you move all the custom fields data? Not... | 0 | 2021-11-09T01:54:39 | https://metabox.io/migrate-custom-fields-data-acf-meta-box-plugin/ | metabox, migrate, acf, customfields | If you are willing to change from ACF to Meta Box, how can you move all the custom fields data? Not only you but many others care about this matter. Therefore, recently Meta Box has released a new free extension called <strong>MB ACF Migration</strong>. This extension helps users <strong>migrate custom fields data from ACF to Meta Box with ONLY ONE CLICK</strong>. In this post, I will show you how to do that at the drop of a hat.
<!--more-->
Well, if you are still confused about what ACF and Meta Box are different or which is better, you can read <a href="http://metabox.io/meta-box-vs-acf">this comparison</a> first.
<h2>Introduction of MB ACF Migration</h2>
MB ACF Migration is a free extension released by the Meta Box team. This plugin helps users easily <strong>migrate custom fields data from ACF to Meta Box</strong>. In the past, it took a lot of time to do it. But now, it's so much easier with <strong>ONLY ONE CLICK</strong> thanks to MB ACF Migration.
With MB ACF Migration, you can easily migrate these types of data from ACF to Meta Box:
<ul>
<li>Field group's settings with location rules</li>
<li>Data of most field types, including relationships, groups,</li>
<li>repeaters, flexible contents</li>
<li>Data of conditional logic</li>
<li>Data of option pages</li>
<li>Data of posts, terms, users</li>
</ul>
<h2>Preparation</h2>
<ul>
<li><a href="https://wordpress.org/plugins/meta-box/">Meta Box core plugin</a>: the framework to deal with custom fields. You can download and install it from wordpress.org.</li>
<li><a href="https://metabox.io/plugins/meta-box-builder/">Meta Box Builder</a>: A Meta Box premium extension that provides UI to create and manage custom fields on the backend.</li>
<li><a href="https://metabox.io/plugins/mb-acf-migration/">MB ACF Migration</a>: This extension is also available in the WordPress repo. Besides, if you use Meta Box AIO or Meta Box Core (in the premium bundle), go to <strong>Meta Box</strong> > <strong>Extension</strong> and you will see <strong>MB ACF Migration</strong> in the extension list. Just tick to enable it. You may need to update the latest version of Meta Box AIO to have this extension.</li>
</ul>
<img class="aligncenter" src="https://i.imgur.com/E58Bxgs.png" alt="Activate MB ACF Migration in Meta Box AIO." width="1200" height="549" />
Besides these above plugins, remember to install all the needed Meta Box extensions that are corresponding to the features being migrated. For example, if you have fields in a group created by ACF, you have to enable <a href="https://metabox.io/plugins/meta-box-group/">Meta Box Group</a> to migrate the group field data. Or in ACF, when you set a location to display a field group in taxonomy then you have to activate the <a href="https://metabox.io/plugins/mb-term-meta/">MB Term Meta</a> extension in Meta Box.
To know more about all the Meta Box extensions, please go to <a href="https://metabox.io/plugins/">this Meta Box extension page</a>.
Note that in the process of moving data, you have to enable all the plugins I mentioned above.
<h2>Move Data from ACF to Meta Box</h2>
I used ACF to create a group of fields as below. These fields are Text, Email, Gallery, and Repeater. In Repeater, there are sub-fields: Checkbox, Text, and Gallery.
<img src="https://i.imgur.com/AHnxr9W.png" alt="Custom Fields created with ACF" width="1200" height="494" /> Fields created with ACF[/caption]
<img src="https://i.imgur.com/OEJTRO1.png" alt="Sub-fields in a group field created with ACF" width="1200" height="579" /> Sub-fields in a group field in ACF[/caption]
Besides, I used conditional logic to display the Image field when users choose Project Type as Web Design. The field group that I created by ACF is displayed like this:
<img class="aligncenter" src="https://i.imgur.com/5Wa0fr9.gif" alt="the field group created by ACF is displayed." />
Similar to all the above features in ACF, I will use these extensions of Meta Box:
<ul>
<li><a href="https://metabox.io/plugins/meta-box-group/">Meta box Group</a>: to have Group field, corresponding to Group + Repeater in ACF</li>
<li><a href="https://metabox.io/plugins/meta-box-conditional-logic/">MB Conditional Logic</a>: to have the conditional logic feature.</li>
</ul>
<img class="aligncenter" src="https://i.imgur.com/G8liOLu.png" alt="Use extensions of Meta Box: Meta Box Group & MB Conditional Logic." width="1200" height="549" />
I'd like to remind you a bit that to migrate custom fields data from ACF to Meta Box, you have to activate all the necessary plugins, even ACF as well.
After installing and activating MB ACF Migration, a new <strong>ACF Migration</strong> menu appears in the Meta Box menu. Go there and click <strong>Migrate</strong>. Then, wait about 1 minute for a message that notices the moving process has been completed.
<img class="aligncenter" src="https://i.imgur.com/IBNKBdn.png" alt="Using MB ACF Migration to move custom fields data from ACF to Meta Box" width="1200" height="549" />
Next, deactivate ACF and go to a post. Then, you can see that the fields are displayed exactly the same as when you use ACF. All the features like group and conditional logic also work well.
<img class="aligncenter" src="https://i.imgur.com/seKiUlQ.gif" alt="Fields are displayed exactly the same as when you use ACF after using MB ACF Migration " width="1366" height="625" />
Here are the fields are shown in the field edit. All the information such as field group ID and ID of each field have remained:
<img class="aligncenter" src="https://i.imgur.com/CenXI0i.png" alt="Field group ID and ID of each field have remained after moving custom fields data from ACF to Meta box" width="1200" height="383" />
<h2>Last Words</h2>
Just with one click, you can migrate custom fields data from ACF to Meta Box in an easy and fast way. However, ACF doesn't have the feature to create custom post types and custom taxonomies so you need CPT UI plugin. Therefore, if you want to move data from CPT UI to Meta Box, you can do it the same way as I mentioned in the tutorial on <a href="https://metabox.io/move-custom-post-type-custom-field-data-from-pods-to-meta-box/">migrating custom fields data from Pods to Meta Box</a>. You just have to create custom post types and custom taxonomies by Meta Box with the same title and ID them as in CPT UI.
What do you think about this Meta Box feature? Let us know in the comment section! | wpmetabox |
892,536 | 使用 urequests 請記得關閉連線釋放佔用的資源 | 在 MicroPython 中要使用 http 協定存取網路服務, 最簡單的方式就是藉助內建的 urequests 模組, 一般的使用情境大概會是這樣: import network import... | 0 | 2021-11-09T04:02:48 | https://dev.to/codemee/shi-yong-urequests-qing-ji-de-guan-bi-lian-xian-shi-fang-zhan-yong-de-zi-yuan-3fkf | micropython, urequests | 在 MicroPython 中要使用 http 協定存取網路服務, 最簡單的方式就是藉助內建的 urequests 模組, 一般的使用情境大概會是這樣:
```python
import network
import urequests
# 連線至無線網路
sta=network.WLAN(network.STA_IF)
sta.active(True)
sta.connect('FLAG-SCHOOL','12345678')
while not sta.isconnected() :
pass
print('Wi-Fi connected.')
res = urequests.get("https://flagtech.github.io/flag.txt")
if(res.status_code == 200):
print("Success.")
else:
print("Oops.")
```
不過您可能沒有注意到的是到上面的寫法 get 並沒有完成, 而是只接收到 http 回應的表頭而以, 也就是說整個連線還佔著。如果我們會重複進行 get, 像是以下這樣的極端狀況:
```python
import network
import urequests
import time
# 連線至無線網路
sta=network.WLAN(network.STA_IF)
sta.active(True)
sta.connect('FLAG-SCHOOL','12345678')
while not sta.isconnected() :
pass
print('Wi-Fi connected.')
while True:
res = urequests.get("https://flagtech.github.io/flag.txt")
if(res.status_code == 200):
print("Success.")
```
執行後很可能就會很快出錯:
```
>>> %Run -c $EDITOR_CONTENT
Wi-Fi connected.
Success.
Success.
Traceback (most recent call last):
File "<stdin>", line 16, in <module>
File "urequests.py", line 116, in get
File "urequests.py", line 55, in request
OSError: -2
```
才兩次 get 就掛了。
## Response.content 才會關閉連線
如果你看 [ureqests 模組的原始碼](https://github.com/micropython/micropython-lib/blob/43cad179462d965014eaaa6567eabcae2c6f6f25/python-ecosys/urequests/urequests.py#L22), 就會發現你必須取用 Response 物件的 content 屬性, 才會接續收取從伺服器送來跟在表頭後面的內容, 並且關閉連線。取用 Response.text 或是 Responses.json 屬性都會連帶取用 Response.content。因此, 最好的作法就是取用上述這些屬性, 完成整個 http 傳輸過程。如果你並不需要取得伺服器送來的內容, 也可以暴力一點, 直接叫用 Response.close() 關閉連線:
```python
import network
import urequests
import time
# 連線至無線網路
sta=network.WLAN(network.STA_IF)
sta.active(True)
sta.connect('FLAG-SCHOOL','12345678')
while not sta.isconnected() :
pass
print('Wi-Fi connected.')
while True:
res = urequests.get("https://flagtech.github.io/flag.txt")
if(res.status_code == 200):
res.close() # 或是 txt = res.text 也可以
print("Success.")
```
現在就可以正常一直 get 了:
```
>>> %Run -c $EDITOR_CONTENT
Wi-Fi connected.
Success.
Success.
Success.
Success.
Success.
Success.
Success.
...
``` | codemee |
892,598 | My Top Book Recommendations | I deeply enjoy reading books. Here's a short list of some of my favorites. Non... | 0 | 2021-11-09T23:36:44 | https://ivans.io/my-top-book-recommendations/ | readinglist, books, recommendations | ---
title: My Top Book Recommendations
published: true
date: 2021-06-07 16:39:04 UTC
tags: readinglist, books, recommendations
canonical_url: https://ivans.io/my-top-book-recommendations/
---
I deeply enjoy reading books. Here's a short list of some of my favorites.
<!--kg-card-begin: markdown-->
## Non Fiction
Every book on this list has changed my life in a pivotal manner. I invite you to read them for yourself and hope it brings about positive change for you as well.
- [How to Win friends and Influence People](https://www.goodreads.com/book/show/4865.How_to_Win_Friends_and_Influence_People) by Dale Carnegie - great foundation on interacting well with people.
- [Getting Things Done](https://www.goodreads.com/book/show/1633.Getting_Things_Done) by David Allen- the root of my time management philosophy.
- [The Alchemist](https://www.amazon.com/Alchemist-Paulo-Coelho/dp/0061122416) by Paulo Coehlo - great philosophical foundation.
- [Esentialism](https://gregmckeown.com/books/essentialism/) by Greg McKeown - pivotal work on how to priorize in life.
- [Deep Work](https://www.calnewport.com/books/deep-work/) by Cal Newport - a must read on how to work better.
- [Algorithms to Live By](https://www.goodreads.com/book/show/25666050-algorithms-to-live-by) - fun read on how to apply computer algorithms to optimize your daily life.
- [Sapiens](https://www.ynharari.com/book/sapiens-2/) by Yuval Noah Harari - an excellent history of the human race.
- [Give and Take](https://www.adamgrant.net/book/give-and-take/) by Adam Grant - understand different types of people and how to interact best with them.
- [Atomic Habits](https://jamesclear.com/atomic-habits) by James Clear - an actionabe guide on how to set up proper habits in life.
- All books by [Malcolm Gladwell](https://en.wikipedia.org/wiki/Malcolm_Gladwell#Works)
<!--kg-card-end: markdown-->
<!--kg-card-begin: markdown-->
## Fiction
Sometimes you just need to decompress. I like reading books with well developed worlds and consistent logic.
- [Harry Potter and the Methods of Rationality](http://www.hpmor.com/) - A mind blowing fan fiction with deep tenets in rationalism and science. Extremely enjoyable. Familiarity with original Potterverse is a must.
- [Deathworlders](https://deathworlders.com/) - excellent web serial about humans in space. Touches upon all parts of life, and characters and world are incredibly well developed.
- [Mother of Learning](https://www.royalroad.com/fiction/21220/mother-of-learning) - a fun web serial about a mage in a time loop. Download [here](https://github.com/asdkant/bookify-mol/releases).
- [Nexus Trilogy](https://www.goodreads.com/book/show/13642710-nexus) by Ramez Naam - This is a very interesting series about the emergence of superconsciousness and how the world reacts to it. I believe that it is entirely possible that events such as these will unfold in our future here on Earth, and found the description of events here very enlightening and thought provoking.
- [Mistborn Trilogy](https://www.goodreads.com/book/show/68428.Mistborn) by Brandon Sanderson - A very fun read, set in an alternate universe in medieval times. What I liked about this series was that it was more than just action and drama - the author managed to encode some very interesting discussions and thoughts about morality, life, philosophy, and ethics. Very enjoyable read, and quite deep.
- [Tide Lords](https://www.goodreads.com/book/show/2038926.The_Immortal_Prince?from_search=true&from_srp=true&qid=pFOMpQhO9u&rank=1) by Jennifer Fallon - This was definitely more of a fun time killer. Action, magic, and a captivating plot. Grat for a nice vacation.
- All works by [Terry Pratchett](https://en.wikipedia.org/wiki/Terry_Pratchett). Here is the suggested [reading order](https://i.redd.it/fdr5qy7s47051.png).
<!--kg-card-end: markdown--> | issmirnov |
892,610 | What does Elastic Mean? Cloud Concepts Explained | When I first started learning about AWS, I was overwhelmed with so many new words I hadn't seen... | 0 | 2021-11-09T07:26:31 | https://dev.to/aws-builders/what-does-elastic-mean-cloud-concepts-explained-4anb | elastic, aws, beginners, cloudskills | When I first started learning about AWS, I was overwhelmed with so many new words I hadn't seen before. I'm terrible at remembering names, so by far the hardest part of studying for my Certified Cloud Practitioner Exam was remembering all of the names of AWS Products/Services.
I got there in the end, but in hindsight I didn't 100% grasp the concept of elasticity straight away, because it was a familiar word so I ended up glossing over it and focusing on other areas. Today's article will hopefully save you (or someone you're mentoring) from the same mistakes I made.
<sub><sup>_Optional soundtrack for this article:_</sup></sub>
{% youtube A9bldc2q2fU %}
Imagine you're having a **Pizza Party!**
You know your friends are on their way, but you don't know how many of your invitees will actually arrive, or how many guests they're bringing. As a result, when it comes time to order pizza for everyone you just take a guess and hope for the best. You could end up with way too much pizza in the end, or not nearly enough! This is like on-prem infrastructure - you have to pay lots upfront, and you're just guessing capacity, so it can get very expensive and you can end up wasting lots of precious pizza.
In the chart above, you can see that the number of pizzas is constant, and there's times where there isn't enough pizzas for the number of guests when there's a sudden burst (perhaps someone posted photos on instagram which encouraged more guests to arrive?).
It still counts as a pizza party because you have the two key components there (pizza and party) but this isn't a great experience for your guests.
For a different example, say you wanted to have a **Scalable Pizza Party**. The [AWS Well-Architected Framework](https://wa.aws.amazon.com/wellarchitected/2020-07-02T19-33-23/wat.concept.scalability.en.html) defines scalability as:
> Successful, growing, systems often see an increase in demand over time. A system that is scalable can adapt to meet this new level of demand.
This is good news for you, because successful parties also often see increases in demand over time. Scalability is all about making sure you can 'rise to the occasion' and being able to increase capacity (pizzas) to meet the new guests arriving.
As you can see on the chart, the 'pizza line' is really good at increasing when there's more guests, but it often ends up with lots of extra food when there's a decrease in guests. Things can and do scale downwards, but I really wanted to point out that successful scalability is more focused on being able to increase effectively and isn't always focused on the decrease.
If your pizza party was an **Elastic Pizza Party**, the pizza ordering would turn out differently! The [AWS Well-Architected Framework](https://wa.aws.amazon.com/wellarchitected/2020-07-02T19-33-23/wat.concept.elasticity.en.html) defines elasticity as:
> The ability to acquire resources as you need them and release resources when you no longer need them. In the cloud, you want to do this automatically.
This is great news for our pizza party! You can access the right amount of pizza as soon as you need it, and you can also get rid of pizza (without wasting money!) whenever the number of guests falls.
This chart shows a close pairing between the number of pizzas and number of guests which is great news! You'll have the right number of pizza the whole time, and you won't waste any pizza during the dip (perhaps everyone ran out of beverages and had to buy more?).
Another great feature is that you can set this to happen automatically, so you can spend less time trying to figure out the pizza situation and more time with your party guests.

About the Author: [Brooke Jamieson](https://twitter.com/brooke_jamieson) is the Head of Enablement - AI/ML and Data at Blackbook.ai, an Australian consulting firm specialising in AI, Automation, DataOps and Digital. Learn more about Blackbook.ai [here](https://blackbook.ai/) and learn more about Brooke [here](https://www.linkedin.com/in/brookejamieson/).
{% twitter 1455293829897089027 %} | brooke_jamieson |
892,628 | Highcharts: Styled Spline Chart | Beautifully styled simple spline chart. | 0 | 2021-11-09T08:04:10 | https://dev.to/chideraao/highcharts-styled-spline-chart-2131 | codepen, javascript, webdev, datavisualisation | {% codepen https://codepen.io/chideraao/pen/dyzKyJx %}
Beautifully styled simple spline chart. | chideraao |
892,668 | Highcharts: Styled OHLC with MACD Oscillator | Beautifully styled OHLC chart with MACD oscillator | 0 | 2021-11-09T08:42:04 | https://dev.to/chideraao/highcharts-styled-ohlc-with-macd-oscillator-2ekc | programming, datavisualisation, javascript, webdev | {% codepen https://codepen.io/chideraao/pen/XWaYJjL %}
Beautifully styled OHLC chart with MACD oscillator | chideraao |
892,759 | Artificial Intelligence Training in Gurgaon | Artificial Intelligence Course in Gurgaon | https://www.gyansetu.in/courses/deep-learning-ai-artificial-intelligence-training-gurgaon... | 0 | 2021-11-09T09:32:43 | https://dev.to/sanasin04984541/artificial-intelligence-training-in-gurgaon-artificial-intelligence-course-in-gurgaon-29c2 | tutorial, career, beginners, programming | ERROR: type should be string, got "https://www.gyansetu.in/courses/deep-learning-ai-artificial-intelligence-training-gurgaon \n\nArtificial Intelligence is everywhere nowadays. Every Big Company like Google,Facebook,Amazon and Many more are using it to understand their user or Customers. It is Hottest Skill in demand right now. \n\nThere are Many AI job vacancies in top companies but there is a lack of skills. \n\nThis skill Also pays well. \n\nNow Learn Artificial Intelligence Training in Gurgaon with iClass Gyansetu. \nDuring This Course you will work on Live Projects Prediction Analysis, Linear Regression, Image Processing, Audio & Video Analytics, Text Data Processing, IOT and various Machine Learning & Deep Learning Algorithms. You will get 100% Job Placement Assistance, free Course Repetition. \n\nJoin now. Call:- 08130799520\n" | sanasin04984541 |
892,781 | 8 UI/UX tips about password design | With the multiplication of saas (service as a software) these last years and the security problems... | 0 | 2021-11-09T10:25:28 | https://dev.to/indieklem/8-uiux-tips-about-password-design-5bbn | ux, uiweekly, webdev, beginners | With the multiplication of saas (service as a software) these last years and the security problems linked to the fact of having an identical password for each service, I find myself using the « Forgot password » page much more often than before.
If this can be corrected beforehand thanks to password managers such as 1Password or LastPass, with the « no password » methods implemented by tools like Slack or the social login here are a few UI/UX tips to apply to the design of your « Login » and « Forgot password » pages.
Users who try to log in, create a new password or reset their password will be eternally grateful to you.
##1. Add a button to hint the password
The first thing to do to avoid mistakes is to offer your users the possibility to see the characters they just typed in the password field. This feature is often represented by an « eye » icon on the right of the field.
It’s simple, basic, as my favorite singer would say but it’s not always available.
For those who know the browser console (press F12 now and enter a wonderful world) you can simply change the type= »password » of the password field to type= »text » and see what you have written.
##2. Show if the Caps Lock key is on
Tell your users if the Caps Lock key is enabled when they type their password.
But don’t worry if it’s not, there is no need to display the text « Caps Lock is Off ». Few users will see the message and act accordingly.
##3. Show if the Num Lock key is on
The same UI/UX design practice can be applied with the Num Lock key
##4. Limit password conditions and display them
Display precise explanations when creating the password, don’t hide them in an tooltip to bring them out only when your user makes an error. Save him time and frustration. A real time validation is also a real plus.
##5. Show the conditions required when creating the password
Remember… It was 6 months ago, to create his password you asked your user to add:
* At least 1 uppercase
* At least 1 number
* At least 8 character
* And the last 3 digits of his credit card (Wait, what? Did you really ask that?)
A security measure, a fashion effect, a copy cat because the competitor was doing the same or a useless waste of time? It doesn’t matter, you did it. And today he doesn’t remember these constraints that you imposed. So if he makes a mistake while login, make his life easier and remind him. Remind him the conditions required days, weeks, months or years ago, I promise you it will help him.

##6. Delete the password confirmation field
If you follow the previous steps, especially the one that allows the user to see what they are writing, then the password confirmation field that was a safety feature (a long time ago in a galaxy far, far away) to avoid errors becomes obsolete. It’s already a pain to type the password once, don’t make it twice.
##7. Fill the email field on the forgot password page
The process when your user realizes he have forgotten their password often looks like this:
* Comes to the login page
* Types in his credentials
* Receives an error message
* Realizes that he does not remember his login information
* Clicks on the link « Forgot your password »
And that’s where the magic happens, because at this point in the user’s journey, you already know their email address. Yep. They just typed it in a few seconds ago. All you need do to is to fill it on the present page so that they don’t have to write the same things over and over again. Remember in design every second saved matter.
##8. Suggest creating a new password rather than automatically generating a new one
Who’s going to remember your long, complicated machine-generated password? Spoiler Alert: no one. Whether it is for security reasons or to let the user use his password manager, it’s better to let the user create a new password rather than randomly generate one in the email they will receive from you.
##TLDR:
Here is 8 UI Tips to make the life of your user easier on your login and password lost pages. Remember, less friction is more conversion. You don’t want to spend time fighting with bad interface, neither does your user.
1. Add a button to hint the password
2. Show if the Caps Lock key is on
3. Show if the Num Lock key is on
4. Limit password creation conditions and display them
5. Show the conditions required when creating the password
6. Do not add a password confirmation field
7. Pre-fill the email field on the forgot password page
8. Suggest creating a new password rather than automatically generating a new one
👋🏻 Thanks for reading me, this article was originaly posted on [Jimmy Lollipop](https://jimmylollipop.com/). | indieklem |
892,816 | Electron Adventures: Episode 91: Application Logs | I wanted to add some more OS integrations, but a few of them only work with packaged app. Developing... | 14,346 | 2021-11-09T12:02:50 | https://dev.to/taw/electron-adventures-episode-91-application-logs-3c0d | javascript, electron, svelte | I wanted to add some more OS integrations, but a few of them only work with packaged app.
Developing an app and then packaging it is fine, but functionality that only works when packaged is a huge pain to test. First big issue is that there's no `console.log` from the backend process.
There are a few ways to get around this, let's try [`electron-log` package](https://www.npmjs.com/package/electron-log) to log things to a text file.
### Installing
```shell
$ npm install electron-log
```
### Using the logger
After that we can edit `index.js` and replace `console.log` with `log.info`. There are other log levels too, if you need this distinction. Only two lines here are new, but here's the whole file:
```javascript
let { app, BrowserWindow, dialog, Menu } = require("electron")
let settings = require("electron-settings")
let log = require("electron-log")
let isOSX = (process.platform === "darwin")
function createWindow(path) {
log.info("Creating window for", path)
let key = `windowState-${path}`
let windowState = settings.getSync(key) || { width: 1024, height: 768 }
let qs = new URLSearchParams({ path }).toString();
let win = new BrowserWindow({
...windowState,
webPreferences: {
preload: `${__dirname}/preload.js`,
},
})
function saveSettings() {
windowState = win.getBounds()
log.info("Saving window position", path, windowState)
settings.setSync(key, windowState)
}
win.on("resize", saveSettings)
win.on("move", saveSettings)
win.on("close", saveSettings)
win.loadURL(`http://localhost:5000/?${qs}`)
}
async function openFiles() {
let { canceled, filePaths } = await dialog.showOpenDialog({
properties: ["openFile", "multiSelections", "showHiddenFiles"],
filters: [
{ name: "CSV files", extensions: ["csv"] },
{ name: "All Files", extensions: ["*"] }
],
message: "Select a CSV file to open",
defaultPath: `${__dirname}/samples`,
})
if (canceled && !isOSX) {
app.quit()
}
for (let path of filePaths) {
createWindow(path)
}
}
let dockMenu = Menu.buildFromTemplate([
{
label: "Open files",
click() { openFiles() }
}
])
async function startApp() {
if (isOSX) {
app.dock.setMenu(dockMenu)
}
await openFiles()
if (isOSX) {
app.on("activate", function() {
if (BrowserWindow.getAllWindows().length === 0) {
openFiles()
}
})
}
}
app.on("window-all-closed", () => {
if (!isOSX) {
app.quit()
}
})
app.on("ready", startApp)
```
### Viewing the logs
The logs are saved in different location dependig on the operating system. For OSX, they will be at `~/Library/Logs/<application_name>/main.log` - `main` being the Electron word for backend.
If you use the logger from another process (frontend/renderer, or a worker process), it will go to a different file.
So let's take a look at `~/Library/Logs/episode-91-application-logs/main.log`:
```
[2021-11-09 11:55:16.344] [info] Creating window for /Users/taw/electron-adventures/episode-91-application-logs/samples/06-reputation.csv
[2021-11-09 11:55:37.027] [info] Saving window position /Users/taw/electron-adventures/episode-91-application-logs/samples/06-reputation.csv { x: 1116, y: 661, width: 1024, height: 768 }
[2021-11-09 11:55:37.129] [info] Saving window position /Users/taw/electron-adventures/episode-91-application-logs/samples/06-reputation.csv { x: 812, y: 601, width: 1024, height: 768 }
[2021-11-09 11:55:37.235] [info] Saving window position /Users/taw/electron-adventures/episode-91-application-logs/samples/06-reputation.csv { x: 768, y: 589, width: 1024, height: 768 }
[2021-11-09 11:55:37.348] [info] Saving window position /Users/taw/electron-adventures/episode-91-application-logs/samples/06-reputation.csv { x: 767, y: 588, width: 1024, height: 768 }
```
### Results
Now that we have logging working even from a packaged app, let's see if we can integrate drag and dropping files onto Dock in the next episode.
As usual, [all the code for the episode is here](https://github.com/taw/electron-adventures/tree/master/episode-91-application-logs).
| taw |
892,830 | Features influencing the Uber for Alcohol delivery app development cost
| The cost of developing an on-demand alcohol delivery app would be determined by numerous factors. It... | 0 | 2021-11-09T12:40:17 | https://dev.to/jennycwilson/features-influencing-the-uber-for-alcohol-delivery-app-development-cost-3p59 | uberforalcohol, appdevelopment, webdev, productivity | The cost of developing an on-demand alcohol delivery app would be determined by numerous factors. It includes features & functionality, app size & complexity, technology stack, third-party services integration, geographical location of the company or app developers’ team you hire, and the selection of platforms.
In short, the development of an app from scratch cost would be high when compared to opting for a ready-made app. Predominantly, the number of features incorporated will have a direct impact on the cost. It will elevate when the features set added increase. That is, the Uber for alcohol delivery app with the advanced features would cost high in comparison to the one with the basic features. Below are a few sets of crucial features that would influence the cost.
<strong>Take Away option</strong>
Apart from the customers placing orders and getting these delivered on their doorsteps, they can directly pick from the liquor store. Thereby, they can avoid delivery charges.
<strong>Referral program</strong>
The platform owner can gain a larger user base by introducing a referral program. With this, you can reward customers for successful referrals.
<strong>Offer Special Gifts</strong>
Typically, people would like to gift flowers and chocolates. Besides this, you can let them gift alcoholic beverages via the <a href="https://www.uberlikeapp.com/alcohol-delivery-app-development">Uber for alcohol delivery app</a> by placing orders and specifying the destination address of whom you want to gift.
<strong>Resolve customer queries</strong>
The vendors or store owners can directly connect with the customers to resolve queries. This will gradually increase customer satisfaction which will be a ladder for your business success.
<strong>Ad management</strong>
The platform with a separate advertisement space will empower the third party to promote their services or products. The platform owner can manage the ads through the admin panel.
<strong>Concluding note</strong>
We have discussed a few sets of features that will influence the on-demand alcohol delivery app development cost in this blog. It is significant to note that the features & functionality is the major factor determining the Uber for alcohol delivery app development cost.
| jennycwilson |
892,877 | How to use Tatum's gas pump to save on gas fees | If you’ve built or want to build a custodial exchange like Binance or Kraken, a custodial wallet... | 0 | 2021-11-11T08:16:57 | https://dev.to/evanvtatum/how-to-use-tatums-gas-pump-to-save-on-gas-fees-16bg | blockchain, tutorial, programming | If you’ve built or want to build a custodial exchange like Binance or Kraken, a custodial wallet service, or a custodial NFT marketplace, there’s one major headache that you’re bound to encounter: how do you pay the gas fees for sending tokens from your users’ accounts?
Every time a user wants to send tokens from their account, you have to calculate the gas fees, send that amount to their account (a transaction that also incurs gas fees), and send the tokens on their behalf. Two transactions, both of which incur gas fees and can result in minuscule differences of crypto “dust” remaining in user accounts. If you have thousands or millions of addresses, this method creates an enormous amount of work for you as a developer, and astronomical gas fees to run everything.

It can be a huge headache. But there's a workaround that simplifies the whole process and significantly reduces gas fees.
## A smart contract instead of an address
Tatum's gas pump uses smart contracts that function as user wallets and automatically deduct gas fees from a master address. Every time you send tokens from a user wallet, the gas fees are deducted from the master balance, eliminating the need to send crypto to each user address to pay for gas fees. The smart contracts are inexpensive to deploy and pay for themselves in saved gas fees after transferring 1.5 ERC-20 tokens.
Here’s an example of the workflow:



Tatum's gas pump is available on the following blockchains:
- **Ethereum**
- **Binance Smart Chain**
- **Celo**
- **Polygon (MATIC)**
- **Tron**
## How to do it
In this guide, we'll be using REST API calls to perform operations. However, the same operations can be performed with Tatum's JavaScript library. Download and install the SDK [here](https://tatum.io/tatum-js.html).
### 1. First, you’ll need to deploy a smart contract for each user.
[This API call](https://tatum.io/apidoc.php#operation/GenerateCustodialWalletBatch) will do it for you. Each smart contract functions as a wallet/user address that can accept ERC-20, ERC-721, ERC-721, and native assets on the blockchain you deploy it on.
In addition, any combination of tokens can be transferred from a wallet in a batch transaction. This is significantly more efficient and saves enormously on gas fees compared to transferring assets one by one.
Let's deploy 200 gas pump wallets with one API call:
```bash
curl --location --request POST 'https://api-eu1.tatum.io/v3/blockchain/sc/custodial/batch' \
--header 'Content-Type: application/json' \
--header 'x-api-key: YOUR_API_KEY' \
--data-raw '{
"owner": "0x80d8bac9a6901698b3749fe336bbd1385c1f98f2",
"batchCount": 200,
"chain": "MATIC",
"fromPrivateKey": "0x37b091fc4ce46a56da643f021254612551dbe0944679a6e09cb5724d3085c9ab"
}'
```
In the example above, the wallets will be deployed on the Polygon blockchain (as indicated in the by "MATIC" in the **chain** field). **You can deploy on any other blockchain that supports the gas pump functionality by simply changing the name of the chain in the call.**
The response will be a transaction ID:
```JSON
{
"txId": "0x6b9ecce4bf716a06c8dfad19feea13692b99737dc042ceaa1ca4204fdc1556a5"
}
```
### 2. Next, let's get our gas pump wallet addresses.
Next, we'll get the addresses of the gas pump wallets we've just deployed. These will be the addresses you can assign to your users so that they can receive tokens.
We'll use the **transaction ID** returned from the previous call in the following endpoint to get the addresses of the wallets:
```bash
curl --location --request GET 'https://api-eu1.tatum.io/v3/blockchain/sc/custodial/MATIC/0x6b9ecce4bf716a06c8dfad19feea13692b99737dc042ceaa1ca4204fdc1556a5' \
--header 'Content-Type: application/json' \
--header 'x-api-key: YOUR_API_KEY'
```
The response will be the addresses you generated in the first call:
``` JSON
[
"0xc83779f2537fd40082c031fcef91bd6557ee2a13",
"0xb67f45ea6c7466e25635f4154c671955df130977",
"0x6dcc090c52e6427938c29a5dcf03274e5bdf0630",
"0x29696548784515d2884fdd09ad7b4e689c56ed3f",
"0xf12294780cedfa51dee310cba7f3a0968d881246",
"0xe7b002b13a86d533abb74bbc7d5b6a16af2e6b13",
"0x88cf6afd1dd665abaa03cac06e6bde554e1fffd5",
"0xff79ff532723d56eb78c7547b53611e8dc73321e",
"0x17b862cf61212013602290a2a7a1ee7775b51ff6",
"0xba33fa91e471780db0e71771fd8af63aba6a1fb2",
"0xbb5747dc66e35825b9a9da800de15d6743b66b55",
.
.
.
]
```
### 3. Now, we'll transfer some tokens.
[Transferring tokens](https://tatum.io/apidoc#operation/TransferCustodialWallet) from the wallet you have generated can be done with one API call, whether you’re transferring one type of token or multiple types of tokens.
First, let’s look at how to **transfer one type of token** in the following API call:
```bash
curl --location --request POST 'https://api-eu1.tatum.io/v3/blockchain/sc/custodial/transfer' \
--header 'Content-Type: application/json' \
--header 'x-api-key: testnet' \
--data-raw '{
"chain": "MATIC",
"contractType": 0,
"tokenAddress": "0x2d7882bedcbfddce29ba99965dd3cdf7fcb10a1e",
"custodialAddress": "0x4eC40a4A0dA042d46cC4529f918080957003b531",
"recipient": "0x8cb76aEd9C5e336ef961265c6079C14e9cD3D2eA",
"amount": "0.00006",
"fromPrivateKey": "0x37b091fc4ce46a56da643f021254612551dbe0944679a6e09cb5724d3085c9ab"
}'
```
In the call above, the **contractType** field specifies the type of token to be transferred. In this case, **0** refers to the fungible tokens we enabled in the previous call. Again, the chain is **MATIC**.
The addresses that must be specified are:
- **tokenAddress** — the address from which the tokens will be sent
- **custodialAddress** — the address of the wallet
- **recipient** — the address to which the tokens will be sent
The amount to be sent is specified in the **amount** field, and the **fromPrivateKey** field contains the private key associated with the address.
### 4. And finally, let’s transfer multiple assets from the wallet.
```bash
curl --location --request POST 'https://api-eu1.tatum.io/v3/blockchain/sc/custodial/transfer/batch' \
--header 'Content-Type: application/json' \
--header 'x-api-key: YOUR_API_KEY' \
--data-raw '{
"chain": "MATIC",
"contractType": [0,1,2,3],
"tokenId": ["0","100","1","0"],
"amount": ["0.001","0","1","0.009"],
"tokenAddress": [
"0x2d7882bedcbfddce29ba99965dd3cdf7fcb10a1e",
"0x6d8eae641416B8b79e0fB3a92b17448CfFf02b11",
"0x664F97470654e8f00E42433CFFC0d08a5f4f7BC7",
"0"
],
"custodialAddress": "0x4eC40a4A0dA042d46cC4529f918080957003b531",
"recipient": [
"0x8cb76aEd9C5e336ef961265c6079C14e9cD3D2eA",
"0x8cb76aEd9C5e336ef961265c6079C14e9cD3D2eA",
"0x8cb76aEd9C5e336ef961265c6079C14e9cD3D2eA",
"0x8cb76aEd9C5e336ef961265c6079C14e9cD3D2eA"
],
"fromPrivateKey": "0x37b091fc4ce46a56da643f021254612551dbe0944679a6e09cb5724d3085c9ab"
}'
```
In the example above, all four contract types are enabled in the **contractType** field:
- **contractType 0** — ERC-20 token
- **contractType 1** — ERC-721 token
- **contractType 2** — ERC-1155 token
- **contractType 3** — native asset — MATIC
In the **tokenId** field, the token IDs of each respective type of asset are specified. For ERC-20 tokens and the native assets (contract types 0 and 3), the token IDs are **0** because both are fungible tokens and thus do not have unique token IDs.
The amounts of each token to be transferred are specified in the **amount** field:
- **0.001 ERC-20** tokens
- **1 ERC-721** token (the amount is not used for this token type, because each ERC-721 is unique, these the tokenID "100" in the **tokenID** field is what's relevant).
- **1 ERC-1155** token with the **tokenID 1**
- **0.009 MATIC**
Finally, the addresses holding the different tokens are specified in the **tokenAddress** field, the address of the custodial multi-wallet in the **custodialAddress** field, and the addresses of the recipients in the **recipient** field.
### The cost of deployment pays itself off quickly.
The cost of deploying one user wallet using the gas pump is the same as the cost of transferring 1.5 ERC-20 tokens. This means that after a user has transferred 1.5 ERC-20 tokens, they have already paid off the cost of the wallets, and from that point on you’ll just be saving on gas fees. When you’re dealing with hundreds, thousands, or millions of addresses, those fees can really add up.
You’ll never have to worry about the logistics of sending the correct amount to user accounts, crypto dust being left over in their wallets, or incurring extra gas fees while sending funds to cover your users’ transactions. The gas pump takes care of all of that for you.
## How to get started
This gas pump feature is native to Tatum, so you'll need to [sign up for an API key](https://dashboard.tatum.io/sign-up) to communicate with our infrastructure. However, you can do everything with a free plan, and you don’t have to upgrade to a paid plan unless you require more than 5 API requests per second. For help getting started, check out our [how-to guide](https://blog.tatum.io/how-to-get-started-with-blockchain-development-using-tatum-db349d90653).
You can use your API key to make direct REST API calls as we have in this guide, or you can download and install the Tatum JavaScript library [here](https://tatum.io/tatum-js.html).
For more information about the gas pump feature, please refer to our [guide](https://docs.tatum.io/tutorials/how-to-pay-fees-for-token-transfers-from-another-address) and [API documentation](https://tatum.io/apidoc#operation/GenerateCustodialWallet).
If you have any questions or need any help, please drop us a line on the Tatum [Discord](https://discord.com/invite/4TWtSP3vxU) or [subreddit](https://www.reddit.com/r/tatum_io/), and one of our devs will get back to you asap.
## About Tatum
[Tatum](www.tatum.io) is a development platform that unifies 40+ blockchain protocols into a single framework, allowing any developer to build apps with no previous blockchain experience. They provide blockchain infrastructure, SDKs, and a REST API, which eliminate many common obstacles to blockchain development. The platform is used by over 12,000 developers from around the world. Apps built on Tatum are used by tens of millions of end-users and process billions of dollars worth of transactions per month. | evanvtatum |
893,014 | Peculiaridades do JS. Que não são erros! Nem esquisitice! - Objetos | JS é uma linguagem interessante! Além das coisas já bem conhecidas(espero)! Que funções são... | 15,444 | 2021-11-09T17:20:22 | https://dev.to/urielsouza29/peculiaridades-do-js-que-nao-sao-erros-nem-esquisitice-3c40 | javascript, braziliandevs | JS é uma linguagem interessante!
Além das coisas já bem conhecidas(espero)!
Que funções são valores!
O fato de funções serem tratadas como valores!
Funções serem cidadãos de primeira classe! Entre outras coisas da parte funcional do JS!
Mas hoje quero mostrar algo sobre que tudo no JS é objeto!
```javascript
function teste(){}
teste['testeinterno'] = 'oi'
console.log(teste.testeinterno) // 'oi'
for(chave in teste){
console.log(chave)
}
//"testeinterno"
```
Colocamos uma propriedade na função?
Como assim?
Isso acontece pq tudo no JS é objeto.
Inclusive uma função!
E como um bom objeto no JS você pode colocar propriedades nele!
Não é um erro! Nem uma esquisitice.
Vamos ver um array! Que é um objeto :P
```javascript
const arr = ['testar', '09']
//array normal!
arr['oi'] = 'neh'
arr[1.5] = 'hello'
arr[-1] = 'bah'
// como ele é objeto! Podemos por propriedades //e valores!
for(chave in arr){
console.log(chave)
}
//"0" "1" "oi" "1.5" "-1"
console.log(arr) // ["testar", "09"]
console.log(arr.oi) // 'oi'
console.log(arr[-1]) // 'bah'
console.log(arr[-1] + arr[1.5]) //"bahhello"
```
Isso e outras coisas podem aparecer pra você em algum momento!
Por enquanto é isso!
Em breve quero escrever mais textos sobre isso e complementar este!
Brinque no JSBIN
https://jsbin.com/fuxazuniqo/1/edit?js,console
https://www.youtube.com/watch?v=n5uiJr-v0KQ
https://developer.mozilla.org/pt-BR/docs/Web/JavaScript/Guide/Working_with_Objects | urielsouza29 |
893,059 | What's HTML language? | HTML is a word from hyper text markup language, it's not programming language it's markup or coding... | 0 | 2021-11-09T15:50:53 | https://dev.to/coderhcj/whats-html-language-55m7 | html | HTML is a word from hyper text markup language, it's not programming language it's markup or coding language html work by tage for example
<html> </html> ...
and HTML5 is not other language it's version 5 of html and we say HTML5 from
hyper text markup language version 5.
HTML is the basic of anysite.
| coderhcj |
893,137 | Are You A Coder? Here Are 20 Top Tips From The Coding Community | Learning to code is an amazing thing. How you can code something interesting and then view its... | 0 | 2021-11-09T18:13:56 | https://mranand.com/blogs/are-you-a-coder-here-are-20-top-tips-from-the-coding-community/ | programming, codenewbie, productivity, computerscience | Learning to code is an amazing thing. How you can code something interesting and then view its fascinating outcomes. But Doing it in the right way is also very important. While scrolling YouTube I found a video where some developers and community leaders were sharing their tips about programming.
In this Article, I am going to share **20 Top Tips From The Coding Community**
### 1. Use Google
The developers' best friend is Google. I don't know who you are or how much experience you have, no one can remember everything. Learning how to google things itself is a required skill every developer should have. Finding resources to learn or to fix bugs google is going to help you with everything related to your coding journey. Googling is an Art! Learn it.
### 2. Pick Tech You Like
Choose something you like. JavaScript is trending now in web development, if you like it Great!. If you are not intrested in web development fine! choose App development or some other tech. just make sure to learn something you like.
### 3. Learn & Code
Always learn & code at the same time. This will help you to understand concepts properly. If you are learning something solve some questions related to the concepts.
### 4. Support Other Learners
If your classmates or someone is learning something or creating something. Help them with your knowledge, Support them. Supporting someone will going to help you to become a good developer. Talks about the things they did great, talk about the things they need to work upon. Don't humiliate by saying every time: hey you are wrong! this sucks! that's bad, Instead talk about it and explain the solution.
### 5. Write Out Your problem
Suppose you have a coding issue, when you write it out and started explaining it to someone you end up explaining it in your own brain. Sometimes You already figures out the answer before you even going to ask someone by seeing what you have written. So write out your problems before code.
### 6. Build & Practice
If you are learning to code, practice is the most important thing to follow across the learning period. Don't stuck in tutorial hell. Learn and practice to get better.
Suppose you are learning web development, create mini-projects after clearing every concept, and implement it.
### 7. Go At Your Own Pace
This is not a competition. If it takes you a long time to understand concepts, it's OK. Don't compare yourself with others, everyone's mind is different. At the end of the day, the only thing matters are what you learned. Go Slowly! Believe in Yourself!
### 8. Error Message/Bugs
Error messages and bugs are your friends now. Get comfortable with these while coding, it's a part of the job. It's going to help you a lot.
### 9. Take Small Breaks
Always take small breaks between coding sessions, get up from the chair drink water. walk for 5 minutes, see outside the window, and get relaxed. this will boost your productivity.
### 10. Dealing With Imposter Syndrome
Remember that no one knows everything and you are not expected to know everything. So, admit when you don't completely understand something so that others around you can help you and celebrates your win. No matter how big or small they are, when you look back at the time when you first started learning. You are going to see how far you came, Never give up.
### 11. Fun Based Learning
When you code something and going to deploy it remember programming should always be fun. Create small side projects to learn things. Maybe a small game you made helps you to understand the concept faster. when you start enjoying the coding process, you will be going to be a good developer.
### 12. Timebox When You Are Stuck
If you gonna struggle with a problem, give yourself some time like 30 minutes or 1 hour but in limit before going to ask someone or to take help. Neither ask early nor stuck for too long.
### 13. Focus On Small Things
Improve yourself every day, fix a time slot to code every day. like you decided to code for 3 hours daily, so follow this. Don't miss these 3 hours. Coding daily will boost your confidence as well as problem-solving skills. These small things matter. Small things make huge differences. Assess your silly mistakes while doing code to improve yourself.
### 14. Explore & Be Passionate
Always keep exploring new things in the programming world and be passionate about what you are doing or learning. New things always keep coming, find and know about it, keep yourself updated with the latest tools and trends in the coding world. Mastering what you learn but keeping knowledge of changing tech is equally important.
### 15. Real & Desired Projects
Making small projects while learning is a good thing. But when it comes to jobs having a better side project will give you an edge over others. Just make a project which you want to see in this world, give it a try make your imagination real. Failing is OK, at least you should try.
### 16. Find A Mentor and Work With Experienced Peoples
Having a good mentor is all you need to grow in the industry or to come out of problems by following the right path. Mentors can guide you to what you need to learn and what not to.
Working with experienced people helps you to learn from their experiences. while working they can share some insights which will make your life easier in the coding world.
### 17. Find Your Community
Community is everything in this industry. Connecting with people of similar interests and fields is all you need to get better. Having in some good communities is the best thing you can do to grab opportunities and to take help and do help.
### 18. Physical and Mental Health
Staying fit is a huge challenge nowadays. Sitting on a chair for long durations while coding can make you unhealthy, so take proper care of your health. It's most important. Exercise daily! Drink lots of water! Walk around the city! Eat healthily and use the proper desk setup for coding. Do meditation in the morning and wash your eyes with cold water thrice a day. Eyes are most exposed to bright desktop screens.
### 19. Document And Share Experiences
No matter what you learned or achieved, document your journey. Sometimes during your learning process, you got stuck but get the solution after some time. Do share it with the world by writing blogs or making videos. Your experiences gonna help others.
### 20. Contribute To Open-Source
Because most coders overlook open-source contributions, I'm writing this in the final section of this article. You've studied everything, but how will you use your knowledge to work on a vast codebase if you don't understand how real-world projects work? It's also critical to have a thorough understanding of real-world software and projects. Start contributing to open source to help you achieve your goals.
### Some Bonus Tips
- **Learn In Public:** Post your daily learning on Twitter or LinkedIn. This will help you as well as others. By doing this, you are making yourself more open to job opportunities.
- **Use Stack Overflow:** If You get stuck in coding problems and find solutions later share it there so that anyone facing the same issue in the future can take help from it.
- **Some Apps For Student Developers:** Gaming apps to social media apps, everyone is using different apps. But having some proper apps to increase your productivity and boost your coding journey is also important. So Read My Article [here](https://astrodevil.hashnode.dev/some-apps-for-student-developer) about some suggestions.
#### If You ❤️ My Content! Connect Me on [Twitter](https://mobile.twitter.com/Astrodevil_) or Supports Me By Buying Me A Coffee☕👇🏼
<a href="https://www.buymeacoffee.com/Astrodevil"><img src="https://img.buymeacoffee.com/button-api/?text=Buy me a coffee&emoji=Astrodevil&button_colour=FFDD00&font_colour=000000&font_family=Cookie&outline_colour=000000&coffee_colour=ffffff"></a>
| astrodevil |
893,159 | Establishing connections less than 1GB with Direct Connect, Transit Gateway, VPN and Sophos XG on AWS | When we have many environments (development, quality and production) on AWS and we separate in... | 0 | 2021-11-09T18:54:31 | https://dev.to/aws-builders/establishing-connections-less-than-1gb-with-direct-connect-transit-gateway-vpn-and-sophos-xg-on-aws-4kkc | aws, vpn | When we have many environments (development, quality and production) on AWS and we separate in different VPCs or AWS accounts, we can have a **Transit Gateway**; however, when we require an on-premise scenario using **Direct Connect** with less than 1GB to Transit Gateway native is not supported but, in the following description we’ll see an option of how we can solve it applying the mentioned services with **AWS Direct Connect of 100Mbps**.
###Important####
**In the next scenario we are using a telecommunications provider that offers connections lower than 1GB on AWS Direct Connect.**
###Definition###
**AWS Direct Connect** *“AWS Direct Connect links your internal network to an AWS Direct Connect location over a standard Ethernet fiber-optic cable. One end of the cable is connected to your router, the other to an AWS Direct Connect router. With this connection, you can create virtual interfaces directly to public AWS services (for example, to Amazon S3) or to Amazon VPC, bypassing internet service providers in your network path. An AWS Direct Connect location provides access to AWS in the Region with which it is associated. You can use a single connection in a public Region or AWS GovCloud (US) to access public AWS services in all other public Regions.”* [1]
**AWS Transit Gateway** *“A transit gateway is a network transit hub that you can use to interconnect your virtual private clouds (VPCs) and on-premises networks. As your cloud infrastructure expands globally, inter-Region peering connects transit gateways together using the AWS Global Infrastructure. Your data is automatically encrypted and never travels over the public internet.”* [2]
**AWS VPN** *“AWS Virtual Private Network solutions establish secure connections between your on-premises networks, remote offices, client devices, and the AWS global network. AWS VPN is comprised of two services: AWS Site-to-Site VPN and AWS Client VPN. Each service provides a highly-available, managed, and elastic cloud VPN solution to protect your network traffic. AWS Site-to-Site VPN creates encrypted tunnels between your network and your Amazon Virtual Private Clouds or AWS Transit Gateways. For managing remote access, AWS Client VPN connects your users to AWS or on-premises resources using a VPN software client.”* [3]
**SOPHOS** *“Sophos XG Firewall is the only network security solution that is able to fully identify the user and source of an infection on your network and automatically limit access to other network resources in response. ... Using Security Heartbeat, we can do much more than just see the health status of an endpoint.”* [4]
###Diagram description###
1. First, we are using **AWS Control Tower** to segment accounts; we have three AWS accounts in the diagram, an account with the name: Networking; it will be used for interconnection with on-premise and AWS. We also associate the transit gateway attached to the other AWS accounts.
2. There is a connection from on-premise to AWS using Direct Connect 100Mbps with BGP and VIF (Virtual Interfaces) private.
3. We create and configure a floating VPC (Virtual Private Gateway), and this point is very important since it’s floating is not associated with any VPC .
4. We create a transit VPC, it will have four subnets, two private and two public subnets.
5. Deploy and configure two Sophos XG EC2 instances to our communication routers between Direct Connect and Transit Gateway. You can obtain Sophos XG from AWS Marketplace. We use two Sophos XG with HA (high availability) in two different availability zones.
6. As previously presented, when the template is deployed it assigns an Elastic IP reserved to each Sophos XG, which we will use for creating VPC connection.
7. We Configure Transit Gateway on the AWS account of name: “Networking” and we associate the VPC’s AWS accounts QA/DEV and PROD, also the “transit” VPC which have the Sophos XG.
8. We Create and configure a VPN connection with AWS on each Sophos XG using Elastic IP reserved on the EC2 instances. It’s important that at the moment of configuring, we do not use the option of Transit Gateway given, we use floating VPG (Virtual Private Gateway)
###In Sophos XG###
1. We create and configure a VPN connection with AWS and associate the routes for the BGP that we obtained from the configuration file on AWS-VPN console.
2. We configure firewall policy and routes.
###In the route table of VPC and AWS###
Previously, the VPCs that we will use from the three AWS accounts were associated with the Transit Gateway, so now, we only must modify the routing tables to go through Transit Gateway.
At this point, we have a solution created and configured using AWS Direct Connect of 100Mbps with AWS Transit Gateway.
###Comments and recommendations###
1. Understand the use of Transit Gateway, VPN and Direct Connect.
2. Take Transit Gateway Workshops, this is an important service to execute AWS configurations.
3. You can use any router brand (for example: Forti, Checkpoint, etc.).
4. Activate VPC Flow Logs and review blocked and accepted traffic on VPCs.
5. In my case I created a Sandbox VPC in the same region as the AWS account “Networking” to do tests and simulations with other VPC.
###References###
https://aws.amazon.com/blogs/networking-and-content-delivery/integrating-sub-1-gbps-hosted-connections-with-aws-transit-gateway/
https://aws.amazon.com/marketplace/pp/prodview-ga4qvij427bvw?sr=0-5&ref_=beagle&applicationId=AWSMPContessa
[1]: https://docs.aws.amazon.com/directconnect/latest/UserGuide/Welcome.html
[2]: https://aws.amazon.com/transit-gateway/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc
[3]: https://aws.amazon.com/vpn/
[4]: https://www.sophos.com/en-us/medialibrary/PDFs/factsheets/sophos-xg-series-appliances-brna.pdf
| vperezpereira |
893,335 | TUTORIAL: Send An Automated SMS Message When Registering A New User | Automated SMS messages are a great way to help onboard users to your app. In this article, we show... | 0 | 2021-11-09T19:53:18 | https://dev.to/backendless/tutorial-send-an-automated-sms-message-when-registering-a-new-user-p6d | webdev, beginners, programming, tutorial |
Automated SMS messages are a great way to help onboard users to your app. In this article, we show how easy it is to send an SMS message upon a new user registration using [Backendless' Zapier integration](https://backendless.com/integrate-backendless-with-3000-web-apps-using-zapier/).
SMS, or text messaging, is one of the most effective ways to engage your users. It is also a great way to create two-factor authentication (2FA) to prevent bots and malicious actors from spamming your registration process.
Backendless is incredibly feature rich, but no platform can cover every niche use case. That’s why we have a Zapier integration, allowing you to access thousands of third-party tools and quickly integrate them into your Backendless app.
Zapier can connect you with a variety of automation tools. These tools make it easy to automate time-consuming and time sensitive processes, like messages sent after every user registration.
In this demo, we will create an application that will implement the function of sending SMS to a specific phone number every time a new user registers in the app. This foundation will prepare you for applying automated SMS functionality in a variety of useful ways.
##Backendless Setup
First, let’s set up our [Backendless](https://backendless.com/) database and a simple registration form in UI Builder.
To store data about registered users, we will use the Backendless `Users` system table. This table is created automatically when you create a new app. In this table, we will use two fields: `email` and `password`.

For simplicity, our user interface will consist of two input elements and a “Register” button. You may add additional fields, such as first/last name, username, password confirmation, etc.

To learn more about setting up your own user registration page, watch the video below.
[Programming User Registration in UI Builder](https://youtu.be/ZVNZk91BE4U)
Back to our demo, when you click on the “Register” button, data is recorded from the form elements in the “Users” table.

Registration of a new user will be a signal (trigger) for Zapier to take action. On this signal, Zapier will receive data about the new user and transfer it to the “ClickSend SMS” application for sending SMS.
##Zapier Setup
Next, let’s set up the Zapier side of the equation. If you don’t have an account with [Zapier](https://zapier.com/), you will first need to register and log into your Zapier account. A free account is all you will need for this demo.
Creating the automation with Zapier will consist of two steps.
###Step 1
The first step is to define a Trigger (when Zapier needs to start performing an action). In our case, registering a new user will act as a trigger.
Click on the button “Create Zap”.

In the “App Event” field, select Backendless.

In the “Trigger Event” drop-down list, select “User Registered” and click the “Continue” button.

Next, you will need to enter your credentials with which you log into Backendless Console and click the continue button.

If you used a social account to register with Backendless, you will need to add a password for your account. To add a password, visit your User Profile:

In the trigger settings, select the name of your Backendless app and click the continue button.

Then we need to test our trigger.

If the test is successful, an object with data about the registered user will be displayed.

###Step 2
In the second step, we will tell Zapier what action should be performed after the trigger is fired.
Select the “ClickSend SMS” application from the drop-down list and select “Send SMS” from the “Action Event” list. Click the continue button.

Next, you will need to enter your credentials with which you log into “ClickSend SMS” APP and click the continue button (if necessary, register for an account at [ClickSend SMS](https://www.clicksend.com/); you can start with a free trial).
Configure the action as shown below. For this demo, we will set the action up to message ourselves that a new user has registered.
The “To” field should contain the phone number to which SMS will be sent. The “Message” field should contain the message text. If necessary, you can fill in the optional fields. Click the continue button.

Then we’ll test once again.

If we pass the test successfully, you will receive an SMS on your phone with the text displayed in the “Body”.

Click the “Turn on Zap” button and you’re ready to go! Zapier is now up and running.
Be sure to check out our other Zapier demo articles:
* [Creating a language translator using Zapier](https://backendless.com/create-language-translator-with-zapier/)
* More coming soon!
Thanks for reading, and as always, Happy Codeless Coding! | backendless |
893,357 | Advent of PBT 2021 - Day 10 - Solution | Advent of Property Based Testing 2021 - Day 10 - Solution | 0 | 2021-12-10T10:25:33 | https://dev.to/dubzzz/advent-of-pbt-2021-day-10-solution-3a3d | challenge, testing, webdev, javascript | ---
title: Advent of PBT 2021 - Day 10 - Solution
published: true
description: Advent of Property Based Testing 2021 - Day 10 - Solution
tags: challenge,testing,webdev,javascript
//cover_image: https://direct_url_to_image.jpg
---
Our algorithm was: **minimalNumberOfChangesToBeOther**.
[Go to the subject itself for more details](https://dev.to/dubzzz/advent-of-pbt-2021-day-10-3dg6)
CodeSandbox with a possible set of properties you may have come with: https://codesandbox.io/s/advent-of-pbt-day-10-solution-xpf78?file=/src/index.spec.ts&previewwindow=tests
---
## Property 1: should never request any changes when moving a string to itself
One of the first option to consider when trying to cover a code with properties is to find subsets of the problem that have simple to compute solutions. In other words, find some inputs with easy answers but clearly not covering the whole scope of the algorithm.
While they offer a limited coverage of the feature, they are often a very good start and can already be pretty powerful to detect unexpected issues. This first property is a good example of such properties.
> for any string - `value`
> the minimal number of changes to move from `value` to `value` is exactly 0
Written with fast-check:
```ts
it("should never request any changes when moving a string to itself", () => {
fc.assert(
fc.property(fc.fullUnicodeString(), (value) => {
// Arrange / Act
const numChanges = minimalNumberOfChangesToBeOther(value, value);
// Assert
expect(numChanges).toBe(0);
})
);
});
```
## Property 2: should request target.length changes to move from empty to target
Based on the same idea we can write the following property:
> for any string - `target`
> the minimal number of changes to move from the empty string to `target` is the number of characters of `target`
Indeed, if we start from the empty string, the fastest way to build `target` is to add all the characters of `target` one by one. In other words, we need at least "number of characters of `target`" operations.
Written with fast-check:
```ts
it("should request target.length changes to move from empty to target", () => {
fc.assert(
fc.property(fc.fullUnicodeString(), (target) => {
// Arrange / Act
const numChanges = minimalNumberOfChangesToBeOther("", target);
// Assert
expect(numChanges).toBe([...target].length);
})
);
});
```
## Property 3: should request source.length changes to move from source to empty
With the same idea in mind, we can write the reversed version of the second property:
> for any string - `source`
> the minimal number of changes to move from `source` to the empty string is the number of characters of `source`
Written with fast-check:
```ts
it("should request source.length changes to move from source to empty", () => {
fc.assert(
fc.property(fc.fullUnicodeString(), (source) => {
// Arrange / Act
const numChanges = minimalNumberOfChangesToBeOther(source, "");
// Assert
expect(numChanges).toBe([...source].length);
})
);
});
```
## Property 4: should request {start+end}.length changes to move from {start}{mid}{end} to {mid}
Just a small variation mixing a bit of the first property with the third one to make an even more generic property.
> for any strings - `start`, `mid`, `end`
> the minimal number of changes to move from `start+mid+end` to `mid` is the number of characters of `start+end`
Written with fast-check:
```ts
it("should request {start+end}.length changes to move from {start}{mid}{end} to {mid}", () => {
fc.assert(
fc.property(
fc.fullUnicodeString(),
fc.fullUnicodeString(),
fc.fullUnicodeString(),
(start, mid, end) => {
// Arrange / Act
const numChanges = minimalNumberOfChangesToBeOther(
start + mid + end,
mid
);
// Assert
expect(numChanges).toBe([...(start + end)].length);
}
)
);
});
```
While this property seems easy at first glance, it is easy to fall into traps. Properties like:
> for any strings - `start`, `mid`, `end`
> the minimal number of changes to move from `start+mid` to `mid+end` is the number of characters of `start+end`
Would be fully wrong. For instance it would not work for: `start = mid = end = "a"`.
## Property 5: should be independent of the ordering of the arguments
Before covering even more generic cases, we can already back us with basic mathematical properties like `symmetry`.
> for any strings - `source`, `target`
> the number of changes required to move from `source` to `target` is the same as the one required to move from `target` to `source`
Written with fast-check:
```ts
it("should be independent of the ordering of the arguments", () => {
fc.assert(
fc.property(
fc.fullUnicodeString(),
fc.fullUnicodeString(),
(source, after) => {
// Arrange / Act
const numChanges = minimalNumberOfChangesToBeOther(source, target);
const numChangesReversed = minimalNumberOfChangesToBeOther(target, source);
// Assert
expect(numChangesReversed).toBe(numChanges);
}
)
);
});
```
## Property 6: should compute the minimal number of changes to mutate source into target
Let's finally fully cover our algorithm with a property making us sure that the returned number of changes is the minimal one.
In order to do that check an easy trap would be to rewrite the implementation in the test but we will not do that for obvious reasons. Another solution is to have a simpler implementation of the same algorithm: most of the time this trick will be available for algorithms aiming for performances like binary searches as they could be double-checked against naive linear searches. But unfortunately we do not have that chance. The last resort is to find a way to generate our inputs differently to make us able to have some more expectations on the output.
Basically it looks similar to what we have done so far with the properties 1, 2, 3 and 4 but pushed even further. Instead of generating the string, we will generate the array of changes that can lead from the source string to the target one. While this array of changes is possibly not the smallest set of changes to move from source to target it is one of the various possibilities. In other words, our algorithm should find something with at most this number of changes.
> for any set of changes (add/remove/update/no-change)
> the number of changes required to move from `source` to `target` is less of equal to number of generated changes excluding no-change
Basically you can see a change as something like:
```ts
type Change =
| { type: "no-op"; value: string }
| { type: "new"; value: string }
| { type: "delete"; value: string }
| { type: "update"; from: string; to: string };
```
And given an array of changes we can easily build `source`:
```ts
function sourceFromChanges(changes: Change[]): string {
let value = "";
for (const c of changes) {
if (c.type === "no-op") value += c.value;
else if (c.type === "delete") value += c.value;
else if (c.type === "update") value += c.from;
}
return value;
}
```
Or `target`:
```ts
function targetFromChanges(changes: Change[]): string {
let value = "";
for (const c of changes) {
if (c.type === "no-op") value += c.value;
else if (c.type === "new") value += c.value;
else if (c.type === "update") value += c.to;
}
return value;
}
```
The last missing block is the arbitrary making us able to generate our changes, we can implement it as follow with fast-check:
```ts
function changeArb() {
return fc.array(
fc.oneof(
fc.record<Change>({
type: fc.constant("no-op"),
value: fc.fullUnicode()
}),
fc.record<Change>({ type: fc.constant("new"), value: fc.fullUnicode() }),
fc.record<Change>({
type: fc.constant("delete"),
value: fc.fullUnicode()
}),
fc.record<Change>({
type: fc.constant("update"),
from: fc.fullUnicode(),
to: fc.fullUnicode()
})
),
{ minLength: 1 }
);
}
```
Now that we have all the elementary building blocks, we can write our property with fast-check:
```ts
it("should compute the minimal number of changes to mutate source into target", () => {
fc.assert(
fc.property(changeArb(), (changes) => {
// Arrange
const source = sourceFromChanges(changes);
const target = targetFromChanges(changes);
const requestedOperations = changes.filter((d) => d.type !== "no-op").length;
// Act
const numChanges = minimalNumberOfChangesToBeOther(source, target);
// Assert
expect(numChanges).toBeLessThanOrEqual(requestedOperations);
})
);
});
```
---
[Back to "Advent of PBT 2021"](https://dev.to/dubzzz/advent-of-pbt-2021-13ee) to see topics covered during the other days and their solutions.
More about this serie on [@ndubien](https://twitter.com/ndubien) or with the hashtag [#AdventOfPBT](https://twitter.com/search?q=%23AdventOfPBT). | dubzzz |
893,836 | Setting up Anonymous User to Embed Kibana Dashboard to Your Application | Recent works let introduce me some challenges in putting Kibana Dashboard into applications, in... | 0 | 2021-11-10T08:48:29 | https://dev.to/nasrulhazim/setting-up-anonymous-user-to-embed-kibana-dashboard-to-your-application-p7b | kibana, dashboard, anonymous | Recent works let introduce me some challenges in putting Kibana Dashboard into applications, in secured manner. Hence writing up a quick post for setting it up securely.
### Elasticsearch
Enable X-pack Security
```
xpack.security.enabled: true
```
Create credentials for internal communication of Elastic stack:
```
/usr/share/elasticsearch/bin/elasticsearch-setup-password auto
```
Random passwords will be created for you:
```
Changed password for user apm_system
PASSWORD apm_system = some-random-password
Changed password for user kibana_system
PASSWORD kibana_system = some-random-password
Changed password for user kibana
PASSWORD kibana = some-random-password
Changed password for user logstash_system
PASSWORD logstash_system = some-random-password
Changed password for user beats_system
PASSWORD beats_system = some-random-password
Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = some-random-password
Changed password for user elastic
PASSWORD elastic = some-random-password
```
### Kibana
Configure your `kibana.yml`:
```
elasticsearch.username: "kibana"
elasticsearch.password: "<password-generated>"
```
Create encryption keys for your Kibana:
```
/usr/share/kibana/bin/kibana-encryption-keys generate
```
Then update your `kibana.yml` using the keys given in previous step:
```
xpack.encryptedSavedObjects.encryptionKey: some-random-key
xpack.reporting.encryptionKey: some-random-key
xpack.security.encryptionKey: some-random-key
xpack.reporting.capture.browser.chromium.disableSandbox: true
```
Then start your Kibana.
Now, you will prompt to enter username and password - use the `elastic` user in above steps.
Once you are logged in, go to Stack Management.
Create a new role named as `embed_dashboard`. Then:
1. Give privileges to indices you want to expose to public.
2. Create a kibana privilege as well, by Add a new one. Choose targeted space - i used Default. Then in feature privilege, grant access to read only for Dashboard and Visualise Library.
Now save.
Once you are done, go create a new user, assign the role as `embed_dashboard` role.
Then, back to `kibana.yml`, append the config as following:
```
xpack.security.authc.providers:
anonymous.anonymous1:
order: 0
session:
idleTimeout: 1Y
credentials:
username: "anon"
password: "SomeStrongPasswordIGuess"
basic.basic1:
order: 1
```
Then restart your Kibana.
By now, you should be able to have a Public URL for your dashboard and be able to embed the dashboard in any of your applications.
Photo by <a href="https://unsplash.com/@chrisliverani?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Chris Liverani</a> on <a href="https://unsplash.com/s/photos/dashboard?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
| nasrulhazim |
893,874 | Why I don't work Wednesdays anymore | Making the decision to work part-time in my early thirties may well be the best decision I’ve ever... | 0 | 2021-11-10T10:22:04 | https://mstrutt.co.uk/blog/2021/10/why-i-dont-work-wednesdays-anymore/ | career, wellbeing, watercooler, worklifebalance | Making the decision to work part-time in my early thirties may well be the best decision I’ve ever made.
As I write this article, I’m 31 years old. I’m not married. I don’t have kids, or anyone who’s dependent on me in any way. I’m not studying for a new qualification, or any of the other classic reasons to work part-time. For me that’s precisely why it’s the perfect time to start this new chapter in my life.
_A caveat: I recognise that I work in a well-paid industry, and what I’m talking about in this article may not work for everyone._
## How I arrived at this decision
I’ve liked the idea of working part time for many years. The issue I’ve struggled with in the past, is having to take a pay cut to do it. The importance of money had always been right at the forefront of my mind. But what I came to realise more recently, is that it’s not really as important to me as I thought (which is a complicated enough story to form its own post some time probably).
When I reflected on my career, while I had placed a lot of importance on the size paycheck, when I _really_ thought about it, it hadn’t been my main motivation. In my early career, what mattered more to me than anything else was the people. People to get along with, to learn from and to help me grow. Many of these became my close friends. Later as I moved into a leadership position, the importance shifted to good people to teach in a company that cares about its employees. A company with a relaxed culture that respects me and affords me a great deal of flexibility.
As I thought about it more, I had always been protective about my time and peace of mind too. I didn’t go in for freelancing or side work in the evenings and weekends, like some of my friends. I didn’t go into the more stressful or risky tech sectors (like fin-tech or start-ups) that demand more from you, but pay a higher wage.
As strange as it may sound, it was only after all of this reflection that I realised my wellbeing, health and happiness are all way more important to me than money (and always have been). I realised that this focus I’ve had on working towards a comfortable retirement meant sometimes I’d forgotten to live and look after myself along the way. Throughout my career, I’ve clearly been making decisions (sometimes subconsciously) to maintain a certain level of work-life balance. So why not adjust that dial more in favour of life?
## Why the perfect time is right now
Recently, I’ve found myself in a fairly new situation in my career. I found that I’m not getting the same sense of satisfaction out of individual contributor work that I used to. I came to realise that mentoring and helping others work through problems and find direction in their careers was far more rewarding to me than the other aspects of my role. The side that had delighted me for years prior.
I’ve also grown a lot since I started therapy at the beginning of 2020, and as part of that I’m getting more in touch with the person I really am at my core. Some of this is resulting in a shift in my values and what’s important to me, in other cases I’m uncovering values that were guiding me all along. Having some more time to figure out how I could respond to this change, and how I might incorporate it into my career, seemed like it would be particularly helpful.
As I said at the beginning of this article, It’s the perfect time to take some more time for myself right now. I’m in a very fortunate position in life. I had a comfortable start and I’ve worked hard to get to a good position at work. I have a mortgage locked at an affordable rate. I have savings for the future that I can fall back on if really needed. I can afford to take a 20% pay cut in order to work 4 days a week, and all that really means for me financially is that I won’t put as much into savings each month.
I honestly didn’t think there would ever be a better time to give part-time working a go. So I did.
## How I made the switch
The company I work for, [Potato](https://p.ota.to/), has always allowed me a great deal of flexibility in my job. I can take as much holiday as I feel I need, adjust my working hours to fit in around the various demands of life, and more recently a whole host of other benefits.
Not that I’m looking to promote my employer on my non-working day, but I was pretty confident from the start that they’d be accommodating. We have a policy on how to make a flexible working request, which essentially boils down to filling out the right to _[request flexible working form from gov.uk](https://www.gov.uk/government/publications/the-right-to-request-flexible-working-form)_ and then sitting down with our Delivery Director to discuss how this might impact things like casting for projects and the division of my time.
It all happened quite quickly really. In the space of a couple of months it went from an initial musing I had, to my first official non-working Wednesday.
## What I do with the time
One of the main things I do now is **writing**. This very post that you’re reading is a product of my non-working days. It has become a bit of a passion of mine. I really enjoyed [sharing my story at the end of last year](/potatostudios_/one-engineer-s-journey-with-mental-health-17lh). I found the responses to it really encouraging, and I feel a strong sense of purpose when I see some of the impact my writing has had on others. There are more topics that I would like to cover and experiences I’d like to share, but they don’t necessarily tie in with my job. So it’s something I want to continue to pursue in my own time.
**Self care**. Making more time for me. I’ll follow-up with a more detailed post about how I’ve been looking after my mental health this last year, but this can take all sorts of forms: Bike rides, meditation, journaling, taking a bath or anything I find therapeutic to do, like gardening or building something out of LEGO.
As I touched on earlier, I’ve grown a lot in the last 18 months, and with that I’ve honed my values and my sense of what is fulfilling and meaningful to me. I want some time to reflect on this, and to explore what it could mean for me in terms of **role direction** (and maybe this is a big enough topic for an article in its own right). It’s likely that off the back of this exploration, I’ll be working with Potato to make some changes to my current role, in order to find more fulfilment at work. There’s a small chance I’ll decide to pack in the tech industry all together and go in a completely different direction. I really don’t know, but I’m excited by the possibilities, and the time I now have to explore them.
### Why Wednesdays though?
I wanted to make sure that I really use this extra time to my own benefit. I was concerned that if I took it on a Monday or Friday it would feel like just an extension of the weekend. The weekend is where I have social plans, go out and about with my partner, do jobs around that house, or just sit around and play some Xbox. While more time doing any of these things would be awesome, what I really wanted was time dedicated to me. Wednesday is perfect for this. It’s in the middle of the working week, so I have more mental energy, and I'm still in a focused mindset. I haven’t yet dropped into the “switch off and relax” mindset that I aim for at the end of the working week. Nobody else I know has the day off, so I have far less chance of being interrupted or distracted. To top it all off, my working week now essentially consists of two Monday/Friday pairs.
## How is it going?
Quite simply, I love it. I love having a day truly dedicated to myself. I’m looking after myself better, and I’m doing some things that I’ve wanted to for a while. Sometimes I wake up on a Wednesday thinking I have work, then get a rush of excitement when I remember I don’t. Thursdays have never felt so good either. I feel energised when I return to work, and find myself having more headspace and patience.
Some days I feel some kind of obligation to be productive, which can be both a good and a bad thing. I definitely don’t want to “waste” this extra time I’ve afforded myself. Today I had to give myself a bit of a nudge to get started writing, but I’m trying not to set unrealistic expectations. I don’t need to justify this time to anyone, and I don’t have to have any kind of an output to show. There will be some days when the most productive thing I can do for myself is simply to rest, and not begrudge myself for doing activities that may appear “unproductive”.
At work, I’ve fallen a little bit into the classic trap of trying to fit 5 days of work into the remaining 4 days, which obviously isn’t possible. But I feel that I’m far more productive on the days that I _do_ work. While I may not be getting 100% of the things done in a week that I used to, it’s definitely not as low as 80% either, which you might expect it to be with a 20% reduction in time. On any given day, I definitely get more done than I used to. My workload is something I’m still figuring out, and will continue to look at over time. The important thing is that I’m being disciplined about my time, and not working extra hours to compensate.
Not everyone I speak to understands my decision to work part-time, and that’s okay. I was prepared for that. I’ll explain the way I see things, but if it doesn’t resonate with them, I just accept our different views. Plenty of people tell me how lucky I am, or how they wish they worked part-time, but choose to prioritise the money instead, and that’s totally okay too. I know that what I’m doing is right for me, but I’m sure it’s not right for everyone.
Sometimes, I fall back into the monetary mindset and think about how much less I’m earning. In those moments, I remind myself that “money isn’t everything”, and think about how much more valuable my wellbeing is to me.
## Will it be forever?
Maybe. I hope so! I don’t have any great desire to go back to working a 40 hour, 5 day week. I’m a realist though, I understand that it’s quite likely a time will come when I go back to full-time employment for the sake of the extra 20% pay, even if just temporarily.
Given time, maybe the rest of the world will [follow in the footsteps of Iceland](https://www.bbc.co.uk/news/business-57724779) and working 4 days a week will become the norm. I’d love to see it happen, but I think it’s a little way off yet.
For now though, I truly believe that working part-time is the best career move I’ve ever made.
| mstrutt |
894,011 | State of Spring survey 2021 | VMWare recently did a survey of over 1500 individuals who use Spring for their "State of Spring... | 0 | 2021-11-10T11:31:20 | https://dev.to/arpit/state-of-spring-survey-2021-2abl | java, springboot, vmware, spring | ---
title: State of Spring survey 2021
published: true
description:
tags: java, springboot, vmware, spring
//cover_image: https://images.unsplash.com/photo-1559150182-a7144f7628f9?ixlib=rb-1.2.1&q=85&fm=jpg&crop=entropy&cs=srgb&w=6000
---
VMWare recently did a survey of over 1500 individuals who use Spring for their "State of Spring 2021", which you can view [here](https://tanzu.vmware.com/content/ebooks/the-state-of-spring-2021).
I read the survey and here are a few things that I learnt from it.
### Spring (esp. Spring boot) positively impacts developer productivity
Most users (95%) said that Spring boot increases the developer productivity hugely. Similarly for Spring, overall, most developers agreed that it increases the productivity, more than other Java platforms.
Also, in terms of who knows most about Spring in the team, most people said, they do not have a Spring specialist (34%), which I agree with as well. I think since Spring is a framework, rather than a language, most teams leverage their developers, architects, etc. to be up to date on the new features of Spring, and related projects, rather than having someone dedicated for this role. But this also means, each company, needs to make sure, they give their developers enough space, time and resources, to keep themselves updated of the things happening in the spring community.
### Where do people find answers
For a majority of developers, [stackoverflow.com](http://stackoverflow.com) is the way to go for any questions about spring. Spring official documentation on [spring.io](http://spring.io) is a close second. Close to 70% developers still go to the official documentation, which I think is a pretty good number. But VMware acknowledged that they need to focus more on creating demos and improving the docs. The fact that there are multiple resources apart from the official documentation and stackoverflow, it's surprising that they didn't come up as an answer in the survey. If they do publish the raw data, I'm sure we'll find many people who leverage these in their day to day.
### Shiny new modules
Developers love the new shiny modules spring continues to come up with. Half of them said, that's one of the reasons they stay with spring. 39% said they would add new modules to their existing or new projects in the near future. It speaks to the fact that spring keeps up to date with new tech, and keeps adding integrations for them. And who doesn't like a new lego block in their toy box.
### Give me more data !
Spring data is the most popular module, which suggest a lot of database integrations, mostly relational. Although noSQL also seemed to be close behind with Mongo, Redis and Elastic.
Spring security is as popular as spring data, which is good, since that means people are keeping their applications secure!
About picking a new module, or Spring project, people consider documentation and maturity as the main factors.
Another thing that came out, as a winner, is Kotlin ! More than 90% of the surveyors have a positive view about it and ~60% plan to learn or use it for their projects.
### We want more APIs !
Although REST, SOA has been around for very long, the primary use-case for Spring and Spring Boot is still creating and exposing API to internal and external consumers.
Also, a large percentage of people use Modern architectures - like microservices, API management, API Gateways, observability, etc. for their application architectures.
A lot of people are also considering and using GraphQL (20%) and Spring already has an [integration](https://spring.io/blog/2021/07/06/introducing-spring-graphql) with it.
### Native is the new cool kid ?
Spring Native is the newly launched module that allows your Spring applications to start quicker, reduce memory footprint, which has been one of the bigger complaints by developers using Spring. Native solves these issues and seems like a lot of the developers are eagerly reading up on it. The adoption is not still 3%, but it's an early project, so I would not judge this yet. Also, the fact that it's still in Beta and possibly not mature enough, is holding people back for now. A third of people also have issues with the build time, but that is improving and that is essentially the cost you pay for getting a fast startup.
But a lot of people (58%) plan to deploy it in the next few months to a couple of years, which is great adoption for such a new project.
### In Summary...
I think Spring and Spring Boot specifically, is here to stay, because of its ease of use, developer productivity, excellent and always improving documentation and a massive user group. A LinkedIn group called Spring Users, has more than 90,000 members, which speaks about the sheer number of people either using, learning or planning to use it.
Article originally published [here] (https://arpit.dev/State-of-Spring-survey-2021-c6c4f741abda4e248c80e2ae9f5cee75)
| arpit |
894,018 | Top 10 Important Features required in an OTT Video CMS Platform | Businesses using On-Demand video content and live video streaming under marketing strategy to promote... | 0 | 2021-11-10T11:39:37 | https://dev.to/charlote/10-must-have-features-in-an-ott-video-cms-platform-53ma | ott, video, cms, videostreaming | Businesses using On-Demand video content and live video streaming under marketing strategy to promote products or services are very profitable. These massive chunks of data will create problems regarding storage, security and management of content. To solve this issue, this is where Video CMS comes into play. Video CMS effectively manages video content in an OTT platform and delivers video content to end users without any delay. Video CMS simplifies the management and distribution of video content in an OTT platform. In this blog, we will go through the top 10 important features required in an OTT Video CMS Platform
## What Is a Video Content Management System (CMS)?
A video content management system, often known as a **[video streaming CMS](https://flicknexs.com/?utm_source=google&utm_medium=dev&utm_campaign=charlotte&utm_id=ott&utm_term=utm_ott)**, is a centralized dashboard that allows streaming services to store, organize, and manage videos securely. The elements of a content management system (CMS) are specifically developed to make the container handling process easier for the top OTT platforms. Here is the list of the top 10 important features required in an OTT Video CMS Platform
## Top 10 features for an OTT Video CMS Platform
### 1. Smart Upload
**Single/ Bulk Videos** - What if we told you that you could upload your videos in a flash? Yes, Flicknexs video CMS allows you to submit video clips individually or in bulk with a single click. You may also utilize the drag-and-drop tool to make the process even easier.
**Import Content Library** - When a huge amount of content needs to be uploaded to the OTT platform, there are alternatives to import an entire video library.
**Third-Party Import Options** - Regardless of where the information is kept, whether it's on a distant server or a third-party cloud driver like Dropbox, quick upload and transcoding is still feasible.
### 2. Organize A Live Stream
The ultimate goal of live streaming is to reach real-time audiences. Users will only be present to watch your content on any given day if they are aware of your live stream.
As a result, our CMS dashboard allows you to arrange live videos for a specific date and time to increase user interaction. Audiences will be notified with a countdown timer of the actual event scheduled. This also increases FOMO (fear of missing out) among your viewers, boosting the likelihood of watching the live stream.
### 3. Easy Categorization
**[OTT platforms](https://dev.to/charlot/what-exactly-is-ott-and-how-it-will-help-you-in-the-future-5f9h)** must organize their videos so that viewers can find the content they want quickly. The "categorize menu" on the CMS dashboard in Flicknexs allows you to manage video files effectively. You can use this feature to create categories of your choosing, add thumbnail photos, and build subcategories based on the hierarchy.
### 4. User-created playlists
This option is all about allowing a user to create his playlist. Every video includes an "Add to Playlist" button that, when clicked, allows the user to add it to an existing playlist or build a new one based on his preferences. The actions that an end-user can do are as follows:
* Assemble playlists
* Create playlists with videos
* Change the names of your playlists
* Take videos out of playlists
* Remove all playlists
### 5. Management of Metadata
Greater visibility comes with excellent metadata management. As a result, you can optimize the metadata of your videos, including URLs, tags, descriptions, and anything else needed to help you drive more visitors by ranking well in Google searches. Here you will find the most effective SEO methods.
### 6. Multiple Media Formats are Supported
Converting every video file before uploading to your video streaming platform is a lot of work and nearly impossible to do, especially if you have a large content library. As a result, our dashboard supports various video formats, including MP4, M4V, AVI, MPEG-DASH, H.265 Codec, and H.264 Codec, to make things easier for content owners.
### 7. Video Captioning That Is Customized
Adding closed captions to your movies is beneficial in various ways, from improving accessibility to increasing watch time. As a result, depending on your target audiences, our CMS dashboard allows you to add closed captions to your videos in any language. On the user side, users can turn CC on and off and customize the caption size, colour, font, and positioning.
### 8. Sub-Admin Groups can be created
It can be exhausting for an administrator to manage the full material library independently. What if we told you that you could create sub-admin groups to undertake specific duties on your platform, cutting your workload in half? Yes, you may become a super-admin and delegate authority to sub-admins by assigning roles like a publisher, administrator, and moderator to sub-admins based on business needs.
### 9. Management of User Profiles
User profiles are usually established when people fill out the sign-up form with their personal information. However, you may also build user profiles from the backend utilizing this straightforward dashboard's "Create Customer" option. This implies that administrators can insert new customers' names, e-mail addresses, and other information into the database.
### 10. Keep tabs on video analytics.
With OTT competition becoming more fierce by the day, it's more important than ever for a VOD streaming app to retain users by keeping them hooked on your content. And you can only do this in practice if you produce videos that your target viewers want to be based on the data you've gathered.
Flicknex's dashboard provides data on the following aspects to assist business owners in evaluating video performance.
* The number of times a video has been viewed
* Total time spent watching
* The average percentage of people who watched
* Videos with the most views
* Videos with the most comments
* Viewing by region
## To Sum it Up:
When you have a vast video library, you'll need a content management system that's reliable, secure, and simple to use. **[Flicknexs video CMS](https://flicknexs.com/?utm_source=google&utm_medium=dev&utm_campaign=charlotte&utm_id=ott&utm_term=utm_ott)** includes all of these and high-end functionality to meet modern OTT requirements.
| charlote |
894,105 | HTTP Methods And Its Use Case | HTTP is an Application Layer Protocol and the REST API uses HTTP or HTTPS to exchange data between... | 0 | 2021-11-10T14:34:07 | https://dev.to/ruchivora/http-methods-1fdp | webdev, beginners, tutorial | HTTP is an Application Layer Protocol and the REST API uses HTTP or HTTPS to exchange data between Client and Server using HTTP methods like :
1. GET
2. POST
3. PUT
4. PATCH
5. DELETE
These HTTP methods are used to perform CRUD (Create ,Read ,Update ,Delete) operations on the resource.
Here resource can be a row of a relational database or a document in the case of the NoSql database or it can be any other form of a resource.
Let's understand each of the Http methods with an example of a document store. Where each document contains information about an Employee in the company.
1. GET Method : GET method is used to retrieve the resource.
For Eg : If you want to check the details of an Employee
whose id is 10. Then the GET request will look like
```javascript
curl --request GET 'localhost:8080/EmployeeDetail/10'
```
The response of the GET request will be :
```javascript
{
'id' : '10',
'name' : 'ruchi',
'dob' : '02-04-2001',
'location' : 'new york',
'department' : 'IT'
}
```
- The GET request can be cached. If multiple requests are
made to retrieve the data of an Employee whose id is 10 ,
then all of them will receive the same data. So instead of
hitting the server again and again for the same static data
, the response of the request can be cached.
- Also the GET request is Idempotent. Which means that even
though multiple requests are made for an employee with id
as 10 , it returns the same response.
- The various HTTP response code returned by GET requests are
- 200 (OK) - If the resource is found on the server. i.e
If an Employee with id 10 exists then the HTTP response
code 200 along with the resource is returned.
- 404 ( NOT FOUND ) - If the resource does not exists on
server. i.e If a document with Employee id 10 does not
exists on server then HTTP response code 404 is returned
- 400 ( BAD REQUEST ) - GET request itself is not
correctly formed then the server will return the HTTP
response code 400
2. POST Method : POST method is used to create a new
resource.For Eg: If you want to insert the data of a
new Employee who has just joined the company , then in
such case POST method is used . The POST request will look
like
```javascript
curl -d '{
'name':'ram',
'dob' :'06-06-2000',
'location':'Mumbai',
'department':'IT'
}' -X POST -H 'Content-Type: application/json'
localhost:8080/EmployeeDetail
```
Here , We do not pass the Id , assuming that ID is a unique
key generated by server.
- POST request can not be cached.
- POST request is not Idempotent . Hence, if multiple
request with same data is sent to same url then two
documents are created with same data but different Id ,
as Id being the unique key generated by the server.
- The various HTTP response code returned by POST requests
- 201 ( Created ) - If the new resource is created i.e
If a document for new Employee is created then it
returns HTTP response code 201
3. PUT Method : PUT Method is used to perform UPSERT
operation.Which means if the resource does not exists then
it is created and if the resource exists then the whole
resource is updated. For Eg: If we send a request with
Employee Id 100 , and if there exists no Employee with Id
as 100 then the new resource is created(assume that client
can generate an Employee Id and server also accepts the Id
generated by client). If the Employee with Id 100 exists
then the whole resource(document) is updated(even though
there is no change in the data).The PUT request looks like
this :
```javascript
curl -d '{
'id' :'100'
'name':'ram',
'dob' :'06-06-2000',
'location':'Mumbai',
'department':'IT'
}' -X PUT -H 'Content-Type: application/json'
localhost:8080/EmployeeDetail
```
- PUT request can not be cached
- PUT request is idempotent , as if N PUT requests are made
then the very first request will update the resource; the
other N-1 requests will just overwrite the same resource
state again and again – effectively not changing
anything. Hence, PUT is idempotent.
- The various HTTP response code returned by PUT requests
- 201 ( Created ) - If the new resource is created i.e
If a document for new Employee is created then it
returns HTTP response code 201
- 200 ( OK ) - If the existing resource is updated.
- 404 ( Not Found ) - If ID is not found or invalid.
- 405 (Method not allowed) - If you are trying to
update the Employee Id which is the unique key.
4. PATCH Method : PATCH Method is used to make a partial
update to a resource. which means if an Employee with id
10 has changed his department then in order to update only
the department key PATCH Method can be used. The PATCH
method looks like this
```javascript
curl -d '{'department':'IT'}' -X PATCH -H 'Content-Type:
application/json' localhost:8080/EmployeeDetail/10
```
- PATCH request can not be cached
- Most of the PATCH request are Idempotent similar to PUT ,
but some PATCH requests are not Idempotent.
- The various HTTP response code returned by POST requests
- 200 ( OK ) - If the existing resource is
partially updated.
- 404 (Not Found) - If ID is not found or invalid
- 405 (Method not allowed) - If you are trying to
update the Employee Id which is the unique key.
5. DELETE Method : DELETE Method is used to delete a
resource.For Eg: If we want to delete Employee with Id as
10 then the DELETE method looks like this
```javascript
curl -X DELETE -H localhost:8080/EmployeeDetail/10
```
- DELETE request can not be cached.
- DELETE operations are idempotent. If you DELETE a
resource, it’s removed from the collection of resources.
Repeatedly calling DELETE API on that resource will not
change the outcome – however, calling DELETE on a
resource a second time will return a 404 (NOT FOUND)
since it was already removed.
| ruchivora |
894,135 | Cloudflare Developer Challenge: Adding Rust to SvelteKit | Cloudflare Developer Challenge: using SvelteKit, Rust and my other favourites like vanilla-extract and workers, to create an API as a service. | 0 | 2021-11-10T15:18:57 | https://rodneylab.com/cloudflare-developer-challenge/ | svelte, serverless, javascript, rust | ---
title: "Cloudflare Developer Challenge: Adding Rust to SvelteKit"
published: "true"
description: "Cloudflare Developer Challenge: using SvelteKit, Rust and my other favourites like vanilla-extract and workers, to create an API as a service."
tags: "svelte, serverless, javascript, rust"
canonical_url: "https://rodneylab.com/cloudflare-developer-challenge/"
cover_image: "https://dev-to-uploads.s3.amazonaws.com/uploads/articles/6kxeq05b7bd1tpk9ul9k.png"
---
## ✨ Cloudflare Developer Challenge
The Cloudflare Developer Challenge was launched in the summer. Basically you had to build an application which uses two services from Cloudflare's developer platform. I built out <a aria-label="Open the Narcissus demo si/teylab.com/">Narcissus as a proof of concept backendless blog</a> stitching together some of my favourite tools, languages and services. Spoiler alert: if you aren't new here, it won't surprise you to learn that I built it using SvelteKit and Rust! In this post I'll talk a little about the challenge and my entry. I hope you find it interesting as well as useful.

## 😕 Why Choose this Project?
I was quite excited when I saw the tweet announcing the Cloudflare Developer Challenge. I had been using Cloudflare DNS and <a aria-label="Open article on using Cloudflare Warp with Open B S D" href="https://rodneylab.com/how-to-setup-cloudflare-warp-openbsd/">Warp</a> services for a while and had just started trying out Cloudflare Pages and Workers. Because I love trying out new products and services I wanted to work with novel and interesting tools in this project.
### Chosen Toolkit
Here's what I decided to go with:
- **vanilla-extract**: I simply love this tool for working with CSS. <a aria-label="Read aricle on writing C S S in Svelte" href="https://rodneylab.com/using-vanilla-extract-sveltekit/">vanilla-extract let's you write you CSS in TypeScript</a>, making it easier to keep your styling consistent. On top it makes theming easy, works on most modern platforms and separates styles and content into their own files. These last two features made it ideal for this project as I wanted to build a demo site in Astro and other modern frameworks.
- **Rust**: Cloudflare had recently <a aria-label="Read more on Rust Cloud flare workers" href="https://blog.cloudflare.com/workers-rust-sdk/">added first-class support for Rust</a> to Cloudflare Workers. Cloudflare Workers are something like Lambda functions but <a aria-label="Read about using Rust with Cloud flare workers" href="https://rodneylab.com/using-rust-cloudflare-workers/">compile to Web Assembly (WASM) and are optimised to run fast</a>!
- **SvelteKit**: SvelteKit offers the <a aria-label="Open posts on Svelte Kit" href="https://rodneylab.com/tags/sveltekit/">best developer experience</a> currently. Combining SvelteKit's modern Vite tooling and Svelte's ability to compile down to pure JavaScript, I would be able to build a fast site and do it quickly. I got quick feedback with both development code updates reflected instantly in the browser and genuinely, blazingly fast cloud builds, letting me debug issues at warp speed.
- **Supabase**: you must have heard about the new open source alternative to Firebase. Using Supabase with PostgreSQL **Row Level Security** is ideal for this project. Row Level security makes it easy to set access rules on the database itself rather than within your API code. As an example you can build rules into your database only allowing a user to create new messages from their own account in a messaging app (as an example use case). Then on top you can give only the selected recipients and sender read access to the underlying message data. This is a fantastic security addition as writing access rules within your own API can quickly become complex and error-prone as new features are merged.
### Up Next
To sum up I tied all these tools and services together to create the API as a service. Let's see what an API as a service is next and how it can be used to add fantastic features for increasing user engagement in a hassle-free way.
## 🌟 What is an API as a Service?
An Application Programming Interface (API) let's you access a service from your own code. You might already be familiar with Serverless environments where there is a server (somewhere) but the point is you do not have to maintain it or scale resources yourself when traffic ramps up — your service provider takes care of that for you.
In this project I built a proof of concept for a **backendless blog** site. Here you neither have to code up all the logic needed to handle contact form messages, nor pass them on to a delivery service to check them for spam and **filter out bots**. On top you can **forget about the database** too. Instead you just write REST API calls to a single service which runs **Rust Cloudflare Workers**. That service does a lot of the heavy lifting for you. It's different to adding a comment service to your blog as you implement the front end yourself. You can code it up efficiently and style it exactly how you or your client want it. On top you pick and choose the features you want: likes and views, comments or contact form messages.
## 🖤 What is Narcissus?
Narcissus is a proof of concept API as a service for websites. You can build a static or server-side rendered site and integrate access to your data just by calling a REST endpoint. For a static site you might opt to pull in data at build time so that even with JavaScript disabled visitors can see some available comments or likes. With JavaScript enabled, a quick call to the Rust Cloudflare Worker gets the latest data from the **Supabase database** onto your visitor's phone or computer screen.

These features are provided by REST endpoints which the Rust Cloudflare Worker listens on:
- **Message form** — lets website visitors send a message to admins. To avoid abuse by bots <a aria-label="Learn more about h Captcha" href="https://www.hcaptcha.com/">hCaptcha runs a challenge</a> in browser. On the Cloudflare worker side, there is also a check with the <a aria-label="Learn more about Akismet" href="https://akismet.com/">Akismet spam detection service</a>. The worker sends you or admins the details of the message using a **Telegram bot**.
- **View count** — page views are counted automatically and displayed, letting visitors know what the most popular content is.
- **Likes** — the <a aria-label="Open the narcissus repo on Git Hub" href="https://github.com/rodneylab/narcissus">Cloudflare worker</a> records new blog post likes to the <a aria-label="Learn more about Supa base" href="https://supabase.io/">Supabase</a> database.
- **Comments** — comments left by users on blog posts, like contact form messages are checked for spam and bots.
- **Developer friendly** — you style the pages and implement any or all of the features the way you want. Just fetch data from the **API using REST** calls. Your site becomes **backendless** and you save on having to configure and connect multiple services. Add to your site today even though you plan to **move to a new framework** soon.
### Possible Future Features
- Newsletter subscription handling, connecting to your preferred service.
- GraphQL API.
- Alternative <a aria-label="Learn more about Astro" href="https://astro.build/">demo site built with Astro</a> and <a aria-label="Learn more about Remix" href="https://remix.run/">Remix</a>.
Take a look at the current <a aria-label="Open the Narcissus demo site" href="https://narcissus-blog.rodneylab.com/">live demo site running on Cloudflare Pages</a>. Also see the <a aria-label="Open the narcissus repo" href="https://github.com/rodneylab/narcissus">monorepo which is home to both the Cloudflare Worker code and the demo</a> client sites.
## 😢 What are your Website Pain Points?

I mentioned a few possible new features above but even better would be to hear what your current pain points are. What challenges do you face when you are creating and maintaining sites for yourself and clients? If you could change one thing, what would it be? I would love you to leave a comment below or get in touch with me via <a aria-label="Message me via Twitter" href="https://twitter.com/messages/compose?recipient_id=1323579817258831875">@askRodney on Twitter</a> or <a aria-label="Contact Rodney Lab via Telegram" href="https://t.me/askRodney">askRodney on Telegram</a>.
🏁 Cloudflare Developer Challenge: Summary
<Question
position={1}
name="What is Narcissus?"
answer="Narcissus is a proof of concept backend as a service app which lets you create a blog site quicker by managing important blog features like comment and message forms as well as post views and likes."
/>
#h2 🙏🏽 Cloudflare Developer Challenge: Feedback
Have you found the post useful? Would you prefer to see posts on another topic instead? Get in touch with ideas for new posts. Also if you like my writing style, get in touch if I can write some posts for your company site on a consultancy basis. Read on to find ways to get in touch, further below. If you want to support posts similar to this one and can spare a few dollars, euros or pounds, please <a aria-label="Support Rodney Lab via Buy me a Coffee" href="https://rodneylab.com/giving/">consider supporting me through Buy me a Coffee</a>.
Finally, feel free to share the post on your social media accounts for all your followers who will find it useful. As well as leaving a comment below, you can get in touch via <a aria-label="reach out on Twitter" href="https://twitter.com/messages/compose?recipient_id=1323579817258831875">@askRodney</a> on Twitter and also <a aria-label="Contact Rodney Lab via Telegram" href="https://t.me/askRodney">askRodney on Telegram</a>. Also, see <a aria-label="Get in touch with Rodney Lab" href="https://rodneylab.com/contact">further ways to get in touch with Rodney Lab</a>. I post regularly on <a aria-label="See posts on svelte kit" href="https://rodneylab.com/tags/sveltekit/">SvelteKit</a> as well as other topics. Also <a aria-label="Subscribe to the Rodney Lab newsletter" href="https://rodneylab.com/about/#newsletter">subscribe to the newsletter to keep up-to-date</a> with our latest projects. | askrodney |
894,178 | Day 56/100 Bugs and Errors | "Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code... | 15,249 | 2021-11-10T15:31:40 | https://dev.to/riocantre/day-56100-bugs-and-errors-1o89/ | 100daysofcode, programming, challenge, motivation | "Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it."
– Brian Kernighan and P.J. Plauger, The Elements of Programming Style
 | riocantre |
894,307 | Elementor Abschnitte, Spalten, Margin & Padding erklärt - WordPress Layout Anleitung | Wenn du Elementor Sections noch nicht kennst, ist es vielleicht schwer zu verstehen, was diese... | 0 | 2021-11-12T15:05:59 | https://bloggerpilot.com/elementor-layout/ | wordpress, elementor, pagebuilder | ---
title: Elementor Abschnitte, Spalten, Margin & Padding erklärt - WordPress Layout Anleitung
published: true
date: 2021-11-10 14:53:58 UTC
tags: WordPress,elementor,pagebuilder
canonical_url: https://bloggerpilot.com/elementor-layout/
---

Wenn du Elementor Sections noch nicht kennst, ist es vielleicht schwer zu verstehen, was diese Einstellungen eigentlich bewirken. In diesem Blog-Beitrag werden wir sie dir anhand von Beispielen erklären.
Der Original-Artikel erschien auf [Elementor Abschnitte, Spalten, Margin & Padding erklärt - WordPress Layout Anleitung](https://bloggerpilot.com/elementor-layout/).
Wenn du Elementor noch nicht kennst, ist es ein Page Builder Plugin, das von vielen WordPress Plugin-Entwicklern verwendet wird. Es ist ein leichtgewichtiges Plugin, das dir viel Flexibilität bei der Erstellung von Layouts bietet, indem es dir verschiedene Layout-Optionen zur Verfügung stellt, mit denen du dein Layout schnell mit Steuerelementen wie Spalten, Abständen, Rändern, Auffüllungen, Anordnung usw. anpassen kannst. Außerdem ist es sehr einfach zu bedienen. | j0e |
894,422 | Listen to the Season 7 Premiere of DevDiscuss: "Deeply Human Stories in Software with The Changelog" | Listen to S7E1 of DevDiscuss! | 15,466 | 2021-11-10T17:52:18 | https://dev.to/devteam/listen-to-the-season-7-premiere-of-devdiscuss-deeply-human-stories-in-software-with-the-changelog-ip1 | discuss, podcast | ---
title: Listen to the Season 7 Premiere of DevDiscuss: "Deeply Human Stories in Software with The Changelog"
published: true
description: Listen to S7E1 of DevDiscuss!
tags: discuss, podcast
series: DevDiscuss Season 7
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/4db01vlo54hl311zoddy.png
---
## We're super excited to share that season 7 of the DevDiscuss podcast is finally here — and you can listen right here on DEV!
{% podcast https://dev.to/devdiscuss/s7-e1-deeply-human-stories-in-software-with-the-changelog %}
_Quick refresher since it's been a minute — DevDiscuss is the first original podcast from DEV all about the burning topics that impact all our lives as developers._
**Episode Info**
In the season premiere, we’re talking about deeply human stories in software — with some pretty fantastic guests from [The Changelog](https://changelog.com/).
### Hosts:
- @ben — Creator of DEV & Co-Founder of Forem
- @coffeecraftcode — Developer Advocate at Forem
### Guests:
- [Adam Stacoviak](https://twitter.com/adamstac), Founder and Editor-in-Chief of Changelog Media.
- [Jerod Santo](https://twitter.com/jerodsanto), Managing Editor of Changelog Media
Let us know your thoughts on this show in the comments below — or on Twitter ([@thepracticaldev](https://twitter.com/thepracticaldev) ).

---
_You can [follow DevDiscuss](dev.to/devdiscuss) to get episode notifications and listen right in your feed_ — or subscribe on your platform of choice! Plus, if you leave us a review, we'll send you a free pack of thank-you stickers. Details [here](https://airtable.com/shr8oKAIMZgdYnBxx).
## Quick Listening Links
- [Apple Podcasts](https://podcasts.apple.com/us/podcast/s7-e1-deeply-human-stories-in-software-with-the-changelog/id1513053883?i=1000541361862)
- [Spotify](https://open.spotify.com/show/4Jae2mPUqx0XnGychucsE4)
- [Google](https://podcasts.google.com/feed/aHR0cHM6Ly9mZWVkcy5kZXZwb2RzLmRldi9kZXZkaXNjdXNzX3BvZGNhc3QueG1s/episode/aHR0cHM6Ly9kZXZwb2RzLmRldi9wb2RjYXN0cy9kZXZkaXNjdXNzLzUw?sa=X&ved=0CAQQkfYCahcKEwjQzIevrY70AhUAAAAAHQAAAAAQCg)
- [Listen Notes](https://www.listennotes.com/podcasts/devdiscuss/s7e1-deeply-human-stories-in-zND98OeCPQg/)
- [TuneIn](https://tunein.com/podcasts/Technology-Podcasts/DevDiscuss-p1324596/?topicId=167643015)
- [RSS Feed](http://feeds.codenewbie.org/devnews_podcast.xml)
- [DEV Pods Site](http://devpods.herokuapp.com/podcasts/devdiscuss/episodes/228)
---
_Acknowledgements_
- _@levisharpe for producing & mixing the show_
- _Our season seven sponsors: [Microsoft](https://www.microsoft.com/en-us/dev-community/Event/Register?eventId=DevDiscussPodcast_o7nllI4cp4Vg&ocid=aid3038582), [New Relic](https://developer.newrelic.com/), & [Vultr](ource=devdiscuss&utm_medium=syndication&utm_campaign=october21)!_
| thepracticaldev |
894,589 | Storing passwords - the right and wrong ways | In this post, we'll walk through all the ways you can store passwords. We'll see the ideas and... | 0 | 2021-11-10T20:53:15 | https://blog.propelauth.com/securely-storing-passwords/ | security, beginners, auth, javascript | In this post, we'll walk through all the ways you can store passwords. We'll see the ideas and drawbacks behind each approach, and conclude with the current best way to store them.
In each case, the main question we want to answer is "What could an adversary do if they got access to our database?"
### Approach 1: Store them in plaintext
```js
// Using Sequelize for the examples
async function saveUser(email, password) {
await DbUser.create({
email: email,
password: password,
})
}
async function isValidUser(email, password) {
const user = await DbUser.findOne({email: email});
return user && password === user.password
}
```
You've probably already heard that this is a bad idea. If anyone ever gets access to our database, they have immediate access to everyone's passwords. We didn't slow them down at all.
While we tend to think of database access as an attack, it might not even be a malicious thing. Maybe an employee needed read-only access to the DB, and they were given access to the user table too. By storing the passwords in plaintext, it's hard to truly protect our users.
### Approach 2: Encrypt them
```js
const aes256 = require('aes256');
const key = 'shhhhhhhhh';
async function saveUser(email, password) {
const encryptedPassword = aes256.encrypt(key, password);
await DbUser.create({
email: email,
password: encryptedPassword,
})
}
async function isValidUser(email, password) {
const user = await DbUser.findOne({email: email});
if (!user) return false;
// Decrypt the password from the DB and compare it to the provided password
const decryptedPassword = aes256.decrypt(key, user.password);
return decryptedPassword === password
}
```
Unfortunately for us, encrypted data can be decrypted. If an attacker gets access to a key (which doesn't seem unreasonable if they are getting access to our DB), then we are basically back to the plaintext case. This is certainly better than the plaintext case, but we can do better. What if we stored the passwords in a format that cannot be reversed?
### Approach 3: Hash them
```js
const crypto = require('crypto');
async function saveUser(email, password) {
await DbUser.create({
email: email,
password: sha256(password),
})
}
async function isValidUser(email, password) {
const user = await DbUser.findOne({email: email});
return user && sha256(password) === user.password
}
function sha256(text) {
return crypto.createHash('sha256').update(text).digest('hex');
}
```
The advantage of using a hash function over encryption is that the function cannot be reversed. This should mean that the password cannot be recovered from the database.
We can only tell that someone provided a valid password by hashing their input and checking if the hashes match.
This sounds perfect so far, however, a clever attacker can precompute the sha256 hashes of a lot of common passwords. If an attacker got access to the DB and saw someone with password hash `5e884898da28047151d0e56f8dc6292773603d0d6aabbdd62a11ef721d1542d8`, they could quickly figure out that person chose the most common password... `password`
[Large precomputed tables](https://en.wikipedia.org/wiki/Rainbow_table) of common passwords and short strings exist, so we need someway to counteract that.
### Approach 4: Salt our passwords
A "salt" is random data that we add on to our password.
```js
const crypto = require('crypto');
async function saveUser(email, password) {
// The salt is randomly generated each time
const salt = crypto.randomBytes(64).toString('hex')
await DbUser.create({
email: email,
salt: salt, // The salt is stored in the table
password: sha256(salt, password),
})
}
async function isValidUser(email, password) {
const user = await DbUser.findOne({email: email});
// We use the salt loaded from the DB to verify the password
return user && sha256(user.salt, password) === user.password
}
function sha256(salt, text) {
return crypto.createHash('sha256').update(salt + text).digest('hex');
}
```
A few important things to note:
- There is not one global salt. Each user gets their own salt. A global salt would still allow an attacker to precompute password hashes starting with that global salt.
- It doesn't matter how you combine the salt and password. In this case we just prepended it.
Salting is a really powerful technique. A user who chose the password `password` will no longer get the hash `5e884898da28047151d0e56f8dc6292773603d0d6aabbdd62a11ef721d1542d8`, but will instead get the hash of a much larger string that ends with `password`.
We're almost done, there's just one more issue we need to deal with. SHA256 hashes can be computed pretty quickly. If I am an attacker with access to your database, I can carry out targeted attacks against specific people using their salts.
This is done by computing hashes for a specific users salt with a dataset of common passwords. A good password will still be very difficult to crack, but the attacker can use the salts to relatively quickly find people with weak passwords.
What if we could intentionally make our hashing algorithm more difficult to compute?
### Approach 5: Use a modern password hashing algorithm
According to [OWASP](https://cheatsheetseries.owasp.org/cheatsheets/Password_Storage_Cheat_Sheet.html), Argon2id, bcrypt, scrypt, and PBKDF2 are all applicable in different scenarios.
```js
const bcrypt = require('bcrypt');
// bcrypt configuration
const SALT_ROUNDS = 10;
async function saveUser(email, password) {
// The salt is stored in the passwordHash
const passwordHash = await bcrypt.hash(password, SALT_ROUNDS);
await DbUser.create({
email: email,
passwordHash: passwordHash
})
}
async function isValidUser(email, password) {
const user = await DbUser.findOne({email: email});
return user && await bcrypt.compare(password, user.passwordHash)
}
```
A key way in which modern password hashing algorithms differ from something like sha256 is that their performance can be tuned.
`bcrypt` for example, has a "work factor" parameter. A higher work factor means that it takes longer to compute the hash of a password. A user trying to log in will have a slightly slower experience, but an attacker trying to precompute password hashes will too.
This ends up solving a lot of our issues. An attacker with access to our database cannot reverse the passwords to their original form. They cannot precompute lookup tables to easily find users with simple passwords. And if they want to guess someone's password, we have made the guessing process intentionally slower, so it requires more time and resources.
Modern password hashing algorithms still use salts, too. They actually embed the salt in their result, so you don't need a separate `salt` column in your database.
### How do I configure my password hashing algo?
These algorithms are great, but they do have some parameters that need to be set. A good place to start is [OWASP's guide on Password Storage](https://cheatsheetseries.owasp.org/cheatsheets/Password_Storage_Cheat_Sheet.html) which has recommendations for parameters.
### Defense in Depth
While we have covered best practices for actually storing the password, to further protect users you should also consider techniques like [breached password detection](https://blog.propelauth.com/easy-breached-password-detection/) to stop users from using easily guessable passwords.
The code snippets above were simplified for readability, but they are also vulnerable to a simple timing attack. You can read more about protecting yourself from that [here](https://blog.propelauth.com/understanding-timing-attacks-with-code/).
### Conclusions
- Always use a modern hashing algorithm and follow [OWASP's guide](https://cheatsheetseries.owasp.org/cheatsheets/Password_Storage_Cheat_Sheet.html) to help configure it.
- Never store passwords in any reverse-able format
- In the case of a data breach, a good password is your user's best defense. Techniques like [breached password detection](https://blog.propelauth.com/easy-breached-password-detection/) can also help mitigate some of these issues. | propelauthblog |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.